mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
7f5cada968
155
published/20170101 What is Kubernetes.md
Normal file
155
published/20170101 What is Kubernetes.md
Normal file
@ -0,0 +1,155 @@
|
||||
一文了解 Kubernetes 是什么?
|
||||
============================================================
|
||||
|
||||
这是一篇 Kubernetes 的概览。
|
||||
|
||||
Kubernetes 是一个[自动化部署、伸缩和操作应用程序容器的开源平台][25]。
|
||||
|
||||
使用 Kubernetes,你可以快速、高效地满足用户以下的需求:
|
||||
|
||||
* 快速精准地部署应用程序
|
||||
* 即时伸缩你的应用程序
|
||||
* 无缝展现新特征
|
||||
* 限制硬件用量仅为所需资源
|
||||
|
||||
我们的目标是培育一个工具和组件的生态系统,以减缓在公有云或私有云中运行的程序的压力。
|
||||
|
||||
#### Kubernetes 的优势
|
||||
|
||||
* **可移动**: 公有云、私有云、混合云、多态云
|
||||
* **可扩展**: 模块化、插件化、可挂载、可组合
|
||||
* **自修复**: 自动部署、自动重启、自动复制、自动伸缩
|
||||
|
||||
Google 公司于 2014 年启动了 Kubernetes 项目。Kubernetes 是在 [Google 的长达 15 年的成规模的产品级任务的经验下][26]构建的,结合了来自社区的最佳创意和实践经验。
|
||||
|
||||
### 为什么选择容器?
|
||||
|
||||
想要知道你为什么要选择使用 [容器][27]?
|
||||
|
||||

|
||||
|
||||
程序部署的_传统方法_是指通过操作系统包管理器在主机上安装程序。这样做的缺点是,容易混淆程序之间以及程序和主机系统之间的可执行文件、配置文件、库、生命周期。为了达到精准展现和精准回撤,你可以搭建一台不可变的虚拟机镜像。但是虚拟机体量往往过于庞大而且不可转移。
|
||||
|
||||
容器部署的_新的方式_是基于操作系统级别的虚拟化,而非硬件虚拟化。容器彼此是隔离的,与宿主机也是隔离的:它们有自己的文件系统,彼此之间不能看到对方的进程,分配到的计算资源都是有限制的。它们比虚拟机更容易搭建。并且由于和基础架构、宿主机文件系统是解耦的,它们可以在不同类型的云上或操作系统上转移。
|
||||
|
||||
正因为容器又小又快,每一个容器镜像都可以打包装载一个程序。这种一对一的“程序 - 镜像”联系带给了容器诸多便捷。有了容器,静态容器镜像可以在编译/发布时期创建,而非部署时期。因此,每个应用不必再等待和整个应用栈其它部分进行整合,也不必和产品基础架构环境之间进行妥协。在编译/发布时期生成容器镜像建立了一个持续地把开发转化为产品的环境。相似地,容器远比虚拟机更加透明,尤其在设备监控和管理上。这一点,在容器的进程生命周期被基础架构管理而非被容器内的进程监督器隐藏掉时,尤为显著。最终,随着每个容器内都装载了单一的程序,管理容器就等于管理或部署整个应用。
|
||||
|
||||
容器优势总结:
|
||||
|
||||
* **敏捷的应用创建与部署**:相比虚拟机镜像,容器镜像的创建更简便、更高效。
|
||||
* **持续的开发、集成,以及部署**:在快速回滚下提供可靠、高频的容器镜像编译和部署(基于镜像的不可变性)。
|
||||
* **开发与运营的关注点分离**:由于容器镜像是在编译/发布期创建的,因此整个过程与基础架构解耦。
|
||||
* **跨开发、测试、产品阶段的环境稳定性**:在笔记本电脑上的运行结果和在云上完全一致。
|
||||
* **在云平台与 OS 上分发的可转移性**:可以在 Ubuntu、RHEL、CoreOS、预置系统、Google 容器引擎,乃至其它各类平台上运行。
|
||||
* **以应用为核心的管理**: 从在虚拟硬件上运行系统,到在利用逻辑资源的系统上运行程序,从而提升了系统的抽象层级。
|
||||
* **松散耦联、分布式、弹性、无拘束的[微服务][5]**:整个应用被分散为更小、更独立的模块,并且这些模块可以被动态地部署和管理,而不再是存储在大型的单用途机器上的臃肿的单一应用栈。
|
||||
* **资源隔离**:增加程序表现的可预见性。
|
||||
* **资源利用率**:高效且密集。
|
||||
|
||||
#### 为什么我需要 Kubernetes,它能做什么?
|
||||
|
||||
至少,Kubernetes 能在实体机或虚拟机集群上调度和运行程序容器。而且,Kubernetes 也能让开发者斩断联系着实体机或虚拟机的“锁链”,从**以主机为中心**的架构跃至**以容器为中心**的架构。该架构最终提供给开发者诸多内在的优势和便利。Kubernetes 提供给基础架构以真正的**以容器为中心**的开发环境。
|
||||
|
||||
Kubernetes 满足了一系列产品内运行程序的普通需求,诸如:
|
||||
|
||||
* [协调辅助进程][9],协助应用程序整合,维护一对一“程序 - 镜像”模型。
|
||||
* [挂载存储系统][10]
|
||||
* [分布式机密信息][11]
|
||||
* [检查程序状态][12]
|
||||
* [复制应用实例][13]
|
||||
* [使用横向荚式自动缩放][14]
|
||||
* [命名与发现][15]
|
||||
* [负载均衡][16]
|
||||
* [滚动更新][17]
|
||||
* [资源监控][18]
|
||||
* [访问并读取日志][19]
|
||||
* [程序调试][20]
|
||||
* [提供验证与授权][21]
|
||||
|
||||
以上兼具平台即服务(PaaS)的简化和基础架构即服务(IaaS)的灵活,并促进了在平台服务提供商之间的迁移。
|
||||
|
||||
#### Kubernetes 是一个什么样的平台?
|
||||
|
||||
虽然 Kubernetes 提供了非常多的功能,总会有更多受益于新特性的新场景出现。针对特定应用的工作流程,能被流水线化以加速开发速度。特别的编排起初是可接受的,这往往需要拥有健壮的大规模自动化机制。这也是为什么 Kubernetes 也被设计为一个构建组件和工具的生态系统的平台,使其更容易地部署、缩放、管理应用程序。
|
||||
|
||||
[<ruby>标签<rt>label</rt></ruby>][28]可以让用户按照自己的喜好组织资源。 [<ruby>注释<rt>annotation</rt></ruby>][29]让用户在资源里添加客户信息,以优化工作流程,为管理工具提供一个标示调试状态的简单方法。
|
||||
|
||||
此外,[Kubernetes 控制面板][30]是由开发者和用户均可使用的同样的 [API][31] 构建的。用户可以编写自己的控制器,比如 [<ruby>调度器<rt>scheduler</rt></ruby>][32],使用可以被通用的[命令行工具][34]识别的[他们自己的 API][33]。
|
||||
|
||||
这种[设计][35]让大量的其它系统也能构建于 Kubernetes 之上。
|
||||
|
||||
#### Kubernetes 不是什么?
|
||||
|
||||
Kubernetes 不是传统的、全包容的平台即服务(Paas)系统。它尊重用户的选择,这很重要。
|
||||
|
||||
Kubernetes:
|
||||
|
||||
* 并不限制支持的程序类型。它并不检测程序的框架 (例如,[Wildfly][22]),也不限制运行时支持的语言集合 (比如, Java、Python、Ruby),也不仅仅迎合 [12 因子应用程序][23],也不区分 _应用_ 与 _服务_ 。Kubernetes 旨在支持尽可能多种类的工作负载,包括无状态的、有状态的和处理数据的工作负载。如果某程序在容器内运行良好,它在 Kubernetes 上只可能运行地更好。
|
||||
* 不提供中间件(例如消息总线)、数据处理框架(例如 Spark)、数据库(例如 mysql),也不把集群存储系统(例如 Ceph)作为内置服务。但是以上程序都可以在 Kubernetes 上运行。
|
||||
* 没有“点击即部署”这类的服务市场存在。
|
||||
* 不部署源代码,也不编译程序。持续集成 (CI) 工作流程是不同的用户和项目拥有其各自不同的需求和表现的地方。所以,Kubernetes 支持分层 CI 工作流程,却并不监听每层的工作状态。
|
||||
* 允许用户自行选择日志、监控、预警系统。( Kubernetes 提供一些集成工具以保证这一概念得到执行)
|
||||
* 不提供也不管理一套完整的应用程序配置语言/系统(例如 [jsonnet][24])。
|
||||
* 不提供也不配合任何完整的机器配置、维护、管理、自我修复系统。
|
||||
|
||||
另一方面,大量的 PaaS 系统运行_在_ Kubernetes 上,诸如 [Openshift][36]、[Deis][37],以及 [Eldarion][38]。你也可以开发你的自定义 PaaS,整合上你自选的 CI 系统,或者只在 Kubernetes 上部署容器镜像。
|
||||
|
||||
因为 Kubernetes 运营在应用程序层面而不是在硬件层面,它提供了一些 PaaS 所通常提供的常见的适用功能,比如部署、伸缩、负载平衡、日志和监控。然而,Kubernetes 并非铁板一块,这些默认的解决方案是可供选择,可自行增加或删除的。
|
||||
|
||||
|
||||
而且, Kubernetes 不只是一个_编排系统_ 。事实上,它满足了编排的需求。 _编排_ 的技术定义是,一个定义好的工作流程的执行:先做 A,再做 B,最后做 C。相反地, Kubernetes 囊括了一系列独立、可组合的控制流程,它们持续驱动当前状态向需求的状态发展。从 A 到 C 的具体过程并不唯一。集中化控制也并不是必须的;这种方式更像是_编舞_。这将使系统更易用、更高效、更健壮、复用性、扩展性更强。
|
||||
|
||||
#### Kubernetes 这个单词的含义?k8s?
|
||||
|
||||
**Kubernetes** 这个单词来自于希腊语,含义是 _舵手_ 或 _领航员_ 。其词根是 _governor_ 和 [cybernetic][39]。 _K8s_ 是它的缩写,用 8 字替代了“ubernete”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
|
||||
|
||||
作者:[kubernetes.io][a]
|
||||
译者:[songshuang00](https://github.com/songsuhang00)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kubernetes.io/
|
||||
[1]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-do-i-need-kubernetes-and-what-can-it-do
|
||||
[2]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#how-is-kubernetes-a-platform
|
||||
[3]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-kubernetes-is-not
|
||||
[4]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-does-kubernetes-mean-k8s
|
||||
[5]:https://martinfowler.com/articles/microservices.html
|
||||
[6]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#kubernetes-is
|
||||
[7]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-containers
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#whats-next
|
||||
[9]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[10]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[11]:https://kubernetes.io/docs/concepts/configuration/secret/
|
||||
[12]:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
|
||||
[13]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[14]:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
||||
[15]:https://kubernetes.io/docs/concepts/services-networking/connect-applications-service/
|
||||
[16]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[17]:https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller/
|
||||
[18]:https://kubernetes.io/docs/tasks/debug-application-cluster/resource-usage-monitoring/
|
||||
[19]:https://kubernetes.io/docs/concepts/cluster-administration/logging/
|
||||
[20]:https://kubernetes.io/docs/tasks/debug-application-cluster/debug-application-introspection/
|
||||
[21]:https://kubernetes.io/docs/admin/authorization/
|
||||
[22]:http://wildfly.org/
|
||||
[23]:https://12factor.net/
|
||||
[24]:https://github.com/google/jsonnet
|
||||
[25]:http://www.slideshare.net/BrianGrant11/wso2con-us-2015-kubernetes-a-platform-for-automating-deployment-scaling-and-operations
|
||||
[26]:https://research.google.com/pubs/pub43438.html
|
||||
[27]:https://aucouranton.com/2014/06/13/linux-containers-parallels-lxc-openvz-docker-and-more/
|
||||
[28]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[29]:https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/
|
||||
[30]:https://kubernetes.io/docs/concepts/overview/components/
|
||||
[31]:https://kubernetes.io/docs/reference/api-overview/
|
||||
[32]:https://git.k8s.io/community/contributors/devel/scheduler.md
|
||||
[33]:https://git.k8s.io/community/contributors/design-proposals/extending-api.md
|
||||
[34]:https://kubernetes.io/docs/user-guide/kubectl-overview/
|
||||
[35]:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/principles.md
|
||||
[36]:https://www.openshift.org/
|
||||
[37]:http://deis.io/
|
||||
[38]:http://eldarion.cloud/
|
||||
[39]:http://www.etymonline.com/index.php?term=cybernetics
|
||||
@ -0,0 +1,87 @@
|
||||
11 个使用 GNOME 3 桌面环境的理由
|
||||
============================================================
|
||||
|
||||
> GNOME 3 桌面的设计目的是简单、易于访问和可靠。GNOME 的受欢迎程度证明达成了这些目标。
|
||||
|
||||

|
||||
|
||||
去年年底,在我升级到 Fedora 25 后,新版本 [KDE][11] Plasma 出现了一些问题,这使我难以完成任何工作。所以我决定尝试其他的 Linux 桌面环境有两个原因。首先,我需要完成我的工作。第二,多年来一直使用 KDE,我想可能是尝试一些不同的桌面的时候了。
|
||||
|
||||
我尝试了几个星期的第一个替代桌面是我在 1 月份文章中写到的 [Cinnamon][12],然后我写了用了大约八个星期的[LXDE][13],我发现这里有很多事情我都喜欢。我用了 [GNOME 3][14] 几个星期来写了这篇文章。
|
||||
|
||||
像几乎所有的网络世界一样,GNOME 是缩写;它代表 “GNU 网络对象模型”(GNU Network Object Model)。GNOME 3 桌面设计的目的是简单、易于访问和可靠。GNOME 的受欢迎程度证明达成了这些目标。
|
||||
|
||||
GNOME 3 在需要大量屏幕空间的环境中非常有用。这意味着两个具有高分辨率的大屏幕,并最大限度地减少桌面小部件、面板和用来启动新程序之类任务的图标所需的空间。GNOME 项目有一套人机接口指南(HIG),用来定义人类应该如何与计算机交互的 GNOME 哲学。
|
||||
|
||||
### 我使用 GNOME 3 的十一个原因
|
||||
|
||||
1、 **诸多选择:** GNOME 以多种形式出现在我个人喜爱的 Fedora 等一些发行版上。你可以选择的桌面登录选项有 GNOME Classic、Xorg 上的 GNOME、GNOME 和 GNOME(Wayland)。从表面上看,启动后这些都是一样的,但它们使用不同的 X 服务器,或者使用不同的工具包构建。Wayland 在小细节上提供了更多的功能,例如动态滚动,拖放和中键粘贴。
|
||||
|
||||
2、 **入门教程:** 在用户第一次登录时会显示入门教程。它向你展示了如何执行常见任务,并提供了大量的帮助链接。教程在首次启动后关闭后也可轻松访问,以便随时访问该教程。教程非常简单直观,这为 GNOME 新用户提供了一个简单明了开始。要之后返回本教程,请点击 **Activities**,然后点击会显示程序的有九个点的正方形。然后找到并点击标为救生员图标的 **Help**。
|
||||
|
||||
3、 **桌面整洁:** 对桌面环境采用极简方法以减少杂乱,GNOME 设计为仅提供具备可用环境所必需的最低限度。你应该只能看到顶部栏(是的,它就叫这个),其他所有的都被隐藏,直到需要才显示。目的是允许用户专注于手头的任务,并尽量减少桌面上其他东西造成的干扰。
|
||||
|
||||
4、 **顶部栏:** 无论你想做什么,顶部栏总是开始的地方。你可以启动应用程序、注销、关闭电源、启动或停止网络等。不管你想做什么都很简单。除了当前应用程序之外,顶栏通常是桌面上唯一的其他对象。
|
||||
|
||||
5、 **dash:** 如下所示,在默认情况下, dash 包含三个图标。在开始使用应用程序时,会将它们添加到 dash 中,以便在其中显示最常用的应用程序。你也可以从应用程序查看器中将应用程序图标添加到 dash 中。
|
||||
|
||||
|
||||
|
||||
6、 **应用程序浏览器:** 我真的很喜欢这个可以从位于 GNOME 桌面左侧的垂直条上访问应用程序浏览器。除非有一个正在运行的程序,GNOME 桌面通常没有任何东西,所以你必须点击顶部栏上的 **Activities** 选区,点击 dash 底部的九个点组成的正方形,它是应用程序浏览器的图标。
|
||||
|
||||
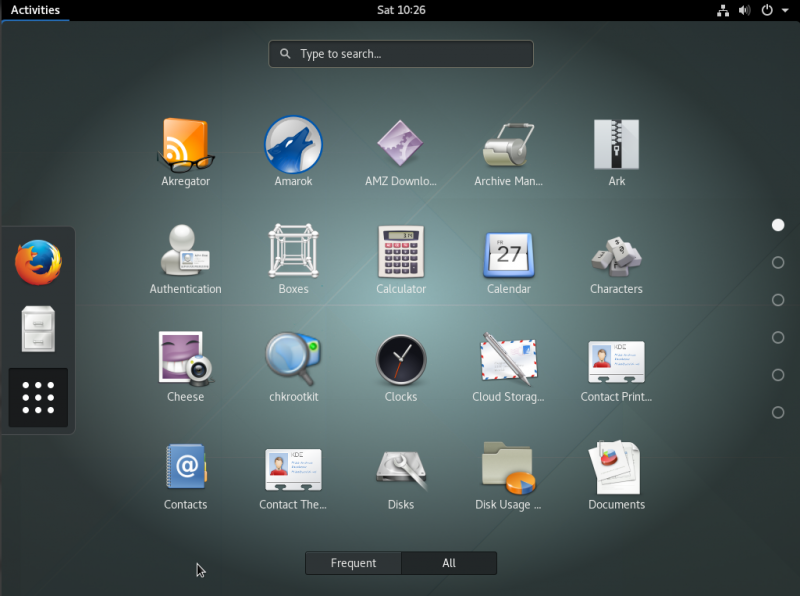
|
||||
|
||||
如上所示,浏览器本身是一个由已安装的应用程序的图标组成的矩阵。矩阵下方有一对互斥的按钮,**Frequent** 和 **All**。默认情况下,应用程序浏览器会显示所有安装的应用。点击 **Frequent** 按钮,它会只显示最常用的应用程序。向上和向下滚动以找到要启动的应用程序。应用程序按名称按字母顺序显示。
|
||||
|
||||
[GNOME][6] 官网和内置的帮助有更多关于浏览器的细节。
|
||||
|
||||
7、 **应用程序就绪通知:** 当新启动的应用程序的窗口打开并准备就绪时,GNOME 会在屏幕顶部显示一个整齐的通知。只需点击通知即可切换到该窗口。与在其他桌面上搜索新打开的应用程序窗口相比,这节省了一些时间。
|
||||
|
||||
8、 **应用程序显示:** 为了访问不可见的其它运行的应用程序,点击 **Activities** 菜单。这将在桌面上的矩阵中显示所有正在运行的应用程序。点击所需的应用程序将其带到前台。虽然当前应用程序显示在顶栏中,但其他正在运行的应用程序不会。
|
||||
|
||||
9、 **最小的窗口装饰:** 桌面上打开窗口也很简单。标题栏上唯一显示的按钮是关闭窗口的 “X”。所有其他功能,如最小化、最大化、移动到另一个桌面等,可以通过在标题栏上右键单击来访问。
|
||||
|
||||
10、 **自动创建的新桌面:** 在使用下一空桌面的时候将自动创建的新的空桌面。这意味着总是有一个空的桌面在需要时可以使用。我使用的所有其他的桌面系统都可以让你在桌面活动时设置桌面数量,但必须使用系统设置手动完成。
|
||||
|
||||
11、 **兼容性:** 与我所使用的所有其他桌面一样,为其他桌面创建的应用程序可在 GNOME 上正常工作。这功能让我有可能测试这些桌面,以便我可以写出它们。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
GNOME 不像我以前用过的桌面。它的主要指导是“简单”。其他一切都要以简单易用为前提。如果你从入门教程开始,学习如何使用 GNOME 需要很少的时间。这并不意味着 GNOME 有所不足。它是一款始终保持不变的功能强大且灵活的桌面。
|
||||
|
||||
(题图:[Gunnar Wortmann][8] 通过 [Pixabay][9]。由 Opensource.com 修改。[CC BY-SA 4.0][10])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both 是位于北卡罗来纳州罗利的 Linux 和开源倡导者。他已经在 IT 行业工作了四十多年,并为 IBM 教授 OS/2 超过 20 年。在 IBM,他在 1981 年为初始的 IBM PC 写了第一个培训课程。他为红帽教授 RHCE 课程,曾在 MCI Worldcom、思科和北卡罗来纳州工作。他一直在使用 Linux 和开源软件近 20 年。
|
||||
|
||||
---------------
|
||||
|
||||
via: https://opensource.com/article/17/5/reasons-gnome
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://www.gnome.org/gnome-3/
|
||||
[7]:https://opensource.com/article/17/5/reasons-gnome?rate=MbGLV210A21ONuGAP8_Qa4REL7cKFvcllqUddib0qMs
|
||||
[8]:https://pixabay.com/en/users/karpartenhund-3077375/
|
||||
[9]:https://pixabay.com/en/garden-gnome-black-and-white-f%C3%B6hr-1584401/
|
||||
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
[12]:https://linux.cn/article-8606-1.html
|
||||
[13]:https://linux.cn/article-8434-1.html
|
||||
[14]:https://www.gnome.org/gnome-3/
|
||||
[15]:https://opensource.com/user/14106/feed
|
||||
[16]:https://opensource.com/article/17/5/reasons-gnome#comments
|
||||
[17]:https://opensource.com/users/dboth
|
||||
@ -1,53 +1,52 @@
|
||||
物联网对 Linux 恶意软件的助长
|
||||
物联网助长了 Linux 恶意软件
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
针对 Linux 系统的恶意软件正在增长,这主要是由于连接到物联网设备的激增。
|
||||
|
||||
这是上周发布的网络安全设备制造商 [WatchGuard Technologies][4] 的一篇报告。
|
||||
这是网络安全设备制造商 [WatchGuard Technologies][4] 上周发布的的一篇报告中所披露的。
|
||||
|
||||
该报告分析了全球 26,000 多件设备收集到的数据,今年第一季度的前 10 中发现了三个针对 Linux 的恶意软件,而上一季度仅有一个。
|
||||
该报告分析了全球 26,000 多件设备收集到的数据,今年第一季度的前 10 名恶意软件中发现了三个针对 Linux 的恶意软件,而上一季度仅有一个。
|
||||
|
||||
WatchGuard 的 CTO Corey Nachreiner 和安全威胁分析师 Marc Laliberte 写道:“Linux 攻击和恶意软件正在兴起。我们相信这是因为 IoT 设备的系统性弱点与其快速增长相结合,它正在将僵尸网络作者转向 Linux 平台。”
|
||||
WatchGuard 的 CTO Corey Nachreiner 和安全威胁分析师 Marc Laliberte 写道:“Linux 上的攻击和恶意软件正在兴起。我们相信这是因为 IoT 设备的系统性弱点与其快速增长相结合的结果,它正在引导僵尸网络的作者们转向 Linux 平台。”
|
||||
|
||||
但是,他们建议“阻止入站 Telnet 和 SSH,以及使用复杂的管理密码,可以防止绝大多数潜在的攻击”。
|
||||
他们建议“阻止入站的 Telnet 和 SSH,以及使用复杂的管理密码,可以防止绝大多数潜在的攻击”。
|
||||
|
||||
### 黑客的新大道
|
||||
|
||||
Laliberte 观察到,Linux 恶意软件在去年年底随着 Mirai 僵尸网络开始增长。Mirai 在九月份曾经用来攻击部分互联网的基础设施,使数百万用户离线。
|
||||
Laliberte 观察到,Linux 恶意软件在去年年底随着 Mirai 僵尸网络开始增长。Mirai 在九月份曾经用来攻击部分互联网的基础设施,迫使数百万用户断线。
|
||||
|
||||
他告诉 LinuxInsider,“现在,随着物联网设备的飞速发展,一条全新的大道正在向攻击者开放。我们相信,随着互联网上新目标的出现,Linux 恶意软件会逐渐增多。”
|
||||
他告诉 LinuxInsider,“现在,随着物联网设备的飞速发展,一条全新的大道正在向攻击者们开放。我们相信,随着互联网上新目标的出现,Linux 恶意软件会逐渐增多。”
|
||||
|
||||
Laliberte 继续说,物联网设备制造商并没有对安全性表现出很大的关注。他们的目标是使他们的设备能够使用、便宜,制造快速。
|
||||
Laliberte 继续说,物联网设备制造商并没有对安全性表现出很大的关注。他们的目标是使他们的设备能够使用、便宜,能够快速制造。
|
||||
|
||||
他说:“他们真的不关心开发过程中的安全。”
|
||||
他说:“开发过程中他们真的不关心安全。”
|
||||
|
||||
### 微不足道的追求
|
||||
### 轻易捕获
|
||||
|
||||
[Alert Logic][5] 的网络安全宣传员 Paul Fletcher说,大多数物联网制造商都使用 Linux 的裁剪版本,因为操作系统需要最少的系统资源来运行。
|
||||
[Alert Logic][5] 的网络安全布道师 Paul Fletcher 说,大多数物联网制造商都使用 Linux 的裁剪版本,因为操作系统需要最少的系统资源来运行。
|
||||
|
||||
他告诉 LinuxInsider,“当你将大量与互联网连接的物联网设备结合在一起时,这相当于在线大量的 Linux 系统,它们可用于攻击。”
|
||||
|
||||
为了使设备易于使用,制造商使用的协议对黑客也是友好的。
|
||||
为了使设备易于使用,制造商使用的协议对黑客来说也是用户友好的。
|
||||
|
||||
Fletcher 说:“攻击者可以访问这些易受攻击的接口,然后上传并执行他们选择的恶意代码。”
|
||||
|
||||
他指出,厂商经常对设备的默认设置很差。
|
||||
他指出,厂商经常给他们的设备很差的默认设置。
|
||||
|
||||
Fletcher说:“通常,管理员帐户是空密码或易于猜测的默认密码,例如‘password123’。”
|
||||
Fletcher 说:“通常,管理员帐户是空密码或易于猜测的默认密码,例如 ‘password123’。”
|
||||
|
||||
[SANS 研究所][6] 首席研究员 Johannes B. Ullrich 表示,安全问题通常是“本身不限定 Linux”。
|
||||
[SANS 研究所][6] 首席研究员 Johannes B. Ullrich 表示,安全问题通常“本身不是 Linux 特有的”。
|
||||
|
||||
他告诉L inuxInsider,“制造商对他们如何配置设备不屑一顾,所以他们使这些设备的利用变得微不足道。”
|
||||
他告诉 LinuxInsider,“制造商对他们如何配置这些设备不屑一顾,所以他们使这些设备的利用变得非常轻易。”
|
||||
|
||||
### 10 大恶意软件
|
||||
|
||||
这些 Linux 恶意软件在 WatchGuard 的第一季度的统计数据中占据了前 10 名:
|
||||
|
||||
* Linux/Exploit,它使用几种木马来扫描可以列入僵尸网络的设备。
|
||||
|
||||
* Linux/Downloader,它使用恶意的 Linux shell 脚本。Linux 运行在许多不同的架构上,如 ARM、MIPS 和传统的 x8 6芯片组。报告解释说,一个根据架构编译的可执行文件不能在不同架构的设备上运行。因此,一些 Linux 攻击利用 dropper shell 脚本下载并安装它们所感染的体系架构的适当恶意组件。
|
||||
这些 Linux 恶意软件在 WatchGuard 的第一季度的统计数据中占据了前 10 名的位置:
|
||||
|
||||
* Linux/Exploit,它使用几种木马来扫描可以加入僵尸网络的设备。
|
||||
* Linux/Downloader,它使用恶意的 Linux shell 脚本。Linux 可以运行在许多不同的架构上,如 ARM、MIPS 和传统的 x86 芯片组。报告解释说,一个为某个架构编译的可执行文件不能在不同架构的设备上运行。因此,一些 Linux 攻击利用 dropper shell 脚本下载并安装适合它们所要感染的体系架构的恶意组件。
|
||||
* Linux/Flooder,它使用了 Linux 分布式拒绝服务工具,如 Tsunami,用于执行 DDoS 放大攻击,以及 Linux 僵尸网络(如 Mirai)使用的 DDoS 工具。报告指出:“正如 Mirai 僵尸网络向我们展示的,基于 Linux 的物联网设备是僵尸网络军队的主要目标。
|
||||
|
||||
### Web 服务器战场
|
||||
@ -56,27 +55,27 @@ WatchGuard 报告指出,敌人攻击网络的方式发生了变化。
|
||||
|
||||
公司发现,到 2016 年底,73% 的 Web 攻击针对客户端 - 浏览器和配套软件。今年头三个月发生了彻底改变,82% 的 Web 攻击集中在 Web 服务器或基于 Web 的服务上。
|
||||
|
||||
报告合著者 Nachreiner 和 Laliberte 写道:“我们不认为下载风格的攻击将会消失,但似乎攻击者已经集中力量和工具来试图利用 Web 服务器攻击。”
|
||||
报告合著者 Nachreiner 和 Laliberte 写道:“我们不认为下载式的攻击将会消失,但似乎攻击者已经集中力量和工具来试图利用 Web 服务器攻击。”
|
||||
|
||||
他们也发现,自 2006 年底以来,杀毒软件的有效性有所下降。
|
||||
|
||||
Nachreiner 和 Laliberte 报道说:“连续的第二季,我们看到使用传统的杀毒软件解决方案漏掉了使用我们更先进的解决方案可以捕获的大量恶意软件,实际上已经从 30% 上升到了 38%。”
|
||||
Nachreiner 和 Laliberte 报道说:“连续的第二个季度,我们看到使用传统的杀毒软件解决方案漏掉了使用我们更先进的解决方案可以捕获的大量恶意软件,实际上已经从 30% 上升到了 38% 漏掉了。”
|
||||
|
||||
他说:“如今网络犯罪分子使用许多精妙的技巧来重新包装恶意软件,从而避免了基于签名的检测。这就是为什么使用基本杀毒的许多网络成为诸如赎金软件之类威胁的受害者。”
|
||||
他说:“如今网络犯罪分子使用许多精妙的技巧来重新包装恶意软件,从而避免了基于签名的检测。这就是为什么使用基本的杀毒软件的许多网络成为诸如赎金软件之类威胁的受害者。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
John P. Mello Jr.自 2003 年以来一直是 ECT 新闻网记者。他的重点领域包括网络安全、IT问题、隐私权、电子商务、社交媒体、人工智能、大数据和消费电子。 他撰写和编辑了众多出版物,包括“波士顿商业杂志”、“波士顿凤凰”、“Megapixel.Net” 和 “政府安全新闻”。给 John 发邮件。
|
||||
John P. Mello Jr.自 2003 年以来一直是 ECT 新闻网记者。他的重点领域包括网络安全、IT问题、隐私权、电子商务、社交媒体、人工智能、大数据和消费电子。 他撰写和编辑了众多出版物,包括“波士顿商业杂志”、“波士顿凤凰”、“Megapixel.Net” 和 “政府安全新闻”。
|
||||
|
||||
-------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84652.html
|
||||
|
||||
作者:[John P. Mello Jr ][a]
|
||||
作者:[John P. Mello Jr][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
免费学习 Docker 的最佳方法:Play-with-docker(PWD)
|
||||
============================================================
|
||||
|
||||
去年在柏林的分布式系统峰会上,Docker 的负责人 [Marcos Nils][15] 和 [Jonathan Leibiusky][16] 宣称已经开始研究浏览器内置 Docker 的方案,帮助人们学习 Docker。 几天后,[Play-with-docker][17](PWD)就诞生了。
|
||||
|
||||
PWD 像是一个 Docker 游乐场,用户在几秒钟内就可以运行 Docker 命令。 还可以在浏览器中安装免费的 Alpine Linux 虚拟机,然后在虚拟机里面构建和运行 Docker 容器,甚至可以使用 [Docker 集群模式][18]创建集群。 有了 Docker-in-Docker(DinD)引擎,甚至可以体验到多个虚拟机/个人电脑的效果。 除了 Docker 游乐场外,PWD 还包括一个培训站点 [training.play-with-docker.com][19],该站点提供大量的难度各异的 Docker 实验和测验。
|
||||
|
||||
如果你错过了峰会,Marcos 和 Jonathan 在最后一场 DockerCon Moby Cool Hack 会议中展示了 PWD。 观看下面的视频,深入了解其基础结构和发展路线图。
|
||||
|
||||
|
||||
|
||||
在过去几个月里,Docker 团队与 Marcos、Jonathan,还有 Docker 社区的其他活跃成员展开了密切合作,为项目添加了新功能,为培训部分增加了 Docker 实验室。
|
||||
|
||||
### PWD: 游乐场
|
||||
|
||||
以下快速的概括了游乐场的新功能:
|
||||
|
||||
#### 1、 PWD Docker Machine 驱动和 SSH
|
||||
|
||||
随着 PWD 成功的成长,社区开始问他们是否可以使用 PWD 来运行自己的 Docker 研讨会和培训。 因此,对项目进行的第一次改进之一就是创建 [PWD Docker Machine 驱动][20],从而用户可以通过自己喜爱的终端轻松创建管理 PWD 主机,包括使用 SSH 相关命令的选项。 下面是它的工作原理:
|
||||
|
||||

|
||||
|
||||
#### 2、 支持文件上传
|
||||
|
||||
Marcos 和 Jonathan 还带来了另一个炫酷的功能就是可以在 PWD 实例中通过拖放文件的方式将 Dockerfile 直接上传到 PWD 窗口。
|
||||
|
||||

|
||||
|
||||
#### 3、 模板会话
|
||||
|
||||
除了文件上传之外,PWD 还有一个功能,可以使用预定义的模板在几秒钟内启动 5 个节点的群集。
|
||||
|
||||

|
||||
|
||||
#### 4、 一键使用 Docker 展示你的应用程序
|
||||
|
||||
PWD 附带的另一个很酷的功能是它的内嵌按钮,你可以在你的站点中使用它来设置 PWD 环境,并快速部署一个构建好的堆栈,另外还有一个 [chrome 扩展][21] ,可以将 “Try in PWD” 按钮添加 DockerHub 最流行的镜像中。 以下是扩展程序的一个简短演示:
|
||||
|
||||

|
||||
|
||||
### PWD 培训站点
|
||||
|
||||
[training.play-with-docker.com][22] 站点提供了大量新的实验。有一些值得注意的两点,包括两个来源于奥斯丁召开的 DockerCon 中的动手实践的实验,还有两个是 Docker 17.06CE 版本中亮眼的新功能:
|
||||
|
||||
* [可以动手实践的 Docker 网络实验][1]
|
||||
* [可以动手实践的 Docker 编排实验][2]
|
||||
* [多阶段构建][3]
|
||||
* [Docker 集群配置文件][4]
|
||||
|
||||
总而言之,现在有 36 个实验,而且一直在增加。 如果你想贡献实验,请从查看 [GitHub 仓库][23]开始。
|
||||
|
||||
### PWD 用例
|
||||
|
||||
根据网站访问量和我们收到的反馈,很可观的说,PWD 现在有很大的吸引力。下面是一些最常见的用例:
|
||||
|
||||
* 紧跟最新开发版本,尝试新功能。
|
||||
* 快速建立集群并启动复制服务。
|
||||
* 通过互动教程学习: [training.play-with-docker.com][5]。
|
||||
* 在会议和集会上做演讲。
|
||||
* 召开需要复杂配置的高级研讨会,例如 Jérôme’的 [Docker 编排高级研讨会][6]。
|
||||
* 和社区成员协作诊断问题检测问题。
|
||||
|
||||
参与 PWD:
|
||||
|
||||
* 通过[向 PWD 提交 PR][7] 做贡献
|
||||
* 向 [PWD 培训站点][8]贡献
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Victor 是 Docker, Inc. 的高级社区营销经理。他喜欢优质的葡萄酒、象棋和足球,上述爱好不分先后顺序。 Victor 的 tweet:@vcoisne 推特。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/best-way-learn-docker-free-play-docker-pwd/
|
||||
|
||||
作者:[Victor][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/victor_c/
|
||||
[1]:http://training.play-with-docker.com/docker-networking-hol/
|
||||
[2]:http://training.play-with-docker.com/orchestration-hol/
|
||||
[3]:http://training.play-with-docker.com/multi-stage/
|
||||
[4]:http://training.play-with-docker.com/swarm-config/
|
||||
[5]:http://training.play-with-docker.com/
|
||||
[6]:https://github.com/docker/labs/tree/master/Docker-Orchestration
|
||||
[7]:https://github.com/play-with-docker/
|
||||
[8]:https://github.com/play-with-docker/training
|
||||
[9]:https://blog.docker.com/author/victor_c/
|
||||
[10]:https://blog.docker.com/tag/docker-labs/
|
||||
[11]:https://blog.docker.com/tag/docker-training/
|
||||
[12]:https://blog.docker.com/tag/docker-workshops/
|
||||
[13]:https://blog.docker.com/tag/play-with-docker/
|
||||
[14]:https://blog.docker.com/tag/pwd/
|
||||
[15]:https://www.twitter.com/marcosnils
|
||||
[16]:https://www.twitter.com/xetorthio
|
||||
[17]:http://play-with-docker.com/
|
||||
[18]:https://docs.docker.com/engine/swarm/
|
||||
[19]:http://training.play-with-docker.com/
|
||||
[20]:https://github.com/play-with-docker/docker-machine-driver-pwd/releases/tag/v0.0.5
|
||||
[21]:https://chrome.google.com/webstore/detail/play-with-docker/kibbhpioncdhmamhflnnmfonadknnoan
|
||||
[22]:http://training.play-with-docker.com/
|
||||
[23]:https://github.com/play-with-docker/play-with-docker.github.io
|
||||
@ -1,177 +0,0 @@
|
||||
[Translating by Snapcrafter]
|
||||
Making your snaps available to the store using snapcraft
|
||||
============================================================
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
Now that Ubuntu Core has been officially released, it might be a good time to get your snaps into the Store!
|
||||
|
||||
**Delivery and Store Concepts **
|
||||
So let’s start with a refresher on what we have available on the Store side to manage your snaps.
|
||||
|
||||
Every time you push a snap to the store, the store will assign it a revision, this revision is unique in the store for this particular snap.
|
||||
|
||||
However to be able to push a snap for the first time, the name needs to be registered which is pretty easy to do given the name is not already taken.
|
||||
|
||||
Any revision on the store can be released to a number of channels which are defined conceptually to give your users the idea of a stability or risk level, these channel names are:
|
||||
|
||||
* stable
|
||||
|
||||
* candidate
|
||||
|
||||
* beta
|
||||
|
||||
* edge
|
||||
|
||||
Ideally anyone with a CI/CD process would push daily or on every source update to the edge channel. During this process there are two things to take into account.
|
||||
|
||||
The first thing to take into account is that at the beginning of the snapping process you will likely get started with a non confined snap as this is where the bulk of the work needs to happen to adapt to this new paradigm. With that in mind, your project gets started with a confinement set to devmode. This makes it possible to get going on the early phases of development and still get your snap into the store. Once everything is fully supported with the security model snaps work in, this confinement entry can be switched to strict. Given the confinement level of devmode this snap is only releasable on the edge and beta channels which hints your users on how much risk they are taking by going there.
|
||||
|
||||
So let’s say you are good to go on the confinement side and you start a CI/CD process against edge but you also want to make sure in some cases that early releases of a new iteration against master never make it to stable or candidate and for this we have a grade entry. If the grade of the snap is set to devel the store will never allow you to release to the most stable channels (stable and candidate). not be possible.
|
||||
|
||||
Somewhere along the way we might want to release a revision into beta which some users are more likely want to track on their side (which given good release management process should be to some level more usable than a random daily build). When that stage in the process is over but want people to keep getting updates we can choose to close the beta channel as we only plan to release to candidate and stable from a certain point in time, by closing this beta channel we will make that channel track the following open channel in the stability list, in this case it is candidate, if candidate is tracking stable whatever is in stable is what we will get.
|
||||
|
||||
**Enter Snapcraft**
|
||||
|
||||
So given all these concepts how do we get going with snapcraft, first of all we need to login:
|
||||
|
||||
```
|
||||
$ snapcraft login
|
||||
Enter your Ubuntu One SSO credentials.
|
||||
Email: sxxxxx.sxxxxxx@canonical.com
|
||||
Password: **************
|
||||
Second-factor auth: 123456
|
||||
```
|
||||
|
||||
After logging in we are ready to get our snap registered, for examples sake let’s say we wanted to register awesome-database, a fantasy snap we want to get started with:
|
||||
|
||||
```
|
||||
$ snapcraft register awesome-database
|
||||
We always want to ensure that users get the software they expect
|
||||
for a particular name.
|
||||
|
||||
If needed, we will rename snaps to ensure that a particular name
|
||||
reflects the software most widely expected by our community.
|
||||
|
||||
For example, most people would expect ‘thunderbird’ to be published by
|
||||
Mozilla. They would also expect to be able to get other snaps of
|
||||
Thunderbird as 'thunderbird-sergiusens'.
|
||||
|
||||
Would you say that MOST users will expect 'a' to come from
|
||||
you, and be the software you intend to publish there? [y/N]: y
|
||||
|
||||
You are now the publisher for 'awesome-database'
|
||||
```
|
||||
|
||||
So assuming we have the snap built already, all we have to do is push it to the store. Let’s take advantage of a shortcut and –release in the same command:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap --release edge
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 1 of 'awesome-database' created.
|
||||
|
||||
Channel Version Revision
|
||||
stable - -
|
||||
candidate - -
|
||||
beta - -
|
||||
edge 0.1 1
|
||||
|
||||
The edge channel is now open.
|
||||
```
|
||||
|
||||
If we try to release this to stable the store will block us:
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 1 stable
|
||||
Revision 1 (devmode) cannot target a stable channel (stable, grade: devel)
|
||||
```
|
||||
|
||||
We are safe from messing up and making this available to our faithful users. Now eventually we will push a revision worthy of releasing to the stable channel:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 10 of 'awesome-database' created.
|
||||
```
|
||||
|
||||
```
|
||||
Notice that the version is just a friendly identifier and what really matters is the revision number the store generates for us. Now let’s go ahead and release this to stable:
|
||||
```
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 10 stable
|
||||
Channel Version Revision
|
||||
stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge 0.1 10
|
||||
|
||||
The 'stable' channel is now open.
|
||||
```
|
||||
|
||||
In this last channel map view for the architecture we are working with, we can see that edge is going to be stuck on revision 10, and that beta and candidate will be following stable which is on revision 10\. For some reason we decide that we will focus on stability and make our CI/CD push to beta instead. This means that our edge channel will slightly fall out of date, in order to avoid things like this we can decide to close the channel:
|
||||
|
||||
```
|
||||
$ snapcraft close awesome-database edge
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
|
||||
The edge channel is now closed.
|
||||
```
|
||||
|
||||
In this current state, all channels are following the stable channel so people subscribed to candidate, beta and edge would be tracking changes to that channel. If revision 11 is ever pushed to stable only, people on the other channels would also see it.
|
||||
|
||||
This listing also provides us with a full architecture view, in this case we have only been working with amd64.
|
||||
|
||||
**Getting more information**
|
||||
|
||||
So some time passed and we want to know what was the history and status of our snap in the store. There are two commands for this, the straightforward one is to run status which will give us a familiar result:
|
||||
|
||||
```
|
||||
$ snapcraft status awesome-database
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
```
|
||||
|
||||
We can also get the full history:
|
||||
|
||||
```
|
||||
$ snapcraft history awesome-database
|
||||
Rev. Uploaded Arch Version Channels
|
||||
3 2016-09-30T12:46:21Z amd64 0.1 stable*
|
||||
...
|
||||
...
|
||||
...
|
||||
2 2016-09-30T12:38:20Z amd64 0.1 -
|
||||
1 2016-09-30T12:33:55Z amd64 0.1 -
|
||||
```
|
||||
|
||||
**Closing remarks**
|
||||
|
||||
I hope this gives an overview of the things you can do with the store and more people start taking advantage of it!
|
||||
|
||||
[Publish a snap][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2016/11/15/making-your-snaps-available-to-the-store-using-snapcraft/
|
||||
|
||||
作者:[Sergio Schvezov ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[1]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[2]:http://snapcraft.io/docs/build-snaps/publish
|
||||
@ -1,4 +1,4 @@
|
||||
Writing a Time Series Database from Scratch
|
||||
Translating by Torival Writing a Time Series Database from Scratch
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,175 @@
|
||||
使用 snapcraft 将 snap 包发布到商店
|
||||
|
||||
==================
|
||||
|
||||

|
||||
|
||||
现在 Ubuntu Core 已经正式发布,也许是时候让你的 snap 包进入商店了!
|
||||
|
||||
### 交付和商店的概念
|
||||
|
||||
首先回顾一下我们是怎么通过商店管理 snap 包的吧。
|
||||
|
||||
每次你上传 snap 包,商店都会为其分配一个修订版本号,并且商店中针对特定 snap 包 的版本号都是唯一的。
|
||||
|
||||
但是第一次上传 snap 包的时候,我们首先要为其注册一个还没有被使用的名字,并且这很容易去做。
|
||||
|
||||
商店中所有的修订版本都可以释放到多个通道中,这些通道只是概念上定义的,以便给用户一个稳定或风险等级的参照,这些通道有:
|
||||
|
||||
* 稳定
|
||||
|
||||
* 候选
|
||||
|
||||
* 测试
|
||||
|
||||
* 边缘
|
||||
|
||||
理想情况下,如果我们设置了 CI/CD 过程,那么每天或在每次更新源码时都会将其推送到边缘通道。在此过程中有两件事需要考虑。
|
||||
|
||||
首先在开始的时候,你最好制作一个不受限制的 snap 包,因为在这种新范例下,snap 包的大部分功能都能不受限制地工作。考虑到这一点,你的项目开始时 confinement (LCTT注:snapcraft.yaml 中的一个键)将被设置为 devmode(LCTT注:snapcraft.yaml 中 confinement 键的一个可选值)。这使得你在开发的早期阶段,仍然可以让你的 snap 包进入商店。一旦所有的东西都得到了 snap 包运行的安全模型的充分支持,那么就可以将 confinement 修改为 strict。
|
||||
|
||||
好了,假设你在限制方面已经做好了,并且也开始了一个对应边缘通道的 CI/CD 过程,但是如果你也想确保在某些情况下,早期版本 master 分支新的迭代永远也不会进入稳定或候选通道,那么我们可以使用 gadge (LCTT注:snapcraft.yaml 中的一个键)。如果 snap 包的 gadge 设置为 devel (LCTT注:snapcraft.yaml 中 gadge 键的一个可选值),商店将会永远禁止你将 snap 包释放到稳定和候选通道。
|
||||
|
||||
在这个过程中,我们有时可能想要发布一个修订版本到测试通道,以便让有些用户更愿意去跟踪它(一个好的发布管理流程应该比一个随机的日常构建更有用)。这个阶段结束后,如果希望人们仍然能保持更新,我们可以选择关闭测试通道来作为我们只计划发布到候选和稳定通道的一个的时间点。通过关闭测试通道我们将确保通道将沿着稳定列表中的开放通道走下去,在这种情况下是候选通道。如果候选通道跟踪稳定后,那么就可以发布到稳定通道了。
|
||||
|
||||
### 进入 Snapcraft
|
||||
|
||||
那么所有这些给定的概念是如何在 snapcraft 中配合使用的?首先我们需要登录:
|
||||
|
||||
```
|
||||
$ snapcraft login
|
||||
Enter your Ubuntu One SSO credentials.
|
||||
Email: sxxxxx.sxxxxxx@canonical.com
|
||||
Password: **************
|
||||
Second-factor auth: 123456
|
||||
```
|
||||
|
||||
在登录之后,我们就可以开始注册 snap 了。例如,我们想要注册一个虚构的 snap 包 awesome-database:
|
||||
|
||||
```
|
||||
$ snapcraft register awesome-database
|
||||
We always want to ensure that users get the software they expect
|
||||
for a particular name.
|
||||
|
||||
If needed, we will rename snaps to ensure that a particular name
|
||||
reflects the software most widely expected by our community.
|
||||
|
||||
For example, most people would expect ‘thunderbird’ to be published by
|
||||
Mozilla. They would also expect to be able to get other snaps of
|
||||
Thunderbird as 'thunderbird-sergiusens'.
|
||||
|
||||
Would you say that MOST users will expect 'a' to come from
|
||||
you, and be the software you intend to publish there? [y/N]: y
|
||||
|
||||
You are now the publisher for 'awesome-database'
|
||||
```
|
||||
|
||||
假设我们已经构建了 snap 包,接下来我们要做的就是把它上传到商店。我们可以在同一个命令中使用快捷方式和 --release 选项:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap --release edge
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 1 of 'awesome-database' created.
|
||||
|
||||
Channel Version Revision
|
||||
stable - -
|
||||
candidate - -
|
||||
beta - -
|
||||
edge 0.1 1
|
||||
|
||||
The edge channel is now open.
|
||||
```
|
||||
|
||||
如果我们试图将其发布到稳定通道,商店将会阻止我们:
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 1 stable
|
||||
Revision 1 (devmode) cannot target a stable channel (stable, grade: devel)
|
||||
```
|
||||
|
||||
我们不会搞砸,也不会让我们的忠实用户使用它。现在,我们将最终推出一个值得发布到稳定通道的修订版本:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 10 of 'awesome-database' created.
|
||||
```
|
||||
|
||||
注意,版本号(LCTT注:这里指的是 snap 包名中 `0.1` 这个版本号)只是一个友好的标识符,真正重要的是商店为我们生成的修订版本号(LCTT注:这里生成的修订版本号为 `10`)。现在让我们把它释放到稳定通道:
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 10 stable
|
||||
Channel Version Revision
|
||||
stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge 0.1 10
|
||||
|
||||
The 'stable' channel is now open.
|
||||
```
|
||||
在这个针对我们正在使用架构最终的通道映射视图中,可以看到边缘通道将会被固定在修订版本 10 上,并且测试和候选通道将会跟随现在修订版本为 10 的稳定通道。由于某些原因,我们决定将专注于稳定性并让我们的 CI/CD 推送到测试通道。这意味着我们的边缘通道将会略微过时,为了避免这种情况,我们可以关闭这个通道:
|
||||
|
||||
```
|
||||
$ snapcraft close awesome-database edge
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
|
||||
The edge channel is now closed.
|
||||
```
|
||||
|
||||
在当前状态下,所有通道都跟随着稳定通道,因此订阅了候选、测试和边缘通道的人也将跟踪稳定通道的改动。比如就算修订版本 11 只发布到稳定通道,其他通道的人们也能看到它。
|
||||
|
||||
这个清单还提供了完整的体系结构视图,在本例中,我们只使用了 amd64。
|
||||
|
||||
### 获得更多的信息
|
||||
|
||||
有时过了一段时间,我们想知道商店中的某个 snap 包的历史记录和现在的状态是什么样的,这里有两个命令,一个是直截了当输出当前的状态,它会给我们一个熟悉的结果:
|
||||
|
||||
```
|
||||
$ snapcraft status awesome-database
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
```
|
||||
|
||||
我们也可以通过下面的命令获得完整的历史记录:
|
||||
|
||||
```
|
||||
$ snapcraft history awesome-database
|
||||
Rev. Uploaded Arch Version Channels
|
||||
3 2016-09-30T12:46:21Z amd64 0.1 stable*
|
||||
...
|
||||
...
|
||||
...
|
||||
2 2016-09-30T12:38:20Z amd64 0.1 -
|
||||
1 2016-09-30T12:33:55Z amd64 0.1 -
|
||||
```
|
||||
|
||||
### 结束语
|
||||
|
||||
希望这篇文章能让你对商店能做的事情有一个大概的了解,并让更多的人开始使用它!
|
||||
|
||||
--------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2016/11/15/making-your-snaps-available-to-the-store-using-snapcraft/
|
||||
|
||||
***译者简介:***
|
||||
> snapcraft.io 的钉子户,对 Ubuntu Core、Snaps 和 Snapcraft 有着浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人的公众号: `Snapcraft`,近期会在上面连载几篇有关 Core snap 发布策略、交付流程和验证流程的文章,欢迎围观 :)
|
||||
|
||||
|
||||
作者:[Sergio Schvezov][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[1]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[2]:http://snapcraft.io/docs/build-snaps/publish
|
||||
@ -1,196 +0,0 @@
|
||||
Kubernetes是什么?What is Kubernetes?
|
||||
============================================================
|
||||
本文是Kubernetes的概览。
|
||||
|
||||
|
||||
* [为什么选择Kubernetes?][7]
|
||||
|
||||
* [为什么我需要Kubernetes,它能做什么?][1]
|
||||
|
||||
* [Kubernetes是一个什么样的平台?][2]
|
||||
|
||||
* [Kubernetes不是什么?][3]
|
||||
|
||||
* [Kubernetes这个单词的含义?k8s?][4]
|
||||
|
||||
* [接下来][8]
|
||||
|
||||
|
||||
Kubernetes 是一款跨集群的 [专门为自动化部署、缩放、操作应用程序容器的开源平台][25] , 提供了以容器为中心的基础架构。
|
||||
|
||||
使用 Kubernetes , 你可以快速、高效地满足用户以下的需求:
|
||||
|
||||
* 快速精准地部署应用程序
|
||||
|
||||
* 即时缩放应用程序
|
||||
|
||||
* 无缝展现新特征
|
||||
|
||||
我们的目标是,在公有或私有云中,培育出可以释放正在运行的程序的负担的一系列工具和组件的生态系统。
|
||||
|
||||
#### Kubernetes 的优势
|
||||
|
||||
* **轻便**: 公有云、私有云、混合云、多态云
|
||||
|
||||
* **可扩展**: 模块化、组件化,可添加插件、可Hook
|
||||
|
||||
* **自动修正**: 自动布局、自动重启、自动复制、自动缩放
|
||||
|
||||
Google 公司于2014年启动了 Kubernetes 项目。Kubernetes 是在[ Google 的长达15年的成规模的产品运行工作量的经验下][26]构建的, 结合了公司中最优秀的创意,并在社区中经历了反复地实践。
|
||||
|
||||
### 为什么选择容器?
|
||||
|
||||
想要知道你为什么要选择使用 [容器][27]?
|
||||
|
||||

|
||||
|
||||
程序部署的 _旧方法_ 是指,通过操作系统包管理器在主机上安装程序。这样做的坏处是,容易混淆程序之间以及程序和主机系统之间的可执行文件、配置文件、库、生命周期。为了达到精准展现和精准回撤,你可以搭建一台不可变的虚拟机映象。但是虚拟机体量往往过于庞大。
|
||||
|
||||
容器部署的 _新方法_ 是基于操作系统级别的可视化,而非硬件可视化。容器彼此是孤立的,相对于主机也是独立的:它们有自己的文件系统,彼此之间不能看到对方的进程,分配到的计算资源都是有边界的。它们比虚拟机更容易搭建。并且由于和基础架构、主机文件系统是解耦的,它们可以在不同类型的云上或分布式OS上应用。
|
||||
|
||||
正因为容器又小又快,每一个容器映象都可以打包装载一个程序。这种一对一的「程序 - 映象」联系带给了容器诸多便捷。有了容器,静态容器映象可以在编译/发布时期创建,而非部署时期。因此,每个应用不必再等待和整个应用栈其它部分进行整合,也不必和产品基础架构环境之间进行妥协。在编译/发布时期生成容器映象建立了一个持续地把开发转化为产品的环境。相似地,容器远比虚拟机更加透明,尤其在设备监控和管理上。这一点,在容器的进程生命周期被基础架构管理而非被容器内的进程监督器隐藏掉时,尤为显著。最终,随着每个容器内都装载了单一的程序,管理容器就等于管理或部署整个应用。
|
||||
|
||||
容器优势总结:
|
||||
|
||||
* **敏捷的应用创建与部署**: 相比虚拟机映象,容器映象的创建更简便、更高效。
|
||||
|
||||
* **持续的开发,集成,以及部署**: 在快速回撤下提供可靠、高频的容器映象编译和部署(基于映象的不可变性)。
|
||||
|
||||
* **开发与运营的关注点分离**: 由于容器映象是在编译/发布期创建的,因此整个过程与基础架构解耦。
|
||||
|
||||
* **跨开发、测试、产品阶段的环境稳定性**: 在笔记本电脑上的运行结果和在云上完全一致。
|
||||
|
||||
* **云平台与分布式OS平台高适应性**: 可以在Ubuntu, RHEL, CoreOS, on-prem, Google 容器引擎,乃至其它各类平台上运行。
|
||||
|
||||
* **以应用为核心的管理**: 从在虚拟硬件上运行系统,到在利用逻辑资源的系统上运行程序,从而提升了系统的抽象层级。
|
||||
|
||||
* **松散耦联、分布式、弹性、无拘束的 [微服务][5]**: 整个应用被分散为更小更独立的模块,并且这些模块可以被动态地部署和管理,而不再是存储在大型单用途机器上的臃肿的单一应用栈。
|
||||
|
||||
* **资源隔离**: 增加程序表现的可预见性。
|
||||
|
||||
* **资源利用率**: 高效且密集。
|
||||
|
||||
#### 为什么我需要Kubernetes,它能做什么?
|
||||
|
||||
至少,Kubernetes 能在实体机或虚拟机集群上安排和运行程序容器。而且,Kubernetes 也能让开发者斩断联系着实体机或虚拟机的「锁链」,从 **主机为中心** 的架构跃至 **容器为中心** 的架构。该架构最终提供给开发者诸多内在的优势和便利。Kubernetes 提供给基础架构以真正的 **容器为中心** 的开发环境。
|
||||
|
||||
Kubernetes 满足了一系列产品内运行程序的普通需求,诸如:
|
||||
|
||||
* [共用地址的帮助进程][9],协助应用程序整合,维护一对一「程序 - 映象」模型。
|
||||
|
||||
* [装备存储系统][10]
|
||||
|
||||
* [分布机密][11]
|
||||
|
||||
* [检查程序状态][12]
|
||||
|
||||
* [复制应用实例][13]
|
||||
|
||||
* [使用横向荚式自动缩放][14]
|
||||
|
||||
* [命名与发现][15]
|
||||
|
||||
* [负载均衡][16]
|
||||
|
||||
* [滚动更新][17]
|
||||
|
||||
* [资源监控][18]
|
||||
|
||||
* [访问并读取日志][19]
|
||||
|
||||
* [程序调试][20]
|
||||
|
||||
* [提供验证与授权][21]
|
||||
|
||||
以上这些共同组成了一套精简的平台即服务 (PaaS) 系统以及相关的灵活的基础架构即服务 (IaaS) 系统。此外还协助跨平台服务提供商增强了适用性。
|
||||
|
||||
#### Kubernetes是一个什么样的平台?
|
||||
|
||||
虽然 Kubernetes 提供了非常多的功能,总会有更多受益于新特性的新场景出现。针对特定应用的工作流程,能被流水线化以加速开发速度。专属设备组合在初始状态就可以被系统接受,这往往需要系统拥有健壮的自动缩放功能。这也是为什么 Kubernetes 同样被设计为以构造为了更方便地部署、缩放、管理程序为目的的工具组生态系统的平台。
|
||||
|
||||
[标签][28] 可以让用户按照自己的喜好组织资源。 [注释][29]让用户在资源里添加客户信息,以优化工作流程、简化管理工具、标示调试状态。
|
||||
|
||||
此外,[Kubernetes 控制面板][30]由同一[API][31]搭建,开发者和用户都可以使用。用户可以编写自己的控制器,比如[schedulers][32],使用[自己的 API][33]可以被通用的[命令行工具][34]识别。
|
||||
|
||||
这种 [设计][35] 让其它系统也能经由 Kubernetes 构建。
|
||||
|
||||
#### Kubernetes不是什么?
|
||||
|
||||
Kubernetes 不是传统的,全包容的平台即服务(Paas)系统。关键时刻,它尊重用户的选择。
|
||||
|
||||
Kubernetes:
|
||||
|
||||
* 并不限制支持的程序类型。它并不检测程序的框架 (例如, [Wildfly][22]),也不限制运行时支持的语言集合 (比如, Java, Python, Ruby),也不仅仅迎合 [12因子应用程序][23],也不区分 _应用_ 与 _服务_ 。Kubernetes 旨在支持尽可能多种类的工作负载,包括无状态的,有状态的,数据处理的工作负载。如果某程序在容器内运行良好,它在 Kubernetes 上只可能运行地更好。
|
||||
|
||||
* 不提供中间件(例如消息总线),数据处理框架(例如Spark),数据库(例如mysql),也不提供集群存储系统(例如Ceph)和内置服务。但是以上程序都可以在 Kubernetes 上运行。
|
||||
|
||||
* 没有「点击即部署」这类营销策略存在。
|
||||
|
||||
* 不部署源代码,也不编译程序。持续集成 (CI) 工作流程是不同的用户和项目拥有其各自不同的需求和表现的地方。所以,Kubernetes 支持分层 CI 工作流程,却并不监听每层的工作状态。
|
||||
|
||||
* 允许用户自行选择日志、监控、预警系统。( Kubernetes 提供一些集成工具以保证这一概念得到执行。)
|
||||
|
||||
* 不提供也不管理一套完整的程序配置语言/系统(例如[jsonnet][24])。
|
||||
|
||||
* 不提供也不配合任何完整的机器配置、维护、管理、自我修复系统。
|
||||
|
||||
另一方面说,一系列 PaaS 系统运行 _在_ Kubernetes 上,诸如 [Openshift][36], [Deis][37], 以及 [Eldarion][38]。你也可以开发你的自定义 PaaS,整合上你自选的 CI 系统,或者只在 Kubernetes 上部署容器映象。
|
||||
|
||||
而且, Kubernetes 不只是一个 _编排系统_ 。其实,它解决了编排的需求。 _编排_ 的技术定义是,对如下工作流程的执行:先做A,再做B,最后做C。相反地, Kubernetes 囊括了一系列独立、可组合的控制进程,它们持续驱动当前状态向需求的状态发展。从A到C的具体过程并不唯一。这将使系统更易用、更高效、更健壮、复用性、扩展性更强。
|
||||
|
||||
既然 Kubernetes 运行在应用层而非硬件层,它提供一些通用的应用特性,与一般 PaaS 提供的类似,如部署、缩放、负载均衡、日志、监控。然而, Kubernetes 并非铁板一块,这些默认的解决方案是可供选择,可自行增加或删除的。
|
||||
|
||||
#### Kubernetes这个单词的含义?k8s?
|
||||
|
||||
**Kubernetes** 这个单词来自于希腊语,含义是 _舵手_ 或 _领航员_ 。它的词根有 _governor_ 和 [cybernetic][39]。 _K8s_ 是它的缩写,用8字替代了「ubernete」。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
|
||||
|
||||
作者:[kubernetes.io][a]
|
||||
译者:[songshuang00](https://github.com/songsuhang00)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kubernetes.io/
|
||||
[1]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-do-i-need-kubernetes-and-what-can-it-do
|
||||
[2]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#how-is-kubernetes-a-platform
|
||||
[3]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-kubernetes-is-not
|
||||
[4]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-does-kubernetes-mean-k8s
|
||||
[5]:https://martinfowler.com/articles/microservices.html
|
||||
[6]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#kubernetes-is
|
||||
[7]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-containers
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#whats-next
|
||||
[9]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[10]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[11]:https://kubernetes.io/docs/concepts/configuration/secret/
|
||||
[12]:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
|
||||
[13]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[14]:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
||||
[15]:https://kubernetes.io/docs/concepts/services-networking/connect-applications-service/
|
||||
[16]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[17]:https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller/
|
||||
[18]:https://kubernetes.io/docs/tasks/debug-application-cluster/resource-usage-monitoring/
|
||||
[19]:https://kubernetes.io/docs/concepts/cluster-administration/logging/
|
||||
[20]:https://kubernetes.io/docs/tasks/debug-application-cluster/debug-application-introspection/
|
||||
[21]:https://kubernetes.io/docs/admin/authorization/
|
||||
[22]:http://wildfly.org/
|
||||
[23]:https://12factor.net/
|
||||
[24]:https://github.com/google/jsonnet
|
||||
[25]:http://www.slideshare.net/BrianGrant11/wso2con-us-2015-kubernetes-a-platform-for-automating-deployment-scaling-and-operations
|
||||
[26]:https://research.google.com/pubs/pub43438.html
|
||||
[27]:https://aucouranton.com/2014/06/13/linux-containers-parallels-lxc-openvz-docker-and-more/
|
||||
[28]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[29]:https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/
|
||||
[30]:https://kubernetes.io/docs/concepts/overview/components/
|
||||
[31]:https://kubernetes.io/docs/reference/api-overview/
|
||||
[32]:https://git.k8s.io/community/contributors/devel/scheduler.md
|
||||
[33]:https://git.k8s.io/community/contributors/design-proposals/extending-api.md
|
||||
[34]:https://kubernetes.io/docs/user-guide/kubectl-overview/
|
||||
[35]:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/principles.md
|
||||
[36]:https://www.openshift.org/
|
||||
[37]:http://deis.io/
|
||||
[38]:http://eldarion.cloud/
|
||||
[39]:http://www.etymonline.com/index.php?term=cybernetics
|
||||
@ -1,126 +1,124 @@
|
||||
# Linux开机引导和启动过程简介
|
||||
|
||||
---
|
||||
>你是否曾经对操作系统为何能够执行应用程序而感到疑惑?那么本文将为你揭开操作系统引导与启动的面纱。
|
||||
Linux 开机引导和启动过程详解
|
||||
===========
|
||||
|
||||
|
||||
理解操作系统开机引导和启动过程对于配置操作系统和解决相关启动问题是至关重要的。该文章陈述了 GRUB2 引导装载程序开机引导装载内核的过程和 systemd 执行开机启动操作系统的过程。
|
||||
> 你是否曾经对操作系统为何能够执行应用程序而感到疑惑?那么本文将为你揭开操作系统引导与启动的面纱。
|
||||
|
||||
事实上,操作系统的启动分为两个阶段:引导和启动。引导阶段开始于打开电源开关,结束于内核初始化完成和 systemd 进程成功拉起。启动阶段接管了剩余工作,直到操作系统可用。
|
||||
理解操作系统开机引导和启动过程对于配置操作系统和解决相关启动问题是至关重要的。该文章陈述了 [GRUB2 引导装载程序][1]开机引导装载内核的过程和 [systemd 初始化系统][2]执行开机启动操作系统的过程。
|
||||
|
||||
总体来说,Linux 的开机引导和启动过程是相当容易理解,下文将分章节对于不同步骤进行详细说明。
|
||||
事实上,操作系统的启动分为两个阶段:<ruby>引导<rt>boot</rt></ruby>和<ruby>启动<rt>startup</rt></ruby>。引导阶段开始于打开电源开关,结束于内核初始化完成和 systemd 进程成功运行。启动阶段接管了剩余工作,直到操作系统进入可操作状态。
|
||||
|
||||
其他Linux参考资源
|
||||
- [What is Linux?](https://opensource.com/resources/what-is-linux?src=linux_resource_menu)
|
||||
- [What are Linux containers?](https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu)
|
||||
- [Managing devices in Linux](https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu)
|
||||
- [Download Now: Linux commands cheat sheet](https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ)
|
||||
- [Our latest Linux articles](https://opensource.com/tags/linux?src=linux_resource_menu)
|
||||
- BIOS POST
|
||||
- Boot loader (GRUB2)
|
||||
- Kernel initialization
|
||||
- Start systemd, the parent of all processes.
|
||||
总体来说,Linux 的开机引导和启动过程是相当容易理解,下文将分节对于不同步骤进行详细说明。
|
||||
|
||||
注意,本文以 GRUB2 和 systemd 为载体讲述操作系统的开机引导和启动过程,是因为两者是目前主流的 linux 发行版本所使用的引导加载内核和初始化系统的软件。当然另外一些过去使用的相关软件仍然在一些 Linux 发行版本中使用。
|
||||
- BIOS 上电自检(POST)
|
||||
- 引导装载程序 (GRUB2)
|
||||
- 内核初始化
|
||||
- 启动 systemd,其是所有进程之父。
|
||||
|
||||
## 引导过程
|
||||
注意,本文以 GRUB2 和 systemd 为载体讲述操作系统的开机引导和启动过程,是因为这二者是目前主流的 linux 发行版本所使用的引导装载程序和初始化软件。当然另外一些过去使用的相关软件仍然在一些 Linux 发行版本中使用。
|
||||
|
||||
发起引导过程的方法有两种。首先,如果系统处于关机状态,那么打开电源按钮将开启系统引导过程。其次,如果操作系统已经运行在一个本地用户(该用户可是 root 或其他非特权用户),那么用户可以借助图形界面或命令行界面通过编程方式发起一个重启操作,从而触发系统引导过程。重启包括了一个关机和启动操作。
|
||||
### 引导过程
|
||||
|
||||
### BIOS上电自检
|
||||
引导过程能以两种方式之一初始化。其一,如果系统处于关机状态,那么打开电源按钮将开启系统引导过程。其二,如果操作系统已经运行在一个本地用户(该用户可以是 root 或其他非特权用户),那么用户可以借助图形界面或命令行界面通过编程方式发起一个重启操作,从而触发系统引导过程。重启包括了一个关机和重新开始的操作。
|
||||
|
||||
上电自检过程中其实 Linux 没有什么也没做,上电自检主要由硬件完成,这对于所有操作系统都一样。当电脑接通电源,电脑开始执行 BIOS(基本输入输出系统)的 POST(上电自检)过程。
|
||||
#### BIOS 上电自检(POST)
|
||||
|
||||
在 1981 年,IBM设计的第一台个人电脑中,BIOS 被设计为初始烧录于硬件组件中。POST作为 BIOS 的组成部分,用于检验电脑硬件基本功能是否正常。如果 POST 失败,那么这个电脑就不能使用,引导过程也将就此中断。
|
||||
上电自检过程中其实 Linux 没有什么也没做,上电自检主要由硬件的部分来完成,这对于所有操作系统都一样。当电脑接通电源,电脑开始执行 BIOS(<ruby>基本输入输出系统<rt>Basic I/O System</rt></ruby>)的 POST(<ruby>上电自检<rt>Power On Self Test</rt></ruby>)过程。
|
||||
|
||||
BIOS 上电自检确认硬件的基本功能正常,然后产生一个 BIOS 中断,INT 13H,该中断指向任何可启动设备的启动记录。如果在该启动扇区中发现一个有效的启动记录,那么BIOS将加载启动记录中的数据到内存中。控制权也将从BIOS转移到此段代码。
|
||||
在 1981 年,IBM 设计的第一台个人电脑中,BIOS 被设计为用来初始化硬件组件。POST 作为 BIOS 的组成部分,用于检验电脑硬件基本功能是否正常。如果 POST 失败,那么这个电脑就不能使用,引导过程也将就此中断。
|
||||
|
||||
设备启动记录中代码加载是引导加载器真正的第一阶段。大多数 Linux 发行版本使用的引导加载器一共有 3 种,GRUB,GRUB2 和 LILO。GRUB2 是最新出现的,也是相对于其他老的选项使用最广泛的。
|
||||
BIOS 上电自检确认硬件的基本功能正常,然后产生一个 BIOS [中断][3] INT 13H,该中断指向某个接入的可引导设备的引导扇区。它所找到的包含有效的引导记录的第一个引导扇区将被装载到内存中,并且控制权也将从引导扇区转移到此段代码。
|
||||
|
||||
### GRUB2
|
||||
引导扇区是引导加载器真正的第一阶段。大多数 Linux 发行版本使用的引导加载器有三种:GRUB、GRUB2 和 LILO。GRUB2 是最新的,也是相对于其他老的同类程序使用最广泛的。
|
||||
|
||||
GRUB2 全称是 Grand Unified BootLoader,Version 2。它是目前流行的大部分 Linux 发行版本的通用启动加载器。GRUB2 是一个用于寻找操作系统内核并加载其到内存的智能程序。由于 GRUB 比 GRUB2 易于书写和阅读,在下文中,除特殊指明以外,GRUB 将代指 GRUB2。
|
||||
#### GRUB2
|
||||
|
||||
GRUB 被设计为兼容多种操作系统引导规范,GRUB 能够用来引导不同版本的 Linux 和其他的开源操作系统;它还能链式加载操作系统的专用引导记录。
|
||||
GRUB2 全称是 GRand Unified BootLoader,Version 2(第二版大一统引导装载程序)。它是目前流行的大部分 Linux 发行版本的主要引导加载程序。GRUB2 是一个用于计算机寻找操作系统内核并加载其到内存的智能程序。由于 GRUB 这个单词比 GRUB2 更易于书写和阅读,在下文中,除特殊指明以外,GRUB 将代指 GRUB2。
|
||||
|
||||
GRUB 允许用户选择任何给定几个 Linux 发行版本内核开机引导操作系统。这个特性使得操作系统,在因为关键软件不兼容或其他某些原因升级失败时,具备恢复先前版本的能力。GRUB 能够通过文件 /boot/grub/grub.conf 进行配置。
|
||||
GRUB 被设计为兼容操作系统[多重引导规范][4],它能够用来引导不同版本的 Linux 和其他的开源操作系统;它还能链式加载专有操作系统的引导记录。
|
||||
|
||||
GRUB1 现在已经逐步被弃用,它已经被更新的版本 GRUB2 所替换。 GRUB2 是在 GRUB1 的基础上重写完成。Red Hat 基础发行版(Fedora 15 和 CentOS/RHEL 7)均升级到 GRUB2。GRUB2 提供了与 GRUB1 同样的引导功能,但是 GRUB2 又像一个基于命令行的 Pre-OS 环境主框架,使得在预引导阶段配置更为方便和易操作。GRUB2 通过 /boot/grub2/grub.cfg 进行配置。
|
||||
GRUB 允许用户从任何给定的 Linux 发行版本的几个不同内核中选择一个进行引导。这个特性使得操作系统,在因为关键软件不兼容或其它某些原因升级失败时,具备引导到先前版本的内核的能力。GRUB 能够通过文件 `/boot/grub/grub.conf` 进行配置。(LCTT 译注:此处指 GRUB1)
|
||||
|
||||
两个 GRUB 的最主要作用都是完成内核加载并启动内核。两个版本的 GRUB 的基本工作方式一致,其主要阶段也保持相同,都可分为3个阶段。在本文将以 GRUB2 为例进行讨论其工作过程。GRUB 或 GRUB2 的配置,以及 GRUB2 的使用命令均超过本文范围,不会在文中进行介绍。
|
||||
GRUB1 现在已经逐步被弃用,在大多数现代发行版上它已经被 GRUB2 所替换,GRUB2 是在 GRUB1 的基础上重写完成。基于 Red Hat 的发行版大约是在 Fedora 15 和 CentOS/RHEL 7 时升级到 GRUB2 的。GRUB2 提供了与 GRUB1 同样的引导功能,但是 GRUB2 也是一个类似主框架(mainframe)系统上的基于命令行的前置操作系统(Pre-OS)环境,使得在预引导阶段配置更为方便和易操作。GRUB2 通过 `/boot/grub2/grub.cfg` 进行配置。
|
||||
|
||||
#### 阶段 1
|
||||
两个 GRUB 的最主要作用都是将内核加载到内存并运行。两个版本的 GRUB 的基本工作方式一致,其主要阶段也保持相同,都可分为 3 个阶段。在本文将以 GRUB2 为例进行讨论其工作过程。GRUB 或 GRUB2 的配置,以及 GRUB2 的命令使用均超过本文范围,不会在文中进行介绍。
|
||||
|
||||
虽然 GRUB2 并未在其三个引导阶段中正式使用这些<ruby>阶段<rt>stage</rt></ruby>名词,但是为了讨论方便,我们在本文中使用它们。
|
||||
|
||||
如上文 POST(上电自检)阶段提到,在 POST 阶段结束时,BIOS 将查找在启动设备中查找引导记录,其通常位于 MBR(主引导记录),它加载该引导记录中代码进入内存,并开始执行此代码。引导代码必须存储于引导记录,由于一个记录的大小为 512 字节且引导记录还必须存储该所在设备的分区信息,导致了引导代码必须非常小。 在实际中,引导代码在住引导扇区中占用的空间大小为 446 字节,该 446 字节的文件通常被叫做引导镜像(boot.img),其中不包含设备的分区信息,分区是一般单独添加到引导记录中。
|
||||
##### 阶段 1
|
||||
|
||||
由于引导记录的大小限制,它不可能非常智能,且不能理解文件系统结构。因此阶段 1 的唯一功能就是加载阶段 1.5 的所需的代码。为了完成此任务,阶段 1.5 的代码必须位于引导记录与设备第一个分区之间的位置。在加载阶段 1.5 代码进入内存后,控制权将有阶段 1 转移到阶段 1.5。
|
||||
如上文 POST(上电自检)阶段提到的,在 POST 阶段结束时,BIOS 将查找在接入的磁盘中查找引导记录,其通常位于 MBR(<ruby>主引导记录<rt>Master Boot Record</rt></ruby>),它加载它找到的第一个引导记录中到内存中,并开始执行此代码。引导代码(及阶段 1 代码)必须非常小,因为它必须连同分区表放到硬盘的第一个 512 字节的扇区中。 在[传统的常规 MBR][5] 中,引导代码实际所占用的空间大小为 446 字节。这个阶段 1 的 446 字节的文件通常被叫做引导镜像(boot.img),其中不包含设备的分区信息,分区是一般单独添加到引导记录中。
|
||||
|
||||
#### 阶段 1.5
|
||||
由于引导记录必须非常的小,它不可能非常智能,且不能理解文件系统结构。因此阶段 1 的唯一功能就是定位并加载阶段 1.5 的代码。为了完成此任务,阶段 1.5 的代码必须位于引导记录与设备第一个分区之间的位置。在加载阶段 1.5 代码进入内存后,控制权将由阶段 1 转移到阶段 1.5。
|
||||
|
||||
如上所述,阶段 1.5 的代码必须位于引导记录与设备第一个分区之间的位置。该空间由于历史技术原因而空闲。第一个分区的开始位置在扇区 63 和 MBR(记录 0)之间遗留下 62 个 512 字节的记录(共 31744 字节),该区域用于存储阶段 2 的代码镜像 core.img 文件。该文件大小为 25389 字节,故此区域有足够大小的空间用来存储 core.img。
|
||||
##### 阶段 1.5
|
||||
|
||||
因为有更大的存储空间用于阶段 1.5,且该空间足够容纳一个通用的文件系统,如标准的EXT,其他的 linux 文件系统,FAT 和 NTFS 等。core.img 必定比 boot.img 更复杂且更强大。这意味着 GRUB2 的阶段 2 能够运行于一个标准的 EXT 文件系统,但是不能运行于逻辑卷上。故阶段 2 的文件可以存放于 /boot 根目录之下,特殊地文件如 /boot/grub2 等都存放于该目录下。
|
||||
如上所述,阶段 1.5 的代码必须位于引导记录与设备第一个分区之间的位置。该空间由于历史上的技术原因而空闲。第一个分区的开始位置在扇区 63 和 MBR(扇区 0)之间遗留下 62 个 512 字节的扇区(共 31744 字节),该区域用于存储阶段 1.5 的代码镜像 core.img 文件。该文件大小为 25389 字节,故此区域有足够大小的空间用来存储 core.img。
|
||||
|
||||
注意 /boot 目录必须是一个 GRUB 所支持的文件系统(并不是所有的文件系统均可)。阶段 1.5 的功能是启动阶段 2 所需要的文件系统,并将阶段 2 需要的文件存储到 /boot 根目录下,且加载相关的驱动程序。
|
||||
因为有更大的存储空间用于阶段 1.5,且该空间足够容纳一些通用的文件系统驱动程序,如标准的 EXT 和其它的 Linux 文件系统,如 FAT 和 NTFS 等。GRUB2 的 core.img 远比更老的 GRUB1 阶段 1.5 更复杂且更强大。这意味着 GRUB2 的阶段 2 能够放在标准的 EXT 文件系统内,但是不能放在逻辑卷内。故阶段 2 的文件可以存放于 `/boot` 文件系统中,一般在 `/boot/grub2` 目录下。
|
||||
|
||||
#### 阶段 2
|
||||
注意 `/boot` 目录必须放在一个 GRUB 所支持的文件系统(并不是所有的文件系统均可)。阶段 1.5 的功能是开始执行存放阶段 2 文件的 `/boot` 文件系统的驱动程序,并加载相关的驱动程序。
|
||||
|
||||
GRUB 阶段 2 所有的文件都已存放于 /boot/grub2 目录及其几个子目录之下。该阶段没有一个类似于阶段 1 与阶段 1.5 的镜像文件。相应地,该阶段主要需要从 /boot/grub2/i386-pc 目录下加载一些内核运行时模块。
|
||||
##### 阶段 2
|
||||
|
||||
GRUB 阶段 2的主要功能是定位和加载 Linux 内核到内存中,并转移控制权到内核。内核的相关文件位于 /boot 目录下,这些内核文件可以通过其文件名进行识别,其文件名均带有前缀 vmlinuz。你可以使用 ll 命令查看操作系统中当前已经安装的内核文件。
|
||||
GRUB 阶段 2 所有的文件都已存放于 `/boot/grub2` 目录及其几个子目录之下。该阶段没有一个类似于阶段 1 与阶段 1.5 的镜像文件。相应地,该阶段主要需要从 `/boot/grub2/i386-pc` 目录下加载一些内核运行时模块。
|
||||
|
||||
GRUB2 根 GRUB1 类似,支持选择从某个内核文件引导启动。Red Hat 包管理器(DNF)支持保持多个内核版本,以防最新版本内核发生问题而无法启动时,恢复老版本系统。GRUB 在安装系统时提供一个预引导菜单,其中包括问题诊断菜单(recuse)以及恢复菜单(如果配置已经设置恢复镜像)。
|
||||
GRUB 阶段 2 的主要功能是定位和加载 Linux 内核到内存中,并转移控制权到内核。内核的相关文件位于 `/boot` 目录下,这些内核文件可以通过其文件名进行识别,其文件名均带有前缀 vmlinuz。你可以列出 `/boot` 目录中的内容来查看操作系统中当前已经安装的内核。
|
||||
|
||||
阶段 2 加载选择的内核到内存中,并转移控制权到内核代码。
|
||||
GRUB2 跟 GRUB1 类似,支持从 Linux 内核选择之一引导启动。Red Hat 包管理器(DNF)支持保留多个内核版本,以防最新版本内核发生问题而无法启动时,可以恢复老版本的内核。默认情况下,GRUB 提供了一个已安装内核的预引导菜单,其中包括问题诊断菜单(recuse)以及恢复菜单(如果配置已经设置恢复镜像)。
|
||||
|
||||
### 内核
|
||||
阶段 2 加载选定的内核到内存中,并转移控制权到内核代码。
|
||||
|
||||
内核文件都是以一种自解压的压缩格式存储,它与一个初始化的内存映像和存储设备映射表都存储于 /boot 目录之下。
|
||||
#### 内核
|
||||
|
||||
在被选择内核加载到内存中,并开始执行后,在其进行任何工作之前,内核文件首先必须从压缩格式自解压。一旦内核自解压完成,则启动systemd进程(该进程是替换老的 systemV 系统的 init 进程),并转移控制权到 systemd。
|
||||
内核文件都是以一种自解压的压缩格式存储以节省空间,它与一个初始化的内存映像和存储设备映射表都存储于 `/boot` 目录之下。
|
||||
|
||||
在引导过程的结束时,Linux 内核和 systemd 处于运行状态,但是由于没有其他任何程序在执行,故其不能执行任何有关用户的功能性任务。
|
||||
在选定的内核加载到内存中并开始执行后,在其进行任何工作之前,内核文件首先必须从压缩格式解压自身。一旦内核自解压完成,则加载 [systemd][6] 进程(其是老式 System V 系统的 [init][7] 程序的替代品),并转移控制权到 systemd。
|
||||
|
||||
## 启动过程
|
||||
这就是引导过程的结束。此刻,Linux 内核和 systemd 处于运行状态,但是由于没有其他任何程序在执行,故其不能执行任何有关用户的功能性任务。
|
||||
|
||||
启动过程紧随引导过程之后,启动过程使 Linux 系统进入可操作状态,并能够执行用户功能性任务。具体来说,就是系统启动相关的系统守护进程。
|
||||
### 启动过程
|
||||
|
||||
### systemd
|
||||
启动过程紧随引导过程之后,启动过程使 Linux 系统进入可操作状态,并能够执行用户功能性任务。
|
||||
|
||||
systemd 是所有进程的父进程。它负责拉起宿主操作系统到一个用户可操作状态(可以执行功能任务)。systemd 相对于 init 进程扩展了一些管理该宿主进程各个方面的新功能,包括文件系统挂载,以及开启和管理系统服务等具体业务功能,但是 systemd 的任何与系统启动过程无关的功能均不在此文的讨论范围。
|
||||
#### systemd
|
||||
|
||||
首先,systemd 挂载文件系统是在 **/etc/fstab** 配置,包括内存交换分区和设备分区。据此,systemd 必须能够访问位于 /etc 目录下的配置文件。systemd 借助配置文件 **/etc/systemd/system/default.target** 决定 Linux 系统应该启动达到哪个状态。**default.target** 是一个真实文件的符号链接。对于桌面系统,其链接到 **graphical.target**,该文件相当于老的 systemV init 方式的 **runlevel 5**。对于一个服务器操作系统来说,**default.target** 链接到 **multi-user.target** 相当于 systemV 系统的 **runlevel 3**。 **emergency.target** 相当于单用户模式。
|
||||
systemd 是所有进程的父进程。它负责将 Linux 主机带到一个用户可操作状态(可以执行功能任务)。systemd 的一些功能远较旧式 init 程序更丰富,可以管理运行中的 Linux 主机的许多方面,包括挂载文件系统,以及开启和管理 Linux 主机的系统服务等。但是 systemd 的任何与系统启动过程无关的功能均不在此文的讨论范围。
|
||||
|
||||
注意,所有的状态点(targets)和服务(services)均为 systemd 的组成单元。
|
||||
首先,systemd 挂载在 `/etc/fstab` 中配置的文件系统,包括内存交换文件或分区。据此,systemd 必须能够访问位于 `/etc` 目录下的配置文件,包括它自己的。systemd 借助其配置文件 `/etc/systemd/system/default.target` 决定 Linux 系统应该启动达到哪个状态(或<ruby>目标态<rt>target</rt></ruby>)。`default.target` 是一个真实的 target 文件的符号链接。对于桌面系统,其链接到 `graphical.target`,该文件相当于旧式 systemV init 方式的 **runlevel 5**。对于一个服务器操作系统来说,`default.target` 更多是默认链接到 `multi-user.target`, 相当于 systemV 系统的 **runlevel 3**。 `emergency.target` 相当于单用户模式。
|
||||
|
||||
(LCTT 译注:“target” 是 systemd 新引入的概念,目前尚未发现有官方的准确译名,考虑到其作用和使用的上下文环境,我们认为翻译为“目标态”比较贴切。以及,“unit” 是指 systemd 中服务和目标态等各个对象/文件,在此依照语境译作“单元”。)
|
||||
|
||||
如下表 1 是 systemd 启动的 targets 和老版 systemV init 启动状态点对比。这个 **systemd target aliases** (systemd 状态别名)是为了 systemd 向前兼容 systemV 而提供。这个 target 别名允许系统管理员(包括我自己)用 systemV 命令(例如 init 3)改变运行级别。当然,该 systemV 命令也可以转发到 systemd 进行解释和执行。
|
||||
注意,所有的<ruby>目标态<rt>target</rt></ruby>和<ruby>服务<rt>service</rt></ruby>均是 systemd 的<ruby>单元<rt>unit</rt></ruby>。
|
||||
|
||||
|SystemV 运行级别 | systemd target | systemd target 别名 | 描述 |
|
||||
|:---:|---|---|---|
|
||||
| | halt.target | | 在不下电的情况下停止系统. |
|
||||
| 0 | poweroff.target | runlevel0.target | 停止系统运行并切断电源. |
|
||||
| S | emergency.target | | 单用户模式,没有服务进程运行,文件系统也没挂载。这是用于紧急救援模式的一个基本的运行状态,仅仅能够通过在本地运行 shell 与系统进行交互。|
|
||||
| 1 | rescue.target | runlevel1.target | 该状态是一个挂在了文件系统,仅运行了部分基本服务进程的基本系统,并在主控制台启动了一个 shell 访问入口用于诊断。 |
|
||||
| 2 | | runlevel2.target | 多用户,没有挂在 NFS 文件系统,但是所有的非图形界面服务进程已经运行。 |
|
||||
| 3 | multi-user.target | runlevel3.target | 所有服务都已运行,只支持命令接口访问. |
|
||||
| 4 | | runlevel4.target | 暂未使用. |
|
||||
| 5 | graphical.target | runlevel5.target | 多用户,且支持图形界面接口. |
|
||||
| 6 | reboot.target | runlevel6.target | 重启 |
|
||||
| | default.target | | 这个状态是对于多用户或图形界面状态的一个代指。systemd 总是通过 default.target 启动系统。default.target 绝不应该代指 halt.target, poweroff.target 或 reboot.target。 |
|
||||
如下表 1 是 systemd 启动的<ruby>目标态<rt>target</rt></ruby>和老版 systemV init 启动<ruby>运行级别<rt>runlevel</rt></ruby>的对比。这个 **systemd 目标态别名** 是为了 systemd 向前兼容 systemV 而提供。这个目标态别名允许系统管理员(包括我自己)用 systemV 命令(例如 `init 3`)改变运行级别。当然,该 systemV 命令是被转发到 systemd 进行解释和执行的。
|
||||
|
||||
*表 1 systemd 与老版本 systemV的启动状态点比较*
|
||||
|SystemV 运行级别 | systemd 目标态 | systemd 目标态别名 | 描述 |
|
||||
|:---:|---|---|---|
|
||||
| | `halt.target` | | 停止系统运行但不切断电源。 |
|
||||
| 0 | `poweroff.target` | `runlevel0.target` | 停止系统运行并切断电源. |
|
||||
| S | `emergency.target` | | 单用户模式,没有服务进程运行,文件系统也没挂载。这是一个最基本的运行级别,仅在主控制台上提供一个 shell 用于用户与系统进行交互。|
|
||||
| 1 | `rescue.target` | `runlevel1.target` | 挂载了文件系统,仅运行了最基本的服务进程的基本系统,并在主控制台启动了一个 shell 访问入口用于诊断。 |
|
||||
| 2 | | `runlevel2.target` | 多用户,没有挂载 NFS 文件系统,但是所有的非图形界面的服务进程已经运行。 |
|
||||
| 3 | `multi-user.target` | `runlevel3.target` | 所有服务都已运行,但只支持命令行接口访问。 |
|
||||
| 4 | | `runlevel4.target` | 未使用。|
|
||||
| 5 | `graphical.target` | `runlevel5.target` | 多用户,且支持图形界面接口。|
|
||||
| 6 | `reboot.target` | `runlevel6.target` | 重启。 |
|
||||
| | `default.target` | | 这个<ruby>目标态<rt>target</rt></ruby>是总是 `multi-user.target` 或 `graphical.target` 的一个符号链接的别名。systemd 总是通过 `default.target` 启动系统。`default.target` 绝不应该指向 `halt.target`、 `poweroff.target` 或 `reboot.target`。 |
|
||||
|
||||
每个 target 在配置文件中配置一个依赖集,systemd 需要首先启动该 target 所需依赖,指定运行级别的系统依赖于其对应服务进程的运行。当配置文件中所有的依赖服务都加载并运行后,即说明系统处于在运行级别。
|
||||
*表 1 老版本 systemV 的 运行级别与 systemd 与<ruby>目标态<rt>target</rt></ruby>或目标态别名的比较*
|
||||
|
||||
systemd 也会查看 systemV init 遗留的目录中是否存在相关启动文件,若存在,则 systemd 根据这些配置文件的内容启动对应的服务。在 Fedora 系统中,这个过时的网络服务就是通过该方式启动的一个实例。
|
||||
每个<ruby>目标态<rt>target</rt></ruby>有一个在其配置文件中描述的依赖集,systemd 需要首先启动其所需依赖,这些依赖服务是 Linux 主机运行在特定的功能级别所要求的服务。当配置文件中所有的依赖服务都加载并运行后,即说明系统运行于该目标级别。
|
||||
|
||||
如下图 1 是直接从 bootup 的 man 页面拷贝而来。它展示了在一个系统成功启动的过程一般的事件序列和基本的顺序要求。
|
||||
systemd 也会查看老式的 systemV init 目录中是否存在相关启动文件,若存在,则 systemd 根据这些配置文件的内容启动对应的服务。在 Fedora 系统中,过时的网络服务就是通过该方式启动的一个实例。
|
||||
|
||||
**sysinit.target** 和 **basic.target** 启动过程中的两个状态检查点。尽管 systemd 的设计初衷是并行启动系统服务,但是部分服务进程或功能模块的启动是以其他服务或功能启动为前提的。系统将暂停于检查点直到其所要求的条件都满足为止。
|
||||
如下图 1 是直接从 bootup 的 man 页面拷贝而来。它展示了在 systemd 启动过程中一般的事件序列和确保成功的启动的基本的顺序要求。
|
||||
|
||||
**sysinit.target** 状态的到达是以其所依赖的所有资源模块都正常启动为前提的。其包括文件系统挂载,交换文件设置,设备管理器的启动,随机数生成器种子设置,低级别系统服务初始化,加解密服务启动(如果一个或者多个文件系统加密,则此项必须启动)等,在 **sysinit.target** 中这些服务与模块是可以并行启动的。
|
||||
`sysinit.target` 和 `basic.target` 目标态可以被视作启动过程中的状态检查点。尽管 systemd 的设计初衷是并行启动系统服务,但是部分服务或功能目标态是其它服务或目标态的启动的前提。系统将暂停于检查点直到其所要求的服务和目标态都满足为止。
|
||||
|
||||
**sysinit.target** 启动所有最基本的低级别服务和资源,这些服务和资源都是进行下一阶段 basic.target 工作的必要前提。
|
||||
`sysinit.target` 状态的到达是以其所依赖的所有资源模块都正常启动为前提的,所有其它的单元,如文件系统挂载、交换文件设置、设备管理器的启动、随机数生成器种子设置、低级别系统服务初始化、加解密服务启动(如果一个或者多个文件系统加密的话)等都必须完成,但是在 **sysinit.target** 中这些服务与模块是可以并行启动的。
|
||||
|
||||
`sysinit.target` 启动所有的低级别服务和系统初具功能所需的单元,这些都是进入下一阶段 basic.target 的必要前提。
|
||||
|
||||
```
|
||||
local-fs-pre.target
|
||||
@ -169,25 +167,25 @@ systemd 也会查看 systemV init 遗留的目录中是否存在相关启动文
|
||||
```
|
||||
*图 1:systemd 的启动流程*
|
||||
|
||||
在 **sysinit.target** 满足以后,systemd 进入完成 basic.target 状态, 启动 **basic.target** 要求的所有资源。 basic.target 启动下一状态需要的前置功能或服务,包括可执行目录,通信 sockets,以及定时器等。
|
||||
在 `sysinit.target` 的条件满足以后,systemd 接下来启动 `basic.target`,启动其所要求的所有单元。 `basic.target` 通过启动下一目标态所需的单元而提供了更多的功能,这包括各种可执行文件的目录路径、通信 sockets,以及定时器等。
|
||||
|
||||
最后,将到达用户状态(**multi-user.target** 或 **graphical.target**),应该注意的是 **graphical.target** 是以 **multi-user.target** 为基础的。
|
||||
最后,用户级目标态(`multi-user.target` 或 `graphical.target`) 可以初始化了,应该注意的是 `multi-user.target` 必须在满足图形化目标态 `graphical.target` 的依赖项之前先达成。
|
||||
|
||||
图 1 中,以*开头的状态(target)是通用的启动状态。当到达其中的某一状态,则说明系统已经成功启动。如果 **multi-user.target** 是默认的目标状态,则成功启动的系统将以命令行登录界面呈现于用户。如果 **graphical.target** 是默认的目标状态,则成功启动的系统将以图形登陆界面呈现于用户,界面的具体样式将根据系统所配置的显示管理器而定。
|
||||
图 1 中,以 `*` 开头的目标态是通用的启动状态。当到达其中的某一目标态,则说明系统已经启动完成了。如果 `multi-user.target` 是默认的目标态,则成功启动的系统将以命令行登录界面呈现于用户。如果 `graphical.target` 是默认的目标态,则成功启动的系统将以图形登录界面呈现于用户,界面的具体样式将根据系统所配置的[显示管理器][8]而定。
|
||||
|
||||
## 问题讨论
|
||||
### 故障讨论
|
||||
|
||||
最近我需要将将一台 Linux 电脑的内核引导方式从旧版 GRUB1 更改为 GRUB2。我发现一些 GRUB2 的命令在我的系统上不能用,也可能是我使用方法不正确。至今,我仍然不知道是何原因导致,此问题需要进一步探究。
|
||||
最近我需要改变一台使用 GRUB2 的 Linux 电脑的默认引导内核。我发现一些 GRUB2 的命令在我的系统上不能用,也可能是我使用方法不正确。至今,我仍然不知道是何原因导致,此问题需要进一步探究。
|
||||
|
||||
**grub2-set-default** 命令没能在配置文件 **/etc/default/grub** 中成功设置内核引导索引,以至于期望的内核并没有被引导启动。故在该配置文件中我手动更改 **GRUB_DEFAULT=saved** 为 **GRUB_DEFAULT=2**,2 是我需要引导安装的内核文件所在设备的索引。然后我执行命令 **grub2-mkconfig > /boot/grub2/grub.cfg** 创建了新的 GRUB 配置文件,该方法成功规避了命令行无效的问题,并成功更改了系统引导方式。
|
||||
`grub2-set-default` 命令没能在配置文件 `/etc/default/grub` 中成功地设置默认内核索引,以至于期望的替代内核并没有被引导启动。故在该配置文件中我手动更改 `GRUB_DEFAULT=saved` 为 `GRUB_DEFAULT=2`,2 是我需要引导的安装好的内核文件的索引。然后我执行命令 `grub2-mkconfig > /boot/grub2/grub.cfg` 创建了新的 GRUB 配置文件,该方法如预期的规避了问题,并成功引导了替代的内核。
|
||||
|
||||
## 结论
|
||||
### 结论
|
||||
|
||||
GRUB2, systemd 和 init 都是发行版 Linux 引导和启动的关键组件。尽管在实际中, systemd 的使用还存在一些争议,但是 GRUB2 与 systemd 结合的方式能够方便地引导内核并成功启动系统。
|
||||
GRUB2、systemd 初始化系统是大多数现代 Linux 发行版引导和启动的关键组件。尽管在实际中,systemd 的使用还存在一些争议,但是 GRUB2 与 systemd 可以密切地配合先加载内核,然后启动一个业务系统所需要的系统服务。
|
||||
|
||||
尽管 GRUB2 和 systemd 都比其前任要更加复杂,但是它们更加容易学习和管理。在 man 页面有大量关于 systemd 的帮助说明,freedesktop.org 也在线收录了完整的此帮助说明。下面有更多相关信息链接。
|
||||
尽管 GRUB2 和 systemd 都比其前任要更加复杂,但是它们更加容易学习和管理。在 man 页面有大量关于 systemd 的帮助说明,freedesktop.org 也在线收录了完整的此[帮助说明][9]。下面有更多相关信息链接。
|
||||
|
||||
## 附加资源
|
||||
### 附加资源
|
||||
|
||||
- [GNU GRUB](https://en.wikipedia.org/wiki/GNU_GRUB) (Wikipedia)
|
||||
- [GNU GRUB Manual](https://www.gnu.org/software/grub/manual/grub.html) (GNU.org)
|
||||
@ -198,13 +196,27 @@ GRUB2, systemd 和 init 都是发行版 Linux 引导和启动的关键组件。
|
||||
- [systemd index of man pages](https://www.freedesktop.org/software/systemd/man/index.html) (Freedesktop.org)
|
||||
|
||||
---
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both 居住在美国北卡罗纳州的首府罗利,是一个 Linux 开源贡献者。他已经从事 IT 行业 40 余年,在 IBM 教授 OS/2 20余年。1981 年,他在 IBM 开发了第一个关于 最初的 IBM 个人电脑的培训课程。他也曾在 Red Hat 教授 RHCE 课程,也曾供职于 MCI worldcom,Cico 以及北卡罗纳州等。他已经为 Linux 开源社区工作进 20 年。
|
||||
David Both 居住在美国北卡罗纳州的首府罗利,是一个 Linux 开源贡献者。他已经从事 IT 行业 40 余年,在 IBM 教授 OS/2 20余年。1981 年,他在 IBM 开发了第一个关于最初的 IBM 个人电脑的培训课程。他也曾在 Red Hat 教授 RHCE 课程,也曾供职于 MCI worldcom,Cico 以及北卡罗纳州等。他已经为 Linux 开源社区工作近 20 年。
|
||||
|
||||
---
|
||||
原文链接: [https://opensource.com/article/17/2/linux-boot-and-startup](https://opensource.com/article/17/2/linux-boot-and-startup)
|
||||
via: https://opensource.com/article/17/2/linux-boot-and-startup
|
||||
|
||||
作者:[David Both](https://opensource.com/users/dboth) 译者:penghuster 校对:校对者ID
|
||||
作者:[David Both](https://opensource.com/users/dboth)
|
||||
译者: [penghuster](https://github.com/penghuster)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]: https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[2]: https://en.wikipedia.org/wiki/Systemd
|
||||
[3]: https://en.wikipedia.org/wiki/BIOS_interrupt_call
|
||||
[4]: https://en.wikipedia.org/wiki/Multiboot_Specification
|
||||
[5]: https://en.wikipedia.org/wiki/Master_boot_record
|
||||
[6]: https://en.wikipedia.org/wiki/Systemd
|
||||
[7]: https://en.wikipedia.org/wiki/Init#SysV-style
|
||||
[8]: https://opensource.com/article/16/12/yearbook-best-couple-2016-display-manager-and-window-manager
|
||||
[9]: https://www.freedesktop.org/software/systemd/man/index.html
|
||||
@ -1,98 +0,0 @@
|
||||
11 个在 Linux 中使用 GNOME 3 桌面环境的理由
|
||||
============================================================
|
||||
|
||||
### GNOME 3 桌面的设计目的是简单、易于访问和可靠。GNOME 的受欢迎程度证明了这些目标的实现。
|
||||
|
||||

|
||||
>图片来源: [Gunnar Wortmann][8] 通过 [Pixabay][9]。由 Opensource.com 修改。[CC BY-SA 4.0][10].
|
||||
|
||||
去年年底,升级到 Fedora 25 后,新版本 [KDE][11] Plasma 出现了一些问题,这使我难以完成任何工作。所以我决定尝试其他的 Linux 桌面环境有两个原因。首先,我需要完成我的工作。第二,多年来一直使用 KDE,我想可能是尝试一些不同的桌面的时候了。
|
||||
|
||||
我尝试了几个星期的第一个替代桌面是我在 1 月份写的 [Cinnamon][12],然后我写了用了大约八个星期的[LXDE][13],我发现这里有很多事情我都喜欢。我用了 [GNOME 3][14] 几个星期来研究这篇文章。
|
||||
|
||||
更多的 Linux 资源
|
||||
|
||||
* [什么是 Linux?][1]
|
||||
|
||||
* [什么是 Linux 容器?][2]
|
||||
|
||||
* [立即下载:Linux 命令速查表][3]
|
||||
|
||||
* [高级 Linux 命令速查表][4]
|
||||
|
||||
* [我们最新的 Linux 文章][5]
|
||||
|
||||
像几乎所有的网络世界一样,GNOME 是缩写;它代表“GNU 网络对象模型”(GNU Network Object Model)。GNOME 3 桌面设计的目的是简单、易于访问和可靠。GNOME 的受欢迎程度证明了这些目标的实现。
|
||||
|
||||
GNOME 3 在需要大量屏幕的环境中非常有用。这意味着两个大屏幕都具有高分辨率,并最大限度地减少桌面小部件、面板和图标所需的空间,以允许启动新程序之类的任务。GNOME 项目有一套人机接口指南(HIG),用来定义人类应该如何与计算机交互的 GNOME 哲学。
|
||||
|
||||
### 我使用 GNOME 3 的十一个原因
|
||||
|
||||
1. **选择:** GNOME 在我个人喜爱的 Fedora 等一些发行版上提供多种形式。你可以选择的桌面登录选项有 GNOME Classic、Xorg 上的 GNOME、GNOME 和 GNOME(Wayland)。从表面上看,启动后这些都是一样的,但它们使用不同的 X 服务器,或者使用不同的工具包构建。Wayland 在小细节上提供了更多的功能,例如动态滚动,拖放和中键粘贴。
|
||||
|
||||
2. **入门教程:** 在用户第一次登录时会显示入门教程。它向你展示了如何执行常见任务,并提供了大量的帮助链接。教程在首次启动后被关闭后也可轻松访问,以便随时访问该教程。教程非常简单直观,这为 GNOME 新用户提供了一个简单明了开始。要之后返回本教程,请点击 **Activities**,然后点击会显示程序的有九个点的正方形。然后找到并点击标为 **Help** 的救生员图标。
|
||||
|
||||
3. **清洁的桌面:** 对桌面环境采用极简方法以减少杂乱,GNOME 设计为仅提供具备可用环境所必需的最低限度。你应该只能看到顶部栏(是的,这就是所谓的),其他所有的都被隐藏,直到需要才显示。目的是允许用户专注于手头的任务,并尽量减少桌面上其他东西造成的干扰。
|
||||
|
||||
4. **顶部栏:** 无论你想做什么,顶部栏总是开始的地方。你可以启动应用程序、注销、关闭电源、启动或停止网络等。当你想做任何事情的时候,这让生活变得简单。除了当前应用程序之外,顶栏通常是桌面上唯一的其他对象。
|
||||
|
||||
5. **dash:** 如下所示,在默认情况下, dash 包含三图标。在开始使用应用程序时, 会将它们添加到 dash 中, 以便在其中显示最常用的应用程序。你也可以从应用程序查看器中将应用程序图标添加到 dash 中。
|
||||
|
||||

|
||||
|
||||
6. **应用程序浏览器*:* 我真的很喜欢这个可以从位于 GNOME 桌面左侧的垂直条上访问应用程序浏览器。除非有一个正在运行的程序,GNOME 桌面通常没有任何东西,所以你必须点击顶部栏上的 **Activities** 选项,点击 dash 底部的九个点组成的正方形,它是浏览器的图标。
|
||||
|
||||

|
||||
|
||||
浏览者本身就是一个由如上所示已安装的应用程序的图标组成的矩阵。矩阵下方有一对互斥的按钮,**Frequent** 和 **All**。默认情况下,应用程序浏览器会显示所有安装的应用。点击 **Frequent** 按钮,它会只显示最常用的应用程序。向上和向下滚动以找到要启动的应用程序。应用程序按名称按字母顺序显示。
|
||||
|
||||
[GNOME][6] 官网和内置的帮助有更多关于浏览器的细节。
|
||||
|
||||
7. **应用程序就绪通知:** 当新启动的应用程序的窗口打开并准备就绪时,GNOME 会在屏幕顶部显示一个整齐的通知。只需点击通知即可切换到该窗口。与在其他桌面上搜索新打开的应用程序窗口相比,这节省了一些时间。
|
||||
|
||||
8. **应用程序显示:** 为了访问不可见的不同运行的应用程序,点击活动菜单。这将在桌面上的矩阵中显示所有正在运行的应用程序。点击所需的应用程序将其带到前台。虽然当前应用程序显示在顶栏中,但其他正在运行的应用程序不会。
|
||||
|
||||
9. **最小的窗口装饰:** 桌面上打开窗口也很简单。标题栏上唯一显示的按钮是关闭窗口的 “X”。所有其他功能,如最小化、最大化、移动到另一个桌面等,可以通过在标题栏上右键单击来访问。
|
||||
|
||||
10. **自动创建的新桌面:** 在使用下一空桌面的时候将自动创建的新的空桌面。这意味着总是有一个空的桌面在需要时可以使用。我使用的所有其他桌面都可以让你在桌面活动时设置桌面数量,但必须使用系统设置手动完成。
|
||||
|
||||
11. **兼容性:** 与我所使用的所有其他桌面一样,为其他桌面创建的应用程序可在 GNOME 上正常工作。这功能让我有可能测试这些桌面,以便我可以写出它们。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
GNOME 不像我以前用过的桌面。它的主要指导是“简单”。其他一切都要以简单易用为前提。如果你从入门教程开始,学习如何使用 GNOME 需要很少的时间。这并不意味着 GNOME 有不足。它是一款始终保持不变的功能强大且灵活的桌面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both 是位于北卡罗来纳州罗利的 Linux 和开源倡导者。他已经在 IT 行业工作了四十多年,并为 IBM 教授 OS/2 超过 20 年。在 IBM,他在 1981 年为初始的 IBM PC 写了第一个培训课程。他为红帽教授 RHCE 课程,曾在 MCI Worldcom、思科和北卡罗来纳州工作。他一直在使用 Linux 和开源软件近 20 年。
|
||||
|
||||
---------------
|
||||
|
||||
via: https://opensource.com/article/17/5/reasons-gnome
|
||||
|
||||
作者:[David Both ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://www.gnome.org/gnome-3/
|
||||
[7]:https://opensource.com/article/17/5/reasons-gnome?rate=MbGLV210A21ONuGAP8_Qa4REL7cKFvcllqUddib0qMs
|
||||
[8]:https://pixabay.com/en/users/karpartenhund-3077375/
|
||||
[9]:https://pixabay.com/en/garden-gnome-black-and-white-f%C3%B6hr-1584401/
|
||||
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
[12]:https://opensource.com/article/17/1/cinnamon-desktop-environment
|
||||
[13]:https://opensource.com/article/17/3/8-reasons-use-lxde
|
||||
[14]:https://www.gnome.org/gnome-3/
|
||||
[15]:https://opensource.com/user/14106/feed
|
||||
[16]:https://opensource.com/article/17/5/reasons-gnome#comments
|
||||
[17]:https://opensource.com/users/dboth
|
||||
@ -1,118 +0,0 @@
|
||||
免费学习docker的最佳方法:PLAY-WITH-DOCKER(PWD)
|
||||
============================================================
|
||||
|
||||
去年在柏林的分布式系统峰会上,Docker的负责人[ Marcos Nils][15] 和[ Jonathan Leibiusky][16]宣称已经开始研究浏览器内置docker的方案,帮助人们学习Docker。 几天后,[Play-with-docker][17](PWD)就诞生了。
|
||||
|
||||
PWD像是一个Docker游乐场,用户在几秒钟内就可以运行Docker命令。 还可以在浏览器中安装免费的Alpine Linux虚拟机的,然后在虚拟机里面构建和运行Docker容器,甚至使用[ Docker 集群模式][18]创建集群。 有了Docker-in-Docker(DinD)引擎,甚至可以体验到多个虚拟机/个人电脑的效果。 除了Docker游乐场外,PWD还包括一个培训站点[training.play-with-docker.com][19],该站点提供大量的难度各异的Docker实验和测验。
|
||||
|
||||
如果你错过了峰会,Marcos和Jonathan在最后一个DockerCon Moby Cool Hack会议中提供了PWD。 观看下面的视频,深入了解基础结构和路线图。
|
||||
|
||||
在过去几个月里,Docker团队与Marcos,Jonathan,还有Docker社区的其他活跃成员展开了密切合作,为项目添加了新功能,为培训部分增加了Docker实验。
|
||||
|
||||
### PWD: 游乐场
|
||||
|
||||
以下快速的概括了游乐场的新功能:
|
||||
|
||||
##### 1\. PWD Docker机器驱动和SSH
|
||||
|
||||
随着PWD成功的成长,社区开始问他们是否可以使用PWD来运行自己的Docker研讨会和培训。 因此,对项目进行的第一次改进之一就是创建[PWD Docker机器驱动][20],从而用户可以通过自己喜爱的终端轻松创建管理PWD主机,包括使用ssh相关命令的选项。 下面是它的工作原理:
|
||||
|
||||

|
||||
|
||||
##### 2\. 支持文件上传
|
||||
|
||||
Marcos和Jonathan还带来了另一个炫酷的功能就是可以在PWD实例中通过拖放文件的方式将Dockerfile直接上传到PWD窗口。
|
||||
|
||||

|
||||
|
||||
##### 3\. 模板会话
|
||||
|
||||
除了文件上传之外,PWD还有一个功能,可以使用预定义的模板在几秒钟内启动5个节点的群集。
|
||||
|
||||
#####
|
||||

|
||||
|
||||
##### 4\. 一键使用Docker展示你的应用程序
|
||||
|
||||
PWD附带的另一个很酷的功能是它的嵌入式按钮,你可以在你的站点中使用它来设置PWD环境,还可以快速部署一个构建好的堆栈,另外还有一个[chrome 扩展][21] ,可以将“Try in PWD”按钮添加DockerHub最流行的镜像中。 以下是扩展程序的一个简短演示:
|
||||
|
||||

|
||||
|
||||
### PWD: 培训站点
|
||||
|
||||
[training.play-with-docker.com][22]站点提供了大量新的实验。有一些值得注意的两点,包括两个来源于Austind DockerCon中的可以动手实践的实验,还有两个在Docker 17.06CE版本中亮眼的新功能
|
||||
|
||||
* [可以动手实践的Docker网络实验][1]
|
||||
|
||||
* [可以动手实践的Docker编排实验][2]
|
||||
|
||||
* [多阶段构建][3]
|
||||
|
||||
* [Docker群组配置文件][4]
|
||||
|
||||
总而言之,现在有36个实验,而且一直在增加。 如果你想贡献实验,请查看[GitHub 仓库][23]然后开始。
|
||||
|
||||
### PWD: 使用情况
|
||||
|
||||
根据网站运行时我们收到的反馈,很可观的说,PWD现在有很大的牵引力。下面是一些最常见的反馈情况:
|
||||
|
||||
* 紧跟最新开发版本,尝试新功能。
|
||||
|
||||
* 快速建立集群并启动复制服务。
|
||||
|
||||
* 了解互动教程: [training.play-with-docker.com][5]。
|
||||
|
||||
* 在会议和集会上做演讲。
|
||||
|
||||
* 展开需要复杂配置的高级研讨会,例如 Jérôme’的 [先进的 Docker 编排研讨会][6]。
|
||||
|
||||
* 和社区成员写作诊断问题检测问题。
|
||||
|
||||
参与 PWD:
|
||||
|
||||
* 通过[向PWD提交PR][7]做贡献
|
||||
|
||||
* 向 [PWD 培训站点][8]贡献
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Victor是Docker, Inc. 的高级社区营销经理。他喜欢优质的葡萄酒,象棋和足球,三三项爱好部分先后顺序。 Victor 的tweet:@vcoisne推特。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/best-way-learn-docker-free-play-docker-pwd/
|
||||
|
||||
作者:[Victor ][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/victor_c/
|
||||
[1]:http://training.play-with-docker.com/docker-networking-hol/
|
||||
[2]:http://training.play-with-docker.com/orchestration-hol/
|
||||
[3]:http://training.play-with-docker.com/multi-stage/
|
||||
[4]:http://training.play-with-docker.com/swarm-config/
|
||||
[5]:http://training.play-with-docker.com/
|
||||
[6]:https://github.com/docker/labs/tree/master/Docker-Orchestration
|
||||
[7]:https://github.com/play-with-docker/
|
||||
[8]:https://github.com/play-with-docker/training
|
||||
[9]:https://blog.docker.com/author/victor_c/
|
||||
[10]:https://blog.docker.com/tag/docker-labs/
|
||||
[11]:https://blog.docker.com/tag/docker-training/
|
||||
[12]:https://blog.docker.com/tag/docker-workshops/
|
||||
[13]:https://blog.docker.com/tag/play-with-docker/
|
||||
[14]:https://blog.docker.com/tag/pwd/
|
||||
[15]:https://www.twitter.com/marcosnils
|
||||
[16]:https://www.twitter.com/xetorthio
|
||||
[17]:http://play-with-docker.com/
|
||||
[18]:https://docs.docker.com/engine/swarm/
|
||||
[19]:http://training.play-with-docker.com/
|
||||
[20]:https://github.com/play-with-docker/docker-machine-driver-pwd/releases/tag/v0.0.5
|
||||
[21]:https://chrome.google.com/webstore/detail/play-with-docker/kibbhpioncdhmamhflnnmfonadknnoan
|
||||
[22]:http://training.play-with-docker.com/
|
||||
[23]:https://github.com/play-with-docker/play-with-docker.github.io
|
||||
Loading…
Reference in New Issue
Block a user