mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
7fb5e2b329
@ -1,60 +1,58 @@
|
||||
如何将树莓派配置为打印服务器
|
||||
======
|
||||
|
||||
> 用树莓派和 CUPS 打印服务器将你的打印机变成网络打印机。
|
||||
|
||||

|
||||
|
||||
我喜欢在家做一些小项目,因此,今年我选择使用一个 [树莓派 3 Model B][1],这是一个像我这样的业余爱好者非常适合的东西。使用树莓派 3 Model B 的无线功能,我可以不使用线缆将树莓派连接到我的家庭网络中。这样可以很容易地将树莓派用到各种它所需要的地方。
|
||||
我喜欢在家做一些小项目,因此,今年我买了一个 [树莓派 3 Model B][1],这是一个非常适合像我这样的业余爱好者的东西。使用树莓派 3 Model B 的内置无线功能,我可以不使用线缆就将树莓派连接到我的家庭网络中。这样可以很容易地将树莓派用到各种所需要的地方。
|
||||
|
||||
在家里,我和我的妻子都使用笔记本电脑,但是我们只有一台打印机:一台使用的并不频繁的 HP 彩色激光打印机。因为我们的打印机并不内置无线网卡,因此,它不能直接连接到无线网络中,一般情况下,使用我的笔记本电脑时,我并不连接打印机,因为,我做的大多数工作并不需要打印。虽然这种安排在大多数时间都没有问题,但是,有时候,我的妻子想在不 “麻烦” 我的情况下,自己去打印一些东西。
|
||||
|
||||
### 基本设置
|
||||
在家里,我和我的妻子都使用笔记本电脑,但是我们只有一台打印机:一台使用的并不频繁的 HP 彩色激光打印机。因为我们的打印机并不内置无线网卡,因此,它不能直接连接到无线网络中,我们一般把打印机连接到我的笔记本电脑上,因为通常是我在打印。虽然这种安排在大多数时间都没有问题,但是,有时候,我的妻子想在不 “麻烦” 我的情况下,自己去打印一些东西。
|
||||
|
||||
我觉得我们需要一个将打印机连接到无线网络的解决方案,以便于我们都能够随时随地打印。我本想买一个无线打印服务器将我的 USB 打印机连接到家里的无线网络上。后来,我决定使用我的树莓派,将它设置为打印服务器,这样就可以让家里的每个人都可以随时来打印。
|
||||
|
||||
设置树莓派是非常简单的事。我下载了 [Raspbian][2] 镜像,并将它写入到我的 microSD 卡中。然后,使用它引导连接了一个 HDMI 显示器、一个 USB 键盘和一个 USB 鼠标的树莓派。之后,我们开始对它进行设置!
|
||||
### 基本设置
|
||||
|
||||
设置树莓派是非常简单的事。我下载了 [Raspbian][2] 镜像,并将它写入到我的 microSD 卡中。然后,使用它来引导一个连接了 HDMI 显示器、 USB 键盘和 USB 鼠标的树莓派。之后,我们开始对它进行设置!
|
||||
|
||||
这个树莓派系统自动引导到一个图形桌面,然后我做了一些基本设置:设置键盘语言、连接无线网络、设置普通用户帐户(`pi`)的密码、设置管理员用户(`root`)的密码。
|
||||
|
||||
我并不打算将树莓派运行在桌面环境下。我一般是通过我的普通的 Linux 计算机远程来使用它。因此,我使用树莓派的图形化管理工具,去设置将树莓派引导到控制台模式,而且不以 `pi` 用户自动登入。
|
||||
我并不打算将树莓派运行在桌面环境下。我一般是通过我的普通的 Linux 计算机远程来使用它。因此,我使用树莓派的图形化管理工具,去设置将树莓派引导到控制台模式,但不以 `pi` 用户自动登入。
|
||||
|
||||
重新启动树莓派之后,我需要做一些其它的系统方面的小调整,以便于我在家用网络中使用树莓派做为 “服务器”。我设置它的 DHCP 客户端为使用静态 IP 地址;默认情况下,DHCP 客户端可能任选一个可用的网络地址,这样我会不知道应该用哪个地址连接到树莓派。我的家用网络使用一个私有的 A 类地址,因此,我的路由器的 IP 地址是 `10.0.0.1`,并且我的全部可用地 IP 地址是 `10.0.0.x`。在我的案例中,低位的 IP 地址是安全的,因此,我通过在 `/etc/dhcpcd.conf` 中添加如下的行,设置它的无线网络使用 `10.0.0.11` 这个静态地址。
|
||||
|
||||
```
|
||||
interface wlan0
|
||||
|
||||
static ip_address=10.0.0.11/24
|
||||
|
||||
static routers=10.0.0.1
|
||||
|
||||
static domain_name_servers=8.8.8.8 8.8.4.4
|
||||
|
||||
```
|
||||
|
||||
在我再次重启之前,我需要去确认安全 shell 守护程序(SSHD)已经正常运行(你可以在 “偏好” 中设置哪些服务在引导时启动它)。这样我就可以使用 SSH 从普通的 Linux 系统上基于网络连接到树莓派中。
|
||||
|
||||
### 打印设置
|
||||
|
||||
现在,我的树莓派已经在网络上正常工作了,我通过 SSH 从我的 Linux 电脑上远程连接它,接着做剩余的设置。在继续设置之前,确保你的打印机已经连接到树莓派上。
|
||||
现在,我的树莓派已经连到网络上了,我通过 SSH 从我的 Linux 电脑上远程连接它,接着做剩余的设置。在继续设置之前,确保你的打印机已经连接到树莓派上。
|
||||
|
||||
设置打印机很容易。现代的打印服务器被称为 CUPS,意即“通用 Unix 打印系统”。任何最新的 Unix 系统都可以通过 CUPS 打印服务器来打印。为了在树莓派上设置 CUPS 打印服务器。你需要通过几个命令去安装 CUPS 软件,并使用新的配置来重启打印服务器,这样就可以允许其它系统来打印了。
|
||||
|
||||
设置打印机很容易。现在的打印服务器都称为 CUPS,它是标准的通用 Unix 打印系统。任何最新的 Unix 系统都可以通过 CUPS 打印服务器来打印。为了在树莓派上设置 CUPS 打印服务器。你需要通过几个命令去安装 CUPS 软件,并使用新的配置来重启打印服务器,这样就可以允许其它系统来打印了。
|
||||
```
|
||||
$ sudo apt-get install cups
|
||||
|
||||
$ sudo cupsctl --remote-any
|
||||
|
||||
$ sudo /etc/init.d/cups restart
|
||||
|
||||
```
|
||||
|
||||
在 CUPS 中设置打印机也是非常简单的,你可以通过一个 Web 界面来完成。CUPS 监听端口是 631,因此你可以在浏览器中收藏这个地址:
|
||||
在 CUPS 中设置打印机也是非常简单的,你可以通过一个 Web 界面来完成。CUPS 监听端口是 631,因此你用常用的浏览器来访问这个地址:
|
||||
|
||||
```
|
||||
https://10.0.0.11:631/
|
||||
|
||||
```
|
||||
|
||||
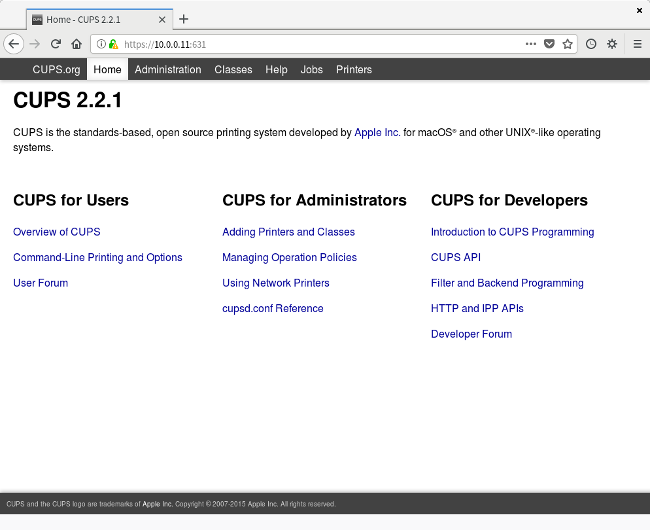
你的 Web 浏览器可能会弹出警告,因为它不认可这个 Web 浏览器的 https 证书;选择 ”接受它“,然后以管理员用户登入系统,你将看到如下的标准的 CUPS 面板:
|
||||
你的 Web 浏览器可能会弹出警告,因为它不认可这个 Web 浏览器的 https 证书;选择 “接受它”,然后以管理员用户登入系统,你将看到如下的标准的 CUPS 面板:
|
||||
|
||||
|
||||
|
||||
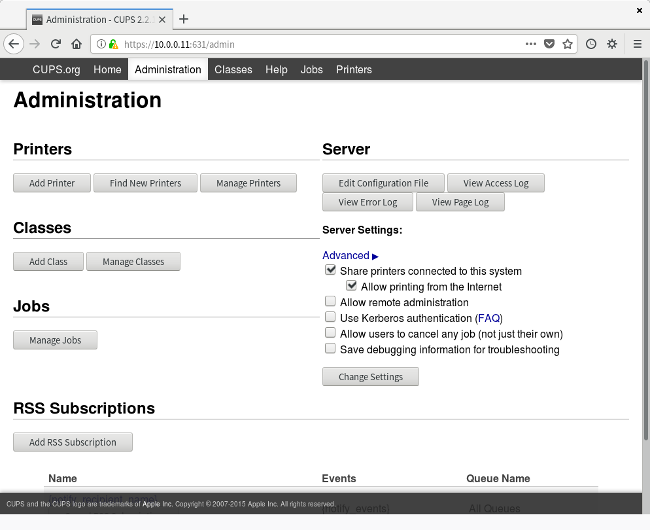
这时候,导航到管理标签,选择 “Add Printer"。
|
||||
这时候,导航到管理标签,选择 “Add Printer”。
|
||||
|
||||
|
||||
|
||||
@ -64,9 +62,9 @@ https://10.0.0.11:631/
|
||||
|
||||
### 客户端设置
|
||||
|
||||
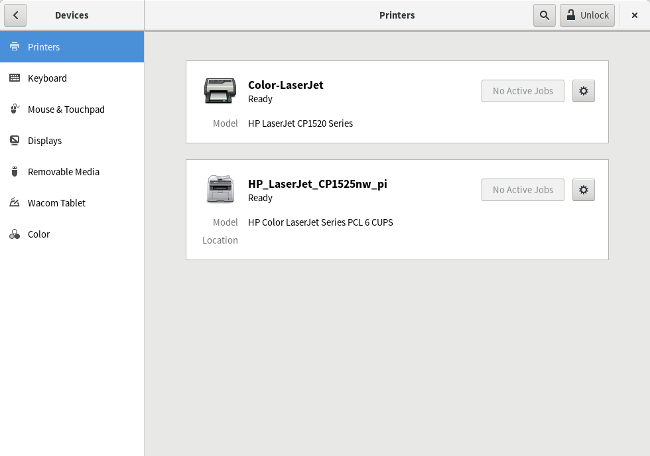
从 Linux 中设置一台网络打印机非常简单。我的桌面环境是 GNOME,你可以从 GNOME 的设置应用程序中添加网络打印机。只需要导航到设备和打印机,然后解锁这个面板。点击 “Add" 按钮去添加打印机。
|
||||
从 Linux 中设置一台网络打印机非常简单。我的桌面环境是 GNOME,你可以从 GNOME 的“设置”应用程序中添加网络打印机。只需要导航到“设备和打印机”,然后解锁这个面板。点击 “添加” 按钮去添加打印机。
|
||||
|
||||
在我的系统中,GNOME 设置为 ”自动发现网络打印机并添加它“。如果你的系统不是这样,你需要通过树莓派的 IP 地址,手动去添加打印机。
|
||||
在我的系统中,GNOME 的“设置”应用程序会自动发现网络打印机并添加它。如果你的系统不是这样,你需要通过树莓派的 IP 地址,手动去添加打印机。
|
||||
|
||||
|
||||
|
||||
@ -78,7 +76,7 @@ via: https://opensource.com/article/18/3/print-server-raspberry-pi
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,77 +1,74 @@
|
||||
在 Linux 下 9 个有用的 touch 命令示例
|
||||
=====
|
||||
|
||||
touch 命令用于创建空文件,并且更改 Unix 和 Linux 系统上现有文件时间戳。这里更改时间戳意味着更新文件和目录的访问以及修改时间。
|
||||
`touch` 命令用于创建空文件,也可以更改 Unix 和 Linux 系统上现有文件时间戳。这里所说的更改时间戳意味着更新文件和目录的访问以及修改时间。
|
||||
|
||||
[![touch-command-examples-linux][1]![touch-command-examples-linux][2]][2]
|
||||
![touch-command-examples-linux][2]
|
||||
|
||||
让我们来看看 touch 命令的语法和选项:
|
||||
让我们来看看 `touch` 命令的语法和选项:
|
||||
|
||||
**语法**: # touch {选项} {文件}
|
||||
**语法**:
|
||||
|
||||
touch 命令中使用的选项:
|
||||
```
|
||||
# touch {选项} {文件}
|
||||
```
|
||||
|
||||
![touch-command-options][1]
|
||||
`touch` 命令中使用的选项:
|
||||
|
||||
![touch-command-options][3]
|
||||
|
||||
在这篇文章中,我们将介绍 Linux 中 9 个有用的 touch 命令示例。
|
||||
在这篇文章中,我们将介绍 Linux 中 9 个有用的 `touch` 命令示例。
|
||||
|
||||
### 示例:1 使用 touch 创建一个空文件
|
||||
### 示例:1 使用 touch 创建一个空文件
|
||||
|
||||
要在 Linux 系统上使用 `touch` 命令创建空文件,键入 `touch`,然后输入文件名。如下所示:
|
||||
|
||||
要在 Linux 系统上使用 touch 命令创建空文件,键入 touch,然后输入文件名。如下所示:
|
||||
```
|
||||
[root@linuxtechi ~]# touch devops.txt
|
||||
[root@linuxtechi ~]# ls -l devops.txt
|
||||
-rw-r--r--. 1 root root 0 Mar 29 22:39 devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:2 使用 touch 创建批量空文件
|
||||
### 示例:2 使用 touch 创建批量空文件
|
||||
|
||||
可能会出现一些情况,我们必须为某些测试创建大量空文件,这可以使用 `touch` 命令轻松实现:
|
||||
|
||||
可能会出现一些情况,我们必须为某些测试创建大量空文件,这可以使用 touch 命令轻松实现:
|
||||
```
|
||||
[root@linuxtechi ~]# touch sysadm-{1..20}.txt
|
||||
|
||||
```
|
||||
|
||||
在上面的例子中,我们创建了 20 个名为 sysadm-1.txt 到 sysadm-20.txt 的空文件,你可以根据需要更改名称和数字。
|
||||
在上面的例子中,我们创建了 20 个名为 `sysadm-1.txt` 到 `sysadm-20.txt` 的空文件,你可以根据需要更改名称和数字。
|
||||
|
||||
### 示例:3 改变/更新文件和目录的访问时间
|
||||
### 示例:3 改变/更新文件和目录的访问时间
|
||||
|
||||
假设我们想要改变名为 `devops.txt` 文件的访问时间,在 `touch` 命令中使用 `-a` 选项,然后输入文件名。如下所示:
|
||||
|
||||
假设我们想要改变名为 **devops.txt** 文件的访问时间,在 touch 命令中使用 **-a** 选项,然后输入文件名。如下所示:
|
||||
```
|
||||
[root@linuxtechi ~]# touch -a devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
现在使用 `stat` 命令验证文件的访问时间是否已更新:
|
||||
```
|
||||
[root@linuxtechi ~]# stat devops.txt
|
||||
File: ‘devops.txt’
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
File: 'devops.txt'
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Context: unconfined_u:object_r:admin_home_t:s0
|
||||
Access: 2018-03-29 23:03:10.902000000 -0400
|
||||
Modify: 2018-03-29 22:39:29.365000000 -0400
|
||||
Change: 2018-03-29 23:03:10.902000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
Birth: -
|
||||
```
|
||||
|
||||
**改变目录的访问时间**
|
||||
**改变目录的访问时间:**
|
||||
|
||||
假设我们在 `/mnt` 目录下有一个 `nfsshare` 文件夹,让我们用下面的命令改变这个文件夹的访问时间:
|
||||
|
||||
假设我们在 /mnt 目录下有一个 ‘nfsshare’ 文件夹,让我们用下面的命令改变这个文件夹的访问时间:
|
||||
```
|
||||
[root@linuxtechi ~]# touch -m /mnt/nfsshare/
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
[root@linuxtechi ~]# stat /mnt/nfsshare/
|
||||
File: ‘/mnt/nfsshare/’
|
||||
File: '/mnt/nfsshare/'
|
||||
Size: 6 Blocks: 0 IO Block: 4096 directory
|
||||
Device: fd00h/64768d Inode: 2258 Links: 2
|
||||
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
@ -80,37 +77,34 @@ Access: 2018-03-29 23:34:38.095000000 -0400
|
||||
Modify: 2018-03-03 10:42:45.194000000 -0500
|
||||
Change: 2018-03-29 23:34:38.095000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:4 更改访问时间而不用创建新文件
|
||||
### 示例:4 更改访问时间而不用创建新文件
|
||||
|
||||
在某些情况下,如果文件存在,我们希望更改文件的访问时间,并避免创建文件。在 touch 命令中使用 `-c` 选项即可,如果文件存在,那么我们可以改变文件的访问时间,如果不存在,我们也可不会创建它。
|
||||
|
||||
在某些情况下,如果文件存在,我们希望更改文件的访问时间,并避免创建文件。在 touch 命令中使用 **-c** 选项即可,如果文件存在,那么我们可以改变文件的访问时间,如果不存在,我们也可不会创建它。
|
||||
```
|
||||
[root@linuxtechi ~]# touch -c sysadm-20.txt
|
||||
[root@linuxtechi ~]# touch -c winadm-20.txt
|
||||
[root@linuxtechi ~]# ls -l winadm-20.txt
|
||||
ls: cannot access winadm-20.txt: No such file or directory
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:5 更改文件和目录的修改时间
|
||||
### 示例:5 更改文件和目录的修改时间
|
||||
|
||||
在 touch 命令中使用 **-m** 选项,我们可以更改文件和目录的修改时间。
|
||||
在 `touch` 命令中使用 `-m` 选项,我们可以更改文件和目录的修改时间。
|
||||
|
||||
让我们更改名为 `devops.txt` 文件的更改时间:
|
||||
|
||||
让我们更改名为 “devops.txt” 文件的更改时间:
|
||||
```
|
||||
[root@linuxtechi ~]# touch -m devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
现在使用 stat 命令来验证修改时间是否改变:
|
||||
现在使用 `stat` 命令来验证修改时间是否改变:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# stat devops.txt
|
||||
File: ‘devops.txt’
|
||||
File: 'devops.txt'
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
@ -119,21 +113,19 @@ Access: 2018-03-29 23:03:10.902000000 -0400
|
||||
Modify: 2018-03-29 23:59:49.106000000 -0400
|
||||
Change: 2018-03-29 23:59:49.106000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
同样的,我们可以改变一个目录的修改时间:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# touch -m /mnt/nfsshare/
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
使用 stat 交叉验证访问和修改时间:
|
||||
使用 `stat` 交叉验证访问和修改时间:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# stat devops.txt
|
||||
File: ‘devops.txt’
|
||||
File: 'devops.txt'
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
@ -142,47 +134,47 @@ Access: 2018-03-30 00:06:20.145000000 -0400
|
||||
Modify: 2018-03-30 00:06:20.145000000 -0400
|
||||
Change: 2018-03-30 00:06:20.145000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:7 将访问和修改时间设置为特定的日期和时间
|
||||
### 示例:7 将访问和修改时间设置为特定的日期和时间
|
||||
|
||||
每当我们使用 touch 命令更改文件和目录的访问和修改时间时,它将当前时间设置为该文件或目录的访问和修改时间。
|
||||
每当我们使用 `touch` 命令更改文件和目录的访问和修改时间时,它将当前时间设置为该文件或目录的访问和修改时间。
|
||||
|
||||
假设我们想要将特定的日期和时间设置为文件的访问和修改时间,这可以使用 touch 命令中的 ‘-c’ 和 ‘-t’ 选项来实现。
|
||||
假设我们想要将特定的日期和时间设置为文件的访问和修改时间,这可以使用 `touch` 命令中的 `-c` 和 `-t` 选项来实现。
|
||||
|
||||
日期和时间可以使用以下格式指定:{CCYY}MMDDhhmm.ss
|
||||
日期和时间可以使用以下格式指定:
|
||||
|
||||
```
|
||||
{CCYY}MMDDhhmm.ss
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
* CC – 年份的前两位数字
|
||||
* YY – 年份的后两位数字
|
||||
* MM – 月份 (01-12)
|
||||
* DD – 天 (01-31)
|
||||
* hh – 小时 (00-23)
|
||||
* mm – 分钟 (00-59)
|
||||
* `CC` – 年份的前两位数字
|
||||
* `YY` – 年份的后两位数字
|
||||
* `MM` – 月份 (01-12)
|
||||
* `DD` – 天 (01-31)
|
||||
* `hh` – 小时 (00-23)
|
||||
* `mm` – 分钟 (00-59)
|
||||
|
||||
让我们将 `devops.txt` 文件的访问和修改时间设置为未来的一个时间(2025 年 10 月 19 日 18 时 20 分)。
|
||||
|
||||
让我们将 devops.txt file 文件的访问和修改时间设置为未来的一个时间( 2025 年, 10 月, 19 日, 18 时 20 分)。
|
||||
```
|
||||
[root@linuxtechi ~]# touch -c -t 202510191820 devops.txt
|
||||
|
||||
```
|
||||
|
||||
使用 stat 命令查看更新访问和修改时间:
|
||||
|
||||
![stat-command-output-linux][1]
|
||||
使用 `stat` 命令查看更新访问和修改时间:
|
||||
|
||||
![stat-command-output-linux][4]
|
||||
|
||||
根据日期字符串设置访问和修改时间,在 touch 命令中使用 ‘-d’ 选项,然后指定日期字符串,后面跟文件名。如下所示:
|
||||
根据日期字符串设置访问和修改时间,在 `touch` 命令中使用 `-d` 选项,然后指定日期字符串,后面跟文件名。如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# touch -c -d "2010-02-07 20:15:12.000000000 +0530" sysadm-29.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
使用 stat 命令验证文件的状态:
|
||||
使用 `stat` 命令验证文件的状态:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# stat sysadm-20.txt
|
||||
File: ‘sysadm-20.txt’
|
||||
@ -194,39 +186,43 @@ Access: 2010-02-07 20:15:12.000000000 +0530
|
||||
Modify: 2010-02-07 20:15:12.000000000 +0530
|
||||
Change: 2018-03-30 10:23:31.584000000 +0530
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
**注意:**在上述命令中,如果我们不指定 ‘-c’,那么 touch 命令将创建一个新文件以防系统中存在该文件,并将时间戳设置为命令中给出的。
|
||||
**注意:**在上述命令中,如果我们不指定 `-c`,如果系统中不存在该文件那么 `touch` 命令将创建一个新文件,并将时间戳设置为命令中给出的。
|
||||
|
||||
### 示例:8 使用参考文件设置时间戳(-r)
|
||||
### 示例:8 使用参考文件设置时间戳(-r)
|
||||
|
||||
在 touch 命令中,我们可以使用参考文件来设置文件或目录的时间戳。假设我想在 “devops.txt” 文件上设置与文件 “sysadm-20.txt” 文件相同的时间戳,touch 命令中使用 ‘-r’ 选项可以轻松实现。
|
||||
在 `touch` 命令中,我们可以使用参考文件来设置文件或目录的时间戳。假设我想在 `devops.txt` 文件上设置与文件 `sysadm-20.txt` 文件相同的时间戳,`touch` 命令中使用 `-r` 选项可以轻松实现。
|
||||
|
||||
**语法:**
|
||||
|
||||
```
|
||||
# touch -r {参考文件} 真正文件
|
||||
```
|
||||
|
||||
**语法:**# touch -r {参考文件} 真正文件
|
||||
```
|
||||
[root@linuxtechi ~]# touch -r sysadm-20.txt devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:9 在符号链接文件上更改访问和修改时间
|
||||
### 示例:9 在符号链接文件上更改访问和修改时间
|
||||
|
||||
默认情况下,每当我们尝试使用 touch 命令更改符号链接文件的时间戳时,它只会更改原始文件的时间戳。如果你想更改符号链接文件的时间戳,则可以使用 touch 命令中的 ‘-h’ 选项来实现。
|
||||
默认情况下,每当我们尝试使用 `touch` 命令更改符号链接文件的时间戳时,它只会更改原始文件的时间戳。如果你想更改符号链接文件的时间戳,则可以使用 `touch` 命令中的 `-h` 选项来实现。
|
||||
|
||||
**语法:**
|
||||
|
||||
```
|
||||
# touch -h {符号链接文件}
|
||||
```
|
||||
|
||||
**语法:** # touch -h {符号链接文件}
|
||||
```
|
||||
[root@linuxtechi opt]# ls -l /root/linuxgeeks.txt
|
||||
lrwxrwxrwx. 1 root root 15 Mar 30 10:56 /root/linuxgeeks.txt -> linuxadmins.txt
|
||||
[root@linuxtechi ~]# touch -t 203010191820 -h linuxgeeks.txt
|
||||
[root@linuxtechi ~]# ls -l linuxgeeks.txt
|
||||
lrwxrwxrwx. 1 root root 15 Oct 19 2030 linuxgeeks.txt -> linuxadmins.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
这就是本教程的全部了。我希望这些例子能帮助你理解 touch 命令。请分享你的宝贵意见和评论。
|
||||
这就是本教程的全部了。我希望这些例子能帮助你理解 `touch` 命令。请分享你的宝贵意见和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -234,7 +230,7 @@ via: https://www.linuxtechi.com/9-useful-touch-command-examples-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
119
sources/tech/20171109 Testing IPv6 Networking in KVM- Part 2.md
Normal file
119
sources/tech/20171109 Testing IPv6 Networking in KVM- Part 2.md
Normal file
@ -0,0 +1,119 @@
|
||||
Testing IPv6 Networking in KVM: Part 2
|
||||
======
|
||||
|
||||

|
||||
When last we met, in [Testing IPv6 Networking in KVM: Part 1][1], we learned about IPv6 private addressing. Today, we're going to use KVM to create networks for testing IPv6 to our heart's content.
|
||||
|
||||
Should you desire a refresh in using KVM, see [Creating Virtual Machines in KVM: Part 1][2] and [Creating Virtual Machines in KVM: Part 2 - Networking][3].
|
||||
|
||||
### Creating Networks in KVM
|
||||
|
||||
You need at least two virtual machines in KVM. Of course, you may create as many as you like. My little setup has Fedora, Ubuntu, and openSUSE. To create a new IPv6 network, open Edit > Connection Details > Virtual Networks in the main Virtual Machine Manager window. Click on the button with the green cross on the bottom left to create a new network (Figure 1).
|
||||
|
||||

|
||||
Figure 1: Create a network.
|
||||
|
||||
Give your new network a name, then click the Forward button. You may opt to not create an IPv4 network if you wish. When you create a new IPv4 network the Virtual Machine Manager will not let you create a duplicate network, or one with an invalid address. On my host Ubuntu system a valid address is highlighted in green, and an invalid address is highlighted in a tasteful rosy hue. On my openSUSE machine there are no colored highlights. Enable DHCP or not, and create a static route or not, then move on to the next window.
|
||||
|
||||
Check "Enable IPv6 network address space definition" and enter your private address range. You may use any IPv6 address class you wish, being careful, of course, to not allow your experiments to leak out of your network. We shall use the nice IPv6 unique local addresses (ULA), and use the online address generator at [Simple DNS Plus][4] to create our network address. Copy the "Combined/CID" address into the Network field (Figure 2).
|
||||
|
||||
|
||||
![network address][6]
|
||||
|
||||
Figure 2: Copy the "Combined/CID" address into the Network field.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
Virtual Machine Manager thinks my address is not valid, as evidenced by the rose highlight. Can it be right? Let us use ipv6calc to check:
|
||||
```
|
||||
$ ipv6calc -qi fd7d:844d:3e17:f3ae::/64
|
||||
Address type: unicast, unique-local-unicast, iid, iid-local
|
||||
Registry for address: reserved(RFC4193#3.1)
|
||||
Address type has SLA: f3ae
|
||||
Interface identifier: 0000:0000:0000:0000
|
||||
Interface identifier is probably manual set
|
||||
|
||||
```
|
||||
|
||||
ipv6calc thinks it's fine. Just for fun, change one of the numbers to something invalid, like the letter g, and try it again. (Asking "What if...?" and trial and error is the awesomest way to learn.)
|
||||
|
||||
Let us carry on and enable DHCPv6 (Figure 3). You can accept the default values, or set your own.
|
||||
|
||||

|
||||
|
||||
We shall skip creating a default route definition and move on to the next screen, where we shall enable "Isolated Virtual Network" and "Enable IPv6 internal routing/networking".
|
||||
|
||||
### VM Network Selection
|
||||
|
||||
Now you can configure your virtual machines to use your new network. Open your VMs, and then click the "i" button at the top left to open its "Show virtual hardware details" screen. In the "Add Hardware" column click on the NIC button to open the network selector, and select your nice new IPv6 network. Click Apply, and then reboot. (Or use your favorite method for restarting networking, or renewing your DHCP lease.)
|
||||
|
||||
### Testing
|
||||
|
||||
What does ifconfig tell us?
|
||||
```
|
||||
$ ifconfig
|
||||
ens3: flags=4163 UP,BROADCAST,RUNNING,MULTICAST mtu 1500
|
||||
inet 192.168.30.207 netmask 255.255.255.0
|
||||
broadcast 192.168.30.255
|
||||
inet6 fd7d:844d:3e17:f3ae::6314
|
||||
prefixlen 128 scopeid 0x0
|
||||
inet6 fe80::4821:5ecb:e4b4:d5fc
|
||||
prefixlen 64 scopeid 0x20
|
||||
|
||||
```
|
||||
|
||||
And there is our nice new ULA, fd7d:844d:3e17:f3ae::6314, and the auto-generated link-local address that is always present. Let's have some ping fun, pinging another VM on the network:
|
||||
```
|
||||
vm1 ~$ ping6 -c2 fd7d:844d:3e17:f3ae::2c9f
|
||||
PING fd7d:844d:3e17:f3ae::2c9f(fd7d:844d:3e17:f3ae::2c9f) 56 data bytes
|
||||
64 bytes from fd7d:844d:3e17:f3ae::2c9f: icmp_seq=1 ttl=64 time=0.635 ms
|
||||
64 bytes from fd7d:844d:3e17:f3ae::2c9f: icmp_seq=2 ttl=64 time=0.365 ms
|
||||
|
||||
vm2 ~$ ping6 -c2 fd7d:844d:3e17:f3ae:a:b:c:6314
|
||||
PING fd7d:844d:3e17:f3ae:a:b:c:6314(fd7d:844d:3e17:f3ae:a:b:c:6314) 56 data bytes
|
||||
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=1 ttl=64 time=0.744 ms
|
||||
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=2 ttl=64 time=0.364 ms
|
||||
|
||||
```
|
||||
|
||||
When you're struggling to understand subnetting, this gives you a fast, easy way to try different addresses and see whether they work. You can assign multiple IP addresses to a single interface and then ping them to see what happens. In a ULA, the interface, or host, portion of the IP address is the last four quads, so you can do anything to those and still be in the same subnet, which in this example is f3ae. This example changes only the interface ID on one of my VMs, to show how you really can do whatever you want with those four quads:
|
||||
```
|
||||
vm1 ~$ sudo /sbin/ip -6 addr add fd7d:844d:3e17:f3ae:a:b:c:6314 dev ens3
|
||||
|
||||
vm2 ~$ ping6 -c2 fd7d:844d:3e17:f3ae:a:b:c:6314
|
||||
PING fd7d:844d:3e17:f3ae:a:b:c:6314(fd7d:844d:3e17:f3ae:a:b:c:6314) 56 data bytes
|
||||
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=1 ttl=64 time=0.744 ms
|
||||
64 bytes from fd7d:844d:3e17:f3ae:a:b:c:6314: icmp_seq=2 ttl=64 time=0.364 ms
|
||||
|
||||
```
|
||||
|
||||
Now try it with a different subnet, which in this example is f4ae instead of f3ae:
|
||||
```
|
||||
$ ping6 -c2 fd7d:844d:3e17:f4ae:a:b:c:6314
|
||||
PING fd7d:844d:3e17:f4ae:a:b:c:6314(fd7d:844d:3e17:f4ae:a:b:c:6314) 56 data bytes
|
||||
From fd7d:844d:3e17:f3ae::1 icmp_seq=1 Destination unreachable: No route
|
||||
From fd7d:844d:3e17:f3ae::1 icmp_seq=2 Destination unreachable: No route
|
||||
|
||||
```
|
||||
|
||||
This is also a great time to practice routing, which we will do in a future installment along with setting up auto-addressing without DHCP.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-2
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
[2]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-1
|
||||
[3]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-2-networking
|
||||
[4]:http://simpledns.com/private-ipv6.aspx
|
||||
[5]:/files/images/kvm-fig-2png
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/floated_images/public/kvm-fig-2.png?itok=gncdPGj- (network address)
|
||||
[7]:https://www.linux.com/licenses/category/used-permission
|
||||
@ -1,375 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
How To Manage NodeJS Packages Using Npm
|
||||
======
|
||||
|
||||

|
||||
|
||||
A while ago, we have published a guide to [**manage Python packages using PIP**][1]. Today, we are going to discuss how to manage NodeJS packages using Npm. NPM is the largest software registry that contains over 600,000 packages. Everyday, developers across the world shares and downloads packages through npm. In this guide, I will explain the the basics of working with npm, such as installing packages(locally and globally), installing certain version of a package, updating, removing and managing NodeJS packages and so on.
|
||||
|
||||
### Manage NodeJS Packages Using Npm
|
||||
|
||||
##### Installing NPM
|
||||
|
||||
Since npm is written in NodeJS, we need to install NodeJS in order to use npm. To install NodeJS on different Linux distributions, refer the following link.
|
||||
|
||||
Once installed, ensure that NodeJS and NPM have been properly installed. There are couple ways to do this.
|
||||
|
||||
To check where node has been installed:
|
||||
```
|
||||
$ which node
|
||||
/home/sk/.nvm/versions/node/v9.4.0/bin/node
|
||||
```
|
||||
|
||||
Check its version:
|
||||
```
|
||||
$ node -v
|
||||
v9.4.0
|
||||
```
|
||||
|
||||
Log in to Node REPL session:
|
||||
```
|
||||
$ node
|
||||
> .help
|
||||
.break Sometimes you get stuck, this gets you out
|
||||
.clear Alias for .break
|
||||
.editor Enter editor mode
|
||||
.exit Exit the repl
|
||||
.help Print this help message
|
||||
.load Load JS from a file into the REPL session
|
||||
.save Save all evaluated commands in this REPL session to a file
|
||||
> .exit
|
||||
```
|
||||
|
||||
Check where npm installed:
|
||||
```
|
||||
$ which npm
|
||||
/home/sk/.nvm/versions/node/v9.4.0/bin/npm
|
||||
```
|
||||
|
||||
And the version:
|
||||
```
|
||||
$ npm -v
|
||||
5.6.0
|
||||
```
|
||||
|
||||
Great! Node and NPM have been installed and are working! As you may have noticed, I have installed NodeJS and NPM in my $HOME directory to avoid permission issues while installing modules globally. This is the recommended method by NodeJS team.
|
||||
|
||||
Well, let us go ahead to see managing NodeJS modules (or packages) using npm.
|
||||
|
||||
##### Installing NodeJS modules
|
||||
|
||||
NodeJS modules can either be installed locally or globally(system wide). Now I am going to show how to install a package locally.
|
||||
|
||||
**Install packages locally**
|
||||
|
||||
To manage packages locally, we normally use **package.json** file.
|
||||
|
||||
First, let us create our project directory.
|
||||
```
|
||||
$ mkdir demo
|
||||
```
|
||||
```
|
||||
$ cd demo
|
||||
```
|
||||
|
||||
Create a package.json file inside your project's directory. To do so, run:
|
||||
```
|
||||
$ npm init
|
||||
```
|
||||
|
||||
Enter the details of your package such as name, version, author, github page etc., or just hit ENTER key to accept the default values and type **YES** to confirm.
|
||||
```
|
||||
This utility will walk you through creating a package.json file.
|
||||
It only covers the most common items, and tries to guess sensible defaults.
|
||||
|
||||
See `npm help json` for definitive documentation on these fields
|
||||
and exactly what they do.
|
||||
|
||||
Use `npm install <pkg>` afterwards to install a package and
|
||||
save it as a dependency in the package.json file.
|
||||
|
||||
Press ^C at any time to quit.
|
||||
package name: (demo)
|
||||
version: (1.0.0)
|
||||
description: demo nodejs app
|
||||
entry point: (index.js)
|
||||
test command:
|
||||
git repository:
|
||||
keywords:
|
||||
author:
|
||||
license: (ISC)
|
||||
About to write to /home/sk/demo/package.json:
|
||||
|
||||
{
|
||||
"name": "demo",
|
||||
"version": "1.0.0",
|
||||
"description": "demo nodejs app",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC"
|
||||
}
|
||||
|
||||
Is this ok? (yes) yes
|
||||
```
|
||||
|
||||
The above command initializes your project and create package.json file.
|
||||
|
||||
You can also do this non-interactively using command:
|
||||
```
|
||||
npm init --y
|
||||
```
|
||||
|
||||
This will create a package.json file quickly with default values without the user interaction.
|
||||
|
||||
Now let us install package named [**commander**][2].
|
||||
```
|
||||
$ npm install commander
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
npm notice created a lockfile as package-lock.json. You should commit this file.
|
||||
npm WARN demo@1.0.0 No repository field.
|
||||
|
||||
+ commander@2.13.0
|
||||
added 1 package in 2.519s
|
||||
```
|
||||
|
||||
This will create a directory named **" node_modules"** (if it doesn't exist already) in the project's root directory and download the packages in it.
|
||||
|
||||
Let us check the package.json file.
|
||||
```
|
||||
$ cat package.json
|
||||
{
|
||||
"name": "demo",
|
||||
"version": "1.0.0",
|
||||
"description": "demo nodejs app",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC",
|
||||
**"dependencies": {**
|
||||
**"commander": "^2.13.0"**
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You will see the dependencies have been added. The caret ( **^** ) at the front of the version number indicates that when installing, npm will pull the highest version of the package it can find.
|
||||
```
|
||||
$ ls node_modules/
|
||||
commander
|
||||
```
|
||||
|
||||
The advantage of package.json file is if you had the package.json file in your project's directory, you can just type "npm install", then npm will look into the dependencies that listed in the file and download all of them. You can even share it with other developers or push into your GitHub repository, so when they type "npm install", they will get all the same packages that you have.
|
||||
|
||||
You may also noticed another json file named **package-lock.json**. This file ensures that the dependencies remain the same on all systems the project is installed on.
|
||||
|
||||
To use the installed package in your program, create a file **index.js** (or any name of you choice) in the project's directory with the actual code, and then run it using command:
|
||||
```
|
||||
$ node index.js
|
||||
```
|
||||
|
||||
**Install packages globally**
|
||||
|
||||
If you want to use a package as a command line tool, then it is better to install it globally. This way, it works no matter which directory is your current directory.
|
||||
```
|
||||
$ npm install async -g
|
||||
+ async@2.6.0
|
||||
added 2 packages in 4.695s
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ npm install async --global
|
||||
```
|
||||
|
||||
To install a specific version of a package, we do:
|
||||
```
|
||||
$ npm install async@2.6.0 --global
|
||||
```
|
||||
|
||||
##### Updating NodeJS modules
|
||||
|
||||
To update the local packages, go the the project's directory where the package.json is located and run:
|
||||
```
|
||||
$ npm update
|
||||
```
|
||||
|
||||
Then, run the following command to ensure all packages were updated.
|
||||
```
|
||||
$ npm outdated
|
||||
```
|
||||
|
||||
If there is no update, then it returns nothing.
|
||||
|
||||
To find out which global packages need to be updated, run:
|
||||
```
|
||||
$ npm outdated -g --depth=0
|
||||
```
|
||||
|
||||
If there is no output, then all packages are updated.
|
||||
|
||||
To update the a single global package, run:
|
||||
```
|
||||
$ npm update -g <package-name>
|
||||
```
|
||||
|
||||
To update all global packages, run:
|
||||
```
|
||||
$ npm update -g <package>
|
||||
```
|
||||
|
||||
##### Listing NodeJS modules
|
||||
|
||||
To list the local packages, go the project's directory and run:
|
||||
```
|
||||
$ npm list
|
||||
demo@1.0.0 /home/sk/demo
|
||||
└── commander@2.13.0
|
||||
```
|
||||
|
||||
As you see, I have installed "commander" package in local mode.
|
||||
|
||||
To list global packages, run this command from any location:
|
||||
```
|
||||
$ npm list -g
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
/home/sk/.nvm/versions/node/v9.4.0/lib
|
||||
├─┬ async@2.6.0
|
||||
│ └── lodash@4.17.4
|
||||
└─┬ npm@5.6.0
|
||||
├── abbrev@1.1.1
|
||||
├── ansi-regex@3.0.0
|
||||
├── ansicolors@0.3.2
|
||||
├── ansistyles@0.1.3
|
||||
├── aproba@1.2.0
|
||||
├── archy@1.0.0
|
||||
[...]
|
||||
```
|
||||
|
||||
This command will list all modules and their dependencies.
|
||||
|
||||
To list only the top level modules, use -depth=0 option:
|
||||
```
|
||||
$ npm list -g --depth=0
|
||||
/home/sk/.nvm/versions/node/v9.4.0/lib
|
||||
├── async@2.6.0
|
||||
└── npm@5.6.0
|
||||
```
|
||||
|
||||
##### Searching NodeJS modules
|
||||
|
||||
To search for a module, use "npm search" command:
|
||||
```
|
||||
npm search <search-string>
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
$ npm search request
|
||||
```
|
||||
|
||||
This command will display all modules that contains the search string "request".
|
||||
|
||||
##### Removing NodeJS modules
|
||||
|
||||
To remove a local package, go to the project's directory and run following command to remove the package from your **node_modules** directory:
|
||||
```
|
||||
$ npm uninstall <package-name>
|
||||
```
|
||||
|
||||
To remove it from the dependencies in **package.json** file, use the **save** flag like below:
|
||||
```
|
||||
$ npm uninstall --save <package-name>
|
||||
|
||||
```
|
||||
|
||||
To remove the globally installed packages, run:
|
||||
```
|
||||
$ npm uninstall -g <package>
|
||||
```
|
||||
|
||||
##### Cleaning NPM cache
|
||||
|
||||
By default, NPM keeps the copy of a installed package in the cache folder named npm in your $HOME directory when installing it. So, you can install it next time without having to download again.
|
||||
|
||||
To view the cached modules:
|
||||
```
|
||||
$ ls ~/.npm
|
||||
```
|
||||
|
||||
The cache folder gets flooded with all old packages over time. It is better to clean the cache from time to time.
|
||||
|
||||
As of npm@5, the npm cache self-heals from corruption issues and data extracted from the cache is guaranteed to be valid. If you want to make sure everything is consistent, run:
|
||||
```
|
||||
$ npm cache verify
|
||||
```
|
||||
|
||||
To clear the entire cache, run:
|
||||
```
|
||||
$ npm cache clean --force
|
||||
```
|
||||
|
||||
##### Viewing NPM configuration
|
||||
|
||||
To view the npm configuration, type:
|
||||
```
|
||||
$ npm config list
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ npm config ls
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
; cli configs
|
||||
metrics-registry = "https://registry.npmjs.org/"
|
||||
scope = ""
|
||||
user-agent = "npm/5.6.0 node/v9.4.0 linux x64"
|
||||
|
||||
; node bin location = /home/sk/.nvm/versions/node/v9.4.0/bin/node
|
||||
; cwd = /home/sk
|
||||
; HOME = /home/sk
|
||||
; "npm config ls -l" to show all defaults.
|
||||
```
|
||||
|
||||
To display the current global location:
|
||||
```
|
||||
$ npm config get prefix
|
||||
/home/sk/.nvm/versions/node/v9.4.0
|
||||
```
|
||||
|
||||
And, that's all for now. What we have just covered here is just the basics. NPM is a vast topic. For more details, head over to the the [**NPM Getting Started**][3] guide.
|
||||
|
||||
Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[2]:https://www.npmjs.com/package/commander
|
||||
[3]:https://docs.npmjs.com/getting-started/
|
||||
@ -1,349 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
How To Edit Multiple Files Using Vim Editor
|
||||
======
|
||||
|
||||

|
||||
Sometimes, you will find yourself in a situation where you want to make changes in multiple files or you might want to copy the contents of one file to another. If you’re on GUI mode, you could simply open the files in any graphical text editor, like gedit, and use CTRL+C and CTRL+V to copy/paste the contents. In CLI mode, you can’t use such editors. No worries! Where there is vim editor, there is a way! In this tutorial, we are going to learn to edit multiple files at the same time using Vim editor. Trust me, this is very interesting read.
|
||||
|
||||
### Installing Vim
|
||||
|
||||
Vim editor is available in the official repositories of most Linux distributions. So you can install it using the default package manager. For example, on Arch Linux and its variants you can install it using command:
|
||||
```
|
||||
$ sudo pacman -S vim
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu:
|
||||
```
|
||||
$ sudo apt-get install vim
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
```
|
||||
$ sudo yum install vim
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
```
|
||||
$ sudo dnf install vim
|
||||
|
||||
```
|
||||
|
||||
On openSUSE:
|
||||
```
|
||||
$ sudo zypper install vim
|
||||
|
||||
```
|
||||
|
||||
### Edit multiple files at a time using Vim editor in Linux
|
||||
|
||||
Let us now get down to the business. We can do this in two methods.
|
||||
|
||||
#### Method 1
|
||||
|
||||
I have two files namely **file1.txt** and **file2.txt** , with a bunch of random words. Let us have a look at them.
|
||||
```
|
||||
$ cat file1.txt
|
||||
ostechnix
|
||||
open source
|
||||
technology
|
||||
linux
|
||||
unix
|
||||
|
||||
$ cat file2.txt
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
Now, let us edit these two files at a time. To do so, run:
|
||||
```
|
||||
$ vim file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
Vim will display the contents of the files in an order. The first file’s contents will be shown first and then second file and so on.
|
||||
|
||||
![][2]
|
||||
|
||||
**Switch between files**
|
||||
|
||||
To move to the next file, type:
|
||||
```
|
||||
:n
|
||||
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
To go back to previous file, type:
|
||||
```
|
||||
:N
|
||||
|
||||
```
|
||||
|
||||
Vim won’t allow you to move to the next file if there are any unsaved changes. To save the changes in the current file, type:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
Please note that it is double capital letters ZZ (SHIFT+zz).
|
||||
|
||||
To abandon the changes and move to the previous file, type:
|
||||
```
|
||||
:N!
|
||||
|
||||
```
|
||||
|
||||
To view the files which are being currently edited, type:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
You will see the list of loaded files at the bottom.
|
||||
|
||||
![][5]
|
||||
|
||||
To switch to the next file, type **:buffer** followed by the buffer number. For example, to switch to the first file, type:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
**Opening additional files for editing**
|
||||
|
||||
We are currently editing two files namely file1.txt, file2.txt. I want to open another file named **file3.txt** for editing.
|
||||
What will you do? It’s easy! Just type **:e** followed by the file name like below.
|
||||
```
|
||||
:e file3.txt
|
||||
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
Now you can edit file3.txt.
|
||||
|
||||
To view how many files are being edited currently, type:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
Please note that you can not switch between opened files with **:e** using either **:n** or **:N**. To switch to another file, type **:buffer** followed by the file buffer number.
|
||||
|
||||
**Copying contents of one file into another**
|
||||
|
||||
You know how to open and edit multiple files at the same time. Sometimes, you might want to copy the contents of one file into another. It is possible too. Switch to a file of your choice. For example, let us say you want to copy the contents of file1.txt into file2.txt.
|
||||
|
||||
To do so, first switch to file1.txt:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
Place the move cursor in-front of a line that wants to copy and type **yy** to yank(copy) the line. Then. move to file2.txt:
|
||||
```
|
||||
:buffer 2
|
||||
|
||||
```
|
||||
|
||||
Place the mouse cursor where you want to paste the copied lines from file1.txt and type **p**. For example, you want to paste the copied line between line2 and line3. To do so, put the mouse cursor before line and type **p**.
|
||||
|
||||
Sample output:
|
||||
```
|
||||
line1
|
||||
line2
|
||||
ostechnix
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
To save the changes made in the current file, type:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
Again, please note that this is double capital ZZ (SHIFT+z).
|
||||
|
||||
To save the changes in all files and exit vim editor. type:
|
||||
```
|
||||
:wq
|
||||
|
||||
```
|
||||
|
||||
Similarly, you can copy any line from any file to other files.
|
||||
|
||||
**Copying entire file contents into another**
|
||||
|
||||
We know how to copy a single line. What about the entire file contents? That’s also possible. Let us say, you want to copy the entire contents of file1.txt into file2.txt.
|
||||
|
||||
To do so, open the file2.txt first:
|
||||
```
|
||||
$ vim file2.txt
|
||||
|
||||
```
|
||||
|
||||
If the files are already loaded, you can switch to file2.txt by typing:
|
||||
```
|
||||
:buffer 2
|
||||
|
||||
```
|
||||
|
||||
Move the cursor to the place where you wanted to copy the contents of file1.txt. I want to copy the contents of file1.txt after line5 in file2.txt, so I moved the cursor to line 5. Then, type the following command and hit ENTER key:
|
||||
```
|
||||
:r file1.txt
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
Here, **r** means **read**.
|
||||
|
||||
Now you will see the contents of file1.txt is pasted after line5 in file2.txt.
|
||||
```
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
ostechnix
|
||||
open source
|
||||
technology
|
||||
linux
|
||||
unix
|
||||
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
To save the changes in the current file, type:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
To save all changes in all loaded files and exit vim editor, type:
|
||||
```
|
||||
:wq
|
||||
|
||||
```
|
||||
|
||||
#### Method 2
|
||||
|
||||
The another method to open multiple files at once is by using either **-o** or **-O** flags.
|
||||
|
||||
To open multiple files in horizontal windows, run:
|
||||
```
|
||||
$ vim -o file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
To switch between windows, press **CTRL-w w** (i.e Press **CTRL+w** and again press **w** ). Or, you the following shortcuts to move between windows.
|
||||
|
||||
* **CTRL-w k** – top window
|
||||
* **CTRL-w j** – bottom window
|
||||
|
||||
|
||||
|
||||
To open multiple files in vertical windows, run:
|
||||
```
|
||||
$ vim -O file1.txt file2.txt file3.txt
|
||||
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
To switch between windows, press **CTRL-w w** (i.e Press **CTRL+w** and again press **w** ). Or, use the following shortcuts to move between windows.
|
||||
|
||||
* **CTRL-w l** – left window
|
||||
* **CTRL-w h** – right window
|
||||
|
||||
|
||||
|
||||
Everything else is same as described in method 1.
|
||||
|
||||
For example, to list currently loaded files, run:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
To switch between files:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
To open an additional file, type:
|
||||
```
|
||||
:e file3.txt
|
||||
|
||||
```
|
||||
|
||||
To copy entire contents of a file into another:
|
||||
```
|
||||
:r file1.txt
|
||||
|
||||
```
|
||||
|
||||
The only difference in method 2 is once you saved the changes in the current file using **ZZ** , the file will automatically close itself. Also, you need to close the files one by one by typing **:wq**. But, had you followed the method 1, when typing **:wq** all changes will be saved in all files and all files will be closed at once.
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man vim
|
||||
|
||||
```
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
You know now how to edit multiples files using vim editor in Linux. As you can see, editing multiple files is not that difficult. Vim editor has more powerful features. We will write more about Vim editor in the days to come.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-edit-multiple-files-using-vim-editor/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-1-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-5.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-6.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-7.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-8.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-10-1.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-11.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-12.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-13.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/03/Edit-multiple-files-16.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/03/Edit-multiple-files-17.png
|
||||
@ -1,93 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to reset a root password on Fedora
|
||||
======
|
||||
|
||||

|
||||
A system administrator can easily reset a password for a user that has forgotten their password. But what happens if the system administrator forgets the root password? This guide will show you how to reset a lost or forgotten root password. Note that to reset the root password, you need to have physical access to the machine in order to reboot and to access GRUB settings. Additionally, if the system is encrypted, you will also need to know the LUKS passphrase.
|
||||
|
||||
### Edit the GRUB settings
|
||||
|
||||
First you need to interrupt the boot process. So you’ll need to turn on the system or restart, if it’s already powered on. The first step is tricky because the grub menu tends to flash by very quickly on the screen.
|
||||
|
||||
Press **E** on your keyboard when you see the GRUB menu:
|
||||
|
||||
![][1]
|
||||
|
||||
After pressing ‘e’ the following screen is shown:
|
||||
|
||||
![][2]
|
||||
|
||||
Use your arrow keys to move the the **linux16** line.
|
||||
|
||||
![][3]
|
||||
|
||||
Using your **del** key or **backspace** key, remove **rhgb quiet** and replace with the following.
|
||||
```
|
||||
rd.break enforcing=0
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
After editing the lines, Press **Ctrl-x** to start the system. If the system is encrypted, you will be prompted for the LUKS passphase here.
|
||||
|
||||
**Note:** Setting enforcing=0, avoids performing a complete system SELinux relabeling. Once the system is rebooted, restore the correct SELinux context for the /etc/shadow file. (this is explained a little further in this process)
|
||||
|
||||
### Mounting the filesystem
|
||||
|
||||
The system will now be in emergency mode. Remount the hard drive with read-write access:
|
||||
```
|
||||
# mount –o remount,rw /sysroot
|
||||
|
||||
```
|
||||
|
||||
### **Password Change
|
||||
|
||||
**
|
||||
|
||||
Run chroot to access the system.
|
||||
```
|
||||
# chroot /sysroot
|
||||
|
||||
```
|
||||
|
||||
You can now change the root password.
|
||||
```
|
||||
# passwd
|
||||
|
||||
```
|
||||
|
||||
Type the new root password twice when prompted. If you are successful, you should see a message that **all authentication tokens updated successfully.**
|
||||
|
||||
Type **exit** , twice to reboot the system.
|
||||
|
||||
Log in as root and restore the SELinux label to the /etc/shadow file.
|
||||
```
|
||||
# restorecon -v /etc/shadow
|
||||
|
||||
```
|
||||
|
||||
Turn SELinux back to enforcing mode.
|
||||
```
|
||||
# setenforce 1
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/reset-root-password-fedora/
|
||||
|
||||
作者:[Curt Warfield][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/rcurtiswarfield/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub2.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub3.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub4.png
|
||||
@ -2,6 +2,7 @@ Configuring local storage in Linux with Stratis
|
||||
======
|
||||
|
||||

|
||||
|
||||
Configuring local storage is something desktop Linux users do very infrequently—maybe only once, during installation. Linux storage tech moves slowly, and many storage tools used 20 years ago are still used regularly today. But some things have improved since then. Why aren't people taking advantage of these new capabilities?
|
||||
|
||||
This article is about Stratis, a new project that aims to bring storage advances to all Linux users, from the simple laptop single SSD to a hundred-disk array. Linux has the capabilities, but its lack of an easy-to-use solution has hindered widespread adoption. Stratis's goal is to make Linux's advanced storage features accessible.
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
What Stratis learned from ZFS, Btrfs, and Linux Volume Manager | Opensource.com
|
||||
======
|
||||
|
||||

|
||||
|
||||
As discussed in [Part 1][1] of this series, Stratis is a volume-managing filesystem (VMF) with functionality similar to [ZFS][2] and [Btrfs][3]. In designing Stratis, we studied the choices that developers of existing solutions made.
|
||||
|
||||
135
sources/tech/20180427 3 Python template libraries compared.md
Normal file
135
sources/tech/20180427 3 Python template libraries compared.md
Normal file
@ -0,0 +1,135 @@
|
||||
3 Python template libraries compared
|
||||
======
|
||||
|
||||

|
||||
In my day job, I spend a lot of time wrangling data from various sources into human-readable information. While a lot of the time this just takes the form of a spreadsheet or some type of chart or other data visualization, there are other times when it makes sense to present the data instead in a written format.
|
||||
|
||||
But a pet peeve of mine is copying and pasting. If you’re moving data from its source to a standardized template, you shouldn’t be copying and pasting either. It’s error-prone, and honestly, it’s not a good use of your time.
|
||||
|
||||
So for any piece of information I send out regularly which follows a common pattern, I tend to find some way to automate at least a chunk of it. Maybe that involves creating a few formulas in a spreadsheet, a quick shell script, or some other solution to autofill a template with information pulled from an outside source.
|
||||
|
||||
But lately, I’ve been exploring Python templating to do much of the work of creating reports and graphs from other datasets.
|
||||
|
||||
Python templating engines are hugely powerful. My use case of simplifying report creation only scratches the surface of what they can be put to work for. Many developers are making use of these tools to build full-fledged web applications and content management systems. But you don’t have to have a grand vision of a complicated web app to make use of Python templating tools.
|
||||
|
||||
### Why templating?
|
||||
|
||||
Each templating tool is a little different, and you should read the documentation to understand the exact usage. But let’s create a hypothetical example. Let’s say I’d like to create a short page listing all of the Python topics I've written about recently. Something like this:
|
||||
```
|
||||
html>
|
||||
|
||||
head>
|
||||
|
||||
title>/title>
|
||||
|
||||
/head>
|
||||
|
||||
body>
|
||||
|
||||
p>/p>
|
||||
|
||||
ul>
|
||||
|
||||
li>/li>
|
||||
|
||||
li>/li>
|
||||
|
||||
li>/li>
|
||||
|
||||
/ul>
|
||||
|
||||
/body>
|
||||
|
||||
/html>My Python articlesThese are some of the things I have written about Python:Python GUIsPython IDEsPython web scrapers
|
||||
|
||||
```
|
||||
|
||||
Simple enough to maintain when it’s just these three items. But what happens when I want to add a fourth, or fifth, or sixty-seventh? Rather than hand-coding this page, could I generate it from a CSV or other data file containing a list of all of my pages? Could I easily create duplicates of this for every topic I've written on? Could I programmatically change the text or title or heading on each one of those pages? That's where a templating engine can come into play.
|
||||
|
||||
There are many different options to choose from, and today I'll share with you three, in no particular order: [Mako][6], [Jinja2][7], and [Genshi][8].
|
||||
|
||||
### Mako
|
||||
|
||||
[Mako][6] is a Python templating tool released under the MIT license that is designed for fast performance (not unlike Jinja2). Mako has been used by Reddit to power their web pages, as well as being the default templating language for web frameworks like Pyramid and Pylons. It's also fairly simple and straightforward to use; you can design templates with just a couple of lines of code. Supporting both Python 2.x and 3.x, it's a powerful and feature-rich tool with [good documentation][9], which I consider a must. Features include filters, inheritance, callable blocks, and a built-in caching system, which could be import for large or complex web projects.
|
||||
|
||||
### Jinja2
|
||||
|
||||
Jinja2 is another speedy and full-featured option, available for both Python 2.x and 3.x under a BSD license. Jinja2 has a lot of overlap from a feature perspective with Mako, so for a newcomer, your choice between the two may come down to which formatting style you prefer. Jinja2 also compiles your templates to bytecode, and has features like HTML escaping, sandboxing, template inheritance, and the ability to sandbox portions of templates. Its users include Mozilla, SourceForge, NPR, Instagram, and others, and also features [strong documentation][10]. Unlike Mako, which uses Python inline for logic inside your templates, Jinja2 uses its own syntax.
|
||||
|
||||
### Genshi
|
||||
|
||||
[Genshi][8] is the third option I'll mention. It's really an XML tool which has a strong templating component, so if the data you are working with is already in XML format, or you need to work with formatting beyond a web page, Genshi might be a good solution for you. HTML is basically a type of XML (well, not precisely, but that's beyond the scope of this article and a bit pedantic), so formatting them is quite similar. Since a lot of the data I work with commonly is in one flavor of XML or another, I appreciated working with a tool I could use for multiple things.
|
||||
|
||||
The release version currently only supports Python 2.x, although Python 3 support exists in trunk, I would caution you that it does not appear to be receiving active development. Genshi is made available under a BSD license.
|
||||
|
||||
### Example
|
||||
|
||||
So in our hypothetical example above, rather than update the HTML file every time I write about a new topic, I can update it programmatically. I can create a template, which might look like this:
|
||||
```
|
||||
html>
|
||||
|
||||
head>
|
||||
|
||||
title>/title>
|
||||
|
||||
/head>
|
||||
|
||||
body>
|
||||
|
||||
p>/p>
|
||||
|
||||
ul>
|
||||
|
||||
%for topic in topics:
|
||||
|
||||
li>/li>
|
||||
|
||||
%endfor
|
||||
|
||||
/ul>
|
||||
|
||||
/body>
|
||||
|
||||
/html>My Python articlesThese are some of the things I have written about Python:%for topic in topics:${topic}%endfor
|
||||
|
||||
```
|
||||
|
||||
And then I can iterate across each topic with my templating library, in this case, Mako, like this:
|
||||
```
|
||||
from mako.template import Template
|
||||
|
||||
|
||||
|
||||
mytemplate = Template(filename='template.txt')
|
||||
|
||||
print(mytemplate.render(topics=("Python GUIs","Python IDEs","Python web scrapers")))
|
||||
|
||||
```
|
||||
|
||||
Of course, in a real-world usage, rather than listing the contents manually in a variable, I would likely pull them from an outside data source, like a database or an API.
|
||||
|
||||
These are not the only Python templating engines out there. If you’re starting down the path of creating a new project which will make heavy use of templates, you’ll want to consider more than just these three. Check out this much more comprehensive list on the [Python wiki][11] for more projects that are worth considering.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/resources/python/template-libraries
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[2]:https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[3]:https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[4]:https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[5]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[6]:http://www.makotemplates.org/
|
||||
[7]:http://jinja.pocoo.org/
|
||||
[8]:https://genshi.edgewall.org/
|
||||
[9]:http://docs.makotemplates.org/en/latest/
|
||||
[10]:http://jinja.pocoo.org/docs/2.10/
|
||||
[11]:https://wiki.python.org/moin/Templating
|
||||
144
sources/tech/20180427 How to Compile a Linux Kernel.md
Normal file
144
sources/tech/20180427 How to Compile a Linux Kernel.md
Normal file
@ -0,0 +1,144 @@
|
||||
How to Compile a Linux Kernel
|
||||
======
|
||||
|
||||

|
||||
|
||||
Once upon a time the idea of upgrading the Linux kernel sent fear through the hearts of many a user. Back then, the process of upgrading the kernel involved a lot of steps and even more time. Now, installing a new kernel can be easily handled with package managers like apt. With the addition of certain repositories, you can even easily install experimental or specific kernels (such as real-time kernels for audio production) without breaking a sweat.
|
||||
|
||||
Considering how easy it is to upgrade your kernel, why would you bother compiling one yourself? Here are a few possible reasons:
|
||||
|
||||
* You simply want to know how it’s done.
|
||||
|
||||
* You need to enable or disable specific options into a kernel that simply aren’t available via the standard options.
|
||||
|
||||
* You want to enable hardware support that might not be found in the standard kernel.
|
||||
|
||||
* You’re using a distribution that requires you compile the kernel.
|
||||
|
||||
* You’re a student and this is an assignment.
|
||||
|
||||
|
||||
|
||||
|
||||
Regardless of why, knowing how to compile a Linux kernel is very useful and can even be seen as a right of passage. When I first compiled a new Linux kernel (a long, long time ago) and managed to boot from said kernel, I felt a certain thrill coursing through my system (which was quickly crushed the next time I attempted and failed).
|
||||
With that said, let’s walk through the process of compiling a Linux kernel. I’ll be demonstrating on Ubuntu 16.04 Server. After running through a standard sudo apt upgrade, the installed kernel is 4.4.0-121. I want to upgrade to kernel 4.17. Let’s take care of that.
|
||||
|
||||
A word of warning: I highly recommend you practice this procedure on a virtual machine. By working with a VM, you can always create a snapshot and back out of any problems with ease. DO NOT upgrade the kernel this way on a production machine… not until you know what you’re doing.
|
||||
|
||||
### Downloading the kernel
|
||||
|
||||
The first thing to do is download the kernel source file. This can be done by finding the URL of the kernel you want to download (from [Kernel.org][1]). Once you have the URL, download the source file with the following command (I’ll demonstrate with kernel 4.17 RC2):
|
||||
```
|
||||
wget https://git.kernel.org/torvalds/t/linux-4.17-rc2.tar.gz
|
||||
|
||||
```
|
||||
|
||||
While that file is downloading, there are a few bits to take care of.
|
||||
|
||||
### Installing requirements
|
||||
|
||||
In order to compile the kernel, we’ll need to first install a few requirements. This can be done with a single command:
|
||||
```
|
||||
sudo apt-get install git fakeroot build-essential ncurses-dev xz-utils libssl-dev bc flex libelf-dev bison
|
||||
|
||||
```
|
||||
|
||||
Do note: You will need at least 12GB of free space on your local drive to get through the kernel compilation process. So make sure you have enough space.
|
||||
|
||||
### Extracting the source
|
||||
|
||||
From within the directory housing our newly downloaded kernel, extract the kernel source with the command:
|
||||
```
|
||||
tar xvzf linux-4.17-rc2.tar.gz
|
||||
|
||||
```
|
||||
|
||||
Change into the newly created directory with the command cd linux-4.17-rc2.
|
||||
|
||||
### Configuring the kernel
|
||||
|
||||
Before we actually compile the kernel, we must first configure which modules to include. There is actually a really easy way to do this. With a single command, you can copy the current kernel’s config file and then use the tried and true menuconfig command to make any necessary changes. To do this, issue the command:
|
||||
```
|
||||
cp /boot/config-$(uname -r) .config
|
||||
|
||||
```
|
||||
|
||||
Now that you have a configuration file, issue the command make menuconfig. This command will open up a configuration tool (Figure 1) that allows you to go through every module available and enable or disable what you need or don’t need.
|
||||
|
||||
|
||||
![menuconfig][3]
|
||||
|
||||
Figure 1: The make menuconfig in action.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
It is quite possible you might disable a critical portion of the kernel, so step through menuconfig with care. If you’re not sure about an option, leave it alone. Or, better yet, stick with the configuration we just copied from the running kernel (as we know it works). Once you’ve gone through the entire list (it’s quite long), you’re ready to compile!
|
||||
|
||||
### Compiling and installing
|
||||
|
||||
Now it’s time to actually compile the kernel. The first step is to compile using the make command. So issue make and then answer the necessary questions (Figure 2). The questions asked will be determined by what kernel you’re upgrading from and what kernel you’re upgrading to. Trust me when I say there’s a ton of questions to answer, so give yourself plenty of time here.
|
||||
|
||||
|
||||
![make][6]
|
||||
|
||||
Figure 2: Answering the questions for the make command.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
After answering the litany of questions, you can then install the modules you’ve enabled with the command:
|
||||
```
|
||||
make modules_install
|
||||
|
||||
```
|
||||
|
||||
Once again, this command will take some time, so either sit back and watch the output, or go do something else (as it will not require your input). Chances are, you’ll want to undertake another task (unless you really enjoy watching output fly by in a terminal).
|
||||
|
||||
Now we install the kernel with the command:
|
||||
```
|
||||
sudo make install
|
||||
|
||||
```
|
||||
|
||||
Again, another command that’s going to take a significant amount of time. In fact, the make install command will take even longer than the make modules_install command. Go have lunch, configure a router, install Linux on a few servers, or take a nap.
|
||||
|
||||
### Enable the kernel for boot
|
||||
|
||||
Once the make install command completes, it’s time to enable the kernel for boot. To do this, issue the command:
|
||||
```
|
||||
sudo update-initramfs -c -k 4.17-rc2
|
||||
|
||||
```
|
||||
|
||||
Of course, you would substitute the kernel number above for the kernel you’ve compiled. When that command completes, update grub with the command:
|
||||
```
|
||||
sudo update-grub
|
||||
|
||||
```
|
||||
|
||||
You should now be able to restart your system and select the newly installed kernel.
|
||||
|
||||
### Congratulations!
|
||||
|
||||
You’ve compiled a Linux kernel! It’s a process that may take some time; but, in the end, you’ll have a custom kernel for your Linux distribution, as well as an important skill that many Linux admins tend to overlook.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][7] course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/4/how-compile-linux-kernel-0
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.kernel.org/
|
||||
[2]:/files/images/kernelcompile1jpg
|
||||
[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kernel_compile_1.jpg?itok=ZNybYgEt (menuconfig)
|
||||
[4]:/licenses/category/used-permission
|
||||
[5]:/files/images/kernelcompile2jpg
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kernel_compile_2.jpg?itok=TYfV02wC (make)
|
||||
[7]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to use FIND in Linux
|
||||
======
|
||||
|
||||
|
||||
311
sources/tech/20180428 A Beginners Guide To Flatpak.md
Normal file
311
sources/tech/20180428 A Beginners Guide To Flatpak.md
Normal file
@ -0,0 +1,311 @@
|
||||
A Beginners Guide To Flatpak
|
||||
======
|
||||
|
||||

|
||||
|
||||
A while, we have written about [**Ubuntu’s Snaps**][1]. Snaps are introduced by Canonical for Ubuntu operating system, and later it was adopted by other Linux distributions such as Arch, Gentoo, and Fedora etc. A snap is a single binary package bundled with all required libraries and dependencies, and you can install it on any Linux distribution, regardless of its version and architecture. Similar to Snaps, there is also another tool called **Flatpak**. As you may already know, packaging distributed applications for different Linux distributions are quite time consuming and difficult process. Each distributed application has different set of libraries and dependencies for various Linux distributions. But, Flatpak, the new framework for desktop applications that completely reduces this burden. Now, you can build a single Flatpak app and install it on various operating systems. How cool, isn’t it?
|
||||
|
||||
Also, the users don’t have to worry about the libraries and dependencies, everything is bundled within the app itself. Most importantly, Flaptpak apps are sandboxed and isolated from the rest of the host operating system, and other applications. Another notable feature is we can install multiple versions of the same application at the same time in the same system. For example, you can install VLC player version 2.1, 2.2, and 2.3 on the same system. So, the developers can test different versions of same application at a time.
|
||||
|
||||
In this tutorial, we will see how to install Flatpak in GNU/Linux.
|
||||
|
||||
### Install Flatpak
|
||||
|
||||
Flatpak is available for many popular Linux distributions such as Arch Linux, Debian, Fedora, Gentoo, Red Hat, Linux Mint, openSUSE, Solus, Mageia and Ubuntu distributions.
|
||||
|
||||
To install Flatpak on Arch Linux, run:
|
||||
```
|
||||
$ sudo pacman -S flatpak
|
||||
|
||||
```
|
||||
|
||||
Flatpak is available in the default repositories of Debian Stretch and newer. To install it, run:
|
||||
```
|
||||
$ sudo apt install flatpak
|
||||
|
||||
```
|
||||
|
||||
On Fedora, Flatpak is installed by default. All you have to do is enable enable Flathub as described in the next section.
|
||||
|
||||
Just in case, it is not installed for any reason, run:
|
||||
```
|
||||
$ sudo dnf install flatpak
|
||||
|
||||
```
|
||||
|
||||
On RHEL 7, run:
|
||||
```
|
||||
$ sudo yum install flatpak
|
||||
|
||||
```
|
||||
|
||||
On Linux Mint 18.3, flatpak is installed by default. So, no setup required.
|
||||
|
||||
On openSUSE Tumbleweed, Flatpak can also be installed using Zypper:
|
||||
```
|
||||
$ sudo zypper install flatpak
|
||||
|
||||
```
|
||||
|
||||
On Ubuntu, add the following repository and install Flatpak as shown below.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alexlarsson/flatpak
|
||||
|
||||
$ sudo apt update
|
||||
|
||||
$ sudo apt install flatpak
|
||||
|
||||
```
|
||||
|
||||
The Flatpak plugin for the Software app makes it possible to install apps without needing the command line. To install this plugin, run:
|
||||
```
|
||||
$ sudo apt install gnome-software-plugin-flatpak
|
||||
|
||||
```
|
||||
|
||||
For other Linux distributions, refer the official installation [**link**][2].
|
||||
|
||||
### Getting Started With Flatpak
|
||||
|
||||
There are many popular applications such as Gimp, Kdenlive, Steam, Spotify, Visual studio code etc., available as flatpaks.
|
||||
|
||||
Let us now see the basic usage of flatpak command.
|
||||
|
||||
First of all, we need to add remote repositories.
|
||||
|
||||
#### Adding Remote Repositories**
|
||||
|
||||
**Enable Flathub Repository:**
|
||||
|
||||
**Flathub** is nothing but a central repository where all flatpak applications available to users. To enable it, just run:
|
||||
```
|
||||
$ sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
|
||||
```
|
||||
|
||||
Flathub is enough to install most popular apps. Just in case you wanted to try some GNOME apps, add the GNOME repository.
|
||||
|
||||
**Enable GNOME Repository:**
|
||||
|
||||
The GNOME repository contains all GNOME core applications. GNOME flatpak repository itself is available as two versions, **stable** and **nightly**.
|
||||
|
||||
To add GNOME stable repository, run the following commands:
|
||||
```
|
||||
$ wget https://sdk.gnome.org/keys/gnome-sdk.gpg
|
||||
|
||||
$ sudo flatpak remote-add --gpg-import=gnome-sdk.gpg --if-not-exists gnome-apps https://sdk.gnome.org/repo-apps/
|
||||
|
||||
```
|
||||
|
||||
Applications in this repository require the **3.20 version of the org.gnome.Platform runtime**.
|
||||
|
||||
To install the stable runtimes, run:
|
||||
```
|
||||
$ sudo flatpak remote-add --gpg-import=gnome-sdk.gpg gnome https://sdk.gnome.org/repo/
|
||||
|
||||
```
|
||||
|
||||
To add the GNOME nightly apps repository, run:
|
||||
```
|
||||
$ wget https://sdk.gnome.org/nightly/keys/nightly.gpg
|
||||
|
||||
$ sudo flatpak remote-add --gpg-import=nightly.gpg --if-not-exists gnome-nightly-apps https://sdk.gnome.org/nightly/repo-apps/
|
||||
|
||||
```
|
||||
|
||||
Applications in this repository require the **nightly version of the org.gnome.Platform runtime**.
|
||||
|
||||
To install the nightly runtimes, run:
|
||||
```
|
||||
$ sudo flatpak remote-add --gpg-import=nightly.gpg gnome-nightly https://sdk.gnome.org/nightly/repo/
|
||||
|
||||
```
|
||||
|
||||
#### Listing Remotes
|
||||
|
||||
To list all configured remote repositories, run:
|
||||
```
|
||||
$ flatpak remotes
|
||||
Name Options
|
||||
flathub system
|
||||
gnome system
|
||||
gnome-apps system
|
||||
gnome-nightly system
|
||||
gnome-nightly-apps system
|
||||
|
||||
```
|
||||
|
||||
As you can see, the above command lists the remotes that you have added in your system. It also lists whether the remote has been added per-user or system-wide.
|
||||
|
||||
#### Removing Remotes
|
||||
|
||||
To remove a remote, for example flathub, simply do;
|
||||
```
|
||||
$ sudo flatpak remote-delete flathub
|
||||
|
||||
```
|
||||
|
||||
Here **flathub** is remote name.
|
||||
|
||||
#### Installing Flatpak Applications
|
||||
|
||||
In this section, we will see how to install flatpak apps. To install a flatpak application
|
||||
|
||||
To install an application, simply do:
|
||||
```
|
||||
$ sudo flatpak install flathub com.spotify.Client
|
||||
|
||||
```
|
||||
|
||||
All the apps in the GNOME stable repository uses the version name of “stable”.
|
||||
|
||||
To install any Stable GNOME applications, for example **Evince** , run:
|
||||
```
|
||||
$ sudo flatpak install gnome-apps org.gnome.Evince stable
|
||||
|
||||
```
|
||||
|
||||
All the apps in the GNOME nightly repository uses the version name of “master”.
|
||||
|
||||
For example, to install gedit, run:
|
||||
```
|
||||
$ sudo flatpak install gnome-nightly-apps org.gnome.gedit master
|
||||
|
||||
```
|
||||
|
||||
If you don’t want to install apps system-wide, you also can install flatpak apps per-user like below.
|
||||
```
|
||||
$ flatpak install --user <name-of-app>
|
||||
|
||||
```
|
||||
|
||||
All installed apps will be stored in **$HOME/.var/app/** location.
|
||||
```
|
||||
$ ls $HOME/.var/app/
|
||||
com.spotify.Client
|
||||
|
||||
```
|
||||
|
||||
#### Running Flatpak Applications
|
||||
|
||||
You can launch the installed applications at any time from the application launcher. From command line, you can run it, for example Spotify, using command:
|
||||
```
|
||||
$ flatpak run com.spotify.Client
|
||||
|
||||
```
|
||||
|
||||
#### Listing Applications
|
||||
|
||||
To view the installed applications and runtimes, run:
|
||||
```
|
||||
$ flatpak list
|
||||
|
||||
```
|
||||
|
||||
To view only the applications, not run times, use this command instead.
|
||||
```
|
||||
$ flatpak list --app
|
||||
|
||||
```
|
||||
|
||||
You can also view the list of available applications and runtimes from all remotes using command:
|
||||
```
|
||||
$ flatpak remote-ls
|
||||
|
||||
```
|
||||
|
||||
To list only applications not runtimes, run:
|
||||
```
|
||||
$ flatpak remote-ls --app
|
||||
|
||||
```
|
||||
|
||||
To list applications and runtimes from a specific repository, for example **gnome-apps** , run:
|
||||
```
|
||||
$ flatpak remote-ls gnome-apps
|
||||
|
||||
```
|
||||
|
||||
To list only the applications from a remote repository, run:
|
||||
```
|
||||
$ flatpak remote-ls flathub --app
|
||||
|
||||
```
|
||||
|
||||
#### Updating Applications
|
||||
|
||||
To update all your flatpak applications, run:
|
||||
```
|
||||
$ flatpak update
|
||||
|
||||
```
|
||||
|
||||
To update a specific application, we do:
|
||||
```
|
||||
$ flatpak update com.spotify.Client
|
||||
|
||||
```
|
||||
|
||||
#### Getting Details Of Applications
|
||||
|
||||
To display the details of a installed application, run:
|
||||
```
|
||||
$ flatpak info io.github.mmstick.FontFinder
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
Ref: app/io.github.mmstick.FontFinder/x86_64/stable
|
||||
ID: io.github.mmstick.FontFinder
|
||||
Arch: x86_64
|
||||
Branch: stable
|
||||
Origin: flathub
|
||||
Date: 2018-04-11 15:10:31 +0000
|
||||
Subject: Workaround appstream issues (391ef7f5)
|
||||
Commit: 07164e84148c9fc8b0a2a263c8a468a5355b89061b43e32d95008fc5dc4988f4
|
||||
Parent: dbff9150fce9fdfbc53d27e82965010805f16491ec7aa1aa76bf24ec1882d683
|
||||
Location: /var/lib/flatpak/app/io.github.mmstick.FontFinder/x86_64/stable/07164e84148c9fc8b0a2a263c8a468a5355b89061b43e32d95008fc5dc4988f4
|
||||
Installed size: 2.5 MB
|
||||
Runtime: org.gnome.Platform/x86_64/3.28
|
||||
|
||||
```
|
||||
|
||||
#### Removing Applications
|
||||
|
||||
To remove a flatpak application, run:
|
||||
```
|
||||
$ sudo flatpak uninstall com.spotify.Client
|
||||
|
||||
```
|
||||
|
||||
For details, refer flatpak help section.
|
||||
```
|
||||
$ flatpak --help
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope you had basic idea about Flatpak.
|
||||
|
||||
If you find this guide useful, please share it on your social, professional networks and support OSTechNix.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://www.ostechnix.com/introduction-ubuntus-snap-packages/
|
||||
[2]:https://flatpak.org/setup/
|
||||
@ -0,0 +1,633 @@
|
||||
3 practical Python tools: magic methods, iterators and generators, and method magic
|
||||
======
|
||||
|
||||

|
||||
Python offers a unique set of tools and language features that help make your code more elegant, readable, and intuitive. By selecting the right tool for the right problem, your code will be easier to maintain. In this article, we'll examine three of those tools: magic methods, iterators and generators, and method magic.
|
||||
|
||||
### Magic methods
|
||||
|
||||
|
||||
Magic methods can be considered the plumbing of Python. They're the methods that are called "under the hood" for certain built-in methods, symbols, and operations. A common magic method you may be familiar with is, `__init__()`,which is called when we want to initialize a new instance of a class.
|
||||
|
||||
You may have seen other common magic methods, like `__str__` and `__repr__`. There is a whole world of magic methods, and by implementing a few of them, we can greatly modify the behavior of an object or even make it behave like a built-in datatype, such as a number, list, or dictionary.
|
||||
|
||||
Let's take this `Money` class for example:
|
||||
```
|
||||
class Money:
|
||||
|
||||
|
||||
|
||||
currency_rates = {
|
||||
|
||||
'$': 1,
|
||||
|
||||
'€': 0.88,
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
def __init__(self, symbol, amount):
|
||||
|
||||
self.symbol = symbol
|
||||
|
||||
self.amount = amount
|
||||
|
||||
|
||||
|
||||
def __repr__(self):
|
||||
|
||||
return '%s%.2f' % (self.symbol, self.amount)
|
||||
|
||||
|
||||
|
||||
def convert(self, other):
|
||||
|
||||
""" Convert other amount to our currency """
|
||||
|
||||
new_amount = (
|
||||
|
||||
other.amount / self.currency_rates[other.symbol]
|
||||
|
||||
* self.currency_rates[self.symbol])
|
||||
|
||||
|
||||
|
||||
return Money(self.symbol, new_amount)
|
||||
|
||||
```
|
||||
|
||||
The class defines a currency rate for a given symbol and exchange rate, specifies an initializer (also known as a constructor), and implements `__repr__`, so when we print out the class, we see a nice representation such as `$2.00` for an instance `Money('$', 2.00)` with the currency symbol and amount. Most importantly, it defines a method that allows you to convert between different currencies with different exchange rates.
|
||||
|
||||
Using a Python shell, let's say we've defined the costs for two food items in different currencies, like so:
|
||||
```
|
||||
>>> soda_cost = Money('$', 5.25)
|
||||
|
||||
>>> soda_cost
|
||||
|
||||
$5.25
|
||||
|
||||
|
||||
|
||||
>>> pizza_cost = Money('€', 7.99)
|
||||
|
||||
>>> pizza_cost
|
||||
|
||||
€7.99
|
||||
|
||||
```
|
||||
|
||||
We could use magic methods to help instances of this class interact with each other. Let's say we wanted to be able to add two instances of this class together, even if they were in different currencies. To make that a reality, we could implement the `__add__` magic method on our `Money` class:
|
||||
```
|
||||
class Money:
|
||||
|
||||
|
||||
|
||||
# ... previously defined methods ...
|
||||
|
||||
|
||||
|
||||
def __add__(self, other):
|
||||
|
||||
""" Add 2 Money instances using '+' """
|
||||
|
||||
new_amount = self.amount + self.convert(other).amount
|
||||
|
||||
return Money(self.symbol, new_amount)
|
||||
|
||||
```
|
||||
|
||||
Now we can use this class in a very intuitive way:
|
||||
```
|
||||
>>> soda_cost = Money('$', 5.25)
|
||||
|
||||
|
||||
|
||||
>>> pizza_cost = Money('€', 7.99)
|
||||
|
||||
|
||||
|
||||
>>> soda_cost + pizza_cost
|
||||
|
||||
$14.33
|
||||
|
||||
|
||||
|
||||
>>> pizza_cost + soda_cost
|
||||
|
||||
€12.61
|
||||
|
||||
```
|
||||
|
||||
When we add two instances together, we get a result in the first defined currency. All the conversion is done seamlessly under the hood. If we wanted to, we could also implement `__sub__` for subtraction, `__mul__` for multiplication, and many more. Read about [emulating numeric types][1], or read this [guide to magic methods][2] for others.
|
||||
|
||||
We learned that `__add__` maps to the built-in operator `+`. Other magic methods can map to symbols like `[]`. For example, to access an item by index or key (in the case of a dictionary), use the `__getitem__` method:
|
||||
```
|
||||
>>> d = {'one': 1, 'two': 2}
|
||||
|
||||
|
||||
|
||||
>>> d['two']
|
||||
|
||||
2
|
||||
|
||||
>>> d.__getitem__('two')
|
||||
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
Some magic methods even map to built-in functions, such as `__len__()`, which maps to `len()`.
|
||||
```
|
||||
class Alphabet:
|
||||
|
||||
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
|
||||
|
||||
|
||||
|
||||
def __len__(self):
|
||||
|
||||
return len(self.letters)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
>>> my_alphabet = Alphabet()
|
||||
|
||||
>>> len(my_alphabet)
|
||||
|
||||
26
|
||||
|
||||
```
|
||||
|
||||
### Custom iterators
|
||||
|
||||
Custom iterators are an incredibly powerful but unfortunately confusing topic to new and seasoned Pythonistas alike.
|
||||
|
||||
Many built-in types, such as lists, sets, and dictionaries, already implement the protocol that allows them to be iterated over under the hood. This allows us to easily loop over them.
|
||||
```
|
||||
>>> for food in ['Pizza', 'Fries']:
|
||||
|
||||
print(food + '. Yum!')
|
||||
|
||||
|
||||
|
||||
Pizza. Yum!
|
||||
|
||||
Fries. Yum!
|
||||
|
||||
```
|
||||
|
||||
How can we iterate over our own custom classes? First, let's clear up some terminology.
|
||||
|
||||
* To be iterable, a class needs to implement `__iter__()`
|
||||
* The `__iter__()` method needs to return an iterator
|
||||
* To be an iterator, a class needs to implement `__next__()` (or `next()` [in Python 2][3]), which must raise a `StopIteration` exception when there are no more items to iterate over.
|
||||
|
||||
|
||||
|
||||
Whew! It sounds complicated, but once you remember these fundamental concepts, you'll be able to iterate in your sleep.
|
||||
|
||||
When might we want to use a custom iterator? Let's imagine a scenario where we have a `Server` instance running different services such as `http` and `ssh` on different ports. Some of these services have an `active` state while others are `inactive`.
|
||||
```
|
||||
class Server:
|
||||
|
||||
|
||||
|
||||
services = [
|
||||
|
||||
{'active': False, 'protocol': 'ftp', 'port': 21},
|
||||
|
||||
{'active': True, 'protocol': 'ssh', 'port': 22},
|
||||
|
||||
{'active': True, 'protocol': 'http', 'port': 80},
|
||||
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
When we loop over our `Server` instance, we only want to loop over `active` services. Let's create a new class, an `IterableServer`:
|
||||
```
|
||||
class IterableServer:
|
||||
|
||||
|
||||
|
||||
def __init__(self):
|
||||
|
||||
self.current_pos = 0
|
||||
|
||||
|
||||
|
||||
def __next__(self):
|
||||
|
||||
pass # TODO: Implement and remember to raise StopIteration
|
||||
|
||||
```
|
||||
|
||||
First, we initialize our current position to `0`. Then, we define a `__next__()` method, which will return the next item. We'll also ensure that we raise `StopIteration` when there are no more items to return. So far so good! Now, let's implement this `__next__()` method.
|
||||
```
|
||||
class IterableServer:
|
||||
|
||||
|
||||
|
||||
def __init__(self):
|
||||
|
||||
self.current_pos = 0. # we initialize our current position to zero
|
||||
|
||||
|
||||
|
||||
def __iter__(self): # we can return self here, because __next__ is implemented
|
||||
|
||||
return self
|
||||
|
||||
|
||||
|
||||
def __next__(self):
|
||||
|
||||
while self.current_pos < len(self.services):
|
||||
|
||||
service = self.services[self.current_pos]
|
||||
|
||||
self.current_pos += 1
|
||||
|
||||
if service['active']:
|
||||
|
||||
return service['protocol'], service['port']
|
||||
|
||||
raise StopIteration
|
||||
|
||||
|
||||
|
||||
next = __next__ # optional python2 compatibility
|
||||
|
||||
```
|
||||
|
||||
We keep looping over the services in our list while our current position is less than the length of the services but only returning if the service is active. Once we run out of services to iterate over, we raise a `StopIteration` exception.
|
||||
|
||||
Because we implement a `__next__()` method that raises `StopIteration` when it is exhausted, we can return `self` from `__iter__()` because the `IterableServer` class adheres to the `iterable` protocol.
|
||||
|
||||
Now we can loop over an instance of `IterableServer`, which will allow us to look at each active service, like so:
|
||||
```
|
||||
>>> for protocol, port in IterableServer():
|
||||
|
||||
print('service %s is running on port %d' % (protocol, port))
|
||||
|
||||
|
||||
|
||||
service ssh is running on port 22
|
||||
|
||||
service http is running on port 21
|
||||
|
||||
```
|
||||
|
||||
That's pretty great, but we can do better! In an instance like this, where our iterator doesn't need to maintain a lot of state, we can simplify our code and use a [generator][4] instead.
|
||||
```
|
||||
class Server:
|
||||
|
||||
|
||||
|
||||
services = [
|
||||
|
||||
{'active': False, 'protocol': 'ftp', 'port': 21},
|
||||
|
||||
{'active': True, 'protocol': 'ssh', 'port': 22},
|
||||
|
||||
{'active': True, 'protocol': 'http', 'port': 21},
|
||||
|
||||
]
|
||||
|
||||
|
||||
|
||||
def __iter__(self):
|
||||
|
||||
for service in self.services:
|
||||
|
||||
if service['active']:
|
||||
|
||||
yield service['protocol'], service['port']
|
||||
|
||||
```
|
||||
|
||||
What exactly is the `yield` keyword? Yield is used when defining a generator function. It's sort of like a `return`. While a `return` exits the function after returning the value, `yield` suspends execution until the next time it's called. This allows your generator function to maintain state until it resumes. Check out [yield's documentation][5] to learn more. With a generator, we don't have to manually maintain state by remembering our position. A generator knows only two things: what it needs to do right now and what it needs to do to calculate the next item. Once we reach a point of execution where `yield` isn't called again, we know to stop iterating.
|
||||
|
||||
This works because of some built-in Python magic. In the [Python documentation for `__iter__()`][6] we can see that if `__iter__()` is implemented as a generator, it will automatically return an iterator object that supplies the `__iter__()` and `__next__()` methods. Read this great article for a deeper dive of [iterators, iterables, and generators][7].
|
||||
|
||||
### Method magic
|
||||
|
||||
Due to its unique aspects, Python provides some interesting method magic as part of the language.
|
||||
|
||||
One example of this is aliasing functions. Since functions are just objects, we can assign them to multiple variables. For example:
|
||||
```
|
||||
>>> def foo():
|
||||
|
||||
return 'foo'
|
||||
|
||||
|
||||
|
||||
>>> foo()
|
||||
|
||||
'foo'
|
||||
|
||||
|
||||
|
||||
>>> bar = foo
|
||||
|
||||
|
||||
|
||||
>>> bar()
|
||||
|
||||
'foo'
|
||||
|
||||
```
|
||||
|
||||
We'll see later on how this can be useful.
|
||||
|
||||
Python provides a handy built-in, [called `getattr()`][8], that takes the `object, name, default` parameters and returns the attribute `name` on `object`. This programmatically allows us to access instance variables and methods. For example:
|
||||
```
|
||||
>>> class Dog:
|
||||
|
||||
sound = 'Bark'
|
||||
|
||||
def speak(self):
|
||||
|
||||
print(self.sound + '!', self.sound + '!')
|
||||
|
||||
|
||||
|
||||
>>> fido = Dog()
|
||||
|
||||
|
||||
|
||||
>>> fido.sound
|
||||
|
||||
'Bark'
|
||||
|
||||
>>> getattr(fido, 'sound')
|
||||
|
||||
'Bark'
|
||||
|
||||
|
||||
|
||||
>>> fido.speak
|
||||
|
||||
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
|
||||
|
||||
>>> getattr(fido, 'speak')
|
||||
|
||||
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
>>> fido.speak()
|
||||
|
||||
Bark! Bark!
|
||||
|
||||
>>> speak_method = getattr(fido, 'speak')
|
||||
|
||||
>>> speak_method()
|
||||
|
||||
Bark! Bark!
|
||||
|
||||
```
|
||||
|
||||
Cool trick, but how could we practically use `getattr`? Let's look at an example that allows us to write a tiny command-line tool to dynamically process commands.
|
||||
```
|
||||
class Operations:
|
||||
|
||||
def say_hi(self, name):
|
||||
|
||||
print('Hello,', name)
|
||||
|
||||
|
||||
|
||||
def say_bye(self, name):
|
||||
|
||||
print ('Goodbye,', name)
|
||||
|
||||
|
||||
|
||||
def default(self, arg):
|
||||
|
||||
print ('This operation is not supported.')
|
||||
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
operations = Operations()
|
||||
|
||||
|
||||
|
||||
# let's assume we do error handling
|
||||
|
||||
command, argument = input('> ').split()
|
||||
|
||||
func_to_call = getattr(operations, command, operations.default)
|
||||
|
||||
func_to_call(argument)
|
||||
|
||||
```
|
||||
|
||||
The output of our script is:
|
||||
```
|
||||
$ python getattr.py
|
||||
|
||||
|
||||
|
||||
> say_hi Nina
|
||||
|
||||
Hello, Nina
|
||||
|
||||
|
||||
|
||||
> blah blah
|
||||
|
||||
This operation is not supported.
|
||||
|
||||
```
|
||||
|
||||
Next, we'll look at `partial`. For example, **`functool.partial(func, *args, **kwargs)`** allows you to return a new [partial object][9] that behaves like `func` called with `args` and `kwargs`. If more `args` are passed in, they're appended to `args`. If more `kwargs` are passed in, they extend and override `kwargs`. Let's see it in action with a brief example:
|
||||
```
|
||||
>>> from functools import partial
|
||||
|
||||
>>> basetwo = partial(int, base=2)
|
||||
|
||||
>>> basetwo
|
||||
|
||||
<functools.partial object at 0x1085a09f0>
|
||||
|
||||
|
||||
|
||||
>>> basetwo('10010')
|
||||
|
||||
18
|
||||
|
||||
|
||||
|
||||
# This is the same as
|
||||
|
||||
>>> int('10010', base=2)
|
||||
|
||||
```
|
||||
|
||||
Let's see how this method magic ties together in some sample code from a library I enjoy using [called][10]`agithub`, which is a (poorly named) REST API client with transparent syntax that allows you to rapidly prototype any REST API (not just GitHub) with minimal configuration. I find this project interesting because it's incredibly powerful yet only about 400 lines of Python. You can add support for any REST API in about 30 lines of configuration code. `agithub` knows everything it needs to about protocol (`REST`, `HTTP`, `TCP`), but it assumes nothing about the upstream API. Let's dive into the implementation.
|
||||
|
||||
Here's a simplified version of how we'd define an endpoint URL for the GitHub API and any other relevant connection properties. View the [full code][11] instead.
|
||||
```
|
||||
class GitHub(API):
|
||||
|
||||
|
||||
|
||||
def __init__(self, token=None, *args, **kwargs):
|
||||
|
||||
props = ConnectionProperties(api_url = kwargs.pop('api_url', 'api.github.com'))
|
||||
|
||||
self.setClient(Client(*args, **kwargs))
|
||||
|
||||
self.setConnectionProperties(props)
|
||||
|
||||
```
|
||||
|
||||
Then, once your [access token][12] is configured, you can start using the [GitHub API][13].
|
||||
```
|
||||
>>> gh = GitHub('token')
|
||||
|
||||
>>> status, data = gh.user.repos.get(visibility='public', sort='created')
|
||||
|
||||
>>> # ^ Maps to GET /user/repos
|
||||
|
||||
>>> data
|
||||
|
||||
... ['tweeter', 'snipey', '...']
|
||||
|
||||
```
|
||||
|
||||
Note that it's up to you to spell things correctly. There's no validation of the URL. If the URL doesn't exist or anything else goes wrong, the error thrown by the API will be returned. So, how does this all work? Let's figure it out. First, we'll check out a simplified example of the [`API` class][14]:
|
||||
```
|
||||
class API:
|
||||
|
||||
|
||||
|
||||
# ... other methods ...
|
||||
|
||||
|
||||
|
||||
def __getattr__(self, key):
|
||||
|
||||
return IncompleteRequest(self.client).__getattr__(key)
|
||||
|
||||
__getitem__ = __getattr__
|
||||
|
||||
```
|
||||
|
||||
Each call on the `API` class ferries the call to the [`IncompleteRequest` class][15] for the specified `key`.
|
||||
```
|
||||
class IncompleteRequest:
|
||||
|
||||
|
||||
|
||||
# ... other methods ...
|
||||
|
||||
|
||||
|
||||
def __getattr__(self, key):
|
||||
|
||||
if key in self.client.http_methods:
|
||||
|
||||
htmlMethod = getattr(self.client, key)
|
||||
|
||||
return partial(htmlMethod, url=self.url)
|
||||
|
||||
else:
|
||||
|
||||
self.url += '/' + str(key)
|
||||
|
||||
return self
|
||||
|
||||
__getitem__ = __getattr__
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
class Client:
|
||||
|
||||
http_methods = ('get') # ... and post, put, patch, etc.
|
||||
|
||||
|
||||
|
||||
def get(self, url, headers={}, **params):
|
||||
|
||||
return self.request('GET', url, None, headers)
|
||||
|
||||
```
|
||||
|
||||
If the last call is not an HTTP method (like 'get', 'post', etc.), it returns an `IncompleteRequest` with an appended path. Otherwise, it gets the right function for the specified HTTP method from the [`Client` class][16] and returns a `partial` .
|
||||
|
||||
What happens if we give a non-existent path?
|
||||
```
|
||||
>>> status, data = this.path.doesnt.exist.get()
|
||||
|
||||
>>> status
|
||||
|
||||
... 404
|
||||
|
||||
```
|
||||
|
||||
And because `__getitem__` is aliased to `__getattr__`:
|
||||
```
|
||||
>>> owner, repo = 'nnja', 'tweeter'
|
||||
|
||||
>>> status, data = gh.repos[owner][repo].pulls.get()
|
||||
|
||||
>>> # ^ Maps to GET /repos/nnja/tweeter/pulls
|
||||
|
||||
>>> data
|
||||
|
||||
.... # {....}
|
||||
|
||||
```
|
||||
|
||||
Now that's some serious method magic!
|
||||
|
||||
### Learn more
|
||||
|
||||
Python provides plenty of tools that allow you to make your code more elegant and easier to read and understand. The challenge is finding the right tool for the job, but I hope this article added some new ones to your toolbox. And, if you'd like to take this a step further, you can read about decorators, context managers, context generators, and `NamedTuple`s on my blog [nnja.io][17]. As you become a better Python developer, I encourage you to get out there and read some source code for well-architected projects. [Requests][18] and [Flask][19] are two great codebases to start with.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/elegant-solutions-everyday-python-problems
|
||||
|
||||
作者:[Nina Zakharenko][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nnja
|
||||
[1]:https://docs.python.org/3/reference/datamodel.html#emulating-numeric-types
|
||||
[2]:https://rszalski.github.io/magicmethods/
|
||||
[3]:https://docs.python.org/2/library/stdtypes.html#iterator.next
|
||||
[4]:https://docs.python.org/3/library/stdtypes.html#generator-types
|
||||
[5]:https://docs.python.org/3/reference/expressions.html#yieldexpr
|
||||
[6]:https://docs.python.org/3/reference/datamodel.html#object.__iter__
|
||||
[7]:http://nvie.com/posts/iterators-vs-generators/
|
||||
[8]:https://docs.python.org/3/library/functions.html#getattr
|
||||
[9]:https://docs.python.org/3/library/functools.html#functools.partial
|
||||
[10]:https://github.com/mozilla/agithub
|
||||
[11]:https://github.com/mozilla/agithub/blob/master/agithub/GitHub.py
|
||||
[12]:https://github.com/settings/tokens
|
||||
[13]:https://developer.github.com/v3/repos/#list-your-repositories
|
||||
[14]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L30-L58
|
||||
[15]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L60-L100
|
||||
[16]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L102-L231
|
||||
[17]:http://nnja.io
|
||||
[18]:https://github.com/requests/requests
|
||||
[19]:https://github.com/pallets/flask
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/164/
|
||||
[21]:https://us.pycon.org/2018/
|
||||
@ -0,0 +1,87 @@
|
||||
Easily Search And Install Google Web Fonts In Linux
|
||||
======
|
||||
|
||||

|
||||
**Font Finder** is the Rust implementation of good old [**Typecatcher**][1], which is used to easily search and install Google web fonts from [**Google’s font archive**][2]. It helps you to install hundreds of free and open source fonts in your Linux desktop. In case you’re looking for beautiful fonts for your web projects and apps and whatever else, Font Finder can easily get them for you. It is free, open source GTK3 application written in Rust programming language. Unlike Typecatcher, which is written using Python, Font Finder can filter fonts by their categories, has zero Python runtime dependencies, and has much better performance and resource consumption.
|
||||
|
||||
In this brief tutorial, we are going to see how to install and use Font Finder in Linux.
|
||||
|
||||
### Install Font Finder
|
||||
|
||||
Since Fond Finder is written using Rust programming language, you need to install Rust in your system as described below.
|
||||
|
||||
After installing Rust, run the following command to install Font Finder:
|
||||
```
|
||||
$ cargo install fontfinder
|
||||
|
||||
```
|
||||
|
||||
Font Finder is also available as [**flatpak app**][3]. First install Flatpak in your system as described in the link below.
|
||||
|
||||
Then, install Font Finder using command:
|
||||
```
|
||||
$ flatpak install flathub io.github.mmstick.FontFinder
|
||||
|
||||
```
|
||||
|
||||
### Search And Install Google Web Fonts In Linux Using Font Finder
|
||||
|
||||
You can launch font finder either from the application launcher or run the following command to launch it.
|
||||
```
|
||||
$ flatpak run io.github.mmstick.FontFinder
|
||||
|
||||
```
|
||||
|
||||
This is how Font Finder default interface looks like.
|
||||
|
||||
![][5]
|
||||
|
||||
As you can see, Font Finder user interface is very simple. All Google web fonts are listed in the left pane and the preview of the respective font is given at the right pane. You can type any words in the preview box to view how the words will look like in the selected font. There is also a search box on the top left which allows you to quickly search for a font of your choice.
|
||||
|
||||
By default, Font Finder displays all type of fonts. You can, however, display the fonts by category-wise from the category drop-down box above the the search box.
|
||||
|
||||
![][6]
|
||||
|
||||
To install a font, just choose it and click the **Install** button on the top.
|
||||
|
||||
![][7]
|
||||
|
||||
You can test the newly installed fonts in any text processing applications.
|
||||
|
||||
![][8]
|
||||
|
||||
Similarly, to remove a font, just choose it from the Font Finder dashboard and click the **Uninstall** button. It’s that simple!
|
||||
|
||||
The Settings button (the gear button) on the top left corner provides the option to switch to dark preview.
|
||||
|
||||
![][9]
|
||||
|
||||
As you can see, Font Finder is very simple and does the job exactly as advertised in its home page. If you’re looking for an application to install Google web fonts, Font Finder is one such application.
|
||||
|
||||
And, that’s all for now. Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/font-finder-easily-search-and-install-google-web-fonts-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/install-google-web-fonts-ubuntu/
|
||||
[2]:https://fonts.google.com/
|
||||
[3]:https://flathub.org/apps/details/io.github.mmstick.FontFinder
|
||||
[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/04/font-finder-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/04/font-finder-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/04/font-finder-3.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/04/font-finder-5.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/04/font-finder-4.png
|
||||
@ -0,0 +1,136 @@
|
||||
PCGen: An easy way to generate RPG characters
|
||||
======
|
||||
|
||||
|
||||
Do you remember the first time you built a role-playing game (RPG) character? It was exciting and full of possibility, and your imagination ran wild. If you're an avid gamer, it was probably a major milestone for you.
|
||||
|
||||
But do you also remember struggling to decipher an empty character sheet and what you were supposed to write down in each box? Remember poring over the core rulebook, cross-referencing one table with a class write-up, the spellbook with your chosen school of magic, and skills to your race?
|
||||
|
||||
Whether you thought it was fun or perplexing—or both, if you play RPGs, the process of building and tracking a character is probably as natural to you now as using a computer.
|
||||
|
||||
That's an appropriate analogy, because, as we all know, character sheets have been computerized. It's a sensible match; computers are great for tracking information that changes frequently. They certainly handle it a lot better than scratches on paper worn thin by repeated erasing and scribbling and more erasing.
|
||||
|
||||
Sure, you could build custom spreadsheets in [Libre Office][1], but then again you could also try [PCGen][2], a Java-based application that makes character creation and maintenance sublimely simple without taking the fun out of either. While it doesn't have a mobile version, there is a [PCGen viewer][3] for Android so you can access your build whenever you need to.
|
||||
|
||||
### Downloading and installing
|
||||
|
||||
PCGen is a Java application, so it runs on anything that has Java installed. This isn't quite the same thing as Java in your web browser; PCGen is a downloadable application that runs locally on your computer. You likely already have Java installed; if not, download and install it from your distribution's repository. If you're not sure whether you have it installed, you can [download PCGen][4] first, try to run it, and install Java if it fails to run.
|
||||
|
||||
Since PCGen is a Java application, you don't have to install it after you download it (because you've already got the Java runtime installed). The application should just run if you double-click the `pcgen.jar` file, but if your computer hasn't been told what to do with a Java app yet, you may need to tell it explicitly to run in Java. You usually do this by right-clicking and specifying what application to open the file in. The application you want, of course, is Java or, if you're asked to input the application launch command manually, `java -jar`.
|
||||
|
||||
Linux and BSD users can customize this experience:
|
||||
|
||||
1. Download PCGen to a directory, such as `/opt` or `~/bin`.
|
||||
2. Unzip the archive with `unzip pcgen-x.yy.zz-full.zip`.
|
||||
3. Download a suitable icon (e.g., `wget https://openclipart.org/image/300px/svg_to_png/285672/d20-blank.png -O pcgen/d20.png`.
|
||||
4. Create a file called `pcgen.desktop` in your `~/.local/share/applications` directory. Open it in a text editor and type the following, adjusting as appropriate:
|
||||
|
||||
|
||||
```
|
||||
[Desktop Entry] Version=1.0 Type=Application Name=PCGen Exec="/home/your-username/bin/pcgen/pcgen.sh" Encoding=UTF-8 Icon=/home/your-username/bin/pcgen/d20.png
|
||||
|
||||
```
|
||||
|
||||
Now you can launch PCGen from your system's application menu as you would any other applications.
|
||||
|
||||
### Player agency
|
||||
|
||||
Many hours of my childhood were spent poring over my friends' D&D Player Handbooks, rolling up characters that I'd never play (thanks to the infamous "satanic panic," I wasn't allowed to play the game). What I learned from this is creating a character for an RPG is a kind of mini-game itself. There are rules to follow, important choices to make, and ultimately a needed narrative to make it all come together.
|
||||
|
||||
A new player might think it's a good idea to allow an application to do a build for them, but most experienced players probably agree that the best way to learn is by doing. And besides, letting something build your character would rob you of the mini-game that is character building. If an application is nothing more than a pre-gen factory, one of the most important parts of being a player is removed from the game, and nobody wants that.
|
||||
|
||||
On the other hand, nobody wants the character building process to discourage new players.
|
||||
|
||||
PCGen manages to strike a perfect balance between guiding you through a character build and staying out of your way as you tinker. Primarily it does this by using an unobtrusive alert system that keeps you updated about any required tasks left in your character build. It's helpful without grabbing the steering wheel out of your hands to take over completely.
|
||||
|
||||
|
||||
![PCGen to-do list][6]
|
||||
|
||||
No annoying Clippy, but plenty of helpful hints
|
||||
|
||||
### Getting started
|
||||
|
||||
PCGen essentially has two modes: the character build and the character sheet. When you launch it, PCGen first asks you to choose the game system you're building for.
|
||||
|
||||
![System selection][8]
|
||||
|
||||
Selecting your game system
|
||||
|
||||
Included systems are OGL (Open Game License) systems, including D&D 5e (3 and 3.5 editions), Pathfinder, and Fantasy Craft. Better still, PCGen comes preloaded with all manner of add-on material, so not only can you design characters from advanced and third-party modules, the dungeon master (DM) can even create stats for monsters and villains.
|
||||
|
||||
Once you've double-clicked the system you're using, you're presented with a helpful screen letting you either load an existing build you have saved or start building a new one. Each new character gets its own tab in PCGen, so if you want to build a whole party or if a DM wants to track a whole hoard of monsters, it's easy to load up a cast of characters and have them at the ready.
|
||||
|
||||
Starting from the top left, your character build starts with the basics: choosing a name, gender, and alignment. PCGen includes a random-name generator with lots of knobs and switches to adjust for etymology (real and fantasy), race, and gender.
|
||||
|
||||
### Rolling for abilities
|
||||
|
||||
When it's time to roll for ability scores, PCGen has lots of options. It defaults to manual entry. You roll physical dice and enter the numbers.
|
||||
|
||||
Alternately, you can let PCGen roll for you, and you can set the rolling style. You can have PCGen roll 4d6 and drop the lowest, roll 3d6, or roll 2d6 and add 6.
|
||||
|
||||
You can also choose to use a point-purchasing mode with a budget of anything between 15 and 25. This method might appeal to players coming from video games, many of which use this method to allocate attributes.
|
||||
|
||||
### Classes and levels
|
||||
|
||||
Once you pick a class and add your first level, your attributes are locked in and you get a budget for all remaining class- and level-dependent aspects of your character. What exactly those are, of course, depends on what system you're playing, but PCGen keeps you updated on any remaining required tasks as you go.
|
||||
|
||||
There are a lot of tabs in PCGen, and it can sometimes seem just as overwhelming as staring at a physical 300-page Player's Handbook, but as long as you follow the tips, PCGen can keep you on the straight and narrow.
|
||||
|
||||
### Character sheets
|
||||
|
||||
As if building your character wasn't enough fun, the most satisfying step is yet to come: seeing all your choices laid out in a proper character-sheet format.
|
||||
|
||||
The final tab of PCGen is the Character Sheet tab, and it formats your character's attributes into a layout of your choice. The default is a standard, generic layout. It's easily printable and easy to understand.
|
||||
|
||||
There are several variations and addendums available, too. For spellcasters, there's a spellbook sheet that lists available spells, and there are several alternate layouts, some optimized for screen and others for print.
|
||||
|
||||
If you're using PCGen as you play, you can add temporary effects to your character sheet to let PCGen adjust your attributes accordingly.
|
||||
|
||||
If you export your character and import it into the PCGen Importer on your Android phone or tablet, you can use your digital character sheet to track spells and current health and make temporary adjustments to armour class and other attribute modifiers.
|
||||
|
||||
![Exported character sheet on Android][10]
|
||||
|
||||
Exported character sheet on Android
|
||||
|
||||
### PCGen's advantages
|
||||
|
||||
The market is full of digital character-sheet trackers, but PCGen stands out for several reasons. First, it's cross-platform. That may or may not mean much to you, because we tend to standardize our workflow to devices that play nice with one another. In my gaming groups, though, we have Linux users and Windows users, and we have people who want to work off a mobile device and others who prefer a proper computer. Choosing an application that everyone can use and become comfortable with makes the process of updating stats more efficient.
|
||||
|
||||
Second, because PCGen is open source, all your character data remains in an open and parsable format. As an XML fan, I find it invaluable to get my character data as an XML dump, and it's doubly useful to me as a DM as I prepare for an upcoming adventure and need custom monster stat blocks to insert in my notes.
|
||||
|
||||
On a related note, knowing that PCGen will always be available regardless of a player's financial circumstance is also nice. When I changed jobs a year ago, I was lucky to go from one job to the next without interruption in income. In one of my gaming groups, however, two members have been made redundant recently and a third is a university student without much disposable income. The fact that we don't have to worry about monthly membership fees or whether we can all afford to invest in software that is, at the end of the day, a minor convenience over pen and paper gives us confidence in our choice of using digital tools.
|
||||
|
||||
PCGen's open source license also lends itself to rapid development and expansion and ensured maintenance. The reason there's a mobile edition is that the code and data are open. Who knows what's next?
|
||||
|
||||
While PCGen's default datasets revolve, naturally, around OGL content (because the OGL is open and allows content to be freely redistributed), since the application is also open, you can add whatever data you want. It's not necessarily trivial, but games like Open Legend, Dungeon Delvers, and other openly licensed games are ripe for porting to PCGen.
|
||||
|
||||
### Pen and paper
|
||||
|
||||
The pen-and-paper tradition remains important. PCGen strikes a healthy balance between the desire to make stats accounting more convenient by leveraging the latest technology while maintaining the joy of manually updating characters.
|
||||
|
||||
Whether you're an old-school gamer who banishes digital devices from your table or a progressive gamer who embraces technology, it's fair to say most of us have encountered a few times when a game has come to a halt because of a phone or tablet. The fact is, everyone has a mobile device now (even me, even if it's only because my job pays for it), so they will make their way onto your game table. I have found that encouraging game-relevant information to be on screens has helped focus players on the game; I'd rather my players stare at their character sheets and game reference documents than surf social media sites on their devices.
|
||||
|
||||
PCGen, in my experience, is the most true-to-form digital character sheet available. It allows for user control, it offers useful guidance as needed, and it's as close to pen-and-paper convenience as possible. Take a look at it, open gamers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/pcgen-rpg-character-generator
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:http://libreoffice.org
|
||||
[2]:http://pcgen.org
|
||||
[3]:https://play.google.com/store/apps/details?id=com.dysfunctional.apps.pcgencharactersheet
|
||||
[4]:http://pcgen.org/download/
|
||||
[5]:/file/394491
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/pcgen_tip.jpg?itok=GXOz_OJ_ (PCGen to-do list)
|
||||
[7]:/file/394486
|
||||
[8]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/pcgen_sys.jpg?itok=Zn0_9hkQ (System selection)
|
||||
[9]:/file/394481
|
||||
[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/pcgen_screen.jpg?itok=4V6AZPud (Exported character sheet on Android)
|
||||
@ -0,0 +1,80 @@
|
||||
Reset a lost root password in under 5 minutes
|
||||
======
|
||||
|
||||

|
||||
|
||||
A system administrator can easily reset passwords for users who have forgotten theirs. But what happens if the system administrator forgets the root password, or leaves the company? This guide will show you how to reset a lost or forgotten root password on a Red Hat-compatible system, including Fedora and CentOS, in less than 5 minutes.
|
||||
|
||||
Please note, if the entire system hard disk has been encrypted with LUKS, you would need to provide the LUKS password when prompted. Also, this procedure is applicable to systems running systemd which has been the default init system since Fedora 15, CentOS 7.14.04, and Red Hat Enterprise Linux 7.0.
|
||||
|
||||
First, you need to interrupt the boot process, so you'll need to turn the system on or restart it if it’s already powered on. The first step is tricky because the GRUB menu tends to flash very quickly on the screen. You may need to try this a few times until you are able to do it.
|
||||
|
||||
Press **e** on your keyboard when you see this screen:
|
||||
|
||||
|
||||
|
||||
If you've done this correctly, you should see a screen similar to this one:
|
||||
|
||||
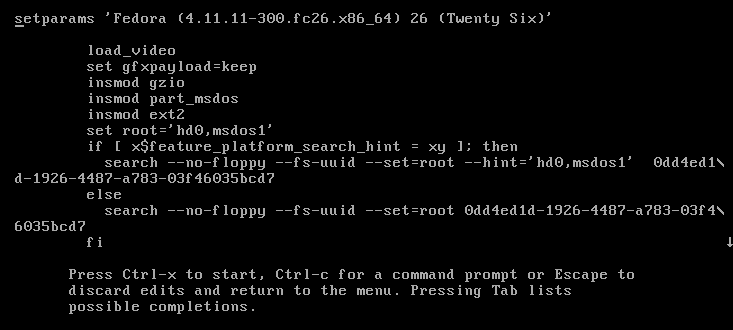
|
||||
|
||||
Use your arrow keys to move to the Linux16 line:
|
||||
|
||||

|
||||
|
||||
Using your **del** key or your **backspace** key, remove `rhgb quiet` and replace with the following:
|
||||
|
||||
`rd.break enforcing=0`
|
||||
|
||||
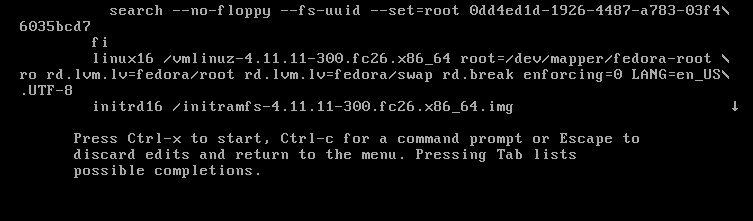
|
||||
|
||||
Setting `enforcing=0` will allow you to avoid performing a complete system SELinux relabeling. Once the system is rebooted, you'll only have to restore the correct SELinux context for the `/etc/shadow` file. I'll show you how to do this too.
|
||||
|
||||
Press **Ctrl-x** to start.
|
||||
|
||||
**The system will now be in emergency mode.**
|
||||
|
||||
Remount the hard drive with read-write access:
|
||||
```
|
||||
# mount –o remount,rw /sysroot
|
||||
|
||||
```
|
||||
|
||||
Run `chroot` to access the system:
|
||||
```
|
||||
# chroot /sysroot
|
||||
|
||||
```
|
||||
|
||||
You can now change the root password:
|
||||
```
|
||||
# passwd
|
||||
|
||||
```
|
||||
|
||||
Type the new root password twice when prompted. If you are successful, you should see a message that reads " **all authentication tokens updated successfully**. "
|
||||
|
||||
Type **exit** twice to reboot the system.
|
||||
|
||||
Log in as root and restore the SELinux label to the `/etc/shadow` file.
|
||||
```
|
||||
# restorecon -v /etc/shadow
|
||||
|
||||
```
|
||||
|
||||
Turn SELinux back to enforcing mode:
|
||||
```
|
||||
# setenforce 1
|
||||
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/reset-lost-root-password
|
||||
|
||||
作者:[Curt Warfield][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rcurtiswarfield
|
||||
@ -0,0 +1,368 @@
|
||||
如何使用 Npm 管理 NodeJS 包
|
||||
=====
|
||||
|
||||

|
||||
|
||||
前一段时间,我们发布了一个[**使用 PIP 管理 Python 包**][3]的指南。今天,我们将讨论如何使用 Npm 管理 NodeJS 包。NPM 是最大的软件注册中心,包含 600,000 多个包。每天,世界各地的开发人员通过 npm 共享和下载软件包。在本指南中,我将解释使用 npm 基础知识,例如安装包(本地和全局)、安装特定版本的包、更新、删除和管理 NodeJS 包等等。
|
||||
|
||||
### 使用 Npm 管理 NodeJS 包
|
||||
|
||||
##### 安装 NPM
|
||||
|
||||
用于 npm 是用 NodeJS 编写的,我们需要安装 NodeJS 才能使用 npm。要在不同的 Linux 发行版上安装 NodeJS,请参考下面的链接。
|
||||
|
||||
检查 node 安装的位置:
|
||||
```
|
||||
$ which node
|
||||
/home/sk/.nvm/versions/node/v9.4.0/bin/node
|
||||
```
|
||||
|
||||
检查它的版本:
|
||||
```
|
||||
$ node -v
|
||||
v9.4.0
|
||||
```
|
||||
|
||||
进入 Node 交互式解释器:
|
||||
```
|
||||
$ node
|
||||
> .help
|
||||
.break Sometimes you get stuck, this gets you out
|
||||
.clear Alias for .break
|
||||
.editor Enter editor mode
|
||||
.exit Exit the repl
|
||||
.help Print this help message
|
||||
.load Load JS from a file into the REPL session
|
||||
.save Save all evaluated commands in this REPL session to a file
|
||||
> .exit
|
||||
```
|
||||
|
||||
检查 npm 安装的位置:
|
||||
```
|
||||
$ which npm
|
||||
/home/sk/.nvm/versions/node/v9.4.0/bin/npm
|
||||
```
|
||||
|
||||
还有版本:
|
||||
```
|
||||
$ npm -v
|
||||
5.6.0
|
||||
```
|
||||
|
||||
棒极了!Node 和 NPM 已安装并能工作!正如你可能已经注意到,我已经在我的 $HOME 目录中安装了 NodeJS 和 NPM,这样是为了避免在全局模块时出现权限问题。这是 NodeJS 团队推荐的方法。
|
||||
|
||||
那么,让我们继续看看如何使用 npm 管理 NodeJS 模块(或包)。
|
||||
|
||||
##### 安装 NodeJS 模块
|
||||
|
||||
NodeJS 模块可以安装在本地或全局(系统范围)。现在我将演示如何在本地安装包。
|
||||
|
||||
**在本地安装包**
|
||||
|
||||
为了在本地管理包,我们通常使用 **package.json** 文件来管理。
|
||||
|
||||
首先,让我们创建我们的项目目录。
|
||||
```
|
||||
$ mkdir demo
|
||||
```
|
||||
```
|
||||
$ cd demo
|
||||
```
|
||||
|
||||
在项目目录中创建一个 package.json 文件。为此,运行:
|
||||
```
|
||||
$ npm init
|
||||
```
|
||||
|
||||
输入你的包的详细信息,例如名称,版本,作者,github 页面等等,或者按下 ENTER 键接受默认值并键入 **YES** 确认。
|
||||
```
|
||||
This utility will walk you through creating a package.json file.
|
||||
It only covers the most common items, and tries to guess sensible defaults.
|
||||
|
||||
See `npm help json` for definitive documentation on these fields
|
||||
and exactly what they do.
|
||||
|
||||
Use `npm install <pkg>` afterwards to install a package and
|
||||
save it as a dependency in the package.json file.
|
||||
|
||||
Press ^C at any time to quit.
|
||||
package name: (demo)
|
||||
version: (1.0.0)
|
||||
description: demo nodejs app
|
||||
entry point: (index.js)
|
||||
test command:
|
||||
git repository:
|
||||
keywords:
|
||||
author:
|
||||
license: (ISC)
|
||||
About to write to /home/sk/demo/package.json:
|
||||
|
||||
{
|
||||
"name": "demo",
|
||||
"version": "1.0.0",
|
||||
"description": "demo nodejs app",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC"
|
||||
}
|
||||
|
||||
Is this ok? (yes) yes
|
||||
```
|
||||
|
||||
上面的命令初始化你的项目并创建了 package.json 文件。
|
||||
|
||||
你也可以使用命令以非交互式方式执行此操作:
|
||||
```
|
||||
npm init --y
|
||||
```
|
||||
|
||||
现在让我们安装名为 [**commander**][2] 的包。
|
||||
```
|
||||
$ npm install commander
|
||||
```
|
||||
|
||||
示例输出:
|
||||
```
|
||||
npm notice created a lockfile as package-lock.json. You should commit this file.
|
||||
npm WARN demo@1.0.0 No repository field.
|
||||
|
||||
+ commander@2.13.0
|
||||
added 1 package in 2.519s
|
||||
```
|
||||
|
||||
这将在项目的根目录中创建一个名为 **" node_modules"** 的目录(如果它不存在的话),并在其中下载包。
|
||||
|
||||
让我们检查 pachage.json 文件。
|
||||
```
|
||||
$ cat package.json
|
||||
{
|
||||
"name": "demo",
|
||||
"version": "1.0.0",
|
||||
"description": "demo nodejs app",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC",
|
||||
**"dependencies": {**
|
||||
**"commander": "^2.13.0"**
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
你会看到添加了依赖文件,版本号前面的插入符号 ( **^** ) 表示在安装时,npm 将取出它可以找到的最高版本的包。
|
||||
```
|
||||
$ ls node_modules/
|
||||
commander
|
||||
```
|
||||
|
||||
package.json 文件的优点是,如果你的项目目录中有 package.json 文件,只需键入 "npm install",那么 npm 将查看文件中列出的依赖关系并下载它们。你甚至可以与其他开发人员共享它或将其推送到你的 GitHub 仓库。因此,当他们键入 “npm install” 时,他们将获得你拥有的所有相同的包。
|
||||
|
||||
你也可能会注意到另一个名为 **package-lock.json** 的文件,该文件确保在项目安装的所有系统上都保持相同的依赖关系。
|
||||
|
||||
要在你的程序中使用已安装的包,使用实际代码在项目目录中创建一个 **index.js**(或者其他任何名称)文件,然后使用以下命令运行它:
|
||||
```
|
||||
$ node index.js
|
||||
```
|
||||
|
||||
**在全局安装包**
|
||||
|
||||
如果你想使用一个包作为命令行工具,那么最好在全局安装它。这样,无论你的当前目录是哪个目录,它都能正常工作。
|
||||
```
|
||||
$ npm install async -g
|
||||
+ async@2.6.0
|
||||
added 2 packages in 4.695s
|
||||
```
|
||||
|
||||
或者
|
||||
```
|
||||
$ npm install async --global
|
||||
```
|
||||
|
||||
要安装特定版本的包,我们可以:
|
||||
```
|
||||
$ npm install async@2.6.0 --global
|
||||
```
|
||||
|
||||
##### 更新 NodeJS 模块
|
||||
|
||||
要更新本地包,转到 package.json 所在的项目目录并运行:
|
||||
```
|
||||
$ npm update
|
||||
```
|
||||
|
||||
然后,运行以下命令确保所有包都更新了。
|
||||
```
|
||||
$ npm outdated
|
||||
```
|
||||
|
||||
如果没有需要更新的,那么它返回空。
|
||||
|
||||
要找出哪一个全局包需要更新,运行:
|
||||
```
|
||||
$ npm outdated -g --depth=0
|
||||
```
|
||||
|
||||
如果没有输出,意味着所有包都已更新。
|
||||
|
||||
更新单个全局包,运行:
|
||||
```
|
||||
$ npm update -g <package-name>
|
||||
```
|
||||
|
||||
更新所有的全局包,运行:
|
||||
```
|
||||
$ npm update -g <package>
|
||||
```
|
||||
|
||||
##### 列出 NodeJS 模块
|
||||
|
||||
列出本地包,转到项目目录并运行:
|
||||
```
|
||||
$ npm list
|
||||
demo@1.0.0 /home/sk/demo
|
||||
└── commander@2.13.0
|
||||
```
|
||||
|
||||
如你所见,我在本地安装了 "commander" 这个包。
|
||||
|
||||
要列出全局包,从任何位置都可以运行以下命令:
|
||||
```
|
||||
$ npm list -g
|
||||
```
|
||||
|
||||
示例输出:
|
||||
```
|
||||
/home/sk/.nvm/versions/node/v9.4.0/lib
|
||||
├─┬ async@2.6.0
|
||||
│ └── lodash@4.17.4
|
||||
└─┬ npm@5.6.0
|
||||
├── abbrev@1.1.1
|
||||
├── ansi-regex@3.0.0
|
||||
├── ansicolors@0.3.2
|
||||
├── ansistyles@0.1.3
|
||||
├── aproba@1.2.0
|
||||
├── archy@1.0.0
|
||||
[...]
|
||||
```
|
||||
|
||||
该命令将列出所有模块及其依赖关系。
|
||||
|
||||
要仅仅列出顶级模块,使用 -depth=0 选项:
|
||||
```
|
||||
$ npm list -g --depth=0
|
||||
/home/sk/.nvm/versions/node/v9.4.0/lib
|
||||
├── async@2.6.0
|
||||
└── npm@5.6.0
|
||||
```
|
||||
|
||||
##### 寻找 NodeJS 模块
|
||||
|
||||
要搜索一个模块,使用 "npm search" 命令:
|
||||
```
|
||||
npm search <search-string>
|
||||
```
|
||||
|
||||
例如:
|
||||
```
|
||||
$ npm search request
|
||||
```
|
||||
|
||||
该命令将显示包含搜索字符串 "request" 的所有模块。
|
||||
|
||||
##### 移除 NodeJS 模块
|
||||
|
||||
要删除本地包,转到项目目录并运行以下命令,这会从 **node_modules** 目录中删除包:
|
||||
```
|
||||
$ npm uninstall <package-name>
|
||||
```
|
||||
|
||||
要从 **package.json** 文件中的依赖关系中删除它,使用如下所示的 **save** 标志:
|
||||
```
|
||||
$ npm uninstall --save <package-name>
|
||||
|
||||
```
|
||||
|
||||
要删除已安装的全局包,运行:
|
||||
```
|
||||
$ npm uninstall -g <package>
|
||||
```
|
||||
|
||||
##### 清楚 NPM 缓存
|
||||
|
||||
默认情况下,NPM 在安装包时,会将其副本保存在 $HOME 目录中名为 npm 的缓存文件夹中。所以,你可以在下次安装时不必再次下载。
|
||||
|
||||
查看缓存模块:
|
||||
```
|
||||
$ ls ~/.npm
|
||||
```
|
||||
|
||||
随着时间的推移,缓存文件夹会充斥着大量旧的包。所以不时清理缓存会好一些。
|
||||
|
||||
从 npm@5 开始,npm 缓存可以从 corruption 问题中自行修复,并且保证从缓存中提取的数据有效。如果你想确保一切都一致,运行:
|
||||
```
|
||||
$ npm cache verify
|
||||
```
|
||||
|
||||
清楚整个缓存,运行:
|
||||
```
|
||||
$ npm cache clean --force
|
||||
```
|
||||
|
||||
##### 查看 NPM 配置
|
||||
|
||||
要查看 NPM 配置,键入:
|
||||
```
|
||||
$ npm config list
|
||||
```
|
||||
|
||||
或者
|
||||
```
|
||||
$ npm config ls
|
||||
```
|
||||
|
||||
示例输出:
|
||||
```
|
||||
; cli configs
|
||||
metrics-registry = "https://registry.npmjs.org/"
|
||||
scope = ""
|
||||
user-agent = "npm/5.6.0 node/v9.4.0 linux x64"
|
||||
|
||||
; node bin location = /home/sk/.nvm/versions/node/v9.4.0/bin/node
|
||||
; cwd = /home/sk
|
||||
; HOME = /home/sk
|
||||
; "npm config ls -l" to show all defaults.
|
||||
```
|
||||
|
||||
要显示当前的全局位置:
|
||||
```
|
||||
$ npm config get prefix
|
||||
/home/sk/.nvm/versions/node/v9.4.0
|
||||
```
|
||||
|
||||
好吧,这就是全部了。我们刚才介绍的只是基础知识,NPM 是一个广泛话题。有关更多详细信息,参阅 [**NPM Getting Started**][3] 指南。
|
||||
|
||||
希望这对你有帮助。更多好东西即将来临,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[2]:https://www.npmjs.com/package/commander
|
||||
[3]:https://docs.npmjs.com/getting-started/
|
||||
@ -0,0 +1,351 @@
|
||||
如何使用 Vim 编辑器编辑多个文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
有时候,您可能需要修改多个文件,或要将一个文件的内容复制到另一个文件中。在图形用户界面中,您可以在任何图形文本编辑器(如 gedit)中打开文件,并使用 CTRL + C 和 CTRL + V 复制和粘贴内容。在命令行模式下,您不能使用这种编辑器。不过别担心,只要有 vim 编辑器就有办法。在本教程中,我们将学习使用 Vim 编辑器同时编辑多个文件。相信我,很有意思哒。
|
||||
|
||||
### 安装 Vim
|
||||
|
||||
Vim 编辑器可在大多数 Linux 发行版的官方软件仓库中找到,所以您可以用默认的软件包管理器来安装它。例如,在 Arch Linux 及其变体上,您可以使用如下命令:
|
||||
```
|
||||
$ sudo pacman -S vim
|
||||
|
||||
```
|
||||
|
||||
在 Debian 和 Ubuntu 上:
|
||||
```
|
||||
$ sudo apt-get install vim
|
||||
|
||||
```
|
||||
|
||||
在 RHEL 和 CentOS 上:
|
||||
```
|
||||
$ sudo yum install vim
|
||||
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
```
|
||||
$ sudo dnf install vim
|
||||
|
||||
```
|
||||
|
||||
在 openSUSE 上:
|
||||
```
|
||||
$ sudo zypper install vim
|
||||
|
||||
```
|
||||
|
||||
### 使用 Linux 的 Vim 编辑器同时编辑多个文件
|
||||
|
||||
现在让我们谈谈正事,我们可以用两种方法做到这一点。
|
||||
|
||||
#### 方法一
|
||||
|
||||
有两个文件,即 **file1.txt** 和 **file2.txt**,带有一堆随机单词:
|
||||
```
|
||||
$ cat file1.txt
|
||||
ostechnix
|
||||
open source
|
||||
technology
|
||||
linux
|
||||
unix
|
||||
|
||||
$ cat file2.txt
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
现在,让我们同时编辑这两个文件。请运行:
|
||||
```
|
||||
$ vim file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
Vim 将按顺序显示文件的内容。首先显示第一个文件的内容,然后显示第二个文件,依此类推。
|
||||
|
||||
![][2]
|
||||
|
||||
**在文件中切换**
|
||||
|
||||
要移至下一个文件,请键入:
|
||||
```
|
||||
:n
|
||||
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
要返回到前一个文件,请键入:
|
||||
```
|
||||
:N
|
||||
|
||||
```
|
||||
|
||||
如果有任何未保存的更改,Vim 将不允许您移动到下一个文件。要保存当前文件中的更改,请键入:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
请注意,是两个大写字母 ZZ(SHIFT + zz)。
|
||||
|
||||
要放弃更改并移至上一个文件,请键入:
|
||||
```
|
||||
:N!
|
||||
|
||||
```
|
||||
|
||||
要查看当前正在编辑的文件,请键入:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
您将在底部看到加载文件的列表。
|
||||
|
||||
![][5]
|
||||
|
||||
要切换到下一个文件,请输入 **:buffer**,后跟缓冲区编号。例如,要切换到第一个文件,请键入:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
**打开其他文件进行编辑**
|
||||
|
||||
目前我们正在编辑两个文件,即 file1.txt 和 file2.txt。我想打开另一个名为 **file3.txt** 的文件进行编辑。
|
||||
|
||||
您会怎么做?这很容易。只需键入 **:e**,然后输入如下所示的文件名即可:
|
||||
```
|
||||
:e file3.txt
|
||||
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
现在你可以编辑 file3.txt 了。
|
||||
|
||||
要查看当前正在编辑的文件数量,请键入:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
请注意,对于使用 **:e** 打开的文件,您无法使用 **:n** 或 **:N** 进行切换。要切换到另一个文件,请输入 **:buffer**,然后输入文件缓冲区编号。
|
||||
|
||||
**将一个文件的内容复制到另一个文件中**
|
||||
|
||||
您已经知道了如何同时打开和编辑多个文件。有时,您可能想要将一个文件的内容复制到另一个文件中。这也是可以做到的。切换到您选择的文件,例如,假设您想将 file1.txt 的内容复制到 file2.txt 中:
|
||||
|
||||
首先,请切换到 file1.txt:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
将光标移动至在想要复制的行的前面,并键入**yy** 以抽出(复制)该行。然后,移至 file2.txt:
|
||||
```
|
||||
:buffer 2
|
||||
|
||||
```
|
||||
|
||||
将光标移至要从 file1.txt 粘贴复制行的位置,然后键入 **p**。例如,您想要将复制的行粘贴到 line2 和 line3 之间,请将鼠标光标置于行前并键入 **p**。
|
||||
|
||||
输出示例:
|
||||
```
|
||||
line1
|
||||
line2
|
||||
ostechnix
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
要保存当前文件中所做的更改,请键入:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
再次提醒,是两个大写字母 ZZ(SHIFT + z)。
|
||||
|
||||
保存所有文件的更改并退出 vim 编辑器,键入:
|
||||
```
|
||||
:wq
|
||||
|
||||
```
|
||||
|
||||
同样,您可以将任何文件的任何行复制到其他文件中。
|
||||
|
||||
**将整个文件内容复制到另一个文件中**
|
||||
|
||||
我们知道如何复制一行,那么整个文件的内容呢?也是可以的。比如说,您要将 file1.txt 的全部内容复制到 file2.txt 中。
|
||||
|
||||
先打开 file2.txt:
|
||||
```
|
||||
$ vim file2.txt
|
||||
|
||||
```
|
||||
|
||||
如果文件已经加载,您可以通过输入以下命令切换到 file2.txt:
|
||||
```
|
||||
:buffer 2
|
||||
|
||||
```
|
||||
|
||||
将光标移动到您想要粘贴 file1.txt 内容的位置。我想在 file2.txt 的第 5 行之后粘贴 file1.txt 的内容,所以我将光标移动到第 5 行。然后,键入以下命令并按回车键:
|
||||
```
|
||||
:r file1.txt
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
这里,**r** 代表 **read**。
|
||||
|
||||
现在您会看到 file1.txt 的内容被粘贴在 file2.txt 的第 5 行之后。
|
||||
```
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
ostechnix
|
||||
open source
|
||||
technology
|
||||
linux
|
||||
unix
|
||||
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
要保存当前文件中的更改,请键入:
|
||||
```
|
||||
ZZ
|
||||
|
||||
```
|
||||
|
||||
要保存所有文件的所有更改并退出 vim 编辑器,请输入:
|
||||
```
|
||||
:wq
|
||||
|
||||
```
|
||||
|
||||
#### 方法二
|
||||
|
||||
另一种同时打开多个文件的方法是使用 **-o** 或 **-O** 标志。
|
||||
|
||||
要在水平窗口中打开多个文件,请运行:
|
||||
```
|
||||
$ vim -o file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
要在窗口之间切换,请按 **CTRL-w w**(即按 **CTRL + w** 并再次按 **w**)。或者,您可以使用以下快捷方式在窗口之间移动:
|
||||
|
||||
* **CTRL-w k** – 上面的窗口
|
||||
* **CTRL-w j** – 下面的窗口
|
||||
|
||||
|
||||
|
||||
要在垂直窗口中打开多个文件,请运行:
|
||||
```
|
||||
$ vim -O file1.txt file2.txt file3.txt
|
||||
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
要在窗口之间切换,请按 **CTRL-w w**(即按 **CTRL + w** 并再次按 **w**)。或者,使用以下快捷方式在窗口之间移动:
|
||||
|
||||
* **CTRL-w l** – 左面的窗口
|
||||
* **CTRL-w h** – 右面的窗口
|
||||
|
||||
|
||||
|
||||
其他的一切都与方法一的描述相同。
|
||||
|
||||
例如,要列出当前加载的文件,请运行:
|
||||
```
|
||||
:buffers
|
||||
|
||||
```
|
||||
|
||||
在文件之间切换:
|
||||
```
|
||||
:buffer 1
|
||||
|
||||
```
|
||||
|
||||
打开其他文件,请键入:
|
||||
```
|
||||
:e file3.txt
|
||||
|
||||
```
|
||||
|
||||
将文件的全部内容复制到另一个文件中:
|
||||
```
|
||||
:r file1.txt
|
||||
|
||||
```
|
||||
|
||||
方法二的唯一区别是,只要您使用 **ZZ** 保存对当前文件的更改,文件将自动关闭。然后,您需要依次键入 **:wq ** 来关闭文件。但是,如果您按照方法一进行操作,输入 **:wq** 时,所有更改将保存在所有文件中,并且所有文件将立即关闭。
|
||||
|
||||
有关更多详细信息,请参阅手册页。
|
||||
```
|
||||
$ man vim
|
||||
|
||||
```
|
||||
|
||||
|
||||
**建议阅读:**
|
||||
|
||||
您现在掌握了如何在 Linux 中使用 vim 编辑器编辑多个文件。正如您所见,编辑多个文件并不难。Vim 编辑器还有更强大的功能。我们接下来会提供更多关于 Vim 编辑器的内容。
|
||||
|
||||
再见!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-edit-multiple-files-using-vim-editor/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-1-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-5.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-6.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-7.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-8.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-10-1.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-11.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-12.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/03/edit-multiple-files-13.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/03/Edit-multiple-files-16.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/03/Edit-multiple-files-17.png
|
||||
@ -0,0 +1,89 @@
|
||||
如何重置 Fedora 上的 root 密码
|
||||
======
|
||||
|
||||

|
||||
系统管理员可以轻松地为忘记密码的用户重置密码。但是如果系统管理员忘记 root 密码会发生什么?本指南将告诉你如何重置遗失或忘记的 root 密码。请注意,要重置 root 密码,你需要能够接触到本机以重新启动并访问 GRUB 设置。此外,如果系统已加密,你还需要知道 LUKS 密码。
|
||||
|
||||
### 编辑 GRUB 设置
|
||||
|
||||
首先你需要中断启动过程。所以你需要打开系统,如果已经打开就重新启动。第一步很棘手,因为 grub 菜单往往会在屏幕上快速闪过。
|
||||
|
||||
当你看到 GRUB 菜单时,请按键盘上的 **E** 键:
|
||||
|
||||
![][1]
|
||||
|
||||
按下 ‘e’ 后显示以下屏幕:
|
||||
|
||||
![][2]
|
||||
|
||||
使用箭头键移动到 **linux16** 这行。
|
||||
|
||||
![][3]
|
||||
|
||||
使用您的**删除**键或**后退**键,删除 **rhgb quiet** 并替换为以下内容。
|
||||
```
|
||||
rd.break enforcing=0
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
编辑好后,按下 **Ctrl-x** 启动系统。如果系统已加密,则系统会提示你输入 LUKS 密码。
|
||||
|
||||
**注意:** 设置 enforcing=0,避免执行完整的系统 SELinux 重新标记。系统重启后,为 /etc/shadow 恢复正确的 SELinux 上下文。(这个会进一步解释)
|
||||
|
||||
### 挂载文件系统
|
||||
|
||||
系统现在将处于紧急模式。以读写权限重新挂载硬盘:
|
||||
```
|
||||
# mount –o remount,rw /sysroot
|
||||
|
||||
```
|
||||
|
||||
### 更改密码
|
||||
|
||||
运行 chroot 访问系统。
|
||||
```
|
||||
# chroot /sysroot
|
||||
|
||||
```
|
||||
|
||||
你现在可以更改 root 密码。
|
||||
```
|
||||
# passwd
|
||||
|
||||
```
|
||||
|
||||
出现提示时输入新的 root 密码两次。如果成功,你应该看到一条 **all authentication tokens updated successfully** 消息。
|
||||
|
||||
输入 **exit** 两次重新启动系统。
|
||||
|
||||
以 root 身份登录并将 SELinux 标签恢复到 /etc/shadow 中。
|
||||
```
|
||||
# restorecon -v /etc/shadow
|
||||
|
||||
```
|
||||
|
||||
将 SELinux 变回 enforce 模式。
|
||||
```
|
||||
# setenforce 1
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/reset-root-password-fedora/
|
||||
|
||||
作者:[Curt Warfield][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/rcurtiswarfield/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub2.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub3.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub4.png
|
||||
Loading…
Reference in New Issue
Block a user