diff --git a/published/20180528 What is behavior-driven Python.md b/published/20180528 What is behavior-driven Python.md
new file mode 100644
index 0000000000..943d96e5f1
--- /dev/null
+++ b/published/20180528 What is behavior-driven Python.md
@@ -0,0 +1,242 @@
+什么是行为驱动的 Python?
+======
+
+> 使用 Python behave 框架的行为驱动开发模式可以帮助你的团队更好的协作和测试自动化。
+
+
+
+您是否听说过[行为驱动开发][1](BDD),并好奇这是个什么东西?也许你发现了团队成员在谈论“嫩瓜”(LCTT 译注:“嫩瓜” 是一种简单的英语文本语言,工具 cucumber 通过解释它来执行测试脚本,见下文),而你却不知所云。或许你是一个 Python 人,正在寻找更好的方法来测试你的代码。 无论在什么情况下,了解 BDD 都可以帮助您和您的团队实现更好的协作和测试自动化,而 Python 的 [behave][21] 框架是一个很好的起点。
+
+### 什么是 BDD?
+
+在软件中,*行为*是指在明确定义的输入、动作和结果场景中功能是如何运转的。 产品可以表现出无数的行为,例如:
+
+ * 在网站上提交表单
+ * 搜索想要的结果
+ * 保存文档
+ * 进行 REST API 调用
+ * 运行命令行界面命令
+
+根据产品的行为定义产品的功能可以更容易地描述产品,并对其进行开发和测试。 BDD 的核心是:使行为成为软件开发的焦点。在开发早期使用示例语言的规范来定义行为。最常见的行为规范语言之一是 Gherkin,Cucumber项目中的Given-When-Then场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
+
+下面是用Gherkin编写的行为规范的示例:
+
+根据产品的行为定义产品的功能可以更容易地描述产品,开发产品并对其进行测试。 这是BDD的核心:使行为成为软件开发的焦点。 在开发早期使用[示例规范][2]的语言来定义行为。 最常见的行为规范语言之一是[Gherkin][3],来自 [Cucumber][4] 项目中的 Given-When-Then 场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和聚焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
+
+下面是用 Gherkin 编写的行为规范的示例:
+
+```
+Scenario: Basic DuckDuckGo Search
+ Given the DuckDuckGo home page is displayed
+ When the user searches for "panda"
+ Then results are shown for "panda"
+```
+
+快速浏览一下,行为是直观易懂的。 除少数关键字外,该语言为自由格式。 场景简洁而有意义。 一个真实的例子说明了这种行为。 步骤以声明的方式表明应该发生什么——而不会陷入如何如何的细节中。
+
+[BDD 的主要优点][5]是良好的协作和自动化。 每个人都可以为行为开发做出贡献,而不仅仅是程序员。从流程开始就定义并理解预期的行为。测试可以与它们涵盖的功能一起自动化。每个测试都包含一个单一的、独特的行为,以避免重复。最后,现有的步骤可以通过新的行为规范重用,从而产生雪球效果。
+
+### Python 的 behave 框架
+
+behave 是 Python 中最流行的 BDD 框架之一。 它与其他基于 Gherkin 的 Cucumber 框架非常相似,尽管没有得到官方的 Cucumber 定名。 behave 有两个主要层:
+
+1. 用 Gherkin 的 `.feature` 文件编写的行为规范
+2. 用 Python 模块编写的步骤定义和钩子,用于实现 Gherkin 步骤
+
+如上例所示,Gherkin 场景有三部分格式:
+
+1. 鉴于(Given)一些初始状态
+2. 每当(When)行为发生时
+3. 然后(Then)验证结果
+
+当 behave 运行测试时,每个步骤由装饰器“粘合”到 Python 函数。
+
+### 安装
+
+作为先决条件,请确保在你的计算机上安装了 Python 和 `pip`。 我强烈建议使用 Python 3.(我还建议使用 [pipenv][6],但以下示例命令使用更基本的 `pip`。)
+
+behave 框架只需要一个包:
+
+```
+pip install behave
+```
+
+其他包也可能有用,例如:
+
+```
+pip install requests # 用于调用 REST API
+pip install selenium # 用于 web 浏览器交互
+```
+
+GitHub 上的 [behavior-driven-Python][7] 项目包含本文中使用的示例。
+
+### Gherkin 特点
+
+behave 框架使用的 Gherkin 语法实际上是符合官方的 Cucumber Gherkin 标准的。`.feature` 文件包含了功能(`Feature`)部分,而场景部分又包含具有 Given-When-Then 步骤的场景(`Scenario`) 部分。 以下是一个例子:
+
+```
+Feature: Cucumber Basket
+ As a gardener,
+ I want to carry many cucumbers in a basket,
+ So that I don’t drop them all.
+
+ @cucumber-basket
+ Scenario: Add and remove cucumbers
+ Given the basket is empty
+ When "4" cucumbers are added to the basket
+ And "6" more cucumbers are added to the basket
+ But "3" cucumbers are removed from the basket
+ Then the basket contains "7" cucumbers
+```
+
+这里有一些重要的事情需要注意:
+
+- `Feature` 和 `Scenario` 部分都有[简短的描述性标题][8]。
+- 紧跟在 `Feature` 标题后面的行是会被 behave 框架忽略掉的注释。将功能描述放在那里是一种很好的做法。
+- `Scenario` 和 `Feature` 可以有标签(注意 `@cucumber-basket` 标记)用于钩子和过滤(如下所述)。
+- 步骤都遵循[严格的 Given-When-Then 顺序][9]。
+- 使用 `And` 和 `But` 可以为任何类型添加附加步骤。
+- 可以使用输入对步骤进行参数化——注意双引号里的值。
+
+通过使用场景大纲(`Scenario Outline`),场景也可以写为具有多个输入组合的模板:
+
+```
+Feature: Cucumber Basket
+
+ @cucumber-basket
+ Scenario Outline: Add cucumbers
+ Given the basket has “” cucumbers
+ When "" cucumbers are added to the basket
+ Then the basket contains "" cucumbers
+
+ Examples: Cucumber Counts
+ | initial | more | total |
+ | 0 | 1 | 1 |
+ | 1 | 2 | 3 |
+ | 5 | 4 | 9 |
+```
+
+场景大纲总是有一个示例(`Examples`)表,其中第一行给出列标题,后续每一行给出一个输入组合。 只要列标题出现在由尖括号括起的步骤中,行值就会被替换。 在上面的示例中,场景将运行三次,因为有三行输入组合。 场景大纲是避免重复场景的好方法。
+
+Gherkin 语言还有其他元素,但这些是主要的机制。 想了解更多信息,请阅读 Automation Panda 这个网站的文章 [Gherkin by Example][10] 和 [Writing Good Gherkin][11]。
+
+### Python 机制
+
+每个 Gherkin 步骤必须“粘合”到步骤定义——即提供了实现的 Python 函数。 每个函数都有一个带有匹配字符串的步骤类型装饰器。它还接收共享的上下文和任何步骤参数。功能文件必须放在名为 `features/` 的目录中,而步骤定义模块必须放在名为 `features/steps/` 的目录中。 任何功能文件都可以使用任何模块中的步骤定义——它们不需要具有相同的名称。 下面是一个示例 Python 模块,其中包含 cucumber basket 功能的步骤定义。
+
+```
+from behave import *
+from cucumbers.basket import CucumberBasket
+
+@given('the basket has "{initial:d}" cucumbers')
+def step_impl(context, initial):
+ context.basket = CucumberBasket(initial_count=initial)
+
+@when('"{some:d}" cucumbers are added to the basket')
+def step_impl(context, some):
+ context.basket.add(some)
+
+@then('the basket contains "{total:d}" cucumbers')
+def step_impl(context, total):
+ assert context.basket.count == total
+```
+
+可以使用三个[步骤匹配器][12]:`parse`、`cfparse` 和 `re`。默认的,也是最简单的匹配器是 `parse`,如上例所示。注意如何解析参数化值并将其作为输入参数传递给函数。一个常见的最佳实践是在步骤中给参数加双引号。
+
+每个步骤定义函数还接收一个[上下文][13]变量,该变量保存当前正在运行的场景的数据,例如 `feature`、`scenario` 和 `tags` 字段。也可以添加自定义字段,用于在步骤之间共享数据。始终使用上下文来共享数据——永远不要使用全局变量!
+
+behave 框架还支持[钩子][14]来处理 Gherkin 步骤之外的自动化问题。钩子是一个将在步骤、场景、功能或整个测试套件之前或之后运行的功能。钩子让人联想到[面向方面的编程][15]。它们应放在 `features/` 目录下的特殊 `environment.py` 文件中。钩子函数也可以检查当前场景的标签,因此可以有选择地应用逻辑。下面的示例显示了如何使用钩子为标记为 `@web` 的任何场景生成和销毁一个 Selenium WebDriver 实例。
+
+```
+from selenium import webdriver
+
+def before_scenario(context, scenario):
+ if 'web' in context.tags:
+ context.browser = webdriver.Firefox()
+ context.browser.implicitly_wait(10)
+
+def after_scenario(context, scenario):
+ if 'web' in context.tags:
+ context.browser.quit()
+```
+
+注意:也可以使用 [fixtures][16] 进行构建和清理。
+
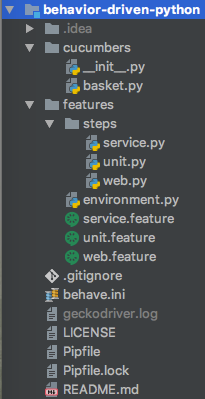
+要了解一个 behave 项目应该是什么样子,这里是示例项目的目录结构:
+
+
+
+任何 Python 包和自定义模块都可以与 behave 框架一起使用。 使用良好的设计模式构建可扩展的测试自动化解决方案。步骤定义代码应简明扼要。
+
+### 运行测试
+
+要从命令行运行测试,请切换到项目的根目录并运行 behave 命令。 使用 `-help` 选项查看所有可用选项。
+
+以下是一些常见用例:
+
+```
+# run all tests
+behave
+
+# run the scenarios in a feature file
+behave features/web.feature
+
+# run all tests that have the @duckduckgo tag
+behave --tags @duckduckgo
+
+# run all tests that do not have the @unit tag
+behave --tags ~@unit
+
+# run all tests that have @basket and either @add or @remove
+behave --tags @basket --tags @add,@remove
+```
+
+为方便起见,选项可以保存在 [config][17] 文件中。
+
+### 其他选择
+
+behave 不是 Python 中唯一的 BDD 测试框架。其他好的框架包括:
+
+- pytest-bdd,是 pytest 的插件,和 behave 一样,它使用 Gherkin 功能文件和步骤定义模块,但它也利用了 pytest 的所有功能和插件。例如,它可以使用 pytest-xdist 并行运行 Gherkin 场景。 BDD 和非 BDD 测试也可以与相同的过滤器一起执行。pytest-bdd 还提供更灵活的目录布局。
+- radish 是一个 “Gherkin 增强版”框架——它将场景循环和前提条件添加到标准的 Gherkin 语言中,这使得它对程序员更友好。它还像 behave 一样提供了丰富的命令行选项。
+- lettuce 是一种较旧的 BDD 框架,与 behave 非常相似,在框架机制方面存在细微差别。然而,GitHub 最近显示该项目的活动很少(截至2018 年 5 月)。
+
+任何这些框架都是不错的选择。
+
+另外,请记住,Python 测试框架可用于任何黑盒测试,即使对于非 Python 产品也是如此! BDD 框架非常适合 Web 和服务测试,因为它们的测试是声明性的,而 Python 是一种[很好的测试自动化语言][18]。
+
+本文基于作者的 [PyCon Cleveland 2018][19] 演讲“[行为驱动的Python][20]”。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/behavior-driven-python
+
+作者:[Andrew Knight][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[Flowsnow](https://github.com/Flowsnow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/andylpk247
+[1]:https://automationpanda.com/bdd/
+[2]:https://en.wikipedia.org/wiki/Specification_by_example
+[3]:https://automationpanda.com/2017/01/26/bdd-101-the-gherkin-language/
+[4]:https://cucumber.io/
+[5]:https://automationpanda.com/2017/02/13/12-awesome-benefits-of-bdd/
+[6]:https://docs.pipenv.org/
+[7]:https://github.com/AndyLPK247/behavior-driven-python
+[8]:https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
+[9]:https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
+[10]:https://automationpanda.com/2017/01/27/bdd-101-gherkin-by-example/
+[11]:https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
+[12]:http://behave.readthedocs.io/en/latest/api.html#step-parameters
+[13]:http://behave.readthedocs.io/en/latest/api.html#detecting-that-user-code-overwrites-behave-context-attributes
+[14]:http://behave.readthedocs.io/en/latest/api.html#environment-file-functions
+[15]:https://en.wikipedia.org/wiki/Aspect-oriented_programming
+[16]:http://behave.readthedocs.io/en/latest/api.html#fixtures
+[17]:http://behave.readthedocs.io/en/latest/behave.html#configuration-files
+[18]:https://automationpanda.com/2017/01/21/the-best-programming-language-for-test-automation/
+[19]:https://us.pycon.org/2018/
+[20]:https://us.pycon.org/2018/schedule/presentation/87/
+[21]:https://behave.readthedocs.io/en/latest/
diff --git a/translated/tech/20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md b/published/20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md
similarity index 68%
rename from translated/tech/20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md
rename to published/20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md
index c65e756ff4..20283a0109 100644
--- a/translated/tech/20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md
+++ b/published/20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md
@@ -3,7 +3,7 @@

-我们已经讲解了 [在 Ubuntu 18.04 上配置 Oracle VirtualBox][1] 无头服务器。在本教程中,我们将讨论如何使用 **KVM** 去配置无头虚拟化服务器,以及如何从一个远程客户端去管理访客系统。正如你所知道的,KVM(**K** ernel-based **v** irtual **m** achine)是开源的,是对 Linux 的完全虚拟化。使用 KVM,我们可以在几分钟之内,很轻松地将任意 Linux 服务器转换到一个完全的虚拟化环境中,以及部署不同种类的虚拟机,比如 GNU/Linux、*BSD、Windows 等等。
+我们已经讲解了 [在 Ubuntu 18.04 无头服务器上配置 Oracle VirtualBox][1] 。在本教程中,我们将讨论如何使用 **KVM** 去配置无头虚拟化服务器,以及如何从一个远程客户端去管理访客系统。正如你所知道的,KVM(**K**ernel-based **v**irtual **m**achine)是开源的,是 Linux 上的全虚拟化。使用 KVM,我们可以在几分钟之内,很轻松地将任意 Linux 服务器转换到一个完全的虚拟化环境中,以及部署不同种类的虚拟机,比如 GNU/Linux、*BSD、Windows 等等。
### 使用 KVM 配置无头虚拟化服务器
@@ -13,86 +13,81 @@
**KVM 虚拟化服务器:**
- * **宿主机操作系统** – 最小化安装的 Ubuntu 18.04 LTS(没有 GUI)
- * **宿主机操作系统的 IP 地址**:192.168.225.22/24
- * **访客操作系统**(它将运行在 Ubuntu 18.04 的宿主机上):Ubuntu 16.04 LTS server
-
-
+* **宿主机操作系统** – 最小化安装的 Ubuntu 18.04 LTS(没有 GUI)
+* **宿主机操作系统的 IP 地址**:192.168.225.22/24
+* **访客操作系统**(它将运行在 Ubuntu 18.04 的宿主机上):Ubuntu 16.04 LTS server
**远程桌面客户端:**
- * **操作系统** – Arch Linux
-
-
+* **操作系统** – Arch Linux
### 安装 KVM
首先,我们先检查一下我们的系统是否支持硬件虚拟化。为此,需要在终端中运行如下的命令:
+
```
$ egrep -c '(vmx|svm)' /proc/cpuinfo
-
```
-假如结果是 **zero (0)**,说明系统不支持硬件虚拟化,或者在 BIOS 中禁用了虚拟化。进入你的系统 BIOS 并检查虚拟化选项,然后启用它。
+假如结果是 `zero (0)`,说明系统不支持硬件虚拟化,或者在 BIOS 中禁用了虚拟化。进入你的系统 BIOS 并检查虚拟化选项,然后启用它。
-假如结果是 **1** 或者 **更大的数**,说明系统将支持硬件虚拟化。然而,在你运行上面的命令之前,你需要始终保持 BIOS 中的虚拟化选项是启用的。
+假如结果是 `1` 或者 **更大的数**,说明系统将支持硬件虚拟化。然而,在你运行上面的命令之前,你需要始终保持 BIOS 中的虚拟化选项是启用的。
或者,你也可以使用如下的命令去验证它。但是为了使用这个命令你需要先安装 KVM。
+
```
$ kvm-ok
-
```
-**示例输出:**
+示例输出:
```
INFO: /dev/kvm exists
KVM acceleration can be used
-
```
如果输出的是如下这样的错误,你仍然可以在 KVM 中运行访客虚拟机,但是它的性能将非常差。
+
```
INFO: Your CPU does not support KVM extensions
INFO: For more detailed results, you should run this as root
HINT: sudo /usr/sbin/kvm-ok
-
```
当然,还有其它的方法来检查你的 CPU 是否支持虚拟化。更多信息参考接下来的指南。
+- [如何知道 CPU 是否支持虚拟技术(VT)](https://www.ostechnix.com/how-to-find-if-a-cpu-supports-virtualization-technology-vt/)
+
接下来,安装 KVM 和在 Linux 中配置虚拟化环境所需要的其它包。
在 Ubuntu 和其它基于 DEB 的系统上,运行如下命令:
+
```
$ sudo apt-get install qemu-kvm libvirt-bin virtinst bridge-utils cpu-checker
-
```
KVM 安装完成后,启动 libvertd 服务(如果它没有启动的话):
+
```
$ sudo systemctl enable libvirtd
-
$ sudo systemctl start libvirtd
-
```
### 创建虚拟机
-所有的虚拟机文件和其它的相关文件都保存在 **/var/lib/libvirt/** 下。ISO 镜像的默认路径是 **/var/lib/libvirt/boot/**。
+所有的虚拟机文件和其它的相关文件都保存在 `/var/lib/libvirt/` 下。ISO 镜像的默认路径是 `/var/lib/libvirt/boot/`。
首先,我们先检查一下是否有虚拟机。查看可用的虚拟机列表,运行如下的命令:
+
```
$ sudo virsh list --all
-
```
-**示例输出:**
+示例输出:
```
Id Name State
----------------------------------------------------
-
```
![][3]
@@ -102,14 +97,14 @@ Id Name State
现在,我们来创建一个。
例如,我们来创建一个有 512 MB 内存、1 个 CPU 核心、8 GB 硬盘的 Ubuntu 16.04 虚拟机。
+
```
$ sudo virt-install --name Ubuntu-16.04 --ram=512 --vcpus=1 --cpu host --hvm --disk path=/var/lib/libvirt/images/ubuntu-16.04-vm1,size=8 --cdrom /var/lib/libvirt/boot/ubuntu-16.04-server-amd64.iso --graphics vnc
-
```
-请确保在路径 **/var/lib/libvirt/boot/** 中有一个 Ubuntu 16.04 的 ISO 镜像文件,或者在上面命令中给定的其它路径中有相应的镜像文件。
+请确保在路径 `/var/lib/libvirt/boot/` 中有一个 Ubuntu 16.04 的 ISO 镜像文件,或者在上面命令中给定的其它路径中有相应的镜像文件。
-**示例输出:**
+示例输出:
```
WARNING Graphics requested but DISPLAY is not set. Not running virt-viewer.
@@ -121,37 +116,38 @@ Domain installation still in progress. Waiting for installation to complete.
Domain has shutdown. Continuing.
Domain creation completed.
Restarting guest.
-
```
![][4]
我们来分别讲解以上的命令和看到的每个选项的作用。
- * **–name** : 这个选项定义虚拟机名字。在我们的案例中,这个虚拟机的名字是 **Ubuntu-16.04**。
- * **–ram=512** : 给虚拟机分配 512MB 内存。
- * **–vcpus=1** : 指明虚拟机中 CPU 核心的数量。
- * **–cpu host** : 通过暴露宿主机 CPU 的配置给访客系统来优化 CPU 属性。
- * **–hvm** : 要求完整的硬件虚拟化。
- * **–disk path** : 虚拟机硬盘的位置和大小。在我们的示例中,我分配了 8GB 的硬盘。
- * **–cdrom** : 安装 ISO 镜像的位置。请注意你必须在这个位置真的有一个 ISO 镜像。
- * **–graphics vnc** : 允许 VNC 从远程客户端访问虚拟机。
-
-
+ * `–name`:这个选项定义虚拟机名字。在我们的案例中,这个虚拟机的名字是 `Ubuntu-16.04`。
+ * `–ram=512`:给虚拟机分配 512MB 内存。
+ * `–vcpus=1`:指明虚拟机中 CPU 核心的数量。
+ * `–cpu host`:通过暴露宿主机 CPU 的配置给访客系统来优化 CPU 属性。
+ * `–hvm`:要求完整的硬件虚拟化。
+ * `–disk path`:虚拟机硬盘的位置和大小。在我们的示例中,我分配了 8GB 的硬盘。
+ * `–cdrom`:安装 ISO 镜像的位置。请注意你必须在这个位置真的有一个 ISO 镜像。
+ * `–graphics vnc`:允许 VNC 从远程客户端访问虚拟机。
### 使用 VNC 客户端访问虚拟机
现在,我们在远程桌面系统上使用 SSH 登入到 Ubuntu 服务器上(虚拟化服务器),如下所示。
-在这里,**sk** 是我的 Ubuntu 服务器的用户名,而 **192.168.225.22** 是它的 IP 地址。
+```
+$ ssh sk@192.168.225.22
+```
+
+在这里,`sk` 是我的 Ubuntu 服务器的用户名,而 `192.168.225.22` 是它的 IP 地址。
运行如下的命令找出 VNC 的端口号。我们从一个远程系统上访问虚拟机需要它。
+
```
$ sudo virsh dumpxml Ubuntu-16.04 | grep vnc
-
```
-**示例输出:**
+示例输出:
```
@@ -160,10 +156,10 @@ $ sudo virsh dumpxml Ubuntu-16.04 | grep vnc
![][5]
-记下那个端口号 **5900**。安装任意的 VNC 客户端应用程序。在本指南中,我们将使用 TigerVnc。TigerVNC 是 Arch Linux 默认仓库中可用的客户端。在 Arch 上安装它,运行如下命令:
+记下那个端口号 `5900`。安装任意的 VNC 客户端应用程序。在本指南中,我们将使用 TigerVnc。TigerVNC 是 Arch Linux 默认仓库中可用的客户端。在 Arch 上安装它,运行如下命令:
+
```
$ sudo pacman -S tigervnc
-
```
在安装有 VNC 客户端的远程客户端系统上输入如下的 SSH 端口转发命令。
@@ -172,11 +168,11 @@ $ sudo pacman -S tigervnc
$ ssh sk@192.168.225.22 -L 5900:127.0.0.1:5900
```
-再强调一次,**192.168.225.22** 是我的 Ubuntu 服务器(虚拟化服务器)的 IP 地址。
+再强调一次,`192.168.225.22` 是我的 Ubuntu 服务器(虚拟化服务器)的 IP 地址。
然后,从你的 Arch Linux(客户端)打开 VNC 客户端。
-在 VNC 服务器框中输入 **localhost:5900**,然后点击 **Connect** 按钮。
+在 VNC 服务器框中输入 `localhost:5900`,然后点击 “Connect” 按钮。
![][6]
@@ -188,43 +184,42 @@ $ ssh sk@192.168.225.22 -L 5900:127.0.0.1:5900
同样的,你可以根据你的服务器的硬件情况配置多个虚拟机。
-或者,你可以使用 **virt-viewer** 实用程序在访客机器中安装操作系统。virt-viewer 在大多数 Linux 发行版的默认仓库中都可以找到。安装完 virt-viewer 之后,运行下列的命令去建立到虚拟机的访问连接。
+或者,你可以使用 `virt-viewer` 实用程序在访客机器中安装操作系统。`virt-viewer` 在大多数 Linux 发行版的默认仓库中都可以找到。安装完 `virt-viewer` 之后,运行下列的命令去建立到虚拟机的访问连接。
+
```
$ sudo virt-viewer --connect=qemu+ssh://192.168.225.22/system --name Ubuntu-16.04
-
```
### 管理虚拟机
-使用管理用户接口 virsh 从命令行去管理虚拟机是非常有趣的。命令非常容易记。我们来看一些例子。
+使用管理用户接口 `virsh` 从命令行去管理虚拟机是非常有趣的。命令非常容易记。我们来看一些例子。
查看运行的虚拟机,运行如下命令:
+
```
$ sudo virsh list
-
```
或者,
+
```
$ sudo virsh list --all
-
```
-**示例输出:**
+示例输出:
```
Id Name State
----------------------------------------------------
2 Ubuntu-16.04 running
-
```
![][9]
启动一个虚拟机,运行如下命令:
+
```
$ sudo virsh start Ubuntu-16.04
-
```
或者,也可以使用虚拟机 id 去启动它。
@@ -232,94 +227,85 @@ $ sudo virsh start Ubuntu-16.04
![][10]
正如在上面的截图所看到的,Ubuntu 16.04 虚拟机的 Id 是 2。因此,启动它时,你也可以像下面一样只指定它的 ID。
+
```
$ sudo virsh start 2
-
```
重启动一个虚拟机,运行如下命令:
```
$ sudo virsh reboot Ubuntu-16.04
-
```
-**示例输出:**
+示例输出:
```
Domain Ubuntu-16.04 is being rebooted
-
```
![][11]
暂停一个运行中的虚拟机,运行如下命令:
+
```
$ sudo virsh suspend Ubuntu-16.04
-
```
-**示例输出:**
+示例输出:
```
Domain Ubuntu-16.04 suspended
-
```
让一个暂停的虚拟机重新运行,运行如下命令:
+
```
$ sudo virsh resume Ubuntu-16.04
-
```
-**示例输出:**
+示例输出:
```
Domain Ubuntu-16.04 resumed
-
```
关闭一个虚拟机,运行如下命令:
+
```
$ sudo virsh shutdown Ubuntu-16.04
-
```
-**示例输出:**
+示例输出:
```
Domain Ubuntu-16.04 is being shutdown
-
```
完全移除一个虚拟机,运行如下的命令:
+
```
$ sudo virsh undefine Ubuntu-16.04
-
$ sudo virsh destroy Ubuntu-16.04
-
```
-**示例输出:**
+示例输出:
```
Domain Ubuntu-16.04 destroyed
-
```
![][12]
关于它的更多选项,建议你去查看 man 手册页:
+
```
$ man virsh
-
```
今天就到这里吧。开始在你的新的虚拟化环境中玩吧。对于研究和开发者、以及测试目的,KVM 虚拟化将是很好的选择,但它能做的远不止这些。如果你有充足的硬件资源,你可以将它用于大型的生产环境中。如果你还有其它好玩的发现,不要忘记在下面的评论区留下你的高见。
谢谢!
-
-
--------------------------------------------------------------------------------
via: https://www.ostechnix.com/setup-headless-virtualization-server-using-kvm-ubuntu/
@@ -327,7 +313,7 @@ via: https://www.ostechnix.com/setup-headless-virtualization-server-using-kvm-ub
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201808/20180813 Tips for using the top command in Linux.md b/published/201808/20180813 Tips for using the top command in Linux.md
index 5985907a19..29d83084a1 100644
--- a/published/201808/20180813 Tips for using the top command in Linux.md
+++ b/published/201808/20180813 Tips for using the top command in Linux.md
@@ -128,7 +128,7 @@ CPU 任务优先级或类型:
* 蓝色:低优先级
* 绿色:正常优先级
* 红色:内核任务
-* 蓝色:虚拟任务
+* 蓝绿色:虚拟任务
* 条状图末尾的值是已用 CPU 的百分比
内存:
diff --git a/translated/tech/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md b/published/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md
similarity index 75%
rename from translated/tech/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md
rename to published/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md
index 3a0a0592cc..9b0c6608dd 100644
--- a/translated/tech/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md
+++ b/published/20180817 How To Lock The Keyboard And Mouse, But Not The Screen In Linux.md
@@ -3,33 +3,38 @@

-我四岁的侄女是个好奇的孩子,她非常喜爱“阿凡达”电影,当阿凡达电影在播放时,她是如此的专注,好似眼睛粘在了屏幕上。但问题是当她观看电影时,她经常会碰到键盘上的某个键或者移动了鼠标,又或者是点击了鼠标的按钮。有时她非常意外地按了键盘上的某个键,从而将电影关闭或者暂停了。所以我就想找个方法来将键盘和鼠标都锁住,但屏幕不会被锁住。幸运的是,我在 Ubuntu 论坛上找到了一个完美的解决方法。假如在你正看着屏幕上的某些重要的事情时,你不想让你的小猫或者小狗在你的键盘上行走,或者让你的孩子在键盘上瞎搞一气,那我建议你试试 **xtrlock** 这个工具。它很简单但非常实用,你可以锁定屏幕的显示直到用户在键盘上输入自己设定的密码(译者注:就是用户自己的密码,例如用来打开屏保的那个密码,不需要单独设定)。在这篇简单的教程中,我将为你展示如何在 Linux 下锁住键盘和鼠标,而不锁掉屏幕。这个技巧几乎可以在所有的 Linux 操作系统中生效。
+我四岁的侄女是个好奇的孩子,她非常喜爱“阿凡达”电影,当阿凡达电影在播放时,她是如此的专注,好似眼睛粘在了屏幕上。但问题是当她观看电影时,她经常会碰到键盘上的某个键或者移动了鼠标,又或者是点击了鼠标的按钮。有时她非常意外地按了键盘上的某个键,从而将电影关闭或者暂停了。所以我就想找个方法来将键盘和鼠标都锁住,但屏幕不会被锁住。幸运的是,我在 Ubuntu 论坛上找到了一个完美的解决方法。假如在你正看着屏幕上的某些重要的事情时,你不想让你的小猫或者小狗在你的键盘上行走,或者让你的孩子在键盘上瞎搞一气,那我建议你试试 **xtrlock** 这个工具。它很简单但非常实用,你可以锁定屏幕的显示直到用户在键盘上输入自己设定的密码(LCTT 译注:就是用户自己的密码,例如用来打开屏保的那个密码,不需要单独设定)。在这篇简单的教程中,我将为你展示如何在 Linux 下锁住键盘和鼠标,而不锁掉屏幕。这个技巧几乎可以在所有的 Linux 操作系统中生效。
### 安装 xtrlock
xtrlock 软件包在大多数 Linux 操作系统的默认软件仓库中都可以获取到。所以你可以使用你安装的发行版的包管理器来安装它。
在 **Arch Linux** 及其衍生发行版中,运行下面的命令来安装它:
+
```
$ sudo pacman -S xtrlock
```
在 **Fedora** 上使用:
+
```
$ sudo dnf install xtrlock
```
-在 **RHEL, CentOS** 上使用:
+在 **RHEL、CentOS** 上使用:
+
```
$ sudo yum install xtrlock
```
在 **SUSE/openSUSE** 上使用:
+
```
$ sudo zypper install xtrlock
```
-在 **Debian, Ubuntu, Linux Mint** 上使用:
+在 **Debian、Ubuntu、Linux Mint** 上使用:
+
```
$ sudo apt-get install xtrlock
```
@@ -38,41 +43,50 @@ $ sudo apt-get install xtrlock
安装好 xtrlock 后,你需要根据你的选择来创建一个快捷键,通过这个快捷键来锁住键盘和鼠标。
-在 **/usr/local/bin** 目录下创建一个名为 **lockkbmouse** 的新文件:
+(LCTT 译注:译者在自己的系统(Arch + Deepin)中发现这里的到下面创建快捷键的部分可以不必做,依然生效。)
+
+在 `/usr/local/bin` 目录下创建一个名为 `lockkbmouse` 的新文件:
+
```
$ sudo vi /usr/local/bin/lockkbmouse
```
然后将下面的命令添加到这个文件中:
+
```
#!/bin/bash
sleep 1 && xtrlock
```
+
保存并关闭这个文件。
然后使用下面的命令来使得它可以被执行:
+
```
$ sudo chmod a+x /usr/local/bin/lockkbmouse
```
接着,我们就需要创建快捷键了。
+#### 创建快捷键
+
**在 Arch Linux MATE 桌面中**
-依次点击 **System -> Preferences -> Hardware -> keyboard Shortcuts**
+依次点击 “System -> Preferences -> Hardware -> keyboard Shortcuts”
-然后点击 **Add** 来创建快捷键。
+然后点击 “Add” 来创建快捷键。
![][2]
-首先键入你的这个快捷键的名称,然后将下面的命令填入命令框中,最后点击 **Apply** 按钮。
+首先键入你的这个快捷键的名称,然后将下面的命令填入命令框中,最后点击 “Apply” 按钮。
+
```
bash -c "sleep 1 && xtrlock"
```
![][3]
-为了能够给这个快捷键赋予快捷方式,需要选中它或者双击它然后输入你选定的快捷键组合,例如我使用 **Alt+k** 这组快捷键。
+为了能够给这个快捷键赋予快捷方式,需要选中它或者双击它然后输入你选定的快捷键组合,例如我使用 `Alt+k` 这组快捷键。
![][4]
@@ -80,16 +94,17 @@ bash -c "sleep 1 && xtrlock"
**在 Ubuntu GNOME 桌面中**
-依次进入 **System Settings -> Devices -> Keyboard**,然后点击 **+** 这个符号。
+依次进入 “System Settings -> Devices -> Keyboard”,然后点击 “+” 这个符号。
+
+键入你快捷键的名称并将下面的命令加到命令框里面,然后点击 “Add” 按钮。
-键入你快捷键的名称并将下面的命令加到命令框里面,然后点击 **Add** 按钮。
```
bash -c "sleep 1 && xtrlock"
```
![][5]
-接下来为这个新建的快捷键赋予快捷方式。我们只需要选择或者双击 **“Set shortcut”** 这个按钮就可以了。
+接下来为这个新建的快捷键赋予快捷方式。我们只需要选择或者双击 “Set shortcut” 这个按钮就可以了。
![][6]
@@ -97,7 +112,7 @@ bash -c "sleep 1 && xtrlock"
![][7]
-输入你选定的快捷键组合,例如我使用 **Alt+k**。
+输入你选定的快捷键组合,例如我使用 `Alt+k`。
![][8]
@@ -113,23 +128,26 @@ bash -c "sleep 1 && xtrlock"
### 将键盘和鼠标解锁
-要将键盘和鼠标解锁,只需要输入你的密码然后敲击“Enter”键就可以了,在输入的过程中你将看不到密码。只需要输入然后敲 `ENTER` 键就可以了。在你输入了正确的密码后,鼠标和键盘就可以再工作了。假如你输入了一个错误的密码,你将听到警告声。按 **ESC** 来清除输入的错误密码,然后重新输入正确的密码。要去掉未完全输入完的密码中的一个字符,只需要按 **BACKSPACE** 或者 **DELETE** 键就可以了。
+要将键盘和鼠标解锁,只需要输入你的密码然后敲击回车键就可以了,在输入的过程中你将看不到密码。只需要输入然后敲回车键就可以了。在你输入了正确的密码后,鼠标和键盘就可以再工作了。假如你输入了一个错误的密码,你将听到警告声。按 `ESC` 来清除输入的错误密码,然后重新输入正确的密码。要去掉未完全输入完的密码中的一个字符,只需要按 `BACKSPACE` 或者 `DELETE` 键就可以了。
### 要是我被永久地锁住了怎么办?
-以防你被永久地锁定了屏幕,切换至一个 TTY(例如 CTRL+ALT+F2)然后运行:
+以防你被永久地锁定了屏幕,切换至一个 TTY(例如 `CTRL+ALT+F2`)然后运行:
+
```
$ sudo killall xtrlock
```
-或者你还可以使用 **chvt** 命令来在 TTY 和 X 会话之间切换。
+或者你还可以使用 `chvt` 命令来在 TTY 和 X 会话之间切换。
例如,如果要切换到 TTY1,则运行:
+
```
$ sudo chvt 1
```
要切换回 X 会话,则键入:
+
```
$ sudo chvt 7
```
@@ -137,6 +155,7 @@ $ sudo chvt 7
不同的发行版使用了不同的快捷键组合来在不同的 TTY 间切换。请参考你安装的对应发行版的官方网站了解更多详情。
如果想知道更多 xtrlock 的信息,请参考 man 页:
+
```
$ man xtrlock
```
@@ -145,7 +164,7 @@ $ man xtrlock
**资源:**
- * [**Ubuntu 论坛**][10]
+* [**Ubuntu 论坛**][10]
--------------------------------------------------------------------------------
@@ -154,7 +173,7 @@ via: https://www.ostechnix.com/lock-keyboard-mouse-not-screen-linux/
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[FSSlc](https://github.com/FSSlc)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -167,5 +186,5 @@ via: https://www.ostechnix.com/lock-keyboard-mouse-not-screen-linux/
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/set-shortcut-key-1.png
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/set-shortcut-key-2.png
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/set-shortcut-key-3.png
-[9]:http://www.ostechnix.com/wp-content/uploads/2018/01/xtrlock-1.png
+[9]:http://www.ostechnix.com/wp-content/uploads/2018/01/xtrclock-1.png
[10]:https://ubuntuforums.org/showthread.php?t=993800
diff --git a/translated/talk/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md b/published/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md
similarity index 80%
rename from translated/talk/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md
rename to published/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md
index 32a839ed81..92cbda95bd 100644
--- a/translated/talk/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md
+++ b/published/20180919 Linux Has a Code of Conduct and Not Everyone is Happy With it.md
@@ -1,7 +1,7 @@
Linux 拥有了新的行为准则,但是许多人都对此表示不满
=====
-**Linux 内核有了新的行为准则(CoC)。但在这条行为准则被签署以及发布仅仅 30 分钟之后,Linus Torvalds 就暂时离开了 Linux 内核的开发工作。因为新行为准则的作者那富有争议的过去,现在这件事成为了热点话题。许多人都对这新的行为准则表示不满。**
+> Linux 内核有了新的行为准则(CoC)。但在这条行为准则被签署以及发布仅仅 30 分钟之后,Linus Torvalds 就暂时离开了 Linux 内核的开发工作。因为新行为准则的作者那富有争议的过去,现在这件事成为了热点话题。许多人都对这新的行为准则表示不满。
如果你还不了解这件事,请参阅 [Linus Torvalds 对于自己之前的不良态度致歉并开始休假,以改善自己的行为态度][1]
@@ -9,17 +9,15 @@ Linux 拥有了新的行为准则,但是许多人都对此表示不满
Linux 内核开发者并不是以前没有需要遵守的行为准则,但是之前的[冲突准则][2]现在被替换成了以“给内核开发社区营造更加热情,更方便他人参与的氛围”为目的的行为准则。
->“为营造一个开放并且热情的社区环境,我们,贡献者与维护者,许诺让每一个参与进我们项目和社区的人享受一个没有骚扰的体验。无关于他们的年纪,体型,身体残疾,种族,性别,性别认知与表达,社会经验,教育水平,社会或者经济地位,国籍,外表,人种,信仰,性认同和性取向。
+> “为营造一个开放并且热情的社区环境,我们,贡献者与维护者,许诺让每一个参与进我们项目和社区的人享受一个没有骚扰的体验。无关于他们的年纪、体型、身体残疾、种族、性别、性别认知与表达、社会经验、教育水平、社会或者经济地位、国籍、外表、人种、信仰、性认同和性取向。�”
-你可以在这里阅读整篇行为准则
-
-[Linux 行为准则][33]
+你可以在这里阅读整篇行为准则:[Linux 行为准则][33]。
### Linus Torvalds 是被迫道歉并且休假的吗?
![Linus Torvalds 的道歉][3]
-这个新的行为准则由 Linus Torvalds 和 Greg Kroah-Hartman (仅次于 Torvalds 的二把手)签发。来自 Intel 的 Dan Williams 和来自 Facebook 的 Chris Mason 也是该准则的签署者。
+这个新的行为准则由 Linus Torvalds 和 Greg Kroah-Hartman (仅次于 Torvalds 的二把手)签发。来自 Intel 的 Dan Williams 和来自 Facebook 的 Chris Mason 也是该准则的签署者之一。
如果我正确地解读了时间线,在签署这个行为准则的半小时之后,Torvalds [发送了一封邮件,对自己之前的不良态度致歉][4]。他同时宣布会进行休假,以改善自己的行为态度。
@@ -31,18 +29,19 @@ Linux 内核开发者并不是以前没有需要遵守的行为准则,但是
### 有关贡献者盟约作者 Coraline Ada Ehmke 的争议
-Linux 的行为准则基于[贡献者盟约1.4 版本][5]。贡献者盟约[被上百个开源项目所接纳][6],包括 Eclipse, Angular, Ruby, Kubernetes等项目。
+Linux 的行为准则基于[贡献者盟约1.4 版本][5]。贡献者盟约[被上百个开源项目所接纳][6],包括 Eclipse、Angular、Ruby、Kubernetes 等项目。
贡献者盟约由 [Coraline Ada Ehmke][7] 创作,她是一个软件工程师,开源支持者,以及 [LGBT][8] 活动家。她对于促进开源世界的多样性做了显著的贡献。
-Coraline 对于唯才是用的反对立场同样十分鲜明。[唯才是用][9]这个词语源自拉丁文,本意为个人在系统内部的进步取决于他的“功绩”,例如智力水平,取得的证书以及教育程度。但[类似 Coraline 的活动家们认为][10]唯才是用是个糟糕的体系,因为他们只是通过人的智力产出来度量一个人,而并不重视他们的人性。
+Coraline 对于精英主义的反对立场同样十分鲜明。[精英主义][9]这个词语源自拉丁文,本意为系统内的进步取决于“精英”,例如智力水平、取得的证书以及教育程度。但[类似 Coraline 的活动家们认为][10]唯才是用是个糟糕的体系,因为它只是通过人的智力产出来度量一个人,而并不重视他们的人性。
[![croraline meritocracy][11]][12]
-图片来源:推特用户@nickmon1112
+
+*图片来源:推特用户@nickmon1112*
[Linus Torvalds 不止一次地说到,他在意的只是代码而并非写代码的人][13]。所以很明显,这忤逆了 Coraline 有关唯才是用体系的观点。
-具体来说,Coraline 那被人关注饱受争议的过去,是一个关于 [Opal 项目][14]的事件。那是一个发生[在推特上的讨论][15],Elia,来自意大利的 Opal 项目核心开发者说“(那些变性人)不接受现实才是问题所在。”
+具体来说,Coraline 那被人关注饱受争议的过去,是一个关于 [Opal 项目][14]贡献者的事件。那是一个发生[在推特上的讨论][15],Elia,来自意大利的 Opal 项目核心开发者说“(那些变性人)不接受现实才是问题所在。”
Coraline 并没有参加讨论,也不是 Opal 项目的贡献者。不过作为 LGBT 活动家,她以 Elia 发表“冒犯变性人群体的发言”为由,[要求他退出 Opal 项目][16]。 Coraline 和她的支持者——他们给这个项目做过贡献,通过在 GitHub 仓库平台上冗长且激烈的争论,试图将 Elia——此项目的核心开发者移出项目。
@@ -50,11 +49,11 @@ Coraline 并没有参加讨论,也不是 Opal 项目的贡献者。不过作
不过故事到这里并没有结束。贡献者盟约稍后被更改,[加入了一些针对 Elia 的新条款][17]。这些新条款将行为准则的管束范围扩展到公共领域。不过这些更改稍后[被维护者们标记为恶意篡改][18]。最后 Opal 项目摆脱了贡献者盟约,并用自己的行为准则取而代之。
-这个例子非常好的说明了,某些被冒犯的少数人群——他们并没有给这个项目哪怕一点贡献,是怎样试图去驱逐这个项目的核心开发者的。
+这个例子非常好的说明了,某些被冒犯的少数人群——哪怕他们并没有给这个项目做过一点贡献,是怎样试图去驱逐这个项目的核心开发者的。
### 人们对于 Linux 新的行为准则的以及 Torvalds 道歉的反映。
-Linux 行为准则以及 Torvalds 的道歉一发布,社交媒体与论坛上就开始盛传种种谣言与[推测][19]。虽然很多人对新的行为准则感到满意,但仍有些人认为这是 [SJW 尝试渗透 Linux 社区][20]的阴谋。
+Linux 行为准则以及 Torvalds 的道歉一发布,社交媒体与论坛上就开始盛传种种谣言与[推测][19]。虽然很多人对新的行为准则感到满意,但仍有些人认为这是 [SJW 尝试渗透 Linux 社区][20]的阴谋。(LCTT 译注:SJW——Social Justice Warrior 所谓“为社会正义而战的人”。)
Caroline 发布的一个富有嘲讽意味的推特让争论愈发激烈。
@@ -81,7 +80,7 @@ Nick Monroe,一位自由记者,宣称 Linux 行为准则远没有表面上
Nick 并不是唯一一个反对 Linux 新的行为准则的人。[SJW][26] 的参与引发了更多的阴谋论猜测。
->我猜今天关于 Linux 的大新闻就是现在,Linux 内核被一个post meritocracy世界观下的行为准则给掌控了。
+>我猜今天关于 Linux 的大新闻就是现在,Linux 内核被一个 “后精英政治” 世界观下的行为准则给掌控了。
>
>这个行为准则的宗旨看起来不错。不过在实际操作中,它们通常被当作 SJW 分子攻击他们不喜之人的工具。况且,很多人都被 SJW 分子所厌恶。
>
@@ -107,31 +106,33 @@ Torvalds 的道歉引起了广泛关注 ;)
>
>— Verónica. (@maria_fibonacci) [9 月 17 日, 2018][30]
-不继续开玩笑了。有关 Linus 道歉的关注是由 Sharp 挑起的。他因为“恶劣的社区环境”于 2015 年退出了 Linux 内核的开发。
+不继续开玩笑了。有关 Linus 道歉的关注是由 Sharp 挑起的。她因为“恶劣的社区环境”于 2015 年[退出了 Linux 内核的开发][31]。(LCTT 译注,Sarah Sharp 现在改名为“Sage Sharp”,并要求别人称其为“them”而不是“she”或“he”。)
->现在我们要面对的问题是,这个成就 Linus,给予他肆意辱骂特权的社区能否迎来改变。不仅仅是 Linus 个人,Linux 内核开发社区也急需改变。
+>现在我们要面对的问题是,这个成就了 Linus,给予他肆意辱骂特权的社区能否迎来改变。不仅仅是 Linus 个人,Linux 内核开发社区也急需改变。
>
->— Sage Sharp (@sagesharp) 9 月 17 日, 2018
+>— Sage Sharp (@sagesharp) [9 月 17 日, 2018][32]
### 你对于 Linux 行为准则怎么看?
-如果你问我的观点,我认为目前社区的确是需要一个行为准则。它能指导人们尊重他人,不因为他人的种族,宗教信仰,国籍,政治观点(左派或者右派)而歧视,营造出一个积极向上的社区氛围。
+如果你问我的观点,我认为目前社区的确是需要一个行为准则。它能指导人们尊重他人,不因为他人的种族、宗教信仰、国籍、政治观点(左派或者右派)而歧视,营造出一个积极向上的社区氛围。
对于这个事件,你怎么看?你认为这个行为准则能够帮助 Linux 内核的开发,或者说因为 SJW 成员们的加入,情况会变得更糟?
在 FOSS 里我们没有行为准则,不过我们都会持着文明友好的态度讨论问题。
+-------
+
via: https://itsfoss.com/linux-code-of-conduct/
作者:[Abhishek Prakash][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[thecyanbird](https://github.com/thecyanbird)
- 校对:[校对者ID](https://github.com/校对者ID)
+ 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]: https://itsfoss.com/author/abhishek/
- [1]: https://itsfoss.com/torvalds-takes-a-break-from-linux/
+ [1]: https://linux.cn/article-10022-1.html
[2]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/CodeOfConflict?id=ddbd2b7ad99a418c60397901a0f3c997d030c65e
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linus-torvalds-apologizes.jpeg
[4]: https://lkml.org/lkml/2018/9/16/167
diff --git a/translated/tech/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md b/published/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md
similarity index 56%
rename from translated/tech/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md
rename to published/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md
index b1e566f1a9..d79d79e6f3 100644
--- a/translated/tech/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md
+++ b/published/20180925 How to Boot Ubuntu 18.04 - Debian 9 Server in Rescue (Single User mode) - Emergency Mode.md
@@ -1,34 +1,35 @@
如何在救援(单用户模式)/紧急模式下启动 Ubuntu 18.04/Debian 9 服务器
======
-将 Linux 服务器引导到单用户模式或**救援模式**是 Linux 管理员在关键时刻恢复服务器时通常使用的重要故障排除方法之一。在 Ubuntu 18.04 和 Debian 9 中,单用户模式被称为救援模式。
-除了救援模式外,Linux 服务器可以在**紧急模式**下启动,它们之间的主要区别在于,紧急模式加载了带有只读根文件系统文件系统的最小环境,也没有启用任何网络或其他服务。但救援模式尝试挂载所有本地文件系统并尝试启动一些重要的服务,包括网络。
+将 Linux 服务器引导到单用户模式或救援模式是 Linux 管理员在关键时刻恢复服务器时通常使用的重要故障排除方法之一。在 Ubuntu 18.04 和 Debian 9 中,单用户模式被称为救援模式。
+
+除了救援模式外,Linux 服务器可以在紧急模式下启动,它们之间的主要区别在于,紧急模式加载了带有只读根文件系统文件系统的最小环境,没有启用任何网络或其他服务。但救援模式尝试挂载所有本地文件系统并尝试启动一些重要的服务,包括网络。
在本文中,我们将讨论如何在救援模式和紧急模式下启动 Ubuntu 18.04 LTS/Debian 9 服务器。
#### 在单用户/救援模式下启动 Ubuntu 18.04 LTS 服务器:
-重启服务器并进入启动加载程序 (Grub) 屏幕并选择 “**Ubuntu**”,启动加载器页面如下所示,
+重启服务器并进入启动加载程序 (Grub) 屏幕并选择 “Ubuntu”,启动加载器页面如下所示,

-按下 “**e**”,然后移动到以 “**linux**” 开头的行尾,并添加 “**systemd.unit=rescue.target**”。如果存在单词 “**$vt_handoff**” 就删除它。
+按下 `e`,然后移动到以 `linux` 开头的行尾,并添加 `systemd.unit=rescue.target`。如果存在单词 `$vt_handoff` 就删除它。

-现在按 Ctrl-x 或 F10 启动,
+现在按 `Ctrl-x` 或 `F10` 启动,

-现在按回车键,然后你将得到所有文件系统都以读写模式挂载的 shell 并进行故障排除。完成故障排除后,可以使用 “**reboot**” 命令重新启动服务器。
+现在按回车键,然后你将得到所有文件系统都以读写模式挂载的 shell 并进行故障排除。完成故障排除后,可以使用 `reboot` 命令重新启动服务器。
#### 在紧急模式下启动 Ubuntu 18.04 LTS 服务器
-重启服务器并进入启动加载程序页面并选择 “**Ubuntu**”,然后按 “**e**” 并移动到以 linux 开头的行尾,并添加 “**systemd.unit=emergency.target**“。
+重启服务器并进入启动加载程序页面并选择 “Ubuntu”,然后按 `e` 并移动到以 `linux` 开头的行尾,并添加 `systemd.unit=emergency.target`。

-现在按 Ctlr-x 或 F10 以紧急模式启动,你将获得一个 shell 并从那里进行故障排除。正如我们已经讨论过的那样,在紧急模式下,文件系统将以只读模式挂载,并且在这种模式下也不会有网络,
+现在按 `Ctrl-x` 或 `F10` 以紧急模式启动,你将获得一个 shell 并从那里进行故障排除。正如我们已经讨论过的那样,在紧急模式下,文件系统将以只读模式挂载,并且在这种模式下也不会有网络,

@@ -43,17 +44,17 @@
#### 将 Debian 9 引导到救援和紧急模式
-重启 Debian 9.x 服务器并进入 grub页面选择 “**Debian GNU/Linux**”。
+重启 Debian 9.x 服务器并进入 grub页面选择 “Debian GNU/Linux”。

-按下 “**e**” 并移动到 linux 开头的行尾并添加 “**systemd.unit=rescue.target**” 以在救援模式下启动系统, 要在紧急模式下启动,那就添加 “**systemd.unit=emergency.target**“
+按下 `e` 并移动到 linux 开头的行尾并添加 `systemd.unit=rescue.target` 以在救援模式下启动系统, 要在紧急模式下启动,那就添加 `systemd.unit=emergency.target`。
#### 救援模式:

-现在按 Ctrl-x 或 F10 以救援模式启动
+现在按 `Ctrl-x` 或 `F10` 以救援模式启动

@@ -63,11 +64,11 @@

-现在按下 ctrl-x 或 F10 以紧急模式启动系统
+现在按下 `ctrl-x` 或 `F10` 以紧急模式启动系统

-按下回车获取 shell 并使用 “**mount -o remount,rw /**” 命令以读写模式挂载根文件系统。
+按下回车获取 shell 并使用 `mount -o remount,rw /` 命令以读写模式挂载根文件系统。
**注意:**如果已经在 Ubuntu 18.04 和 Debian 9 Server 中设置了 root 密码,那么你必须输入 root 密码才能在救援和紧急模式下获得 shell
@@ -81,7 +82,7 @@ via: https://www.linuxtechi.com/boot-ubuntu-18-04-debian-9-rescue-emergency-mode
作者:[Pradeep Kumar][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180927 How To Find And Delete Duplicate Files In Linux.md b/published/20180927 How To Find And Delete Duplicate Files In Linux.md
similarity index 64%
rename from translated/tech/20180927 How To Find And Delete Duplicate Files In Linux.md
rename to published/20180927 How To Find And Delete Duplicate Files In Linux.md
index c1b637bf2f..316b1d1f10 100644
--- a/translated/tech/20180927 How To Find And Delete Duplicate Files In Linux.md
+++ b/published/20180927 How To Find And Delete Duplicate Files In Linux.md
@@ -3,59 +3,51 @@

-在编辑或修改配置文件或旧文件前,我经常会把它们备份到硬盘的某个地方,因此我如果意外地改错了这些文件,我可以从备份中恢复它们。但问题是如果我忘记清理备份文件,一段时间之后,我的磁盘会被这些大量重复文件填满。我觉得要么是懒得清理这些旧文件,要么是担心可能会删掉重要文件。如果你们像我一样,在类 Unix 操作系统中,大量多版本的相同文件放在不同的备份目录,你可以使用下面的工具找到并删除重复文件。
+在编辑或修改配置文件或旧文件前,我经常会把它们备份到硬盘的某个地方,因此我如果意外地改错了这些文件,我可以从备份中恢复它们。但问题是如果我忘记清理备份文件,一段时间之后,我的磁盘会被这些大量重复文件填满 —— 我觉得要么是懒得清理这些旧文件,要么是担心可能会删掉重要文件。如果你们像我一样,在类 Unix 操作系统中,大量多版本的相同文件放在不同的备份目录,你可以使用下面的工具找到并删除重复文件。
**提醒一句:**
-在删除重复文件的时请尽量小心。如果你不小心,也许会导致[**意外丢失数据**][1]。我建议你在使用这些工具的时候要特别注意。
+在删除重复文件的时请尽量小心。如果你不小心,也许会导致[意外丢失数据][1]。我建议你在使用这些工具的时候要特别注意。
### 在 Linux 中找到并删除重复文件
-
出于本指南的目的,我将讨论下面的三个工具:
1. Rdfind
2. Fdupes
3. FSlint
+这三个工具是自由开源的,且运行在大多数类 Unix 系统中。
+#### 1. Rdfind
-这三个工具是免费的、开源的,且运行在大多数类 Unix 系统中。
-
-##### 1. Rdfind
-
-**Rdfind** 代表找到找到冗余数据,是一个通过访问目录和子目录来找出重复文件的免费、开源的工具。它是基于文件内容而不是文件名来比较。Rdfind 使用**排序**算法来区分原始文件和重复文件。如果你有两个或者更多的相同文件,Rdfind 会很智能的找到原始文件并认定剩下的文件为重复文件。一旦找到副本文件,它会向你报告。你可以决定是删除还是使用[**硬链接**或者**符号(软)链接**][2]代替它们。
+**Rdfind** 意即 **r**edundant **d**ata **find**(冗余数据查找),是一个通过访问目录和子目录来找出重复文件的自由开源的工具。它是基于文件内容而不是文件名来比较。Rdfind 使用**排序**算法来区分原始文件和重复文件。如果你有两个或者更多的相同文件,Rdfind 会很智能的找到原始文件并认定剩下的文件为重复文件。一旦找到副本文件,它会向你报告。你可以决定是删除还是使用[硬链接或者符号(软)链接][2]代替它们。
**安装 Rdfind**
-Rdfind 存在于 [**AUR**][3] 中。因此,在基于 Arch 的系统中,你可以像下面一样使用任一如 [**Yay**][4] AUR 程序助手安装它。
+Rdfind 存在于 [AUR][3] 中。因此,在基于 Arch 的系统中,你可以像下面一样使用任一如 [Yay][4] AUR 程序助手安装它。
```
$ yay -S rdfind
-
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install rdfind
-
```
在 Fedora 上:
```
$ sudo dnf install rdfind
-
```
在 RHEL、CentOS 上:
```
$ sudo yum install epel-release
-
$ sudo yum install rdfind
-
```
**用法**
@@ -64,12 +56,11 @@ $ sudo yum install rdfind
```
$ rdfind ~/Downloads
-
```
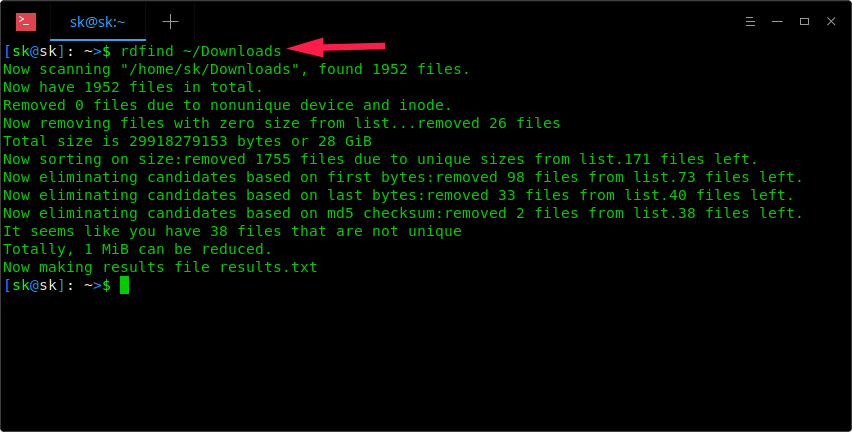
-正如你看到上面的截屏,Rdfind 命令将扫描 ~/Downloads 目录,并将结果存储到当前工作目录下一个名为 **results.txt** 的文件中。你可以在 results.txt 文件中看到可能是重复文件的名字。
+正如你看到上面的截屏,Rdfind 命令将扫描 `~/Downloads` 目录,并将结果存储到当前工作目录下一个名为 `results.txt` 的文件中。你可以在 `results.txt` 文件中看到可能是重复文件的名字。
```
$ cat results.txt
@@ -84,13 +75,12 @@ DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperle
```
-通过检查 results.txt 文件,你可以很容易的找到那些重复文件。如果愿意你可以手动的删除它们。
+通过检查 `results.txt` 文件,你可以很容易的找到那些重复文件。如果愿意你可以手动的删除它们。
-此外,你可在不修改其他事情情况下使用 **-dryrun** 选项找出所有重复文件,并在终端上输出汇总信息。
+此外,你可在不修改其他事情情况下使用 `-dryrun` 选项找出所有重复文件,并在终端上输出汇总信息。
```
$ rdfind -dryrun true ~/Downloads
-
```
一旦找到重复文件,你可以使用硬链接或符号链接代替他们。
@@ -99,21 +89,18 @@ $ rdfind -dryrun true ~/Downloads
```
$ rdfind -makehardlinks true ~/Downloads
-
```
使用符号链接/软链接代替所有重复文件,运行:
```
$ rdfind -makesymlinks true ~/Downloads
-
```
-目录中有一些空文件,也许你想忽略他们,你可以像下面一样使用 **-ignoreempty** 选项:
+目录中有一些空文件,也许你想忽略他们,你可以像下面一样使用 `-ignoreempty` 选项:
```
$ rdfind -ignoreempty true ~/Downloads
-
```
如果你不再想要这些旧文件,删除重复文件,而不是使用硬链接或软链接代替它们。
@@ -122,33 +109,29 @@ $ rdfind -ignoreempty true ~/Downloads
```
$ rdfind -deleteduplicates true ~/Downloads
-
```
如果你不想忽略空文件,并且和所哟重复文件一起删除。运行:
```
$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
-
```
更多细节,参照帮助部分:
```
$ rdfind --help
-
```
手册页:
```
$ man rdfind
-
```
-##### 2. Fdupes
+#### 2. Fdupes
-**Fdupes** 是另一个在指定目录以及子目录中识别和移除重复文件的命令行工具。这是一个使用 **C** 语言编写的免费、开源工具。Fdupes 通过对比文件大小、部分 MD5 签名、全部 MD5 签名,最后执行逐个字节对比校验来识别重复文件。
+**Fdupes** 是另一个在指定目录以及子目录中识别和移除重复文件的命令行工具。这是一个使用 C 语言编写的自由开源工具。Fdupes 通过对比文件大小、部分 MD5 签名、全部 MD5 签名,最后执行逐个字节对比校验来识别重复文件。
与 Rdfind 工具类似,Fdupes 附带非常少的选项来执行操作,如:
@@ -159,8 +142,6 @@ $ man rdfind
* 使用不同的拥有者/组或权限位来排除重复文件
* 更多
-
-
**安装 Fdupes**
Fdupes 存在于大多数 Linux 发行版的默认仓库中。
@@ -169,39 +150,33 @@ Fdupes 存在于大多数 Linux 发行版的默认仓库中。
```
$ sudo pacman -S fdupes
-
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install fdupes
-
```
在 Fedora 上:
```
$ sudo dnf install fdupes
-
```
在 RHEL、CentOS 上:
```
$ sudo yum install epel-release
-
$ sudo yum install fdupes
-
```
**用法**
-Fdupes 用法非常简单。仅运行下面的命令就可以在目录中找到重复文件,如:**~/Downloads**.
+Fdupes 用法非常简单。仅运行下面的命令就可以在目录中找到重复文件,如:`~/Downloads`。
```
$ fdupes ~/Downloads
-
```
我系统中的样例输出:
@@ -209,69 +184,61 @@ $ fdupes ~/Downloads
```
/home/sk/Downloads/Hyperledger.pdf
/home/sk/Downloads/Hyperledger(1).pdf
-
```
-你可以看到,在 **/home/sk/Downloads/** 目录下有一个重复文件。它仅显示了父级目录中的重复文件。如何显示子目录中的重复文件?像下面一样,使用 **-r** 选项。
+
+你可以看到,在 `/home/sk/Downloads/` 目录下有一个重复文件。它仅显示了父级目录中的重复文件。如何显示子目录中的重复文件?像下面一样,使用 `-r` 选项。
```
$ fdupes -r ~/Downloads
-
```
-现在你将看到 **/home/sk/Downloads/** 目录以及子目录中的重复文件。
+现在你将看到 `/home/sk/Downloads/` 目录以及子目录中的重复文件。
Fdupes 也可用来从多个目录中迅速查找重复文件。
```
$ fdupes ~/Downloads ~/Documents/ostechnix
-
```
你甚至可以搜索多个目录,递归搜索其中一个目录,如下:
```
$ fdupes ~/Downloads -r ~/Documents/ostechnix
-
```
-上面的命令将搜索 “~/Downloads” 目录,“~/Documents/ostechnix” 目录和它的子目录中的重复文件。
+上面的命令将搜索 `~/Downloads` 目录,`~/Documents/ostechnix` 目录和它的子目录中的重复文件。
-有时,你可能想要知道一个目录中重复文件的大小。你可以使用 **-S** 选项,如下:
+有时,你可能想要知道一个目录中重复文件的大小。你可以使用 `-S` 选项,如下:
```
$ fdupes -S ~/Downloads
403635 bytes each:
/home/sk/Downloads/Hyperledger.pdf
/home/sk/Downloads/Hyperledger(1).pdf
-
```
-类似的,为了显示父目录和子目录中重复文件的大小,使用 **-Sr** 选项。
+类似的,为了显示父目录和子目录中重复文件的大小,使用 `-Sr` 选项。
-我们可以在计算时分别使用 **-n** 和 **-A** 选项排除空白文件以及排除隐藏文件。
+我们可以在计算时分别使用 `-n` 和 `-A` 选项排除空白文件以及排除隐藏文件。
```
$ fdupes -n ~/Downloads
-
$ fdupes -A ~/Downloads
-
```
在搜索指定目录的重复文件时,第一个命令将排除零长度文件,后面的命令将排除隐藏文件。
-汇总重复文件信息,使用 **-m** 选项。
+汇总重复文件信息,使用 `-m` 选项。
```
$ fdupes -m ~/Downloads
1 duplicate files (in 1 sets), occupying 403.6 kilobytes
-
```
-删除所有重复文件,使用 **-d** 选项。
+删除所有重复文件,使用 `-d` 选项。
```
$ fdupes -d ~/Downloads
-
```
样例输出:
@@ -281,59 +248,51 @@ $ fdupes -d ~/Downloads
[2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf
Set 1 of 1, preserve files [1 - 2, all]:
-
```
这个命令将提示你保留还是删除所有其他重复文件。输入任一号码保留相应的文件,并删除剩下的文件。当使用这个选项的时候需要更加注意。如果不小心,你可能会删除原文件。
-如果你想要每次保留每个重复文件集合的第一个文件,且无提示的删除其他文件,使用 **-dN** 选项(不推荐)。
+如果你想要每次保留每个重复文件集合的第一个文件,且无提示的删除其他文件,使用 `-dN` 选项(不推荐)。
```
$ fdupes -dN ~/Downloads
-
```
-当遇到重复文件时删除它们,使用 **-I** 标志。
+当遇到重复文件时删除它们,使用 `-I` 标志。
```
$ fdupes -I ~/Downloads
-
```
关于 Fdupes 的更多细节,查看帮助部分和 man 页面。
```
$ fdupes --help
-
$ man fdupes
-
```
-##### 3. FSlint
+#### 3. FSlint
-**FSlint** 是另外一个查找重复文件的工具,有时我用它去掉 Linux 系统中不需要的重复文件并释放磁盘空间。不像另外两个工具,FSlint 有 GUI 和 CLI 两种模式。因此对于新手来说它更友好。FSlint 不仅仅找出重复文件,也找出坏符号链接、坏名字文件、临时文件、坏 IDS、空目录和非剥离二进制文件等等。
+**FSlint** 是另外一个查找重复文件的工具,有时我用它去掉 Linux 系统中不需要的重复文件并释放磁盘空间。不像另外两个工具,FSlint 有 GUI 和 CLI 两种模式。因此对于新手来说它更友好。FSlint 不仅仅找出重复文件,也找出坏符号链接、坏名字文件、临时文件、坏的用户 ID、空目录和非精简的二进制文件等等。
**安装 FSlint**
-FSlint 存在于 [**AUR**][5],因此你可以使用任一 AUR 助手安装它。
+FSlint 存在于 [AUR][5],因此你可以使用任一 AUR 助手安装它。
```
$ yay -S fslint
-
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install fslint
-
```
在 Fedora 上:
```
$ sudo dnf install fslint
-
```
在 RHEL,CentOS 上:
@@ -341,7 +300,6 @@ $ sudo dnf install fslint
```
$ sudo yum install epel-release
$ sudo yum install fslint
-
```
一旦安装完成,从菜单或者应用程序启动器启动它。
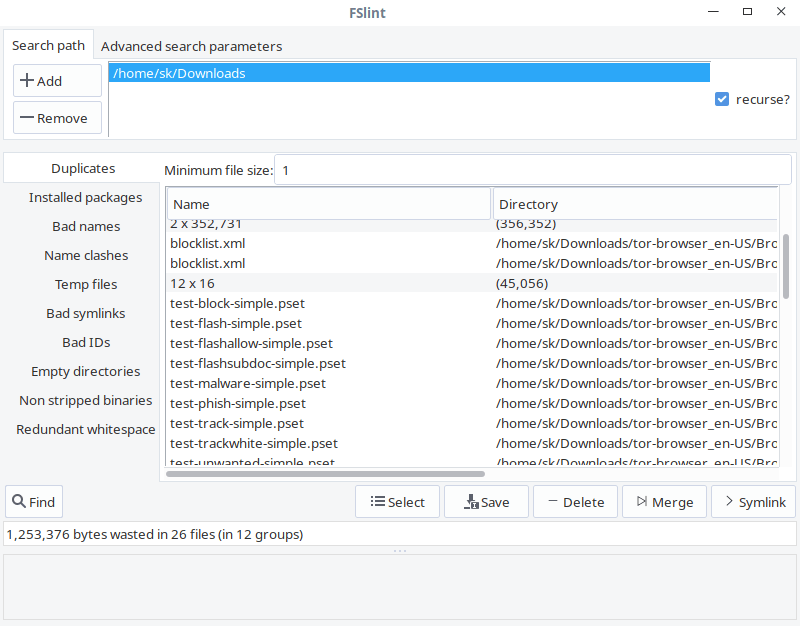
@@ -350,13 +308,13 @@ FSlint GUI 展示如下:
-如你所见,FSlint 接口友好、一目了然。在 **Search path** 栏,添加你要扫描的目录路径,点击左下角 **Find** 按钮查找重复文件。验证递归选项可以在目录和子目录中递归的搜索重复文件。FSlint 将快速的扫描给定的目录并列出重复文件。
+如你所见,FSlint 界面友好、一目了然。在 “Search path” 栏,添加你要扫描的目录路径,点击左下角 “Find” 按钮查找重复文件。验证递归选项可以在目录和子目录中递归的搜索重复文件。FSlint 将快速的扫描给定的目录并列出重复文件。
-从列表中选择那些要清理的重复文件,也可以选择 Save、Delete、Merge 和 Symlink 操作他们。
+从列表中选择那些要清理的重复文件,也可以选择 “Save”、“Delete”、“Merge” 和 “Symlink” 操作他们。
-在 **Advanced search parameters** 栏,你可以在搜索重复文件的时候指定排除的路径。
+在 “Advanced search parameters” 栏,你可以在搜索重复文件的时候指定排除的路径。

@@ -364,52 +322,47 @@ FSlint GUI 展示如下:
FSlint 提供下面的 CLI 工具集在你的文件系统中查找重复文件。
- * **findup** — 查找重复文件
- * **findnl** — 查找 Lint 名称文件(有问题的文件名)
- * **findu8** — 查找非法的 utf8 编码文件
- * **findbl** — 查找坏链接(有问题的符号链接)
- * **findsn** — 查找同名文件(可能有冲突的文件名)
- * **finded** — 查找空目录
- * **findid** — 查找死用户的文件
- * **findns** — 查找非剥离的可执行文件
- * **findrs** — 查找文件中多于的空白
- * **findtf** — 查找临时文件
- * **findul** — 查找可能未使用的库
- * **zipdir** — 回收 ext2 目录实体下浪费的空间
+ * `findup` — 查找重复文件
+ * `findnl` — 查找名称规范(有问题的文件名)
+ * `findu8` — 查找非法的 utf8 编码的文件名
+ * `findbl` — 查找坏链接(有问题的符号链接)
+ * `findsn` — 查找同名文件(可能有冲突的文件名)
+ * `finded` — 查找空目录
+ * `findid` — 查找死用户的文件
+ * `findns` — 查找非精简的可执行文件
+ * `findrs` — 查找文件名中多余的空白
+ * `findtf` — 查找临时文件
+ * `findul` — 查找可能未使用的库
+ * `zipdir` — 回收 ext2 目录项下浪费的空间
-所有这些工具位于 **/usr/share/fslint/fslint/fslint** 下面。
+所有这些工具位于 `/usr/share/fslint/fslint/fslint` 下面。
例如,在给定的目录中查找重复文件,运行:
```
$ /usr/share/fslint/fslint/findup ~/Downloads/
-
```
类似的,找出空目录命令是:
```
$ /usr/share/fslint/fslint/finded ~/Downloads/
-
```
-获取每个工具更多细节,例如:**findup**,运行:
+获取每个工具更多细节,例如:`findup`,运行:
```
$ /usr/share/fslint/fslint/findup --help
-
```
关于 FSlint 的更多细节,参照帮助部分和 man 页。
```
$ /usr/share/fslint/fslint/fslint --help
-
$ man fslint
-
```
##### 总结
@@ -427,7 +380,7 @@ via: https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[pygmalion666](https://github.com/pygmalion666)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/talk/20180926 CPU Power Manager - Control And Manage CPU Frequency In Linux.md b/sources/talk/20180926 CPU Power Manager - Control And Manage CPU Frequency In Linux.md
index aeffd1f144..d1275d5e30 100644
--- a/sources/talk/20180926 CPU Power Manager - Control And Manage CPU Frequency In Linux.md
+++ b/sources/talk/20180926 CPU Power Manager - Control And Manage CPU Frequency In Linux.md
@@ -1,3 +1,4 @@
+(translating by runningwater)
CPU Power Manager – Control And Manage CPU Frequency In Linux
======
@@ -64,7 +65,7 @@ via: https://www.ostechnix.com/cpu-power-manager-control-and-manage-cpu-frequenc
作者:[EDITOR][a]
选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
+译者:[runningwater](https://github.com/runningwater)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/talk/20181008 3 areas to drive DevOps change.md b/sources/talk/20181008 3 areas to drive DevOps change.md
index 733158a81b..21330b0ea2 100644
--- a/sources/talk/20181008 3 areas to drive DevOps change.md
+++ b/sources/talk/20181008 3 areas to drive DevOps change.md
@@ -1,3 +1,5 @@
+HankChow translating
+
3 areas to drive DevOps change
======
Driving large-scale organizational change is painful, but when it comes to DevOps, the payoff is worth the pain.
diff --git a/sources/tech/20171204 Improve your Bash scripts with Argbash.md b/sources/tech/20171204 Improve your Bash scripts with Argbash.md
deleted file mode 100644
index 8b9b565ec1..0000000000
--- a/sources/tech/20171204 Improve your Bash scripts with Argbash.md
+++ /dev/null
@@ -1,116 +0,0 @@
-Translating by MjSeven
-
-
-# [Improve your Bash scripts with Argbash][1]
-
-
-
-Do you write or maintain non-trivial bash scripts? If so, you probably want them to accept command-line arguments in a standard and robust way. Fedora recently got [a nice addition][2] which can help you produce better scripts. And don’t worry, it won’t cost you much of your time or energy.
-
-### Why Argbash?
-
-Bash is an interpreted command-line language with no standard library. Therefore, if you write bash scripts and want command-line interfaces that conform to [POSIX][3] and [GNU CLI][4] standards, you’re used to only two options:
-
-1. Write the argument-parsing functionality tailored to your script yourself (possibly using the `getopts` builtin).
-
-2. Use an external bash module.
-
-The first option looks incredibly silly as implementing the interface properly is not trivial. However, it is suggested as the best choice on various sites ranging from [Stack Overflow][5] to the [Bash Hackers][6] wiki.
-
-The second option looks smarter, but using a module has its issues. The biggest is you have to bundle its code with your script. This may mean either:
-
-* You distribute the library as a separate file, or
-
-* You include the library code at the beginning of your script.
-
-Having two files instead of one is awkward. So is polluting your bash scripts with a chunk of complex code over thousand lines long.
-
-This was the main reason why the Argbash [project came to life][7]. Argbash is a code generator, so it generates a tailor-made parsing library for your script. Unlike the generic code of other bash modules, it produces minimal code your script needs. Moreover, you can request even simpler code if you don’t need 100% conformance to these CLI standards.
-
-### Example
-
-### Analysis
-
-Let’s say you want to implement a script that [draws a bar][8] across the terminal window. You do that by repeating a single character of your choice multiple times. This means you need to get the following information from the command-line:
-
-* _The character which is the element of the line. If not specified, use a dash._ On the command-line, this would be a single-valued positional argument _character_ with a default value of -.
-
-* _Length of the line. If not specified, go for 80._ This is a single-valued optional argument _–length_ with a default of 80.
-
-* _Verbose mode (for debugging)._ This is a boolean argument _verbose_ , off by default.
-
-As the body of the script is really simple, this article focuses on getting the input of the user from the command-line to appropriate script variables. Argbash generates code that saves parsing results to shell variables __arg_character_ , __arg_length_ and __arg_verbose_ .
-
-### Execution
-
-In order to proceed, you need the _argbash-init_ and _argbash_ bash scripts that are parts of the _argbash_ package. Therefore, run this command:
-
-```
-sudo dnf install argbash
-```
-
-Then, use _argbash-init_ to generate a template for _argbash_ , which generates the executable script. You want three arguments: a positional one called _character_ , an optional _length_ and an optional boolean _verbose_ . Tell this to _argbash-init_ , and then pass the output to _argbash_ :
-
-```
-argbash-init --pos character --opt length --opt-bool verbose script-template.sh
-argbash script-template.sh -o script
-./script
-```
-
-See the help message? Looks like the script doesn’t know about the default option for the character argument. So take a look at the [Argbash API][9], and then fix the issue by editing the template section of the script:
-
-```
-# ...
-# ARG_OPTIONAL_SINGLE([length],[l],[Length of the line],[80])
-# ARG_OPTIONAL_BOOLEAN([verbose],[V],[Debug mode])
-# ARG_POSITIONAL_SINGLE([character],[The element of the line],[-])
-# ARG_HELP([The line drawer])
-# ...
-```
-
-Argbash is so smart that it tries to make every generated script a template of itself. This means you don’t have to worry about storing source templates for further use. You just shouldn’t lose your generated bash scripts. Now, try to regenerate the future line drawer to work as expected:
-
-```
-argbash script -o script
-./script
-```
-
-As you can see, everything is working all right. The only thing left to do is fill in the line drawing functionality itself.
-
-### Conclusion
-
-You might find the section containing parsing code quite long, but consider that it allows you to call _./script.sh x -Vl50_ and it will be understood the same way as _./script -V -l 50 x. I_ t does require some code to get this right.
-
-However, you can shift the balance between generated code complexity and parsing abilities towards more simple code by calling _argbash-init_ with argument _–mode_ set to _minimal_ . This option reduces the size of the script by about 20 lines, which corresponds to a roughly 25% decrease of the generated parsing code size. On the other hand, the _full_ mode makes the script even smarter.
-
-If you want to examine the generated code, give _argbash_ the argument _–commented_ , which puts comments into the parsing code that reveal the intent behind various sections. Compare that to other argument parsing libraries such as [shflags][10], [argsparse][11] or [bash-modules/arguments][12], and you’ll see the powerful simplicity of Argbash. If something goes horribly wrong and you need to fix a glitch in the parsing functionality quickly, Argbash allows you to do that as well.
-
-As you’re most likely a Fedora user, you can enjoy the luxury of having command-line Argbash installed from the official repositories. However, there is also an [online parsing code generator][13] at your service. Furthermore, if you’re working on a server with Docker, you can appreciate the [Argbash Docker image][14].
-
-So enjoy and make sure that your scripts have a command-line interface that pleases your users. Argbash is here to help, with minimal effort required from your side.
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/improve-bash-scripts-argbash/
-
-作者:[Matěj Týč ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://fedoramagazine.org/author/bubla/
-[1]:https://fedoramagazine.org/improve-bash-scripts-argbash/
-[2]:https://argbash.readthedocs.io/
-[3]:http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap12.html
-[4]:https://www.gnu.org/prep/standards/html_node/Command_002dLine-Interfaces.html
-[5]:https://stackoverflow.com/questions/192249/how-do-i-parse-command-line-arguments-in-bash
-[6]:http://wiki.bash-hackers.org/howto/getopts_tutorial
-[7]:https://argbash.readthedocs.io/
-[8]:http://wiki.bash-hackers.org/snipplets/print_horizontal_line
-[9]:http://argbash.readthedocs.io/en/stable/guide.html#argbash-api
-[10]:https://raw.githubusercontent.com/Anvil/bash-argsparse/master/argsparse.sh
-[11]:https://raw.githubusercontent.com/Anvil/bash-argsparse/master/argsparse.sh
-[12]:https://raw.githubusercontent.com/vlisivka/bash-modules/master/main/bash-modules/src/bash-modules/arguments.sh
-[13]:https://argbash.io/generate
-[14]:https://hub.docker.com/r/matejak/argbash/
diff --git a/sources/tech/20180329 How to configure multiple websites with Apache web server.md b/sources/tech/20180329 How to configure multiple websites with Apache web server.md
index 0f759cc5fe..671feb17b0 100644
--- a/sources/tech/20180329 How to configure multiple websites with Apache web server.md
+++ b/sources/tech/20180329 How to configure multiple websites with Apache web server.md
@@ -1,3 +1,6 @@
+Translating by MjSeven
+
+
How to configure multiple websites with Apache web server
======
diff --git a/sources/tech/20180715 Why is Python so slow.md b/sources/tech/20180715 Why is Python so slow.md
deleted file mode 100644
index 5c39a528a1..0000000000
--- a/sources/tech/20180715 Why is Python so slow.md
+++ /dev/null
@@ -1,207 +0,0 @@
-HankChow translating
-
-Why is Python so slow?
-============================================================
-
-Python is booming in popularity. It is used in DevOps, Data Science, Web Development and Security.
-
-It does not, however, win any medals for speed.
-
-
-
-
-> How does Java compare in terms of speed to C or C++ or C# or Python? The answer depends greatly on the type of application you’re running. No benchmark is perfect, but The Computer Language Benchmarks Game is [a good starting point][5].
-
-I’ve been referring to the Computer Language Benchmarks Game for over a decade; compared with other languages like Java, C#, Go, JavaScript, C++, Python is [one of the slowest][6]. This includes [JIT][7] (C#, Java) and [AOT][8] (C, C++) compilers, as well as interpreted languages like JavaScript.
-
- _NB: When I say “Python”, I’m talking about the reference implementation of the language, CPython. I will refer to other runtimes in this article._
-
-> I want to answer this question: When Python completes a comparable application 2–10x slower than another language, _why is it slow_ and can’t we _make it faster_ ?
-
-Here are the top theories:
-
-* “ _It’s the GIL (Global Interpreter Lock)_ ”
-
-* “ _It’s because its interpreted and not compiled_ ”
-
-* “ _It’s because its a dynamically typed language_ ”
-
-Which one of these reasons has the biggest impact on performance?
-
-### “It’s the GIL”
-
-Modern computers come with CPU’s that have multiple cores, and sometimes multiple processors. In order to utilise all this extra processing power, the Operating System defines a low-level structure called a thread, where a process (e.g. Chrome Browser) can spawn multiple threads and have instructions for the system inside. That way if one process is particularly CPU-intensive, that load can be shared across the cores and this effectively makes most applications complete tasks faster.
-
-My Chrome Browser, as I’m writing this article, has 44 threads open. Keep in mind that the structure and API of threading are different between POSIX-based (e.g. Mac OS and Linux) and Windows OS. The operating system also handles the scheduling of threads.
-
-IF you haven’t done multi-threaded programming before, a concept you’ll need to quickly become familiar with locks. Unlike a single-threaded process, you need to ensure that when changing variables in memory, multiple threads don’t try and access/change the same memory address at the same time.
-
-When CPython creates variables, it allocates the memory and then counts how many references to that variable exist, this is a concept known as reference counting. If the number of references is 0, then it frees that piece of memory from the system. This is why creating a “temporary” variable within say, the scope of a for loop, doesn’t blow up the memory consumption of your application.
-
-The challenge then becomes when variables are shared within multiple threads, how CPython locks the reference count. There is a “global interpreter lock” that carefully controls thread execution. The interpreter can only execute one operation at a time, regardless of how many threads it has.
-
-#### What does this mean to the performance of Python application?
-
-If you have a single-threaded, single interpreter application. It will make no difference to the speed. Removing the GIL would have no impact on the performance of your code.
-
-If you wanted to implement concurrency within a single interpreter (Python process) by using threading, and your threads were IO intensive (e.g. Network IO or Disk IO), you would see the consequences of GIL-contention.
-
-
-From David Beazley’s GIL visualised post [http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html][1]
-
-If you have a web-application (e.g. Django) and you’re using WSGI, then each request to your web-app is a separate Python interpreter, so there is only 1 lock _per_ request. Because the Python interpreter is slow to start, some WSGI implementations have a “Daemon Mode” [which keep Python process(es) on the go for you.][9]
-
-#### What about other Python runtimes?
-
-[PyPy has a GIL][10] and it is typically >3x faster than CPython.
-
-[Jython does not have a GIL][11] because a Python thread in Jython is represented by a Java thread and benefits from the JVM memory-management system.
-
-#### How does JavaScript do this?
-
-Well, firstly all Javascript engines [use mark-and-sweep Garbage Collection][12]. As stated, the primary need for the GIL is CPython’s memory-management algorithm.
-
-JavaScript does not have a GIL, but it’s also single-threaded so it doesn’t require one. JavaScript’s event-loop and Promise/Callback pattern are how asynchronous-programming is achieved in place of concurrency. Python has a similar thing with the asyncio event-loop.
-
-### “It’s because its an interpreted language”
-
-I hear this a lot and I find it a gross-simplification of the way CPython actually works. If at a terminal you wrote `python myscript.py` then CPython would start a long sequence of reading, lexing, parsing, compiling, interpreting and executing that code.
-
-If you’re interested in how that process works, I’ve written about it before:
-
-[Modifying the Python language in 6 minutes
-This week I raised my first pull-request to the CPython core project, which was declined :-( but as to not completely…hackernoon.com][13][][14]
-
-An important point in that process is the creation of a `.pyc` file, at the compiler stage, the bytecode sequence is written to a file inside `__pycache__/`on Python 3 or in the same directory in Python 2\. This doesn’t just apply to your script, but all of the code you imported, including 3rd party modules.
-
-So most of the time (unless you write code which you only ever run once?), Python is interpreting bytecode and executing it locally. Compare that with Java and C#.NET:
-
-> Java compiles to an “Intermediate Language” and the Java Virtual Machine reads the bytecode and just-in-time compiles it to machine code. The .NET CIL is the same, the .NET Common-Language-Runtime, CLR, uses just-in-time compilation to machine code.
-
-So, why is Python so much slower than both Java and C# in the benchmarks if they all use a virtual machine and some sort of Bytecode? Firstly, .NET and Java are JIT-Compiled.
-
-JIT or Just-in-time compilation requires an intermediate language to allow the code to be split into chunks (or frames). Ahead of time (AOT) compilers are designed to ensure that the CPU can understand every line in the code before any interaction takes place.
-
-The JIT itself does not make the execution any faster, because it is still executing the same bytecode sequences. However, JIT enables optimizations to be made at runtime. A good JIT optimizer will see which parts of the application are being executed a lot, call these “hot spots”. It will then make optimizations to those bits of code, by replacing them with more efficient versions.
-
-This means that when your application does the same thing again and again, it can be significantly faster. Also, keep in mind that Java and C# are strongly-typed languages so the optimiser can make many more assumptions about the code.
-
-PyPy has a JIT and as mentioned in the previous section, is significantly faster than CPython. This performance benchmark article goes into more detail —
-
-[Which is the fastest version of Python?
-Of course, “it depends”, but what does it depend on and how can you assess which is the fastest version of Python for…hackernoon.com][15][][16]
-
-#### So why doesn’t CPython use a JIT?
-
-There are downsides to JITs: one of those is startup time. CPython startup time is already comparatively slow, PyPy is 2–3x slower to start than CPython. The Java Virtual Machine is notoriously slow to boot. The .NET CLR gets around this by starting at system-startup, but the developers of the CLR also develop the Operating System on which the CLR runs.
-
-If you have a single Python process running for a long time, with code that can be optimized because it contains “hot spots”, then a JIT makes a lot of sense.
-
-However, CPython is a general-purpose implementation. So if you were developing command-line applications using Python, having to wait for a JIT to start every time the CLI was called would be horribly slow.
-
-CPython has to try and serve as many use cases as possible. There was the possibility of [plugging a JIT into CPython][17] but this project has largely stalled.
-
-> If you want the benefits of a JIT and you have a workload that suits it, use PyPy.
-
-### “It’s because its a dynamically typed language”
-
-In a “Statically-Typed” language, you have to specify the type of a variable when it is declared. Those would include C, C++, Java, C#, Go.
-
-In a dynamically-typed language, there are still the concept of types, but the type of a variable is dynamic.
-
-```
-a = 1
-a = "foo"
-```
-
-In this toy-example, Python creates a second variable with the same name and a type of `str` and deallocates the memory created for the first instance of `a`
-
-Statically-typed languages aren’t designed as such to make your life hard, they are designed that way because of the way the CPU operates. If everything eventually needs to equate to a simple binary operation, you have to convert objects and types down to a low-level data structure.
-
-Python does this for you, you just never see it, nor do you need to care.
-
-Not having to declare the type isn’t what makes Python slow, the design of the Python language enables you to make almost anything dynamic. You can replace the methods on objects at runtime, you can monkey-patch low-level system calls to a value declared at runtime. Almost anything is possible.
-
-It’s this design that makes it incredibly hard to optimise Python.
-
-To illustrate my point, I’m going to use a syscall tracing tool that works in Mac OS called Dtrace. CPython distributions do not come with DTrace builtin, so you have to recompile CPython. I’m using 3.6.6 for my demo
-
-```
-wget https://github.com/python/cpython/archive/v3.6.6.zip
-unzip v3.6.6.zip
-cd v3.6.6
-./configure --with-dtrace
-make
-```
-
-Now `python.exe` will have Dtrace tracers throughout the code. [Paul Ross wrote an awesome Lightning Talk on Dtrace][19]. You can [download DTrace starter files][20] for Python to measure function calls, execution time, CPU time, syscalls, all sorts of fun. e.g.
-
-`sudo dtrace -s toolkit/.d -c ‘../cpython/python.exe script.py’`
-
-The `py_callflow` tracer shows all the function calls in your application
-
-
-
-
-So, does Python’s dynamic typing make it slow?
-
-* Comparing and converting types is costly, every time a variable is read, written to or referenced the type is checked
-
-* It is hard to optimise a language that is so dynamic. The reason many alternatives to Python are so much faster is that they make compromises to flexibility in the name of performance
-
-* Looking at [Cython][2], which combines C-Static Types and Python to optimise code where the types are known[ can provide ][3]an 84x performanceimprovement.
-
-### Conclusion
-
-> Python is primarily slow because of its dynamic nature and versatility. It can be used as a tool for all sorts of problems, where more optimised and faster alternatives are probably available.
-
-There are, however, ways of optimising your Python applications by leveraging async, understanding the profiling tools, and consider using multiple-interpreters.
-
-For applications where startup time is unimportant and the code would benefit a JIT, consider PyPy.
-
-For parts of your code where performance is critical and you have more statically-typed variables, consider using [Cython][4].
-
-#### Further reading
-
-Jake VDP’s excellent article (although slightly dated) [https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/][21]
-
-Dave Beazley’s talk on the GIL [http://www.dabeaz.com/python/GIL.pdf][22]
-
-All about JIT compilers [https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/][23]
-
---------------------------------------------------------------------------------
-
-via: https://hackernoon.com/why-is-python-so-slow-e5074b6fe55b
-
-作者:[Anthony Shaw][a]
-选题:[oska874][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://hackernoon.com/@anthonypjshaw?source=post_header_lockup
-[b]:https://github.com/oska874
-[1]:http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html
-[2]:http://cython.org/
-[3]:http://notes-on-cython.readthedocs.io/en/latest/std_dev.html
-[4]:http://cython.org/
-[5]:http://algs4.cs.princeton.edu/faq/
-[6]:https://benchmarksgame-team.pages.debian.net/benchmarksgame/faster/python.html
-[7]:https://en.wikipedia.org/wiki/Just-in-time_compilation
-[8]:https://en.wikipedia.org/wiki/Ahead-of-time_compilation
-[9]:https://www.slideshare.net/GrahamDumpleton/secrets-of-a-wsgi-master
-[10]:http://doc.pypy.org/en/latest/faq.html#does-pypy-have-a-gil-why
-[11]:http://www.jython.org/jythonbook/en/1.0/Concurrency.html#no-global-interpreter-lock
-[12]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Memory_Management
-[13]:https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14
-[14]:https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14
-[15]:https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b
-[16]:https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b
-[17]:https://www.slideshare.net/AnthonyShaw5/pyjion-a-jit-extension-system-for-cpython
-[18]:https://github.com/python/cpython/archive/v3.6.6.zip
-[19]:https://github.com/paulross/dtrace-py#the-lightning-talk
-[20]:https://github.com/paulross/dtrace-py/tree/master/toolkit
-[21]:https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/
-[22]:http://www.dabeaz.com/python/GIL.pdf
-[23]:https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/
diff --git a/sources/tech/20180911 Know Your Storage- Block, File - Object.md b/sources/tech/20180911 Know Your Storage- Block, File - Object.md
index 186b41d41a..24f179d9d5 100644
--- a/sources/tech/20180911 Know Your Storage- Block, File - Object.md
+++ b/sources/tech/20180911 Know Your Storage- Block, File - Object.md
@@ -1,4 +1,3 @@
-translating by name1e5s
Know Your Storage: Block, File & Object
======
diff --git a/sources/tech/20181004 PyTorch 1.0 Preview Release- Facebook-s newest Open Source AI.md b/sources/tech/20181004 PyTorch 1.0 Preview Release- Facebook-s newest Open Source AI.md
deleted file mode 100644
index 08551028b2..0000000000
--- a/sources/tech/20181004 PyTorch 1.0 Preview Release- Facebook-s newest Open Source AI.md
+++ /dev/null
@@ -1,182 +0,0 @@
-distant1219 is translating
-PyTorch 1.0 Preview Release: Facebook’s newest Open Source AI
-======
-Facebook already uses its own Open Source AI, PyTorch quite extensively in its own artificial intelligence projects. Recently, they have gone a league ahead by releasing a pre-release preview version 1.0.
-
-For those who are not familiar, [PyTorch][1] is a Python-based library for Scientific Computing.
-
-PyTorch harnesses the [superior computational power of Graphical Processing Units (GPUs)][2] for carrying out complex [Tensor][3] computations and implementing [deep neural networks][4]. So, it is used widely across the world by numerous researchers and developers.
-
-This new ready-to-use [Preview Release][5] was announced at the [PyTorch Developer Conference][6] at [The Midway][7], San Francisco, CA on Tuesday, October 2, 2018.
-
-### Highlights of PyTorch 1.0 Release Candidate
-
-![PyTorhc is Python based open source AI framework from Facebook][8]
-
-Some of the main new features in the release candidate are:
-
-#### 1\. JIT
-
-JIT is a set of compiler tools to bring research close to production. It includes a Python-based language called Torch Script and also ways to make existing code compatible with itself.
-
-#### 2\. New torch.distributed library: “C10D”
-
-“C10D” enables asynchronous operation on different backends with performance improvements on slower networks and more.
-
-#### 3\. C++ frontend (experimental)
-
-Though it has been specifically mentioned as an unstable API (expected in a pre-release), this is a pure C++ interface to the PyTorch backend that follows the API and architecture of the established Python frontend to enable research in high performance, low latency and C++ applications installed directly on hardware.
-
-To know more, you can take a look at the complete [update notes][9] on GitHub.
-
-The first stable version PyTorch 1.0 will be released in summer.
-
-### Installing PyTorch on Linux
-
-To install PyTorch v1.0rc0, the developers recommend using [conda][10] while there also other ways to do that as shown on their [local installation page][11] where they have documented everything necessary in detail.
-
-#### Prerequisites
-
- * Linux
- * Pip
- * Python
- * [CUDA][12] (For Nvidia GPU owners)
-
-
-
-As we recently showed you [how to install and use Pip][13], let’s get to know how we can install PyTorch with it.
-
-Note that PyTorch has GPU and CPU-only variants. You should install the one that suits your hardware.
-
-#### Installing old and stable version of PyTorch
-
-If you want the stable release (version 0.4) for your GPU, use:
-
-```
-pip install torch torchvision
-
-```
-
-Use these two commands in succession for a CPU-only stable release:
-
-```
-pip install http://download.pytorch.org/whl/cpu/torch-0.4.1-cp27-cp27mu-linux_x86_64.whl
-pip install torchvision
-
-```
-
-#### Installing PyTorch 1.0 Release Candidate
-
-You install PyTorch 1.0 RC GPU version with this command:
-
-```
-pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu92/torch_nightly.html
-
-```
-
-If you do not have a GPU and would prefer a CPU-only version, use:
-
-```
-pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
-
-```
-
-#### Verifying your PyTorch installation
-
-Startup the python console on a terminal with the following simple command:
-
-```
-python
-
-```
-
-Now enter the following sample code line by line to verify your installation:
-
-```
-from __future__ import print_function
-import torch
-x = torch.rand(5, 3)
-print(x)
-
-```
-
-You should get an output like:
-
-```
-tensor([[0.3380, 0.3845, 0.3217],
- [0.8337, 0.9050, 0.2650],
- [0.2979, 0.7141, 0.9069],
- [0.1449, 0.1132, 0.1375],
- [0.4675, 0.3947, 0.1426]])
-
-```
-
-To check whether you can use PyTorch’s GPU capabilities, use the following sample code:
-
-```
-import torch
-torch.cuda.is_available()
-
-```
-
-The resulting output should be:
-
-```
-True
-
-```
-
-Support for AMD GPUs for PyTorch is still under development, so complete test coverage is not yet provided as reported [here][14], suggesting this [resource][15] in case you have an AMD GPU.
-
-Lets now look into some research projects that extensively use PyTorch:
-
-### Ongoing Research Projects based on PyTorch
-
- * [Detectron][16]: Facebook AI Research’s software system to intelligently detect and classify objects. It is based on Caffe2. Earlier this year, Caffe2 and PyTorch [joined forces][17] to create a Research + Production enabled PyTorch 1.0 we talk about.
- * [Unsupervised Sentiment Discovery][18]: Such methods are extensively used with social media algorithms.
- * [vid2vid][19]: Photorealistic video-to-video translation
- * [DeepRecommender][20] (We covered how such systems work on our past [Netflix AI article][21])
-
-
-
-Nvidia, leading GPU manufacturer covered more on this with their own [update][22] on this recent development where you can also read about ongoing collaborative research endeavours.
-
-### How should we react to such PyTorch capabilities?
-
-To think Facebook applies such amazingly innovative projects and more in its social media algorithms, should we appreciate all this or get alarmed? This is almost [Skynet][23]! This newly improved production-ready pre-release of PyTorch will certainly push things further ahead! Feel free to share your thoughts with us in the comments below!
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/pytorch-open-source-ai-framework/
-
-作者:[Avimanyu Bandyopadhyay][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/avimanyu/
-[1]: https://pytorch.org/
-[2]: https://en.wikipedia.org/wiki/General-purpose_computing_on_graphics_processing_units
-[3]: https://en.wikipedia.org/wiki/Tensor
-[4]: https://www.techopedia.com/definition/32902/deep-neural-network
-[5]: https://code.fb.com/ai-research/facebook-accelerates-ai-development-with-new-partners-and-production-capabilities-for-pytorch-1-0
-[6]: https://pytorch.fbreg.com/
-[7]: https://www.themidwaysf.com/
-[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/pytorch.jpeg
-[9]: https://github.com/pytorch/pytorch/releases/tag/v1.0rc0
-[10]: https://conda.io/
-[11]: https://pytorch.org/get-started/locally/
-[12]: https://www.pugetsystems.com/labs/hpc/How-to-install-CUDA-9-2-on-Ubuntu-18-04-1184/
-[13]: https://itsfoss.com/install-pip-ubuntu/
-[14]: https://github.com/pytorch/pytorch/issues/10657#issuecomment-415067478
-[15]: https://rocm.github.io/install.html#installing-from-amd-rocm-repositories
-[16]: https://github.com/facebookresearch/Detectron
-[17]: https://caffe2.ai/blog/2018/05/02/Caffe2_PyTorch_1_0.html
-[18]: https://github.com/NVIDIA/sentiment-discovery
-[19]: https://github.com/NVIDIA/vid2vid
-[20]: https://github.com/NVIDIA/DeepRecommender/
-[21]: https://itsfoss.com/netflix-open-source-ai/
-[22]: https://news.developer.nvidia.com/pytorch-1-0-accelerated-on-nvidia-gpus/
-[23]: https://en.wikipedia.org/wiki/Skynet_(Terminator)
diff --git a/sources/tech/20181012 Command line quick tips- Reading files different ways.md b/sources/tech/20181012 Command line quick tips- Reading files different ways.md
index 30c82c1843..87e6e77d1e 100644
--- a/sources/tech/20181012 Command line quick tips- Reading files different ways.md
+++ b/sources/tech/20181012 Command line quick tips- Reading files different ways.md
@@ -1,3 +1,5 @@
+translating by distant1219
+
Command line quick tips: Reading files different ways
======
diff --git a/sources/tech/20181013 How to Install GRUB on Arch Linux (UEFI).md b/sources/tech/20181013 How to Install GRUB on Arch Linux (UEFI).md
index 97cb5e0362..e456c1ee0e 100644
--- a/sources/tech/20181013 How to Install GRUB on Arch Linux (UEFI).md
+++ b/sources/tech/20181013 How to Install GRUB on Arch Linux (UEFI).md
@@ -1,3 +1,5 @@
+translating---geekpi
+
How to Install GRUB on Arch Linux (UEFI)
======
diff --git a/sources/tech/20181015 How To Browse And Read Entire Arch Wiki As Linux Man Pages.md b/sources/tech/20181015 How To Browse And Read Entire Arch Wiki As Linux Man Pages.md
new file mode 100644
index 0000000000..fe61f32dda
--- /dev/null
+++ b/sources/tech/20181015 How To Browse And Read Entire Arch Wiki As Linux Man Pages.md
@@ -0,0 +1,151 @@
+How To Browse And Read Entire Arch Wiki As Linux Man Pages
+======
+
+
+A while ago, I wrote a guide that described how to browse the Arch Wiki from your Terminal using a command line script named [**arch-wiki-cli**][1]. Using this script, anyone can easily navigate through entire Arch Wiki website and read it with a text browser of your choice. Obviously, an active Internet connection is required to use this script. Today, I stumbled upon a similar utility named **“Arch-wiki-man”**. As the name says, it is also used to read the Arch Wiki from command line, but it doesn’t require Internet connection. Arch-wiki-man program helps you to browse and read entire Arch Wiki as Linux man pages. It will display any article from Arch Wiki in man pages format. Also, you need not to be online to browse Arch Wiki. The entire Arch Wiki will be downloaded locally and the updates are pushed automatically every two days. So, you always have an up-to-date, local copy of the Arch Wiki on your system.
+
+### Installing Arch-wiki-man
+
+Arch-wiki-man is available in [**AUR**][2], so you can install it using any AUR helper programs, for example [**Yay**][3].
+
+```
+ $ yay -S arch-wiki-man
+```
+
+Alternatively, it can be installed using NPM package manager like below. Make sure you have [**installed NodeJS**][4] and run the following command to install it:
+
+```
+ $ npm install -g arch-wiki-man
+```
+
+### Browse And Read Entire Arch Wiki As Linux Man Pages
+
+The typical syntax of Arch-wiki-man is:
+
+```
+ $ awman
+```
+
+Let me show you some examples.
+
+**Search with one or more matches**
+
+Let us search for a [**Arch Linux installation guide**][5]. To do so, simply run:
+
+```
+ $ awman Installation guide
+```
+
+The above command will search for the matches that contains the search term “Installation guide” in the Arch Wiki. If there are multiple matches for the given search term, a selection menu will appear. Choose the guide you want to read using **UP/DOWN arrows** or Vim-style keybindings ( **j/k** ) and hit ENTER to open it. The resulting guide will open in man pages format like below.
+
+![][6]
+
+Here, awman refers **a** rch **w** iki **m** an.
+
+All man command options are supported, so you can navigate through guide as the way you do when reading a man page. To view the help section, press **h**.
+
+![][7]
+
+To exit the selection menu without entering **man** , simply press **Ctrl+c**.
+
+To go back and/or quit man, type **q**.
+
+**Search matches in titles and descriptions**
+
+By default, Awman will search for the matches in titles only. You can, however, direct it to search for the matches in both the titles and descriptions as well.
+
+```
+ $ awman -d vim
+```
+
+Or,
+
+```
+ $ awman --desc-search vim
+```
+
+**Search for matches in contents**
+
+Apart from searching for matches in titles and descriptions, it is also possible to scan the contents for a match as well. Please note that this will significantly slower the search process.
+
+```
+ $ awman -k emacs
+```
+
+Or,
+
+```
+ $ awman --apropos emacs
+```
+
+**Open the search results in web browser**
+
+If you don’t want to view the arch wiki guides in man page format, you can open it in a web browser. To do so, run:
+
+```
+ $ awman -w pacman
+```
+
+Or,
+
+```
+ $ awman --web pacman
+```
+
+This command will open the resulting match in the default web browser rather than with **man** command. Please note that you need Internet connection to use this option.
+
+**Search in other languages**
+
+By default, Awman will open the Arch wiki pages in English. If you want to view the results in other languages, for example **Spanish** , simply do:
+
+```
+ $ awman -l spanish codecs
+```
+
+![][8]
+
+To view the list of available language options, run:
+
+```
+
+ $ awman --list-languages
+
+```
+
+**Update the local copy of Arch Wiki**
+
+Like I already said, the updates are pushed automatically every two days. If you want to update it manually, simply run:
+
+```
+$ awman-update
+arch-wiki-man@1.3.0 /usr/lib/node_modules/arch-wiki-man
+└── arch-wiki-md-repo@0.10.84
+
+arch-wiki-md-repo has been successfully updated or reinstalled.
+```
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-browse-and-read-entire-arch-wiki-as-linux-man-pages/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/search-arch-wiki-website-commandline/
+[2]: https://aur.archlinux.org/packages/arch-wiki-man/
+[3]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[4]: https://www.ostechnix.com/install-node-js-linux/
+[5]: https://www.ostechnix.com/install-arch-linux-latest-version/
+[6]: http://www.ostechnix.com/wp-content/uploads/2018/10/awman-1.gif
+[7]: http://www.ostechnix.com/wp-content/uploads/2018/10/awman-2.png
+[8]: https://www.ostechnix.com/wp-content/uploads/2018/10/awman-3-1.png
diff --git a/sources/tech/20181016 Final JOS project.md b/sources/tech/20181016 Final JOS project.md
new file mode 100644
index 0000000000..929c1e7caa
--- /dev/null
+++ b/sources/tech/20181016 Final JOS project.md
@@ -0,0 +1,119 @@
+Final JOS project
+======
+Piazza Discussion Due, November 2, 2018 Proposals Due, November 8, 2018 Code repository Due, December 6, 2018 Check-off and in-class demos, Week of December 10, 2018
+
+### Introduction
+
+For the final project you have two options:
+
+* Work on your own and do [lab 6][1], including one challenge exercise in lab 6\. (You are free, of course, to extend lab 6, or any part of JOS, further in interesting ways, but it isn't required.)
+
+* Work in a team of one, two or three, on a project of your choice that involves your JOS. This project must be of the same scope as lab 6 or larger (if you are working in a team).
+
+The goal is to have fun and explore more advanced O/S topics; you don't have to do novel research.
+
+If you are doing your own project, we'll grade you on how much you got working, how elegant your design is, how well you can explain it, and how interesting and creative your solution is. We do realize that time is limited, so we don't expect you to re-write Linux by the end of the semester. Try to make sure your goals are reasonable; perhaps set a minimum goal that's definitely achievable (e.g., something of the scale of lab 6) and a more ambitious goal if things go well.
+
+If you are doing lab 6, we will grade you on whether you pass the tests and the challenge exercise.
+
+### Deliverables
+
+```
+Nov 3: Piazza discussion and form groups of 1, 2, or 3 (depending on which final project option you are choosing). Use the lab7 tag/folder on Piazza. Discuss ideas with others in comments on their Piazza posting. Use these postings to help find other students interested in similar ideas for forming a group. Course staff will provide feedback on project ideas on Piazza; if you'd like more detailed feedback, come chat with us in person.
+```
+
+```
+Nov 9: Submit a proposal at [the submission website][19], just a paragraph or two. The proposal should include your group members list, the problem you want to address, how you plan to address it, and what are you proposing to specifically design and implement. (If you are doing lab 6, there is nothing to do for this deliverable.)
+```
+
+```
+Dec 7: submit source code along with a brief write-up. Put the write-up under the top-level source directory with the name "README.pdf". Since some of you will be working in groups for this lab assignment, you may want to use git to share your project code between group members. You will need to decide on whose source code you will use as a starting point for your group project. Make sure to create a branch for your final project, and name it lab7\. (If you do lab 6, follow the lab 6 submission instructions.)
+```
+
+```
+Week of Dec 11: short in-class demonstration. Prepare a short in-class demo of your JOS project. We will provide a projector that you can use to demonstrate your project. Depending on the number of groups and the kinds of projects that each group chooses, we may decide to limit the total number of presentations, and some groups might end up not presenting in class.
+```
+
+```
+Week of Dec 11: check-off with TAs. Demo your project to the TAs so that we can ask you some questions and find out in more detail what you did.
+```
+
+### Project ideas
+
+If you are not doing lab 6, here's a list of ideas to get you started thinking. But, you should feel free to pursue your own ideas. Some of the ideas are starting points and by themselves not of the scope of lab 6, and others are likely to be much of larger scope.
+
+* Build a virtual machine monitor that can run multiple guests (for example, multiple instances of JOS), using [x86 VM support][2].
+
+* Do something useful with the hardware protection of Intel SGX. [Here is a recent paper using Intel SGX][3].
+
+* Make the JOS file system support writing, file creation, logging for durability, etc., perhaps taking ideas from Linux EXT3.
+
+* Use file system ideas from [Soft updates][4], [WAFL][5], ZFS, or another advanced file system.
+
+* Add snapshots to a file system, so that a user can look at the file system as it appeared at various points in the past. You'll probably want to use some kind of copy-on-write for disk storage to keep space consumption down.
+
+* Build a [distributed shared memory][6] (DSM) system, so that you can run multi-threaded shared memory parallel programs on a cluster of machines, using paging to give the appearance of real shared memory. When a thread tries to access a page that's on another machine, the page fault will give the DSM system a chance to fetch the page over the network from whatever machine currently stores it.
+
+* Allow processes to migrate from one machine to another over the network. You'll need to do something about the various pieces of a process's state, but since much state in JOS is in user-space it may be easier than process migration on Linux.
+
+* Implement [paging][7] to disk in JOS, so that processes can be bigger than RAM. Extend your pager with swapping.
+
+* Implement [mmap()][8] of files for JOS.
+
+* Use [xfi][9] to sandbox code within a process.
+
+* Support x86 [2MB or 4MB pages][10].
+
+* Modify JOS to have kernel-supported threads inside processes. See [in-class uthread assignment][11] to get started. Implementing scheduler activations would be one way to do this project.
+
+* Use fine-grained locking or lock-free concurrency in JOS in the kernel or in the file server (after making it multithreaded). The linux kernel uses [read copy update][12] to be able to perform read operations without holding locks. Explore RCU by implementing it in JOS and use it to support a name cache with lock-free reads.
+
+* Implement ideas from the [Exokernel papers][13], for example the packet filter.
+
+* Make JOS have soft real-time behavior. You will have to identify some application for which this is useful.
+
+* Make JOS run on 64-bit CPUs. This includes redoing the virtual memory system to use 4-level pages tables. See [reference page][14] for some documentation.
+
+* Port JOS to a different microprocessor. The [osdev wiki][15] may be helpful.
+
+* A window system for JOS, including graphics driver and mouse. See [reference page][16] for some documentation. [sqrt(x)][17] is an example JOS window system (and writeup).
+
+* Implement [dune][18] to export privileged hardware instructions to user-space applications in JOS.
+
+* Write a user-level debugger; add strace-like functionality; hardware register profiling (e.g. Oprofile); call-traces
+
+* Binary emulation for (static) Linux executables
+
+
+--------------------------------------------------------------------------------
+
+via: https://pdos.csail.mit.edu/6.828/2018/labs/lab7/
+
+作者:[csail.mit][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://pdos.csail.mit.edu
+[b]: https://github.com/lujun9972
+[1]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/index.html
+[2]: http://www.intel.com/technology/itj/2006/v10i3/1-hardware/3-software.htm
+[3]: https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-baumann.pdf
+[4]: http://www.ece.cmu.edu/~ganger/papers/osdi94.pdf
+[5]: https://ng.gnunet.org/sites/default/files/10.1.1.40.3691.pdf
+[6]: http://www.cdf.toronto.edu/~csc469h/fall/handouts/nitzberg91.pdf
+[7]: http://en.wikipedia.org/wiki/Paging
+[8]: http://en.wikipedia.org/wiki/Mmap
+[9]: http://static.usenix.org/event/osdi06/tech/erlingsson.html
+[10]: http://en.wikipedia.org/wiki/Page_(computer_memory)
+[11]: http://pdos.csail.mit.edu/6.828/2018/homework/xv6-uthread.html
+[12]: http://en.wikipedia.org/wiki/Read-copy-update
+[13]: http://pdos.csail.mit.edu/6.828/2018/readings/engler95exokernel.pdf
+[14]: http://pdos.csail.mit.edu/6.828/2018/reference.html
+[15]: http://wiki.osdev.org/Main_Page
+[16]: http://pdos.csail.mit.edu/6.828/2018/reference.html
+[17]: http://web.mit.edu/amdragon/www/pubs/sqrtx-6.828.html
+[18]: https://www.usenix.org/system/files/conference/osdi12/osdi12-final-117.pdf
+[19]: https://6828.scripts.mit.edu/2018/handin.py/
diff --git a/sources/tech/20181016 Lab 4- Preemptive Multitasking.md b/sources/tech/20181016 Lab 4- Preemptive Multitasking.md
new file mode 100644
index 0000000000..9e510ed7c6
--- /dev/null
+++ b/sources/tech/20181016 Lab 4- Preemptive Multitasking.md
@@ -0,0 +1,595 @@
+Lab 4: Preemptive Multitasking
+======
+### Lab 4: Preemptive Multitasking
+
+**Part A due Thursday, October 18, 2018
+Part B due Thursday, October 25, 2018
+Part C due Thursday, November 1, 2018**
+
+#### Introduction
+
+In this lab you will implement preemptive multitasking among multiple simultaneously active user-mode environments.
+
+In part A you will add multiprocessor support to JOS, implement round-robin scheduling, and add basic environment management system calls (calls that create and destroy environments, and allocate/map memory).
+
+In part B, you will implement a Unix-like `fork()`, which allows a user-mode environment to create copies of itself.
+
+Finally, in part C you will add support for inter-process communication (IPC), allowing different user-mode environments to communicate and synchronize with each other explicitly. You will also add support for hardware clock interrupts and preemption.
+
+##### Getting Started
+
+Use Git to commit your Lab 3 source, fetch the latest version of the course repository, and then create a local branch called `lab4` based on our lab4 branch, `origin/lab4`:
+
+```
+ athena% cd ~/6.828/lab
+ athena% add git
+ athena% git pull
+ Already up-to-date.
+ athena% git checkout -b lab4 origin/lab4
+ Branch lab4 set up to track remote branch refs/remotes/origin/lab4.
+ Switched to a new branch "lab4"
+ athena% git merge lab3
+ Merge made by recursive.
+ ...
+ athena%
+```
+
+Lab 4 contains a number of new source files, some of which you should browse before you start:
+| kern/cpu.h | Kernel-private definitions for multiprocessor support |
+| kern/mpconfig.c | Code to read the multiprocessor configuration |
+| kern/lapic.c | Kernel code driving the local APIC unit in each processor |
+| kern/mpentry.S | Assembly-language entry code for non-boot CPUs |
+| kern/spinlock.h | Kernel-private definitions for spin locks, including the big kernel lock |
+| kern/spinlock.c | Kernel code implementing spin locks |
+| kern/sched.c | Code skeleton of the scheduler that you are about to implement |
+
+##### Lab Requirements
+
+This lab is divided into three parts, A, B, and C. We have allocated one week in the schedule for each part.
+
+As before, you will need to do all of the regular exercises described in the lab and _at least one_ challenge problem. (You do not need to do one challenge problem per part, just one for the whole lab.) Additionally, you will need to write up a brief description of the challenge problem that you implemented. If you implement more than one challenge problem, you only need to describe one of them in the write-up, though of course you are welcome to do more. Place the write-up in a file called `answers-lab4.txt` in the top level of your `lab` directory before handing in your work.
+
+#### Part A: Multiprocessor Support and Cooperative Multitasking
+
+In the first part of this lab, you will first extend JOS to run on a multiprocessor system, and then implement some new JOS kernel system calls to allow user-level environments to create additional new environments. You will also implement _cooperative_ round-robin scheduling, allowing the kernel to switch from one environment to another when the current environment voluntarily relinquishes the CPU (or exits). Later in part C you will implement _preemptive_ scheduling, which allows the kernel to re-take control of the CPU from an environment after a certain time has passed even if the environment does not cooperate.
+
+##### Multiprocessor Support
+
+We are going to make JOS support "symmetric multiprocessing" (SMP), a multiprocessor model in which all CPUs have equivalent access to system resources such as memory and I/O buses. While all CPUs are functionally identical in SMP, during the boot process they can be classified into two types: the bootstrap processor (BSP) is responsible for initializing the system and for booting the operating system; and the application processors (APs) are activated by the BSP only after the operating system is up and running. Which processor is the BSP is determined by the hardware and the BIOS. Up to this point, all your existing JOS code has been running on the BSP.
+
+In an SMP system, each CPU has an accompanying local APIC (LAPIC) unit. The LAPIC units are responsible for delivering interrupts throughout the system. The LAPIC also provides its connected CPU with a unique identifier. In this lab, we make use of the following basic functionality of the LAPIC unit (in `kern/lapic.c`):
+
+ * Reading the LAPIC identifier (APIC ID) to tell which CPU our code is currently running on (see `cpunum()`).
+ * Sending the `STARTUP` interprocessor interrupt (IPI) from the BSP to the APs to bring up other CPUs (see `lapic_startap()`).
+ * In part C, we program LAPIC's built-in timer to trigger clock interrupts to support preemptive multitasking (see `apic_init()`).
+
+
+
+A processor accesses its LAPIC using memory-mapped I/O (MMIO). In MMIO, a portion of _physical_ memory is hardwired to the registers of some I/O devices, so the same load/store instructions typically used to access memory can be used to access device registers. You've already seen one IO hole at physical address `0xA0000` (we use this to write to the VGA display buffer). The LAPIC lives in a hole starting at physical address `0xFE000000` (32MB short of 4GB), so it's too high for us to access using our usual direct map at KERNBASE. The JOS virtual memory map leaves a 4MB gap at `MMIOBASE` so we have a place to map devices like this. Since later labs introduce more MMIO regions, you'll write a simple function to allocate space from this region and map device memory to it.
+
+```
+Exercise 1. Implement `mmio_map_region` in `kern/pmap.c`. To see how this is used, look at the beginning of `lapic_init` in `kern/lapic.c`. You'll have to do the next exercise, too, before the tests for `mmio_map_region` will run.
+```
+
+###### Application Processor Bootstrap
+
+Before booting up APs, the BSP should first collect information about the multiprocessor system, such as the total number of CPUs, their APIC IDs and the MMIO address of the LAPIC unit. The `mp_init()` function in `kern/mpconfig.c` retrieves this information by reading the MP configuration table that resides in the BIOS's region of memory.
+
+The `boot_aps()` function (in `kern/init.c`) drives the AP bootstrap process. APs start in real mode, much like how the bootloader started in `boot/boot.S`, so `boot_aps()` copies the AP entry code (`kern/mpentry.S`) to a memory location that is addressable in the real mode. Unlike with the bootloader, we have some control over where the AP will start executing code; we copy the entry code to `0x7000` (`MPENTRY_PADDR`), but any unused, page-aligned physical address below 640KB would work.
+
+After that, `boot_aps()` activates APs one after another, by sending `STARTUP` IPIs to the LAPIC unit of the corresponding AP, along with an initial `CS:IP` address at which the AP should start running its entry code (`MPENTRY_PADDR` in our case). The entry code in `kern/mpentry.S` is quite similar to that of `boot/boot.S`. After some brief setup, it puts the AP into protected mode with paging enabled, and then calls the C setup routine `mp_main()` (also in `kern/init.c`). `boot_aps()` waits for the AP to signal a `CPU_STARTED` flag in `cpu_status` field of its `struct CpuInfo` before going on to wake up the next one.
+
+```
+Exercise 2. Read `boot_aps()` and `mp_main()` in `kern/init.c`, and the assembly code in `kern/mpentry.S`. Make sure you understand the control flow transfer during the bootstrap of APs. Then modify your implementation of `page_init()` in `kern/pmap.c` to avoid adding the page at `MPENTRY_PADDR` to the free list, so that we can safely copy and run AP bootstrap code at that physical address. Your code should pass the updated `check_page_free_list()` test (but might fail the updated `check_kern_pgdir()` test, which we will fix soon).
+```
+
+```
+Question
+
+ 1. Compare `kern/mpentry.S` side by side with `boot/boot.S`. Bearing in mind that `kern/mpentry.S` is compiled and linked to run above `KERNBASE` just like everything else in the kernel, what is the purpose of macro `MPBOOTPHYS`? Why is it necessary in `kern/mpentry.S` but not in `boot/boot.S`? In other words, what could go wrong if it were omitted in `kern/mpentry.S`?
+Hint: recall the differences between the link address and the load address that we have discussed in Lab 1.
+```
+
+
+###### Per-CPU State and Initialization
+
+When writing a multiprocessor OS, it is important to distinguish between per-CPU state that is private to each processor, and global state that the whole system shares. `kern/cpu.h` defines most of the per-CPU state, including `struct CpuInfo`, which stores per-CPU variables. `cpunum()` always returns the ID of the CPU that calls it, which can be used as an index into arrays like `cpus`. Alternatively, the macro `thiscpu` is shorthand for the current CPU's `struct CpuInfo`.
+
+Here is the per-CPU state you should be aware of:
+
+ * **Per-CPU kernel stack**.
+Because multiple CPUs can trap into the kernel simultaneously, we need a separate kernel stack for each processor to prevent them from interfering with each other's execution. The array `percpu_kstacks[NCPU][KSTKSIZE]` reserves space for NCPU's worth of kernel stacks.
+
+In Lab 2, you mapped the physical memory that `bootstack` refers to as the BSP's kernel stack just below `KSTACKTOP`. Similarly, in this lab, you will map each CPU's kernel stack into this region with guard pages acting as a buffer between them. CPU 0's stack will still grow down from `KSTACKTOP`; CPU 1's stack will start `KSTKGAP` bytes below the bottom of CPU 0's stack, and so on. `inc/memlayout.h` shows the mapping layout.
+
+ * **Per-CPU TSS and TSS descriptor**.
+A per-CPU task state segment (TSS) is also needed in order to specify where each CPU's kernel stack lives. The TSS for CPU _i_ is stored in `cpus[i].cpu_ts`, and the corresponding TSS descriptor is defined in the GDT entry `gdt[(GD_TSS0 >> 3) + i]`. The global `ts` variable defined in `kern/trap.c` will no longer be useful.
+
+ * **Per-CPU current environment pointer**.
+Since each CPU can run different user process simultaneously, we redefined the symbol `curenv` to refer to `cpus[cpunum()].cpu_env` (or `thiscpu->cpu_env`), which points to the environment _currently_ executing on the _current_ CPU (the CPU on which the code is running).
+
+ * **Per-CPU system registers**.
+All registers, including system registers, are private to a CPU. Therefore, instructions that initialize these registers, such as `lcr3()`, `ltr()`, `lgdt()`, `lidt()`, etc., must be executed once on each CPU. Functions `env_init_percpu()` and `trap_init_percpu()` are defined for this purpose.
+
+
+
+```
+Exercise 3. Modify `mem_init_mp()` (in `kern/pmap.c`) to map per-CPU stacks starting at `KSTACKTOP`, as shown in `inc/memlayout.h`. The size of each stack is `KSTKSIZE` bytes plus `KSTKGAP` bytes of unmapped guard pages. Your code should pass the new check in `check_kern_pgdir()`.
+```
+
+```
+Exercise 4. The code in `trap_init_percpu()` (`kern/trap.c`) initializes the TSS and TSS descriptor for the BSP. It worked in Lab 3, but is incorrect when running on other CPUs. Change the code so that it can work on all CPUs. (Note: your new code should not use the global `ts` variable any more.)
+```
+
+When you finish the above exercises, run JOS in QEMU with 4 CPUs using make qemu CPUS=4 (or make qemu-nox CPUS=4), you should see output like this:
+
+```
+ ...
+ Physical memory: 66556K available, base = 640K, extended = 65532K
+ check_page_alloc() succeeded!
+ check_page() succeeded!
+ check_kern_pgdir() succeeded!
+ check_page_installed_pgdir() succeeded!
+ SMP: CPU 0 found 4 CPU(s)
+ enabled interrupts: 1 2
+ SMP: CPU 1 starting
+ SMP: CPU 2 starting
+ SMP: CPU 3 starting
+```
+
+###### Locking
+
+Our current code spins after initializing the AP in `mp_main()`. Before letting the AP get any further, we need to first address race conditions when multiple CPUs run kernel code simultaneously. The simplest way to achieve this is to use a _big kernel lock_. The big kernel lock is a single global lock that is held whenever an environment enters kernel mode, and is released when the environment returns to user mode. In this model, environments in user mode can run concurrently on any available CPUs, but no more than one environment can run in kernel mode; any other environments that try to enter kernel mode are forced to wait.
+
+`kern/spinlock.h` declares the big kernel lock, namely `kernel_lock`. It also provides `lock_kernel()` and `unlock_kernel()`, shortcuts to acquire and release the lock. You should apply the big kernel lock at four locations:
+
+ * In `i386_init()`, acquire the lock before the BSP wakes up the other CPUs.
+ * In `mp_main()`, acquire the lock after initializing the AP, and then call `sched_yield()` to start running environments on this AP.
+ * In `trap()`, acquire the lock when trapped from user mode. To determine whether a trap happened in user mode or in kernel mode, check the low bits of the `tf_cs`.
+ * In `env_run()`, release the lock _right before_ switching to user mode. Do not do that too early or too late, otherwise you will experience races or deadlocks.
+
+
+```
+Exercise 5. Apply the big kernel lock as described above, by calling `lock_kernel()` and `unlock_kernel()` at the proper locations.
+```
+
+How to test if your locking is correct? You can't at this moment! But you will be able to after you implement the scheduler in the next exercise.
+
+```
+Question
+
+ 2. It seems that using the big kernel lock guarantees that only one CPU can run the kernel code at a time. Why do we still need separate kernel stacks for each CPU? Describe a scenario in which using a shared kernel stack will go wrong, even with the protection of the big kernel lock.
+```
+
+```
+Challenge! The big kernel lock is simple and easy to use. Nevertheless, it eliminates all concurrency in kernel mode. Most modern operating systems use different locks to protect different parts of their shared state, an approach called _fine-grained locking_. Fine-grained locking can increase performance significantly, but is more difficult to implement and error-prone. If you are brave enough, drop the big kernel lock and embrace concurrency in JOS!
+
+It is up to you to decide the locking granularity (the amount of data that a lock protects). As a hint, you may consider using spin locks to ensure exclusive access to these shared components in the JOS kernel:
+
+ * The page allocator.
+ * The console driver.
+ * The scheduler.
+ * The inter-process communication (IPC) state that you will implement in the part C.
+```
+
+
+##### Round-Robin Scheduling
+
+Your next task in this lab is to change the JOS kernel so that it can alternate between multiple environments in "round-robin" fashion. Round-robin scheduling in JOS works as follows:
+
+ * The function `sched_yield()` in the new `kern/sched.c` is responsible for selecting a new environment to run. It searches sequentially through the `envs[]` array in circular fashion, starting just after the previously running environment (or at the beginning of the array if there was no previously running environment), picks the first environment it finds with a status of `ENV_RUNNABLE` (see `inc/env.h`), and calls `env_run()` to jump into that environment.
+ * `sched_yield()` must never run the same environment on two CPUs at the same time. It can tell that an environment is currently running on some CPU (possibly the current CPU) because that environment's status will be `ENV_RUNNING`.
+ * We have implemented a new system call for you, `sys_yield()`, which user environments can call to invoke the kernel's `sched_yield()` function and thereby voluntarily give up the CPU to a different environment.
+
+
+
+```
+Exercise 6. Implement round-robin scheduling in `sched_yield()` as described above. Don't forget to modify `syscall()` to dispatch `sys_yield()`.
+
+Make sure to invoke `sched_yield()` in `mp_main`.
+
+Modify `kern/init.c` to create three (or more!) environments that all run the program `user/yield.c`.
+
+Run make qemu. You should see the environments switch back and forth between each other five times before terminating, like below.
+
+Test also with several CPUS: make qemu CPUS=2.
+
+ ...
+ Hello, I am environment 00001000.
+ Hello, I am environment 00001001.
+ Hello, I am environment 00001002.
+ Back in environment 00001000, iteration 0.
+ Back in environment 00001001, iteration 0.
+ Back in environment 00001002, iteration 0.
+ Back in environment 00001000, iteration 1.
+ Back in environment 00001001, iteration 1.
+ Back in environment 00001002, iteration 1.
+ ...
+
+After the `yield` programs exit, there will be no runnable environment in the system, the scheduler should invoke the JOS kernel monitor. If any of this does not happen, then fix your code before proceeding.
+```
+
+```
+Question
+
+ 3. In your implementation of `env_run()` you should have called `lcr3()`. Before and after the call to `lcr3()`, your code makes references (at least it should) to the variable `e`, the argument to `env_run`. Upon loading the `%cr3` register, the addressing context used by the MMU is instantly changed. But a virtual address (namely `e`) has meaning relative to a given address context--the address context specifies the physical address to which the virtual address maps. Why can the pointer `e` be dereferenced both before and after the addressing switch?
+ 4. Whenever the kernel switches from one environment to another, it must ensure the old environment's registers are saved so they can be restored properly later. Why? Where does this happen?
+```
+
+```
+Challenge! Add a less trivial scheduling policy to the kernel, such as a fixed-priority scheduler that allows each environment to be assigned a priority and ensures that higher-priority environments are always chosen in preference to lower-priority environments. If you're feeling really adventurous, try implementing a Unix-style adjustable-priority scheduler or even a lottery or stride scheduler. (Look up "lottery scheduling" and "stride scheduling" in Google.)
+
+Write a test program or two that verifies that your scheduling algorithm is working correctly (i.e., the right environments get run in the right order). It may be easier to write these test programs once you have implemented `fork()` and IPC in parts B and C of this lab.
+```
+
+```
+Challenge! The JOS kernel currently does not allow applications to use the x86 processor's x87 floating-point unit (FPU), MMX instructions, or Streaming SIMD Extensions (SSE). Extend the `Env` structure to provide a save area for the processor's floating point state, and extend the context switching code to save and restore this state properly when switching from one environment to another. The `FXSAVE` and `FXRSTOR` instructions may be useful, but note that these are not in the old i386 user's manual because they were introduced in more recent processors. Write a user-level test program that does something cool with floating-point.
+```
+
+##### System Calls for Environment Creation
+
+Although your kernel is now capable of running and switching between multiple user-level environments, it is still limited to running environments that the _kernel_ initially set up. You will now implement the necessary JOS system calls to allow _user_ environments to create and start other new user environments.
+
+Unix provides the `fork()` system call as its process creation primitive. Unix `fork()` copies the entire address space of calling process (the parent) to create a new process (the child). The only differences between the two observable from user space are their process IDs and parent process IDs (as returned by `getpid` and `getppid`). In the parent, `fork()` returns the child's process ID, while in the child, `fork()` returns 0. By default, each process gets its own private address space, and neither process's modifications to memory are visible to the other.
+
+You will provide a different, more primitive set of JOS system calls for creating new user-mode environments. With these system calls you will be able to implement a Unix-like `fork()` entirely in user space, in addition to other styles of environment creation. The new system calls you will write for JOS are as follows:
+
+ * `sys_exofork`:
+This system call creates a new environment with an almost blank slate: nothing is mapped in the user portion of its address space, and it is not runnable. The new environment will have the same register state as the parent environment at the time of the `sys_exofork` call. In the parent, `sys_exofork` will return the `envid_t` of the newly created environment (or a negative error code if the environment allocation failed). In the child, however, it will return 0. (Since the child starts out marked as not runnable, `sys_exofork` will not actually return in the child until the parent has explicitly allowed this by marking the child runnable using....)
+ * `sys_env_set_status`:
+Sets the status of a specified environment to `ENV_RUNNABLE` or `ENV_NOT_RUNNABLE`. This system call is typically used to mark a new environment ready to run, once its address space and register state has been fully initialized.
+ * `sys_page_alloc`:
+Allocates a page of physical memory and maps it at a given virtual address in a given environment's address space.
+ * `sys_page_map`:
+Copy a page mapping ( _not_ the contents of a page!) from one environment's address space to another, leaving a memory sharing arrangement in place so that the new and the old mappings both refer to the same page of physical memory.
+ * `sys_page_unmap`:
+Unmap a page mapped at a given virtual address in a given environment.
+
+
+
+For all of the system calls above that accept environment IDs, the JOS kernel supports the convention that a value of 0 means "the current environment." This convention is implemented by `envid2env()` in `kern/env.c`.
+
+We have provided a very primitive implementation of a Unix-like `fork()` in the test program `user/dumbfork.c`. This test program uses the above system calls to create and run a child environment with a copy of its own address space. The two environments then switch back and forth using `sys_yield` as in the previous exercise. The parent exits after 10 iterations, whereas the child exits after 20.
+
+```
+Exercise 7. Implement the system calls described above in `kern/syscall.c` and make sure `syscall()` calls them. You will need to use various functions in `kern/pmap.c` and `kern/env.c`, particularly `envid2env()`. For now, whenever you call `envid2env()`, pass 1 in the `checkperm` parameter. Be sure you check for any invalid system call arguments, returning `-E_INVAL` in that case. Test your JOS kernel with `user/dumbfork` and make sure it works before proceeding.
+```
+
+```
+Challenge! Add the additional system calls necessary to _read_ all of the vital state of an existing environment as well as set it up. Then implement a user mode program that forks off a child environment, runs it for a while (e.g., a few iterations of `sys_yield()`), then takes a complete snapshot or _checkpoint_ of the child environment, runs the child for a while longer, and finally restores the child environment to the state it was in at the checkpoint and continues it from there. Thus, you are effectively "replaying" the execution of the child environment from an intermediate state. Make the child environment perform some interaction with the user using `sys_cgetc()` or `readline()` so that the user can view and mutate its internal state, and verify that with your checkpoint/restart you can give the child environment a case of selective amnesia, making it "forget" everything that happened beyond a certain point.
+```
+
+This completes Part A of the lab; make sure it passes all of the Part A tests when you run make grade, and hand it in using make handin as usual. If you are trying to figure out why a particular test case is failing, run ./grade-lab4 -v, which will show you the output of the kernel builds and QEMU runs for each test, until a test fails. When a test fails, the script will stop, and then you can inspect `jos.out` to see what the kernel actually printed.
+
+#### Part B: Copy-on-Write Fork
+
+As mentioned earlier, Unix provides the `fork()` system call as its primary process creation primitive. The `fork()` system call copies the address space of the calling process (the parent) to create a new process (the child).
+
+xv6 Unix implements `fork()` by copying all data from the parent's pages into new pages allocated for the child. This is essentially the same approach that `dumbfork()` takes. The copying of the parent's address space into the child is the most expensive part of the `fork()` operation.
+
+However, a call to `fork()` is frequently followed almost immediately by a call to `exec()` in the child process, which replaces the child's memory with a new program. This is what the the shell typically does, for example. In this case, the time spent copying the parent's address space is largely wasted, because the child process will use very little of its memory before calling `exec()`.
+
+For this reason, later versions of Unix took advantage of virtual memory hardware to allow the parent and child to _share_ the memory mapped into their respective address spaces until one of the processes actually modifies it. This technique is known as _copy-on-write_. To do this, on `fork()` the kernel would copy the address space _mappings_ from the parent to the child instead of the contents of the mapped pages, and at the same time mark the now-shared pages read-only. When one of the two processes tries to write to one of these shared pages, the process takes a page fault. At this point, the Unix kernel realizes that the page was really a "virtual" or "copy-on-write" copy, and so it makes a new, private, writable copy of the page for the faulting process. In this way, the contents of individual pages aren't actually copied until they are actually written to. This optimization makes a `fork()` followed by an `exec()` in the child much cheaper: the child will probably only need to copy one page (the current page of its stack) before it calls `exec()`.
+
+In the next piece of this lab, you will implement a "proper" Unix-like `fork()` with copy-on-write, as a user space library routine. Implementing `fork()` and copy-on-write support in user space has the benefit that the kernel remains much simpler and thus more likely to be correct. It also lets individual user-mode programs define their own semantics for `fork()`. A program that wants a slightly different implementation (for example, the expensive always-copy version like `dumbfork()`, or one in which the parent and child actually share memory afterward) can easily provide its own.
+
+##### User-level page fault handling
+
+A user-level copy-on-write `fork()` needs to know about page faults on write-protected pages, so that's what you'll implement first. Copy-on-write is only one of many possible uses for user-level page fault handling.
+
+It's common to set up an address space so that page faults indicate when some action needs to take place. For example, most Unix kernels initially map only a single page in a new process's stack region, and allocate and map additional stack pages later "on demand" as the process's stack consumption increases and causes page faults on stack addresses that are not yet mapped. A typical Unix kernel must keep track of what action to take when a page fault occurs in each region of a process's space. For example, a fault in the stack region will typically allocate and map new page of physical memory. A fault in the program's BSS region will typically allocate a new page, fill it with zeroes, and map it. In systems with demand-paged executables, a fault in the text region will read the corresponding page of the binary off of disk and then map it.
+
+This is a lot of information for the kernel to keep track of. Instead of taking the traditional Unix approach, you will decide what to do about each page fault in user space, where bugs are less damaging. This design has the added benefit of allowing programs great flexibility in defining their memory regions; you'll use user-level page fault handling later for mapping and accessing files on a disk-based file system.
+
+###### Setting the Page Fault Handler
+
+In order to handle its own page faults, a user environment will need to register a _page fault handler entrypoint_ with the JOS kernel. The user environment registers its page fault entrypoint via the new `sys_env_set_pgfault_upcall` system call. We have added a new member to the `Env` structure, `env_pgfault_upcall`, to record this information.
+
+```
+Exercise 8. Implement the `sys_env_set_pgfault_upcall` system call. Be sure to enable permission checking when looking up the environment ID of the target environment, since this is a "dangerous" system call.
+```
+
+###### Normal and Exception Stacks in User Environments
+
+During normal execution, a user environment in JOS will run on the _normal_ user stack: its `ESP` register starts out pointing at `USTACKTOP`, and the stack data it pushes resides on the page between `USTACKTOP-PGSIZE` and `USTACKTOP-1` inclusive. When a page fault occurs in user mode, however, the kernel will restart the user environment running a designated user-level page fault handler on a different stack, namely the _user exception_ stack. In essence, we will make the JOS kernel implement automatic "stack switching" on behalf of the user environment, in much the same way that the x86 _processor_ already implements stack switching on behalf of JOS when transferring from user mode to kernel mode!
+
+The JOS user exception stack is also one page in size, and its top is defined to be at virtual address `UXSTACKTOP`, so the valid bytes of the user exception stack are from `UXSTACKTOP-PGSIZE` through `UXSTACKTOP-1` inclusive. While running on this exception stack, the user-level page fault handler can use JOS's regular system calls to map new pages or adjust mappings so as to fix whatever problem originally caused the page fault. Then the user-level page fault handler returns, via an assembly language stub, to the faulting code on the original stack.
+
+Each user environment that wants to support user-level page fault handling will need to allocate memory for its own exception stack, using the `sys_page_alloc()` system call introduced in part A.
+
+###### Invoking the User Page Fault Handler
+
+You will now need to change the page fault handling code in `kern/trap.c` to handle page faults from user mode as follows. We will call the state of the user environment at the time of the fault the _trap-time_ state.
+
+If there is no page fault handler registered, the JOS kernel destroys the user environment with a message as before. Otherwise, the kernel sets up a trap frame on the exception stack that looks like a `struct UTrapframe` from `inc/trap.h`:
+
+```
+ <-- UXSTACKTOP
+ trap-time esp
+ trap-time eflags
+ trap-time eip
+ trap-time eax start of struct PushRegs
+ trap-time ecx
+ trap-time edx
+ trap-time ebx
+ trap-time esp
+ trap-time ebp
+ trap-time esi
+ trap-time edi end of struct PushRegs
+ tf_err (error code)
+ fault_va <-- %esp when handler is run
+
+```
+
+The kernel then arranges for the user environment to resume execution with the page fault handler running on the exception stack with this stack frame; you must figure out how to make this happen. The `fault_va` is the virtual address that caused the page fault.
+
+If the user environment is _already_ running on the user exception stack when an exception occurs, then the page fault handler itself has faulted. In this case, you should start the new stack frame just under the current `tf->tf_esp` rather than at `UXSTACKTOP`. You should first push an empty 32-bit word, then a `struct UTrapframe`.
+
+To test whether `tf->tf_esp` is already on the user exception stack, check whether it is in the range between `UXSTACKTOP-PGSIZE` and `UXSTACKTOP-1`, inclusive.
+
+```
+Exercise 9. Implement the code in `page_fault_handler` in `kern/trap.c` required to dispatch page faults to the user-mode handler. Be sure to take appropriate precautions when writing into the exception stack. (What happens if the user environment runs out of space on the exception stack?)
+```
+
+###### User-mode Page Fault Entrypoint
+
+Next, you need to implement the assembly routine that will take care of calling the C page fault handler and resume execution at the original faulting instruction. This assembly routine is the handler that will be registered with the kernel using `sys_env_set_pgfault_upcall()`.
+
+```
+Exercise 10. Implement the `_pgfault_upcall` routine in `lib/pfentry.S`. The interesting part is returning to the original point in the user code that caused the page fault. You'll return directly there, without going back through the kernel. The hard part is simultaneously switching stacks and re-loading the EIP.
+```
+
+Finally, you need to implement the C user library side of the user-level page fault handling mechanism.
+
+```
+Exercise 11. Finish `set_pgfault_handler()` in `lib/pgfault.c`.
+```
+
+###### Testing
+
+Run `user/faultread` (make run-faultread). You should see:
+
+```
+ ...
+ [00000000] new env 00001000
+ [00001000] user fault va 00000000 ip 0080003a
+ TRAP frame ...
+ [00001000] free env 00001000
+```
+
+Run `user/faultdie`. You should see:
+
+```
+ ...
+ [00000000] new env 00001000
+ i faulted at va deadbeef, err 6
+ [00001000] exiting gracefully
+ [00001000] free env 00001000
+```
+
+Run `user/faultalloc`. You should see:
+
+```
+ ...
+ [00000000] new env 00001000
+ fault deadbeef
+ this string was faulted in at deadbeef
+ fault cafebffe
+ fault cafec000
+ this string was faulted in at cafebffe
+ [00001000] exiting gracefully
+ [00001000] free env 00001000
+```
+
+If you see only the first "this string" line, it means you are not handling recursive page faults properly.
+
+Run `user/faultallocbad`. You should see:
+
+```
+ ...
+ [00000000] new env 00001000
+ [00001000] user_mem_check assertion failure for va deadbeef
+ [00001000] free env 00001000
+```
+
+Make sure you understand why `user/faultalloc` and `user/faultallocbad` behave differently.
+
+```
+Challenge! Extend your kernel so that not only page faults, but _all_ types of processor exceptions that code running in user space can generate, can be redirected to a user-mode exception handler. Write user-mode test programs to test user-mode handling of various exceptions such as divide-by-zero, general protection fault, and illegal opcode.
+```
+
+##### Implementing Copy-on-Write Fork
+
+You now have the kernel facilities to implement copy-on-write `fork()` entirely in user space.
+
+We have provided a skeleton for your `fork()` in `lib/fork.c`. Like `dumbfork()`, `fork()` should create a new environment, then scan through the parent environment's entire address space and set up corresponding page mappings in the child. The key difference is that, while `dumbfork()` copied _pages_ , `fork()` will initially only copy page _mappings_. `fork()` will copy each page only when one of the environments tries to write it.
+
+The basic control flow for `fork()` is as follows:
+
+ 1. The parent installs `pgfault()` as the C-level page fault handler, using the `set_pgfault_handler()` function you implemented above.
+
+ 2. The parent calls `sys_exofork()` to create a child environment.
+
+ 3. For each writable or copy-on-write page in its address space below UTOP, the parent calls `duppage`, which should map the page copy-on-write into the address space of the child and then _remap_ the page copy-on-write in its own address space. [ Note: The ordering here (i.e., marking a page as COW in the child before marking it in the parent) actually matters! Can you see why? Try to think of a specific case where reversing the order could cause trouble. ] `duppage` sets both PTEs so that the page is not writeable, and to contain `PTE_COW` in the "avail" field to distinguish copy-on-write pages from genuine read-only pages.
+
+The exception stack is _not_ remapped this way, however. Instead you need to allocate a fresh page in the child for the exception stack. Since the page fault handler will be doing the actual copying and the page fault handler runs on the exception stack, the exception stack cannot be made copy-on-write: who would copy it?
+
+`fork()` also needs to handle pages that are present, but not writable or copy-on-write.
+
+ 4. The parent sets the user page fault entrypoint for the child to look like its own.
+
+ 5. The child is now ready to run, so the parent marks it runnable.
+
+
+
+
+Each time one of the environments writes a copy-on-write page that it hasn't yet written, it will take a page fault. Here's the control flow for the user page fault handler:
+
+ 1. The kernel propagates the page fault to `_pgfault_upcall`, which calls `fork()`'s `pgfault()` handler.
+ 2. `pgfault()` checks that the fault is a write (check for `FEC_WR` in the error code) and that the PTE for the page is marked `PTE_COW`. If not, panic.
+ 3. `pgfault()` allocates a new page mapped at a temporary location and copies the contents of the faulting page into it. Then the fault handler maps the new page at the appropriate address with read/write permissions, in place of the old read-only mapping.
+
+
+
+The user-level `lib/fork.c` code must consult the environment's page tables for several of the operations above (e.g., that the PTE for a page is marked `PTE_COW`). The kernel maps the environment's page tables at `UVPT` exactly for this purpose. It uses a [clever mapping trick][1] to make it to make it easy to lookup PTEs for user code. `lib/entry.S` sets up `uvpt` and `uvpd` so that you can easily lookup page-table information in `lib/fork.c`.
+
+``````
+Exercise 12. Implement `fork`, `duppage` and `pgfault` in `lib/fork.c`.
+
+Test your code with the `forktree` program. It should produce the following messages, with interspersed 'new env', 'free env', and 'exiting gracefully' messages. The messages may not appear in this order, and the environment IDs may be different.
+
+ 1000: I am ''
+ 1001: I am '0'
+ 2000: I am '00'
+ 2001: I am '000'
+ 1002: I am '1'
+ 3000: I am '11'
+ 3001: I am '10'
+ 4000: I am '100'
+ 1003: I am '01'
+ 5000: I am '010'
+ 4001: I am '011'
+ 2002: I am '110'
+ 1004: I am '001'
+ 1005: I am '111'
+ 1006: I am '101'
+```
+
+```
+Challenge! Implement a shared-memory `fork()` called `sfork()`. This version should have the parent and child _share_ all their memory pages (so writes in one environment appear in the other) except for pages in the stack area, which should be treated in the usual copy-on-write manner. Modify `user/forktree.c` to use `sfork()` instead of regular `fork()`. Also, once you have finished implementing IPC in part C, use your `sfork()` to run `user/pingpongs`. You will have to find a new way to provide the functionality of the global `thisenv` pointer.
+```
+
+```
+Challenge! Your implementation of `fork` makes a huge number of system calls. On the x86, switching into the kernel using interrupts has non-trivial cost. Augment the system call interface so that it is possible to send a batch of system calls at once. Then change `fork` to use this interface.
+
+How much faster is your new `fork`?
+
+You can answer this (roughly) by using analytical arguments to estimate how much of an improvement batching system calls will make to the performance of your `fork`: How expensive is an `int 0x30` instruction? How many times do you execute `int 0x30` in your `fork`? Is accessing the `TSS` stack switch also expensive? And so on...
+
+Alternatively, you can boot your kernel on real hardware and _really_ benchmark your code. See the `RDTSC` (read time-stamp counter) instruction, defined in the IA32 manual, which counts the number of clock cycles that have elapsed since the last processor reset. QEMU doesn't emulate this instruction faithfully (it can either count the number of virtual instructions executed or use the host TSC, neither of which reflects the number of cycles a real CPU would require).
+```
+
+This ends part B. Make sure you pass all of the Part B tests when you run make grade. As usual, you can hand in your submission with make handin.
+
+#### Part C: Preemptive Multitasking and Inter-Process communication (IPC)
+
+In the final part of lab 4 you will modify the kernel to preempt uncooperative environments and to allow environments to pass messages to each other explicitly.
+
+##### Clock Interrupts and Preemption
+
+Run the `user/spin` test program. This test program forks off a child environment, which simply spins forever in a tight loop once it receives control of the CPU. Neither the parent environment nor the kernel ever regains the CPU. This is obviously not an ideal situation in terms of protecting the system from bugs or malicious code in user-mode environments, because any user-mode environment can bring the whole system to a halt simply by getting into an infinite loop and never giving back the CPU. In order to allow the kernel to _preempt_ a running environment, forcefully retaking control of the CPU from it, we must extend the JOS kernel to support external hardware interrupts from the clock hardware.
+
+###### Interrupt discipline
+
+External interrupts (i.e., device interrupts) are referred to as IRQs. There are 16 possible IRQs, numbered 0 through 15. The mapping from IRQ number to IDT entry is not fixed. `pic_init` in `picirq.c` maps IRQs 0-15 to IDT entries `IRQ_OFFSET` through `IRQ_OFFSET+15`.
+
+In `inc/trap.h`, `IRQ_OFFSET` is defined to be decimal 32. Thus the IDT entries 32-47 correspond to the IRQs 0-15. For example, the clock interrupt is IRQ 0. Thus, IDT[IRQ_OFFSET+0] (i.e., IDT[32]) contains the address of the clock's interrupt handler routine in the kernel. This `IRQ_OFFSET` is chosen so that the device interrupts do not overlap with the processor exceptions, which could obviously cause confusion. (In fact, in the early days of PCs running MS-DOS, the `IRQ_OFFSET` effectively _was_ zero, which indeed caused massive confusion between handling hardware interrupts and handling processor exceptions!)
+
+In JOS, we make a key simplification compared to xv6 Unix. External device interrupts are _always_ disabled when in the kernel (and, like xv6, enabled when in user space). External interrupts are controlled by the `FL_IF` flag bit of the `%eflags` register (see `inc/mmu.h`). When this bit is set, external interrupts are enabled. While the bit can be modified in several ways, because of our simplification, we will handle it solely through the process of saving and restoring `%eflags` register as we enter and leave user mode.
+
+You will have to ensure that the `FL_IF` flag is set in user environments when they run so that when an interrupt arrives, it gets passed through to the processor and handled by your interrupt code. Otherwise, interrupts are _masked_ , or ignored until interrupts are re-enabled. We masked interrupts with the very first instruction of the bootloader, and so far we have never gotten around to re-enabling them.
+
+```
+Exercise 13. Modify `kern/trapentry.S` and `kern/trap.c` to initialize the appropriate entries in the IDT and provide handlers for IRQs 0 through 15. Then modify the code in `env_alloc()` in `kern/env.c` to ensure that user environments are always run with interrupts enabled.
+
+Also uncomment the `sti` instruction in `sched_halt()` so that idle CPUs unmask interrupts.
+
+The processor never pushes an error code when invoking a hardware interrupt handler. You might want to re-read section 9.2 of the [80386 Reference Manual][2], or section 5.8 of the [IA-32 Intel Architecture Software Developer's Manual, Volume 3][3], at this time.
+
+After doing this exercise, if you run your kernel with any test program that runs for a non-trivial length of time (e.g., `spin`), you should see the kernel print trap frames for hardware interrupts. While interrupts are now enabled in the processor, JOS isn't yet handling them, so you should see it misattribute each interrupt to the currently running user environment and destroy it. Eventually it should run out of environments to destroy and drop into the monitor.
+```
+
+###### Handling Clock Interrupts
+
+In the `user/spin` program, after the child environment was first run, it just spun in a loop, and the kernel never got control back. We need to program the hardware to generate clock interrupts periodically, which will force control back to the kernel where we can switch control to a different user environment.
+
+The calls to `lapic_init` and `pic_init` (from `i386_init` in `init.c`), which we have written for you, set up the clock and the interrupt controller to generate interrupts. You now need to write the code to handle these interrupts.
+
+```
+Exercise 14. Modify the kernel's `trap_dispatch()` function so that it calls `sched_yield()` to find and run a different environment whenever a clock interrupt takes place.
+
+You should now be able to get the `user/spin` test to work: the parent environment should fork off the child, `sys_yield()` to it a couple times but in each case regain control of the CPU after one time slice, and finally kill the child environment and terminate gracefully.
+```
+
+This is a great time to do some _regression testing_. Make sure that you haven't broken any earlier part of that lab that used to work (e.g. `forktree`) by enabling interrupts. Also, try running with multiple CPUs using make CPUS=2 _target_. You should also be able to pass `stresssched` now. Run make grade to see for sure. You should now get a total score of 65/80 points on this lab.
+
+##### Inter-Process communication (IPC)
+
+(Technically in JOS this is "inter-environment communication" or "IEC", but everyone else calls it IPC, so we'll use the standard term.)
+
+We've been focusing on the isolation aspects of the operating system, the ways it provides the illusion that each program has a machine all to itself. Another important service of an operating system is to allow programs to communicate with each other when they want to. It can be quite powerful to let programs interact with other programs. The Unix pipe model is the canonical example.
+
+There are many models for interprocess communication. Even today there are still debates about which models are best. We won't get into that debate. Instead, we'll implement a simple IPC mechanism and then try it out.
+
+###### IPC in JOS
+
+You will implement a few additional JOS kernel system calls that collectively provide a simple interprocess communication mechanism. You will implement two system calls, `sys_ipc_recv` and `sys_ipc_try_send`. Then you will implement two library wrappers `ipc_recv` and `ipc_send`.
+
+The "messages" that user environments can send to each other using JOS's IPC mechanism consist of two components: a single 32-bit value, and optionally a single page mapping. Allowing environments to pass page mappings in messages provides an efficient way to transfer more data than will fit into a single 32-bit integer, and also allows environments to set up shared memory arrangements easily.
+
+###### Sending and Receiving Messages
+
+To receive a message, an environment calls `sys_ipc_recv`. This system call de-schedules the current environment and does not run it again until a message has been received. When an environment is waiting to receive a message, _any_ other environment can send it a message - not just a particular environment, and not just environments that have a parent/child arrangement with the receiving environment. In other words, the permission checking that you implemented in Part A will not apply to IPC, because the IPC system calls are carefully designed so as to be "safe": an environment cannot cause another environment to malfunction simply by sending it messages (unless the target environment is also buggy).
+
+To try to send a value, an environment calls `sys_ipc_try_send` with both the receiver's environment id and the value to be sent. If the named environment is actually receiving (it has called `sys_ipc_recv` and not gotten a value yet), then the send delivers the message and returns 0. Otherwise the send returns `-E_IPC_NOT_RECV` to indicate that the target environment is not currently expecting to receive a value.
+
+A library function `ipc_recv` in user space will take care of calling `sys_ipc_recv` and then looking up the information about the received values in the current environment's `struct Env`.
+
+Similarly, a library function `ipc_send` will take care of repeatedly calling `sys_ipc_try_send` until the send succeeds.
+
+###### Transferring Pages
+
+When an environment calls `sys_ipc_recv` with a valid `dstva` parameter (below `UTOP`), the environment is stating that it is willing to receive a page mapping. If the sender sends a page, then that page should be mapped at `dstva` in the receiver's address space. If the receiver already had a page mapped at `dstva`, then that previous page is unmapped.
+
+When an environment calls `sys_ipc_try_send` with a valid `srcva` (below `UTOP`), it means the sender wants to send the page currently mapped at `srcva` to the receiver, with permissions `perm`. After a successful IPC, the sender keeps its original mapping for the page at `srcva` in its address space, but the receiver also obtains a mapping for this same physical page at the `dstva` originally specified by the receiver, in the receiver's address space. As a result this page becomes shared between the sender and receiver.
+
+If either the sender or the receiver does not indicate that a page should be transferred, then no page is transferred. After any IPC the kernel sets the new field `env_ipc_perm` in the receiver's `Env` structure to the permissions of the page received, or zero if no page was received.
+
+###### Implementing IPC
+
+```
+Exercise 15. Implement `sys_ipc_recv` and `sys_ipc_try_send` in `kern/syscall.c`. Read the comments on both before implementing them, since they have to work together. When you call `envid2env` in these routines, you should set the `checkperm` flag to 0, meaning that any environment is allowed to send IPC messages to any other environment, and the kernel does no special permission checking other than verifying that the target envid is valid.
+
+Then implement the `ipc_recv` and `ipc_send` functions in `lib/ipc.c`.
+
+Use the `user/pingpong` and `user/primes` functions to test your IPC mechanism. `user/primes` will generate for each prime number a new environment until JOS runs out of environments. You might find it interesting to read `user/primes.c` to see all the forking and IPC going on behind the scenes.
+```
+
+```
+Challenge! Why does `ipc_send` have to loop? Change the system call interface so it doesn't have to. Make sure you can handle multiple environments trying to send to one environment at the same time.
+```
+
+```
+Challenge! The prime sieve is only one neat use of message passing between a large number of concurrent programs. Read C. A. R. Hoare, ``Communicating Sequential Processes,'' _Communications of the ACM_ 21(8) (August 1978), 666-667, and implement the matrix multiplication example.
+```
+
+```
+Challenge! One of the most impressive examples of the power of message passing is Doug McIlroy's power series calculator, described in [M. Douglas McIlroy, ``Squinting at Power Series,'' _Software--Practice and Experience_ , 20(7) (July 1990), 661-683][4]. Implement his power series calculator and compute the power series for _sin_ ( _x_ + _x_ ^3).
+```
+
+```
+Challenge! Make JOS's IPC mechanism more efficient by applying some of the techniques from Liedtke's paper, [Improving IPC by Kernel Design][5], or any other tricks you may think of. Feel free to modify the kernel's system call API for this purpose, as long as your code is backwards compatible with what our grading scripts expect.
+```
+
+**This ends part C.** Make sure you pass all of the make grade tests and don't forget to write up your answers to the questions and a description of your challenge exercise solution in `answers-lab4.txt`.
+
+Before handing in, use git status and git diff to examine your changes and don't forget to git add answers-lab4.txt. When you're ready, commit your changes with git commit -am 'my solutions to lab 4', then make handin and follow the directions.
+
+--------------------------------------------------------------------------------
+
+via: https://pdos.csail.mit.edu/6.828/2018/labs/lab4/
+
+作者:[csail.mit][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://pdos.csail.mit.edu
+[b]: https://github.com/lujun9972
+[1]: https://pdos.csail.mit.edu/6.828/2018/labs/lab4/uvpt.html
+[2]: https://pdos.csail.mit.edu/6.828/2018/labs/readings/i386/toc.htm
+[3]: https://pdos.csail.mit.edu/6.828/2018/labs/readings/ia32/IA32-3A.pdf
+[4]: https://swtch.com/~rsc/thread/squint.pdf
+[5]: http://dl.acm.org/citation.cfm?id=168633
diff --git a/sources/tech/20181016 Lab 5- File system, Spawn and Shell.md b/sources/tech/20181016 Lab 5- File system, Spawn and Shell.md
new file mode 100644
index 0000000000..e7e623db11
--- /dev/null
+++ b/sources/tech/20181016 Lab 5- File system, Spawn and Shell.md
@@ -0,0 +1,345 @@
+Lab 5: File system, Spawn and Shell
+======
+
+**Due Thursday, November 15, 2018
+**
+
+### Introduction
+
+In this lab, you will implement `spawn`, a library call that loads and runs on-disk executables. You will then flesh out your kernel and library operating system enough to run a shell on the console. These features need a file system, and this lab introduces a simple read/write file system.
+
+#### Getting Started
+
+Use Git to fetch the latest version of the course repository, and then create a local branch called `lab5` based on our lab5 branch, `origin/lab5`:
+
+```
+ athena% cd ~/6.828/lab
+ athena% add git
+ athena% git pull
+ Already up-to-date.
+ athena% git checkout -b lab5 origin/lab5
+ Branch lab5 set up to track remote branch refs/remotes/origin/lab5.
+ Switched to a new branch "lab5"
+ athena% git merge lab4
+ Merge made by recursive.
+ .....
+ athena%
+```
+
+The main new component for this part of the lab is the file system environment, located in the new `fs` directory. Scan through all the files in this directory to get a feel for what all is new. Also, there are some new file system-related source files in the `user` and `lib` directories,
+
+| fs/fs.c | Code that mainipulates the file system's on-disk structure. |
+| fs/bc.c | A simple block cache built on top of our user-level page fault handling facility. |
+| fs/ide.c | Minimal PIO-based (non-interrupt-driven) IDE driver code. |
+| fs/serv.c | The file system server that interacts with client environments using file system IPCs. |
+| lib/fd.c | Code that implements the general UNIX-like file descriptor interface. |
+| lib/file.c | The driver for on-disk file type, implemented as a file system IPC client. |
+| lib/console.c | The driver for console input/output file type. |
+| lib/spawn.c | Code skeleton of the spawn library call. |
+
+You should run the pingpong, primes, and forktree test cases from lab 4 again after merging in the new lab 5 code. You will need to comment out the `ENV_CREATE(fs_fs)` line in `kern/init.c` because `fs/fs.c` tries to do some I/O, which JOS does not allow yet. Similarly, temporarily comment out the call to `close_all()` in `lib/exit.c`; this function calls subroutines that you will implement later in the lab, and therefore will panic if called. If your lab 4 code doesn't contain any bugs, the test cases should run fine. Don't proceed until they work. Don't forget to un-comment these lines when you start Exercise 1.
+
+If they don't work, use git diff lab4 to review all the changes, making sure there isn't any code you wrote for lab4 (or before) missing from lab 5. Make sure that lab 4 still works.
+
+#### Lab Requirements
+
+As before, you will need to do all of the regular exercises described in the lab and _at least one_ challenge problem. Additionally, you will need to write up brief answers to the questions posed in the lab and a short (e.g., one or two paragraph) description of what you did to solve your chosen challenge problem. If you implement more than one challenge problem, you only need to describe one of them in the write-up, though of course you are welcome to do more. Place the write-up in a file called `answers-lab5.txt` in the top level of your `lab5` directory before handing in your work.
+
+### File system preliminaries
+
+The file system you will work with is much simpler than most "real" file systems including that of xv6 UNIX, but it is powerful enough to provide the basic features: creating, reading, writing, and deleting files organized in a hierarchical directory structure.
+
+We are (for the moment anyway) developing only a single-user operating system, which provides protection sufficient to catch bugs but not to protect multiple mutually suspicious users from each other. Our file system therefore does not support the UNIX notions of file ownership or permissions. Our file system also currently does not support hard links, symbolic links, time stamps, or special device files like most UNIX file systems do.
+
+### On-Disk File System Structure
+
+Most UNIX file systems divide available disk space into two main types of regions: _inode_ regions and _data_ regions. UNIX file systems assign one _inode_ to each file in the file system; a file's inode holds critical meta-data about the file such as its `stat` attributes and pointers to its data blocks. The data regions are divided into much larger (typically 8KB or more) _data blocks_ , within which the file system stores file data and directory meta-data. Directory entries contain file names and pointers to inodes; a file is said to be _hard-linked_ if multiple directory entries in the file system refer to that file's inode. Since our file system will not support hard links, we do not need this level of indirection and therefore can make a convenient simplification: our file system will not use inodes at all and instead will simply store all of a file's (or sub-directory's) meta-data within the (one and only) directory entry describing that file.
+
+Both files and directories logically consist of a series of data blocks, which may be scattered throughout the disk much like the pages of an environment's virtual address space can be scattered throughout physical memory. The file system environment hides the details of block layout, presenting interfaces for reading and writing sequences of bytes at arbitrary offsets within files. The file system environment handles all modifications to directories internally as a part of performing actions such as file creation and deletion. Our file system does allow user environments to _read_ directory meta-data directly (e.g., with `read`), which means that user environments can perform directory scanning operations themselves (e.g., to implement the `ls` program) rather than having to rely on additional special calls to the file system. The disadvantage of this approach to directory scanning, and the reason most modern UNIX variants discourage it, is that it makes application programs dependent on the format of directory meta-data, making it difficult to change the file system's internal layout without changing or at least recompiling application programs as well.
+
+#### Sectors and Blocks
+
+Most disks cannot perform reads and writes at byte granularity and instead perform reads and writes in units of _sectors_. In JOS, sectors are 512 bytes each. File systems actually allocate and use disk storage in units of _blocks_. Be wary of the distinction between the two terms: _sector size_ is a property of the disk hardware, whereas _block size_ is an aspect of the operating system using the disk. A file system's block size must be a multiple of the sector size of the underlying disk.
+
+The UNIX xv6 file system uses a block size of 512 bytes, the same as the sector size of the underlying disk. Most modern file systems use a larger block size, however, because storage space has gotten much cheaper and it is more efficient to manage storage at larger granularities. Our file system will use a block size of 4096 bytes, conveniently matching the processor's page size.
+
+#### Superblocks
+
+![Disk layout][1]
+
+File systems typically reserve certain disk blocks at "easy-to-find" locations on the disk (such as the very start or the very end) to hold meta-data describing properties of the file system as a whole, such as the block size, disk size, any meta-data required to find the root directory, the time the file system was last mounted, the time the file system was last checked for errors, and so on. These special blocks are called _superblocks_.
+
+Our file system will have exactly one superblock, which will always be at block 1 on the disk. Its layout is defined by `struct Super` in `inc/fs.h`. Block 0 is typically reserved to hold boot loaders and partition tables, so file systems generally do not use the very first disk block. Many "real" file systems maintain multiple superblocks, replicated throughout several widely-spaced regions of the disk, so that if one of them is corrupted or the disk develops a media error in that region, the other superblocks can still be found and used to access the file system.
+
+#### File Meta-data
+
+![File structure][2]
+The layout of the meta-data describing a file in our file system is described by `struct File` in `inc/fs.h`. This meta-data includes the file's name, size, type (regular file or directory), and pointers to the blocks comprising the file. As mentioned above, we do not have inodes, so this meta-data is stored in a directory entry on disk. Unlike in most "real" file systems, for simplicity we will use this one `File` structure to represent file meta-data as it appears _both on disk and in memory_.
+
+The `f_direct` array in `struct File` contains space to store the block numbers of the first 10 (`NDIRECT`) blocks of the file, which we call the file's _direct_ blocks. For small files up to 10*4096 = 40KB in size, this means that the block numbers of all of the file's blocks will fit directly within the `File` structure itself. For larger files, however, we need a place to hold the rest of the file's block numbers. For any file greater than 40KB in size, therefore, we allocate an additional disk block, called the file's _indirect block_ , to hold up to 4096/4 = 1024 additional block numbers. Our file system therefore allows files to be up to 1034 blocks, or just over four megabytes, in size. To support larger files, "real" file systems typically support _double-_ and _triple-indirect blocks_ as well.
+
+#### Directories versus Regular Files
+
+A `File` structure in our file system can represent either a _regular_ file or a directory; these two types of "files" are distinguished by the `type` field in the `File` structure. The file system manages regular files and directory-files in exactly the same way, except that it does not interpret the contents of the data blocks associated with regular files at all, whereas the file system interprets the contents of a directory-file as a series of `File` structures describing the files and subdirectories within the directory.
+
+The superblock in our file system contains a `File` structure (the `root` field in `struct Super`) that holds the meta-data for the file system's root directory. The contents of this directory-file is a sequence of `File` structures describing the files and directories located within the root directory of the file system. Any subdirectories in the root directory may in turn contain more `File` structures representing sub-subdirectories, and so on.
+
+### The File System
+
+The goal for this lab is not to have you implement the entire file system, but for you to implement only certain key components. In particular, you will be responsible for reading blocks into the block cache and flushing them back to disk; allocating disk blocks; mapping file offsets to disk blocks; and implementing read, write, and open in the IPC interface. Because you will not be implementing all of the file system yourself, it is very important that you familiarize yourself with the provided code and the various file system interfaces.
+
+### Disk Access
+
+The file system environment in our operating system needs to be able to access the disk, but we have not yet implemented any disk access functionality in our kernel. Instead of taking the conventional "monolithic" operating system strategy of adding an IDE disk driver to the kernel along with the necessary system calls to allow the file system to access it, we instead implement the IDE disk driver as part of the user-level file system environment. We will still need to modify the kernel slightly, in order to set things up so that the file system environment has the privileges it needs to implement disk access itself.
+
+It is easy to implement disk access in user space this way as long as we rely on polling, "programmed I/O" (PIO)-based disk access and do not use disk interrupts. It is possible to implement interrupt-driven device drivers in user mode as well (the L3 and L4 kernels do this, for example), but it is more difficult since the kernel must field device interrupts and dispatch them to the correct user-mode environment.
+
+The x86 processor uses the IOPL bits in the EFLAGS register to determine whether protected-mode code is allowed to perform special device I/O instructions such as the IN and OUT instructions. Since all of the IDE disk registers we need to access are located in the x86's I/O space rather than being memory-mapped, giving "I/O privilege" to the file system environment is the only thing we need to do in order to allow the file system to access these registers. In effect, the IOPL bits in the EFLAGS register provides the kernel with a simple "all-or-nothing" method of controlling whether user-mode code can access I/O space. In our case, we want the file system environment to be able to access I/O space, but we do not want any other environments to be able to access I/O space at all.
+
+```
+Exercise 1. `i386_init` identifies the file system environment by passing the type `ENV_TYPE_FS` to your environment creation function, `env_create`. Modify `env_create` in `env.c`, so that it gives the file system environment I/O privilege, but never gives that privilege to any other environment.
+
+Make sure you can start the file environment without causing a General Protection fault. You should pass the "fs i/o" test in make grade.
+```
+
+```
+Question
+
+ 1. Do you have to do anything else to ensure that this I/O privilege setting is saved and restored properly when you subsequently switch from one environment to another? Why?
+```
+
+
+Note that the `GNUmakefile` file in this lab sets up QEMU to use the file `obj/kern/kernel.img` as the image for disk 0 (typically "Drive C" under DOS/Windows) as before, and to use the (new) file `obj/fs/fs.img` as the image for disk 1 ("Drive D"). In this lab our file system should only ever touch disk 1; disk 0 is used only to boot the kernel. If you manage to corrupt either disk image in some way, you can reset both of them to their original, "pristine" versions simply by typing:
+
+```
+ $ rm obj/kern/kernel.img obj/fs/fs.img
+ $ make
+```
+
+or by doing:
+
+```
+ $ make clean
+ $ make
+```
+
+Challenge! Implement interrupt-driven IDE disk access, with or without DMA. You can decide whether to move the device driver into the kernel, keep it in user space along with the file system, or even (if you really want to get into the micro-kernel spirit) move it into a separate environment of its own.
+
+### The Block Cache
+
+In our file system, we will implement a simple "buffer cache" (really just a block cache) with the help of the processor's virtual memory system. The code for the block cache is in `fs/bc.c`.
+
+Our file system will be limited to handling disks of size 3GB or less. We reserve a large, fixed 3GB region of the file system environment's address space, from 0x10000000 (`DISKMAP`) up to 0xD0000000 (`DISKMAP+DISKMAX`), as a "memory mapped" version of the disk. For example, disk block 0 is mapped at virtual address 0x10000000, disk block 1 is mapped at virtual address 0x10001000, and so on. The `diskaddr` function in `fs/bc.c` implements this translation from disk block numbers to virtual addresses (along with some sanity checking).
+
+Since our file system environment has its own virtual address space independent of the virtual address spaces of all other environments in the system, and the only thing the file system environment needs to do is to implement file access, it is reasonable to reserve most of the file system environment's address space in this way. It would be awkward for a real file system implementation on a 32-bit machine to do this since modern disks are larger than 3GB. Such a buffer cache management approach may still be reasonable on a machine with a 64-bit address space.
+
+Of course, it would take a long time to read the entire disk into memory, so instead we'll implement a form of _demand paging_ , wherein we only allocate pages in the disk map region and read the corresponding block from the disk in response to a page fault in this region. This way, we can pretend that the entire disk is in memory.
+
+```
+Exercise 2. Implement the `bc_pgfault` and `flush_block` functions in `fs/bc.c`. `bc_pgfault` is a page fault handler, just like the one your wrote in the previous lab for copy-on-write fork, except that its job is to load pages in from the disk in response to a page fault. When writing this, keep in mind that (1) `addr` may not be aligned to a block boundary and (2) `ide_read` operates in sectors, not blocks.
+
+The `flush_block` function should write a block out to disk _if necessary_. `flush_block` shouldn't do anything if the block isn't even in the block cache (that is, the page isn't mapped) or if it's not dirty. We will use the VM hardware to keep track of whether a disk block has been modified since it was last read from or written to disk. To see whether a block needs writing, we can just look to see if the `PTE_D` "dirty" bit is set in the `uvpt` entry. (The `PTE_D` bit is set by the processor in response to a write to that page; see 5.2.4.3 in [chapter 5][3] of the 386 reference manual.) After writing the block to disk, `flush_block` should clear the `PTE_D` bit using `sys_page_map`.
+
+Use make grade to test your code. Your code should pass "check_bc", "check_super", and "check_bitmap".
+```
+
+`fs_init` function in `fs/fs.c` is a prime example of how to use the block cache. After initializing the block cache, it simply stores pointers into the disk map region in the `super` global variable. After this point, we can simply read from the `super` structure as if they were in memory and our page fault handler will read them from disk as necessary.
+
+```
+Challenge! The block cache has no eviction policy. Once a block gets faulted in to it, it never gets removed and will remain in memory forevermore. Add eviction to the buffer cache. Using the `PTE_A` "accessed" bits in the page tables, which the hardware sets on any access to a page, you can track approximate usage of disk blocks without the need to modify every place in the code that accesses the disk map region. Be careful with dirty blocks.
+```
+
+### The Block Bitmap
+
+After `fs_init` sets the `bitmap` pointer, we can treat `bitmap` as a packed array of bits, one for each block on the disk. See, for example, `block_is_free`, which simply checks whether a given block is marked free in the bitmap.
+
+```
+Exercise 3. Use `free_block` as a model to implement `alloc_block` in `fs/fs.c`, which should find a free disk block in the bitmap, mark it used, and return the number of that block. When you allocate a block, you should immediately flush the changed bitmap block to disk with `flush_block`, to help file system consistency.
+
+Use make grade to test your code. Your code should now pass "alloc_block".
+```
+
+### File Operations
+
+We have provided a variety of functions in `fs/fs.c` to implement the basic facilities you will need to interpret and manage `File` structures, scan and manage the entries of directory-files, and walk the file system from the root to resolve an absolute pathname. Read through _all_ of the code in `fs/fs.c` and make sure you understand what each function does before proceeding.
+
+```
+Exercise 4. Implement `file_block_walk` and `file_get_block`. `file_block_walk` maps from a block offset within a file to the pointer for that block in the `struct File` or the indirect block, very much like what `pgdir_walk` did for page tables. `file_get_block` goes one step further and maps to the actual disk block, allocating a new one if necessary.
+
+Use make grade to test your code. Your code should pass "file_open", "file_get_block", and "file_flush/file_truncated/file rewrite", and "testfile".
+```
+
+`file_block_walk` and `file_get_block` are the workhorses of the file system. For example, `file_read` and `file_write` are little more than the bookkeeping atop `file_get_block` necessary to copy bytes between scattered blocks and a sequential buffer.
+
+```
+Challenge! The file system is likely to be corrupted if it gets interrupted in the middle of an operation (for example, by a crash or a reboot). Implement soft updates or journalling to make the file system crash-resilient and demonstrate some situation where the old file system would get corrupted, but yours doesn't.
+```
+
+### The file system interface
+
+Now that we have the necessary functionality within the file system environment itself, we must make it accessible to other environments that wish to use the file system. Since other environments can't directly call functions in the file system environment, we'll expose access to the file system environment via a _remote procedure call_ , or RPC, abstraction, built atop JOS's IPC mechanism. Graphically, here's what a call to the file system server (say, read) looks like
+
+```
+ Regular env FS env
+ +---------------+ +---------------+
+ | read | | file_read |
+ | (lib/fd.c) | | (fs/fs.c) |
+...|.......|.......|...|.......^.......|...............
+ | v | | | | RPC mechanism
+ | devfile_read | | serve_read |
+ | (lib/file.c) | | (fs/serv.c) |
+ | | | | ^ |
+ | v | | | |
+ | fsipc | | serve |
+ | (lib/file.c) | | (fs/serv.c) |
+ | | | | ^ |
+ | v | | | |
+ | ipc_send | | ipc_recv |
+ | | | | ^ |
+ +-------|-------+ +-------|-------+
+ | |
+ +-------------------+
+
+```
+
+Everything below the dotted line is simply the mechanics of getting a read request from the regular environment to the file system environment. Starting at the beginning, `read` (which we provide) works on any file descriptor and simply dispatches to the appropriate device read function, in this case `devfile_read` (we can have more device types, like pipes). `devfile_read` implements `read` specifically for on-disk files. This and the other `devfile_*` functions in `lib/file.c` implement the client side of the FS operations and all work in roughly the same way, bundling up arguments in a request structure, calling `fsipc` to send the IPC request, and unpacking and returning the results. The `fsipc` function simply handles the common details of sending a request to the server and receiving the reply.
+
+The file system server code can be found in `fs/serv.c`. It loops in the `serve` function, endlessly receiving a request over IPC, dispatching that request to the appropriate handler function, and sending the result back via IPC. In the read example, `serve` will dispatch to `serve_read`, which will take care of the IPC details specific to read requests such as unpacking the request structure and finally call `file_read` to actually perform the file read.
+
+Recall that JOS's IPC mechanism lets an environment send a single 32-bit number and, optionally, share a page. To send a request from the client to the server, we use the 32-bit number for the request type (the file system server RPCs are numbered, just like how syscalls were numbered) and store the arguments to the request in a `union Fsipc` on the page shared via the IPC. On the client side, we always share the page at `fsipcbuf`; on the server side, we map the incoming request page at `fsreq` (`0x0ffff000`).
+
+The server also sends the response back via IPC. We use the 32-bit number for the function's return code. For most RPCs, this is all they return. `FSREQ_READ` and `FSREQ_STAT` also return data, which they simply write to the page that the client sent its request on. There's no need to send this page in the response IPC, since the client shared it with the file system server in the first place. Also, in its response, `FSREQ_OPEN` shares with the client a new "Fd page". We'll return to the file descriptor page shortly.
+
+```
+Exercise 5. Implement `serve_read` in `fs/serv.c`.
+
+`serve_read`'s heavy lifting will be done by the already-implemented `file_read` in `fs/fs.c` (which, in turn, is just a bunch of calls to `file_get_block`). `serve_read` just has to provide the RPC interface for file reading. Look at the comments and code in `serve_set_size` to get a general idea of how the server functions should be structured.
+
+Use make grade to test your code. Your code should pass "serve_open/file_stat/file_close" and "file_read" for a score of 70/150.
+```
+
+```
+Exercise 6. Implement `serve_write` in `fs/serv.c` and `devfile_write` in `lib/file.c`.
+
+Use make grade to test your code. Your code should pass "file_write", "file_read after file_write", "open", and "large file" for a score of 90/150.
+```
+
+### Spawning Processes
+
+We have given you the code for `spawn` (see `lib/spawn.c`) which creates a new environment, loads a program image from the file system into it, and then starts the child environment running this program. The parent process then continues running independently of the child. The `spawn` function effectively acts like a `fork` in UNIX followed by an immediate `exec` in the child process.
+
+We implemented `spawn` rather than a UNIX-style `exec` because `spawn` is easier to implement from user space in "exokernel fashion", without special help from the kernel. Think about what you would have to do in order to implement `exec` in user space, and be sure you understand why it is harder.
+
+```
+Exercise 7. `spawn` relies on the new syscall `sys_env_set_trapframe` to initialize the state of the newly created environment. Implement `sys_env_set_trapframe` in `kern/syscall.c` (don't forget to dispatch the new system call in `syscall()`).
+
+Test your code by running the `user/spawnhello` program from `kern/init.c`, which will attempt to spawn `/hello` from the file system.
+
+Use make grade to test your code.
+```
+
+```
+Challenge! Implement Unix-style `exec`.
+```
+
+```
+Challenge! Implement `mmap`-style memory-mapped files and modify `spawn` to map pages directly from the ELF image when possible.
+```
+
+### Sharing library state across fork and spawn
+
+The UNIX file descriptors are a general notion that also encompasses pipes, console I/O, etc. In JOS, each of these device types has a corresponding `struct Dev`, with pointers to the functions that implement read/write/etc. for that device type. `lib/fd.c` implements the general UNIX-like file descriptor interface on top of this. Each `struct Fd` indicates its device type, and most of the functions in `lib/fd.c` simply dispatch operations to functions in the appropriate `struct Dev`.
+
+`lib/fd.c` also maintains the _file descriptor table_ region in each application environment's address space, starting at `FDTABLE`. This area reserves a page's worth (4KB) of address space for each of the up to `MAXFD` (currently 32) file descriptors the application can have open at once. At any given time, a particular file descriptor table page is mapped if and only if the corresponding file descriptor is in use. Each file descriptor also has an optional "data page" in the region starting at `FILEDATA`, which devices can use if they choose.
+
+We would like to share file descriptor state across `fork` and `spawn`, but file descriptor state is kept in user-space memory. Right now, on `fork`, the memory will be marked copy-on-write, so the state will be duplicated rather than shared. (This means environments won't be able to seek in files they didn't open themselves and that pipes won't work across a fork.) On `spawn`, the memory will be left behind, not copied at all. (Effectively, the spawned environment starts with no open file descriptors.)
+
+We will change `fork` to know that certain regions of memory are used by the "library operating system" and should always be shared. Rather than hard-code a list of regions somewhere, we will set an otherwise-unused bit in the page table entries (just like we did with the `PTE_COW` bit in `fork`).
+
+We have defined a new `PTE_SHARE` bit in `inc/lib.h`. This bit is one of the three PTE bits that are marked "available for software use" in the Intel and AMD manuals. We will establish the convention that if a page table entry has this bit set, the PTE should be copied directly from parent to child in both `fork` and `spawn`. Note that this is different from marking it copy-on-write: as described in the first paragraph, we want to make sure to _share_ updates to the page.
+
+```
+Exercise 8. Change `duppage` in `lib/fork.c` to follow the new convention. If the page table entry has the `PTE_SHARE` bit set, just copy the mapping directly. (You should use `PTE_SYSCALL`, not `0xfff`, to mask out the relevant bits from the page table entry. `0xfff` picks up the accessed and dirty bits as well.)
+
+Likewise, implement `copy_shared_pages` in `lib/spawn.c`. It should loop through all page table entries in the current process (just like `fork` did), copying any page mappings that have the `PTE_SHARE` bit set into the child process.
+```
+
+Use make run-testpteshare to check that your code is behaving properly. You should see lines that say "`fork handles PTE_SHARE right`" and "`spawn handles PTE_SHARE right`".
+
+Use make run-testfdsharing to check that file descriptors are shared properly. You should see lines that say "`read in child succeeded`" and "`read in parent succeeded`".
+
+### The keyboard interface
+
+For the shell to work, we need a way to type at it. QEMU has been displaying output we write to the CGA display and the serial port, but so far we've only taken input while in the kernel monitor. In QEMU, input typed in the graphical window appear as input from the keyboard to JOS, while input typed to the console appear as characters on the serial port. `kern/console.c` already contains the keyboard and serial drivers that have been used by the kernel monitor since lab 1, but now you need to attach these to the rest of the system.
+
+```
+Exercise 9. In your `kern/trap.c`, call `kbd_intr` to handle trap `IRQ_OFFSET+IRQ_KBD` and `serial_intr` to handle trap `IRQ_OFFSET+IRQ_SERIAL`.
+```
+
+We implemented the console input/output file type for you, in `lib/console.c`. `kbd_intr` and `serial_intr` fill a buffer with the recently read input while the console file type drains the buffer (the console file type is used for stdin/stdout by default unless the user redirects them).
+
+Test your code by running make run-testkbd and type a few lines. The system should echo your lines back to you as you finish them. Try typing in both the console and the graphical window, if you have both available.
+
+### The Shell
+
+Run make run-icode or make run-icode-nox. This will run your kernel and start `user/icode`. `icode` execs `init`, which will set up the console as file descriptors 0 and 1 (standard input and standard output). It will then spawn `sh`, the shell. You should be able to run the following commands:
+
+```
+ echo hello world | cat
+ cat lorem |cat
+ cat lorem |num
+ cat lorem |num |num |num |num |num
+ lsfd
+```
+
+Note that the user library routine `cprintf` prints straight to the console, without using the file descriptor code. This is great for debugging but not great for piping into other programs. To print output to a particular file descriptor (for example, 1, standard output), use `fprintf(1, "...", ...)`. `printf("...", ...)` is a short-cut for printing to FD 1. See `user/lsfd.c` for examples.
+
+```
+Exercise 10.
+
+The shell doesn't support I/O redirection. It would be nice to run sh