mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
7fec10650c
@ -1,5 +1,6 @@
|
||||
如何设置在Quagga BGP路由器中设置IPv6的BGP对等体和过滤
|
||||
如何设置在 Quagga BGP 路由器中设置 IPv6 的 BGP 对等体和过滤
|
||||
================================================================================
|
||||
|
||||
在之前的教程中,我们演示了如何使用Quagga建立一个[完备的BGP路由器][1]和配置[前缀过滤][2]。在本教程中,我们会向你演示如何创建IPv6 BGP对等体并通过BGP通告IPv6前缀。同时我们也将演示如何使用前缀列表和路由映射特性来过滤通告的或者获取到的IPv6前缀。
|
||||
|
||||
### 拓扑 ###
|
||||
@ -47,7 +48,7 @@ Quagga内部提供一个叫作vtysh的shell,其界面与那些主流路由厂
|
||||
|
||||
# vtysh
|
||||
|
||||
提示将改为:
|
||||
提示符将改为:
|
||||
|
||||
router-a#
|
||||
|
||||
@ -65,7 +66,7 @@ Quagga内部提供一个叫作vtysh的shell,其界面与那些主流路由厂
|
||||
|
||||
router-a# configure terminal
|
||||
|
||||
提示将变更成:
|
||||
提示符将变更成:
|
||||
|
||||
router-a(config)#
|
||||
|
||||
@ -246,13 +247,13 @@ Quagga内部提供一个叫作vtysh的shell,其界面与那些主流路由厂
|
||||
via: http://xmodulo.com/ipv6-bgp-peering-filtering-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
[1]:https://linux.cn/article-4232-1.html
|
||||
[2]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
[3]:http://ask.xmodulo.com/open-port-firewall-centos-rhel.html
|
||||
[4]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
@ -1,8 +1,9 @@
|
||||
如何在 Docker 中通过 Kitematic 交互式执行任务
|
||||
如何在 Windows 上通过 Kitematic 使用 Docker
|
||||
================================================================================
|
||||
在本篇文章中,我们会学习如何在 Windows 操作系统上安装 Kitematic 以及部署一个 Hello World Nginx Web 服务器。Kitematic 是一个自由开源软件,它有现代化的界面设计使得允许我们在 Docker 中交互式执行任务。Kitematic 设计非常漂亮、界面也很不错。我们可以简单快速地开箱搭建我们的容器而不需要输入命令,我们可以在图形用户界面中通过简单的点击从而在容器上部署我们的应用。Kitematic 集成了 Docker Hub,允许我们搜索、拉取任何需要的镜像,并在上面部署应用。它同时也能很好地切换到命令行用户接口模式。目前,它包括了自动映射端口、可视化更改环境变量、配置卷、精简日志以及其它功能。
|
||||
|
||||
下面是在 Windows 上安装 Kitematic 并部署 Hello World Nginx Web 服务器的 3 个简单步骤。
|
||||
在本篇文章中,我们会学习如何在 Windows 操作系统上安装 Kitematic 以及部署一个测试性的 Nginx Web 服务器。Kitematic 是一个具有现代化的界面设计的自由开源软件,它可以让我们在 Docker 中交互式执行任务。Kitematic 设计的非常漂亮、界面美观。使用它,我们可以简单快速地开箱搭建我们的容器而不需要输入命令,可以在图形用户界面中通过简单的点击从而在容器上部署我们的应用。Kitematic 集成了 Docker Hub,允许我们搜索、拉取任何需要的镜像,并在上面部署应用。它同时也能很好地切换到命令行用户接口模式。目前,它包括了自动映射端口、可视化更改环境变量、配置卷、流式日志以及其它功能。
|
||||
|
||||
下面是在 Windows 上安装 Kitematic 并部署测试性 Nginx Web 服务器的 3 个简单步骤。
|
||||
|
||||
### 1. 下载 Kitematic ###
|
||||
|
||||
@ -16,15 +17,15 @@
|
||||
|
||||
### 2. 安装 Kitematic ###
|
||||
|
||||
下载好可执行安装程序之后,我们现在打算在我们的 Windows 操作系统上安装 Kitematic。安装程序现在会开始下载并安装运行 Kitematic 需要的依赖,包括 Virtual Box 和 Docker。如果已经在系统上安装了 Virtual Box,它会把它升级到最新版本。安装程序会在几分钟内完成,但取决于你网络和系统的速度。如果你还没有安装 Virtual Box,它会问你是否安装 Virtual Box 网络驱动。建议安装它,因为它有助于 Virtual Box 的网络。
|
||||
下载好可执行安装程序之后,我们现在就可以在我们的 Windows 操作系统上安装 Kitematic了。安装程序现在会开始下载并安装运行 Kitematic 需要的依赖软件,包括 Virtual Box 和 Docker。如果已经在系统上安装了 Virtual Box,它会把它升级到最新版本。安装程序会在几分钟内完成,但取决于你网络和系统的速度。如果你还没有安装 Virtual Box,它会问你是否安装 Virtual Box 网络驱动。建议安装它,因为它用于 Virtual Box 的网络功能。
|
||||
|
||||

|
||||
|
||||
需要的依赖 Docker 和 Virtual Box 安装完成并运行后,会让我们登录到 Docker Hub。如果我们还没有账户或者还不想登录,可以点击 **SKIP FOR NOW** 继续后面的步骤。
|
||||
所需的依赖 Docker 和 Virtual Box 安装完成并运行后,会让我们登录到 Docker Hub。如果我们还没有账户或者还不想登录,可以点击 **SKIP FOR NOW** 继续后面的步骤。
|
||||
|
||||

|
||||
|
||||
如果你还没有账户,你可以在应用程序上点击注册链接并在 Docker Hub 上创建账户。
|
||||
如果你还没有账户,你可以在应用程序上点击注册(Sign Up)链接并在 Docker Hub 上创建账户。
|
||||
|
||||
完成之后,就会出现 Kitematic 应用程序的第一个界面。正如下面看到的这样。我们可以搜索可用的 docker 镜像。
|
||||
|
||||
@ -50,7 +51,11 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们终于成功在 Windows 操作系统上安装了 Kitematic 并部署了一个 Hello World Ngnix 服务器。总是推荐下载安装 Kitematic 最新的发行版,因为会增加很多新的高级功能。由于 Docker 运行在 64 位平台,当前 Kitematic 也是为 64 位操作系统构建。它只能在 Windows 7 以及更高版本上运行。在这篇教程中,我们部署了一个 Nginx Web 服务器,类似地我们可以在 Kitematic 中简单的点击就能通过镜像部署任何 docker 容器。Kitematic 已经有可用的 Mac OS X 和 Windows 版本,Linux 版本也在开发中很快就会发布。如果你有任何疑问、建议或者反馈,请在下面的评论框中写下来以便我们更改地改进或更新我们的内容。非常感谢!Enjoy :-)
|
||||
我们终于成功在 Windows 操作系统上安装了 Kitematic 并部署了一个 Hello World Ngnix 服务器。推荐下载安装 Kitematic 最新的发行版,因为会增加很多新的高级功能。由于 Docker 运行在 64 位平台,当前 Kitematic 也是为 64 位操作系统构建。它只能在 Windows 7 以及更高版本上运行。
|
||||
|
||||
在这篇教程中,我们部署了一个 Nginx Web 服务器,类似地我们可以在 Kitematic 中简单的点击就能通过镜像部署任何 docker 容器。Kitematic 已经有可用的 Mac OS X 和 Windows 版本,Linux 版本也在开发中很快就会发布。
|
||||
|
||||
如果你有任何疑问、建议或者反馈,请在下面的评论框中写下来以便我们更改地改进或更新我们的内容。非常感谢!Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -58,7 +63,7 @@ via: http://linoxide.com/linux-how-to/interactively-docker-kitematic/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,129 @@
|
||||
如何使用 Weave 以及 Docker 搭建 Nginx 反向代理/负载均衡服务器
|
||||
================================================================================
|
||||
|
||||
Hi, 今天我们将会学习如何使用 Weave 和 Docker 搭建 Nginx 的反向代理/负载均衡服务器。Weave 可以创建一个虚拟网络将 Docker 容器彼此连接在一起,支持跨主机部署及自动发现。它可以让我们更加专注于应用的开发,而不是基础架构。Weave 提供了一个如此棒的环境,仿佛它的所有容器都属于同个网络,不需要端口/映射/连接等的配置。容器中的应用提供的服务在 weave 网络中可以轻易地被外部世界访问,不论你的容器运行在哪里。在这个教程里我们将会使用 weave 快速并且简单地将 nginx web 服务器部署为一个负载均衡器,反向代理一个运行在 Amazon Web Services 里面多个节点上的 docker 容器中的简单 php 应用。这里我们将会介绍 WeaveDNS,它提供一个不需要改变代码就可以让容器利用主机名找到的简单方式,并且能够让其他容器通过主机名连接彼此。
|
||||
|
||||
在这篇教程里,我们将使用 nginx 来将负载均衡分配到一个运行 Apache 的容器集合。最简单轻松的方法就是使用 Weave 来把运行在 ubuntu 上的 docker 容器中的 nginx 配置成负载均衡服务器。
|
||||
|
||||
### 1. 搭建 AWS 实例 ###
|
||||
|
||||
首先,我们需要搭建 Amzaon Web Service 实例,这样才能在 ubuntu 下用 weave 跑 docker 容器。我们将会使用[AWS 命令行][1] 来搭建和配置两个 AWS EC2 实例。在这里,我们使用最小的可用实例,t1.micro。我们需要一个有效的**Amazon Web Services 账户**使用 AWS 命令行界面来搭建和配置。我们先在 AWS 命令行界面下使用下面的命令将 github 上的 weave 仓库克隆下来。
|
||||
|
||||
$ git clone http://github.com/fintanr/weave-gs
|
||||
$ cd weave-gs/aws-nginx-ubuntu-simple
|
||||
|
||||
在克隆完仓库之后,我们执行下面的脚本,这个脚本将会部署两个 t1.micro 实例,每个实例中都是 ubuntu 作为操作系统并用 weave 跑着 docker 容器。
|
||||
|
||||
$ sudo ./demo-aws-setup.sh
|
||||
|
||||
在这里,我们将会在以后用到这些实例的 IP 地址。这些地址储存在一个 weavedemo.env 文件中,这个文件创建于执行 demo-aws-setup.sh 脚本期间。为了获取这些 IP 地址,我们需要执行下面的命令,命令输出类似下面的信息。
|
||||
|
||||
$ cat weavedemo.env
|
||||
|
||||
export WEAVE_AWS_DEMO_HOST1=52.26.175.175
|
||||
export WEAVE_AWS_DEMO_HOST2=52.26.83.141
|
||||
export WEAVE_AWS_DEMO_HOSTCOUNT=2
|
||||
export WEAVE_AWS_DEMO_HOSTS=(52.26.175.175 52.26.83.141)
|
||||
|
||||
请注意这些不是固定的 IP 地址,AWS 会为我们的实例动态地分配 IP 地址。
|
||||
|
||||
我们在 bash 下执行下面的命令使环境变量生效。
|
||||
|
||||
. ./weavedemo.env
|
||||
|
||||
### 2. 启动 Weave 和 WeaveDNS ###
|
||||
|
||||
在安装完实例之后,我们将会在每台主机上启动 weave 以及 weavedns。Weave 以及 weavedns 使得我们能够轻易地将容器部署到一个全新的基础架构以及配置中, 不需要改变代码,也不需要去理解像 Ambassador 容器以及 Link 机制之类的概念。下面是在第一台主机上启动 weave 以及 weavedns 的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch
|
||||
$ sudo weave launch-dns 10.2.1.1/24
|
||||
|
||||
下一步,我也准备在第二台主机上启动 weave 以及 weavedns。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave launch $WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch-dns 10.2.1.2/24
|
||||
|
||||
### 3. 启动应用容器 ###
|
||||
|
||||
现在,我们准备跨两台主机启动六个容器,这两台主机都用 Apache2 Web 服务实例跑着简单的 php 网站。为了在第一个 Apache2 Web 服务器实例跑三个容器, 我们将会使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.1/24 -h ws1.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.2/24 -h ws2.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.3/24 -h ws3.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
在那之后,我们将会在第二个实例上启动另外三个容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave run --with-dns 10.3.1.4/24 -h ws4.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.5/24 -h ws5.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.6/24 -h ws6.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
注意: 在这里,--with-dns 选项告诉容器使用 weavedns 来解析主机名,-h x.weave.local 则使得 weavedns 能够解析该主机。
|
||||
|
||||
### 4. 启动 Nginx 容器 ###
|
||||
|
||||
在应用容器如预期的运行后,我们将会启动 nginx 容器,它将会在六个应用容器服务之间轮询并提供反向代理或者负载均衡。 为了启动 nginx 容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.7/24 -ti -h nginx.weave.local -d -p 80:80 fintanr/weave-gs-nginx-simple
|
||||
|
||||
因此,我们的 nginx 容器在 $WEAVE_AWS_DEMO_HOST1 上公开地暴露成为一个 http 服务器。
|
||||
|
||||
### 5. 测试负载均衡服务器 ###
|
||||
|
||||
为了测试我们的负载均衡服务器是否可以工作,我们执行一段可以发送 http 请求给 nginx 容器的脚本。我们将会发送6个请求,这样我们就能看到 nginx 在一次的轮询中服务于每台 web 服务器之间。
|
||||
|
||||
$ ./access-aws-hosts.sh
|
||||
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws1.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws2.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws3.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws4.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws5.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws6.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
|
||||
### 结束语 ###
|
||||
|
||||
我们最终成功地将 nginx 配置成一个反向代理/负载均衡服务器,通过使用 weave 以及运行在 AWS(Amazon Web Service)EC2 里面的 ubuntu 服务器中的 docker。从上面的步骤输出可以清楚的看到我们已经成功地配置了 nginx。我们可以看到请求在一次轮询中被发送到6个应用容器,这些容器在 Apache2 Web 服务器中跑着 PHP 应用。在这里,我们部署了一个容器化的 PHP 应用,使用 nginx 横跨多台在 AWS EC2 上的主机而不需要改变代码,利用 weavedns 使得每个容器连接在一起,只需要主机名就够了,眼前的这些便捷, 都要归功于 weave 以及 weavedns。
|
||||
|
||||
如果你有任何的问题、建议、反馈,请在评论中注明,这样我们才能够做得更好,谢谢:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/nginx-load-balancer-weave-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
418
published/20150803 Managing Linux Logs.md
Normal file
418
published/20150803 Managing Linux Logs.md
Normal file
@ -0,0 +1,418 @@
|
||||
Linux 日志管理指南
|
||||
================================================================================
|
||||
|
||||
管理日志的一个最好做法是将你的日志集中或整合到一个地方,特别是在你有许多服务器或多层级架构时。我们将告诉你为什么这是一个好主意,然后给出如何更容易的做这件事的一些小技巧。
|
||||
|
||||
### 集中管理日志的好处 ###
|
||||
|
||||
如果你有很多服务器,查看某个日志文件可能会很麻烦。现代的网站和服务经常包括许多服务器层级、分布式的负载均衡器,等等。找到正确的日志将花费很长时间,甚至要花更长时间在登录服务器的相关问题上。没什么比发现你找的信息没有被保存下来更沮丧的了,或者本该保留的日志文件正好在重启后丢失了。
|
||||
|
||||
集中你的日志使它们查找更快速,可以帮助你更快速的解决产品问题。你不用猜测那个服务器存在问题,因为所有的日志在同一个地方。此外,你可以使用更强大的工具去分析它们,包括日志管理解决方案。一些解决方案能[转换纯文本日志][1]为一些字段,更容易查找和分析。
|
||||
|
||||
集中你的日志也可以使它们更易于管理:
|
||||
|
||||
- 它们更安全,当它们备份归档到一个单独区域时会有意无意地丢失。如果你的服务器宕机或者无响应,你可以使用集中的日志去调试问题。
|
||||
- 你不用担心ssh或者低效的grep命令在陷入困境的系统上需要更多的资源。
|
||||
- 你不用担心磁盘占满,这个能让你的服务器死机。
|
||||
- 你能保持你的产品服务器的安全性,只是为了查看日志无需给你所有团队登录权限。给你的团队从日志集中区域访问日志权限更安全。
|
||||
|
||||
随着集中日志管理,你仍需处理由于网络联通性不好或者耗尽大量网络带宽从而导致不能传输日志到中心区域的风险。在下面的章节我们将要讨论如何聪明的解决这些问题。
|
||||
|
||||
### 流行的日志归集工具 ###
|
||||
|
||||
在 Linux 上最常见的日志归集是通过使用 syslog 守护进程或者日志代理。syslog 守护进程支持本地日志的采集,然后通过syslog 协议传输日志到中心服务器。你可以使用很多流行的守护进程来归集你的日志文件:
|
||||
|
||||
- [rsyslog][2] 是一个轻量后台程序,在大多数 Linux 分支上已经安装。
|
||||
- [syslog-ng][3] 是第二流行的 Linux 系统日志后台程序。
|
||||
- [logstash][4] 是一个重量级的代理,它可以做更多高级加工和分析。
|
||||
- [fluentd][5] 是另一个具有高级处理能力的代理。
|
||||
|
||||
Rsyslog 是集中日志数据最流行的后台程序,因为它在大多数 Linux 分支上是被默认安装的。你不用下载或安装它,并且它是轻量的,所以不需要占用你太多的系统资源。
|
||||
|
||||
如果你需要更多先进的过滤或者自定义分析功能,如果你不在乎额外的系统负载,Logstash 是另一个最流行的选择。
|
||||
|
||||
### 配置 rsyslog.conf ###
|
||||
|
||||
既然 rsyslog 是最广泛使用的系统日志程序,我们将展示如何配置它为日志中心。它的全局配置文件位于 /etc/rsyslog.conf。它加载模块,设置全局指令,和包含位于目录 /etc/rsyslog.d 中的应用的特有的配置。目录中包含的 /etc/rsyslog.d/50-default.conf 指示 rsyslog 将系统日志写到文件。在 [rsyslog 文档][6]中你可以阅读更多相关配置。
|
||||
|
||||
rsyslog 配置语言是是[RainerScript][7]。你可以给日志指定输入,就像将它们输出到另外一个位置一样。rsyslog 已经配置标准输入默认是 syslog ,所以你通常只需增加一个输出到你的日志服务器。这里有一个 rsyslog 输出到一个外部服务器的配置例子。在本例中,**BEBOP** 是一个服务器的主机名,所以你应该替换为你的自己的服务器名。
|
||||
|
||||
action(type="omfwd" protocol="tcp" target="BEBOP" port="514")
|
||||
|
||||
你可以发送你的日志到一个有足够的存储容量的日志服务器来存储,提供查询,备份和分析。如果你存储日志到文件系统,那么你应该建立[日志轮转][8]来防止你的磁盘爆满。
|
||||
|
||||
作为一种选择,你可以发送这些日志到一个日志管理方案。如果你的解决方案是安装在本地你可以发送到系统文档中指定的本地主机和端口。如果你使用基于云提供商,你将发送它们到你的提供商特定的主机名和端口。
|
||||
|
||||
### 日志目录 ###
|
||||
|
||||
你可以归集一个目录或者匹配一个通配符模式的所有文件。nxlog 和 syslog-ng 程序支持目录和通配符(*)。
|
||||
|
||||
常见的 rsyslog 不能直接监控目录。作为一种解决办法,你可以设置一个定时任务去监控这个目录的新文件,然后配置 rsyslog 来发送这些文件到目的地,比如你的日志管理系统。举个例子,日志管理提供商 Loggly 有一个开源版本的[目录监控脚本][9]。
|
||||
|
||||
### 哪个协议: UDP、TCP 或 RELP? ###
|
||||
|
||||
当你使用网络传输数据时,有三个主流协议可以选择。UDP 在你自己的局域网是最常用的,TCP 用在互联网。如果你不能失去(任何)日志,就要使用更高级的 RELP 协议。
|
||||
|
||||
[UDP][10] 发送一个数据包,那只是一个单一的信息包。它是一个只外传的协议,所以它不会发送给你回执(ACK)。它只尝试发送包。当网络拥堵时,UDP 通常会巧妙的降级或者丢弃日志。它通常使用在类似局域网的可靠网络。
|
||||
|
||||
[TCP][11] 通过多个包和返回确认发送流式信息。TCP 会多次尝试发送数据包,但是受限于 [TCP 缓存][12]的大小。这是在互联网上发送送日志最常用的协议。
|
||||
|
||||
[RELP][13] 是这三个协议中最可靠的,但是它是为 rsyslog 创建的,而且很少有行业采用。它在应用层接收数据,如果有错误就会重发。请确认你的日志接受位置也支持这个协议。
|
||||
|
||||
### 用磁盘辅助队列可靠的传送 ###
|
||||
|
||||
如果 rsyslog 在存储日志时遭遇错误,例如一个不可用网络连接,它能将日志排队直到连接还原。队列日志默认被存储在内存里。无论如何,内存是有限的并且如果问题仍然存在,日志会超出内存容量。
|
||||
|
||||
**警告:如果你只存储日志到内存,你可能会失去数据。**
|
||||
|
||||
rsyslog 能在内存被占满时将日志队列放到磁盘。[磁盘辅助队列][14]使日志的传输更可靠。这里有一个例子如何配置rsyslog 的磁盘辅助队列:
|
||||
|
||||
$WorkDirectory /var/spool/rsyslog # 暂存文件(spool)放置位置
|
||||
$ActionQueueFileName fwdRule1 # 暂存文件的唯一名字前缀
|
||||
$ActionQueueMaxDiskSpace 1g # 1gb 空间限制(尽可能大)
|
||||
$ActionQueueSaveOnShutdown on # 关机时保存日志到磁盘
|
||||
$ActionQueueType LinkedList # 异步运行
|
||||
$ActionResumeRetryCount -1 # 如果主机宕机,不断重试
|
||||
|
||||
### 使用 TLS 加密日志 ###
|
||||
|
||||
如果你担心你的数据的安全性和隐私性,你应该考虑加密你的日志。如果你使用纯文本在互联网传输日志,嗅探器和中间人可以读到你的日志。如果日志包含私人信息、敏感的身份数据或者政府管制数据,你应该加密你的日志。rsyslog 程序能使用 TLS 协议加密你的日志保证你的数据更安全。
|
||||
|
||||
建立 TLS 加密,你应该做如下任务:
|
||||
|
||||
1. 生成一个[证书授权(CA)][15]。在 /contrib/gnutls 有一些证书例子,可以用来测试,但是你需要为产品环境创建自己的证书。如果你正在使用一个日志管理服务,它会给你一个证书。
|
||||
1. 为你的服务器生成一个[数字证书][16]使它能启用 SSL 操作,或者使用你自己的日志管理服务提供商的一个数字证书。
|
||||
1. 配置你的 rsyslog 程序来发送 TLS 加密数据到你的日志管理系统。
|
||||
|
||||
这有一个 rsyslog 配置 TLS 加密的例子。替换 CERT 和 DOMAIN_NAME 为你自己的服务器配置。
|
||||
|
||||
$DefaultNetstreamDriverCAFile /etc/rsyslog.d/keys/ca.d/CERT.crt
|
||||
$ActionSendStreamDriver gtls
|
||||
$ActionSendStreamDriverMode 1
|
||||
$ActionSendStreamDriverAuthMode x509/name
|
||||
$ActionSendStreamDriverPermittedPeer *.DOMAIN_NAME.com
|
||||
|
||||
### 应用日志的最佳管理方法 ###
|
||||
|
||||
除 Linux 默认创建的日志之外,归集重要的应用日志也是一个好主意。几乎所有基于 Linux 的服务器应用都把它们的状态信息写入到独立、专门的日志文件中。这包括数据库产品,像 PostgreSQL 或者 MySQL,网站服务器,像 Nginx 或者 Apache,防火墙,打印和文件共享服务,目录和 DNS 服务等等。
|
||||
|
||||
管理员安装一个应用后要做的第一件事是配置它。Linux 应用程序典型的有一个放在 /etc 目录里 .conf 文件。它也可能在其它地方,但是那是大家找配置文件首先会看的地方。
|
||||
|
||||
根据应用程序有多复杂多庞大,可配置参数的数量可能会很少或者上百行。如前所述,大多数应用程序可能会在某种日志文件写它们的状态:配置文件是定义日志设置和其它东西的地方。
|
||||
|
||||
如果你不确定它在哪,你可以使用locate命令去找到它:
|
||||
|
||||
[root@localhost ~]# locate postgresql.conf
|
||||
/usr/pgsql-9.4/share/postgresql.conf.sample
|
||||
/var/lib/pgsql/9.4/data/postgresql.conf
|
||||
|
||||
#### 设置一个日志文件的标准位置 ####
|
||||
|
||||
Linux 系统一般保存它们的日志文件在 /var/log 目录下。一般是这样,但是需要检查一下应用是否保存它们在 /var/log 下的特定目录。如果是,很好,如果不是,你也许想在 /var/log 下创建一个专用目录?为什么?因为其它程序也在 /var/log 下保存它们的日志文件,如果你的应用保存超过一个日志文件 - 也许每天一个或者每次重启一个 - 在这么大的目录也许有点难于搜索找到你想要的文件。
|
||||
|
||||
如果在你网络里你有运行多于一个的应用实例,这个方法依然便利。想想这样的情景,你也许有一打 web 服务器在你的网络运行。当排查任何一个机器的问题时,你就很容易知道确切的位置。
|
||||
|
||||
#### 使用一个标准的文件名 ####
|
||||
|
||||
给你的应用最新的日志使用一个标准的文件名。这使一些事变得容易,因为你可以监控和追踪一个单独的文件。很多应用程序在它们的日志文件上追加一种时间戳。它让 rsyslog 更难于找到最新的文件和设置文件监控。一个更好的方法是使用日志轮转给老的日志文件增加时间。这样更易去归档和历史查询。
|
||||
|
||||
#### 追加日志文件 ####
|
||||
|
||||
日志文件会在每个应用程序重启后被覆盖吗?如果这样,我们建议关掉它。每次重启 app 后应该去追加日志文件。这样,你就可以追溯重启前最后的日志。
|
||||
|
||||
#### 日志文件追加 vs. 轮转 ####
|
||||
|
||||
要是应用程序每次重启后写一个新日志文件,如何保存当前日志?追加到一个单独的、巨大的文件?Linux 系统并不以频繁重启或者崩溃而出名:应用程序可以运行很长时间甚至不间歇,但是也会使日志文件非常大。如果你查询分析上周发生连接错误的原因,你可能无疑的要在成千上万行里搜索。
|
||||
|
||||
我们建议你配置应用每天半晚轮转(rotate)它的日志文件。
|
||||
|
||||
为什么?首先它将变得可管理。找一个带有特定日期的文件名比遍历一个文件中指定日期的条目更容易。文件也小的多:你不用考虑当你打开一个日志文件时 vi 僵住。第二,如果你正发送日志到另一个位置 - 也许每晚备份任务拷贝到归集日志服务器 - 这样不会消耗你的网络带宽。最后第三点,这样帮助你做日志保留。如果你想剔除旧的日志记录,这样删除超过指定日期的文件比用一个应用解析一个大文件更容易。
|
||||
|
||||
#### 日志文件的保留 ####
|
||||
|
||||
你保留你的日志文件多长时间?这绝对可以归结为业务需求。你可能被要求保持一个星期的日志信息,或者管理要求保持一年的数据。无论如何,日志需要在一个时刻或其它情况下从服务器删除。
|
||||
|
||||
在我们看来,除非必要,只在线保持最近一个月的日志文件,并拷贝它们到第二个地方如日志服务器。任何比这更旧的日志可以被转到一个单独的介质上。例如,如果你在 AWS 上,你的旧日志可以被拷贝到 Glacier。
|
||||
|
||||
#### 给日志单独的磁盘分区 ####
|
||||
|
||||
更好的,Linux 通常建议挂载到 /var 目录到一个单独的文件系统。这是因为这个目录的高 I/O。我们推荐挂载 /var/log 目录到一个单独的磁盘系统下。这样可以节省与主要的应用数据的 I/O 竞争。另外,如果一些日志文件变的太多,或者一个文件变的太大,不会占满整个磁盘。
|
||||
|
||||
#### 日志条目 ####
|
||||
|
||||
每个日志条目中应该捕获什么信息?
|
||||
|
||||
这依赖于你想用日志来做什么。你只想用它来排除故障,或者你想捕获所有发生的事?这是一个捕获每个用户在运行什么或查看什么的规则条件吗?
|
||||
|
||||
如果你正用日志做错误排查的目的,那么只保存错误,报警或者致命信息。没有理由去捕获调试信息,例如,应用也许默认记录了调试信息或者另一个管理员也许为了故障排查而打开了调试信息,但是你应该关闭它,因为它肯定会很快的填满空间。在最低限度上,捕获日期、时间、客户端应用名、来源 ip 或者客户端主机名、执行的动作和信息本身。
|
||||
|
||||
#### 一个 PostgreSQL 的实例 ####
|
||||
|
||||
作为一个例子,让我们看看 vanilla PostgreSQL 9.4 安装的主配置文件。它叫做 postgresql.conf,与其它Linux 系统中的配置文件不同,它不保存在 /etc 目录下。下列的代码段,我们可以在我们的 Centos 7 服务器的 /var/lib/pgsql 目录下找到它:
|
||||
|
||||
root@localhost ~]# vi /var/lib/pgsql/9.4/data/postgresql.conf
|
||||
...
|
||||
#------------------------------------------------------------------------------
|
||||
# ERROR REPORTING AND LOGGING
|
||||
#------------------------------------------------------------------------------
|
||||
# - Where to Log -
|
||||
log_destination = 'stderr'
|
||||
# Valid values are combinations of
|
||||
# stderr, csvlog, syslog, and eventlog,
|
||||
# depending on platform. csvlog
|
||||
# requires logging_collector to be on.
|
||||
# This is used when logging to stderr:
|
||||
logging_collector = on
|
||||
# Enable capturing of stderr and csvlog
|
||||
# into log files. Required to be on for
|
||||
# csvlogs.
|
||||
# (change requires restart)
|
||||
# These are only used if logging_collector is on:
|
||||
log_directory = 'pg_log'
|
||||
# directory where log files are written,
|
||||
# can be absolute or relative to PGDATA
|
||||
log_filename = 'postgresql-%a.log' # log file name pattern,
|
||||
# can include strftime() escapes
|
||||
# log_file_mode = 0600 .
|
||||
# creation mode for log files,
|
||||
# begin with 0 to use octal notation
|
||||
log_truncate_on_rotation = on # If on, an existing log file with the
|
||||
# same name as the new log file will be
|
||||
# truncated rather than appended to.
|
||||
# But such truncation only occurs on
|
||||
# time-driven rotation, not on restarts
|
||||
# or size-driven rotation. Default is
|
||||
# off, meaning append to existing files
|
||||
# in all cases.
|
||||
log_rotation_age = 1d
|
||||
# Automatic rotation of logfiles will happen after that time. 0 disables.
|
||||
log_rotation_size = 0 # Automatic rotation of logfiles will happen after that much log output. 0 disables.
|
||||
# These are relevant when logging to syslog:
|
||||
#syslog_facility = 'LOCAL0'
|
||||
#syslog_ident = 'postgres'
|
||||
# This is only relevant when logging to eventlog (win32):
|
||||
#event_source = 'PostgreSQL'
|
||||
# - When to Log -
|
||||
#client_min_messages = notice # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# log
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
#log_min_messages = warning # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic
|
||||
#log_min_error_statement = error # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic (effectively off)
|
||||
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
|
||||
# and their durations, > 0 logs only
|
||||
# statements running at least this number
|
||||
# of milliseconds
|
||||
# - What to Log
|
||||
#debug_print_parse = off
|
||||
#debug_print_rewritten = off
|
||||
#debug_print_plan = off
|
||||
#debug_pretty_print = on
|
||||
#log_checkpoints = off
|
||||
#log_connections = off
|
||||
#log_disconnections = off
|
||||
#log_duration = off
|
||||
#log_error_verbosity = default
|
||||
# terse, default, or verbose messages
|
||||
#log_hostname = off
|
||||
log_line_prefix = '< %m >' # special values:
|
||||
# %a = application name
|
||||
# %u = user name
|
||||
# %d = database name
|
||||
# %r = remote host and port
|
||||
# %h = remote host
|
||||
# %p = process ID
|
||||
# %t = timestamp without milliseconds
|
||||
# %m = timestamp with milliseconds
|
||||
# %i = command tag
|
||||
# %e = SQL state
|
||||
# %c = session ID
|
||||
# %l = session line number
|
||||
# %s = session start timestamp
|
||||
# %v = virtual transaction ID
|
||||
# %x = transaction ID (0 if none)
|
||||
# %q = stop here in non-session
|
||||
# processes
|
||||
# %% = '%'
|
||||
# e.g. '<%u%%%d> '
|
||||
#log_lock_waits = off # log lock waits >= deadlock_timeout
|
||||
#log_statement = 'none' # none, ddl, mod, all
|
||||
#log_temp_files = -1 # log temporary files equal or larger
|
||||
# than the specified size in kilobytes;5# -1 disables, 0 logs all temp files5
|
||||
log_timezone = 'Australia/ACT'
|
||||
|
||||
虽然大多数参数被加上了注释,它们使用了默认值。我们可以看见日志文件目录是 pg_log(log_directory 参数,在 /var/lib/pgsql/9.4/data/ 下的子目录),文件名应该以 postgresql 开头(log_filename参数),文件每天轮转一次(log_rotation_age 参数)然后每行日志记录以时间戳开头(log_line_prefix参数)。特别值得说明的是 log_line_prefix 参数:全部的信息你都可以包含在这。
|
||||
|
||||
看 /var/lib/pgsql/9.4/data/pg_log 目录下展现给我们这些文件:
|
||||
|
||||
[root@localhost ~]# ls -l /var/lib/pgsql/9.4/data/pg_log
|
||||
total 20
|
||||
-rw-------. 1 postgres postgres 1212 May 1 20:11 postgresql-Fri.log
|
||||
-rw-------. 1 postgres postgres 243 Feb 9 21:49 postgresql-Mon.log
|
||||
-rw-------. 1 postgres postgres 1138 Feb 7 11:08 postgresql-Sat.log
|
||||
-rw-------. 1 postgres postgres 1203 Feb 26 21:32 postgresql-Thu.log
|
||||
-rw-------. 1 postgres postgres 326 Feb 10 01:20 postgresql-Tue.log
|
||||
|
||||
所以日志文件名只有星期命名的标签。我们可以改变它。如何做?在 postgresql.conf 配置 log_filename 参数。
|
||||
|
||||
查看一个日志内容,它的条目仅以日期时间开头:
|
||||
|
||||
[root@localhost ~]# cat /var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.log
|
||||
...
|
||||
< 2015-02-27 01:21:27.020 EST >LOG: received fast shutdown request
|
||||
< 2015-02-27 01:21:27.025 EST >LOG: aborting any active transactions
|
||||
< 2015-02-27 01:21:27.026 EST >LOG: autovacuum launcher shutting down
|
||||
< 2015-02-27 01:21:27.036 EST >LOG: shutting down
|
||||
< 2015-02-27 01:21:27.211 EST >LOG: database system is shut down
|
||||
|
||||
### 归集应用的日志 ###
|
||||
|
||||
#### 使用 imfile 监控日志 ####
|
||||
|
||||
习惯上,应用通常记录它们数据在文件里。文件容易在一个机器上寻找,但是多台服务器上就不是很恰当了。你可以设置日志文件监控,然后当新的日志被添加到文件尾部后就发送事件到一个集中服务器。在 /etc/rsyslog.d/ 里创建一个新的配置文件然后增加一个配置文件,然后输入如下:
|
||||
|
||||
$ModLoad imfile
|
||||
$InputFilePollInterval 10
|
||||
$PrivDropToGroup adm
|
||||
|
||||
-----
|
||||
# Input for FILE1
|
||||
$InputFileName /FILE1
|
||||
$InputFileTag APPNAME1
|
||||
$InputFileStateFile stat-APPNAME1 #this must be unique for each file being polled
|
||||
$InputFileSeverity info
|
||||
$InputFilePersistStateInterval 20000
|
||||
$InputRunFileMonitor
|
||||
|
||||
替换 FILE1 和 APPNAME1 为你自己的文件名和应用名称。rsyslog 将发送它到你配置的输出目标中。
|
||||
|
||||
#### 本地套接字日志与 imuxsock ####
|
||||
|
||||
套接字类似 UNIX 文件句柄,所不同的是套接字内容是由 syslog 守护进程读取到内存中,然后发送到目的地。不需要写入文件。作为一个例子,logger 命令发送它的日志到这个 UNIX 套接字。
|
||||
|
||||
如果你的服务器 I/O 有限或者你不需要本地文件日志,这个方法可以使系统资源有效利用。这个方法缺点是套接字有队列大小的限制。如果你的 syslog 守护进程宕掉或者不能保持运行,然后你可能会丢失日志数据。
|
||||
|
||||
rsyslog 程序将默认从 /dev/log 套接字中读取,但是你需要使用如下命令来让 [imuxsock 输入模块][17] 启用它:
|
||||
|
||||
$ModLoad imuxsock
|
||||
|
||||
#### UDP 日志与 imupd ####
|
||||
|
||||
一些应用程序使用 UDP 格式输出日志数据,这是在网络上或者本地传输日志文件的标准 syslog 协议。你的 syslog 守护进程接受这些日志,然后处理它们或者用不同的格式传输它们。备选的,你可以发送日志到你的日志服务器或者到一个日志管理方案中。
|
||||
|
||||
使用如下命令配置 rsyslog 通过 UDP 来接收标准端口 514 的 syslog 数据:
|
||||
|
||||
$ModLoad imudp
|
||||
|
||||
----------
|
||||
|
||||
$UDPServerRun 514
|
||||
|
||||
### 用 logrotate 管理日志 ###
|
||||
|
||||
日志轮转是当日志到达指定的时期时自动归档日志文件的方法。如果不介入,日志文件一直增长,会用尽磁盘空间。最后它们将破坏你的机器。
|
||||
|
||||
logrotate 工具能随着日志的日期截取你的日志,腾出空间。你的新日志文件保持该文件名。你的旧日志文件被重命名加上后缀数字。每次 logrotate 工具运行,就会创建一个新文件,然后现存的文件被逐一重命名。你来决定何时旧文件被删除或归档的阈值。
|
||||
|
||||
当 logrotate 拷贝一个文件,新的文件会有一个新的 inode,这会妨碍 rsyslog 监控新文件。你可以通过增加copytruncate 参数到你的 logrotate 定时任务来缓解这个问题。这个参数会拷贝现有的日志文件内容到新文件然后从现有文件截短这些内容。因为日志文件还是同一个,所以 inode 不会改变;但它的内容是一个新文件。
|
||||
|
||||
logrotate 工具使用的主配置文件是 /etc/logrotate.conf,应用特有设置在 /etc/logrotate.d/ 目录下。DigitalOcean 有一个详细的 [logrotate 教程][18]
|
||||
|
||||
### 管理很多服务器的配置 ###
|
||||
|
||||
当你只有很少的服务器,你可以登录上去手动配置。一旦你有几打或者更多服务器,你可以利用工具的优势使这变得更容易和更可扩展。基本上,所有的事情就是拷贝你的 rsyslog 配置到每个服务器,然后重启 rsyslog 使更改生效。
|
||||
|
||||
#### pssh ####
|
||||
|
||||
这个工具可以让你在很多服务器上并行的运行一个 ssh 命令。使用 pssh 部署仅用于少量服务器。如果你其中一个服务器失败,然后你必须 ssh 到失败的服务器,然后手动部署。如果你有很多服务器失败,那么手动部署它们会话费很长时间。
|
||||
|
||||
#### Puppet/Chef ####
|
||||
|
||||
Puppet 和 Chef 是两个不同的工具,它们能在你的网络按你规定的标准自动的配置所有服务器。它们的报表工具可以使你了解错误情况,然后定期重新同步。Puppet 和 Chef 都有一些狂热的支持者。如果你不确定那个更适合你的部署配置管理,你可以拜读一下 [InfoWorld 上这两个工具的对比][19]
|
||||
|
||||
一些厂商也提供一些配置 rsyslog 的模块或者方法。这有一个 Loggly 上 Puppet 模块的例子。它提供给 rsyslog 一个类,你可以添加一个标识令牌:
|
||||
|
||||
node 'my_server_node.example.net' {
|
||||
# Send syslog events to Loggly
|
||||
class { 'loggly::rsyslog':
|
||||
customer_token => 'de7b5ccd-04de-4dc4-fbc9-501393600000',
|
||||
}
|
||||
}
|
||||
|
||||
#### Docker ####
|
||||
|
||||
Docker 使用容器去运行应用,不依赖于底层服务。所有东西都运行在内部的容器,你可以把它想象为一个功能单元。ZDNet 有一篇关于在你的数据中心[使用 Docker][20] 的深入文章。
|
||||
|
||||
这里有很多方式从 Docker 容器记录日志,包括链接到一个日志容器,记录到一个共享卷,或者直接在容器里添加一个 sysllog 代理。其中最流行的日志容器叫做 [logspout][21]。
|
||||
|
||||
#### 供应商的脚本或代理 ####
|
||||
|
||||
大多数日志管理方案提供一些脚本或者代理,可以从一个或更多服务器相对容易地发送数据。重量级代理会耗尽额外的系统资源。一些供应商像 Loggly 提供配置脚本,来使用现存的 syslog 守护进程更轻松。这有一个 Loggly 上的例子[脚本][22],它能运行在任意数量的服务器上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/managing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.esrreycnpnbl
|
||||
[2]:http://www.rsyslog.com/
|
||||
[3]:http://www.balabit.com/network-security/syslog-ng/opensource-logging-system
|
||||
[4]:http://logstash.net/
|
||||
[5]:http://www.fluentd.org/
|
||||
[6]:http://www.rsyslog.com/doc/rsyslog_conf.html
|
||||
[7]:http://www.rsyslog.com/doc/master/rainerscript/index.html
|
||||
[8]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.eck7acdxin87
|
||||
[9]:https://www.loggly.com/docs/file-monitoring/
|
||||
[10]:http://www.networksorcery.com/enp/protocol/udp.htm
|
||||
[11]:http://www.networksorcery.com/enp/protocol/tcp.htm
|
||||
[12]:http://blog.gerhards.net/2008/04/on-unreliability-of-plain-tcp-syslog.html
|
||||
[13]:http://www.rsyslog.com/doc/relp.html
|
||||
[14]:http://www.rsyslog.com/doc/queues.html
|
||||
[15]:http://www.rsyslog.com/doc/tls_cert_ca.html
|
||||
[16]:http://www.rsyslog.com/doc/tls_cert_machine.html
|
||||
[17]:http://www.rsyslog.com/doc/v8-stable/configuration/modules/imuxsock.html
|
||||
[18]:https://www.digitalocean.com/community/tutorials/how-to-manage-log-files-with-logrotate-on-ubuntu-12-10
|
||||
[19]:http://www.infoworld.com/article/2614204/data-center/puppet-or-chef--the-configuration-management-dilemma.html
|
||||
[20]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[21]:https://github.com/progrium/logspout
|
||||
[22]:https://www.loggly.com/docs/sending-logs-unixlinux-system-setup/
|
||||
@ -1,10 +1,10 @@
|
||||
Linux有问必答——如何启用Open vSwitch的日志功能以便调试和排障
|
||||
Linux有问必答:如何启用Open vSwitch的日志功能以便调试和排障
|
||||
================================================================================
|
||||
> **问题** 我试着为我的Open vSwitch部署排障,鉴于此,我想要检查它的由内建日志机制生成的调试信息。我怎样才能启用Open vSwitch的日志功能,并且修改它的日志等级(如,修改成INFO/DEBUG级别)以便于检查更多详细的调试信息呢?
|
||||
|
||||
Open vSwitch(OVS)是Linux平台上用于虚拟切换的最流行的开源部署。由于当今的数据中心日益依赖于软件定义的网络(SDN)架构,OVS被作为数据中心的SDN部署中实际上的标准网络元素而快速采用。
|
||||
Open vSwitch(OVS)是Linux平台上最流行的开源的虚拟交换机。由于当今的数据中心日益依赖于软件定义网络(SDN)架构,OVS被作为数据中心的SDN部署中的事实标准上的网络元素而得到飞速应用。
|
||||
|
||||
Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允许你在各种切换组件中启用并自定义日志,由VLOG生成的日志信息可以被发送到一个控制台,syslog以及一个独立日志文件组合,以供检查。你可以通过一个名为`ovs-appctl`的命令行工具在运行时动态配置OVS日志。
|
||||
Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允许你在各种网络交换组件中启用并自定义日志,由VLOG生成的日志信息可以被发送到一个控制台、syslog以及一个便于查看的单独日志文件。你可以通过一个名为`ovs-appctl`的命令行工具在运行时动态配置OVS日志。
|
||||
|
||||
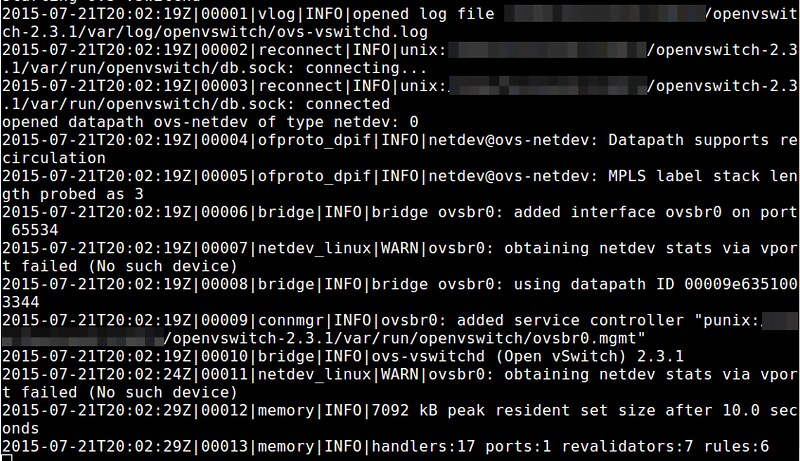
|
||||
|
||||
@ -14,7 +14,7 @@ Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允
|
||||
|
||||
$ sudo ovs-appctl vlog/set module[:facility[:level]]
|
||||
|
||||
- **Module**:OVS中的任何合法组件的名称(如netdev,ofproto,dpif,vswitchd,以及其它大量组件)
|
||||
- **Module**:OVS中的任何合法组件的名称(如netdev,ofproto,dpif,vswitchd等等)
|
||||
- **Facility**:日志信息的目的地(必须是:console,syslog,或者file)
|
||||
- **Level**:日志的详细程度(必须是:emer,err,warn,info,或者dbg)
|
||||
|
||||
@ -36,13 +36,13 @@ Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允
|
||||
|
||||
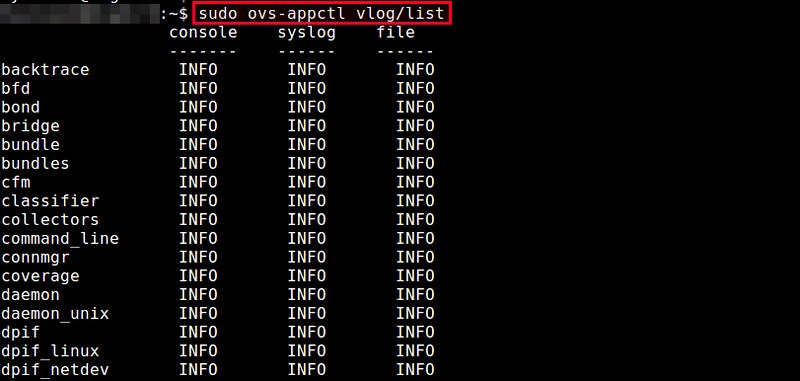
|
||||
|
||||
输出结果显示了用于三个工具(console,syslog,file)的各个模块的调试级别。默认情况下,所有模块的日志等级都被设置为INFO。
|
||||
输出结果显示了用于三个场合(facility:console,syslog,file)的各个模块的调试级别。默认情况下,所有模块的日志等级都被设置为INFO。
|
||||
|
||||
指定任何一个OVS模块,你可以选择性地修改任何特定工具的调试级别。例如,如果你想要在控制台屏幕中查看dpif更为详细的调试信息,可以运行以下命令。
|
||||
指定任何一个OVS模块,你可以选择性地修改任何特定场合的调试级别。例如,如果你想要在控制台屏幕中查看dpif更为详细的调试信息,可以运行以下命令。
|
||||
|
||||
$ sudo ovs-appctl vlog/set dpif:console:dbg
|
||||
|
||||
你将看到dpif模块的console工具已经将其日志等级修改为DBG,而其它两个工具syslog和file的日志级别仍然没有改变。
|
||||
你将看到dpif模块的console工具已经将其日志等级修改为DBG,而其它两个场合syslog和file的日志级别仍然没有改变。
|
||||
|
||||
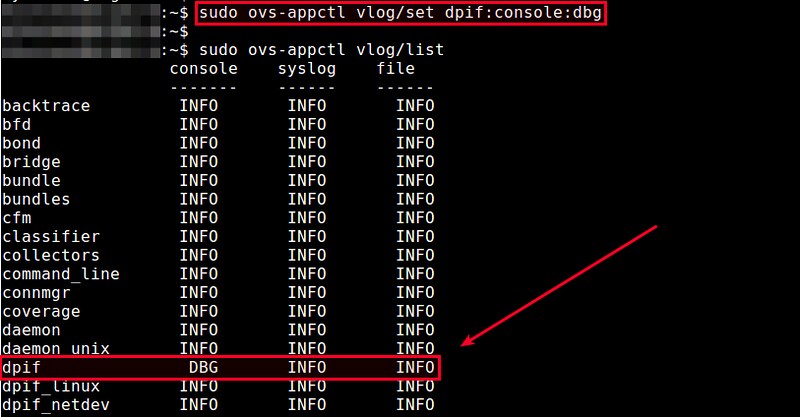
|
||||
|
||||
@ -52,7 +52,7 @@ Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允
|
||||
|
||||
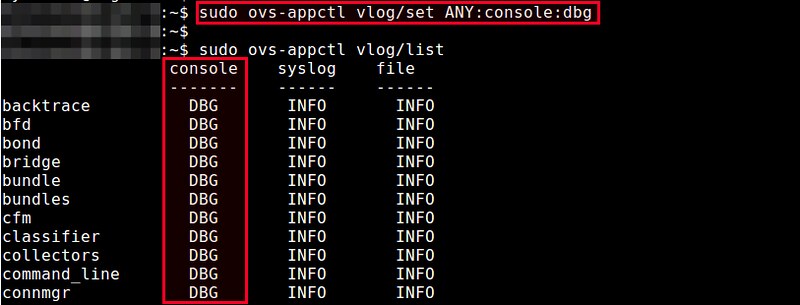
|
||||
|
||||
同时,如果你想要一次性修改所有三个工具的日志级别,你可以指定“ANY”作为工具名。例如,下面的命令将修改每个模块的所有工具的日志级别为DBG。
|
||||
同时,如果你想要一次性修改所有三个场合的日志级别,你可以指定“ANY”作为场合名。例如,下面的命令将修改每个模块的所有场合的日志级别为DBG。
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:ANY:dbg
|
||||
|
||||
@ -62,7 +62,7 @@ via: http://ask.xmodulo.com/enable-logging-open-vswitch.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
在Ubuntu 15.04中如何安装和使用Snort
|
||||
在 Ubuntu 15.04 中如何安装和使用 Snort
|
||||
================================================================================
|
||||
对于IT安全而言入侵检测是一件非常重要的事。入侵检测系统用于检测网络中非法与恶意的请求。Snort是一款知名的开源入侵检测系统。Web界面(Snorby)可以用于更好地分析警告。Snort使用iptables/pf防火墙来作为入侵检测系统。本篇中,我们会安装并配置一个开源的IDS系统snort。
|
||||
|
||||
对于网络安全而言入侵检测是一件非常重要的事。入侵检测系统(IDS)用于检测网络中非法与恶意的请求。Snort是一款知名的开源的入侵检测系统。其 Web界面(Snorby)可以用于更好地分析警告。Snort使用iptables/pf防火墙来作为入侵检测系统。本篇中,我们会安装并配置一个开源的入侵检测系统snort。
|
||||
|
||||
### Snort 安装 ###
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
snort所使用的数据采集库(DAQ)用于抽象地调用采集库。这个在snort上就有。下载过程如下截图所示。
|
||||
snort所使用的数据采集库(DAQ)用于一个调用包捕获库的抽象层。这个在snort上就有。下载过程如下截图所示。
|
||||
|
||||

|
||||
|
||||
@ -48,7 +49,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||
创建安装目录并在脚本中设置prefix参数。同样也建议启用包性能监控(PPM)标志。
|
||||
创建安装目录并在脚本中设置prefix参数。同样也建议启用包性能监控(PPM)的sourcefire标志。
|
||||
|
||||
#mkdir /usr/local/snort
|
||||
|
||||
@ -56,7 +57,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||
配置脚本由于缺少libpcre-dev、libdumbnet-dev 和zlib开发库而报错。
|
||||
配置脚本会由于缺少libpcre-dev、libdumbnet-dev 和zlib开发库而报错。
|
||||
|
||||
配置脚本由于缺少libpcre库报错。
|
||||
|
||||
@ -96,7 +97,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||
最终snort在/usr/local/snort/bin中运行。现在它对eth0的所有流量都处在promisc模式(包转储模式)。
|
||||
最后,从/usr/local/snort/bin中运行snort。现在它对eth0的所有流量都处在promisc模式(包转储模式)。
|
||||
|
||||

|
||||
|
||||
@ -106,14 +107,17 @@ make和make install 命令的结果如下所示。
|
||||
|
||||
#### Snort的规则和配置 ####
|
||||
|
||||
从源码安装的snort需要规则和安装配置,因此我们会从/etc/snort下面复制规则和配置。我们已经创建了单独的bash脚本来用于规则和配置。它会设置下面这些snort设置。
|
||||
从源码安装的snort还需要设置规则和配置,因此我们需要复制规则和配置到/etc/snort下面。我们已经创建了单独的bash脚本来用于设置规则和配置。它会设置下面这些snort设置。
|
||||
|
||||
- 在linux中创建snort用户用于snort IDS服务。
|
||||
- 在linux中创建用于snort IDS服务的snort用户。
|
||||
- 在/etc下面创建snort的配置文件和文件夹。
|
||||
- 权限设置并从etc中复制snortsnort源代码
|
||||
- 权限设置并从源代码的etc目录中复制数据。
|
||||
- 从snort文件中移除规则中的#(注释符号)。
|
||||
|
||||
#!/bin/bash##PATH of source code of snort
|
||||
-
|
||||
|
||||
#!/bin/bash#
|
||||
# snort源代码的路径
|
||||
snort_src="/home/test/Downloads/snort-2.9.7.3"
|
||||
echo "adding group and user for snort..."
|
||||
groupadd snort &> /dev/null
|
||||
@ -141,15 +145,15 @@ make和make install 命令的结果如下所示。
|
||||
sed -i 's/include \$RULE\_PATH/#include \$RULE\_PATH/' /etc/snort/snort.conf
|
||||
echo "---DONE---"
|
||||
|
||||
改变脚本中的snort源目录并运行。下面是成功的输出。
|
||||
改变脚本中的snort源目录路径并运行。下面是成功的输出。
|
||||
|
||||

|
||||
|
||||
上面的脚本从snort源中复制下面的文件/文件夹到/etc/snort配置文件中
|
||||
上面的脚本从snort源中复制下面的文件和文件夹到/etc/snort配置文件中
|
||||
|
||||

|
||||
|
||||
、snort的配置非常复杂,然而为了IDS能正常工作需要进行下面必要的修改。
|
||||
snort的配置非常复杂,要让IDS能正常工作需要进行下面必要的修改。
|
||||
|
||||
ipvar HOME_NET 192.168.1.0/24 # LAN side
|
||||
|
||||
@ -173,7 +177,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||
下载[下载社区][1]规则并解压到/etc/snort/rules。启用snort.conf中的社区及紧急威胁规则。
|
||||
现在[下载社区规则][1]并解压到/etc/snort/rules。启用snort.conf中的社区及紧急威胁规则。
|
||||
|
||||

|
||||
|
||||
@ -187,7 +191,7 @@ make和make install 命令的结果如下所示。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇中,我们致力于开源IDPS系统snort在Ubuntu上的安装和配置。默认它用于监控时间,然而它可以被配置成用于网络保护的内联模式。snort规则可以在离线模式中可以使用pcap文件测试和分析
|
||||
本篇中,我们关注了开源IDPS系统snort在Ubuntu上的安装和配置。通常它用于监控事件,然而它可以被配置成用于网络保护的在线模式。snort规则可以在离线模式中可以使用pcap捕获文件进行测试和分析
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -195,7 +199,7 @@ via: http://linoxide.com/security/install-snort-usage-ubuntu-15-04/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,11 @@
|
||||
Linux小技巧:Chrome小游戏,文字说话,计划作业,重复执行命令
|
||||
Linux 小技巧:Chrome 小游戏,让文字说话,计划作业,重复执行命令
|
||||
================================================================================
|
||||
|
||||
重要的事情说两遍,我完成了一个[Linux提示与彩蛋][1]系列,让你的Linux获得更多创造和娱乐。
|
||||
|
||||

|
||||
|
||||
Linux提示与彩蛋系列
|
||||
*Linux提示与彩蛋系列*
|
||||
|
||||
本文,我将会讲解Google-chrome内建小游戏,在终端中如何让文字说话,使用‘at’命令设置作业和使用watch命令重复执行命令。
|
||||
|
||||
@ -17,7 +17,7 @@ Linux提示与彩蛋系列
|
||||
|
||||

|
||||
|
||||
不能连接到互联网
|
||||
*不能连接到互联网*
|
||||
|
||||
按下空格键来激活Google-chrome彩蛋游戏。游戏没有时间限制。并且还不需要浪费时间安装使用。
|
||||
|
||||
@ -27,27 +27,25 @@ Linux提示与彩蛋系列
|
||||
|
||||

|
||||
|
||||
Google Chrome中玩游戏
|
||||
*Google Chrome中玩游戏*
|
||||
|
||||
### 2. Linux 终端中朗读文字 ###
|
||||
|
||||
对于那些不能文字朗读的设备,有个小工具可以实现文字说话的转换器。
|
||||
espeak支持多种语言,可以及时朗读输入文字。
|
||||
对于那些不能文字朗读的设备,有个小工具可以实现文字说话的转换器。用各种语言写一些东西,espeak就可以朗读给你。
|
||||
|
||||
系统应该默认安装了Espeak,如果你的系统没有安装,你可以使用下列命令来安装:
|
||||
|
||||
# apt-get install espeak (Debian)
|
||||
# yum install espeak (CentOS)
|
||||
# dnf install espeak (Fedora 22 onwards)
|
||||
# dnf install espeak (Fedora 22 及其以后)
|
||||
|
||||
You may ask espeak to accept Input Interactively from standard Input device and convert it to speech for you. You may do:
|
||||
你可以设置接受从标准输入的交互地输入并及时转换成语音朗读出来。这样设置:
|
||||
你可以让espeak接受标准输入的交互输入并及时转换成语音朗读出来。如下:
|
||||
|
||||
$ espeak [按回车键]
|
||||
|
||||
更详细的输出你可以这样做:
|
||||
|
||||
$ espeak --stdout | aplay [按回车键][这里需要双击]
|
||||
$ espeak --stdout | aplay [按回车键][再次回车]
|
||||
|
||||
espeak设置灵活,也可以朗读文本文件。你可以这样设置:
|
||||
|
||||
@ -55,29 +53,29 @@ espeak设置灵活,也可以朗读文本文件。你可以这样设置:
|
||||
|
||||
espeak可以设置朗读速度。默认速度是160词每分钟。使用-s参数来设置。
|
||||
|
||||
设置30词每分钟:
|
||||
设置每分钟30词的语速:
|
||||
|
||||
$ espeak -s 30 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
设置200词每分钟:
|
||||
设置每分钟200词的语速:
|
||||
|
||||
$ espeak -s 200 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
让其他语言说北印度语(作者母语),这样设置:
|
||||
说其他语言,比如北印度语(作者母语),这样设置:
|
||||
|
||||
$ espeak -v hindi --stdout 'टेकमिंट विश्व की एक बेहतरीन लाइंक्स आधारित वेबसाइट है|' | aplay
|
||||
|
||||
espeak支持多种语言,支持自定义设置。使用下列命令来获得语言表:
|
||||
你可以使用各种语言,让espeak如上面说的以你选择的语言朗读。使用下列命令来获得语言列表:
|
||||
|
||||
$ espeak --voices
|
||||
|
||||
### 3. 快速计划作业 ###
|
||||
### 3. 快速调度任务 ###
|
||||
|
||||
我们已经非常熟悉使用[cron][2]后台执行一个计划命令。
|
||||
我们已经非常熟悉使用[cron][2]守护进程执行一个计划命令。
|
||||
|
||||
Cron是一个Linux系统管理的高级命令,用于计划定时任务如备份或者指定时间或间隔的任何事情。
|
||||
|
||||
但是,你是否知道at命令可以让你计划一个作业或者命令在指定时间?at命令可以指定时间和指定内容执行作业。
|
||||
但是,你是否知道at命令可以让你在指定时间调度一个任务或者命令?at命令可以指定时间执行指定内容。
|
||||
|
||||
例如,你打算在早上11点2分执行uptime命令,你只需要这样做:
|
||||
|
||||
@ -85,17 +83,17 @@ Cron是一个Linux系统管理的高级命令,用于计划定时任务如备
|
||||
uptime >> /home/$USER/uptime.txt
|
||||
Ctrl+D
|
||||
|
||||

|
||||

|
||||
|
||||
Linux中计划作业
|
||||
*Linux中计划任务*
|
||||
|
||||
检查at命令是否成功设置,使用:
|
||||
|
||||
$ at -l
|
||||
|
||||

|
||||

|
||||
|
||||
浏览计划作业
|
||||
*浏览计划任务*
|
||||
|
||||
at支持计划多个命令,例如:
|
||||
|
||||
@ -117,17 +115,17 @@ at支持计划多个命令,例如:
|
||||
|
||||

|
||||
|
||||
Linux中查看日期和时间
|
||||
*Linux中查看日期和时间*
|
||||
|
||||
为了查看这个命令每三秒的输出,我需要运行下列命令:
|
||||
为了每三秒查看一下这个命令的输出,我需要运行下列命令:
|
||||
|
||||
$ watch -n 3 'date +"%H:%M:%S"'
|
||||
|
||||

|
||||
|
||||
Linux中watch命令
|
||||
*Linux中watch命令*
|
||||
|
||||
watch命令的‘-n’开关设定时间间隔。在上诉命令中,我们定义了时间间隔为3秒。你可以按你的需求定义。同样watch
|
||||
watch命令的‘-n’开关设定时间间隔。在上述命令中,我们定义了时间间隔为3秒。你可以按你的需求定义。同样watch
|
||||
也支持其他命令或者脚本。
|
||||
|
||||
至此。希望你喜欢这个系列的文章,让你的linux更有创造性,获得更多快乐。所有的建议欢迎评论。欢迎你也看看其他文章,谢谢。
|
||||
@ -138,7 +136,7 @@ via: http://www.tecmint.com/text-to-speech-in-terminal-schedule-a-job-and-watch-
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
440
published/20150813 Linux file system hierarchy v2.0.md
Normal file
440
published/20150813 Linux file system hierarchy v2.0.md
Normal file
@ -0,0 +1,440 @@
|
||||
Linux 文件系统结构介绍
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
Linux中的文件是什么?它的文件系统又是什么?那些配置文件又在哪里?我下载好的程序保存在哪里了?在 Linux 中文件系统是标准结构的吗?好了,上图简明地阐释了Linux的文件系统的层次关系。当你苦于寻找配置文件或者二进制文件的时候,这便显得十分有用了。我在下方添加了一些解释以及例子,不过“篇幅较长,可以有空再看”。
|
||||
|
||||
另外一种情况便是当你在系统中获取配置以及二进制文件时,出现了不一致性问题,如果你是在一个大型组织中,或者只是一个终端用户,这也有可能会破坏你的系统(比如,二进制文件运行在旧的库文件上了)。若然你在[你的Linux系统上做安全审计][1]的话,你将会发现它很容易遭到各种攻击。所以,保持一个清洁的操作系统(无论是Windows还是Linux)都显得十分重要。
|
||||
|
||||
### Linux的文件是什么? ###
|
||||
|
||||
对于UNIX系统来说(同样适用于Linux),以下便是对文件简单的描述:
|
||||
|
||||
> 在UNIX系统中,一切皆为文件;若非文件,则为进程
|
||||
|
||||
这种定义是比较正确的,因为有些特殊的文件不仅仅是普通文件(比如命名管道和套接字),不过为了让事情变的简单,“一切皆为文件”也是一个可以让人接受的说法。Linux系统也像UNIX系统一样,将文件和目录视如同物,因为目录只是一个包含了其他文件名的文件而已。程序、服务、文本、图片等等,都是文件。对于系统来说,输入和输出设备,基本上所有的设备,都被当做是文件。
|
||||
|
||||
题图版本历史:
|
||||
|
||||
- Version 2.0 – 17-06-2015
|
||||
- – Improved: 添加标题以及版本历史
|
||||
- – Improved: 添加/srv,/meida和/proc
|
||||
- – Improved: 更新了反映当前的Linux文件系统的描述
|
||||
- – Fixed: 多处的打印错误
|
||||
- – Fixed: 外观和颜色
|
||||
- Version 1.0 – 14-02-2015
|
||||
- – Created: 基本的图表
|
||||
- – Note: 摒弃更低的版本
|
||||
|
||||
### 下载链接 ###
|
||||
|
||||
以下是大图的下载地址。如果你需要其他格式,请跟原作者联系,他会尝试制作并且上传到某个地方以供下载
|
||||
|
||||
- [大图 (PNG 格式) – 2480×1755 px – 184KB][2]
|
||||
- [最大图 (PDF 格式) – 9919x7019 px – 1686KB][3]
|
||||
|
||||
**注意**: PDF格式文件是打印的最好选择,因为它画质很高。
|
||||
|
||||
### Linux 文件系统描述 ###
|
||||
|
||||
为了有序地管理那些文件,人们习惯把这些文件当做是硬盘上的有序的树状结构,正如我们熟悉的'MS-DOS'(磁盘操作系统)就是一个例子。大的分枝包括更多的分枝,分枝的末梢是树的叶子或者普通的文件。现在我们将会以这树形图为例,但晚点我们会发现为什么这不是一个完全准确的一幅图。
|
||||
|
||||
<table cellspacing="2" border="4" style="border-collapse: collapse; width: 731px; height: 2617px;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th scope="col">目录</th>
|
||||
<th scope="col">描述</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/</code>
|
||||
</td>
|
||||
<td><i>主层次</i> 的根,也是整个文件系统层次结构的根目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/bin</code>
|
||||
</td>
|
||||
<td>存放在单用户模式可用的必要命令二进制文件,所有用户都可用,如 cat、ls、cp等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/boot</code>
|
||||
</td>
|
||||
<td>存放引导加载程序文件,例如kernels、initrd等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/dev</code>
|
||||
</td>
|
||||
<td>存放必要的设备文件,例如<code>/dev/null</code> </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/etc</code>
|
||||
</td>
|
||||
<td>存放主机特定的系统级配置文件。其实这里有个关于它名字本身意义上的的争议。在贝尔实验室的UNIX实施文档的早期版本中,/etc表示是“其他(etcetera)目录”,因为从历史上看,这个目录是存放各种不属于其他目录的文件(然而,文件系统目录标准 FSH 限定 /etc 用于存放静态配置文件,这里不该存有二进制文件)。早期文档出版后,这个目录名又重新定义成不同的形式。近期的解释中包含着诸如“可编辑文本配置”或者“额外的工具箱”这样的重定义</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/opt</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存储着新增包的配置文件 <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/sgml</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存放配置文件,比如 catalogs,用于那些处理SGML(译者注:标准通用标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/X11</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>X Window 系统11版本的的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/xml</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>配置文件,比如catalogs,用于那些处理XML(译者注:可扩展标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/home</code>
|
||||
</td>
|
||||
<td>用户的主目录,包括保存的文件,个人配置,等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/lib</code>
|
||||
</td>
|
||||
<td><code>/bin/</code> 和 <code>/sbin/</code>中的二进制文件的必需的库文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/lib<架构位数></code>
|
||||
</td>
|
||||
<td>备用格式的必要的库文件。 这样的目录是可选的,但如果他们存在的话肯定是有需要用到它们的程序</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/media</code>
|
||||
</td>
|
||||
<td>可移动的多媒体(如CD-ROMs)的挂载点。(出现于 FHS-2.3)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/mnt</code>
|
||||
</td>
|
||||
<td>临时挂载的文件系统</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/opt</code>
|
||||
</td>
|
||||
<td>可选的应用程序软件包</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/proc</code>
|
||||
</td>
|
||||
<td>以文件形式提供进程以及内核信息的虚拟文件系统,在Linux中,对应进程文件系统(procfs )的挂载点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/root</code>
|
||||
</td>
|
||||
<td>根用户的主目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/sbin</code>
|
||||
</td>
|
||||
<td>必要的系统级二进制文件,比如, init, ip, mount</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/srv</code>
|
||||
</td>
|
||||
<td>系统提供的站点特定数据</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/tmp</code>
|
||||
</td>
|
||||
<td>临时文件 (另见 <code>/var/tmp</code>). 通常在系统重启后删除</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/usr</code>
|
||||
</td>
|
||||
<td><i>二级层级</i>存储用户的只读数据; 包含(多)用户主要的公共文件以及应用程序</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/bin</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>非必要的命令二进制文件 (在单用户模式中不需要用到的);用于所有用户</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/include</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>标准的包含文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/lib</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>库文件,用于<code>/usr/bin/</code> 和 <code>/usr/sbin/</code>中的二进制文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/lib<架构位数></code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>备用格式库(可选的)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/local</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td><i>三级层次</i> 用于本地数据,具体到该主机上的。通常会有下一个子目录, <i>比如</i>, <code>bin/</code>, <code>lib/</code>, <code>share/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/local/sbin</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>非必要系统的二进制文件,比如用于不同网络服务的守护进程</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/share</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>架构无关的 (共享) 数据.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/src</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>源代码,比如内核源文件以及与它相关的头文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/X11R6</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>X Window系统,版本号:11,发行版本:6</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/var</code>
|
||||
</td>
|
||||
<td>各式各样的(Variable)文件,一些随着系统常规操作而持续改变的文件就放在这里,比如日志文件,脱机文件,还有临时的电子邮件文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/cache</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>应用程序缓存数据. 这些数据是由耗时的I/O(输入/输出)的或者是运算本地生成的结果。这些应用程序是可以重新生成或者恢复数据的。当没有数据丢失的时候,可以删除缓存文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/lib</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>状态信息。这些信息随着程序的运行而不停地改变,比如,数据库,软件包系统的元数据等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/lock</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>锁文件。这些文件用于跟踪正在使用的资源</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/log</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>日志文件。包含各种日志。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/mail</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>内含用户邮箱的相关文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/opt</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>来自附加包的各种数据都会存储在 <code>/var/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/run</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存放当前系统上次启动以来的相关信息,例如当前登入的用户以及当前运行的<a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons(守护进程)</a>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/spool</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>该spool主要用于存放将要被处理的任务,比如打印队列以及邮件外发队列</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
|
||||
|
||||
<code>/var/mail</code>
|
||||
|
||||
|
||||
|
||||
|
||||
</td>
|
||||
<td>过时的位置,用于放置用户邮箱文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/tmp</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存放重启后保留的临时文件</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Linux的文件类型 ###
|
||||
|
||||
大多数文件仅仅是普通文件,他们被称为`regular`文件;他们包含普通数据,比如,文本、可执行文件、或者程序、程序的输入或输出等等
|
||||
|
||||
虽然你可以认为“在Linux中,一切你看到的皆为文件”这个观点相当保险,但这里仍有着一些例外。
|
||||
|
||||
- `目录`:由其他文件组成的文件
|
||||
- `特殊文件`:用于输入和输出的途径。大多数特殊文件都储存在`/dev`中,我们将会在后面讨论这个问题。
|
||||
- `链接文件`:让文件或者目录出现在系统文件树结构上多个地方的机制。我们将详细地讨论这个链接文件。
|
||||
- `(域)套接字`:特殊的文件类型,和TCP/IP协议中的套接字有点像,提供进程间网络通讯,并受文件系统的访问控制机制保护。
|
||||
- `命名管道` : 或多或少有点像sockets(套接字),提供一个进程间的通信机制,而不用网络套接字协议。
|
||||
|
||||
### 现实中的文件系统 ###
|
||||
|
||||
对于大多数用户和常规系统管理任务而言,“文件和目录是一个有序的类树结构”是可以接受的。然而,对于电脑而言,它是不会理解什么是树,或者什么是树结构。
|
||||
|
||||
每个分区都有它自己的文件系统。想象一下,如果把那些文件系统想成一个整体,我们可以构思一个关于整个系统的树结构,不过这并没有这么简单。在文件系统中,一个文件代表着一个`inode`(索引节点),这是一种包含着构建文件的实际数据信息的序列号:这些数据表示文件是属于谁的,还有它在硬盘中的位置。
|
||||
|
||||
每个分区都有一套属于他们自己的inode,在一个系统的不同分区中,可以存在有相同inode的文件。
|
||||
|
||||
每个inode都表示着一种在硬盘上的数据结构,保存着文件的属性,包括文件数据的物理地址。当硬盘被格式化并用来存储数据时(通常发生在初始系统安装过程,或者是在一个已经存在的系统中添加额外的硬盘),每个分区都会创建固定数量的inode。这个值表示这个分区能够同时存储各类文件的最大数量。我们通常用一个inode去映射2-8k的数据块。当一个新的文件生成后,它就会获得一个空闲的inode。在这个inode里面存储着以下信息:
|
||||
|
||||
- 文件属主和组属主
|
||||
- 文件类型(常规文件,目录文件......)
|
||||
- 文件权限
|
||||
- 创建、最近一次读文件和修改文件的时间
|
||||
- inode里该信息被修改的时间
|
||||
- 文件的链接数(详见下一章)
|
||||
- 文件大小
|
||||
- 文件数据的实际地址
|
||||
|
||||
唯一不在inode的信息是文件名和目录。它们存储在特殊的目录文件。通过比较文件名和inode的数目,系统能够构造出一个便于用户理解的树结构。用户可以通过ls -i查看inode的数目。在硬盘上,inodes有他们独立的空间。
|
||||
|
||||
------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/18/linux-file-system-hierarchy-v2-0/
|
||||
|
||||
译者:[tnuoccalanosrep](https://github.com/tnuoccalanosrep)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.blackmoreops.com/2015/02/15/in-light-of-recent-linux-exploits-linux-security-audit-is-a-must/
|
||||
[2]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-file-system-hierarchy-v2.0-2480px-blackMORE-Ops.png
|
||||
[3]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-File-System-Hierarchy-blackMORE-Ops.pdf
|
||||
@ -1,13 +1,10 @@
|
||||
看这些孩子在Ubuntu的Linux终端下玩耍
|
||||
看这些孩子在 Ubuntu 的 Linux 终端下玩耍
|
||||
================================================================================
|
||||
我发现了一个孩子们在他们的计算机教室里玩得很开心的视频。我不知道他们在哪里,但我猜测是在印度尼西亚或者马来西亚。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="640" height="390" frameborder="0" allowfullscreen="true" src="http://www.youtube.com/embed/z8taQPomp0Y?version=3&rel=1&fs=1&showsearch=0&showinfo=1&iv_load_policy=1&wmode=transparent" type="text/html" class="youtube-player"></iframe>
|
||||
我发现了一个孩子们在他们的计算机教室里玩得很开心的视频。我不知道他们在哪里,但我猜测是在印度尼西亚或者马来西亚。视频请自行搭梯子: http://www.youtube.com/z8taQPomp0Y
|
||||
|
||||
### 在Linux终端下面跑火车 ###
|
||||
|
||||
这里没有魔术。只是一个叫做“sl”的命令行工具。我假定它是在把ls打错的情况下为了好玩而开发的。如果你曾经在Linux的命令行下工作,你会知道ls是一个最常使用的一个命令,也许也是一个最经常打错的命令。
|
||||
这里没有魔术。只是一个叫做“sl”的命令行工具。我想它是在把ls打错的情况下为了好玩而开发的。如果你曾经在Linux的命令行下工作,你会知道ls是一个最常使用的一个命令,也许也是一个最经常打错的命令。
|
||||
|
||||
如果你想从这个终端下的火车获得一些乐趣,你可以使用下面的命令安装它。
|
||||
|
||||
@ -30,7 +27,7 @@ via: http://itsfoss.com/ubuntu-terminal-train/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,295 @@
|
||||
如何为你的平台部署一个公开的系统状态页
|
||||
================================================================================
|
||||
|
||||
如果你是一个系统管理员,负责关键的 IT 基础设置或公司的服务,你将明白有效的沟通在日常任务中的重要性。假设你的线上存储服务器故障了。你希望团队所有人达成共识你好尽快的解决问题。当你忙来忙去时,你不会想一半的人问你为什么他们不能访问他们的文档。当一个维护计划快到时间了你想在计划前提醒相关人员,这样避免了不必要的开销。
|
||||
|
||||
这一切的要求或多或少改进了你、你的团队、和你服务的用户之间沟通渠道。一个实现它的方法是维护一个集中的系统状态页面,报告和记录故障停机详情、进度更新和维护计划等。这样,在故障期间你避免了不必要的打扰,也可以提醒一些相关方,以及加入一些可选的状态更新。
|
||||
|
||||
有一个不错的**开源, 自承载系统状态页解决方案**叫做 [Cachet][1]。在这个教程,我将要描述如何用 Cachet 部署一个自承载系统状态页面。
|
||||
|
||||
### Cachet 特性 ###
|
||||
|
||||
在详细的配置 Cachet 之前,让我简单的介绍一下它的主要特性。
|
||||
|
||||
- **全 JSON API**:Cachet API 可以让你使用任意的外部程序或脚本(例如,uptime 脚本)连接到 Cachet 来自动报告突发事件或更新状态。
|
||||
- **认证**:Cachet 支持基础认证和 JSON API 的 API 令牌,所以只有认证用户可以更新状态页面。
|
||||
- **衡量系统**:这通常用来展现随着时间推移的自定义数据(例如,服务器负载或者响应时间)。
|
||||
- **通知**:可选地,你可以给任一注册了状态页面的人发送突发事件的提示邮件。
|
||||
- **多语言**:状态页被翻译为11种不同的语言。
|
||||
- **双因子认证**:这允许你使用 Google 的双因子认证来提升 Cachet 管理账户的安全性。
|
||||
- **跨数据库支持**:你可以选择 MySQL,SQLite,Redis,APC 和 PostgreSQL 作为后端存储。
|
||||
|
||||
剩下的教程,我会说明如何在 Linux 上安装配置 Cachet。
|
||||
|
||||
### 第一步:下载和安装 Cachet ###
|
||||
|
||||
Cachet 需要一个 web 服务器和一个后端数据库来运转。在这个教程中,我将使用 LAMP 架构。以下是一些特定发行版上安装 Cachet 和 LAMP 架构的指令。
|
||||
|
||||
#### Debian,Ubuntu 或者 Linux Mint ####
|
||||
|
||||
$ sudo apt-get install curl git apache2 mysql-server mysql-client php5 php5-mysql
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R www-data:www-data .
|
||||
|
||||
在基于 Debian 的系统上设置 LAMP 架构的更多细节,参考这个[教程][2]。
|
||||
|
||||
#### Fedora, CentOS 或 RHEL ####
|
||||
|
||||
在基于 Red Hat 系统上,你首先需要[设置 REMI 软件库][3](以满足 PHP 的版本需求)。然后执行下面命令。
|
||||
|
||||
$ sudo yum install curl git httpd mariadb-server
|
||||
$ sudo yum --enablerepo=remi-php56 install php php-mysql php-mbstring
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R apache:apache .
|
||||
$ sudo firewall-cmd --permanent --zone=public --add-service=http
|
||||
$ sudo firewall-cmd --reload
|
||||
$ sudo systemctl enable httpd.service; sudo systemctl start httpd.service
|
||||
$ sudo systemctl enable mariadb.service; sudo systemctl start mariadb.service
|
||||
|
||||
在基于 Red Hat 系统上设置 LAMP 的更多细节,参考这个[教程][4]。
|
||||
|
||||
### 配置 Cachet 的后端数据库###
|
||||
|
||||
下一步是配置后端数据库。
|
||||
|
||||
登录到 MySQL/MariaDB 服务,然后创建一个空的数据库称为‘cachet’。
|
||||
|
||||
$ sudo mysql -uroot -p
|
||||
|
||||
----------
|
||||
|
||||
mysql> create database cachet;
|
||||
mysql> quit
|
||||
|
||||
现在用一个示例配置文件创建一个 Cachet 配置文件。
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo mv .env.example .env
|
||||
|
||||
在 .env 文件里,填写你自己设置的数据库信息(例如,DB\_\*)。其他的字段先不改变。
|
||||
|
||||
APP_ENV=production
|
||||
APP_DEBUG=false
|
||||
APP_URL=http://localhost
|
||||
APP_KEY=SomeRandomString
|
||||
|
||||
DB_DRIVER=mysql
|
||||
DB_HOST=localhost
|
||||
DB_DATABASE=cachet
|
||||
DB_USERNAME=root
|
||||
DB_PASSWORD=<root-password>
|
||||
|
||||
CACHE_DRIVER=apc
|
||||
SESSION_DRIVER=apc
|
||||
QUEUE_DRIVER=database
|
||||
|
||||
MAIL_DRIVER=smtp
|
||||
MAIL_HOST=mailtrap.io
|
||||
MAIL_PORT=2525
|
||||
MAIL_USERNAME=null
|
||||
MAIL_PASSWORD=null
|
||||
MAIL_ADDRESS=null
|
||||
MAIL_NAME=null
|
||||
|
||||
REDIS_HOST=null
|
||||
REDIS_DATABASE=null
|
||||
REDIS_PORT=null
|
||||
|
||||
### 第三步:安装 PHP 依赖和执行数据库迁移 ###
|
||||
|
||||
下面,我们将要安装必要的PHP依赖包。我们会使用 composer 来安装。如果你的系统还没有安装 composer,先安装它:
|
||||
|
||||
$ curl -sS https://getcomposer.org/installer | sudo php -- --install-dir=/usr/local/bin --filename=composer
|
||||
|
||||
现在开始用 composer 安装 PHP 依赖包。
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo composer install --no-dev -o
|
||||
|
||||
下面执行一次性的数据库迁移。这一步会在我们之前创建的数据库里面创建那些所需的表。
|
||||
|
||||
$ sudo php artisan migrate
|
||||
|
||||
假设在 /var/www/cachet/.env 的数据库配置无误,数据库迁移应该像下面显示一样成功完成。
|
||||
|
||||
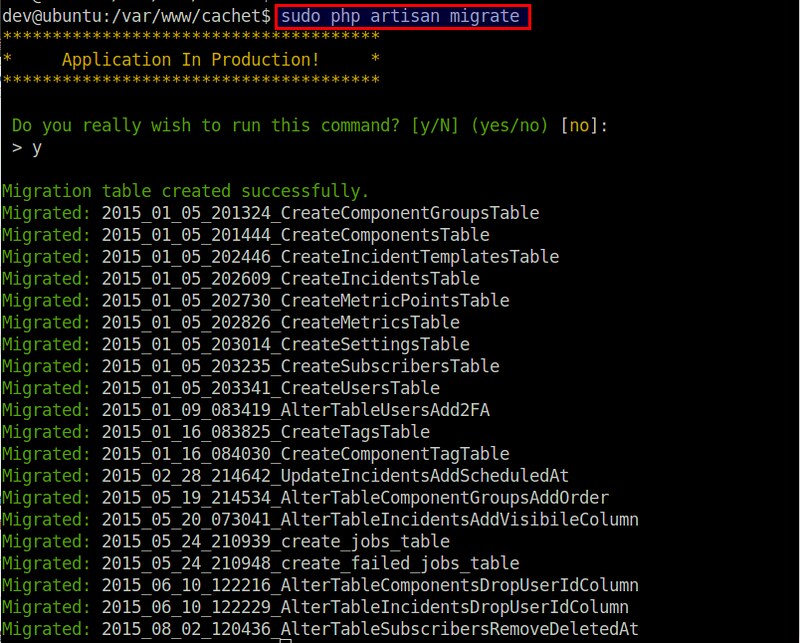
|
||||
|
||||
下面,创建一个密钥,它将用来加密进入 Cachet 的数据。
|
||||
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||
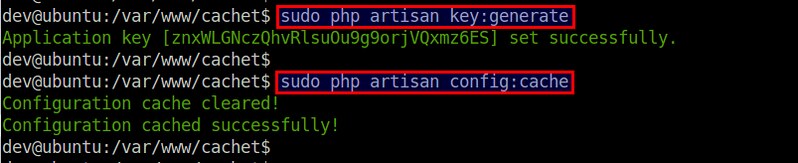
|
||||
|
||||
生成的应用密钥将自动添加到你的 .env 文件 APP\_KEY 变量中。你不需要自己编辑 .env。
|
||||
|
||||
### 第四步:配置 Apache HTTP 服务 ###
|
||||
|
||||
现在到了配置运行 Cachet 的 web 服务的时候了。我们使用 Apache HTTP 服务器,为 Cachet 创建一个新的[虚拟主机][5],如下:
|
||||
|
||||
#### Debian,Ubuntu 或 Linux Mint ####
|
||||
|
||||
$ sudo vi /etc/apache2/sites-available/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
启用新虚拟主机和 mod_rewrite:
|
||||
|
||||
$ sudo a2ensite cachet.conf
|
||||
$ sudo a2enmod rewrite
|
||||
$ sudo service apache2 restart
|
||||
|
||||
#### Fedora, CentOS 或 RHEL ####
|
||||
|
||||
在基于 Red Hat 系统上,创建一个虚拟主机文件,如下:
|
||||
|
||||
$ sudo vi /etc/httpd/conf.d/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
现在重载 Apache 配置:
|
||||
|
||||
$ sudo systemctl reload httpd.service
|
||||
|
||||
### 第五步:配置 /etc/hosts 来测试 Cachet ###
|
||||
|
||||
这时候,初始的 Cachet 状态页面应该启动运行了,现在测试一下。
|
||||
|
||||
由于 Cachet 被配置为Apache HTTP 服务的虚拟主机,我们需要调整你的客户机的 /etc/hosts 来访问他。你将从这个客户端电脑访问 Cachet 页面。(LCTT 译注:如果你给了这个页面一个正式的主机地址,则不需要这一步。)
|
||||
|
||||
打开 /etc/hosts,加入如下行:
|
||||
|
||||
$ sudo vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
<cachet 服务器的 IP 地址> cachethost
|
||||
|
||||
上面名为“cachethost”必须匹配 Cachet 的 Apache 虚拟主机文件的 ServerName。
|
||||
|
||||
### 测试 Cachet 状态页面 ###
|
||||
|
||||
现在你准备好访问 Cachet 状态页面。在你浏览器地址栏输入 http://cachethost。你将被转到如下的 Cachet 状态页的初始化设置页面。
|
||||
|
||||
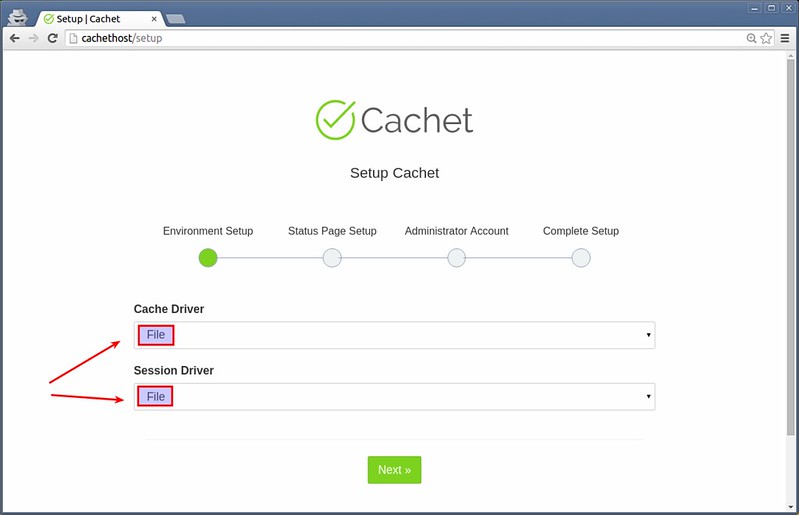
|
||||
|
||||
选择 cache/session 驱动。这里 cache 和 session 驱动两个都选“File”。
|
||||
|
||||
下一步,输入关于状态页面的基本信息(例如,站点名称、域名、时区和语言),以及管理员认证账户。
|
||||
|
||||
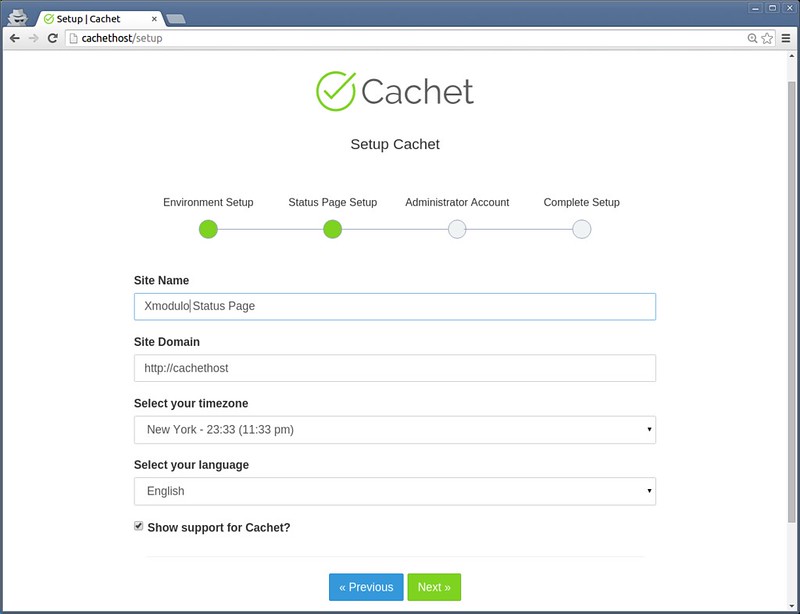
|
||||
|
||||
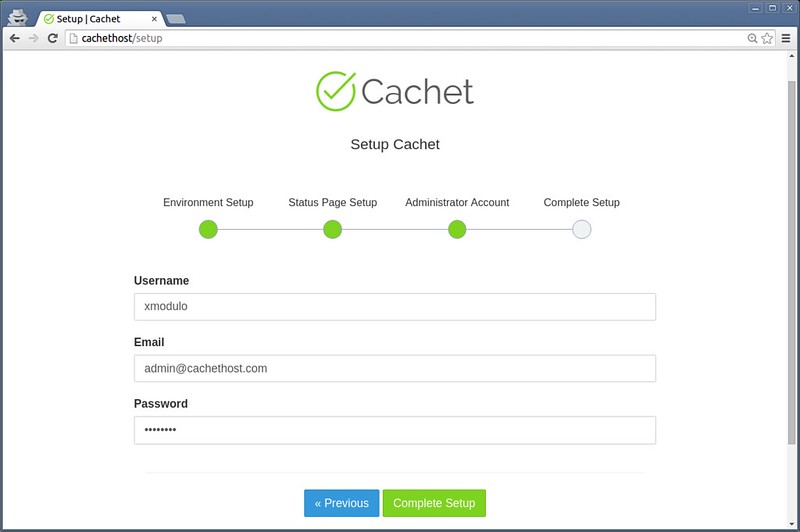
|
||||
|
||||
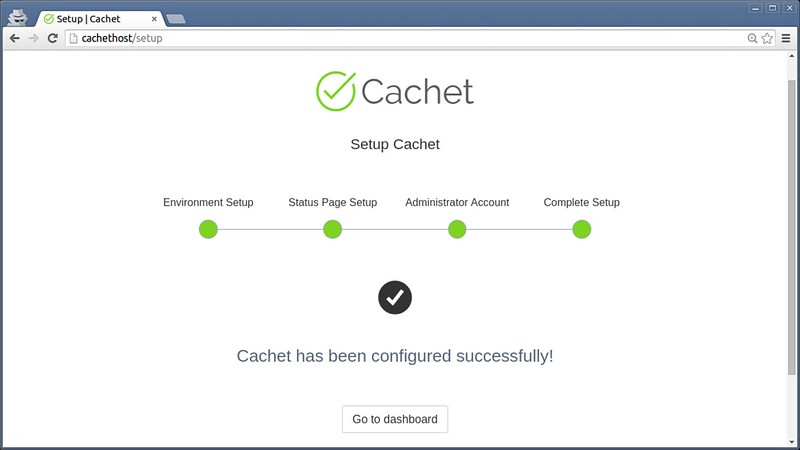
|
||||
|
||||
你的状态页初始化就要完成了。
|
||||
|
||||
|
||||
|
||||
继续创建组件(你的系统单元)、事件或者任意你要做的维护计划。
|
||||
|
||||
例如,增加一个组件:
|
||||
|
||||
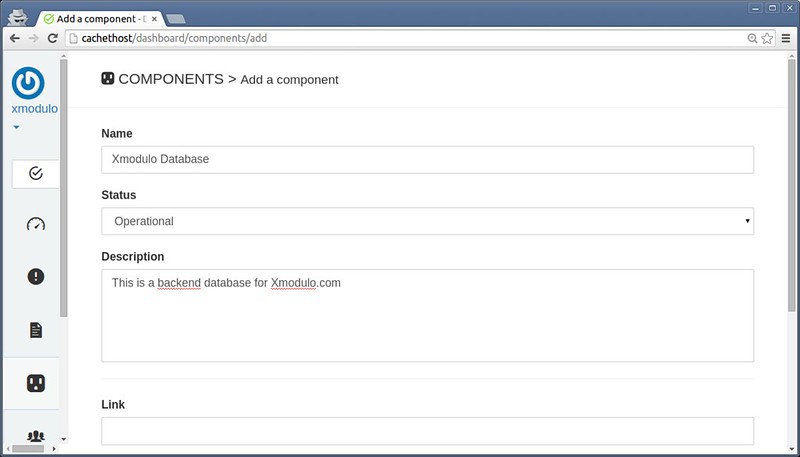
|
||||
|
||||
增加一个维护计划:
|
||||
|
||||
公共 Cachet 状态页就像这样:
|
||||
|
||||
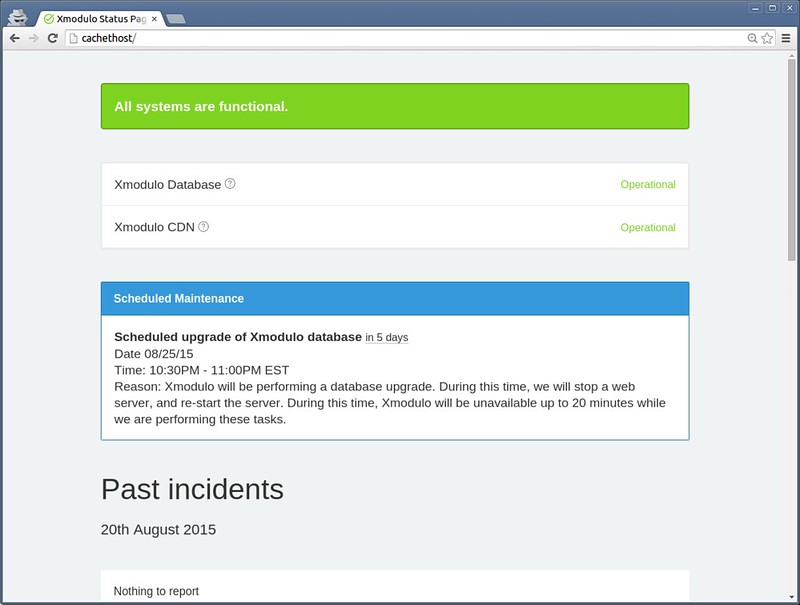
|
||||
|
||||
集成了 SMTP,你可以在状态更新时发送邮件给订阅者。并且你可以使用 CSS 和 markdown 格式来完全自定义布局和状态页面。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
Cachet 是一个相当易于使用,自托管的状态页面软件。Cachet 一个高级特性是支持全 JSON API。使用它的 RESTful API,Cachet 可以轻松连接单独的监控后端(例如,[Nagios][6]),然后回馈给 Cachet 事件报告并自动更新状态。比起手工管理一个状态页它更快和有效率。
|
||||
|
||||
最后一句,我喜欢提及一个事。用 Cachet 设置一个漂亮的状态页面是很简单的,但要将这个软件用好并不像安装它那么容易。你需要完全保障所有 IT 团队习惯准确及时的更新状态页,从而建立公共信息的准确性。同时,你需要教用户去查看状态页面。最后,如果没有很好的填充数据,部署状态页面就没有意义,并且/或者没有一个人查看它。记住这个,尤其是当你考虑在你的工作环境中部署 Cachet 时。
|
||||
|
||||
### 故障排查 ###
|
||||
|
||||
补充,万一你安装 Cachet 时遇到问题,这有一些有用的故障排查的技巧。
|
||||
|
||||
1. Cachet 页面没有加载任何东西,并且你看到如下报错。
|
||||
|
||||
production.ERROR: exception 'RuntimeException' with message 'No supported encrypter found. The cipher and / or key length are invalid.' in /var/www/cachet/bootstrap/cache/compiled.php:6695
|
||||
|
||||
**解决方案**:确保你创建了一个应用密钥,以及明确配置缓存如下所述。
|
||||
|
||||
$ cd /path/to/cachet
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||
2. 调用 composer 命令时有如下报错。
|
||||
|
||||
- danielstjules/stringy 1.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- laravel/framework v5.1.8 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- league/commonmark 0.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
|
||||
**解决方案**:确保在你的系统上安装了必要的 PHP 扩展 mbstring ,并且兼容你的 PHP 版本。在基于 Red Hat 的系统上,由于我们从 REMI-56 库安装PHP,所以要从同一个库安装扩展。
|
||||
|
||||
$ sudo yum --enablerepo=remi-php56 install php-mbstring
|
||||
|
||||
3. 你访问 Cachet 状态页面时得到一个白屏。HTTP 日志显示如下错误。
|
||||
|
||||
PHP Fatal error: Uncaught exception 'UnexpectedValueException' with message 'The stream or file "/var/www/cachet/storage/logs/laravel-2015-08-21.log" could not be opened: failed to open stream: Permission denied' in /var/www/cachet/bootstrap/cache/compiled.php:12851
|
||||
|
||||
**解决方案**:尝试如下命令。
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo php artisan cache:clear
|
||||
$ sudo chmod -R 777 storage
|
||||
$ sudo composer dump-autoload
|
||||
|
||||
如果上面的方法不起作用,试试禁止SELinux:
|
||||
|
||||
$ sudo setenforce 0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-system-status-page.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://cachethq.io/
|
||||
[2]:http://xmodulo.com/install-lamp-stack-ubuntu-server.html
|
||||
[3]:https://linux.cn/article-4192-1.html
|
||||
[4]:https://linux.cn/article-5789-1.html
|
||||
[5]:http://xmodulo.com/configure-virtual-hosts-apache-http-server.html
|
||||
[6]:http://xmodulo.com/monitor-common-services-nagios.html
|
||||
@ -0,0 +1,86 @@
|
||||
在 Ubuntu 中如何安装或升级 Linux 内核到4.2
|
||||
================================================================================
|
||||

|
||||
|
||||
Linux 内核 4.2已经发布了。Linus Torvalds 在 [lkml.org][1] 上写到:
|
||||
|
||||
> 通过这周这么小的变动,看来在最后一周 发布 4.2 版本应该不会有问题,当然还有几个修正,但是看起来也并不需要延迟一周。
|
||||
> 所以这就到了,而且 4.3 的合并窗口现已打开。我已经有了几个等待处理的合并请求,明天我开始处理它们,然后在适当的时候放出来。
|
||||
> 从 rc8 以来的简短日志很小,已经附加。这个补丁也很小...
|
||||
|
||||
### 新内核 4.2 有哪些改进?: ###
|
||||
|
||||
- 重写英特尔的x86汇编代码
|
||||
- 支持新的 ARM 板和 SoC
|
||||
- 对 F2FS 的 per-file 加密
|
||||
- AMDGPU 的内核 DRM 驱动程序
|
||||
- 对 Radeon DRM 驱动的 VCE1 视频编码支持
|
||||
- 初步支持英特尔的 Broxton Atom SoC
|
||||
- 支持 ARCv2 和 HS38 CPU 内核
|
||||
- 增加了队列自旋锁的支持
|
||||
- 许多其他的改进和驱动更新。
|
||||
|
||||
### 在 Ubuntu 中如何下载4.2内核 : ###
|
||||
|
||||
此内核版本的二进制包可供下载链接如下:
|
||||
|
||||
- [下载 4.2 内核(.DEB)][1]
|
||||
|
||||
首先检查你的操作系统类型,32位(i386)的或64位(amd64)的,然后使用下面的方式依次下载并安装软件包:
|
||||
|
||||
1. linux-headers-4.2.0-xxx_all.deb
|
||||
1. linux-headers-4.2.0-xxx-generic_xxx_i386/amd64.deb
|
||||
1. linux-image-4.2.0-xxx-generic_xxx_i386/amd64.deb
|
||||
|
||||
安装内核后,在终端((Ctrl+Alt+T))运行`sudo update-grub`命令来更新 grub boot-loader。
|
||||
|
||||
如果你需要一个低延迟系统(例如用于录制音频),请下载并安装下面的包:
|
||||
|
||||
1. linux-headers-4.2.0_xxx_all.deb
|
||||
1. linux-headers-4.2.0-xxx-lowlatency_xxx_i386/amd64.deb
|
||||
1. linux-image-4.2.0-xxx-lowlatency_xxx_i386/amd64.deb
|
||||
|
||||
对于没有图形用户界面的 Ubuntu 服务器,你可以运行下面的命令通过 wget 来逐一抓下载,并通过 dpkg 来安装:
|
||||
|
||||
对于64位的系统请运行:
|
||||
|
||||
cd /tmp/
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200_4.2.0-040200.201508301530_all.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200-generic_4.2.0-040200.201508301530_amd64.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-image-4.2.0-040200-generic_4.2.0-040200.201508301530_amd64.deb
|
||||
|
||||
sudo dpkg -i linux-headers-4.2.0-*.deb linux-image-4.2.0-*.deb
|
||||
|
||||
对于32位的系统,请运行:
|
||||
|
||||
cd /tmp/
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200_4.2.0-040200.201508301530_all.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200-generic_4.2.0-040200.201508301530_i386.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-image-4.2.0-040200-generic_4.2.0-040200.201508301530_i386.deb
|
||||
|
||||
sudo dpkg -i linux-headers-4.2.0-*.deb linux-image-4.2.0-*.deb
|
||||
|
||||
最后,重新启动计算机才能生效。
|
||||
|
||||
要恢复或删除旧的内核,请参阅[通过脚本安装内核][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/08/upgrade-kernel-4-2-ubuntu/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:https://lkml.org/lkml/2015/8/30/96
|
||||
[2]:http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/
|
||||
[3]:http://ubuntuhandbook.org/index.php/2015/08/install-latest-kernel-script/
|
||||
@ -0,0 +1,53 @@
|
||||
如何在 Linux 上自动调整屏幕亮度保护眼睛
|
||||
================================================================================
|
||||
|
||||
当你开始在计算机前花费大量时间的时候,问题自然开始显现。这健康吗?怎样才能舒缓我眼睛的压力呢?为什么光线灼烧着我?尽管解答这些问题的研究仍然在不断进行着,许多程序员已经采用了一些应用来改变他们的日常习惯,让他们的眼睛更健康点。在这些应用中,我发现了两个特别有趣的东西:Calise和Redshift。
|
||||
|
||||
### Calise ###
|
||||
|
||||
处于时断时续的开发中,[Calise][1]的意思是“相机光感应器(Camera Light Sensor)”。换句话说,它是一个根据摄像头接收到的光强度计算屏幕最佳的背光级别的开源程序。更进一步地说,Calise可以基于你的地理坐标来考虑你所在地区的天气。我喜欢它是因为它兼容各个桌面,甚至非X系列。
|
||||
|
||||

|
||||
|
||||
它同时附带了命令行界面和图形界面,支持多用户配置,而且甚至可以导出数据为CSV。安装完后,你必须在见证奇迹前对它进行快速校正。
|
||||
|
||||

|
||||
|
||||
不怎么令人喜欢的是,如果你和我一样有被偷窥妄想症,在你的摄像头前面贴了一条胶带,那就会比较不幸了,这会大大影响Calise的精确度。除此之外,Calise还是个很棒的应用,值得我们关注和支持。正如我先前提到的,它在过去几年中经历了一段修修补补的艰难阶段,所以我真的希望这个项目继续开展下去。
|
||||
|
||||

|
||||
|
||||
### Redshift ###
|
||||
|
||||
如果你想过要减少由屏幕导致的眼睛的压力,那么你很可能听过f.lux,它是一个免费的专有软件,用于根据一天中的时间来修改显示器的亮度和配色。然而,如果真的偏好于开源软件,那么一个可选方案就是:[Redshift][2]。灵感来自f.lux,Redshift也可以改变配色和亮度来加强你夜间坐在屏幕前的体验。启动时,你可以使用经度和纬度来配置地理坐标,然后就可以让它在托盘中运行了。Redshift将根据太阳的位置平滑地调整你的配色或者屏幕。在夜里,你可以看到屏幕的色温调向偏暖色,这会让你的眼睛少遭些罪。
|
||||
|
||||

|
||||
|
||||
和Calise一样,它提供了一个命令行界面,同时也提供了一个图形客户端。要快速启动Redshift,只需使用命令:
|
||||
|
||||
$ redshift -l [LAT]:[LON]
|
||||
|
||||
替换[LAT]:[LON]为你的维度和经度。
|
||||
|
||||
然而,它也可以通过gpsd模块来输入你的坐标。对于Arch Linux用户,我推荐你读一读这个[维基页面][3]。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
总而言之,Linux用户没有理由不去保护自己的眼睛,Calise和Redshift两个都很棒。我真希望它们的开发能够继续下去,让它们获得应有的支持。当然,还有比这两个更多的程序可以满足保护眼睛和保持健康的目的,但是我感觉Calise和Redshift会是一个不错的开端。
|
||||
|
||||
如果你有一个经常用来舒缓眼睛的压力的喜欢的程序,请在下面的评论中留言吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/automatically-dim-your-screen-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://calise.sourceforge.net/
|
||||
[2]:http://jonls.dk/redshift/
|
||||
[3]:https://wiki.archlinux.org/index.php/Redshift#Automatic_location_based_on_GPS
|
||||
@ -0,0 +1,182 @@
|
||||
在 Ubuntu 上配置高性能的 HHVM 环境
|
||||
================================================================================
|
||||
|
||||
HHVM全称为 HipHop Virtual Machine,它是一个开源虚拟机,用来运行由 Hack(一种编程语言)和 PHP 开发应用。HHVM 在保证了 PHP 程序员最关注的高灵活性的要求下,通过使用最新的编译方式来取得了非凡的性能。到目前为止,相对于 PHP + [APC (Alternative PHP Cache)][1] ,HHVM 为 FaceBook 在 HTTP 请求的吞吐量上提高了9倍的性能,在内存的占用上,减少了5倍左右的内存占用。
|
||||
|
||||
同时,HHVM 也可以与基于 FastCGI 的 Web 服务器(如 Nginx 或者 Apache )协同工作。
|
||||
|
||||

|
||||
|
||||
*安装 HHVM,Nginx和 Apache 还有 MariaDB*
|
||||
|
||||
在本教程中,我们一起来配置 Nginx/Apache web 服务器、 数据库服务器 MariaDB 和 HHVM 。我们将使用 Ubuntu 15.04 (64 位),因为 HHVM 只能运行在64位系统上。同时,该教程也适用于 Debian 和 Linux Mint。
|
||||
|
||||
### 第一步: 安装 Nginx 或者 Apache 服务器 ###
|
||||
|
||||
1、首先,先进行一次系统的升级并更新软件仓库列表,命令如下
|
||||
|
||||
# apt-get update && apt-get upgrade
|
||||
|
||||

|
||||
|
||||
*系统升级*
|
||||
|
||||
2、 正如我之前说的,HHVM 能和 Nginx 和 Apache 进行集成。所以,究竟使用哪个服务器,这是你的自由,不过,我们会教你如何安装这两个服务器。
|
||||
|
||||
#### 安装 Nginx ####
|
||||
|
||||
我们通过下面的命令安装 Nginx/Apache 服务器
|
||||
|
||||
# apt-get install nginx
|
||||
|
||||

|
||||
|
||||
*安装 Nginx 服务器*
|
||||
|
||||
#### 安装 Apache ####
|
||||
|
||||
# apt-get install apache2
|
||||
|
||||

|
||||
|
||||
*安装 Apache 服务器*
|
||||
|
||||
完成这一步,你能通过以下的链接看到 Nginx 或者 Apache 的默认页面
|
||||
|
||||
http://localhost
|
||||
或
|
||||
http://IP-Address
|
||||
|
||||
|
||||

|
||||
|
||||
*Nginx 默认页面*
|
||||
|
||||

|
||||
|
||||
*Apache 默认页面*
|
||||
|
||||
### 第二步: 安装和配置 MariaDB ###
|
||||
|
||||
3、 这一步,我们将通过如下命令安装 MariaDB,它是一个比 MySQL 性能更好的数据库
|
||||
|
||||
# apt-get install mariadb-client mariadb-server
|
||||
|
||||

|
||||
|
||||
*安装 MariaDB*
|
||||
|
||||
4、 在 MariaDB 成功安装之后,你可以启动它,并且设置 root 密码来保护数据库:
|
||||
|
||||
|
||||
# systemctl start mysql
|
||||
# mysql_secure_installation
|
||||
|
||||
回答以下问题,只需要按下`y`或者 `n`并且回车。请确保你仔细的阅读过说明。
|
||||
|
||||
Enter current password for root (enter for none) = press enter
|
||||
Set root password? [Y/n] = y
|
||||
Remove anonymous users[y/n] = y
|
||||
Disallow root login remotely[y/n] = y
|
||||
Remove test database and access to it [y/n] = y
|
||||
Reload privileges tables now[y/n] = y
|
||||
|
||||
5、 在设置了密码之后,你就可以登录 MariaDB 了。
|
||||
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
|
||||
### 第三步: 安装 HHVM ###
|
||||
|
||||
6、 在此阶段,我们将安装 HHVM。我们需要添加 HHVM 的仓库到你的`sources.list`文件中,然后更新软件列表。
|
||||
|
||||
# wget -O - http://dl.hhvm.com/conf/hhvm.gpg.key | apt-key add -
|
||||
# echo deb http://dl.hhvm.com/ubuntu DISTRIBUTION_VERSION main | sudo tee /etc/apt/sources.list.d/hhvm.list
|
||||
# apt-get update
|
||||
|
||||
**重要**:不要忘记用你的 Ubuntu 发行版代号替换上述的 DISTRIBUTION_VERSION (比如:lucid, precise, trusty) 或者是 Debian 的 jessie 或者 wheezy。在 Linux Mint 中也是一样的,不过只支持 petra。
|
||||
|
||||
添加了 HHVM 仓库之后,你就可以轻松安装了。
|
||||
|
||||
# apt-get install -y hhvm
|
||||
|
||||
安装之后,就可以启动它,但是它并没有做到开机启动。可以用如下命令做到开机启动。
|
||||
|
||||
# update-rc.d hhvm defaults
|
||||
|
||||
### 第四步: 配置 Nginx/Apache 连接 HHVM ###
|
||||
|
||||
7、 现在,nginx/apache 和 HHVM 都已经安装完成了,并且都独立运行起来了,所以我们需要对它们进行设置,来让它们互相关联。这个关键的步骤,就是需要告知 nginx/apache 将所有的 php 文件,都交给 HHVM 进行处理。
|
||||
|
||||
如果你用了 Nginx,请按照如下步骤:
|
||||
|
||||
nginx 的配置文件在 /etc/nginx/sites-available/default, 并且这些配置文件会在 /usr/share/nginx/html 中寻找文件执行,不过,它不知道如何处理 PHP。
|
||||
|
||||
为了确保 Nginx 可以连接 HHVM,我们需要执行所带的如下脚本。它可以帮助我们正确的配置 Nginx,将 hhvm.conf 放到 上面提到的配置文件 nginx.conf 的头部。
|
||||
|
||||
这个脚本可以确保 Nginx 可以对 .hh 和 .php 的做正确的处理,并且将它们通过 fastcgi 发送给 HHVM。
|
||||
|
||||
# /usr/share/hhvm/install_fastcgi.sh
|
||||
|
||||

|
||||
|
||||
*配置 Nginx、HHVM*
|
||||
|
||||
**重要**: 如果你使用的是 Apache,这里不需要进行配置。
|
||||
|
||||
8、 接下来,你需要使用 hhvm 来提供 php 的运行环境。
|
||||
|
||||
# /usr/bin/update-alternatives --install /usr/bin/php php /usr/bin/hhvm 60
|
||||
|
||||
以上步骤完成之后,你现在可以启动并且测试它了。
|
||||
|
||||
# systemctl start hhvm
|
||||
|
||||
### 第五步: 测试 HHVM 和 Nginx/Apache ###
|
||||
|
||||
9、 为了确认 hhvm 是否工作,你需要在 nginx/apache 的文档根目录下建立 hello.php。
|
||||
|
||||
# nano /usr/share/nginx/html/hello.php [对于 Nginx]
|
||||
或
|
||||
# nano /var/www/html/hello.php [对于 Nginx 和 Apache]
|
||||
|
||||
在文件中添加如下代码:
|
||||
|
||||
<?php
|
||||
if (defined('HHVM_VERSION')) {
|
||||
echo 'HHVM is working';
|
||||
phpinfo();
|
||||
} else {
|
||||
echo 'HHVM is not working';
|
||||
}
|
||||
?>
|
||||
|
||||
然后访问如下链接,确认自己能否看到 "hello world"
|
||||
|
||||
http://localhost/info.php
|
||||
或
|
||||
http://IP-Address/info.php
|
||||
|
||||

|
||||
|
||||
*HHVM 页面*
|
||||
|
||||
如果 “HHVM” 的页面出现了,那就说明你成功了。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
以上的步骤都是非常简单的,希望你能觉得这是一篇有用的教程,如果你在以上的步骤中遇到了问题,给我们留一个评论,我们将全力解决。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-hhvm-and-nginx-apache-with-mariadb-on-debian-ubuntu/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://www.tecmint.com/install-apc-alternative-php-cache-in-rhel-centos-fedora/
|
||||
@ -0,0 +1,313 @@
|
||||
RHCSA 系列(一): 回顾基础命令及系统文档
|
||||
================================================================================
|
||||
|
||||
RHCSA (红帽认证系统工程师) 是由 RedHat 公司举行的认证考试,这家公司给商业公司提供开源操作系统和软件,除此之外,还为这些企业和机构提供支持、训练以及咨询服务等。
|
||||
|
||||

|
||||
|
||||
*RHCSA 考试准备指南*
|
||||
|
||||
RHCSA 考试(考试编号 EX200)通过后可以获取由 RedHat 公司颁发的证书. RHCSA 考试是 RHCT(红帽认证技师)的升级版,而且 RHCSA 必须在新的 Red Hat Enterprise Linux(红帽企业版)下完成。RHCT 和 RHCSA 的主要变化就是 RHCT 基于 RHEL5,而 RHCSA 基于 RHEL6 或者7,这两个认证的等级也有所不同。
|
||||
|
||||
红帽认证管理员最起码可以在红帽企业版的环境下执行如下系统管理任务:
|
||||
|
||||
- 理解并会使用命令管理文件、目录、命令行以及系统/软件包的文档
|
||||
- 在不同的启动等级操作运行中的系统,识别和控制进程,启动或停止虚拟机
|
||||
- 使用分区和逻辑卷管理本地存储
|
||||
- 创建并且配置本地文件系统和网络文件系统,设置他们的属性(权限、加密、访问控制表)
|
||||
- 部署、配置、并且控制系统,包括安装、升级和卸载软件
|
||||
- 管理系统用户和组,以及使用集中制的 LDAP 目录进行用户验证
|
||||
- 确保系统安全,包括基础的防火墙规则和 SELinux 配置
|
||||
|
||||
关于你所在国家的考试注册和费用请参考 [RHCSA 认证页面][1]。
|
||||
|
||||
在这个有15章的 RHCSA(红帽认证管理员)备考系列中,我们将覆盖以下的关于红帽企业 Linux 第七版的最新的信息:
|
||||
|
||||
- Part 1: 回顾基础命令及系统文档
|
||||
- Part 2: 在 RHEL7 中如何进行文件和目录管理
|
||||
- Part 3: 在 RHEL7 中如何管理用户和组
|
||||
- Part 4: 使用 nano 和 vim 管理命令,使用 grep 和正则表达式分析文本
|
||||
- Part 5: RHEL7 的进程管理:启动,关机,以及这之间的各种事情
|
||||
- Part 6: 使用 'Parted' 和 'SSM' 来管理和加密系统存储
|
||||
- Part 7: 使用 ACL(访问控制表)并挂载 Samba/NFS 文件分享
|
||||
- Part 8: 加固 SSH,设置主机名并开启网络服务
|
||||
- Part 9: 安装、配置和加固一个 Web 和 FTP 服务器
|
||||
- Part 10: Yum 包管理方式,使用 Cron 进行自动任务管理以及监控系统日志
|
||||
- Part 11: 使用 FirewallD 和 Iptables 设置防火墙,控制网络流量
|
||||
- Part 12: 使用 Kickstart 自动安装 RHEL 7
|
||||
- Part 13: RHEL7:什么是 SeLinux?他的原理是什么?
|
||||
- Part 14: 在 RHEL7 中使用基于 LDAP 的权限控制
|
||||
- Part 15: 虚拟化基础和用KVM管理虚拟机
|
||||
|
||||
在第一章,我们讲解如何在终端或者 Shell 窗口输入和运行正确的命令,并且讲解如何找到、查阅,以及使用系统文档。
|
||||
|
||||

|
||||
|
||||
*RHCSA:回顾必会的 Linux 命令 - 第一部分*
|
||||
|
||||
#### 前提: ####
|
||||
|
||||
至少你要熟悉如下命令
|
||||
|
||||
- [cd 命令][2] (改变目录)
|
||||
- [ls 命令][3] (列举文件)
|
||||
- [cp 命令][4] (复制文件)
|
||||
- [mv 命令][5] (移动或重命名文件)
|
||||
- [touch 命令][6] (创建一个新的文件或更新已存在文件的时间表)
|
||||
- rm 命令 (删除文件)
|
||||
- mkdir 命令 (创建目录)
|
||||
|
||||
在这篇文章中你将会找到更多的关于如何更好的使用他们的正确用法和特殊用法.
|
||||
|
||||
虽然没有严格的要求,但是作为讨论常用的 Linux 命令和在 Linux 中搜索信息方法,你应该安装 RHEL7 来尝试使用文章中提到的命令。这将会使你学习起来更省力。
|
||||
|
||||
- [红帽企业版 Linux(RHEL)7 安装指南][7]
|
||||
|
||||
### 使用 Shell 进行交互 ###
|
||||
|
||||
如果我们使用文本模式登录 Linux,我们就会直接进入到我们的默认 shell 中。另一方面,如果我们使用图形化界面登录,我们必须通过启动一个终端来开启 shell。无论那种方式,我们都会看到用户提示符,并且我们可以在这里输入并且执行命令(当按下回车时,命令就会被执行)。
|
||||
|
||||
命令是由两个部分组成的:
|
||||
|
||||
- 命令本身
|
||||
- 参数
|
||||
|
||||
某些参数,称为选项(通常使用一个连字符开头),会改变命令的行为方式,而另外一些则指定了命令所操作的对象。
|
||||
|
||||
type 命令可以帮助我们识别某一个特定的命令是由 shell 内置的还是由一个单独的包提供的。这样的区别在于我们能够在哪里找到更多关于该命令的更多信息。对 shell 内置的命令,我们需要看 shell 的手册页;如果是其他的,我们需要看软件包自己的手册页。
|
||||
|
||||
|
||||
|
||||
*检查Shell的内置命令*
|
||||
|
||||
在上面的例子中, `cd` 和 `type` 是 shell 内置的命令,`top` 和 `less` 是由 shell 之外的其他的二进制文件提供的(在这种情况下,type将返回命令的位置)。
|
||||
|
||||
其他的内置命令:
|
||||
|
||||
- [echo 命令][8]: 展示字符串
|
||||
- [pwd 命令][9]: 输出当前的工作目录
|
||||
|
||||

|
||||
|
||||
*其它内置命令*
|
||||
|
||||
**exec 命令**
|
||||
|
||||
它用来运行我们指定的外部程序。请注意在多数情况下,只需要输入我们想要运行的程序的名字就行,不过` exec` 命令有一个特殊的特性:不是在 shell 之外创建新的进程运行,而是这个新的进程会替代原来的 shell,可以通过下列命令来验证。
|
||||
|
||||
# ps -ef | grep [shell 进程的PID]
|
||||
|
||||
当新的进程终止时,Shell 也随之终止。运行 `exec top` ,然后按下 `q` 键来退出 top,你会注意到 shell 会话也同时终止,如下面的屏幕录像展示的那样:
|
||||
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://dn-linuxcn.qbox.me/static/video/Linux%20exec%20Command%20Demonstration.mp4"></iframe>
|
||||
|
||||
**export 命令**
|
||||
|
||||
给之后执行的命令的输出环境变量。
|
||||
|
||||
**history 命令**
|
||||
|
||||
展示数行之前的历史命令。命令编号前面前缀上感叹号可以再次执行这个命令。如果我们需要编辑历史列表中的命令,我们可以按下 `Ctrl + r` 并输入与命令相关的第一个字符。我们可以看到的命令会自动补全,可以根据我们目前的需要来编辑它:
|
||||
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://dn-linuxcn.qbox.me/static/video/Linux%20history%20Command%20Demonstration.mp4"></iframe>
|
||||
|
||||
命令列表会保存在一个叫 `.bash_history` 的文件里。`history` 命令是一个非常有用的用于减少输入次数的工具,特别是进行命令行编辑的时候。默认情况下,bash 保留最后输入的500个命令,不过可以通过修改 HISTSIZE 环境变量来增加:
|
||||
|
||||

|
||||
|
||||
*Linux history 命令*
|
||||
|
||||
但上述变化,在我们的下一次启动不会保留。为了保持 HISTSIZE 变量的变化,我们需要通过手工修改文件编辑:
|
||||
|
||||
# 要设置 history 长度,请看 bash(1)文档中的 HISTSIZE 和 HISTFILESIZE
|
||||
HISTSIZE=1000
|
||||
|
||||
**重要**: 我们的更改不会立刻生效,除非我们重启了 shell 。
|
||||
|
||||
**alias 命令**
|
||||
|
||||
没有参数或使用 `-p` 选项时将会以“名称=值”的标准形式输出别名列表。当提供了参数时,就会按照给定的名字和值定义一个别名。
|
||||
|
||||
使用 `alias` ,我们可以创建我们自己的命令,或使用所需的参数修改现有的命令。举个例子,假设我们将 `ls` 定义别名为 `ls –color=auto` ,这样就可以使用不同颜色输出文件、目录、链接等等。
|
||||
|
||||
|
||||
# alias ls='ls --color=auto'
|
||||
|
||||
|
||||
|
||||
*Linux 别名命令*
|
||||
|
||||
**注意**: 你可以给你的“新命令”起任何的名字,并且使用单引号包括很多命令,但是你要用分号区分开它们。如下:
|
||||
|
||||
# alias myNewCommand='cd /usr/bin; ls; cd; clear'
|
||||
|
||||
**exit 命令**
|
||||
|
||||
`exit` 和 `logout` 命令都可以退出 shell 。`exit` 命令可以退出所有的 shell,`logout` 命令只注销登录的 shell(即你用文本模式登录时自动启动的那个)。
|
||||
|
||||
**man 和 info 命令**
|
||||
如果你对某个程序有疑问,可以参考它的手册页,可以使用 `man` 命令调出它。此外,还有一些关于重要文件(inittab、fstab、hosts 等等)、库函数、shell、设备及其他功能的手册页。
|
||||
|
||||
举例:
|
||||
|
||||
- man uname (输出系统信息,如内核名称、处理器、操作系统类型、架构等)
|
||||
- man inittab (初始化守护进程的设置)
|
||||
|
||||
另外一个重要的信息的来源是由 `info` 命令提供的,`info` 命令常常被用来读取 info 文件。这些文件往往比手册页 提供了更多信息。可以通过 `info keyword` 调用某个命令的信息:
|
||||
|
||||
# info ls
|
||||
# info cut
|
||||
|
||||
另外,在 `/usr/share/doc` 文件夹包含了大量的子目录,里面可以找到大量的文档。它们是文本文件或其他可读格式。
|
||||
|
||||
你要习惯于使用这三种方法去查找命令的信息。重点关注每个命令文档中介绍的详细的语法。
|
||||
|
||||
**使用 expand 命令把制表符转换为空格**
|
||||
|
||||
有时候文本文档包含了制表符,但是程序无法很好的处理。或者我们只是简单的希望将制表符转换成空格。这就是用到 `expand` 地方(由GNU核心组件包提供) 。
|
||||
|
||||
举个例子,我们有个文件 NumberList.txt,让我们使用 `expand` 处理它,将制表符转换为一个空格,并且显示在标准输出上。
|
||||
|
||||
# expand --tabs=1 NumbersList.txt
|
||||
|
||||

|
||||
|
||||
*Linux expand 命令*
|
||||
|
||||
unexpand命令可以实现相反的功能(将空格转为制表符)
|
||||
|
||||
**使用 head 输出文件首行及使用 tail 输出文件尾行**
|
||||
|
||||
通常情况下,`head` 命令后跟着文件名时,将会输出该文件的前十行,我们可以通过 `-n` 参数来自定义具体的行数。
|
||||
|
||||
# head -n3 /etc/passwd
|
||||
# tail -n3 /etc/passwd
|
||||
|
||||

|
||||
|
||||
*Linux 的 head 和 tail 命令*
|
||||
|
||||
`tail` 最有意思的一个特性就是能够显示增长的输入文件(`tail -f my.log`,my.log 是我们需要监视的文件。)这在我们监控一个持续增加的日志文件时非常有用。
|
||||
|
||||
- [使用 head 和 tail 命令有效地管理文件][10]
|
||||
|
||||
**使用 paste 按行合并文本文件**
|
||||
|
||||
`paste` 命令一行一行的合并文件,默认会以制表符来区分每个文件的行,或者你可以自定义的其它分隔符。(下面的例子就是输出中的字段使用等号分隔)。
|
||||
|
||||
# paste -d= file1 file2
|
||||
|
||||
|
||||
|
||||
*Linux 中的 merge 命令*
|
||||
|
||||
**使用 split 命令将文件分块**
|
||||
|
||||
`split` 命令常常用于把一个文件切割成两个或多个由我们自定义的前缀命名的文件。可以根据大小、区块、行数等进行切割,生成的文件会有一个数字或字母的后缀。在下面的例子中,我们将切割 bash.pdf ,每个文件 50KB (-b 50KB),使用数字后缀 (-d):
|
||||
|
||||
# split -b 50KB -d bash.pdf bash_
|
||||
|
||||

|
||||
|
||||
*在 Linux 下切割文件*
|
||||
|
||||
你可以使用如下命令来合并这些文件,生成原来的文件:
|
||||
|
||||
# cat bash_00 bash_01 bash_02 bash_03 bash_04 bash_05 > bash.pdf
|
||||
|
||||
**使用 tr 命令替换字符**
|
||||
|
||||
`tr` 命令多用于一对一的替换(改变)字符,或者使用字符范围。和之前一样,下面的实例我们将使用之前的同样文件file2,我们将做:
|
||||
|
||||
- 小写字母 o 变成大写
|
||||
- 所有的小写字母都变成大写字母
|
||||
|
||||
-
|
||||
# cat file2 | tr o O
|
||||
# cat file2 | tr [a-z] [A-Z]
|
||||
|
||||
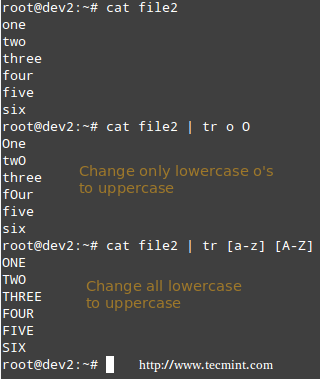
|
||||
|
||||
*在 Linux 中替换字符*
|
||||
|
||||
**使用 uniq 和 sort 检查或删除重复的文字**
|
||||
|
||||
`uniq` 命令可以帮我们查出或删除文件中的重复的行,默认会输出到标准输出,我们应当注意,`uniq`只能查出相邻的相同行,所以,`uniq` 往往和 `sort` 一起使用(`sort` 一般用于对文本文件的内容进行排序)
|
||||
|
||||
默认情况下,`sort` 以第一个字段(使用空格分隔)为关键字段。想要指定不同关键字段,我们需要使用 -k 参数,请注意如何使用 `sort` 和 `uniq` 输出我们想要的字段,具体可以看下面的例子:
|
||||
|
||||
# cat file3
|
||||
# sort file3 | uniq
|
||||
# sort -k2 file3 | uniq
|
||||
# sort -k3 file3 | uniq
|
||||
|
||||

|
||||
|
||||
*删除文件中重复的行*
|
||||
|
||||
**从文件中提取文本的命令**
|
||||
|
||||
`cut` 命令基于字节(-b)、字符(-c)、或者字段(-f)的数量,从输入文件(标准输入或文件)中提取到的部分将会以标准输出上。
|
||||
|
||||
当我们使用字段 `cut` 时,默认的分隔符是一个制表符,不过你可以通过 -d 参数来自定义分隔符。
|
||||
|
||||
# cut -d: -f1,3 /etc/passwd # 这个例子提取了第一和第三字段的文本
|
||||
# cut -d: -f2-4 /etc/passwd # 这个例子提取了第二到第四字段的文本
|
||||
|
||||

|
||||
|
||||
*从文件中提取文本*
|
||||
|
||||
注意,简洁起见,上方的两个输出的结果是截断的。
|
||||
|
||||
**使用 fmt 命令重新格式化文件**
|
||||
|
||||
`fmt` 被用于去“清理”有大量内容或行的文件,或者有多级缩进的文件。新的段落格式每行不会超过75个字符宽,你能通过 -w (width 宽度)参数改变这个设定,它可以设置行宽为一个特定的数值。
|
||||
|
||||
举个例子,让我们看看当我们用 `fmt` 显示定宽为100个字符的时候的文件 /etc/passwd 时会发生什么。再次,输出截断了。
|
||||
|
||||
# fmt -w100 /etc/passwd
|
||||
|
||||

|
||||
|
||||
*Linux 文件重新格式化*
|
||||
|
||||
**使用 pr 命令格式化打印内容**
|
||||
|
||||
`pr` 分页并且在按列或多列的方式显示一个或多个文件。 换句话说,使用 `pr` 格式化一个文件使它打印出来时看起来更好。举个例子,下面这个命令:
|
||||
|
||||
# ls -a /etc | pr -n --columns=3 -h "Files in /etc"
|
||||
|
||||
以一个友好的排版方式(3列)输出/etc下的文件,自定义了页眉(通过 -h 选项实现)、行号(-n)。
|
||||
|
||||

|
||||
|
||||
*Linux的文件格式化*
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我们已经讨论了如何在 Shell 或终端以正确的语法输入和执行命令,并解释如何找到,查阅和使用系统文档。正如你看到的一样简单,这就是你成为 RHCSA 的第一大步。
|
||||
|
||||
如果你希望添加一些其他的你经常使用的能够有效帮你完成你的日常工作的基础命令,并愿意分享它们,请在下方留言。也欢迎提出问题。我们期待您的回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://www.redhat.com/en/services/certification/rhcsa
|
||||
[2]:http://linux.cn/article-2479-1.html
|
||||
[3]:https://linux.cn/article-5109-1.html
|
||||
[4]:http://linux.cn/article-2687-1.html
|
||||
[5]:http://www.tecmint.com/rename-multiple-files-in-linux/
|
||||
[6]:http://linux.cn/article-2740-1.html
|
||||
[7]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[8]:https://linux.cn/article-3948-1.html
|
||||
[9]:https://linux.cn/article-3422-1.html
|
||||
[10]:http://www.tecmint.com/view-contents-of-file-in-linux/
|
||||
@ -1,68 +1,63 @@
|
||||
RHCSA 系列: 如何执行文件并进行文件管理 – Part 2
|
||||
RHCSA 系列(二): 如何进行文件和目录管理
|
||||
================================================================================
|
||||
|
||||
在本篇(RHCSA 第二篇:文件和目录管理)中,我们江回顾一些系统管理员日常任务需要的技能
|
||||
在本篇中,我们将回顾一些系统管理员日常任务需要的技能。
|
||||
|
||||

|
||||
|
||||
*RHCSA: 运行文件以及进行文件夹管理 - 第二部分*
|
||||
|
||||
RHCSA : 运行文件以及进行文件夹管理 - 第二章
|
||||
### 创建,删除,复制和移动文件及目录 ###
|
||||
### 创建、删除、复制和移动文件及目录 ###
|
||||
|
||||
文件和目录管理是每一个系统管理员都应该掌握的必要的技能.它包括了从头开始的创建、删除文本文件(每个程序的核心配置)以及目录(你用来组织文件和其他目录),以及识别存在的文件的类型
|
||||
文件和目录管理是每一个系统管理员都应该掌握的必备技能。它包括了从头开始的创建、删除文本文件(每个程序的核心配置)以及目录(你用来组织文件和其它目录),以及识别已有文件的类型。
|
||||
|
||||
[touch 命令][1] 不仅仅能用来创建空文件,还能用来更新已存在的文件的权限和时间表
|
||||
[`touch` 命令][1] 不仅仅能用来创建空文件,还能用来更新已有文件的访问时间和修改时间。
|
||||
|
||||

|
||||
|
||||
touch 命令示例
|
||||
*touch 命令示例*
|
||||
|
||||
你可以使用 `file [filename]`来判断一个文件的类型 (在你用文本编辑器编辑之前,判断类型将会更方便编辑).
|
||||
你可以使用 `file [filename]`来判断一个文件的类型 (在你用文本编辑器编辑之前,判断类型将会更方便编辑)。
|
||||
|
||||
|
||||
|
||||
file 命令示例
|
||||
*file 命令示例*
|
||||
|
||||
使用`rm [filename]` 可以删除文件
|
||||
使用`rm [filename]` 可以删除文件。
|
||||
|
||||

|
||||
|
||||
rm 命令示例
|
||||
|
||||
对于目录,你可以使用`mkdir [directory]`在已经存在的路径中创建目录,或者使用 `mkdir -p [/full/path/to/directory].`带全路径创建文件夹
|
||||
*rm 命令示例*
|
||||
|
||||
对于目录,你可以使用`mkdir [directory]`在已经存在的路径中创建目录,或者使用 `mkdir -p [/full/path/to/directory]`带全路径创建文件夹。
|
||||
|
||||

|
||||
|
||||
mkdir 命令示例
|
||||
*mkdir 命令示例*
|
||||
|
||||
当你想要去删除目录时,在你使用`rmdir [directory]` 前,你需要先确保目录是空的,或者使用更加强力的命令(小心使用它)`rm -rf [directory]`.后者会强制删除`[directory]`以及他的内容.所以使用这个命令存在一定的风险
|
||||
当你想要去删除目录时,在你使用`rmdir [directory]` 前,你需要先确保目录是空的,或者使用更加强力的命令(小心使用它!)`rm -rf [directory]`。后者会强制删除`[directory]`以及它的内容,所以使用这个命令存在一定的风险。
|
||||
|
||||
### 输入输出重定向以及管道 ###
|
||||
|
||||
命令行环境提供了两个非常有用的功能:允许命令重定向的输入和输出到文件和发送到另一个文件,分别称为重定向和管道
|
||||
命令行环境提供了两个非常有用的功能:允许重定向命令的输入和输出为另一个文件,以及发送命令的输出到另一个命令,这分别称为重定向和管道。
|
||||
|
||||
To understand those two important concepts, we must first understand the three most important types of I/O (Input and Output) streams (or sequences) of characters, which are in fact special files, in the *nix sense of the word.
|
||||
为了理解这两个重要概念,我们首先需要理解通常情况下三个重要的输入输出流的形式
|
||||
为了理解这两个重要概念,我们首先需要理解三个最重要的字符输入输出流类型,以 *nix 的话来说,它们实际上是特殊的文件。
|
||||
|
||||
- 标准输入 (aka stdin) 是指默认使用键盘链接. 换句话说,键盘是输入命令到命令行的标准输入设备。
|
||||
- 标准输出 (aka stdout) 是指默认展示再屏幕上, 显示器接受输出命令,并且展示在屏幕上。
|
||||
- 标准错误 (aka stderr), 是指命令的状态默认输出, 同时也会展示在屏幕上
|
||||
- 标准输入 (即 stdin),默认连接到键盘。 换句话说,键盘是输入命令到命令行的标准输入设备。
|
||||
- 标准输出 (即 stdout),默认连接到屏幕。 找个设备“接受”命令的输出,并展示到屏幕上。
|
||||
- 标准错误 (即 stderr),默认是命令的状态消息出现的地方,它也是屏幕。
|
||||
|
||||
In the following example, the output of `ls /var` is sent to stdout (the screen), as well as the result of ls /tecmint. But in the latter case, it is stderr that is shown.
|
||||
在下面的例子中,`ls /var`的结果被发送到stdout(屏幕展示),就像ls /tecmint 的结果。但在后一种情况下,它是标准错误输出。
|
||||
在下面的例子中,`ls /var`的结果被发送到stdout(屏幕展示),ls /tecmint 的结果也一样。但在后一种情况下,它显示在标准错误输出上。
|
||||
|
||||

|
||||
输入和输出命令实例
|
||||
|
||||
为了更容易识别这些特殊文件,每个文件都被分配有一个文件描述符(用于控制他们的抽象标识)。主要要理解的是,这些文件就像其他人一样,可以被重定向。这就意味着你可以从一个文件或脚本中捕获输出,并将它传送到另一个文件、命令或脚本中。你就可以在在磁盘上存储命令的输出结果,用于稍后的分析
|
||||
*输入和输出命令实例*
|
||||
|
||||
To redirect stdin (fd 0), stdout (fd 1), or stderr (fd 2), the following operators are available.
|
||||
为了更容易识别这些特殊文件,每个文件都被分配有一个文件描述符,这是用于访问它们的抽象标识。主要要理解的是,这些文件就像其它的一样,可以被重定向。这就意味着你可以从一个文件或脚本中捕获输出,并将它传送到另一个文件、命令或脚本中。这样你就可以在磁盘上存储命令的输出结果,用于稍后的分析。
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="226"></colgroup>
|
||||
<colgroup width="743"></colgroup>
|
||||
要重定向 stdin (fd 0)、 stdout (fd 1) 或 stderr (fd 2),可以使用如下操作符。
|
||||
|
||||
<table cellpadding="4" border="1">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">转向操作</span></b></td>
|
||||
@ -70,102 +65,98 @@ To redirect stdin (fd 0), stdout (fd 1), or stderr (fd 2), the following operato
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">标准输出到一个文件。如果目标文件存在,内容就会被重写</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">重定向标准输出到一个文件。如果目标文件存在,内容就会被重写。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准输出到文件尾部</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准输出到文件尾部。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">标准错误输出到一个文件。如果目标文件存在,内容就会被重写</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">重定向标准错误输出到一个文件。如果目标文件存在,内容就会被重写。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准错误输出到文件尾部.</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准错误输出到文件尾部。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">&></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">标准错误和标准输出都到一个文件。如果目标文件存在,内容就会被重写</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">重定向标准错误和标准输出到一个文件。如果目标文件存在,内容就会被重写。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><</span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输出</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输入。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输出和标准错误</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输入和标准输出。</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
相比与重定向,管道是通过在命令后添加一个竖杠`(|)`再添加另一个命令 .
|
||||
与重定向相比,管道是通过在命令后和另外一个命令前之间添加一个竖杠`(|)`。
|
||||
|
||||
记得:
|
||||
|
||||
- 重定向是用来定向命令的输出到一个文件,或定向一个文件作为输入到一个命令。
|
||||
- 管道是用来将命令的输出转发到另一个命令作为输入。
|
||||
- *重定向*是用来定向命令的输出到一个文件,或把一个文件发送作为到一个命令的输入。
|
||||
- *管道*是用来将命令的输出转发到另一个命令作为其输入。
|
||||
|
||||
#### 重定向和管道的使用实例 ####
|
||||
|
||||
** 例1:将一个命令的输出到文件 **
|
||||
**例1:将一个命令的输出到文件**
|
||||
|
||||
有些时候,你需要遍历一个文件列表。要做到这样,你可以先将该列表保存到文件中,然后再按行读取该文件。虽然你可以遍历直接ls的输出,不过这个例子是用来说明重定向。
|
||||
有些时候,你需要遍历一个文件列表。要做到这样,你可以先将该列表保存到文件中,然后再按行读取该文件。虽然你可以直接遍历ls的输出,不过这个例子是用来说明重定向。
|
||||
|
||||
# ls -1 /var/mail > mail.txt
|
||||
|
||||
|
||||
|
||||
将一个命令的输出到文件
|
||||
*将一个命令的输出重定向到文件*
|
||||
|
||||
** 例2:重定向stdout和stderr到/dev/null **
|
||||
**例2:重定向stdout和stderr到/dev/null**
|
||||
|
||||
如果不想让标准输出和标准错误展示在屏幕上,我们可以把文件描述符重定向到 `/dev/null` 请注意在执行这个命令时该如何更改输出
|
||||
如果不想让标准输出和标准错误展示在屏幕上,我们可以把这两个文件描述符重定向到 `/dev/null`。请注意对于同样的命令,重定向是如何改变了输出。
|
||||
|
||||
# ls /var /tecmint
|
||||
# ls /var/ /tecmint &> /dev/null
|
||||
|
||||

|
||||
|
||||
重定向stdout和stderr到/dev/null
|
||||
*重定向stdout和stderr到/dev/null*
|
||||
|
||||
#### 例3:使用一个文件作为命令的输入 ####
|
||||
**例3:使用一个文件作为命令的输入**
|
||||
|
||||
当官方的[cat 命令][2]的语法如下时
|
||||
[cat 命令][2]的经典用法如下
|
||||
|
||||
# cat [file(s)]
|
||||
|
||||
您还可以使用正确的重定向操作符传送一个文件作为输入。
|
||||
您还可以使用正确的重定向操作符发送一个文件作为输入。
|
||||
|
||||
# cat < mail.txt
|
||||
|
||||
|
||||
|
||||
cat 命令实例
|
||||
*cat 命令实例*
|
||||
|
||||
#### 例4:发送一个命令的输出作为另一个命令的输入 ####
|
||||
**例4:发送一个命令的输出作为另一个命令的输入**
|
||||
|
||||
如果你有一个较大的目录或进程列表,并且想快速定位,你或许需要将列表通过管道传送给grep
|
||||
如果你有一个较大的目录或进程列表,并且想快速定位,你或许需要将列表通过管道传送给grep。
|
||||
|
||||
接下来我们使用管道在下面的命令中,第一个是查找所需的关键词,第二个是除去产生的 `grep command`.这个例子列举了所有与apache用户有关的进程
|
||||
接下来我们会在下面的命令中使用管道,第一个管道是查找所需的关键词,第二个管道是除去产生的 `grep command`。这个例子列举了所有与apache用户有关的进程:
|
||||
|
||||
# ps -ef | grep apache | grep -v grep
|
||||
|
||||

|
||||
|
||||
发送一个命令的输出作为另一个命令的输入
|
||||
*发送一个命令的输出作为另一个命令的输入*
|
||||
|
||||
### 归档,压缩,解包,解压文件 ###
|
||||
|
||||
如果你需要传输,备份,或者通过邮件发送一组文件,你可以使用一个存档(或文件夹)如 [tar][3]工具,通常使用gzip,bzip2,或XZ压缩工具.
|
||||
如果你需要传输、备份、或者通过邮件发送一组文件,你可以使用一个存档(或打包)工具,如 [tar][3],通常与gzip,bzip2,或 xz 等压缩工具配合使用。
|
||||
|
||||
您选择的压缩工具每一个都有自己的定义的压缩速度和速率的。这三种压缩工具,gzip是最古老和提供最小压缩的工具,bzip2提供经过改进的压缩,以及XZ提供最信和最好的压缩。通常情况下,这些文件都是被压缩的如.gz .bz2或.xz
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="165"></colgroup>
|
||||
<colgroup width="137"></colgroup>
|
||||
<colgroup width="366"></colgroup>
|
||||
您选择的压缩工具每一个都有自己不同的压缩速度和压缩率。这三种压缩工具,gzip是最古老和可以较小压缩的工具,bzip2提供经过改进的压缩,以及xz是最新的而且压缩最大。通常情况下,使用这些压缩工具压缩的文件的扩展名依次是.gz、.bz2或.xz。
|
||||
|
||||
<table cellpadding="4" border="1">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">命令</span></b></td>
|
||||
@ -180,12 +171,12 @@ cat 命令实例
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –concatenate</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">A</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">向归档中添加tar文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加tar归档到另外一个归档中</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –append</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">r</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">向归档中添加非tar文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加非tar归档到另外一个归档中</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –update</span></td>
|
||||
@ -195,26 +186,22 @@ cat 命令实例
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –diff or –compare</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">d</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">将归档和硬盘的文件夹进行对比</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">将归档中的文件和硬盘的文件进行对比</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="20" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –list</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">t</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">列举一个tar的压缩包</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">列举一个tar压缩包的内容</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –extract or –get</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">x</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">从归档中解压文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">从归档中提取文件</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="258"></colgroup>
|
||||
<colgroup width="152"></colgroup>
|
||||
<colgroup width="803"></colgroup>
|
||||
<table cellpadding="4" border="1">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">操作参数</span></b></td>
|
||||
@ -234,34 +221,34 @@ cat 命令实例
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –verbose</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> v</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">列举所有文件用于读取或提取,这里包含列表,并显示文件的大小、所有权和时间戳</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">列举所有读取或提取的文件,如果和 --list 参数一起使用,也会显示文件的大小、所有权和时间戳</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>exclude file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> —</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">排除存档文件。在这种情况下,文件可以是一个实际的文件或目录。</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">从存档中排除文件。在这种情况下,文件可以是一个实际的文件或匹配模式。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>gzip or <span style="font-family: Courier New;">—</span>gunzip</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> z</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用gzip压缩文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用gzip压缩归档</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –bzip2</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> j</span></td>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;">使用bzip2压缩文件</td>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;">使用bzip2压缩归档</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –xz</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> J</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用xz压缩文件</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用xz压缩归档</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### 例5:创建一个文件,然后使用三种压缩工具压缩####
|
||||
**例5:创建一个tar文件,然后使用三种压缩工具压缩**
|
||||
|
||||
在决定使用一个或另一个工具之前,您可能想比较每个工具的压缩效率。请注意压缩小文件或几个文件,结果可能不会有太大的差异,但可能会给你看出他们的差异
|
||||
在决定使用这个还是那个工具之前,您可能想比较每个工具的压缩效率。请注意压缩小文件或几个文件,结果可能不会有太大的差异,但可能会给你看出它们的差异。
|
||||
|
||||
# tar cf ApacheLogs-$(date +%Y%m%d).tar /var/log/httpd/* # Create an ordinary tarball
|
||||
# tar czf ApacheLogs-$(date +%Y%m%d).tar.gz /var/log/httpd/* # Create a tarball and compress with gzip
|
||||
@ -270,42 +257,42 @@ cat 命令实例
|
||||
|
||||

|
||||
|
||||
tar 命令实例
|
||||
*tar 命令实例*
|
||||
|
||||
#### 例6:归档时同时保存原始权限和所有权 ####
|
||||
**例6:归档时同时保存原始权限和所有权**
|
||||
|
||||
如果你创建的是用户的主目录的备份,你需要要存储的个人文件与原始权限和所有权,而不是通过改变他们的用户帐户或守护进程来执行备份。下面的命令可以在归档时保留文件属性
|
||||
如果你正在从用户的主目录创建备份,你需要要存储的个人文件与原始权限和所有权,而不是通过改变它们的用户帐户或守护进程来执行备份。下面的命令可以在归档时保留文件属性。
|
||||
|
||||
# tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* --same-permissions --same-owner
|
||||
|
||||
### 创建软连接和硬链接 ###
|
||||
|
||||
在Linux中,有2种类型的链接文件:硬链接和软(也称为符号)链接。因为硬链接文件代表另一个名称是由同一点确定,然后链接到实际的数据;符号链接指向的文件名,而不是实际的数据
|
||||
在Linux中,有2种类型的链接文件:硬链接和软(也称为符号)链接。因为硬链接文件只是现存文件的另一个名字,使用相同的 inode 号,它指向实际的数据;而符号链接只是指向的文件名。
|
||||
|
||||
此外,硬链接不占用磁盘上的空间,而符号链接做占用少量的空间来存储的链接本身的文本。硬链接的缺点就是要求他们必须在同一个innode内。而符号链接没有这个限制,符号链接因为只保存了文件名和目录名,所以可以跨文件系统.
|
||||
此外,硬链接不占用磁盘上的空间,而符号链接则占用少量的空间来存储的链接本身的文本。硬链接的缺点就是要求它们必须在同一个文件系统内,因为 inode 在一个文件系统内是唯一的。而符号链接没有这个限制,它们通过文件名而不是 inode 指向其它文件或目录,所以可以跨文件系统。
|
||||
|
||||
创建链接的基本语法看起来是相似的:
|
||||
|
||||
# ln TARGET LINK_NAME #从Link_NAME到Target的硬链接
|
||||
# ln -s TARGET LINK_NAME #从Link_NAME到Target的软链接
|
||||
|
||||
#### 例7:创建硬链接和软链接 ####
|
||||
**例7:创建硬链接和软链接**
|
||||
|
||||
没有更好的方式来形象的说明一个文件和一个指向它的符号链接的关系,而不是创建这些链接。在下面的截图中你会看到文件的硬链接指向它共享相同的节点都是由466个字节的磁盘使用情况确定。
|
||||
没有更好的方式来形象的说明一个文件和一个指向它的硬链接或符号链接的关系,而不是创建这些链接。在下面的截图中你会看到文件和指向它的硬链接共享相同的inode,都是使用了相同的466个字节的磁盘。
|
||||
|
||||
另一方面,在别的磁盘创建一个硬链接将占用5个字节,并不是说你将耗尽存储容量,而是这个例子足以说明一个硬链接和软链接之间的区别。
|
||||
另一方面,在别的磁盘创建一个硬链接将占用5个字节,这并不是说你将耗尽存储容量,而是这个例子足以说明一个硬链接和软链接之间的区别。
|
||||
|
||||

|
||||
|
||||
软连接和硬链接之间的不同
|
||||
*软连接和硬链接之间的不同*
|
||||
|
||||
符号链接的典型用法是在Linux系统的版本文件参考。假设有需要一个访问文件foo X.Y 想图书馆一样经常被访问,你想更新一个就可以而不是更新所有的foo X.Y,这时使用软连接更为明智和安全。有文件被看成foo X.Y的链接符号,从而找到foo X.Y
|
||||
在Linux系统上符号链接的典型用法是指向一个带版本的文件。假设有几个程序需要访问文件fooX.Y,但麻烦是版本经常变化(像图书馆一样)。每次版本更新时我们都需要更新指向 fooX.Y 的单一引用,而更安全、更快捷的方式是,我们可以让程序寻找名为 foo 的符号链接,它实际上指向 fooX.Y。
|
||||
|
||||
这样的话,当你的X和Y发生变化后,你只需更新一个文件,而不是更新每个文件。
|
||||
这样的话,当你的X和Y发生变化后,你只需更新符号链接 foo 到新的目标文件,而不用跟踪每个对目标文件的使用并更新。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我们回顾了一些基本的文件和目录管理技能,这是每个系统管理员的工具集的一部分。请确保阅读了本系列的其他部分,以及复习并将这些主题与本教程所涵盖的内容相结合。
|
||||
在这篇文章中,我们回顾了一些基本的文件和目录管理技能,这是每个系统管理员的工具集的一部分。请确保阅读了本系列的其它部分,并将这些主题与本教程所涵盖的内容相结合。
|
||||
|
||||
如果你有任何问题或意见,请随时告诉我们。我们总是很高兴从读者那获取反馈.
|
||||
|
||||
@ -315,11 +302,11 @@ via: http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[1]:https://linux.cn/article-2740-1.html
|
||||
[2]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
@ -1,68 +0,0 @@
|
||||
Translating by Ping
|
||||
Xtreme Download Manager Updated With Fresh GUI
|
||||
================================================================================
|
||||

|
||||
|
||||
[Xtreme Download Manager][1], unarguably one of the [best download managers for Linux][2], has a new version named XDM 2015 which brings a fresh new look to it.
|
||||
|
||||
Xtreme Download Manager, also known as XDM or XDMAN, is a popular cross-platform download manager available for Linux, Windows and Mac OS X. It is also compatible with all major web browsers such as Chrome, Firefox, Safari enabling you to download directly from XDM when you try to download something in your web browser.
|
||||
|
||||
Applications such as XDM are particularly useful when you have slow/limited network connectivity and you need to manage your downloads. Imagine downloading a huge file from internet on a slow network. What if you could pause and resume the download at will? XDM helps you in such situations.
|
||||
|
||||
Some of the main features of XDM are:
|
||||
|
||||
- Pause and resume download
|
||||
- [Download videos from YouTube][3] and other video sites
|
||||
- Force assemble
|
||||
- Download speed acceleration
|
||||
- Schedule downloads
|
||||
- Limit download speed
|
||||
- Web browser integration
|
||||
- Support for proxy servers
|
||||
|
||||
Here you can see the difference between the old and new XDM.
|
||||
|
||||

|
||||
|
||||
Old XDM
|
||||
|
||||

|
||||
|
||||
New XDM
|
||||
|
||||
### Install Xtreme Download Manager in Ubuntu based Linux distros ###
|
||||
|
||||
Thanks to the PPA by Noobslab, you can easily install Xtreme Download Manager using the commands below. XDM requires Java but thanks to the PPA, you don’t need to bother with installing dependencies separately.
|
||||
|
||||
sudo add-apt-repository ppa:noobslab/apps
|
||||
sudo apt-get update
|
||||
sudo apt-get install xdman
|
||||
|
||||
The above PPA should be available for Ubuntu and other Ubuntu based Linux distributions such as Linux Mint, elementary OS, Linux Lite etc.
|
||||
|
||||
#### Remove XDM ####
|
||||
|
||||
To remove XDM (installed using the PPA), use the commands below:
|
||||
|
||||
sudo apt-get remove xdman
|
||||
sudo add-apt-repository --remove ppa:noobslab/apps
|
||||
|
||||
For other Linux distributions, you can download it from the link below:
|
||||
|
||||
- [Download Xtreme Download Manager][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/xtreme-download-manager-install/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://xdman.sourceforge.net/
|
||||
[2]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[3]:http://itsfoss.com/download-youtube-videos-ubuntu/
|
||||
[4]:http://xdman.sourceforge.net/download.html
|
||||
@ -0,0 +1,60 @@
|
||||
FISH – A smart and user-friendly command line shell for Linux
|
||||
================================================================================
|
||||
The friendly interactive shell (FISH). fish is a user friendly command line shell intended mostly for interactive use. A shell is a program used to execute other programs.
|
||||
|
||||
### FISH Features ###
|
||||
|
||||
#### Autosuggestions ####
|
||||
|
||||
fish suggests commands as you type based on history and completions, just like a web browser. Watch out, Netscape Navigator 4.0!
|
||||
|
||||
#### Glorious VGA Color ####
|
||||
|
||||
fish natively supports term256, the state of the art in terminal technology. You'll have an astonishing 256 colors available for use!
|
||||
|
||||
#### Sane Scripting ####
|
||||
|
||||
fish is fully scriptable, and its syntax is simple, clean, and consistent. You'll never write esac again.
|
||||
|
||||
#### Web Based configuration ####
|
||||
|
||||
For those lucky few with a graphical computer, you can set your colors and view functions, variables, and history all from a web page.
|
||||
|
||||
#### Man Page Completions ####
|
||||
|
||||
Other shells support programmable completions, but only fish generates them automatically by parsing your installed man pages.
|
||||
|
||||
#### Works Out Of The Box ####
|
||||
|
||||
fish will delight you with features like tab completions and syntax highlighting that just work, with nothing new to learn or configure.
|
||||
|
||||
### Install FISH On ubuntu 15.04 ###
|
||||
|
||||
Open the terminal and run the following commands
|
||||
|
||||
sudo apt-add-repository ppa:fish-shell/release-2
|
||||
sudo apt-get update
|
||||
sudo apt-get install fish
|
||||
|
||||
**Using FISH**
|
||||
|
||||
Open the terminal and run the following command to start FISH
|
||||
|
||||
fish
|
||||
|
||||
Welcome to fish, the friendly interactive shell Type help for instructions on how to use fish
|
||||
|
||||
Check [FISH Documentation][1] How to use.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/fish-a-smart-and-user-friendly-command-line-shell-for-linux.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://fishshell.com/docs/current/index.html#introduction
|
||||
@ -1,3 +1,4 @@
|
||||
[bazz222]
|
||||
How to filter BGP routes in Quagga BGP router
|
||||
================================================================================
|
||||
In the [previous tutorial][1], we demonstrated how to turn a CentOS box into a BGP router using Quagga. We also covered basic BGP peering and prefix exchange setup. In this tutorial, we will focus on how we can control incoming and outgoing BGP prefixes by using **prefix-list** and **route-map**.
|
||||
@ -198,4 +199,4 @@ via: http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
|
||||
@ -1,103 +0,0 @@
|
||||
ictlyh Translating
|
||||
Howto Run JBoss Data Virtualization GA with OData in Docker Container
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn how to run JBoss Data Virtualization 6.0.0.GA with OData in a Docker Container. JBoss Data Virtualization is a data supply and integration solution platform that transforms various scatered multiple sources data, treats them as single source and delivers the required data into actionable information at business speed to any applications or users. JBoss Data Virtualization can help us easily combine and transform data into reusable business friendly data models and make unified data easily consumable through open standard interfaces. It offers comprehensive data abstraction, federation, integration, transformation, and delivery capabilities to combine data from one or multiple sources into reusable for agile data utilization and sharing.For more information about JBoss Data Virtualization, we can check out [its official page][1]. Docker is an open source platform that provides an open platform to pack, ship and run any application as a lightweight container. Running JBoss Data Virtualization with OData in Docker Container makes us easy to handle and launch.
|
||||
|
||||
Here are some easy to follow tutorial on how we can run JBoss Data Virtualization with OData in Docker Container.
|
||||
|
||||
### 1. Cloning the Repository ###
|
||||
|
||||
First of all, we'll wanna clone the repository of OData with Data Virtualization ie [https://github.com/jbossdemocentral/dv-odata-docker-integration-demo][2] using git command. As we have an Ubuntu 15.04 distribution of linux running in our machine. We'll need to install git initially using apt-get command.
|
||||
|
||||
# apt-get install git
|
||||
|
||||
Then after installing git, we'll wanna clone the repository by running the command below.
|
||||
|
||||
# git clone https://github.com/jbossdemocentral/dv-odata-docker-integration-demo
|
||||
|
||||
Cloning into 'dv-odata-docker-integration-demo'...
|
||||
remote: Counting objects: 96, done.
|
||||
remote: Total 96 (delta 0), reused 0 (delta 0), pack-reused 96
|
||||
Unpacking objects: 100% (96/96), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
### 2. Downloading JBoss Data Virtualization Installer ###
|
||||
|
||||
Now, we'll need to download JBoss Data Virtualization Installer from the Download Page ie [http://www.jboss.org/products/datavirt/download/][3] . After we download **jboss-dv-installer-6.0.0.GA-redhat-4.jar**, we'll need to keep it under the directory named **software**.
|
||||
|
||||
### 3. Building the Docker Image ###
|
||||
|
||||
Next, after we have downloaded the JBoss Data Virtualization installer, we'll then go for building the docker image using the Dockerfile and its resources we had just cloned from the repository.
|
||||
|
||||
# cd dv-odata-docker-integration-demo/
|
||||
# docker build -t jbossdv600 .
|
||||
|
||||
...
|
||||
Step 22 : USER jboss
|
||||
---> Running in 129f701febd0
|
||||
---> 342941381e37
|
||||
Removing intermediate container 129f701febd0
|
||||
Step 23 : EXPOSE 8080 9990 31000
|
||||
---> Running in 61e6d2c26081
|
||||
---> 351159bb6280
|
||||
Removing intermediate container 61e6d2c26081
|
||||
Step 24 : CMD $JBOSS_HOME/bin/standalone.sh -c standalone.xml -b 0.0.0.0 -bmanagement 0.0.0.0
|
||||
---> Running in a9fed69b3000
|
||||
---> 407053dc470e
|
||||
Removing intermediate container a9fed69b3000
|
||||
Successfully built 407053dc470e
|
||||
|
||||
Note: Here, we assume that you have already installed docker and is running in your machine.
|
||||
|
||||
### 4. Starting the Docker Container ###
|
||||
|
||||
As we have built the Docker Image of JBoss Data Virtualization with oData, we'll now gonna run the docker container and expose its port with -P flag. To do so, we'll run the following command.
|
||||
|
||||
# docker run -p 8080:8080 -d -t jbossdv600
|
||||
|
||||
7765dee9cd59c49ca26850e88f97c21f46859d2dc1d74166353d898773214c9c
|
||||
|
||||
### 5. Getting the Container IP ###
|
||||
|
||||
After we have started the Docker Container, we'll wanna get the IP address of the running docker container. To do so, we'll run the docker inspect command followed by the running container id.
|
||||
|
||||
# docker inspect <$containerID>
|
||||
|
||||
...
|
||||
"NetworkSettings": {
|
||||
"Bridge": "",
|
||||
"EndpointID": "3e94c5900ac5954354a89591a8740ce2c653efde9232876bc94878e891564b39",
|
||||
"Gateway": "172.17.42.1",
|
||||
"GlobalIPv6Address": "",
|
||||
"GlobalIPv6PrefixLen": 0,
|
||||
"HairpinMode": false,
|
||||
"IPAddress": "172.17.0.8",
|
||||
"IPPrefixLen": 16,
|
||||
"IPv6Gateway": "",
|
||||
"LinkLocalIPv6Address": "",
|
||||
"LinkLocalIPv6PrefixLen": 0,
|
||||
|
||||
### 6. Web Interface ###
|
||||
|
||||
Now, if everything went as expected as done above, we'll gonna see the login screen of JBoss Data Virtualization with oData when pointing our web browser to http://container-ip:8080/ and the JBoss Management from http://container-ip:9990. The Management credentials for username is admin and password is redhat1! whereas the Data virtualization credentials for username is user and password is user . After that, we can navigate the contents via the web interface.
|
||||
|
||||
**Note**: It is strongly recommended to change the password as soon as possible after the first login. Thanks :)
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally we've successfully run Docker Container running JBoss Data Virtualization with OData Multisource Virtual Database. JBoss Data Virtualization is really an awesome platform for the virtualization of data from different multiple source and transform them into reusable business friendly data models and produces data easily consumable through open standard interfaces. The deployment of JBoss Data Virtualization with OData Multisource Virtual Database has been very easy, secure and fast to setup with the Docker Technology. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/run-jboss-data-virtualization-ga-odata-docker-container/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.redhat.com/en/technologies/jboss-middleware/data-virtualization
|
||||
[2]:https://github.com/jbossdemocentral/dv-odata-docker-integration-demo
|
||||
[3]:http://www.jboss.org/products/datavirt/download/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Ping
|
||||
|
||||
How to switch from NetworkManager to systemd-networkd on Linux
|
||||
================================================================================
|
||||
In the world of Linux, adoption of [systemd][1] has been a subject of heated controversy, and the debate between its proponents and critics is still going on. As of today, most major Linux distributions have adopted systemd as a default init system.
|
||||
@ -162,4 +164,4 @@ via: http://xmodulo.com/switch-from-networkmanager-to-systemd-networkd.html
|
||||
[1]:http://xmodulo.com/use-systemd-system-administration-debian.html
|
||||
[2]:http://xmodulo.com/disable-network-manager-linux.html
|
||||
[3]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
|
||||
[4]:http://www.freedesktop.org/software/systemd/man/systemd.network.html
|
||||
[4]:http://www.freedesktop.org/software/systemd/man/systemd.network.html
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
wyangsun translating
|
||||
Linux workstation security checklist
|
||||
================================================================================
|
||||
This is a set of recommendations used by the Linux Foundation for their systems
|
||||
@ -797,4 +798,4 @@ via: https://github.com/lfit/itpol/blob/master/linux-workstation-security.md#lin
|
||||
[12]: http://shop.kernelconcepts.de/
|
||||
[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
|
||||
[14]: https://wiki.debian.org/Subkeys
|
||||
[15]: https://github.com/lfit/ssh-gpg-smartcard-config
|
||||
[15]: https://github.com/lfit/ssh-gpg-smartcard-config
|
||||
|
||||
@ -1,125 +0,0 @@
|
||||
How to Defragment Linux Systems
|
||||
================================================================================
|
||||

|
||||
|
||||
There is a common myth that Linux disks never need defragmentation at all. In most cases, this is true, due mostly to the excellent journaling filesystems Linux uses (ext2, 3, 4, btrfs, etc.) to handle the filesystem. However, in some specific cases, fragmentation might still occur. If that happens to you, the solution is fortunately very simple.
|
||||
|
||||
### What is fragmentation? ###
|
||||
|
||||
Fragmentation occurs when a file system updates files in little chunks, but these chunks do not form a contiguous whole and are scattered around the disk instead. This is particularly true for FAT and FAT32 filesystems. It was somewhat mitigated in NTFS and almost never happens in Linux (extX). Here is why.
|
||||
|
||||
In filesystems such as FAT and FAT32, files are written right next to each other on the disk. There is no room left for file growth or updates:
|
||||
|
||||

|
||||
|
||||
The NTFS leaves somewhat more room between the files, so there is room to grow. As the space between chunks is limited, fragmentation will still occur over time.
|
||||
|
||||

|
||||
|
||||
Linux’s journaling filesystems take a different approach. Instead of placing files beside each other, each file is scattered all over the disk, leaving generous amounts of free space between each file. There is sufficient room for file updates/growth and fragmentation rarely occurs.
|
||||
|
||||

|
||||
|
||||
Additionally, if fragmentation does happen, most Linux filesystems would attempt to shuffle files and chunks around to make them contiguous again.
|
||||
|
||||
### Disk fragmentation on Linux ###
|
||||
|
||||
Disk fragmentation seldom occurs in Linux unless you have a small hard drive, or it is running out of space. Some possible fragmentation cases include:
|
||||
|
||||
- if you edit large video files or raw image files, and disk space is limited
|
||||
- if you use older hardware like an old laptop, and you have a small hard drive
|
||||
- if your hard drives start filling up (above 85% used)
|
||||
- if you have many small partitions cluttering your home folder
|
||||
|
||||
The best solution is to buy a larger hard drive. If it’s not possible, this is where defragmentation becomes useful.
|
||||
|
||||
### How to check for fragmentation ###
|
||||
|
||||
The `fsck` command will do this for you – that is, if you have an opportunity to run it from a live CD, with **all affected partitions unmounted**.
|
||||
|
||||
This is very important: **RUNNING FSCK ON A MOUNTED PARTITION CAN AND WILL SEVERELY DAMAGE YOUR DATA AND YOUR DISK**.
|
||||
|
||||
You have been warned. Before proceeding, make a full system backup.
|
||||
|
||||
**Disclaimer**: The author of this article and Make Tech Easier take no responsibility for any damage to your files, data, system, or any other damage, caused by your actions after following this advice. You may proceed at your own risk. If you do proceed, you accept and acknowledge this.
|
||||
|
||||
You should just boot into a live session (like an installer disk, system rescue CD, etc.) and run `fsck` on your UNMOUNTED partitions. To check for any problems, run the following command with root permission:
|
||||
|
||||
fsck -fn [/path/to/your/partition]
|
||||
|
||||
You can check what the `[/path/to/your/partition]` is by running
|
||||
|
||||
sudo fdisk -l
|
||||
|
||||
There is a way to run `fsck` (relatively) safely on a mounted partition – that is by using the `-n` switch. This will result in a read only file system check without touching anything. Of course, there is no guarantee of safety here, and you should only proceed after creating a backup. On an ext2 filesystem, running
|
||||
|
||||
sudo fsck.ext2 -fn /path/to/your/partition
|
||||
|
||||
would result in plenty of output – most of them error messages resulting from the fact that the partition is mounted. In the end it will give you fragmentation related information.
|
||||
|
||||

|
||||
|
||||
If your fragmentation is above 20%, you should proceed to defragment your system.
|
||||
|
||||
### How to easily defragment Linux filesystems ###
|
||||
|
||||
All you need to do is to back up **ALL** your files and data to another drive (by manually **copying** them over), format the partition, and copy your files back (don’t use a backup program for this). The journalling file system will handle them as new files and place them neatly to the disk without fragmentation.
|
||||
|
||||
To back up your files, run
|
||||
|
||||
cp -afv [/path/to/source/partition]/* [/path/to/destination/folder]
|
||||
|
||||
Mind the asterix (*); it is important.
|
||||
|
||||
Note: It is generally agreed that to copy large files or large amounts of data, the dd command might be best. This is a very low level operation and does copy everything “as is”, including the empty space, and even the junk left over. This is not what we want, so it is probably better to use `cp`.
|
||||
|
||||
Now you only need to remove all the original files.
|
||||
|
||||
sudo rm -rf [/path/to/source/partition]/*
|
||||
|
||||
**Optional**: you can fill the empty space with zeros. You could achieve this with formatting as well, but if for example you did not copy the whole partition, only large files (which are most likely to cause fragmentation), this might not be an option.
|
||||
|
||||
sudo dd if=/dev/zero of=[/path/to/source/partition]/temp-zero.txt
|
||||
|
||||
Wait for it to finish. You could also monitor the progress with `pv`.
|
||||
|
||||
sudo apt-get install pv
|
||||
sudo pv -tpreb | of=[/path/to/source/partition]/temp-zero.txt
|
||||
|
||||

|
||||
|
||||
When it is done, just delete the temporary file.
|
||||
|
||||
sudo rm [/path/to/source/partition]/temp-zero.txt
|
||||
|
||||
After you zeroed out the empty space (or just skipped that step entirely), copy your files back, reversing the first cp command:
|
||||
|
||||
cp -afv [/path/to/original/destination/folder]/* [/path/to/original/source/partition]
|
||||
|
||||
### Using e4defrag ###
|
||||
|
||||
If you prefer a simpler approach, install `e2fsprogs`,
|
||||
|
||||
sudo apt-get install e2fsprogs
|
||||
|
||||
and run `e4defrag` as root on the affected partition. If you don’t want to or cannot unmount the partition, you can use its mount point instead of its path. To defragment your whole system, run
|
||||
|
||||
sudo e4defrag /
|
||||
|
||||
It is not guaranteed to succeed while mounted (you should also stop using your system while it is running), but it is much easier than copying all files away and back.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Fragmentation should rarely be an issue on a Linux system due to the the journalling filesystem’s efficient data handling. If you do run into fragmentation due to any circumstances, there are simple ways to reallocate your disk space like copying all files away and back or using `e4defrag`. It is important, however, to keep your data safe, so before attempting any operation that would affect all or most of your files, make sure you make a backup just to be on the safe side.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/defragment-linux/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
@ -1,89 +0,0 @@
|
||||
translation by strugglingyouth
|
||||
How to Install / Upgrade to Linux Kernel 4.2 in Ubuntu
|
||||
================================================================================
|
||||

|
||||
|
||||
Linux Kernel 4.2 was released yesterday, at noon. Linus Torvalds wrote on [lkml.org][1]:
|
||||
|
||||
> So judging by how little happened this week, it wouldn’t have been a mistake to release 4.2 last week after all, but hey, there’s certainly a few fixes here, and it’s not like delaying 4.2 for a week should have caused any problems either.
|
||||
>
|
||||
> So here it is, and the merge window for 4.3 is now open. I already have a few pending early pull requests, but as usual I’ll start processing them tomorrow and give the release some time to actually sit.
|
||||
>
|
||||
> The shortlog from rc8 is tiny, and appended. The patch is pretty tiny too…
|
||||
|
||||
### What’s New in Kernel 4.2: ###
|
||||
|
||||
- rewrites of Intel Assembly x86 code
|
||||
- support for new ARM boards and SoCs
|
||||
- F2FS per-file encryption
|
||||
- The AMDGPU kernel DRM driver
|
||||
- VCE1 video encode support for the Radeon DRM driver
|
||||
- Initial support for Intel Broxton Atom SoCs
|
||||
- Support for ARCv2 and HS38 CPU cores.
|
||||
- added queue spinlocks support
|
||||
- many other improvements and updated drivers.
|
||||
|
||||
### How to Install Kernel 4.2 in Ubuntu: ###
|
||||
|
||||
The binary packages of this kernel release are available for download at link below:
|
||||
|
||||
- [Download Kernel 4.2 (.DEB)][1]
|
||||
|
||||
First check out your OS type, 32-bit (i386) or 64-bit (amd64), then download and install the packages below in turn:
|
||||
|
||||
1. linux-headers-4.2.0-xxx_all.deb
|
||||
1. linux-headers-4.2.0-xxx-generic_xxx_i386/amd64.deb
|
||||
1. linux-image-4.2.0-xxx-generic_xxx_i386/amd64.deb
|
||||
|
||||
After installing the kernel, you may run `sudo update-grub` command in terminal (Ctrl+Alt+T) to refresh grub boot-loader.
|
||||
|
||||
If you need a low latency system (e.g. for recording audio) then download & install below packages instead:
|
||||
|
||||
1. linux-headers-4.2.0_xxx_all.deb
|
||||
1. linux-headers-4.2.0-xxx-lowlatency_xxx_i386/amd64.deb
|
||||
1. linux-image-4.2.0-xxx-lowlatency_xxx_i386/amd64.deb
|
||||
|
||||
For Ubuntu Server without a graphical UI, you may run below commands one by one to grab packages via wget and install them via dpkg:
|
||||
|
||||
For 64-bit system run:
|
||||
|
||||
cd /tmp/
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200_4.2.0-040200.201508301530_all.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200-generic_4.2.0-040200.201508301530_amd64.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-image-4.2.0-040200-generic_4.2.0-040200.201508301530_amd64.deb
|
||||
|
||||
sudo dpkg -i linux-headers-4.2.0-*.deb linux-image-4.2.0-*.deb
|
||||
|
||||
For 32-bit system, run:
|
||||
|
||||
cd /tmp/
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200_4.2.0-040200.201508301530_all.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-headers-4.2.0-040200-generic_4.2.0-040200.201508301530_i386.deb
|
||||
|
||||
wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/linux-image-4.2.0-040200-generic_4.2.0-040200.201508301530_i386.deb
|
||||
|
||||
sudo dpkg -i linux-headers-4.2.0-*.deb linux-image-4.2.0-*.deb
|
||||
|
||||
Finally restart your computer to take effect.
|
||||
|
||||
To revert back, remove old kernels, see [install kernel simply via a script][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/08/upgrade-kernel-4-2-ubuntu/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:https://lkml.org/lkml/2015/8/30/96
|
||||
[2]:http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.2-unstable/
|
||||
[3]:http://ubuntuhandbook.org/index.php/2015/08/install-latest-kernel-script/
|
||||
@ -1,52 +0,0 @@
|
||||
How to automatically dim your screen on Linux
|
||||
================================================================================
|
||||
When you start spending the majority of your time in front of a computer, natural questions start arising. Is this healthy? How can I diminish the strain on my eyes? Why is the sunlight burning me? Although active research is still going on to answer these questions, a lot of programmers have already adopted a few applications to make their daily habits a little healthier for their eyes. Among those applications, there are two which I found particularly interesting: Calise and Redshift.
|
||||
|
||||
### Calise ###
|
||||
|
||||
In and out of development limbo, [Calise][1] stands for "Camera Light Sensor." In other terms, it is an open source program that computes the best backlight level for your screen based on the light intensity received by your webcam. And for more precision, Calise is capable of taking in account the weather in your area based on your geographical coordinates. What I like about it is the compatibility with every desktops, even non-X ones.
|
||||
|
||||

|
||||
|
||||
It comes with a command line interface and a GUI, supports multiple user profiles, and can even export its data to CSV. After installation, you will have to calibrate it quickly before the magic happens.
|
||||
|
||||

|
||||
|
||||
What is less likeable is unfortunately that if you are as paranoid as I am, you have a little piece of tape in front of your webcam, which greatly affects Calise's precision. But that aside, Calise is a great application, which deserves our attention and support. As I mentioned earlier, it has gone through some rough patches in its development schedule over the last couple of years, so I really hope that this project will continue.
|
||||
|
||||

|
||||
|
||||
### Redshift ###
|
||||
|
||||
If you already considered decreasing the strain on your eyes caused by your screen, it is possible that you have heard of f.lux, a free proprietary software that modifies the luminosity and color scheme of your display based on the time of the day. However, if you really prefer open source software, there is an alternative: [Redshift][2]. Inspired by f.lux, Redshift also alters the color scheme and luminosity to enhance the experience of sitting in front of your screen at night. On startup, you can configure it with you geographic position as longitude and latitude, and then let it run in tray. Redshift will smoothly adjust the color scheme or your screen based on the position of the sun. At night, you will see the screen's color temperature turn towards red, making it a lot less painful for your eyes.
|
||||
|
||||

|
||||
|
||||
Just like Calise, it proposes a command line interface as well as a GUI client. To start Redshift quickly, just use the command:
|
||||
|
||||
$ redshift -l [LAT]:[LON]
|
||||
|
||||
Replacing [LAT]:[LON] by your latitude and longitude.
|
||||
|
||||
However, it is also possible to input your coordinates by GPS via the gpsd module. For Arch Linux users, I recommend this [wiki page][3].
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
To conclude, Linux users have no excuse for not taking care of their eyes. Calise and Redshift are both amazing. I really hope that their development will continue and that they get the support they deserve. Of course, there are more than just two programs out there to fulfill the purpose of protecting your eyes and staying healthy, but I feel that Calise and Redshift are a good start.
|
||||
|
||||
If there is a program that you really like and that you use regularly to reduce the strain on your eyes, please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/automatically-dim-your-screen-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://calise.sourceforge.net/
|
||||
[2]:http://jonls.dk/redshift/
|
||||
[3]:https://wiki.archlinux.org/index.php/Redshift#Automatic_location_based_on_GPS
|
||||
@ -1,79 +0,0 @@
|
||||
Install The Latest Linux Kernel in Ubuntu Easily via A Script
|
||||
================================================================================
|
||||

|
||||
|
||||
Want to install the latest Linux Kernel? A simple script can always do the job and make things easier in Ubuntu.
|
||||
|
||||
Michael Murphy has created a script makes installing the latest RC, stable, or lowlatency Kernel easier in Ubuntu. The script asks some questions and automatically downloads and installs the latest Kernel packages from [Ubuntu kernel mainline page][1].
|
||||
|
||||
### Install / Upgrade Linux Kernel via the Script: ###
|
||||
|
||||
1. Download the script from the right sidebar of the [github page][2] (click the “Download Zip” button).
|
||||
|
||||
2. Decompress the Zip archive by right-clicking on it in your user Downloads folder and select “Extract Here”.
|
||||
|
||||
3. Navigate to the result folder in terminal by right-clicking on that folder and select “Open in Terminal”:
|
||||
|
||||
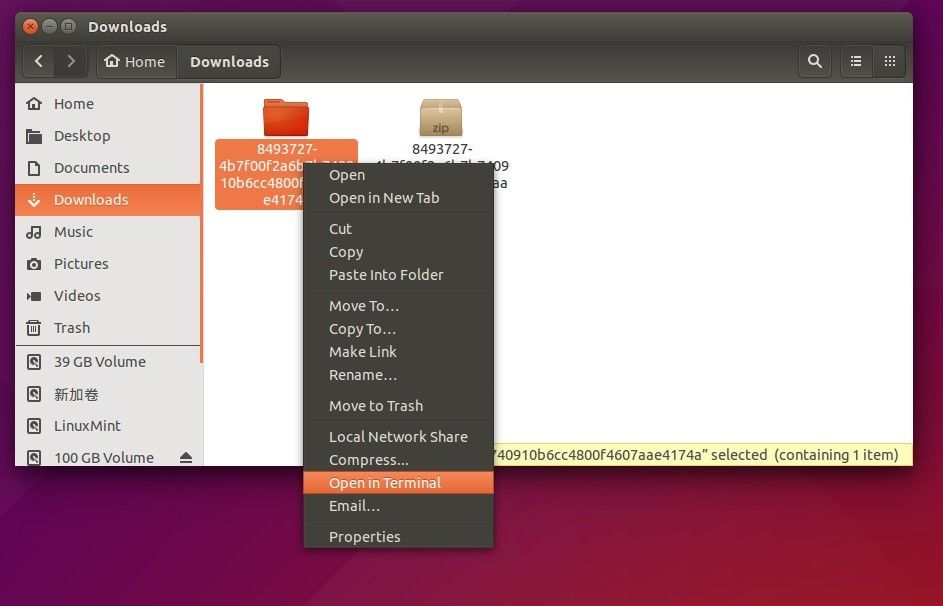
|
||||
|
||||
It opens a terminal window and automatically navigates into the result folder. If you **DON’T** find the “Open in Terminal” option, search for and install `nautilus-open-terminal` in Ubuntu Software Center and then log out and back in (or run `nautilus -q` command in terminal instead to apply changes).
|
||||
|
||||
4. When you’re in terminal, give the script executable permission for once.
|
||||
|
||||
chmod +x *
|
||||
|
||||
FINALLY run the script every time you want to install / upgrade Linux Kernel in Ubuntu:
|
||||
|
||||
./*
|
||||
|
||||
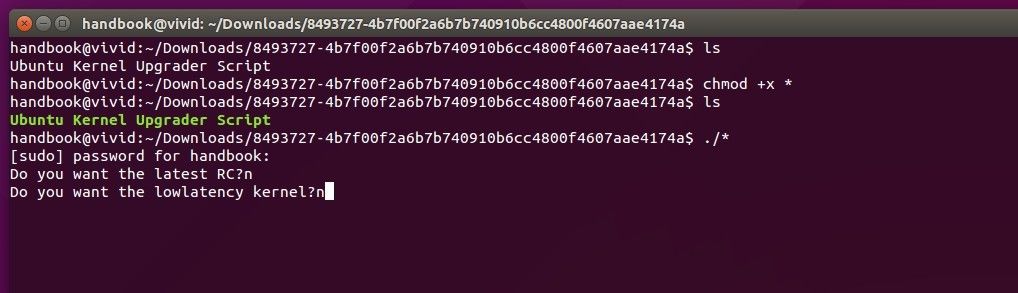
|
||||
|
||||
I use * instead of the SCRIPT NAME in both commands since it’s the only file in that folder.
|
||||
|
||||
If the script runs successfully, restart your computer when done.
|
||||
|
||||
### Revert back and Uninstall the new Kernel: ###
|
||||
|
||||
To revert back and remove the new kernel for any reason, restart your computer and select boot with the old kernel entry under **Advanced Options** menu when you’re at Grub boot-loader.
|
||||
|
||||
When it boots up, see below section.
|
||||
|
||||
### How to Remove the old (or new) Kernels: ###
|
||||
|
||||
1. Install Synaptic Package Manager from Ubuntu Software Center.
|
||||
|
||||
2. Launch Synaptic Package Manager and do:
|
||||
|
||||
- click the **Reload** button in case you want to remove the new kernel.
|
||||
- select **Status -> Installed** on the left pane to make search list clear.
|
||||
- search **linux-image**- using Quick filter box.
|
||||
- select a kernel image “linux-image-x.xx.xx-generic” and mark for (complete) removal
|
||||
- finally apply changes
|
||||
|
||||
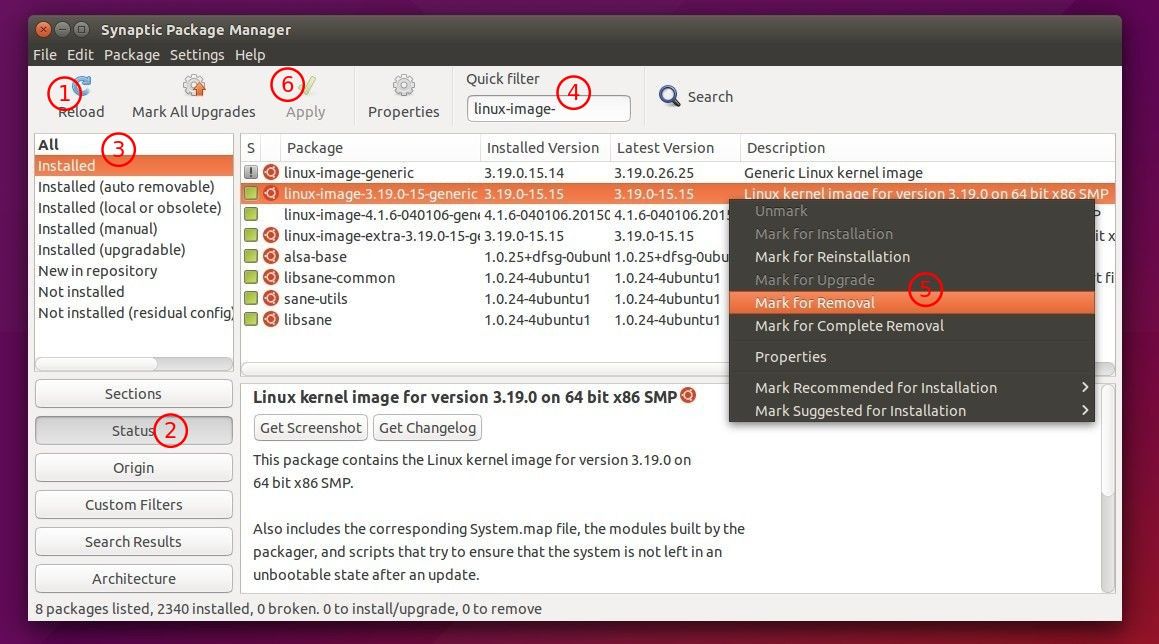
|
||||
|
||||
Repeat until you removed all unwanted kernels. DON’T carelessly remove the current running kernel, check it out via `uname -r` (see below pic.) command.
|
||||
|
||||
For Ubuntu Server, you may run below commands one by one:
|
||||
|
||||
uname -r
|
||||
|
||||
dpkg -l | grep linux-image-
|
||||
|
||||
sudo apt-get autoremove KERNEL_IMAGE_NAME
|
||||
|
||||
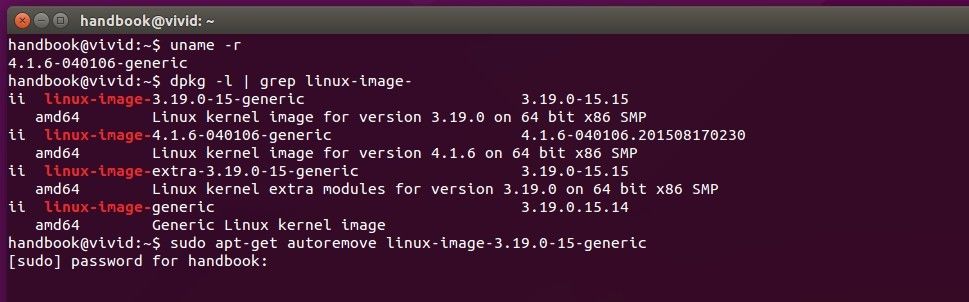
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/08/install-latest-kernel-script/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[2]:https://gist.github.com/mmstick/8493727
|
||||
@ -1,182 +0,0 @@
|
||||
Setting Up High-Performance ‘HHVM’ and Nginx/Apache with MariaDB on Debian/Ubuntu
|
||||
================================================================================
|
||||
HHVM stands for HipHop Virtual Machine, is an open source virtual machine created for running Hack (it’s a programming language for HHVM) and PHP written applications. HHVM uses a last minute compilation path to achieve remarkable performance while keeping the flexibility that PHP programmers are addicted to. Till date, HHVM has achieved over a 9x increase in http request throughput and more than 5x cut in memory utilization (when running on low system memory) for Facebook compared with the PHP engine + [APC (Alternative PHP Cache)][1].
|
||||
|
||||
HHVM can also be used along with a FastCGI-based web-server like Nginx or Apache.
|
||||
|
||||

|
||||
|
||||
Install HHVM, Nginx and Apache with MariaDB
|
||||
|
||||
In this tutorial we shall look at steps for setting up Nginx/Apache web server, MariaDB database server and HHVM. For this setup, we will use Ubuntu 15.04 (64-bit) as HHVM runs on 64-bit system only, although Debian and Linux Mint distributions are also supported.
|
||||
|
||||
### Step 1: Installing Nginx and Apache Web Server ###
|
||||
|
||||
1. First do a system upgrade to update repository list with the help of following commands.
|
||||
|
||||
# apt-get update && apt-get upgrade
|
||||
|
||||

|
||||
|
||||
System Upgrade
|
||||
|
||||
2. As I said HHVM can be used with both Nginx and Apache web server. So, it’s your choice which web server you will going to use, but here we will show you both web servers installation and how to use them with HHVM.
|
||||
|
||||
#### Installing Nginx ####
|
||||
|
||||
In this step, we will install Nginx/Apache web server from the packages repository using following command.
|
||||
|
||||
# apt-get install nginx
|
||||
|
||||

|
||||
|
||||
Install Nginx Web Server
|
||||
|
||||
#### Installing Apache ####
|
||||
|
||||
# apt-get install apache2
|
||||
|
||||

|
||||
|
||||
Install Apache Web Server
|
||||
|
||||
At this point, you should be able to navigate to following URL and you will able to see Nginx or Apache default page.
|
||||
|
||||
http://localhost
|
||||
OR
|
||||
http://IP-Address
|
||||
|
||||
#### Nginx Default Page ####
|
||||
|
||||

|
||||
|
||||
Nginx Welcome Page
|
||||
|
||||
#### Apache Default Page ####
|
||||
|
||||

|
||||
|
||||
Apache Default Page
|
||||
|
||||
### Step 2: Install and Configure MariaDB ###
|
||||
|
||||
3. In this step, we will install MariaDB, as it providers better performance as compared to MySQL.
|
||||
|
||||
# apt-get install mariadb-client mariadb-server
|
||||
|
||||

|
||||
|
||||
Install MariaDB Database
|
||||
|
||||
4. After MariaDB successful installation, you can start MariaDB and set root password to secure the database:
|
||||
|
||||
# systemctl start mysql
|
||||
# mysql_secure_installation
|
||||
|
||||
Answer the following questions by typing `y` or `n` and press enter. Make sure you read the instructions carefully before answering the questions.
|
||||
|
||||
Enter current password for root (enter for none) = press enter
|
||||
Set root password? [Y/n] = y
|
||||
Remove anonymous users[y/n] = y
|
||||
Disallow root login remotely[y/n] = y
|
||||
Remove test database and access to it [y/n] = y
|
||||
Reload privileges tables now[y/n] = y
|
||||
|
||||
5. After setting root password for MariaDB, you can connect to MariaDB prompt with the new root password.
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
### Step 3: Installation of HHVM ###
|
||||
|
||||
6. At this stage we shall install and configure HHVM. You need to add the HHVM repository to your `sources.list` file and then you have to update your repository list using following series of commands.
|
||||
|
||||
# wget -O - http://dl.hhvm.com/conf/hhvm.gpg.key | apt-key add -
|
||||
# echo deb http://dl.hhvm.com/ubuntu DISTRIBUTION_VERSION main | sudo tee /etc/apt/sources.list.d/hhvm.list
|
||||
# apt-get update
|
||||
|
||||
**Important**: Don’t forget to replace DISTRIBUTION_VERSION with your Ubuntu distribution version (i.e. lucid, precise, or trusty.) and also on Debian replace with jessie or wheezy. On Linux Mint installation instructions are same, but petra is the only currently supported distribution.
|
||||
|
||||
After adding HHVM repository, you can easily install it as shown.
|
||||
|
||||
# apt-get install -y hhvm
|
||||
|
||||
Installing HHVM will start it up now, but it not configured to auto start at next system boot. To set auto start at next boot use the following command.
|
||||
|
||||
# update-rc.d hhvm defaults
|
||||
|
||||
### Step 4: Configuring Nginx/Apache to Talk to HHVM ###
|
||||
|
||||
7. Now, nginx/apache and HHVM are installed and running as independent, so we need to configure both web servers to talk to each other. The crucial part is that we have to tell nginx/apache to forward all PHP files to HHVM to execute.
|
||||
|
||||
If you are using Nginx, follow this instructions as explained..
|
||||
|
||||
By default, the nginx configuration lives under /etc/nginx/sites-available/default and these config looks in /usr/share/nginx/html for files to execute, but it don’t know what to do with PHP.
|
||||
|
||||
To make Nginx to talk with HHVM, we need to run the following include script that will configure nginx correctly by placing a hhvm.conf at the beginning of the nginx config as mentioned above.
|
||||
|
||||
This script makes the nginx to talk to any file that ends with .hh or .php and send it to HHVM via fastcgi.
|
||||
|
||||
# /usr/share/hhvm/install_fastcgi.sh
|
||||
|
||||

|
||||
|
||||
Configure Nginx for HHVM
|
||||
|
||||
**Important**: If you are using Apache, there isn’t any configuration is needed now.
|
||||
|
||||
8. Next, you need to use /usr/bin/hhvm to provide /usr/bin/php (php) by running this command below.
|
||||
|
||||
# /usr/bin/update-alternatives --install /usr/bin/php php /usr/bin/hhvm 60
|
||||
|
||||
After all the above steps are done, you can now start HHVM and test it.
|
||||
|
||||
# systemctl start hhvm
|
||||
|
||||
### Step 5: Testing HHVM with Nginx/Apache ###
|
||||
|
||||
9. To verify that hhvm working, you need to create a hello.php file under nginx/apache document root directory.
|
||||
|
||||
# nano /usr/share/nginx/html/hello.php [For Nginx]
|
||||
OR
|
||||
# nano /var/www/html/hello.php [For Nginx and Apache]
|
||||
|
||||
Add the following snippet to this file.
|
||||
|
||||
<?php
|
||||
if (defined('HHVM_VERSION')) {
|
||||
echo 'HHVM is working';
|
||||
phpinfo();
|
||||
}
|
||||
else {
|
||||
echo 'HHVM is not working';
|
||||
}
|
||||
?>
|
||||
|
||||
and then navigate to the following URL and verify to see “hello world“.
|
||||
|
||||
http://localhost/info.php
|
||||
OR
|
||||
http://IP-Address/info.php
|
||||
|
||||

|
||||
|
||||
HHVM Page
|
||||
|
||||
If “HHVM” page appears, then it means you’re all set!
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
These steps are very easy to follow and hope your find this tutorial useful and if you get any error during installation of any packages, post a comment and we shall find solutions together. And any additional ideas are welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-hhvm-and-nginx-apache-with-mariadb-on-debian-ubuntu/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://www.tecmint.com/install-apc-alternative-php-cache-in-rhel-centos-fedora/
|
||||
@ -0,0 +1,53 @@
|
||||
Do Simple Math In Ubuntu And elementary OS With NaSC
|
||||
================================================================================
|
||||

|
||||
|
||||
[NaSC][1], abbreviation Not a Soulver Clone, is a third party app developed for elementary OS. Whatever the name suggests, NaSC is heavily inspired by [Soulver][2], an OS X app for doing maths like a normal person.
|
||||
|
||||
elementary OS itself draws from OS X and it is not a surprise that a number of the third party apps it has got, are also inspired by OS X apps.
|
||||
|
||||
Coming back to NaSC, what exactly it means by “maths like a normal person “? Well, it means to write like how you think in your mind. As per the description of the app:
|
||||
|
||||
> “Its an app where you do maths like a normal person. It lets you type whatever you want and smartly figures out what is math and spits out an answer on the right pane. Then you can plug those answers in to future equations and if that answer changes, so does the equations its used in.”
|
||||
|
||||
Still not convinced? Here, take a look at this screenshot.
|
||||
|
||||

|
||||
|
||||
Now, you see what is ‘math for normal person’? Honestly, I am not a fan of such apps but it might be useful for some of you perhaps. Let’s see how can you install NaSC in elementary OS, Ubuntu and Linux Mint.
|
||||
|
||||
### Install NaSC in Ubuntu, elementary OS and Mint ###
|
||||
|
||||
There is a PPA available for installing NaSC. The PPA says ‘daily’ which could mean daily build (i.e. unstable) but in my quick test, it worked just fine.
|
||||
|
||||
Open a terminal and use the following commands:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
sudo apt-get update
|
||||
sudo apt-get install nasc
|
||||
|
||||
Here is a screenshot of NaSC in Ubuntu 15.04:
|
||||
|
||||

|
||||
|
||||
If you want to remove it, you can use the following commands:
|
||||
|
||||
sudo apt-get remove nasc
|
||||
sudo apt-add-repository --remove ppa:nasc-team/daily
|
||||
|
||||
If you try it, do share your experience with it. In addition to this, you can also try [Vocal podcast app for Linux][3] from third party elementary OS apps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/math-ubuntu-nasc/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://parnold-x.github.io/nasc/
|
||||
[2]:http://www.acqualia.com/soulver/
|
||||
[3]:http://itsfoss.com/podcast-app-vocal-linux/
|
||||
@ -0,0 +1,116 @@
|
||||
How To Manage Log Files With Logrotate On Ubuntu 12.10
|
||||
================================================================================
|
||||
#### About Logrotate ####
|
||||
|
||||
Logrotate is a utility/tool that manages activities like automatic rotation, removal and compression of log files in a system. This is an excellent tool to manage your logs conserve precious disk space. By having a simple yet powerful configuration file, different parameters of logrotation can be controlled. This gives complete control over the way logs can be automatically managed and need not necessitate manual intervention.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
As a prerequisite, we are assuming that you have gone through the article on how to set up your droplet or VPS. If not, you can find the article [here][1]. This tutorial requires you to have a VPS up and running and have you log into it.
|
||||
|
||||
#### Setup Logrotate ####
|
||||
|
||||
### Step 1—Update System and System Packages ###
|
||||
|
||||
Run the following command to update the package lists from apt-get and get the information on the newest versions of packages and their dependencies.
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
### Step 2—Install Logrotate ###
|
||||
|
||||
If logrotate is not already on your VPS, install it now through apt-get.
|
||||
|
||||
sudo apt-get install logrotate
|
||||
|
||||
### Step 3 — Confirmation ###
|
||||
|
||||
To verify that logrotate was successfully installed, run this in the command prompt.
|
||||
|
||||
logrotate
|
||||
|
||||
Since the logrotate utility is based on configuration files, the above command will not rotate any files and will show you a brief overview of the usage and the switch options available.
|
||||
|
||||
### Step 4—Configure Logrotate ###
|
||||
|
||||
Configurations and default options for the logrotate utility are present in:
|
||||
|
||||
/etc/logrotate.conf
|
||||
|
||||
Some of the important configuration settings are : rotation-interval, log-file-size, rotation-count and compression.
|
||||
|
||||
Application-specific log file information (to override the defaults) are kept at:
|
||||
|
||||
/etc/logrotate.d/
|
||||
|
||||
We will have a look at a few examples to understand the concept better.
|
||||
|
||||
### Step 5—Example ###
|
||||
|
||||
An example application configuration setting would be the dpkg (Debian package management system), that is stored in /etc/logrotate.d/dpkg. One of the entries in this file would be:
|
||||
|
||||
/var/log/dpkg.log {
|
||||
monthly
|
||||
rotate 12
|
||||
compress
|
||||
delaycompress
|
||||
missingok
|
||||
notifempty
|
||||
create 644 root root
|
||||
}
|
||||
|
||||
What this means is that:
|
||||
|
||||
- the logrotation for dpkg monitors the /var/log/dpkg.log file and does this on a monthly basis this is the rotation interval.
|
||||
- 'rotate 12' signifies that 12 days worth of logs would be kept.
|
||||
- logfiles can be compressed using the gzip format by specifying 'compress' and 'delaycompress' delays the compression process till the next log rotation. 'delaycompress' will work only if 'compress' option is specified.
|
||||
- 'missingok' avoids halting on any error and carries on with the next log file.
|
||||
- 'notifempty' avoid log rotation if the logfile is empty.
|
||||
- 'create <mode> <owner> <group>' creates a new empty file with the specified properties after log-rotation.
|
||||
|
||||
Though missing in the above example, 'size' is also an important setting if you want to control the sizing of the logs growing in the system.
|
||||
|
||||
A configuration setting of around 100MB would look like:
|
||||
|
||||
size 100M
|
||||
|
||||
Note that If both size and rotation interval are set, then size is taken as a higher priority. That is, if a configuration file has the following settings:
|
||||
|
||||
monthly
|
||||
size 100M
|
||||
|
||||
then the logs are rotated once the file size reaches 100M and this need not wait for the monthly cycle.
|
||||
|
||||
### Step 6—Cron Job ###
|
||||
|
||||
You can also set the logrotation as a cron so that the manual process can be avoided and this is taken care of automatically. By specifying an entry in /etc/cron.daily/logrotate , the rotation is triggered daily.
|
||||
|
||||
### Step 7—Status Check and Verification ###
|
||||
|
||||
To verify if a particular log is indeed rotating or not and to check the last date and time of its rotation, check the /var/lib/logrotate/status file. This is a neatly formatted file that contains the log file name and the date on which it was last rotated.
|
||||
|
||||
cat /var/lib/logrotate/status
|
||||
|
||||
A few entries from this file, for example:
|
||||
|
||||
"/var/log/lpr.log" 2013-4-11
|
||||
"/var/log/dpkg.log" 2013-4-11
|
||||
"/var/log/pm-suspend.log" 2013-4-11
|
||||
"/var/log/syslog" 2013-4-11
|
||||
"/var/log/mail.info" 2013-4-11
|
||||
"/var/log/daemon.log" 2013-4-11
|
||||
"/var/log/apport.log" 2013-4-11
|
||||
|
||||
Congratulations! You have logrotate installed in your system. Now, change the configuration settings as per your requirements.
|
||||
|
||||
Try 'man logrotate' or 'logrotate -?' for more details.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/how-to-manage-log-files-with-logrotate-on-ubuntu-12-10
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.digitalocean.com/community/articles/initial-server-setup-with-ubuntu-12-04
|
||||
102
sources/tech/20150906 How To Set Up Your FTP Server In Linux.md
Normal file
102
sources/tech/20150906 How To Set Up Your FTP Server In Linux.md
Normal file
@ -0,0 +1,102 @@
|
||||
How To Set Up Your FTP Server In Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
In this lesson, I will explain to you how to Set up your FTP server. But first, let me quickly tell you what is FTP.
|
||||
|
||||
### What is FTP? ###
|
||||
|
||||
[FTP][1] is an acronym for File Transfer Protocol. As the name suggests, FTP is used to transfer files between computers on a network. You can use FTP to exchange files between computer accounts, transfer files between an account and a desktop computer, or access online software archives. Keep in mind, however, that many FTP sites are heavily used and require several attempts before connecting.
|
||||
|
||||
An FTP address looks a lot like an HTTP or website address except it uses the prefix ftp:// instead of http://.
|
||||
|
||||
### What is an FTP Server? ###
|
||||
|
||||
Typically, a computer with an FTP address is dedicated to receive an FTP connection. A computer dedicated to receiving an FTP connection is referred to as an FTP server or FTP site.
|
||||
|
||||
Now, let’s begin a special adventure. We will make FTP server to share files with friends and family. I will use [vsftpd][2] for this purpose.
|
||||
|
||||
VSFTPD is an FTP server software which claims to be the most secure FTP software. In fact, the first two letters in VSFTPD, stand for “very secure”. The software was built around the vulnerabilities of the FTP protocol.
|
||||
|
||||
Nevertheless, you should always remember that there are better solutions for secure transfer and management of files such as SFTP (uses [OpenSSH][3]). The FTP protocol is particularly useful for sharing non-sensitive data and is very reliable at that.
|
||||
|
||||
#### Installing VSFTPD in rpm distributions: ####
|
||||
|
||||
You can quickly install VSFTPD on your server through the command line interface with:
|
||||
|
||||
dnf -y install vsftpd
|
||||
|
||||
#### Installing VSFTPD in deb distributions: ####
|
||||
|
||||
You can quickly install VSFTPD on your server through the command line interface with:
|
||||
|
||||
sudo apt-get install vsftpd
|
||||
|
||||
#### Installing VSFTPD in Arch distribution: ####
|
||||
|
||||
You can quickly install VSFTPD on your server through the command line interface with:
|
||||
|
||||
sudo pacman -S vsftpd
|
||||
|
||||
#### Configuring FTP server ####
|
||||
|
||||
Most VSFTPD’s configuration takes place in /etc/vsftpd.conf. The file itself is well-documented, so this section only highlights some important changes you may want to make. For all available options and basic documentation see the man pages:
|
||||
|
||||
man vsftpd.conf
|
||||
|
||||
Files are served by default from /srv/ftp as per the Filesystem Hierarchy Standard.
|
||||
|
||||
**Enable Uploading:**
|
||||
|
||||
The “write_enable” flag must be set to YES in order to allow changes to the filesystem, such as uploading:
|
||||
|
||||
write_enable=YES
|
||||
|
||||
**Allow Local Users to Login:**
|
||||
|
||||
In order to allow users in /etc/passwd to login, the “local_enable” directive must look like this:
|
||||
|
||||
local_enable=YES
|
||||
|
||||
**Anonymous Login**
|
||||
|
||||
The following lines control whether anonymous users can login:
|
||||
|
||||
# Allow anonymous login
|
||||
|
||||
anonymous_enable=YES
|
||||
# No password is required for an anonymous login (Optional)
|
||||
no_anon_password=YES
|
||||
# Maximum transfer rate for an anonymous client in Bytes/second (Optional)
|
||||
anon_max_rate=30000
|
||||
# Directory to be used for an anonymous login (Optional)
|
||||
anon_root=/example/directory/
|
||||
|
||||
**Chroot Jail**
|
||||
|
||||
It is possible to set up a chroot environment, which prevents the user from leaving his home directory. To enable this, add/change the following lines in the configuration file:
|
||||
|
||||
chroot_list_enable=YES chroot_list_file=/etc/vsftpd.chroot_list
|
||||
|
||||
The “chroot_list_file” variable specifies the file in which the jailed users are contained to.
|
||||
|
||||
In the end you must restart your ftp server. Type in your command line
|
||||
|
||||
sudo systemctl restart vsftpd
|
||||
|
||||
That’s it. Your FTP server is up and running.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/set-ftp-server-linux/
|
||||
|
||||
作者:[alimiracle][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/ali/
|
||||
[1]:https://en.wikipedia.org/wiki/File_Transfer_Protocol
|
||||
[2]:https://security.appspot.com/vsftpd.html
|
||||
[3]:http://www.openssh.com/
|
||||
219
sources/tech/20150906 How to Configure OpenNMS on CentOS 7.x.md
Normal file
219
sources/tech/20150906 How to Configure OpenNMS on CentOS 7.x.md
Normal file
@ -0,0 +1,219 @@
|
||||
How to Configure OpenNMS on CentOS 7.x
|
||||
================================================================================
|
||||
Systems management and monitoring services are very important that provides information to view important systems management information that allow us to to make decisions based on this information. To make sure the network is running at its best and to minimize the network downtime we need to improve application performance. So, in this article we will make you understand the step by step procedure to setup OpenNMS in your IT infrastructure. OpenNMS is a free open source enterprise level network monitoring and management platform that provides information to allow us to make decisions in regards to future network and capacity planning.
|
||||
|
||||
OpenNMS designed to manage tens of thousands of devices from a single server as well as manage unlimited devices using a cluster of servers. It includes a discovery engine to automatically configure and manage network devices without operator intervention. It is written in Java and is published under the GNU General Public License. OpenNMS is known for its scalability with its main functional areas in services monitoring, data collection using SNMP and event management and notifications.
|
||||
|
||||
### Installing OpenNMS RPM Repository ###
|
||||
|
||||
We will start from the installation of OpenNMS RPM for our CentOs 7.1 operating system as its available for most of the RPM-based distributions through Yum at their official link http://yum.opennms.org/ .
|
||||
|
||||

|
||||
|
||||
Then open your command line interface of CentOS 7.1 and login with root credentials to run the below command with “wget” to get the required RPM.
|
||||
|
||||
[root@open-nms ~]# wget http://yum.opennms.org/repofiles/opennms-repo-stable-rhel7.noarch.rpm
|
||||
|
||||

|
||||
|
||||
Now we need to install this repository so that the OpenNMS package information could be available through yum for installation. Let’s run the command below with same root level credentials to do so.
|
||||
|
||||
[root@open-nms ~]# rpm -Uvh opennms-repo-stable-rhel7.noarch.rpm
|
||||
|
||||

|
||||
|
||||
### Installing Prerequisite Packages for OpenNMS ###
|
||||
|
||||
Now before we start installation of OpenNMS, let’s make sure you’ve done the following prerequisites.
|
||||
|
||||
**Install JDK 7**
|
||||
|
||||
Its recommended that you install the latest stable Java 7 JDK from Oracle for the best performance to integrate JDK in our YUM repository as a fallback. Let’s go to the Oracle Java 7 SE JDK download page, accept the license if you agree, choose the platform and architecture. Once it has finished downloading, execute it from the command-line and then install the resulting JDK rpm.
|
||||
|
||||
Else run the below command to install using the Yum from the the available system repositories.
|
||||
|
||||
[root@open-nms ~]# yum install java-1.7.0-openjdk-1.7.0.85-2.6.1.2.el7_1
|
||||
|
||||
Once you have installed the Java you can confirm its installation using below command and check its installed version.
|
||||
|
||||
[root@open-nms ~]# java -version
|
||||
|
||||

|
||||
|
||||
**Install PostgreSQL**
|
||||
|
||||
Now we will install the PostgreSQL that is a must requirement to setup the database for OpenNMS. PostgreSQL is included in all of the major YUM-based distributions. To install, simply run the below command.
|
||||
|
||||
[root@open-nms ~]# yum install postgresql postgresql-server
|
||||
|
||||

|
||||
|
||||
### Prepare the Database for OpenNMS ###
|
||||
|
||||
Once you have installed PostgreSQL, now you'll need to make sure that PostgreSQL is up and active. Let’s run the below command to first initialize the database and then start its services.
|
||||
|
||||
[root@open-nms ~]# /sbin/service postgresql initdb
|
||||
[root@open-nms ~]# /sbin/service postgresql start
|
||||
|
||||

|
||||
|
||||
Now to confirm the status of your PostgreSQL database you can run the below command.
|
||||
|
||||
[root@open-nms ~]# service postgresql status
|
||||
|
||||

|
||||
|
||||
To ensure that PostgreSQL will start after a reboot, use the “systemctl”command to enable start on bootup using below command.
|
||||
|
||||
[root@open-nms ~]# systemctl enable postgresql
|
||||
ln -s '/usr/lib/systemd/system/postgresql.service' '/etc/systemd/system/multi-user.target.wants/postgresql.service'
|
||||
|
||||
### Configure PostgreSQL ###
|
||||
|
||||
Locate the Postgres “data” directory. Often this is located in /var/lib/pgsql/data directory and Open the postgresql.conf file in text editor and configure the following parameters as shown.
|
||||
|
||||
[root@open-nms ~]# vim /var/lib/pgsql/data/postgresql.conf
|
||||
|
||||
----------
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# CONNECTIONS AND AUTHENTICATION
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
listen_addresses = 'localhost'
|
||||
max_connections = 256
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# RESOURCE USAGE (except WAL)
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
shared_buffers = 1024MB
|
||||
|
||||
**User Access to the Database**
|
||||
|
||||
PostgreSQL only allows you to connect if you are logged in to the local account name that matches the PostgreSQL user. Since OpenNMS runs as root, it cannot connect as a "postgres" or "opennms" user by default, so we have to change the configuration to allow user access to the database by opening the below configuration file.
|
||||
|
||||
[root@open-nms ~]# vim /var/lib/pgsql/data/pg_hba.conf
|
||||
|
||||
Update the configuration file as shown below and change the METHOD settings from "ident" to "trust"
|
||||
|
||||

|
||||
|
||||
Write and quit the file to make saved changes and then restart PostgreSQL services.
|
||||
|
||||
[root@open-nms ~]# service postgresql restart
|
||||
|
||||
### Starting OpenNMS Installation ###
|
||||
|
||||
Now we are ready go with installation of OpenNMS as we have almost don with its prerequisites. Using the YUM packaging system will download and install all of the required components and their dependencies, if they are not already installed on your system.
|
||||
So let's riun th belwo command to start OpenNMS installation that will pull everything you need to have a working OpenNMS, including the OpenNMS core, web UI, and a set of common plugins.
|
||||
|
||||
[root@open-nms ~]# yum -y install opennms
|
||||
|
||||

|
||||
|
||||
The above command will ends up with successful installation of OpenNMS and its derivative packages.
|
||||
|
||||
### Configure JAVA for OpenNMS ###
|
||||
|
||||
In order to integrate the default version of Java with OpenNMS we will run the below command.
|
||||
|
||||
[root@open-nms ~]# /opt/opennms/bin/runjava -s
|
||||
|
||||

|
||||
|
||||
### Run the OpenNMS installer ###
|
||||
|
||||
Now it's time to start the OpenNMS installer that will create and configure the OpenNMS database, while the same command will be used in case we want to update it to the latest version. To do so, we will run the following command.
|
||||
|
||||
[root@open-nms ~]# /opt/opennms/bin/install -dis
|
||||
|
||||
The above install command will take many options with following mechanism.
|
||||
|
||||
-d - to update the database
|
||||
-i - to insert any default data that belongs in the database
|
||||
-s - to create or update the stored procedures OpenNMS uses for certain kinds of data access
|
||||
|
||||
==============================================================================
|
||||
OpenNMS Installer
|
||||
==============================================================================
|
||||
|
||||
Configures PostgreSQL tables, users, and other miscellaneous settings.
|
||||
|
||||
DEBUG: Platform is IPv6 ready: true
|
||||
- searching for libjicmp.so:
|
||||
- trying to load /usr/lib64/libjicmp.so: OK
|
||||
- searching for libjicmp6.so:
|
||||
- trying to load /usr/lib64/libjicmp6.so: OK
|
||||
- searching for libjrrd.so:
|
||||
- trying to load /usr/lib64/libjrrd.so: OK
|
||||
- using SQL directory... /opt/opennms/etc
|
||||
- using create.sql... /opt/opennms/etc/create.sql
|
||||
17:27:51.178 [Main] INFO org.opennms.core.schema.Migrator - PL/PgSQL call handler exists
|
||||
17:27:51.180 [Main] INFO org.opennms.core.schema.Migrator - PL/PgSQL language exists
|
||||
- checking if database "opennms" is unicode... ALREADY UNICODE
|
||||
- Creating imports directory (/opt/opennms/etc/imports... OK
|
||||
- Checking for old import files in /opt/opennms/etc... DONE
|
||||
INFO 16/08/15 17:27:liquibase: Reading from databasechangelog
|
||||
Installer completed successfully!
|
||||
|
||||
==============================================================================
|
||||
OpenNMS Upgrader
|
||||
==============================================================================
|
||||
|
||||
OpenNMS is currently stopped
|
||||
Found upgrade task SnmpInterfaceRrdMigratorOnline
|
||||
Found upgrade task KscReportsMigrator
|
||||
Found upgrade task JettyConfigMigratorOffline
|
||||
Found upgrade task DataCollectionConfigMigratorOffline
|
||||
Processing RequisitionsMigratorOffline: Remove non-ip-snmp-primary and non-ip-interfaces from requisitions: NMS-5630, NMS-5571
|
||||
- Running pre-execution phase
|
||||
Backing up: /opt/opennms/etc/imports
|
||||
- Running post-execution phase
|
||||
Removing backup /opt/opennms/etc/datacollection.zip
|
||||
|
||||
Finished in 0 seconds
|
||||
|
||||
Upgrade completed successfully!
|
||||
|
||||
### Firewall configurations to Allow OpenNMS ###
|
||||
|
||||
Here we have to allow OpenNMS management interface port 8980 through firewall or router to access the management web interface from the remote systems. So use the following commands to do so.
|
||||
|
||||
[root@open-nms etc]# firewall-cmd --permanent --add-port=8980/tcp
|
||||
[root@open-nms etc]# firewall-cmd --reload
|
||||
|
||||
### Start OpenNMS and Login to Web Interface ###
|
||||
|
||||
Let's start OpenNMS service and enable to it start at each bootup by using the below command.
|
||||
|
||||
[root@open-nms ~]#systemctl start opennms
|
||||
[root@open-nms ~]#systemctl enable opennms
|
||||
|
||||
Once the services are up are ready to go with its web management interface. Open your web browser and access it with your server's IP address and 8980 port.
|
||||
|
||||
http://servers_ip:8980/
|
||||
|
||||
Give the username and password where as the default username and password is admin/admin.
|
||||
|
||||

|
||||
|
||||
After successful authentication with your provided username and password you will be directed towards the the Home page of OpenNMS where you can configure the new monitoring devices/nodes/services etc.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Congratulations! we have successfully setup OpenNMS on CentOS 7.1. So, at the end of this tutorial, you are now able to install and configure OpenNMS with its prerequisites that included PostgreSQL and JAVA setup. So let's enjoy with the great network monitoring system with open source roots using OpenNMS that provide a bevy of features at no cost than their high-end competitors, and can scale to monitor large numbers of network nodes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/monitoring-2/install-configure-opennms-centos-7-x/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,174 @@
|
||||
How to Install DNSCrypt and Unbound in Arch Linux
|
||||
================================================================================
|
||||
**DNSCrypt** is a protocol that encrypt and authenticate communications between a DNS client and a DNS resolver. Prevent from DNS spoofing or man in the middle-attack. DNSCrypt are available for most operating system, including Linux, Windows, MacOSX android and iOS. And in this tutorial I'm using archlinux with kernel 4.1.
|
||||
|
||||
Unbound is a DNS cache server used to resolve any DNS query received. If the user requests a new query, then unbound will store it as a cache, and when the user requests the same query for the second time, then unbound would take from the cache that have been saved. This will be faster than the first request query.
|
||||
|
||||
And now I will try to install "DNSCrypt" to secure the dns communication, and make it faster with dns cache "Unbound".
|
||||
|
||||
### Step 1 - Install yaourt ###
|
||||
|
||||
Yaourt is one of AUR(Arch User Repository) helper that make archlinux users easy to install a program from AUR. Yaourt use same syntax as pacman, so you can install the program with yaourt. and this is easy way to install yaourt :
|
||||
|
||||
1. Edit the arch repository configuration file with nano or vi, stored in a file "/etc/pacman.conf".
|
||||
|
||||
$ nano /etc/pacman.conf
|
||||
|
||||
2. Add at the bottom line yaourt repository, just paste script below :
|
||||
|
||||
[archlinuxfr]
|
||||
SigLevel = Never
|
||||
Server = http://repo.archlinux.fr/$arch
|
||||
|
||||
3. Save it with press "Ctrl + x" and then "Y".
|
||||
|
||||
4. Now update the repository database and install yaourt with pacman command :
|
||||
|
||||
$ sudo pacman -Sy yaourt
|
||||
|
||||
### Step 2 - Install DNSCrypt and Unbound ###
|
||||
|
||||
DNSCrypt and unbound available on archlinux repository, then you can install it with pacman command :
|
||||
|
||||
$ sudo pacman -S dnscrypt-proxy unbound
|
||||
|
||||
wait it and press "Y" for proceed with installation.
|
||||
|
||||
### Step 3 - Install dnscrypt-autoinstall ###
|
||||
|
||||
Dnscrypt-autoinstall is A script for installing and automatically configuring DNSCrypt on Linux-based systems. Dnscrypt-autoinstall available in AUR(Arch User Repository), and you must use "yaourt" command to install it :
|
||||
|
||||
$ yaourt -S dnscrypt-autoinstall
|
||||
|
||||
Note :
|
||||
|
||||
-S = it is same as pacman -S to install a software/program.
|
||||
|
||||
### Step 4 - Run dnscrypt-autoinstall ###
|
||||
|
||||
run the command "dnscrypt-autoinstall" with root privileges to configure DNSCrypt automatically :
|
||||
|
||||
$ sudo dnscrypt-autoinstall
|
||||
|
||||
Press "Enter" for the next configuration, and then type "y" and choose the DNS provider you want to use, I'm here use DNSCrypt.eu featured with no logs and DNSSEC.
|
||||
|
||||

|
||||
|
||||
### Step 5 - Configure DNSCrypt and Unbound ###
|
||||
|
||||
1. Open the dnscrypt configuration file "/etc/conf.d/dnscrypt-config" and make sure the configuration of "DNSCRYPT_LOCALIP" point to **localhost IP**, and for port configuration "DNSCRYPT_LOCALPORT" it's up to you, I`m here use port **40**.
|
||||
|
||||
$ nano /etc/conf.d/dnscrypt-config
|
||||
|
||||
DNSCRYPT_LOCALIP=127.0.0.1
|
||||
DNSCRYPT_LOCALIP2=127.0.0.2
|
||||
DNSCRYPT_LOCALPORT=40
|
||||
|
||||

|
||||
|
||||
Save and exit.
|
||||
|
||||
2. Now you can edit unbound configuration in "/etc/unbound/". edit the file configuration with nano editor :
|
||||
|
||||
$ nano /etc/unbound/unbound.conf
|
||||
|
||||
3. Add the following script in the end of line :
|
||||
|
||||
do-not-query-localhost: no
|
||||
forward-zone:
|
||||
name: "."
|
||||
forward-addr: 127.0.0.1@40
|
||||
|
||||
Make sure the "**forward-addr**" port is same with "**DNSCRYPT_LOCALPORT**" configuration in DNSCrypt. You can see the I`m use port **40**.
|
||||
|
||||

|
||||
|
||||
and then save and exit.
|
||||
|
||||
### Step 6 - Run DNSCrypt and Unbound, then Add to startup/Boot ###
|
||||
|
||||
Please run DNSCrypt and unbound with root privileges, you can run with systemctl command :
|
||||
|
||||
$ sudo systemctl start dnscrypt-proxy unbound
|
||||
|
||||
Add the service at the boot time/startup. You can do it by running "systemctl enable" :
|
||||
|
||||
$ sudo systemctl enable dnscrypt-proxy unbound
|
||||
|
||||
the command will create the symlink of the service to "/usr/lib/systemd/system/" directory.
|
||||
|
||||
### Step 7 - Configure resolv.conf and restart all services ###
|
||||
|
||||
Resolv.conf is a file used by linux to configure Domain Name Server(DNS) resolver. it is just plain-text created by administrator, so you must edit by root privileges and make it immutable/no one can edit it.
|
||||
|
||||
Edit it with nano editor :
|
||||
|
||||
$ nano /etc/resolv.conf
|
||||
|
||||
and add the localhost IP "**127.0.0.1**". and now make it immutable with "chattr" command :
|
||||
|
||||
$ chattr +i /etc/resolv.conf
|
||||
|
||||
Note :
|
||||
|
||||
If you want to edit it again, make it writable with command "chattr -i /etc/resolv.conf".
|
||||
|
||||
Now yo need to restart the DNSCrypt, unbound and the network :
|
||||
|
||||
$ sudo systemctl restart dnscrypt-proxy unbound netctl
|
||||
|
||||
If you see the error, check your configuration file.
|
||||
|
||||
### Testing ###
|
||||
|
||||
1. Test DNSCrypt
|
||||
|
||||
You can be sure that DNSCrypt had acted correctly by visiting https://dnsleaktest.com/, then click on "Standard Test" or "Extended Test" and wait the process running.
|
||||
|
||||
And now you can see that DNSCrypt is working with DNSCrypt.eu as your DNS provider.
|
||||
|
||||

|
||||
|
||||
And now you can see that DNSCrypt is working with DNSCrypt.eu as your DNS provider.
|
||||
|
||||
2. Test Unbound
|
||||
|
||||
Now you should ensure that the unbound is working correctly with "dig" or "drill" command.
|
||||
|
||||
This is the results for dig command :
|
||||
|
||||
$ dig linoxide.com
|
||||
|
||||
Now see in the results, the "Query time" is "533 msec" :
|
||||
|
||||
;; Query time: 533 msec
|
||||
;; SERVER: 127.0.0.1#53(127.0.0.1)
|
||||
;; WHEN: Sun Aug 30 14:48:19 WIB 2015
|
||||
;; MSG SIZE rcvd: 188
|
||||
|
||||
and try again with the same command. And you will see the "Query time" is "0 msec".
|
||||
|
||||
;; Query time: 0 msec
|
||||
;; SERVER: 127.0.0.1#53(127.0.0.1)
|
||||
;; WHEN: Sun Aug 30 14:51:05 WIB 2015
|
||||
;; MSG SIZE rcvd: 188
|
||||
|
||||

|
||||
|
||||
And in the end DNSCrypt secure communications between the DNS clients and DNS resolver is working perfectly, and then Unbound make it faster if there is the same request in another time by taking the cache that have been saved.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
DNSCrypt is a protocol that can encrypt data flow between the DNS client and DNS resolver. DNSCrypt can run on various operating systems, either mobile or desktop. Choose DNS provider also includes something important, choose which provide a DNSSEC and no logs. Unbound can be used as a DNS cache, thus speeding up the resolve process resolv, because Unbound will store a request as the cache, then when a client request same query in the next time, then unbound would take from the cache that have been saved. DNSCrypt and Unbound is a powerful combination for the safety and speed.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-dnscrypt-unbound-archlinux/
|
||||
|
||||
作者:[Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arulm/
|
||||
@ -0,0 +1,113 @@
|
||||
How to Install QGit Viewer in Ubuntu 14.04
|
||||
================================================================================
|
||||
QGit is a free and Open Source GUI git viewer written on Qt and C++ by Marco Costalba. It is a better git viewer which provides us the ability to browse revisions history, view commits and patches applied to the files under a simple GUI environment. It utilizes git command line to process execute the commands and to display the output. It has some common features like to view revisions, diffs, files history, files annotation, archive tree. We can format and apply patch series with the selected commits, drag and drop commits between two instances and more with QGit Viewer. It allows us to create custom buttons with which we can add more buttons to execute a specific command when pressed using its builtin Action Builder.
|
||||
|
||||
Here are some easy steps on how we can compile and install QGit Viewer from its source code in Ubuntu 14.04 LTS "Trusty".
|
||||
|
||||
### 1. Installing QT4 Libraries ###
|
||||
|
||||
First of all, we'll need have QT4 Libraries installed in order to run QGit viewer in our ubuntu machine. As apt is the default package manager of ubuntu and QT4 packages is available in the official repository of ubutnu, we'll gonna install qt4-default using apt-get command as shown below.
|
||||
|
||||
$ sudo apt-get install qt4-default
|
||||
|
||||
### 2. Downloading QGit Tarball ###
|
||||
|
||||
After installing Qt4 libraries, we'll gonna install git so that we can clone the Git repository of QGit Viewer for Qt 4 . To do so, we'll run the following apt-get command.
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||
Now, we'll clone the repository using git command as shown below.
|
||||
|
||||
$ git clone git://repo.or.cz/qgit4/redivivus.git
|
||||
|
||||
Cloning into 'redivivus'...
|
||||
remote: Counting objects: 7128, done.
|
||||
remote: Compressing objects: 100% (2671/2671), done.
|
||||
remote: Total 7128 (delta 5464), reused 5711 (delta 4438)
|
||||
Receiving objects: 100% (7128/7128), 2.39 MiB | 470.00 KiB/s, done.
|
||||
Resolving deltas: 100% (5464/5464), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
### 3. Compiling QGit ###
|
||||
|
||||
After we have cloned the repository, we'll now enter into the directory named redivivus and create the makefile which we'll require to compile qgit viewer. So, to enter into the directory, we'll run the following command.
|
||||
|
||||
$ cd redivivus
|
||||
|
||||
Next, we'll run the following command in order to generate a new Makefile from qmake project file ie qgit.pro.
|
||||
|
||||
$ qmake qgit.pro
|
||||
|
||||
After the Makefile has been generated, we'll now finally compile the source codes of qgit and get the binary as output. To do so, first we'll need to install make and g++ package so that we can compile, as it is a program written in C++ .
|
||||
|
||||
$ sudo apt-get install make g++
|
||||
|
||||
Now, we'll gonna compile the codes using make command.
|
||||
|
||||
$ make
|
||||
|
||||
### 4. Installing QGit ###
|
||||
|
||||
As we have successfully compiled the source code of QGit viewer, now we'll surely wanna install it in our Ubuntu 14.04 machine so that we can execute it from our system. To do so, we'll run the following command.
|
||||
|
||||
$ sudo make install
|
||||
|
||||
cd src/ && make -f Makefile install
|
||||
make[1]: Entering directory `/home/arun/redivivus/src'
|
||||
make -f Makefile.Release install
|
||||
make[2]: Entering directory `/home/arun/redivivus/src'
|
||||
install -m 755 -p "../bin/qgit" "/usr/lib/x86_64-linux-gnu/qt4/bin/qgit"
|
||||
strip "/usr/lib/x86_64-linux-gnu/qt4/bin/qgit"
|
||||
make[2]: Leaving directory `/home/arun/redivivus/src'
|
||||
make[1]: Leaving directory `/home/arun/redivivus/src'
|
||||
|
||||
Next, we'll need to copy the built qgit binary file from bin directory to /usr/bin/ directory so that it will be available as global command.
|
||||
|
||||
$ sudo cp bin/qgit /usr/bin/
|
||||
|
||||
### 5. Creating Desktop File ###
|
||||
|
||||
As we have successfully installed qgit in our Ubuntu box, we'll now go for create a desktop file so that QGit will be available under Menu or Launcher of our Desktop Environment. To do so, we'll need to create a new file named qgit.desktop under /usr/share/applications/ directory.
|
||||
|
||||
$ sudo nano /usr/share/applications/qgit.desktop
|
||||
|
||||
Then, we'll need to paste the following lines into the file.
|
||||
|
||||
[Desktop Entry]
|
||||
Name=qgit
|
||||
GenericName=git GUI viewer
|
||||
Exec=qgit
|
||||
Icon=qgit
|
||||
Type=Application
|
||||
Comment=git GUI viewer
|
||||
Terminal=false
|
||||
MimeType=inode/directory;
|
||||
Categories=Qt;Development;RevisionControl;
|
||||
|
||||
After done, we'll simply save the file and exit.
|
||||
|
||||
### 6. Running QGit Viewer ###
|
||||
|
||||
After QGit is installed successfully in our Ubuntu box, we can now run it from any launcher or application menu. In order to run QGit from the terminal, we'll need to run as follows.
|
||||
|
||||
$ qgit
|
||||
|
||||
This will open the Qt4 Framework based QGit Viewer in GUI mode.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
QGit is really an awesome QT based git viewer. It is available on all three platforms Linux, Mac OSX and Microsoft Windows. It helps us to easily navigate to the history, revisions, branches and more from the available git repository. It reduces the need of running git command line for the common stuffs like viewing revisions, history, diff, etc as graphical interface of it makes easy to do tasks. The latest version of qgit is also available in the default repository of ubuntu which we can install using **apt-get install qgit** command. So, qgit makes our work pretty fast and easy to do with its simple GUI.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-qgit-viewer-ubuntu-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,197 @@
|
||||
How to install Suricata intrusion detection system on Linux
|
||||
================================================================================
|
||||
With incessant security threats, intrusion detection system (IDS) has become one of the most critical requirements in today's data center environments. However, as more and more servers upgrade their NICs to 10GB/40GB Ethernet, it is increasingly difficult to implement compute-intensive intrusion detection on commodity hardware at line rates. One approach to scaling IDS performance is **multi-threaded IDS**, where CPU-intensive deep packet inspection workload is parallelized into multiple concurrent tasks. Such parallelized inspection can exploit multi-core hardware to scale up IDS throughput easily. Two well-known open-source efforts in this area are [Suricata][1] and [Bro][2].
|
||||
|
||||
In this tutorial, I am going to demonstrate **how to install and configure Suricata IDS on Linux server**.
|
||||
|
||||
### Install Suricata IDS on Linux ###
|
||||
|
||||
Let's build Suricata from the source. You first need to install several required dependencies as follows.
|
||||
|
||||
#### Install Dependencies on Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
$ sudo apt-get install wget build-essential libpcre3-dev libpcre3-dbg automake autoconf libtool libpcap-dev libnet1-dev libyaml-dev zlib1g-dev libcap-ng-dev libjansson-dev
|
||||
|
||||
#### Install Dependencies on CentOS, Fedora or RHEL ####
|
||||
|
||||
$ sudo yum install wget libpcap-devel libnet-devel pcre-devel gcc-c++ automake autoconf libtool make libyaml-devel zlib-devel file-devel jansson-devel nss-devel
|
||||
|
||||
Once you install all required packages, go ahead and install Suricata as follows.
|
||||
|
||||
First, download the latest Suricata source code from [http://suricata-ids.org/download/][3], and build it. As of this writing, the latest version is 2.0.8.
|
||||
|
||||
$ wget http://www.openinfosecfoundation.org/download/suricata-2.0.8.tar.gz
|
||||
$ tar -xvf suricata-2.0.8.tar.gz
|
||||
$ cd suricata-2.0.8
|
||||
$ ./configure --sysconfdir=/etc --localstatedir=/var
|
||||
|
||||
Here is the example output of configuration.
|
||||
|
||||
Suricata Configuration:
|
||||
AF_PACKET support: yes
|
||||
PF_RING support: no
|
||||
NFQueue support: no
|
||||
NFLOG support: no
|
||||
IPFW support: no
|
||||
DAG enabled: no
|
||||
Napatech enabled: no
|
||||
Unix socket enabled: yes
|
||||
Detection enabled: yes
|
||||
|
||||
libnss support: yes
|
||||
libnspr support: yes
|
||||
libjansson support: yes
|
||||
Prelude support: no
|
||||
PCRE jit: yes
|
||||
LUA support: no
|
||||
libluajit: no
|
||||
libgeoip: no
|
||||
Non-bundled htp: no
|
||||
Old barnyard2 support: no
|
||||
CUDA enabled: no
|
||||
|
||||
Now compile and install it.
|
||||
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
Suricata source code comes with default configuration files. Let's install these default configuration files as follows.
|
||||
|
||||
$ sudo make install-conf
|
||||
|
||||
As you know, Suricata is useless without IDS rule sets. Conveniently, the Makefile comes with IDS rule installation option. To install IDS rules, run the following command.
|
||||
|
||||
$ sudo make install-rules
|
||||
|
||||
The above rule installation command will download the current snapshot of community rulesets available from [EmergingThreats.net][4], and store them under /etc/suricata/rules.
|
||||
|
||||
|
||||
|
||||
### Configure Suricata IDS the First Time ###
|
||||
|
||||
Now it's time to configure Suricata. The configuration file is located at **/etc/suricata/suricata.yaml**. Open the file with a text editor for editing.
|
||||
|
||||
$ sudo vi /etc/suricata/suricata.yaml
|
||||
|
||||
Here are some basic setup for you to get started.
|
||||
|
||||
The "default-log-dir" keyword should point to the location of Suricata log files.
|
||||
|
||||
default-log-dir: /var/log/suricata/
|
||||
|
||||
Under "vars" section, you will find several important variables used by Suricata. "HOME_NET" should point to the local network to be inspected by Suricata. "!$HOME_NET" (assigned to EXTERNAL_NET) refers to any other networks than the local network. "XXX_PORTS" indicates the port number(s) use by different services. Note that Suricata can automatically detect HTTP traffic regardless of the port it uses. So it is not critical to specify the HTTP_PORTS variable correctly.
|
||||
|
||||
vars:
|
||||
HOME_NET: "[192.168.122.0/24]"
|
||||
EXTERNAL_NET: "!$HOME_NET"
|
||||
HTTP_PORTS: "80"
|
||||
SHELLCODE_PORTS: "!80"
|
||||
SSH_PORTS: 22
|
||||
|
||||
The "host-os-policy" section is used to defend against some well-known attacks which exploit the behavior of an operating system's network stack (e.g., TCP reassembly) to evade detection. As a counter measure, modern IDS came up with so-called "target-based" inspection, where inspection engine fine-tunes its detection algorithm based on a target operating system of the traffic. Thus, if you know what OS individual local hosts are running, you can feed that information to Suricata to potentially enhance its detection rate. This is when "host-os-policy" section is used. In this example, the default IDS policy is Linux; if no OS information is known for a particular IP address, Suricata will apply Linux-based inspection. When traffic for 192.168.122.0/28 and 192.168.122.155 is captured, Suricata will apply Windows-based inspection policy.
|
||||
|
||||
host-os-policy:
|
||||
# These are Windows machines.
|
||||
windows: [192.168.122.0/28, 192.168.122.155]
|
||||
bsd: []
|
||||
bsd-right: []
|
||||
old-linux: []
|
||||
# Make the default policy Linux.
|
||||
linux: [0.0.0.0/0]
|
||||
old-solaris: []
|
||||
solaris: ["::1"]
|
||||
hpux10: []
|
||||
hpux11: []
|
||||
irix: []
|
||||
macos: []
|
||||
vista: []
|
||||
windows2k3: []
|
||||
|
||||
Under "threading" section, you can specify CPU affinity for different Suricata threads. By default, [CPU affinity][5] is disabled ("set-cpu-affinity: no"), meaning that Suricata threads will be scheduled on any available CPU cores. By default, Suricata will create one "detect" thread for each CPU core. You can adjust this behavior by specifying "detect-thread-ratio: N". This will create N*M detect threads, where M is the total number of CPU cores on the host.
|
||||
|
||||
threading:
|
||||
set-cpu-affinity: no
|
||||
detect-thread-ratio: 1.5
|
||||
|
||||
With the above threading settings, Suricata will create 1.5*M detection threads, where M is the total number of CPU cores on the system.
|
||||
|
||||
For more information about Suricata configuration, you can read the default configuration file itself, which is heavily commented for clarity.
|
||||
|
||||
### Perform Intrusion Detection with Suricata ###
|
||||
|
||||
Now it's time to test-run Suricata. Before launching it, there's one more step to do.
|
||||
|
||||
When you are using pcap capture mode, it is highly recommended to turn off any packet offloead features (e.g., LRO/GRO) on the NIC which Suricata is listening on, as those features may interfere with live packet capture.
|
||||
|
||||
Here is how to turn off LRO/GRO on the network interface eth0:
|
||||
|
||||
$ sudo ethtool -K eth0 gro off lro off
|
||||
|
||||
Note that depending on your NIC, you may see the following warning, which you can ignore. It simply means that your NIC does not support LRO.
|
||||
|
||||
Cannot change large-receive-offload
|
||||
|
||||
Suricata supports a number of running modes. A runmode determines how different threads are used for IDS. The following command lists all [available runmodes][6].
|
||||
|
||||
$ sudo /usr/local/bin/suricata --list-runmodes
|
||||
|
||||
|
||||
|
||||
The default runmode used by Suricata is autofp (which stands for "auto flow pinned load balancing"). In this mode, packets from each distinct flow are assigned to a single detect thread. Flows are assigned to threads with the lowest number of unprocessed packets.
|
||||
|
||||
Finally, let's start Suricata, and see it in action.
|
||||
|
||||
$ sudo /usr/local/bin/suricata -c /etc/suricata/suricata.yaml -i eth0 --init-errors-fatal
|
||||
|
||||
|
||||
|
||||
In this example, we are monitoring a network interface eth0 on a 8-core system. As shown above, Suricata creates 13 packet processing threads and 3 management threads. The packet processing threads consist of one PCAP packet capture thread, and 12 detect threads (equal to 8*1.5). This means that the packets captured by one capture thread are load-balanced to 12 detect threads for IDS. The management threads are one flow manager and two counter/stats related threads.
|
||||
|
||||
Here is a thread-view of Suricata process (plotted by [htop][7]).
|
||||
|
||||
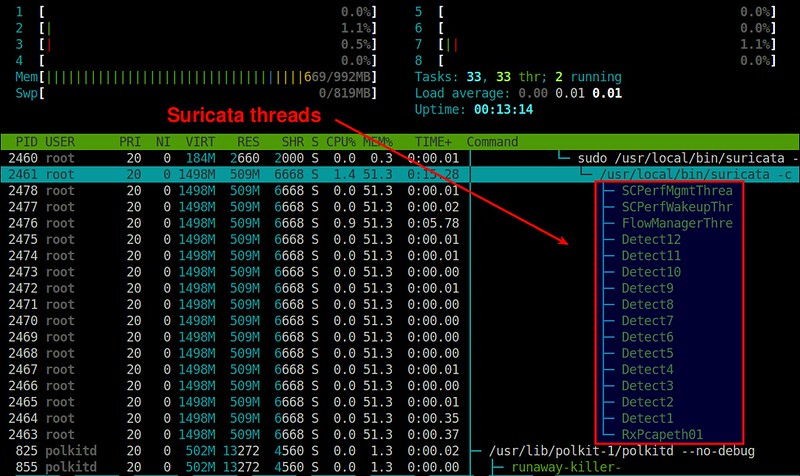
|
||||
|
||||
Suricata detection logs are stored in /var/log/suricata directory.
|
||||
|
||||
$ tail -f /var/log/suricata/fast.log
|
||||
|
||||
----------
|
||||
|
||||
04/01/2015-15:47:12.559075 [**] [1:2200074:1] SURICATA TCPv4 invalid checksum [**] [Classification: (null)] [Priority: 3] {TCP} 172.16.253.158:22 -> 172.16.253.1:46997
|
||||
04/01/2015-15:49:06.565901 [**] [1:2200074:1] SURICATA TCPv4 invalid checksum [**] [Classification: (null)] [Priority: 3] {TCP} 172.16.253.158:22 -> 172.16.253.1:46317
|
||||
04/01/2015-15:49:06.566759 [**] [1:2200074:1] SURICATA TCPv4 invalid checksum [**] [Classification: (null)] [Priority: 3] {TCP} 172.16.253.158:22 -> 172.16.253.1:46317
|
||||
|
||||
For ease of import, the log is also available in JSON format:
|
||||
|
||||
$ tail -f /var/log/suricata/eve.json
|
||||
|
||||
----------
|
||||
{"timestamp":"2015-04-01T15:49:06.565901","event_type":"alert","src_ip":"172.16.253.158","src_port":22,"dest_ip":"172.16.253.1","dest_port":46317,"proto":"TCP","alert":{"action":"allowed","gid":1,"signature_id":2200074,"rev":1,"signature":"SURICATA TCPv4 invalid checksum","category":"","severity":3}}
|
||||
{"timestamp":"2015-04-01T15:49:06.566759","event_type":"alert","src_ip":"172.16.253.158","src_port":22,"dest_ip":"172.16.253.1","dest_port":46317,"proto":"TCP","alert":{"action":"allowed","gid":1,"signature_id":2200074,"rev":1,"signature":"SURICATA TCPv4 invalid checksum","category":"","severity":3}}
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I demonstrated how you can set up Suricata IDS on a multi-core Linux server. Unlike single-threaded [Snort IDS][8], Suricata can easily benefit from multi-core/many-core hardware with multi-threading. There is great deal of customization in Suricata to maximize its performance and detection coverage. Suricata folks maintain [online Wiki][9] quite well, so I strongly recommend you check it out if you want to deploy Suricata in your environment.
|
||||
|
||||
Are you currently using Suricata? If so, feel free to share your experience.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/install-suricata-intrusion-detection-system-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://suricata-ids.org/
|
||||
[2]:https://www.bro.org/
|
||||
[3]:http://suricata-ids.org/download/
|
||||
[4]:http://rules.emergingthreats.net/
|
||||
[5]:http://xmodulo.com/run-program-process-specific-cpu-cores-linux.html
|
||||
[6]:https://redmine.openinfosecfoundation.org/projects/suricata/wiki/Runmodes
|
||||
[7]:http://ask.xmodulo.com/view-threads-process-linux.html
|
||||
[8]:http://xmodulo.com/how-to-compile-and-install-snort-from-source-code-on-ubuntu.html
|
||||
[9]:https://redmine.openinfosecfoundation.org/projects/suricata/wiki
|
||||
@ -0,0 +1,72 @@
|
||||
Install Qmmp 0.9.0 Winamp-like Audio Player in Ubuntu
|
||||
================================================================================
|
||||

|
||||
|
||||
Qmmp, Qt-based audio player with winamp or xmms like user interface, now is at 0.9.0 release. PPA updated for Ubuntu 15.10, Ubuntu 15.04, Ubuntu 14.04, Ubuntu 12.04 and derivatives.
|
||||
|
||||
Qmmp 0.9.0 is a big release with many new features, improvements and some translation updates. It added:
|
||||
|
||||
- audio-channel sequence converter;
|
||||
- 9 channels support to equalizer;
|
||||
- album artist tag support;
|
||||
- asynchronous sorting;
|
||||
- sorting by file modification date;
|
||||
- sorting by album artist;
|
||||
- multiple column support;
|
||||
- feature to hide track length;
|
||||
- feature to disable plugins without qmmp.pri modification (qmake only)
|
||||
- feature to remember playlist scroll position;
|
||||
- feature to exclude cue data files;
|
||||
- feature to change user agent;
|
||||
- feature to change window title;
|
||||
- feature to reset fonts;
|
||||
- feature to restore default shortcuts;
|
||||
- default hotkey for the “Rename List” action;
|
||||
- feature to disable fadeout in the gme plugin;
|
||||
- Simple User Interface (QSUI) with the following changes:
|
||||
- added multiple column support;
|
||||
- added sorting by album artist;
|
||||
- added sorting by file modification date;
|
||||
- added feature to hide song length;
|
||||
- added default hotkey for the “Rename List” action;
|
||||
- added “Save List” action to the tab menu;
|
||||
- added feature to reset fonts;
|
||||
- added feature to reset shortcuts;
|
||||
- improved status bar;
|
||||
|
||||
It also improved playlist changes notification, playlist container, sample rate converter, cmake build scripts, title formatter, ape tags support in the mpeg plugin, fileops plugin, reduced cpu usage, changed default skin (to Glare) and playlist separator.
|
||||
|
||||
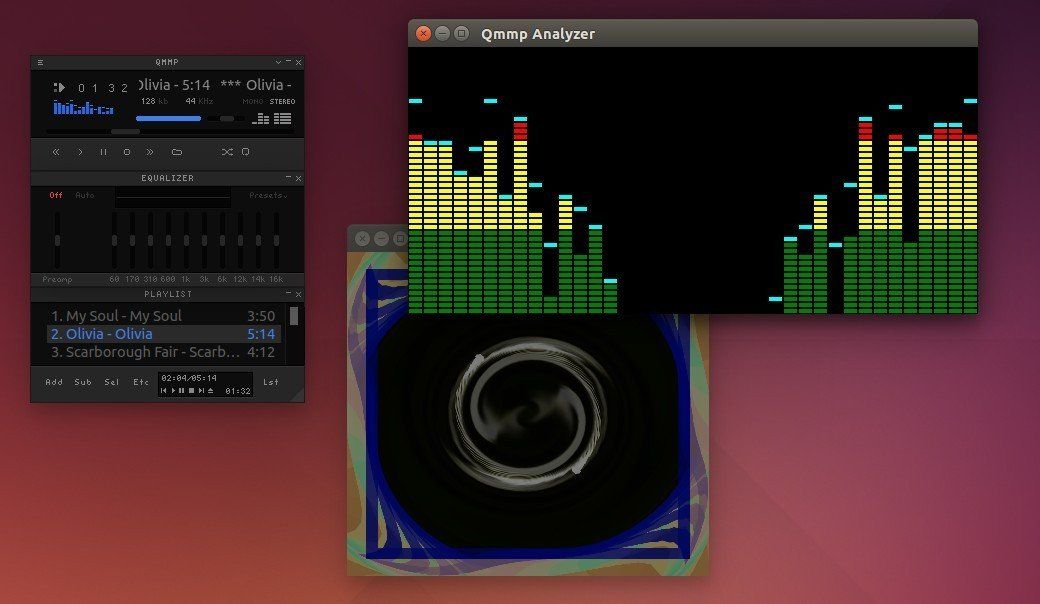
|
||||
|
||||
### Install Qmmp 0.9.0 in Ubuntu: ###
|
||||
|
||||
New release has been made into PPA, available for all current Ubuntu releases and derivatives.
|
||||
|
||||
1. To add the [Qmmp PPA][1].
|
||||
|
||||
Open terminal from the Dash, App Launcher, or via Ctrl+Alt+T shortcut keys. When it opens, run command:
|
||||
|
||||
sudo add-apt-repository ppa:forkotov02/ppa
|
||||
|
||||

|
||||
|
||||
2. After adding the PPA, upgrade Qmmp player through Software Updater. Or refresh system cache and install the software via below commands:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install qmmp qmmp-plugin-pack
|
||||
|
||||
That’s it. Enjoy!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/qmmp-0-9-0-in-ubuntu/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:https://launchpad.net/~forkotov02/+archive/ubuntu/ppa
|
||||
@ -0,0 +1,450 @@
|
||||
Installing NGINX and NGINX Plus With Ansible
|
||||
================================================================================
|
||||
Coming from a production operations background, I have learned to love all things related to automation. Why do something by hand if a computer can do it for you? But creating and implementing automation can be a difficult task given an ever-changing infrastructure and the various technologies surrounding your environments. This is why I love [Ansible][1]. Ansible is an open source tool for IT configuration management, deployment, and orchestration that is extremely easy to use.
|
||||
|
||||
One of my favorite features of Ansible is that it is completely clientless. To manage a system, a connection is made over SSH, using either [Paramiko][2] (a Python library) or native [OpenSSH][3]. Another attractive feature of Ansible is its extensive selection of modules. These modules can be used to perform some of the common tasks of a system administrator. In particular, they make Ansible a powerful tool for installing and configuring any application across multiple servers, environments, and operating systems, all from one central location.
|
||||
|
||||
In this tutorial I will walk you through the steps for using Ansible to install and deploy the open source [NGINX][4] software and [NGINX Plus][5], our commercial product. I’m showing deployment onto a [CentOS][6] server, but I have included details about deploying on Ubuntu servers in [Creating an Ansible Playbook for Installing NGINX and NGINX Plus on Ubuntu][7] below.
|
||||
|
||||
For this tutorial I will be using Ansible version 1.9.2 and performing the deployment from a server running CentOS 7.1.
|
||||
|
||||
$ ansible --version
|
||||
ansible 1.9.2
|
||||
|
||||
$ cat /etc/redhat-release
|
||||
CentOS Linux release 7.1.1503 (Core)
|
||||
|
||||
If you don’t already have Ansible, you can get instructions for installing it [at the Ansible site][8].
|
||||
|
||||
If you are using CentOS, installing Ansible is easy as typing the following command. If you want to compile from source or for other distributions, see the instructions at the Ansible link provided just above.
|
||||
|
||||
$ sudo yum install -y epel-release && sudo yum install -y ansible
|
||||
|
||||
Depending on your environment, some of the commands in this tutorial might require sudo privileges. The path to the files, usernames, and destination servers are all values that will be specific to your environment.
|
||||
|
||||
### Creating an Ansible Playbook for Installing NGINX (CentOS) ###
|
||||
|
||||
First we create a working directory for our NGINX deployment, along with subdirectories and deployment configuration files. I usually recommend creating the directory in your home directory and show that in all examples in this tutorial.
|
||||
|
||||
$ cd $HOME
|
||||
$ mkdir -p ansible-nginx/tasks/
|
||||
$ touch ansible-nginx/deploy.yml
|
||||
$ touch ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
The directory structure now looks like this. You can check by using the tree command.
|
||||
|
||||
$ tree $HOME/ansible-nginx/
|
||||
/home/kjones/ansible-nginx/
|
||||
├── deploy.yml
|
||||
└── tasks
|
||||
└── install_nginx.yml
|
||||
|
||||
1 directory, 2 files
|
||||
|
||||
If you do not have tree installed, you can do so using the following command.
|
||||
|
||||
$ sudo yum install -y tree
|
||||
|
||||
#### Creating the Main Deployment File ####
|
||||
|
||||
Next we open **deploy.yml** in a text editor. I prefer vim for editing configuration files on the command line, and will use it throughout the tutorial.
|
||||
|
||||
$ vim $HOME/ansible-nginx/deploy.yml
|
||||
|
||||
The **deploy.yml** file is our main Ansible deployment file, which we’ll reference when we run the ansible‑playbook command in [Running Ansible to Deploy NGINX][9]. Within this file we specify the inventory for Ansible to use along with any other configuration files to include at runtime.
|
||||
|
||||
In my example I use the [include][10] module to specify a configuration file that has the steps for installing NGINX. While it is possible to create a playbook in one very large file, I recommend that you separate the steps into smaller included files to keep things organized. Sample use cases for an include are copying static content, copying configuration files, or assigning variables for a more advanced deployment with configuration logic.
|
||||
|
||||
Type the following lines into the file. I include the filename at the top in a comment for reference.
|
||||
|
||||
# ./ansible-nginx/deploy.yml
|
||||
|
||||
- hosts: nginx
|
||||
tasks:
|
||||
- include: 'tasks/install_nginx.yml'
|
||||
|
||||
The hosts statement tells Ansible to deploy to all servers in the **nginx** group, which is defined in **/etc/ansible/hosts**. We’ll edit this file in [Creating the List of NGINX Servers below][11].
|
||||
|
||||
The include statement tells Ansible to read in and execute the contents of the **install_nginx.yml** file from the **tasks** directory during deployment. The file includes the steps for downloading, installing, and starting NGINX. We’ll create this file in the next section.
|
||||
|
||||
#### Creating the Deployment File for NGINX ####
|
||||
|
||||
Now let’s save our work to **deploy.yml** and open up **install_nginx.yml** in the editor.
|
||||
|
||||
$ vim $HOME/ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
The file is going to contain the instructions – written in [YAML][12] format – for Ansible to follow when installing and configuring our NGINX deployment. Each section (step in the process) starts with a name statement (preceded by hyphen) that describes the step. The string following name: is written to stdout during the Ansible deployment and can be changed as you wish. The next line of a section in the YAML file is the module that will be used during that deployment step. In the configuration below, both the [yum][13] and [service][14] modules are used. The yum module is used to install packages on CentOS. The service module is used to manage UNIX services. The final line or lines in a section specify any parameters for the module (in the example, these lines start with name and state).
|
||||
|
||||
Type the following lines into the file. As with **deploy.yml**, the first line in our file is a comment that names the file for reference. The first section tells Ansible to install the **.rpm** file for CentOS 7 from the NGINX repository. This directs the package manager to install the most recent stable version of NGINX directly from NGINX. Modify the pathname as necessary for your CentOS version. A list of available packages can be found on the [open source NGINX website][15]. The next two sections tell Ansible to install the latest NGINX version using the yum module and then start NGINX using the service module.
|
||||
|
||||
**Note:** In the first section, the pathname to the CentOS package appears on two lines only for space reasons. Type the entire path on a single line.
|
||||
|
||||
# ./ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
- name: NGINX | Installing NGINX repo rpm
|
||||
yum:
|
||||
name: http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
|
||||
|
||||
- name: NGINX | Installing NGINX
|
||||
yum:
|
||||
name: nginx
|
||||
state: latest
|
||||
|
||||
- name: NGINX | Starting NGINX
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
#### Creating the List of NGINX Servers ####
|
||||
|
||||
Now that we have our Ansible deployment configuration files all set up, we need to tell Ansible exactly which servers to deploy to. We specify this in the Ansible **hosts** file I mentioned earlier. Let’s make a backup of the existing file and create a new one just for our deployment.
|
||||
|
||||
$ sudo mv /etc/ansible/hosts /etc/ansible/hosts.backup
|
||||
$ sudo vim /etc/ansible/hosts
|
||||
|
||||
Type (or edit) the following lines in the file to create a group called **nginx** and list the servers to install NGINX on. You can designate servers by hostname, IP address, or in an array such as **server[1-3].domain.com**. Here I designate one server by its IP address.
|
||||
|
||||
# /etc/ansible/hosts
|
||||
|
||||
[nginx]
|
||||
172.16.239.140
|
||||
|
||||
#### Setting Up Security ####
|
||||
|
||||
We are almost all set, but before deployment we need to ensure that Ansible has authorization to access our destination server over SSH.
|
||||
|
||||
The preferred and most secure method is to add the Ansible deployment server’s RSA SSH key to the destination server’s **authorized_keys** file, which gives Ansible unrestricted SSH permissions on the destination server. To learn more about this configuration, see [Securing OpenSSH][16] on wiki.centos.org. This way you can automate your deployments without user interaction.
|
||||
|
||||
Alternatively, you can request the password interactively during deployment. I strongly recommend that you use this method during testing only, because it is insecure and there is no way to track changes to a destination host’s fingerprint. If you want to do this, change the value of StrictHostKeyChecking from the default yes to no in the **/etc/ssh/ssh_config** file on each of your destination hosts. Then add the --ask-pass flag on the ansible-playbook command to have Ansible prompt for the SSH password.
|
||||
|
||||
Here I illustrate how to edit the **ssh_config** file to disable strict host key checking on the destination server. We manually SSH into the server to which we’ll deploy NGINX and change the value of StrictHostKeyChecking to no.
|
||||
|
||||
$ ssh kjones@172.16.239.140
|
||||
kjones@172.16.239.140's password:***********
|
||||
|
||||
[kjones@nginx ]$ sudo vim /etc/ssh/ssh_config
|
||||
|
||||
After you make the change, save **ssh_config**, and connect to your Ansible server via SSH. The setting should look as below before you save your work.
|
||||
|
||||
# /etc/ssh/ssh_config
|
||||
|
||||
StrictHostKeyChecking no
|
||||
|
||||
#### Running Ansible to Deploy NGINX ####
|
||||
|
||||
If you have followed the steps in this tutorial, you can run the following command to have Ansible deploy NGINX. (Again, if you have set up RSA SSH key authentication, then the --ask-pass flag is not needed.) Run the command on the Ansible server with the configuration files we created above.
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx/deploy.yml
|
||||
|
||||
Ansible prompts for the SSH password and produces output like the following. A recap that reports failed=0 like this one indicates that deployment succeeded.
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx/deploy.yml
|
||||
SSH password:
|
||||
|
||||
PLAY [all] ********************************************************************
|
||||
|
||||
GATHERING FACTS ***************************************************************
|
||||
ok: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX | Installing NGINX repo rpm] *************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX | Installing NGINX] **********************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX | Starting NGINX] ************************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
PLAY RECAP ********************************************************************
|
||||
172.16.239.140 : ok=4 changed=3 unreachable=0 failed=0
|
||||
|
||||
If you didn’t get a successful play recap, you can try running the ansible-playbook command again with the -vvvv flag (verbose with connection debugging) to troubleshoot the deployment process.
|
||||
|
||||
When deployment succeeds (as it did for us on the first try), you can verify that NGINX is running on the remote server by running the following basic [cURL][17] command. Here it returns 200 OK. Success! We have successfully installed NGINX using Ansible.
|
||||
|
||||
$ curl -Is 172.16.239.140 | grep HTTP
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
### Creating an Ansible Playbook for Installing NGINX Plus (CentOS) ###
|
||||
|
||||
Now that I’ve shown you how to install the open source version of NGINX, I’ll walk you through the steps for installing NGINX Plus. This requires some additional changes to the deployment configuration and showcases some of Ansible’s other features.
|
||||
|
||||
#### Copying the NGINX Plus Certificate and Key to the Ansible Server ####
|
||||
|
||||
To install and configure NGINX Plus with Ansible, we first need to copy the key and certificate for our NGINX Plus subscription from the [NGINX Plus Customer Portal][18] to the standard location on the Ansible deployment server.
|
||||
|
||||
Access to the NGINX Plus Customer Portal is available for customers who have purchased NGINX Plus or are evaluating it. If you are interested in evaluating NGINX Plus, you can request a 30-day free trial [here][19]. You will receive a link to your trial certificate and key shortly after you sign up.
|
||||
|
||||
On a Mac or Linux host, use the [scp][20] utility as I show here. On a Microsoft Windows host, you can use [WinSCP][21]. For this tutorial, I downloaded the files to my Mac laptop, then used scp to copy them to the Ansible server. These commands place both the key and certificate in my home directory.
|
||||
|
||||
$ cd /path/to/nginx-repo-files/
|
||||
$ scp nginx-repo.* user@destination-server:.
|
||||
|
||||
Next we SSH to the Ansible server, make sure the SSL directory for NGINX Plus exists, and move the files there.
|
||||
|
||||
$ ssh user@destination-server
|
||||
$ sudo mkdir -p /etc/ssl/nginx/
|
||||
$ sudo mv nginx-repo.* /etc/ssl/nginx/
|
||||
|
||||
Verify that your **/etc/ssl/nginx** directory contains both the certificate (**.crt**) and key (**.key**) files. You can check by using the tree command.
|
||||
|
||||
$ tree /etc/ssl/nginx
|
||||
/etc/ssl/nginx
|
||||
├── nginx-repo.crt
|
||||
└── nginx-repo.key
|
||||
|
||||
0 directories, 2 files
|
||||
|
||||
If you do not have tree installed, you can do so using the following command.
|
||||
|
||||
$ sudo yum install -y tree
|
||||
|
||||
#### Creating the Ansible Directory Structure ####
|
||||
|
||||
The remaining steps are very similar to the ones for open source NGINX that we performed in [Creating an Ansible Playbook for Installing NGINX (CentOS)][22]. First we set up a working directory for our NGINX Plus deployment. Again I prefer creating it as a subdirectory of my home directory.
|
||||
|
||||
$ cd $HOME
|
||||
$ mkdir -p ansible-nginx-plus/tasks/
|
||||
$ touch ansible-nginx-plus/deploy.yml
|
||||
$ touch ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
The directory structure now looks like this.
|
||||
|
||||
$ tree $HOME/ansible-nginx-plus/
|
||||
/home/kjones/ansible-nginx-plus/
|
||||
├── deploy.yml
|
||||
└── tasks
|
||||
└── install_nginx_plus.yml
|
||||
|
||||
1 directory, 2 files
|
||||
|
||||
#### Creating the Main Deployment File ####
|
||||
|
||||
Next we use vim to create the **deploy.yml** file as for open source NGINX.
|
||||
|
||||
$ vim ansible-nginx-plus/deploy.yml
|
||||
|
||||
The only difference from the open source NGINX deployment is that we change the name of the included file to **install_nginx_plus.yml**. As a reminder, the file tells Ansible to deploy NGINX Plus on all servers in the **nginx** group (which is defined in **/etc/ansible/hosts**), and to read in and execute the contents of the **install_nginx_plus.yml** file from the **tasks** directory during deployment.
|
||||
|
||||
# ./ansible-nginx-plus/deploy.yml
|
||||
|
||||
- hosts: nginx
|
||||
tasks:
|
||||
- include: 'tasks/install_nginx_plus.yml'
|
||||
|
||||
If you have not done so already, you also need to create the hosts file as detailed in [Creating the List of NGINX Servers][23] above.
|
||||
|
||||
#### Creating the Deployment File for NGINX Plus ####
|
||||
|
||||
Open **install_nginx_plus.yml** in a text editor. The file is going to contain the instructions for Ansible to follow when installing and configuring your NGINX Plus deployment. The commands and modules are specific to CentOS and some are unique to NGINX Plus.
|
||||
|
||||
$ vim ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
The first section uses the [file][24] module, telling Ansible to create the SSL directory for NGINX Plus as specified by the path and state arguments, set the ownership to root, and change the mode to 0700.
|
||||
|
||||
# ./ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
- name: NGINX Plus | Creating NGINX Plus ssl cert repo directory
|
||||
file: path=/etc/ssl/nginx state=directory group=root mode=0700
|
||||
|
||||
The next two sections use the [copy][25] module to copy the NGINX Plus certificate and key from the Ansible deployment server to the NGINX Plus server during the deployment, again setting ownership to root and the mode to 0700.
|
||||
|
||||
- name: NGINX Plus | Copying NGINX Plus repository certificate
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.crt dest=/etc/ssl/nginx/nginx-repo.crt owner=root group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | Copying NGINX Plus repository key
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.key dest=/etc/ssl/nginx/nginx-repo.key owner=root group=root mode=0700
|
||||
|
||||
Next we tell Ansible to use the [get_url][26] module to download the CA certificate from the NGINX Plus repository at the remote location specified by the url argument, put it in the directory specified by the dest argument, and set the mode to 0700.
|
||||
|
||||
- name: NGINX Plus | Downloading NGINX Plus CA certificate
|
||||
get_url: url=https://cs.nginx.com/static/files/CA.crt dest=/etc/ssl/nginx/CA.crt mode=0700
|
||||
|
||||
Similarly, we tell Ansible to download the NGINX Plus repo file using the get_url module and copy it to the **/etc/yum.repos.d** directory on the NGINX Plus server.
|
||||
|
||||
- name: NGINX Plus | Downloading yum NGINX Plus repository
|
||||
get_url: url=https://cs.nginx.com/static/files/nginx-plus-7.repo dest=/etc/yum.repos.d/nginx-plus-7.repo mode=0700
|
||||
|
||||
The final two name sections tell Ansible to install and start NGINX Plus using the yum and service modules.
|
||||
|
||||
- name: NGINX Plus | Installing NGINX Plus
|
||||
yum:
|
||||
name: nginx-plus
|
||||
state: latest
|
||||
|
||||
- name: NGINX Plus | Starting NGINX Plus
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
#### Running Ansible to Deploy NGINX Plus ####
|
||||
|
||||
After saving the **install_nginx_plus.yml** file, we run the ansible-playbook command to deploy NGINX Plus. Again here we include the --ask-pass flag to have Ansible prompt for the SSH password and pass it to each NGINX Plus server, and specify the path to the main Ansible **deploy.yml** file.
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx-plus/deploy.yml
|
||||
|
||||
PLAY [nginx] ******************************************************************
|
||||
|
||||
GATHERING FACTS ***************************************************************
|
||||
ok: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Creating NGINX Plus ssl cert repo directory] **************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Copying NGINX Plus repository certificate] ****************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Copying NGINX Plus repository key] ************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Downloading NGINX Plus CA certificate] ********************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Downloading yum NGINX Plus repository] ********************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Installing NGINX Plus] ************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Starting NGINX Plus] **************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
PLAY RECAP ********************************************************************
|
||||
172.16.239.140 : ok=8 changed=7 unreachable=0 failed=0
|
||||
|
||||
The playbook recap was successful. Now we can run a quick curl command to verify that NGINX Plus is running. Great, we get 200 OK! Success! We have successfully installed NGINX Plus with Ansible.
|
||||
|
||||
$ curl -Is http://172.16.239.140 | grep HTTP
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
### Creating an Ansible Playbook for Installing NGINX and NGINX Plus on Ubuntu ###
|
||||
|
||||
The process for deploying NGINX and NGINX Plus on [Ubuntu servers][27] is pretty similar to the process on CentOS, so instead of providing step-by-step instructions I’ll show the complete deployment files and and point out the slight differences from CentOS.
|
||||
|
||||
First create the Ansible directory structure and the main Ansible deployment file, as for CentOS. Also create the **/etc/ansible/hosts** file as described in [Creating the List of NGINX Servers][28]. For NGINX Plus, you need to copy over the key and certificate as described in [Copying the NGINX Plus Certificate and Key to the Ansible Server][29].
|
||||
|
||||
Here’s the **install_nginx.yml** deployment file for open source NGINX. In the first section, we use the [apt_key][30] module to import the NGINX signing key. The next two sections use the [lineinfile][31] module to add the package URLs for Ubuntu 14.04 to the **sources.list** file. Lastly we use the [apt][32] module to update the cache and install NGINX (apt replaces the yum module we used for deploying to CentOS).
|
||||
|
||||
# ./ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
- name: NGINX | Adding NGINX signing key
|
||||
apt_key: url=http://nginx.org/keys/nginx_signing.key state=present
|
||||
|
||||
- name: NGINX | Adding sources.list deb url for NGINX
|
||||
lineinfile: dest=/etc/apt/sources.list line="deb http://nginx.org/packages/mainline/ubuntu/ trusty nginx"
|
||||
|
||||
- name: NGINX Plus | Adding sources.list deb-src url for NGINX
|
||||
lineinfile: dest=/etc/apt/sources.list line="deb-src http://nginx.org/packages/mainline/ubuntu/ trusty nginx"
|
||||
|
||||
- name: NGINX | Updating apt cache
|
||||
apt:
|
||||
update_cache: yes
|
||||
|
||||
- name: NGINX | Installing NGINX
|
||||
apt:
|
||||
pkg: nginx
|
||||
state: latest
|
||||
|
||||
- name: NGINX | Starting NGINX
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
Here’s the **install_nginx.yml** deployment file for NGINX Plus. The first four sections set up the NGINX Plus key and certificate. Then we use the apt_key module to import the signing key as for open source NGINX, and the get_url module to download the apt configuration file for NGINX Plus. The [shell][33] module evokes a printf command that writes its output to the **nginx-plus.list** file in the **sources.list.d** directory. The final name modules are the same as for open source NGINX.
|
||||
|
||||
# ./ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
- name: NGINX Plus | Creating NGINX Plus ssl cert repo directory
|
||||
file: path=/etc/ssl/nginx state=directory group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | Copying NGINX Plus repository certificate
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.crt dest=/etc/ssl/nginx/nginx-repo.crt owner=root group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | Copying NGINX Plus repository key
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.key dest=/etc/ssl/nginx/nginx-repo.key owner=root group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | Downloading NGINX Plus CA certificate
|
||||
get_url: url=https://cs.nginx.com/static/files/CA.crt dest=/etc/ssl/nginx/CA.crt mode=0700
|
||||
|
||||
- name: NGINX Plus | Adding NGINX Plus signing key
|
||||
apt_key: url=http://nginx.org/keys/nginx_signing.key state=present
|
||||
|
||||
- name: NGINX Plus | Downloading Apt-Get NGINX Plus repository
|
||||
get_url: url=https://cs.nginx.com/static/files/90nginx dest=/etc/apt/apt.conf.d/90nginx mode=0700
|
||||
|
||||
- name: NGINX Plus | Adding sources.list url for NGINX Plus
|
||||
shell: printf "deb https://plus-pkgs.nginx.com/ubuntu `lsb_release -cs` nginx-plus\n" >/etc/apt/sources.list.d/nginx-plus.list
|
||||
|
||||
- name: NGINX Plus | Running apt-get update
|
||||
apt:
|
||||
update_cache: yes
|
||||
|
||||
- name: NGINX Plus | Installing NGINX Plus via apt-get
|
||||
apt:
|
||||
pkg: nginx-plus
|
||||
state: latest
|
||||
|
||||
- name: NGINX Plus | Start NGINX Plus
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
We’re now ready to run the ansible-playbook command:
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx-plus/deploy.yml
|
||||
|
||||
You should get a successful play recap. If you did not get a success, you can use the verbose flag to help troubleshoot your deployment as described in [Running Ansible to Deploy NGINX][34].
|
||||
|
||||
### Summary ###
|
||||
|
||||
What I demonstrated in this tutorial is just the beginning of what Ansible can do to help automate your NGINX or NGINX Plus deployment. There are many useful modules ranging from user account management to custom configuration templates. If you are interested in learning more about these, please visit the extensive [Ansible documentation][35 site.
|
||||
|
||||
To learn more about Ansible, come hear my talk on deploying NGINX Plus with Ansible at [NGINX.conf 2015][36], September 22–24 in San Francisco.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/
|
||||
|
||||
作者:[Kevin Jones][a]
|
||||
译者:[struggling](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nginx.com/blog/author/kjones/
|
||||
[1]:http://www.ansible.com/
|
||||
[2]:http://www.paramiko.org/
|
||||
[3]:http://www.openssh.com/
|
||||
[4]:http://nginx.org/en/
|
||||
[5]:https://www.nginx.com/products/
|
||||
[6]:http://www.centos.org/
|
||||
[7]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#ubuntu
|
||||
[8]:http://docs.ansible.com/ansible/intro_installation.html#installing-the-control-machine
|
||||
[9]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#deploy-nginx
|
||||
[10]:http://docs.ansible.com/ansible/playbooks_roles.html#task-include-files-and-encouraging-reuse
|
||||
[11]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#list-nginx
|
||||
[12]:http://docs.ansible.com/ansible/YAMLSyntax.html
|
||||
[13]:http://docs.ansible.com/ansible/yum_module.html
|
||||
[14]:http://docs.ansible.com/ansible/service_module.html
|
||||
[15]:http://nginx.org/en/linux_packages.html
|
||||
[16]:http://wiki.centos.org/HowTos/Network/SecuringSSH
|
||||
[17]:http://curl.haxx.se/
|
||||
[18]:https://cs.nginx.com/
|
||||
[19]:https://www.nginx.com/#free-trial
|
||||
[20]:http://linux.die.net/man/1/scp
|
||||
[21]:https://winscp.net/eng/download.php
|
||||
[22]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#playbook-nginx
|
||||
[23]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#list-nginx
|
||||
[24]:http://docs.ansible.com/ansible/file_module.html
|
||||
[25]:http://docs.ansible.com/ansible/copy_module.html
|
||||
[26]:http://docs.ansible.com/ansible/get_url_module.html
|
||||
[27]:http://www.ubuntu.com/
|
||||
[28]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#list-nginx
|
||||
[29]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#copy-cert-key
|
||||
[30]:http://docs.ansible.com/ansible/apt_key_module.html
|
||||
[31]:http://docs.ansible.com/ansible/lineinfile_module.html
|
||||
[32]:http://docs.ansible.com/ansible/apt_module.html
|
||||
[33]:http://docs.ansible.com/ansible/shell_module.html
|
||||
[34]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#deploy-nginx
|
||||
[35]:http://docs.ansible.com/
|
||||
[36]:https://www.nginx.com/nginxconf/
|
||||
@ -0,0 +1,62 @@
|
||||
Make Math Simple in Ubuntu / Elementary OS via NaSC
|
||||
================================================================================
|
||||

|
||||
|
||||
NaSC (Not a Soulver Clone) is an open source software designed for Elementary OS to do arithmetics. It’s kinda similar to the Mac app [Soulver][1].
|
||||
|
||||
> Its an app where you do maths like a normal person. It lets you type whatever you want and smartly figures out what is math and spits out an answer on the right pane. Then you can plug those answers in to future equations and if that answer changes, so does the equations its used in.
|
||||
|
||||
With NaSC you can for example:
|
||||
|
||||
- Perform calculations with strangers you can define yourself
|
||||
- Change the units and values (in m cm, dollar euro …)
|
||||
- Knowing the surface area of a planet
|
||||
- Solve of second-degree polynomial
|
||||
- and more …
|
||||
|
||||
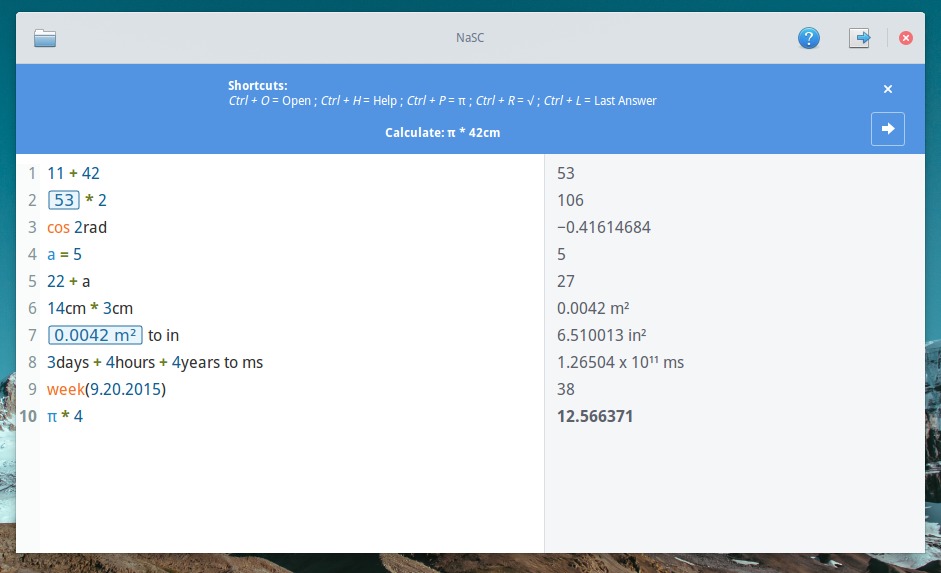
|
||||
|
||||
At the first launch, NaSC offers a tutorial that details possible features. You can later click the help icon on headerbar to get more.
|
||||
|
||||
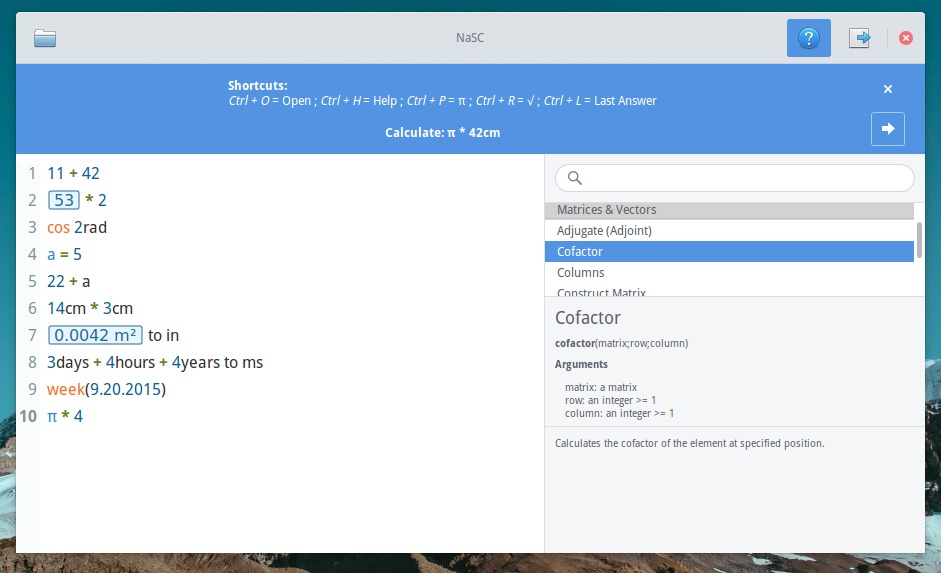
|
||||
|
||||
In addition, the software allows to save your file in order to continue the work. It can be also shared on Pastebin with a defined time.
|
||||
|
||||
### Install NaSC in Ubuntu / Elementary OS Freya: ###
|
||||
|
||||
For Ubuntu 15.04, Ubuntu 15.10, Elementary OS Freya, open terminal from the Dash, App Launcher and run below commands one by one:
|
||||
|
||||
1. Add the [NaSC PPA][2] via command:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
|
||||
|
||||
|
||||
2. If you’ve installed Synaptic Package Manager, search for and install `nasc` via it after clicking Reload button.
|
||||
|
||||
Or run below commands to update system cache and install the software:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install nasc
|
||||
|
||||
3. **(Optional)** To remove the software as well as NaSC, run:
|
||||
|
||||
sudo apt-get remove nasc && sudo add-apt-repository -r ppa:nasc-team/daily
|
||||
|
||||
For those who don’t want to add PPA, grab the .deb package directly from [this page][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/make-math-simple-in-ubuntu-elementary-os-via-nasc/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://www.acqualia.com/soulver/
|
||||
[2]:https://launchpad.net/~nasc-team/+archive/ubuntu/daily/
|
||||
[3]:http://ppa.launchpad.net/nasc-team/daily/ubuntu/pool/main/n/nasc/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc Translating
|
||||
|
||||
RHCSA Series: Firewall Essentials and Network Traffic Control Using FirewallD and Iptables – Part 11
|
||||
================================================================================
|
||||
In simple words, a firewall is a security system that controls the incoming and outgoing traffic in a network based on a set of predefined rules (such as the packet destination / source or type of traffic, for example).
|
||||
@ -188,4 +190,4 @@ via: http://www.tecmint.com/firewalld-vs-iptables-and-control-network-traffic-in
|
||||
[3]:http://www.tecmint.com/configure-iptables-firewall/
|
||||
[4]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Security_Guide/sec-Using_Firewalls.html
|
||||
[5]:http://www.tecmint.com/rhcsa-series-install-and-secure-apache-web-server-and-ftp-in-rhel/
|
||||
[6]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
[6]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
Translated by H-mudcup
|
||||
五大超酷的开源游戏
|
||||
================================================================================
|
||||
在2014年和2015年,Linux 成了一堆流行商业品牌的家,例如备受欢迎的 Borderlands、Witcher、Dead Island 和 CS系列游戏。虽然这是令人激动的消息,但这跟玩家的预算有什么关系?商业品牌很好,但更好的是由了解玩家喜好的开发者开发的免费的替代品。
|
||||
|
||||
前段时间,我偶然看到了一个三年前发布的 YouTube 视频,标题非常的有正能量[5个不算糟糕的开源游戏][1]。虽然视频表扬了一些开源游戏,我还是更喜欢用一个更加热情的方式来切入这个话题,至少如标题所说。所以,下面是我的一份五大超酷开源游戏的清单。
|
||||
|
||||
### Tux Racer ###
|
||||
|
||||
|
||||
|
||||
Tux Racer
|
||||
|
||||
[《Tux Racer》][2]是这份清单上的第一个游戏,因为我对这个游戏很熟悉。我和兄弟与[电脑上的孩子们][4]项目在[最近一次去墨西哥的路途中][3] Tux Racer 是孩子和教师都喜欢玩的游戏之一。在这个游戏中,玩家使用 Linux 吉祥物,企鹅 Tux,在下山雪道上以计时赛的方式进行比赛。玩家们不断挑战他们自己的最佳纪录。目前还没有多玩家版本,但这是有可能改变的。适用于 Linux、OS X、Windows 和 Android。
|
||||
|
||||
### Warsow ###
|
||||
|
||||

|
||||
|
||||
Warsow
|
||||
|
||||
[《Warsow》][5]网站解释道:“设定是有未来感的卡通世界,Warsow 是个完全开放的适用于 Windows、Linux 和 Mac OS X平台的快节奏第一人称射击游戏(FPS)。Warsow 是尊重的艺术和网络中的体育精神。(Warsow is the Art of Respect and Sportsmanship Over the Web.大写字母组成Warsow。)” 我很不情愿的把 FPS 类放到了这个列表中,因为很多人玩过这类的游戏,但是我的确被 Warsow 打动了。它对很多动作进行了优先级排序,游戏节奏很快,一开始就有八个武器。卡通化的风格让玩的过程变得没有那么严肃,更加的休闲,非常适合可以和亲友一同玩。然而,他却以充满竞争的游戏自居,并且当我体验这个游戏时,我发现周围确实有一些专家级的玩家。适用于 Linux、Windows 和 OS X。
|
||||
|
||||
### M.A.R.S——一个荒诞的射击游戏 ###
|
||||
|
||||

|
||||
|
||||
M.A.R.S.——一个荒诞的射击游戏
|
||||
|
||||
[《M.A.R.S——一个荒诞的射击游戏》][6]之所以吸引人是因为他充满活力的色彩和画风。支持两个玩家使用同一个键盘,而一个在线多玩家版本目前正在开发中——这意味着想要和朋友们一起玩暂时还要等等。不论如何,它是个可以使用几个不同飞船和武器的有趣的太空射击游戏。飞船的形状不同,从普通的枪、激光、散射枪到更有趣的武器(随机出来的飞船中有一个会对敌人发射泡泡,这为这款混乱的游戏增添了很多乐趣)。游戏几种模式,比如标准模式和对方进行殊死搏斗以获得高分或先达到某个分数线,还有其他的模式,空间球(Spaceball)、坟坑(Grave-itation Pit)和保加农炮(Cannon Keep)。适用于 Linux、Windows 和 OS X。
|
||||
|
||||
### Valyria Tear ###
|
||||
|
||||
|
||||
|
||||
Valyria Tear
|
||||
|
||||
[Valyria Tear][7] 类似几年来拥有众多粉丝的角色扮演游戏(RPG)。故事设定在梦幻游戏的通用年代,充满了骑士、王国和魔法,以及主要角色 Bronann。设计团队做的非常棒,在设计这个世界和实现玩家对这类游戏所有的期望:隐藏的宝藏、偶遇的怪物、非玩家操纵角色(NPC)的互动以及所有 RPG 不可或缺的:在低级别的怪物上刷经验直到可以面对大 BOSS。我在试玩的时候,时间不允许我太过深入到这个游戏故事中,但是感兴趣的人可以看 YouTube 上由 Yohann Ferriera 用户发的‘[Let’s Play][8]’系列视频。适用于 Linux、Windows 和 OS X。
|
||||
|
||||
### SuperTuxKart ###
|
||||
|
||||

|
||||
|
||||
SuperTuxKart
|
||||
|
||||
最后一个同样好玩的游戏是 [SuperTuxKart][9],一个效仿 Mario Kart(马里奥卡丁车)但丝毫不必原作差的好游戏。它在2000年-2004年间开始以 Tux Kart 开发,但是在成品中有错误,结果开发就停止了几年。从2006年开始重新开发时起,它就一直在改进,直到四个月前0.9版首次发布。在游戏里,我们的老朋友 Tux 与马里奥和其他一些开源吉祥物一同开始。其中一个熟悉的面孔是 Suzanne,Blender 的那只吉祥物猴子。画面很给力,游戏很流畅。虽然在线游戏还在计划阶段,但是分屏多玩家游戏是可以的。一个电脑最多可以四个玩家同时玩。适用于 Linux、Windows、OS X、AmigaOS 4、AROS 和 MorphOS。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2015/08/five-super-cool-open-source-games/
|
||||
|
||||
作者:Hunter Banks
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.youtube.com/watch?v=BEKVl-XtOP8
|
||||
[2]:http://tuxracer.sourceforge.net/download.html
|
||||
[3]:http://fossforce.com/2015/07/banks-family-values-texas-linux-fest/
|
||||
[4]:http://www.kidsoncomputers.org/an-amazing-week-in-oaxaca
|
||||
[5]:https://www.warsow.net/download
|
||||
[6]:http://mars-game.sourceforge.net/
|
||||
[7]:http://valyriatear.blogspot.com/
|
||||
[8]:https://www.youtube.com/channel/UCQ5KrSk9EqcT_JixWY2RyMA
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
@ -0,0 +1,68 @@
|
||||
Xtreme下载管理器升级全新用户界面
|
||||
================================================================================
|
||||

|
||||
|
||||
[Xtreme 下载管理器][1], 毫无疑问是[Linux界最好的下载管理器][2]之一 , 它的新版本名叫 XDM 2015 ,这次的新版本给我们带来了全新的外观体验!
|
||||
|
||||
Xtreme 下载管理器,也被称作 XDM 或 XDMAN,它是一个跨平台的下载管理器,可以用于 Linux、Windows 和 Mac OS X 系统之上。同时它兼容于主流的浏览器,如 Chrome, Firefox, Safari 等,因此当你从浏览器下载东西的时候可以直接使用 XDM 下载。
|
||||
|
||||
当你的网络连接超慢并且需要管理下载文件的时候,像 XDM 这种软件可以帮到你大忙。例如说你在一个慢的要死的网络速度下下载一个超大文件, XDM 可以帮助你暂停并且继续下载。
|
||||
|
||||
XDM 的主要功能:
|
||||
|
||||
- 暂停和继续下载
|
||||
- [从 YouTube 下载视频][3],其他视频网站同样适用
|
||||
- 强制聚合
|
||||
- 下载加速
|
||||
- 计划下载
|
||||
- 下载限速
|
||||
- 与浏览器整合
|
||||
- 支持代理服务器
|
||||
|
||||
下面你可以看到 XDM 新旧版本之间的差别。
|
||||
|
||||

|
||||
|
||||
老版本XDM
|
||||
|
||||

|
||||
|
||||
新版本XDM
|
||||
|
||||
### 在基于 Ubuntu 的 Linux 发行版上安装 Xtreme下载管理器 ###
|
||||
|
||||
感谢 Noobslab 提供的 PPA,你可以使用以下命令来安装 Xtreme 下载管理器。虽然 XDM 依赖 Java,但是托 PPA 的福,你不需要对其进行单独的安装。
|
||||
|
||||
sudo add-apt-repository ppa:noobslab/apps
|
||||
sudo apt-get update
|
||||
sudo apt-get install xdman
|
||||
|
||||
以上的 PPA 可以在 Ubuntu 或者其他基于 Ubuntu 的发行版上使用,如 Linux Mint, elementary OS, Linux Lite 等。
|
||||
|
||||
#### 删除 XDM ####
|
||||
|
||||
如果你是使用 PPA 安装的 XDM ,可以通过以下命令将其删除:
|
||||
|
||||
sudo apt-get remove xdman
|
||||
sudo add-apt-repository --remove ppa:noobslab/apps
|
||||
|
||||
对于其他Linux发行版,可以通过以下连接下载:
|
||||
|
||||
- [Download Xtreme Download Manager][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/xtreme-download-manager-install/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://xdman.sourceforge.net/
|
||||
[2]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[3]:http://itsfoss.com/download-youtube-videos-ubuntu/
|
||||
[4]:http://xdman.sourceforge.net/download.html
|
||||
|
||||
@ -1,126 +0,0 @@
|
||||
如何使用Weave以及Docker搭建Nginx反向代理/负载均衡服务器
|
||||
================================================================================
|
||||
Hi, 今天我们将会学习如何使用如何使用Weave和Docker搭建Nginx反向代理/负载均衡服务器。Weave创建一个虚拟网络将跨主机部署的Docker容器连接在一起并使它们自动暴露给外部世界。它让我们更加专注于应用的开发,而不是基础架构。Weave提供了一个如此棒的环境,仿佛它的所有容器都属于同个网络,不需要端口/映射/连接等的配置。容器中的应用提供的服务在weave网络中可以轻易地被外部世界访问,不论你的容器运行在哪里。在这个教程里我们将会使用weave快速并且轻易地将nginx web服务器部署为一个负载均衡器,反向代理一个运行在Amazon Web Services里面多个节点上的docker容器中的简单php应用。这里我们将会介绍WeaveDNS,它提供一个简单的方式让容器利用主机名找到彼此,不需要改变代码,并且能够告诉其他容器连接到这些主机名。
|
||||
|
||||
在这篇教程里,我们需要一个运行的容器集合来配置nginx负载均衡服务器。最简单轻松的方法就是使用Weave在ubuntu的docker容器中搭建nginx负载均衡服务器。
|
||||
|
||||
### 1. 搭建AWS实例 ###
|
||||
|
||||
首先,我们需要搭建Amzaon Web Service实例,这样才能在ubuntu下用weave跑docker容器。我们将会使用[AWS CLI][1]来搭建和配置两个AWS EC2实例。在这里,我们使用最小的有效实例,t1.micro。我们需要一个有效的**Amazon Web Services账户**用以AWS命令行界面的搭建和配置。我们先在AWS命令行界面下使用下面的命令将github上的weave仓库克隆下来。
|
||||
|
||||
$ git clone http://github.com/fintanr/weave-gs
|
||||
$ cd weave-gs/aws-nginx-ubuntu-simple
|
||||
|
||||
在克隆完仓库之后,我们执行下面的脚本,这个脚本将会部署两个t1.micro实例,每个实例中都是ubuntu作为操作系统并用weave跑着docker容器。
|
||||
|
||||
$ sudo ./demo-aws-setup.sh
|
||||
|
||||
在这里,我们将会在以后用到这些实例的IP地址。这些地址储存在一个weavedemo.env文件中,这个文件在执行demo-aws-setup.sh脚本的期间被创建。为了获取这些IP地址,我们需要执行下面的命令,命令输出类似下面的信息。
|
||||
|
||||
$ cat weavedemo.env
|
||||
|
||||
export WEAVE_AWS_DEMO_HOST1=52.26.175.175
|
||||
export WEAVE_AWS_DEMO_HOST2=52.26.83.141
|
||||
export WEAVE_AWS_DEMO_HOSTCOUNT=2
|
||||
export WEAVE_AWS_DEMO_HOSTS=(52.26.175.175 52.26.83.141)
|
||||
|
||||
请注意这些不是固定的IP地址,AWS会为我们的实例动态地分配IP地址。
|
||||
|
||||
我们在bash下执行下面的命令使环境变量生效。
|
||||
|
||||
. ./weavedemo.env
|
||||
|
||||
### 2. 启动Weave and WeaveDNS ###
|
||||
|
||||
在安装完实例之后,我们将会在每台主机上启动weave以及weavedns。Weave以及weavedns使得我们能够轻易地将容器部署到一个全新的基础架构以及配置中, 不需要改变代码,也不需要去理解像Ambassador容器以及Link机制之类的概念。下面是在第一台主机上启动weave以及weavedns的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch
|
||||
$ sudo weave launch-dns 10.2.1.1/24
|
||||
|
||||
下一步,我也准备在第二台主机上启动weave以及weavedns。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave launch $WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch-dns 10.2.1.2/24
|
||||
|
||||
### 3. 启动应用容器 ###
|
||||
|
||||
现在,我们准备跨两台主机启动六个容器,这两台主机都用Apache2 Web服务实例跑着简单的php网站。为了在第一个Apache2 Web服务器实例跑三个容器, 我们将会使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.1/24 -h ws1.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.2/24 -h ws2.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.3/24 -h ws3.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
在那之后,我们将会在第二个实例上启动另外三个容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave run --with-dns 10.3.1.4/24 -h ws4.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.5/24 -h ws5.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.6/24 -h ws6.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
注意: 在这里,--with-dns选项告诉容器使用weavedns来解析主机名,-h x.weave.local则使得weavedns能够解析指定主机。
|
||||
|
||||
### 4. 启动Nginx容器 ###
|
||||
|
||||
在应用容器运行得有如意料中的稳定之后,我们将会启动nginx容器,它将会在六个应用容器服务之间轮询并提供反向代理或者负载均衡。 为了启动nginx容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.7/24 -ti -h nginx.weave.local -d -p 80:80 fintanr/weave-gs-nginx-simple
|
||||
|
||||
因此,我们的nginx容器在$WEAVE_AWS_DEMO_HOST1上公开地暴露成为一个http服务器。
|
||||
|
||||
### 5. 测试负载均衡服务器 ###
|
||||
|
||||
为了测试我们的负载均衡服务器是否可以工作,我们执行一段可以发送http请求给nginx容器的脚本。我们将会发送6个请求,这样我们就能看到nginx在一次的轮询中服务于每台web服务器之间。
|
||||
|
||||
$ ./access-aws-hosts.sh
|
||||
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws1.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws2.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws3.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws4.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws5.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws6.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
|
||||
### 结束语 ###
|
||||
|
||||
我们最终成功地将nginx配置成一个反向代理/负载均衡服务器,通过使用weave以及运行在AWS(Amazon Web Service)EC2之中的ubuntu服务器里面的docker。从上面的步骤输出可以清楚的看到我们已经成功地配置了nginx。我们可以看到请求在一次循环中被发送到6个应用容器,这些容器在Apache2 Web服务器中跑着PHP应用。在这里,我们部署了一个容器化的PHP应用,使用nginx横跨多台在AWS EC2上的主机而不需要改变代码,利用weavedns使得每个容器连接在一起,只需要主机名就够了,眼前的这些便捷, 都要归功于weave以及weavedns。 如果你有任何的问题、建议、反馈,请在评论中注明,这样我们才能够做得更好,谢谢:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/nginx-load-balancer-weave-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
@ -1,418 +0,0 @@
|
||||
Linux日志管理
|
||||
================================================================================
|
||||
管理日志的一个关键典型做法是集中或整合你的日志到一个地方,特别是如果你有许多服务器或多层级架构。我们将告诉你为什么这是一个好主意然后给出如何更容易的做这件事的一些小技巧。
|
||||
|
||||
### 集中管理日志的好处 ###
|
||||
|
||||
如果你有很多服务器,查看单独的一个日志文件可能会很麻烦。现代的网站和服务经常包括许多服务器层级,分布式的负载均衡器,还有更多。这将花费很长时间去获取正确的日志,甚至花更长时间在登录服务器的相关问题上。没什么比发现你找的信息没有被捕获更沮丧的了,或者本能保留答案时正好在重启后丢失了日志文件。
|
||||
|
||||
集中你的日志使他们查找更快速,可以帮助你更快速的解决产品问题。你不用猜测那个服务器存在问题,因为所有的日志在同一个地方。此外,你可以使用更强大的工具去分析他们,包括日志管理解决方案。一些解决方案能[转换纯文本日志][1]为一些字段,更容易查找和分析。
|
||||
|
||||
集中你的日志也可以是他们更易于管理:
|
||||
|
||||
- 他们更安全,当他们备份归档一个单独区域时意外或者有意的丢失。如果你的服务器宕机或者无响应,你可以使用集中的日志去调试问题。
|
||||
- 你不用担心ssh或者低效的grep命令需要更多的资源在陷入困境的系统。
|
||||
- 你不用担心磁盘占满,这个能让你的服务器死机。
|
||||
- 你能保持你的产品服务安全性,只是为了查看日志无需给你所有团队登录权限。给你的团队从中心区域访问日志权限更安全。
|
||||
|
||||
随着集中日志管理,你仍需处理由于网络联通性不好或者用尽大量网络带宽导致不能传输日志到中心区域的风险。在下面的章节我们将要讨论如何聪明的解决这些问题。
|
||||
|
||||
### 流行的日志归集工具 ###
|
||||
|
||||
在Linux上最常见的日志归集是通过使用系统日志守护进程或者代理。系统日志守护进程支持本地日志的采集,然后通过系统日志协议传输日志到中心服务器。你可以使用很多流行的守护进程来归集你的日志文件:
|
||||
|
||||
- [rsyslog][2]是一个轻量后台程序在大多数Linux分支上已经安装。
|
||||
- [syslog-ng][3]是第二流行的Linux系统日志后台程序。
|
||||
- [logstash][4]是一个重量级的代理,他可以做更多高级加工和分析。
|
||||
- [fluentd][5]是另一个有高级处理能力的代理。
|
||||
|
||||
Rsyslog是集中日志数据最流行的后台程序因为他在大多数Linux分支上是被默认安装的。你不用下载或安装它,并且它是轻量的,所以不需要占用你太多的系统资源。
|
||||
|
||||
如果你需要更多先进的过滤或者自定义分析功能,如果你不在乎额外的系统封装Logstash是下一个最流行的选择。
|
||||
|
||||
### 配置Rsyslog.conf ###
|
||||
|
||||
既然rsyslog成为最广泛使用的系统日志程序,我们将展示如何配置它为日志中心。全局配置文件位于/etc/rsyslog.conf。它加载模块,设置全局指令,和包含应用特有文件位于目录/etc/rsyslog.d中。这些目录包含/etc/rsyslog.d/50-default.conf命令rsyslog写系统日志到文件。在[rsyslog文档][6]你可以阅读更多相关配置。
|
||||
|
||||
rsyslog配置语言是是[RainerScript][7]。你建立特定的日志输入就像输出他们到另一个目标。Rsyslog已经配置为系统日志输入的默认标准,所以你通常只需增加一个输出到你的日志服务器。这里有一个rsyslog输出到一个外部服务器的配置例子。在举例中,**BEBOP**是一个服务器的主机名,所以你应该替换为你的自己的服务器名。
|
||||
|
||||
action(type="omfwd" protocol="tcp" target="BEBOP" port="514")
|
||||
|
||||
你可以发送你的日志到一个有丰富存储的日志服务器来存储,提供查询,备份和分析。如果你正存储日志在文件系统,然后你应该建立[日志转储][8]来防止你的磁盘报满。
|
||||
|
||||
作为一种选择,你可以发送这些日志到一个日志管理方案。如果你的解决方案是安装在本地你可以发送到您的本地系统文档中指定主机和端口。如果你使用基于云提供商,你将发送他们到你的提供商特定的主机名和端口。
|
||||
|
||||
### 日志目录 ###
|
||||
|
||||
你可以归集一个目录或者匹配一个通配符模式的所有文件。nxlog和syslog-ng程序支持目录和通配符(*)。
|
||||
|
||||
rsyslog的通用形式不支持直接的监控目录。一种解决方案,你可以设置一个定时任务去监控这个目录的新文件,然后配置rsyslog来发送这些文件到目的地,比如你的日志管理系统。作为一个例子,日志管理提供商Loggly有一个开源版本的[目录监控脚本][9]。
|
||||
|
||||
### 哪个协议: UDP, TCP, or RELP? ###
|
||||
|
||||
当你使用网络传输数据时,你可以选择三个主流的协议。UDP在你自己的局域网是最常用的,TCP是用在互联网。如果你不能失去日志,就要使用更高级的RELP协议。
|
||||
|
||||
[UDP][10]发送一个数据包,那只是一个简单的包信息。它是一个只外传的协议,所以他不发送给你回执(ACK)。它只尝试发送包。当网络拥堵时,UDP通常会巧妙的降级或者丢弃日志。它通常使用在类似局域网的可靠网络。
|
||||
|
||||
[TCP][11]通过多个包和返回确认发送流信息。TCP会多次尝试发送数据包,但是受限于[TCP缓存][12]大小。这是在互联网上发送送日志最常用的协议。
|
||||
|
||||
[RELP][13]是这三个协议中最可靠的,但是它是为rsyslog创建而且很少有行业应用。它在应用层接收数据然后再发出是否有错误。确认你的目标也支持这个协议。
|
||||
|
||||
### 用磁盘辅助队列可靠的传送 ###
|
||||
|
||||
如果rsyslog在存储日志时遭遇错误,例如一个不可用网络连接,他能将日志排队直到连接还原。队列日志默认被存储在内存里。无论如何,内存是有限的并且如果问题仍然存在,日志会超出内存容量。
|
||||
|
||||
**警告:如果你只存储日志到内存,你可能会失去数据。**
|
||||
|
||||
Rsyslog能在内存被占满时将日志队列放到磁盘。[磁盘辅助队列][14]使日志的传输更可靠。这里有一个例子如何配置rsyslog的磁盘辅助队列:
|
||||
|
||||
$WorkDirectory /var/spool/rsyslog # where to place spool files
|
||||
$ActionQueueFileName fwdRule1 # unique name prefix for spool files
|
||||
$ActionQueueMaxDiskSpace 1g # 1gb space limit (use as much as possible)
|
||||
$ActionQueueSaveOnShutdown on # save messages to disk on shutdown
|
||||
$ActionQueueType LinkedList # run asynchronously
|
||||
$ActionResumeRetryCount -1 # infinite retries if host is down
|
||||
|
||||
### 使用TLS加密日志 ###
|
||||
|
||||
当你的安全隐私数据是一个关心的事,你应该考虑加密你的日志。如果你使用纯文本在互联网传输日志,嗅探器和中间人可以读到你的日志。如果日志包含私人信息、敏感的身份数据或者政府管制数据,你应该加密你的日志。rsyslog程序能使用TLS协议加密你的日志保证你的数据更安全。
|
||||
|
||||
建立TLS加密,你应该做如下任务:
|
||||
|
||||
1. 生成一个[证书授权][15](CA)。在/contrib/gnutls有一些简单的证书,只是有助于测试,但是你需要创建自己的产品证书。如果你正在使用一个日志管理服务,它将有一个证书给你。
|
||||
1. 为你的服务器生成一个[数字证书][16]使它能SSL运算,或者使用你自己的日志管理服务提供商的一个数字证书。
|
||||
1. 配置你的rsyslog程序来发送TLS加密数据到你的日志管理系统。
|
||||
|
||||
这有一个rsyslog配置TLS加密的例子。替换CERT和DOMAIN_NAME为你自己的服务器配置。
|
||||
|
||||
$DefaultNetstreamDriverCAFile /etc/rsyslog.d/keys/ca.d/CERT.crt
|
||||
$ActionSendStreamDriver gtls
|
||||
$ActionSendStreamDriverMode 1
|
||||
$ActionSendStreamDriverAuthMode x509/name
|
||||
$ActionSendStreamDriverPermittedPeer *.DOMAIN_NAME.com
|
||||
|
||||
### 应用日志的最佳管理方法 ###
|
||||
|
||||
除Linux默认创建的日志之外,归集重要的应用日志也是一个好主意。几乎所有基于Linux的服务器的应用把他们的状态信息写入到独立专门的日志文件。这包括数据库产品,像PostgreSQL或者MySQL,网站服务器像Nginx或者Apache,防火墙,打印和文件共享服务还有DNS服务等等。
|
||||
|
||||
管理员要做的第一件事是安装一个应用后配置它。Linux应用程序典型的有一个.conf文件在/etc目录里。它也可能在其他地方,但是那是大家找配置文件首先会看的地方。
|
||||
|
||||
根据应用程序有多复杂多庞大,可配置参数的数量可能会很少或者上百行。如前所述,大多数应用程序可能会在某种日志文件写他们的状态:配置文件是日志设置的地方定义了其他的东西。
|
||||
|
||||
如果你不确定它在哪,你可以使用locate命令去找到它:
|
||||
|
||||
[root@localhost ~]# locate postgresql.conf
|
||||
/usr/pgsql-9.4/share/postgresql.conf.sample
|
||||
/var/lib/pgsql/9.4/data/postgresql.conf
|
||||
|
||||
#### 设置一个日志文件的标准位置 ####
|
||||
|
||||
Linux系统一般保存他们的日志文件在/var/log目录下。如果是,很好,如果不是,你也许想在/var/log下创建一个专用目录?为什么?因为其他程序也在/var/log下保存他们的日志文件,如果你的应用报错多于一个日志文件 - 也许每天一个或者每次重启一个 - 通过这么大的目录也许有点难于搜索找到你想要的文件。
|
||||
|
||||
如果你有多于一个的应用实例在你网络运行,这个方法依然便利。想想这样的情景,你也许有一打web服务器在你的网络运行。当排查任何一个盒子的问题,你将知道确切的位置。
|
||||
|
||||
#### 使用一个标准的文件名 ####
|
||||
|
||||
给你的应用最新的日志使用一个标准的文件名。这使一些事变得容易,因为你可以监控和追踪一个单独的文件。很多应用程序在他们的日志上追加一种时间戳。他让rsyslog更难于找到最新的文件和设置文件监控。一个更好的方法是使用日志转储增加时间戳到老的日志文件。这样更易去归档和历史查询。
|
||||
|
||||
#### 追加日志文件 ####
|
||||
|
||||
日志文件会在每个应用程序重启后被覆盖?如果这样,我们建议关掉它。每次重启app后应该去追加日志文件。这样,你就可以追溯重启前最后的日志。
|
||||
|
||||
#### 日志文件追加 vs. 转储 ####
|
||||
|
||||
虽然应用程序每次重启后写一个新日志文件,如何保存当前日志?追加到一个单独文件,巨大的文件?Linux系统不是因频繁重启或者崩溃出名的:应用程序可以运行很长时间甚至不间歇,但是也会使日志文件非常大。如果你查询分析上周发生连接错误的原因,你可能无疑的要在成千上万行里搜索。
|
||||
|
||||
我们建议你配置应用每天半晚转储它的日志文件。
|
||||
|
||||
为什么?首先它将变得可管理。找一个有特定日期部分的文件名比遍历一个文件指定日期的条目更容易。文件也小的多:你不用考虑当你打开一个日志文件时vi僵住。第二,如果你正发送日志到另一个位置 - 也许每晚备份任务拷贝到归集日志服务器 - 这样不会消耗你的网络带宽。最后第三点,这样帮助你做日志保持。如果你想剔除旧的日志记录,这样删除超过指定日期的文件比一个应用解析一个大文件更容易。
|
||||
|
||||
#### 日志文件的保持 ####
|
||||
|
||||
你保留你的日志文件多长时间?这绝对可以归结为业务需求。你可能被要求保持一个星期的日志信息,或者管理要求保持一年的数据。无论如何,日志需要在一个时刻或其他从服务器删除。
|
||||
|
||||
在我们看来,除非必要,只在线保持最近一个月的日志文件,加上拷贝他们到第二个地方如日志服务器。任何比这更旧的日志可以被转到一个单独的介质上。例如,如果你在AWS上,你的旧日志可以被拷贝到Glacier。
|
||||
|
||||
#### 给日志单独的磁盘分区 ####
|
||||
|
||||
Linux最典型的方式通常建议挂载到/var目录到一个单独度的文件系统。这是因为这个目录的高I/Os。我们推荐挂在/var/log目录到一个单独的磁盘系统下。这样可以节省与主应用的数据I/O竞争。另外,如果一些日志文件变的太多,或者一个文件变的太大,不会占满整个磁盘。
|
||||
|
||||
#### 日志条目 ####
|
||||
|
||||
每个日志条目什么信息应该被捕获?
|
||||
|
||||
这依赖于你想用日志来做什么。你只想用它来排除故障,或者你想捕获所有发生的事?这是一个规则条件去捕获每个用户在运行什么或查看什么?
|
||||
|
||||
如果你正用日志做错误排查的目的,只保存错误,报警或者致命信息。没有理由去捕获调试信息,例如,应用也许默认记录了调试信息或者另一个管理员也许为了故障排查使用打开了调试信息,但是你应该关闭它,因为它肯定会很快的填满空间。在最低限度上,捕获日期,时间,客户端应用名,原ip或者客户端主机名,执行动作和它自身信息。
|
||||
|
||||
#### 一个PostgreSQL的实例 ####
|
||||
|
||||
作为一个例子,让我们看看vanilla(这是一个开源论坛)PostgreSQL 9.4安装主配置文件。它叫做postgresql.conf与其他Linux系统中的配置文件不同,他不保存在/etc目录下。在代码段下,我们可以在我们的Centos 7服务器的/var/lib/pgsql目录下看见:
|
||||
|
||||
root@localhost ~]# vi /var/lib/pgsql/9.4/data/postgresql.conf
|
||||
...
|
||||
#------------------------------------------------------------------------------
|
||||
# ERROR REPORTING AND LOGGING
|
||||
#------------------------------------------------------------------------------
|
||||
# - Where to Log -
|
||||
log_destination = 'stderr'
|
||||
# Valid values are combinations of
|
||||
# stderr, csvlog, syslog, and eventlog,
|
||||
# depending on platform. csvlog
|
||||
# requires logging_collector to be on.
|
||||
# This is used when logging to stderr:
|
||||
logging_collector = on
|
||||
# Enable capturing of stderr and csvlog
|
||||
# into log files. Required to be on for
|
||||
# csvlogs.
|
||||
# (change requires restart)
|
||||
# These are only used if logging_collector is on:
|
||||
log_directory = 'pg_log'
|
||||
# directory where log files are written,
|
||||
# can be absolute or relative to PGDATA
|
||||
log_filename = 'postgresql-%a.log' # log file name pattern,
|
||||
# can include strftime() escapes
|
||||
# log_file_mode = 0600 .
|
||||
# creation mode for log files,
|
||||
# begin with 0 to use octal notation
|
||||
log_truncate_on_rotation = on # If on, an existing log file with the
|
||||
# same name as the new log file will be
|
||||
# truncated rather than appended to.
|
||||
# But such truncation only occurs on
|
||||
# time-driven rotation, not on restarts
|
||||
# or size-driven rotation. Default is
|
||||
# off, meaning append to existing files
|
||||
# in all cases.
|
||||
log_rotation_age = 1d
|
||||
# Automatic rotation of logfiles will happen after that time. 0 disables.
|
||||
log_rotation_size = 0 # Automatic rotation of logfiles will happen after that much log output. 0 disables.
|
||||
# These are relevant when logging to syslog:
|
||||
#syslog_facility = 'LOCAL0'
|
||||
#syslog_ident = 'postgres'
|
||||
# This is only relevant when logging to eventlog (win32):
|
||||
#event_source = 'PostgreSQL'
|
||||
# - When to Log -
|
||||
#client_min_messages = notice # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# log
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
#log_min_messages = warning # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic
|
||||
#log_min_error_statement = error # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic (effectively off)
|
||||
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
|
||||
# and their durations, > 0 logs only
|
||||
# statements running at least this number
|
||||
# of milliseconds
|
||||
# - What to Log
|
||||
#debug_print_parse = off
|
||||
#debug_print_rewritten = off
|
||||
#debug_print_plan = off
|
||||
#debug_pretty_print = on
|
||||
#log_checkpoints = off
|
||||
#log_connections = off
|
||||
#log_disconnections = off
|
||||
#log_duration = off
|
||||
#log_error_verbosity = default
|
||||
# terse, default, or verbose messages
|
||||
#log_hostname = off
|
||||
log_line_prefix = '< %m >' # special values:
|
||||
# %a = application name
|
||||
# %u = user name
|
||||
# %d = database name
|
||||
# %r = remote host and port
|
||||
# %h = remote host
|
||||
# %p = process ID
|
||||
# %t = timestamp without milliseconds
|
||||
# %m = timestamp with milliseconds
|
||||
# %i = command tag
|
||||
# %e = SQL state
|
||||
# %c = session ID
|
||||
# %l = session line number
|
||||
# %s = session start timestamp
|
||||
# %v = virtual transaction ID
|
||||
# %x = transaction ID (0 if none)
|
||||
# %q = stop here in non-session
|
||||
# processes
|
||||
# %% = '%'
|
||||
# e.g. '<%u%%%d> '
|
||||
#log_lock_waits = off # log lock waits >= deadlock_timeout
|
||||
#log_statement = 'none' # none, ddl, mod, all
|
||||
#log_temp_files = -1 # log temporary files equal or larger
|
||||
# than the specified size in kilobytes;5# -1 disables, 0 logs all temp files5
|
||||
log_timezone = 'Australia/ACT'
|
||||
|
||||
虽然大多数参数被加上了注释,他们呈现了默认数值。我们可以看见日志文件目录是pg_log(log_directory参数),文件名应该以postgresql开头(log_filename参数),文件每天转储一次(log_rotation_age参数)然后日志记录以时间戳开头(log_line_prefix参数)。特别说明有趣的是log_line_prefix参数:你可以包含很多整体丰富的信息在这。
|
||||
|
||||
看/var/lib/pgsql/9.4/data/pg_log目录下展现给我们这些文件:
|
||||
|
||||
[root@localhost ~]# ls -l /var/lib/pgsql/9.4/data/pg_log
|
||||
total 20
|
||||
-rw-------. 1 postgres postgres 1212 May 1 20:11 postgresql-Fri.log
|
||||
-rw-------. 1 postgres postgres 243 Feb 9 21:49 postgresql-Mon.log
|
||||
-rw-------. 1 postgres postgres 1138 Feb 7 11:08 postgresql-Sat.log
|
||||
-rw-------. 1 postgres postgres 1203 Feb 26 21:32 postgresql-Thu.log
|
||||
-rw-------. 1 postgres postgres 326 Feb 10 01:20 postgresql-Tue.log
|
||||
|
||||
所以日志文件命只有工作日命名的标签。我们可以改变他。如何做?在postgresql.conf配置log_filename参数。
|
||||
|
||||
查看一个日志内容,它的条目仅以日期时间开头:
|
||||
|
||||
[root@localhost ~]# cat /var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.log
|
||||
...
|
||||
< 2015-02-27 01:21:27.020 EST >LOG: received fast shutdown request
|
||||
< 2015-02-27 01:21:27.025 EST >LOG: aborting any active transactions
|
||||
< 2015-02-27 01:21:27.026 EST >LOG: autovacuum launcher shutting down
|
||||
< 2015-02-27 01:21:27.036 EST >LOG: shutting down
|
||||
< 2015-02-27 01:21:27.211 EST >LOG: database system is shut down
|
||||
|
||||
### 集中应用日志 ###
|
||||
|
||||
#### 使用Imfile监控日志 ####
|
||||
|
||||
习惯上,应用通常记录他们数据在文件里。文件容易在一个机器上寻找但是多台服务器上就不是很恰当了。你可以设置日志文件监控然后当新的日志被添加到底部就发送事件到一个集中服务器。在/etc/rsyslog.d/里创建一个新的配置文件然后增加一个文件输入,像这样:
|
||||
|
||||
$ModLoad imfile
|
||||
$InputFilePollInterval 10
|
||||
$PrivDropToGroup adm
|
||||
|
||||
----------
|
||||
|
||||
# Input for FILE1
|
||||
$InputFileName /FILE1
|
||||
$InputFileTag APPNAME1
|
||||
$InputFileStateFile stat-APPNAME1 #this must be unique for each file being polled
|
||||
$InputFileSeverity info
|
||||
$InputFilePersistStateInterval 20000
|
||||
$InputRunFileMonitor
|
||||
|
||||
替换FILE1和APPNAME1位你自己的文件和应用名称。Rsyslog将发送它到你配置的输出中。
|
||||
|
||||
#### 本地套接字日志与Imuxsock ####
|
||||
|
||||
套接字类似UNIX文件句柄,所不同的是套接字内容是由系统日志程序读取到内存中,然后发送到目的地。没有文件需要被写入。例如,logger命令发送他的日志到这个UNIX套接字。
|
||||
|
||||
如果你的服务器I/O有限或者你不需要本地文件日志,这个方法使系统资源有效利用。这个方法缺点是套接字有队列大小的限制。如果你的系统日志程序宕掉或者不能保持运行,然后你可能会丢失日志数据。
|
||||
|
||||
rsyslog程序将默认从/dev/log套接字中种读取,但是你要用[imuxsock输入模块][17]如下命令使它生效:
|
||||
|
||||
$ModLoad imuxsock
|
||||
|
||||
#### UDP日志与Imupd ####
|
||||
|
||||
一些应用程序使用UDP格式输出日志数据,这是在网络上或者本地传输日志文件的标准系统日志协议。你的系统日志程序收集这些日志然后处理他们或者用不同的格式传输他们。交替地,你可以发送日志到你的日志服务器或者到一个日志管理方案中。
|
||||
|
||||
使用如下命令配置rsyslog来接收标准端口514的UDP系统日志数据:
|
||||
|
||||
$ModLoad imudp
|
||||
|
||||
----------
|
||||
|
||||
$UDPServerRun 514
|
||||
|
||||
### 用Logrotate管理日志 ###
|
||||
|
||||
日志转储是当日志到达指定的时期时自动归档日志文件的方法。如果不介入,日志文件一直增长,会用尽磁盘空间。最后他们将破坏你的机器。
|
||||
|
||||
logrotate实例能随着日志的日期截取你的日志,腾出空间。你的新日志文件保持文件名。你的旧日志文件被重命名为后缀加上数字。每次logrotate实例运行,一个新文件被建立然后现存的文件被逐一重命名。你来决定何时旧文件被删除或归档的阈值。
|
||||
|
||||
当logrotate拷贝一个文件,新的文件已经有一个新的索引节点,这会妨碍rsyslog监控新文件。你可以通过增加copytruncate参数到你的logrotate定时任务来缓解这个问题。这个参数拷贝现有的日志文件内容到新文件然后从现有文件截短这些内容。这个索引节点从不改变,因为日志文件自己保持不变;它的内容是一个新文件。
|
||||
|
||||
logrotate实例使用的主配置文件是/etc/logrotate.conf,应用特有设置在/etc/logrotate.d/目录下。DigitalOcean有一个详细的[logrotate教程][18]
|
||||
|
||||
### 管理很多服务器的配置 ###
|
||||
|
||||
当你只有很少的服务器,你可以登陆上去手动配置。一旦你有几打或者更多服务器,你可以用高级工具使这变得更容易和更可扩展。基本上,所有的事情就是拷贝你的rsyslog配置到每个服务器,然后重启rsyslog使更改生效。
|
||||
|
||||
#### Pssh ####
|
||||
|
||||
这个工具可以让你在很多服务器上并行的运行一个ssh命令。使用pssh部署只有一小部分的服务器。如果你其中一个服务器失败,然后你必须ssh到失败的服务器,然后手动部署。如果你有很多服务器失败,那么手动部署他们会话费很长时间。
|
||||
|
||||
#### Puppet/Chef ####
|
||||
|
||||
Puppet和Chef是两个不同的工具,他们能在你的网络按你规定的标准自动的配置所有服务器。他们的报表工具使你知道关于错误然后定期重新同步。Puppet和Chef有一些狂热的支持者。如果你不确定那个更适合你的部署配置管理,你可以领会一下[InfoWorld上这两个工具的对比][19]
|
||||
|
||||
一些厂商也提供一些配置rsyslog的模块或者方法。这有一个Loggly上Puppet模块的例子。它提供给rsyslog一个类,你可以添加一个标识令牌:
|
||||
|
||||
node 'my_server_node.example.net' {
|
||||
# Send syslog events to Loggly
|
||||
class { 'loggly::rsyslog':
|
||||
customer_token => 'de7b5ccd-04de-4dc4-fbc9-501393600000',
|
||||
}
|
||||
}
|
||||
|
||||
#### Docker ####
|
||||
|
||||
Docker使用容器去运行应用不依赖底层服务。所有东西都从内部的容器运行,你可以想象为一个单元功能。ZDNet有一个深入文章关于在你的数据中心[使用Docker][20]。
|
||||
|
||||
这有很多方式从Docker容器记录日志,包括链接到一个日志容器,记录到一个共享卷,或者直接在容器里添加一个系统日志代理。其中最流行的日志容器叫做[logspout][21]。
|
||||
|
||||
#### 供应商的脚本或代理 ####
|
||||
|
||||
大多数日志管理方案提供一些脚本或者代理,从一个或更多服务器比较简单的发送数据。重量级代理会耗尽额外的系统资源。一些供应商像Loggly提供配置脚本,来使用现存的系统日志程序更轻松。这有一个Loggly上的例子[脚本][22],它能运行在任意数量的服务器上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/managing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.esrreycnpnbl
|
||||
[2]:http://www.rsyslog.com/
|
||||
[3]:http://www.balabit.com/network-security/syslog-ng/opensource-logging-system
|
||||
[4]:http://logstash.net/
|
||||
[5]:http://www.fluentd.org/
|
||||
[6]:http://www.rsyslog.com/doc/rsyslog_conf.html
|
||||
[7]:http://www.rsyslog.com/doc/master/rainerscript/index.html
|
||||
[8]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.eck7acdxin87
|
||||
[9]:https://www.loggly.com/docs/file-monitoring/
|
||||
[10]:http://www.networksorcery.com/enp/protocol/udp.htm
|
||||
[11]:http://www.networksorcery.com/enp/protocol/tcp.htm
|
||||
[12]:http://blog.gerhards.net/2008/04/on-unreliability-of-plain-tcp-syslog.html
|
||||
[13]:http://www.rsyslog.com/doc/relp.html
|
||||
[14]:http://www.rsyslog.com/doc/queues.html
|
||||
[15]:http://www.rsyslog.com/doc/tls_cert_ca.html
|
||||
[16]:http://www.rsyslog.com/doc/tls_cert_machine.html
|
||||
[17]:http://www.rsyslog.com/doc/v8-stable/configuration/modules/imuxsock.html
|
||||
[18]:https://www.digitalocean.com/community/tutorials/how-to-manage-log-files-with-logrotate-on-ubuntu-12-10
|
||||
[19]:http://www.infoworld.com/article/2614204/data-center/puppet-or-chef--the-configuration-management-dilemma.html
|
||||
[20]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[21]:https://github.com/progrium/logspout
|
||||
[22]:https://www.loggly.com/docs/sending-logs-unixlinux-system-setup/
|
||||
@ -0,0 +1,105 @@
|
||||
如何在 Docker 容器中运行支持 OData 的 JBoss 数据虚拟化 GA
|
||||
Howto Run JBoss Data Virtualization GA with OData in Docker Container
|
||||
================================================================================
|
||||
大家好,我们今天来学习如何在一个 Docker 容器中运行支持 OData(译者注:Open Data Protocol,开放数据协议) 的 JBoss 数据虚拟化 6.0.0 GA(译者注:GA,General Availability,具体定义可以查看[WIKI][4])。JBoss 数据虚拟化是数据提供和集成解决方案平台,有多种分散的数据源时,转换为一种数据源统一对待,在正确的时间将所需数据传递给任意的应用或者用户。JBoss 数据虚拟化可以帮助我们将数据快速组合和转换为可重用的商业友好的数据模型,通过开放标准接口简单可用。它提供全面的数据抽取、联合、集成、转换,以及传输功能,将来自一个或多个源的数据组合为可重复使用和共享的灵活数据。要了解更多关于 JBoss 数据虚拟化的信息,可以查看它的[官方文档][1]。Docker 是一个提供开放平台用于打包,装载和以轻量级容器运行任何应用的开源平台。使用 Docker 容器我们可以轻松处理和启用支持 OData 的 JBoss 数据虚拟化。
|
||||
|
||||
下面是该指南中在 Docker 容器中运行支持 OData 的 JBoss 数据虚拟化的简单步骤。
|
||||
|
||||
### 1. 克隆仓库 ###
|
||||
|
||||
首先,我们要用 git 命令从 [https://github.com/jbossdemocentral/dv-odata-docker-integration-demo][2] 克隆带数据虚拟化的 OData 仓库。假设我们的机器上运行着 Ubuntu 15.04 linux 发行版。我们要使用 apt-get 命令安装 git。
|
||||
|
||||
# apt-get install git
|
||||
|
||||
安装完 git 之后,我们运行下面的命令克隆仓库。
|
||||
|
||||
# git clone https://github.com/jbossdemocentral/dv-odata-docker-integration-demo
|
||||
|
||||
Cloning into 'dv-odata-docker-integration-demo'...
|
||||
remote: Counting objects: 96, done.
|
||||
remote: Total 96 (delta 0), reused 0 (delta 0), pack-reused 96
|
||||
Unpacking objects: 100% (96/96), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
### 2. 下载 JBoss 数据虚拟化安装器 ###
|
||||
|
||||
现在,我们需要从下载页 [http://www.jboss.org/products/datavirt/download/][3] 下载 JBoss 数据虚拟化安装器。下载了 **jboss-dv-installer-6.0.0.GA-redhat-4.jar** 后,我们把它保存在名为 **software** 的目录下。
|
||||
|
||||
### 3. 创建 Docker 镜像 ###
|
||||
|
||||
下一步,下载了 JBoss 数据虚拟化安装器之后,我们打算使用 Dockerfile 和刚从仓库中克隆的资源创建 docker 镜像。
|
||||
|
||||
# cd dv-odata-docker-integration-demo/
|
||||
# docker build -t jbossdv600 .
|
||||
|
||||
...
|
||||
Step 22 : USER jboss
|
||||
---> Running in 129f701febd0
|
||||
---> 342941381e37
|
||||
Removing intermediate container 129f701febd0
|
||||
Step 23 : EXPOSE 8080 9990 31000
|
||||
---> Running in 61e6d2c26081
|
||||
---> 351159bb6280
|
||||
Removing intermediate container 61e6d2c26081
|
||||
Step 24 : CMD $JBOSS_HOME/bin/standalone.sh -c standalone.xml -b 0.0.0.0 -bmanagement 0.0.0.0
|
||||
---> Running in a9fed69b3000
|
||||
---> 407053dc470e
|
||||
Removing intermediate container a9fed69b3000
|
||||
Successfully built 407053dc470e
|
||||
|
||||
注意:在这里我们假设你已经安装了 docker 并正在运行。
|
||||
|
||||
### 4. 启动 Docker 容器 ###
|
||||
|
||||
创建了支持 oData 的 JBoss 数据虚拟化 Docker 镜像之后,我们打算运行 docker 容器并用 -P 标签指定端口。我们运行下面的命令来实现。
|
||||
|
||||
# docker run -p 8080:8080 -d -t jbossdv600
|
||||
|
||||
7765dee9cd59c49ca26850e88f97c21f46859d2dc1d74166353d898773214c9c
|
||||
|
||||
### 5. 获取容器 IP ###
|
||||
|
||||
启动了 Docker 容器之后,我们想要获取正在运行的 docker 容器的 IP 地址。要做到这点,我们运行后面添加了正在运行容器 id 号的 docker inspect 命令。
|
||||
|
||||
# docker inspect <$containerID>
|
||||
|
||||
...
|
||||
"NetworkSettings": {
|
||||
"Bridge": "",
|
||||
"EndpointID": "3e94c5900ac5954354a89591a8740ce2c653efde9232876bc94878e891564b39",
|
||||
"Gateway": "172.17.42.1",
|
||||
"GlobalIPv6Address": "",
|
||||
"GlobalIPv6PrefixLen": 0,
|
||||
"HairpinMode": false,
|
||||
"IPAddress": "172.17.0.8",
|
||||
"IPPrefixLen": 16,
|
||||
"IPv6Gateway": "",
|
||||
"LinkLocalIPv6Address": "",
|
||||
"LinkLocalIPv6PrefixLen": 0,
|
||||
|
||||
### 6. Web 界面 ###
|
||||
### 6. Web Interface ###
|
||||
|
||||
现在,如果一切如期望的那样进行,当我们用浏览器打开 http://container-ip:8080/ 和 http://container-ip:9990 时会看到支持 oData 的 JBoss 数据虚拟化登录界面和 JBoss 管理界面。管理验证的用户名和密码分别是 admin 和 redhat1!数据虚拟化验证的用户名和密码都是 user。之后,我们可以通过 web 界面在内容间导航。
|
||||
|
||||
**注意**: 强烈建议在第一次登录后尽快修改密码。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
终于我们成功地运行了跑着支持 OData 多源虚拟数据库的 JBoss 数据虚拟化 的 Docker 容器。JBoss 数据虚拟化真的是一个很棒的平台,它为多种不同来源的数据进行虚拟化,并将它们转换为商业友好的数据模型,产生通过开放标准接口简单可用的数据。使用 Docker 技术可以简单、安全、快速地部署支持 OData 多源虚拟数据库的 JBoss 数据虚拟化。如果你有任何疑问、建议或者反馈,请在下面的评论框中写下来,以便我们可以改进和更新内容。非常感谢!Enjoy:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/run-jboss-data-virtualization-ga-odata-docker-container/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.redhat.com/en/technologies/jboss-middleware/data-virtualization
|
||||
[2]:https://github.com/jbossdemocentral/dv-odata-docker-integration-demo
|
||||
[3]:http://www.jboss.org/products/datavirt/download/
|
||||
[4]:https://en.wikipedia.org/wiki/Software_release_life_cycle#General_availability_.28GA.29
|
||||
@ -1,432 +0,0 @@
|
||||
translating by tnuoccalanosrep
|
||||
Linux文件系统结构 v2.0
|
||||
================================================================================
|
||||
Linux中的文件是什么?它的文件系统又是什么?那些配置文件又在哪里?我下载好的程序保存在哪里了?好了,上图简明地阐释了Linux的文件系统的层次关系。当你苦于寻找配置文件或者二进制文件的时候,这便显得十分有用了。我在下方添加了一些解释以及例子,但“篇幅过长,没有阅读”。
|
||||
|
||||
有一种情况便是当你在系统中获取配置以及二进制文件时,出现了不一致性问题,如果你是一个大型组织,或者只是一个终端用户,这也有可能会破坏你的系统(比如,二进制文件运行在就旧的库文件上了)。若然你在你的Linux系统上做安全审计([security audit of your Linux system][1])的话,你将会发现它很容易遭到不同的攻击。所以,清洁操作(无论是Windows还是Linux)都显得十分重要。
|
||||
### What is a file in Linux? ###
|
||||
Linux的文件是什么?
|
||||
对于UNIX系统来说(同样适用于Linux),以下便是对文件简单的描述:
|
||||
> 在UNIX系统中,一切皆为文件;若非文件,则为进程
|
||||
|
||||
> 这种定义是比较正确的,因为有些特殊的文件不仅仅是普通文件(比如命名管道和套接字),不过为了让事情变的简单,“一切皆为文件”也是一个可以让人接受的说法。Linux系统也像UNXI系统一样,将文件和目录视如同物,因为目录只是一个包含了其他文件名的文件而已。程序,服务,文本,图片等等,都是文件。对于系统来说,输入和输出设备,基本上所有的设备,都被当做是文件。
|
||||

|
||||
|
||||
- Version 2.0 – 17-06-2015
|
||||
- – Improved: 添加标题以及版本历史
|
||||
- – Improved: 添加/srv,/meida和/proc
|
||||
- – Improved: 更新了反映当前的Linux文件系统的描述
|
||||
- – Fixed: 多处的打印错误
|
||||
- – Fixed: 外观和颜色
|
||||
- Version 1.0 – 14-02-2015
|
||||
- – Created: 基本的图表
|
||||
- – Note: 摒弃更低的版本
|
||||
|
||||
### Download Links ###
|
||||
以下是结构图的下载地址。如果你需要其他结构,请跟原作者联系,他会尝试制作并且上传到某个地方以供下载
|
||||
- [Large (PNG) Format – 2480×1755 px – 184KB][2]
|
||||
- [Largest (PDF) Format – 9919x7019 px – 1686KB][3]
|
||||
|
||||
**注意**: PDF格式文件是打印的最好选择,因为它画质很高。
|
||||
### Linux 文件系统描述 ###
|
||||
为了有序地管理那些文件,人们习惯把这些文件当做是硬盘上的有序的类树结构体,正如我们熟悉的'MS-DOS'(硬盘操作系统)。大的分枝包括更多的分枝,分枝的末梢是树的叶子或者普通的文件。现在我们将会以这树形图为例,但晚点我们会发现为什么这不是一个完全准确的一幅图。
|
||||
注:表格
|
||||
<table cellspacing="2" border="4" style="border-collapse: collapse; width: 731px; height: 2617px;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th scope="col">Directory(目录)</th>
|
||||
<th scope="col">Description(描述)</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/</code></dd>
|
||||
</dl></td>
|
||||
<td><i>主层次</i> 的根,也是整个文件系统层次结构的根目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl></td>
|
||||
<td>存放在单用户模式可用的必要命令二进制文件,对于所有用户而言,则是像cat,ls,cp等等的文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/boot</code></dd>
|
||||
</dl></td>
|
||||
<td>存放引导加载程序文件,例如kernels,initrd等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/dev</code></dd>
|
||||
</dl></td>
|
||||
<td>存放必要的设备文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/etc</code></dd>
|
||||
</dl></td>
|
||||
<td>存放主机特定的系统范围内的配置文件。其实这里有个关于它名字本身意义上的的争议。在贝尔实验室的早期UNIX实施文档版本中,/etc表示是“其他目录”,因为从历史上看,这个目录是存放各种不属于其他目录的文件(然而,FSH(文件系统目录标准)限定 /ect是用于存放静态配置文件,这里不该存有二进制文件)。早期文档出版后,这个目录名又重新定义成不同的形式。近期的解释中包含着诸如“可编辑文本配置”或者“额外的工具箱”这样的重定义</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>存储着新增包的配置文件 <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sgml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>存放配置文件,比如目录,还有那些处理SGML(译者注:标准通用标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>X Window系统的配置文件,版本号为11</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/xml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>配置文件,比如目录,处理XML(译者注:可扩展标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/home</code></dd>
|
||||
</dl></td>
|
||||
<td>用户的主目录,包括保存的文件, 个人配置, 等等.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl></td>
|
||||
<td><code>/bin/</code> and <code>/sbin/</code>中的二进制文件必不可少的库文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl></td>
|
||||
<td>备用格式的必要的库文件. 这样的目录视可选的,但如果他们存在的话, 他们还有一些要求.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/media</code></dd>
|
||||
</dl></td>
|
||||
<td>可移动的多媒体(如CD-ROMs)的挂载点.(出现于 FHS-2.3)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/mnt</code></dd>
|
||||
</dl></td>
|
||||
<td>临时挂载的文件系统</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl></td>
|
||||
<td>自定义应用程序软件包</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/proc</code></dd>
|
||||
</dl></td>
|
||||
<td>以文件形式提供进程以及内核信息的虚拟文件系统,在Linux中,对应进程文件系统的挂载点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/root</code></dd>
|
||||
</dl></td>
|
||||
<td>根用户的主目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl></td>
|
||||
<td>必要系统二进制文件, <i>比如</i>, init, ip, mount.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/srv</code></dd>
|
||||
</dl></td>
|
||||
<td>系统提供的站点特定数据</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl></td>
|
||||
<td>临时文件 (另见 <code>/var/tmp</code>). 通常在系统重启后删除</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/usr</code></dd>
|
||||
</dl></td>
|
||||
<td><i>二级层级</i> 存储用户的只读数据; 包含(多)用户主要的公共文件以及应用程序</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>非必要的命令二进制文件 (在单用户模式中不需要用到的); 用于所有用户.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/include</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>标准的包含文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>库文件,用于<code>/usr/bin/</code> 和 <code>/usr/sbin/</code>.中的二进制文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>备用格式库(可选的).</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/local</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td><i>三级层次</i> 用于本地数据, 具体到该主机上的.通常会有下一个子目录, <i>比如</i>, <code>bin/</code>, <code>lib/</code>, <code>share/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>非必要系统的二进制文件, <i>比如</i>,用于不同网络服务的守护进程</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/share</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>独立架构的 (共享) 数据.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/src</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>源代码, <i>比如</i>, 内核源文件以及与它相关的头文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11R6</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>X Window系统,版本号:11,发行版本:6</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/var</code></dd>
|
||||
</dl></td>
|
||||
<td>各式各样的文件,一些随着系统常规操作而持续改变的文件就放在这里,比如日志文件,脱机文件,还有临时的电子邮件文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/cache</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>应用程序缓存数据. 这些数据是根据I/O(输入/输出)的耗时结果或者是运算生成的.这些应用程序是可以重新生成或者恢复数据的.当没有数据丢失的时候,可以删除缓存文件.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>状态信息.这些信息随着程序的运行而不停地改变,比如,数据库,系统元数据的打包等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lock</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>锁文件。这些文件会持续监控正在使用的资源</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/log</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>日志文件. 包含各种日志.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>内含用户邮箱的相关文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>来自附加包的各种数据都会存储在 <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/run</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Information about the running system since last boot, <i>e.g.</i>, currently logged-in users and running <a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons</a>.</td>
|
||||
<td>存放当前系统上次启动的相关信息, <i>例如</i>, 当前登入的用户以及当前运行的<a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons(守护进程)</a>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/spool</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>该spool主要用于存放将要被处理的任务, <i>比如</i>, 打印队列以及邮件传出队列</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>过时的位置,用于放置用户邮箱文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>存放重启之前的临时接口</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Types of files in Linux ###
|
||||
### Linux的文件类型 ###
|
||||
大多数文件也仅仅是文件,他们被称为`regular`文件;他们包含普通数据,比如,文本,可执行文件,或者程序,程序输入或输出文件等等
|
||||
While it is reasonably safe to suppose that everything you encounter on a Linux system is a file, there are some exceptions.
|
||||
虽然你可以认为“在Linux中,一切你看到的皆为文件”这个观点相当保险,但这里仍有着一些例外。
|
||||
|
||||
- `目录`:由其他文件组成的文件
|
||||
- `特殊文件`:用于输入和输出的途径。大多数特殊文件都储存在`/dev`中,我们将会在后面讨论这个问题。
|
||||
- `链接文件`:让文件或者目录在系统文件树结构上可见的机制。我们将详细地讨论这个链接文件。
|
||||
- `(域)套接字`:特殊的文件类型,和TCP/IP协议中的套接字有点像,提供进程网络,并受文件系统的访问控制机制保护。
|
||||
-`命名管道` : 或多或少有点像sockets(套接字),提供一个进程间的通信机制,而不用网络套接字协议。
|
||||
### File system in reality ###
|
||||
### 现实中的文件系统 ###
|
||||
对于大多数用户和常规系统管理任务而言,"文件和目录是一个有序的类树结构"是可以接受的。然而,对于电脑而言,它是不会理解什么是树,或者什么是树结构。
|
||||
|
||||
每个分区都有它自己的文件系统。想象一下,如果把那些文件系统想成一个整体,我们可以构思一个关于整个系统的树结构,不过这并没有这么简单。在文件系统中,一个文件代表着一个`inode`(索引节点),一种包含着构建文件的实际数据信息的序列号:这些数据表示文件是属于谁的,还有它在硬盘中的位置。
|
||||
|
||||
每个分区都有一套属于他们自己的inodes,在一个系统的不同分区中,可以存在有相同inodes的文件。
|
||||
|
||||
每个inode都表示着一种在硬盘上的数据结构,保存着文件的属性,包括文件数据的物理地址。当硬盘被格式化并用来存储数据时(通常发生在初始系统安装过程,或者是在一个已经存在的系统中添加额外的硬盘),每个分区都会创建关于inodes的固定值。这个值表示这个分区能够同时存储各类文件的最大数量。我们通常用一个inode去映射2-8k的数据块。当一个新的文件生成后,它就会获得一个空闲的indoe。在这个inode里面存储着以下信息:
|
||||
|
||||
- 文件属主和组属主
|
||||
- 文件类型(常规文件,目录文件......)
|
||||
- 文件权限
|
||||
- 创建、最近一次读文件和修改文件的时间
|
||||
- inode里该信息被修改的时间
|
||||
- 文件的链接数(详见下一章)
|
||||
- 文件大小
|
||||
- 文件数据的实际地址
|
||||
|
||||
唯一不在inode的信息是文件名和目录。它们存储在特殊的目录文件。通过比较文件名和inodes的数目,系统能够构造出一个便于用户理解的树结构。用户可以通过ls -i查看inode的数目。在硬盘上,inodes有他们独立的空间。
|
||||
|
||||
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/18/linux-file-system-hierarchy-v2-0/
|
||||
|
||||
译者:[译者ID](https://github.com/tnuoccalanosrep)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.blackmoreops.com/2015/02/15/in-light-of-recent-linux-exploits-linux-security-audit-is-a-must/
|
||||
[2]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-file-system-hierarchy-v2.0-2480px-blackMORE-Ops.png
|
||||
[3]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-File-System-Hierarchy-blackMORE-Ops.pdf
|
||||
@ -1,294 +0,0 @@
|
||||
如何部署一个你的公共系统状态页面
|
||||
================================================================================
|
||||
如果你是一个系统管理员,负责关键的IT基础设置或你公司的服务,你将明白有效的沟通在日常任务中的重要性。假设你的线上存储服务器故障了。你希望团队所有人达成共识你好尽快的解决问题。当你忙来忙去时,你不想一半的人问你为什么他们不能访问他们的文档。当一个维护计划快到时间了你想在计划前提醒相关人员,这样避免了不必要的开销。
|
||||
|
||||
这一切的要求或多或少改进了你和你的团队,用户和你的服务的沟通渠道。一个实现它方法是维护一个集中的系统状态页面,故障停机详情,进度更新和维护计划会被报告和记录。这样,在故障期间你避免了不必要的打扰,也有一些相关方提供的资料和任何选状态更新择性加入。
|
||||
|
||||
一个不错的**开源, 自承载系统状态页面**是is [Cachet][1]。在这个教程,我将要描述如何用Cachet部署一个自承载系统状态页面。
|
||||
|
||||
### Cachet 特性 ###
|
||||
|
||||
在详细的配置Cachet之前,让我简单的介绍一下它的主要特性。
|
||||
|
||||
- **全JSON API**:Cachet API允许你使用任意外部程序或脚本(例如,uptime脚本)链接到Cachet来报告突发事件或自动更新状态。
|
||||
- **认证**:Cachet支持基础认证和JSON API的API令牌,所以只有认证用户可以更新状态页面。
|
||||
- **衡量系统**:这通常用来展现随着时间推移的自定义数据(例如,服务器负载或者相应时间)。
|
||||
- **通知**:你可以随意的发送通知邮件,报告事件给任一注册了状态页面的人。
|
||||
- **多语言**:状态也可以被转换为11种不同的语言。
|
||||
- **双因子认证**:这允许你使用Google的双因子认证管理账户锁定你的Cachet(什么事Google?呵呵!)。
|
||||
- **支持交叉数据库**:你可以选择MySQL,SQLite,Redis,APC和PostgreSQL作为后端存储。
|
||||
|
||||
剩下的教程,我说明如何在Linux上安装配置Cachet。
|
||||
|
||||
### 第一步:下载和安装Cachet ###
|
||||
|
||||
Cachet需要一个web服务器和一个后端数据库来运转。在这个教程中,我将使用LAMP架构。这里有特定发行版安装Cachet和LAMP架构的指令。
|
||||
|
||||
#### Debian, Ubuntu 或者 Linux Mint ####
|
||||
|
||||
$ sudo apt-get install curl git apache2 mysql-server mysql-client php5 php5-mysql
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R www-data:www-data .
|
||||
|
||||
在基于Debian的系统上更多详细的设置LAMP架构,参考这个[教程][2]。
|
||||
|
||||
#### Fedora, CentOS 或 RHEL ####
|
||||
|
||||
在基于Red Hat系统上,你首先需要[设置REMI资源库][3](以满足PHP版本需求)。然后执行下面命令。
|
||||
|
||||
$ sudo yum install curl git httpd mariadb-server
|
||||
$ sudo yum --enablerepo=remi-php56 install php php-mysql php-mbstring
|
||||
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
|
||||
$ cd /var/www/cachet
|
||||
$ sudo git checkout v1.1.1
|
||||
$ sudo chown -R apache:apache .
|
||||
$ sudo firewall-cmd --permanent --zone=public --add-service=http
|
||||
$ sudo firewall-cmd --reload
|
||||
$ sudo systemctl enable httpd.service; sudo systemctl start httpd.service
|
||||
$ sudo systemctl enable mariadb.service; sudo systemctl start mariadb.service
|
||||
|
||||
在基于Red Hat系统上更多详细设置LAMP,参考这个[教程][4]。
|
||||
|
||||
### 配置Cachet的后端数据库###
|
||||
|
||||
下一步是配置后端数据库。
|
||||
|
||||
登陆到MySQL/MariaDB服务,然后创建一个空的数据库称为‘cachet’。
|
||||
|
||||
$ sudo mysql -uroot -p
|
||||
|
||||
----------
|
||||
|
||||
mysql> create database cachet;
|
||||
mysql> quit
|
||||
|
||||
现在用一个样本配置文件创建一个Cachet配置文件。
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo mv .env.example .env
|
||||
|
||||
在.env文件里,填写你自己设置的数据库信息(例如,DB\_\*)。其他的字段先不改变。
|
||||
|
||||
APP_ENV=production
|
||||
APP_DEBUG=false
|
||||
APP_URL=http://localhost
|
||||
APP_KEY=SomeRandomString
|
||||
|
||||
DB_DRIVER=mysql
|
||||
DB_HOST=localhost
|
||||
DB_DATABASE=cachet
|
||||
DB_USERNAME=root
|
||||
DB_PASSWORD=<root-password>
|
||||
|
||||
CACHE_DRIVER=apc
|
||||
SESSION_DRIVER=apc
|
||||
QUEUE_DRIVER=database
|
||||
|
||||
MAIL_DRIVER=smtp
|
||||
MAIL_HOST=mailtrap.io
|
||||
MAIL_PORT=2525
|
||||
MAIL_USERNAME=null
|
||||
MAIL_PASSWORD=null
|
||||
MAIL_ADDRESS=null
|
||||
MAIL_NAME=null
|
||||
|
||||
REDIS_HOST=null
|
||||
REDIS_DATABASE=null
|
||||
REDIS_PORT=null
|
||||
|
||||
### 第三步:安装PHP依赖和执行数据库迁移 ###
|
||||
|
||||
下面,我们将要安装必要的PHP依赖包。所以我们将使用composer。如果你的系统还没有安装composer,先安装它:
|
||||
|
||||
$ curl -sS https://getcomposer.org/installer | sudo php -- --install-dir=/usr/local/bin --filename=composer
|
||||
|
||||
现在开始用composer安装PHP依赖包。
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo composer install --no-dev -o
|
||||
|
||||
下面执行一次数据库迁移。这一步将我们早期创建的必要表填充到数据库。
|
||||
|
||||
$ sudo php artisan migrate
|
||||
|
||||
假设数据库配置在/var/www/cachet/.env是正确的,数据库迁移应该像下面显示一样完成成功。
|
||||
|
||||

|
||||
|
||||
下面,创建一个密钥,它将用来加密进入Cachet的数据。
|
||||
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||

|
||||
|
||||
生成的应用密钥将自动添加到你的.env文件APP\_KEY变量中。你不需要单独编辑.env。
|
||||
|
||||
### 第四步:配置Apache HTTP服务 ###
|
||||
|
||||
现在到了配置web服务的时候,Cachet将运行在上面。我们使用Apache HTTP服务器,为Cachet创建一个新的[虚拟主机][5]如下所述。
|
||||
|
||||
#### Debian, Ubuntu 或 Linux Mint ####
|
||||
|
||||
$ sudo vi /etc/apache2/sites-available/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
启用新虚拟主机和mod_rewrite:
|
||||
|
||||
$ sudo a2ensite cachet.conf
|
||||
$ sudo a2enmod rewrite
|
||||
$ sudo service apache2 restart
|
||||
|
||||
#### Fedora, CentOS 或 RHEL ####
|
||||
|
||||
在基于Red Hat系统上,创建一个虚拟主机文件如下所述。
|
||||
|
||||
$ sudo vi /etc/httpd/conf.d/cachet.conf
|
||||
|
||||
----------
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName cachethost
|
||||
ServerAlias cachethost
|
||||
DocumentRoot "/var/www/cachet/public"
|
||||
<Directory "/var/www/cachet/public">
|
||||
Require all granted
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
现在重载Apache配置:
|
||||
|
||||
$ sudo systemctl reload httpd.service
|
||||
|
||||
### 第五步:配置/etc/hosts来测试Cachet ###
|
||||
|
||||
这时候,初始的Cachet状态页面应该启动运行了,现在测试一下。
|
||||
|
||||
由于Cachet被配置为Apache HTTP服务的虚拟主机,我们需要调整你的客户机的/etc/hosts来访问他。你将从这个客户端电脑访问Cachet页面。
|
||||
|
||||
Open /etc/hosts, and add the following entry.
|
||||
|
||||
$ sudo vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
<cachet-server-ip-address> cachethost
|
||||
|
||||
上面名为“cachethost”必须匹配Cachet的Apache虚拟主机文件的ServerName。
|
||||
|
||||
### 测试Cachet状态页面 ###
|
||||
|
||||
现在你准备好访问Cachet状态页面。在你浏览器地址栏输入http://cachethost。你将被转到初始Cachet状态页如下。
|
||||
|
||||

|
||||
|
||||
选择cache/session驱动。这里cache和session驱动两个都选“File”。
|
||||
|
||||
下一步,输入关于状态页面的基本信息(例如,站点名称,域名,时区和语言),以及管理员认证账户。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
你的初始状态页将要最终完成。
|
||||
|
||||

|
||||
|
||||
继续创建组件(你的系统单位),事件或者任意你想要的维护计划。
|
||||
|
||||
例如,增加一个组件:
|
||||
|
||||

|
||||
|
||||
增加一个维护计划:
|
||||
|
||||
公共Cachet状态页就像这样:
|
||||
|
||||

|
||||
|
||||
集成SMTP,你可以在状态更新时发送邮件给订阅者。并且你可以完全自定义布局和状态页面使用的CSS和markdown格式。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
Cachet是一个相当易于使用,自托管的状态页面软件。Cachet一个高级特性是支持全JSON API。使用它的RESTful API,Cachet可以轻松连接单独的监控后端(例如,[Nagios][6]),然后回馈给Cachet事件报告并自动更新状态。比起手段管理一个状态页它更快和有效率。
|
||||
|
||||
最后一句,我喜欢提及一个事。用Cachet简单的设置一个花哨的状态页面同时,使用最佳的软件不像安装它那么容易。你需要完全保障所有IT团队习惯准确及时的更新状态页,从而建立公共信息的准确性。同时,你需要教用户去查看状态页面。在今天最后,如果不很好的填充,部署状态页面将没有意义,并且/或者没有一个人查看它。记住这个,当你考虑部署Cachet在你的工作环境中时。
|
||||
|
||||
### 故障排查 ###
|
||||
|
||||
作为奖励,万一你安装Cachet时遇到问题,这有一些有用的故障排查的技巧。
|
||||
|
||||
1. Cachet页面没有加载任何东西,并且你看到如下报错。
|
||||
|
||||
production.ERROR: exception 'RuntimeException' with message 'No supported encrypter found. The cipher and / or key length are invalid.' in /var/www/cachet/bootstrap/cache/compiled.php:6695
|
||||
|
||||
**解决方案**:确保你创建了一个应用密钥,以及明确配置缓存如下所述。
|
||||
|
||||
$ cd /path/to/cachet
|
||||
$ sudo php artisan key:generate
|
||||
$ sudo php artisan config:cache
|
||||
|
||||
2. 调用composer命令时有如下报错。
|
||||
|
||||
- danielstjules/stringy 1.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- laravel/framework v5.1.8 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
- league/commonmark 0.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
|
||||
|
||||
**解决方案**:确保安装了必要的PHP扩展mbstring到你的系统上,并且兼容你的PHP。在基于Red Hat的系统上,由于我们从REMI-56库安装PHP,要从同一个库安装扩展。
|
||||
|
||||
$ sudo yum --enablerepo=remi-php56 install php-mbstring
|
||||
|
||||
3. 你访问Cachet状态页面时得到一个白屏。HTTP日志显示如下错误。
|
||||
|
||||
PHP Fatal error: Uncaught exception 'UnexpectedValueException' with message 'The stream or file "/var/www/cachet/storage/logs/laravel-2015-08-21.log" could not be opened: failed to open stream: Permission denied' in /var/www/cachet/bootstrap/cache/compiled.php:12851
|
||||
|
||||
**解决方案**:尝试如下命令。
|
||||
|
||||
$ cd /var/www/cachet
|
||||
$ sudo php artisan cache:clear
|
||||
$ sudo chmod -R 777 storage
|
||||
$ sudo composer dump-autoload
|
||||
|
||||
如果上面的方法不起作用,试试禁止SELinux:
|
||||
|
||||
$ sudo setenforce 0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-system-status-page.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://cachethq.io/
|
||||
[2]:http://xmodulo.com/install-lamp-stack-ubuntu-server.html
|
||||
[3]:http://ask.xmodulo.com/install-remi-repository-centos-rhel.html
|
||||
[4]:http://xmodulo.com/install-lamp-stack-centos.html
|
||||
[5]:http://xmodulo.com/configure-virtual-hosts-apache-http-server.html
|
||||
[6]:http://xmodulo.com/monitor-common-services-nagios.html
|
||||
125
translated/tech/20150901 How to Defragment Linux Systems.md
Normal file
125
translated/tech/20150901 How to Defragment Linux Systems.md
Normal file
@ -0,0 +1,125 @@
|
||||
如何在Linux中整理磁盘碎片
|
||||
================================================================================
|
||||

|
||||
|
||||
有一神话是linux的磁盘从来不需要整理碎片。在大多数情况下这是真的,大多数因为是使用的是优秀的日志系统(ext2、3、4等等)来处理文件系统。然而,在一些特殊情况下,碎片仍旧会产生。如果正巧发生在你身上,解决方法很简单。
|
||||
|
||||
### 什么是磁盘碎片 ###
|
||||
|
||||
碎片发生在不同的小块中更新文件时,但是这些快没有形成连续完整的文件而是分布在磁盘的各个角落中。这对于FAT和FAT32文件系统而言是这样的。这在NTFS中有所减轻,在Linux(extX)中几乎不会发生。下面是原因。
|
||||
|
||||
在像FAT和FAT32这类文件系统中,文件紧挨着写入到磁盘中。文件之间没有空间来用于增长或者更新:
|
||||
|
||||

|
||||
|
||||
NTFS中在文件之间保留了一些空间,因此有空间进行增长。因为块之间的空间是有限的,碎片也会随着时间出现。
|
||||
|
||||

|
||||
|
||||
Linux的日志文件系统采用了一个不同的方案。与文件之间挨着不同,每个文件分布在磁盘的各处,每个文件之间留下了大量的剩余空间。这里有很大的空间用于更新和增长,并且碎片很少会发生。
|
||||
|
||||

|
||||
|
||||
此外,碎片一旦出现了,大多数Linux文件系统会尝试将文件和块重新连续起来。
|
||||
|
||||
### Linux中的磁盘整理 ###
|
||||
|
||||
除非你用的是一个很小的硬盘或者空间不够了,不然Linux很少会需要磁盘整理。一些可能需要磁盘整理的情况包括:
|
||||
|
||||
- 如果你编辑的是大型视频文件或者原生照片,但磁盘空间有限
|
||||
- if you use older hardware like an old laptop, and you have a small hard drive
|
||||
- 如果你的磁盘开始满了(大约使用了85%)
|
||||
- 如果你的家目录中有许多小分区
|
||||
|
||||
最好的解决方案是购买一个大硬盘。如果不可能,磁盘碎片整理就很有用了。
|
||||
|
||||
### 如何检查碎片 ###
|
||||
|
||||
`fsck`命令会为你做这个 -也就是说如果你可以在liveCD中运行它,那么就可以**卸载所有的分区**。
|
||||
|
||||
这一点很重要:**在已经挂载的分区中运行fsck将会严重危害到你的数据和磁盘**。
|
||||
|
||||
你已经被警告过了。开始之前,先做一个完整的备份。
|
||||
|
||||
**免责声明**: 本文的作者与Make Tech Easier将不会对您的文件、数据、系统或者其他损害负责。你需要自己承担风险。如果你继续,你需要接收并了解这点。
|
||||
|
||||
你应该启动到一个live会话中(如安装磁盘,系统救援CD等)并运行`fsck`卸载分区。要检查是否有任何问题,请在运行root权限下面的命令:
|
||||
|
||||
fsck -fn [/path/to/your/partition]
|
||||
|
||||
您可以检查一下运行中的分区的路径
|
||||
|
||||
sudo fdisk -l
|
||||
|
||||
有一个(相对)安全地在已挂载的分区中运行`fsck`的方法是使用‘-n’开关。这会让分区处在只读模式而不能创建任何文件。当然,这里并不能保证安全,你应该在创建备份之后进行。在ext2中,运行
|
||||
|
||||
sudo fsck.ext2 -fn /path/to/your/partition
|
||||
|
||||
会产生大量的输出-- 大多数错误信息的原因是分区已经挂载了。最后会给出一个碎片相关的信息。
|
||||
|
||||

|
||||
|
||||
如果碎片大于20%了,那么你应该开始整理你的磁盘碎片了。
|
||||
|
||||
### 如何简单地在Linux中整理碎片 ###
|
||||
|
||||
你要做的是备份你**所有**的文件和数据到另外一块硬盘中(手动**复制**他们)。格式化分区然后重新复制回去(不要使用备份软件)。日志系统会把它们作为新的文件,并将它们整齐地放置到磁盘中而不产生碎片。
|
||||
|
||||
要备份你的文件,运行
|
||||
|
||||
cp -afv [/path/to/source/partition]/* [/path/to/destination/folder]
|
||||
|
||||
记住星号(*)是很重要的。
|
||||
|
||||
注意:通常认为复制大文件或者大量文件,使用dd或许是最好的。这是一个非常底层的操作,它会复制一切,包含空闲的空间甚至是留下的垃圾。这不是我们想要的,因此这里最好使用`cp`。
|
||||
|
||||
现在你只需要删除源文件。
|
||||
|
||||
sudo rm -rf [/path/to/source/partition]/*
|
||||
|
||||
**可选**:你可以将空闲空间置零。你也可以用格式化来达到这点,但是例子中你并没有复制整个分区而仅仅是大文件(这很可能会造成碎片)。这恐怕不能成为一个选项。
|
||||
|
||||
sudo dd if=/dev/zero of=[/path/to/source/partition]/temp-zero.txt
|
||||
|
||||
等待它结束。你可以用`pv`来监测进程。
|
||||
|
||||
sudo apt-get install pv
|
||||
sudo pv -tpreb | of=[/path/to/source/partition]/temp-zero.txt
|
||||
|
||||

|
||||
|
||||
这就完成了,只要删除临时文件就行。
|
||||
|
||||
sudo rm [/path/to/source/partition]/temp-zero.txt
|
||||
|
||||
待你清零了空闲空间(或者跳过了这步)。重新复制回文件,将第一个cp命令翻转一下:
|
||||
|
||||
cp -afv [/path/to/original/destination/folder]/* [/path/to/original/source/partition]
|
||||
|
||||
### 使用 e4defrag ###
|
||||
|
||||
如果你想要简单的方法,安装`e2fsprogs`,
|
||||
|
||||
sudo apt-get install e2fsprogs
|
||||
|
||||
用root权限在分区中运行 `e4defrag`。如果你不想卸载分区,你可以使用它的挂载点而不是路径。要整理整个系统的碎片,运行:
|
||||
|
||||
sudo e4defrag /
|
||||
|
||||
在挂载的情况下不保证成功(你也应该保证在它运行时停止使用你的系统),但是它比服务全部文件再重新复制回来简单多了。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
linux系统中很少会出现碎片因为它的文件系统有效的数据处理。如果你因任何原因产生了碎片,简单的方法是重新分配你的磁盘如复制所有文件并复制回来,或者使用`e4defrag`。然而重要的是保证你数据的安全,因此在进行任何可能影响你全部或者大多数文件的操作之前,确保你的文件已经被备份到了另外一个安全的地方去了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/defragment-linux/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
@ -0,0 +1,79 @@
|
||||
使用脚本便捷地在Ubuntu系统中安装最新的Linux内核
|
||||
================================================================================
|
||||

|
||||
|
||||
想要安装最新的Linux内核吗?一个简单的脚本就可以在Ubuntu系统中方便的完成这项工作。
|
||||
|
||||
Michael Murphy 写了一个脚本用来将最新的候选版、标准版、或者低延时版内核安装到 Ubuntu 系统中。这个脚本会在询问一些问题后从 [Ubuntu kernel mainline page][1] 下载安装最新的 Linux 内核包。
|
||||
|
||||
### 通过脚本来安装、升级Linux内核: ###
|
||||
|
||||
1. 点击 [github page][2] 右上角的 “Download Zip” 来下载脚本。
|
||||
|
||||
2. 鼠标右键单击用户下载目录下的 Zip 文件,选择 “Extract Here” 将其解压到此处。
|
||||
|
||||
3. 右键点击解压后的文件夹,选择 “Open in Terminal” 在终端中导航到此文件夹下。
|
||||
|
||||

|
||||
|
||||
此时将会打开一个终端,并且自动导航到结果文件夹下。如果你找不到 “Open in Terminal” 选项的话,在 Ubuntu 软件中心搜索安装 `nautilus-open-terminal` ,然后重新登录系统即可(也可以再终端中运行 `nautilus -q` 来取代重新登录系统的操作)。
|
||||
4. 当进入终端后,运行以下命令来赋予脚本执行本次操作的权限。
|
||||
|
||||
chmod +x *
|
||||
|
||||
最后,每当你想要安装或升级 Ubuntu 的 linux 内核时都可以运行此脚本。
|
||||
|
||||
./*
|
||||
|
||||

|
||||
|
||||
这里之所以使用 * 替代脚本名称是因为文件夹中只有它一个文件。
|
||||
|
||||
如果脚本运行成功,重启电脑即可。
|
||||
|
||||
### 恢复并且卸载新版内核 ###
|
||||
|
||||
如果因为某些原因要恢复并且移除新版内核的话,请重启电脑,在 Grub 启动器的 **高级选项** 菜单下选择旧版内核来启动系统。
|
||||
|
||||
当系统启动后,参照下边章节继续执行。
|
||||
|
||||
### 如何移除旧的(或新的)内核: ###
|
||||
|
||||
1. 从Ubuntu软件中心安装 Synaptic Package Manager。
|
||||
|
||||
2. 打开 Synaptic Package Manager 然后如下操作:
|
||||
|
||||
- 点击 **Reload** 按钮,让想要被删除的新内核显示出来.
|
||||
- 在左侧面板中选择 **Status -> Installed** ,让查找列表更清晰一些。
|
||||
- 在 Quick filter 输入框中输入 **linux-image-** 用于查询。
|
||||
- 选择一个内核镜像 “linux-image-x.xx.xx-generic” 然后将其标记为removal(或者Complete Removal)
|
||||
- 最后,应用变更
|
||||
|
||||

|
||||
|
||||
重复以上操作直到移除所有你不需要的内核。注意,不要随意移除此刻正在运行的内核,你可以通过 `uname -r` 命令来查看运行的内核。
|
||||
|
||||
对于 Ubuntu 服务器来说,你可以一步步运行下面的命令:
|
||||
|
||||
uname -r
|
||||
|
||||
dpkg -l | grep linux-image-
|
||||
|
||||
sudo apt-get autoremove KERNEL_IMAGE_NAME
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/08/install-latest-kernel-script/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[2]:https://gist.github.com/mmstick/8493727
|
||||
|
||||
@ -1,320 +0,0 @@
|
||||
[translating by xiqingongzi]
|
||||
|
||||
RHCSA系列: 复习基础命令及系统文档 – 第一部分
|
||||
================================================================================
|
||||
RHCSA (红帽认证系统工程师) 是由给商业公司提供开源操作系统和软件的RedHat公司举行的认证考试, 除此之外,红帽公司还为这些企业和机构提供支持、训练以及咨询服务
|
||||
|
||||

|
||||
|
||||
RHCSA 考试准备指南
|
||||
|
||||
RHCSA 考试(考试编号 EX200)通过后可以获取由Red Hat 公司颁发的证书. RHCSA 考试是RHCT(红帽认证技师)的升级版,而且RHCSA必须在新的Red Hat Enterprise Linux(红帽企业版)下完成.RHCT和RHCSA的主要变化就是RHCT基于 RHEL5 , 而RHCSA基于RHEL6或者7, 这两个认证的等级也有所不同.
|
||||
|
||||
红帽认证管理员所会的最基础的是在红帽企业版的环境下执行如下系统管理任务:
|
||||
|
||||
- 理解并会使用命令管理文件、目录、命令行以及系统/软件包的文档
|
||||
- 使用不同的启动等级启动系统,认证和控制进程,启动或停止虚拟机
|
||||
- 使用分区和逻辑卷管理本地存储
|
||||
- 创建并且配置本地文件系统和网络文件系统,设置他们的属性(许可、加密、访问控制表)
|
||||
- 部署、配置、并且控制系统,包括安装、升级和卸载软件
|
||||
- 管理系统用户和组,独立使用集中制的LDAP目录权限控制
|
||||
- 确保系统安全,包括基础的防火墙规则和SELinux配置
|
||||
|
||||
|
||||
关于你所在国家的考试注册费用参考 [RHCSA Certification page][1].
|
||||
|
||||
关于你所在国家的考试注册费用参考RHCSA 认证页面
|
||||
|
||||
|
||||
在这个有15章的RHCSA(红帽认证管理员)备考系列,我们将覆盖以下的关于红帽企业Linux第七版的最新的信息
|
||||
|
||||
- Part 1: 回顾必会的命令和系统文档
|
||||
- Part 2: 在RHEL7如何展示文件和管理目录
|
||||
- Part 3: 在RHEL7中如何管理用户和组
|
||||
- Part 4: 使用nano和vim管理命令/ 使用grep和正则表达式分析文本
|
||||
- Part 5: RHEL7的进程管理:启动,关机,以及其他介于二者之间的.
|
||||
- Part 6: 使用 'Parted'和'SSM'来管理和加密系统存储
|
||||
- Part 7: 使用ACLs(访问控制表)并挂载 Samba /NFS 文件分享
|
||||
- Part 8: 加固SSH,设置主机名并开启网络服务
|
||||
- Part 9: 安装、配置和加固一个Web,FTP服务器
|
||||
- Part 10: Yum 包管理方式,使用Cron进行自动任务管理以及监控系统日志
|
||||
- Part 11: 使用FirewallD和Iptables设置防火墙,控制网络流量
|
||||
- Part 12: 使用Kickstart 自动安装RHEL 7
|
||||
- Part 13: RHEL7:什么是SeLinux?他的原理是什么?
|
||||
- Part 14: 在RHEL7 中使用基于LDAP的权限控制
|
||||
- Part 15: RHEL7的虚拟化:KVM 和虚拟机管理
|
||||
|
||||
在第一章,我们讲解如何输入和运行正确的命令在终端或者Shell窗口,并且讲解如何找到、插入,以及使用系统文档
|
||||
|
||||

|
||||
|
||||
RHCSA:回顾必会的Linux命令 - 第一部分
|
||||
|
||||
#### 前提: ####
|
||||
|
||||
至少你要熟悉如下命令
|
||||
|
||||
- [cd command][2] (改变目录)
|
||||
- [ls command][3] (列举文件)
|
||||
- [cp command][4] (复制文件)
|
||||
- [mv command][5] (移动或重命名文件)
|
||||
- [touch command][6] (创建一个新的文件或更新已存在文件的时间表)
|
||||
- rm command (删除文件)
|
||||
- mkdir command (创建目录)
|
||||
|
||||
在这篇文章中你将会找到更多的关于如何更好的使用他们的正确用法和特殊用法.
|
||||
|
||||
虽然没有严格的要求,但是作为讨论常用的Linux命令和方法,你应该安装RHEL7 来尝试使用文章中提到的命令.这将会使你学习起来更省力.
|
||||
|
||||
- [红帽企业版Linux(RHEL)7 安装指南][7]
|
||||
|
||||
### 使用Shell进行交互 ###
|
||||
如果我们使用文本模式登陆Linux,我们就无法使用鼠标在默认的shell。另一方面,如果我们使用图形化界面登陆,我们将会通过启动一个终端来开启shell,无论那种方式,我们都会看到用户提示,并且我们可以开始输入并且执行命令(当按下Enter时,命令就会被执行)
|
||||
|
||||
|
||||
当我们使用文本模式登陆Linux时,
|
||||
命令是由两个部分组成的:
|
||||
|
||||
- 命令本身
|
||||
- 参数
|
||||
|
||||
某些参数,称为选项(通常使用一个连字符区分),改变了由其他参数定义的命令操作.
|
||||
|
||||
命令的类型可以帮助我们识别某一个特定的命令是由shell内建的还是由一个单独的包提供。这样的区别在于我们能够找到更多关于该信息的命令,对shell内置的命令,我们需要看shell的ManPage,如果是其他提供的,我们需要看它自己的ManPage.
|
||||
|
||||

|
||||
|
||||
检查Shell的内建命令
|
||||
|
||||
在上面的例子中, cd 和 type 是shell内建的命令,top和 less 是由其他的二进制文件提供的(在这种情况下,type将返回命令的位置)
|
||||
其他的内建命令
|
||||
|
||||
- [echo command][8]: 展示字符串
|
||||
- [pwd command][9]: 输出当前的工作目录
|
||||
|
||||

|
||||
|
||||
更多内建函数
|
||||
|
||||
**exec 命令**
|
||||
|
||||
运行我们指定的外部程序。请注意,最好是只输入我们想要运行的程序的名字,不过exec命令有一个特殊的特性:使用旧的shell运行,而不是创建新的进程,可以作为子请求的验证.
|
||||
|
||||
# ps -ef | grep [shell 进程的PID]
|
||||
|
||||
当新的进程注销,Shell也随之注销,运行 exec top 然后按下 q键来退出top,你会注意到shell 会话会结束,如下面的屏幕录像展示的那样:
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/f02w4WT73LE"></iframe>
|
||||
|
||||
**export 命令**
|
||||
|
||||
输出之后执行的命令的环境的变量
|
||||
|
||||
**history 命令**
|
||||
|
||||
展示数行之前的历史命令.在感叹号前输入命令编号可以再次执行这个命令.如果我们需要编辑历史列表中的命令,我们可以按下 Ctrl + r 并输入与命令相关的第一个字符.
|
||||
当我们看到的命令自动补全,我们可以根据我们目前的需要来编辑它:
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/69vafdSMfU4"></iframe>
|
||||
|
||||
命令列表会保存在一个叫 .bash_history的文件里.history命令是一个非常有用的用于减少输入次数的工具,特别是进行命令行编辑的时候.默认情况下,bash保留最后输入的500个命令,不过可以通过修改 HISTSIZE 环境变量来增加:
|
||||
|
||||
|
||||

|
||||
|
||||
Linux history 命令
|
||||
|
||||
但上述变化,在我们的下一次启动不会保留。为了保持HISTSIZE变量的变化,我们需要通过手工修改文件编辑:
|
||||
|
||||
# 设置history请看 HISTSIZE 和 HISTFILESIZE 在 bash(1)的文档
|
||||
HISTSIZE=1000
|
||||
|
||||
**重要**: 我们的更改不会生效,除非我们重启了系统
|
||||
|
||||
**alias 命令**
|
||||
没有参数或使用-p参数将会以 名称=值的标准形式输出alias 列表.当提供了参数时,一个alias 将被定义给给定的命令和值
|
||||
|
||||
使用alias ,我们可以创建我们自己的命令,或修改现有的命令,包括需要的参数.举个例子,假设我们想别名 ls 到 ls –color=auto ,这样就可以使用不同颜色输出文件、目录、链接
|
||||
|
||||
|
||||
# alias ls='ls --color=auto'
|
||||
|
||||

|
||||
|
||||
Linux 别名命令
|
||||
|
||||
**Note**: 你可以给你的新命令起任何的名字,并且附上足够多的使用单引号分割的参数,但是这样的情况下你要用分号区分开他们.
|
||||
|
||||
# alias myNewCommand='cd /usr/bin; ls; cd; clear'
|
||||
|
||||
**exit 命令**
|
||||
|
||||
Exit和logout命令都是退出shell.exit命令退出所有的shell,logout命令只注销登陆的shell,其他的自动以文本模式启动的shell不算.
|
||||
|
||||
如果我们对某个程序由疑问,我们可以看他的man Page,可以使用man命令调出它,额外的,还有一些重要的文件的手册页(inittab,fstab,hosts等等),库函数,shells,设备及其他功能
|
||||
|
||||
#### 举例: ####
|
||||
|
||||
- man uname (输出系统信息,如内核名称、处理器、操作系统类型、架构等).
|
||||
- man inittab (初始化守护设置).
|
||||
|
||||
另外一个重要的信息的来源就是info命令提供的,info命令常常被用来读取信息文件.这些文件往往比manpage 提供更多信息.通过info 关键词调用某个命令的信息
|
||||
|
||||
# info ls
|
||||
# info cut
|
||||
|
||||
|
||||
另外,在/usr/share/doc 文件夹包含了大量的子目录,里面可以找到大量的文档.他们包含文本文件或其他友好的格式.
|
||||
确保你使用这三种方法去查找命令的信息。重点关注每个命令文档中介绍的详细的语法
|
||||
|
||||
**使用expand命令把tabs转换为空格**
|
||||
|
||||
有时候文本文档包含了tabs但是程序无法很好的处理的tabs.或者我们只是简单的希望将tabs转换成空格.这就是为什么expand (GNU核心组件提供)工具出现,
|
||||
|
||||
举个例子,给我们一个文件 NumberList.txt,让我们使用expand处理它,将tabs转换为一个空格.并且以标准形式输出.
|
||||
|
||||
# expand --tabs=1 NumbersList.txt
|
||||
|
||||

|
||||
|
||||
Linux expand 命令
|
||||
|
||||
unexpand命令可以实现相反的功能(将空格转为tab)
|
||||
|
||||
**使用head输出文件首行及使用tail输出文件尾行**
|
||||
|
||||
通常情况下,head命令后跟着文件名时,将会输出该文件的前十行,我们可以通过 -n 参数来自定义具体的行数。
|
||||
|
||||
# head -n3 /etc/passwd
|
||||
# tail -n3 /etc/passwd
|
||||
|
||||

|
||||
|
||||
Linux 的 head 和 tail 命令
|
||||
|
||||
tail 最有意思的一个特性就是能够展现信息(最后一行)就像我们输入文件(tail -f my.log,一行一行的,就像我们在观察它一样。)这在我们监控一个持续增加的日志文件时非常有用
|
||||
|
||||
更多: [Manage Files Effectively using head and tail Commands][10]
|
||||
|
||||
**使用paste合并文本文件**
|
||||
paste命令一行一行的合并文件,默认会以tab来区分每一行,或者其他你自定义的分行方式.(下面的例子就是输出使用等号划分行的文件).
|
||||
# paste -d= file1 file2
|
||||
|
||||

|
||||
|
||||
Merge Files in Linux
|
||||
|
||||
**使用split命令将文件分块**
|
||||
|
||||
split 命令常常用于把一个文件切割成两个或多个文由我们自定义的前缀命名的件文件.这些文件可以通过大小、区块、行数,生成的文件会有一个数字或字母的后缀.在下面的例子中,我们将切割bash.pdf ,每个文件50KB (-b 50KB) ,使用命名后缀 (-d):
|
||||
|
||||
# split -b 50KB -d bash.pdf bash_
|
||||
|
||||

|
||||
|
||||
在Linux下划分文件
|
||||
|
||||
你可以使用如下命令来合并这些文件,生成源文件:
|
||||
|
||||
# cat bash_00 bash_01 bash_02 bash_03 bash_04 bash_05 > bash.pdf
|
||||
|
||||
**使用tr命令改变字符**
|
||||
|
||||
tr 命令多用于变化(改变)一个一个的字符活使用字符范围.和之前一样,下面的实例我们江使用同样的文件file2,我们将实习:
|
||||
|
||||
- 小写字母 o 变成大写
|
||||
- 所有的小写字母都变成大写字母
|
||||
|
||||
# cat file2 | tr o O
|
||||
# cat file2 | tr [a-z] [A-Z]
|
||||
|
||||

|
||||
|
||||
在Linux中替换文字
|
||||
|
||||
**使用uniq和sort检查或删除重复的文字**
|
||||
|
||||
uniq命令可以帮我们查出或删除文件中的重复的行,默认会写出到stdout.我们应当注意, uniq 只能查出相邻的两个相同的单纯,所以, uniq 往往和sort 一起使用(sort一般用于对文本文件的内容进行排序)
|
||||
|
||||
|
||||
默认的,sort 以第一个参数(使用空格区分)为关键字.想要定义特殊的关键字,我们需要使用 -k参数,请注意如何使用sort 和uniq输出我们想要的字段,具体可以看下面的例子
|
||||
|
||||
# cat file3
|
||||
# sort file3 | uniq
|
||||
# sort -k2 file3 | uniq
|
||||
# sort -k3 file3 | uniq
|
||||
|
||||

|
||||
|
||||
删除文件中重复的行
|
||||
|
||||
**从文件中提取文本的命令**
|
||||
|
||||
Cut命令基于字节(-b),字符(-c),或者区块(-f)从stdin活文件中提取到的部分将会以标准的形式展现在屏幕上
|
||||
|
||||
当我们使用区块切割时,默认的分隔符是一个tab,不过你可以通过 -d 参数来自定义分隔符.
|
||||
|
||||
# cut -d: -f1,3 /etc/passwd # 这个例子提取了第一块和第三块的文本
|
||||
# cut -d: -f2-4 /etc/passwd # 这个例子提取了第一块到第三块的文本
|
||||
|
||||

|
||||
|
||||
从文件中提取文本
|
||||
|
||||
|
||||
注意,上方的两个输出的结果是十分简洁的。
|
||||
|
||||
**使用fmt命令重新格式化文件**
|
||||
|
||||
fmt 被用于去“清理”有大量内容或行的文件,或者有很多缩进的文件.新的锻炼格式每行不会超过75个字符款,你能改变这个设定通过 -w(width 宽度)参数,它可以设置行宽为一个特定的数值
|
||||
|
||||
举个例子,让我们看看当我们用fmt显示定宽为100个字符的时候的文件/etc/passwd 时会发生什么.再来一次,输出值变得更加简洁.
|
||||
|
||||
# fmt -w100 /etc/passwd
|
||||
|
||||

|
||||
|
||||
Linux文件重新格式化
|
||||
|
||||
**使用pr命令格式化打印内容**
|
||||
|
||||
pr 分页并且在列中展示一个或多个用于打印的文件. 换句话说,使用pr格式化一个文件使他打印出来时看起来更好.举个例子,下面这个命令
|
||||
|
||||
# ls -a /etc | pr -n --columns=3 -h "Files in /etc"
|
||||
|
||||
以一个友好的排版方式(3列)输出/etc下的文件,自定义了页眉(通过 -h 选项实现),行号(-n)
|
||||
|
||||

|
||||
|
||||
Linux的文件格式
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我们已经讨论了如何在Shell或终端以正确的语法输入和执行命令,并解释如何找到,检查和使用系统文档。正如你看到的一样简单,这就是你成为RHCSA的第一大步
|
||||
|
||||
如果你想添加一些其他的你经常使用的能够有效帮你完成你的日常工作的基础命令,并为分享他们而感到自豪,请在下方留言.也欢迎提出问题.我们期待您的回复.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://www.redhat.com/en/services/certification/rhcsa
|
||||
[2]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[3]:http://www.tecmint.com/ls-command-interview-questions/
|
||||
[4]:http://www.tecmint.com/advanced-copy-command-shows-progress-bar-while-copying-files/
|
||||
[5]:http://www.tecmint.com/rename-multiple-files-in-linux/
|
||||
[6]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[7]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[8]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[9]:http://www.tecmint.com/pwd-command-examples/
|
||||
[10]:http://www.tecmint.com/view-contents-of-file-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user