mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-10 22:21:11 +08:00
commit
80121dfe19
@ -0,0 +1,264 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tt67wq)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13452-1.html)
|
||||
[#]: subject: (Start using systemd as a troubleshooting tool)
|
||||
[#]: via: (https://opensource.com/article/20/5/systemd-troubleshooting-tool)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
使用 systemd 作为问题定位工具
|
||||
======
|
||||
|
||||
> 虽然 systemd 并非真正的故障定位工具,但其输出中的信息为解决问题指明了方向。
|
||||
|
||||

|
||||
|
||||
没有人会认为 systemd 是一个故障定位工具,但当我的 web 服务器遇到问题时,我对 systemd 和它的一些功能的不断了解帮助我找到并规避了问题。
|
||||
|
||||
我遇到的问题是这样,我的服务器 yorktown 为我的家庭办公网络提供名称服务 、DHCP、NTP、HTTPD 和 SendMail 邮件服务,它在正常启动时未能启动 Apache HTTPD 守护程序。在我意识到它没有运行之后,我不得不手动启动它。这个问题已经持续了一段时间,我最近才开始尝试去解决它。
|
||||
|
||||
你们中的一些人会说,systemd 本身就是这个问题的原因,根据我现在了解的情况,我同意你们的看法。然而,我在使用 SystemV 时也遇到了类似的问题。(在本系列文章的 [第一篇][2] 中,我探讨了围绕 systemd 作为旧有 SystemV 启动程序和启动脚本的替代品所产生的争议。如果你有兴趣了解更多关于 systemd 的信息,也可以阅读 [第二篇][3] 和 [第三篇][4] 文章。)没有完美的软件,systemd 和 SystemV 也不例外,但 systemd 为解决问题提供的信息远远多于 SystemV。
|
||||
|
||||
### 确定问题所在
|
||||
|
||||
找到这个问题根源的第一步是确定 httpd 服务的状态:
|
||||
|
||||
```
|
||||
[root@yorktown ~]# systemctl status httpd
|
||||
● httpd.service - The Apache HTTP Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
|
||||
Active: failed (Result: exit-code) since Thu 2020-04-16 11:54:37 EDT; 15min ago
|
||||
Docs: man:httpd.service(8)
|
||||
Process: 1101 ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND (code=exited, status=1/FAILURE)
|
||||
Main PID: 1101 (code=exited, status=1/FAILURE)
|
||||
Status: "Reading configuration..."
|
||||
CPU: 60ms
|
||||
|
||||
Apr 16 11:54:35 yorktown.both.org systemd[1]: Starting The Apache HTTP Server...
|
||||
Apr 16 11:54:37 yorktown.both.org httpd[1101]: (99)Cannot assign requested address: AH00072: make_sock: could not bind to address 192.168.0.52:80
|
||||
Apr 16 11:54:37 yorktown.both.org httpd[1101]: no listening sockets available, shutting down
|
||||
Apr 16 11:54:37 yorktown.both.org httpd[1101]: AH00015: Unable to open logs
|
||||
Apr 16 11:54:37 yorktown.both.org systemd[1]: httpd.service: Main process exited, code=exited, status=1/FAILURE
|
||||
Apr 16 11:54:37 yorktown.both.org systemd[1]: httpd.service: Failed with result 'exit-code'.
|
||||
Apr 16 11:54:37 yorktown.both.org systemd[1]: Failed to start The Apache HTTP Server.
|
||||
[root@yorktown ~]#
|
||||
```
|
||||
|
||||
这种状态信息是 systemd 的功能之一,我觉得比 SystemV 提供的任何功能都要有用。这里的大量有用信息使我很容易得出逻辑性的结论,让我找到正确的方向。我从旧的 `chkconfig` 命令中得到的是服务是否在运行,以及如果它在运行的话,进程 ID(PID)是多少。这可没多大帮助。
|
||||
|
||||
该状态报告中的关键条目显示,HTTPD 不能与 IP 地址绑定,这意味着它不能接受传入的请求。这表明网络启动速度不够快,因为 IP 地址还没有设置好,所以 HTTPD 服务还没有准备好与 IP 地址绑定。这是不应该发生的,所以我查看了我的网络服务的 systemd 启动配置文件;在正确的 `after` 和 `requires` 语句下,所有这些似乎都没问题。下面是我服务器上的 `/lib/systemd/system/httpd.service` 文件:
|
||||
|
||||
```
|
||||
# Modifying this file in-place is not recommended, because changes
|
||||
# will be overwritten during package upgrades. To customize the
|
||||
# behaviour, run "systemctl edit httpd" to create an override unit.
|
||||
|
||||
# For example, to pass additional options (such as -D definitions) to
|
||||
# the httpd binary at startup, create an override unit (as is done by
|
||||
# systemctl edit) and enter the following:
|
||||
|
||||
# [Service]
|
||||
# Environment=OPTIONS=-DMY_DEFINE
|
||||
|
||||
[Unit]
|
||||
Description=The Apache HTTP Server
|
||||
Wants=httpd-init.service
|
||||
After=network.target remote-fs.target nss-lookup.target httpd-init.service
|
||||
Documentation=man:httpd.service(8)
|
||||
|
||||
[Service]
|
||||
Type=notify
|
||||
Environment=LANG=C
|
||||
|
||||
ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND
|
||||
ExecReload=/usr/sbin/httpd $OPTIONS -k graceful
|
||||
# Send SIGWINCH for graceful stop
|
||||
KillSignal=SIGWINCH
|
||||
KillMode=mixed
|
||||
PrivateTmp=true
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
`httpd.service` 单元文件明确规定,它应该在 `network.target` 和 `httpd-init.service`(以及其他)之后加载。我试着用 `systemctl list-units` 命令找到所有这些服务,并在结果数据流中搜索它们。所有这些服务都存在,应该可以确保在设置网络 IP 地址之前,httpd 服务没有加载。
|
||||
|
||||
### 第一个解决方案
|
||||
|
||||
在互联网上搜索了一下,证实其他人在 httpd 和其他服务也遇到了类似的问题。这似乎是由于其中一个所需的服务向 systemd 表示它已经完成了启动,但实际上它却启动了一个尚未完成的子进程。通过更多搜索,我想到了一个规避方法。
|
||||
|
||||
我搞不清楚为什么花了这么久才把 IP 地址分配给网卡。所以我想,如果我可以将 HTTPD 服务的启动推迟合理的一段时间,那么 IP 地址就会在那个时候分配。
|
||||
|
||||
幸运的是,上面的 `/lib/systemd/system/httpd.service` 文件提供了一些方向。虽然它说不要修改它,但是它还是指出了如何操作:使用 `systemctl edit httpd` 命令,它会自动创建一个新文件(`/etc/systemd/system/httpd.service.d/override.conf`)并打开 [GNU Nano][5] 编辑器(如果你对 Nano 不熟悉,一定要看一下 Nano 界面底部的提示)。
|
||||
|
||||
在新文件中加入以下代码并保存:
|
||||
|
||||
```
|
||||
[root@yorktown ~]# cd /etc/systemd/system/httpd.service.d/
|
||||
[root@yorktown httpd.service.d]# ll
|
||||
total 4
|
||||
-rw-r--r-- 1 root root 243 Apr 16 11:43 override.conf
|
||||
[root@yorktown httpd.service.d]# cat override.conf
|
||||
# Trying to delay the startup of httpd so that the network is
|
||||
# fully up and running so that httpd can bind to the correct
|
||||
# IP address
|
||||
#
|
||||
# By David Both, 2020-04-16
|
||||
|
||||
[Service]
|
||||
ExecStartPre=/bin/sleep 30
|
||||
```
|
||||
|
||||
这个覆盖文件的 `[Service]` 段有一行代码,将 HTTPD 服务的启动时间推迟了 30 秒。下面的状态命令显示了等待时间里的服务状态:
|
||||
|
||||
```
|
||||
[root@yorktown ~]# systemctl status httpd
|
||||
● httpd.service - The Apache HTTP Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
|
||||
Drop-In: /etc/systemd/system/httpd.service.d
|
||||
└─override.conf
|
||||
/usr/lib/systemd/system/httpd.service.d
|
||||
└─php-fpm.conf
|
||||
Active: activating (start-pre) since Thu 2020-04-16 12:14:29 EDT; 28s ago
|
||||
Docs: man:httpd.service(8)
|
||||
Cntrl PID: 1102 (sleep)
|
||||
Tasks: 1 (limit: 38363)
|
||||
Memory: 260.0K
|
||||
CPU: 2ms
|
||||
CGroup: /system.slice/httpd.service
|
||||
└─1102 /bin/sleep 30
|
||||
|
||||
Apr 16 12:14:29 yorktown.both.org systemd[1]: Starting The Apache HTTP Server...
|
||||
Apr 16 12:15:01 yorktown.both.org systemd[1]: Started The Apache HTTP Server.
|
||||
[root@yorktown ~]#
|
||||
```
|
||||
|
||||
这个命令显示了 30 秒延迟过后 HTTPD 服务的状态。该服务已经启动并正常运行。
|
||||
|
||||
```
|
||||
[root@yorktown ~]# systemctl status httpd
|
||||
● httpd.service - The Apache HTTP Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
|
||||
Drop-In: /etc/systemd/system/httpd.service.d
|
||||
└─override.conf
|
||||
/usr/lib/systemd/system/httpd.service.d
|
||||
└─php-fpm.conf
|
||||
Active: active (running) since Thu 2020-04-16 12:15:01 EDT; 1min 18s ago
|
||||
Docs: man:httpd.service(8)
|
||||
Process: 1102 ExecStartPre=/bin/sleep 30 (code=exited, status=0/SUCCESS)
|
||||
Main PID: 1567 (httpd)
|
||||
Status: "Total requests: 0; Idle/Busy workers 100/0;Requests/sec: 0; Bytes served/sec: 0 B/sec"
|
||||
Tasks: 213 (limit: 38363)
|
||||
Memory: 21.8M
|
||||
CPU: 82ms
|
||||
CGroup: /system.slice/httpd.service
|
||||
├─1567 /usr/sbin/httpd -DFOREGROUND
|
||||
├─1569 /usr/sbin/httpd -DFOREGROUND
|
||||
├─1570 /usr/sbin/httpd -DFOREGROUND
|
||||
├─1571 /usr/sbin/httpd -DFOREGROUND
|
||||
└─1572 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
Apr 16 12:14:29 yorktown.both.org systemd[1]: Starting The Apache HTTP Server...
|
||||
Apr 16 12:15:01 yorktown.both.org systemd[1]: Started The Apache HTTP Server.
|
||||
```
|
||||
|
||||
我本来可以实验下更短的延迟时间是否也能奏效,但是我的系统并不用那么严格,所以我觉得不这样做。目前系统的工作状态很可靠,所以我很高兴。
|
||||
|
||||
因为我收集了所有这些信息,我将其作为 Bug[1825554][6] 报告给红帽 Bugzilla。我相信报告 Bug 比抱怨 Bug 更有有用。
|
||||
|
||||
### 更好的解决方案
|
||||
|
||||
把这个问题作为 bug 上报几天后,我收到了回复,表示 systemd 只是一个管理工具,如果 httpd 需要在满足某些要求之后被拉起,需要在单元文件中表达出来。这个回复指引我去查阅 `httpd.service` 的手册页。我希望我能早点发现这个,因为它是比我自己想出的更优秀的解决方案。这种方案明确的针对了前置目标单元,而不仅仅是随机延迟。
|
||||
|
||||
来自 [httpd.service 手册页][7]:
|
||||
|
||||
> **在启动时开启服务**
|
||||
>
|
||||
> `httpd.service` 和 `httpd.socket` 单元默认是 _禁用_ 的。为了在启动阶段开启 httpd 服务,执行:`systemctl enable httpd.service`。在默认配置中,httpd 守护进程会接受任何配置好的 IPv4 或 IPv6 地址的 80 口上的连接(如果安装了 mod_ssl,就会接受 443 端口上的 TLS 连接)。
|
||||
>
|
||||
> 如果 httpd 被配置成依赖任一特定的 IP 地址(比如使用 `Listen` 指令),该地址可能只在启动阶段可用,又或者 httpd 依赖其他服务(比如数据库守护进程),那么必须配置该服务,以确保正确的启动顺序。
|
||||
>
|
||||
> 例如,为了确保 httpd 在所有配置的网络接口配置完成之后再运行,可以创建一个带有以下代码段的 drop-in 文件(如上述):
|
||||
>
|
||||
> ```
|
||||
> [Unit]
|
||||
> After=network-online.target
|
||||
> Wants=network-online.target
|
||||
> ```
|
||||
|
||||
|
||||
我仍然觉得这是个 bug,因为在 `httpd.conf` 配置文件中使用 Listen 指令是很常见的,至少在我的经验中。我一直在使用 Listen 指令,即使在只有一个 IP 地址的主机上,在多个网卡和 IP 地址的机器上这显然也是有必要的。在 `/usr/lib/systemd/system/httpd.service` 默认配置文件中加入上述几行,对不使用 `Listen` 指令的不会造成问题,对使用 `Listen` 指令的则会规避这个问题。
|
||||
|
||||
同时,我将使用建议的方法。
|
||||
|
||||
### 下一步
|
||||
|
||||
本文描述了一个我在服务器上启动 Apache HTTPD 服务时遇到的一个问题。它指引你了解我在解决这个问题上的思路,并说明了我是如何使用 systemd 来协助解决问题。我也介绍了我用 systemd 实现的规避方法,以及我按照我的 bug 报告得到的更好的解决方案。
|
||||
|
||||
如我在开头处提到的那样,这有很大可能是一个 systemd 的问题,特别是 httpd 启动的配置问题。尽管如此,systemd 还是提供了工具让我找到了问题的可能来源,并制定和实现了规避方案。两种方案都没有真正令我满意地解决问题。目前,这个问题根源依旧存在,必须要解决。如果只是在 `/usr/lib/systemd/system/httpd.service` 文件中添加推荐的代码,那对我来说是可行的。
|
||||
|
||||
在这个过程中我发现了一件事,我需要了解更多关于定义服务启动顺序的知识。我会在下一篇文章中探索这个领域,即本系列的第五篇。
|
||||
|
||||
### 资源
|
||||
|
||||
网上有大量的关于 systemd 的参考资料,但是大部分都有点简略、晦涩甚至有误导性。除了本文中提到的资料,下列的网页提供了跟多可靠且详细的 systemd 入门信息。
|
||||
|
||||
- Fedora 项目有一篇切实好用的 [systemd 入门][8],它囊括了几乎所有你需要知道的关于如何使用 systemd 配置、管理和维护 Fedora 计算机的信息。
|
||||
- Fedora 项目也有一个不错的 [备忘录][9],交叉引用了过去 SystemV 命令和 systemd 命令做对比。
|
||||
- 关于 systemd 的技术细节和创建这个项目的原因,请查看 [Freedesktop.org][10] 上的 [systemd 描述][11]。
|
||||
- [Linux.com][12] 的“更多 systemd 的乐趣”栏目提供了更多高级的 systemd [信息和技巧][13]。
|
||||
|
||||
此外,还有一系列深度的技术文章,是由 systemd 的设计者和主要开发者 Lennart Poettering 为 Linux 系统管理员撰写的。这些文章写于 2010 年 4 月至 2011 年 9 月间,但它们现在和当时一样具有现实意义。关于 systemd 及其生态的许多其他好文章都是基于这些文章:
|
||||
|
||||
* [Rethinking PID 1][14]
|
||||
* [systemd for Administrators,Part I][15]
|
||||
* [systemd for Administrators,Part II][16]
|
||||
* [systemd for Administrators,Part III][17]
|
||||
* [systemd for Administrators,Part IV][18]
|
||||
* [systemd for Administrators,Part V][19]
|
||||
* [systemd for Administrators,Part VI][20]
|
||||
* [systemd for Administrators,Part VII][21]
|
||||
* [systemd for Administrators,Part VIII][22]
|
||||
* [systemd for Administrators,Part IX][23]
|
||||
* [systemd for Administrators,Part X][24]
|
||||
* [systemd for Administrators,Part XI][25]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/systemd-troubleshooting-tool
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tt67wq](https://github.com/tt67wq)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||
[2]: https://opensource.com/article/20/4/systemd
|
||||
[3]: https://opensource.com/article/20/4/systemd-startup
|
||||
[4]: https://opensource.com/article/20/4/understanding-and-using-systemd-units
|
||||
[5]: https://www.nano-editor.org/
|
||||
[6]: https://bugzilla.redhat.com/show_bug.cgi?id=1825554
|
||||
[7]: https://www.mankier.com/8/httpd.service#Description-Starting_the_service_at_boot_time
|
||||
[8]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html
|
||||
[9]: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
|
||||
[10]: http://Freedesktop.org
|
||||
[11]: http://www.freedesktop.org/wiki/Software/systemd
|
||||
[12]: http://Linux.com
|
||||
[13]: https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/
|
||||
[14]: http://0pointer.de/blog/projects/systemd.html
|
||||
[15]: http://0pointer.de/blog/projects/systemd-for-admins-1.html
|
||||
[16]: http://0pointer.de/blog/projects/systemd-for-admins-2.html
|
||||
[17]: http://0pointer.de/blog/projects/systemd-for-admins-3.html
|
||||
[18]: http://0pointer.de/blog/projects/systemd-for-admins-4.html
|
||||
[19]: http://0pointer.de/blog/projects/three-levels-of-off.html
|
||||
[20]: http://0pointer.de/blog/projects/changing-roots
|
||||
[21]: http://0pointer.de/blog/projects/blame-game.html
|
||||
[22]: http://0pointer.de/blog/projects/the-new-configuration-files.html
|
||||
[23]: http://0pointer.de/blog/projects/on-etc-sysinit.html
|
||||
[24]: http://0pointer.de/blog/projects/instances.html
|
||||
[25]: http://0pointer.de/blog/projects/inetd.html
|
||||
@ -1,23 +1,24 @@
|
||||
[#]: collector: (Chao-zhi)
|
||||
[#]: translator: (Chao-zhi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13136-1.html)
|
||||
[#]: subject: (Typeset your docs with LaTeX and TeXstudio on Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/typeset-latex-texstudio-fedora/)
|
||||
[#]: author: (Julita Inca Chiroque )
|
||||
[#]: author: (Julita Inca Chiroque https://fedoramagazine.org/author/yulytas/)
|
||||
|
||||
Typeset your docs with LaTeX and TeXstudio on Fedora
|
||||
使用 LaTeX 和 TeXstudio 排版文档
|
||||
======
|
||||
|
||||

|
||||
|
||||
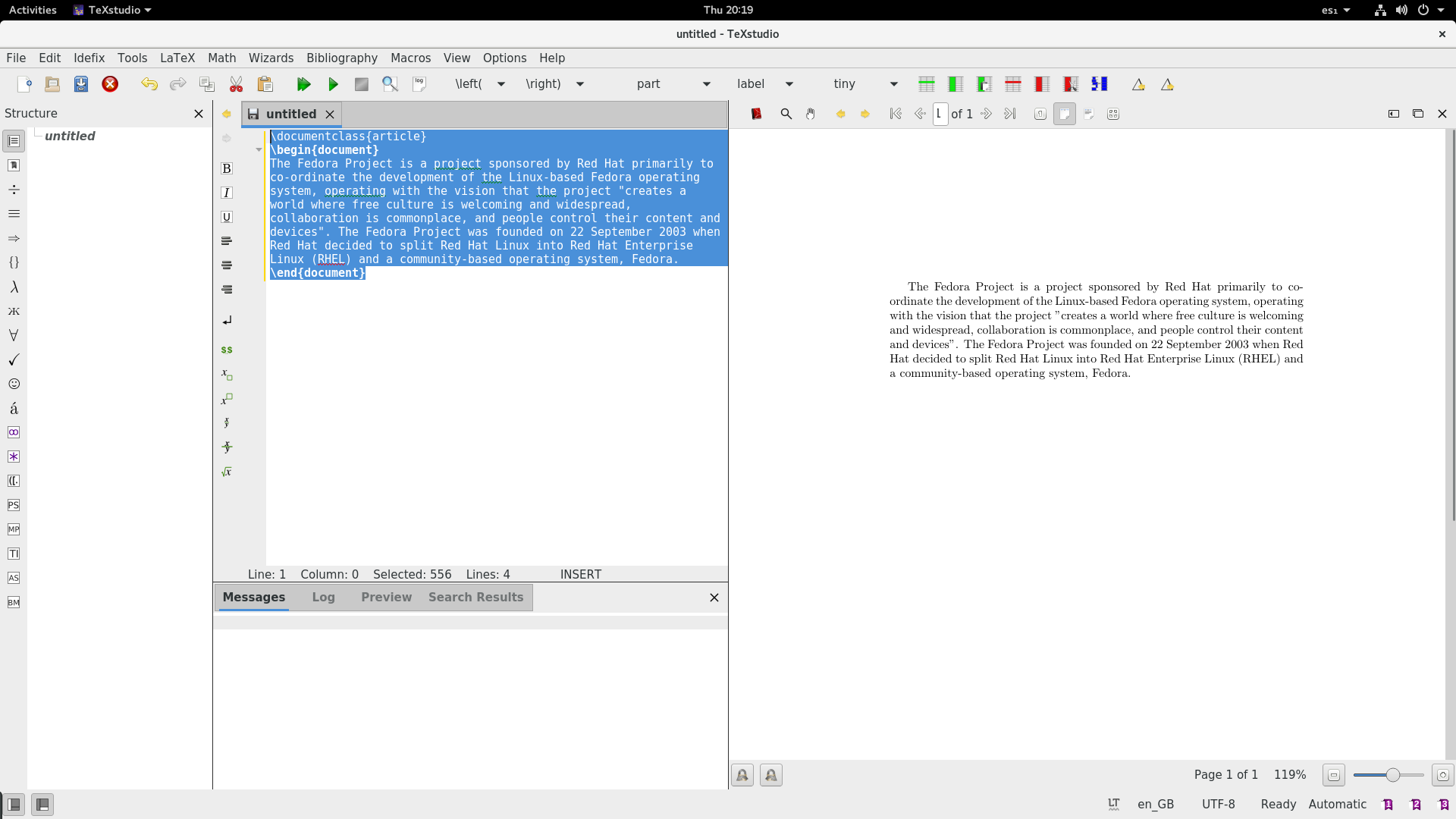
LaTeX is [a document preparation system][1] for high-quality typesetting. It’s often used for larger technical or scientific documents. However, you can use LaTeX for almost any form of publishing. Teachers can edit their exams and syllabi, and students can present their thesis and reports for classes. This article gets you started with the TeXstudio app. TeXstudio makes it easy to edit LaTeX documents.
|
||||
LaTeX 是一个服务于高质量排版的[文档准备系统][1]。通常用于大量的技术和科学文档的排版。不过,你也可以使用 LaTex 排版各种形式的文档。教师可以编辑他们的考试和教学大纲,学生可以展示他们的论文和报告。这篇文章让你尝试使用 TeXstudio。TeXstudio 是一个便于编辑 LaTeX 文档的软件。
|
||||
|
||||
### Launching TeXstudio
|
||||
### 启动 TeXstudio
|
||||
|
||||
If you’re using Fedora Workstation, launch Software, and type TeXstudio to search for the app. Then select Install to add TeXstudio to your system. You can also launch the app from Software, or go to the shell overview as usual.
|
||||
如果你使用的是 Fedora Workstation,请启动软件管理,然后输入 TeXstudio 以搜索该应用程序。然后选择安装并添加 TeXstudio 到你的系统。你可以从软件管理中启动这个程序,或者像以往一样在概览中启动这个软件。
|
||||
|
||||
Alternately, if you use a terminal, type texstudio. If the package isn’t installed, the system prompts you to install it. Type y to start the installation.
|
||||
或者,如果你使用终端,请输入 `texstudio`。如果未安装该软件包,系统将提示你安装它。键入 `y` 开始安装。
|
||||
|
||||
```
|
||||
$ texstudio
|
||||
@ -25,9 +26,11 @@ bash: texstudio: command not found...
|
||||
Install package 'texstudio' to provide command 'texstudio'? [N/y] y
|
||||
```
|
||||
|
||||
LaTeX commands typically start with a backslash (), and command parameters are enclosed in curly braces { }. Start by declaring the type of the documentclass. This example shows you the document class is an article.
|
||||
### 你的第一份文档
|
||||
|
||||
Then, once you declare the documentclass, mark the beginning and the end of the document with begin and end. In between these commands, write a paragraph similar to the following:
|
||||
LaTeX 命令通常以反斜杠 `\` 开头,命令参数用大括号 `{}` 括起来。首先声明 `documentclass` 的类型。这个例子向你展示了该文档的类是一篇文章。
|
||||
|
||||
然后,在声明 `documentclass` 之后,用 `begin` 和 `end` 标记文档的开始和结束。在这些命令之间,写一段类似以下的内容:
|
||||
|
||||
```
|
||||
\documentclass{article}
|
||||
@ -38,13 +41,13 @@ The Fedora Project is a project sponsored by Red Hat primarily to co-ordinate th
|
||||
|
||||
|
||||
|
||||
### Working with spacing
|
||||
### 使用间距
|
||||
|
||||
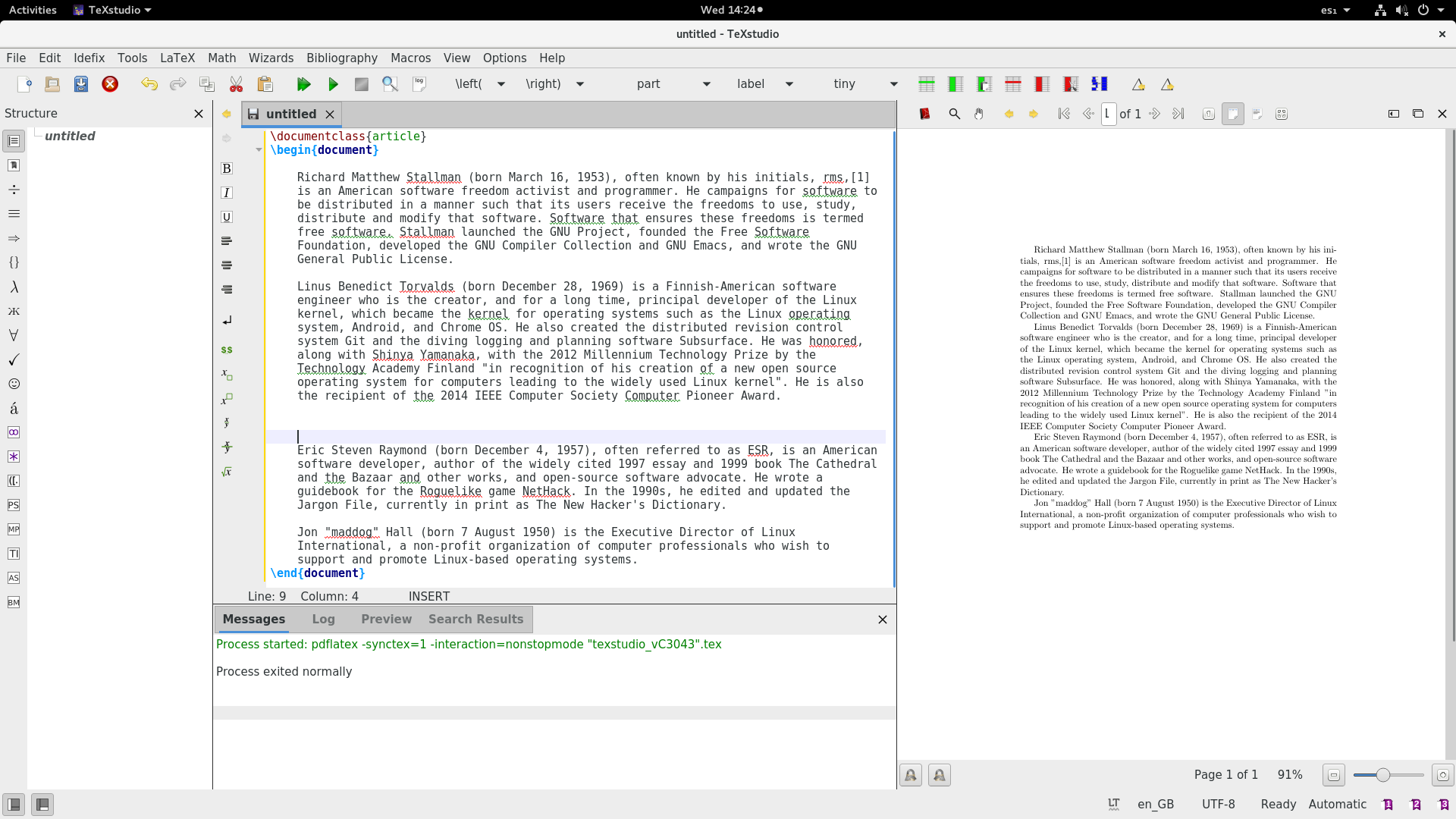
To create a paragraph break, leave one or more blank spaces between text. Here’s an example with four paragraphs:
|
||||
要创建段落分隔符,请在文本之间保留一个或多个换行符。下面是一个包含四个段落的示例:
|
||||
|
||||
|
||||
|
||||
You can see from the example that more than one line break doesn’t create additional blank space between paragraphs. However, if you do need to leave additional space, use the commands hspace and vspace. These add horizontal and vertical space, respectively. Here is some example code that shows additional spacing around paragraphs:
|
||||
从该示例中可以看出,多个换行符不会在段落之间创建额外的空格。但是,如果你确实需要留出额外的空间,请使用 `hspace` 和 `vspace` 命令。这两个命令分别添加水平和垂直空间。下面是一些示例代码,显示了段落周围的附加间距:
|
||||
|
||||
```
|
||||
\documentclass{article}
|
||||
@ -65,13 +68,15 @@ The freedom to distribute copies of your modified versions to others (freedom 3)
|
||||
\end{document}
|
||||
```
|
||||
|
||||
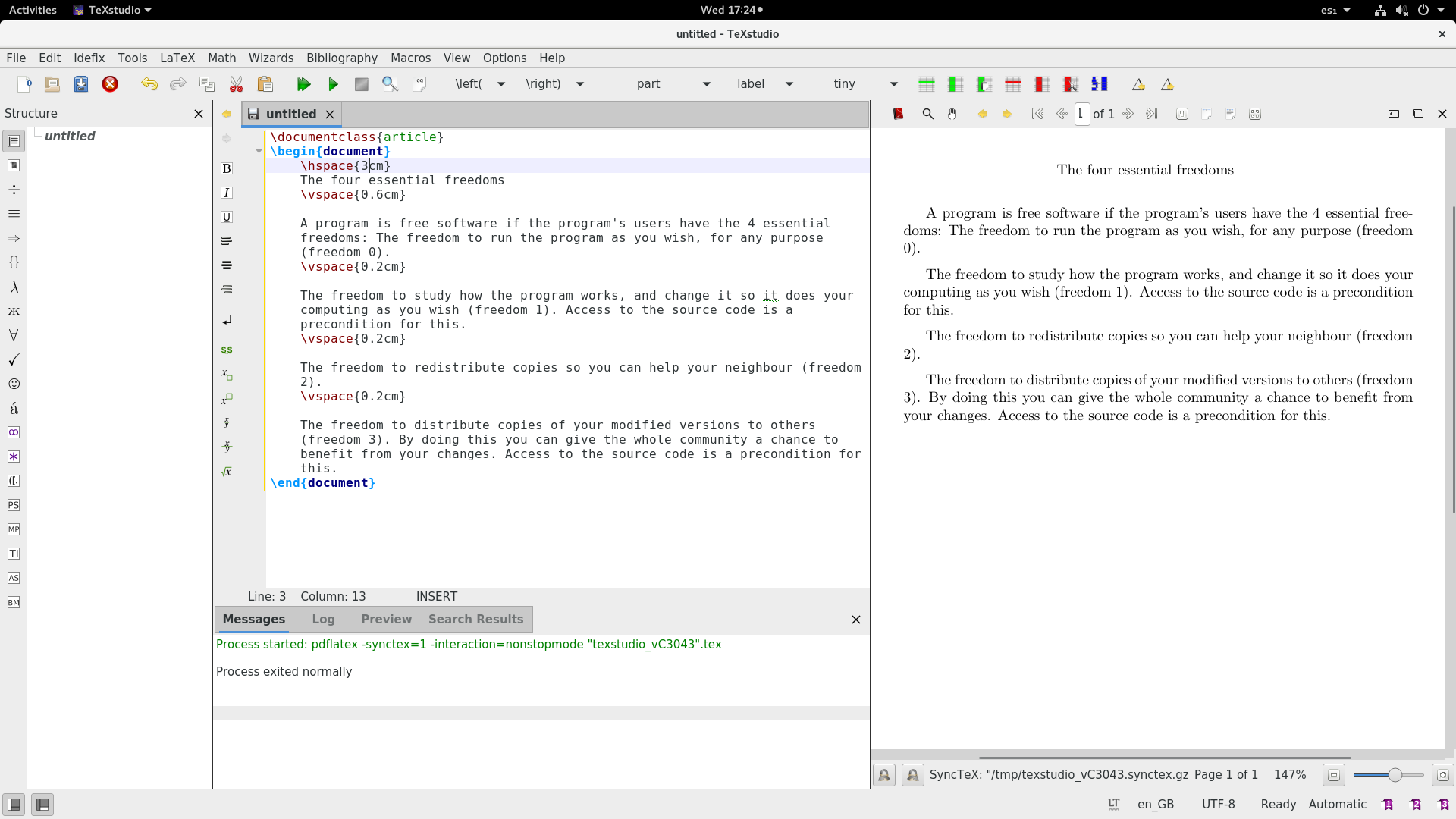
如果需要,你也可以使用 `noindent` 命令来避免缩进。这里是上面 LaTeX 源码的结果:
|
||||
|
||||
|
||||
|
||||
### Using Lists and Formats
|
||||
### 使用列表和格式
|
||||
|
||||
This example would look better if it presented the four essential freedoms of free software as a list. Set the list structure by using \begin{itemize} at the beginning of the list, and \end{itemize} at the end. Precede each item with the command \item.
|
||||
如果把自由软件的四大基本自由列为一个清单,这个例子看起来会更好。通过在列表的开头使用`\begin{itemize}`,在末尾使用 `\end{itemize}` 来设置列表结构。在每个项目前面加上 `\item` 命令。
|
||||
|
||||
Additional format also helps make the text more readable. Useful commands for formatting include bold, italic, underline, huge, large, tiny and textsc to help emphasize text:
|
||||
额外的格式也有助于使文本更具可读性。用于格式化的有用命令包括粗体、斜体、下划线、超大、大、小和 textsc 以帮助强调文本:
|
||||
|
||||
```
|
||||
\documentclass{article}
|
||||
@ -93,15 +98,17 @@ Additional format also helps make the text more readable. Useful commands for fo
|
||||
\end{document}
|
||||
```
|
||||
|
||||
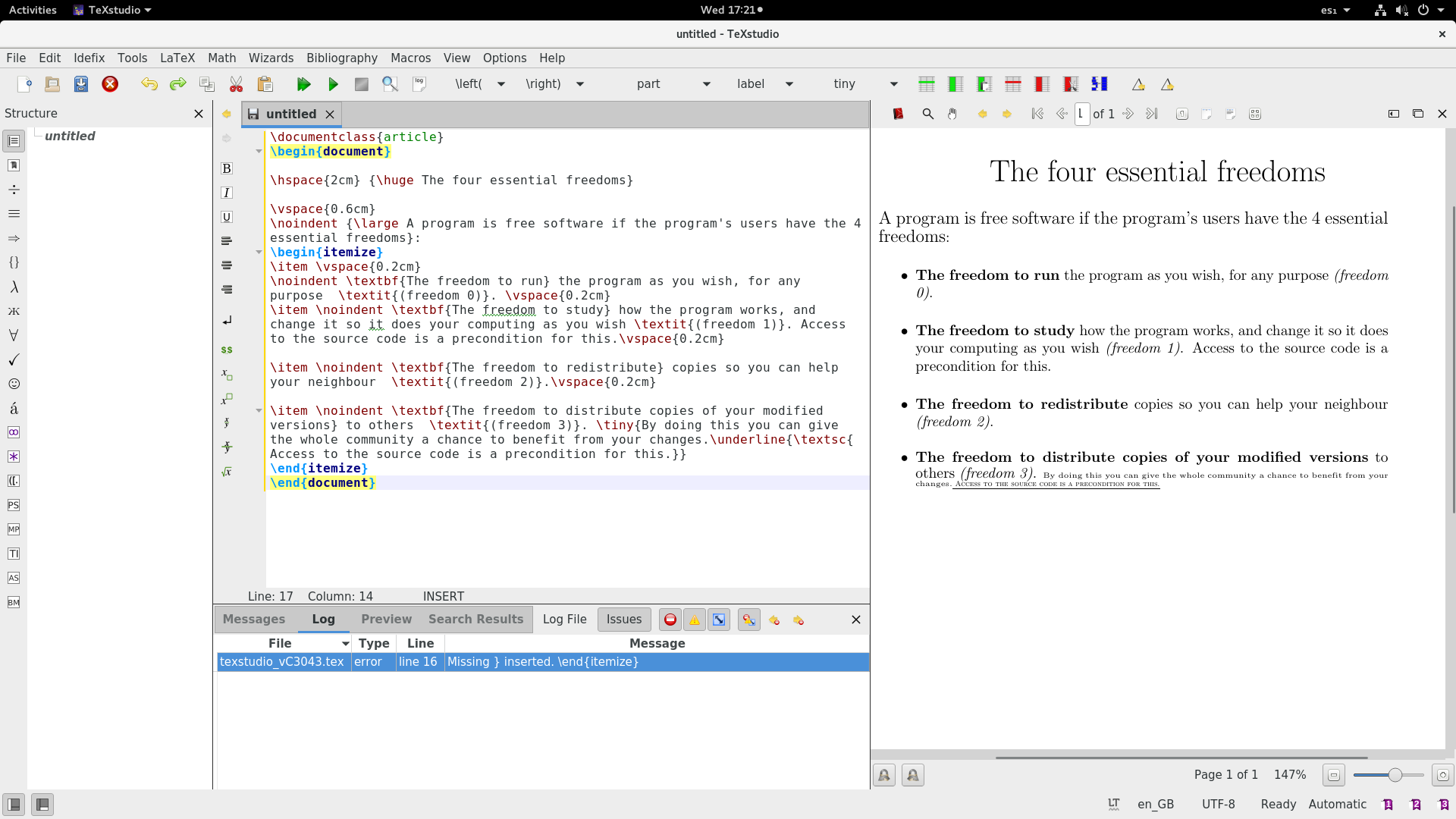
### Adding columns, images and links
|
||||
|
||||
|
||||
Columns, images and links help add further information to your text. LaTeX includes functions for some advanced features as packages. The \usepackage command loads the package so you can make use of these features.
|
||||
### 添加列、图像和链接
|
||||
|
||||
For example, to make an image visible, you might use the command \usepackage{graphicx}. Or, to set up columns and links, use \usepackage{multicol} and \usepackage{hyperref}, respectively.
|
||||
列、图像和链接有助于为文本添加更多信息。LaTeX 包含一些高级功能的函数作为宏包。`\usepackage` 命令加载宏包以便你可以使用这些功能。
|
||||
|
||||
The \includegraphics command places an image inline in your document. (For simplicity, include the graphics file in the same directory as your LaTeX source file.)
|
||||
例如,要使用图像,可以使用命令 `\usepackage{graphicx}`。或者,要设置列和链接,请分别使用 `\usepackage{multicol}` 和 `\usepackage{hyperref}`。
|
||||
|
||||
Here’s an example that uses all these concepts. It also uses two PNG graphics files that were downloaded. Try your own graphics to see how they work.
|
||||
`\includegraphics` 命令将图像内联放置在文档中。(为简单起见,请将图形文件包含在与 LaTeX 源文件相同的目录中。)
|
||||
|
||||
下面是一个使用所有这些概念的示例。它还使用下载的两个 PNG 图片。试试你自己的图片,看看它们是如何工作的。
|
||||
|
||||
```
|
||||
\documentclass{article}
|
||||
@ -132,9 +139,9 @@ Here’s an example that uses all these concepts. It also uses two PNG graphics
|
||||
\end{document}
|
||||
```
|
||||
|
||||
[][2]
|
||||
|
||||
|
||||
The features here only scratch the surface of LaTeX capabilities. You can learn more about them at the project [help and documentation site][3].
|
||||
这里的功能只触及 LaTeX 功能的表面。你可以在该项目的[帮助和文档站点][3]了解更多关于它们的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -143,7 +150,7 @@ via: https://fedoramagazine.org/typeset-latex-texstudio-fedora/
|
||||
作者:[Julita Inca Chiroque][a]
|
||||
选题:[Chao-zhi][b]
|
||||
译者:[Chao-zhi][b]
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,344 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "MjSeven"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-13142-1.html"
|
||||
[#]: subject: "Ansible Automation Tool Installation, Configuration and Quick Start Guide"
|
||||
[#]: via: "https://www.2daygeek.com/install-configure-ansible-automation-tool-linux-quick-start-guide/"
|
||||
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
|
||||
|
||||
Ansible 自动化工具安装、配置和快速入门指南
|
||||
======
|
||||
|
||||

|
||||
|
||||
市面上有很多自动化工具。我可以举几个例子,例如 Puppet、Chef、CFEngine、Foreman、Katello、Saltstock、Space Walk,它们被许多组织广泛使用。
|
||||
|
||||
### 自动化工具可以做什么?
|
||||
|
||||
自动化工具可以自动执行例行任务,无需人工干预,从而使 Linux 管理员的工作变得更加轻松。这些工具允许用户执行配置管理,应用程序部署和资源调配。
|
||||
|
||||
### 为什么喜欢 Ansible?
|
||||
|
||||
Ansible 是一种无代理的自动化工具,使用 SSH 执行所有任务,但其它工具需要在客户端节点上安装代理。
|
||||
|
||||
### 什么是 Ansible?
|
||||
|
||||
Ansible 是一个开源、易于使用的功能强大的 IT 自动化工具,通过 SSH 在客户端节点上执行任务。
|
||||
|
||||
它是用 Python 构建的,这是当今世界上最流行、最强大的编程语言之一。两端都需要使用 Python 才能执行所有模块。
|
||||
|
||||
它可以配置系统、部署软件和安排高级 IT 任务,例如连续部署或零停机滚动更新。你可以通过 Ansible 轻松执行任何类型的自动化任务,包括简单和复杂的任务。
|
||||
|
||||
在开始之前,你需要了解一些 Ansible 术语,这些术语可以帮助你更好的创建任务。
|
||||
|
||||
### Ansible 如何工作?
|
||||
|
||||
Ansible 通过在客户端节点上推送称为 ansible 模块的小程序来工作,这些模块临时存储在客户端节点中,通过 JSON 协议与 Ansible 服务器进行通信。
|
||||
|
||||
Ansible 通过 SSH 运行这些模块,并在完成后将其删除。
|
||||
|
||||
模块是用 Python 或 Perl 等编写的一些脚本。
|
||||
|
||||
![][1]
|
||||
|
||||
*控制节点,用于控制剧本的全部功能,包括客户端节点(主机)。*
|
||||
|
||||
* <ruby>控制节点<rt>Control node</rt></ruby>:使用 Ansible 在受控节点上执行任务的主机。你可以有多个控制节点,但不能使用 Windows 系统主机当作控制节点。
|
||||
* <ruby>受控节点<rt>Managed node</rt></ruby>:控制节点配置的主机列表。
|
||||
* <ruby>清单<rt>Inventory</rt></ruby>:控制节点管理的一个主机列表,这些节点在 `/etc/ansible/hosts` 文件中配置。它包含每个节点的信息,比如 IP 地址或其主机名,还可以根据需要对这些节点进行分组。
|
||||
* <ruby>模块<rt>Module</rt></ruby>:每个模块用于执行特定任务,目前有 3387 个模块。
|
||||
* <ruby>点对点<rt>ad-hoc</rt></ruby>:它允许你一次性运行一个任务,它使用 `/usr/bin/ansible` 二进制文件。
|
||||
* <ruby>任务<rt>Task</rt></ruby>:每个<ruby>动作<rt>Play</rt></ruby>都有一个任务列表。任务按顺序执行,在受控节点中一次执行一个任务。
|
||||
* <ruby>剧本<rt>Playbook</rt></ruby>:你可以使用剧本同时执行多个任务,而使用点对点只能执行一个任务。剧本使用 YAML 编写,易于阅读。将来,我们将会写一篇有关剧本的文章,你可以用它来执行复杂的任务。
|
||||
|
||||
### 测试环境
|
||||
|
||||
此环境包含一个控制节点(`server.2g.lab`)和三个受控节点(`node1.2g.lab`、`node2.2g.lab`、`node3.2g.lab`),它们均在虚拟环境中运行,操作系统分别为:
|
||||
|
||||
| System Purpose | Hostname | IP Address | OS |
|
||||
|----------------------|---------------|-------------|---------------|
|
||||
| Ansible Control Node | server.2g.lab | 192.168.1.7 | Manjaro 18 |
|
||||
| Managed Node1 | node1.2g.lab | 192.168.1.6 | CentOS7 |
|
||||
| Managed Node2 | node2.2g.lab | 192.168.1.5 | CentOS8 |
|
||||
| Managed Node3 | node3.2g.lab | 192.168.1.9 | Ubuntu 18.04 |
|
||||
| User: daygeek |
|
||||
|
||||
### 前置条件
|
||||
|
||||
* 在 Ansible 控制节点和受控节点之间启用无密码身份验证。
|
||||
* 控制节点必须是 Python 2(2.7 版本) 或 Python 3(3.5 或更高版本)。
|
||||
* 受控节点必须是 Python 2(2.6 或更高版本) 或 Python 3(3.5 或更高版本)。
|
||||
* 如果在远程节点上启用了 SELinux,则在 Ansible 中使用任何与复制、文件、模板相关的功能之前,还需要在它们上安装 `libselinux-python`。
|
||||
|
||||
### 如何在控制节点上安装 Ansible
|
||||
|
||||
对于 Fedora/RHEL 8/CentOS 8 系统,使用 [DNF 命令][2] 来安装 Ansible。
|
||||
|
||||
注意:你需要在 RHEL/CentOS 系统上启用 [EPEL 仓库][3],因为 Ansible 软件包在发行版官方仓库中不可用。
|
||||
|
||||
```
|
||||
$ sudo dnf install ansible
|
||||
```
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][4] 或 [APT 命令][5] 来安装 Ansible。
|
||||
|
||||
配置下面的 PPA 以便在 Ubuntu 上安装最新稳定版本的 Ansible。
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install software-properties-common
|
||||
$ sudo apt-add-repository --yes --update ppa:ansible/ansible
|
||||
$ sudo apt install ansible
|
||||
```
|
||||
|
||||
对于 Debian 系统,配置以下源列表:
|
||||
|
||||
```
|
||||
$ echo "deb http://ppa.launchpad.net/ansible/ansible/ubuntu trusty main" | sudo tee -a /etc/apt/sources.list.d/ansible.list
|
||||
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 93C4A3FD7BB9C367
|
||||
$ sudo apt update
|
||||
$ sudo apt install ansible
|
||||
```
|
||||
|
||||
对于 Arch Linux 系统,使用 [Pacman 命令][6] 来安装 Ansible:
|
||||
|
||||
```
|
||||
$ sudo pacman -S ansible
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][7] 来安装 Ansible:
|
||||
|
||||
```
|
||||
$ sudo yum install ansible
|
||||
```
|
||||
|
||||
对于 openSUSE 系统,使用 [Zypper 命令][8] 来安装 Ansible:
|
||||
|
||||
```
|
||||
$ sudo zypper install ansible
|
||||
```
|
||||
|
||||
或者,你可以使用 [Python PIP 包管理工具][9] 来安装:
|
||||
|
||||
```
|
||||
$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
|
||||
$ sudo python get-pip.py
|
||||
$ sudo pip install ansible
|
||||
```
|
||||
|
||||
在控制节点上检查安装的 Ansible 版本:
|
||||
|
||||
```
|
||||
$ ansible --version
|
||||
|
||||
ansible 2.9.2
|
||||
config file = /etc/ansible/ansible.cfg
|
||||
configured module search path = ['/home/daygeek/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
|
||||
ansible python module location = /usr/lib/python3.8/site-packages/ansible
|
||||
executable location = /usr/bin/ansible
|
||||
python version = 3.8.1 (default, Jan 8 2020, 23:09:20) [GCC 9.2.0]
|
||||
```
|
||||
|
||||
### 如何在受控节点上安装 Python?
|
||||
|
||||
使用以下命令在受控节点上安装 python:
|
||||
|
||||
```
|
||||
$ sudo yum install -y python
|
||||
$ sudo dnf install -y python
|
||||
$ sudo zypper install -y python
|
||||
$ sudo pacman -S python
|
||||
$ sudo apt install -y python
|
||||
```
|
||||
|
||||
### 如何在 Linux 设置 SSH 密钥身份验证(无密码身份验证)
|
||||
|
||||
使用以下命令创建 ssh 密钥,然后将其复制到远程计算机。
|
||||
|
||||
```
|
||||
$ ssh-keygen
|
||||
$ ssh-copy-id daygeek@node1.2g.lab
|
||||
$ ssh-copy-id daygeek@node2.2g.lab
|
||||
$ ssh-copy-id daygeek@node3.2g.lab
|
||||
```
|
||||
|
||||
具体参考这篇文章《[在 Linux 上设置 SSH 密钥身份验证(无密码身份验证)][10]》。
|
||||
|
||||
### 如何创建 Ansible 主机清单
|
||||
|
||||
在 `/etc/ansible/hosts` 文件中添加要管理的节点列表。如果没有该文件,则可以创建一个新文件。以下是我的测试环境的主机清单文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/ansible/hosts
|
||||
|
||||
[web]
|
||||
node1.2g.lab
|
||||
node2.2g.lab
|
||||
|
||||
[app]
|
||||
node3.2g.lab
|
||||
```
|
||||
|
||||
让我们看看是否可以使用以下命令查找所有主机。
|
||||
|
||||
```
|
||||
$ ansible all --list-hosts
|
||||
|
||||
hosts (3):
|
||||
node1.2g.lab
|
||||
node2.2g.lab
|
||||
node3.2g.lab
|
||||
```
|
||||
|
||||
对单个组运行以下命令:
|
||||
|
||||
```
|
||||
$ ansible web --list-hosts
|
||||
|
||||
hosts (2):
|
||||
node1.2g.lab
|
||||
node2.2g.lab
|
||||
```
|
||||
|
||||
### 如何使用点对点命令执行任务
|
||||
|
||||
一旦完成主机清单验证检查后,你就可以上路了。干的漂亮!
|
||||
|
||||
**语法:**
|
||||
|
||||
```
|
||||
ansible [pattern] -m [module] -a "[module options]"
|
||||
|
||||
Details:
|
||||
========
|
||||
ansible: A command
|
||||
pattern: Enter the entire inventory or a specific group
|
||||
-m [module]: Run the given module name
|
||||
-a [module options]: Specify the module arguments
|
||||
```
|
||||
|
||||
使用 Ping 模块对主机清单中的所有节点执行 ping 操作:
|
||||
|
||||
```
|
||||
$ ansible all -m ping
|
||||
|
||||
node3.2g.lab | SUCCESS => {
|
||||
"ansible_facts": {
|
||||
"discovered_interpreter_python": "/usr/bin/python"
|
||||
},
|
||||
"changed": false,
|
||||
"ping": "pong"
|
||||
}
|
||||
node1.2g.lab | SUCCESS => {
|
||||
"ansible_facts": {
|
||||
"discovered_interpreter_python": "/usr/bin/python"
|
||||
},
|
||||
"changed": false,
|
||||
"ping": "pong"
|
||||
}
|
||||
node2.2g.lab | SUCCESS => {
|
||||
"ansible_facts": {
|
||||
"discovered_interpreter_python": "/usr/libexec/platform-python"
|
||||
},
|
||||
"changed": false,
|
||||
"ping": "pong"
|
||||
}
|
||||
```
|
||||
|
||||
所有系统都返回了成功,但什么都没有改变,只返回了 `pong` 代表成功。
|
||||
|
||||
你可以使用以下命令获取可用模块的列表。
|
||||
|
||||
```
|
||||
$ ansible-doc -l
|
||||
```
|
||||
|
||||
当前有 3387 个内置模块,它们会随着 Ansible 版本的递增而增加:
|
||||
|
||||
```
|
||||
$ ansible-doc -l | wc -l
|
||||
3387
|
||||
```
|
||||
|
||||
使用 command 模块对主机清单中的所有节点执行命令:
|
||||
|
||||
```
|
||||
$ ansible all -m command -a "uptime"
|
||||
|
||||
node3.2g.lab | CHANGED | rc=0 >>
|
||||
18:05:07 up 1:21, 3 users, load average: 0.12, 0.06, 0.01
|
||||
node1.2g.lab | CHANGED | rc=0 >>
|
||||
06:35:06 up 1:21, 4 users, load average: 0.01, 0.03, 0.05
|
||||
node2.2g.lab | CHANGED | rc=0 >>
|
||||
18:05:07 up 1:25, 3 users, load average: 0.01, 0.01, 0.00
|
||||
```
|
||||
|
||||
对指定组执行 command 模块。
|
||||
|
||||
检查 app 组主机的内存使用情况:
|
||||
|
||||
```
|
||||
$ ansible app -m command -a "free -m"
|
||||
|
||||
node3.2g.lab | CHANGED | rc=0 >>
|
||||
total used free shared buff/cache available
|
||||
Mem: 1993 1065 91 6 836 748
|
||||
Swap: 1425 0 1424
|
||||
```
|
||||
|
||||
要对 web 组运行 `hostnamectl` 命令,使用以下格式:
|
||||
|
||||
```
|
||||
$ ansible web -m command -a "hostnamectl"
|
||||
|
||||
node1.2g.lab | CHANGED | rc=0 >>
|
||||
Static hostname: CentOS7.2daygeek.com
|
||||
Icon name: computer-vm
|
||||
Chassis: vm
|
||||
Machine ID: 002f47b82af248f5be1d67b67e03514c
|
||||
Boot ID: dc38f9b8089d4b2d9304e526e00c6a8f
|
||||
Virtualization: kvm
|
||||
Operating System: CentOS Linux 7 (Core)
|
||||
CPE OS Name: cpe:/o:centos:centos:7
|
||||
Kernel: Linux 3.10.0-957.el7.x86_64
|
||||
Architecture: x86-64
|
||||
node2.2g.lab | CHANGED | rc=0 >>
|
||||
Static hostname: node2.2g.lab
|
||||
Icon name: computer-vm
|
||||
Chassis: vm
|
||||
Machine ID: e39e3a27005d44d8bcbfcab201480b45
|
||||
Boot ID: 27b46a09dde546da95ace03420fe12cb
|
||||
Virtualization: oracle
|
||||
Operating System: CentOS Linux 8 (Core)
|
||||
CPE OS Name: cpe:/o:centos:centos:8
|
||||
Kernel: Linux 4.18.0-80.el8.x86_64
|
||||
Architecture: x86-64
|
||||
```
|
||||
|
||||
参考:[Ansible 文档][11]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/install-configure-ansible-automation-tool-linux-quick-start-guide/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/wp-content/uploads/2020/01/ansible-architecture-2daygeek.png
|
||||
[2]: https://www.2daygeek.com/linux-dnf-command-examples-manage-packages-fedora-centos-rhel-systems/
|
||||
[3]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-oracle-linux/
|
||||
[4]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[6]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[7]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[8]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[9]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
|
||||
[10]: https://www.2daygeek.com/configure-setup-passwordless-ssh-key-based-authentication-linux/
|
||||
[11]: https://docs.ansible.com/ansible/latest/user_guide/index.html
|
||||
@ -0,0 +1,294 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "MjSeven"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-13163-1.html"
|
||||
[#]: subject: "Ansible Ad-hoc Command Quick Start Guide with Examples"
|
||||
[#]: via: "https://www.2daygeek.com/ansible-ad-hoc-command-quick-start-guide-with-examples/"
|
||||
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
|
||||
|
||||
Ansible 点对点命令快速入门指南示例
|
||||
======
|
||||
|
||||

|
||||
|
||||
之前,我们写了一篇有关 [Ansible 安装和配置][1] 的文章。在那个教程中只包含了一些使用方法的示例。如果你是 Ansible 新手,建议你阅读上篇文章。一旦你熟悉了,就可以继续阅读本文了。
|
||||
|
||||
默认情况下,Ansible 仅使用 5 个并行进程。如果要在多个主机上执行任务,需要通过添加 `-f [进程数]` 选项来手动设置进程数。
|
||||
|
||||
### 什么是<ruby>点对点<rt>ad-hoc</rt></ruby>命令?
|
||||
|
||||
点对点命令用于在一个或多个受控节点上自动执行任务。它非常简单,但是不可重用。它使用 `/usr/bin/ansible` 二进制文件执行所有操作。
|
||||
|
||||
点对点命令最适合运行一次的任务。例如,如果要检查指定用户是否可用,你可以使用一行命令而无需编写剧本。
|
||||
|
||||
#### 为什么你要了解点对点命令?
|
||||
|
||||
点对点命令证明了 Ansible 的简单性和强大功能。从 2.9 版本开始,它支持 3389 个模块,因此你需要了解和学习要定期使用的 Ansible 模块列表。
|
||||
|
||||
如果你是一个 Ansible 新手,可以借助点对点命令轻松地练习这些模块及参数。
|
||||
|
||||
你在这里学习到的概念将直接移植到剧本中。
|
||||
|
||||
**点对点命令的一般语法:**
|
||||
|
||||
```
|
||||
ansible [模式] -m [模块] -a "[模块选项]"
|
||||
```
|
||||
|
||||
点对点命令包含四个部分,详细信息如下:
|
||||
|
||||
| 部分 | 描述 |
|
||||
|----------|-----------------------------------|
|
||||
| `ansible`| 命令 |
|
||||
| 模式 | 输入清单或指定组 |
|
||||
| 模块 | 运行指定的模块名称 |
|
||||
| 模块选项 | 指定模块参数 |
|
||||
|
||||
#### 如何使用 Ansible 清单文件
|
||||
|
||||
如果使用 Ansible 的默认清单文件 `/etc/ansible/hosts`,你可以直接调用它。否则你可以使用 `-i` 选项指定 Ansible 清单文件的路径。
|
||||
|
||||
#### 什么是模式以及如何使用它?
|
||||
|
||||
Ansible 模式可以代指某个主机、IP 地址、清单组、一组主机或者清单中的所有主机。它允许你对它们运行命令和剧本。模式非常灵活,你可以根据需要使用它们。
|
||||
|
||||
例如,你可以排除主机、使用通配符或正则表达式等等。
|
||||
|
||||
下表描述了常见的模式以及用法。但是,如果它不能满足你的需求,你可以在 `ansible-playbook` 中使用带有 `-e` 参数的模式中的变量。
|
||||
|
||||
| 描述 | 模式 | 目标 |
|
||||
|-----|------|-----|
|
||||
| 所有主机 | `all`(或 `*`) | 对清单中的所有服务器运行 Ansible |
|
||||
| 一台主机 | `host1` | 只针对给定主机运行 Ansible |
|
||||
| 多台主机 | `host1:host2`(或 `host1,host2`)| 对上述多台主机运行 Ansible |
|
||||
| 一组 | `webservers` | 在 `webservers` 群组中运行 Ansible |
|
||||
| 多组 | `webservers:dbservers` | `webservers` 中的所有主机加上 `dbservers` 中的所有主机 |
|
||||
| 排除组 | `webservers:!atlanta` | `webservers` 中除 `atlanta` 以外的所有主机 |
|
||||
| 组之间的交集 | `webservers:&staging` | `webservers` 中也在 `staging` 的任何主机 |
|
||||
|
||||
#### 什么是 Ansible 模块,它干了什么?
|
||||
|
||||
模块,也称为“任务插件”或“库插件”,它是一组代码单元,可以直接或通过剧本在远程主机上执行指定任务。
|
||||
|
||||
Ansible 在远程目标节点上执行指定模块并收集其返回值。
|
||||
|
||||
每个模块都支持多个参数,可以满足用户的需求。除少数模块外,几乎所有模块都采用 `key=value` 参数。你可以一次添加带有空格的多个参数,而 `command` 或 `shell` 模块会直接运行你输入的字符串。
|
||||
|
||||
我们将添加一个包含最常用的“模块选项”参数的表。
|
||||
|
||||
列出所有可用的模块,运行以下命令:
|
||||
|
||||
```
|
||||
$ ansible-doc -l
|
||||
```
|
||||
|
||||
运行以下命令来阅读指定模块的文档:
|
||||
|
||||
```
|
||||
$ ansible-doc [模块]
|
||||
```
|
||||
|
||||
### 1)如何在 Linux 上使用 Ansible 列出目录的内容
|
||||
|
||||
可以使用 Ansible `command` 模块来完成这项操作,如下所示。我们列出了 `node1.2g.lab` 和 `nod2.2g.lab`* 远程服务器上 `daygeek` 用户主目录的内容。
|
||||
|
||||
```
|
||||
$ ansible web -m command -a "ls -lh /home/daygeek"
|
||||
|
||||
node1.2g.lab | CHANGED | rc=0 >>
|
||||
total 12K
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Desktop
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Documents
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Downloads
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Music
|
||||
-rwxr-xr-x. 1 daygeek daygeek 159 Mar 4 2019 passwd-up.sh
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Pictures
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Public
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Templates
|
||||
-rwxrwxr-x. 1 daygeek daygeek 138 Mar 10 2019 user-add.sh
|
||||
-rw-rw-r--. 1 daygeek daygeek 18 Mar 10 2019 user-list1.txt
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Feb 15 2019 Videos
|
||||
|
||||
node2.2g.lab | CHANGED | rc=0 >>
|
||||
total 0
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Desktop
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Documents
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Downloads
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Music
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Pictures
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Public
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Templates
|
||||
drwxr-xr-x. 2 daygeek daygeek 6 Nov 9 09:55 Videos
|
||||
```
|
||||
|
||||
### 2)如何在 Linux 使用 Ansible 管理文件
|
||||
|
||||
Ansible 的 `copy` 模块将文件从本地系统复制到远程系统。使用 Ansible `command` 模块将文件移动或复制到远程计算机。
|
||||
|
||||
```
|
||||
$ ansible web -m copy -a "src=/home/daygeek/backup/CentOS7.2daygeek.com-20191025.tar dest=/home/u1" --become
|
||||
|
||||
node1.2g.lab | CHANGED => {
|
||||
"ansible_facts": {
|
||||
"discovered_interpreter_python": "/usr/bin/python"
|
||||
},
|
||||
"changed": true,
|
||||
"checksum": "ad8aadc0542028676b5fe34c94347829f0485a8c",
|
||||
"dest": "/home/u1/CentOS7.2daygeek.com-20191025.tar",
|
||||
"gid": 0,
|
||||
"group": "root",
|
||||
"md5sum": "ee8e778646e00456a4cedd5fd6458cf5",
|
||||
"mode": "0644",
|
||||
"owner": "root",
|
||||
"secontext": "unconfined_u:object_r:user_home_t:s0",
|
||||
"size": 30720,
|
||||
"src": "/home/daygeek/.ansible/tmp/ansible-tmp-1579726582.474042-118186643704900/source",
|
||||
"state": "file",
|
||||
"uid": 0
|
||||
}
|
||||
|
||||
node2.2g.lab | CHANGED => {
|
||||
"ansible_facts": {
|
||||
"discovered_interpreter_python": "/usr/libexec/platform-python"
|
||||
},
|
||||
"changed": true,
|
||||
"checksum": "ad8aadc0542028676b5fe34c94347829f0485a8c",
|
||||
"dest": "/home/u1/CentOS7.2daygeek.com-20191025.tar",
|
||||
"gid": 0,
|
||||
"group": "root",
|
||||
"md5sum": "ee8e778646e00456a4cedd5fd6458cf5",
|
||||
"mode": "0644",
|
||||
"owner": "root",
|
||||
"secontext": "unconfined_u:object_r:user_home_t:s0",
|
||||
"size": 30720,
|
||||
"src": "/home/daygeek/.ansible/tmp/ansible-tmp-1579726582.4793239-237229399335623/source",
|
||||
"state": "file",
|
||||
"uid": 0
|
||||
}
|
||||
```
|
||||
|
||||
我们可以运行以下命令进行验证:
|
||||
|
||||
```
|
||||
$ ansible web -m command -a "ls -lh /home/u1" --become
|
||||
|
||||
node1.2g.lab | CHANGED | rc=0 >>
|
||||
total 36K
|
||||
-rw-r--r--. 1 root root 30K Jan 22 14:56 CentOS7.2daygeek.com-20191025.tar
|
||||
-rw-r--r--. 1 root root 25 Dec 9 03:31 user-add.sh
|
||||
|
||||
node2.2g.lab | CHANGED | rc=0 >>
|
||||
total 36K
|
||||
-rw-r--r--. 1 root root 30K Jan 23 02:26 CentOS7.2daygeek.com-20191025.tar
|
||||
-rw-rw-r--. 1 u1 u1 18 Jan 23 02:21 magi.txt
|
||||
```
|
||||
|
||||
要将文件从一个位置复制到远程计算机上的另一个位置,使用以下命令:
|
||||
|
||||
```
|
||||
$ ansible web -m command -a "cp /home/u2/magi/ansible-1.txt /home/u2/magi/2g" --become
|
||||
```
|
||||
|
||||
移动文件,使用以下命令:
|
||||
|
||||
```
|
||||
$ ansible web -m command -a "mv /home/u2/magi/ansible.txt /home/u2/magi/2g" --become
|
||||
```
|
||||
|
||||
在 `u1` 用户目录下创建一个名为 `ansible.txt` 的新文件,运行以下命令:
|
||||
|
||||
```
|
||||
$ ansible web -m file -a "dest=/home/u1/ansible.txt owner=u1 group=u1 state=touch" --become
|
||||
```
|
||||
|
||||
在 `u1` 用户目录下创建一个名为 `magi` 的新目录,运行以下命令:
|
||||
|
||||
```
|
||||
$ ansible web -m file -a "dest=/home/u1/magi mode=755 owner=u2 group=u2 state=directory" --become
|
||||
```
|
||||
|
||||
将 `u1` 用户目录下的 `ansible.txt`* 文件权限更改为 `777`,运行以下命令:
|
||||
|
||||
```
|
||||
$ ansible web -m file -a "dest=/home/u1/ansible.txt mode=777" --become
|
||||
```
|
||||
|
||||
删除 `u1` 用户目录下的 `ansible.txt` 文件,运行以下命令:
|
||||
|
||||
```
|
||||
$ ansible web -m file -a "dest=/home/u2/magi/ansible-1.txt state=absent" --become
|
||||
```
|
||||
|
||||
使用以下命令删除目录,它将递归删除指定目录:
|
||||
|
||||
```
|
||||
$ ansible web -m file -a "dest=/home/u2/magi/2g state=absent" --become
|
||||
```
|
||||
|
||||
### 3)用户管理
|
||||
|
||||
你可以使用 Ansible 轻松执行用户管理活动。例如创建、删除用户以及向一个组添加用户。
|
||||
|
||||
```
|
||||
$ ansible all -m user -a "name=foo password=[crypted password here]"
|
||||
```
|
||||
|
||||
运行以下命令删除用户:
|
||||
|
||||
```
|
||||
$ ansible all -m user -a "name=foo state=absent"
|
||||
```
|
||||
|
||||
### 4)管理包
|
||||
|
||||
使用合适的 Ansible 包管理器模块可以轻松地管理安装包。例如,我们将使用 `yum` 模块来管理 CentOS 系统上的软件包。
|
||||
|
||||
安装最新的 Apache(httpd):
|
||||
|
||||
```
|
||||
$ ansible web -m yum -a "name=httpd state=latest"
|
||||
```
|
||||
|
||||
卸载 Apache(httpd) 包:
|
||||
|
||||
```
|
||||
$ ansible web -m yum -a "name=httpd state=absent"
|
||||
```
|
||||
|
||||
### 5)管理服务
|
||||
|
||||
使用以下 Ansible 模块命令可以在 Linux 上管理任何服务。
|
||||
|
||||
停止 httpd 服务:
|
||||
|
||||
```
|
||||
$ ansible web -m service -a "name=httpd state=stopped"
|
||||
```
|
||||
|
||||
启动 httpd 服务:
|
||||
|
||||
```
|
||||
$ ansible web -m service -a "name=httpd state=started"
|
||||
```
|
||||
|
||||
重启 httpd 服务:
|
||||
|
||||
```
|
||||
$ ansible web -m service -a "name=httpd state=restarted"
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/ansible-ad-hoc-command-quick-start-guide-with-examples/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-13142-1.html
|
||||
@ -1,23 +1,22 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Chao-zhi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (LaTeX typesetting part 2 (tables))
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13146-1.html)
|
||||
[#]: subject: (LaTeX typesetting part 2 \(tables\))
|
||||
[#]: via: (https://fedoramagazine.org/latex-typesetting-part-2-tables/)
|
||||
[#]: author: (Earl Ramirez https://fedoramagazine.org/author/earlramirez/)
|
||||
|
||||
|
||||
LaTex 排版 (2):表格
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
LaTeX 提供了许多工具来创建和定制表格,在本系列中,我们将使用 tabular 和 tabularx 环境来创建和定制表。
|
||||
LaTeX 提供了许多工具来创建和定制表格,在本系列中,我们将使用 `tabular` 和 `tabularx` 环境来创建和定制表。
|
||||
|
||||
### 基础表格
|
||||
|
||||
要创建表,只需指定环境 `\begin{tabular}{ 列选项}`
|
||||
要创建表,只需指定环境 `\begin{tabular}{列选项}`:
|
||||
|
||||
```
|
||||
\begin{tabular}{c|c}
|
||||
@ -35,25 +34,25 @@ LaTeX 提供了许多工具来创建和定制表格,在本系列中,我们
|
||||
|
||||
参数 | 位置
|
||||
|:---:|:---
|
||||
c | 将文本置于中间
|
||||
l | 将文本左对齐
|
||||
r | 将文本右对齐
|
||||
p{width} | 文本对齐单元格顶部
|
||||
m{width} | 文本对齐单元格中间
|
||||
b{width} | 文本对齐单元格底部
|
||||
`c` | 将文本置于中间
|
||||
`l` | 将文本左对齐
|
||||
`r` | 将文本右对齐
|
||||
`p{宽度}` | 文本对齐单元格顶部
|
||||
`m{宽度}` | 文本对齐单元格中间
|
||||
`b{宽度}` | 文本对齐单元格底部
|
||||
|
||||
> m{width} 和 b{width} 都要求在最前面指定数组包。
|
||||
> `m{宽度}` 和 `b{宽度}` 都要求在最前面指定数组包。
|
||||
|
||||
使用上面的例子,让我们来详细讲解使用的要点,并描述您将在本系列中看到的更多选项
|
||||
使用上面的例子,让我们来详细讲解使用的要点,并描述你将在本系列中看到的更多选项:
|
||||
|
||||
选项 | 意义
|
||||
|:-:|:-|
|
||||
& | 定义每个单元格,这个符号仅用于第二列
|
||||
\ | 这将终止该行并开始一个新行
|
||||
\| | 指定表格中的垂直线(可选)
|
||||
\hline | 指定表格中水平线(可选)
|
||||
*{num}{form} | 当您有许多列时,可以使用这个,并且是限制重复的有效方法
|
||||
\|\| | 指定表格中垂直双线
|
||||
`&` | 定义每个单元格,这个符号仅用于第二列
|
||||
`\\` | 这将终止该行并开始一个新行
|
||||
`|` | 指定表格中的垂直线(可选)
|
||||
`\hline` | 指定表格中的水平线(可选)
|
||||
`*{数量}{格式}` | 当你有许多列时,可以使用这个,并且是限制重复的有效方法
|
||||
`||` | 指定表格中垂直双线
|
||||
|
||||
### 定制表格
|
||||
|
||||
@ -77,7 +76,7 @@ b{width} | 文本对齐单元格底部
|
||||
|
||||
如果列中有很多文本,那么它的格式就不好处理,看起来也不好看。
|
||||
|
||||
下面的示例显示了文本的格式长度,我们将在导言区中使用 “blindtext”,以便生成示例文本。
|
||||
下面的示例显示了文本的格式长度,我们将在导言区中使用 `blindtext`,以便生成示例文本。
|
||||
|
||||
```
|
||||
\begin{tabular}{|l|l|}\hline
|
||||
@ -88,15 +87,14 @@ b{width} | 文本对齐单元格底部
|
||||
|
||||
![Default Formatting][4]
|
||||
|
||||
正如您所看到的,文本超出了页面宽度;但是,有几个选项可以克服这个问题。
|
||||
|
||||
* 指定列宽,例如 m{5cm}
|
||||
* 利用 tablarx 环境,这需要在导言区中引用 tablarx 宏包。
|
||||
正如你所看到的,文本超出了页面宽度;但是,有几个选项可以克服这个问题。
|
||||
|
||||
* 指定列宽,例如 `m{5cm}`
|
||||
* 利用 `tablarx` 环境,这需要在导言区中引用 `tablarx` 宏包。
|
||||
|
||||
#### 使用列宽管理长文本
|
||||
|
||||
通过指定列宽,文本将被包装为如下示例所示的宽度。
|
||||
通过指定列宽,文本将被折行为如下示例所示的宽度。
|
||||
|
||||
```
|
||||
\begin{tabular}{|l|m{14cm}|} \hline
|
||||
@ -105,14 +103,11 @@ b{width} | 文本对齐单元格底部
|
||||
\end{tabular}\vspace{3mm}
|
||||
```
|
||||
|
||||
![Column width][5]
|
||||
![Column Width][5]
|
||||
|
||||
#### 使用 tabularx 管理长文本
|
||||
|
||||
在我们利用表格之前,我们需要在导言区中加上它。TABLARX 方法见以下示例
|
||||
|
||||
`\begin{tabularx}{ 宽度}{列选项}`
|
||||
|
||||
在我们利用表格之前,我们需要在导言区中加上它。`tabularx` 方法见以下示例:`\begin{tabularx}{宽度}{列选项}`。
|
||||
|
||||
```
|
||||
\begin{tabularx}{\textwidth}{|l|X|} \hline
|
||||
@ -121,18 +116,17 @@ Text &\blindtext \\ \hline
|
||||
\end{tabularx}
|
||||
```
|
||||
|
||||
|
||||
![Tabularx][6]
|
||||
|
||||
请注意,我们需要处理长文本的列在花括号中指定了大写 “X”。
|
||||
请注意,我们需要处理长文本的列在花括号中指定了大写 `X`。
|
||||
|
||||
### 合并行合并列
|
||||
|
||||
有时需要合并行或列。本节描述了如何完成。要使用 multirow 和 multicolumn,请将 multirow 添加到导言区。
|
||||
有时需要合并行或列。本节描述了如何完成。要使用 `multirow` 和 `multicolumn`,请将 `multirow` 添加到导言区。
|
||||
|
||||
#### 合并行
|
||||
|
||||
Multirow 采用以下参数 `\multirow{ 行的数量}{宽度}{文本}`,让我们看看下面的示例。
|
||||
`multirow` 采用以下参数 `\multirow{行的数量}{宽度}{文本}`,让我们看看下面的示例。
|
||||
|
||||
```
|
||||
\begin{tabular}{|l|l|}\hline
|
||||
@ -145,11 +139,11 @@ Multirow 采用以下参数 `\multirow{ 行的数量}{宽度}{文本}`,让我
|
||||
|
||||
![MultiRow][7]
|
||||
|
||||
在上面的示例中,指定了两行,'*'告诉 LaTeX 自动管理单元格的大小。
|
||||
在上面的示例中,指定了两行,`*` 告诉 LaTeX 自动管理单元格的大小。
|
||||
|
||||
#### 合并列
|
||||
|
||||
Multicolumn 参数是 `{Multicolumn{ 列的数量}{单元格选项}{位置}{文本}`,下面的示例演示 Multicolumn。
|
||||
`multicolumn` 参数是 `{multicolumn{列的数量}{单元格选项}{位置}{文本}`,下面的示例演示合并列。
|
||||
|
||||
```
|
||||
\begin{tabular}{|l|l|l|}\hline
|
||||
@ -165,14 +159,14 @@ Multicolumn 参数是 `{Multicolumn{ 列的数量}{单元格选项}{位置}{文
|
||||
|
||||
可以为文本、单个单元格或整行指定颜色。此外,我们可以为每一行配置交替的颜色。
|
||||
|
||||
在给表添加颜色之前,我们需要在导言区引用 `\usepackage[table]{xcolor}`。我们还可以使用以下颜色参考 [LaTeX Color][9] 或在颜色前缀后面添加感叹号(从 0 到 100 的阴影)来定义颜色。例如,`gray!30`
|
||||
在给表添加颜色之前,我们需要在导言区引用 `\usepackage[table]{xcolor}`。我们还可以使用以下颜色参考 [LaTeX Color][9] 或在颜色前缀后面添加感叹号(从 0 到 100 的阴影)来定义颜色。例如,`gray!30`。
|
||||
|
||||
```
|
||||
\definecolor{darkblue}{rgb}{0.0, 0.0, 0.55}
|
||||
\definecolor{darkgray}{rgb}{0.66, 0.66, 0.66}
|
||||
```
|
||||
|
||||
下面的示例演示了一个具有各种颜色的表,`\rowcolors` 采用以下选项 `\rowcolors{ 起始行颜色}{偶数行颜色}{奇数行颜色}`。
|
||||
下面的示例演示了一个具有各种颜色的表,`\rowcolors` 采用以下选项 `\rowcolors{起始行颜色}{偶数行颜色}{奇数行颜色}`。
|
||||
|
||||
```
|
||||
\rowcolors{2}{darkgray}{gray!20}
|
||||
@ -207,7 +201,7 @@ Multicolumn 参数是 `{Multicolumn{ 列的数量}{单元格选项}{位置}{文
|
||||
让我们讲解一下为解决合并行替换颜色问题而实施的更改。
|
||||
|
||||
* 第一行从合并行上方开始
|
||||
* 行数从 2 更改为 -2,这意味着从上面的行开始读取
|
||||
* 行数从 `2` 更改为 `-2`,这意味着从上面的行开始读取
|
||||
* `\rowcolor` 是为每一行指定的,更重要的是,多行必须具有相同的颜色,这样才能获得所需的结果。
|
||||
|
||||
关于颜色的最后一个注意事项是,要更改列的颜色,需要创建新的列类型并定义颜色。下面的示例说明了如何定义新的列颜色。
|
||||
@ -216,10 +210,10 @@ Multicolumn 参数是 `{Multicolumn{ 列的数量}{单元格选项}{位置}{文
|
||||
\newcolumntype{g}{>{\columncolor{darkblue}}l}
|
||||
```
|
||||
|
||||
我们把它分解一下
|
||||
我们把它分解一下:
|
||||
|
||||
* `\newcolumntype{g}`:将字母 _g_ 定义为新列
|
||||
* `{>{\columncolor{darkblue}}l}`:在这里我们选择我们想要的颜色,并且 `l` 告诉列左对齐,这可以用 `c` 或 `r` 代替
|
||||
* `\newcolumntype{g}`:将字母 `g` 定义为新列
|
||||
* `{>{\columncolor{darkblue}}l}`:在这里我们选择我们想要的颜色,并且 `l` 告诉列左对齐,这可以用 `c` 或 `r` 代替。
|
||||
|
||||
```
|
||||
\begin{tabular}{g|l}
|
||||
@ -234,7 +228,7 @@ Multicolumn 参数是 `{Multicolumn{ 列的数量}{单元格选项}{位置}{文
|
||||
|
||||
### 横向表
|
||||
|
||||
有时,您的表可能有许多列,纵向排列会很不好看。在导言区加入 “rotating” 包,您将能够创建一个横向表。下面的例子说明了这一点。
|
||||
有时,你的表可能有许多列,纵向排列会很不好看。在导言区加入 `rotating` 包,你将能够创建一个横向表。下面的例子说明了这一点。
|
||||
|
||||
对于横向表,我们将使用 `sidewaystable` 环境并在其中添加表格环境,我们还指定了其他选项。
|
||||
|
||||
@ -260,7 +254,7 @@ Multicolumn 参数是 `{Multicolumn{ 列的数量}{单元格选项}{位置}{文
|
||||
|
||||
### 列表和表格
|
||||
|
||||
要将列表包含到表中,可以使用 tabularx,并将列表包含在指定的列中。另一个办法是使用表格格式,但必须指定列宽。
|
||||
要将列表包含到表中,可以使用 `tabularx`,并将列表包含在指定的列中。另一个办法是使用表格格式,但必须指定列宽。
|
||||
|
||||
#### 用 tabularx 处理列表
|
||||
|
||||
@ -279,7 +273,6 @@ Multicolumn 参数是 `{Multicolumn{ 列的数量}{单元格选项}{位置}{文
|
||||
|
||||
#### 用 tabular 处理列表
|
||||
|
||||
|
||||
```
|
||||
\begin{tabular}{|l|m{6cm}|}\hline
|
||||
Fedora Version &amp;amp;Editions \\\ \hline
|
||||
@ -293,9 +286,9 @@ Multicolumn 参数是 `{Multicolumn{ 列的数量}{单元格选项}{位置}{文
|
||||
|
||||
![List in tabular][16]
|
||||
|
||||
### 结论
|
||||
### 总结
|
||||
|
||||
LaTeX 提供了许多使用 tablar 和 tablarx 自定义表的方法,您还可以在表环境 (\begin\table) 中添加 tablar 和 tablarx 来添加表的名称和定位表。
|
||||
LaTeX 提供了许多使用 `tablar` 和 `tablarx` 自定义表的方法,你还可以在表环境 (`\begin\table`) 中添加 `tablar` 和 `tablarx` 来添加表的名称和定位表。
|
||||
|
||||
### LaTeX 宏包
|
||||
|
||||
@ -324,7 +317,7 @@ via: https://fedoramagazine.org/latex-typesetting-part-2-tables/
|
||||
作者:[Earl Ramirez][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,283 @@
|
||||
[#]: collector: (Chao-zhi)
|
||||
[#]: translator: (Chao-zhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13154-1.html)
|
||||
[#]: subject: (LaTeX typesetting,Part 3: formatting)
|
||||
[#]: via: (https://fedoramagazine.org/latex-typesetting-part-3-formatting/)
|
||||
[#]: author: (Earl Ramirez https://fedoramagazine.org/author/earlramirez/)
|
||||
|
||||
LaTeX 排版(3):排版
|
||||
======
|
||||
|
||||

|
||||
|
||||
本 [系列][1] 介绍了 LaTeX 中的基本格式。[第 1 部分][2] 介绍了列表。[第 2 部分][3] 阐述了表格。在第 3 部分中,你将了解 LaTeX 的另一个重要特性:细腻灵活的文档排版。本文介绍如何自定义页面布局、目录、标题部分和页面样式。
|
||||
|
||||
### 页面维度
|
||||
|
||||
当你第一次编写 LaTeX 文档时,你可能已经注意到默认边距比你想象的要大一些。页边距与指定的纸张类型有关,例如 A4、letter 和 documentclass(article、book、report) 等等。要修改页边距,有几个选项,最简单的选项之一是使用 [fullpage][4] 包。
|
||||
|
||||
> 该软件包设置页面的主体,可以使主体几乎占满整个页面。
|
||||
>
|
||||
> —— FULLPAGE PACKAGE DOCUMENTATION
|
||||
|
||||
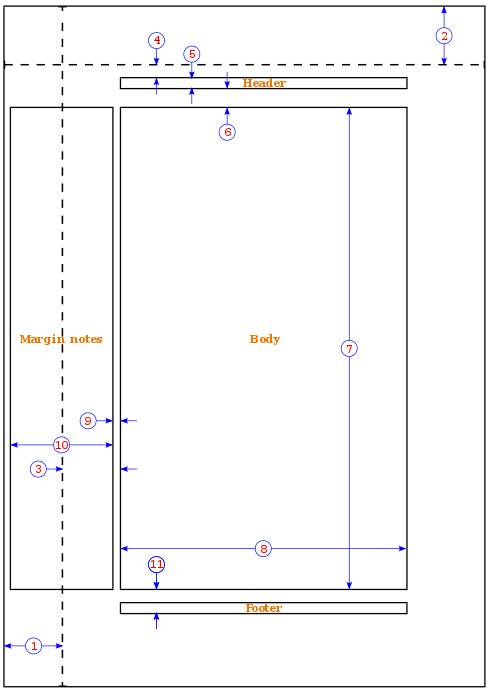
另一个选择是使用 [geometry][5] 包。在探索 `geometry` 包如何操纵页边距之前,请首先查看如下所示的页面尺寸。
|
||||
|
||||
|
||||
|
||||
1. 1 英寸 + `\hoffset`
|
||||
2. 1 英寸 + `\voffset`
|
||||
3. `\oddsidemargin` = 31pt
|
||||
4. `\topmargin` = 20pt
|
||||
5. `\headheight` = 12pt
|
||||
6. `\headsep` = 25pt
|
||||
7. `\textheight` = 592pt
|
||||
8. `\textwidth` = 390pt
|
||||
9. `\marginparsep` = 35pt
|
||||
10. `\marginparwidth` = 35pt
|
||||
11. `\footskip` = 30pt
|
||||
|
||||
要使用 `geometry` 包将边距设置为 1 英寸,请使用以下示例
|
||||
|
||||
```
|
||||
\usepackage{geometry}
|
||||
\geometry{a4paper, margin=1in}
|
||||
```
|
||||
|
||||
除上述示例外,`geometry` 命令还可以修改纸张尺寸和方向。要更改纸张尺寸,请使用以下示例:
|
||||
|
||||
```
|
||||
\usepackage[a4paper, total={7in, 8in}]{geometry}
|
||||
```
|
||||
|
||||

|
||||
|
||||
要更改页面方向,需要将横向(`landscape`)添加到 `geometery` 选项中,如下所示:
|
||||
|
||||
```
|
||||
\usepackage{geometery}
|
||||
\geometry{a4paper, landscape, margin=1.5in
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 目录
|
||||
|
||||
默认情况下,目录的标题为 “contents”。有时,你想将标题更改为 “Table of Content”,更改目录和章节第一节之间的垂直间距,或者只更改文本的颜色。
|
||||
|
||||
若要更改文本,请在导言区中添加以下行,用所需语言替换英语(`english`):
|
||||
|
||||
```
|
||||
\usepackage[english]{babel}
|
||||
\addto\captionsenglish{
|
||||
\renewcommand{\contentsname}
|
||||
{\bfseries{Table of Contents}}}
|
||||
```
|
||||
|
||||
要操纵目录与图、小节和章节列表之间的虚拟间距,请使用 `tocloft` 软件包。本文中使用的两个选项是 `cftbeforesecskip` 和 `cftaftertoctitleskip`。
|
||||
|
||||
> tocloft 包提供了控制目录、图表列表和表格列表的排版方法。
|
||||
>
|
||||
> —— TOCLOFT PACKAGE DOUCMENTATION
|
||||
|
||||
```
|
||||
\usepackage{tocloft}
|
||||
\setlength\ctfbeforesecskip{2pt}
|
||||
\setlength\cftaftertoctitleskip{30pt}
|
||||
```
|
||||
|
||||

|
||||
|
||||
*默认目录*
|
||||
|
||||

|
||||
|
||||
*定制目录*
|
||||
|
||||
### 边框
|
||||
|
||||
在文档中使用包 [hyperref][6] 时,目录中的 LaTeX 章节列表和包含 `\url` 的引用都有边框,如下图所示。
|
||||
|
||||

|
||||
|
||||
要删除这些边框,请在导言区中包括以下内容,你将看到目录中没有任何边框。
|
||||
|
||||
```
|
||||
\usepackage{hyperref}
|
||||
\hypersetup{ pdfborder = {0 0 0}}
|
||||
```
|
||||
|
||||
要修改标题部分的字体、样式或颜色,请使用程序包 [titlesec][7]。在本例中,你将更改节、子节和三级子节的字体大小、字体样式和字体颜色。首先,在导言区中增加以下内容。
|
||||
|
||||
```
|
||||
\usepackage{titlesec}
|
||||
\titleformat*{\section}{\Huge\bfseries\color{darkblue}}
|
||||
\titleformat*{\subsection}{\huge\bfseries\color{darkblue}}
|
||||
\titleformat*{\subsubsection}{\Large\bfseries\color{darkblue}}
|
||||
```
|
||||
|
||||
仔细看看代码,`\titleformat*{\section}` 指定要使用的节的深度。上面的示例最多使用第三个深度。`{\Huge\bfseries\color{darkblue}}` 部分指定字体大小、字体样式和字体颜色。
|
||||
|
||||
### 页面样式
|
||||
|
||||
要自定义的页眉和页脚,请使用 [fancyhdr][8]。此示例使用此包修改页面样式、页眉和页脚。下面的代码简要描述了每个选项的作用。
|
||||
|
||||
```
|
||||
\pagestyle{fancy} %for header to be on each page
|
||||
\fancyhead[L]{} %keep left header blank
|
||||
\fancyhead[C]{} %keep centre header blank
|
||||
\fancyhead[R]{\leftmark} %add the section/chapter to the header right
|
||||
\fancyfoot[L]{Static Content} %add static test to the left footer
|
||||
\fancyfoot[C]{} %keep centre footer blank
|
||||
\fancyfoot[R]{\thepage} %add the page number to the right footer
|
||||
\setlength\voffset{-0.25in} %space between page border and header (1in + space)
|
||||
\setlength\headheight{12pt} %height of the actual header.
|
||||
\setlength\headsep{25pt} %separation between header and text.
|
||||
\renewcommand{\headrulewidth}{2pt} % add header horizontal line
|
||||
\renewcommand{\footrulewidth}{1pt} % add footer horizontal line
|
||||
```
|
||||
|
||||
结果如下所示:
|
||||
|
||||

|
||||
|
||||
*页眉*
|
||||
|
||||

|
||||
|
||||
*页脚*
|
||||
|
||||
### 小贴士
|
||||
|
||||
#### 集中导言区
|
||||
|
||||
如果要编写许多 TeX 文档,可以根据文档类别创建一个包含所有导言区的 `.tex` 文件并引用此文件。例如,我使用结构 `.tex` 如下所示。
|
||||
|
||||
```
|
||||
$ cat article_structure.tex
|
||||
\usepackage[english]{babel}
|
||||
\addto\captionsenglish{
|
||||
\renewcommand{\contentsname}
|
||||
{\bfseries{\color{darkblue}Table of Contents}}
|
||||
} % Relable the contents
|
||||
%\usepackage[margin=0.5in]{geometry} % specifies the margin of the document
|
||||
\usepackage[utf8]{inputenc}
|
||||
\usepackage[T1]{fontenc}
|
||||
\usepackage{graphicx} % allows you to add graphics to the document
|
||||
\usepackage{hyperref} % permits redirection of URL from a PDF document
|
||||
\usepackage{fullpage} % formate the content to utilise the full page
|
||||
%\usepackage{a4wide}
|
||||
\usepackage[export]{adjustbox} % to force image position
|
||||
%\usepackage[section]{placeins} % to have multiple images in a figure
|
||||
\usepackage{tabularx} % for wrapping text in a table
|
||||
%\usepackage{rotating}
|
||||
\usepackage{multirow}
|
||||
\usepackage{subcaption} % to have multiple images in a figure
|
||||
%\usepackage{smartdiagram} % initialise smart diagrams
|
||||
\usepackage{enumitem} % to manage the spacing between lists and enumeration
|
||||
\usepackage{fancyhdr} %, graphicx} %for header to be on each page
|
||||
\pagestyle{fancy} %for header to be on each page
|
||||
%\fancyhf{}
|
||||
\fancyhead[L]{}
|
||||
\fancyhead[C]{}
|
||||
\fancyhead[R]{\leftmark}
|
||||
\fancyfoot[L]{Static Content} %\includegraphics[width=0.02\textwidth]{virgin_voyages.png}}
|
||||
\fancyfoot[C]{} % clear center
|
||||
\fancyfoot[R]{\thepage}
|
||||
\setlength\voffset{-0.25in} %Space between page border and header (1in + space)
|
||||
\setlength\headheight{12pt} %Height of the actual header.
|
||||
\setlength\headsep{25pt} %Separation between header and text.
|
||||
\renewcommand{\headrulewidth}{2pt} % adds horizontal line
|
||||
\renewcommand{\footrulewidth}{1pt} % add horizontal line (footer)
|
||||
%\renewcommand{\oddsidemargin}{2pt} % adjuct the margin spacing
|
||||
%\renewcommand{\pagenumbering}{roman} % change the numbering style
|
||||
%\renewcommand{\hoffset}{20pt}
|
||||
%\usepackage{color}
|
||||
\usepackage[table]{xcolor}
|
||||
\hypersetup{ pdfborder = {0 0 0}} % removes the red boarder from the table of content
|
||||
%\usepackage{wasysym} %add checkbox
|
||||
%\newcommand\insq[1]{%
|
||||
% \Square\ #1\quad%
|
||||
%} % specify the command to add checkbox
|
||||
%\usepackage{xcolor}
|
||||
%\usepackage{colortbl}
|
||||
%\definecolor{Gray}{gray}{0.9} % create new colour
|
||||
%\definecolor{LightCyan}{rgb}{0.88,1,1} % create new colour
|
||||
%\usepackage[first=0,last=9]{lcg}
|
||||
%\newcommand{\ra}{\rand0.\arabic{rand}}
|
||||
%\newcolumntype{g}{>{\columncolor{LightCyan}}c} % create new column type g
|
||||
%\usesmartdiagramlibrary{additions}
|
||||
%\setcounter{figure}{0}
|
||||
\setcounter{secnumdepth}{0} % sections are level 1
|
||||
\usepackage{csquotes} % the proper was of using double quotes
|
||||
%\usepackage{draftwatermark} % Enable watermark
|
||||
%\SetWatermarkText{DRAFT} % Specify watermark text
|
||||
%\SetWatermarkScale{5} % Toggle watermark size
|
||||
\usepackage{listings} % add code blocks
|
||||
\usepackage{titlesec} % Manipulate section/subsection
|
||||
\titleformat{\section}{\Huge\bfseries\color{darkblue}} % update sections to bold with the colour blue \titleformat{\subsection}{\huge\bfseries\color{darkblue}} % update subsections to bold with the colour blue
|
||||
\titleformat*{\subsubsection}{\Large\bfseries\color{darkblue}} % update subsubsections to bold with the colour blue
|
||||
\usepackage[toc]{appendix} % Include appendix in TOC
|
||||
\usepackage{xcolor}
|
||||
\usepackage{tocloft} % For manipulating Table of Content virtical spacing
|
||||
%\setlength\cftparskip{-2pt}
|
||||
\setlength\cftbeforesecskip{2pt} %spacing between the sections
|
||||
\setlength\cftaftertoctitleskip{30pt} % space between the first section and the text ``Table of Contents''
|
||||
\definecolor{navyblue}{rgb}{0.0,0.0,0.5}
|
||||
\definecolor{zaffre}{rgb}{0.0, 0.08, 0.66}
|
||||
\definecolor{white}{rgb}{1.0, 1.0, 1.0}
|
||||
\definecolor{darkblue}{rgb}{0.0, 0.2, 0.6}
|
||||
\definecolor{darkgray}{rgb}{0.66, 0.66, 0.66}
|
||||
\definecolor{lightgray}{rgb}{0.83, 0.83, 0.83}
|
||||
%\pagenumbering{roman}
|
||||
```
|
||||
|
||||
在你的文章中,请参考以下示例中所示的方法引用 `structure.tex` 文件:
|
||||
|
||||
```
|
||||
\documentclass[a4paper,11pt]{article}
|
||||
\input{/path_to_structure.tex}}
|
||||
\begin{document}
|
||||
......
|
||||
\end{document}
|
||||
```
|
||||
|
||||
#### 添加水印
|
||||
|
||||
要在 LaTeX 文档中启用水印,请使用 [draftwatermark][9] 软件包。下面的代码段和图像演示了如何在文档中添加水印。默认情况下,水印颜色为灰色,可以将其修改为所需的颜色。
|
||||
|
||||
```
|
||||
\usepackage{draftwatermark}
|
||||
\SetWatermarkText{\color{red}Classified} %add watermark text
|
||||
\SetWatermarkScale{4} %specify the size of the text
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
在本系列中,你了解了 LaTeX 提供的一些基本但丰富的功能,这些功能可用于自定义文档以满足你的需要或将文档呈现给的受众。LaTeX 海洋中,还有许多软件包需要大家自行去探索。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/latex-typesetting-part-3-formatting/
|
||||
|
||||
作者:[Earl Ramirez][a]
|
||||
选题:[Chao-zhi][b]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/earlramirez/
|
||||
[b]: https://github.com/Chao-zhi
|
||||
[1]:https://fedoramagazine.org/tag/latex/
|
||||
[2]:https://linux.cn/article-13112-1.html
|
||||
[3]:https://linux.cn/article-13146-1.html
|
||||
[4]:https://www.ctan.org/pkg/fullpage
|
||||
[5]:https://www.ctan.org/geometry
|
||||
[6]:https://www.ctan.org/pkg/hyperref
|
||||
[7]:https://www.ctan.org/pkg/titlesec
|
||||
[8]:https://www.ctan.org/pkg/fancyhdr
|
||||
[9]:https://www.ctan.org/pkg/draftwatermark
|
||||
@ -0,0 +1,124 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13137-1.html)
|
||||
[#]: subject: (Navigating your Linux files with ranger)
|
||||
[#]: via: (https://www.networkworld.com/article/3583890/navigating-your-linux-files-with-ranger.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
用 ranger 在 Linux 文件的海洋中导航
|
||||
=====
|
||||
|
||||
> ranger 是一个很好的工具,它为你的 Linux 文件提供了一个多级视图,并允许你使用方向键和一些方便的命令进行浏览和更改。
|
||||
|
||||

|
||||
|
||||
`ranger` 是一款独特且非常方便的文件系统导航器,它允许你在 Linux 文件系统中移动,进出子目录,查看文本文件内容,甚至可以在不离开该工具的情况下对文件进行修改。
|
||||
|
||||
它运行在终端窗口中,并允许你按下方向键进行导航。它提供了一个多级的文件显示,让你很容易看到你在哪里、在文件系统中移动、并选择特定的文件。
|
||||
|
||||
要安装 `ranger`,请使用标准的安装命令(例如,`sudo apt install ranger`)。要启动它,只需键入 `ranger`。它有一个很长的、非常详细的手册页面,但开始使用 `ranger` 非常简单。
|
||||
|
||||
### ranger 的显示方式
|
||||
|
||||
你需要马上习惯的最重要的一件事就是 `ranger` 的文件显示方式。一旦你启动了 `ranger`,你会看到四列数据。第一列是你启动 `ranger` 的位置的上一级。例如,如果你从主目录开始,`ranger` 将在第一列中列出所有的主目录。第二列将显示你的主目录(或者你开始的目录)中的目录和文件的第一屏内容。
|
||||
|
||||
这里的关键是超越你可能有的任何习惯,将每一行显示的细节看作是相关的。第二列中的所有条目与第一列中的单个条目相关,第四列中的内容与第二列中选定的文件或目录相关。
|
||||
|
||||
与一般的命令行视图不同的是,目录将被列在第一位(按字母数字顺序),文件将被列在第二位(也是按字母数字顺序)。从你的主目录开始,显示的内容可能是这样的:
|
||||
|
||||
```
|
||||
shs@dragonfly /home/shs/backups <== current selection
|
||||
bugfarm backups 0 empty
|
||||
dory bin 59
|
||||
eel Buttons 15
|
||||
nemo Desktop 0
|
||||
shark Documents 0
|
||||
shs Downloads 1
|
||||
^ ^ ^ ^
|
||||
| | | |
|
||||
homes directories # files listing
|
||||
in selected in each of files in
|
||||
home directory selected directory
|
||||
```
|
||||
|
||||
`ranger` 显示的最上面一行告诉你在哪里。在这个例子中,当前目录是 `/home/shs/backups`。我们看到高亮显示的是 `empty`,因为这个目录中没有文件。如果我们按下方向键选择 `bin`,我们会看到一个文件列表:
|
||||
|
||||
```
|
||||
shs@dragonfly /home/shs/bin <== current selection
|
||||
bugfarm backups 0 append
|
||||
dory bin 59 calcPower
|
||||
eel Buttons 15 cap
|
||||
nemo Desktop 0 extract
|
||||
shark Documents 0 finddups
|
||||
shs Downloads 1 fix
|
||||
^ ^ ^ ^
|
||||
| | | |
|
||||
homes directories # files listing
|
||||
in selected in each of files in
|
||||
home directory selected directory
|
||||
```
|
||||
|
||||
每一列中高亮显示的条目显示了当前的选择。使用右方向键可移动到更深的目录或查看文件内容。
|
||||
|
||||
如果你继续按下方向键移动到列表的文件部分,你会注意到第三列将显示文件大小(而不是文件的数量)。“当前选择”行也会显示当前选择的文件名,而最右边的一列则会尽可能地显示文件内容。
|
||||
|
||||
```
|
||||
shs@dragonfly /home/shs/busy_wait.c <== current selection
|
||||
bugfarm BushyRidge.zip 170 K /*
|
||||
dory busy_wait.c 338 B * program that does a busy wait
|
||||
eel camper.jpg 5.55 M * it's used to show ASLR, and that's it
|
||||
nemo check_lockscreen 80 B */
|
||||
shark chkrootkit-output 438 B #include <stdio.h>
|
||||
^ ^ ^ ^
|
||||
| | | |
|
||||
homes files sizes file content
|
||||
```
|
||||
|
||||
在该显示的底行会显示一些文件和目录的详细信息:
|
||||
|
||||
```
|
||||
-rw-rw-r—- shs shs 338B 2019-01-05 14:44 1.52G, 365G free 67/488 11%
|
||||
```
|
||||
|
||||
如果你选择了一个目录并按下回车键,你将进入该目录。然后,在你的显示屏中最左边的一列将是你的主目录的内容列表,第二列将是该目录内容的文件列表。然后你可以检查子目录的内容和文件的内容。
|
||||
|
||||
按左方向键可以向上移动一级。
|
||||
|
||||
按 `q` 键退出 `ranger`。
|
||||
|
||||
### 做出改变
|
||||
|
||||
你可以按 `?` 键,在屏幕底部弹出一条帮助行。它看起来应该是这样的:
|
||||
|
||||
```
|
||||
View [m]an page, [k]ey bindings, [c]commands or [s]ettings? (press q to abort)
|
||||
```
|
||||
|
||||
按 `c` 键,`ranger` 将提供你可以在该工具内使用的命令信息。例如,你可以通过输入 `:chmod` 来改变当前文件的权限,后面跟着预期的权限。例如,一旦选择了一个文件,你可以输入 `:chmod 700` 将权限设置为 `rwx------`。
|
||||
|
||||
输入 `:edit` 可以在 `nano` 中打开该文件,允许你进行修改,然后使用 `nano` 的命令保存文件。
|
||||
|
||||
### 总结
|
||||
|
||||
使用 `ranger` 的方法比本篇文章所描述的更多。该工具提供了一种非常不同的方式来列出 Linux 系统上的文件并与之交互,一旦你习惯了它的多级的目录和文件列表方式,并使用方向键代替 `cd` 命令来移动,就可以很轻松地在 Linux 的文件中导航。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3583890/navigating-your-linux-files-with-ranger.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://unsplash.com/photos/mHC0qJ7l-ls
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
150
published/202102/20201103 How the Kubernetes scheduler works.md
Normal file
150
published/202102/20201103 How the Kubernetes scheduler works.md
Normal file
@ -0,0 +1,150 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MZqk)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13155-1.html)
|
||||
[#]: subject: (How the Kubernetes scheduler works)
|
||||
[#]: via: (https://opensource.com/article/20/11/kubernetes-scheduler)
|
||||
[#]: author: (Mike Calizo https://opensource.com/users/mcalizo)
|
||||
|
||||
Kubernetes 调度器是如何工作的
|
||||
=====
|
||||
|
||||
> 了解 Kubernetes 调度器是如何发现新的吊舱并将其分配到节点。
|
||||
|
||||

|
||||
|
||||
[Kubernetes][2] 已经成为容器和容器化工作负载的标准编排引擎。它提供一个跨公有云和私有云环境的通用和开源的抽象层。
|
||||
|
||||
对于那些已经熟悉 Kuberbetes 及其组件的人,他们的讨论通常围绕着如何尽量发挥 Kuberbetes 的功能。但当你刚刚开始学习 Kubernetes 时,尝试在生产环境中使用前,明智的做法是从一些关于 Kubernetes 相关组件(包括 [Kubernetes 调度器][3]) 开始学习,如下抽象视图中所示:
|
||||
|
||||
![][4]
|
||||
|
||||
Kubernetes 也分为控制平面和工作节点:
|
||||
|
||||
1. **控制平面:** 也称为主控,负责对集群做出全局决策,以及检测和响应集群事件。控制平面组件包括:
|
||||
* etcd
|
||||
* kube-apiserver
|
||||
* kube-controller-manager
|
||||
* 调度器
|
||||
2. **工作节点:** 也称节点,这些节点是工作负载所在的位置。它始终和主控联系,以获取工作负载运行所需的信息,并与集群外部进行通讯和连接。工作节点组件包括:
|
||||
* kubelet
|
||||
* kube-proxy
|
||||
* CRI
|
||||
|
||||
我希望这个背景信息可以帮助你理解 Kubernetes 组件是如何关联在一起的。
|
||||
|
||||
### Kubernetes 调度器是如何工作的
|
||||
|
||||
Kubernetes <ruby>[吊舱][5]<rt>pod</rt></ruby> 由一个或多个容器组成组成,共享存储和网络资源。Kubernetes 调度器的任务是确保每个吊舱分配到一个节点上运行。
|
||||
|
||||
(LCTT 译注:容器技术领域大量使用了航海比喻,pod 一词,意为“豆荚”,在航海领域指“吊舱” —— 均指盛装多个物品的容器。常不翻译,考虑前后文,可译做“吊舱”。)
|
||||
|
||||
在更高层面下,Kubernetes 调度器的工作方式是这样的:
|
||||
|
||||
1. 每个需要被调度的吊舱都需要加入到队列
|
||||
2. 新的吊舱被创建后,它们也会加入到队列
|
||||
3. 调度器持续地从队列中取出吊舱并对其进行调度
|
||||
|
||||
[调度器源码][6](`scheduler.go`)很大,约 9000 行,且相当复杂,但解决了重要问题:
|
||||
|
||||
#### 等待/监视吊舱创建的代码
|
||||
|
||||
监视吊舱创建的代码始于 `scheduler.go` 的 8970 行,它持续等待新的吊舱:
|
||||
|
||||
```
|
||||
// Run begins watching and scheduling. It waits for cache to be synced, then starts a goroutine and returns immediately.
|
||||
|
||||
func (sched *Scheduler) Run() {
|
||||
if !sched.config.WaitForCacheSync() {
|
||||
return
|
||||
}
|
||||
|
||||
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)
|
||||
```
|
||||
|
||||
#### 负责对吊舱进行排队的代码
|
||||
|
||||
负责对吊舱进行排队的功能是:
|
||||
|
||||
```
|
||||
// queue for pods that need scheduling
|
||||
podQueue *cache.FIFO
|
||||
```
|
||||
|
||||
负责对吊舱进行排队的代码始于 `scheduler.go` 的 7360 行。当事件处理程序触发,表明新的吊舱显示可用时,这段代码将新的吊舱加入队列中:
|
||||
|
||||
```
|
||||
func (f *ConfigFactory) getNextPod() *v1.Pod {
|
||||
for {
|
||||
pod := cache.Pop(f.podQueue).(*v1.Pod)
|
||||
if f.ResponsibleForPod(pod) {
|
||||
glog.V(4).Infof("About to try and schedule pod %v", pod.Name)
|
||||
return pod
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 处理错误代码
|
||||
|
||||
在吊舱调度中不可避免会遇到调度错误。以下代码是处理调度程序错误的方法。它监听 `podInformer` 然后抛出一个错误,提示此吊舱尚未调度并被终止:
|
||||
|
||||
```
|
||||
// scheduled pod cache
|
||||
podInformer.Informer().AddEventHandler(
|
||||
cache.FilteringResourceEventHandler{
|
||||
FilterFunc: func(obj interface{}) bool {
|
||||
switch t := obj.(type) {
|
||||
case *v1.Pod:
|
||||
return assignedNonTerminatedPod(t)
|
||||
default:
|
||||
runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj))
|
||||
return false
|
||||
}
|
||||
},
|
||||
```
|
||||
|
||||
换句话说,Kubernetes 调度器负责如下:
|
||||
|
||||
* 将新创建的吊舱调度至具有足够空间的节点上,以满足吊舱的资源需求。
|
||||
* 监听 kube-apiserver 和控制器是否创建新的吊舱,然后调度它至集群内一个可用的节点。
|
||||
* 监听未调度的吊舱,并使用 `/binding` 子资源 API 将吊舱绑定至节点。
|
||||
|
||||
例如,假设正在部署一个需要 1 GB 内存和双核 CPU 的应用。因此创建应用吊舱的节点上需有足够资源可用,然后调度器会持续运行监听是否有吊舱需要调度。
|
||||
|
||||
### 了解更多
|
||||
|
||||
要使 Kubernetes 集群工作,你需要使以上所有组件一起同步运行。调度器有一段复杂的的代码,但 Kubernetes 是一个很棒的软件,目前它仍是我们在讨论或采用云原生应用程序时的首选。
|
||||
|
||||
学习 Kubernetes 需要精力和时间,但是将其作为你的专业技能之一能为你的职业生涯带来优势和回报。有很多很好的学习资源可供使用,而且 [官方文档][7] 也很棒。如果你有兴趣了解更多,建议从以下内容开始:
|
||||
|
||||
* [Kubernetes the hard way][8]
|
||||
* [Kubernetes the hard way on bare metal][9]
|
||||
* [Kubernetes the hard way on AWS][10]
|
||||
|
||||
你喜欢的 Kubernetes 学习方法是什么?请在评论中分享吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/11/kubernetes-scheduler
|
||||
|
||||
作者:[Mike Calizo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MZqk](https://github.com/MZqk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mcalizo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/containers_modules_networking_hardware_parts.png?itok=rPpVj92- (Parts, modules, containers for software)
|
||||
[2]: https://kubernetes.io/
|
||||
[3]: https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler/
|
||||
[4]: https://lh4.googleusercontent.com/egB0SSsAglwrZeWpIgX7MDF6u12oxujfoyY6uIPa8WLqeVHb8TYY_how57B4iqByELxvitaH6-zjAh795wxAB8zenOwoz2YSMIFRqHsMWD9ohvUTc3fNLCzo30r7lUynIHqcQIwmtRo
|
||||
[5]: https://kubernetes.io/docs/concepts/workloads/pods/
|
||||
[6]: https://github.com/kubernetes/kubernetes/blob/e4551d50e57c089aab6f67333412d3ca64bc09ae/plugin/pkg/scheduler/scheduler.go
|
||||
[7]: https://kubernetes.io/docs/home/
|
||||
[8]: https://github.com/kelseyhightower/kubernetes-the-hard-way
|
||||
[9]: https://github.com/Praqma/LearnKubernetes/blob/master/kamran/Kubernetes-The-Hard-Way-on-BareMetal.md
|
||||
[10]: https://github.com/Praqma/LearnKubernetes/blob/master/kamran/Kubernetes-The-Hard-Way-on-AWS.md
|
||||
119
published/202102/20210119 Set up a Linux cloud on bare metal.md
Normal file
119
published/202102/20210119 Set up a Linux cloud on bare metal.md
Normal file
@ -0,0 +1,119 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13161-1.html)
|
||||
[#]: subject: (Set up a Linux cloud on bare metal)
|
||||
[#]: via: (https://opensource.com/article/21/1/cloud-image-virt-install)
|
||||
[#]: author: (Sumantro Mukherjee https://opensource.com/users/sumantro)
|
||||
|
||||
在裸机上建立 Linux 云实例
|
||||
======
|
||||
|
||||
> 在 Fedora 上用 virt-install 创建云镜像。
|
||||
|
||||

|
||||
|
||||
虚拟化是使用最多的技术之一。Fedora Linux 使用 [Cloud Base 镜像][2] 来创建通用虚拟机(VM),但设置 Cloud Base 镜像的方法有很多。最近,用于调配虚拟机的 `virt-install` 命令行工具增加了对 `cloud-init` 的支持,因此现在可以使用它在本地配置和运行云镜像。
|
||||
|
||||
本文介绍了如何在裸机上设置一个基本的 Fedora 云实例。同样的步骤可以用于任何 raw 或Qcow2 Cloud Base 镜像。
|
||||
|
||||
### 什么是 --cloud-init?
|
||||
|
||||
`virt-install` 命令使用 `libvirt` 创建一个 KVM、Xen 或 [LXC][3] 客户机。`--cloud-init` 选项使用一个本地文件(称为 “nocloud 数据源”),所以你不需要网络连接来创建镜像。在第一次启动时,`nocloud` 方法会从 iso9660 文件系统(`.iso` 文件)中获取访客机的用户数据和元数据。当你使用这个选项时,`virt-install` 会为 root 用户账户生成一个随机的(临时)密码,提供一个串行控制台,以便你可以登录并更改密码,然后在随后的启动中禁用 `--cloud-init` 选项。
|
||||
|
||||
### 设置 Fedora Cloud Base 镜像
|
||||
|
||||
首先,[下载一个 Fedora Cloud Base(for OpenStack)镜像][2]。
|
||||
|
||||
![Fedora Cloud 网站截图][4]
|
||||
|
||||
然后安装 `virt-install` 命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install virt-install
|
||||
```
|
||||
|
||||
一旦 `virt-install` 安装完毕并下载了 Fedora Cloud Base 镜像,请创建一个名为`cloudinit-user-data.yaml` 的小型 YAML 文件,其中包含 `virt-install` 将使用的一些配置行:
|
||||
|
||||
```
|
||||
#cloud-config
|
||||
password: 'r00t'
|
||||
chpasswd: { expire: false }
|
||||
```
|
||||
|
||||
这个简单的云配置可以设置默认的 `fedora` 用户的密码。如果你想使用会过期的密码,可以将其设置为登录后过期。
|
||||
|
||||
创建并启动虚拟机:
|
||||
|
||||
```
|
||||
$ virt-install --name local-cloud18012709 \
|
||||
--memory 2000 --noreboot \
|
||||
--os-variant detect=on,name=fedora-unknown \
|
||||
--cloud-init user-data="/home/r3zr/cloudinit-user-data.yaml" \
|
||||
--disk=size=10,backing_store="/home/r3zr/Downloads/Fedora-Cloud-Base-33-1.2.x86_64.qcow2"
|
||||
```
|
||||
|
||||
在这个例子中,`local-cloud18012709` 是虚拟机的名称,内存设置为 2000MiB,磁盘大小(虚拟硬盘)设置为 10GB,`--cloud-init` 和 `backing_store` 分别带有你创建的 YAML 配置文件和你下载的 Qcow2 镜像的绝对路径。
|
||||
|
||||
### 登录
|
||||
|
||||
在创建镜像后,你可以用用户名 `fedora` 和 YAML 文件中设置的密码登录(在我的例子中,密码是 `r00t`,但你可能用了别的密码)。一旦你第一次登录,请更改你的密码。
|
||||
|
||||
要关闭虚拟机的电源,执行 `sudo poweroff` 命令,或者按键盘上的 `Ctrl+]`。
|
||||
|
||||
### 启动、停止和销毁虚拟机
|
||||
|
||||
`virsh` 命令用于启动、停止和销毁虚拟机。
|
||||
|
||||
要启动任何停止的虚拟机:
|
||||
|
||||
```
|
||||
$ virsh start <vm-name>
|
||||
```
|
||||
|
||||
要停止任何运行的虚拟机:
|
||||
|
||||
```
|
||||
$ virsh shutdown <vm-name>
|
||||
```
|
||||
|
||||
要列出所有处于运行状态的虚拟机:
|
||||
|
||||
```
|
||||
$ virsh list
|
||||
```
|
||||
|
||||
要销毁虚拟机:
|
||||
|
||||
```
|
||||
$ virsh destroy <vm-name>
|
||||
```
|
||||
|
||||
![销毁虚拟机][6]
|
||||
|
||||
### 快速而简单
|
||||
|
||||
`virt-install` 命令与 `--cloud-init` 选项相结合,可以快速轻松地创建云就绪镜像,而无需担心是否有云来运行它们。无论你是在为重大部署做准备,还是在学习容器,都可以试试`virt-install --cloud-init`。
|
||||
|
||||
在云计算工作中,你有喜欢的工具吗?请在评论中告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/1/cloud-image-virt-install
|
||||
|
||||
作者:[Sumantro Mukherjee][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sumantro
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bus-cloud.png?itok=vz0PIDDS (Sky with clouds and grass)
|
||||
[2]: https://alt.fedoraproject.org/cloud/
|
||||
[3]: https://www.redhat.com/sysadmin/exploring-containers-lxc
|
||||
[4]: https://opensource.com/sites/default/files/uploads/fedoracloud.png (Fedora Cloud website)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/destroyvm.png (Destroying a VM)
|
||||
@ -1,67 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13135-1.html)
|
||||
[#]: subject: (Why choose Plausible for an open source alternative to Google Analytics)
|
||||
[#]: via: (https://opensource.com/article/21/2/plausible)
|
||||
[#]: author: (Ben Rometsch https://opensource.com/users/flagsmith)
|
||||
|
||||
为什么选择 Plausible 作为 Google Analytics 的开源替代品?
|
||||
======
|
||||
Plausible作为Google Analytics 的可行,有效的替代方案正在引起用户的关注。
|
||||
![Analytics: Charts and Graphs][1]
|
||||
|
||||
发挥 Google Analytics 的威力似乎是一个巨大的挑战。实际上,你可以说这听起来似乎不合理。但这正是 [Plausible.io][2]取得巨大成功的原因,自 2018 年以来已注册了数千名新用户。
|
||||
> Plausible 作为 Google Analytics 的可行、有效的替代方案正在引起用户的关注。
|
||||
|
||||
Plausible 的联合创始人 Uku Taht 和 Marko Saric 最近出现在 [The Craft of Open Source][3] 播客上,谈论了这个项目以及他们如何:
|
||||
|
||||
|
||||
替代 Google Analytics 似乎是一个巨大的挑战。实际上,你可以说这听起来似乎不合理(LCTT 译注:Plausible 意即“貌似合理”)。但这正是 [Plausible.io][2] 取得巨大成功的原因,自 2018 年以来已注册了数千名新用户。
|
||||
|
||||
Plausible 的联合创始人 Uku Taht 和 Marko Saric 最近出现在 [The Craft of Open Source][3] 播客上,谈论了这个项目以及他们是如何:
|
||||
|
||||
* 创建了一个可行的替代 Google Analytics 的方案
|
||||
* 在不到两年的时间里获得了如此大的发展势头
|
||||
* 通过开源项目外包实现其目标
|
||||
|
||||
|
||||
* 通过开源他们的项目实现其目标
|
||||
|
||||
请继续阅读他们与播客主持人和 Flagsmith 创始人 Ben Rometsch 的对话摘要。
|
||||
|
||||
### Plausible 是如何开始的
|
||||
|
||||
2018年 冬天,Uku 开始编写一个他认为急需的项目:一个可行的、有效的 Google Analytics 替代方案。因为他对 Google 产品的发展方向感到失望,而且所有其他数据解决方案似乎都把 Google 当作“数据处理中间人”。
|
||||
2018 年冬天,Uku 开始编写一个他认为急需的项目:一个可行的、有效的 Google Analytics 替代方案。因为他对 Google 产品的发展方向感到失望,而且所有其他数据解决方案似乎都把 Google 当作“数据处理中间人”。
|
||||
|
||||
Uku 的第一直觉是利用现有的数据库解决方案专注于分析方面的工作。马上,他就遇到了一些挑战。第一次尝试使用了 PostgreSQL,这在技术上很幼稚,因为它很快就变得不堪重负,效率很低。因此,他的目标蜕变成了做一个分析产品,可以处理大量的数据点,而且性能不会有明显的下降。长话短说,Uku 成功了,Plausible 现在每月可以摄取超过 8000 万条记录。
|
||||
Uku 的第一直觉是利用现有的数据库解决方案专注于分析方面的工作。马上,他就遇到了一些挑战。开始尝试使用了 PostgreSQL,这在技术上很幼稚,因为它很快就变得不堪重负,效率低下。因此,他的目标蜕变成了做一个分析产品,可以处理大量的数据点,而且性能不会有明显的下降。简而言之,Uku 成功了,Plausible 现在每月可以收取超过 8000 万条记录。
|
||||
|
||||
Plausible 的第一个版本于 2019 年夏天发布。2020 年 3 月,Marko 加入,负责项目的传播和营销方面的工作。从那时起,它的受欢迎程度以相当大的势头增长。
|
||||
Plausible 的第一个版本于 2019 年夏天发布。2020 年 3 月,Marko 加入,负责项目的传播和营销方面的工作。从那时起,它它的受欢迎程度有了很大的增长。
|
||||
|
||||
### 为什么要开源?
|
||||
|
||||
Uku 热衷于遵循“独立黑客”的软件开发路线:创建一个产品,把它放在那里,然后看看它如何成长。开源在这方面是有意义的,因为你可以迅速发展一个社区并获得人气。
|
||||
Uku 热衷于遵循“独立黑客”的软件开发路线:创建一个产品,把它投放出去,然后看看它如何成长。开源在这方面是有意义的,因为你可以迅速发展一个社区并获得人气。
|
||||
|
||||
但 Plausible 一开始并不是开源的。Uku 最初担心软件的敏感代码,比如计费代码,但他很快就发布了,因为这对没有 API 令牌的人来说是没有用的。
|
||||
|
||||
现在,Plausible 是在 [AGPL][4] 下完全开源的,他们选择了 AGPL 而不是 MIT 许可。Uku 解释说,在 MIT 许可下,任何人都可以不受限制地对代码做任何事情。在 AGPL 下,如果有人修改代码,他们必须将他们的修改开源,并将代码回馈给社区。这意味着,大公司不能拿着原始代码在此基础上进行构建,然后获得所有的回报。他们必须共享,使得竞争环境更加公平。例如,如果一家公司想插入他们的计费或登录系统,他们有法律义务发布代码。
|
||||
|
||||
现在,Plausible 是在 [AGPL][4] 下完全开源的,他们选择了 AGPL 而不是 MIT 许可。Uku 解释说,在 MIT 许可下,任何人都可以不受限制地对代码做任何事情。在 AGPL 下,如果有人修改代码,他们必须将他们的修改开源,并将代码回馈给社区。这意味着,大公司不能拿着原始代码,在此基础上进行构建,然后获得所有的回报。他们必须共享,使得竞争环境更加公平。例如,如果一家公司想插入他们的计费或登录系统,他们将有法律义务发布代码。
|
||||
|
||||
|
||||
在播客中,Uku 问我关于 Flagsmith 的授权,目前Flagsmith的授权采用 BSD 3-Clause 许可,该许可证是高度允许的,但我即将把一些功能移到更严格的许可后面。到目前为止,Flagsmith 社区已经理解了这一变化,因为他们意识到这将带来更多更好的功能。
|
||||
在播客中,Uku 向我询问了关于 Flagsmith 的授权,目前 Flagsmith 的授权采用 BSD 三句版许可,该许可证是高度开放的,但我即将把一些功能移到更严格的许可后面。到目前为止,Flagsmith 社区已经理解了这一变化,因为他们意识到这将带来更多更好的功能。
|
||||
|
||||
### Plausible vs. Google Analytics
|
||||
|
||||
Uku说,在他看来,开源的精神是,代码应该是开放的,任何人都可以进行商业使用,并与社区共享,但你可以把一个闭源的 API 模块作为专有附加组件保留下来。这样一来,Plausible 和其他公司就可以通过创建和销售定制的 API 附加许可来满足不同的使用场景。
|
||||
Uku 说,在他看来,开源的精神是,代码应该是开放的,任何人都可以进行商业使用,并与社区共享,但你可以把一个闭源的 API 模块作为专有附加组件保留下来。这样一来,Plausible 和其他公司就可以通过创建和销售定制的 API 附加许可来满足不同的使用场景。
|
||||
|
||||
Marko 职位上是一名开发者,但从营销方面来说,他努力让这个项目在 Hacker News 和 Lobster 等网站上得到报道,并建立了 Twitter 帐户以帮助产生动力。这种宣传带来的热潮也意味着该项目在 GitHub 上起飞,从 500 颗星到 4300 颗星。随着流量的增长,Plausible 出现在 GitHub 的趋势列表中,这帮助它的人气滚起了雪球。
|
||||
Marko 职位上是一名开发者,但从营销方面来说,他努力让这个项目在 Hacker News 和 Lobster 等网站上得到报道,并建立了 Twitter 帐户以帮助产生动力。这种宣传带来的热潮也意味着该项目在 GitHub 上起飞,从 500 颗星到 4300 颗星。随着流量的增长,Plausible 出现在 GitHub 的趋势列表中,这让其受欢迎程度像滚雪球一样。
|
||||
|
||||
Marko 还非常注重发布和推广博客文章。这一策略得到了回报,在最初的 6 个月里,有四五篇文章进入了病毒式传播,他利用这些峰值来放大营销信息,加速了增长。
|
||||
|
||||
Plausible 成长过程中最大的挑战是让人们从 Google Analytics 上转换过来。这个项目的主要目标是创建一个有用、高效、准确的网络分析产品。它还需要符合法规,并为企业和网站访问者提供高度的隐私。
|
||||
|
||||
Plausible 现在已经在 8000 多个网站上运行。通过与客户的交谈,Uku 估计其中约 90% 的客户会已经用过 Google Analytics。
|
||||
Plausible 现在已经在 8000 多个网站上运行。通过与客户的交谈,Uku 估计其中约 90% 的客户运行过 Google Analytics。
|
||||
|
||||
Plausible 以标准的软件即服务 (SaaS) 订阅模式运行。为了让事情更公平,它按月页面浏览量收费,而不是按网站收费。对于季节性网站来说,这可能会有麻烦,比如说电子商务网站在节假日会激增,或者美国大选网站每四年激增一次。这些可能会导致月度订阅模式下的定价问题,但它通常对大多数网站很好。
|
||||
|
||||
|
||||
### 查看播客
|
||||
|
||||
想要了解更多关于 Uku 和 Marko 如何以惊人的速度发展开源 Plausible 项目,并使其获得商业上的成功,请[收听播客][3],并查看[其他集锦][5],了解更多关于“开源软件社区的来龙去脉”。
|
||||
想要了解更多关于 Uku 和 Marko 如何以惊人的速度发展开源 Plausible 项目,并使其获得商业上的成功,请[收听播客][3],并查看[其他剧集][5],了解更多关于“开源软件社区的来龙去脉”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -70,7 +67,7 @@ via: https://opensource.com/article/21/2/plausible
|
||||
作者:[Ben Rometsch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,18 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13139-1.html)
|
||||
[#]: subject: (Viper Browser: A Lightweight Qt5-based Web Browser With A Focus on Privacy and Minimalism)
|
||||
[#]: via: (https://itsfoss.com/viper-browser/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Viper 浏览器:一款基于 Qt5 的轻量级浏览器,注重隐私和简约
|
||||
Viper 浏览器:一款注重隐私和简约的轻量级 Qt5 浏览器
|
||||
======
|
||||
|
||||
**简介:Viper 浏览器是一个基于 Qt 的浏览器,它提供了简单的用户体验,同时考虑到隐私问题。**_
|
||||

|
||||
|
||||
> Viper 浏览器是一个基于 Qt 的浏览器,它提供了简单易用的用户体验,同时考虑到隐私问题。
|
||||
|
||||
虽然大多数流行的浏览器都运行在 Chromium 之上,但像 [Firefox][1]、[Beaker 浏览器][2]以及其他一些 [chrome 替代品][3]这样独特的替代品不应该停止存在。
|
||||
|
||||
@ -20,11 +22,9 @@ Viper 浏览器:一款基于 Qt5 的轻量级浏览器,注重隐私和简约
|
||||
|
||||
### Viper 浏览器:一个基于 Qt5 的开源浏览器
|
||||
|
||||
_**注意**:Viper 浏览器是一个只有几个贡献者的相当新的项目。它缺乏某些功能,我将在下文提及。_
|
||||
**注意**:Viper 浏览器是一个只有几个贡献者的相当新的项目。它缺乏某些功能,我将在下文提及。
|
||||
|
||||
![][7]
|
||||
|
||||
Viper 是一款有趣的网络浏览器,在利用 [QtWebEngine][8] 的同时,它专注于成为一个强大而又轻巧的选择。
|
||||
Viper 是一款有趣的 Web 浏览器,在利用 [QtWebEngine][8] 的同时,它专注于成为一个强大而又轻巧的选择。
|
||||
|
||||
QtWebEngine 借用了 Chromium 的代码,但它不包括连接到 Google 平台的二进制文件和服务。
|
||||
|
||||
@ -49,8 +49,6 @@ QtWebEngine 借用了 Chromium 的代码,但它不包括连接到 Google 平
|
||||
* 禁用 JavaScript 的选项
|
||||
* 能够阻止图像加载
|
||||
|
||||
|
||||
|
||||
除了这些亮点之外,你还可以轻松地调整隐私设置,以删除你的历史记录、清理已有 cookies,以及一些更多的选项。
|
||||
|
||||
![][12]
|
||||
@ -61,7 +59,7 @@ QtWebEngine 借用了 Chromium 的代码,但它不包括连接到 Google 平
|
||||
|
||||
如果你需要帮助,你也可以参考我们的[在 Linux 上使用 AppImage 文件][14]指南。如果你好奇,你可以在 [GitHub][5] 上探索更多关于它的内容。
|
||||
|
||||
[Viper 浏览器][5]
|
||||
- [Viper 浏览器][5]
|
||||
|
||||
### 我对使用 Viper 浏览器的看法
|
||||
|
||||
@ -86,7 +84,7 @@ via: https://itsfoss.com/viper-browser/
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (amorsu)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13157-1.html)
|
||||
[#]: subject: (4 reasons to choose Linux for art and design)
|
||||
[#]: via: (https://opensource.com/article/21/2/linux-art-design)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
选择 Linux 来做艺术设计的 4 个理由
|
||||
======
|
||||
|
||||
> 开源会强化你的创造力。因为它把你带出专有的思维定势,开阔你的视野,从而带来更多的可能性。让我们探索一些开源的创意项目。
|
||||
|
||||

|
||||
|
||||
2021 年,人们比以前的任何时候都更有理由来爱上 Linux。在这个系列,我会分享 21 个选择 Linux 的原因。今天,让我来解释一下,为什么 Linux 是艺术设计的绝佳选择。
|
||||
|
||||
Linux 在服务器和云计算方面获得很多的赞誉。让不少人感到惊讶的是,Linux 刚好也有一系列的很棒的创意设计工具,并且这些工具在用户体验和质量方面可以媲美那些流行的创意设计工具。我第一次使用开源的设计工具时,并不是因为我没有其他工具可以选择。相反的,我是在接触了大量的这些领先的公司提供的专有设计工具后,才开始使用开源设计工具。我之所以最后选择开源设计工具是因为开源更有意义,而且我能获得更好的产出。这些都是一些笼统的说法,所以请允许我解释一下。
|
||||
|
||||
### 高可用性意味着高生产力
|
||||
|
||||
“生产力”这一次对于不同的人来说含义不一样。当我想到生产力,就是当你坐下来做事情,并能够完成你给自己设定的所有任务的时候,这时就很有成就感。但是当你总是被一些你无法掌控的事情打断,那你的生产力就下降了。
|
||||
|
||||
计算机看起来是不可预测的,诚然有很多事情会出错。电脑是由很多的硬件组成的,它们任何一个都有可能在任何时间出问题。软件会有 bug,也有修复这些 bug 的更新,而更新后又会带来新的 bug。如果你对电脑不了解,它可能就像一个定时炸弹,等着爆发。带着数字世界里的这么多的潜在问题,去接受一个当某些条件不满足(比如许可证,或者订阅费)就会不工作的软件,对我来说就显得很不理智。
|
||||
|
||||
![Inkscape 应用][2]
|
||||
|
||||
开源的创意设计应用不需要订阅费,也不需要许可证。在你需要的时候,它们都能获取得到,并且通常都是跨平台的。这就意味着,当你坐在工作的电脑面前,你就能确定你能用到那些必需的软件。而如果某天你很忙碌,却发现你面前的电脑不工作了,解决办法就是找到一个能工作的,安装你的创意设计软件,然后开始工作。
|
||||
|
||||
例如,要找到一台无法运行 Inkscape 的电脑,比找到一台可以运行那些专有软件的电脑要难得多。这就叫做高可用。这是游戏规则的改变者。我从来不曾遇到因为软件用不了而不得不干等,浪费我数小时时间的事情。
|
||||
|
||||
### 开放访问更有利于多样性
|
||||
|
||||
我在设计行业工作的时候,我的很多同事都是通过自学的方式来学习艺术和技术方面的知识,这让我感到惊讶。有的通过使用那些最新的昂贵的“专业”软件来自学,但总有一大群人是通过使用自由和开源的软件来完善他们的数字化的职业技能。因为,对于孩子,或者没钱的大学生来说,这才是他们能负担的起,而且很容易就能获得的。
|
||||
|
||||
这是一种不同的高可用性,但这对我和许多其他用户来说很重要,如果不是因为开源,他们就不会从事创意行业。即使那些有提供付费订阅的开源项目,比如 Ardour,都能确保他的用户在不需要支付任何费用的时候也能使用软件。
|
||||
|
||||
![Ardour 界面][4]
|
||||
|
||||
当你不限制别人用你的软件的时候,你其实拥有了更多的潜在用户。如果你这样做了,那么你就开放了一个接收多样的创意声音的窗口。艺术钟爱影响力,你可以借鉴的经验和想法越多就越好。这就是开源设计软件所带来的可能性。
|
||||
|
||||
### 文件格式支持更具包容性
|
||||
|
||||
我们都知道在几乎所有行业里面包容性的价值。在各种意义上,邀请更多的人到派对可以造就更壮观的场面。知道这一点,当看到有的项目或者创新公司只邀请某些人去合作,只接受某些文件格式,就让我感到很痛苦。这看起来很陈旧,就像某个远古时代的精英主义的遗迹,而这是即使在今天都在发生的真实问题。
|
||||
|
||||
令人惊讶和不幸的是,这不是因为技术上的限制。专有软件可以访问开源的文件格式,因为这些格式是开源的,而且可以自由地集成到各种应用里面。集成这些格式不需要任何回报。而相比之下,专有的文件格式被笼罩在秘密之中,只被限制于提供给几个愿意付钱的人使用。这很糟糕,而且常常,你无法在没有这些专有软件的情况下打开一些文件来获取你的数据。令人惊喜的是,开源的设计软件却是尽力的支持更多的专有文件格式。以下是一些 Inkscape 所支持的令人难以置信的列表样本:
|
||||
|
||||
![可用的 Inkscape 文件格式][5]
|
||||
|
||||
而这大部分都是在没有这些专有格式厂商的支持下开发出来的。
|
||||
|
||||
支持开放的文件格式可以更包容,对所有人都更好。
|
||||
|
||||
### 对新的创意没有限制
|
||||
|
||||
我之所以爱上开源的其中一个原因是,解决一个指定任务时,有彻底的多样性。当你在专有软件周围时,你所看到的世界是基于你所能够获取得到的东西。比如说,你过你打算处理一些照片,你通常会把你的意图局限在你所知道的可能性上面。你从你的架子上的 4 款或 10 款应用中,挑选出 3 款,因为它们是目前你唯一能够获取得到的选项。
|
||||
|
||||
在开源领域,你通常会有好几个“显而易见的”必备解决方案,但同时你还有一打的角逐者在边缘转悠,供你选择。这些选项有时只是半成品,或者它们超级专注于某项任务,又或者它们学起来有点挑战性,但最主要的是,它们是独特的,而且充满创新的。有时候,它们是被某些不按“套路”出牌的人所开发的,因此处理的方法和市场上现有的产品截然不同。其他时候,它们是被那些熟悉做事情的“正确”方式,但还是在尝试不同策略的人所开发的。这就像是一个充满可能性的巨大的动态的头脑风暴。
|
||||
|
||||
这种类型的日常创新能够引领出闪现的灵感、光辉时刻,或者影响广泛的通用性改进。比如说,著名的 GIMP 滤镜,(用于从图像中移除项目并自动替换背景)是如此的受欢迎以至于后来被专有图片编辑软件商拿去“借鉴”。这是成功的一步,但是对于一个艺术家而言,个人的影响才是最关键的。我常感叹于新的 Linux 用户的创意,而我只是在技术展会上展示给他们一个简单的音频,或者视频滤镜,或者绘图应用。没有任何的指导,或者应用场景,从简单的交互中喷发出来的关于新的工具的主意,是令人兴奋和充满启发的,通过实验中一些简单的工具,一个全新的艺术系列可以轻而易举的浮现出来。
|
||||
|
||||
只要在适当的工具集都有的情况下,有很多方式来更有效的工作。虽然私有软件通常也不会反对更聪明的工作习惯的点子,专注于实现自动化任务让用户可以更轻松的工作,对他们也没有直接的收益。Linux 和开源软件就是很大程度专为 [自动化和编排][6] 而建的,而不只是服务器。像 [ImageMagick][7] 和 [GIMP 脚本][8] 这样的工具改变了我的处理图片的方式,包括批量处理方面和纯粹实验方面。
|
||||
|
||||
你永远不知道你可以创造什么,如果你有一个你从来想象不到会存在的工具的话。
|
||||
|
||||
### Linux 艺术家
|
||||
|
||||
这里有 [使用开源的艺术家社区][9],从 [photography][10] 到 [makers][11] 到 [musicians][12],还有更多更多。如果你想要创新,试试 Linux 吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/linux-art-design
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[amorsu](https://github.com/amorsu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/painting_computer_screen_art_design_creative.png?itok=LVAeQx3_ (Painting art on a computer screen)
|
||||
[2]: https://opensource.com/sites/default/files/inkscape_0.jpg
|
||||
[3]: https://community.ardour.org/subscribe
|
||||
[4]: https://opensource.com/sites/default/files/ardour.jpg
|
||||
[5]: https://opensource.com/sites/default/files/formats.jpg
|
||||
[6]: https://opensource.com/article/20/11/orchestration-vs-automation
|
||||
[7]: https://opensource.com/life/16/6/fun-and-semi-useless-toys-linux#imagemagick
|
||||
[8]: https://opensource.com/article/21/1/gimp-scripting
|
||||
[9]: https://librearts.org
|
||||
[10]: https://pixls.us
|
||||
[11]: https://www.redhat.com/en/blog/channel/red-hat-open-studio
|
||||
[12]: https://linuxmusicians.com
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13140-1.html)
|
||||
[#]: subject: (A practical guide to JavaScript closures)
|
||||
[#]: via: (https://opensource.com/article/21/2/javascript-closures)
|
||||
[#]: author: (Nimisha Mukherjee https://opensource.com/users/nimisha)
|
||||
@ -12,7 +12,7 @@ JavaScript 闭包实践
|
||||
|
||||
> 通过深入了解 JavaScript 的高级概念之一:闭包,更好地理解 JavaScript 代码的工作和执行方式。
|
||||
|
||||
![女性编程][1]
|
||||

|
||||
|
||||
在《[JavaScript 如此受欢迎的 4 个原因][2]》中,我提到了一些高级 JavaScript 概念。在本文中,我将深入探讨其中的一个概念:<ruby>闭包<rt>closure</rt></ruby>。
|
||||
|
||||
@ -123,7 +123,7 @@ via: https://opensource.com/article/21/2/javascript-closures
|
||||
作者:[Nimisha Mukherjee][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13151-1.html)
|
||||
[#]: subject: (Meet Plots: A Mathematical Graph Plotting App for Linux Desktop)
|
||||
[#]: via: (https://itsfoss.com/plots-graph-app/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
认识 Plots:一款适用于 Linux 桌面的数学图形绘图应用
|
||||
======
|
||||
|
||||

|
||||
|
||||
Plots 是一款图形绘图应用,它可以轻松实现数学公式的可视化。你可以用它来绘制任意三角函数、双曲函数、指数函数和对数函数的和与积。
|
||||
|
||||
### 在 Linux 上使用 Plots 绘制数学图形
|
||||
|
||||
[Plots][1] 是一款简单的应用,它的灵感来自于像 [Desmos][2] 这样的 Web 图形绘图应用。它能让你绘制不同数学函数的图形,你可以交互式地输入这些函数,还可以自定义绘图的颜色。
|
||||
|
||||
Plots 是用 Python 编写的,它使用 [OpenGL][3] 来利用现代硬件。它使用 GTK 3,因此可以很好地与 GNOME 桌面集成。
|
||||
|
||||
![][4]
|
||||
|
||||
使用 Plots 非常直白。要添加一个新的方程,点击加号。点击垃圾箱图标可以删除方程。还可以选择撤销和重做。你也可以放大和缩小。
|
||||
|
||||
![][5]
|
||||
|
||||
你输入方程的文本框是友好的。菜单中有一个“帮助”选项可以访问文档。你可以在这里找到关于如何编写各种数学符号的有用提示。你也可以复制粘贴方程。
|
||||
|
||||
![][6]
|
||||
|
||||
在深色模式下,侧栏公式区域变成了深色,但主绘图区域仍然是白色。我相信这也许是这样设计的。
|
||||
|
||||
你可以使用多个函数,并将它们全部绘制在一张图中:
|
||||
|
||||
![][7]
|
||||
|
||||
我发现它在尝试粘贴一些它无法理解的方程时崩溃了。如果你写了一些它不能理解的东西,或者与现有的方程冲突,所有图形都会消失,去掉不正确的方程就会恢复图形。
|
||||
|
||||
不幸的是,没有导出绘图或复制到剪贴板的选项。你可以随时 [在 Linux 中截图][8],并在你要添加图像的文档中使用它。
|
||||
|
||||
### 在 Linux 上安装 Plots
|
||||
|
||||
Plots 为各种发行版提供了不同的安装方式。
|
||||
|
||||
Ubuntu 20.04 和 20.10 用户可以[使用 PPA][11]:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:apandada1/plots
|
||||
sudo apt update
|
||||
sudo apt install plots
|
||||
```
|
||||
|
||||
对于其他基于 Debian 的发行版,你可以使用 [这里][13] 的 [deb 文件安装][12]。
|
||||
|
||||
我没有在 AUR 软件包列表中找到它,但是作为 Arch Linux 用户,你可以使用 Flatpak 软件包或者使用 Python 安装它。
|
||||
|
||||
- [Plots Flatpak 软件包][14]
|
||||
|
||||
如果你感兴趣,可以在它的 GitHub 仓库中查看源代码。如果你喜欢这款应用,请考虑在 GitHub 上给它 star。
|
||||
|
||||
- [GitHub 上的 Plots 源码][1]
|
||||
|
||||
### 结论
|
||||
|
||||
Plots 主要用于帮助学生学习数学或相关科目,但它在很多其他场景下也能发挥作用。我知道不是每个人都需要,但肯定会对学术界和学校的人有帮助。
|
||||
|
||||
不过我倒是希望能有导出图片的功能。也许开发者可以在未来的版本中加入这个功能。
|
||||
|
||||
你知道有什么类似的绘图应用吗?Plots 与它们相比如何?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/plots-graph-app/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/alexhuntley/Plots/
|
||||
[2]: https://www.desmos.com/
|
||||
[3]: https://www.opengl.org/
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/fourier-graph-plots.png?resize=800%2C492&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/plots-app-linux-1.png?resize=800%2C518&ssl=1
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/plots-app-linux.png?resize=800%2C527&ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/multiple-equations-plots.png?resize=800%2C492&ssl=1
|
||||
[8]: https://itsfoss.com/take-screenshot-linux/
|
||||
[10]: https://itsfoss.com/keenwrite/
|
||||
[11]: https://itsfoss.com/ppa-guide/
|
||||
[12]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[13]: https://launchpad.net/~apandada1/+archive/ubuntu/plots/+packages
|
||||
[14]: https://flathub.org/apps/details/com.github.alexhuntley.Plots
|
||||
@ -0,0 +1,75 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13160-1.html)
|
||||
[#]: subject: (5 reasons to use Linux package managers)
|
||||
[#]: via: (https://opensource.com/article/21/2/linux-package-management)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 Linux 软件包管理器的 5 个理由
|
||||
======
|
||||
|
||||
> 包管理器可以跟踪你安装的软件的所有组件,使得更新、重装和故障排除更加容易。
|
||||
|
||||

|
||||
|
||||
在 2021 年,人们喜欢 Linux 的理由比以往任何时候都多。在这个系列中,我将分享 21 个使用 Linux 的不同理由。今天,我将谈谈软件仓库。
|
||||
|
||||
在我使用 Linux 之前,我认为在计算机上安装的应用是理所当然的。我会根据需要安装应用,如果我最后没有使用它们,我就会把它们忘掉,让它们占用我的硬盘空间。终于有一天,我的硬盘空间会变得稀缺,我就会疯狂地删除应用,为更重要的数据腾出空间。但不可避免的是,应用只能释放出有限的空间,所以我将注意力转移到与这些应用一起安装的所有其他零碎内容上,无论是媒体内容还是配置文件和文档。这不是一个管理电脑的好方法。我知道这一点,但我并没有想过要有其他的选择,因为正如人们所说,你不知道自己不知道什么。
|
||||
|
||||
当我改用 Linux 时,我发现安装应用的方式有些不同。在 Linux 上,会建议你不要去网站上找应用的安装程序。取而代之的是,运行一个命令,应用就会被安装到系统上,并记录每个单独的文件、库、配置文件、文档和媒体资产。
|
||||
|
||||
### 什么是软件仓库?
|
||||
|
||||
在 Linux 上安装应用的默认方法是从发行版软件仓库中安装。这可能听起来像应用商店,那是因为现代应用商店借鉴了很多软件仓库的概念。[Linux 也有应用商店][2],但软件仓库是独一无二的。你通过一个*包管理器*从软件仓库中获得一个应用,它使你的 Linux 系统能够记录和跟踪你所安装的每一个组件。
|
||||
|
||||
这里有五个原因可以让你确切地知道你的系统上有什么东西,可以说是非常有用。
|
||||
|
||||
#### 1、移除旧应用
|
||||
|
||||
当你的计算机知道应用安装的每一个文件时,卸载你不再需要的文件真的很容易。在 Linux 上,安装 [31 个不同的文本编辑器][3],然后卸载 30 个你不喜欢的文本编辑器是没有问题的。当你在 Linux 上卸载的时候,你就真的卸载了。
|
||||
|
||||
#### 2、按你的意思重新安装
|
||||
|
||||
不仅卸载要彻底,*重装*也很有意义。在许多平台上,如果一个应用出了问题,有时会建议你重新安装它。通常情况下,谁也说不清为什么要重装一个应用。不过,人们还是经常会隐隐约约地怀疑某个地方的文件已经损坏了(换句话说,数据写入错误),所以希望重装可以覆盖坏的文件以让软件重新工作。这是个不错的建议,但对于任何技术人员来说,不知道是什么地方出了问题都是令人沮丧的。更糟糕的是,如果不仔细跟踪,就不能保证所有的文件都会在重装过程中被刷新,因为通常没有办法知道与应用程序一起安装的所有文件在第一时间就删除了。有了软件包管理器,你可以强制彻底删除旧文件,以确保新文件的全新安装。同样重要的是,你可以研究每个文件并可能找出导致问题的文件,但这是开源和 Linux 的一个特点,而不是包管理。
|
||||
|
||||
#### 3、保持你应用的更新
|
||||
|
||||
不要听别人告诉你的 Linux 比其他操作系统“更安全”。计算机是由代码组成的,而我们人类每天都会以新的、有趣的方式找到利用这些代码的方法。因为 Linux 上的绝大多数应用都是开源的,所以许多漏洞都会以“<ruby>常见漏洞和暴露<rt>Common Vulnerability and Exposures</rt></ruby>”(CVE)的形式公开。大量涌入的安全漏洞报告似乎是一件坏事,但这绝对是一个*知道*远比*不知道*好的案例。毕竟,没有人告诉你有问题,并不意味着没有问题。漏洞报告是好的。它们对每个人都有好处。而且,当开发人员修复安全漏洞时,对你而言,及时获得这些修复程序很重要,最好不用自己记着动手修复。
|
||||
|
||||
包管理器正是为了实现这一点而设计的。当应用收到更新时,无论是修补潜在的安全问题还是引入令人兴奋的新功能,你的包管理器应用都会提醒你可用的更新。
|
||||
|
||||
#### 4、保持轻便
|
||||
|
||||
假设你有应用 A 和应用 B,这两个应用都需要库 C。在某些操作系统上,通过得到 A 和 B,就会得到了两个 C 的副本。这显然是多余的,所以想象一下,每个应用都会发生几次。冗余的库很快就会增加,而且由于对一个给定的库没有单一的“正确”来源,所以几乎不可能确保你使用的是最新的甚至是一致的版本。
|
||||
|
||||
我承认我不会整天坐在这里琢磨软件库,但我确实记得我琢磨的日子,尽管我不知道这就是困扰我的原因。在我还没有改用 Linux 之前,我在处理工作用的媒体文件时遇到错误,或者在玩不同的游戏时出现故障,或者在阅读 PDF 时出现怪异的现象,等等,这些都不是什么稀奇的事情。当时我花了很多时间去调查这些错误。我仍然记得,我的系统上有两个主要的应用分别捆绑了相同(但有区别)的图形后端技术。当一个程序的输出导入到另一个程序时,这种不匹配会导致错误。它本来是可以工作的,但是由于同一个库文件集合的旧版本中的一个错误,一个应用的热修复程序并没有给另一个应用带来好处。
|
||||
|
||||
包管理器知道每个应用需要哪些后端(被称为*依赖关系*),并且避免重新安装已经在你系统上的软件。
|
||||
|
||||
#### 5、保持简单
|
||||
|
||||
作为一个 Linux 用户,我要感谢包管理器,因为它帮助我的生活变得简单。我不必考虑我安装的软件,我需要更新的东西,也不必考虑完成后是否真的将其卸载了。我毫不犹豫地试用软件。而当我在安装一台新电脑时,我运行 [一个简单的 Ansible 脚本][4] 来自动安装我所依赖的所有软件的最新版本。这很简单,很智能,也是一种独特的解放。
|
||||
|
||||
### 更好的包管理
|
||||
|
||||
Linux 从整体看待应用和操作系统。毕竟,开源是建立在其他开源工作基础上的,所以发行版维护者理解依赖*栈*的概念。Linux 上的包管理了解你的整个系统、系统上的库和支持文件以及你安装的应用。这些不同的部分协调工作,为你提供了一套高效、优化和强大的应用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/linux-package-management
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_gift_giveaway_box_520x292.png?itok=w1YQhNH1 (Gift box opens with colors coming out)
|
||||
[2]: http://flathub.org
|
||||
[3]: https://opensource.com/article/21/1/text-editor-roundup
|
||||
[4]: https://opensource.com/article/20/9/install-packages-ansible
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13143-1.html)
|
||||
[#]: subject: (Use this bootable USB drive on Linux to rescue Windows users)
|
||||
[#]: via: (https://opensource.com/article/21/2/linux-woeusb)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
如何在 Linux 中创建 USB 启动盘来拯救 Windows 用户
|
||||
======
|
||||
|
||||
> WoeUSB 可以在 Linux 中制作 Windows 启动盘,并帮助你的朋友解锁他们罢工的机器。
|
||||
|
||||

|
||||
|
||||
人们经常要求我帮助他们恢复被锁死或损坏的 Windows 电脑。有时,我可以使用 Linux USB 启动盘来挂载 Windows 分区,然后从损坏的系统中传输和备份文件。
|
||||
|
||||
有的时候,客户丢失了他们的密码或以其他方式锁死了他们的登录账户凭证。解锁账户的一种方法是创建一个 Windows 启动盘来修复计算机。微软允许你从网站下载 Windows 的副本,并提供创建 USB 启动盘的工具。但要使用它们,你需要一台 Windows 电脑,这意味着,作为一个 Linux 用户,我需要其他方法来创建一个 DVD 或 USB 启动盘。我发现在 Linux 上创建 Windows USB 很困难。我的可靠工具,如 [Etcher.io][2]、[Popsicle][3](适用于 Pop!_OS)和 [UNetbootin][4],或者从命令行使用 `dd` 来创建可启动媒体,都不是很成功。
|
||||
|
||||
直到我发现了 [WoeUSB-ng][5],一个 [GPL 3.0][6] 许可的 Linux 工具,它可以为 Windows Vista、7、8 和 10 创建一个 USB 启动盘。这个开源软件有两个程序:一个命令行工具和一个图形用户界面 (GUI) 版本。
|
||||
|
||||
### 安装 WoeUSB-ng
|
||||
|
||||
GitHub 仓库包含了在 Arch、Ubuntu、Fedora 或使用 pip3 [安装][7] WoeUSB-ng 的说明。
|
||||
|
||||
如果你是受支持的 Linux 发行版,你可以使用你的包管理器安装 WoeUSB-ng。或者,你可以使用 Python 的包管理器 [pip][8] 来安装应用程序。这在任何 Linux 发行版中都是通用的。这些方法在功能上没有区别,所以使用你熟悉的任何一种。
|
||||
|
||||
我运行的是 Pop!_OS,它是 Ubuntu 的衍生版本,但由于对 Python 很熟悉,我选择了 pip3 安装:
|
||||
|
||||
```
|
||||
$ sudo pip3 install WoeUSB-ng
|
||||
```
|
||||
|
||||
### 创建一个启动盘
|
||||
|
||||
你可以从命令行或 GUI 版本使用 WoeUSB-ng。
|
||||
|
||||
要从命令行创建一个启动盘,语法要求命令包含 Windows ISO 文件的路径和一个设备。(本例中是 `/dev/sdX`。使用 `lsblk` 命令来确定你的驱动器)
|
||||
|
||||
```
|
||||
$ sudo woeusb --device Windows.iso /dev/sdX
|
||||
```
|
||||
|
||||
你也可以启动该程序,以获得简单易用的界面。在 WoeUSB-ng 应用程序窗口中,找到 `Windows.iso` 文件并选择它。选择你的 USB 目标设备(你想变成 Windows 启动盘的驱动器)。这将会删除这个驱动器上的所有信息,所以要谨慎选择,然后仔细检查(再三检查)你的选择!
|
||||
|
||||
当你确认正确选择目标驱动器后,点击 **Install** 按钮。
|
||||
|
||||
![WoeUSB-ng UI][9]
|
||||
|
||||
创建该介质需要 5 到 10 分钟,这取决于你的 Linux 电脑的处理器、内存、USB 端口速度等。请耐心等待。
|
||||
|
||||
当这个过程完成并验证后,你将有可用的 Windows USB 启动盘,以帮助其他人修复 Windows 计算机。
|
||||
|
||||
### 帮助他人
|
||||
|
||||
开源就是为了帮助他人。很多时候,你可以通过使用基于 Linux 的[系统救援 CD][11] 来帮助 Windows 用户。但有时,唯一的帮助方式是直接从 Windows 中获取,而 WoeUSB-ng 是一个很好的开源工具,它可以让这成为可能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/linux-woeusb
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
|
||||
[2]: https://etcher.io/
|
||||
[3]: https://github.com/pop-os/popsicle
|
||||
[4]: https://github.com/unetbootin/unetbootin
|
||||
[5]: https://github.com/WoeUSB/WoeUSB-ng
|
||||
[6]: https://github.com/WoeUSB/WoeUSB-ng/blob/master/COPYING
|
||||
[7]: https://github.com/WoeUSB/WoeUSB-ng#installation
|
||||
[8]: https://opensource.com/downloads/pip-cheat-sheet
|
||||
[9]: https://opensource.com/sites/default/files/uploads/woeusb-ng-gui.png (WoeUSB-ng UI)
|
||||
[10]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]: https://www.system-rescue.org/
|
||||
90
published/202102/20210218 5 must-have Linux media players.md
Normal file
90
published/202102/20210218 5 must-have Linux media players.md
Normal file
@ -0,0 +1,90 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13148-1.html)
|
||||
[#]: subject: (5 must-have Linux media players)
|
||||
[#]: via: (https://opensource.com/article/21/2/linux-media-players)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
5 款值得拥有的 Linux 媒体播放器
|
||||
======
|
||||
|
||||
> 无论是电影还是音乐,Linux 都能为你提供一些优秀的媒体播放器。
|
||||
|
||||

|
||||
|
||||
在 2021 年,人们有更多的理由喜欢 Linux。在这个系列中,我将分享 21 个使用 Linux 的不同理由。媒体播放是我最喜欢使用 Linux 的理由之一。
|
||||
|
||||
你可能更喜欢黑胶唱片和卡带,或者录像带和激光影碟,但你很有可能还是在数字设备上播放你喜欢的大部分媒体。电脑上的媒体有一种无法比拟的便利性,这主要是因为我们大多数人一天中的大部分时间都在电脑附近。许多现代电脑用户并没有过多考虑有哪些应用可以用来听音乐和看电影,因为大多数操作系统都默认提供了媒体播放器,或者因为他们订阅了流媒体服务,因此并没有把媒体文件放在自己身边。但如果你的口味超出了通常的热门音乐和节目列表,或者你以媒体工作为乐趣或利润,那么你就会有你想要播放的本地文件。你可能还对现有用户界面有意见。在 Linux 上,*选择*是一种权利,因此你可以选择无数种播放媒体的方式。
|
||||
|
||||
以下是我在 Linux 上必备的五个媒体播放器。
|
||||
|
||||
### 1、mpv
|
||||
|
||||
![mpv interface][2]
|
||||
|
||||
一个现代、干净、简约的媒体播放器。得益于它的 Mplayer、[ffmpeg][3] 和 `libmpv` 后端,它可以播放你可能会扔给它的任何类型媒体。我说“扔给它”,是因为播放一个文件的最快捷、最简单的方法就是把文件拖到 mpv 窗口中。如果你拖动多个文件,mpv 会为你创建一个播放列表。
|
||||
|
||||
当你把鼠标放在上面时,它提供了直观的覆盖控件,但最好还是通过键盘操作界面。例如,`Alt+1` 会使 mpv 窗口变成全尺寸,而 `Alt+0` 会使其缩小到一半大小。你可以使用 `,` 和 `.` 键逐帧浏览视频,`[` 和 `]` 键调整播放速度,`/` 和 `*` 调整音量,`m` 静音等等。这些主控功能可以让你快速调整,一旦你学会了这些功能,你几乎可以在想到要调整播放的时候快速调整。无论是工作还是娱乐,mpv 都是我播放媒体的首选。
|
||||
|
||||
### 2、Kaffeine 和 Rhythmbox
|
||||
|
||||
![Kaffeine interface][4]
|
||||
|
||||
KDE Plasma 和 GNOME 桌面都提供了音乐应用([Kaffeine][5] 和 [Rhythmbox][]),可以作为你个人音乐库的前端。它们会让你为你的音乐文件提供一个标准的位置,然后扫描你的音乐收藏,这样你就可以根据专辑、艺术家等来浏览。这两款软件都很适合那些你无法完全决定你想听什么,而又想用一种简单的方式来浏览现有音乐的时候。
|
||||
|
||||
[Kaffeine][5] 其实不仅仅是一个音乐播放器。它可以播放视频文件、DVD、CD,甚至数字电视(假设你有输入信号)。我已经整整几天没有关闭 Kaffeine 了,因为不管我是想听音乐还是看电影,Kaffeine 都能让我轻松地开始播放。
|
||||
|
||||
### 3、Audacious
|
||||
|
||||
![Audacious interface][6]
|
||||
|
||||
[Audacious][7] 媒体播放器是一个轻量级的应用,它可以播放你的音乐文件(甚至是 MIDI 文件)或来自互联网的流媒体音乐。对我来说,它的主要吸引力在于它的模块化架构,它鼓励开发插件。这些插件可以播放几乎所有你能想到的音频媒体格式,用图形均衡器调整声音,应用效果,甚至可以重塑整个应用,改变其界面。
|
||||
|
||||
很难把 Audacious 仅仅看作是一个应用,因为它很容易让它变成你想要的应用。无论你是 Linux 上的 XMMS、Windows 上的 WinAmp,还是任何其他替代品,你大概都可以用 Audacious 来近似它们。Audacious 还提供了一个终端命令,`audtool`,所以你可以从命令行控制一个正在运行的 Audacious 实例,所以它甚至可以近似于一个终端媒体播放器!
|
||||
|
||||
### 4、VLC
|
||||
|
||||
![vlc interface][8]
|
||||
|
||||
[VLC][9] 播放器可能是向用户介绍开源的应用之首。作为一款久经考验的多媒体播放器,VLC 可以播放音乐、视频、光盘。它还可以通过网络摄像头或麦克风进行流式传输和录制,从而使其成为捕获快速视频或语音消息的简便方法。像 mpv 一样,大多数情况下都可以通过按单个字母的键盘操作来控制它,但它也有一个有用的右键菜单。它可以将媒体从一种格式转换为另一种格式、创建播放列表、跟踪你的媒体库等。VLC 是最好的,大多数播放器甚至无法在功能上与之匹敌。无论你在什么平台上,它都是一款必备的应用。
|
||||
|
||||
### 5、Music player daemon
|
||||
|
||||
![mpd with the ncmpc interface][10]
|
||||
|
||||
[music player daemon(mpd)][11] 是一个特别有用的播放器,因为它在服务器上运行。这意味着你可以在 [树莓派][12] 上启动它,然后让它处于空闲状态,这样你就可以在任何时候播放一首曲子。mpd 的客户端有很多,但我用的是 [ncmpc][13]。有了 ncmpc 或像 [netjukebox][14] 这样的 Web 客户端,我可以从本地主机或远程机器上连接 mpd,选择一张专辑,然后从任何地方播放它。
|
||||
|
||||
### Linux 上的媒体播放
|
||||
|
||||
在 Linux 上播放媒体是很容易的,这要归功于它出色的编解码器支持和惊人的播放器选择。我只提到了我最喜欢的五个播放器,但还有更多的播放器供你探索。试试它们,找到最好的,然后坐下来放松一下。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/linux-media-players
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LIFE_film.png?itok=aElrLLrw (An old-fashioned video camera)
|
||||
[2]: https://opensource.com/sites/default/files/mpv_0.png
|
||||
[3]: https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats
|
||||
[4]: https://opensource.com/sites/default/files/kaffeine.png
|
||||
[5]: https://apps.kde.org/en/kaffeine
|
||||
[6]: https://opensource.com/sites/default/files/audacious.png
|
||||
[7]: https://audacious-media-player.org/
|
||||
[8]: https://opensource.com/sites/default/files/vlc_0.png
|
||||
[9]: http://videolan.org
|
||||
[10]: https://opensource.com/sites/default/files/mpd-ncmpc.png
|
||||
[11]: https://www.musicpd.org/
|
||||
[12]: https://opensource.com/article/21/1/raspberry-pi-hifi
|
||||
[13]: https://www.musicpd.org/clients/ncmpc/
|
||||
[14]: http://www.netjukebox.nl/
|
||||
[15]: https://wiki.gnome.org/Apps/Rhythmbox
|
||||
@ -0,0 +1,132 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13145-1.html)
|
||||
[#]: subject: (7 Ways to Customize Cinnamon Desktop in Linux [Beginner’s Guide])
|
||||
[#]: via: (https://itsfoss.com/customize-cinnamon-desktop/)
|
||||
[#]: author: (Dimitrios https://itsfoss.com/author/dimitrios/)
|
||||
|
||||
初级:在 Linux 中自定义 Cinnamon 桌面的 7 种方法
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux Mint 是最好的 [适合初学者的 Linux 发行版][1] 之一。尤其是想 [转战 Linux][2] 的 Windows 用户,会发现它的 Cinnamon 桌面环境非常熟悉。
|
||||
|
||||
Cinnamon 给人一种传统的桌面体验,很多用户喜欢它的样子。这并不意味着你必须满足于它提供的东西。Cinnamon 提供了几种自定义桌面的方式。
|
||||
|
||||
在阅读了 [MATE][3] 和 [KDE 自定义][4] 指南后,很多读者要求为 Linux Mint Cinnamon 也提供类似的教程。因此,我创建了这个关于调整 Cinnamon 桌面的外观和感觉的基本指南。
|
||||
|
||||
### 7 种自定义 Cinnamon 桌面的不同方法
|
||||
|
||||
在本教程中,我使用的是 [Linux Mint Debian Edition][5](LMDE 4)。你可以在任何运行 Cinnamon 的 Linux 发行版上使用这篇文章的方法。如果你不确定,这里有 [如何检查你使用的桌面环境][6]。
|
||||
|
||||
当需要改变 Cinnamon 桌面外观时,我发现非常简单,因为只需点击两下即可。如下图所示,点击菜单图标,然后点击“设置”。
|
||||
|
||||
![][7]
|
||||
|
||||
所有的外观设置都放在该窗口的顶部。在“系统设置”窗口上的一切都显得整齐划一。
|
||||
|
||||
![][8]
|
||||
|
||||
#### 1、效果
|
||||
|
||||
效果选项简单,不言自明,一目了然。你可以开启或关闭桌面不同元素的特效,或者通过改变特效风格来改变窗口过渡。如果你想改变效果的速度,可以通过自定义标签来实现。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 2、字体选择
|
||||
|
||||
在这个部分,你可以区分整个系统中使用的字体大小和类型,通过字体设置,你可以对外观进行微调。
|
||||
|
||||
![][10]
|
||||
|
||||
#### 3、主题和图标
|
||||
|
||||
我曾经做了几年的 Linux Mint 用户,一个原因是你不需要到处去改变你想要的东西。窗口管理器、图标和面板定制都在一个地方!
|
||||
|
||||
你可以将面板改成深色或浅色,窗口边框也可以根据你要的而改变。默认的 Cinnamon 外观设置在我眼里是最好的,我甚至在测试 [Ubuntu Cinnamon Remix][11] 时也应用了一模一样的设置,不过是橙色的。
|
||||
|
||||
![][12]
|
||||
|
||||
#### 4、Cinnamon 小程序
|
||||
|
||||
Cinnamon 小程序是所有包含在底部面板的元素,如日历或键盘布局切换器。在管理选项卡中,你可以添加/删除已经安装的小程序。
|
||||
|
||||
你一定要探索一下可以下载的小程序,如天气和 [CPU 温度][13]指示小程序是我额外选择的。
|
||||
|
||||
![][14]
|
||||
|
||||
#### 5、Cinnamon Desklets
|
||||
|
||||
Cinnamon Desklets 是可以直接放置在桌面上的应用。和其他所有的自定义选项一样,Desklets 可以从设置菜单中访问,各种各样的选择可以吸引任何人的兴趣。谷歌日历是一个方便的应用,可以直接在桌面上跟踪你的日程安排。
|
||||
|
||||
![][15]
|
||||
|
||||
#### 6、桌面壁纸
|
||||
|
||||
要改变 Cinnamon 桌面的背景,只需在桌面上点击右键,选择“改变桌面背景”。它将打开一个简单易用的窗口,在左侧列出了可用的背景系统文件夹,右侧有每个文件夹内的图片预览。
|
||||
|
||||
![][16]
|
||||
|
||||
你可以通过点击加号(`+`)并选择路径来添加自己的文件夹。在“设置”选项卡中,你可以选择你的背景是静态还是幻灯片,以及背景在屏幕上的位置。
|
||||
|
||||
![][17]
|
||||
|
||||
#### 7、自定义桌面屏幕上的内容
|
||||
|
||||
背景并不是你唯一可以改变的桌面元素。如果你在桌面上点击右键,然后点击“自定义”,你可以找到更多的选项。
|
||||
|
||||
![][18]
|
||||
|
||||
你可以改变图标的大小,将摆放方式从垂直改为水平,并改变它们在两个轴上的间距。如果你不喜欢你所做的,点击重置网格间距回到默认值。
|
||||
|
||||
![][19]
|
||||
|
||||
此外,如果你点击“桌面设置”,将显示更多的选项。你可以禁用桌面上的图标,将它们放在主显示器或副显示器上,甚至两个都可以。如你所见,你可以选择一些图标出现在桌面上。
|
||||
|
||||
![][20]
|
||||
|
||||
### 总结
|
||||
|
||||
Cinnamon 桌面是最好的选择之一,尤其是当你正在 [从 windows 切换到 Linux][21] 的时候,同时对一个简单而优雅的桌面追求者也是如此。
|
||||
|
||||
Cinnamon 桌面非常稳定,在我手上从来没有崩溃过,这也是在各种 Linux 发行版之间,我使用它这么久的主要原因之一。
|
||||
|
||||
我没有讲得太详细,但给了你足够的指导,让你自己去探索设置。欢迎反馈你对 Cinnamon 的定制。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/customize-cinnamon-desktop/
|
||||
|
||||
作者:[Dimitrios][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/dimitrios/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-beginners/
|
||||
[2]: https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[3]: https://itsfoss.com/ubuntu-mate-customization/
|
||||
[4]: https://itsfoss.com/kde-customization/
|
||||
[5]: https://itsfoss.com/lmde-4-release/
|
||||
[6]: https://itsfoss.com/find-desktop-environment/
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/6-Cinnamon-settings.png?resize=800%2C680&ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/7-Cinnamon-Settings.png?resize=800%2C630&ssl=1
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/8-cinnamon-effects.png?resize=800%2C630&ssl=1
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/11-font-selection.png?resize=800%2C650&ssl=1
|
||||
[11]: https://itsfoss.com/ubuntu-cinnamon-remix-review/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/10-cinnamon-themes-and-icons.png?resize=800%2C630&ssl=1
|
||||
[13]: https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/
|
||||
[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/12-cinnamon-applets.png?resize=800%2C630&ssl=1
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/13-cinnamon-desklets.png?resize=800%2C630&ssl=1
|
||||
[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/1.-Cinnamon-change-desktop-background.png?resize=800%2C400&ssl=1
|
||||
[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/2-Cinnamon-change-desktop-background.png?resize=800%2C630&ssl=1
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/1.-desktop-additional-customization.png?resize=800%2C400&ssl=1
|
||||
[19]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/4-desktop-additional-customization.png?resize=800%2C480&ssl=1
|
||||
[20]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/5-desktop-additional-customization.png?resize=800%2C630&ssl=1
|
||||
[21]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (max27149)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13149-1.html)
|
||||
[#]: subject: (Unlock your Chromebook's hidden potential with Linux)
|
||||
[#]: via: (https://opensource.com/article/21/2/chromebook-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Linux 释放你 Chromebook 的隐藏潜能
|
||||
======
|
||||
|
||||
> Chromebook 是令人惊叹的工具,但通过解锁它内部的 Linux 系统,你可以让它变得更加不同凡响。
|
||||
|
||||

|
||||
|
||||
Google Chromebook 运行在 Linux 系统之上,但通常它运行的 Linux 系统对普通用户而言,并不是十分容易就能访问得到。Linux 被用作基于开源的 [Chromium OS][2] 运行时环境的后端技术,然后 Google 将其转换为 Chrome OS。大多数用户体验到的界面是一个电脑桌面,可以用来运行 Chrome 浏览器及其应用程序。然而,在这一切的背后,有一个 Linux 系统等待被你发现。如果你知道怎么做,你可以在 Chromebook 上启用 Linux,把一台可能价格相对便宜、功能相对基础的电脑变成一个严谨的笔记本,获取数百个应用和你需要的所有能力,使它成为一个通用计算机。
|
||||
|
||||
### 什么是 Chromebook?
|
||||
|
||||
Chromebook 是专为 Chrome OS 创造的笔记本电脑,它本身专为特定的笔记本电脑型号而设计。Chrome OS 不是像 Linux 或 Windows 这样的通用操作系统,而是与 Android 或 iOS 有更多的共同点。如果你决定购买 Chromebook,你会发现有许多不同制造商的型号,包括惠普、华硕和联想等等。有些是为学生而设计,而另一些是为家庭或商业用户而设计的。主要的区别通常分别集中在电池功率或处理能力上。
|
||||
|
||||
无论你决定买哪一款,Chromebook 都会运行 Chrome OS,并为你提供现代计算机所期望的基本功能。有连接到互联网的网络管理器、蓝牙、音量控制、文件管理器、桌面等等。
|
||||
|
||||
![Chrome OS desktop][3]
|
||||
|
||||
*Chrome OS 桌面截图*
|
||||
|
||||
不过,想从这个简单易用的操作系统中获得更多,你只需要激活 Linux。
|
||||
|
||||
### 启用 Chromebook 的开发者模式
|
||||
|
||||
如果我让你觉得启用 Linux 看似简单,那是因为它确实简单但又有欺骗性。之所以说有欺骗性,是因为在启用 Linux 之前,你*必须*备份数据。
|
||||
|
||||
这个过程虽然简单,但它确实会将你的计算机重置回出厂默认状态。你必须重新登录到你的笔记本电脑中,如果你有数据存储在 Google 云盘帐户上,你必须得把它重新同步回计算机中。启用 Linux 还需要为 Linux 预留硬盘空间,因此无论你的 Chromebook 硬盘容量是多少,都将减少一半或四分之一(自主选择)。
|
||||
|
||||
在 Chromebook 上接入 Linux 仍被 Google 视为测试版功能,因此你必须选择使用开发者模式。开发者模式的目的是允许软件开发者测试新功能,安装新版本的操作系统等等,但它可以为你解锁仍在开发中的特殊功能。
|
||||
|
||||
要启用开发者模式,请首先关闭你的 Chromebook。假定你已经备份了设备上的所有重要信息。
|
||||
|
||||
接下来,按下键盘上的 `ESC` 和 `⟳`,再按 **电源键** 启动 Chromebook。
|
||||
|
||||
![ESC and refresh buttons][4]
|
||||
|
||||
*ESC 键和 ⟳ 键*
|
||||
|
||||
当提示开始恢复时,按键盘上的 `Ctrl+D`。
|
||||
|
||||
恢复结束后,你的 Chromebook 已重置为出厂设置,且没有默认的使用限制。
|
||||
|
||||
### 开机启动进入开发者模式
|
||||
|
||||
在开发者模式下运行意味着每次启动 Chromebook 时,都会提醒你处于开发者模式。你可以按 `Ctrl+D` 跳过启动延迟。有些 Chromebook 会在几秒钟后发出蜂鸣声来提醒你处于开发者模式,使得 `Ctrl+D` 操作几乎是强制的。从理论上讲,这个操作很烦人,但在实践中,我不经常启动我的 Chromebook,因为我只是唤醒它,所以当我需要这样做的时候,`Ctrl+D` 只不过是整个启动过程中小小的一步。
|
||||
|
||||
启用开发者模式后的第一次启动时,你必须重新设置你的设备,就好像它是全新的一样。你只需要这样做一次(除非你在未来某个时刻停用开发者模式)。
|
||||
|
||||
### 启用 Chromebook 上的 Linux
|
||||
|
||||
现在,你已经运行在开发者模式下,你可以激活 Chrome OS 中的 **Linux Beta** 功能。要做到这一点,请打开 **设置**,然后单击左侧列表中的 **Linux Beta**。
|
||||
|
||||
激活 **Linux Beta**,并为你的 Linux 系统和应用程序分配一些硬盘空间。在最糟糕的时候,Linux 是相当轻量级的,所以你真的不需要分配太多硬盘空间,但它显然取决于你打算用 Linux 来做多少事。4 GB 的空间对于 Linux 以及几百个终端命令还有二十多个图形应用程序是足够的。我的 Chromebook 有一个 64 GB 的存储卡,我给了 Linux 系统 30 GB,那是因为我在 Chromebook 上所做的大部分事情都是在 Linux 内完成的。
|
||||
|
||||
一旦你的 **Linux Beta** 环境准备就绪,你可以通过按键盘上的**搜索**按钮和输入 `terminal` 来启动终端。如果你还是 Linux 新手,你可能不知道当前进入的终端能用来安装什么。当然,这取决于你想用 Linux 来做什么。如果你对 Linux 编程感兴趣,那么你可能会从 Bash(它已经在终端中安装和运行了)和 Python 开始。如果你对 Linux 中的那些迷人的开源应用程序感兴趣,你可以试试 GIMP、MyPaint、LibreOffice 或 Inkscape 等等应用程序。
|
||||
|
||||
Chrome OS 的 **Linux Beta** 模式不包含图形化的软件安装程序,但 [应用程序可以从终端安装][5]。可以使用 `sudo apt install` 命令安装应用程序。
|
||||
|
||||
* `sudo` 命令可以允许你使用超级管理员权限来执行某些命令(即 Linux 中的 `root`)。
|
||||
* `apt` 命令是一个应用程序的安装工具。
|
||||
* `install` 是命令选项,即告诉 `apt` 命令要做什么。
|
||||
|
||||
你还必须把想要安装的软件包的名字和 `apt` 命令写在一起。以安装 LibreOffice 举例:
|
||||
|
||||
```
|
||||
sudo apt install libreoffice
|
||||
```
|
||||
当有提示是否继续时,输入 `y`(代表“确认”),然后按 **回车键**。
|
||||
|
||||
一旦应用程序安装完毕,你可以像在 Chrome OS 上启动任何应用程序一样启动它:只需要在应用程序启动器输入它的名字。
|
||||
|
||||
了解 Linux 应用程序的名字和它的包名需要花一些时间,但你也可以用 `apt search` 命令来搜索。例如,可以用以下的方法是找到关于照片的应用程序:
|
||||
|
||||
```
|
||||
apt search photo
|
||||
```
|
||||
|
||||
因为 Linux 中有很多的应用程序,所以你可以找一些感兴趣的东西,然后尝试一下!
|
||||
|
||||
### 与 Linux 共享文件和设备
|
||||
|
||||
**Linux Beta** 环境运行在 [容器][7] 中,因此 Chrome OS 需要获得访问 Linux 文件的权限。要授予 Chrome OS 与你在 Linux 上创建的文件的交互权限,请右击要共享的文件夹并选择 **管理 Linux 共享**。
|
||||
|
||||
![Chrome OS Manage Linux sharing interface][8]
|
||||
|
||||
*Chrome OS 的 Linux 管理共享界面*
|
||||
|
||||
你可以通过 Chrome OS 的 **设置** 程序来管理共享设置以及其他设置。
|
||||
|
||||
![Chrome OS Settings menu][9]
|
||||
|
||||
*Chrome OS 设置菜单*
|
||||
|
||||
### 学习 Linux
|
||||
|
||||
如果你肯花时间学习 Linux,你不仅能够解锁你 Chromebook 中隐藏的潜力,还能最终学到很多关于计算机的知识。Linux 是一个有价值的工具,一个非常有趣的玩具,一个通往比常规计算更令人兴奋的事物的大门。去了解它吧,你可能会惊讶于你自己和你 Chromebook 的无限潜能。
|
||||
|
||||
---
|
||||
|
||||
源自: https://opensource.com/article/21/2/chromebook-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[max27149](https://github.com/max27149)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/wfh_work_home_laptop_work.png?itok=VFwToeMy (Working from home at a laptop)
|
||||
[2]: https://www.chromium.org/chromium-os
|
||||
[3]: https://opensource.com/sites/default/files/chromeos.png
|
||||
[4]: https://opensource.com/sites/default/files/esc-refresh.png
|
||||
[5]: https://opensource.com/article/18/1/how-install-apps-linux
|
||||
[6]: https://opensource.com/tags/linux
|
||||
[7]: https://opensource.com/resources/what-are-linux-containers
|
||||
[8]: https://opensource.com/sites/default/files/chromeos-manage-linux-sharing.png
|
||||
[9]: https://opensource.com/sites/default/files/chromeos-beta-linux.png
|
||||
@ -0,0 +1,180 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13152-1.html)
|
||||
[#]: subject: (Starship: Open-Source Customizable Prompt for Any Shell)
|
||||
[#]: via: (https://itsfoss.com/starship/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Starship:跨 shell 的可定制的提示符
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 如果你很在意你的终端的外观的话,一个跨 shell 的提示符可以让你轻松地定制和配置 Linux 终端提示符。
|
||||
|
||||
虽然我已经介绍了一些帮助你 [自定义终端外观][1] 的技巧,但我也发现了一些有趣的跨 shell 提示符的建议。
|
||||
|
||||
### Starship:轻松地调整你的 Linux Shell 提示符
|
||||
|
||||
![][2]
|
||||
|
||||
[Starship][3] 是一个用 [Rust][4] 编写的开源项目,它可以帮助你建立一个精简、快速、可定制的 shell 提示符。
|
||||
|
||||
无论你是使用 bash、fish、还是 Windows 上的 PowerShell,抑或其他 shell,你都可以利用Starship 来定制外观。
|
||||
|
||||
请注意,你必须了解它的 [官方文档][5] 才能对所有你喜欢的东西进行高级配置,但在这里,我将包括一个简单的示例配置,以有一个良好的开端,以及一些关于 Startship 的关键信息。
|
||||
|
||||
Startship 专注于为你提供一个精简的、快速的、有用的默认 shell 提示符。它甚至会记录并显示执行一个命令所需的时间。例如,这里有一张截图:
|
||||
|
||||
![][6]
|
||||
|
||||
不仅如此,根据自己的喜好定制提示符也相当简单。下面是一张官方 GIF,展示了它的操作:
|
||||
|
||||
![][7]
|
||||
|
||||
让我帮你设置一下。我是在 Ubuntu 上使用 bash shell 来测试的。你可以参考我提到的步骤,或者你可以看看 [官方安装说明][8],以获得在你的系统上安装它的更多选择。
|
||||
|
||||
### Starship 的亮点
|
||||
|
||||
* 跨平台
|
||||
* 跨 shell 支持
|
||||
* 能够添加自定义命令
|
||||
* 定制 git 体验
|
||||
* 定制使用特定编程语言时的体验
|
||||
* 轻松定制提示符的每一个方面,而不会对性能造成实质影响
|
||||
|
||||
### 在 Linux 上安装 Starship
|
||||
|
||||
> 安装 Starship 需要下载一个 bash 脚本,然后用 root 权限运行该脚本。
|
||||
>
|
||||
> 如果你不习惯这样做,你可以使用 snap。
|
||||
>
|
||||
> ```
|
||||
> sudo snap install starship
|
||||
> ```
|
||||
|
||||
**注意**:你需要安装 [Nerd 字体][9] 才能获得完整的体验。
|
||||
|
||||
要开始使用,请确保你安装了 [curl][10]。你可以通过键入如下命令来轻松安装它:
|
||||
|
||||
```
|
||||
sudo apt install curl
|
||||
```
|
||||
|
||||
完成后,输入以下内容安装 Starship:
|
||||
|
||||
```
|
||||
curl -fsSL https://starship.rs/install.sh | bash
|
||||
```
|
||||
|
||||
这应该会以 root 身份将 Starship 安装到 `usr/local/bin`。你可能会被提示输入密码。看起来如下:
|
||||
|
||||
![][11]
|
||||
|
||||
### 在 bash 中添加 Starship
|
||||
|
||||
如截图所示,你会在终端本身得到设置的指令。在这里,我们需要在 `.bashrc` 用户文件的末尾添加以下一行:
|
||||
|
||||
```
|
||||
eval "$(starship init bash)"
|
||||
```
|
||||
|
||||
要想轻松添加,只需键入:
|
||||
|
||||
```
|
||||
nano .bashrc
|
||||
```
|
||||
|
||||
然后,通过向下滚动导航到文件的末尾,并在文件末尾添加如下图所示的行:
|
||||
|
||||
![][12]
|
||||
|
||||
完成后,只需重启终端或重启会话即可看到一个精简的提示符。对于你的 shell 来说,它可能看起来有点不同,但默认情况下应该是一样的。
|
||||
|
||||
![][13]
|
||||
|
||||
设置好后,你就可以继续自定义和配置提示符了。让我给你看一个我做的配置示例:
|
||||
|
||||
### 配置 Starship 提示符:基础
|
||||
|
||||
开始你只需要在 `.config` 目录下制作一个配置文件([TOML文件][14])。如果你已经有了这个目录,直接导航到该目录并创建配置文件。
|
||||
|
||||
下面是创建目录和配置文件时需要输入的内容:
|
||||
|
||||
```
|
||||
mkdir -p ~/.config && touch ~/.config/starship.toml
|
||||
```
|
||||
|
||||
请注意,这是一个隐藏目录。所以,当你试图使用文件管理器从主目录访问它时,请确保在继续之前 [启用查看隐藏文件][15]。
|
||||
|
||||
接下来如果你想探索一些你喜欢的东西,你应该参考配置文档。
|
||||
|
||||
举个例子,我配置了一个简单的自定义提示,看起来像这样:
|
||||
|
||||
![][16]
|
||||
|
||||
为了实现这个目标,我的配置文件是这样的:
|
||||
|
||||
![][17]
|
||||
|
||||
根据他们的官方文档,这是一个基本的自定义格式。但是,如果你不想要自定义格式,只是想用一种颜色或不同的符号来自定义默认的提示,那就会像这样:
|
||||
|
||||
![][18]
|
||||
|
||||
上述定制的配置文件是这样的:
|
||||
|
||||
![][19]
|
||||
|
||||
当然,这不是我能做出的最好看的提示符,但我希望你能理解其配置方式。
|
||||
|
||||
你可以通过包括图标或表情符来定制目录的外观,你可以调整变量、格式化字符串、显示 git 提交,或者根据使用特定编程语言而调整。
|
||||
|
||||
不仅如此,你还可以创建在你的 shell 中使用的自定义命令,让事情变得更简单或舒适。
|
||||
|
||||
你可以在他们的 [官方网站][3] 和它的 [GitHub 页面][20] 中探索更多的信息。
|
||||
|
||||
- [Starship.rs][3]
|
||||
|
||||
### 结论
|
||||
|
||||
如果你只是想做一些小的调整,这文档可能会太复杂了。但是,即使如此,它也可以让你用很少的努力实现一个自定义的提示符或精简的提示符,你可以应用于任何普通的 shell 和你正在使用的系统。
|
||||
|
||||
总的来说,我不认为它非常有用,但有几个读者建议使用它,看来人们确实喜欢它。我很想看看你是如何 [自定义 Linux 终端][1] 以适应不同的使用方式。
|
||||
|
||||
欢迎在下面的评论中分享你的看法,如果你喜欢的话。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/starship/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/customize-linux-terminal/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-screenshot.png?resize=800%2C577&ssl=1
|
||||
[3]: https://starship.rs/
|
||||
[4]: https://www.rust-lang.org/
|
||||
[5]: https://starship.rs/config/
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-time.jpg?resize=800%2C281&ssl=1
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-demo.gif?resize=800%2C501&ssl=1
|
||||
[8]: https://starship.rs/guide/#%F0%9F%9A%80-installation
|
||||
[9]: https://www.nerdfonts.com
|
||||
[10]: https://curl.se/
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/install-starship.png?resize=800%2C534&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/startship-bashrc-file.png?resize=800%2C545&ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-prompt.png?resize=800%2C552&ssl=1
|
||||
[14]: https://en.wikipedia.org/wiki/TOML
|
||||
[15]: https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
|
||||
[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-custom.png?resize=800%2C289&ssl=1
|
||||
[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-custom-config.png?resize=800%2C320&ssl=1
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-different-symbol.png?resize=800%2C224&ssl=1
|
||||
[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/starship-symbol-change.jpg?resize=800%2C167&ssl=1
|
||||
[20]: https://github.com/starship/starship
|
||||
@ -0,0 +1,161 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13158-1.html)
|
||||
[#]: subject: (Not Comfortable Using youtube-dl in Terminal? Use These GUI Apps)
|
||||
[#]: via: (https://itsfoss.com/youtube-dl-gui-apps/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
不习惯在终端使用 youtube-dl?可以使用这些 GUI 应用
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你一直在关注我们,可能已经知道 [youtube-dl 项目曾被 GitHub 暂时下架][1] 以合规。但它现在已经恢复并完全可以访问,可以说它并不是一个非法的工具。
|
||||
|
||||
它是一个非常有用的命令行工具,可以让你 [从 YouTube][2] 和其他一些网站下载视频。使用 [youtube-dl][3] 并不复杂,但我明白使用命令来完成这种任务并不是每个人都喜欢的方式。
|
||||
|
||||
好在有一些应用为 `youtube-dl` 工具提供了 GUI 前端。
|
||||
|
||||
### 使用 youtube-dl GUI 应用的先决条件
|
||||
|
||||
在你尝试下面提到的一些选择之前,你可能需要在你的系统上安装 `youtube-dl` 和 [FFmpeg][4],才能够下载/选择不同的格式进行下载。
|
||||
|
||||
你可以按照我们的 [ffmpeg 使用完整指南][5] 进行设置,并探索更多关于它的内容。
|
||||
|
||||
要安装 [youtube-dl][6],你可以在 Linux 终端输入以下命令:
|
||||
|
||||
```
|
||||
sudo curl -L https://yt-dl.org/downloads/latest/youtube-dl -o /usr/local/bin/youtube-dl
|
||||
```
|
||||
|
||||
下载最新版本后,你只需要输入以下内容使其可执行就可使用:
|
||||
|
||||
```
|
||||
sudo chmod a+rx /usr/local/bin/youtube-dl
|
||||
```
|
||||
|
||||
如果你需要其他方法安装它,也可以按照[官方安装说明][7]进行安装。
|
||||
|
||||
### Youtube-dl GUI 应用
|
||||
|
||||
大多数 Linux 上的下载管理器也允许你从 YouTube 和其他网站下载视频。然而,youtube-dl GUI 应用可能有额外的选项,如只提取音频或下载特定分辨率和视频格式。
|
||||
|
||||
请注意,下面的列表没有特别的排名顺序。你可以根据你的要求选择。
|
||||
|
||||
#### 1、AllTube Download
|
||||
|
||||
![][8]
|
||||
|
||||
**主要特点:**
|
||||
|
||||
* Web GUI
|
||||
* 开源
|
||||
* 可以自托管
|
||||
|
||||
AllTube 是一个开源的 web GUI,你可以通过 <https://alltubedownload.net/> 来访问。
|
||||
|
||||
如果你选择使用这款软件,你不需要在系统上安装 youtube-dl 或 ffmpeg。它提供了一个简单的用户界面,你只需要粘贴视频的 URL,然后继续选择你喜欢的文件格式下载。你也可以选择将其部署在你的服务器上。
|
||||
|
||||
请注意,你不能使用这个工具提取视频的 MP3 文件,它只适用于视频。你可以通过他们的 [GitHub 页面][9]探索更多关于它的信息。
|
||||
|
||||
- [AllTube Download Web GUI][10]
|
||||
|
||||
#### 2、youtube-dl GUI
|
||||
|
||||
![][11]
|
||||
|
||||
**主要特点:**
|
||||
|
||||
* 跨平台
|
||||
* 显示预计下载大小
|
||||
* 有音频和视频下载选择
|
||||
|
||||
一个使用 electron 和 node.js 制作的有用的跨平台 GUI 应用。你可以很容易地下载音频和视频,以及选择各种可用的文件格式的选项。
|
||||
|
||||
如果你愿意的话,你还可以下载一个频道或播放列表的部分内容。特别是当你下载高质量的视频文件时,预计的下载大小绝对是非常方便的。
|
||||
|
||||
如上所述,它也适用于 Windows 和 MacOS。而且,你会在它的 [GitHub 发布][12]中得到一个适用于 Linux 的 AppImage 文件。
|
||||
|
||||
- [Youtube-dl GUI][13]
|
||||
|
||||
#### 3、Videomass
|
||||
|
||||
![][14]
|
||||
|
||||
**主要特点:**
|
||||
|
||||
* 跨平台
|
||||
* 转换音频/视频格式
|
||||
* 支持多个 URL
|
||||
* 适用于也想使用 FFmpeg 的用户
|
||||
|
||||
如果你想从 YouTube 下载视频或音频,并将它们转换为你喜欢的格式,Videomass 可以是一个不错的选择。
|
||||
|
||||
要做到这点,你需要在你的系统上同时安装 youtube-dl 和 ffmpeg。你可以轻松的添加多个 URL 来下载,还可以根据自己的喜好设置输出目录。
|
||||
|
||||
![][15]
|
||||
|
||||
你还可以获得一些高级设置来禁用 youtube-dl,改变文件首选项,以及随着你的探索,还有一些更方便的选项。
|
||||
|
||||
它为 Ubuntu 用户提供了一个 PPA,为任何其他 Linux 发行版提供了一个 AppImage 文件。在它的 [Github 页面][16]探索更多信息。
|
||||
|
||||
- [Videomass][17]
|
||||
|
||||
#### 附送:Haruna Video Player
|
||||
|
||||
![][18]
|
||||
|
||||
**主要特点:**
|
||||
|
||||
* 播放/流式传输 YouTube 视频
|
||||
|
||||
Haruna Video Player 原本是 [MPV][19] 的前端。虽然使用它不能下载 YouTube 视频,但可以通过 youtube-dl 观看/流式传输 YouTube 视频。
|
||||
|
||||
你可以在我们的[文章][20]中探索更多关于视频播放器的内容。
|
||||
|
||||
### 总结
|
||||
|
||||
尽管你可能会在 GitHub 和其他平台上找到更多的 youtube-dl GUI,但它们中的大多数都不能很好地运行,最终会显示出多个错误,或者不再积极开发。
|
||||
|
||||
[Tartube][21] 就是这样的一个选择,你可以尝试一下,但可能无法达到预期的效果。我用 Pop!_OS 和 Ubuntu MATE 20.04(全新安装)进行了测试。每次我尝试下载一些东西时,无论我怎么做都会失败(即使系统中安装了 youtube-dl 和 ffmpeg)。
|
||||
|
||||
所以,我个人最喜欢的似乎是 Web GUI([AllTube Download][9]),它不依赖于安装在你系统上的任何东西,也可以自托管。
|
||||
|
||||
如果我错过了你最喜欢的选择,请在评论中告诉我什么是最适合你的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/youtube-dl-gui-apps/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/youtube-dl-github-takedown/
|
||||
[2]: https://itsfoss.com/download-youtube-videos-ubuntu/
|
||||
[3]: https://itsfoss.com/download-youtube-linux/
|
||||
[4]: https://ffmpeg.org/
|
||||
[5]: https://itsfoss.com/ffmpeg/#install
|
||||
[6]: https://youtube-dl.org/
|
||||
[7]: https://ytdl-org.github.io/youtube-dl/download.html
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/alltube-download.jpg?resize=772%2C593&ssl=1
|
||||
[9]: https://github.com/Rudloff/alltube
|
||||
[10]: https://alltubedownload.net/
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/youtube-dl-gui.jpg?resize=800%2C548&ssl=1
|
||||
[12]: https://github.com/jely2002/youtube-dl-gui/releases/tag/v1.8.7
|
||||
[13]: https://github.com/jely2002/youtube-dl-gui
|
||||
[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/videomass.jpg?resize=800%2C537&ssl=1
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/videomass-1.jpg?resize=800%2C542&ssl=1
|
||||
[16]: https://github.com/jeanslack/Videomass
|
||||
[17]: https://jeanslack.github.io/Videomass/
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/haruna-video-player-dark.jpg?resize=800%2C512&ssl=1
|
||||
[19]: https://mpv.io/
|
||||
[20]: https://itsfoss.com/haruna-video-player/
|
||||
[21]: https://github.com/axcore/tartube
|
||||
@ -0,0 +1,296 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (bestony)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13180-1.html)
|
||||
[#]: subject: (lawyer The MIT License, Line by Line)
|
||||
[#]: via: (https://writing.kemitchell.com/2016/09/21/MIT-License-Line-by-Line.html)
|
||||
[#]: author: (Kyle E. Mitchell https://kemitchell.com/)
|
||||
|
||||
逐行解读 MIT 许可证
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 每个程序员都应该明白的 171 个字。
|
||||
|
||||
[MIT 许可证][1] 是世界上最流行的开源软件许可证。以下是它的逐行解读。
|
||||
|
||||
### 阅读许可证
|
||||
|
||||
如果你参与了开源软件,但还没有花时间从头到尾的阅读过这个许可证(它只有 171 个单词),你需要现在就去读一下。尤其是如果许可证不是你日常每天都会接触的,把任何看起来不对劲或不清楚的地方记下来,然后继续阅读。我会分段、按顺序、加入上下文和注释,把每一个词再重复一遍。但最重要的还是要有个整体概念。
|
||||
|
||||
> The MIT License (MIT)
|
||||
>
|
||||
> Copyright (c) \<year> \<copyright holders>
|
||||
>
|
||||
> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
||||
>
|
||||
> The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
||||
>
|
||||
> *The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealings in the Software.*
|
||||
|
||||
(LCTT 译注:MIT 许可证并无官方的中文文本,我们也没找到任何可靠的、精确的非官方中文文本。在本文中,我们仅作为参考目的提供一份逐字逐行而没有经过润色的中文翻译文本,但该文本及对其的理解**不能**作为 MIT 许可证使用,我们也不为此中文翻译文本的使用承担任何责任,这份中文文本,我们贡献给公共领域。)
|
||||
|
||||
> MIT 许可证(MIT)
|
||||
>
|
||||
> 版权 (c) <年份> <版权人>
|
||||
>
|
||||
> 特此免费授予任何获得本软件副本和相关文档文件(下称“软件”)的人不受限制地处置该软件的权利,包括不受限制地使用、复制、修改、合并、发布、分发、转授许可和/或出售该软件副本,以及再授权被配发了本软件的人如上的权利,须在下列条件下:
|
||||
>
|
||||
> 上述版权声明和本许可声明应包含在该软件的所有副本或实质成分中。
|
||||
>
|
||||
> 本软件是“如此”提供的,没有任何形式的明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和不侵权的保证。在任何情况下,作者或版权持有人都不对任何索赔、损害或其他责任负责,无论这些追责来自合同、侵权或其它行为中,还是产生于、源于或有关于本软件以及本软件的使用或其它处置。
|
||||
|
||||
该许可证分为五段,按照逻辑划分如下:
|
||||
|
||||
* **头部**
|
||||
* **许可证名称**:“MIT 许可证”
|
||||
* **版权说明**:“版权 (c) …”
|
||||
* **许可证授予**:“特此授予 …”
|
||||
* **授予范围**:“… 处置软件 …”
|
||||
* **条件**:“… 须在 …”
|
||||
* **归因和声明**:“上述 … 应包含在 …”
|
||||
* **免责声明**:“本软件是‘如此’提供的 …”
|
||||
* **责任限制**:“在任何情况下 …”
|
||||
|
||||
接下来详细看看。
|
||||
|
||||
### 头部
|
||||
|
||||
#### 许可证名称
|
||||
|
||||
> The MIT License (MIT)
|
||||
|
||||
> MIT 许可证(MIT)
|
||||
|
||||
“MIT 许可证”不是一个单一的许可证,而是根据<ruby>麻省理工学院<rt>Massachusetts Institute of Technology</rt></ruby>(MIT)为发行版本准备的语言衍生出来一系列许可证形式。多年来,无论是对于使用它的原始项目,还是作为其他项目的范本,它经历了许多变化。Fedora 项目一直保持着 [收藏 MIT 许可证的好奇心][2],以纯文本的方式记录了那些平淡的变化,如同泡在甲醛中的解剖标本一般,追溯了它的各种演变。
|
||||
|
||||
幸运的是,<ruby>[开放源码倡议组织][3]<rt>Open Source Initiative</rt></ruby>(OSI) 和 <ruby>[软件数据包交换][4]<rt>Software Package Data eXchange</rt></ruby>组织(SPDX)已经将一种通用的 MIT 式的许可证形式标准化为“<ruby>MIT 许可证<rt>The MIT License</rt></ruby>”。OSI 反过来又采用了 SPDX 通用开源许可证的标准化 [字符串标志符][5],并将其中的 “MIT” 明确指向了标准化形式的“MIT 许可证”。如果你想为一个新项目使用 MIT 式的条款,请使用其 [标准化的形式][1]。
|
||||
|
||||
即使你在 `LICENSE` 文件中包含 “The MIT License” 或 “SPDX:MIT”,任何负责的审查者仍会将文本与标准格式进行比较,以确保安全。尽管自称为“MIT 许可证”的各种许可证形式只在细微的细节上有所不同,但所谓的“MIT 许可证”的松散性已经诱使了一些作者加入麻烦的“自定义”。典型的糟糕、不好的、非常坏的例子是 [JSON 许可证][6],一个 MIT 家族的许可证被加上了“本软件应用于善,而非恶”。这件事情可能是“非常克罗克福特”的(LCTT 译者注,Crockford 是 JSON 格式和 JSON.org 的作者)。这绝对是一件麻烦事,也许这个玩笑本来是开在律师身上的,但他们却笑得前仰后合。
|
||||
|
||||
这个故事的寓意是:“MIT 许可证”本身就是模棱两可的。大家可能很清楚你的意思,但你只需要把标准的 MIT 许可证文本复制到你的项目中,就可以节省每个人的时间。如果使用元数据(如包管理器中的元数据文件)来指定 “MIT 许可证”,请确保 `LICENSE` 文件和任何头部的注释都使用标准的许可证文本。所有的这些都可以 [自动化完成][7]。
|
||||
|
||||
#### 版权声明
|
||||
|
||||
> Copyright (c) <year> <copyright holders>
|
||||
|
||||
> 版权 (c) <年份> <版权持有人>
|
||||
|
||||
在 1976 年(美国)《版权法》颁布之前,美国的版权法规要求采取具体的行动,即所谓的“手续”来确保创意作品的版权。如果你不遵守这些手续,你起诉他人未经授权使用你的作品的权力就会受到限制,往往会完全丧失权力,其中一项手续就是“<ruby>声明<rt>notice</rt></ruby>”。在你的作品上打上记号,以其他方式让市场知道你拥有版权。“©” 是一个标准符号,用于标记受版权保护的作品,以发出版权声明。ASCII 字符集没有 © 符号,但 `Copyright (c)` 可以表达同样的意思。
|
||||
|
||||
1976 年的《版权法》“落实”了国际《<ruby>伯尔尼公约<rt>Berne Convention</rt></ruby>》的许多要求,取消了确保版权的手续。至少在美国,著作权人在起诉侵权之前,仍然需要对自己的版权作品进行登记,如果在侵权行为开始之前进行登记,可能会获得更高的赔偿。但在实践中,很多人在对某个人提起诉讼之前,都会先注册版权。你并不会因为没有在上面贴上声明、注册它、向国会图书馆寄送副本等而失去版权。
|
||||
|
||||
即使版权声明不像过去那样绝对必要,但它们仍然有很多用处。说明作品的创作年份和版权属于谁,可以让人知道作品的版权何时到期,从而使作品纳入公共领域。作者或作者们的身份也很有用。美国法律对个人作者和“公司”作者的版权条款的计算方式不同。特别是在商业用途中,公司在使用已知竞争对手的软件时,可能也要三思而行,即使许可条款给予了非常慷慨的许可。如果你希望别人看到你的作品并想从你这里获得许可,版权声明可以很好地起到归属作用。
|
||||
|
||||
至于“<ruby>版权持有人<rt>copyright holder</rt></ruby>”。并非所有标准形式的许可证都有写明这一点的空间。最新的许可证形式,如 [Apache 2.0][8] 和 [GPL 3.0][9],发布的许可证文本是要逐字复制的,并在其他地方加上标题注释和单独文件,以表明谁拥有版权并提供许可证。这些办法巧妙地阻止了对“标准”文本的意外或故意的修改。这还使自动许可证识别更加可靠。
|
||||
|
||||
MIT 许可证是从为机构发布的代码而写的语言演变而来。对于机构发布的代码,只有一个明确的“版权持有人”,即发布代码的机构。其他机构抄袭了这些许可证,用他们自己的名字代替了 “MIT”,最终形成了我们现在拥有的通用形式。这一过程同样适用于该时代的其他简短的机构许可证,特别是加州大学伯克利分校的最初的 <ruby>[四条款 BSD 许可证][10]<rt>four-clause BSD License</rt></ruby> 成为了现在使用的 [三条款][11] 和 [两条款][12] 变体,以及 MIT 许可证的变体<ruby>互联网系统联盟<rt>Internet Systems Consortium</rt></ruby>的 [ISC 许可证][13]。
|
||||
|
||||
在每一种情况下,该机构都根据版权所有权规则将自己列为版权持有人,这些规则称为“[雇佣作品][14]”规则,这些规则赋予雇主和客户在其雇员和承包商代表其从事的某些工作中的版权所有权。这些规则通常不适用于自愿提交代码的分布式协作者。这给项目监管型基金会(如 Apache 基金会和 Eclipse 基金会)带来了一个问题,因为它们接受来自更多不同的贡献者的贡献。到目前为止,通常的基础方法是使用一个单一的许可证,它规定了一个版权持有者,如 [Apache 2.0][8] 和 [EPL 1.0][15],并由<ruby>贡献者许可协议<rt>contributor license agreements</rt></ruby> [Apache CLA][16] 以及 [Eclipse CLA][17] 为后盾,以从贡献者中收集权利。在像 GPL 这样的<ruby>左版<rt>copyleft</rt></ruby>许可证下,将版权所有权收集在一个地方就更加重要了,因为 GPL 依靠版权所有者来执行许可证条件,以促进软件自由的价值。
|
||||
|
||||
如今,大量没有机构或商业管理人的项目都在使用 MIT 风格的许可条款。SPDX 和 OSI 通过标准化不涉及特定实体或机构版权持有人的 MIT 和 ISC 之类的许可证形式,为这些用例提供了帮助。有了这些许可证形式,项目作者的普遍做法是在许可证的版权声明中尽早填上自己的名字...也许还会在这里或那里填上年份。至少根据美国的版权法,由此产生的版权声明并不能说明全部情况。
|
||||
|
||||
软件的原始所有者保留其工作的所有权。但是,尽管 MIT 风格的许可条款赋予了他人开发和更改软件的权利,创造了法律上所谓的“衍生作品”,但它们并没有赋予原始作者对他人的贡献的所有权。相反,每个贡献者在以现有代码为起点所做的任何作品都拥有版权,[即使是稍做了一点创意][18]。
|
||||
|
||||
这些项目大多数也对接受<ruby>贡献者许可协议<rt>contributor license agreements</rt></ruby>(CLA)的想法嗤之以鼻,更不用说签署版权转让协议了。这既幼稚又可以理解。尽管一些较新的开源开发人员认为,在 GitHub 上发送<ruby>拉取请求<rt>Pull Request</rt></ruby>,就会“自动”根据项目现有的许可证条款授权分发贡献,但美国法律不承认任何此类规则。强有力的版权保护是默认的,而不是宽松许可。
|
||||
|
||||
> 更新:GitHub 后来修改了全站的服务条款,包括试图至少在 GitHub.com 上改变这一默认值。我在 [另一篇文章][19] 中写了一些对这一发展的想法,并非所有想法都是积极的。
|
||||
|
||||
为了填补法律上有效的、有据可查的贡献权利授予与完全没有纸质痕迹之间的差距,一些项目采用了 <ruby>[开发者原创证书][20]<rt>Developer Certificate of Origin</rt></ruby>,这是贡献者在 Git 提交中使用 `Signed-Off-By` 元数据标签暗示的标准声明。开发者原创证书是在臭名昭著的 SCO 诉讼之后为 Linux 内核开发而开发的,该诉讼称 Linux 的大部分代码源自 SCO 拥有的 Unix 源代码。作为创建显示 Linux 的每一行都来自贡献者的书面记录的一种方法,开发者原创证书的功能良好。尽管开发者原创证书不是许可证,但它确实提供了大量证据,证明提交代码的人希望项目分发其代码,并让其他人根据内核现有的许可证条款使用该代码。内核还维护着一个机器可读的 `CREDITS` 文件,其中列出了贡献者的名字、所属机构、贡献领域和其他元数据。我做了 [一些][21] [实验][22],把这种方法改编成适用于不使用内核开发流程的项目。
|
||||
|
||||
### 许可证授权
|
||||
|
||||
> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”),
|
||||
|
||||
> 特此免费授予任何获得本软件副本和相关文档文件(下称“软件”)的人
|
||||
|
||||
MIT 许可证的实质是许可证(你猜对了)。一般来说,许可证是一个人或法律实体(“<ruby>许可人<rt>licensor</rt></ruby>”)给予另一个人(“<ruby>被许可人<rt>licensee</rt></ruby>”)做一些法律允许他们起诉的事情的许可。MIT 许可证是一种不起诉的承诺。
|
||||
|
||||
法律有时将许可证与给予许可证的承诺区分开来。如果有人违背了提供许可证的承诺,你可以起诉他们违背了承诺,但你最终可能得不到许可证。“<ruby>特此<rt>Hereby</rt></ruby>”是律师们永远摆脱不了的一个矫揉造作、老生常谈的词。这里使用它来表明,许可证文本本身提供了许可证,而不仅仅是许可证的承诺。这是一个合法的 [即调函数表达式(IIFE)][23]。
|
||||
|
||||
尽管许多许可证都是授予特定的、指定的被许可人的,但 MIT 许可证是一个“<ruby>公共许可证<rt>public license</rt></ruby>”。公共许可证授予所有人(整个公众)许可。这是开源许可中的三大理念之一。MIT 许可证通过“向任何获得……软件副本的人”授予许可证来体现这一思想。稍后我们将看到,获得此许可证还有一个条件,以确保其他人也可以了解他们的许可。
|
||||
|
||||
在美国式法律文件中,括号中带引号的首字母大写词汇是赋予术语特定含义的标准方式(“定义”)。当法庭看到文件中其他地方使用了一个已定义的大写术语时,法庭会可靠地回顾定义中的术语。
|
||||
|
||||
#### 授权范围
|
||||
|
||||
> to deal in the Software without restriction,
|
||||
|
||||
> 不受限制地处置该软件的权利,
|
||||
|
||||
从被许可人的角度来看,这是 MIT 许可证中最重要的七个字。主要的法律问题就是因侵犯版权而被起诉,和因侵犯专利而被起诉。无论是版权法还是专利法都没有将 “<ruby>处置<rt>to deal in</rt></ruby>” 作为一个术语,它在法庭上没有特定的含义。因此,任何法庭在裁决许可人和被许可人之间的纠纷时,都会询问当事人对这一措辞的含义和理解。法庭将看到的是,该措辞有意宽泛和开放。它为被许可人提供了一个强有力的论据,反对许可人提出的任何主张 —— 即他们不允许被许可人使用该软件做那件特定的事情,即使在授予许可证时双方都没有明显想到。
|
||||
|
||||
> including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so,
|
||||
|
||||
> 包括不受限制地使用、复制、修改、合并、发布、分发、转授许可和/或出售该软件副本,以及再授权被配发了本软件的人如上的权利,
|
||||
|
||||
没有一篇法律是完美的、“意义上完全确定”、或明确无误的。小心那些假装不然的人。这是 MIT 许可证中最不完美的部分。主要有三个问题:
|
||||
|
||||
首先,“<ruby>包括不受限制地<rt>including without limitation</rt></ruby>”是一种法律反模式。它有多种衍生:
|
||||
|
||||
* <ruby>包括,但不受限制<rt>including, without limitation</rt></ruby>
|
||||
* <ruby>包括,但不限于前述的一般性<rt>including, without limiting the generality of the foregoing</rt></ruby>
|
||||
* <ruby>包括,但不限于<rt>including, but not limited to</rt></ruby>
|
||||
* 很多、很多毫无意义的变化
|
||||
|
||||
所有这些都有一个共同的目标,但都未能可靠地实现。从根本上说,使用它们的起草者也会尽量试探着去做。在 MIT 许可证中,这意味着引入“<ruby>处置软件<rt>dealing in the Software</rt></ruby>”的具体例子 — “使用、复制、修改”等等,但不意味着被许可方的行为必须与给出的例子类似,才能算作“处置”。问题是,如果你最终需要法庭来审查和解释许可证的条款,法庭将把它的工作看作是找出这些语言的含义。如果法庭需要决定“<ruby>处置<rt>deal in</rt></ruby>”的含义,它不能“无视”这些例子,即使你告诉它。我认为,“不受限制地处置本软件”本身对被许可人更好,也更短。
|
||||
|
||||
其次,作为“<ruby>处置<rt>deal in</rt></ruby>”的例子的那些动词是一个大杂烩。有些在版权法或专利法下有特定的含义,有些稍微有或根本没有含义:
|
||||
|
||||
* “<ruby>使用<rt>use</rt></ruby>”出现在 [《美国法典》第 35 篇,第 271(a)节][24],这是专利法中专利权人可以起诉他人未经许可的行为的清单。
|
||||
* “<ruby>复制<rt>copy</rt></ruby>”出现在 [《美国法典》第 17 篇,第 106 节][25],即版权法列出的版权所有人可以起诉他人未经许可的行为。
|
||||
* “<ruby>修改<rt>modify</rt></ruby>”既不出现在版权法中,也不出现在专利法中。它可能最接近版权法下的“<ruby>准备衍生作品<rt>prepare derivative works</rt></ruby>”,但也可能涉及改进或其他衍生发明。
|
||||
* 无论是在版权法还是专利法中,“<ruby>合并<rt>merge</rt></ruby>”都没有出现。“<ruby>合并<rt>merger</rt></ruby>”在版权方面有特定的含义,但这显然不是这里的意图。相反,法庭可能会根据其在行业中的含义来解读“合并”,如“合并代码”。
|
||||
* 无论是在版权法还是专利法中,都没有“<ruby>发布<rt>publish</rt></ruby>”。由于“软件”是被发布的内容,根据《[版权法][25]》,它可能最接近于“<ruby>分发<rt>distribute</rt></ruby>”。该法令还包括“公开”表演和展示作品的权利,但这些权利只适用于特定类型的受版权保护的作品,如戏剧、录音和电影。
|
||||
* “<ruby>分发<rt>distribute</rt></ruby>”出现在《[版权法][25]》中。
|
||||
* “<ruby>转授许可<rt>sublicense</rt></ruby>”是知识产权法中的一个总称。转授许可的权利是指把自己的许可证授予他人,有权进行你所许可的部分或全部活动。实际上,MIT 许可证的转授许可的权利在开源代码许可证中并不常见。通常的做法是 Heather Meeker 所说的“<ruby>直接许可<rt>direct licensing</rt></ruby>”方式,在这种方法中,每个获得该软件及其许可证条款副本的人都直接从所有者那里获得授权。任何可能根据 MIT 许可证获得转授许可的人都可能会得到一份许可证副本,告诉他们其也有直接许可证。
|
||||
* “<ruby>出售副本<rt>sell copies</rt></ruby>”是个混杂品。它接近于《[专利法][24]》中的“<ruby>要约出售<rt>offer to sell</rt></ruby>”和“<ruby>出售<rt>sell</rt></ruby>”,但指的是“<ruby>副本<rt>coyies</rt></ruby>”,这是一种版权概念。在版权方面,它似乎接近于“<ruby>分发<rt>distribute</rt></ruby>”,但《[版权法][25]》没有提到销售。
|
||||
* “<ruby>允许被配发了本软件的人这样做<rt>permit persons to whom the Software is furnished to do so</rt></ruby>”似乎是多余的“转授许可”。这也是不必要的,因为获得副本的人也可以直接获得许可证。
|
||||
|
||||
最后,由于这种法律、行业、一般知识产权和一般使用条款的混杂,并不清楚 MIT 许可证是否包括专利许可。一般性语言“<ruby>处置<rt>deal in</rt></ruby>”和一些例子动词,尤其是“使用”,指向了一个专利许可,尽管是一个非常不明确的许可。许可证来自于版权持有人,而版权持有人可能对软件中的发明拥有或不拥有专利权,以及大多数的例子动词和“<ruby>软件<rt>the Software</rt></ruby>”本身的定义,都强烈地指向版权许可证。诸如 [Apache 2.0][8] 之类的较新的宽容开源许可分别具体地处理了版权、专利甚至商标问题。
|
||||
|
||||
#### 三个许可条件
|
||||
|
||||
> subject to the following conditions:
|
||||
|
||||
> 须在下列条件下:
|
||||
|
||||
总有一个陷阱!MIT 许可证有三个!
|
||||
|
||||
如果你不遵守 MIT 许可证的条件,你就得不到许可证提供的许可。因此,如果不能履行条件,至少从理论上说,会让你面临一场诉讼,很可能是一场版权诉讼。
|
||||
|
||||
开源软件的第二个伟大思想是,利用软件对被许可人的价值来激励被许可人遵守条件,即使被许可人没有支付任何许可费用。最后一个伟大思想,在 MIT 许可证中没有,它构建了许可证条件:像 [GNU 通用公共许可证][9](GPL)这样的左版许可证,使用许可证条件来控制如何对修改后的版本进行许可和发布。
|
||||
|
||||
#### 声明条件
|
||||
|
||||
> The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
||||
|
||||
> 上述版权声明和本许可声明应包含在该软件的所有副本或实质成分中。
|
||||
|
||||
如果你给别人一份软件的副本,你需要包括许可证文本和任何版权声明。这有几个关键目的:
|
||||
|
||||
1. 给别人一个声明,说明他们有权使用该公共许可证下的软件。这是直接授权模式的一个关键部分,在这种模式下,每个用户直接从版权持有人那里获得许可证。
|
||||
2. 让人们知道谁是软件的幕后人物,这样他们就可以得到赞美、荣耀和冷冰冰的现金捐赠。
|
||||
3. 确保保修免责声明和责任限制(在后面)伴随该软件。每个得到该副本的人也应该得到一份这些许可人保护的副本。
|
||||
|
||||
没有什么可以阻止你对提供一个副本、甚至是一个没有源代码的编译形式的副本而收费。但是当你这么做的时候,你不能假装 MIT 代码是你自己的专有代码,也不能在其他许可证下提供。接受的人要知道自己在“公共许可证”下的权利。
|
||||
|
||||
坦率地说,遵守这个条件正在崩溃。几乎所有的开源许可证都有这样的“<ruby>归因<rt>attribution</rt></ruby>”条件。系统和装机软件的制作者往往明白,他们需要为自己的每一个发行版本编制一个声明文件或“许可证信息”屏,并附上库和组件的许可证文本副本。项目监管型基金会在教授这些做法方面起到了重要作用。但是整个 Web 开发者群体还没有取得这种经验。这不能用缺乏工具来解释,工具有很多,也不能用 npm 和其他资源库中的包的高度模块化来解释,它们统一了许可证信息的元数据格式。所有好的 JavaScript 压缩器都有保存许可证标题注释的命令行标志。其他工具可以从包树中串联 `LICENSE` 文件。这实在是没有借口。
|
||||
|
||||
#### 免责声明
|
||||
|
||||
> The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement.
|
||||
|
||||
> 本软件是“如此”提供的,没有任何形式的明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和不侵权的保证。
|
||||
|
||||
美国几乎每个州都颁布了一个版本的《<ruby>统一商业法典<rt>Uniform Commercial Code</rt></ruby>》(UCC),这是一部规范商业交易的示范性法律。UCC 的第 2 条(加利福尼亚州的“第 2 部分”)规定了商品销售合同,包括了从二手汽车的购买到向制造厂运送大量工业化学品。
|
||||
|
||||
UCC 关于销售合同的某些规则是强制性的。这些规则始终适用,无论买卖双方是否喜欢。其他只是“默认”。除非买卖双方以书面形式选择不适用这些默认,否则 UCC 潜在视作他们希望在 UCC 文本中找到交易的基准规则。默认规则中包括隐含的“<ruby>免责<rt>warranties</rt></ruby>”,或卖方对买方关于所售商品的质量和可用性的承诺。
|
||||
|
||||
关于诸如 MIT 许可证之类的公共许可证是合同(许可方和被许可方之间的可执行协议)还是仅仅是许可证(单向的,但可能有附加条件),这在理论上存在很大争议。关于软件是否被视为“商品”,从而触发 UCC 规则的争论较少。许可人之间没有就赔偿责任进行辩论:如果他们免费提供的软件出现故障、导致问题、无法正常工作或以其他方式引起麻烦,他们不想被起诉和被要求巨额赔偿。这与“<ruby>默示保证<rt>implied warranty</rt></ruby>”的三个默认规则完全相反:
|
||||
|
||||
1. 据 [UCC 第 2-314 节][26],“<ruby>适销性<rt>merchantability</rt></ruby>”的默示保证是一种承诺:“商品”(即软件)的质量至少为平均水平,并经过适当包装和标记,并适用于其常规用途。仅当提供该软件的人是该软件的“商人”时,此保证才适用,这意味着他们从事软件交易,并表现出对软件的熟练程度。
|
||||
2. 据 [UCC 第 2-315 节][27],当卖方知道买方依靠他们提供用于特定目的的货物时,“<ruby>适用于某一特定目的<rt>fitness for a particular purpose</rt></ruby>”的默示保证就会生效。商品实际上需要“适用”这一目的。
|
||||
3. “<ruby>非侵权<rt>noninfringement</rt></ruby>”的默示保证不是 UCC 的一部分,而是一般合同法的共同特征。如果事实证明买方收到的商品侵犯了他人的知识产权,则这种默示的承诺将保护买方。如果根据 MIT 许可证获得的软件实际上并不属于尝试许可该软件的许可人,或者属于他人拥有的专利,那就属于这种情况。
|
||||
|
||||
UCC 的 [第2-316(3)节][28] 要求,选择不适用或“排除”适销性和适用于某一特定目的的默示保证措辞必须醒目。“醒目”意味着书面化或格式化,以引起人们的注意,这与旨在从不小心的消费者身边溜走的细小字体相反。各州法律可以对不侵权的免责声明提出类似的引人注目的要求。
|
||||
|
||||
长期以来,律师们都有一种错觉,认为用“全大写”写任何东西都符合明显的要求。这是不正确的。法庭曾批评律师协会自以为是,而且大多数人都认为,全大写更多的是阻止阅读,而不是强制阅读。同样的,大多数开源许可证的形式都将其免责声明设置为全大写,部分原因是这是在纯文本的 `LICENSE` 文件中唯一明显的方式。我更喜欢使用星号或其他 ASCII 艺术,但那是很久很久以前的事了。
|
||||
|
||||
#### 责任限制
|
||||
|
||||
> In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the Software or the use or other dealings in the Software.
|
||||
|
||||
> 在任何情况下,作者或版权持有人都不对任何索赔、损害或其他责任负责,无论这些追责来自合同、侵权或其它行为中,还是产生于、源于或有关于本软件以及本软件的使用或其它处置。
|
||||
|
||||
MIT 许可证授予软件“免费”许可,但法律并不认为接受免费许可证的人在出错时放弃了起诉的权利,而许可人应该受到责备。“责任限制”,通常与“损害赔偿排除”条款搭配使用,其作用与许可证很像,是不起诉的承诺。但这些都是保护许可人免受被许可人起诉的保护措施。
|
||||
|
||||
一般来说,法庭对责任限制和损害赔偿排除条款的解读非常谨慎,因为这些条款可以将大量的风险从一方转移到另一方。为了保护社会的切身利益,让民众有办法纠正在法庭上所犯的错误,他们“严格地”用措辞限制责任,尽可能地对受其保护的一方进行解读。责任限制必须具体才能成立。特别是在“消费者”合同和其他放弃起诉权的人缺乏成熟度或讨价还价能力的情况下,法庭有时会拒绝尊重那些似乎被埋没在视线之外的措辞。部分是出于这个原因,部分是出于习惯,律师们往往也会给责任限制以全大写处理。
|
||||
|
||||
再往下看,“责任限制”部分是对被许可人可以起诉的金额上限。在开源许可证中,这个上限总是没有钱,0 元,“不承担责任”。相比之下,在商业许可证中,它通常是过去 12 个月内支付的许可证费用的倍数,尽管它通常是经过谈判的。
|
||||
|
||||
“排除”部分具体列出了各种法律主张,即请求赔偿的理由,许可人不能使用。像许多其他法律形式一样,MIT 许可证 提到了“<ruby>违约<rt>of contract</rt></ruby>”行为(即违反合同)和“<ruby>侵权<rt>of tort</rt></ruby>”行为。侵权规则是防止粗心或恶意伤害他人的一般规则。如果你在发短信时在路上撞倒了人,你就犯了侵权行为。如果你的公司销售的有问题的耳机会烧伤人们的耳朵,则说明贵公司已经侵权。如果合同没有明确排除侵权索赔,那么法庭有时会在合同中使用排除措辞以防止合同索赔。出于很好的考虑,MIT 许可证抛出“或其它”字样,只是为了截住奇怪的海事法或其它异国情调的法律主张。
|
||||
|
||||
“<ruby>产生于、源于或有关于<rt>arising from, out of or in connection with</rt></ruby>”这句话是法律起草人固有的、焦虑的不安全感反复出现的症状。关键是,任何与软件有关的诉讼都被这些限制和排除范围所覆盖。万一某些事情可以“<ruby>产生于<rt>arising from</rt></ruby>”,但不能“<ruby>源于<rt>out of</rt></ruby>”或“<ruby>有关于<rt>in connection with</rt></ruby>”,那就最好把这三者都写在里面,所以要把它们打包在一起。更不用说,任何被迫在这部分内容中斤斤计较的法庭将不得不为每个词提出不同的含义,前提是专业的起草者不会在一行中使用不同的词来表示同一件事。更不用说,在实践中,如果法庭对一开始就不利的限制感觉不好,那么他们会更愿意狭隘地解读范围触发器。但我离题了,同样的语言出现在数以百万计的合同中。
|
||||
|
||||
### 总结
|
||||
|
||||
所有这些诡辩都有点像在进教堂的路上吐口香糖。MIT 许可证是一个法律经典,且有效。它绝不是解决所有软件知识产权弊病的灵丹妙药,尤其是它比已经出现的软件专利灾难还要早几十年。但 MIT 风格的许可证发挥了令人钦佩的作用,实现了一个狭隘的目的,用最少的、谨慎的法律工具组合扭转了版权、销售和合同法等棘手的默认规则。在计算机技术的大背景下,它的寿命是惊人的。MIT 许可证已经超过、并将要超过绝大多数软件许可证。我们只能猜测,当它最终失去青睐时,它能提供多少年的忠实法律服务。对于那些无法提供自己的律师的人来说,这尤其慷慨。
|
||||
|
||||
我们已经看到,我们今天所知道的 MIT 许可证是如何成为一套具体的、标准化的条款,使机构特有的、杂乱无章的变化终于有了秩序。
|
||||
|
||||
我们已经看到了它对归因和版权声明的处理方法如何为学术、标准、商业和基金会机构的知识产权管理实践提供信息。
|
||||
|
||||
我们已经看到了 MIT 许可证是如何运行所有人免费试用软件的,但前提是要保护许可人不受担保和责任的影响。
|
||||
|
||||
我们已经看到,尽管有一些生硬的措辞和律师的矫揉造作,但一百七十一个小词可以完成大量的法律工作,为开源软件在知识产权和合同的密集丛林中开辟一条道路。
|
||||
|
||||
我非常感谢所有花时间阅读这篇相当长的文章的人,让我知道他们发现它很有用,并帮助改进它。一如既往,我欢迎你通过 [e-mail][29]、[Twitter][30] 和 [GitHub][31] 发表评论。
|
||||
|
||||
---
|
||||
|
||||
有很多人问,他们在哪里可以读到更多的东西,或者找到其他许可证,比如 GNU 通用公共许可证或 Apache 2.0 许可证。无论你的兴趣是什么,我都会向你推荐以下书籍:
|
||||
|
||||
* Andrew M. St. Laurent 的 [Understanding Open Source & Free Software Licensing][32],来自 O’Reilly。
|
||||
> 我先说这本,因为虽然它有些过时,但它的方法也最接近上面使用的逐行方法。O'Reilly 已经把它[放在网上][33]。
|
||||
* Heather Meeker 的 [Open (Source) for Business][34]
|
||||
> 在我看来,这是迄今为止关于 GNU 通用公共许可证和更广泛的左版的最佳著作。这本书涵盖了历史、许可证、它们的发展,以及兼容性和合规性。这本书是我给那些考虑或处理 GPL 的客户的书。
|
||||
* Larry Rosen 的 [Open Source Licensing][35],来自 Prentice Hall。
|
||||
> 一本很棒的入门书,也可以免费 [在线阅读][36]。对于从零开始的程序员来说,这是开源许可和相关法律的最好介绍。这本在一些具体细节上也有点过时了,但 Larry 的许可证分类法和对开源商业模式的简洁总结经得起时间的考验。
|
||||
|
||||
所有这些都对我作为一个开源许可律师的教育至关重要。它们的作者都是我的职业英雄。请读一读吧 — K.E.M
|
||||
|
||||
我将此文章基于 [Creative Commons Attribution-ShareAlike 4.0 license][37] 授权
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://writing.kemitchell.com/2016/09/21/MIT-License-Line-by-Line.html
|
||||
|
||||
作者:[Kyle E. Mitchell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://kemitchell.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://spdx.org/licenses/MIT
|
||||
[2]: https://fedoraproject.org/wiki/Licensing:MIT?rd=Licensing/MIT
|
||||
[3]: https://opensource.org
|
||||
[4]: https://spdx.org
|
||||
[5]: http://spdx.org/licenses/
|
||||
[6]: https://spdx.org/licenses/JSON
|
||||
[7]: https://www.npmjs.com/package/licensor
|
||||
[8]: https://www.apache.org/licenses/LICENSE-2.0
|
||||
[9]: https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[10]: http://spdx.org/licenses/BSD-4-Clause
|
||||
[11]: https://spdx.org/licenses/BSD-3-Clause
|
||||
[12]: https://spdx.org/licenses/BSD-2-Clause
|
||||
[13]: http://www.isc.org/downloads/software-support-policy/isc-license/
|
||||
[14]: http://worksmadeforhire.com/
|
||||
[15]: https://www.eclipse.org/legal/epl-v10.html
|
||||
[16]: https://www.apache.org/licenses/#clas
|
||||
[17]: https://wiki.eclipse.org/ECA
|
||||
[18]: https://en.wikipedia.org/wiki/Feist_Publications,_Inc.,_v._Rural_Telephone_Service_Co.
|
||||
[19]: https://writing.kemitchell.com/2017/02/16/Against-Legislating-the-Nonobvious.html
|
||||
[20]: http://developercertificate.org/
|
||||
[21]: https://github.com/berneout/berneout-pledge
|
||||
[22]: https://github.com/berneout/authors-certificate
|
||||
[23]: https://en.wikipedia.org/wiki/Immediately-invoked_function_expression
|
||||
[24]: https://www.govinfo.gov/app/details/USCODE-2017-title35/USCODE-2017-title35-partIII-chap28-sec271
|
||||
[25]: https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106
|
||||
[26]: https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2314.&lawCode=COM
|
||||
[27]: https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2315.&lawCode=COM
|
||||
[28]: https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2316.&lawCode=COM
|
||||
[29]: mailto:kyle@kemitchell.com
|
||||
[30]: https://twitter.com/kemitchell
|
||||
[31]: https://github.com/kemitchell/writing/tree/master/_posts/2016-09-21-MIT-License-Line-by-Line.md
|
||||
[32]: https://lccn.loc.gov/2006281092
|
||||
[33]: http://www.oreilly.com/openbook/osfreesoft/book/
|
||||
[34]: https://www.amazon.com/dp/1511617772
|
||||
[35]: https://lccn.loc.gov/2004050558
|
||||
[36]: http://www.rosenlaw.com/oslbook.htm
|
||||
[37]: https://creativecommons.org/licenses/by-sa/4.0/legalcode
|
||||
262
published/202103/20190221 Testing Bash with BATS.md
Normal file
262
published/202103/20190221 Testing Bash with BATS.md
Normal file
@ -0,0 +1,262 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (stevenzdg988)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13194-1.html)
|
||||
[#]: subject: (Testing Bash with BATS)
|
||||
[#]: via: (https://opensource.com/article/19/2/testing-bash-bats)
|
||||
[#]: author: (Darin London https://opensource.com/users/dmlond)
|
||||
|
||||
利用 BATS 测试 Bash 脚本和库
|
||||
======
|
||||
|
||||
> Bash 自动测试系统可以使 Bash 代码也通过 Java、Ruby 和 Python 开发人员所使用的同类测试过程。
|
||||
|
||||

|
||||
|
||||
用 Java、Ruby 和 Python 等语言编写应用程序的软件开发人员拥有复杂的库,可以帮助他们随着时间的推移保持软件的完整性。他们可以创建测试,以在结构化环境中通过执行一系列动作来运行应用程序,以确保其软件所有的方面均按预期工作。
|
||||
|
||||
当这些测试在持续集成(CI)系统中自动进行时,它们的功能就更加强大了,每次推送到源代码库都会触发测试,并且在测试失败时会立即通知开发人员。这种快速反馈提高了开发人员对其应用程序功能完整性的信心。
|
||||
|
||||
<ruby>Bash 自动测试系统<rt>Bash Automated Testing System</rt></ruby>([BATS][1])使编写 Bash 脚本和库的开发人员能够将 Java、Ruby、Python 和其他开发人员所使用的相同惯例应用于其 Bash 代码中。
|
||||
|
||||
### 安装 BATS
|
||||
|
||||
BATS GitHub 页面包含了安装指令。有两个 BATS 辅助库提供更强大的断言或允许覆写 BATS 使用的 Test Anything Protocol([TAP][2])输出格式。这些库可以安装在一个标准位置,并被所有的脚本引用。更方便的做法是,将 BATS 及其辅助库的完整版本包含在 Git 仓库中,用于要测试的每组脚本或库。这可以通过 [git 子模块][3] 系统来完成。
|
||||
|
||||
以下命令会将 BATS 及其辅助库安装到 Git 知识库中的 `test` 目录中。
|
||||
|
||||
```
|
||||
git submodule init
|
||||
git submodule add https://github.com/sstephenson/bats test/libs/bats
|
||||
git submodule add https://github.com/ztombol/bats-assert test/libs/bats-assert
|
||||
git submodule add https://github.com/ztombol/bats-support test/libs/bats-support
|
||||
git add .
|
||||
git commit -m 'installed bats'
|
||||
```
|
||||
|
||||
要克隆 Git 仓库并同时安装其子模块,请在 `git clone` 时使用
|
||||
`--recurse-submodules` 标记。
|
||||
|
||||
每个 BATS 测试脚本必须由 `bats` 可执行文件执行。如果你将 BATS 安装到源代码仓库的 `test/libs` 目录中,则可以使用以下命令调用测试:
|
||||
|
||||
```
|
||||
./test/libs/bats/bin/bats <测试脚本的路径>
|
||||
```
|
||||
|
||||
或者,将以下内容添加到每个 BATS 测试脚本的开头:
|
||||
|
||||
```
|
||||
#!/usr/bin/env ./test/libs/bats/bin/bats
|
||||
load 'libs/bats-support/load'
|
||||
load 'libs/bats-assert/load'
|
||||
```
|
||||
|
||||
并且执行命令 `chmod +x <测试脚本的路径>`。 这将 a、使它们可与安装在 `./test/libs/bats` 中的 BATS 一同执行,并且 b、包含这些辅助库。BATS 测试脚本通常存储在 `test` 目录中,并以要测试的脚本命名,扩展名为 `.bats`。例如,一个测试 `bin/build` 的 BATS 脚本应称为 `test/build.bats`。
|
||||
|
||||
你还可以通过向 BATS 传递正则表达式来运行一整套 BATS 测试文件,例如 `./test/lib/bats/bin/bats test/*.bats`。
|
||||
|
||||
### 为 BATS 覆盖率而组织库和脚本
|
||||
|
||||
Bash 脚本和库必须以一种有效地方式将其内部工作原理暴露给 BATS 进行组织。通常,在调用或执行时库函数和运行诸多命令的 Shell 脚本不适合进行有效的 BATS 测试。
|
||||
|
||||
例如,[build.sh][4] 是许多人都会编写的典型脚本。本质上是一大堆代码。有些人甚至可能将这堆代码放入库中的函数中。但是,在 BATS 测试中运行一大堆代码,并在单独的测试用例中覆盖它可能遇到的所有故障类型是不可能的。测试这堆代码并有足够的覆盖率的唯一方法就是把它分解成许多小的、可重用的、最重要的是可独立测试的函数。
|
||||
|
||||
向库添加更多的函数很简单。额外的好处是其中一些函数本身可以变得出奇的有用。将库函数分解为许多较小的函数后,你可以在 BATS 测试中<ruby>援引<rt>source</er></ruby>这些库,并像测试任何其他命令一样运行这些函数。
|
||||
|
||||
Bash 脚本也必须分解为多个函数,执行脚本时,脚本的主要部分应调用这些函数。此外,还有一个非常有用的技巧,可以让你更容易地用 BATS 测试 Bash 脚本:将脚本主要部分中执行的所有代码都移到一个函数中,称为 `run_main`。然后,将以下内容添加到脚本的末尾:
|
||||
|
||||
```
|
||||
if [[ "${BASH_SOURCE[0]}" == "${0}" ]]
|
||||
then
|
||||
run_main
|
||||
fi
|
||||
```
|
||||
|
||||
这段额外的代码做了一些特别的事情。它使脚本在作为脚本执行时与使用<ruby>援引<rt>source</er></ruby>进入环境时的行为有所不同。通过援引并测试单个函数,这个技巧使得脚本的测试方式和库的测试方式变得一样。例如,[这是重构的 build.sh,以获得更好的 BATS 可测试性][5]。
|
||||
|
||||
### 编写和运行测试
|
||||
|
||||
如上所述,BATS 是一个 TAP 兼容的测试框架,其语法和输出对于使用过其他 TAP 兼容测试套件(例如 JUnit、RSpec 或 Jest)的用户来说将是熟悉的。它的测试被组织成单个测试脚本。测试脚本被组织成一个或多个描述性 `@test` 块中,它们描述了被测试应用程序的单元。每个 `@test` 块将运行一系列命令,这些命令准备测试环境、运行要测试的命令,并对被测试命令的退出和输出进行断言。许多断言函数是通过 `bats`、`bats-assert` 和 `bats-support` 库导入的,这些库在 BATS 测试脚本的开头加载到环境中。下面是一个典型的 BATS 测试块:
|
||||
|
||||
```
|
||||
@test "requires CI_COMMIT_REF_SLUG environment variable" {
|
||||
unset CI_COMMIT_REF_SLUG
|
||||
assert_empty "${CI_COMMIT_REF_SLUG}"
|
||||
run some_command
|
||||
assert_failure
|
||||
assert_output --partial "CI_COMMIT_REF_SLUG"
|
||||
}
|
||||
```
|
||||
|
||||
如果 BATS 脚本包含 `setup`(安装)和/或 `teardown`(拆卸) 函数,则 BATS 将在每个测试块运行之前和之后自动执行它们。这样就可以创建环境变量、测试文件以及执行一个或所有测试所需的其他操作,然后在每次测试运行后将其拆卸。[Build.bats][6] 是对我们新格式化的 `build.sh` 脚本的完整 BATS 测试。(此测试中的 `mock_docker` 命令将在以下关于模拟/打标的部分中进行说明。)
|
||||
|
||||
当测试脚本运行时,BATS 使用 `exec`(执行)来将每个 `@test` 块作为单独的子进程运行。这样就可以在一个 `@test` 中导出环境变量甚至函数,而不会影响其他 `@test` 或污染你当前的 Shell 会话。测试运行的输出是一种标准格式,可以被人理解,并且可以由 TAP 使用端以编程方式进行解析或操作。下面是 `CI_COMMIT_REF_SLUG` 测试块失败时的输出示例:
|
||||
|
||||
```
|
||||
✗ requires CI_COMMIT_REF_SLUG environment variable
|
||||
(from function `assert_output' in file test/libs/bats-assert/src/assert.bash, line 231,
|
||||
in test file test/ci_deploy.bats, line 26)
|
||||
`assert_output --partial "CI_COMMIT_REF_SLUG"' failed
|
||||
|
||||
-- output does not contain substring --
|
||||
substring (1 lines):
|
||||
CI_COMMIT_REF_SLUG
|
||||
output (3 lines):
|
||||
./bin/deploy.sh: join_string_by: command not found
|
||||
oc error
|
||||
Could not login
|
||||
--
|
||||
|
||||
** Did not delete , as test failed **
|
||||
|
||||
1 test, 1 failure
|
||||
```
|
||||
|
||||
下面是成功测试的输出:
|
||||
|
||||
```
|
||||
✓ requires CI_COMMIT_REF_SLUG environment variable
|
||||
```
|
||||
|
||||
### 辅助库
|
||||
|
||||
像任何 Shell 脚本或库一样,BATS 测试脚本可以包括辅助库,以在测试之间共享通用代码或增强其性能。这些辅助库,例如 `bats-assert` 和 `bats-support` 甚至可以使用 BATS 进行测试。
|
||||
|
||||
库可以和 BATS 脚本放在同一个测试目录下,如果测试目录下的文件数量过多,也可以放在 `test/libs` 目录下。BATS 提供了 `load` 函数,该函数接受一个相对于要测试的脚本的 Bash 文件的路径(例如,在我们的示例中的 `test`),并援引该文件。文件必须以后缀 `.bash` 结尾,但是传递给 `load` 函数的文件路径不能包含后缀。`build.bats` 加载 `bats-assert` 和 `bats-support` 库、一个小型 [helpers.bash][7] 库以及 `docker_mock.bash` 库(如下所述),以下代码位于测试脚本的开头,解释器魔力行下方:
|
||||
|
||||
```
|
||||
load 'libs/bats-support/load'
|
||||
load 'libs/bats-assert/load'
|
||||
load 'helpers'
|
||||
load 'docker_mock'
|
||||
```
|
||||
|
||||
### 打标测试输入和模拟外部调用
|
||||
|
||||
大多数 Bash 脚本和库运行时都会执行函数和/或可执行文件。通常,它们被编程为基于这些函数或可执行文件的输出状态或输出(`stdout`、`stderr`)以特定方式运行。为了正确地测试这些脚本,通常需要制作这些命令的伪版本,这些命令被设计成在特定测试过程中以特定方式运行,称为“<ruby>打标<rt>stubbing</rt></ruby>”。可能还需要监视正在测试的程序,以确保其调用了特定命令,或者使用特定参数调用了特定命令,此过程称为“<ruby>模拟<rt>mocking</rt></ruby>”。有关更多信息,请查看在 Ruby RSpec 中 [有关模拟和打标的讨论][8],它适用于任何测试系统。
|
||||
|
||||
Bash shell 提供了一些技巧,可以在你的 BATS 测试脚本中使用这些技巧进行模拟和打标。所有这些都需要使用带有 `-f` 标志的 Bash `export` 命令来导出一个覆盖了原始函数或可执行文件的函数。必须在测试程序执行之前完成此操作。下面是重写可执行命令 `cat` 的简单示例:
|
||||
|
||||
```
|
||||
function cat() { echo "THIS WOULD CAT ${*}" }
|
||||
export -f cat
|
||||
```
|
||||
|
||||
此方法以相同的方式覆盖了函数。如果一个测试需要覆盖要测试的脚本或库中的函数,则在对函数进行打标或模拟之前,必须先声明已测试脚本或库,这一点很重要。否则,在声明脚本时,打标/模拟将被原函数替代。另外,在运行即将进行的测试命令之前确认打标/模拟。下面是`build.bats` 的示例,该示例模拟 `build.sh` 中描述的`raise` 函数,以确保登录函数会引发特定的错误消息:
|
||||
|
||||
```
|
||||
@test ".login raises on oc error" {
|
||||
source ${profile_script}
|
||||
function raise() { echo "${1} raised"; }
|
||||
export -f raise
|
||||
run login
|
||||
assert_failure
|
||||
assert_output -p "Could not login raised"
|
||||
}
|
||||
```
|
||||
|
||||
一般情况下,没有必要在测试后复原打标/模拟的函数,因为 `export`(输出)仅在当前 `@test` 块的 `exec`(执行)期间影响当前子进程。但是,可以模拟/打标 BATS `assert` 函数在内部使用的命令(例如 `cat`、`sed` 等)是可能的。在运行这些断言命令之前,必须对这些模拟/打标函数进行 `unset`(复原),否则它们将无法正常工作。下面是 `build.bats` 中的一个示例,该示例模拟 `sed`,运行 `build_deployable` 函数并在运行任何断言之前复原 `sed`:
|
||||
|
||||
```
|
||||
@test ".build_deployable prints information, runs docker build on a modified Dockerfile.production and publish_image when its not a dry_run" {
|
||||
local expected_dockerfile='Dockerfile.production'
|
||||
local application='application'
|
||||
local environment='environment'
|
||||
local expected_original_base_image="${application}"
|
||||
local expected_candidate_image="${application}-candidate:${environment}"
|
||||
local expected_deployable_image="${application}:${environment}"
|
||||
source ${profile_script}
|
||||
mock_docker build --build-arg OAUTH_CLIENT_ID --build-arg OAUTH_REDIRECT --build-arg DDS_API_BASE_URL -t "${expected_deployable_image}" -
|
||||
function publish_image() { echo "publish_image ${*}"; }
|
||||
export -f publish_image
|
||||
function sed() {
|
||||
echo "sed ${*}" >&2;
|
||||
echo "FROM application-candidate:environment";
|
||||
}
|
||||
export -f sed
|
||||
run build_deployable "${application}" "${environment}"
|
||||
assert_success
|
||||
unset sed
|
||||
assert_output --regexp "sed.*${expected_dockerfile}"
|
||||
assert_output -p "Building ${expected_original_base_image} deployable ${expected_deployable_image} FROM ${expected_candidate_image}"
|
||||
assert_output -p "FROM ${expected_candidate_image} piped"
|
||||
assert_output -p "build --build-arg OAUTH_CLIENT_ID --build-arg OAUTH_REDIRECT --build-arg DDS_API_BASE_URL -t ${expected_deployable_image} -"
|
||||
assert_output -p "publish_image ${expected_deployable_image}"
|
||||
}
|
||||
```
|
||||
|
||||
有的时候相同的命令,例如 `foo`,将在被测试的同一函数中使用不同的参数多次调用。这些情况需要创建一组函数:
|
||||
|
||||
* `mock_foo`:将期望的参数作为输入,并将其持久化到 TMP 文件中
|
||||
* `foo`:命令的模拟版本,该命令使用持久化的预期参数列表处理每个调用。必须使用 `export -f` 将其导出。
|
||||
* `cleanup_foo`:删除 TMP 文件,用于拆卸函数。这可以进行测试以确保在删除之前成功完成 `@test` 块。
|
||||
|
||||
由于此功能通常在不同的测试中重复使用,因此创建一个可以像其他库一样加载的辅助库会变得有意义。
|
||||
|
||||
[docker_mock.bash][9] 是一个很棒的例子。它被加载到 `build.bats` 中,并在任何测试调用 Docker 可执行文件的函数的测试块中使用。使用 `docker_mock` 典型的测试块如下所示:
|
||||
|
||||
```
|
||||
@test ".publish_image fails if docker push fails" {
|
||||
setup_publish
|
||||
local expected_image="image"
|
||||
local expected_publishable_image="${CI_REGISTRY_IMAGE}/${expected_image}"
|
||||
source ${profile_script}
|
||||
mock_docker tag "${expected_image}" "${expected_publishable_image}"
|
||||
mock_docker push "${expected_publishable_image}" and_fail
|
||||
run publish_image "${expected_image}"
|
||||
assert_failure
|
||||
assert_output -p "tagging ${expected_image} as ${expected_publishable_image}"
|
||||
assert_output -p "tag ${expected_image} ${expected_publishable_image}"
|
||||
assert_output -p "pushing image to gitlab registry"
|
||||
assert_output -p "push ${expected_publishable_image}"
|
||||
}
|
||||
```
|
||||
|
||||
该测试建立了一个使用不同的参数两次调用 Docker 的预期。在对Docker 的第二次调用失败时,它会运行测试命令,然后测试退出状态和对 Docker 调用的预期。
|
||||
|
||||
一方面 BATS 利用 `mock_docker.bash` 引入 `${BATS_TMPDIR}` 环境变量,BATS 在测试开始的位置对其进行了设置,以允许测试和辅助程序在标准位置创建和销毁 TMP 文件。如果测试失败,`mock_docker.bash` 库不会删除其持久化的模拟文件,但会打印出其所在位置,以便可以查看和删除它。你可能需要定期从该目录中清除旧的模拟文件。
|
||||
|
||||
关于模拟/打标的一个注意事项:`build.bats` 测试有意识地违反了关于测试声明的规定:[不要模拟没有拥有的!][10] 该规定要求调用开发人员没有编写代码的测试命令,例如 `docker`、`cat`、`sed` 等,应封装在自己的库中,应在使用它们脚本的测试中对其进行模拟。然后应该在不模拟外部命令的情况下测试封装库。
|
||||
|
||||
这是一个很好的建议,而忽略它是有代价的。如果 Docker CLI API 发生变化,则测试脚本不会检测到此变化,从而导致错误内容直到经过测试的 `build.sh` 脚本在使用新版本 Docker 的生产环境中运行后才显示出来。测试开发人员必须确定要严格遵守此标准的程度,但是他们应该了解其所涉及的权衡。
|
||||
|
||||
### 总结
|
||||
|
||||
在任何软件开发项目中引入测试制度,都会在以下两方面产生权衡: a、增加开发和维护代码及测试所需的时间和组织,b、增加开发人员在对应用程序整个生命周期中完整性的信心。测试制度可能不适用于所有脚本和库。
|
||||
|
||||
通常,满足以下一个或多个条件的脚本和库才可以使用 BATS 测试:
|
||||
|
||||
* 值得存储在源代码管理中
|
||||
* 用于关键流程中,并依靠它们长期稳定运行
|
||||
* 需要定期对其进行修改以添加/删除/修改其功能
|
||||
* 可以被其他人使用
|
||||
|
||||
一旦决定将测试规则应用于一个或多个 Bash 脚本或库,BATS 就提供其他软件开发环境中可用的全面测试功能。
|
||||
|
||||
致谢:感谢 [Darrin Mann][11] 向我引荐了 BATS 测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/testing-bash-bats
|
||||
|
||||
作者:[Darin London][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dmlond
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/sstephenson/bats
|
||||
[2]: http://testanything.org/
|
||||
[3]: https://git-scm.com/book/en/v2/Git-Tools-Submodules
|
||||
[4]: https://github.com/dmlond/how_to_bats/blob/preBats/build.sh
|
||||
[5]: https://github.com/dmlond/how_to_bats/blob/master/bin/build.sh
|
||||
[6]: https://github.com/dmlond/how_to_bats/blob/master/test/build.bats
|
||||
[7]: https://github.com/dmlond/how_to_bats/blob/master/test/helpers.bash
|
||||
[8]: https://www.codewithjason.com/rspec-mocks-stubs-plain-english/
|
||||
[9]: https://github.com/dmlond/how_to_bats/blob/master/test/docker_mock.bash
|
||||
[10]: https://github.com/testdouble/contributing-tests/wiki/Don't-mock-what-you-don't-own
|
||||
[11]: https://github.com/dmann
|
||||
@ -0,0 +1,299 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (stevenzdg988)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13233-1.html)
|
||||
[#]: subject: (Using Python to explore Google's Natural Language API)
|
||||
[#]: via: (https://opensource.com/article/19/7/python-google-natural-language-api)
|
||||
[#]: author: (JR Oakes https://opensource.com/users/jroakes)
|
||||
|
||||
利用 Python 探究 Google 的自然语言 API
|
||||
======
|
||||
|
||||
> Google API 可以凸显出有关 Google 如何对网站进行分类的线索,以及如何调整内容以改进搜索结果的方法。
|
||||
|
||||

|
||||
|
||||
作为一名技术性的搜索引擎优化人员,我一直在寻找以新颖的方式使用数据的方法,以更好地了解 Google 如何对网站进行排名。我最近研究了 Google 的 [自然语言 API][2] 能否更好地揭示 Google 是如何分类网站内容的。
|
||||
|
||||
尽管有 [开源 NLP 工具][3],但我想探索谷歌的工具,前提是它可能在其他产品中使用同样的技术,比如搜索。本文介绍了 Google 的自然语言 API,并探究了常见的自然语言处理(NLP)任务,以及如何使用它们来为网站内容创建提供信息。
|
||||
|
||||
### 了解数据类型
|
||||
|
||||
首先,了解 Google 自然语言 API 返回的数据类型非常重要。
|
||||
|
||||
#### 实体
|
||||
|
||||
<ruby>实体<rt>Entities</rt></ruby>是可以与物理世界中的某些事物联系在一起的文本短语。<ruby>命名实体识别<rt>Named Entity Recognition</rt></ruby>(NER)是 NLP 的难点,因为工具通常需要查看关键字的完整上下文才能理解其用法。例如,<ruby>同形异义字<rt>homographs</rt></ruby>拼写相同,但是具有多种含义。句子中的 “lead” 是指一种金属:“铅”(名词),使某人移动:“牵领”(动词),还可能是剧本中的主要角色(也是名词)?Google 有 12 种不同类型的实体,还有第 13 个名为 “UNKNOWN”(未知)的统称类别。一些实体与维基百科的文章相关,这表明 [知识图谱][4] 对数据的影响。每个实体都会返回一个显著性分数,即其与所提供文本的整体相关性。
|
||||
|
||||
![实体][5]
|
||||
|
||||
#### 情感
|
||||
|
||||
<ruby>情感<rt>Sentiment</rt></ruby>,即对某事的看法或态度,是在文件和句子层面以及文件中发现的单个实体上进行衡量。情感的<ruby>得分<rt>score</rt></ruby>范围从 -1.0(消极)到 1.0(积极)。<ruby>幅度<rt>magnitude</rt></ruby>代表情感的<ruby>非归一化<rt>non-normalized</rt></ruby>强度;它的范围是 0.0 到无穷大。
|
||||
|
||||
![情感][6]
|
||||
|
||||
#### 语法
|
||||
|
||||
<ruby>语法<rt>Syntax</rt></ruby>解析包含了大多数在较好的库中常见的 NLP 活动,例如 <ruby>[词形演变][7]<rt>lemmatization</rt></ruby>、<ruby>[词性标记][8]<rt>part-of-speech tagging</rt></ruby> 和 <ruby>[依赖树解析][9]<rt>dependency-tree parsing</rt></ruby>。NLP 主要处理帮助机器理解文本和关键字之间的关系。语法解析是大多数语言处理或理解任务的基础部分。
|
||||
|
||||
![语法][10]
|
||||
|
||||
#### 分类
|
||||
|
||||
<ruby>分类<rt>Categories</rt></ruby>是将整个给定内容分配给特定行业或主题类别,其<ruby>置信度<rt>confidence</rt></ruby>得分从 0.0 到 1.0。这些分类似乎与其他 Google 工具使用的受众群体和网站类别相同,如 AdWords。
|
||||
|
||||
![分类][11]
|
||||
|
||||
### 提取数据
|
||||
|
||||
现在,我将提取一些示例数据进行处理。我使用 Google 的 [搜索控制台 API][12] 收集了一些搜索查询及其相应的网址。Google 搜索控制台是一个报告人们使用 Google Search 查找网站页面的术语的工具。这个 [开源的 Jupyter 笔记本][13] 可以让你提取有关网站的类似数据。在此示例中,我在 2019 年 1 月 1 日至 6 月 1 日期间生成的一个网站(我没有提及名字)上提取了 Google 搜索控制台数据,并将其限制为至少获得一次点击(而不只是<ruby>曝光<rt>impressions</rt></ruby>)的查询。
|
||||
|
||||
该数据集包含 2969 个页面和在 Google Search 的结果中显示了该网站网页的 7144 条查询的信息。下表显示,绝大多数页面获得的点击很少,因为该网站侧重于所谓的长尾(越特殊通常就更长尾)而不是短尾(非常笼统,搜索量更大)搜索查询。
|
||||
|
||||
![所有页面的点击次数柱状图][14]
|
||||
|
||||
为了减少数据集的大小并仅获得效果最好的页面,我将数据集限制为在此期间至少获得 20 次曝光的页面。这是精炼数据集的按页点击的柱状图,其中包括 723 个页面:
|
||||
|
||||
![部分网页的点击次数柱状图][15]
|
||||
|
||||
### 在 Python 中使用 Google 自然语言 API 库
|
||||
|
||||
要测试 API,在 Python 中创建一个利用 [google-cloud-language][16] 库的小脚本。以下代码基于 Python 3.5+。
|
||||
|
||||
首先,激活一个新的虚拟环境并安装库。用环境的唯一名称替换 `<your-env>` 。
|
||||
|
||||
```
|
||||
virtualenv <your-env>
|
||||
source <your-env>/bin/activate
|
||||
pip install --upgrade google-cloud-language
|
||||
pip install --upgrade requests
|
||||
```
|
||||
|
||||
该脚本从 URL 提取 HTML,并将 HTML 提供给自然语言 API。返回一个包含 `sentiment`、 `entities` 和 `categories` 的字典,其中这些键的值都是列表。我使用 Jupyter 笔记本运行此代码,因为使用同一内核注释和重试代码更加容易。
|
||||
|
||||
```
|
||||
# Import needed libraries
|
||||
import requests
|
||||
import json
|
||||
|
||||
from google.cloud import language
|
||||
from google.oauth2 import service_account
|
||||
from google.cloud.language import enums
|
||||
from google.cloud.language import types
|
||||
|
||||
# Build language API client (requires service account key)
|
||||
client = language.LanguageServiceClient.from_service_account_json('services.json')
|
||||
|
||||
# Define functions
|
||||
def pull_googlenlp(client, url, invalid_types = ['OTHER'], **data):
|
||||
|
||||
html = load_text_from_url(url, **data)
|
||||
|
||||
if not html:
|
||||
return None
|
||||
|
||||
document = types.Document(
|
||||
content=html,
|
||||
type=language.enums.Document.Type.HTML )
|
||||
|
||||
features = {'extract_syntax': True,
|
||||
'extract_entities': True,
|
||||
'extract_document_sentiment': True,
|
||||
'extract_entity_sentiment': True,
|
||||
'classify_text': False
|
||||
}
|
||||
|
||||
response = client.annotate_text(document=document, features=features)
|
||||
sentiment = response.document_sentiment
|
||||
entities = response.entities
|
||||
|
||||
response = client.classify_text(document)
|
||||
categories = response.categories
|
||||
|
||||
def get_type(type):
|
||||
return client.enums.Entity.Type(entity.type).name
|
||||
|
||||
result = {}
|
||||
|
||||
result['sentiment'] = []
|
||||
result['entities'] = []
|
||||
result['categories'] = []
|
||||
|
||||
if sentiment:
|
||||
result['sentiment'] = [{ 'magnitude': sentiment.magnitude, 'score':sentiment.score }]
|
||||
|
||||
for entity in entities:
|
||||
if get_type(entity.type) not in invalid_types:
|
||||
result['entities'].append({'name': entity.name, 'type': get_type(entity.type), 'salience': entity.salience, 'wikipedia_url': entity.metadata.get('wikipedia_url', '-') })
|
||||
|
||||
for category in categories:
|
||||
result['categories'].append({'name':category.name, 'confidence': category.confidence})
|
||||
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def load_text_from_url(url, **data):
|
||||
|
||||
timeout = data.get('timeout', 20)
|
||||
|
||||
results = []
|
||||
|
||||
try:
|
||||
|
||||
print("Extracting text from: {}".format(url))
|
||||
response = requests.get(url, timeout=timeout)
|
||||
|
||||
text = response.text
|
||||
status = response.status_code
|
||||
|
||||
if status == 200 and len(text) > 0:
|
||||
return text
|
||||
|
||||
return None
|
||||
|
||||
|
||||
except Exception as e:
|
||||
print('Problem with url: {0}.'.format(url))
|
||||
return None
|
||||
```
|
||||
|
||||
要访问该 API,请按照 Google 的 [快速入门说明][17] 在 Google 云主控台中创建一个项目,启用该 API 并下载服务帐户密钥。之后,你应该拥有一个类似于以下内容的 JSON 文件:
|
||||
|
||||
![services.json 文件][18]
|
||||
|
||||
命名为 `services.json`,并上传到项目文件夹。
|
||||
|
||||
然后,你可以通过运行以下程序来提取任何 URL(例如 Opensource.com)的 API 数据:
|
||||
|
||||
```
|
||||
url = "https://opensource.com/article/19/6/how-ssh-running-container"
|
||||
pull_googlenlp(client,url)
|
||||
```
|
||||
|
||||
如果设置正确,你将看到以下输出:
|
||||
|
||||
![拉取 API 数据的输出][19]
|
||||
|
||||
为了使入门更加容易,我创建了一个 [Jupyter 笔记本][20],你可以下载并使用它来测试提取网页的实体、类别和情感。我更喜欢使用 [JupyterLab][21],它是 Jupyter 笔记本的扩展,其中包括文件查看器和其他增强的用户体验功能。如果你不熟悉这些工具,我认为利用 [Anaconda][22] 是开始使用 Python 和 Jupyter 的最简单途径。它使安装和设置 Python 以及常用库变得非常容易,尤其是在 Windows 上。
|
||||
|
||||
### 处理数据
|
||||
|
||||
使用这些函数,可抓取给定页面的 HTML 并将其传递给自然语言 API,我可以对 723 个 URL 进行一些分析。首先,我将通过查看所有页面中返回的顶级分类的数量来查看与网站相关的分类。
|
||||
|
||||
#### 分类
|
||||
|
||||
![来自示例站点的分类数据][23]
|
||||
|
||||
这似乎是该特定站点的关键主题的相当准确的代表。通过查看一个效果最好的页面进行排名的单个查询,我可以比较同一查询在 Google 搜索结果中的其他排名页面。
|
||||
|
||||
* URL 1 |顶级类别:/法律和政府/与法律相关的(0.5099999904632568)共 1 个类别。
|
||||
* 未返回任何类别。
|
||||
* URL 3 |顶级类别:/互联网与电信/移动与无线(0.6100000143051147)共 1 个类别。
|
||||
* URL 4 |顶级类别:/计算机与电子产品/软件(0.5799999833106995)共有 2 个类别。
|
||||
* URL 5 |顶级类别:/互联网与电信/移动与无线/移动应用程序和附件(0.75)共有 1 个类别。
|
||||
* 未返回任何类别。
|
||||
* URL 7 |顶级类别:/计算机与电子/软件/商业与生产力软件(0.7099999785423279)共 2 个类别。
|
||||
* URL 8 |顶级类别:/法律和政府/与法律相关的(0.8999999761581421)共 3 个类别。
|
||||
* URL 9 |顶级类别:/参考/一般参考/类型指南和模板(0.6399999856948853)共有 1 个类别。
|
||||
* 未返回任何类别。
|
||||
|
||||
上方括号中的数字表示 Google 对页面内容与该分类相关的置信度。对于相同分类,第八个结果比第一个结果具有更高的置信度,因此,这似乎不是定义排名相关性的灵丹妙药。此外,分类太宽泛导致无法满足特定搜索主题的需要。
|
||||
|
||||
通过排名查看平均置信度,这两个指标之间似乎没有相关性,至少对于此数据集而言如此:
|
||||
|
||||
![平均置信度排名分布图][24]
|
||||
|
||||
这两种方法对网站进行规模审查是有意义的,以确保内容类别易于理解,并且样板或销售内容不会使你的页面与你的主要专业知识领域无关。想一想,如果你出售工业用品,但是你的页面返回 “Marketing(销售)” 作为主要分类。似乎没有一个强烈的迹象表明,分类相关性与你的排名有什么关系,至少在页面级别如此。
|
||||
|
||||
#### 情感
|
||||
|
||||
我不会在情感上花很多时间。在所有从 API 返回情感的页面中,它们分为两个区间:0.1 和 0.2,这几乎是中立的情感。根据直方图,很容易看出情感没有太大价值。对于新闻或舆论网站而言,测量特定页面的情感到中位数排名之间的相关性将是一个更加有趣的指标。
|
||||
|
||||
![独特页面的情感柱状图][25]
|
||||
|
||||
#### 实体
|
||||
|
||||
在我看来,实体是 API 中最有趣的部分。这是在所有页面中按<ruby>显著性<rt>salience</rt></ruby>(或与页面的相关性)选择的顶级实体。请注意,对于相同的术语(销售清单),Google 会推断出不同的类型,可能是错误的。这是由于这些术语出现在内容中的不同上下文中引起的。
|
||||
|
||||
![示例网站的顶级实体][26]
|
||||
|
||||
然后,我分别查看了每个实体类型,并一起查看了该实体的显著性与页面的最佳排名位置之间是否存在任何关联。对于每种类型,我匹配了与该类型匹配的顶级实体的显著性(与页面的整体相关性),按显著性排序(降序)。
|
||||
|
||||
有些实体类型在所有示例中返回的显著性为零,因此我从下面的图表中省略了这些结果。
|
||||
|
||||
![显著性与最佳排名位置的相关性][27]
|
||||
|
||||
“Consumer Good(消费性商品)” 实体类型具有最高的正相关性,<ruby>皮尔森相关度<rt>Pearson correlation</rt></ruby>为 0.15854,尽管由于较低编号的排名更好,所以 “Person” 实体的结果最好,相关度为 -0.15483。这是一个非常小的样本集,尤其是对于单个实体类型,我不能对数据做太多的判断。我没有发现任何具有强相关性的值,但是 “Person” 实体最有意义。网站通常都有关于其首席执行官和其他主要雇员的页面,这些页面很可能在这些查询的搜索结果方面做得好。
|
||||
|
||||
继续,当从整体上看站点,根据实体名称和实体类型,出现了以下主题。
|
||||
|
||||
![基于实体名称和实体类型的主题][28]
|
||||
|
||||
我模糊了几个看起来过于具体的结果,以掩盖网站的身份。从主题上讲,名称信息是在你(或竞争对手)的网站上局部查看其核心主题的一种好方法。这样做仅基于示例网站的排名网址,而不是基于所有网站的可能网址(因为 Search Console 数据仅记录 Google 中展示的页面),但是结果会很有趣,尤其是当你使用像 [Ahrefs][29] 之类的工具提取一个网站的主要排名 URL,该工具会跟踪许多查询以及这些查询的 Google 搜索结果。
|
||||
|
||||
实体数据中另一个有趣的部分是标记为 “CONSUMER_GOOD” 的实体倾向于 “看起来” 像我在看到 “<ruby>知识结果<rt>Knowledge Results</rt></ruby>”的结果,即页面右侧的 Google 搜索结果。
|
||||
|
||||
![Google 搜索结果][30]
|
||||
|
||||
在我们的数据集中具有三个或三个以上关键字的 “Consumer Good(消费性商品)” 实体名称中,有 5.8% 的知识结果与 Google 对该实体命名的结果相同。这意味着,如果你在 Google 中搜索术语或短语,则右侧的框(例如,上面显示 Linux 的知识结果)将显示在搜索结果页面中。由于 Google 会 “挑选” 代表实体的示例网页,因此这是一个很好的机会,可以在搜索结果中识别出具有唯一特征的机会。同样有趣的是,5.8% 的在 Google 中显示这些知识结果名称中,没有一个实体的维基百科 URL 从自然语言 API 中返回。这很有趣,值得进行额外的分析。这将是非常有用的,特别是对于传统的全球排名跟踪工具(如 Ahrefs)数据库中没有的更深奥的主题。
|
||||
|
||||
如前所述,知识结果对于那些希望自己的内容在 Google 中被收录的网站所有者来说是非常重要的,因为它们在桌面搜索中加强高亮显示。假设,它们也很可能与 Google [Discover][31] 的知识库主题保持一致,这是一款适用于 Android 和 iOS 的产品,它试图根据用户感兴趣但没有明确搜索的主题为用户浮现内容。
|
||||
|
||||
### 总结
|
||||
|
||||
本文介绍了 Google 的自然语言 API,分享了一些代码,并研究了此 API 对网站所有者可能有用的方式。关键要点是:
|
||||
|
||||
* 学习使用 Python 和 Jupyter 笔记本可以为你的数据收集任务打开到一个由令人难以置信的聪明和有才华的人建立的不可思议的 API 和开源项目(如 Pandas 和 NumPy)的世界。
|
||||
* Python 允许我为了一个特定目的快速提取和测试有关 API 值的假设。
|
||||
* 通过 Google 的分类 API 传递网站页面可能是一项很好的检查,以确保其内容分解成正确的主题分类。对于竞争对手的网站执行此操作还可以提供有关在何处进行调整或创建内容的指导。
|
||||
* 对于示例网站,Google 的情感评分似乎并不是一个有趣的指标,但是对于新闻或基于意见的网站,它可能是一个有趣的指标。
|
||||
* Google 发现的实体从整体上提供了更细化的网站的主题级别视图,并且像分类一样,在竞争性内容分析中使用将非常有趣。
|
||||
* 实体可以帮助定义机会,使你的内容可以与搜索结果或 Google Discover 结果中的 Google 知识块保持一致。我们将 5.8% 的结果设置为更长的(字计数)“Consumer Goods(消费商品)” 实体,显示这些结果,对于某些网站来说,可能有机会更好地优化这些实体的页面显著性分数,从而有更好的机会在 Google 搜索结果或 Google Discovers 建议中抓住这个重要作用的位置。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/python-google-natural-language-api
|
||||
|
||||
作者:[JR Oakes][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jroakes
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_issue_bug_programming.png?itok=XPrh7fa0 (magnifying glass on computer screen)
|
||||
[2]: https://cloud.google.com/natural-language/#natural-language-api-demo
|
||||
[3]: https://opensource.com/article/19/3/natural-language-processing-tools
|
||||
[4]: https://en.wikipedia.org/wiki/Knowledge_Graph
|
||||
[5]: https://opensource.com/sites/default/files/uploads/entities.png (Entities)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/sentiment.png (Sentiment)
|
||||
[7]: https://en.wikipedia.org/wiki/Lemmatisation
|
||||
[8]: https://en.wikipedia.org/wiki/Part-of-speech_tagging
|
||||
[9]: https://en.wikipedia.org/wiki/Parse_tree#Dependency-based_parse_trees
|
||||
[10]: https://opensource.com/sites/default/files/uploads/syntax.png (Syntax)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/categories.png (Categories)
|
||||
[12]: https://developers.google.com/webmaster-tools/
|
||||
[13]: https://github.com/MLTSEO/MLTS/blob/master/Demos.ipynb
|
||||
[14]: https://opensource.com/sites/default/files/uploads/histogram_1.png (Histogram of clicks for all pages)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/histogram_2.png (Histogram of clicks for subset of pages)
|
||||
[16]: https://pypi.org/project/google-cloud-language/
|
||||
[17]: https://cloud.google.com/natural-language/docs/quickstart
|
||||
[18]: https://opensource.com/sites/default/files/uploads/json_file.png (services.json file)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/output.png (Output from pulling API data)
|
||||
[20]: https://github.com/MLTSEO/MLTS/blob/master/Tutorials/Google_Language_API_Intro.ipynb
|
||||
[21]: https://github.com/jupyterlab/jupyterlab
|
||||
[22]: https://www.anaconda.com/distribution/
|
||||
[23]: https://opensource.com/sites/default/files/uploads/categories_2.png (Categories data from example site)
|
||||
[24]: https://opensource.com/sites/default/files/uploads/plot.png (Plot of average confidence by ranking position )
|
||||
[25]: https://opensource.com/sites/default/files/uploads/histogram_3.png (Histogram of sentiment for unique pages)
|
||||
[26]: https://opensource.com/sites/default/files/uploads/entities_2.png (Top entities for example site)
|
||||
[27]: https://opensource.com/sites/default/files/uploads/salience_plots.png (Correlation between salience and best ranking position)
|
||||
[28]: https://opensource.com/sites/default/files/uploads/themes.png (Themes based on entity name and entity type)
|
||||
[29]: https://ahrefs.com/
|
||||
[30]: https://opensource.com/sites/default/files/uploads/googleresults.png (Google search results)
|
||||
[31]: https://www.blog.google/products/search/introducing-google-discover/
|
||||
@ -0,0 +1,232 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (stevenzdg988)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13206-1.html)
|
||||
[#]: subject: (9 favorite open source tools for Node.js developers)
|
||||
[#]: via: (https://opensource.com/article/20/1/open-source-tools-nodejs)
|
||||
[#]: author: (Hiren Dhadhuk https://opensource.com/users/hirendhadhuk)
|
||||
|
||||
9 个 Node.js 开发人员最喜欢的开源工具
|
||||
======
|
||||
|
||||
> 在众多可用于简化 Node.js 开发的工具中,以下 9 种是最佳选择。
|
||||
|
||||

|
||||
|
||||
我最近在 [StackOverflow][2] 上读到了一项调查,该调查称超过 49% 的开发人员在其项目中使用了 Node.js。这结果对我来说并不意外。
|
||||
|
||||
作为一个狂热的技术使用者,我可以肯定地说 Node.js 的引入引领了软件开发的新时代。现在,它是软件开发最受欢迎的技术之一,仅次于JavaScript。
|
||||
|
||||
### Node.js 是什么,为什么如此受欢迎?
|
||||
|
||||
Node.js 是一个跨平台的开源运行环境,用于在浏览器之外执行 JavaScript 代码。它也是建立在 Chrome 的 JavaScript 运行时之上的首选运行时环境,主要用于构建快速、可扩展和高效的网络应用程序。
|
||||
|
||||
我记得当时我们要花费几个小时来协调前端和后端开发人员,他们分别编写不同脚本。当 Node.js 出现后,所有这些都改变了。我相信,促使开发人员采用这项技术是因为它的双向效率。
|
||||
|
||||
使用 Node.js,你可以让你的代码同时运行在客户端和服务器端,从而加快了整个开发过程。Node.js 弥合了前端和后端开发之间的差距,并使开发过程更加高效。
|
||||
|
||||
### Node.js 工具浪潮
|
||||
|
||||
对于 49% 的开发人员(包括我)来说,Node.js 处于在前端和后端开发的金字塔顶端。有大量的 [Node.js 用例][3] 帮助我和我的团队在截止日期之内交付复杂的项目。幸运的是,Node.js 的日益普及也产生了一系列开源项目和工具,以帮助开发人员使用该环境。
|
||||
|
||||
近来,对使用 Node.js 构建的项目的需求突然增加。有时,我发现管理这些项目,并同时保持交付高质量项目的步伐非常具有挑战性。因此,我决定使用为 Node.js 开发人员提供的许多开源工具中一些最高效的,使某些方面的开发自动化。
|
||||
|
||||
根据我在 Node.js 方面的丰富经验,我使用了许多的工具,这些工具对整个开发过程都非常有帮助:从简化编码过程,到监测再到内容管理。
|
||||
|
||||
为了帮助我的 Node.js 开发同道,我整理了这个列表,其中包括我最喜欢的 9 个简化 Node.js 开发的开源工具。
|
||||
|
||||
### Webpack
|
||||
|
||||
[Webpack][4] 是一个容易使用的 JavaScript <ruby>模块捆绑程序<rt>module bundler</rt></ruby>,用于简化前端开发。它会检测具有依赖的模块,并将其转换为描述模块的静态<ruby>素材<rt>asset</rt></ruby>。
|
||||
|
||||
可以通过软件包管理器 npm 或 Yarn 安装该工具。
|
||||
|
||||
利用 npm 命令安装如下:
|
||||
|
||||
```
|
||||
npm install --save-dev webpack
|
||||
```
|
||||
|
||||
利用 Yarn 命令安装如下:
|
||||
|
||||
```
|
||||
yarn add webpack --dev
|
||||
```
|
||||
|
||||
Webpack 可以创建在运行时异步加载的单个捆绑包或多个素材链。不必单独加载。使用 Webpack 工具可以快速高效地打包这些素材并提供服务,从而改善用户整体体验,并减少开发人员在管理加载时间方面的困难。
|
||||
|
||||
### Strapi
|
||||
|
||||
[Strapi][5] 是一个开源的<ruby>无界面<rt>headless</rt></ruby>内容管理系统(CMS)。无界面 CMS 是一种基础软件,可以管理内容而无需预先构建好的前端。它是一个使用 RESTful API 函数的只有后端的系统。
|
||||
|
||||
可以通过软件包管理器 Yarn 或 npx 安装 Strapi。
|
||||
|
||||
利用 Yarn 命令安装如下:
|
||||
|
||||
```
|
||||
yarn create strapi-app my-project --quickstart
|
||||
```
|
||||
|
||||
利用 npx 命令安装如下:
|
||||
|
||||
```
|
||||
npx create-strapi-app my-project --quickstart
|
||||
```
|
||||
|
||||
Strapi 的目标是在任何设备上以结构化的方式获取和交付内容。CMS 可以使你轻松管理应用程序的内容,并确保它们是动态的,可以在任何设备上访问。
|
||||
|
||||
它提供了许多功能,包括文件上传、内置的电子邮件系统、JSON Web Token(JWT)验证和自动生成文档。我发现它非常方便,因为它简化了整个 CMS,并为我提供了编辑、创建或删除所有类型内容的完全自主权。
|
||||
|
||||
另外,通过 Strapi 构建的内容结构非常灵活,因为你可以创建和重用内容组和可定制的 API。
|
||||
|
||||
### Broccoli
|
||||
|
||||
[Broccoli][6] 是一个功能强大的构建工具,运行在 [ES6][7] 模块上。构建工具是一种软件,可让你将应用程序或网站中的所有各种素材(例如图像、CSS、JavaScript 等)组合成一种可分发的格式。Broccoli 将自己称为 “雄心勃勃的应用程序的素材管道”。
|
||||
|
||||
使用 Broccoli 你需要一个项目目录。有了项目目录后,可以使用以下命令通过 npm 安装 Broccoli:
|
||||
|
||||
```
|
||||
npm install --save-dev broccoli
|
||||
npm install --global broccoli-cli
|
||||
```
|
||||
|
||||
你也可以使用 Yarn 进行安装。
|
||||
|
||||
当前版本的 Node.js 就是使用该工具的最佳版本,因为它提供了长期支持。它可以帮助你避免进行更新和重新安装过程中的麻烦。安装过程完成后,可以在 `Brocfile.js` 文件中包含构建规范。
|
||||
|
||||
在 Broccoli 中,抽象单位是“树”,该树将文件和子目录存储在特定子目录中。因此,在构建之前,你必须有一个具体的想法,你希望你的构建是什么样子的。
|
||||
|
||||
最好的是,Broccoli 带有用于开发的内置服务器,可让你将素材托管在本地 HTTP 服务器上。Broccoli 非常适合流线型重建,因为其简洁的架构和灵活的生态系统可提高重建和编译速度。Broccoli 可让你井井有条,以节省时间并在开发过程中最大限度地提高生产力。
|
||||
|
||||
### Danger
|
||||
|
||||
[Danger][8] 是一个非常方便的开源工具,用于简化你的<ruby>拉取请求<rt>pull request</rt></ruby>(PR)检查。正如 Danger 库描述所说,该工具可通过管理 PR 检查来帮助 “正规化” 你的代码审查系统。Danger 可以与你的 CI 集成在一起,帮助你加快审核过程。
|
||||
|
||||
将 Danger 与你的项目集成是一个简单的逐步过程:你只需要包括 Danger 模块,并为每个项目创建一个 Danger 文件。然而,创建一个 Danger 帐户(通过 GitHub 或 Bitbucket 很容易做到),并且为开源软件项目设置访问令牌更加方便。
|
||||
|
||||
可以通过 NPM 或 Yarn 安装 Danger。要使用 Yarn,请添加 `danger -D` 到 `package.JSON` 中。
|
||||
|
||||
将 Danger 添加到 CI 后,你可以:
|
||||
|
||||
* 高亮显示重要的创建工件
|
||||
* 通过强制链接到 Trello 和 Jira 之类的工具来管理 sprint
|
||||
* 强制生成更新日志
|
||||
* 使用描述性标签
|
||||
* 以及更多
|
||||
|
||||
例如,你可以设计一个定义团队文化并为代码审查和 PR 检查设定特定规则的系统。根据 Danger 提供的元数据及其广泛的插件生态系统,可以解决常见的<ruby>议题<rt>issue</rt></ruby>。
|
||||
|
||||
### Snyk
|
||||
|
||||
网络安全是开发人员的主要关注点。[Snyk][9] 是修复开源组件中漏洞的最著名工具之一。它最初是一个用于修复 Node.js 项目漏洞的项目,并且已经演变为可以检测并修复 Ruby、Java、Python 和 Scala 应用程序中的漏洞。Snyk 主要分四个阶段运行:
|
||||
|
||||
* 查找漏洞依赖性
|
||||
* 修复特定漏洞
|
||||
* 通过 PR 检查预防安全风险
|
||||
* 持续监控应用程序
|
||||
|
||||
Snyk 可以集成在项目的任何阶段,包括编码、CI/CD 和报告。我发现这对于测试 Node.js 项目非常有帮助,可以测试或构建 npm 软件包时检查是否存在安全风险。你还可以在 GitHub 中为你的应用程序运行 PR 检查,以使你的项目更安全。Synx 还提供了一系列集成,可用于监控依赖关系并解决特定问题。
|
||||
|
||||
要在本地计算机上运行 Snyk,可以通过 NPM 安装它:
|
||||
|
||||
```
|
||||
npm install -g snyk
|
||||
```
|
||||
|
||||
### Migrat
|
||||
|
||||
[Migrat][10] 是一款使用纯文本的数据迁移工具,非常易于使用。 它可在各种软件堆栈和进程中工作,从而使其更加实用。你可以使用简单的代码行安装 Migrat:
|
||||
|
||||
```
|
||||
$ npm install -g migrat
|
||||
```
|
||||
|
||||
Migrat 并不需要特别的数据库引擎。它支持多节点环境,因为迁移可以在一个全局节点上运行,也可以在每个服务器上运行一次。Migrat 之所以方便,是因为它便于向每个迁移传递上下文。
|
||||
|
||||
你可以定义每个迁移的用途(例如,数据库集、连接、日志接口等)。此外,为了避免随意迁移,即多个服务器在全局范围内进行迁移,Migrat 可以在进程运行时进行全局锁定,从而使其只能在全局范围内运行一次。它还附带了一系列用于 SQL 数据库、Slack、HipChat 和 Datadog 仪表盘的插件。你可以将实时迁移状况发送到这些平台中的任何一个。
|
||||
|
||||
### Clinic.js
|
||||
|
||||
[Clinic.js][11] 是一个用于 Node.js 项目的开源监视工具。它结合了三种不同的工具 Doctor、Bubbleprof 和 Flame,帮助你监控、检测和解决 Node.js 的性能问题。
|
||||
|
||||
你可以通过运行以下命令从 npm 安装 Clinic.js:
|
||||
|
||||
```
|
||||
$ npm install clinic
|
||||
```
|
||||
|
||||
你可以根据要监视项目的某个方面以及要生成的报告,选择要使用的 Clinic.js 包含的三个工具中的一个:
|
||||
|
||||
* Doctor 通过注入探针来提供详细的指标,并就项目的总体运行状况提供建议。
|
||||
* Bubbleprof 非常适合分析,并使用 `async_hooks` 生成指标。
|
||||
* Flame 非常适合发现代码中的热路径和瓶颈。
|
||||
|
||||
### PM2
|
||||
|
||||
监视是后端开发过程中最重要的方面之一。[PM2][12] 是一款 Node.js 的进程管理工具,可帮助开发人员监视项目的多个方面,例如日志、延迟和速度。该工具与 Linux、MacOS 和 Windows 兼容,并支持从 Node.js 8.X 开始的所有 Node.js 版本。
|
||||
|
||||
你可以使用以下命令通过 npm 安装 PM2:
|
||||
|
||||
```
|
||||
$ npm install pm2 --g
|
||||
```
|
||||
|
||||
如果尚未安装 Node.js,则可以使用以下命令安装:
|
||||
|
||||
```
|
||||
wget -qO- https://getpm2.com/install.sh | bash
|
||||
```
|
||||
|
||||
安装完成后,使用以下命令启动应用程序:
|
||||
|
||||
```
|
||||
$ pm2 start app.js
|
||||
```
|
||||
|
||||
关于 PM2 最好的地方是可以在集群模式下运行应用程序。可以同时为多个 CPU 内核生成一个进程。这样可以轻松增强应用程序性能并最大程度地提高可靠性。PM2 也非常适合更新工作,因为你可以使用 “热重载” 选项更新应用程序并以零停机时间重新加载应用程序。总体而言,它是为 Node.js 应用程序简化进程管理的好工具。
|
||||
|
||||
### Electrode
|
||||
|
||||
[Electrode][13] 是 Walmart Labs 的一个开源应用程序平台。该平台可帮助你以结构化方式构建大规模通用的 React/Node.js 应用程序。
|
||||
|
||||
Electrode 应用程序生成器使你可以构建专注于代码的灵活内核,提供一些出色的模块以向应用程序添加复杂功能,并附带了广泛的工具来优化应用程序的 Node.js 包。
|
||||
|
||||
可以使用 npm 安装 Electrode。安装完成后,你可以使用 Ignite 启动应用程序,并深入研究 Electrode 应用程序生成器。
|
||||
|
||||
你可以使用 NPM 安装 Electrode:
|
||||
|
||||
```
|
||||
npm install -g electrode-ignite xclap-cli
|
||||
```
|
||||
|
||||
### 你最喜欢哪一个?
|
||||
|
||||
这些只是不断增长的开源工具列表中的一小部分,在使用 Node.js 时,这些工具可以在不同阶段派上用场。你最喜欢使用哪些开源 Node.js 工具?请在评论中分享你的建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/open-source-tools-nodejs
|
||||
|
||||
作者:[Hiren Dhadhuk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/hirendhadhuk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tools_hardware_purple.png?itok=3NdVoYhl (Tools illustration)
|
||||
[2]: https://insights.stackoverflow.com/survey/2019#technology-_-other-frameworks-libraries-and-tools
|
||||
[3]: https://www.simform.com/nodejs-use-case/
|
||||
[4]: https://webpack.js.org/
|
||||
[5]: https://strapi.io/
|
||||
[6]: https://broccoli.build/
|
||||
[7]: https://en.wikipedia.org/wiki/ECMAScript#6th_Edition_-_ECMAScript_2015
|
||||
[8]: https://danger.systems/
|
||||
[9]: https://snyk.io/
|
||||
[10]: https://github.com/naturalatlas/migrat
|
||||
[11]: https://clinicjs.org/
|
||||
[12]: https://pm2.keymetrics.io/
|
||||
[13]: https://www.electrode.io/
|
||||
@ -0,0 +1,152 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "wyxplus"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-13215-1.html"
|
||||
[#]: subject: "Managing processes on Linux with kill and killall"
|
||||
[#]: via: "https://opensource.com/article/20/1/linux-kill-killall"
|
||||
[#]: author: "Jim Hall https://opensource.com/users/jim-hall"
|
||||
|
||||
在 Linux 上使用 kill 和 killall 命令来管理进程
|
||||
======
|
||||
|
||||
> 了解如何使用 ps、kill 和 killall 命令来终止进程并回收系统资源。
|
||||
|
||||

|
||||
|
||||
在 Linux 中,每个程序和<ruby>守护程序<rt>daemon</rt></ruby>都是一个“<ruby>进程<rt>process</rt></ruby>”。 大多数进程代表一个正在运行的程序。而另外一些程序可以派生出其他进程,比如说它会侦听某些事件的发生,然后对其做出响应。并且每个进程都需要一定的内存和处理能力。你运行的进程越多,所需的内存和 CPU 使用周期就越多。在老式电脑(例如我使用了 7 年的笔记本电脑)或轻量级计算机(例如树莓派)上,如果你关注过后台运行的进程,就能充分利用你的系统。
|
||||
|
||||
你可以使用 `ps` 命令来查看正在运行的进程。你通常会使用 `ps` 命令的参数来显示出更多的输出信息。我喜欢使用 `-e` 参数来查看每个正在运行的进程,以及 `-f` 参数来获得每个进程的全部细节。以下是一些例子:
|
||||
|
||||
```
|
||||
$ ps
|
||||
PID TTY TIME CMD
|
||||
88000 pts/0 00:00:00 bash
|
||||
88052 pts/0 00:00:00 ps
|
||||
88053 pts/0 00:00:00 head
|
||||
```
|
||||
```
|
||||
$ ps -e | head
|
||||
PID TTY TIME CMD
|
||||
1 ? 00:00:50 systemd
|
||||
2 ? 00:00:00 kthreadd
|
||||
3 ? 00:00:00 rcu_gp
|
||||
4 ? 00:00:00 rcu_par_gp
|
||||
6 ? 00:00:02 kworker/0:0H-events_highpri
|
||||
9 ? 00:00:00 mm_percpu_wq
|
||||
10 ? 00:00:01 ksoftirqd/0
|
||||
11 ? 00:00:12 rcu_sched
|
||||
12 ? 00:00:00 migration/0
|
||||
```
|
||||
```
|
||||
$ ps -ef | head
|
||||
UID PID PPID C STIME TTY TIME CMD
|
||||
root 1 0 0 13:51 ? 00:00:50 /usr/lib/systemd/systemd --switched-root --system --deserialize 36
|
||||
root 2 0 0 13:51 ? 00:00:00 [kthreadd]
|
||||
root 3 2 0 13:51 ? 00:00:00 [rcu_gp]
|
||||
root 4 2 0 13:51 ? 00:00:00 [rcu_par_gp]
|
||||
root 6 2 0 13:51 ? 00:00:02 [kworker/0:0H-kblockd]
|
||||
root 9 2 0 13:51 ? 00:00:00 [mm_percpu_wq]
|
||||
root 10 2 0 13:51 ? 00:00:01 [ksoftirqd/0]
|
||||
root 11 2 0 13:51 ? 00:00:12 [rcu_sched]
|
||||
root 12 2 0 13:51 ? 00:00:00 [migration/0]
|
||||
```
|
||||
|
||||
最后的例子显示最多的细节。在每一行,`UID`(用户 ID)显示了该进程的所有者。`PID`(进程 ID)代表每个进程的数字 ID,而 `PPID`(父进程 ID)表示其父进程的数字 ID。在任何 Unix 系统中,进程是从 1 开始编号,是内核启动后运行的第一个进程。在这里,`systemd` 是第一个进程,它催生了 `kthreadd`,而 `kthreadd` 还创建了其他进程,包括 `rcu_gp`、`rcu_par_gp` 等一系列进程。
|
||||
|
||||
### 使用 kill 命令来管理进程
|
||||
|
||||
系统会处理大多数后台进程,所以你不需要操心这些进程。你只需要关注那些你所运行的应用创建的进程。虽然许多应用一次只运行一个进程(如音乐播放器、终端模拟器或游戏等),但其他应用则可能创建后台进程。其中一些应用可能当你退出后还在后台运行,以便下次你使用的时候能快速启动。
|
||||
|
||||
当我运行 Chromium(作为谷歌 Chrome 浏览器所基于的开源项目)时,进程管理便成了问题。 Chromium 在我的笔记本电脑上运行非常吃力,并产生了许多额外的进程。现在我仅打开五个选项卡,就能看到这些 Chromium 进程:
|
||||
|
||||
```
|
||||
$ ps -ef | fgrep chromium
|
||||
jhall 66221 [...] /usr/lib64/chromium-browser/chromium-browser [...]
|
||||
jhall 66230 [...] /usr/lib64/chromium-browser/chromium-browser [...]
|
||||
[...]
|
||||
jhall 66861 [...] /usr/lib64/chromium-browser/chromium-browser [...]
|
||||
jhall 67329 65132 0 15:45 pts/0 00:00:00 grep -F chromium
|
||||
```
|
||||
|
||||
我已经省略一些行,其中有 20 个 Chromium 进程和一个正在搜索 “chromium" 字符的 `grep` 进程。
|
||||
|
||||
```
|
||||
$ ps -ef | fgrep chromium | wc -l
|
||||
21
|
||||
```
|
||||
|
||||
但是在我退出 Chromium 之后,这些进程仍旧运行。如何关闭它们并回收这些进程占用的内存和 CPU 呢?
|
||||
|
||||
`kill` 命令能让你终止一个进程。在最简单的情况下,你告诉 `kill` 命令终止你想终止的进程的 PID。例如,要终止这些进程,我需要对 20 个 Chromium 进程 ID 都执行 `kill` 命令。一种方法是使用命令行获取 Chromium 的 PID,而另一种方法针对该列表运行 `kill`:
|
||||
|
||||
|
||||
```
|
||||
$ ps -ef | fgrep /usr/lib64/chromium-browser/chromium-browser | awk '{print $2}'
|
||||
66221
|
||||
66230
|
||||
66239
|
||||
66257
|
||||
66262
|
||||
66283
|
||||
66284
|
||||
66285
|
||||
66324
|
||||
66337
|
||||
66360
|
||||
66370
|
||||
66386
|
||||
66402
|
||||
66503
|
||||
66539
|
||||
66595
|
||||
66734
|
||||
66848
|
||||
66861
|
||||
69702
|
||||
|
||||
$ ps -ef | fgrep /usr/lib64/chromium-browser/chromium-browser | awk '{print $2}' > /tmp/pids
|
||||
$ kill $(cat /tmp/pids)
|
||||
```
|
||||
|
||||
最后两行是关键。第一个命令行为 Chromium 浏览器生成一个进程 ID 列表。第二个命令行针对该进程 ID 列表运行 `kill` 命令。
|
||||
|
||||
### 介绍 killall 命令
|
||||
|
||||
一次终止多个进程有个更简单方法,使用 `killall` 命令。你或许可以根据名称猜测出,`killall` 会终止所有与该名字匹配的进程。这意味着我们可以使用此命令来停止所有流氓 Chromium 进程。这很简单:
|
||||
|
||||
```
|
||||
$ killall /usr/lib64/chromium-browser/chromium-browser
|
||||
```
|
||||
|
||||
但是要小心使用 `killall`。该命令能够终止与你所给出名称相匹配的所有进程。这就是为什么我喜欢先使用 `ps -ef` 命令来检查我正在运行的进程,然后针对要停止的命令的准确路径运行 `killall`。
|
||||
|
||||
你也可以使用 `-i` 或 `--interactive` 参数,来让 `killkill` 在停止每个进程之前提示你。
|
||||
|
||||
`killall` 还支持使用 `-o` 或 `--older-than` 参数来查找比特定时间更早的进程。例如,如果你发现了一组已经运行了好几天的恶意进程,这将会很有帮助。又或是,你可以查找比特定时间更晚的进程,例如你最近启动的失控进程。使用 `-y` 或 `--young-than` 参数来查找这些进程。
|
||||
|
||||
### 其他管理进程的方式
|
||||
|
||||
进程管理是系统维护重要的一部分。在我作为 Unix 和 Linux 系统管理员的早期职业生涯中,杀死非法作业的能力是保持系统正常运行的关键。在如今,你可能不需要亲手在 Linux 上的终止流氓进程,但是知道 `kill` 和 `killall` 能够在最终出现问题时为你提供帮助。
|
||||
|
||||
你也能寻找其他方式来管理进程。在我这个案例中,我并不需要在我退出浏览器后,使用 `kill` 或 `killall` 来终止后台 Chromium 进程。在 Chromium 中有个简单设置就可以进行控制:
|
||||
|
||||
![Chromium background processes setting][2]
|
||||
|
||||
不过,始终关注系统上正在运行哪些进程,并且在需要的时候进行干预是一个明智之举。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/linux-kill-killall
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 "Penguin with green background"
|
||||
[2]: https://opensource.com/sites/default/files/uploads/chromium-settings-continue-running.png "Chromium background processes setting"
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "MjSeven"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-13167-1.html"
|
||||
[#]: subject: "Ansible Playbooks Quick Start Guide with Examples"
|
||||
[#]: via: "https://www.2daygeek.com/ansible-playbooks-quick-start-guide-with-examples/"
|
||||
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
|
||||
@ -14,22 +14,20 @@ Ansible 剧本快速入门指南
|
||||
|
||||
如果你是 Ansible 新手,我建议你阅读下面这两篇文章,它会教你一些 Ansible 的基础以及它是什么。
|
||||
|
||||
* **第一篇: [在 Linux 如何安装和配置 Ansible][1]**
|
||||
* **第二篇: [Ansible ad-hoc 命令快速入门指南][2]**
|
||||
* 第一篇: [Ansible 自动化工具安装、配置和快速入门指南][1]
|
||||
* 第二篇: [Ansible 点对点命令快速入门指南示例][2]
|
||||
|
||||
如果你已经阅读过了,那么在阅读本文时你才不会感到突兀。
|
||||
|
||||
### 什么是 Ansible 剧本?
|
||||
|
||||
剧本比临时命令模式更强大,而且完全不同。
|
||||
<ruby>剧本<rt>playbook</rt></ruby>比点对点命令模式更强大,而且完全不同。
|
||||
|
||||
它使用了 **"/usr/bin/ansible-playbook"** 二进制文件,并且提供丰富的特性使得复杂的任务变得更容易。
|
||||
它使用了 `/usr/bin/ansible-playbook` 二进制文件,并且提供丰富的特性使得复杂的任务变得更容易。
|
||||
|
||||
如果你想经常运行一个任务,剧本是非常有用的。
|
||||
如果你想经常运行一个任务,剧本是非常有用的。此外,如果你想在服务器组上执行多个任务,它也是非常有用的。
|
||||
|
||||
此外,如果你想在服务器组上执行多个任务,它也是非常有用的。
|
||||
|
||||
剧本由 YAML 语言编写。YAML 代表一种标记语言,它比其它常见的数据格式(如 XML 或 JSON)更容易读写。
|
||||
剧本是由 YAML 语言编写。YAML 代表一种标记语言,它比其它常见的数据格式(如 XML 或 JSON)更容易读写。
|
||||
|
||||
下面这张 Ansible 剧本流程图将告诉你它的详细结构。
|
||||
|
||||
@ -37,21 +35,21 @@ Ansible 剧本快速入门指南
|
||||
|
||||
### 理解 Ansible 剧本的术语
|
||||
|
||||
* **控制节点:** Ansible 安装的机器,它负责管理客户端节点。
|
||||
* **被控节点:** 被控制节点管理的主机列表。
|
||||
* **剧本:** 一个剧本文件,包含一组自动化任务。
|
||||
* **主机清单:*** 这个文件包含有关管理的服务器的信息。
|
||||
* **任务:** 每个剧本都有大量的任务。任务在指定机器上依次执行(一个主机或多个主机)。
|
||||
* **模块:** 模块是一个代码单元,用于从客户端节点收集信息。
|
||||
* **角色:** 角色是根据已知文件结构自动加载一些变量文件、任务和处理程序的方法。
|
||||
* **Play:** 每个剧本含有大量的 play, 一个 play 从头到尾执行一个特定的自动化。
|
||||
* **Handlers:** 它可以帮助你减少在剧本中的重启任务。处理程序任务列表实际上与常规任务没有什么不同,更改由通知程序通知。如果处理程序没有收到任何通知,它将不起作用。
|
||||
* <ruby>控制节点<rt>Control node</rt></ruby>:Ansible 安装的机器,它负责管理客户端节点。
|
||||
* <ruby>受控节点<rt>Managed node</rt></ruby>:控制节点管理的主机列表。
|
||||
* <ruby>剧本<rt>playbook</rt></ruby>:一个剧本文件包含一组自动化任务。
|
||||
* <ruby>主机清单<rt>Inventory</rt></ruby>:这个文件包含有关管理的服务器的信息。
|
||||
* <ruby>任务<rt>Task</rt></ruby>:每个剧本都有大量的任务。任务在指定机器上依次执行(一个主机或多个主机)。
|
||||
* <ruby>模块<rt>Module</rt></ruby>: 模块是一个代码单元,用于从客户端节点收集信息。
|
||||
* <ruby>角色<rt>Role</rt></ruby>:角色是根据已知文件结构自动加载一些变量文件、任务和处理程序的方法。
|
||||
* <ruby>动作<rt>Play</rt></ruby>:每个剧本含有大量的动作,一个动作从头到尾执行一个特定的自动化。
|
||||
* <ruby>处理程序<rt>Handler</rt></ruby>: 它可以帮助你减少在剧本中的重启任务。处理程序任务列表实际上与常规任务没有什么不同,更改由通知程序通知。如果处理程序没有收到任何通知,它将不起作用。
|
||||
|
||||
### 基本的剧本是怎样的?
|
||||
|
||||
下面是一个剧本的模板:
|
||||
|
||||
```yaml
|
||||
```
|
||||
--- [YAML 文件应该以三个破折号开头]
|
||||
- name: [脚本描述]
|
||||
hosts: group [添加主机或主机组]
|
||||
@ -69,14 +67,14 @@ Ansible 剧本快速入门指南
|
||||
|
||||
Ansible 剧本的输出有四种颜色,下面是具体含义:
|
||||
|
||||
* **绿色:** **ok –** 代表成功,关联的任务数据已经存在,并且已经根据需要进行了配置。
|
||||
* **黄色: 已更改 –** 指定的数据已经根据任务的需要更新或修改。
|
||||
* **红色: 失败–** 如果在执行任务时出现任何问题,它将返回一个失败消息,它可能是任何东西,你需要相应地修复它。
|
||||
* **白色:** 表示有多个参数。
|
||||
* **绿色**:`ok` 代表成功,关联的任务数据已经存在,并且已经根据需要进行了配置。
|
||||
* **黄色**:`changed` 指定的数据已经根据任务的需要更新或修改。
|
||||
* **红色**:`FAILED` 如果在执行任务时出现任何问题,它将返回一个失败消息,它可能是任何东西,你需要相应地修复它。
|
||||
* **白色**:表示有多个参数。
|
||||
|
||||
为此,创建一个剧本目录,将它们都放在同一个地方。
|
||||
|
||||
```bash
|
||||
```
|
||||
$ sudo mkdir /etc/ansible/playbooks
|
||||
```
|
||||
|
||||
@ -84,7 +82,7 @@ $ sudo mkdir /etc/ansible/playbooks
|
||||
|
||||
这个示例剧本允许你在指定的目标机器上安装 Apache Web 服务器:
|
||||
|
||||
```bash
|
||||
```
|
||||
$ sudo nano /etc/ansible/playbooks/apache.yml
|
||||
|
||||
---
|
||||
@ -102,7 +100,7 @@ $ sudo nano /etc/ansible/playbooks/apache.yml
|
||||
state: started
|
||||
```
|
||||
|
||||
```bash
|
||||
```
|
||||
$ ansible-playbook apache1.yml
|
||||
```
|
||||
|
||||
@ -112,7 +110,7 @@ $ ansible-playbook apache1.yml
|
||||
|
||||
使用以下命令来查看语法错误。如果没有发现错误,它只显示剧本文件名。如果它检测到任何错误,你将得到一个如下所示的错误,但内容可能根据你的输入文件而有所不同。
|
||||
|
||||
```bash
|
||||
```
|
||||
$ ansible-playbook apache1.yml --syntax-check
|
||||
|
||||
ERROR! Syntax Error while loading YAML.
|
||||
@ -139,9 +137,9 @@ Should be written as:
|
||||
|
||||
或者,你可以使用这个 URL [YAML Lint][4] 在线检查 Ansible 剧本内容。
|
||||
|
||||
执行以下命令进行**“演练”**。当你运行带有 **"-check"** 选项的剧本时,它不会对远程机器进行任何修改。相反,它会告诉你它将要做什么改变但不是真的执行。
|
||||
执行以下命令进行“演练”。当你运行带有 `--check` 选项的剧本时,它不会对远程机器进行任何修改。相反,它会告诉你它将要做什么改变但不是真的执行。
|
||||
|
||||
```bash
|
||||
```
|
||||
$ ansible-playbook apache.yml --check
|
||||
|
||||
PLAY [Install and Configure Apache Webserver] ********************************************************************
|
||||
@ -163,9 +161,9 @@ node1.2g.lab : ok=3 changed=2 unreachable=0 failed=0 s
|
||||
node2.2g.lab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
|
||||
```
|
||||
|
||||
如果你想要知道 ansible 剧本实现的详细信息,使用 **"-vv"** 选项,它会展示如何收集这些信息。
|
||||
如果你想要知道 ansible 剧本实现的详细信息,使用 `-vv` 选项,它会展示如何收集这些信息。
|
||||
|
||||
```bash
|
||||
```
|
||||
$ ansible-playbook apache.yml --check -vv
|
||||
|
||||
ansible-playbook 2.9.2
|
||||
@ -210,7 +208,7 @@ node2.2g.lab : ok=3 changed=2 unreachable=0 failed=0 s
|
||||
|
||||
这个示例剧本允许你在指定的目标节点上安装 Apache Web 服务器。
|
||||
|
||||
```bash
|
||||
```
|
||||
$ sudo nano /etc/ansible/playbooks/apache-ubuntu.yml
|
||||
|
||||
---
|
||||
@ -248,9 +246,9 @@ $ sudo nano /etc/ansible/playbooks/apache-ubuntu.yml
|
||||
|
||||
这个示例剧本允许你在指定的目标节点上安装软件包。
|
||||
|
||||
**方法-1:**
|
||||
**方法-1:**
|
||||
|
||||
```bash
|
||||
```
|
||||
$ sudo nano /etc/ansible/playbooks/packages-redhat.yml
|
||||
|
||||
---
|
||||
@ -267,9 +265,9 @@ $ sudo nano /etc/ansible/playbooks/packages-redhat.yml
|
||||
- htop
|
||||
```
|
||||
|
||||
**方法-2:**
|
||||
**方法-2:**
|
||||
|
||||
```bash
|
||||
```
|
||||
$ sudo nano /etc/ansible/playbooks/packages-redhat-1.yml
|
||||
|
||||
---
|
||||
@ -286,9 +284,9 @@ $ sudo nano /etc/ansible/playbooks/packages-redhat-1.yml
|
||||
- htop
|
||||
```
|
||||
|
||||
**方法-3: 使用数组变量**
|
||||
**方法-3:使用数组变量**
|
||||
|
||||
```bash
|
||||
```
|
||||
$ sudo nano /etc/ansible/playbooks/packages-redhat-2.yml
|
||||
|
||||
---
|
||||
@ -307,7 +305,7 @@ $ sudo nano /etc/ansible/playbooks/packages-redhat-2.yml
|
||||
|
||||
这个示例剧本允许你在基于 Red Hat 或 Debian 的 Linux 系统上安装更新。
|
||||
|
||||
```bash
|
||||
```
|
||||
$ sudo nano /etc/ansible/playbooks/security-update.yml
|
||||
|
||||
---
|
||||
@ -331,13 +329,13 @@ via: https://www.2daygeek.com/ansible-playbooks-quick-start-guide-with-examples/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/install-configure-ansible-automation-tool-linux-quick-start-guide/
|
||||
[2]: https://www.2daygeek.com/ansible-ad-hoc-command-quick-start-guide-with-examples/
|
||||
[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[1]: https://linux.cn/article-13142-1.html
|
||||
[2]: https://linux.cn/article-13163-1.html
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2020/01/ansible-playbook-structure-flow-chart-explained.png
|
||||
[4]: http://www.yamllint.com/
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cooljelly)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13239-1.html)
|
||||
[#]: subject: (Multicloud, security integration drive massive SD-WAN adoption)
|
||||
[#]: via: (https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
多云融合和安全集成推动 SD-WAN 的大规模应用
|
||||
======
|
||||
|
||||
> 2022 年 SD-WAN 市场 40% 的同比增长主要来自于包括 Cisco、VMWare、Juniper 和 Arista 在内的网络供应商和包括 AWS、Microsoft Azure,Google Anthos 和 IBM RedHat 在内的服务提供商之间的紧密联系。
|
||||
|
||||

|
||||
|
||||
越来越多的云应用,以及越来越完善的网络安全性、可视化特性和可管理性,正以惊人的速度推动企业<ruby>软件定义广域网<rt>software-defined WAN</rt></ruby>([SD-WAN][3])的部署。
|
||||
|
||||
IDC(LCTT 译注:International Data Corporation)公司的网络基础架构副总裁 Rohit Mehra 表示,根据 IDC 的研究,过去一年中,特别是软件和基础设施即服务(SaaS 和 IaaS)产品推动了 SD-WAN 的实施。
|
||||
|
||||
例如,IDC 表示,根据其最近的客户调查结果,有 95% 的客户将在两年内使用 [SD-WAN][7] 技术,而 42% 的客户已经部署了它。IDC 还表示,到 2022 年,SD-WAN 基础设施市场将达到 45 亿美元,此后每年将以每年 40% 的速度增长。
|
||||
|
||||
“SD-WAN 的增长是一个广泛的趋势,很大程度上是由企业希望优化远程站点的云连接性的需求推动的。” Mehra 说。
|
||||
|
||||
思科最近撰文称,多云网络的发展正在促使许多企业改组其网络,以更好地使用 SD-WAN 技术。SD-WAN 对于采用云服务的企业至关重要,它是园区网、分支机构、[物联网][8]、[数据中心][9] 和云之间的连接中间件。思科公司表示,根据调查,平均每个思科的企业客户有 30 个付费的 SaaS 应用程序,而他们实际使用的 SaaS 应用会更多——在某些情况下甚至超过 100 种。
|
||||
|
||||
这种趋势的部分原因是由网络供应商(例如 Cisco、VMware、Juniper、Arista 等)(LCTT 译注:这里的网络供应商指的是提供硬件或软件并可按需组网的厂商)与服务提供商(例如 Amazon AWS、Microsoft Azure、Google Anthos 和 IBM RedHat 等)建立的关系推动的。
|
||||
|
||||
去年 12 月,AWS 为其云产品发布了关键服务,其中包括诸如 [AWS Transit Gateway][10] 等新集成技术的关键服务,这标志着 SD-WAN 与多云场景关系的日益重要。使用 AWS Transit Gateway 技术,客户可以将 AWS 中的 VPC(<ruby>虚拟私有云<rt>Virtual Private Cloud</rt></ruby>)和其自有网络均连接到相同的网关。Aruba、Aviatrix Cisco、Citrix Systems、Silver Peak 和 Versa 已经宣布支持该技术,这将简化和增强这些公司的 SD-WAN 产品与 AWS 云服务的集成服务的性能和表现。
|
||||
|
||||
Mehra 说,展望未来,对云应用的友好兼容和完善的性能监控等增值功能将是 SD-WAN 部署的关键部分。
|
||||
|
||||
随着 SD-WAN 与云的关系不断发展,SD-WAN 对集成安全功能的需求也在不断增长。
|
||||
|
||||
Mehra 说,SD-WAN 产品集成安全性的方式比以往单独打包的广域网安全软件或服务要好得多。SD-WAN 是一个更加敏捷的安全环境。SD-WAN 公认的主要组成部分包括安全功能,数据分析功能和广域网优化功能等,其中安全功能则是下一代 SD-WAN 解决方案的首要需求。
|
||||
|
||||
Mehra 说,企业将越来越少地关注仅解决某个具体问题的 SD-WAN 解决方案,而将青睐于能够解决更广泛的网络管理和安全需求的 SD-WAN 平台。他们将寻找可以与他们的 IT 基础设施(包括企业数据中心网络、企业园区局域网、[公有云][12] 资源等)集成更紧密的 SD-WAN 平台。他说,企业将寻求无缝融合的安全服务,并希望有其他各种功能的支持,例如可视化、数据分析和统一通信功能。
|
||||
|
||||
“随着客户不断将其基础设施与软件集成在一起,他们可以做更多的事情,例如根据其局域网和广域网上的用户、设备或应用程序的需求,实现一致的管理和安全策略,并最终获得更好的整体使用体验。” Mehra 说。
|
||||
|
||||
一个新兴趋势是 SD-WAN 产品包需要支持 [SD-branch][13] 技术。 Mehra 说,超过 70% 的 IDC 受调查客户希望在明年使用 SD-Branch。在最近几周,[Juniper][14] 和 [Aruba][15] 公司已经优化了 SD-branch 产品,这一趋势预计将在今年持续下去。
|
||||
|
||||
SD-Branch 技术建立在 SD-WAN 的概念和支持的基础上,但更专注于满足分支机构中局域网的组网和管理需求。展望未来,SD-Branch 如何与其他技术集成,例如数据分析、音视频、统一通信等,将成为该技术的主要驱动力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[cooljelly](https://github.com/cooljelly)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/07/branches_branching_trees_bare_black_and_white_by_gratisography_cc0_via_pexels_1200x800-100763250-large.jpg
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[4]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[5]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[6]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[7]: https://www.networkworld.com/article/3489938/what-s-hot-at-the-edge-for-2020-everything.html
|
||||
[8]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
|
||||
[9]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[10]: https://aws.amazon.com/transit-gateway/
|
||||
[11]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[12]: https://www.networkworld.com/article/2159885/cloud-computing-gartner-5-things-a-private-cloud-is-not.html
|
||||
[13]: https://www.networkworld.com/article/3250664/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[14]: https://www.networkworld.com/article/3487801/juniper-broadens-sd-branch-management-switch-options.html
|
||||
[15]: https://www.networkworld.com/article/3513357/aruba-reinforces-sd-branch-with-security-management-upgrades.html
|
||||
[16]: https://www.facebook.com/NetworkWorld/
|
||||
[17]: https://www.linkedin.com/company/network-world
|
||||
148
published/202103/20200410 Get started with Bash programming.md
Normal file
148
published/202103/20200410 Get started with Bash programming.md
Normal file
@ -0,0 +1,148 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (stevenzdg988)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13210-1.html)
|
||||
[#]: subject: (Get started with Bash programming)
|
||||
[#]: via: (https://opensource.com/article/20/4/bash-programming-guide)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何入门 Bash 编程
|
||||
======
|
||||
|
||||
> 了解如何在 Bash 中编写定制程序以自动执行重复性操作任务。
|
||||
|
||||

|
||||
|
||||
Unix 最初的希望之一是,让计算机的日常用户能够微调其计算机,以适应其独特的工作风格。几十年来,人们对计算机定制的期望已经降低,许多用户认为他们的应用程序和网站的集合就是他们的 “定制环境”。原因之一是许多操作系统的组件未不开源,普通用户无法使用其源代码。
|
||||
|
||||
但是对于 Linux 用户而言,定制程序是可以实现的,因为整个系统都围绕着可通过终端使用的命令啦进行的。终端不仅是用于快速命令或深入排除故障的界面;也是一个脚本环境,可以通过为你处理日常任务来减少你的工作量。
|
||||
|
||||
### 如何学习编程
|
||||
|
||||
如果你以前从未进行过任何编程,可能面临考虑两个不同的挑战:一个是了解怎样编写代码,另一个是了解要编写什么代码。你可以学习 _语法_,但是如果你不知道 _语言_ 中有哪些可用的关键字,你将无法继续。在实践中,要同时开始学习这两个概念,是因为如果没有关键字的堆砌就无法学习语法,因此,最初你要使用基本命令和基本编程结构来编写简单的任务。一旦熟悉了基础知识,就可以探索更多编程语言的内容,从而使你的程序能够做越来越重要的事情。
|
||||
|
||||
在 [Bash][2] 中,你使用的大多数 _关键字_ 是 Linux 命令。 _语法_ 就是 Bash。如果你已经频繁地使用过了 Bash,则向 Bash 编程的过渡相对容易。但是,如果你不曾使用过 Bash,你会很高兴地了解到它是一种为清晰和简单而构建的简单语言。
|
||||
|
||||
### 交互设计
|
||||
|
||||
有时,学习编程时最难搞清楚的事情就是计算机可以为你做些什么。显然,如果一台计算机可以自己完成你要做的所有操作,那么你就不必再碰计算机了。但是现实是,人类很重要。找到你的计算机可以帮助你的事情的关键是注意到你一周内需要重复执行的任务。计算机特别擅长于重复的任务。
|
||||
|
||||
但是,为了能告知计算机为你做某事,你必须知道怎么做。这就是 Bash 擅长的领域:交互式编程。在终端中执行一个动作时,你也在学习如何编写脚本。
|
||||
|
||||
例如,我曾经负责将大量 PDF 书籍转换为低墨和友好打印的版本。一种方法是在 PDF 编辑器中打开 PDF,从数百张图像(页面背景和纹理都算作图像)中选择每张图像,删除它们,然后将其保存到新的 PDF中。仅仅是一本书,这样就需要半天时间。
|
||||
|
||||
我的第一个想法是学习如何编写 PDF 编辑器脚本,但是经过数天的研究,我找不到可以编写编辑 PDF 应用程序的脚本(除了非常丑陋的鼠标自动化技巧)。因此,我将注意力转向了从终端内找出完成任务的方法。这让我有了几个新发现,包括 GhostScript,它是 PostScript 的开源版本(PDF 基于的打印机语言)。通过使用 GhostScript 处理了几天的任务,我确认这是解决我的问题的方法。
|
||||
|
||||
编写基本的脚本来运行命令,只不过是复制我用来从 PDF 中删除图像的命令和选项,并将其粘贴到文本文件中而已。将这个文件作为脚本运行,大概也会产生同样的结果。
|
||||
|
||||
### 向 Bash 脚本传参数
|
||||
|
||||
在终端中运行命令与在 Shell 脚本中运行命令之间的区别在于前者是交互式的。在终端中,你可以随时进行调整。例如,如果我刚刚处理 `example_1.pdf` 并准备处理下一个文档,以适应我的命令,则只需要更改文件名即可。
|
||||
|
||||
Shell 脚本不是交互式的。实际上,Shell _脚本_ 存在的唯一原因是让你不必亲自参与。这就是为什么命令(以及运行它们的 Shell 脚本)会接受参数的原因。
|
||||
|
||||
在 Shell 脚本中,有一些预定义的可以反映脚本启动方式的变量。初始变量是 `$0`,它代表了启动脚本的命令。下一个变量是 `$1` ,它表示传递给 Shell 脚本的第一个 “参数”。例如,在命令 `echo hello` 中,命令 `echo` 为 `$0,`,关键字 `hello` 为 `$1`,而 `world` 是 `$2`。
|
||||
|
||||
在 Shell 中交互如下所示:
|
||||
|
||||
```
|
||||
$ echo hello world
|
||||
hello world
|
||||
```
|
||||
|
||||
在非交互式 Shell 脚本中,你 _可以_ 以非常直观的方式执行相同的操作。将此文本输入文本文件并将其另存为 `hello.sh`:
|
||||
|
||||
```
|
||||
echo hello world
|
||||
```
|
||||
|
||||
执行这个脚本:
|
||||
|
||||
```
|
||||
$ bash hello.sh
|
||||
hello world
|
||||
```
|
||||
|
||||
同样可以,但是并没有利用脚本可以接受输入这一优势。将 `hello.sh` 更改为:
|
||||
|
||||
```
|
||||
echo $1
|
||||
```
|
||||
|
||||
用引号将两个参数组合在一起来运行脚本:
|
||||
|
||||
```
|
||||
$ bash hello.sh "hello bash"
|
||||
hello bash
|
||||
```
|
||||
|
||||
对于我的 PDF 瘦身项目,我真的需要这种非交互性,因为每个 PDF 都花了几分钟来压缩。但是通过创建一个接受我的输入的脚本,我可以一次将几个 PDF 文件全部提交给脚本。该脚本按顺序处理了每个文件,这可能需要半小时或稍长一点时间,但是我可以用半小时来完成其他任务。
|
||||
|
||||
### 流程控制
|
||||
|
||||
创建 Bash 脚本是完全可以接受的,从本质上讲,这些脚本是你开始实现需要重复执行任务的准确过程的副本。但是,可以通过控制信息流的方式来使脚本更强大。管理脚本对数据响应的常用方法是:
|
||||
|
||||
* `if`/`then` 选择结构语句
|
||||
* `for` 循环结构语句
|
||||
* `while` 循环结构语句
|
||||
* `case` 语句
|
||||
|
||||
计算机不是智能的,但是它们擅长比较和分析数据。如果你在脚本中构建一些数据分析,则脚本会变得更加智能。例如,基本的 `hello.sh` 脚本运行后不管有没有内容都会显示:
|
||||
|
||||
```
|
||||
$ bash hello.sh foo
|
||||
foo
|
||||
$ bash hello.sh
|
||||
|
||||
$
|
||||
```
|
||||
|
||||
如果在没有接收输入的情况下提供帮助消息,将会更加容易使用。如下是一个 `if`/`then` 语句,如果你以一种基本的方式使用 Bash,则你可能不知道 Bash 中存在这样的语句。但是编程的一部分是学习语言,通过一些研究,你将了解 `if/then` 语句:
|
||||
|
||||
```
|
||||
if [ "$1" = "" ]; then
|
||||
echo "syntax: $0 WORD"
|
||||
echo "If you provide more than one word, enclose them in quotes."
|
||||
else
|
||||
echo "$1"
|
||||
fi
|
||||
```
|
||||
|
||||
运行新版本的 `hello.sh` 输出如下:
|
||||
|
||||
```
|
||||
$ bash hello.sh
|
||||
syntax: hello.sh WORD
|
||||
If you provide more than one word, enclose them in quotes.
|
||||
$ bash hello.sh "hello world"
|
||||
hello world
|
||||
```
|
||||
|
||||
### 利用脚本工作
|
||||
|
||||
无论你是从 PDF 文件中查找要删除的图像,还是要管理混乱的下载文件夹,抑或要创建和提供 Kubernetes 镜像,学习编写 Bash 脚本都需要先使用 Bash,然后学习如何将这些脚本从仅仅是一个命令列表变成响应输入的东西。通常这是一个发现的过程:你一定会找到新的 Linux 命令来执行你从未想象过可以通过文本命令执行的任务,你会发现 Bash 的新功能,使你的脚本可以适应所有你希望它们运行的不同方式。
|
||||
|
||||
学习这些技巧的一种方法是阅读其他人的脚本。了解人们如何在其系统上自动化死板的命令。看看你熟悉的,并寻找那些陌生事物的更多信息。
|
||||
|
||||
另一种方法是下载我们的 [Bash 编程入门][3] 电子书。它向你介绍了特定于 Bash 的编程概念,并且通过学习的构造,你可以开始构建自己的命令。当然,它是免费的,并根据 [创作共用许可证][4] 进行下载和分发授权,所以今天就来获取它吧。
|
||||
|
||||
- [下载我们介绍用 Bash 编程的电子书!][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/bash-programming-guide
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/command_line_prompt.png?itok=wbGiJ_yg (Command line prompt)
|
||||
[2]: https://opensource.com/resources/what-bash
|
||||
[3]: https://opensource.com/downloads/bash-programming-guide
|
||||
[4]: https://opensource.com/article/20/1/what-creative-commons
|
||||
@ -0,0 +1,414 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wyxplus)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13242-1.html)
|
||||
[#]: subject: (How to automate your cryptocurrency trades with Python)
|
||||
[#]: via: (https://opensource.com/article/20/4/python-crypto-trading-bot)
|
||||
[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
|
||||
|
||||
|
||||
如何使用 Python 来自动交易加密货币
|
||||
======
|
||||
|
||||
> 在本教程中,教你如何设置和使用 Pythonic 来编程。它是一个图形化编程工具,用户可以很容易地使用现成的函数模块创建 Python 程序。
|
||||
|
||||

|
||||
|
||||
然而,不像纽约证券交易所这样的传统证券交易所一样,有一段固定的交易时间。对于加密货币而言,则是 7×24 小时交易,这使得任何人都无法独自盯着市场。
|
||||
|
||||
在以前,我经常思考与加密货币交易相关的问题:
|
||||
|
||||
- 一夜之间发生了什么?
|
||||
- 为什么没有日志记录?
|
||||
- 为什么下单?
|
||||
- 为什么不下单?
|
||||
|
||||
通常的解决手段是使用加密交易机器人,当在你做其他事情时,例如睡觉、与家人在一起或享受空闲时光,代替你下单。虽然有很多商业解决方案可用,但是我选择开源的解决方案,因此我编写了加密交易机器人 [Pythonic][2]。 正如去年 [我写过的文章][3] 一样,“Pythonic 是一种图形化编程工具,它让用户可以轻松使用现成的函数模块来创建 Python 应用程序。” 最初它是作为加密货币机器人使用,并具有可扩展的日志记录引擎以及经过精心测试的可重用部件,例如调度器和计时器。
|
||||
|
||||
### 开始
|
||||
|
||||
本教程将教你如何开始使用 Pythonic 进行自动交易。我选择 <ruby>[币安][6]<rt>Binance</rt></ruby> 交易所的 <ruby>[波场][4]<rt>Tron</rt></ruby> 与 <ruby>[比特币][3]<rt>Bitcoin</rt></ruby> 交易对为例。我之所以选择这个加密货币对,是因为它们彼此之间的波动性大,而不是出于个人喜好。
|
||||
|
||||
机器人将根据 <ruby>[指数移动平均][7]<rt>exponential moving averages</rt></ruby> (EMA)来做出决策。
|
||||
|
||||
![TRX/BTC 1-hour candle chart][8]
|
||||
|
||||
*TRX/BTC 1 小时 K 线图*
|
||||
|
||||
EMA 指标通常是一个加权的移动平均线,可以对近期价格数据赋予更多权重。尽管移动平均线可能只是一个简单的指标,但我对它很有经验。
|
||||
|
||||
上图中的紫色线显示了 EMA-25 指标(这表示要考虑最近的 25 个值)。
|
||||
|
||||
机器人监视当前的 EMA-25 值(t0)和前一个 EMA-25 值(t-1)之间的差距。如果差值超过某个值,则表示价格上涨,机器人将下达购买订单。如果差值低于某个值,则机器人将下达卖单。
|
||||
|
||||
差值将是做出交易决策的主要指标。在本教程中,它称为交易参数。
|
||||
|
||||
### 工具链
|
||||
|
||||
将在本教程使用如下工具:
|
||||
|
||||
- 币安专业交易视图(已经有其他人做了数据可视化,所以不需要重复造轮子)
|
||||
- Jupyter 笔记本:用于数据科学任务
|
||||
- Pythonic:作为整体框架
|
||||
- PythonicDaemon :作为终端运行(仅适用于控制台和 Linux)
|
||||
|
||||
### 数据挖掘
|
||||
|
||||
为了使加密货币交易机器人尽可能做出正确的决定,以可靠的方式获取资产的<ruby>美国线<rt>open-high-low-close chart</rt></ruby>([OHLC][9])数据是至关重要。你可以使用 Pythonic 的内置元素,还可以根据自己逻辑来对其进行扩展。
|
||||
|
||||
一般的工作流程:
|
||||
|
||||
1. 与币安时间同步
|
||||
2. 下载 OHLC 数据
|
||||
3. 从文件中把 OHLC 数据加载到内存
|
||||
4. 比较数据集并扩展更新数据集
|
||||
|
||||
这个工作流程可能有点夸张,但是它能使得程序更加健壮,甚至在停机和断开连接时,也能平稳运行。
|
||||
|
||||
一开始,你需要 <ruby>**币安 OHLC 查询**<rt>Binance OHLC Query</rt></ruby> 元素和一个 <ruby>**基础操作**<rt>Basic Operation</rt></ruby> 元素来执行你的代码。
|
||||
|
||||
![Data-mining workflow][10]
|
||||
|
||||
*数据挖掘工作流程*
|
||||
|
||||
OHLC 查询设置为每隔一小时查询一次 **TRXBTC** 资产对(波场/比特币)。
|
||||
|
||||
![Configuration of the OHLC query element][11]
|
||||
|
||||
*配置 OHLC 查询元素*
|
||||
|
||||
其中输出的元素是 [Pandas DataFrame][12]。你可以在 **基础操作** 元素中使用 <ruby>**输入**<rt>input</rt></ruby> 变量来访问 DataFrame。其中,将 Vim 设置为 **基础操作** 元素的默认代码编辑器。
|
||||
|
||||
![Basic Operation element set up to use Vim][13]
|
||||
|
||||
*使用 Vim 编辑基础操作元素*
|
||||
|
||||
具体代码如下:
|
||||
|
||||
```
|
||||
import pickle, pathlib, os
|
||||
import pandas as pd
|
||||
|
||||
outout = None
|
||||
|
||||
if isinstance(input, pd.DataFrame):
|
||||
file_name = 'TRXBTC_1h.bin'
|
||||
home_path = str(pathlib.Path.home())
|
||||
data_path = os.path.join(home_path, file_name)
|
||||
|
||||
try:
|
||||
df = pickle.load(open(data_path, 'rb'))
|
||||
n_row_cnt = df.shape[0]
|
||||
df = pd.concat([df,input], ignore_index=True).drop_duplicates(['close_time'])
|
||||
df.reset_index(drop=True, inplace=True)
|
||||
n_new_rows = df.shape[0] - n_row_cnt
|
||||
log_txt = '{}: {} new rows written'.format(file_name, n_new_rows)
|
||||
except:
|
||||
log_txt = 'File error - writing new one: {}'.format(e)
|
||||
df = input
|
||||
|
||||
pickle.dump(df, open(data_path, "wb" ))
|
||||
output = df
|
||||
```
|
||||
|
||||
首先,检查输入是否为 DataFrame 元素。然后在用户的家目录(`~/`)中查找名为 `TRXBTC_1h.bin` 的文件。如果存在,则将其打开,执行新代码段(`try` 部分中的代码),并删除重复项。如果文件不存在,则触发异常并执行 `except` 部分中的代码,创建一个新文件。
|
||||
|
||||
只要启用了复选框 <ruby>**日志输出**<rt>log output</rt></ruby>,你就可以使用命令行工具 `tail` 查看日志记录:
|
||||
|
||||
|
||||
```
|
||||
$ tail -f ~/Pythonic_2020/Feb/log_2020_02_19.txt
|
||||
```
|
||||
|
||||
出于开发目的,现在跳过与币安时间的同步和计划执行,这将在下面实现。
|
||||
|
||||
### 准备数据
|
||||
|
||||
下一步是在单独的 <ruby>网格<rt>Grid</rt></ruby> 中处理评估逻辑。因此,你必须借助<ruby>**返回元素**<rt>Return element</rt></ruby> 将 DataFrame 从网格 1 传递到网格 2 的第一个元素。
|
||||
|
||||
在网格 2 中,通过使 DataFrame 通过 <ruby>**基础技术分析**<rt>Basic Technical Analysis</rt></ruby> 元素,将 DataFrame 扩展包含 EMA 值的一列。
|
||||
|
||||
![Technical analysis workflow in Grid 2][14]
|
||||
|
||||
*在网格 2 中技术分析工作流程*
|
||||
|
||||
配置技术分析元素以计算 25 个值的 EMA。
|
||||
|
||||
![Configuration of the technical analysis element][15]
|
||||
|
||||
*配置技术分析元素*
|
||||
|
||||
当你运行整个程序并开启 <ruby>**技术分析**<rt>Technical Analysis</rt></ruby> 元素的调试输出时,你将发现 EMA-25 列的值似乎都相同。
|
||||
|
||||
![Missing decimal places in output][16]
|
||||
|
||||
*输出中精度不够*
|
||||
|
||||
这是因为调试输出中的 EMA-25 值仅包含六位小数,即使输出保留了 8 个字节完整精度的浮点值。
|
||||
|
||||
为了能进行进一步处理,请添加 **基础操作** 元素:
|
||||
|
||||
![Workflow in Grid 2][17]
|
||||
|
||||
*网格 2 中的工作流程*
|
||||
|
||||
使用 **基础操作** 元素,将 DataFrame 与添加的 EMA-25 列一起转储,以便可以将其加载到 Jupyter 笔记本中;
|
||||
|
||||
![Dump extended DataFrame to file][18]
|
||||
|
||||
*将扩展后的 DataFrame 存储到文件中*
|
||||
|
||||
### 评估策略
|
||||
|
||||
在 Juypter 笔记本中开发评估策略,让你可以更直接地访问代码。要加载 DataFrame,你需要使用如下代码:
|
||||
|
||||
![Representation with all decimal places][19]
|
||||
|
||||
*用全部小数位表示*
|
||||
|
||||
你可以使用 [iloc][20] 和列名来访问最新的 EMA-25 值,并且会保留所有小数位。
|
||||
|
||||
你已经知道如何来获得最新的数据。上面示例的最后一行仅显示该值。为了能将该值拷贝到不同的变量中,你必须使用如下图所示的 `.at` 方法方能成功。
|
||||
|
||||
你也可以直接计算出你下一步所需的交易参数。
|
||||
|
||||
![Buy/sell decision][21]
|
||||
|
||||
*买卖决策*
|
||||
|
||||
### 确定交易参数
|
||||
|
||||
如上面代码所示,我选择 0.009 作为交易参数。但是我怎么知道 0.009 是决定交易的一个好参数呢? 实际上,这个参数确实很糟糕,因此,你可以直接计算出表现最佳的交易参数。
|
||||
|
||||
假设你将根据收盘价进行买卖。
|
||||
|
||||
![Validation function][22]
|
||||
|
||||
*回测功能*
|
||||
|
||||
在此示例中,`buy_factor` 和 `sell_factor` 是预先定义好的。因此,发散思维用直接计算出表现最佳的参数。
|
||||
|
||||
![Nested for loops for determining the buy and sell factor][23]
|
||||
|
||||
*嵌套的 for 循环,用于确定购买和出售的参数*
|
||||
|
||||
这要跑 81 个循环(9x9),在我的机器(Core i7 267QM)上花费了几分钟。
|
||||
|
||||
![System utilization while brute forcing][24]
|
||||
|
||||
*在暴力运算时系统的利用率*
|
||||
|
||||
在每个循环之后,它将 `buy_factor`、`sell_factor` 元组和生成的 `profit` 元组追加到 `trading_factors` 列表中。按利润降序对列表进行排序。
|
||||
|
||||
![Sort profit with related trading factors in descending order][25]
|
||||
|
||||
*将利润与相关的交易参数按降序排序*
|
||||
|
||||
当你打印出列表时,你会看到 0.002 是最好的参数。
|
||||
|
||||
![Sorted list of trading factors and profit][26]
|
||||
|
||||
*交易要素和收益的有序列表*
|
||||
|
||||
当我在 2020 年 3 月写下这篇文章时,价格的波动还不足以呈现出更理想的结果。我在 2 月份得到了更好的结果,但即使在那个时候,表现最好的交易参数也在 0.002 左右。
|
||||
|
||||
### 分割执行路径
|
||||
|
||||
现在开始新建一个网格以保持逻辑清晰。使用 **返回** 元素将带有 EMA-25 列的 DataFrame 从网格 2 传递到网格 3 的 0A 元素。
|
||||
|
||||
在网格 3 中,添加 **基础操作** 元素以执行评估逻辑。这是该元素中的代码:
|
||||
|
||||
![Implemented evaluation logic][27]
|
||||
|
||||
*实现评估策略*
|
||||
|
||||
如果输出 `1` 表示你应该购买,如果输出 `2` 则表示你应该卖出。 输出 `0` 表示现在无需操作。使用 <ruby>**分支**<rt>Branch</rt></ruby> 元素来控制执行路径。
|
||||
|
||||
![Branch element: Grid 3 Position 2A][28]
|
||||
|
||||
*分支元素:网格 3,2A 位置*
|
||||
|
||||
因为 `0` 和 `-1` 的处理流程一样,所以你需要在最右边添加一个分支元素来判断你是否应该卖出。
|
||||
|
||||
![Branch element: Grid 3 Position 3B][29]
|
||||
|
||||
*分支元素:网格 3,3B 位置*
|
||||
|
||||
网格 3 应该现在如下图所示:
|
||||
|
||||
![Workflow on Grid 3][30]
|
||||
|
||||
*网格 3 的工作流程*
|
||||
|
||||
### 下单
|
||||
|
||||
由于无需在一个周期中购买两次,因此必须在周期之间保留一个持久变量,以指示你是否已经购买。
|
||||
|
||||
你可以利用 <ruby>**栈**<rt>Stack</rt></ruby> 元素来实现。顾名思义,栈元素表示可以用任何 Python 数据类型来放入的基于文件的栈。
|
||||
|
||||
你需要定义栈仅包含一个布尔类型,该布尔类型决定是否购买了(`True`)或(`False`)。因此,你必须使用 `False` 来初始化栈。例如,你可以在网格 4 中简单地通过将 `False` 传递给栈来进行设置。
|
||||
|
||||
![Forward a False-variable to the subsequent Stack element][31]
|
||||
|
||||
*将 False 变量传输到后续的栈元素中*
|
||||
|
||||
在分支树后的栈实例可以进行如下配置:
|
||||
|
||||
![Configuration of the Stack element][32]
|
||||
|
||||
*设置栈元素*
|
||||
|
||||
在栈元素设置中,将 <ruby>对输入的操作<rt>Do this with input</rt></ruby> 设置成 <ruby>无<rt>Nothing</rt></ruby>。否则,布尔值将被 `1` 或 `0` 覆盖。
|
||||
|
||||
该设置确保仅将一个值保存于栈中(`True` 或 `False`),并且只能读取一个值(为了清楚起见)。
|
||||
|
||||
在栈元素之后,你需要另外一个 **分支** 元素来判断栈的值,然后再放置 <ruby>币安订单<rt>Binance Order</rt></ruby> 元素。
|
||||
|
||||
![Evaluate the variable from the stack][33]
|
||||
|
||||
*判断栈中的变量*
|
||||
|
||||
将币安订单元素添加到分支元素的 `True` 路径。网格 3 上的工作流现在应如下所示:
|
||||
|
||||
![Workflow on Grid 3][34]
|
||||
|
||||
*网格 3 的工作流程*
|
||||
|
||||
币安订单元素应如下配置:
|
||||
|
||||
![Configuration of the Binance Order element][35]
|
||||
|
||||
*编辑币安订单元素*
|
||||
|
||||
你可以在币安网站上的帐户设置中生成 API 和密钥。
|
||||
|
||||
![Creating an API key in Binance][36]
|
||||
|
||||
*在币安账户设置中创建一个 API 密钥*
|
||||
|
||||
在本文中,每笔交易都是作为市价交易执行的,交易量为 10,000 TRX(2020 年 3 月约为 150 美元)(出于教学的目的,我通过使用市价下单来演示整个过程。因此,我建议至少使用限价下单。)
|
||||
|
||||
如果未正确执行下单(例如,网络问题、资金不足或货币对不正确),则不会触发后续元素。因此,你可以假定如果触发了后续元素,则表示该订单已下达。
|
||||
|
||||
这是一个成功的 XMRBTC 卖单的输出示例:
|
||||
|
||||
![Output of a successfully placed sell order][37]
|
||||
|
||||
*成功卖单的输出*
|
||||
|
||||
该行为使后续步骤更加简单:你可以始终假设只要成功输出,就表示订单成功。因此,你可以添加一个 **基础操作** 元素,该元素将简单地输出 **True** 并将此值放入栈中以表示是否下单。
|
||||
|
||||
如果出现错误的话,你可以在日志信息中查看具体细节(如果启用日志功能)。
|
||||
|
||||
![Logging output of Binance Order element][38]
|
||||
|
||||
*币安订单元素中的输出日志信息*
|
||||
|
||||
### 调度和同步
|
||||
|
||||
对于日程调度和同步,请在网格 1 中将整个工作流程置于 <ruby>币安调度器<rt>Binance Scheduler</rt></ruby> 元素的前面。
|
||||
|
||||
![Binance Scheduler at Grid 1, Position 1A][39]
|
||||
|
||||
*在网格 1,1A 位置的币安调度器*
|
||||
|
||||
由于币安调度器元素只执行一次,因此请在网格 1 的末尾拆分执行路径,并通过将输出传递回币安调度器来强制让其重新同步。
|
||||
|
||||
![Grid 1: Split execution path][40]
|
||||
|
||||
*网格 1:拆分执行路径*
|
||||
|
||||
5A 元素指向 网格 2 的 1A 元素,并且 5B 元素指向网格 1 的 1A 元素(币安调度器)。
|
||||
|
||||
### 部署
|
||||
|
||||
你可以在本地计算机上全天候 7×24 小时运行整个程序,也可以将其完全托管在廉价的云系统上。例如,你可以使用 Linux/FreeBSD 云系统,每月约 5 美元,但通常不提供图形化界面。如果你想利用这些低成本的云,可以使用 PythonicDaemon,它能在终端中完全运行。
|
||||
|
||||
![PythonicDaemon console interface][41]
|
||||
|
||||
*PythonicDaemon 控制台*
|
||||
|
||||
PythonicDaemon 是基础程序的一部分。要使用它,请保存完整的工作流程,将其传输到远程运行的系统中(例如,通过<ruby>安全拷贝协议<rt>Secure Copy</rt></ruby> SCP),然后把工作流程文件作为参数来启动 PythonicDaemon:
|
||||
|
||||
```
|
||||
$ PythonicDaemon trading_bot_one
|
||||
```
|
||||
|
||||
为了能在系统启动时自启 PythonicDaemon,可以将一个条目添加到 crontab 中:
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
```
|
||||
|
||||
![Crontab on Ubuntu Server][42]
|
||||
|
||||
*在 Ubuntu 服务器上的 Crontab*
|
||||
|
||||
### 下一步
|
||||
|
||||
正如我在一开始时所说的,本教程只是自动交易的入门。对交易机器人进行编程大约需要 10% 的编程和 90% 的测试。当涉及到让你的机器人用金钱交易时,你肯定会对编写的代码再三思考。因此,我建议你编码时要尽可能简单和易于理解。
|
||||
|
||||
如果你想自己继续开发交易机器人,接下来所需要做的事:
|
||||
|
||||
- 收益自动计算(希望你有正收益!)
|
||||
- 计算你想买的价格
|
||||
- 比较你的预订单(例如,订单是否填写完整?)
|
||||
|
||||
你可以从 [GitHub][2] 上获取完整代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/4/python-crypto-trading-bot
|
||||
|
||||
作者:[Stephan Avenwedde][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/hansic99
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calculator_money_currency_financial_tool.jpg?itok=2QMa1y8c "scientific calculator"
|
||||
[2]: https://github.com/hANSIc99/Pythonic
|
||||
[3]: https://opensource.com/article/19/5/graphically-programming-pythonic
|
||||
[4]: https://tron.network/
|
||||
[5]: https://bitcoin.org/en/
|
||||
[6]: https://www.binance.com/
|
||||
[7]: https://www.investopedia.com/terms/e/ema.asp
|
||||
[8]: https://opensource.com/sites/default/files/uploads/1_ema-25.png "TRX/BTC 1-hour candle chart"
|
||||
[9]: https://en.wikipedia.org/wiki/Open-high-low-close_chart
|
||||
[10]: https://opensource.com/sites/default/files/uploads/2_data-mining-workflow.png "Data-mining workflow"
|
||||
[11]: https://opensource.com/sites/default/files/uploads/3_ohlc-query.png "Configuration of the OHLC query element"
|
||||
[12]: https://pandas.pydata.org/pandas-docs/stable/getting_started/dsintro.html#dataframe
|
||||
[13]: https://opensource.com/sites/default/files/uploads/4_edit-basic-operation.png "Basic Operation element set up to use Vim"
|
||||
[14]: https://opensource.com/sites/default/files/uploads/6_grid2-workflow.png "Technical analysis workflow in Grid 2"
|
||||
[15]: https://opensource.com/sites/default/files/uploads/7_technical-analysis-config.png "Configuration of the technical analysis element"
|
||||
[16]: https://opensource.com/sites/default/files/uploads/8_missing-decimals.png "Missing decimal places in output"
|
||||
[17]: https://opensource.com/sites/default/files/uploads/9_basic-operation-element.png "Workflow in Grid 2"
|
||||
[18]: https://opensource.com/sites/default/files/uploads/10_dump-extended-dataframe.png "Dump extended DataFrame to file"
|
||||
[19]: https://opensource.com/sites/default/files/uploads/11_load-dataframe-decimals.png "Representation with all decimal places"
|
||||
[20]: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html
|
||||
[21]: https://opensource.com/sites/default/files/uploads/12_trade-factor-decision.png "Buy/sell decision"
|
||||
[22]: https://opensource.com/sites/default/files/uploads/13_validation-function.png "Validation function"
|
||||
[23]: https://opensource.com/sites/default/files/uploads/14_brute-force-tf.png "Nested for loops for determining the buy and sell factor"
|
||||
[24]: https://opensource.com/sites/default/files/uploads/15_system-utilization.png "System utilization while brute forcing"
|
||||
[25]: https://opensource.com/sites/default/files/uploads/16_sort-profit.png "Sort profit with related trading factors in descending order"
|
||||
[26]: https://opensource.com/sites/default/files/uploads/17_sorted-trading-factors.png "Sorted list of trading factors and profit"
|
||||
[27]: https://opensource.com/sites/default/files/uploads/18_implemented-evaluation-logic.png "Implemented evaluation logic"
|
||||
[28]: https://opensource.com/sites/default/files/uploads/19_output.png "Branch element: Grid 3 Position 2A"
|
||||
[29]: https://opensource.com/sites/default/files/uploads/20_editbranch.png "Branch element: Grid 3 Position 3B"
|
||||
[30]: https://opensource.com/sites/default/files/uploads/21_grid3-workflow.png "Workflow on Grid 3"
|
||||
[31]: https://opensource.com/sites/default/files/uploads/22_pass-false-to-stack.png "Forward a False-variable to the subsequent Stack element"
|
||||
[32]: https://opensource.com/sites/default/files/uploads/23_stack-config.png "Configuration of the Stack element"
|
||||
[33]: https://opensource.com/sites/default/files/uploads/24_evaluate-stack-value.png "Evaluate the variable from the stack"
|
||||
[34]: https://opensource.com/sites/default/files/uploads/25_grid3-workflow.png "Workflow on Grid 3"
|
||||
[35]: https://opensource.com/sites/default/files/uploads/26_binance-order.png "Configuration of the Binance Order element"
|
||||
[36]: https://opensource.com/sites/default/files/uploads/27_api-key-binance.png "Creating an API key in Binance"
|
||||
[37]: https://opensource.com/sites/default/files/uploads/28_sell-order.png "Output of a successfully placed sell order"
|
||||
[38]: https://opensource.com/sites/default/files/uploads/29_binance-order-output.png "Logging output of Binance Order element"
|
||||
[39]: https://opensource.com/sites/default/files/uploads/30_binance-scheduler.png "Binance Scheduler at Grid 1, Position 1A"
|
||||
[40]: https://opensource.com/sites/default/files/uploads/31_split-execution-path.png "Grid 1: Split execution path"
|
||||
[41]: https://opensource.com/sites/default/files/uploads/32_pythonic-daemon.png "PythonicDaemon console interface"
|
||||
[42]: https://opensource.com/sites/default/files/uploads/33_crontab.png "Crontab on Ubuntu Server"
|
||||
@ -0,0 +1,136 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (stevenzdg988)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13200-1.html)
|
||||
[#]: subject: (6 best practices for managing Git repos)
|
||||
[#]: via: (https://opensource.com/article/20/7/git-repos-best-practices)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
6 个最佳的 Git 仓库管理实践
|
||||
======
|
||||
|
||||
> 抵制在 Git 中添加一些会增加管理难度的东西的冲动;这里有替代方法。
|
||||
|
||||

|
||||
|
||||
有权访问源代码使对安全性的分析以及应用程序的安全成为可能。但是,如果没有人真正看过代码,问题就不会被发现,即使人们主动地看代码,通常也要看很多东西。幸运的是,GitHub 拥有一个活跃的安全团队,最近,他们 [发现了已提交到多个 Git 仓库中的特洛伊木马病毒][2],甚至仓库的所有者也偷偷溜走了。尽管我们无法控制其他人如何管理自己的仓库,但我们可以从他们的错误中吸取教训。为此,本文回顾了将文件添加到自己的仓库中的一些最佳实践。
|
||||
|
||||
### 了解你的仓库
|
||||
|
||||
![Git 仓库终端][3]
|
||||
|
||||
这对于安全的 Git 仓库来可以说是头号规则。作为项目维护者,无论是你自己创建的还是采用别人的,你的工作是了解自己仓库中的内容。你可能无法记住代码库中每一个文件,但是你需要了解你所管理的内容的基本组成部分。如果在几十个合并后出现一个游离的文件,你会很容易地发现它,因为你不知道它的用途,你需要检查它来刷新你的记忆。发生这种情况时,请查看该文件,并确保准确了解为什么它是必要的。
|
||||
|
||||
### 禁止二进制大文件
|
||||
|
||||
![终端中 Git 的二进制检查命令][4]
|
||||
|
||||
Git 是为文本而生的,无论是用纯文本编写的 C 或 Python 还是 Java 文本,亦或是 JSON、YAML、XML、Markdown、HTML 或类似的文本。Git 对于二进制文件不是很理想。
|
||||
|
||||
两者之间的区别是:
|
||||
|
||||
```
|
||||
$ cat hello.txt
|
||||
This is plain text.
|
||||
It's readable by humans and machines alike.
|
||||
Git knows how to version this.
|
||||
|
||||
$ git diff hello.txt
|
||||
diff --git a/hello.txt b/hello.txt
|
||||
index f227cc3..0d85b44 100644
|
||||
--- a/hello.txt
|
||||
+++ b/hello.txt
|
||||
@@ -1,2 +1,3 @@
|
||||
This is plain text.
|
||||
+It's readable by humans and machines alike.
|
||||
Git knows how to version this.
|
||||
```
|
||||
|
||||
和
|
||||
|
||||
```
|
||||
$ git diff pixel.png
|
||||
diff --git a/pixel.png b/pixel.png
|
||||
index 563235a..7aab7bc 100644
|
||||
Binary files a/pixel.png and b/pixel.png differ
|
||||
|
||||
$ cat pixel.png
|
||||
<EFBFBD>PNG
|
||||
▒
|
||||
IHDR7n<EFBFBD>$gAMA<4D><41>
|
||||
<20>abKGD݊<44>tIME<4D>
|
||||
|
||||
-2R<32><52>
|
||||
IDA<EFBFBD>c`<60>!<21>3%tEXtdate:create2020-06-11T11:45:04+12:00<30><30>r.%tEXtdate:modify2020-06-11T11:45:04+12:00<30><30>ʒIEND<4E>B`<60>
|
||||
```
|
||||
|
||||
二进制文件中的数据不能像纯文本一样被解析,因此,如果二进制文件发生任何更改,则必须重写整个内容。一个版本与另一个版本之间唯一的区别就是全部不同,这会快速增加仓库大小。
|
||||
|
||||
更糟糕的是,Git 仓库维护者无法合理地审计二进制数据。这违反了头号规则:应该对仓库的内容了如指掌。
|
||||
|
||||
除了常用的 [POSIX][5] 工具之外,你还可以使用 `git diff` 检测二进制文件。当你尝试使用 `--numstat` 选项来比较二进制文件时,Git 返回空结果:
|
||||
|
||||
```
|
||||
$ git diff --numstat /dev/null pixel.png | tee
|
||||
- - /dev/null => pixel.png
|
||||
$ git diff --numstat /dev/null file.txt | tee
|
||||
5788 0 /dev/null => list.txt
|
||||
```
|
||||
|
||||
如果你正在考虑将二进制大文件(BLOB)提交到仓库,请停下来先思考一下。如果它是二进制文件,那它是由什么生成的。是否有充分的理由不在构建时生成它们,而是将它们提交到仓库?如果你认为提交二进制数据是有意义的,请确保在 `README` 文件或类似文件中指明二进制文件的位置、为什么是二进制文件的原因以及更新它们的协议是什么。必须谨慎对其更新,因为你每提交一个二进制大文件的变化,它的存储空间实际上都会加倍。
|
||||
|
||||
### 让第三方库留在第三方
|
||||
|
||||
第三方库也不例外。尽管它是开源的众多优点之一,你可以不受限制地重用和重新分发不是你编写的代码,但是有很多充分的理由不把第三方库存储在你自己的仓库中。首先,除非你自己检查了所有代码(以及将来的合并),否则你不能为第三方完全担保。其次,当你将第三方库复制到你的 Git 仓库中时,会将焦点从真正的上游源代码中分离出来。从技术上讲,对库有信心的人只对该库的主副本有把握,而不是对随机仓库的副本有把握。如果你需要锁定特定版本的库,请给开发者提供一个合理的项目所需的发布 URL,或者使用 [Git 子模块][6]。
|
||||
|
||||
### 抵制盲目的 git add
|
||||
|
||||
![Git 手动添加命令终端中][7]
|
||||
|
||||
如果你的项目已编译,请抵制住使用 `git add .` 的冲动(其中 `.` 是当前目录或特定文件夹的路径),因为这是一种添加任何新东西的简单方法。如果你不是手动编译项目,而是使用 IDE 为你管理项目,这一点尤其重要。用 IDE 管理项目时,跟踪添加到仓库中的内容会非常困难,因此仅添加你实际编写的内容非常重要,而不是添加项目文件夹中出现的任何新对象。
|
||||
|
||||
如果你使用了 `git add .`,请在推送之前检查暂存区里的内容。如果在运行 `make clean` 或等效命令后,执行 `git status` 时在项目文件夹中看到一个陌生的对象,请找出它的来源,以及为什么仍然在项目的目录中。这是一种罕见的构建工件,不会在编译期间重新生成,因此在提交前请三思。
|
||||
|
||||
### 使用 Git ignore
|
||||
|
||||
![终端中的 `Git ignore` 命令][8]
|
||||
|
||||
许多为程序员打造的便利也非常杂乱。任何项目的典型项目目录,无论是编程的,还是艺术的或其他的,到处都是隐藏的文件、元数据和遗留的工件。你可以尝试忽略这些对象,但是 `git status` 中的提示越多,你错过某件事的可能性就越大。
|
||||
|
||||
你可以通过维护一个良好的 `gitignore` 文件来为你过滤掉这种噪音。因为这是使用 Git 的用户的共同要求,所以有一些入门级的 `gitignore` 文件。[Github.com/github/gitignore][9] 提供了几个专门创建的 `gitignore` 文件,你可以下载这些文件并将其放置到自己的项目中,[Gitlab.com][10] 在几年前就将`gitignore` 模板集成到了仓库创建工作流程中。使用这些模板来帮助你为项目创建适合的 `gitignore` 策略并遵守它。
|
||||
|
||||
### 查看合并请求
|
||||
|
||||
![Git 合并请求][11]
|
||||
|
||||
当你通过电子邮件收到一个合并/拉取请求或补丁文件时,不要只是为了确保它能正常工作而进行测试。你的工作是阅读进入代码库的新代码,并了解其是如何产生结果的。如果你不同意这个实现,或者更糟的是,你不理解这个实现,请向提交该实现的人发送消息,并要求其进行说明。质疑那些希望成为版本库永久成员的代码并不是一种社交失误,但如果你不知道你把什么合并到用户使用的代码中,那就是违反了你和用户之间的社交契约。
|
||||
|
||||
### Git 责任
|
||||
|
||||
社区致力于开源软件良好的安全性。不要鼓励你的仓库中不良的 Git 实践,也不要忽视你克隆的仓库中的安全威胁。Git 功能强大,但它仍然只是一个计算机程序,因此要以人为本,确保每个人的安全。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/7/git-repos-best-practices
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/wfh_work_home_laptop_work.png?itok=VFwToeMy (Working from home at a laptop)
|
||||
[2]: https://securitylab.github.com/research/octopus-scanner-malware-open-source-supply-chain/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/git_repo.png (Git repository )
|
||||
[4]: https://opensource.com/sites/default/files/uploads/git-binary-check.jpg (Git binary check)
|
||||
[5]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[6]: https://git-scm.com/book/en/v2/Git-Tools-Submodules
|
||||
[7]: https://opensource.com/sites/default/files/uploads/git-cola-manual-add.jpg (Git manual add)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/git-ignore.jpg (Git ignore)
|
||||
[9]: https://github.com/github/gitignore
|
||||
[10]: https://about.gitlab.com/releases/2016/05/22/gitlab-8-8-released
|
||||
[11]: https://opensource.com/sites/default/files/uploads/git_merge_request.png (Git merge request)
|
||||
@ -0,0 +1,315 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (stevenzdg988)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13212-1.html)
|
||||
[#]: subject: (Improve your time management with Jupyter)
|
||||
[#]: via: (https://opensource.com/article/20/9/calendar-jupyter)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
使用 Jupyter 改善你的时间管理
|
||||
======
|
||||
|
||||
> 在 Jupyter 里使用 Python 来分析日历,以了解你是如何使用时间的。
|
||||
|
||||

|
||||
|
||||
[Python][2] 在探索数据方面具有令人难以置信的可扩展性。利用 [Pandas][3] 或 [Dask][4],你可以将 [Jupyter][5] 扩展到大数据领域。但是小数据、个人资料、私人数据呢?
|
||||
|
||||
JupyterLab 和 Jupyter Notebook 为我提供了一个绝佳的环境,可以让我审视我的笔记本电脑生活。
|
||||
|
||||
我的探索是基于以下事实:我使用的几乎每个服务都有一个 Web API。我使用了诸多此类服务:待办事项列表、时间跟踪器、习惯跟踪器等。还有一个几乎每个人都会使用到:_日历_。相同的思路也可以应用于其他服务,但是日历具有一个很酷的功能:几乎所有 Web 日历都支持的开放标准 —— CalDAV。
|
||||
|
||||
### 在 Jupyter 中使用 Python 解析日历
|
||||
|
||||
大多数日历提供了导出为 CalDAV 格式的方法。你可能需要某种身份验证才能访问这些私有数据。按照你的服务说明进行操作即可。如何获得凭据取决于你的服务,但是最终,你应该能够将这些凭据存储在文件中。我将我的凭据存储在根目录下的一个名为 `.caldav` 的文件中:
|
||||
|
||||
```
|
||||
import os
|
||||
with open(os.path.expanduser("~/.caldav")) as fpin:
|
||||
username, password = fpin.read().split()
|
||||
```
|
||||
|
||||
切勿将用户名和密码直接放在 Jupyter Notebook 的笔记本中!它们可能会很容易因 `git push` 的错误而导致泄漏。
|
||||
|
||||
下一步是使用方便的 PyPI [caldav][6] 库。我找到了我的电子邮件服务的 CalDAV 服务器(你可能有所不同):
|
||||
|
||||
```
|
||||
import caldav
|
||||
client = caldav.DAVClient(url="https://caldav.fastmail.com/dav/", username=username, password=password)
|
||||
```
|
||||
|
||||
CalDAV 有一个称为 `principal`(主键)的概念。它是什么并不重要,只要知道它是你用来访问日历的东西就行了:
|
||||
|
||||
```
|
||||
principal = client.principal()
|
||||
calendars = principal.calendars()
|
||||
```
|
||||
|
||||
从字面上讲,日历就是关于时间的。访问事件之前,你需要确定一个时间范围。默认一星期就好:
|
||||
|
||||
```
|
||||
from dateutil import tz
|
||||
import datetime
|
||||
now = datetime.datetime.now(tz.tzutc())
|
||||
since = now - datetime.timedelta(days=7)
|
||||
```
|
||||
|
||||
大多数人使用的日历不止一个,并且希望所有事件都在一起出现。`itertools.chain.from_iterable` 方法使这一过程变得简单:
|
||||
|
||||
```
|
||||
import itertools
|
||||
|
||||
raw_events = list(
|
||||
itertools.chain.from_iterable(
|
||||
calendar.date_search(start=since, end=now, expand=True)
|
||||
for calendar in calendars
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
将所有事件读入内存很重要,以 API 原始的本地格式进行操作是重要的实践。这意味着在调整解析、分析和显示代码时,无需返回到 API 服务刷新数据。
|
||||
|
||||
但 “原始” 真的是原始,事件是以特定格式的字符串出现的:
|
||||
|
||||
```
|
||||
print(raw_events[12].data)
|
||||
```
|
||||
|
||||
```
|
||||
BEGIN:VCALENDAR
|
||||
VERSION:2.0
|
||||
PRODID:-//CyrusIMAP.org/Cyrus
|
||||
3.3.0-232-g4bdb081-fm-20200825.002-g4bdb081a//EN
|
||||
BEGIN:VEVENT
|
||||
DTEND:20200825T230000Z
|
||||
DTSTAMP:20200825T181915Z
|
||||
DTSTART:20200825T220000Z
|
||||
SUMMARY:Busy
|
||||
UID:
|
||||
1302728i-040000008200E00074C5B7101A82E00800000000D939773EA578D601000000000
|
||||
000000010000000CD71CC3393651B419E9458134FE840F5
|
||||
END:VEVENT
|
||||
END:VCALENDAR
|
||||
```
|
||||
|
||||
幸运的是,PyPI 可以再次使用另一个辅助库 [vobject][7] 解围:
|
||||
|
||||
```
|
||||
import io
|
||||
import vobject
|
||||
|
||||
def parse_event(raw_event):
|
||||
data = raw_event.data
|
||||
parsed = vobject.readOne(io.StringIO(data))
|
||||
contents = parsed.vevent.contents
|
||||
return contents
|
||||
```
|
||||
|
||||
```
|
||||
parse_event(raw_events[12])
|
||||
```
|
||||
|
||||
```
|
||||
{'dtend': [<DTEND{}2020-08-25 23:00:00+00:00>],
|
||||
'dtstamp': [<DTSTAMP{}2020-08-25 18:19:15+00:00>],
|
||||
'dtstart': [<DTSTART{}2020-08-25 22:00:00+00:00>],
|
||||
'summary': [<SUMMARY{}Busy>],
|
||||
'uid': [<UID{}1302728i-040000008200E00074C5B7101A82E00800000000D939773EA578D601000000000000000010000000CD71CC3393651B419E9458134FE840F5>]}
|
||||
```
|
||||
|
||||
好吧,至少好一点了。
|
||||
|
||||
仍有一些工作要做,将其转换为合理的 Python 对象。第一步是 _拥有_ 一个合理的 Python 对象。[attrs][8] 库提供了一个不错的开始:
|
||||
|
||||
```
|
||||
import attr
|
||||
from __future__ import annotations
|
||||
@attr.s(auto_attribs=True, frozen=True)
|
||||
class Event:
|
||||
start: datetime.datetime
|
||||
end: datetime.datetime
|
||||
timezone: Any
|
||||
summary: str
|
||||
```
|
||||
|
||||
是时候编写转换代码了!
|
||||
|
||||
第一个抽象从解析后的字典中获取值,不需要所有的装饰:
|
||||
|
||||
```
|
||||
def get_piece(contents, name):
|
||||
return contents[name][0].value
|
||||
get_piece(_, "dtstart")
|
||||
datetime.datetime(2020, 8, 25, 22, 0, tzinfo=tzutc())
|
||||
```
|
||||
|
||||
日历事件总有一个“开始”、有一个“结束”、有一个 “持续时间”。一些谨慎的解析逻辑可以将两者协调为同一个 Python 对象:
|
||||
|
||||
```
|
||||
def from_calendar_event_and_timezone(event, timezone):
|
||||
contents = parse_event(event)
|
||||
start = get_piece(contents, "dtstart")
|
||||
summary = get_piece(contents, "summary")
|
||||
try:
|
||||
end = get_piece(contents, "dtend")
|
||||
except KeyError:
|
||||
end = start + get_piece(contents, "duration")
|
||||
return Event(start=start, end=end, summary=summary, timezone=timezone)
|
||||
```
|
||||
|
||||
将事件放在 _本地_ 时区而不是 UTC 中很有用,因此使用本地时区:
|
||||
|
||||
```
|
||||
my_timezone = tz.gettz()
|
||||
from_calendar_event_and_timezone(raw_events[12], my_timezone)
|
||||
Event(start=datetime.datetime(2020, 8, 25, 22, 0, tzinfo=tzutc()), end=datetime.datetime(2020, 8, 25, 23, 0, tzinfo=tzutc()), timezone=tzfile('/etc/localtime'), summary='Busy')
|
||||
```
|
||||
|
||||
既然事件是真实的 Python 对象,那么它们实际上应该具有附加信息。幸运的是,可以将方法添加到类中。
|
||||
|
||||
但是要弄清楚哪个事件发生在哪一天不是很直接。你需要在 _本地_ 时区中选择一天:
|
||||
|
||||
```
|
||||
def day(self):
|
||||
offset = self.timezone.utcoffset(self.start)
|
||||
fixed = self.start + offset
|
||||
return fixed.date()
|
||||
Event.day = property(day)
|
||||
```
|
||||
|
||||
```
|
||||
print(_.day)
|
||||
2020-08-25
|
||||
```
|
||||
|
||||
事件在内部始终是以“开始”/“结束”的方式表示的,但是持续时间是有用的属性。持续时间也可以添加到现有类中:
|
||||
|
||||
```
|
||||
def duration(self):
|
||||
return self.end - self.start
|
||||
Event.duration = property(duration)
|
||||
```
|
||||
|
||||
```
|
||||
print(_.duration)
|
||||
1:00:00
|
||||
```
|
||||
|
||||
现在到了将所有事件转换为有用的 Python 对象了:
|
||||
|
||||
```
|
||||
all_events = [from_calendar_event_and_timezone(raw_event, my_timezone)
|
||||
for raw_event in raw_events]
|
||||
```
|
||||
|
||||
全天事件是一种特例,可能对分析生活没有多大用处。现在,你可以忽略它们:
|
||||
|
||||
```
|
||||
# ignore all-day events
|
||||
all_events = [event for event in all_events if not type(event.start) == datetime.date]
|
||||
```
|
||||
|
||||
事件具有自然顺序 —— 知道哪个事件最先发生可能有助于分析:
|
||||
|
||||
```
|
||||
all_events.sort(key=lambda ev: ev.start)
|
||||
```
|
||||
|
||||
现在,事件已排序,可以将它们加载到每天:
|
||||
|
||||
```
|
||||
import collections
|
||||
events_by_day = collections.defaultdict(list)
|
||||
for event in all_events:
|
||||
events_by_day[event.day].append(event)
|
||||
```
|
||||
|
||||
有了这些,你就有了作为 Python 对象的带有日期、持续时间和序列的日历事件。
|
||||
|
||||
### 用 Python 报到你的生活
|
||||
|
||||
现在是时候编写报告代码了!带有适当的标题、列表、重要内容以粗体显示等等,有醒目的格式是很意义。
|
||||
|
||||
这就是一些 HTML 和 HTML 模板。我喜欢使用 [Chameleon][9]:
|
||||
|
||||
```
|
||||
template_content = """
|
||||
<html><body>
|
||||
<div tal:repeat="item items">
|
||||
<h2 tal:content="item[0]">Day</h2>
|
||||
<ul>
|
||||
<li tal:repeat="event item[1]"><span tal:replace="event">Thing</span></li>
|
||||
</ul>
|
||||
</div>
|
||||
</body></html>"""
|
||||
```
|
||||
|
||||
Chameleon 的一个很酷的功能是使用它的 `html` 方法渲染对象。我将以两种方式使用它:
|
||||
|
||||
* 摘要将以粗体显示
|
||||
* 对于大多数活动,我都会删除摘要(因为这是我的个人信息)
|
||||
|
||||
```
|
||||
def __html__(self):
|
||||
offset = my_timezone.utcoffset(self.start)
|
||||
fixed = self.start + offset
|
||||
start_str = str(fixed).split("+")[0]
|
||||
summary = self.summary
|
||||
if summary != "Busy":
|
||||
summary = "<REDACTED>"
|
||||
return f"<b>{summary[:30]}</b> -- {start_str} ({self.duration})"
|
||||
Event.__html__ = __html__
|
||||
```
|
||||
|
||||
为了简洁起见,将该报告切成每天的:
|
||||
|
||||
```
|
||||
import chameleon
|
||||
from IPython.display import HTML
|
||||
template = chameleon.PageTemplate(template_content)
|
||||
html = template(items=itertools.islice(events_by_day.items(), 3, 4))
|
||||
HTML(html)
|
||||
```
|
||||
|
||||
渲染后,它将看起来像这样:
|
||||
|
||||
**2020-08-25**
|
||||
|
||||
- **\<REDACTED>** -- 2020-08-25 08:30:00 (0:45:00)
|
||||
- **\<REDACTED>** -- 2020-08-25 10:00:00 (1:00:00)
|
||||
- **\<REDACTED>** -- 2020-08-25 11:30:00 (0:30:00)
|
||||
- **\<REDACTED>** -- 2020-08-25 13:00:00 (0:25:00)
|
||||
- Busy -- 2020-08-25 15:00:00 (1:00:00)
|
||||
- **\<REDACTED>** -- 2020-08-25 15:00:00 (1:00:00)
|
||||
- **\<REDACTED>** -- 2020-08-25 19:00:00 (1:00:00)
|
||||
- **\<REDACTED>** -- 2020-08-25 19:00:12 (1:00:00)
|
||||
|
||||
### Python 和 Jupyter 的无穷选择
|
||||
|
||||
通过解析、分析和报告各种 Web 服务所拥有的数据,这只是你可以做的事情的表面。
|
||||
|
||||
为什么不对你最喜欢的服务试试呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/9/calendar-jupyter
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calendar.jpg?itok=jEKbhvDT (Calendar close up snapshot)
|
||||
[2]: https://opensource.com/resources/python
|
||||
[3]: https://pandas.pydata.org/
|
||||
[4]: https://dask.org/
|
||||
[5]: https://jupyter.org/
|
||||
[6]: https://pypi.org/project/caldav/
|
||||
[7]: https://pypi.org/project/vobject/
|
||||
[8]: https://opensource.com/article/19/5/python-attrs
|
||||
[9]: https://chameleon.readthedocs.io/en/latest/
|
||||
@ -0,0 +1,181 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (stevenzdg988)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13190-1.htmlhttps://linux.cn/article-13190-1.html)
|
||||
[#]: subject: (Teach a virtual class with Moodle on Linux)
|
||||
[#]: via: (https://opensource.com/article/20/10/moodle)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
基于 Linux 的 Moodle 虚拟课堂教学
|
||||
======
|
||||
|
||||
> 基于 Linux 的 Moodle 学习管理系统进行远程教学。
|
||||
|
||||

|
||||
|
||||
这次大流行对远程教育的需求比以往任何时候都更大。使得像 [Moodle][2] 这样的<ruby>学习管理系统<rt>learning management system</rt></ruby>(LMS)比以往任何时候都重要,因为越来越多的学校教育是借助虚拟现实技术的提供。
|
||||
|
||||
Moodle 是用 PHP 编写的免费 LMS,并以开源 [GNU 公共许可证][3](GPL)分发。它是由 [Martin Dougiamas][4] 开发的,自 2002 年发布以来一直在不断发展。Moodle 可用于混合学习、远程学习、<ruby>翻转课堂<rt>flipped classroom</rt></ruby>和其他形式的在线学习。目前,全球有超过 [1.9 亿用户][5] 和 145,000 个注册的 Moodle 网站。
|
||||
|
||||
我曾作为 Moodle 管理员、教师和学生等角色使用过 Moodle,在本文中,我将向你展示如何设置并开始使用它。
|
||||
|
||||
### 在 Linux 系统上安装 Moodle
|
||||
|
||||
Moodle 对 [系统要求][6] 适中,并且有大量文档可为你提供帮助。我最喜欢的安装方法是从 [Turnkey Linux][7] 下载并制作 ISO,然后在 VirtualBox 中安装 Moodle 网站。
|
||||
|
||||
首先,下载 [Moodle ISO][8] 保存到电脑中。
|
||||
|
||||
下一步,安装 VirtualBox 的 Linux 命令行如下:
|
||||
|
||||
```
|
||||
$ sudo apt install virtualbox
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ sudo dnf install virtualbox
|
||||
```
|
||||
|
||||
当下载完成后,启动 VirtualBox 并在控制台中选择“<ruby>新建<rt>New</rt></ruby>”按钮。
|
||||
|
||||
![创建一个新的 VirtualBox 虚拟机][9]
|
||||
|
||||
选择使用的虚拟机的名称、操作系统(Linux)和 Linux 类型(例如 Debian 64 位)。
|
||||
|
||||
![命名 VirtualBox 虚拟机][11]
|
||||
|
||||
下一步,配置虚拟机内存大小,使用默认值 1024 MB。接下来选择 “<ruby>动态分配<rt>dynamically allocated</rt></ruby>”虚拟磁盘并在虚拟机中添加 `Moodle.iso` 镜像。
|
||||
|
||||
![添加 Moodle.iso 到虚拟机][12]
|
||||
|
||||
将你的网络设置从 NAT 更改为 “<ruby>桥接模式<rt>Bridged adapter</rt></ruby>”。然后启动虚拟机并安装 ISO 以创建 Moodle 虚拟机。在安装过程中,系统将提示为 root 帐户、MySQL 和Moodle 创建密码。Moodle 密码必须至少包含八个字符,至少一个大写字母和至少一个特殊字符。
|
||||
|
||||
重启虚拟机。安装完成后,请确保将 Moodle 应用配置内容记录在安全的地方。(安装后,可以根据需要删除 ISO 文件。)
|
||||
|
||||
![Moodle 应用配置][13]
|
||||
|
||||
重要提示,在互联网上的任何人还看不到你的 Moodle 实例。它仅存在于你的本地网络中:现在只有建筑物中与你连接到相同的路由器或 wifi 接入点的人可以访问你的站点。全世界的互联网无法连接到它,因为你位于防火墙(可能嵌入在路由器中,还可能嵌入在计算机中)的后面。有关网络配置的更多信息,请阅读 Seth Kenlon 关于 [打开端口和通过防火墙进行流量路由][14] 的文章。
|
||||
|
||||
### 开始使用 Moodle
|
||||
|
||||
现在你可以登录到 Moodle 机器并熟悉该软件了。使用默认的用户名 `admin` 和创建 Moodle VM 时设置的密码登录 Moodle。
|
||||
|
||||
![Moodle 登录界面][15]
|
||||
|
||||
首次登录后,你将看到初始的 Moodle 网站的主仪表盘。
|
||||
|
||||
![Moodle 管理员仪表盘][16]
|
||||
|
||||
默认的应用名称是 “Turnkey Moodle”,但是可以很容易地对其进行更改以适合你的学校、课堂或其他需要和选择。要使你的 Moodle 网站个性化,请在用户界面左侧的菜单中,选择“站点首页<rt>Site home</rt></ruby>”。然后,点击屏幕右侧的 “<ruby>设置<rt>Settings</rt></ruby>” 图标,然后选择 “<ruby>编辑设置<rt>Edit settings</rt></ruby>”。
|
||||
|
||||
![Moodle 设置][17]
|
||||
|
||||
你可以根据需要更改站点名称,并添加简短名称和站点描述。
|
||||
|
||||
![Moodle 网站名][18]
|
||||
|
||||
确保滚动到底部并保存更改。现在,你的网站已定制好。
|
||||
|
||||
![Moodle 保存更改][19]
|
||||
|
||||
默认类别为其他,这不会帮助人们识别你网站的目的。要添加类别,请返回主仪表盘,然后从左侧菜单中选择 “<ruby>站点管理<rt>Site administration</rt></ruby>”。 在 “<ruby>课程<rt>Courses</rt></ruby>”下,选择 “<ruby>添加类别<rt>Add a category</rt></ruby>”并输入有关你的网站的详细信息。
|
||||
|
||||
![在 Moodle 中添加类别选项][20]
|
||||
|
||||
要添加课程,请返回 “<ruby>站点管理<rt>Site administration</rt></ruby>”,然后单击 “<ruby>添加新课程<rt>Add a new course</rt></ruby>”。你将看到一系列选项,例如为课程命名、提供简短名称、设定类别以及设置课程的开始和结束日期。你还可以为课程形式设置选项,例如社交、每周式课程、主题,以及其外观、文件上传大小、完成情况跟踪等等。
|
||||
|
||||
![在 Moodle 中添加课程选项][21]
|
||||
|
||||
### 添加和管理用户
|
||||
|
||||
现在,你已经设置了课程,你可以添加用户。有多种方法可以做到这一点。如果你是家庭教师,则手动输入是一个不错的开始。Moodle 支持基于电子邮件的注册、[LDAP][22]、[Shibboleth(口令或暗语)][23] 和许多其他方式等。校区和其他较大的机构可以用逗号分隔的文件上传用户。也可以批量添加密码,并在首次登录时强制更改密码。有关更多信息,一定要查阅 Moodle [文档][24]。
|
||||
|
||||
Moodle 是一个非常细化的、面向许可的环境。使用 Moodle 的菜单将策略和角色分配给用户并执行这些分配很容易。
|
||||
|
||||
Moodle 中有许多角色,每个角色都有特定的特权和许可。默认角色有管理员、课程创建者、教师、非编辑教师、学生、来宾和经过身份验证的用户,但你可以添加其他角色。
|
||||
|
||||
### 为课程添加内容
|
||||
|
||||
一旦搭建了 Moodle 网站并设置了课程,就可以向课程中添加内容。Moodle 拥有创建出色内容所需要的所有工具,并且它建立在强调 [社会建构主义][25] 观点的坚实教学法之上。
|
||||
|
||||
我创建了一个名为 “Code with [Mu][26]” 的示例课程。它在 “<ruby>编程<rt>Programming</rt></ruby>” 类别和 “Python” 子类别中。
|
||||
|
||||
![Moodle 课程列表][27]
|
||||
|
||||
我为课程选择了每周式课程,默认为四个星期。使用编辑工具,我隐藏了除课程第一周以外的所有内容。这样可以确保我的学生始终专注于材料。
|
||||
|
||||
作为教师或 Moodle 管理员,我可以通过单击 “<ruby>添加活动或资源<rt>Add an activity or resource</rt></ruby>” 来将活动添加到每周的教学中。
|
||||
|
||||
![在 Moodle 中添加活动][28]
|
||||
|
||||
我会看到一个弹出窗口,其中包含可以分配给我的学生的各种活动。
|
||||
|
||||
![Moodle 活动菜单][29]
|
||||
|
||||
Moodle 的工具和活动使我可以轻松地创建学习材料,并以一个简短的测验来结束一周的学习。
|
||||
|
||||
![Moodle 活动清单][30]
|
||||
|
||||
你可以使用 1600 多个插件来扩展 Moodle,包括新的活动、问题类型,与其他系统的集成等等。例如,[BigBlueButton][31] 插件支持幻灯片共享、白板、音频和视频聊天以及分组讨论。其他值得考虑的包括用于视频会议的 [Jitsi][32] 插件、[抄袭检查器][33] 和用于颁发徽章的 [开放徽章工厂][34]。
|
||||
|
||||
### 继续探索 Moodle
|
||||
|
||||
Moodle 是一个功能强大的 LMS,我希望此介绍能引起你的兴趣,以了解更多信息。有很多出色的 [指南][35] 可以帮助你提高技能,如果想要查看 Moodle 的内容,可以在其 [演示站点][36] 上查看运行中的 Moodle;如果你想了解 Moodle 的底层结构或为开发做出 [贡献][38],也可以访问 [Moodle 的源代码][37]。如果你喜欢在旅途中工作,Moodle 也有一款出色的 [移动应用][39],适用于 iOS 和 Android。在 [Twitter][40]、[Facebook][41] 和 [LinkedIn][42] 上关注 Moodle,以了解最新消息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/moodle
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_desk_home_laptop_browser.png?itok=Y3UVpY0l (Digital images of a computer desktop)
|
||||
[2]: https://moodle.org/
|
||||
[3]: https://docs.moodle.org/19/en/GNU_General_Public_License
|
||||
[4]: https://dougiamas.com/about/
|
||||
[5]: https://docs.moodle.org/39/en/History
|
||||
[6]: https://docs.moodle.org/39/en/Installation_quick_guide#Basic_Requirements
|
||||
[7]: https://www.turnkeylinux.org/
|
||||
[8]: https://www.turnkeylinux.org/download?file=turnkey-moodle-16.0-buster-amd64.iso
|
||||
[9]: https://opensource.com/sites/default/files/uploads/virtualbox_new.png (Create a new VirtualBox)
|
||||
[10]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]: https://opensource.com/sites/default/files/uploads/virtualbox_namevm.png (Naming the VirtualBox VM)
|
||||
[12]: https://opensource.com/sites/default/files/uploads/virtualbox_attach-iso.png (Attaching Moodle.iso to VM)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/moodle_appliance.png (Moodle appliance settings)
|
||||
[14]: https://opensource.com/article/20/9/firewall
|
||||
[15]: https://opensource.com/sites/default/files/uploads/moodle_login.png (Moodle login screen)
|
||||
[16]: https://opensource.com/sites/default/files/uploads/moodle_dashboard.png (Moodle admin dashboard)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/moodle_settings.png (Moodle settings)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/moodle_name-site.png (Name Moodle site)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/moodle_saved.png (Moodle changes saved)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/moodle_addcategory.png (Add category option in Moodle)
|
||||
[21]: https://opensource.com/sites/default/files/uploads/moodle_addcourse.png (Add course option in Moodle)
|
||||
[22]: https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol
|
||||
[23]: https://www.shibboleth.net/
|
||||
[24]: https://docs.moodle.org/39/en/Main_page
|
||||
[25]: https://docs.moodle.org/39/en/Pedagogy#How_Moodle_tries_to_support_a_Social_Constructionist_view
|
||||
[26]: https://opensource.com/article/20/9/teach-python-mu
|
||||
[27]: https://opensource.com/sites/default/files/uploads/moodle_choosecourse.png (Moodle course list)
|
||||
[28]: https://opensource.com/sites/default/files/uploads/moodle_addactivity_0.png (Add activity in Moodle)
|
||||
[29]: https://opensource.com/sites/default/files/uploads/moodle_activitiesmenu.png (Moodle activities menu)
|
||||
[30]: https://opensource.com/sites/default/files/uploads/moodle_activitieschecklist.png (Moodle activities checklist)
|
||||
[31]: https://moodle.org/plugins/mod_bigbluebuttonbn
|
||||
[32]: https://moodle.org/plugins/mod_jitsi
|
||||
[33]: https://moodle.org/plugins/plagiarism_unicheck
|
||||
[34]: https://moodle.org/plugins/local_obf
|
||||
[35]: https://learn.moodle.org/
|
||||
[36]: https://school.moodledemo.net/
|
||||
[37]: https://git.in.moodle.com/moodle/moodle
|
||||
[38]: https://git.in.moodle.com/moodle/moodle/-/blob/master/CONTRIBUTING.txt
|
||||
[39]: https://download.moodle.org/mobile/
|
||||
[40]: https://twitter.com/moodle
|
||||
[41]: https://www.facebook.com/moodle
|
||||
[42]: https://www.linkedin.com/company/moodle/
|
||||
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (AmorSu)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13170-1.html)
|
||||
[#]: subject: (6 container concepts you need to understand)
|
||||
[#]: via: (https://opensource.com/article/20/12/containers-101)
|
||||
[#]: author: (Mike Calizo https://opensource.com/users/mcalizo)
|
||||
|
||||
6 个必知必会的关于容器的概念
|
||||
======
|
||||
|
||||
> 容器现在是无所不在,它们已经快速的改变了 IT 格局。关于容器你需要知道一些什么呢?
|
||||
|
||||

|
||||
|
||||
因为容器给企业所带来的巨大的价值和大量的好处,它快速的改变了 IT 格局。几乎所有最新的业务创新,都有容器化贡献的一部分因素,甚至是主要因素。
|
||||
|
||||
在现代化应用架构中,能够快速的把变更交付到生产环境的能力,让你比你的竞争对手更胜一筹。容器通过使用微服务架构,帮助开发团队开发功能、更小的失败、更快的恢复,从而加快交付速度。容器化还让应用软件能够快速启动、按需自动扩展云资源。还有,[DevOps][2] 通过灵活性、移动性、和有效性让产品可以尽快进入市场,从而将容器化的所能带来的好处最大化。
|
||||
|
||||
在 DevOps 中,虽然速度、敏捷、灵活是容器化的主要保障,但安全则是一个重要的因素。这就导致了 DevSecOps 的出现。它从一开始,到贯穿容器化应用的整个生命周期,都始终将安全融合到应用的开发中。默认情况下,容器化大大地增强了安全性,因为它将应用和宿主机以及其他的容器化应用相互隔离开来。
|
||||
|
||||
### 什么是容器?
|
||||
|
||||
容器是单体式应用程序所遗留的问题的解决方案。虽然单体式有它的优点,但是它阻碍了组织以敏捷的方式快速前进。而容器则让你能够将单体式分解成 [微服务][3]。
|
||||
|
||||
本质上来说,容器只是一些轻量化组件的应用集,比如软件依赖、库、配置文件等等,然后运行在一个隔离的环境之中,这个隔离的环境又是运行在传统操作系统之上的,或者为了可移植性和灵活性而运行在虚拟化环境之上。
|
||||
|
||||
![容器的架构][4]
|
||||
|
||||
总而言之,容器通过利用像 cgroup、 [内核命名空间][6] 和 [SELinux][7] 这样的内核技术来实现隔离。容器跟宿主机共用一个内核,因此比虚拟机占用更少的资源。
|
||||
|
||||
### 容器的优势
|
||||
|
||||
这种架构所带来的敏捷性是虚拟机所不可能做到的。此外,在计算和内存资源方面,容器支持一种更灵活的模型,而且它支持突发资源模式,因此应用程序可以在需要的时候,在限定的范围内,使用更多的资源。用另一句话来说,容器提供的扩展性和灵活性,是你在虚拟机上运行的应用程序中所无法实现的。
|
||||
|
||||
容器让在公有云或者私有云上部署和分享应用变得非常容易。更重要的是,它所提供的连贯性,帮助运维和开发团队降低了在跨平台部署的过程中的复杂度。
|
||||
|
||||
容器还可以实现一套通用的构建组件,可以在开发的任何阶段拿来复用,从而可以重建出一样的环境供开发、测试、预备、生产使用,将“一次编写、到处执行”的概念加以扩展。
|
||||
|
||||
和虚拟化相比,容器使实现灵活性、连贯性和快速部署应用的能力变得更加简单 —— 这是 DevOps 的主要原则。
|
||||
|
||||
### Docker 因素
|
||||
|
||||
[Docker][8] 已经变成了容器的代名词。Docker 让容器技术发生彻底变革并得以推广普及,虽然早在 Docker 之前容器技术就已经存在。这些容器技术包括 AIX 工作负载分区、 Solaris 容器、以及 Linux 容器([LXC][9]),后者被用来 [在一台 Linux 宿主机上运行多个 Linux 环境][10]。
|
||||
|
||||
### Kubernetes 效应
|
||||
|
||||
Kubernetes 如今已被广泛认为是 [编排引擎][11] 中的领导者。在过去的几年里,[Kubernetes 的普及][12] 加上容器技术的应用日趋成熟,为运维、开发、以及安全团队可以拥抱日益变革的行业,创造了一个理想的环境。
|
||||
|
||||
Kubernetes 为容器的管理提供了完整全面的解决方案。它可以在一个集群中运行容器,从而实现类似自动扩展云资源这样的功能,这些云资源包括:自动的、分布式的事件驱动的应用需求。这就保证了“免费的”高可用性。(比如,开发和运维都不需要花太大的劲就可以实现)
|
||||
|
||||
此外,在 OpenShift 和 类似 Kubernetes 这样的企业的帮助下,容器的应用变得更加的容易。
|
||||
|
||||
![Kubernetes 集群][13]
|
||||
|
||||
### 容器会替代虚拟机吗?
|
||||
|
||||
[KubeVirt][14] 和类似的 [开源][15] 项目很大程度上表明,容器将会取代虚拟机。KubeVirt 通过将虚拟机转化成容器,把虚拟机带入到容器化的工作流中,因此它们就可以利用容器化应用的优势。
|
||||
|
||||
现在,容器和虚拟机更多的是互补的关系,而不是相互竞争的。容器在虚拟机上面运行,因此增加可用性,特别是对于那些要求有持久性的应用。同时容器可以利用虚拟化技术的优势,让硬件的基础设施(如:内存和网络)的管理更加便捷。
|
||||
|
||||
### 那么 Windows 容器呢?
|
||||
|
||||
微软和开源社区方面都对 Windows 容器的成功实现做了大量的推动。Kubernetes <ruby>操作器<rt>Operator</rt></ruby> 加速了 Windows 容器的应用进程。还有像 OpenShift 这样的产品现在可以启用 [Windows 工作节点][16] 来运行 Windows 容器。
|
||||
|
||||
Windows 的容器化创造出巨大的诱人的可能性。特别是对于使用混合环境的企业。在 Kubernetes 集群上运行你最关键的应用程序,是你成功实现混合云/多种云环境的目标迈出的一大步。
|
||||
|
||||
### 容器的未来
|
||||
|
||||
容器在 IT 行业日新月异的变革中扮演着重要的角色,因为企业在向着快速、敏捷的交付软件及解决方案的方向前进,以此来 [超越竞争对手][17]。
|
||||
|
||||
容器会继续存在下去。在不久的将来,其他的使用场景,比如边缘计算中的无服务器,将会浮现出来,并且更深地影响我们对从数字设备来回传输数据的速度的认知。唯一在这种变化中存活下来的方式,就是去应用它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/12/containers-101
|
||||
|
||||
作者:[Mike Calizo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[AmorSu](https://github.com/amorsu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mcalizo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/kubernetes_containers_ship_lead.png?itok=9EUnSwci (Ships at sea on the web)
|
||||
[2]: https://opensource.com/resources/devops
|
||||
[3]: https://opensource.com/resources/what-are-microservices
|
||||
[4]: https://opensource.com/sites/default/files/uploads/container_architecture.png (Container architecture)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://opensource.com/article/19/10/namespaces-and-containers-linux
|
||||
[7]: https://opensource.com/article/20/11/selinux-containers
|
||||
[8]: https://opensource.com/resources/what-docker
|
||||
[9]: https://linuxcontainers.org/
|
||||
[10]: https://opensource.com/article/18/11/behind-scenes-linux-containers
|
||||
[11]: https://opensource.com/article/20/11/orchestration-vs-automation
|
||||
[12]: https://enterprisersproject.com/article/2020/6/kubernetes-statistics-2020
|
||||
[13]: https://opensource.com/sites/default/files/uploads/kubernetes_cluster.png (Kubernetes cluster)
|
||||
[14]: https://kubevirt.io/
|
||||
[15]: https://opensource.com/resources/what-open-source
|
||||
[16]: https://www.openshift.com/blog/announcing-the-community-windows-machine-config-operator-on-openshift-4.6
|
||||
[17]: https://www.imd.org/research-knowledge/articles/the-battle-for-digital-disruption-startups-vs-incumbents/
|
||||
@ -0,0 +1,83 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13209-1.html)
|
||||
[#]: subject: (Turn your Raspberry Pi into a HiFi music system)
|
||||
[#]: via: (https://opensource.com/article/21/1/raspberry-pi-hifi)
|
||||
[#]: author: (Peter Czanik https://opensource.com/users/czanik)
|
||||
|
||||
把你的树莓派变成一个 HiFi 音乐系统
|
||||
======
|
||||
|
||||
> 为你的朋友、家人、同事或其他任何拥有廉价发烧设备的人播放音乐。
|
||||
|
||||

|
||||
|
||||
在过去的 10 年里,我大部分时间都是远程工作,但当我走进办公室时,我坐在一个充满内向的同伴的房间里,他们很容易被环境噪音和谈话所干扰。我们发现,听音乐可以抑制办公室的噪音,让声音不那么扰人,用愉快的音乐提供一个愉快的工作环境。
|
||||
|
||||
起初,我们的一位同事带来了一些老式的有源电脑音箱,把它们连接到他的桌面电脑上,然后问我们想听什么。它可以工作,但音质不是很好,而且只有当他在办公室的时候才可以使用。接下来,我们又买了一对 Altec Lansing 音箱。音质有所改善,但没有什么灵活性。
|
||||
|
||||
不久之后,我们得到了一台通用 ARM 单板计算机(SBC),这意味着任何人都可以通过 Web 界面控制播放列表和音箱。但一块普通的 ARM 开发板意味着我们不能使用流行的音乐设备软件。由于非标准的内核,更新操作系统是一件很痛苦的事情,而且 Web 界面也经常出现故障。
|
||||
|
||||
当团队壮大并搬进更大的房间后,我们开始梦想着有更好音箱和更容易处理软件和硬件组合的方法。
|
||||
|
||||
为了用一种相对便宜、灵活、音质好的方式解决我们的问题,我们用树莓派、音箱和开源软件开发了一个办公室 HiFi。
|
||||
|
||||
### HiFi 硬件
|
||||
|
||||
用一个专门的 PC 来播放背景音乐就有点过分了。它昂贵、嘈杂(除非是静音的,但那就更贵了),而且不环保。即使是最便宜的 ARM 板也能胜任这个工作,但从软件的角度来看,它们往往存在问题。树莓派还是比较便宜的,虽然不是标准的计算机,但在硬件和软件方面都有很好的支持。
|
||||
|
||||
接下来的问题是:用什么音箱。质量好的、有源的音箱很贵。无源音箱的成本较低,但需要一个功放,这需要为这套设备增加另一个盒子。它们还必须使用树莓派的音频输出;虽然可以工作,但并不是最好的,特别是当你已经在高质量的音箱和功放上投入资金的时候。
|
||||
|
||||
幸运的是,在数以千计的树莓派硬件扩展中,有内置数字模拟转换器(DAC)的功放。我们选择了 [HiFiBerry 的 Amp][2]。它在我们买来后不久就停产了(被采样率更好的 Amp+ 型号取代),但对于我们的目的来说,它已经足够好了。在开着空调的情况下,我想无论如何你也听不出 48kHz 或 192kHz 的 DAC 有什么不同。
|
||||
|
||||
音箱方面,我们选择了 [Audioengine P4][3],是在某店家清仓大甩卖的时候买的,价格超低。它很容易让我们的办公室房间充满了声音而不失真(并且还能传到我们的房间之外,有一些失真,隔壁的工程师往往不喜欢)。
|
||||
|
||||
### HiFi 软件
|
||||
|
||||
在我们旧的通用 ARM SBC 上我们需要维护一个 Ubuntu,使用一个固定的、古老的、在软件包仓库外的系统内核,这是有问题的。树莓派操作系统包括一个维护良好的内核包,使其成为一个稳定且易于更新的基础系统,但它仍然需要我们定期更新 Python 脚本来访问 Spotify 和 YouTube。对于我们的目的来说,这有点过于高维护。
|
||||
|
||||
幸运的是,使用树莓派作为基础意味着有许多现成的软件设备可用。
|
||||
|
||||
我们选择了 [Volumio][4],这是一个将树莓派变成音乐播放设备的开源项目。安装是一个简单的*一步步完成*的过程。安装和升级是完全无痛的,而不用辛辛苦苦地安装和维护一个操作系统,并定期调试破损的 Python 代码。配置 HiFiBerry 功放不需要编辑任何配置文件,你只需要从列表中选择即可。当然,习惯新的用户界面需要一定的时间,但稳定性和维护的便捷性让这个改变是值得的。
|
||||
|
||||
![Volumio interface][5]
|
||||
|
||||
### 播放音乐并体验
|
||||
|
||||
虽然大流行期间我们都在家里办公,不过我把办公室的 HiFi 安装在我的家庭办公室里,这意味着我可以自由支配它的运行。一个不断变化的用户界面对于一个团队来说会很痛苦,但对于一个有研发背景的人来说,自己玩一个设备,变化是很有趣的。
|
||||
|
||||
我不是一个程序员,但我有很强的 Linux 和 Unix 系统管理背景。这意味着,虽然我觉得修复坏掉的 Python 代码很烦人,但 Volumio 对我来说却足够完美,足够无聊(这是一个很好的“问题”)。幸运的是,在树莓派上播放音乐还有很多其他的可能性。
|
||||
|
||||
作为一个终端狂人(我甚至从终端窗口启动 LibreOffice),我主要使用 Music on Console([MOC][6])来播放我的网络存储(NAS)中的音乐。我有几百张 CD,都转换成了 [FLAC][7] 文件。而且我还从 [BandCamp][8] 或 [Society of Sound][9] 等渠道购买了许多数字专辑。
|
||||
|
||||
另一个选择是 [音乐播放器守护进程(MPD)][10]。把它运行在树莓派上,我可以通过网络使用 Linux 和 Android 的众多客户端之一与我的音乐进行远程交互。
|
||||
|
||||
### 音乐不停歇
|
||||
|
||||
正如你所看到的,创建一个廉价的 HiFi 系统在软件和硬件方面几乎是无限可能的。我们的解决方案只是众多解决方案中的一个,我希望它能启发你建立适合你环境的东西。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/1/raspberry-pi-hifi
|
||||
|
||||
作者:[Peter Czanik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/czanik
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/hi-fi-stereo-vintage.png?itok=KYY3YQwE (HiFi vintage stereo)
|
||||
[2]: https://www.hifiberry.com/products/amp/
|
||||
[3]: https://audioengineusa.com/shop/passivespeakers/p4-passive-speakers/
|
||||
[4]: https://volumio.org/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/volumeio.png (Volumio interface)
|
||||
[6]: https://en.wikipedia.org/wiki/Music_on_Console
|
||||
[7]: https://xiph.org/flac/
|
||||
[8]: https://bandcamp.com/
|
||||
[9]: https://realworldrecords.com/news/society-of-sound-statement/
|
||||
[10]: https://www.musicpd.org/
|
||||
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13172-1.html)
|
||||
[#]: subject: (KDE Customization Guide: Here are 11 Ways You Can Change the Look and Feel of Your KDE-Powered Linux Desktop)
|
||||
[#]: via: (https://itsfoss.com/kde-customization/)
|
||||
[#]: author: (Dimitrios Savvopoulos https://itsfoss.com/author/dimitrios/)
|
||||
|
||||
KDE 桌面环境定制指南
|
||||
======
|
||||
|
||||

|
||||
|
||||
[KDE Plasma 桌面][1] 无疑是定制化的巅峰,因为你几乎可以改变任何你想要的东西。你甚至可以让它充当 [平铺窗口管理器][2]。
|
||||
|
||||
KDE Plasma 提供的定制化程度会让初学者感到困惑。用户会迷失在层层深入的选项之中。
|
||||
|
||||
为了解决这个问题,我将向你展示你应该注意的 KDE Plasma 定制的关键点。这里有 11 种方法可以改变你的 KDE 桌面的外观和感觉。
|
||||
|
||||
![][3]
|
||||
|
||||
### 定制 KDE Plasma
|
||||
|
||||
我在本教程中使用了 [KDE Neon][4],但你可以在任何使用 KDE Plasma 桌面的发行版中遵循这些方法。
|
||||
|
||||
#### 1、Plasma 桌面小工具
|
||||
|
||||
桌面小工具可以增加用户体验的便利性,因为你可以立即访问桌面上的重要项目。
|
||||
|
||||
现在学生和专业人士使用电脑的时候越来越多,其中一个有用的小部件是便签。
|
||||
|
||||
右键点击桌面,选择“<ruby>添加小工具<rt>Add Widgets</rt></ruby>”。
|
||||
|
||||
![][5]
|
||||
|
||||
选择你喜欢的小部件,然后简单地将其拖放到桌面上。
|
||||
|
||||
![][6]
|
||||
|
||||
#### 2、桌面壁纸
|
||||
|
||||
不用说,更换壁纸可以改变桌面的外观。
|
||||
|
||||
![][7]
|
||||
|
||||
在“<ruby>壁纸<rt>Wallpaper</rt></ruby>”选项卡中,你可以改变的不仅仅是壁纸。从“<ruby>布局<rt>Layout</rt></ruby>”下拉菜单中,你还可以选择桌面是否放置图标。
|
||||
|
||||
“<ruby>文件夹视图<rt>Folder View</rt></ruby>”布局的命名来自于主目录中的传统桌面文件夹,你可以在那里访问你的桌面文件。因此,“<ruby>文件夹视图<rt>Folder View</rt></ruby>”选项将保留桌面上的图标。
|
||||
|
||||
如果你选择“<ruby>桌面<rt>Desktop</rt></ruby>”布局,它会使你的桌面图标保持自由而普通。当然,你仍然可以访问主目录下的桌面文件夹。
|
||||
|
||||
![][8]
|
||||
|
||||
在“<ruby>壁纸类型<rt>Wallpaper Type</rt></ruby>”中,你可以选择是否要壁纸,是静止的还是变化的,最后在“<ruby>位置<rt>Positioning</rt></ruby>”中,选择它在屏幕上的样子。
|
||||
|
||||
#### 3、鼠标动作
|
||||
|
||||
每一个鼠标按键都可以配置为以下动作之一:
|
||||
|
||||
* <ruby>切换窗口<rt>Switch Window</rt></ruby>
|
||||
* <ruby>切换桌面<rt>Switch Desktop</rt></ruby>
|
||||
* <ruby>粘贴<rt>Paste</rt></ruby>
|
||||
* <ruby>标准菜单<rt>Standard Menu</rt></ruby>
|
||||
* <ruby>应用程序启动器<rt>Application Launcher</rt></ruby>
|
||||
* <ruby>切换活动区<rt>Switch Activity</rt></ruby>
|
||||
|
||||
右键默认设置为<ruby>标准菜单<rt>Standard Menu</rt></ruby>,也就是在桌面上点击右键时的菜单。点击旁边的设置图标可以更改动作。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 4、桌面内容的位置
|
||||
|
||||
只有在壁纸选项卡中选择“文件夹视图”时,该选项才可用。默认情况下,桌面上显示的内容是你在主目录下的“<ruby>桌面<rt>Desktop</rt></ruby>”文件夹中的内容。这个位置选项卡让你可以选择不同的文件夹来改变桌面上的内容。
|
||||
|
||||
![][10]
|
||||
|
||||
#### 5、桌面图标
|
||||
|
||||
在这里,你可以选择图标的排列方式(水平或垂直)、左右对齐、排序标准及其大小。如果这些还不够,你还可以探索其他的美学功能。
|
||||
|
||||
![][11]
|
||||
|
||||
#### 6、桌面过滤器
|
||||
|
||||
让我们坦然面对自己吧! 相信每个用户最后都会在某些时候出现桌面凌乱的情况。如果你的桌面变得乱七八糟,找不到文件,你可以按名称或类型应用过滤器,找到你需要的文件。虽然,最好是养成一个良好的文件管理习惯!
|
||||
|
||||
![][12]
|
||||
|
||||
#### 7、应用仪表盘
|
||||
|
||||
如果你喜欢 GNOME 3 的应用程序启动器,那么你可以试试 KDE 应用程序仪表板。你所要做的就是右击菜单图标 > “<ruby>显示替代品<rt>Show Alternatives</rt></ruby>”。
|
||||
|
||||
![][13]
|
||||
|
||||
点击“<ruby>应用仪表盘<rt>Application Dashboard</rt></ruby>”。
|
||||
|
||||
![][14]
|
||||
|
||||
#### 8、窗口管理器主题
|
||||
|
||||
就像你在 [Xfce 自定义教程][15] 中看到的那样,你也可以在 KDE 中独立改变窗口管理器的主题。这样你就可以为面板选择一种主题,为窗口管理器选择另外一种主题。如果预装的主题不够用,你可以下载更多的主题。
|
||||
|
||||
不过受 [MX Linux][16] Xfce 版的启发,我还是忍不住选择了我最喜欢的 “Arc Dark”。
|
||||
|
||||
导航到“<ruby>设置<rt>Settings</rt></ruby>” > “<ruby>应用风格<rt>Application Style</rt></ruby>” > “<ruby>窗口装饰<rt>Window decorations</rt></ruby>” > “<ruby>主题<rt>Theme</rt></ruby>”。
|
||||
|
||||
![][17]
|
||||
|
||||
#### 9、全局主题
|
||||
|
||||
如上所述,KDE Plasma 面板的外观和感觉可以从“<ruby>设置<rt>Settings</rt></ruby>” > “<ruby>全局主题<rt>Global theme</rt></ruby>”选项卡中进行配置。预装的主题数量并不多,但你可以下载一个适合自己口味的主题。不过默认的 “Breeze Dark” 是一款养眼的主题。
|
||||
|
||||
![][18]
|
||||
|
||||
#### 10、系统图标
|
||||
|
||||
系统图标样式对桌面的外观有很大的影响。无论你选择哪一种,如果你的全局主题是深色的,你应该选择深色图标版本。唯一的区别在于图标文字对比度上,图标文字对比度应该与面板颜色反色,使其具有可读性。你可以在系统设置中轻松访问“<ruby>图标<rt>Icons</rt></ruby>”标签。
|
||||
|
||||
![][19]
|
||||
|
||||
#### 11、系统字体
|
||||
|
||||
系统字体并不是定制的重点,但如果你每天有一半的时间都在屏幕前,它可能是眼睛疲劳的因素之一。有阅读障碍的用户会喜欢 [OpenDyslexic][20] 字体。我个人选择的是 Ubuntu 字体,不仅我觉得美观,而且是在屏幕前度过一天的好字体。
|
||||
|
||||
当然,你也可以通过下载外部资源来 [在 Linux 系统上安装更多的字体][21]。
|
||||
|
||||
![][22]
|
||||
|
||||
### 总结
|
||||
|
||||
KDE Plasma 是 Linux 社区最灵活和可定制的桌面之一。无论你是否是一个修理工,KDE Plasma 都是一个不断发展的桌面环境,具有惊人的现代功能。更好的是,它也可以在性能中等的系统配置上进行管理。
|
||||
|
||||
现在,我试图让本指南对初学者友好。当然,可以有更多的高级定制,比如那个 [窗口切换动画][23]。如果你知道一些别的技巧,为什么不在评论区与我们分享呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/kde-customization/
|
||||
|
||||
作者:[Dimitrios Savvopoulos][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/dimitrios/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://kde.org/plasma-desktop/
|
||||
[2]: https://github.com/kwin-scripts/kwin-tiling
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/kde-neon-neofetch.png?resize=800%2C600&ssl=1
|
||||
[4]: https://itsfoss.com/kde-neon-review/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/16-kde-neon-add-widgets.png?resize=800%2C500&ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/17-kde-neon-widgets.png?resize=800%2C768&ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/1-kde-neon-configure-desktop.png?resize=800%2C500&ssl=1
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/2-kde-neon-wallpaper.png?resize=800%2C600&ssl=1
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/3-kde-neon-mouse-actions.png?resize=800%2C600&ssl=1
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/10-kde-neon-location.png?resize=800%2C650&ssl=1
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/4-kde-neon-desktop-icons.png?resize=798%2C635&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/11-kde-neon-desktop-icons-filter.png?resize=800%2C650&ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/5-kde-neon-show-alternatives.png?resize=800%2C500&ssl=1
|
||||
[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/6-kde-neon-application-dashboard.png?resize=800%2C450&ssl=1
|
||||
[15]: https://itsfoss.com/customize-xfce/
|
||||
[16]: https://itsfoss.com/mx-linux-kde-edition/
|
||||
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/12-kde-neon-window-manager.png?resize=800%2C512&ssl=1
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/15-kde-neon-global-theme.png?resize=800%2C524&ssl=1
|
||||
[19]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/13-kde-neon-system-icons.png?resize=800%2C524&ssl=1
|
||||
[20]: https://www.opendyslexic.org/about
|
||||
[21]: https://itsfoss.com/install-fonts-ubuntu/
|
||||
[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/14-kde-neon-fonts.png?resize=800%2C524&ssl=1
|
||||
[23]: https://itsfoss.com/customize-task-switcher-kde/
|
||||
@ -0,0 +1,244 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13240-1.html)
|
||||
[#]: subject: (Convert your Windows install into a VM on Linux)
|
||||
[#]: via: (https://opensource.com/article/21/1/virtualbox-windows-linux)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
在 Linux 上将你的 Windows 系统转换为虚拟机
|
||||
======
|
||||
|
||||
> 下面是我如何配置 VirtualBox 虚拟机以在我的 Linux 工作站上使用物理的 Windows 操作系统。
|
||||
|
||||

|
||||
|
||||
我经常使用 VirtualBox 来创建虚拟机来测试新版本的 Fedora、新的应用程序和很多管理工具,比如 Ansible。我甚至使用 VirtualBox 来测试创建一个 Windows 访客主机。
|
||||
|
||||
我从来没有在我的任何一台个人电脑上使用 Windows 作为我的主要操作系统,甚至也没在虚拟机中执行过一些用 Linux 无法完成的冷门任务。不过,我确实为一个需要使用 Windows 下的财务程序的组织做志愿者。这个程序运行在办公室经理的电脑上,使用的是预装的 Windows 10 Pro。
|
||||
|
||||
这个财务应用程序并不特别,[一个更好的 Linux 程序][2] 可以很容易地取代它,但我发现许多会计和财务主管极不愿意做出改变,所以我还没能说服我们组织中的人迁移。
|
||||
|
||||
这一系列的情况,加上最近的安全恐慌,使得我非常希望将运行 Windows 的主机转换为 Fedora,并在该主机上的虚拟机中运行 Windows 和会计程序。
|
||||
|
||||
重要的是要明白,我出于多种原因极度不喜欢 Windows。主要原因是,我不愿意为了在新的虚拟机上安装它而再花钱购买一个 Windows 许可证(Windows 10 Pro 大约需要 200 美元)。此外,Windows 10 在新系统上设置时或安装后需要足够的信息,如果微软的数据库被攻破,破解者就可以窃取一个人的身份。任何人都不应该为了注册软件而需要提供自己的姓名、电话号码和出生日期。
|
||||
|
||||
### 开始
|
||||
|
||||
这台实体电脑已经在主板上唯一可用的 m.2 插槽中安装了一个 240GB 的 NVMe m.2 的 SSD 存储设备。我决定在主机上安装一个新的 SATA SSD,并将现有的带有 Windows 的 SSD 作为 Windows 虚拟机的存储设备。金士顿在其网站上对各种 SSD 设备、外形尺寸和接口做了很好的概述。
|
||||
|
||||
这种方法意味着我不需要重新安装 Windows 或任何现有的应用软件。这也意味着,在这台电脑上工作的办公室经理将使用 Linux 进行所有正常的活动,如电子邮件、访问 Web、使用 LibreOffice 创建文档和电子表格。这种方法增加了主机的安全性。唯一会使用 Windows 虚拟机的时间是运行会计程序。
|
||||
|
||||
### 先备份
|
||||
|
||||
在做其他事情之前,我创建了整个 NVMe 存储设备的备份 ISO 镜像。我在 500GB 外置 USB 存储盘上创建了一个分区,在其上创建了一个 ext4 文件系统,然后将该分区挂载到 `/mnt`。我使用 `dd` 命令来创建镜像。
|
||||
|
||||
我在主机中安装了新的 500GB SATA SSD,并从<ruby>临场<rt>live</rt></ruby> USB 上安装了 Fedora 32 Xfce <ruby>偏好版<rt>spin</rt></ruby>。在安装后的初次重启时,在 GRUB2 引导菜单上,Linux 和 Windows 操作系统都是可用的。此时,主机可以在 Linux 和 Windows 之间进行双启动。
|
||||
|
||||
### 在网上寻找帮助
|
||||
|
||||
现在我需要一些关于创建一个使用物理硬盘或 SSD 作为其存储设备的虚拟机的信息。我很快就在 VirtualBox 文档和互联网上发现了很多关于如何做到这一点的信息。虽然 VirtualBox 文档初步帮助了我,但它并不完整,遗漏了一些关键信息。我在互联网上找到的大多数其他信息也很不完整。
|
||||
|
||||
在我们的记者 Joshua Holm 的帮助下,我得以突破这些残缺的信息,并以一个可重复的流程来完成这项工作。
|
||||
|
||||
### 让它发挥作用
|
||||
|
||||
这个过程其实相当简单,虽然需要一个玄妙的技巧才能实现。当我准备好这一步的时候,Windows 和 Linux 操作系统已经到位了。
|
||||
|
||||
首先,我在 Linux 主机上安装了最新版本的 VirtualBox。VirtualBox 可以从许多发行版的软件仓库中安装,也可以直接从 Oracle VirtualBox 仓库中安装,或者从 VirtualBox 网站上下载所需的包文件并在本地安装。我选择下载 AMD64 版本,它实际上是一个安装程序而不是一个软件包。我使用这个版本来规避一个与这个特定项目无关的问题。
|
||||
|
||||
安装过程总是在 `/etc/group` 中创建一个 `vboxusers` 组。我把打算运行这个虚拟机的用户添加到 `/etc/group` 中的 `vboxusers` 和 `disk` 组。将相同的用户添加到 `disk` 组是很重要的,因为 VirtualBox 是以启动它的用户身份运行的,而且还需要直接访问 `/dev/sdx` 特殊设备文件才能在这种情况下工作。将用户添加到 `disk` 组可以提供这种级别的访问权限,否则他们就不会有这种权限。
|
||||
|
||||
然后,我创建了一个目录来存储虚拟机,并赋予它 `root.vboxusers` 的所有权和 `775` 的权限。我使用 `/vms` 用作该目录,但可以是任何你想要的目录。默认情况下,VirtualBox 会在创建虚拟机的用户的子目录中创建新的虚拟机。这将使多个用户之间无法共享对虚拟机的访问,从而不会产生巨大的安全漏洞。将虚拟机目录放置在一个可访问的位置,可以共享虚拟机。
|
||||
|
||||
我以非 root 用户的身份启动 VirtualBox 管理器。然后,我使用 VirtualBox 的“<ruby>偏好<rt>Preferences</rt></ruby> => <ruby>一般<rt>General</rt></ruby>”菜单将“<ruby>默认机器文件夹<rt>Default Machine Folder</rt></ruby>”设置为 `/vms` 目录。
|
||||
|
||||
我创建的虚拟机没有虚拟磁盘。“<ruby>类型<rt>Type<rt></ruby>” 应该是 `Windows`,“<ruby>版本<rt>Version</rt></ruby>”应该设置为 `Windows 10 64-bit`。为虚拟机设置一个合理的内存量,但只要虚拟机处于关闭状态,以后可以更改。在安装的“<ruby>硬盘<rt>Hard disk</rt></ruby>”页面,我选择了 “<ruby>不要添加虚拟硬盘<rt>Do not add a virtual hard disk</rt></ruby>”,点击“<ruby>创建<rt>Create</rt></ruby>”。新的虚拟机出现在VirtualBox 管理器窗口中。这个过程也创建了 `/vms/Test1` 目录。
|
||||
|
||||
我使用“<ruby>高级<rt>Advanced</rt></ruby>”菜单在一个页面上设置了所有的配置,如图 1 所示。“<ruby>向导模式<rt>Guided Mode</rt></ruby>”可以获得相同的信息,但需要更多的点击,以通过一个窗口来进行每个配置项目。它确实提供了更多的帮助内容,但我并不需要。
|
||||
|
||||
![VirtualBox 对话框:创建新的虚拟机,但不添加硬盘][3]
|
||||
|
||||
*图 1:创建一个新的虚拟机,但不要添加硬盘。*
|
||||
|
||||
然后,我需要知道 Linux 给原始 Windows 硬盘分配了哪个设备。在终端会话中以 root 身份使用 `lshw` 命令来发现 Windows 磁盘的设备分配情况。在本例中,代表整个存储设备的设备是 `/dev/sdb`。
|
||||
|
||||
```
|
||||
# lshw -short -class disk,volume
|
||||
H/W path Device Class Description
|
||||
=========================================================
|
||||
/0/100/17/0 /dev/sda disk 500GB CT500MX500SSD1
|
||||
/0/100/17/0/1 volume 2047MiB Windows FAT volume
|
||||
/0/100/17/0/2 /dev/sda2 volume 4GiB EXT4 volume
|
||||
/0/100/17/0/3 /dev/sda3 volume 459GiB LVM Physical Volume
|
||||
/0/100/17/1 /dev/cdrom disk DVD+-RW DU-8A5LH
|
||||
/0/100/17/0.0.0 /dev/sdb disk 256GB TOSHIBA KSG60ZMV
|
||||
/0/100/17/0.0.0/1 /dev/sdb1 volume 649MiB Windows FAT volume
|
||||
/0/100/17/0.0.0/2 /dev/sdb2 volume 127MiB reserved partition
|
||||
/0/100/17/0.0.0/3 /dev/sdb3 volume 236GiB Windows NTFS volume
|
||||
/0/100/17/0.0.0/4 /dev/sdb4 volume 989MiB Windows NTFS volume
|
||||
[root@office1 etc]#
|
||||
```
|
||||
|
||||
VirtualBox 不需要把虚拟存储设备放在 `/vms/Test1` 目录中,而是需要有一种方法来识别要从其启动的物理硬盘。这种识别是通过创建一个 `*.vmdk` 文件来实现的,该文件指向将作为虚拟机存储设备的原始物理磁盘。作为非 root 用户,我创建了一个 vmdk 文件,指向整个 Windows 设备 `/dev/sdb`。
|
||||
|
||||
```
|
||||
$ VBoxManage internalcommands createrawvmdk -filename /vms/Test1/Test1.vmdk -rawdisk /dev/sdb
|
||||
RAW host disk access VMDK file /vms/Test1/Test1.vmdk created successfully.
|
||||
```
|
||||
|
||||
然后,我使用 VirtualBox 管理器 “<ruby>文件<rt>File</rt></ruby> => <ruby>虚拟介质管理器<rt>Virtual Media Manager</rt></ruby>” 对话框将 vmdk 磁盘添加到可用硬盘中。我点击了“<ruby>添加<rt>Add</rt></ruby>”,文件管理对话框中显示了默认的 `/vms` 位置。我选择了 `Test1` 目录,然后选择了 `Test1.vmdk` 文件。然后我点击“<ruby>打开<rt>Open</rt></ruby>”,`Test1.vmdk` 文件就显示在可用硬盘列表中。我选择了它,然后点击“<ruby>关闭<rt>Close</rt></ruby>”。
|
||||
|
||||
下一步就是将这个 vmdk 磁盘添加到我们的虚拟机的存储设备中。在 “Test1 VM” 的设置菜单中,我选择了 “<ruby>存储<rt>Storage</rt></ruby>”,并点击了添加硬盘的图标。这时打开了一个对话框,在一个名为“<ruby>未连接<rt>Not attached</rt></ruby>”的列表中显示了 `Test1vmdk` 虚拟磁盘文件。我选择了这个文件,并点击了“<ruby>选择<rt>Choose</rt></ruby>”按钮。这个设备现在显示在连接到 “Test1 VM” 的存储设备列表中。这个虚拟机上唯一的其他存储设备是一个空的 CD/DVD-ROM 驱动器。
|
||||
|
||||
我点击了“<ruby>确定<rt>OK</rt></ruby>”,完成了将此设备添加到虚拟机中。
|
||||
|
||||
在新的虚拟机工作之前,还有一个项目需要配置。使用 VirtualBox 管理器设置对话框中的 “Test1 VM”,我导航到 “<ruby>系统<rt>System</rt></ruby> => <ruby>主板<rt>Motherboard</rt></ruby>”页面,并在 “<ruby>启用 EFI<rt>Enable EFI</rt></ruby>”的方框中打上勾。如果你不这样做,当你试图启动这个虚拟机时,VirtualBox 会产生一个错误,说明它无法找到一个可启动的介质。
|
||||
|
||||
现在,虚拟机从原始的 Windows 10 硬盘驱动器启动。然而,我无法登录,因为我在这个系统上没有一个常规账户,而且我也无法获得 Windows 管理员账户的密码。
|
||||
|
||||
### 解锁驱动器
|
||||
|
||||
不,本节并不是要破解硬盘的加密,而是要绕过众多 Windows 管理员账户之一的密码,而这些账户是不属于组织中某个人的。
|
||||
|
||||
尽管我可以启动 Windows 虚拟机,但我无法登录,因为我在该主机上没有账户,而向人们索要密码是一种可怕的安全漏洞。尽管如此,我还是需要登录这个虚拟机来安装 “VirtualBox Guest Additions”,它可以提供鼠标指针的无缝捕捉和释放,允许我将虚拟机调整到大于 1024x768 的大小,并在未来进行正常的维护。
|
||||
|
||||
这是一个完美的用例,Linux 的功能就是更改用户密码。尽管我是访问之前的管理员的账户来启动,但在这种情况下,他不再支持这个系统,我也无法辨别他的密码或他用来生成密码的模式。我就直接清除了上一个系统管理员的密码。
|
||||
|
||||
有一个非常不错的开源软件工具,专门用于这个任务。在 Linux 主机上,我安装了 `chntpw`,它的意思大概是:“更改 NT 的密码”。
|
||||
|
||||
```
|
||||
# dnf -y install chntpw
|
||||
```
|
||||
|
||||
我关闭了虚拟机的电源,然后将 `/dev/sdb3` 分区挂载到 `/mnt` 上。我确定 `/dev/sdb3` 是正确的分区,因为它是我在之前执行 `lshw` 命令的输出中看到的第一个大的 NTFS 分区。一定不要在虚拟机运行时挂载该分区,那样会导致虚拟机存储设备上的数据严重损坏。请注意,在其他主机上分区可能有所不同。
|
||||
|
||||
导航到 `/mnt/Windows/System32/config` 目录。如果当前工作目录(PWD)不在这里,`chntpw` 实用程序就无法工作。请启动该程序。
|
||||
|
||||
```
|
||||
# chntpw -i SAM
|
||||
chntpw version 1.00 140201, (c) Petter N Hagen
|
||||
Hive <SAM> name (from header): <\SystemRoot\System32\Config\SAM>
|
||||
ROOT KEY at offset: 0x001020 * Subkey indexing type is: 686c <lh>
|
||||
File size 131072 [20000] bytes, containing 11 pages (+ 1 headerpage)
|
||||
Used for data: 367/44720 blocks/bytes, unused: 14/24560 blocks/bytes.
|
||||
|
||||
<>========<> chntpw Main Interactive Menu <>========<>
|
||||
|
||||
Loaded hives: <SAM>
|
||||
|
||||
1 - Edit user data and passwords
|
||||
2 - List groups
|
||||
- - -
|
||||
9 - Registry editor, now with full write support!
|
||||
q - Quit (you will be asked if there is something to save)
|
||||
|
||||
|
||||
What to do? [1] ->
|
||||
```
|
||||
|
||||
`chntpw` 命令使用 TUI(文本用户界面),它提供了一套菜单选项。当选择其中一个主要菜单项时,通常会显示一个次要菜单。按照明确的菜单名称,我首先选择了菜单项 `1`。
|
||||
|
||||
```
|
||||
What to do? [1] -> 1
|
||||
|
||||
===== chntpw Edit User Info & Passwords ====
|
||||
|
||||
| RID -|---------- Username ------------| Admin? |- Lock? --|
|
||||
| 01f4 | Administrator | ADMIN | dis/lock |
|
||||
| 03eb | john | ADMIN | dis/lock |
|
||||
| 01f7 | DefaultAccount | | dis/lock |
|
||||
| 01f5 | Guest | | dis/lock |
|
||||
| 01f8 | WDAGUtilityAccount | | dis/lock |
|
||||
|
||||
Please enter user number (RID) or 0 to exit: [3e9]
|
||||
```
|
||||
|
||||
接下来,我选择了我们的管理账户 `john`,在提示下输入 RID。这将显示用户的信息,并提供额外的菜单项来管理账户。
|
||||
|
||||
```
|
||||
Please enter user number (RID) or 0 to exit: [3e9] 03eb
|
||||
================= USER EDIT ====================
|
||||
|
||||
RID : 1003 [03eb]
|
||||
Username: john
|
||||
fullname:
|
||||
comment :
|
||||
homedir :
|
||||
|
||||
00000221 = Users (which has 4 members)
|
||||
00000220 = Administrators (which has 5 members)
|
||||
|
||||
Account bits: 0x0214 =
|
||||
[ ] Disabled | [ ] Homedir req. | [ ] Passwd not req. |
|
||||
[ ] Temp. duplicate | [X] Normal account | [ ] NMS account |
|
||||
[ ] Domain trust ac | [ ] Wks trust act. | [ ] Srv trust act |
|
||||
[X] Pwd don't expir | [ ] Auto lockout | [ ] (unknown 0x08) |
|
||||
[ ] (unknown 0x10) | [ ] (unknown 0x20) | [ ] (unknown 0x40) |
|
||||
|
||||
Failed login count: 0, while max tries is: 0
|
||||
Total login count: 47
|
||||
|
||||
- - - - User Edit Menu:
|
||||
1 - Clear (blank) user password
|
||||
2 - Unlock and enable user account [probably locked now]
|
||||
3 - Promote user (make user an administrator)
|
||||
4 - Add user to a group
|
||||
5 - Remove user from a group
|
||||
q - Quit editing user, back to user select
|
||||
Select: [q] > 2
|
||||
```
|
||||
|
||||
这时,我选择了菜单项 `2`,“<ruby>解锁并启用用户账户<rt>Unlock and enable user account</rt></ruby>”,这样就可以删除密码,使我可以不用密码登录。顺便说一下 —— 这就是自动登录。然后我退出了该程序。在继续之前,一定要先卸载 `/mnt`。
|
||||
|
||||
我知道,我知道,但为什么不呢! 我已经绕过了这个硬盘和主机的安全问题,所以一点也不重要。这时,我确实登录了旧的管理账户,并为自己创建了一个新的账户,并设置了安全密码。然后,我以自己的身份登录,并删除了旧的管理账户,这样别人就无法使用了。
|
||||
|
||||
网上也有 Windows Administrator 账号的使用说明(上面列表中的 `01f4`)。如果它不是作为组织管理账户,我可以删除或更改该账户的密码。还要注意的是,这个过程也可以从目标主机上运行临场 USB 来执行。
|
||||
|
||||
### 重新激活 Windows
|
||||
|
||||
因此,我现在让 Windows SSD 作为虚拟机在我的 Fedora 主机上运行了。然而,令人沮丧的是,在运行了几个小时后,Windows 显示了一条警告信息,表明我需要“激活 Windows”。
|
||||
|
||||
在看了许许多多的死胡同网页之后,我终于放弃了使用现有激活码重新激活的尝试,因为它似乎已经以某种方式被破坏了。最后,当我试图进入其中一个在线虚拟支持聊天会话时,虚拟的“获取帮助”应用程序显示我的 Windows 10 Pro 实例已经被激活。这怎么可能呢?它一直希望我激活它,然而当我尝试时,它说它已经被激活了。
|
||||
|
||||
### 或者不
|
||||
|
||||
当我在三天内花了好几个小时做研究和实验时,我决定回到原来的 SSD 启动到 Windows 中,以后再来处理这个问题。但后来 Windows —— 即使从原存储设备启动,也要求重新激活。
|
||||
|
||||
在微软支持网站上搜索也无济于事。在不得不与之前一样的自动支持大费周章之后,我拨打了提供的电话号码,却被自动响应系统告知,所有对 Windows 10 Pro 的支持都只能通过互联网提供。到现在,我已经晚了将近一天才让电脑运行起来并安装回办公室。
|
||||
|
||||
### 回到未来
|
||||
|
||||
我终于吸了一口气,购买了一份 Windows 10 Home,大约 120 美元,并创建了一个带有虚拟存储设备的虚拟机,将其安装在上面。
|
||||
|
||||
我将大量的文档和电子表格文件复制到办公室经理的主目录中。我重新安装了一个我们需要的 Windows 程序,并与办公室经理验证了它可以工作,数据都在那里。
|
||||
|
||||
### 总结
|
||||
|
||||
因此,我的目标达到了,实际上晚了一天,花了 120 美元,但使用了一种更标准的方法。我仍在对权限进行一些调整,并恢复 Thunderbird 通讯录;我有一些 CSV 备份,但 `*.mab` 文件在 Windows 驱动器上包含的信息很少。我甚至用 Linux 的 `find` 命令来定位原始存储设备上的所有。
|
||||
|
||||
我走了很多弯路,每次都要自己重新开始。我遇到了一些与这个项目没有直接关系的问题,但却影响了我的工作。这些问题包括一些有趣的事情,比如把 Windows 分区挂载到我的 Linux 机器的 `/mnt` 上,得到的信息是该分区已经被 Windows 不正确地关闭(是的,在我的 Linux 主机上),并且它已经修复了不一致的地方。即使是 Windows 通过其所谓的“恢复”模式多次重启后也做不到这一点。
|
||||
|
||||
也许你从 `chntpw` 工具的输出数据中发现了一些线索。出于安全考虑,我删掉了主机上显示的其他一些用户账号,但我从这些信息中看到,所有的用户都是管理员。不用说,我也改了。我仍然对我遇到的糟糕的管理方式感到惊讶,但我想我不应该这样。
|
||||
|
||||
最后,我被迫购买了一个许可证,但这个许可证至少比原来的要便宜一些。我知道的一点是,一旦我找到了所有必要的信息,Linux 这一块就能完美地工作。问题是处理 Windows 激活的问题。你们中的一些人可能已经成功地让 Windows 重新激活了。如果是这样,我还是想知道你们是怎么做到的,所以请把你们的经验添加到评论中。
|
||||
|
||||
这是我不喜欢 Windows,只在自己的系统上使用 Linux 的又一个原因。这也是我将组织中所有的计算机都转换为 Linux 的原因之一。只是需要时间和说服力。我们只剩下这一个会计程序了,我需要和财务主管一起找到一个适合她的程序。我明白这一点 —— 我喜欢自己的工具,我需要它们以一种最适合我的方式工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/1/virtualbox-windows-linux
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
|
||||
[2]: https://opensource.com/article/20/7/godbledger
|
||||
[3]: https://opensource.com/sites/default/files/virtualbox.png
|
||||
@ -0,0 +1,243 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13181-1.html)
|
||||
[#]: subject: (5 Tweaks to Customize the Look of Your Linux Terminal)
|
||||
[#]: via: (https://itsfoss.com/customize-linux-terminal/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
定制你的 Linux 终端外观的 5 项调整
|
||||
======
|
||||
|
||||

|
||||
|
||||
终端仿真器(或简称终端)是任何 Linux 发行版中不可或缺的一部分。
|
||||
|
||||
当你改变发行版的主题时,往往终端也会自动得到改造。但这并不意味着你不能进一步定制终端。
|
||||
|
||||
事实上,很多读者都问过我们,为什么我们截图或视频中的终端看起来那么酷,我们用的是什么字体等等。
|
||||
|
||||
为了回答这个经常被问到的问题,我将向你展示一些简单或复杂的调整来改变终端的外观。你可以在下图中对比一下视觉上的差异:
|
||||
|
||||
![][1]
|
||||
|
||||
### 自定义 Linux 终端
|
||||
|
||||
本教程利用 Pop!_OS 上的 GNOME 终端来定制和调整终端的外观。但是,大多数建议也应该适用于其他终端。
|
||||
|
||||
对于大多数元素,如颜色、透明度和字体,你可以利用 GUI 来调整它,而不需要输入任何特殊的命令。
|
||||
|
||||
打开你的终端。在右上角寻找汉堡菜单。在这里,点击 “偏好设置”,如下图所示:
|
||||
|
||||
![][2]
|
||||
|
||||
在这里你可以找到改变终端外观的所有设置。
|
||||
|
||||
#### 技巧 0:使用独立的终端配置文件进行定制
|
||||
|
||||
我建议你建立一个新的配置文件用于你的定制。为什么要这样做?因为这样一来,你的改变就不会影响到终端的主配置文件。假设你做了一些奇怪的改变,却想不起默认值?配置文件有助于分离你的定制。
|
||||
|
||||
如你所见,我有个单独的配置文件,用于截图和制作视频。
|
||||
|
||||
![终端配置文件][3]
|
||||
|
||||
你可以轻松地更改终端配置文件,并使用新的配置文件打开一个新的终端窗口。
|
||||
|
||||
![更改终端配置文件][4]
|
||||
|
||||
这就是我想首先提出的建议。现在,让我们看看这些调整。
|
||||
|
||||
#### 技巧 1:使用深色/浅色终端主题
|
||||
|
||||
你可以改变系统主题,终端主题也会随之改变。除此之外,如果你不想改变系统主题。你也可以切换终端的深色主题或浅色主题,
|
||||
|
||||
一旦你进入“偏好设置”,你会注意到在“常规”选项中可以改变主题和其他设置。
|
||||
|
||||
![][5]
|
||||
|
||||
#### 技巧 2:改变字体和大小
|
||||
|
||||
选择你要自定义的配置文件。现在你可以选择自定义文本外观、字体大小、字体样式、间距、光标形状,还可以切换终端铃声。
|
||||
|
||||
对于字体,你只能改成你系统上可用的字体。如果你想要不同的字体,请先在你的 Linux 系统上下载并安装字体。
|
||||
|
||||
还有一点! 要使用等宽字体,否则字体可能会重叠,文字可能无法清晰阅读。如果你想要一些建议,可以选择 [Share Tech Mono][6](开源)或 [Larabiefont][7](不开源)。
|
||||
|
||||
在“文本”选项卡下,选择“自定义字体”,然后更改字体及其大小(如果需要)。
|
||||
|
||||
![][8]
|
||||
|
||||
#### 技巧 3:改变调色板和透明度
|
||||
|
||||
除了文字和间距,你还可以进入“颜色”选项,改变终端的文字和背景的颜色。你还可以调整透明度,让它看起来更酷。
|
||||
|
||||
正如你所注意到的那样,你可以从一组预先配置的选项中选择调色板,也可以自己调整。
|
||||
|
||||
![][9]
|
||||
|
||||
如果你想和我一样启用透明,点击“使用透明背景”选项。
|
||||
|
||||
如果你想要和你的系统主题类似的颜色设置,你也可以选择使用系统主题的颜色。
|
||||
|
||||
![][10]
|
||||
|
||||
#### 技巧 4:调整 bash 提示符变量
|
||||
|
||||
通常当你启动终端时,无需任何修改你就会看到你的用户名和主机名(你的发行版名称)作为 bash 提示符。
|
||||
|
||||
例如,在我的例子中,它会是 “ankushdas@pop-os:~$”。然而,我把 [主机名永久地改成了][11] “itsfoss”,所以现在看起来像这样:
|
||||
|
||||
![][12]
|
||||
|
||||
要改变主机名,你可以键入:
|
||||
|
||||
```
|
||||
hostname 定制名称
|
||||
```
|
||||
|
||||
然而,这只适用于当前会话。因此,当你重新启动时,它将恢复到默认值。要永久地更改主机名,你需要输入:
|
||||
|
||||
```
|
||||
sudo hostnamectl set-hostname 定制名称
|
||||
```
|
||||
|
||||
同样,你也可以改变你的用户名,但它需要一些额外的配置,包括杀死所有与活动用户名相关联的当前进程,所以我们会跳过用它来改变终端的外观/感觉。
|
||||
|
||||
#### 技巧 5:不推荐:改变 bash 提示符的字体和颜色(面向高级用户)
|
||||
|
||||
然而,你可以使用命令调整 bash 提示符的字体和颜色。
|
||||
|
||||
你需要利用 `PS1` 环境变量来控制提示符的显示内容。你可以在 [手册页][14] 中了解更多关于它的信息。
|
||||
|
||||
例如,当你键入:
|
||||
|
||||
```
|
||||
echo $PS1
|
||||
```
|
||||
|
||||
在我这里输出:
|
||||
|
||||
```
|
||||
\[\e]0;\u@\h: \w\a\]${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$
|
||||
```
|
||||
|
||||
我们需要关注的是该输出的第一部分:
|
||||
|
||||
```
|
||||
\[\e]0;\u@\h: \w\a\]$
|
||||
```
|
||||
|
||||
在这里,你需要知道以下几点:
|
||||
|
||||
* `\e` 是一个特殊的字符,表示一个颜色序列的开始。
|
||||
* `\u` 表示用户名,后面可以跟着 `@` 符号。
|
||||
* `\h` 表示系统的主机名。
|
||||
* `\w` 表示基本目录。
|
||||
* `\a` 表示活动目录。
|
||||
* `$` 表示非 root 用户。
|
||||
|
||||
在你的情况下输出可能不一样,但变量是一样的,所以你需要根据你的输出来试验下面提到的命令。
|
||||
|
||||
在你这样做之前,请记住这些:
|
||||
|
||||
* 文本格式代码:`0` 代表正常文本,`1` 代表粗体,`3` 代表斜体,`4` 代表下划线文本。
|
||||
* 背景色的颜色范围:`40` - `47`。
|
||||
* 文本颜色的颜色范围:`30` - `37`。
|
||||
|
||||
你只需要键入以下内容来改变颜色和字体:
|
||||
|
||||
```
|
||||
PS1="\e[41;3;32m[\u@\h:\w\a\$]"
|
||||
```
|
||||
|
||||
这是输入该命令后 bash 提示符的样子:
|
||||
|
||||
![][15]
|
||||
|
||||
如果你注意到这个命令,就像上面提到的,`\e` 可以帮助我们分配一个颜色序列。
|
||||
|
||||
在上面的命令中,我先分配了一个**背景色**,然后是**文字样式**,接着是**字体颜色**,然后是 `m`。这里,`m` 表示颜色序列的结束。
|
||||
|
||||
所以,你要做的就是,调整这部分:
|
||||
|
||||
```
|
||||
41;3;32
|
||||
```
|
||||
|
||||
命令其余部分应该是不变的,你只需要分配不同的数字来改变背景色、文字样式和文字颜色。
|
||||
|
||||
要注意的是,这并没有特定的顺序,你可以先指定文字样式,再指定背景色,最后指定文字颜色,如 `3;41;32`,这里的命令就变成了:
|
||||
|
||||
```
|
||||
PS1="\e[3;41;32m[\u@\h:\w\a\$]"
|
||||
```
|
||||
|
||||
![][16]
|
||||
|
||||
正如你所注意到的,无论顺序如何,颜色的定制都是一样的。所以,只要记住自定义的代码,并在你确定你想把它作为一个永久的变化之前,试试它。
|
||||
|
||||
上面我提到的命令会临时定制当前会话的 bash 提示符。如果你关闭了会话,你将失去这个自定义设置。
|
||||
|
||||
所以,要想把它变成一个永久的改变,你需要把它添加到 `.bashrc` 文件中(这是一个配置文件,每次加载会话时都会加载)。
|
||||
|
||||
![][17]
|
||||
|
||||
简单键入如下命令来访问该文件:
|
||||
|
||||
```
|
||||
nano ~/.bashrc
|
||||
```
|
||||
|
||||
除非你明确知道你在做什么,否则不要改变任何东西。而且,为了可以恢复设置,你应该把 `PS1` 环境变量的备份(默认情况下复制粘贴其中的内容)保存到一个文本文件中。
|
||||
|
||||
所以,即使你需要默认的字体和颜色,你也可以再次编辑 `.bashrc` 文件并粘贴 `PS1` 环境变量。
|
||||
|
||||
#### 附赠技巧:根据你的墙纸改变终端的调色板
|
||||
|
||||
如果你想改变终端的背景和文字颜色,但又不知道该选哪种颜色,你可以使用一个基于 Python 的工具 Pywal,它可以 [根据你的壁纸][18] 或你提供的图片自动改变终端的颜色。
|
||||
|
||||
![][19]
|
||||
|
||||
如果你有兴趣使用这个工具,我之前已经详细[介绍][18]过了。
|
||||
|
||||
### 总结
|
||||
|
||||
当然,使用 GUI 定制很容易,同时也可以更好地控制你可以改变的东西。但是,需要知道命令也是必要的,万一你开始 [使用 WSL][21] 或者使用 SSH 访问远程服务器,无论如何都可以定制你的体验。
|
||||
|
||||
你是如何定制 Linux 终端的?在评论中与我们分享你的秘方。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/customize-linux-terminal/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/default-terminal.jpg?resize=773%2C493&ssl=1
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/linux-terminal-preferences.jpg?resize=800%2C350&ssl=1
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/terminal-profiles.jpg?resize=800%2C619&ssl=1
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/change-terminal-profile.jpg?resize=796%2C347&ssl=1
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/terminal-theme.jpg?resize=800%2C363&ssl=1
|
||||
[6]: https://fonts.google.com/specimen/Share+Tech+Mono
|
||||
[7]: https://www.dafont.com/larabie-font.font
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/terminal-customization-1.jpg?resize=800%2C500&ssl=1
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/terminal-color-customization.jpg?resize=759%2C607&ssl=1
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/linux-terminal.jpg?resize=800%2C571&ssl=1
|
||||
[11]: https://itsfoss.com/change-hostname-ubuntu/
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/01/itsfoss-hostname.jpg?resize=800%2C188&ssl=1
|
||||
[13]: https://itsfoss.com/cdn-cgi/l/email-protection
|
||||
[14]: https://linux.die.net/man/1/bash
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/terminal-bash-prompt-customization.jpg?resize=800%2C190&ssl=1
|
||||
[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/01/linux-terminal-customization-1s.jpg?resize=800%2C158&ssl=1
|
||||
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/01/bashrch-customization-terminal.png?resize=800%2C615&ssl=1
|
||||
[18]: https://itsfoss.com/pywal/
|
||||
[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/08/wallpy-2.jpg?resize=800%2C442&ssl=1
|
||||
[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/08/pywal-linux.jpg?fit=800%2C450&ssl=1
|
||||
[21]: https://itsfoss.com/install-bash-on-windows/
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (ShuyRoy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13229-1.html)
|
||||
[#]: subject: (Get started with distributed tracing using Grafana Tempo)
|
||||
[#]: via: (https://opensource.com/article/21/2/tempo-distributed-tracing)
|
||||
[#]: author: (Annanay Agarwal https://opensource.com/users/annanayagarwal)
|
||||
|
||||
使用 Grafana Tempo 进行分布式跟踪
|
||||
======
|
||||
|
||||
> Grafana Tempo 是一个新的开源、大容量分布式跟踪后端。
|
||||
|
||||

|
||||
|
||||
Grafana 的 [Tempo][2] 是出自 Grafana 实验室的一个简单易用、大规模的、分布式的跟踪后端。Tempo 集成了 [Grafana][3]、[Prometheus][4] 以及 [Loki][5],并且它只需要对象存储进行操作,因此成本低廉,操作简单。
|
||||
|
||||
我从一开始就参与了这个开源项目,所以我将介绍一些关于 Tempo 的基础知识,并说明为什么云原生社区会注意到它。
|
||||
|
||||
### 分布式跟踪
|
||||
|
||||
想要收集对应用程序请求的遥测数据是很常见的。但是在现在的服务器中,单个应用通常被分割为多个微服务,可能运行在几个不同的节点上。
|
||||
|
||||
分布式跟踪是一种获得关于应用的性能细粒度信息的方式,该应用程序可能由离散的服务组成。当请求到达一个应用时,它提供了该请求的生命周期的统一视图。Tempo 的分布式跟踪可以用于单体应用或微服务应用,它提供 [请求范围的信息][6],使其成为可观察性的第三个支柱(另外两个是度量和日志)。
|
||||
|
||||
接下来是一个分布式跟踪系统生成应用程序甘特图的示例。它使用 Jaeger [HotROD][7] 的演示应用生成跟踪,并把它们存到 Grafana 云托管的 Tempo 上。这个图展示了按照服务和功能划分的请求处理时间。
|
||||
|
||||
![Gantt chart from Grafana Tempo][8]
|
||||
|
||||
### 减少索引的大小
|
||||
|
||||
在丰富且定义良好的数据模型中,跟踪包含大量信息。通常,跟踪后端有两种交互:使用元数据选择器(如服务名或者持续时间)筛选跟踪,以及筛选后的可视化跟踪。
|
||||
|
||||
为了加强搜索,大多数的开源分布式跟踪框架会对跟踪中的许多字段进行索引,包括服务名称、操作名称、标记和持续时间。这会导致索引很大,并迫使你使用 Elasticsearch 或者 [Cassandra][10] 这样的数据库。但是,这些很难管理,而且大规模运营成本很高,所以我在 Grafana 实验室的团队开始提出一个更好的解决方案。
|
||||
|
||||
在 Grafana 中,我们的待命调试工作流从使用指标报表开始(我们使用 [Cortex][11] 来存储我们应用中的指标,它是一个云原生基金会孵化的项目,用于扩展 Prometheus),深入研究这个问题,筛选有问题服务的日志(我们将日志存储在 Loki 中,它就像 Prometheus 一样,只不过 Loki 是存日志的),然后查看跟踪给定的请求。我们意识到,我们过滤时所需的所有索引信息都可以在 Cortex 和 Loki 中找到。但是,我们需要一个强大的集成,以通过这些工具实现跟踪的可发现性,并需要一个很赞的存储,以根据跟踪 ID 进行键值查找。
|
||||
|
||||
这就是 [Grafana Tempo][12] 项目的开始。通过专注于给定检索跟踪 ID 的跟踪,我们将 Tempo 设计为最小依赖性、大容量、低成本的分布式跟踪后端。
|
||||
|
||||
### 操作简单,性价比高
|
||||
|
||||
Tempo 使用对象存储后端,这是它唯一的依赖。它既可以被用于单一的二进制下,也可以用于微服务模式(请参考仓库中的 [例子][13],了解如何轻松上手)。使用对象存储还意味着你可以存储大量的应用程序的痕迹,而无需任何采样。这可以确保你永远不会丢弃那百万分之一的出错或具有较高延迟的请求的跟踪。
|
||||
|
||||
### 与开源工具的强大集成
|
||||
|
||||
[Grafana 7.3 包括了 Tempo 数据源][14],这意味着你可以在 Grafana UI 中可视化来自Tempo 的跟踪。而且,[Loki 2.0 的新查询特性][15] 使得 Tempo 中的跟踪更简单。为了与 Prometheus 集成,该团队正在添加对<ruby>范例<rt>exemplar</rt></ruby>的支持,范例是可以添加到时间序列数据中的高基数元数据信息。度量存储后端不会对它们建立索引,但是你可以在 Grafana UI 中检索和显示度量值。尽管范例可以存储各种元数据,但是在这个用例中,存储跟踪 ID 是为了与 Tempo 紧密集成。
|
||||
|
||||
这个例子展示了使用带有请求延迟直方图的范例,其中每个范例数据点都链接到 Tempo 中的一个跟踪。
|
||||
|
||||
![Using exemplars in Tempo][16]
|
||||
|
||||
### 元数据一致性
|
||||
|
||||
作为容器化应用程序运行的应用发出的遥测数据通常具有一些相关的元数据。这可以包括集群 ID、命名空间、吊舱 IP 等。这对于提供基于需求的信息是好的,但如果你能将元数据中包含的信息用于生产性的东西,那就更好了。
|
||||
|
||||
例如,你可以使用 [Grafana 云代理将跟踪信息导入 Tempo 中][17],代理利用 Prometheus 服务发现机制轮询 Kubernetes API 以获取元数据信息,并且将这些标记添加到应用程序发出的跨域数据中。由于这些元数据也在 Loki 中也建立了索引,所以通过元数据转换为 Loki 标签选择器,可以很容易地从跟踪跳转到查看给定服务的日志。
|
||||
|
||||
下面是一个一致元数据的示例,它可用于Tempo跟踪中查看给定范围的日志。
|
||||
|
||||
![][18]
|
||||
|
||||
### 云原生
|
||||
|
||||
Grafana Tempo 可以作为容器化应用,你可以在如 Kubernetes、Mesos 等编排引擎上运行它。根据获取/查询路径上的工作负载,各种服务可以水平伸缩。你还可以使用云原生的对象存储,如谷歌云存储、Amazon S3 或者 Tempo Azure 博客存储。更多的信息,请阅读 Tempo 文档中的 [架构部分][19]。
|
||||
|
||||
### 试一试 Tempo
|
||||
|
||||
如果这对你和我们一样有用,可以 [克隆 Tempo 仓库][20]试一试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/tempo-distributed-tracing
|
||||
|
||||
作者:[Annanay Agarwal][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[RiaXu](https://github.com/ShuyRoy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/annanayagarwal
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_space_graphic_cosmic.png?itok=wu493YbB (Computer laptop in space)
|
||||
[2]: https://grafana.com/oss/tempo/
|
||||
[3]: http://grafana.com/oss/grafana
|
||||
[4]: https://prometheus.io/
|
||||
[5]: https://grafana.com/oss/loki/
|
||||
[6]: https://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
|
||||
[7]: https://github.com/jaegertracing/jaeger/tree/master/examples/hotrod
|
||||
[8]: https://opensource.com/sites/default/files/uploads/tempo_gantt.png (Gantt chart from Grafana Tempo)
|
||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[10]: https://opensource.com/article/19/8/how-set-apache-cassandra-cluster
|
||||
[11]: https://cortexmetrics.io/
|
||||
[12]: http://github.com/grafana/tempo
|
||||
[13]: https://grafana.com/docs/tempo/latest/getting-started/example-demo-app/
|
||||
[14]: https://grafana.com/blog/2020/10/29/grafana-7.3-released-support-for-the-grafana-tempo-tracing-system-new-color-palettes-live-updates-for-dashboard-viewers-and-more/
|
||||
[15]: https://grafana.com/blog/2020/11/09/trace-discovery-in-grafana-tempo-using-prometheus-exemplars-loki-2.0-queries-and-more/
|
||||
[16]: https://opensource.com/sites/default/files/uploads/tempo_exemplar.png (Using exemplars in Tempo)
|
||||
[17]: https://grafana.com/blog/2020/11/17/tracing-with-the-grafana-cloud-agent-and-grafana-tempo/
|
||||
[18]: https://lh5.googleusercontent.com/vNqk-ygBOLjKJnCbTbf2P5iyU5Wjv2joR7W-oD7myaP73Mx0KArBI2CTrEDVi04GQHXAXecTUXdkMqKRq8icnXFJ7yWUEpaswB1AOU4wfUuADpRV8pttVtXvTpVVv8_OfnDINgfN
|
||||
[19]: https://grafana.com/docs/tempo/latest/architecture/architecture/
|
||||
[20]: https://github.com/grafana/tempo
|
||||
144
published/202103/20210216 How to install Linux in 3 steps.md
Normal file
144
published/202103/20210216 How to install Linux in 3 steps.md
Normal file
@ -0,0 +1,144 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13164-1.html)
|
||||
[#]: subject: (How to install Linux in 3 steps)
|
||||
[#]: via: (https://opensource.com/article/21/2/linux-installation)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
安装 Linux,只需三步
|
||||
======
|
||||
|
||||
> 操作系统的安装看似神秘,但其实很简单。以下是成功安装 Linux 的步骤。
|
||||
|
||||

|
||||
|
||||
在 2021 年,有更多让人们喜欢 Linux 的理由。在这个系列中,我将分享 21 种使用 Linux 的不同理由。下面是如何安装 Linux。
|
||||
|
||||
安装一个操作系统(OS)总是令人生畏。对大多数人来说,这是一个难题。安装操作系统不能从操作系统内部进行,因为它要么没有被安装,要么即将被另一个操作系统取代,那么它是如何发生的呢?更糟糕的是,它通常会涉及到硬盘格式、安装位置、时区、用户名、密码等一系列你通常不会想到的混乱问题。Linux 发行版知道这一点,所以它们多年来一直在努力将你在操作系统安装程序中花费的时间减少到最低限度。
|
||||
|
||||
### 安装时发生了什么
|
||||
|
||||
无论你安装的是一个应用程序还是整个操作系统,*安装*的过程只是将文件从一种媒介复制到另一种媒介的一种花哨方式。不管是什么用户界面,还是用动画将安装过程伪装成多么高度专业化的东西,最终都是一回事:曾经存储在光盘或驱动器上的文件被复制到硬盘上的特定位置。
|
||||
|
||||
当安装的是一个应用程序时,放置这些文件的有效位置被高度限制在你的*文件系统*或你的操作系统知道它可以使用的硬盘驱动器的部分。这一点很重要,因为它可以将硬盘分割成不同的空间(苹果公司在本世纪初的 Bootcamp 中使用了这一技巧,允许用户将 macOS 和 Windows 安装到一个硬盘上,但作为单独的实体)。当你安装一个操作系统时,一些特殊的文件会被安装到硬盘上通常是禁区的地方。更重要的是,至少在默认情况下,你的硬盘上的所有现有数据都会被擦除,以便为新系统腾出空间,所以创建一个备份是*必要的*。
|
||||
|
||||
### 安装程序
|
||||
|
||||
从技术上讲,你实际上不需要用安装程序来安装应用程序甚至操作系统。不管你信不信,有些人通过挂载一块空白硬盘、编译代码并复制文件来手动安装 Linux。这是在一个名为 [Linux From Scratch(LFS)][2] 的项目的帮助下完成的。这个项目旨在帮助爱好者、学生和未来的操作系统设计者更多地了解计算机的工作原理以及每个组件执行的功能。这并不是安装 Linux 的推荐方法,但你会发现,在开源中,通常是这样的:*如果*有些事情可以做,那么就有人在做。而这也是一件好事,因为这些小众的兴趣往往会带来令人惊讶的有用的创新。
|
||||
|
||||
假设你不是想对 Linux 进行逆向工程,那么正常的安装方式是使用安装光盘或镜像。
|
||||
|
||||
### 3 个简单的步骤来安装 Linux
|
||||
|
||||
当你从一个 Linux 安装 DVD 或 U 盘启动时,你会置身于一个最小化的操作环境中,这个环境是为了运行一个或多个有用的应用程序。安装程序是最主要的应用程序,但由于 Linux 是一个如此灵活的系统,你通常也可以运行标准的桌面应用程序,以在你决定安装它之前感受一下这个操作系统是什么样子的。
|
||||
|
||||
不同的 Linux 发行版有不同的安装程序界面。下面是两个例子。
|
||||
|
||||
Fedora Linux 有一个灵活的安装程序(称为 Anaconda),能够进行复杂的系统配置:
|
||||
|
||||
![Fedora 上的 Anaconda 安装界面][3]
|
||||
|
||||
*Fedora 上的 Anaconda 安装程序*
|
||||
|
||||
Elementary OS 有一个简单的安装程序,主要是为了在个人电脑上安装而设计的:
|
||||
|
||||
![Elementary OS 安装程序][4]
|
||||
|
||||
*Elementary OS 安装程序*
|
||||
|
||||
#### 1、获取安装程序
|
||||
|
||||
安装 Linux 的第一步是下载一个安装程序。你可以从你选择尝试的发行版中获得一个 Linux 安装镜像。
|
||||
|
||||
* [Fedora][5] 以率先更新软件而闻名。
|
||||
* [Linux Mint][6] 提供了安装缺失驱动程序的简易选项。
|
||||
* [Elementary][7] 提供了一个美丽的桌面体验和几个特殊的、定制的应用程序。
|
||||
|
||||
Linux 安装程序是 `.iso` 文件,是 DVD 介质的“蓝图”。如果你还在使用光学介质,你可以把 `.iso` 文件刻录到 DVD-R 上,或者你可以把它烧录到 U 盘上(确保它是一个空的 U 盘,因为当镜像被烧录到它上时,它的所有内容都会被删除)。要将镜像烧录到 U 盘上,你可以 [使用开源的 Etcher 应用程序][8]。
|
||||
|
||||
![Etcher 用于烧录 U 盘][9]
|
||||
|
||||
*Etcher 应用程序可以烧录 U 盘。*
|
||||
|
||||
现在你可以安装 Linux 了。
|
||||
|
||||
#### 2、引导顺序
|
||||
|
||||
要在电脑上安装操作系统,你必须引导到操作系统安装程序。这对于一台电脑来说并不是常见的行为,因为很少有人这样做。理论上,你只需要安装一次操作系统,然后你就会不断更新它。当你选择在电脑上安装不同的操作系统时,你就中断了这个正常的生命周期。这不是一件坏事。这是你的电脑,所以你有权力对它进行重新规划。然而,这与电脑的默认行为不同,它的默认行为是开机后立即启动到硬盘上找到的任何操作系统。
|
||||
|
||||
在安装 Linux 之前,你必须备份你在目标计算机上的任何数据,因为这些数据在安装时都会被清除。
|
||||
|
||||
假设你已经将数据保存到了一个外部硬盘上,然后你将它秘密地存放在安全的地方(而不是连接到你的电脑上),那么你就可以继续了。
|
||||
|
||||
首先,将装有 Linux 安装程序的 U 盘连接到电脑上。打开电脑电源,观察屏幕上是否有一些如何中断其默认启动序列的指示。这通常是像 `F2`、`F8`、`Esc` 甚至 `Del` 这样的键,但根据你的主板制造商不同而不同。如果你错过了这个时间窗口,只需等待默认操作系统加载,然后重新启动并再次尝试。
|
||||
|
||||
当你中断启动序列时,电脑会提示你引导指令。具体来说,嵌入主板的固件需要知道该到哪个驱动器寻找可以加载的操作系统。在这种情况下,你希望计算机从包含 Linux 镜像的 U 盘启动。如何提示你这些信息取决于主板制造商。有时,它会直接问你,并配有一个菜单:
|
||||
|
||||
![引导设备菜单][10]
|
||||
|
||||
*启动设备选择菜单*
|
||||
|
||||
其他时候,你会被带入一个简陋的界面,你可以用来设置启动顺序。计算机通常默认设置为先查看内部硬盘。如果引导失败,它就会移动到 U 盘、网络驱动器或光驱。你需要告诉你的计算机先寻找一个 U 盘,这样它就会绕过自己的内部硬盘驱动器,而引导 U 盘上的 Linux 镜像。
|
||||
|
||||
![BIOS 选择屏幕][11]
|
||||
|
||||
*BIOS 选择屏幕*
|
||||
|
||||
起初,这可能会让人望而生畏,但一旦你熟悉了界面,这就是一个快速而简单的任务。一旦安装了Linux,你就不必这样做了,因为,在这之后,你会希望你的电脑再次从内部硬盘启动。这是一个很好的技巧,因为在 U 盘上使用 Linux 的关键原因,是在安装前测试计算机的 Linux 兼容性,以及无论涉及什么操作系统的一般性故障排除。
|
||||
|
||||
一旦你选择了你的 U 盘作为引导设备,保存你的设置,让电脑复位,然后启动到 Linux 镜像。
|
||||
|
||||
#### 3、安装 Linux
|
||||
|
||||
一旦你启动进入 Linux 安装程序,就只需通过提示进行操作。
|
||||
|
||||
Fedora 安装程序 Anaconda 为你提供了一个“菜单”,上面有你在安装前可以自定义的所有事项。大多数设置为合理的默认值,可能不需要你的互动,但有些则用警示符号标记,表示不能安全地猜测出你的配置,因此需要设置。这些配置包括你想安装操作系统的硬盘位置,以及你想为账户使用的用户名。在你解决这些问题之前,你不能继续进行安装。
|
||||
|
||||
对于硬盘的位置,你必须知道你要擦除哪个硬盘,然后用你选择的 Linux 发行版重新写入。对于只有一个硬盘的笔记本来说,这可能是一个显而易见的选择。
|
||||
|
||||
![选择安装驱动器的屏幕][12]
|
||||
|
||||
*选择要安装操作系统的硬盘(本例中只有一个硬盘)。*
|
||||
|
||||
如果你的电脑里有不止一个硬盘,而你只想在其中一个硬盘上安装 Linux,或者你想把两个硬盘当作一个硬盘,那么你必须帮助安装程序了解你的目标。最简单的方法是只给 Linux 分配一个硬盘,让安装程序执行自动分区和格式化,但对于高级用户来说,还有很多其他的选择。
|
||||
|
||||
你的电脑必须至少有一个用户,所以要为自己创建一个用户账户。完成后,你可以最后点击 **Done** 按钮,安装 Linux。
|
||||
|
||||
![Anaconda 选项完成并准备安装][13]
|
||||
|
||||
*Anaconda 选项已经完成,可以安装了*
|
||||
|
||||
其他的安装程序可能会更简单,所以你看到的可能与本文中的图片不同。无论怎样,除了预装的操作系统之外,这个安装过程都是最简单的操作系统安装过程之一,所以不要让安装操作系统的想法吓到你。这是你的电脑。你可以、也应该安装一个你拥有所有权的操作系统。
|
||||
|
||||
### 拥有你的电脑
|
||||
|
||||
最终,Linux 成为了你的操作系统。它是一个由来自世界各地的人们开发的操作系统,其核心是一个:创造一种参与、共同拥有、合作管理的计算文化。如果你有兴趣更好地了解开源,那么就请你迈出一步,了解它的一个光辉典范 Linux,并安装它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/linux-installation
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bash_command_line.png?itok=k4z94W2U (bash logo on green background)
|
||||
[2]: http://www.linuxfromscratch.org
|
||||
[3]: https://opensource.com/sites/default/files/anaconda-installer.png
|
||||
[4]: https://opensource.com/sites/default/files/elementary-installer.png
|
||||
[5]: http://getfedora.org
|
||||
[6]: http://linuxmint.com
|
||||
[7]: http://elementary.io
|
||||
[8]: https://opensource.com/article/18/7/getting-started-etcherio
|
||||
[9]: https://opensource.com/sites/default/files/etcher_0.png
|
||||
[10]: https://opensource.com/sites/default/files/boot-menu.jpg
|
||||
[11]: https://opensource.com/sites/default/files/bios_1.jpg
|
||||
[12]: https://opensource.com/sites/default/files/install-harddrive-chooser.png
|
||||
[13]: https://opensource.com/sites/default/files/anaconda-done.png
|
||||
166
published/202103/20210216 What does being -technical- mean.md
Normal file
166
published/202103/20210216 What does being -technical- mean.md
Normal file
@ -0,0 +1,166 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Chao-zhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13168-1.html)
|
||||
[#]: subject: (What does being 'technical' mean?)
|
||||
[#]: via: (https://opensource.com/article/21/2/what-technical)
|
||||
[#]: author: (Dawn Parzych https://opensource.com/users/dawnparzych)
|
||||
|
||||
“技术”是什么意思?
|
||||
======
|
||||
|
||||
> 用“技术”和“非技术”的标签对人们进行分类,会伤害个人和组织。本文作为本系列的第 1 篇,将阐述这个问题。
|
||||
|
||||

|
||||
|
||||
“<ruby>技术<rt>technical</rt></ruby>”一词描述了许多项目和学科:**技术**淘汰赛、**技术性**犯规、攀岩比赛的**技术**课程和花样滑冰运动的**技术**得分。广受欢迎的烹饪节目 “_The Great British Bake-Off_” 包括一个“烘焙**技术**挑战”。任何参加过剧院演出的人都可能熟悉**技术**周,即戏剧或音乐剧首演前的一周。
|
||||
|
||||
如你所见,**技术**一词并不严格适用于软件工程和软件操作,所以当我们称一个人或一个角色为“技术”时,我们的意思是什么,为什么使用这个术语?
|
||||
|
||||
在我 20 年的技术生涯中,这些问题引起了我的兴趣,所以我决定通过一系列的采访来探讨这个问题。我不是工程师,也不写代码,但这并不意味着我是**非技术型**的。但我经常被贴上这样的标签。我认为自己是**技术型**的,通过这个系列,我希望你会明白为什么。
|
||||
|
||||
我知道我不是孤独一个人。群众讨论是很重要的,因为如何定义和看待一个人或一个角色会影响他们做好工作的信心和能力。如果他们感到被压垮或不受尊重,就会降低他们的工作质量,挤压创新和新思想。你看,这一切都是循序渐进的,那么我们怎样才能改善这种状况呢?
|
||||
|
||||
我首先采访了 7 个不同角色的人。
|
||||
|
||||
在本系列中,我将探讨“技术”一词背后的含义、技术的连续性、将人分类为技术型或非技术型的意外副作用,以及通常被认为是非技术性的技术角色。
|
||||
|
||||
### 定义技术和非技术
|
||||
|
||||
首先,我们需要做个名词解释。根据字典网,“技术/技术性的”是一个具有多重含义的形容词,包括:
|
||||
|
||||
* 属于或与艺术、科学等学科有关的
|
||||
* 精通或熟悉某一特定的艺术或行业的实际操作
|
||||
* 技术要求高或困难(通常用于体育或艺术)
|
||||
|
||||
而“非技术性”一词在科技公司中经常被用来描述非工程人员。但是“非技术性”的定义是“不涉及、不具有某个特定活动领域及其术语的特点,或不熟练”。
|
||||
|
||||
作为一个写作和谈论技术的人,我认为自己是技术型的。如果你不熟悉这个领域和术语,就不可能书写或谈论一个技术主题。有了这种理解,每个从事技术工作的人都是技术人员。
|
||||
|
||||
### 为什么要分配标签?
|
||||
|
||||
那么,为什么划分技术与非技术?这在技术领域有什么意义呢?我们试图通过分配这些标签来实现什么?有没有一个好的理由?而我们有没有重新评估这些理由?让我们讨论一下。
|
||||
|
||||
当我听到人们谈论技术人员和非技术人员时,我不禁想起 Seuss 教授写的童话故事 《[The Sneetches][2]》。Sneetches 有没有星星被演化为一种渴望。Sneetches 们进入了一个无限循环,试图达到正确的状态。
|
||||
|
||||
标签可以起到一定的作用,但当它们迫使一个群体的等级被视为比另一个更好时,它们就会变得危险。想想你的组织或部门:销售、资源、营销、质控、工程等,哪一组的在重要性上高于或低于另一组?
|
||||
|
||||
即使它不是直接说的或写在什么地方,也可能是被人们默认的。这些等级划分通常也存在于规章制度中。技术内容经理 Liz Harris 表示,“在技术写作界存在着一个技术含量的评级,你越是偏技术的文章,你得到的报酬就越高,而且往往在技术写作社区里你得到的关注就越多。”
|
||||
|
||||
术语“技术”通常用于指一个人在某一主题上的深度或专业知识水平。销售人员也有可能会要求需要懂技术以更好的帮助客户。从事技术工作的人,他们是技术型的,但是也许更专业的技术人员才能胜任这个项目。因此,请求技术支援可能是含糊不清的表述。你需要一个对产品有深入了解的人吗?你需要一位了解基础设施堆栈的人员吗?还是需要一个能写下如何配置 API 的步骤的人?
|
||||
|
||||
我们应该要把技术能力看作是一个连续体,而不是把人简单的看作技术型的或非技术型的。这是什么意思?开发人员关系主管 Mary thengwall 描述了她如何对特定角色所需的不同深度的技术知识进行分类。例如,项目可能需要一个开发人员、一个具有开发人员背景的人员,或一个精通技术的人员。就是那些被归类为精通技术的人也经常被贴上非技术的标签。
|
||||
|
||||
根据 Mary 的说法,如果“你能解释(一个技术性的)话题,你知道你的产品工作方式,你知道该说什么和不该说什么的基本知识,那么你就是技术高手。你不必有技术背景,但你需要知道高层次的技术信息,然后还要知道向谁提供更多信息。”
|
||||
|
||||
### 标签带来的问题
|
||||
|
||||
当我们使用标签来具体说明我们需要完成一项工作时,它们可能会很有帮助,比如“开发人员”、“有开发人员背景”和“技术达人”。但是当我们使用标签的范围太广时,将人们分为两组中的一组可能会产生“弱于”和“优于”的感觉
|
||||
|
||||
当一个标签成为现实时,无论是有意还是无意,我们都必须审视自己,重新评估自己的措辞、标签和意图。
|
||||
|
||||
高级产品经理 Leon Stigter 提出了他的观点:“作为一个集体行业,我们正在构建更多的技术,让每个人都更容易参与。如果我们对每个人说:‘你不是技术型的’,或者说:‘你是技术型的’,然后把他们分成几个小组,那些被贴上非技术型标签的人可能永远不会去想:‘其实我自己就能完成这个项目’,实际上,我们需要所有这些人真正思考我们行业和社区的发展方向,我认为每一个人都应该有这个主观能动性。”
|
||||
|
||||
#### 身份
|
||||
|
||||
如果我们把我们的身份贴在一个标签上,当我们认为这个标签不再适用时会发生什么?当 Adam Gordon Bell 从一个开发人员转变为一个管理人员时,他很纠结,因为他总是认为自己是技术人员,而作为一个管理人员,这些技术技能没有被使用。他觉得自己不再有价值了。编写代码并不能提供比帮助团队成员发展事业或确保项目按时交付更大的价值。所有角色都有价值,因为它们都是确保商品和服务的创建、执行和交付所必需的。
|
||||
|
||||
“我想我成为一名经理的原因是,我们有一支非常聪明的团队和很多非常有技能的人,但是我们并不总是能完成最出色的工作。所以技术不是限制因素,对吧?”Adam 说:“我想通常不是技术限制了团队的发挥”。
|
||||
|
||||
Leon Stigter 说,让人们一起合作并完成令人惊叹的工作的能力是一项很有价值的技能,不应低于技术角色的价值。
|
||||
|
||||
#### 自信
|
||||
|
||||
<ruby>[冒充者综合症][3]<rt>Impostor syndrome</rt></ruby> 是指无法认识到自己的能力和知识,从而导致信心下降,以及完成工作和做好工作的能力下降。当你申请在会议上发言,向科技刊物提交文章,或申请工作时,冒充者综合症就会发作。冒充者综合症是一种微小的声音,它说:
|
||||
|
||||
* “我技术不够胜任这个角色。”
|
||||
* “我认识更多的技术人员,他们在演讲中会做得更好。”
|
||||
* “我在市场部工作,所以我无法为这样的技术网站写文章。”
|
||||
|
||||
当你把某人或你自己贴上非技术型标签的时候,这些声音就会变得更响亮。这很容易导致在会议上听不到新的声音或失去团队中的人才。
|
||||
|
||||
#### 刻板印象
|
||||
|
||||
当你认为某人是技术人员时,你会看到什么样的印象?他们穿什么?他们还有什么特点?他们是外向健谈,还是害羞安静?
|
||||
|
||||
Shailvi Wakhlu 是一位高级数据总监,她的职业生涯始于软件工程师,并过渡到数据和分析领域。“当我是一名软件工程师的时候,很多人都认为我不太懂技术,因为我很健谈,很明显这就意味着你不懂技术。他们认为你不孤独的待在角落就是不懂技术。”她说。
|
||||
|
||||
我们对谁是技术型与非技术型的刻板印象会影响招聘决策或我们的社区是否具有包容性。你也可能冒犯别人,甚至是能够帮助你的人。几年前,我在某个展台工作,问别人我能不能帮他们。“我要找最专业的人帮忙”他回答说。然后他就出发去寻找他的问题的答案。几分钟后,摊位上的销售代表和那位先生走到我跟前说:“Dawn,你是回答这个人问题的最佳人选。”
|
||||
|
||||
#### 污名化
|
||||
|
||||
随着时间的推移,我们夸大了“技术”技能的重要性,这导致了“非技术”的标签被贬义地使用。随着技术的蓬勃发展,编程人员的价值也随之增加,因为这种技能为市场带来了新产品和新的商业方式,并直接帮助了盈利。然而,现在我们看到人们故意将技术角色凌驾于非技术角色之上,阻碍了公司的发展和成功。
|
||||
|
||||
人际交往技能通常被称为非技术技能。然而,它们有着高度的技术性,比如提供如何完成一项任务的分步指导,或者确定最合适的词语来传达信息或观点。这些技能往往也是决定你能否在工作中取得成功的更重要因素。
|
||||
|
||||
通读“<ruby>城市词典<rt>Urban Dictionary</rt></ruby>”上的文章和定义,难怪人们会觉得自己的标签有道理,而其他人会患上冒充者综合症,或者觉得自己失去了身份。在线搜索时,“城市词典”定义通常出现在搜索结果的顶部。这个网站大约 20 年前开始是一个定义俚语、文化表达和其他术语的众包词典,现在变成了一个充满敌意和负面定义的网站。
|
||||
|
||||
这里有几个例子:“城市词典”将非技术经理定义为“不知道他们管理的人应该做什么的人”
|
||||
|
||||
提供如何与“非技术”人员交谈技巧的文章包括以下短语:
|
||||
|
||||
* “如果我抗争,非技术人员究竟是如何应对的?”
|
||||
* “在当今的职业专业人士中,开发人员和工程师拥有一些最令人印象深刻的技能,这些技能是由多年的技术培训和实际经验磨练而成的。”
|
||||
|
||||
这些句子意味着非工程师是低人一等的,他们多年的训练和现实世界的经验在某种程度上没有那么令人印象深刻。对于这样的说辞,我可以举一个反例:Therese Eberhard,她的工作被许多人认为是非技术性的。她是个风景画家。她为电影和戏剧画道具和风景。她的工作是确保像甘道夫的手杖这样的道具看起来栩栩如生,而不是像塑料玩具。要想在这个角色上取得成功,需要有很多解决问题和实验化学反应的方法。Therese 在多年的实战经验中磨练了这些技能,对我来说,这相当令人印象深刻。
|
||||
|
||||
#### 守门人行为
|
||||
|
||||
使用标签会设置障碍,并导致守门人行为,这决定谁可以进入我们的组织,我们的团队,我们的社区。
|
||||
|
||||
据一位开源开发者 Eddie Jaoude 所说,“`技术’、`开发人员‘或`测试人员’的头衔在不应该出现的地方制造了障碍或权威。我们应该将重点放在谁能为团队或项目增加价值,而头衔是无关紧要的。”
|
||||
|
||||
如果我们把每个人看作一个团队成员,他们应该以这样或那样的方式贡献价值,而不是看他们是否编写文档、测试用例或代码,那么我们将根据真正重要的东西来重视他们,并创建一个能完成惊人工作的团队。如果测试工程师想学习编写代码,或者程序员想学习如何在活动中与人交谈,为什么要设置障碍来阻止这种成长呢?拥抱团队成员学习、改变和向任何方向发展的渴望,为团队和公司的使命服务。
|
||||
|
||||
如果有人在某个角色上失败了,与其把他们说成“技术不够”,不如去看看问题到底是什么。你是否需要一个精通 JavaScript 的人,而这个人又是另一种编程语言的专家?并不是说他们不专业,是技能和知识不匹配。你需要合适的人来扮演合适的角色。如果你强迫一个精通业务分析和编写验收标准的人去编写自动化测试用例,他们就会失败。
|
||||
|
||||
### 如何取消标签
|
||||
|
||||
如果你已经准备好改变你对技术性和非技术性标签的看法,这里有帮助你改变的提示。
|
||||
|
||||
#### 寻找替代词
|
||||
|
||||
我问我采访过的每个人,我们可以用什么词来代替技术和非技术。没有人能回答!我认为这里的挑战是我们不能把它归结为一个词。要替换术语,你需要使用更多的词。正如我之前写的,我们需要做的是变得更加具体。
|
||||
|
||||
你说过或听到过多少次这样的话:
|
||||
|
||||
* “我正在为这个项目寻找技术资源。”
|
||||
* “那个候选人技术不够。”
|
||||
* “我们的软件是为非技术用户设计的。”
|
||||
|
||||
技术和非技术词语的这些用法是模糊的,不能表达它们的全部含义。更真实、更详细地了解你的需求那么你应该说:
|
||||
|
||||
* “我想找一个对如何配置 Kubernetes 有深入了解的人。”
|
||||
* “那个候选人对 Go 的了解不够深入。”
|
||||
* “我们的软件是为销售和营销团队设计的。”
|
||||
|
||||
#### 拥抱成长心态
|
||||
|
||||
知识和技能不是天生的。它们是经过数小时或数年的实践和经验形成的。认为“我只是技术不够”或“我不能学习如何做营销”反映了一种固定的心态。你可以向任何你想发展的方向学习技能。列一张清单,列出你认为哪些是技术技能,或非技术技能,但要具体(如上面的清单)。
|
||||
|
||||
#### 认可每个人的贡献
|
||||
|
||||
如果你在科技行业工作,你就是技术人员。在一个项目或公司的成功中,每个人都有自己的作用。与所有做出贡献的人分享荣誉,而不仅仅是少数人。认可提出新功能的产品经理,而不仅仅是开发新功能的工程师。认可一个作家,他的文章在你的公司迅速传播并产生了新的线索。认可在数据中发现新模式的数据分析师。
|
||||
|
||||
### 下一步
|
||||
|
||||
在本系列的下一篇文章中,我将探讨技术中经常被标记为“非技术”的非工程角色。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/what-technical
|
||||
|
||||
作者:[Dawn Parzych][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dawnparzych
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/question-mark_chalkboard.jpg?itok=DaG4tje9 (question mark in chalk)
|
||||
[2]: https://en.wikipedia.org/wiki/The_Sneetches_and_Other_Stories
|
||||
[3]: https://opensource.com/business/15/9/tips-avoiding-impostor-syndrome
|
||||
[4]: https://enterprisersproject.com/article/2019/8/why-soft-skills-core-to-IT
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Chao-zhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13178-1.html)
|
||||
[#]: subject: (4 tech jobs for people who don't code)
|
||||
[#]: via: (https://opensource.com/article/21/2/non-engineering-jobs-tech)
|
||||
[#]: author: (Dawn Parzych https://opensource.com/users/dawnparzych)
|
||||
|
||||
不懂代码的人也可以干的 4 种技术工作
|
||||
======
|
||||
|
||||
> 对于不是工程师的人来说也有很多技术工作可以做。本文作为本系列的第二篇,就具体阐述这些工作。
|
||||
|
||||

|
||||
|
||||
在 [本系列的第一篇文章][2] 中,我解释了技术行业如何将人员和角色划分为“技术”或“非技术”类别,以及与此相关的问题。科技行业使得那些对科技感兴趣但不懂编程的人很难找到适合自己的角色。
|
||||
|
||||
如果你对技术或开源感兴趣,但对编程不感兴趣,这也有一些工作适合你。科技公司的任何一个职位都可能需要一个精通科技但不一定会写代码的人。但是,你确实需要了解术语并理解产品。
|
||||
|
||||
我最近注意到,在诸如技术客户经理、技术产品经理、技术社区经理等职位头衔上增加了“技术”一词。这反映了几年前的趋势,即在头衔上加上“工程师”一词,以表示该职位的技术需要。过了一段时间,每个人的头衔中都有“工程师”这个词,这样的分类就失去了一些吸引力。
|
||||
|
||||
当我坐下来写这些文章时,Tim Banks 的这条推特出现在我的通知栏上:
|
||||
|
||||
> 已经将职业生涯规划为技术行业的非开发人员(除了信息安全、数据科学/分析师、基础设施工程师等以外的人员)的女性,你希望知道的事情有哪些,有价值的资源有哪些,或者对希望做出类似改变的人有哪些建议?
|
||||
>
|
||||
> —— Tim Banks is a buttery biscuit (@elchefe) [December 15,2020][3]
|
||||
|
||||
这遵循了我第一篇文章中的建议:Tim 并不是简单地询问“非技术角色”;他提供了更重要的详细描述。在 Twitter 这样的媒体上,每一个字符都很重要,这些额外的字符会产生不同的效果。这些是技术角色。如果为了节约笔墨,而简单的称呼他们为“非技术人员”,会改变你的原意,产生不好的影响。
|
||||
|
||||
以下是需要技术知识的非工程类角色的示例。
|
||||
|
||||
### 技术作者
|
||||
|
||||
[技术作者的工作][4] 是在两方或多方之间传递事实信息。传统上,技术作者提供有关如何使用技术产品的说明或文档。最近,我看到术语“技术作者”指的是写其他形式内容的人。科技公司希望一个人为他们的开发者读者写博客文章,而这种技巧不同于文案或内容营销。
|
||||
|
||||
**需要的技术技能:**
|
||||
|
||||
* 写作
|
||||
* 特定技术或产品的用户知识或经验
|
||||
* 快速跟上新产品或新特性的速度的能力
|
||||
* 在各种环境中创作的技能
|
||||
|
||||
**适合人群:**
|
||||
|
||||
* 可以清楚地提供分步说明
|
||||
* 享受合作
|
||||
* 对活跃的声音和音乐有热情
|
||||
* 喜欢描述事物和解释原理
|
||||
|
||||
### 产品经理
|
||||
|
||||
[产品经理][5] 负责领导产品战略。职责可能包括收集客户需求并确定其优先级,撰写业务案例,以及培训销售人员。产品经理跨职能工作,利用创造性和技术技能的结合,成功地推出产品。产品经理需要深厚的产品专业知识。
|
||||
|
||||
**所需技术技能:**
|
||||
|
||||
* 掌握产品知识,并且会配置或运行演示模型
|
||||
* 与产品相关的技术生态系统知识
|
||||
* 分析和研究技能
|
||||
|
||||
**适合以下人群:**
|
||||
|
||||
* 享受制定战略和规划下一步的工作
|
||||
* 在不同的人的需求中可以看到一条共同的线索
|
||||
* 能够清楚地表达业务需求和要求
|
||||
* 喜欢描述原因
|
||||
|
||||
### 数据分析师
|
||||
|
||||
数据分析师负责收集和解释数据,以帮助推动业务决策,如是否进入新市场、瞄准哪些客户或在何处投资。这个角色需要知道如何使用所有可用的潜在数据来做出决策。我们常常希望把事情简单化,而数据分析往往过于简单化。获取正确的信息并不像编写查询 `select all limit 10` 来获取前 10 行那么简单。你需要知道要加入哪些表。你需要知道如何分类。你需要知道是否需要在运行查询之前或之后以某种方式清理数据。
|
||||
|
||||
**所需技术技能:**
|
||||
|
||||
* 了解 SQL、Python 和 R
|
||||
* 能够看到和提取数据中的样本
|
||||
* 了解事物如何端到端运行
|
||||
* 批判性思维
|
||||
* 机器学习
|
||||
|
||||
**适合以下人群:**
|
||||
|
||||
* 享受解决问题的乐趣
|
||||
* 渴望学习和提出问题
|
||||
|
||||
### 开发者关系
|
||||
|
||||
[开发者关系][6] 是一门相对较新的技术学科。它包括 <ruby>[开发者代言人][7]<rt> developer advocate</rt></ruby>、<ruby>开发者传道者<rt>developer evangelist</rt></ruby>和<ruby>开发者营销<rt>developer marketing</rt></ruby>等角色。这些角色要求你与开发人员沟通,与他们建立关系,并帮助他们提高工作效率。你向公司倡导开发者的需求,并向开发者代表公司。开发者关系可以包括撰写文章、创建教程、录制播客、在会议上发言以及创建集成和演示。有人说你需要做过开发才能进入开发者关系。我没有走那条路,我知道很多人没有。
|
||||
|
||||
**所需技术技能:**
|
||||
|
||||
这些将高度依赖于公司和具体角色。你需要部分技能(不是全部)取决于你自己。
|
||||
|
||||
* 了解与产品相关的技术概念
|
||||
* 写作
|
||||
* 教程和播客的视频和音频编辑
|
||||
* 说话
|
||||
|
||||
**适合以下人群:**
|
||||
|
||||
* 有同情心,想要教导和授权他人
|
||||
* 可以为他人辩护
|
||||
* 你很有创意
|
||||
|
||||
### 无限的可能性
|
||||
|
||||
这并不是一个完整的清单,并没有列出技术领域中所有的非工程类角色,而是一些不喜欢每天编写代码的人可以尝试的工作。如果你对科技职业感兴趣,看看你的技能和什么角色最适合。可能性是无穷的。为了帮助你完成旅程,在本系列的最后一篇文章中,我将与这些角色的人分享一些建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/non-engineering-jobs-tech
|
||||
|
||||
作者:[Dawn Parzych][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dawnparzych
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tips_map_guide_ebook_help_troubleshooting_lightbulb_520.png?itok=L0BQHgjr (Looking at a map)
|
||||
[2]: https://linux.cn/article-13168-1.html
|
||||
[3]: https://twitter.com/elchefe/status/1338933320147750915?ref_src=twsrc%5Etfw
|
||||
[4]: https://opensource.com/article/17/5/technical-writing-job-interview-tips
|
||||
[5]: https://opensource.com/article/20/2/product-management-open-source-company
|
||||
[6]: https://www.marythengvall.com/blog/2019/5/22/what-is-developer-relations-and-why-should-you-care
|
||||
[7]: https://opensource.com/article/20/10/open-source-developer-advocates
|
||||
@ -0,0 +1,98 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13184-1.html)
|
||||
[#]: subject: (Run your favorite Windows applications on Linux)
|
||||
[#]: via: (https://opensource.com/article/21/2/linux-wine)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在 Linux 上运行你最喜欢的 Windows 应用程序
|
||||
======
|
||||
|
||||
> WINE 是一个开源项目,它可以协助很多 Windows 应用程序在 Linux 上运行,就好像它们是原生程序一样。
|
||||
|
||||

|
||||
|
||||
在 2021 年,有很多比以往更喜欢 Linux 的原因。在这系列中,我将分享使用 Linux 的 21 种原因。这里是如何使用 WINE 来实现从 Windows 到 Linux 的无缝切换。
|
||||
|
||||
你有只能在 Windows 上运行的应用程序吗?那一个应用程序阻碍你切换到 Linux 的唯一因素吗?如果是这样的话,你将会很高兴知道 WINE,这是一个开源项目,它几乎重新发明了关键的 Windows 库,使为 Windows 编译的应用程序可以在 Linux 上运行。
|
||||
|
||||
WINE 代表着“Wine Is Not an Emulator” ,它指的是驱动这项技术的代码。开源开发者从 1993 年就开始致力将应用程序的任何传入 Windows API 调用翻译为 [POSIX][2] 调用。
|
||||
|
||||
这是一个令人十分惊讶的编程壮举,尤其是考虑到这个项目是独立运行的,没有来自微软的帮助(至少可以这样说),但是也有局限性。一个应用程序偏离 Windows API 的 “内核” 越远,WINE 就越不能预期应用程序的请求。有一些供应商可以弥补这一点,尤其是 [Codeweavers][3] 和 [Valve Software][4]。在需要翻译应用程序的制作者和翻译的人们及公司之间没有协调配合,因此,比如说一个更新的软件作品和从 [WINE 总部][5] 获得完美适配状态之间可能会有一些时间上的滞后。
|
||||
|
||||
然而,如果你想在 Linux 上运行一个著名的 Windows 应用程序,WINE 可能已经为它准备好了可能性。
|
||||
|
||||
### 安装 WINE
|
||||
|
||||
你可以从你的 Linux 发行版的软件包存储库中安装 WINE 。在 Fedora、CentOS Stream 或 RHEL 系统上:
|
||||
|
||||
```
|
||||
$ sudo dnf install wine
|
||||
```
|
||||
|
||||
在 Debian、Linux Mint、Elementary 及相似的系统上:
|
||||
|
||||
```
|
||||
$ sudo apt install wine
|
||||
```
|
||||
|
||||
WINE 不是一个你自己启动的应用程序。当启动一个 Windows 应用程序时,它是一个被调用的后端。你与 WINE 的第一次交互很可能就发生在你启动一个 Windows 应用程序的安装程序时。
|
||||
|
||||
### 安装一个应用程序
|
||||
|
||||
[TinyCAD][6] 是一个极好的用于设计电路的开源应用程序,但是它仅在 Windows 上可用。虽然它是一个小型的应用程序,但是它确实包含一些 .NET 组件,因此应该能对 WINE 进行一些压力测试。
|
||||
|
||||
首先,下载 TinyCAD 的安装程序。Windows 安装程序通常都是这样,它是一个 `.exe` 文件。在下载后,双击文件来启动它。
|
||||
|
||||
![WINE TinyCAD 安装向导][7]
|
||||
|
||||
*TinyCAD 的 WINE 安装向导*
|
||||
|
||||
像你在 Windows 上一样逐步完成安装程序。通常最好接受默认选项,尤其是与 WINE 有关的地方。WINE 环境基本上是独立的,隐藏在你的硬盘驱动器上的一个 `drive_c` 目录中,作为 Windows 应用程序使用的一个文件系统的仿真根目录。
|
||||
|
||||
![WINE TinyCAD 安装和目标驱动器][8]
|
||||
|
||||
*WINE TinyCAD 目标驱动器*
|
||||
|
||||
安装完成后,应用程序通常会为你提供启动机会。如果你正准备测试一下它的话,启动应用程序。
|
||||
|
||||
### 启动 Windows 应用程序
|
||||
|
||||
除了在安装后的第一次启动外,在正常情况下,你启动一个 WINE 应用程序的方式与你启动一个本地 Linux 应用程序相同。不管你使用应用程序菜单、活动屏幕或者只是在运行器中输入应用程序的名称,在 WINE 中运行的桌面 Windows 应用程序都会被视为在 Linux 上的本地应用程序。
|
||||
|
||||
![TinyCAD 使用 WINE 运行][9]
|
||||
|
||||
*通过 WINE 的支持来运行 TinyCAD*
|
||||
|
||||
### 当 WINE 失败时
|
||||
|
||||
我在 WINE 中的大多数应用程序,包括 TinyCAD ,都能如期运行。不过,也会有例外。在这些情况下,你可以等几个月来查看 WINE 开发者 (或者,如果是一款游戏,就等候 Valve Software)是否进行追加修补,或者你可以联系一个像 Codeweavers 这样的供应商来查看他们是否出售对你所需要的应用程序的服务支持。
|
||||
|
||||
### WINE 是种欺骗,但它用于正道
|
||||
|
||||
一些 Linux 用户觉得:如果你使用 WINE 的话,你就是在“欺骗” Linux。它可能会让人有这种感觉,但是 WINE 是一个开源项目,它使用户能够切换到 Linux ,并且仍然能够运行工作或爱好所需的应用程序。如果 WINE 解决了你的问题,让你使用 Linux,那就使用它,并拥抱 Linux 的灵活性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/linux-wine
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_screen_windows_files.png?itok=kLTeQUbY (Computer screen with files or windows open)
|
||||
[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[3]: https://www.codeweavers.com/crossover
|
||||
[4]: https://github.com/ValveSoftware/Proton
|
||||
[5]: http://winehq.org
|
||||
[6]: https://sourceforge.net/projects/tinycad/
|
||||
[7]: https://opensource.com/sites/default/files/wine-tinycad-install.jpg
|
||||
[8]: https://opensource.com/sites/default/files/wine-tinycad-drive_0.jpg
|
||||
[9]: https://opensource.com/sites/default/files/wine-tinycad-running.jpg
|
||||
@ -0,0 +1,126 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13174-1.html)
|
||||
[#]: subject: (A guide to Python virtual environments with virtualenvwrapper)
|
||||
[#]: via: (https://opensource.com/article/21/2/python-virtualenvwrapper)
|
||||
[#]: author: (Ben Nuttall https://opensource.com/users/bennuttall)
|
||||
|
||||
使用 virtualenvwrapper 构建 Python 虚拟环境
|
||||
======
|
||||
|
||||
> 虚拟环境是安全地使用不同版本的 Python 和软件包组合的关键。
|
||||
|
||||

|
||||
|
||||
Python 对管理虚拟环境的支持,已经提供了一段时间了。Python 3.3 甚至增加了内置的 `venv` 模块,用于创建没有第三方库的环境。Python 程序员可以使用几种不同的工具来管理他们的环境,我使用的工具叫做 [virtualenvwrapper][2]。
|
||||
|
||||
虚拟环境是将你的 Python 项目及其依赖关系与你的系统安装的 Python 分离的一种方式。如果你使用的是基于 macOS 或 Linux 的操作系统,它很可能在安装中附带了一个 Python 版本,事实上,它很可能依赖于那个特定版本的 Python 才能正常运行。但这是你的计算机,你可能想用它来达到自己的目的。你可能需要安装另一个版本的 Python,而不是操作系统提供的版本。你可能还需要安装一些额外的库。尽管你可以升级你的系统 Python,但不推荐这样做。你也可以安装其他库,但你必须注意不要干扰系统所依赖的任何东西。
|
||||
|
||||
虚拟环境是创建隔离的关键,你需要安全地修改不同版本的 Python 和不同组合的包。它们还允许你为不同的项目安装同一库的不同版本,这解决了在相同环境满足所有项目需求这个不可能的问题。
|
||||
|
||||
为什么选择 `virtualenvwrapper` 而不是其他工具?简而言之:
|
||||
|
||||
* 与 `venv` 需要在项目目录内或旁边有一个 `venv` 目录不同,`virtualenvwrapper` 将所有环境保存在一个地方:默认在 `~/.virtualenvs` 中。
|
||||
* 它提供了用于创建和激活环境的命令,而且激活环境不依赖于找到正确的 `activate` 脚本。它只需要(从任何地方)`workon projectname`而不需要 `source ~/Projects/flashylights-env/bin/activate`。
|
||||
|
||||
### 开始使用
|
||||
|
||||
首先,花点时间了解一下你的系统 Python 是如何配置的,以及 `pip` 工具是如何工作的。
|
||||
|
||||
以树莓派系统为例,该系统同时安装了 Python 2.7 和 3.7。它还提供了单独的 `pip` 实例,每个版本一个:
|
||||
|
||||
* 命令 `python` 运行 Python 2.7,位于 `/usr/bin/python`。
|
||||
* 命令 `python3` 运行 Python 3.7,位于 `/usr/bin/python3`。
|
||||
* 命令 `pip` 安装 Python 2.7 的软件包,位于 `/usr/bin/pip`。
|
||||
* 命令 `pip3` 安装 Python 3.7 的包,位于 `/usr/bin/pip3`。
|
||||
|
||||
![Python commands on Raspberry Pi][3]
|
||||
|
||||
在开始使用虚拟环境之前,验证一下使用 `python` 和 `pip` 命令的状态是很有用的。关于你的 `pip` 实例的更多信息可以通过运行 `pip debug` 或 `pip3 debug` 命令找到。
|
||||
|
||||
在我运行 Ubuntu Linux 的电脑上几乎是相同的信息(除了它是 Python 3.8)。在我的 Macbook 上也很相似,除了唯一的系统 Python 是 2.6,而我用 `brew` 安装 Python 3.8,所以它位于 `/usr/local/bin/python3`(和 `pip3` 一起)。
|
||||
|
||||
### 安装 virtualenvwrapper
|
||||
|
||||
你需要使用系统 Python 3 的 `pip` 安装 `virtualenvwrapper`:
|
||||
|
||||
|
||||
```
|
||||
sudo pip3 install virtualenvwrapper
|
||||
```
|
||||
|
||||
下一步是配置你的 shell 来加载 `virtualenvwrapper` 命令。你可以通过编辑 shell 的 RC 文件(例如 `.bashrc`、`.bash_profile` 或 `.zshrc`)并添加以下几行:
|
||||
|
||||
```
|
||||
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
|
||||
export VIRTUALENVWRAPPER_VIRTUALENV=/usr/local/bin/virtualenv
|
||||
source /usr/local/bin/virtualenvwrapper.sh
|
||||
```
|
||||
|
||||
![bashrc][5]
|
||||
|
||||
如果你的 Python 3 位于其他地方,请根据你的设置修改第一行。
|
||||
|
||||
关闭你的终端,然后重新打开它,这样才能生效。第一次打开终端时,你应该看到 `virtualenvwrapper` 的一些输出。这只会发生一次,因为一些目录是作为设置的一部分被创建的。
|
||||
|
||||
现在你应该可以输入 `mkvirtualenv --version` 命令来验证 `virtualenvwrapper` 是否已经安装。
|
||||
|
||||
### 创建一个新的虚拟环境
|
||||
|
||||
假设你正在进行一个名为 `flashylights` 的项目。要用这个名字创建一个虚拟环境,请运行该命令:
|
||||
|
||||
```
|
||||
mkvirtualenv flashylights
|
||||
```
|
||||
|
||||
环境已经创建并激活,所以你会看到 `(flashlylights)` 出现在你的提示前:
|
||||
|
||||
![Flashylights prompt][6]
|
||||
|
||||
现在环境被激活了,事情发生了变化。`python` 现在指向一个与你之前在系统中识别的 Python 实例完全不同的 Python 实例。它为你的环境创建了一个目录,并在其中放置了 Python 3 二进制文件、pip 命令等的副本。输入 `which python` 和 `which pip` 来查看它们的位置。
|
||||
|
||||
![Flashylights command][7]
|
||||
|
||||
如果你现在运行一个 Python 程序,你可以用 `python` 代替 `python3` 来运行,你可以用 `pip` 代替 `pip3`。你使用 `pip`安装的任何包都将只安装在这个环境中,它们不会干扰你的其他项目、其他环境或系统安装。
|
||||
|
||||
要停用这个环境,运行 `deactivate` 命令。要重新启用它,运行 `workon flashylights`。
|
||||
|
||||
你可以用 `workon` 或使用 `lsvirtualenv` 列出所有可用的环境。你可以用 `rmvirtualenv flashylights` 删除一个环境。
|
||||
|
||||
在你的开发流程中添加虚拟环境是一件明智的事情。根据我的经验,它可以防止我在系统范围内安装我正在试验的库,这可能会导致问题。我发现 `virtualenvwrapper` 是最简单的可以让我进入流程的方法,并无忧无虑地管理我的项目环境,而不需要考虑太多,也不需要记住太多命令。
|
||||
|
||||
### 高级特性
|
||||
|
||||
* 你可以在你的系统上安装多个 Python 版本(例如,在 Ubuntu 上使用 [deadsnakes PPA][8]),并使用该版本创建一个虚拟环境,例如,`mkvirtualenv -p /usr/bin/python3.9 myproject`。
|
||||
* 可以在进入和离开目录时自动激活、停用。
|
||||
* 你可以使用 `postmkvirtualenv` 钩子在每次创建新环境时安装常用工具。
|
||||
|
||||
更多提示请参见[文档][9]。
|
||||
|
||||
_本文基于 Ben Nuttall 在 [Tooling Tuesday 上关于 virtualenvwrapper 的帖子][10],经许可后重用。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/python-virtualenvwrapper
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_python.jpg?itok=G04cSvp_ (Python in a coffee cup.)
|
||||
[2]: https://virtualenvwrapper.readthedocs.io/en/latest/index.html
|
||||
[3]: https://opensource.com/sites/default/files/uploads/pi-python-cmds.png (Python commands on Raspberry Pi)
|
||||
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/bashrc.png (bashrc)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/flashylights-activated-prompt.png (Flashylights prompt)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/flashylights-activated-cmds.png (Flashylights command)
|
||||
[8]: https://tooling.bennuttall.com/deadsnakes/
|
||||
[9]: https://virtualenvwrapper.readthedocs.io/en/latest/tips.html
|
||||
[10]: https://tooling.bennuttall.com/virtualenvwrapper/
|
||||
@ -0,0 +1,117 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13165-1.html)
|
||||
[#]: subject: (Check Your Disk Usage Using ‘duf’ Terminal Tool [Friendly Alternative to du and df commands])
|
||||
[#]: via: (https://itsfoss.com/duf-disk-usage/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
使用 duf 终端工具检查你的磁盘使用情况
|
||||
======
|
||||
|
||||

|
||||
|
||||
> `duf` 是一个终端工具,旨在增强传统的 Linux 命令 `df` 和 `du`。它可以让你轻松地检查可用磁盘空间,对输出进行分类,并以用户友好的方式呈现。
|
||||
|
||||
### duf:一个用 Golang 编写的跨平台磁盘使用情况工具
|
||||
|
||||
![][1]
|
||||
|
||||
在我知道这个工具之前,我更喜欢使用像 [Stacer][2] 这样的 GUI 程序或者预装的 GNOME 磁盘使用情况程序来 [检查可用的磁盘空间][3] 和系统的磁盘使用量。
|
||||
|
||||
不过,[duf][4] 似乎是一个有用的终端工具,可以检查磁盘使用情况和可用空间,它是用 [Golang][5] 编写的。Abhishek 建议我试一试它,但我对它很感兴趣,尤其是考虑到我目前正在学习 Golang,真是太巧了!
|
||||
|
||||
无论你是终端大师还是只是一个对终端不适应的初学者,它都相当容易使用。当然,它比 [检查磁盘空间利用率命令 df][6] 更容易理解。
|
||||
|
||||
在你把它安装到你的系统上之前,让我重点介绍一下它的一些主要功能和用法。
|
||||
|
||||
### duf 的特点
|
||||
|
||||
![][7]
|
||||
|
||||
* 提供所有挂载设备的概览且易于理解。
|
||||
* 能够指定目录/文件名并检查该挂载点的可用空间。
|
||||
* 更改/删除输出中的列。
|
||||
* 列出 [inode][8] 信息。
|
||||
* 输出排序。
|
||||
* 支持 JSON 输出。
|
||||
* 如果不能自动检测终端的主题,可以指定主题。
|
||||
|
||||
### 在 Linux 上安装和使用 duf
|
||||
|
||||
你可以在 [AUR][9] 中找到一个 Arch Linux 的软件包。如果你使用的是 [Nix 包管理器][10],也可以找到一个包。
|
||||
|
||||
对于基于 Debian 的发行版和 RPM 包,你可以去它的 [GitHub 发布区][11] 中获取适合你系统的包。
|
||||
|
||||
它也适用于 Windows、Android、macOS 和 FreeBSD。
|
||||
|
||||
在我这里,我需要 [安装 DEB 包][12],然后就可以使用了。安装好后,使用起来很简单,你只要输入:
|
||||
|
||||
```
|
||||
duf
|
||||
```
|
||||
|
||||
这应该会给你提供所有本地设备、已挂载的任何云存储设备以及任何其他特殊设备(包括临时存储位置等)的详细信息。
|
||||
|
||||
如果你想一目了然地查看所有 `duf` 的可用命令,你可以输入:
|
||||
|
||||
```
|
||||
duf --help
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
例如,如果你只想查看本地连接设备的详细信息,而不是其他的,你只需要输入:
|
||||
|
||||
```
|
||||
duf --only local
|
||||
```
|
||||
|
||||
另一个例子是根据大小按特定顺序对输出进行排序,下面是你需要输入的内容:
|
||||
|
||||
```
|
||||
duf --sort size
|
||||
```
|
||||
|
||||
输出应该是像这样的:
|
||||
|
||||
![][14]
|
||||
|
||||
你可以探索它的 [GitHub 页面][4],以获得更多关于额外命令和安装说明的信息。
|
||||
|
||||
- [下载 duf][4]
|
||||
|
||||
### 结束语
|
||||
|
||||
我发现终端工具 `duf` 相当方便,可以在不需要使用 GUI 程序的情况下,随时查看可用磁盘空间或使用情况。
|
||||
|
||||
你知道有什么类似的工具吗?欢迎在下面的评论中告诉我你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/duf-disk-usage/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/duf-screenshot.jpg?resize=800%2C481&ssl=1
|
||||
[2]: https://itsfoss.com/optimize-ubuntu-stacer/
|
||||
[3]: https://itsfoss.com/check-free-disk-space-linux/
|
||||
[4]: https://github.com/muesli/duf
|
||||
[5]: https://golang.org/
|
||||
[6]: https://linuxhandbook.com/df-command/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/duf-local.jpg?resize=800%2C195&ssl=1
|
||||
[8]: https://linuxhandbook.com/inode-linux/
|
||||
[9]: https://itsfoss.com/aur-arch-linux/
|
||||
[10]: https://github.com/NixOS/nixpkgs
|
||||
[11]: https://github.com/muesli/duf/releases
|
||||
[12]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/duf-commands.jpg?resize=800%2C443&ssl=1
|
||||
[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/duf-sort-example.jpg?resize=800%2C365&ssl=1
|
||||
161
published/202103/20210224 Set your path in FreeDOS.md
Normal file
161
published/202103/20210224 Set your path in FreeDOS.md
Normal file
@ -0,0 +1,161 @@
|
||||
[#]: subject: (Set your path in FreeDOS)
|
||||
[#]: via: (https://opensource.com/article/21/2/path-freedos)
|
||||
[#]: author: (Kevin O'Brien https://opensource.com/users/ahuka)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13218-1.html)
|
||||
|
||||
在 FreeDOS 中设置你的路径
|
||||
======
|
||||
|
||||
> 学习 FreeDOS 路径的知识,如何设置它,并且如何使用它。
|
||||
|
||||
![查看职业生涯地图][1]
|
||||
|
||||
你在开源 [FreeDOS][2] 操作系统中所做的一切工作都是通过命令行完成的。命令行以一个 _提示符_ 开始,这是计算机说法的方式,“我准备好了。请给我一些事情来做。”你可以配置你的提示符的外观,但是默认情况下,它是:
|
||||
|
||||
```
|
||||
C:\>
|
||||
```
|
||||
|
||||
从命令行中,你可以做两件事:运行一个内部命令或运行一个程序。外部命令是在你的 `FDOS` 目录中可找到的以单独文件形式存在的程序,以便运行程序包括运行外部命令。它也意味着你可以使用你的计算机运行应用程序软件来做一些东西。你也可以运行一个批处理文件,但是在这种情况下,你所做的全部工作就变成了运行批处理文件中所列出的一系列命令或程序。
|
||||
|
||||
### 可执行应用程序文件
|
||||
|
||||
FreeDOS 可以运行三种类型的应用程序文件:
|
||||
|
||||
1. **COM** 是一个用机器语言写的,且小于 64 KB 的文件。
|
||||
2. **EXE** 也是一个用机器语言写的文件,但是它可以大于 64 KB 。此外,在 EXE 文件的开头部分有信息,用于告诉 DOS 系统该文件是什么类型的以及如何加载和运行。
|
||||
3. **BAT** 是一个使用文本编辑器以 ASCII 文本格式编写的 _批处理文件_ ,其中包含以批处理模式执行的 FreeDOS 命令。这意味着每个命令都会按顺序执行到文件的结尾。
|
||||
|
||||
如果你所输入的一个文件名称不能被 FreeDOS 识别为一个内部命令或一个程序,你将收到一个错误消息 “Bad command or filename” 。如果你看到这个错误,它意味着会是下面三种情况中的其中一种:
|
||||
|
||||
1. 由于某些原因,你所给予的名称是错误的。你可能拼错了文件名称,或者你可能正在使用错误的命令名称。检查名称和拼写,并再次尝试。
|
||||
2. 可能你正在尝试运行的程序并没有安装在计算机上。请确认它已经安装了。
|
||||
3. 文件确实存在,但是 FreeDOS 不知道在哪里可以找到它。
|
||||
|
||||
在清单上的最后一项就是这篇文章的主题,它被称为路径。如果你已经习惯于使用 Linux 或 Unix ,你可能已经理解 [PATH 变量][3] 的概念。如果你是命令行的新手,那么路径是一个非常重要的足以让你舒适的东西。
|
||||
|
||||
### 路径
|
||||
|
||||
当你输入一个可执行应用程序文件的名称时,FreeDOS 必须能找到它。FreeDOS 会在一个具体指定的位置层次结构中查找文件:
|
||||
|
||||
1. 首先,它查找当前驱动器的活动目录(称为 _工作目录_)。如果你正在目录 `C:\FDOS` 中,接着,你输入名称 `FOOBAR.EXE`,FreeDOS 将在 `C:\FDOS` 中查找带有这个名称的文件。你甚至不需要输入完整的名称。如果你输入 `FOOBAR` ,FreeDOS 将查找任何带有这个名称的可执行文件,不管它是 `FOOBAR.EXE`,`FOOBAR.COM`,或 `FOOBAR.BAT`。只要 FreeDOS 能找到一个匹配该名称的文件,它就会运行该可执行文件。
|
||||
2. 如果 FreeDOS 不能找到你所输入名称的文件,它将查询被称为 `PATH` 的一些东西。每当 DOS 不能在当前活动命令中找到文件时,会指示 DOS 检查这个列表中目录。
|
||||
|
||||
你可以随时使用 `path` 命令来查看你的计算机的路径。只需要在 FreeDOS 提示符中输入 `path` ,FreeDOS 就会返回你的路径设置:
|
||||
|
||||
```
|
||||
C:\>path
|
||||
PATH=C:\FDOS\BIN
|
||||
```
|
||||
|
||||
第一行是提示符和命令,第二行是计算机返回的东西。你可以看到 DOS 第一个查看的位置就是位于 `C` 驱动器上的 `FDOS\BIN`。如果你想更改你的路径,你可以输入一个 `path` 命令以及你想使用的新路径:
|
||||
|
||||
```
|
||||
C:\>path=C:\HOME\BIN;C:\FDOS\BIN
|
||||
```
|
||||
|
||||
在这个示例中,我设置我的路径到我个人的 `BIN` 文件夹,我把它放在一个叫 `HOME` 的自定义目录中,然后再设置为 `FDOS/BIN`。现在,当你检查你的路径时:
|
||||
|
||||
```
|
||||
C:\>path
|
||||
PATH=C:\HOME\BIN;C:\FDOS\BIN
|
||||
```
|
||||
|
||||
路径设置是按所列目录的顺序处理的。
|
||||
|
||||
你可能会注意到有一些字符是小写的,有一些字符是大写的。你使用哪一种都真的不重要。FreeDOS 是不区分大小写的,并且把所有的东西都作为大写字母对待。在内部,FreeDOS 使用的全是大写字母,这就是为什么你看到来自你命令的输出都是大写字母的原因。如果你以小写字母的形式输入命令和文件名称,在一个转换器将自动转换它们为大写字母后,它们将被执行。
|
||||
|
||||
输入一个新的路径来替换先前设置的路径。
|
||||
|
||||
### autoexec.bat 文件
|
||||
|
||||
你可能遇到的下一个问题的是 FreeDOS 默认使用的第一个路径来自何处。这与其它一些重要的设置一起定义在你的 `C` 驱动器的根目录下的 `AUTOEXEC.BAT` 文件中。这是一个批处理文件,它在你启动 FreeDOS 时会自动执行(由此得名)。你可以使用 FreeDOS 程序 `EDIT` 来编辑这个文件。为查看或编辑这个文件的内容,输入下面的命令:
|
||||
|
||||
```
|
||||
C:\>edit autoexec.bat
|
||||
```
|
||||
|
||||
这一行出现在顶部附近:
|
||||
|
||||
```
|
||||
SET PATH=%dosdir%\BIN
|
||||
```
|
||||
|
||||
这一行定义默认路径的值。
|
||||
|
||||
在你查看 `AUTOEXEC.BAT` 后,你可以通过依次按下面的按键来退出 EDIT 应用程序:
|
||||
|
||||
1. `Alt`
|
||||
2. `f`
|
||||
3. `x`
|
||||
|
||||
你也可以使用键盘快捷键 `Alt+X`。
|
||||
|
||||
### 使用完整的路径
|
||||
|
||||
如果你在你的路径中忘记包含 `C:\FDOS\BIN` ,那么你将不能快速访问存储在这里的任何应用程序,因为 FreeDOS 不知道从哪里找到它们。例如,假设我设置我的路径到我个人应用程序集合:
|
||||
|
||||
```
|
||||
C:\>path=C:\HOME\BIN
|
||||
```
|
||||
|
||||
内置在命令行中应用程序仍然能正常工作:
|
||||
|
||||
```
|
||||
C:\cd HOME
|
||||
C:\HOME>dir
|
||||
ARTICLES
|
||||
BIN
|
||||
CHEATSHEETS
|
||||
GAMES
|
||||
DND
|
||||
```
|
||||
|
||||
不过,外部的命令将不能运行:
|
||||
|
||||
```
|
||||
C:HOME\ARTICLES>BZIP2 -c example.txt
|
||||
Bad command or filename - "BZIP2"
|
||||
```
|
||||
|
||||
通过提供命令的一个 _完整路径_ ,你可以总是执行一个在你的系统上且不在你的路径中的命令:
|
||||
|
||||
```
|
||||
C:HOME\ARTICLES>C:\FDOS\BIN\BZIP2 -c example.txt
|
||||
C:HOME\ARTICLES>DIR
|
||||
example.txb
|
||||
```
|
||||
|
||||
你可以使用同样的方法从外部介质或其它目录执行应用程序。
|
||||
|
||||
### FreeDOS 路径
|
||||
|
||||
通常情况下,你很可能希望在路径中保留 `C:\PDOS\BIN` ,因为它包含所有使用 FreeDOS 分发的默认应用程序。
|
||||
|
||||
除非你更改 `AUTOEXEC.BAT` 中的路径,否则将在重新启动后恢复默认路径。
|
||||
|
||||
现在,你知道如何在 FreeDOS 中管理你的路径,你能够以最适合你的方式了执行命令和维护你的工作环境。
|
||||
|
||||
_致谢 [DOS 课程 5: 路径][4] (在 CC BY-SA 4.0 协议下发布) 为本文提供的一些信息。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/path-freedos
|
||||
|
||||
作者:[Kevin O'Brien][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ahuka
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/career_journey_road_gps_path_map_520.png?itok=PpL6jJgY (Looking at a map for career journey)
|
||||
[2]: https://www.freedos.org/
|
||||
[3]: https://opensource.com/article/17/6/set-path-linux
|
||||
[4]: https://www.ahuka.com/dos-lessons-for-self-study-purposes/dos-lesson-5-the-path/
|
||||
59
published/202103/20210225 4 new open source licenses.md
Normal file
59
published/202103/20210225 4 new open source licenses.md
Normal file
@ -0,0 +1,59 @@
|
||||
[#]: subject: (4 new open source licenses)
|
||||
[#]: via: (https://opensource.com/article/21/2/osi-licenses-cal-cern-ohl)
|
||||
[#]: author: (Pam Chestek https://opensource.com/users/pchestek)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wyxplus)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13224-1.html)
|
||||
|
||||
四个新式开源许可证
|
||||
======
|
||||
|
||||
> 让我们来看看 OSI 最新批准的加密自治许可证和 CERN 开源硬件许可协议。
|
||||
|
||||

|
||||
|
||||
作为 <ruby>[开源定义][2]<rt>Open Source Defintion</rt></ruby>(OSD)的管理者,<ruby>[开源促进会][3]<rt>Open Source Initiative</rt></ruby>(OSI)20 年来一直在批准“开源”许可证。这些许可证是开源软件生态系统的基础,可确保每个人都可以使用、改进和共享软件。当一个许可证获批为“开源”时,是因为 OSI 认为该许可证可以促进相互的协作和共享,从而使得每个参与开源生态的人获益。
|
||||
|
||||
在过去的 20 年里,世界发生了翻天覆地的变化。现如今,软件以新的甚至是无法想象的方式在被使用。OSI 已经预料到,曾经被人们所熟知的开源许可证现已无法满足如今的要求。因此,许可证管理者已经加强了工作,为更广泛的用途提交了几个新的许可证。OSI 所面临的挑战是在评估这些新的许可证概念是否会继续推动共享和合作,是否被值得称为“开源”许可证,最终 OSI 批准了一些用于特殊领域的新式许可证。
|
||||
|
||||
### 四个新式许可证
|
||||
|
||||
第一个是 <ruby>[加密自治许可证][4]<rt>Cryptographic Autonomy License</rt></ruby>(CAL)。该许可证是为分布式密码应用程序而设计的。此许可证所解决的问题是,现有的开源许可证无法保证开放性,因为如果没有义务也与其他对等体共享数据,那么一个对等体就有可能损害网络的运行。因此,除了是一个强有力的版权保护许可外,CAL 还包括向第三方提供独立使用和修改软件所需的权限和资料的义务,而不会让第三方有数据或功能的损失。
|
||||
|
||||
随着越来越多的人使用加密结构进行点对点共享,那么更多的开发人员发现自己需要诸如 CAL 之类的法律工具也就不足为奇了。 OSI 的两个邮件列表 License-Discuss 和 License-Review 上的社区,讨论了拟议的新开源许可证,并询问了有关此许可证的诸多问题。我们希望由此产生的许可证清晰易懂,并希望对其他开源从业者有所裨益。
|
||||
|
||||
接下来是,欧洲核研究组织(CERN)提交的 CERN <ruby>开放硬件许可证<rt>Open Hardware Licence</rt></ruby>(OHL)系列许可证以供审议。它包括三个许可证,其主要用于开放硬件,这是一个与开源软件相似的开源访问领域,但有其自身的挑战和细微差别。硬件和软件之间的界线现已变得相当模糊,因此应用单独的硬件和软件许可证变得越来越困难。欧洲核子研究组织(CERN)制定了一个可以确保硬件和软件自由的许可证。
|
||||
|
||||
OSI 可能在开始时就没考虑将开源硬件许可证添加到其开源许可证列表中,但是世界早已发生变革。因此,尽管 CERN 许可证中的措词涵盖了硬件术语,但它也符合 OSI 认可的所有开源软件许可证的条件。
|
||||
|
||||
CERN 开源硬件许可证包括一个 [宽松许可证][5]、一个 [弱互惠许可证][6] 和一个 [强互惠许可证][7]。最近,该许可证已被一个国际研究项目采用,该项目正在制造可用于 COVID-19 患者的简单、易于生产的呼吸机。
|
||||
|
||||
### 了解更多
|
||||
|
||||
CAL 和 CERN OHL 许可证是针对特殊用途的,并且 OSI 不建议把它们用于其它领域。但是 OSI 想知道这些许可证是否会按预期发展,从而有助于在较新的计算机领域中培育出健壮的开源生态。
|
||||
|
||||
可以从 OSI 获得关于 [许可证批准过程][8] 的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/osi-licenses-cal-cern-ohl
|
||||
|
||||
作者:[Pam Chestek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pchestek
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LAW_lawdotgov3.png?itok=e4eFKe0l "Law books in a library"
|
||||
[2]: https://opensource.org/osd
|
||||
[3]: https://opensource.org/
|
||||
[4]: https://opensource.org/licenses/CAL-1.0
|
||||
[5]: https://opensource.org/CERN-OHL-P
|
||||
[6]: https://opensource.org/CERN-OHL-W
|
||||
[7]: https://opensource.org/CERN-OHL-S
|
||||
[8]: https://opensource.org/approval
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: subject: (3 Linux terminals you need to try)
|
||||
[#]: via: (https://opensource.com/article/21/2/linux-terminals)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13186-1.html)
|
||||
|
||||
值得尝试的 3 个 Linux 终端
|
||||
======
|
||||
|
||||
> Linux 让你能够选择你喜欢的终端界面,而不是它强加的界面。
|
||||
|
||||
|
||||
|
||||
在 2021 年,人们喜欢 Linux 的理由比以往任何时候都多。在这个系列中,我将分享 21 个使用 Linux 的不同理由。能够选择自己的终端是使用 Linux 的一个重要原因。
|
||||
|
||||
很多人认为一旦你用过一个终端界面,你就已经用过所有的终端了。但喜欢终端的用户都知道,它们之间有一些细微但重要的区别。本文将介绍我最喜欢的三种。
|
||||
|
||||
不过在深入研究它们之前,先要了解 shell 和<ruby>终端<rt>terminal</rt></ruby>之间的区别。终端(技术上说是<ruby>终端模拟器<rt>terminal emulator</rt></ruby>,因为终端曾经是物理硬件设备)是一个在桌面上的窗口中运行的应用。shell 是在终端窗口中对你可见的引擎。流行的 shell 有 [Bash][2]、[tcsh][3] 和 [zsh][4],它们都在终端中运行。
|
||||
|
||||
在现代 Linux 上几乎不用说,至少本文中所有的终端都有标签界面。
|
||||
|
||||
### Xfce 终端
|
||||
|
||||
![Xfce ][5]
|
||||
|
||||
[轻量级 Xfce 桌面][7] 提供了一个轻量级的终端,很好地平衡了功能和简单性。它提供了对 shell 的访问(如预期的那样),并且它可以轻松访问几个重要的配置选项。你可以设置当你双击文本时哪些字符会断字、选择你的默认字符编码,并禁用终端窗口的 Alt 快捷方式,这样你最喜欢的 Bash 快捷方式就会传递到 shell。你还可以设置字体和新的颜色主题,或者从常用预设列表中加载颜色主题。它甚至在顶部有一个可选的工具栏,方便你访问你最喜欢的功能。
|
||||
|
||||
对我来说,Xfce 的亮点功能是可以非常容易地为你打开的每一个标签页改变背景颜色。当在服务器上运行远程 shell 时,这是非常有价值的。它让我知道自己在哪个标签页中,从而避免了我犯愚蠢的错误。
|
||||
|
||||
### rxvt-unicode
|
||||
|
||||
![rxvt][8]
|
||||
|
||||
[rxvt 终端][9] 是我最喜欢的轻量级控制台。它有许多老式 [xterm][10] 终端仿真器的功能,但它的扩展性更强。它的配置是在 `~/.Xdefaults` 中定义的,所以没有偏好面板或设置菜单,但这使得它很容易管理和备份你的设置。通过使用一些 Perl 库,rxvt 可以有标签,并且通过 xrdb,它可以访问字体和任何你能想到的颜色主题。你可以设置像 `URxvt.urlLancher: firefox` 这样的属性来设置当你打开 URL 时启动的网页浏览器,改变滚动条的外观,修改键盘快捷键等等。
|
||||
|
||||
最初的 rxvt 不支持 Unicode(因为当时 Unicode 还不存在),但 `rxvt-unicode`(有时也叫 `urxvt`)包提供了一个完全支持 Unicode 的补丁版本。
|
||||
|
||||
我在每台电脑上都有 rxvt,因为对我来说它是最好的通用终端。它不一定是所有用户的最佳终端(例如,它没有拖放界面)。不过,对于寻找快速和灵活终端的中高级用户来说,rxvt 是一个简单的选择。
|
||||
|
||||
### Konsole
|
||||
|
||||
![Konsole][11]
|
||||
|
||||
Konsole 是 KDE Plasma 桌面的终端,是我转到 Linux 后使用的第一个终端,所以它是我对所有其他终端的标准。它确实设定了一个很高的标准。Konsole 有所有通常的不错的功能(还有些其他的),比如简单的颜色主题加上配置文件支持、字体选择、编码、可分离标签、可重命名标签等等。但这在现代桌面上是可以预期的(至少,如果你的桌面运行的是 Plasma 的话)。
|
||||
|
||||
Konsole 比其他终端领先许多年(或者几个月)。它可以垂直或水平地分割窗口。你可以把输入复制到所有的标签页上(就像 [tmux][12] 一样)。你可以将其设置为监视自身是否静音或活动并配置通知。如果你在 Android 手机上使用 KDE Connect,这意味着当一个任务完成时,你可以在手机上收到通知。你可以将 Konsole 的输出保存到文本或 HTML 文件中,为打开的标签页添加书签,克隆标签页,调整搜索设置等等。
|
||||
|
||||
Konsole 是一个真正的高级用户终端,但它也非常适合新用户。你可以将文件拖放到 Konsole 中,将目录改为硬盘上的特定位置,也可以将路径粘贴进去,甚至可以将文件复制到 Konsole 的当前工作目录中。这让使用终端变得很简单,这也是所有用户都能理解的。
|
||||
|
||||
### 尝试一个终端
|
||||
|
||||
你的审美观念是黑暗的办公室和黑色背景下绿色文字的温暖光芒吗?还是喜欢阳光明媚的休息室和屏幕上舒缓的墨黑色字体?无论你对完美电脑设置的愿景是什么,如果你喜欢通过输入命令高效地与操作系统交流,那么 Linux 已经为你提供了一个接口。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/2/linux-terminals
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/freedos.png?itok=aOBLy7Ky (4 different color terminal windows with code)
|
||||
[2]: https://opensource.com/resources/what-bash
|
||||
[3]: https://opensource.com/article/20/8/tcsh
|
||||
[4]: https://opensource.com/article/19/9/getting-started-zsh
|
||||
[5]: https://opensource.com/sites/default/files/uploads/terminal-xfce.jpg (Xfce )
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://opensource.com/article/19/12/xfce-linux-desktop
|
||||
[8]: https://opensource.com/sites/default/files/uploads/terminal-rxvt.jpg (rxvt)
|
||||
[9]: https://opensource.com/article/19/10/why-use-rxvt-terminal
|
||||
[10]: https://opensource.com/article/20/7/xterm
|
||||
[11]: https://opensource.com/sites/default/files/uploads/terminal-konsole.jpg (Konsole)
|
||||
[12]: https://opensource.com/article/20/1/tmux-console
|
||||
@ -0,0 +1,120 @@
|
||||
[#]: subject: (How to Install the Latest Erlang on Ubuntu Linux)
|
||||
[#]: via: (https://itsfoss.com/install-erlang-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13182-1.html)
|
||||
|
||||
如何在 Ubuntu Linux 上安装最新的 Erlang
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Erlang][1] 是一种用于构建大规模可扩展实时系统的函数式编程语言。Erlang 最初是由 [爱立信][2] 创建的专有软件,后来被开源。
|
||||
|
||||
Erlang 在 [Ubuntu 的 Universe 仓库][3] 中可用。启用该仓库后,你可以使用下面的命令轻松安装它:
|
||||
|
||||
```
|
||||
sudo apt install erlang
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
但是,*Ubuntu 仓库提供的 Erlang 版本可能不是最新的*。
|
||||
|
||||
如果你想要 Ubuntu 上最新的 Erlang 版本,你可以添加 [Erlang Solutions 提供的][5]仓库。它们为各种 Linux 发行版、Windows 和 macOS 提供了预编译的二进制文件。
|
||||
|
||||
如果你之前安装了一个名为 `erlang` 的包,那么它将会被升级到由添加的仓库提供的较新版本。
|
||||
|
||||
### 在 Ubuntu 上安装最新版本的 Erlang
|
||||
|
||||
你需要[在 Linux 终端下载密钥文件][6]。你可以使用 `wget` 工具,所以请确保你已经安装了它:
|
||||
|
||||
```
|
||||
sudo apt install wget
|
||||
```
|
||||
|
||||
接下来,使用 `wget` 下载 Erlang Solution 仓库的 GPG 密钥,并将其添加到你的 apt 打包系统中。添加了密钥后,你的系统就会信任来自该仓库的包。
|
||||
|
||||
```
|
||||
wget -O- https://packages.erlang-solutions.com/ubuntu/erlang_solutions.asc | sudo apt-key add -
|
||||
```
|
||||
|
||||
现在,你应该在你的 APT `sources.list.d` 目录下为 Erlang 添加一个文件,这个文件将包含有关仓库的信息,APT 包管理器将使用它来获取包和未来的更新。
|
||||
|
||||
对于 Ubuntu 20.04(和 Ubuntu 20.10),使用以下命令:
|
||||
|
||||
```
|
||||
echo "deb https://packages.erlang-solutions.com/ubuntu focal contrib" | sudo tee /etc/apt/sources.list.d/erlang-solution.list
|
||||
```
|
||||
|
||||
我知道上面的命令提到了 Ubuntu 20.04 focal,但它也适用于 Ubuntu 20.10 groovy。
|
||||
|
||||
对于 **Ubuntu 18.04**,使用以下命令:
|
||||
|
||||
```
|
||||
echo "deb https://packages.erlang-solutions.com/ubuntu bionic contrib" | sudo tee /etc/apt/sources.list.d/erlang-solution.list
|
||||
```
|
||||
|
||||
你必须更新本地的包缓存,以通知它关于新添加的仓库的包。
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
你会注意到,它建议你进行一些升级。如果你列出了可用的升级,你会在那里找到 erlang 包。要更新现有的 erlang 版本或重新安装,使用这个命令:
|
||||
|
||||
```
|
||||
sudo apt install erlang
|
||||
```
|
||||
|
||||
安装好后,你可以测试一下。
|
||||
|
||||
![][7]
|
||||
|
||||
要退出 Erlang shell,使用 `Ctrl+g`,然后输入 `q`,由于我从来没有用过 Erlang,所以我只好尝试了一些按键,然后发现了操作方法。
|
||||
|
||||
#### 删除 erlang
|
||||
|
||||
要删除该程序,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt remove erlang
|
||||
```
|
||||
|
||||
还会有一些依赖关系。你可以用下面的命令删除它们:
|
||||
|
||||
```
|
||||
sudo apt autoremove
|
||||
```
|
||||
|
||||
如果你愿意,你也可以删除添加的仓库文件。
|
||||
|
||||
```
|
||||
sudo rm /etc/apt/sources.list.d/erlang-solution.list
|
||||
```
|
||||
|
||||
就是这样。享受在 Ubuntu Linux 上使用 Erlang 学习和编码的乐趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-erlang-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.erlang.org/
|
||||
[2]: https://www.ericsson.com/en
|
||||
[3]: https://itsfoss.com/ubuntu-repositories/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/install-erlang-ubuntu.png?resize=800%2C445&ssl=1
|
||||
[5]: https://www.erlang-solutions.com/downloads/
|
||||
[6]: https://itsfoss.com/download-files-from-linux-terminal/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/erlang-shell.png?resize=800%2C274&ssl=1
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: subject: (4 open source tools for running a Linux server)
|
||||
[#]: via: (https://opensource.com/article/21/3/linux-server)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13192-1.html)
|
||||
|
||||
4 个打造多媒体和共享服务器的开源工具
|
||||
======
|
||||
|
||||
> 通过 Linux,你可以将任何设备变成服务器,以共享数据、媒体文件,以及其他资源。
|
||||
|
||||

|
||||
|
||||
在 2021 年,人们喜欢 Linux 的理由比以往任何时候都多。在这个系列中,我将分享 21 个使用 Linux 的不同理由。这里有四个开源工具,可以将任何设备变成 Linux 服务器。
|
||||
|
||||
有时,我会发现有关服务器概念的某种神秘色彩。许多人,如果他们在脑海中有一个形象的话,他们认为服务器一定是又大又重的机架式机器,由一个谨慎的系统管理员和一群神奇的修理工精心维护。另一些人则把服务器设想成虚无缥缈的云朵,以某种方式为互联网提供动力。
|
||||
|
||||
虽然这种敬畏对 IT 工作的安全性是有好处的,但事实上,在开源计算中,没有人认为服务器是或应该是专家的专属领域。文件和资源共享是开源不可或缺的,而开源让它变得比以往任何时候都更容易,正如这四个开源服务器项目所展示的那样。
|
||||
|
||||
### Samba
|
||||
|
||||
[Samba 项目][2] 是 Linux 和 Unix 的 Windows 互操作程序套件。尽管它是大多数用户从未与之交互的底层代码,但它的重要性却不容小觑。从历史上看,早在微软争相消灭 Linux 和开源的时候,它就是最大最重要的目标。时代变了,微软已经与 Samba 团队会面以提供支持(至少目前是这样),在这一切中,该项目继续确保 Linux 和 Windows 计算机可以轻松地在同一网络上共存。换句话说,无论你使用什么平台,Samba 都可以让你可以轻松地在本地网络上共享文件。
|
||||
|
||||
在 [KDE Plasma][3] 桌面上,你可以右键点击自己的任何目录,选择**属性**。在**属性**对话框中,点击**共享**选项卡,并启用**与 Samba 共享(Microsoft Windows)**。
|
||||
|
||||
![Samba][4]
|
||||
|
||||
就这样,你已经为本地网络上的用户打开了一个只读访问的目录。也就是说,当你在家的时候,你家同一个 WiFi 网络上的任何人都可以访问该文件夹,如果你在工作,工作场所网络上的任何人都可以访问该文件夹。当然,要访问它,其他用户需要知道在哪里可以找到它。通往计算机的路径可以用 [IP 地址][6] 表示,也可以根据你的网络配置,用主机名表示。
|
||||
|
||||
### Snapdrop
|
||||
|
||||
如果通过 IP 地址和主机名来打开网络是令人困惑的,或者如果你不喜欢打开一个文件夹进行共享而忘记它是开放的,那么你可能更喜欢 [Snapdrop][7]。这是一个开源项目,你可以自己运行,也可以使用互联网上的演示实例通过 WebRTC 连接计算机。WebRTC 可以通过 Web 浏览器实现点对点的连接,也就是说同一网络上的两个用户可以通过 Snapdrop 找到对方,然后直接进行通信,而不需要通过外部服务器。
|
||||
|
||||
![Snapdrop][8]
|
||||
|
||||
一旦两个或更多的客户端连接了同一个 Snapdrop 服务,用户就可以通过本地网络来回交换文件和聊天信息。传输的速度很快,而且你的数据也保持在本地。
|
||||
|
||||
### VLC
|
||||
|
||||
流媒体服务比以往任何时候都更常见,但我在音乐和电影方面有非常规的口味,所以典型的服务似乎很少有我想要的东西。幸运的是,通过连接到媒体驱动器,我可以很容易地将自己的内容从我的电脑上传送到我的房子各个角落。例如,当我想在电脑显示器以外的屏幕上观看一部电影时,我可以在我的网络上串流电影文件,并通过任何可以接收 HTTP 的应用来播放它,无论该应用是在我的电视、游戏机还是手机上。
|
||||
|
||||
[VLC][9] 可以轻松设置流媒体。事实上,它是**媒体**菜单中的一个选项,或者你可以按下键盘 `Ctrl+S`。将一个文件或一组文件添加到你的流媒体队列中,然后点击 **Stream** 按钮。
|
||||
|
||||
![VLC][10]
|
||||
|
||||
VLC 通过配置向导来帮助你决定流媒体数据时使用什么协议。我倾向于使用 HTTP,因为它通常在任何设备上可用。当 VLC 开始播放文件时,请进入播放文件计算机的 IP 或主机名以及给它分配的端口 (当使用 HTTP 时,默认是 8080), 然后坐下来享受。
|
||||
|
||||
### PulseAudio
|
||||
|
||||
我最喜欢的现代 Linux 功能之一是 [PulseAudio][11]。Pulse 为 Linux 上的音频实现了惊人的灵活性,包括可自动发现的本地网络流媒体。这个功能对我来说的好处是,我可以在办公室的工作站上播放播客和技术会议视频,并通过手机串流音频。无论我走进厨房、休息室还是后院最远的地方,我都能获得完美的音频。此功能在 PulseAudio 之前很久就存在,但是 Pulse 使它像单击按钮一样容易。
|
||||
|
||||
需要进行一些设置。首先,你必须确保安装 PulseAudio 设置包(**paprefs**),以便在 PulseAudio 配置中启用网络音频。
|
||||
|
||||
![PulseAudio][12]
|
||||
|
||||
在 **paprefs** 中,启用网络访问你的本地声音设备,可能不需要认证(假设你信任本地网络上的其他人),并启用你的计算机作为 **Multicast/RTP 发送者**。我通常只选择串流通过我的扬声器播放的任何音频,但你可以在 Pulse 输出选项卡中创建一个单独的音频设备,这样你就可以准确地选择串流的内容。你在这里有三个选项:
|
||||
|
||||
* 串流任何在扬声器上播放的音频
|
||||
* 串流所有输出的声音
|
||||
* 只将音频直接串流到多播设备(按需)。
|
||||
|
||||
一旦启用,你的声音就会串流到网络中,并可被其他本地 Linux 设备接收。这是简单和动态的音频共享。
|
||||
|
||||
### 分享的不仅仅是代码
|
||||
|
||||
Linux 是共享的。它在服务器领域很有名,因为它很擅长*服务*。无论是提供音频流、视频流、文件,还是出色的用户体验,每一台 Linux 电脑都是一台出色的 Linux 服务器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/3/linux-server
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rack_server_sysadmin_cloud_520.png?itok=fGmwhf8I (A rack of servers, blue background)
|
||||
[2]: http://samba.org
|
||||
[3]: https://opensource.com/article/19/12/linux-kde-plasma
|
||||
[4]: https://opensource.com/sites/default/files/uploads/samba_0.jpg (Samba)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://opensource.com/article/18/5/how-find-ip-address-linux
|
||||
[7]: https://github.com/RobinLinus/snapdrop
|
||||
[8]: https://opensource.com/sites/default/files/uploads/snapdrop.jpg (Snapdrop)
|
||||
[9]: https://www.videolan.org/index.html
|
||||
[10]: https://opensource.com/sites/default/files/uploads/vlc-stream.jpg (VLC)
|
||||
[11]: https://www.freedesktop.org/wiki/Software/PulseAudio/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/pulse.jpg (PulseAudio)
|
||||
@ -0,0 +1,130 @@
|
||||
[#]: subject: (Meet SysMonTask: A Windows Task Manager Lookalike for Linux)
|
||||
[#]: via: (https://itsfoss.com/sysmontask/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13189-1.html)
|
||||
|
||||
SysMonTask:一个类似于 Windows 任务管理器的 Linux 系统监控器
|
||||
======
|
||||
|
||||

|
||||
|
||||
得益于桌面环境,几乎所有的 [Linux 发行版都带有任务管理器应用程序][1]。除此之外,还有 [一些其他的 Linux 的系统监控应用程序][2],它们具有更多的功能。
|
||||
|
||||
但最近我遇到了一个为 Linux 创建的任务管理器,它看起来像……嗯……Windows 的任务管理器。
|
||||
|
||||
你自己看看就知道了。
|
||||
|
||||
![][3]
|
||||
|
||||
就我个人而言,我不确定用户界面的相似性是否有意义,但开发者和其他一些 Linux 用户可能不同意我的观点。
|
||||
|
||||
### SysMonTask: 一个具有 Windows 任务管理器外观的系统监控器
|
||||
|
||||
![][4]
|
||||
|
||||
开源软件 [SysMonTask][5] 将自己描述为“具有 Windows 任务管理器的紧凑性和实用性的 Linux 系统监控器,以实现更高的控制和监控”。
|
||||
|
||||
SysMonTask 以 Python 编写,拥有以下功能:
|
||||
|
||||
* 系统监控图。
|
||||
* 显示 CPU、内存、磁盘、网络适配器、单个 Nvidia GPU 的统计数据。
|
||||
* 在最近的版本中增加了对挂载磁盘列表的支持。
|
||||
* 用户进程选项卡可以进行进程过滤,显示递归-CPU、递归-内存和列头的汇总值。
|
||||
* 当然,你可以在进程选项卡中杀死一个进程。
|
||||
* 还支持系统主题(深色和浅色)。
|
||||
|
||||
### 体验 SysMonTask
|
||||
|
||||
SysMonTask 需要提升权限。当你启动它时,你会被要求提供你的管理员密码。我不喜欢一个任务管理器一直用 `sudo` 运行,但这只是我的喜好。
|
||||
|
||||
我玩了一下,探索它的功能。磁盘的使用量基本稳定不变,所以我把一个 10GB 的文件从外部 SSD 复制到笔记本的磁盘上几次。你可以看到文件传输时对应的峰值。
|
||||
|
||||
![][6]
|
||||
|
||||
进程标签也很方便。它在列的顶部显示了累积的资源利用率。
|
||||
|
||||
杀死按钮被添加在底部,所以你要做的就是选择一个进程,然后点击“Killer” 按钮。它在 [杀死进程][7] 之前会询问你的确认。
|
||||
|
||||
![][8]
|
||||
|
||||
### 在 Linux 发行版上安装 SysMonTask
|
||||
|
||||
对于一个简单的应用程序,它需要下载 50 MB 的存档文件,并占用了大约 200 MB 的磁盘。我想这是因为 Python 的依赖性。
|
||||
|
||||
还有就是它读取的是 env。
|
||||
|
||||
在写这篇文章的时候,SysMonTask 可以通过 [PPA][9] 在基于 Ubuntu 的发行版上使用。
|
||||
|
||||
在基于 Ubuntu 的发行版上,打开一个终端,使用以下命令添加 PPA 仓库:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:camel-neeraj/sysmontask
|
||||
```
|
||||
|
||||
当然,你会被要求输入密码。在新版本中,仓库列表会自动更新。所以,你可以直接安装应用程序:
|
||||
|
||||
```
|
||||
sudo apt install sysmontask
|
||||
```
|
||||
|
||||
基于 Debian 的发行版也可以尝试从 deb 文件中安装它。它可以在发布页面找到。
|
||||
|
||||
对于其他发行版,没有现成的软件包。令我惊讶的是,它基本上是一个 Python 应用程序,所以可以为其他发行版添加一个 PIP 安装程序。也许开发者会在未来的版本中添加它。
|
||||
|
||||
由于它是开源软件,你可以随时得到源代码。
|
||||
|
||||
- [SysMonTask Deb 文件和源代码][10]
|
||||
|
||||
安装完毕后,在菜单中寻找 SysMonTask,并从那里启动它。
|
||||
|
||||
#### 删除 SysMonTask
|
||||
|
||||
如果你想删除它,使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt remove sysmontask
|
||||
```
|
||||
|
||||
最好也 [删除 PPA][11]:
|
||||
|
||||
```
|
||||
sudo add-apt-repository -r ppa:camel-neeraj/sysmontask
|
||||
```
|
||||
|
||||
你也可以在这里 [使用 PPA 清除][12] 工具,这是一个处理 PPA 应用程序删除的方便工具。
|
||||
|
||||
### 你会尝试吗?
|
||||
|
||||
对我来说,功能比外观更重要。SysMonTask 确实有额外的功能,监测磁盘性能和检查 GPU 统计数据,这是其他系统监视器通常不包括的东西。
|
||||
|
||||
如果你尝试并喜欢它,也许你会喜欢添加 `Ctrl+Alt+Del` 快捷键来启动 SysMonTask,以获得完整的感觉 :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/sysmontask/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/task-manager-linux/
|
||||
[2]: https://itsfoss.com/linux-system-monitoring-tools/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/sysmontask-1.png?resize=800%2C559&ssl=1
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/SysMonTask-CPU.png?resize=800%2C537&ssl=1
|
||||
[5]: https://github.com/KrispyCamel4u/SysMonTask
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/02/sysmontask-disk-usage.png?resize=800%2C498&ssl=1
|
||||
[7]: https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/kill-process-sysmontask.png?resize=800%2C500&ssl=1
|
||||
[9]: https://itsfoss.com/ppa-guide/
|
||||
[10]: https://github.com/KrispyCamel4u/SysMonTask/releases
|
||||
[11]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
|
||||
[12]: https://itsfoss.com/ppa-purge/
|
||||
@ -0,0 +1,102 @@
|
||||
[#]: subject: (Guake Terminal: A Customizable Linux Terminal for Power Users [Inspired by an FPS Game])
|
||||
[#]: via: (https://itsfoss.com/guake-terminal/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13187-1.html)
|
||||
|
||||
Guake 终端:一个灵感来自于 FPS 游戏的 Linux 终端
|
||||
======
|
||||
|
||||
> 使用 Guake 终端这个可自定义且强大的适合各种用户的工具快速访问你的终端。
|
||||
|
||||
### Guake 终端:GNOME 桌面中自上而下终端
|
||||
|
||||

|
||||
|
||||
[Guake][2] 是一款为 GNOME 桌面量身定做的终端模拟器,采用下拉式设计。
|
||||
|
||||
它最初的灵感来自于一款 FPS 游戏([Quake][3])中的终端。尽管它最初是作为一个快速和易于使用的终端而设计的,但它的功能远不止于此。
|
||||
|
||||
Guake 终端提供了大量的功能,以及可定制的选项。在这里,我将重点介绍终端的主要功能,以及如何将它安装到你的任何 Linux 发行版上。
|
||||
|
||||
### Guake 终端的特点
|
||||
|
||||
![][4]
|
||||
|
||||
* 按下键盘快捷键(`F12`)以覆盖方式在任何地方启动终端
|
||||
* Guake 终端在后台运行,以便持久访问
|
||||
* 能够横向和纵向分割标签页
|
||||
* 从可用的 shell 中(如果有的话)更改默认的 shell
|
||||
* 重新对齐
|
||||
* 从多种调色板中选择改变终端的外观
|
||||
* 能够使用 GUI 方式将终端内容保存到文件中
|
||||
* 需要时切换全屏
|
||||
* 你可以轻松地保存标签,或在需要时打开新的标签
|
||||
* 恢复标签的能力
|
||||
* 可选择配置和学习新的键盘快捷键,以快速访问终端和执行任务
|
||||
* 改变特定选项卡的颜色
|
||||
* 轻松重命名标签,快速访问你需要的内容
|
||||
* 快速打开功能,只需点击一下,就可直接在终端中用你最喜欢的编辑器打开文件
|
||||
* 能够在启动或显示 Guake 终端时添加自己的命令或脚本。
|
||||
* 支持多显示器
|
||||
|
||||
![][5]
|
||||
|
||||
只是出于乐趣,你可以做很多事情。但是,我也相信,高级用户可以利用这些功能使他们的终端体验更轻松,更高效。
|
||||
|
||||
就我用它来测试一些东西和写这篇文章的时候,说实话,我觉得我是在召唤终端。所以,我绝对觉得它很酷!
|
||||
|
||||
### 在 Linux 上安装 Guake
|
||||
|
||||
![][6]
|
||||
|
||||
在 Ubuntu、Fedora 和 Arch 的默认仓库中都有 Guake 终端。
|
||||
|
||||
你可以按照它的官方说明来了解你可以使用的命令,如果你使用的是基于 Ubuntu 的发行版,只需输入:
|
||||
|
||||
```
|
||||
sudo apt install guake
|
||||
```
|
||||
|
||||
请注意,使用这种方法可能无法获得最新版本。所以,如果你想获得最新的版本,你可以选择使用 [Linux Uprising][7] 的 PPA 来获得最新版本:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:linuxuprising/guake
|
||||
sudo apt update
|
||||
sudo apt install guake
|
||||
```
|
||||
|
||||
无论是哪种情况,你也可以使用 [Pypi][8] 或者参考[官方文档][9]或从 [GitHub 页面][10]获取源码。
|
||||
|
||||
- [Guake Terminal][10]
|
||||
|
||||
你觉得 Guake 终端怎么样?你认为它是一个有用的终端仿真器吗?你知道有什么类似的软件吗?
|
||||
|
||||
欢迎在下面的评论中告诉我你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/guake-terminal/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/guake-terminal-1.png?resize=800%2C363&ssl=1
|
||||
[2]: http://guake-project.org/
|
||||
[3]: https://quake.bethesda.net/en
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/guake-terminal.jpg?resize=800%2C245&ssl=1
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/02/guake-preferences.jpg?resize=800%2C559&ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/02/guake-terminal-2.png?resize=800%2C432&ssl=1
|
||||
[7]: https://www.linuxuprising.com/
|
||||
[8]: https://pypi.org/
|
||||
[9]: https://guake.readthedocs.io/en/latest/user/installing.html
|
||||
[10]: https://github.com/Guake/guake
|
||||
84
published/202103/20210304 An Introduction to WebAssembly.md
Normal file
84
published/202103/20210304 An Introduction to WebAssembly.md
Normal file
@ -0,0 +1,84 @@
|
||||
[#]: subject: (An Introduction to WebAssembly)
|
||||
[#]: via: (https://www.linux.com/news/an-introduction-to-webassembly/)
|
||||
[#]: author: (Marco Fioretti https://training.linuxfoundation.org/announcements/an-introduction-to-webassembly/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13197-1.html)
|
||||
|
||||
WebAssembly 介绍
|
||||
======
|
||||
|
||||

|
||||
|
||||
### 到底什么是 WebAssembly?
|
||||
|
||||
[WebAssembly][1],也叫 Wasm,是一种为 Web 优化的代码格式和 API(应用编程接口),它可以大大提高网站的性能和能力。WebAssembly 的 1.0 版本于 2017 年发布,并于 2019 年成为 W3C 官方标准。
|
||||
|
||||
该标准得到了所有主流浏览器供应商的积极支持,原因显而易见:官方列出的 [“浏览器内部”用例][2] 中提到了,其中包括视频编辑、3D 游戏、虚拟和增强现实、p2p 服务和科学模拟。除了让浏览器的功能比JavaScript 强大得多,该标准甚至可以延长网站的寿命:例如,正是 WebAssembly 为 [互联网档案馆的 Flash 动画和游戏][3] 提供了持续的支持。
|
||||
|
||||
不过,WebAssembly 并不只用于浏览器,目前它还被用于移动和基于边缘环境的 Cloudflare Workers 等产品中。
|
||||
|
||||
### WebAssembly 如何工作?
|
||||
|
||||
.wasm 格式的文件包含低级二进制指令(字节码),可由使用通用栈的虚拟机以“接近 CPU 原生速度”执行。这些代码被打包成模块(可以被浏览器直接执行的对象),每个模块可以被一个网页多次实例化。模块内部定义的函数被列在一个专用数组中,或称为<ruby>表<rt>Table</rt></ruby>,相应的数据被包含在另一个结构中,称为 <ruby>缓存数组<rt>arraybuffer</rt></ruby>。开发者可以通过 Javascript `WebAssembly.memory()` 的调用,为 .wasm 代码显式分配内存。
|
||||
|
||||
.wasm 格式也有纯文本版本,它可以大大简化学习和调试。然而,WebAssembly 并不是真的要供人直接使用。从技术上讲,.wasm 只是一个与浏览器兼容的**编译目标**:一种用高级编程语言编写的软件编译器可以自动翻译的代码格式。
|
||||
|
||||
这种选择正是使开发人员能够使用数十亿人熟悉的语言(C/C++、Python、Go、Rust 等)直接为用户界面进行编程的方式,但以前浏览器无法对其进行有效利用。更妙的是,至少在理论上程序员可以利用它们,无需直接查看 WebAssembly 代码,也无需担心物理 CPU 实际运行他们的代码(因为目标是一个**虚拟**机)。
|
||||
|
||||
### 但是我们已经有了 JavaScript,我们真的需要 WebAssembly 吗?
|
||||
|
||||
是的,有几个原因。首先,作为二进制指令,.wasm 文件比同等功能的 JavaScript 文件小得多,下载速度也快得多。最重要的是,Javascript 文件必须在浏览器将其转换为其内部虚拟机可用的字节码之前进行完全解析和验证。
|
||||
|
||||
而 .wasm 文件则可以一次性验证和编译,从而使“流式编译”成为可能:浏览器在开始**下载它们**的那一刻就可以开始编译和执行它们,就像串流电影一样。
|
||||
|
||||
这就是说,并不是所有可以想到的 WebAssembly 应用都肯定会比由专业程序员手动优化的等效 JavaScript 应用更快或更小。例如,如果一些 .wasm 需要包含 JavaScript 不需要的库,这种情况可能会发生。
|
||||
|
||||
### WebAssembly 是否会让 JavaScript 过时?
|
||||
|
||||
一句话:不会。暂时不会,至少在浏览器内不会。WebAssembly 模块仍然需要 JavaScript,因为在设计上它们不能访问文档对象模型 (DOM)—— [主要用于修改网页的 API][4]。此外,.wasm 代码不能进行系统调用或读取浏览器的内存。WebAssembly 只能在沙箱中运行,一般来说,它能与外界的交互甚至比 JavaScript 更少,而且只能通过 JavaScript 接口进行。
|
||||
|
||||
因此,至少在不久的将来 .wasm 模块将只是通过 JavaScript 提供那些如果用 JavaScript 语言编写会消耗更多带宽、内存或 CPU 时间的部分。
|
||||
|
||||
### Web 浏览器如何运行 WebAssembly?
|
||||
|
||||
一般来说,浏览器至少需要两块来处理动态应用:运行应用代码的虚拟机(VM),以及可以同时修改浏览器行为和网页显示的 API。
|
||||
|
||||
现代浏览器内部的虚拟机通过以下方式同时支持 JavaScript 和 WebAssembly:
|
||||
|
||||
1. 浏览器下载一个用 HTML 标记语言编写的网页,然后进行渲染
|
||||
2. 如果该 HTML 调用 JavaScript 代码,浏览器的虚拟机就会执行该代码。但是...
|
||||
3. 如果 JavaScript 代码中包含了 WebAssembly 模块的实例,那么就按照上面的描述获取该实例,然后根据需要通过 JavaScript 的 WebAssembly API 来使用该实例
|
||||
4. 当 WebAssembly 代码产生的东西将修改 DOM(即“宿主”网页)的结构,JavaScript 代码就会接收到,并继续进行实际的修改。
|
||||
|
||||
### 我如何才能创建可用的 WebAssembly 代码?
|
||||
|
||||
越来越多的编程语言社区支持直接编译到 Wasm,我们建议从 webassembly.org 的 [入门指南][5] 开始,这取决于你使用什么语言。请注意,并不是所有的编程语言都有相同水平的 Wasm 支持,因此你的工作量可能会有所不同。
|
||||
|
||||
我们计划在未来几个月内发布一系列文章,提供更多关于 WebAssembly 的信息。要自己开始使用它,你可以报名参加 Linux 基金会的免费 [WebAssembly 介绍][6]在线培训课程。
|
||||
|
||||
这篇[WebAssembly 介绍][7]首次发布在 [Linux Foundation – Training][8]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/an-introduction-to-webassembly/
|
||||
|
||||
作者:[Dan Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://training.linuxfoundation.org/announcements/an-introduction-to-webassembly/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://webassembly.org/
|
||||
[2]: https://webassembly.org/docs/use-cases/
|
||||
[3]: https://blog.archive.org/2020/11/19/flash-animations-live-forever-at-the-internet-archive/
|
||||
[4]: https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Introduction
|
||||
[5]: https://webassembly.org/getting-started/developers-guide/
|
||||
[6]: https://training.linuxfoundation.org/training/introduction-to-webassembly-lfd133/
|
||||
[7]: https://training.linuxfoundation.org/announcements/an-introduction-to-webassembly/
|
||||
[8]: https://training.linuxfoundation.org/
|
||||
@ -0,0 +1,301 @@
|
||||
[#]: subject: (Learn to debug code with the GNU Debugger)
|
||||
[#]: via: (https://opensource.com/article/21/3/debug-code-gdb)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13203-1.html)
|
||||
|
||||
学习使用 GDB 调试代码
|
||||
======
|
||||
|
||||
> 使用 GNU 调试器来解决你的代码问题。
|
||||
|
||||

|
||||
|
||||
GNU 调试器常以它的命令 `gdb` 称呼它,它是一个交互式的控制台,可以帮助你浏览源代码、分析执行的内容,其本质上是对错误的应用程序中出现的问题进行逆向工程。
|
||||
|
||||
故障排除的麻烦在于它很复杂。[GNU 调试器][2] 并不是一个特别复杂的应用程序,但如果你不知道从哪里开始,甚至不知道何时和为何你可能需要求助于 GDB 来进行故障排除,那么它可能会让人不知所措。如果你一直使用 `print`、`echo` 或 [printf 语句][3]来调试你的代码,当你开始思考是不是还有更强大的东西时,那么本教程就是为你准备的。
|
||||
|
||||
### 有错误的代码
|
||||
|
||||
要开始使用 GDB,你需要一些代码。这里有一个用 C++ 写的示例应用程序(如果你一般不使用 C++ 编写程序也没关系,在所有语言中原理都是一样的),其来源于 [猜谜游戏系列][4] 中的一个例子。
|
||||
|
||||
```
|
||||
#include <iostream>
|
||||
#include <stdlib.h> //srand
|
||||
#include <stdio.h> //printf
|
||||
|
||||
using namespace std;
|
||||
|
||||
int main () {
|
||||
|
||||
srand (time(NULL));
|
||||
int alpha = rand() % 8;
|
||||
cout << "Hello world." << endl;
|
||||
int beta = 2;
|
||||
|
||||
printf("alpha is set to is %s\n", alpha);
|
||||
printf("kiwi is set to is %s\n", beta);
|
||||
|
||||
return 0;
|
||||
} // main
|
||||
```
|
||||
|
||||
这个代码示例中有一个 bug,但它确实可以编译(至少在 GCC 5 的时候)。如果你熟悉 C++,你可能已经看到了,但这是一个简单的问题,可以帮助新的 GDB 用户了解调试过程。编译并运行它就可以看到错误:
|
||||
|
||||
```
|
||||
$ g++ -o buggy example.cpp
|
||||
$ ./buggy
|
||||
Hello world.
|
||||
Segmentation fault
|
||||
```
|
||||
|
||||
### 排除段故障
|
||||
|
||||
从这个输出中,你可以推测变量 `alpha` 的设置是正确的,因为否则的话,你就不会看到它*后面*的那行代码执行。当然,这并不总是正确的,但这是一个很好的工作理论,如果你使用 `printf` 作为日志和调试器,基本上也会得出同样的结论。从这里,你可以假设 bug 在于成功打印的那一行之后的*某行*。然而,不清楚错误是在下一行还是在几行之后。
|
||||
|
||||
GNU 调试器是一个交互式的故障排除工具,所以你可以使用 `gdb` 命令来运行错误的代码。为了得到更好的结果,你应该从包含有*调试符号*的源代码中重新编译你的错误应用程序。首先,看看 GDB 在不重新编译的情况下能提供哪些信息:
|
||||
|
||||
```
|
||||
$ gdb ./buggy
|
||||
Reading symbols from ./buggy...done.
|
||||
(gdb) start
|
||||
Temporary breakpoint 1 at 0x400a44
|
||||
Starting program: /home/seth/demo/buggy
|
||||
|
||||
Temporary breakpoint 1, 0x0000000000400a44 in main ()
|
||||
(gdb)
|
||||
```
|
||||
|
||||
当你以一个二进制可执行文件作为参数启动 GDB 时,GDB 会加载该应用程序,然后等待你的指令。因为这是你第一次在这个可执行文件上运行 GDB,所以尝试重复这个错误是有意义的,希望 GDB 能够提供进一步的见解。很直观,GDB 用来启动它所加载的应用程序的命令就是 `start`。默认情况下,GDB 内置了一个*断点*,所以当它遇到你的应用程序的 `main` 函数时,它会暂停执行。要让 GDB 继续执行,使用命令 `continue`:
|
||||
|
||||
```
|
||||
(gdb) continue
|
||||
Continuing.
|
||||
Hello world.
|
||||
|
||||
Program received signal SIGSEGV, Segmentation fault.
|
||||
0x00007ffff71c0c0b in vfprintf () from /lib64/libc.so.6
|
||||
(gdb)
|
||||
```
|
||||
|
||||
毫不意外:应用程序在打印 “Hello world” 后不久就崩溃了,但 GDB 可以提供崩溃发生时正在发生的函数调用。这有可能就足够你找到导致崩溃的 bug,但为了更好地了解 GDB 的功能和一般的调试过程,想象一下,如果问题还没有变得清晰,你想更深入地挖掘这段代码发生了什么。
|
||||
|
||||
### 用调试符号编译代码
|
||||
|
||||
要充分利用 GDB,你需要将调试符号编译到你的可执行文件中。你可以用 GCC 中的 `-g` 选项来生成这个符号:
|
||||
|
||||
```
|
||||
$ g++ -g -o debuggy example.cpp
|
||||
$ ./debuggy
|
||||
Hello world.
|
||||
Segmentation fault
|
||||
```
|
||||
|
||||
将调试符号编译到可执行文件中的结果是得到一个大得多的文件,所以通常不会分发它们,以增加便利性。然而,如果你正在调试开源代码,那么用调试符号重新编译测试是有意义的:
|
||||
|
||||
```
|
||||
$ ls -l *buggy* *cpp
|
||||
-rw-r--r-- 310 Feb 19 08:30 debug.cpp
|
||||
-rwxr-xr-x 11624 Feb 19 10:27 buggy*
|
||||
-rwxr-xr-x 22952 Feb 19 10:53 debuggy*
|
||||
```
|
||||
|
||||
### 用 GDB 调试
|
||||
|
||||
加载新的可执行文件(本例中为 `debuggy`)以启动 GDB:
|
||||
|
||||
```
|
||||
$ gdb ./debuggy
|
||||
Reading symbols from ./debuggy...done.
|
||||
(gdb) start
|
||||
Temporary breakpoint 1 at 0x400a44
|
||||
Starting program: /home/seth/demo/debuggy
|
||||
|
||||
Temporary breakpoint 1, 0x0000000000400a44 in main ()
|
||||
(gdb)
|
||||
```
|
||||
|
||||
如前所述,使用 `start` 命令进行:
|
||||
|
||||
```
|
||||
(gdb) start
|
||||
Temporary breakpoint 1 at 0x400a48: file debug.cpp, line 9.
|
||||
Starting program: /home/sek/demo/debuggy
|
||||
|
||||
Temporary breakpoint 1, main () at debug.cpp:9
|
||||
9 srand (time(NULL));
|
||||
(gdb)
|
||||
```
|
||||
|
||||
这一次,自动的 `main` 断点可以指明 GDB 暂停的行号和该行包含的代码。你可以用 `continue` 恢复正常操作,但你已经知道应用程序在完成之前就会崩溃,因此,你可以使用 `next` 关键字逐行步进检查你的代码:
|
||||
|
||||
```
|
||||
(gdb) next
|
||||
10 int alpha = rand() % 8;
|
||||
(gdb) next
|
||||
11 cout << "Hello world." << endl;
|
||||
(gdb) next
|
||||
Hello world.
|
||||
12 int beta = 2;
|
||||
(gdb) next
|
||||
14 printf("alpha is set to is %s\n", alpha);
|
||||
(gdb) next
|
||||
|
||||
Program received signal SIGSEGV, Segmentation fault.
|
||||
0x00007ffff71c0c0b in vfprintf () from /lib64/libc.so.6
|
||||
(gdb)
|
||||
```
|
||||
|
||||
从这个过程可以确认,崩溃不是发生在设置 `beta` 变量的时候,而是执行 `printf` 行的时候。这个 bug 在本文中已经暴露了好几次(破坏者:向 `printf` 提供了错误的数据类型),但暂时假设解决方案仍然不明确,需要进一步调查。
|
||||
|
||||
### 设置断点
|
||||
|
||||
一旦你的代码被加载到 GDB 中,你就可以向 GDB 询问到目前为止代码所产生的数据。要尝试数据自省,通过再次发出 `start` 命令来重新启动你的应用程序,然后进行到第 11 行。一个快速到达 11 行的简单方法是设置一个寻找特定行号的断点:
|
||||
|
||||
```
|
||||
(gdb) start
|
||||
The program being debugged has been started already.
|
||||
Start it from the beginning? (y or n) y
|
||||
Temporary breakpoint 2 at 0x400a48: file debug.cpp, line 9.
|
||||
Starting program: /home/sek/demo/debuggy
|
||||
|
||||
Temporary breakpoint 2, main () at debug.cpp:9
|
||||
9 srand (time(NULL));
|
||||
(gdb) break 11
|
||||
Breakpoint 3 at 0x400a74: file debug.cpp, line 11.
|
||||
```
|
||||
|
||||
建立断点后,用 `continue` 继续执行:
|
||||
|
||||
```
|
||||
(gdb) continue
|
||||
Continuing.
|
||||
|
||||
Breakpoint 3, main () at debug.cpp:11
|
||||
11 cout << "Hello world." << endl;
|
||||
(gdb)
|
||||
```
|
||||
|
||||
现在暂停在第 11 行,就在 `alpha` 变量被设置之后,以及 `beta` 被设置之前。
|
||||
|
||||
### 用 GDB 进行变量自省
|
||||
|
||||
要查看一个变量的值,使用 `print` 命令。在这个示例代码中,`alpha` 的值是随机的,所以你的实际结果可能与我的不同:
|
||||
|
||||
```
|
||||
(gdb) print alpha
|
||||
$1 = 3
|
||||
(gdb)
|
||||
```
|
||||
|
||||
当然,你无法看到一个尚未建立的变量的值:
|
||||
|
||||
```
|
||||
(gdb) print beta
|
||||
$2 = 0
|
||||
```
|
||||
|
||||
|
||||
### 使用流程控制
|
||||
|
||||
要继续进行,你可以步进代码行来到达将 `beta` 设置为一个值的位置:
|
||||
|
||||
```
|
||||
(gdb) next
|
||||
Hello world.
|
||||
12 int beta = 2;
|
||||
(gdb) next
|
||||
14 printf("alpha is set to is %s\n", alpha);
|
||||
(gdb) print beta
|
||||
$3 = 2
|
||||
```
|
||||
|
||||
另外,你也可以设置一个观察点,它就像断点一样,是一种控制 GDB 执行代码流程的方法。在这种情况下,你知道 `beta` 变量应该设置为 `2`,所以你可以设置一个观察点,当 `beta` 的值发生变化时提醒你:
|
||||
|
||||
```
|
||||
(gdb) watch beta > 0
|
||||
Hardware watchpoint 5: beta > 0
|
||||
(gdb) continue
|
||||
Continuing.
|
||||
|
||||
Breakpoint 3, main () at debug.cpp:11
|
||||
11 cout << "Hello world." << endl;
|
||||
(gdb) continue
|
||||
Continuing.
|
||||
Hello world.
|
||||
|
||||
Hardware watchpoint 5: beta > 0
|
||||
|
||||
Old value = false
|
||||
New value = true
|
||||
main () at debug.cpp:14
|
||||
14 printf("alpha is set to is %s\n", alpha);
|
||||
(gdb)
|
||||
```
|
||||
|
||||
你可以用 `next` 手动步进完成代码的执行,或者你可以用断点、观察点和捕捉点来控制代码的执行。
|
||||
|
||||
### 用 GDB 分析数据
|
||||
|
||||
你可以以不同格式查看数据。例如,以八进制值查看 `beta` 的值:
|
||||
|
||||
```
|
||||
(gdb) print /o beta
|
||||
$4 = 02
|
||||
```
|
||||
|
||||
要查看其在内存中的地址:
|
||||
|
||||
```
|
||||
(gdb) print /o &beta
|
||||
$5 = 0x2
|
||||
```
|
||||
|
||||
你也可以看到一个变量的数据类型:
|
||||
|
||||
```
|
||||
(gdb) whatis beta
|
||||
type = int
|
||||
```
|
||||
|
||||
### 用 GDB 解决错误
|
||||
|
||||
这种自省不仅能让你更好地了解什么代码正在执行,还能让你了解它是如何执行的。在这个例子中,对变量运行的 `whatis` 命令给了你一个线索,即你的 `alpha` 和 `beta` 变量是整数,这可能会唤起你对 `printf` 语法的记忆,使你意识到在你的 `printf` 语句中,你必须使用 `%d` 来代替 `%s`。做了这个改变,就可以让应用程序按预期运行,没有更明显的错误存在。
|
||||
|
||||
当代码编译后发现有 bug 存在时,特别令人沮丧,但最棘手的 bug 就是这样,如果它们很容易被发现,那它们就不是 bug 了。使用 GDB 是猎取并消除它们的一种方法。
|
||||
|
||||
### 下载我们的速查表
|
||||
|
||||
生活的真相就是这样,即使是最基本的编程,代码也会有 bug。并不是所有的错误都会导致应用程序无法运行(甚至无法编译),也不是所有的错误都是由错误的代码引起的。有时,bug 是基于一个特别有创意的用户所做的意外的选择组合而间歇性发生的。有时,程序员从他们自己的代码中使用的库中继承了 bug。无论原因是什么,bug 基本上无处不在,程序员的工作就是发现并消除它们。
|
||||
|
||||
GNU 调试器是一个寻找 bug 的有用工具。你可以用它做的事情比我在本文中演示的要多得多。你可以通过 GNU Info 阅读器来了解它的许多功能:
|
||||
|
||||
```
|
||||
$ info gdb
|
||||
```
|
||||
|
||||
无论你是刚开始学习 GDB 还是专业人员的,提醒一下你有哪些命令是可用的,以及这些命令的语法是什么,都是很有帮助的。
|
||||
|
||||
- [下载 GDB 速查表][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/3/debug-code-gdb
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/mistake_bug_fix_find_error.png?itok=PZaz3dga (magnifying glass on computer screen, finding a bug in the code)
|
||||
[2]: https://www.gnu.org/software/gdb/
|
||||
[3]: https://opensource.com/article/20/8/printf
|
||||
[4]: https://linux.cn/article-12985-1.html
|
||||
[5]: https://opensource.com/downloads/gnu-debugger-cheat-sheet
|
||||
@ -0,0 +1,104 @@
|
||||
[#]: subject: (You Can Now Install Official Evernote Client on Ubuntu and Debian-based Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/install-evernote-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13195-1.html)
|
||||
|
||||
在 Linux 上安装官方 Evernote 客户端
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Evernote][1] 是一款流行的笔记应用。它在推出时是一个革命性的产品。从那时起,已经有好几个这样的应用,可以将网络剪报、笔记等保存为笔记本格式。
|
||||
|
||||
多年来,Evernote 一直没有在 Linux 上使用的桌面客户端。前段时间 Evernote 承诺推出 Linux 应用,其测试版终于可以在基于 Ubuntu 的发行版上使用了。
|
||||
|
||||
> 非 FOSS 警报!
|
||||
>
|
||||
> Evernote Linux 客户端不是开源的。之所以在这里介绍它,是因为该应用是在 Linux 上提供的,我们也会不定期地介绍 Linux 用户常用的非 FOSS 应用。这对普通桌面 Linux 用户有帮助。
|
||||
|
||||
### 在 Ubuntu 和基于 Debian 的 Linux 发行版上安装 Evernote
|
||||
|
||||
进入这个 Evernote 的[网站页面][2]。
|
||||
|
||||
向下滚动一点,接受“早期测试计划”的条款和条件。你会看到一个“立即安装”的按钮出现在屏幕上。点击它来下载 DEB 文件。
|
||||
|
||||
![][3]
|
||||
|
||||
要 [从 DEB 文件安装应用][4],请双击它。它应该会打开软件中心,并给你选择安装它。
|
||||
|
||||
![][5]
|
||||
|
||||
安装完成后,在系统菜单中搜索 Evernote 并启动它。
|
||||
|
||||
![][6]
|
||||
|
||||
当你第一次启动应用时,你需要登录到你的 Evernote 账户。
|
||||
|
||||
![][7]
|
||||
|
||||
第一次运行会带你进入“主页面”,在这里你可以整理你的笔记本,以便更快速地访问。
|
||||
|
||||
![][8]
|
||||
|
||||
你现在可以享受在 Linux 上使用 Evernote 了。
|
||||
|
||||
### 体验 Evernote 的 Linux 测试版客户端
|
||||
|
||||
由于软件处于测试版,因此这里或那里会有些问题。
|
||||
|
||||
如上图所示,Evernote Linux 客户端检测到 [Ubuntu 中的深色模式][9] 并自动切换到深色主题。然而,当我把系统主题改为浅色或标准主题时,它并没有立即改变应用主题。这些变化是在我重启 Evernote 应用后才生效的。
|
||||
|
||||
另一个问题是关于关闭应用。如果你点击 “X” 按钮关闭 Evernote,程序会进入后台而不是退出。
|
||||
|
||||
有一个似乎可以启动最小化的 Evernote 的应用指示器,就像 [Linux 上的 Skype][10]。不幸的是,事实并非如此。它打开了便笺,让你快速输入笔记。
|
||||
|
||||
这为你提供了另一个 [Linux 上的笔记应用][11],但它也带来了一个问题。这里没有退出 Evernote 的选项。它只用于打开快速记事应用。
|
||||
|
||||
![][12]
|
||||
|
||||
那么,如何退出 Evernote 应用呢?为此,再次打开 Evernote 应用。如果它在后台运行,在菜单中搜索它,并启动它,就像你重新打开它一样。
|
||||
|
||||
当 Evernote 应用在前台运行时,点击 “文件->退出” 来退出 Evernote。
|
||||
|
||||
![][13]
|
||||
|
||||
这一点开发者应该在未来的版本中寻求改进。
|
||||
|
||||
我也不能说测试版的程序将来会如何更新。它没有添加任何仓库。我只是希望程序本身能够通知用户有新的版本,这样用户就可以下载新的 DEB 文件。
|
||||
|
||||
我并没有订阅 Evernote Premium,但我仍然可以在没有网络连接的情况下访问保存的网络文章和笔记。很奇怪,对吧?
|
||||
|
||||
总的来说,我很高兴看到 Evernote 终于努力把这个应用带到了 Linux 上。现在,你不必再尝试第三方应用来在 Linux 上使用 Evernote 了,至少在 Ubuntu 和基于 Debian 的发行版上是这样。当然,你可以使用 [Evernote 替代品][14],比如 [Joplin][15],它们都是开源的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-evernote-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://evernote.com/
|
||||
[2]: https://evernote.com/intl/en/b1433t1422
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-early-access-linux.png?resize=799%2C495&ssl=1
|
||||
[4]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/install-evernote-linux.png?resize=800%2C539&ssl=1
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-ubuntu.jpg?resize=800%2C230&ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-running-ubuntu.png?resize=800%2C505&ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-on-ubuntu.png?resize=800%2C537&ssl=1
|
||||
[9]: https://itsfoss.com/dark-mode-ubuntu/
|
||||
[10]: https://itsfoss.com/install-skype-ubuntu-1404/
|
||||
[11]: https://itsfoss.com/note-taking-apps-linux/
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/evernote-app-indicator.png?resize=800%2C480&ssl=1
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/03/quit-evernote-linux.png?resize=799%2C448&ssl=1
|
||||
[14]: https://itsfoss.com/5-evernote-alternatives-linux/
|
||||
[15]: https://itsfoss.com/joplin/
|
||||
@ -0,0 +1,171 @@
|
||||
[#]: subject: (5 surprising things you can do with LibreOffice from the command line)
|
||||
[#]: via: (https://opensource.com/article/21/3/libreoffice-command-line)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13219-1.html)
|
||||
|
||||
5 个用命令行操作 LibreOffice 的技巧
|
||||
======
|
||||
|
||||
> 直接在命令行中对文件进行转换、打印、保护等操作。
|
||||
|
||||

|
||||
|
||||
LibreOffice 拥有所有你想要的办公软件套件的生产力功能,使其成为微软 Office 或谷歌套件的流行的开源替代品。LibreOffice 的能力之一是可以从命令行操作。例如,Seth Kenlon 最近解释了如何使用 LibreOffice 用全局 [命令行选项将多个文件][2] 从 DOCX 转换为 EPUB。他的文章启发我分享一些其他 LibreOffice 命令行技巧和窍门。
|
||||
|
||||
在查看 LibreOffice 命令的一些隐藏功能之前,你需要了解如何使用应用选项。并不是所有的应用都接受选项(除了像 `--help` 选项这样的基本选项,它在大多数 Linux 应用中都可以使用)。
|
||||
|
||||
```
|
||||
$ libreoffice --help
|
||||
```
|
||||
|
||||
这将返回 LibreOffice 接受的其他选项的描述。有些应用没有太多选项,但 LibreOffice 好几页有用的选项,所以有很多东西可以玩。
|
||||
|
||||
就是说,你可以在终端上使用 LibreOffice 进行以下五项有用的操作,来让使软件更加有用。
|
||||
|
||||
### 1、自定义你的启动选项
|
||||
|
||||
你可以修改你启动 LibreOffice 的方式。例如,如果你想只打开 LibreOffice 的文字处理器组件:
|
||||
|
||||
```
|
||||
$ libreoffice --writer # 启动文字处理器
|
||||
```
|
||||
|
||||
你可以类似地打开它的其他组件:
|
||||
|
||||
|
||||
```
|
||||
$ libreoffice --calc # 启动一个空的电子表格
|
||||
$ libreoffice --draw # 启动一个空的绘图文档
|
||||
$ libreoffice --web # 启动一个空的 HTML 文档
|
||||
```
|
||||
|
||||
你也可以从命令行访问特定的帮助文件:
|
||||
|
||||
```
|
||||
$ libreoffice --helpwriter
|
||||
```
|
||||
|
||||
![LibreOffice Writer help][3]
|
||||
|
||||
或者如果你需要电子表格应用方面的帮助:
|
||||
|
||||
```
|
||||
$ libreoffice --helpcalc
|
||||
```
|
||||
|
||||
你可以在不显示启动屏幕的情况下启动 LibreOffice:
|
||||
|
||||
```
|
||||
$ libreoffice --writer --nologo
|
||||
```
|
||||
|
||||
你甚至可以在你完成当前窗口的工作时,让它在后台最小化启动:
|
||||
|
||||
```
|
||||
$ libreoffice --writer --minimized
|
||||
```
|
||||
|
||||
### 2、以只读模式打开一个文件
|
||||
|
||||
你可以使用 `--view` 以只读模式打开文件,以防止意外地对重要文件进行修改和保存:
|
||||
|
||||
```
|
||||
$ libreoffice --view example.odt
|
||||
```
|
||||
|
||||
### 3、打开一个模板文档
|
||||
|
||||
你是否曾经创建过用作信头或发票表格的文档?LibreOffice 具有丰富的内置模板系统,但是你可以使用 `-n` 选项将任何文档作为模板:
|
||||
|
||||
```
|
||||
$ libreoffice --writer -n example.odt
|
||||
```
|
||||
|
||||
你的文档将在 LibreOffice 中打开,你可以对其进行修改,但保存时不会覆盖原始文件。
|
||||
|
||||
### 4、转换文档
|
||||
|
||||
当你需要做一个小任务,比如将一个文件转换为新的格式时,应用启动的时间可能与完成任务的时间一样长。解决办法是 `--headless` 选项,它可以在不启动图形用户界面的情况下执行 LibreOffice 进程。
|
||||
|
||||
例如,在 LibreOffic 中,将一个文档转换为 EPUB 是一个非常简单的任务,但使用 `libreoffice` 命令就更容易:
|
||||
|
||||
```
|
||||
$ libreoffice --headless --convert-to epub example.odt
|
||||
```
|
||||
|
||||
使用通配符意味着你可以一次转换几十个文档:
|
||||
|
||||
```
|
||||
$ libreoffice --headless --convert-to epub *.odt
|
||||
```
|
||||
|
||||
你可以将文件转换为多种格式,包括 PDF、HTML、DOC、DOCX、EPUB、纯文本等。
|
||||
|
||||
### 5、从终端打印
|
||||
|
||||
你可以从命令行打印 LibreOffice 文档,而无需打开应用:
|
||||
|
||||
```
|
||||
$ libreoffice --headless -p example.odt
|
||||
```
|
||||
|
||||
这个选项不需要打开 LibreOffice 就可以使用默认打印机打印,它只是将文档发送到你的打印机。
|
||||
|
||||
要打印一个目录中的所有文件:
|
||||
|
||||
```
|
||||
$ libreoffice -p *.odt
|
||||
```
|
||||
|
||||
(我不止一次执行了这个命令,然后用完了纸,所以在你开始之前,确保你的打印机里有足够的纸张。)
|
||||
|
||||
你也可以把文件输出成 PDF。通常这和使用 `--convert-to-pdf` 选项没有什么区别,但是很容易记住:
|
||||
|
||||
|
||||
```
|
||||
$ libreoffice --print-to-file example.odt --headless
|
||||
```
|
||||
|
||||
### 额外技巧:Flatpak 和命令选项
|
||||
|
||||
如果你是使用 [Flatpak][5] 安装的 LibreOffice,所有这些命令选项都可以使用,但你必须通过 Flatpak 传递。下面是一个例子:
|
||||
|
||||
```
|
||||
$ flatpak run org.libreoffice.LibreOffice --writer
|
||||
```
|
||||
|
||||
它比本地安装要麻烦得多,所以你可能会受到启发 [写一个 Bash 别名][6] 来使它更容易直接与 LibreOffice 交互。
|
||||
|
||||
### 令人惊讶的终端选项
|
||||
|
||||
通过查阅手册页面,了解如何从命令行扩展 LibreOffice 的功能:
|
||||
|
||||
```
|
||||
$ man libreoffice
|
||||
```
|
||||
|
||||
你是否知道 LibreOffice 具有如此丰富的命令行选项? 你是否发现了其他人似乎都不了解的其他选项? 请在评论中分享它们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/3/libreoffice-command-line
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/shortcut_command_function_editing_key.png?itok=a0sEc5vo (hot keys for shortcuts or features on computer keyboard)
|
||||
[2]: https://opensource.com/article/21/2/linux-workday
|
||||
[3]: https://opensource.com/sites/default/files/uploads/libreoffice-help.png (LibreOffice Writer help)
|
||||
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[5]: https://www.libreoffice.org/download/flatpak/
|
||||
[6]: https://opensource.com/article/19/7/bash-aliases
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: subject: (Track your family calendar with a Raspberry Pi and a low-power display)
|
||||
[#]: via: (https://opensource.com/article/21/3/family-calendar-raspberry-pi)
|
||||
[#]: author: (Javier Pena https://opensource.com/users/jpena)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wyxplus)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13222-1.html)
|
||||
|
||||
利用树莓派和低功耗显示器来跟踪你的家庭日程表
|
||||
======
|
||||
|
||||
> 通过利用开源工具和电子墨水屏,让每个人都清楚家庭的日程安排。
|
||||
|
||||

|
||||
|
||||
有些家庭的日程安排很复杂:孩子们有上学活动和放学后的活动,你想要记住的重要事情,每个人都有多个约会等等。虽然你可以使用手机和应用程序来关注所有事情,但在家中放置一个大型低功耗显示器以显示家人的日程不是更好吗?电子墨水日程表刚好满足!
|
||||
|
||||
![E Ink calendar][2]
|
||||
|
||||
### 硬件
|
||||
|
||||
这个项目是作为假日项目开始,因此我试着尽可能多的旧物利用。其中包括一台已经闲置了太长时间树莓派 2。由于我没有电子墨水屏,因此我需要购买一个。幸运的是,我找到了一家供应商,该供应商为支持树莓派的屏幕提供了 [开源驱动程序和示例][4],该屏幕使用 [GPIO][5] 端口连接。
|
||||
|
||||
我的家人还想在不同的日程表之间切换,因此需要某种形式的输入。我没有添加 USB 键盘,而是选择了一种更简单的解决方案,并购买了一个类似于在 [这篇文章][6] 中所描述 1x4 大小的键盘。这使我可以将键盘连接到树莓派中的某些 GPIO 端口。
|
||||
|
||||
最后,我需要一个相框来容纳整个设置。虽然背面看起来有些凌乱,但它能完成工作。
|
||||
|
||||
![Calendar internals][7]
|
||||
|
||||
### 软件
|
||||
|
||||
我从 [一个类似的项目][8] 中获得了灵感,并开始为我的项目编写 Python 代码。我需要从两个地方获取数据:
|
||||
|
||||
* 天气信息:从 [OpenWeather API][9] 获取
|
||||
* 时间信息:我打算使用 [CalDav 标准][10] 连接到一个在我家服务器上运行的日程表
|
||||
|
||||
由于必须等待一些零件的送达,因此我使用了模块化的方法来进行输入和显示,这样我可以在没有硬件的情况下调试大多数代码。日程表应用程序需要驱动程序,于是我编写了一个 [Pygame][11] 驱动程序以便能在台式机上运行它。
|
||||
|
||||
编写代码最好的部分是能够重用现有的开源项目,所以访问不同的 API 很容易。我可以专注于设计用户界面,其中包括每个人的周历和每个人的日历,以及允许使用小键盘来选择日程。并且我花时间又添加了一些额外的功能,例如特殊日子的自定义屏幕保护程序。
|
||||
|
||||
![E Ink calendar screensaver][12]
|
||||
|
||||
最后的集成步骤将确保我的日程表应用程序将在启动时运行,并且能够容错。我使用了一个基本的 [树莓派系统][13] 镜像,并将该应用程序配置到 systemd 服务,以便它可以在出现故障和系统重新启动依旧运行。
|
||||
|
||||
做完所有工作,我把代码上传到了 [GitHub][14]。因此,如果你要创建类似的日历,可以随时查看并重构它!
|
||||
|
||||
### 结论
|
||||
|
||||
日程表已成为我们厨房中的日常工具。它可以帮助我们记住我们的日常活动,甚至我们的孩子在上学前,都可以使用它来查看日程的安排。
|
||||
|
||||
对我而言,这个项目让我感受到开源的力量。如果没有开源的驱动程序、库以及开放 API,我们依旧还在用纸和笔来安排日程。很疯狂,不是吗?
|
||||
|
||||
需要确保你的日程不冲突吗?学习如何使用这些免费的开源项目来做到这点。
|
||||
|
||||
------
|
||||
via: https://opensource.com/article/21/3/family-calendar-raspberry-pi
|
||||
|
||||
作者:[Javier Pena][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jpena
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calendar-coffee.jpg?itok=9idm1917 "Calendar with coffee and breakfast"
|
||||
[2]: https://opensource.com/sites/default/files/uploads/calendar.jpg "E Ink calendar"
|
||||
[3]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[4]: https://github.com/waveshare/e-Paper
|
||||
[5]: https://opensource.com/article/19/3/gpio-pins-raspberry-pi
|
||||
[6]: https://www.instructables.com/1x4-Membrane-Keypad-w-Arduino/
|
||||
[7]: https://opensource.com/sites/default/files/uploads/calendar_internals.jpg "Calendar internals"
|
||||
[8]: https://github.com/zli117/EInk-Calendar
|
||||
[9]: https://openweathermap.org
|
||||
[10]: https://en.wikipedia.org/wiki/CalDAV
|
||||
[11]: https://github.com/pygame/pygame
|
||||
[12]: https://opensource.com/sites/default/files/uploads/calendar_screensaver.jpg "E Ink calendar screensaver"
|
||||
[13]: https://www.raspberrypi.org/software/
|
||||
[14]: https://github.com/javierpena/eink-calendar
|
||||
@ -0,0 +1,200 @@
|
||||
[#]: subject: (How to use Poetry to manage your Python projects on Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/how-to-use-poetry-to-manage-your-python-projects-on-fedora/)
|
||||
[#]: author: (Kader Miyanyedi https://fedoramagazine.org/author/moonkat/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13202-1.html)
|
||||
|
||||
如何在 Fedora 上使用 Poetry 来管理你的 Python 项目?
|
||||
======
|
||||
|
||||
![Python & Poetry on Fedora][1]
|
||||
|
||||
Python 开发人员经常创建一个新的虚拟环境来分离项目依赖,然后用 `pip`、`pipenv` 等工具来管理它们。Poetry 是一个简化 Python 中依赖管理和打包的工具。这篇文章将向你展示如何在 Fedora 上使用 Poetry 来管理你的 Python 项目。
|
||||
|
||||
与其他工具不同,Poetry 只使用一个配置文件来进行依赖管理、打包和发布。这消除了对不同文件的需求,如 `Pipfile`、`MANIFEST.in`、`setup.py` 等。这也比使用多个工具更快。
|
||||
|
||||
下面详细介绍一下开始使用 Poetry 时使用的命令。
|
||||
|
||||
### 在 Fedora 上安装 Poetry
|
||||
|
||||
如果你已经使用 Fedora 32 或以上版本,你可以使用这个命令直接从命令行安装 Poetry:
|
||||
|
||||
```
|
||||
$ sudo dnf install poetry
|
||||
```
|
||||
|
||||
编者注:在 Fedora Silverblue 或 CoreOs上,Python 3.9.2 是核心提交的一部分,你可以用下面的命令安装 Poetry:
|
||||
|
||||
```
|
||||
rpm-ostree install poetry
|
||||
```
|
||||
|
||||
### 初始化一个项目
|
||||
|
||||
使用 `new` 命令创建一个新项目:
|
||||
|
||||
```
|
||||
$ poetry new poetry-project
|
||||
```
|
||||
|
||||
用 Poetry 创建的项目结构是这样的:
|
||||
|
||||
```
|
||||
├── poetry_project
|
||||
│ └── init.py
|
||||
├── pyproject.toml
|
||||
├── README.rst
|
||||
└── tests
|
||||
├── init.py
|
||||
└── test_poetry_project.py
|
||||
```
|
||||
|
||||
Poetry 使用 `pyproject.toml` 来管理项目的依赖。最初,这个文件看起来类似于这样:
|
||||
|
||||
```
|
||||
[tool.poetry]
|
||||
name = "poetry-project"
|
||||
version = "0.1.0"
|
||||
description = ""
|
||||
authors = ["Kadermiyanyedi <kadermiyanyedi@hotmail.com>"]
|
||||
|
||||
[tool.poetry.dependencies]
|
||||
python = "^3.9"
|
||||
|
||||
[tool.poetry.dev-dependencies]
|
||||
pytest = "^5.2"
|
||||
|
||||
[build-system]
|
||||
requires = ["poetry>=0.12"]
|
||||
build-backend = "poetry.masonry.api"
|
||||
```
|
||||
|
||||
这个文件包含 4 个部分:
|
||||
|
||||
* 第一部分包含描述项目的信息,如项目名称、项目版本等。
|
||||
* 第二部分包含项目的依赖。这些依赖是构建项目所必需的。
|
||||
* 第三部分包含开发依赖。
|
||||
* 第四部分描述的是符合 [PEP 517][2] 的构建系统。
|
||||
|
||||
如果你已经有一个项目,或者创建了自己的项目文件夹,并且你想使用 Poetry,请在你的项目中运行 `init` 命令。
|
||||
|
||||
```
|
||||
$ poetry init
|
||||
```
|
||||
|
||||
在这个命令之后,你会看到一个交互式的 shell 来配置你的项目。
|
||||
|
||||
### 创建一个虚拟环境
|
||||
|
||||
如果你想创建一个虚拟环境或激活一个现有的虚拟环境,请使用以下命令:
|
||||
|
||||
```
|
||||
$ poetry shell
|
||||
```
|
||||
|
||||
Poetry 默认在 `/home/username/.cache/pypoetry` 项目中创建虚拟环境。你可以通过编辑 Poetry 配置来更改默认路径。使用下面的命令查看配置列表:
|
||||
|
||||
```
|
||||
$ poetry config --list
|
||||
|
||||
cache-dir = "/home/username/.cache/pypoetry"
|
||||
virtualenvs.create = true
|
||||
virtualenvs.in-project = true
|
||||
virtualenvs.path = "{cache-dir}/virtualenvs"
|
||||
```
|
||||
|
||||
修改 `virtualenvs.in-project` 配置变量,在项目目录下创建一个虚拟环境。Poetry 命令是:
|
||||
|
||||
```
|
||||
$ poetry config virtualenv.in-project true
|
||||
```
|
||||
|
||||
### 添加依赖
|
||||
|
||||
使用 `poetry add` 命令为项目安装一个依赖:
|
||||
|
||||
```
|
||||
$ poetry add django
|
||||
```
|
||||
|
||||
你可以使用带有 `--dev` 选项的 `add` 命令来识别任何只用于开发环境的依赖:
|
||||
|
||||
```
|
||||
$ poetry add black --dev
|
||||
```
|
||||
|
||||
`add` 命令会创建一个 `poetry.lock` 文件,用来跟踪软件包的版本。如果 `poetry.lock` 文件不存在,那么会安装 `pyproject.toml` 中所有依赖项的最新版本。如果 `poetry.lock` 存在,Poetry 会使用文件中列出的确切版本,以确保每个使用这个项目的人的软件包版本是一致的。
|
||||
|
||||
使用 `poetry install` 命令来安装当前项目中的所有依赖:
|
||||
|
||||
```
|
||||
$ poetry install
|
||||
```
|
||||
|
||||
通过使用 `--no-dev` 选项防止安装开发依赖:
|
||||
|
||||
```
|
||||
$ poetry install --no-dev
|
||||
```
|
||||
|
||||
### 列出软件包
|
||||
|
||||
`show` 命令会列出所有可用的软件包。`--tree` 选项将以树状列出软件包:
|
||||
|
||||
```
|
||||
$ poetry show --tree
|
||||
|
||||
django 3.1.7 A high-level Python Web framework that encourages rapid development and clean, pragmatic design.
|
||||
├── asgiref >=3.2.10,<4
|
||||
├── pytz *
|
||||
└── sqlparse >=0.2.2
|
||||
```
|
||||
|
||||
包含软件包名称,以列出特定软件包的详细信息:
|
||||
|
||||
```
|
||||
$ poetry show requests
|
||||
|
||||
name : requests
|
||||
version : 2.25.1
|
||||
description : Python HTTP for Humans.
|
||||
|
||||
dependencies
|
||||
- certifi >=2017.4.17
|
||||
- chardet >=3.0.2,<5
|
||||
- idna >=2.5,<3
|
||||
- urllib3 >=1.21.1,<1.27
|
||||
```
|
||||
|
||||
最后,如果你想知道软件包的最新版本,你可以通过 `--latest` 选项:
|
||||
|
||||
```
|
||||
$ poetry show --latest
|
||||
|
||||
idna 2.10 3.1 Internationalized Domain Names in Applications
|
||||
asgiref 3.3.1 3.3.1 ASGI specs, helper code, and adapters
|
||||
```
|
||||
|
||||
### 更多信息
|
||||
|
||||
Poetry 的更多详情可在[文档][3]中获取。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/how-to-use-poetry-to-manage-your-python-projects-on-fedora/
|
||||
|
||||
作者:[Kader Miyanyedi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/moonkat/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2021/03/Poetry_Python-816x345.jpg
|
||||
[2]: https://www.python.org/dev/peps/pep-0517/
|
||||
[3]: https://python-poetry.org/docs/
|
||||
@ -0,0 +1,150 @@
|
||||
[#]: subject: (Learn Python dictionary values with Jupyter)
|
||||
[#]: via: (https://opensource.com/article/21/3/dictionary-values-python)
|
||||
[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeo)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (DCOLIVERSUN)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13236-1.html)
|
||||
|
||||
用 Jupyter 学习 Python 字典
|
||||
======
|
||||
|
||||
> 字典数据结构可以帮助你快速访问信息。
|
||||
|
||||

|
||||
|
||||
字典是 Python 编程语言使用的数据结构。一个 Python 字典由多个键值对组成;每个键值对将键映射到其关联的值上。
|
||||
|
||||
例如你是一名老师,想把学生姓名与成绩对应起来。你可以使用 Python 字典,将学生姓名映射到他们关联的成绩上。此时,键值对中键是姓名,值是对应的成绩。
|
||||
|
||||
如果你想知道某个学生的考试成绩,你可以从字典中访问。这种快捷查询方式可以为你节省解析整个列表找到学生成绩的时间。
|
||||
|
||||
本文介绍了如何通过键访问对应的字典值。学习前,请确保你已经安装了 [Anaconda 包管理器][2]和 [Jupyter 笔记本][3]。
|
||||
|
||||
### 1、在 Jupyter 中打开一个新的笔记本
|
||||
|
||||
首先在 Web 浏览器中打开并运行 Jupyter。然后,
|
||||
|
||||
1. 转到左上角的 “File”。
|
||||
2. 选择 “New Notebook”,点击 “Python 3”。
|
||||
|
||||
![新建 Jupyter 笔记本][4]
|
||||
|
||||
开始时,新建的笔记本是无标题的,你可以将其重命名为任何名称。我为我的笔记本取名为 “OpenSource.com Data Dictionary Tutorial”。
|
||||
|
||||
笔记本中标有行号的位置就是你写代码的区域,也是你输入的位置。
|
||||
|
||||
在 macOS 上,可以同时按 `Shift + Return` 键得到输出。在创建新的代码区域前,请确保完成上述动作;否则,你写的任何附加代码可能无法运行。
|
||||
|
||||
### 2、新建一个键值对
|
||||
|
||||
在字典中输入你希望访问的键与值。输入前,你需要在字典上下文中定义它们的含义:
|
||||
|
||||
```
|
||||
empty_dictionary = {}
|
||||
grades = {
|
||||
"Kelsey": 87,
|
||||
"Finley": 92
|
||||
}
|
||||
|
||||
one_line = {a: 1, b: 2}
|
||||
```
|
||||
|
||||
![定义字典键值对的代码][6]
|
||||
|
||||
这段代码让字典将特定键与其各自的值关联起来。字典按名称存储数据,从而可以更快地查询。
|
||||
|
||||
### 3、通过键访问字典值
|
||||
|
||||
现在你想查询指定的字典值;在上述例子中,字典值指特定学生的成绩。首先,点击 “Insert” 后选择 “Insert Cell Below”。
|
||||
|
||||
![在 Jupyter 插入新建单元格][7]
|
||||
|
||||
在新单元格中,定义字典中的键与值。
|
||||
|
||||
然后,告诉字典打印该值的键,找到需要的值。例如,查询名为 Kelsey 的学生的成绩:
|
||||
|
||||
```
|
||||
# 访问字典中的数据
|
||||
grades = {
|
||||
"Kelsey": 87,
|
||||
"Finley": 92
|
||||
}
|
||||
|
||||
print(grades["Kelsey"])
|
||||
87
|
||||
```
|
||||
|
||||
![查询特定值的代码][8]
|
||||
|
||||
当你查询 Kelsey 的成绩(也就是你想要查询的值)时,如果你用的是 macOS,只需要同时按 `Shift+Return` 键。
|
||||
|
||||
你会在单元格下方看到 Kelsey 的成绩。
|
||||
|
||||
### 4、更新已有的键
|
||||
|
||||
当把一位学生的错误成绩添加到字典时,你会怎么办?可以通过更新字典、存储新值来修正这类错误。
|
||||
|
||||
首先,选择你想更新的那个键。在上述例子中,假设你错误地输入了 Finley 的成绩,那么 Finley 就是你需要更新的键。
|
||||
|
||||
为了更新 Finley 的成绩,你需要在下方插入新的单元格,然后创建一个新的键值对。同时按 `Shift+Return` 键打印字典全部信息:
|
||||
|
||||
```
|
||||
grades["Finley"] = 90
|
||||
print(grades)
|
||||
|
||||
{'Kelsey': 87; "Finley": 90}
|
||||
```
|
||||
|
||||
![更新键的代码][9]
|
||||
|
||||
单元格下方输出带有 Finley 更新成绩的字典。
|
||||
|
||||
### 5、添加新键
|
||||
|
||||
假设你得到一位新学生的考试成绩。你可以用新键值对将那名学生的姓名与成绩补充到字典中。
|
||||
|
||||
插入新的单元格,以键值对形式添加新学生的姓名与成绩。当你完成这些后,同时按 `Shift+Return` 键打印字典全部信息:
|
||||
|
||||
```
|
||||
grades["Alex"] = 88
|
||||
print(grades)
|
||||
|
||||
{'Kelsey': 87, 'Finley': 90, 'Alex': 88}
|
||||
```
|
||||
|
||||
![添加新键][10]
|
||||
|
||||
所有的键值对输出在单元格下方。
|
||||
|
||||
### 使用字典
|
||||
|
||||
请记住,键与值可以是任意数据类型,但它们很少是<ruby>[扩展数据类型][11]<rt>non-primitive types</rt></ruby>。此外,字典不能以指定的顺序存储、组织里面的数据。如果你想要数据有序,最好使用 Python 列表,而非字典。
|
||||
|
||||
如果你考虑使用字典,首先要确认你的数据结构是否是合适的,例如像电话簿的结构。如果不是,列表、元组、树或者其他数据结构可能是更好的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/3/dictionary-values-python
|
||||
|
||||
作者:[Lauren Maffeo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lmaffeo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python-programming-code-keyboard.png?itok=fxiSpmnd (Hands on a keyboard with a Python book )
|
||||
[2]: https://docs.anaconda.com/anaconda/
|
||||
[3]: https://opensource.com/article/18/3/getting-started-jupyter-notebooks
|
||||
[4]: https://opensource.com/sites/default/files/uploads/new-jupyter-notebook.png (Create Jupyter notebook)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/define-keys-values.png (Code for defining key-value pairs in the dictionary)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/jupyter_insertcell.png (Inserting a new cell in Jupyter)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/lookforvalue.png (Code to look for a specific value)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/jupyter_updatekey.png (Code for updating a key)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/jupyter_addnewkey.png (Add a new key)
|
||||
[11]: https://www.datacamp.com/community/tutorials/data-structures-python
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user