mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
7cf37b53d5
@ -1,14 +1,14 @@
|
||||
使用IBM Bluemix构建,部署和管理自定义应用程序
|
||||
使用 IBM Bluemix 构建,部署和管理自定义应用程序
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
IBM Bluemix 为开发人员提供了构建,部署和管理自定义应用程序的机会。Bluemix 建立在 Cloud Foundry 上。它支持多种编程语言,包括 IBM 的 OpenWhisk ,还允许开发人员无需资源管理就调用任何函数。
|
||||
IBM Bluemix 为开发人员提供了构建、部署和管理自定义应用程序的机会。Bluemix 建立在 Cloud Foundry 上。它支持多种编程语言,包括 IBM 的 OpenWhisk ,还允许开发人员无需资源管理就调用任何函数。
|
||||
|
||||
Bluemix 是由 IBM 实现的开放标准的基于云的平台。它具有开放的架构,其允许组织能够在云上创建,开发和管理其应用程序。它基于 Cloud Foundry ,因此可以被视为平台即服务(PaaS)。使用 Bluemix,开发人员不必关心云端配置,可以专注于他们的应用程序。 云端配置将由 Bluemix 自动完成。
|
||||
Bluemix 是由 IBM 实现的基于开放标准的云平台。它具有开放的架构,其允许组织能够在云上创建、开发和管理其应用程序。它基于 Cloud Foundry ,因此可以被视为平台即服务(PaaS)。使用 Bluemix,开发人员不必关心云端配置,可以专注于他们的应用程序。 云端配置将由 Bluemix 自动完成。
|
||||
|
||||
Bluemix 还提供了一个仪表板,通过它,开发人员可以创建,管理和查看服务和应用程序,同时还可以监控资源使用情况。
|
||||
|
||||
它支持以下编程语言:
|
||||
|
||||
* Java
|
||||
@ -21,143 +21,132 @@ Bluemix 还提供了一个仪表板,通过它,开发人员可以创建,管
|
||||
|
||||

|
||||
|
||||
图1 IBM Bluemix 概述
|
||||
*图1 IBM Bluemix 概述*
|
||||
|
||||

|
||||
|
||||
图2 IBM Bluemix 体系结构
|
||||
*图2 IBM Bluemix 体系结构*
|
||||
|
||||

|
||||
|
||||
图3 在 IBM Bluemix 中创建组织
|
||||
*图3 在 IBM Bluemix 中创建组织*
|
||||
|
||||
**IBM Bluemix 如何工作**
|
||||
### IBM Bluemix 如何工作
|
||||
|
||||
Bluemix 构建在 IBM 的 SoftLayer IaaS(基础架构即服务)之上。它使用 Cloud Foundry 作为开源 PaaS 平台。一切起于通过 Cloud Foundry 来推送代码,它扮演着整合代码和根据编写应用所使用的编程语言所适配的运行时环境的角色。IBM 服务、第三方服务或社区构建的服务可用于不同的功能。安全连接器可用于连接本地系统到云。
|
||||
Bluemix 构建在 IBM 的 SoftLayer IaaS(基础架构即服务)之上。它使用 Cloud Foundry 作为开源 PaaS 平台。一切起于通过 Cloud Foundry 来推送代码,它扮演着将代码和编写应用所使用的编程语言运行时环境整合起来的角色。IBM 服务、第三方服务或社区构建的服务可用于不同的功能。安全连接器可用于将本地系统连接到云。
|
||||
|
||||
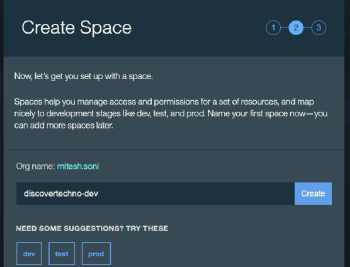
|
||||
|
||||
图4 在 IBM Bluemix 中设置空间
|
||||
*图4 在 IBM Bluemix 中设置空间*
|
||||
|
||||

|
||||
|
||||
图5 应用程序模板
|
||||
*图5 应用程序模板*
|
||||
|
||||
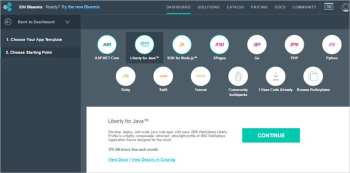
|
||||
|
||||
图6 IBM Bluemix 支持的编程语言
|
||||
*图6 IBM Bluemix 支持的编程语言*
|
||||
|
||||
### 在 Bluemix 中创建应用程序
|
||||
|
||||
**在 Bluemix 中创建应用程序**
|
||||
在本文中,我们将使用 Liberty for Java 的入门包在 IBM Bluemix 中创建一个示例“Hello World”应用程序,只需几个简单的步骤。
|
||||
|
||||
1. 打开 [_https://console.ng.bluemix.net/registration/_][2]
|
||||
1、 打开 [https://console.ng.bluemix.net/registration/][2]
|
||||
|
||||
2. 注册 Bluemix 帐户
|
||||
2、 注册 Bluemix 帐户
|
||||
|
||||
3. 点击邮件中的确认链接完成注册过程
|
||||
3、 点击邮件中的确认链接完成注册过程
|
||||
|
||||
4. 输入您的电子邮件 ID,然后点击 _Continue_ 进行登录
|
||||
4、 输入您的电子邮件 ID,然后点击 Continue 进行登录
|
||||
|
||||
5. 输入密码并点击 _Log in_
|
||||
5、 输入密码并点击 Log in
|
||||
|
||||
6. 进入 _Set up_ -> _Environment_ 设置特定区域中的资源共享
|
||||
6、 进入 Set up -> Environment 设置特定区域中的资源共享
|
||||
|
||||
7. 创建空间方便管理访问控制和在 Bluemix 中回滚操作。 我们可以将空间映射到多个开发阶段,如 dev, test,uat,pre-prod 和 prod
|
||||
7、 创建空间方便管理访问控制和在 Bluemix 中回滚操作。 我们可以将空间映射到多个开发阶段,如 dev, test,uat,pre-prod 和 prod
|
||||
|
||||

|
||||
|
||||
图7 命名应用程序
|
||||
*图7 命名应用程序*
|
||||
|
||||

|
||||
|
||||
图8 了解应用程序何时准备就绪
|
||||
*图8 了解应用程序何时准备就绪*
|
||||
|
||||
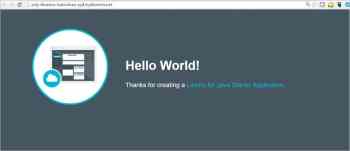
|
||||
|
||||
图9 IBM Bluemix Java 应用程序
|
||||
*图9 IBM Bluemix Java 应用程序*
|
||||
|
||||
8. 完成初始配置后,单击 _I'm ready_ -> _Good to Go_ !
|
||||
8、 完成初始配置后,单击 I'm ready -> Good to Go !
|
||||
|
||||
9. 成功登录后,此时检查 IBM Bluemix 仪表板,特别是 Cloud Foundry Apps(其中2GB可用)和 Virtual Server(其中0个实例可用)的部分
|
||||
9、 成功登录后,此时检查 IBM Bluemix 仪表板,特别是 Cloud Foundry Apps(其中 2GB 可用)和 Virtual Server(其中 0 个实例可用)的部分
|
||||
|
||||
10. 点击 _Create app_,选择应用创建模板。在我们的例子中,我们将使用一个 Web 应用程序
|
||||
10、 点击 Create app,选择应用创建模板。在我们的例子中,我们将使用一个 Web 应用程序
|
||||
|
||||
11. 如何开始?单击 Liberty for Java ,然后查看其描述
|
||||
11、 如何开始?单击 Liberty for Java ,然后查看其描述
|
||||
|
||||
12. 单击 _Continue_
|
||||
12、 单击 Continue
|
||||
|
||||
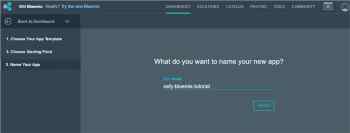
13. 为新应用命名。对于本文,让我们使用 osfy-bluemix-tutorial 命名然后单击 _Finish_
|
||||
13、 为新应用命名。对于本文,让我们使用 osfy-bluemix-tutorial 命名然后单击 Finish
|
||||
|
||||
14. 在 Bluemix 上创建资源和托管应用程序需要等待一些时间。
|
||||
14、 在 Bluemix 上创建资源和托管应用程序需要等待一些时间
|
||||
|
||||
15. 几分钟后,应用程式就会开始运作。注意应用程序的URL。
|
||||
15、 几分钟后,应用程式就会开始运作。注意应用程序的URL
|
||||
|
||||
16. 访问应用程序的URL _http://osfy-bluemix-tutorial.au-syd.mybluemix.net/_, Bingo,我们的第一个在 IBM Bluemix 上的 Java 应用程序成功运行。
|
||||
16、 访问应用程序的URL http://osfy-bluemix-tutorial.au-syd.mybluemix.net/, 不错,我们的第一个在 IBM Bluemix 上的 Java 应用程序成功运行
|
||||
|
||||
17. 为了检查源代码,请单击 _Files_ 并在门户中导航到不同文件和文件夹
|
||||
17、 为了检查源代码,请单击 Files 并在门户中导航到不同文件和文件夹
|
||||
|
||||
18. _Logs_ 部分提供包括从应用程序的创建时起的所有活动日志。
|
||||
18、 Logs 部分提供包括从应用程序的创建时起的所有活动日志。
|
||||
|
||||
19. _Environment Variables_ 部分提供关于 VCAP_Services 的所有环境变量以及用户定义的环境变量的详细信息
|
||||
19、 Environment Variables 部分提供关于 VCAP\_Services 的所有环境变量以及用户定义的环境变量的详细信息
|
||||
|
||||
20. 要检查应用程序的资源消耗,需要到 Liberty for Java 那一部分。
|
||||
20、 要检查应用程序的资源消耗,需要到 Liberty for Java 那一部分。
|
||||
|
||||
21. 默认情况下,每个应用程序的 _Overview_ 部分包含资源,应用程序的运行状况和活动日志的详细信息
|
||||
21、 默认情况下,每个应用程序的 Overview 部分包含资源,应用程序的运行状况和活动日志的详细信息
|
||||
|
||||
22. 打开 Eclipse,转到帮助菜单,然后单击 _Eclipse Marketplace_
|
||||
22、 打开 Eclipse,转到帮助菜单,然后单击 _Eclipse Marketplace_
|
||||
|
||||
23. 查找 _IBM Eclipse tools for Bluemix_ 并单击 _Install_
|
||||
23、 查找 IBM Eclipse tools for Bluemix 并单击 Install
|
||||
|
||||
24. 确认所选的功能并将其安装在 Eclipse 中
|
||||
24、 确认所选的功能并将其安装在 Eclipse 中
|
||||
|
||||
25. 下载应用程序启动器代码。点击 _File Menu_,将它导入到 Eclipse 中,选择 _Import Existing Projects_ -> _Workspace_, 然后开始修改代码
|
||||
25、 下载应用程序启动器代码。点击 File Menu,将它导入到 Eclipse 中,选择 Import Existing Projects -> Workspace, 然后开始修改代码
|
||||
|
||||
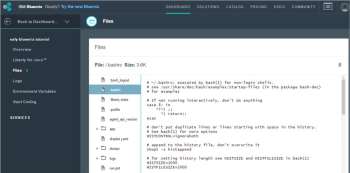
|
||||
|
||||
图10 Java 应用程序源文件
|
||||
*图10 Java 应用程序源文件*
|
||||
|
||||
|
||||
|
||||
图11 Java 应用程序日志
|
||||
*图11 Java 应用程序日志*
|
||||
|
||||

|
||||
|
||||
图12 Java 应用程序 - Liberty for Java
|
||||
*图12 Java 应用程序 - Liberty for Java*
|
||||
|
||||
### 为什么选择 IBM Bluemix?
|
||||
|
||||
**为什么选择 IBM Bluemix?**
|
||||
以下是使用 IBM Bluemix 的一些令人信服的理由:
|
||||
|
||||
* 支持多种语言和平台
|
||||
* 免费试用
|
||||
|
||||
1. 简化的注册过程
|
||||
|
||||
2. 不需要信用卡
|
||||
|
||||
3. 30 天试用期 - 配额 2GB 的运行时,支持 20 个服务,500 个 route
|
||||
|
||||
4. 无限制地访问标准支持
|
||||
|
||||
5. 没有生产使用限制
|
||||
|
||||
* 仅为每个使用的运行时和服务付费
|
||||
* 快速设置 - 从而加快上架时间
|
||||
* 持续交付新功能
|
||||
* 与本地资源的安全集成
|
||||
* 用例
|
||||
|
||||
1. Web 应用程序和移动后端
|
||||
|
||||
2. API 和内部集成
|
||||
|
||||
* DevOps 服务可部署在云上的 SaaS ,并支持持续交付:
|
||||
|
||||
1. Web IDE
|
||||
|
||||
2. SCM
|
||||
|
||||
3. 敏捷规划
|
||||
|
||||
4. 交货管道服务
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -1,38 +1,39 @@
|
||||
使用 Exercism 提升你的编程技巧
|
||||
============================================================
|
||||
|
||||
### 这些练习目前已经支持 33 种编程语言了。
|
||||
> 这些练习目前已经支持 33 种编程语言了。
|
||||
|
||||

|
||||
|
||||
>图片提供: opensource.com
|
||||
|
||||
我们中的很多人有 2017 年的目标,将提高编程能力或学习如何编程放在第一位。虽然我们有许多资源可以访问,但练习独立于特定职业的代码开发的艺术还是需要一些规划。[Exercism.io][1] 就是为此目的而设计的一种资源。
|
||||
我们中的很多人的 2017 年目标,将提高编程能力或学习如何编程放在第一位。虽然我们有许多资源可以访问,但练习独立于特定职业的代码开发的艺术还是需要一些规划。[Exercism.io][1] 就是为此目的而设计的一种资源。
|
||||
|
||||
Exercism 是一个 [开源][2] 项目和服务,通过发现和协作,帮助人们提高他们的编程技能。Exercism 提供了几十种不同编程语言的练习。实践者完成每个练习,并获得反馈,从而可以从他们的同行小组的经验中学习。
|
||||
Exercism 是一个 [开源][2] 的项目和服务,通过发现和协作,帮助人们提高他们的编程技能。Exercism 提供了几十种不同编程语言的练习。实践者完成每个练习,并获得反馈,从而可以从他们的同行小组的经验中学习。
|
||||
|
||||
这里有这么多同行! Exercism 在 2016 年留下了一些令人印象深刻的统计:
|
||||
|
||||
* 有来自201个不同国家的参与者
|
||||
* 有来自 201 个不同国家的参与者
|
||||
* 自 2013 年 6 月以来,29,000 名参与者提交了练习,其中仅在 2016 年就有 15,500 名参加者提交练习
|
||||
* 自 2013 年 6 月以来,15,000 名参与者就练习解决方案提供反馈,其中 2016 年有 5,500 人提供反馈
|
||||
* 每月 50,000 名访客,每周超过 12,000 名访客
|
||||
* 目前练习支持 33 种编程语言,另外 22 种语言在筹备工作中
|
||||
* 目前的练习已经支持 33 种编程语言,另外 22 种语言在筹备工作中
|
||||
|
||||
该项目为所有级别的参与者提供了一系列小小的胜利,使他们能够“即使在低水平也能发展到高度流利”,Exercism 的创始人 [Katrina Owen][3] 这样说到。Exercism 并不旨在教导学员成为一名职业程序员,但它的练习使他们对一种语言及其瑕疵有深刻的了解。这种熟悉性消除了学习者对语言的认知负担(流利),使他们能够专注于更困难的架构和最佳实践(熟练)的问题。
|
||||
该项目为各种级别的参与者提供了一系列小小的挑战,使他们能够“即使在低水平也能发展到高度谙熟”,Exercism 的创始人 [Katrina Owen][3] 这样说到。Exercism 并不旨在教导学员成为一名职业程序员,但它的练习使他们对一种语言及其瑕疵有深刻的了解。这种熟悉性消除了学习者对语言的认知负担(使之更谙熟),使他们能够专注于更困难的架构和最佳实践的问题。
|
||||
|
||||
Exercism 通过一系列练习(还有什么?)来做到这一点。程序员下载[命令行客户端][4],检索第一个练习,添加完成练习的代码,然后提交解决方案。提交解决方案后,程序员可以研究他人的解决方案,并学习到对同一个问题不同的解决方式。更重要的是,每个解决方案都会收到来自其他参与者的反馈。
|
||||
Exercism 通过一系列练习(或者还有别的?)来做到这一点。程序员下载[命令行客户端][4],检索第一个练习,添加完成练习的代码,然后提交解决方案。提交解决方案后,程序员可以研究他人的解决方案,并学习到对同一个问题不同的解决方式。更重要的是,每个解决方案都会收到来自其他参与者的反馈。
|
||||
|
||||
反馈是 Exercism 的超级力量。鼓励所有参与者不仅接收反馈而且提供反馈。根据 Owen 说的,Exercism 的社区成员提供反馈比完成练习学到更多。她说:“这是一个强大的学习经验,你被迫发表内心感受,并检查你的假设、习惯和偏见”。她还指出,反馈可以有多种形式。
|
||||
反馈是 Exercism 的超级力量。鼓励所有参与者不仅接收反馈而且提供反馈。根据 Owen 说的,Exercism 的社区成员提供反馈比完成练习学到更多。她说:“这是一个强大的学习经验,你需要发表内心感受,并检查你的假设、习惯和偏见”。她还指出,反馈可以有多种形式。
|
||||
|
||||
欧文说:“只需进入,观察并问问题”。
|
||||
欧文说:“只需进入,观察并发问”。
|
||||
|
||||
那些刚刚接触编程,甚至只是一种特定语言的人,可以通过质疑假设来提供有价值的反馈,同时通过协作和对话来学习。
|
||||
那些刚刚接触编程,甚至只是接触了一种特定语言的人,可以通过预设好的问题来提供有价值的反馈,同时通过协作和对话来学习。
|
||||
|
||||
除了对新语言的 <ruby>“微课”学习<rt>bite-sized learning</rt></ruby> 之外,Exercism 本身还强烈支持和鼓励项目的新贡献者。在 [SitePoint.com][5] 的一篇文章中,欧文强调:“如果你想为开源贡献代码,你所需要的技能水平只要‘够用’即可。” Exercism 不仅鼓励新的贡献者,它还尽可能地帮助新贡献者发布他们项目中的第一个补丁。到目前为止,有近 1000 人是[ Exercism 项目][6]的贡献者。
|
||||
除了对新语言的 <ruby>“微课”学习<rt>bite-sized learning</rt></ruby> 之外,Exercism 本身还强烈支持和鼓励项目的新贡献者。在 [SitePoint.com][5] 的一篇文章中,欧文强调:“如果你想为开源贡献代码,你所需要的技能水平只要‘够用’即可。” Exercism 不仅鼓励新的贡献者,它还尽可能地帮助新贡献者发布他们项目中的第一个补丁。到目前为止,有近 1000 人成为 [Exercism 项目][6]的贡献者。
|
||||
|
||||
新贡献者会有大量工作让他们忙碌。 Exercism 目前正在审查[其语言轨道的健康状况][7],目的是使所有轨道可持续并避免维护者的倦怠。它还在寻求[捐赠][8]和赞助,聘请设计师提高网站的可用性。
|
||||
新贡献者会有大量工作让他们忙碌。 Exercism 目前正在审查[其语言发展轨迹的健康状况][7],目的是使所有发展轨迹可持续并避免维护者的倦怠。它还在寻求[捐赠][8]和赞助,聘请设计师提高网站的可用性。
|
||||
|
||||
Owen 说:“这些改进对于网站的健康以及为了 Exercism 参与者的发展是有必要的,这些变化还鼓励新贡献者加入并简化了加入的途径。” 她说:“如果我们可以重新设计,产品方面将更加可维护。。。当用户体验一团糟,华丽的代码一点用也没有”。该项目有一个非常活跃的[讨论仓库][9],这里社区成员合作来发现最好的新方法和功能。
|
||||
Owen 说:“这些改进对于网站的健康以及为了 Exercism 参与者的发展是有必要的,这些变化还鼓励新贡献者加入并简化了加入的途径。” 她说:“如果我们可以重新设计,产品方面将更加可维护……当用户体验一团糟时,华丽的代码一点用也没有”。该项目有一个非常活跃的[讨论仓库][9],这里社区成员合作来发现最好的新方法和功能。
|
||||
|
||||
那些想关注项目但还没有参与的人可以关注[邮件列表][10]。
|
||||
|
||||
@ -42,10 +43,12 @@ Owen 说:“这些改进对于网站的健康以及为了 Exercism 参与者
|
||||
|
||||

|
||||
|
||||
VM(Vicky)Brasseur - VM(也称为 Vicky)是技术人员、项目、流程、产品和 p^Hbusinesses 的经理。在她超过 18 年的科技行业从业中,她曾是分析师、程序员、产品经理、软件工程经理和软件工程总监。 目前,她是 Hewlett Packard Enterprise 上游开源开发团队的高级工程经理。 VM 的博客在 anonymoushash.vmbrasseur.com,tweets 在 @vmbrasseur。
|
||||
VM(Vicky)Brasseur - VM(也称为 Vicky)是技术人员、项目、流程、产品和 p\^Hbusinesses 的经理。在她超过 18 年的科技行业从业中,她曾是分析师、程序员、产品经理、软件工程经理和软件工程总监。 目前,她是 Hewlett Packard Enterprise 上游开源开发团队的高级工程经理。 VM 的博客在 anonymoushash.vmbrasseur.com,tweets 在 @vmbrasseur。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/exercism-learning-programming
|
||||
|
||||
作者:[VM (Vicky) Brasseur][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
@ -1,26 +1,24 @@
|
||||
|
||||
What engineers and marketers can learn from each other
|
||||
============================================================
|
||||
工程师和市场营销人员之间能够相互学习什么?
|
||||
============================================================
|
||||
|
||||
### 营销人员觉得工程师在工作中都太严谨了;而工程师则认为营销人员都很懒散。但是他们都错了。
|
||||
> 营销人员觉得工程师在工作中都太严谨了;而工程师则认为营销人员毫无用处。但是他们都错了。
|
||||
|
||||

|
||||
图片来源 :
|
||||
|
||||
opensource.com
|
||||
|
||||
图片来源:opensource.com
|
||||
|
||||
在 B2B 行业从事多年的销售实践过程中,我经常听到工程师对营销人员的各种误解。下面这些是比较常见的:
|
||||
|
||||
* ”搞市场营销真是浪费钱,还不如把更多的资金投入到实际的产品开发中来。“
|
||||
* ”那些营销人员只是一个劲儿往墙上贴各种广告,还祈祷着它们不要掉下来。这么做有啥科学依据啊?“
|
||||
* ”谁愿意去看哪些广告啊?“
|
||||
* ”对待一个营销人员最好的办法就是不订阅,不关注,也不理睬。“
|
||||
* “搞市场营销真是浪费钱,还不如把更多的资金投入到实际的产品开发中来。”
|
||||
* “那些营销人员只是一个劲儿往墙上贴各种广告,还祈祷着它们不要掉下来。这么做有啥科学依据啊?”
|
||||
* “谁愿意去看哪些广告啊?”
|
||||
* “对待一个营销人员最好的办法就是不听,不看,也不理睬。”
|
||||
|
||||
这是我最感兴趣的一点:
|
||||
_“营销人员都很懒散。”_
|
||||
|
||||
_“市场营销无足轻重。”_
|
||||
|
||||
最后一点说的不对,不够全面,懒散实际上是阻碍一个公司发展的巨大绊脚石。
|
||||
最后一点说的不对,而且不仅如此,它实际上是阻碍一个公司创新的巨大绊脚石。
|
||||
|
||||
我来跟大家解释一下原因吧。
|
||||
|
||||
@ -28,27 +26,27 @@ _“营销人员都很懒散。”_
|
||||
|
||||
这些工程师的的评论让我十分的苦恼,因为我从中看到了自己当年的身影。
|
||||
|
||||
你们知道吗?我曾经也跟你们一样是一位自豪的技术极客。我在 Rensselaer Polytechnic 学院的电气工程专业本科毕业后便在美国空军开始了我的职业生涯,而且美国空军在那段时间还发动了军事上的沙漠风暴行动。在那里我主要负责开发并部属一套智能的实时战况分析系统,用于根据各种各样的数据源来构建出战场上的画面。
|
||||
你们知道吗?我曾经也跟你们一样是一位自豪的技术极客。我在 Rensselaer Polytechnic 学院的电气工程专业本科毕业后便在美国空军担任军官开始了我的职业生涯,而且美国空军在那段时间还发动了沙漠风暴行动。在那里我主要负责开发并部属一套智能的实时战况分析系统,用于综合几个的数据源来构建出战场态势。
|
||||
|
||||
在我离开空军之后,我本打算去麻省理工学院攻读博士学位。但是上校强烈建议我去报读这个学校的商学院。“你真的想一辈子待实验室里吗?”他问我。“你想就这么去大学里当个教书匠吗? Jackie ,你在组织管理那些复杂的工作中比较有天赋。我觉得你非常有必要去了解下 MIT 的斯隆商学院。”
|
||||
在我离开空军之后,我本打算去麻省理工学院攻读博士学位。但是上校强烈建议我去报读这个学校的商学院。“你真的想一辈子待实验室里吗?”他问我。“你想就这么去大学里当个教书匠吗?Jackie ,你在组织管理那些复杂的工作中比较有天赋。我觉得你非常有必要去了解下 MIT 的斯隆商学院。”
|
||||
|
||||
我觉得自己也可以同时参加一些 MIT 技术方面的课程,因此我采纳了他的建议。但是,如果要参加市场营销管理方面的课程,我还有很长的路要走,这完全是在浪费时间。因此,在日常工作学习中,我始终是用自己所擅长的分析能力去解决一切问题。
|
||||
我觉得自己也可以同时参加一些 MIT 技术方面的课程,因此我采纳了他的建议。然而,如果要参加市场营销管理方面的课程,我还有很长的路要走,这完全是在浪费时间。因此,在日常工作学习中,我始终是用自己所擅长的分析能力去解决一切问题。
|
||||
|
||||
不久后,我在波士顿咨询集团公司做咨询顾问工作。在那六年的时间里,我经常听到大家对我的评论: Jackie ,你太没远见了。考虑问题也不够周全。你总是通过自己的分析数据去找答案。“
|
||||
不久后,我在波士顿咨询集团公司做咨询顾问工作。在那六年的时间里,我经常听到大家对我的评论: “Jackie ,你太没远见了。考虑问题也不够周全。你总是通过自己的分析去找答案。”
|
||||
|
||||
确实如此啊,我很赞同他们的想法——因为这个世界的工作方式本该如此,任何问题都要基于数据进行分析,不对吗?直到现在我才意识到(我多么希望自己早一些发现自己的问题)自己以前惯用的分析问题的方法遗漏了很多重要的东西:开放的心态,艺术修养,情感——人和创造性思维相关的因素。
|
||||
确实如此啊,我很赞同他们的想法——因为这个世界的工作方式本该如此,任何问题都要基于数据进行分析,不对吗?直到现在我才意识到(我多么希望自己早一些发现自己的问题)自己以前惯用的分析问题的方法遗漏了很多重要的东西:开放的心态、艺术修养、情感——人和创造性思维相关的因素。
|
||||
|
||||
我在 2001 年 9 月 11 日加入达美航空公司不久后,被调去管理消费者市场部门,之前我意识到的所有问题变得更加明显。这本来不是我的强项,但是在公司需要的情况下,我也愿意出手相肋。
|
||||
我在 2001 年 9 月 11 日加入达美航空公司不久后,被调去管理消费者市场部门,之前我意识到的所有问题变得更加明显。市场方面本来不是我的强项,但是在公司需要的情况下,我也愿意出手相肋。
|
||||
|
||||
但是突然之间,我一直惯用的方法获取到的常规数据分析结果却与实际情况完全相反。这个问题导致上千人(包括航线内外的人)受到影响。我忽略了一个很重要的人本身的情感因素。我所面临的问题需要各种各样的解决方案才能处理,而不是简单的从那些死板的分析数据中就能得到答案。
|
||||
但是突然之间,我一直惯用的方法获取到的分析结果却与实际情况完全相反。这个问题导致上千人(包括航线内外的人)受到影响。我忽略了一个很重要的人本身的情感因素。我所面临的问题需要各种各样的解决方案才能处理,而不是简单的从那些死板的数据中就能得到答案。
|
||||
|
||||
那段时间,我快速地学到了很多东西,因为如果我们想把达美航空公司恢复到正常状态,还需要做很多的工作——市场营销更像是一个以解决问题为导向,以用户为中心的充满挑战性的大工程,只是销售人员和工程师这两大阵营都没有迅速地意识到这个问题。
|
||||
那段时间,我快速地学到了很多东西,因为如果我们想把达美航空公司恢复到正常状态,还需要做很多的工作——市场营销更像是一个以解决问题为导向、以用户为中心的充满挑战性的大工程,只是销售人员和工程师这两大阵营都没有迅速地意识到这个问题。
|
||||
|
||||
### 两大文化差异
|
||||
|
||||
工程管理和市场营销之间的这个“巨大鸿沟”确实是根深蒂固的,这跟 C.P. Snow (英语物理化学家和小说家)提出的[“两大文化差异"问题][1]很相似。具有科学素质的工程师和具有艺术细胞的营销人员操着不同的语言,不同的文化观念导致他们不同的价值取向。
|
||||
工程管理和市场营销之间的这个“巨大鸿沟”确实是根深蒂固的,这跟(著名的科学家、小说家) C.P. Snow 提出的[“两大文化差异”问题][1]很相似。具有科学素质的工程师和具有艺术细胞的营销人员操着不同的语言,不同的文化观念导致他们不同的价值取向。
|
||||
|
||||
但是,事实上他们比想象中有更多的相似之处。华盛顿大学[最新研究][2](由微软、谷歌和美国国家科学基金会共同赞助)发现”一个伟大软件工程师必须具备哪些优秀的素质,“毫无疑问,一个伟大的销售人员同样也应该具备这些素质。例如,专家们给出的一些优秀品质如下:
|
||||
但是,事实上他们比想象中有更多的相似之处。一个由微软、谷歌和美国国家科学基金会共同赞助的华盛顿大学的[最新研究][2]发现了“一个伟大软件工程师必须具备哪些优秀的素质”,毫无疑问,一个伟大的销售人员同样也应该具备这些素质。例如,专家们给出的一些优秀品质如下:
|
||||
|
||||
* 充满激情
|
||||
* 性格开朗
|
||||
@ -56,29 +54,29 @@ _“营销人员都很懒散。”_
|
||||
* 技艺精湛
|
||||
* 解决复杂难题的能力
|
||||
|
||||
这些只是其中很小的一部分!当然,并不是所有的素质都适用于市场营销人员,但是如果用文氏图来表示这“两大文化“的交集,就很容易看出营销人员和工程师之间的关系要远比我们想象中密切得多。他们都是竭力去解决与用户或客户相关的难题,只是他们所采取的方式和角度不一致罢了。
|
||||
这些只是其中很小的一部分!当然,并不是所有的素质都适用于市场营销人员,但是如果用文氏图来表示这“两大文化”的交集,就很容易看出营销人员和工程师之间的关系要远比我们想象中密切得多。他们都是竭力去解决与用户或客户相关的难题,只是他们所采取的方式和角度不一致罢了。
|
||||
|
||||
看到上面的那几点后,我深深的陷入思考:_要是这两类员工彼此之间再多了解对方一些会怎样呢?这会给公司带来很强大的动力吧?_
|
||||
|
||||
确实如此。我在红帽公司就亲眼看到过样的情形,我身边都是一些“思想极端”的员工,要是之前,肯定早被我炒鱿鱼了。我相信公司里绝对发生过很多次类似这样的事情,一个销售人员看完工程师递交上来的分析报表后,心想,“这些书呆子,思想太局限了。真是一叶障目,不见泰山;两豆塞耳,不闻雷霆。”
|
||||
确实如此。我在红帽公司就亲眼看到过样的情形,我身边都是一些早些年肯定被我当成“想法疯狂”而无视的人。而且我猜销售人员看到工程师后(同时或某一次),心想,“这些数据呆瓜,真是只见树木不见森林。”
|
||||
|
||||
现在我才明白了公司里有这两种人才的重要性。在现实工作当中,工程师和营销人员都是围绕着客户、创新及数据分析来完成工作。如果他们能够懂得相互尊重、彼此理解、相辅相成,那么我们将会看到公司里所产生的那种积极强大的动力,这种超乎寻常的革新力量要远比两个独立的团队强大得多。
|
||||
|
||||
### 听一听他们的想法
|
||||
### 听一听疯子(和呆瓜)的想法
|
||||
|
||||
成功案例:_建立开放式组织_
|
||||
成功案例:《开放式组织》
|
||||
|
||||
在红帽任职期间,我的主要工作就是想办法提升公司的品牌影响力——但是我从未想过让公司的 CEO 去写一本书。我把公司多个部门的“想法极端”的同事召集在一起,希望他们帮我设计出一个新颖的解决方案来提升公司的影响力,结果他们提出让公司的 CEO 写书这样一个想法。
|
||||
在红帽任职期间,我的主要工作就是想办法提升公司的品牌影响力——但是就是给我一百万年我也不会想到让公司的 CEO 去写一本书。我把公司多个部门的“想法疯狂”的同事召集在一起,希望他们帮我设计出一个新颖的解决方案来提升公司的影响力,结果他们提出让公司的 CEO 写书这样一个想法。
|
||||
|
||||
当我听到这个想法的时候,我很快意识到应该把红帽公司一些经典的管理模式写入到这本书里:它将对整个开源社区的创业者带来很重要的参考价值,同时也有助于宣扬开源精神。通过优先考虑这两方面的作用,我们提升了红帽在整个开源软件世界中的品牌价值,红帽是一个可靠的随时准备着为客户在[数字化颠覆][3]年代指明方向的公司。
|
||||
当我听到这个想法的时候,我很快意识到这正是典型的红帽方式:它将对整个开源社区的从业者带来很重要的参考价值,同时也有助于宣扬开源精神。通过优先考虑这两方面的作用,我们提升了红帽在整个开源软件世界中的品牌价值——红帽是一个可靠的随时准备着为客户在[数字化颠覆][3]年代指明方向的公司。
|
||||
|
||||
这一点才是主要的:确切的说是指导红帽工程师解决代码问题的共同精神力量。 Red Hatters 小组一直在催着我赶紧把开放式组织的模式在全公司推广起来,以显示出内外部程序员共同推动整个开源社区发展的强大动力之一:那就是强烈的共享欲望。
|
||||
这一点才是主要的:确切的说是指导红帽工程师解决代码问题的共同精神力量。 Red Hatters 小组敦促我出版《开放式组织》,这显示出来自内部和外部社区的程序员共同推动整个开源社区发展的强大动力之一:那就是强烈的共享欲望。
|
||||
|
||||
最后,要把开放式组织的管理模式完全推广起来,还需要大家的共同能力,包括工程师们强大的数据分析能力和营销人员美好的艺术素养。这个项目让我更加坚定自己的想法,工程师和营销人员有更多的相似之处。
|
||||
最后,要把《开放式组织》这本书完成,还需要大家的共同能力,包括工程师们强大的数据分析能力和营销人员美好的艺术素养。这个项目让我更加坚定自己的想法,工程师和营销人员有更多的相似之处。
|
||||
|
||||
但是,有些东西我还得强调下:开放模式的实现,要求公司上下没有任何偏见,不能偏袒工程师和市场营销人员任何一方文化。一个更加理想的开放式环境能够促使员工之间和平共处,并在这个组织规定的范围内点燃大家的热情。
|
||||
|
||||
所以,这绝对不是我听到大家所说的懒散之意。
|
||||
这对我来说如春风拂面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -94,7 +92,7 @@ via: https://opensource.com/open-organization/17/1/engineers-marketers-can-learn
|
||||
|
||||
作者:[Jackie Yeaney][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[Bestony](https://github.com/Bestony)
|
||||
校对:[Bestony](https://github.com/Bestony), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,20 +1,17 @@
|
||||
使用AWS的GO SDK获取区域与终端节点信息
|
||||
使用 AWS 的 GO SDK 获取区域与终端节点信息
|
||||
============================================================
|
||||
|
||||
<section itemprop="articleBody" style="font-family: HelveticaNeue, Helvetica, Helvetica, Arial, sans-serif;">
|
||||
LCTT 译注: 终端节点(Endpoint),详情请见: [http://docs.amazonaws.cn/general/latest/gr/rande.html](http://docs.amazonaws.cn/general/latest/gr/rande.html)
|
||||
|
||||
译注: Endpoint(终端节点)[详情请见: http://docs.amazonaws.cn/general/latest/gr/rande.html](http://docs.amazonaws.cn/general/latest/gr/rande.html)
|
||||
最新发布的 GO 的 SDK [v1.6.0][1] 版本,加入了获取区域与终端节点信息的功能。它可以很方便地列出区域、服务和终端节点的相关信息。可以通过 [github.com/aws/aws-sdk-go/aws/endpoints][3] 包使用这些功能。
|
||||
|
||||
最新发布的GO的SDK[v1.6.0][1]版本, 加入了获取区域与终端节点信息的功能. 它可以很方便地列出区域, 服务 和终端节点的相关信息.可以通过[github.com/aws/aws-sdk-go/aws/endpoints][3]包使用这些功能.
|
||||
|
||||
endpoints包提供了一个易用的接口,可以获取到一个服务的终端节点的url列表和区域列表信息.并且我们将相关信息根据AWS服务区域进行了分组,如 AWS 标准, AWS 中国, and AWS GovCloud (美国).
|
||||
endpoints 包提供了一个易用的接口,可以获取到一个服务的终端节点的 url 列表和区域列表信息。并且我们将相关信息根据 AWS 服务区域进行了分组,如 AWS 标准、AWS 中国和 AWS GovCloud(美国)。
|
||||
|
||||
### 解析终端节点
|
||||
|
||||
设置SDK的默认配置时, SDK会自动地使用endpoints.DefaultResolver函数. 你也可以自己调用包中的EndpointFor方法来解析终端节点.
|
||||
设置 SDK 的默认配置时, SDK 会自动地使用 `endpoints.DefaultResolver` 函数。你也可以自己调用包中的`EndpointFor` 方法来解析终端节点。
|
||||
|
||||
Go
|
||||
```
|
||||
```Go
|
||||
// 解析在us-west-2区域的S3服务的终端节点
|
||||
resolver := endpoints.DefaultResolver()
|
||||
endpoint, err := resolver.EndpointFor(endpoints.S3ServiceID, endpoints.UsWest2RegionID)
|
||||
@ -26,12 +23,12 @@ if err != nil {
|
||||
fmt.Println("Resolved URL:", endpoint.URL)
|
||||
```
|
||||
|
||||
如果你需要自定义终端节点的解析逻辑,你可以实现endpoints.Resolver接口, 并传值给aws.Config.EndpointResolver. 当你打算编写自定义的终端节点逻辑,让sdk可以用来解析服务的终端节点时候,这个功能就会很有用.
|
||||
如果你需要自定义终端节点的解析逻辑,你可以实现 `endpoints.Resolver` 接口,并传值给`aws.Config.EndpointResolver`。当你打算编写自定义的终端节点逻辑,让 SDK 可以用来解析服务的终端节点时候,这个功能就会很有用。
|
||||
|
||||
以下示例, 创建了一个配置好的Session, 然后[Amazon S3][4]服务的客服端就可以使用这个自定义的终端节点.
|
||||
以下示例,创建了一个配置好的 Session,然后 [Amazon S3][4] 服务的客户端就可以使用这个自定义的终端节点。
|
||||
|
||||
Go
|
||||
```
|
||||
|
||||
```Go
|
||||
s3CustResolverFn := func(service, region string, optFns ...func(*endpoints.Options)) (endpoints.ResolvedEndpoint, error) {
|
||||
if service == "s3" {
|
||||
return endpoints.ResolvedEndpoint{
|
||||
@ -52,10 +49,9 @@ sess := session.Must(session.NewSessionWithOptions(session.Options{
|
||||
|
||||
### 分区
|
||||
|
||||
endpoints.DefaultResolver函数的返回值可以被endpoints.EnumPartitions接口使用.这样就可以获取SDK使用的分区片段,也可以列出每个分区的分区信息。
|
||||
`endpoints.DefaultResolver` 函数的返回值可以被 `endpoints.EnumPartitions`接口使用。这样就可以获取 SDK 使用的分区片段,也可以列出每个分区的分区信息。
|
||||
|
||||
Go
|
||||
```
|
||||
```Go
|
||||
// 迭代所有分区表打印每个分区的ID
|
||||
resolver := endpoints.DefaultResolver()
|
||||
partitions := resolver.(endpoints.EnumPartitions).Partitions()
|
||||
@ -65,10 +61,9 @@ for _, p := range partitions {
|
||||
}
|
||||
```
|
||||
|
||||
除了分区表之外, endpoints包也提供了每个分区组的getter函数. 这些工具函数可以方便列出指定分区,而不用执行默认解析器列出所有的分区.
|
||||
除了分区表之外,endpoints 包也提供了每个分区组的 getter 函数。这些工具函数可以方便列出指定分区,而不用执行默认解析器列出所有的分区。
|
||||
|
||||
Go
|
||||
```
|
||||
```Go
|
||||
partition := endpoints.AwsPartition()
|
||||
region := partition.Regions()[endpoints.UsWest2RegionID]
|
||||
|
||||
@ -78,19 +73,18 @@ for id, _ := range region.Services() {
|
||||
}
|
||||
```
|
||||
|
||||
当你获取区域和服务值后, 可以调用ResolveEndpoint. 这样解析端点时,就可以提供分区的过滤视图.
|
||||
当你获取区域和服务值后,可以调用 `ResolveEndpoint`。这样解析端点时,就可以提供分区的过滤视图。
|
||||
|
||||
获取更多AWS SDK for GO信息, 请关注[开源库][5]. 若你有更好的看法,请留言评论.
|
||||
获取更多 AWS SDK for GO 信息, 请关注[其开源仓库][5]。若你有更好的看法,请留言评论。
|
||||
|
||||
</section>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://aws.amazon.com/cn/blogs/developer/using-the-aws-sdk-for-gos-regions-and-endpoints-metadata
|
||||
|
||||
作者:[ Jason Del Ponte][a]
|
||||
作者:[Jason Del Ponte][a]
|
||||
译者:[Vic020](http://vicyu.com)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,17 @@
|
||||
Linux 系统可视化的比较与合并工具 Meld 的新手使用教程
|
||||
Linux 系统上的可视化比较与合并工具 Meld
|
||||
============================================================
|
||||
|
||||
### 本页内容
|
||||
|
||||
1. [关于 Meld][1]
|
||||
2. [安装 Meld][2]
|
||||
3. [使用 Meld][3]
|
||||
4. [总结][4]
|
||||
|
||||
我们已经[讲过][5] Linux 中[一些][6]基于命令行的比较和合并工具,再来讲解该系统的一些可视化的比较与合并工具也很合理。首要的原因是,不是每个人都习惯使用命令行,而且对于某些人来说,基于命令行的比较工具可能很难学习和理解。
|
||||
我们已经[讲过][5] Linux 中[一些][6]基于命令行的比较和合并工具,再来讲解该系统的一些可视化的比较与合并工具也很合理。首要的原因是,不是每个人都习惯使用命令行,而且对于某些人来说,基于命令行的比较工具可能很难学习和理解。
|
||||
|
||||
因此,我们将会推出关于可视化工具 **Meld** 的系列文章。
|
||||
|
||||
在跳到安装和介绍部分前,分享这篇教程所有指令和用例是很有用的,而且它们已经在 Ubuntu 14.04 中测试过了,我们使用的 Meld 版本是 3.14.2。
|
||||
在跳到安装和介绍部分前,我需要说明这篇教程里所有的指令和用例是都是可用的,而且它们已经在 Ubuntu 14.04 中测试过了,我们使用的 Meld 版本是 3.14.2。
|
||||
|
||||
### 关于 Meld
|
||||
|
||||
[Meld][7] 主要是一个可视化的比较和合并的工具,目标人群是开发者(当然,我们将要讲到的其它部分也会考虑到终端用户)。这个工具同时支持双向和三向的比较,不仅仅是比较文件,还可以比较目录,以及版本控制的项目。
|
||||
[Meld][7] 主要是一个可视化的比较和合并的工具,目标人群是开发者(当然,我们将要讲到的其它部分也会考虑到最终用户)。这个工具同时支持双向和三向的比较,不仅仅是比较文件,还可以比较目录,以及版本控制的项目。
|
||||
|
||||
“Meld 帮你回顾代码改动,理解补丁,”官网如是说。“它甚至可以告知你如果你不进行合并将会发生什么事情。”该工具使用 GPL v2 协议进行授权。
|
||||
“Meld 可以帮你回顾代码改动,理解补丁,”其官网如是说。“它甚至可以告知你如果你不进行合并将会发生什么事情。”该工具使用 GPL v2 协议进行授权。
|
||||
|
||||
### 安装 Meld
|
||||
|
||||
@ -28,11 +21,13 @@ Linux 系统可视化的比较与合并工具 Meld 的新手使用教程
|
||||
sudo apt-get install meld
|
||||
```
|
||||
|
||||
或者你也可以用系统自带的包管理软件下载这个工具。比如在 Ubuntu 上,你可以用 Ubuntu 软件中心(Ubuntu Software Center),或者用 [Ubuntu Software][8],Ubuntu Software 从 Ubuntu 16.04 版本开始取代了软件中心。
|
||||
或者你也可以用系统自带的包管理软件下载这个工具。比如在 Ubuntu 上,你可以用 Ubuntu 软件中心(Ubuntu Software Center),或者用 [Ubuntu 软件][8],它从 Ubuntu 16.04 版本开始取代了 Ubuntu 软件中心。
|
||||
|
||||
当然,Ubuntu 官方仓库里的 Meld 版本很有可能比较陈旧。因此如果你想要用更新的版本,你可以在[这里][9]下载软件包。如果你要用这个方法,你要做的就是解压下载好的软件包,然后运行 “bin” 目录下的 “meld” 程序。
|
||||
当然,Ubuntu 官方仓库里的 Meld 版本很有可能比较陈旧。因此如果你想要用更新的版本,你可以在[这里][9]下载软件包。如果你要用这个方法,你要做的就是解压下载好的软件包,然后运行 `bin` 目录下的 `meld` 程序。
|
||||
|
||||
~/Downloads/meld-3.14.2/bin$ **./meld**
|
||||
```
|
||||
~/Downloads/meld-3.14.2/bin$ ./meld
|
||||
```
|
||||
|
||||
以下是 Meld 依赖的软件,仅供参考:
|
||||
|
||||
@ -67,9 +62,9 @@ sudo apt-get install meld
|
||||
|
||||
][12]
|
||||
|
||||
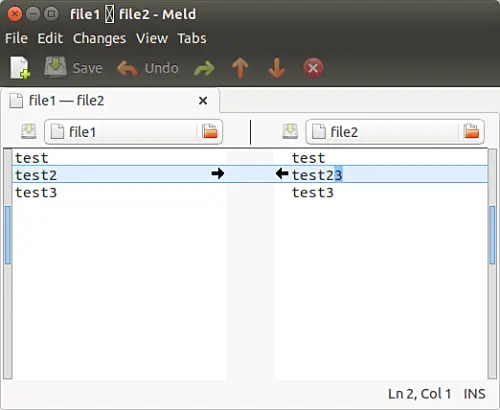
两个文件的不同之处在第二行,差别在于 “file2” 文件的第二行多了一个 “3”。你看到的黑色箭头是用来进行合并或修改的操作的。该例中,向右的箭头将会把 “file2” 文件的第二行改成文件 “file1” 中对应行的内容。左向箭头做的事情相反。
|
||||
两个文件的不同之处在第二行,差别在于 `file2` 文件的第二行多了一个 `3`。你看到的黑色箭头是用来进行合并或修改的操作的。该例中,向右的箭头将会把 `file2` 文件的第二行改成文件 `file1` 中对应行的内容。左向箭头做的事情相反。
|
||||
|
||||
做完修改后,按下 Ctrl+s 来保存。
|
||||
做完修改后,按下 `Ctrl+s` 来保存。
|
||||
|
||||
这个简单的例子,让你知道 Meld 的基本用法。让我们看一看稍微复杂一点的比较:
|
||||
|
||||
@ -77,13 +72,13 @@ sudo apt-get install meld
|
||||
|
||||
][13]
|
||||
|
||||
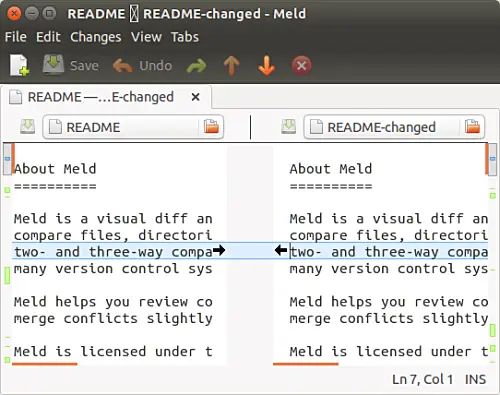
在讨论这些变化前,这里提一下, Meld GUI 中有几个区域,可以给出文件之间的差异,让概况变得直观。这里特别需要注意窗口的左右两边垂直的栏。比如下面这个截图:
|
||||
在讨论这些变化前,这里提一下, Meld 的界面中有几个区域,可以给出文件之间的差异,让概况变得直观。这里特别需要注意窗口的左右两边垂直的栏。比如下面这个截图:
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
仔细观察,图中的这个栏包含几个不同颜色的区块。这些区块是用来让你对文件之间的差异有个大概的了解。“每一个上色的区块表示一个部分,这个部分可能是插入、删除、修改或者有差别的,取决于区块所用的颜色。”官方文档是这样说的。
|
||||
仔细观察,图中的这个栏包含几个不同颜色的区块。这些区块是用来让你对文件之间的差异有个大概的了解。“每一个着色的区块表示一个部分,这个部分可能是插入、删除、修改或者有差别的,取决于区块所用的颜色。”官方文档是这样说的。
|
||||
|
||||
现在,让我们回到我们之前讨论的例子中。接下来的截图展示了用 Meld 理解文件的改动是很简单的(以及合并这些改动):
|
||||
|
||||
@ -105,19 +100,19 @@ sudo apt-get install meld
|
||||
|
||||
][18]
|
||||
|
||||
这些是你使用 Meld 时做的一般性的事情:可以用标准的 “Ctrl+f” 组合键在编辑区域内进行查找,按 “F11” 键让软件进入全屏模式,再按 “Ctrl+f” 来刷新(通常在所有要比较的文件改变的时候使用)。
|
||||
这些是你使用 Meld 时做的一般性的事情:可以用标准的 `Ctrl+f` 组合键在编辑区域内进行查找,按 `F11` 键让软件进入全屏模式,再按 `Ctrl+r` 来刷新(通常在所有要比较的文件改变的时候使用)。
|
||||
|
||||
以下是 Meld 官方网站宣传的重要特性:
|
||||
|
||||
* 文件和目录的双向及三向比较
|
||||
* 输入即更新文件的比较
|
||||
* 自动合并模式,改动区块的动作让合并更加简单
|
||||
* 自动合并模式,按块改动的动作让合并更加简单
|
||||
* 可视化让比较文件更简单
|
||||
* 支持 Git,Bazaar,Mercurial,Subversion 等等
|
||||
|
||||
注意还不仅仅只有以上所列的。网站上有个专门的[特性页面][19],里面提到了 Meld 提供的所有特性。这个页面列出的所有特性分为几个部分,以该软件是用来做文件比较,目录比较,版本控制还是处于合并模式下为基础进行划分。
|
||||
注意还不仅仅只有以上所列的。网站上有个专门的[特性页面][19],里面提到了 Meld 提供的所有特性。这个页面列出的所有特性分为几个部分,以该软件是用来做文件比较、目录比较、版本控制还是处于合并模式下为基础进行划分。
|
||||
|
||||
和其它软件相似,有些事情 Meld 做不到。官方网站上列出了其中的一部分:“当 Meld 展示文件之间的差异时,它同时显示两个文件,看起来就像在普通的文本编辑器中。它不会添加额外的行,让左右两边文件的特殊改动是同样的行数。没有做这个事情的选项。”
|
||||
和其它软件相似,有些事情 Meld 做不到。官方网站上列出了其中的一部分:“当 Meld 展示文件之间的差异时,它同时显示两个文件,看起来就像在普通的文本编辑器中。它不会添加额外的行,让左右两边文件的特殊改动处于同样的行数。没有做这个事情的选项。”
|
||||
|
||||
### 总结
|
||||
|
||||
@ -129,7 +124,7 @@ via: https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-me
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,25 @@
|
||||
印度社区如何支持隐私和软件自由
|
||||
印度的社区如何支持隐私和软件自由
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片提供: opensource.com
|
||||
|
||||
印度的自由和开源社区,特别是 Mozilla 和 Wikimedia 社区,它们正在引领两个独特的全球性活动,以提高隐私及支持自由软件。
|
||||
印度的自由和开源社区,特别是 Mozilla 和 Wikimedia 社区,它们正在引领两个独特的全球性活动,以提高隐私保护及支持自由软件。
|
||||
|
||||
[1 月份的隐私月][3]是由印度 Mozilla 社区领导,通过在线和线下活动向群众教育网络隐私。而[ 2 月份的自由月][4]是由[互联网与社会中心][5]领导,教育内容创作者如博主和摄影师就如何在[开放许可证][6]下捐赠内容。
|
||||
|
||||
### 1 月隐私月
|
||||
|
||||
从[去年开始][7]的 Mozilla “1 月隐私月”用来帮助庆祝年度[数据隐私日][8]。在 2016 年,该活动举办了几场涉及[全球 10 个国家 14,339,443 人][9]的线下和线上活动。其中一个核心组织者,[Ankit Gadgil][10]这样说到:“每天分享一个隐私提示,持续一个月 31 天是有可能的。今年,我们共有三个重点领域,首先是我们让这个运动更加开放和全球化。巴西、意大利、捷克共和国的 Mozilla 社区今年正在积极参与,所有的必要文件都是本地化的,所以我们可以针对更多的用户。其次,我们在线下活动中教导用户营销 Firefox 以及 Mozilla 的其他产品,以便用户可以亲身体验使用这些工具来帮助保护他们的隐私。第三点,我们鼓励大家参加线下活动并记录他们的学习,例如,最近在印度古吉拉特邦的一个节目中,他们使用 Mozilla 产品来教授隐私。”
|
||||
从[去年开始][7]的 Mozilla “1 月隐私月”用来帮助庆祝年度[数据隐私日(Data Privacy Day)][8]。在 2016 年,该活动举办了几场涉及到[全球 10 个国家 14,339,443 人][9]的线下和线上活动。其中一个核心组织者,[Ankit Gadgil][10] 这样说到:“每天分享一个隐私提示,持续一个月就能分享 31 天。”今年,我们共有三个重点领域,首先是我们让这个运动更加开放和全球化。巴西、意大利、捷克共和国的 Mozilla 社区今年正在积极参与,所有必要的文档都是本地化的,所以我们可以针对更多的用户。其次,我们在线下活动中教导用户推广 Firefox 以及 Mozilla 的其他产品,以便用户可以亲身体验使用这些工具来帮助保护他们的隐私。第三点,我们鼓励大家参加线下活动并把他们的学习写到博客里面去,例如,最近在印度古吉拉特邦的一个节目中,他们使用 Mozilla 产品来教授隐私方面的知识。”
|
||||
|
||||
今年的活动继续有线下和线上活动。关注 #PrivacyAware 参加。
|
||||
|
||||
### 安全提示
|
||||
#### 安全提示
|
||||
|
||||
像 Firefox 这样的 Mozilla 产品具有安全性设置-同时还有[内建][11]还有附加的对残疾人完全[可用][12]的库-这有助于保护用户的隐私和安全性,这些都是协同构建的并且是开源的。
|
||||
像 Firefox 这样的 Mozilla 产品具有安全性设置-有[内置的][11]还有对残疾人完全[可用][12]的附件库-这有助于保护用户的隐私和安全性,这些都是协同构建的并且是开源的。
|
||||
|
||||
[Chrome][14] 和[ Opera][15] 中的 [HTTPS Everywhere][13] 可用于加密用户通信,使外部网站无法查看用户信息。该项目由 [Tor Project][16]以及[电子前沿基金会][17]合作建成。
|
||||
[Chrome][14] 和[ Opera][15] 中的 [HTTPS Everywhere][13] 插件可用于加密用户通信,使外部网站无法查看用户信息。该项目由 [Tor Project][16] 以及[电子前沿基金会][17]合作建成。
|
||||
|
||||
### 2 月自由月
|
||||
|
||||
@ -27,15 +28,15 @@
|
||||
** 参加规则:**
|
||||
|
||||
* 你在二月份制作或出版的作品必须获得[自由许可证][1]许可。
|
||||
* 内容类型包括博客帖子、其他文字和图像。
|
||||
* 内容类型包括博客文章、其他文字和图像。
|
||||
|
||||
多媒体,基于文本的内容,艺术和设计等创意作品可以通过多个[知识共享许可证][20](CC)进行许可,其他类型的文档可以根据[ GNU 免费文档许可][21](GFDL)许可。Wikipedia 上可以找到很好的例子,其内容根据 CC 和 GFDL 许可证获得许可,允许人们使用、分享、混合和分发衍生用于商业上和非商业性的作品。此外,还有允许开发人员共享他们的软件和软件相关文档的[自由软件许可证][22]。
|
||||
多媒体,基于文本的内容,艺术和设计等创意作品可以通过多个[知识共享许可证][20](CC)进行许可,其他类型的文档可以根据 [GNU 免费文档许可][21](GFDL)许可。Wikipedia 上可以找到很好的例子,其内容根据 CC 和 GFDL 许可证获得许可,允许人们使用、分享、混合和分发衍生用于商业上和非商业性的作品。此外,还有允许开发人员共享他们的软件和软件相关文档的[自由软件许可证][22]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Subhashish Panigrahi - Subhashish Panigrahi(@shhapa)是 Mozilla 参与团队的亚洲社区催化师,并从 Wikimedia 基金会印度计划的早期扮演了互联网及社会知识获取中心项目官的角色,另外他是一名印度教育者,
|
||||
Subhashish Panigrahi(@shhapa)是 Mozilla 参与团队的亚洲社区催化师,并在 Wikimedia 基金会印度计划的早期扮演了互联网及社会知识获取中心项目官的角色,另外他是一名印度教育工作者,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -43,7 +44,7 @@ via: https://opensource.com/article/17/1/how-communities-india-support-privacy-s
|
||||
|
||||
作者:[Subhashish Panigrahi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,38 +1,30 @@
|
||||
### 在Linux上使用Nginx和Gunicorn托管Django
|
||||
在 Linux 上使用 Nginx 和 Gunicorn 托管 Django 应用
|
||||
==========
|
||||
|
||||

|
||||
|
||||
内容
|
||||
|
||||
* * [1. 介绍][4]
|
||||
* [2. Gunicorn][5]
|
||||
* [2.1. 安装][1]
|
||||
* [2.2. 配置][2]
|
||||
* [2.3. 运行][3]
|
||||
* [3. Nginx][6]
|
||||
* [4. 结语][7]
|
||||
|
||||
### 介绍
|
||||
|
||||
托管Django Web应用程序相当简单,虽然它比标准的PHP应用程序更复杂一些。 处理带Web服务器的Django接口的方法有很多。 Gunicorn就是其中最简单的一个。
|
||||
托管 Django Web 应用程序相当简单,虽然它比标准的 PHP 应用程序更复杂一些。 让 Web 服务器对接 Django 的方法有很多。 Gunicorn 就是其中最简单的一个。
|
||||
|
||||
Gunicorn(Green Unicorn的缩写)在你的Web服务器Django之间作为中间服务器使用,在这里,Web服务器就是Nginx。 Gunicorn服务于应用程序,而Nginx处理静态内容。
|
||||
Gunicorn(Green Unicorn 的缩写)在你的 Web 服务器 Django 之间作为中间服务器使用,在这里,Web 服务器就是 Nginx。 Gunicorn 服务于应用程序,而 Nginx 处理静态内容。
|
||||
|
||||
### Gunicorn
|
||||
|
||||
### 安装
|
||||
#### 安装
|
||||
|
||||
使用Pip安装Gunicorn是超级简单的。 如果你已经使用virtualenv搭建好了你的Django项目,那么你就有了Pip,并且应该熟悉Pip的工作方式。 所以,在你的virtualenv中安装Gunicorn。
|
||||
使用 Pip 安装 Gunicorn 是超级简单的。 如果你已经使用 virtualenv 搭建好了你的 Django 项目,那么你就有了 Pip,并且应该熟悉 Pip 的工作方式。 所以,在你的 virtualenv 中安装 Gunicorn。
|
||||
|
||||
```
|
||||
$ pip install gunicorn
|
||||
```
|
||||
|
||||
### 配置
|
||||
#### 配置
|
||||
|
||||
Gunicorn 最有吸引力的一个地方就是它的配置非常简单。处理配置最好的方法就是在Django项目的根目录下创建一个名叫Gunicorn的文件夹。然后 在该文件夹内,创建一个配置文件。
|
||||
Gunicorn 最有吸引力的一个地方就是它的配置非常简单。处理配置最好的方法就是在 Django 项目的根目录下创建一个名叫 `Gunicorn` 的文件夹。然后在该文件夹内,创建一个配置文件。
|
||||
|
||||
在本篇教程中,配置文件名称是`gunicorn-conf.py`。在改文件中,创建类似于下面的配置
|
||||
在本篇教程中,配置文件名称是 `gunicorn-conf.py`。在该文件中,创建类似于下面的配置:
|
||||
|
||||
```
|
||||
import multiprocessing
|
||||
@ -42,25 +34,27 @@ workers = multiprocessing.cpu_count() * 2 + 1
|
||||
reload = True
|
||||
daemon = True
|
||||
```
|
||||
在上述配置的情况下,Gunicorn会在`/tmp/`目录下创建一个名为`gunicorn1.sock`的Unix套接字。 还会启动一些工作进程,进程数量相当于CPU内核数量的2倍。 它还会自动重新加载并作为守护进程运行。
|
||||
|
||||
### 运行
|
||||
在上述配置的情况下,Gunicorn 会在 `/tmp/` 目录下创建一个名为 `gunicorn1.sock` 的 Unix 套接字。 还会启动一些工作进程,进程数量相当于 CPU 内核数量的 2 倍。 它还会自动重新加载并作为守护进程运行。
|
||||
|
||||
Gunicorn的运行命令有点长,指定了一些附加的配置项。 最重要的部分是将Gunicorn指向你项目的`.wsgi`文件。
|
||||
#### 运行
|
||||
|
||||
Gunicorn 的运行命令有点长,指定了一些附加的配置项。 最重要的部分是将 Gunicorn 指向你项目的 `.wsgi` 文件。
|
||||
|
||||
```
|
||||
gunicorn -c gunicorn/gunicorn-conf.py -D --error-logfile gunicorn/error.log yourproject.wsgi
|
||||
```
|
||||
上面的命令应该从项目的根目录运行。 Gunicorn会使用你用`-c`选项创建的配置。 `-D`再次指定gunicorn为守护进程。 最后一部分指定Gunicorn的错误日志文件在`Gunicorn`文件夹中的位置。 命令结束部分就是为Gunicorn指定`.wsgi`file的位置。
|
||||
|
||||
上面的命令应该从项目的根目录运行。 `-c` 选项告诉 Gunicorn 使用你创建的配置文件。 `-D` 再次指定 gunicorn 为守护进程。 最后一部分指定 Gunicorn 的错误日志文件在你创建 `Gunicorn` 文件夹中的位置。 命令结束部分就是为 Gunicorn 指定 `.wsgi` 文件的位置。
|
||||
|
||||
### Nginx
|
||||
|
||||
现在Gunicorn配置好了并且已经开始运行了,你可以设置Nginx连接它,为你的静态文件提供服务。 本指南假定你已经配置了Nginx,而且你通过它托管的站点使用了单独的服务块。 它还将包括一些SSL信息。
|
||||
现在 Gunicorn 配置好了并且已经开始运行了,你可以设置 Nginx 连接它,为你的静态文件提供服务。 本指南假定你已经配置好了 Nginx,而且你通过它托管的站点使用了单独的 server 块。 它还将包括一些 SSL 信息。
|
||||
|
||||
如果你想知道如何让你的网站获得免费的SSL证书,请查看我们的[LetsEncrypt指南][8]。
|
||||
如果你想知道如何让你的网站获得免费的 SSL 证书,请查看我们的 [Let'sEncrypt 指南][8]。
|
||||
|
||||
```nginx
|
||||
# 连接到Gunicorn
|
||||
# 连接到 Gunicorn
|
||||
upstream yourproject-gunicorn {
|
||||
server unix:/tmp/gunicorn1.sock fail_timeout=0;
|
||||
}
|
||||
@ -83,7 +77,7 @@ server {
|
||||
access_log /var/log/nginx/yourwebsite.access_log main;
|
||||
error_log /var/log/nginx/yourwebsite.error_log info;
|
||||
|
||||
# 将nginx指向你的ssl证书
|
||||
# 告诉 nginx 你的 ssl 证书
|
||||
ssl on;
|
||||
ssl_certificate /etc/letsencrypt/live/yourwebsite.com/fullchain.pem;
|
||||
ssl_certificate_key /etc/letsencrypt/live/yourwebsite.com/privkey.pem;
|
||||
@ -91,7 +85,7 @@ server {
|
||||
# 设置根目录
|
||||
root /var/www/yourvirtualenv/yourproject;
|
||||
|
||||
# 为Nginx指定静态文件路径
|
||||
# 为 Nginx 指定静态文件路径
|
||||
location /static/ {
|
||||
# Autoindex the files to make them browsable if you want
|
||||
autoindex on;
|
||||
@ -104,7 +98,7 @@ server {
|
||||
proxy_ignore_headers "Set-Cookie";
|
||||
}
|
||||
|
||||
# 为Nginx指定你上传文件的路径
|
||||
# 为 Nginx 指定你上传文件的路径
|
||||
location /media/ {
|
||||
Autoindex if you want
|
||||
autoindex on;
|
||||
@ -122,7 +116,7 @@ server {
|
||||
try_files $uri @proxy_to_app;
|
||||
}
|
||||
|
||||
# 将请求传递给Gunicorn
|
||||
# 将请求传递给 Gunicorn
|
||||
location @proxy_to_app {
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header Host $http_host;
|
||||
@ -130,7 +124,7 @@ server {
|
||||
proxy_pass http://njc-gunicorn;
|
||||
}
|
||||
|
||||
# 缓存HTML,XML和JSON
|
||||
# 缓存 HTML、XML 和 JSON
|
||||
location ~* \.(html?|xml|json)$ {
|
||||
expires 1h;
|
||||
}
|
||||
@ -144,18 +138,19 @@ server {
|
||||
}
|
||||
}
|
||||
```
|
||||
配置文件有点长,但是还可以更长一些。其中重点是指向 Gunicorn 的`upstream`块以及将流量传递给 Gunicorn 的`location`块。大多数其他的配置项都是可选,但是你应该按照一定的形式来配置。配置中的注释应该可以帮助你了解具体细节。
|
||||
配置文件有点长,但是还可以更长一些。其中重点是指向 Gunicorn 的 `upstream` 块以及将流量传递给 Gunicorn 的 `location` 块。大多数其他的配置项都是可选,但是你应该按照一定的形式来配置。配置中的注释应该可以帮助你了解具体细节。
|
||||
|
||||
保存文件之后,你可以重启Nginx,让修改的配置生效。
|
||||
保存文件之后,你可以重启 Nginx,让修改的配置生效。
|
||||
|
||||
```
|
||||
# systemctl restart nginx
|
||||
```
|
||||
一旦Nginx在线生效,你的站点就可以通过域名访问了。
|
||||
|
||||
一旦 Nginx 在线生效,你的站点就可以通过域名访问了。
|
||||
|
||||
### 结语
|
||||
|
||||
如果你想深入研究,Nginx可以做很多事情。但是,上面提供的配置是一个很好的开始,并且你可以用于实践中。 如果你习惯于Apache和臃肿的PHP应用程序,像这样的服务器配置的速度应该是一个惊喜。
|
||||
如果你想深入研究,Nginx 可以做很多事情。但是,上面提供的配置是一个很好的开始,并且你可以用于实践中。 如果你见惯了 Apache 和臃肿的 PHP 应用程序,像这样的服务器配置的速度应该是一个惊喜。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -163,7 +158,7 @@ via: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,38 +1,25 @@
|
||||
理解 sudo 与 su 之间的区别
|
||||
深入理解 sudo 与 su 之间的区别
|
||||
============================================================
|
||||
|
||||
### 本文导航
|
||||
|
||||
1. [Linux su 命令][7]
|
||||
1. [su -][1]
|
||||
2. [su -c][2]
|
||||
2. [Sudo vs Su][8]
|
||||
2. [Sudo vs Su][8]
|
||||
1. [关于密码][3]
|
||||
2. [默认行为][4]
|
||||
3. [日志记录][5]
|
||||
4. [灵活性][6]
|
||||
3. [Sudo su][9]
|
||||
|
||||
在[早前的一篇文章][11]中,我们深入讨论了 `sudo` 命令的相关内容。同时,在该文章的末尾有提到相关的命令 `su` 的部分内容。本文,我们将详细讨论关于 su 命令与 sudo 命令之间的区别。
|
||||
在[早前的一篇文章][11]中,我们深入讨论了 `sudo` 命令的相关内容。同时,在该文章的末尾有提到相关的命令 `su` 的部分内容。本文,我们将详细讨论关于 `su` 命令与 `sudo` 命令之间的区别。
|
||||
|
||||
在开始之前有必要说明一下,文中所涉及到的示例教程都已经在 Ubuntu 14.04 LTS 上测试通过。
|
||||
|
||||
### Linux su 命令
|
||||
|
||||
su 命令的主要作用是让你可以在已登录的会话中切换到另外一个用户。换句话说,这个工具可以让你在不登出当前用户的情况下登录另外一个用户(以该用户的身份)。
|
||||
`su` 命令的主要作用是让你可以在已登录的会话中切换到另外一个用户。换句话说,这个工具可以让你在不登出当前用户的情况下登录为另外一个用户。
|
||||
|
||||
su 命令经常被用于切换到超级用户或 root 用户(因为在命令行下工作,经常需要 root 权限),但是 - 正如前面所提到的 - su 命令也可以用于切换到任意非 root 用户。
|
||||
`su` 命令经常被用于切换到超级用户或 root 用户(因为在命令行下工作,经常需要 root 权限),但是 - 正如前面所提到的 - su 命令也可以用于切换到任意非 root 用户。
|
||||
|
||||
如何使用 su 命令切换到 root 用户,如下:
|
||||
如何使用 `su` 命令切换到 root 用户,如下:
|
||||
|
||||
[
|
||||
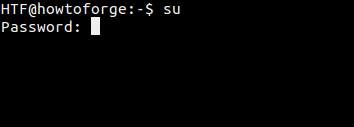
|
||||
][12]
|
||||
|
||||
如上,su 命令要求输入的密码是 root 用户密码。所以,一般 su 命令需要输入目标用户的密码。在输入正确的密码之后,su 命令会在终端的当前会话中打开一个子会话。
|
||||
如上,`su` 命令要求输入的密码是 root 用户的密码。所以,一般 `su` 命令需要输入目标用户的密码。在输入正确的密码之后,`su` 命令会在终端的当前会话中打开一个子会话。
|
||||
|
||||
### su -
|
||||
#### su -
|
||||
|
||||
还有一种方法可以切换到 root 用户:运行 `su -` 命令,如下:
|
||||
|
||||
@ -40,41 +27,36 @@ su 命令经常被用于切换到超级用户或 root 用户(因为在命令
|
||||
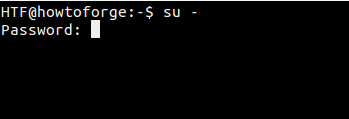
|
||||
][13]
|
||||
|
||||
那么,`su` 命令与 `su -` 命令之间有什么区别呢?前者在切换到 root 用户之后仍然保持旧的或原始用户的环境,而后者则是创建一个新的环境(由 root 用户 ~/.bashrc 文件所设置的环境),相当于使用 root 用户正常登录(从登录屏幕显示登录)。
|
||||
那么,`su` 命令与 `su -` 命令之间有什么区别呢?前者在切换到 root 用户之后仍然保持旧的(或者说原始用户的)环境,而后者则是创建一个新的环境(由 root 用户 `~/.bashrc` 文件所设置的环境),相当于使用 root 用户正常登录(从登录屏幕登录)。
|
||||
|
||||
`su` 命令手册页很清楚地说明了这一点:
|
||||
|
||||
```
|
||||
可选参数 `-` 可提供的环境为用户在直接登录时的环境。
|
||||
```
|
||||
> 可选参数 `-` 可提供的环境为用户在直接登录时的环境。
|
||||
|
||||
因此,你会觉得使用 `su -` 登录更有意义。但是,同时存在 `su` 命令,那么大家可能会想知道它在什么时候用到。以下内容摘自[ArchLinux wiki website][14] - 关于 `su` 命令的好处和坏处:
|
||||
因此,你会觉得使用 `su -` 登录更有意义。但是, `su` 命令也是有用的,那么大家可能会想知道它在什么时候用到。以下内容摘自 [ArchLinux wiki 网站][14] - 关于 `su` 命令的好处和坏处:
|
||||
|
||||
* 有的时候,对于系统管理员来讲,使用其他普通用户的 Shell 账户而不是自己的 Shell 账户更会好一些。尤其是在处理用户问题时,最有效的方法就是是:登录目标用户以便重现以及调试问题。
|
||||
* 有的时候,对于系统管理员(root)来讲,使用其他普通用户的 Shell 账户而不是自己的 root Shell 账户更会好一些。尤其是在处理用户问题时,最有效的方法就是是:登录目标用户以便重现以及调试问题。
|
||||
* 然而,在多数情况下,当从普通用户切换到 root 用户进行操作时,如果还使用普通用户的环境变量的话,那是不可取甚至是危险的操作。因为是在无意间切换使用普通用户的环境,所以当使用 root 用户进行程序安装或系统更改时,会产生与正常使用 root 用户进行操作时不相符的结果。例如,以普通用户安装程序会给普通用户意外损坏系统或获取对某些数据的未授权访问的能力。
|
||||
|
||||
* 然而,在多数情况下,当从普通用户切换到 root 用户进行操作时,如果还使用普通用户的环境变量的话,那是不可取甚至是危险的操作。因为是在无意间切换使用普通用户的环境,所以当使用 root 用户进行程序安装或系统更改时,会产生与正常使用 root 用户进行操作时不相符的结果。例如,可以给普通用户安装电源意外损坏系统的程序或获取对某些数据的未授权访问的程序。
|
||||
注意:如果你想在 `su -` 命令的 `-` 后面传递更多的参数,那么你必须使用 `su -l` 而不是 `su -`。以下是 `-` 和 `-l` 命令行选项的说明:
|
||||
|
||||
注意:如果你想在 `su -` 命令后面传递更多的参数,那么你必须使用 `su -l` 来实现。以下是 `-` 和 `-l` 命令行选项的说明:
|
||||
> `-`, `-l`, `--login`
|
||||
|
||||
```
|
||||
-, -l, --login
|
||||
提供相当于用户在直接登录时所期望的环境。
|
||||
> 提供相当于用户在直接登录时所期望的环境。
|
||||
|
||||
当使用 - 时,必须放在 su 命令的最后一个选项。其他选项(-l 和 --login)无此限制。
|
||||
```
|
||||
> 当使用 - 时,必须放在 `su` 命令的最后一个选项。其他选项(`-l` 和 `--login`)无此限制。
|
||||
|
||||
### su -c
|
||||
#### su -c
|
||||
|
||||
还有一个值得一提的 `su` 命令行选项为:`-c`。该选项允许你提供在切换到目标用户之后要运行的命令。
|
||||
|
||||
`su` 命令手册页是这样说明:
|
||||
|
||||
```
|
||||
-c, --command COMMAND
|
||||
使用 -c 选项指定由 Shell 调用的命令。
|
||||
> `-c`, `--command COMMAND`
|
||||
|
||||
被执行的命令无法控制终端。所以,此选项不能用于执行需要控制 TTY 的交互式程序。
|
||||
```
|
||||
> 使用 `-c` 选项指定由 Shell 调用的命令。
|
||||
|
||||
> 被执行的命令无法控制终端。所以,此选项不能用于执行需要控制 TTY 的交互式程序。
|
||||
|
||||
参考示例:
|
||||
|
||||
@ -90,11 +72,11 @@ su [target-user] -c [command-to-run]
|
||||
|
||||
示例中的 `shell` 类型将会被目标用户在 `/etc/passwd` 文件中定义的登录 shell 类型所替代。
|
||||
|
||||
### Sudo vs Su
|
||||
### sudo vs. su
|
||||
|
||||
现在,我们已经讨论了关于 `su` 命令的基础知识,是时候来探讨一下 `sudo` 和 `su` 命令之间的区别了。
|
||||
|
||||
### 关于密码
|
||||
#### 关于密码
|
||||
|
||||
两个命令的最大区别是:`sudo` 命令需要输入当前用户的密码,`su` 命令需要输入 root 用户的密码。
|
||||
|
||||
@ -102,28 +84,27 @@ su [target-user] -c [command-to-run]
|
||||
|
||||
此外,如果要撤销特定用户的超级用户/root 用户的访问权限,唯一的办法就是更改 root 密码,然后再告知所有其他用户新的 root 密码。
|
||||
|
||||
而使用 `sudo` 命令就不一样了,你可以很好的处理以上的两种情况。鉴于 `sudo` 命令要求输入的是其他用户的密码,所以,不需要共享 root 密码。同时,想要阻止特定用户访问 root 权限,只需要调整 `sudoers` 文件中的相应配置即可。
|
||||
而使用 `sudo` 命令就不一样了,你可以很好的处理以上的两种情况。鉴于 `sudo` 命令要求输入的是其他用户自己的密码,所以,不需要共享 root 密码。同时,想要阻止特定用户访问 root 权限,只需要调整 `sudoers` 文件中的相应配置即可。
|
||||
|
||||
### 默认行为
|
||||
#### 默认行为
|
||||
|
||||
两个命令之间的另外一个区别是默认行为。`sudo` 命令只允许使用提升的权限运行单个命令,而 `su` 命令会启动一个新的 shell,同时允许使用 root 权限运行尽可能多的命令,直到显示退出登录。
|
||||
两个命令之间的另外一个区别是其默认行为。`sudo` 命令只允许使用提升的权限运行单个命令,而 `su` 命令会启动一个新的 shell,同时允许使用 root 权限运行尽可能多的命令,直到明确退出登录。
|
||||
|
||||
因此,`su` 命令的默认行为是有风险的,因为用户很有可能会忘记他们正在以 root 用户身份进行工作,于是,无意中做出了一些不可恢复的更改(例如:对错误的目录运行 `rm -rf` 命令)。关于为什么不鼓励以 root 用户身份进行工作的详细内容,请参考[这里][10]
|
||||
因此,`su` 命令的默认行为是有风险的,因为用户很有可能会忘记他们正在以 root 用户身份进行工作,于是,无意中做出了一些不可恢复的更改(例如:对错误的目录运行 `rm -rf` 命令!)。关于为什么不鼓励以 root 用户身份进行工作的详细内容,请参考[这里][10]。
|
||||
|
||||
### 日志记录
|
||||
#### 日志记录
|
||||
|
||||
尽管 `sudo` 命令是以目标用户(默认情况下是 root 用户)的身份执行命令,但是他们会使用 sudoer 所配置的用户名来记录是谁执行命令。而 `su` 命令是无法直接跟踪记录用户切换到 root 用户之后执行了什么操作。
|
||||
尽管 `sudo` 命令是以目标用户(默认情况下是 root 用户)的身份执行命令,但是它们会使用 `sudoer` 所配置的用户名来记录是谁执行命令。而 `su` 命令是无法直接跟踪记录用户切换到 root 用户之后执行了什么操作。
|
||||
|
||||
### 灵活性
|
||||
#### 灵活性
|
||||
|
||||
`sudo` 命令会比 `su` 命令灵活很多,因为你甚至可以限制 sudo 用户可以访问哪些命令。换句话说,用户通过 `sudo` 命令只能访问他们工作需要的命令。而 `su` 命令让用户有权限做任何事情。
|
||||
`sudo` 命令比 `su` 命令灵活很多,因为你甚至可以限制 sudo 用户可以访问哪些命令。换句话说,用户通过 `sudo` 命令只能访问他们工作需要的命令。而 `su` 命令让用户有权限做任何事情。
|
||||
|
||||
### Sudo su
|
||||
#### sudo su
|
||||
|
||||
大概是因为使用 `su` 命令或直接以 root 用户身份登录有风险,所以,一些 Linux 发行版(如 Ubuntu)默认禁用 root 用户帐户。鼓励用户在需要 root 权限时使用 `sudo` 命令。
|
||||
|
||||
However, you can still do 'su' successfully, i.e, without entering the root password. All you need to do is to run the following command:
|
||||
然而,您还是可以成功执行 `su` 命令,即不用输入 root 用户的密码。运行以下命令:
|
||||
然而,您还是可以成功执行 `su` 命令,而不用输入 root 用户的密码。运行以下命令:
|
||||
|
||||
```
|
||||
sudo su
|
||||
@ -131,7 +112,7 @@ sudo su
|
||||
|
||||
由于你使用 `sudo` 运行命令,你只需要输入当前用户的密码。所以,一旦完成操作,`su` 命令将会以 root 用户身份运行,这意味着它不会再要求输入任何密码。
|
||||
|
||||
** PS **:如果你想在系统中启用 root 用户帐户(虽然强烈反对,但你还是可以使用 `sudo` 命令或 `sudo su` 命令),你必须手动设置 root 用户密码 可以使用以下命令:
|
||||
**PS**:如果你想在系统中启用 root 用户帐户(强烈反对,因为你可以使用 `sudo` 命令或 `sudo su` 命令),你必须手动设置 root 用户密码,可以使用以下命令:
|
||||
|
||||
```
|
||||
sudo passwd root
|
||||
@ -139,7 +120,7 @@ sudo passwd root
|
||||
|
||||
### 结论
|
||||
|
||||
这篇文章以及之前的教程(其中侧重于 `sudo` 命令)应该能给你一个比较好的建议,当你需要可用的工具来提升(或一组完全不同的)权限来执行任务时。 如果您也想分享关于 `su` 或 `sudo` 的相关内容或者经验,欢迎您在下方进行评论。
|
||||
当你需要可用的工具来提升(或一组完全不同的)权限来执行任务时,这篇文章以及之前的教程(其中侧重于 `sudo` 命令)应该能给你一个比较好的建议。 如果您也想分享关于 `su` 或 `sudo` 的相关内容或者经验,欢迎您在下方进行评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -147,7 +128,7 @@ via: https://www.howtoforge.com/tutorial/sudo-vs-su/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[zhb127](https://github.com/zhb127)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,13 @@
|
||||
Create a Shared Directory on Samba AD DC and Map to Windows/Linux Clients – Part 7
|
||||
Samba 系列(七):在 Samba AD DC 服务器上创建共享目录并映射到 Windows/Linux 客户机
|
||||
============================================================
|
||||
在 Samba AD DC 服务器上创建共享目录并映射到 Windows/Linux 客户机 ——(七)
|
||||
|
||||
这篇文章将指导你如何在 Samba AD DC 服务器上创建共享目录,然后通过 GPO 把共享目录挂载到域中的其它 Windows 成员机,并且从 Windows 域控的角度来管理共享权限。
|
||||
|
||||
这篇文章也包括在加入域的 Linux 机器上如何使用 Samba4 域帐号来访问及挂载共享文件。
|
||||
|
||||
#### 需求:
|
||||
### 需求:
|
||||
|
||||
1. [在 Ubuntu 系统上使用 Samba4 创建活动目录架构][1]
|
||||
1. [在 Ubuntu 系统上使用 Samba4 创建活动目录架构][1]
|
||||
|
||||
### 第一步:创建 Samba 文件共享
|
||||
|
||||
@ -21,12 +20,13 @@ Create a Shared Directory on Samba AD DC and Map to Windows/Linux Clients – Pa
|
||||
# chmod -R 775 /nas
|
||||
# chown -R root:"domain users" /nas
|
||||
# ls -alh | grep nas
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
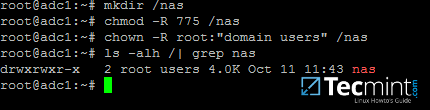
|
||||
][2]
|
||||
|
||||
创建 Samba 共享目录
|
||||
*创建 Samba 共享目录*
|
||||
|
||||
2、当你在 Samba4 AD DC 服务器上创建完成共享目录之后,你还得修改 samba 配置文件,添加下面的参数以允许通过 SMB 协议来共享文件。
|
||||
|
||||
@ -41,11 +41,12 @@ Create a Shared Directory on Samba AD DC and Map to Windows/Linux Clients – Pa
|
||||
path = /nas
|
||||
read only = no
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
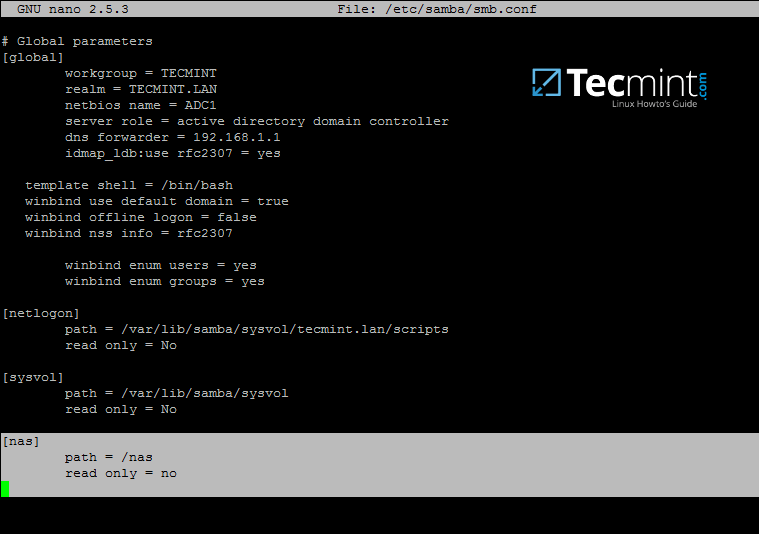
|
||||
][3]
|
||||
|
||||
配置 Samba 共享目录
|
||||
*配置 Samba 共享目录*
|
||||
|
||||
3、最后,你需要通过下面的命令重启 Samba AD DC 服务,以让修改的配置生效:
|
||||
|
||||
@ -57,117 +58,119 @@ read only = no
|
||||
|
||||
4、我们准备使用在 Samba AD DC 服务器上创建的域帐号(包括用户和组)来访问这个共享目录(禁止 Linux 系统用户访问共享目录)。
|
||||
|
||||
可以直接通过 Windows 资源管理器来完成 Samba 共享权限的管理,就跟你在 Windows 资源管理器中设置其它文件夹权限的方法一样。
|
||||
可以直接通过 Windows 资源管理器来完成 Samba 共享权限的管理,就跟你在 Windows 资源管理器中设置其它文件夹权限的方法一样。
|
||||
|
||||
首先,使用具有管理员权限的 Samba4 AD 域帐号登录到 Windows 机器。然而在 Windows 机器上的资源管理器中输入双斜杠和 Samba AD DC 服务器的 IP 地址或主机名或者是 FQDN 来访问共享文件和设置权限。
|
||||
|
||||
```
|
||||
\\adc1
|
||||
Or
|
||||
或
|
||||
\\192.168.1.254
|
||||
Or
|
||||
或
|
||||
\\adc1.tecmint.lan
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
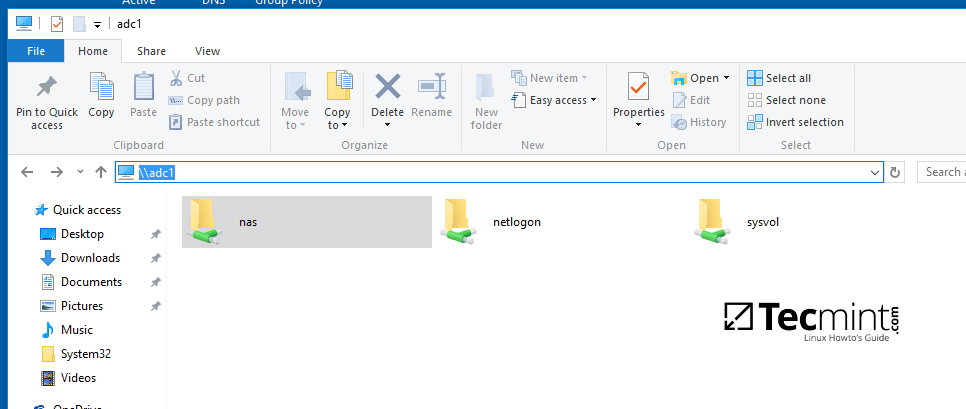
|
||||
][4]
|
||||
|
||||
从 Windows 机器访问 Samba 共享目录
|
||||
*从 Windows 机器访问 Samba 共享目录*
|
||||
|
||||
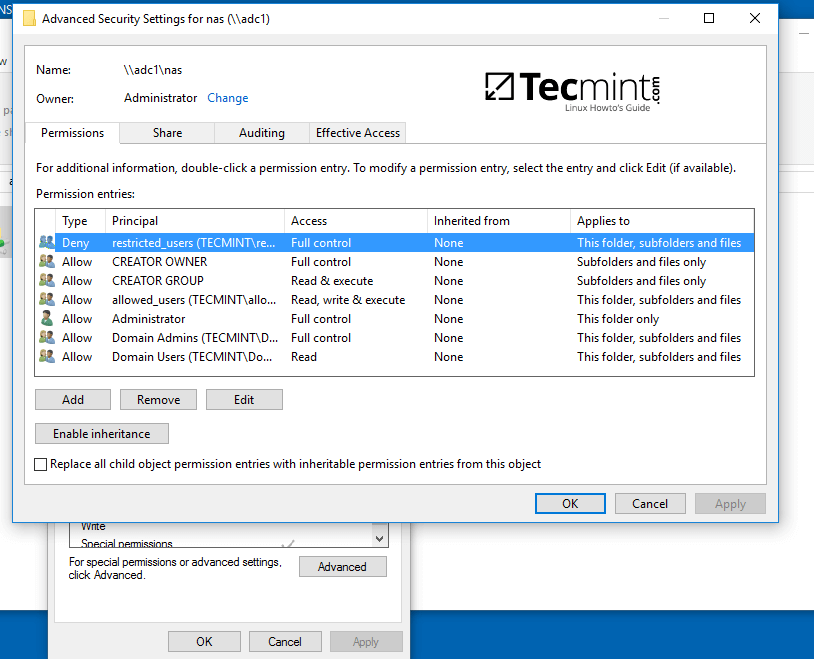
5、右键单击共享文件,选择属性来设置权限。打开安全选项卡,依次修改域账号和组权限。使用高级选项来调整权限。
|
||||
|
||||
[
|
||||

|
||||
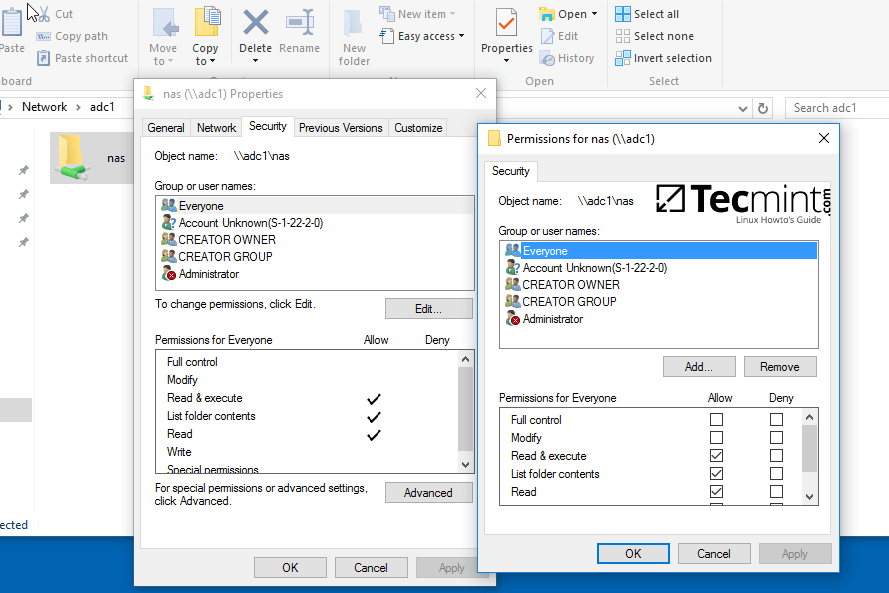
|
||||
][5]
|
||||
|
||||
配置 Samba 共享目录权限
|
||||
*配置 Samba 共享目录权限*
|
||||
|
||||
可参考下面的截图来为指定 Samba AD DC 认证用户设置权限。
|
||||
可参考下面的截图来为指定 Samba AD DC 认证用户设置权限。
|
||||
|
||||
[
|
||||

|
||||
|
||||
][6]
|
||||
|
||||
设置 Samba 共享目录用户权限
|
||||
*设置 Samba 共享目录用户权限*
|
||||
|
||||
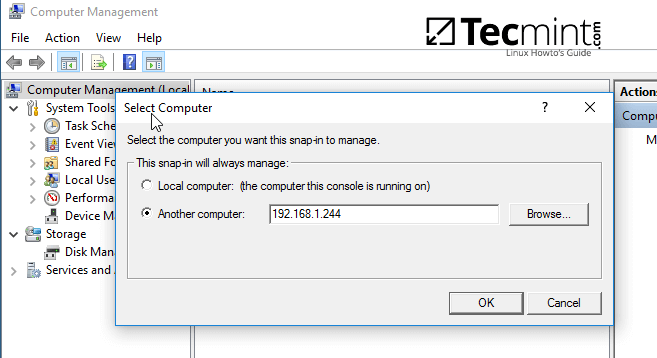
6、你也可以使用其它方法来设置共享权限,打开计算机管理-->连接到另外一台计算机。
|
||||
|
||||
找到共享目录,右键单击你想修改权限的目录,选择属性,打开安全选项卡。你可以在这里修改任何权限,就跟上图的修改共享文件夹权限的方法一样。
|
||||
|
||||
[
|
||||

|
||||
|
||||
][7]
|
||||
|
||||
连接到 Samba 共享目录服务器
|
||||
*连接到 Samba 共享目录服务器*
|
||||
|
||||
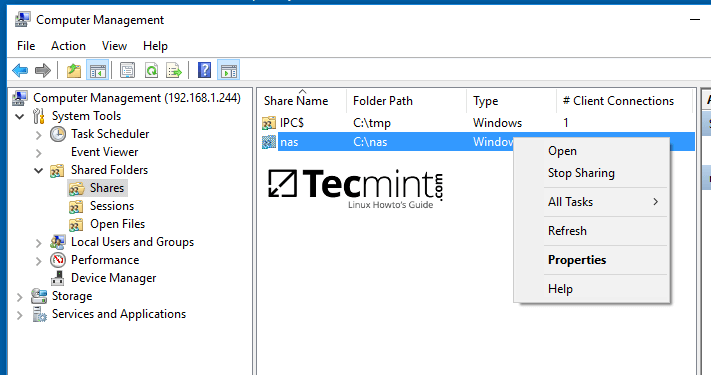
[
|
||||

|
||||
|
||||
][8]
|
||||
|
||||
管理 Samba 共享目录属性
|
||||
*管理 Samba 共享目录属性*
|
||||
|
||||
[
|
||||

|
||||

|
||||
][9]
|
||||
|
||||
为域用户授予共享目录权限
|
||||
*为域用户授予共享目录权限*
|
||||
|
||||
### 第三步:通过 GPO 来映射 Samba 文件共享
|
||||
|
||||
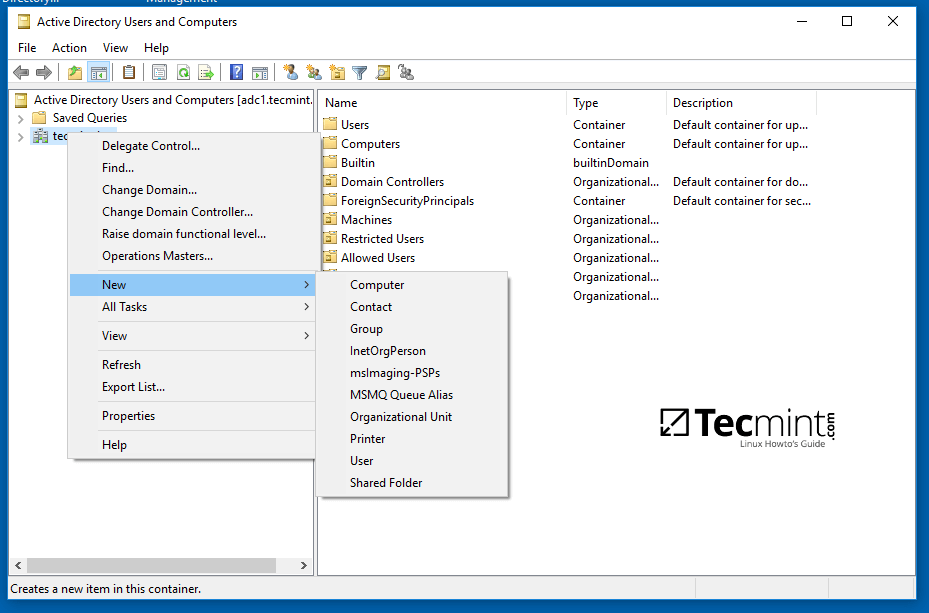
7、要想通过域组策略来挂载 Samba 共享的目录,你得先到一台[已安装了 RSAT 工具][10] 的服务器上,打开 AD DC 工具,右键单击域名,选择新建-->共享文件平。
|
||||
7、要想通过域组策略来挂载 Samba 共享的目录,你得先到一台[已安装了 RSAT 工具][10] 的服务器上,打开 AD DC 工具,右键单击域名,选择新建-->共享文件夹。
|
||||
|
||||
[
|
||||

|
||||
|
||||
][11]
|
||||
|
||||
映射 Samba 共享文件夹
|
||||
*映射 Samba 共享文件夹*
|
||||
|
||||
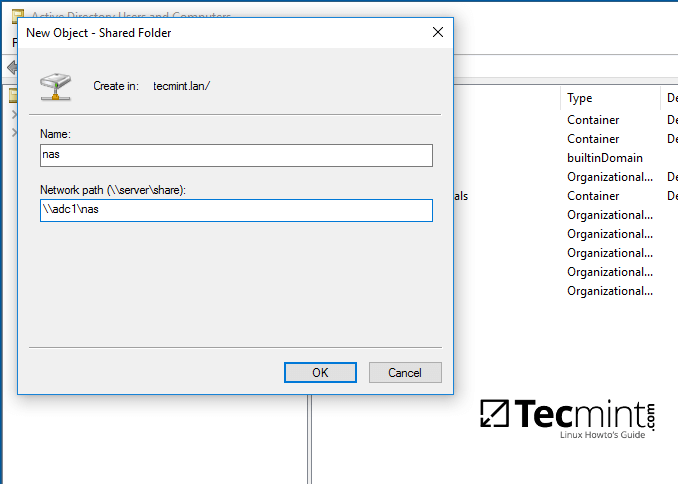
8、为共享文件夹添加一个名字,然后输入共享文件夹的网络路径,如下图所示。完成后单击 OK 按钮,你就可以在右侧看到文件夹了。
|
||||
|
||||
[
|
||||

|
||||
|
||||
][12]
|
||||
|
||||
设置 Samba 共享文件夹名称及路径
|
||||
*设置 Samba 共享文件夹名称及路径*
|
||||
|
||||
9、下一步,打开组策略管理控制台,找到当前域的默认域策略脚本,然后打开并编辑该文件。
|
||||
|
||||
在 GPM 编辑器界面,打开 GPM 编辑器,找到用户配置 --> 首选项 --> Windows 设置,然而右键单击驱动器映射,选择新建 --> 映射驱动。
|
||||
|
||||
[
|
||||

|
||||

|
||||
][13]
|
||||
|
||||
在 Windows 机器上映射 Samba 共享文件夹
|
||||
*在 Windows 机器上映射 Samba 共享文件夹*
|
||||
|
||||
10、通过单击右边的三个小点,在新窗口中查询并添加共享目录的网络位置,勾选重新连接复选框,为该目录添加一个标签,选择驱动盘符,然后单击 OK 按钮来保存和应用配置。
|
||||
|
||||
[
|
||||

|
||||

|
||||
][14]
|
||||
|
||||
配置 Samba 共享目录的网络位置
|
||||
*配置 Samba 共享目录的网络位置*
|
||||
|
||||
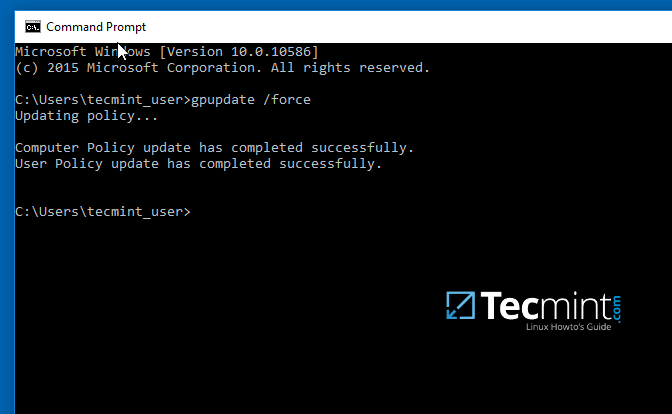
11、最后,为了在本地机器上强制应用 GPO 更改而不重启系统,打开命令行提示符,然而执行下面的命令。
|
||||
|
||||
```
|
||||
gpupdate /force
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
|
||||
][15]
|
||||
|
||||
应用 GPO 更改
|
||||
*应用 GPO 更改*
|
||||
|
||||
12、当你在本地机器上成功应用策略后,打开 Windows 资源管理器,你就可以看到并访问共享的网络文件夹了,能否正常访问共享目录取决于你在前一步的授权操作。
|
||||
|
||||
如果没有在命令行下强制应用组策略,你网络中的其它客户机需要重启或重新登录系统才可以看到共享目录。
|
||||
|
||||
[
|
||||

|
||||

|
||||
][16]
|
||||
|
||||
Windows 机器上挂载的 Samba 网络磁盘
|
||||
*Windows 机器上挂载的 Samba 网络磁盘*
|
||||
|
||||
### 第四步:从 Linux 客户端访问 Samba 共享目录
|
||||
|
||||
@ -183,14 +186,15 @@ $ sudo apt-get install smbclient cifs-utils
|
||||
|
||||
```
|
||||
$ smbclient –L your_domain_controller –U%
|
||||
or
|
||||
或
|
||||
$ smbclient –L \\adc1 –U%
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||

|
||||

|
||||
][17]
|
||||
|
||||
在 Linux 机器上列出 Samba 共享目录
|
||||
*在 Linux 机器上列出 Samba 共享目录*
|
||||
|
||||
15、在命令行下使用域帐号以交互试方式连接到 Samba 共享目录:
|
||||
|
||||
@ -198,13 +202,13 @@ $ smbclient –L \\adc1 –U%
|
||||
$ sudo smbclient //adc/share_name -U domain_user
|
||||
```
|
||||
|
||||
在命令行下,你可以列出共享目录内容,下载或上传文件到共享目录,或者执行其它操作。使用 ? 来查询所有可用的 smbclient 命令。
|
||||
在命令行下,你可以列出共享目录内容,下载或上传文件到共享目录,或者执行其它操作。使用 `?` 来查询所有可用的 smbclient 命令。
|
||||
|
||||
[
|
||||

|
||||

|
||||
][18]
|
||||
|
||||
在 Linux 机器上连接 Samba 共享目录
|
||||
*在 Linux 机器上连接 Samba 共享目录*
|
||||
|
||||
16、在 Linux 机器上使用下面的命令来挂载 samba 共享目录。
|
||||
|
||||
@ -212,16 +216,16 @@ $ sudo smbclient //adc/share_name -U domain_user
|
||||
$ sudo mount //adc/share_name /mnt -o username=domain_user
|
||||
```
|
||||
[
|
||||

|
||||
|
||||
][19]
|
||||
|
||||
在 Linux 机器上挂载 samba 共享目录
|
||||
*在 Linux 机器上挂载 samba 共享目录*
|
||||
|
||||
根据实际情况,依次替换主机名、共享目录名、挂载点和域帐号。使用 mount 命令加上管道符和 grep 参数来过滤出 cifs 类型的文件系统。
|
||||
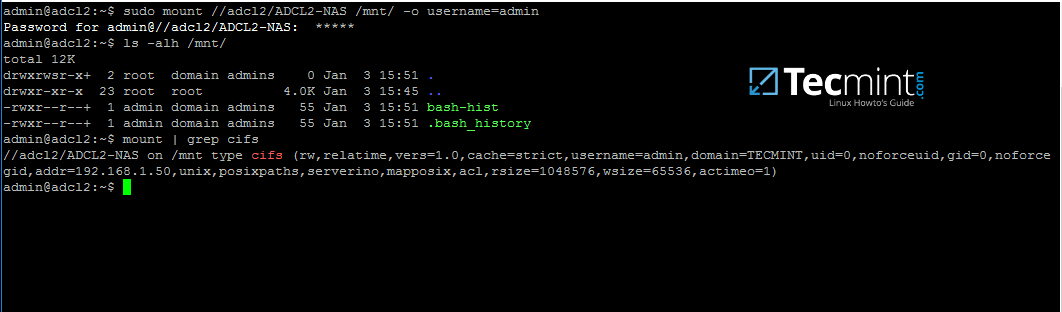
根据实际情况,依次替换主机名、共享目录名、挂载点和域帐号。使用 `mount` 命令加上管道符和 `grep` 命令来过滤出 cifs 类型的文件系统。
|
||||
|
||||
通过上面的测试,我们可以看出,在 Samba4 AD DC 服务器上配置共享目录仅使用 Windows 访问控制列表( ACL ),而不是 POSIX ACL 。
|
||||
|
||||
通过文件共享把 Samba 配置为域成员以使用其它网络共享功能。同时,在另一个域控制器上[配置 Windbindd 服务][20] ——第二步——在你开始发起网络共享文件之前。
|
||||
通过文件共享把 Samba 配置为域成员以使用其它网络共享功能。同时,在另一个域控制器上[配置 Windbindd 服务][20] ——在你开始发起网络共享文件之前。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -230,6 +234,7 @@ $ sudo mount //adc/share_name /mnt -o username=domain_user
|
||||
我是一个电脑迷,开源 Linux 系统和软件爱好者,有 4 年多的 Linux 桌面、服务器系统使用和 Base 编程经验。
|
||||
|
||||
译者简介:
|
||||
|
||||
春城初春/春水初生/春林初盛/春風十裏不如妳
|
||||
[rusking](https://github.com/rusking)
|
||||
|
||||
@ -239,7 +244,7 @@ via: http://www.tecmint.com/create-shared-directory-on-samba-ad-dc-and-map-to-wi
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -254,7 +259,7 @@ via: http://www.tecmint.com/create-shared-directory-on-samba-ad-dc-and-map-to-wi
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/Connect-to-Samba-Share-Directory-Machine.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/Manage-Samba-Share-Directory-Properties.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/Assign-Samba-Share-Directory-Permissions-to-Users.png
|
||||
[10]:http://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[10]:https://linux.cn/article-8097-1.html
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/02/Map-Samba-Share-Folder.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/02/Set-Samba-Shared-Folder-Name-Location.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/02/Map-Samba-Share-Folder-in-Windows.png
|
||||
@ -264,7 +269,7 @@ via: http://www.tecmint.com/create-shared-directory-on-samba-ad-dc-and-map-to-wi
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/02/List-Samba-Share-Directory-in-Linux.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2017/02/Connect-Samba-Share-Directory-in-Linux.png
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2017/02/Mount-Samba-Share-Directory-in-Linux.png
|
||||
[20]:http://www.tecmint.com/manage-samba4-active-directory-linux-command-line/
|
||||
[20]:https://linux.cn/article-8070-1.html
|
||||
[21]:http://www.tecmint.com/author/cezarmatei/
|
||||
[22]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[23]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,127 @@
|
||||
如何在 Ubuntu 和 Linux Mint 上启用桌面共享
|
||||
============================================================
|
||||
|
||||
桌面共享是指通过图形终端仿真器在计算机桌面上实现远程访问和远程协作的技术。桌面共享允许两个或多个连接到网络的计算机用户在不同位置对同一个文件进行操作。
|
||||
|
||||
在这篇文章中,我将向你展示如何在 Ubuntu 和 Linux Mint 中启用桌面共享,并展示一些重要的安全特性。
|
||||
|
||||
### 在 Ubuntu 和 Linux Mint 上启用桌面共享
|
||||
|
||||
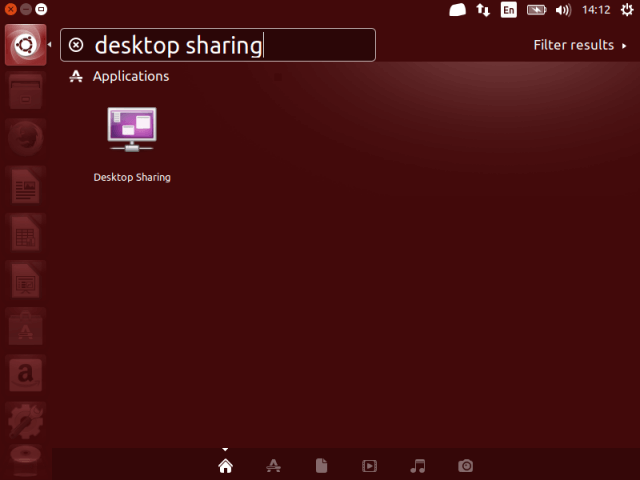
1、在 Ubuntu Dash 或 Linux Mint 菜单中,像下面的截图这样搜索 `desktop sharing`,搜索到以后,打开它。
|
||||
|
||||
[
|
||||
|
||||
][1]
|
||||
|
||||
*在 Ubuntu 中搜索 Desktop sharing*
|
||||
|
||||
2、打开 Desktop sharing 以后,有三个关于桌面共享设置的选项:共享、安全以及通知设置。
|
||||
|
||||
在共享选项下面,选中选项“允许其他用户查看桌面”来启用桌面共享。另外,你还可以选中选项“允许其他用户控制你的桌面”,从而允许其他用户远程控制你的桌面。
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
*桌面共享偏好*
|
||||
|
||||
3、接下来,在“安全”部分,你可以通过勾选选项“你必须确认任何对该计算机的访问”来手动确认每个远程连接。
|
||||
|
||||
另外,另一个有用的安全特性是通过选项“需要用户输入密码”创建一个确定的共享密码。这样当用户每次想要访问你的桌面时需要知道并输入密码。
|
||||
|
||||
4、对于通知,你可以勾选“仅当有人连接上时”来监视远程连接,这样每次当有人远程连接到你的桌面时,可以在通知区域查看。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
*配置桌面共享设置*
|
||||
|
||||
当所有的桌面共享选项都设置好以后,点击“关闭”。现在,你已经在你的 Ubuntu 或 Linux Mint 上成功启用了桌面共享。
|
||||
|
||||
### 测试 Ubuntu 的远程桌面共享
|
||||
|
||||
你可以通过使用一个远程连接应用来进行测试,从而确保桌面共享可用。在这个例子中,我将展示上面设置的一些选项是如何工作的。
|
||||
|
||||
5、我将使用 VNC(虚拟网络计算)协议通过 [remmina 远程连接应用][4]连接到我的 Ubuntu PC。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
*Remmina 桌面共享工具*
|
||||
|
||||
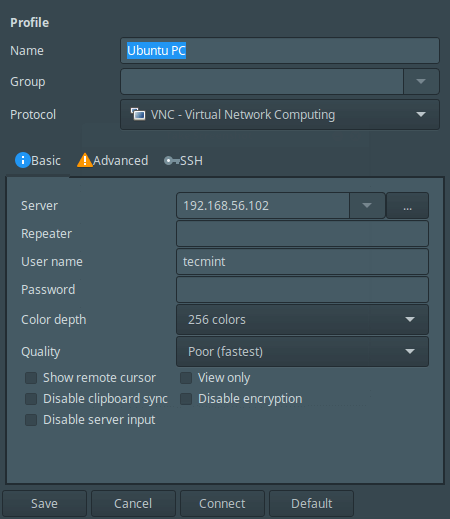
6、在点击 Ubuntu PC 以后,将会出现下面这个配置连接设置的界面,
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
*Remmina 桌面共享偏好*
|
||||
|
||||
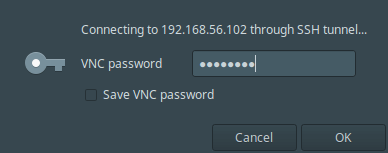
7、当执行好所有设置以后,点击连接。然后,给用户名提供 SSH 密码并点击 OK 。
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
*输入 SSH 用户密码*
|
||||
|
||||
点击确定以后,出现下面这个黑屏,这是因为在远程机器上,连接还没有确认。
|
||||
|
||||
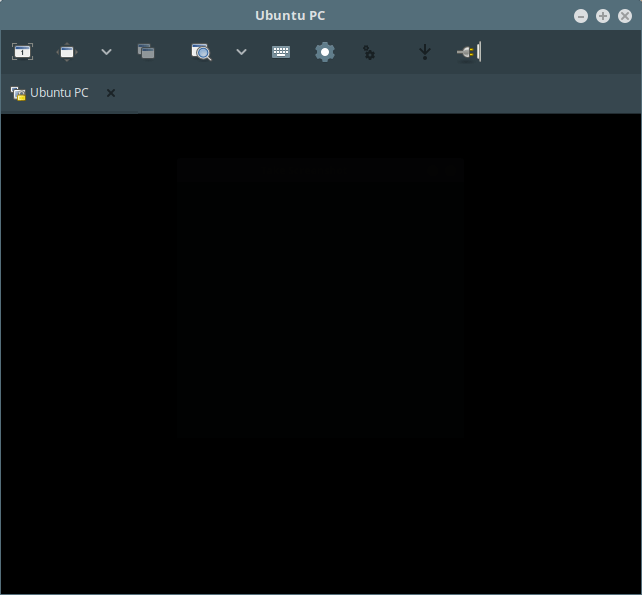
[
|
||||
|
||||
][8]
|
||||
|
||||
*连接确认前的黑屏*
|
||||
|
||||
8、现在,在远程机器上,我需要如下一个屏幕截图显示的那样点击 `Allow` 来接受远程访问请求。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*允许远程桌面共享*
|
||||
|
||||
9、在接受请求以后,我就成功地连接到了远程 Ubuntu 机器的桌面。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
*远程 Ubuntu 桌面*
|
||||
|
||||
这就是全部内容了,在这篇文章中,我们讲解了如何在 Ubuntu 和 Linux Mint 中启用桌面共享。你使用评论部分给我们写反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux 系统管理员和网络开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/enable-desktop-sharing-in-ubuntu-linux-mint/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2017/03/search-for-desktop-sharing.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/03/desktop-sharing-settings-inte.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Desktop-Sharing-Set.png
|
||||
[4]:http://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Desktop-Sharing-Tool.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Configure-Remote-Desk.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/shared-pass.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/black-screen-before-confirmat.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/accept-remote-access-request.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/successfully-connected-to-rem.png
|
||||
[11]:http://www.tecmint.com/author/aaronkili/
|
||||
[12]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[13]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,233 +0,0 @@
|
||||
translating by XLCYun
|
||||
|
||||
Reactive programming vs. Reactive systems
|
||||
============================================================
|
||||
|
||||
>Landing on a set of simple reactive design principles in a sea of constant confusion and overloaded expectations.
|
||||
|
||||

|
||||
|
||||
Download Konrad Malawski's free ebook "[Why Reactive? Foundational Principles for Enterprise Adoption][5]" to dive deeper into the technical aspects and benefits of Reactive.
|
||||
|
||||
Since co-authoring the "[Reactive Manifesto][23]" in 2013, we’ve seen the topic of reactive go from being a virtually unacknowledged technique for constructing applications—used by only fringe projects within a select few corporations—to become part of the overall platform strategy in numerous big players in the middleware field. This article aims to define and clarify the different aspects of reactive by looking at the differences between writing code in a _reactive programming_ style, and the design of _reactive systems_ as a cohesive whole.
|
||||
|
||||
### Reactive is a set of design principles
|
||||
|
||||
One recent indicator of success is that "reactive" has become an overloaded term and is now being associated with several different things to different people—in good company with words like "streaming," "lightweight," and "real-time."
|
||||
|
||||
Consider the following analogy: When looking at an athletic team (think: baseball, basketball, etc.) it’s not uncommon to see it composed of exceptional individuals, yet when they come together something doesn’t click and they lack the synergy to operate effectively as a team and lose to an "inferior" team.From the perspective of this article, reactive is a set of design principles, a way of thinking about systems architecture and design in a distributed environment where implementation techniques, tooling, and design patterns are components of a larger whole—a system.
|
||||
|
||||
This analogy illustrates the difference between a set of reactive applications put together without thought—even though _individually_ they’re great—and a reactive system. In a reactive system, it’s the _interaction between the individual parts_ that makes all the difference, which is the ability to operate individually yet act in concert to achieve their intended result.
|
||||
|
||||
_A reactive system_ is an architectural style that allows multiple individual applications to coalesce as a single unit, reacting to its surroundings, while remaining aware of each other—this could manifest as being able to scale up/down, load balancing, and even taking some of these steps proactively.
|
||||
|
||||
It’s possible to write a single application in a reactive style (i.e. using reactive programming); however, that’s merely one piece of the puzzle. Though each of the above aspects may seem to qualify as "reactive," in and of themselves they do not make a _system_ reactive.
|
||||
|
||||
When people talk about "reactive" in the context of software development and design, they generally mean one of three things:
|
||||
|
||||
* Reactive systems (architecture and design)
|
||||
* Reactive programming (declarative event-based)
|
||||
* Functional reactive programming (FRP)
|
||||
|
||||
We’ll examine what each of these practices and techniques mean, with emphasis on the first two. More specifically, we’ll discuss when to use them, how they relate to each other, and what you can expect the benefits from each to be—particularly in the context of building systems for multicore, cloud, and mobile architectures.
|
||||
|
||||
Let’s start by talking about functional reactive programming, and why we chose to exclude it from further discussions in this article.
|
||||
|
||||
### Functional reactive programming (FRP)
|
||||
|
||||
_Functional reactive programming_, commonly called _FRP_, is most frequently misunderstood. FRP was very [precisely defined][24] 20 years ago by Conal Elliott. The term has most recently been used incorrectly[1][8] to describe technologies like Elm, Bacon.js, and Reactive Extensions (RxJava, Rx.NET, RxJS) amongst others. Most libraries claiming to support FRP are almost exclusively talking about _reactive programming_ and it will therefore not be discussed further.
|
||||
|
||||
### Reactive programming
|
||||
|
||||
_Reactive programming_, not to be confused with _functional reactive programming_, is a subset of asynchronous programming and a paradigm where the availability of new information drives the logic forward rather than having control flow driven by a thread-of-execution.
|
||||
|
||||
It supports decomposing the problem into multiple discrete steps where each can be executed in an asynchronous and non-blocking fashion, and then be composed to produce a workflow—possibly unbounded in its inputs or outputs.
|
||||
|
||||
[Asynchronous][25] is defined by the Oxford Dictionary as “not existing or occurring at the same time,” which in this context means that the processing of a message or event is happening at some arbitrary time, possibly in the future. This is a very important technique in reactive programming since it allows for [non-blocking][26] execution—where threads of execution competing for a shared resource don’t need to wait by blocking (preventing the thread of execution from performing other work until current work is done), and can as such perform other useful work while the resource is occupied. Amdahl’s Law[2][9] tells us that contention is the biggest enemy of scalability, and therefore a reactive program should rarely, if ever, have to block.
|
||||
|
||||
Reactive programming is generally _event-driven_, in contrast to reactive systems, which are _message-driven_—the distinction between event-driven and message-driven is clarified later in this article.
|
||||
|
||||
The application program interface (API) for reactive programming libraries are generally either:
|
||||
|
||||
* Callback-based—where anonymous side-effecting callbacks are attached to event sources, and are being invoked when events pass through the dataflow chain.
|
||||
* Declarative—through functional composition, usually using well-established combinators like _map_, _filter_, _fold_etc.
|
||||
|
||||
Most libraries provide a mix of these two styles, often with the addition of stream-based operators like windowing, counts, triggers, etc.
|
||||
|
||||
It would be reasonable to claim that reactive programming is related to [dataflow programming][27], since the emphasis is on the _flow of data_ rather than the _flow of control_.
|
||||
|
||||
Examples of programming abstractions that support this programming technique are:
|
||||
|
||||
* [Futures/Promises][10]—containers of a single value, many-read/single-write semantics where asynchronous transformations of the value can be added even if it is not yet available.
|
||||
* Streams—as in [reactive streams][11]: unbounded flows of data processing, enabling asynchronous, non-blocking, back-pressured transformation pipelines between a multitude of sources and destinations.
|
||||
* [Dataflow variables][12]—single assignment variables (memory-cells) which can depend on input, procedures and other cells, so that they are automatically updated on change. A practical example is spreadsheets—where the change of the value in a cell ripples through all dependent functions, producing new values downstream.
|
||||
|
||||
Popular libraries supporting the reactive programming techniques on the JVM include, but are not limited to, Akka Streams, Ratpack, Reactor, RxJava, and Vert.x. These libraries implement the reactive streams specification, which is a standard for interoperability between reactive programming libraries on the JVM, and according to its own description is “...an initiative to provide a standard for asynchronous stream processing with non-blocking back pressure.”
|
||||
|
||||
The primary benefits of reactive programming are: increased utilization of computing resources on multicore and multi-CPU hardware; and increased performance by reducing serialization points as per Amdahl’s Law and, by extension, Günther’s Universal Scalability Law[3][13].
|
||||
|
||||
A secondary benefit is one of developer productivity as traditional programming paradigms have all struggled to provide a straightforward and maintainable approach to dealing with asynchronous and non-blocking computation and I/O. Reactive programming solves most of the challenges here since it typically removes the need for explicit coordination between active components.
|
||||
|
||||
Where reactive programming shines is in the creation of components and composition of workflows. In order to take full advantage of asynchronous execution, the inclusion of [back-pressure][28] is crucial to avoid over-utilization, or rather unbounded consumption of resources.
|
||||
|
||||
Even though reactive programming is a very useful piece when constructing modern software, in order to reason about a system at a higher level one has to use another tool: _reactive architecture_—the process of designing reactive systems. Furthermore, it is important to remember that there are many programming paradigms and reactive programming is but one of them, so just as with any tool, it is not intended for any and all use-cases.
|
||||
|
||||
### Event-driven vs. message-driven
|
||||
|
||||
As mentioned previously, reactive programming—focusing on computation through ephemeral dataflow chains—tend to be _event-driven_, while reactive systems—focusing on resilience and elasticity through the communication, and coordination, of distributed systems—is [_message-driven_][29][4][14](also referred to as _messaging_).
|
||||
|
||||
The main difference between a message-driven system with long-lived addressable components, and an event-driven dataflow-driven model, is that messages are inherently directed, events are not. Messages have a clear (single) destination, while events are facts for others to observe. Furthermore, messaging is preferably asynchronous, with the sending and the reception decoupled from the sender and receiver respectively.
|
||||
|
||||
The glossary in the Reactive Manifesto [defines the conceptual difference as][30]:
|
||||
|
||||
> A message is an item of data that is sent to a specific destination. An event is a signal emitted by a component upon reaching a given state. In a message-driven system addressable recipients await the arrival of messages and react to them, otherwise lying dormant. In an event-driven system notification listeners are attached to the sources of events such that they are invoked when the event is emitted. This means that an event-driven system focuses on addressable event sources while a message-driven system concentrates on addressable recipients.
|
||||
|
||||
Messages are needed to communicate across the network and form the basis for communication in distributed systems, while events on the other hand are emitted locally. It is common to use messaging under the hood to bridge an event-driven system across the network by sending events inside messages. This allows maintaining the relative simplicity of the event-driven programming model in a distributed context and can work very well for specialized and well-scoped use cases (e.g., AWS Lambda, Distributed Stream Processing products like Spark Streaming, Flink, Kafka, and Akka Streams over Gearpump, and distributed Publish Subscribe products like Kafka and Kinesis).
|
||||
|
||||
However, it is a trade-off: what one gains in abstraction and simplicity of the programming model, one loses in terms of control. Messaging forces us to embrace the reality and constraints of distributed systems—things like partial failures, failure detection, dropped/duplicated/reordered messages, eventual consistency, managing multiple concurrent realities, etc.—and tackle them head on instead of hiding them behind a leaky abstraction—pretending that the network is not there—as has been done too many times in the past (e.g. EJB, [RPC][31], [CORBA][32], and [XA][33]).
|
||||
|
||||
These differences in semantics and applicability have profound implications in the application design, including things like _resilience_, _elasticity_, _mobility_, _location transparency,_ and _management_ of the complexity of distributed systems, which will be explained further in this article.
|
||||
|
||||
In a reactive system, especially one which uses reactive programming, both events and messages will be present—as one is a great tool for communication (messages), and another is a great way of representing facts (events).
|
||||
|
||||
### Reactive systems and architecture
|
||||
|
||||
_Reactive systems_—as defined by the Reactive Manifesto—is a set of architectural design principles for building modern systems that are well prepared to meet the increasing demands that applications face today.
|
||||
|
||||
The principles of reactive systems are most definitely not new, and can be traced back to the '70s and '80s and the seminal work by Jim Gray and Pat Helland on the [Tandem System][34] and Joe Armstrong and Robert Virding on [Erlang][35]. However, these people were ahead of their time and it is not until the last 5-10 years that the technology industry have been forced to rethink current best practices for enterprise system development and learn to apply the hard-won knowledge of the reactive principles on today’s world of multicore, cloud computing, and the Internet of Things.
|
||||
|
||||
The foundation for a reactive system is _message-passing_, which creates a temporal boundary between components that allows them to be decoupled in _time_—this allows for concurrency—and _space_—which allows for distribution and mobility. This decoupling is a requirement for full [isolation][36]between components, and forms the basis for both _resilience_ and _elasticity_.
|
||||
|
||||
### From programs to systems
|
||||
|
||||
The world is becoming increasingly interconnected. We are no longer building _programs_—end-to-end logic to calculate something for a single operator—as much as we are building _systems_.
|
||||
|
||||
Systems are complex by definition—each consisting of a multitude of components, who in and of themselves also can be systems—which mean software is increasingly dependent on other software to function properly.
|
||||
|
||||
The systems we create today are to be operated on computers small and large, few and many, near each other or half a world away. And at the same time users’ expectations have become harder and harder to meet as everyday human life is increasingly dependent on the availability of systems to function smoothly.
|
||||
|
||||
In order to deliver systems that users—and businesses—can depend on, they have to be _responsive_, for it does not matter if something provides the correct response if the response is not available when it is needed. In order to achieve this, we need to make sure that responsiveness can be maintained under failure (_resilience_) and under load (_elasticity_). To make that happen, we make these systems _message-driven_, and we call them _reactive systems_.
|
||||
|
||||
### The resilience of reactive systems
|
||||
|
||||
Resilience is about responsiveness _under failure_ and is an inherent functional property of the system, something that needs to be designed for, and not something that can be added in retroactively. Resilience is beyond fault-tolerance—it’s not about graceful degradation—even though that is a very useful trait for systems—but about being able to fully recover from failure: to _self-heal_. This requires component isolation and containment of failures in order to avoid failures spreading to neighbouring components—resulting in, often catastrophic, cascading failure scenarios.
|
||||
|
||||
So the key to building resilient, self-healing systems is to allow failures to be: contained, reified as messages, sent to other components (that act as supervisors), and managed from a safe context outside the failed component. Here, being message-driven is the enabler: moving away from strongly coupled, brittle, deeply nested synchronous call chains that everyone learned to suffer through, or ignore. The idea is to decouple the management of failures from the call chain, freeing the client from the responsibility of handling the failures of the server.
|
||||
|
||||
### The elasticity of reactive systems
|
||||
|
||||
[Elasticity][37] is about _responsiveness under load_—meaning that the throughput of a system scales up or down (as well as in or out) automatically to meet varying demand as resources are proportionally added or removed. It is the essential element needed to take advantage of the promises of cloud computing: allowing systems to be resource efficient, cost-efficient, environment-friendly and pay-per-use.
|
||||
|
||||
Systems need to be adaptive—allow intervention-less auto-scaling, replication of state and behavior, load-balancing of communication, failover, and upgrades, without rewriting or even reconfiguring the system. The enabler for this is _location transparency_: the ability to scale the system in the same way, using the same programming abstractions, with the same semantics, _across all dimensions of scale_—from CPU cores to data centers.
|
||||
|
||||
As the Reactive Manifesto [puts it][38]:
|
||||
|
||||
> One key insight that simplifies this problem immensely is to realize that we are all doing distributed computing. This is true whether we are running our systems on a single node (with multiple independent CPUs communicating over the QPI link) or on a cluster of nodes (with independent machines communicating over the network). Embracing this fact means that there is no conceptual difference between scaling vertically on multicore or horizontally on the cluster. This decoupling in space [...], enabled through asynchronous message-passing, and decoupling of the runtime instances from their references is what we call Location Transparency.
|
||||
|
||||
So no matter where the recipient resides, we communicate with it in the same way. The only way that can be done semantically equivalent is via messaging.
|
||||
|
||||
### The productivity of reactive systems
|
||||
|
||||
As most systems are inherently complex by nature, one of the most important aspects is to make sure that a system architecture will impose a minimal reduction of productivity, in the development and maintenance of components, while at the same time reducing the operational _accidental complexity_ to a minimum.
|
||||
|
||||
This is important since during the lifecycle of a system—if not properly designed—it will become harder and harder to maintain, and require an ever-increasing amount of time and effort to understand, in order to localize and to rectify problems.
|
||||
|
||||
Reactive systems are the most _productive_ systems architecture that we know of (in the context of multicore, cloud and mobile architectures):
|
||||
|
||||
* Isolation of failures offer [bulkheads][15] between components, preventing failures to cascade, which limits the scope and severity of failures.
|
||||
* Supervisor hierarchies offer multiple levels of defenses paired with self-healing capabilities, which remove a lot of transient failures from ever incurring any operational cost to investigate.
|
||||
* Message-passing and location transparency allow for components to be taken offline and replaced or rerouted without affecting the end-user experience, reducing the cost of disruptions, their relative urgency, and also the resources required to diagnose and rectify.
|
||||
* Replication reduces the risk of data loss, and lessens the impact of failure on the availability of retrieval and storage of information.
|
||||
* Elasticity allows for conservation of resources as usage fluctuates, allowing for minimizing operational costs when load is low, and minimizing the risk of outages or urgent investment into scalability as load increases.
|
||||
|
||||
Thus, reactive systems allows for the creation systems that cope well under failure, varying load and change over time—all while offering a low cost of ownership over time.
|
||||
|
||||
### How does reactive programming relate to reactive systems?
|
||||
|
||||
Reactive programming is a great technique for managing internal logic and dataflow transformation, locally within the components, as a way of optimizing code clarity, performance and resource efficiency. Reactive systems, being a set of architectural principles, puts the emphasis on distributed communication and gives us tools to tackle resilience and elasticity in distributed systems.
|
||||
|
||||
One common problem with only leveraging reactive programming is that its tight coupling between computation stages in an event-driven callback-based or declarative program makes _resilience_ harder to achieve as its transformation chains are often ephemeral and its stages—the callbacks or combinators—are anonymous, i.e. not addressable.
|
||||
|
||||
This means that they usually handle success or failure directly without signaling it to the outside world. This lack of addressability makes recovery of individual stages harder to achieve as it is typically unclear where exceptions should, or even could, be propagated. As a result, failures are tied to ephemeral client requests instead of to the overall health of the component—if one of the stages in the dataflow chain fails, then the whole chain needs to be restarted, and the client notified. This is in contrast to a message-driven reactive system which has the ability to self-heal, without necessitating notifying the client.
|
||||
|
||||
Another contrast to the reactive systems approach is that pure reactive programming allows decoupling in _time_, but not _space_ (unless leveraging message-passing to distribute the dataflow graph under the hood, across the network, as discussed previously). As mentioned, decoupling in time allows for _concurrency_, but it is decoupling in space that allows for _distribution_, and _mobility_—allowing for not only static but also dynamic topologies—which is essential for _elasticity_.
|
||||
|
||||
A lack of location transparency makes it hard to scale out a program purely based on reactive programming techniques adaptively in an elastic fashion and therefore requires layering additional tools, such as a message bus, data grid, or bespoke network protocols on top. This is where the message-driven programming of reactive systems shines, since it is a communication abstraction that maintains its programming model and semantics across all dimensions of scale, and therefore reduces system complexity and cognitive overhead.
|
||||
|
||||
A commonly cited problem of callback-based programming is that while writing such programs may be comparatively easy, it can have real consequences in the long run.
|
||||
|
||||
For example, systems based on anonymous callbacks provide very little insight when you need to reason about them, maintain them, or most importantly figure out what, where, and why production outages and misbehavior occur.
|
||||
|
||||
Libraries and platforms designed for reactive systems (such as the [Akka][39] project and the [Erlang][40] platform) have long learned this lesson and are relying on long-lived addressable components that are easier to reason about in the long run. When failures occurs, the component is uniquely identifiable along with the message that caused the failure. With the concept of addressability at the core of the component model, monitoring solutions have a _meaningful_ way to present data that is gathered—leveraging the identities that are propagated.
|
||||
|
||||
The choice of a good programming paradigm, one that enforces things like addressability and failure management, has proven to be invaluable in production, as it is designed with the harshness of reality in mind, to _expect and embrace failure_ rather than the lost cause of trying to prevent it.
|
||||
|
||||
All in all, reactive programming is a very useful implementation technique, which can be used in a reactive architecture. Remember that it will only help manage one part of the story: dataflow management through asynchronous and nonblocking execution—usually only within a single node or service. Once there are multiple nodes, there is a need to start thinking hard about things like data consistency, cross-node communication, coordination, versioning, orchestration, failure management, separation of concerns and responsibilities etc.—i.e. system architecture.
|
||||
|
||||
Therefore, to maximize the value of reactive programming, use it as one of the tools to construct a reactive system. Building a reactive system requires more than abstracting away OS-specific resources and sprinkling asynchronous APIs and [circuit breakers][41] on top of an existing, legacy, software stack. It should be about embracing the fact that you are building a distributed system comprising multiple services—that all need to work together, providing a consistent and responsive experience, not just when things work as expected but also in the face of failure and under unpredictable load.
|
||||
|
||||
### Summary
|
||||
|
||||
Enterprises and middleware vendors alike are beginning to embrace reactive, with 2016 witnessing a huge growth in corporate interest in adopting reactive. In this article, we have described reactive systems as being the end goal—assuming the context of multicore, cloud and mobile architectures—for enterprises, with reactive programming serving as one of the important tools.
|
||||
|
||||
Reactive programming offers productivity for developers—through performance and resource efficiency—at the component level for internal logic and dataflow transformation. Reactive systems offer productivity for architects and DevOps practitioners—through resilience and elasticity—at the system level, for building _cloud native_ and other large-scale distributed systems. We recommend combining the techniques of reactive programming within the design principles of reactive systems.
|
||||
|
||||
```
|
||||
1 According to Conal Elliott, the inventor of FRP, in [this presentation][16][↩][17]
|
||||
2 [Amdahl’s Law][18] shows that the theoretical speedup of a system is limited by the serial parts, which means that the system can experience diminishing returns as new resources are added. [↩][19]
|
||||
3 Neil Günter’s [Universal Scalability Law][20] is an essential tool in understanding the effects of contention and coordination in concurrent and distributed systems, and shows that the cost of coherency in a system can lead to negative results, as new resources are added to the system.[↩][21]
|
||||
4 Messaging can be either synchronous (requiring the sender and receiver to be available at the same time) or asynchronous (allowing them to be decoupled in time). Discussing the semantic differences is out scope for this article.[↩][22]
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems
|
||||
|
||||
作者:[Jonas Bonér][a] , [Viktor Klang][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/e0b57-jonas-boner
|
||||
[b]:https://www.oreilly.com/people/f96106d4-4ce6-41d9-9d2b-d24590598fcd
|
||||
[1]:https://www.flickr.com/photos/pixel_addict/2301302732
|
||||
[2]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[3]:https://www.oreilly.com/people/e0b57-jonas-boner
|
||||
[4]:https://www.oreilly.com/people/f96106d4-4ce6-41d9-9d2b-d24590598fcd
|
||||
[5]:http://www.oreilly.com/programming/free/why-reactive.csp?intcmp=il-webops-free-product-na_new_site_reactive_programming_vs_reactive_systems_text_cta
|
||||
[6]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[7]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[8]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-1
|
||||
[9]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-2
|
||||
[10]:https://en.wikipedia.org/wiki/Futures_and_promises
|
||||
[11]:http://reactive-streams.org/
|
||||
[12]:https://en.wikipedia.org/wiki/Oz_(programming_language)#Dataflow_variables_and_declarative_concurrency
|
||||
[13]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-3
|
||||
[14]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-4
|
||||
[15]:http://skife.org/architecture/fault-tolerance/2009/12/31/bulkheads.html
|
||||
[16]:https://begriffs.com/posts/2015-07-22-essence-of-frp.html
|
||||
[17]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-1
|
||||
[18]:https://en.wikipedia.org/wiki/Amdahl%2527s_law
|
||||
[19]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-2
|
||||
[20]:http://www.perfdynamics.com/Manifesto/USLscalability.html
|
||||
[21]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-3
|
||||
[22]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-4
|
||||
[23]:http://www.reactivemanifesto.org/
|
||||
[24]:http://conal.net/papers/icfp97/
|
||||
[25]:http://www.reactivemanifesto.org/glossary#Asynchronous
|
||||
[26]:http://www.reactivemanifesto.org/glossary#Non-Blocking
|
||||
[27]:https://en.wikipedia.org/wiki/Dataflow_programming
|
||||
[28]:http://www.reactivemanifesto.org/glossary#Back-Pressure
|
||||
[29]:http://www.reactivemanifesto.org/glossary#Message-Driven
|
||||
[30]:http://www.reactivemanifesto.org/glossary#Message-Driven
|
||||
[31]:https://christophermeiklejohn.com/pl/2016/04/12/rpc.html
|
||||
[32]:https://queue.acm.org/detail.cfm?id=1142044
|
||||
[33]:https://cs.brown.edu/courses/cs227/archives/2012/papers/weaker/cidr07p15.pdf
|
||||
[34]:http://www.hpl.hp.com/techreports/tandem/TR-86.2.pdf
|
||||
[35]:http://erlang.org/download/armstrong_thesis_2003.pdf
|
||||
[36]:http://www.reactivemanifesto.org/glossary#Isolation
|
||||
[37]:http://www.reactivemanifesto.org/glossary#Elasticity
|
||||
[38]:http://www.reactivemanifesto.org/glossary#Location-Transparency
|
||||
[39]:http://akka.io/
|
||||
[40]:https://www.erlang.org/
|
||||
[41]:http://martinfowler.com/bliki/CircuitBreaker.html
|
||||
@ -1,266 +0,0 @@
|
||||
willcoderwang 翻译中
|
||||
How to Install Jenkins Automation Server with Apache on Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
|
||||
Jenkins is an automation server forked from the Hudson project. Jenkins is a server based application running in a Java servlet container, it has support for many SCM (Source Control Management) software systems including Git, SVN, and Mercurial. Jenkins provides hundreds of plugins to automate your project. Jenkins created by Kohsuke Kawaguchi, first released in 2011 under MIT License, and it's free software.
|
||||
|
||||
In this tutorial, I will show you how to install the latest Jenkins version on Ubuntu Server 16.04\. We will run Jenkins on our own domain name, and we will to install and configure Jenkins to run under the apache web server with the reverse proxy for Jenkins.
|
||||
|
||||
### Prerequisite
|
||||
|
||||
* Ubuntu Server 16.04 - 64bit
|
||||
* Root Privileges
|
||||
|
||||
### Step 1 - Install Java OpenJDK 7
|
||||
|
||||
Jenkins is based on Java, so we need to install Java OpenJDK version 7 on the server. In this step, we will install Java 7 from a PPA repository which we will add first.
|
||||
|
||||
By default, Ubuntu 16.04 ships without the python-software-properties package for managing PPA repositories, so we must install this package first. Install python-software-properties with apt command.
|
||||
|
||||
apt-get install python-software-properties
|
||||
|
||||
Next, add Java PPA repository to the server.
|
||||
|
||||
add-apt-repository ppa:openjdk-r/ppa
|
||||
Just Press ENTER
|
||||
|
||||
Update the Ubuntu repository and install the Java OpenJDK with apt command.
|
||||
|
||||
apt-get update
|
||||
apt-get install openjdk-7-jdk
|
||||
|
||||
Verify the installation by typing the command below:
|
||||
|
||||
java -version
|
||||
|
||||
and you will get the Java version that is installed on the server.
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
### Step 2 - Install Jenkins
|
||||
|
||||
Jenkins provides an Ubuntu repository for the installation packages and we will install Jenkins from this repository.
|
||||
|
||||
Add Jenkins key and repository to the system with the command below.
|
||||
|
||||
wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -
|
||||
echo 'deb https://pkg.jenkins.io/debian-stable binary/' | tee -a /etc/apt/sources.list
|
||||
|
||||
Update the repository and install Jenkins.
|
||||
|
||||
apt-get update
|
||||
apt-get install jenkins
|
||||
|
||||
When the installation is done, start Jenkins with this systemctl command.
|
||||
|
||||
systemctl start jenkins
|
||||
|
||||
Verify that Jenkins is running by checking the default port used by Jenkins (port 8080). I will check it with the netstat command below:
|
||||
|
||||
netstat -plntu
|
||||
|
||||
Jenkins is installed and running on port 8080.
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
### Step 3 - Install and Configure Apache as Reverse Proxy for Jenkins
|
||||
|
||||
In this tutorial we will run Jenkins behind an apache web server, we will configure apache as the reverse proxy for Jenkins. First I will install apache and enable some require modules, and then I'll create the virtual host file with domain name my.jenkins.id for Jenkins. Please use your own domain name here and replace it in all config files wherever it appears.
|
||||
|
||||
Install apache2 web server from Ubuntu repository.
|
||||
|
||||
apt-get install apache2
|
||||
|
||||
When the installation is done, enable the proxy and proxy_http modules so we can configure apache as frontend server/reverse proxy for Jenkins.
|
||||
|
||||
a2enmod proxy
|
||||
a2enmod proxy_http
|
||||
|
||||
Next, create a new virtual host file in the sites-available directory.
|
||||
|
||||
cd /etc/apache2/sites-available/
|
||||
vim jenkins.conf
|
||||
|
||||
Paste virtual host configuration below.
|
||||
|
||||
```
|
||||
<Virtualhost *:80>
|
||||
ServerName my.jenkins.id
|
||||
ProxyRequests Off
|
||||
ProxyPreserveHost On
|
||||
AllowEncodedSlashes NoDecode
|
||||
|
||||
<Proxy http://localhost:8080/*>
|
||||
Order deny,allow
|
||||
Allow from all
|
||||
</Proxy>
|
||||
|
||||
ProxyPass / http://localhost:8080/ nocanon
|
||||
ProxyPassReverse / http://localhost:8080/
|
||||
ProxyPassReverse / http://my.jenkins.id/
|
||||
</Virtualhost>
|
||||
```
|
||||
|
||||
Save the file. Then activate the Jenkins virtual host with the a2ensite command.
|
||||
|
||||
a2ensite jenkins
|
||||
|
||||
Restart Apache and Jenkins.
|
||||
|
||||
systemctl restart apache2
|
||||
systemctl restart jenkins
|
||||
|
||||
Check that port 80 and 8000 are in use by Jenkins and Apache.
|
||||
|
||||
netstat -plntu
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
### Step 4 - Configure Jenkins
|
||||
|
||||
Jenkins is running on the domain name 'my.jenkins.id'. Open your web browser and type in the URL. You will get the screen that requests you to enter the initial admin password. A password has been generated by Jenkins already, so we just need to show and copy the results to the password box.
|
||||
|
||||
Show initial admin password Jenkins with cat command.
|
||||
|
||||
cat /var/lib/jenkins/secrets/initialAdminPassword
|
||||
|
||||
a1789d1561bf413c938122c599cf65c9
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Paste the results to the screen and click '**Continue**'.
|
||||
|
||||
[
|
||||
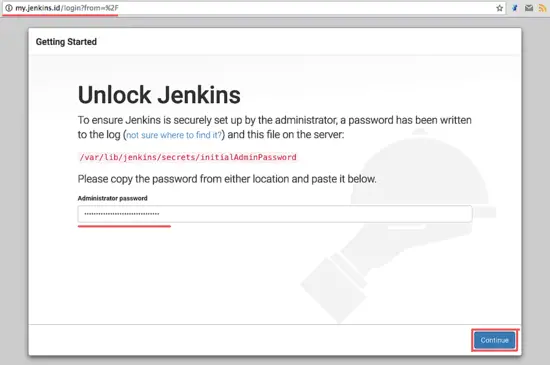
|
||||
][13]
|
||||
|
||||
Now we should install some plugins in Jenkins to get a good foundation for later use. Choose '**Install Suggested Plugins**', click on it.
|
||||
|
||||
[
|
||||
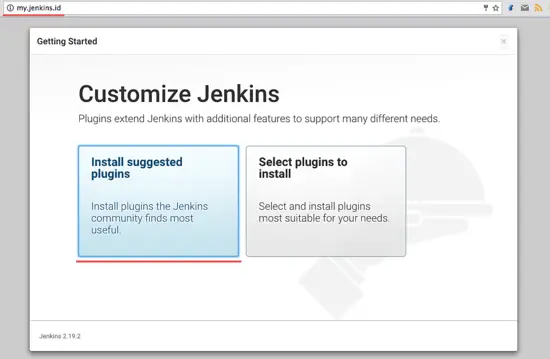
|
||||
][14]
|
||||
|
||||
Jenkins plugins installations in progress.
|
||||
|
||||
[
|
||||
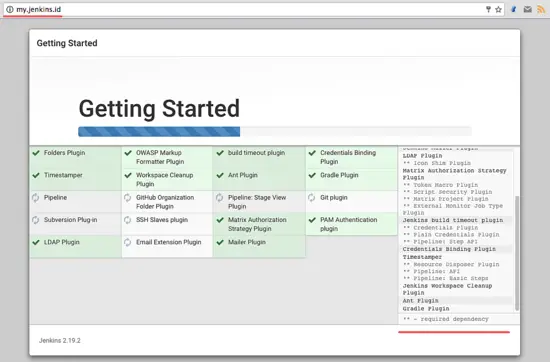
|
||||
][15]
|
||||
|
||||
After plugin installation, we have to create a new admin password. Type in your admin username, password, email etc. and click on '**Save and Finish**'.
|
||||
|
||||
[
|
||||
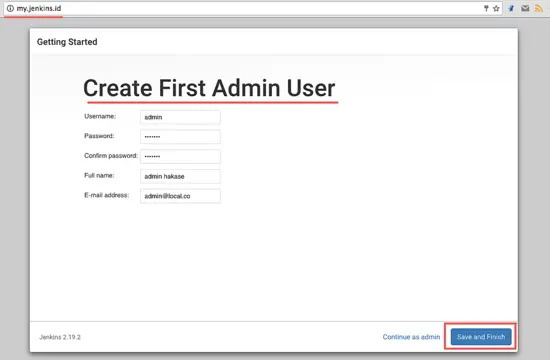
|
||||
][16]
|
||||
|
||||
Click start and start using Jenkins. You will be redirected to the Jenkins admin dashboard.
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
Jenkins installation and Configuration finished successfully
|
||||
|
||||
[
|
||||
|
||||
][18]
|
||||
|
||||
### Step 5 - Jenkins Security
|
||||
|
||||
From the Jenkins admin dashboard, we need to configure the standard security settings for Jenkins, click on '**Manage Jenkins**' and then '**Configure Global Security**'.
|
||||
|
||||
[
|
||||
|
||||
][19]
|
||||
|
||||
Jenkins provides several authorization methods in the '**Access Control**' section. I select '**Matrix-based Security**' to be able to control all user privileges. Enable the admin user at the box '**User/Group**' and click **add**. Give the admin all privileges by **checking all options**, and give the anonymous just read permissions. Now Click '**Save**'.
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
You will be redirected to the dashboard, and if there is login option, just type your admin user and password.
|
||||
|
||||
### Step 6 - Testing a simple automation job
|
||||
|
||||
In this section, I just want to test a simple job for the Jenkins server. I will create a simple job for testing Jenkins and to find out the server load with the top command.
|
||||
|
||||
From the Jenkins admin dashboard, click '**Create New Job**'.
|
||||
|
||||
[
|
||||
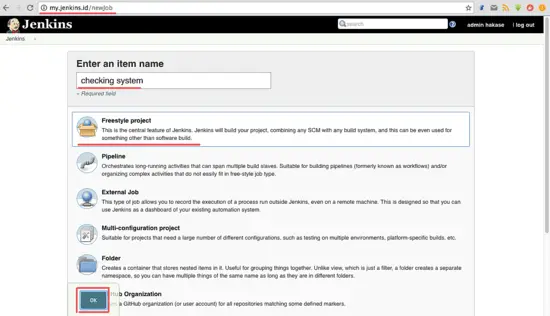
|
||||
][21]
|
||||
|
||||
Enter the job name, I'll use 'Checking System' here, select '**Freestyle Project**' and click '**OK**'.
|
||||
|
||||
[
|
||||
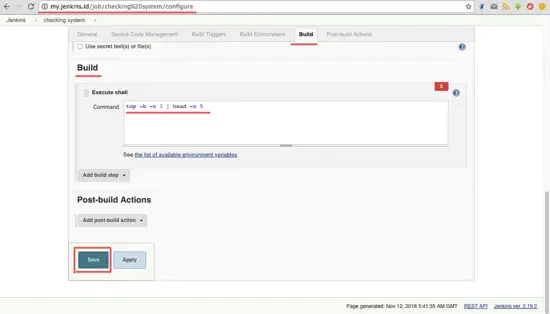
|
||||
][22]
|
||||
|
||||
Go to the '**Build**' tab. On the '**Add build step**', select the option '**Execute shell**'.
|
||||
|
||||
Type in the command below into the box.
|
||||
|
||||
top -b -n 1 | head -n 5
|
||||
|
||||
Click '**Save**'.
|
||||
|
||||
[
|
||||
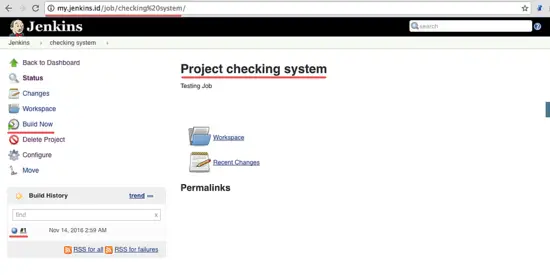
|
||||
][23]
|
||||
|
||||
Now you are on the job page of the job 'Project checking system'. Click '**Build Now**' to execute the job 'checking system'.
|
||||
|
||||
After the job has been executed, you will see the '**Build History**', click on the first job to see the results.
|
||||
|
||||
Here are the results from the job executed by Jenkins.
|
||||
|
||||
[
|
||||
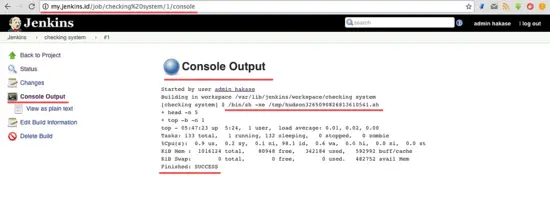
|
||||
][24]
|
||||
|
||||
Jenkins installation with Apache web server on Ubuntu 16.04 completed successfully.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#prerequisite
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-install-java-openjdk-
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-install-jenkins
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-install-and-configure-apache-as-reverse-proxy-for-jenkins
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-configure-jenkins
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-jenkins-security
|
||||
[7]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-testing-a-simple-automation-job
|
||||
[8]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#reference
|
||||
[9]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/1.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/2.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/3.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/4.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/5.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/6.png
|
||||
[15]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/7.png
|
||||
[16]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/8.png
|
||||
[17]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/9.png
|
||||
[18]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/10.png
|
||||
[19]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/11.png
|
||||
[20]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/12.png
|
||||
[21]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/13.png
|
||||
[22]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/14.png
|
||||
[23]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/15.png
|
||||
[24]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/16.png
|
||||
@ -1,69 +0,0 @@
|
||||
Why we need an open model to design and evaluate public policy
|
||||
============================================================
|
||||
|
||||
### Imagine an app that allows citizens to test drive proposed policies.
|
||||
|
||||
[up][3]
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
In the months leading up to political elections, public debate intensifies and citizens are exposed to a proliferation of information around policy options. In a data-driven society where new insights have been informing decision-making, a deeper understanding of this information has never been more important, yet the public still hasn't realized the full potential of public policy modeling.
|
||||
|
||||
At a time where the concept of "open government" is constantly evolving to keep pace with new technological advances, government policy models and analysis could be the new generation of open knowledge.
|
||||
|
||||
Government Open Source Models (GOSMs) refer to the idea that government-developed models, whose purpose is to design and evaluate policy, are freely available to everyone to use, distribute, and modify without restrictions. The community could potentially improve the quality, reliability, and accuracy of policy modeling, creating new data-driven apps that benefit the public.
|
||||
|
||||
Today's generation interacts with technology like it's second nature, absorbing vast amounts of information tacitly. What if we could interact with different public policies in a virtual, immersive environment using a GOSM?
|
||||
|
||||
Imagine an app that allows citizens to test drive proposed policies to determine the future in which they want to live. They would instinctively learn the key drivers and what to expect. Before long the public would have a deeper understanding of public policy impacts and become more savvy at navigating the controversial terrains of public debate.
|
||||
|
||||
Why haven't we had greater access to these models before? The reason lies behind the veils of public policy modeling.
|
||||
|
||||
In a society as complex as the one we live in, quantifying policy impacts is a difficult task and has been described as a "fine-art." Moreover, most government policy models are based on administrative and other privately held data. Nevertheless, policy analysts valiantly go about their quest with the aim of guiding policy design, and many a political battle has been won with a quantitative call to arms.
|
||||
|
||||
Numbers are powerful. They build credibility and are often used as a rationale for introducing new policies. The development of public policy models lends power to both politicians and bureaucrats, who may be reluctant to disrupt the status quo. Giving that up may not be easy, but GOSMs provide an opportunity for unprecedented public policy reform.
|
||||
|
||||
GOSMs level the playing field for everyone: politicians, the media, lobby groups, stakeholders, and the general public. By opening the doors of policy evaluation to the community, governments can tap into new and undiscovered capabilities for creativity, innovation, and efficiency within the public sphere. But what are the practical implications for the strategic interactions between stakeholders and governments in public policy design?
|
||||
|
||||
GOSMs are unique because they are primarily a tool for designing public policy and do not necessarily require re-distribution for private gains. Stakeholders and lobby groups could potentially employ GOSMs along with their own privately held information to gain new insights into the workings of the policy environment in which they are economic players for private benefit.
|
||||
|
||||
Could GOSMs become a weapon where stakeholders hold the balance of power in public debate and strategize for optimal benefit?
|
||||
|
||||
Being a modifiable public good, GOSMs are, in notion, funded by the taxpayer and attributed to the state. Would it be ethically appropriate for private entities to gain from GOSMs without passing on the benefits to society? Unlike apps that may be used for more efficient service provision, alternate policy proposals are more likely to be used by consultancies and contribute to public debate.
|
||||
|
||||
The open source community has frequently used the "copyleft license" to ensure that code and any derivative works under this license remains open to everyone. This works well when the product of value is the code itself, which requires re-distribution for maximum benefit. However, what if the code or GOSM redistribution is incidental to the main product, which may be new strategic insights into the existing policy environment?
|
||||
|
||||
At a time when privately collected data is becoming prolific, the real value behind GOSMs may be the underlying data, which could be used to refine the models themselves. Ultimately, government is the only consumer with the authority to implement policy, and stakeholders may choose to share their modified GOSMs in negotiations.
|
||||
|
||||
The big challenge government has when publicly releasing policy models is increasing transparency while protecting privacy. Ideally, releasing GOSMs would require securing closed data in a way that preserves the key features of the modeling.
|
||||
|
||||
Publicly releasing GOSMs empower citizens by promoting a greater understanding and participation into our democracy, which would lead to improved policy outcomes and greater public satisfaction. In an open government utopia, open public policy development will be a collaborative effort between government and the community, where knowledge, data, and analysis are freely available to everyone.
|
||||
|
||||
_Learn more in Audrey Lobo-Pulo's talk at linux.conf.au 2017 ([#lca2017][1]) in Hobart: [Publicly Releasing Government Models][2]._
|
||||
|
||||
_Disclaimer: The views presented in this article belong to Audrey Lobo-Pulo and are not necessarily those of the Australian Government._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Audrey Lobo-Pulo - Dr. Audrey Lobo-Pulo is a co-founder of Phoensight and is an advocate for open government and open source software in government modelling. A physicist, she moved to working in economic policy modelling after joining the Australian Public Service. Audrey has been involved in modelling a wide range of economic policy options and is currently interested in government open data and open policy modelling. Audrey's vision for government is to bring data science to public policy analytics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/government-open-source-models
|
||||
|
||||
作者:[Audrey Lobo-Pulo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/audrey-lobo-pulo
|
||||
[1]:https://twitter.com/search?q=%23lca2017&src=typd
|
||||
[2]:https://linux.conf.au/schedule/presentation/31/
|
||||
[3]:https://opensource.com/article/17/1/government-open-source-models?rate=p9P_dJ3xMrvye9a6xiz6K_Hc8pdKmRvMypzCNgYthA0
|
||||
@ -1,726 +0,0 @@
|
||||
|
||||
|
||||
tranlating by xiaow6
|
||||
Git in 2016
|
||||
============================================================
|
||||
|
||||
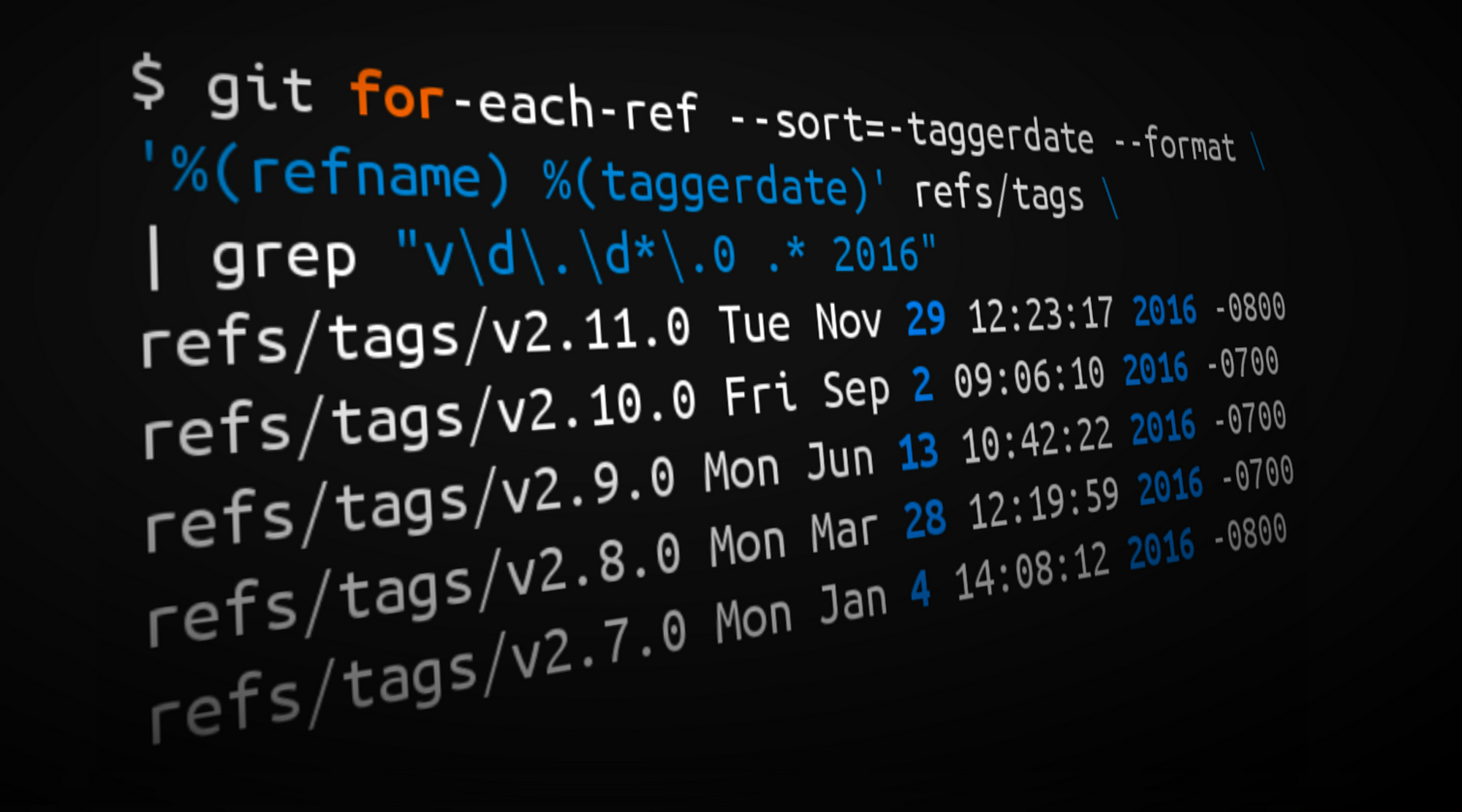
|
||||
|
||||
|
||||
Git had a _huge_ year in 2016, with five feature releases[¹][57] ( _v2.7_ through _v2.11_ ) and sixteen patch releases[²][58]. 189 authors[³][59] contributed 3,676 commits[⁴][60] to `master`, which is up 15%[⁵][61] over 2015! In total, 1,545 files were changed with 276,799 lines added and 100,973 lines removed[⁶][62].
|
||||
|
||||
However, commit counts and LOC are pretty terrible ways to measure productivity. Until deep learning develops to the point where it can qualitatively grok code, we’re going to be stuck with human judgment as the arbiter of productivity.
|
||||
|
||||
With that in mind, I decided to put together a retrospective of sorts that covers changes improvements made to six of my favorite Git features over the course of the year. This article is pretty darn long for a Medium post, so I will forgive you if you want to skip ahead to a feature that particularly interests you:
|
||||
|
||||
* [Rounding out the ][41]`[git worktree][25]`[ command][42]
|
||||
* [More convenient ][43]`[git rebase][26]`[ options][44]
|
||||
* [Dramatic performance boosts for ][45]`[git lfs][27]`
|
||||
* [Experimental algorithms and better defaults for ][46]`[git diff][28]`
|
||||
* `[git submodules][29]`[ with less suck][47]
|
||||
* [Nifty enhancements to ][48]`[git stash][30]`
|
||||
|
||||
Before we begin, note that many operating systems ship with legacy versions of Git, so it’s worth checking that you’re on the latest and greatest. If running `git --version` from your terminal returns anything less than Git `v2.11.0`, head on over to Atlassian's quick guide to [upgrade or install Git][63] on your platform of choice.
|
||||
|
||||
### [`Citation` needed]
|
||||
|
||||
One more quick stop before we jump into the qualitative stuff: I thought I’d show you how I generated the statistics from the opening paragraph (and the rather over-the-top cover image). You can use the commands below to do a quick _year in review_ for your own repositories as well!
|
||||
|
||||
```
|
||||
¹ Tags from 2016 matching the form vX.Y.0
|
||||
```
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format \
|
||||
'%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.0 .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
² Tags from 2016 matching the form vX.Y.Z
|
||||
```
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format '%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.[^0] .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
³ Commits by author in 2016
|
||||
```
|
||||
|
||||
```
|
||||
$ git shortlog -s -n --since=2016-01-01 --until=2017-01-01
|
||||
```
|
||||
|
||||
```
|
||||
⁴ Count commits in 2016
|
||||
```
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2016-01-01 --until=2017-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁵ ... and in 2015
|
||||
```
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2015-01-01 --until=2016-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁶ Net LOC added/removed in 2016
|
||||
```
|
||||
|
||||
```
|
||||
$ git diff --shortstat `git rev-list -1 --until=2016-01-01 master` \
|
||||
`git rev-list -1 --until=2017-01-01 master`
|
||||
```
|
||||
|
||||
The commands above were are run on Git’s `master` branch, so don’t represent any unmerged work on outstanding branches. If you use these command, remember that commit counts and LOC are not metrics to live by. Please don’t use them to rate the performance of your teammates!
|
||||
|
||||
And now, on with the retrospective…
|
||||
|
||||
### Rounding out Git worktrees
|
||||
|
||||
The `git worktree` command first appeared in Git v2.5 but had some notable enhancements in 2016\. Two valuable new features were introduced in v2.7 — the `list` subcommand, and namespaced refs for bisecting — and the `lock`/`unlock` subcommands were implemented in v2.10.
|
||||
|
||||
#### What’s a worktree again?
|
||||
|
||||
The `[git worktree][49]` command lets you check out and work on multiple repository branches in separate directories simultaneously. For example, if you need to make a quick hotfix but don't want to mess with your working copy, you can check out a new branch in a new directory with:
|
||||
|
||||
```
|
||||
$ git worktree add -b hotfix/BB-1234 ../hotfix/BB-1234
|
||||
Preparing ../hotfix/BB-1234 (identifier BB-1234)
|
||||
HEAD is now at 886e0ba Merged in bedwards/BB-13430-api-merge-pr (pull request #7822)
|
||||
```
|
||||
|
||||
Worktrees aren’t just for branches. You can check out multiple tags as different worktrees in order to build or test them in parallel. For example, I created worktrees from the Git v2.6 and v2.7 tags in order to examine the behavior of different versions of Git:
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.6.0 v2.6.0
|
||||
Preparing ../git-v2.6.0 (identifier git-v2.6.0)
|
||||
HEAD is now at be08dee Git 2.6
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.7.0 v2.7.0
|
||||
Preparing ../git-v2.7.0 (identifier git-v2.7.0)
|
||||
HEAD is now at 7548842 Git 2.7
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
/Users/kannonboy/src/git 7548842 [master]
|
||||
/Users/kannonboy/src/git-v2.6.0 be08dee (detached HEAD)
|
||||
/Users/kannonboy/src/git-v2.7.0 7548842 (detached HEAD)
|
||||
```
|
||||
|
||||
```
|
||||
$ cd ../git-v2.7.0 && make
|
||||
```
|
||||
|
||||
You could use the same technique to build and run different versions of your own applications side-by-side.
|
||||
|
||||
#### Listing worktrees
|
||||
|
||||
The `git worktree list` subcommand (introduced in Git v2.7) displays all of the worktrees associated with a repository:
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
/Users/kannonboy/src/bitbucket/bitbucket 37732bd [master]
|
||||
/Users/kannonboy/src/bitbucket/staging d5924bc [staging]
|
||||
/Users/kannonboy/src/bitbucket/hotfix-1234 37732bd [hotfix/1234]
|
||||
```
|
||||
|
||||
#### Bisecting worktrees
|
||||
|
||||
`[git bisect][50]` is a neat Git command that lets you perform a binary search of your commit history. It's usually used to find out which commit introduced a particular regression. For example, if a test is failing on the tip commit of my `master` branch, I can use `git bisect` to traverse the history of my repository looking for the commit that first broke it:
|
||||
|
||||
```
|
||||
$ git bisect start
|
||||
```
|
||||
|
||||
```
|
||||
# indicate the last commit known to be passing the tests
|
||||
# (e.g. the latest release tag)
|
||||
$ git bisect good v2.0.0
|
||||
```
|
||||
|
||||
```
|
||||
# indicate a known broken commit (e.g. the tip of master)
|
||||
$ git bisect bad master
|
||||
```
|
||||
|
||||
```
|
||||
# tell git bisect a script/command to run; git bisect will
|
||||
# find the oldest commit between "good" and "bad" that causes
|
||||
# this script to exit with a non-zero status
|
||||
$ git bisect run npm test
|
||||
```
|
||||
|
||||
Under the hood, bisect uses refs to track the good and bad commits used as the upper and lower bounds of the binary search range. Unfortunately for worktree fans, these refs were stored under the generic `.git/refs/bisect`namespace, meaning that `git bisect` operations that are run in different worktrees could interfere with each other.
|
||||
|
||||
As of v2.7, the bisect refs have been moved to`.git/worktrees/$worktree_name/refs/bisect`, so you can run bisect operations concurrently across multiple worktrees.
|
||||
|
||||
#### Locking worktrees
|
||||
|
||||
When you’re finished with a worktree, you can simply delete it and then run `git worktree prune` or wait for it to be garbage collected automatically. However, if you're storing a worktree on a network share or removable media, then it will be cleaned up if the worktree directory isn't accessible during pruning — whether you like it or not! Git v2.10 introduced the `git worktree lock` and `unlock` subcommands to prevent this from happening:
|
||||
|
||||
```
|
||||
# to lock the git-v2.7 worktree on my USB drive
|
||||
$ git worktree lock /Volumes/Flash_Gordon/git-v2.7 --reason \
|
||||
"In case I remove my removable media"
|
||||
```
|
||||
|
||||
```
|
||||
# to unlock (and delete) the worktree when I'm finished with it
|
||||
$ git worktree unlock /Volumes/Flash_Gordon/git-v2.7
|
||||
$ rm -rf /Volumes/Flash_Gordon/git-v2.7
|
||||
$ git worktree prune
|
||||
```
|
||||
|
||||
The `--reason` flag lets you leave a note for your future self, describing why the worktree is locked. `git worktree unlock` and `lock` both require you to specify the path to the worktree. Alternatively, you can `cd` to the worktree directory and run `git worktree lock .` for the same effect.
|
||||
|
||||
### More Git r`ebase` options
|
||||
|
||||
In March, Git v2.8 added the ability to interactively rebase whilst pulling with a `git pull --rebase=interactive`. Conversely, June's Git v2.9 release implemented support for performing a rebase exec without needing to drop into interactive mode via `git rebase -x`.
|
||||
|
||||
#### Re-wah?
|
||||
|
||||
Before we dive in, I suspect there may be a few readers who aren’t familiar or completely comfortable with the rebase command or interactive rebasing. Conceptually, it’s pretty simple, but as with many of Git’s powerful features, the rebase is steeped in some complex-sounding terminology. So, before we dive in, let’s quickly review what a rebase is.
|
||||
|
||||
Rebasing means rewriting one or more commits on a particular branch. The `git rebase` command is heavily overloaded, but the name rebase originates from the fact that it is often used to change a branch's base commit (the commit that you created the branch from).
|
||||
|
||||
Conceptually, rebase unwinds the commits on your branch by temporarily storing them as a series of patches, and then reapplying them in order on top of the target commit.
|
||||
|
||||
|
||||
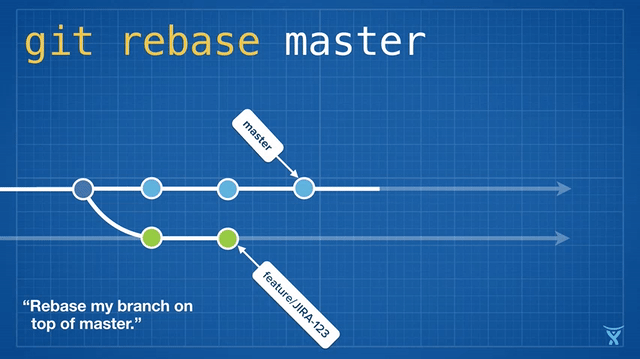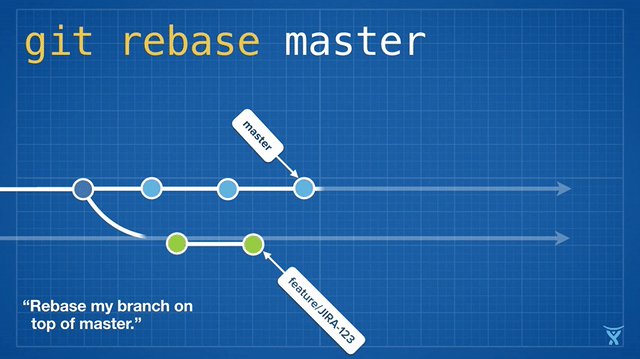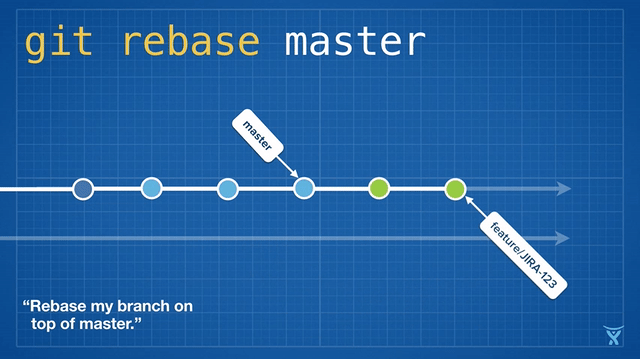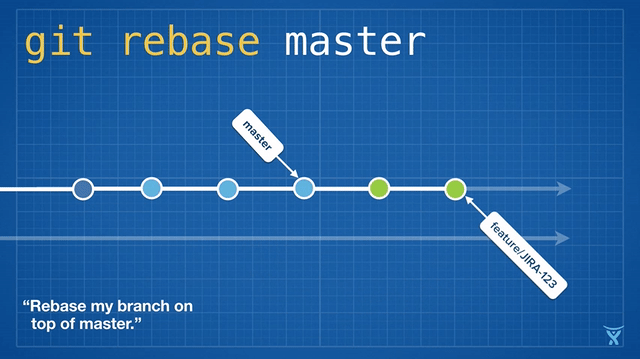
|
||||
|
||||
Rebasing a feature branch on master (`git rebase master`) is a great way to "freshen" your feature branch with the latest changes from master. For long-lived feature branches, regular rebasing minimizes the chance and severity of conflicts down the road.
|
||||
|
||||
Some teams also choose to rebase immediately before merging their changes onto master in order to achieve a fast-forward merge (`git merge --ff <feature>` ). Fast-forwarding merges your commits onto master by simply making the master ref point at the tip of your rewritten branch without creating a merge commit:
|
||||
|
||||

|
||||
|
||||
Rebasing is so convenient and powerful that it has been baked into some other common Git commands, such as `git pull`. If you have some unpushed changes on your local master branch, running `git pull` to pull your teammates' changes from the origin will create an unnecessary merge commit:
|
||||
|
||||
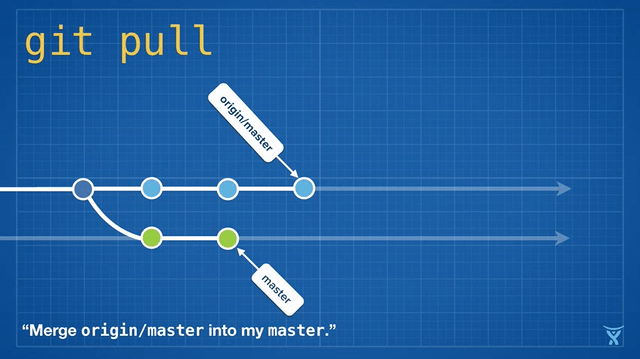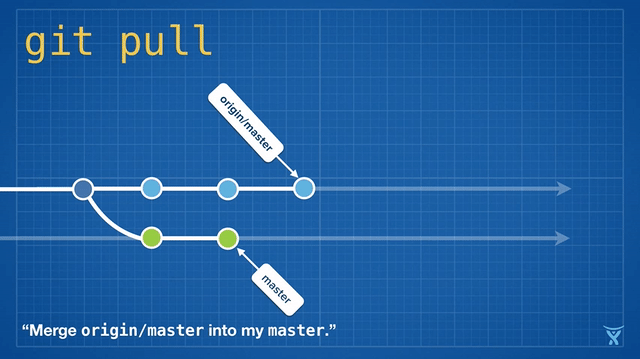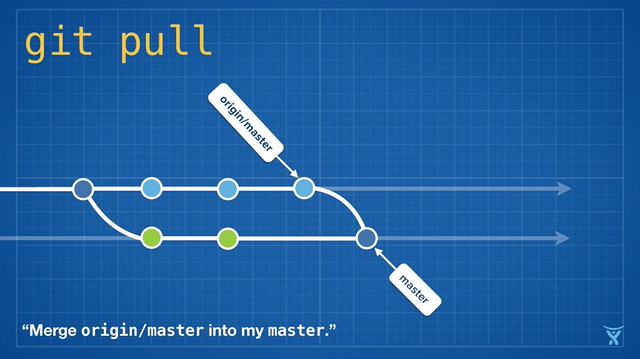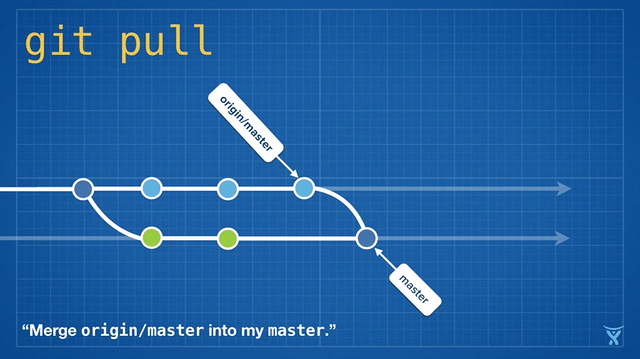
|
||||
|
||||
This is kind of messy, and on busy teams, you’ll get heaps of these unnecessary merge commits. `git pull --rebase` rebases your local changes on top of your teammates' without creating a merge commit:
|
||||
|
||||
|
||||
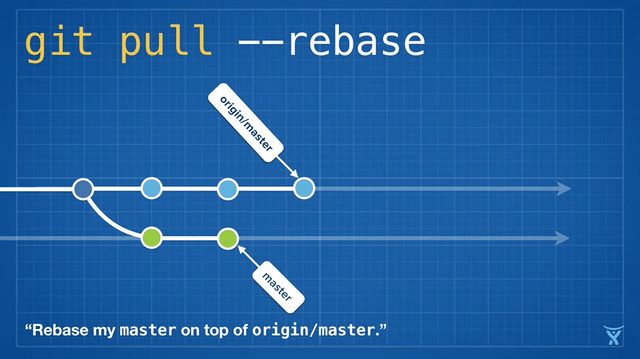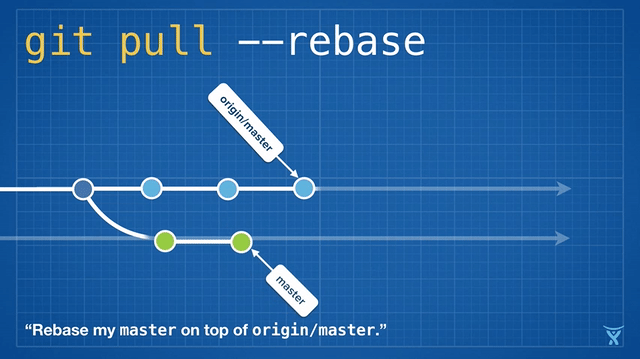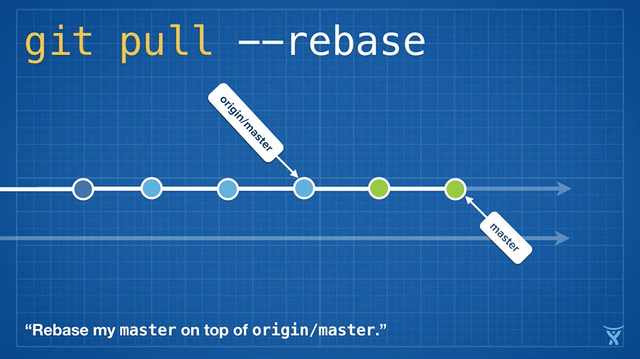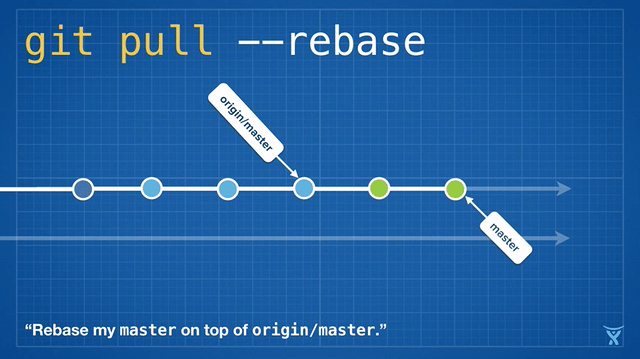
|
||||
|
||||
This is pretty neat! Even cooler, Git v2.8 introduced a feature that lets you rebase _interactively_ whilst pulling.
|
||||
|
||||
#### Interactive rebasing
|
||||
|
||||
Interactive rebasing is a more powerful form of rebasing. Like a standard rebase, it rewrites commits, but it also gives you a chance to modify them interactively as they are reapplied onto the new base.
|
||||
|
||||
When you run `git rebase --interactive` (or `git pull --rebase=interactive`), you'll be presented with a list of commits in your text editor of choice:
|
||||
|
||||
```
|
||||
$ git rebase master --interactive
|
||||
```
|
||||
|
||||
```
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
pick ed93626 ACE-1294: removed pull request service from test
|
||||
pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 commands)
|
||||
#
|
||||
# Commands:
|
||||
# p, pick = use commit
|
||||
# r, reword = use commit, but edit the commit message
|
||||
# e, edit = use commit, but stop for amending
|
||||
# s, squash = use commit, but meld into previous commit
|
||||
# f, fixup = like "squash", but discard this commit's log message
|
||||
# x, exec = run command (the rest of the line) using shell
|
||||
# d, drop = remove commit
|
||||
#
|
||||
# These lines can be re-ordered; they are executed from top to
|
||||
# bottom.
|
||||
#
|
||||
# If you remove a line here THAT COMMIT WILL BE LOST.
|
||||
```
|
||||
|
||||
Notice that each commit has the word `pick` next to it. That's rebase-speak for, "Keep this commit as-is." If you quit your text editor now, it will perform a normal rebase as described in the last section. However, if you change `pick` to `edit` or one of the other rebase commands, rebase will let you mutate the commit before it is reapplied! There are several available rebase commands:
|
||||
|
||||
* `reword`: Edit the commit message.
|
||||
* `edit`: Edit the files that were committed.
|
||||
* `squash`: Combine the commit with the previous commit (the one above it in the file), concatenating the commit messages.
|
||||
* `fixup`: Combine the commit with the commit above it, and uses the previous commit's log message verbatim (this is handy if you created a second commit for a small change that should have been in the original commit, i.e., you forgot to stage a file).
|
||||
* `exec`: Run an arbitrary shell command (we'll look at a neat use-case for this later, in the next section).
|
||||
* `drop`: This kills the commit.
|
||||
|
||||
You can also reorder commits within the file, which changes the order in which they’re reapplied. This is handy if you have interleaved commits that are addressing different topics and you want to use `squash` or `fixup` to combine them into logically atomic commits.
|
||||
|
||||
Once you’ve set up the commands and saved the file, Git will iterate through each commit, pausing at each `reword` and `edit` for you to make your desired changes and automatically applying any `squash`, `fixup`, `exec`, and `drop` commands for you.
|
||||
|
||||
#### Non-interactive exec
|
||||
|
||||
When you rebase, you’re essentially rewriting history by applying each of your new commits on top of the specified base. `git pull --rebase` can be a little risky because depending on the nature of the changes from the upstream branch, you may encounter test failures or even compilation problems for certain commits in your newly created history. If these changes cause merge conflicts, the rebase process will pause and allow you to resolve them. However, changes that merge cleanly may still break compilation or tests, leaving broken commits littering your history.
|
||||
|
||||
However, you can instruct Git to run your project’s test suite for each rewritten commit. Prior to Git v2.9, you could do this with a combination of `git rebase −−interactive` and the `exec` command. For example, this:
|
||||
|
||||
```
|
||||
$ git rebase master −−interactive −−exec=”npm test”
|
||||
```
|
||||
|
||||
…would generate an interactive rebase plan that invokes `npm test` after rewriting each commit, ensuring that your tests still pass:
|
||||
|
||||
```
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
exec npm test
|
||||
pick ed93626 ACE-1294: removed pull request service from test
|
||||
exec npm test
|
||||
pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
exec npm test
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
exec npm test
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 command(s))
|
||||
```
|
||||
|
||||
In the event that a test fails, rebase will pause to let you fix the tests (and apply your changes to that commit):
|
||||
|
||||
```
|
||||
291 passing
|
||||
1 failing
|
||||
```
|
||||
|
||||
```
|
||||
1) Host request “after all” hook:
|
||||
Uncaught Error: connect ECONNRESET 127.0.0.1:3001
|
||||
…
|
||||
npm ERR! Test failed.
|
||||
Execution failed: npm test
|
||||
You can fix the problem, and then run
|
||||
git rebase −−continue
|
||||
```
|
||||
|
||||
This is handy, but needing to do an interactive rebase is a bit clunky. As of Git v2.9, you can perform a non-interactive rebase exec, with:
|
||||
|
||||
```
|
||||
$ git rebase master -x “npm test”
|
||||
```
|
||||
|
||||
Just replace `npm test` with `make`, `rake`, `mvn clean install`, or whatever you use to build and test your project.
|
||||
|
||||
#### A word of warning
|
||||
|
||||
Just like in the movies, rewriting history is risky business. Any commit that is rewritten as part of a rebase will have it’s SHA-1 ID changed, which means that Git will treat it as a totally different commit. If rewritten history is mixed with the original history, you’ll get duplicate commits, which can cause a lot of confusion for your team.
|
||||
|
||||
To avoid this problem, you only need to follow one simple rule:
|
||||
|
||||
> _Never rebase a commit that you’ve already pushed!_
|
||||
|
||||
Stick to that and you’ll be fine.
|
||||
|
||||
### Performance boosts for `Git LFS`
|
||||
|
||||
[Git is a distributed version control system][64], meaning the entire history of the repository is transferred to the client during the cloning process. For projects that contain large files — particularly large files that are modified regularly _ — _ the initial clone can be expensive, as every version of every file has to be downloaded by the client. [Git LFS (Large File Storage)][65] is a Git extension developed by Atlassian, GitHub, and a few other open source contributors that reduces the impact of large files in your repository by downloading the relevant versions of them lazily. Specifically, large files are downloaded as needed during the checkout process rather than during cloning or fetching.
|
||||
|
||||
Alongside Git’s five huge releases in 2016, Git LFS had four feature-packed releases of its own: v1.2 through v1.5. You could write a retrospective series on Git LFS in its own right, but for this article, I’m going to focus on one of the most important themes tackled in 2016: speed. A series of improvements to both Git and Git LFS have greatly improved the performance of transferring files to and from the server.
|
||||
|
||||
#### Long-running filter processes
|
||||
|
||||
When you `git add` a file, Git's system of clean filters can be used to transform the file’s contents before being written to the Git object store. Git LFS reduces your repository size by using a clean filter to squirrel away large file content in the LFS cache and adds a tiny “pointer” file to the Git object store instead.
|
||||
|
||||
|
||||
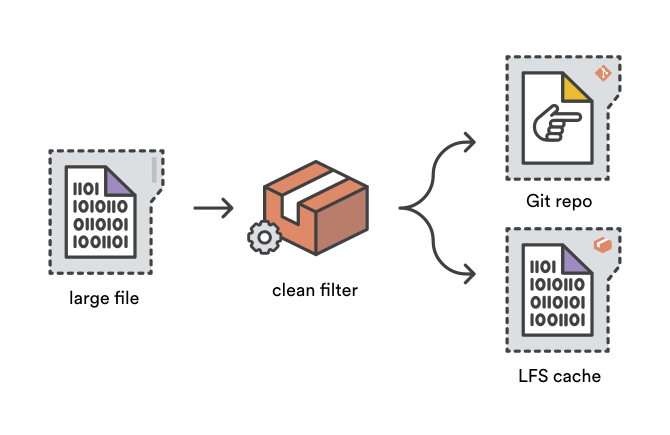
|
||||
|
||||
Smudge filters are the opposite of clean filters — hence the name. When file content is read from the Git object store during a `git checkout`, smudge filters have a chance to transform it before it’s written to the user’s working copy. The Git LFS smudge filter transforms pointer files by replacing them with the corresponding large file, either from your LFS cache or by reading through to your Git LFS store on Bitbucket.
|
||||
|
||||
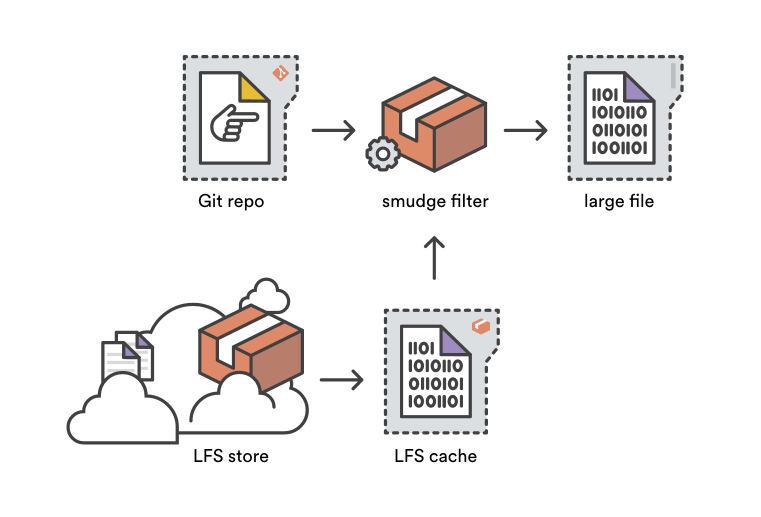
|
||||
|
||||
Traditionally, smudge and clean filter processes were invoked once for each file that was being added or checked out. So, a project with 1,000 files tracked by Git LFS invoked the `git-lfs-smudge` command 1,000 times for a fresh checkout! While each operation is relatively quick, the overhead of spinning up 1,000 individual smudge processes is costly.
|
||||
|
||||
As of Git v2.11 (and Git LFS v1.5), smudge and clean filters can be defined as long-running processes that are invoked once for the first filtered file, then fed subsequent files that need smudging or cleaning until the parent Git operation exits. [Lars Schneider][66], who contributed long-running filters to Git, neatly summarized the impact of the change on Git LFS performance:
|
||||
|
||||
> The filter process is 80x faster on macOS and 58x faster on Windows for the test repo with 12k files. On Windows, that means the tests runs in 57 seconds instead of 55 minutes!
|
||||
|
||||
That’s a seriously impressive performance gain!
|
||||
|
||||
#### Specialized LFS clones
|
||||
|
||||
Long-running smudge and clean filters are great for speeding up reads and writes to the local LFS cache, but they do little to speed up transferring of large objects to and from your Git LFS server. Each time the Git LFS smudge filter can’t find a file in the local LFS cache, it has to make two HTTP calls to retrieve it: one to locate the file and one to download it. During a `git clone`, your local LFS cache is empty, so Git LFS will naively make two HTTP calls for every LFS tracked file in your repository:
|
||||
|
||||
|
||||
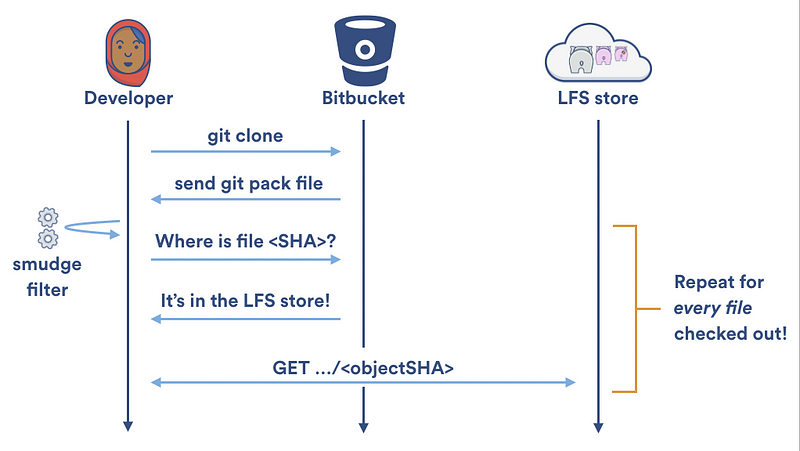
|
||||
|
||||
Fortunately, Git LFS v1.2 shipped the specialized `[git lfs clone][51]` command. Rather than downloading files one at a time; `git lfs clone` disables the Git LFS smudge filter, waits until the checkout is complete, and then downloads any required files as a batch from the Git LFS store. This allows downloads to be parallelized and halves the number of required HTTP requests:
|
||||
|
||||
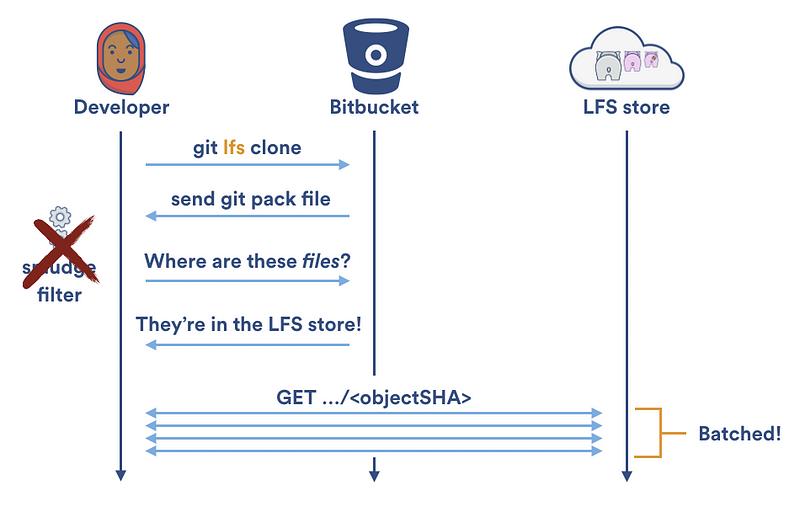
|
||||
|
||||
### Custom Transfer Adapters
|
||||
|
||||
As discussed earlier, Git LFS shipped support for long running filter processes in v1.5\. However, support for another type of pluggable process actually shipped earlier in the year. Git LFS v1.3 included support for pluggable transfer adapters so that different Git LFS hosting services could define their own protocols for transferring files to and from LFS storage.
|
||||
|
||||
As of the end of 2016, Bitbucket is the only hosting service to implement their own Git LFS transfer protocol via the [Bitbucket LFS Media Adapter][67]. This was done to take advantage of a unique feature of Bitbucket’s LFS storage API called chunking. Chunking means large files are broken down into 4MB chunks before uploading or downloading.
|
||||

|
||||
|
||||
Chunking gives Bitbucket’s Git LFS support three big advantages:
|
||||
|
||||
1. Parallelized downloads and uploads. By default, Git LFS transfers up to three files in parallel. However, if only a single file is being transferred (which is the default behavior of the Git LFS smudge filter), it is transferred via a single stream. Bitbucket’s chunking allows multiple chunks from the same file to be uploaded or downloaded simultaneously, often dramatically improving transfer speed.
|
||||
2. Resumable chunk transfers. File chunks are cached locally, so if your download or upload is interrupted, Bitbucket’s custom LFS media adapter will resume transferring only the missing chunks the next time you push or pull.
|
||||
3. Deduplication. Git LFS, like Git itself, is content addressable; each LFS file is identified by a SHA-256 hash of its contents. So, if you flip a single bit, the file’s SHA-256 changes and you have to re-upload the entire file. Chunking allows you to re-upload only the sections of the file that have actually changed. To illustrate, imagine we have a 41MB spritesheet for a video game tracked in Git LFS. If we add a new 2MB layer to the spritesheet and commit it, we’d typically need to push the entire new 43MB file to the server. However, with Bitbucket’s custom transfer adapter, we only need to push ~7Mb: the first 4MB chunk (because the file’s header information will have changed) and the last 3MB chunk containing the new layer we’ve just added! The other unchanged chunks are skipped automatically during the upload process, saving a huge amount of bandwidth and time.
|
||||
|
||||
Customizable transfer adapters are a great feature for Git LFS, as they allow different hosts to experiment with optimized transfer protocols to suit their services without overloading the core project.
|
||||
|
||||
### Better `git diff` algorithms and defaults
|
||||
|
||||
Unlike some other version control systems, Git doesn’t explicitly store the fact that files have been renamed. For example, if I edited a simple Node.js application and renamed `index.js` to `app.js` and then ran `git diff`, I’d get back what looks like a file deletion and an addition:
|
||||
|
||||
|
||||

|
||||
|
||||
I guess moving or renaming a file is technically just a delete followed by an add, but this isn’t the most human-friendly way to show it. Instead, you can use the `-M` flag to instruct Git to attempt to detect renamed files on the fly when computing a diff. For the above example, `git diff -M` gives us:
|
||||
|
||||

|
||||
|
||||
The similarity index on the second line tells us how similar the content of the files compared was. By default, `-M` will consider any two files that are more than 50% similar. That is, you need to modify less than 50% of their lines to make them identical as a renamed file. You can choose your own similarity index by appending a percentage, i.e., `-M80%`.
|
||||
|
||||
As of Git v2.9, the `git diff` and `git log` commands will both detect renames by default as if you'd passed the `-M` flag. If you dislike this behavior (or, more realistically, are parsing the diff output via a script), then you can disable it by explicitly passing the `−−no-renames` flag.
|
||||
|
||||
#### Verbose Commits
|
||||
|
||||
Do you ever invoke `git commit` and then stare blankly at your shell trying to remember all the changes you just made? The verbose flag is for you!
|
||||
|
||||
Instead of:
|
||||
|
||||
```
|
||||
Ah crap, which dependency did I just rev?
|
||||
```
|
||||
|
||||
```
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with ‘#’ will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
# Your branch is up-to-date with ‘origin/master’.
|
||||
#
|
||||
# Changes to be committed:
|
||||
# new file: package.json
|
||||
#
|
||||
```
|
||||
|
||||
…you can invoke `git commit −−verbose` to view an inline diff of your changes. Don’t worry, it won’t be included in your commit message:
|
||||
|
||||
|
||||
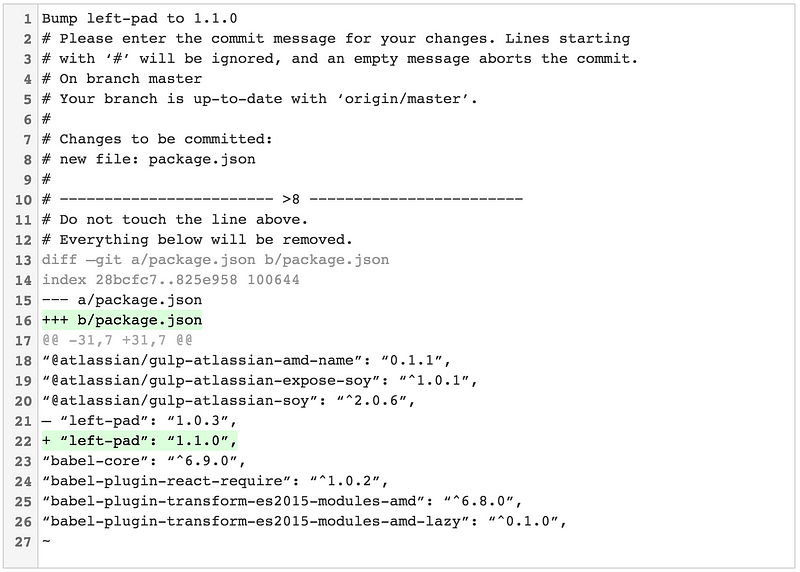
|
||||
|
||||
The `−−verbose` flag isn’t new, but as of Git v2.9 you can enable it permanently with `git config --global commit.verbose true`.
|
||||
|
||||
#### Experimental Diff Improvements
|
||||
|
||||
`git diff` can produce some slightly confusing output when the lines before and after a modified section are the same. This can happen when you have two or more similarly structured functions in a file. For a slightly contrived example, imagine we have a JS file that contains a single function:
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
return "Bitbucket";
|
||||
}
|
||||
```
|
||||
|
||||
Now imagine we’ve committed a change that prepends _another_ function that does something similar:
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productId() {
|
||||
return "Bitbucket";
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
return "Bitbucket";
|
||||
}
|
||||
```
|
||||
|
||||
You’d expect `git diff` to show the top five lines as added, but it actually incorrectly attributes the very first line to the original commit:
|
||||
|
||||
|
||||

|
||||
|
||||
The wrong comment is included in the diff! Not the end of the world, but the couple of seconds of cognitive overhead from the _Whaaat?_ every time this happens can add up.
|
||||
|
||||
In December, Git v2.11 introduced a new experimental diff option, `--indent-heuristic`, that attempts to produce more aesthetically pleasing diffs:
|
||||
|
||||
|
||||

|
||||
|
||||
Under the hood, `--indent-heuristic` cycles through the possible diffs for each change and assigns each a “badness” score. This is based on heuristics like whether the diff block starts and ends with different levels of indentation (which is aesthetically bad) and whether the diff block has leading and trailing blank lines (which is aesthetically pleasing). Then, the block with the lowest badness score is output.
|
||||
|
||||
This feature is experimental, but you can test it out ad-hoc by applying the `--indent-heuristic` option to any `git diff` command. Or, if you like to live on the bleeding edge, you can enable it across your system with:
|
||||
|
||||
```
|
||||
$ git config --global diff.indentHeuristic true
|
||||
```
|
||||
|
||||
### Submodules with less suck
|
||||
|
||||
Submodules allow you to reference and include other Git repositories from inside your Git repository. This is commonly used by some projects to manage source dependencies that are also tracked in Git, or by some companies as an alternative to a [monorepo][68] containing a collection of related projects.
|
||||
|
||||
Submodules get a bit of a bad rap due to some usage complexities and the fact that it’s reasonably easy to break them with an errant command.
|
||||
|
||||
|
||||
|
||||
|
||||
However, they do have their uses and are, I think, still the best choice for vendoring dependencies. Fortunately, 2016 was a great year to be a submodule user, with some significant performance and feature improvements landing across several releases.
|
||||
|
||||
#### Parallelized fetching
|
||||
|
||||
When cloning or fetching a repository, appending the `--recurse-submodules`option means any referenced submodules will be cloned or updated, as well. Traditionally, this was done serially, with each submodule being fetched one at a time. As of Git v2.8, you can append the `--jobs=n` option to fetch submodules in _n_ parallel threads.
|
||||
|
||||
I recommend configuring this option permanently with:
|
||||
|
||||
```
|
||||
$ git config --global submodule.fetchJobs 4
|
||||
```
|
||||
|
||||
…or whatever degree of parallelization you choose to use.
|
||||
|
||||
#### Shallow submodules
|
||||
|
||||
Git v2.9 introduced the `git clone -−shallow-submodules` flag. It allows you to grab a full clone of your repository and then recursively shallow clone any referenced submodules to a depth of one commit. This is useful if you don’t need the full history of your project’s dependencies.
|
||||
|
||||
For example, consider a repository with a mixture of submodules containing vendored dependencies and other projects that you own. You may wish to clone with shallow submodules initially and then selectively deepen the few projects you want to work with.
|
||||
|
||||
Another scenario would be configuring a continuous integration or deployment job. Git needs the super repository as well as the latest commit from each of your submodules in order to actually perform the build. However, you probably don’t need the full history for every submodule, so retrieving just the latest commit will save you both time and bandwidth.
|
||||
|
||||
#### Submodule alternates
|
||||
|
||||
The `--reference` option can be used with `git clone` to specify another local repository as an alternate object store to save recopying objects over the network that you already have locally. The syntax is:
|
||||
|
||||
```
|
||||
$ git clone --reference <local repo> <url>
|
||||
```
|
||||
|
||||
As of Git v2.11, you can use the `--reference` option in combination with `--recurse-submodules` to set up submodule alternates pointing to submodules from another local repository. The syntax is:
|
||||
|
||||
```
|
||||
$ git clone --recurse-submodules --reference <local repo> <url>
|
||||
```
|
||||
|
||||
This can potentially save a huge amount of bandwidth and local disk but it will fail if the referenced local repository does not have all the required submodules of the remote repository that you’re cloning from.
|
||||
|
||||
Fortunately, the handy `--reference-if-able` option will fail gracefully and fall back to a normal clone for any submodules that are missing from the referenced local repository:
|
||||
|
||||
```
|
||||
$ git clone --recurse-submodules --reference-if-able \
|
||||
<local repo> <url>
|
||||
```
|
||||
|
||||
#### Submodule diffs
|
||||
|
||||
Prior to Git v2.11, Git had two modes for displaying diffs of commits that updated your repository’s submodules:
|
||||
|
||||
`git diff --submodule=short` displays the old commit and new commit from the submodule referenced by your project (this is also the default if you omit the `--submodule` option altogether):
|
||||
|
||||
|
||||
|
||||
`git diff --submodule=log` is slightly more verbose, displaying the summary line from the commit message of any new or removed commits in the updated submodule:
|
||||
|
||||
|
||||

|
||||
|
||||
Git v2.11 introduces a third much more useful option: `--submodule=diff`. This displays a full diff of all changes in the updated submodule:
|
||||
|
||||
|
||||
|
||||
### Nifty enhancements to `git stash`
|
||||
|
||||
Unlike submodules, `[git stash][52]` is almost universally beloved by Git users. `git stash` temporarily shelves (or _stashes_ ) changes you've made to your working copy so you can work on something else, and then come back and re-apply them later on.
|
||||
|
||||
#### Autostash
|
||||
|
||||
If you’re a fan of `git rebase`, you might be familiar with the `--autostash`option. It automatically stashes any local changes made to your working copy before rebasing and reapplies them after the rebase is completed.
|
||||
|
||||
```
|
||||
$ git rebase master --autostash
|
||||
Created autostash: 54f212a
|
||||
HEAD is now at 8303dca It's a kludge, but put the tuple from the database in the cache.
|
||||
First, rewinding head to replay your work on top of it...
|
||||
Applied autostash.
|
||||
```
|
||||
|
||||
This is handy, as it allows you to rebase from a dirty worktree. There’s also a handy config flag named `rebase.autostash` to make this behavior the default, which you can enable globally with:
|
||||
|
||||
```
|
||||
$ git config --global rebase.autostash true
|
||||
```
|
||||
|
||||
`rebase.autostash` has actually been available since [Git v1.8.4][69], but v2.7 introduces the ability to cancel this flag with the `--no-autostash` option. If you use this option with unstaged changes, the rebase will abort with a dirty worktree warning:
|
||||
|
||||
```
|
||||
$ git rebase master --no-autostash
|
||||
Cannot rebase: You have unstaged changes.
|
||||
Please commit or stash them.
|
||||
```
|
||||
|
||||
#### Stashes as Patches
|
||||
|
||||
Speaking of config flags, Git v2.7 also introduces `stash.showPatch`. The default behavior of `git stash show` is to display a summary of your stashed files.
|
||||
|
||||
```
|
||||
$ git stash show
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
Passing the `-p` flag puts `git stash show` into "patch mode," which displays the full diff:
|
||||
|
||||
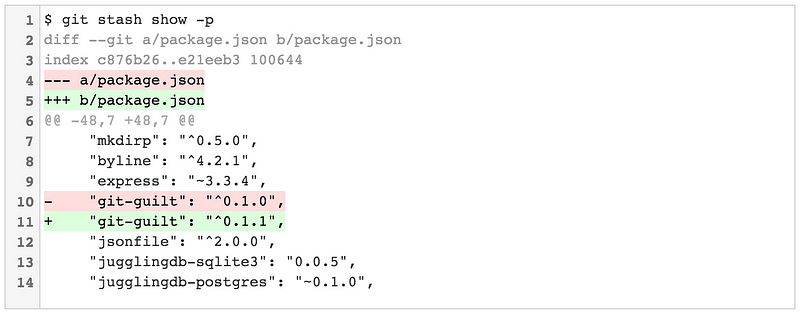
|
||||
|
||||
`stash.showPatch` makes this behavior the default. You can enable it globally with:
|
||||
|
||||
```
|
||||
$ git config --global stash.showPatch true
|
||||
```
|
||||
|
||||
If you enable `stash.showPatch` but then decide you want to view just the file summary, you can get the old behavior back by passing the `--stat` option instead.
|
||||
|
||||
```
|
||||
$ git stash show --stat
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
As an aside: `--no-patch` is a valid option but it doesn't negate `stash.showPatch` as you'd expect. Instead, it gets passed along to the underlying `git diff` command used to generate the patch, and you'll end up with no output at all!
|
||||
|
||||
#### Simple Stash IDs
|
||||
|
||||
If you’re a `git stash` fan, you probably know that you can shelve multiple sets of changes, and then view them with `git stash list`:
|
||||
|
||||
```
|
||||
$ git stash list
|
||||
stash@{0}: On master: crazy idea that might work one day
|
||||
stash@{1}: On master: desperate samurai refactor; don't apply
|
||||
stash@{2}: On master: perf improvement that I forgot I stashed
|
||||
stash@{3}: On master: pop this when we use Docker in production
|
||||
```
|
||||
|
||||
However, you may not know why Git’s stashes have such awkward identifiers (`stash@{1}`, `stash@{2}`, etc.) and may have written them off as "just one of those Git idiosyncrasies." It turns out that like many Git features, these weird IDs are actually a symptom of a very clever use (or abuse) of the Git data model.
|
||||
|
||||
Under the hood, the `git stash` command actually creates a set of special commit objects that encode your stashed changes and maintains a [reflog][70]that holds references to these special commits. This is why the output from `git stash list` looks a lot like the output from the `git reflog` command. When you run `git stash apply stash@{1}`, you're actually saying, “Apply the commit at position 1 from the stash reflog.”
|
||||
|
||||
As of Git v2.11, you no longer have to use the full `stash@{n}` syntax. Instead, you can reference stashes with a simple integer indicating their position in the stash reflog:
|
||||
|
||||
```
|
||||
$ git stash show 1
|
||||
$ git stash apply 1
|
||||
$ git stash pop 1
|
||||
```
|
||||
|
||||
And so forth. If you’d like to learn more about how stashes are stored, I wrote a little bit about it in [this tutorial][71].
|
||||
|
||||
### </2016> <2017>
|
||||
|
||||
And we’re done. Thanks for reading! I hope you enjoyed reading this behemoth as much as I enjoyed spelunking through Git’s source code, release notes, and `man` pages to write it. If you think I missed anything big, please leave a comment or let me know [on Twitter][72] and I'll endeavor to write a follow-up piece.
|
||||
|
||||
As for what’s next for Git, that’s up to the maintainers and contributors (which [could be you!][73]). With ever-increasing adoption, I’m guessing that simplification, improved UX, and better defaults will be strong themes for Git in 2017\. As Git repositories get bigger and older, I suspect we’ll also see continued focus on performance and improved handling of large files, deep trees, and long histories.
|
||||
|
||||
If you’re into Git and excited to meet some of the developers behind the project, consider coming along to [Git Merge][74] in Brussels in a few weeks time. I’m [speaking there][75]! But more importantly, many of the developers who maintain Git will be in attendance for the conference and the annual Git Contributors Summit, which will likely drive much of the direction for the year ahead.
|
||||
|
||||
Or if you can’t wait ’til then, head over to Atlassian’s excellent selection of [Git tutorials][76] for more tips and tricks to improve your workflow.
|
||||
|
||||
_If you scrolled to the end looking for the footnotes from the first paragraph, please jump to the _ [ _[Citation needed]_ ][77] _ section for the commands used to generate the stats. Gratuitous cover image generated using _ [ _instaco.de_ ][78] _ ❤️_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/git-in-2016-fad96ae22a15#.t5c5cm48f
|
||||
|
||||
作者:[Tim Pettersen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@kannonboy?source=post_header_lockup
|
||||
[1]:https://medium.com/@g.kylafas/the-git-config-command-is-missing-a-yes-at-the-end-as-in-git-config-global-commit-verbose-yes-7e126365750e?source=responses---------1----------
|
||||
[2]:https://medium.com/@kannonboy/thanks-giorgos-fixed-f3b83c61589a?source=responses---------1----------
|
||||
[3]:https://medium.com/@TomSwirly/i-read-the-whole-thing-from-start-to-finish-415a55d89229?source=responses---------0-31---------
|
||||
[4]:https://medium.com/@g.kylafas
|
||||
[5]:https://medium.com/@g.kylafas?source=responses---------1----------
|
||||
[6]:https://medium.com/@kannonboy
|
||||
[7]:https://medium.com/@kannonboy?source=responses---------1----------
|
||||
[8]:https://medium.com/@TomSwirly
|
||||
[9]:https://medium.com/@TomSwirly?source=responses---------0-31---------
|
||||
[10]:https://medium.com/@g.kylafas/the-git-config-command-is-missing-a-yes-at-the-end-as-in-git-config-global-commit-verbose-yes-7e126365750e?source=responses---------1----------#--responses
|
||||
[11]:https://hackernoon.com/@kannonboy
|
||||
[12]:https://hackernoon.com/@kannonboy?source=placement_card_footer_grid---------0-44
|
||||
[13]:https://medium.freecodecamp.com/@BillSourour
|
||||
[14]:https://medium.freecodecamp.com/@BillSourour?source=placement_card_footer_grid---------1-43
|
||||
[15]:https://blog.uncommon.is/@lut4rp
|
||||
[16]:https://blog.uncommon.is/@lut4rp?source=placement_card_footer_grid---------2-43
|
||||
[17]:https://medium.com/@kannonboy
|
||||
[18]:https://medium.com/@kannonboy
|
||||
[19]:https://medium.com/@g.kylafas/the-git-config-command-is-missing-a-yes-at-the-end-as-in-git-config-global-commit-verbose-yes-7e126365750e?source=responses---------1----------
|
||||
[20]:https://medium.com/@kannonboy/thanks-giorgos-fixed-f3b83c61589a?source=responses---------1----------
|
||||
[21]:https://medium.com/@TomSwirly/i-read-the-whole-thing-from-start-to-finish-415a55d89229?source=responses---------0-31---------
|
||||
[22]:https://hackernoon.com/setting-breakpoints-on-a-snowy-evening-df34fc3168e2?source=placement_card_footer_grid---------0-44
|
||||
[23]:https://medium.freecodecamp.com/the-code-im-still-ashamed-of-e4c021dff55e?source=placement_card_footer_grid---------1-43
|
||||
[24]:https://blog.uncommon.is/using-git-to-generate-versionname-and-versioncode-for-android-apps-aaa9fc2c96af?source=placement_card_footer_grid---------2-43
|
||||
[25]:https://hackernoon.com/git-in-2016-fad96ae22a15#fd10
|
||||
[26]:https://hackernoon.com/git-in-2016-fad96ae22a15#cc52
|
||||
[27]:https://hackernoon.com/git-in-2016-fad96ae22a15#42b9
|
||||
[28]:https://hackernoon.com/git-in-2016-fad96ae22a15#4208
|
||||
[29]:https://hackernoon.com/git-in-2016-fad96ae22a15#a5c3
|
||||
[30]:https://hackernoon.com/git-in-2016-fad96ae22a15#c230
|
||||
[31]:https://hackernoon.com/tagged/git?source=post
|
||||
[32]:https://hackernoon.com/tagged/web-development?source=post
|
||||
[33]:https://hackernoon.com/tagged/software-development?source=post
|
||||
[34]:https://hackernoon.com/tagged/programming?source=post
|
||||
[35]:https://hackernoon.com/tagged/atlassian?source=post
|
||||
[36]:https://hackernoon.com/@kannonboy
|
||||
[37]:https://hackernoon.com/?source=footer_card
|
||||
[38]:https://hackernoon.com/setting-breakpoints-on-a-snowy-evening-df34fc3168e2?source=placement_card_footer_grid---------0-44
|
||||
[39]:https://medium.freecodecamp.com/the-code-im-still-ashamed-of-e4c021dff55e?source=placement_card_footer_grid---------1-43
|
||||
[40]:https://blog.uncommon.is/using-git-to-generate-versionname-and-versioncode-for-android-apps-aaa9fc2c96af?source=placement_card_footer_grid---------2-43
|
||||
[41]:https://hackernoon.com/git-in-2016-fad96ae22a15#fd10
|
||||
[42]:https://hackernoon.com/git-in-2016-fad96ae22a15#fd10
|
||||
[43]:https://hackernoon.com/git-in-2016-fad96ae22a15#cc52
|
||||
[44]:https://hackernoon.com/git-in-2016-fad96ae22a15#cc52
|
||||
[45]:https://hackernoon.com/git-in-2016-fad96ae22a15#42b9
|
||||
[46]:https://hackernoon.com/git-in-2016-fad96ae22a15#4208
|
||||
[47]:https://hackernoon.com/git-in-2016-fad96ae22a15#a5c3
|
||||
[48]:https://hackernoon.com/git-in-2016-fad96ae22a15#c230
|
||||
[49]:https://git-scm.com/docs/git-worktree
|
||||
[50]:https://git-scm.com/book/en/v2/Git-Tools-Debugging-with-Git#Binary-Search
|
||||
[51]:https://www.atlassian.com/git/tutorials/git-lfs/#speeding-up-clones
|
||||
[52]:https://www.atlassian.com/git/tutorials/git-stash/
|
||||
[53]:https://hackernoon.com/@kannonboy?source=footer_card
|
||||
[54]:https://hackernoon.com/?source=footer_card
|
||||
[55]:https://hackernoon.com/@kannonboy?source=post_header_lockup
|
||||
[56]:https://hackernoon.com/@kannonboy?source=post_header_lockup
|
||||
[57]:https://hackernoon.com/git-in-2016-fad96ae22a15#c8e9
|
||||
[58]:https://hackernoon.com/git-in-2016-fad96ae22a15#408a
|
||||
[59]:https://hackernoon.com/git-in-2016-fad96ae22a15#315b
|
||||
[60]:https://hackernoon.com/git-in-2016-fad96ae22a15#dbfb
|
||||
[61]:https://hackernoon.com/git-in-2016-fad96ae22a15#2220
|
||||
[62]:https://hackernoon.com/git-in-2016-fad96ae22a15#bc78
|
||||
[63]:https://www.atlassian.com/git/tutorials/install-git/
|
||||
[64]:https://www.atlassian.com/git/tutorials/what-is-git/
|
||||
[65]:https://www.atlassian.com/git/tutorials/git-lfs/
|
||||
[66]:https://twitter.com/kit3bus
|
||||
[67]:https://confluence.atlassian.com/bitbucket/bitbucket-lfs-media-adapter-856699998.html
|
||||
[68]:https://developer.atlassian.com/blog/2015/10/monorepos-in-git/
|
||||
[69]:https://blogs.atlassian.com/2013/08/what-you-need-to-know-about-the-new-git-1-8-4/
|
||||
[70]:https://www.atlassian.com/git/tutorials/refs-and-the-reflog/
|
||||
[71]:https://www.atlassian.com/git/tutorials/git-stash/#how-git-stash-works
|
||||
[72]:https://twitter.com/kannonboy
|
||||
[73]:https://git.kernel.org/cgit/git/git.git/tree/Documentation/SubmittingPatches
|
||||
[74]:http://git-merge.com/
|
||||
[75]:http://git-merge.com/#git-aliases
|
||||
[76]:https://www.atlassian.com/git/tutorials
|
||||
[77]:https://hackernoon.com/git-in-2016-fad96ae22a15#87c4
|
||||
[78]:http://instaco.de/
|
||||
[79]:https://medium.com/@Medium/personalize-your-medium-experience-with-users-publications-tags-26a41ab1ee0c#.hx4zuv3mg
|
||||
[80]:https://hackernoon.com/
|
||||
@ -1,3 +1,5 @@
|
||||
vim-kakali translating
|
||||
|
||||
3 open source music players: Aqualung, Lollypop, and GogglesMM
|
||||
============================================================
|
||||

|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
lnav – An Advanced Console Based Log File Viewer for Linux
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
# Recover from a badly corrupt Linux EFI installation
|
||||
|
||||
In the past decade or so, Linux distributions would occasionally fail before, during and after the installation, but I was always able to somehow recover the system and continue working normally. Well, [Solus][1]broke my laptop. Literally.
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
8 reasons to use LXDE
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Yoo-4x Translating
|
||||
|
||||
OpenGL & Go Tutorial Part 1: Hello, OpenGL
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by chenxinlong
|
||||
AWS cloud terminology
|
||||
============================================================
|
||||
|
||||
@ -17,7 +18,7 @@ As of today, AWS offers total of 71 services which are grouped together in
|
||||
|
||||
* * *
|
||||
|
||||
_Compute _
|
||||
_Compute_
|
||||
|
||||
Its a cloud computing means virtual server provisioning. This group provides below services.
|
||||
|
||||
@ -210,7 +211,7 @@ Its desktop app streaming over cloud.
|
||||
via: http://kerneltalks.com/virtualization/aws-cloud-terminology/
|
||||
|
||||
作者:[Shrikant Lavhate][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[chenxinlong](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,166 +0,0 @@
|
||||
How to Add a New Disk to an Existing Linux Server
|
||||
============================================================
|
||||
|
||||
|
||||
As system administrators, we would have got requirements wherein we need to configure raw hard disks to the existing servers as part of upgrading server capacity or sometimes disk replacement in case of disk failure.
|
||||
|
||||
In this article, I will take you through the steps by which we can add the new raw hard disk to an existing Linux server such as RHEL/CentOS or Debian/Ubuntu.
|
||||
|
||||
**Suggested Read:** [How to Add a New Disk Larger Than 2TB to An Existing Linux][1]
|
||||
|
||||
Important: Please note that the purpose of this article is to show only how to create a new partition and doesn’t include partition extension or any other switches.
|
||||
|
||||
I am using [fdisk utility][2] to do this configuration.
|
||||
|
||||
I have added a hard disk of 20GB capacity to be mounted as a `/data` partition.
|
||||
|
||||
fdisk is a command line utility to view and manage hard disks and partitions on Linux systems.
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
|
||||
This will list the current partitions and configurations.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Find Linux Partition Details
|
||||
|
||||
After attaching the hard disk of 20GB capacity, the `fdisk -l` will give the below output.
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
[
|
||||
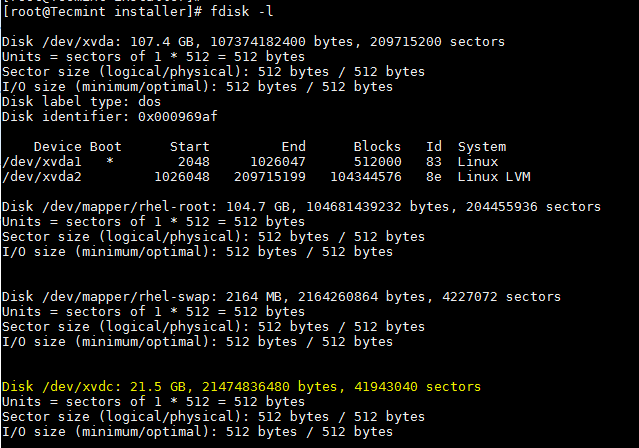
|
||||
][4]
|
||||
|
||||
Find New Partition Details
|
||||
|
||||
New disk added is shown as `/dev/xvdc`. If we are adding physical disk it will show as `/dev/sda` based of the disk type. Here I used a virtual disk.
|
||||
|
||||
To partition a particular hard disk, for example /dev/xvdc.
|
||||
|
||||
```
|
||||
# fdisk /dev/xvdc
|
||||
```
|
||||
|
||||
Commonly used fdisk commands.
|
||||
|
||||
* `n` – Create partition
|
||||
* `p` – print partition table
|
||||
* `d` – delete a partition
|
||||
* `q` – exit without saving the changes
|
||||
* `w` – write the changes and exit.
|
||||
|
||||
Here since we are creating a partition use `n` option.
|
||||
|
||||
[
|
||||
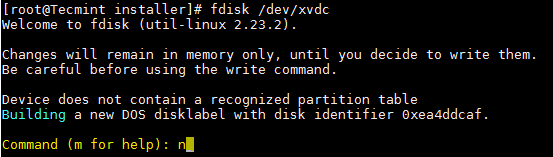
|
||||
][5]
|
||||
|
||||
Create New Partition in Linux
|
||||
|
||||
Create either primary/extended partitions. By default we can have upto 4 primary partitions.
|
||||
|
||||
[
|
||||
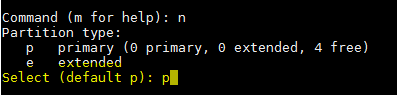
|
||||
][6]
|
||||
|
||||
Create Primary Partition
|
||||
|
||||
Give the partition number as desired. Recommended to go for the default value `1`.
|
||||
|
||||
[
|
||||
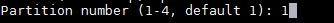
|
||||
][7]
|
||||
|
||||
Assign a Partition Number
|
||||
|
||||
Give the value of the first sector. If it is a new disk, always select default value. If you are creating a second partition on the same disk, we need to add `1` to the last sector of the previous partition.
|
||||
|
||||
[
|
||||
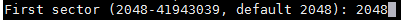
|
||||
][8]
|
||||
|
||||
Assign Sector to Partition
|
||||
|
||||
Give the value of the last sector or the partition size. Always recommended to give the size of the partition. Always prefix `+` to avoid value out of range error.
|
||||
|
||||
[
|
||||
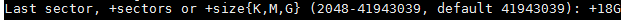
|
||||
][9]
|
||||
|
||||
Assign Partition Size
|
||||
|
||||
Save the changes and exit.
|
||||
|
||||
[
|
||||
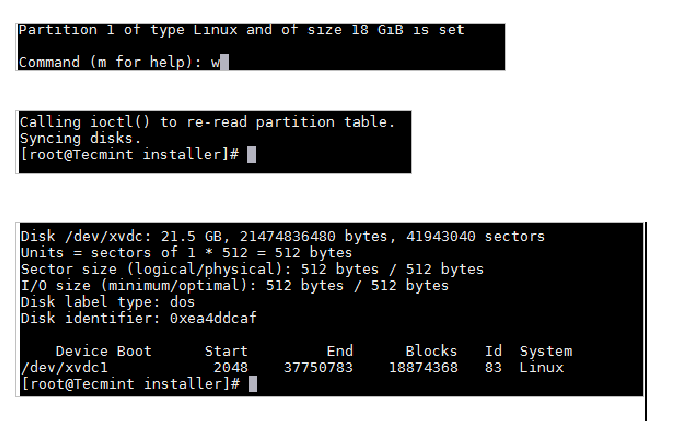
|
||||
][10]
|
||||
|
||||
Save Partition Changes
|
||||
|
||||
Now format the disk with mkfs command.
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/xvdc1
|
||||
```
|
||||
[
|
||||
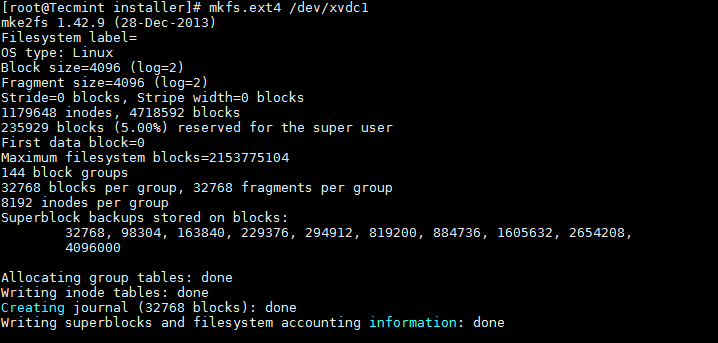
|
||||
][11]
|
||||
|
||||
Format New Partition
|
||||
|
||||
Once formatting has been completed, now mount the partition as shown below.
|
||||
|
||||
```
|
||||
# mount /dev/xvdc1 /data
|
||||
```
|
||||
|
||||
Make an entry in /etc/fstab file for permanent mount at boot time.
|
||||
|
||||
```
|
||||
/dev/xvdc1 /data ext4 defaults 0 0
|
||||
```
|
||||
|
||||
##### Conclusion
|
||||
|
||||
Now you know how to partition a raw disk using [fdisk command][12] and mount the same.
|
||||
|
||||
We need to be extra cautious while working with the partitions especially when you are editing the configured disks. Please share your feedback and suggestions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I work on various platforms including IBM-AIX, Solaris, HP-UX, and storage technologies ONTAP and OneFS and have hands on experience on Oracle Database.
|
||||
|
||||
-----------------------
|
||||
|
||||
via: http://www.tecmint.com/add-new-disk-to-an-existing-linux/
|
||||
|
||||
作者:[Lakshmi Dhandapani][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/lakshmi/
|
||||
[1]:http://www.tecmint.com/add-disk-larger-than-2tb-to-an-existing-linux/
|
||||
[2]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Partition-Details.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-New-Partition-Details.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Create-New-Partition-in-Linux.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Create-Primary-Partition.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-a-Partition-Number.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-Sector-to-Partition.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-Partition-Size.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Save-Partition-Changes.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Format-New-Partition.png
|
||||
[12]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[13]:http://www.tecmint.com/author/lakshmi/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
How to deploy Node.js Applications with pm2 and Nginx on Ubuntu
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
All You Need To Know About Processes in Linux [Comprehensive Guide]
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,188 +0,0 @@
|
||||
ucasFL is Translating
|
||||
pyDash – A Web Based Linux Performance Monitoring Tool
|
||||
============================================================
|
||||
|
||||
pydash is a lightweight [web-based monitoring tool for Linux][1] written in Python and [Django][2] plus Chart.js. It has been tested and can run on the following mainstream Linux distributions: CentOS, Fedora, Ubuntu, Debian, Arch Linux, Raspbian as well as Pidora.
|
||||
|
||||
You can use it to keep an eye on your Linux PC/server resources such as CPUs, RAM, network stats, processes including online users and more. The dashboard is developed entirely using Python libraries provided in the main Python distribution, therefore it has a few dependencies; you don’t need to install many packages or libraries to run it.
|
||||
|
||||
In this article, we will show you how to install pydash to monitor Linux server performance.
|
||||
|
||||
### How to Install pyDash in Linux System
|
||||
|
||||
1. First install required packages: git and Python pip as follows:
|
||||
|
||||
```
|
||||
-------------- On Debian/Ubuntu --------------
|
||||
$ sudo apt-get install git python-pip
|
||||
-------------- On CentOS/RHEL --------------
|
||||
# yum install epel-release
|
||||
# yum install git python-pip
|
||||
-------------- On Fedora 22+ --------------
|
||||
# dnf install git python-pip
|
||||
```
|
||||
|
||||
2. If you have git and Python pip installed, next, install virtualenv which helps to deal with dependency issues for Python projects, as below:
|
||||
|
||||
```
|
||||
# pip install virtualenv
|
||||
OR
|
||||
$ sudo pip install virtualenv
|
||||
```
|
||||
|
||||
3. Now using git command, clone the pydash directory into your home directory like so:
|
||||
|
||||
```
|
||||
# git clone https://github.com/k3oni/pydash.git
|
||||
# cd pydash
|
||||
```
|
||||
|
||||
4. Next, create a virtual environment for your project called pydashtest using the virtualenv command below.
|
||||
|
||||
```
|
||||
$ virtualenv pydashtest #give a name for your virtual environment like pydashtest
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Create Virtual Environment
|
||||
|
||||
Important: Take note the virtual environment’s bin directory path highlighted in the screenshot above, yours could be different depending on where you cloned the pydash folder.
|
||||
|
||||
5. Once you have created the virtual environment (pydashtest), you must activate it before using it as follows.
|
||||
|
||||
```
|
||||
$ source /home/aaronkilik/pydash/pydashtest/bin/activate
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Active Virtual Environment
|
||||
|
||||
From the screenshot above, you’ll note that the PS1 prompt changes indicating that your virtual environment has been activated and is ready for use.
|
||||
|
||||
6. Now install the pydash project requirements; if you are curious enough, view the contents of requirements.txt using the [cat command][5] and the install them using as shown below.
|
||||
|
||||
```
|
||||
$ cat requirements.txt
|
||||
$ pip install -r requirements.txt
|
||||
```
|
||||
|
||||
7. Now move into the pydash directory containing settings.py or simple run the command below to open this file to change the SECRET_KEY to a custom value.
|
||||
|
||||
```
|
||||
$ vi pydash/settings.py
|
||||
```
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Set Secret Key
|
||||
|
||||
Save the file and exit.
|
||||
|
||||
8. Afterward, run the django command below to create the project database and install Django’s auth system and create a project super user.
|
||||
|
||||
```
|
||||
$ python manage.py syncdb
|
||||
```
|
||||
|
||||
Answer the questions below according to your scenario:
|
||||
|
||||
```
|
||||
Would you like to create one now? (yes/no): yes
|
||||
Username (leave blank to use 'root'): admin
|
||||
Email address: aaronkilik@gmail.com
|
||||
Password: ###########
|
||||
Password (again): ############
|
||||
```
|
||||
[
|
||||
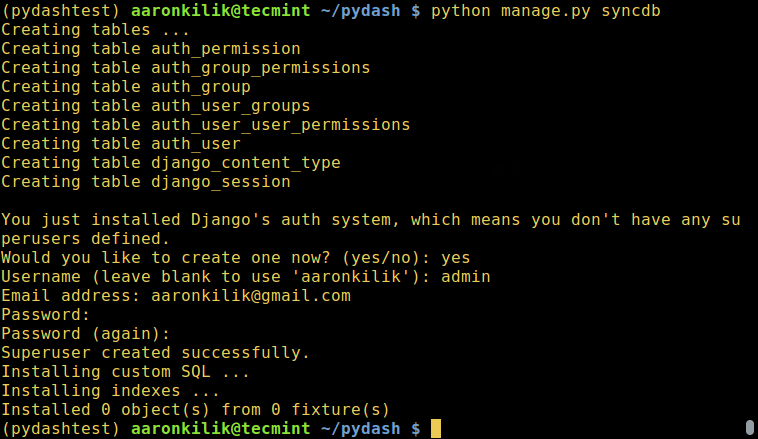
|
||||
][7]
|
||||
|
||||
Create Project Database
|
||||
|
||||
9. At this point, all should be set, now run the following command to start the Django development server.
|
||||
|
||||
```
|
||||
$ python manage.py runserver
|
||||
```
|
||||
|
||||
10. Next, open your web browser and type the URL: http://127.0.0.1:8000/ to get the web dashboard login interface. Enter the super user name and password you created while creating the database and installing Django’s auth system in step 8 and click Sign In.
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
pyDash Login Interface
|
||||
|
||||
11. Once you login into pydash main interface, you will get a section for monitoring general system info, CPU, memory and disk usage together with system load average.
|
||||
|
||||
Simply scroll down to view more sections.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
pyDash Server Performance Overview
|
||||
|
||||
12. Next, screenshot of the pydash showing a section for keeping track of interfaces, IP addresses, Internet traffic, disk read/writes, online users and netstats.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
pyDash Network Overview
|
||||
|
||||
13. Next is a screenshot of the pydash main interface showing a section to keep an eye on active processes on the system.
|
||||
|
||||
[
|
||||
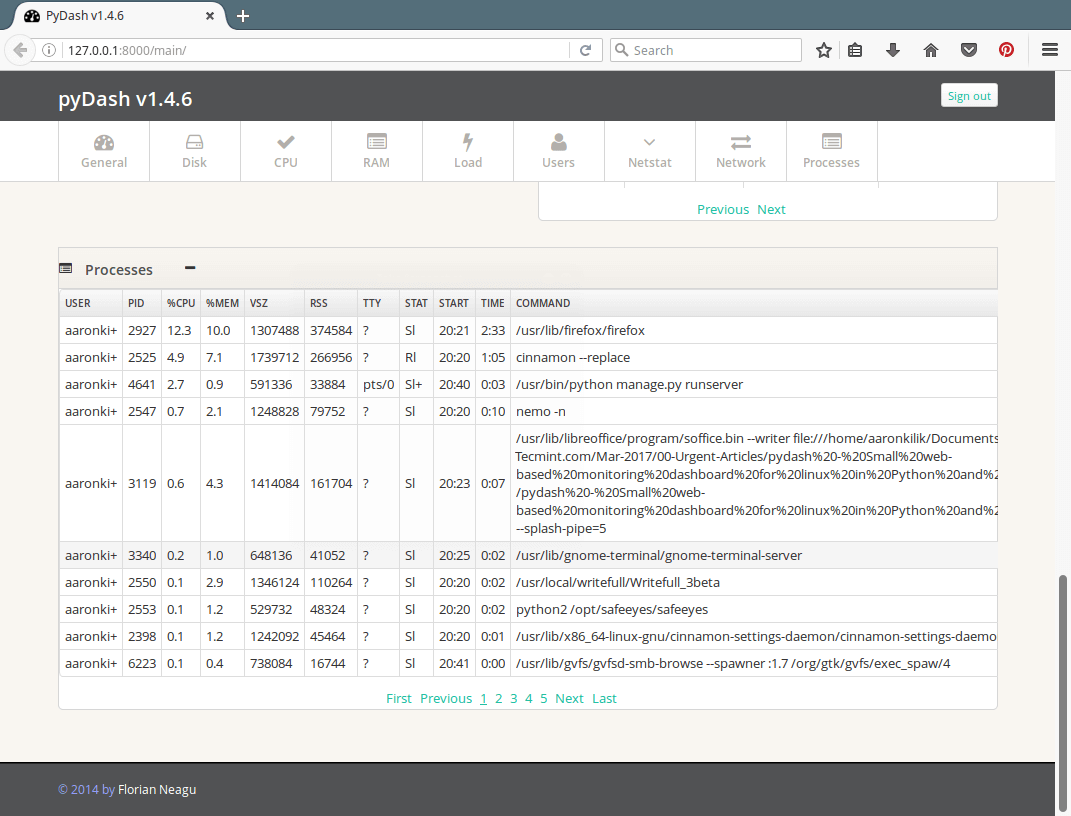
|
||||
][11]
|
||||
|
||||
pyDash Active Linux Processes
|
||||
|
||||
For more information, check out pydash on Github: [https://github.com/k3oni/pydash][12].
|
||||
|
||||
That’s it for now! In this article, we showed you how to setup and test the main features of pydash in Linux. Share any thoughts with us via the feedback section below and in case you know of any useful and similar tools out there, let us know as well in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
I am Ravi Saive, creator of TecMint. A Computer Geek and Linux Guru who loves to share tricks and tips on Internet. Most Of My Servers runs on Open Source Platform called Linux. Follow Me: [Twitter][00], [Facebook][01] and [Google+][02]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/pydash-a-web-based-linux-performance-monitoring-tool/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[00]:https://twitter.com/ravisaive
|
||||
[01]:https://www.facebook.com/ravi.saive
|
||||
[02]:https://plus.google.com/u/0/+RaviSaive
|
||||
|
||||
[1]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[2]:http://www.tecmint.com/install-and-configure-django-web-framework-in-centos-debian-ubuntu/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/create-virtual-environment.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/after-activating-virtualenv.png
|
||||
[5]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/change-secret-key.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/python-manage.py-syncdb.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-web-login-interface.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-Server-Performance-Overview.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-Network-Overview.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-Active-Linux-Processes.png
|
||||
[12]:https://github.com/k3oni/pydash
|
||||
[13]:http://www.tecmint.com/author/admin/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,129 +0,0 @@
|
||||
ucasFL is Translating
|
||||
How To Enable Desktop Sharing In Ubuntu and Linux Mint
|
||||
============================================================
|
||||
|
||||
|
||||
Desktop sharing refers to technologies that enable remote access and remote collaboration on a computer desktop via a graphical terminal emulator. Desktop sharing allows two or more Internet-enabled computer users to work on the same files from different locations.
|
||||
|
||||
In this article, we will show you how to enable desktop sharing in Ubuntu and Linux Mint, with a few vital security features.
|
||||
|
||||
### Enabling Desktop Sharing in Ubuntu and Linux Mint
|
||||
|
||||
1. In the Ubuntu Dash or Linux Mint Menu, search for “desktop sharing” as shown in the following screenshot, once you get it, launch it.
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
Search for Desktop Sharing in Ubuntu
|
||||
|
||||
2. Once you launch Desktop sharing, there are three categories of desktop sharing settings: sharing, security and notification settings.
|
||||
|
||||
Under sharing, check the option “Allow others users to view your desktop” to enable desktop sharing. Optionally, you can also permit other users to remotely control your desktops by checking the option “Allow others users to control your desktop”.
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Desktop Sharing Preferences
|
||||
|
||||
3. Next in security section, you can choose to manually confirm each remote connection by checking the option “You must confirm each access to this computer”.
|
||||
|
||||
Again, another useful security feature is creating a certain shared password using the option “Require user to enter this password”, that remote users must know and enter each time they want to access your desktop.
|
||||
|
||||
4. Concerning notifications, you can keep an eye on remote connections by choosing to show the notification area icon each time there is a remote connection to your desktops by selecting “Only when someone is connected”.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Configure Desktop Sharing Set
|
||||
|
||||
When you have set all the desktop sharing options, click Close. Now you have successfully permitted desktop sharing on your Ubuntu or Linux Mint desktop.
|
||||
|
||||
### Testing Desktop Sharing in Ubuntu Remotely
|
||||
|
||||
You can test to ensure that it’s working using a remote connection application. In this example, I will show you how some of the options we set above work.
|
||||
|
||||
5. I will connect to my Ubuntu PC using VNC (Virtual Network Computing) protocol via [remmina remote connection application][4].
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Remmina Desktop Sharing Tool
|
||||
|
||||
6. After clicking on Ubuntu PC item, I get the interface below to configure my connection settings.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Remmina Desktop Sharing Preferences
|
||||
|
||||
7. After performing all the settings, I will click Connect. Then provide the SSH password for the username and click OK.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Enter SSH User Password
|
||||
|
||||
I have got this black screen after clicking OK because, on the remote machine, the connection has not been confirmed yet.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Black Screen Before Confirmation
|
||||
|
||||
8. Now on the remote machine, I have to accept the remote access request by clicking on “Allow” as shown in the next screenshot.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Allow Remote Desktop Sharing
|
||||
|
||||
9. After accepting the request, I have successfully connected, remotely to my Ubuntu desktop machine.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Remote Ubuntu Desktop
|
||||
|
||||
That’s it! In this article, we described how to enable desktop sharing in Ubuntu and Linux Mint. Use the comment section below to write back to us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/enable-desktop-sharing-in-ubuntu-linux-mint/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2017/03/search-for-desktop-sharing.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/03/desktop-sharing-settings-inte.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Desktop-Sharing-Set.png
|
||||
[4]:http://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Desktop-Sharing-Tool.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Remmina-Configure-Remote-Desk.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/shared-pass.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/black-screen-before-confirmat.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/accept-remote-access-request.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/successfully-connected-to-rem.png
|
||||
[11]:http://www.tecmint.com/author/aaronkili/
|
||||
[12]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[13]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
Cpustat – Monitors CPU Utilization by Running Processes in Linux
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,234 @@
|
||||
响应式编程vs.响应式系统
|
||||
============================================================
|
||||
|
||||
>在恒久的迷惑与过多期待的海洋中,登上一组简单响应式设计原则的小岛。
|
||||
|
||||
>
|
||||
|
||||

|
||||
|
||||
下载 Konrad Malawski 的免费电子书[《为什么选择响应式?企业应用中的基本原则》][5],深入了解更多响应式技术的知识与好处。
|
||||
|
||||
自从2013年一起合作写了[《响应式宣言》][23]之后,我们看着响应式从一种几乎无人知晓的软件构建技术——当时只有少数几个公司的边缘项目使用了这一技术——最后成为中间件领域(middleware field)大佬们全平台战略中的一部分。本文旨在定义和澄清响应式各个方面的概念,方法是比较在_响应式编程_风格下,以及把_响应式系统_视作一个紧密整体的设计方法下写代码的不同。
|
||||
|
||||
### 响应式是一组设计原则
|
||||
响应式技术目前成功的标志之一是“响应式”成为了一个热词,并且跟一些不同的事物与人联系在了一起——常常伴随着像“流(streaming)”,“轻量级(lightweight)”和“实时(real-time)”这样的词。
|
||||
|
||||
举个例子:当我们看到一支运动队时(像棒球队或者篮球队),我们一般会把他们看成一个个单独个体的组合,但是当他们之间碰撞不出火花,无法像一个团队一样高效地协作时,他们就会输给一个“更差劲”的队伍。从这篇文章的角度来看,响应式是一组设计原则,一种关于系统架构与设计的思考方式,一种关于在一个分布式环境下,当实现技术(implementation techniques),工具和设计模式都只是一个更大系统的一部分时如何设计的思考方式。
|
||||
|
||||
这个例子展示了不经考虑地将一堆软件拼揍在一起——尽管单独来看,这些软件都很优秀——和响应式系统之间的不同。在一个响应式系统中,正是_不同组件(parts)间的相互作用_让响应式系统如此不同,它使得不同组件能够独立地运作,同时又一致协作从而达到最终想要的结果。
|
||||
|
||||
_一个响应式系统_ 是一种架构风格(architectural style),它允许许多独立的应用结合在一起成为一个单元,共同响应它们所处的环境,同时保留着对单元内其它应用的“感知”——这能够表现为它能够做到放大/缩小规模(scale up/down),负载平衡,甚至能够主动地执行这些步骤。
|
||||
|
||||
以响应式的风格(或者说,通过响应式编程)写一个软件是可能的;然而,那也不过是拼图中的一块罢了。虽然在上面的提到的各个方面似乎都足以称其为“响应式的”,但仅就其它们自身而言,还不足以让一个_系统_成为响应式的。
|
||||
|
||||
当人们在软件开发与设计的语境下谈论“响应式”时,他们的意思通常是以下三者之一:
|
||||
|
||||
* 响应式系统(架构与设计)
|
||||
* 响应式编程(基于声明的事件的)
|
||||
* 函数响应式编程(FRP)
|
||||
|
||||
我们将检查这些做法与技术的意思,特别是前两个。更明确地说,我们会在使用它们的时候讨论它们,例如它们是怎么联系在一起的,从它们身上又能到什么样的好处——特别是在为多核、云或移动架构搭建系统的情境下。
|
||||
|
||||
让我们先来说一说函数响应式编程吧,以及我们在本文后面不再讨论它的原因。
|
||||
|
||||
### 函数响应式编程(FRP)
|
||||
|
||||
_函数响应式编程_,通常被称作_FRP_,是最常被误解的。FRP在二十年前就被Conal Elliott[精确地定义][24]了。但是最近这个术语却被错误地用来描述一些像Elm,Bacon.js的技术以及其它技术中的响应式插件(RxJava, Rx.NET, RxJS)。许多的库(libraries)声称他们支持FRP,事实上他们说的并非_响应式编程_,因此我们不会再进一步讨论它们。
|
||||
|
||||
### 响应式编程
|
||||
|
||||
_响应式编程_,不要把它跟_函数响应式编程_混淆了,它是异步编程下的一个子集,也是一种范式,在这种范式下,由新信息的有效性(availability)推动逻辑的前进,而不是让一条执行线程(a thread-of-execution)去推动控制流(control flow)。
|
||||
|
||||
它能够把问题分解为多个独立的步骤,这些独立的步骤可以以异步且非阻塞(non-blocking)的方式被执行,最后再组合在一起产生一条工作流(workflow)——它的输入和输出可能是非绑定的(unbounded)。
|
||||
|
||||
[“异步地(Asynchronous)”][25]被牛津词典定义为“不在同一时刻存在或发生”,在我们的语境下,它意味着一条消息或者一个事件可发生在任何时刻,有可能是在未来。这在响应式编程中是非常重要的一项技术,因为响应式编程允许[非阻塞式(non-blocking)]的执行方式——执行线程在竞争一块共享资源时不会因为阻塞(blocking)而陷入等待(防止执行线程在当前的工作完成之前执行任何其它操作),而是在共享资源被占用的期间转而去做其它工作。阿姆达尔定律(Amdahl's Law)[2][9]告诉我们,竞争是可伸缩性(scalability)最大的敌人,所以一个响应式系统应当在极少数的情况下才不得不做阻塞工作。
|
||||
|
||||
响应式编程一般是_事件驱动(event-driven)_ ,相比之下,响应式系统则是_消息驱动(message-driven)_ 的——事件驱动与消息驱动之间的差别会在文章后面阐明。
|
||||
|
||||
响应式编程库的应用程序接口(API)一般是以下二者之一:
|
||||
|
||||
* 基于回调的(Callback-based)——匿名的间接作用(side-effecting)回调函数被绑定在事件源(event sources)上,当事件被放入数据流(dataflow chain)中时,回调函数被调用。
|
||||
* 声明式的(Declarative)——通过函数的组合,通常是使用一些固定的函数,像 _map_, _filter_, _fold_ 等等。
|
||||
|
||||
大部分的库会混合这两种风格,一般还带有基于流(stream-based)的操作符(operators),像windowing, counts, triggers。
|
||||
|
||||
说响应式编程跟[数据流编程(dataflow programming)][27]有关是很合理的,因为它强调的是_数据流_而不是_控制流_。
|
||||
|
||||
举几个为这种编程技术提供支持的的编程抽象概念:
|
||||
|
||||
* [Futures/Promises][10]——一个值的容器,具有读共享/写独占(many-read/single-write)的语义,即使变量尚不可用也能够添加异步的值转换操作。
|
||||
* 流(streams)-[响应式流][11]——无限制的数据处理流,支持异步,非阻塞式,支持多个源与目的的反压转换管道(back-pressured transformation pipelines)。
|
||||
* [数据流变量][12]——依赖于输入,过程(procedures)或者其它单元的单赋值变量(存储单元)(single assignment variables),它能够自动更新值的改变。其中一个应用例子是表格软件——一个单元的值的改变会像涟漪一样荡开,影响到所有依赖于它的函数,顺流而下地使它们产生新的值。
|
||||
|
||||
在JVM中,支持响应式编程的流行库有Akka Streams、Ratpack、Reactor、RxJava和Vert.x等等。这些库实现了响应式编程的规范,成为JVM上响应式编程库之间的互通标准(standard for interoperability),并且根据它自身的叙述是“……一个为如何处理非阻塞式反压异步流提供标准的倡议”
|
||||
|
||||
响应式编程的基本好处是:提高多核和多CPU硬件的计算资源利用率;根据阿姆达尔定律以及引申的Günther的通用可伸缩性定律[3][13](Günther’s Universal Scalability Law),通过减少序列化点(serialization points)来提高性能。
|
||||
|
||||
另一个好处是开发者生产效率,传统的编程范式都尽力想提供一个简单直接的可持续的方法来处理异步非阻塞式计算和I/O。在响应式编程中,因活动(active)组件之间通常不需要明确的协作,从而也就解决了其中大部分的挑战。
|
||||
|
||||
响应式编程真正的发光点在于组件的创建跟工作流的组合。为了在异步执行上取得最大的优势,把[反压(back-pressure)][28]加进来是很重要,这样能避免过度使用,或者确切地说,无限度的消耗资源。
|
||||
|
||||
尽管如此,响应式编程在搭建现代软件上仍然非常有用,为了在更高层次上理解(reason about)一个系统,那么必须要使用到另一个工具:_响应式架构_——设计响应式系统的方法。此外,要记住编程范式有很多,而响应式编程仅仅只是其中一个,所以如同其它工具一样,响应式编程并不是万金油,它不意图适用于任何情况。
|
||||
|
||||
### 事件驱动 vs. 消息驱动
|
||||
如上面提到的,响应式编程——专注于短时间的数据流链条上的计算——因此倾向于_事件驱动_,而响应式系统——关注于通过分布式系统的通信和协作所得到的弹性和韧性——则是[_消息驱动的_][29][4][14](或者称之为 _消息式(messaging)_ 的)。
|
||||
|
||||
一个拥有长期存活的可寻址(long-lived addressable)组件的消息驱动系统跟一个事件驱动的数据流驱动模型的不同在于,消息具有固定的导向,而事件则没有。消息会有明确的(一个)去向,而事件则只是一段等着被观察(observe)的信息。另外,消息式(messaging)更适用于异步,因为消息的发送与接收和发送者和接收者是分离的。
|
||||
|
||||
响应式宣言中的术语表定义了两者之间[概念上的不同][30]:
|
||||
> 一条消息就是一则被送往一个明确目的地的数据。一个事件则是达到某个给定状态的组件发出的一个信号。在一个消息驱动系统中,可寻址到的接收者等待消息的到来然后响应它,否则保持休眠状态。在一个事件驱动系统中,通知的监听者被绑定到消息源上,这样当消息被发出时它就会被调用。这意味着一个事件驱动系统专注于可寻址的事件源而消息驱动系统专注于可寻址的接收者。
|
||||
|
||||
分布式系统需要通过消息在网络上传输进行交流,以实现其沟通基础,与之相反,事件的发出则是本地的。在底层通过发送包裹着事件的消息来搭建跨网络的事件驱动系统的做法很常见。这样能够维持在分布式环境下事件驱动编程模型的相对简易性并且在某些特殊的和合理范围内的使用案例上工作得很好。
|
||||
|
||||
然而,这是有利有弊的:在编程模型的抽象性和简易性上得一分,在控制上就减一分。消息强迫我们去拥抱分布式系统的真实性和一致性——像局部错误(partial failures),错误侦测(failure detection),丢弃/复制/重排序 消息(dropped/duplicated/reordered messages),最后还有一致性,管理多个并发真实性等等——然后直面它们,去处理它们,而不是像过去无数次一样,藏在一个蹩脚的抽象面罩后——假装网络并不存在(例如EJB, [RPC][31], [CORBA][32], 和 [XA][33])。
|
||||
|
||||
这些在语义学和适用性上的不同在应用设计中有着深刻的含义,包括分布式系统的复杂性(complexity)中的 _弹性(resilience)_, _韧性(elasticity)_,_移动性(mobility)_,_位置透明性(location transparency)_ 和 _管理(management)_,这些在文章后面再进行介绍。
|
||||
|
||||
在一个响应式系统中,特别是使用了响应式编程技术的,这样的系统中就即有事件也有消息——一个是用于沟通的强大工具(消息),而另一个则呈现现实(事件)。
|
||||
|
||||
### 响应式系统和架构
|
||||
|
||||
_响应式系统_ —— 如同在《响应式宣言》中定义的那样——是一组用于搭建现代系统——已充分准备好满足如今应用程序所面对的不断增长的需求的现代系统——的架构设计原则。
|
||||
|
||||
响应式系统的原则决对不是什么新东西,它可以被追溯到70和80年代Jim Gray和Pat Helland在[串级系统(Tandem System)][34]上和Joe aomstrong和Robert Virding在[Erland][35]上做出的重大工作。然而,这些人在当时都超越了时代,只有到了最近5-10年,技术行业才被不得不反思当前企业系统最好的开发实践活动并且学习如何将来之不易的响应式原则应用到今天这个多核、云计算和物联网的世界中。
|
||||
|
||||
响应式系统的基石是_消息传递(message-passing)_ ,消息传递为两个组件之间创建一条暂时的边界,使得他们能够在 _时间_ 上分离——实现并发性——和 _空间(space)_ ——实现分布式(distribution)与移动性(mobility)。这种分离是两个组件完全[隔离(isolation)][36]以及实现 _弹性(resilience)_ 和 _韧性(elasticity)_ 基础的必需条件。
|
||||
|
||||
### 从程序到系统
|
||||
|
||||
这个世界的连通性正在变得越来越高。我们构建 _程序_ ——为单个操作子计算某些东西的端到端逻辑——已经不如我们构建 _系统_ 来得多了。
|
||||
|
||||
系统从定义上来说是复杂的——每一部分都包含多个组件,每个组件的自身或其子组件也可以是一个系统——这意味着软件要正常工作已经越来越依赖于其它软件。
|
||||
|
||||
我们今天构建的系统会在多个计算机上被操作,小型的或大型的,数量少的或数量多的,相近的或远隔半个地球的。同时,由于人们的生活正变得越来越依赖于系统顺畅运行的有效性,用户的期望也变得越得越来越难以满足。
|
||||
|
||||
为了实现用户——和企业——能够依赖的系统,这些系统必须是 _灵敏的(responsive)_ ,这样无论是某个东西提供了一个正确的响应,还是当需要一个响应时响应无法使用,都不会有影响。为了达到这一点,我们必须保证在错误( _弹性_ )和欠载( _韧性_ )下,系统仍然能够保持灵敏性。为了实现这一点,我们把系统设计为 _消息驱动的_ ,我们称其为 _响应式系统_ 。
|
||||
|
||||
### 响应式系统的弹性
|
||||
|
||||
弹性是与 _错误下_ 的灵敏性(responsiveness)有关的,它是系统内在的功能特性,是需要被设计的东西,而不是能够被动的加入系统中的东西。弹性是大于容错性的——弹性无关于故障退化(graceful degradation)——虽然故障退化对于系统来说是很有用的一种特性——与弹性相关的是与从错误中完全恢复达到 _自愈_ 的能力。这就需要组件的隔离以及组件对错误的包容,以免错误散播到其相邻组件中去——否则,通常会导致灾难性的连锁故障。
|
||||
|
||||
因此构建一个弹性的,自愈(self-healing)系统的关键是允许错误被:容纳,具体化为消息,发送给其他的(担当监管者的(supervisors))组件,从而在错误组件之外修复出一个安全环境。在这,消息驱动是其促成因素:远离高度耦合的、脆弱的深层嵌套的同步调用链,大家长期要么学会忍受其煎熬或直接忽略。解决的想法是将调用链中的错误管理分离,将客户端从处理服务端错误的责任中解放出来。
|
||||
|
||||
### 响应式系统的韧性
|
||||
|
||||
[韧性(Elasticity)][37]是关于 _欠载下的灵敏性(responsiveness)_ 的——意味着一个系统的吞吐量在资源增加或减少时能够自动地相应增加或减少(scales up or down)(同样能够向内或外扩展(scales in or out))以满足不同的需求。这是利用云计算承诺的特性所必需的因素:使系统利用资源更加有效,成本效益更佳,对环境友好以及实现按次付费。
|
||||
|
||||
系统必须能够在不重写甚至不重新设置的情况下,适应性地——即无需介入自动伸缩——响应状态及行为,沟通负载均衡,故障转移(failover),以及升级。实现这些的就是 _位置透明性(location transparency)_ :使用同一个方法,同样的编程抽象,同样的语义,在所有向度中伸缩(scaling)系统的能力——从CPU核心到数据中心。
|
||||
|
||||
如同《响应式宣言》所述:
|
||||
|
||||
> 一个极大地简化问题的关键洞见在于意识到我们都在使用分布式计算。无论我们的操作系统是运行在一个单一结点上(拥有多个独立的CPU,并通过QPI链接进行交流),还是在一个节点集群(cluster of nodes,独立的机器,通过网络进行交流)上。拥抱这个事实意味着在垂直方向上多核的伸缩与在水平方面上集群的伸缩并无概念上的差异。在空间上的解耦 [...],是通过异步消息传送以及运行时实例与其引用解耦从而实现的,这就是我们所说的位置透明性。
|
||||
|
||||
因此,不论接收者在哪里,我们都以同样的方式与它交流。唯一能够在语义上等同实现的方式是消息传送。
|
||||
|
||||
### 响应式系统的生产效率
|
||||
|
||||
既然大多数的系统生来即是复杂的,那么其中一个最重要的点即是保证一个系统架构在开发和维护组件时,最小程度地减低生产效率,同时将操作的 _偶发复杂性(accidental complexity_ 降到最低。
|
||||
|
||||
这一点很重要,因为在一个系统的生命周期中——如果系统的设计不正确——系统的维护会变得越来越困难,理解、定位和解决问题所需要花费时间和精力会不断地上涨。
|
||||
|
||||
响应式系统是我们所知的最具 _生产效率_ 的系统架构(在多核、云及移动架构的背景下):
|
||||
|
||||
* 错误的隔离为组件与组件之间裹上[舱壁][15](译者注:当船遭到损坏进水时,舱壁能够防止水从损坏的船舱流入其他船舱),防止引发连锁错误,从而限制住错误的波及范围以及严重性。
|
||||
|
||||
* 监管者的层级制度提供了多个等级的防护,搭配以自我修复能力,避免了许多曾经在侦查(inverstigate)时引发的操作代价(cost)——大量的瞬时故障(transient failures)。
|
||||
|
||||
* 消息传送和位置透明性允许组件被卸载下线、代替或重新布线(rerouted)同时不影响终端用户的使用体验,并降低中断的代价、它们的相对紧迫性以及诊断和修正所需的资源。
|
||||
|
||||
* 复制减少了数据丢失的风险,减轻了数据检索(retrieval)和存储的有效性错误的影响。
|
||||
|
||||
* 韧性允许在使用率波动时保存资源,允许在负载很低时,最小化操作开销,并且允许在负载增加时,最小化运行中断(outgae)或紧急投入(urgent investment)伸缩性的风险。
|
||||
|
||||
因此,响应式系统使生成系统(creation systems)很好的应对错误、随时间变化的负载——同时还能保持低运营成本。
|
||||
|
||||
### 响应式编程与响应式系统的关联
|
||||
|
||||
响应式编程是一种管理内部逻辑(internal logic)和数据流转换(dataflow transformation)的好技术,在本地的组件中,做为一种优化代码清晰度、性能以及资源利用率的方法。响应式系统,是一组架构上的原则,旨在强调分布式信息交流并为我们提供一种处理分布式系统弹性与韧性的工具。
|
||||
|
||||
只使用响应式编程常遇到的一个问题,是一个事件驱动的基于回调的或声明式的程序中两个计算阶段的高度耦合(tight coupling),使得 _弹性_ 难以实现,因此时它的转换链通常存活时间短,并且它的各个阶段——回调函数或组合子(combinator)——是匿名的,也就是不可寻址的。
|
||||
|
||||
这意味着,它通常在内部处理成功与错误的状态而不会向外界发送相应的信号。这种寻址能力的缺失导致单个阶段(stages)很难恢复,因为它通常并不清楚异常应该,甚至不清楚异常可以,发送到何处去。
|
||||
|
||||
另一个与响应式系统方法的不同之处在于单纯的响应式编程允许 _时间_ 上的解耦(decoupling),但不允许 _空间_ 上的(除非是如上面所述的,在底层通过网络传送消息来分发(distribute)数据流)。正如叙述的,在时间上的解耦使 _并发性_ 成为可能,但是是空间上的解耦使 _分布(distribution)_ 和 _移动性(mobility)_ (使得不仅仅静态拓扑可用,还包括了动态拓扑)成为可能的——而这些正是 _韧性_ 所必需的要素。
|
||||
|
||||
位置透明性的缺失使得很难以韧性方式对一个基于适应性响应式编程技术的程序进行向外扩展,因为这样就需要分附加工具,例如消息总线(message bus),数据网格(data grid)或者在顶层的定制网络协议(bespoke network protocol)。而这点正是响应式系统的消息驱动编程的闪光的地方,因为它是一个包含了其编程模型和所有伸缩向度语义的交流抽象概念,因此降低了复杂性与认知超载。
|
||||
|
||||
对于基于回调的编程,常会被提及的一个问题是写这样的程序或许相对来说会比较简单,但最终会引发一些真正的后果。
|
||||
|
||||
例如,对于基于匿名回调的系统,当你想理解它们,维护它们或最重要的是在生产供应中断(production outages)或错误行为发生时,你想知道到底发生了什么、发生在哪以及为什么发生,但此时它们只提供极少的内部信息。
|
||||
|
||||
为响应式系统设计的库与平台(例如[Akka][39]项目和[Erlang][40]平台)学到了这一点,它们依赖于那些更容易理解的长期存活的可寻址组件。当错误发生时,根据导致错误的消息可以找到唯一的组件。当可寻址的概念存在组件模型的核心中时,监控方案(monitoring solution)就有了一个 _有意义_ 的方式来呈现它收集的数据——利用传播(propagated)的身份标识。
|
||||
|
||||
一个好的编程范式的选择,一个选择实现像可寻址能力和错误管理这些东西的范式,已经被证明在生产中是无价的,因它在设计中承认了现实并非一帆风顺,_接受并拥抱错误的出现_ 而不是毫无希望地去尝试避免错误。
|
||||
|
||||
总而言之,响应式编程是一个非常有用的实现技术,可以用在响应式架构当中。但是记住这只能帮助管理一部分:异步且非阻塞执行下的数据流管理——通常只在单个结点或服务中。当有多个结点时,就需要开始认真地考虑像数据一致性(data consistency)、跨结点沟通(cross-node communication)、协调(coordination)、版本控制(versioning)、编制(orchestration)、错误管理(failure management)、关注与责任(concerns and responsibilities)的分离等等的东西——也即是:系统架构。
|
||||
|
||||
因此,要最大化响应式编程的价值,就把它作为构建响应式系统的工具来使用。构建一个响应式系统需要的不仅是在一个已存在的遗留下来的软件栈(software stack)上抽象掉特定的操作系统资源和少量的异步API和[断路器(circuit breakers)][41]。此时应该拥抱你在创建一个包含多个服务的分布式系统这一事实——这意味着所有东西都要共同合作,提供一致性与灵敏的体验,而不仅仅是如预期工作,但同时还要在发生错误和不可预料的负载下正常工作。
|
||||
|
||||
### 总结
|
||||
|
||||
企业和中间件供应商在目睹了应用响应式所带来的企业利润增长后,同样开始拥抱响应式。在本文中,我们把响应式系统做为企业最终目标进行描述——假设了多核、云和移动架构的背景——而响应式编程则从中担任重要工具的角色。
|
||||
|
||||
响应式编程在内部逻辑及数据流转换的组件层次上为开发者提高了生产率——通过性能与资源的有效利用实现。而响应式系统在构建 _原生云(cloud native)_ 和其它大型分布式系统的系统层次上为架构师及DevOps从业者提高了生产率——通过弹性与韧性。我们建议在响应式系统设计原则中结合响应式编程技术。
|
||||
|
||||
```
|
||||
1 参考Conal Elliott,FRP的发明者,见[这个演示][16][↩][17]
|
||||
2 [Amdahl 定律][18]揭示了系统理论上的加速会被一系列的子部件限制,这意味着系统在新的资源加入后会出现收益递减(diminishing returns)。 [↩][19]
|
||||
3 Neil Günter的[通用可伸缩性定律(Universal Scalability Law)][20]是理解并发与分布式系统的竞争与协作的重要工具,它揭示了当新资源加入到系统中时,保持一致性的开销会导致不好的结果。
|
||||
4 消息可以是同步的(要求发送者和接受者同时存在),也可以是异步的(允许他们在时间上解耦)。其语义上的区别超出本文的讨论范围。[↩][22]
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems
|
||||
|
||||
作者:[Jonas Bonér][a] , [Viktor Klang][b]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/e0b57-jonas-boner
|
||||
[b]:https://www.oreilly.com/people/f96106d4-4ce6-41d9-9d2b-d24590598fcd
|
||||
[1]:https://www.flickr.com/photos/pixel_addict/2301302732
|
||||
[2]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[3]:https://www.oreilly.com/people/e0b57-jonas-boner
|
||||
[4]:https://www.oreilly.com/people/f96106d4-4ce6-41d9-9d2b-d24590598fcd
|
||||
[5]:http://www.oreilly.com/programming/free/why-reactive.csp?intcmp=il-webops-free-product-na_new_site_reactive_programming_vs_reactive_systems_text_cta
|
||||
[6]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[7]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[8]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-1
|
||||
[9]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-2
|
||||
[10]:https://en.wikipedia.org/wiki/Futures_and_promises
|
||||
[11]:http://reactive-streams.org/
|
||||
[12]:https://en.wikipedia.org/wiki/Oz_(programming_language)#Dataflow_variables_and_declarative_concurrency
|
||||
[13]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-3
|
||||
[14]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#dfref-footnote-4
|
||||
[15]:http://skife.org/architecture/fault-tolerance/2009/12/31/bulkheads.html
|
||||
[16]:https://begriffs.com/posts/2015-07-22-essence-of-frp.html
|
||||
[17]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-1
|
||||
[18]:https://en.wikipedia.org/wiki/Amdahl%2527s_law
|
||||
[19]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-2
|
||||
[20]:http://www.perfdynamics.com/Manifesto/USLscalability.html
|
||||
[21]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-3
|
||||
[22]:https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems#ref-footnote-4
|
||||
[23]:http://www.reactivemanifesto.org/
|
||||
[24]:http://conal.net/papers/icfp97/
|
||||
[25]:http://www.reactivemanifesto.org/glossary#Asynchronous
|
||||
[26]:http://www.reactivemanifesto.org/glossary#Non-Blocking
|
||||
[27]:https://en.wikipedia.org/wiki/Dataflow_programming
|
||||
[28]:http://www.reactivemanifesto.org/glossary#Back-Pressure
|
||||
[29]:http://www.reactivemanifesto.org/glossary#Message-Driven
|
||||
[30]:http://www.reactivemanifesto.org/glossary#Message-Driven
|
||||
[31]:https://christophermeiklejohn.com/pl/2016/04/12/rpc.html
|
||||
[32]:https://queue.acm.org/detail.cfm?id=1142044
|
||||
[33]:https://cs.brown.edu/courses/cs227/archives/2012/papers/weaker/cidr07p15.pdf
|
||||
[34]:http://www.hpl.hp.com/techreports/tandem/TR-86.2.pdf
|
||||
[35]:http://erlang.org/download/armstrong_thesis_2003.pdf
|
||||
[36]:http://www.reactivemanifesto.org/glossary#Isolation
|
||||
[37]:http://www.reactivemanifesto.org/glossary#Elasticity
|
||||
[38]:http://www.reactivemanifesto.org/glossary#Location-Transparency
|
||||
[39]:http://akka.io/
|
||||
[40]:https://www.erlang.org/
|
||||
[41]:http://martinfowler.com/bliki/CircuitBreaker.html
|
||||
@ -0,0 +1,266 @@
|
||||
如何在 Ubuntu16.04 中用 Apache 部署 Jenkins 自动化服务器
|
||||
============================================================
|
||||
|
||||
|
||||
Jenkins 是从 Hudson 项目衍生出来的自动化服务器。Jenkins 是一个基于服务器的应用程序,运行在 Java servlet 容器中,它支持包括 Git、SVN 以及 Mercurial 在内的多种 SCM(Source Control Management,源码控制工具)。Jenkins 提供了上百种插件帮助你的项目实现自动化。Jenkins 由 Kohsuke Kawaguchi 开发,在 2011 年使用 MIT 协议发布了第一个发行版,它是个免费软件。
|
||||
|
||||
在这篇指南中,我会向你介绍如何在 Ubuntu 16.04 中安装最新版本的 Jenkins。我们会用自己的域名运行 Jenkins,在 apache web 服务器中安装和配置 Jenkins,而且支持反向代理。
|
||||
|
||||
### 前提
|
||||
|
||||
* Ubuntu 16.04 服务器 - 64 位
|
||||
* Root 权限
|
||||
|
||||
### 第一步 - 安装 Java OpenJDK 7
|
||||
|
||||
Jenkins 基于 Java,因此我们需要在服务器上安装 Java OpenJDK 7。在这里,我们会从一个 PPA 仓库安装 Java 7,首先我们需要添加这个仓库。
|
||||
|
||||
默认情况下,Ubuntu 16.04 没有安装用于管理 PPA 仓库的 python-software-properties 软件包,因此我们首先需要安装这个软件。使用 apt 命令安装 python-software-properties。
|
||||
|
||||
`apt-get install python-software-properties`
|
||||
|
||||
下一步,添加 Java PPA 仓库到服务器中。
|
||||
|
||||
`add-apt-repository ppa:openjdk-r/ppa`
|
||||
|
||||
输入回车键
|
||||
|
||||
用 apt 命令更新 Ubuntu 仓库并安装 Java OpenJDK。`
|
||||
|
||||
`apt-get update`
|
||||
`apt-get install openjdk-7-jdk`
|
||||
|
||||
输入下面的命令验证安装:
|
||||
|
||||
`java -version`
|
||||
|
||||
你会看到安装到服务器上的 Java 版本。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
### 第二步 - 安装 Jenkins
|
||||
|
||||
Jenkins 给软件安装包提供了一个 Ubuntu 仓库,我们会从这个仓库中安装 Jenkins。
|
||||
|
||||
用下面的命令添加 Jenkins 密钥和仓库到系统中。
|
||||
|
||||
`wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -`
|
||||
`echo 'deb https://pkg.jenkins.io/debian-stable binary/' | tee -a /etc/apt/sources.list`
|
||||
|
||||
更新仓库并安装 Jenkins。
|
||||
|
||||
`apt-get update`
|
||||
`apt-get install jenkins`
|
||||
|
||||
安装完成后,用下面的命令启动 Jenkins。
|
||||
|
||||
`systemctl start jenkins`
|
||||
|
||||
通过检查 Jenkins 默认使用的端口(端口 8080)验证 Jenkins 正在运行。我会像下面这样用 netstat 命令检测:
|
||||
|
||||
`netstat -plntu`
|
||||
|
||||
Jenkins 已经安装好了并运行在 8080 端口。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
### 第三步 - 为 Jenkins 安装和配置 Apache 作为反向代理
|
||||
|
||||
在这篇指南中,我们会在一个 apache web 服务器中运行 Jenkins,我们会为 Jenkins 配置 apache 作为反向代理。首先我会安装 apache 并启用一些需要的模块,然后我会为 Jenkins 用域名 my.jenkins.id 创建虚拟 host 文件。请在这里使用你自己的域名并在所有配置文件中出现的地方替换。
|
||||
|
||||
从 Ubuntu 仓库安装 apache2 web 服务器。
|
||||
|
||||
`apt-get install apache2`
|
||||
|
||||
安装完成后,启用 proxy 和 proxy_http 模块以便将 apache 配置为 Jenkins 的前端服务器/反向代理。
|
||||
|
||||
`a2enmod proxy`
|
||||
`a2enmod proxy_http`
|
||||
|
||||
下一步,在 sites-available 目录创建新的虚拟 host 文件。
|
||||
|
||||
`cd /etc/apache2/sites-available/`
|
||||
`vim jenkins.conf`
|
||||
|
||||
粘贴下面的虚拟 host 配置。
|
||||
|
||||
```
|
||||
<Virtualhost *:80>
|
||||
ServerName my.jenkins.id
|
||||
ProxyRequests Off
|
||||
ProxyPreserveHost On
|
||||
AllowEncodedSlashes NoDecode
|
||||
|
||||
<Proxy http://localhost:8080/*>
|
||||
Order deny,allow
|
||||
Allow from all
|
||||
</Proxy>
|
||||
|
||||
ProxyPass / http://localhost:8080/ nocanon
|
||||
ProxyPassReverse / http://localhost:8080/
|
||||
ProxyPassReverse / http://my.jenkins.id/
|
||||
</Virtualhost>
|
||||
```
|
||||
|
||||
保存文件。然后用 a2ensite 命令激活 Jenkins 虚拟 host。
|
||||
|
||||
`a2ensite jenkins`
|
||||
|
||||
重启 Apache 和 Jenkins。
|
||||
|
||||
`systemctl restart apache2`
|
||||
`systemctl restart jenkins`
|
||||
|
||||
检查 Jenkins 和 Apache 正在使用 80 和 8080 端口。
|
||||
|
||||
`netstat -plntu`
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
### 第四步 - 配置 Jenkins
|
||||
|
||||
Jenkins 用域名 'my.jenkins.id' 运行。打开你的 web 浏览器然后输入 URL。你会看到要求你输入初始管理员密码的页面。Jenkins 已经生成了一个密码,因此我们只需要显示并把结果复制到密码框。
|
||||
|
||||
用 cat 命令显示 Jenkins 初始管理员密码。
|
||||
|
||||
`cat /var/lib/jenkins/secrets/initialAdminPassword`
|
||||
|
||||
a1789d1561bf413c938122c599cf65c9
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
将结果粘贴到密码框然后点击 ‘**Continue**’。
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
现在为了后面能比较好的使用,我们需要在 Jenkins 中安装一些插件。选择 ‘**Install Suggested Plugin**’,点击它。
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Jenkins 插件安装过程
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
安装完插件后,我们需要创建一个新的管理员密码。输入你的管理员用户名、密码、电子邮件等,然后点击 ‘**Save and Finish**’。
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
点击 start 开始使用 Jenkins。你会被重定向到 Jenkins 管理员面板。
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
成功完成 Jenkins 安装和配置。
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
### 第五步 - Jenkins 安全
|
||||
|
||||
在 Jenkins 管理员面板,我们需要为 Jenkins 配置标准的安全,点击 ‘**Manage Jenkins**’ 和 ‘**Configure Global Security**’。
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
Jenkins 在 ‘**Access Control**’ 部分提供了多种认证方法。为了能够控制所有的用户权限,我选择了 ‘**Matrix-based Security**’。在复选框 ‘**User/Group**’ 中启用 admin 用户。通过**勾选所有选项**给 admin 所有权限,给 anonymous 只读权限。现在点击 ‘**Save**’。
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
你会被重定向到面板,如果出现了登录选项,只需输入你的管理员账户和密码。
|
||||
|
||||
### 第六步 - 测试一个简单的自动化任务
|
||||
|
||||
在这一部分,我想为 Jenkins 服务测试一个简单的任务。为了测试 Jenkins 我会创建一个简单的任务,并用 top 命令查看服务器的负载。
|
||||
|
||||
在 Jenkins 管理员面板上,点击 ‘**Create New Job**’。
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
输入任务的名称,在这里我用 ‘Checking System’,选择 ‘**Freestyle Project**’ 然后点击 ‘**OK**’。
|
||||
|
||||
[
|
||||

|
||||
][22]
|
||||
|
||||
进入 ‘**Build**’ 标签页。在 ‘**Add build step**’,选择选项 ‘**Execute shell**’。
|
||||
|
||||
在输入框输入下面的命令。
|
||||
|
||||
`top -b -n 1 | head -n 5`
|
||||
|
||||
点击 ‘**Save**’。
|
||||
|
||||
[
|
||||

|
||||
][23]
|
||||
|
||||
现在你是在任务 ‘Project checking system’的任务页。点击 ‘**Build Now**’ 执行任务 ‘checking system’。
|
||||
|
||||
任务执行完成后,你会看到 ‘**Build History**’,点击第一个任务查看结果。
|
||||
|
||||
下面是 Jenkins 任务执行的结果。
|
||||
|
||||
[
|
||||

|
||||
][24]
|
||||
|
||||
到这里就介绍完了在 Ubuntu 16.04 中用 Apache web 服务器安装 Jenkins 的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul ][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#prerequisite
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-install-java-openjdk-
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-install-jenkins
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-install-and-configure-apache-as-reverse-proxy-for-jenkins
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-configure-jenkins
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-jenkins-security
|
||||
[7]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-testing-a-simple-automation-job
|
||||
[8]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#reference
|
||||
[9]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/1.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/2.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/3.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/4.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/5.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/6.png
|
||||
[15]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/7.png
|
||||
[16]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/8.png
|
||||
[17]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/9.png
|
||||
[18]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/10.png
|
||||
[19]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/11.png
|
||||
[20]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/12.png
|
||||
[21]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/13.png
|
||||
[22]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/14.png
|
||||
[23]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/15.png
|
||||
[24]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/16.png
|
||||
@ -1,29 +1,35 @@
|
||||
探索传统 JavaScript 基准测试
|
||||
============================================================
|
||||
|
||||
可以很公平地说,[JavaScript][22] 是当下软件工程最重要的技术。对于那些深入接触过编程语言、编译器和虚拟机的人来说,这仍然有点令人惊讶,因为在语言设计者看来,JavaScript 不是十分优雅;在编译器工程师看来,它没有多少可优化的地方;而且还没有一个伟大的标准库。这取决于你和谁吐槽,JavaScript 的缺点你花上数周都枚举不完,不过你总会找到一些你从所未知的神奇的东西。尽管这看起来明显困难重重,不过 JavaScript 还是成为当今 web 的核心,并且还成为服务器端/云端的主导技术(通过 [Node.js][23]),甚至还开辟了进军物联网空间的道路。
|
||||
可以很公平地说,[JavaScript][22] 是当下软件工程最重要的技术。对于那些深入接触过编程语言、编译器和虚拟机的人来说,这仍然有点令人惊讶,因为在语言设计者们看来,JavaScript 不是十分优雅;在编译器工程师们看来,它没有多少可优化的地方;而且还没有一个伟大的标准库。这取决于你和谁吐槽,JavaScript 的缺点你花上数周都枚举不完,不过你总会找到一些你从所未知的神奇的东西。尽管这看起来明显困难重重,不过 JavaScript 还是成为了当今 web 的核心,并且还(通过 [Node.js][23])成为服务器端/云端的主导技术,甚至还开辟了进军物联网空间的道路。
|
||||
|
||||
问题来了,为什么 JavaScript 如此受欢迎?或者说如此成功?我知道没有一个很好的答案。如今我们有许多使用 JavaScript 的好理由,或许最重要的是围绕其构建的庞大的生态系统,以及今天大量可用的资源。但所有这一切实际上是发展到一定程度的后果。为什么 JavaScript 变得流行起来了?嗯,你或许会说,这是 web 多年来的通用语了。但是在很长一段时间里,人们极其讨厌 JavaScript。回顾过去,似乎第一波 JavaScript 浪潮爆发在上个年代的后半段。不出所料,那个时候 JavaScript 引擎加速了各种不同的任务的执行,这可能让很多人对 JavaScript 刮目相看。
|
||||
问题来了,为什么 JavaScript 如此受欢迎?或者说如此成功?我知道没有一个很好的答案。如今我们有许多使用 JavaScript 的好理由,或许最重要的是围绕其构建的庞大的生态系统,以及今天大量可用的资源。但所有这一切实际上是发展到一定程度的后果。为什么 JavaScript 变得流行起来了?嗯,你或许会说,这是 web 多年来的通用语了。但是在很长一段时间里,人们极其讨厌 JavaScript。回顾过去,似乎第一波 JavaScript 浪潮爆发在上个年代的后半段。那个时候 JavaScript 引擎加速了各种不同的任务的执行,很自然的,这可能让很多人对 JavaScript 刮目相看。
|
||||
|
||||
回到过去那些日子,这些加速测试使用了现在所谓的传统 JavaScript 基准——从苹果的 [SunSpider 基准][24](JavaScript 微基准之母)到 Mozilla 的 [Kraken 基准][25] 和谷歌的 V8 基准。后来,V8 基准被 [Octane 基准][26] 取代,而苹果发布了新的 [JetStream 基准][27]。这些传统的 JavaScript 基准测试驱动了无数人的努力,使 JavaScript 的性能达到了本世纪初没人能预料到的水平。据报道加速达到了 1000 倍,一夜之间在网站使用 `<script>` 标签不再是魔鬼的舞蹈,做客户端不再仅仅是可能的了,甚至是被鼓励的。
|
||||
回到过去那些日子,这些加速测试使用了现在所谓的传统 JavaScript 基准——从苹果的 [SunSpider 基准][24](JavaScript 微基准之母)到 Mozilla 的 [Kraken 基准][25] 和谷歌的 V8 基准。后来,V8 基准被 [Octane 基准][26] 取代,而苹果发布了新的 [JetStream 基准][27]。这些传统的 JavaScript 基准测试驱动了无数人的努力,使 JavaScript 的性能达到了本世纪初没人能预料到的水平。据报道其性能加速达到了 1000 倍,一夜之间在网站使用 `<script>` 标签不再是魔鬼的舞蹈,做客户端不再仅仅是可能的了,甚至是被鼓励的。
|
||||
|
||||
[][28]
|
||||
|
||||
现在是 2016 年,所有(相关的)JavaScript 引擎的性能都达到了一个令人难以置信的水平,web 应用像原生应用一样快(或者能够像本地应用一样快)。引擎配有复杂的优化编译器,通过收集过去关于类型/形状的反馈来推测某些操作(例如属性访问、二进制操作、比较、调用等),生成高度优化的机器代码的短序列。大多数优化是由 SunSpider 或 Kraken 等微基准以及 Octane 和 JetStream 等静态测试套件驱动的。由于有像 [asm.js][29] 和 [Emscripten][30] 这样的 JavaScript 技术,我们甚至可以将大型 C++ 应用程序编译成 JavaScript,并在你的浏览器上运行,而无需下载或安装任何东西。例如,现在你可以在 web 上玩 [AngryBots][31],无需沙盒,而过去的 web 游戏需要安装一堆诸如 Adobe Flash 或 Chrome PNaCl 的插件。
|
||||
(来源: [Advanced JS performance with V8 and Web Assembly](https://www.youtube.com/watch?v=PvZdTZ1Nl5o), Chrome Developer Summit 2016, @s3ththompson。)
|
||||
|
||||
这些成就绝大多数都要归功于这些微基准和静态性能测试套件,以及这些传统 JavaScript 基准间至关重要的竞争。你可以对 SunSpider 表示不满,但很显然,没有 SunSpider,JavaScript 的性能可能达不到今天的高度。好吧,赞美到此为止。现在看看另一方面,所有静态性能测试——无论是微基准还是大型应用的宏基准,都注定要随着时间的推移变得不相关!为什么?因为在开始摆弄它之前,基准只能教你这么多。一旦达到某个阔值以上(或以下),那么有益于特定基准的优化的一般适用性将呈指数下降。例如,我们将 Octane 作为现实世界中 web 应用性能的代理,并且在相当长的一段时间里,它可能做得很不错,但是现在,Octane 与现实场景中的时间分布是截然不同的,因此即使眼下再优化 Octane 乃至超越自身,可能在现实世界中还是得不到任何显著的改进(无论是通用 web 还是 Node.js 的工作负载)。
|
||||
现在是 2016 年,所有(相关的)JavaScript 引擎的性能都达到了一个令人难以置信的水平,web 应用像原生应用一样快(或者能够像原生应用一样快)。引擎配有复杂的优化编译器,通过收集之前的关于类型/形状的反馈来推测某些操作(例如属性访问、二进制操作、比较、调用等),生成高度优化的机器代码的短序列。大多数优化是由 SunSpider 或 Kraken 等微基准以及 Octane 和 JetStream 等静态测试套件驱动的。由于有像 [asm.js][29] 和 [Emscripten][30] 这样的 JavaScript 技术,我们甚至可以将大型 C++ 应用程序编译成 JavaScript,并在你的浏览器上运行,而无需下载或安装任何东西。例如,现在你可以在 web 上玩 [AngryBots][31],无需沙盒,而过去的 web 游戏需要安装一堆诸如 Adobe Flash 或 Chrome PNaCl 的插件。
|
||||
|
||||
这些成就绝大多数都要归功于这些微基准和静态性能测试套件的出现,以及与这些传统 JavaScript 基准间的竞争的结果。你可以对 SunSpider 表示不满,但很显然,没有 SunSpider,JavaScript 的性能可能达不到今天的高度。好吧,赞美到此为止。现在看看另一方面,所有静态性能测试——无论是微基准还是大型应用的宏基准,都注定要随着时间的推移变成噩梦!为什么?因为在开始摆弄它之前,基准只能教你这么多。一旦达到某个阔值以上(或以下),那么有益于特定基准的优化的一般适用性将呈指数下降。例如,我们将 Octane 作为现实世界中 web 应用性能的代表,并且在相当长的一段时间里,它可能做得很不错,但是现在,Octane 与现实场景中的时间分布是截然不同的,因此即使眼下再优化 Octane 乃至超越自身,可能在现实世界中还是得不到任何显著的改进(无论是通用 web 还是 Node.js 的工作负载)。
|
||||
|
||||
[][32]
|
||||
|
||||
由于传统 JavaScript 基准(包括最新版的 JetStream 和 Octane)可能已经超越其有用性变得越来越明显,我们开始调查新的方法来测量年初现实场景的性能,为 V8 和 `Chrome` 添加了大量新的性能追踪钩子。我们还特意添加一些机制来查看我们在浏览 web 时的时间开销,即是否是脚本执行、垃圾回收、编译等,并且这些调查的结果非常有趣和令人惊讶。从上面的幻灯片可以看出,运行 Octane 花费超过 70% 的时间执行 JavaScript 和回收垃圾,而浏览 web 的时候,通常执行 JavaScript 花费的时间不到 30%,垃圾回收占用的时间永远不会超过 5%。反而花费大量时间来解析和编译,这不像 Octane 的作风。因此,将更多的时间用在优化 JavaScript 执行上将提高你的 Octane 跑分,但不会对加载 [youtube.com][33] 有任何积极的影响。事实上,花费更多的时间来优化 JavaScript 执行甚至可能有损你现实场景的性能,因为编译器需要更多的时间,或者你需要跟踪更多的反馈,最终为编译、IC 和运行时桶开销更多的时间。
|
||||
(来源:[Real-World JavaScript Performance](https://youtu.be/xCx4uC7mn6Y),BlinkOn 6 conference,@tverwaes)
|
||||
|
||||
由于传统 JavaScript 基准(包括最新版的 JetStream 和 Octane)可能已经背离其有用性变得越来越远,我们开始在年初寻找新的方法来测量现实场景的性能,为 V8 和 Chrome 添加了大量新的性能追踪钩子。我们还特意添加一些机制来查看我们在浏览 web 时的时间开销,例如,是否是脚本执行、垃圾回收、编译等,并且这些调查的结果非常有趣和令人惊讶。从上面的幻灯片可以看出,运行 Octane 花费超过 70% 的时间去执行 JavaScript 和回收垃圾,而浏览 web 的时候,通常执行 JavaScript 花费的时间不到 30%,垃圾回收占用的时间永远不会超过 5%。在 Octane 中并没有体现出它花费了大量时间来解析和编译。因此,将更多的时间用在优化 JavaScript 执行上将提高你的 Octane 跑分,但不会对加载 [youtube.com][33] 有任何积极的影响。事实上,花费更多的时间来优化 JavaScript 执行甚至可能有损你现实场景的性能,因为编译器需要更多的时间,或者你需要跟踪更多的反馈,最终在编译、IC 和运行时桶开销了更多的时间。
|
||||
|
||||
[][34]
|
||||
|
||||
还有另外一组基准测试用于测量浏览器整体性能(包括 JavaScript 和 `DOM` 性能),最新推出的是 [Speedometer 基准][35]。基准试图通过运行一个用不同的主流 web 框架实现的简单的 [TodoMVC][36] 应用(现在看来有点过时了,不过新版本正在研发中)以捕获真实性能。各种在 Octane 下的测试(Angular、Ember、React、Vanilla、Flight 和 Backbone)都罗列在幻灯片中,你可以看到这些测试似乎更好地代表了现在的性能指标。但是请注意,这些数据收集在本文撰写将近 6 个月以前,而且我们优化了更多的现实场景模式(例如我们正在重构 IC 系统以显著地降低开销,并且 [解析器也正在重新设计][37])。还要注意的是,虽然这看起来像是只和浏览器相关,但我们有非常强有力的证据表明传统的峰值性能基准也不是现实场景中 Node.js 应用性能的一个好代理。
|
||||
还有另外一组基准测试用于测量浏览器整体性能(包括 JavaScript 和 DOM 性能),最新推出的是 [Speedometer 基准][35]。该基准试图通过运行一个用不同的主流 web 框架实现的简单的 [TodoMVC][36] 应用(现在看来有点过时了,不过新版本正在研发中)以捕获真实性能。上述幻灯片中的各种测试 (Angular、Ember、React、Vanilla、Flight 和 Backbone)挨着放在 Octane 之后,你可以看到这些测试似乎更好地代表了现在的性能指标。但是请注意,这些数据收集在本文撰写将近 6 个月以前,而且我们优化了更多的现实场景模式(例如我们正在重构垃圾回收系统以显著地降低开销,并且 [解析器也正在重新设计][37])。还要注意的是,虽然这看起来像是只和浏览器相关,但我们有非常强有力的证据表明传统的峰值性能基准也不能很好的代表现实场景中 Node.js 应用性能。
|
||||
|
||||
[][38]
|
||||
|
||||
所有这一切可能已经路人皆知了,因此我将用本文剩下的部分强调一些关于我为什么认为这不仅有用,而且对于 JavaScript 社区的健康(必须停止关注某一阔值的静态峰值性能基准测试)很关键的具体案例。让我通过一些例子说明 JavaScript 引擎怎样来玩弄基准。
|
||||
(来源: [Real-World JavaScript Performance](https://youtu.be/xCx4uC7mn6Y), BlinkOn 6 conference, @tverwaes.)
|
||||
|
||||
所有这一切可能已经路人皆知了,因此我将用本文剩下的部分强调一些具体案例,它们对关于我为什么认为这不仅有用,而且必须停止关注某一阔值的静态峰值性能基准测试对于 JavaScript 社区的健康是很关键的。让我通过一些例子说明 JavaScript 引擎怎样来玩弄基准的。
|
||||
|
||||
### 臭名昭著的 SunSpider 案例
|
||||
|
||||
@ -135,7 +141,7 @@ $
|
||||
|
||||
就实现而言,有不同的方案,不过就我所知,没有一个在现实场景中产生了任何积极的影响。V8 使用了一个相当简单的技巧:由于每个 SunSpider 套件都运行在一个新的 `<iframe>` 中,这对应于 V8 中一个新的本地上下文,我们只需检测快速的 `<iframe>` 创建和处理(所有的 SunSpider 测试花费的时间小于 50ms),在这种情况下,在处理和创建之间执行垃圾回收,以确保我们在实际运行测试的时候不会触发 `GC`。这个技巧很好,99.9% 的案例没有与实际用途冲突;除了每时每刻,无论你在做什么,都让你看起来像是 V8 的 SunSpider 测试驱动程序,那么你可能会遇到困难,或许你可以通过强制 `GC` 来解决,不过这对你的应用可能会有负面影响。所以紧记一点:**不要让你的应用看起来像 SunSpider!**
|
||||
|
||||
我可以继续展示更多 SunSpider 示例,但我不认为这非常有用。到目前为止,应该清楚的是,SunSpider 为刷新业绩而做的进一步优化在现实场景中没有带来任何好处。事实上,世界可能会因为没有 SunSpider 而更美好,因为引擎可以放弃只是用于 SunSpider 的奇淫技巧,甚至可以伤害到现实中的用例。不幸的是,SunSpider 仍然被(科技)媒体大量地用来比较他们眼中的浏览器性能,或者甚至用来比较手机!所以手机制造商和安卓制造商对于让 SunSpider(以及其它现在毫无意义的基准 `FWIW`) 上的 `Chrome` 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 SunSpider 中得分较高的旧版 V8,向他们的用户展示各种未修复的安全漏洞(在新版中早已被修复),并保护用户免受最新版本的 V8 的任何现实场景的性能优势!
|
||||
我可以继续展示更多 SunSpider 示例,但我不认为这非常有用。到目前为止,应该清楚的是,SunSpider 为刷新业绩而做的进一步优化在现实场景中没有带来任何好处。事实上,世界可能会因为没有 SunSpider 而更美好,因为引擎可以放弃只是用于 SunSpider 的奇淫技巧,甚至可以伤害到现实中的用例。不幸的是,SunSpider 仍然被(科技)媒体大量地用来比较他们眼中的浏览器性能,或者甚至用来比较手机!所以手机制造商和安卓制造商对于让 SunSpider(以及其它现在毫无意义的基准 `FWIW`) 上的 Chrome 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 SunSpider 中得分较高的旧版 V8,向他们的用户展示各种未修复的安全漏洞(在新版中早已被修复),并保护用户免受最新版本的 V8 的任何现实场景的性能优势!
|
||||
|
||||
[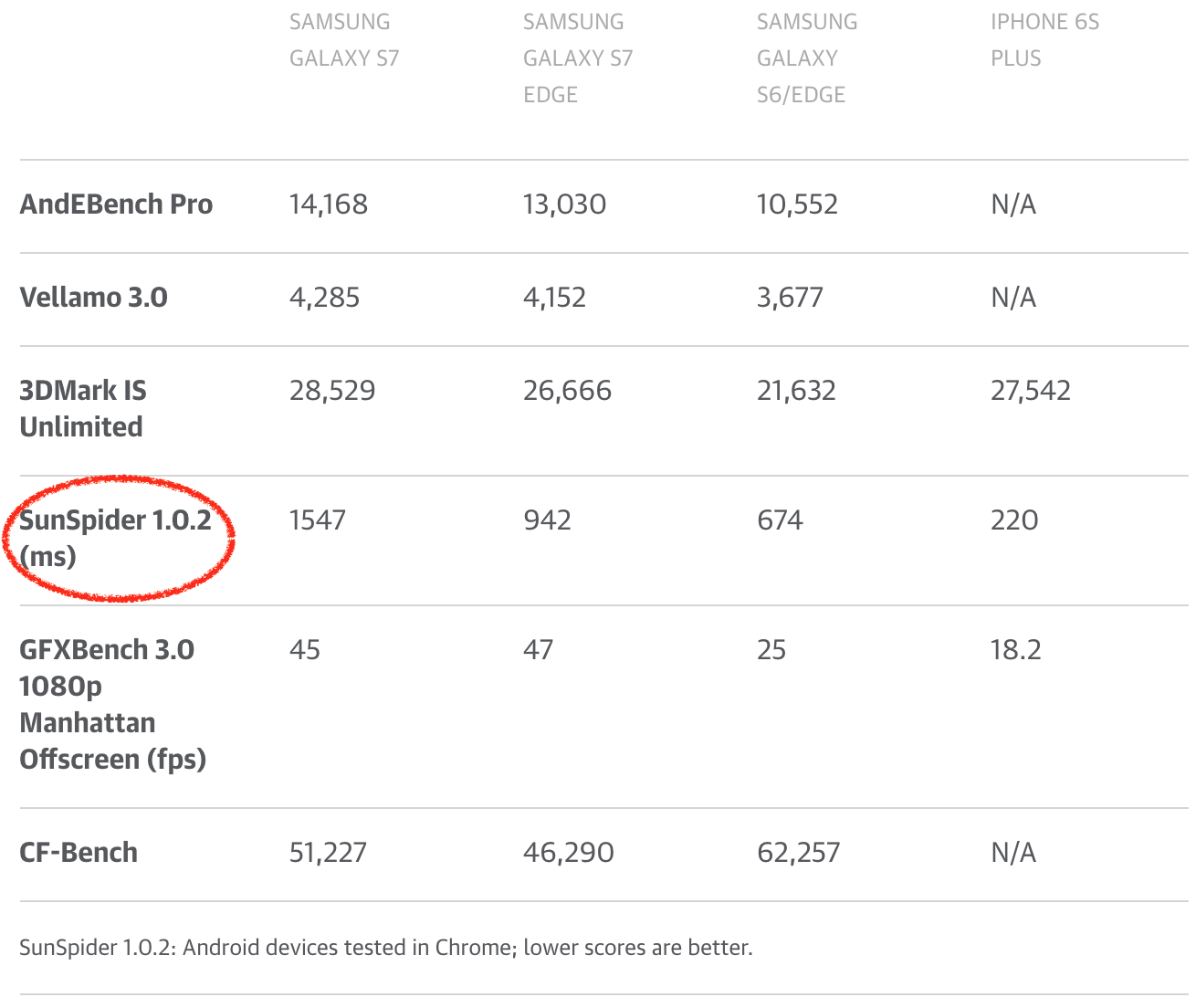][55]
|
||||
|
||||
@ -546,7 +552,7 @@ $
|
||||
|
||||

|
||||
|
||||
结束语:不要用传统的 JavaScript 基准来比较手机。这是真正最没用的事情,因为 JavaScript 的性能通常取决于软件,而不一定是硬件,并且 `Chrome` 每 6 周发布一个新版本,所以你在三月的测试结果到了四月就已经毫不相关了。如果在浏览器中发送一个数字都一部手机不可避免,那么至少请使用一个现代健全的浏览器基准来测试,至少这个基准要知道人们会用浏览器来干什么,比如 [Speedometer 基准][100]。
|
||||
结束语:不要用传统的 JavaScript 基准来比较手机。这是真正最没用的事情,因为 JavaScript 的性能通常取决于软件,而不一定是硬件,并且 Chrome 每 6 周发布一个新版本,所以你在三月的测试结果到了四月就已经毫不相关了。如果在浏览器中发送一个数字都一部手机不可避免,那么至少请使用一个现代健全的浏览器基准来测试,至少这个基准要知道人们会用浏览器来干什么,比如 [Speedometer 基准][100]。
|
||||
|
||||
感谢你花时间阅读!
|
||||
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
为何我们需要一个开放模型来设计评估公共政策
|
||||
============================================================
|
||||
|
||||
### 想象一个 app 可以让市民测试驱动提出的政策。
|
||||
|
||||
[up][3]
|
||||

|
||||
图片提供:
|
||||
|
||||
opensource.com
|
||||
|
||||
在政治选举之前的几个月中,公众辩论会加剧,并且公民面临大量的政策选择信息。在数据驱动的社会中,新的见解一直在为决策提供信息,对这些信息的深入了解从未如此重要,但公众仍然没有意识到公共政策建模的全部潜力。
|
||||
|
||||
在“开放政府”的概念不断演变以跟上新技术进步的时代,政府的政策模型和分析可能是新一代的开放知识。
|
||||
|
||||
政府开源模型 (GOSM) 是指政府开发的模型,其目的是设计和评估政策,免费提供给所有人使用、分发、不受限制地修改。社区可以提高政策建模的质量、可靠性和准确性,创造有利于公众的新的数据驱动程序。
|
||||
|
||||
今天的这代与技术相互作用,就像它的第二大本质,它默认吸收了大量的信息。如果我们可以在使用 GOSM 的虚拟、沉浸式环境中与不同的公共政策进行互动那会如何?
|
||||
|
||||
想象一下有一个允许公民测试推动政策来确定他们想要生活的未来的程序。他们会本能地学习关键的驱动因素和所需要的东西。不久之后,公众将更深入地了解公共政策的影响,并更加精明地引导有争议的公众辩论。
|
||||
|
||||
为什么我们以前没有更好的使用这些模型?原因在于公共政策建模的神秘面纱。
|
||||
|
||||
在一个如我们所生活的复杂的社会中,量化政策影响是一项艰巨的任务,并被被描述为一种“美好艺术”。此外,大多数政府政策模型都是基于行政和其他私人持有的数据。然而,政策分析师为了指导政策设计而勇于追求,多次以大量武力而获得政治斗争。
|
||||
|
||||
数字是很有说服力的。它们构建可信度并常常被用作引入新政策的理由。公共政策模型的发展赋予政治家和官僚权力,这些政治家和官僚们可能不愿意破坏现状。给予这一点可能并不容易,但 GOSM 为前所未有的公共政策改革提供了机会。
|
||||
|
||||
GOSM 将所有人的竞争环境均衡化:政治家、媒体、游说团体、利益相关者和公众。通过向社区开放政策评估的大门, 政府可以利用新的和未发现的能力用来创造、创新在公共领域的效率。但在公共政策设计中,利益相关者和政府之间战略互动有哪些实际影响?
|
||||
|
||||
GOSM 是独一无二的,因为它们主要是设计公共政策的工具,而不一定需要重新分配私人收益。利益相关者和游说团体可能会将 GOSM 与其私人信息一起使用,以获得对经济参与者私人利益的政策环境运作的新见解。
|
||||
|
||||
GOSM 可以成为利益相关者在公共辩论中保持权力平衡的武器,并为战略争取最佳利益么?
|
||||
|
||||
作为一个可变的公共资源,GOSM 在概念上由纳税人资助,并属于国家。私有实体在不向社会带来利益的情况下从 GOSM 中获得资源是合乎道德的吗?与可能用于更有效的服务提供的程序不同,替代政策建议更有可能由咨询机构使用,并有助于公众辩论。
|
||||
|
||||
开源社区经常使用“ copyleft 许可证” 来确保代码和根据此许可证的任何衍生作品对所有人都开放。当产品价值是代码本身,这需要重新分配才能获得最大利益,它需要重新分发来获得最大的利益。但是,如果代码或 GOSM 重新分发是主要产品附带的,那它会是对现有政策环境的新战略洞察么?
|
||||
|
||||
在私人收集的数据变得越来越多的时候,GOSM 背后的真正价值可能是底层数据,它可以用来改进模型本身。最终,政府是唯一有权实施政策的消费者,利益相关者可以选择在谈判中分享修改后的 GOSM。
|
||||
|
||||
政府在公开发布政策模型时面临的巨大挑战是提高透明度的同时保护隐私。理想情况下,发布 GOSM 将需要以保护建模关键特征的方式保护封闭数据。
|
||||
|
||||
公开发布 GOSM 通过促进市民对民主的更多了解和参与,使公民获得权力,从而改善政策成果和提高公众满意度。在开放的政府乌托邦中,开放的公共政策发展将是政府和社区之间的合作性努力,这里知识、数据和分析可供大家免费使用。
|
||||
|
||||
_在霍巴特举行的 linux.conf.au 2017([#lca2017][1])了解更多 Audrey Lobo-Pulo 的讲话:[公开发布的政府模型][2]。_
|
||||
|
||||
_声明:本文中提出的观点属于 Audrey Lobo-Pulo,不一定是澳大利亚政府的观点。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Audrey Lobo-Pulo - Audrey Lobo-Pulo 博士是 Phoensight 的联合创始人,并且开放政府以及政府建模开源软件的倡导者。一位物理学家,在加入澳大利亚公共服务部后,她转而从事经济政策建模工作。Audrey 参与了各种经济政策选择的建模,目前对政府开放数据和开放式政策建模感兴趣。 Audrey 对政府的愿景是将数据科学纳入公共政策分析。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/government-open-source-models
|
||||
|
||||
作者:[Audrey Lobo-Pulo ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/audrey-lobo-pulo
|
||||
[1]:https://twitter.com/search?q=%23lca2017&src=typd
|
||||
[2]:https://linux.conf.au/schedule/presentation/31/
|
||||
[3]:https://opensource.com/article/17/1/government-open-source-models?rate=p9P_dJ3xMrvye9a6xiz6K_Hc8pdKmRvMypzCNgYthA0
|
||||
682
translated/tech/20170111 Git in 2016.md
Normal file
682
translated/tech/20170111 Git in 2016.md
Normal file
@ -0,0 +1,682 @@
|
||||
|
||||
2016 Git 新视界
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
2016 年 Git 发生了 _惊天动地_ 地变化,发布了五大新特性[¹][57] (从 _v2.7_ 到 _v2.11_ )和十六个补丁[²][58]。189 位作者[³][59]贡献了 3676 个提交[⁴][60]到 `master` 分支,比 2015 年多了 15%[⁵][61]!总计有 1545 个文件被修改,其中增加了 276799 行并移除了 100973 行。
|
||||
|
||||
但是,通过统计提交的数量和代码行数来衡量生产力是一种十分愚蠢的方法。除了深度研究过的开发者可以做到凭直觉来判断代码质量的地步,我们普通人来作仲裁难免会因我们常人的判断有失偏颇。
|
||||
|
||||
谨记这一条于心,我决定整理这一年里六个我最喜爱的 Git 特性涵盖的改进,来做一次分类回顾 。这篇文章作为一篇中篇推文有点太过长了,所以我不介意你们直接跳到你们特别感兴趣的特性去。
|
||||
|
||||
* [完成][41]`[git worktree][25]`[命令][42]
|
||||
* [更多方便的][43]`[git rebase][26]`[选项][44]
|
||||
* `[git lfs][27]`[梦幻的性能加速][45]
|
||||
* `[git diff][28]`[实验性的算法和更好的默认结果][46]
|
||||
* `[git submodules][29]`[差强人意][47]
|
||||
* `[git stash][30]`的[90 个增强][48]
|
||||
|
||||
在我们开始之前,请注意在大多数操作系统上都自带有 Git 的旧版本,所以你需要检查你是否在使用最新并且最棒的版本。如果在终端运行 `git --version` 返回的结果小于 Git `v2.11.0`,请立刻跳转到 Atlassian 的快速指南 [更新或安装 Git][63] 并根据你的平台做出选择。
|
||||
|
||||
|
||||
|
||||
###[`引用` 是需要的]
|
||||
|
||||
在我们进入高质量内容之前还需要做一个短暂的停顿:我觉得我需要为你展示我是如何从公开文档(以及开篇的封面图片)生成统计信息的。你也可以使用下面的命令来对你自己的仓库做一个快速的 *年度回顾*!
|
||||
|
||||
```
|
||||
¹ Tags from 2016 matching the form vX.Y.0
|
||||
```
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format \
|
||||
'%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.0 .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
² Tags from 2016 matching the form vX.Y.Z
|
||||
```
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format '%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.[^0] .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
³ Commits by author in 2016
|
||||
```
|
||||
|
||||
```
|
||||
$ git shortlog -s -n --since=2016-01-01 --until=2017-01-01
|
||||
```
|
||||
|
||||
```
|
||||
⁴ Count commits in 2016
|
||||
```
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2016-01-01 --until=2017-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁵ ... and in 2015
|
||||
```
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2015-01-01 --until=2016-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁶ Net LOC added/removed in 2016
|
||||
```
|
||||
|
||||
```
|
||||
$ git diff --shortstat `git rev-list -1 --until=2016-01-01 master` \
|
||||
`git rev-list -1 --until=2017-01-01 master`
|
||||
```
|
||||
|
||||
以上的命令是在 Git 的 `master` 分支运行的,所以不会显示其他出色的分支上没有合并的工作。如果你使用这些命令,请记住提交的数量和代码行数不是应该值得信赖的度量方式。请不要使用它们来衡量你的团队成员的贡献。
|
||||
|
||||
现在,让我们开始说好的回顾……
|
||||
|
||||
### 完成 Git worktress
|
||||
`git worktree` 命令首次出现于 Git v2.5 但是在 2016 年有了一些显著的增强。两个有价值的新特性在 v2.7 被引入—— `list` 子命令,和为二分搜索增加了命令空间的 refs——而 `lock`/`unlock` 子命令则是在 v2.10被引入。
|
||||
|
||||
#### 什么是 worktree 呢?
|
||||
`[git worktree][49]` 命令允许你同步地检出和操作处于不同路径下的同一仓库的多个分支。例如,假如你需要做一次快速的修复工作但又不想扰乱你当前的工作区,你可以使用以下命令在一个新路径下检出一个新分支
|
||||
```
|
||||
$ git worktree add -b hotfix/BB-1234 ../hotfix/BB-1234
|
||||
Preparing ../hotfix/BB-1234 (identifier BB-1234)
|
||||
HEAD is now at 886e0ba Merged in bedwards/BB-13430-api-merge-pr (pull request #7822)
|
||||
```
|
||||
|
||||
Worktree 不仅仅是为分支工作。你可以检出多个里程碑(tags)作为不同的工作树来并行构建或测试它们。例如,我从 Git v2.6 和 v2.7 的里程碑中创建工作树来检验不同版本 Git 的行为特征。
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.6.0 v2.6.0
|
||||
Preparing ../git-v2.6.0 (identifier git-v2.6.0)
|
||||
HEAD is now at be08dee Git 2.6
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.7.0 v2.7.0
|
||||
Preparing ../git-v2.7.0 (identifier git-v2.7.0)
|
||||
HEAD is now at 7548842 Git 2.7
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
/Users/kannonboy/src/git 7548842 [master]
|
||||
/Users/kannonboy/src/git-v2.6.0 be08dee (detached HEAD)
|
||||
/Users/kannonboy/src/git-v2.7.0 7548842 (detached HEAD)
|
||||
```
|
||||
|
||||
```
|
||||
$ cd ../git-v2.7.0 && make
|
||||
```
|
||||
|
||||
你也使用同样的技术来并行构造和运行你自己应用程序的不同版本。
|
||||
|
||||
#### 列出工作树
|
||||
|
||||
`git worktree list` 子命令(于 Git v2.7引入)显示所有与当前仓库有关的工作树。
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
/Users/kannonboy/src/bitbucket/bitbucket 37732bd [master]
|
||||
/Users/kannonboy/src/bitbucket/staging d5924bc [staging]
|
||||
/Users/kannonboy/src/bitbucket/hotfix-1234 37732bd [hotfix/1234]
|
||||
```
|
||||
|
||||
#### 二分查找工作树
|
||||
|
||||
`[gitbisect][50]` 是一个简洁的 Git 命令,可以让我们对提交记录执行一次二分搜索。通常用来找到哪一次提交引入了一个指定的退化。例如,如果在我的 `master` 分支最后的提交上有一个测试没有通过,我可以使用 `git bisect` 来贯穿仓库的历史来找寻第一次造成这个错误的提交。
|
||||
|
||||
```
|
||||
$ git bisect start
|
||||
```
|
||||
|
||||
```
|
||||
# indicate the last commit known to be passing the tests
|
||||
# (e.g. the latest release tag)
|
||||
$ git bisect good v2.0.0
|
||||
```
|
||||
|
||||
```
|
||||
# indicate a known broken commit (e.g. the tip of master)
|
||||
$ git bisect bad master
|
||||
```
|
||||
|
||||
```
|
||||
# tell git bisect a script/command to run; git bisect will
|
||||
# find the oldest commit between "good" and "bad" that causes
|
||||
# this script to exit with a non-zero status
|
||||
$ git bisect run npm test
|
||||
```
|
||||
|
||||
在后台,bisect 使用 refs 来跟踪 好 与 坏 的提交来作为二分搜索范围的上下界限。不幸的是,对工作树的粉丝来说,这些 refs 都存储在寻常的 `.git/refs/bisect` 命名空间,意味着 `git bisect` 操作如果运行在不同的工作树下可能会互相干扰。
|
||||
到了 v2.7 版本,bisect 的 refs 移到了 `.git/worktrees/$worktree_name/refs/bisect`, 所以你可以并行运行 bisect 操作于多个工作树中。
|
||||
|
||||
#### 锁定工作树
|
||||
当你完成了一颗工作树的工作,你可以直接删除它,然后通过运行 `git worktree prune` 等它被当做垃圾自动回收。但是,如果你在网络共享或者可移除媒介上存储了一颗工作树,如果工作树目录在删除期间不可访问,工作树会被完全清除——不管你喜不喜欢!Git v2.10 引入了 `git worktree lock` 和 `unlock` 子命令来防止这种情况发生。
|
||||
```
|
||||
# to lock the git-v2.7 worktree on my USB drive
|
||||
$ git worktree lock /Volumes/Flash_Gordon/git-v2.7 --reason \
|
||||
"In case I remove my removable media"
|
||||
```
|
||||
|
||||
```
|
||||
# to unlock (and delete) the worktree when I'm finished with it
|
||||
$ git worktree unlock /Volumes/Flash_Gordon/git-v2.7
|
||||
$ rm -rf /Volumes/Flash_Gordon/git-v2.7
|
||||
$ git worktree prune
|
||||
```
|
||||
|
||||
`--reason` 标签允许为未来的你留一个记号,描述为什么当初工作树被锁定。`git worktree unlock` 和 `lock` 都要求你指定工作树的路径。或者,你可以 `cd` 到工作树目录然后运行 `git worktree lock .` 来达到同样的效果。
|
||||
|
||||
|
||||
|
||||
### 更多 Git `reabse` 选项
|
||||
2016 年三月,Git v2.8 增加了在拉取过程中交互进行 rebase 的命令 `git pull --rebase=interactive` 。对应地,六月份 Git v2.9 发布了通过 `git rebase -x` 命令对执行变基操作而不需要进入交互模式的支持。
|
||||
|
||||
#### Re-啥?
|
||||
|
||||
在我们继续深入前,我假设读者中有些并不是很熟悉或者没有完全习惯变基命令或者交互式变基。从概念上说,它很简单,但是与很多 Git 的强大特性一样,变基散发着听起来很复杂的专业术语的气息。所以,在我们深入前,先来快速的复习一下什么是 rebase。
|
||||
|
||||
变基操作意味着将一个或多个提交在一个指定分支上重写。`git rebase` 命令是被深度重载了,但是 rebase 名字的来源事实上还是它经常被用来改变一个分支的基准提交(你基于此提交创建了这个分支)。
|
||||
|
||||
从概念上说,rebase 通过将你的分支上的提交存储为一系列补丁包临时释放了它们,接着将这些补丁包按顺序依次打在目标提交之上。
|
||||
|
||||

|
||||
|
||||
对 master 分支的一个功能分支执行变基操作 (`git reabse master`)是一种通过将 master 分支上最新的改变合并到功能分支的“保鲜法”。对于长期存在的功能分支,规律的变基操作能够最大程度的减少开发过程中出现冲突的可能性和严重性。
|
||||
|
||||
有些团队会选择在合并他们的改动到 master 前立即执行变基操作以实现一次快速合并 (`git merge --ff <feature>`)。对 master 分支快速合并你的提交是通过简单的将 master ref 指向你的重写分支的顶点而不需要创建一个合并提交。
|
||||
|
||||

|
||||
|
||||
变基是如此方便和功能强大以致于它已经被嵌入其他常见的 Git 命令中,例如 `git pull`。如果你在本地 master 分支有未推送的提交,运行 `git pull` 命令从 origin 拉取你队友的改动会造成不必要的合并提交。
|
||||
|
||||

|
||||
|
||||
这有点混乱,而且在繁忙的团队,你会获得成堆的不必要的合并提交。`git pull --rebase` 将你本地的提交在你队友的提交上执行变基而不产生一个合并提交。
|
||||

|
||||
|
||||
这很整洁吧!甚至更酷,Git v2.8 引入了一个新特性,允许你在拉取时 _交互地_ 变基。
|
||||
|
||||
#### 交互式变基
|
||||
|
||||
交互式变基是变基操作的一种更强大的形态。和标准变基操作相似,它可以重写提交,但它也可以向你提供一个机会让你能够交互式地修改这些将被重新运用在新基准上的提交。
|
||||
|
||||
当你运行 `git rebase --interactive` (或 `git pull --rebase=interactive`)时,你会在你的文本编辑器中得到一个可供选择的提交列表视图。
|
||||
```
|
||||
$ git rebase master --interactive
|
||||
```
|
||||
|
||||
```
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
pick ed93626 ACE-1294: removed pull request service from test
|
||||
pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 commands)
|
||||
#
|
||||
# Commands:
|
||||
# p, pick = use commit
|
||||
# r, reword = use commit, but edit the commit message
|
||||
# e, edit = use commit, but stop for amending
|
||||
# s, squash = use commit, but meld into previous commit
|
||||
# f, fixup = like "squash", but discard this commit's log message
|
||||
# x, exec = run command (the rest of the line) using shell
|
||||
# d, drop = remove commit
|
||||
#
|
||||
# These lines can be re-ordered; they are executed from top to
|
||||
# bottom.
|
||||
#
|
||||
# If you remove a line here THAT COMMIT WILL BE LOST.
|
||||
```
|
||||
|
||||
注意到每一条提交旁都有一个 `pick`。这是对 rebase 而言,"照原样留下这个提交"。如果你现在就退出文本编辑器,它会执行一次如上文所述的普通变基操作。但是,如果你将 `pick` 改为 `edit` 或者其他 rebase 命令中的一个,变基操作会允许你在它被重新运用前改变它。有效的变基命令有如下几种:
|
||||
* `reword`: 编辑提交信息。
|
||||
* `edit`: 编辑提交了的文件。
|
||||
* `squash`: 将提交与之前的提交(同在文件中)合并,并将提交信息拼接。
|
||||
* `fixup`: 将本提交与上一条提交合并,并且逐字使用上一条提交的提交信息(这很方便,如果你为一个很小的改动创建了第二个提交,而它本身就应该属于上一条提交,例如,你忘记暂存了一个文件)。
|
||||
* `exec`: 运行一条任意的 shell 命令(我们将会在下一节看到本例一次简洁的使用场景)。
|
||||
* `drop`: 这将丢弃这条提交。
|
||||
|
||||
你也可以在文件内重新整理提交,这样会改变他们被重新运用的顺序。这会很顺手当你对不同的主题创建了交错的提交时,你可以使用 `squash` 或者 `fixup` 来将其合并成符合逻辑的原子提交。
|
||||
|
||||
当你设置完命令并且保存这个文件后,Git 将递归每一条提交,在每个 `reword` 和 `edit` 命令处为你暂停来执行你设计好的改变并且自动运行 `squash`, `fixup`,`exec` 和 `drop`命令。
|
||||
|
||||
####非交互性式执行
|
||||
当你执行变基操作时,本质上你是在通过将你每一条新提交应用于指定基址的头部来重写历史。`git pull --rebase` 可能会有一点危险,因为根据上游分支改动的事实,你的新建历史可能会由于特定的提交遭遇测试失败甚至编译问题。如果这些改动引起了合并冲突,变基过程将会暂停并且允许你来解决它们。但是,整洁的合并改动仍然有可能打断编译或测试过程,留下破败的提交弄乱你的提交历史。
|
||||
|
||||
但是,你可以指导 Git 为每一个重写的提交来运行你的项目测试套件。在 Git v2.9 之前,你可以通过绑定 `git rebase --interactive` 和 `exec` 命令来实现。例如这样:
|
||||
```
|
||||
$ git rebase master −−interactive −−exec=”npm test”
|
||||
```
|
||||
|
||||
...会生成在重写每条提交后执行 `npm test` 这样的一个交互式变基计划,保证你的测试仍然会通过:
|
||||
|
||||
```
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
exec npm test
|
||||
pick ed93626 ACE-1294: removed pull request service from test
|
||||
exec npm test
|
||||
pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
exec npm test
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
exec npm test
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 command(s))
|
||||
```
|
||||
|
||||
如果出现了测试失败的情况,变基会暂停并让你修复这些测试(并且将你的修改应用于相应提交):
|
||||
```
|
||||
291 passing
|
||||
1 failing
|
||||
```
|
||||
|
||||
```
|
||||
1) Host request “after all” hook:
|
||||
Uncaught Error: connect ECONNRESET 127.0.0.1:3001
|
||||
…
|
||||
npm ERR! Test failed.
|
||||
Execution failed: npm test
|
||||
You can fix the problem, and then run
|
||||
git rebase −−continue
|
||||
```
|
||||
|
||||
这很方便,但是使用交互式变基有一点臃肿。到了 Git v2.9,你可以这样来实现非交互式变基:
|
||||
```
|
||||
$ git rebase master -x “npm test”
|
||||
```
|
||||
|
||||
简单替换 `npm test` 为 `make`,`rake`,`mvn clean install`,或者任何你用来构建或测试你的项目的命令。
|
||||
|
||||
####小小警告
|
||||
就像电影里一样,重写历史可是一个危险的行当。任何提交被重写为变基操作的一部分都将改变它的 SHA-1 ID,这意味着 Git 会把它当作一个全新的提交对待。如果重写的历史和原来的历史混杂,你将获得重复的提交,而这可能在你的团队中引起不少的疑惑。
|
||||
|
||||
为了避免这个问题,你仅仅需要遵照一条简单的规则:
|
||||
> _永远不要变基一条你已经推送的提交!_
|
||||
|
||||
坚持这一点你会没事的。
|
||||
|
||||
|
||||
|
||||
### `Git LFS` 的性能提升
|
||||
[Git 是一个分布式版本控制系统][64],意味着整个仓库的历史会在克隆阶段被传送到客户端。对包含大文件的项目——尤其是大文件经常被修改——初始克隆会非常耗时,因为每一个版本的每一个文件都必须下载到客户端。[Git LFS(Large File Storage 大文件存储)][65] 是一个 Git 拓展包,由 Atlassian,GitHub 和其他一些开源贡献者开发,通过消极地下载大文件的相对版本来减少仓库中大文件的影响。更明确地说,大文件是在检出过程中按需下载的而不是在克隆或抓取过程中。
|
||||
|
||||
在 Git 2016 年的五大发布中,Git LFS 自身有四个功能丰富的发布:v1.2 到 v1.5。你可以凭 Git LFS 自身来写一系列回顾文章,但是就这篇文章而言,我将专注于 2016 年解决的一项最重要的主题:速度。一系列针对 Git 和 Git LFS 的改进极大程度地优化了将文件传入/传出服务器的性能。
|
||||
|
||||
#### 长期过滤进程
|
||||
|
||||
当你 `git add` 一个文件时,Git 的净化过滤系统会被用来在文件被写入 Git 目标存储前转化文件的内容。Git LFS 通过使用净化过滤器将大文件内容存储到 LFS 缓存中以缩减仓库的大小,并且增加一个小“指针”文件到 Git 目标存储中作为替代。
|
||||
|
||||
|
||||

|
||||
|
||||
污化过滤器是净化过滤器的对立面——正如其名。在 `git checkout` 过程中从一个 Git 目标仓库读取文件内容时,污化过滤系统有机会在文件被写入用户的工作区前将其改写。Git LFS 污化过滤器通过将指针文件替代为对应的大文件将其转化,可以是从 LFS 缓存中获得或者通过读取存储在 Bitbucket 的 Git LFS。
|
||||
|
||||

|
||||
|
||||
传统上,污化和净化过滤进程在每个文件被增加和检出时只能被唤起一次。所以,一个项目如果有 1000 个文件在被 Git LFS 追踪 ,做一次全新的检出需要唤起 `git-lfs-smudge` 命令 1000 次。尽管单次操作相对很迅速,但是经常执行 1000 次独立的污化进程总耗费惊人。、
|
||||
|
||||
针对 Git v2.11(和 Git LFS v1.5),污化和净化过滤器可以被定义为长期进程,为第一个需要过滤的文件调用一次,然后为之后的文件持续提供污化或净化过滤直到父 Git 操作结束。[Lars Schneider][66],Git 的长期过滤系统的贡献者,简洁地总结了对 Git LFS 性能改变带来的影响。
|
||||
> 使用 12k 个文件的测试仓库的过滤进程在 macOS 上快了80 倍,在 Windows 上 快了 58 倍。在 Windows 上,这意味着测试运行了 57 秒而不是 55 分钟。
|
||||
> 这真是一个让人印象深刻的性能增强!
|
||||
|
||||
#### LFS 专有克隆
|
||||
|
||||
长期运行的污化和净化过滤器在对向本地缓存读写的加速做了很多贡献,但是对大目标传入/传出 Git LFS 服务器的速度提升贡献很少。 每次 Git LFS 污化过滤器在本地 LFS 缓存中无法找到一个文件时,它不得不使用两个 HTTP 请求来获得该文件:一个用来定位文件,另外一个用来下载它。在一次 `git clone` 过程中,你的本地 LFS 缓存是空的,所以 Git LFS 会天真地为你的仓库中每个 LFS 所追踪的文件创建两个 HTTP 请求:
|
||||
|
||||

|
||||
|
||||
幸运的是,Git LFS v1.2 提供了专门的 `[git lfs clone][51]` 命令。不再是一次下载一个文件; `git lfs clone` 禁止 Git LFS 污化过滤器,等待检出结束,然后从 Git LFS 存储中按批下载任何需要的文件。这允许了并行下载并且将需要的 HTTP 请求数量减半。
|
||||
|
||||

|
||||
|
||||
###自定义传输路由器
|
||||
|
||||
正如之前讨论过的,Git LFS 在 v1.5 中 发起了对长期过滤进程的支持。不过,对另外一种可插入进程的支持早在今年年初就发布了。 Git LFS 1.3 包含了对可插拔传输路由器的支持,因此不同的 Git LFS 托管服务可以定义属于它们自己的协议来向或从 LFS 存储中传输文件。
|
||||
|
||||
直到 2016 年底,Bitbucket 是唯一一个执行专属 Git LFS 传输协议 [Bitbucket LFS Media Adapter][67] 的托管服务商。这是为了从 Bitbucket 的一个独特的被称为 chunking 的 LFS 存储 API 特性中获利。Chunking 意味着在上传或下载过程中,大文件被分解成 4MB 的文件块(chunk)。
|
||||

|
||||
|
||||
分块给予了 Bitbucket 支持的 Git LFS 三大优势:
|
||||
1. 并行下载与上传。默认地,Git LFS 最多并行传输三个文件。但是,如果只有一个文件被单独传输(这也是 Git LFS 污化过滤器的默认行为),它会在一个单独的流中被传输。Bitbucket 的分块允许同一文件的多个文件块同时被上传或下载,经常能够梦幻地提升传输速度。
|
||||
2. 可恢复文件块传输。文件块都在本地缓存,所以如果你的下载或上传被打断,Bitbucket 的自定义 LFS 流媒体路由器会在下一次你推送或拉取时仅为丢失的文件块恢复传输。
|
||||
3. 免重复。Git LFS,正如 Git 本身,是内容索位;每一个 LFS 文件都由它的内容生成的 SHA-256 哈希值认证。所以,哪怕你稍微修改了一位数据,整个文件的 SHA-256 就会修改而你不得不重新上传整个文件。分块允许你仅仅重新上传文件真正被修改的部分。举个例子,想想一下Git LFS 在追踪一个 41M 的电子游戏精灵表。如果我们增加在此精灵表上增加 2MB 的新层并且提交它,传统上我们需要推送整个新的 43M 文件到服务器端。但是,使用 Bitbucket 的自定义传输路由,我们仅仅需要推送 ~7MB:先是 4MB 文件块(因为文件的信息头会改变)和我们刚刚添加的包含新层的 3MB 文件块!其余未改变的文件块在上传过程中被自动跳过,节省了巨大的带宽和时间消耗。
|
||||
|
||||
可自定义的传输路由器是 Git LFS 一个伟大的特性,它们使得不同服务商在不过载核心项目的前提下体验适合其服务器的优化后的传输协议。
|
||||
|
||||
### 更佳的 `git diff` 算法与默认值
|
||||
|
||||
不像其他的版本控制系统,Git 不会明确地存储文件被重命名了的事实。例如,如果我编辑了一个简单的 Node.js 应用并且将 `index.js` 重命名为 `app.js`,然后运行 `git diff`,我会得到一个看起来像一个文件被删除另一个文件被新建的结果。
|
||||
|
||||

|
||||
|
||||
我猜测移动或重命名一个文件从技术上来讲是一次删除后跟一次新建,但这不是对人类最友好的方式来诉说它。其实,你可以使用 `-M` 标志来指示 Git 在计算差异时抽空尝试检测重命名文件。对之前的例子,`git diff -M` 给我们如下结果:
|
||||

|
||||
|
||||
第二行显示的 similarity index 告诉我们文件内容经过比较后的相似程度。默认地,`-M` 会考虑任意两个文件都有超过 50% 相似度。这意味着,你需要编辑少于 50% 的行数来确保它们被识别成一个重命名后的文件。你可以通过加上一个百分比来选择你自己的 similarity index,如,`-M80%`。
|
||||
|
||||
到 Git v2.9 版本,如果你使用了 `-M` 标志 `git diff` 和 `git log` 命令都会默认检测重命名。如果不喜欢这种行为(或者,更现实的情况,你在通过一个脚本来解析 diff 输出),那么你可以通过显示的传递 `--no-renames` 标志来禁用它。
|
||||
|
||||
#### 详细的提交
|
||||
|
||||
你经历过调用 `git commit` 然后盯着空白的 shell 试图想起你刚刚做过的所有改动吗?verbose 标志就为此而来!
|
||||
|
||||
不像这样:
|
||||
```
|
||||
Ah crap, which dependency did I just rev?
|
||||
```
|
||||
|
||||
```
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with ‘#’ will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
# Your branch is up-to-date with ‘origin/master’.
|
||||
#
|
||||
# Changes to be committed:
|
||||
# new file: package.json
|
||||
#
|
||||
```
|
||||
|
||||
...你可以调用 `git commit --verbose` 来查看你改动造成的内联差异。不用担心,这不会包含在你的提交信息中:
|
||||
|
||||

|
||||
|
||||
`--verbose` 标志不是最新的,但是直到 Git v2.9 你可以通过 `git config --global commit.verbose true` 永久的启用它。
|
||||
|
||||
#### 实验性的 Diff 改进
|
||||
|
||||
当一个被修改部分前后几行相同时,`git diff` 可能产生一些稍微令人迷惑的输出。如果在一个文件中有两个或者更多相似结构的函数时这可能发生。来看一个有些刻意人为的例子,想象我们有一个 JS 文件包含一个单独的函数:
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
return "Bitbucket";
|
||||
}
|
||||
```
|
||||
|
||||
现在想象一下我们刚提交的改动包含一个预谋的 _另一个_可以做相似事情的函数:
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productId() {
|
||||
return "Bitbucket";
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
return "Bitbucket";
|
||||
}
|
||||
```
|
||||
|
||||
我们希望 `git diff` 显示开头五行被新增,但是实际上它不恰当地将最初提交的第一行也包含进来。
|
||||
|
||||

|
||||
|
||||
错误的注释被包含在了 diff 中!这虽不是世界末日,但每次发生这种事情总免不了花费几秒钟的意识去想 _啊?_
|
||||
在十二月,Git v2.11 介绍了一个新的实验性的 diff 选项,`--indent-heuristic`,尝试生成从美学角度来看更赏心悦目的 diff。
|
||||
|
||||

|
||||
|
||||
在后台,`--indent-heuristic` 在每一次改动造成的所有可能的 diff 中循环,并为它们分别打上一个 "不良" 分数。这是基于试探性的如差异文件块是否以不同等级的缩进开始和结束(从美学角度讲不良)以及差异文件块前后是否有空白行(从美学角度讲令人愉悦)。最后,有着最低不良分数的块就是最终输出。
|
||||
|
||||
这个特性还是实验性的,但是你可以通过应用 `--indent-heuristic` 选项到任何 `git diff` 命令来专门测试它。如果,如果你喜欢在刀口上讨生活,你可以这样将其在你的整个系统内使能:
|
||||
```
|
||||
$ git config --global diff.indentHeuristic true
|
||||
```
|
||||
|
||||
### Submodules 差强人意
|
||||
|
||||
子模块允许你从 Git 仓库内部引用和包含其他 Git 仓库。这通常被用在当一些项目管理的源依赖也在被 Git 跟踪时,或者被某些公司用来作为包含一系列相关项目的 [monorepo][68] 的替代品。
|
||||
|
||||
由于某些用法的复杂性以及使用错误的命令相当容易破坏它们的事实,Submodule 得到了一些坏名声。
|
||||
|
||||

|
||||
|
||||
但是,它们还是有着它们的用处,而且,我想,仍然对其他方案有依赖时的最好的选择。 幸运的是,2016 对 submodule 用户来说是伟大的一年,在几次发布中落地了许多意义重大的性能和特性提升。
|
||||
|
||||
#### 并行抓取
|
||||
当克隆或则抓取一个仓库时,加上 `--recurse-submodules` 选项意味着任何引用的 submodule 也将被克隆或更新。传统上,这会被串行执行,每次只抓取一个 submodule。直到 Git v2.8,你可以附加 `--jobs=n` 选项来使用 _n_ 个并行线程来抓取 submodules。
|
||||
|
||||
我推荐永久的配置这个选项:
|
||||
|
||||
```
|
||||
$ git config --global submodule.fetchJobs 4
|
||||
```
|
||||
|
||||
...或者你可以选择使用任意程度的平行化。
|
||||
|
||||
#### 浅层子模块
|
||||
Git v2.9 介绍了 `git clone —shallow-submodules` 标志。它允许你抓取你仓库的完整克隆,然后递归的浅层克隆所有引用的子模块的一个提交。如果你不需要项目的依赖的完整记录时会很有用。
|
||||
|
||||
例如,一个仓库有着一些混合了的子模块,其中包含有其他方案商提供的依赖和你自己其它的项目。你可能希望初始化时执行浅层子模块克隆然后深度选择几个你想要与之工作的项目。
|
||||
|
||||
另一种情况可能是配置一次持续性的集成或调度工作。Git 需要超级仓库以及每个子模块最新的提交以便能够真正执行构建。但是,你可能并不需要每个子模块全部的历史记录,所以仅仅检索最新的提交可以为你省下时间和带宽。
|
||||
|
||||
#### 子模块的替代品
|
||||
|
||||
`--reference` 选项可以和 `git clone` 配合使用来指定另一个本地仓库作为一个目标存储来保存你本地已经存在的又通过网络传输的重复制目标。语法为:
|
||||
|
||||
```
|
||||
$ git clone --reference <local repo> <url>
|
||||
```
|
||||
|
||||
直到 Git v2.11,你可以使用 `—reference` 选项与 `—recurse-submodules` 结合来设置子模块替代品从另一个本地仓库指向子模块。其语法为:
|
||||
|
||||
```
|
||||
$ git clone --recurse-submodules --reference <local repo> <url>
|
||||
```
|
||||
|
||||
这潜在的可以省下很大数量的带宽和本地磁盘空间,但是如果引用的本地仓库不包含你所克隆自的远程仓库所必需的所有子模块时,它可能会失败。。
|
||||
|
||||
幸运的是,方便的 `—-reference-if-able` 选项将会让它优雅地失败,然后为丢失了的被引用的本地仓库的所有子模块回退为一次普通的克隆。
|
||||
|
||||
```
|
||||
$ git clone --recurse-submodules --reference-if-able \
|
||||
<local repo> <url>
|
||||
```
|
||||
|
||||
#### 子模块的 diff
|
||||
|
||||
在 Git v2.11 之前,Git 有两种模式来显示对更新了仓库子模块的提交之间的差异。
|
||||
|
||||
`git diff —-submodule=short` 显示你的项目引用的子模块中的旧提交和新提交( 这也是如果你整体忽略 `--submodule` 选项的默认结果):
|
||||
|
||||

|
||||
|
||||
`git diff —submodule=log` 有一点啰嗦,显示更新了的子模块中任意新建或移除的提交的信息中统计行。
|
||||
|
||||

|
||||
|
||||
Git v2.11 引入了第三个更有用的选项:`—-submodule=diff`。这会显示更新后的子模块所有改动的完整的 diff。
|
||||
|
||||

|
||||
|
||||
### `git stash` 的 90 个增强
|
||||
|
||||
不像 submodules,几乎没有 Git 用户不钟爱 `[git stash][52]`。 `git stash` 临时搁置(或者 _藏匿_)你对工作区所做的改动使你能够先处理其他事情,结束后重新将搁置的改动恢复到先前状态。
|
||||
|
||||
#### 自动搁置
|
||||
|
||||
如果你是 `git rebase` 的粉丝,你可能很熟悉 `--autostash` 选项。它会在变基之前自动搁置工作区所有本地修改然后等变基结束再将其复用。
|
||||
```
|
||||
$ git rebase master --autostash
|
||||
Created autostash: 54f212a
|
||||
HEAD is now at 8303dca It's a kludge, but put the tuple from the database in the cache.
|
||||
First, rewinding head to replay your work on top of it...
|
||||
Applied autostash.
|
||||
```
|
||||
|
||||
这很方便,因为它使得你可以在一个不洁的工作区执行变基。有一个方便的配置标志叫做 `rebase.autostash` 可以将这个特性设为默认,你可以这样来全局使能它:
|
||||
```
|
||||
$ git config --global rebase.autostash true
|
||||
```
|
||||
|
||||
`rebase.autostash` 实际上自从 [Git v1.8.4][69] 就可用了,但是 v2.7 引入了通过 `--no-autostash` 选项来取消这个标志的功能。如果你对未暂存的改动使用这个选项,变基会被一条工作树被污染的警告禁止:
|
||||
```
|
||||
$ git rebase master --no-autostash
|
||||
Cannot rebase: You have unstaged changes.
|
||||
Please commit or stash them.
|
||||
```
|
||||
|
||||
#### 补丁式搁置
|
||||
|
||||
说到配置标签,Git v2.7 也引入了 `stash.showPatch`。`git stash show` 的默认行为是显示你搁置文件的汇总。
|
||||
```
|
||||
$ git stash show
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
将 `-p` 标志传入会将 `git stash show` 变为 "补丁模式",这将会显示完整的 diff:
|
||||

|
||||
|
||||
`stash.showPatch` 将这个行为定为默认。你可以将其全局使能:
|
||||
```
|
||||
$ git config --global stash.showPatch true
|
||||
```
|
||||
|
||||
如果你使能 `stash.showPatch` 但却之后决定你仅仅想要查看文件总结,你可以通过传入 `--stat` 选项来重新获得之前的行为。
|
||||
```
|
||||
$ git stash show --stat
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
顺便一提:`--no-patch` 是一个有效选项但它不会如你所希望的改写 `stash.showPatch` 的结果。不仅如此,它会传递给用来生成补丁时潜在调用的 `git diff` 命令,然后你会发现完全没有任何输出。
|
||||
|
||||
#### 简单的搁置标识
|
||||
如果你是 `git stash` 的粉丝,你可能知道你可以搁置多次改动然后通过 `git stash list` 来查看它们:
|
||||
```
|
||||
$ git stash list
|
||||
stash@{0}: On master: crazy idea that might work one day
|
||||
stash@{1}: On master: desperate samurai refactor; don't apply
|
||||
stash@{2}: On master: perf improvement that I forgot I stashed
|
||||
stash@{3}: On master: pop this when we use Docker in production
|
||||
```
|
||||
|
||||
但是,你可能不知道为什么 Git 的搁置有着这么难以理解的标识(`stash@{1}`, `stash@{2}`, 等)也可能将它们勾勒成 "仅仅是 Git 的一个特性吧"。实际上就像很多 Git 特性一样,这些奇怪的标志实际上是 Git 数据模型一个非常巧妙使用(或者说是滥用了的)的特性。
|
||||
|
||||
在后台,`git stash` 命令实际创建了一系列特别的提交目标,这些目标对你搁置的改动做了编码并且维护一个 [reglog][70] 来保存对这些特殊提交的参考。 这也是为什么 `git stash list` 的输出看起来很像 `git reflog` 的输出。当你运行 `git stash apply stash@{1}` 时,你实际上在说,"从stash reflog 的位置 1 上应用这条提交 "
|
||||
|
||||
直到 Git v2.11,你不再需要使用完整的 `stash@{n}` 语句。相反,你可以通过一个简单的整数指出搁置在 stash reflog 中的位置来引用它们。
|
||||
|
||||
```
|
||||
$ git stash show 1
|
||||
$ git stash apply 1
|
||||
$ git stash pop 1
|
||||
```
|
||||
|
||||
讲了很多了。如果你还想要多学一些搁置是怎么保存的,我在 [这篇教程][71] 中写了一点这方面的内容。
|
||||
### <2016> <2017>
|
||||
好了,结束了。感谢您的阅读!我希望您享受阅读这份长篇大论,正如我享受在 Git 的源码,发布文档,和 `man` 手册中探险一番来撰写它。如果你认为我忘记了一些重要的事,请留下一条评论或者在 [Twitter][72] 上让我知道,我会努力写一份后续篇章。
|
||||
|
||||
至于 Git 接下来会发生什么,这要靠广大维护者和贡献者了(其中有可能就是你!)。随着日益增长的采用,我猜测简化,改进后的用户体验,和更好的默认结果将会是 2017 年 Git 主要的主题。随着 Git 仓库变得又大又旧,我猜我们也可以看到继续持续关注性能和对大文件、深度树和长历史的改进处理。
|
||||
|
||||
如果你关注 Git 并且很期待能够和一些项目背后的开发者会面,请考虑来 Brussels 花几周时间来参加 [Git Merge][74] 。我会在[那里发言][75]!但是更重要的是,很多维护 Git 的开发者将会出席这次会议而且一年一度的 Git 贡献者峰会很可能会指定来年发展的方向。
|
||||
|
||||
或者如果你实在等不及,想要获得更多的技巧和指南来改进你的工作流,请参看这份 Atlassian 的优秀作品: [Git 教程][76] 。
|
||||
|
||||
|
||||
*如果你翻到最下方来找第一节的脚注,请跳转到 [ [引用是需要的] ][77]一节去找生成统计信息的命令。免费的封面图片是由 [ instaco.de ][78] 生成的 ❤️。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/git-in-2016-fad96ae22a15#.t5c5cm48f
|
||||
|
||||
作者:[Tim Pettersen][a]
|
||||
译者:[xiaow6](https://github.com/xiaow6)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@kannonboy?source=post_header_lockup
|
||||
[1]:https://medium.com/@g.kylafas/the-git-config-command-is-missing-a-yes-at-the-end-as-in-git-config-global-commit-verbose-yes-7e126365750e?source=responses---------1----------
|
||||
[2]:https://medium.com/@kannonboy/thanks-giorgos-fixed-f3b83c61589a?source=responses---------1----------
|
||||
[3]:https://medium.com/@TomSwirly/i-read-the-whole-thing-from-start-to-finish-415a55d89229?source=responses---------0-31---------
|
||||
[4]:https://medium.com/@g.kylafas
|
||||
[5]:https://medium.com/@g.kylafas?source=responses---------1----------
|
||||
[6]:https://medium.com/@kannonboy
|
||||
[7]:https://medium.com/@kannonboy?source=responses---------1----------
|
||||
[8]:https://medium.com/@TomSwirly
|
||||
[9]:https://medium.com/@TomSwirly?source=responses---------0-31---------
|
||||
[10]:https://medium.com/@g.kylafas/the-git-config-command-is-missing-a-yes-at-the-end-as-in-git-config-global-commit-verbose-yes-7e126365750e?source=responses---------1----------#--responses
|
||||
[11]:https://hackernoon.com/@kannonboy
|
||||
[12]:https://hackernoon.com/@kannonboy?source=placement_card_footer_grid---------0-44
|
||||
[13]:https://medium.freecodecamp.com/@BillSourour
|
||||
[14]:https://medium.freecodecamp.com/@BillSourour?source=placement_card_footer_grid---------1-43
|
||||
[15]:https://blog.uncommon.is/@lut4rp
|
||||
[16]:https://blog.uncommon.is/@lut4rp?source=placement_card_footer_grid---------2-43
|
||||
[17]:https://medium.com/@kannonboy
|
||||
[18]:https://medium.com/@kannonboy
|
||||
[19]:https://medium.com/@g.kylafas/the-git-config-command-is-missing-a-yes-at-the-end-as-in-git-config-global-commit-verbose-yes-7e126365750e?source=responses---------1----------
|
||||
[20]:https://medium.com/@kannonboy/thanks-giorgos-fixed-f3b83c61589a?source=responses---------1----------
|
||||
[21]:https://medium.com/@TomSwirly/i-read-the-whole-thing-from-start-to-finish-415a55d89229?source=responses---------0-31---------
|
||||
[22]:https://hackernoon.com/setting-breakpoints-on-a-snowy-evening-df34fc3168e2?source=placement_card_footer_grid---------0-44
|
||||
[23]:https://medium.freecodecamp.com/the-code-im-still-ashamed-of-e4c021dff55e?source=placement_card_footer_grid---------1-43
|
||||
[24]:https://blog.uncommon.is/using-git-to-generate-versionname-and-versioncode-for-android-apps-aaa9fc2c96af?source=placement_card_footer_grid---------2-43
|
||||
[25]:https://hackernoon.com/git-in-2016-fad96ae22a15#fd10
|
||||
[26]:https://hackernoon.com/git-in-2016-fad96ae22a15#cc52
|
||||
[27]:https://hackernoon.com/git-in-2016-fad96ae22a15#42b9
|
||||
[28]:https://hackernoon.com/git-in-2016-fad96ae22a15#4208
|
||||
[29]:https://hackernoon.com/git-in-2016-fad96ae22a15#a5c3
|
||||
[30]:https://hackernoon.com/git-in-2016-fad96ae22a15#c230
|
||||
[31]:https://hackernoon.com/tagged/git?source=post
|
||||
[32]:https://hackernoon.com/tagged/web-development?source=post
|
||||
[33]:https://hackernoon.com/tagged/software-development?source=post
|
||||
[34]:https://hackernoon.com/tagged/programming?source=post
|
||||
[35]:https://hackernoon.com/tagged/atlassian?source=post
|
||||
[36]:https://hackernoon.com/@kannonboy
|
||||
[37]:https://hackernoon.com/?source=footer_card
|
||||
[38]:https://hackernoon.com/setting-breakpoints-on-a-snowy-evening-df34fc3168e2?source=placement_card_footer_grid---------0-44
|
||||
[39]:https://medium.freecodecamp.com/the-code-im-still-ashamed-of-e4c021dff55e?source=placement_card_footer_grid---------1-43
|
||||
[40]:https://blog.uncommon.is/using-git-to-generate-versionname-and-versioncode-for-android-apps-aaa9fc2c96af?source=placement_card_footer_grid---------2-43
|
||||
[41]:https://hackernoon.com/git-in-2016-fad96ae22a15#fd10
|
||||
[42]:https://hackernoon.com/git-in-2016-fad96ae22a15#fd10
|
||||
[43]:https://hackernoon.com/git-in-2016-fad96ae22a15#cc52
|
||||
[44]:https://hackernoon.com/git-in-2016-fad96ae22a15#cc52
|
||||
[45]:https://hackernoon.com/git-in-2016-fad96ae22a15#42b9
|
||||
[46]:https://hackernoon.com/git-in-2016-fad96ae22a15#4208
|
||||
[47]:https://hackernoon.com/git-in-2016-fad96ae22a15#a5c3
|
||||
[48]:https://hackernoon.com/git-in-2016-fad96ae22a15#c230
|
||||
[49]:https://git-scm.com/docs/git-worktree
|
||||
[50]:https://git-scm.com/book/en/v2/Git-Tools-Debugging-with-Git#Binary-Search
|
||||
[51]:https://www.atlassian.com/git/tutorials/git-lfs/#speeding-up-clones
|
||||
[52]:https://www.atlassian.com/git/tutorials/git-stash/
|
||||
[53]:https://hackernoon.com/@kannonboy?source=footer_card
|
||||
[54]:https://hackernoon.com/?source=footer_card
|
||||
[55]:https://hackernoon.com/@kannonboy?source=post_header_lockup
|
||||
[56]:https://hackernoon.com/@kannonboy?source=post_header_lockup
|
||||
[57]:https://hackernoon.com/git-in-2016-fad96ae22a15#c8e9
|
||||
[58]:https://hackernoon.com/git-in-2016-fad96ae22a15#408a
|
||||
[59]:https://hackernoon.com/git-in-2016-fad96ae22a15#315b
|
||||
[60]:https://hackernoon.com/git-in-2016-fad96ae22a15#dbfb
|
||||
[61]:https://hackernoon.com/git-in-2016-fad96ae22a15#2220
|
||||
[62]:https://hackernoon.com/git-in-2016-fad96ae22a15#bc78
|
||||
[63]:https://www.atlassian.com/git/tutorials/install-git/
|
||||
[64]:https://www.atlassian.com/git/tutorials/what-is-git/
|
||||
[65]:https://www.atlassian.com/git/tutorials/git-lfs/
|
||||
[66]:https://twitter.com/kit3bus
|
||||
[67]:https://confluence.atlassian.com/bitbucket/bitbucket-lfs-media-adapter-856699998.html
|
||||
[68]:https://developer.atlassian.com/blog/2015/10/monorepos-in-git/
|
||||
[69]:https://blogs.atlassian.com/2013/08/what-you-need-to-know-about-the-new-git-1-8-4/
|
||||
[70]:https://www.atlassian.com/git/tutorials/refs-and-the-reflog/
|
||||
[71]:https://www.atlassian.com/git/tutorials/git-stash/#how-git-stash-works
|
||||
[72]:https://twitter.com/kannonboy
|
||||
[73]:https://git.kernel.org/cgit/git/git.git/tree/Documentation/SubmittingPatches
|
||||
[74]:http://git-merge.com/
|
||||
[75]:http://git-merge.com/#git-aliases
|
||||
[76]:https://www.atlassian.com/git/tutorials
|
||||
[77]:https://hackernoon.com/git-in-2016-fad96ae22a15#87c4
|
||||
[78]:http://instaco.de/
|
||||
[79]:https://medium.com/@Medium/personalize-your-medium-experience-with-users-publications-tags-26a41ab1ee0c#.hx4zuv3mg
|
||||
[80]:https://hackernoon.com/
|
||||
@ -1,31 +1,33 @@
|
||||
vim-kakali translating
|
||||
|
||||
Inxi – A Powerful Feature-Rich Commandline System Information Tool for Linux
|
||||
Inxi —— 一个功能强大的获取 Linux 系统信息的命令行工具
|
||||
============================================================
|
||||
|
||||
Inxi 最初是为控制台和 IRC(网络中继聊天)开发的一个强大且优秀的系统命令行工具。现在可以使用它获取用户的硬件和系统信息,它也能作为一个调试器使用或者一个社区技术支持工具。
|
||||
|
||||
Inxi is a powerful and remarkable command line-system information script designed for both console and IRC (Internet Relay Chat). It can be employed to instantly deduce user system configuration and hardware information, and also functions as a debugging, and forum technical support tool.
|
||||
使用 Inxi 可以很容易的获取所有的硬件信息:硬盘、声卡、显卡、网卡、CPU 和 RAM 等。同时也能够获取大量的操作系统信息,比如硬件驱动、Xorg 、桌面环境、内核、GCC 版本,进程,开机时间和内存等信息。
|
||||
|
||||
It displays handy information concerning system hardware (hard disk, sound cards, graphic card, network cards, CPU, RAM, and more), together with system information about drivers, Xorg, desktop environment, kernel, GCC version(s), processes, uptime, memory, and a wide array of other useful information.
|
||||
|
||||
However, it’s output slightly differs between the command line and IRC, with a few default filters and color options applicable to IRC usage. The supported IRC clients include: BitchX, Gaim/Pidgin, ircII, Irssi, Konversation, Kopete, KSirc, KVIrc, Weechat, and Xchat plus any others that are capable of showing either built in or external Inxi output.
|
||||
命令行和 IRC 上的 Inxi 输出略有不同,IRC 上会有一些可供用户使用的过滤器和颜色选项。支持 IRC 的客户端有:BitchX、Gaim/Pidgin、ircII、Irssi、 Konversation、 Kopete、 KSirc、 KVIrc、 Weechat 和 Xchat ;其他的一些客户端都会有一些过滤器和颜色选项,或者用 Inxi 的输出体现出这种区别。
|
||||
|
||||
### How to Install Inxi in Linux System
|
||||
|
||||
Inix is available in most mainstream Linux distribution repositories, and runs on BSDs as well.
|
||||
|
||||
### 在 Linux 系统上安装 Inxi
|
||||
|
||||
大多数主流 Linux 发行版的仓库中都有 Inxi ,包括大多数 BSD 系统。
|
||||
|
||||
|
||||
```
|
||||
$ sudo apt-get install inxi [On Debian/Ubuntu/Linux Mint]
|
||||
$ sudo yum install inxi [On CentOs/RHEL/Fedora]
|
||||
$ sudo dnf install inxi [On Fedora 22+]
|
||||
```
|
||||
在使用 Inxi 之前,用下面的命令查看 Inxi 的介绍信息,包括各种各样的文件夹和需要安装的包。
|
||||
|
||||
Before we start using it, we can run the command that follows to check all application dependencies plus recommends, and various directories, and display what package(s) we need to install to add support for a given feature.
|
||||
|
||||
```
|
||||
$ inxi --recommends
|
||||
```
|
||||
Inxi Checking
|
||||
Inxi 的输出:
|
||||
```
|
||||
inxi will now begin checking for the programs it needs to operate. First a check of the main languages and tools
|
||||
inxi uses. Python is only for debugging data collection.
|
||||
@ -120,22 +122,22 @@ File: /var/run/dmesg.boot
|
||||
All tests completed.
|
||||
```
|
||||
|
||||
### Basic Usage of Inxi Tool in Linux
|
||||
|
||||
Below are some basic Inxi options we can use to collect machine plus system information.
|
||||
用下面的操作获取系统和硬件的详细信息。
|
||||
|
||||
#### Show Linux System Information
|
||||
#### 获取系统信息
|
||||
Inix 不加任何选项就能输出下面的信息:CPU 、内核、开机时长、内存大小、硬盘大小、进程数、登陆终端以及 Inxi 版本。
|
||||
|
||||
When run without any flags, Inxi will produce output to do with system CPU, kernel, uptime, memory size, hard disk size, number of processes, client used and inxi version:
|
||||
|
||||
```
|
||||
$ inxi
|
||||
CPU~Dual core Intel Core i5-4210U (-HT-MCP-) speed/max~2164/2700 MHz Kernel~4.4.0-21-generic x86_64 Up~3:15 Mem~3122.0/7879.9MB HDD~1000.2GB(20.0% used) Procs~234 Client~Shell inxi~2.2.35
|
||||
```
|
||||
|
||||
#### Show Linux Kernel and Distribution Info
|
||||
#### 获取内核和发行版本信息
|
||||
|
||||
使用 Inxi 的 `-S` 选项查看本机系统信息:
|
||||
|
||||
The command below will show sample system info (hostname, kernel info, desktop environment and disto) using the `-S` flag:
|
||||
|
||||
```
|
||||
$ inxi -S
|
||||
@ -143,9 +145,10 @@ System: Host: TecMint Kernel: 4.4.0-21-generic x86_64 (64 bit) Desktop: Cinnamon
|
||||
Distro: Linux Mint 18 Sarah
|
||||
```
|
||||
|
||||
#### Find Linux Laptop or PC Model Information
|
||||
|
||||
To print machine data-same as product details (system, product id, version, Mobo, model, BIOS etc), we can use the option `-M` as follows:
|
||||
### 获取电脑机型
|
||||
使用 `-M` 选项查看机型(笔记本/台式机)、产品 ID 、机器版本、主板、制造商和 BIOS 等信息:
|
||||
|
||||
|
||||
```
|
||||
$ inxi -M
|
||||
@ -153,9 +156,9 @@ Machine: System: LENOVO (portable) product: 20354 v: Lenovo Z50-70
|
||||
Mobo: LENOVO model: Lancer 5A5 v: 31900059WIN Bios: LENOVO v: 9BCN26WW date: 07/31/2014
|
||||
```
|
||||
|
||||
#### Find Linux CPU and CPU Speed Information
|
||||
### 获取 CPU 及主频信息
|
||||
使用 `-C` 选项查看完整的 CPU 信息,包括每核 CPU 的频率及可用的最大主频。
|
||||
|
||||
We can display complete CPU information, including per CPU clock-speed and CPU max speed (if available) with the `-C` flag as follows:
|
||||
|
||||
```
|
||||
$ inxi -C
|
||||
@ -163,9 +166,10 @@ CPU: Dual core Intel Core i5-4210U (-HT-MCP-) cache: 3072 KB
|
||||
clock speeds: max: 2700 MHz 1: 1942 MHz 2: 1968 MHz 3: 1734 MHz 4: 1710 MHz
|
||||
```
|
||||
|
||||
#### Find Graphic Card Information in Linux
|
||||
|
||||
The option `-G` can be used to show graphics card info (card type, display server, resolution, GLX renderer and GLX version) like so:
|
||||
#### 获取显卡信息
|
||||
使用 `-G` 选项查看显卡信息,包括显卡类型、图形服务器、系统分辨率、GLX 渲染器(译者注: GLX 是一个 X 窗口系统的 OpenGL 扩展)和 GLX 版本。
|
||||
|
||||
|
||||
```
|
||||
$ inxi -G
|
||||
@ -175,9 +179,10 @@ Display Server: X.Org 1.18.4 drivers: intel (unloaded: fbdev,vesa) Resolution: 1
|
||||
GLX Renderer: Mesa DRI Intel Haswell Mobile GLX Version: 3.0 Mesa 11.2.0
|
||||
```
|
||||
|
||||
#### Find Audio/Sound Card Information in Linux
|
||||
|
||||
To get info about system audio/sound card, we use the `-A` flag:
|
||||
#### 获取声卡信息
|
||||
使用 `-A` 选项查看声卡信息:
|
||||
|
||||
|
||||
```
|
||||
$ inxi -A
|
||||
@ -185,9 +190,9 @@ Audio: Card-1 Intel 8 Series HD Audio Controller driver: snd_hda_intel Sound
|
||||
Card-2 Intel Haswell-ULT HD Audio Controller driver: snd_hda_intel
|
||||
```
|
||||
|
||||
#### Find Linux Network Card Information
|
||||
|
||||
To display network card info, we can make use of `-N` flag:
|
||||
#### 获取网卡信息
|
||||
使用 `-N` 选项查看网卡信息:
|
||||
|
||||
```
|
||||
$ inxi -N
|
||||
@ -195,19 +200,19 @@ Network: Card-1: Realtek RTL8111/8168/8411 PCI Express Gigabit Ethernet Contro
|
||||
Card-2: Realtek RTL8723BE PCIe Wireless Network Adapter driver: rtl8723be
|
||||
```
|
||||
|
||||
#### Find Linux Hard Disk Information
|
||||
#### 获取硬盘信息
|
||||
使用 `-D` 选项查看硬盘信息(大小、ID、型号):
|
||||
|
||||
To view full hard disk information,(size, id, model) we can use the flag `-D`:
|
||||
|
||||
```
|
||||
$ inxi -D
|
||||
Drives: HDD Total Size: 1000.2GB (20.0% used) ID-1: /dev/sda model: ST1000LM024_HN size: 1000.2GB
|
||||
```
|
||||
|
||||
#### Summarize Full Linux System Information Together
|
||||
|
||||
To show a summarized system information; combining all the information above, we need to use the `-b` flag as below:
|
||||
#### 获取简要的系统信息
|
||||
|
||||
使用 `-b` 选项显示简要系统信息:
|
||||
```
|
||||
$ inxi -b
|
||||
System: Host: TecMint Kernel: 4.4.0-21-generic x86_64 (64 bit) Desktop: Cinnamon 3.0.7
|
||||
@ -225,9 +230,9 @@ Drives: HDD Total Size: 1000.2GB (20.0% used)
|
||||
Info: Processes: 233 Uptime: 3:23 Memory: 3137.5/7879.9MB Client: Shell (bash) inxi: 2.2.35
|
||||
```
|
||||
|
||||
#### Find Linux Hard Disk Partition Details
|
||||
#### 获取硬盘分区信息
|
||||
使用 `-p` 选项输出完整的硬盘分区信息,包括每个分区的分区大小、已用空间、可用空间、文件系统以及文件系统类型。
|
||||
|
||||
The next command will enable us view complete list of hard disk partitions in relation to size, used and available space, filesystem as well as filesystem type on each partition with the `-p` flag:
|
||||
|
||||
```
|
||||
$ inxi -p
|
||||
@ -235,9 +240,9 @@ Partition: ID-1: / size: 324G used: 183G (60%) fs: ext4 dev: /dev/sda10
|
||||
ID-2: swap-1 size: 4.00GB used: 0.00GB (0%) fs: swap dev: /dev/sda9
|
||||
```
|
||||
|
||||
#### Shows Full Linux System Information
|
||||
|
||||
In order to show complete Inxi output, we use the `-F` flag as below (note that certain data is filtered for security reasons such as WAN IP):
|
||||
#### 获取完整的 Linux 系统信息
|
||||
使用 `-F` 选项查看可以完整的 Inxi 输出(安全起见比如网络 IP 地址信息不会显示,下面的示例只显示部分输出信息):
|
||||
|
||||
```
|
||||
$ inxi -F
|
||||
@ -266,22 +271,21 @@ Fan Speeds (in rpm): cpu: N/A
|
||||
Info: Processes: 234 Uptime: 3:26 Memory: 3188.9/7879.9MB Client: Shell (bash) inxi: 2.2.35
|
||||
```
|
||||
|
||||
### Linux System Monitoring with Inxi Tool
|
||||
### 使用 Inxi 工具监控 Linux 系统
|
||||
|
||||
Following are few options used to monitor Linux system processes, uptime, memory etc.
|
||||
下面是监控 Linux 系统进程、开机时间和内存的几个选项的使用方法。
|
||||
|
||||
#### Monitor Linux Processes Memory Usage
|
||||
|
||||
Get summarized system info in relation to total number of processes, uptime and memory usage:
|
||||
#### 监控 Linux 进程的内存使用
|
||||
|
||||
使用下面的命令查看进程数、开机时间和内存使用情况:
|
||||
```
|
||||
$ inxi -I
|
||||
Info: Processes: 232 Uptime: 3:35 Memory: 3256.3/7879.9MB Client: Shell (bash) inxi: 2.2.35
|
||||
```
|
||||
|
||||
#### Monitoring Processes by CPU and Memory Usage
|
||||
|
||||
By default, it can help us determine the [top 5 processes consuming CPU or memory][1]. The `-t` option used together with `c` (CPU) and/or `m` (memory) options lists the top 5 most active processes eating up CPU and/or memory as shown below:
|
||||
#### 监控进程占用的 CPU 和内存资源
|
||||
Inxi 默认显示 [前 5 个最消耗 CPU 和内存的进程][1]。 `-t` 选项和 `c` 选项一起使用查看前 5 个最消耗 CPU 资源的进程,查看最消耗内存的进程使用 `-t` 选项和 `m` 选项; `-t`选项 和 `cm` 选项一起使用显示前 5 个最消耗 CPU 和内存资源的进程。
|
||||
|
||||
```
|
||||
----------------- Linux CPU Usage -----------------
|
||||
@ -321,7 +325,7 @@ Memory: MB / % used - Used/Total: 3223.6/7879.9MB - top 5 active
|
||||
4: mem: 244.45MB (3.1%) command: chrome pid: 7405
|
||||
5: mem: 211.68MB (2.6%) command: chrome pid: 6146
|
||||
```
|
||||
|
||||
可以在选项 `cm` 后跟一个整数(在 1-20 之间)设置显示多少个进程,下面的命令显示了前 10 个最消耗 CPU 和内存的进程:
|
||||
We can use `cm` number (number can be 1-20) to specify a number other than 5, the command below will show us the [top 10 most active processes][2] eating up CPU and memory.
|
||||
|
||||
```
|
||||
@ -350,9 +354,9 @@ Memory: MB / % used - Used/Total: 3163.1/7879.9MB - top 10 active
|
||||
10: mem: 151.83MB (1.9%) command: mysqld pid: 1259
|
||||
```
|
||||
|
||||
#### Monitor Linux Network Interfaces
|
||||
#### 监控网络设备
|
||||
下面的命令会列出网卡信息,包括接口信息、网络频率、mac 地址、网卡状态和网络 IP 等信息。
|
||||
|
||||
The command that follows will show us advanced network card information including interface, speed, mac id, state, IPs, etc:
|
||||
|
||||
```
|
||||
$ inxi -Nni
|
||||
@ -364,9 +368,9 @@ WAN IP: 111.91.115.195 IF: wlp2s0 ip-v4: N/A
|
||||
IF: enp1s0 ip-v4: 192.168.0.103
|
||||
```
|
||||
|
||||
#### Monitor Linux CPU Temperature and Fan Speed
|
||||
#### 监控 CPU 温度和电脑风扇转速
|
||||
可以使用 `-s` 选项监控 [配置了传感器的机器][2] 获取温度和风扇转速:
|
||||
|
||||
We can keep track of the [hardware installed/configured sensors][3] output by using the -s option:
|
||||
|
||||
```
|
||||
$ inxi -s
|
||||
@ -374,9 +378,9 @@ Sensors: System Temperatures: cpu: 53.0C mobo: N/A
|
||||
Fan Speeds (in rpm): cpu: N/A
|
||||
```
|
||||
|
||||
#### Find Weather Report in Linux
|
||||
#### 用 Linux 查看天气预报
|
||||
使用 `-w` 选项查看本地区的天气情况(虽然使用的 API 可能不是很可靠),使用 `-w` `<different_location>` 设置所在的地区。
|
||||
|
||||
We can also view whether info (though API used is unreliable) for the current location with the `-w` or `-W``<different_location>` to set a different location.
|
||||
|
||||
```
|
||||
$ inxi -w
|
||||
@ -387,9 +391,9 @@ $ inxi -W Nairobi,Kenya
|
||||
Weather: Conditions: 70 F (21 C) - Mostly Cloudy Time: February 20, 11:08 AM EAT
|
||||
```
|
||||
|
||||
#### Find All Linux Repsitory Information
|
||||
#### 查看所有的 Linux 仓库信息。
|
||||
另外,可以使用 `-r` 选项查看一个 Linux 发行版的仓库信息:
|
||||
|
||||
We can additionally view a distro repository data with the `-r` flag:
|
||||
|
||||
```
|
||||
$ inxi -r
|
||||
@ -422,34 +426,35 @@ Active apt sources in file: /etc/apt/sources.list.d/ubuntu-mozilla-security-ppa-
|
||||
deb http://ppa.launchpad.net/ubuntu-mozilla-security/ppa/ubuntu xenial main
|
||||
deb-src http://ppa.launchpad.net/ubuntu-mozilla-security/ppa/ubuntu xenial main
|
||||
```
|
||||
下面是查看 Inxi 的安装版本、快速帮助和打开 man 主页的方法,以及更多的 Inxi 使用细节。
|
||||
|
||||
To view it’s current installed version, a quick help, and open the man page for a full list of options and detailed usage info plus lots more, type:
|
||||
|
||||
```
|
||||
$ inxi -v #show version
|
||||
$ inxi -h #quick help
|
||||
$ man inxi #open man page
|
||||
$ inxi -v #显示版本信息
|
||||
$ inxi -h #快速帮助
|
||||
$ man inxi #打开 man 主页
|
||||
```
|
||||
|
||||
浏览 Inxi 的官方 GitHub 主页 [https://github.com/smxi/inxi][4] 查看更多的信息。
|
||||
For more information, visit official GitHub Repository: [https://github.com/smxi/inxi][4]
|
||||
|
||||
That’s all for now! In this article, we reviewed Inxi, a full featured and remarkable command line tool for collecting machine hardware and system info. This is one of the best CLI based [hardware/system information collection tools][5] for Linux, I have ever used.
|
||||
Inxi 是一个功能强大的获取硬件和系统信息的命令行工具。这也是我使用过的最好的 [获取硬件和系统信息的命令行工具][5] 之一。
|
||||
|
||||
写下你的评论。如果你知道其他的像 Inxi 这样的工具,我们很高兴和你一起讨论。
|
||||
|
||||
To share your thoughts about it, use the comment form below. Lastly, in case you know of other, such useful tools as Inxi out there, you can inform us and we will be delighted to review them as well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S(译者注:一个 Linux 开源门户网站)的狂热爱好者,即任的 Linux 系统管理员,web 开发者,TecMint 网站的专栏作者,他喜欢使用计算机工作,并且乐于分享计算机技术。
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/inxi-command-to-find-linux-system-information/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,166 @@
|
||||
如何在现有的 Linux 系统上添加新的磁盘
|
||||
============================================================
|
||||
|
||||
|
||||
作为一个系统管理员,我们会有这样的一些需求:作为升级服务器容量的一部分、或者有时出现磁盘故障时更换磁盘,我们需要将新的硬盘配置到现有服务器。
|
||||
|
||||
在这篇文章中,我会向你逐步介绍添加新硬盘到现有 RHEL/CentOS 或者 Debian/Ubuntu Linux 系统的步骤。
|
||||
|
||||
**推荐阅读:** [如何将超过 2TB 的新硬盘添加到现有 Linux][1]
|
||||
|
||||
重要:请注意这篇文章的目的只是告诉你如何创建新的分区,而不包括分区扩展或者其它选项。
|
||||
|
||||
我使用 [fdisk 工具][2] 完成这些配置。
|
||||
|
||||
我已经添加了一块 20GB 容量的硬盘,挂载到了 `/data` 分区。
|
||||
|
||||
fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行工具。
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
|
||||
这个命令会列出当前分区和配置。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
查看 Linux 分区详情
|
||||
|
||||
添加了 20GB 容量的硬盘后,`fdisk -l` 的输出像下面这样。
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
查看新分区详情
|
||||
|
||||
新添加的磁盘显示为 `/dev/xvdc`。如果我们添加的是物理磁盘,基于磁盘类型它会显示类似 `/dev/sda`。这里我使用的是虚拟磁盘。
|
||||
|
||||
要在特定硬盘上分区,例如 `/dev/xvdc`。
|
||||
|
||||
```
|
||||
# fdisk /dev/xvdc
|
||||
```
|
||||
|
||||
常用 fdisk 命令。
|
||||
|
||||
* `n` - 创建分区
|
||||
* `p` - 打印分区表
|
||||
* `d` - 删除一个分区
|
||||
* `q` - 不保存更改退出
|
||||
* `w` - 保存更改并退出
|
||||
|
||||
这里既然我们是要创建一个分区,就用 `n` 选项。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
在 Linux上创建新分区
|
||||
|
||||
创建主分区或者扩展分区。默认情况下我们最多可以有 4 个主分区。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
创建主分区
|
||||
|
||||
按需求输入分区编号。推荐使用默认的值 `1`。
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
分配分区编号
|
||||
|
||||
输入第一个扇区的大小。如果是一个新的磁盘,通常选择默认值。如果你是在同一个磁盘上创建第二个分区,我们需要在前一个分区的最后一个扇区的基础上加 `1`。
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
为分区分配扇区
|
||||
|
||||
输入最后一个扇区或者分区大小的值。通常推荐输入分区的大小。总是添加前缀 `+` 以防止值超出范围错误。
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
分配分区大小
|
||||
|
||||
保存更改并退出。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
保存分区更改
|
||||
|
||||
现在使用 mkfs 命令格式化磁盘。
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/xvdc1
|
||||
```
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
格式化新分区
|
||||
|
||||
格式化完成后,按照下面的命令挂载分区。
|
||||
|
||||
```
|
||||
# mount /dev/xvdc1 /data
|
||||
```
|
||||
|
||||
在 `/etc/fstab` 文件中添加条目以便永久启动时自动挂载。
|
||||
|
||||
```
|
||||
/dev/xvdc1 /data ext4 defaults 0 0
|
||||
```
|
||||
|
||||
##### 总结
|
||||
|
||||
现在你知道如何使用 [fdisk 命令][12] 在新磁盘上创建分区并挂载了。
|
||||
|
||||
当处理分区、尤其是编辑已配置磁盘的时候我们需要格外的小心。请分享你的反馈和建议吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我的工作内容包括 IBM-AIX、Solaris、HP-UX 多种平台以及存储技术 ONTAP 和 OneFS,并具有 Oracle 数据库的经验。
|
||||
|
||||
-----------------------
|
||||
|
||||
via: http://www.tecmint.com/add-new-disk-to-an-existing-linux/
|
||||
|
||||
作者:[Lakshmi Dhandapani][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/lakshmi/
|
||||
[1]:http://www.tecmint.com/add-disk-larger-than-2tb-to-an-existing-linux/
|
||||
[2]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Partition-Details.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-New-Partition-Details.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Create-New-Partition-in-Linux.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Create-Primary-Partition.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-a-Partition-Number.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-Sector-to-Partition.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-Partition-Size.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Save-Partition-Changes.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Format-New-Partition.png
|
||||
[12]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[13]:http://www.tecmint.com/author/lakshmi/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -5,75 +5,75 @@ python 是慢,但是爷就喜欢它
|
||||
|
||||

|
||||
|
||||
我从关于Python中的asyncio这个标准库的讨论中休息一会,这次讨论是要谈论我最近正在思考的一些东西:Python的速度。相比那些不了解Python的人,我是一个Python的粉丝,而且我在我能想到的所有地方都积极地使用Python。人们对Python最大的抱怨之一就是它的速度比较慢,有些人甚至拒绝尝试使用Python,因为它比其他语言更慢的速度。这里我对于为什么你应该尝试使用Python的一些想法,尽管它是有点慢。
|
||||
我从关于 Python 中的 asyncio 这个标准库的讨论中休息一会,谈谈我最近正在思考的一些东西:Python 的速度。对不了解我的人说明一下,我是一个 Python 的粉丝,而且我在我能想到的所有地方都积极地使用 Python。人们对 Python 最大的抱怨之一就是它的速度比较慢,有些人甚至拒绝尝试使用 Python,因为它比其他语言速度慢。这里说说为什么我认为应该尝试使用 Python,尽管它是有点慢。
|
||||
|
||||
### 速度不再重要
|
||||
|
||||
过去的情形是,程序需要花费很长的时间来运行,CPU比较贵,内存更加贵。程序的运行时间是一个很重要的指标。计算机非常的昂贵,计算机运行所需要的电也是相当贵的。对这些资源进行优化是因为一个永恒的商业法则:
|
||||
过去的情形是,程序需要花费很长的时间来运行,CPU 比较贵,内存也很贵。程序的运行时间是一个很重要的指标。计算机非常的昂贵,计算机运行所需要的电也是相当贵的。对这些资源进行优化是因为一个永恒的商业法则:
|
||||
|
||||
> 优化你最贵的资源
|
||||
> <ruby>优化你最贵的资源<rt>Optimize your most expensive resource</rt></ruby>。
|
||||
|
||||
在过去,最贵的资源是计算机的运行时间。这就是导致计算机科学致力于研究不同算法的效率的原因。然而,这已经不再是正确的,因为现在硅芯片很便宜,确实很便宜。运行时间不再是你最贵的资源。公司最贵的资源现在是它的员工的时间。或者换句话说,就是你。把事情做完比快速地做事更加重要。实际上,这是相当的重要,我将把它再次放在这里,仿佛它是一个引用一样(对于那些只是粗略浏览的人):
|
||||
|
||||
> 把事情做完比快速地做事更加重要。
|
||||
> <ruby>把事情做完比快速地做事更加重要<rt>It’s more important to get stuff done than to make it go fast</rt></ruby>。
|
||||
|
||||
你可能会说:"我的公司在意速度,我开发一个web应用程序,那么所有的响应时间必须少于x毫秒。"或者,"我们失去了客户,因为他们认为我们的app运行太慢了。"我并不是想说速度一点也不重要,我只是想说速度不再是最重要的东西;它不再是你最贵的资源。
|
||||
你可能会说:“我的公司在意速度,我开发一个 web 应用程序,那么所有的响应时间必须少于 x 毫秒。”或者,“我们失去了客户,因为他们认为我们的 app 运行太慢了。”我并不是想说速度一点也不重要,我只是想说速度不再是最重要的东西;它不再是你最贵的资源。
|
||||
|
||||

|
||||
|
||||
### 速度是唯一重要的东西
|
||||
|
||||
当你在编程的背景下说 _速度_ 时,你通常意味着性能,也就是CPU周期。当你的CEO在编程的背景下说 _速度_ 时,他指的是业务速度,最重要的指标是产品上市的时间。基本上,你的产品/web程序是多么的快并不重要。它是用什么语言写的也不重要。甚至它需要花费多少钱也不重要。在一天结束时,让你的公司存活下来或者死去的唯一事物就是产品上市时间。我不只是说创业公司的想法--你开始赚钱需要花费多久,更多的是"从想法到客户手中"的时间期限。企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。如果在你将立产品上市之前,你的竞争对手已经提前上市了,那么你想出了多少好的主意也将不再重要。你不得不成为第一个上市的,或者至少能跟上。你但你放慢了脚步,你就输了。
|
||||
当你在编程的背景下说 _速度_ 时,你通常意味着性能,也就是 CPU 周期。当你的 CEO 在编程的背景下说 _速度_ 时,他指的是业务速度,最重要的指标是产品上市的时间。基本上,你的产品/web 程序是多么的快并不重要。它是用什么语言写的也不重要。甚至它需要花费多少钱也不重要。在一天结束时,让你的公司存活下来或者死去的唯一事物就是产品上市时间。我不只是说创业公司的想法 -- 你开始赚钱需要花费多久,更多的是“从想法到客户手中”的时间期限。企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。如果在你的产品上市之前,你的竞争对手已经提前上市了,那么你想出了多少好的主意也将不再重要。你必须第一个上市,或者至少能跟上。一但你放慢了脚步,你就输了。
|
||||
|
||||
> 企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。
|
||||
> <ruby>企业能够存活下来的唯一方法就是比你的竞争对手更快地创新<rt>The only way to survive in business is to innovate faster than your competitors</rt></ruby>。
|
||||
|
||||
### 一个微服务的案例
|
||||
#### 一个微服务的案例
|
||||
|
||||
像Amazon、Google和Netflix这样的公司明白快速前进的重要性。他们创建了一个业务系统,他们可以使用这个系统迅速地前进和快速的创新。微服务是针对他们的问题的解决方案。这篇文章与你是否应该使用微服务没有关系,但是至少得接受Amazon和Google认为他们应该使用微服务。
|
||||
像 Amazon、Google 和 Netflix 这样的公司明白快速前进的重要性。他们创建了一个业务系统,可以使用这个系统迅速地前进和快速的创新。微服务是针对他们的问题的解决方案。这篇文章不谈你是否应该使用微服务,但是至少要接受 Amazon 和 Google 认为他们应该使用微服务。
|
||||
|
||||

|
||||
|
||||
微服务本来就很慢。微服务的一个恰当的概念是用网络调用来打破一个边界。这意味着你正在采取一个函数调用(几个cpu周期)并把这转变为一个网络调用。没有什么比这更影响性能了。和CPU想比较,网络调用真的很慢。但是这些大公司仍然选择使用微服务。我所知道的架构里面没有任何一个比微服务还要慢。微服务最大的弊端就是它的性能,但是最大的长处就是上市的时间。通过团结较小的项目和代码库建立团队,一个公司能够以更快的速度进行迭代和创新。这恰恰表明了,非常大的公司也很在意上市时间,而不仅仅只是只有创业公司。
|
||||
微服务本来就很慢。微服务的主要概念是用网络调用来打破边界。这意味着你正在使用一个函数调用(几个 cpu 周期)并将它转变为一个网络调用。没有什么比这更影响性能了。和 CPU 相比较,网络调用真的很慢。但是这些大公司仍然选择使用微服务。我所知道的架构里面没有比微服务还要慢的了。微服务最大的弊端就是它的性能,但是最大的长处就是上市的时间。通过在较小的项目和代码库上建立团队,一个公司能够以更快的速度进行迭代和创新。这恰恰表明了,非常大的公司也很在意上市时间,而不仅仅只是只有创业公司。
|
||||
|
||||
### CPU不是你的瓶颈
|
||||
#### CPU不是你的瓶颈
|
||||
|
||||

|
||||
|
||||
如果你在写一个网络应用程序,如web服务器,很有可能的情况会是,CPU时间并不是你的程序的瓶颈。当你的web服务器处理一个请求时,可能会进行几次网络调用,例如数据库,或者像Redis这样的缓存服务器。虽然这些服务本身可能比较快速,但是对它们的网络调用却很慢。[有一篇很好的关于特定操作的速度差异的博客文章][1]。在这篇文章里,作者把CPU周期时间缩放到更容易理解的人类时间。如果一个单独的周期等同于1秒,那么一个从California到New York的网络调用将相当于4年。那就说明了网络调用是多少的慢。对于一些粗略估计,我们可以假设在同一数据中心内的普通网络调用大约需要3ms。这相当于我们“人类比例”3个月。现在假设你的程序是高CPU密集型,这需要100000个CPU周期来对单一调用进行响应。这相当于刚刚超过1天。现在让我们假设你使用的是一种要慢5倍的语言,这将需要大约5天。很好,将那与我们3个月的网络调用时间相比,4天的差异就显得并不是很重要了。如果有人为了一个包裹不得不至少等待3个月,我不认为额外的4天对他们来说真的很重要。
|
||||
如果你在写一个网络应用程序,如 web 服务器,很有可能的情况会是,CPU 时间并不是你的程序的瓶颈。当你的 web 服务器处理一个请求时,可能会进行几次网络调用,例如到数据库,或者像 Redis 这样的缓存服务器。虽然这些服务本身可能比较快速,但是对它们的网络调用却很慢。[有一篇很好的关于特定操作的速度差异的博客文章][1]。在这篇文章里,作者把 CPU 周期时间缩放到更容易理解的人类时间。如果一个单独的周期等同于 1 秒,那么一个从 California 到 New York 的网络调用将相当于 4 年。那就说明了网络调用是多少的慢。按一些粗略估计,我们可以假设在同一数据中心内的普通网络调用大约需要 3 ms。这相当于我们“人类比例” 3 个月。现在假设你的程序是高 CPU 密集型,这需要 100000 个 CPU 周期来对单一调用进行响应。这相当于刚刚超过 1 天。现在让我们假设你使用的是一种要慢 5 倍的语言,这将需要大约 5 天。很好,将那与我们 3 个月的网络调用时间相比,4 天的差异就显得并不是很重要了。如果有人为了一个包裹不得不至少等待 3 个月,我不认为额外的 4 天对他们来说真的很重要。
|
||||
|
||||
上面所说的终极意思是,尽管Python速度慢,但是这并不重要。语言的速度(或者CPU时间)几乎从来不是问题。实际上谷歌曾经就这一概念做过一个研究,[并且他们发表过一篇关于这的论文][2]。那篇论文论述了设计高吞吐量的系统。在结论里,他们说到:
|
||||
上面所说的终极意思是,尽管 Python 速度慢,但是这并不重要。语言的速度(或者 CPU 时间)几乎从来不是问题。实际上谷歌曾经就这一概念做过一个研究,[并且他们就此发表过一篇论文][2]。那篇论文论述了设计高吞吐量的系统。在结论里,他们说到:
|
||||
|
||||
> 在高吞吐量的环境中使用解释性语言似乎是矛盾的,但是我们已经发现CPU时间几乎不是限制因素;语言的表达性是指,大多数程序是源程序,同时花费它们的大多数时间在I/O读写和本机运行时代码。而且,解释性语言无论是在语言层面的轻松实验还是在允许我们在很多机器上探索分布计算的方法都是很有帮助的,
|
||||
> 在高吞吐量的环境中使用解释性语言似乎是矛盾的,但是我们已经发现 CPU 时间几乎不是限制因素;语言的表达性是指,大多数程序是源程序,同时花费它们的大多数时间在 I/O 读写和本机运行时代码。而且,解释性语言无论是在语言层面的轻松实验还是在允许我们在很多机器上探索分布计算的方法都是很有帮助的,
|
||||
|
||||
再次强调:
|
||||
> CPU时间几乎不是限制因素。
|
||||
> <ruby>CPU 时间几乎不是限制因素<rt>the CPU time is rarely the limiting factor</rt></ruby>。
|
||||
|
||||
### 如果CPU时间是一个问题怎么办?
|
||||
### 如果 CPU 时间是一个问题怎么办?
|
||||
|
||||
你可能会说,"前面说的情况真是太好了,但是我们确实有过一些问题,这些问题中CPU成为了我们的瓶颈,并造成了我们的web应用的速度十分缓慢",或者"在服务器上X语言比Y语言需要需要更少的硬件资源来运行。"这些都可能是对的。关于web服务器有这样的美妙的事情:你可以几乎无限地负载均衡它们。换句话说,可以在web服务器上投入更多的硬件。当然,Python可能会比其他语言要求更好的硬件资源,比如c语言。只是把硬件投入在CPU问题上。相比于你的时间,硬件就显得非常的便宜了。如果你在一年内节省了两周的生产力时间,那将远远多于所增加的硬件开销的回报。
|
||||
你可能会说,“前面说的情况真是太好了,但是我们确实有过一些问题,这些问题中 CPU 成为了我们的瓶颈,并造成了我们的 web 应用的速度十分缓慢”,或者“在服务器上 X 语言比 Y 语言需要更少的硬件资源来运行。”这些都可能是对的。关于 web 服务器有这样的美妙的事情:你可以几乎无限地负载均衡它们。换句话说,可以在 web 服务器上投入更多的硬件。当然,Python 可能会比其他语言要求更好的硬件资源,比如 c 语言。只是把硬件投入在 CPU 问题上。相比于你的时间,硬件就显得非常的便宜了。如果你在一年内节省了两周的生产力时间,那将远远多于所增加的硬件开销的回报。
|
||||
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
### 那么,Python是更快吗?
|
||||
### 那么,Python 是更快吗?
|
||||
|
||||
这一次我一直在谈论最重要的是开发时间。所以问题依然存在:当就开发时间而言,Python要比其他语言更快吗?按常规惯例来看,我、[google][3][还有][4][其他][5][几个人][6]可以告诉你Python是多么的[高效][7]。它为你抽象出很多东西,帮助你关注那些你真正应该编写代码的地方,而不会被困在琐碎事情的杂草里,比如你是否应该使用一个向量或者一个数组。但你可能不喜欢别人的对Python说的些话,所以让我们来看一些更多的经验数据。
|
||||
这一次我一直在谈论最重要的是开发时间。所以问题依然存在:当就开发时间而言,Python 要比其他语言更快吗?按常规惯例来看,我、[google][3] [还有][4][其他][5][几个人][6]可以告诉你 Python 是多么的[高效][7]。它为你抽象出很多东西,帮助你关注那些你真正应该编写代码的地方,而不会被困在琐碎事情的杂草里,比如你是否应该使用一个向量或者一个数组。但你可能不喜欢只是听别人说的这些话,所以让我们来看一些更多的经验数据。
|
||||
|
||||
在大多数情况下,关于python是否是更高效语言的争论可以归结为脚本语言(或动态语言)与静态类型语言两者的争论。我认为人们普遍接受的是静态类型语言的生产力较低,但是,[这里有一篇解释了为什么是这样的优秀的论文][8]。就Python而言,这里是一项研究中的给出的一个很好的总结][9],这项研究调查了用不同的语言编写对字符串处理的代码所需要花费的时间。
|
||||
在大多数情况下,关于 python 是否是更高效语言的争论可以归结为脚本语言(或动态语言)与静态类型语言两者的争论。我认为人们普遍接受的是静态类型语言的生产力较低,但是,[这有一篇优秀的论文][8]解释了为什么不是这样。就 Python 而言,这里有一项[研究][9],它调查了不同语言编写字符串处理的代码所需要花费的时间,供参考。
|
||||
|
||||
|
||||
|
||||
|
||||
在上述研究中,Python的效率比Java高出2倍。有一些其他研究也显示相似的东西。 Rosetta Code对编程语言的差异进行了[深入的研究][10]。在论文中,他们把python与其他脚本语言/解释性语言相比较,得出结论:
|
||||
在上述研究中,Python 的效率比 Java 高出 2 倍。有一些其他研究也显示相似的东西。 Rosetta Code 对编程语言的差异进行了[深入的研究][10]。在论文中,他们把 python 与其他脚本语言/解释性语言相比较,得出结论:
|
||||
|
||||
> Python侧重于更简洁,甚至反对函数式语言(平均要短1.2到1.6倍)
|
||||
>
|
||||
> Python 更简洁,即使与函数式语言相比较(平均要短 1.2 到 1.6 倍)
|
||||
>
|
||||
|
||||
普遍的趋势似乎是Python中的代码行总是更少。代码行听起来可能像一个可怕的指标,但是包括上面已经提到到的两项研究在内的[多项研究][11]表明每种语言中每行代码所需要花费的时间大约是一样的。因此,通过限制代码行数提高生产效率。甚至codinghorror(一名C#程序员)他本人[写了一篇关于Python是如何更有效率的文章][12]。
|
||||
普遍的趋势似乎是 Python 中的代码行总是更少。代码行听起来可能像一个可怕的指标,但是包括上面已经提到的两项研究在内的[多项研究][11]表明,每种语言中每行代码所需要花费的时间大约是一样的。因此,限制代码行数就可以提高生产效率。甚至 codinghorror(一名 C# 程序员)本人[写了一篇关于 Python 是如何更有效率的文章][12]。
|
||||
|
||||
我认为说Python比其他的很多语言更加的有效率是公正的。这主要是由于 Python 有大量的自带以及第三方库。[这里是一篇讨论Python和其他语言间的差异的简单的文章][13]。如果你不知道为何Python是如此的小巧和高效,我邀请你借此机会学习一点python,自己多实践。这儿是你的第一个程序:
|
||||
我认为说 Python 比其他的很多语言更加的有效率是公正的。这主要是由于 Python 有大量的自带以及第三方库。[这里是一篇讨论 Python 和其他语言间的差异的简单的文章][13]。如果你不知道为何 Python 是如此的小巧和高效,我邀请你借此机会学习一点 python,自己多实践。这儿是你的第一个程序:
|
||||
|
||||
_import __hello___
|
||||
|
||||
@ -83,10 +83,11 @@ python 是慢,但是爷就喜欢它
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
|
||||
via: https://hackernoon.com/yes-python-is-slow-and-i-dont-care-13763980b5a1
|
||||
|
||||
作者:[Nick Humrich ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,189 @@
|
||||
pyDash — 一个基于 web 的 Linux 性能监测工具
|
||||
============================================================
|
||||
|
||||
pyDash 是一个轻量且[基于 web 的 Linux 性能监测工具][1],它是用 Python 和 [Django][2] 加上 Chart.js 来写的。经测试,在下面这些主流 Linux 发行版上可运行:CentOS、Fedora、Ubuntu、Debian、Raspbian 以及 Pidora 。
|
||||
|
||||
你可以使用这个工具来监视你的 Linux 个人电脑/服务器资源,比如 CPU、内存
|
||||
、网络统计,包括在线用户以及更多的进程。仪表盘是完全使用主要的 Python 版本提供的 Python 库开发的,因此它的依赖关系很少,你不需要安装许多包或库来运行它。
|
||||
|
||||
在这篇文章中,我将展示如果安装 pyDash 来监测 Linux 服务器性能。
|
||||
|
||||
#### 如何在 Linux 系统下安装 pyDash
|
||||
|
||||
1、首先,像下面这样安装需要的软件包 git 和 Python pip:
|
||||
|
||||
```
|
||||
-------------- 在 Debian/Ubuntu 上 --------------
|
||||
$ sudo apt-get install git python-pip
|
||||
-------------- 在 CentOS/RHEL 上 --------------
|
||||
# yum install epel-release
|
||||
# yum install git python-pip
|
||||
-------------- 在 Fedora 22+ 上 --------------
|
||||
# dnf install git python-pip
|
||||
```
|
||||
|
||||
2、如果安装好了 git 和 Python pip,那么接下来,像下面这样安装 virtualenv,它有助于处理针对 Python 项目的依赖关系:
|
||||
|
||||
```
|
||||
# pip install virtualenv
|
||||
或
|
||||
$ sudo pip install virtualenv
|
||||
```
|
||||
|
||||
3、现在,像下面这样使用 git 命令,把 pyDash 仓库克隆到 home 目录中:
|
||||
|
||||
```
|
||||
# git clone https://github.com/k3oni/pydash.git
|
||||
# cd pydash
|
||||
```
|
||||
|
||||
4、下一步,使用下面的 virtualenv 命令为项目创建一个叫做 pydashtest 虚拟环境:
|
||||
|
||||
```
|
||||
$ virtualenv pydashtest #give a name for your virtual environment like pydashtest
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
*创建虚拟环境*
|
||||
|
||||
重点:请注意,上面的屏幕截图中,虚拟环境的 bin 目录被高亮显示,你的可能和这不一样,取决于你把 pyDash 目录克隆到什么位置。
|
||||
|
||||
5、创建好虚拟环境(pydashtest)以后,你需要在使用前像下面这样激活它:
|
||||
|
||||
```
|
||||
$ source /home/aaronkilik/pydash/pydashtest/bin/activate
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*激活虚拟环境*
|
||||
|
||||
从上面的屏幕截图中,你可以注意到,提示字符串 1(PS1)已经发生改变,这表明虚拟环境已经被激活,而且可以开始使用。
|
||||
|
||||
6、现在,安装 pydash 项目 requirements;如何你是一个细心的人,那么可以使用 [cat 命令][5]查看 requirements.txt 的内容,然后像下面展示这样进行安装:
|
||||
|
||||
```
|
||||
$ cat requirements.txt
|
||||
$ pip install -r requirements.txt
|
||||
```
|
||||
|
||||
7、现在,进入 `pydash` 目录,里面包含一个名为 `settings.py` 的文件,也可直接运行下面的命令打开这个文件,然后把 `SECRET_KEY` 改为一个特定值:
|
||||
|
||||
```
|
||||
$ vi pydash/settings.py
|
||||
```
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
*设置密匙*
|
||||
|
||||
保存文件然后退出。
|
||||
|
||||
8、之后,运行下面的命令来创建一个项目数据库和安装 Django 的身份验证系统,并创建一个项目的超级用户:
|
||||
|
||||
```
|
||||
$ python manage.py syncdb
|
||||
```
|
||||
|
||||
根据你的情况回答下面的问题:
|
||||
|
||||
```
|
||||
Would you like to create one now? (yes/no): yes
|
||||
Username (leave blank to use 'root'): admin
|
||||
Email address: aaronkilik@gmail.com
|
||||
Password: ###########
|
||||
Password (again): ############
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*创建项目数据库*
|
||||
|
||||
9、这个时候,一切都设置好了,然后,运行下面的命令来启用 Django 开发服务器:
|
||||
|
||||
```
|
||||
$ python manage.py runserver
|
||||
```
|
||||
|
||||
10、接下来,打开你的 web 浏览器,输入网址:http://127.0.0.1:8000/ 进入 web 控制台登录界面,输入你在第 8 步中创建数据库和安装 Django 身份验证系统时创建的超级用户名和密码,然后点击登录。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
*pyDash 登录界面*
|
||||
|
||||
11、登录到 pydash 主页面以后,你将会得到一段监测系统的基本信息,包括 CPU、内存和硬盘使用量以及系统平均负载。
|
||||
|
||||
向下滚动便可查看更多部分的信息。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*pydash 服务器性能概述*
|
||||
|
||||
12、下一个屏幕截图显示的是一段 pydash 的跟踪界面,包括 IP 地址、互联网流量、硬盘读/写、在线用户以及 netstats 。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
*pyDash 网络概述*
|
||||
|
||||
13、下一个 pydash 主页面的截图显示了一部分系统中被监视的活跃进程。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
*pyDash 监视活跃 Linux 进程*
|
||||
|
||||
如果想了解更多信息,请在 GitHub 上查看 pydash:[https://github.com/k3oni/pydash][12]
|
||||
|
||||
这就是全部内容了。在这篇文章中,我们展示了在 Linux 中如何安装 pyDash 并测试它的主要特性。如果你有什么想法,可以通过下面的反馈部分联系我们;如果你知道任何有用或类似的工具,也可以在评论中告知我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我叫 Ravi Saive,是 TecMint 的创建者,是一个喜欢在网上分享技巧和知识的计算机极客和 Linux Guru 。我的大多数服务器都运行在叫做 Linux 的开源平台上。请关注我:[Twitter][10]、[Facebook][01] 以及 [Google+][02] 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/pydash-a-web-based-linux-performance-monitoring-tool/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[00]:https://twitter.com/ravisaive
|
||||
[01]:https://www.facebook.com/ravi.saive
|
||||
[02]:https://plus.google.com/u/0/+RaviSaive
|
||||
|
||||
[1]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[2]:http://www.tecmint.com/install-and-configure-django-web-framework-in-centos-debian-ubuntu/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/create-virtual-environment.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/after-activating-virtualenv.png
|
||||
[5]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/change-secret-key.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/python-manage.py-syncdb.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-web-login-interface.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-Server-Performance-Overview.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-Network-Overview.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/pyDash-Active-Linux-Processes.png
|
||||
[12]:https://github.com/k3oni/pydash
|
||||
[13]:http://www.tecmint.com/author/admin/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,33 +1,33 @@
|
||||
# Anbox
|
||||
|
||||
Anbox 是一个基于容器的方式来在像 Ubuntu 这样的常规的 GNU Linux 系统上启动一个完整的 Android 系统。
|
||||
Anbox 是一个基于容器的方式,在像 Ubuntu 这样的常规的 GNU Linux 系统上启动一个完整的 Android 系统。
|
||||
|
||||
## 概述
|
||||
|
||||
Anbox 使用 Linux 命名空间(user、pid、uts、net、mount、ipc)来在容器中运行完整的 Android 系统并提供任何基于 GNU Linux 平台的 Android 程序。
|
||||
Anbox 使用 Linux 命名空间(user、pid、uts、net、mount、ipc)来在容器中运行完整的 Android 系统,并提供任何基于 GNU Linux 平台的 Android 程序。
|
||||
|
||||
容器内的 Android 无法直接访问任何硬件。所有硬件访问都通过主机上的 anbox 守护进程进行。我们重用基于QEMU的模拟器实现的 Android 中的 GL、ES 加速渲染。容器内的 Android 系统使用不同的管道与主机系统通信并通过它发送所有硬件访问命令。
|
||||
容器内的 Android 无法直接访问任何硬件。所有硬件访问都通过主机上的 anbox 守护进程进行。我们重用基于 QEMU 的模拟器实现的 Android 中的 GL、ES 加速渲染。容器内的 Android 系统使用不同的管道与主机系统通信,并通过它发送所有硬件访问命令。
|
||||
|
||||
有关更多详细信息,请参考下文档:
|
||||
|
||||
* [Android 硬件 OpenGL ES 仿真设计概述](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/android-emugl/DESIGN)
|
||||
* [Android QEMU 快速管道](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMU-PIPE.TXT)
|
||||
* [Android 的 "qemud" 复用守护进程](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMUD.TXT)
|
||||
* [Android 的 “qemud” 复用守护进程](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMUD.TXT)
|
||||
* [Android qemud 服务](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMUD-SERVICES.TXT)
|
||||
|
||||
Anbox 目前适合桌面使用,但也可使用移动操作系统,如 Ubuntu Touch、Sailfish OS 或 Lune OS。然而,由于目前 Android 程序映射针对桌面环境,因此这还需要额外的工作来支持其他的用户界面。
|
||||
Anbox 目前适合桌面使用,但也可使用移动操作系统,如 Ubuntu Touch、Sailfish OS 或 Lune OS。然而,由于 Android 程序映射目前只针对桌面环境,因此还需要额外的工作来支持其他的用户界面。
|
||||
|
||||
Android 运行时环境带有一个基于[ Android 开源项目](https://source.android.com/)镜像的最小自定义 Android 系统。所使用的镜像目前基于 Android 7.1.1
|
||||
Android 运行时环境带有一个基于[ Android 开源项目](https://source.android.com/)镜像的最小自定义 Android 系统。所使用的镜像目前基于 Android 7.1.1。
|
||||
|
||||
## 安装
|
||||
|
||||
安装过程目前由几个需要添加其他组件到系统中的步骤组成。包括:
|
||||
目前,安装过程包括一些添加额外组件到系统的步骤。包括:
|
||||
|
||||
* 没有分发版内核同时启用的 binder 和 ashmen 原始内核模块
|
||||
* 使用 udev 规则为 /dev/binder 和 /dev/ashmem 设置正确权限
|
||||
* 能够启动 Anbox 会话管理器作为用户会话的一个启动任务
|
||||
* 没有分发版内核同时启用的 binder 和 ashmen 原始内核模块。
|
||||
* 使用 udev 规则为 /dev/binder 和 /dev/ashmem 设置正确权限。
|
||||
* 能够启动 Anbox 会话管理器作为用户会话的一个启动任务。
|
||||
|
||||
为了使这个过程尽可能简单,我们做了一个简单的步骤(见 https://snapcraft.io),称为 “anbox-installer”。这个安装程序会执行所有必要的步骤。你可以在所有支持 snap 的系统运行下面的命令安装它。
|
||||
为了使这个过程尽可能简单,我们将必要的步骤绑定在一个 snap(见 https://snapcraft.io) 中,称为“anbox-installer”。这个安装程序会执行所有必要的步骤。你可以在所有支持 snap 的系统运行下面的命令安装它。
|
||||
|
||||
```
|
||||
$ snap install --classic anbox-installer
|
||||
@ -39,7 +39,7 @@ $ snap install --classic anbox-installer
|
||||
$ wget https://raw.githubusercontent.com/anbox/anbox-installer/master/installer.sh -O anbox-installer
|
||||
```
|
||||
|
||||
请注意,我们还不支持除本文列出的其他 Linux 发行版。请查看下面的章节了解支持的发行版。
|
||||
请注意,我们还不支持除所有 Linux 发行版。请查看下面的章节了解支持的发行版。
|
||||
|
||||
运行下面的命令进行安装。
|
||||
|
||||
@ -47,11 +47,11 @@ $ wget https://raw.githubusercontent.com/anbox/anbox-installer/master/installer.
|
||||
$ anbox-installer
|
||||
```
|
||||
|
||||
本篇会引导你完成安装过程。
|
||||
它会引导你完成安装过程。
|
||||
|
||||
**注意:** Anbox 目前处于** pre-alpha 的开发状态**。不要指望它具有生产环境你需要的所有功能。你肯定会遇到错误和崩溃。如果你遇到了,请不要犹豫并报告他们!
|
||||
**注意:** Anbox 目前处于** pre-alpha 开发状态**。不要指望它具有生产环境你需要的所有功能。你肯定会遇到错误和崩溃。如果你遇到了,请不要犹豫并报告它们!
|
||||
|
||||
**注意:** Anbox snap 目前 **完全没有约束**,这是因为它只能从前沿频道获取。正确的约束是我们想要在未来实现的,但由于 Anbox 的性质和复杂性,这不是一个简单的任务。
|
||||
**注意:** Anbox snap 目前 **完全没有约束**,因此它只能从边缘渠道获取。正确的约束是我们想要在未来实现的,但由于 Anbox 的性质和复杂性,这不是一个简单的任务。
|
||||
|
||||
## 已支持的 Linux 发行版
|
||||
|
||||
@ -69,7 +69,7 @@ $ anbox-installer
|
||||
|
||||
## 从源码构建
|
||||
|
||||
要构建 Anbox 运行时不需要特别了解什么,我们使用 cmake 作为构建系统。你系统中只需要一点构建依赖:
|
||||
要构建 Anbox 运行时不需要特别了解什么,我们使用 cmake 作为构建系统。你的主机系统中应已有下面这些构建依赖:
|
||||
|
||||
* libdbus
|
||||
* google-mock
|
||||
@ -112,14 +112,12 @@ $ cmake ..
|
||||
$ make
|
||||
```
|
||||
|
||||
一个简单的
|
||||
一个简单的命令会将必要的二进制安装到你的系统中,如下。
|
||||
|
||||
```
|
||||
$ make install
|
||||
```
|
||||
|
||||
会将必要的二进制安装到你的系统中。
|
||||
|
||||
如果你想要构建 anbox snap,你可以按照下面的步骤:
|
||||
|
||||
```
|
||||
@ -128,7 +126,7 @@ $ cp /path/to/android.img android-images/android.img
|
||||
$ snapcraft
|
||||
```
|
||||
|
||||
T结果是会有一个 .snap 文件,你可以在支持 snap 的系统上安装。
|
||||
结果会有一个 .snap 文件,你可以在支持 snap 的系统上安装。
|
||||
|
||||
```
|
||||
$ snap install --dangerous --devmode anbox_1_amd64.snap
|
||||
@ -136,7 +134,7 @@ $ snap install --dangerous --devmode anbox_1_amd64.snap
|
||||
|
||||
## 运行 Anbox
|
||||
|
||||
要从本地构建运行 Anbox ,你需要了解更多一点。请参考["运行时步骤"](docs/runtime-setup.md)文档。
|
||||
要从本地构建运行 Anbox ,你需要了解更多一点。请参考[“运行时步骤”](docs/runtime-setup.md)文档。
|
||||
|
||||
## 文档
|
||||
|
||||
@ -157,7 +155,7 @@ $ snap install --dangerous --devmode anbox_1_amd64.snap
|
||||
|
||||
## 版权与许可
|
||||
|
||||
Anbox 重用了像 Android QEMU 模拟器这样的其他项目。这些项目可在外部、带有许可声明的子目录中得到。
|
||||
Anbox 重用了像 Android QEMU 模拟器这样的其他项目的代码。这些项目可在外部/带有许可声明的子目录中得到。
|
||||
|
||||
anbox 源码本身,如果没有在相关源码中声明其他的许可,默认是 GPLv3 许可。
|
||||
|
||||
@ -167,7 +165,7 @@ via: https://github.com/anbox/anbox/blob/master/README.md
|
||||
|
||||
作者:[ Anbox][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
259
translated/tech/GDB-common-commands.md
Normal file
259
translated/tech/GDB-common-commands.md
Normal file
@ -0,0 +1,259 @@
|
||||
# 常用的 GDB 命令中文释义
|
||||
|
||||
## 目录
|
||||
|
||||
- [break](#break) -- 缩写 `b`,在指定的行或函数处设置断点
|
||||
- [info breakpoints](#info-breakpoints) -- 简写 `i b`,打印未删除的所有断点,观察点和捕获点的列表
|
||||
- [disable](#disable) -- 禁用断点,可以缩写为 `dis`
|
||||
- [enable](#enable) -- 启用断点
|
||||
- [clear](#clear) -- 清除指定行或函数处的断点
|
||||
- [delete](#delete) -- 缩写 `d`,删除断点
|
||||
- [tbreak](#tbreak) -- 设置临时断点,参数同 `break`,但在程序第一次停住后会被自动删除
|
||||
- [watch](#watch) -- 为表达式(或变量)设置观察点,当表达式(或变量)的值有变化时,停住程序
|
||||
|
||||
- [step](#step) -- 缩写 `s`,单步跟踪,如果有函数调用,会进入该函数
|
||||
- [reverse-step](#reverse-step) -- 反向单步跟踪,如果有函数调用,会进入该函数
|
||||
- [next](#next) -- 缩写 `n`,单步跟踪,如果有函数调用,不会进入该函数
|
||||
- [reverse-next](#reverse-next) -- 反向单步跟踪,如果有函数调用,不会进入该函数
|
||||
- [return](#return) -- 使选定的栈帧返回到其调用者
|
||||
- [finish](#finish) -- 缩写 `fin`,执行直到选择的栈帧返回
|
||||
- [until](#until) -- 缩写 `u`,执行直到...(用于跳过循环、递归函数调用)
|
||||
- [continue](#continue) -- 同义词 `c`,恢复程序执行
|
||||
|
||||
- [print](#print) -- 缩写 `p`,打印表达式 EXP 的值
|
||||
- [x](#x) -- 查看内存
|
||||
|
||||
- [display](#display) -- 每次程序停止时打印表达式 EXP 的值(自动显示)
|
||||
- [info display](#info-display) -- 打印早先设置为自动显示的表达式列表
|
||||
- [disable display](#disable-display) -- 禁用自动显示
|
||||
- [enable display](#enable-display) -- 启用自动显示
|
||||
- [undisplay](#undisplay) -- 删除自动显示项
|
||||
|
||||
- [help](#help) -- 缩写 `h`,打印命令列表(带参数时查找命令的帮助)
|
||||
|
||||
- [attach](#attach) -- 挂接到已在运行的进程来调试
|
||||
- [run](#run) -- 缩写 `r`,启动被调试的程序
|
||||
|
||||
- [backtrace](#backtrace) -- 缩写 `bt`,查看程序调用栈的信息
|
||||
|
||||
|
||||
************
|
||||
|
||||
## break
|
||||
使用 `break` 命令(缩写 `b`)来设置断点。 参见[官方文档][1]。
|
||||
|
||||
- `break` 当不带参数时,在所选栈帧中执行的下一条指令处设置断点。
|
||||
- `break <function-name>` 在函数体入口处打断点,在 C++ 中可以使用 `class::function` 或 `function(type, ...)` 格式来指定函数名。
|
||||
- `break <line-number>` 在当前源码文件指定行的开始处打断点。
|
||||
- `break -N` `break +N` 在当前源码行前面或后面的 `N` 行开始处打断点,`N` 为正整数。
|
||||
- `break <filename:linenum>` 在源码文件 `filename` 的 `linenum` 行处打断点。
|
||||
- `break <filename:function>` 在源码文件 `filename` 的 `function` 函数入口处打断点。
|
||||
- `break <address>` 在程序指令的地址处打断点。
|
||||
- `break ... if <cond>` 设置条件断点,`...` 代表上述参数之一(或无参数),`cond` 为条件表达式,仅在 `cond` 值非零时停住程序。
|
||||
|
||||
## info breakpoints
|
||||
查看断点,观察点和捕获点的列表。用法:
|
||||
`info breakpoints [list…]`
|
||||
`info break [list…]`
|
||||
`list…` 用来指定若干个断点的编号(可省略),可以是 `2`, `1-3`, `2 5` 等。
|
||||
|
||||
## disable
|
||||
禁用一些断点。 参见[官方文档][2]。
|
||||
参数是用空格分隔的断点编号。
|
||||
要禁用所有断点,不加参数。
|
||||
禁用的断点不会被忘记,但直到重新启用才有效。
|
||||
用法: `disable [breakpoints] [list…]`
|
||||
`breakpoints` 是 `disable` 的子命令(可省略),`list…` 同 `info breakpoints` 中的描述。
|
||||
|
||||
## enable
|
||||
启用一些断点。 参见[官方文档][2]。
|
||||
给出断点编号(以空格分隔)作为参数。
|
||||
没有参数时,所有断点被启用。
|
||||
|
||||
- `enable [breakpoints] [list…]` 启用指定的断点(或所有定义的断点)。
|
||||
- `enable [breakpoints] once list…` 临时启用指定的断点。GDB 在停止您的程序后立即禁用这些断点。
|
||||
- `enable [breakpoints] delete list…` 使指定的断点启用一次,然后删除。一旦您的程序停止,GDB 就会删除这些断点。等效于用 `tbreak` 设置的断点。
|
||||
|
||||
`breakpoints` 同 `disable` 中的描述。
|
||||
|
||||
## clear
|
||||
在指定行或函数处清除断点。 参见[官方文档][3]。
|
||||
参数可以是行号,函数名称或 "*" 跟一个地址。
|
||||
|
||||
- `clear` 当不带参数时,清除所选栈帧在执行的源码行中的所有断点。
|
||||
- `clear <function>`, `clear <filename:function>` 删除在命名函数的入口处设置的任何断点。
|
||||
- `clear <linenum>`, `clear <filename:linenum>` 删除在指定的文件指定的行号的代码中设置的任何断点。
|
||||
- `clear <address>` 清除指定程序指令的地址处的断点。
|
||||
|
||||
## delete
|
||||
删除一些断点或自动显示表达式。 参见[官方文档][3]。
|
||||
参数是用空格分隔的断点编号。
|
||||
要删除所有断点,不加参数。
|
||||
用法: `delete [breakpoints] [list…]`
|
||||
|
||||
## tbreak
|
||||
设置临时断点。参数形式同 `break` 一样。 参见[官方文档][1]。
|
||||
除了断点是临时的之外像 `break` 一样,所以在命中时会被删除。
|
||||
|
||||
## watch
|
||||
为表达式设置观察点。 参见[官方文档][4]。
|
||||
用法: `watch [-l|-location] <expr>`
|
||||
每当一个表达式的值改变时,观察点就会停止执行您的程序。
|
||||
如果给出了 `-l` 或者 `-location`,则它会对 `expr` 求值并观察它所指向的内存。
|
||||
例如,`watch *(int *)0x12345678` 将在指定的地址处观察一个 4 字节的区域(假设 int 占用 4 个字节)。
|
||||
|
||||
## step
|
||||
单步执行程序,直到到达不同的源码行。 参见[官方文档][5]。
|
||||
用法: `step [N]`
|
||||
参数 `N` 表示执行 N 次(或由于另一个原因直到程序停止)。
|
||||
警告:如果当控制在没有调试信息的情况下编译的函数中使用 `step` 命令,则执行将继续进行,
|
||||
直到控制到达具有调试信息的函数。 同样,它不会进入没有调试信息编译的函数。
|
||||
要执行没有调试信息的函数,请使用 `stepi` 命令,后文再述。
|
||||
|
||||
## reverse-step
|
||||
反向步进程序,直到到达另一个源码行的开头。 参见[官方文档][6]。
|
||||
用法: `reverse-step [N]`
|
||||
参数 `N` 表示执行 N 次(或由于另一个原因直到程序停止)。
|
||||
|
||||
## next
|
||||
单步执行程序,执行完子程序调用。 参见[官方文档][5]。
|
||||
用法: `next [N]`
|
||||
与 `step` 不同,如果当前的源代码行调用子程序,则此命令不会进入子程序,而是继续执行,将其视为单个源代码行。
|
||||
|
||||
## reverse-next
|
||||
反向步进程序,执行完子程序调用。 参见[官方文档][6]。
|
||||
用法: `reverse-next [N]`
|
||||
如果要执行的源代码行调用子程序,则此命令不会进入子程序,调用被视为一个指令。
|
||||
参数 `N` 表示执行 N 次(或由于另一个原因直到程序停止)。
|
||||
|
||||
## return
|
||||
您可以使用 `return` 命令取消函数调用的执行。 参见[官方文档][7]。
|
||||
如果你给出一个表达式参数,它的值被用作函数的返回值。
|
||||
`return <expression>` 将 `expression` 的值作为函数的返回值并使函数直接返回。
|
||||
|
||||
## finish
|
||||
执行直到选定的栈帧返回。 参见[官方文档][5]。
|
||||
用法: `finish`
|
||||
返回后,返回的值将被打印并放入到值历史记录中。
|
||||
|
||||
## until
|
||||
执行直到程序到达大于当前栈帧或当前栈帧中的指定位置(与 [break](#break) 命令相同的参数)的源码行。 参见[官方文档][5]。
|
||||
此命令用于通过一个多次的循环,以避免单步执行。
|
||||
`until <location>` 或 `u <location>` 继续运行程序,直到达到指定的位置,或者当前栈帧返回。
|
||||
|
||||
## continue
|
||||
在信号或断点之后,继续运行被调试的程序。 参见[官方文档][5]。
|
||||
用法: `continue [N]`
|
||||
如果从断点开始,可以使用数字 `N` 作为参数,这意味着将该断点的忽略计数设置为 `N - 1`(以便断点在第 N 次到达之前不会中断)。
|
||||
如果启用了非停止模式(使用 `show non-stop` 查看),则仅继续当前线程,否则程序中的所有线程都将继续。
|
||||
|
||||
## print
|
||||
求值并打印表达式 EXP 的值。 参见[官方文档][8]。
|
||||
可访问的变量是所选栈帧的词法环境,以及范围为全局或整个文件的所有变量。
|
||||
用法: `print [expr]` 或 `print /f [expr]`
|
||||
`expr` 是一个(在源代码语言中的)表达式。
|
||||
默认情况下,`expr` 的值以适合其数据类型的格式打印;您可以通过指定 `/f` 来选择不同的格式,其中 `f` 是一个指定格式的字母;参见[输出格式][9]。
|
||||
如果省略 `expr`,GDB 再次显示最后一个值。
|
||||
|
||||
## x
|
||||
检查内存。 参见[官方文档][10]。
|
||||
用法: `x/nfu <addr>` 或 `x <addr>`
|
||||
`n`, `f`, 和 `u` 都是可选参数,用于指定要显示的内存以及如何格式化。
|
||||
`addr` 是要开始显示内存的地址的表达式。
|
||||
`n` 重复次数(默认值是 1),指定要显示多少个单位(由 `u` 指定)的内存值。
|
||||
`f` 显示格式(初始默认值是 `x`),显示格式是 `print('x','d','u','o','t','a','c','f','s')` 使用的格式之一,再加 `i`(机器指令)。
|
||||
`u` 单位大小,`b` 表示单字节,`h` 表示双字节,`w` 表示四字节,`g` 表示八字节。
|
||||
例如,`x/3uh 0x54320` 表示从地址 0x54320 开始以无符号十进制整数的方式,双字节为单位显示 3 个内存值。
|
||||
|
||||
## display
|
||||
每次程序停止时打印表达式 EXP 的值。 参见[官方文档][11]。
|
||||
用法: `display <expr>`, `display/fmt <expr>` 或 `display/fmt <addr>`
|
||||
`fmt` 用于指定显示格式。像 [print](#print) 命令里的 `/f` 一样。
|
||||
对于格式 `i` 或 `s`,或者包括单位大小或单位数量,将表达式 `addr` 添加为每次程序停止时要检查的内存地址。
|
||||
|
||||
## info display
|
||||
打印自动显示的表达式列表,每个表达式都带有项目编号,但不显示其值。
|
||||
包括被禁用的表达式和不能立即显示的表达式(当前不可用的自动变量)。
|
||||
|
||||
## undisplay
|
||||
取消某些表达式在程序停止时自动显示。
|
||||
参数是表达式的编号(使用 `info display` 查询编号)。
|
||||
不带参数表示取消所有自动显示表达式。
|
||||
`delete display` 具有与此命令相同的效果。
|
||||
|
||||
## disable display
|
||||
禁用某些表达式在程序停止时自动显示。
|
||||
禁用的显示项目不会被自动打印,但不会被忘记。 它可能稍后再次被启用。
|
||||
参数是表达式的编号(使用 `info display` 查询编号)。
|
||||
不带参数表示禁用所有自动显示表达式。
|
||||
|
||||
## enable display
|
||||
启用某些表达式在程序停止时自动显示。
|
||||
参数是重新显示的表达式的编号(使用 `info display` 查询编号)。
|
||||
不带参数表示启用所有自动显示表达式。
|
||||
|
||||
## help
|
||||
打印命令列表。 参见[官方文档][12]。
|
||||
您可以使用不带参数的 `help`(缩写为 `h`)来显示命令的类别名的简短列表。
|
||||
使用 `help <class>` 您可以获取该类中各个命令的列表。
|
||||
使用 `help <command>` 显示如何使用该命令的简述。
|
||||
|
||||
## attach
|
||||
挂接到 GDB 之外的进程或文件。 参见[官方文档][13]。
|
||||
该命令可以将进程 ID 或设备文件作为参数。
|
||||
对于进程 ID,您必须具有向进程发送信号的权限,并且必须具有与调试器相同的有效的 uid。
|
||||
用法: `attach <process-id>`
|
||||
GDB 在安排调试指定的进程之后做的第一件事是停住它。
|
||||
您可以使用所有通过 `run` 命令启动进程时可以使用的 GDB 命令来检查和修改挂接的进程。
|
||||
|
||||
## run
|
||||
启动被调试的程序。 参见[官方文档][14]。
|
||||
可以直接指定参数,也可以用 [set args][15] 设置(启动所需的)参数。
|
||||
例如: `run arg1 arg2 ...` 等效于
|
||||
```
|
||||
set args arg1 arg2 ...
|
||||
run
|
||||
```
|
||||
还允许使用 ">", "<", 或 ">>" 进行输入和输出重定向。
|
||||
|
||||
## backtrace
|
||||
打印整个栈的回溯。 参见[官方文档][16]。
|
||||
|
||||
- `bt` 打印整个栈的回溯,每个栈帧一行。
|
||||
- `bt n` 类似于上,但只打印最内层的 n 个栈帧。
|
||||
- `bt -n` 类似于上,但只打印最外层的 n 个栈帧。
|
||||
- `bt full n` 类似于 `bt n`,还打印局部变量的值。
|
||||
|
||||
`where` 和 `info stack`(缩写 `info s`) 是 `backtrace` 的别名。
|
||||
|
||||
************
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [Debugging with GDB](https://sourceware.org/gdb/current/onlinedocs/gdb/)
|
||||
- [用 GDB 调试程序(二)](http://blog.csdn.net/haoel/article/details/2880)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
编译者:[robot527](https://github.com/robot527)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://sourceware.org/gdb/current/onlinedocs/gdb/Set-Breaks.html
|
||||
[2]:https://sourceware.org/gdb/current/onlinedocs/gdb/Disabling.html
|
||||
[3]:https://sourceware.org/gdb/current/onlinedocs/gdb/Delete-Breaks.html
|
||||
[4]:https://sourceware.org/gdb/current/onlinedocs/gdb/Set-Watchpoints.html
|
||||
[5]:https://sourceware.org/gdb/current/onlinedocs/gdb/Continuing-and-Stepping.html
|
||||
[6]:https://sourceware.org/gdb/current/onlinedocs/gdb/Reverse-Execution.html
|
||||
[7]:https://sourceware.org/gdb/current/onlinedocs/gdb/Returning.html
|
||||
[8]:https://sourceware.org/gdb/current/onlinedocs/gdb/Data.html
|
||||
[9]:https://sourceware.org/gdb/current/onlinedocs/gdb/Output-Formats.html
|
||||
[10]:https://sourceware.org/gdb/current/onlinedocs/gdb/Memory.html
|
||||
[11]:https://sourceware.org/gdb/current/onlinedocs/gdb/Auto-Display.html
|
||||
[12]:https://sourceware.org/gdb/current/onlinedocs/gdb/Help.html
|
||||
[13]:https://sourceware.org/gdb/current/onlinedocs/gdb/Attach.html
|
||||
[14]:https://sourceware.org/gdb/current/onlinedocs/gdb/Starting.html
|
||||
[15]:https://sourceware.org/gdb/current/onlinedocs/gdb/Arguments.html
|
||||
[16]:https://sourceware.org/gdb/current/onlinedocs/gdb/Backtrace.html
|
||||
|
||||
Loading…
Reference in New Issue
Block a user