mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-07 22:11:09 +08:00
commit
7f8d210395
@ -0,0 +1,53 @@
|
||||
如果总统候选人们要使用 Linux 发行版,他们会选择哪个?
|
||||
================================================================================
|
||||

|
||||
|
||||
*共和党总统候选人 Donald Trump【译者注:唐纳德·特朗普,美国地产大亨、作家、主持人】*
|
||||
|
||||
如果要竞选总统的人们使用 Linux 或其他的开源操作系统,那么会使用哪个发行版呢?问题的关键是存在许多其它的因素,比如,一些“政治立场”问题,或者是给一个发行版的名字添加上感叹号是否合适——而这问题一直被忽视。先不管这些忽视:接下来是时事新闻工作者关于总统大选和 Linux 发行版的报道。
|
||||
|
||||
对于那些已经看了很多年我的文字的人来说(除了我亲爱的的编辑之外,他们一直听我的瞎扯是不是倒霉到家了?),这篇文章听起来很熟悉,这是因为我在去年的总统选举期间写了一篇[类似的文章][1]。一些读者把这篇文章的内容看的比我想象的还要严肃,所以我会花点时间阐述我的观点:事实上,我不认为开源软件和政治运动彼此之间有多大的关系。我写那样的文章仅仅是新的一周的自我消遣罢了。
|
||||
|
||||
当然,你也可以认为它们彼此相关,毕竟你才是读者。
|
||||
|
||||
### Linux 发行版之选:共和党人们 ###
|
||||
|
||||
今天,我只是谈及一些有关共和党人们的话题,我甚至只会谈论他们的其中一部分。因为共和党的提名人太多了,以至于我写满了整篇文章。由此开始:
|
||||
|
||||
如果 **Jeb (Jeb!?) Bush** 使用 Linux,它一定是 [Debian][2]。Debian 属于一个相当无趣的分支,它是为真正意义上的、成熟的黑客设计的,这些人将清理那些由经验不甚丰富的开源爱好者所造成的混乱视为一大使命。当然,这也使得 Debian 显得很枯燥,所以它已有的用户基数一直在缩减。
|
||||
|
||||
**Scott Walker** ,对于他来说,应该是一个 [Damn Small Linux][3] (DSL) 用户。这个系统仅仅需要 50MB 的硬盘空间和 16MB 的 RAM 便可运行。DSL 可以使一台 20 年前的 486 计算机焕发新春,而这恰好符合了 **Scott Walker** 所主张的消减成本计划。当然,你在 DSL 上的用户体验也十分原始,这个系统平台只能够运行一个浏览器。但是至少你你不用浪费钱财购买新的电脑硬件,你那台 1993 年购买的机器仍然可以为你好好的工作。
|
||||
|
||||
**Chris Christie** 会使用哪种系统呢?他肯定会使用 [Relax-and-Recover Linux][4],它号称“一次搞定(Setup-and-forget)的裸机 Linux 灾难恢复方案” 。从那次不幸的华盛顿大桥事故后,“一次搞定(Setup-and-forget)”基本上便成了 Christie 的政治主张。不管灾难恢复是否能够让 Christie 最终挽回一切,但是当他的电脑死机的时候,至少可以找到一两封意外丢失的机密邮件。
|
||||
|
||||
至于 **Carly Fiorina**,她无疑将要使用 [惠普][6] (HPQ)为“[The Machine][5]”开发的操作系统,她在 1999 年到 2005 年这 6 年期间管理的这个公司。事实上,The Machine 可以运行几种不同的操作系统,也许是基于 Linux 的,也许不是,我们并不太清楚,它的开发始于 **Carly Fiorina** 在惠普公司的任期结束后。不管怎么说,作为 IT 圈里一个成功的管理者,这是她履历里面重要的组成部分,同时这也意味着她很难与惠普彻底断绝关系。
|
||||
|
||||
最后,但并不是不重要,你也猜到了——**Donald Trump**。他显然会动用数百万美元去雇佣一个精英黑客团队去定制属于自己的操作系统——尽管他原本是想要免费获得一个完美的、现成的操作系统——然后还能向别人炫耀自己的财力。他可能会吹嘘自己的操作系统是目前最好的系统,虽然它可能没有兼容 POSIX 或者一些其它的标准,因为那样的话就需要花掉更多的钱。同时这个系统也将根本不会提供任何文档,因为如果 **Donald Trump** 向人们解释他的系统的实际运行方式,他会冒着所有机密被泄露至伊斯兰国家的风险,绝对是这样的。
|
||||
|
||||
另外,如果 **Donald Trump** 非要选择一种已有的 Linux 平台的话, [Ubuntu][7] 应该是明智的选择。就像 **Donald Trump** 一样, Ubuntu 的开发者秉承“我们做自己想要做的”原则,通过他们自己的实现来构建开源软件。自由软件纯化论者却很反感 Ubuntu 这一点,但是很多普通用户却更喜欢一些。当然,无论你是不是一个纯粹论者,无论是在软件领域还是政治领域,还需要时间才能知道分晓。
|
||||
|
||||
### 敬请期待 ###
|
||||
|
||||
如果你想知道为什么我还没有提到民主党候选人,别想多了。我没有在这篇文章中提及他们,是因为我对民主党并不比共和党喜欢更多或更少一点(我个人认为,这种只有两个政党的美国特色是不荒谬的,根本不能体现民主,我也不相信这些党派候选人)。
|
||||
|
||||
另一方面,也可能会有很多人关心民主党候选人使用的 Linux 发行版。后续的帖子中我会提及的,请拭目以待。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/081715/which-open-source-linux-distributions-would-presidential-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki), [wxy](https://github.com/wxy/)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://thevarguy.com/open-source-application-software-companies/aligning-linux-distributions-presidential-hopefuls
|
||||
[2]:http://debian.org/
|
||||
[3]:http://www.damnsmalllinux.org/
|
||||
[4]:http://relax-and-recover.org/
|
||||
[5]:http://thevarguy.com/open-source-application-software-companies/061614/hps-machine-open-source-os-truly-revolutionary
|
||||
[6]:http://hp.com/
|
||||
[7]:http://ubuntu.com/
|
||||
@ -4,10 +4,9 @@ Linux 内核里的数据结构——双向链表
|
||||
双向链表
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Linux 内核中自己实现了双向链表,可以在 [include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h) 找到定义。我们将会首先从双向链表数据结构开始介绍**内核里的数据结构**。为什么?因为它在内核里使用的很广泛,你只需要在 [free-electrons.com](http://lxr.free-electrons.com/ident?i=list_head) 检索一下就知道了。
|
||||
|
||||
Linux 内核自己实现了双向链表,可以在[include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h)找到定义。我们将会从双向链表数据结构开始介绍`内核里的数据结构`。为什么?因为它在内核里使用的很广泛,你只需要在[free-electrons.com](http://lxr.free-electrons.com/ident?i=list_head) 检索一下就知道了。
|
||||
|
||||
首先让我们看一下在[include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) 里的主结构体:
|
||||
首先让我们看一下在 [include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) 里的主结构体:
|
||||
|
||||
```C
|
||||
struct list_head {
|
||||
@ -15,7 +14,7 @@ struct list_head {
|
||||
};
|
||||
```
|
||||
|
||||
你可能注意到这和你以前见过的双向链表的实现方法是不同的。举个例子来说,在[glib](http://www.gnu.org/software/libc/) 库里是这样实现的:
|
||||
你可能注意到这和你以前见过的双向链表的实现方法是不同的。举个例子来说,在 [glib](http://www.gnu.org/software/libc/) 库里是这样实现的:
|
||||
|
||||
```C
|
||||
struct GList {
|
||||
@ -25,7 +24,7 @@ struct GList {
|
||||
};
|
||||
```
|
||||
|
||||
通常来说一个链表结构会包含一个指向某个项目的指针。但是Linux内核中的链表实现并没有这样做。所以问题来了:`链表在哪里保存数据呢?`。实际上,内核里实现的链表是`侵入式链表`。侵入式链表并不在节点内保存数据-它的节点仅仅包含指向前后节点的指针,以及指向链表节点数据部分的指针——数据就是这样附加在链表上的。这就使得这个数据结构是通用的,使用起来就不需要考虑节点数据的类型了。
|
||||
通常来说一个链表结构会包含一个指向某个项目的指针。但是 Linux 内核中的链表实现并没有这样做。所以问题来了:**链表在哪里保存数据呢?**。实际上,内核里实现的链表是**侵入式链表(Intrusive list)**。侵入式链表并不在节点内保存数据-它的节点仅仅包含指向前后节点的指针,以及指向链表节点数据部分的指针——数据就是这样附加在链表上的。这就使得这个数据结构是通用的,使用起来就不需要考虑节点数据的类型了。
|
||||
|
||||
比如:
|
||||
|
||||
@ -36,7 +35,7 @@ struct nmi_desc {
|
||||
};
|
||||
```
|
||||
|
||||
让我们看几个例子来理解一下在内核里是如何使用`list_head` 的。如上所述,在内核里有很多很多不同的地方都用到了链表。我们来看一个在杂项字符驱动里面的使用的例子。在 [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) 的杂项字符驱动API 被用来编写处理小型硬件或虚拟设备的小驱动。这些驱动共享相同的主设备号:
|
||||
让我们看几个例子来理解一下在内核里是如何使用 `list_head` 的。如上所述,在内核里有很多很多不同的地方都用到了链表。我们来看一个在杂项字符驱动里面的使用的例子。在 [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) 的杂项字符驱动 API 被用来编写处理小型硬件或虚拟设备的小驱动。这些驱动共享相同的主设备号:
|
||||
|
||||
```C
|
||||
#define MISC_MAJOR 10
|
||||
@ -68,7 +67,7 @@ crw------- 1 root root 10, 63 Mar 21 12:01 vga_arbiter
|
||||
crw------- 1 root root 10, 137 Mar 21 12:01 vhci
|
||||
```
|
||||
|
||||
现在让我们看看它是如何使用链表的。首先看一下结构体`miscdevice`:
|
||||
现在让我们看看它是如何使用链表的。首先看一下结构体 `miscdevice`:
|
||||
|
||||
```C
|
||||
struct miscdevice
|
||||
@ -97,13 +96,13 @@ static LIST_HEAD(misc_list);
|
||||
struct list_head name = LIST_HEAD_INIT(name)
|
||||
```
|
||||
|
||||
然后使用宏`LIST_HEAD_INIT` 进行初始化,这会使用变量`name` 的地址来填充`prev`和`next` 结构体的两个变量。
|
||||
然后使用宏 `LIST_HEAD_INIT` 进行初始化,这会使用变量`name` 的地址来填充`prev`和`next` 结构体的两个变量。
|
||||
|
||||
```C
|
||||
#define LIST_HEAD_INIT(name) { &(name), &(name) }
|
||||
```
|
||||
|
||||
现在来看看注册杂项设备的函数`misc_register`。它在开始就用函数 `INIT_LIST_HEAD` 初始化了`miscdevice->list`。
|
||||
现在来看看注册杂项设备的函数`misc_register`。它在一开始就用函数 `INIT_LIST_HEAD` 初始化了`miscdevice->list`。
|
||||
|
||||
```C
|
||||
INIT_LIST_HEAD(&misc->list);
|
||||
@ -125,7 +124,7 @@ static inline void INIT_LIST_HEAD(struct list_head *list)
|
||||
list_add(&misc->list, &misc_list);
|
||||
```
|
||||
|
||||
内核文件`list.h` 提供了向链表添加新项的API 接口。我们来看看它的实现:
|
||||
内核文件`list.h` 提供了向链表添加新项的 API 接口。我们来看看它的实现:
|
||||
|
||||
|
||||
```C
|
||||
@ -205,9 +204,9 @@ int main() {
|
||||
}
|
||||
```
|
||||
|
||||
最终会打印`2`
|
||||
最终会打印出`2`
|
||||
|
||||
下一点就是`typeof`,它也很简单。就如你从名字所理解的,它仅仅返回了给定变量的类型。当我第一次看到宏`container_of`的实现时,让我觉得最奇怪的就是表达式`((type *)0)`中的0.实际上这个指针巧妙的计算了从结构体特定变量的偏移,这里的`0`刚好就是位宽里的零偏移。让我们看一个简单的例子:
|
||||
下一点就是`typeof`,它也很简单。就如你从名字所理解的,它仅仅返回了给定变量的类型。当我第一次看到宏`container_of`的实现时,让我觉得最奇怪的就是表达式`((type *)0)`中的0。实际上这个指针巧妙的计算了从结构体特定变量的偏移,这里的`0`刚好就是位宽里的零偏移。让我们看一个简单的例子:
|
||||
|
||||
```C
|
||||
#include <stdio.h>
|
||||
@ -236,21 +235,23 @@ int main() {
|
||||
|
||||
当然了`list_add` 和 `list_entry`不是`<linux/list.h>`提供的唯一功能。双向链表的实现还提供了如下API:
|
||||
|
||||
* list_add
|
||||
* list_add_tail
|
||||
* list_del
|
||||
* list_replace
|
||||
* list_move
|
||||
* list_is_last
|
||||
* list_empty
|
||||
* list_cut_position
|
||||
* list_splice
|
||||
* list_for_each
|
||||
* list_for_each_entry
|
||||
* list\_add
|
||||
* list\_add\_tail
|
||||
* list\_del
|
||||
* list\_replace
|
||||
* list\_move
|
||||
* list\_is\_last
|
||||
* list\_empty
|
||||
* list\_cut\_position
|
||||
* list\_splice
|
||||
* list\_for\_each
|
||||
* list\_for\_each\_entry
|
||||
|
||||
等等很多其它API。
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
|
||||
----
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/DataStructures/dlist.md
|
||||
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
@ -13,7 +13,7 @@
|
||||
- 意外的文件删除
|
||||
- 文件或文件系统损坏
|
||||
- 服务器完全毁坏,包括由于火灾或其他问题导致的同盘备份毁坏
|
||||
- 硬盘或SSD崩溃
|
||||
- 硬盘或 SSD 崩溃
|
||||
- 病毒或勒索软件破坏或删除文件
|
||||
|
||||
你可以使用磁带归档备份整个服务器并将其离线存储。
|
||||
@ -22,7 +22,7 @@
|
||||
|
||||
|
||||
|
||||
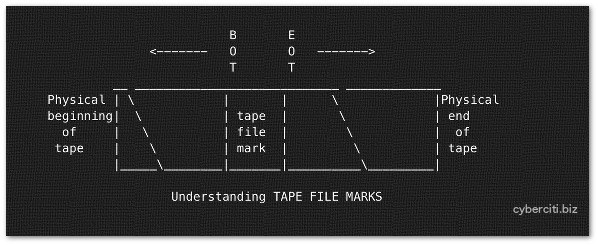
图01:磁带文件标记
|
||||
*图01:磁带文件标记*
|
||||
|
||||
每个磁带设备能存储多个备份文件。磁带备份文件通过 cpio,tar,dd 等命令创建。同时,磁带设备可以由多种程序打开、写入数据、及关闭。你可以存储若干备份(磁带文件)到一个物理磁带上。在每个磁带文件之间有个“磁带文件标记”。这用来指示一个物理磁带上磁带文件的结尾以及另一个文件的开始。你需要使用 mt 命令来定位磁带(快进,倒带和标记)。
|
||||
|
||||
@ -30,7 +30,7 @@
|
||||
|
||||
|
||||
|
||||
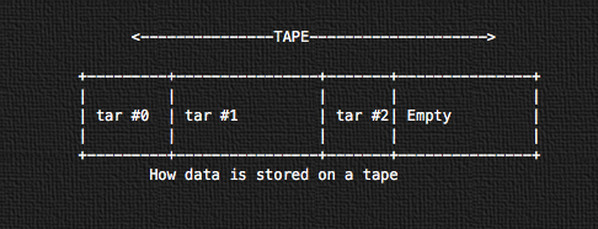
图02:磁带上的数据是如何存储的
|
||||
*图02:磁带上的数据是如何存储的*
|
||||
|
||||
所有的数据使用 tar 以连续磁带存储格式连续地存储。第一个磁带归档会从磁带的物理开始端开始存储(tar #0)。接下来的就是 tar #1,以此类推。
|
||||
|
||||
@ -60,22 +60,22 @@
|
||||
|
||||
输入下列命令:
|
||||
|
||||
## Linux(更多信息参阅 man) ##
|
||||
### Linux(更多信息参阅 man) ###
|
||||
lsscsi
|
||||
lsscsi -g
|
||||
|
||||
## IBM AIX ##
|
||||
### IBM AIX ###
|
||||
lsdev -Cc tape
|
||||
lsdev -Cc adsm
|
||||
lscfg -vl rmt*
|
||||
|
||||
## Solaris Unix ##
|
||||
### Solaris Unix ###
|
||||
cfgadm –a
|
||||
cfgadm -al
|
||||
luxadm probe
|
||||
iostat -En
|
||||
|
||||
## HP-UX Unix ##
|
||||
### HP-UX Unix ###
|
||||
ioscan Cf
|
||||
ioscan -funC tape
|
||||
ioscan -fnC tape
|
||||
@ -86,11 +86,11 @@
|
||||
|
||||
|
||||
|
||||
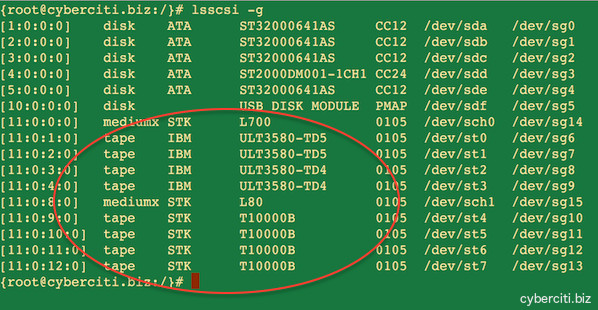
图03:Linux 服务器上已安装的磁带设备
|
||||
*图03:Linux 服务器上已安装的磁带设备*
|
||||
|
||||
### mt 命令示例 ###
|
||||
|
||||
在 Linux 和类Unix系统上,mt 命令用来控制磁带驱动器的操作,比如查看状态或查找磁带上的文件或写入磁带控制标记。下列大多数命令需要作为 root 用户执行。语法如下:
|
||||
在 Linux 和类 Unix 系统上,mt 命令用来控制磁带驱动器的操作,比如查看状态或查找磁带上的文件或写入磁带控制标记。下列大多数命令需要作为 root 用户执行。语法如下:
|
||||
|
||||
mt -f /tape/device/name operation
|
||||
|
||||
@ -98,7 +98,7 @@
|
||||
|
||||
你可以设置 TAPE shell 变量。这是磁带驱动器的路径名。在 FreeBSD 上默认的(如果变量没有设置,而不是 null)是 /dev/nsa0。可以通过 mt 命令的 -f 参数传递变量覆盖它,就像下面解释的那样。
|
||||
|
||||
## 添加到你的 shell 配置文件 ##
|
||||
### 添加到你的 shell 配置文件 ###
|
||||
TAPE=/dev/st1 #Linux
|
||||
TAPE=/dev/rmt/2 #Unix
|
||||
TAPE=/dev/nsa3 #FreeBSD
|
||||
@ -106,11 +106,11 @@
|
||||
|
||||
### 1:显示磁带/驱动器状态 ###
|
||||
|
||||
mt status #Use default
|
||||
mt -f /dev/rmt/0 status #Unix
|
||||
mt -f /dev/st0 status #Linux
|
||||
mt -f /dev/nsa0 status #FreeBSD
|
||||
mt -f /dev/rmt/1 status #Unix unity 1 也就是 tape device no. 1
|
||||
mt status ### Use default
|
||||
mt -f /dev/rmt/0 status ### Unix
|
||||
mt -f /dev/st0 status ### Linux
|
||||
mt -f /dev/nsa0 status ### FreeBSD
|
||||
mt -f /dev/rmt/1 status ### Unix unity 1 也就是 tape device no. 1
|
||||
|
||||
你可以像下面一样使用 shell 循环语句遍历一个系统并定位其所有的磁带驱动器:
|
||||
|
||||
@ -208,7 +208,7 @@
|
||||
|
||||
mt -f /dev/st0 rewind; dd if=/dev/st0 of=-
|
||||
|
||||
## tar 格式 ##
|
||||
### tar 格式 ###
|
||||
tar tvf {DEVICE} {Directory-FileName}
|
||||
tar tvf /dev/st0
|
||||
tar tvf /dev/st0 desktop
|
||||
@ -216,40 +216,40 @@
|
||||
|
||||
### 12:使用 dump 或 ufsdump 备份分区 ###
|
||||
|
||||
## Unix 备份 c0t0d0s2 分区 ##
|
||||
### Unix 备份 c0t0d0s2 分区 ###
|
||||
ufsdump 0uf /dev/rmt/0 /dev/rdsk/c0t0d0s2
|
||||
|
||||
## Linux 备份 /home 分区 ##
|
||||
### Linux 备份 /home 分区 ###
|
||||
dump 0uf /dev/nst0 /dev/sda5
|
||||
dump 0uf /dev/nst0 /home
|
||||
|
||||
## FreeBSD 备份 /usr 分区 ##
|
||||
### FreeBSD 备份 /usr 分区 ###
|
||||
dump -0aL -b64 -f /dev/nsa0 /usr
|
||||
|
||||
### 12:使用 ufsrestore 或 restore 恢复分区 ###
|
||||
|
||||
## Unix ##
|
||||
### Unix ###
|
||||
ufsrestore xf /dev/rmt/0
|
||||
## Unix 交互式恢复 ##
|
||||
### Unix 交互式恢复 ###
|
||||
ufsrestore if /dev/rmt/0
|
||||
|
||||
## Linux ##
|
||||
### Linux ###
|
||||
restore rf /dev/nst0
|
||||
## 从磁带媒介上的第6个备份交互式恢复 ##
|
||||
### 从磁带媒介上的第6个备份交互式恢复 ###
|
||||
restore isf 6 /dev/nst0
|
||||
|
||||
## FreeBSD 恢复 ufsdump 格式 ##
|
||||
### FreeBSD 恢复 ufsdump 格式 ###
|
||||
restore -i -f /dev/nsa0
|
||||
|
||||
### 13:从磁带开头开始写入(见图02) ###
|
||||
|
||||
## 这会覆盖磁带上的所有数据 ##
|
||||
### 这会覆盖磁带上的所有数据 ###
|
||||
mt -f /dev/st1 rewind
|
||||
|
||||
### 备份 home ##
|
||||
### 备份 home ###
|
||||
tar cvf /dev/st1 /home
|
||||
|
||||
## 离线并卸载磁带 ##
|
||||
### 离线并卸载磁带 ###
|
||||
mt -f /dev/st0 offline
|
||||
|
||||
从磁带开头开始恢复:
|
||||
@ -260,22 +260,22 @@
|
||||
|
||||
### 14:从最后一个 tar 后开始写入(见图02) ###
|
||||
|
||||
## 这会保留之前写入的数据 ##
|
||||
### 这会保留之前写入的数据 ###
|
||||
mt -f /dev/st1 eom
|
||||
|
||||
### 备份 home ##
|
||||
### 备份 home ###
|
||||
tar cvf /dev/st1 /home
|
||||
|
||||
## 卸载 ##
|
||||
### 卸载 ###
|
||||
mt -f /dev/st0 offline
|
||||
|
||||
### 15:从 tar number 2 后开始写入(见图02) ###
|
||||
|
||||
## 在 tar number 2 之后写入(应该是 2+1)
|
||||
### 在 tar number 2 之后写入(应该是 2+1)###
|
||||
mt -f /dev/st0 asf 3
|
||||
tar cvf /dev/st0 /usr
|
||||
|
||||
## asf 等效于 fsf ##
|
||||
### asf 等效于 fsf ###
|
||||
mt -f /dev/sf0 rewind
|
||||
mt -f /dev/st0 fsf 2
|
||||
|
||||
@ -1,20 +1,22 @@
|
||||
安装 openSUSE Leap 42.1 之后要做的 8 件事
|
||||
================================================================================
|
||||

|
||||
致谢:[Metropolitan Transportation/Flicrk][1]
|
||||
|
||||
> 你已经在你的电脑上安装了 openSUSE,这是你接下来要做的。
|
||||
*致谢:[Metropolitan Transportation/Flicrk][1]*
|
||||
|
||||
[openSUSE Leap 确实是个巨大的飞跃][2],它允许用户运行一个和 SUSE Linux 企业版拥有一样基因的发行版。和其它系统一样,为了实现最佳的使用效果,在使用它之前需要做些优化设置。
|
||||
> 如果你已经在你的电脑上安装了 openSUSE,这就是你接下来要做的。
|
||||
|
||||
下面是一些我在我的电脑上安装 openSUSE Leap 之后做的一些事情(不适用于服务器)。这里面没有强制性要求的设置,基本安装对你来说也可能足够了。但如果你想获得更好的 openSUSE Leap 体验,那就跟着我往下看吧。
|
||||
[openSUSE Leap 确实是个巨大的飞跃][2],它允许用户运行一个和 SUSE Linux 企业版拥有同样基因的发行版。和其它系统一样,为了实现最佳的使用效果,在使用它之前需要做些优化设置。
|
||||
|
||||
下面是一些我在我的电脑上安装 openSUSE Leap 之后做的一些事情(不适用于服务器)。这里面没有强制性的设置,基本安装对你来说也可能足够了。但如果你想获得更好的 openSUSE Leap 体验,那就跟着我往下看吧。
|
||||
|
||||
### 1. 添加 Packman 仓库 ###
|
||||
|
||||
由于专利和授权等原因,openSUSE 和许多 Linux 发行版一样,不通过官方仓库(repos)提供一些软件、解码器,以及驱动等。取而代之的是通过第三方或社区仓库来提供。第一个也是最重要的仓库是“Packman”。因为这些仓库不是默认启用的,我们需要添加它们。你可以通过 YaST(openSUSE 的特色之一)或者命令行完成(如下方介绍)。
|
||||
|
||||
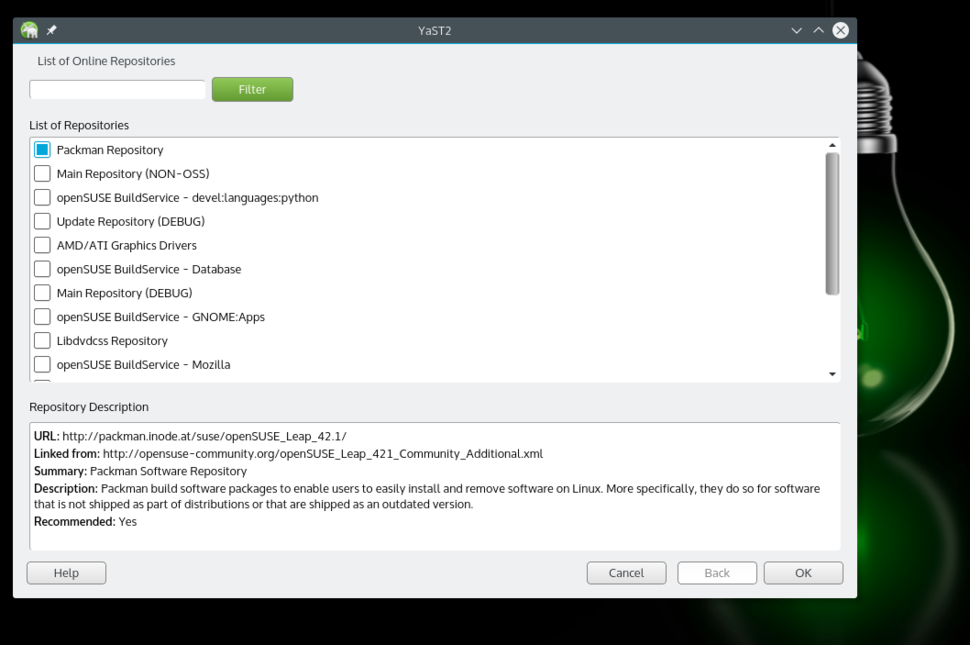
|
||||
添加 Packman 仓库。
|
||||
|
||||
*添加 Packman 仓库。*
|
||||
|
||||
使用 YaST,打开软件源部分。点击“添加”按钮并选择“社区仓库(Community Repositories)”。点击“下一步”。一旦仓库列表加载出来了,选择 Packman 仓库。点击“确认”,然后点击“信任”导入信任的 GnuPG 密钥。
|
||||
|
||||
@ -58,7 +60,7 @@ openSUSE 的默认浏览器是 Firefox。但是因为 Firefox 不能够播放专
|
||||
|
||||
### 5. 安装 Nvidia 驱动 ###
|
||||
|
||||
即便你有 Nvidia 或 ATI 显卡,openSUSE Leap 也能够开箱即用。但是,如果你需要专有驱动来游戏或其它目的,你可以安装这些驱动,但需要一点额外的工作。
|
||||
即便你使用 Nvidia 或 ATI 显卡,openSUSE Leap 也能够开箱即用。但是,如果你需要专有驱动来游戏或其它目的,你可以安装这些驱动,但需要一点额外的工作。
|
||||
|
||||
首先你需要添加 Nvidia 源;它的步骤和使用 YaST 添加 Packman 仓库是一样的。唯一的不同是你需要在社区仓库部分选择 Nvidia。添加好了之后,到 **软件管理 > 附加** 去并选择“附加/安装所有匹配的推荐包”。
|
||||
|
||||
@ -76,14 +78,15 @@ openSUSE 的默认浏览器是 Firefox。但是因为 Firefox 不能够播放专
|
||||
|
||||
### 7. 安装你喜欢的电子邮件客户端 ###
|
||||
|
||||
openSUSE 自带 Kmail 或 Evolution,这取决于你安装的桌面环境。我用的是 Plasma,自带 Kmail,这个邮件客户端还有许多地方有待改进。我建议可以试试 Thunderbird 或 Evolution。所有主要的邮件客户端都能在官方仓库找到。你还可以看看我[精心挑选的 Linux 最佳邮件客户端][7]。
|
||||
openSUSE 自带 Kmail 或 Evolution,这取决于你安装的桌面环境。我用的是 KDE Plasma 自带的 Kmail,这个邮件客户端还有许多地方有待改进。我建议可以试试 Thunderbird 或 Evolution。所有主要的邮件客户端都能在官方仓库找到。你还可以看看我[精心挑选的 Linux 最佳邮件客户端][7]。
|
||||
|
||||
### 8. 在防火墙允许 Samba 服务 ###
|
||||
|
||||
相比于其它发行版,openSUSE 默认提供了更加安全的系统。但对新用户来说它也需要一点设置。如果你正在使用 Samba 协议分享文件到本地网络的话,你需要在防火墙允许该服务。
|
||||
|
||||
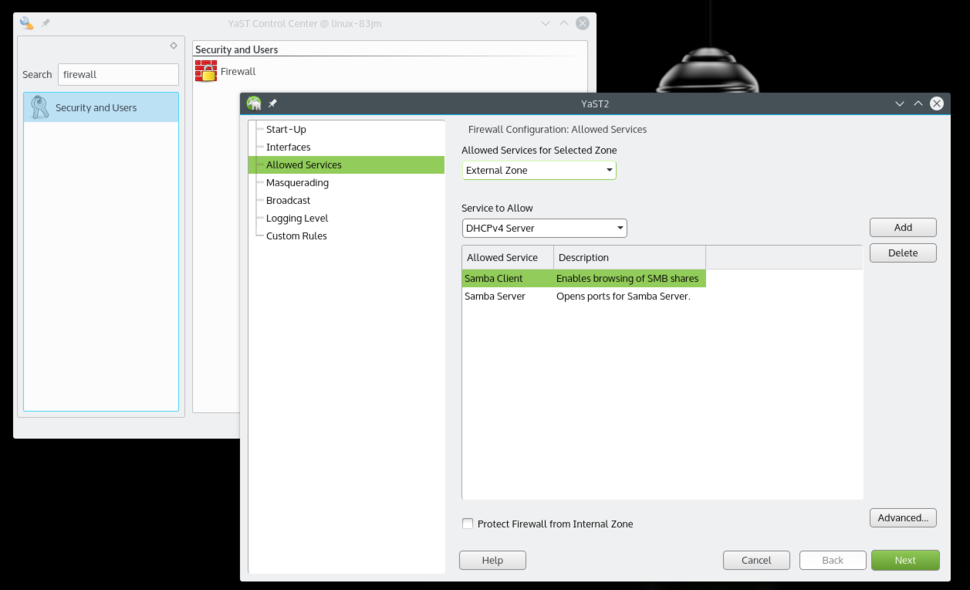
|
||||
在防火墙设置里允许 Samba 客户端和服务端
|
||||
|
||||
*在防火墙设置里允许 Samba 客户端和服务端*
|
||||
|
||||
打开 YaST 并搜索 Firewall。在防火墙设置里,进入到“允许的服务(Allowed Services)”,你会在“要允许的服务(Service to allow)”下面看到一个下拉列表。选择“Samba 客户端”,然后点击“添加”。同样方法添加“Samba 服务器”。都添加了之后,点击“下一步”,然后点击“完成”,现在你就可以通过本地网络从你的 openSUSE 分享文件以及访问其它机器了。
|
||||
|
||||
@ -1,55 +0,0 @@
|
||||
vim-kakali translating
|
||||
|
||||
Which Open Source Linux Distributions Would Presidential Hopefuls Run?
|
||||
================================================================================
|
||||

|
||||
|
||||
Republican presidential candidate Donald Trump
|
||||
|
||||
If people running for president used Linux or another open source operating system, which distribution would it be? That's a key question that the rest of the press—distracted by issues of questionable relevance such as "policy platforms" and whether it's appropriate to add an exclamation point to one's Christian name—has been ignoring. But the ignorance ends here: Read on for this sometime-journalist's take on presidential elections and Linux distributions.
|
||||
|
||||
If this sounds like a familiar topic to those of you who have been reading my drivel for years (is anyone, other than my dear editor, unfortunate enough to have actually done that?), it's because I wrote a [similar post][1] during the last presidential election cycle. Some kind readers took that article more seriously than I intended, so I'll take a moment to point out that I don't actually believe that open source software and political campaigns have anything meaningful to do with one another. I am just trying to amuse myself at the start of a new week.
|
||||
|
||||
But you can make of this what you will. You're the reader, after all.
|
||||
|
||||
### Linux Distributions of Choice: Republicans ###
|
||||
|
||||
Today, I'll cover just the Republicans. And I won't even discuss all of them, since the candidates hoping for the Republican party's nomination are too numerous to cover fully here in one post. But for starters:
|
||||
|
||||
If **Jeb (Jeb!?) Bush** ran Linux, it would be [Debian][2]. It's a relatively boring distribution designed for serious, grown-up hackers—the kind who see it as their mission to be the adults in the pack and clean up the messes that less-experienced open source fans create. Of course, this also makes Debian relatively unexciting, and its user base remains perennially small as a result.
|
||||
|
||||
**Scott Walker**, for his part, would be a [Damn Small Linux][3] (DSL) user. Requiring merely 50MB of disk space and 16MB of RAM to run, DSL can breathe new life into 20-year-old 486 computers—which is exactly what a cost-cutting guru like Walker would want. Of course, the user experience you get from DSL is damn primitive; the platform barely runs a browser. But at least you won't be wasting money on new computer hardware when the stuff you bought in 1993 can still serve you perfectly well.
|
||||
|
||||
How about **Chris Christie**? He'd obviously be clinging to [Relax-and-Recover Linux][4], which bills itself as a "setup-and-forget Linux bare metal disaster recovery solution." "Setup-and-forget" has basically been Christie's political strategy ever since that unfortunate incident on the George Washington Bridge stymied his political momentum. Disaster recovery may or may not bring back everything for Christie in the end, but at least he might succeed in recovering a confidential email or two that accidentally disappeared when his computer crashed.
|
||||
|
||||
As for **Carly Fiorina**, she'd no doubt be using software developed for "[The Machine][5]" operating system from [Hewlett-Packard][6] (HPQ), the company she led from 1999 to 2005. The Machine actually may run several different operating systems, which may or may not be based on Linux—details remain unclear—and its development began well after Fiorina's tenure at HP came to a conclusion. Still, her roots as a successful executive in the IT world form an important part of her profile today, meaning that her ties to HP have hardly been severed fully.
|
||||
|
||||
Last but not least—and you knew this was coming—there's **Donald Trump**. He'd most likely pay a team of elite hackers millions of dollars to custom-build an operating system just for him—even though he could obtain a perfectly good, ready-made operating system for free—to show off how much money he has to waste. He'd then brag about it being the best operating system ever made, though it would of course not be compliant with POSIX or anything else, because that would mean catering to the establishment. The platform would also be totally undocumented, since, if Trump explained how his operating system actually worked, he'd risk giving away all his secrets to the Islamic State—obviously.
|
||||
|
||||
Alternatively, if Trump had to go with a Linux platform already out there, [Ubuntu][7] seems like the most obvious choice. Like Trump, the Ubuntu developers have taken a we-do-what-we-want approach to building open source software by implementing their own, sometimes proprietary applications and interfaces. Free-software purists hate Ubuntu for that, but plenty of ordinary people like it a lot. Of course, whether playing purely by your own rules—in the realms of either software or politics—is sustainable in the long run remains to be seen.
|
||||
|
||||
### Stay Tuned ###
|
||||
|
||||
If you're wondering why I haven't yet mentioned the Democratic candidates, worry not. I am not leaving them out of today's writing because I like them any more or less than the Republicans. (Personally, I think the peculiar American practice of having only two viable political parties—which virtually no other functioning democracy does—is ridiculous, and I am suspicious of all of these candidates as a result.)
|
||||
|
||||
On the contrary, there's plenty to say about the Linux distributions the Democrats might use, too. And I will, in a future post. Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/081715/which-open-source-linux-distributions-would-presidential-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://thevarguy.com/open-source-application-software-companies/aligning-linux-distributions-presidential-hopefuls
|
||||
[2]:http://debian.org/
|
||||
[3]:http://www.damnsmalllinux.org/
|
||||
[4]:http://relax-and-recover.org/
|
||||
[5]:http://thevarguy.com/open-source-application-software-companies/061614/hps-machine-open-source-os-truly-revolutionary
|
||||
[6]:http://hp.com/
|
||||
[7]:http://ubuntu.com/
|
||||
@ -1,3 +1,7 @@
|
||||
vim-kakali translating
|
||||
|
||||
|
||||
|
||||
Confessions of a cross-platform developer
|
||||
=============================================
|
||||
|
||||
|
||||
@ -0,0 +1,46 @@
|
||||
Linus Torvalds Talks IoT, Smart Devices, Security Concerns, and More[video]
|
||||
===========================================================================
|
||||
|
||||

|
||||
>Dirk Hohndel interviews Linus Torvalds at ELC.
|
||||
|
||||
For the first time in the 11-year history of the [Embedded Linux Conference (ELC)][0], held in San Diego, April 4-6, the keynotes included a discussion with Linus Torvalds. The creator and lead overseer of the Linux kernel, and “the reason we are all here,” in the words of his interviewer, Intel Chief Linux and Open Source Technologist Dirk Hohndel, seemed upbeat about the state of Linux in embedded and Internet of Things applications. Torvalds very presence signaled that embedded Linux, which has often been overshadowed by Linux desktop, server, and cloud technologies, had come of age.
|
||||
|
||||

|
||||
>Linus Torvalds speaking at Embedded Linux Conference.
|
||||
|
||||
IoT was the main topic at ELC, which included an OpenIoT Summit track, and the chief topic in the Torvalds interview.
|
||||
|
||||
“Maybe you won’t see Linux at the IoT leaf nodes, but anytime you have a hub, you will need it,” Torvalds told Hohndel. “You need smart devices especially if you have 23 [IoT standards]. If you have all these stupid devices that don’t necessarily run Linux, and they all talk with slightly different standards, you will need a lot of smart devices. We will never have one completely open standard, one ring to rule them all, but you will have three of four major protocols, and then all these smart hubs that translate.”
|
||||
|
||||
Torvalds remained customarily philosophical when Hohndel asked about the gaping security holes in IoT. “I don’t worry about security because there’s not a lot we can do,” he said. “IoT is unpatchable -- it’s a fact of life.”
|
||||
|
||||
The Linux creator seemed more concerned about the lack of timely upstream contributions from one-off embedded projects, although he noted there have been significant improvements in recent years, partially due to consolidation on hardware.
|
||||
|
||||
“The embedded world has traditionally been hard to interact with as an open source developer, but I think that’s improving,” Torvalds said. “The ARM community has become so much better. Kernel people can now actually keep up with some of the hardware improvements. It’s improving, but we’re not nearly there yet.”
|
||||
|
||||
Torvalds admitted to being more at home on the desktop than in embedded and to having “two left hands” when it comes to hardware.
|
||||
|
||||
“I’ve destroyed things with a soldering iron many times,” he said. “I’m not really set up to do hardware.” On the other hand, Torvalds guessed that if he were a teenager today, he would be fiddling around with a Raspberry Pi or BeagleBone. “The great part is if you’re not great at soldering, you can just buy a new one.”
|
||||
|
||||
Meanwhile, Torvalds vowed to continue fighting for desktop Linux for another 25 years. “I’ll wear them down,” he said with a smile.
|
||||
|
||||
Watch the full video, below.
|
||||
|
||||
Get the Latest on Embedded Linux and IoT. Access 150+ recorded sessions from Embedded Linux Conference 2016. [Watch Now][1].
|
||||
|
||||
[video](https://youtu.be/tQKUWkR-wtM)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[0]: http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[1]: http://go.linuxfoundation.org/elc-openiot-summit-2016-videos?utm_source=lf&utm_medium=blog&utm_campaign=linuxcom
|
||||
@ -0,0 +1,63 @@
|
||||
65% of companies are contributing to open source projects
|
||||
==========================================================
|
||||
|
||||

|
||||
|
||||
This year marks the 10th annual Future of Open Source Survey to examine trends in open source, hosted by Black Duck and North Bridge. The big takeaway from the survey this year centers around the mainstream acceptance of open source today and how much has changed over the last decade.
|
||||
|
||||
The [2016 Future of Open Source Survey][1] analyzed responses from nearly 3,400 professionals. Developers made their voices heard in the survey this year, comprising roughly 70% of the participants. The group that showed exponential growth were security professionals, whose participation increased by over 450%. Their participation shows the increasing interest in ensuring that the open source community pays attention to security issues in open source software and securing new technologies as they emerge.
|
||||
|
||||
Black Duck's [Open Source Rookies][2] of the Year awards identify some of these emerging technologies, like Docker and Kontena in containers. Containers themselves have seen huge growth this year–76% of respondents say their company has some plans to use containers. And an amazing 59% of respondents are already using containers in a variety of deployments, from development and testing to internal and external production environment. The developer community has embraced containers as a way to get their code out quickly and easily.
|
||||
|
||||
It's not surprising that the survey shows a miniscule number of organizations having no developers contributing to open source software. When large corporations like Microsoft and Apple open source some of their solutions, developers gain new opportunities to participate in open source. I certainly hope this trend will continue, with more software developers contributing to open source projects at work and outside of work.
|
||||
|
||||
### Highlights from the 2016 survey
|
||||
|
||||
#### Business value
|
||||
|
||||
* Open source is an essential element in development strategy with more than 65% of respondents relying on open source to speed development.
|
||||
* More than 55% leverage open source within their production environments.
|
||||
|
||||
#### Engine for innovation
|
||||
|
||||
* Respondents reported use of open source to drive innovation through faster, more agile development; accelerated time to market and vastly superior interoperability.
|
||||
* Additional innovation is afforded by open source's quality of solutions; competitive features and technical capabilities; and ability to customize.
|
||||
|
||||
#### Proliferation of open source business models and investment
|
||||
|
||||
* More diverse business models are emerging that promise to deliver more value to open source companies than ever before. They are not as dependent on SaaS and services/support.
|
||||
* Open source private financing has increased almost 4x in five years.
|
||||
|
||||
#### Security and management
|
||||
|
||||
The development of best-in-class open source security and management practices has not kept pace with growth in adoption. Despite a proliferation of expensive, high-profile open source breaches in recent years, the survey revealed that:
|
||||
|
||||
* 50% of companies have no formal policy for selecting and approving open source code.
|
||||
* 47% of companies don’t have formal processes in place to track open source code, limiting their visibility into their open source and therefore their ability to control it.
|
||||
* More than one-third of companies have no process for identifying, tracking or remediating known open source vulnerabilities.
|
||||
|
||||
#### Open source participation on the rise
|
||||
|
||||
The survey revealed an active corporate open source community that spurs innovation, delivers exponential value and shares camaraderie:
|
||||
|
||||
* 67% of respondents report actively encouraging developers to engage in and contribute to open source projects.
|
||||
* 65% of companies are contributing to open source projects.
|
||||
* One in three companies have a fulltime resource dedicated to open source projects.
|
||||
* 59% of respondents participate in open source projects to gain competitive edge.
|
||||
|
||||
Black Duck and North Bridge learned a great deal this year about security, policy, business models and more from the survey, and we’re excited to share these findings. Thank you to our many collaborators and all the respondents for taking the time to take the survey. It’s been a great ten years, and I am happy that we can safely say that the future of open source is full of possibilities.
|
||||
|
||||
Learn more, see the [full results][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/2016-future-open-source-survey
|
||||
|
||||
作者:[Haidee LeClair][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/blackduck2016
|
||||
[1]: http://www.slideshare.net/blackducksoftware/2016-future-of-open-source-survey-results
|
||||
[2]: https://info.blackducksoftware.com/OpenSourceRookies2015.html
|
||||
[3]: http://www.slideshare.net/blackducksoftware/2016-future-of-open-source-survey-results%C2%A0
|
||||
@ -0,0 +1,56 @@
|
||||
Linux gives me all the tools I need
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
[Linux][0] is all around us. It's [on our phones][1] in the form of Android. It's [used on the International Space Station][2]. It [provides much of the backbone of the Internet][3]. And yet many people never notice it. Discovering Linux is a rewarding endeavor. Lots of other people have [shared their Linux stories][4] on Opensource.com, and now it's my turn.
|
||||
|
||||
I still remember when I first discovered Linux in 2008. The person who helped me discover Linux was my father, Socrates Ballais. He was an economics professor here in Tacloban City, Philippines. He was also a technology enthusiast. He taught me a lot about computers and technology, but only advocated using Linux as a fallback operating system in case Windows fails.
|
||||
|
||||
### My earliest days
|
||||
|
||||
Before we had a computer in the home, I was a Windows user. I played games, created documents, and did all the other things kids do with computers. I didn't know what Linux was or what it was used for. The Windows logo was my symbol for a computer.
|
||||
|
||||
When we got our first computer, my father installed Linux ([Ubuntu][5] 8.04) on it. Being the curious kid I was, I booted into the operating system. I was astonished with the interface. It was beautiful. I found it to be very user friendly. For some time, all I did in Ubuntu was play the bundled games. I would do my school work in Windows.
|
||||
|
||||
### The first install
|
||||
|
||||
Four years later, I decided that I would reinstall Windows on our family computer. Without hesitation, I also decided to install Ubuntu. With that, I had fallen in love with Linux (again). Over time, I became more adept with Ubuntu and would casually advocate its use to my friends. When I got my first laptop, I installed it right away.
|
||||
|
||||
### Today
|
||||
|
||||
Today, Linux is my go-to operating system. When I need to do something on a computer, I do it in Linux. For documents and presentations, I use Microsoft Office via [Wine][6]. For my web needs, there's [Chrome and Firefox][7]. For email, there's [Geary][8]. You can do pretty much everything with Linux.
|
||||
|
||||
Most, if not all, of my programming work is done in Linux. The lack of a standard Integrated Development Environment (IDE) like [Visual Studio][9] or [XCode][10] taught me to be flexible and learn more things as a programmer. Now a text editor and a compiler/interpreter are all I need to start coding. I only use an IDE in cases when it's the best tool for accomplishing a task at hand. I find Linux to be more developer-friendly than Windows. To generalize, Linux gives me all the tools I need to develop software.
|
||||
|
||||
Today, I am the co-founder and CTO of a startup called [Creatomiv Studios][11]. I use Linux to develop code for the backend server of our latest project, Basyang. I'm also an amateur photographer, and use [GIMP][12] and [Darktable][13] to edit and manage photos. For communication with my team, I use [Telegram][14].
|
||||
|
||||
### The beauty of Linux
|
||||
|
||||
Many may see Linux as an operating system only for those who love solving complicated problems and working on the command line. Others may see it as a rubbish operating system lacking the support of many companies. However, I see Linux as a thing of beauty and a tool for creation. I love Linux the way it is and hope to see it continue to grow.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-sean-ballais
|
||||
|
||||
作者:[Sean Francis N. Ballais][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/seanballais
|
||||
[0]: https://opensource.com/resources/what-is-linux
|
||||
[1]: http://www.howtogeek.com/189036/android-is-based-on-linux-but-what-does-that-mean/
|
||||
[2]: http://www.extremetech.com/extreme/155392-international-space-station-switches-from-windows-to-linux-for-improved-reliability
|
||||
[3]: https://www.youtube.com/watch?v=JzsLkbwi1LA
|
||||
[4]: https://opensource.com/tags/my-linux-story
|
||||
[5]: http://ubuntu.com/
|
||||
[6]: https://www.winehq.org/
|
||||
[7]: https://www.google.com/chrome/browser/desktop/index.html
|
||||
[8]: https://wiki.gnome.org/Apps/Geary
|
||||
[9]: https://www.visualstudio.com/en-us/visual-studio-homepage-vs.aspx
|
||||
[10]: https://developer.apple.com/xcode/
|
||||
[11]: https://www.facebook.com/CreatomivStudios/
|
||||
[12]: https://www.gimp.org/
|
||||
[13]: http://www.darktable.org/
|
||||
[14]: https://telegram.org/
|
||||
@ -0,0 +1,49 @@
|
||||
Growing a career alongside Linux
|
||||
==================================
|
||||
|
||||

|
||||
|
||||
My Linux story started in 1998 and continues today. Back then, I worked for The Gap managing thousands of desktops running [OS/2][1] (and a few years later, [Warp 3.0][2]). As an OS/2 guy, I was really happy then. The desktops hummed along and it was quite easy to support thousands of users with the tools the GAP had built. Changes were coming, though.
|
||||
|
||||
In November of 1998, I received an invitation to join a brand new startup which would focus on Linux in the enterprise. This startup became quite famous as [Linuxcare][2].
|
||||
|
||||
### My time at Linuxcare
|
||||
|
||||
I had played with Linux a bit, but had never considered delivering it to enterprise customers. Mere months later (which is a turn of the corner in startup time and space), I was managing a line of business that let enterprises get their hardware, software, and even books certified on a few flavors of Linux that were popular back then.
|
||||
|
||||
I supported customers like IBM, Dell, and HP in ensuring their hardware ran Linux successfully. You hear a lot now about preloading Linux on hardware today, but way back then I was invited to Dell to discuss getting a laptop certified to run Linux for an upcoming trade show. Very exciting times! We also supported IBM and HP on a number of certification efforts that spanned a few years.
|
||||
|
||||
Linux was changing fast, much like it always has. It gained hardware support for more key devices like sound, network, graphics. At around that time, I shifted from RPM-based systems to [Debian][3] for my personal use.
|
||||
|
||||
### Using Linux through the years
|
||||
|
||||
Fast forward some years and I worked at a number of companies that did Linux as hardened appliances, Linux as custom software, and Linux in the data center. By the mid 2000s, I was busy doing consulting for that rather large software company in Redmond around some analysis and verification of Linux compared to their own solutions. My personal use had not changed though—I would still run Debian testing systems on anything I could.
|
||||
|
||||
I really appreciated the flexibility of a distribution that floated and was forever updated. Debian is one of the most fun and well supported distributions and has the best community I've ever been a part of.
|
||||
|
||||
When I look back at my own adoption of Linux, I remember with fondness the numerous Linux Expo trade shows in San Jose, San Francisco, Boston, and New York in the early and mid 2000's. At Linuxcare we always did fun and funky booths, and walking the show floor always resulted in getting re-acquainted with old friends. Rumors of work were always traded, and the entire thing underscored the fun of using Linux in real endeavors.
|
||||
|
||||
The rise of virtualization and cloud has really made the use of Linux even more interesting. When I was with Linuxcare, we partnered with a small 30-person company in Palo Alto. We would drive to their offices and get things ready for a trade show that they would attend with us. Who would have ever known that little startup would become VMware?
|
||||
|
||||
I have so many stories, and there were so many people I was so fortunate to meet and work with. Linux has evolved in so many ways and has become so important. And even with its increasing importance, Linux is still fun to use. I think its openness and the ability to modify it has contributed to a legion of new users, which always astounds me.
|
||||
|
||||
### Today
|
||||
|
||||
I've moved away from doing mainstream Linux things over the past five years. I manage large scale infrastructure projects that include a variety of OSs (both proprietary and open), but my heart has always been with Linux.
|
||||
|
||||
The constant evolution and fun of using Linux has been a driving force for me for over the past 18 years. I started with the 2.0 Linux kernel and have watched it become what it is now. It's a remarkable thing. An organic thing. A cool thing.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-michael-perry
|
||||
|
||||
作者:[Michael Perry][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/mpmilestogo
|
||||
[1]: https://en.wikipedia.org/wiki/OS/2
|
||||
[2]: https://archive.org/details/IBMOS2Warp3Collection
|
||||
[3]: https://en.wikipedia.org/wiki/Linuxcare
|
||||
[4]: https://www.debian.org/
|
||||
[5]:
|
||||
@ -0,0 +1,54 @@
|
||||
After a nasty computer virus, sys admin looks to Linux
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
My first brush with open source came while I was working for my university as a part-time system administrator in 2001. I was part of a small group that created business case studies for teaching not just in the university, but elsewhere in academia.
|
||||
|
||||
As the team grew, the need for a robust LAN setup with file serving, intranet applications, domain logons, etc. emerged. Our IT infrastructure consisted mostly of bootstrapped Windows 98 computers that had become too old for the university's IT labs and were reassigned to our department.
|
||||
|
||||
### Discovering Linux
|
||||
|
||||
One day, as part of the university's IT procurement plan, our department received an IBM server. We planned to use it as an Internet gateway, domain controller, file and backup server, and intranet application host.
|
||||
|
||||
Upon unboxing, we noticed that it came with Red Hat Linux CDs. No one on our 22-person team (including me) knew anything about Linux. After a few days of research, I met a friend of a friend who did Linux RTOS programming for a living. I asked him for some help installing it.
|
||||
|
||||
It was heady stuff as I watched the friend load up the CD drive with the first of the installation CDs and boot into the Anaconda install system. In about an hour we had completed the basic installation, but still had no working internet connection.
|
||||
|
||||
Another hour of tinkering got us connected to the Internet, but we still weren't anywhere near domain logons or Internet gateway functionality. After another weekend of tinkering, we were able to instruct our Windows 98 terminals to accept the IP of the the Linux PC as the proxy so that we had a working shared Internet connection. But domain logons were still some time away.
|
||||
|
||||
We downloaded [Samba][1] over our awfully slow phone modem connection and hand configured it to serve as the domain controller. File services were also enabled via NFS Kernel Server and creating user directories and making the necessary adjustments and configurations on Windows 98 in Network Neighborhood.
|
||||
|
||||
This setup ran flawlessly for quite some time, and we eventually decided to get started with Intranet applications for timesheet management and some other things. By this time, I was leaving the organization and had handed over most of the sys admin stuff to someone who replaced me.
|
||||
|
||||
### A second Linux experience
|
||||
|
||||
In 2004, I got into Linux once again. My wife ran an independent staff placement business that used data from services like Monster.com to connect clients with job seekers.
|
||||
|
||||
Being the more computer literate of the two of us, it was my job to set things right with the computer or Internet when things went wrong. We also needed to experiment with a lot of tools for sifting through the mountains of resumes and CVs she had to go through on a daily basis.
|
||||
|
||||
Windows [BSoDs][2] were a routine affair, but that was tolerable as long as the data we paid for was safe. I had to spend a few hours each week creating backups.
|
||||
|
||||
One day, we had a virus that simply would not go away. Little did we know what was happening to the data on the slave disk. When it finally failed, we plugged in the week-old slave backup and it failed a week later. Our second backup simply refused to boot up. It was time for professional help, so we took our PC to a reputable repair shop. After two days, we learned that some malware or virus had wiped certain file types, including our paid data, clean.
|
||||
|
||||
This was a body blow to my wife's business plans and meant lost contracts and delayed invoice payments. I had in the interim travelled abroad on business and purchased my first laptop computer from [Computex 2004][3] in Taiwan. It had Windows XP pre-installed, but I wanted to replace it with Linux. I had read that Linux was ready for the desktop and that [Mandrake Linux][4] was a good choice. My first attempt at installation went without a glitch. Everything worked beautifully. I used [OpenOffice][5] for my writing, presentation, and spreadsheet needs.
|
||||
|
||||
We got new hard drives for our computer and installed Mandrake Linux on them. OpenOffice replaced Microsoft Office. We relied on webmail for mailing needs, and [Mozilla Firefox][6] was a welcome change in November 2004. My wife saw the benefits immediately, as there were no crashes or virus/malware infections. More importantly, we bade goodbye to the frequent crashes that plagued Windows 98 and XP. She continued to use the same distribution.
|
||||
|
||||
I, on the other hand, started playing around with other distributions. I love distro-hopping and trying out new ones every once in a while. I also regularly try and test out web applications like Drupal, Joomla, and WordPress on Apache and NGINX stacks. And now our son, who was born in 2006, grew up on Linux. He's very happy with Tux Paint, Gcompris, and SMPlayer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-soumya-sarkar
|
||||
|
||||
作者:[Soumya Sarkar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/ssarkarhyd
|
||||
[1]: https://www.samba.org/
|
||||
[2]: https://en.wikipedia.org/wiki/Blue_Screen_of_Death
|
||||
[3]: https://en.wikipedia.org/wiki/Computex_Taipei
|
||||
[4]: https://en.wikipedia.org/wiki/Mandriva_Linux
|
||||
[5]: http://www.openoffice.org/
|
||||
[6]: https://www.mozilla.org/en-US/firefox/new/
|
||||
@ -1,3 +1,4 @@
|
||||
hkurj translating
|
||||
A four year, action-packed experience with Wikipedia
|
||||
=======================================================
|
||||
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
Aspiring sys admin works his way up in Linux
|
||||
===============================================
|
||||
|
||||

|
||||
|
||||
I first saw Linux in action around 2001 at my first job. I was as an account manager for an Austrian automotive industry supplier and shared an office with our IT guy. He was creating a CD burning station (one of those huge things that can burn and print several CDs simultaneously) so that we could create and send CDs of our car parts catalogue to customers. While the burning station was originally designed for Windows, he just could not get it to work. He eventually gave up on Windows and turned to Linux, and it worked flawlessly.
|
||||
|
||||
For me, it was all kind of arcane. Most of the work was done on the command line, which looked like DOS but was much more powerful (even back then, I recognized this). I had been a Mac user since 1993, and a CLI (command line interface) seemed a bit old fashioned to me at the time.
|
||||
|
||||
It was not until years later—I believe around 2009—that I really discovered Linux for myself. By then, I had moved to the Netherlands and found a job working for a retail supplier. It was a small company (about 20 people) where, aside from my normal job as a key account manager, I had involuntarily become the first line of IT support. Whenever something didn't work, people first came to me before calling the expensive external IT consultant.
|
||||
|
||||
One of my colleagues had fallen for a phishing attack and clicked on an .exe file in an email that appeared to be from DHL. (Yes, it does happen.) His computer got completely taken over and he could not do anything. Even a complete reformat wouldn't help, as the virus kept rearing it's ugly head. I only later learned that it probably had written itself to the MBR (Master Boot Record). By this time, the contract with the external IT consultant had been terminated due to cost savings.
|
||||
|
||||
I turned to Ubuntu to get my colleague to work again. And work it did—like a charm. The computer was humming along again, and I got all the important applications to work like they should. In some ways it wasn't the most elegant solution, I'll admit, yet he (and I) liked the speed and stability of the system.
|
||||
|
||||
However, my colleague was so entrenched in the Windows world that he just couldn't get used to the fact that some things were done differently. He just kept complaining. (Sound familiar?)
|
||||
|
||||
While my colleague couldn't bear that things were done differently, I noticed that this was much less of an issue for me as a Mac user. There were more similarities. I was intrigued. So, I installed a dual boot with Ubuntu on my work laptop and found that I got much more work done in less time and it was much easier to get the machine to do what I wanted. Ever since then I've been regularly using several Linux distros, with Ubuntu and Elementary being my personal favorites.
|
||||
|
||||
At the moment, I am unemployed and hence have a lot of time to educate myself. Because I've always had an interest in IT, I am working to get into Linux systems administration. But is awfully hard to get a chance to show your knowledge nowadays because 95% of what I have learned over the years can't be shown on a paper with a stamp on it. Interviews are the place for me to have a conversation about what I know. So, I signed up for Linux certifications that I hope give me the boost I need.
|
||||
|
||||
I have also been contributing to open source for some time. I started by doing translations (English to German) for the xTuple ERP and have since moved on to doing Mozilla "customer service" on Twitter, filing bug reports, etc. I evangelize for free and open software (with varying degrees of success) and financially support several FOSS advocate organizations (DuckDuckGo, bof.nl, EFF, GIMP, LibreCAD, Wikipedia, and many others) whenever I can. I am also currently working to set up a regional privacy cafe.
|
||||
|
||||
Aside from that, I have started working on my first book. It's supposed to be a lighthearted field manual for normal people about computer privacy and security, which I hope to self-publish by the end of the year. (The book will be licensed under Creative Commons.) As for content, you can expect that I will explain in detail why privacy is important and what is wrong with the whole "I have nothing to hide" mentality. But the biggest part will be instructions how to get rid of pesky ad-trackers, encrypting your hard disk and mail, chat OTR, how to use TOR, etc. While it's a manual first, I aim for a tone that is casual and easy to understand spiced up with stories of personal experiences.
|
||||
|
||||
I still love my Macs and will use them whenever I can afford it (mainly because of the great construction), but Linux is always there in a VM and is used for most of my daily work. Nothing fancy here, though: word processing (LibreOffice and Scribus), working on my website and blog (Wordpress and Jekyll), editing some pictures (Shotwell and Gimp), listening to music (Rhythmbox), and pretty much every other task that comes along.
|
||||
|
||||
Whichever way my job hunt turns out, I know that Linux will always be my go-to system.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/my-linux-story-rene-raggl
|
||||
|
||||
作者:[Rene Raggl][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/rraggl
|
||||
@ -1,179 +0,0 @@
|
||||
How to Install OsTicket Ticketing System in Fedora 22 / Centos 7
|
||||
================================================================================
|
||||
In this article, we'll learn how to setup help desk ticketing system with osTicket in our machine or server running Fedora 22 or CentOS 7 as operating system. osTicket is a free and open source popular customer support ticketing system developed and maintained by [Enhancesoft][1] and its contributors. osTicket is the best solution for help and support ticketing system and management for better communication and support assistance with clients and customers. It has the ability to easily integrate with inquiries created via email, phone and web based forms into a beautiful multi-user web interface. osTicket makes us easy to manage, organize and log all our support requests and responses in one single place. It is a simple, lightweight, reliable, open source, web-based and easy to setup and use help desk ticketing system.
|
||||
|
||||
Here are some easy steps on how we can setup Help Desk ticketing system with osTicket in Fedora 22 or CentOS 7 operating system.
|
||||
|
||||
### 1. Installing LAMP stack ###
|
||||
|
||||
First of all, we'll need to install LAMP Stack to make osTicket working. LAMP stack is the combination of Apache web server, MySQL or MariaDB database system and PHP. To install a complete suit of LAMP stack that we need for the installation of osTicket, we'll need to run the following commands in a shell or a terminal.
|
||||
|
||||
**On Fedora 22**
|
||||
|
||||
LAMP stack is available on the official repository of Fedora 22. As the default package manager of Fedora 22 is the latest DNF package manager, we'll need to run the following command.
|
||||
|
||||
$ sudo dnf install httpd mariadb mariadb-server php php-mysql php-fpm php-cli php-xml php-common php-gd php-imap php-mbstring wget
|
||||
|
||||
**On CentOS 7**
|
||||
|
||||
As there is LAMP stack available on the official repository of CentOS 7, we'll gonna install it using yum package manager.
|
||||
|
||||
$ sudo yum install httpd mariadb mariadb-server php php-mysql php-fpm php-cli php-xml php-common php-gd php-imap php-mbstring wget
|
||||
|
||||
### 2. Starting Apache Web Server and MariaDB ###
|
||||
|
||||
Next, we'll gonna start MariaDB server and Apache Web Server to get started.
|
||||
|
||||
$ sudo systemctl start mariadb httpd
|
||||
|
||||
Then, we'll gonna enable them to start on every boot of the system.
|
||||
|
||||
$ sudo systemctl enable mariadb httpd
|
||||
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/mariadb.service to /usr/lib/systemd/system/mariadb.service.
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
|
||||
|
||||
### 3. Downloading osTicket package ###
|
||||
|
||||
Next, we'll gonna download the latest release of osTicket ie version 1.9.9 . We can download it from the official download page [http://osticket.com/download][2] or from the official github repository. [https://github.com/osTicket/osTicket-1.8/releases][3] . Here, in this tutorial we'll download the tarball of the latest release of osTicket from the github release page using wget command.
|
||||
|
||||
$ cd /tmp/
|
||||
$ wget https://github.com/osTicket/osTicket-1.8/releases/download/v1.9.9/osTicket-v1.9.9-1-gbe2f138.zip
|
||||
|
||||
--2015-07-16 09:14:23-- https://github.com/osTicket/osTicket-1.8/releases/download/v1.9.9/osTicket-v1.9.9-1-gbe2f138.zip
|
||||
Resolving github.com (github.com)... 192.30.252.131
|
||||
...
|
||||
Connecting to s3.amazonaws.com (s3.amazonaws.com)|54.231.244.4|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7150871 (6.8M) [application/octet-stream]
|
||||
Saving to: ‘osTicket-v1.9.9-1-gbe2f138.zip’
|
||||
osTicket-v1.9.9-1-gb 100%[========================>] 6.82M 1.25MB/s in 12s
|
||||
2015-07-16 09:14:37 (604 KB/s) - ‘osTicket-v1.9.9-1-gbe2f138.zip’ saved [7150871/7150871]
|
||||
|
||||
### 4. Extracting the osTicket ###
|
||||
|
||||
After we have successfully downloaded the osTicket zipped package, we'll now gonna extract the zip. As the default root directory of Apache web server is /var/www/html/ , we'll gonna create a directory called "**support**" where we'll extract the whole directory and files of the compressed zip file. To do so, we'll need to run the following commands in a terminal or a shell.
|
||||
|
||||
$ unzip osTicket-v1.9.9-1-gbe2f138.zip
|
||||
|
||||
Then, we'll move the whole extracted files to it.
|
||||
|
||||
$ sudo mv /tmp/upload /var/www/html/support
|
||||
|
||||
### 5. Fixing Ownership and Permission ###
|
||||
|
||||
Now, we'll gonna assign the ownership of the directories and files under /var/ww/html/support to apache to enable writable access to the apache process owner. To do so, we'll need to run the following command.
|
||||
|
||||
$ sudo chown apache: -R /var/www/html/support
|
||||
|
||||
Then, we'll also need to copy a sample configuration file to its default configuration file. To do so, we'll need to run the below command.
|
||||
|
||||
$ cd /var/www/html/support/
|
||||
$ sudo cp include/ost-sampleconfig.php include/ost-config.php
|
||||
$ sudo chmod 0666 include/ost-config.php
|
||||
|
||||
If you have SELinux enabled on the system, run the following command.
|
||||
|
||||
$ sudo chcon -R -t httpd_sys_content_t /var/www/html/vtigercrm
|
||||
$ sudo chcon -R -t httpd_sys_rw_content_t /var/www/html/vtigercrm
|
||||
|
||||
### 6. Configuring MariaDB ###
|
||||
|
||||
As this is the first time we're going to configure MariaDB, we'll need to create a password for the root user of mariadb so that we can use it to login and create the database for our osTicket installation. To do so, we'll need to run the following command in a terminal or a shell.
|
||||
|
||||
$ sudo mysql_secure_installation
|
||||
|
||||
...
|
||||
Enter current password for root (enter for none):
|
||||
OK, successfully used password, moving on...
|
||||
|
||||
Setting the root password ensures that nobody can log into the MariaDB
|
||||
root user without the proper authorisation.
|
||||
|
||||
Set root password? [Y/n] y
|
||||
New password:
|
||||
Re-enter new password:
|
||||
Password updated successfully!
|
||||
Reloading privilege tables..
|
||||
Success!
|
||||
...
|
||||
All done! If you've completed all of the above steps, your MariaDB
|
||||
installation should now be secure.
|
||||
|
||||
Thanks for using MariaDB!
|
||||
|
||||
Note: Above, we are asked to enter the root password of the mariadb server but as we are setting for the first time and no password has been set yet, we'll simply hit enter while asking the current mariadb root password. Then, we'll need to enter twice the new password we wanna set. Then, we can simply hit enter in every argument in order to set default configurations.
|
||||
|
||||
### 7. Creating osTicket Database ###
|
||||
|
||||
As osTicket needs a database system to store its data and information, we'll be configuring MariaDB for osTicket. So, we'll need to first login into the mariadb command environment. To do so, we'll need to run the following command.
|
||||
|
||||
$ sudo mysql -u root -p
|
||||
|
||||
Now, we'll gonna create a new database "**osticket_db**" with user "**osticket_user**" and password "osticket_password" which will be granted access to the database. To do so, we'll need to run the following commands inside the MariaDB command environment.
|
||||
|
||||
> CREATE DATABASE osticket_db;
|
||||
> CREATE USER 'osticket_user'@'localhost' IDENTIFIED BY 'osticket_password';
|
||||
> GRANT ALL PRIVILEGES on osticket_db.* TO 'osticket_user'@'localhost' ;
|
||||
> FLUSH PRIVILEGES;
|
||||
> EXIT;
|
||||
|
||||
**Note**: It is strictly recommended to replace the database name, user and password as your desire for security issue.
|
||||
|
||||
### 8. Allowing Firewall ###
|
||||
|
||||
If we are running a firewall program, we'll need to configure our firewall to allow port 80 so that the Apache web server's default port will be accessible externally. This will allow us to navigate our web browser to osTicket's web interface with the default http port 80. To do so, we'll need to run the following command.
|
||||
|
||||
$ sudo firewall-cmd --zone=public --add-port=80/tcp --permanent
|
||||
|
||||
After done, we'll need to reload our firewall service.
|
||||
|
||||
$ sudo firewall-cmd --reload
|
||||
|
||||
### 9. Web based Installation ###
|
||||
|
||||
Finally, is everything is done as described above, we'll now should be able to navigate osTicket's Installer by pointing our web browser to http://domain.com/support or http://ip-address/support . Now, we'll be shown if the dependencies required by osTicket are installed or not. As we've already installed all the necessary packages, we'll be welcomed with **green colored tick** to proceed forward.
|
||||
|
||||

|
||||
|
||||
After that, we'll be required to enter the details for our osTicket instance as shown below. We'll need to enter the database name, username, password and hostname and other important account information that we'll require while logging into the admin panel.
|
||||
|
||||

|
||||
|
||||
After the installation has been completed successfully, we'll be welcomed by a Congratulations screen. There we can see two links, one for our Admin Panel and the other for the support center as the homepage of the osTicket Support Help Desk.
|
||||
|
||||

|
||||
|
||||
If we click on http://ip-address/support or http://domain.com/support, we'll be redirected to the osTicket support page which is as shown below.
|
||||
|
||||

|
||||
|
||||
Next, to login into the admin panel, we'll need to navigate our web browser to http://ip-address/support/scp or http://domain.com/support/scp . Then, we'll need to enter the login details we had just created above while configuring the database and other information in the web installer. After successful login, we'll be able to access our dashboard and other admin sections.
|
||||
|
||||

|
||||
|
||||
### 10. Post Installation ###
|
||||
|
||||
After we have finished the web installation of osTicket, we'll now need to secure some of our configuration files. To do so, we'll need to run the following command.
|
||||
|
||||
$ sudo rm -rf /var/www/html/support/setup/
|
||||
$ sudo chmod 644 /var/www/html/support/include/ost-config.php
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
osTicket is an awesome help desk ticketing system providing several new features. It supports rich text or HTML emails, ticket filters, agent collision avoidance, auto-responder and many more features. The user interface of osTicket is very beautiful with easy to use control panel. It is a complete set of tools required for a help and support ticketing system. It is the best solution for providing customers a better way to communicate with the support team. It helps a company to make their customers happy with them regarding the support and help desk. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-osticket-fedora-22-centos-7/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.enhancesoft.com/
|
||||
[2]:http://osticket.com/download
|
||||
[3]:https://github.com/osTicket/osTicket-1.8/releases
|
||||
@ -1,219 +0,0 @@
|
||||
How to Configure OpenNMS on CentOS 7.x
|
||||
================================================================================
|
||||
Systems management and monitoring services are very important that provides information to view important systems management information that allow us to to make decisions based on this information. To make sure the network is running at its best and to minimize the network downtime we need to improve application performance. So, in this article we will make you understand the step by step procedure to setup OpenNMS in your IT infrastructure. OpenNMS is a free open source enterprise level network monitoring and management platform that provides information to allow us to make decisions in regards to future network and capacity planning.
|
||||
|
||||
OpenNMS designed to manage tens of thousands of devices from a single server as well as manage unlimited devices using a cluster of servers. It includes a discovery engine to automatically configure and manage network devices without operator intervention. It is written in Java and is published under the GNU General Public License. OpenNMS is known for its scalability with its main functional areas in services monitoring, data collection using SNMP and event management and notifications.
|
||||
|
||||
### Installing OpenNMS RPM Repository ###
|
||||
|
||||
We will start from the installation of OpenNMS RPM for our CentOs 7.1 operating system as its available for most of the RPM-based distributions through Yum at their official link http://yum.opennms.org/ .
|
||||
|
||||

|
||||
|
||||
Then open your command line interface of CentOS 7.1 and login with root credentials to run the below command with “wget” to get the required RPM.
|
||||
|
||||
[root@open-nms ~]# wget http://yum.opennms.org/repofiles/opennms-repo-stable-rhel7.noarch.rpm
|
||||
|
||||

|
||||
|
||||
Now we need to install this repository so that the OpenNMS package information could be available through yum for installation. Let’s run the command below with same root level credentials to do so.
|
||||
|
||||
[root@open-nms ~]# rpm -Uvh opennms-repo-stable-rhel7.noarch.rpm
|
||||
|
||||

|
||||
|
||||
### Installing Prerequisite Packages for OpenNMS ###
|
||||
|
||||
Now before we start installation of OpenNMS, let’s make sure you’ve done the following prerequisites.
|
||||
|
||||
**Install JDK 7**
|
||||
|
||||
Its recommended that you install the latest stable Java 7 JDK from Oracle for the best performance to integrate JDK in our YUM repository as a fallback. Let’s go to the Oracle Java 7 SE JDK download page, accept the license if you agree, choose the platform and architecture. Once it has finished downloading, execute it from the command-line and then install the resulting JDK rpm.
|
||||
|
||||
Else run the below command to install using the Yum from the the available system repositories.
|
||||
|
||||
[root@open-nms ~]# yum install java-1.7.0-openjdk-1.7.0.85-2.6.1.2.el7_1
|
||||
|
||||
Once you have installed the Java you can confirm its installation using below command and check its installed version.
|
||||
|
||||
[root@open-nms ~]# java -version
|
||||
|
||||

|
||||
|
||||
**Install PostgreSQL**
|
||||
|
||||
Now we will install the PostgreSQL that is a must requirement to setup the database for OpenNMS. PostgreSQL is included in all of the major YUM-based distributions. To install, simply run the below command.
|
||||
|
||||
[root@open-nms ~]# yum install postgresql postgresql-server
|
||||
|
||||

|
||||
|
||||
### Prepare the Database for OpenNMS ###
|
||||
|
||||
Once you have installed PostgreSQL, now you'll need to make sure that PostgreSQL is up and active. Let’s run the below command to first initialize the database and then start its services.
|
||||
|
||||
[root@open-nms ~]# /sbin/service postgresql initdb
|
||||
[root@open-nms ~]# /sbin/service postgresql start
|
||||
|
||||

|
||||
|
||||
Now to confirm the status of your PostgreSQL database you can run the below command.
|
||||
|
||||
[root@open-nms ~]# service postgresql status
|
||||
|
||||

|
||||
|
||||
To ensure that PostgreSQL will start after a reboot, use the “systemctl”command to enable start on bootup using below command.
|
||||
|
||||
[root@open-nms ~]# systemctl enable postgresql
|
||||
ln -s '/usr/lib/systemd/system/postgresql.service' '/etc/systemd/system/multi-user.target.wants/postgresql.service'
|
||||
|
||||
### Configure PostgreSQL ###
|
||||
|
||||
Locate the Postgres “data” directory. Often this is located in /var/lib/pgsql/data directory and Open the postgresql.conf file in text editor and configure the following parameters as shown.
|
||||
|
||||
[root@open-nms ~]# vim /var/lib/pgsql/data/postgresql.conf
|
||||
|
||||
----------
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# CONNECTIONS AND AUTHENTICATION
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
listen_addresses = 'localhost'
|
||||
max_connections = 256
|
||||
|
||||
#------------------------------------------------------------------------------
|
||||
# RESOURCE USAGE (except WAL)
|
||||
#------------------------------------------------------------------------------
|
||||
|
||||
shared_buffers = 1024MB
|
||||
|
||||
**User Access to the Database**
|
||||
|
||||
PostgreSQL only allows you to connect if you are logged in to the local account name that matches the PostgreSQL user. Since OpenNMS runs as root, it cannot connect as a "postgres" or "opennms" user by default, so we have to change the configuration to allow user access to the database by opening the below configuration file.
|
||||
|
||||
[root@open-nms ~]# vim /var/lib/pgsql/data/pg_hba.conf
|
||||
|
||||
Update the configuration file as shown below and change the METHOD settings from "ident" to "trust"
|
||||
|
||||

|
||||
|
||||
Write and quit the file to make saved changes and then restart PostgreSQL services.
|
||||
|
||||
[root@open-nms ~]# service postgresql restart
|
||||
|
||||
### Starting OpenNMS Installation ###
|
||||
|
||||
Now we are ready go with installation of OpenNMS as we have almost don with its prerequisites. Using the YUM packaging system will download and install all of the required components and their dependencies, if they are not already installed on your system.
|
||||
So let's riun th belwo command to start OpenNMS installation that will pull everything you need to have a working OpenNMS, including the OpenNMS core, web UI, and a set of common plugins.
|
||||
|
||||
[root@open-nms ~]# yum -y install opennms
|
||||
|
||||

|
||||
|
||||
The above command will ends up with successful installation of OpenNMS and its derivative packages.
|
||||
|
||||
### Configure JAVA for OpenNMS ###
|
||||
|
||||
In order to integrate the default version of Java with OpenNMS we will run the below command.
|
||||
|
||||
[root@open-nms ~]# /opt/opennms/bin/runjava -s
|
||||
|
||||

|
||||
|
||||
### Run the OpenNMS installer ###
|
||||
|
||||
Now it's time to start the OpenNMS installer that will create and configure the OpenNMS database, while the same command will be used in case we want to update it to the latest version. To do so, we will run the following command.
|
||||
|
||||
[root@open-nms ~]# /opt/opennms/bin/install -dis
|
||||
|
||||
The above install command will take many options with following mechanism.
|
||||
|
||||
-d - to update the database
|
||||
-i - to insert any default data that belongs in the database
|
||||
-s - to create or update the stored procedures OpenNMS uses for certain kinds of data access
|
||||
|
||||
==============================================================================
|
||||
OpenNMS Installer
|
||||
==============================================================================
|
||||
|
||||
Configures PostgreSQL tables, users, and other miscellaneous settings.
|
||||
|
||||
DEBUG: Platform is IPv6 ready: true
|
||||
- searching for libjicmp.so:
|
||||
- trying to load /usr/lib64/libjicmp.so: OK
|
||||
- searching for libjicmp6.so:
|
||||
- trying to load /usr/lib64/libjicmp6.so: OK
|
||||
- searching for libjrrd.so:
|
||||
- trying to load /usr/lib64/libjrrd.so: OK
|
||||
- using SQL directory... /opt/opennms/etc
|
||||
- using create.sql... /opt/opennms/etc/create.sql
|
||||
17:27:51.178 [Main] INFO org.opennms.core.schema.Migrator - PL/PgSQL call handler exists
|
||||
17:27:51.180 [Main] INFO org.opennms.core.schema.Migrator - PL/PgSQL language exists
|
||||
- checking if database "opennms" is unicode... ALREADY UNICODE
|
||||
- Creating imports directory (/opt/opennms/etc/imports... OK
|
||||
- Checking for old import files in /opt/opennms/etc... DONE
|
||||
INFO 16/08/15 17:27:liquibase: Reading from databasechangelog
|
||||
Installer completed successfully!
|
||||
|
||||
==============================================================================
|
||||
OpenNMS Upgrader
|
||||
==============================================================================
|
||||
|
||||
OpenNMS is currently stopped
|
||||
Found upgrade task SnmpInterfaceRrdMigratorOnline
|
||||
Found upgrade task KscReportsMigrator
|
||||
Found upgrade task JettyConfigMigratorOffline
|
||||
Found upgrade task DataCollectionConfigMigratorOffline
|
||||
Processing RequisitionsMigratorOffline: Remove non-ip-snmp-primary and non-ip-interfaces from requisitions: NMS-5630, NMS-5571
|
||||
- Running pre-execution phase
|
||||
Backing up: /opt/opennms/etc/imports
|
||||
- Running post-execution phase
|
||||
Removing backup /opt/opennms/etc/datacollection.zip
|
||||
|
||||
Finished in 0 seconds
|
||||
|
||||
Upgrade completed successfully!
|
||||
|
||||
### Firewall configurations to Allow OpenNMS ###
|
||||
|
||||
Here we have to allow OpenNMS management interface port 8980 through firewall or router to access the management web interface from the remote systems. So use the following commands to do so.
|
||||
|
||||
[root@open-nms etc]# firewall-cmd --permanent --add-port=8980/tcp
|
||||
[root@open-nms etc]# firewall-cmd --reload
|
||||
|
||||
### Start OpenNMS and Login to Web Interface ###
|
||||
|
||||
Let's start OpenNMS service and enable to it start at each bootup by using the below command.
|
||||
|
||||
[root@open-nms ~]#systemctl start opennms
|
||||
[root@open-nms ~]#systemctl enable opennms
|
||||
|
||||
Once the services are up are ready to go with its web management interface. Open your web browser and access it with your server's IP address and 8980 port.
|
||||
|
||||
http://servers_ip:8980/
|
||||
|
||||
Give the username and password where as the default username and password is admin/admin.
|
||||
|
||||

|
||||
|
||||
After successful authentication with your provided username and password you will be directed towards the the Home page of OpenNMS where you can configure the new monitoring devices/nodes/services etc.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Congratulations! we have successfully setup OpenNMS on CentOS 7.1. So, at the end of this tutorial, you are now able to install and configure OpenNMS with its prerequisites that included PostgreSQL and JAVA setup. So let's enjoy with the great network monitoring system with open source roots using OpenNMS that provide a bevy of features at no cost than their high-end competitors, and can scale to monitor large numbers of network nodes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/monitoring-2/install-configure-opennms-centos-7-x/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -1,322 +0,0 @@
|
||||
Getting Started to Calico Virtual Private Networking on Docker
|
||||
================================================================================
|
||||
Calico is a free and open source software for virtual networking in data centers. It is a pure Layer 3 approach to highly scalable datacenter for cloud virtual networking. It seamlessly integrates with cloud orchestration system such as openstack, docker clusters in order to enable secure IP communication between virtual machines and containers. It implements a highly productive vRouter in each node that takes advantage of the existing Linux kernel forwarding engine. Calico works in such an awesome technology that it has the ability to peer directly with the data center’s physical fabric whether L2 or L3, without the NAT, tunnels on/off ramps, or overlays. Calico makes full utilization of docker to run its containers in the nodes which makes it multi-platform and very easy to ship, pack and deploy. Calico has the following salient features out of the box.
|
||||
|
||||
- It can scale tens of thousands of servers and millions of workloads.
|
||||
- Calico is easy to deploy, operate and diagnose.
|
||||
- It is open source software licensed under Apache License version 2 and uses open standards.
|
||||
- It supports container, virtual machines and bare metal workloads.
|
||||
- It supports both IPv4 and IPv6 internet protocols.
|
||||
- It is designed internally to support rich, flexible and secure network policy.
|
||||
|
||||
In this tutorial, we'll perform a virtual private networking between two nodes running Calico in them with Docker Technology. Here are some easy steps on how we can do that.
|
||||
|
||||
### 1. Installing etcd ###
|
||||
|
||||
To get started with the calico virtual private networking, we'll need to have a linux machine running etcd. As CoreOS comes preinstalled and preconfigured with etcd, we can use CoreOS but if we want to configure Calico in other linux distributions, then we'll need to setup it in our machine. As we are running Ubuntu 14.04 LTS, we'll need to first install and configure etcd in our machine. To install etcd in our Ubuntu box, we'll need to add the official ppa repository of Calico by running the following command in the machine which we want to run etcd server. Here, we'll be installing etcd in our 1st node.
|
||||
|
||||
# apt-add-repository ppa:project-calico/icehouse
|
||||
|
||||
The primary source of Ubuntu packages for Project Calico based on OpenStack Icehouse, an open source solution for virtual networking in cloud data centers. Find out more at http://www.projectcalico.org/
|
||||
More info: https://launchpad.net/~project-calico/+archive/ubuntu/icehouse
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmpi9zcmls1/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmpi9zcmls1/pubring.gpg' created
|
||||
gpg: requesting key 3D40A6A7 from hkp server keyserver.ubuntu.com
|
||||
gpg: /tmp/tmpi9zcmls1/trustdb.gpg: trustdb created
|
||||
gpg: key 3D40A6A7: public key "Launchpad PPA for Project Calico" imported
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
Then, we'll need to edit /etc/apt/preferences and make changes to prefer Calico-provided packages for Nova and Neutron.
|
||||
|
||||
# nano /etc/apt/preferences
|
||||
|
||||
We'll need to add the following lines into it.
|
||||
|
||||
Package: *
|
||||
Pin: release o=LP-PPA-project-calico-*
|
||||
Pin-Priority: 100
|
||||
|
||||

|
||||
|
||||
Next, we'll also need to add the official BIRD PPA for Ubuntu 14.04 LTS so that bugs fixes are installed before its available on the Ubuntu repo.
|
||||
|
||||
# add-apt-repository ppa:cz.nic-labs/bird
|
||||
|
||||
The BIRD Internet Routing Daemon PPA (by upstream & .deb maintainer)
|
||||
More info: https://launchpad.net/~cz.nic-labs/+archive/ubuntu/bird
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmphxqr5hjf/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmphxqr5hjf/pubring.gpg' created
|
||||
gpg: requesting key F9C59A45 from hkp server keyserver.ubuntu.com
|
||||
apt-ggpg: /tmp/tmphxqr5hjf/trustdb.gpg: trustdb created
|
||||
gpg: key F9C59A45: public key "Launchpad Datov<6F> schr<68>nky" imported
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
Now, after the PPA jobs are done, we'll now gonna update the local repository index and then install etcd in our machine.
|
||||
|
||||
# apt-get update
|
||||
|
||||
To install etcd in our ubuntu machine, we'll gonna run the following apt command.
|
||||
|
||||
# apt-get install etcd python-etcd
|
||||
|
||||
### 2. Starting Etcd ###
|
||||
|
||||
After the installation is complete, we'll now configure the etcd configuration file. Here, we'll edit **/etc/init/etcd.conf** using a text editor and append the line exec **/usr/bin/etcd** and make it look like below configuration.
|
||||
|
||||
# nano /etc/init/etcd.conf
|
||||
exec /usr/bin/etcd --name="node1" \
|
||||
--advertise-client-urls="http://10.130.65.71:2379,http://10.130.65.71:4001" \
|
||||
--listen-client-urls="http://0.0.0.0:2379,http://0.0.0.0:4001" \
|
||||
--listen-peer-urls "http://0.0.0.0:2380" \
|
||||
--initial-advertise-peer-urls "http://10.130.65.71:2380" \
|
||||
--initial-cluster-token $(uuidgen) \
|
||||
--initial-cluster "node1=http://10.130.65.71:2380" \
|
||||
--initial-cluster-state "new"
|
||||
|
||||

|
||||
|
||||
**Note**: In the above configuration, we'll need to replace 10.130.65.71 and node-1 with the private ip address and hostname of your etcd server box. After done with editing, we'll need to save and exit the file.
|
||||
|
||||
We can get the private ip address of our etcd server by running the following command.
|
||||
|
||||
# ifconfig
|
||||
|
||||

|
||||
|
||||
As our etcd configuration is done, we'll now gonna start our etcd service in our Ubuntu node. To start etcd daemon, we'll gonna run the following command.
|
||||
|
||||
# service etcd start
|
||||
|
||||
After done, we'll have a check if etcd is really running or not. To ensure that, we'll need to run the following command.
|
||||
|
||||
# service etcd status
|
||||
|
||||
### 3. Installing Docker ###
|
||||
|
||||
Next, we'll gonna install Docker in both of our nodes running Ubuntu. To install the latest release of docker, we'll simply need to run the following command.
|
||||
|
||||
# curl -sSL https://get.docker.com/ | sh
|
||||
|
||||

|
||||
|
||||
After the installation is completed, we'll gonna start the docker daemon in-order to make sure that its running before we move towards Calico.
|
||||
|
||||
# service docker restart
|
||||
|
||||
docker stop/waiting
|
||||
docker start/running, process 3056
|
||||
|
||||
### 3. Installing Calico ###
|
||||
|
||||
We'll now install calico in our linux machine in-order to run the calico containers. We'll need to install Calico in every node which we're wanting to connect into the Calico network. To install Calico, we'll need to run the following command under root or sudo permission.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# wget https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
|
||||
--2015-09-28 12:08:59-- https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
Resolving github.com (github.com)... 192.30.252.129
|
||||
Connecting to github.com (github.com)|192.30.252.129|:443... connected.
|
||||
...
|
||||
Resolving github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)... 54.231.9.9
|
||||
Connecting to github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)|54.231.9.9|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 6166661 (5.9M) [application/octet-stream]
|
||||
Saving to: 'calicoctl'
|
||||
100%[=========================================>] 6,166,661 1.47MB/s in 6.7s
|
||||
2015-09-28 12:09:08 (898 KB/s) - 'calicoctl' saved [6166661/6166661]
|
||||
|
||||
# chmod +x calicoctl
|
||||
|
||||
After done with making it executable, we'll gonna make the binary calicoctl available as the command in any directory. To do so, we'll need to run the following command.
|
||||
|
||||
# mv calicoctl /usr/bin/
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# wget https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
|
||||
--2015-09-28 12:09:03-- https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
Resolving github.com (github.com)... 192.30.252.131
|
||||
Connecting to github.com (github.com)|192.30.252.131|:443... connected.
|
||||
...
|
||||
Resolving github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)... 54.231.8.113
|
||||
Connecting to github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)|54.231.8.113|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 6166661 (5.9M) [application/octet-stream]
|
||||
Saving to: 'calicoctl'
|
||||
100%[=========================================>] 6,166,661 1.47MB/s in 5.9s
|
||||
2015-09-28 12:09:11 (1022 KB/s) - 'calicoctl' saved [6166661/6166661]
|
||||
|
||||
# chmod +x calicoctl
|
||||
|
||||
After done with making it executable, we'll gonna make the binary calicoctl available as the command in any directory. To do so, we'll need to run the following command.
|
||||
|
||||
# mv calicoctl /usr/bin/
|
||||
|
||||
Likewise, we'll need to execute the above commands to install in every other nodes.
|
||||
|
||||
### 4. Starting Calico services ###
|
||||
|
||||
After we have installed calico on each of our nodes, we'll gonna start our Calico services. To start the calico services, we'll need to run the following commands.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# calicoctl node
|
||||
|
||||
WARNING: Unable to detect the xt_set module. Load with `modprobe xt_set`
|
||||
WARNING: Unable to detect the ipip module. Load with `modprobe ipip`
|
||||
No IP provided. Using detected IP: 10.130.61.244
|
||||
Pulling Docker image calico/node:v0.6.0
|
||||
Calico node is running with id: fa0ca1f26683563fa71d2ccc81d62706e02fac4bbb08f562d45009c720c24a43
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
Next, we'll gonna export a global variable in order to connect our calico nodes to the same etcd server which is hosted in node1 in our case. To do so, we'll need to run the following command in each of our nodes.
|
||||
|
||||
# export ETCD_AUTHORITY=10.130.61.244:2379
|
||||
|
||||
Then, we'll gonna run calicoctl container in our every our second node.
|
||||
|
||||
# calicoctl node
|
||||
|
||||
WARNING: Unable to detect the xt_set module. Load with `modprobe xt_set`
|
||||
WARNING: Unable to detect the ipip module. Load with `modprobe ipip`
|
||||
No IP provided. Using detected IP: 10.130.61.245
|
||||
Pulling Docker image calico/node:v0.6.0
|
||||
Calico node is running with id: 70f79c746b28491277e28a8d002db4ab49f76a3e7d42e0aca8287a7178668de4
|
||||
|
||||
This command should be executed in every nodes in which we want to start our Calico services. The above command start a container in the respective node. To check if the container is running or not, we'll gonna run the following docker command.
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
If we see the output something similar to the output shown below then we can confirm that Calico containers are up and running.
|
||||
|
||||
### 5. Starting Containers ###
|
||||
|
||||
Next, we'll need to start few containers in each of our nodes running Calico services. We'll assign a different name to each of the containers running ubuntu. Here, workload-A, workload-B, etc has been assigned as the unique name for each of the containers. To do so, we'll need to run the following command.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# docker run --net=none --name workload-A -tid ubuntu
|
||||
|
||||
Unable to find image 'ubuntu:latest' locally
|
||||
latest: Pulling from library/ubuntu
|
||||
...
|
||||
91e54dfb1179: Already exists
|
||||
library/ubuntu:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security.
|
||||
Digest: sha256:73fbe2308f5f5cb6e343425831b8ab44f10bbd77070ecdfbe4081daa4dbe3ed1
|
||||
Status: Downloaded newer image for ubuntu:latest
|
||||
a1ba9105955e9f5b32cbdad531cf6ecd9cab0647d5d3d8b33eca0093605b7a18
|
||||
|
||||
# docker run --net=none --name workload-B -tid ubuntu
|
||||
|
||||
89dd3d00f72ac681bddee4b31835c395f14eeb1467300f2b1b9fd3e704c28b7d
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# docker run --net=none --name workload-C -tid ubuntu
|
||||
|
||||
Unable to find image 'ubuntu:latest' locally
|
||||
latest: Pulling from library/ubuntu
|
||||
...
|
||||
91e54dfb1179: Already exists
|
||||
library/ubuntu:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security.
|
||||
Digest: sha256:73fbe2308f5f5cb6e343425831b8ab44f10bbd77070ecdfbe4081daa4dbe3ed1
|
||||
Status: Downloaded newer image for ubuntu:latest
|
||||
24e2d5d7d6f3990b534b5643c0e483da5b4620a1ac2a5b921b2ba08ebf754746
|
||||
|
||||
# docker run --net=none --name workload-D -tid ubuntu
|
||||
|
||||
c6f28d1ab8f7ac1d9ccc48e6e4234972ed790205c9ca4538b506bec4dc533555
|
||||
|
||||
Similarly, if we have more nodes, we can run ubuntu docker container into it by running the above command with assigning a different container name.
|
||||
|
||||
### 6. Assigning IP addresses ###
|
||||
|
||||
After we have got our docker containers running in each of our hosts, we'll go for adding a networking support to the containers. Now, we'll gonna assign a new ip address to each of the containers using calicoctl. This will add a new network interface to the containers with the assigned ip addresses. To do so, we'll need to run the following commands in the hosts running the containers.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# calicoctl container add workload-A 192.168.0.1
|
||||
# calicoctl container add workload-B 192.168.0.2
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# calicoctl container add workload-C 192.168.0.3
|
||||
# calicoctl container add workload-D 192.168.0.4
|
||||
|
||||
### 7. Adding Policy Profiles ###
|
||||
|
||||
After our containers have got networking interfaces and ip address assigned, we'll now need to add policy profiles to enable networking between the containers each other. After adding the profiles, the containers will be able to communicate to each other only if they have the common profiles assigned. That means, if they have different profiles assigned, they won't be able to communicate to eachother. So, before being able to assign. we'll need to first create some new profiles. That can be done in either of the hosts. Here, we'll run the following command in 1st Node.
|
||||
|
||||
# calicoctl profile add A_C
|
||||
|
||||
Created profile A_C
|
||||
|
||||
# calicoctl profile add B_D
|
||||
|
||||
Created profile B_D
|
||||
|
||||
After the profile has been created, we'll simply add our workload to the required profile. Here, in this tutorial, we'll place workload A and workload C in a common profile A_C and workload B and D in a common profile B_D. To do so, we'll run the following command in our hosts.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# calicoctl container workload-A profile append A_C
|
||||
# calicoctl container workload-B profile append B_D
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# calicoctl container workload-C profile append A_C
|
||||
# calicoctl container workload-D profile append B_D
|
||||
|
||||
### 8. Testing the Network ###
|
||||
|
||||
After we've added a policy profile to each of our containers using Calicoctl, we'll now test whether our networking is working as expected or not. We'll take a node and a workload and try to communicate with the other containers running in same or different nodes. And due to the profile, we should be able to communicate only with the containers having a common profile. So, in this case, workload A should be able to communicate with only C and vice versa whereas workload A shouldn't be able to communicate with B or D. To test the network, we'll gonna ping the containers having common profiles from the 1st host running workload A and B.
|
||||
|
||||
We'll first ping workload-C having ip 192.168.0.3 using workload-A as shown below.
|
||||
|
||||
# docker exec workload-A ping -c 4 192.168.0.3
|
||||
|
||||
Then, we'll ping workload-D having ip 192.168.0.4 using workload-B as shown below.
|
||||
|
||||
# docker exec workload-B ping -c 4 192.168.0.4
|
||||
|
||||

|
||||
|
||||
Now, we'll check if we're able to ping the containers having different profiles. We'll now ping workload-D having ip address 192.168.0.4 using workload-A.
|
||||
|
||||
# docker exec workload-A ping -c 4 192.168.0.4
|
||||
|
||||
After done, we'll try to ping workload-C having ip address 192.168.0.3 using workload-B.
|
||||
|
||||
# docker exec workload-B ping -c 4 192.168.0.3
|
||||
|
||||

|
||||
|
||||
Hence, the workloads having same profiles could ping each other whereas having different profiles couldn't ping to each other.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Calico is an awesome project providing an easy way to configure a virtual network using the latest docker technology. It is considered as a great open source solution for virtual networking in cloud data centers. Calico is being experimented by people in different cloud platforms like AWS, DigitalOcean, GCE and more these days. As Calico is currently under experiment, its stable version hasn't been released yet and is still in pre-release. The project consists a well documented documentations, tutorials and manuals in their [official documentation site][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/calico-virtual-private-networking-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://docs.projectcalico.org/
|
||||
@ -1,119 +0,0 @@
|
||||
ezio
|
||||
|
||||
5 great Raspberry Pi projects for the classroom
|
||||
=====================================================
|
||||
|
||||
|
||||
5 个很适合在课堂上演示的树莓派项目
|
||||
=====================================================
|
||||
|
||||

|
||||
|
||||
### 1. 我的世界 Pi
|
||||
|
||||
|
||||
>Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0][1].
|
||||
|
||||
Minecraft is the favorite game of pretty much every teenager in the world—and it's one of the most creative games ever to capture the attention of young people. The version that comes with every Raspberry Pi is not only a creative thinking building game, but comes with a programming interface allowing for additional interaction with the Minecraft world through Python code.
|
||||
|
||||
我的世界是世界上很多青少年最喜欢的一个游戏,而且他也是目前最能激发年轻人创造力的一款游戏。这个树莓派版上自带的我的世界不仅仅是一个具有创造性的建筑游戏,他还是一个具有编程接口、可以通过 Python 与之交互的版本。
|
||||
|
||||
Minecraft: Pi Edition is a great way for teachers to engage students with problem solving and writing code to perform tasks. You can use the Python API to build a house and have it follow you wherever you go, build a bridge wherever you walk, make it rain lava, show the temperature in the sky, and anything else your imagination can create.
|
||||
|
||||
我的世界:Pi 版对于老师来说是一个非常好的教授学生解决问题和编写代码完成任务的途径。你可以使用 Python API 创建一个房子,并且一直跟随这你的脚步移动,当你需要桥梁的时候给你建造一座桥,让老天呀下雨,显示天空的温度,以及其它你可以想象到的一切东西。
|
||||
|
||||
Read more in "[Getting Started with Minecraft Pi][2]."
|
||||
|
||||
详情请见 "[Getting Started with Minecraft Pi][2]."
|
||||
|
||||
### 2. 反应游戏和交通灯 Reaction game and traffic lights
|
||||
|
||||

|
||||
>Courtesy of [Low Voltage Labs][3]. [CC BY-SA 4.0][1].
|
||||
|
||||
It's really easy to get started with physical computing on Raspberry Pi—just connect up LEDs and buttons to the GPIO pins, and with a few lines of code you can turn lights on and control things with button presses. Once you know the code to do the basics, it's down to your imagination as to what you do next!
|
||||
|
||||
使用树莓派可以很轻松的进行物理计算——只需要连接几个 LED 和按钮到 开发板上的 GPIO 接口,再用几行代码你就可以按下按钮来开灯。一旦你指导了如何使用代码来做这些基本的东西,接下来就可以根据你的想象来做其它事情了。
|
||||
|
||||
If you know how to flash one light, you can flash three. Pick out three LEDs in traffic light colors and you can code the traffic light sequence. If you know how to use a button to a trigger an event, then you have a pedestrian crossing! Also look out for great pre-built traffic light add-ons like [PI-TRAFFIC][4], [PI-STOP][5], [Traffic HAT][6], and more.
|
||||
|
||||
如果你知道如何让一个灯闪烁,你就可以让三个灯开始闪烁。挑选三个和交通灯一样颜色的 LED 灯,然后编写控制交通灯的代码。如果你知道如何使用按钮触发实践,那么你就可以模拟行人过马路。同时你可以参考其它已经完成的交通灯附件,比如[PI-TRAFFIC][4], [PI-STOP][5], [Traffic HAT][6],等等。
|
||||
|
||||
It's not always about the code—this can be used as an exercise in understanding how real world systems are devised. Computational thinking is a useful skill in any walk of life.
|
||||
|
||||
代码并不是全部——这些联系只是让你理解真是世界里使如何完成这些事的。计算思维是一个在你一生中都会很有用的技能。
|
||||
|
||||

|
||||
>Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0][1].
|
||||
|
||||
Next, try wiring up two buttons and an LED and making a two-player reaction game—let the light come on after a random amount of time and see who can press the button first!
|
||||
|
||||
接下来试着接通两个按钮和 LED 灯的电源,实现一个反应游戏 —— 让 LED 灯随机的点亮,然后看是最先按下按钮。
|
||||
|
||||
To learn more, check out [GPIO Zero recipes][7]. Everything you need is in [CamJam EduKit 1][8].
|
||||
|
||||
要想了解更多可以看看 [GPIO Zero recipes][7]。你所需要的资料都可以在 [CamJam EduKit 1][8] 找到。
|
||||
|
||||
### 3. 电子宠物 Sense HAT Pixel Pet
|
||||
|
||||
The Astro Pi—an augmented Raspberry Pi—is going to space this December, but you haven't missed your chance to get your hands on the hardware. The Sense HAT is the sensor board add-on used in the Astro Pi mission and it's available for anyone to buy. You can use it for data collection, science experiments, games and more. Watch this Gurl Geek Diaries video from Raspberry Pi's Carrie Anne for a great way to get started—by bringing to life an animated pixel pet of your own design on the Sense HAT display:
|
||||
|
||||
Astro Pi —— 一个增强版的树莓派 —— 将在 12 月问世,但是你并没有错过亲手把玩这个硬件的机会。Sense HAT 是 Astro Pi 的一个传感器扩展板,现在已经开放购买了。你可以使用它来进行数据搜集,科学实验,游戏和其它很多事。可以看看下面树莓派的 Carrie Anne 拍摄的 Gurl Geek Diaries 的视频,里面演示了一种很棒的入门途径——给生活添加一个你自己创造的生动的像素宠物:
|
||||
|
||||
[video](https://youtu.be/gfRDFvEVz-w)
|
||||
|
||||
>Learn more in "[Exploring the Sense HAT][9]."
|
||||
>详见 "[探索 Sense HAT][9]."
|
||||
|
||||
### 4. 红外鸟笼 Infrared bird box
|
||||
|
||||

|
||||
>Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0][1].
|
||||
|
||||
A great exercise for the whole class to get involved with—place a Raspberry Pi and the NoIR camera module inside a bird box along with some infra-red lights so you can see in the dark, then stream video from the Pi over the network or on the internet. Wait for birds to nest and you can observe them without disturbing them in their habitat.
|
||||
|
||||
|
||||
|
||||
Learn all about infrared and the light spectrum, and how to adjust the camera focus and control the camera in software.
|
||||
|
||||
Learn more in "[Make an infrared bird box][10]."
|
||||
|
||||
### 5. 机器人 Robotics
|
||||
|
||||

|
||||
>Courtesy of Low Voltage Labs. [CC BY-SA 4.0][1].
|
||||
|
||||
With a Raspberry Pi and as little as a couple of motors and a motor controller board, you can build your own robot. There is a vast range of robots you can make, from basic buggies held together by sellotape and a homemade chassis, all the way to self-aware, sensor-laden metallic stallions with camera attachments driven by games controllers.
|
||||
|
||||
Learn how to control individual motors with something straightforward like the RTK Motor Controller Board (£8/$12), or dive into the new CamJam robotics kit (£17/$25) which comes with motors, wheels and a couple of sensors—great value and plenty of learning potential.
|
||||
|
||||
Alternatively, if you'd like something more hardcore, try PiBorg's [4Borg][11] (£99/$150) or [DiddyBorg][12] (£180/$273) or go the whole hog and treat yourself to their DoodleBorg Metal edition (£250/$380)—and build a mini version of their infamous [DoodleBorg tank][13] (unfortunately not for sale).
|
||||
|
||||
Check out the [CamJam robotics kit worksheets][14].
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/education/15/12/5-great-raspberry-pi-projects-classroom
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[1]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]: https://opensource.com/life/15/5/getting-started-minecraft-pi
|
||||
[3]: http://lowvoltagelabs.com/
|
||||
[4]: http://lowvoltagelabs.com/products/pi-traffic/
|
||||
[5]: http://4tronix.co.uk/store/index.php?rt=product/product&product_id=390
|
||||
[6]: https://ryanteck.uk/hats/1-traffichat-0635648607122.html
|
||||
[7]: http://pythonhosted.org/gpiozero/recipes/
|
||||
[8]: http://camjam.me/?page_id=236
|
||||
[9]: https://opensource.com/life/15/10/exploring-raspberry-pi-sense-hat
|
||||
[10]: https://www.raspberrypi.org/learning/infrared-bird-box/
|
||||
[11]: https://www.piborg.org/4borg
|
||||
[12]: https://www.piborg.org/diddyborg
|
||||
[13]: https://www.piborg.org/doodleborg
|
||||
[14]: http://camjam.me/?page_id=1035#worksheets
|
||||
@ -1,39 +0,0 @@
|
||||
Vic020
|
||||
|
||||
Master OpenStack with 5 new tutorials
|
||||
=======================================
|
||||
|
||||

|
||||
|
||||
|
||||
Returning from OpenStack Summit this week, I am reminded of just how vast the open source cloud ecosystem is and just how many different projects and concepts you need to be familiar with in order to succeed. Although, we're actually quite fortunate with the resources available for keeping up. In addition to the [official documentation][1], many great educational tools are out there, from third party training and certification, to in-person events, and many community-contributed tutorials as well.
|
||||
|
||||
To help you stay on top of things, every month we round up a collection of new tutorials, how-tos, guides, and tips created by the OpenStack community. Here are some of the great pieces published this past month.
|
||||
|
||||
- First up, if you're looking for a (reasonably) affordable home OpenStack test lab, the Intel NUC is a great platform to consider. Small in form factor, but reasonably well-powered, you can get a literal stack of them running OpenStack pretty quickly with this guide to using [TripleO to deploy OpenStack][2] on the NUC, and read about some common quirks to watch out for.
|
||||
- After you've been running OpenStack for a while, the various processes keeping your cloud alive have probably generated quite a pile of log files. While some are probably safe to purge, you still need to have a plan for managing them. Here are some [quick thoughts][3] on managing logs in Ceilometer after nine-months in to a production deployment.
|
||||
- The OpenStack infrastructure project can be an intimidating place for a newcomer just trying to land a patch. What's a gate job, what's a test, and what are all of these steps my commit is going through? Get a quick overview of the whole process from Arie Bregman in this [handy blog post][4].
|
||||
- Compute hosts fail occasionally, and whether the cause is hardware or software, the good news is that OpenStack makes it easy to migrate your running instance to another host. However, some people have found the commands to perform this migration a little confusing. Learn the difference between the migrate and evacuate commands in plain English in [this great writeup][5].
|
||||
- Network Functions Virtualization technologies require some functionality from OpenStack that are outside of what other users might be familiar with. For example, SR-IOV and PCI passthrough are ways of exposing physical hardware directly for maximizing performance. Learn the [steps involved][6] to make this happen within an OpenStack deployment.
|
||||
|
||||
That wraps up our collection for this month, but if you're still looking for more, be sure to check out our past archive of [OpenStack tutorials][7] for even more learning resources. And if there's a tutorial or guide you think we ought to include in our next roundup, be sure to let us know in the comments below.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/4/master-openstack-new-tutorials
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
|
||||
[1]: http://docs.openstack.org/
|
||||
[2]: http://acksyn.org/posts/2016/03/tripleo-on-nucs/
|
||||
[3]: http://silverskysoft.com/open-stack-xwrpr/2016/03/long-term-openstack-usage-summary/
|
||||
[4]: http://abregman.com/2016/03/05/openstack-infra-jenkins-jobs/
|
||||
[5]: http://www.danplanet.com/blog/2016/03/03/evacuate-in-nova-one-command-to-confuse-us-all/
|
||||
[6]: https://trickycloud.wordpress.com/2016/03/28/openstack-for-nfv-applications-sr-iov-and-pci-passthrough/
|
||||
[7]: https://opensource.com/resources/openstack-tutorials
|
||||
@ -1,53 +0,0 @@
|
||||
zpl1025
|
||||
The intersection of Drupal, IoT, and open hardware
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
|
||||
Meet [Amber Matz][1], a Production Manager and Trainer at [Drupalize.Me][3], a service of Lullabot Education. When she's not tinkering around with Arduinos, Raspberry Pis, and electronic wearables, you can find her wrangling presenters for the Portland Drupal User Group.
|
||||
|
||||
Coming up at [DrupalCon NOLA][3], Amber will host a session about Drupal and IoT. If you're attending and want to learn about the intersection of open hardware, IoT, and Drupal, this session is for you. If you're not able to join us in New Orleans, Amber has some pretty cool things to share. In this interview, she tells us how she got involved with Drupal, a few of her favorite open hardware projects, and what the future holds for IoT and Drupal.
|
||||
|
||||

|
||||
|
||||
**How did you get involved with the Drupal community?**
|
||||
|
||||
Back in the day, I was working at a large nonprofit in the "webmaster's office" of the marketing department and was churning out custom PHP/MySQL forms like nobody's business. I finally got weary of that and starting hunting around the web for a better way. I found Drupal 6 and starting diving in on my own. Years later, after a career shift and a move, I discovered the Portland Drupal User Group and landed a job as a full-time Drupal developer. I continued to regularly attend the meetups in Portland, which I found to be a great source of community, friendships, and professional development. Eventually, I landed a job with Lullabot as a trainer creating content for Drupalize.Me. Now, I'm managing the Drupalize.Me content pipeline, creating Drupal 8 content, and am very much involved in the Portland Drupal community. I'm this year's coordinator, finding and scheduling speakers.
|
||||
|
||||
**We have to know: What is Arduino prototyping, how did you discover it, and what's the coolest thing you've done with an Arduino?**
|
||||
|
||||
Arduino, Raspberry Pi, and wearable electronics have been these terms that I've heard thrown around for years. I found [Adafruit's Wearable Electronics][4] with Becky Stern YouTube show years ago (which, up until recently, when Becky moved on, aired every Wednesday). I was fascinated by wearables and even ordered an LED sewing kit but never did anything with it. I just didn't get it. I had no background in electronics whatsoever, and while I was fascinated by the projects I was finding, I didn't see how I could ever make anything like that. It seemed so out of reach.
|
||||
|
||||
Finally, I found a Coursera "Internet of Things" specialization. (So trendy, right?) But I was immediately hooked! I finally got an explanation of what an Arduino was, along with all these other important terms and concepts. I ordered the recommended Arduino starter kit, which came with a getting started booklet. When I made that first LED blink, it was pure delight. I had two weeks' vacation over the holidays and after Christmas, and I did nothing but make and program Arduino circuits from the getting started booklet. It was oddly so relaxing! I enjoyed it so much.
|
||||
|
||||
In January, I started creating my own prototypes. When I found out I was emceeing our company retreat's lightning talks, I created a Lightning Talk Visual Timer prototype with five LEDs and an Arduino.
|
||||
|
||||

|
||||
|
||||
It was a huge hit. I also made my first wearable project, a glowing hoodie, using the Arduino IDE compatible Gemma microcontroller, a tiny round sewable component, to which I sewed using conductive thread, a conductive slider connected to a hoodie's drawstring, which controlled the colors of five NeoPixels sewn around the inside of the hood. So that's what I mean by prototyping: Making crazy projects that are fun and maybe even a little practical.
|
||||
|
||||
**What are the biggest opportunities for Drupal and IoT?**
|
||||
|
||||
IoT isn't that much different than the web services and decoupling Drupal trends. It's the movement of data from thing one to thing two and the rendering of that data into something useful. But how does it get there? And what do you do with it? You think there are a lot of solutions, and apps, and frameworks, and APIs out there now? With IoT, that's only going to continue to increase—exponentially. What I've found is that given any device or any "thing", there is a way to connect it to the Internet—many ways. And there are plenty of code libraries out there to help makers get their data from thing one to thing two.
|
||||
|
||||
So where does Drupal fit in? Web services, for one, is going to be the first obvious place. But as a maker, I don't want to spend my time coding custom modules in Drupal. I want to plug and play! So I would love to see modules emerge that connect with IoT Cloud APIs and services like ThingSpeak and Adafruit.io and IFTTT and others. I think there's an opportunity, too, for a business to build an IoT cloud service in Drupal that allows people to send and store their sensor data, visualize it charts and graphs, and build widgets that react to certain values or thresholds. Each of these IoT Cloud API services fill a slightly different niche, and there's plenty of room for others.
|
||||
|
||||
**What are a few things you're looking forward to at DrupalCon?**
|
||||
|
||||
I love reconnecting with Drupal friends, meeting new people, and also seeing Lullabot and Drupalize.Me co-workers (we're distributed companies)! There's so much to learn with Drupal 8 and it's been overwhelming at times to put together training materials for our customers. So, I'm looking forward to attending Drupal 8-related sessions and getting up-to-speed on the latest developments. Finally, I'm really curious about New Orleans! I haven't been there since 2004 and I'm excited to see what's changed.
|
||||
|
||||
**Tell us about your DrupalCon talk Beyond the blink: Add Drupal to your IoT playground. Why should someone attend? What are the major takeaways?**
|
||||
|
||||
My session title, Beyond the blink: Add Drupal to your IoT playground, in itself is so full of assumptions that first off I'm going to get everyone up to speed and on the same page. You don't need to know anything about Arduino, the Internet of Things, or even Drupal to follow along. We'll start with making an LED blink with an Arduino, and then I want to talk about what the main takeaways have been for me: Play, learn, teach, and make. I'll show examples that have inspired me and that will hopefully inspire and encourage others in the audience to give it a try. Then, it's demo time!
|
||||
|
||||
First, thing one. Thing one is a Build Notifier Tower Light. In this demo, I'll show how I connected the Tower Light to the Internet and how I got it to respond to data received from a Cloud API service. Next, Thing two. Thing two is a "weather watch" in the form of a steampunk iPhone case. It's got small LED matrix that displays an icon of the local-to-me weather, a barometric pressure and temperature sensor, a GPS module, and a Bluetooth LE module, all connected and controlled with an Adafruit Flora microcontroller. Thing two sends weather and location data to Adafruit.io by connecting to an app on my iPhone over Bluetooth and sends it up to the cloud using an MQTT protocol! Then, on the Drupal side, I'm pulling down that data from the cloud, updating a block with the weather, and updating a map. So folks will get a taste of what you can do with web services, maps, and blocks in Drupal 8, too.
|
||||
|
||||
It's been a brain-melting adventure learning and making these demo prototypes, and I hope others will come to the session and catch a little of this contagious enthusiasm I have for this intersection of technologies! I'm very excited to share what I've discovered.
|
||||
|
||||
|
||||
|
||||
[1]: https://www.drupal.org/u/amber-himes-matz
|
||||
[2]: https://drupalize.me/
|
||||
[3]: https://events.drupal.org/neworleans2016/
|
||||
[4]: https://www.adafruit.com/beckystern
|
||||
@ -0,0 +1,63 @@
|
||||
4 Container Networking Tools to Know
|
||||
=======================================
|
||||
|
||||

|
||||
>[Creative Commons Zero][1]
|
||||
|
||||
With so many new cloud computing technologies, tools, and techniques to keep track of, it can be hard to know where to start learning new skills. This series on [next-gen cloud technologies][2] aims to help you get up to speed on the important projects and products in emerging and rapidly changing areas such as software-defined networking (SDN) , containers, and the space where they coincide: container networking.
|
||||
|
||||
The relationship between containers and networks remains challenging for enterprise container deployment. Containers need networking functionality to connect distributed applications. Part of the challenge, according to a recent [Enterprise Networking Planet][3] article, is “to deploy containers in a way that provides the isolation they need to function as their own self-contained data environments while still maintaining effective connectivity.”
|
||||
|
||||
[Docker][4], the popular container platform, uses software-defined virtual networks to connect containers with the local network. Additionally, it uses Linux bridging features and virtual extensible LAN (VXLAN) technology so containers can communicate with each other in the same Swarm, or cluster. Docker’s plug-in architecture also allows other network management tools, such as those listed below, to control containers.
|
||||
|
||||
Innovation in container networking has enabled containers to connect with other containers across hosts. This enables developers to start an application in a container on a host in a development environment and transition it across testing and then into a production environment enabling continuous integration, agility, and rapid deployment.
|
||||
|
||||
Container networking tools help accomplish container networking scalability, mainly by:
|
||||
|
||||
1) enabling complex, multi-host systems to be distributed across multiple container hosts.
|
||||
|
||||
2) enabling orchestration for container systems spanning a tremendous number of hosts across multiple public and private cloud platforms.
|
||||
|
||||

|
||||
>John Willis speaking at Open Networking Summit 2016.
|
||||
|
||||
For more information, check out the [Docker Networking Tutorial][5] video, which was presented by Brent Salisbury and John Willis at the recent [Open Networking Summit (ONS)][6]. This and many other ONS keynotes and presentations can be found [here][7].
|
||||
|
||||
Container networking tools and projects you should know about include:
|
||||
|
||||
[Calico][8] -- The Calico project (from [Metaswitch][9]) leverages Border Gateway Protocol (BGP) and integrates with cloud orchestration systems for secure IP communication between virtual machines and containers.
|
||||
|
||||
[Flannel][10] -- Flannel (previously called rudder) from [CoreOS][11] provides an overlay network that can be used as an alternative to existing SDN solutions.
|
||||
|
||||
[Weaveworks][12] -- The Weaveworks projects for managing containers include [Weave Net][13], Weave Scope, and Weave Flux. Weave Net is a tool for building and deploying Docker container networks.
|
||||
|
||||
[Canal][14] -- Just this week, CoreOS and Tigera announced the formation of a new open source project called Canal. According to the announcement, the Canal project aims to combine aspects of Calico and Flannel, "weaving security policy into both the network fabric and the cloud orchestrator."
|
||||
|
||||
You can learn more about container management, software-defined networking, and other next-gen cloud technologies through The Linux Foundation’s free “Cloud Infrastructure Technologies” course -- a massively open online course being offered through edX. [Registration for this course is open now][15], and course content will be available in June.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/4-container-networking-tools-know
|
||||
|
||||
作者:[AMBER ANKERHOLZ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/aankerholz
|
||||
[1]: https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]: https://www.linux.com/news/5-next-gen-cloud-technologies-you-should-know
|
||||
[3]: http://www.enterprisenetworkingplanet.com/datacenter/datacenter-blog/container-networking-challenges-for-the-enterprise.html
|
||||
[4]: https://docs.docker.com/engine/userguide/networking/dockernetworks/
|
||||
[5]: https://youtu.be/Le0bEg4taak
|
||||
[6]: http://events.linuxfoundation.org/events/open-networking-summit
|
||||
[7]: https://www.linux.com/watch-videos-from-ons2016
|
||||
[8]: https://www.projectcalico.org/
|
||||
[9]: http://www.metaswitch.com/cloud-network-virtualization
|
||||
[10]: https://coreos.com/blog/introducing-rudder/
|
||||
[11]: https://coreos.com/
|
||||
[12]: https://www.weave.works/
|
||||
[13]: https://www.weave.works/products/weave-net/
|
||||
[14]: https://github.com/tigera/canal
|
||||
[15]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-cloud-infrastructure-technologies?utm_source=linuxcom&utm_medium=article&utm_campaign=cloud%20mooc%20article%201
|
||||
@ -0,0 +1,50 @@
|
||||
An introduction to data processing with Cassandra and Spark
|
||||
==============================================================
|
||||
|
||||

|
||||
|
||||
|
||||
There's been a huge surge of interest around the Apache Cassandra database due to the increasing uptime and performance demands of modern cloud applications.
|
||||
|
||||
So, what is Apache Cassandra? A distributed OLTP database built for high availability and linear scalability. When people ask what Cassandra is used for, think about the type of system you want close to the customer. This is ultimately the system that our users interact with. Applications that must always be available: product catalogs, IoT, medical systems, and mobile applications. In these categories downtime can mean loss of revenue or even more dire outcomes depending on your specific use case. Netflix was one of the earliest adopters of this project, which was open sourced in 2008, and their contributions, along with successes, put it on the radar of the masses.
|
||||
|
||||
Cassandra became a top level Apache Software Foundation project in 2010 and has been riding the wave in popularity since then. Now even knowledge in Cassandra gets you serious returns in the job market. It's both crazy and awesome to consider a NoSQL and open source technology could perform this sort of disruption next to the giants of enterprise SQL. This begs the question, what makes it so popular?
|
||||
|
||||
Cassandra has the ability to be always on in spite of massive hardware and network failures by utilizing a design first widely discussed in [the Dynamo paper from Amazon][1]. By using a peer to peer model, with no single point of failure, we can survive rack failure and even complete network partitions. We can deal with an entire data center failure without impacting our customer's experience. A distributed system that plans for failure is a properly planned distributed system, because frankly, failures are just going to happen. With Cassandra, we accept that cruel fact of life, and bake it into the database's architecture and functionality.
|
||||
|
||||
We know what you’re thinking, "But, I’m coming from a relational background, isn't this going to be a daunting transition?" The answer is somewhat yes and no. Data modeling with Cassandra will feel familiar to developers coming from the relational world. We use tables to model our data, and CQL, the Cassandra Query Language, to query the database. However, unlike SQL, Cassandra supports more complex data structures such as nested and user defined types. For instance, instead of creating a dedicated table to store likes on a cat photo, we can store that data in a collection with the photo itself enabling faster, sequential lookups. That's expressed very naturally in CQL. In our photo table we may want to track the name, URL, and the people that liked the photo.
|
||||
|
||||

|
||||
|
||||
In a high performance system milliseconds matter for both user experience and for customer retention. Expensive JOIN operations limit our ability to scale out by adding unpredictable network calls. By denormalizing our data so it can be fetched in as few requests as possible, we profit from the trend of decreasing costs in disk space and in return get predictable, high performance applications. We embrace the concept of denormalization with Cassandra because it offers a pretty appealing tradeoff.
|
||||
|
||||
We're obviously not just limited to storing likes on cat photos. Cassandra is a optimized for high write throughput. This makes it the perfect solution for big data applications where we’re constantly ingesting data. Time series and IoT use cases are growing at a steady rate in both demand and appearance in the market, and we're continuously finding ways to utilize the data we collect to improve our technological application.
|
||||
|
||||
This brings us to the next step, we've talked about storing our data in a modern, cost-effective fashion, but how do we get even more horsepower? Meaning, once we've collected all that data, what do we do with it? How can we analyze hundreds of terabytes efficiently? How can we react to information we're receiving in real-time, making decisions in seconds rather than hours? Enter Apache Spark.
|
||||
|
||||
Spark is the next step in the evolution of big data processing. Hadoop and MapReduce were revolutionary projects, giving the big data world an opportunity to crunch all the data we've collected. Spark takes our big data analysis to the next level by drastically improving performance and massively decreasing code complexity. Through Spark, we can perform massive batch processing calculations, react quickly to stream processing, make smart decisions through machine learning, and understand complex, recursive relationships through graph traversals. It’s not just about offering your customers a fast and reliable connection to their application (which is what Cassandra offers), it's also about being able to leverage insights from the data Cassandra stores to make more intelligent business decisions and better cater to customer needs.
|
||||
|
||||
You can check out the [Spark-Cassandra Connector][2] (open source) and give it a shot. To learn more about both technologies, we highly recommend the free self-paced courses on [DataStax Academy][3].
|
||||
|
||||
Have fun digging in and learning some killer new technology! If you want to learn more, check out our [OSCON tutorial][4], with a hands on exploration into the worlds of both Cassandra and Spark.
|
||||
|
||||
We also love taking questions on Twitter, so give us a shout and we’ll try to help: [Dani][5] and [Jon][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/basics-cassandra-and-spark-data-processing
|
||||
|
||||
作者:[Jon Haddad][a],[Dani Traphagen][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/rustyrazorblade
|
||||
[b]: https://opensource.com/users/dtrapezoid
|
||||
[1]: http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
|
||||
[2]: https://github.com/datastax/spark-cassandra-connector
|
||||
[3]: https://academy.datastax.com/
|
||||
[4]: http://conferences.oreilly.com/oscon/open-source-us/public/schedule/detail/49162
|
||||
[5]: https://twitter.com/dtrapezoid
|
||||
[6]: https://twitter.com/rustyrazorblade
|
||||
@ -1,368 +0,0 @@
|
||||
ictlyh Translating
|
||||
Part 7 - LFCS: Managing System Startup Process and Services (SysVinit, Systemd and Upstart)
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, an exciting new program whose aim is allowing individuals from all ends of the world to get certified in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-hand problem-finding and analysis, plus the ability to decide when to raise issues to engineering teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 7
|
||||
|
||||
The following video describes an brief introduction to The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 7 of a 10-tutorial series, here in this part, we will explain how to Manage Linux System Startup Process and Services, that are required for the LFCS certification exam.
|
||||
|
||||
### Managing the Linux Startup Process ###
|
||||
|
||||
The boot process of a Linux system consists of several phases, each represented by a different component. The following diagram briefly summarizes the boot process and shows all the main components involved.
|
||||
|
||||

|
||||
|
||||
Linux Boot Process
|
||||
|
||||
When you press the Power button on your machine, the firmware that is stored in a EEPROM chip in the motherboard initializes the POST (Power-On Self Test) to check on the state of the system’s hardware resources. When the POST is finished, the firmware then searches and loads the 1st stage boot loader, located in the MBR or in the EFI partition of the first available disk, and gives control to it.
|
||||
|
||||
#### MBR Method ####
|
||||
|
||||
The MBR is located in the first sector of the disk marked as bootable in the BIOS settings and is 512 bytes in size.
|
||||
|
||||
- First 446 bytes: The bootloader contains both executable code and error message text.
|
||||
- Next 64 bytes: The Partition table contains a record for each of four partitions (primary or extended). Among other things, each record indicates the status (active / not active), size, and start / end sectors of each partition.
|
||||
- Last 2 bytes: The magic number serves as a validation check of the MBR.
|
||||
|
||||
The following command performs a backup of the MBR (in this example, /dev/sda is the first hard disk). The resulting file, mbr.bkp can come in handy should the partition table become corrupt, for example, rendering the system unbootable.
|
||||
|
||||
Of course, in order to use it later if the need arises, we will need to save it and store it somewhere else (like a USB drive, for example). That file will help us restore the MBR and will get us going once again if and only if we do not change the hard drive layout in the meanwhile.
|
||||
|
||||
**Backup MBR**
|
||||
|
||||
# dd if=/dev/sda of=mbr.bkp bs=512 count=1
|
||||
|
||||

|
||||
|
||||
Backup MBR in Linux
|
||||
|
||||
**Restoring MBR**
|
||||
|
||||
# dd if=mbr.bkp of=/dev/sda bs=512 count=1
|
||||
|
||||
|
||||
|
||||
Restore MBR in Linux
|
||||
|
||||
#### EFI/UEFI Method ####
|
||||
|
||||
For systems using the EFI/UEFI method, the UEFI firmware reads its settings to determine which UEFI application is to be launched and from where (i.e., in which disk and partition the EFI partition is located).
|
||||
|
||||
Next, the 2nd stage boot loader (aka boot manager) is loaded and run. GRUB [GRand Unified Boot] is the most frequently used boot manager in Linux. One of two distinct versions can be found on most systems used today.
|
||||
|
||||
- GRUB legacy configuration file: /boot/grub/menu.lst (older distributions, not supported by EFI/UEFI firmwares).
|
||||
- GRUB2 configuration file: most likely, /etc/default/grub.
|
||||
|
||||
Although the objectives of the LFCS exam do not explicitly request knowledge about GRUB internals, if you’re brave and can afford to mess up your system (you may want to try it first on a virtual machine, just in case), you need to run.
|
||||
|
||||
# update-grub
|
||||
|
||||
As root after modifying GRUB’s configuration in order to apply the changes.
|
||||
|
||||
Basically, GRUB loads the default kernel and the initrd or initramfs image. In few words, initrd or initramfs help to perform the hardware detection, the kernel module loading and the device discovery necessary to get the real root filesystem mounted.
|
||||
|
||||
Once the real root filesystem is up, the kernel executes the system and service manager (init or systemd, whose process identification or PID is always 1) to begin the normal user-space boot process in order to present a user interface.
|
||||
|
||||
Both init and systemd are daemons (background processes) that manage other daemons, as the first service to start (during boot) and the last service to terminate (during shutdown).
|
||||
|
||||

|
||||
|
||||
Systemd and Init
|
||||
|
||||
### Starting Services (SysVinit) ###
|
||||
|
||||
The concept of runlevels in Linux specifies different ways to use a system by controlling which services are running. In other words, a runlevel controls what tasks can be accomplished in the current execution state = runlevel (and which ones cannot).
|
||||
|
||||
Traditionally, this startup process was performed based on conventions that originated with System V UNIX, with the system passing executing collections of scripts that start and stop services as the machine entered a specific runlevel (which, in other words, is a different mode of running the system).
|
||||
|
||||
Within each runlevel, individual services can be set to run, or to be shut down if running. Latest versions of some major distributions are moving away from the System V standard in favour of a rather new service and system manager called systemd (which stands for system daemon), but usually support sysv commands for compatibility purposes. This means that you can run most of the well-known sysv init tools in a systemd-based distribution.
|
||||
|
||||
- Read Also: [Why ‘systemd’ replaces ‘init’ in Linux][1]
|
||||
|
||||
Besides starting the system process, init looks to the /etc/inittab file to decide what runlevel must be entered.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="85">
|
||||
</colgroup>
|
||||
<colgroup width="1514">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;"><b>Runlevel</b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><b> Description</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">0</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Halt the system. Runlevel 0 is a special transitional state used to shutdown the system quickly.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="20" style="border: 1px solid #000001;">1</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Also aliased to s, or S, this runlevel is sometimes called maintenance mode. What services, if any, are started at this runlevel varies by distribution. It’s typically used for low-level system maintenance that may be impaired by normal system operation.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">2</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Multiuser. On Debian systems and derivatives, this is the default runlevel, and includes -if available- a graphical login. On Red-Hat based systems, this is multiuser mode without networking.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">3</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> On Red-Hat based systems, this is the default multiuser mode, which runs everything except the graphical environment. This runlevel and levels 4 and 5 usually are not used on Debian-based systems.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">4</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Typically unused by default and therefore available for customization.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">5</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> On Red-Hat based systems, full multiuser mode with GUI login. This runlevel is like level 3, but with a GUI login available.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">6</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Reboot the system.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
To switch between runlevels, we can simply issue a runlevel change using the init command: init N (where N is one of the runlevels listed above). Please note that this is not the recommended way of taking a running system to a different runlevel because it gives no warning to existing logged-in users (thus causing them to lose work and processes to terminate abnormally).
|
||||
|
||||
Instead, the shutdown command should be used to restart the system (which first sends a warning message to all logged-in users and blocks any further logins; it then signals init to switch runlevels); however, the default runlevel (the one the system will boot to) must be edited in the /etc/inittab file first.
|
||||
|
||||
For that reason, follow these steps to properly switch between runlevels, As root, look for the following line in /etc/inittab.
|
||||
|
||||
id:2:initdefault:
|
||||
|
||||
and change the number 2 for the desired runlevel with your preferred text editor, such as vim (described in [How to use vi/vim editor in Linux – Part 2][2] of this series).
|
||||
|
||||
Next, run as root.
|
||||
|
||||
# shutdown -r now
|
||||
|
||||
That last command will restart the system, causing it to start in the specified runlevel during next boot, and will run the scripts located in the /etc/rc[runlevel].d directory in order to decide which services should be started and which ones should not. For example, for runlevel 2 in the following system.
|
||||
|
||||

|
||||
|
||||
Change Runlevels in Linux
|
||||
|
||||
#### Manage Services using chkconfig ####
|
||||
|
||||
To enable or disable system services on boot, we will use [chkconfig command][3] in CentOS / openSUSE and sysv-rc-conf in Debian and derivatives. This tool can also show us what is the preconfigured state of a service for a particular runlevel.
|
||||
|
||||
- Read Also: [How to Stop and Disable Unwanted Services in Linux][4]
|
||||
|
||||
Listing the runlevel configuration for a service.
|
||||
|
||||
# chkconfig --list [service name]
|
||||
# chkconfig --list postfix
|
||||
# chkconfig --list mysqld
|
||||
|
||||

|
||||
|
||||
Listing Runlevel Configuration
|
||||
|
||||
In the above image we can see that postfix is set to start when the system enters runlevels 2 through 5, whereas mysqld will be running by default for runlevels 2 through 4. Now suppose that this is not the expected behaviour.
|
||||
|
||||
For example, we need to turn on mysqld for runlevel 5 as well, and turn off postfix for runlevels 4 and 5. Here’s what we would do in each case (run the following commands as root).
|
||||
|
||||
**Enabling a service for a particular runlevel**
|
||||
|
||||
# chkconfig --level [level(s)] service on
|
||||
# chkconfig --level 5 mysqld on
|
||||
|
||||
**Disabling a service for particular runlevels**
|
||||
|
||||
# chkconfig --level [level(s)] service off
|
||||
# chkconfig --level 45 postfix off
|
||||
|
||||
|
||||
|
||||
Enable Disable Services
|
||||
|
||||
We will now perform similar tasks in a Debian-based system using sysv-rc-conf.
|
||||
|
||||
#### Manage Services using sysv-rc-conf ####
|
||||
|
||||
Configuring a service to start automatically on a specific runlevel and prevent it from starting on all others.
|
||||
|
||||
1. Let’s use the following command to see what are the runlevels where mdadm is configured to start.
|
||||
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||

|
||||
|
||||
Check Runlevel of Service Running
|
||||
|
||||
2. We will use sysv-rc-conf to prevent mdadm from starting on all runlevels except 2. Just check or uncheck (with the space bar) as desired (you can move up, down, left, and right with the arrow keys).
|
||||
|
||||
# sysv-rc-conf
|
||||
|
||||

|
||||
|
||||
SysV Runlevel Config
|
||||
|
||||
Then press q to quit.
|
||||
|
||||
3. We will restart the system and run again the command from STEP 1.
|
||||
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||

|
||||
|
||||
Verify Service Runlevel
|
||||
|
||||
In the above image we can see that mdadm is configured to start only on runlevel 2.
|
||||
|
||||
### What About systemd? ###
|
||||
|
||||
systemd is another service and system manager that is being adopted by several major Linux distributions. It aims to allow more processing to be done in parallel during system startup (unlike sysvinit, which always tends to be slower because it starts processes one at a time, checks whether one depends on another, and waits for daemons to launch so more services can start), and to serve as a dynamic resource management to a running system.
|
||||
|
||||
Thus, services are started when needed (to avoid consuming system resources) instead of being launched without a solid reason during boot.
|
||||
|
||||
Viewing the status of all the processes running on your system, both systemd native and SysV services, run the following command.
|
||||
|
||||
# systemctl
|
||||
|
||||

|
||||
|
||||
Check All Running Processes
|
||||
|
||||
The LOAD column shows whether the unit definition (refer to the UNIT column, which shows the service or anything maintained by systemd) was properly loaded, while the ACTIVE and SUB columns show the current status of such unit.
|
||||
Displaying information about the current status of a service
|
||||
|
||||
When the ACTIVE column indicates that an unit’s status is other than active, we can check what happened using.
|
||||
|
||||
# systemctl status [unit]
|
||||
|
||||
For example, in the image above, media-samba.mount is in failed state. Let’s run.
|
||||
|
||||
# systemctl status media-samba.mount
|
||||
|
||||

|
||||
|
||||
Check Service Status
|
||||
|
||||
We can see that media-samba.mount failed because the mount process on host dev1 was unable to find the network share at //192.168.0.10/gacanepa.
|
||||
|
||||
### Starting or Stopping Services ###
|
||||
|
||||
Once the network share //192.168.0.10/gacanepa becomes available, let’s try to start, then stop, and finally restart the unit media-samba.mount. After performing each action, let’s run systemctl status media-samba.mount to check on its status.
|
||||
|
||||
# systemctl start media-samba.mount
|
||||
# systemctl status media-samba.mount
|
||||
# systemctl stop media-samba.mount
|
||||
# systemctl restart media-samba.mount
|
||||
# systemctl status media-samba.mount
|
||||
|
||||

|
||||
|
||||
Starting Stoping Services
|
||||
|
||||
**Enabling or disabling a service to start during boot**
|
||||
|
||||
Under systemd you can enable or disable a service when it boots.
|
||||
|
||||
# systemctl enable [service] # enable a service
|
||||
# systemctl disable [service] # prevent a service from starting at boot
|
||||
|
||||
The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links in the /etc/systemd/system/multi-user.target.wants directory.
|
||||
|
||||

|
||||
|
||||
Enabling Disabling Services
|
||||
|
||||
Alternatively, you can find out a service’s current status (enabled or disabled) with the command.
|
||||
|
||||
# systemctl is-enabled [service]
|
||||
|
||||
For example,
|
||||
|
||||
# systemctl is-enabled postfix.service
|
||||
|
||||
In addition, you can reboot or shutdown the system with.
|
||||
|
||||
# systemctl reboot
|
||||
# systemctl shutdown
|
||||
|
||||
### Upstart ###
|
||||
|
||||
Upstart is an event-based replacement for the /sbin/init daemon and was born out of the need for starting services only, when they are needed (also supervising them while they are running), and handling events as they occur, thus surpassing the classic, dependency-based sysvinit system.
|
||||
|
||||
It was originally developed for the Ubuntu distribution, but is used in Red Hat Enterprise Linux 6.0. Though it was intended to be suitable for deployment in all Linux distributions as a replacement for sysvinit, in time it was overshadowed by systemd. On February 14, 2014, Mark Shuttleworth (founder of Canonical Ltd.) announced that future releases of Ubuntu would use systemd as the default init daemon.
|
||||
|
||||
Because the SysV startup script for system has been so common for so long, a large number of software packages include SysV startup scripts. To accommodate such packages, Upstart provides a compatibility mode: It runs SysV startup scripts in the usual locations (/etc/rc.d/rc?.d, /etc/init.d/rc?.d, /etc/rc?.d, or a similar location). Thus, if we install a package that doesn’t yet include an Upstart configuration script, it should still launch in the usual way.
|
||||
|
||||
Furthermore, if we have installed utilities such as [chkconfig][5], you should be able to use them to manage your SysV-based services just as we would on sysvinit based systems.
|
||||
|
||||
Upstart scripts also support starting or stopping services based on a wider variety of actions than do SysV startup scripts; for example, Upstart can launch a service whenever a particular hardware device is attached.
|
||||
|
||||
A system that uses Upstart and its native scripts exclusively replaces the /etc/inittab file and the runlevel-specific SysV startup script directories with .conf scripts in the /etc/init directory.
|
||||
|
||||
These *.conf scripts (also known as job definitions) generally consists of the following:
|
||||
|
||||
- Description of the process.
|
||||
- Runlevels where the process should run or events that should trigger it.
|
||||
- Runlevels where process should be stopped or events that should stop it.
|
||||
- Options.
|
||||
- Command to launch the process.
|
||||
|
||||
For example,
|
||||
|
||||
# My test service - Upstart script demo description "Here goes the description of 'My test service'" author "Dave Null <dave.null@example.com>"
|
||||
# Stanzas
|
||||
|
||||
#
|
||||
# Stanzas define when and how a process is started and stopped
|
||||
# See a list of stanzas here: http://upstart.ubuntu.com/wiki/Stanzas#respawn
|
||||
# When to start the service
|
||||
start on runlevel [2345]
|
||||
# When to stop the service
|
||||
stop on runlevel [016]
|
||||
# Automatically restart process in case of crash
|
||||
respawn
|
||||
# Specify working directory
|
||||
chdir /home/dave/myfiles
|
||||
# Specify the process/command (add arguments if needed) to run
|
||||
exec bash backup.sh arg1 arg2
|
||||
|
||||
To apply changes, you will need to tell upstart to reload its configuration.
|
||||
|
||||
# initctl reload-configuration
|
||||
|
||||
Then start your job by typing the following command.
|
||||
|
||||
$ sudo start yourjobname
|
||||
|
||||
Where yourjobname is the name of the job that was added earlier with the yourjobname.conf script.
|
||||
|
||||
A more complete and detailed reference guide for Upstart is available in the project’s web site under the menu “[Cookbook][6]”.
|
||||
|
||||
### Summary ###
|
||||
|
||||
A knowledge of the Linux boot process is necessary to help you with troubleshooting tasks as well as with adapting the computer’s performance and running services to your needs.
|
||||
|
||||
In this article we have analyzed what happens from the moment when you press the Power switch to turn on the machine until you get a fully operational user interface. I hope you have learned reading it as much as I did while putting it together. Feel free to leave your comments or questions below. We always look forward to hearing from our readers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
[4]:http://www.tecmint.com/remove-unwanted-services-from-linux/
|
||||
[5]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
[6]:http://upstart.ubuntu.com/cookbook/
|
||||
@ -1,3 +1,6 @@
|
||||
ezio is translating
|
||||
|
||||
|
||||
Part 4 - LXD 2.0: Resource control
|
||||
======================================
|
||||
|
||||
|
||||
@ -1,6 +1,145 @@
|
||||
Part 7 - LXD 2.0: Docker in LXD
|
||||
==================================
|
||||
|
||||
<正文待补充>
|
||||
This is the seventh blog post [in this series about LXD 2.0][0].
|
||||
|
||||
原文: https://www.stgraber.org/2016/04/13/lxd-2-0-docker-in-lxd-712/
|
||||

|
||||
|
||||
### Why run Docker inside LXD
|
||||
|
||||
As I briefly covered in the [first post of this series][1], LXD’s focus is system containers. That is, we run a full unmodified Linux distribution inside our containers. LXD for all intent and purposes doesn’t care about the workload running in the container. It just sets up the container namespaces and security policies, then spawns /sbin/init and waits for the container to stop.
|
||||
|
||||
Application containers such as those implemented by Docker or Rkt are pretty different in that they are used to distribute applications, will typically run a single main process inside them and be much more ephemeral than a LXD container.
|
||||
|
||||
Those two container types aren’t mutually exclusive and we certainly see the value of using Docker containers to distribute applications. That’s why we’ve been working hard over the past year to make it possible to run Docker inside LXD.
|
||||
|
||||
This means that with Ubuntu 16.04 and LXD 2.0, you can create containers for your users who will then be able to connect into them just like a normal Ubuntu system and then run Docker to install the services and applications they want.
|
||||
|
||||
### Requirements
|
||||
|
||||
There are a lot of moving pieces to make all of this working and we got it all included in Ubuntu 16.04:
|
||||
|
||||
- A kernel with CGroup namespace support (4.4 Ubuntu or 4.6 mainline)
|
||||
- LXD 2.0 using LXC 2.0 and LXCFS 2.0
|
||||
- A custom version of Docker (or one built with all the patches that we submitted)
|
||||
- A Docker image which behaves when confined by user namespaces, or alternatively make the parent LXD container a privileged container (security.privileged=true)
|
||||
|
||||
### Running a basic Docker workload
|
||||
|
||||
Enough talking, lets run some Docker containers!
|
||||
|
||||
First of all, you need an Ubuntu 16.04 container which you can get with:
|
||||
|
||||
```
|
||||
lxc launch ubuntu-daily:16.04 docker -p default -p docker
|
||||
```
|
||||
|
||||
The “-p default -p docker” instructs LXD to apply both the “default” and “docker” profiles to the container. The default profile contains the basic network configuration while the docker profile tells LXD to load a few required kernel modules and set up some mounts for the container. The docker profile also enables container nesting.
|
||||
|
||||
Now lets make sure the container is up to date and install docker:
|
||||
|
||||
```
|
||||
lxc exec docker -- apt update
|
||||
lxc exec docker -- apt dist-upgrade -y
|
||||
lxc exec docker -- apt install docker.io -y
|
||||
```
|
||||
|
||||
And that’s it! You’ve got Docker installed and running in your container.
|
||||
Now lets start a basic web service made of two Docker containers:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec docker -- docker run --detach --name app carinamarina/hello-world-app
|
||||
Unable to find image 'carinamarina/hello-world-app:latest' locally
|
||||
latest: Pulling from carinamarina/hello-world-app
|
||||
efd26ecc9548: Pull complete
|
||||
a3ed95caeb02: Pull complete
|
||||
d1784d73276e: Pull complete
|
||||
72e581645fc3: Pull complete
|
||||
9709ddcc4d24: Pull complete
|
||||
2d600f0ec235: Pull complete
|
||||
c4cf94f61cbd: Pull complete
|
||||
c40f2ab60404: Pull complete
|
||||
e87185df6de7: Pull complete
|
||||
62a11c66eb65: Pull complete
|
||||
4c5eea9f676d: Pull complete
|
||||
498df6a0d074: Pull complete
|
||||
Digest: sha256:6a159db50cb9c0fbe127fb038ed5a33bb5a443fcdd925ec74bf578142718f516
|
||||
Status: Downloaded newer image for carinamarina/hello-world-app:latest
|
||||
c8318f0401fb1e119e6c5bb23d1e706e8ca080f8e44b42613856ccd0bf8bfb0d
|
||||
|
||||
stgraber@dakara:~$ lxc exec docker -- docker run --detach --name web --link app:helloapp -p 80:5000 carinamarina/hello-world-web
|
||||
Unable to find image 'carinamarina/hello-world-web:latest' locally
|
||||
latest: Pulling from carinamarina/hello-world-web
|
||||
efd26ecc9548: Already exists
|
||||
a3ed95caeb02: Already exists
|
||||
d1784d73276e: Already exists
|
||||
72e581645fc3: Already exists
|
||||
9709ddcc4d24: Already exists
|
||||
2d600f0ec235: Already exists
|
||||
c4cf94f61cbd: Already exists
|
||||
c40f2ab60404: Already exists
|
||||
e87185df6de7: Already exists
|
||||
f2d249ff479b: Pull complete
|
||||
97cb83fe7a9a: Pull complete
|
||||
d7ce7c58a919: Pull complete
|
||||
Digest: sha256:c31cf04b1ab6a0dac40d0c5e3e64864f4f2e0527a8ba602971dab5a977a74f20
|
||||
Status: Downloaded newer image for carinamarina/hello-world-web:latest
|
||||
d7b8963401482337329faf487d5274465536eebe76f5b33c89622b92477a670f
|
||||
```
|
||||
|
||||
With those two Docker containers now running, we can then get the IP address of our LXD container and access the service!
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list
|
||||
+--------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+--------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
| docker | RUNNING | 172.17.0.1 (docker0) | 2001:470:b368:4242:216:3eff:fe55:45f4 (eth0) | PERSISTENT | 0 |
|
||||
| | | 10.178.150.73 (eth0) | | | |
|
||||
+--------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
|
||||
stgraber@dakara:~$ curl http://10.178.150.73
|
||||
The linked container said... "Hello World!"
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
That’s it! It’s really that simple to run Docker containers inside a LXD container.
|
||||
|
||||
Now as I mentioned earlier, not all Docker images will behave as well as my example, that’s typically because of the extra confinement that comes with LXD, specifically the user namespace.
|
||||
|
||||
Only the overlayfs storage driver of Docker works in this mode. That storage driver may come with its own set of limitation which may further limit how many images will work in this environment.
|
||||
|
||||
If your workload doesn’t work properly and you trust the user inside the LXD container, you can try:
|
||||
|
||||
```
|
||||
lxc config set docker security.privileged true
|
||||
lxc restart docker
|
||||
```
|
||||
|
||||
That will de-activate the user namespace and will run the container in privileged mode.
|
||||
|
||||
Note however that in this mode, root inside the container is the same uid as root on the host. There are a number of known ways for users to escape such containers and gain root privileges on the host, so you should only ever do that if you’d trust the user inside your LXD container with root privileges on the host.
|
||||
|
||||
### Extra information
|
||||
|
||||
The main LXD website is at: <https://linuxcontainers.org/lxd>
|
||||
Development happens on Github at: <https://github.com/lxc/lxd>
|
||||
Mailing-list support happens on: <https://lists.linuxcontainers.org>
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/04/13/lxd-2-0-docker-in-lxd-712/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://www.stgraber.org/2016/03/11/lxd-2-0-introduction-to-lxd-112/
|
||||
[2]: https://linuxcontainers.org/lxd/try-it/
|
||||
|
||||
@ -1,6 +1,126 @@
|
||||
Part 8 - LXD 2.0: LXD in LXD
|
||||
==============================
|
||||
|
||||
<原文待补充>
|
||||
This is the eighth blog post [in this series about LXD 2.0][0].
|
||||
|
||||
原文:https://www.stgraber.org/2016/04/14/lxd-2-0-lxd-in-lxd-812/
|
||||

|
||||
|
||||
### Introduction
|
||||
|
||||
In the previous post I covered how to run [Docker inside LXD][1] which is a good way to get access to the portfolio of application provided by Docker while running in the safety of the LXD environment.
|
||||
|
||||
One use case I mentioned was offering a LXD container to your users and then have them use their container to run Docker. Well, what if they themselves want to run other Linux distributions inside their container using LXD, or even allow another group of people to have access to a Linux system by running a container for them?
|
||||
|
||||
Turns out, LXD makes it very simple to allow your users to run nested containers.
|
||||
|
||||
### Nesting LXD
|
||||
|
||||
The most simple case can be shown by using an Ubuntu 16.04 image. Ubuntu 16.04 cloud images come with LXD pre-installed. The daemon itself isn’t running as it’s socket-activated so it doesn’t use any resources until you actually talk to it.
|
||||
|
||||
So lets start an Ubuntu 16.04 container with nesting enabled:
|
||||
|
||||
```
|
||||
lxc launch ubuntu-daily:16.04 c1 -c security.nesting=true
|
||||
```
|
||||
|
||||
You can also set the security.nesting key on an existing container with:
|
||||
|
||||
```
|
||||
lxc config set <container name> security.nesting true
|
||||
```
|
||||
|
||||
Or for all containers using a particular profile with:
|
||||
|
||||
```
|
||||
lxc profile set <profile name> security.nesting true
|
||||
```
|
||||
|
||||
With that container started, you can now get a shell inside it, configure LXD and spawn a container:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc launch ubuntu-daily:16.04 c1 -c security.nesting=true
|
||||
Creating c1
|
||||
Starting c1
|
||||
|
||||
stgraber@dakara:~$ lxc exec c1 bash
|
||||
root@c1:~# lxd init
|
||||
Name of the storage backend to use (dir or zfs): dir
|
||||
|
||||
We detected that you are running inside an unprivileged container.
|
||||
This means that unless you manually configured your host otherwise,
|
||||
you will not have enough uid and gid to allocate to your containers.
|
||||
|
||||
LXD can re-use your container's own allocation to avoid the problem.
|
||||
Doing so makes your nested containers slightly less safe as they could
|
||||
in theory attack their parent container and gain more privileges than
|
||||
they otherwise would.
|
||||
|
||||
Would you like to have your containers share their parent's allocation (yes/no)? yes
|
||||
Would you like LXD to be available over the network (yes/no)? no
|
||||
Do you want to configure the LXD bridge (yes/no)? yes
|
||||
Warning: Stopping lxd.service, but it can still be activated by:
|
||||
lxd.socket
|
||||
LXD has been successfully configured.
|
||||
|
||||
root@c1:~# lxc launch ubuntu:14.04 trusty
|
||||
Generating a client certificate. This may take a minute...
|
||||
If this is your first time using LXD, you should also run: sudo lxd init
|
||||
|
||||
Creating trusty
|
||||
Retrieving image: 100%
|
||||
Starting trusty
|
||||
|
||||
root@c1:~# lxc list
|
||||
+--------+---------+-----------------------+----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+--------+---------+-----------------------+----------------------------------------------+------------+-----------+
|
||||
| trusty | RUNNING | 10.153.141.124 (eth0) | fd7:f15d:d1d6:da14:216:3eff:fef1:4002 (eth0) | PERSISTENT | 0 |
|
||||
+--------+---------+-----------------------+----------------------------------------------+------------+-----------+
|
||||
root@c1:~#
|
||||
```
|
||||
|
||||
It really is that simple!
|
||||
|
||||
### The online demo server
|
||||
|
||||
As this post is pretty short, I figured I would spend a bit of time to talk about the [demo server][2] we’re running. We also just reached the 10000 sessions mark earlier today!
|
||||
|
||||
That server is basically just a normal LXD running inside a pretty beefy virtual machine with a tiny daemon implementing the REST API used by our website.
|
||||
|
||||
When you accept the terms of service, a new LXD container is created for you with security.nesting enabled as we saw above. You are then attached to that container as you would when using “lxc exec” except that we’re doing it using websockets and javascript.
|
||||
|
||||
The containers you then create inside this environment are all nested LXD containers.
|
||||
You can then nest even further in there if you want to.
|
||||
|
||||
We are using the whole range of [LXD resource limitations][3] to prevent one user’s actions from impacting the others and pretty closely monitor the server for any sign of abuse.
|
||||
|
||||
If you want to run your own similar server, you can grab the code for our website and the daemon with:
|
||||
|
||||
```
|
||||
git clone https://github.com/lxc/linuxcontainers.org
|
||||
git clone https://github.com/lxc/lxd-demo-server
|
||||
```
|
||||
|
||||
### Extra information
|
||||
|
||||
The main LXD website is at: <https://linuxcontainers.org/lxd>
|
||||
Development happens on Github at: <https://github.com/lxc/lxd>
|
||||
Mailing-list support happens on: <https://lists.linuxcontainers.org>
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/04/14/lxd-2-0-lxd-in-lxd-812/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://www.stgraber.org/2016/04/13/lxd-2-0-docker-in-lxd-712/
|
||||
[2]: https://linuxcontainers.org/lxd/try-it/
|
||||
[3]: https://www.stgraber.org/2016/03/26/lxd-2-0-resource-control-412/
|
||||
|
||||
@ -1,6 +1,328 @@
|
||||
Part 9 - LXD 2.0: Live migration
|
||||
=================================
|
||||
|
||||
<正文待补充>
|
||||
This is the ninth blog post [in this series about LXD 2.0][0].
|
||||
|
||||
原文:https://www.stgraber.org/2016/04/25/lxd-2-0-live-migration-912/
|
||||

|
||||
|
||||
### Introduction
|
||||
|
||||
One of the very exciting feature of LXD 2.0, albeit experimental, is the support for container checkpoint and restore.
|
||||
|
||||
Simply put, checkpoint/restore means that the running container state can be serialized down to disk and then restored, either on the same host as a stateful snapshot of the container or on another host which equates to live migration.
|
||||
|
||||
### Requirements
|
||||
|
||||
To have access to container live migration and stateful snapshots, you need the following:
|
||||
|
||||
- A very recent Linux kernel, 4.4 or higher.
|
||||
- CRIU 2.0, possibly with some cherry-picked commits depending on your exact kernel configuration.
|
||||
- Run LXD directly on the host. It’s not possible to use those features with container nesting.
|
||||
- For migration, the target machine must at least implement the instruction set of the source, the target kernel must at least offer the same syscalls as the source and any kernel filesystem which was mounted on the source must also be mountable on the target.
|
||||
|
||||
All the needed dependencies are provided by Ubuntu 16.04 LTS, in which case, all you need to do is install CRIU itself:
|
||||
|
||||
```
|
||||
apt install criu
|
||||
```
|
||||
|
||||
### Using the thing
|
||||
|
||||
#### Stateful snapshots
|
||||
|
||||
A normal container snapshot looks like:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc snapshot c1 first
|
||||
stgraber@dakara:~$ lxc info c1 | grep first
|
||||
first (taken at 2016/04/25 19:35 UTC) (stateless)
|
||||
```
|
||||
|
||||
A stateful snapshot instead looks like:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc snapshot c1 second --stateful
|
||||
stgraber@dakara:~$ lxc info c1 | grep second
|
||||
second (taken at 2016/04/25 19:36 UTC) (stateful)
|
||||
```
|
||||
|
||||
This means that all the container runtime state was serialized to disk and included as part of the snapshot. Restoring one such snapshot is done as you would a stateless one:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc restore c1 second
|
||||
stgraber@dakara:~$
|
||||
```
|
||||
|
||||
#### Stateful stop/start
|
||||
|
||||
Say you want to reboot your server for a kernel update or similar maintenance. Rather than have to wait for all the containers to start from scratch after reboot, you can do:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc stop c1 --stateful
|
||||
```
|
||||
|
||||
The container state will be written to disk and then picked up the next time you start it.
|
||||
|
||||
You can even look at what the state looks like:
|
||||
|
||||
```
|
||||
root@dakara:~# tree /var/lib/lxd/containers/c1/rootfs/state/
|
||||
/var/lib/lxd/containers/c1/rootfs/state/
|
||||
├── cgroup.img
|
||||
├── core-101.img
|
||||
├── core-102.img
|
||||
├── core-107.img
|
||||
├── core-108.img
|
||||
├── core-109.img
|
||||
├── core-113.img
|
||||
├── core-114.img
|
||||
├── core-122.img
|
||||
├── core-125.img
|
||||
├── core-126.img
|
||||
├── core-127.img
|
||||
├── core-183.img
|
||||
├── core-1.img
|
||||
├── core-245.img
|
||||
├── core-246.img
|
||||
├── core-50.img
|
||||
├── core-52.img
|
||||
├── core-95.img
|
||||
├── core-96.img
|
||||
├── core-97.img
|
||||
├── core-98.img
|
||||
├── dump.log
|
||||
├── eventfd.img
|
||||
├── eventpoll.img
|
||||
├── fdinfo-10.img
|
||||
├── fdinfo-11.img
|
||||
├── fdinfo-12.img
|
||||
├── fdinfo-13.img
|
||||
├── fdinfo-14.img
|
||||
├── fdinfo-2.img
|
||||
├── fdinfo-3.img
|
||||
├── fdinfo-4.img
|
||||
├── fdinfo-5.img
|
||||
├── fdinfo-6.img
|
||||
├── fdinfo-7.img
|
||||
├── fdinfo-8.img
|
||||
├── fdinfo-9.img
|
||||
├── fifo-data.img
|
||||
├── fifo.img
|
||||
├── filelocks.img
|
||||
├── fs-101.img
|
||||
├── fs-113.img
|
||||
├── fs-122.img
|
||||
├── fs-183.img
|
||||
├── fs-1.img
|
||||
├── fs-245.img
|
||||
├── fs-246.img
|
||||
├── fs-50.img
|
||||
├── fs-52.img
|
||||
├── fs-95.img
|
||||
├── fs-96.img
|
||||
├── fs-97.img
|
||||
├── fs-98.img
|
||||
├── ids-101.img
|
||||
├── ids-113.img
|
||||
├── ids-122.img
|
||||
├── ids-183.img
|
||||
├── ids-1.img
|
||||
├── ids-245.img
|
||||
├── ids-246.img
|
||||
├── ids-50.img
|
||||
├── ids-52.img
|
||||
├── ids-95.img
|
||||
├── ids-96.img
|
||||
├── ids-97.img
|
||||
├── ids-98.img
|
||||
├── ifaddr-9.img
|
||||
├── inetsk.img
|
||||
├── inotify.img
|
||||
├── inventory.img
|
||||
├── ip6tables-9.img
|
||||
├── ipcns-var-10.img
|
||||
├── iptables-9.img
|
||||
├── mm-101.img
|
||||
├── mm-113.img
|
||||
├── mm-122.img
|
||||
├── mm-183.img
|
||||
├── mm-1.img
|
||||
├── mm-245.img
|
||||
├── mm-246.img
|
||||
├── mm-50.img
|
||||
├── mm-52.img
|
||||
├── mm-95.img
|
||||
├── mm-96.img
|
||||
├── mm-97.img
|
||||
├── mm-98.img
|
||||
├── mountpoints-12.img
|
||||
├── netdev-9.img
|
||||
├── netlinksk.img
|
||||
├── netns-9.img
|
||||
├── netns-ct-9.img
|
||||
├── netns-exp-9.img
|
||||
├── packetsk.img
|
||||
├── pagemap-101.img
|
||||
├── pagemap-113.img
|
||||
├── pagemap-122.img
|
||||
├── pagemap-183.img
|
||||
├── pagemap-1.img
|
||||
├── pagemap-245.img
|
||||
├── pagemap-246.img
|
||||
├── pagemap-50.img
|
||||
├── pagemap-52.img
|
||||
├── pagemap-95.img
|
||||
├── pagemap-96.img
|
||||
├── pagemap-97.img
|
||||
├── pagemap-98.img
|
||||
├── pages-10.img
|
||||
├── pages-11.img
|
||||
├── pages-12.img
|
||||
├── pages-13.img
|
||||
├── pages-1.img
|
||||
├── pages-2.img
|
||||
├── pages-3.img
|
||||
├── pages-4.img
|
||||
├── pages-5.img
|
||||
├── pages-6.img
|
||||
├── pages-7.img
|
||||
├── pages-8.img
|
||||
├── pages-9.img
|
||||
├── pipes-data.img
|
||||
├── pipes.img
|
||||
├── pstree.img
|
||||
├── reg-files.img
|
||||
├── remap-fpath.img
|
||||
├── route6-9.img
|
||||
├── route-9.img
|
||||
├── rule-9.img
|
||||
├── seccomp.img
|
||||
├── sigacts-101.img
|
||||
├── sigacts-113.img
|
||||
├── sigacts-122.img
|
||||
├── sigacts-183.img
|
||||
├── sigacts-1.img
|
||||
├── sigacts-245.img
|
||||
├── sigacts-246.img
|
||||
├── sigacts-50.img
|
||||
├── sigacts-52.img
|
||||
├── sigacts-95.img
|
||||
├── sigacts-96.img
|
||||
├── sigacts-97.img
|
||||
├── sigacts-98.img
|
||||
├── signalfd.img
|
||||
├── stats-dump
|
||||
├── timerfd.img
|
||||
├── tmpfs-dev-104.tar.gz.img
|
||||
├── tmpfs-dev-109.tar.gz.img
|
||||
├── tmpfs-dev-110.tar.gz.img
|
||||
├── tmpfs-dev-112.tar.gz.img
|
||||
├── tmpfs-dev-114.tar.gz.img
|
||||
├── tty.info
|
||||
├── unixsk.img
|
||||
├── userns-13.img
|
||||
└── utsns-11.img
|
||||
|
||||
0 directories, 154 files
|
||||
```
|
||||
|
||||
Restoring the container can be done with a simple:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc start c1
|
||||
```
|
||||
|
||||
### Live migration
|
||||
|
||||
Live migration is basically the same as the stateful stop/start above, except that the container directory and configuration happens to be moved to another machine too.
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list c1
|
||||
+------+---------+-----------------------+----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+------+---------+-----------------------+----------------------------------------------+------------+-----------+
|
||||
| c1 | RUNNING | 10.178.150.197 (eth0) | 2001:470:b368:4242:216:3eff:fe19:27b0 (eth0) | PERSISTENT | 2 |
|
||||
+------+---------+-----------------------+----------------------------------------------+------------+-----------+
|
||||
|
||||
stgraber@dakara:~$ lxc list s-tollana:
|
||||
+------+-------+------+------+------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+------+-------+------+------+------+-----------+
|
||||
|
||||
stgraber@dakara:~$ lxc move c1 s-tollana:
|
||||
|
||||
stgraber@dakara:~$ lxc list c1
|
||||
+------+-------+------+------+------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+------+-------+------+------+------+-----------+
|
||||
|
||||
stgraber@dakara:~$ lxc list s-tollana:
|
||||
+------+---------+-----------------------+----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+------+---------+-----------------------+----------------------------------------------+------------+-----------+
|
||||
| c1 | RUNNING | 10.178.150.197 (eth0) | 2001:470:b368:4242:216:3eff:fe19:27b0 (eth0) | PERSISTENT | 2 |
|
||||
+------+---------+-----------------------+----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
### Limitations
|
||||
|
||||
As I said before, checkpoint/restore of containers is still pretty new and we’re still very much working on this feature, fixing issues as we are made aware of them. We do need more people trying this feature and sending us feedback, I would however not recommend using this in production just yet.
|
||||
|
||||
The current list of issues we’re tracking is [available on Launchpad][1].
|
||||
|
||||
We expect a basic Ubuntu container with a few services to work properly with CRIU in Ubuntu 16.04. However more complex containers, using device passthrough, complex network services or special storage configurations are likely to fail.
|
||||
|
||||
Whenever possible, CRIU will fail at dump time, rather than at restore time. In such cases, the source container will keep running, the snapshot or migration will simply fail and a log file will be generated for debugging.
|
||||
|
||||
In rare cases, CRIU fails to restore the container, in which case the source container will still be around but will be stopped and will have to be manually restarted.
|
||||
|
||||
### Sending bug reports
|
||||
|
||||
We’re tracking bugs related to checkpoint/restore against the CRIU Ubuntu package on Launchpad. Most of the work to fix those bugs will then happen upstream either on CRIU itself or the Linux kernel, but it’s easier for us to track things this way.
|
||||
|
||||
To file a new bug report, head here.
|
||||
|
||||
Please make sure to include:
|
||||
|
||||
The command you ran and the error message as displayed to you
|
||||
|
||||
- Output of “lxc info” (*)
|
||||
- Output of “lxc info <container name>”
|
||||
- Output of “lxc config show –expanded <container name>”
|
||||
- Output of “dmesg” (*)
|
||||
- Output of “/proc/self/mountinfo” (*)
|
||||
- Output of “lxc exec <container name> — cat /proc/self/mountinfo”
|
||||
- Output of “uname -a” (*)
|
||||
- The content of /var/log/lxd.log (*)
|
||||
- The content of /etc/default/lxd-bridge (*)
|
||||
- A tarball of /var/log/lxd/<container name>/ (*)
|
||||
|
||||
If reporting a migration bug as opposed to a stateful snapshot or stateful stop bug, please include the data for both the source and target for any of the above which has been marked with a (*).
|
||||
|
||||
### Extra information
|
||||
|
||||
The CRIU website can be found at: <https://criu.org>
|
||||
|
||||
The main LXD website is at: <https://linuxcontainers.org/lxd>
|
||||
|
||||
Development happens on Github at: <https://github.com/lxc/lxd>
|
||||
|
||||
Mailing-list support happens on: <https://lists.linuxcontainers.org>
|
||||
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/03/19/lxd-2-0-your-first-lxd-container-312/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://bugs.launchpad.net/ubuntu/+source/criu/+bugs
|
||||
[3]: https://launchpad.net/ubuntu/+source/criu/+filebug?no-redirect
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
Linux内核数据结构
|
||||
Linux内核中的数据结构 —— 基数树
|
||||
================================================================================
|
||||
|
||||
基数树 Radix tree
|
||||
--------------------------------------------------------------------------------
|
||||
正如你所知道的,Linux内核提供了许多不同的库和函数,它们实现了不同的数据结构和算法。在这部分,我们将研究其中一种数据结构——[基数树 Radix tree](http://en.wikipedia.org/wiki/Radix_tree)。在Linux内核中,有两个与基数树实现和API相关的文件:
|
||||
正如你所知道的,Linux内核提供了许多不同的库和函数,它们实现了不同的数据结构和算法。在这部分,我们将研究其中一种数据结构——[基数树 Radix tree](http://en.wikipedia.org/wiki/Radix_tree)。在 Linux 内核中,有两个文件与基数树的实现和API相关:
|
||||
|
||||
* [include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)
|
||||
* [lib/radix-tree.c](https://github.com/torvalds/linux/blob/master/lib/radix-tree.c)
|
||||
|
||||
让我们讨论什么是`基数树`吧。基数树是一种`压缩的字典树`,而[字典树](http://en.wikipedia.org/wiki/Trie)是实现了关联数组接口并允许以`键值对`方式存储值的一种数据结构。该键通常是字符串,但能够使用任何数据类型。字典树因为它的节点而与`n叉树`不同。字典树的节点不存储键;相反,字典树的一个节点存储单个字符的标签。与一个给定节点关联的键可以通过从根遍历到该节点获得。举个例子:
|
||||
让我们先说说什么是 `基数树` 吧。基数树是一种 `压缩的字典树 (compressed trie)` ,而[字典树](http://en.wikipedia.org/wiki/Trie)是实现了关联数组接口并允许以 `键值对` 方式存储值的一种数据结构。这里的键通常是字符串,但可以使用任意数据类型。字典树因为它的节点而与 `n叉树` 不同。字典树的节点不存储键,而是存储单个字符的标签。与一个给定节点关联的键可以通过从根遍历到该节点获得。举个例子:
|
||||
|
||||
```
|
||||
+-----------+
|
||||
@ -39,9 +39,9 @@ Linux内核数据结构
|
||||
+-----------+
|
||||
```
|
||||
|
||||
因此在这个例子中,我们可以看到一个有着两个键`go`和`cat`的`字典树`。压缩的字典树或者`基数树`和`字典树`不同于所有只有一个孩子的中间节点都被删除。
|
||||
因此在这个例子中,我们可以看到一个有着两个键 `go` 和 `cat` 的 `字典树` 。压缩的字典树或者说 `基数树` ,它和 `字典树` 的不同之处在于,所有只有一个孩子的中间节点都被删除。
|
||||
|
||||
Linu内核中的基数树是映射值到整形键的一种数据结构。[include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)文件中的以下结构体表示了基数树:
|
||||
Linux 内核中的基数树是把值映射到整形键的一种数据结构。[include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)文件中的以下结构体描述了基数树:
|
||||
|
||||
```C
|
||||
struct radix_tree_root {
|
||||
@ -51,15 +51,15 @@ struct radix_tree_root {
|
||||
};
|
||||
```
|
||||
|
||||
这个结构体表示了一个基数树的根,并包含了3个域成员:
|
||||
这个结构体描述了一个基数树的根,它包含了3个域成员:
|
||||
|
||||
* `height` - 树的高度;
|
||||
* `gfp_mask` - 告诉如何执行动态内存分配;
|
||||
* `gfp_mask` - 告知如何执行动态内存分配;
|
||||
* `rnode` - 孩子节点指针.
|
||||
|
||||
我们第一个要讨论的域是`gfp_mask`:
|
||||
我们第一个要讨论的字段是 `gfp_mask` :
|
||||
|
||||
底层内核内存动态分配函数以一组标志作为` gfp_mask `,用于描述如何执行动态内存分配。这些控制分配进程的`GFP_`标志拥有以下值:(`GF_NOIO`标志)意味着睡眠等待内存,(`__GFP_HIGHMEM`标志)意味着高端内存能够被使用,(`GFP_ATOMIC`标志)意味着分配进程拥有高优先级并不能睡眠等等。
|
||||
底层内核的内存动态分配函数以一组标志作为 `gfp_mask` ,用于描述如何执行动态内存分配。这些控制分配进程的 `GFP_` 标志拥有以下值:( `GF_NOIO` 标志)意味着睡眠以及等待内存,( `__GFP_HIGHMEM` 标志)意味着高端内存能够被使用,( `GFP_ATOMIC` 标志)意味着分配进程拥有高优先级并不能睡眠等等。
|
||||
|
||||
* `GFP_NOIO` - 睡眠等待内存
|
||||
* `__GFP_HIGHMEM` - 高端内存能够被使用;
|
||||
@ -67,7 +67,7 @@ struct radix_tree_root {
|
||||
|
||||
等等。
|
||||
|
||||
下一个域是`rnode`:
|
||||
下一个字段是`rnode`:
|
||||
|
||||
```C
|
||||
struct radix_tree_node {
|
||||
@ -86,7 +86,7 @@ struct radix_tree_node {
|
||||
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
|
||||
};
|
||||
```
|
||||
这个结构体包含的信息有父节点中的偏移以及到底端(叶节点)的高度、孩子节点的个数以及用于访问和释放节点的域成员。这些域成员描述如下:
|
||||
这个结构体包含的信息有父节点中的偏移以及到底端(叶节点)的高度、孩子节点的个数以及用于访问和释放节点的字段成员。这些字段成员描述如下:
|
||||
|
||||
* `path` - 父节点中的偏移和到底端(叶节点)的高度
|
||||
* `count` - 孩子节点的个数;
|
||||
@ -95,20 +95,20 @@ struct radix_tree_node {
|
||||
* `rcu_head` - 用于释放节点;
|
||||
* `private_list` - 由树的用户使用;
|
||||
|
||||
`radix_tree_node`的最后两个成员——`tags`和`slots`非常重要且令人关注。Linux内核基数树的每个节点都包含一组存储指向数据指针的slots。Linux内核基数树实现的空slots存储`NULL`值。Linux内核中的基数树也支持与`radix_tree_node`结构体的`tags`域相关联的标签。标签允许在基数树存储的记录中设置各个位。
|
||||
`radix_tree_node` 的最后两个成员—— `tags` 和 `slots` 非常重要且令人关注。Linux 内核基数树的每个节点都包含了一组指针槽( slots ),槽里存储着指向数据的指针。在Linux内核基数树的实现中,空槽存储的是 `NULL` 。Linux内核中的基数树也支持标签( tags ),它与 `radix_tree_node` 结构体的 `tags` 字段相关联。有了标签,我们就可以对基数树中存储的记录以单个比特位( bit )进行设置。
|
||||
|
||||
既然我们了解了基数树的结构,那么该是时候看一下它的API了。
|
||||
|
||||
Linux内核基数树API
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
我们从结构体的初始化开始。有两种方法初始化一个新的基数树。第一种是使用`RADIX_TREE`宏:
|
||||
我们从结构体的初始化开始。有两种方法初始化一个新的基数树。第一种是使用 `RADIX_TREE` 宏:
|
||||
|
||||
```C
|
||||
RADIX_TREE(name, gfp_mask);
|
||||
````
|
||||
|
||||
正如你所看到的,我们传递`name`参数,所以使用`RADIX_TREE`宏,我们能够定义和初始化基数树为给定的名字。`RADIX_TREE`的实现是简单的:
|
||||
正如你所看到的,我们传递了 `name` 参数,所以通过 `RADIX_TREE` 宏,我们能够定义和初始化基数树为给定的名字。`RADIX_TREE` 的实现很简单:
|
||||
|
||||
```C
|
||||
#define RADIX_TREE(name, mask) \
|
||||
@ -121,16 +121,16 @@ RADIX_TREE(name, gfp_mask);
|
||||
}
|
||||
```
|
||||
|
||||
在`RADIX_TREE`宏的开始,我们使用给定的名字定义`radix_tree_root`结构体实例,并使用给定的mask调用`RADIX_TREE_INIT`宏。`RADIX_TREE_INIT`宏只是初始化`radix_tree_root`结构体为默认值和给定的mask而已。
|
||||
在 `RADIX_TREE` 宏的开始,我们使用给定的名字定义 `radix_tree_root` 结构体实例,并使用给定的 mask 调用 `RADIX_TREE_INIT` 宏。 而 `RADIX_TREE_INIT` 宏则是使用默认值和给定的mask对 `radix_tree_root` 结构体进行了初始化。
|
||||
|
||||
第二种方法是亲手定义`radix_tree_root`结构体,并且将它和mask传给`INIT_RADIX_TREE`宏:
|
||||
第二种方法是手动定义`radix_tree_root`结构体,并且将它和mask传给 `INIT_RADIX_TREE` 宏:
|
||||
|
||||
```C
|
||||
struct radix_tree_root my_radix_tree;
|
||||
INIT_RADIX_TREE(my_tree, gfp_mask_for_my_radix_tree);
|
||||
```
|
||||
|
||||
where:
|
||||
`INIT_RADIX_TREE` 宏的定义如下:
|
||||
|
||||
```C
|
||||
#define INIT_RADIX_TREE(root, mask) \
|
||||
@ -141,20 +141,20 @@ do { \
|
||||
} while (0)
|
||||
```
|
||||
|
||||
和`RADIX_TREE_INIT`宏所做的初始化一样,初始化为默认值。
|
||||
和`RADIX_TREE_INIT`宏所做的初始化工作一样,`INIT_RADIX_TREE` 宏使用默认值和给定的 mask 完成初始化工作。
|
||||
|
||||
接下来是用于从基数树插入和删除数据的两个函数:
|
||||
接下来是用于向基数树插入和删除数据的两个函数:
|
||||
|
||||
* `radix_tree_insert`;
|
||||
* `radix_tree_delete`;
|
||||
|
||||
第一个函数`radix_tree_insert`需要3个参数:
|
||||
第一个函数 `radix_tree_insert` 需要3个参数:
|
||||
|
||||
* 基数树的根;
|
||||
* 索引键;
|
||||
* 插入的数据;
|
||||
|
||||
`radix_tree_delete`函数需要和`radix_tree_insert`一样的一组参数,但是没有data。
|
||||
`radix_tree_delete` 函数需要和 `radix_tree_insert` 一样的一组参数,但是不需要传入要删除的数据。
|
||||
|
||||
基数树的搜索以两种方法实现:
|
||||
|
||||
@ -167,7 +167,7 @@ do { \
|
||||
* 基数树的根;
|
||||
* 索引键;
|
||||
|
||||
这个函数尝试在树中查找给定的键,并返回和该键相关联的记录。第二个函数`radix_tree_gang_lookup`有以下的函数签名:
|
||||
这个函数尝试在树中查找给定的键,并返回和该键相关联的记录。第二个函数 `radix_tree_gang_lookup` 有以下的函数签名:
|
||||
|
||||
```C
|
||||
unsigned int radix_tree_gang_lookup(struct radix_tree_root *root,
|
||||
@ -176,9 +176,9 @@ unsigned int radix_tree_gang_lookup(struct radix_tree_root *root,
|
||||
unsigned int max_items);
|
||||
```
|
||||
|
||||
和返回记录的个数,(results指向的数据)按键排序并从第一个索引开始。返回的记录个数将不会超过`max_items`。
|
||||
它返回的是记录的个数。 `results` 中的结果,按键排序,并从第一个索引开始。返回的记录个数将不会超过 `max_items` 的值。
|
||||
|
||||
最后一个函数`radix_tree_lookup_slot`将会返回包含数据的slot。
|
||||
最后一个函数`radix_tree_lookup_slot`将会返回包含数据的指针槽。
|
||||
|
||||
链接
|
||||
---------------------------------------------------------------------------------
|
||||
@ -192,7 +192,7 @@ via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/radix-tree
|
||||
|
||||
作者:[0xAX]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
排名前4的开源漏洞追踪工具
|
||||
开源问题跟踪管理工具Top4
|
||||
========================================
|
||||
|
||||
生活充满了漏洞。
|
||||
生活充满了bug。
|
||||
|
||||
无论怎样小心计划,无论花多少时间去设计,在执行阶段当轮胎压在路上,任何工程都会有未知的问题。也无妨。也许对于任何一个组织的最佳弹性衡量不是他们如何一切都按计划运行地处理事情,而是,当出现磕磕碰碰时他们处理速度。
|
||||
无论怎样小心计划,无论花多少时间去设计,在执行阶段当轮胎压在路上,任何工程都会有未知的问题。也无妨。也许对于任何一个组织的最佳弹性衡量不是他们如何一切都按计划运行地处理事情,而是,当出现磕磕碰碰时他们如何驾驭。
|
||||
|
||||
一个任意工程管理流程的关键工具,特别是在软件开发领域,是一个问题追踪系统。基础很简单;允许漏洞在合作的方式被打开,追踪,和解决,同时很容易跟随进展。除了基本功能,还有很多专注于满足特定需求的选择,和使用案例,包括软件开发和更多。你可能熟悉托管版本的这些工具,像 [GitHub Issues](https://guides.github.com/features/issues/)或者[Launchpad](https://launchpad.net/),这些是他们自己开放的资源。
|
||||
对任何一个项目管理流程来说,特别是在软件开发领域,都需要一个关键工具——问题跟踪管理系统。其基本功能很简单:可以对bug进行查看、追踪,并以协作的方式解决bug,有了它,我们更容易跟随整个过程的进展。除了基本功能,还有很多专注于满足特定需求的选项及功能,使用场景不仅限于软件开发。你可能已经熟悉某些托管版本的工具,像 [GitHub Issues](https://guides.github.com/features/issues/)或者[Launchpad](https://launchpad.net/),其中一些工具已经有了自己的开源社区。
|
||||
|
||||
让我们看一看四个管理漏洞和问题的优秀选择,全部开源代码、易于下载和自我托管。要清楚,我们可能没有办法在这里列出每一个问题跟踪工具;然而,这有四个我们偏爱的,基于功能丰富和项目背后的社区项目的规模。还有其他,可以肯定的是,如果你有一个好的理由你喜欢的没有列在这里,一定要让我们知道这是你最喜欢的工具,在下面的评论中使它脱颖而出。
|
||||
接下来,这四个bug问题跟踪管理软件的极佳备选,全部开源、易于下载,自己就可以部署。先说好,我们可能没有办法在这里列出每一个问题跟踪工具;相反,我们列出这四个,基于的是其丰富的功能和项目背后的社区规模。当然,肯定还有其他类似软件,如果你喜欢的没有列在这里,如果你有一个好的理由,一定要让我们知道,在下面的评论中使它脱颖而出吧。
|
||||
|
||||
## Redmine
|
||||
|
||||
[Redmine](http://www.redmine.org/) 是一个流行的漏洞追踪工具建立在Ruby on Rails和可以追溯到2006年。很多类似于Trac,另一方面我们最爱的是,Redmine可以管理多个项目然后整合了多种版本控制系统。除了基本问题追踪,Redmine也提供论坛,wiki,时间跟踪工具,和生成甘特图和日历的能力来跟踪项目的进展。
|
||||
[Redmine](http://www.redmine.org/) 是一个很流行的追踪管理工具,基于Ruby on Rails构建,可以追溯到2006年。很多方面类似于Trac(另一个我们的最爱),Redmine可以管理多个项目,整合了多种版本控制系统。除了基本问题追踪,Redmine也提供论坛,wiki,时间跟踪工具,同时,它还具有生成甘特图表(Gantt charts)和日历的能力,用来跟踪项目的进展。
|
||||
|
||||
Redmine的设置相当灵活,支持多种数据库后端和几十种语言,还是可定制的,可以添加自定义字段到问题,用户,工程和更多。通过社区创建的插件和主题它可以进一步定制。
|
||||
Redmine的设置相当灵活,支持多种数据库后端和几十种语言,还是可定制的,可以向问题(issue)、用户、工程等添加自定义字段。通过社区创建的插件和主题它可以进一步定制。
|
||||
|
||||
如果你想试一试,一个[在线演示](http://demo.redmine.org/)可提供使用。Redmine在开源[GPL版本2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html)下许可;开源代码可以在工程的[svn仓库](https://svn.redmine.org/redmine)或在[GitHub](https://github.com/redmine/redmine)镜像上找到。
|
||||
|
||||
@ -21,19 +21,19 @@ Redmine的设置相当灵活,支持多种数据库后端和几十种语言,
|
||||
|
||||
## Bugzilla
|
||||
|
||||
[Bugzilla](https://www.bugzilla.org/)是另一个流行的有漏洞追踪功能的开发工具。从名字您可能已经猜到了,Bugzilla最初是[Mozilla基金会](https://www.mozilla.org/en-US/)创建,用来跟踪当时称为网景通信套件开发漏洞的。为了更好的通过性从原来的Tcl移植到Perl路径,Bugzilla是一个比较老的和更广泛采用的问题跟踪系统,因为它用在许多著名的开源项目如GNOME,KDE,Linux内核本身。
|
||||
[Bugzilla](https://www.bugzilla.org/)是另一个流行的具备问题跟踪能力的开发工具。从名字您可能已经猜到了,Bugzilla最初是[Mozilla基金会](https://www.mozilla.org/en-US/)创建的,用来跟踪当时称为网景通信套件中的bug。为了更好的可读性,它从原来的Tcl移植到Perl,Bugzilla是一个比较老,但却广泛采用的问题跟踪系统,它被用在许多著名的开源项目如GNOME、KDE,以及Linux内核本身。
|
||||
|
||||
拥有一些先进的工具,从通知到共享搜索重复的漏洞检测,Bugzilla是一个功能更丰富的选项。Bugzilla有高级搜索系统与全面的报表工具,生成图表和自动化计划报告的能力。像Redmine,Bugzilla是可扩展和可定制的,两者在字段本身像能创建自定义漏洞工作流一样。它也支持多种后端数据库,和自带的多语言支持。
|
||||
从通知到重复bug检测再到搜索共享,Bugzilla拥有许多高级工具,是一个功能更丰富的选项。Bugzilla拥有一套高级搜索系统以及全面的报表工具,具有生成图表和自动化按计划生成报告的能力。像Redmine一样,Bugzilla是可扩展和可定制的,除了字段本身,还能针对bug创建自定义工作流。它也支持多种后端数据库,和自带的多语言支持。
|
||||
|
||||
Bugzilla在[Mozilla公共许可证](https://en.wikipedia.org/wiki/Mozilla_Public_License)下许可,你可以读取他们[未来路线图](https://www.bugzilla.org/status/roadmap.html)还有在官网尝试一个[示例服务](https://landfill.bugzilla.org/)
|
||||
Bugzilla在[Mozilla公共许可证](https://en.wikipedia.org/wiki/Mozilla_Public_License)下许可,你可以读取他们的[未来路线图](https://www.bugzilla.org/status/roadmap.html)还有在官网尝试一个[示例服务](https://landfill.bugzilla.org/)
|
||||
|
||||
|
||||
|
||||
## Trac
|
||||
|
||||
[Trac](http://trac.edgewall.org/browser)自称是使用简单的方法基于web的软件工程管理软件,但不要混淆极简主义与缺乏功能。
|
||||
[Trac](http://trac.edgewall.org/browser)自称是基于web的极简主义软件工程管理软件,这里请不要混淆极简主义与缺乏功能。
|
||||
|
||||
python编写,Trac紧密结合它的漏洞跟踪与它的wiki系统和你选择的版本控制系统。项目管理能力突出,如生成的里程碑和路线图,一个可定制的报表系统,大事记,支持多资源库,内置的垃圾邮件过滤,还可以使用很多一般的语言。如其他漏洞追踪软件我们已经看到,有很多插件可进一步扩展其基本特性。
|
||||
由python编写的Trac,将其漏洞跟踪能力与它的wiki系统和版本控制系统轻度整合。项目管理能力突出,如生成里程碑和路线图,一个可定制的报表系统,大事记,支持多资源库,内置的垃圾邮件过滤,还可以使用很多通用语言。如其他我们已经看到的漏洞追踪软件,有很多插件可进一步扩展其基本特性。
|
||||
|
||||
Trac是在改进的[BSD许可](http://trac.edgewall.org/wiki/TracLicense)下获得开放源码许可,虽然更老的版本发布在GPL下。你可以在一个[自托管仓库](http://trac.edgewall.org/browser)预览Trac的源码或者查看他们的[路线图](http://trac.edgewall.org/wiki/TracRoadmap)对未来的规划。
|
||||
|
||||
@ -41,13 +41,13 @@ Trac是在改进的[BSD许可](http://trac.edgewall.org/wiki/TracLicense)下获
|
||||
|
||||
## Mantis
|
||||
|
||||
[Mantis](https://www.mantisbt.org/)是这次收集中我们将看的最后一个工具,一个基于PHP且有16年历史的漏洞跟踪工具。另外漏洞跟踪支持多种不同的版本控制系统和一个事件驱动的通知系统,Mantis有一个与其他工具类似的功能设置。虽然它不本身包含一个wiki,它整合很多流行的wiki平台且本地化到多种语言。
|
||||
[Mantis](https://www.mantisbt.org/)是这次合集中我们将看到的最后一个工具,基于PHP,且有16年历史。作为另一个支持多种不同版本控制系统和事件驱动通知系统的bug跟踪管理软件,Mantis有一个与其他工具类似的功能设置。虽然它不本身包含wiki,但它整合了很多流行的wiki平台且本地化到多种语言。
|
||||
|
||||
Mantis在[GPL版本2](http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html)下获得开源许可证书;你可以在[GitHub](https://github.com/mantisbt/mantisbt)浏览他的源代码或查看自托管[路线图](https://www.mantisbt.org/bugs/roadmap_page.php?project=mantisbt&version=1.3.x)对未来的规划。一个示例,你可以查看他们的内部[漏洞跟踪](https://www.mantisbt.org/bugs/my_view_page.php)。
|
||||
|
||||
|
||||
|
||||
正如我们指出的,这四个不是唯一的选项。想要探索更多?[Apache Bloodhound](https://issues.apache.org/bloodhound/),[Fossil](http://fossil-scm.org/index.html/doc/trunk/www/index.wiki),[The Bug Genie](http://www.thebuggenie.com/),还有很多可替换品都有专注的追随者,每个都有不同的优点和缺点。另外,一些工具在我们[项目管理](https://opensource.com/business/15/1/top-project-management-tools-2015)摘要有问题跟踪功能。所以,哪个是你首选的跟踪和挤压漏洞的工具?
|
||||
正如我们指出的,这四个不是唯一的选项。想要探索更多?[Apache Bloodhound](https://issues.apache.org/bloodhound/),[Fossil](http://fossil-scm.org/index.html/doc/trunk/www/index.wiki),[The Bug Genie](http://www.thebuggenie.com/),还有很多可替换品都有专注的追随者,每个都有不同的优点和缺点。另外,一些工具在我们[项目管理](https://opensource.com/business/15/1/top-project-management-tools-2015)摘要有问题跟踪功能。所以,哪个是你首选的跟踪和碾压bug的工具?
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
@ -56,7 +56,7 @@ via: https://opensource.com/business/16/2/top-issue-support-and-bug-tracking-too
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -4,27 +4,27 @@
|
||||
|
||||

|
||||
|
||||
这个已逝的夏天,我是位于格伦的 [NASA](http://www.nasa.gov/centers/glenn/home/index.html) [GVIS](https://ocio.grc.nasa.gov/gvis/) 实验室的研究生,我将我对开源的热情带到了那里。我的任务是提高我们实验室对 Dan Schroeder 开发的一个开源流体动力学模拟器的贡献。原本的模拟器为用户呈现出可以用鼠标绘制的障碍,用来计算流体动力学模型。我们团队的贡献是加入图像处理的代码,这些代码分析实况视频的每一帧以显示一个物体如何与液体相互作用。而且,我们还要做更多事情。
|
||||
在刚结束的这个夏天里,我是 [NASA 格伦中心][1] [GVIS][2] 实验室的实习生,我将我对开源的热情带到了那里。我的任务是改进我们实验室对 Dan Schroeder 开发的一个开源流体动力学模拟器的贡献。原本的模拟器可以显示用户用鼠标绘制的障碍物,并建立计算流体动力学模型。我们团队的贡献是加入图像处理的代码,分析实况视频的每一帧以显示特定的物体如何与液体相互作用。而且,我们还要做更多事情。
|
||||
|
||||
我们想要让图像处理部分更加健全,所以我致力于改善图像处理库。
|
||||
我们想要让图像处理部分更加健壮,所以我致力于改善图像处理库。
|
||||
|
||||
基于新的库,模拟器可以检测轮廓、进行空间坐标变换以及找到物体的质心。图像处理并不直接与流体动力学模拟器物理相关。它用摄像头检测物体,并且获取物体轮廓,为流体模拟器创建一个障碍物。然后,流体模拟器启动,输出结果会被投射到真实物体上。
|
||||
得益于新的库,模拟器可以检测轮廓、进行空间坐标变换以及找到物体的质心。图像处理并不直接与流体动力学模拟器物理相关。它用摄像头检测物体,并且获取物体轮廓,为流体模拟器创建一个障碍物。随后,流体模拟器开始运行,而输出结果会被投射到真实物体上。
|
||||
|
||||
我的目标是通过以下三种方式改进模拟器:
|
||||
我的目标是通过以下三个方面改进模拟器:
|
||||
|
||||
1. 找寻物体的轮廓
|
||||
2. 找寻物体的质心
|
||||
3. 能对物体中心进行相关的精确转换
|
||||
|
||||
我的导师建议我安装 [Node.js](http://nodejs.org/), [OpenCV](http://opencv.org/), 和 [Node.js bindings for OpenCV](https://github.com/peterbraden/node-opencv).。在等待软件安装的过程中,我查看了 OpenCV 的 [GitHub 主页](https://github.com/peterbraden/node-opencv) 上的示例源码。我发现示例源码使用 JavaScript 写的,而我还不懂 JavaScript ,所以我在 Codecademy 上学了一些课程。两天后,我对 JavaScript 依旧生疏,不过我还是开始了我的项目。。。它包含了更多的JavaScript。
|
||||
我的导师建议我安装 [Node.js](http://nodejs.org/) 、 [OpenCV](http://opencv.org/) 和 [Node.js bindings for OpenCV](https://github.com/peterbraden/node-opencv)。在等待软件安装的过程中,我查看了 OpenCV 的 [GitHub 主页][3]上的示例源码。我发现示例源码使用 JavaScript 写的,而我还不懂 JavaScript ,所以我在 Codecademy 上学了一些课程。两天后,我对 JavaScript 依旧生疏,不过我还是开始了我的项目…它包含了更多的 JavaScript 。
|
||||
|
||||
示例的轮廓检测代码工作得很好。事实上,它使得我用几个小时就完成了第一个目标!为了获取一幅图片的轮廓,它看起来像这样:
|
||||
检测轮廓的示例代码工作得很好。事实上,它使得我用几个小时就完成了第一个目标!获取一幅图片的轮廓,它看起来像这样:
|
||||
|
||||
|
||||
|
||||
> 包括所有轮廓的原始图,
|
||||
|
||||
示例的检测轮廓的代码工作得有点好过头了。不仅物体的轮廓被检测到了,整个图片中的轮廓都检测到了。这会导致模拟器要与那些没用的轮廓打交道。这是一个严重的问题,因为它会返回错误的数据。为了避免模拟器接触到不想要的轮廓,我加了一个区域约束。轮廓要位于一定的区域范围内才会被画出来。区域约束使得轮廓变干净了。
|
||||
检测轮廓的示例代码工作得有点好过头了。不仅物体的轮廓被检测到了,整个图片中的轮廓都检测到了。这会导致模拟器要与那些没用的轮廓打交道。这是一个严重的问题,因为它会返回错误的数据。为了避免模拟器接触到不想要的轮廓,我加了一个区域约束。轮廓要位于一定的区域范围内才会被画出来。区域约束使得轮廓变干净了。
|
||||
|
||||
|
||||
|
||||
@ -44,21 +44,25 @@
|
||||
|
||||
> 最后的干净轮廓。
|
||||
|
||||
这个时候,我可以获取干净的轮廓、计算质心了。可惜的是,我没有足够的时间去完成质心的相关变换。因为我的实习时间不多了,我开始考虑我在这段有限时间内能做的其它事情。其中一个就是边界矩形。边界矩形是包含了图片轮廓的最小四边形。边界矩形很重要,因为它是在页面上缩放轮廓的关键。虽然很遗憾我没时间利用边界矩形做更多事情,但是我仍然想去了解更多,因为这是个很有用的工具。
|
||||
这个时候,我可以获取干净的轮廓、计算质心了。可惜的是,我没有足够的时间去完成质心的相关变换。由于我的实习时间只剩下几天了,我开始考虑我在这段有限时间内能做的其它事情。其中一个就是边界矩形。边界矩形是包含了图片轮廓的最小四边形。边界矩形很重要,因为它是在页面上缩放轮廓的关键。虽然很遗憾我没时间利用边界矩形做更多事情,但是我仍然想学习它,因为它是个很有用的工具。
|
||||
|
||||
最后,经过以上的努力,我完成了对图像的处理!
|
||||
|
||||
|
||||
|
||||
> 最后图像,红色的边界矩形和质心。
|
||||
> 最终图像,红色的边界矩形和质心。
|
||||
|
||||
当这些图像处理代码写完之后,我用我的代码替代了模拟器中的老代码。非常意外的,它可以工作。
|
||||
当这些图像处理代码写完之后,我用我的代码替代了模拟器中的老代码。令我意外的是,它可以工作。
|
||||
|
||||
嗯,基本可以。
|
||||
|
||||
程序有内存泄露,每 1/10 秒泄露 100MB 。我很高兴原因不是我的代码。坏消息是修复它并不是我能控制的。好消息是有个解决方法我可以使用。它并不是最理想的,方法是不断检查模拟器使用的内存,当使用内存超过 1 GB,重新启动模拟器。
|
||||
<iframe width="520" height="315" src="https://www.youtube.com/embed/0ejnN2clcIE" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
在 NASA 实验室,我们使用很多的开源软件,没有这些开源软件的帮助,我不可能完成这些工作。
|
||||
( Youtube 演示视频)
|
||||
|
||||
程序有内存泄露,每 1/10 秒泄露 100MB 。我很高兴原因不是我的代码。坏消息是我并不能修复它。好消息是仍然有解决方法。它并非最理想的,但我可以使用。这个方法是不断检查模拟器使用的内存,当使用内存超过 1GB 时,重新启动模拟器。
|
||||
|
||||
在 NASA 实验室,我们会使用很多的开源软件,没有这些开源软件的帮助,我不可能完成这些工作。
|
||||
|
||||
* * *
|
||||
|
||||
@ -66,6 +70,10 @@ via: [https://opensource.com/life/16/3/image-processing-nasa](https://opensource
|
||||
|
||||
作者:[Lauren Egts](https://opensource.com/users/laurenegts)
|
||||
译者:[willowyoung](https://github.com/willowyoung)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: http://www.nasa.gov/centers/glenn/home/index.html
|
||||
[2]: https://ocio.grc.nasa.gov/gvis/
|
||||
[3]: https://github.com/peterbraden/node-opencv
|
||||
|
||||
@ -0,0 +1,37 @@
|
||||
Master OpenStack with 5 new tutorials
|
||||
5篇文章快速掌握OpenStack
|
||||
=======================================
|
||||
|
||||

|
||||
|
||||
回顾这周的 OpenStack 峰会,我仍然回味着开源云生态系统的浩瀚无垠,并且需要熟悉多少个不同的项目和概念才能获得成功。但是,我们是幸运的,因为有许多资源让我们跟随项目的脚步。除了[官方文档][1]外,我们还有许多来自三方组织的培训和认证、个人分享,以及许多社区贡献的学习资源。
|
||||
|
||||
为了让我们保持获得最新消息,每个月我们将会整合发布 OpenStack 社区的最新教程、指导和小贴士等。下面是我们过去几个月最棒的发布分享。
|
||||
|
||||
- 首先,如果你正在寻找一个靠谱实惠的 OpenStack 测试实验室, Intel NUC 是最值得考虑的平台.麻雀虽小,五脏俱全,通过指导文章,可以很轻松的按照教程在 NUC 上使用 [TripleO 部署 OpenStack][2] ,并且还可以轻松预防一些常见的怪异问题。
|
||||
- 当你已经运行的一段时间 OpenStack 后,你会发现在你的云系统上许多组件生成了大量日志。其中一些是可以安全删除的,而你需要一个管理这些日志的方案。参考在部署生产 9 个月后使用 Celiometer 管理日志的[一些思考][3]。
|
||||
- 对于 OpenStack 基础设施项目的新手,想要提交补丁到 OpenStack 是相当困难的。入口在哪里,测试怎么做,我的提交步骤是怎么样的?可以通过 Arie Bregman 的[博客文章][4]快速了解整个提交过程。
|
||||
- 突发计算节点失效,不知道是硬件还是软件问题。好消息是 OpenStack 提供了一套非常简单的迁移计划可以让迁移当机节点到别的主机。然而,迁移过程中使用的命令令许多人感到困惑。可以通过[这篇文章][5]来理解 migrate 和 evacuate 命令的不同。
|
||||
- 网络功能虚拟化技术需要 OpenStack 中的额外的功能,而用户可能不熟悉它们。例如, SR-IOV 和 PCI 直通是最大限度地提高物理硬件性能的方式。可以学习[部署步骤][6]以使 OpenStack 的性能最大化。
|
||||
|
||||
这些文章基本涵盖了本月(译者注: 4 月)推送,如果你还需要更多文章,可以检索过去推送的 [OpenStack 文献][7]来获取更多资源。如果有你认为我们应该推荐的新教程,请在评论中告诉我们,谢谢。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/4/master-openstack-new-tutorials
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
|
||||
[1]: http://docs.openstack.org/
|
||||
[2]: http://acksyn.org/posts/2016/03/tripleo-on-nucs/
|
||||
[3]: http://silverskysoft.com/open-stack-xwrpr/2016/03/long-term-openstack-usage-summary/
|
||||
[4]: http://abregman.com/2016/03/05/openstack-infra-jenkins-jobs/
|
||||
[5]: http://www.danplanet.com/blog/2016/03/03/evacuate-in-nova-one-command-to-confuse-us-all/
|
||||
[6]: https://trickycloud.wordpress.com/2016/03/28/openstack-for-nfv-applications-sr-iov-and-pci-passthrough/
|
||||
[7]: https://opensource.com/resources/openstack-tutorials
|
||||
@ -0,0 +1,62 @@
|
||||
Drupal, IoT 和开源硬件的交叉点
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
|
||||
认识一下 [Amber Matz][1],来自由 Lullabot Education 提供的 [Drupalize.Me][3] 的生产经理以及培训师。当她没有倒腾 Arduino,Raspberry Pi 以及电子穿戴设备时,通常会在波特兰 Drupal 用户组里和主持人争论。
|
||||
|
||||
在即将举行的 [DrupalCon NOLA][3] 大会上,Amber 将主持一个关于 Drupal 和 IoT 的主题。如果你会去参加,也想了解下开源硬件,IoT 和 Drupal 之间的交叉点,那这个将很合适。如果你去不了新奥尔良的现场也没关系,Amber 还分享了许多很酷的事情。在这次采访中,她讲述了自己参与 Drupal 的原因,一些她自己喜欢的开源硬件项目,以及 IoT 和 Drupal 的未来。
|
||||
|
||||

|
||||
|
||||
**你是怎么加入 Drupal 社区的?**
|
||||
|
||||
在这之前,我在一家大型非盈利性机构市场部的“站长办公室”工作,大量产出没人喜欢的定制 PHP/MySQL 表格。终于我觉得这样很烦并开始在网上寻找更好的方式。然后我找到了 Drupal 6 并开始自己沉迷进去。多年以后,在准备职业转换的时候,发现了波特兰 Drupal 用户组,然后在里面找了一份全职的 Drupal 开发者工作。我一直经常参加在波特兰的聚会,我觉得它是一种很好的社区,交友,以及专业开发的资源。一个偶然的机会,我在 Lullabot 找了一份培训师的工作为 Drupalize.Me 提供内容。现在,我管理着 Drupalize.Me 的内容管道,创建 Drupal 8 的内容,还很大程度地参与到波特兰 Drupal 社区中。我是今年的协调员,寻找并规划演讲者。
|
||||
|
||||
**我们得明白:什么是 Arduino 原型,你是怎么找到它的,以及你用 Arduino 做过的最酷的事是什么?**
|
||||
|
||||
Arduino,Raspberry Pi,以及可穿戴电子设备,这些年到处都能听到这些术语。我在几年前通过 Becky Stern YouTube 秀(最近由 Becky 继续主持,每周三播出)发现了 [Adafruit 的可穿戴电子设备][4]。我被那些可穿戴设备迷住了,还订了一套 LED 缝制工具,不过没做出任何东西。我就是没搞懂。我没有任何电子相关的背景,而且在我被那些项目吸引的时候,我根本不知道怎么做出那样的东西。看上去太遥远了。
|
||||
|
||||
后来,我找到一个 Coursera 的“物联网”专题。(很时髦,对吧?)但我很快就喜欢上了。我最终找到了 Arduino 是什么的解释,以及所有这些其他的重要术语和概念。我订了一套推荐的 Arduino 初学者套件,还附带了一本如何上手的小册子。当我第一次让 LED 闪烁的时候,开心极了。我在圣诞节以及之后有两个星期的假期,然后我什么都没干,就一直根据初学者小册子给 Arduino 电路编程。很奇怪我觉得很放松!我太喜欢了。
|
||||
|
||||
一月份的时候,我开始构思我自己的原型设备。在知道我要主持公司培训的开场白时,我用五个 LED 灯和 Arduino 搭建了一个开场白视觉计时器。
|
||||
|
||||

|
||||
|
||||
这是一次巨大的成功。我还做了我的第一个可穿戴项目,一件会发光的连帽衫,使用了和 Arduino IDE 兼容的 Gemma 微控制器,一个小的圆形可缝制部件,然后用可导电的线缝起来,将一个滑动可变电阻和衣服帽口的收缩绳连在一起,用来控制缝到帽子里的五个 NeoPixel 灯的颜色。这就是我对原型设计的看法:开展一些很好玩也可能会有点实际用途的疯狂项目。
|
||||
|
||||
**Drupal 和 IoT 带来的最大机遇是什么??**
|
||||
|
||||
IoT 和网站服务以及 Drupal 分层趋势实际并没有太大差别。就是将数据从一个物体传送到另一个物体,然后将数据转换成一些有用的东西。但数据是如何送达?能用来做点什么?你觉得现在就有一大堆现成的解决方案,应用,中间层,以及 API?采用 IoT,这只会继续成指数增长。我觉得,给我任何一个设备或“物体”,需要只用一种方式来将它连接到因特网的无线可能上。然后有现成的各种代码库来帮助制作者将他们的数据从一个物体送到另一个物体。
|
||||
|
||||
那么 Drupal 在这里处于什么位置?首先,网站服务将是第一个明显的地方。但作为一个制作者,我不希望将时间花在编写 Drupal 的订制模块上。我想要的是即插即用!所以我很高兴出现这样的模块能连接 IoT 云端 API 和服务,比如 ThingSpeak,Adafruit.io,IFTTT,以及其他的。我觉得也有一个很好的商业机会,在 Drupal 里构建一套 IoT 云服务,允许用户发送和存储他们的传感器数据,并可以制成表格和图像,还可以写一些插件可以响应特定数据或阙值。每一个 IoT 云 API 服务都是一个细分的机会,所以能留下很大空间给其他人。
|
||||
|
||||
**这次 DrupalCon 你有哪些期待?**
|
||||
|
||||
我喜欢重新联系 Drupal 上的朋友,认识一些新的人,还能见到 Lullabot 和 Drupalize.Me 的同事(我们是分布式的公司)!Drupal 8 有太多东西可以去探索了,不可抗拒地要帮我们的客户收集培训资料。所以,我很期待参与一些 Drupal 8 相关的主题,以及跟上最新的开发活动。最后,我对新奥尔良也很感兴趣!我曾经在 2004 年去过,很期待将这次将看到哪些改变。
|
||||
|
||||
**谈一谈你这次 DrupalCon 上的演讲,超越闪烁:将 Drupal 加到你的 IoT 游乐场中。别人为什么要参与?他们最重要的收获会是什么?**
|
||||
|
||||
我的主题的标题是,超越闪烁:将 Drupal 加到你的 IoT 游乐场中,本身有很多假设,我将让所有人都放在同一速度和层次。你不需要了解任何关于 Arduino,物联网,甚至是 Drupal,都能跟上。我将从用 Arduino 让 LED 灯闪烁开始,然后我会谈一下我自己在这里面的最大收获:玩,学,教,和做。我会列出一些曾经激发过我的例子,它们也很有希望能激发和鼓励其他听众去尝试一下。然后,就是展示时间!
|
||||
|
||||
首先,第一个东西。它是一个构建提醒信号灯。在这个展示里,我会说明如何将信号灯连到互联网上,以及如何响应从云 API 服务收到的数据。然后,第二个东西。它是一个蒸汽朋克风格 iPhone 外壳形式的“天气手表”。有一个小型 LED 矩阵用来显示我的天气的图标,一个气压和温度传感器,一个 GPS 模块,以及一个 Bluetooth LE 模块,都连接到一个 Adafruit Flora 微控制器上。第二个东西能通过蓝牙连接到我的 iPhone 上的一个应用,并将天气和位置数据通过 MQTT 协议发到 Adafruit.io 的服务器!然后,在 Drupal 这边,我会从云端下载这些数据,根据天气更新一个功能块,然后更新地图。所以大家也能体验一下通过网站服务,地图和 Drupal 8 的功能块所能做的事情。
|
||||
|
||||
学习和制作这些展示原型是一次烧脑的探险,我也希望有人能参与这个主题并感染一点我对这个技术交叉的传染性热情!我很兴奋能分享一些我的发现。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/drupalcon-interview-amber-matz
|
||||
|
||||
作者:[Jason Hibbets][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jhibbets
|
||||
[1]: https://www.drupal.org/u/amber-himes-matz
|
||||
[2]: https://drupalize.me/
|
||||
[3]: https://events.drupal.org/neworleans2016/
|
||||
[4]: https://www.adafruit.com/beckystern
|
||||
@ -0,0 +1,117 @@
|
||||
如何为登录和 sudo 设置双重认证
|
||||
==========================================================
|
||||
|
||||

|
||||
>[Used with permission][1]
|
||||
|
||||
安全就是一切。我们生活的当今世界,数据具有令人难以置信的价值,而你也一直处于数据丢失的风险之中。因此,你必须想尽办法保证你桌面系统和服务器中东西的安全。结果,管理员和用户就会创建极其复杂的密码、使用密码管理器甚至其它更复杂的东西。但是,如果我告诉你你可以只需要一步-至多两步就能登录到你的 Linux 服务器或桌面系统中呢?多亏了 [Google Authenticator][2],现在你可以做到了。在这之上配置也极其简单。
|
||||
|
||||
我会给你简要介绍为登录和 sudo 设值双重认证的步骤。我基于 Ubuntu 16.04 桌面系统进行介绍,但这些步骤也适用于其它服务器。为了做到双重认证,我会使用 Google Authenticator。
|
||||
|
||||
这里有个非常重要的警告:一旦你设置了认证,没有一个从认证器中获得的由 6 个数字组成的验证码你就不可能登录账户(或者执行 sudo 命令)。这也给你增加了一步额外的操作,因此如果你不想每次登录到 Linux 服务器(或者使用 sudo)的时候都要拿出你的智能手机,这个方案就不适合你。但你也要记住,这额外的一个步骤也给你带来一层其它方法无法给予的保护。
|
||||
|
||||
话不多说,开始吧。
|
||||
|
||||
### 安装必要的组件
|
||||
|
||||
安装 Google 认证,首先要解决两个问题。一是安装智能机应用。下面是如何从 Google 应用商店安装的方法:
|
||||
|
||||
1. 在你的安卓设备中打开 Google 应用商店
|
||||
|
||||
2. 搜索 google 认证
|
||||
|
||||
3. 找到并点击有 Google 标识的应用
|
||||
|
||||
4. 点击安装
|
||||
|
||||
5. 点击 接受
|
||||
|
||||
6. 等待安装完成
|
||||
|
||||
接下来,我们继续在你的 Linux 机器上安装认证。步骤如下:
|
||||
|
||||
1. 打开一个终端窗口
|
||||
|
||||
2. 输入命令 sudo apt-get install google-authenticator
|
||||
|
||||
3. 输入你的 sudo 密码并敲击回车
|
||||
|
||||
4. 如果有弹窗提示,输入 y 并敲击回车
|
||||
|
||||
5. 等待安装完成
|
||||
|
||||
接下来配置使用 google-authenticator 进行登录。
|
||||
|
||||
### 配置
|
||||
|
||||
要为登录和 sudo 添加两阶段认证只需要编辑一个文件。也就是 /etc/pam.d/common-auth。打开并找到如下一行:
|
||||
Just one file must be edited to add two-step authentication for both login and sudo usage. The file is /etc/pam.d/common-auth. Open it and look for the line
|
||||
|
||||
```
|
||||
auth [success=1 default=ignore] pam_unix.so nullok_secure
|
||||
```
|
||||
|
||||
在这行上面添加:
|
||||
|
||||
```
|
||||
auth required pam_google_authenticator.so
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
下一步就是为系统中的每个用户设置 google-authenticator(否则会不允许他们登录)。为了简单起见,我们假设你的系统中有两个用户:jack 和 olivia。首先为 jack 设置(我们假设这是我们一直使用的账户)。
|
||||
|
||||
打开一个终端窗口并输入命令 google-authenticator。之后会问你一系列的问题(每个问题你都应该用 y 回答)。问题包括:
|
||||
|
||||
* 是否允许更新你的 "/home/jlwallen/.google_authenticator" 文件 (y/n) y
|
||||
|
||||
* 是否禁止多个用户使用同一个认证令牌?这会限制你每 30 秒内只能登录一次,但能增加你注意到甚至防止中间人攻击的可能 (y/n)
|
||||
|
||||
* 默认情况下令牌时长为 30 秒即可,为了补偿客户端和服务器之间可能出现的时间偏差,我们允许添加一个当前时间之前或之后的令牌。如果你无法进行时间同步,你可以把时间窗口由默认的 1:30 分钟增加到 4 分钟。是否希望如此 (y/n)
|
||||
|
||||
* 如果你尝试登陆的计算机没有针对蛮力登陆进行加固,你可以为验证模块启用速率限制。默认情况下,限制攻击者每 30 秒不能尝试登陆超过 3 次。是否启用速率限制 (y/n)
|
||||
|
||||
一旦完成了问题回答,你就会看到你的密钥、验证码以及 5 个紧急刮码。把刮码输出保存起来。你可以在无法使用手机的时候使用它们(每个刮码仅限使用一次)。密钥用于你在 Google Authenticator 上设置账户,验证码是你能立即使用(如果需要)的一次性验证码。
|
||||
|
||||
### 设置应用
|
||||
|
||||
现在你已经配置好了用户 jack。在设置用户 olivia 之前,你需要在 Google Authenticator 应用上为 jack 添加账户。在主屏幕上打开应用,点击 菜单 按钮(右上角三个竖排点)。点击添加账户然后输入提供的密钥。在下一个窗口(示意图1),你需要输入你运行 google-authenticator 应用时提供的 16 个数字的密钥。给账户取个名字(以便你记住这用于哪个账户),然后点击添加。
|
||||
|
||||

|
||||
>Figure 1: 在 Google Authenticator 应用上新建账户
|
||||
|
||||
添加完账户之后,你就会看到一个 6 个数字的密码,你每次登录或者使用 sudo 的时候都会需要这个密码。
|
||||
|
||||
最后,在系统上设置其它账户。正如之前提到的,我们会设置一个叫 olivia 的账户。步骤如下:
|
||||
|
||||
1. 打开一个终端窗口
|
||||
|
||||
2. 输入命令 sudo su olivia
|
||||
|
||||
3. 在智能机上打开 Google Authenticator
|
||||
|
||||
4. 在终端窗口(示意图2)中输入(应用提供的) 6 位数字验证码并敲击回车
|
||||
|
||||
5. 输入你的 sudo 密码并敲击回车
|
||||
|
||||
6. 以新用户输入命令 google-authenticator,回答问题并记录生成的密钥和验证码。
|
||||
|
||||
成功为 olivia 用户设置好之后,用 google-authenticator 命令,在 Google Authenticator 应用上根据用户信息(和之前为第一个用户添加账户相同)添加一个新的账户。现在你在 Google Authenticator 应用上就会有 jack 和 olivia 两个账户了。
|
||||
|
||||

|
||||
>Figure 2: 为 sudo 输入 6位数字验证码
|
||||
|
||||
好了,就是这些。每次你尝试登陆系统(或者使用 sudo) 的时候,在你输入用户密码之前,都会要求你输入提供的 6 位数字验证码。现在你的 Linux 机器就比添加双重认证之前安全多了。虽然有些人会认为这非常麻烦,我仍然推荐使用,尤其是那些保存了敏感数据的机器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/auth_b.png?itok=FH36V1r0
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[1]: https://www.linux.com/licenses/category/used-permission
|
||||
[2]: https://play.google.com/store/apps/details?id=com.google.android.apps.authenticator2
|
||||
|
||||
@ -0,0 +1,371 @@
|
||||
LFCS 系列第七讲: 通过 SysVinit、Systemd 和 Upstart 管理系统自启动进程和服务
|
||||
================================================================================
|
||||
几个月前, Linux 基金会宣布 LFCS(Linux 基金会认证系统管理员) 认证诞生了,这个令人兴奋的新计划定位于让来自全球各地的初级到中级的 Linux 系统管理员得到认证。这其中包括维护已经在运行的系统和服务能力、第一手的问题查找和分析能力、以及决定何时向开发团队提交问题的能力。
|
||||
|
||||

|
||||
|
||||
第七讲: Linux 基金会认证系统管理员
|
||||
|
||||
下面的视频简要介绍了 Linux 基金会认证计划。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
这篇博文是 10 指南系列中的第七篇,在这篇文章中,我们会介绍如何管理 Linux 系统自启动进程和服务,这是 LFCS 认证考试要求的一部分。
|
||||
|
||||
### 管理 Linux 自启动进程 ###
|
||||
|
||||
Linux 系统的启动程序包括多个阶段,每个阶段由一个不同的组件表示。下面的图示简要总结了启动过程以及所有包括的主要组件。
|
||||
|
||||

|
||||
|
||||
Linux 启动过程
|
||||
|
||||
当你按下你机器上的电源键时, 存储在主板 EEPROM 芯片中的固件初始化 POST(通电自检) 检查系统硬件资源的状态。POST 结束后,固件会搜索并加载位于第一块可用磁盘上的 MBR 或 EFI 分区的第一阶段引导程序,并把控制权交给引导程序。
|
||||
|
||||
#### MBR 方式 ####
|
||||
|
||||
MBR 是位于 BISO 设置中标记为可启动磁盘上的第一个扇区,大小是 512 个字节。
|
||||
|
||||
- 前面 446 个字节:包括可执行代码和错误信息文本的引导程序
|
||||
- 接下来的 64 个字节:四个分区(主分区或扩展分区)中每个分区一条记录的分区表。其中,每条记录标示了每个一个分区的状态(是否活跃)、大小以及开始和结束扇区。
|
||||
- 最后 2 个字节: MBR 有效性检查的魔数。
|
||||
|
||||
下面的命令对 MBR 进行备份(在本例中,/dev/sda 是第一块硬盘)。结果文件 mbr.bkp 在分区表被破坏、例如系统不可引导时能排上用场。
|
||||
|
||||
当然,为了后面需要的时候能使用它,我们需要把它保存到别的地方(例如一个 USB 设备)。该文件能帮助我们重新恢复 MBR,这只在我们操作过程中没有改变硬盘驱动布局时才有效。
|
||||
|
||||
**备份 MBR**
|
||||
|
||||
# dd if=/dev/sda of=mbr.bkp bs=512 count=1
|
||||
|
||||

|
||||
|
||||
在 Linux 中备份 MBR
|
||||
|
||||
**恢复 MBR**
|
||||
|
||||
# dd if=mbr.bkp of=/dev/sda bs=512 count=1
|
||||
|
||||

|
||||
|
||||
在 Linux 中恢复 MBR
|
||||
|
||||
#### EFI/UEFI 方式 ####
|
||||
|
||||
对于使用 EFI/UEFI 方式的系统, UEFI 固件读取它的设置来决定从哪里启动哪个 UEFI 应用。(例如, EFI 分区位于哪块磁盘或分区。
|
||||
|
||||
接下来,加载并运行第二阶段引导程序(又名引导管理器)。GRUB[GRand Unified Boot] 是 Linux 中最常使用的引导管理器。今天大部分使用的系统中都能找到它两个中的其中一个版本。
|
||||
|
||||
- GRUB 有效配置文件: /boot/grub/menu.lst(旧发行版, EFI/UEFI 固件不支持)。
|
||||
- GRUB2 配置文件: 通常是 /etc/default/grub。
|
||||
|
||||
尽管 LFCS 考试目标没有明确要求了解 GRUB 内部知识,但如果你足够大胆并且不怕把你的系统搞乱(为了以防万一,你可以先在虚拟机上进行尝试)你可以运行:
|
||||
|
||||
# update-grub
|
||||
|
||||
为了使更改生效,你需要以 root 用户修改 GRUB 的配置。
|
||||
|
||||
首先, GRUB 加载默认的内核以及 initrd 或 initramfs 镜像。补充一句,initrd 或者 initramfs 帮助完成硬件检测、内核模块加载、以及发现挂载根目录文件系统需要的设备。
|
||||
|
||||
一旦真正的根目录文件系统启动,为了显示用户界面,内核就会执行系统和服务管理器(init 或 systemd,进程号 PID 一般为 1)开始普通用户态的引导程序。
|
||||
|
||||
init 和 systemd 都是管理其它守护进程的守护进程(后台进程),它们总是最先启动(系统引导时),最后结束(系统关闭时)。
|
||||
|
||||

|
||||
|
||||
Systemd 和 Init
|
||||
|
||||
### 自启动服务(SysVinit) ###
|
||||
|
||||
Linux 中运行等级的概念表示通过控制运行哪些服务来以不同方式使用系统。换句话说,运行等级控制着当前执行状态下可以完成什么任务(以及什么不能完成)。
|
||||
|
||||
传统上,这个启动过程是基于起源于 System V Unix 的形式,通过执行脚本启动或者停止服务从而使机器进入指定的运行等级(换句话说,是一个不同的系统运行模式)。
|
||||
|
||||
在每个运行等级中,独立服务可以设置为运行、或者在运行时关闭。一些主流发行版的最新版本中,已经移除了标准的 System V,而用一个称为 systemd(表示系统守护进程)的新服务和系统管理器代替,但为了兼容性,通常也支持 sysv 命令。这意味着你可以在基于 systemd 的发行版中运行大部分有名的 sysv 初始化工具。
|
||||
|
||||
- 推荐阅读: [Linux 为什么用 ‘systemd’ 代替 ‘init’][1]
|
||||
|
||||
除了启动系统进程,init 还会查看 /etc/inittab 来决定进入哪个运行等级。
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="85">
|
||||
</colgroup>
|
||||
<colgroup width="1514">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;"><b>Runlevel</b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><b> Description</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">0</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 停止系统。运行等级 0 是一个用于快速关闭系统的特殊过渡状态。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="20" style="border: 1px solid #000001;">1</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 别名为 s 或 S,这个运行等级有时候也称为维护模式。在这个运行等级启动的服务由于发行版不同而不同。通常用于正常系统操作损坏时低级别的系统维护。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">2</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 多用户。在 Debian 系统及其衍生版中,这是默认的运行等级,还包括了一个图形化登录(如果有的话)。在基于红帽的系统中,这是没有网络的多用户模式。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">3</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 在基于红帽的系统中,这是默认的多用户模式,运行除了图形化环境以外的所有东西。基于 Debian 的系统中通常不会使用这个运行等级以及等级 4 和 5。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">4</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 通常默认情况下不使用,可用于自定制。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">5</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 基于红帽的系统中,支持 GUI 登录的完全多用户模式。这个运行等级和等级 3 类似,但是有可用的 GUI 登录。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">6</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 重启系统。</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
要在运行等级之间切换,我们只需要使用 init 命令更改运行等级:init N(其中 N 是上面列出的一个运行等级)。
|
||||
请注意这并不是运行中的系统切换运行等级的推荐方式,因为它不会给已经登录的用户发送警告(因而导致他们丢失工作以及进程异常终结)。
|
||||
|
||||
相反,应该用 shutdown 命令重启系统(它首先发送警告信息给所有已经登录的用户,并锁住任何新的登录;然后再给 init 发送信号切换运行等级)但是,首先要在 /etc/inittab 文件中设置好默认的运行等级(系统引导到的等级)。
|
||||
|
||||
因为这个原因,按照下面的步骤切当地切换运行等级。以 root 用户在 /etc/inittab 中查找下面的行。
|
||||
|
||||
id:2:initdefault:
|
||||
|
||||
并用你喜欢的文本编辑器,例如 vim(本系列的[第二讲 : 如何在 Linux 中使用 vi/vim 编辑器][2]),更改数字 2 为想要的运行等级。
|
||||
|
||||
然后,以 root 用户执行
|
||||
|
||||
# shutdown -r now
|
||||
|
||||
最后一个命令会重启系统,并使它在下一次引导时进入指定的运行等级,并会执行保存在 /etc/rc[runlevel].d 目录中的脚本以决定应该启动什么服务、不应该启动什么服务。例如,在下面的系统中运行等级 2。
|
||||
|
||||

|
||||
|
||||
在 Linux 中更改运行等级
|
||||
|
||||
#### 使用 chkconfig 管理服务 ####
|
||||
|
||||
为了在启动时启动或者停用系统服务,我们可以在 CentOS / openSUSE 中使用 [chkconfig 命令][3],在 Debian 及其衍生版中使用 sysv-rc-conf 命令。这个工具还能告诉我们对于一个指定的运行等级预先配置的状态是什么。
|
||||
|
||||
- 推荐阅读: [如何在 Linux 中停止和停用不想要的服务][4]
|
||||
|
||||
列出某个服务的运行等级配置。
|
||||
|
||||
# chkconfig --list [service name]
|
||||
# chkconfig --list postfix
|
||||
# chkconfig --list mysqld
|
||||
|
||||

|
||||
|
||||
列出运行等级配置
|
||||
|
||||
从上图中我们可以看出,当系统进入运行等级 2 到 5 的时候就会启动 postfix,而默认情况下运行等级 2 到 4 时会运行 mysqld。现在假设我们并不希望如此。
|
||||
|
||||
例如,我们希望运行等级为 5 时也启动 mysqld,运行等级为 4 或 5 时关闭 postfix。下面分别针对两种情况进行设置(以 root 用户执行以下命令)。
|
||||
|
||||
**为特定运行等级启用服务**
|
||||
|
||||
# chkconfig --level [level(s)] service on
|
||||
# chkconfig --level 5 mysqld on
|
||||
|
||||
**为特定运行等级停用服务**
|
||||
|
||||
# chkconfig --level [level(s)] service off
|
||||
# chkconfig --level 45 postfix off
|
||||
|
||||

|
||||
|
||||
启用/停用服务
|
||||
|
||||
我们在基于 Debian 的系统中使用 sysv-rc-conf 完成类似任务。
|
||||
|
||||
#### 使用 sysv-rc-conf 管理服务 ####
|
||||
|
||||
配置服务自动启动时进入指定运行等级,同时禁止启动时进入其它运行等级。
|
||||
|
||||
1. 我们可以用下面的命令查看启动 mdadm 时的运行等级。
|
||||
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||
|
||||

|
||||
|
||||
查看运行中服务的运行等级
|
||||
|
||||
2. 我们使用 sysv-rc-conf 设置防止 mdadm 在运行等级2 之外的其它等级启动。只需根据需要(你可以使用上下左右按键)选中或取消选中(通过空格键)。
|
||||
|
||||
# sysv-rc-conf
|
||||
|
||||

|
||||
|
||||
Sysv 运行等级配置
|
||||
|
||||
然后输入 q 退出。
|
||||
|
||||
3. 重启系统并从步骤 1 开始再操作一遍。
|
||||
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||

|
||||
|
||||
验证服务运行等级
|
||||
|
||||
从上图中我们可以看出 mdadm 配置为只在运行等级 2 上启动。
|
||||
|
||||
### 那关于 systemd 呢? ###
|
||||
|
||||
systemd 是另外一个被多种主流 Linux 发行版采用的服务和系统管理器。它的目标是允许系统启动时多个任务尽可能并行(而 sysvinit 并非如此,sysvinit 一般比较慢,因为它每次只启动一个进程,而且会检查彼此之间是否有依赖,在启动其它服务之前还要等待守护进程启动),充当运行中系统动态资源管理的角色。
|
||||
|
||||
因此,服务只在需要的时候启动,而不是系统启动时毫无缘由地启动(为了防止消耗系统资源)。
|
||||
|
||||
要查看你系统中运行的原生 systemd 服务和 Sysv 服务,可以用以下的命令。
|
||||
|
||||
# systemctl
|
||||
|
||||

|
||||
|
||||
查看运行中的进程
|
||||
|
||||
LOAD 一列显示了单元(UNIT 列,显示服务或者由 systemd 维护的其它进程)是否正确加载,ACTIVE 和 SUB 列则显示了该单元当前的状态。
|
||||
|
||||
显示服务当前状态的信息
|
||||
|
||||
当 ACTIVE 列显示某个单元状态并非活跃时,我们可以使用以下命令查看具体原因。
|
||||
|
||||
# systemctl status [unit]
|
||||
|
||||
例如,上图中 media-samba.mount 处于失败状态。我们可以运行:
|
||||
|
||||
# systemctl status media-samba.mount
|
||||
|
||||

|
||||
|
||||
查看服务状态
|
||||
|
||||
我们可以看到 media-samba.mount 失败的原因是 host dev1 上的挂载进程无法找到 //192.168.0.10/gacanepa 上的共享网络。
|
||||
|
||||
### 启动或停止服务 ###
|
||||
|
||||
一旦 //192.168.0.10/gacanepa 上的共享网络可用,我们可以再来尝试启动、停止以及重启 media-samba.mount 单元。执行每次操作之后,我们都执行 systemctl stats media-samba.mout 来查看它的状态。
|
||||
|
||||
# systemctl start media-samba.mount
|
||||
# systemctl status media-samba.mount
|
||||
# systemctl stop media-samba.mount
|
||||
# systemctl restart media-samba.mount
|
||||
# systemctl status media-samba.mount
|
||||
|
||||

|
||||
|
||||
启动停止服务
|
||||
|
||||
**启用或停用某服务随系统启动**
|
||||
|
||||
使用 systemd 你可以在系统启动时启用或停用某服务
|
||||
|
||||
# systemctl enable [service] # 启用服务
|
||||
# systemctl disable [service] # 阻止服务随系统启动
|
||||
|
||||
|
||||
启用或停用某服务随系统启动包括在 /etc/systemd/system/multi-user.target.wants 目录添加或者删除符号链接。
|
||||
|
||||

|
||||
|
||||
启用或停用服务
|
||||
|
||||
你也可以用下面的命令查看某个服务的当前状态(启用或者停用)。
|
||||
|
||||
# systemctl is-enabled [service]
|
||||
|
||||
例如,
|
||||
|
||||
# systemctl is-enabled postfix.service
|
||||
|
||||
另外,你可以用下面的命令重启或者关闭系统。
|
||||
|
||||
# systemctl reboot
|
||||
# systemctl shutdown
|
||||
|
||||
### Upstart ###
|
||||
|
||||
基于事件的 Upstart 是 /sbin/init 守护进程的替代品,它仅为在需要那些服务的时候启动服务而生,(或者当它们在运行时管理它们),以及处理发生的实践,因此 Upstart 优于基于依赖的 sysvinit 系统。
|
||||
|
||||
一开始它是为 Ubuntu 发行版开发的,但在红帽企业版 Linux 6.0 中得到使用。尽管希望它能在所有 Linux 发行版中替代 sysvinit,但它已经被 systemd 超越。2014 年 2 月 14 日,Mark Shuttleworth(Canonical Ltd. 创建者)发布声明之后的 Ubuntu 发行版采用 systemd 作为默认初始化守护进程。
|
||||
|
||||
由于 Sysv 启动脚本已经流行很长时间了,很多软件包中都包括了 Sysv 启动脚本。为了兼容这些软件, Upstart 提供了兼容模式:它可以运行保存在常用位置(/etc/rc.d/rc?.d, /etc/init.d/rc?.d, /etc/rc?.d或其它类似的位置)的Sysv 启动脚本。因此,如果我们安装了一个还没有 Upstart 配置脚本的软件,仍然可以用原来的方式启动它。
|
||||
|
||||
另外,如果我们还安装了类似 [chkconfig][5] 的工具,你还可以和在基于 sysvinit 的系统中一样用它们管理基于 Sysv 的服务。
|
||||
|
||||
Upstart 脚本除了支持 Sysv 启动脚本,还支持基于多种方式启动或者停用服务;例如, Upstart 可以在一个特定硬件设备连接上的时候启动一个服务。
|
||||
|
||||
使用 Upstart以及它原生脚本的系统替换了 /etc/inittab 文件和 /etc/init 目录下和运行等级相关的以 .conf 作为后缀的 Sysv 启动脚本目录。
|
||||
|
||||
这些 *.conf 脚本(也称为任务定义)通常包括以下几部分:
|
||||
|
||||
- 进程描述
|
||||
- 进程的运行等级或者应该触发它们的事件
|
||||
- 应该停止进程的运行等级或者触发停止进程的事件
|
||||
- 选项
|
||||
- 启动进程的命令
|
||||
|
||||
例如,
|
||||
|
||||
# My test service - Upstart script demo description "Here goes the description of 'My test service'" author "Dave Null <dave.null@example.com>"
|
||||
# Stanzas
|
||||
|
||||
#
|
||||
# Stanzas define when and how a process is started and stopped
|
||||
# See a list of stanzas here: http://upstart.ubuntu.com/wiki/Stanzas#respawn
|
||||
# When to start the service
|
||||
start on runlevel [2345]
|
||||
# When to stop the service
|
||||
stop on runlevel [016]
|
||||
# Automatically restart process in case of crash
|
||||
respawn
|
||||
# Specify working directory
|
||||
chdir /home/dave/myfiles
|
||||
# Specify the process/command (add arguments if needed) to run
|
||||
exec bash backup.sh arg1 arg2
|
||||
|
||||
要使更改生效,你要让 upstart 重新加载它的配置文件。
|
||||
|
||||
# initctl reload-configuration
|
||||
|
||||
然后用下面的命令启动你的任务。
|
||||
|
||||
$ sudo start yourjobname
|
||||
|
||||
其中 yourjobname 是之前 yourjobname.conf 脚本中添加的任务名称。
|
||||
|
||||
关于 Upstart 更完整和详细的介绍可以参考该项目网站的 “[Cookbook][6]” 栏目。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
了解 Linux 启动进程对于你进行错误处理、调整计算机系统以及根据需要运行服务非常有用。
|
||||
|
||||
在这篇文章中,我们分析了你按下电源键启动机器的一刻到你看到完整的可操作用户界面这段时间发生了什么。我希望你能像我一样把它们放在一起阅读。欢迎在下面留下你的评论或者疑问。我们总是期待听到读者的回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
[4]:http://www.tecmint.com/remove-unwanted-services-from-linux/
|
||||
[5]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
[6]:http://upstart.ubuntu.com/cookbook/
|
||||
@ -1,5 +1,3 @@
|
||||
translating by ezio
|
||||
|
||||
Part 2 - LXD 2.0: 安装与配置
|
||||
=================================================
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user