mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-19 00:30:12 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
7dffa5fd49
@ -0,0 +1,89 @@
|
||||
区块链能如何补充开源
|
||||
======
|
||||
|
||||
> 了解区块链如何成为去中心化的开源补贴模型。
|
||||
|
||||

|
||||
|
||||
《<ruby>[大教堂与集市][1]<rt>The Cathedral and The Bazaar</rt></ruby>》是 20 年前由<ruby>埃里克·史蒂文·雷蒙德<rt>Eric Steven Raymond<rt></ruby>(ESR)撰写的经典开源故事。在这个故事中,ESR 描述了一种新的革命性的软件开发模型,其中复杂的软件项目是在没有(或者很少的)集中管理的情况下构建的。这个新模型就是<ruby>开源<rt>open source</rt></ruby>。
|
||||
|
||||
ESR 的故事比较了两种模式:
|
||||
|
||||
* 经典模型(由“大教堂”所代表),其中软件由一小群人在封闭和受控的环境中通过缓慢而稳定的发布制作而成。
|
||||
* 以及新模式(由“集市”所代表),其中软件是在开放的环境中制作的,个人可以自由参与,但仍然可以产生一个稳定和连贯的系统。
|
||||
|
||||
开源如此成功的一些原因可以追溯到 ESR 所描述的创始原则。尽早发布、经常发布,并接受许多头脑必然比一个更好的事实,让开源项目进入全世界的人才库(很少有公司能够使用闭源模式与之匹敌)。
|
||||
|
||||
在 ESR 对黑客社区的反思分析 20 年后,我们看到开源成为占据主导地位的的模式。它不再仅仅是为了满足开发人员的个人喜好,而是创新发生的地方。甚至是全球[最大][2]软件公司也正在转向这种模式,以便继续占据主导地位。
|
||||
|
||||
### 易货系统
|
||||
|
||||
如果我们仔细研究开源模型在实践中的运作方式,我们就会意识到它是一个封闭系统,只对开源开发者和技术人员开放。影响项目方向的唯一方法是加入开源社区,了解成文和不成文的规则,学习如何贡献、编码标准等,并自己亲力完成。
|
||||
|
||||
这就是集市的运作方式,也是这个易货系统类比的来源。易货系统是一种交换服务和货物以换取其他服务和货物的方法。在市场中(即软件的构建地)这意味着为了获取某些东西,你必须自己也是一个生产者并回馈一些东西——那就是通过交换你的时间和知识来完成任务。集市是开源开发者与其他开源开发者交互并以开源方式生成开源软件的地方。
|
||||
|
||||
易货系统向前迈出了一大步,从自给自足的状态演变而来,而在自给自足的状态下,每个人都必须成为所有行业的杰出人选。使用易货系统的集市(开源模式)允许具有共同兴趣和不同技能的人们收集、协作和创造个人无法自行创造的东西。易货系统简单,没有现代货币系统那么复杂,但也有一些局限性,例如:
|
||||
|
||||
* 缺乏可分性:在没有共同的交换媒介的情况下,不能将较大的不可分割的商品/价值兑换成较小的商品/价值。例如,如果你想在开源项目中进行一些哪怕是小的更改,有时你可能仍需要经历一个高进入门槛。
|
||||
* 存储价值:如果一个项目对贵公司很重要,你可能需要投入大量投资/承诺。但由于它是开源开发者之间的易货系统,因此拥有强大发言权的唯一方法是雇佣许多开源贡献者,但这并非总是可行的。
|
||||
* 转移价值:如果你投资了一个项目(受过培训的员工、雇用开源开发者)并希望将重点转移到另一个项目,却不可能快速转移(你在上一个项目中拥有的)专业知识、声誉和影响力。
|
||||
* 时间脱钩:易货系统没有为延期或提前承诺提供良好的机制。在开源世界中,这意味着用户无法提前或在未来期间以可衡量的方式表达对项目的承诺或兴趣。
|
||||
|
||||
下面,我们将探讨如何使用集市的后门解决这些限制。
|
||||
|
||||
### 货币系统
|
||||
|
||||
人们因为不同的原因勾连于集市上:有些人在那里学习,有些是出于满足开发者个人的喜好,有些人为大型软件工厂工作。因为在集市中拥有发言权的唯一方法是成为开源社区的一份子并加入这个易货系统,为了在开源世界获得信誉,许多大型软件公司雇用这些开发者并以货币方式支付薪酬。这代表可以使用货币系统来影响集市,开源不再只是为了满足开发者个人的喜好,它也占据全球整体软件生产的重要部分,并且有许多人想要施加影响。
|
||||
|
||||
开源设定了开发人员交互的指导原则,并以分布式方式构建一致的系统。它决定了项目的治理方式、软件的构建方式以及其成果如何分发给用户。它是分散的实体共同构建高质量软件的开放共识模型。但是开源模型并没有包括如何补贴开源的部分,无论是直接还是间接地,通过内在或外在动机的赞助,都与集市无关。
|
||||
|
||||
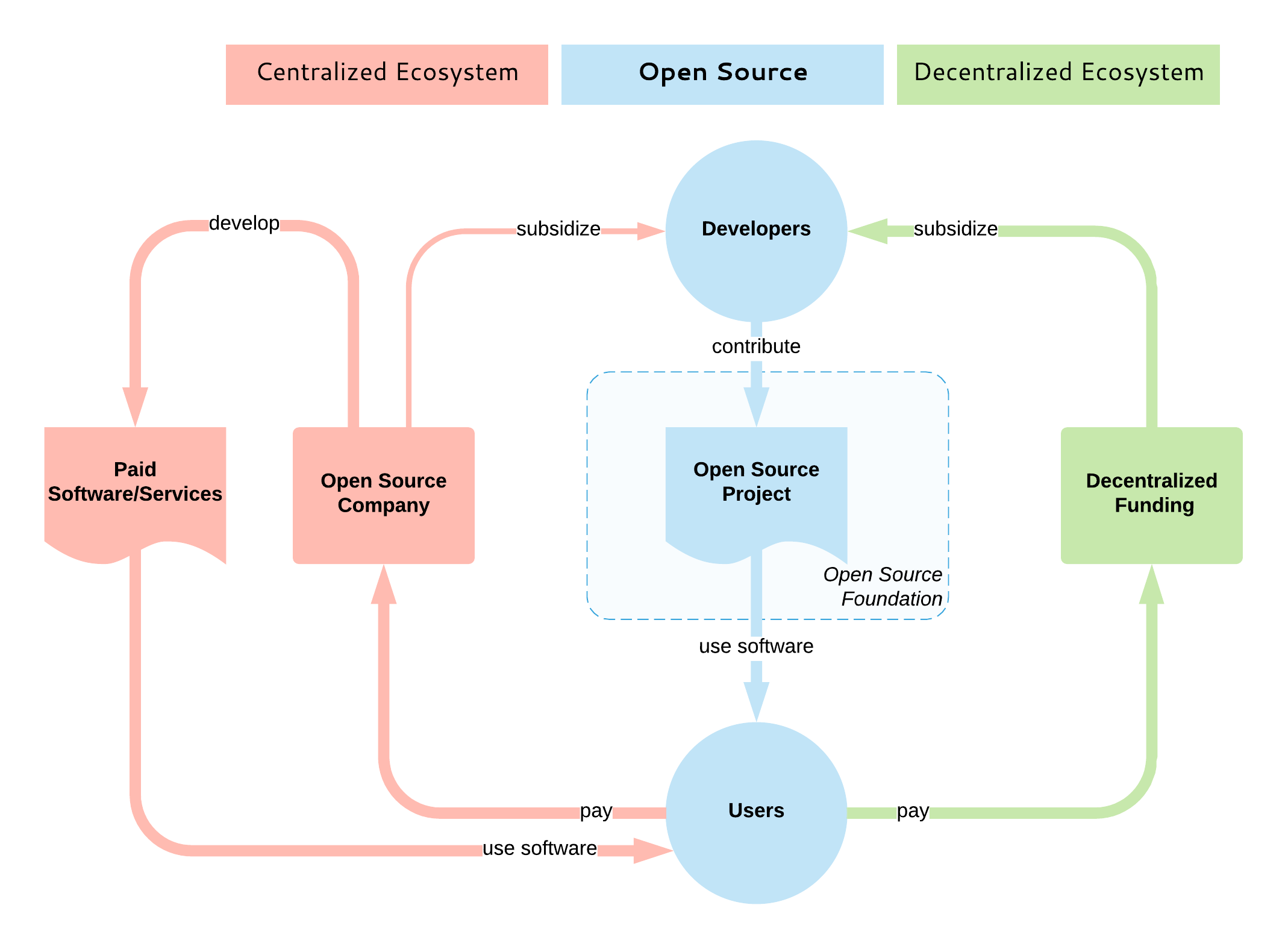
|
||||
|
||||
目前,没有相当于以补贴为目的的去中心化式开源开发模型。大多数开源补贴都是集中式的,通常一家公司通过雇用该项目的主要开源开发者来主导该项目。说实话,这是目前最好的状况,因为它保证了开发人员将长期获得报酬,项目也将继续蓬勃发展。
|
||||
|
||||
项目垄断情景也有例外情况:例如,一些云原生计算基金会(CNCF)项目是由大量的竞争公司开发的。此外,Apache 软件基金会(ASF)旨在通过鼓励不同的贡献者来使他们管理的项目不被单一供应商所主导,但实际上大多数受欢迎的项目仍然是单一供应商项目。
|
||||
|
||||
我们缺少的是一个开放的、去中心化的模式,就像一个没有集中协调和所有权的集市一样,消费者(开源用户)和生产者(开源开发者)在市场力量和开源价值的驱动下相互作用。为了补充开源,这样的模型也必须是开放和去中心化的,这就是为什么我认为区块链技术[最适合][3]的原因。
|
||||
|
||||
旨在补贴开源开发的大多数现有区块链(和非区块链)平台主要针对的是漏洞赏金、小型和零碎的任务。少数人还专注于资助新的开源项目。但并没有多少平台旨在提供维持开源项目持续开发的机制 —— 基本上,这个系统可以模仿开源服务提供商公司或开放核心、基于开源的 SaaS 产品公司的行为:确保开发人员可以获得持续和可预测的激励,并根据激励者(即用户)的优先事项指导项目开发。这种模型将解决上面列出的易货系统的局限性:
|
||||
|
||||
* 允许可分性:如果你想要一些小的修复,你可以支付少量费用,而不是成为项目的开源开发者的全部费用。
|
||||
* 存储价值:你可以在项目中投入大量资金,并确保其持续发展和你的发言权。
|
||||
* 转移价值:在任何时候,你都可以停止投资项目并将资金转移到其他项目中。
|
||||
* 时间脱钩:允许定期定期付款和订阅。
|
||||
|
||||
还有其他好处,纯粹是因为这种基于区块链的系统是透明和去中心化的:根据用户的承诺、开放的路线图承诺、去中心化决策等来量化项目的价值/实用性。
|
||||
|
||||
### 总结
|
||||
|
||||
一方面,我们看到大公司雇用开源开发者并收购开源初创公司甚至基础平台(例如微软收购 GitHub)。许多(甚至大多数)能够长期成功运行的开源项目都集中在单个供应商周围。开源的重要性及其集中化是一个事实。
|
||||
|
||||
另一方面,[维持开源软件][4]的挑战正变得越来越明显,许多人正在更深入地研究这个领域及其基本问题。有一些项目具有很高的知名度和大量的贡献者,但还有许多其他也重要的项目缺乏足够的贡献者和维护者。
|
||||
|
||||
有[许多努力][3]试图通过区块链来解决开源的挑战。这些项目应提高透明度、去中心化和补贴,并在开源用户和开发人员之间建立直接联系。这个领域还很年轻,但是进展很快,随着时间的推移,集市将会有一个加密货币系统。
|
||||
|
||||
如果有足够的时间和足够的技术,去中心化就会发生在很多层面:
|
||||
|
||||
* 互联网是一种去中心化的媒介,它释放了全球分享和获取知识的潜力。
|
||||
* 开源是一种去中心化的协作模式,它释放了全球的创新潜力。
|
||||
* 同样,区块链可以补充开源,成为去中心化的开源补贴模式。
|
||||
|
||||
请在[推特][5]上关注我在这个领域的其他帖子。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/barter-currency-system
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bibryam
|
||||
[1]: http://catb.org/
|
||||
[2]: http://oss.cash/
|
||||
[3]: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
[4]: https://www.youtube.com/watch?v=VS6IpvTWwkQ
|
||||
[5]: http://twitter.com/bibryam
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,174 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing Ansible environments on MacOS with Conda)
|
||||
[#]: via: (https://opensource.com/article/19/8/using-conda-ansible-administration-macos)
|
||||
[#]: author: (James Farrell https://opensource.com/users/jamesf)
|
||||
|
||||
Managing Ansible environments on MacOS with Conda
|
||||
======
|
||||
Conda corrals everything you need for Ansible into a virtual environment
|
||||
and keeps it separate from your other projects.
|
||||
![CICD with gears][1]
|
||||
|
||||
If you are a Python developer using MacOS and involved with Ansible administration, you may want to use the Conda package manager to keep your Ansible work separate from your core OS and other local projects.
|
||||
|
||||
Ansible is based on Python. Conda is not required to make Ansible work on MacOS, but it does make managing Python versions and package dependencies easier. This allows you to use an upgraded Python version on MacOS and keep Python package dependencies separate between your system, Ansible, and other programming projects.
|
||||
|
||||
There are other ways to install Ansible on MacOS. You could use [Homebrew][2], but if you are into Python development (or Ansible development), you might find managing Ansible in a Python virtual environment reduces some confusion. I find this to be simpler; rather than trying to load a Python version and dependencies into the system or in **/usr/local**, Conda helps me corral everything I need for Ansible into a virtual environment and keep it all completely separate from other projects.
|
||||
|
||||
This article focuses on using Conda to manage Ansible as a Python project to keep it clean and separated from other projects. Read on to learn how to install Conda, create a new virtual environment, install Ansible, and test it.
|
||||
|
||||
### Prelude
|
||||
|
||||
Recently, I wanted to learn [Ansible][3], so I needed to figure out the best way to install it.
|
||||
|
||||
I am generally wary of installing things into my daily use workstation. I especially dislike applying manual updates to the vendor's default OS installation (a preference I developed from years of Unix system administration). I really wanted to use Python 3.7, but MacOS packages the older 2.7, and I was not going to install any global Python packages that might interfere with the core MacOS system.
|
||||
|
||||
So, I started my Ansible work using a local Ubuntu 18.04 virtual machine. This provided a real level of safe isolation, but I soon found that managing it was tedious. I set out to see how to get a flexible but isolated Ansible system on native MacOS.
|
||||
|
||||
Since Ansible is based on Python, Conda seemed to be the ideal solution.
|
||||
|
||||
### Installing Conda
|
||||
|
||||
Conda is an open source utility that provides convenient package- and environment-management features. It can help you manage multiple versions of Python, install package dependencies, perform upgrades, and maintain project isolation. If you are manually managing Python virtual environments, Conda will help streamline and manage your work. Surf on over to the [Conda documentation][4] for all the details.
|
||||
|
||||
I chose the [Miniconda][5] Python 3.7 installation for my workstation because I wanted the latest Python version. Regardless of which version you select, you can always install new virtual environments with other versions of Python.
|
||||
|
||||
To install Conda, download the PKG format file, do the usual double-click, and select the "Install for me only" option. The install took about 158MB of space on my system.
|
||||
|
||||
After the installation, bring up a terminal to see what you have. You should see:
|
||||
|
||||
* A new **miniconda3** directory in your **home**
|
||||
* The shell prompt modified to prepend the word "(base)"
|
||||
* **.bash_profile** updated with Conda-specific settings
|
||||
|
||||
|
||||
|
||||
Now that the base is installed, you have your first Python virtual environment. Running the usual Python version check should prove this, and your PATH will point to the new location:
|
||||
|
||||
|
||||
```
|
||||
(base) $ which python
|
||||
/Users/jfarrell/miniconda3/bin/python
|
||||
(base) $ python --version
|
||||
Python 3.7.1
|
||||
```
|
||||
|
||||
Now that Conda is installed, the next step is to set up a virtual environment, then get Ansible installed and running.
|
||||
|
||||
### Creating a virtual environment for Ansible
|
||||
|
||||
I want to keep Ansible separate from my other Python projects, so I created a new virtual environment and switched over to it:
|
||||
|
||||
|
||||
```
|
||||
(base) $ conda create --name ansible-env --clone base
|
||||
(base) $ conda activate ansible-env
|
||||
(ansible-env) $ conda env list
|
||||
```
|
||||
|
||||
The first command clones the Conda base into a new virtual environment called **ansible-env**. The clone brings in the Python 3.7 version and a bunch of default Python modules that you can add to, remove, or upgrade as needed.
|
||||
|
||||
The second command changes the shell context to this new **ansible-env** environment. It sets the proper paths for Python and the modules it contains. Notice that your shell prompt changes after the **conda activate ansible-env** command.
|
||||
|
||||
The third command is not required; it lists what Python modules are installed with their version and other data.
|
||||
|
||||
You can always switch out of a virtual environment and into another with Conda's **activate** command. This will bring you back to the base: **conda activate base**.
|
||||
|
||||
### Installing Ansible
|
||||
|
||||
There are various ways to install Ansible, but using Conda keeps the Ansible version and all desired dependencies packaged in one place. Conda provides the flexibility both to keep everything separated and to add in other new environments as needed (as I'll demonstrate later).
|
||||
|
||||
To install a relatively recent version of Ansible, use:
|
||||
|
||||
|
||||
```
|
||||
(base) $ conda activate ansible-env
|
||||
(ansible-env) $ conda install -c conda-forge ansible
|
||||
```
|
||||
|
||||
Since Ansible is not part of Conda's default channels, the **-c** is used to search and install from an alternate channel. Ansible is now installed into the **ansible-env** virtual environment and is ready to use.
|
||||
|
||||
### Using Ansible
|
||||
|
||||
Now that you have installed a Conda virtual environment, you're ready to use it. First, make sure the node you want to control has your workstation's SSH key installed to the right user account.
|
||||
|
||||
Bring up a new shell and run some basic Ansible commands:
|
||||
|
||||
|
||||
```
|
||||
(base) $ conda activate ansible-env
|
||||
(ansible-env) $ ansible --version
|
||||
ansible 2.8.1
|
||||
config file = None
|
||||
configured module search path = ['/Users/jfarrell/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
|
||||
ansible python module location = /Users/jfarrell/miniconda3/envs/ansibleTest/lib/python3.7/site-packages/ansible
|
||||
executable location = /Users/jfarrell/miniconda3/envs/ansibleTest/bin/ansible
|
||||
python version = 3.7.1 (default, Dec 14 2018, 13:28:58) [Clang 4.0.1 (tags/RELEASE_401/final)]
|
||||
(ansible-env) $ ansible all -m ping -u ansible
|
||||
192.168.99.200 | SUCCESS => {
|
||||
"ansible_facts": {
|
||||
"discovered_interpreter_python": "/usr/bin/python"
|
||||
},
|
||||
"changed": false,
|
||||
"ping": "pong"
|
||||
}
|
||||
```
|
||||
|
||||
Now that Ansible is working, you can pull your playbooks out of source control and start using them from your MacOS workstation.
|
||||
|
||||
### Cloning the new Ansible for Ansible development
|
||||
|
||||
This part is purely optional; it's only needed if you want additional virtual environments to modify Ansible or to safely experiment with questionable Python modules. You can clone your main Ansible environment into a development copy with:
|
||||
|
||||
|
||||
```
|
||||
(ansible-env) $ conda create --name ansible-dev --clone ansible-env
|
||||
(ansible-env) $ conda activte ansible-dev
|
||||
(ansible-dev) $
|
||||
```
|
||||
|
||||
### Gotchas to look out for
|
||||
|
||||
Occasionally you may get into trouble with Conda. You can usually delete a bad environment with:
|
||||
|
||||
|
||||
```
|
||||
$ conda activate base
|
||||
$ conda remove --name ansible-dev --all
|
||||
```
|
||||
|
||||
If you get errors that you cannot resolve, you can usually delete the environment directly by finding it in **~/miniconda3/envs** and removing the entire directory. If the base becomes corrupt, you can remove the entire **~/miniconda3** directory and reinstall it from the PKG file. Just be sure to preserve any desired environments you have in **~/miniconda3/envs**, or use the Conda tools to dump the environment configuration and recreate it later.
|
||||
|
||||
The **sshpass** program is not included on MacOS. It is needed only if your Ansible work requires you to supply Ansible with an SSH login password. You can find the current [sshpass source][6] on SourceForge.
|
||||
|
||||
Finally, the base Conda Python module list may lack some Python modules you need for your work. If you need to install one, the **conda install <package>** command is preferred, but **pip** can be used where needed, and Conda will recognize the install modules.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Ansible is a powerful automation utility that's worth all the effort to learn. Conda is a simple and effective Python virtual environment management tool.
|
||||
|
||||
Keeping software installs separated on your MacOS environment is a prudent approach to maintain stability and sanity with your daily work environment. Conda can be especially helpful to upgrade your Python version, separate Ansible from your other projects, and safely hack on Ansible.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/using-conda-ansible-administration-macos
|
||||
|
||||
作者:[James Farrell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jamesf
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://brew.sh/
|
||||
[3]: https://docs.ansible.com/?extIdCarryOver=true&sc_cid=701f2000001OH6uAAG
|
||||
[4]: https://conda.io/projects/conda/en/latest/index.html
|
||||
[5]: https://docs.conda.io/en/latest/miniconda.html
|
||||
[6]: https://sourceforge.net/projects/sshpass/
|
||||
@ -0,0 +1,197 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Configure SFTP Server with Chroot in Debian 10)
|
||||
[#]: via: (https://www.linuxtechi.com/configure-sftp-chroot-debian10/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
How to Configure SFTP Server with Chroot in Debian 10
|
||||
======
|
||||
|
||||
**SFTP** stands for Secure File Transfer Protocol / SSH File Transfer Protocol, it is one of the most common method which is used to transfer files securely over ssh from our local system to remote server and vice-versa. The main advantage of sftp is that we don’t need to install any additional package except ‘**openssh-server**’, in most of the Linux distributions ‘openssh-server’ package is the part of default installation. Other benefit of sftp is that we can allow user to use sftp only not ssh.
|
||||
|
||||
[![Configure-sftp-debian10][1]][2]
|
||||
|
||||
Recently Debian 10, Code name ‘Buster’ has been released, in this article we will demonstrate how to configure sftp with Chroot ‘Jail’ like environment in Debian 10 System. Here Chroot Jail like environment means that user’s cannot go beyond from their respective home directories or users cannot change directories from their home directories. Following are the lab details:
|
||||
|
||||
* OS = Debian 10
|
||||
* IP Address = 192.168.56.151
|
||||
|
||||
|
||||
|
||||
Let’s jump into SFTP Configuration Steps,
|
||||
|
||||
### Step:1) Create a Group for sftp using groupadd command
|
||||
|
||||
Open the terminal, create a group with a name “**sftp_users**” using below groupadd command,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# groupadd sftp_users
|
||||
```
|
||||
|
||||
### Step:2) Add Users to Group ‘sftp_users’ and set permissions
|
||||
|
||||
In case you want to create new user and want to add that user to ‘sftp_users’ group, then run the following command,
|
||||
|
||||
**Syntax:** # useradd -m -G sftp_users <user_name>
|
||||
|
||||
Let’s suppose user name is ’Jonathan’
|
||||
|
||||
```
|
||||
root@linuxtechi:~# useradd -m -G sftp_users jonathan
|
||||
```
|
||||
|
||||
set the password using following chpasswd command,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# echo "jonathan:<enter_password>" | chpasswd
|
||||
```
|
||||
|
||||
In case you want to add existing users to ‘sftp_users’ group then run beneath usermod command, let’s suppose already existing user name is ‘chris’
|
||||
|
||||
```
|
||||
root@linuxtechi:~# usermod -G sftp_users chris
|
||||
```
|
||||
|
||||
Now set the required permissions on Users,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# chown root /home/jonathan /home/chris/
|
||||
```
|
||||
|
||||
Create an upload folder in both the user’s home directory and set the correct ownership,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# mkdir /home/jonathan/upload
|
||||
root@linuxtechi:~# mkdir /home/chris/upload
|
||||
root@linuxtechi:~# chown jonathan /home/jonathan/upload
|
||||
root@linuxtechi:~# chown chris /home/chris/upload
|
||||
```
|
||||
|
||||
**Note:** User like Jonathan and Chris can upload files and directories to upload folder from their local systems.
|
||||
|
||||
### Step:3) Edit sftp configuration file (/etc/ssh/sshd_config)
|
||||
|
||||
As we have already stated that sftp operations are done over the ssh, so it’s configuration file is “**/etc/ssh/sshd_config**“, Before making any changes I would suggest first take the backup and then edit this file and add the following content,
|
||||
|
||||
```
|
||||
root@linuxtechi:~# cp /etc/ssh/sshd_config /etc/ssh/sshd_config-org
|
||||
root@linuxtechi:~# vim /etc/ssh/sshd_config
|
||||
………
|
||||
#Subsystem sftp /usr/lib/openssh/sftp-server
|
||||
Subsystem sftp internal-sftp
|
||||
|
||||
Match Group sftp_users
|
||||
X11Forwarding no
|
||||
AllowTcpForwarding no
|
||||
ChrootDirectory %h
|
||||
ForceCommand internal-sftp
|
||||
…………
|
||||
```
|
||||
|
||||
Save & exit the file.
|
||||
|
||||
To make above changes into the affect, restart ssh service using following systemctl command
|
||||
|
||||
```
|
||||
root@linuxtechi:~# systemctl restart sshd
|
||||
```
|
||||
|
||||
In above ‘sshd_config’ file we have commented out the line which starts with “Subsystem” and added new entry “Subsystem sftp internal-sftp” and new lines like,
|
||||
|
||||
“**Match Group sftp_users”** –> It means if a user is a part of ‘sftp_users’ group then apply rules which are mentioned below to this entry.
|
||||
|
||||
“**ChrootDierctory %h**” –> It means users can only change directories within their respective home directories, they cannot go beyond their home directories, or in other words we can say users are not permitted to change directories, they will get jai like environment within their directories and can’t access any other user’s and system’s directories.
|
||||
|
||||
“**ForceCommand internal-sftp**” –> It means users are limited to sftp command only.
|
||||
|
||||
### Step:4) Test and Verify sftp
|
||||
|
||||
Login to any other Linux system which is on the same network of your sftp server and then try to ssh sftp server via the users that we have mapped in ‘sftp_users’ group.
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ssh root@linuxtechi
|
||||
root@linuxtechi's password:
|
||||
Write failed: Broken pipe
|
||||
[root@linuxtechi ~]# ssh root@linuxtechi
|
||||
root@linuxtechi's password:
|
||||
Write failed: Broken pipe
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Above confirms that users are not allowed to SSH , now try sftp using following commands,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# sftp root@linuxtechi
|
||||
root@linuxtechi's password:
|
||||
Connected to 192.168.56.151.
|
||||
sftp> ls -l
|
||||
drwxr-xr-x 2 root 1001 4096 Sep 14 07:52 debian10-pkgs
|
||||
-rw-r--r-- 1 root 1001 155 Sep 14 07:52 devops-actions.txt
|
||||
drwxr-xr-x 2 1001 1002 4096 Sep 14 08:29 upload
|
||||
```
|
||||
|
||||
Let’s try to download a file using sftp ‘**get**‘ command
|
||||
|
||||
```
|
||||
sftp> get devops-actions.txt
|
||||
Fetching /devops-actions.txt to devops-actions.txt
|
||||
/devops-actions.txt 100% 155 0.2KB/s 00:00
|
||||
sftp>
|
||||
sftp> cd /etc
|
||||
Couldn't stat remote file: No such file or directory
|
||||
sftp> cd /root
|
||||
Couldn't stat remote file: No such file or directory
|
||||
sftp>
|
||||
```
|
||||
|
||||
Above output confirms that we are able to download file from our sftp server to local machine and apart from this we have also tested that users cannot change directories.
|
||||
|
||||
Let’s try to upload a file under “**upload**” folder,
|
||||
|
||||
```
|
||||
sftp> cd upload/
|
||||
sftp> put metricbeat-7.3.1-amd64.deb
|
||||
Uploading metricbeat-7.3.1-amd64.deb to /upload/metricbeat-7.3.1-amd64.deb
|
||||
metricbeat-7.3.1-amd64.deb 100% 38MB 38.4MB/s 00:01
|
||||
sftp> ls -l
|
||||
-rw-r--r-- 1 1001 1002 40275654 Sep 14 09:18 metricbeat-7.3.1-amd64.deb
|
||||
sftp>
|
||||
```
|
||||
|
||||
This confirms that we have successfully uploaded a file from our local system to sftp server.
|
||||
|
||||
Now test the SFTP server with winscp tool, enter the sftp server ip address along user’s credentials,
|
||||
|
||||
[![Winscp-sftp-debian10][1]][3]
|
||||
|
||||
Click on Login and then try to download and upload files
|
||||
|
||||
[![Download-file-winscp-debian10-sftp][1]][4]
|
||||
|
||||
Now try to upload files in upload folder,
|
||||
|
||||
[![Upload-File-using-winscp-Debian10-sftp][1]][5]
|
||||
|
||||
Above window confirms that uploading is also working fine, that’s all from this article. If these steps help you to configure SFTP server with chroot environment in Debian 10 then please do share your feedback and comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/configure-sftp-chroot-debian10/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Configure-sftp-debian10.jpg
|
||||
[3]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Winscp-sftp-debian10.jpg
|
||||
[4]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Download-file-winscp-debian10-sftp.jpg
|
||||
[5]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Upload-File-using-winscp-Debian10-sftp.jpg
|
||||
@ -1,87 +0,0 @@
|
||||
区块链是如何补充开源的
|
||||
======
|
||||
|
||||

|
||||
|
||||
[大教堂与集市][1]是 20 年前由<ruby>埃里克·史蒂文·雷蒙德<rt>Eric Steven Raymond<rt></ruby>(ESR)撰写的经典开源故事。在这个故事中,ESR 描述了一种新的革命性软件开发模型,其中复杂的软件项目是在没有(或者很少的)集中管理的情况下构建的。这个新模型就是开源。
|
||||
|
||||
ESR 的故事比较了两种模式:
|
||||
|
||||
* 经典模型(由“大教堂”代表),其中软件由一小群人在封闭和受控的环境中通过缓慢而稳定的发布版本制作而成。
|
||||
* 以及新模式(由“集市”代表),其中软件是在开放的环境中制作的,个人可以自由参与,但仍然可以产生一个稳定和连贯的系统。
|
||||
|
||||
开源如此成功的一些原因可以追溯到 ESR 所描述的基础原则。尽早发布、经常发布,并接受许多头脑必然比一个更好的事实,会让开源项目进入全世界的人才库(很少有公司能够使用闭源模式与之匹敌)。
|
||||
|
||||
在 ESR 对黑客社区的反思分析 20 年后,我们看到开源成为占据主导地位的的模式。它不再仅仅是开发人员的个人癖好的模式,而是创新发生的地方。即使是全球[最大][2]软件公司也正在转向这种模式,以便继续占据主导地位。
|
||||
|
||||
### 易货系统
|
||||
|
||||
如果我们仔细研究开源模型在实践中的运作方式,我们就会发现它是一个封闭的系统,专属于开源开发人员和技术人员。影响项目方向的唯一方法是加入开源社区,了解成文和不成文的规则,学习如何贡献,编码标准等,并自己亲力完成。
|
||||
|
||||
这就是集市的运作方式,也是易货系统类比的来源。易货系统是一种交换服务和货物以换取其他服务和货物的方法。在市场中(即软件的构建)这意味着为了获取某些东西,你必须自己也是一个生产者并回馈一些东西——那就是通过交换你的时间和知识来完成任务。集市是开源开发人员与其他开源开发人员交互并以开源方式生成开源软件的地方。
|
||||
|
||||
易货系统向前迈出了一大步,从自给自足的状态演变而来,而在自给自足的状态下,每个人都必须成为所有行业的杰出人选。使用易货系统的集市(开源模式)允许具有共同兴趣和不同技能的人们收集、协作和创造个人无法自己创造的东西。易货系统简单,而不像现代货币系统那么复杂,但也有一些局限性,例如:
|
||||
|
||||
* 缺乏可分性:在没有共同的交换媒介的情况下,不能将较大的不可分割的商品/价值换成较小的商品/价值。例如,如果你想在开源项目中进行一些小的更改,有时你可能仍需要经历一个高进入门槛。
|
||||
* 存储价值:如果项目对贵公司很重要,你可能想要投入大量投资/承诺。但由于它是开源开发人员之间的易货系统,因此拥有强大发言权的唯一方法是雇佣许多开源贡献者,但这并非总是可行的。
|
||||
* 转移价值:如果你投资了一个项目(受过培训的员工、雇用开源开发人员)并希望将重点转移到另一个项目,却不可能快速转移(你在上一个项目中拥有的)专业知识、声誉和影响力。
|
||||
* 时间脱钩:易货系统没有为延期或提前承诺提供良好的机制。在开源世界中,这意味着用户无法提前或在未来期间以可衡量的方式表达对项目的承诺或兴趣。
|
||||
|
||||
下面,我们将探讨如何使用集市的后门解决这些限制。
|
||||
|
||||
### 货币系统
|
||||
|
||||
人们因为不同的原因勾连在集市上:有些人在那里学习,有些是出于满足开发人员个人的喜好,有些人在大型软件工厂工作。因为在集市中拥有发言权的唯一方法是成为开源社区的一份子并加入这个易货系统,为了在开源世界获得信誉,许多大型软件公司雇用这些开发者并以货币方式支付薪酬。这代表使用货币系统来影响集市。开源不再只是为了满足开发人员个人的喜好。它也占据全球整体软件生产的重要部分,并且有许多人想要产生影响。
|
||||
|
||||
开源设置了开发人员交互的指导原则,并以分布式方式构建一致的系统。它决定了项目的治理方式、软件的构建方式以及其成果如何分配给用户。它是分散实体共同构建高质量软件的开放共识模型。但是开源模型并没有包括如何补贴开源。无论是直接还是间接地通过内在或外在动机的赞助,都与集市无关。
|
||||
|
||||

|
||||
|
||||
目前,没有相当于以补贴为目的的去中心化式开源开发模型。大多数开源补贴都是集中式的,通常一家公司通过雇用该项目的主要开源开发人员来支配该项目。说实话,这是目前最好的情况,因为它保证了开发人员将长期获得报酬,项目也将继续蓬勃发展。
|
||||
|
||||
项目垄断情景也有例外情况:例如,一些云原生计算基金会(CNCF)项目是由大量的竞争公司开发的。此外,Apache 软件基金会(ASF)旨在通过鼓励不同的贡献者来使他们的项目不被单一供应商所主导,但实际上大多数受欢迎的项目仍然是单一供应商项目。
|
||||
|
||||
我们缺少的是一个开放的、去中心化的模式,就像一个没有集中协调和所有权的集市一样,消费者(开源用户)和生产者(开源开发者)在市场力量和开源价值的驱动下相互作用。为了补充开源,这样的模型也必须是开放和去中心化的,这就是为什么我认为区块链技术[最适合][3]的原因。
|
||||
|
||||
旨在补贴开源开发的大多数现有区块链(和非区块链)平台主要针对的是错误赏金、小型和零碎的任务。少数人还专注于资助新的开源项目。但并没有很多人的目标是提供维持开源项目持续开发的机制 —— 基本上,这个系统可以模仿开源服务提供商公司或开放核心、基于开源的 SaaS 产品公司的行为:确保开发人员继续进行可预测的激励措施,并根据激励者(即用户)的优先事项指导项目开发。这种模型将解决上面列出的易货系统的局限性:
|
||||
|
||||
* 允许可分性:如果你想要一些小的修复,你可以支付少量费用,而不是成为项目的开源开发人员的全部费用。
|
||||
* 存储价值:你可以在项目中投入大量资金,并确保其持续发展和你的发言权。
|
||||
* 转移价值:在任何时候,你都可以停止投资项目并将资金转移到其他项目中。
|
||||
* 时间脱钩:允许定期定期付款和订阅。
|
||||
|
||||
还有其他好处,纯粹是因为这种基于区块链的系统是透明和去中心化的:根据用户的承诺、开放的路线图承诺、去中心化决策等来量化项目的价值/实用性。
|
||||
|
||||
### 总结
|
||||
|
||||
一方面,我们看到大公司雇用开源开发人员并收购开源初创公司甚至基础平台(例如微软收购 GitHub)。许多(甚至大多数)长期成功的开源项目集中在一个供应商周围。开源的重要性及其集中化是一个事实。
|
||||
|
||||
另一方面,围绕[持续开源][4]软件的挑战正变得越来越明显,许多人正在更深入地研究这个领域及其基础问题。有一些项目具有很高的知名度和大量的贡献者,但还有许多其他一样重要的项目缺乏足够的贡献者和维护者。
|
||||
|
||||
有[许多努力][3]试图通过区块链来解决开源的挑战。这些项目应提高透明度、去中心化和补贴,并在开源用户和开发人员之间建立直接联系。这个领域还很年轻,但是进展很快,随着时间的推移,集市将会有一个加密货币系统。
|
||||
|
||||
如果有足够的时间和足够的技术,去中心化就会发生在很多层面:
|
||||
|
||||
* 互联网是一种去中心化的媒介,它释放了全球分享和获取知识的潜力。
|
||||
* 开源是一种去中心化的协作模式,它释放了全球的创新潜力。
|
||||
* 同样,区块链可以补充开源,成为去中心化的开源补贴模式。
|
||||
|
||||
请在[推特][5]上关注我在这个领域的其他帖子。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/barter-currency-system
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bibryam
|
||||
[1]: http://catb.org/
|
||||
[2]: http://oss.cash/
|
||||
[3]: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
[4]: https://www.youtube.com/watch?v=VS6IpvTWwkQ
|
||||
[5]: http://twitter.com/bibryam
|
||||
@ -0,0 +1,172 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing Ansible environments on MacOS with Conda)
|
||||
[#]: via: (https://opensource.com/article/19/8/using-conda-ansible-administration-macos)
|
||||
[#]: author: (James Farrell https://opensource.com/users/jamesf)
|
||||
|
||||
|
||||
使用 Conda 管理 MacOS 上的 Ansible 环境
|
||||
=====
|
||||
|
||||
Conda 将 Ansible 所需的一切都收集到虚拟环境中并将其与其他项目分开。
|
||||
![CICD with gears][1]
|
||||
|
||||
如果您是一名使用 MacOS 并参与 Ansible 管理的 Python 开发人员,您可能希望使用 Conda 包管理器将 Ansible 的工作内容与核心操作系统和其他本地项目分开。
|
||||
|
||||
Ansible 基于 Python的。让 Ansible 在 MacOS 上工作 Conda 并不是必须要的,但是它确实让您管理 Python 版本和包依赖变得更加容易。这允许您在 MacOS 上使用升级的 Python 版本,并在您的系统中、Ansible 和其他编程项目之间保持 Python 包的依赖性是相互独立的。
|
||||
|
||||
在 MacOS 上安装 Ansible 还有其他方法。您可以使用[Homebrew][2],但是如果您对 Python 开发(或 Ansible 开发)感兴趣,您可能会发现在一个独立 Python 虚拟环境中管理 Ansible 可以减少一些混乱。我觉得这更简单;与其试图将 Python 版本和依赖项加载到系统或在 **/usr/local** 目录中 ,还不如使用 Conda 帮助我将 Ansible 所需的一切都收集到一个虚拟环境中,并将其与其他项目完全分开。
|
||||
|
||||
本文着重于使用 Conda 作为 Python 项目来管理 Ansible ,以保持它的干净并与其他项目分开。请继续阅读,并了解如何安装 Conda、创建新的虚拟环境、安装 Ansible 并对其进行测试。
|
||||
|
||||
### 序幕
|
||||
|
||||
最近,我想学习[Ansible][3],所以我需要找到安装它的最佳方法。
|
||||
|
||||
我通常对在我的日常工作站上安装东西很谨慎。我尤其不喜欢对供应商的默认操作系统安装应用手动更新(这是我多年作为 Unix 系统管理的首选)。我真的很想使用 Python 3.7,但是 MacOS 包是旧的2.7,我不会安装任何可能干扰核心 MacOS 系统的全局 Python 包。
|
||||
|
||||
所以,我使用本地 Ubuntu 18.04 虚拟机上开始了我的 Ansible 工作。这提供了真正意义上的的安全隔离,但我很快发现管理它是非常乏味的。所以我着手研究如何在本机 MacOS 上获得一个灵活但独立的 Ansible 系统。
|
||||
|
||||
由于 Ansible 基于 Python,Conda 似乎是理想的解决方案。
|
||||
|
||||
### 安装 Conda
|
||||
|
||||
Conda 是一个开源软件,它提供方便的包和环境管理功能。它可以帮助您管理多个版本的 Python 、安装软件包依赖关系、执行升级和维护项目隔离。如果您手动管理 Python 虚拟环境,Conda 将有助于简化和管理您的工作。浏览 [Conda 文档][4]可以了解更多细节。
|
||||
|
||||
我选择了 [Miniconda][5] Python 3.7 安装在我的工作站中,因为我想要最新的 Python 版本。无论选择哪个版本,您都可以使用其他版本的 Python 安装新的虚拟环境。
|
||||
|
||||
要安装 Conda,请下载 PKG 格式的文件,进行通常的双击,并选择 “Install for me only” 选项。安装在我的系统上占用了大约158兆的空间。
|
||||
|
||||
安装完成后,调出一个终端来查看您有什么了。您应该看到:
|
||||
|
||||
* 一个 **miniconda3** 目录在您的 **home** 目录中
|
||||
* shell 提示符被修改为 "(base)"
|
||||
* **.bash_profile** 文件被 Conda-specific 设置内容更新
|
||||
|
||||
现在已经安装了基础,您就有了第一个 Python 虚拟环境。运行 Python 版本检查可以证明这一点,您的 PATH 将指向新的位置:
|
||||
|
||||
```
|
||||
(base) $ which python
|
||||
/Users/jfarrell/miniconda3/bin/python
|
||||
(base) $ python --version
|
||||
Python 3.7.1
|
||||
```
|
||||
现在安装了 Conda ,下一步是建立一个虚拟环境,然后安装 Ansible 并运行。
|
||||
|
||||
### 为 Ansible 创建虚拟环境
|
||||
|
||||
|
||||
|
||||
我想将 Ansible 与我的其他 Python 项目分开,所以我创建了一个新的虚拟环境并切换到它:
|
||||
|
||||
```
|
||||
(base) $ conda create --name ansible-env --clone base
|
||||
(base) $ conda activate ansible-env
|
||||
(ansible-env) $ conda env list
|
||||
```
|
||||
|
||||
|
||||
第一个命令将 Conda 库克隆到一个名为 **ansible-env** 的新虚拟环境中。克隆引入了 Python 3.7 版本和一系列默认的 Python 模块,您可以根据需要添加、删除或升级这些模块。
|
||||
|
||||
第二个命令将 shell 上下文更改为这个新的环境。它为 Python 及其包含的模块设置了正确的路径。请注意,在 **conda activate ansible-env** 命令后,您的 shell 提示符会发生变化。
|
||||
|
||||
第三个命令不是必须的;它列出了安装了哪些 Python 模块及其版本和其他数据。
|
||||
|
||||
您可以随时使用 Conda 的 **activate** 命令切换到另一个虚拟环境。这将带您回到基本的: **conda base**。
|
||||
|
||||
### 安装 Ansible
|
||||
|
||||
安装 Ansible 有多种方法,但是使用 Conda 可以将 Ansible 版本和所有需要的依赖项打包在一个地方。Conda 提供了灵活的,既可以将所有内容分开,又可以根据需要添加其他新环境(我将在后面演示)。
|
||||
|
||||
要安装 Ansible 的相对较新版本,请使用:
|
||||
|
||||
|
||||
```
|
||||
(base) $ conda activate ansible-env
|
||||
(ansible-env) $ conda install -c conda-forge ansible
|
||||
```
|
||||
|
||||
由于 Ansible 不是 Conda 默认的一部分,因此**-c**用于从备用通道搜索和安装。Ansible 现已安装到**ansible-env**虚拟环境中,可以使用了。
|
||||
|
||||
|
||||
### 使用 Ansible
|
||||
|
||||
既然您已经安装了 Conda 虚拟环境,就可以使用它了。首先,确保要控制的节点已将工作站的 SSH 密钥安装到正确的用户帐户。
|
||||
|
||||
调出一个新的 shell 并运行一些基本的Ansible命令:
|
||||
|
||||
|
||||
```
|
||||
(base) $ conda activate ansible-env
|
||||
(ansible-env) $ ansible --version
|
||||
ansible 2.8.1
|
||||
config file = None
|
||||
configured module search path = ['/Users/jfarrell/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
|
||||
ansible python module location = /Users/jfarrell/miniconda3/envs/ansibleTest/lib/python3.7/site-packages/ansible
|
||||
executable location = /Users/jfarrell/miniconda3/envs/ansibleTest/bin/ansible
|
||||
python version = 3.7.1 (default, Dec 14 2018, 13:28:58) [Clang 4.0.1 (tags/RELEASE_401/final)]
|
||||
(ansible-env) $ ansible all -m ping -u ansible
|
||||
192.168.99.200 | SUCCESS => {
|
||||
"ansible_facts": {
|
||||
"discovered_interpreter_python": "/usr/bin/python"
|
||||
},
|
||||
"changed": false,
|
||||
"ping": "pong"
|
||||
}
|
||||
```
|
||||
|
||||
现在 Ansible 正在工作了,您可以在控制台中抽身,并从您的 MacOS 工作站中使用它们。
|
||||
|
||||
### 克隆新的 Ansible 进行 Ansible 开发
|
||||
|
||||
这部分完全是可选的;只有当您想要额外的虚拟环境来修改 Ansible 或者安全地使用有问题的 Python 模块时,才需要它。您可以通过以下方式将主 Ansible 环境克隆到开发副本中:
|
||||
|
||||
```
|
||||
(ansible-env) $ conda create --name ansible-dev --clone ansible-env
|
||||
(ansible-env) $ conda activte ansible-dev
|
||||
(ansible-dev) $
|
||||
```
|
||||
|
||||
### 需要注意的问题
|
||||
|
||||
偶尔您可能遇到使用 Conda 的麻烦。您通常可以通过以下方式删除不良环境:
|
||||
|
||||
```
|
||||
$ conda activate base
|
||||
$ conda remove --name ansible-dev --all
|
||||
```
|
||||
如果出现无法解决的错误,通常可以通过在 **~/miniconda3/envs** 中找到环境并删除整个目录来直接删除环境。如果基础损坏了,您可以删除整个 **~/miniconda3**,然后从 PKG 文件中重新安装。只要确保保留 **~/miniconda3/envs** ,或使用 Conda 工具导出环境配置并在以后重新创建即可。
|
||||
|
||||
MacOS 上不包括 **sshpass** 程序。只有当您的 Ansible 工作要求您向 Ansible 提供SSH登录密码时,才需要它。您可以在 SourceForge 上找到当前的[sshpass source][6]。
|
||||
|
||||
|
||||
最后,基础 Conda Python 模块列表可能缺少您工作所需的一些 Python 模块。如果您需要安装一个模块,**conda install <package>** 命令是首选的,但是 **pip** 可以在需要的地方使用,Conda会识别安装模块。
|
||||
|
||||
### 结论
|
||||
|
||||
Ansible 是一个强大的自动化工具,值得我们去学习。Conda是一个简单有效的 Python 虚拟环境管理工具。
|
||||
|
||||
在您的 MacOS 环境中保持软件安装分离是保持日常工作环境的稳定性和健全性的谨慎方法。Conda 尤其有助于升级您的Python 版本,将 Ansible 从其他项目中分离出来,并安全地使用 Ansible。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/using-conda-ansible-administration-macos
|
||||
|
||||
作者:[James Farrell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jamesf
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://brew.sh/
|
||||
[3]: https://docs.ansible.com/?extIdCarryOver=true&sc_cid=701f2000001OH6uAAG
|
||||
[4]: https://conda.io/projects/conda/en/latest/index.html
|
||||
[5]: https://docs.conda.io/en/latest/miniconda.html
|
||||
[6]: https://sourceforge.net/projects/sshpass/
|
||||
@ -7,36 +7,37 @@
|
||||
[#]: via: (https://www.2daygeek.com/linux-get-average-cpu-memory-utilization-from-sar-data-report/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How to Get Average CPU and Memory Usage from SAR Reports Using the Bash Script
|
||||
如何使用 Bash 脚本从 SAR 报告中获取 CPU 和内存的平均使用情况
|
||||
======
|
||||
|
||||
Most Linux administrator monitor system performance with **[SAR report][1]** because it collect performance data for a week.
|
||||
大多数 Linux 管理员使用 **[SAR 报告][1]**监控系统性能,因为它会收集一周的性能数据。
|
||||
|
||||
But you can easily extend this to four weeks by making changes to the “/etc/sysconfig/sysstat” file.
|
||||
|
||||
Also, this period can be extended beyond one month. If the value exceeds 28, the log files are placed in multiple directories, one for each month.
|
||||
但是,你可以通过更改 “/etc/sysconfig/sysstat” 文件轻松地将其延长到四周。
|
||||
|
||||
To extend the coverage period to 28 days, make the following change to the “/etc/sysconfig/sysstat” file.
|
||||
同样,这段时间可以延长一个月以上。如果超过 28,那么日志文件将放在多个目录中,每月一个。
|
||||
|
||||
Edit the sysstat file and change HISTORY=7 to HISTORY=28.
|
||||
要将覆盖期延长至 28 天,请对 “/etc/sysconfig/sysstat” 文件做以下更改。
|
||||
|
||||
In this article we have added three bash scripts that will help you to easily view each data file averages in one place.
|
||||
编辑 sysstat 文件并将 HISTORY=7 更改为 HISTORY=28.。
|
||||
|
||||
We have added many useful shell scripts in the past. If you want to check out that collection, go to the link below.
|
||||
在本文中,我们添加了三个 bash 脚本,它们可以帮助你在一个地方轻松查看每个数据文件的平均值。
|
||||
|
||||
* **[How to automate daily operations using shell script][2]**
|
||||
我们过去加过许多有用的 shell 脚本。如果你想查看它们,请进入下面的链接。
|
||||
|
||||
* **[如何使用 shell 脚本自动化日常操作][2]**
|
||||
|
||||
|
||||
|
||||
These scripts are simple and straightforward. For testing purposes, we have included only two performance metrics, namely CPU and memory.
|
||||
这些脚本简单明了。出于测试目的,我们仅包括两个性能指标,即 CPU 和内存。
|
||||
|
||||
You can modify other performance metrics in the script to suit your needs.
|
||||
你可以修改脚本中的其他性能指标以满足你的需求。
|
||||
|
||||
### Script-1: Bash Script to Get Average CPU Utilization from SAR Reports
|
||||
### 脚本 1:从 SAR 报告中获取平均 CPU 利用率的 Bash 脚本
|
||||
|
||||
This bash script collects the CPU average from each data file and display it on one page.
|
||||
该 bash 脚本从每个数据文件中收集 CPU 平均值并将其显示在一个页面上。
|
||||
|
||||
Since this is a month end, it shows 28 days data for August 2019.
|
||||
由于是月末,它显示了 2019 年 8 月的 28 天数据。
|
||||
|
||||
```
|
||||
# vi /opt/scripts/sar-cpu-avg.sh
|
||||
@ -62,7 +63,7 @@ done
|
||||
echo "+----------------------------------------------------------------------------------+"
|
||||
```
|
||||
|
||||
Once you run the script, you will get an output like the one below.
|
||||
运行脚本后,你将看到如下输出。
|
||||
|
||||
```
|
||||
# sh /opt/scripts/sar-cpu-avg.sh
|
||||
@ -88,11 +89,11 @@ Once you run the script, you will get an output like the one below.
|
||||
+----------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
### Script-2: Bash Script to Get Average Memory Utilization from SAR Reports
|
||||
### 脚本 2:从 SAR 报告中获取平均内存利用率的 Bash 脚本
|
||||
|
||||
This bash script will collect memory averages from each data file and display it on one page.
|
||||
该 bash 脚本从每个数据文件中收集内存平均值并将其显示在一个页面上。
|
||||
|
||||
Since this is a month end, it shows 28 days data for August 2019.
|
||||
由于是月末,它显示了 2019 年 8 月的 28 天数据。
|
||||
|
||||
```
|
||||
# vi /opt/scripts/sar-memory-avg.sh
|
||||
@ -118,7 +119,7 @@ done
|
||||
echo "+-------------------------------------------------------------------------------------------------------------------+"
|
||||
```
|
||||
|
||||
Once you run the script, you will get an output like the one below.
|
||||
运行脚本后,你将看到如下输出。
|
||||
|
||||
```
|
||||
# sh /opt/scripts/sar-memory-avg.sh
|
||||
@ -144,11 +145,11 @@ Once you run the script, you will get an output like the one below.
|
||||
+-------------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
### Script-3: Bash Script to Get Average CPU & Memory Utilization from SAR Reports
|
||||
### 脚本 3:从 SAR 报告中获取 CPU 和内存平均利用率的 Bash 脚本
|
||||
|
||||
This bash script collects the CPU & memory averages from each data file and displays them on a page.
|
||||
该 bash 脚本从每个数据文件中收集 CPU 和内存平均值并将其显示在一个页面上。
|
||||
|
||||
This bash script is slightly different compared to the above script. It shows the average of both (CPU & Memory) in one location, not the other data.
|
||||
该脚本与上面相比稍微不同。它在同一位置同时显示两者(CPU 和内存)平均值,而不是其他数据。
|
||||
|
||||
```
|
||||
# vi /opt/scripts/sar-cpu-mem-avg.sh
|
||||
@ -172,7 +173,7 @@ do
|
||||
done
|
||||
```
|
||||
|
||||
Once you run the script, you will get an output like the one below.
|
||||
运行脚本后,你将看到如下输出。
|
||||
|
||||
```
|
||||
# sh /opt/scripts/sar-cpu-mem-avg.sh
|
||||
@ -221,7 +222,7 @@ via: https://www.2daygeek.com/linux-get-average-cpu-memory-utilization-from-sar-
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user