mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
Merge pull request #10401 from lujun9972/add-MjAxODA5MjYgMyBvcGVuIHNvdXJjZSBkaXN0cmlidXRlZCB0cmFjaW5nIHRvb2xzLm1kCg==
选题: 3 open source distributed tracing tools
This commit is contained in:
commit
7fdaa0a9cc
@ -0,0 +1,88 @@
|
||||
3 open source distributed tracing tools
|
||||
======
|
||||
|
||||
Find performance issues quickly with these tools, which provide a graphical view of what's happening across complex software systems.
|
||||
|
||||

|
||||
|
||||
Distributed tracing systems enable users to track a request through a software system that is distributed across multiple applications, services, and databases as well as intermediaries like proxies. This allows for a deeper understanding of what is happening within the software system. These systems produce graphical representations that show how much time the request took on each step and list each known step.
|
||||
|
||||
A user reviewing this content can determine where the system is experiencing latencies or blockages. Instead of testing the system like a binary search tree when requests start failing, operators and developers can see exactly where the issues begin. This can also reveal where performance changes might be occurring from deployment to deployment. It’s always better to catch regressions automatically by alerting to the anomalous behavior than to have your customers tell you.
|
||||
|
||||
How does this tracing thing work? Well, each request gets a special ID that’s usually injected into the headers. This ID uniquely identifies that transaction. This transaction is normally called a trace. The trace is the overall abstract idea of the entire transaction. Each trace is made up of spans. These spans are the actual work being performed, like a service call or a database request. Each span also has a unique ID. Spans can create subsequent spans called child spans, and child spans can have multiple parents.
|
||||
|
||||
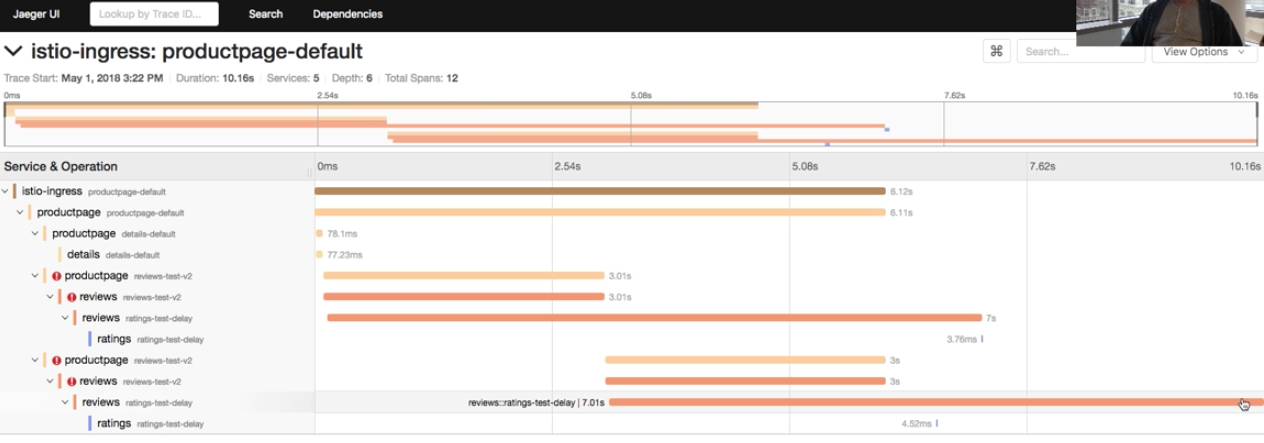
Once a transaction (or trace) has run its course, it can be searched in a presentation layer. There are several tools in this space that we’ll discuss later, but the picture below shows [Jaeger][1] from my [Istio walkthrough][2]. It shows multiple spans of a single trace. The power of this is immediately clear as you can better understand the transaction’s story at a glance.
|
||||
|
||||
|
||||
|
||||
This demo uses Istio’s built-in OpenTracing implementation, so I can get tracing without even modifying my application. It also uses Jaeger, which is OpenTracing-compatible.
|
||||
|
||||
So what is OpenTracing? Let’s find out.
|
||||
|
||||
### OpenTracing API
|
||||
|
||||
[OpenTracing][3] is a spec that grew out of [Zipkin][4] to provide cross-platform compatibility. It offers a vendor-neutral API for adding tracing to applications and delivering that data into distributed tracing systems. A library written for the OpenTracing spec can be used with any system that is OpenTracing-compliant. Zipkin, Jaeger, and Appdash are examples of open source tools that have adopted the open standard, but even proprietary tools like [Datadog][5] and [Instana][6] are adopting it. This is expected to continue as OpenTracing reaches ubiquitous status.
|
||||
|
||||
### OpenCensus
|
||||
|
||||
Okay, we have OpenTracing, but what is this [OpenCensus][7] thing that keeps popping up in my searches? Is it a competing standard, something completely different, or something complementary?
|
||||
|
||||
The answer depends on who you ask. I will do my best to explain the difference (as I understand it): OpenCensus takes a more holistic or all-inclusive approach. OpenTracing is focused on establishing an open API and spec and not on open implementations for each language and tracing system. OpenCensus provides not only the specification but also the language implementations and wire protocol. It also goes beyond tracing by including additional metrics that are normally outside the scope of distributed tracing systems.
|
||||
|
||||
OpenCensus allows viewing data on the host where the application is running, but it also has a pluggable exporter system for exporting data to central aggregators. The current exporters produced by the OpenCensus team include Zipkin, Prometheus, Jaeger, Stackdriver, Datadog, and SignalFx, but anyone can create an exporter.
|
||||
|
||||
From my perspective, there’s a lot of overlap. One isn’t necessarily better than the other, but it’s important to know what each does and doesn’t do. OpenTracing is primarily a spec, with others doing the implementation and opinionation. OpenCensus provides a holistic approach for the local component with more opinionation but still requires other systems for remote aggregation.
|
||||
|
||||
### Tool options
|
||||
|
||||
#### Zipkin
|
||||
|
||||
Zipkin was one of the first systems of this kind. It was developed by Twitter based on the [Google Dapper paper][8] about the internal system Google uses. Zipkin was written using Java, and it can use Cassandra or ElasticSearch as a scalable backend. Most companies should be satisfied with one of those options. The lowest supported Java version is Java 6. It also uses the [Thrift][9] binary communication protocol, which is popular in the Twitter stack and is hosted as an Apache project.
|
||||
|
||||
The system consists of reporters (clients), collectors, a query service, and a web UI. Zipkin is meant to be safe in production by transmitting only a trace ID within the context of a transaction to inform receivers that a trace is in process. The data collected in each reporter is then transmitted asynchronously to the collectors. The collectors store these spans in the database, and the web UI presents this data to the end user in a consumable format. The delivery of data to the collectors can occur in three different methods: HTTP, Kafka, and Scribe.
|
||||
|
||||
The [Zipkin community][10] has also created [Brave][11], a Java client implementation compatible with Zipkin. It has no dependencies, so it won’t drag your projects down or clutter them with libraries that are incompatible with your corporate standards. There are many other implementations, and Zipkin is compatible with the OpenTracing standard, so these implementations should also work with other distributed tracing systems. The popular Spring framework has a component called [Spring Cloud Sleuth][12] that is compatible with Zipkin.
|
||||
|
||||
#### Jaeger
|
||||
|
||||
[Jaeger][1] is a newer project from Uber Technologies that the [CNCF][13] has since adopted as an Incubating project. It is written in Golang, so you don’t have to worry about having dependencies installed on the host or any overhead of interpreters or language virtual machines. Similar to Zipkin, Jaeger also supports Cassandra and ElasticSearch as scalable storage backends. Jaeger is also fully compatible with the OpenTracing standard.
|
||||
|
||||
Jaeger’s architecture is similar to Zipkin, with clients (reporters), collectors, a query service, and a web UI, but it also has an agent on each host that locally aggregates the data. The agent receives data over a UDP connection, which it batches and sends to a collector. The collector receives that data in the form of the [Thrift][14] protocol and stores that data in Cassandra or ElasticSearch. The query service can access the data store directly and provide that information to the web UI.
|
||||
|
||||
By default, a user won’t get all the traces from the Jaeger clients. The system samples 0.1% (1 in 1,000) of traces that pass through each client. Keeping and transmitting all traces would be a bit overwhelming to most systems. However, this can be increased or decreased by configuring the agents, which the client consults with for its configuration. This sampling isn’t completely random, though, and it’s getting better. Jaeger uses probabilistic sampling, which tries to make an educated guess at whether a new trace should be sampled or not. [Adaptive sampling is on its roadmap][15], which will improve the sampling algorithm by adding additional context for making decisions.
|
||||
|
||||
#### Appdash
|
||||
|
||||
[Appdash][16] is a distributed tracing system written in Golang, like Jaeger. It was created by [Sourcegraph][17] based on Google’s Dapper and Twitter’s Zipkin. Similar to Jaeger and Zipkin, Appdash supports the OpenTracing standard; this was a later addition and requires a component that is different from the default component. This adds risk and complexity.
|
||||
|
||||
At a high level, Appdash’s architecture consists mostly of three components: a client, a local collector, and a remote collector. There’s not a lot of documentation, so this description comes from testing the system and reviewing the code. The client in Appdash gets added to your code. Appdash provides Python, Golang, and Ruby implementations, but OpenTracing libraries can be used with Appdash’s OpenTracing implementation. The client collects the spans and sends them to the local collector. The local collector then sends the data to a centralized Appdash server running its own local collector, which is the remote collector for all other nodes in the system.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/distributed-tracing-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.jaegertracing.io/
|
||||
[2]: https://www.youtube.com/watch?v=T8BbeqZ0Rls
|
||||
[3]: http://opentracing.io/
|
||||
[4]: https://zipkin.io/
|
||||
[5]: https://www.datadoghq.com/
|
||||
[6]: https://www.instana.com/
|
||||
[7]: https://opencensus.io/
|
||||
[8]: https://research.google.com/archive/papers/dapper-2010-1.pdf
|
||||
[9]: https://thrift.apache.org/
|
||||
[10]: https://zipkin.io/pages/community.html
|
||||
[11]: https://github.com/openzipkin/brave
|
||||
[12]: https://cloud.spring.io/spring-cloud-sleuth/
|
||||
[13]: https://www.cncf.io/
|
||||
[14]: https://en.wikipedia.org/wiki/Apache_Thrift
|
||||
[15]: https://www.jaegertracing.io/docs/roadmap/#adaptive-sampling
|
||||
[16]: https://github.com/sourcegraph/appdash
|
||||
[17]: https://about.sourcegraph.com/
|
||||
Loading…
Reference in New Issue
Block a user