mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
7f5521b53c
@ -0,0 +1,138 @@
|
||||
A history of low-level Linux container runtimes
|
||||
============================================================
|
||||
|
||||
### "Container runtime" is an overloaded term.
|
||||
|
||||
|
||||

|
||||
Image credits : Rikki Endsley. [CC BY-SA 4.0][12]
|
||||
|
||||
At Red Hat we like to say, "Containers are Linux—Linux is Containers." Here is what this means. Traditional containers are processes on a system that usually have the following three characteristics:
|
||||
|
||||
### 1\. Resource constraints
|
||||
|
||||
Linux Containers
|
||||
|
||||
* [What are Linux containers?][1]
|
||||
|
||||
* [What is Docker?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [An introduction to container terminology][4]
|
||||
|
||||
When you run lots of containers on a system, you do not want to have any container monopolize the operating system, so we use resource constraints to control things like CPU, memory, network bandwidth, etc. The Linux kernel provides the cgroups feature, which can be configured to control the container process resources.
|
||||
|
||||
### 2\. Security constraints
|
||||
|
||||
Usually, you do not want your containers being able to attack each other or attack the host system. We take advantage of several features of the Linux kernel to set up security separation, such as SELinux, seccomp, capabilities, etc.
|
||||
|
||||
### 3\. Virtual separation
|
||||
|
||||
Container processes should not have a view of any processes outside the container. They should be on their own network. Container processes need to be able to bind to port 80 in different containers. Each container needs a different view of its image, needs its own root filesystem (rootfs). In Linux we use kernel namespaces to provide virtual separation.
|
||||
|
||||
Therefore, a process that runs in a cgroup, has security settings, and runs in namespaces can be called a container. Looking at PID 1, systemd, on a Red Hat Enterprise Linux 7 system, you see that systemd runs in a cgroup.
|
||||
|
||||
```
|
||||
# tail -1 /proc/1/cgroup
|
||||
1:name=systemd:/
|
||||
```
|
||||
|
||||
The `ps` command shows you that the system process has an SELinux label ...
|
||||
|
||||
```
|
||||
# ps -eZ | grep systemd
|
||||
system_u:system_r:init_t:s0 1 ? 00:00:48 systemd
|
||||
```
|
||||
|
||||
and capabilities.
|
||||
|
||||
```
|
||||
# grep Cap /proc/1/status
|
||||
...
|
||||
CapEff: 0000001fffffffff
|
||||
CapBnd: 0000001fffffffff
|
||||
CapBnd: 0000003fffffffff
|
||||
```
|
||||
|
||||
Finally, if you look at the `/proc/1/ns` subdir, you will see the namespace that systemd runs in.
|
||||
|
||||
```
|
||||
ls -l /proc/1/ns
|
||||
lrwxrwxrwx. 1 root root 0 Jan 11 11:46 mnt -> mnt:[4026531840]
|
||||
lrwxrwxrwx. 1 root root 0 Jan 11 11:46 net -> net:[4026532009]
|
||||
lrwxrwxrwx. 1 root root 0 Jan 11 11:46 pid -> pid:[4026531836]
|
||||
...
|
||||
```
|
||||
|
||||
If PID 1 (and really every other process on the system) has resource constraints, security settings, and namespaces, I argue that every process on the system is in a container.
|
||||
|
||||
Container runtime tools just modify these resource constraints, security settings, and namespaces. Then the Linux kernel executes the processes. After the container is launched, the container runtime can monitor PID 1 inside the container or the container's `stdin`/`stdout`—the container runtime manages the lifecycles of these processes.
|
||||
|
||||
### Container runtimes
|
||||
|
||||
You might say to yourself, well systemd sounds pretty similar to a container runtime. Well, after having several email discussions about why container runtimes do not use `systemd-nspawn` as a tool for launching containers, I decided it would be worth discussing container runtimes and giving some historical context.
|
||||
|
||||
[Docker][13] is often called a container runtime, but "container runtime" is an overloaded term. When folks talk about a "container runtime," they're really talking about higher-level tools like Docker, [CRI-O][14], and [RKT][15] that come with developer functionality. They are API driven. They include concepts like pulling the container image from the container registry, setting up the storage, and finally launching the container. Launching the container often involves running a specialized tool that configures the kernel to run the container, and these are also referred to as "container runtimes." I will refer to them as "low-level container runtimes." Daemons like Docker and CRI-O, as well as command-line tools like [Podman][16] and [Buildah][17], should probably be called "container managers" instead.
|
||||
|
||||
When Docker was originally written, it launched containers using the `lxc` toolset, which predates `systemd-nspawn`. Red Hat's original work with Docker was to try to integrate `[libvirt][6]` (`libvirt-lxc`) into Docker as an alternative to the `lxc` tools, which were not supported in RHEL. `libvirt-lxc` also did not use `systemd-nspawn`. At that time, the systemd team was saying that `systemd-nspawn` was only a tool for testing, not for production.
|
||||
|
||||
At the same time, the upstream Docker developers, including some members of my Red Hat team, decided they wanted a golang-native way to launch containers, rather than launching a separate application. Work began on libcontainer, as a native golang library for launching containers. Red Hat engineering decided that this was the best path forward and dropped `libvirt-lxc`.
|
||||
|
||||
Later, the [Open Container Initiative][18] (OCI) was formed, party because people wanted to be able to launch containers in additional ways. Traditional namespace-separated containers were popular, but people also had the desire for virtual machine-level isolation. Intel and [Hyper.sh][19] were working on KVM-separated containers, and Microsoft was working on Windows-based containers. The OCI wanted a standard specification defining what a container is, so the [OCI Runtime Specification][20] was born.
|
||||
|
||||
The OCI Runtime Specification defines a JSON file format that describes what binary should be run, how it should be contained, and the location of the rootfs of the container. Tools can generate this JSON file. Then other tools can read this JSON file and execute a container on the rootfs. The libcontainer parts of Docker were broken out and donated to the OCI. The upstream Docker engineers and our engineers helped create a new frontend tool to read the OCI Runtime Specification JSON file and interact with libcontainer to run the container. This tool, called `[runc][7]`, was also donated to the OCI. While `runc` can read the OCI JSON file, users are left to generate it themselves. `runc` has since become the most popular low-level container runtime. Almost all container-management tools support `runc`, including CRI-O, Docker, Buildah, Podman, and [Cloud Foundry Garden][21]. Since then, other tools have also implemented the OCI Runtime Spec to execute OCI-compliant containers.
|
||||
|
||||
Both [Clear Containers][22] and Hyper.sh's `runV` tools were created to use the OCI Runtime Specification to execute KVM-based containers, and they are combining their efforts in a new project called [Kata][23]. Last year, Oracle created a demonstration version of an OCI runtime tool called [RailCar][24], written in Rust. It's been two months since the GitHub project has been updated, so it's unclear if it is still in development. A couple of years ago, Vincent Batts worked on adding a tool, `[nspawn-oci][8]`, that interpreted an OCI Runtime Specification file and launched `systemd-nspawn`, but no one really picked up on it, and it was not a native implementation.
|
||||
|
||||
If someone wants to implement a native `systemd-nspawn --oci OCI-SPEC.json` and get it accepted by the systemd team for support, then CRI-O, Docker, and eventually Podman would be able to use it in addition to `runc `and Clear Container/runV ([Kata][25]). (No one on my team is working on this.)
|
||||
|
||||
The bottom line is, back three or four years, the upstream developers wanted to write a low-level golang tool for launching containers, and this tool ended up becoming `runc`. Those developers at the time had a C-based tool for doing this called `lxc` and moved away from it. I am pretty sure that at the time they made the decision to build libcontainer, they would not have been interested in `systemd-nspawn` or any other non-native (golang) way of running "namespace" separated containers.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][26] Daniel J Walsh - Daniel Walsh has worked in the computer security field for almost 30 years. Dan joined Red Hat in August 2001\. Dan leads the RHEL Docker enablement team since August 2013, but has been working on container technology for several years. He has led the SELinux project, concentrating on the application space and policy development. Dan helped developed sVirt, Secure Virtualization. He also created the SELinux Sandbox, the Xguest user and the Secure Kiosk. Previously, Dan worked Netect/Bindview... [more about Daniel J Walsh][9][More about me][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/history-low-level-container-runtimes
|
||||
|
||||
作者:[Daniel J Walsh ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[2]:https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[4]:https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[5]:https://opensource.com/article/18/1/history-low-level-container-runtimes?rate=05T2m7ayQ7DRxtzQFjGcfBAlaTF5ffHN-EH1kEqSt9Q
|
||||
[6]:https://libvirt.org/
|
||||
[7]:https://github.com/opencontainers/runc
|
||||
[8]:https://github.com/vbatts/nspawn-oci
|
||||
[9]:https://opensource.com/users/rhatdan
|
||||
[10]:https://opensource.com/users/rhatdan
|
||||
[11]:https://opensource.com/user/16673/feed
|
||||
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[13]:https://github.com/docker
|
||||
[14]:https://github.com/kubernetes-incubator/cri-o
|
||||
[15]:https://github.com/rkt/rkt
|
||||
[16]:https://github.com/projectatomic/libpod/tree/master/cmd/podman
|
||||
[17]:https://github.com/projectatomic/buildah
|
||||
[18]:https://www.opencontainers.org/
|
||||
[19]:https://www.hyper.sh/
|
||||
[20]:https://github.com/opencontainers/runtime-spec
|
||||
[21]:https://github.com/cloudfoundry/garden
|
||||
[22]:https://clearlinux.org/containers
|
||||
[23]:https://clearlinux.org/containers
|
||||
[24]:https://github.com/oracle/railcar
|
||||
[25]:https://github.com/kata-containers
|
||||
[26]:https://opensource.com/users/rhatdan
|
||||
[27]:https://opensource.com/users/rhatdan
|
||||
[28]:https://opensource.com/users/rhatdan
|
||||
[29]:https://opensource.com/tags/containers
|
||||
[30]:https://opensource.com/tags/linux
|
||||
[31]:https://opensource.com/tags/containers-column
|
||||
@ -0,0 +1,94 @@
|
||||
6 pivotal moments in open source history
|
||||
============================================================
|
||||
|
||||
### Here's how open source developed from a printer jam solution at MIT to a major development model in the tech industry today.
|
||||
|
||||

|
||||
Image credits : [Alan Levine][4]. [CC0 1.0][5]
|
||||
|
||||
Open source has taken a prominent role in the IT industry today. It is everywhere from the smallest embedded systems to the biggest supercomputer, from the phone in your pocket to the software running the websites and infrastructure of the companies we engage with every day. Let's explore how we got here and discuss key moments from the past 40 years that have paved a path to the current day.
|
||||
|
||||
### 1\. RMS and the printer
|
||||
|
||||
In the late 1970s, [Richard M. Stallman (RMS)][6] was a staff programmer at MIT. His department, like those at many universities at the time, shared a PDP-10 computer and a single printer. One problem they encountered was that paper would regularly jam in the printer, causing a string of print jobs to pile up in a queue until someone fixed the jam. To get around this problem, the MIT staff came up with a nice social hack: They wrote code for the printer driver so that when it jammed, a message would be sent to everyone who was currently waiting for a print job: "The printer is jammed, please fix it." This way, it was never stuck for long.
|
||||
|
||||
In 1980, the lab accepted a donation of a brand-new laser printer. When Stallman asked for the source code for the printer driver, however, so he could reimplement the social hack to have the system notify users on a paper jam, he was told that this was proprietary information. He heard of a researcher in a different university who had the source code for a research project, and when the opportunity arose, he asked this colleague to share it—and was shocked when they refused. They had signed an NDA, which Stallman took as a betrayal of the hacker culture.
|
||||
|
||||
The late '70s and early '80s represented an era where software, which had traditionally been given away with the hardware in source code form, was seen to be valuable. Increasingly, MIT researchers were starting software companies, and selling licenses to the software was key to their business models. NDAs and proprietary software licenses became the norms, and the best programmers were hired from universities like MIT to work on private development projects where they could no longer share or collaborate.
|
||||
|
||||
As a reaction to this, Stallman resolved that he would create a complete operating system that would not deprive users of the freedom to understand how it worked, and would allow them to make changes if they wished. It was the birth of the free software movement.
|
||||
|
||||
### 2\. Creation of GNU and the advent of free software
|
||||
|
||||
By late 1983, Stallman was ready to announce his project and recruit supporters and helpers. In September 1983, [he announced the creation of the GNU project][7] (GNU stands for GNU's Not Unix—a recursive acronym). The goal of the project was to clone the Unix operating system to create a system that would give complete freedom to users.
|
||||
|
||||
In January 1984, he started working full-time on the project, first creating a compiler system (GCC) and various operating system utilities. Early in 1985, he published "[The GNU Manifesto][8]," which was a call to arms for programmers to join the effort, and launched the Free Software Foundation in order to accept donations to support the work. This document is the founding charter of the free software movement.
|
||||
|
||||
### 3\. The writing of the GPL
|
||||
|
||||
Until 1989, software written and released by the [Free Software Foundation][9] and RMS did not have a single license. Emacs was released under the Emacs license, GCC was released under the GCC license, and so on; however, after a company called Unipress forced Stallman to stop distributing copies of an Emacs implementation they had acquired from James Gosling (of Java fame), he felt that a license to secure user freedoms was important.
|
||||
|
||||
The first version of the GNU General Public License was released in 1989, and it encapsulated the values of copyleft (a play on words—what is the opposite of copyright?): You may use, copy, distribute, and modify the software covered by the license, but if you make changes, you must share the modified source code alongside the modified binaries. This simple requirement to share modified software, in combination with the advent of the internet in the 1990s, is what enabled the decentralized, collaborative development model of the free software movement to flourish.
|
||||
|
||||
### 4\. "The Cathedral and the Bazaar"
|
||||
|
||||
By the mid-1990s, Linux was starting to take off, and free software had become more mainstream—or perhaps "less fringe" would be more accurate. The Linux kernel was being developed in a way that was completely different to anything people had been seen before, and was very successful doing it. Out of the chaos of the kernel community came order, and a fast-moving project.
|
||||
|
||||
In 1997, Eric S. Raymond published the seminal essay, "[The Cathedral and the Bazaar][10]," comparing and contrasting the development methodologies and social structure of GCC and the Linux kernel and talking about his own experiences with a "bazaar" development model with the Fetchmail project. Many of the principles that Raymond describes in this essay will later become central to agile development and the DevOps movement—"release early, release often," refactoring of code, and treating users as co-developers are all fundamental to modern software development.
|
||||
|
||||
This essay has been credited with bringing free software to a broader audience, and with convincing executives at software companies at the time that releasing their software under a free software license was the right thing to do. Raymond went on to be instrumental in the coining of the term "open source" and the creation of the Open Source Institute.
|
||||
|
||||
"The Cathedral and the Bazaar" was credited as a key document in the 1998 release of the source code for the Netscape web browser Mozilla. At the time, this was the first major release of an existing, widely used piece of desktop software as free software, which brought it further into the public eye.
|
||||
|
||||
### 5\. Open source
|
||||
|
||||
As far back as 1985, the ambiguous nature of the word "free", used to describe software freedom, was identified as problematic by RMS himself. In the GNU Manifesto, he identified "give away" and "for free" as terms that confused zero price and user freedom. "Free as in freedom," "Speech not beer," and similar mantras were common when free software hit a mainstream audience in the late 1990s, but a number of prominent community figures argued that a term was needed that made the concept more accessible to the general public.
|
||||
|
||||
After Netscape released the source code for Mozilla in 1998 (see #4), a group of people, including Eric Raymond, Bruce Perens, Michael Tiemann, Jon "Maddog" Hall, and many of the leading lights of the free software world, gathered in Palo Alto to discuss an alternative term. The term "open source" was [coined by Christine Peterson][11] to describe free software, and the Open Source Institute was later founded by Bruce Perens and Eric Raymond. The fundamental difference with proprietary software, they argued, was the availability of the source code, and so this was what should be put forward first in the branding.
|
||||
|
||||
Later that year, at a summit organized by Tim O'Reilly, an extended group of some of the most influential people in the free software world at the time gathered to debate various new brands for free software. In the end, "open source" edged out "sourceware," and open source began to be adopted by many projects in the community.
|
||||
|
||||
There was some disagreement, however. Richard Stallman and the Free Software Foundation continued to champion the term "free software," because to them, the fundamental difference with proprietary software was user freedom, and the availability of source code was just a means to that end. Stallman argued that removing the focus on freedom would lead to a future where source code would be available, but the user of the software would not be able to avail of the freedom to modify the software. With the advent of web-deployed software-as-a-service and open source firmware embedded in devices, the battle continues to be waged today.
|
||||
|
||||
### 6\. Corporate investment in open source—VA Linux, Red Hat, IBM
|
||||
|
||||
In the late 1990s, a series of high-profile events led to a huge increase in the professionalization of free and open source software. Among these, the highest-profile events were the IPOs of VA Linux and Red Hat in 1999\. Both companies had massive gains in share price on their opening days as publicly traded companies, proving that open source was now going commercial and mainstream.
|
||||
|
||||
Also in 1999, IBM announced that they were supporting Linux by investing $1 billion in its development, making is less risky to traditional enterprise users. The following year, Sun Microsystems released the source code to its cross-platform office suite, StarOffice, and created the [OpenOffice.org][12] project.
|
||||
|
||||
The combined effect of massive Silicon Valley funding of open source projects, the attention of Wall Street for young companies built around open source software, and the market credibility that tech giants like IBM and Sun Microsystems brought had combined to create the massive adoption of open source, and the embrace of the open development model that helped it thrive have led to the dominance of Linux and open source in the tech industry today.
|
||||
|
||||
_Which pivotal moments would you add to the list? Let us know in the comments._
|
||||
|
||||
### About the author
|
||||
|
||||
[][13] Dave Neary - Dave Neary is a member of the Open Source and Standards team at Red Hat, helping make Open Source projects important to Red Hat be successful. Dave has been around the free and open source software world, wearing many different hats, since sending his first patch to the GIMP in 1999.[More about me][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/pivotal-moments-history-open-source
|
||||
|
||||
作者:[Dave Neary ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dneary
|
||||
[1]:https://opensource.com/article/18/2/pivotal-moments-history-open-source?rate=gsG-JrjfROWACP7i9KUoqmH14JDff8-31C2IlNPPyu8
|
||||
[2]:https://opensource.com/users/dneary
|
||||
[3]:https://opensource.com/user/16681/feed
|
||||
[4]:https://www.flickr.com/photos/cogdog/6476689463/in/photolist-aSjJ8H-qHAvo4-54QttY-ofm5ZJ-9NnUjX-tFxS7Y-bPPjtH-hPYow-bCndCk-6NpFvF-5yQ1xv-7EWMXZ-48RAjB-5EzYo3-qAFAdk-9gGty4-a2BBgY-bJsTcF-pWXATc-6EBTmq-SkBnSJ-57QJco-ddn815-cqt5qG-ddmYSc-pkYxRz-awf3n2-Rvnoxa-iEMfeG-bVfq5-jXy74D-meCC1v-qx22rx-fMScsJ-ci1435-ie8P5-oUSXhp-xJSm9-bHgApk-mX7ggz-bpsxd7-8ukud7-aEDmBj-qWkytq-ofwhdM-b7zSeD-ddn5G7-ddn5gb-qCxnB2-S74vsk
|
||||
[5]:https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[6]:https://en.wikipedia.org/wiki/Richard_Stallman
|
||||
[7]:https://groups.google.com/forum/#!original/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
|
||||
[8]:https://www.gnu.org/gnu/manifesto.en.html
|
||||
[9]:https://www.fsf.org/
|
||||
[10]:https://en.wikipedia.org/wiki/The_Cathedral_and_the_Bazaar
|
||||
[11]:https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
[12]:http://www.openoffice.org/
|
||||
[13]:https://opensource.com/users/dneary
|
||||
[14]:https://opensource.com/users/dneary
|
||||
[15]:https://opensource.com/users/dneary
|
||||
[16]:https://opensource.com/article/18/2/pivotal-moments-history-open-source#comments
|
||||
[17]:https://opensource.com/tags/licensing
|
||||
103
sources/talk/20180201 How I coined the term open source.md
Normal file
103
sources/talk/20180201 How I coined the term open source.md
Normal file
@ -0,0 +1,103 @@
|
||||
How I coined the term 'open source'
|
||||
============================================================
|
||||
|
||||
### Christine Peterson finally publishes her account of that fateful day, 20 years ago.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
In a few days, on February 3, the 20th anniversary of the introduction of the term "[open source software][6]" is upon us. As open source software grows in popularity and powers some of the most robust and important innovations of our time, we reflect on its rise to prominence.
|
||||
|
||||
I am the originator of the term "open source software" and came up with it while executive director at Foresight Institute. Not a software developer like the rest, I thank Linux programmer Todd Anderson for supporting the term and proposing it to the group.
|
||||
|
||||
This is my account of how I came up with it, how it was proposed, and the subsequent reactions. Of course, there are a number of accounts of the coining of the term, for example by Eric Raymond and Richard Stallman, yet this is mine, written on January 2, 2006.
|
||||
|
||||
It has never been published, until today.
|
||||
|
||||
* * *
|
||||
|
||||
The introduction of the term "open source software" was a deliberate effort to make this field of endeavor more understandable to newcomers and to business, which was viewed as necessary to its spread to a broader community of users. The problem with the main earlier label, "free software," was not its political connotations, but that—to newcomers—its seeming focus on price is distracting. A term was needed that focuses on the key issue of source code and that does not immediately confuse those new to the concept. The first term that came along at the right time and fulfilled these requirements was rapidly adopted: open source.
|
||||
|
||||
This term had long been used in an "intelligence" (i.e., spying) context, but to my knowledge, use of the term with respect to software prior to 1998 has not been confirmed. The account below describes how the term [open source software][7] caught on and became the name of both an industry and a movement.
|
||||
|
||||
### Meetings on computer security
|
||||
|
||||
In late 1997, weekly meetings were being held at Foresight Institute to discuss computer security. Foresight is a nonprofit think tank focused on nanotechnology and artificial intelligence, and software security is regarded as central to the reliability and security of both. We had identified free software as a promising approach to improving software security and reliability and were looking for ways to promote it. Interest in free software was starting to grow outside the programming community, and it was increasingly clear that an opportunity was coming to change the world. However, just how to do this was unclear, and we were groping for strategies.
|
||||
|
||||
At these meetings, we discussed the need for a new term due to the confusion factor. The argument was as follows: those new to the term "free software" assume it is referring to the price. Oldtimers must then launch into an explanation, usually given as follows: "We mean free as in freedom, not free as in beer." At this point, a discussion on software has turned into one about the price of an alcoholic beverage. The problem was not that explaining the meaning is impossible—the problem was that the name for an important idea should not be so confusing to newcomers. A clearer term was needed. No political issues were raised regarding the free software term; the issue was its lack of clarity to those new to the concept.
|
||||
|
||||
### Releasing Netscape
|
||||
|
||||
On February 2, 1998, Eric Raymond arrived on a visit to work with Netscape on the plan to release the browser code under a free-software-style license. We held a meeting that night at Foresight's office in Los Altos to strategize and refine our message. In addition to Eric and me, active participants included Brian Behlendorf, Michael Tiemann, Todd Anderson, Mark S. Miller, and Ka-Ping Yee. But at that meeting, the field was still described as free software or, by Brian, "source code available" software.
|
||||
|
||||
While in town, Eric used Foresight as a base of operations. At one point during his visit, he was called to the phone to talk with a couple of Netscape legal and/or marketing staff. When he was finished, I asked to be put on the phone with them—one man and one woman, perhaps Mitchell Baker—so I could bring up the need for a new term. They agreed in principle immediately, but no specific term was agreed upon.
|
||||
|
||||
Between meetings that week, I was still focused on the need for a better name and came up with the term "open source software." While not ideal, it struck me as good enough. I ran it by at least four others: Eric Drexler, Mark Miller, and Todd Anderson liked it, while a friend in marketing and public relations felt the term "open" had been overused and abused and believed we could do better. He was right in theory; however, I didn't have a better idea, so I thought I would try to go ahead and introduce it. In hindsight, I should have simply proposed it to Eric Raymond, but I didn't know him well at the time, so I took an indirect strategy instead.
|
||||
|
||||
Todd had agreed strongly about the need for a new term and offered to assist in getting the term introduced. This was helpful because, as a non-programmer, my influence within the free software community was weak. My work in nanotechnology education at Foresight was a plus, but not enough for me to be taken very seriously on free software questions. As a Linux programmer, Todd would be listened to more closely.
|
||||
|
||||
### The key meeting
|
||||
|
||||
Later that week, on February 5, 1998, a group was assembled at VA Research to brainstorm on strategy. Attending—in addition to Eric Raymond, Todd, and me—were Larry Augustin, Sam Ockman, and attending by phone, Jon "maddog" Hall.
|
||||
|
||||
The primary topic was promotion strategy, especially which companies to approach. I said little, but was looking for an opportunity to introduce the proposed term. I felt that it wouldn't work for me to just blurt out, "All you technical people should start using my new term." Most of those attending didn't know me, and for all I knew, they might not even agree that a new term was greatly needed, or even somewhat desirable.
|
||||
|
||||
Fortunately, Todd was on the ball. Instead of making an assertion that the community should use this specific new term, he did something less directive—a smart thing to do with this community of strong-willed individuals. He simply used the term in a sentence on another topic—just dropped it into the conversation to see what happened. I went on alert, hoping for a response, but there was none at first. The discussion continued on the original topic. It seemed only he and I had noticed the usage.
|
||||
|
||||
Not so—memetic evolution was in action. A few minutes later, one of the others used the term, evidently without noticing, still discussing a topic other than terminology. Todd and I looked at each other out of the corners of our eyes to check: yes, we had both noticed what happened. I was excited—it might work! But I kept quiet: I still had low status in this group. Probably some were wondering why Eric had invited me at all.
|
||||
|
||||
Toward the end of the meeting, the [question of terminology][8] was brought up explicitly, probably by Todd or Eric. Maddog mentioned "freely distributable" as an earlier term, and "cooperatively developed" as a newer term. Eric listed "free software," "open source," and "sourceware" as the main options. Todd advocated the "open source" model, and Eric endorsed this. I didn't say much, letting Todd and Eric pull the (loose, informal) consensus together around the open source name. It was clear that to most of those at the meeting, the name change was not the most important thing discussed there; a relatively minor issue. Only about 10% of my notes from this meeting are on the terminology question.
|
||||
|
||||
But I was elated. These were some key leaders in the community, and they liked the new name, or at least didn't object. This was a very good sign. There was probably not much more I could do to help; Eric Raymond was far better positioned to spread the new meme, and he did. Bruce Perens signed on to the effort immediately, helping set up [Opensource.org][9] and playing a key role in spreading the new term.
|
||||
|
||||
For the name to succeed, it was necessary, or at least highly desirable, that Tim O'Reilly agree and actively use it in his many projects on behalf of the community. Also helpful would be use of the term in the upcoming official release of the Netscape Navigator code. By late February, both O'Reilly & Associates and Netscape had started to use the term.
|
||||
|
||||
### Getting the name out
|
||||
|
||||
After this, there was a period during which the term was promoted by Eric Raymond to the media, by Tim O'Reilly to business, and by both to the programming community. It seemed to spread very quickly.
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key leaders in the field. Announced in advance as the first "[Freeware Summit][10]," by April 14 it was referred to as the first "[Open Source Summit][11]."
|
||||
|
||||
These months were extremely exciting for open source. Every week, it seemed, a new company announced plans to participate. Reading Slashdot became a necessity, even for those like me who were only peripherally involved. I strongly believe that the new term was helpful in enabling this rapid spread into business, which then enabled wider use by the public.
|
||||
|
||||
A quick Google search indicates that "open source" appears more often than "free software," but there still is substantial use of the free software term, which remains useful and should be included when communicating with audiences who prefer it.
|
||||
|
||||
### A happy twinge
|
||||
|
||||
When an [early account][12] of the terminology change written by Eric Raymond was posted on the Open Source Initiative website, I was listed as being at the VA brainstorming meeting, but not as the originator of the term. This was my own fault; I had neglected to tell Eric the details. My impulse was to let it pass and stay in the background, but Todd felt otherwise. He suggested to me that one day I would be glad to be known as the person who coined the name "open source software." He explained the situation to Eric, who promptly updated his site.
|
||||
|
||||
Coming up with a phrase is a small contribution, but I admit to being grateful to those who remember to credit me with it. Every time I hear it, which is very often now, it gives me a little happy twinge.
|
||||
|
||||
The big credit for persuading the community goes to Eric Raymond and Tim O'Reilly, who made it happen. Thanks to them for crediting me, and to Todd Anderson for his role throughout. The above is not a complete account of open source history; apologies to the many key players whose names do not appear. Those seeking a more complete account should refer to the links in this article and elsewhere on the net.
|
||||
|
||||
### About the author
|
||||
|
||||
[][13] Christine Peterson - Christine Peterson writes, lectures, and briefs the media on coming powerful technologies, especially nanotechnology, artificial intelligence, and longevity. She is Cofounder and Past President of Foresight Institute, the leading nanotech public interest group. Foresight educates the public, technical community, and policymakers on coming powerful technologies and how to guide their long-term impact. She serves on the Advisory Board of the [Machine Intelligence... ][2][more about Christine Peterson][3][More about me][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
|
||||
作者:[ Christine Peterson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/christine-peterson
|
||||
[1]:https://opensource.com/article/18/2/coining-term-open-source-software?rate=HFz31Mwyy6f09l9uhm5T_OFJEmUuAwpI61FY-fSo3Gc
|
||||
[2]:http://intelligence.org/
|
||||
[3]:https://opensource.com/users/christine-peterson
|
||||
[4]:https://opensource.com/users/christine-peterson
|
||||
[5]:https://opensource.com/user/206091/feed
|
||||
[6]:https://opensource.com/resources/what-open-source
|
||||
[7]:https://opensource.org/osd
|
||||
[8]:https://wiki2.org/en/Alternative_terms_for_free_software
|
||||
[9]:https://opensource.org/
|
||||
[10]:http://www.oreilly.com/pub/pr/636
|
||||
[11]:http://www.oreilly.com/pub/pr/796
|
||||
[12]:https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html
|
||||
[13]:https://opensource.com/users/christine-peterson
|
||||
[14]:https://opensource.com/users/christine-peterson
|
||||
[15]:https://opensource.com/users/christine-peterson
|
||||
[16]:https://opensource.com/article/18/2/coining-term-open-source-software#comments
|
||||
@ -0,0 +1,75 @@
|
||||
Open source software: 20 years and counting
|
||||
============================================================
|
||||
|
||||
### On the 20th anniversary of the coining of the term "open source software," how did it rise to dominance and what's next?
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Twenty years ago, in February 1998, the term "open source" was first applied to software. Soon afterwards, the Open Source Definition was created and the seeds that became the Open Source Initiative (OSI) were sown. As the OSD’s author [Bruce Perens relates][9],
|
||||
|
||||
> “Open source” is the proper name of a campaign to promote the pre-existing concept of free software to business, and to certify licenses to a rule set.
|
||||
|
||||
Twenty years later, that campaign has proven wildly successful, beyond the imagination of anyone involved at the time. Today open source software is literally everywhere. It is the foundation for the internet and the web. It powers the computers and mobile devices we all use, as well as the networks they connect to. Without it, cloud computing and the nascent Internet of Things would be impossible to scale and perhaps to create. It has enabled new ways of doing business to be tested and proven, allowing giant corporations like Google and Facebook to start from the top of a mountain others already climbed.
|
||||
|
||||
Like any human creation, it has a dark side as well. It has also unlocked dystopian possibilities for surveillance and the inevitably consequent authoritarian control. It has provided criminals with new ways to cheat their victims and unleashed the darkness of bullying delivered anonymously and at scale. It allows destructive fanatics to organize in secret without the inconvenience of meeting. All of these are shadows cast by useful capabilities, just as every human tool throughout history has been used both to feed and care and to harm and control. We need to help the upcoming generation strive for irreproachable innovation. As [Richard Feynman said][10],
|
||||
|
||||
> To every man is given the key to the gates of heaven. The same key opens the gates of hell.
|
||||
|
||||
As open source has matured, the way it is discussed and understood has also matured. The first decade was one of advocacy and controversy, while the second was marked by adoption and adaptation.
|
||||
|
||||
1. In the first decade, the key question concerned business models—“how can I contribute freely yet still be paid?”—while during the second, more people asked about governance—“how can I participate yet keep control/not be controlled?”
|
||||
|
||||
2. Open source projects of the first decade were predominantly replacements for off-the-shelf products; in the second decade, they were increasingly components of larger solutions.
|
||||
|
||||
3. Projects of the first decade were often run by informal groups of individuals; in the second decade, they were frequently run by charities created on a project-by-project basis.
|
||||
|
||||
4. Open source developers of the first decade were frequently devoted to a single project and often worked in their spare time. In the second decade, they were increasingly employed to work on a specific technology—professional specialists.
|
||||
|
||||
5. While open source was always intended as a way to promote software freedom, during the first decade, conflict arose with those preferring the term “free software.” In the second decade, this conflict was largely ignored as open source adoption accelerated.
|
||||
|
||||
So what will the third decade bring?
|
||||
|
||||
1. _The complexity business model_ —The predominant business model will involve monetizing the solution of the complexity arising from the integration of many open source parts, especially from deployment and scaling. Governance needs will reflect this.
|
||||
|
||||
2. _Open source mosaics_ —Open source projects will be predominantly families of component parts, together with being built into stacks of components. The resultant larger solutions will be a mosaic of open source parts.
|
||||
|
||||
3. _Families of projects_ —More and more projects will be hosted by consortia/trade associations like the Linux Foundation and OpenStack, and by general-purpose charities like Apache and the Software Freedom Conservancy.
|
||||
|
||||
4. _Professional generalists_ —Open source developers will increasingly be employed to integrate many technologies into complex solutions and will contribute to a range of projects.
|
||||
|
||||
5. _Software freedom redux_ —As new problems arise, software freedom (the application of the Four Freedoms to user and developer flexibility) will increasingly be applied to identify solutions that work for collaborative communities and independent deployers.
|
||||
|
||||
I’ll be expounding on all this in conference keynotes around the world during 2018\. Watch for [OSI’s 20th Anniversary World Tour][11]!
|
||||
|
||||
_This article was originally published on [Meshed Insights Ltd.][2] and is reprinted with permission. This article, as well as my work at OSI, is supported by [Patreon patrons][3]._
|
||||
|
||||
### About the author
|
||||
|
||||
[][12] Simon Phipps - Computer industry and open source veteran Simon Phipps started [Public Software][4], a European host for open source projects, and volunteers as President at OSI and a director at The Document Foundation. His posts are sponsored by [Patreon patrons][5] - become one if you'd like to see more! Over a 30+ year career he has been involved at a strategic level in some of the world’s leading... [more about Simon Phipps][6][More about me][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/open-source-20-years-and-counting
|
||||
|
||||
作者:[Simon Phipps ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/simonphipps
|
||||
[1]:https://opensource.com/article/18/2/open-source-20-years-and-counting?rate=TZxa8jxR6VBcYukor0FDsTH38HxUrr7Mt8QRcn0sC2I
|
||||
[2]:https://meshedinsights.com/2017/12/21/20-years-and-counting/
|
||||
[3]:https://patreon.com/webmink
|
||||
[4]:https://publicsoftware.eu/
|
||||
[5]:https://patreon.com/webmink
|
||||
[6]:https://opensource.com/users/simonphipps
|
||||
[7]:https://opensource.com/users/simonphipps
|
||||
[8]:https://opensource.com/user/12532/feed
|
||||
[9]:https://perens.com/2017/09/26/on-usage-of-the-phrase-open-source/
|
||||
[10]:https://www.brainpickings.org/2013/07/19/richard-feynman-science-morality-poem/
|
||||
[11]:https://opensource.org/node/905
|
||||
[12]:https://opensource.com/users/simonphipps
|
||||
[13]:https://opensource.com/users/simonphipps
|
||||
[14]:https://opensource.com/users/simonphipps
|
||||
@ -0,0 +1,102 @@
|
||||
How to Install Tripwire IDS (Intrusion Detection System) on Linux
|
||||
============================================================
|
||||
|
||||
|
||||
Tripwire is a popular Linux Intrusion Detection System (IDS) that runs on systems in order to detect if unauthorized filesystem changes occurred over time.
|
||||
|
||||
In CentOS and RHEL distributions, tripwire is not a part of official repositories. However, the tripwire package can be installed via [Epel repositories][1].
|
||||
|
||||
To begin, first install Epel repositories in CentOS and RHEL system, by issuing the below command.
|
||||
|
||||
```
|
||||
# yum install epel-release
|
||||
```
|
||||
|
||||
After you’ve installed Epel repositories, make sure you update the system with the following command.
|
||||
|
||||
```
|
||||
# yum update
|
||||
```
|
||||
|
||||
After the update process finishes, install Tripwire IDS software by executing the below command.
|
||||
|
||||
```
|
||||
# yum install tripwire
|
||||
```
|
||||
|
||||
Fortunately, tripwire is a part of Ubuntu and Debian default repositories and can be installed with following commands.
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install tripwire
|
||||
```
|
||||
|
||||
On Ubuntu and Debian, the tripwire installation will be asked to choose and confirm a site key and local key passphrase. These keys are used by tripwire to secure its configuration files.
|
||||
|
||||
[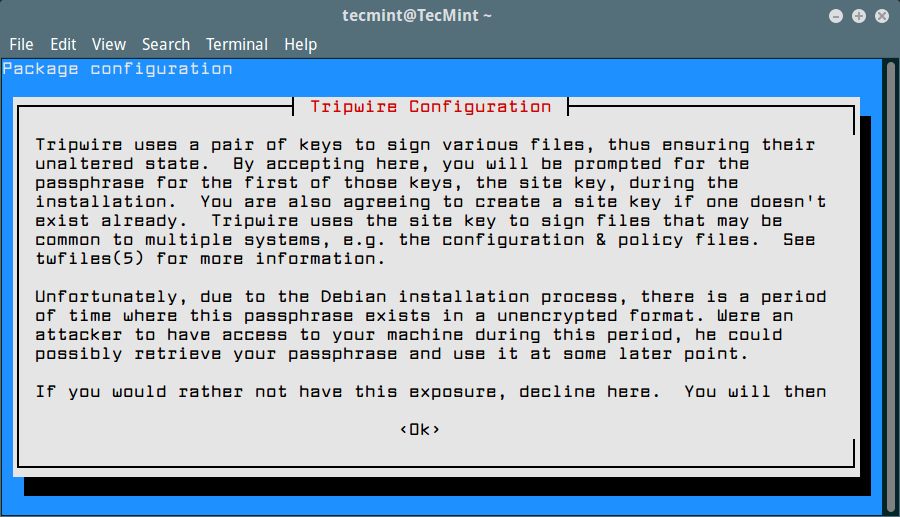][2]
|
||||
|
||||
Create Tripwire Site and Local Key
|
||||
|
||||
On CentOS and RHEL, you need to create tripwire keys with the below command and supply a passphrase for site key and local key.
|
||||
|
||||
```
|
||||
# tripwire-setup-keyfiles
|
||||
```
|
||||
[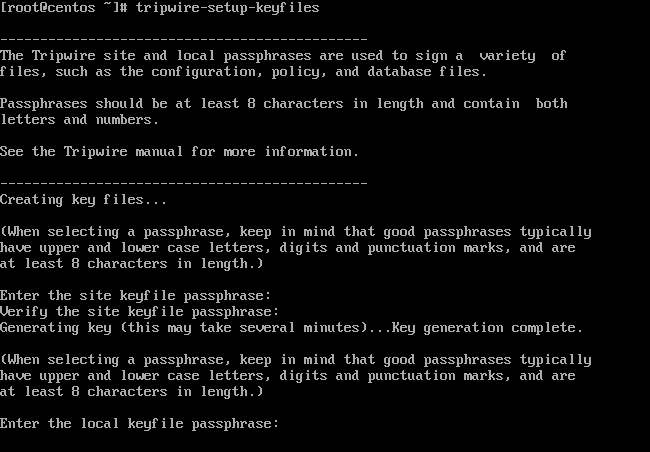][3]
|
||||
|
||||
Create Tripwire Keys
|
||||
|
||||
In order to validate your system, you need to initialize Tripwire database with the following command. Due to the fact that the database hasn’t been initialized yet, tripwire will display a lot of false-positive warnings.
|
||||
|
||||
```
|
||||
# tripwire --init
|
||||
```
|
||||
[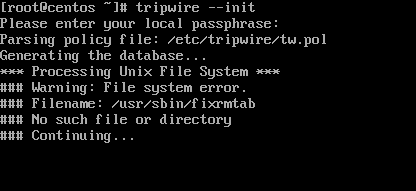][4]
|
||||
|
||||
Initialize Tripwire Database
|
||||
|
||||
Finally, generate a tripwire system report in order to check the configurations by issuing the below command. Use `--help` switch to list all tripwire check command options.
|
||||
|
||||
```
|
||||
# tripwire --check --help
|
||||
# tripwire --check
|
||||
```
|
||||
|
||||
After tripwire check command completes, review the report by opening the file with the extension `.twr` from /var/lib/tripwire/report/ directory with your favorite text editor command, but before that you need to convert to text file.
|
||||
|
||||
```
|
||||
# twprint --print-report --twrfile /var/lib/tripwire/report/tecmint-20170727-235255.twr > report.txt
|
||||
# vi report.txt
|
||||
```
|
||||
[][5]
|
||||
|
||||
Tripwire System Report
|
||||
|
||||
That’s It! you have successfully installed Tripwire on Linux server. I hope you can now easily configure your [Tripwire IDS][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
-------
|
||||
|
||||
via: https://www.tecmint.com/install-tripwire-ids-intrusion-detection-system-on-linux/
|
||||
|
||||
作者:[ Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2018/01/Create-Site-and-Local-key.png
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2018/01/Create-Tripwire-Keys.png
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2018/01/Initialize-Tripwire-Database.png
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2018/01/Tripwire-System-Report.png
|
||||
[6]:https://www.tripwire.com/
|
||||
[7]:https://www.tecmint.com/author/cezarmatei/
|
||||
[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,68 @@
|
||||
A look inside Facebook's open source program
|
||||
============================================================
|
||||
|
||||
### Facebook developer Christine Abernathy discusses how open source helps the company share insights and boost innovation.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
|
||||
Open source becomes more ubiquitous every year, appearing everywhere from [government municipalities][11] to [universities][12]. Companies of all sizes are also increasingly turning to open source software. In fact, some companies are taking open source a step further by supporting projects financially or working with developers.
|
||||
|
||||
Facebook's open source program, for example, encourages others to release their code as open source, while working and engaging with the community to support open source projects. [Christine Abernathy][13], a Facebook developer, open source advocate, and member of the company's open source team, visited the Rochester Institute of Technology last November, presenting at the [November edition][14] of the FOSS Talks speaker series. In her talk, Abernathy explained how Facebook approaches open source and why it's an important part of the work the company does.
|
||||
|
||||
### Facebook and open source
|
||||
|
||||
Abernathy said that open source plays a fundamental role in Facebook's mission to create community and bring the world closer together. This ideological match is one motivating factor for Facebook's participation in open source. Additionally, Facebook faces unique infrastructure and development challenges, and open source provides a platform for the company to share solutions that could help others. Open source also provides a way to accelerate innovation and create better software, helping engineering teams produce better software and work more transparently. Today, Facebook's 443 projects on GitHub comprise 122,000 forks, 292,000 commits, and 732,000 followers.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
Some of the Facebook projects released as open source include React, GraphQL, Caffe2, and others. (Image by Christine Abernathy, used with permission)
|
||||
|
||||
### Lessons learned
|
||||
|
||||
Abernathy emphasized that Facebook has learned many lessons from the open source community, and it looks forward to learning many more. She identified the three most important ones:
|
||||
|
||||
* Share what's useful
|
||||
|
||||
* Highlight your heroes
|
||||
|
||||
* Fix common pain points
|
||||
|
||||
_Christine Abernathy visited RIT as part of the FOSS Talks speaker series. Every month, a guest speaker from the open source world shares wisdom, insight, and advice about the open source world with students interested in free and open source software. The [FOSS @ MAGIC][3] community is thankful to have Abernathy attend as a speaker._
|
||||
|
||||
### About the author
|
||||
|
||||
[][15] Justin W. Flory - Justin is a student at the [Rochester Institute of Technology][4]majoring in Networking and Systems Administration. He is currently a contributor to the [Fedora Project][5]. In Fedora, Justin is the editor-in-chief of the [Fedora Magazine][6], the lead of the [Community... ][7][more about Justin W. Flory][8][More about me][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/inside-facebooks-open-source-program
|
||||
|
||||
作者:[Justin W. Flory ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jflory
|
||||
[1]:https://opensource.com/file/383786
|
||||
[2]:https://opensource.com/article/18/1/inside-facebooks-open-source-program?rate=H9_bfSwXiJfi2tvOLiDxC_tbC2xkEOYtCl-CiTq49SA
|
||||
[3]:http://foss.rit.edu/
|
||||
[4]:https://www.rit.edu/
|
||||
[5]:https://fedoraproject.org/wiki/Overview
|
||||
[6]:https://fedoramagazine.org/
|
||||
[7]:https://fedoraproject.org/wiki/CommOps
|
||||
[8]:https://opensource.com/users/jflory
|
||||
[9]:https://opensource.com/users/jflory
|
||||
[10]:https://opensource.com/user/74361/feed
|
||||
[11]:https://opensource.com/article/17/8/tirana-government-chooses-open-source
|
||||
[12]:https://opensource.com/article/16/12/2016-election-night-hackathon
|
||||
[13]:https://twitter.com/abernathyca
|
||||
[14]:https://www.eventbrite.com/e/fossmagic-talks-open-source-facebook-with-christine-abernathy-tickets-38955037566#
|
||||
[15]:https://opensource.com/users/jflory
|
||||
[16]:https://opensource.com/users/jflory
|
||||
[17]:https://opensource.com/users/jflory
|
||||
[18]:https://opensource.com/article/18/1/inside-facebooks-open-source-program#comments
|
||||
@ -0,0 +1,189 @@
|
||||
What Happens When You Want to Create a Special File with All Special Characters in Linux?
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Learn how to handle creation of a special file filled with special characters.[Used with permission][1]
|
||||
|
||||
I recently joined Holberton School as a student, hoping to learn full-stack software development. What I did not expect was that in two weeks I would be pretty much proficient with creating shell scripts that would make my coding life easy and fast!
|
||||
|
||||
So what is the post about? It is about a novel problem that my peers and I faced when we were asked to create a file with no regular alphabets/ numbers but instead special characters!! Just to give you a look at what kind of file name we were dealing with —
|
||||
|
||||
### \*\\’”Holberton School”\’\\*$\?\*\*\*\*\*:)
|
||||
|
||||
What a novel file name! Of course, this question was met with the collective groaning and long drawn sighs of all 55 (batch #5) students!
|
||||
|
||||

|
||||
|
||||
Some proceeded to make their lives easier by breaking the file name into pieces on a doc file and adding in the **“\\” or “\”** in front of certain special character which kind of resulted in this format -
|
||||
|
||||
#### \\*\\\\’\”Holberton School\”\\’\\\\*$\\?\\*\\*\\*\\*\\*:)
|
||||
|
||||

|
||||
|
||||
Everyone trying to get the \\ right
|
||||
|
||||
bamboozled? me, too! I did not want to believe that this was the only way to solve this, as I was getting frustrated with every “\\” or “\” that was required to escape and print those special characters as normal characters!
|
||||
|
||||
If you’re new to shell scripting, here is a quick walk through on why so many “\\” , “\” were required and where.
|
||||
|
||||
In shell scripting “ ” and ‘ ’ have special usage and once you understand and remember when and where to use them it can make your life easier!
|
||||
|
||||
#### Double Quoting
|
||||
|
||||
The first type of quoting we will look at is double quotes. **If you place text inside double quotes, all the special characters used by the shell lose their special meaning and are treated as ordinary characters. The exceptions are “$”, “\” (backslash), and “`” (back- quote).**This means that word-splitting, pathname expansion, tilde expansion, and brace expansion are suppressed, but parameter expansion, arithmetic expansion, and command substitution are still carried out. Using double quotes, we can cope with filenames containing embedded spaces.
|
||||
|
||||
So this means that you can create file with names that have spaces between words — if that is your thing, but I would suggest you to not do that as it is inconvenient and rather an unpleasant experience for you to try to find that file when you need !
|
||||
|
||||
**Quoting “THE” guide for linux I follow and read like it is the Harry Potter of the linux coding world —**
|
||||
|
||||
Say you were the unfortunate victim of a file called two words.txt. If you tried to use this on the command line, word-splitting would cause this to be treated as two separate arguments rather than the desired single argument:
|
||||
|
||||
**[[me@linuxbox][3] me]$ ls -l two words.txt**
|
||||
|
||||
```
|
||||
ls: cannot access two: No such file or directory
|
||||
ls: cannot access words.txt: No such file or directory
|
||||
```
|
||||
|
||||
By using double quotes, you can stop the word-splitting and get the desired result; further, you can even repair the damage:
|
||||
|
||||
```
|
||||
[me@linuxbox me]$ ls -l “two words.txt”
|
||||
-rw-rw-r — 1 me me 18 2008–02–20 13:03 two words.txt
|
||||
[me@linuxbox me]$ mv “two words.txt” two_words.t
|
||||
```
|
||||
|
||||
There! Now we don’t have to keep typing those pesky double quotes.
|
||||
|
||||
Now, let us talk about single quotes and what is their significance in shell —
|
||||
|
||||
#### Single Quotes
|
||||
|
||||
Enclosing characters in single quotes (‘’’) preserves the literal value of each character within the quotes. A single quote may not occur between single quotes, even when preceded by a backslash.
|
||||
|
||||
Yes! that got me and I was wondering how will I use it, apparently when I was googling to find and easier way to do it I stumbled across this piece of information on the internet —
|
||||
|
||||
### Strong quoting
|
||||
|
||||
Strong quoting is very easy to explain:
|
||||
|
||||
Inside a single-quoted string **nothing** is interpreted, except the single-quote that closes the string.
|
||||
|
||||
```
|
||||
echo 'Your PATH is: $PATH'
|
||||
```
|
||||
|
||||
`$PATH` won't be expanded, it's interpreted as ordinary text because it's surrounded by strong quotes.
|
||||
|
||||
In practice that means to produce a text like `Here's my test…` as a single-quoted string, **you have to leave and re-enter the single quoting to get the character "`'`" as literal text:**
|
||||
|
||||
```
|
||||
# WRONG
|
||||
echo 'Here's my test...'
|
||||
```
|
||||
|
||||
```
|
||||
# RIGHT
|
||||
echo 'Here'\''s my test...'
|
||||
```
|
||||
|
||||
```
|
||||
# ALTERNATIVE: It's also possible to mix-and-match quotes for readability:
|
||||
echo "Here's my test"
|
||||
```
|
||||
|
||||
Well now you’re wondering — “well that explains the quotes but what about the “\”??”
|
||||
|
||||
So for certain characters we need a special way to escape those pesky “\” we saw in that file name.
|
||||
|
||||
#### Escaping Characters
|
||||
|
||||
Sometimes you only want to quote a single character. To do this, you can precede a character with a backslash, which in this context is called the _escape character_ . Often this is done inside double quotes to selectively prevent an expansion:
|
||||
|
||||
```
|
||||
[me@linuxbox me]$ echo “The balance for user $USER is: \$5.00”
|
||||
The balance for user me is: $5.00
|
||||
```
|
||||
|
||||
It is also common to use escaping to eliminate the special meaning of a character in a filename. For example, it is possible to use characters in filenames that normally have special meaning to the shell. These would include “$”, “!”, “&”, “ “, and others. To include a special character in a filename you can to this:
|
||||
|
||||
```
|
||||
[me@linuxbox me]$ mv bad\&filename good_filename
|
||||
```
|
||||
|
||||
> _**To allow a backslash character to appear, escape it by typing “\\”. Note that within single quotes, the backslash loses its special meaning and is treated as an ordinary character.**_
|
||||
|
||||
Looking at the filename now we can understand better as to why the “\\” were used in front of all those “\”s.
|
||||
|
||||
So, to print the file name without losing “\” and other special characters what others did was to suppress the “\” with “\\” and to print the single quotes there are a few ways you can do that.
|
||||
|
||||
```
|
||||
1. echo $'It\'s Shell Programming' # ksh, bash, and zsh only, does not expand variables
|
||||
2. echo "It's Shell Programming" # all shells, expands variables
|
||||
3. echo 'It'\''s Shell Programming' # all shells, single quote is outside the quotes
|
||||
4\. echo 'It'"'"'s Shell Programming' # all shells, single quote is inside double quotes
|
||||
```
|
||||
|
||||
```
|
||||
for further reading please follow this link
|
||||
```
|
||||
|
||||
Looking at option 3, I realized this would mean that I would only need to use “\” and single quotes at certain places to be able to write the whole file without getting frustrated with “\\” placements.
|
||||
|
||||
So with the hope in mind and lesser trial and errors I was actually able to print out the file name like this:
|
||||
|
||||
#### ‘\*\\’\’’”Holberton School”\’\’’\\*$\?\*\*\*\*\*:)’
|
||||
|
||||
to understand better I have added an **“a”** instead of my single quotes so that the file name and process becomes more clearer. For a better understanding, I’ll break them down into modules:
|
||||
|
||||

|
||||
|
||||
#### a\*\\a \’ a”Holberton School”\a \’ a\\*$\?\*\*\*\*\*:)a
|
||||
|
||||
#### Module 1 — a\*\\a
|
||||
|
||||
Here the use of single quote (a) creates a safe suppression for \*\\ and as mentioned before in strong quoting, the only way we can print the ‘ is to leave and re-enter the single quoting to get the character.
|
||||
|
||||
#### Module 2 , 4— \’
|
||||
|
||||
The \ suppresses the single quote as a standalone module.
|
||||
|
||||
#### Module 3 — a”Holberton School”\a
|
||||
|
||||
Here the use of single quote (a) creates a safe suppression for double quotes and \ along with regular text.
|
||||
|
||||
#### Module 5 — a\\*$\?\*\*\*\*\*:)a
|
||||
|
||||
Here the use of single quote (a) creates a safe suppression for all special characters being used such as *, \, $, ?, : and ).
|
||||
|
||||
so in the end I was able to be lazy and maintain my sanity, and got away with only using single quotes to create small modules and “\” in certain places.
|
||||
|
||||

|
||||
|
||||
And, that is how I was able to get the file to work right! After a few misses, it felt amazing and it was great to learn a new way to do things!
|
||||
|
||||

|
||||
|
||||
Handled that curve-ball pretty well! Hope this helps you in the future when, someday you might need to create a special file for a special reason in shell!
|
||||
|
||||
_**Mitali Sengupta **is a former digital marketing professional, currently enrolled as a full-stack engineering student at Holberton School. She is passionate about innovation in AI and Blockchain technologies.. You can contact Mitali on [Twitter][4], [LinkedIn][5] or [GitHub][6]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/what-happens-when-you-want-create-special-file-all-special-characters-linux
|
||||
|
||||
作者:[MITALI SENGUPTA ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mitalisengupta
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/files/images/special-charspng
|
||||
[3]:mailto:me@linuxbox
|
||||
[4]:https://twitter.com/aadhiBangalan
|
||||
[5]:https://www.linkedin.com/in/mitali-sengupta-auger
|
||||
[6]:https://github.com/MitaliSengupta
|
||||
[7]:http://mywiki.wooledge.org/Quotes#Examples
|
||||
@ -0,0 +1,147 @@
|
||||
How to Manage PGP and SSH Keys with Seahorse
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Learn how to manage both PGP and SSH keys with the Seahorse GUI tool.[Creative Commons Zero][6]
|
||||
|
||||
Security is tantamount to peace of mind. After all, security is a big reason why so many users migrated to Linux in the first place. But why stop with merely adopting the platform, when you can also employ several techniques and technologies to help secure your desktop or server systems.
|
||||
|
||||
One such technology involves keys—in the form of PGP and SSH. PGP keys allow you to encrypt and decrypt emails and files, and SSH keys allow you to log into servers with an added layer of security.
|
||||
|
||||
Sure, you can manage these keys via the command-line interface (CLI), but what if you’re working on a desktop with a resplendent GUI? Experienced Linux users may cringe at the idea of shrugging off the command line, but not all users have the same skill set and comfort level there. Thus, the GUI!
|
||||
|
||||
In this article, I will walk you through the process of managing both PGP and SSH keys through the [Seahorse][14] GUI tool. Seahorse has a pretty impressive feature set; it can:
|
||||
|
||||
* Encrypt/decrypt/sign files and text.
|
||||
|
||||
* Manage your keys and keyring.
|
||||
|
||||
* Synchronize your keys and your keyring with remote key servers.
|
||||
|
||||
* Sign and publish keys.
|
||||
|
||||
* Cache your passphrase.
|
||||
|
||||
* Backup both keys and keyring.
|
||||
|
||||
* Add an image in any GDK supported format as a OpenPGP photo ID.
|
||||
|
||||
* Create, configure, and cache SSH keys.
|
||||
|
||||
For those that don’t know, Seahorse is a GNOME application for managing both encryption keys and passwords within the GNOME keyring. But fear not, Seahorse is available for installation on numerous desktops. And since Seahorse is found in the standard repositories, you can open up your desktop’s app store (such as Ubuntu Software or Elementary OS AppCenter) and install. To do this, locate Seahorse in your distribution’s application store and click to install. Once you have Seahorse installed, you’re ready to start making use of a very handy tool.
|
||||
|
||||
Let’s do just that.
|
||||
|
||||
### PGP Keys
|
||||
|
||||
The first thing we’re going to do is create a new PGP key. As I said earlier, PGP keys can be used to encrypt email (with tools like [Thunderbird][15]’s [Enigmail][16] or the built-in encryption function with [Evolution][17]). A PGP key also allows you to encrypt files. Anyone with your public key will be able to decrypt those emails or files. Without a PGP key, no can do.
|
||||
|
||||
Creating a new PGP key pair is incredibly simple with Seahorse. Here’s what you do:
|
||||
|
||||
1. Open the Seahorse app
|
||||
|
||||
2. Click the + button in the upper left corner of the main pane
|
||||
|
||||
3. Select PGP Key (Figure 1)
|
||||
|
||||
4. Click Continue
|
||||
|
||||
5. When prompted, type a full name and email address
|
||||
|
||||
6. Click Create
|
||||
|
||||
|
||||

|
||||
Figure 1: Creating a PGP key with Seahorse.[Used with permission][1]
|
||||
|
||||
While creating your PGP key, you can click to expand the Advanced key options section, where you can configure a comment for the key, encryption type, key strength, and expiration date (Figure 2).
|
||||
|
||||
|
||||

|
||||
Figure 2: PGP key advanced options.[Used with permission][2]
|
||||
|
||||
The comment section is very handy to help you remember a key’s purpose (or other informative bits).
|
||||
With your PGP created, double-click on it from the key listing. In the resulting window, click on the Names and Signatures tab. In this window, you can sign your key (to indicate you trust this key). Click the Sign button and then (in the resulting window) indicate how carefully you’ve checked this key and how others will see the signature (Figure 3).
|
||||
|
||||
|
||||

|
||||
Figure 3: Signing a key to indicate trust level.[Used with permission][3]
|
||||
|
||||
Signing keys is very important when you’re dealing with other people’s keys, as a signed key will ensure your system (and you) you’ve done the work and can fully trust an imported key.
|
||||
|
||||
Speaking of imported keys, Seahorse allows you to easily import someone’s public key file (the file will end in .asc). Having someone’s public key on your system means you can decrypt emails and files sent to you from them. However, Seahorse has suffered a [known bug][18] for quite some time. The problem is that Seahorse imports using gpg version one, but displays with gpg version two. This means, until this long-standing bug is fixed, importing public keys will always fail. If you want to import a public PGP key into Seahorse, you’re going to have to use the command line. So, if someone has sent you the file olivia.asc, and you want to import it so it can be used with Seahorse, you would issue the command gpg2 --import olivia.asc. That key would then appear in the GnuPG Keys listing. You can open the key, click the I trust signatures button, and then click the Sign this key button to indicate how carefully you’ve checked the key in question.
|
||||
|
||||
### SSH Keys
|
||||
|
||||
Now we get to what I consider to be the most important aspect of Seahorse—SSH keys. Not only does Seahorse make it easy to generate an SSH key, it makes it easy to send that key to a server, so you can take advantage of SSH key authentication. Here’s how you generate a new key and then export it to a remote server.
|
||||
|
||||
1. Open up Seahorse
|
||||
|
||||
2. Click the + button
|
||||
|
||||
3. Select Secure Shell Key
|
||||
|
||||
4. Click Continue
|
||||
|
||||
5. Give the key a description
|
||||
|
||||
6. Click Create and Set Up
|
||||
|
||||
7. Type and verify a passphrase for the key
|
||||
|
||||
8. Click OK
|
||||
|
||||
9. Type the address of the remote server and a remote login name found on the server (Figure 4)
|
||||
|
||||
10. Type the password for the remote user
|
||||
|
||||
11. Click OK
|
||||
|
||||
|
||||

|
||||
Figure 4: Uploading an SSH key to a remote server.[Used with permission][4]
|
||||
|
||||
The new key will be uploaded to the remote server and is ready to use. If your server is set up for SSH key authentication, you’re good to go.
|
||||
|
||||
Do note, during the creation of an SSH key, you can click to expand the Advanced key options and configure Encryption Type and Key Strength (Figure 5).
|
||||
|
||||
|
||||

|
||||
Figure 5: Advanced SSH key options.[Used with permission][5]
|
||||
|
||||
### A must-use for new Linux users
|
||||
|
||||
Any new-to-Linux user should get familiar with Seahorse. Even with its flaws, Seahorse is still an incredibly handy tool to have at the ready. At some point, you will likely want (or need) to encrypt or decrypt an email/file, or manage secure shell keys for SSH key authentication. If you want to do this, while avoiding the command line, Seahorse is the tool to use.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][13]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/how-manage-pgp-and-ssh-keys-seahorse
|
||||
|
||||
作者:[JACK WALLEN ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[7]:https://www.linux.com/files/images/seahorse1jpg
|
||||
[8]:https://www.linux.com/files/images/seahorse2jpg
|
||||
[9]:https://www.linux.com/files/images/seahorse3jpg
|
||||
[10]:https://www.linux.com/files/images/seahorse4jpg
|
||||
[11]:https://www.linux.com/files/images/seahorse5jpg
|
||||
[12]:https://www.linux.com/files/images/fish-19076071920jpg
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[14]:https://wiki.gnome.org/Apps/Seahorse
|
||||
[15]:https://www.mozilla.org/en-US/thunderbird/
|
||||
[16]:https://enigmail.net/index.php/en/
|
||||
[17]:https://wiki.gnome.org/Apps/Evolution
|
||||
[18]:https://bugs.launchpad.net/ubuntu/+source/seahorse/+bug/1577198
|
||||
@ -0,0 +1,59 @@
|
||||
Which Linux Kernel Version Is ‘Stable’?
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Konstantin Ryabitsev explains which Linux kernel versions are considered "stable" and how to choose what's right for you.[Creative Commons Zero][1]
|
||||
|
||||
Almost every time Linus Torvalds releases [a new mainline Linux kernel][4], there's inevitable confusion about which kernel is the "stable" one now. Is it the brand new X.Y one, or the previous X.Y-1.Z one? Is the brand new kernel too new? Should you stick to the previous release?
|
||||
|
||||
The [kernel.org][5] page doesn't really help clear up this confusion. Currently, right at the top of the page. we see that 4.15 is the latest stable kernel -- but then in the table below, 4.14.16 is listed as "stable," and 4.15 as "mainline." Frustrating, eh?
|
||||
|
||||
Unfortunately, there are no easy answers. We use the word "stable" for two different things here: as the name of the Git tree where the release originated, and as indicator of whether the kernel should be considered “stable” as in “production-ready.”
|
||||
|
||||
Due to the distributed nature of Git, Linux development happens in a number of [various forked repositories][6]. All bug fixes and new features are first collected and prepared by subsystem maintainers and then submitted to Linus Torvalds for inclusion into [his own Linux tree][7], which is considered the “master” Git repository. We call this the “mainline” Linux tree.
|
||||
|
||||
### Release Candidates
|
||||
|
||||
Before each new kernel version is released, it goes through several “release candidate” cycles, which are used by developers to test and polish all the cool new features. Based on the feedback he receives during this cycle, Linus decides whether the final version is ready to go yet or not. Usually, there are 7 weekly pre-releases, but that number routinely goes up to -rc8, and sometimes even up to -rc9 and above. When Linus is convinced that the new kernel is ready to go, he makes the final release, and we call this release “stable” to indicate that it’s not a “release candidate.”
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
As any kind of complex software written by imperfect human beings, each new version of the Linux kernel contains bugs, and those bugs require fixing. The rule for bug fixes in the Linux Kernel is very straightforward: all fixes must first go into Linus’s tree. Once the bug is fixed in the mainline repository, it may then be applied to previously released kernels that are still maintained by the Kernel development community. All fixes backported to stable releases must meet a [set of important criteria][8] before they are considered -- and one of them is that they “must already exist in Linus’s tree.” There is a [separate Git repository][9] used for the purpose of maintaining backported bug fixes, and it is called the “stable” tree -- because it is used to track previously released stable kernels. It is maintained and curated by Greg Kroah-Hartman.
|
||||
|
||||
### Latest Stable Kernel
|
||||
|
||||
So, whenever you visit kernel.org looking for the latest stable kernel, you should use the version that is in the Big Yellow Button that says “Latest Stable Kernel.”
|
||||
|
||||

|
||||
|
||||
Ah, but now you may wonder -- if both 4.15 and 4.14.16 are stable, then which one is more stable? Some people avoid using ".0" releases of kernel because they think a particular version is not stable enough until there is at least a ".1". It's hard to either prove or disprove this, and there are pro and con arguments for both, so it's pretty much up to you to decide which you prefer.
|
||||
|
||||
On the one hand, anything that goes into a stable tree release must first be accepted into the mainline kernel and then backported. This means that mainline kernels will always have fresher bug fixes than what is released in the stable tree, and therefore you should always use mainline “.0” releases if you want fewest “known bugs.”
|
||||
|
||||
On the other hand, mainline is where all the cool new features are added -- and new features bring with them an unknown quantity of “new bugs” that are not in the older stable releases. Whether new, unknown bugs are more worrisome than older, known, but yet unfixed bugs -- well, that is entirely your call. However, it is worth pointing out that many bug fixes are only thoroughly tested against mainline kernels. When patches are backported into older kernels, chances are they will work just fine, but there are fewer integration tests performed against older stable releases. More often than not, it is assumed that "previous stable" is close enough to current mainline that things will likely "just work." And they usually do, of course, but this yet again shows how hard it is to say "which kernel is actually more stable."
|
||||
|
||||
So, basically, there is no quantitative or qualitative metric we can use to definitively say which kernel is more stable -- 4.15 or 4.14.16\. The most we can do is to unhelpfully state that they are "differently stable.”
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/2/which-linux-kernel-version-stable
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/apple1jpg
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[4]:https://www.linux.com/blog/intro-to-linux/2018/1/linux-kernel-415-unusual-release-cycle
|
||||
[5]:https://www.kernel.org/
|
||||
[6]:https://git.kernel.org/pub/scm/linux/kernel/git/
|
||||
[7]:https://git.kernel.org/torvalds/c/v4.15
|
||||
[8]:https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html
|
||||
[9]:https://git.kernel.org/stable/linux-stable/c/v4.14.16
|
||||
Loading…
Reference in New Issue
Block a user