mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
Merge branch 'master' of github.com:LCTT/TranslateProject
This commit is contained in:
commit
7ad96ab03c
@ -60,6 +60,7 @@ LCTT 的组成
|
||||
* 2017/03/13 制作了 LCTT 主页、成员列表和成员主页,LCTT 主页将移动至 https://linux.cn/lctt 。
|
||||
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
||||
* 2017/04/11 启用头衔制,为各位重要成员颁发头衔。
|
||||
* 2017/11/21 鉴于 qhwdw 快速而上佳的翻译质量,提升 qhwdw 为新的 Core 成员。
|
||||
|
||||
核心成员
|
||||
-------------------------------
|
||||
@ -86,6 +87,7 @@ LCTT 的组成
|
||||
- 核心成员 @Locez,
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @qhwdw,
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
|
||||
@ -0,0 +1,347 @@
|
||||
理解多区域配置中的 firewalld
|
||||
============================================================
|
||||
|
||||
现在的新闻里充斥着服务器被攻击和数据失窃事件。对于一个阅读过安全公告博客的人来说,通过访问错误配置的服务器,利用最新暴露的安全漏洞或通过窃取的密码来获得系统控制权,并不是件多困难的事情。在一个典型的 Linux 服务器上的任何互联网服务都可能存在漏洞,允许未经授权的系统访问。
|
||||
|
||||
因为在应用程序层面上强化系统以防范任何可能的威胁是不可能做到的事情,而防火墙可以通过限制对系统的访问提供了安全保证。防火墙基于源 IP、目标端口和协议来过滤入站包。因为这种方式中,仅有几个 IP/端口/协议的组合与系统交互,而其它的方式做不到过滤。
|
||||
|
||||
Linux 防火墙是通过 netfilter 来处理的,它是内核级别的框架。这十几年来,iptables 被作为 netfilter 的用户态抽象层(LCTT 译注: userland,一个基本的 UNIX 系统是由 kernel 和 userland 两部分构成,除 kernel 以外的称为 userland)。iptables 将包通过一系列的规则进行检查,如果包与特定的 IP/端口/协议的组合匹配,规则就会被应用到这个包上,以决定包是被通过、拒绝或丢弃。
|
||||
|
||||
Firewalld 是最新的 netfilter 用户态抽象层。遗憾的是,由于缺乏描述多区域配置的文档,它强大而灵活的功能被低估了。这篇文章提供了一个示例去改变这种情况。
|
||||
|
||||
### Firewalld 的设计目标
|
||||
|
||||
firewalld 的设计者认识到大多数的 iptables 使用案例仅涉及到几个单播源 IP,仅让每个符合白名单的服务通过,而其它的会被拒绝。这种模式的好处是,firewalld 可以通过定义的源 IP 和/或网络接口将入站流量分类到不同<ruby>区域<rt>zone</rt></ruby>。每个区域基于指定的准则按自己配置去通过或拒绝包。
|
||||
|
||||
另外的改进是基于 iptables 进行语法简化。firewalld 通过使用服务名而不是它的端口和协议去指定服务,使它更易于使用,例如,是使用 samba 而不是使用 UDP 端口 137 和 138 和 TCP 端口 139 和 445。它进一步简化语法,消除了 iptables 中对语句顺序的依赖。
|
||||
|
||||
最后,firewalld 允许交互式修改 netfilter,允许防火墙独立于存储在 XML 中的永久配置而进行改变。因此,下面的的临时修改将在下次重新加载时被覆盖:
|
||||
|
||||
```
|
||||
# firewall-cmd <some modification>
|
||||
```
|
||||
|
||||
而,以下的改变在重加载后会永久保存:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent <some modification>
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
### 区域
|
||||
|
||||
在 firewalld 中最上层的组织是区域。如果一个包匹配区域相关联的网络接口或源 IP/掩码 ,它就是区域的一部分。可用的几个预定义区域:
|
||||
|
||||
```
|
||||
# firewall-cmd --get-zones
|
||||
block dmz drop external home internal public trusted work
|
||||
```
|
||||
|
||||
任何配置了一个**网络接口**和/或一个**源**的区域就是一个<ruby>活动区域<rt>active zone</rt></ruby>。列出活动的区域:
|
||||
|
||||
```
|
||||
# firewall-cmd --get-active-zones
|
||||
public
|
||||
interfaces: eno1 eno2
|
||||
```
|
||||
|
||||
**Interfaces** (接口)是系统中的硬件和虚拟的网络适配器的名字,正如你在上面的示例中所看到的那样。所有的活动的接口都将被分配到区域,要么是默认的区域,要么是用户指定的一个区域。但是,一个接口不能被分配给多于一个的区域。
|
||||
|
||||
在缺省配置中,firewalld 设置所有接口为 public 区域,并且不对任何区域设置源。其结果是,`public` 区域是唯一的活动区域。
|
||||
|
||||
**Sources** (源)是入站 IP 地址的范围,它也可以被分配到区域。一个源(或重叠的源)不能被分配到多个区域。这样做的结果是产生一个未定义的行为,因为不清楚应该将哪些规则应用于该源。
|
||||
|
||||
因为指定一个源不是必需的,任何包都可以通过接口匹配而归属于一个区域,而不需要通过源匹配来归属一个区域。这表示通过使用优先级方式,优先到达多个指定的源区域,稍后将详细说明这种情况。首先,我们来检查 `public` 区域的配置:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services: dhcpv6-client ssh
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
default
|
||||
```
|
||||
|
||||
逐行说明如下:
|
||||
|
||||
* `public (default, active)` 表示 `public` 区域是默认区域(当接口启动时会自动默认),并且它是活动的,因为,它至少有一个接口或源分配给它。
|
||||
* `interfaces: eno1 eno2` 列出了这个区域上关联的接口。
|
||||
* `sources:` 列出了这个区域的源。现在这里什么都没有,但是,如果这里有内容,它们应该是这样的格式 xxx.xxx.xxx.xxx/xx。
|
||||
* `services: dhcpv6-client ssh` 列出了允许通过这个防火墙的服务。你可以通过运行 `firewall-cmd --get-services` 得到一个防火墙预定义服务的详细列表。
|
||||
* `ports:` 列出了一个允许通过这个防火墙的目标端口。它是用于你需要去允许一个没有在 firewalld 中定义的服务的情况下。
|
||||
* `masquerade: no` 表示这个区域是否允许 IP 伪装。如果允许,它将允许 IP 转发,它可以让你的计算机作为一个路由器。
|
||||
* `forward-ports:` 列出转发的端口。
|
||||
* `icmp-blocks:` 阻塞的 icmp 流量的黑名单。
|
||||
* `rich rules:` 在一个区域中优先处理的高级配置。
|
||||
* `default` 是目标区域,它决定了与该区域匹配而没有由上面设置中显式处理的包的动作。
|
||||
|
||||
### 一个简单的单区域配置示例
|
||||
|
||||
如果只是简单地锁定你的防火墙。简单地在删除公共区域上当前允许的服务,并重新加载:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --zone=public --remove-service=dhcpv6-client
|
||||
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
在下面的防火墙上这些命令的结果是:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services:
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
default
|
||||
```
|
||||
|
||||
本着尽可能严格地保证安全的精神,如果发生需要在你的防火墙上临时开放一个服务的情况(假设是 ssh),你可以增加这个服务到当前会话中(省略 `--permanent`),并且指示防火墙在一个指定的时间之后恢复修改:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=public --add-service=ssh --timeout=5m
|
||||
```
|
||||
|
||||
这个 `timeout` 选项是一个以秒(`s`)、分(`m`)或小时(`h`)为单位的时间值。
|
||||
|
||||
### 目标
|
||||
|
||||
当一个区域处理它的源或接口上的一个包时,但是,没有处理该包的显式规则时,这时区域的<ruby>目标<rt>target</rt></ruby>决定了该行为:
|
||||
|
||||
* `ACCEPT`:通过这个包。
|
||||
* `%%REJECT%%`:拒绝这个包,并返回一个拒绝的回复。
|
||||
* `DROP`:丢弃这个包,不回复任何信息。
|
||||
* `default`:不做任何事情。该区域不再管它,把它踢到“楼上”。
|
||||
|
||||
在 firewalld 0.3.9 中有一个 bug (已经在 0.3.10 中修复),对于一个目标是除了“default”以外的源区域,不管允许的服务是什么,这的目标都会被应用。例如,一个使用目标 `DROP` 的源区域,将丢弃所有的包,甚至是白名单中的包。遗憾的是,这个版本的 firewalld 被打包到 RHEL7 和它的衍生版中,使它成为一个相当常见的 bug。本文中的示例避免了可能出现这种行为的情况。
|
||||
|
||||
### 优先权
|
||||
|
||||
活动区域中扮演两个不同的角色。关联接口行为的区域作为接口区域,并且,关联源行为的区域作为源区域(一个区域能够扮演两个角色)。firewalld 按下列顺序处理一个包:
|
||||
|
||||
1. 相应的源区域。可以存在零个或一个这样的区域。如果这个包满足一个<ruby>富规则<rt>rich rule</rt></ruby>、服务是白名单中的、或者目标没有定义,那么源区域处理这个包,并且在这里结束。否则,向上传递这个包。
|
||||
2. 相应的接口区域。肯定有一个这样的区域。如果接口处理这个包,那么到这里结束。否则,向上传递这个包。
|
||||
3. firewalld 默认动作。接受 icmp 包并拒绝其它的一切。
|
||||
|
||||
这里的关键信息是,源区域优先于接口区域。因此,对于多区域的 firewalld 配置的一般设计模式是,创建一个优先源区域来允许指定的 IP 对系统服务的提升访问,并在一个限制性接口区域限制其它访问。
|
||||
|
||||
### 一个简单的多区域示例
|
||||
|
||||
为演示优先权,让我们在 `public` 区域中将 `http` 替换成 `ssh`,并且为我们喜欢的 IP 地址,如 1.1.1.1,设置一个默认的 `internal` 区域。以下的命令完成这个任务:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=internal --add-source=1.1.1.1
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
这些命令的结果是生成如下的配置:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services: dhcpv6-client http
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
default
|
||||
# firewall-cmd --zone=internal --list-all
|
||||
internal (active)
|
||||
interfaces:
|
||||
sources: 1.1.1.1
|
||||
services: dhcpv6-client mdns samba-client ssh
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=internal --get-target
|
||||
default
|
||||
```
|
||||
|
||||
在上面的配置中,如果有人尝试从 1.1.1.1 去 `ssh`,这个请求将会成功,因为这个源区域(`internal`)被首先应用,并且它允许 `ssh` 访问。
|
||||
|
||||
如果有人尝试从其它的地址,如 2.2.2.2,去访问 `ssh`,它不是这个源区域的,因为和这个源区域不匹配。因此,这个请求被直接转到接口区域(`public`),它没有显式处理 `ssh`,因为,public 的目标是 `default`,这个请求被传递到默认动作,它将被拒绝。
|
||||
|
||||
如果 1.1.1.1 尝试进行 `http` 访问会怎样?源区域(`internal`)不允许它,但是,目标是 `default`,因此,请求将传递到接口区域(`public`),它被允许访问。
|
||||
|
||||
现在,让我们假设有人从 3.3.3.3 拖你的网站。要限制从那个 IP 的访问,简单地增加它到预定义的 `drop` 区域,正如其名,它将丢弃所有的连接:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --zone=drop --add-source=3.3.3.3
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
下一次 3.3.3.3 尝试去访问你的网站,firewalld 将转发请求到源区域(`drop`)。因为目标是 `DROP`,请求将被拒绝,并且它不会被转发到接口区域(`public`)。
|
||||
|
||||
### 一个实用的多区域示例
|
||||
|
||||
假设你为你的组织的一台服务器配置防火墙。你希望允许全世界使用 `http` 和 `https` 的访问,你的组织(1.1.0.0/16)和工作组(1.1.1.0/8)使用 `ssh` 访问,并且你的工作组可以访问 `samba` 服务。使用 firewalld 中的区域,你可以用一个很直观的方式去实现这个配置。
|
||||
|
||||
`public` 这个命名,它的逻辑似乎是把全世界访问指定为公共区域,而 `internal` 区域用于为本地使用。从在 `public` 区域内设置使用 `http` 和 `https` 替换 `dhcpv6-client` 和 `ssh` 服务来开始:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --zone=public --remove-service=dhcpv6-client
|
||||
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=public --add-service=https
|
||||
```
|
||||
|
||||
然后,取消 `internal` 区域的 `mdns`、`samba-client` 和 `dhcpv6-client` 服务(仅保留 `ssh`),并增加你的组织为源:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --zone=internal --remove-service=mdns
|
||||
# firewall-cmd --permanent --zone=internal --remove-service=samba-client
|
||||
# firewall-cmd --permanent --zone=internal --remove-service=dhcpv6-client
|
||||
# firewall-cmd --permanent --zone=internal --add-source=1.1.0.0/16
|
||||
```
|
||||
|
||||
为容纳你提升的 `samba` 的权限,增加一个富规则:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --zone=internal --add-rich-rule='rule family=ipv4 source address="1.1.1.0/8" service name="samba" accept'
|
||||
```
|
||||
|
||||
最后,重新加载,把这些变化拉取到会话中:
|
||||
|
||||
```
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
仅剩下少数的细节了。从一个 `internal` 区域以外的 IP 去尝试通过 `ssh` 到你的服务器,结果是回复一个拒绝的消息。它是 firewalld 默认的。更为安全的作法是去显示不活跃的 IP 行为并丢弃该连接。改变 `public` 区域的目标为 `DROP`,而不是 `default` 来实现它:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --zone=public --set-target=DROP
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
但是,等等,你不再可以 ping 了,甚至是从内部区域!并且 icmp (ping 使用的协议)并不在 firewalld 可以列入白名单的服务列表中。那是因为,icmp 是第 3 层的 IP 协议,它没有端口的概念,不像那些捆绑了端口的服务。在设置公共区域为 `DROP` 之前,ping 能够通过防火墙是因为你的 `default` 目标通过它到达防火墙的默认动作(default),即允许它通过。但现在它已经被删除了。
|
||||
|
||||
为恢复内部网络的 ping,使用一个富规则:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --zone=internal --add-rich-rule='rule protocol value="icmp" accept'
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
结果如下,这里是两个活动区域的配置:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services: http https
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
DROP
|
||||
# firewall-cmd --zone=internal --list-all
|
||||
internal (active)
|
||||
interfaces:
|
||||
sources: 1.1.0.0/16
|
||||
services: ssh
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
rule family=ipv4 source address="1.1.1.0/8" service name="samba" accept
|
||||
rule protocol value="icmp" accept
|
||||
# firewall-cmd --permanent --zone=internal --get-target
|
||||
default
|
||||
```
|
||||
|
||||
这个设置演示了一个三层嵌套的防火墙。最外层,`public`,是一个接口区域,包含全世界的访问。紧接着的一层,`internal`,是一个源区域,包含你的组织,它是 `public` 的一个子集。最后,一个富规则增加到最内层,包含了你的工作组,它是 `internal` 的一个子集。
|
||||
|
||||
这里的关键信息是,当在一个场景中可以突破到嵌套层,最外层将使用接口区域,接下来的将使用一个源区域,并且在源区域中额外使用富规则。
|
||||
|
||||
### 调试
|
||||
|
||||
firewalld 采用直观范式来设计防火墙,但比它的前任 iptables 更容易产生歧义。如果产生无法预料的行为,或者为了更好地理解 firewalld 是怎么工作的,则可以使用 iptables 描述 netfilter 是如何配置操作的。前一个示例的输出如下,为了简单起见,将输出和日志进行了修剪:
|
||||
|
||||
```
|
||||
# iptables -S
|
||||
-P INPUT ACCEPT
|
||||
... (forward and output lines) ...
|
||||
-N INPUT_ZONES
|
||||
-N INPUT_ZONES_SOURCE
|
||||
-N INPUT_direct
|
||||
-N IN_internal
|
||||
-N IN_internal_allow
|
||||
-N IN_internal_deny
|
||||
-N IN_public
|
||||
-N IN_public_allow
|
||||
-N IN_public_deny
|
||||
-A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
|
||||
-A INPUT -i lo -j ACCEPT
|
||||
-A INPUT -j INPUT_ZONES_SOURCE
|
||||
-A INPUT -j INPUT_ZONES
|
||||
-A INPUT -p icmp -j ACCEPT
|
||||
-A INPUT -m conntrack --ctstate INVALID -j DROP
|
||||
-A INPUT -j REJECT --reject-with icmp-host-prohibited
|
||||
... (forward and output lines) ...
|
||||
-A INPUT_ZONES -i eno1 -j IN_public
|
||||
-A INPUT_ZONES -i eno2 -j IN_public
|
||||
-A INPUT_ZONES -j IN_public
|
||||
-A INPUT_ZONES_SOURCE -s 1.1.0.0/16 -g IN_internal
|
||||
-A IN_internal -j IN_internal_deny
|
||||
-A IN_internal -j IN_internal_allow
|
||||
-A IN_internal_allow -p tcp -m tcp --dport 22 -m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p udp -m udp --dport 137 -m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p udp -m udp --dport 138 -m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p tcp -m tcp --dport 139 -m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p tcp -m tcp --dport 445 -m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -p icmp -m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_public -j IN_public_deny
|
||||
-A IN_public -j IN_public_allow
|
||||
-A IN_public -j DROP
|
||||
-A IN_public_allow -p tcp -m tcp --dport 80 -m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_public_allow -p tcp -m tcp --dport 443 -m conntrack --ctstate NEW -j ACCEPT
|
||||
```
|
||||
|
||||
在上面的 iptables 输出中,新的链(以 `-N` 开始的行)是被首先声明的。剩下的规则是附加到(以 `-A` 开始的行) iptables 中的。已建立的连接和本地流量是允许通过的,并且入站包被转到 `INPUT_ZONES_SOURCE` 链,在那里如果存在相应的区域,IP 将被发送到那个区域。从那之后,流量被转到 `INPUT_ZONES` 链,从那里它被路由到一个接口区域。如果在那里它没有被处理,icmp 是允许通过的,无效的被丢弃,并且其余的都被拒绝。
|
||||
|
||||
### 结论
|
||||
|
||||
firewalld 是一个文档不足的防火墙配置工具,它的功能远比大多数人认识到的更为强大。以创新的区域范式,firewalld 允许系统管理员去分解流量到每个唯一处理它的分类中,简化了配置过程。因为它直观的设计和语法,它在实践中不但被用于简单的单一区域中也被用于复杂的多区域配置中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/understanding-firewalld-multi-zone-configurations?page=0,0
|
||||
|
||||
作者:[Nathan Vance][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxjournal.com/users/nathan-vance
|
||||
[1]:https://www.linuxjournal.com/tag/firewalls
|
||||
[2]:https://www.linuxjournal.com/tag/howtos
|
||||
[3]:https://www.linuxjournal.com/tag/networking
|
||||
[4]:https://www.linuxjournal.com/tag/security
|
||||
[5]:https://www.linuxjournal.com/tag/sysadmin
|
||||
[6]:https://www.linuxjournal.com/users/william-f-polik
|
||||
[7]:https://www.linuxjournal.com/users/nathan-vance
|
||||
@ -1,36 +1,28 @@
|
||||
Translating By LHRchina
|
||||
|
||||
|
||||
Ubuntu Core in LXD containers
|
||||
使用 LXD 容器运行 Ubuntu Core
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
### What’s Ubuntu Core?
|
||||
### Ubuntu Core 是什么?
|
||||
|
||||
Ubuntu Core is a version of Ubuntu that’s fully transactional and entirely based on snap packages.
|
||||
Ubuntu Core 是完全基于 snap 包构建,并且完全事务化的 Ubuntu 版本。
|
||||
|
||||
Most of the system is read-only. All installed applications come from snap packages and all updates are done using transactions. Meaning that should anything go wrong at any point during a package or system update, the system will be able to revert to the previous state and report the failure.
|
||||
该系统大部分是只读的,所有已安装的应用全部来自 snap 包,完全使用事务化更新。这意味着不管在系统更新还是安装软件的时候遇到问题,整个系统都可以回退到之前的状态并且记录这个错误。
|
||||
|
||||
The current release of Ubuntu Core is called series 16 and was released in November 2016.
|
||||
最新版是在 2016 年 11 月发布的 Ubuntu Core 16。
|
||||
|
||||
Note that on Ubuntu Core systems, only snap packages using confinement can be installed (no “classic” snaps) and that a good number of snaps will not fully work in this environment or will require some manual intervention (creating user and groups, …). Ubuntu Core gets improved on a weekly basis as new releases of snapd and the “core” snap are put out.
|
||||
注意,Ubuntu Core 限制只能够安装 snap 包(而非 “传统” 软件包),并且有相当数量的 snap 包在当前环境下不能正常运行,或者需要人工干预(创建用户和用户组等)才能正常运行。随着新版的 snapd 和 “core” snap 包发布,Ubuntu Core 每周都会得到改进。
|
||||
|
||||
### Requirements
|
||||
### 环境需求
|
||||
|
||||
As far as LXD is concerned, Ubuntu Core is just another Linux distribution. That being said, snapd does require unprivileged FUSE mounts and AppArmor namespacing and stacking, so you will need the following:
|
||||
就 LXD 而言,Ubuntu Core 仅仅相当于另一个 Linux 发行版。也就是说,snapd 需要挂载无特权的 FUSE 和 AppArmor 命名空间以及软件栈,像下面这样:
|
||||
|
||||
* An up to date Ubuntu system using the official Ubuntu kernel
|
||||
* 一个新版的使用 Ubuntu 官方内核的系统
|
||||
* 一个新版的 LXD
|
||||
|
||||
* An up to date version of LXD
|
||||
### 创建一个 Ubuntu Core 容器
|
||||
|
||||
### Creating an Ubuntu Core container
|
||||
|
||||
The Ubuntu Core images are currently published on the community image server.
|
||||
You can launch a new container with:
|
||||
当前 Ubuntu Core 镜像发布在社区的镜像服务器。你可以像这样启动一个新的容器:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc launch images:ubuntu-core/16 ubuntu-core
|
||||
@ -38,9 +30,9 @@ Creating ubuntu-core
|
||||
Starting ubuntu-core
|
||||
```
|
||||
|
||||
The container will take a few seconds to start, first executing a first stage loader that determines what read-only image to use and setup the writable layers. You don’t want to interrupt the container in that stage and “lxc exec” will likely just fail as pretty much nothing is available at that point.
|
||||
这个容器启动需要一点点时间,它会先执行第一阶段的加载程序,加载程序会确定使用哪一个镜像(镜像是只读的),并且在系统上设置一个可读层,你不要在这一阶段中断容器执行,这个时候什么都没有,所以执行 `lxc exec` 将会出错。
|
||||
|
||||
Seconds later, “lxc list” will show the container IP address, indicating that it’s booted into Ubuntu Core:
|
||||
几秒钟之后,执行 `lxc list` 将会展示容器的 IP 地址,这表明已经启动了 Ubuntu Core:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list
|
||||
@ -51,7 +43,7 @@ stgraber@dakara:~$ lxc list
|
||||
+-------------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
You can then interact with that container the same way you would any other:
|
||||
之后你就可以像使用其他的交互一样和这个容器进行交互:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
@ -63,11 +55,11 @@ pc-kernel 4.4.0-45-4 37 canonical -
|
||||
root@ubuntu-core:~#
|
||||
```
|
||||
|
||||
### Updating the container
|
||||
### 更新容器
|
||||
|
||||
If you’ve been tracking the development of Ubuntu Core, you’ll know that those versions above are pretty old. That’s because the disk images that are used as the source for the Ubuntu Core LXD images are only refreshed every few months. Ubuntu Core systems will automatically update once a day and then automatically reboot to boot onto the new version (and revert if this fails).
|
||||
如果你一直关注着 Ubuntu Core 的开发,你应该知道上面的版本已经很老了。这是因为被用作 Ubuntu LXD 镜像的代码每隔几个月才会更新。Ubuntu Core 系统在重启时会检查更新并进行自动更新(更新失败会回退)。
|
||||
|
||||
If you want to immediately force an update, you can do it with:
|
||||
如果你想现在强制更新,你可以这样做:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
@ -81,7 +73,7 @@ series 16
|
||||
root@ubuntu-core:~#
|
||||
```
|
||||
|
||||
And then reboot the system and check the snapd version again:
|
||||
然后重启一下 Ubuntu Core 系统,然后看看 snapd 的版本。
|
||||
|
||||
```
|
||||
root@ubuntu-core:~# reboot
|
||||
@ -95,7 +87,7 @@ series 16
|
||||
root@ubuntu-core:~#
|
||||
```
|
||||
|
||||
You can get an history of all snapd interactions with
|
||||
你也可以像下面这样查看所有 snapd 的历史记录:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core snap changes
|
||||
@ -105,9 +97,9 @@ ID Status Spawn Ready Summary
|
||||
3 Done 2017-01-31T05:21:30Z 2017-01-31T05:22:45Z Refresh all snaps in the system
|
||||
```
|
||||
|
||||
### Installing some snaps
|
||||
### 安装 Snap 软件包
|
||||
|
||||
Let’s start with the simplest snaps of all, the good old Hello World:
|
||||
以一个最简单的例子开始,经典的 Hello World:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
@ -117,7 +109,7 @@ root@ubuntu-core:~# hello-world
|
||||
Hello World!
|
||||
```
|
||||
|
||||
And then move on to something a bit more useful:
|
||||
接下来让我们看一些更有用的:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
@ -125,9 +117,9 @@ root@ubuntu-core:~# snap install nextcloud
|
||||
nextcloud 11.0.1snap2 from 'nextcloud' installed
|
||||
```
|
||||
|
||||
Then hit your container over HTTP and you’ll get to your newly deployed Nextcloud instance.
|
||||
之后通过 HTTP 访问你的容器就可以看到刚才部署的 Nextcloud 实例。
|
||||
|
||||
If you feel like testing the latest LXD straight from git, you can do so with:
|
||||
如果你想直接通过 git 测试最新版 LXD,你可以这样做:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc config set ubuntu-core security.nesting true
|
||||
@ -156,7 +148,7 @@ What IPv6 address should be used (CIDR subnet notation, “auto” or “none”
|
||||
LXD has been successfully configured.
|
||||
```
|
||||
|
||||
And because container inception never gets old, lets run Ubuntu Core 16 inside Ubuntu Core 16:
|
||||
已经设置过的容器不能回退版本,但是可以在 Ubuntu Core 16 中运行另一个 Ubuntu Core 16 容器:
|
||||
|
||||
```
|
||||
root@ubuntu-core:~# lxc launch images:ubuntu-core/16 nested-core
|
||||
@ -170,28 +162,29 @@ root@ubuntu-core:~# lxc list
|
||||
+-------------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
### 写在最后
|
||||
|
||||
If you ever wanted to try Ubuntu Core, this is a great way to do it. It’s also a great tool for snap authors to make sure their snap is fully self-contained and will work in all environments.
|
||||
如果你只是想试用一下 Ubuntu Core,这是一个不错的方法。对于 snap 包开发者来说,这也是一个不错的工具来测试你的 snap 包能否在不同的环境下正常运行。
|
||||
|
||||
Ubuntu Core is a great fit for environments where you want to ensure that your system is always up to date and is entirely reproducible. This does come with a number of constraints that may or may not work for you.
|
||||
如果你希望你的系统总是最新的,并且整体可复制,Ubuntu Core 是一个很不错的方案,不过这也会带来一些相应的限制,所以可能不太适合你。
|
||||
|
||||
And lastly, a word of warning. Those images are considered as good enough for testing, but aren’t officially supported at this point. We are working towards getting fully supported Ubuntu Core LXD images on the official Ubuntu image server in the near future.
|
||||
最后是一个警告,对于测试来说,这些镜像是足够的,但是当前并没有被正式的支持。在不久的将来,官方的 Ubuntu server 可以完整的支持 Ubuntu Core LXD 镜像。
|
||||
|
||||
### Extra information
|
||||
### 附录
|
||||
|
||||
The main LXD website is at: [https://linuxcontainers.org/lxd][2] Development happens on Github at: [https://github.com/lxc/lxd][3]
|
||||
Mailing-list support happens on: [https://lists.linuxcontainers.org][4]
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
Try LXD online: [https://linuxcontainers.org/lxd/try-it][5]
|
||||
- LXD 主站:[https://linuxcontainers.org/lxd][2]
|
||||
- Github:[https://github.com/lxc/lxd][3]
|
||||
- 邮件列表:[https://lists.linuxcontainers.org][4]
|
||||
- IRC:#lxcontainers on irc.freenode.net
|
||||
- 在线试用:[https://linuxcontainers.org/lxd/try-it][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/02/27/ubuntu-core-in-lxd-containers/
|
||||
|
||||
作者:[Stéphane Graber ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[aiwhj](https://github.com/aiwhj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,67 @@
|
||||
了解用于 Linux 和 Windows 容器的 Docker “容器主机”与“容器操作系统”
|
||||
=================
|
||||
|
||||
让我们来探讨一下“容器主机”和“容器操作系统”之间的关系,以及它们在 Linux 和 Windows 容器之间的区别。
|
||||
|
||||
### 一些定义
|
||||
|
||||
* <ruby>容器主机<rt>Container Host</rt></ruby>:也称为<ruby>主机操作系统<rt>Host OS</rt></ruby>。主机操作系统是 Docker 客户端和 Docker 守护程序在其上运行的操作系统。在 Linux 和非 Hyper-V 容器的情况下,主机操作系统与运行中的 Docker 容器共享内核。对于 Hyper-V,每个容器都有自己的 Hyper-V 内核。
|
||||
* <ruby>容器操作系统<rt>Container OS</rt></ruby>:也被称为<ruby>基础操作系统<rt>Base OS</rt></ruby>。基础操作系统是指包含操作系统如 Ubuntu、CentOS 或 windowsservercore 的镜像。通常情况下,你将在基础操作系统镜像之上构建自己的镜像,以便可以利用该操作系统的部分功能。请注意,Windows 容器需要一个基础操作系统,而 Linux 容器不需要。
|
||||
* <ruby>操作系统内核<rt>Operating System Kernel</rt></ruby>:内核管理诸如内存、文件系统、网络和进程调度等底层功能。
|
||||
|
||||
### 如下的一些图
|
||||
|
||||

|
||||
|
||||
在上面的例子中:
|
||||
|
||||
* 主机操作系统是 Ubuntu。
|
||||
* Docker 客户端和 Docker 守护进程(一起被称为 Docker 引擎)正在主机操作系统上运行。
|
||||
* 每个容器共享主机操作系统内核。
|
||||
* CentOS 和 BusyBox 是 Linux 基础操作系统镜像。
|
||||
* “No OS” 容器表明你不需要基础操作系统以在 Linux 中运行一个容器。你可以创建一个含有 [scratch][1] 基础镜像的 Docker 文件,然后运行直接使用内核的二进制文件。
|
||||
* 查看[这篇][2]文章来比较基础 OS 的大小。
|
||||
|
||||

|
||||
|
||||
在上面的例子中:
|
||||
|
||||
* 主机操作系统是 Windows 10 或 Windows Server。
|
||||
* 每个容器共享主机操作系统内核。
|
||||
* 所有 Windows 容器都需要 [nanoserver][3] 或 [windowsservercore][4] 的基础操作系统。
|
||||
|
||||

|
||||
|
||||
在上面的例子中:
|
||||
|
||||
* 主机操作系统是 Windows 10 或 Windows Server。
|
||||
* 每个容器都托管在自己的轻量级 Hyper-V 虚拟机中。
|
||||
* 每个容器使用 Hyper-V 虚拟机内的内核,它在容器之间提供额外的分离层。
|
||||
* 所有 Windows 容器都需要 [nanoserver][5] 或 [windowsservercore][6] 的基础操作系统。
|
||||
|
||||
### 几个好的链接
|
||||
|
||||
* [关于 Windows 容器][7]
|
||||
* [深入实现 Windows 容器,包括多用户模式和“写时复制”来节省资源][8]
|
||||
* [Linux 容器如何通过使用“写时复制”来节省资源][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://floydhilton.com/docker/2017/03/31/Docker-ContainerHost-vs-ContainerOS-Linux-Windows.html
|
||||
|
||||
作者:[Floyd Hilton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://floydhilton.com/about/
|
||||
[1]:https://hub.docker.com/_/scratch/
|
||||
[2]:https://www.brianchristner.io/docker-image-base-os-size-comparison/
|
||||
[3]:https://hub.docker.com/r/microsoft/nanoserver/
|
||||
[4]:https://hub.docker.com/r/microsoft/windowsservercore/
|
||||
[5]:https://hub.docker.com/r/microsoft/nanoserver/
|
||||
[6]:https://hub.docker.com/r/microsoft/windowsservercore/
|
||||
[7]:https://docs.microsoft.com/en-us/virtualization/windowscontainers/about/
|
||||
[8]:http://blog.xebia.com/deep-dive-into-windows-server-containers-and-docker-part-2-underlying-implementation-of-windows-server-containers/
|
||||
[9]:https://docs.docker.com/engine/userguide/storagedriver/imagesandcontainers/#the-copy-on-write-strategy
|
||||
@ -0,0 +1,48 @@
|
||||
肯特·贝克:改变人生的代码整理魔法
|
||||
==========
|
||||
|
||||
> 本文作者<ruby>肯特·贝克<rt>Kent Beck</rt></ruby>,是最早研究软件开发的模式和重构的人之一,是敏捷开发的开创者之一,更是极限编程和测试驱动开发的创始人,同时还是 Smalltalk 和 JUnit 的作者,对当今世界的软件开发影响深远。现在 Facebook 工作。
|
||||
|
||||
本周我一直在整理 Facebook 代码,而且我喜欢这个工作。我的职业生涯中已经整理了数千小时的代码,我有一套使这种整理更加安全、有趣和高效的规则。
|
||||
|
||||
整理工作是通过一系列短小而安全的步骤进行的。事实上,规则一就是**如果这很难,那就不要去做**。我以前在晚上做填字游戏。如果我卡住那就去睡觉,第二天晚上那些没有发现的线索往往很容易发现。与其想要一心搞个大的,不如在遇到阻力的时候停下来。
|
||||
|
||||
整理会陷入这样一种感觉:你错失的要比你从一个个成功中获得的更多(稍后会细说)。第二条规则是**当你充满活力时开始,当你累了时停下来**。起来走走。如果还没有恢复精神,那这一天的工作就算做完了。
|
||||
|
||||
只有在仔细追踪其它变化的时候(我把它和最新的差异搞混了),整理工作才可以与开发同步进行。第三条规则是**立即完成每个环节的工作**。与功能开发所不同的是,功能开发只有在完成一大块工作时才有意义,而整理是基于时间一点点完成的。
|
||||
|
||||
整理在任何步骤中都只需要付出不多的努力,所以我会在任何步骤遇到麻烦的时候放弃。所以,规则四是**两次失败后恢复**。如果我整理代码,运行测试,并遇到测试失败,那么我会立即修复它。如果我修复失败,我会立即恢复到上次已知最好的状态。
|
||||
|
||||
即便没有闪亮的新设计的愿景,整理也是有用的。不过,有时候我想看看事情会如何发展,所以第五条就是**实践**。执行一系列的整理和还原。第二次将更快,你会更加熟悉避免哪些坑。
|
||||
|
||||
只有在附带损害的风险较低,审查整理变化的成本也较低的时候整理才有用。规则六是**隔离整理**。如果你错过了在编写代码中途整理的机会,那么接下来可能很困难。要么完成并接着整理,要么还原、整理并进行修改。
|
||||
|
||||
试试这些。将临时申明的变量移动到它第一次使用的位置,简化布尔表达式(`return expression == True`?),提取一个 helper,将逻辑或状态的范围缩小到实际使用的位置。
|
||||
|
||||
### 规则
|
||||
|
||||
- 规则一、 如果这很难,那就不要去做
|
||||
- 规则二、 当你充满活力时开始,当你累了时停下来
|
||||
- 规则三、 立即完成每个环节工作
|
||||
- 规则四、 两次失败后恢复
|
||||
- 规则五、 实践
|
||||
- 规则六、 隔离整理
|
||||
|
||||
### 尾声
|
||||
|
||||
我通过严格地整理改变了架构、提取了框架。这种方式可以安全地做出重大改变。我认为这是因为,虽然每次整理的成本是不变的,但回报是指数级的,但我需要数据和模型来解释这个假说。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.facebook.com/notes/kent-beck/the-life-changing-magic-of-tidying-up-code/1544047022294823/
|
||||
|
||||
作者:[KENT BECK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.facebook.com/kentlbeck
|
||||
[1]:https://www.facebook.com/notes/kent-beck/the-life-changing-magic-of-tidying-up-code/1544047022294823/?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#
|
||||
[2]:https://www.facebook.com/kentlbeck
|
||||
[3]:https://www.facebook.com/notes/kent-beck/the-life-changing-magic-of-tidying-up-code/1544047022294823/
|
||||
@ -0,0 +1,33 @@
|
||||
Let’s Encrypt :2018 年 1 月发布通配证书
|
||||
============================================================
|
||||
|
||||
Let’s Encrypt 将于 2018 年 1 月开始发放通配证书。通配证书是一个经常需要的功能,并且我们知道在一些情况下它可以使 HTTPS 部署更简单。我们希望提供通配证书有助于加速网络向 100% HTTPS 进展。
|
||||
|
||||
Let’s Encrypt 目前通过我们的全自动 DV 证书颁发和管理 API 保护了 4700 万个域名。自从 Let's Encrypt 的服务于 2015 年 12 月发布以来,它已经将加密网页的数量从 40% 大大地提高到了 58%。如果你对通配证书的可用性以及我们达成 100% 的加密网页的使命感兴趣,我们请求你为我们的[夏季筹款活动][1](LCTT 译注:之前的夏季活动,原文发布于今年夏季)做出贡献。
|
||||
|
||||
通配符证书可以保护基本域的任何数量的子域名(例如 *.example.com)。这使得管理员可以为一个域及其所有子域使用单个证书和密钥对,这可以使 HTTPS 部署更加容易。
|
||||
|
||||
通配符证书将通过我们[即将发布的 ACME v2 API 终端][2]免费提供。我们最初只支持通过 DNS 进行通配符证书的基础域验证,但是随着时间的推移可能会探索更多的验证方式。我们鼓励人们在我们的[社区论坛][3]上提出任何关于通配证书支持的问题。
|
||||
|
||||
我们决定在夏季筹款活动中宣布这一令人兴奋的进展,因为我们是一个非营利组织,这要感谢使用我们服务的社区的慷慨支持。如果你想支持一个更安全和保密的网络,[现在捐赠吧][4]!
|
||||
|
||||
我们要感谢我们的[社区][5]和我们的[赞助者][6],使我们所做的一切成为可能。如果你的公司或组织能够赞助 Let's Encrypt,请发送电子邮件至 [sponsor@letsencrypt.org][7]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://letsencrypt.org/2017/07/06/wildcard-certificates-coming-jan-2018.html
|
||||
|
||||
作者:[Josh Aas][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://letsencrypt.org/2017/07/06/wildcard-certificates-coming-jan-2018.html
|
||||
[1]:https://letsencrypt.org/donate/
|
||||
[2]:https://letsencrypt.org/2017/06/14/acme-v2-api.html
|
||||
[3]:https://community.letsencrypt.org/
|
||||
[4]:https://letsencrypt.org/donate/
|
||||
[5]:https://letsencrypt.org/getinvolved/
|
||||
[6]:https://letsencrypt.org/sponsors/
|
||||
[7]:mailto:sponsor@letsencrypt.org
|
||||
@ -0,0 +1,149 @@
|
||||
Linux 用户的手边工具:Guide to Linux
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> “Guide to Linux” 这个应用并不完美,但它是一个非常好的工具,可以帮助你学习 Linux 命令。
|
||||
|
||||
还记得你初次使用 Linux 时的情景吗?对于有些人来说,他的学习曲线可能有些挑战性。比如,在 `/usr/bin` 中能找到许多命令。在我目前使用的 Elementary OS 系统中,命令的数量是 1944 个。当然,这并不全是真实的命令(或者,我会使用到的命令数量),但这个数目是很多的。
|
||||
|
||||
正因为如此(并且不同平台不一样),现在,新用户(和一些已经熟悉的用户)需要一些帮助。
|
||||
|
||||
对于每个管理员来说,这些技能是必须具备的:
|
||||
|
||||
* 熟悉平台
|
||||
* 理解命令
|
||||
* 编写 Shell 脚本
|
||||
|
||||
当你寻求帮助时,有时,你需要去“阅读那些该死的手册”(Read the Fine/Freaking/Funky Manual,LCTT 译注:一个网络用语,简写为 RTFM),但是当你自己都不知道要找什么的时候,它就没办法帮到你了。在那个时候,你就会为你拥有像 [Guide to Linux][15] 这样的手机应用而感到高兴。
|
||||
|
||||
不像你在 Linux.com 上看到的那些大多数的内容,这篇文章只是介绍一个 Android 应用的。为什么呢?因为这个特殊的 应用是用来帮助用户学习 Linux 的。
|
||||
|
||||
而且,它做的很好。
|
||||
|
||||
关于这个应用我清楚地告诉你 —— 它并不完美。Guide to Linux 里面充斥着很烂的英文,糟糕的标点符号,并且(如果你是一个纯粹主义者),它从来没有提到过 GNU。在这之上,它有一个特别的功能(通常它对用户非常有用)功能不是很有用(LCTT 译注:是指终端模拟器,后面会详细解释)。除此之外,我敢说 Guide to Linux 可能是 Linux 平台上最好的一个移动端的 “口袋指南”。
|
||||
|
||||
对于这个应用,你可能会喜欢它的如下特性:
|
||||
|
||||
* 离线使用
|
||||
* Linux 教程
|
||||
* 基础的和高级的 Linux 命令的详细介绍
|
||||
* 包含了命令示例和语法
|
||||
* 专用的 Shell 脚本模块
|
||||
|
||||
除此以外,Guide to Linux 是免费提供的(尽管里面有一些广告)。如果你想去除广告,它有一个应用内的购买,($2.99 USD/年)可以去消除广告。
|
||||
|
||||
让我们来安装这个应用,来看一看它的构成。
|
||||
|
||||
### 安装
|
||||
|
||||
像所有的 Android 应用一样,安装 Guide to Linux 是非常简单的。按照以下简单的几步就可以安装它了:
|
||||
|
||||
1. 打开你的 Android 设备上的 Google Play 商店
|
||||
2. 搜索 Guide to Linux
|
||||
3. 找到 Essence Infotech 的那个,并轻触进入
|
||||
4. 轻触 Install
|
||||
5. 允许安装
|
||||
|
||||
安装完成后,你可以在你的<ruby>应用抽屉<rt>App Drawer</rt></ruby>或主屏幕上(或者两者都有)上找到它去启动 Guide to Linux 。轻触图标去启动这个应用。
|
||||
|
||||
### 使用
|
||||
|
||||
让我们看一下 Guide to Linux 的每个功能。我发现某些功能比其它的更有帮助,或许你的体验会不一样。在我们分别讲解之前,我将重点提到其界面。开发者在为这个应用创建一个易于使用的界面方面做的很好。
|
||||
|
||||
从主窗口中(图 1),你可以获取四个易于访问的功能。
|
||||
|
||||

|
||||
|
||||
*图 1: The Guide to Linux 主窗口。[已获授权][1]*
|
||||
|
||||
轻触四个图标中的任何一个去启动一个功能,然后,准备去学习。
|
||||
|
||||
### 教程
|
||||
|
||||
让我们从这个应用教程的最 “新手友好” 的功能开始。打开“Tutorial”功能,然后,将看到该教程的欢迎部分,“Linux 操作系统介绍”(图 2)。
|
||||
|
||||

|
||||
|
||||
*图 2:教程开始。[已获授权][2]*
|
||||
|
||||
如果你轻触 “汉堡包菜单” (左上角的三个横线),显示了内容列表(图 3),因此,你可以在教程中选择任何一个可用部分。
|
||||
|
||||

|
||||
|
||||
*图 3:教程的内容列表。[已获授权][3]*
|
||||
|
||||
如果你现在还没有注意到,Guide to Linux 教程部分是每个主题的一系列短文的集合。短文包含图片和链接(有时候),链接将带你到指定的 web 网站(根据主题的需要)。这里没有交互,仅仅只能阅读。但是,这是一个很好的起点,由于开发者在描述各个部分方面做的很好(虽然有语法问题)。
|
||||
|
||||
尽管你可以在窗口的顶部看到一个搜索选项,但是,我还是没有发现这一功能的任何效果 —— 但是,你可以试一下。
|
||||
|
||||
对于 Linux 新手来说,如果希望获得 Linux 管理的技能,你需要去阅读整个教程。完成之后,转到下一个主题。
|
||||
|
||||
### 命令
|
||||
|
||||
命令功能类似于手机上的 man 页面一样,是大量的频繁使用的 Linux 命令。当你首次打开它,欢迎页面将详细解释使用命令的益处。
|
||||
|
||||
读完之后,你可以轻触向右的箭头(在屏幕底部)或轻触 “汉堡包菜单” ,然后从侧边栏中选择你想去学习的其它命令。(图 4)
|
||||
|
||||

|
||||
|
||||
*图 4:命令侧边栏允许你去查看列出的命令。[已获授权][4]*
|
||||
|
||||
轻触任意一个命令,你可以阅读这个命令的解释。每个命令解释页面和它的选项都提供了怎么去使用的示例。
|
||||
|
||||
### Shell 脚本
|
||||
|
||||
在这个时候,你开始熟悉 Linux 了,并对命令已经有一定程序的掌握。现在,是时候去熟悉 shell 脚本了。这个部分的设置方式与教程部分和命令部分相同。
|
||||
|
||||
你可以打开内容列表的侧边栏,然后打开包含 shell 脚本教程的任意部分(图 5)。
|
||||
|
||||

|
||||
|
||||
*图 5:Shell 脚本节看上去很熟悉。[已获授权][5]*
|
||||
|
||||
开发者在解释如何最大限度地利用 shell 脚本方面做的很好。对于任何有兴趣学习 shell 脚本细节的人来说,这是个很好的起点。
|
||||
|
||||
### 终端
|
||||
|
||||
现在我们到了一个新的地方,开发者在这个应用中包含了一个终端模拟器。遗憾的是,当你在一个没有 “root” 权限的 Android 设备上安装这个应用时,你会发现你被限制在一个只读文件系统中,在那里,大部分命令根本无法工作。但是,我在一台 Pixel 2 (通过 Android 应用商店)安装的 Guide to Linux 中,可以使用更多的这个功能(还只是较少的一部分)。在一台 OnePlus 3 (非 root 过的)上,不管我改变到哪个目录,我都是得到相同的错误信息 “permission denied”,甚至是一个简单的命令也如此。
|
||||
|
||||
在 Chromebook 上,不管怎么操作,它都是正常的(图 6)。可以说,它可以一直很好地工作在一个只读操作系统中(因此,你不能用它进行真正的工作或创建新文件)。
|
||||
|
||||

|
||||
|
||||
*图 6: 可以完美地(可以这么说)用一个终端模拟器去工作。[已获授权][6]*
|
||||
|
||||
记住,这并不是真实的成熟终端,但却是一个新用户去熟悉终端是怎么工作的一种方法。遗憾的是,大多数用户只会发现自己对这个工具的终端功能感到沮丧,仅仅是因为,它们不能使用他们在其它部分学到的东西。开发者可能将这个终端功能打造成了一个 Linux 文件系统沙箱,因此,用户可以真实地使用它去学习。每次用户打开那个工具,它将恢复到原始状态。这只是我一个想法。
|
||||
|
||||
### 写在最后…
|
||||
|
||||
尽管终端功能被一个只读文件系统所限制(几乎到了没法使用的程序),Guide to Linux 仍然是一个新手学习 Linux 的好工具。在 guide to Linux 中,你将学习关于 Linux、命令、和 shell 脚本的很多知识,以便在你安装你的第一个发行版之前,让你学习 Linux 有一个好的起点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/8/guide-linux-app-handy-tool-every-level-linux-user
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/used-permission
|
||||
[7]:https://www.linux.com/licenses/category/used-permission
|
||||
[8]:https://www.linux.com/files/images/guidetolinux1jpg
|
||||
[9]:https://www.linux.com/files/images/guidetolinux2jpg
|
||||
[10]:https://www.linux.com/files/images/guidetolinux3jpg-0
|
||||
[11]:https://www.linux.com/files/images/guidetolinux4jpg
|
||||
[12]:https://www.linux.com/files/images/guidetolinux-5-newjpg
|
||||
[13]:https://www.linux.com/files/images/guidetolinux6jpg-0
|
||||
[14]:https://www.linux.com/files/images/guide-linuxpng
|
||||
[15]:https://play.google.com/store/apps/details?id=com.essence.linuxcommands
|
||||
[16]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[17]:https://www.addtoany.com/share#url=https%3A%2F%2Fwww.linux.com%2Flearn%2Fintro-to-linux%2F2017%2F8%2Fguide-linux-app-handy-tool-every-level-linux-user&title=Guide%20to%20Linux%20App%20Is%20a%20Handy%20Tool%20for%20Every%20Level%20of%20Linux%20User
|
||||
@ -0,0 +1,85 @@
|
||||
放弃你的代码,而不是你的时间
|
||||
============================================================
|
||||
|
||||
作为软件开发人员,我认为我们可以认同开源代码^注1 已经[改变了世界][9]。它的公共性质去除了壁垒,可以让软件可以变的最好。但问题是,太多有价值的项目由于领导者的精力耗尽而停滞不前:
|
||||
|
||||
>“我没有时间和精力去投入开源了。我在开源上没有得到任何收入,所以我在那上面花的时间,我可以用在‘生活上的事’,或者写作上……正因为如此,我决定现在结束我所有的开源工作。”
|
||||
>
|
||||
>—[Ryan Bigg,几个 Ruby 和 Elixir 项目的前任维护者][1]
|
||||
>
|
||||
>“这也是一个巨大的机会成本,由于我无法同时学习或者完成很多事情,FubuMVC 占用了我很多的时间,这是它现在必须停下来的主要原因。”
|
||||
>
|
||||
>—[前 FubuMVC 项目负责人 Jeremy Miller][2]
|
||||
>
|
||||
>“当我们决定要孩子的时候,我可能会放弃开源,我预计最终解决我问题的方案将是:核武器。”
|
||||
>
|
||||
>—[Nolan Lawson,PouchDB 的维护者之一][3]
|
||||
|
||||
我们需要的是一种新的行业规范,即项目领导者将_总是_能获得(其付出的)时间上的补偿。我们还需要抛弃的想法是, 任何提交问题或合并请求的开发人员都自动会得到维护者的注意。
|
||||
|
||||
我们先来回顾一下开源代码在市场上的作用。它是一个积木。它是[实用软件][10],是企业为了在别处获利而必须承担的成本。如果用户能够理解该代码的用途并且发现它比替代方案(闭源专用、定制的内部解决方案等)更有价值,那么围绕该软件的社区就会不断增长。它可以更好,更便宜,或两者兼而有之。
|
||||
|
||||
如果一个组织需要改进该代码,他们可以自由地聘请任何他们想要的开发人员。通常情况下[为了他们的利益][11]会将改进贡献给社区,因为由于代码合并的复杂性,这是他们能够轻松地从其他用户获得未来改进的唯一方式。这种“引力”倾向于把社区聚集在一起。
|
||||
|
||||
但是它也会加重项目维护者的负担,因为他们必须对这些改进做出反应。他们得到了什么回报?最好的情况是,这些社区贡献可能是他们将来可以使用的东西,但现在不是。最坏的情况下,这只不过是一个带着利他主义面具的自私请求罢了。
|
||||
|
||||
有一类开源项目避免了这个陷阱。Linux、MySQL、Android、Chromium 和 .NET Core 除了有名,有什么共同点么?他们都对一个或多个大型企业具有_战略性重要意义_,因为它们满足了这些利益。[聪明的公司商品化他们的商品][12],没有什么比开源软件便宜的商品了。红帽需要那些使用 Linux 的公司来销售企业级 Linux,Oracle 使用 MySQL 作为销售 MySQL Enterprise 的引子,谷歌希望世界上每个人都拥有电话和浏览器,而微软则试图将开发者锁定在平台上然后将它们拉入 Azure 云。这些项目全部由各自公司直接资助。
|
||||
|
||||
但是那些其他的项目呢,那些不是大玩家核心战略的项目呢?
|
||||
|
||||
如果你是其中一个项目的负责人,请向社区成员收取年费。_开放的源码,封闭的社区_。给用户的信息应该是“尽你所愿地使用代码,但如果你想影响项目的未来,请_为我们的时间支付_。”将非付费用户锁定在论坛和问题跟踪之外,并忽略他们的电子邮件。不支付的人应该觉得他们错过了派对。
|
||||
|
||||
还要向贡献者收取合并非普通的合并请求的时间花费。如果一个特定的提交不会立即给你带来好处,请为你的时间收取全价。要有原则并[记住 YAGNI][13]。
|
||||
|
||||
这会导致一个极小的社区和更多的分支么?绝对。但是,如果你坚持不懈地构建自己的愿景,并为其他人创造价值,他们会尽快为要做的贡献而支付。_合并贡献的意愿是[稀缺资源][4]_。如果没有它,用户必须反复地将它们的变化与你发布的每个新版本进行协调。
|
||||
|
||||
如果你想在代码库中保持高水平的[概念完整性][14],那么限制社区是特别重要的。有[自由贡献政策][15]的无领导者项目没有必要收费。
|
||||
|
||||
为了实现更大的愿景,而不是单独为自己的业务支付成本,而是可能使其他人受益,去[众筹][16]吧。有许多成功的故事:
|
||||
|
||||
- [Font Awesome 5][5]
|
||||
- [Ruby enVironment Management (RVM)][6]
|
||||
- [Django REST framework 3][7]
|
||||
|
||||
[众筹有局限性][17]。它[不适合][18][大型项目][19]。但是,开源代码也是实用软件,它不需要雄心勃勃、冒险的破局者。它已经一点点地[渗透到每个行业][20]。
|
||||
|
||||
这些观点代表着一条可持续发展的道路,也可以解决[开源的多样性问题][21],这可能源于其历史上无偿的性质。但最重要的是,我们要记住,[我们一生中只留下那么多的按键次数][22],而且我们总有一天会后悔那些我们浪费的东西。
|
||||
|
||||
- 注 1 :当我说“开源”时,我的意思是代码[许可][8]以某种方式来构建专有的东西。这通常意味着一个宽松许可证(MIT 或 Apache 或 BSD),但并非总是如此。Linux 是当今科技行业的核心,但是是以 GPL 授权的。_
|
||||
|
||||
感谢 Jason Haley、Don McNamara、Bryan Hogan 和 Nadia Eghbal 阅读了这篇文章的草稿。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://wgross.net/essays/give-away-your-code-but-never-your-time
|
||||
|
||||
作者:[William Gross][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://wgross.net/#about-section
|
||||
[1]:http://ryanbigg.com/2015/11/open-source-work
|
||||
[2]:https://jeremydmiller.com/2014/04/03/im-throwing-in-the-towel-in-fubumvc/
|
||||
[3]:https://nolanlawson.com/2017/03/05/what-it-feels-like-to-be-an-open-source-maintainer/
|
||||
[4]:https://hbr.org/2010/11/column-to-win-create-whats-scarce
|
||||
[5]:https://www.kickstarter.com/projects/232193852/font-awesome-5
|
||||
[6]:https://www.bountysource.com/teams/rvm/fundraiser
|
||||
[7]:https://www.kickstarter.com/projects/tomchristie/django-rest-framework-3
|
||||
[8]:https://choosealicense.com/
|
||||
[9]:https://www.wired.com/insights/2013/07/in-a-world-without-open-source/
|
||||
[10]:https://martinfowler.com/bliki/UtilityVsStrategicDichotomy.html
|
||||
[11]:https://tessel.io/blog/67472869771/monetizing-open-source
|
||||
[12]:https://www.joelonsoftware.com/2002/06/12/strategy-letter-v/
|
||||
[13]:https://martinfowler.com/bliki/Yagni.html
|
||||
[14]:http://wiki.c2.com/?ConceptualIntegrity
|
||||
[15]:https://opensource.com/life/16/5/growing-contributor-base-modern-open-source
|
||||
[16]:https://poststatus.com/kickstarter-open-source-project/
|
||||
[17]:http://blog.felixbreuer.net/2013/04/24/crowdfunding-for-open-source.html
|
||||
[18]:https://www.indiegogo.com/projects/geary-a-beautiful-modern-open-source-email-client#/
|
||||
[19]:http://www.itworld.com/article/2708360/open-source-tools/canonical-misses-smartphone-crowdfunding-goal-by--19-million.html
|
||||
[20]:http://www.infoworld.com/article/2914643/open-source-software/rise-and-rise-of-open-source.html
|
||||
[21]:http://readwrite.com/2013/12/11/open-source-diversity/
|
||||
[22]:http://keysleft.com/
|
||||
[23]:http://wgross.net/essays/give-away-your-code-but-never-your-time
|
||||
250
published/20171002 Scaling the GitLab database.md
Normal file
250
published/20171002 Scaling the GitLab database.md
Normal file
@ -0,0 +1,250 @@
|
||||
在 GitLab 我们是如何扩展数据库的
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 在扩展 GitLab 数据库和我们应用的解决方案,去帮助解决我们的数据库设置中的问题时,我们深入分析了所面临的挑战。
|
||||
|
||||
很长时间以来 GitLab.com 使用了一个单个的 PostgreSQL 数据库服务器和一个用于灾难恢复的单个复制。在 GitLab.com 最初的几年,它工作的还是很好的,但是,随着时间的推移,我们看到这种设置的很多问题,在这篇文章中,我们将带你了解我们在帮助解决 GitLab.com 和 GitLab 实例所在的主机时都做了些什么。
|
||||
|
||||
例如,数据库长久处于重压之下, CPU 使用率几乎所有时间都处于 70% 左右。并不是因为我们以最好的方式使用了全部的可用资源,而是因为我们使用了太多的(未经优化的)查询去“冲击”服务器。我们意识到需要去优化设置,这样我们就可以平衡负载,使 GitLab.com 能够更灵活地应对可能出现在主数据库服务器上的任何问题。
|
||||
|
||||
在我们使用 PostgreSQL 去跟踪这些问题时,使用了以下的四种技术:
|
||||
|
||||
1. 优化你的应用程序代码,以使查询更加高效(并且理论上使用了很少的资源)。
|
||||
2. 使用一个连接池去减少必需的数据库连接数量(及相关的资源)。
|
||||
3. 跨多个数据库服务器去平衡负载。
|
||||
4. 分片你的数据库
|
||||
|
||||
在过去的两年里,我们一直在积极地优化应用程序代码,但它不是一个完美的解决方案,甚至,如果你改善了性能,当流量也增加时,你还需要去应用其它的几种技术。出于本文的目的,我们将跳过优化应用代码这个特定主题,而专注于其它技术。
|
||||
|
||||
### 连接池
|
||||
|
||||
在 PostgreSQL 中,一个连接是通过启动一个操作系统进程来处理的,这反过来又需要大量的资源,更多的连接(及这些进程)将使用你的数据库上的更多的资源。 PostgreSQL 也在 [max_connections][5] 设置中定义了一个强制的最大连接数量。一旦达到这个限制,PostgreSQL 将拒绝新的连接, 比如,下面的图表示的设置:
|
||||
|
||||

|
||||
|
||||
这里我们的客户端直接连接到 PostgreSQL,这样每个客户端请求一个连接。
|
||||
|
||||
通过连接池,我们可以有多个客户端侧的连接重复使用一个 PostgreSQL 连接。例如,没有连接池时,我们需要 100 个 PostgreSQL 连接去处理 100 个客户端连接;使用连接池后,我们仅需要 10 个,或者依据我们配置的 PostgreSQL 连接。这意味着我们的连接图表将变成下面看到的那样:
|
||||
|
||||

|
||||
|
||||
这里我们展示了一个示例,四个客户端连接到 pgbouncer,但不是使用了四个 PostgreSQL 连接,而是仅需要两个。
|
||||
|
||||
对于 PostgreSQL 有两个最常用的连接池:
|
||||
|
||||
* [pgbouncer][1]
|
||||
* [pgpool-II][2]
|
||||
|
||||
pgpool 有一点特殊,因为它不仅仅是连接池:它有一个内置的查询缓存机制,可以跨多个数据库负载均衡、管理复制等等。
|
||||
|
||||
另一个 pgbouncer 是很简单的:它就是一个连接池。
|
||||
|
||||
### 数据库负载均衡
|
||||
|
||||
数据库级的负载均衡一般是使用 PostgreSQL 的 “<ruby>[热备机][6]<rt>hot-standby</rt></ruby>” 特性来实现的。 热备机是允许你去运行只读 SQL 查询的 PostgreSQL 副本,与不允许运行任何 SQL 查询的普通<ruby>备用机<rt>standby</rt></ruby>相反。要使用负载均衡,你需要设置一个或多个热备服务器,并且以某些方式去平衡这些跨主机的只读查询,同时将其它操作发送到主服务器上。扩展这样的一个设置是很容易的:(如果需要的话)简单地增加多个热备机以增加只读流量。
|
||||
|
||||
这种方法的另一个好处是拥有一个更具弹性的数据库集群。即使主服务器出现问题,仅使用次级服务器也可以继续处理 Web 请求;当然,如果这些请求最终使用主服务器,你可能仍然会遇到错误。
|
||||
|
||||
然而,这种方法很难实现。例如,一旦它们包含写操作,事务显然需要在主服务器上运行。此外,在写操作完成之后,我们希望继续使用主服务器一会儿,因为在使用异步复制的时候,热备机服务器上可能还没有这些更改。
|
||||
|
||||
### 分片
|
||||
|
||||
分片是水平分割你的数据的行为。这意味着数据保存在特定的服务器上并且使用一个分片键检索。例如,你可以按项目分片数据并且使用项目 ID 做为分片键。当你的写负载很高时,分片数据库是很有用的(除了一个多主设置外,均衡写操作没有其它的简单方法),或者当你有_大量_的数据并且你不再使用传统方式保存它也是有用的(比如,你不能把它简单地全部放进一个单个磁盘中)。
|
||||
|
||||
不幸的是,设置分片数据库是一个任务量很大的过程,甚至,在我们使用诸如 [Citus][7] 的软件时也是这样。你不仅需要设置基础设施 (不同的复杂程序取决于是你运行在你自己的数据中心还是托管主机的解决方案),你还得需要调整你的应用程序中很大的一部分去支持分片。
|
||||
|
||||
#### 反对分片的案例
|
||||
|
||||
在 GitLab.com 上一般情况下写负载是非常低的,同时大多数的查询都是只读查询。在极端情况下,尖峰值达到每秒 1500 元组写入,但是,在大多数情况下不超过每秒 200 元组写入。另一方面,我们可以在任何给定的次级服务器上轻松达到每秒 1000 万元组读取。
|
||||
|
||||
存储方面,我们也不使用太多的数据:大约 800 GB。这些数据中的很大一部分是在后台迁移的,这些数据一经迁移后,我们的数据库收缩的相当多。
|
||||
|
||||
接下来的工作量就是调整应用程序,以便于所有查询都可以正确地使用分片键。 我们的一些查询包含了一个项目 ID,它是我们使用的分片键,也有许多查询没有包含这个分片键。分片也会影响提交到 GitLab 的改变内容的过程,每个提交者现在必须确保在他们的查询中包含分片键。
|
||||
|
||||
最后,是完成这些工作所需要的基础设施。服务器已经完成设置,监视也添加了、工程师们必须培训,以便于他们熟悉上面列出的这些新的设置。虽然托管解决方案可能不需要你自己管理服务器,但它不能解决所有问题。工程师们仍然需要去培训(很可能非常昂贵)并需要为此支付账单。在 GitLab 上,我们也非常乐意提供我们用过的这些工具,这样社区就可以使用它们。这意味着如果我们去分片数据库, 我们将在我们的 Omnibus 包中提供它(或至少是其中的一部分)。确保你提供的服务的唯一方法就是你自己去管理它,这意味着我们不能使用主机托管的解决方案。
|
||||
|
||||
最终,我们决定不使用数据库分片,因为它是昂贵的、费时的、复杂的解决方案。
|
||||
|
||||
### GitLab 的连接池
|
||||
|
||||
对于连接池我们有两个主要的诉求:
|
||||
|
||||
1. 它必须工作的很好(很显然这是必需的)。
|
||||
2. 它必须易于在我们的 Omnibus 包中运用,以便于我们的用户也可以从连接池中得到好处。
|
||||
|
||||
用下面两步去评估这两个解决方案(pgpool 和 pgbouncer):
|
||||
|
||||
1. 执行各种技术测试(是否有效,配置是否容易,等等)。
|
||||
2. 找出使用这个解决方案的其它用户的经验,他们遇到了什么问题?怎么去解决的?等等。
|
||||
|
||||
pgpool 是我们考察的第一个解决方案,主要是因为它提供的很多特性看起来很有吸引力。我们其中的一些测试数据可以在 [这里][8] 找到。
|
||||
|
||||
最终,基于多个因素,我们决定不使用 pgpool 。例如, pgpool 不支持<ruby>粘连接<rt>sticky connection</rt></ruby>。 当执行一个写入并(尝试)立即显示结果时,它会出现问题。想像一下,创建一个<ruby>工单<rt>issue</rt></ruby>并立即重定向到这个页面, 没有想到会出现 HTTP 404,这是因为任何用于只读查询的服务器还没有收到数据。针对这种情况的一种解决办法是使用同步复制,但这会给表带来更多的其它问题,而我们希望避免这些问题。
|
||||
|
||||
另一个问题是, pgpool 的负载均衡逻辑与你的应用程序是不相干的,是通过解析 SQL 查询并将它们发送到正确的服务器。因为这发生在你的应用程序之外,你几乎无法控制查询运行在哪里。这实际上对某些人也可能是有好处的, 因为你不需要额外的应用程序逻辑。但是,它也妨碍了你在需要的情况下调整路由逻辑。
|
||||
|
||||
由于配置选项非常多,配置 pgpool 也是很困难的。或许促使我们最终决定不使用它的原因是我们从过去使用过它的那些人中得到的反馈。即使是在大多数的案例都不是很详细的情况下,我们收到的反馈对 pgpool 通常都持有负面的观点。虽然出现的报怨大多数都与早期版本的 pgpool 有关,但仍然让我们怀疑使用它是否是个正确的选择。
|
||||
|
||||
结合上面描述的问题和反馈,最终我们决定不使用 pgpool 而是使用 pgbouncer 。我们用 pgbouncer 执行了一套类似的测试,并且对它的结果是非常满意的。它非常容易配置(而且一开始不需要很多的配置),运用相对容易,仅专注于连接池(而且它真的很好),而且没有明显的负载开销(如果有的话)。也许我唯一的报怨是,pgbouncer 的网站有点难以导航。
|
||||
|
||||
使用 pgbouncer 后,通过使用<ruby>事务池<rt>transaction pooling</rt></ruby>我们可以将活动的 PostgreSQL 连接数从几百个降到仅 10 - 20 个。我们选择事务池是因为 Rails 数据库连接是持久的。这个设置中,使用<ruby>会话池<rt>session pooling</rt></ruby>不能让我们降低 PostgreSQL 连接数,从而受益(如果有的话)。通过使用事务池,我们可以调低 PostgreSQL 的 `max_connections` 的设置值,从 3000 (这个特定值的原因我们也不清楚) 到 300 。这样配置的 pgbouncer ,即使在尖峰时,我们也仅需要 200 个连接,这为我们提供了一些额外连接的空间,如 `psql` 控制台和维护任务。
|
||||
|
||||
对于使用事务池的负面影响方面,你不能使用预处理语句,因为 `PREPARE` 和 `EXECUTE` 命令也许最终在不同的连接中运行,从而产生错误的结果。 幸运的是,当我们禁用了预处理语句时,并没有测量到任何响应时间的增加,但是我们 _确定_ 测量到在我们的数据库服务器上内存使用减少了大约 20 GB。
|
||||
|
||||
为确保我们的 web 请求和后台作业都有可用连接,我们设置了两个独立的池: 一个有 150 个连接的后台进程连接池,和一个有 50 个连接的 web 请求连接池。对于 web 连接需要的请求,我们很少超过 20 个,但是,对于后台进程,由于在 GitLab.com 上后台运行着大量的进程,我们的尖峰值可以很容易达到 100 个连接。
|
||||
|
||||
今天,我们提供 pgbouncer 作为 GitLab EE 高可用包的一部分。对于更多的信息,你可以参考 “[Omnibus GitLab PostgreSQL High Availability][9]”。
|
||||
|
||||
### GitLab 上的数据库负载均衡
|
||||
|
||||
使用 pgpool 和它的负载均衡特性,我们需要一些其它的东西去分发负载到多个热备服务器上。
|
||||
|
||||
对于(但不限于) Rails 应用程序,它有一个叫 [Makara][10] 的库,它实现了负载均衡的逻辑并包含了一个 ActiveRecord 的缺省实现。然而,Makara 也有一些我们认为是有些遗憾的问题。例如,它支持的粘连接是非常有限的:当你使用一个 cookie 和一个固定的 TTL 去执行一个写操作时,连接将粘到主服务器。这意味着,如果复制极大地滞后于 TTL,最终你可能会发现,你的查询运行在一个没有你需要的数据的主机上。
|
||||
|
||||
Makara 也需要你做很多配置,如所有的数据库主机和它们的角色,没有服务发现机制(我们当前的解决方案也不支持它们,即使它是将来计划的)。 Makara 也 [似乎不是线程安全的][11],这是有问题的,因为 Sidekiq (我们使用的后台进程)是多线程的。 最终,我们希望尽可能地去控制负载均衡的逻辑。
|
||||
|
||||
除了 Makara 之外 ,还有一个 [Octopus][12] ,它也是内置的负载均衡机制。但是 Octopus 是面向分片数据库的,而不仅是均衡只读查询的。因此,最终我们不考虑使用 Octopus。
|
||||
|
||||
最终,我们直接在 GitLab EE构建了自己的解决方案。 添加初始实现的<ruby>合并请求<rt>merge request</rt></ruby>可以在 [这里][13]找到,尽管一些更改、提升和修复是以后增加的。
|
||||
|
||||
我们的解决方案本质上是通过用一个处理查询的路由的代理对象替换 `ActiveRecord::Base.connection` 。这可以让我们均衡负载尽可能多的查询,甚至,包括不是直接来自我们的代码中的查询。这个代理对象基于调用方式去决定将查询转发到哪个主机, 消除了解析 SQL 查询的需要。
|
||||
|
||||
#### 粘连接
|
||||
|
||||
粘连接是通过在执行写入时,将当前 PostgreSQL WAL 位置存储到一个指针中实现支持的。在请求即将结束时,指针短期保存在 Redis 中。每个用户提供他自己的 key,因此,一个用户的动作不会导致其他的用户受到影响。下次请求时,我们取得指针,并且与所有的次级服务器进行比较。如果所有的次级服务器都有一个超过我们的指针的 WAL 指针,那么我们知道它们是同步的,我们可以为我们的只读查询安全地使用次级服务器。如果一个或多个次级服务器没有同步,我们将继续使用主服务器直到它们同步。如果 30 秒内没有写入操作,并且所有的次级服务器还没有同步,我们将恢复使用次级服务器,这是为了防止有些人的查询永远运行在主服务器上。
|
||||
|
||||
检查一个次级服务器是否就绪十分简单,它在如下的 `Gitlab::Database::LoadBalancing::Host#caught_up?` 中实现:
|
||||
|
||||
```
|
||||
def caught_up?(location)
|
||||
string = connection.quote(location)
|
||||
|
||||
query = "SELECT NOT pg_is_in_recovery() OR " \
|
||||
"pg_xlog_location_diff(pg_last_xlog_replay_location(), #{string}) >= 0 AS result"
|
||||
|
||||
row = connection.select_all(query).first
|
||||
|
||||
row && row['result'] == 't'
|
||||
ensure
|
||||
release_connection
|
||||
end
|
||||
|
||||
```
|
||||
这里的大部分代码是运行原生查询(raw queries)和获取结果的标准的 Rails 代码,查询的最有趣的部分如下:
|
||||
|
||||
```
|
||||
SELECT NOT pg_is_in_recovery()
|
||||
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER) >= 0 AS result"
|
||||
|
||||
```
|
||||
|
||||
这里 `WAL-POINTER` 是 WAL 指针,通过 PostgreSQL 函数 `pg_current_xlog_insert_location()` 返回的,它是在主服务器上执行的。在上面的代码片断中,该指针作为一个参数传递,然后它被引用或转义,并传递给查询。
|
||||
|
||||
使用函数 `pg_last_xlog_replay_location()` 我们可以取得次级服务器的 WAL 指针,然后,我们可以通过函数 `pg_xlog_location_diff()` 与我们的主服务器上的指针进行比较。如果结果大于 0 ,我们就可以知道次级服务器是同步的。
|
||||
|
||||
当一个次级服务器被提升为主服务器,并且我们的 GitLab 进程还不知道这一点的时候,添加检查 `NOT pg_is_in_recovery()` 以确保查询不会失败。在这个案例中,主服务器总是与它自己是同步的,所以它简单返回一个 `true`。
|
||||
|
||||
#### 后台进程
|
||||
|
||||
我们的后台进程代码 _总是_ 使用主服务器,因为在后台执行的大部分工作都是写入。此外,我们不能可靠地使用一个热备机,因为我们无法知道作业是否在主服务器执行,也因为许多作业并没有直接绑定到用户上。
|
||||
|
||||
#### 连接错误
|
||||
|
||||
要处理连接错误,比如负载均衡器不会使用一个视作离线的次级服务器,会增加主机上(包括主服务器)的连接错误,将会导致负载均衡器多次重试。这是确保,在遇到偶发的小问题或数据库失败事件时,不会立即显示一个错误页面。当我们在负载均衡器级别上处理 [热备机冲突][14] 的问题时,我们最终在次级服务器上启用了 `hot_standby_feedback` ,这样就解决了热备机冲突的所有问题,而不会对表膨胀造成任何负面影响。
|
||||
|
||||
我们使用的过程很简单:对于次级服务器,我们在它们之间用无延迟试了几次。对于主服务器,我们通过使用越来越快的回退尝试几次。
|
||||
|
||||
更多信息你可以查看 GitLab EE 上的源代码:
|
||||
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb][3]
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing][4]
|
||||
|
||||
数据库负载均衡首次引入是在 GitLab 9.0 中,并且 _仅_ 支持 PostgreSQL。更多信息可以在 [9.0 release post][15] 和 [documentation][16] 中找到。
|
||||
|
||||
### Crunchy Data
|
||||
|
||||
我们与 [Crunchy Data][17] 一起协同工作来部署连接池和负载均衡。不久之前我还是唯一的 [数据库专家][18],它意味着我有很多工作要做。此外,我对 PostgreSQL 的内部细节的和它大量的设置所知有限 (或者至少现在是),这意味着我能做的也有限。因为这些原因,我们雇用了 Crunchy 去帮我们找出问题、研究慢查询、建议模式优化、优化 PostgreSQL 设置等等。
|
||||
|
||||
在合作期间,大部分工作都是在相互信任的基础上完成的,因此,我们共享私人数据,比如日志。在合作结束时,我们从一些资料和公开的内容中删除了敏感数据,主要的资料在 [gitlab-com/infrastructure#1448][19],这又反过来导致产生和解决了许多分立的问题。
|
||||
|
||||
这次合作的好处是巨大的,它帮助我们发现并解决了许多的问题,如果必须我们自己来做的话,我们可能需要花上几个月的时间来识别和解决它。
|
||||
|
||||
幸运的是,最近我们成功地雇佣了我们的 [第二个数据库专家][20] 并且我们希望以后我们的团队能够发展壮大。
|
||||
|
||||
### 整合连接池和数据库负载均衡
|
||||
|
||||
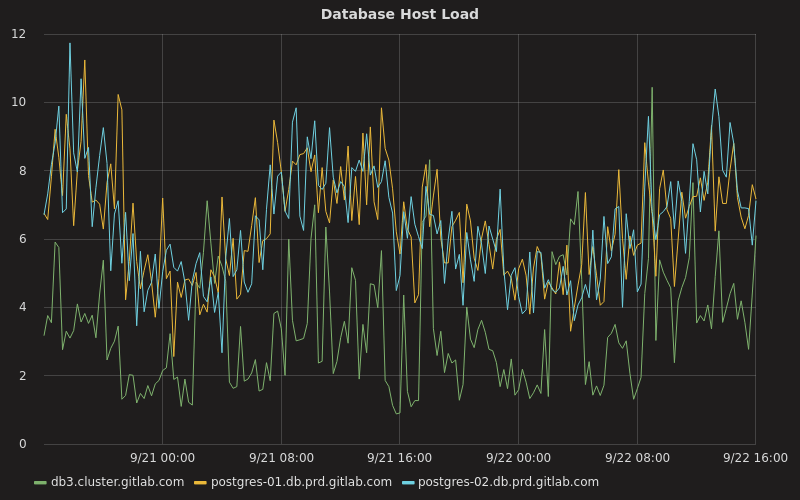
整合连接池和数据库负载均衡可以让我们去大幅减少运行数据库集群所需要的资源和在分发到热备机上的负载。例如,以前我们的主服务器 CPU 使用率一直徘徊在 70%,现在它一般在 10% 到 20% 之间,而我们的两台热备机服务器则大部分时间在 20% 左右:
|
||||
|
||||

|
||||
|
||||
在这里, `db3.cluster.gitlab.com` 是我们的主服务器,而其它的两台是我们的次级服务器。
|
||||
|
||||
其它的负载相关的因素,如平均负载、磁盘使用、内存使用也大为改善。例如,主服务器现在的平均负载几乎不会超过 10,而不像以前它一直徘徊在 20 左右:
|
||||
|
||||
|
||||
|
||||
在业务繁忙期间,我们的次级服务器每秒事务数在 12000 左右(大约为每分钟 740000),而主服务器每秒事务数在 6000 左右(大约每分钟 340000):
|
||||
|
||||

|
||||
|
||||
可惜的是,在部署 pgbouncer 和我们的数据库负载均衡器之前,我们没有关于事务速率的任何数据。
|
||||
|
||||
我们的 PostgreSQL 的最新统计数据的摘要可以在我们的 [public Grafana dashboard][21] 上找到。
|
||||
|
||||
我们的其中一些 pgbouncer 的设置如下:
|
||||
|
||||
| 设置 | 值 |
|
||||
| --- | --- |
|
||||
| `default_pool_size` | 100 |
|
||||
| `reserve_pool_size` | 5 |
|
||||
| `reserve_pool_timeout` | 3 |
|
||||
| `max_client_conn` | 2048 |
|
||||
| `pool_mode` | transaction |
|
||||
| `server_idle_timeout` | 30 |
|
||||
|
||||
除了前面所说的这些外,还有一些工作要作,比如: 部署服务发现([#2042][22]), 持续改善如何检查次级服务器是否可用([#2866][23]),和忽略落后于主服务器太多的次级服务器 ([#2197][24])。
|
||||
|
||||
值得一提的是,到目前为止,我们还没有任何计划将我们的负载均衡解决方案,独立打包成一个你可以在 GitLab 之外使用的库,相反,我们的重点是为 GitLab EE 提供一个可靠的负载均衡解决方案。
|
||||
|
||||
如果你对它感兴趣,并喜欢使用数据库、改善应用程序性能、给 GitLab上增加数据库相关的特性(比如: [服务发现][25]),你一定要去查看一下我们的 [招聘职位][26] 和 [数据库专家手册][27] 去获取更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/
|
||||
|
||||
作者:[Yorick Peterse][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://about.gitlab.com/team/#yorickpeterse
|
||||
[1]:https://pgbouncer.github.io/
|
||||
[2]:http://pgpool.net/mediawiki/index.php/Main_Page
|
||||
[3]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb
|
||||
[4]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing
|
||||
[5]:https://www.postgresql.org/docs/9.6/static/runtime-config-connection.html#GUC-MAX-CONNECTIONS
|
||||
[6]:https://www.postgresql.org/docs/9.6/static/hot-standby.html
|
||||
[7]:https://www.citusdata.com/
|
||||
[8]:https://gitlab.com/gitlab-com/infrastructure/issues/259#note_23464570
|
||||
[9]:https://docs.gitlab.com/ee/administration/high_availability/alpha_database.html
|
||||
[10]:https://github.com/taskrabbit/makara
|
||||
[11]:https://github.com/taskrabbit/makara/issues/151
|
||||
[12]:https://github.com/thiagopradi/octopus
|
||||
[13]:https://gitlab.com/gitlab-org/gitlab-ee/merge_requests/1283
|
||||
[14]:https://www.postgresql.org/docs/current/static/hot-standby.html#HOT-STANDBY-CONFLICT
|
||||
[15]:https://about.gitlab.com/2017/03/22/gitlab-9-0-released/
|
||||
[16]:https://docs.gitlab.com/ee/administration/database_load_balancing.html
|
||||
[17]:https://www.crunchydata.com/
|
||||
[18]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
[19]:https://gitlab.com/gitlab-com/infrastructure/issues/1448
|
||||
[20]:https://gitlab.com/_stark
|
||||
[21]:http://monitor.gitlab.net/dashboard/db/postgres-stats?refresh=5m&orgId=1
|
||||
[22]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[23]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2866
|
||||
[24]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2197
|
||||
[25]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[26]:https://about.gitlab.com/jobs/specialist/database/
|
||||
[27]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
@ -1,29 +1,31 @@
|
||||
PostgreSQL 的哈希索引现在很酷
|
||||
======
|
||||
由于我刚刚提交了最后一个改进 PostgreSQL 11 哈希索引的补丁,并且大部分哈希索引的改进都致力于预计下周发布的 PostgreSQL 10,因此现在似乎是对过去 18 个月左右所做的工作进行简要回顾的好时机。在版本 10 之前,哈希索引在并发性能方面表现不佳,缺少预写日志记录,因此在宕机或复制时都是不安全的,并且还有其他二等公民。在 PostgreSQL 10 中,这在很大程度上被修复了。
|
||||
|
||||
虽然我参与了一些设计,但改进哈希索引的首要功劳来自我的同事 Amit Kapila,[他在这个话题下的博客值得一读][1]。哈希索引的问题不仅在于没有人打算写预写日志记录的代码,还在于代码没有以某种方式进行结构化,使其可以添加实际上正常工作的预写日志记录。要拆分一个桶,系统将锁定已有的桶(使用一种十分低效的锁定机制),将半个元组移动到新的桶中,压缩已有的桶,然后松开锁。即使记录了个别更改,在错误的时刻发生崩溃也会使索引处于损坏状态。因此,Aimt 首先做的是重新设计锁定机制。[新的机制][2]在某种程度上允许扫描和拆分并行进行,并且允许稍后完成那些因报错或崩溃而被中断的拆分。一完成一系列漏洞的修复和一些重构工作,Aimt 就打了另一个补丁,[添加了支持哈希索引的预写日志记录][3]。
|
||||
由于我刚刚提交了最后一个改进 PostgreSQL 11 哈希索引的补丁,并且大部分哈希索引的改进都致力于预计下周发布的 PostgreSQL 10(LCTT 译注:已发布),因此现在似乎是对过去 18 个月左右所做的工作进行简要回顾的好时机。在版本 10 之前,哈希索引在并发性能方面表现不佳,缺少预写日志记录,因此在宕机或复制时都是不安全的,并且还有其他二等公民。在 PostgreSQL 10 中,这在很大程度上被修复了。
|
||||
|
||||
与此同时,我们发现哈希索引已经错过了许多已应用于 B 树多年的相当明显的性能改进。因为哈希索引不支持预写日志记录,以及旧的锁定机制十分笨重,所以没有太多的动机去提升其他的性能。而这意味着如果哈希索引会成为一个非常有用的技术,那么需要做的事只是添加预写日志记录而已。PostgreSQL 索引存取方法的抽象层允许索引保留有关其信息的后端专用缓存,避免了重复查询索引本身来获取相关的元数据。B 树和 SQLite 的索引正在使用这种机制,但哈希索引没有,所以我的同事 Mithun Cy 写了一个补丁来[使用此机制缓存哈希索引的元页][4]。同样,B 树索引有一个称为“单页回收”的优化,它巧妙地从索引页移除没用的索引指针,从而防止了大量索引膨胀,否则这将发生。我的同事 Ashutosh Sharma 打了一个补丁将[这个逻辑移植到哈希索引上][5],也大大减少了索引的膨胀。最后,B 树索引[自 2006 年以来][6]就有了一个功能,可以避免重复锁定和解锁同一个索引页——所有元组都在页中一次性删除,然后一次返回一个。Ashutosh Sharma 也[将此逻辑移植到了哈希索引中][7],但是由于缺少时间,这个优化没有在版本 10 中完成。在这个博客提到的所有内容中,这是唯一一个直到版本 11 才会出现的改进。
|
||||
虽然我参与了一些设计,但改进哈希索引的首要功劳来自我的同事 Amit Kapila,[他在这个话题下的博客值得一读][1]。哈希索引的问题不仅在于没有人打算写预写日志记录的代码,还在于代码没有以某种方式进行结构化,使其可以添加实际上正常工作的预写日志记录。要拆分一个桶,系统将锁定已有的桶(使用一种十分低效的锁定机制),将半个元组移动到新的桶中,压缩已有的桶,然后松开锁。即使记录了个别更改,在错误的时刻发生崩溃也会使索引处于损坏状态。因此,Aimt 首先做的是重新设计锁定机制。[新的机制][2]在某种程度上允许扫描和拆分并行进行,并且允许稍后完成那些因报错或崩溃而被中断的拆分。完成了一系列漏洞的修复和一些重构工作,Aimt 就打了另一个补丁,[添加了支持哈希索引的预写日志记录][3]。
|
||||
|
||||
关于哈希索引的工作有一个更有趣的地方是,很难确定行为是否真的正确。锁定行为的更改只可能在繁重的并发状态下失败,而预写日志记录中的错误可能仅在崩溃恢复的情况下显示出来。除此之外,在每种情况下,问题可能是微妙的。没有东西崩溃还不够;它们还必须在所有情况下产生正确的答案,并且这似乎很难去验证。为了协助这项工作,我的同事 Kuntal Ghosh 先后跟进了最初由 Heikki Linnakangas 和 Michael Paquier 开始的工作,并且制作了一个 WAL 一致性检查器,它不仅可以作为开发人员测试的专用补丁,还能真正[致力于 PostgreSQL][8]。在提交之前,我们对哈希索引的预写日志代码使用此工具进行了广泛的测试,并十分成功地查找到了一些漏洞。这个工具并不仅限于哈希索引,相反:它也可用于其他模块的预写日志记录代码,包括堆,当今的 AMS 索引,以及一些以后开发的其他东西。事实上,它已经成功地[在 BRIN 中找到了一个漏洞][9]。
|
||||
与此同时,我们发现哈希索引已经错过了许多已应用于 B 树索引多年的相当明显的性能改进。因为哈希索引不支持预写日志记录,以及旧的锁定机制十分笨重,所以没有太多的动机去提升其他的性能。而这意味着如果哈希索引会成为一个非常有用的技术,那么需要做的事只是添加预写日志记录而已。PostgreSQL 索引存取方法的抽象层允许索引保留有关其信息的后端专用缓存,避免了重复查询索引本身来获取相关的元数据。B 树和 SQLite 的索引正在使用这种机制,但哈希索引没有,所以我的同事 Mithun Cy 写了一个补丁来[使用此机制缓存哈希索引的元页][4]。同样,B 树索引有一个称为“单页回收”的优化,它巧妙地从索引页移除没用的索引指针,从而防止了大量索引膨胀。我的同事 Ashutosh Sharma 打了一个补丁将[这个逻辑移植到哈希索引上][5],也大大减少了索引的膨胀。最后,B 树索引[自 2006 年以来][6]就有了一个功能,可以避免重复锁定和解锁同一个索引页——所有元组都在页中一次性删除,然后一次返回一个。Ashutosh Sharma 也[将此逻辑移植到了哈希索引中][7],但是由于缺少时间,这个优化没有在版本 10 中完成。在这个博客提到的所有内容中,这是唯一一个直到版本 11 才会出现的改进。
|
||||
|
||||
关于哈希索引的工作有一个更有趣的地方是,很难确定行为是否真的正确。锁定行为的更改只可能在繁重的并发状态下失败,而预写日志记录中的错误可能仅在崩溃恢复的情况下显示出来。除此之外,在每种情况下,问题可能是微妙的。没有东西崩溃还不够;它们还必须在所有情况下产生正确的答案,并且这似乎很难去验证。为了协助这项工作,我的同事 Kuntal Ghosh 先后跟进了最初由 Heikki Linnakangas 和 Michael Paquier 开始的工作,并且制作了一个 WAL 一致性检查器,它不仅可以作为开发人员测试的专用补丁,还能真正[提交到 PostgreSQL][8]。在提交之前,我们对哈希索引的预写日志代码使用此工具进行了广泛的测试,并十分成功地查找到了一些漏洞。这个工具并不仅限于哈希索引,相反:它也可用于其他模块的预写日志记录代码,包括堆,当今的所有 AM 索引,以及一些以后开发的其他东西。事实上,它已经成功地[在 BRIN 中找到了一个漏洞][9]。
|
||||
|
||||
虽然 WAL 一致性检查是主要的开发者工具——尽管它也适合用户使用,如果怀疑有错误——也可以升级到专为数据库管理人员提供的几种工具。Jesper Pedersen 写了一个补丁来[升级 pageinspect contrib 模块来支持哈希索引][10],Ashutosh Sharma 做了进一步的工作,Peter Eisentraut 提供了测试用例(这是一个很好的办法,因为这些测试用例迅速失败,引发了几轮漏洞修复)。多亏了 Ashutosh Sharma 的工作,pgstattuple contrib 模块[也支持哈希索引了][11]。
|
||||
|
||||
一路走来,也有一些其他性能的改进。我一开始没有意识到的是,当一个哈希索引开始新一轮的桶拆分时,磁盘上的大小会突然加倍,这对于 1MB 的索引来说并不是一个问题,但是如果你碰巧有一个 64GB 的索引,那就有些不幸了。Mithun Cy 通过编写一个补丁,把加倍[分为四个阶段][12]在某个程度上解决了这一问题,这意味着我们将从 64GB 到 80GB 到 96GB 到 112GB 到 128GB,而不是一次性从 64GB 到 128GB。这个问题可以进一步改进,但需要对磁盘格式进行更深入的重构,并且需要仔细考虑对查找性能的影响。
|
||||
一路走来,也有一些其他性能的改进。我一开始没有意识到的是,当一个哈希索引开始新一轮的桶拆分时,磁盘上的大小会突然加倍,这对于 1MB 的索引来说并不是一个问题,但是如果你碰巧有一个 64GB 的索引,那就有些不幸了。Mithun Cy 通过编写一个补丁,把加倍过程[分为四个阶段][12]在某个程度上解决了这一问题,这意味着我们将从 64GB 到 80GB 到 96GB 到 112GB 到 128GB,而不是一次性从 64GB 到 128GB。这个问题可以进一步改进,但需要对磁盘格式进行更深入的重构,并且需要仔细考虑对查找性能的影响。
|
||||
|
||||
七月时,一份[来自于“AP”测试人员][13]的报告使我们感到需要做进一步的调整。AP 发现,若试图将 20 亿行数据插入到新创建的哈希索引中会导致错误。为了解决这个问题,Amit 修改了拆分桶的代码,[使得在每次拆分之后清理旧的桶][14],大大减少了溢出页的累积。为了得以确保,Aimt 和我也[增加了四倍的位图页的最大数量][15],用于跟踪溢出页分配。
|
||||
|
||||
虽然还是有更多的事情要做,但我觉得,我和我的同事们——以及在 PostgreSQL 团队中的其他人的帮助下——已经完成了我们的目标,使哈希索引成为一个一流的功能,而不是被严重忽视的半成品。不过,你或许会问,这个功能可能有哪些应用场景。我在文章开头提到的(以及链接中的)Amit 的博客内容表明,即使是 pgbench 的工作负载,哈希索引页也可能在低级和高级并发发面优于 B 树。然而,从某种意义上说,这确实是最坏的情况。哈希索引的卖点之一是,索引存储的是字段的哈希值,而不是原始值——所以,我希望像 UUID 或者长字符串的宽键将有更大的改进。它们可能会在读取繁重的工作负载时做得更好。我们没有像优化读取那种程度来优化写入,但我鼓励任何对此技术感兴趣的人去尝试并将结果发到邮件列表(或发私人电子邮件),因为对于开发一个功能而言,真正关键的并不是一些开发人员去思考在实验室中会发生什么,而是在实际中发生了什么。
|
||||
虽然还是有更多的事情要做,但我觉得,我和我的同事们——以及在 PostgreSQL 团队中的其他人的帮助下——已经完成了我们的目标,使哈希索引成为一个一流的功能,而不是被严重忽视的半成品。不过,你或许会问,这个功能可能有哪些应用场景。我在文章开头提到的(以及链接中的)Amit 的博客内容表明,即使是 pgbench 的工作负载,哈希索引页也可能在低级和高级并发方面优于 B 树。然而,从某种意义上说,这确实是最坏的情况。哈希索引的卖点之一是,索引存储的是字段的哈希值,而不是原始值——所以,我希望像 UUID 或者长字符串的宽键将有更大的改进。它们可能会在读取繁重的工作负载时做得更好。我们没有像优化读取那种程度来优化写入,但我鼓励任何对此技术感兴趣的人去尝试并将结果发到邮件列表(或发私人电子邮件),因为对于开发一个功能而言,真正关键的并不是一些开发人员去思考在实验室中会发生什么,而是在实际中发生了什么。
|
||||
|
||||
最后,我要感谢 Jeff Janes 和 Jesper Pedersen 为这个项目及其相关所做的宝贵的测试工作。这样一个规模适当的项目并不易得,以及有一群坚持不懈的测试人员,他们勇于打破任何废旧的东西的决心起了莫大的帮助。除了以上提到的人之外,其他人同样在测试,审查以及各种各样的日常帮助方面值得赞扬,其中包括 Andreas Seltenreich,Dilip Kumar,Tushar Ahuja,Alvaro Herrera,Micheal Paquier,Mark Kirkwood,Tom Lane,Kyotaro Horiguchi。谢谢你们,也同样感谢那些本该被提及却被我无意中忽略的所有朋友。
|
||||
|
||||
---
|
||||
via:https://rhaas.blogspot.jp/2017/09/postgresqls-hash-indexes-are-now-cool.html?showComment=1507079869582#c6521238465677174123
|
||||
via:https://rhaas.blogspot.jp/2017/09/postgresqls-hash-indexes-are-now-cool.html
|
||||
|
||||
作者:[Robert Haas][a]
|
||||
译者:[polebug](https://github.com/polebug)
|
||||
校对:[校对者ID](https://github.com/id)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由[LCTT](https://github.com/LCTT/TranslateProject)原创编译,[Linux中国](https://linux.cn/)荣誉推出
|
||||
|
||||
[a]:http://rhaas.blogspot.jp
|
||||
@ -0,0 +1,66 @@
|
||||
不,Linux 桌面版并没有突然流行起来
|
||||
============================================================
|
||||
|
||||
> 最近流传着这样一个传闻,Linux 桌面版已经突然流行起来了,并且使用者超过了 macOS。其实,并不是的。
|
||||
|
||||
有一些传闻说,Linux 桌面版的市场占有率从通常的 1.5% - 3% 翻了一番,达到 5%。那些报道是基于 [NetMarketShare][4] 的桌面操作系统分析报告而来的,据其显示,在七月份,Linux 桌面版的市场占有率从 2.5% 飙升,在九月份几乎达到 5%。但对 Linux 爱好者来说,很不幸,它并不是真的。
|
||||
|
||||
它也不是因为加入了谷歌推出的 Chrome OS,它在 [NetMarketShare][4] 和 [StatCounter][5] 的桌面操作系统的数据中被低估,它被认为是 Linux。但请注意,那是公正的,因为 [Chrome OS 是基于 Linux 的][6]。
|
||||
|
||||
真正的解释要简单的多。这似乎只是一个错误。NetMarketShare 的市场营销高管 Vince Vizzaccaro 告诉我,“Linux 份额是不正确的。我们意识到这个问题,目前正在调查此事”。
|
||||
|
||||
如果这听起来很奇怪,那是因为你可能认为,NetMarketShare 和 StatCounter 只是计算用户数量。但他们不是这样的。相反,他们都使用自己的秘密的方法去统计这些操作系统的数据。
|
||||
|
||||
NetMarketShare 的方法是对 “[从网站访问者的浏览器中收集数据][7]到我们专用的请求式 HitsLink 分析网络中和 SharePost 客户端。该网络包括超过 4 万个网站,遍布全球。我们‘计数’访问我们的网络站点的唯一访客,并且一个唯一访客每天每个网络站点只计数一次。”
|
||||
|
||||
然后,公司按国家对数据进行加权。“我们将我们的流量与 CIA 互联网流量按国家进行比较,并相应地对我们的数据进行加权。例如,如果我们的全球数据显示巴西占我们网络流量的 2%,而 CIA 的数据显示巴西占全球互联网流量的 4%,那么我们将统计每一个来自巴西的唯一访客两次。”
|
||||
|
||||
他们究竟如何 “权衡” 每天访问一个站点的数据?我们不知道。
|
||||
|
||||
StatCounter 也有自己的方法。它使用 “[在全球超过 200 万个站点上安装的跟踪代码][8]。这些网站涵盖了各种类型和不同的地理位置。每个月,我们都会记录在这些站点上的数十亿页的页面访问。对于每个页面访问,我们分析其使用的浏览器/操作系统/屏幕分辨率(如果页面访问来自移动设备)。 ... 我们统计了所有这些数据以获取我们的全球统计信息。
|
||||
|
||||
我们为互联网使用趋势提供独立的、公正的统计数据。我们不与任何其他信息源核对我们的统计数据,也 [没有使用人为加权][9]。”
|
||||
|
||||
他们如何汇总他们的数据?你猜猜看?其它我们也不知道。
|
||||
|
||||
因此,无论何时,你看到的他们这些经常被引用的操作系统或浏览器的数字,使用它们要有很大的保留余地。
|
||||
|
||||
对于更精确的,以美国为对象的操作系统和浏览器数量,我更喜欢使用联邦政府的 [数字分析计划(DAP)][10]。
|
||||
|
||||
与其它的不同, DAP 的数字来自在过去的 90 天访问过 [400 个美国政府行政机构域名][11] 的数十亿访问者。那里有 [大概 5000 个网站][12],并且包含每个内阁部门。 DAP 从一个谷歌分析帐户中得到原始数据。 DAP [开源了它在这个网站上显示其数据的代码][13] 以及它的 [数据收集代码][14]。最重要的是,与其它的不同,你可以以 [JSON][15] 格式下载它的数据,这样你就可以自己分析原始数据了。
|
||||
|
||||
在 [美国分析][16] 网站上,它汇总了 DAP 的数据,你可以找到 Linux 桌面版,和往常一样,它仍以 1.5% 列在 “其它” 中。Windows 仍然是高达 45.9%,接下来是 Apple iOS,占 25.5%,Android 占 18.6%,而 macOS 占 8.5%。
|
||||
|
||||
对不起,伙计们,我也希望它更高,但是,这就是事实。没有人,即使是 DAP,似乎都无法很好地将基于 Linux 的 Chrome OS 数据单列出来。尽管如此,Linux 桌面版仍然是 Linux 高手、软件开发者、系统管理员和工程师的专利。Linux 爱好者们还只能对其它所有的计算机设备 —— 服务器、云、超级计算机等等的(Linux)操作系统表示自豪。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/no-the-linux-desktop-hasnt-jumped-in-popularity/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[2]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[3]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[4]:https://www.netmarketshare.com/
|
||||
[5]:https://statcounter.com/
|
||||
[6]:http://www.zdnet.com/article/the-secret-origins-of-googles-chrome-os/
|
||||
[7]:http://www.netmarketshare.com/faq.aspx#Methodology
|
||||
[8]:http://gs.statcounter.com/faq#methodology
|
||||
[9]:http://gs.statcounter.com/faq#no-weighting
|
||||
[10]:https://www.digitalgov.gov/services/dap/
|
||||
[11]:https://analytics.usa.gov/data/live/second-level-domains.csv
|
||||
[12]:https://analytics.usa.gov/data/live/sites.csv
|
||||
[13]:https://github.com/GSA/analytics.usa.gov
|
||||
[14]:https://github.com/18F/analytics-reporter
|
||||
[15]:http://json.org/
|
||||
[16]:https://analytics.usa.gov/
|
||||
[17]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[18]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[19]:http://www.zdnet.com/blog/open-source/
|
||||
[20]:http://www.zdnet.com/topic/enterprise-software/
|
||||
@ -0,0 +1,163 @@
|
||||
瞬间提升命令行的生产力 100%
|
||||
============================================================
|
||||
|
||||
关于生产力的话题总是让人充满兴趣的。
|
||||
|
||||
这里有许多方式提升你的生产力。今天,我共享一些命令行的小技巧,以及让你的人生更轻松的小秘诀。
|
||||
|
||||
### TL;DR
|
||||
|
||||
在本文中讨论的内容的全部设置及更多的信息,可以查看: [https://github.com/sobolevn/dotfiles][9] 。
|
||||
|
||||
### Shell
|
||||
|
||||
使用一个好用的,并且稳定的 shell 对你的命令行生产力是非常关键的。这儿有很多选择,我喜欢 `zsh` 和 `oh-my-zsh`。它是非常神奇的,理由如下:
|
||||
|
||||
* 自动补完几乎所有的东西
|
||||
* 大量的插件
|
||||
* 确实有用且能定制化的“提示符”
|
||||
|
||||
你可以通过下列的步骤去安装它:
|
||||
|
||||
1. 安装 `zsh`: [https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH][1]
|
||||
2. 安装 `oh-my-zsh`: [http://ohmyz.sh/][2]
|
||||
3. 选择对你有用的插件: [https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins][3]
|
||||
|
||||
你也可以调整你的设置以 [关闭自动补完的大小写敏感][10] ,或改变你的 [命令行历史的工作方式][11]。
|
||||
|
||||
就是这样。你将立马获得 +50% 的生产力提升。现在你可以打开足够多的选项卡(tab)了!(LCTT 译注:指多选项卡的命令行窗口)
|
||||
|
||||
### 主题
|
||||
|
||||
选择主题也很重要,因为你从头到尾都在看它。它必须是有用且漂亮的。我也喜欢简约的主题,因为它不包含一些视觉噪音和没用的信息。
|
||||
|
||||
你的主题将为你展示:
|
||||
|
||||
* 当前文件夹
|
||||
* 当前的版本分支
|
||||
* 当前版本库状态:干净或脏的(LCTT 译注:指是否有未提交版本库的内容)
|
||||
* 任何的错误返回码(如果有)(LCTT 译注:Linux 命令如果执行错误,会返回错误码)
|
||||
|
||||
我也喜欢我的主题可以在新起的一行输入新命令,这样就有足够的空间去阅读和书写命令了。
|
||||
|
||||
我个人使用 [`sobole`][12] 主题。它看起来非常棒,它有两种模式。
|
||||
|
||||
亮色的:
|
||||
|
||||
[][13]
|
||||
|
||||
以及暗色的:
|
||||
|
||||
[][14]
|
||||
|
||||
你得到了另外 +15% 的提升,以及一个看起来很漂亮的主题。
|
||||
|
||||
### 语法高亮
|
||||
|
||||
对我来说,从我的 shell 中得到足够的可视信息对做出正确的判断是非常重要的。比如 “这个命令有没有拼写错误?” 或者 “这个命令有相应的作用域吗?” 这样的提示。我经常会有拼写错误。
|
||||
|
||||
因此, [`zsh-syntax-highlighting`][15] 对我是非常有用的。 它有合适的默认值,当然你可以 [改变任何你想要的设置][16]。
|
||||
|
||||
这个步骤可以带给我们额外的 +5% 的提升。
|
||||
|
||||
### 文件处理
|
||||
|
||||
我在我的目录中经常遍历许多文件,至少看起来很多。我经常做这些事情:
|
||||
|
||||
* 来回导航
|
||||
* 列出文件和目录
|
||||
* 显示文件内容
|
||||
|
||||
我喜欢去使用 [`z`][17] 导航到我已经去过的文件夹。这个工具是非常棒的。 它使用“<ruby>近常<rt>frecency</rt></ruby>” 方法来把你输入的 `.dot TAB` 转换成 `~/dev/shell/config/.dotfiles`。真的很不错!
|
||||
|
||||
当你显示文件时,你通常要了解如下几个内容:
|
||||
|
||||
* 文件名
|
||||
* 权限
|
||||
* 所有者
|
||||
* 这个文件的 git 版本状态
|
||||
* 修改日期
|
||||
* 人类可读形式的文件大小
|
||||
|
||||
你也或许希望缺省展示隐藏文件。因此,我使用 [`exa`][18] 来替代标准的 `ls`。为什么呢?因为它缺省启用了很多的东西:
|
||||
|
||||
[][19]
|
||||
|
||||
要显示文件内容,我使用标准的 `cat`,或者,如果我希望看到语法高亮,我使用一个定制的别名:
|
||||
|
||||
```
|
||||
# exa:
|
||||
alias la="exa -abghl --git --color=automatic"
|
||||
|
||||
# `cat` with beautiful colors. requires: pip install -U Pygments
|
||||
alias c='pygmentize -O style=borland -f console256 -g'
|
||||
```
|
||||
|
||||
现在,你已经掌握了导航。它使你的生产力提升 +15% 。
|
||||
|
||||
### 搜索
|
||||
|
||||
当你在应用程序的源代码中搜索时,你不会想在你的搜索结果中缺省包含像 `node_modules` 或 `bower_components` 这样的文件夹。或者,当你想搜索执行的更快更流畅时。
|
||||
|
||||
这里有一个比内置的搜索方式更好的替代: [`the_silver_searcher`][20]。
|
||||
|
||||
它是用纯 `C` 写成的,并且使用了很多智能化的逻辑让它工作的更快。
|
||||
|
||||
在命令行 `history` 中,使用 `ctrl` + `R` 进行 [反向搜索][21] 是非常有用的。但是,你有没有发现你自己甚至不能完全记住一个命令呢?如果有一个工具可以模糊搜索而且用户界面更好呢?
|
||||
|
||||
这里确实有这样一个工具。它叫做 `fzf`:
|
||||
|
||||
[][22]
|
||||
|
||||
它可以被用于任何模糊查询,而不仅是在命令行历史中,但它需要 [一些配置][23]。
|
||||
|
||||
你现在有了一个搜索工具,可以额外提升 +15% 的生产力。
|
||||
|
||||
### 延伸阅读
|
||||
|
||||
更好地使用命令行: [https://dev.to/sobolevn/using-better-clis-6o8][24]。
|
||||
|
||||
### 总结
|
||||
|
||||
通过这些简单的步骤,你可以显著提升你的命令行的生产力 +100% 以上(数字是估计的)。
|
||||
|
||||
这里还有其它的工具和技巧,我将在下一篇文章中介绍。
|
||||
|
||||
你喜欢阅读软件开发方面的最新趋势吗?在这里订阅我们的愽客吧 [https://medium.com/wemake-services][25]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dev.to/sobolevn/instant-100-command-line-productivity-boost
|
||||
|
||||
作者:[Nikita Sobolev][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dev.to/sobolevn
|
||||
[1]:https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH
|
||||
[2]:http://ohmyz.sh/
|
||||
[3]:https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins
|
||||
[4]:https://dev.to/sobolevn
|
||||
[5]:http://github.com/sobolevn
|
||||
[6]:https://dev.to/t/commandline
|
||||
[7]:https://dev.to/t/dotfiles
|
||||
[8]:https://dev.to/t/productivity
|
||||
[9]:https://github.com/sobolevn/dotfiles
|
||||
[10]:https://github.com/sobolevn/dotfiles/blob/master/zshrc#L12
|
||||
[11]:https://github.com/sobolevn/dotfiles/blob/master/zshrc#L24
|
||||
[12]:https://github.com/sobolevn/sobole-zsh-theme
|
||||
[13]:https://res.cloudinary.com/practicaldev/image/fetch/s--Lz_uthoR--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/env-and-user.png
|
||||
[14]:https://res.cloudinary.com/practicaldev/image/fetch/s--4o6hZwL9--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/dark-mode.png
|
||||
[15]:https://github.com/zsh-users/zsh-syntax-highlighting
|
||||
[16]:https://github.com/zsh-users/zsh-syntax-highlighting/blob/master/docs/highlighters.md
|
||||
[17]:https://github.com/rupa/z
|
||||
[18]:https://github.com/ogham/exa
|
||||
[19]:https://res.cloudinary.com/practicaldev/image/fetch/s--n_YCO9Hj--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/ogham/exa/master/screenshots.png
|
||||
[20]:https://github.com/ggreer/the_silver_searcher
|
||||
[21]:https://unix.stackexchange.com/questions/73498/how-to-cycle-through-reverse-i-search-in-bash
|
||||
[22]:https://res.cloudinary.com/practicaldev/image/fetch/s--hykHvwjq--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://thepracticaldev.s3.amazonaws.com/i/erts5tffgo5i0rpi8q3r.png
|
||||
[23]:https://github.com/sobolevn/dotfiles/blob/master/shell/.external#L19
|
||||
[24]:https://dev.to/sobolevn/using-better-clis-6o8
|
||||
[25]:https://medium.com/wemake-services
|
||||
@ -1,30 +1,29 @@
|
||||
博客中最好的 8 种语言
|
||||
如何分析博客中最流行的编程语言
|
||||
============================================================
|
||||
|
||||
|
||||
长文示警:这篇文章我们将对一些各种各样的博客的流行度相对于他们在谷歌上的排名进行一个分析。所有代码可以在 [github][38] 上找到.
|
||||
摘要:这篇文章我们将对一些各种各样的博客的流行度相对于他们在谷歌上的排名进行一个分析。所有代码可以在 [github][38] 上找到.
|
||||
|
||||
### 想法来源
|
||||
|
||||
我一直在想,各种各样的博客每天到底都有多少页面浏览量,以及在博客阅读中最受欢迎的是什么编程语言。我也很感兴趣的是,它们在谷歌的网站排名是否与它们的受欢迎程度直接相关。
|
||||
我一直在想,各种各样的博客每天到底都有多少页面浏览量,以及在博客阅读受众中最受欢迎的是什么编程语言。我也很感兴趣的是,它们在谷歌的网站排名是否与它们的受欢迎程度直接相关。
|
||||
|
||||
为了回答这些问题,我决定做一个 Scrapy 项目,它将收集一些数据,然后对所获得的信息执行特定的数据分析和数据可视化。
|
||||
|
||||
### 第一部分:Scrapy
|
||||
|
||||
我们将使用 [Scrapy][39] 为我们的工作,因为它为抓取和管理处理请求的反馈提供了干净和健壮的框架。我们还将使用 [Splash][40] 来解析需要处理的 Javascript 页面。Splash 使用自己的 Web 服务器充当代理,并处理 Javascript 响应,然后再将其重定向到我们的爬虫进程。
|
||||
我们将使用 [Scrapy][39] 为我们的工作,因为它为抓取和对该请求处理后的反馈进行管理提供了干净和健壮的框架。我们还将使用 [Splash][40] 来解析需要处理的 Javascript 页面。Splash 使用自己的 Web 服务器充当代理,并处理 Javascript 响应,然后再将其重定向到我们的爬虫进程。
|
||||
|
||||
我这里没有描述 Scrapy 的设置,也没有描述 Splash 的集成。你可以在[这里][34]找到 Scrapy 的示例,而[这里][35]还有 Scrapy+Splash 指南。
|
||||
> 我这里没有描述 Scrapy 的设置,也没有描述 Splash 的集成。你可以在[这里][34]找到 Scrapy 的示例,而[这里][35]还有 Scrapy+Splash 指南。
|
||||
|
||||
#### 获得相关的博客
|
||||
|
||||
第一步显然是获取数据。我们需要谷歌关于编程博客的搜索结果。你看,如果我们开始仅仅用谷歌自己来搜索,比如说查询 “Python”,除了博客,我们还会得到很多其他的东西。我们需要的是做一些过滤,只留下特定的博客。幸运的是,有一种叫做 [Google 自定义搜索引擎][41]的东西,它能做到这一点。还有一个网站 [www.blogsearchengine.org][42],它可以执行我们需要的东西,将用户请求委托给 CSE,这样我们就可以查看它的查询并重复它们。
|
||||
第一步显然是获取数据。我们需要关于编程博客的谷歌搜索结果。你看,如果我们开始仅仅用谷歌自己来搜索,比如说查询 “Python”,除了博客,我们还会得到很多其它的东西。我们需要的是做一些过滤,只留下特定的博客。幸运的是,有一种叫做 [Google 自定义搜索引擎(CSE)][41]的东西,它能做到这一点。还有一个网站 [www.blogsearchengine.org][42],它正好可以满足我们需要,它会将用户请求委托给 CSE,这样我们就可以查看它的查询并重复利用它们。
|
||||
|
||||
所以,我们要做的是到 [www.blogsearchengine.org][43] 网站,搜索 “python”,在网络标签页旁边将打开一个Chrome开发者工具。这截图是我们将要看到的。
|
||||
所以,我们要做的是到 [www.blogsearchengine.org][43] 网站,搜索 “python”,并在一侧打开 Chrome 开发者工具中的网络标签页。这截图是我们将要看到的:
|
||||
|
||||

|
||||
|
||||
突出显示的搜索请求是博客搜索引擎向谷歌委派的,所以我们将复制它并在我们的 scraper 中使用。
|
||||
突出显示的是 blogsearchengine 向谷歌委派的一个搜索请求,所以我们将复制它,并在我们的 scraper 中使用。
|
||||
|
||||
这个博客抓取爬行器类会是如下这样的:
|
||||
|
||||
@ -38,13 +37,9 @@ class BlogsSpider(scrapy.Spider):
|
||||
self.queries = queries
|
||||
```
|
||||
|
||||
[view raw][3] [blogs.py][4] 代码托管于
|
||||
|
||||
[GitHub][5]
|
||||
|
||||
与典型的 Scrapy 爬虫不同,我们的方法覆盖了 `__init__` 方法,它接受额外的参数 `queries`,它指定了我们想要执行的查询列表。
|
||||
|
||||
现在,最重要的部分是构建和执行这个实际的查询。这个过程是在执行 `start_requests` 爬虫的方法,我们愉快地覆盖下来:
|
||||
现在,最重要的部分是构建和执行这个实际的查询。这个过程放在 `start_requests` 爬虫的方法里面执行,我们愉快地覆盖它:
|
||||
|
||||
```
|
||||
def start_requests(self):
|
||||
@ -78,13 +73,9 @@ class BlogsSpider(scrapy.Spider):
|
||||
args={'wait': 0.5})
|
||||
```
|
||||
|
||||
[view raw][6] [blogs.py][7] 代码托管于
|
||||
在这里你可以看到相当复杂的 `params_dict` 字典,它控制所有我们之前找到的 Google CSE URL 的参数。然后我们准备好 `url_template` 里的一切,除了已经填好的查询和页码。我们对每种编程语言请求 10 页,每一页包含 10 个链接,所以是每种语言有 100 个不同的博客用来分析。
|
||||
|
||||
[GitHub][8]
|
||||
|
||||
在这里你可以看到相当复杂的 `params_dict` 字典持有所有我们之前找到的 Google CSE URL 的参数。然后我们准备 `url_template` 一切,除了已经填好的查询和页码。我们对每种编程语言请求10页,每一页包含10个链接,所以是每种语言有100个不同的博客用来分析。
|
||||
|
||||
在 `42-43` 行,我使用一个特殊的类 `SplashRequest` 来代替 Scrapy 自带的 Request 类。它可以抓取 Splash 库中的重定向逻辑,所以我们无需为此担心。十分整洁。
|
||||
在 `42-43` 行,我使用一个特殊的类 `SplashRequest` 来代替 Scrapy 自带的 Request 类。它封装了 Splash 库内部的重定向逻辑,所以我们无需为此担心。十分整洁。
|
||||
|
||||
最后,这是解析程序:
|
||||
|
||||
@ -107,19 +98,15 @@ class BlogsSpider(scrapy.Spider):
|
||||
}
|
||||
```
|
||||
|
||||
[view raw][9] [blogs.py][10] 代码托管于
|
||||
|
||||
[GitHub][11]
|
||||
|
||||
所有 scraper 的心脏和灵魂就是解析器的逻辑。可以有多种方法来理解响应页面结构和构建 XPath 查询字符串。您可以使用 [Scrapy shell][44] 尝试和调整你的 XPath 查询在没有运行爬虫的 fly 上。不过我更喜欢可视化的方法。它再次涉及到谷歌 Chrome 的开发人员控制台。只需右键单击你想要用在你的爬虫里的元素,然后按下 Inspect。控制台将定位到你指定位置的 HTML 代码。在本例中,我们想要得到实际的搜索结果链接。他们的源位置是这样的:
|
||||
所有 Scraper 的核心和灵魂就是解析器逻辑。可以有多种方法来理解响应页面的结构并构建 XPath 查询字符串。您可以使用 [Scrapy shell][44] 尝试并随时调整你的 XPath 查询,而不用运行爬虫。不过我更喜欢可视化的方法。它需要再次用到谷歌 Chrome 开发人员控制台。只需右键单击你想要用在你的爬虫里的元素,然后按下 Inspect。它将打开控制台,并定位到你指定位置的 HTML 源代码。在本例中,我们想要得到实际的搜索结果链接。他们的源代码定位是这样的:
|
||||
|
||||

|
||||
|
||||
在查看这个元素的描述后我们看到所找到的 `<div>` 有一个 `.gsc-table-cell-thumbnail` 类,它是 `.gs-title` 的子类,所以我们把它放到响应对象的 `css` 方法(`46` 行)。然后,我们只需要得到博客文章的 URL。它很容易通过`'./a/@href'` XPath 字符串来获得,它能从我们的 `<div>` 子类中将 `href` 属性的标签找到。
|
||||
在查看这个元素的描述后我们看到所找的 `<div>` 有一个 `.gsc-table-cell-thumbnail` CSS 类,它是 `.gs-title` `<div>` 的子元素,所以我们把它放到响应对象的 `css` 方法(`46` 行)。然后,我们只需要得到博客文章的 URL。它很容易通过`'./a/@href'` XPath 字符串来获得,它能从我们的 `<div>` 直接子元素的 `href` 属性找到。(LCTT 译注:此处图文对不上)
|
||||
|
||||
#### 发现流量数据
|
||||
#### 寻找流量数据
|
||||
|
||||
下一个任务是估测每个博客每天接收到的查看 数量。有[各种各样的选择][45],可以获得免费和付费的数据。在快速搜索之后,我决定坚持使用这个简单且免费的网站 [www.statshow.com][46]。我们在前一步获得的博客的 URL 将用作这个网站的爬虫,通过它们并添加流量信息。爬虫的初始化是这样的:
|
||||
下一个任务是估测每个博客每天得到的页面浏览量。得到这样的数据有[各种方式][45],有免费的,也有付费的。在快速搜索之后,我决定基于简单且免费的原因使用网站 [www.statshow.com][46] 来做。爬虫将抓取这个网站,我们在前一步获得的博客的 URL 将作为这个网站的输入参数,获得它们的流量信息。爬虫的初始化是这样的:
|
||||
|
||||
```
|
||||
class TrafficSpider(scrapy.Spider):
|
||||
@ -131,11 +118,7 @@ class TrafficSpider(scrapy.Spider):
|
||||
self.blogs_data = blogs_data
|
||||
```
|
||||
|
||||
[view raw][12][traffic.py][13] 代码托管于
|
||||
|
||||
[GitHub][14]
|
||||
|
||||
`blogs_data` 将被格式化为词典的列表项:`{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}`.
|
||||
`blogs_data` 应该是以下格式的词典列表:`{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}`。
|
||||
|
||||
请求构建函数如下:
|
||||
|
||||
@ -150,11 +133,7 @@ class TrafficSpider(scrapy.Spider):
|
||||
yield request
|
||||
```
|
||||
|
||||
[view raw][15][traffic.py][16] 代码托管于
|
||||
|
||||
[GitHub][17]
|
||||
|
||||
它相当的简单,我们只是添加了字符串 `/www/web-site-url/` 到 `'www.statshow.com'` URL 中。
|
||||
它相当的简单,我们只是把字符串 `/www/web-site-url/` 添加到 `'www.statshow.com'` URL 中。
|
||||
|
||||
现在让我们看一下语法解析器是什么样子的:
|
||||
|
||||
@ -172,17 +151,13 @@ class TrafficSpider(scrapy.Spider):
|
||||
yield blog_data
|
||||
```
|
||||
|
||||
[view raw][18][traffic.py][19] 代码托管于
|
||||
|
||||
[GitHub][20]
|
||||
|
||||
与博客解析程序类似,我们只是通过 StatShow 示例的返回页面,并跟踪包含每日页面查看 和每日访问者的元素。这两个参数都确定了网站的受欢迎程度,所以我们只需要为我们的分析选择页面查看 。
|
||||
与博客解析程序类似,我们只是通过 StatShow 示例的返回页面,然后找到包含每日页面浏览量和每日访问者的元素。这两个参数都确定了网站的受欢迎程度,对于我们的分析只需要使用页面浏览量即可 。
|
||||
|
||||
### 第二部分:分析
|
||||
|
||||
这部分是分析我们搜集到的所有数据。然后,我们用名为 [Bokeh][47] 的库来可视化准备好的数据集。我在这里没有给出其他的可视化代码,但是它可以在 [GitHub repo][48] 中找到,包括你在这篇文章中看到的和其他一切东西。
|
||||
这部分是分析我们搜集到的所有数据。然后,我们用名为 [Bokeh][47] 的库来可视化准备好的数据集。我在这里没有给出运行器和可视化的代码,但是它可以在 [GitHub repo][48] 中找到,包括你在这篇文章中看到的和其他一切东西。
|
||||
|
||||
最初的结果集含有少许偏离中心过大的数据,(如 google.com、linkedin.com、Oracle.com 等)。它们显然不应该被考虑。即使有些人有博客,他们也不是特定的语言。这就是为什么我们基于这个 [this StackOverflow answer][36] 中所建议的方法来过滤异常值。
|
||||
> 最初的结果集含有少许偏离过大的数据,(如 google.com、linkedin.com、Oracle.com 等)。它们显然不应该被考虑。即使其中有些有博客,它们也不是针对特定语言的。这就是为什么我们基于这个 [StackOverflow 回答][36] 中所建议的方法来过滤异常值。
|
||||
|
||||
#### 语言流行度比较
|
||||
|
||||
@ -208,23 +183,19 @@ def get_languages_popularity(data):
|
||||
|
||||
```
|
||||
|
||||
[view raw][21][analysis.py][22] 代码托管于
|
||||
在这里,我们首先按语言(词典中的关键字“query”)来分组我们的数据,然后使用 python 的 `groupby` 函数,这是一个从 SQL 中借来的奇妙函数,从我们的数据列表中生成一组条目,每个条目都表示一些编程语言。然后,在第 `14` 行我们计算每一种语言的总页面浏览量,然后添加 `('Language', rank)` 形式的元组到 `popularity` 列表中。在循环之后,我们根据总浏览量对流行度数据进行排序,并将这些元组展开到两个单独的列表中,然后在 `result` 变量中返回它们。
|
||||
|
||||
[GitHub][23]
|
||||
|
||||
在这里,我们首先使用语言(词典中的关键字“query”)来分组我们的数据,然后使用 python 的 `groupby` 函数,这是一个从 SQL 中借来的奇妙函数,从我们的数据列表中生成一组条目,每个条目都表示一些编程语言。然后,在第 `14` 行我们计算的每一种语言的总页面查看 ,然后添加表单的元组`('Language', rank)`到 `popularity` 列表中。在循环之后,我们根据总查看 对流行数据进行排序,并将这些元组解压缩到两个单独的列表中,并在 `result` 变量中返回这些元组。
|
||||
|
||||
最初的数据集有很大的偏差。我检查了到底发生了什么,并意识到如果我在 [blogsearchengine.org][37] 上查询“C”,我就会得到很多无关的链接,其中包含了 “C” 的字母。因此,我必须将 C 排除在分析之外。它几乎不会在“R”和其他类似 C 的名称中出现:“C++”,“C”。
|
||||
> 最初的数据集有很大的偏差。我检查了到底发生了什么,并意识到如果我在 [blogsearchengine.org][37] 上查询“C”,我就会得到很多无关的链接,其中包含了 “C” 的字母。因此,我必须将 C 排除在分析之外。这种情况几乎不会在 “R” 和其他类似 C 的名称中出现:“C++”、“C”。
|
||||
|
||||
因此,如果我们将 C 从考虑中移除并查看其他语言,我们可以看到如下图:
|
||||
|
||||
|
||||
|
||||
据评估。Java 每天有超过 400 万的浏览量,PHP 和 Go 有超过 200 万,R 和 JavaScript 也突破了百万大关。
|
||||
评估结论:Java 每天有超过 400 万的浏览量,PHP 和 Go 有超过 200 万,R 和 JavaScript 也突破了百万大关。
|
||||
|
||||
#### 每日网页浏览量与谷歌排名
|
||||
|
||||
现在让我们来看看每日访问量的数量和谷歌的博客排名之间的联系。从逻辑上来说,不那么受欢迎的博客应该排名靠后,但这并不容易,因为其他因素也会影响排名,例如,如果在人气较低的博客上的文章是最近的,那么它很可能会首先出现。
|
||||
现在让我们来看看每日访问量和谷歌的博客排名之间的联系。从逻辑上来说,不那么受欢迎的博客应该排名靠后,但这并没那么简单,因为其他因素也会影响排名,例如,如果在人气较低的博客上的文章更新一些,那么它很可能会首先出现。
|
||||
|
||||
数据准备工作以下列方式进行:
|
||||
|
||||
@ -245,11 +216,7 @@ def get_languages_popularity(data):
|
||||
return result
|
||||
```
|
||||
|
||||
[view raw][24][analysis.py][25] 代码托管于
|
||||
|
||||
[GitHub][26]
|
||||
|
||||
该函数需要考虑接受爬到的数据和语言列表。我们对这些数据进行排序,就像我们对语言的受欢迎程度一样。后来,在类似的语言分组循环中,我们构建了 `(rank, views_number)` 元组(以1为基础)被转换为 2 个单独的列表。然后将这一对列表写入到生成的字典中。
|
||||
该函数接受爬取到的数据和需要考虑的语言列表。我们对这些数据以语言的流行程度进行排序。后来,在类似的语言分组循环中,我们构建了 `(rank, views_number)` 元组(从 1 开始的排名)被转换为 2 个单独的列表。然后将这一对列表写入到生成的字典中。
|
||||
|
||||
前 8 位 GitHub 语言(除了 C)是如下这些:
|
||||
|
||||
@ -257,41 +224,33 @@ def get_languages_popularity(data):
|
||||
|
||||
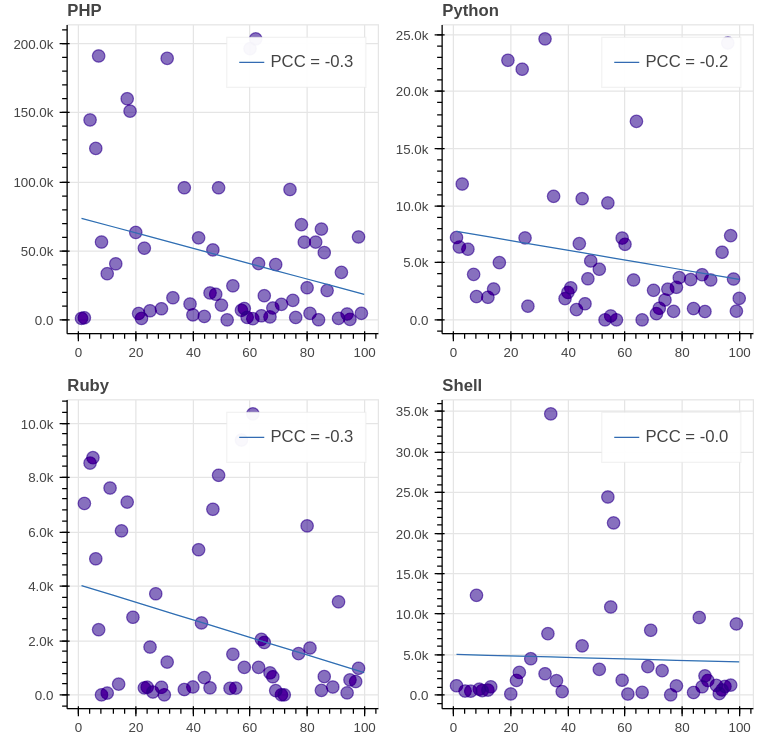
|
||||
|
||||
据评估。我们看到,[PCC (皮尔逊相关系数)][49]的所有图都远离 1/-1,这表示每日查看 与排名之间缺乏相关性。值得注意的是,在大多数图表(7/8)中,相关性是负的,这意味着排名的下降会导致查看的减少。
|
||||
评估结论:我们看到,所有图的 [PCC (皮尔逊相关系数)][49]都远离 1/-1,这表示每日浏览量与排名之间缺乏相关性。值得注意的是,在大多数图表(8 个中的 7 个)中,相关性是负的,这意味着排名的降低会导致浏览量的减少。
|
||||
|
||||
### 结论
|
||||
|
||||
因此,根据我们的分析,Java 是目前最流行的编程语言,其次是 PHP、Go、R 和 JavaScript。在谷歌的日常浏览和排名中,排名前 8 的语言都没有很强的相关性,所以即使你刚刚开始写博客,你也可以在搜索结果中获得很高的评价。不过,成为热门博客究竟需要什么,可以留待下次讨论。
|
||||
因此,根据我们的分析,Java 是目前最流行的编程语言,其次是 PHP、Go、R 和 JavaScript。在日常浏览量和谷歌排名上,排名前 8 的语言都没有很强的相关性,所以即使你刚刚开始写博客,你也可以在搜索结果中获得很高的评价。不过,成为热门博客究竟需要什么,可以留待下次讨论。
|
||||
|
||||
这些结果是相当有偏差的,如果没有额外的分析,就不能过分的考虑这些结果。首先,在较长的一段时间内收集更多的流量信息,然后分析每日查看和排名的平均值(中值)值是一个好主意。也许我以后还会再回来讨论这个。
|
||||
> 这些结果是相当有偏差的,如果没有更多的分析,就不能过分的考虑这些结果。首先,在较长的一段时间内收集更多的流量信息,然后分析每日浏览量和排名的平均值(中值)值是一个好主意。也许我以后还会再回来讨论这个。
|
||||
|
||||
### 引用
|
||||
|
||||
1. Scraping:
|
||||
|
||||
2. [blog.scrapinghub.com: Handling Javascript In Scrapy With Splash][27]
|
||||
|
||||
3. [BlogSearchEngine.org][28]
|
||||
|
||||
4. [twingly.com: Twingly Real-Time Blog Search][29]
|
||||
|
||||
5. [searchblogspot.com: finding blogs on blogspot platform][30]
|
||||
|
||||
6. Traffic estimation:
|
||||
|
||||
7. [labnol.org: Find Out How Much Traffic a Website Gets][31]
|
||||
|
||||
8. [quora.com: What are the best free tools that estimate visitor traffic…][32]
|
||||
|
||||
9. [StatShow.com: The Stats Maker][33]
|
||||
1. 抓取:
|
||||
2. [blog.scrapinghub.com: Handling Javascript In Scrapy With Splash][27]
|
||||
3. [BlogSearchEngine.org][28]
|
||||
4. [twingly.com: Twingly Real-Time Blog Search][29]
|
||||
5. [searchblogspot.com: finding blogs on blogspot platform][30]
|
||||
6. 流量评估:
|
||||
7. [labnol.org: Find Out How Much Traffic a Website Gets][31]
|
||||
8. [quora.com: What are the best free tools that estimate visitor traffic…][32]
|
||||
9. [StatShow.com: The Stats Maker][33]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.databrawl.com/2017/10/08/blog-analysis/
|
||||
|
||||
作者:[Serge Mosin ][a]
|
||||
作者:[Serge Mosin][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,71 @@
|
||||
CyberShaolin:培养下一代网络安全专家
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> CyberShaolin 联合创始人 Reuben Paul 将在布拉格的开源峰会上发表演讲,强调网络安全意识对于孩子们的重要性。
|
||||
|
||||
Reuben Paul 并不是唯一一个玩电子游戏的孩子,但是他对游戏和电脑的痴迷使他走上了一段独特的好奇之旅,引起了他对网络安全教育和宣传的早期兴趣,并创立了 CyberShaolin,一个帮助孩子理解网络攻击的威胁。现年 11 岁的 Paul 将在[布拉格开源峰会](LCTT 译注:已于 10 月 28 举办)上发表主题演讲,分享他的经验,并强调玩具、设备和日常使用的其他技术的不安全性。
|
||||
|
||||

|
||||
|
||||
*CyberShaolin 联合创始人 Reuben Paul*
|
||||
|
||||
我们采访了 Paul 听取了他的故事,并讨论 CyberShaolin 及其教育、赋予孩子(及其父母)的网络安全危险和防御知识。
|
||||
|
||||
Linux.com:你对电脑的迷恋是什么时候开始的?
|
||||
|
||||
Reuben Paul:我对电脑的迷恋始于电子游戏。我喜欢手机游戏以及视频游戏。(我记得是)当我大约 5 岁时,我通过 Gameloft 在手机上玩 “Asphalt” 赛车游戏。这是一个简单而有趣的游戏。我得触摸手机右侧加快速度,触摸手机左侧减慢速度。我问我爸,“游戏怎么知道我触摸了哪里?”
|
||||
|
||||
他研究发现,手机屏幕是一个 xy 坐标系统,所以他告诉我,如果 x 值大于手机屏幕宽度的一半,那么它是右侧的触摸。否则,这是左侧接触。为了帮助我更好地理解这是如何工作的,他给了我一个线性的方程,它是 y = mx + b,并问:“你能找每个 x 值 对应的 y 值吗?”大约 30 分钟后,我计算出了所有他给我的 x 对应的 y 值。
|
||||
|
||||
当我父亲意识到我能够学习编程的一些基本逻辑时,他给我介绍了 Scratch,并且使用鼠标指针的 x 和 y 值编写了我的第一个游戏 - 名为 “大鱼吃小鱼”。然后,我爱上了电脑。
|
||||
|
||||
Linux.com:你对网络安全感兴趣吗?
|
||||
|
||||
Paul:我的父亲 Mano Paul 曾经在网络安全方面培训他的商业客户。每当他在家里工作,我都会听到他的电话交谈。到了我 6 岁的时候,我就知道互联网、防火墙和云计算等东西。当我的父亲意识到我有兴趣和学习的潜力,他开始教我安全方面,如社会工程技术、克隆网站、中间人攻击技术、hack 移动应用等等。当我第一次从目标测试机器上获得一个 meterpreter shell 时,我的感觉就像 Peter Parker 刚刚发现他的蜘蛛侠的能力一样。
|
||||
|
||||
Linux.com:你是如何以及为什么创建 CyberShaolin 的?
|
||||
|
||||
Paul:当我 8 岁的时候,我首先在 DerbyCon 上做了主题为“来自(8 岁大)孩子之口的安全信息”的演讲。那是在 2014 年 9 月。那次会议之后,我收到了几个邀请函,2014 年底之前,我还在其他三个会议上做了主题演讲。
|
||||
|
||||
所以,当孩子们开始听到我在这些不同的会议上发言时,他们开始写信给我,要我教他们。我告诉我的父母,我想教别的孩子,他们问我怎么想。我说:“也许我可以制作一些视频,并在像 YouTube 这样的频道上发布。”他们问我是否要收费,而我说“不”。我希望我的视频可以免费供在世界上任何地方的任何孩子使用。CyberShaolin 就是这样创建的。
|
||||
|
||||
Linux.com:CyberShaolin 的目标是什么?
|
||||
|
||||
Paul:CyberShaolin 是我父母帮助我创立的非营利组织。它的任务是教育、赋予孩子(和他们的父母)掌握网络安全的危险和防范知识,我在学校的空闲时间开发了这些视频和其他训练材料,连同功夫、体操、游泳、曲棍球、钢琴和鼓等。迄今为止,我已经在 www.CyberShaolin.org 网站上发布了大量的视频,并计划开发更多的视频。我也想制作游戏和漫画来支持安全学习。
|
||||
|
||||
CyberShaolin 来自两个词:网络和少林。网络这个词当然是来自技术。少林来自功夫武术,我和我的父亲都是黑带 2 段。在功夫方面,我们有显示知识进步的缎带,你可以想像 CyberShaolin 像数码技术方面的功夫,在我们的网站上学习和考试后,孩子们可以成为网络黑带。
|
||||
|
||||
Linux.com:你认为孩子对网络安全的理解有多重要?
|
||||
|
||||
Paul:我们生活在一个技术和设备不仅存在我们家里,还在我们学校和几乎任何你去的地方的时代。世界也正在与物联网联系起来,这些物联网很容易成为威胁网(Internet of Threats)。儿童是这些技术和设备的主要用户之一。不幸的是,这些设备和设备上的应用程序不是很安全,可能会给儿童和家庭带来严重的问题。例如,最近(2017 年 5 月),我演示了如何攻入智能玩具泰迪熊,并将其变成远程侦察设备。孩子也是下一代。如果他们对网络安全没有意识和训练,那么未来(我们的未来)将不会很好。
|
||||
|
||||
Linux.com:该项目如何帮助孩子?
|
||||
|
||||
Paul:正如我之前提到的,CyberShaolin 的使命是教育、赋予孩子(和他们的父母)网络安全的危险和防御知识。
|
||||
|
||||
当孩子们受到网络欺凌、中间人、钓鱼、隐私、在线威胁、移动威胁等网络安全危害的教育时,他们将具备知识和技能,从而使他们能够在网络空间做出明智的决定并保持安全。而且,正如我永远不会用我的功夫技能去伤害某个人一样,我希望所有的 CyberShaolin 毕业生都能利用他们的网络功夫技能为人类的利益创造一个安全的未来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Swapnil Bhartiya 是一名记者和作家,专注在 Linux 和 Open Source 上 10 多年。
|
||||
|
||||
-------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/cybershaolin-teaching-next-generation-cybersecurity-experts/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/sbhartiya/
|
||||
[1]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[2]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[3]:https://www.linuxfoundation.org/author/sbhartiya/
|
||||
[4]:https://www.linuxfoundation.org/category/blog/
|
||||
[5]:https://www.linuxfoundation.org/category/campaigns/events-campaigns/
|
||||
[6]:https://www.linuxfoundation.org/category/blog/qa/
|
||||
@ -1,16 +1,17 @@
|
||||
怎么在一台树莓派上安装 Postgres 数据库
|
||||
============================================================
|
||||
|
||||
### 在你的下一个树莓派项目上安装和配置流行的开源数据库 Postgres 并去使用它。
|
||||
> 在你的下一个树莓派项目上安装和配置流行的开源数据库 Postgres 并去使用它。
|
||||
|
||||

|
||||
|
||||
Image credits : Raspberry Pi Foundation. [CC BY-SA 4.0][12].
|
||||
|
||||
保存你的项目或应用程序持续增加的数据,数据库是一种很好的方式。你可以在一个会话中将数据写入到数据库,并且在下次你需要查找的时候找到它。一个设计良好的数据库可以在巨大的数据集中高效地找到数据,只要告诉它你想去找什么,而不用去考虑它是如何查找的。为一个基本的 [CRUD][13] (创建、记录、更新、删除) 应用程序安装一个数据库是非常简单的, 它是一个很通用的模式,并且也适用于很多项目。
|
||||
保存你的项目或应用程序持续增加的数据,数据库是一种很好的方式。你可以在一个会话中将数据写入到数据库,并且在下次你需要查找的时候找到它。一个设计良好的数据库可以做到在巨大的数据集中高效地找到数据,只要告诉它你想去找什么,而不用去考虑它是如何查找的。为一个基本的 [CRUD][13] (创建、记录、更新、删除)应用程序安装一个数据库是非常简单的, 它是一个很通用的模式,并且也适用于很多项目。
|
||||
|
||||
为什么 [PostgreSQL][14],一般被为 Postgres? 它被认为是在功能和性能方面最好的开源数据库。如果你使用过 MySQL,它们是很相似的。但是,如果你希望使用它更高级的功能,你会发现优化 Postgres 是比较容易的。它便于安装、容易使用、方便安全, 而且在树莓派 3 上运行的非常好。
|
||||
为什么 [PostgreSQL][14],一般被为 Postgres? 它被认为是功能和性能最好的开源数据库。如果你使用过 MySQL,它们是很相似的。但是,如果你希望使用它更高级的功能,你会发现优化 Postgres 是比较容易的。它便于安装、容易使用、方便安全, 而且在树莓派 3 上运行的非常好。
|
||||
|
||||
本教程介绍了怎么在一个树莓派上去安装 Postgres;创建一个表;写简单查询;在树莓派上使用 pgAdmin 图形用户界面, 一台 PC,或者一台 Mac,从 Python 中与数据库互相配合。
|
||||
本教程介绍了怎么在一个树莓派上去安装 Postgres;创建一个表;写简单查询;在树莓派、PC,或者 Mac 上使用 pgAdmin 图形用户界面;从 Python 中与数据库交互。
|
||||
|
||||
你掌握了这些基础知识后,你可以让你的应用程序使用复合查询连接多个表,那个时候你需要考虑的是,怎么去使用主键或外键优化及最佳实践等等。
|
||||
|
||||
@ -23,8 +24,6 @@ sudo apt install postgresql libpq-dev postgresql-client
|
||||
postgresql-client-common -y
|
||||
```
|
||||
|
||||
### [postgres-install.png][1]
|
||||
|
||||

|
||||
|
||||
当安装完成后,切换到 Postgres 用户去配置数据库:
|
||||
@ -33,32 +32,30 @@ postgresql-client-common -y
|
||||
sudo su postgres
|
||||
```
|
||||
|
||||
现在,你可以创建一个数据库用户。如果你创建了一个与你的 Unix 用户帐户相同名字的用户,那个用户将被自动授权访问数据库。因此在本教程中,为简单起见,我们将假设你使用了一个缺省的 pi 用户。继续去运行 **createuser** 命令:
|
||||
现在,你可以创建一个数据库用户。如果你创建了一个与你的 Unix 用户帐户相同名字的用户,那个用户将被自动授权访问该数据库。因此在本教程中,为简单起见,我们将假设你使用了默认用户 `pi` 。运行 `createuser` 命令以继续:
|
||||
|
||||
```
|
||||
createuser pi -P --interactive
|
||||
```
|
||||
|
||||
当提示时,输入一个密码 (并记住它), 选择 **n** 使它成为一个超级用户,接下来两个问题选择 **y** 。
|
||||
|
||||
### [postgres-createuser.png][2]
|
||||
当得到提示时,输入一个密码 (并记住它), 选择 `n` 使它成为一个非超级用户(LCTT 译注:此处原文有误),接下来两个问题选择 `y`(LCTT 译注:分别允许创建数据库和其它用户)。
|
||||
|
||||

|
||||
|
||||
现在,使用 shell 连接到 Postgres 去创建一个测试数据库:
|
||||
现在,使用 Postgres shell 连接到 Postgres 去创建一个测试数据库:
|
||||
|
||||
```
|
||||
$ psql
|
||||
> create database test;
|
||||
```
|
||||
|
||||
退出 psql shell,然后,按下 Ctrl+D 两次从 Postgres 中退出,再次以 pi 用户登入。从你创建了一个名为 pi 的 Postgres 用户后,你可以从这里无需登陆凭据访问 Postgres shell:
|
||||
按下 `Ctrl+D` **两次**从 psql shell 和 postgres 用户中退出,再次以 `pi` 用户登入。你创建了一个名为 `pi` 的 Postgres 用户后,你可以从这里无需登录凭据即可访问 Postgres shell:
|
||||
|
||||
```
|
||||
$ psql test
|
||||
```
|
||||
|
||||
你现在已经连接到 "test" 数据库。这个数据库当前是空的,不包含任何表。你可以从 psql shell 上创建一个简单的表:
|
||||
你现在已经连接到 "test" 数据库。这个数据库当前是空的,不包含任何表。你可以在 psql shell 里创建一个简单的表:
|
||||
|
||||
```
|
||||
test=> create table people (name text, company text);
|
||||
@ -84,8 +81,6 @@ test=> select * from people;
|
||||
(2 rows)
|
||||
```
|
||||
|
||||
### [postgres-query.png][3]
|
||||
|
||||

|
||||
|
||||
```
|
||||
@ -99,55 +94,47 @@ test=> select name from people where company = 'Red Hat';
|
||||
|
||||
### pgAdmin
|
||||
|
||||
如果希望使用一个图形工具去访问数据库,你可以找到它。 PgAdmin 是一个全功能的 PostgreSQL GUI,它允许你去创建和管理数据库和用户、创建和修改表、执行查询,和在熟悉的视图中像电子表格一样浏览结果。psql 命令行工具可以很好地进行简单查询,并且你会发现很多高级用户一直在使用它,因为它的执行速度很快 (并且因为他们不需要借助 GUI),但是,一般用户学习和操作数据库,使用 pgAdmin 是一个更适合的方式。
|
||||
如果希望使用一个图形工具去访问数据库,你可以使用它。 PgAdmin 是一个全功能的 PostgreSQL GUI,它允许你去创建和管理数据库和用户、创建和修改表、执行查询,和如同在电子表格一样熟悉的视图中浏览结果。psql 命令行工具可以很好地进行简单查询,并且你会发现很多高级用户一直在使用它,因为它的执行速度很快 (并且因为他们不需要借助 GUI),但是,一般用户学习和操作数据库,使用 pgAdmin 是一个更适合的方式。
|
||||
|
||||
关于 pgAdmin 可以做的其它事情:你可以用它在树莓派上直接连接数据库,或者用它在其它的电脑上远程连接到树莓派上的数据库。
|
||||
|
||||
如果你想去访问树莓派,你可以用 **apt** 去安装它:
|
||||
如果你想去访问树莓派,你可以用 `apt` 去安装它:
|
||||
|
||||
```
|
||||
sudo apt install pgadmin3
|
||||
```
|
||||
|
||||
它是和基于 Debian 的系统如 Ubuntu 是完全相同的;如果你在其它分发版上安装,尝试与你的系统相关的等价的命令。 或者,如果你在 Windows 或 macOS 上,尝试从 [pgAdmin.org][15] 上下载 pgAdmin。注意,在 **apt** 上的可用版本是 pgAdmin3,而最新的版本 pgAdmin4,在网站上可以找到。
|
||||
它是和基于 Debian 的系统如 Ubuntu 是完全相同的;如果你在其它发行版上安装,尝试与你的系统相关的等价的命令。 或者,如果你在 Windows 或 macOS 上,尝试从 [pgAdmin.org][15] 上下载 pgAdmin。注意,在 `apt` 上的可用版本是 pgAdmin3,而最新的版本 pgAdmin4,在其网站上可以找到。
|
||||
|
||||
在同一台树莓派上使用 pgAdmin 连接到你的数据库,从主菜单上简单地打开 pgAdmin3 ,点击 **new connection** 图标,然后完成注册,这时,你将需要一个名字(选择连接名,比如 test),改变用户为 "pi",然后剩下的输入框留空 (或者像他们一样)。点击 OK,然后你在左侧的侧面版中将发现一个连接。
|
||||
|
||||
### [pgadmin-connect.png][4]
|
||||
在同一台树莓派上使用 pgAdmin 连接到你的数据库,从主菜单上简单地打开 pgAdmin3 ,点击 **new connection** 图标,然后完成注册,这时,你将需要一个名字(连接名,比如 test),改变用户为 “pi”,然后剩下的输入框留空 (或者如它们原本不动)。点击 OK,然后你在左侧的侧面版中将发现一个新的连接。
|
||||
|
||||

|
||||
|
||||
从另外一台电脑上使用 pgAdmin 连接到你的树莓派数据库上,你首先需要编辑 PostgreSQL 配置允许远程连接:
|
||||
要从另外一台电脑上使用 pgAdmin 连接到你的树莓派数据库上,你首先需要编辑 PostgreSQL 配置允许远程连接:
|
||||
|
||||
1\. 编辑 PostgreSQL 配置文件 **/etc/postgresql/9.6/main/postgresql.conf** ,去取消注释 **listen_addresses** 行并改变它的值,从 **localhost** 到 *****。然后保存并退出。
|
||||
1、 编辑 PostgreSQL 配置文件 `/etc/postgresql/9.6/main/postgresql.conf` ,取消 `listen_addresses` 行的注释,并把它的值从 `localhost` 改变成 `*`。然后保存并退出。
|
||||
|
||||
2、 编辑 pg_hba 配置文件 `/etc/postgresql/9.6/main/postgresql.conf`,将 `127.0.0.1/32` 改变成 `0.0.0.0/0` (对于IPv4)和将 `::1/128` 改变成 `::/0` (对于 IPv6)。然后保存并退出。
|
||||
|
||||
2\. 编辑 **pg_hba** 配置文件 **/etc/postgresql/9.6/main/postgresql.conf** ,去改变 **127.0.0.1/32** 到 **0.0.0.0/0** (对于IPv4)和 **::1/128** 到 **::/0** (对于IPv6)。然后保存并退出。
|
||||
3、 重启 PostgreSQL 服务: `sudo service postgresql restart`。
|
||||
|
||||
3\. 重启 PostgreSQL 服务: **sudo service postgresql restart**。
|
||||
|
||||
注意,如果你使用一个旧的 Raspbian image 或其它分发版,版本号可能不一样。
|
||||
|
||||
### [postgres-config.png][5]
|
||||
注意,如果你使用一个旧的 Raspbian 镜像或其它发行版,版本号可能不一样。
|
||||
|
||||

|
||||
|
||||
做完这些之后,在其它的电脑上打开 pgAdmin 并创建一个新的连接。这时,需要提供一个连接名,输入树莓派的 IP 地址作为主机 (这可以在任务栏的 WiFi 图标上或者在一个终端中输入 **hostname -I** 找到)。
|
||||
|
||||
### [pgadmin-remote.png][6]
|
||||
做完这些之后,在其它的电脑上打开 pgAdmin 并创建一个新的连接。这时,需要提供一个连接名,输入树莓派的 IP 地址作为主机(这可以在任务栏的 WiFi 图标上悬停鼠标找到,或者在一个终端中输入 `hostname -I` 找到)。
|
||||
|
||||

|
||||
|
||||
不论你连接的是本地的还是远程的数据库,点击打开 **Server Groups > Servers > test > Schemas > public > Tables**,右键单击 **people** 表,然后选择 **View Data > View top 100 Rows**。你现在将看到你前面输入的数据。
|
||||
|
||||
### [pgadmin-view.png][7]
|
||||
|
||||

|
||||
|
||||
你现在可以创建和修改数据库和表、管理用户,和使用 GUI 去写你自己的查询。你可能会发现这种可视化方法比命令行更易于管理。
|
||||
你现在可以创建和修改数据库和表、管理用户,和使用 GUI 去写你自己的查询了。你可能会发现这种可视化方法比命令行更易于管理。
|
||||
|
||||
### Python
|
||||
|
||||
从一个 Python 脚本连接到你的数据库,你将需要 [Psycopg2][16] 这个 Python 包。你可以用 [pip][17] 来安装它:
|
||||
要从一个 Python 脚本连接到你的数据库,你将需要 [Psycopg2][16] 这个 Python 包。你可以用 [pip][17] 来安装它:
|
||||
|
||||
```
|
||||
sudo pip3 install psycopg2
|
||||
@ -169,14 +156,14 @@ for result in results:
|
||||
print(result)
|
||||
```
|
||||
|
||||
运行这个代码去看查询结果。注意,如果你连接的是远程数据库,在连接字符串中你将提供更多的凭据,比如,增加主机 IP、用户名,和数据库密码:
|
||||
运行这个代码去看查询结果。注意,如果你连接的是远程数据库,在连接字符串中你将需要提供更多的凭据,比如,增加主机 IP、用户名,和数据库密码:
|
||||
|
||||
```
|
||||
conn = psycopg2.connect('host=192.168.86.31 user=pi
|
||||
password=raspberry dbname=test')
|
||||
```
|
||||
|
||||
你甚至可以创建一个函数去查找特定的查询:
|
||||
你甚至可以创建一个函数去运行特定的查询:
|
||||
|
||||
```
|
||||
def get_all_people():
|
||||
@ -190,7 +177,7 @@ def get_all_people():
|
||||
return cur.fetchall()
|
||||
```
|
||||
|
||||
和一个包含的查询:
|
||||
和一个包含参数的查询:
|
||||
|
||||
```
|
||||
def get_people_by_company(company):
|
||||
@ -221,29 +208,25 @@ def add_person(name, company):
|
||||
cur.execute(query, values)
|
||||
```
|
||||
|
||||
注意,这里使用了一个注入字符串到查询的安全的方法, 你不希望通过 [little bobby tables][18] 被抓住!
|
||||
|
||||
### [python-postgres.png][8]
|
||||
注意,这里使用了一个注入字符串到查询中的安全的方法, 你不希望被 [小鲍勃的桌子][18] 害死!
|
||||
|
||||

|
||||
|
||||
现在你知道了这些基础知识,如果你想去进一步掌握 Postgres ,查看在 [Full Stack Python][19] 上的文章。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ben Nuttall - 树莓派社区的管理者。除了它为树莓派基金会所做的工作之外 ,他也投入开源软件、数学、皮艇运动、GitHub、探险活动和Futurama。在 Twitter [@ben_nuttall][10] 上关注他。
|
||||
Ben Nuttall - 树莓派社区的管理者。除了它为树莓派基金会所做的工作之外 ,他也投入开源软件、数学、皮艇运动、GitHub、探险活动和 Futurama。在 Twitter [@ben_nuttall][10] 上关注他。
|
||||
|
||||
-------------
|
||||
|
||||
via: https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
|
||||
|
||||
作者:[Ben Nuttall ][a]
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
开源软件对于商业机构的六个好处
|
||||
============================================================
|
||||
|
||||
> 这就是为什么商业机构应该选择开源模式的原因
|
||||
|
||||

|
||||
|
||||
图片来源 : opensource.com
|
||||
|
||||
在相同的基础上,开源软件要优于专有软件。想知道为什么?这里有六个商业机构及政府部门可以从开源技术中获得好处的原因。
|
||||
|
||||
### 1、 让供应商审核更简单
|
||||
|
||||
在你投入工程和金融资源将一个产品整合到你的基础设施之前,你需要知道你选择了正确的产品。你想要一个处于积极开发的产品,它有定期的安全更新和漏洞修复,同时在你有需求时,产品能有相应的更新。这最后一点也许比你想的还要重要:没错,解决方案一定是满足你的需求的。但是产品的需求随着市场的成熟以及你商业的发展在变化。如果该产品随之改变,在未来你需要花费很大的代价来进行迁移。
|
||||
|
||||
你怎么才能知道你没有正在把你的时间和资金投入到一个正在消亡的产品?在开源的世界里,你可以不选择一个只有卖家有话语权的供应商。你可以通过考虑[发展速度以及社区健康程度][3]来比较供应商。一到两年之后,一个更活跃、多样性和健康的社区将开发出一个更好的产品,这是一个重要的考虑因素。当然,就像这篇 [关于企业开源软件的博文][4] 指出的,供应商必须有能力处理由于项目发展创新带来的不稳定性。寻找一个有长支持周期的供应商来避免混乱的更新。
|
||||
|
||||
### 2、 来自独立性的长寿
|
||||
|
||||
福布斯杂志指出 [90%的初创公司是失败的][5] ,而他们中不到一半的中小型公司能存活超过五年。当你不得不迁移到一个新的供应商时,你花费的代价是昂贵的。所以最好避免一些只有一个供应商支持的产品。
|
||||
|
||||
开源使得社区成员能够协同编写软件。例如 OpenStack [是由许多公司以及个人志愿者一起编写的][6],这给客户提供了一个保证,不管任何一个独立供应商发生问题,也总会有一个供应商能提供支持。随着软件的开源,企业会长期投入开发团队,以实现产品开发。能够使用开源代码可以确保你总是能从贡献者中雇佣到人来保持你的开发活跃。当然,如果没有一个大的、活跃的社区,也就只有少量的贡献者能被雇佣,所以活跃贡献者的数量是重要的。
|
||||
|
||||
### 3、 安全性
|
||||
|
||||
安全是一件复杂的事情。这就是为什么开源开发是构建安全解决方案的关键因素和先决条件。同时每一天安全都在变得更重要。当开发以开源方式进行,你能直接的校验供应商是否积极的在追求安全,以及看到供应商是如何对待安全问题的。研究代码和执行独立代码审计的能力可以让供应商尽可能早的发现和修复漏洞。一些供应商给社区提供上千的美金的[漏洞奖金][7]作为额外的奖励来鼓励开发者发现他们产品的安全漏洞,这同时也展示了供应商对于自己产品的信任。
|
||||
|
||||
除了代码,开源开发同样意味着开源过程,所以你能检查和看到供应商是否遵循 ISO27001、 [云安全准则][8] 及其他标准所推荐的工业级的开发过程。当然,一个可信组织外部检查提供了额外的保障,就像我们在 Nextcloud 与 [NCC小组][9]合作的一样。
|
||||
|
||||
### 4、 更多的顾客导向
|
||||
|
||||
由于用户和顾客能直接看到和参与到产品的开发中,开源项目比那些只关注于营销团队回应的闭源软件更加的贴合用户的需求。你可以注意到开源软件项目趋向于以“宽松”方式发展。一个商业供应商也许关注在某个特定的事情方面,而一个社区则有许多要做的事情并致力于开发更多的功能,而这些全都是公司或个人贡献者中的某人或某些人所感兴趣的。这导致更少的为了销售而发布的版本,因为各种改进混搭在一起根本就不是一回事。但是它创造了许多对用户更有价值的产品。
|
||||
|
||||
### 5、 更好的支持
|
||||
|
||||
专有供应商通常是你遇到问题时唯一能给你提供帮助的一方。但如果他们不提供你所需要的服务,或者对调整你的商务需求收取额外昂贵的费用,那真是不好运。对专有软件提供的支持是一个典型的 “[柠檬市场][10]”。 随着软件的开源,供应商要么提供更大的支持,要么就有其它人来填补空白——这是自由市场的最佳选择,这可以确保你总是能得到最好的服务支持。
|
||||
|
||||
### 6、 更佳的许可
|
||||
|
||||
典型的软件许可证[充斥着令人不愉快的条款][11],通常都是强制套利,你甚至不会有机会起诉供应商的不当行为。其中一个问题是你仅仅被授予了软件的使用权,这通常完全由供应商自行决定。如果软件不运行或者停止运行或者如果供应商要求支付更多的费用,你得不到软件的所有权或其他的权利。像 GPL 一类的开源许可证是为保护客户专门设计的,而不是保护供应商,它确保你可以如你所需的使用软件,而没有专制限制,只要你喜欢就行。
|
||||
|
||||
由于它们的广泛使用,GPL 的含义及其衍生出来的其他许可证得到了广泛的理解。例如,你能确保该许可允许你现存的基础设施(开源或闭源)通过设定好的 API 去进行连接,其没有时间或者是用户人数上的限制,同时也不会强迫你公开软件架构或者是知识产权(例如公司商标)。
|
||||
|
||||
这也让合规变得更加的容易;使用专有软件意味着你面临着苛刻的法规遵从性条款和高额的罚款。更糟糕的是一些<ruby>开源内核<rt>open core</rt></ruby>的产品在混合了 GPL 软件和专有软件。这[违反了许可证规定][12]并将顾客置于风险中。同时 Gartner 指出,开源内核模式意味着你[不能从开源中获利][13]。纯净的开源许可的产品避免了所有这些问题。取而代之,你只需要遵从一个规则:如果你对代码做出了修改(不包括配置、商标或其他类似的东西),你必须将这些与你的软件分发随同分享,如果他们要求的话。
|
||||
|
||||
显然开源软件是更好的选择。它易于选择正确的供应商(不会被供应商锁定),加之你也可以受益于更安全、对客户更加关注和更好的支持。而最后,你将处于法律上的安全地位。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
一个善于与人打交道的技术爱好者和开源传播者。Nextcloud 的销售主管,曾是 ownCloud 和 SUSE 的社区经理,同时还是一个有多年经验的 KDE 销售人员。喜欢骑自行车穿越柏林和为家人朋友做饭。[点击这里找到我的博客][16]。
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/10/6-reasons-choose-open-source-software
|
||||
|
||||
作者:[Jos Poortvliet Feed][a]
|
||||
译者:[ZH1122](https://github.com/ZH1122)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jospoortvliet
|
||||
[1]:https://opensource.com/article/17/10/6-reasons-choose-open-source-software?rate=um7KfpRlV5lROQDtqJVlU4y8lBa9rsZ0-yr2aUd8fXY
|
||||
[2]:https://opensource.com/user/27446/feed
|
||||
[3]:https://nextcloud.com/blog/nextcloud-the-most-active-open-source-file-sync-and-share-project/
|
||||
[4]:http://www.redhat-cloudstrategy.com/open-source-for-business-people/
|
||||
[5]:http://www.forbes.com/sites/neilpatel/2015/01/16/90-of-startups-will-fail-heres-what-you-need-to-know-about-the-10/
|
||||
[6]:http://stackalytics.com/
|
||||
[7]:https://hackerone.com/nextcloud
|
||||
[8]:https://www.ncsc.gov.uk/guidance/implementing-cloud-security-principles
|
||||
[9]:https://nextcloud.com/secure
|
||||
[10]:https://en.wikipedia.org/wiki/The_Market_for_Lemons
|
||||
[11]:http://boingboing.net/2016/11/01/why-are-license-agreements.html
|
||||
[12]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPluginsInNF
|
||||
[13]:http://blogs.gartner.com/brian_prentice/2010/03/31/open-core-the-emperors-new-clothes/
|
||||
[14]:https://opensource.com/users/jospoortvliet
|
||||
[15]:https://opensource.com/users/jospoortvliet
|
||||
[16]:http://blog.jospoortvliet.com/
|
||||
|
||||
@ -0,0 +1,121 @@
|
||||
原生云计算:你所不知道的 Kubernetes 特性和工具
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 开放容器计划(OCI)和原生云计算基金会(CNCF)的代表说,Kubernetes 和容器可以在降低程序员和系统管理成本的同时加速部署进程,从被忽视的 Kubernetes 特性(比如命令空间)开始,去利用 Kubernetes 和它的相关工具运行一个原生云架构。
|
||||
|
||||
[Kubernetes][2] 不止是一个云容器管理器。正如 Steve Pousty,他是 [Red Hat][3] 支持的 [OpenShift][4] 的首席开发者,在 [Linux 基金会][5]的[开源峰会][6]上的讲演中解释的那样,Kubernetes 提供了一个 “使用容器进行原生云计算的通用操作平台”。
|
||||
|
||||
Pousty 的意思是什么?先让我们复习一下基础知识。
|
||||
|
||||
[开源容器计划][7](OCI)和 [原生云计算基金会][8] (CNCF)的执行董事 Chris Aniszczyk 的解释是,“原生云计算使用开源软件栈将应用程序部署为微服务,打包每一个部分到其容器中,并且动态地编排这些容器以优化资源使用”。[Kubernetes 一直在关注着原生云计算的最新要素][9]。这将最终将导致 IT 中很大的一部分发生转变,如从服务器到虚拟机,从<ruby>构建包<rt>buildpack</rt></ruby>到现在的 [容器][10]。
|
||||
|
||||
会议主持人表示,数据中心的演变将节省相当可观的成本,部分原因是它需要更少的专职员工。例如,据 Aniszczyk 说,通过使用 Kubernetes,谷歌每 10000 台机器仅需要一个网站可靠性工程师(LCTT 译注:即 SRE)。
|
||||
|
||||
实际上,系统管理员可以利用新的 Kubernetes 相关的工具的优势,并了解那些被低估的功能。
|
||||
|
||||
### 构建一个原生云平台
|
||||
|
||||
Pousty 解释说,“对于 Red Hat 来说,Kubernetes 是云 Linux 的内核。它是每个人都可以构建于其上的基础设施”。
|
||||
|
||||
例如,假如你在一个容器镜像中有一个应用程序。你怎么知道它是安全的呢? Red Hat 和其它的公司使用 [OpenSCAP][11],它是基于 <ruby>[安全内容自动化协议][12]<rt>Security Content Automation Protocol</rt></ruby>(SCAP)的,是使用标准化的方式表达和操作安全数据的一个规范。OpenSCAP 项目提供了一个开源的强化指南和配置基准。选择一个合适的安全策略,然后,使用 OpenSCAP 认可的安全工具去使某些由 Kubernetes 控制的容器中的程序遵守这些定制的安全标准。
|
||||
|
||||
Red Hat 将使用<ruby>[原子扫描][13]<rt>Atomic Scan</rt></ruby>来自动处理这个过程;它借助 OpenSCAP <ruby>提供者<rt>provider</rt></ruby>来扫描容器镜像中已知的安全漏洞和策略配置问题。原子扫描会以只读方式加载文件系统。这些通过扫描的容器,会在一个可写入的目录存放扫描器的输出。
|
||||
|
||||
Pousty 指出,这种方法有几个好处,主要是,“你可以扫描一个容器镜像而不用实际运行它”。因此,如果在容器中有糟糕的代码或有缺陷的安全策略,它不会影响到你的系统。
|
||||
|
||||
原子扫描比手动运行 OpenSCAP 快很多。 因为容器从启用到消毁可能就在几分钟或几小时内,原子扫描允许 Kubernetes 用户在(很快的)容器生命期间保持容器安全,而不是在更缓慢的系统管理时间跨度里进行。
|
||||
|
||||
### 关于工具
|
||||
|
||||
帮助系统管理员和 DevOps 管理大部分 Kubernetes 操作的另一个工具是 [CRI-O][14]。这是一个基于 OCI 实现的 [Kubernetes 容器运行时接口][15]。CRI-O 是一个守护进程, Kubernetes 可以用于运行存储在 Docker 仓库中的容器镜像,Dan Walsh 解释说,他是 Red Hat 的顾问工程师和 [SELinux][16] 项目领导者。它允许你直接从 Kubernetes 中启动容器镜像,而不用花费时间和 CPU 处理时间在 [Docker 引擎][17] 上启动。并且它的镜像格式是与容器无关的。
|
||||
|
||||
在 Kubernetes 中, [kubelet][18] 管理 pod(容器集群)。使用 CRI-O,Kubernetes 及其 kubelet 可以管理容器的整个生命周期。这个工具也不是和 Docker 镜像捆绑在一起的。你也可以使用新的 [OCI 镜像格式][19] 和 [CoreOS 的 rkt][20] 容器镜像。
|
||||
|
||||
同时,这些工具正在成为一个 Kubernetes 栈:编排系统、[容器运行时接口][21] (CRI)和 CRI-O。Kubernetes 首席工程师 Kelsey Hightower 说,“我们实际上不需要这么多的容器运行时——无论它是 Docker 还是 [rkt][22]。只需要给我们一个到内核的 API 就行”,这个结果是这些技术人员的承诺,是推动容器比以往更快发展的强大动力。
|
||||
|
||||
Kubernetes 也可以加速构建容器镜像。目前为止,有[三种方法来构建容器][23]。第一种方法是通过一个 Docker 或者 CoreOS 去构建容器。第二种方法是注入定制代码到一个预构建镜像中。最后一种方法是,<ruby>资产生成管道<rt>Asset Generation Pipeline</rt></ruby>使用容器去编译那些<ruby>资产<rt>asset</rt></ruby>,然后其被包含到使用 Docker 的<ruby>[多阶段构建][24]<rt>Multi-Stage Build</rt></ruby>所构建的随后镜像中。
|
||||
|
||||
现在,还有一个 Kubernetes 原生的方法:Red Hat 的 [Buildah][25], 这是[一个脚本化的 shell 工具][26] 用于快速、高效地构建 OCI 兼容的镜像和容器。Buildah 降低了容器环境的学习曲线,简化了创建、构建和更新镜像的难度。Pousty 说。你可以使用它和 Kubernetes 一起基于应用程序的调用来自动创建和使用容器。Buildah 也更节省系统资源,因为它不需要容器运行时守护进程。
|
||||
|
||||
因此,比起真实地引导一个容器和在容器内按步骤操作,Pousty 说,“挂载该文件系统,就如同它是一个常规的文件系统一样做一些正常操作,并且在最后提交”。
|
||||
|
||||
这意味着你可以从一个仓库中拉取一个镜像,创建它所匹配的容器,并且优化它。然后,你可以使用 Kubernetes 中的 Buildah 在你需要时去创建一个新的运行镜像。最终结果是,他说,运行 Kubernetes 管理的容器化应用程序比以往速度更快,需要的资源更少。
|
||||
|
||||
### 你所不知道的 Kubernetes 拥有的特性
|
||||
|
||||
你不需要在其它地方寻找工具。Kubernetes 有几个被低估的特性。
|
||||
|
||||
根据谷歌云全球产品经理 Allan Naim 的说法,其中一个是 [Kubernetes 命名空间][27]。Naim 在开源峰会上谈及 “Kubernetes 最佳实践”,他说,“很少有人使用命名空间,这是一个失误。”
|
||||
|
||||
“命名空间是将一个单个的 Kubernetes 集群分成多个虚拟集群的方法”,Naim 说。例如,“你可以认为命名空间就是<ruby>姓氏<rt>family name</rt></ruby>”,因此,假如说 “Simth” 用来标识一个家族,如果有个成员 Steve Smith,他的名字就是 “Steve”,但是,家族范围之外的,它就是 “Steve Smith” 或称 “来自 Chicago 的 Steve Smith”。
|
||||
|
||||
严格来说,“命名空间是一个逻辑分区技术,它允许一个 Kubernetes 集群被多个用户、用户团队或者一个用户的多个不能混淆的应用程序所使用。Naim 解释说,“每个用户、用户团队、或者应用程序都可以存在于它的命名空间中,与集群中的其他用户是隔离的,并且可以像你是这个集群的唯一用户一样操作它。”
|
||||
|
||||
Practically 说,你可以使用命名空间去构建一个企业的多个业务/技术的实体进入 Kubernetes。例如,云架构可以通过映射产品、地点、团队和成本中心为命名空间,从而定义公司的命名空间策略。
|
||||
|
||||
Naim 建议的另外的方法是,去使用命名空间将软件开发<ruby>流程<rt>pipeline</rt></ruby>划分到分离的命名空间中,如测试、质量保证、<ruby>预演<rt>staging</rt></ruby>和成品等常见阶段。或者命名空间也可以用于管理单独的客户。例如,你可以为每个客户、客户项目、或者客户业务单元去创建一个单独的命名空间。它可以更容易地区分项目,避免重用相同名字的资源。
|
||||
|
||||
然而,Kubernetes 现在还没有提供一个跨命名空间访问的控制机制。因此,Naim 建议你不要使用这种方法去对外公开程序。还要注意的是,命名空间也不是一个管理的“万能药”。例如,你不能将命名空间嵌套在另一个命名空间中。另外,也没有跨命名空间的强制安全机制。
|
||||
|
||||
尽管如此,小心地使用命名空间,还是很有用的。
|
||||
|
||||
### 以人为中心的建议
|
||||
|
||||
从谈论较深奥的技术换到项目管理。Pousty 建议,在转移到原生云和微服务架构时,在你的团队中要有一个微服务操作人员。“如果你去做微服务,你的团队最终做的就是 Ops-y。并且,不去使用已经知道这种操作的人是愚蠢的行为”,他说。“你需要一个正确的团队核心能力。我不想开发人员重新打造运维的轮子”。
|
||||
|
||||
而是,将你的工作流彻底地改造成一个能够使用容器和云的过程,对此,Kubernetes 是很适用的。
|
||||
|
||||
### 使用 Kubernetes 的原生云计算:领导者的课程
|
||||
|
||||
* 迅速扩大的原生云生态系统。寻找可以扩展你使用容器的方法的工具。
|
||||
* 探索鲜为人知的 Kubernetes 特性,如命名空间。它们可以改善你的组织和自动化程度。
|
||||
* 确保部署到容器的开发团队有一个 Ops 人员参与。否则,冲突将不可避免。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Steven J. Vaughan-Nichols, Vaughan-Nichols & Associates 的 CEO
|
||||
|
||||
Steven J. Vaughan-Nichols,即 sjvn,是一个技术方面的作家,从 CP/M-80 还是前沿技术、PC 操作系统、300bps 是非常快的因特网连接、WordStar 是最先进的文字处理程序的那个时候开始,一直从事于商业技术的写作,而且喜欢它。他的作品已经发布在了从高科技出版物(IEEE Computer、ACM Network、 Byte)到商业出版物(eWEEK、 InformationWeek、ZDNet),从大众科技(Computer Shopper、PC Magazine、PC World)再到主流出版商(Washington Post、San Francisco Chronicle、BusinessWeek) 等媒体之上。
|
||||
|
||||
---------------------
|
||||
|
||||
via: https://insights.hpe.com/articles/how-to-implement-cloud-native-computing-with-kubernetes-1710.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.hpe.com/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_insights~510287587~Containers_Dummies~sjvn_Kubernetes
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.redhat.com/en
|
||||
[4]:https://www.openshift.com/
|
||||
[5]:https://www.linuxfoundation.org/
|
||||
[6]:http://events.linuxfoundation.org/events/open-source-summit-north-america
|
||||
[7]:https://www.opencontainers.org/
|
||||
[8]:https://www.cncf.io/
|
||||
[9]:https://insights.hpe.com/articles/the-basics-explaining-kubernetes-mesosphere-and-docker-swarm-1702.html
|
||||
[10]:https://insights.hpe.com/articles/when-to-use-containers-and-when-not-to-1705.html
|
||||
[11]:https://www.open-scap.org/
|
||||
[12]:https://scap.nist.gov/
|
||||
[13]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||
[14]:http://cri-o.io/
|
||||
[15]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[16]:https://wiki.centos.org/HowTos/SELinux
|
||||
[17]:https://docs.docker.com/engine/
|
||||
[18]:https://kubernetes.io/docs/admin/kubelet/
|
||||
[19]:http://www.zdnet.com/article/containers-consolidation-open-container-initiative-1-0-released/
|
||||
[20]:https://coreos.com/rkt/docs/latest/
|
||||
[21]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[22]:https://coreos.com/rkt/
|
||||
[23]:http://chris.collins.is/2017/02/24/three-docker-build-strategies/
|
||||
[24]:https://docs.docker.com/engine/userguide/eng-image/multistage-build/#use-multi-stage-builds
|
||||
[25]:https://github.com/projectatomic/buildah
|
||||
[26]:https://www.projectatomic.io/blog/2017/06/introducing-buildah/
|
||||
[27]:https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||
@ -0,0 +1,66 @@
|
||||
容器和微服务是如何改变了安全性
|
||||
============================================================
|
||||
|
||||
> 云原生程序和基础架构需要完全不同的安全方式。牢记这些最佳实践
|
||||
|
||||

|
||||
|
||||
>thinkstock
|
||||
|
||||
如今,大大小小的组织正在探索云原生技术的采用。“<ruby>云原生<rt>Cloud-native</rt></ruby>”是指将软件打包到被称为容器的标准化单元中的方法,这些单元组织成微服务,它们必须对接以形成程序,并确保正在运行的应用程序完全自动化以实现更高的速度、灵活性和可伸缩性。
|
||||
|
||||
由于这种方法从根本上改变了软件的构建、部署和运行方式,它也从根本上改变了软件需要保护的方式。云原生程序和基础架构为安全专业人员带来了若干新的挑战,他们需要建立新的安全计划来支持其组织对云原生技术的使用。
|
||||
|
||||
让我们来看看这些挑战,然后我们将讨论安全团队应该采取的哪些最佳实践来解决这些挑战。首先挑战是:
|
||||
|
||||
* **传统的安全基础设施缺乏容器可视性。** 大多数现有的基于主机和网络的安全工具不具备监视或捕获容器活动的能力。这些工具是为了保护单个操作系统或主机之间的流量,而不是其上运行的应用程序,从而导致容器事件、系统交互和容器间流量的可视性缺乏。
|
||||
* **攻击面可以快速更改。**云原生应用程序由许多较小的组件组成,这些组件称为微服务,它们是高度分布式的,每个都应该分别进行审计和保护。因为这些应用程序的设计是通过编排系统进行配置和调整的,所以其攻击面也在不断变化,而且比传统的独石应用程序要快得多。
|
||||
* **分布式数据流需要持续监控。**容器和微服务被设计为轻量级的,并且以可编程方式与对方或外部云服务进行互连。这会在整个环境中产生大量的快速移动数据,需要进行持续监控,以便应对攻击和危害指标以及未经授权的数据访问或渗透。
|
||||
* **检测、预防和响应必须自动化。** 容器生成的事件的速度和容量压倒了当前的安全操作流程。容器的短暂寿命也成为难以捕获、分析和确定事故的根本原因。有效的威胁保护意味着自动化数据收集、过滤、关联和分析,以便能够对新事件作出足够快速的反应。
|
||||
|
||||
面对这些新的挑战,安全专业人员将需要建立新的安全计划以支持其组织对云原生技术的使用。自然地,你的安全计划应该解决云原生程序的整个生命周期的问题,这些应用程序可以分为两个不同的阶段:构建和部署阶段以及运行时阶段。每个阶段都有不同的安全考虑因素,必须全部加以解决才能形成一个全面的安全计划。
|
||||
|
||||
### 确保容器的构建和部署
|
||||
|
||||
构建和部署阶段的安全性侧重于将控制应用于开发人员工作流程和持续集成和部署管道,以降低容器启动后可能出现的安全问题的风险。这些控制可以包含以下准则和最佳实践:
|
||||
|
||||
* **保持镜像尽可能小。**容器镜像是一个轻量级的可执行文件,用于打包应用程序代码及其依赖项。将每个镜像限制为软件运行所必需的内容, 从而最小化从镜像启动的每个容器的攻击面。从最小的操作系统基础镜像(如 Alpine Linux)开始,可以减少镜像大小,并使镜像更易于管理。
|
||||
* **扫描镜像的已知问题。**当镜像构建后,应该检查已知的漏洞披露。可以扫描构成镜像的每个文件系统层,并将结果与定期更新的常见漏洞披露数据库(CVE)进行比较。然后开发和安全团队可以在镜像被用来启动容器之前解决发现的漏洞。
|
||||
* **数字签名的镜像。**一旦建立镜像,应在部署之前验证它们的完整性。某些镜像格式使用被称为摘要的唯一标识符,可用于检测镜像内容何时发生变化。使用私钥签名镜像提供了加密的保证,以确保每个用于启动容器的镜像都是由可信方创建的。
|
||||
* **强化并限制对主机操作系统的访问。**由于在主机上运行的容器共享相同的操作系统,因此必须确保它们以适当限制的功能集启动。这可以通过使用内核安全功能和 Seccomp、AppArmor 和 SELinux 等模块来实现。
|
||||
* **指定应用程序级别的分割策略。**微服务之间的网络流量可以被分割,以限制它们彼此之间的连接。但是,这需要根据应用级属性(如标签和选择器)进行配置,从而消除了处理传统网络详细信息(如 IP 地址)的复杂性。分割带来的挑战是,必须事先定义策略来限制通信,而不会影响容器在环境内部和环境之间进行通信的能力,这是正常活动的一部分。
|
||||
* **保护容器所使用的秘密信息。**微服务彼此相互之间频繁交换敏感数据,如密码、令牌和密钥,这称之为<ruby>秘密信息<rt>secret</rt></ruby>。如果将这些秘密信息存储在镜像或环境变量中,则可能会意外暴露这些。因此,像 Docker 和 Kubernetes 这样的多个编排平台都集成了秘密信息管理,确保只有在需要的时候才将秘密信息分发给使用它们的容器。
|
||||
|
||||
来自诸如 Docker、Red Hat 和 CoreOS 等公司的几个领先的容器平台和工具提供了部分或全部这些功能。开始使用这些方法之一是在构建和部署阶段确保强大安全性的最简单方法。
|
||||
|
||||
但是,构建和部署阶段控制仍然不足以确保全面的安全计划。提前解决容器开始运行之前的所有安全事件是不可能的,原因如下:首先,漏洞永远不会被完全消除,新的漏洞会一直出现。其次,声明式的容器元数据和网络分段策略不能完全预见高度分布式环境中的所有合法应用程序活动。第三,运行时控制使用起来很复杂,而且往往配置错误,就会使应用程序容易受到威胁。
|
||||
|
||||
### 在运行时保护容器
|
||||
|
||||
运行时阶段的安全性包括所有功能(可见性、检测、响应和预防),这些功能是发现和阻止容器运行后发生的攻击和策略违规所必需的。安全团队需要对安全事件的根源进行分类、调查和确定,以便对其进行全面补救。以下是成功的运行时阶段安全性的关键方面:
|
||||
|
||||
* **检测整个环境以得到持续可见性。**能够检测攻击和违规行为始于能够实时捕获正在运行的容器中的所有活动,以提供可操作的“真相源”。捕获不同类型的容器相关数据有各种检测框架。选择一个能够处理容器的容量和速度的方案至关重要。
|
||||
* **关联分布式威胁指标。** 容器设计为基于资源可用性以跨计算基础架构而分布。由于应用程序可能由数百或数千个容器组成,因此危害指标可能分布在大量主机上,使得难以确定那些与主动威胁相关的相关指标。需要大规模,快速的相关性来确定哪些指标构成特定攻击的基础。
|
||||
* **分析容器和微服务行为。**微服务和容器使得应用程序可以分解为执行特定功能的最小组件,并被设计为不可变的。这使得比传统的应用环境更容易理解预期行为的正常模式。偏离这些行为基准可能反映恶意行为,可用于更准确地检测威胁。
|
||||
* **通过机器学习增强威胁检测。**容器环境中生成的数据量和速度超过了传统的检测技术。自动化和机器学习可以实现更有效的行为建模、模式识别和分类,从而以更高的保真度和更少的误报来检测威胁。注意使用机器学习的解决方案只是为了生成静态白名单,用于警报异常,这可能会导致严重的警报噪音和疲劳。
|
||||
* **拦截并阻止未经授权的容器引擎命令。**发送到容器引擎(例如 Docker)的命令用于创建、启动和终止容器以及在正在运行的容器中运行命令。这些命令可以反映危害容器的意图,这意味着可以禁止任何未经授权的命令。
|
||||
* **自动响应和取证。**容器的短暂寿命意味着它们往往只能提供很少的事件信息,以用于事件响应和取证。此外,云原生架构通常将基础设施视为不可变的,自动将受影响的系统替换为新系统,这意味着在调查时的容器可能会消失。自动化可以确保足够快地捕获、分析和升级信息,以减轻攻击和违规的影响。
|
||||
|
||||
基于容器技术和微服务架构的云原生软件正在迅速实现应用程序和基础架构的现代化。这种模式转变迫使安全专业人员重新考虑有效保护其组织所需的计划。随着容器的构建、部署和运行,云原生软件的全面安全计划将解决整个应用程序生命周期问题。通过使用上述指导方针实施计划,组织可以为容器基础设施以及运行在上面的应用程序和服务构建安全的基础。
|
||||
|
||||
_WeLien Dang 是 StackRox 的产品副总裁,StackRox 是一家为容器提供自适应威胁保护的安全公司。此前,他曾担任 CoreOS 产品负责人,并在亚马逊、Splunk 和 Bracket Computing 担任安全和云基础架构的高级产品管理职位。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3233139/cloud-computing/how-cloud-native-applications-change-security.html
|
||||
|
||||
作者:[Wei Lien Dang][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/blog/new-tech-forum/
|
||||
[1]:https://www.stackrox.com/
|
||||
[2]:https://www.infoworld.com/article/3204171/what-is-docker-linux-containers-explained.html#tk.ifw-infsb
|
||||
[3]:https://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker.html#tk.ifw-infsb
|
||||
@ -0,0 +1,362 @@
|
||||
通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程
|
||||
============================================================
|
||||
|
||||
> 不论是经验丰富的老程序员,还是没有经验的新手,Python 都是一个非常好的编程语言。
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
[Python][9] 是一个非常流行的编程语言,它可以用于创建桌面应用程序、3D 图形、视频游戏、甚至是网站。它是非常好的首选编程语言,因为它易于学习,不像一些复杂的语言,比如,C、 C++、 或 Java。 即使如此, Python 依然也是强大且健壮的,足以创建高级的应用程序,并且几乎适用于所有使用电脑的行业。不论是经验丰富的老程序员,还是没有经验的新手,Python 都是一个非常好的编程语言。
|
||||
|
||||
### 安装 Python
|
||||
|
||||
在学习 Python 之前,你需要先去安装它:
|
||||
|
||||
**Linux: **如果你使用的是 Linux 系统, Python 是已经包含在里面了。但是,你如果确定要使用 Python 3 。应该去检查一下你安装的 Python 版本,打开一个终端窗口并输入:
|
||||
|
||||
```
|
||||
python3 -V
|
||||
```
|
||||
|
||||
如果提示该命令没有找到,你需要从你的包管理器中去安装 Python 3。
|
||||
|
||||
**MacOS:** 如果你使用的是一台 Mac,可以看上面 Linux 的介绍来确认是否安装了 Python 3。MacOS 没有内置的包管理器,因此,如果发现没有安装 Python 3,可以从 [python.org/downloads/mac-osx][10] 安装它。即使 macOS 已经安装了 Python 2,你还是应该学习 Python 3。
|
||||
|
||||
**Windows:** 微软 Windows 当前是没有安装 Python 的。从 [python.org/downloads/windows][11] 安装它。在安装向导中一定要选择 **Add Python to PATH** 来将 Python 执行程序放到搜索路径。
|
||||
|
||||
### 在 IDE 中运行
|
||||
|
||||
在 Python 中写程序,你需要准备一个文本编辑器,使用一个集成开发环境(IDE)是非常实用的。IDE 在一个文本编辑器中集成了一些方便而有用的 Python 功能。IDLE 3 和 NINJA-IDE 是你可以考虑的两种选择:
|
||||
|
||||
#### IDLE 3
|
||||
|
||||
Python 自带的一个基本的 IDE 叫做 IDLE。
|
||||
|
||||

|
||||
|
||||
它有关键字高亮功能,可以帮助你检测拼写错误,并且有一个“运行”按钮可以很容易地快速测试代码。
|
||||
|
||||
要使用它:
|
||||
|
||||
* 在 Linux 或 macOS 上,启动一个终端窗口并输入 `idle3`。
|
||||
* 在 Windows,从开始菜单中启动 Python 3。
|
||||
* 如果你在开始菜单中没有看到 Python,在开始菜单中通过输入 `cmd` 启动 Windows 命令提示符,然后输入 `C:\Windows\py.exe`。
|
||||
* 如果它没有运行,试着重新安装 Python。并且确认在安装向导中选择了 “Add Python to PATH”。参考 [docs.python.org/3/using/windows.html][1] 中的详细介绍。
|
||||
* 如果仍然不能运行,那就使用 Linux 吧!它是免费的,只要将你的 Python 文件保存到一个 U 盘中,你甚至不需要安装它就可以使用。
|
||||
|
||||
#### Ninja-IDE
|
||||
|
||||
[Ninja-IDE][12] 是一个优秀的 Python IDE。它有关键字高亮功能可以帮助你检测拼写错误、引号和括号补全以避免语法错误,行号(在调试时很有帮助)、缩进标记,以及运行按钮可以很容易地进行快速代码测试。
|
||||
|
||||

|
||||
|
||||
要使用它:
|
||||
|
||||
1. 安装 Ninja-IDE。如果你使用的是 Linux,使用包管理器安装是非常简单的;否则, 从 NINJA-IDE 的网站上 [下载][7] 合适的安装版本。
|
||||
2. 启动 Ninja-IDE。
|
||||
3. 转到 Edit 菜单,并选择 Preferences 设置。
|
||||
4. 在 Preferences 窗口中,点击 Execution 选项卡。
|
||||
5. 在 Execution 选项卡上,更改 `python` 为 `python3`。
|
||||
|
||||

|
||||
|
||||
*Ninja-IDE 中的 Python3*
|
||||
|
||||
### 告诉 Python 想做什么
|
||||
|
||||
关键字可以告诉 Python 你想要做什么。不论是在 IDLE 还是在 Ninja 中,转到 File 菜单并创建一个新文件。对于 Ninja 用户:不要创建一个新项目,仅创建一个新文件。
|
||||
|
||||
在你的新的空文件中,在 IDLE 或 Ninja 中输入以下内容:
|
||||
|
||||
```
|
||||
print("Hello world.")
|
||||
```
|
||||
|
||||
* 如果你使用的是 IDLE,转到 Run 菜单并选择 Run module 选项。
|
||||
* 如果你使用的是 Ninja,在左侧按钮条中点击 Run File 按钮。
|
||||
|
||||

|
||||
|
||||
*在 Ninja 中运行文件*
|
||||
|
||||
关键字 `print` 告诉 Python 去打印输出在圆括号中引用的文本内容。
|
||||
|
||||
虽然,这并不是特别刺激。在其内部, Python 只能访问基本的关键字,像 `print`、 `help`,最基本的数学函数,等等。
|
||||
|
||||
可以使用 `import` 关键字加载更多的关键字。在 IDLE 或 Ninja 中开始一个新文件,命名为 `pen.py`。
|
||||
|
||||
**警告:**不要命名你的文件名为 `turtle.py`,因为名为 `turtle.py` 的文件是包含在你正在控制的 turtle (海龟)程序中的。命名你的文件名为 `turtle.py` ,将会把 Python 搞糊涂,因为它会认为你将导入你自己的文件。
|
||||
|
||||
在你的文件中输入下列的代码,然后运行它:
|
||||
|
||||
```
|
||||
import turtle
|
||||
```
|
||||
|
||||
Turtle 是一个非常有趣的模块,试着这样做:
|
||||
|
||||
```
|
||||
turtle.begin_fill()
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.end_fill()
|
||||
```
|
||||
|
||||
看一看你现在用 turtle 模块画出了一个什么形状。
|
||||
|
||||
要擦除你的海龟画图区,使用 `turtle.clear()` 关键字。想想看,使用 `turtle.color("blue")` 关键字会出现什么情况?
|
||||
|
||||
尝试更复杂的代码:
|
||||
|
||||
```
|
||||
import turtle as t
|
||||
import time
|
||||
|
||||
t.color("blue")
|
||||
t.begin_fill()
|
||||
|
||||
counter=0
|
||||
|
||||
while counter < 4:
|
||||
t.forward(100)
|
||||
t.left(90)
|
||||
counter = counter+1
|
||||
|
||||
t.end_fill()
|
||||
time.sleep(5)
|
||||
```
|
||||
|
||||
运行完你的脚本后,是时候探索更有趣的模块了。
|
||||
|
||||
### 通过创建一个游戏来学习 Python
|
||||
|
||||
想学习更多的 Python 关键字,和用图形编程的高级特性,让我们来关注于一个游戏逻辑。在这个教程中,我们还将学习一些关于计算机程序是如何构建基于文本的游戏的相关知识,在游戏里面计算机和玩家掷一个虚拟骰子,其中掷的最高的是赢家。
|
||||
|
||||
#### 规划你的游戏
|
||||
|
||||
在写代码之前,最重要的事情是考虑怎么去写。在他们写代码 _之前_,许多程序员是先 [写简单的文档][13],这样,他们就有一个编程的目标。如果你想给这个程序写个文档的话,这个游戏看起来应该是这样的:
|
||||
|
||||
1. 启动掷骰子游戏并按下 Return 或 Enter 去掷骰子
|
||||
2. 结果打印在你的屏幕上
|
||||
3. 提示你再次掷骰子或者退出
|
||||
|
||||
这是一个简单的游戏,但是,文档会告诉你需要做的事很多。例如,它告诉你写这个游戏需要下列的组件:
|
||||
|
||||
* 玩家:你需要一个人去玩这个游戏。
|
||||
* AI:计算机也必须去掷,否则,就没有什么输或赢了
|
||||
* 随机数:一个常见的六面骰子表示从 1-6 之间的一个随机数
|
||||
* 运算:一个简单的数学运算去比较一个数字与另一个数字的大小
|
||||
* 一个赢或者输的信息
|
||||
* 一个再次玩或退出的提示
|
||||
|
||||
#### 制作掷骰子游戏的 alpha 版
|
||||
|
||||
很少有程序,一开始就包含其所有的功能,因此,它们的初始版本仅实现最基本的功能。首先是几个定义:
|
||||
|
||||
**变量**是一个经常要改变的值,它在 Python 中使用的非常多。每当你需要你的程序去“记住”一些事情的时候,你就要使用一个变量。事实上,运行于代码中的信息都保存在变量中。例如,在数学方程式 `x + 5 = 20` 中,变量是 `x` ,因为字母 `x` 是一个变量占位符。
|
||||
|
||||
**整数**是一个数字, 它可以是正数也可以是负数。例如,`1` 和 `-1` 都是整数,因此,`14`、`21`,甚至 `10947` 都是。
|
||||
|
||||
在 Python 中变量创建和使用是非常容易的。这个掷骰子游戏的初始版使用了两个变量: `player` 和 `ai`。
|
||||
|
||||
在命名为 `dice_alpha.py` 的新文件中输入下列代码:
|
||||
|
||||
```
|
||||
import random
|
||||
|
||||
player = random.randint(1,6)
|
||||
ai = random.randint(1,6)
|
||||
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
else:
|
||||
print("You lose")
|
||||
```
|
||||
|
||||
启动你的游戏,确保它能工作。
|
||||
|
||||
这个游戏的基本版本已经工作的非常好了。它实现了游戏的基本目标,但是,它看起来不像是一个游戏。玩家不知道他们摇了什么,电脑也不知道摇了什么,并且,即使玩家还想玩但是游戏已经结束了。
|
||||
|
||||
这是软件的初始版本(通常称为 alpha 版)。现在你已经确信实现了游戏的主要部分(掷一个骰子),是时候该加入到程序中了。
|
||||
|
||||
#### 改善这个游戏
|
||||
|
||||
在你的游戏的第二个版本中(称为 beta 版),将做一些改进,让它看起来像一个游戏。
|
||||
|
||||
##### 1、 描述结果
|
||||
|
||||
不要只告诉玩家他们是赢是输,他们更感兴趣的是他们掷的结果。在你的代码中尝试做如下的改变:
|
||||
|
||||
```
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + player)
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolled " + ai)
|
||||
```
|
||||
|
||||
现在,如果你运行这个游戏,它将崩溃,因为 Python 认为你在尝试做数学运算。它认为你试图在 `player` 变量上加字母 `You rolled` ,而保存在其中的是数字。
|
||||
|
||||
你必须告诉 Python 处理在 `player` 和 `ai` 变量中的数字,就像它们是一个句子中的单词(一个字符串)而不是一个数学方程式中的一个数字(一个整数)。
|
||||
|
||||
在你的代码中做如下的改变:
|
||||
|
||||
```
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + str(player) )
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolled " + str(ai) )
|
||||
```
|
||||
|
||||
现在运行你的游戏将看到该结果。
|
||||
|
||||
##### 2、 让它慢下来
|
||||
|
||||
计算机运行的非常快。人有时可以很快,但是在游戏中,产生悬念往往更好。你可以使用 Python 的 `time` 函数,在这个紧张时刻让你的游戏慢下来。
|
||||
|
||||
```
|
||||
import random
|
||||
import time
|
||||
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + str(player) )
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolls...." )
|
||||
time.sleep(2)
|
||||
print("The computer has rolled a " + str(player) )
|
||||
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
else:
|
||||
print("You lose")
|
||||
```
|
||||
|
||||
启动你的游戏去测试变化。
|
||||
|
||||
##### 3、 检测关系
|
||||
|
||||
如果你多玩几次你的游戏,你就会发现,即使你的游戏看起来运行很正确,它实际上是有一个 bug 在里面:当玩家和电脑摇出相同的数字的时候,它就不知道该怎么办了。
|
||||
|
||||
去检查一个值是否与另一个值相等,Python 使用 `==`。那是个“双”等号标记,不是一个。如果你仅使用一个,Python 认为你尝试去创建一个新变量,但是,实际上你是去尝试做数学运算。
|
||||
|
||||
当你想有比两个选项(即,赢或输)更多的选择时,你可以使用 Python 的 `elif` 关键字,它的意思是“否则,如果”。这允许你的代码去检查,是否在“许多”结果中有一个是 `true`, 而不是只检查“一个”是 `true`。
|
||||
|
||||
像这样修改你的代码:
|
||||
|
||||
```
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
elif player == ai:
|
||||
print("Tie game.")
|
||||
else:
|
||||
print("You lose")
|
||||
```
|
||||
|
||||
多运行你的游戏几次,去看一下你能否和电脑摇出一个平局。
|
||||
|
||||
#### 编写最终版
|
||||
|
||||
你的掷骰子游戏的 beta 版的功能和感觉比起 alpha 版更像游戏了,对于最终版,让我们来创建你的第一个 Python **函数**。
|
||||
|
||||
函数是可以作为一个独立的单元来调用的一组代码的集合。函数是非常重要的,因为,大多数应用程序里面都有许多代码,但不是所有的代码都只运行一次。函数可以启用应用程序并控制什么时候可以发生什么事情。
|
||||
|
||||
将你的代码变成这样:
|
||||
|
||||
```
|
||||
import random
|
||||
import time
|
||||
|
||||
def dice():
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + str(player) )
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolls...." )
|
||||
time.sleep(2)
|
||||
print("The computer has rolled a " + str(player) )
|
||||
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
else:
|
||||
print("You lose")
|
||||
|
||||
print("Quit? Y/N")
|
||||
cont = input()
|
||||
|
||||
if cont == "Y" or cont == "y":
|
||||
exit()
|
||||
elif cont == "N" or cont == "n":
|
||||
pass
|
||||
else:
|
||||
print("I did not understand that. Playing again.")
|
||||
```
|
||||
|
||||
游戏的这个版本,在他们玩游戏之后会询问玩家是否退出。如果他们用一个 `Y` 或 `y` 去响应, Python 就会调用它的 `exit` 函数去退出游戏。
|
||||
|
||||
更重要的是,你将创建一个称为 `dice` 的你自己的函数。这个 `dice` 函数并不会立即运行,事实上,如果在这个阶段你尝试去运行你的游戏,它不会崩溃,但它也不会正式运行。要让 `dice` 函数真正运行起来做一些事情,你必须在你的代码中去**调用它**。
|
||||
|
||||
在你的现有代码下面增加这个循环,前两行就是上文中的前两行,不需要再次输入,并且要注意哪些需要缩进哪些不需要。**要注意缩进格式**。
|
||||
|
||||
```
|
||||
else:
|
||||
print("I did not understand that. Playing again.")
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
print("Press return to roll your die.")
|
||||
roll = input()
|
||||
dice()
|
||||
```
|
||||
|
||||
`while True` 代码块首先运行。因为 `True` 被定义为总是真,这个代码块将一直运行,直到 Python 告诉它退出为止。
|
||||
|
||||
`while True` 代码块是一个循环。它首先提示用户去启动这个游戏,然后它调用你的 `dice` 函数。这就是游戏的开始。当 `dice` 函数运行结束,根据玩家的回答,你的循环再次运行或退出它。
|
||||
|
||||
使用循环来运行程序是编写应用程序最常用的方法。循环确保应用程序保持长时间的可用,以便计算机用户使用应用程序中的函数。
|
||||
|
||||
### 下一步
|
||||
|
||||
现在,你已经知道了 Python 编程的基础知识。这个系列的下一篇文章将描述怎么使用 [PyGame][14] 去编写一个视频游戏,一个比 turtle 模块有更多功能的模块,但它也更复杂一些。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Seth Kenlon - 一个独立的多媒体大师,自由文化的倡导者,和 UNIX 极客。他同时从事电影和计算机行业。他是基于 slackwarers 的多媒体制作项目的维护者之一, http://slackermedia.info
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/python-101
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:https://docs.python.org/3/using/windows.html
|
||||
[2]:https://opensource.com/file/374606
|
||||
[3]:https://opensource.com/file/374611
|
||||
[4]:https://opensource.com/file/374621
|
||||
[5]:https://opensource.com/file/374616
|
||||
[6]:https://opensource.com/article/17/10/python-101?rate=XlcW6PAHGbAEBboJ3z6P_4Sx-hyMDMlga9NfoauUA0w
|
||||
[7]:http://ninja-ide.org/downloads/
|
||||
[8]:https://opensource.com/user/15261/feed
|
||||
[9]:https://www.python.org/
|
||||
[10]:https://www.python.org/downloads/mac-osx/
|
||||
[11]:https://www.python.org/downloads/windows
|
||||
[12]:http://ninja-ide.org/
|
||||
[13]:https://opensource.com/article/17/8/doc-driven-development
|
||||
[14]:https://www.pygame.org/news
|
||||
[15]:https://opensource.com/users/seth
|
||||
[16]:https://opensource.com/users/seth
|
||||
[17]:https://opensource.com/article/17/10/python-101#comments
|
||||
@ -0,0 +1,100 @@
|
||||
由 KRACK 攻击想到的确保网络安全的小贴士
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 最近的 KRACK (密钥重装攻击,这是一个安全漏洞名称或该漏洞利用攻击行为的名称)漏洞攻击的目标是位于你的设备和 Wi-Fi 访问点之间的链路,这个访问点或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器。这些提示能帮你提升你的连接的安全性。
|
||||
|
||||
[KRACK 漏洞攻击][4] 出现已经一段时间了,并且已经在 [相关技术网站][5] 上有很多详细的讨论,因此,我将不在这里重复攻击的技术细节。攻击方式的总结如下:
|
||||
|
||||
* 在 WPA2 无线握手协议中的一个缺陷允许攻击者在你的设备和 wi-fi 访问点之间嗅探或操纵通讯。
|
||||
* 这个问题在 Linux 和 Android 设备上尤其严重,由于在 WPA2 标准中的措辞含糊不清,也或许是在实现它时的错误理解,事实上,在底层的操作系统打完补丁以前,该漏洞一直可以强制无线流量以无加密方式通讯。
|
||||
* 还好这个漏洞可以在客户端上修补,因此,天并没有塌下来,而且,WPA2 加密标准并没有像 WEP 标准那样被淘汰(不要通过切换到 WEP 加密的方式去“修复”这个问题)。
|
||||
* 大多数流行的 Linux 发行版都已经通过升级修复了这个客户端上的漏洞,因此,老老实实地去更新它吧。
|
||||
* Android 也很快修复了这个漏洞。如果你的设备在接收 Android 安全补丁,你会很快修复这个漏洞。如果你的设备不再接收这些更新,那么,这个特别的漏洞将是你停止使用你的旧设备的一个理由。
|
||||
|
||||
即使如此,从我的观点来看, Wi-Fi 是不可信任的基础设施链中的另一个环节,并且,我们应该完全避免将其视为可信任的通信通道。
|
||||
|
||||
### Wi-Fi 是不受信任的基础设备
|
||||
|
||||
如果从你的笔记本电脑或移动设备中读到这篇文章,那么,你的通信链路看起来应该是这样:
|
||||
|
||||

|
||||
|
||||
KRACK 攻击目标是在你的设备和 Wi-Fi 访问点之间的链接,访问点或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器。
|
||||
|
||||

|
||||
|
||||
实际上,这个图示应该看起来像这样:
|
||||
|
||||

|
||||
|
||||
Wi-Fi 仅仅是在我们所不应该信任的信道上的长长的通信链的第一个链路。让我来猜猜,你使用的 Wi-Fi 路由器或许从开始使用的第一天气就没有得到过一个安全更新,并且,更糟糕的是,它或许使用了一个从未被更改过的、缺省的、易猜出的管理凭据(用户名和密码)。除非你自己安装并配置你的路由器,并且你能记得你上次更新的它的固件的时间,否则,你应该假设现在它已经被一些人控制并不能信任的。
|
||||
|
||||
在 Wi-Fi 路由器之后,我们的通讯进入一般意义上的常见不信任区域 —— 这要根据你的猜疑水平。这里有上游的 ISP 和接入提供商,其中的很多已经被指认监视、更改、分析和销售我们的流量数据,试图从我们的浏览习惯中挣更多的钱。通常他们的安全补丁计划辜负了我们的期望,最终让我们的流量暴露在一些恶意者眼中。
|
||||
|
||||
一般来说,在互联网上,我们还必须担心强大的国家级的参与者能够操纵核心网络协议,以执行大规模的网络监视和状态级的流量过滤。
|
||||
|
||||
### HTTPS 协议
|
||||
|
||||
值的庆幸的是,我们有一个基于不信任的介质进行安全通讯的解决方案,并且,我们可以每天都能使用它 —— 这就是 HTTPS 协议,它加密你的点对点的互联网通讯,并且确保我们可以信任站点与我们之间的通讯。
|
||||
|
||||
Linux 基金会的一些措施,比如像 [Let’s Encrypt][7] 使世界各地的网站所有者都可以很容易地提供端到端的加密,这有助于确保我们的个人设备与我们试图访问的网站之间的任何有安全隐患的设备不再是个问题。
|
||||
|
||||

|
||||
|
||||
是的... 基本没关系。
|
||||
|
||||
### DNS —— 剩下的一个问题
|
||||
|
||||
虽然,我们可以尽量使用 HTTPS 去创建一个可信的通信信道,但是,这里仍然有一个攻击者可以访问我们的路由器或修改我们的 Wi-Fi 流量的机会 —— 在使用 KRACK 的这个案例中 —— 可以欺骗我们的通讯进入一个错误的网站。他们可以利用我们仍然非常依赖 DNS 的这一事实 —— 这是一个未加密的、易受欺骗的 [诞生自上世纪 80 年代的协议][8]。
|
||||
|
||||

|
||||
|
||||
DNS 是一个将像 “linux.com” 这样人类友好的域名,转换成计算机可以用于和其它计算机通讯的 IP 地址的一个系统。要转换一个域名到一个 IP 地址,计算机将会查询解析器软件 —— 它通常运行在 Wi-Fi 路由器或一个系统上。解析器软件将查询一个分布式的“根”域名服务器网络,去找到在互联网上哪个系统有 “linux.com” 域名所对应的 IP 地址的“权威”信息。
|
||||
|
||||
麻烦就在于,所有发生的这些通讯都是未经认证的、[易于欺骗的][9]、明文协议、并且响应可以很容易地被攻击者修改,去返回一个不正确的数据。如果有人去欺骗一个 DNS 查询并且返回错误的 IP 地址,他们可以操纵我们的系统最终发送 HTTP 请求到那里。
|
||||
|
||||
幸运的是,HTTPS 有一些内置的保护措施去确保它不会很容易地被其它人诱导至其它假冒站点。恶意服务器上的 TLS 凭据必须与你请求的 DNS 名字匹配 —— 并且它必须由一个你的浏览器认可的信誉良好的 [认证机构(CA)][10] 所签发。如果不是这种情况,你的浏览器将在你试图去与他们告诉你的地址进行通讯时出现一个很大的警告。如果你看到这样的警告,在选择不理会警告之前,请你格外小心,因为,它有可能会把你的秘密泄露给那些可能会对付你的人。
|
||||
|
||||
如果攻击者完全控制了路由器,他们可以在一开始时,通过拦截来自服务器指示你建立一个安全连接的响应,以阻止你使用 HTTPS 连接(这被称为 “[SSL 脱衣攻击][11]”)。 为了帮助你防护这种类型的攻击,网站可以增加一个 [特殊响应头(HSTS)][12] 去告诉你的浏览器以后与它通讯时总是使用 HTTPS 协议,但是,这仅仅是在你首次访问之后的事。对于一些非常流行的站点,浏览器现在包含一个 [硬编码的域名列表][13],即使是首次连接,它也将总是使用 HTTPS 协议访问。
|
||||
|
||||
现在已经有了 DNS 欺骗的解决方案,它被称为 [DNSSEC][14],由于有重大的障碍 —— 真实和可感知的(LCTT 译注,指的是要求实名认证),它看起来接受程度很慢。在 DNSSEC 被普遍使用之前,我们必须假设,我们接收到的 DNS 信息是不能完全信任的。
|
||||
|
||||
### 使用 VPN 去解决“最后一公里”的安全问题
|
||||
|
||||
因此,如果你不能信任固件太旧的 Wi-Fi 和/或无线路由器,我们能做些什么来确保发生在你的设备与常说的互联网之间的“最后一公里”通讯的完整性呢?
|
||||
|
||||
一个可接受的解决方案是去使用信誉好的 VPN 供应商的服务,它将在你的系统和他们的基础设施之间建立一条安全的通讯链路。这里有一个期望,就是它比你的路由器提供者和你的当前互联网供应商更注重安全,因为,他们处于一个更好的位置去确保你的流量不会受到恶意的攻击或欺骗。在你的工作站和移动设备之间使用 VPN,可以确保免受像 KRACK 这样的漏洞攻击,不安全的路由器不会影响你与外界通讯的完整性。
|
||||
|
||||

|
||||
|
||||
这有一个很重要的警告是,当你选择一个 VPN 供应商时,你必须确信他们的信用;否则,你将被一拨恶意的人出卖给其它人。远离任何人提供的所谓“免费 VPN”,因为,它们可以通过监视你和向市场营销公司销售你的流量来赚钱。 [这个网站][2] 是一个很好的资源,你可以去比较他们提供的各种 VPN,去看他们是怎么互相竞争的。
|
||||
|
||||
注意,你所有的设备都应该在它上面安装 VPN,那些你每天使用的网站,你的私人信息,尤其是任何与你的钱和你的身份(政府、银行网站、社交网络、等等)有关的东西都必须得到保护。VPN 并不是对付所有网络级漏洞的万能药,但是,当你在机场使用无法保证的 Wi-Fi 时,或者下次发现类似 KRACK 的漏洞时,它肯定会保护你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2017/10/tips-secure-your-network-wake-krack
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.vpnmentor.com/bestvpns/overall/
|
||||
[3]:https://www.linux.com/files/images/krack-securityjpg
|
||||
[4]:https://www.krackattacks.com/
|
||||
[5]:https://blog.cryptographyengineering.com/2017/10/16/falling-through-the-kracks/
|
||||
[6]:https://en.wikipedia.org/wiki/BGP_hijacking
|
||||
[7]:https://letsencrypt.org/
|
||||
[8]:https://en.wikipedia.org/wiki/Domain_Name_System#History
|
||||
[9]:https://en.wikipedia.org/wiki/DNS_spoofing
|
||||
[10]:https://en.wikipedia.org/wiki/Certificate_authority
|
||||
[11]:https://en.wikipedia.org/wiki/Moxie_Marlinspike#Notable_research
|
||||
[12]:https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security
|
||||
[13]:https://hstspreload.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions
|
||||
@ -0,0 +1,317 @@
|
||||
用 Kubernetes 和 Docker 部署 Java 应用
|
||||
==========================
|
||||
|
||||
> 大规模容器应用编排起步
|
||||
|
||||
通过《[面向 Java 开发者的 Kubernetes][3]》,学习基本的 Kubernetes 概念和自动部署、维护和扩展你的 Java 应用程序的机制。[下载该电子书的免费副本][3]
|
||||
|
||||
在 《[Java 的容器化持续交付][23]》 中,我们探索了在 Docker 容器内打包和部署 Java 应用程序的基本原理。这只是创建基于容器的生产级系统的第一步。在真实的环境中运行容器还需要一个容器编排和计划的平台,并且,现在已经存在了很多个这样的平台(如,Docker Swarm、Apach Mesos、AWS ECS),而最受欢迎的是 [Kubernetes][24]。Kubernetes 被用于很多组织的产品中,并且,它现在由[原生云计算基金会(CNCF)][25]所管理。在这篇文章中,我们将使用以前的一个简单的基于 Java 的电子商务商店,我们将它打包进 Docker 容器内,并且在 Kubernetes 上运行它。
|
||||
|
||||
### “Docker Java Shopfront” 应用程序
|
||||
|
||||
我们将打包进容器,并且部署在 Kubernetes 上的 “Docker Java Shopfront” 应用程序的架构,如下面的图所示:
|
||||
|
||||
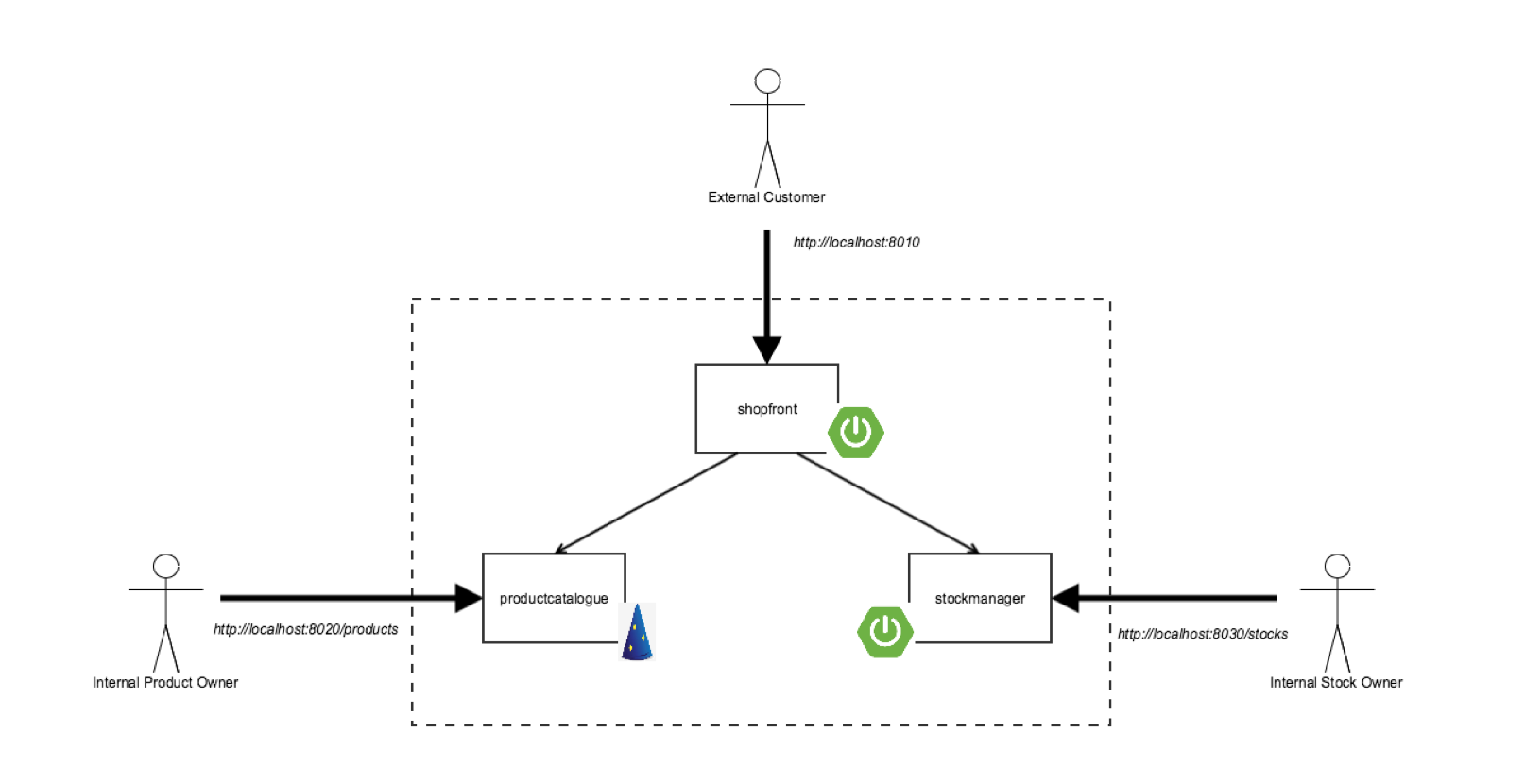
|
||||
|
||||
在我们开始去创建一个所需的 Kubernetes 部署配置文件之前,让我们先学习一下关于容器编排平台中的一些核心概念。
|
||||
|
||||
### Kubernetes 101
|
||||
|
||||
Kubernetes 是一个最初由谷歌开发的开源的部署容器化应用程序的<ruby>编排器<rt>orchestrator</rt></ruby>。谷歌已经运行容器化应用程序很多年了,并且,由此产生了 [Borg 容器编排器][26],它是应用于谷歌内部的,是 Kubernetes 创意的来源。如果你对这个技术不熟悉,一些出现的许多核心概念刚开始你会不理解,但是,实际上它们都很强大。首先, Kubernetes 采用了不可变的基础设施的原则。部署到容器中的内容(比如应用程序)是不可变的,不能通过登录到容器中做成改变。而是要以部署新的版本替代。第二,Kubernetes 内的任何东西都是<ruby>声明式<rt>declaratively</rt></ruby>配置。开发者或运维指定系统状态是通过部署描述符和配置文件进行的,并且,Kubernetes 是可以响应这些变化的——你不需要去提供命令,一步一步去进行。
|
||||
|
||||
不可变基础设施和声明式配置的这些原则有许多好处:它容易防止配置<ruby>偏移<rt>drift</rt></ruby>,或者 “<ruby>雪花<rt>snowflake</rt></ruby>” 应用程序实例;声明部署配置可以保存在版本控制中,与代码在一起;并且, Kubernetes 大部分都可以自我修复,比如,如果系统经历失败,假如是一个底层的计算节点失败,系统可以重新构建,并且根据在声明配置中指定的状态去重新均衡应用程序。
|
||||
|
||||
Kubernetes 提供几个抽象概念和 API,使之可以更容易地去构建这些分布式的应用程序,比如,如下的这些基于微服务架构的:
|
||||
|
||||
* [<ruby>豆荚<rt>Pod</rt></ruby>][5] —— 这是 Kubernetes 中的最小部署单元,并且,它本质上是一组容器。 <ruby>豆荚<rt>Pod</rt></ruby>可以让一个微服务应用程序容器与其它“挎斗” 容器,像日志、监视或通讯管理这样的系统服务一起被分组。在一个豆荚中的容器共享同一个文件系统和网络命名空间。注意,一个单个的容器也是可以被部署的,但是,通常的做法是部署在一个豆荚中。
|
||||
* [服务][6] —— Kubernetes 服务提供负载均衡、命名和发现,以将一个微服务与其它隔离。服务是通过[复制控制器][7]支持的,它反过来又负责维护在系统内运行期望数量的豆荚实例的相关细节。服务、复制控制器和豆荚在 Kubernetes 中通过使用“[标签][8]”连接到一起,并通过它进行命名和选择。
|
||||
|
||||
现在让我们来为我们的基于 Java 的微服务应用程序创建一个服务。
|
||||
|
||||
### 构建 Java 应用程序和容器镜像
|
||||
|
||||
在我们开始创建一个容器和相关的 Kubernetes 部署配置之前,我们必须首先确认,我们已经安装了下列必需的组件:
|
||||
|
||||
* 适用于 [Mac][11] / [Windows][12] / [Linux][13] 的 Docker - 这允许你在本地机器上,在 Kubernetes 之外去构建、运行和测试 Docker 容器。
|
||||
* [Minikube][14] - 这是一个工具,它可以通过虚拟机,在你本地部署的机器上很容易地去运行一个单节点的 Kubernetes 测试集群。
|
||||
* 一个 [GitHub][15] 帐户和本地安装的 [Git][16] - 示例代码保存在 GitHub 上,并且通过使用本地的 Git,你可以复刻该仓库,并且去提交改变到该应用程序的你自己的副本中。
|
||||
* [Docker Hub][17] 帐户 - 如果你想跟着这篇教程进行,你将需要一个 Docker Hub 帐户,以便推送和保存你将在后面创建的容器镜像的拷贝。
|
||||
* [Java 8][18] (或 9) SDK 和 [Maven][19] - 我们将使用 Maven 和附属的工具使用 Java 8 特性去构建代码。
|
||||
|
||||
从 GitHub 克隆项目库代码(可选,你可以<ruby>复刻<rt>fork</rt></ruby>这个库,并且克隆一个你个人的拷贝),找到 “shopfront” 微服务应用: [https://github.com/danielbryantuk/oreilly-docker-java-shopping/][27]。
|
||||
|
||||
```
|
||||
$ git clone git@github.com:danielbryantuk/oreilly-docker-java-shopping.git
|
||||
$ cd oreilly-docker-java-shopping/shopfront
|
||||
```
|
||||
|
||||
请加载 shopfront 代码到你选择的编辑器中,比如,IntelliJ IDE 或 Eclipse,并去研究它。让我们使用 Maven 来构建应用程序。最终生成包含该应用的可运行的 JAR 文件位于 `./target` 的目录中。
|
||||
|
||||
```
|
||||
$ mvn clean install
|
||||
…
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] BUILD SUCCESS
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] Total time: 17.210 s
|
||||
[INFO] Finished at: 2017-09-30T11:28:37+01:00
|
||||
[INFO] Final Memory: 41M/328M
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
```
|
||||
|
||||
现在,我们将构建 Docker 容器镜像。一个容器镜像的操作系统选择、配置和构建步骤,一般情况下是通过一个 Dockerfile 指定的。我们看一下,我们的示例中位于 shopfront 目录中的 Dockerfile:
|
||||
|
||||
```
|
||||
FROM openjdk:8-jre
|
||||
ADD target/shopfront-0.0.1-SNAPSHOT.jar app.jar
|
||||
EXPOSE 8010
|
||||
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
|
||||
```
|
||||
|
||||
第一行指定了,我们的容器镜像将被 “<ruby>从<rt>from</rt></ruby>” 这个 openjdk:8-jre 基础镜像中创建。[openjdk:8-jre][28] 镜像是由 OpenJDK 团队维护的,并且包含了我们在 Docker 容器(就像一个安装和配置了 OpenJDK 8 JDK的操作系统)中运行 Java 8 应用程序所需要的一切东西。第二行是,将我们上面构建的可运行的 JAR “<ruby>添加<rt>add</rt></ruby>” 到这个镜像。第三行指定了端口号是 8010,我们的应用程序将在这个端口号上监听,如果外部需要可以访问,必须要 “<ruby>暴露<rt>exposed</rt></ruby>” 它,第四行指定 “<ruby>入口<rt>entrypoint</rt></ruby>” ,即当容器初始化后去运行的命令。现在,我们来构建我们的容器:
|
||||
|
||||
|
||||
```
|
||||
$ docker build -t danielbryantuk/djshopfront:1.0 .
|
||||
Successfully built 87b8c5aa5260
|
||||
Successfully tagged danielbryantuk/djshopfront:1.0
|
||||
```
|
||||
|
||||
现在,我们推送它到 Docker Hub。如果你没有通过命令行登入到 Docker Hub,现在去登入,输入你的用户名和密码:
|
||||
|
||||
```
|
||||
$ docker login
|
||||
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
|
||||
Username:
|
||||
Password:
|
||||
Login Succeeded
|
||||
$
|
||||
$ docker push danielbryantuk/djshopfront:1.0
|
||||
The push refers to a repository [docker.io/danielbryantuk/djshopfront]
|
||||
9b19f75e8748: Pushed
|
||||
...
|
||||
cf4ecb492384: Pushed
|
||||
1.0: digest: sha256:8a6b459b0210409e67bee29d25bb512344045bd84a262ede80777edfcff3d9a0 size: 2210
|
||||
```
|
||||
|
||||
### 部署到 Kubernetes 上
|
||||
|
||||
现在,让我们在 Kubernetes 中运行这个容器。首先,切换到项目根目录的 `kubernetes` 目录:
|
||||
|
||||
```
|
||||
$ cd ../kubernetes
|
||||
```
|
||||
|
||||
打开 Kubernetes 部署文件 `shopfront-service.yaml`,并查看内容:
|
||||
|
||||
```
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: shopfront
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
type: NodePort
|
||||
selector:
|
||||
app: shopfront
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 8010
|
||||
name: http
|
||||
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ReplicationController
|
||||
metadata:
|
||||
name: shopfront
|
||||
spec:
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
containers:
|
||||
- name: shopfront
|
||||
image: danielbryantuk/djshopfront:latest
|
||||
ports:
|
||||
- containerPort: 8010
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /health
|
||||
port: 8010
|
||||
initialDelaySeconds: 30
|
||||
timeoutSeconds: 1
|
||||
```
|
||||
|
||||
这个 yaml 文件的第一节创建了一个名为 “shopfront” 的服务,它将到该服务(8010 端口)的 TCP 流量路由到标签为 “app: shopfront” 的豆荚中 。配置文件的第二节创建了一个 `ReplicationController` ,其通知 Kubernetes 去运行我们的 shopfront 容器的一个复制品(实例),它是我们标为 “app: shopfront” 的声明(spec)的一部分。我们也指定了暴露在我们的容器上的 8010 应用程序端口,并且声明了 “livenessProbe” (即健康检查),Kubernetes 可以用于去决定我们的容器应用程序是否正确运行并准备好接受流量。让我们来启动 `minikube` 并部署这个服务(注意,根据你部署的机器上的可用资源,你可能需要去修 `minikube` 中的指定使用的 CPU 和<ruby>内存<rt>memory</rt></ruby>):
|
||||
|
||||
```
|
||||
$ minikube start --cpus 2 --memory 4096
|
||||
Starting local Kubernetes v1.7.5 cluster...
|
||||
Starting VM...
|
||||
Getting VM IP address...
|
||||
Moving files into cluster...
|
||||
Setting up certs...
|
||||
Connecting to cluster...
|
||||
Setting up kubeconfig...
|
||||
Starting cluster components...
|
||||
Kubectl is now configured to use the cluster.
|
||||
$ kubectl apply -f shopfront-service.yaml
|
||||
service "shopfront" created
|
||||
replicationcontroller "shopfront" created
|
||||
```
|
||||
|
||||
你可以通过使用 `kubectl get svc` 命令查看 Kubernetes 中所有的服务。你也可以使用 `kubectl get pods` 命令去查看所有相关的豆荚(注意,你第一次执行 get pods 命令时,容器可能还没有创建完成,并被标记为未准备好):
|
||||
|
||||
```
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 18h
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 12s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 0/1 ContainerCreating 0 18s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 1/1 Running 0 2m
|
||||
```
|
||||
|
||||
我们现在已经成功地在 Kubernetes 中部署完成了我们的第一个服务。
|
||||
|
||||
### 是时候进行烟雾测试了
|
||||
|
||||
现在,让我们使用 curl 去看一下,我们是否可以从 shopfront 应用程序的健康检查端点中取得数据:
|
||||
|
||||
```
|
||||
$ curl $(minikube service shopfront --url)/health
|
||||
{"status":"UP"}
|
||||
```
|
||||
|
||||
你可以从 curl 的结果中看到,应用的 health 端点是启用的,并且是运行中的,但是,在应用程序按我们预期那样运行之前,我们需要去部署剩下的微服务应用程序容器。
|
||||
|
||||
### 构建剩下的应用程序
|
||||
|
||||
现在,我们有一个容器已经运行,让我们来构建剩下的两个微服务应用程序和容器:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd productcatalogue/
|
||||
$ mvn clean install
|
||||
…
|
||||
$ docker build -t danielbryantuk/djproductcatalogue:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djproductcatalogue:1.0
|
||||
...
|
||||
$ cd ..
|
||||
$ cd stockmanager/
|
||||
$ mvn clean install
|
||||
...
|
||||
$ docker build -t danielbryantuk/djstockmanager:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djstockmanager:1.0
|
||||
...
|
||||
```
|
||||
|
||||
这个时候, 我们已经构建了所有我们的微服务和相关的 Docker 镜像,也推送镜像到 Docker Hub 上。现在,我们去在 Kubernetes 中部署 `productcatalogue` 和 `stockmanager` 服务。
|
||||
|
||||
### 在 Kubernetes 中部署整个 Java 应用程序
|
||||
|
||||
与我们上面部署 shopfront 服务时类似的方式去处理它,我们现在可以在 Kubernetes 中部署剩下的两个微服务:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd kubernetes/
|
||||
$ kubectl apply -f productcatalogue-service.yaml
|
||||
service "productcatalogue" created
|
||||
replicationcontroller "productcatalogue" created
|
||||
$ kubectl apply -f stockmanager-service.yaml
|
||||
service "stockmanager" created
|
||||
replicationcontroller "stockmanager" created
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 19h
|
||||
productcatalogue 10.0.0.37 <nodes> 8020:31803/TCP 42s
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 13m
|
||||
stockmanager 10.0.0.149 <nodes> 8030:30723/TCP 16s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
productcatalogue-79qn4 1/1 Running 0 55s
|
||||
shopfront-0w1js 1/1 Running 0 13m
|
||||
stockmanager-lmgj9 1/1 Running 0 29s
|
||||
```
|
||||
|
||||
取决于你执行 “kubectl get pods” 命令的速度,你或许会看到所有都处于不再运行状态的豆荚。在转到这篇文章的下一节之前,我们要等着这个命令展示出所有豆荚都运行起来(或许,这个时候应该来杯咖啡!)
|
||||
|
||||
### 查看完整的应用程序
|
||||
|
||||
在所有的微服务部署完成并且所有相关的豆荚都正常运行后,我们现在将去通过 shopfront 服务的 GUI 去访问我们完整的应用程序。我们可以通过执行 `minikube` 命令在默认浏览器中打开这个服务:
|
||||
|
||||
```
|
||||
$ minikube service shopfront
|
||||
```
|
||||
|
||||
如果一切正常,你将在浏览器中看到如下的页面:
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
在这篇文章中,我们已经完成了由三个 Java Spring Boot 和 Dropwizard 微服务组成的应用程序,并且将它部署到 Kubernetes 上。未来,我们需要考虑的事还很多,比如,调试服务(或许是通过工具,像 [Telepresence][29] 和 [Sysdig][30]),通过一个像 [Jenkins][31] 或 [Spinnaker][32] 这样的可持续交付的过程去测试和部署,并且观察我们的系统运行。
|
||||
|
||||
* * *
|
||||
|
||||
_本文是与 NGINX 协作创建的。 [查看我们的编辑独立性声明][22]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel Bryant 是一名独立技术顾问,他是 SpectoLabs 的 CTO。他目前关注于通过识别价值流、创建构建过程、和实施有效的测试策略,从而在组织内部实现持续交付。Daniel 擅长并关注于“DevOps”工具、云/容器平台和微服务实现。他也贡献了几个开源项目,并定期为 InfoQ、 O’Reilly、和 Voxxed 撰稿...
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java
|
||||
|
||||
作者:[Daniel Bryant][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/d3f4d647-482d-4dce-a0e5-a09773b77150
|
||||
[1]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[2]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[3]:https://www.nginx.com/resources/library/kubernetes-for-java-developers/
|
||||
[4]:https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021
|
||||
[5]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[6]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[7]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[9]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[10]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[11]:https://docs.docker.com/docker-for-mac/install/
|
||||
[12]:https://docs.docker.com/docker-for-windows/install/
|
||||
[13]:https://docs.docker.com/engine/installation/linux/ubuntu/
|
||||
[14]:https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||
[15]:https://github.com/
|
||||
[16]:https://git-scm.com/
|
||||
[17]:https://hub.docker.com/
|
||||
[18]:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
|
||||
[19]:https://maven.apache.org/
|
||||
[20]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[21]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[22]:http://www.oreilly.com/about/editorial_independence.html
|
||||
[23]:https://www.nginx.com/resources/library/containerizing-continuous-delivery-java/
|
||||
[24]:https://kubernetes.io/
|
||||
[25]:https://www.cncf.io/
|
||||
[26]:https://research.google.com/pubs/pub44843.html
|
||||
[27]:https://github.com/danielbryantuk/oreilly-docker-java-shopping/
|
||||
[28]:https://hub.docker.com/_/openjdk/
|
||||
[29]:https://telepresence.io/
|
||||
[30]:https://www.sysdig.org/
|
||||
[31]:https://wiki.jenkins.io/display/JENKINS/Kubernetes+Plugin
|
||||
[32]:https://www.spinnaker.io/
|
||||
@ -0,0 +1,127 @@
|
||||
为什么 Ubuntu 放弃 Unity?创始人如是说
|
||||
===========
|
||||
|
||||

|
||||
|
||||
Mark Shuttleworth 是 Ubuntu 的创始人
|
||||
|
||||
Ubuntu 之前[在 4 月份][4]宣布决定放弃 Unity 让包括我在内的所有人都大感意外。
|
||||
|
||||
现在,Ubuntu 的创始人 [Mark Shuttleworth][7] 分享了关于 Ubuntu 为什么会选择放弃 Unity 的更多细节。
|
||||
|
||||
答案可能会出乎意料……
|
||||
|
||||
或许不会,因为答案也在情理之中。
|
||||
|
||||
### 为什么 Ubuntu 放弃 Unity?
|
||||
|
||||
上周(10 月 20 日)[Ubuntu 17.10][8] 已经发布,这是自 [2011 年引入][9] Unity 以来,Ubuntu 第一次没有带 Unity 桌面发布。
|
||||
|
||||
当然,主流媒体对 Unity 的未来感到好奇,因此 Mark Shuttleworth [向 eWeek][10] 详细介绍了他决定在 Ubuntu 路线图中抛弃 Unity 的原因。
|
||||
|
||||
简而言之就是他把驱逐 Unity 作为节约成本的一部分,旨在使 Canonical 走上 IPO 的道路。
|
||||
|
||||
是的,投资者来了。
|
||||
|
||||
但是完整采访提供了更多关于这个决定的更多内容,并且披露了放弃曾经悉心培养的桌面对他而言是多么艰难。
|
||||
|
||||
### “Ubuntu 已经进入主流”
|
||||
|
||||
Mark Shuttleworth 和 [Sean Michael Kerner][12] 的谈话,首先提醒了我们 Ubuntu 有多么伟大:
|
||||
|
||||
> “Ubuntu 的美妙之处在于,我们创造了一个对终端用户免费,并围绕其提供商业服务的平台,在这个梦想中,我们可以用各种不同的方式定义未来。
|
||||
|
||||
> 我们确实已经看到,Ubuntu 在很多领域已经进入了主流。”
|
||||
|
||||
但是受欢迎并不意味着盈利,Mark 指出:
|
||||
|
||||
> “我们现在所做的一些事情很明显在商业上是不可能永远持续的,而另外一些事情无疑商业上是可持续发展的,或者已经在商业上可持续。
|
||||
|
||||
> 只要我们还是一个纯粹的私人公司,我们就有完全的自由裁量权来决定是否支持那些商业上不可持续的事情。”
|
||||
|
||||
Shuttleworth 说,他和 Canonical 的其他“领导”通过协商一致认为,他们应该让公司走上成为上市公司的道路。
|
||||
|
||||
为了吸引潜在的投资者,公司必须把重点放在盈利领域 —— 而 Unity、Ubuntu 电话、Unity 8 以及<ruby>融合<rt>convergence</rt></ruby>不属于这个部分:
|
||||
|
||||
> “[这个决定]意味着我们不能让我们的名册中拥有那些根本没有商业前景实际上却非常重大的项目。
|
||||
|
||||
> 这并不意味着我们会考虑改变 Ubuntu 的条款,因为它是我们所做的一切的基础。而且实际上,我们也没有必要。”
|
||||
|
||||
### “Ubuntu 本身现在完全可持续发展”
|
||||
|
||||
钱可能意味着 Unity 的消亡,但会让更广泛的 Ubuntu 项目健康发展。正如 Shuttleworth 解释说的:
|
||||
|
||||
> “我最为自豪的事情之一就是在过去的 7 年中,Ubuntu 本身变得完全可持续发展。即使明天我被车撞倒,而 Ubuntu 也可以继续发展下去。
|
||||
|
||||
> 这很神奇吧?对吧?这是一个世界级的企业平台,它不仅完全免费,而且是可持续的。
|
||||
|
||||
> 这主要要感谢 Jane Silber。” (LCTT 译注:Canonical 公司的 CEO)
|
||||
|
||||
虽然桌面用户都会关注桌面,但比起我们期待的每 6 个月发布的版本,对 Canonical 公司的关注显然要多得多。
|
||||
|
||||
失去 Unity 对桌面用户可能是一个沉重打击,但它有助于平衡公司的其他部分:
|
||||
|
||||
> “除此之外,我们在企业中还有巨大的可能性,比如在真正定义云基础设施是如何构建的方面,云应用程序是如何操作的等等。而且,在物联网中,看看下一波的可能性,那些创新者们正在基于物联网创造的东西。
|
||||
|
||||
> 所有这些都足以让我们在这方面进行 IPO。”
|
||||
|
||||
然而,对于 Mark 来说,放弃 Unity 并不容易,
|
||||
|
||||
> “我们在 Unity 上做了很多工作,我真的很喜欢它。
|
||||
|
||||
> 我认为 Unity 8 工程非常棒,而且如何将这些不同形式的要素结合在一起的深层理念是非常迷人的。”
|
||||
|
||||
> “但是,如果我们要走上 IPO 的道路,我不能再为将它留在 Canonical 来争论了。
|
||||
|
||||
> 在某个阶段你们应该会看到,我想我们很快就会宣布,没有 Unity, 我们实际上已经几乎打破了我们在商业上所做的所有事情。”
|
||||
|
||||
在这之后不久,他说公司可能会进行第一轮用于增长的投资,以此作为转变为正式上市公司前的过渡。
|
||||
|
||||
但 Mark 并不想让任何人认为投资者会 “毁了派对”:
|
||||
|
||||
> “我们还没沦落到需要根据风投的指示来行动的地步。我们清楚地看到了我们的客户喜欢什么,我们已经找到了适用于云和物联网的很好的市场着力点和产品。”
|
||||
|
||||
Mark 补充到,Canonical 公司的团队对这个决定 “无疑很兴奋”。
|
||||
|
||||
> “在情感上,我不想再经历这样的过程。我对 Unity 做了一些误判。我曾天真的认为业界会支持一个独立自由平台的想法。
|
||||
|
||||
> 但我也不后悔做过这件事。很多人会抱怨他们的选择,而不去创造其他选择。
|
||||
|
||||
> 事实证明,这需要一点勇气以及相当多的钱去尝试和创造这些选择。”
|
||||
|
||||
### OMG! IPO? NO!
|
||||
|
||||
在对 Canonical(可能)成为一家上市公司的观念进行争辩之前,我们要记住,**RedHat 已经是一家 20 年之久的上市公司了**。GNOME 桌面和 Fedora 在没有任何 “赚钱” 措施的干预下也都活得很不错。
|
||||
|
||||
Canonical 的 IPO 不太可能对 Ubuntu 产生突然的引人注目的的改变,因为就像 Shuttleworth 自己所说的那样,这是其它所有东西得以成立的基础。
|
||||
|
||||
Ubuntu 是已被认可的。这是云上的头号操作系统。它是世界上最受欢迎的 Linux 发行版(除了 [Distrowatch 排名][13])。并且它似乎在物联网上也有巨大的应用前景。
|
||||
|
||||
Mark 说 Ubuntu 现在是完全可持续发展的。
|
||||
|
||||
随着一个[迎接 Ubuntu 17.10 到来的热烈招待会][14],以及一个新的 LTS 将要发布,事情看起来相当不错……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/10/why-did-ubuntu-drop-unity-mark-shuttleworth-explains
|
||||
|
||||
作者:[JOEY SNEDDON][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter),[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://trw.431.night8.win/yy.php/H5aIh_2F/ywcKfGz_/2BKS471c/l3mPrAOp/L1WrIpnn/GpPc4TFY/yHh6t5Cu/gk7ZPrW2/omFcT6ao/A9I_3D/b0/
|
||||
[2]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU38e9i0/RMyYqikJ/lzgv8Nfz/0gk_3D/b0/
|
||||
[3]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU38e9i0/RMyYqikO/nDs5/b0/
|
||||
[4]:https://linux.cn/article-8428-1.html
|
||||
[5]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJLa_2FH/EIgGEu68/W3whyDb7/Om4zhPVa/LtGc511Z/WysilILZ/4JLodYKV/r1TGTQPz/vy99PlQJ/jKI1w_3D/b0/
|
||||
[7]:https://en.wikipedia.org/wiki/Mark_Shuttleworth
|
||||
[8]:https://linux.cn/article-8980-1.html
|
||||
[9]:http://www.omgubuntu.co.uk/2010/10/ubuntu-11-04-unity-default-desktop
|
||||
[10]:http://www.eweek.com/enterprise-apps/canonical-on-path-to-ipo-as-ubuntu-unity-linux-desktop-gets-ditched
|
||||
[11]:https://en.wikipedia.org/wiki/Initial_public_offering
|
||||
[12]:https://twitter.com/TechJournalist
|
||||
[13]:http://distrowatch.com/table.php?distribution=ubuntu
|
||||
[14]:http://www.omgubuntu.co.uk/2017/10/ubuntu-17-10-review-roundup
|
||||
@ -0,0 +1,223 @@
|
||||
如何使用 BorgBackup、Rclone 和 Wasabi 云存储推出自己的备份解决方案
|
||||
============================================================
|
||||
|
||||
> 使用基于开源软件和廉价云存储的自动备份解决方案来保护你的数据。
|
||||
|
||||

|
||||
|
||||
图片提供: opensource.com
|
||||
|
||||
几年来,我用 CrashPlan 来备份我家的电脑,包括属于我妻子和兄弟姐妹的电脑。CrashPlan 本质上是“永远在线”,不需要为它操心就可以做的规律性的备份,这真是太棒了。此外,能使用时间点恢复的能力多次派上用场。因为我通常是家庭的 IT 人员,所以我对其用户界面非常容易使用感到高兴,家人可以在没有我帮助的情况下恢复他们的数据。
|
||||
|
||||
最近 [CrashPlan 宣布][5],它正在放弃其消费者订阅,专注于其企业客户。我想,这是有道理的,因为它不能从像我这样的人赚到很多钱,而我们的家庭计划在其系统上使用了大量的存储空间。
|
||||
|
||||
我决定,我需要一个合适的替代功能,包括:
|
||||
|
||||
* 跨平台支持 Linux 和 Mac
|
||||
* 自动化(所以没有必要记得点击“备份”)
|
||||
* 时间点恢复(可以关闭),所以如果你不小心删除了一个文件,但直到后来才注意到,它仍然可以恢复
|
||||
* 低成本
|
||||
* 备份有多份存储,这样数据存在于多个地方(即,不仅仅是备份到本地 USB 驱动器上)
|
||||
* 加密以防备份文件落入坏人手中
|
||||
|
||||
我四处搜寻,问我的朋友有关类似于 CrashPlan 的服务。我对其中一个 [Arq][6] 非常满意,但没有 Linux 支持意味着对我没用。[Carbonite][7] 与 CrashPlan 类似,但会很昂贵,因为我有多台机器需要备份。[Backblaze][8] 以优惠的价格(每月 5 美金)提供无限备份,但其备份客户端不支持 Linux。[BackupPC][9] 是一个强有力的竞争者,但在我想起它之前,我已经开始测试我的解决方案了。我看到的其它选项都不符合我要的一切。这意味着我必须找出一种方法来复制 CrashPlan 为我和我的家人提供的服务。
|
||||
|
||||
我知道在 Linux 系统上备份文件有很多好的选择。事实上,我一直在使用 [rdiff-backup][10] 至少 10 年了,通常用于本地保存远程文件系统的快照。我希望能够找到可以去除备份数据中重复部分的工具,因为我知道有些(如音乐库和照片)会存储在多台计算机上。
|
||||
|
||||
我认为我所做的工作非常接近实现我的目标。
|
||||
|
||||
### 我的备份解决方案
|
||||
|
||||

|
||||
|
||||
最终,我的目标落在 [BorgBackup][11]、[Rclone][12] 和 [Wasabi 云存储][13]的组合上,我的决定让我感到无比快乐。Borg 符合我所有的标准,并有一个非常健康的[用户和贡献者社区][14]。它提供重复数据删除和压缩功能,并且在 PC、Mac 和 Linux 上运行良好。我使用 Rclone 将来自 Borg 主机的备份仓库同步到 Wasabi 上的 S3 兼容存储。任何与 S3 兼容的存储都可以工作,但是我选择了 Wasabi,因为它的价格好,而且它的性能超过了亚马逊的 S3。使用此设置,我可以从本地 Borg 主机或从 Wasabi 恢复文件。
|
||||
|
||||
在我的机器上安装 Borg 只要 `sudo apt install borgbackup`。我的备份主机是一台连接有 1.5TB USB 驱动器的 Linux 机器。如果你没有可用的机器,那么备份主机可以像 Raspberry Pi 一样轻巧。只要确保所有的客户端机器都可以通过 SSH 访问这个服务器,那么你就能用了。
|
||||
|
||||
在备份主机上,使用以下命令初始化新的备份仓库:
|
||||
|
||||
```
|
||||
$ borg init /mnt/backup/repo1
|
||||
```
|
||||
|
||||
根据你要备份的内容,你可能会选择在每台计算机上创建多个仓库,或者为所有计算机创建一个大型仓库。由于 Borg 有重复数据删除功能,如果在多台计算机上有相同的数据,那么从所有这些计算机向同一个仓库发送备份可能是有意义的。
|
||||
|
||||
在 Linux 上安装 Borg 非常简单。在 Mac OS X 上,我需要首先安装 XCode 和 Homebrew。我遵循 [how-to][15] 来安装命令行工具,然后使用 `pip3 install borgbackup`。
|
||||
|
||||
### 备份
|
||||
|
||||
每台机器都有一个 `backup.sh` 脚本(见下文),由 cron 任务定期启动。它每天只做一个备份集,但在同一天尝试几次也没有什么不好的。笔记本电脑每隔两个小时就会尝试备份一次,因为不能保证它们在某个特定的时间开启,但很可能在其中一个时间开启。这可以通过编写一个始终运行的守护进程来改进,并在笔记本电脑唤醒时触发备份尝试。但现在,我对它的运作方式感到满意。
|
||||
|
||||
我可以跳过 cron 任务,并为每个用户提供一个相对简单的方法来使用 [BorgWeb][16] 来触发备份,但是我真的不希望任何人必须记得备份。我倾向于忘记点击那个备份按钮,直到我急需修复(这时太迟了!)。
|
||||
|
||||
我使用的备份脚本来自 Borg 的[快速入门][17]文档,另外我在顶部添加了一些检查,看 Borg 是否已经在运行,如果之前的备份运行仍在进行这个脚本就会退出。这个脚本会创建一个新的备份集,并用主机名和当前日期来标记它。然后用简单的保留计划来整理旧的备份集。
|
||||
|
||||
这是我的 `backup.sh` 脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
REPOSITORY=borg@borgserver:/mnt/backup/repo1
|
||||
|
||||
#Bail if borg is already running, maybe previous run didn't finish
|
||||
if pidof -x borg >/dev/null; then
|
||||
echo "Backup already running"
|
||||
exit
|
||||
fi
|
||||
|
||||
# Setting this, so you won't be asked for your repository passphrase:
|
||||
export BORG_PASSPHRASE='thisisnotreallymypassphrase'
|
||||
# or this to ask an external program to supply the passphrase:
|
||||
export BORG_PASSCOMMAND='pass show backup'
|
||||
|
||||
# Backup all of /home and /var/www except a few
|
||||
# excluded directories
|
||||
borg create -v --stats \
|
||||
$REPOSITORY::'{hostname}-{now:%Y-%m-%d}' \
|
||||
/home/doc \
|
||||
--exclude '/home/doc/.cache' \
|
||||
--exclude '/home/doc/.minikube' \
|
||||
--exclude '/home/doc/Downloads' \
|
||||
--exclude '/home/doc/Videos' \
|
||||
--exclude '/home/doc/Music' \
|
||||
|
||||
# Use the `prune` subcommand to maintain 7 daily, 4 weekly and 6 monthly
|
||||
# archives of THIS machine. The '{hostname}-' prefix is very important to
|
||||
# limit prune's operation to this machine's archives and not apply to
|
||||
# other machine's archives also.
|
||||
borg prune -v --list $REPOSITORY --prefix '{hostname}-' \
|
||||
--keep-daily=7 --keep-weekly=4 --keep-monthly=6
|
||||
```
|
||||
|
||||
备份的输出如下所示:
|
||||
|
||||
```
|
||||
------------------------------------------------------------------------------
|
||||
Archive name: x250-2017-10-05
|
||||
Archive fingerprint: xxxxxxxxxxxxxxxxxxx
|
||||
Time (start): Thu, 2017-10-05 03:09:03
|
||||
Time (end): Thu, 2017-10-05 03:12:11
|
||||
Duration: 3 minutes 8.12 seconds
|
||||
Number of files: 171150
|
||||
------------------------------------------------------------------------------
|
||||
Original size Compressed size Deduplicated size
|
||||
This archive: 27.75 GB 27.76 GB 323.76 MB
|
||||
All archives: 3.08 TB 3.08 TB 262.76 GB
|
||||
|
||||
Unique chunks Total chunks
|
||||
Chunk index: 1682989 24007828
|
||||
------------------------------------------------------------------------------
|
||||
[...]
|
||||
Keeping archive: x250-2017-09-17 Sun, 2017-09-17 03:09:02
|
||||
Pruning archive: x250-2017-09-28 Thu, 2017-09-28 03:09:02
|
||||
```
|
||||
|
||||
我在将所有的机器备份到主机上后,我遵循[安装预编译的 Rclone 二进制文件指导][18],并将其设置为访问我的 Wasabi 帐户。
|
||||
|
||||
此脚本每天晚上运行以将任何更改同步到备份集:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
repos=( repo1 repo2 repo3 )
|
||||
|
||||
#Bail if rclone is already running, maybe previous run didn't finish
|
||||
if pidof -x rclone >/dev/null; then
|
||||
echo "Process already running"
|
||||
exit
|
||||
fi
|
||||
|
||||
for i in "${repos[@]}"
|
||||
do
|
||||
#Lets see how much space is used by directory to back up
|
||||
#if directory is gone, or has gotten small, we will exit
|
||||
space=`du -s /mnt/backup/$i|awk '{print $1}'`
|
||||
|
||||
if (( $space < 34500000 )); then
|
||||
echo "EXITING - not enough space used in $i"
|
||||
exit
|
||||
fi
|
||||
|
||||
/usr/bin/rclone -v sync /mnt/backup/$i wasabi:$i >> /home/borg/wasabi-sync.log 2>&1
|
||||
done
|
||||
```
|
||||
|
||||
第一次用 Rclone 同步备份集到 Wasabi 花了好几天,但是我大约有 400GB 的新数据,而且我的出站连接速度不是很快。但是每日的增量是非常小的,能在几分钟内完成。
|
||||
|
||||
### 恢复文件
|
||||
|
||||
恢复文件并不像 CrashPlan 那样容易,但是相对简单。最快的方法是从存储在 Borg 备份服务器上的备份中恢复。以下是一些用于恢复的示例命令:
|
||||
|
||||
```
|
||||
#List which backup sets are in the repo
|
||||
$ borg list borg@borgserver:/mnt/backup/repo1
|
||||
Remote: Authenticated with partial success.
|
||||
Enter passphrase for key ssh://borg@borgserver/mnt/backup/repo1:
|
||||
x250-2017-09-17 Sun, 2017-09-17 03:09:02
|
||||
#List contents of a backup set
|
||||
$ borg list borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 | less
|
||||
#Restore one file from the repo
|
||||
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc/somefile.jpg
|
||||
#Restore a whole directory
|
||||
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc
|
||||
```
|
||||
|
||||
如果本地的 Borg 服务器或拥有所有备份仓库的 USB 驱动器发生问题,我也可以直接从 Wasabi 直接恢复。如果机器安装了 Rclone,使用 [rclone mount][3],我可以将远程存储仓库挂载到本地文件系统:
|
||||
|
||||
```
|
||||
#Mount the S3 store and run in the background
|
||||
$ rclone mount wasabi:repo1 /mnt/repo1 &
|
||||
#List archive contents
|
||||
$ borg list /mnt/repo1
|
||||
#Extract a file
|
||||
$ borg extract /mnt/repo1::x250-2017-09-17 home/doc/somefile.jpg
|
||||
```
|
||||
|
||||
### 它工作得怎样
|
||||
|
||||
现在我已经使用了这个备份方法几个星期了,我可以说我真的很高兴。设置所有这些并使其运行当然比安装 CrashPlan 要复杂得多,但这就是使用你自己的解决方案和使用服务之间的区别。我将不得不密切关注以确保备份继续运行,数据与 Wasabi 正确同步。
|
||||
|
||||
但是,总的来说,以一个非常合理的价格替换 CrashPlan 以提供相似的备份覆盖率,结果比我预期的要容易一些。如果你看到有待改进的空间,请告诉我。
|
||||
|
||||
_这最初发表在 [Local Conspiracy][19],并被许可转载。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Christopher Aedo - Christopher Aedo 自从大学时开始就一直在用开源软件工作并为之作出贡献。最近他在领导一支非常棒的 IBM 上游开发团队,他们也是开发支持者。当他不在工作或在会议上发言时,他可能在俄勒冈州波特兰市使用 RaspberryPi 酿造和发酵美味的自制啤酒。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/backing-your-machines-borg
|
||||
|
||||
作者:[Christopher Aedo][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/docaedo
|
||||
[1]:https://opensource.com/file/375066
|
||||
[2]:https://opensource.com/article/17/10/backing-your-machines-borg?rate=Aa1IjkXuXy95tnvPGLWcPQJCKBih4Wo9hNPxhDs-mbQ
|
||||
[3]:https://rclone.org/commands/rclone_mount/
|
||||
[4]:https://opensource.com/user/145976/feed
|
||||
[5]:https://www.crashplan.com/en-us/consumer/nextsteps/
|
||||
[6]:https://www.arqbackup.com/
|
||||
[7]:https://www.carbonite.com/
|
||||
[8]:https://www.backblaze.com/
|
||||
[9]:http://backuppc.sourceforge.net/BackupPCServerStatus.html
|
||||
[10]:http://www.nongnu.org/rdiff-backup/
|
||||
[11]:https://www.borgbackup.org/
|
||||
[12]:https://rclone.org/
|
||||
[13]:https://wasabi.com/
|
||||
[14]:https://github.com/borgbackup/borg/
|
||||
[15]:http://osxdaily.com/2014/02/12/install-command-line-tools-mac-os-x/
|
||||
[16]:https://github.com/borgbackup/borgweb
|
||||
[17]:https://borgbackup.readthedocs.io/en/stable/quickstart.html
|
||||
[18]:https://rclone.org/install/
|
||||
[19]:http://localconspiracy.com/2017/10/backup-everything.html
|
||||
[20]:https://opensource.com/users/docaedo
|
||||
[21]:https://opensource.com/users/docaedo
|
||||
[22]:https://opensource.com/article/17/10/backing-your-machines-borg#comments
|
||||
97
published/20171026 But I dont know what a container is .md
Normal file
97
published/20171026 But I dont know what a container is .md
Normal file
@ -0,0 +1,97 @@
|
||||
很遗憾,我也不知道什么是容器!
|
||||
========================
|
||||
|
||||
|
||||

|
||||
|
||||
> 题图抽象的形容了容器和虚拟机是那么的相似,又是那么的不同!
|
||||
|
||||
在近期的一些会议和学术交流会上,我一直在讲述有关 DevOps 的安全问题(亦称为 DevSecOps)^注1 。通常,我首先都会问一个问题:“在座的各位有谁知道什么是容器吗?” 通常并没有很多人举手^注2 ,所以我都会先简单介绍一下什么是容器^注3 ,然后再进行深层次的讨论交流。
|
||||
|
||||
更准确的说,在运用 DevOps 或者 DevSecOps 的时候,容器并不是必须的。但容器能很好的融于 DevOps 和 DevSecOps 方案中,结果就是,虽然不用容器便可以运用 DevOps ,但我还是假设大部分人依然会使用容器。
|
||||
|
||||
### 什么是容器
|
||||
|
||||
几个月前的一个会议上,一个同事正在容器上操作演示,因为大家都不是这个方面的专家,所以该同事就很简单的开始了他的演示。他说了诸如“在 Linux 内核源码中没有一处提及到<ruby>容器<rt>container</rt></ruby>。“之类的话。事实上,在这样的特殊群体中,这种描述表达是很危险的。就在几秒钟内,我和我的老板(坐在我旁边)下载了最新版本的内核源代码并且查找统计了其中 “container” 单词出现的次数。很显然,这位同事的说法并不准确。更准确来说,我在旧版本内核(4.9.2)代码中发现有 15273 行代码包含 “container” 一词^注4 。我和我老板会心一笑,确认同事的说法有误,并在休息时纠正了他这个有误的描述。
|
||||
|
||||
后来我们搞清楚同事想表达的意思是 Linux 内核中并没有明确提及容器这个概念。换句话说,容器使用了 Linux 内核中的一些概念、组件、工具以及机制,并没有什么特殊的东西;这些东西也可以用于其他目的^注 5 。所以才有会说“从 Linux 内核角度来看,并没有容器这样的东西。”
|
||||
|
||||
然后,什么是容器呢?我有着虚拟化(<ruby>管理器<rt>hypervisor</rt></ruby>和虚拟机)技术的背景,在我看来, 容器既像虚拟机(VM)又不像虚拟机。我知道这种解释好像没什么用,不过请听我细细道来。
|
||||
|
||||
### 容器和虚拟机相似之处有哪些?
|
||||
|
||||
容器和虚拟机相似的一个主要方面就是它是一个可执行单元。将文件打包生成镜像文件,然后它就可以运行在合适的主机平台上。和虚拟机一样,它运行于主机上,同样,它的运行也受制于该主机。主机平台为容器的运行提供软件环境和硬件资源(诸如 CPU 资源、网络环境、存储资源等等),除此之外,主机还需要负责以下的任务:
|
||||
|
||||
1. 为每一个工作单元(这里指虚拟机和容器)提供保护机制,这样可以保证即使某一个工作单元出现恶意的、有害的以及不能写入的情况时不会影响其他的工作单元。
|
||||
2. 主机保护自己不会受一些恶意运行或出现故障的工作单元影响。
|
||||
|
||||
虚拟机和容器实现这种隔离的原理并不一样,虚拟机的隔离是由管理器对硬件资源划分,而容器的隔离则是通过 Linux 内核提供的软件功能实现的^注6 。这种软件控制机制通过不同的“命名空间”保证了每一个容器的文件、用户以及网络连接等互不可见,当然容器和主机之间也互不可见。这种功能也能由 SELinux 之类软件提供,它们提供了进一步隔离容器的功能。
|
||||
|
||||
### 容器和虚拟机不同之处又有哪些?
|
||||
|
||||
以上描述有个问题,如果你对<ruby>管理器<rt>hypervisor</rt></ruby>机制概念比较模糊,也许你会认为容器就是虚拟机,但它确实不是。
|
||||
|
||||
首先,最为重要的一点^注7 ,容器是一种包格式。也许你会惊讶的反问我“什么,你不是说过容器是某种可执行文件么?” 对,容器确实是可执行文件,但容器如此迷人的一个主要原因就是它能很容易的生成比虚拟机小很多的实体化镜像文件。由于这些原因,容器消耗很少的内存,并且能非常快的启动与关闭。你可以在几分钟或者几秒钟(甚至毫秒级别)之内就启动一个容器,而虚拟机则不具备这些特点。
|
||||
|
||||
正因为容器是如此轻量级且易于替换,人们使用它们来创建微服务——应用程序拆分而成的最小组件,它们可以和一个或多个其它微服务构成任何你想要的应用。假使你只在一个容器内运行某个特定功能或者任务,你也可以让容器变得很小,这样丢弃旧容器创建新容器将变得很容易。我将在后续的文章中继续跟进这个问题以及它们对安全性的可能影响,当然,也包括 DevSecOps 。
|
||||
|
||||
希望这是一次对容器的有用的介绍,并且能带动你有动力去学习 DevSecOps 的知识(如果你不是,假装一下也好)。
|
||||
|
||||
---
|
||||
|
||||
- 注 1:我觉得 DevSecOps 读起来很奇怪,而 DevOpsSec 往往有多元化的理解,然后所讨论的主题就不一样了。
|
||||
- 注 2:我应该注意到这不仅仅会被比较保守、不太喜欢被人注意的英国听众所了解,也会被加拿大人和美国人所了解,他们的性格则和英国人不一样。
|
||||
- 注 3:当然,我只是想讨论 Linux 容器。我知道关于这个问题,是有历史根源的,所以它也值得注意,而不是我故弄玄虚。
|
||||
- 注 4:如果你感兴趣的话,我使用的是命令 `grep -ir container linux-4.9.2 | wc -l`
|
||||
- 注 5:公平的说,我们快速浏览一下,一些用途与我们讨论容器的方式无关,我们讨论的是 Linux 容器,它是抽象的,可以用来包含其他元素,因此在逻辑上被称为容器。
|
||||
- 注 6:也有一些巧妙的方法可以将容器和虚拟机结合起来以发挥它们各自的优势,那个不在我今天的主题范围内。
|
||||
- 注 7:很明显,除了我们刚才介绍的执行位。
|
||||
|
||||
*原文来自 [Alice, Eve, and Bob—a security blog][7] ,转载请注明*
|
||||
|
||||
(题图: opensource.com )
|
||||
|
||||
---
|
||||
|
||||
**作者简介**:
|
||||
|
||||
原文作者 Mike Bursell 是一名居住在英国、喜欢威士忌的开源爱好者, Red Hat 首席安全架构师。其自从 1997 年接触开源世界以来,生活和工作中一直使用 Linux (尽管不是一直都很容易)。更多信息请参考作者的博客 https://aliceevebob.com ,作者会不定期的更新一些有关安全方面的文章。
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
via: https://opensource.com/article/17/10/what-are-containers
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[jrglinux](https://github.com/jrglinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mikecamel
|
||||
[1]: https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[2]: https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[3]: https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[4]: https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[5]: https://opensource.com/article/17/10/what-are-containers?rate=sPHuhiD4Z3D3vJ6ZqDT-wGp8wQjcQDv-iHf2OBG_oGQ
|
||||
[6]: https://opensource.com/article/17/10/what-are-containers#*******
|
||||
[7]: https://aliceevebob.wordpress.com/2017/07/04/but-i-dont-know-what-a-container-is/
|
||||
[8]: https://opensource.com/user/105961/feed
|
||||
[9]: https://opensource.com/article/17/10/what-are-containers#*
|
||||
[10]: https://opensource.com/article/17/10/what-are-containers#**
|
||||
[11]: https://opensource.com/article/17/10/what-are-containers#***
|
||||
[12]: https://opensource.com/article/17/10/what-are-containers#******
|
||||
[13]: https://opensource.com/article/17/10/what-are-containers#*****
|
||||
[14]: https://opensource.com/users/mikecamel
|
||||
[15]: https://opensource.com/users/mikecamel
|
||||
[16]: https://opensource.com/article/17/10/what-are-containers#****
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
270
published/20171101 How to use cron in Linux.md
Normal file
270
published/20171101 How to use cron in Linux.md
Normal file
@ -0,0 +1,270 @@
|
||||
在 Linux 中怎么使用 cron 计划任务
|
||||
============================================================
|
||||
|
||||
> 没有时间运行命令?使用 cron 的计划任务意味着你不用熬夜程序也可以运行。
|
||||
|
||||

|
||||
Image by : [Internet Archive Book Images][11]. Modified by Opensource.com. [CC BY-SA 4.0][12]
|
||||
|
||||
系统管理员(在许多好处中)的挑战之一是在你该睡觉的时候去运行一些任务。例如,一些任务(包括定期循环运行的任务)需要在没有人使用计算机资源的时候去运行,如午夜或周末。在下班后,我没有时间去运行命令或脚本。而且,我也不想在晚上去启动备份或重大更新。
|
||||
|
||||
取而代之的是,我使用两个服务功能在我预定的时间去运行命令、程序和任务。[cron][13] 和 at 服务允许系统管理员去安排任务运行在未来的某个特定时间。at 服务指定在某个时间去运行一次任务。cron 服务可以安排任务在一个周期上重复,比如天、周、或月。
|
||||
|
||||
在这篇文章中,我将介绍 cron 服务和怎么去使用它。
|
||||
|
||||
### 常见(和非常见)的 cron 用途
|
||||
|
||||
我使用 cron 服务去安排一些常见的事情,比如,每天凌晨 2:00 发生的定期备份,我也使用它去做一些不常见的事情。
|
||||
|
||||
* 许多电脑上的系统时钟(比如,操作系统时间)都设置为使用网络时间协议(NTP)。 NTP 设置系统时间后,它不会去设置硬件时钟,它可能会“漂移”。我使用 cron 基于系统时间去设置硬件时钟。
|
||||
* 我还有一个 Bash 程序,我在每天早晨运行它,去在每台电脑上创建一个新的 “每日信息” (MOTD)。它包含的信息有当前的磁盘使用情况等有用的信息。
|
||||
* 许多系统进程和服务,像 [Logwatch][7]、[logrotate][8]、和 [Rootkit Hunter][9],使用 cron 服务去安排任务和每天运行程序。
|
||||
|
||||
crond 守护进程是一个完成 cron 功能的后台服务。
|
||||
|
||||
cron 服务检查在 `/var/spool/cron` 和 `/etc/cron.d` 目录中的文件,以及 `/etc/anacrontab` 文件。这些文件的内容定义了以不同的时间间隔运行的 cron 作业。个体用户的 cron 文件是位于 `/var/spool/cron`,而系统服务和应用生成的 cron 作业文件放在 `/etc/cron.d` 目录中。`/etc/anacrontab` 是一个特殊的情况,它将在本文中稍后部分介绍。
|
||||
|
||||
### 使用 crontab
|
||||
|
||||
cron 实用程序运行基于一个 cron 表(`crontab`)中指定的命令。每个用户,包括 root,都有一个 cron 文件。这些文件缺省是不存在的。但可以使用 `crontab -e` 命令创建在 `/var/spool/cron` 目录中,也可以使用该命令去编辑一个 cron 文件(看下面的脚本)。我强烈建议你,_不要_使用标准的编辑器(比如,Vi、Vim、Emacs、Nano、或者任何其它可用的编辑器)。使用 `crontab` 命令不仅允许你去编辑命令,也可以在你保存并退出编辑器时,重启动 crond 守护进程。`crontab` 命令使用 Vi 作为它的底层编辑器,因为 Vi 是预装的(至少在大多数的基本安装中是预装的)。
|
||||
|
||||
现在,cron 文件是空的,所以必须从头添加命令。 我增加下面示例中定义的作业到我的 cron 文件中,这是一个快速指南,以便我知道命令中的各个部分的意思是什么,你可以自由拷贝它,供你自己使用。
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
SHELL=/bin/bash
|
||||
MAILTO=root@example.com
|
||||
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
|
||||
|
||||
# For details see man 4 crontabs
|
||||
|
||||
# Example of job definition:
|
||||
# .---------------- minute (0 - 59)
|
||||
# | .------------- hour (0 - 23)
|
||||
# | | .---------- day of month (1 - 31)
|
||||
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
|
||||
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
|
||||
# | | | | |
|
||||
# * * * * * user-name command to be executed
|
||||
|
||||
# backup using the rsbu program to the internal 4TB HDD and then 4TB external
|
||||
01 01 * * * /usr/local/bin/rsbu -vbd1 ; /usr/local/bin/rsbu -vbd2
|
||||
|
||||
# Set the hardware clock to keep it in sync with the more accurate system clock
|
||||
03 05 * * * /sbin/hwclock --systohc
|
||||
|
||||
# Perform monthly updates on the first of the month
|
||||
# 25 04 1 * * /usr/bin/dnf -y update
|
||||
```
|
||||
|
||||
*`crontab` 命令用于查看或编辑 cron 文件。*
|
||||
|
||||
上面代码中的前三行设置了一个缺省环境。对于给定用户,环境变量必须是设置的,因为,cron 不提供任何方式的环境。`SHELL` 变量指定命令运行使用的 shell。这个示例中,指定为 Bash shell。`MAILTO` 变量设置发送 cron 作业结果的电子邮件地址。这些电子邮件提供了 cron 作业(备份、更新、等等)的状态,和你从命令行中手动运行程序时看到的结果是一样的。第三行为环境设置了 `PATH` 变量。但即使在这里设置了路径,我总是使用每个程序的完全限定路径。
|
||||
|
||||
在上面的示例中有几个注释行,它详细说明了定义一个 cron 作业所要求的语法。我将在下面分别讲解这些命令,然后,增加更多的 crontab 文件的高级特性。
|
||||
|
||||
```
|
||||
01 01 * * * /usr/local/bin/rsbu -vbd1 ; /usr/local/bin/rsbu -vbd2
|
||||
```
|
||||
|
||||
*在我的 `/etc/crontab` 中的这一行运行一个脚本,用于为我的系统执行备份。*
|
||||
|
||||
这一行运行我自己编写的 Bash shell 脚本 `rsbu`,它对我的系统做完全备份。这个作业每天的凌晨 1:01 (`01 01`) 运行。在这三、四、五位置上的星号(*),像文件通配符一样代表一个特定的时间,它们代表 “一个月中的每天”、“每个月” 和 “一周中的每天”,这一行会运行我的备份两次,一次备份内部专用的硬盘驱动器,另外一次运行是备份外部的 USB 驱动器,使用它这样我可以很保险。
|
||||
|
||||
接下来的行我设置了一个硬件时钟,它使用当前系统时钟作为源去设置硬件时钟。这一行设置为每天凌晨 5:03 分运行。
|
||||
|
||||
```
|
||||
03 05 * * * /sbin/hwclock --systohc
|
||||
```
|
||||
|
||||
*这一行使用系统时间作为源来设置硬件时钟。*
|
||||
|
||||
我使用的第三个也是最后一个的 cron 作业是去执行一个 `dnf` 或 `yum` 更新,它在每个月的第一天的凌晨 04:25 运行,但是,我注释掉了它,以后不再运行。
|
||||
|
||||
```
|
||||
# 25 04 1 * * /usr/bin/dnf -y update
|
||||
```
|
||||
|
||||
*这一行用于执行一个每月更新,但是,我也把它注释掉了。*
|
||||
|
||||
#### 其它的定时任务技巧
|
||||
|
||||
现在,让我们去做一些比基本知识更有趣的事情。假设你希望在每周四下午 3:00 去运行一个特别的作业:
|
||||
|
||||
```
|
||||
00 15 * * Thu /usr/local/bin/mycronjob.sh
|
||||
```
|
||||
|
||||
这一行会在每周四下午 3:00 运行 `mycronjob.sh` 这个脚本。
|
||||
|
||||
或者,或许你需要在每个季度末去运行一个季度报告。cron 服务没有为 “每个月的最后一天” 设置选项,因此,替代方式是使用下一个月的第一天,像如下所示(这里假设当作业准备运行时,报告所需要的数据已经准备好了)。
|
||||
|
||||
```
|
||||
02 03 1 1,4,7,10 * /usr/local/bin/reports.sh
|
||||
```
|
||||
|
||||
*在季度末的下一个月的第一天运行这个 cron 作业。*
|
||||
|
||||
下面展示的这个作业,在每天的上午 9:01 到下午 5:01 之间,每小时运行一次。
|
||||
|
||||
```
|
||||
01 09-17 * * * /usr/local/bin/hourlyreminder.sh
|
||||
```
|
||||
|
||||
*有时,你希望作业在业务期间定时运行。*
|
||||
|
||||
我遇到一个情况,需要作业在每二、三或四小时去运行。它需要用期望的间隔去划分小时,比如, `*/3` 为每三个小时,或者 `6-18/3` 为上午 6 点到下午 6 点每三个小时运行一次。其它的时间间隔的划分也是类似的。例如,在分钟位置的表达式 `*/15` 意思是 “每 15 分钟运行一次作业”。
|
||||
|
||||
```
|
||||
*/5 08-18/2 * * * /usr/local/bin/mycronjob.sh
|
||||
```
|
||||
|
||||
*这个 cron 作业在上午 8:00 到下午 18:59 之间,每五分钟运行一次作业。*
|
||||
|
||||
需要注意的一件事情是:除法表达式的结果必须是余数为 0(即整除)。换句话说,在这个例子中,这个作业被设置为在上午 8 点到下午 6 点之间的偶数小时每 5 分钟运行一次(08:00、08:05、 08:10、 08:15……18:55 等等),而不运行在奇数小时。另外,这个作业不能运行在下午 7:00 到上午 7:59 之间。(LCTT 译注:此处本文表述有误,根据正确情况修改)
|
||||
|
||||
我相信,你可以根据这些例子想到许多其它的可能性。
|
||||
|
||||
#### 限制访问 cron
|
||||
|
||||
普通用户使用 cron 访问可能会犯错误,例如,可能导致系统资源(比如内存和 CPU 时间)被耗尽。为避免这种可能的问题, 系统管理员可以通过创建一个 `/etc/cron.allow` 文件去限制用户访问,它包含了一个允许去创建 cron 作业的用户列表。(不管是否列在这个列表中,)不能阻止 root 用户使用 cron。
|
||||
|
||||
通过阻止非 root 用户创建他们自己的 cron 作业,那也许需要将非 root 用户的 cron 作业添加到 root 的 crontab 中, “但是,等等!” 你说,“不是以 root 去运行这些作业?” 不一定。在这篇文章中的第一个示例中,出现在注释中的用户名字段可以用于去指定一个运行作业的用户 ID。这可以防止特定的非 root 用户的作业以 root 身份去运行。下面的示例展示了一个作业定义,它以 “student” 用户去运行这个作业:
|
||||
|
||||
```
|
||||
04 07 * * * student /usr/local/bin/mycronjob.sh
|
||||
```
|
||||
|
||||
如果没有指定用户,这个作业将以 contab 文件的所有者用户去运行,在这个情况中是 root。
|
||||
|
||||
#### cron.d
|
||||
|
||||
目录 `/etc/cron.d` 中是一些应用程序,比如 [SpamAssassin][14] 和 [sysstat][15] 安装的 cron 文件。因为,这里没有 spamassassin 或者 sysstat 用户,这些程序需要一个位置去放置 cron 文件,因此,它们被放在 `/etc/cron.d` 中。
|
||||
|
||||
下面的 `/etc/cron.d/sysstat` 文件包含系统活动报告(SAR)相关的 cron 作业。这些 cron 文件和用户 cron 文件格式相同。
|
||||
|
||||
```
|
||||
# Run system activity accounting tool every 10 minutes
|
||||
*/10 * * * * root /usr/lib64/sa/sa1 1 1
|
||||
# Generate a daily summary of process accounting at 23:53
|
||||
53 23 * * * root /usr/lib64/sa/sa2 -A
|
||||
```
|
||||
|
||||
*sysstat 包安装了 `/etc/cron.d/sysstat` cron 文件来运行程序生成 SAR。*
|
||||
|
||||
该 sysstat cron 文件有两行执行任务。第一行每十分钟去运行 `sa1` 程序去收集数据,存储在 `/var/log/sa` 目录中的一个指定的二进制文件中。然后,在每天晚上的 23:53, `sa2` 程序运行来创建一个每日汇总。
|
||||
|
||||
#### 计划小贴士
|
||||
|
||||
我在 crontab 文件中设置的有些时间看上起似乎是随机的,在某种程度上说,确实是这样的。尝试去安排 cron 作业可能是件很具有挑战性的事, 尤其是作业的数量越来越多时。我通常在我的每个电脑上仅有一些任务,它比起我工作用的那些生产和实验环境中的电脑简单多了。
|
||||
|
||||
我管理的一个系统有 12 个每天晚上都运行 cron 作业,另外 3、4 个在周末或月初运行。那真是个挑战,因为,如果有太多作业在同一时间运行,尤其是备份和编译系统,会耗尽内存并且几乎填满交换文件空间,这会导致系统性能下降甚至是超负荷,最终什么事情都完不成。我增加了一些内存并改进了如何计划任务。我还删除了一些写的很糟糕、使用大量内存的任务。
|
||||
|
||||
crond 服务假设主机计算机 24 小时运行。那意味着如果在一个计划运行的期间关闭计算机,这些计划的任务将不再运行,直到它们计划的下一次运行时间。如果这里有关键的 cron 作业,这可能导致出现问题。 幸运的是,在定期运行的作业上,还有一个其它的选择: `anacron`。
|
||||
|
||||
### anacron
|
||||
|
||||
[anacron][16] 程序执行和 cron 一样的功能,但是它增加了运行被跳过的作业的能力,比如,如果计算机已经关闭或者其它的原因导致无法在一个或多个周期中运行作业。它对笔记本电脑或其它被关闭或进行睡眠模式的电脑来说是非常有用的。
|
||||
|
||||
只要电脑一打开并引导成功,anacron 会检查过去是否有计划的作业被错过。如果有,这些作业将立即运行,但是,仅运行一次(而不管它错过了多少次循环运行)。例如,如果一个每周运行的作业在最近三周因为休假而系统关闭都没有运行,它将在你的电脑一启动就立即运行,但是,它仅运行一次,而不是三次。
|
||||
|
||||
anacron 程序提供了一些对周期性计划任务很好用的选项。它是安装在你的 `/etc/cron.[hourly|daily|weekly|monthly]` 目录下的脚本。 根据它们需要的频率去运行。
|
||||
|
||||
它是怎么工作的呢?接下来的这些要比前面的简单一些。
|
||||
|
||||
1、 crond 服务运行在 `/etc/cron.d/0hourly` 中指定的 cron 作业。
|
||||
|
||||
```
|
||||
# Run the hourly jobs
|
||||
SHELL=/bin/bash
|
||||
PATH=/sbin:/bin:/usr/sbin:/usr/bin
|
||||
MAILTO=root
|
||||
01 * * * * root run-parts /etc/cron.hourly
|
||||
```
|
||||
|
||||
*`/etc/cron.d/0hourly` 中的内容使位于 `/etc/cron.hourly` 中的 shell 脚本运行。*
|
||||
|
||||
2、 在 `/etc/cron.d/0hourly` 中指定的 cron 作业每小时运行一次 `run-parts` 程序。
|
||||
|
||||
3、 `run-parts` 程序运行所有的在 `/etc/cron.hourly` 目录中的脚本。
|
||||
|
||||
4、 `/etc/cron.hourly` 目录包含的 `0anacron` 脚本,它使用如下的 `/etdc/anacrontab` 配置文件去运行 anacron 程序。
|
||||
|
||||
```
|
||||
# /etc/anacrontab: configuration file for anacron
|
||||
|
||||
# See anacron(8) and anacrontab(5) for details.
|
||||
|
||||
SHELL=/bin/sh
|
||||
PATH=/sbin:/bin:/usr/sbin:/usr/bin
|
||||
MAILTO=root
|
||||
# the maximal random delay added to the base delay of the jobs
|
||||
RANDOM_DELAY=45
|
||||
# the jobs will be started during the following hours only
|
||||
START_HOURS_RANGE=3-22
|
||||
|
||||
#period in days delay in minutes job-identifier command
|
||||
1 5 cron.daily nice run-parts /etc/cron.daily
|
||||
7 25 cron.weekly nice run-parts /etc/cron.weekly
|
||||
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
|
||||
```
|
||||
|
||||
*`/etc/anacrontab` 文件中的内容在合适的时间运行在 `cron.[daily|weekly|monthly]` 目录中的可执行文件。*
|
||||
|
||||
5、 anacron 程序每日运行一次位于 `/etc/cron.daily` 中的作业。它每周运行一次位于 `/etc/cron.weekly` 中的作业。以及每月运行一次 `cron.monthly` 中的作业。注意,在每一行指定的延迟时间,它可以帮助避免这些作业与其它 cron 作业重叠。
|
||||
|
||||
我在 `/usr/local/bin` 目录中放置它们,而不是在 `cron.X` 目录中放置完整的 Bash 程序,这会使我从命令行中运行它们更容易。然后,我在 cron 目录中增加一个符号连接,比如,`/etc/cron.daily`。
|
||||
|
||||
anacron 程序不是设计用于在指定时间运行程序的。而是,用于在一个指定的时间开始,以一定的时间间隔去运行程序,比如,从每天的凌晨 3:00(看上面脚本中的 `START_HOURS_RANGE` 行)、从周日(每周第一天)和这个月的第一天。如果任何一个或多个循环错过,anacron 将立即运行这个错过的作业。
|
||||
|
||||
### 更多的关于设置限制
|
||||
|
||||
我在我的计算机上使用了很多运行计划任务的方法。所有的这些任务都需要一个 root 权限去运行。在我的经验中,很少有普通用户去需要运行 cron 任务,一种情况是开发人员需要一个 cron 作业去启动一个开发实验室的每日编译。
|
||||
|
||||
限制非 root 用户去访问 cron 功能是非常重要的。然而,在一些特殊情况下,用户需要去设置一个任务在预先指定时间运行,而 cron 可以允许他们去那样做。许多用户不理解如何正确地配置 cron 去完成任务,并且他们会出错。这些错误可能是无害的,但是,往往不是这样的,它们可能导致问题。通过设置功能策略,使用户与管理员互相配合,可以使个别的 cron 作业尽可能地不干扰其它的用户和系统功能。
|
||||
|
||||
可以给为单个用户或组分配的资源设置限制,但是,这是下一篇文章中的内容。
|
||||
|
||||
更多信息,在 [cron][17]、[crontab][18]、[anacron][19]、[anacrontab][20]、和 [run-parts][21] 的 man 页面上,所有的这些信息都描述了 cron 系统是如何工作的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - 是一位 Linux 和开源软件的倡导者,居住在 Raleigh,North Carolina。他从事 IT 行业超过四十年,并且在 IBM 教授 OS/2 超过 20 年时间,他在 1981 年 IBM 期间,为最初的 IBM PC 写了第一部培训教程。他为 Red Hat 教授 RHCE 系列课程,并且他也为 MCI Worldcom、 Cisco、和 North Carolina 州工作。他使用 Linux 和开源软件工作差不多 20 年了。
|
||||
|
||||
---------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/how-use-cron-linux
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/article/17/11/how-use-cron-linux?rate=9R7lrdQXsne44wxIh0Wu91ytYaxxi86zT1-uHo1a1IU
|
||||
[7]:https://sourceforge.net/projects/logwatch/files/
|
||||
[8]:https://github.com/logrotate/logrotate
|
||||
[9]:http://rkhunter.sourceforge.net/
|
||||
[10]:https://opensource.com/user/14106/feed
|
||||
[11]:https://www.flickr.com/photos/internetarchivebookimages/20570945848/in/photolist-xkMtw9-xA5zGL-tEQLWZ-wFwzFM-aNwxgn-aFdWBj-uyFKYv-7ZCCBU-obY1yX-UAPafA-otBzDF-ovdDo6-7doxUH-obYkeH-9XbHKV-8Zk4qi-apz7Ky-apz8Qu-8ZoaWG-orziEy-aNwxC6-od8NTv-apwpMr-8Zk4vn-UAP9Sb-otVa3R-apz6Cb-9EMPj6-eKfyEL-cv5mwu-otTtHk-7YjK1J-ovhxf6-otCg2K-8ZoaJf-UAPakL-8Zo8j7-8Zk74v-otp4Ls-8Zo8h7-i7xvpR-otSosT-9EMPja-8Zk6Zi-XHpSDB-hLkuF3-of24Gf-ouN1Gv-fJzkJS-icfbY9
|
||||
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[13]:https://en.wikipedia.org/wiki/Cron
|
||||
[14]:http://spamassassin.apache.org/
|
||||
[15]:https://github.com/sysstat/sysstat
|
||||
[16]:https://en.wikipedia.org/wiki/Anacron
|
||||
[17]:http://man7.org/linux/man-pages/man8/cron.8.html
|
||||
[18]:http://man7.org/linux/man-pages/man5/crontab.5.html
|
||||
[19]:http://man7.org/linux/man-pages/man8/anacron.8.html
|
||||
[20]:http://man7.org/linux/man-pages/man5/anacrontab.5.html
|
||||
[21]:http://manpages.ubuntu.com/manpages/zesty/man8/run-parts.8.html
|
||||
[22]:https://opensource.com/users/dboth
|
||||
[23]:https://opensource.com/users/dboth
|
||||
[24]:https://opensource.com/article/17/11/how-use-cron-linux#comments
|
||||
@ -0,0 +1,340 @@
|
||||
Linux 中管理 EXT2、 EXT3 和 EXT4 健康状况的 4 个工具
|
||||
============================================================
|
||||
|
||||
文件系统是一个在计算机上帮你去管理数据怎么去存储和检索的数据结构。文件系统也可以被视作是磁盘上的物理(或扩展)分区。如果它没有很好地被维护或定期监视,它可能在长期运行中出现各种各样的错误或损坏。
|
||||
|
||||
这里有几个可能导致文件系统出问题的因素:系统崩溃、硬件或软件故障、 有问题的驱动和程序、不正确的优化、大量的数据过载加上一些小故障。
|
||||
|
||||
这其中的任何一个问题都可以导致 Linux 不能顺利地挂载(或卸载)一个文件系统,从而导致系统故障。
|
||||
|
||||
扩展阅读:[Linux 中判断文件系统类型(Ext2, Ext3 或 Ext4)的 7 种方法][7]
|
||||
|
||||
另外,受损的文件系统运行在你的系统上可能导致操作系统中的组件或用户应用程序的运行时错误,它可能会进一步扩大到服务器数据的丢失。为避免文件系统错误或损坏,你需要去持续关注它的健康状况。
|
||||
|
||||
在这篇文章中,我们将介绍监视或维护一个 ext2、ext3 和 ext4 文件系统健康状况的工具。在这里描述的所有工具都需要 root 用户权限,因此,需要使用 [sudo 命令][8]去运行它们。
|
||||
|
||||
### 怎么去查看 EXT2/EXT3/EXT4 文件系统信息
|
||||
|
||||
`dumpe2fs` 是一个命令行工具,用于去转储 ext2/ext3/ext4 文件系统信息,这意味着它可以显示设备上文件系统的超级块和块组信息。
|
||||
|
||||
在运行 `dumpe2fs` 之前,先去运行 [df -hT][9] 命令,确保知道文件系统的设备名。
|
||||
|
||||
```
|
||||
$ sudo dumpe2fs /dev/sda10
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
dumpe2fs 1.42.13 (17-May-2015)
|
||||
Filesystem volume name:
|
||||
Last mounted on: /
|
||||
Filesystem UUID: bb29dda3-bdaa-4b39-86cf-4a6dc9634a1b
|
||||
Filesystem magic number: 0xEF53
|
||||
Filesystem revision #: 1 (dynamic)
|
||||
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
|
||||
Filesystem flags: signed_directory_hash
|
||||
Default mount options: user_xattr acl
|
||||
Filesystem state: clean
|
||||
Errors behavior: Continue
|
||||
Filesystem OS type: Linux
|
||||
Inode count: 21544960
|
||||
Block count: 86154752
|
||||
Reserved block count: 4307737
|
||||
Free blocks: 22387732
|
||||
Free inodes: 21026406
|
||||
First block: 0
|
||||
Block size: 4096
|
||||
Fragment size: 4096
|
||||
Reserved GDT blocks: 1003
|
||||
Blocks per group: 32768
|
||||
Fragments per group: 32768
|
||||
Inodes per group: 8192
|
||||
Inode blocks per group: 512
|
||||
Flex block group size: 16
|
||||
Filesystem created: Sun Jul 31 16:19:36 2016
|
||||
Last mount time: Mon Nov 6 10:25:28 2017
|
||||
Last write time: Mon Nov 6 10:25:19 2017
|
||||
Mount count: 432
|
||||
Maximum mount count: -1
|
||||
Last checked: Sun Jul 31 16:19:36 2016
|
||||
Check interval: 0 ()
|
||||
Lifetime writes: 2834 GB
|
||||
Reserved blocks uid: 0 (user root)
|
||||
Reserved blocks gid: 0 (group root)
|
||||
First inode: 11
|
||||
Inode size: 256
|
||||
Required extra isize: 28
|
||||
Desired extra isize: 28
|
||||
Journal inode: 8
|
||||
First orphan inode: 6947324
|
||||
Default directory hash: half_md4
|
||||
Directory Hash Seed: 9da5dafb-bded-494d-ba7f-5c0ff3d9b805
|
||||
Journal backup: inode blocks
|
||||
Journal features: journal_incompat_revoke
|
||||
Journal size: 128M
|
||||
Journal length: 32768
|
||||
Journal sequence: 0x00580f0c
|
||||
Journal start: 12055
|
||||
```
|
||||
|
||||
你可以通过 `-b` 选项来显示文件系统中的任何保留块,比如坏块(无输出说明没有坏块):
|
||||
|
||||
```
|
||||
$ sudo dumpe2fs -b
|
||||
```
|
||||
|
||||
### 检查 EXT2/EXT3/EXT4 文件系统的错误
|
||||
|
||||
`e2fsck` 用于去检查 ext2/ext3/ext4 文件系统的错误。`fsck` 可以检查并且可选地 [修复 Linux 文件系统][10];它实际上是底层 Linux 提供的一系列文件系统检查器 (fsck.fstype,例如 fsck.ext3、fsck.sfx 等等) 的前端程序。
|
||||
|
||||
记住,在系统引导时,Linux 会为 `/etc/fstab` 配置文件中被标为“检查”的分区自动运行 `e2fsck`/`fsck`。而在一个文件系统没有被干净地卸载时,一般也会运行它。
|
||||
|
||||
注意:不要在已挂载的文件系统上运行 e2fsck 或 fsck,在你运行这些工具之前,首先要去卸载分区,如下所示。
|
||||
|
||||
```
|
||||
$ sudo unmount /dev/sda10
|
||||
$ sudo fsck /dev/sda10
|
||||
```
|
||||
|
||||
此外,可以使用 `-V` 开关去启用详细输出,使用 `-t` 去指定文件系统类型,像这样:
|
||||
|
||||
```
|
||||
$ sudo fsck -Vt ext4 /dev/sda10
|
||||
```
|
||||
|
||||
### 调优 EXT2/EXT3/EXT4 文件系统
|
||||
|
||||
我们前面提到过,导致文件系统损坏的其中一个因素就是不正确的调优。你可以使用 `tune2fs` 实用程序去改变 ext2/ext3/ext4 文件系统的可调优参数,像下面讲的那样。
|
||||
|
||||
去查看文件系统的超级块,包括参数的当前值,使用 `-l` 选项,如下所示。
|
||||
|
||||
```
|
||||
$ sudo tune2fs -l /dev/sda10
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
tune2fs 1.42.13 (17-May-2015)
|
||||
Filesystem volume name:
|
||||
Last mounted on: /
|
||||
Filesystem UUID: bb29dda3-bdaa-4b39-86cf-4a6dc9634a1b
|
||||
Filesystem magic number: 0xEF53
|
||||
Filesystem revision #: 1 (dynamic)
|
||||
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
|
||||
Filesystem flags: signed_directory_hash
|
||||
Default mount options: user_xattr acl
|
||||
Filesystem state: clean
|
||||
Errors behavior: Continue
|
||||
Filesystem OS type: Linux
|
||||
Inode count: 21544960
|
||||
Block count: 86154752
|
||||
Reserved block count: 4307737
|
||||
Free blocks: 22387732
|
||||
Free inodes: 21026406
|
||||
First block: 0
|
||||
Block size: 4096
|
||||
Fragment size: 4096
|
||||
Reserved GDT blocks: 1003
|
||||
Blocks per group: 32768
|
||||
Fragments per group: 32768
|
||||
Inodes per group: 8192
|
||||
Inode blocks per group: 512
|
||||
Flex block group size: 16
|
||||
Filesystem created: Sun Jul 31 16:19:36 2016
|
||||
Last mount time: Mon Nov 6 10:25:28 2017
|
||||
Last write time: Mon Nov 6 10:25:19 2017
|
||||
Mount count: 432
|
||||
Maximum mount count: -1
|
||||
Last checked: Sun Jul 31 16:19:36 2016
|
||||
Check interval: 0 ()
|
||||
Lifetime writes: 2834 GB
|
||||
Reserved blocks uid: 0 (user root)
|
||||
Reserved blocks gid: 0 (group root)
|
||||
First inode: 11
|
||||
Inode size: 256
|
||||
Required extra isize: 28
|
||||
Desired extra isize: 28
|
||||
Journal inode: 8
|
||||
First orphan inode: 6947324
|
||||
Default directory hash: half_md4
|
||||
Directory Hash Seed: 9da5dafb-bded-494d-ba7f-5c0ff3d9b805
|
||||
Journal backup: inode blocks
|
||||
```
|
||||
|
||||
接下来,使用 `-c` 标识,你可以设置文件系统在挂载多少次后将进行 `e2fsck` 检查。下面这个命令指示系统每挂载 4 次之后,去对 `/dev/sda10` 运行 `e2fsck`。
|
||||
|
||||
```
|
||||
$ sudo tune2fs -c 4 /dev/sda10
|
||||
tune2fs 1.42.13 (17-May-2015)
|
||||
Setting maximal mount count to 4
|
||||
```
|
||||
|
||||
你也可以使用 `-i` 选项定义两次文件系统检查的时间间隔。下列的命令在两次文件系统检查之间设置了一个 2 天的时间间隔。
|
||||
|
||||
```
|
||||
$ sudo tune2fs -i 2d /dev/sda10
|
||||
tune2fs 1.42.13 (17-May-2015)
|
||||
Setting interval between checks to 172800 seconds
|
||||
```
|
||||
|
||||
现在,如果你运行下面的命令,你可以看到对 `/dev/sda10` 已经设置了文件系统检查的时间间隔。
|
||||
|
||||
```
|
||||
$ sudo tune2fs -l /dev/sda10
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
Filesystem created: Sun Jul 31 16:19:36 2016
|
||||
Last mount time: Mon Nov 6 10:25:28 2017
|
||||
Last write time: Mon Nov 6 13:49:50 2017
|
||||
Mount count: 432
|
||||
Maximum mount count: 4
|
||||
Last checked: Sun Jul 31 16:19:36 2016
|
||||
Check interval: 172800 (2 days)
|
||||
Next check after: Tue Aug 2 16:19:36 2016
|
||||
Lifetime writes: 2834 GB
|
||||
Reserved blocks uid: 0 (user root)
|
||||
Reserved blocks gid: 0 (group root)
|
||||
First inode: 11
|
||||
Inode size: 256
|
||||
Required extra isize: 28
|
||||
Desired extra isize: 28
|
||||
Journal inode: 8
|
||||
First orphan inode: 6947324
|
||||
Default directory hash: half_md4
|
||||
Directory Hash Seed: 9da5dafb-bded-494d-ba7f-5c0ff3d9b805
|
||||
Journal backup: inode blocks
|
||||
```
|
||||
|
||||
要改变缺省的日志参数,可以使用 `-J` 选项。这个选项也有子选项: `size=journal-size` (设置日志的大小)、`device=external-journal` (指定日志存储的设备)和 `location=journal-location` (定义日志的位置)。
|
||||
|
||||
注意,这里一次仅可以为文件系统设置一个日志大小或设备选项:
|
||||
|
||||
```
|
||||
$ sudo tune2fs -J size=4MB /dev/sda10
|
||||
```
|
||||
|
||||
最后,同样重要的是,可以去使用 `-L` 选项设置文件系统的卷标,如下所示。
|
||||
|
||||
```
|
||||
$ sudo tune2fs -L "ROOT" /dev/sda10
|
||||
```
|
||||
|
||||
### 调试 EXT2/EXT3/EXT4 文件系统
|
||||
|
||||
`debugfs` 是一个简单的、交互式的、基于 ext2/ext3/ext4 文件系统的命令行调试器。它允许你去交互式地修改文件系统参数。输入 `?` 查看子命令或请求。
|
||||
|
||||
```
|
||||
$ sudo debugfs /dev/sda10
|
||||
```
|
||||
|
||||
缺省情况下,文件系统将以只读模式打开,使用 `-w` 标识去以读写模式打开它。使用 `-c` 选项以灾难(catastrophic)模式打开它。
|
||||
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
debugfs 1.42.13 (17-May-2015)
|
||||
debugfs: ?
|
||||
Available debugfs requests:
|
||||
show_debugfs_params, params
|
||||
Show debugfs parameters
|
||||
open_filesys, open Open a filesystem
|
||||
close_filesys, close Close the filesystem
|
||||
freefrag, e2freefrag Report free space fragmentation
|
||||
feature, features Set/print superblock features
|
||||
dirty_filesys, dirty Mark the filesystem as dirty
|
||||
init_filesys Initialize a filesystem (DESTROYS DATA)
|
||||
show_super_stats, stats Show superblock statistics
|
||||
ncheck Do inode->name translation
|
||||
icheck Do block->inode translation
|
||||
change_root_directory, chroot
|
||||
....
|
||||
```
|
||||
|
||||
要展示未使用空间的碎片,使用 `freefrag` 请求,像这样:
|
||||
|
||||
```
|
||||
debugfs: freefrag
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
Device: /dev/sda10
|
||||
Blocksize: 4096 bytes
|
||||
Total blocks: 86154752
|
||||
Free blocks: 22387732 (26.0%)
|
||||
Min. free extent: 4 KB
|
||||
Max. free extent: 2064256 KB
|
||||
Avg. free extent: 2664 KB
|
||||
Num. free extent: 33625
|
||||
HISTOGRAM OF FREE EXTENT SIZES:
|
||||
Extent Size Range : Free extents Free Blocks Percent
|
||||
4K... 8K- : 4883 4883 0.02%
|
||||
8K... 16K- : 4029 9357 0.04%
|
||||
16K... 32K- : 3172 15824 0.07%
|
||||
32K... 64K- : 2523 27916 0.12%
|
||||
64K... 128K- : 2041 45142 0.20%
|
||||
128K... 256K- : 2088 95442 0.43%
|
||||
256K... 512K- : 2462 218526 0.98%
|
||||
512K... 1024K- : 3175 571055 2.55%
|
||||
1M... 2M- : 4551 1609188 7.19%
|
||||
2M... 4M- : 2870 1942177 8.68%
|
||||
4M... 8M- : 1065 1448374 6.47%
|
||||
8M... 16M- : 364 891633 3.98%
|
||||
16M... 32M- : 194 984448 4.40%
|
||||
32M... 64M- : 86 873181 3.90%
|
||||
64M... 128M- : 77 1733629 7.74%
|
||||
128M... 256M- : 11 490445 2.19%
|
||||
256M... 512M- : 10 889448 3.97%
|
||||
512M... 1024M- : 2 343904 1.54%
|
||||
1G... 2G- : 22 10217801 45.64%
|
||||
debugfs:
|
||||
```
|
||||
|
||||
通过去简单浏览它所提供的简要描述,你可以试试更多的请求,比如,创建或删除文件或目录,改变当前工作目录等等。要退出 `debugfs`,使用 `q`。
|
||||
|
||||
现在就这些!我们收集了不同分类下的相关文章,你可以在里面找到对你有用的内容。
|
||||
|
||||
**文件系统使用信息:**
|
||||
|
||||
1. [12 Useful “df” Commands to Check Disk Space in Linux][1]
|
||||
2. [Pydf an Alternative “df” Command to Check Disk Usage in Different Colours][2]
|
||||
3. [10 Useful du (Disk Usage) Commands to Find Disk Usage of Files and Directories][3]
|
||||
|
||||
**检查磁盘或分区健康状况:**
|
||||
|
||||
1. [3 Useful GUI and Terminal Based Linux Disk Scanning Tools][4]
|
||||
2. [How to Check Bad Sectors or Bad Blocks on Hard Disk in Linux][5]
|
||||
3. [How to Repair and Defragment Linux System Partitions and Directories][6]
|
||||
|
||||
维护一个健康的文件系统可以提升你的 Linux 系统的整体性能。如果你有任何问题或更多的想法,可以使用下面的评论去分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.tecmint.com/manage-ext2-ext3-and-ext4-health-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[2]:https://www.tecmint.com/pyd-command-to-check-disk-usage/
|
||||
[3]:https://www.tecmint.com/check-linux-disk-usage-of-files-and-directories/
|
||||
[4]:https://www.tecmint.com/linux-disk-scanning-tools/
|
||||
[5]:https://www.tecmint.com/check-linux-hard-disk-bad-sectors-bad-blocks/
|
||||
[6]:https://www.tecmint.com/defragment-linux-system-partitions-and-directories/
|
||||
[7]:https://linux.cn/article-8289-1.html
|
||||
[8]:https://linux.cn/article-8278-1.html
|
||||
[9]:https://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[10]:https://www.tecmint.com/defragment-linux-system-partitions-and-directories/
|
||||
[11]:https://www.tecmint.com/author/aaronkili/
|
||||
[12]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[13]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
162
published/20171106 Finding Files with mlocate.md
Normal file
162
published/20171106 Finding Files with mlocate.md
Normal file
@ -0,0 +1,162 @@
|
||||
使用 mlocate 查找文件
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
在这一系列的文章中,我们将来看下 `mlocate`,来看看如何快速、轻松地满足你的需求。
|
||||
|
||||
[Creative Commons Zero][1]Pixabay
|
||||
|
||||
对于一个系统管理员来说,草中寻针一样的查找文件的事情并不少见。在一台拥挤的机器上,文件系统中可能存在数十万个文件。当你需要确定一个特定的配置文件是最新的,但是你不记得它在哪里时怎么办?
|
||||
|
||||
如果你使用过一些类 Unix 机器,那么你肯定用过 `find` 命令。毫无疑问,它是非常复杂和功能强大的。以下是一个只搜索目录中的符号链接,而忽略文件的例子:
|
||||
|
||||
```
|
||||
# find . -lname "*"
|
||||
```
|
||||
|
||||
你可以用 `find` 命令做几乎无尽的事情,这是不容否认的。`find` 命令好用的时候是很好且简洁的,但是它也可以很复杂。这不一定是因为 `find` 命令本身的原因,而是它与 `xargs` 结合,你可以传递各种选项来调整你的输出,并删除你找到的那些文件。
|
||||
|
||||
### 位置、位置,让人沮丧
|
||||
|
||||
然而,通常情况下简单是最好的选择,特别是当一个脾气暴躁的老板搭着你的肩膀,闲聊着时间的重要性时。你还在模糊地猜测这个你从来没有见过的文件的路径,而你的老板却肯定它在拥挤的 /var 分区的某处。
|
||||
|
||||
进一步看下 `mlocate`。你也许注意过它的一个近亲:`slocate`,它安全地(注意前缀字母 s 代表安全)记录了相关的文件权限,以防止非特权用户看到特权文件。此外,还有它们所起源的一个更老的,原始 `locate` 命令。
|
||||
|
||||
`mlocate` 与其家族的其他成员(至少包括 `slocate`)的不同之处在于,在扫描文件系统时,`mlocate` 不需要持续重新扫描所有的文件系统。相反,它将其发现的文件(注意前面的 m 代表合并)与现有的文件列表合并在一起,使其可以借助系统缓存从而性能更高、更轻量级。
|
||||
|
||||
在本系列文章中,我们将更仔细地了解 `mlocate` (由于其流行,所以也简称其为 `locate`),并研究如何快速轻松地将其调整到你心中所想的方式。
|
||||
|
||||
### 小巧和 紧凑
|
||||
|
||||
除非你经常重复使用复杂的命令,否则就会像我一样,最终会忘记它们而需要在用的时候寻找它们。`locate` 命令的优点是可以快速查询整个文件系统,而不用担心你处于顶层目录、根目录和所在路径,只需要简单地使用 `locate` 命令。
|
||||
|
||||
以前你可能已经发现 `find` 命令非常不听话,让你经常抓耳挠腮。你知道,丢失了一个分号或一个没有正确转义的特殊的字符就会这样。现在让我们离开这个复杂的 `find` 命令,放松一下,看一下这个聪明的小命令。
|
||||
|
||||
你可能需要首先通过运行以下命令来检查它是否在你的系统上:
|
||||
|
||||
对于 Red Hat 家族:
|
||||
|
||||
```
|
||||
# yum install mlocate
|
||||
```
|
||||
|
||||
对于 Debian 家族:
|
||||
|
||||
```
|
||||
# apt-get install mlocate
|
||||
```
|
||||
|
||||
发行版之间不应该有任何区别,但版本之间几乎肯定有细微差别。小心。
|
||||
|
||||
接下来,我们将介绍 `locate` 命令的一个关键组件,名为 `updatedb`。正如你可能猜到的那样,这是**更新** `locate` 命令的**数据库**的命令。这名字非常符合直觉。
|
||||
|
||||
这个数据库是我之前提到的 `locate` 命令的文件列表。该列表被保存在一个相对简单而高效的数据库中。`updatedb` 通过 cron 任务定期运行,通常在一天中的安静时间运行。在下面的清单 1 中,我们可以看到文件 `/etc/cron.daily/mlocate.cron` 的内部(该文件的路径及其内容可能因发行版不同)。
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
nodevs=$(< /proc/filesystems awk '$1 == "nodev" { print $2 }')
|
||||
|
||||
renice +19 -p $$ >/dev/null 2>&1
|
||||
|
||||
ionice -c2 -n7 -p $$ >/dev/null 2>&1
|
||||
|
||||
/usr/bin/updatedb -f "$nodevs"
|
||||
```
|
||||
|
||||
**清单 1:** 每天如何触发 “updatedb” 命令。
|
||||
|
||||
如你所见,`mlocate.cron` 脚本使用了优秀的 `nice` 命令来尽可能少地影响系统性能。我还没有明确指出这个命令每天都在设定的时间运行(但如果我没有记错的话,原始的 `locate` 命令与你在午夜时的计算机减速有关)。这是因为,在一些 “cron” 版本上,延迟现在被引入到隔夜开始时间。
|
||||
|
||||
这可能是因为所谓的 “<ruby>河马之惊群<rt>Thundering Herd of Hippos</rt></ruby>”问题。想象许多计算机(或饥饿的动物)同时醒来从单一或有限的来源要求资源(或食物)。当所有的“河马”都使用 NTP 设置它们的手表时,这可能会发生(好吧,这个寓言扯多了,但请忍受一下)。想象一下,正好每五分钟(就像一个 “cron 任务”),它们都要求获得食物或其他东西。
|
||||
|
||||
如果你不相信我,请看下配置文件 - 清单 2 中名为 `anacron` 的 cron 版本,这是文件 `/etc/anacrontab` 的内容。
|
||||
|
||||
```
|
||||
# /etc/anacrontab: configuration file for anacron
|
||||
|
||||
# See anacron(8) and anacrontab(5) for details.
|
||||
|
||||
SHELL=/bin/sh
|
||||
|
||||
PATH=/sbin:/bin:/usr/sbin:/usr/bin
|
||||
|
||||
MAILTO=root
|
||||
|
||||
# the maximal random delay added to the base delay of the jobs
|
||||
|
||||
RANDOM_DELAY=45
|
||||
|
||||
# the jobs will be started during the following hours only
|
||||
|
||||
START_HOURS_RANGE=3-22
|
||||
|
||||
#period in days delay in minutes job-identifier command
|
||||
|
||||
1 5 cron.daily nice run-parts /etc/cron.daily
|
||||
|
||||
7 25 cron.weekly nice run-parts /etc/cron.weekly
|
||||
|
||||
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
|
||||
```
|
||||
|
||||
**清单 2:** 运行 “cron” 任务时延迟是怎样被带入的。
|
||||
|
||||
从清单 2 可以看到 `RANDOM_DELAY` 和 “delay in minutes” 列。如果你不熟悉 cron 这个方面,那么你可以在这找到更多的东西:
|
||||
|
||||
```
|
||||
# man anacrontab
|
||||
```
|
||||
|
||||
否则,如果你愿意,你可以自己延迟一下。有个[很棒的网页][3](现在已有十多年的历史)以非常合理的方式讨论了这个问题。本网站讨论如何使用 `sleep` 来引入一个随机性,如清单 3 所示。
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
# Grab a random value between 0-240.
|
||||
value=$RANDOM
|
||||
while [ $value -gt 240 ] ; do
|
||||
value=$RANDOM
|
||||
done
|
||||
|
||||
# Sleep for that time.
|
||||
sleep $value
|
||||
|
||||
# Syncronize.
|
||||
/usr/bin/rsync -aqzC --delete --delete-after masterhost::master /some/dir/
|
||||
```
|
||||
|
||||
**清单 3:**在触发事件之前引入随机延迟的 shell 脚本,以避免[河马之惊群][4]。
|
||||
|
||||
在提到这些(可能令人惊讶的)延迟时,是指 `/etc/crontab` 或 root 用户自己的 crontab 文件。如果你想改变 `locate` 命令运行的时间,特别是由于磁盘访问速度减慢时,那么它不是太棘手。实现它可能会有更优雅的方式,但是你也可以把文件 `/etc/cron.daily/mlocate.cron` 移到别的地方(我使用 `/usr/local/etc` 目录),使用 root 用户添加一条记录到 root 用户的 crontab,粘贴以下内容:
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
|
||||
33 3 * * * /usr/local/etc/mlocate.cron
|
||||
```
|
||||
|
||||
使用 anacron,而不是通过 `/var/log/cron` 以及它的旧的、轮转的版本,你可以快速地告诉它上次 cron.daily 任务被触发的时间:
|
||||
|
||||
```
|
||||
# ls -hal /var/spool/anacron
|
||||
```
|
||||
|
||||
下一次,我们会看更多的使用 `locate`、`updatedb` 和其他工具来查找文件的方法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2017/11/finding-files-mlocate
|
||||
|
||||
作者:[CHRIS BINNIE][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/chrisbinnie
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/question-markjpg
|
||||
[3]:http://www.moundalexis.com/archives/000076.php
|
||||
[4]:http://www.moundalexis.com/archives/000076.php
|
||||
@ -0,0 +1,53 @@
|
||||
Linux 基金会发布了新的企业开源指南
|
||||
===============
|
||||
|
||||

|
||||
|
||||
Linux 基金会在其企业开源指南文集中为开发和使用开源软件增加了三篇新的指南。
|
||||
|
||||
这个有着 17 年历史的非营利组织的主要任务是支持开源社区,并且,作为该任务的一部分,它在 9 月份发布了六篇 [企业开源指南][2],涉及从招募开发人员到使用开源代码的各个主题。
|
||||
|
||||
最近一段时间以来,Linux 基金会与开源专家组 [TODO Group][3](Talk Openly, Develop Openly)合作发布了三篇指南。
|
||||
|
||||
这一系列的指南用于在多个层次上帮助企业员工 —— 执行官、开源计划经理、开发者、律师和其他决策者 —— 学习怎么在开源活动中取得更好的收益。
|
||||
|
||||
该组织是这样描述这三篇指南的:
|
||||
|
||||
* **提升你的开源开发的影响力**, —— 来自 Ibrahim Haddad,三星美国研究院。该指南涵盖了企业可以采用的一些做法,以帮助企业扩大他们在大型开源项目中的影响。
|
||||
* **启动一个开源项目**,—— 来自 Christine Abernathy,Facebook;Ibrahim Haddad;Guy Martin,Autodesk;John Mertic,Linux 基金会;Jared Smith,第一资本(Capital One)。这个指南帮助已经熟悉开源的企业学习怎么去开始自己的开源项目。
|
||||
* **开源阅读列表**。一个开源程序管理者必读书清单,由 TODO Group 成员编制完成的。
|
||||
|
||||

|
||||
|
||||
*企业开源指南的 ‘阅读列表’ 中的一部分产品 (来源:Linux 基金会)*
|
||||
|
||||
在九月份发布的六篇指南包括:
|
||||
|
||||
* **创建一个开源计划:** 学习怎么去建立一个计划去管理内部开源使用和外部贡献。
|
||||
* **开源管理工具:** 一系列可用于跟踪和管理开源项目的工具。
|
||||
* **衡量你的开源计划是否成功:** 了解更多关于顶级组织评估其开源计划和贡献的 ROI 的方法。
|
||||
* **招聘开发人员:** 学习如何通过创建开源文化和贡献开源项目来招募开发人员或从内部挖掘人才。
|
||||
* **参与开源社区:** 了解奉献内部开发者资源去参与开源社区的重要性,和怎么去操作的最佳方法。
|
||||
* **使用开源代码:** 在你的商业产品中集成开源代码时,确保你的组织符合它的法律责任。
|
||||
|
||||
更多的指南正在编制中,它们将和这些指南一样发布在 Linux 基金会和 [GitHub][5] 的网站上。
|
||||
|
||||
TODO Group 也发布了四个 [案例研究][6] 的补充材料,详细描述了 Autodesk、Comcast、Facebook 和 Salesforce 在构建他们的开源计划中的经验。以后,还有更多的计划。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://adtmag.com/articles/2017/11/06/open-source-guides.aspx
|
||||
|
||||
作者:[David Ramel][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://adtmag.com/forms/emailtoauthor.aspx?AuthorItem={53762E17-6187-46B4-8C04-9DFA282EBB67}&ArticleItem={855B2913-5DCF-4871-8563-6D88DA5A7C3C}
|
||||
[1]:https://adtmag.com/forms/emailtoauthor.aspx?AuthorItem={53762E17-6187-46B4-8C04-9DFA282EBB67}&ArticleItem={855B2913-5DCF-4871-8563-6D88DA5A7C3C}
|
||||
[2]:https://www.linuxfoundation.org/resources/open-source-guides/
|
||||
[3]:http://todogroup.org/
|
||||
[4]:https://adtmag.com/articles/2017/11/06/~/media/ECG/adtmag/Images/2017/11/open_source_list.asxh
|
||||
[5]:https://github.com/todogroup/guides
|
||||
[6]:https://github.com/todogroup/guides/tree/master/casestudies
|
||||
@ -0,0 +1,62 @@
|
||||
大多数公司对开源社区不得要领,正确的打开方式是什么?
|
||||
============================================================
|
||||
|
||||
> Red Hat 已经学会了跟随开源社区,并将其商业化。你也可以。
|
||||
|
||||
开源中最强大但最困难的事情之一就是社区。红帽首席执行官 Jim Whitehurst 在与 Slashdot 的[最近一次采访][7]中宣称:“有强大社区的存在,开源总是赢得胜利”。但是建设这个社区很难。真的,真的很难。尽管[预测开源社区蓬勃发展的必要组成部分][8]很简单,但是预测这些部分在何时何地将会组成像 Linux 或 Kubernetes 这样的社区则极其困难。
|
||||
|
||||
这就是为什么聪明的资金似乎在随社区而动,而不是试图创建它们。
|
||||
|
||||
### 可爱的开源寄生虫
|
||||
|
||||
在阅读 Whitehurst 的 Slashdot 采访时,这个想法让我感到震惊。虽然他谈及了从 Linux 桌面到 systemd 的很多内容,但 Whitehurst 关于社区的评论对我来说是最有说服力的:
|
||||
|
||||
> 建立一个新社区是困难的。我们在红帽开始做一点,但大部分时间我们都在寻找已经拥有强大社区的现有项目。在强大的社区存在的情况下,开源始终是胜利的。
|
||||
|
||||
虽然这种方法 —— 加强现有的、不断发展的社区,似乎是一种逃避,它实际上是最明智的做法。早期,开源几乎总是支离破碎的,因为每个项目都试图获得足够的成员。在某些时候,人们开始聚集两到三名获胜者身边(例如 KDE vs. Gnome,或者 Kubernetes vs. Docker Swarm 与 Apache Mesos)。但最终,很难维持不同的社区“标准”,每个人都最终围拢到一个赢家身边(例如 Kubernetes)。
|
||||
|
||||
**参见:[混合云和开源:红帽数字化转型的秘诀][5](Tech Pro Research)**
|
||||
|
||||
这不是投降 —— 这是培养资源和推动标准化的更好方式。例如,Linux 已经成为如此强大的力量的一个原因是,它鼓励在一个地方进行操作系统创新,即使存在不同的分支社区(以及贡献代码的大量的各个公司和个人)不断为它做贡献。红帽的发展很快,部分原因是它在早期就做出了聪明的社区选择,选择了一个赢家(比如 Kubernetes),并帮助它取得更大的成功。
|
||||
|
||||
而这反过来又为其商业模式提供动力。
|
||||
|
||||
### 从社区混乱中赚钱
|
||||
|
||||
对红帽而言一件很好的事是社区越多,项目就越成功。但是,开源的“成功”并不一定意味着企业会接受该项目,这仅仅意味着他们_愿意_这样做。红帽公司早期的直觉和不断地支付分红,就是理解那些枯燥、平庸的企业想要开源的活力,而不要,好吧,还是活力。他们需要把它驯服,变得枯燥而又平庸。Whitehurst 在采访中完美地表达了这一点:
|
||||
|
||||
> 红帽是成功的,因为我们沉迷于寻找方法来增加我们每个产品的代码价值。我们认为自己是帮助企业客户轻松消费开源创新的。
|
||||
>
|
||||
> 仅举一例:对于我们所有的产品,我们关注生命周期。开源是一个伟大的开发模式,但其“尽早发布、频繁发布”的风格使其在生产中难以实施。我们在 Linux 中发挥的一个重要价值是,我们在受支持的内核中支持 bug 修复和安全更新十多年,同时从不破坏 API 兼容性。这对于运行长期应用程序的企业具有巨大的价值。我们通过这种类型的流程来应对我们选择进行产品化的所有项目,以确定我们如何增加源代码之外的价值。
|
||||
|
||||
对于大多数想要开源的公司来说,挑战在于他们可能认识到社区的价值,但是不知道怎么不去销售代码。毕竟,销售软件几十年来一直是一个非常有利可图的商业模式,并产生了一些地球上最有价值的公司。
|
||||
|
||||
**参看[红帽如何使 Kubernetes 乏味并且成功][6]**
|
||||
|
||||
然而, 正如 Whitehurst 指出的那样,开源需要一种不同的方法。他在采访中断言:“**你不能出售功能**, 因为它是免费的”。相反, 你必须找到其他的价值,比如在很长一段周期内让开源得到支持。这是枯燥的工作,但对红帽而言每年值数十亿美元。
|
||||
|
||||
所有这一切都从社区开始。社区更有活力,更好的是它能使开源产品市场化,并能赚钱。为什么?嗯,因为更多的发展的部分等价于更大的价值,随之让自由发展的项目对企业消费而言更加稳定。这是一个成功的公式,并可以发挥所有开源的好处,而不会将它受制于二十世纪的商业模式。
|
||||
|
||||
 Image: iStockphoto/ipopba
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.techrepublic.com/article/most-companies-cant-buy-an-open-source-community-clue-heres-how-to-do-it-right/
|
||||
|
||||
作者:[Matt Asay][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.techrepublic.com/meet-the-team/us/matt-asay/
|
||||
[1]:https://www.techrepublic.com/article/git-everything-the-pros-need-to-know/
|
||||
[2]:https://www.techrepublic.com/article/ditching-windows-for-linux-led-to-major-difficulties-says-open-source-champion-munich/
|
||||
[3]:http://www.techproresearch.com/downloads/securing-linux-policy/
|
||||
[4]:https://www.techrepublic.com/newsletters/
|
||||
[5]:http://www.techproresearch.com/article/hybrid-cloud-and-open-source-red-hats-recipe-for-digital-transformation/
|
||||
[6]:https://www.techrepublic.com/article/how-red-hat-aims-to-make-kubernetes-boring-and-successful/
|
||||
[7]:https://linux.slashdot.org/story/17/10/30/0237219/interviews-red-hat-ceo-jim-whitehurst-answers-your-questions
|
||||
[8]:http://asay.blogspot.com/2005/09/so-you-want-to-build-open-source.html
|
||||
[9]:https://www.techrepublic.com/meet-the-team/us/matt-asay/
|
||||
[10]:https://twitter.com/intent/user?screen_name=mjasay
|
||||
@ -0,0 +1,75 @@
|
||||
AWS 采用自制的 KVM 作为新的管理程序
|
||||
============================================================
|
||||
|
||||
> 摆脱了 Xen,新的 C5 实例和未来的虚拟机将采用“核心 KVM 技术”
|
||||
|
||||
AWS 透露说它已经创建了一个基于 KVM 的新的<ruby>管理程序<rt>hypervisor</rt></ruby>,而不是多年来依赖的 Xen 管理程序。
|
||||
|
||||
新的虚拟机管理程序披露在 EC2 新实例类型的[新闻][3]脚注里,新实例类型被称为 “C5”,由英特尔的 Skylake Xeon 提供支持。AWS 关于新实例的 [FAQ][4] 提及“C5 实例使用新的基于核心 KVM 技术的 EC2 虚拟机管理程序”。
|
||||
|
||||
这是爆炸性的新闻,因为 AWS 长期以来一直支持 Xen 管理程序。Xen 项目从最强大的公共云使用其开源软件的这个事实中吸取了力量。Citrix 将其大部分 Xen 服务器运行了 AWS 的管理程序的闭源版本。
|
||||
|
||||
更有趣的是,AWS 新闻中说:“未来,我们将使用这个虚拟机管理程序为其他实例类型提供动力。” 这个互联网巨头的文章中计划在“一系列 AWS re:Invent 会议中分享更多的技术细节”。
|
||||
|
||||
这听上去和很像 AWS 要放弃 Xen。
|
||||
|
||||
新的管理程序还有很长的路要走,这解释了为什么 AWS 是[最后一个运行 Intel 新的 Skylake Xeon CPU 的大型云服务商][5],因为 AWS 还透露了新的 C5 实例运行在它所描述的“定制处理器上,针对 EC2 进行了优化。”
|
||||
|
||||
Intel 和 AWS 都表示这是一款定制的 3.0 GHz Xeon Platinum 8000 系列处理器。Chipzilla 提供了一些该 CPU 的[新闻发布级别的细节][6],称它与 AWS 合作开发了“使用最新版本的 Intel 数学核心库优化的 AI/深度学习引擎”,以及“ MXNet 和其他深度学习框架为在 Amazon EC2 C5 实例上运行进行了高度优化。”
|
||||
|
||||
Intel 之前定制了 Xeons,将其提供给 [Oracle][7] 等等。AWS 大量购买 CPU,所以英特尔再次这样做并不意外。
|
||||
|
||||
迁移到 KVM 更令人惊讶,但是 AWS 可以根据需要来调整云服务以获得最佳性能。如果这意味着构建一个虚拟机管理程序,并确保它使用自定义的 Xeon,那就这样吧。
|
||||
|
||||
不管它在三周内发布了什么,AWS 现在都在说 C5 实例和它们的新虚拟机管理程序有更高的吞吐量,新的虚拟机在连接到弹性块存储 (EBS) 的网络和带宽都超过了之前的最佳记录。
|
||||
|
||||
以下是 AWS 在 FAQ 中的说明:
|
||||
|
||||
> 随着 C5 实例的推出,Amazon EC2 的新管理程序是一个主要为 C5 实例提供 CPU 和内存隔离的组件。VPC 网络和 EBS 存储资源是由所有当前 EC2 实例家族的一部分的专用硬件组件实现的。
|
||||
|
||||
> 它基于核心的 Linux 内核虚拟机(KVM)技术,但不包括通用的操作系统组件。
|
||||
|
||||
换句话说,网络和存储在其他地方完成,而不是集中在隔离 CPU 和内存资源的管理程序上:
|
||||
|
||||
> 新的 EC2 虚拟机管理程序通过删除主机系统软件组件,为 EC2 虚拟化实例提供一致的性能和增长的计算和内存资源。该硬件使新的虚拟机管理程序非常小,并且对用于网络和存储的数据处理任务没有影响。
|
||||
|
||||
> 最终,所有新实例都将使用新的 EC2 虚拟机管理程序,但是在近期内,根据平台的需求,一些新的实例类型将使用 Xen。
|
||||
|
||||
> 运行在新 EC2 虚拟机管理程序上的实例最多支持 27 个用于 EBS 卷和 VPC ENI 的附加 PCI 设备。每个 EBS 卷或 VPC ENI 使用一个 PCI 设备。例如,如果将 3 个附加网络接口连接到使用新 EC2 虚拟机管理程序的实例,则最多可以为该实例连接 24 个 EBS 卷。
|
||||
|
||||
> 所有面向公众的与运行新的 EC2 管理程序的 EC2 交互 API 都保持不变。例如,DescribeInstances 响应的 “hypervisor” 字段将继续为所有 EC2 实例报告 “xen”,即使是在新的管理程序下运行的实例也是如此。这个字段可能会在未来版本的 EC2 API 中删除。
|
||||
|
||||
你应该查看 FAQ 以了解 AWS 转移到其新虚拟机管理程序的全部影响。以下是新的基于 KVM 的 C5 实例的统计数据:
|
||||
|
||||
|
||||
| 实例名 | vCPU | RAM(GiB) | EBS*带宽 | 网络带宽 |
|
||||
|:--|:--|:--|:--|:--|
|
||||
| c5.large | 2 | 4 | 最高 2.25 Gbps | 最高 10 Gbps |
|
||||
| c5.xlarge | 4 | 8 | 最高 2.25 Gbps | 最高 10 Gbps |
|
||||
| c5.2xlarge | 8 | 16 | 最高 2.25 Gbps | 最高 10 Gbps |
|
||||
| c5.4xlarge | 16 | 32 | 2.25 Gbps | 最高 10 Gbps |
|
||||
| c5.9xlarge | 36 | 72 | 4.5 Gbps | 10 Gbps |
|
||||
| c5.18xlarge | 72 | 144 | 9 Gbps | 25 Gbps |
|
||||
|
||||
每个 vCPU 都是 Amazon 购买的物理 CPU 上的一个线程。
|
||||
|
||||
现在,在 AWS 的美国东部、美国西部(俄勒冈州)和欧盟地区,可以使用 C5 实例作为按需或点播服务器。该公司承诺其他地区将尽快提供。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theregister.co.uk/2017/11/07/aws_writes_new_kvm_based_hypervisor_to_make_its_cloud_go_faster/
|
||||
|
||||
作者:[Simon Sharwood][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.theregister.co.uk/Author/Simon-Sharwood
|
||||
[1]:https://www.theregister.co.uk/Author/Simon-Sharwood
|
||||
[2]:https://forums.theregister.co.uk/forum/1/2017/11/07/aws_writes_new_kvm_based_hypervisor_to_make_its_cloud_go_faster/
|
||||
[3]:https://aws.amazon.com/blogs/aws/now-available-compute-intensive-c5-instances-for-amazon-ec2/
|
||||
[4]:https://aws.amazon.com/ec2/faqs/#compute-optimized
|
||||
[5]:https://www.theregister.co.uk/2017/10/24/azure_adds_skylakes_in_fv2_instances/
|
||||
[6]:https://newsroom.intel.com/news/intel-xeon-scalable-processors-supercharge-amazon-web-services/
|
||||
[7]:https://www.theregister.co.uk/2015/06/04/oracle_intel_team_on_server_with_a_dimmer_switch/
|
||||
@ -0,0 +1,221 @@
|
||||
怎么在 Fedora 中创建我的第一个 RPM 包?
|
||||
==============
|
||||
|
||||

|
||||
|
||||
过了这个夏天,我把我的桌面环境迁移到了 i3,这是一个瓦片式窗口管理器。当初,切换到 i3 是一个挑战,因为我必须去处理许多以前 GNOME 帮我处理的事情。其中一件事情就是改变屏幕亮度。 xbacklight 这个在笔记本电脑上改变背光亮度的标准方法,它在我的硬件上不工作了。
|
||||
|
||||
最近,我发现一个改变背光亮度的工具 [brightlight][1]。我决定去试一下它,它工作在 root 权限下。但是,我发现 brightligh 在 Fedora 下没有 RPM 包。我决定,是在 Fedora 下尝试创建一个包的时候了,并且可以学习怎么去创建一个 RPM 包。
|
||||
|
||||
在这篇文章中,我将分享以下的内容:
|
||||
|
||||
* 创建 RPM SPEC 文件
|
||||
* 在 Koji 和 Copr 中构建包
|
||||
* 使用调试包处理一个问题
|
||||
* 提交这个包到 Fedora 包集合中
|
||||
|
||||
### 前提条件
|
||||
|
||||
在 Fedora 上,我安装了包构建过程中所有步骤涉及到的包。
|
||||
|
||||
```
|
||||
sudo dnf install fedora-packager fedpkg fedrepo_req copr-cli
|
||||
```
|
||||
|
||||
### 创建 RPM SPEC 文件
|
||||
|
||||
创建 RPM 包的第一步是去创建 SPEC 文件。这些规范,或者是指令,它告诉 RPM 怎么去构建包。这是告诉 RPM 从包的源代码中创建一个二进制文件。创建 SPEC 文件看上去是整个包处理过程中最难的一部分,并且它的难度取决于项目。
|
||||
|
||||
对我而言,幸运的是,brightlight 是一个用 C 写的简单应用程序。维护人员用一个 Makefile 使创建二进制应用程序变得很容易。构建它只是在仓库中简单运行 `make` 的问题。因此,我现在可以用一个简单的项目去学习 RPM 打包。
|
||||
|
||||
#### 查找文档
|
||||
|
||||
谷歌搜索 “how to create an RPM package” 有很多结果。我开始使用的是 [IBM 的文档][2]。然而,我发现它理解起来非常困难,不知所云(虽然十分详细,它可能适用于复杂的 app)。我也在 Fedora 维基上找到了 [创建包][3] 的介绍。这个文档在构建和处理上解释的非常好,但是,我一直困惑于 “怎么去开始呢?”
|
||||
|
||||
最终,我找到了 [RPM 打包指南][4],它是大神 [Adam Miller][5] 写的。这些介绍非常有帮助,并且包含了三个优秀的示例,它们分别是用 Bash、C 和 Python 编写的程序。这个指南帮我很容易地理解了怎么去构建一个 RPM SPEC,并且,更重要的是,解释了怎么把这些片断拼到一起。
|
||||
|
||||
有了这些之后,我可以去写 brightlight 程序的我的 [第一个 SPEC 文件][6] 了。因为它是很简单的,SPEC 很短也很容易理解。我有了 SPEC 文件之后,我发现其中有一些错误。处理掉一些错误之后,我创建了源 RPM (SRPM) 和二进制 RPM,然后,我解决了出现的每个问题。
|
||||
|
||||
```
|
||||
rpmlint SPECS/brightlight.spec
|
||||
rpmbuild -bs SPECS/brightlight.spec
|
||||
rpmlint SRPMS/brightlight-5-1.fc26.src.rpm
|
||||
rpmbuild -bb SPECS/brightlight-5-1.fc26.x86_64.rpm
|
||||
rpmlint RPMS/x86_64/brightlight-5-1.fc26.x86_64.rpm
|
||||
```
|
||||
|
||||
现在,我有了一个可用的 RPM,可以发送到 Fedora 仓库了。
|
||||
|
||||
### 在 Copr 和 Koji 中构建
|
||||
|
||||
接下来,我读了该 [指南][7] 中关于怎么成为一个 Fedora 打包者。在提交之前,他们鼓励打包者通过在在 [Koji][9] 中托管、并在 [Copr][8] 中构建项目来测试要提交的包。
|
||||
|
||||
#### 使用 Copr
|
||||
|
||||
首先,我为 brightlight 创建了一个 [Copr 仓库][10],[Copr][11] 是在 Fedora 的基础设施中的一个服务,它构建你的包,并且为你任意选择的 Fedora 或 EPEL 版本创建一个定制仓库。它对于快速托管你的 RPM 包,并与其它人去分享是非常方便的。你不需要特别操心如何去托管一个 Copr 仓库。
|
||||
|
||||
我从 Web 界面创建了我的 Copr 项目,但是,你也可以使用 `copr-cli` 工具。在 Fedora 开发者网站上有一个 [非常优秀的指南][12]。在该网站上创建了我的仓库之后,我使用这个命令构建了我的包。
|
||||
|
||||
```
|
||||
copr-cli build brightlight SRPMS/brightlight.5-1.fc26.src.rpm
|
||||
```
|
||||
|
||||
我的包在 Corp 上成功构建,并且,我可以很容易地在我的 Fedora 系统上成功安装它。
|
||||
|
||||
#### 使用 Koji
|
||||
|
||||
任何人都可以使用 [Koji][13] 在多种架构和 Fedora 或 CentOS/RHEL 版本上测试他们的包。在 Koji 中测试,你必须有一个源 RPM。我希望 brightlight 包在 Fedora 所有的版本中都支持,因此,我运行如下的命令:
|
||||
|
||||
```
|
||||
koji build --scratch f25 SRPMS/brightlight-5-1.fc26.src.rpm
|
||||
koji build --scratch f26 SRPMS/brightlight-5-1.fc26.src.rpm
|
||||
koji build --scratch f27 SRPMS/brightlight-5-1.fc26.src.rpm
|
||||
```
|
||||
|
||||
它花费了一些时间,但是,Koji 构建了所有的包。我的包可以很完美地运行在 Fedora 25 和 26 中,但是 Fedora 27 失败了。 Koji 模拟构建可以使我走在正确的路线上,并且确保我的包构建成功。
|
||||
|
||||
### 问题:Fedora 27 构建失败!
|
||||
|
||||
现在,我已经知道我的 Fedora 27 上的包在 Koji 上构建失败了。但是,为什么呢?我发现在 Fedora 27 上有两个相关的变化。
|
||||
|
||||
* [Subpackage and Source Debuginfo][14]
|
||||
* [RPM 4.14][15] (特别是,debuginfo 包重写了)
|
||||
|
||||
这些变化意味着 RPM 包必须使用一个 debuginfo 包去构建。这有助于排错或调试一个应用程序。在我的案例中,这并不是关键的或者很必要的,但是,我需要去构建一个。
|
||||
|
||||
感谢 Igor Gnatenko,他帮我理解了为什么我在 Fedora 27 上构建包时需要去将这些增加到我的包的 SPEC 中。在 `%make_build` 宏指令之前,我增加了这些行。
|
||||
|
||||
```
|
||||
export CFLAGS="%{optflags}"
|
||||
export LDFLAGS="%{__global_ldflags}"
|
||||
```
|
||||
|
||||
我构建了一个新的 SRPM 并且提交它到 Koji 去在 Fedora 27 上构建。成功了,它构建成功了!
|
||||
|
||||
### 提交这个包
|
||||
|
||||
现在,我在 Fedora 25 到 27 上成功校验了我的包,是时候为 Fedora 打包了。第一步是提交这个包,为了请求一个包评估,要在 Red Hat Bugzilla 创建一个新 bug。我为 brightlight [创建了一个工单][16]。因为这是我的第一个包,我明确标注它 “这是我的第一个包”,并且我寻找一个发起人。在工单中,我链接 SPEC 和 SRPM 文件到我的 Git 仓库中。
|
||||
|
||||
#### 进入 dist-git
|
||||
|
||||
[Igor Gnatenko][17] 发起我进入 Fedora 打包者群组,并且在我的包上留下反馈。我学习了一些其它的关于 C 应用程序打包的特定的知识。在他响应我之后,我可以在 [dist-git][18] 上申请一个仓库,Fedora 的 RPM 包集合仓库为所有的 Fedora 版本保存了 SPEC 文件。
|
||||
|
||||
一个很方便的 Python 工具使得这一部分很容易。`fedrepo-req` 是一个用于创建一个新的 dist-git 仓库的请求的工具。我用这个命令提交我的请求。
|
||||
|
||||
```
|
||||
fedrepo-req brightlight \
|
||||
--ticket 1505026 \
|
||||
--description "CLI tool to change screen back light brightness" \
|
||||
--upstreamurl https://github.com/multiplexd/brightlight
|
||||
```
|
||||
|
||||
它为我在 fedora-scm-requests 仓库创建了一个新的工单。这是一个我是管理员的 [创建的仓库][19]。现在,我可以开始干了!
|
||||
|
||||

|
||||
|
||||
*My first RPM in Fedora dist-git – woohoo!*
|
||||
|
||||
#### 与 dist-git 一起工作
|
||||
|
||||
接下来,`fedpkg` 是用于和 dist-git 仓库进行交互的工具。我改变当前目录到我的 git 工作目录,然后运行这个命令。
|
||||
|
||||
```
|
||||
fedpkg clone brightlight
|
||||
```
|
||||
|
||||
`fedpkg` 从 dist-git 克隆了我的包的仓库。对于这个仅有的第一个分支,你需要去导入 SRPM。
|
||||
|
||||
```
|
||||
fedpkg import SRPMS/brightlight-5-1.fc26.src.rpm
|
||||
```
|
||||
|
||||
`fedpkg` 导入你的包的 SRPM 到这个仓库中,然后设置源为你的 Git 仓库。这一步对于使用 `fedpkg` 是很重要的,因为它用一个 Fedora 友好的方去帮助规范这个仓库(与手动添加文件相比)。一旦你导入了 SRPM,推送这个改变到 dist-git 仓库。
|
||||
|
||||
```
|
||||
git commit -m "Initial import (#1505026)."
|
||||
git push
|
||||
```
|
||||
|
||||
#### 构建包
|
||||
|
||||
自从你推送第一个包导入到你的 dist-git 仓库中,你已经准备好了为你的项目做一次真实的 Koji 构建。要构建你的项目,运行这个命令。
|
||||
|
||||
```
|
||||
fedpkg build
|
||||
```
|
||||
|
||||
它会在 Koji 中为 Rawhide 构建你的包,这是 Fedora 中的非版本控制的分支。在你为其它分支构建之前,你必须在 Rawhide 分支上构建成功。如果一切构建成功,你现在可以为你的项目的其它分支发送请求了。
|
||||
|
||||
```
|
||||
fedrepo-req brightlight f27 -t 1505026
|
||||
fedrepo-req brightlight f26 -t 1505026
|
||||
fedrepo-req brightlight f25 -t 1505026
|
||||
```
|
||||
|
||||
#### 关于构建其它分支的注意事项
|
||||
|
||||
一旦你最初导入了 SRPM,如果你选择去创建其它分支,记得合并你的主分支到它们。例如,如果你后面为 Fedora 27 请求一个分支,你将需要去使用这些命令。
|
||||
|
||||
```
|
||||
fedpkg switch-branch f27
|
||||
git merge master
|
||||
git push
|
||||
fedpkg build
|
||||
```
|
||||
|
||||
#### 提交更新到 Bodhi
|
||||
|
||||
这个过程的最后一步是,把你的新包作为一个更新包提交到 Bodhi 中。当你初次提交你的更新包时,它将去测试这个仓库。任何人都可以测试你的包并且增加 karma 到该更新中。如果你的更新接收了 3 个以上的投票(或者像 Bodhi 称它为 karma),你的包将自动被推送到稳定仓库。否则,一周之后,推送到测试仓库中。
|
||||
|
||||
要提交你的更新到 Bodhi,你仅需要一个命令。
|
||||
|
||||
```
|
||||
fedpkg update
|
||||
```
|
||||
|
||||
它为你的包用一个不同的配置选项打开一个 Vim 窗口。一般情况下,你仅需要去指定一个 类型(比如,`newpackage`)和一个你的包评估的票据 ID。对于更深入的讲解,在 Fedora 维基上有一篇[更新的指南][23]。
|
||||
|
||||
在保存和退出这个文件后,`fedpkg` 会把你的包以一个更新包提交到 Bodhi,最后,同步到 Fedora 测试仓库。我也可以用这个命令去安装我的包。
|
||||
|
||||
```
|
||||
sudo dnf install brightlight -y --enablerepo=updates-testing --refresh
|
||||
```
|
||||
|
||||
### 稳定仓库
|
||||
|
||||
最近提交了我的包到 [Fedora 26 稳定仓库][20],并且不久将进入 [Fedora 25][21] 和 [Fedora 27][22] 稳定仓库。感谢帮助我完成我的第一个包的每个人。我期待有更多的机会为发行版添加包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.justinwflory.com/2017/11/first-rpm-package-fedora/
|
||||
|
||||
作者:[JUSTIN W. FLORY][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.justinwflory.com/author/jflory7/
|
||||
[1]:https://github.com/multiplexd/brightlight
|
||||
[2]:https://www.ibm.com/developerworks/library/l-rpm1/index.html
|
||||
[3]:https://fedoraproject.org/wiki/How_to_create_an_RPM_package
|
||||
[4]:https://fedoraproject.org/wiki/How_to_create_an_RPM_package
|
||||
[5]:https://github.com/maxamillion
|
||||
[6]:https://src.fedoraproject.org/rpms/brightlight/blob/master/f/brightlight.spec
|
||||
[7]:https://fedoraproject.org/wiki/Join_the_package_collection_maintainers
|
||||
[8]:https://copr.fedoraproject.org/
|
||||
[9]:https://koji.fedoraproject.org/koji/
|
||||
[10]:https://copr.fedorainfracloud.org/coprs/jflory7/brightlight/
|
||||
[11]:https://developer.fedoraproject.org/deployment/copr/about.html
|
||||
[12]:https://developer.fedoraproject.org/deployment/copr/copr-cli.html
|
||||
[13]:https://koji.fedoraproject.org/koji/
|
||||
[14]:https://fedoraproject.org/wiki/Changes/SubpackageAndSourceDebuginfo
|
||||
[15]:https://fedoraproject.org/wiki/Changes/RPM-4.14
|
||||
[16]:https://bugzilla.redhat.com/show_bug.cgi?id=1505026
|
||||
[17]:https://fedoraproject.org/wiki/User:Ignatenkobrain
|
||||
[18]:https://src.fedoraproject.org/
|
||||
[19]:https://src.fedoraproject.org/rpms/brightlight
|
||||
[20]:https://bodhi.fedoraproject.org/updates/brightlight-5-1.fc26
|
||||
[21]:https://bodhi.fedoraproject.org/updates/FEDORA-2017-8071ee299f
|
||||
[22]:https://bodhi.fedoraproject.org/updates/FEDORA-2017-f3f085b86e
|
||||
[23]: https://fedoraproject.org/wiki/Package_update_HOWTO
|
||||
@ -0,0 +1,232 @@
|
||||
使用 Ansible Container 构建和测试应用程序
|
||||
=======
|
||||
|
||||

|
||||
|
||||
容器是一个日益流行的开发环境。作为一名开发人员,你可以选择多种工具来管理你的容器。本文将向你介绍 Ansible Container,并展示如何在类似生产环境中运行和测试你的应用程序。
|
||||
|
||||
### 入门
|
||||
|
||||
这个例子使用了一个简单的 Flask Hello World 程序。这个程序就像在生产环境中一样由 Apache HTTP 服务器提供服务。首先,安装必要的 `docker` 包:
|
||||
|
||||
```
|
||||
sudo dnf install docker
|
||||
```
|
||||
|
||||
Ansible Container 需要通过本地套接字与 Docker 服务进行通信。以下命令将更改套接字所有者,并将你添加到可访问此套接字的 `docker` 用户组:
|
||||
|
||||
```
|
||||
sudo groupadd docker && sudo gpasswd -a $USER docker
|
||||
MYGRP=$(id -g) ; newgrp docker ; newgrp $MYGRP
|
||||
```
|
||||
|
||||
运行 `id` 命令以确保 `docker` 组在你的组成员中列出。最后,[使用 sudo ][2]启用并启动 docker 服务:
|
||||
|
||||
```
|
||||
sudo systemctl enable docker.service
|
||||
sudo systemctl start docker.service
|
||||
```
|
||||
|
||||
### 设置 Ansible Container
|
||||
|
||||
Ansible Container 使你能够构建容器镜像并使用 Ansible playbook 进行编排。该程序在一个 YAML 文件中描述,而不是使用 Dockerfile,列出组成容器镜像的 Ansible 角色。
|
||||
|
||||
不幸的是,Ansible Container 在 Fedora 中没有 RPM 包可用。要安装它,请使用 python3 虚拟环境模块。
|
||||
|
||||
```
|
||||
mkdir ansible-container-flask-example
|
||||
cd ansible-container-flask-example
|
||||
python3 -m venv .venv
|
||||
source .venv/bin/activate
|
||||
pip install ansible-container[docker]
|
||||
```
|
||||
|
||||
这些命令将安装 Ansible Container 及 Docker 引擎。 Ansible Container 提供三种引擎:Docker、Kubernetes 和 Openshift。
|
||||
|
||||
### 设置项目
|
||||
|
||||
现在已经安装了 Ansible Container,接着设置这个项目。Ansible Container 提供了一个简单的命令来创建启动所需的所有文件:
|
||||
|
||||
```
|
||||
ansible-container init
|
||||
```
|
||||
|
||||
来看看这个命令在当前目录中创建的文件:
|
||||
|
||||
* `ansible.cfg`
|
||||
* `ansible-requirements.txt`
|
||||
* `container.yml`
|
||||
* `meta.yml`
|
||||
* `requirements.yml`
|
||||
|
||||
该项目仅使用 `container.yml` 来描述程序服务。有关其他文件的更多信息,请查看 Ansible Container 的[入门][3]文档。
|
||||
|
||||
### 定义容器
|
||||
|
||||
如下更新 `container.yml`:
|
||||
|
||||
```
|
||||
version: "2"
|
||||
settings:
|
||||
conductor:
|
||||
# The Conductor container does the heavy lifting, and provides a portable
|
||||
# Python runtime for building your target containers. It should be derived
|
||||
# from the same distribution as you're building your target containers with.
|
||||
base: fedora:26
|
||||
# roles_path: # Specify a local path containing Ansible roles
|
||||
# volumes: # Provide a list of volumes to mount
|
||||
# environment: # List or mapping of environment variables
|
||||
|
||||
# Set the name of the project. Defaults to basename of the project directory.
|
||||
# For built services, concatenated with service name to form the built image name.
|
||||
project_name: flask-helloworld
|
||||
|
||||
services:
|
||||
# Add your containers here, specifying the base image you want to build from.
|
||||
# To use this example, uncomment it and delete the curly braces after services key.
|
||||
# You may need to run `docker pull ubuntu:trusty` for this to work.
|
||||
web:
|
||||
from: "fedora:26"
|
||||
roles:
|
||||
- base
|
||||
ports:
|
||||
- "5000:80"
|
||||
command: ["/usr/bin/dumb-init", "httpd", "-DFOREGROUND"]
|
||||
volumes:
|
||||
- $PWD/flask-helloworld:/flaskapp:Z
|
||||
```
|
||||
|
||||
`conductor` 部分更新了基本设置以使用 Fedora 26 容器基础镜像。
|
||||
|
||||
`services` 部分添加了 `web` 服务。这个服务使用 Fedora 26,后面有一个名为 `base` 的角色。它还设置容器和主机之间的端口映射。Apache HTTP 服务器为容器的端口 80 上的 Flask 程序提供服务,该容器重定向到主机的端口 5000。然后这个文件定义了一个卷,它将 Flask 程序源代码挂载到容器中的 `/flaskapp` 中。
|
||||
|
||||
最后,容器启动时运行 `command` 配置。这个例子中使用 [dumb-init][4],一个简单的进程管理器并初始化系统启动 Apache HTTP 服务器。
|
||||
|
||||
### Ansible 角色
|
||||
|
||||
现在已经设置完了容器,创建一个 Ansible 角色来安装并配置 Flask 程序所需的依赖关系。首先,创建 `base` 角色。
|
||||
|
||||
```
|
||||
mkdir -p roles/base/tasks
|
||||
touch roles/base/tasks/main.yml
|
||||
```
|
||||
|
||||
现在编辑 `main.yml` ,它看起来像这样:
|
||||
|
||||
```
|
||||
---
|
||||
- name: Install dependencies
|
||||
dnf: pkg={{item}} state=present
|
||||
with_items:
|
||||
- python3-flask
|
||||
- dumb-init
|
||||
- httpd
|
||||
- python3-mod_wsgi
|
||||
|
||||
- name: copy the apache configuration
|
||||
copy:
|
||||
src: flask-helloworld.conf
|
||||
dest: /etc/httpd/conf.d/flask-helloworld.conf
|
||||
owner: apache
|
||||
group: root
|
||||
mode: 655
|
||||
```
|
||||
|
||||
这个 Ansible 角色是简单的。首先它安装依赖关系。然后,复制 Apache HTTP 服务器配置。如果你对 Ansible 角色不熟悉,请查看[角色文档][5]。
|
||||
|
||||
### Apache HTTP 配置
|
||||
|
||||
接下来,通过创建 `flask-helloworld.conf` 来配置 Apache HTTP 服务器:
|
||||
|
||||
```
|
||||
$ mkdir -p roles/base/files
|
||||
$ touch roles/base/files/flask-helloworld.conf
|
||||
```
|
||||
|
||||
最后将以下内容添加到文件中:
|
||||
|
||||
```
|
||||
<VirtualHost *>
|
||||
ServerName example.com
|
||||
|
||||
WSGIDaemonProcess hello_world user=apache group=root
|
||||
WSGIScriptAlias / /flaskapp/flask-helloworld.wsgi
|
||||
|
||||
<Directory /flaskapp>
|
||||
WSGIProcessGroup hello_world
|
||||
WSGIApplicationGroup %{GLOBAL}
|
||||
Require all granted
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
```
|
||||
|
||||
这个文件的重要部分是 `WSGIScriptAlias`。该指令将脚本 `flask-helloworld.wsgi` 映射到 `/`。有关 Apache HTTP 服务器和 mod_wsgi 的更多详细信息,请阅读 [Flask 文档][6]。
|
||||
|
||||
### Flask “hello world”
|
||||
|
||||
最后,创建一个简单的 Flask 程序和 ` flask-helloworld.wsgi` 脚本。
|
||||
|
||||
```
|
||||
mkdir flask-helloworld
|
||||
touch flask-helloworld/app.py
|
||||
touch flask-helloworld/flask-helloworld.wsgi
|
||||
```
|
||||
|
||||
将以下内容添加到 `app.py`:
|
||||
|
||||
```
|
||||
from flask import Flask
|
||||
app = Flask(__name__)
|
||||
|
||||
@app.route("/")
|
||||
def hello():
|
||||
return "Hello World!"
|
||||
```
|
||||
|
||||
然后编辑 `flask-helloworld.wsgi` ,添加这个:
|
||||
|
||||
```
|
||||
import sys
|
||||
sys.path.insert(0, '/flaskapp/')
|
||||
|
||||
from app import app as application
|
||||
```
|
||||
|
||||
### 构建并运行
|
||||
|
||||
现在是时候使用 `ansible-container build` 和 `ansible-container run` 命令来构建和运行容器。
|
||||
|
||||
```
|
||||
ansible-container build
|
||||
```
|
||||
|
||||
这个命令需要一些时间来完成,所以要耐心等待。
|
||||
|
||||
```
|
||||
ansible-container run
|
||||
```
|
||||
|
||||
你现在可以通过以下 URL 访问你的 flask 程序: http://localhost:5000/
|
||||
|
||||
### 结论
|
||||
|
||||
你现在已经看到如何使用 Ansible Container 来管理、构建和配置在容器中运行的程序。本例的所有配置文件和源代码在 [Pagure.io][7] 上。你可以使用此例作为基础来开始在项目中使用 Ansible Container。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/build-test-applications-ansible-container/
|
||||
|
||||
作者:[Clement Verna][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/cverna/
|
||||
[1]:https://fedoramagazine.org/build-test-applications-ansible-container/
|
||||
[2]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[3]:https://docs.ansible.com/ansible-container/getting_started.html
|
||||
[4]:https://github.com/Yelp/dumb-init
|
||||
[5]:http://docs.ansible.com/ansible/latest/playbooks_reuse_roles.html
|
||||
[6]:http://flask.pocoo.org/docs/0.12/deploying/mod_wsgi/
|
||||
[7]:https://pagure.io/ansible-container-flask-example
|
||||
@ -0,0 +1,59 @@
|
||||
Linux “完全统治” 了超级计算机
|
||||
============================================================
|
||||
|
||||
> 它终于发生了。如今,全世界超算 500 强全部都运行着 Linux。
|
||||
|
||||
Linux 统治了超级计算。自 1998 年以来,这一天终于到来了,那时候 Linux 首次出现在 [TOP 500 超级计算机榜单][5]上。如今,[全世界最快的 500 台超级计算机全部运行着 Linux][6]!
|
||||
|
||||
上以期榜单中最后的两台非 Linux 系统,是来自中国的一对运行着 AIX 的 IBM POWER 计算机,掉出了 [2017 年 11 月超级计算机 500 强榜单][7]。
|
||||
|
||||
总体而言,[现在中国引领着超级计算的竞赛,其拥有的 202 台已经超越美国的 144 台][8]。中国的超级计算机的总体性能上也超越了美国。其超级计算机占据了 TOP500 指数的 35.4%,其后的美国占 29.6%。随着一个反科学政权掌管了政府,美利坚共和国如今只能看着它的技术领袖地位在持续下降。
|
||||
|
||||
[在 1993 年 6 月首次编制超级计算机 500 强榜单][9]的时候,Linux 只不过是个“玩具”而已。那时的它甚至还没有用“企鹅”作为它的吉祥物。不久之后,Linux 就开始进军超级计算机领域。
|
||||
|
||||
在 1993/1994 时,在 NASA 的<ruby>戈达德太空飞行中心<rt>Goddard Space Flight Center</rt></ruby>,Donald Becker 和 Thomas Sterling 设计了一个<ruby>货架产品<rt>Commodity Off The Shelf</rt></ruby>(COTS)超级计算机:[Beowulf][10]。因为他们负担不起一台传统的超级计算机,所以他们构建了一个由 16 个 Intel 486 DX4 处理器的计算机集群,它通过以太网信道聚合互联。这台 [Beowulf 超级计算机][11] 当时一时成名。
|
||||
|
||||
到今天,Beowulf 的设计仍然是一个流行的、廉价的超级计算机设计方法。甚至,在最新的 TOP500 榜单上,全世界最快的 437 台计算机仍然采用受益于 Beowulf 的集群设计。
|
||||
|
||||
Linux 首次出现在 Top500 上是 1998 年。在 Linux 领先之前,Unix 是超级计算机的最佳操作系统。自从 2003 年起,Top500 中 Linux 已经占据了重要的地位。从 2004 年开始,Linux 已经完全领先于 UNIX 了。
|
||||
|
||||
[Linux 基金会][12]的报告指出,“Linux [成为] 推进研究和技术创新的计算能力突破的驱动力”。换句话说,Linux 在超级计算中占有重要地位,至少是部分重要地位。因为它正帮助研究人员突破计算能力的极限。
|
||||
|
||||
有两个原因导致这种情况:首先,全球的大部分顶级超级计算机都是为特定的研究任务去构建的,每台机器都是用于有唯一特性和需求优化的单独项目。为节省成本,不可能为每一个超算系统都去定制一个操作系统。然而,对于 Linux,研究团队可以很容易地修改和优化 Linux 的开源代码为的他们的一次性设计。
|
||||
|
||||
例如,最新的 [Linux 4.14][13] 允许超级计算机去使用 [异构内存管理 (HMM)][14]。这允许 GPU 和 CPU 去访问处理器的共享地址空间。确切地说,Top500 中的 102 台使用了 GPU 加速/协处理器技术。这全是因 HHM 而使它们运行的更快。
|
||||
|
||||
并且,同样重要的是,正如 Linux 基金会指出的那样,“定制的、自我支持的 Linux 发行版的授权成本,无论你是使用 20 个节点,还是使用 2000 万个节点,都是一样的。” 因此,“利用巨大的 Linux 开源社区,项目可以获得免费的支持和开发者资源,以保持开发人员成本与其它操作系统相同或低于它们。”
|
||||
|
||||
现在,Linux 已经达到了超级计算之巅,我无法想像它会失去领导地位。即将到来的硬件革命,比如,量子计算,将会动摇 Linux 超级计算的地位。当然,Linux 也许仍然可以保持统治地位,因为,[IBM 开发人员已经准备将 Linux 移植到量子计算机上][15]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/linux-totally-dominates-supercomputers/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://www.zdnet.com/article/linux-totally-dominates-supercomputers/#comments-643ecd13-0265-48a8-b789-7e8d631025ad
|
||||
[2]:http://www.zdnet.com/article/a-problem-solving-approach-it-workers-should-learn-from-robotics-engineers/
|
||||
[3]:http://www.zdnet.com/article/a-problem-solving-approach-it-workers-should-learn-from-robotics-engineers/
|
||||
[4]:http://www.zdnet.com/article/a-problem-solving-approach-it-workers-should-learn-from-robotics-engineers/
|
||||
[5]:https://www.top500.org/
|
||||
[6]:https://www.top500.org/statistics/sublist/
|
||||
[7]:https://www.top500.org/news/china-pulls-ahead-of-us-in-latest-top500-list/
|
||||
[8]:http://www.zdnet.com/article/now-china-outguns-us-in-top-supercomputer-showdown/
|
||||
[9]:http://top500.org/project/introduction
|
||||
[10]:http://www.beowulf.org/overview/faq.html
|
||||
[11]:http://www.beowulf.org/overview/history.html
|
||||
[12]:https://www.linux.com/publications/20-years-top500org-supercomputer-data-links-linux-advances-computing-performance
|
||||
[13]:http://www.zdnet.com/article/the-new-long-term-linux-kernel-linux-4-14-has-arrived/
|
||||
[14]:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=bffc33ec539699f045a9254144de3d4eace05f07
|
||||
[15]:http://www.linuxplumbersconf.org/2017/ocw//system/presentations/4704/original/QC-slides.2017.09.13f.pdf
|
||||
[16]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[17]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[18]:http://www.zdnet.com/blog/open-source/
|
||||
[19]:http://www.zdnet.com/topic/innovation/
|
||||
102
published/20171116 5 Coolest Linux Terminal Emulators.md
Normal file
102
published/20171116 5 Coolest Linux Terminal Emulators.md
Normal file
@ -0,0 +1,102 @@
|
||||
5 款最酷的 Linux 终端模拟器
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
> Carla Schroder 正在看着那些她喜欢的终端模拟器, 包括展示在这儿的 Cool Retro Term。
|
||||
|
||||
虽然,我们可以继续使用老旧的 GNOME 终端、Konsole,以及好笑而孱弱的旧式 xterm。 不过,让我们带着尝试某种新东西的心境,回过头来看看 5 款酷炫并且实用的 Linux 终端。
|
||||
|
||||
### Xiki
|
||||
|
||||
首先我要推荐的第一个终端是 [Xiki][10]。 Xiki 是 Craig Muth 的智慧结晶,他是一个天才程序员,也是一个有趣的人(有趣在此处的意思是幽默,可能还有其它的意思)。 很久以前我在 [遇见 Xiki,Linux 和 Mac OS X 下革命性命令行 Shell][11] 一文中介绍过 Xiki。 Xiki 不仅仅是又一款终端模拟器;它也是一个扩展命令行用途、加快命令行速度的交互式环境。
|
||||
|
||||
视频: https://youtu.be/bUR_eUVcABg
|
||||
|
||||
Xiki 支持鼠标,并且在绝大多数命令行 Shell 上都支持。 它有大量的屏显帮助,而且可以使用鼠标和键盘快速导航。 它体现在速度上的一个简单例子就是增强了 `ls` 命令。 Xiki 可以快速穿过文件系统上的多层目录,而不用持续的重复输入 `ls` 或者 `cd`, 或者利用那些巧妙的正则表达式。
|
||||
|
||||
Xiki 可以与许多文本编辑器相集成, 提供了一个永久的便签, 有一个快速搜索引擎, 同时像他们所说的,还有许许多多的功能。 Xiki 是如此的有特色、如此的不同, 所以学习和了解它的最快的方式可以看 [Craig 的有趣和实用的视频][12]。
|
||||
|
||||
### Cool Retro Term
|
||||
|
||||
我推荐 [Cool Retro Term][13] (如题图显示) 主要因为它的外观,以及它的实用性。 它将我们带回了阴极射线管显示器的时代,这不算很久以前,而我也没有怀旧的意思,我死也不会放弃我的 LCD 屏幕。它基于 [Konsole][14], 因此有着 Konsole 的优秀功能。可以通过 Cool Retro Term 的配置文件菜单来改变它的外观。配置文件包括 Amber、Green、Pixelated、Apple 和 Transparent Green 等等,而且全都包括一个像真的一样的扫描线。并不是全都是有用的,例如 Vintage 配置文件看起来就像一个闪烁着的老旧的球面屏。
|
||||
|
||||
Cool Retro Term 的 GitHub 仓库有着详细的安装指南,且 Ubuntu 用户有 [PPA][15]。
|
||||
|
||||
### Sakura
|
||||
|
||||
你要是想要一个优秀的轻量级、易配置的终端,可以尝试下 [Sakura][16](图 1)。 它依赖少,不像 GNOME 终端 和 Konsole,在 GNOME 和 KDE 中牵扯了很多组件。其大多数选项是可以通过右键菜单配置的,例如选项卡的标签、 颜色、大小、选项卡的默认数量、字体、铃声,以及光标类型。 你可以在你个人的配置文件 `~/.config/sakura/sakura.conf` 里面设置更多的选项,例如绑定快捷键。
|
||||
|
||||

|
||||
|
||||
*图 1: Sakura 是一个优秀的、轻量级的、可配置的终端。*
|
||||
|
||||
命令行选项详见 `man sakura`。可以使用这些来从命令行启动 sakura,或者在你的图形启动器上使用它们。 例如,打开 4 个选项卡并设置窗口标题为 “MyWindowTitle”:
|
||||
|
||||
```
|
||||
$ sakura -t MyWindowTitle -n 4
|
||||
```
|
||||
|
||||
### Terminology
|
||||
|
||||
[Terminology][17] 来自 Enlightenment 图形环境的郁葱可爱的世界,它能够被美化成任何你所想要的样子 (图 2)。 它有许多有用的功能:独立的拆分窗口、打开文件和 URL、文件图标、选项卡,林林总总。 它甚至能运行在没有图形界面的 Linux 控制台上。
|
||||
|
||||

|
||||
|
||||
*图 2: Terminology 也能够运行在没有图形界面的 Linux 控制台上。*
|
||||
|
||||
当你打开多个拆分窗口时,每个窗口都能设置不同的背景,并且背景文件可以是任意媒体文件:图像文件、视频或者音乐文件。它带有一堆便于清晰可读的暗色主题和透明主题,它甚至一个 Nyan 猫主题。它没有滚动条,因此需要使用组合键 `Shift+PageUp` 和 `Shift+PageDown` 进行上下导航。
|
||||
|
||||
它有多个控件:一个右键单击菜单,上下文对话框,以及命令行选项。右键单击菜单里包含世界上最小的字体,且 Miniview 可显示一个微观的文件树,但我没有找到可以使它们易于辨读的选项。当你打开多个标签时,可以点击小标签浏览器来打开一个可以上下滚动的选择器。任何东西都是可配置的;通过 `man terminology` 可以查看一系列的命令和选项,包括一批不错的快捷键快捷方式。奇怪的是,帮助里面没有包括以下命令,这是我偶然发现的:
|
||||
|
||||
* tyalpha
|
||||
* tybg
|
||||
* tycat
|
||||
* tyls
|
||||
* typop
|
||||
* tyq
|
||||
|
||||
使用 `tybg [filename]` 命令来设置背景,不带参数的 `tybg` 命令来移除背景。 运行 `typop [filename]` 来打开文件。 `tyls` 命令以图标视图列出文件。 加上 `-h` 选项运行这些命令可以了解它们是干什么的。 即使有可读性的怪癖,Terminology 依然是快速、漂亮和实用的。
|
||||
|
||||
### Tilda
|
||||
|
||||
已经有几个优秀的下拉式终端模拟器,包括 Guake 和 Yakuake。 [Tilda][18] (图 3) 是其中最简单和轻量级的一个。 打开 Tilda 后它会保持打开状态, 你可以通过快捷键来显示和隐藏它。 Tilda 快捷键是默认设置的, 你可以设置自己喜欢的快捷键。 它一直打开着的,随时准备工作,但是直到你需要它的时候才会出现。
|
||||
|
||||

|
||||
|
||||
*图 3: Tilda 是最简单和轻量级的一个终端模拟器。*
|
||||
|
||||
Tilda 选项方面有很好的补充,包括默认的大小、位置、外观、绑定键、搜索条、鼠标动作,以及标签条。 这些都被右键单击菜单控制。
|
||||
|
||||
_学习更多关于 Linux 的知识可以通过 Linux 基金会 和 edX 的免费课程 ["Linux 介绍" ][9]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/11/5-coolest-linux-terminal-emulators
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[cnobelw](https://github.com/cnobelw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/files/images/fig-1png-9
|
||||
[6]:https://www.linux.com/files/images/fig-2png-6
|
||||
[7]:https://www.linux.com/files/images/fig-3png-3
|
||||
[8]:https://www.linux.com/files/images/banner2png
|
||||
[9]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[10]:http://xiki.org/
|
||||
[11]:https://www.linux.com/learn/meet-xiki-revolutionary-command-shell-linux-and-mac-os-x
|
||||
[12]:http://xiki.org/screencasts/
|
||||
[13]:https://github.com/Swordfish90/cool-retro-term
|
||||
[14]:https://www.linux.com/learn/expert-tips-and-tricks-kate-and-konsole
|
||||
[15]:https://launchpad.net/~bugs-launchpad-net-falkensweb/+archive/ubuntu/cool-retro-term
|
||||
[16]:https://bugs.launchpad.net/sakura
|
||||
[17]:https://www.enlightenment.org/about-terminology
|
||||
[18]:https://github.com/lanoxx/tilda
|
||||
198
published/20171118 Getting started with OpenFaaS on minikube.md
Normal file
198
published/20171118 Getting started with OpenFaaS on minikube.md
Normal file
@ -0,0 +1,198 @@
|
||||
借助 minikube 上手 OpenFaaS
|
||||
============================================================
|
||||
|
||||
本文将介绍如何借助 [minikube][4] 在 Kubernetes 1.8 上搭建 OpenFaaS(让 Serverless Function 变得更简单)。minikube 是一个 [Kubernetes][5] 分发版,借助它,你可以在笔记本电脑上运行 Kubernetes 集群,minikube 支持 Mac 和 Linux 操作系统,但是在 MacOS 上使用得更多一些。
|
||||
|
||||
> 本文基于我们最新的部署手册 [Kubernetes 官方部署指南][6]
|
||||
|
||||
|
||||

|
||||
|
||||
### 安装部署 Minikube
|
||||
|
||||
1、 安装 [xhyve driver][1] 或 [VirtualBox][2] ,然后在上面安装 Linux 虚拟机以部署 minikube 。根据我的经验,VirtualBox 更稳定一些。
|
||||
|
||||
2、 [参照官方文档][3] 安装 minikube 。
|
||||
|
||||
3、 使用 `brew` 或 `curl -sL cli.openfaas.com | sudo sh` 安装 `faas-cli`。
|
||||
|
||||
4、 通过 `brew install kubernetes-helm` 安装 `helm` 命令行。
|
||||
|
||||
5、 运行 minikube :`minikube start`。
|
||||
|
||||
> Docker 船长小贴士:Mac 和 Windows 版本的 Docker 已经集成了对 Kubernetes 的支持。现在我们使用 Kubernetes 的时候,已经不需要再安装额外的软件了。
|
||||
|
||||
### 在 minikube 上面部署 OpenFaaS
|
||||
|
||||
1、 为 Helm 的服务器组件 tiller 新建服务账号:
|
||||
|
||||
```
|
||||
kubectl -n kube-system create sa tiller \
|
||||
&& kubectl create clusterrolebinding tiller \
|
||||
--clusterrole cluster-admin \
|
||||
--serviceaccount=kube-system:tiller
|
||||
```
|
||||
|
||||
2、 安装 Helm 的服务端组件 tiller:
|
||||
|
||||
```
|
||||
helm init --skip-refresh --upgrade --service-account tiller
|
||||
```
|
||||
|
||||
3、 克隆 Kubernetes 的 OpenFaaS 驱动程序 faas-netes:
|
||||
|
||||
```
|
||||
git clone https://github.com/openfaas/faas-netes && cd faas-netes
|
||||
```
|
||||
|
||||
4、 Minikube 没有配置 RBAC,这里我们需要把 RBAC 关闭:
|
||||
|
||||
```
|
||||
helm upgrade --install --debug --reset-values --set async=false --set rbac=false openfaas openfaas/
|
||||
```
|
||||
|
||||
(LCTT 译注:RBAC(Role-Based access control)基于角色的访问权限控制,在计算机权限管理中较为常用,详情请参考以下链接:https://en.wikipedia.org/wiki/Role-based_access_control )
|
||||
|
||||
现在,你可以看到 OpenFaaS pod 已经在你的 minikube 集群上运行起来了。输入 `kubectl get pods` 以查看 OpenFaaS pod:
|
||||
|
||||
```
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
alertmanager-6dbdcddfc4-fjmrf 1/1 Running 0 1m
|
||||
faas-netesd-7b5b7d9d4-h9ftx 1/1 Running 0 1m
|
||||
gateway-965d6676d-7xcv9 1/1 Running 0 1m
|
||||
prometheus-64f9844488-t2mvn 1/1 Running 0 1m
|
||||
```
|
||||
|
||||
30,000ft:
|
||||
|
||||
该 API 网关包含了一个 [用于测试功能的最小化 UI][7],同时开放了用于功能管理的 [RESTful API][8] 。
|
||||
faas-netesd 守护进程是一种 Kubernetes 控制器,用来连接 Kubernetes API 服务器来管理服务、部署和密码。
|
||||
|
||||
Prometheus 和 AlertManager 进程协同工作,实现 OpenFaaS Function 的弹性缩放,以满足业务需求。通过 Prometheus 指标我们可以查看系统的整体运行状态,还可以用来开发功能强悍的仪表盘。
|
||||
|
||||
Prometheus 仪表盘示例:
|
||||
|
||||

|
||||
|
||||
### 构建/迁移/运行
|
||||
|
||||
和很多其他的 FaaS 项目不同,OpenFaaS 使用 Docker 镜像格式来进行 Function 的创建和版本控制,这意味着可以在生产环境中使用 OpenFaaS 实现以下目标:
|
||||
|
||||
* 漏洞扫描(LCTT 译注:此处我觉得应该理解为更快地实现漏洞补丁)
|
||||
* 持续集成/持续开发
|
||||
* 滚动更新
|
||||
|
||||
你也可以在现有的生产环境集群中利用空闲资源部署 OpenFaaS。其核心服务组件内存占用大概在 10-30MB 。
|
||||
|
||||
> OpenFaaS 一个关键的优势在于,它可以使用容器编排平台的 API ,这样可以和 Kubernetes 以及 Docker Swarm 进行本地集成。同时,由于使用 Docker <ruby>存储库<rt>registry</rt></ruby>进行 Function 的版本控制,所以可以按需扩展 Function,而没有按需构建 Function 的框架的额外的延时。
|
||||
|
||||
### 新建 Function
|
||||
|
||||
```
|
||||
faas-cli new --lang python hello
|
||||
```
|
||||
|
||||
以上命令创建文件 `hello.yml` 以及文件夹 `handler`,文件夹有两个文件 `handler.py`、`requirements.txt` 可用于你可能需要的 pip 模块。你可以随时编辑这些文件和文件夹,不需要担心如何维护 Dockerfile —— 我们为你通过以下方式维护:
|
||||
|
||||
* 分级创建
|
||||
* 非 root 用户
|
||||
* 以官方的 Docker Alpine Linux 版本为基础进行镜像构建 (可替换)
|
||||
|
||||
### 构建你的 Function
|
||||
|
||||
先在本地创建 Function,然后推送到 Docker 存储库。 我们这里使用 Docker Hub,打开文件 `hello.yml` 然后输入你的账号名:
|
||||
|
||||
```
|
||||
provider:
|
||||
name: faas
|
||||
gateway: http://localhost:8080
|
||||
functions:
|
||||
hello:
|
||||
lang: python
|
||||
handler: ./hello
|
||||
image: alexellis2/hello
|
||||
```
|
||||
|
||||
现在,发起构建。你的本地系统上需要安装 Docker 。
|
||||
|
||||
```
|
||||
faas-cli build -f hello.yml
|
||||
```
|
||||
|
||||
把封装好 Function 的 Docker 镜像版本推送到 Docker Hub。如果还没有登录 Docker hub ,继续前需要先输入命令 `docker login` 。
|
||||
|
||||
```
|
||||
faas-cli push -f hello.yml
|
||||
```
|
||||
|
||||
当系统中有多个 Function 的时候,可以使用 `--parallel=N` 来调用多核并行处理构建或推送任务。该命令也支持这些选项: `--no-cache`、`--squash` 。
|
||||
|
||||
### 部署及测试 Function
|
||||
|
||||
现在,可以部署、列出、调用 Function 了。每次调用 Function 时,可以通过 Prometheus 收集指标值。
|
||||
|
||||
```
|
||||
$ export gw=http://$(minikube ip):31112
|
||||
$ faas-cli deploy -f hello.yml --gateway $gw
|
||||
Deploying: hello.
|
||||
No existing function to remove
|
||||
Deployed.
|
||||
URL: http://192.168.99.100:31112/function/hello
|
||||
```
|
||||
|
||||
上面给到的是部署时调用 Function 的标准方法,你也可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ echo test | faas-cli invoke hello --gateway $gw
|
||||
```
|
||||
|
||||
现在可以通过以下命令列出部署好的 Function,你将看到调用计数器数值增加。
|
||||
|
||||
```
|
||||
$ faas-cli list --gateway $gw
|
||||
Function Invocations Replicas
|
||||
hello 1 1
|
||||
```
|
||||
|
||||
_提示:这条命令也可以加上 `--verbose` 选项获得更详细的信息。_
|
||||
|
||||
由于我们是在远端集群(Linux 虚拟机)上面运行 OpenFaaS,命令里面加上一条 `--gateway` 用来覆盖环境变量。 这个选项同样适用于云平台上的远程主机。除了加上这条选项以外,还可以通过编辑 .yml 文件里面的 `gateway` 值来达到同样的效果。
|
||||
|
||||
### 迁移到 minikube 以外的环境
|
||||
|
||||
一旦你在熟悉了在 minikube 上运行 OpenFaaS ,就可以在任意 Linux 主机上搭建 Kubernetes 集群来部署 OpenFaaS 了。下图是由来自 WeaveWorks 的 Stefan Prodan 做的 OpenFaaS Demo ,这个 Demo 部署在 Google GKE 平台上的 Kubernetes 上面。图片上展示的是 OpenFaaS 内置的自动扩容的功能:
|
||||
|
||||

|
||||
|
||||
### 继续学习
|
||||
|
||||
我们的 Github 上面有很多手册和博文,可以带你轻松“上车”,把我们的页面保存成书签吧:[openfaas/faas][9][][10] 。
|
||||
|
||||
2017 哥本哈根 Dockercon Moby 峰会上,我做了关于 Serverless 和 OpenFaaS 的概述演讲,这里我把视频放上来,视频不长,大概 15 分钟左右。
|
||||
|
||||
[Youtube视频](https://youtu.be/UaReIKa2of8)
|
||||
|
||||
最后,别忘了关注 [OpenFaaS on Twitter][11] 这里有最潮的新闻、最酷的技术和 Demo 展示。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@alexellisuk/getting-started-with-openfaas-on-minikube-634502c7acdf
|
||||
|
||||
作者:[Alex Ellis][a]
|
||||
译者:[mandeler](https://github.com/mandeler)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@alexellisuk?source=post_header_lockup
|
||||
[1]:https://git.k8s.io/minikube/docs/drivers.md#xhyve-driver
|
||||
[2]:https://www.virtualbox.org/wiki/Downloads
|
||||
[3]:https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||
[4]:https://kubernetes.io/docs/getting-started-guides/minikube/
|
||||
[5]:https://kubernetes.io/
|
||||
[6]:https://github.com/openfaas/faas/blob/master/guide/deployment_k8s.md
|
||||
[7]:https://github.com/openfaas/faas/blob/master/TestDrive.md
|
||||
[8]:https://github.com/openfaas/faas/tree/master/api-docs
|
||||
[9]:https://github.com/openfaas/faas/tree/master/guide
|
||||
[10]:https://github.com/openfaas/faas/tree/master/guide
|
||||
[11]:https://twitter.com/openfaas
|
||||
@ -1,5 +1,3 @@
|
||||
translating by wangs0622
|
||||
|
||||
Book review: Ours to Hack and to Own
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by gitlilys
|
||||
|
||||
GOOGLE CHROME–ONE YEAR IN
|
||||
========================================
|
||||
|
||||
|
||||
87
sources/tech/20090127 Anatomy of a Program in Memory.md
Normal file
87
sources/tech/20090127 Anatomy of a Program in Memory.md
Normal file
@ -0,0 +1,87 @@
|
||||
ezio is translating
|
||||
|
||||
|
||||
Anatomy of a Program in Memory
|
||||
============================================================
|
||||
|
||||
Memory management is the heart of operating systems; it is crucial for both programming and system administration. In the next few posts I’ll cover memory with an eye towards practical aspects, but without shying away from internals. While the concepts are generic, examples are mostly from Linux and Windows on 32-bit x86\. This first post describes how programs are laid out in memory.
|
||||
|
||||
Each process in a multi-tasking OS runs in its own memory sandbox. This sandbox is the virtual address space, which in 32-bit mode is always a 4GB block of memory addresses. These virtual addresses are mapped to physical memory by page tables, which are maintained by the operating system kernel and consulted by the processor. Each process has its own set of page tables, but there is a catch. Once virtual addresses are enabled, they apply to _all software_ running in the machine, _including the kernel itself_ . Thus a portion of the virtual address space must be reserved to the kernel:
|
||||
|
||||
|
||||
|
||||
This does not mean the kernel uses that much physical memory, only that it has that portion of address space available to map whatever physical memory it wishes. Kernel space is flagged in the page tables as exclusive to [privileged code][1] (ring 2 or lower), hence a page fault is triggered if user-mode programs try to touch it. In Linux, kernel space is constantly present and maps the same physical memory in all processes. Kernel code and data are always addressable, ready to handle interrupts or system calls at any time. By contrast, the mapping for the user-mode portion of the address space changes whenever a process switch happens:
|
||||
|
||||
|
||||
|
||||
Blue regions represent virtual addresses that are mapped to physical memory, whereas white regions are unmapped. In the example above, Firefox has used far more of its virtual address space due to its legendary memory hunger. The distinct bands in the address space correspond to memory segments like the heap, stack, and so on. Keep in mind these segments are simply a range of memory addresses and _have nothing to do_ with [Intel-style segments][2]. Anyway, here is the standard segment layout in a Linux process:
|
||||
|
||||
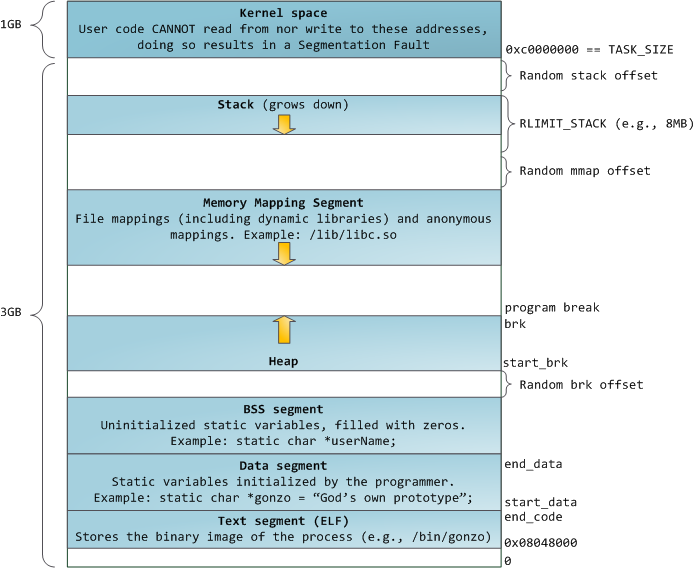
|
||||
|
||||
When computing was happy and safe and cuddly, the starting virtual addresses for the segments shown above were exactly the same for nearly every process in a machine. This made it easy to exploit security vulnerabilities remotely. An exploit often needs to reference absolute memory locations: an address on the stack, the address for a library function, etc. Remote attackers must choose this location blindly, counting on the fact that address spaces are all the same. When they are, people get pwned. Thus address space randomization has become popular. Linux randomizes the [stack][3], [memory mapping segment][4], and [heap][5] by adding offsets to their starting addresses. Unfortunately the 32-bit address space is pretty tight, leaving little room for randomization and [hampering its effectiveness][6].
|
||||
|
||||
The topmost segment in the process address space is the stack, which stores local variables and function parameters in most programming languages. Calling a method or function pushes a new stack frame onto the stack. The stack frame is destroyed when the function returns. This simple design, possible because the data obeys strict [LIFO][7] order, means that no complex data structure is needed to track stack contents – a simple pointer to the top of the stack will do. Pushing and popping are thus very fast and deterministic. Also, the constant reuse of stack regions tends to keep active stack memory in the [cpu caches][8], speeding up access. Each thread in a process gets its own stack.
|
||||
|
||||
It is possible to exhaust the area mapping the stack by pushing more data than it can fit. This triggers a page fault that is handled in Linux by [expand_stack()][9], which in turn calls [acct_stack_growth()][10] to check whether it’s appropriate to grow the stack. If the stack size is below <tt>RLIMIT_STACK</tt> (usually 8MB), then normally the stack grows and the program continues merrily, unaware of what just happened. This is the normal mechanism whereby stack size adjusts to demand. However, if the maximum stack size has been reached, we have a stack overflow and the program receives a Segmentation Fault. While the mapped stack area expands to meet demand, it does not shrink back when the stack gets smaller. Like the federal budget, it only expands.
|
||||
|
||||
Dynamic stack growth is the [only situation][11] in which access to an unmapped memory region, shown in white above, might be valid. Any other access to unmapped memory triggers a page fault that results in a Segmentation Fault. Some mapped areas are read-only, hence write attempts to these areas also lead to segfaults.
|
||||
|
||||
Below the stack, we have the memory mapping segment. Here the kernel maps contents of files directly to memory. Any application can ask for such a mapping via the Linux [mmap()][12] system call ([implementation][13]) or [CreateFileMapping()][14] / [MapViewOfFile()][15] in Windows. Memory mapping is a convenient and high-performance way to do file I/O, so it is used for loading dynamic libraries. It is also possible to create an anonymous memory mapping that does not correspond to any files, being used instead for program data. In Linux, if you request a large block of memory via [malloc()][16], the C library will create such an anonymous mapping instead of using heap memory. ‘Large’ means larger than <tt>MMAP_THRESHOLD</tt> bytes, 128 kB by default and adjustable via [mallopt()][17].
|
||||
|
||||
Speaking of the heap, it comes next in our plunge into address space. The heap provides runtime memory allocation, like the stack, meant for data that must outlive the function doing the allocation, unlike the stack. Most languages provide heap management to programs. Satisfying memory requests is thus a joint affair between the language runtime and the kernel. In C, the interface to heap allocation is [malloc()][18] and friends, whereas in a garbage-collected language like C# the interface is the <tt>new</tt> keyword.
|
||||
|
||||
If there is enough space in the heap to satisfy a memory request, it can be handled by the language runtime without kernel involvement. Otherwise the heap is enlarged via the [brk()][19]system call ([implementation][20]) to make room for the requested block. Heap management is [complex][21], requiring sophisticated algorithms that strive for speed and efficient memory usage in the face of our programs’ chaotic allocation patterns. The time needed to service a heap request can vary substantially. Real-time systems have [special-purpose allocators][22] to deal with this problem. Heaps also become _fragmented_ , shown below:
|
||||
|
||||

|
||||
|
||||
Finally, we get to the lowest segments of memory: BSS, data, and program text. Both BSS and data store contents for static (global) variables in C. The difference is that BSS stores the contents of _uninitialized_ static variables, whose values are not set by the programmer in source code. The BSS memory area is anonymous: it does not map any file. If you say <tt>static int cntActiveUsers</tt>, the contents of <tt>cntActiveUsers</tt> live in the BSS.
|
||||
|
||||
The data segment, on the other hand, holds the contents for static variables initialized in source code. This memory area is not anonymous. It maps the part of the program’s binary image that contains the initial static values given in source code. So if you say <tt>static int cntWorkerBees = 10</tt>, the contents of cntWorkerBees live in the data segment and start out as 10\. Even though the data segment maps a file, it is a private memory mapping, which means that updates to memory are not reflected in the underlying file. This must be the case, otherwise assignments to global variables would change your on-disk binary image. Inconceivable!
|
||||
|
||||
The data example in the diagram is trickier because it uses a pointer. In that case, the _contents_ of pointer <tt>gonzo</tt> – a 4-byte memory address – live in the data segment. The actual string it points to does not, however. The string lives in the text segment, which is read-only and stores all of your code in addition to tidbits like string literals. The text segment also maps your binary file in memory, but writes to this area earn your program a Segmentation Fault. This helps prevent pointer bugs, though not as effectively as avoiding C in the first place. Here’s a diagram showing these segments and our example variables:
|
||||
|
||||
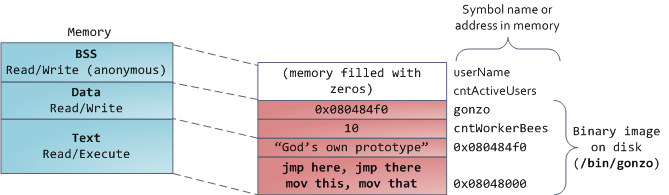
|
||||
|
||||
You can examine the memory areas in a Linux process by reading the file <tt>/proc/pid_of_process/maps</tt>. Keep in mind that a segment may contain many areas. For example, each memory mapped file normally has its own area in the mmap segment, and dynamic libraries have extra areas similar to BSS and data. The next post will clarify what ‘area’ really means. Also, sometimes people say “data segment” meaning all of data + bss + heap.
|
||||
|
||||
You can examine binary images using the [nm][23] and [objdump][24] commands to display symbols, their addresses, segments, and so on. Finally, the virtual address layout described above is the “flexible” layout in Linux, which has been the default for a few years. It assumes that we have a value for <tt>RLIMIT_STACK</tt>. When that’s not the case, Linux reverts back to the “classic” layout shown below:
|
||||
|
||||
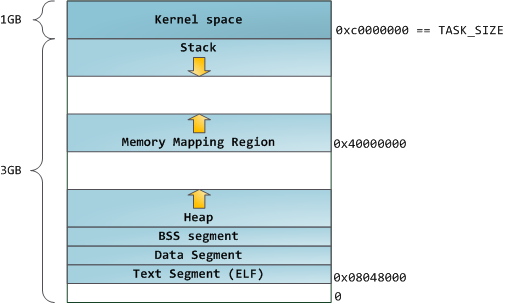
|
||||
|
||||
That’s it for virtual address space layout. The next post discusses how the kernel keeps track of these memory areas. Coming up we’ll look at memory mapping, how file reading and writing ties into all this and what memory usage figures mean.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
|
||||
|
||||
作者:[gustavo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection
|
||||
[2]:http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation
|
||||
[3]:http://lxr.linux.no/linux+v2.6.28.1/fs/binfmt_elf.c#L542
|
||||
[4]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/mmap.c#L84
|
||||
[5]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/process_32.c#L729
|
||||
[6]:http://www.stanford.edu/~blp/papers/asrandom.pdf
|
||||
[7]:http://en.wikipedia.org/wiki/Lifo
|
||||
[8]:http://duartes.org/gustavo/blog/post/intel-cpu-caches
|
||||
[9]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1716
|
||||
[10]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1544
|
||||
[11]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/fault.c#L692
|
||||
[12]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/sys_i386_32.c#L27
|
||||
[14]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[15]:http://msdn.microsoft.com/en-us/library/aa366761(VS.85).aspx
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man3/undocumented.3.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||||
[20]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L248
|
||||
[21]:http://g.oswego.edu/dl/html/malloc.html
|
||||
[22]:http://rtportal.upv.es/rtmalloc/
|
||||
[23]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/nm.1.html
|
||||
[24]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/objdump.1.html
|
||||
@ -0,0 +1,86 @@
|
||||
translating by hopefully2333
|
||||
|
||||
# [The One in Which I Call Out Hacker News][14]
|
||||
|
||||
|
||||
> “Implementing caching would take thirty hours. Do you have thirty extra hours? No, you don’t. I actually have no idea how long it would take. Maybe it would take five minutes. Do you have five minutes? No. Why? Because I’m lying. It would take much longer than five minutes. That’s the eternal optimism of programmers.”
|
||||
>
|
||||
> — Professor [Owen Astrachan][1] during 23 Feb 2004 lecture for [CPS 108][2]
|
||||
|
||||
[Accusing open-source software of being a royal pain to use][5] is not a new argument; it’s been said before, by those much more eloquent than I, and even by some who are highly sympathetic to the open-source movement. Why go over it again?
|
||||
|
||||
On Hacker News on Monday, I was amused to read some people saying that [writing StackOverflow was hilariously easy][6]—and proceeding to back up their claim by [promising to clone it over July 4th weekend][7]. Others chimed in, pointing to [existing][8] [clones][9] as a good starting point.
|
||||
|
||||
Let’s assume, for sake of argument, that you decide it’s okay to write your StackOverflow clone in ASP.NET MVC, and that I, after being hypnotized with a pocket watch and a small club to the head, have decided to hand you the StackOverflow source code, page by page, so you can retype it verbatim. We’ll also assume you type like me, at a cool 100 WPM ([a smidge over eight characters per second][10]), and unlike me, _you_ make zero mistakes. StackOverflow’s *.cs, *.sql, *.css, *.js, and *.aspx files come to 2.3 MB. So merely typing the source code back into the computer will take you about eighty hours if you make zero mistakes.
|
||||
|
||||
Except, of course, you’re not doing that; you’re going to implement StackOverflow from scratch. So even assuming that it took you a mere ten times longer to design, type out, and debug your own implementation than it would take you to copy the real one, that already has you coding for several weeks straight—and I don’t know about you, but I am okay admitting I write new code _considerably_ less than one tenth as fast as I copy existing code.
|
||||
|
||||
_Well, okay_ , I hear you relent. *So not the whole thing. But I can do **most** of it.*
|
||||
|
||||
Okay, so what’s “most”? There’s simply asking and responding to questions—that part’s easy. Well, except you have to implement voting questions and answers up and down, and the questioner should be able to accept a single answer for each question. And you can’t let people upvote or accept their own answers, so you need to block that. And you need to make sure that users don’t upvote or downvote another user too many times in a certain amount of time, to prevent spambots. Probably going to have to implement a spam filter, too, come to think of it, even in the basic design, and you also need to support user icons, and you’re going to have to find a sanitizing HTML library you really trust and that interfaces well with Markdown (provided you do want to reuse [that awesome editor][11] StackOverflow has, of course). You’ll also need to purchase, design, or find widgets for all the controls, plus you need at least a basic administration interface so that moderators can moderate, and you’ll need to implement that scaling karma thing so that you give users steadily increasing power to do things as they go.
|
||||
|
||||
But if you do _all that_ , you _will_ be done.
|
||||
|
||||
Except…except, of course, for the full-text search, especially its appearance in the search-as-you-ask feature, which is kind of indispensable. And user bios, and having comments on answers, and having a main page that shows you important questions but that bubbles down steadily à la reddit. Plus you’ll totally need to implement bounties, and support multiple OpenID logins per user, and send out email notifications for pertinent events, and add a tagging system, and allow administrators to configure badges by a nice GUI. And you’ll need to show users’ karma history, upvotes, and downvotes. And the whole thing has to scale really well, since it could be slashdotted/reddited/StackOverflown at any moment.
|
||||
|
||||
But _then_ ! **Then** you’re done!
|
||||
|
||||
…right after you implement upgrades, internationalization, karma caps, a CSS design that makes your site not look like ass, AJAX versions of most of the above, and G-d knows what else that’s lurking just beneath the surface that you currently take for granted, but that will come to bite you when you start to do a real clone.
|
||||
|
||||
Tell me: which of those features do you feel you can cut and still have a compelling offering? Which ones go under “most” of the site, and which can you punt?
|
||||
|
||||
Developers think cloning a site like StackOverflow is easy for the same reason that open-source software remains such a horrible pain in the ass to use. When you put a developer in front of StackOverflow, they don’t really _see_ StackOverflow. What they actually _see_ is this:
|
||||
|
||||
```
|
||||
create table QUESTION (ID identity primary key,
|
||||
TITLE varchar(255), --- why do I know you thought 255?
|
||||
BODY text,
|
||||
UPVOTES integer not null default 0,
|
||||
DOWNVOTES integer not null default 0,
|
||||
USER integer references USER(ID));
|
||||
create table RESPONSE (ID identity primary key,
|
||||
BODY text,
|
||||
UPVOTES integer not null default 0,
|
||||
DOWNVOTES integer not null default 0,
|
||||
QUESTION integer references QUESTION(ID))
|
||||
```
|
||||
|
||||
If you then tell a developer to replicate StackOverflow, what goes into his head are the above two SQL tables and enough HTML to display them without formatting, and that really _is_ completely doable in a weekend. The smarter ones will realize that they need to implement login and logout, and comments, and that the votes need to be tied to a user, but that’s still totally doable in a weekend; it’s just a couple more tables in a SQL back-end, and the HTML to show their contents. Use a framework like Django, and you even get basic users and comments for free.
|
||||
|
||||
But that’s _not_ what StackOverflow is about. Regardless of what your feelings may be on StackOverflow in general, most visitors seem to agree that the user experience is smooth, from start to finish. They feel that they’re interacting with a polished product. Even if I didn’t know better, I would guess that very little of what actually makes StackOverflow a continuing success has to do with the database schema—and having had a chance to read through StackOverflow’s source code, I know how little really does. There is a _tremendous_ amount of spit and polish that goes into making a major website highly usable. A developer, asked how hard something will be to clone, simply _does not think about the polish_ , because _the polish is incidental to the implementation._
|
||||
|
||||
That is why an open-source clone of StackOverflow will fail. Even if someone were to manage to implement most of StackOverflow “to spec,” there are some key areas that would trip them up. Badges, for example, if you’re targeting end-users, either need a GUI to configure rules, or smart developers to determine which badges are generic enough to go on all installs. What will actually happen is that the developers will bitch and moan about how you can’t implement a really comprehensive GUI for something like badges, and then bikeshed any proposals for standard badges so far into the ground that they’ll hit escape velocity coming out the other side. They’ll ultimately come up with the same solution that bug trackers like Roundup use for their workflow: the developers implement a generic mechanism by which anyone, truly anyone at all, who feels totally comfortable working with the system API in Python or PHP or whatever, can easily add their own customizations. And when PHP and Python are so easy to learn and so much more flexible than a GUI could ever be, why bother with anything else?
|
||||
|
||||
Likewise, the moderation and administration interfaces can be punted. If you’re an admin, you have access to the SQL server, so you can do anything really genuinely administrative-like that way. Moderators can get by with whatever django-admin and similar systems afford you, since, after all, few users are mods, and mods should understand how the sites _work_ , dammit. And, certainly, none of StackOverflow’s interface failings will be rectified. Even if StackOverflow’s stupid requirement that you have to have and know how to use an OpenID (its worst failing) eventually gets fixed, I’m sure any open-source clones will rabidly follow it—just as GNOME and KDE for years slavishly copied off Windows, instead of trying to fix its most obvious flaws.
|
||||
|
||||
Developers may not care about these parts of the application, but end-users do, and take it into consideration when trying to decide what application to use. Much as a good software company wants to minimize its support costs by ensuring that its products are top-notch before shipping, so, too, savvy consumers want to ensure products are good before they purchase them so that they won’t _have_ to call support. Open-source products fail hard here. Proprietary solutions, as a rule, do better.
|
||||
|
||||
That’s not to say that open-source doesn’t have its place. This blog runs on Apache, [Django][12], [PostgreSQL][13], and Linux. But let me tell you, configuring that stack is _not_ for the faint of heart. PostgreSQL needs vacuuming configured on older versions, and, as of recent versions of Ubuntu and FreeBSD, still requires the user set up the first database cluster. MS SQL requires neither of those things. Apache…dear heavens, don’t even get me _started_ on trying to explain to a novice user how to get virtual hosting, MovableType, a couple Django apps, and WordPress all running comfortably under a single install. Hell, just trying to explain the forking vs. threading variants of Apache to a technically astute non-developer can be a nightmare. IIS 7 and Apache with OS X Server’s very much closed-source GUI manager make setting up those same stacks vastly simpler. Django’s a great a product, but it’s nothing _but_ infrastructure—exactly the thing that I happen to think open-source _does_ do well, _precisely_ because of the motivations that drive developers to contribute.
|
||||
|
||||
The next time you see an application you like, think very long and hard about all the user-oriented details that went into making it a pleasure to use, before decrying how you could trivially reimplement the entire damn thing in a weekend. Nine times out of ten, when you think an application was ridiculously easy to implement, you’re completely missing the user side of the story.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bitquabit.com/post/one-which-i-call-out-hacker-news/
|
||||
|
||||
作者:[Benjamin Pollack][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bitquabit.com/meta/about/
|
||||
[1]:http://www.cs.duke.edu/~ola/
|
||||
[2]:http://www.cs.duke.edu/courses/cps108/spring04/
|
||||
[3]:https://bitquabit.com/categories/programming
|
||||
[4]:https://bitquabit.com/categories/technology
|
||||
[5]:http://blog.bitquabit.com/2009/06/30/one-which-i-say-open-source-software-sucks/
|
||||
[6]:http://news.ycombinator.com/item?id=678501
|
||||
[7]:http://news.ycombinator.com/item?id=678704
|
||||
[8]:http://code.google.com/p/cnprog/
|
||||
[9]:http://code.google.com/p/soclone/
|
||||
[10]:http://en.wikipedia.org/wiki/Words_per_minute
|
||||
[11]:http://github.com/derobins/wmd/tree/master
|
||||
[12]:http://www.djangoproject.com/
|
||||
[13]:http://www.postgresql.org/
|
||||
[14]:https://bitquabit.com/post/one-which-i-call-out-hacker-news/
|
||||
55
sources/tech/20141028 When Does Your OS Run.md
Normal file
55
sources/tech/20141028 When Does Your OS Run.md
Normal file
@ -0,0 +1,55 @@
|
||||
Translating by Cwndmiao
|
||||
|
||||
When Does Your OS Run?
|
||||
============================================================
|
||||
|
||||
|
||||
Here’s a question: in the time it takes you to read this sentence, has your OS been _running_ ? Or was it only your browser? Or were they perhaps both idle, just waiting for you to _do something already_ ?
|
||||
|
||||
These questions are simple but they cut through the essence of how software works. To answer them accurately we need a good mental model of OS behavior, which in turn informs performance, security, and troubleshooting decisions. We’ll build such a model in this post series using Linux as the primary OS, with guest appearances by OS X and Windows. I’ll link to the Linux kernel sources for those who want to delve deeper.
|
||||
|
||||
The fundamental axiom here is that _at any given moment, exactly one task is active on a CPU_ . The task is normally a program, like your browser or music player, or it could be an operating system thread, but it is one task. Not two or more. Never zero, either. One. Always.
|
||||
|
||||
This sounds like trouble. For what if, say, your music player hogs the CPU and doesn’t let any other tasks run? You would not be able to open a tool to kill it, and even mouse clicks would be futile as the OS wouldn’t process them. You could be stuck blaring “What does the fox say?” and incite a workplace riot.
|
||||
|
||||
That’s where interrupts come in. Much as the nervous system interrupts the brain to bring in external stimuli – a loud noise, a touch on the shoulder – the [chipset][1] in a computer’s motherboard interrupts the CPU to deliver news of outside events – key presses, the arrival of network packets, the completion of a hard drive read, and so on. Hardware peripherals, the interrupt controller on the motherboard, and the CPU itself all work together to implement these interruptions, called interrupts for short.
|
||||
|
||||
Interrupts are also essential in tracking that which we hold dearest: time. During the [boot process][2] the kernel programs a hardware timer to issue timer interrupts at a periodic interval, for example every 10 milliseconds. When the timer goes off, the kernel gets a shot at the CPU to update system statistics and take stock of things: has the current program been running for too long? Has a TCP timeout expired? Interrupts give the kernel a chance to both ponder these questions and take appropriate actions. It’s as if you set periodic alarms throughout the day and used them as checkpoints: should I be doing what I’m doing right now? Is there anything more pressing? One day you find ten years have got behind you.
|
||||
|
||||
These periodic hijackings of the CPU by the kernel are called ticks, so interrupts quite literally make your OS tick. But there’s more: interrupts are also used to handle some software events like integer overflows and page faults, which involve no external hardware. Interrupts are the most frequent and crucial entry point into the OS kernel. They’re not some oddity for the EE people to worry about, they’re _the_ mechanism whereby your OS runs.
|
||||
|
||||
Enough talk, let’s see some action. Below is a network card interrupt in an Intel Core i5 system. The diagrams now have image maps, so you can click on juicy bits for more information. For example, each device links to its Linux driver.
|
||||
|
||||

|
||||
|
||||
<map id="mapHwInterrupt" name="mapHwInterrupt"><area shape="poly" coords="490,294,490,354,270,354,270,294" href="https://github.com/torvalds/linux/blob/v3.17/drivers/net/ethernet/intel/e1000e/netdev.c"><area shape="poly" coords="754,294,754,354,534,354,534,294" href="https://github.com/torvalds/linux/blob/v3.16/drivers/hid/usbhid/usbkbd.c"><area shape="poly" coords="488,490,488,598,273,598,273,490" href="https://github.com/torvalds/linux/blob/v3.16/arch/x86/kernel/apic/io_apic.c"><area shape="poly" coords="720,490,720,598,506,598,506,490" href="https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/hpet.c"></map>
|
||||
|
||||
Let’s take a look at this. First off, since there are many sources of interrupts, it wouldn’t be very helpful if the hardware simply told the CPU “hey, something happened!” and left it at that. The suspense would be unbearable. So each device is assigned an interrupt request line, or IRQ, during power up. These IRQs are in turn mapped into interrupt vectors, a number between 0 and 255, by the interrupt controller. By the time an interrupt reaches the CPU it has a nice, well-defined number insulated from the vagaries of hardware.
|
||||
|
||||
The CPU in turn has a pointer to what’s essentially an array of 255 functions, supplied by the kernel, where each function is the handler for that particular interrupt vector. We’ll look at this array, the Interrupt Descriptor Table (IDT), in more detail later on.
|
||||
|
||||
Whenever an interrupt arrives, the CPU uses its vector as an index into the IDT and runs the appropriate handler. This happens as a special function call that takes place in the context of the currently running task, allowing the OS to respond to external events quickly and with minimal overhead. So web servers out there indirectly _call a function in your CPU_ when they send you data, which is either pretty cool or terrifying. Below we show a situation where a CPU is busy running a Vim command when an interrupt arrives:
|
||||
|
||||
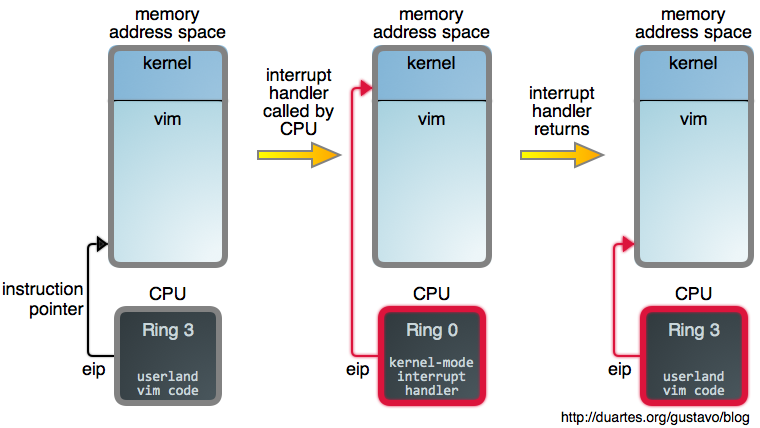
|
||||
|
||||
Notice how the interrupt’s arrival causes a switch to kernel mode and [ring zero][3] but it _does not change the active task_ . It’s as if Vim made a magic function call straight into the kernel, but Vim is _still there_ , its [address space][4] intact, waiting for that call to return.
|
||||
|
||||
Exciting stuff! Alas, I need to keep this post-sized, so let’s finish up for now. I understand we have not answered the opening question and have in fact opened up new questions, but you now suspect ticks were taking place while you read that sentence. We’ll find the answers as we flesh out our model of dynamic OS behavior, and the browser scenario will become clear. If you have questions, especially as the posts come out, fire away and I’ll try to answer them in the posts themselves or as comments. Next installment is tomorrow on [RSS][5] and [Twitter][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/when-does-your-os-run/
|
||||
|
||||
作者:[gustavo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:http://duartes.org/gustavo/blog/post/motherboard-chipsets-memory-map
|
||||
[2]:http://duartes.org/gustavo/blog/post/kernel-boot-process
|
||||
[3]:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection
|
||||
[4]:http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory
|
||||
[5]:http://feeds.feedburner.com/GustavoDuarte
|
||||
[6]:http://twitter.com/food4hackers
|
||||
@ -1,6 +1,4 @@
|
||||
translating by flankershen
|
||||
|
||||
Network automation with Ansible
|
||||
Translating by qhwdw Network automation with Ansible
|
||||
================
|
||||
|
||||
### Network Automation
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by kimii
|
||||
# Kprobes Event Tracing on ARMv8
|
||||
|
||||

|
||||
|
||||
@ -1,413 +0,0 @@
|
||||
(翻译中 by runningwater)
|
||||
Understanding Firewalld in Multi-Zone Configurations
|
||||
============================================================
|
||||
|
||||
Stories of compromised servers and data theft fill today's news. It isn't difficult for someone who has read an informative blog post to access a system via a misconfigured service, take advantage of a recently exposed vulnerability or gain control using a stolen password. Any of the many internet services found on a typical Linux server could harbor a vulnerability that grants unauthorized access to the system.
|
||||
|
||||
Since it's an impossible task to harden a system at the application level against every possible threat, firewalls provide security by limiting access to a system. Firewalls filter incoming packets based on their IP of origin, their destination port and their protocol. This way, only a few IP/port/protocol combinations interact with the system, and the rest do not.
|
||||
|
||||
Linux firewalls are handled by netfilter, which is a kernel-level framework. For more than a decade, iptables has provided the userland abstraction layer for netfilter. iptables subjects packets to a gauntlet of rules, and if the IP/port/protocol combination of the rule matches the packet, the rule is applied causing the packet to be accepted, rejected or dropped.
|
||||
|
||||
Firewalld is a newer userland abstraction layer for netfilter. Unfortunately, its power and flexibility are underappreciated due to a lack of documentation describing multi-zoned configurations. This article provides examples to remedy this situation.
|
||||
|
||||
### Firewalld Design Goals
|
||||
|
||||
#
|
||||
|
||||
The designers of firewalld realized that most iptables usage cases involve only a few unique IP sources, for each of which a whitelist of services is allowed and the rest are denied. To take advantage of this pattern, firewalld categorizes incoming traffic into zones defined by the source IP and/or network interface. Each zone has its own configuration to accept or deny packets based on specified criteria.
|
||||
|
||||
Another improvement over iptables is a simplified syntax. Firewalld makes it easier to specify services by using the name of the service rather than its port(s) and protocol(s)—for example, samba rather than UDP ports 137 and 138 and TCP ports 139 and 445\. It further simplifies syntax by removing the dependence on the order of statements as was the case for iptables.
|
||||
|
||||
Finally, firewalld enables the interactive modification of netfilter, allowing a change in the firewall to occur independently of the permanent configuration stored in XML. Thus, the following is a temporary modification that will be overwritten by the next reload:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd <some modification>
|
||||
|
||||
```
|
||||
|
||||
And, the following is a permanent change that persists across reboots:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent <some modification>
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
### Zones
|
||||
|
||||
The top layer of organization in firewalld is zones. A packet is part of a zone if it matches that zone's associated network interface or IP/mask source. Several predefined zones are available:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --get-zones
|
||||
block dmz drop external home internal public trusted work
|
||||
|
||||
```
|
||||
|
||||
An active zone is any zone that is configured with an interface and/or a source. To list active zones:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --get-active-zones
|
||||
public
|
||||
interfaces: eno1 eno2
|
||||
|
||||
```
|
||||
|
||||
**Interfaces** are the system's names for hardware and virtual network adapters, as you can see in the above example. All active interfaces will be assigned to zones, either to the default zone or to a user-specified one. However, an interface cannot be assigned to more than one zone.
|
||||
|
||||
In its default configuration, firewalld pairs all interfaces with the public zone and doesn't set up sources for any zones. As a result, public is the only active zone.
|
||||
|
||||
**Sources** are incoming IP address ranges, which also can be assigned to zones. A source (or overlapping sources) cannot be assigned to multiple zones. Doing so results in undefined behavior, as it would not be clear which rules should be applied to that source.
|
||||
|
||||
Since specifying a source is not required, for every packet there will be a zone with a matching interface, but there won't necessarily be a zone with a matching source. This indicates some form of precedence with priority going to the more specific source zones, but more on that later. First, let's inspect how the public zone is configured:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services: dhcpv6-client ssh
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
default
|
||||
|
||||
```
|
||||
|
||||
Going line by line through the output:
|
||||
|
||||
* `public (default, active)` indicates that the public zone is the default zone (interfaces default to it when they come up), and it is active because it has at least one interface or source associated with it.
|
||||
|
||||
* `interfaces: eno1 eno2` lists the interfaces associated with the zone.
|
||||
|
||||
* `sources:` lists the sources for the zone. There aren't any now, but if there were, they would be of the form xxx.xxx.xxx.xxx/xx.
|
||||
|
||||
* `services: dhcpv6-client ssh` lists the services allowed through the firewall. You can get an exhaustive list of firewalld's defined services by executing `firewall-cmd --get-services`.
|
||||
|
||||
* `ports:` lists port destinations allowed through the firewall. This is useful if you need to allow a service that isn't defined in firewalld.
|
||||
|
||||
* `masquerade: no` indicates that IP masquerading is disabled for this zone. If enabled, this would allow IP forwarding, with your computer acting as a router.
|
||||
|
||||
* `forward-ports:` lists ports that are forwarded.
|
||||
|
||||
* `icmp-blocks:` a blacklist of blocked icmp traffic.
|
||||
|
||||
* `rich rules:` advanced configurations, processed first in a zone.
|
||||
|
||||
* `default` is the target of the zone, which determines the action taken on a packet that matches the zone yet isn't explicitly handled by one of the above settings.
|
||||
|
||||
### A Simple Single-Zoned Example
|
||||
|
||||
Say you just want to lock down your firewall. Simply remove the services currently allowed by the public zone and reload:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=public --remove-service=dhcpv6-client
|
||||
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
These commands result in the following firewall:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services:
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
default
|
||||
|
||||
```
|
||||
|
||||
In the spirit of keeping security as tight as possible, if a situation arises where you need to open a temporary hole in your firewall (perhaps for ssh), you can add the service to just the current session (omit `--permanent`) and instruct firewalld to revert the modification after a specified amount of time:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --add-service=ssh --timeout=5m
|
||||
|
||||
```
|
||||
|
||||
The timeout option takes time values in seconds (s), minutes (m) or hours (h).
|
||||
|
||||
### Targets
|
||||
|
||||
When a zone processes a packet due to its source or interface, but there is no rule that explicitly handles the packet, the target of the zone determines the behavior:
|
||||
|
||||
* `ACCEPT`: accept the packet.
|
||||
|
||||
* `%%REJECT%%`: reject the packet, returning a reject reply.
|
||||
|
||||
* `DROP`: drop the packet, returning no reply.
|
||||
|
||||
* `default`: don't do anything. The zone washes its hands of the problem, and kicks it "upstairs".
|
||||
|
||||
There was a bug present in firewalld 0.3.9 (fixed in 0.3.10) for source zones with targets other than `default` in which the target was applied regardless of allowed services. For example, a source zone with the target `DROP` would drop all packets, even if they were whitelisted. Unfortunately, this version of firewalld was packaged for RHEL7 and its derivatives, causing it to be a fairly common bug. The examples in this article avoid situations that would manifest this behavior.
|
||||
|
||||
### Precedence
|
||||
|
||||
Active zones fulfill two different roles. Zones with associated interface(s) act as interface zones, and zones with associated source(s) act as source zones (a zone could fulfill both roles). Firewalld handles a packet in the following order:
|
||||
|
||||
1. The corresponding source zone. Zero or one such zones may exist. If the source zone deals with the packet because the packet satisfies a rich rule, the service is whitelisted, or the target is not default, we end here. Otherwise, we pass the packet on.
|
||||
|
||||
2. The corresponding interface zone. Exactly one such zone will always exist. If the interface zone deals with the packet, we end here. Otherwise, we pass the packet on.
|
||||
|
||||
3. The firewalld default action. Accept icmp packets and reject everything else.
|
||||
|
||||
The take-away message is that source zones have precedence over interface zones. Therefore, the general design pattern for multi-zoned firewalld configurations is to create a privileged source zone to allow specific IP's elevated access to system services and a restrictive interface zone to limit the access of everyone else.
|
||||
|
||||
### A Simple Multi-Zoned Example
|
||||
|
||||
To demonstrate precedence, let's swap ssh for http in the public zone and set up the default internal zone for our favorite IP address, 1.1.1.1\. The following commands accomplish this task:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=internal --add-source=1.1.1.1
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
which results in the following configuration:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services: dhcpv6-client http
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
default
|
||||
# firewall-cmd --zone=internal --list-all
|
||||
internal (active)
|
||||
interfaces:
|
||||
sources: 1.1.1.1
|
||||
services: dhcpv6-client mdns samba-client ssh
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=internal --get-target
|
||||
default
|
||||
|
||||
```
|
||||
|
||||
With the above configuration, if someone attempts to `ssh` in from 1.1.1.1, the request would succeed because the source zone (internal) is applied first, and it allows ssh access.
|
||||
|
||||
If someone attempts to `ssh` from somewhere else, say 2.2.2.2, there wouldn't be a source zone, because no zones match that source. Therefore, the request would pass directly to the interface zone (public), which does not explicitly handle ssh. Since public's target is `default`, the request passes to the firewalld default action, which is to reject it.
|
||||
|
||||
What if 1.1.1.1 attempts http access? The source zone (internal) doesn't allow it, but the target is `default`, so the request passes to the interface zone (public), which grants access.
|
||||
|
||||
Now let's suppose someone from 3.3.3.3 is trolling your website. To restrict access for that IP, simply add it to the preconfigured drop zone, aptly named because it drops all connections:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=drop --add-source=3.3.3.3
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
The next time 3.3.3.3 attempts to access your website, firewalld will send the request first to the source zone (drop). Since the target is `DROP`, the request will be denied and won't make it to the interface zone (public) to be accepted.
|
||||
|
||||
### A Practical Multi-Zoned Example
|
||||
|
||||
Suppose you are setting up a firewall for a server at your organization. You want the entire world to have http and https access, your organization (1.1.0.0/16) and workgroup (1.1.1.0/8) to have ssh access, and your workgroup to have samba access. Using zones in firewalld, you can set up this configuration in an intuitive manner.
|
||||
|
||||
Given the naming, it seems logical to commandeer the public zone for your world-wide purposes and the internal zone for local use. Start by replacing the dhcpv6-client and ssh services in the public zone with http and https:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=public --remove-service=dhcpv6-client
|
||||
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=public --add-service=https
|
||||
|
||||
```
|
||||
|
||||
Then trim mdns, samba-client and dhcpv6-client out of the internal zone (leaving only ssh) and add your organization as the source:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=internal --remove-service=mdns
|
||||
# firewall-cmd --permanent --zone=internal --remove-service=samba-client
|
||||
# firewall-cmd --permanent --zone=internal --remove-service=dhcpv6-client
|
||||
# firewall-cmd --permanent --zone=internal --add-source=1.1.0.0/16
|
||||
|
||||
```
|
||||
|
||||
To accommodate your elevated workgroup samba privileges, add a rich rule:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=internal --add-rich-rule='rule
|
||||
↪family=ipv4 source address="1.1.1.0/8" service name="samba"
|
||||
↪accept'
|
||||
|
||||
```
|
||||
|
||||
Finally, reload, pulling the changes into the active session:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
Only a few more details remain. Attempting to `ssh` in to your server from an IP outside the internal zone results in a reject message, which is the firewalld default. It is more secure to exhibit the behavior of an inactive IP and instead drop the connection. Change the public zone's target to `DROP`rather than `default` to accomplish this:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=public --set-target=DROP
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
But wait, you no longer can ping, even from the internal zone! And icmp (the protocol ping goes over) isn't on the list of services that firewalld can whitelist. That's because icmp is an IP layer 3 protocol and has no concept of a port, unlike services that are tied to ports. Before setting the public zone to `DROP`, pinging could pass through the firewall because both of your `default` targets passed it on to the firewalld default, which allowed it. Now it's dropped.
|
||||
|
||||
To restore pinging to the internal network, use a rich rule:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=internal --add-rich-rule='rule
|
||||
↪protocol value="icmp" accept'
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
In summary, here's the configuration for the two active zones:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services: http https
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
DROP
|
||||
# firewall-cmd --zone=internal --list-all
|
||||
internal (active)
|
||||
interfaces:
|
||||
sources: 1.1.0.0/16
|
||||
services: ssh
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
rule family=ipv4 source address="1.1.1.0/8"
|
||||
↪service name="samba" accept
|
||||
rule protocol value="icmp" accept
|
||||
# firewall-cmd --permanent --zone=internal --get-target
|
||||
default
|
||||
|
||||
```
|
||||
|
||||
This setup demonstrates a three-layer nested firewall. The outermost layer, public, is an interface zone and spans the entire world. The next layer, internal, is a source zone and spans your organization, which is a subset of public. Finally, a rich rule adds the innermost layer spanning your workgroup, which is a subset of internal.
|
||||
|
||||
The take-away message here is that when a scenario can be broken into nested layers, the broadest layer should use an interface zone, the next layer should use a source zone, and additional layers should use rich rules within the source zone.
|
||||
|
||||
### Debugging
|
||||
|
||||
Firewalld employs intuitive paradigms for designing a firewall, yet gives rise to ambiguity much more easily than its predecessor, iptables. Should unexpected behavior occur, or to understand better how firewalld works, it can be useful to obtain an iptables description of how netfilter has been configured to operate. Output for the previous example follows, with forward, output and logging lines trimmed for simplicity:
|
||||
|
||||
```
|
||||
|
||||
# iptables -S
|
||||
-P INPUT ACCEPT
|
||||
... (forward and output lines) ...
|
||||
-N INPUT_ZONES
|
||||
-N INPUT_ZONES_SOURCE
|
||||
-N INPUT_direct
|
||||
-N IN_internal
|
||||
-N IN_internal_allow
|
||||
-N IN_internal_deny
|
||||
-N IN_public
|
||||
-N IN_public_allow
|
||||
-N IN_public_deny
|
||||
-A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
|
||||
-A INPUT -i lo -j ACCEPT
|
||||
-A INPUT -j INPUT_ZONES_SOURCE
|
||||
-A INPUT -j INPUT_ZONES
|
||||
-A INPUT -p icmp -j ACCEPT
|
||||
-A INPUT -m conntrack --ctstate INVALID -j DROP
|
||||
-A INPUT -j REJECT --reject-with icmp-host-prohibited
|
||||
... (forward and output lines) ...
|
||||
-A INPUT_ZONES -i eno1 -j IN_public
|
||||
-A INPUT_ZONES -i eno2 -j IN_public
|
||||
-A INPUT_ZONES -j IN_public
|
||||
-A INPUT_ZONES_SOURCE -s 1.1.0.0/16 -g IN_internal
|
||||
-A IN_internal -j IN_internal_deny
|
||||
-A IN_internal -j IN_internal_allow
|
||||
-A IN_internal_allow -p tcp -m tcp --dport 22 -m conntrack
|
||||
↪--ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p udp -m udp --dport 137
|
||||
↪-m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p udp -m udp --dport 138
|
||||
↪-m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p tcp -m tcp --dport 139
|
||||
↪-m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p tcp -m tcp --dport 445
|
||||
↪-m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -p icmp -m conntrack --ctstate NEW
|
||||
↪-j ACCEPT
|
||||
-A IN_public -j IN_public_deny
|
||||
-A IN_public -j IN_public_allow
|
||||
-A IN_public -j DROP
|
||||
-A IN_public_allow -p tcp -m tcp --dport 80 -m conntrack
|
||||
↪--ctstate NEW -j ACCEPT
|
||||
-A IN_public_allow -p tcp -m tcp --dport 443 -m conntrack
|
||||
↪--ctstate NEW -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
In the above iptables output, new chains (lines starting with `-N`) are first declared. The rest are rules appended (starting with `-A`) to iptables. Established connections and local traffic are accepted, and incoming packets go to the `INPUT_ZONES_SOURCE` chain, at which point IPs are sent to the corresponding zone, if one exists. After that, traffic goes to the `INPUT_ZONES` chain, at which point it is routed to an interface zone. If it isn't handled there, icmp is accepted, invalids are dropped, and everything else is rejected.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Firewalld is an under-documented firewall configuration tool with more potential than many people realize. With its innovative paradigm of zones, firewalld allows the system administrator to break up traffic into categories where each receives a unique treatment, simplifying the configuration process. Because of its intuitive design and syntax, it is practical for both simple single-zoned and complex multi-zoned configurations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/understanding-firewalld-multi-zone-configurations?page=0,0
|
||||
|
||||
作者:[ Nathan Vance][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxjournal.com/users/nathan-vance
|
||||
[1]:https://www.linuxjournal.com/tag/firewalls
|
||||
[2]:https://www.linuxjournal.com/tag/howtos
|
||||
[3]:https://www.linuxjournal.com/tag/networking
|
||||
[4]:https://www.linuxjournal.com/tag/security
|
||||
[5]:https://www.linuxjournal.com/tag/sysadmin
|
||||
[6]:https://www.linuxjournal.com/users/william-f-polik
|
||||
[7]:https://www.linuxjournal.com/users/nathan-vance
|
||||
@ -1,4 +1,7 @@
|
||||
Translating by Torival Writing a Time Series Database from Scratch
|
||||
cielong translating
|
||||
----
|
||||
|
||||
Writing a Time Series Database from Scratch
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
108
sources/tech/20170530 How to Improve a Legacy Codebase.md
Normal file
108
sources/tech/20170530 How to Improve a Legacy Codebase.md
Normal file
@ -0,0 +1,108 @@
|
||||
Translating by aiwhj
|
||||
# How to Improve a Legacy Codebase
|
||||
|
||||
|
||||
It happens at least once in the lifetime of every programmer, project manager or teamleader. You get handed a steaming pile of manure, if you’re lucky only a few million lines worth, the original programmers have long ago left for sunnier places and the documentation - if there is any to begin with - is hopelessly out of sync with what is presently keeping the company afloat.
|
||||
|
||||
Your job: get us out of this mess.
|
||||
|
||||
After your first instinctive response (run for the hills) has passed you start on the project knowing full well that the eyes of the company senior leadership are on you. Failure is not an option. And yet, by the looks of what you’ve been given failure is very much in the cards. So what to do?
|
||||
|
||||
I’ve been (un)fortunate enough to be in this situation several times and me and a small band of friends have found that it is a lucrative business to be able to take these steaming piles of misery and to turn them into healthy maintainable projects. Here are some of the tricks that we employ:
|
||||
|
||||
### Backup
|
||||
|
||||
Before you start to do anything at all make a backup of _everything_ that might be relevant. This to make sure that no information is lost that might be of crucial importance somewhere down the line. All it takes is a silly question that you can’t answer to eat up a day or more once the change has been made. Especially configuration data is susceptible to this kind of problem, it is usually not versioned and you’re lucky if it is taken along in the periodic back-up scheme. So better safe than sorry, copy everything to a very safe place and never ever touch that unless it is in read-only mode.
|
||||
|
||||
### Important pre-requisite, make sure you have a build process and that it actually produces what runs in production
|
||||
|
||||
I totally missed this step on the assumption that it is obvious and likely already in place but many HN commenters pointed this out and they are absolutely right: step one is to make sure that you know what is running in production right now and that means that you need to be able to build a version of the software that is - if your platform works that way - byte-for-byte identical with the current production build. If you can’t find a way to achieve this then likely you will be in for some unpleasant surprises once you commit something to production. Make sure you test this to the best of your ability to make sure that you have all the pieces in place and then, after you’ve gained sufficient confidence that it will work move it to production. Be prepared to switch back immediately to whatever was running before and make sure that you log everything and anything that might come in handy during the - inevitable - post mortem.
|
||||
|
||||
### Freeze the DB
|
||||
|
||||
If at all possible freeze the database schema until you are done with the first level of improvements, by the time you have a solid understanding of the codebase and the legacy code has been fully left behind you are ready to modify the database schema. Change it any earlier than that and you may have a real problem on your hand, now you’ve lost the ability to run an old and a new codebase side-by-side with the database as the steady foundation to build on. Keeping the DB totally unchanged allows you to compare the effect your new business logic code has compared to the old business logic code, if it all works as advertised there should be no differences.
|
||||
|
||||
### Write your tests
|
||||
|
||||
Before you make any changes at all write as many end-to-end and integration tests as you can. Make sure these tests produce the right output and test any and all assumptions that you can come up with about how you _think_ the old stuff works (be prepared for surprises here). These tests will have two important functions: they will help to clear up any misconceptions at a very early stage and they will function as guardrails once you start writing new code to replace old code.
|
||||
|
||||
Automate all your testing, if you’re already experienced with CI then use it and make sure your tests run fast enough to run the full set of tests after every commit.
|
||||
|
||||
### Instrumentation and logging
|
||||
|
||||
If the old platform is still available for development add instrumentation. Do this in a completely new database table, add a simple counter for every event that you can think of and add a single function to increment these counters based on the name of the event. That way you can implement a time-stamped event log with a few extra lines of code and you’ll get a good idea of how many events of one kind lead to events of another kind. One example: User opens app, User closes app. If two events should result in some back-end calls those two counters should over the long term remain at a constant difference, the difference is the number of apps currently open. If you see many more app opens than app closes you know there has to be a way in which apps end (for instance a crash). For each and every event you’ll find there is some kind of relationship to other events, usually you will strive for constant relationships unless there is an obvious error somewhere in the system. You’ll aim to reduce those counters that indicate errors and you’ll aim to maximize counters further down in the chain to the level indicated by the counters at the beginning. (For instance: customers attempting to pay should result in an equal number of actual payments received).
|
||||
|
||||
This very simple trick turns every backend application into a bookkeeping system of sorts and just like with a real bookkeeping system the numbers have to match, as long as they don’t you have a problem somewhere.
|
||||
|
||||
This system will over time become invaluable in establishing the health of the system and will be a great companion next to the source code control system revision log where you can determine the point in time that a bug was introduced and what the effect was on the various counters.
|
||||
|
||||
I usually keep these counters at a 5 minute resolution (so 12 buckets for an hour), but if you have an application that generates fewer or more events then you might decide to change the interval at which new buckets are created. All counters share the same database table and so each counter is simply a column in that table.
|
||||
|
||||
### Change only one thing at the time
|
||||
|
||||
Do not fall into the trap of improving both the maintainability of the code or the platform it runs on at the same time as adding new features or fixing bugs. This will cause you huge headaches because you now have to ask yourself every step of the way what the desired outcome is of an action and will invalidate some of the tests you made earlier.
|
||||
|
||||
### Platform changes
|
||||
|
||||
If you’ve decided to migrate the application to another platform then do this first _but keep everything else exactly the same_ . If you want you can add more documentation or tests, but no more than that, all business logic and interdependencies should remain as before.
|
||||
|
||||
### Architecture changes
|
||||
|
||||
The next thing to tackle is to change the architecture of the application (if desired). At this point in time you are free to change the higher level structure of the code, usually by reducing the number of horizontal links between modules, and thus reducing the scope of the code active during any one interaction with the end-user. If the old code was monolithic in nature now would be a good time to make it more modular, break up large functions into smaller ones but leave names of variables and data-structures as they were.
|
||||
|
||||
HN user [mannykannot][1] points - rightfully - out that this is not always an option, if you’re particularly unlucky then you may have to dig in deep in order to be able to make any architecture changes. I agree with that and I should have included it here so hence this little update. What I would further like to add is if you do both do high level changes and low level changes at least try to limit them to one file or worst case one subsystem so that you limit the scope of your changes as much as possible. Otherwise you might have a very hard time debugging the change you just made.
|
||||
|
||||
### Low level refactoring
|
||||
|
||||
By now you should have a very good understanding of what each module does and you are ready for the real work: refactoring the code to improve maintainability and to make the code ready for new functionality. This will likely be the part of the project that consumes the most time, document as you go, do not make changes to a module until you have thoroughly documented it and feel you understand it. Feel free to rename variables and functions as well as datastructures to improve clarity and consistency, add tests (also unit tests, if the situation warrants them).
|
||||
|
||||
### Fix bugs
|
||||
|
||||
Now you’re ready to take on actual end-user visible changes, the first order of battle will be the long list of bugs that have accumulated over the years in the ticket queue. As usual, first confirm the problem still exists, write a test to that effect and then fix the bug, your CI and the end-to-end tests written should keep you safe from any mistakes you make due to a lack of understanding or some peripheral issue.
|
||||
|
||||
### Database Upgrade
|
||||
|
||||
If required after all this is done and you are on a solid and maintainable codebase again you have the option to change the database schema or to replace the database with a different make/model altogether if that is what you had planned to do. All the work you’ve done up to this point will help to assist you in making that change in a responsible manner without any surprises, you can completely test the new DB with the new code and all the tests in place to make sure your migration goes off without a hitch.
|
||||
|
||||
### Execute on the roadmap
|
||||
|
||||
Congratulations, you are out of the woods and are now ready to implement new functionality.
|
||||
|
||||
### Do not ever even attempt a big-bang rewrite
|
||||
|
||||
A big-bang rewrite is the kind of project that is pretty much guaranteed to fail. For one, you are in uncharted territory to begin with so how would you even know what to build, for another, you are pushing _all_ the problems to the very last day, the day just before you go ‘live’ with your new system. And that’s when you’ll fail, miserably. Business logic assumptions will turn out to be faulty, suddenly you’ll gain insight into why that old system did certain things the way it did and in general you’ll end up realizing that the guys that put the old system together weren’t maybe idiots after all. If you really do want to wreck the company (and your own reputation to boot) by all means, do a big-bang rewrite, but if you’re smart about it this is not even on the table as an option.
|
||||
|
||||
### So, the alternative, work incrementally
|
||||
|
||||
To untangle one of these hairballs the quickest path to safety is to take any element of the code that you do understand (it could be a peripheral bit, but it might also be some core module) and try to incrementally improve it still within the old context. If the old build tools are no longer available you will have to use some tricks (see below) but at least try to leave as much of what is known to work alive while you start with your changes. That way as the codebase improves so does your understanding of what it actually does. A typical commit should be at most a couple of lines.
|
||||
|
||||
### Release!
|
||||
|
||||
Every change along the way gets released into production, even if the changes are not end-user visible it is important to make the smallest possible steps because as long as you lack understanding of the system there is a fair chance that only the production environment will tell you there is a problem. If that problem arises right after you make a small change you will gain several advantages:
|
||||
|
||||
* it will probably be trivial to figure out what went wrong
|
||||
|
||||
* you will be in an excellent position to improve the process
|
||||
|
||||
* and you should immediately update the documentation to show the new insights gained
|
||||
|
||||
### Use proxies to your advantage
|
||||
|
||||
If you are doing web development praise the gods and insert a proxy between the end-users and the old system. Now you have per-url control over which requests go to the old system and which you will re-route to the new system allowing much easier and more granular control over what is run and who gets to see it. If your proxy is clever enough you could probably use it to send a percentage of the traffic to the new system for an individual URL until you are satisfied that things work the way they should. If your integration tests also connect to this interface it is even better.
|
||||
|
||||
### Yes, but all this will take too much time!
|
||||
|
||||
Well, that depends on how you look at it. It’s true there is a bit of re-work involved in following these steps. But it _does_ work, and any kind of optimization of this process makes the assumption that you know more about the system than you probably do. I’ve got a reputation to maintain and I _really_ do not like negative surprises during work like this. With some luck the company is already on the skids, or maybe there is a real danger of messing things up for the customers. In a situation like that I prefer total control and an iron clad process over saving a couple of days or weeks if that imperils a good outcome. If you’re more into cowboy stuff - and your bosses agree - then maybe it would be acceptable to take more risk, but most companies would rather take the slightly slower but much more sure road to victory.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jacquesmattheij.com/improving-a-legacy-codebase
|
||||
|
||||
作者:[Jacques Mattheij ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jacquesmattheij.com/
|
||||
[1]:https://news.ycombinator.com/item?id=14445661
|
||||
@ -1,4 +1,6 @@
|
||||
Translating by Snapcrafter
|
||||
Translating by yongshouzhang
|
||||
|
||||
|
||||
A user's guide to links in the Linux filesystem
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,393 +0,0 @@
|
||||
LinchPin: A simplified cloud orchestration tool using Ansible
|
||||
============================================================
|
||||
|
||||
### Launched in late 2016, LinchPin now has a Python API and a growing community.
|
||||
|
||||
|
||||

|
||||
>Image by : [Internet Archive Book Images][10]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
Late last year, [my team announced][11] [LinchPin][12], a hybrid [cloud][13] orchestration tool using Ansible. Provisioning cloud resources has never been easier or faster. With the power of Ansible behind LinchPin, and a focus on simplicity, many cloud resources are available at users' fingertips. In this article, I'll introduce LinchPin and look at how the project has matured in the past 10 months.
|
||||
|
||||
Back when LinchPin was introduced, using the **ansible-playbook** command to run LinchPin was complex. Although that can still be accomplished, LinchPin now has a new front-end command-line user interface (CLI), which is written in [Click][14] and makes LinchPin even simpler than it was before.
|
||||
|
||||
Explore the open source cloud
|
||||
|
||||
* [What is the cloud?][1]
|
||||
|
||||
* [What is OpenStack?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [Why the operating system matters for containers][4]
|
||||
|
||||
* [Keeping Linux containers safe and secure][5]
|
||||
|
||||
Not to be outdone by the CLI, LinchPin now also has a [Python][15] API, which can be used to manage resources, such as Amazon EC2 and OpenStack instances, networks, storage, security groups, and more. The API [documentation][16] can be helpful when you're trying out LinchPin's Python API.
|
||||
|
||||
### Playbooks as a library
|
||||
|
||||
Because the core bits of LinchPin are [Ansible playbooks][17], the roles, modules, filters, and anything else to do with calling Ansible modules has been moved into the LinchPin library. This means that although one can still call the playbooks directly, it's not the preferred mechanism for managing resources. The **linchpin** executable has become the de facto front end for the command-line.
|
||||
|
||||
### Command-line in depth
|
||||
|
||||
Let's have a look at the **linchpin** command in depth:
|
||||
|
||||
```
|
||||
$ linchpin
|
||||
Usage: linchpin [OPTIONS] COMMAND [ARGS]...
|
||||
|
||||
linchpin: hybrid cloud orchestration
|
||||
|
||||
Options:
|
||||
-c, --config PATH Path to config file
|
||||
-w, --workspace PATH Use the specified workspace if the familiar Jenkins
|
||||
$WORKSPACE environment variable is not set
|
||||
-v, --verbose Enable verbose output
|
||||
--version Prints the version and exits
|
||||
--creds-path PATH Use the specified credentials path if WORKSPACE
|
||||
environment variable is not set
|
||||
-h, --help Show this message and exit.
|
||||
|
||||
Commands:
|
||||
init Initializes a linchpin project.
|
||||
up Provisions nodes from the given target(s) in...
|
||||
destroy Destroys nodes from the given target(s) in...
|
||||
```
|
||||
|
||||
What can be seen immediately is a simple description, along with options and arguments that can be passed to the command. The three commands found near the bottom of this help are where the focus will be for this document.
|
||||
|
||||
### Configuration
|
||||
|
||||
In the past, there was **linchpin_config.yml**. This file is no longer, and has been replaced with an ini-style configuration file, called **linchpin.conf**. Although this file can be modified or placed elsewhere, its placement in the library path allows easy lookup of configurations. In most cases, the **linchpin.conf** file should not need to be modified.
|
||||
|
||||
### Workspace
|
||||
|
||||
The workspace is a defined filesystem path, which allows grouping of resources in a logical way. A workspace can be considered a single point for a particular environment, set of services, or other logical grouping. It can also be one big storage bin of all managed resources.
|
||||
|
||||
The workspace can be specified on the command-line with the **--workspace (-w)** option, followed by the workspace path. It can also be specified with an environment variable (e.g., **$WORKSPACE** in bash). The default workspace is the current directory.
|
||||
|
||||
### Initialization (init)
|
||||
|
||||
Running **linchpin init** will generate the directory structure needed, along with an example **PinFile**, **topology**, and **layout** files:
|
||||
|
||||
```
|
||||
$ export WORKSPACE=/tmp/workspace
|
||||
$ linchpin init
|
||||
PinFile and file structure created at /tmp/workspace
|
||||
$ cd /tmp/workspace/
|
||||
$ tree
|
||||
.
|
||||
├── credentials
|
||||
├── hooks
|
||||
├── inventories
|
||||
├── layouts
|
||||
│ └── example-layout.yml
|
||||
├── PinFile
|
||||
├── resources
|
||||
└── topologies
|
||||
└── example-topology.yml
|
||||
```
|
||||
|
||||
At this point, one could execute **linchpin up** and provision a single libvirt virtual machine, with a network named **linchpin-centos71**. An inventory would be generated and placed in **inventories/libvirt.inventory**. This can be known by reading the **topologies/example-topology.yml** and gleaning out the **topology_name** value.
|
||||
|
||||
### Provisioning (linchpin up)
|
||||
|
||||
Once a PinFile, topology, and optionally a layout are in place, provisioning can happen.
|
||||
|
||||
We use the dummy tooling because it is much simpler to configure; it doesn't require anything extra (authentication, network, etc.). The dummy provider creates a temporary file, which represents provisioned hosts. If the temporary file does not have any data, hosts have not been provisioned, or they have been recently destroyed.
|
||||
|
||||
The tree for the dummy provider is simple:
|
||||
|
||||
```
|
||||
$ tree
|
||||
.
|
||||
├── hooks
|
||||
├── inventories
|
||||
├── layouts
|
||||
│ └── dummy-layout.yml
|
||||
├── PinFile
|
||||
├── resources
|
||||
└── topologies
|
||||
└── dummy-cluster.yml
|
||||
```
|
||||
|
||||
The PinFile is also simple; it specifies which topology, and optional layout to use for the **dummy1** target:
|
||||
|
||||
```
|
||||
---
|
||||
dummy1:
|
||||
topology: dummy-cluster.yml
|
||||
layout: dummy-layout.yml
|
||||
```
|
||||
|
||||
The **dummy-cluster.yml** topology file is a reference to provision three (3) resources of type **dummy_node**:
|
||||
|
||||
```
|
||||
---
|
||||
topology_name: "dummy_cluster" # topology name
|
||||
resource_groups:
|
||||
-
|
||||
resource_group_name: "dummy"
|
||||
resource_group_type: "dummy"
|
||||
resource_definitions:
|
||||
-
|
||||
name: "web"
|
||||
type: "dummy_node"
|
||||
count: 3
|
||||
```
|
||||
|
||||
Performing the command **linchpin up** should generate **resources** and **inventory** files based upon the **topology_name** (in this case, **dummy_cluster**):
|
||||
|
||||
```
|
||||
$ linchpin up
|
||||
target: dummy1, action: up
|
||||
|
||||
$ ls {resources,inventories}/dummy*
|
||||
inventories/dummy_cluster.inventory resources/dummy_cluster.output
|
||||
```
|
||||
|
||||
To verify resources with the dummy cluster, check **/tmp/dummy.hosts**:
|
||||
|
||||
```
|
||||
$ cat /tmp/dummy.hosts
|
||||
web-0.example.net
|
||||
web-1.example.net
|
||||
web-2.example.net
|
||||
```
|
||||
|
||||
The Dummy module provides a basic tooling for pretend (or dummy) provisioning. Check out the details for OpenStack, AWS EC2, Google Cloud, and more in the LinchPin [examples][18].
|
||||
|
||||
### Inventory Generation
|
||||
|
||||
As part of the PinFile mentioned above, a **layout** can be specified. If this file is specified and exists in the correct location, an Ansible static inventory file will be generated automatically for the resources provisioned:
|
||||
|
||||
```
|
||||
---
|
||||
inventory_layout:
|
||||
vars:
|
||||
hostname: __IP__
|
||||
hosts:
|
||||
example-node:
|
||||
count: 3
|
||||
host_groups:
|
||||
- example
|
||||
```
|
||||
|
||||
When the **linchpin up** execution is complete, the resources file provides useful details. Specifically, the IP address(es) or host name(s) are interpolated into the static inventory:
|
||||
|
||||
```
|
||||
[example]
|
||||
web-2.example.net hostname=web-2.example.net
|
||||
web-1.example.net hostname=web-1.example.net
|
||||
web-0.example.net hostname=web-0.example.net
|
||||
|
||||
[all]
|
||||
web-2.example.net hostname=web-2.example.net
|
||||
web-1.example.net hostname=web-1.example.net
|
||||
web-0.example.net hostname=web-0.example.net
|
||||
```
|
||||
|
||||
### Teardown (linchpin destroy)
|
||||
|
||||
LinchPin also can perform a teardown of resources. A teardown action generally expects that resources have been provisioned; however, because Ansible is idempotent, **linchpin destroy** will only check to make sure the resources are up. Only if the resources are already up will the teardown happen.
|
||||
|
||||
The command **linchpin destroy** will either use resources and/or topology files to determine the proper teardown procedure.
|
||||
|
||||
The **dummy** Ansible role does not use the resources, only the topology during teardown:
|
||||
|
||||
```
|
||||
$ linchpin destroy
|
||||
target: dummy1, action: destroy
|
||||
|
||||
$ cat /tmp/dummy.hosts
|
||||
-- EMPTY FILE --
|
||||
```
|
||||
|
||||
The teardown functionality is slightly more limited around ephemeral resources, like networking, storage, etc. It is possible that a network resource could be used with multiple cloud instances. In this way, performing a **linchpin destroy**does not teardown certain resources. This is dependent on each provider's implementation. See specific implementations for each of the [providers][19].
|
||||
|
||||
### The LinchPin Python API
|
||||
|
||||
Much of what is implemented in the **linchpin** command-line tool has been written using the Python API. The API, although not complete, has become a vital component of the LinchPin tooling.
|
||||
|
||||
The API consists of three packages:
|
||||
|
||||
* **linchpin**
|
||||
|
||||
* **linchpin.cli**
|
||||
|
||||
* **linchpin.api**
|
||||
|
||||
The command-line tool is managed at the base **linchpin** package; it imports the **linchpin.cli** modules and classes, which is a subclassing of **linchpin.api**. The purpose for this is to allow for other possible implementations of LinchPin using the **linchpin.api**, like a planned RESTful API.
|
||||
|
||||
For more information, see the [Python API library documentation on Read the Docs][20].
|
||||
|
||||
### Hooks
|
||||
|
||||
One of the big improvements in LinchPin 1.0 going forward is hooks. The goal with hooks is to allow additional configuration using external resources in certain specific states during **linchpin** execution. The states currently are as follows:
|
||||
|
||||
* **preup**: Executed before provisioning the topology resources
|
||||
|
||||
* **postup**: Executed after provisioning the topology resources, and generating the optional inventory
|
||||
|
||||
* **predestroy**: Executed before teardown of the topology resources
|
||||
|
||||
* **postdestroy**: Executed after teardown of the topology resources
|
||||
|
||||
In each case, these hooks allow external scripts to run. Several types of hooks exist, including custom ones called _Action Managers_ . Here's a list of built-in Action Managers:
|
||||
|
||||
* **shell**: Allows either inline shell commands, or an executable shell script
|
||||
|
||||
* **python**: Executes a Python script
|
||||
|
||||
* **ansible**: Executes an Ansible playbook, allowing passing of a **vars_file** and **extra_vars** represented as a Python dict
|
||||
|
||||
* **nodejs**: Executes a Node.js script
|
||||
|
||||
* **ruby**: Executes a Ruby script
|
||||
|
||||
A hook is bound to a specific target and must be restated for each target used. In the future, hooks will be able to be global, and then named in the **hooks**section for each target more simply.
|
||||
|
||||
### Using hooks
|
||||
|
||||
Describing hooks is simple enough, understanding their power might not be so simple. This feature exists to provide flexible power to the user for things that the LinchPin developers might not consider. This concept could lead to a simple way to ping a set of systems, for instance, before running another hook.
|
||||
|
||||
Looking into the _workspace_ more closely, one might have noticed the **hooks**directory. Let's have a look inside this directory to see the structure:
|
||||
|
||||
```
|
||||
$ tree hooks/
|
||||
hooks/
|
||||
├── ansible
|
||||
│ ├── ping
|
||||
│ │ └── dummy_ping.yaml
|
||||
└── shell
|
||||
└── database
|
||||
├── init_db.sh
|
||||
└── setup_db.sh
|
||||
```
|
||||
|
||||
In every case, hooks can be used in the **PinFile**, shown here:
|
||||
|
||||
```
|
||||
---
|
||||
dummy1:
|
||||
topology: dummy-cluster.yml
|
||||
layout: dummy-layout.yml
|
||||
hooks:
|
||||
postup:
|
||||
- name: ping
|
||||
type: ansible
|
||||
actions:
|
||||
- dummy_ping.yaml
|
||||
- name: database
|
||||
type: shell
|
||||
actions:
|
||||
- setup_db.sh
|
||||
- init_db.sh
|
||||
```
|
||||
|
||||
The basic concept is that there are three postup actions to complete. Hooks are executed in top-down order. Thus, the Ansible **ping** task would run first, followed by the two shell tasks, **setup_db.sh**, followed by **init_db.sh**. Assuming the hooks execute successfully, a ping of the systems would occur, then a database would be set up and initialized.
|
||||
|
||||
### Authentication Driver
|
||||
|
||||
In the initial design of LinchPin, developers decided to have authentication be managed within the Ansible playbooks; however, moving to a more API and command-line driven tool meant that authentication should be outside of the library where the playbooks now reside, and still pass authentication values along as needed.
|
||||
|
||||
### Configuration
|
||||
|
||||
Letting users use the authentication method provided by the driver used accomplished this task. For instance, if the topology called for OpenStack, the standard method is to use either a yaml file, or similar **OS_** prefixed environment variables. A clouds.yaml file consists of a profile, with an **auth**section:
|
||||
|
||||
```
|
||||
clouds:
|
||||
default:
|
||||
auth:
|
||||
auth_url: http://stack.example.com:5000/v2.0/
|
||||
project_name: factory2
|
||||
username: factory-user
|
||||
password: password-is-not-a-good-password
|
||||
```
|
||||
|
||||
More detail is in the [OpenStack documentation][21].
|
||||
|
||||
This clouds.yaml—or any other authentication file—is located in the **default_credentials_path** (e.g., ~/.config/linchpin) and referenced in the topology:
|
||||
|
||||
```
|
||||
---
|
||||
topology_name: openstack-test
|
||||
resource_groups:
|
||||
-
|
||||
resource_group_name: linchpin
|
||||
resource_group_type: openstack
|
||||
resource_definitions:
|
||||
- name: resource
|
||||
type: os_server
|
||||
flavor: m1.small
|
||||
image: rhel-7.2-server-x86_64-released
|
||||
count: 1
|
||||
keypair: test-key
|
||||
networks:
|
||||
- test-net2
|
||||
fip_pool: 10.0.72.0/24
|
||||
credentials:
|
||||
filename: clouds.yaml
|
||||
profile: default
|
||||
```
|
||||
|
||||
The **default_credentials_path** can be changed by modifying the **linchpin.conf**.
|
||||
|
||||
The topology includes a new **credentials** section at the bottom. With **openstack**, **ec2**, and **gcloud** modules, the credentials can be specified similarly. The Authentication driver will then look in the given _filename_ **clouds.yaml**, and search for the _profile_ named **default**.
|
||||
|
||||
Assuming authentication is found and loaded, provisioning will continue as normal.
|
||||
|
||||
### Simplicity
|
||||
|
||||
Although LinchPin can be complex around topologies, inventory layouts, hooks, and authentication management, the ultimate goal is simplicity. By simplifying with a command-line interface, along with goals to improve the developer experience coming post-1.0, LinchPin continues to show that complex configurations can be managed with simplicity.
|
||||
|
||||
### Community Growth
|
||||
|
||||
Over the past year, LinchPin's community has grown to the point that we now have a [mailing list][22], an IRC channel (#linchpin on chat.freenode.net), and even manage our sprints in the open with [GitHub][23].
|
||||
|
||||
The community membership has grown immensely—from 2 core developers to about 10 contributors over the past year. More people continue to work with the project. If you've got an interest in LinchPin, drop us a line, file an issue on GitHub, join up on IRC, or send us an email.
|
||||
|
||||
_This article is based on Clint Savage's OpenWest talk, [Introducing LinchPin: Hybrid cloud provisioning using Ansible][7]. [OpenWest][8] will be held July 12-15, 2017 in Salt Lake City, Utah._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Clint Savage - Clint Savage works for Red Hat as a Senior Software Engineer for Project Atomic. His job entails automating Atomic server builds for Fedora, CentOS, and Red Hat Enterprise Linux (RHEL).
|
||||
|
||||
-------------
|
||||
|
||||
via: https://opensource.com/article/17/6/linchpin
|
||||
|
||||
作者:[Clint Savage][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/herlo
|
||||
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||
[6]:https://opensource.com/article/17/6/linchpin?rate=yx4feHOc5Kf9gaZe5S4MoVAmf9mgtociUimJKAYgwZs
|
||||
[7]:https://www.openwest.org/custom/description.php?id=166
|
||||
[8]:https://www.openwest.org/
|
||||
[9]:https://opensource.com/user/145261/feed
|
||||
[10]:https://www.flickr.com/photos/internetarchivebookimages/14587478927/in/photolist-oe2Gwy-otuvuy-otus3U-otuuh3-ovwtoH-oe2AXD-otutEw-ovwpd8-oe2Me9-ovf688-oxhaVa-oe2mNh-oe3AN6-ovuyL7-ovf9Kt-oe2m4G-ovwqsH-ovjfJY-ovjfrU-oe2rAU-otuuBw-oe3Dgn-oe2JHY-ovfcrF-oe2Ns1-ovjh2N-oe3AmK-otuwP7-ovwrHt-ovwmpH-ovf892-ovfbsr-ovuAzN-ovf3qp-ovuFcJ-oe2T3U-ovwn8r-oe2L3T-oe3ELr-oe2Dmr-ovuyB9-ovuA9s-otuvPG-oturHA-ovuDAh-ovwkV6-ovf5Yv-ovuCC5-ovfc2x-oxhf1V
|
||||
[11]:http://sexysexypenguins.com/posts/introducing-linch-pin/
|
||||
[12]:http://linch-pin.readthedocs.io/en/develop/
|
||||
[13]:https://opensource.com/resources/cloud
|
||||
[14]:http://click.pocoo.org/
|
||||
[15]:https://opensource.com/resources/python
|
||||
[16]:http://linchpin.readthedocs.io/en/develop/libdocs.html
|
||||
[17]:http://docs.ansible.com/ansible/playbooks.html
|
||||
[18]:https://github.com/CentOS-PaaS-SIG/linchpin/tree/develop/linchpin/examples/topologies
|
||||
[19]:https://github.com/CentOS-PaaS-SIG/linch-pin/tree/develop/linchpin/provision/roles
|
||||
[20]:http://linchpin.readthedocs.io/en/develop/libdocs.html
|
||||
[21]:https://docs.openstack.org/developer/python-openstackclient/configuration.html
|
||||
[22]:https://www.redhat.com/mailman/listinfo/linchpin
|
||||
[23]:https://github.com/CentOS-PaaS-SIG/linch-pin/projects/4
|
||||
[24]:https://opensource.com/users/herlo
|
||||
@ -0,0 +1,165 @@
|
||||
Translating by lonaparte
|
||||
|
||||
Lessons from my first year of live coding on Twitch
|
||||
============================================================
|
||||
|
||||
I gave streaming a go for the first time last July. Instead of gaming, which the majority of streamers on Twitch do, I wanted to stream the open source work I do in my personal time. I work on NodeJS hardware libraries a fair bit (most of them my own). Given that I was already in a niche on Twitch, why not be in an even smaller niche, like JavaScript powered hardware ;) I signed up for [my own channel][1], and have been streaming regularly since.
|
||||
|
||||
Of course I’m not the first to do this. [Handmade Hero][2] was one of the first programmers I watched code online, quickly followed by the developers at Vlambeer who [developed Nuclear Throne live on Twitch][3]. I was fascinated by Vlambeer especially.
|
||||
|
||||
What tipped me over the edge of _wishing_ I could do it to _actually doing it_ is credited to [Nolan Lawson][4], a friend of mine. I watched him [streaming his open source work one weekend][5], and it was awesome. He explained everything he was doing along the way. Everything. Replying to issues on GitHub, triaging bugs, debugging code in branches, you name it. I found it fascinating, as Nolan maintains open source libraries that get a lot of use and activity. His open source life is very different to mine.
|
||||
|
||||
You can even see this comment I left under his video:
|
||||
|
||||
|
||||
|
||||
I gave it a go myself a week or so later, after setting up my Twitch channel and bumbling my way through using OBS. I believe I worked on [Avrgirl-Arduino][6], which I still frequently work on while streaming. It was a rough first stream. I was very nervous, and I had stayed up late rehearsing everything I was going to do the night before.
|
||||
|
||||
The tiny number of viewers I got that Saturday were really encouraging though, so I kept at it. These days I have more than a thousand followers, and a lovely subset of them are regular visitors who I call “the noopkat fam”.
|
||||
|
||||
We have a lot of fun, and I like to call the live coding parts “massively multiplayer online pair programming”. I am truly touched by the kindness and wit of everyone joining me each weekend. One of the funniest moments I have had was when one of the fam pointed out that my Arduino board was not working with my software because the microchip was missing from the board:
|
||||
|
||||
|
||||
I have logged off a stream many a time, only to find in my inbox that someone has sent a pull request for some work that I had mentioned I didn’t have the time to start on. I can honestly say that my open source work has been changed for the better, thanks to the generosity and encouragement of my Twitch community.
|
||||
|
||||
I have so much more to say about the benefits that streaming on Twitch has brought me, but that’s for another blog post probably. Instead, I want to share the lessons I have learned for anyone else who would like to try live coding in this way for themselves. Recently I’ve been asked by a few developers how they can get started, so I’m publishing the same advice I have given them!
|
||||
|
||||
Firstly, I’m linking you to a guide called [“Streaming and Finding Success on Twitch”][7] which helped me a lot. It’s focused towards Twitch and gaming streams specifically, but there are still relevant sections and great advice in there. I’d recommend reading this first before considering any other details about starting your channel (like equipment or software choices).
|
||||
|
||||
My own advice is below, which I have acquired from my own mistakes and the sage wisdom of fellow streamers (you know who you are!).
|
||||
|
||||
### Software
|
||||
|
||||
There’s a lot of free streaming software out there to stream with. I use [Open Broadcaster Software (OBS)][8]. It’s available on most platforms. I found it really intuitive to get up and going, but others sometimes take a while to learn how it works. Your mileage may vary! Here is a screen-grab of what my OBS ‘desktop scene’ setup looks like as of today (click for larger image):
|
||||
|
||||

|
||||
|
||||
You essentially switch between ‘scenes’ while streaming. A scene is a collection of ‘sources’, layered and composited with each other. A source can be things like a camera, microphone, your desktop, a webpage, live text, images, the list goes on. OBS is very powerful.
|
||||
|
||||
This desktop scene above is where I do all of my live coding, and I mostly live here for the duration of the stream. I use iTerm and vim, and also have a browser window handy to switch to in order to look up documentation and triage things on GitHub, etc.
|
||||
|
||||
The bottom black rectangle is my webcam, so folks can see me work and have a more personal connection.
|
||||
|
||||
I have a handful of ‘labels’ for my scenes, many of which are to do with the stats and info in the top banner. The banner just adds personality, and is a nice persistent source of info while streaming. It’s an image I made in [GIMP][9], and you import it as a source in your scene. Some labels are live stats that pull from text files (such as most recent follower). Another label is a [custom one I made][10] which shows the live temperature and humidity of the room I stream from.
|
||||
|
||||
I have also ‘alerts’ set up in my scenes, which show cute banners over the top of my stream whenever someone follows or donates money. I use the web service [Stream Labs][11] to do this, importing it as a browser webpage source into the scene. Stream Labs also creates my recent followers live text file to show in my banner.
|
||||
|
||||
I also have a standby screen that I use when I’m about to be live:
|
||||
|
||||
|
||||
|
||||
I additionally need a scene for when I’m entering secret tokens or API keys. It shows me on the webcam but hides my desktop with an entertaining webpage, so I can work in privacy:
|
||||
|
||||
|
||||
|
||||
As you can see, I don’t take stuff too seriously when streaming, but I like to have a good setup for my viewers to get the most out of my stream.
|
||||
|
||||
But now for an actual secret: I use OBS to crop out the bottom and right edges of my screen, while keeping the same video size ratio as what Twitch expects. That leaves me with space to watch my events (follows, etc) on the bottom, and look at and respond to my channel chat box on the right. Twitch allows you to ‘pop out’ the chatbox in a new window which is really helpful.
|
||||
|
||||
This is what my full desktop _really _ looks like:
|
||||
|
||||
|
||||
|
||||
I started doing this a few months ago and haven’t looked back. I’m not even sure my viewers realise this is how my setup works. I think they take for granted that I can see everything, even though I cannot see what is actually being streamed live when I’m busy programming!
|
||||
|
||||
You might be wondering why I only use one monitor. It’s because two monitors was just too much to manage on top of everything else I was doing while streaming. I figured this out quickly and have stuck with one screen since.
|
||||
|
||||
### Hardware
|
||||
|
||||
I used cheaper stuff to start out, and slowly bought nicer stuff as I realised that streaming was going to be something I stuck with. Use whatever you have when getting started, even if it’s your laptop’s built in microphone and camera.
|
||||
|
||||
Nowadays I use a Logitech Pro C920 webcam, and a Blue Yeti microphone on a microphone arm with a mic shock. Totally worth the money in the end if you have it to spend. It made a difference to the quality of my streams.
|
||||
|
||||
I use a large monitor (27"), because as I mentioned earlier using two monitors just didn’t work for me. I was missing things in the chat because I was not looking over to the second laptop screen enough, etc etc. Your milage may vary here, but having everything on one screen was key for me to pay attention to everything happening.
|
||||
|
||||
That’s pretty much it on the hardware side; I don’t have a very complicated setup.
|
||||
|
||||
If you were interested, my desk looks pretty normal except for the obnoxious looming microphone:
|
||||
|
||||

|
||||
|
||||
### Tips
|
||||
|
||||
This last section has some general tips I’ve picked up, that have made my stream better and more enjoyable overall.
|
||||
|
||||
#### Panels
|
||||
|
||||
Spend some time on creating great panels. Panels are the little content boxes on the bottom of everyone’s channel page. I see them as the new MySpace profile boxes (lol but really). Panel ideas could be things like chat rules, information about when you stream, what computer and equipment you use, your favourite cat breed; anything that creates a personal touch. Look at other channels (especially popular ones) for ideas!
|
||||
|
||||
An example of one of my panels:
|
||||
|
||||
|
||||
|
||||
#### Chat
|
||||
|
||||
Chat is really important. You’re going to get the same questions over and over as people join your stream halfway through, so having chat ‘macros’ can really help. “What are you working on?” is the most common question asked while I’m coding. I have chat shortcut ‘commands’ for that, which I made with [Nightbot][12]. It will put an explanation of something I have entered in ahead of time, by typing a small one word command like _!whatamidoing_
|
||||
|
||||
When folks ask questions or leave nice comments, talk back to them! Say thanks, say their Twitch handle, and they’ll really appreciate the attention and acknowledgement. This is SUPER hard to stay on top of when you first start streaming, but multitasking will come easier as you do more. Try to take a few seconds every couple of minutes to look at the chat for new messages.
|
||||
|
||||
When programming, _explain what you’re doing_ . Talk a lot. Make jokes. Even when I’m stuck, I’ll say, “oh, crap, I forget how to use this method lemme Google it hahaha” and folks are always nice and sometimes they’ll even read along with you and help you out. It’s fun and engaging, and keeps folks watching.
|
||||
|
||||
I lose interest quickly when I’m watching programming streams where the streamer is sitting in silence typing code, ignoring the chat and their new follower alerts.
|
||||
|
||||
It’s highly likely that 99% of folks who find their way to your channel will be friendly and curious. I get the occasional troll, but the moderation tools offered by Twitch and Nightbot really help to discourage this.
|
||||
|
||||
#### Prep time
|
||||
|
||||
Automate your setup as much as possible. My terminal is iTerm, and it lets you save window arrangements and font sizes so you can restore back to them later. I have one window arrangement for streaming and one for non streaming. It’s a massive time saver. I hit one command and everything is the perfect size and in the right position, ready to go.
|
||||
|
||||
There are other apps out there that automate all of your app window placements, have a look to see if any of them would also help.
|
||||
|
||||
Make your font size really large in your terminal and code editor so everyone can see.
|
||||
|
||||
#### Regularity
|
||||
|
||||
Be regular with your schedule. I only stream once a week, but always at the same time. Let folks know if you’re not able to stream during an expected time you normally do. This has netted me a regular audience. Some folks love routine and it’s exactly like catching up with a friend. You’re in a social circle with your community, so treat it that way.
|
||||
|
||||
I want to stream more often, but I know I can’t commit to more than once a week because of travel. I am trying to come up with a way to stream in high quality when on the road, or perhaps just have casual chats and save programming for my regular Sunday stream. I’m still trying to figure this out!
|
||||
|
||||
#### Awkwardness
|
||||
|
||||
It’s going to feel weird when you get started. You’re going to feel nervous about folks watching you code. That’s normal! I felt that really strongly at the beginning, even though I have public speaking experience. I felt like there was nowhere for me to hide, and it scared me. I thought, “everyone is going to think my code is bad, and that I’m a bad developer”. This is a thought pattern that has plagued me my _entire career_ though, it’s nothing new. I knew that with this, I couldn’t quietly refactor code before pushing to GitHub, which is generally much safer for my reputation as a developer.
|
||||
|
||||
I learned a lot about my programming style by live coding on Twitch. I learned that I’m definitely the “make it work, then make it readable, then make it fast” type. I don’t rehearse the night before anymore (I gave that up after 3 or 4 streams right at the beginning), so I write pretty rough code on Twitch and have to be okay with that. I write my best code when alone with my thoughts and not watching a chat box + talking aloud, and that’s okay. I forget method signatures that I’ve used a thousand times, and make ‘silly’ mistakes in almost every single stream. For most, it’s not a productive environment for being at your best.
|
||||
|
||||
My Twitch community never judges me for this, and they help me out a lot. They understand I’m multitasking, and are really great about pragmatic advice and suggestions. Sometimes they bail me out, and other times I have to explain to them why their suggestion won’t work. It’s really just like regular pair programming!
|
||||
|
||||
I think the ‘warts and all’ approach to this medium is a strength, not a weakness. It makes you more relatable, and it’s important to show that there’s no such thing as the perfect programmer, or the perfect code. It’s probably quite refreshing for new coders to see, and humbling for myself as a more experienced coder.
|
||||
|
||||
### Conclusion
|
||||
|
||||
If you’ve been wanting to get into live coding on Twitch, I encourage you to give it a try! I hope this post helped you if you have been wondering where to start.
|
||||
|
||||
If you’d like to join me on Sundays, you can [follow my channel on Twitch][13] :)
|
||||
|
||||
On my last note, I’d like to personally thank [Mattias Johansson][14] for his wisdom and encouragement early on in my streaming journey. He was incredibly generous, and his [FunFunFunction YouTube channel][15] is a continuous source of inspiration.
|
||||
|
||||
Update: a bunch of folks have been asking about my keyboard and other parts of my workstation. [Here is the complete list of what I use][16]. Thanks for the interest!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/lessons-from-my-first-year-of-live-coding-on-twitch-41a32e2f41c1
|
||||
|
||||
作者:[ Suz Hinton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@suzhinton
|
||||
[1]:https://www.twitch.tv/noopkat
|
||||
[2]:https://www.twitch.tv/handmade_hero
|
||||
[3]:http://nuclearthrone.com/twitch/
|
||||
[4]:https://twitter.com/nolanlawson
|
||||
[5]:https://www.youtube.com/watch?v=9FBvpKllTQQ
|
||||
[6]:https://github.com/noopkat/avrgirl-arduino
|
||||
[7]:https://www.reddit.com/r/Twitch/comments/4eyva6/a_guide_to_streaming_and_finding_success_on_twitch/
|
||||
[8]:https://obsproject.com/
|
||||
[9]:https://www.gimp.org/
|
||||
[10]:https://github.com/noopkat/study-temp
|
||||
[11]:https://streamlabs.com/
|
||||
[12]:https://beta.nightbot.tv/
|
||||
[13]:https://www.twitch.tv/noopkat
|
||||
[14]:https://twitter.com/mpjme
|
||||
[15]:https://www.youtube.com/channel/UCO1cgjhGzsSYb1rsB4bFe4Q
|
||||
[16]:https://gist.github.com/noopkat/5de56cb2c5917175c5af3831a274a2c8
|
||||
@ -1,4 +1,3 @@
|
||||
> translating by rieonke
|
||||
Containing System Services in Red Hat Enterprise Linux – Part 1
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
translating by penghuster
|
||||
|
||||
Designing a Microservices Architecture for Failure
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
translating by Flowsnow
|
||||
Translating by geekrainy
|
||||
|
||||
The user’s home dashboard in our app, AlignHow we built our first full-stack JavaScript web app in three weeks
|
||||
============================================================
|
||||
|
||||
@ -1,173 +0,0 @@
|
||||
[JanzenLiu Translating...] Guide to Linux App Is a Handy Tool for Every Level of Linux User
|
||||
============================================================
|
||||
|
||||

|
||||
The Guide to Linux app is not perfect, but it's a great tool to help you learn your way around Linux commands.[Used with permission][7]Essence Infotech LLP
|
||||
|
||||
|
||||
Remember when you first started out with Linux? Depending on the environment you’re coming from, the learning curve can be somewhat challenging. Take, for instance, the number of commands found in _ /usr/bin_ alone. On my current Elementary OS system, that number is 1,944\. Of course, not all of those are actual commands (or commands I would use), but the number is significant.
|
||||
|
||||
Because of that (and many other differences from other platforms), new users (and some already skilled users) need a bit of help now and then.
|
||||
|
||||
For every administrator, there are certain skills that are must-have:
|
||||
|
||||
* Understanding of the platform
|
||||
|
||||
* Understanding commands
|
||||
|
||||
* Shell scripting
|
||||
|
||||
When you seek out assistance, sometimes you’ll be met with RTFM (Read the Fine/Freaking/Funky Manual). That doesn’t always help when you have no idea what you’re looking for. That’s when you’ll be glad for apps like [Guide to Linux][15].
|
||||
|
||||
Unlike most of the content you’ll find here on Linux.com, this particular article is about an Android app. Why? Because this particular app happens to be geared toward helping users learn Linux.
|
||||
|
||||
And it does a fine job.
|
||||
|
||||
I’m going to give you fair warning about this app—it’s not perfect. Guide to Linux is filled with broken English, bad punctuation, and (if you’re a purist) it never mentions GNU. On top of that, one particular feature (one that would normally be very helpful to users) doesn’t function enough to be useful. Outside of that, Guide to Linux might well be one of your best bets for having a mobile “pocket guide” to the Linux platform.
|
||||
|
||||
With this app, you’ll enjoy:
|
||||
|
||||
* Offline usage.
|
||||
|
||||
* Linux Tutorial.
|
||||
|
||||
* Details of all basic and advanced Linux commands of Linux.
|
||||
|
||||
* Includes command examples and syntax.
|
||||
|
||||
* Dedicated Shell Script module.
|
||||
|
||||
On top of that, Guide to Linux is free (although it does contain ads). If you want to get rid of the ads, there’s an in-app purchase ($2.99 USD/year) to take care of that.
|
||||
|
||||
Let’s install this app and then take a look at the constituent parts.
|
||||
|
||||
### Installation
|
||||
|
||||
Like all Android apps, installation of Guide to Linux is incredibly simple. All you have to do is follow these easy steps:
|
||||
|
||||
1. Open up the Google Play Store on your Android device
|
||||
|
||||
2. Search for Guide to Linux
|
||||
|
||||
3. Locate and tap the entry by Essence Infotech
|
||||
|
||||
4. Tap Install
|
||||
|
||||
5. Allow the installation to complete
|
||||
|
||||
### [guidetolinux1.jpg][8]
|
||||
|
||||

|
||||
|
||||
Figure 1: The Guide to Linux main window.[Used with permission][1]
|
||||
|
||||
Once installed, you’ll find the launcher for Guide to Linux in either your App Drawer or on your home screen (or both). Tap the icon to launch the app.
|
||||
|
||||
### Usage
|
||||
|
||||
Let’s take a look at the individual features that make up Guide to Linux. You will probably find some features more helpful than others, and your experience will vary. Before we break it down, I’ll make mention of the interface. The developer has done a great job of creating an easy-to-use interface for the app.
|
||||
|
||||
From the main window (Figure 1), you can gain easy access to the four features.
|
||||
|
||||
Tap any one of the four icons to launch a feature and you’re ready to learn.
|
||||
|
||||
### [guidetolinux2.jpg][9]
|
||||
|
||||

|
||||
|
||||
Figure 2: The tutorial begins at the beginning.[Used with permission][2]
|
||||
|
||||
### Tutorial
|
||||
|
||||
Let’s start out with the most newbie-friendly feature of the app—Tutorial. Open up that feature and you’ll be greeted by the first section of the tutorial, “Introduction to the Linux Operating System” (Figure 2).
|
||||
|
||||
If you tap the “hamburger menu” (three horizontal lines in the top left corner), the Table of Contents are revealed (Figure 3), so you can select any of the available sections within the Tutorial.
|
||||
|
||||
### [guidetolinux3.jpg][10]
|
||||
|
||||

|
||||
|
||||
Figure 3: The Tutorial Table of Contents.[Used with permission][3]
|
||||
|
||||
Unless you haven’t figured it out by now, the Tutorial section of Guide to Linux is a collection of short essays on each topic. The essays include pictures and (in some cases) links that will send you to specific web sites (as needed to suit a topic). There is no interaction here, just reading. However, this is a great place to start, as the developer has done a solid job of describing the various sections (grammar notwithstanding).
|
||||
|
||||
Although you will see a search option at the top of the window, I haven’t found that feature to be even remotely effective—but it’s there for you to try.
|
||||
|
||||
For new Linux users, looking to add Linux administration to their toolkit, you’ll want to read through this entire Tutorial. Once you’ve done that, move on to the next section.
|
||||
|
||||
### Commands
|
||||
|
||||
The Commands feature is like having the man pages, in hand, for many of the most frequently used Linux commands. When you first open this, you will be greeted by an introduction that explains the advantage of using commands.
|
||||
|
||||
### [guidetolinux4.jpg][11]
|
||||
|
||||

|
||||
|
||||
Figure 4: The Commands sidebar allows you to check out any of the listed commands.[Used with permission][4]
|
||||
|
||||
Once you’ve read through that you can either tap the right-facing arrow (at the bottom of the screen) or tap the “hamburger menu” and then select the command you want to learn about from the sidebar (Figure 4).
|
||||
|
||||
Tap on one of the commands and you can then read through the explanation of the command in question. Each page explains the command and its options as well as offers up examples of how to use the command.
|
||||
|
||||
### Shell Script
|
||||
|
||||
At this point, you’re starting to understand Linux and you have a solid grasp on commands. Now it’s time to start understanding shell scripts. This section is set up in the same fashion as is the Tutorial and Commands sections.
|
||||
|
||||
You can open up a sidebar Table of Contents to take and then open up any of the sections that comprise the Shell Script tutorial (Figure 5).
|
||||
|
||||
### [guidetolinux-5-new.jpg][12]
|
||||
|
||||

|
||||
|
||||
Figure 5: The Shell Script section should look familiar by now.[Used with permission][5]
|
||||
|
||||
Once again, the developer has done a great job of explaining how to get the most out of shell scripting. For anyone interested in learning the ins and outs of shell scripting, this is a pretty good place to start.
|
||||
|
||||
### Terminal
|
||||
|
||||
Now we get to the section where your mileage may vary. The developer has included a terminal emulator with the app. Unfortunately, when installing this on an unrooted Android device, you’ll find yourself locked into a read-only file system, where most of the commands simply won’t work. However, I did install Guide to Linux on a Pixel 2 (via the Android app store) and was able to get a bit more usage from the feature (if only slightly). On a OnePlus 3 (not rooted), no matter what directory I change into, I get the same “permission denied” error, even for a simple ls command.
|
||||
|
||||
On the Chromebook, however, all is well (Figure 6). Sort of. We’re still working with a read-only file system (so you cannot actually work with or create new files).
|
||||
|
||||
### [guidetolinux6.jpg][13]
|
||||
|
||||

|
||||
|
||||
Figure 6: Finally able to (sort of) work with the terminal emulator.[Used with permission][6]
|
||||
|
||||
Remember, this isn’t actually a full-blown terminal, but a way for new users to understand how the terminal works. Unfortunately, most users are going to find themselves frustrated with this feature of the tool, simply because they cannot put to use what they’ve learned within the other sections. It might behoove the developer to re-tool the terminal feature as a sandboxed Linux file system, so users could actually learn with it. Every time a user would open that tool, it could revert to its original state. Just a thought.
|
||||
|
||||
### In the end…
|
||||
|
||||
Even with the terminal feature being a bit hamstrung by the read-only filesystem (almost to the point of being useless), Guide to Linux is a great tool for users new to Linux. With this guide to Linux, you’ll learn enough about Linux, commands, and shell scripting to feel like you have a head start, even before you install that first distribution.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][16]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/8/guide-linux-app-handy-tool-every-level-linux-user
|
||||
|
||||
作者:[ JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/used-permission
|
||||
[7]:https://www.linux.com/licenses/category/used-permission
|
||||
[8]:https://www.linux.com/files/images/guidetolinux1jpg
|
||||
[9]:https://www.linux.com/files/images/guidetolinux2jpg
|
||||
[10]:https://www.linux.com/files/images/guidetolinux3jpg-0
|
||||
[11]:https://www.linux.com/files/images/guidetolinux4jpg
|
||||
[12]:https://www.linux.com/files/images/guidetolinux-5-newjpg
|
||||
[13]:https://www.linux.com/files/images/guidetolinux6jpg-0
|
||||
[14]:https://www.linux.com/files/images/guide-linuxpng
|
||||
[15]:https://play.google.com/store/apps/details?id=com.essence.linuxcommands
|
||||
[16]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[17]:https://www.addtoany.com/share#url=https%3A%2F%2Fwww.linux.com%2Flearn%2Fintro-to-linux%2F2017%2F8%2Fguide-linux-app-handy-tool-every-level-linux-user&title=Guide%20to%20Linux%20App%20Is%20a%20Handy%20Tool%20for%20Every%20Level%20of%20Linux%20User
|
||||
@ -1,88 +0,0 @@
|
||||
Translating by Penney94
|
||||
[GIVE AWAY YOUR CODE, BUT NEVER YOUR TIME][23]
|
||||
============================================================
|
||||
|
||||
As software developers, I think we can agree that open-source code has [transformed the world][9]. Its public nature tears down the walls that prevent some pieces of software from becoming the best they can be. The problem is that too many valuable projects stagnate, with burned-out leaders:
|
||||
|
||||
> “I do not have the time or energy to invest in open source any more. I am not being paid at all to do any open source work, and so the work that I do there is time that I could be spending doing ‘life stuff’, or writing…It’s for this reason that I've decided to end all my engagements with open source effective today.”
|
||||
>
|
||||
> —[Ryan Bigg, former maintainer of several Ruby and Elixir projects][1]
|
||||
>
|
||||
> “It’s also been a massive opportunity cost because of all the things I haven’t learned or done in the meantime because FubuMVC takes up so much of my time and that’s the main reason that it has to stop now.”
|
||||
>
|
||||
> —[Jeremy Miller, former project lead of FubuMVC][2]
|
||||
>
|
||||
> “When we decide to start having kids, I will probably quit open source for good…I anticipate that ultimately this will be the solution to my problem: the nuclear option.”
|
||||
>
|
||||
> —[Nolan Lawson, one of the maintainers of PouchDB][3]
|
||||
|
||||
What we need is a new industry norm, that project leaders will _always_ be compensated for their time. We also need to bury the idea that any developer who submits an issue or pull request is automatically entitled to the attention of a maintainer.
|
||||
|
||||
Let’s first review how an open-source code base works in the market. It is a building block. It is [utility software][10], a cost that must be incurred by a business to make profit elsewhere. The community around the software grows if users can both understand the purpose of the code and see that it is a better value than the alternatives (closed-source off-the-shelf, custom in-house solution, etc.). It can be better, cheaper, or both.
|
||||
|
||||
If an organization needs to improve the code, they are free to hire any developer they want. It’s usually [in their interest][11] to contribute the improvement back to the community because, due to the complexity of merging, that’s the only way they can easily receive future improvements from other users. This “gravity” tends to hold communities together.
|
||||
|
||||
But it also burdens project maintainers since they must respond to these incoming improvements. And what do they get in return? At best, a community contribution may be something they can use in the future but not right now. At worst, it is nothing more than a selfish request wearing the mask of altruism.
|
||||
|
||||
One class of open-source projects has avoided this trap. What do Linux, MySQL, Android, Chromium, and .NET Core have in common, besides being famous? They are all _strategically important_ to one or more big-business interests because they complement those interests. [Smart companies commoditize their complements][12] and there’s no commodity cheaper than open-source software. Red Hat needs companies using Linux in order to sell Enterprise Linux, Oracle uses MySQL as a gateway drug that leads to MySQL Enterprise, Google wants everyone in the world to have a phone and web browser, and Microsoft is trying to hook developers on a platform and then pull them into the Azure cloud. These projects are all directly funded by the respective companies.
|
||||
|
||||
But what about the rest of the projects out there, that aren’t at the center of a big player’s strategy?
|
||||
|
||||
If you’re the leader of one of these projects, charge an annual fee for community membership. _Open source, closed community._ The message to users should be “do whatever you want with the code, but _pay us for our time_ if you want to influence the project’s future.” Lock non-paying users out of the forum and issue tracker, and ignore their emails. People who don’t pay should feel like they are missing out on the party.
|
||||
|
||||
Also charge contributors for the time it takes to merge nontrivial pull requests. If a particular submission will not immediately benefit you, charge full price for your time. Be disciplined and [remember YAGNI][13].
|
||||
|
||||
Will this lead to a drastically smaller community, and more forks? Absolutely. But if you persevere in building out your vision, and it delivers value to anyone else, they will pay as soon as they have a contribution to make. _Your willingness to merge contributions is [the scarce resource][4]._ Without it, users must repeatedly reconcile their changes with every new version you release.
|
||||
|
||||
Restricting the community is especially important if you want to maintain a high level of [conceptual integrity][14] in the code base. Headless projects with [liberal contribution policies][15] have less of a need to charge.
|
||||
|
||||
To implement larger pieces of your vision that do not justify their cost for your business alone, but may benefit others, [crowdfund][16]. There are many success stories:
|
||||
|
||||
> [Font Awesome 5][5]
|
||||
>
|
||||
> [Ruby enVironment Management (RVM)][6]
|
||||
>
|
||||
> [Django REST framework 3][7]
|
||||
|
||||
[Crowdfunding has limitations][17]. It [doesn’t work][18] for [huge projects][19]. But again, open-source code is utility software, which doesn’t need ambitious, risky game-changers. It has already [permeated every industry][20] with only incremental updates.
|
||||
|
||||
These ideas represent a sustainable path forward, and they could also fix the [diversity problem in open source][21], which may be rooted in its historically-unpaid nature. But above all, let’s remember that we only have [so many keystrokes left in our lives][22], and that we will someday regret the ones we waste.
|
||||
|
||||
_When I say “open source”, I mean code [licensed][8] in a way that it can be used to build proprietary things. This usually means a permissive license (MIT or Apache or BSD), but not always. Linux is the core of today’s tech industry, yet it is licensed under the GPL._
|
||||
|
||||
Thanks to Jason Haley, Don McNamara, Bryan Hogan, and Nadia Eghbal for reading drafts of this.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://wgross.net/essays/give-away-your-code-but-never-your-time
|
||||
|
||||
作者:[William Gross][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://wgross.net/#about-section
|
||||
[1]:http://ryanbigg.com/2015/11/open-source-work
|
||||
[2]:https://jeremydmiller.com/2014/04/03/im-throwing-in-the-towel-in-fubumvc/
|
||||
[3]:https://nolanlawson.com/2017/03/05/what-it-feels-like-to-be-an-open-source-maintainer/
|
||||
[4]:https://hbr.org/2010/11/column-to-win-create-whats-scarce
|
||||
[5]:https://www.kickstarter.com/projects/232193852/font-awesome-5
|
||||
[6]:https://www.bountysource.com/teams/rvm/fundraiser
|
||||
[7]:https://www.kickstarter.com/projects/tomchristie/django-rest-framework-3
|
||||
[8]:https://choosealicense.com/
|
||||
[9]:https://www.wired.com/insights/2013/07/in-a-world-without-open-source/
|
||||
[10]:https://martinfowler.com/bliki/UtilityVsStrategicDichotomy.html
|
||||
[11]:https://tessel.io/blog/67472869771/monetizing-open-source
|
||||
[12]:https://www.joelonsoftware.com/2002/06/12/strategy-letter-v/
|
||||
[13]:https://martinfowler.com/bliki/Yagni.html
|
||||
[14]:http://wiki.c2.com/?ConceptualIntegrity
|
||||
[15]:https://opensource.com/life/16/5/growing-contributor-base-modern-open-source
|
||||
[16]:https://poststatus.com/kickstarter-open-source-project/
|
||||
[17]:http://blog.felixbreuer.net/2013/04/24/crowdfunding-for-open-source.html
|
||||
[18]:https://www.indiegogo.com/projects/geary-a-beautiful-modern-open-source-email-client#/
|
||||
[19]:http://www.itworld.com/article/2708360/open-source-tools/canonical-misses-smartphone-crowdfunding-goal-by--19-million.html
|
||||
[20]:http://www.infoworld.com/article/2914643/open-source-software/rise-and-rise-of-open-source.html
|
||||
[21]:http://readwrite.com/2013/12/11/open-source-diversity/
|
||||
[22]:http://keysleft.com/
|
||||
[23]:http://wgross.net/essays/give-away-your-code-but-never-your-time
|
||||
@ -1,4 +1,3 @@
|
||||
translate by hwlife
|
||||
[Betting on the Web][27]
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by flowsnow
|
||||
|
||||
High Dynamic Range (HDR) Imaging using OpenCV (C++/Python)
|
||||
============================================================
|
||||
|
||||
@ -396,8 +398,8 @@ via: http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-
|
||||
[4]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr.zip
|
||||
[5]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr.zip
|
||||
[6]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[7]:https://itunes.apple.com/us/app/autobracket-hdr/id923626339?mt=8&ign-mpt=uo%3D8
|
||||
[8]:https://play.google.com/store/apps/details?id=com.almalence.opencam&hl=en
|
||||
[7]:https://itunes.apple.com/us/app/autobracket-hdr/id923626339?mt=8&ign-mpt=uo%3D8
|
||||
[8]:https://play.google.com/store/apps/details?id=com.almalence.opencam&hl=en
|
||||
[9]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-image-sequence.jpg
|
||||
[10]:https://www.howtogeek.com/289712/how-to-see-an-images-exif-data-in-windows-and-macos
|
||||
[11]:https://www.sno.phy.queensu.ca/~phil/exiftool
|
||||
@ -410,9 +412,9 @@ via: http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-
|
||||
[18]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Drago.jpg
|
||||
[19]:https://people.csail.mit.edu/fredo/PUBLI/Siggraph2002/DurandBilateral.pdf
|
||||
[20]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Durand.jpg
|
||||
[21]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.106.8100&rep=rep1&type=pdf
|
||||
[21]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.106.8100&rep=rep1&type=pdf
|
||||
[22]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Reinhard.jpg
|
||||
[23]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.60.4077&rep=rep1&type=pdf
|
||||
[23]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.60.4077&rep=rep1&type=pdf
|
||||
[24]:http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Mantiuk.jpg
|
||||
[25]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
[26]:https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/
|
||||
|
||||
@ -1,622 +0,0 @@
|
||||
[Concurrent Servers: Part 3 - Event-driven][25]
|
||||
============================================================
|
||||
|
||||
GitFuture is Translating
|
||||
|
||||
This is part 3 of a series of posts on writing concurrent network servers. [Part 1][26] introduced the series with some building blocks, and [part 2 - Threads][27] discussed multiple threads as one viable approach for concurrency in the server.
|
||||
|
||||
Another common approach to achieve concurrency is called _event-driven programming_ , or alternatively _asynchronous_ programming [[1]][28]. The range of variations on this approach is very large, so we're going to start by covering the basics - using some of the fundamental APIs than form the base of most higher-level approaches. Future posts in the series will cover higher-level abstractions, as well as various hybrid approaches.
|
||||
|
||||
All posts in the series:
|
||||
|
||||
* [Part 1 - Introduction][12]
|
||||
|
||||
* [Part 2 - Threads][13]
|
||||
|
||||
* [Part 3 - Event-driven][14]
|
||||
|
||||
### Blocking vs. nonblocking I/O
|
||||
|
||||
As an introduction to the topic, let's talk about the difference between blocking and nonblocking I/O. Blocking I/O is easier to undestand, since this is the "normal" way we're used to I/O APIs working. While receiving data from a socket, a call to `recv` _blocks_ until some data is received from the peer connected to the other side of the socket. This is precisely the issue with the sequential server of part 1.
|
||||
|
||||
So blocking I/O has an inherent performance problem. We saw one way to tackle this problem in part 2, using multiple threads. As long as one thread is blocked on I/O, other threads can continue using the CPU. In fact, blocking I/O is usually very efficient on resource usage while the thread is waiting - the thread is put to sleep by the OS and only wakes up when whatever it was waiting for is available.
|
||||
|
||||
_Nonblocking_ I/O is a different approach. When a socket is set to nonblocking mode, a call to `recv` (and to `send`, but let's just focus on receiving here) will always return very quickly, even if there's no data to receive. In this case, it will return a special error status [[2]][15] notifying the caller that there's no data to receive at this time. The caller can then go do something else, or try to call `recv` again.
|
||||
|
||||
The difference between blocking and nonblocking `recv` is easiest to demonstrate with a simple code sample. Here's a small program that listens on a socket, continuously blocking on `recv`; when `recv` returns data, the program just reports how many bytes were received [[3]][16]:
|
||||
|
||||
```
|
||||
int main(int argc, const char** argv) {
|
||||
setvbuf(stdout, NULL, _IONBF, 0);
|
||||
|
||||
int portnum = 9988;
|
||||
if (argc >= 2) {
|
||||
portnum = atoi(argv[1]);
|
||||
}
|
||||
printf("Listening on port %d\n", portnum);
|
||||
|
||||
int sockfd = listen_inet_socket(portnum);
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd = accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
|
||||
while (1) {
|
||||
uint8_t buf[1024];
|
||||
printf("Calling recv...\n");
|
||||
int len = recv(newsockfd, buf, sizeof buf, 0);
|
||||
if (len < 0) {
|
||||
perror_die("recv");
|
||||
} else if (len == 0) {
|
||||
printf("Peer disconnected; I'm done.\n");
|
||||
break;
|
||||
}
|
||||
printf("recv returned %d bytes\n", len);
|
||||
}
|
||||
|
||||
close(newsockfd);
|
||||
close(sockfd);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
The main loop repeatedly calls `recv` and reports what it returned (recall that `recv` returns 0 when the peer has disconnected). To try it out, we'll run this program in one terminal, and in a separate terminal connect to it with `nc`, sending a couple of short lines, separated by a delay of a couple of seconds:
|
||||
|
||||
```
|
||||
$ nc localhost 9988
|
||||
hello # wait for 2 seconds after typing this
|
||||
socket world
|
||||
^D # to end the connection>
|
||||
```
|
||||
|
||||
The listening program will print the following:
|
||||
|
||||
```
|
||||
$ ./blocking-listener 9988
|
||||
Listening on port 9988
|
||||
peer (localhost, 37284) connected
|
||||
Calling recv...
|
||||
recv returned 6 bytes
|
||||
Calling recv...
|
||||
recv returned 13 bytes
|
||||
Calling recv...
|
||||
Peer disconnected; I'm done.
|
||||
```
|
||||
|
||||
Now let's try a nonblocking version of the same listening program. Here it is:
|
||||
|
||||
```
|
||||
int main(int argc, const char** argv) {
|
||||
setvbuf(stdout, NULL, _IONBF, 0);
|
||||
|
||||
int portnum = 9988;
|
||||
if (argc >= 2) {
|
||||
portnum = atoi(argv[1]);
|
||||
}
|
||||
printf("Listening on port %d\n", portnum);
|
||||
|
||||
int sockfd = listen_inet_socket(portnum);
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd = accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
|
||||
// Set nonblocking mode on the socket.
|
||||
int flags = fcntl(newsockfd, F_GETFL, 0);
|
||||
if (flags == -1) {
|
||||
perror_die("fcntl F_GETFL");
|
||||
}
|
||||
|
||||
if (fcntl(newsockfd, F_SETFL, flags | O_NONBLOCK) == -1) {
|
||||
perror_die("fcntl F_SETFL O_NONBLOCK");
|
||||
}
|
||||
|
||||
while (1) {
|
||||
uint8_t buf[1024];
|
||||
printf("Calling recv...\n");
|
||||
int len = recv(newsockfd, buf, sizeof buf, 0);
|
||||
if (len < 0) {
|
||||
if (errno == EAGAIN || errno == EWOULDBLOCK) {
|
||||
usleep(200 * 1000);
|
||||
continue;
|
||||
}
|
||||
perror_die("recv");
|
||||
} else if (len == 0) {
|
||||
printf("Peer disconnected; I'm done.\n");
|
||||
break;
|
||||
}
|
||||
printf("recv returned %d bytes\n", len);
|
||||
}
|
||||
|
||||
close(newsockfd);
|
||||
close(sockfd);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
A couple of notable differences from the blocking version:
|
||||
|
||||
1. The `newsockfd` socket returned by `accept` is set to nonblocking mode by calling `fcntl`.
|
||||
|
||||
2. When examining the return status of `recv`, we check whether `errno` is set to a value saying that no data is available for receiving. In this case we just sleep for 200 milliseconds and continue to the next iteration of the loop.
|
||||
|
||||
The same expermient with `nc` yields the following printout from this nonblocking listener:
|
||||
|
||||
```
|
||||
$ ./nonblocking-listener 9988
|
||||
Listening on port 9988
|
||||
peer (localhost, 37288) connected
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
recv returned 6 bytes
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
recv returned 13 bytes
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Peer disconnected; I'm done.
|
||||
```
|
||||
|
||||
As an exercise, add a timestamp to the printouts and convince yourself that the total time elapsed between fruitful calls to `recv` is more or less the delay in typing the lines into `nc` (rounded to the next 200 ms).
|
||||
|
||||
So there we have it - using nonblocking `recv` makes it possible for the listener the check in with the socket, and regain control if no data is available yet. Another word to describe this in the domain of programming is _polling_ - the main program periodically polls the socket for its readiness.
|
||||
|
||||
It may seem like a potential solution to the sequential serving issue. Nonblocking `recv` makes it possible to work with multiple sockets simulatenously, polling them for data and only handling those that have new data. This is true - concurrent servers _could_ be written this way; but in reality they don't, because the polling approach scales very poorly.
|
||||
|
||||
First, the 200 ms delay I introduced in the code above is nice for the demonstration (the listener prints only a few lines of "Calling recv..." between my typing into `nc` as opposed to thousands), but it also incurs a delay of up to 200 ms to the server's response time, which is almost certainly undesirable. In real programs the delay would have to be much shorter, and the shorter the sleep, the more CPU the process consumes. These are cycles consumed for just waiting, which isn't great, especially on mobile devices where power matters.
|
||||
|
||||
But the bigger problem happens when we actually have to work with multiple sockets this way. Imagine this listener is handling 1000 clients concurrently. This means that in every loop iteration, it has to do a nonblocking `recv` on _each and every one of those 1000 sockets_ , looking for one which has data ready. This is terribly inefficient, and severely limits the number of clients this server can handle concurrently. There's a catch-22 here: the longer we wait between polls, the less responsive the server is; the shorter we wait, the more CPU resources we burn on useless polling.
|
||||
|
||||
Frankly, all this polling also feels like useless work. Surely somewhere in the OS it is known which socket is actually ready with data, so we don't have to scan all of them. Indeed, it is, and the rest of this post will showcase a couple of APIs that let us handle multiple clients much more gracefully.
|
||||
|
||||
### select
|
||||
|
||||
The `select` system call is a portable (POSIX), venerable part of the standard Unix API. It was designed precisely for the problem described towards the end of the previous section - to allow a single thread to "watch" a non-trivial number of file descriptors [[4]][17] for changes, without needlessly spinning in a polling loop. I don't plan to include a comprehensive tutorial for `select` in this post - there are many websites and book chapters for that - but I will describe its API in the context of the problem we're trying to solve, and will present a fairly complete example.
|
||||
|
||||
`select` enables _I/O multiplexing_ - monitoring multiple file descriptors to see if I/O is possible on any of them.
|
||||
|
||||
```
|
||||
int select(int nfds, fd_set *readfds, fd_set *writefds,
|
||||
fd_set *exceptfds, struct timeval *timeout);
|
||||
```
|
||||
|
||||
`readfds` points to a buffer of file descriptors we're watching for read events; `fd_set` is an opaque data structure users manipulate using `FD_*` macros. `writefds` is the same for write events. `nfds` is the highest file descriptor number (file descriptors are just integers) in the watched buffers. `timeout` lets the user specify how long `select` should block waiting for one of the file descriptors to be ready (`timeout == NULL` means block indefinitely). I'll ignore `exceptfds` for now.
|
||||
|
||||
The contract of calling `select` is as follows:
|
||||
|
||||
1. Prior to the call, the user has to create `fd_set` instances for all the different kinds of descriptors to watch. If we want to watch for both read events and write events, both `readfds` and `writefds` should be created and populated.
|
||||
|
||||
2. The user uses `FD_SET` to set specific descriptors to watch in the set. For example, if we want to watch descriptors 2, 7 and 10 for read events, we call `FD_SET` three times on `readfds`, once for each of 2, 7 and 10.
|
||||
|
||||
3. `select` is called.
|
||||
|
||||
4. When `select` returns (let's ignore timeouts for now), it says how many descriptors in the sets passed to it are ready. It also modifies the `readfds` and `writefds` sets to mark only those descriptors that are ready. All the other descriptors are cleared.
|
||||
|
||||
5. At this point the user has to iterate over `readfds` and `writefds` to find which descriptors are ready (using `FD_ISSET`).
|
||||
|
||||
As a complete example, I've reimplemented our protocol in a concurrent server that uses `select`. The [full code is here][18]; what follows is some highlights from the code, with explanations. Warning: this code sample is fairly substantial - so feel free to skip it on first reading if you're short on time.
|
||||
|
||||
### A concurrent server using select
|
||||
|
||||
Using an I/O multiplexing API like `select` imposes certain constraints on the design of our server; these may not be immediately obvious, but are worth discussing since they are key to understanding what event-driven programming is all about.
|
||||
|
||||
Most importantly, always keep in mind that such an approach is, in its core, single-threaded [[5]][19]. The server really is just doing _one thing at a time_ . Since we want to handle multiple clients concurrently, we'll have to structure the code in an unusual way.
|
||||
|
||||
First, let's talk about the main loop. How would that look? To answer this question let's imagine our server during a flurry of activity - what should it watch for? Two kinds of socket activities:
|
||||
|
||||
1. New clients trying to connect. These clients should be `accept`-ed.
|
||||
|
||||
2. Existing client sending data. This data has to go through the usual protocol described in [part 1][11], with perhaps some data being sent back.
|
||||
|
||||
Even though these two activities are somewhat different in nature, we'll have to mix them into the same loop, because there can only be one main loop. Our loop will revolve around calls to `select`. This `select` call will watch for the two kinds of events described above.
|
||||
|
||||
Here's the part of the code that sets up the file descriptor sets and kicks off the main loop with a call to `select`:
|
||||
|
||||
```
|
||||
// The "master" sets are owned by the loop, tracking which FDs we want to
|
||||
// monitor for reading and which FDs we want to monitor for writing.
|
||||
fd_set readfds_master;
|
||||
FD_ZERO(&readfds_master);
|
||||
fd_set writefds_master;
|
||||
FD_ZERO(&writefds_master);
|
||||
|
||||
// The listenting socket is always monitored for read, to detect when new
|
||||
// peer connections are incoming.
|
||||
FD_SET(listener_sockfd, &readfds_master);
|
||||
|
||||
// For more efficiency, fdset_max tracks the maximal FD seen so far; this
|
||||
// makes it unnecessary for select to iterate all the way to FD_SETSIZE on
|
||||
// every call.
|
||||
int fdset_max = listener_sockfd;
|
||||
|
||||
while (1) {
|
||||
// select() modifies the fd_sets passed to it, so we have to pass in copies.
|
||||
fd_set readfds = readfds_master;
|
||||
fd_set writefds = writefds_master;
|
||||
|
||||
int nready = select(fdset_max + 1, &readfds, &writefds, NULL, NULL);
|
||||
if (nready < 0) {
|
||||
perror_die("select");
|
||||
}
|
||||
...
|
||||
```
|
||||
|
||||
A couple of points of interest here:
|
||||
|
||||
1. Since every call to `select` overwrites the sets given to the function, the caller has to maintain a "master" set to keep track of all the active sockets it monitors across loop iterations.
|
||||
|
||||
2. Note how, initially, the only socket we care about is `listener_sockfd`, which is the original socket on which the server accepts new clients.
|
||||
|
||||
3. The return value of `select` is the number of descriptors that are ready among those in the sets passed as arguments. The sets are modified by `select` to mark ready descriptors. The next step is iterating over the descriptors.
|
||||
|
||||
```
|
||||
...
|
||||
for (int fd = 0; fd <= fdset_max && nready > 0; fd++) {
|
||||
// Check if this fd became readable.
|
||||
if (FD_ISSET(fd, &readfds)) {
|
||||
nready--;
|
||||
|
||||
if (fd == listener_sockfd) {
|
||||
// The listening socket is ready; this means a new peer is connecting.
|
||||
...
|
||||
} else {
|
||||
fd_status_t status = on_peer_ready_recv(fd);
|
||||
if (status.want_read) {
|
||||
FD_SET(fd, &readfds_master);
|
||||
} else {
|
||||
FD_CLR(fd, &readfds_master);
|
||||
}
|
||||
if (status.want_write) {
|
||||
FD_SET(fd, &writefds_master);
|
||||
} else {
|
||||
FD_CLR(fd, &writefds_master);
|
||||
}
|
||||
if (!status.want_read && !status.want_write) {
|
||||
printf("socket %d closing\n", fd);
|
||||
close(fd);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This part of the loop checks the _readable_ descriptors. Let's skip the listener socket (for the full scoop - [read the code][20]) and see what happens when one of the client sockets is ready. When this happens, we call a _callback_ function named `on_peer_ready_recv` with the file descriptor for the socket. This call means the client connected to that socket sent some data and a call to `recv` on the socket isn't expected to block [[6]][21]. This callback returns a struct of type `fd_status_t`:
|
||||
|
||||
```
|
||||
typedef struct {
|
||||
bool want_read;
|
||||
bool want_write;
|
||||
} fd_status_t;
|
||||
```
|
||||
|
||||
Which tells the main loop whether the socket should be watched for read events, write events, or both. The code above shows how `FD_SET` and `FD_CLR` are called on the appropriate descriptor sets accordingly. The code for a descriptor being ready for writing in the main loop is similar, except that the callback it invokes is called `on_peer_ready_send`.
|
||||
|
||||
Now it's time to look at the code for the callback itself:
|
||||
|
||||
```
|
||||
typedef enum { INITIAL_ACK, WAIT_FOR_MSG, IN_MSG } ProcessingState;
|
||||
|
||||
#define SENDBUF_SIZE 1024
|
||||
|
||||
typedef struct {
|
||||
ProcessingState state;
|
||||
|
||||
// sendbuf contains data the server has to send back to the client. The
|
||||
// on_peer_ready_recv handler populates this buffer, and on_peer_ready_send
|
||||
// drains it. sendbuf_end points to the last valid byte in the buffer, and
|
||||
// sendptr at the next byte to send.
|
||||
uint8_t sendbuf[SENDBUF_SIZE];
|
||||
int sendbuf_end;
|
||||
int sendptr;
|
||||
} peer_state_t;
|
||||
|
||||
// Each peer is globally identified by the file descriptor (fd) it's connected
|
||||
// on. As long as the peer is connected, the fd is uqique to it. When a peer
|
||||
// disconnects, a new peer may connect and get the same fd. on_peer_connected
|
||||
// should initialize the state properly to remove any trace of the old peer on
|
||||
// the same fd.
|
||||
peer_state_t global_state[MAXFDS];
|
||||
|
||||
fd_status_t on_peer_ready_recv(int sockfd) {
|
||||
assert(sockfd < MAXFDs);
|
||||
peer_state_t* peerstate = &global_state[sockfd];
|
||||
|
||||
if (peerstate->state == INITIAL_ACK ||
|
||||
peerstate->sendptr < peerstate->sendbuf_end) {
|
||||
// Until the initial ACK has been sent to the peer, there's nothing we
|
||||
// want to receive. Also, wait until all data staged for sending is sent to
|
||||
// receive more data.
|
||||
return fd_status_W;
|
||||
}
|
||||
|
||||
uint8_t buf[1024];
|
||||
int nbytes = recv(sockfd, buf, sizeof buf, 0);
|
||||
if (nbytes == 0) {
|
||||
// The peer disconnected.
|
||||
return fd_status_NORW;
|
||||
} else if (nbytes < 0) {
|
||||
if (errno == EAGAIN || errno == EWOULDBLOCK) {
|
||||
// The socket is not *really* ready for recv; wait until it is.
|
||||
return fd_status_R;
|
||||
} else {
|
||||
perror_die("recv");
|
||||
}
|
||||
}
|
||||
bool ready_to_send = false;
|
||||
for (int i = 0; i < nbytes; ++i) {
|
||||
switch (peerstate->state) {
|
||||
case INITIAL_ACK:
|
||||
assert(0 && "can't reach here");
|
||||
break;
|
||||
case WAIT_FOR_MSG:
|
||||
if (buf[i] == '^') {
|
||||
peerstate->state = IN_MSG;
|
||||
}
|
||||
break;
|
||||
case IN_MSG:
|
||||
if (buf[i] == '$') {
|
||||
peerstate->state = WAIT_FOR_MSG;
|
||||
} else {
|
||||
assert(peerstate->sendbuf_end < SENDBUF_SIZE);
|
||||
peerstate->sendbuf[peerstate->sendbuf_end++] = buf[i] + 1;
|
||||
ready_to_send = true;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
// Report reading readiness iff there's nothing to send to the peer as a
|
||||
// result of the latest recv.
|
||||
return (fd_status_t){.want_read = !ready_to_send,
|
||||
.want_write = ready_to_send};
|
||||
}
|
||||
```
|
||||
|
||||
A `peer_state_t` is the full state object used to represent a client connection between callback calls from the main loop. Since a callback is invoked on some partial data sent by the client, it cannot assume it will be able to communicate with the client continuously, and it has to run quickly without blocking. It never blocks because the socket is set to non-blocking mode and `recv` will always return quickly. Other than calling `recv`, all this handler does is manipulate the state - there are no additional calls that could potentially block.
|
||||
|
||||
An an exercise, can you figure out why this code needs an extra state? Our servers so far in the series managed with just two states, but this one needs three.
|
||||
|
||||
Let's also have a look at the "socket ready to send" callback:
|
||||
|
||||
```
|
||||
fd_status_t on_peer_ready_send(int sockfd) {
|
||||
assert(sockfd < MAXFDs);
|
||||
peer_state_t* peerstate = &global_state[sockfd];
|
||||
|
||||
if (peerstate->sendptr >= peerstate->sendbuf_end) {
|
||||
// Nothing to send.
|
||||
return fd_status_RW;
|
||||
}
|
||||
int sendlen = peerstate->sendbuf_end - peerstate->sendptr;
|
||||
int nsent = send(sockfd, peerstate->sendbuf, sendlen, 0);
|
||||
if (nsent == -1) {
|
||||
if (errno == EAGAIN || errno == EWOULDBLOCK) {
|
||||
return fd_status_W;
|
||||
} else {
|
||||
perror_die("send");
|
||||
}
|
||||
}
|
||||
if (nsent < sendlen) {
|
||||
peerstate->sendptr += nsent;
|
||||
return fd_status_W;
|
||||
} else {
|
||||
// Everything was sent successfully; reset the send queue.
|
||||
peerstate->sendptr = 0;
|
||||
peerstate->sendbuf_end = 0;
|
||||
|
||||
// Special-case state transition in if we were in INITIAL_ACK until now.
|
||||
if (peerstate->state == INITIAL_ACK) {
|
||||
peerstate->state = WAIT_FOR_MSG;
|
||||
}
|
||||
|
||||
return fd_status_R;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Same here - the callback calls a non-blocking `send` and performs state manipulation. In asynchronous code, it's critical for callbacks to do their work quickly - any delay blocks the main loop from making progress, and thus blocks the whole server from handling other clients.
|
||||
|
||||
Let's once again repeat a run of the server with the script that connects 3 clients simultaneously. In one terminal window we'll run:
|
||||
|
||||
```
|
||||
$ ./select-server
|
||||
```
|
||||
|
||||
In another:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-26 05:29:15,864:conn1 connected...
|
||||
INFO:2017-09-26 05:29:15,864:conn2 connected...
|
||||
INFO:2017-09-26 05:29:15,864:conn0 connected...
|
||||
INFO:2017-09-26 05:29:15,865:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-26 05:29:15,865:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-26 05:29:15,865:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-26 05:29:15,865:conn1 received b'bcdbcuf'
|
||||
INFO:2017-09-26 05:29:15,865:conn2 received b'bcdbcuf'
|
||||
INFO:2017-09-26 05:29:15,865:conn0 received b'bcdbcuf'
|
||||
INFO:2017-09-26 05:29:16,866:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-26 05:29:16,867:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-26 05:29:16,867:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-26 05:29:16,867:conn1 received b'234'
|
||||
INFO:2017-09-26 05:29:16,868:conn0 received b'234'
|
||||
INFO:2017-09-26 05:29:16,868:conn2 received b'234'
|
||||
INFO:2017-09-26 05:29:17,868:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-26 05:29:17,869:conn1 received b'36bc1111'
|
||||
INFO:2017-09-26 05:29:17,869:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-26 05:29:17,870:conn0 received b'36bc1111'
|
||||
INFO:2017-09-26 05:29:17,870:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-26 05:29:17,870:conn2 received b'36bc1111'
|
||||
INFO:2017-09-26 05:29:18,069:conn1 disconnecting
|
||||
INFO:2017-09-26 05:29:18,070:conn0 disconnecting
|
||||
INFO:2017-09-26 05:29:18,070:conn2 disconnecting
|
||||
```
|
||||
|
||||
Similarly to the threaded case, there's no delay between clients - they are all handled concurrently. And yet, there are no threads in sight in `select-server`! The main loop _multiplexes_ all the clients by efficient polling of multiple sockets using `select`. Recall the sequential vs. multi-threaded client handling diagrams from [part 2][22]. For our `select-server`, the time flow for three clients looks something like this:
|
||||
|
||||
|
||||
|
||||
All clients are handled concurrently within the same thread, by multiplexing - doing some work for a client, switching to another, then another, then going back to the original client, etc. Note that there's no specific round-robin order here - the clients are handled when they send data to the server, which really depends on the client.
|
||||
|
||||
### Synchronous, asynchronous, event-driven, callback-based
|
||||
|
||||
The `select-server` code sample provides a good background for discussing just what is meant by "asynchronous" programming, and how it relates to event-driven and callback-based programming, because all these terms are common in the (rather inconsistent) discussion of concurrent servers.
|
||||
|
||||
Let's start with a quote from `select`'s man page:
|
||||
|
||||
> select, pselect, FD_CLR, FD_ISSET, FD_SET, FD_ZERO - synchronous I/O multiplexing
|
||||
|
||||
So `select` is for _synchronous_ multiplexing. But I've just presented a substantial code sample using `select` as an example of an _asynchronous_ server; what gives?
|
||||
|
||||
The answer is: it depends on your point of view. Synchronous is often used as a synonym for blocking, and the calls to `select` are, indeed, blocking. So are the calls to `send` and `recv` in the sequential and threaded servers presented in parts 1 and 2\. So it is fair to say that `select` is a _synchronous_ API. However, the server design emerging from the use of `select` is actually _asynchronous_ , or _callback-based_ , or _event-driven_ . Note that the `on_peer_*` functions presented in this post are callbacks; they should never block, and they get invoked due to network events. They can get partial data, and are expected to retain coherent state in-between invocations.
|
||||
|
||||
If you've done any amont of GUI programming in the past, all of this is very familiar. There's an "event loop" that's often entirely hidden in frameworks, and the application's "business logic" is built out of callbacks that get invoked by the event loop due to various events - user mouse clicks, menu selections, timers firing, data arriving on sockets, etc. The most ubiquitous model of programming these days is, of course, client-side Javascript, which is written as a bunch of callbacks invoked by user activity on a web page.
|
||||
|
||||
### The limitations of select
|
||||
|
||||
Using `select` for our first example of an asynchronous server makes sense to present the concept, and also because `select` is such an ubiquitous and portable API. But it also has some significant limitations that manifest when the number of watched file descriptors is very large:
|
||||
|
||||
1. Limited file descriptor set size.
|
||||
|
||||
2. Bad performance.
|
||||
|
||||
Let's start with the file descriptor size. `FD_SETSIZE` is a compile-time constant that's usually equal to 1024 on modern systems. It's hard-coded deep in the guts of `glibc`, and isn't easy to modify. It limits the number of file descriptors a `select` call can watch to 1024\. These days folks want to write servers that handle 10s of thousands of concurrent clients and more, so this problem is real. There are workarounds, but they aren't portable and aren't easy.
|
||||
|
||||
The bad performance issue is a bit more subtle, but still very serious. Note that when `select` returns, the information it provides to the caller is the number of "ready" descriptors, and the updated descriptor sets. The descriptor sets map from desrciptor to "ready/not ready" but they don't provide a way to iterate over all the ready descriptors efficiently. If there's only a single descriptor that is ready in the set, in the worst case the caller has to iterate over _the entire set_ to find it. This works OK when the number of descriptors watched is small, but if it gets to high numbers this overhead starts hurting [[7]][23].
|
||||
|
||||
For these reasons `select` has recently fallen out of favor for writing high-performance concurrent servers. Every popular OS has its own, non-portable APIs that permit users to write much more performant event loops; higher-level interfaces like frameworks and high-level languages usually wrap these APIs in a single portable interface.
|
||||
|
||||
### epoll
|
||||
|
||||
As an example, let's look at `epoll`, Linux's solution to the high-volume I/O event notification problem. The key to `epoll`'s efficiency is greater cooperation from the kernel. Instead of using a file descriptor set, `epoll_wait`fills a buffer with events that are currently ready. Only the ready events are added to the buffer, so there is no need to iterate over _all_ the currently watched file descriptors in the client. This changes the process of discovering which descriptors are ready from O(N) in `select`'s case to O(1).
|
||||
|
||||
A full presentation of the `epoll` API is not the goal here - there are plenty of online resources for that. As you may have guessed, though, I am going to write yet another version of our concurrent server - this time using `epoll` instead of `select`. The full code sample [is here][24]. In fact, since the vast majority of the code is the same as `select-server`, I'll only focus on the novelty - the use of `epoll` in the main loop:
|
||||
|
||||
```
|
||||
struct epoll_event accept_event;
|
||||
accept_event.data.fd = listener_sockfd;
|
||||
accept_event.events = EPOLLIN;
|
||||
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listener_sockfd, &accept_event) < 0) {
|
||||
perror_die("epoll_ctl EPOLL_CTL_ADD");
|
||||
}
|
||||
|
||||
struct epoll_event* events = calloc(MAXFDS, sizeof(struct epoll_event));
|
||||
if (events == NULL) {
|
||||
die("Unable to allocate memory for epoll_events");
|
||||
}
|
||||
|
||||
while (1) {
|
||||
int nready = epoll_wait(epollfd, events, MAXFDS, -1);
|
||||
for (int i = 0; i < nready; i++) {
|
||||
if (events[i].events & EPOLLERR) {
|
||||
perror_die("epoll_wait returned EPOLLERR");
|
||||
}
|
||||
|
||||
if (events[i].data.fd == listener_sockfd) {
|
||||
// The listening socket is ready; this means a new peer is connecting.
|
||||
...
|
||||
} else {
|
||||
// A peer socket is ready.
|
||||
if (events[i].events & EPOLLIN) {
|
||||
// Ready for reading.
|
||||
...
|
||||
} else if (events[i].events & EPOLLOUT) {
|
||||
// Ready for writing.
|
||||
...
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We start by configuring `epoll` with a call to `epoll_ctl`. In this case, the configuration amounts to adding the listening socket to the descriptors `epoll` is watching for us. We then allocate a buffer of ready events to pass to `epoll` for modification. The call to `epoll_wait` in the main loop is where the magic's at. It blocks until one of the watched descriptors is ready (or until a timeout expires), and returns the number of ready descriptors. This time, however, instead of blindly iterating over all the watched sets, we know that `epoll_write` populated the `events` buffer passed to it with the ready events, from 0 to `nready-1`, so we iterate only the strictly necessary number of times.
|
||||
|
||||
To reiterate this critical difference from `select`: if we're watching 1000 descriptors and two become ready, `epoll_waits` returns `nready=2` and populates the first two elements of the `events` buffer - so we only "iterate" over two descriptors. With `select` we'd still have to iterate over 1000 descriptors to find out which ones are ready. For this reason `epoll` scales much better than `select` for busy servers with many active sockets.
|
||||
|
||||
The rest of the code is straightforward, since we're already familiar with `select-server`. In fact, all the "business logic" of `epoll-server` is exactly the same as for `select-server` - the callbacks consist of the same code.
|
||||
|
||||
This similarity is tempting to exploit by abstracting away the event loop into a library/framework. I'm going to resist this itch, because so many great programmers succumbed to it in the past. Instead, in the next post we're going to look at `libuv` - one of the more popular event loop abstractions emerging recently. Libraries like `libuv` allow us to write concurrent asynchronous servers without worrying about the greasy details of the underlying system calls.
|
||||
|
||||
* * *
|
||||
|
||||
|
||||
[[1]][1] I tried enlightening myself on the actual semantic difference between the two by doing some web browsing and reading, but got a headache fairly quickly. There are many different opinions ranging from "they're the same thing", to "one is a subset of another" to "they're completely different things". When faced with such divergent views on the semantics, it's best to abandon the issue entirely, focusing instead on specific examples and use cases.
|
||||
|
||||
[[2]][2] POSIX mandates that this can be either `EAGAIN` or `EWOULDBLOCK`, and portable applications should check for both.
|
||||
|
||||
[[3]][3] Similarly to all C samples in this series, this code uses some helper utilities to set up listening sockets. The full code for these utilities lives in the `utils` module [in the repository][4].
|
||||
|
||||
[[4]][5] `select` is not a network/socket-specific function; it watches arbitrary file descriptors, which could be disk files, pipes, terminals, sockets or anything else Unix systems represent with file descriptors. In this post we're focusing on its uses for sockets, of course.
|
||||
|
||||
[[5]][6] There are ways to intermix event-driven programming with multiple threads, but I'll defer this discussion to later in the series.
|
||||
|
||||
|
||||
[[6]][7] Due to various non-trivial reasons it could _still_ block, even after `select` says it's ready. Therefore, all sockets opened by this server are set to nonblocking mode, and if the call to `recv` or `send` returns `EAGAIN` or `EWOULDBLOCK`, the callbacks just assumed no event really happened. Read the code sample comments for more details.
|
||||
|
||||
|
||||
[[7]][8] Note that this still isn't as bad as the asynchronous polling example presented earlier in the post. The polling has to happen _all the time_ , while `select` actually blocks until one or more sockets are ready for reading/writing; far less CPU time is wasted with `select` than with repeated polling.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id3
|
||||
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id4
|
||||
[4]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/utils.h
|
||||
[5]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id5
|
||||
[6]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id6
|
||||
[7]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id8
|
||||
[8]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id9
|
||||
[9]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[10]:https://eli.thegreenplace.net/tag/c-c
|
||||
[11]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[12]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[13]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[14]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[15]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id11
|
||||
[16]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id12
|
||||
[17]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id13
|
||||
[18]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/select-server.c
|
||||
[19]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id14
|
||||
[20]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/select-server.c
|
||||
[21]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id15
|
||||
[22]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[23]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id16
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/epoll-server.c
|
||||
[25]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[26]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[27]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[28]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id10
|
||||
@ -1,6 +1,8 @@
|
||||
Create a Clean-Code App with Kotlin Coroutines and Android Architecture Components
|
||||
============================================================
|
||||
|
||||
Translating by S9mtAt
|
||||
|
||||
### Full demo weather app included.
|
||||
|
||||
Android development is evolving fast. A lot of developers and companies are trying to address common problems and create some great tools or libraries that can totally change the way we structure our apps.
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
"Translating by syys96"
|
||||
How to Install Software from Source Code… and Remove it Afterwards
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
fuzheng1998 translating
|
||||
A Large-Scale Study of Programming Languages and Code Quality in GitHub
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,177 +0,0 @@
|
||||
Translating by qhwdw Instant +100% command line productivity boost
|
||||
============================================================
|
||||
|
||||
Being productive is fun.
|
||||
|
||||
There are a lot of fields to improve your productivity. Today I am going to share some command line tips and tricks to make your life easier.
|
||||
|
||||
### TLDR
|
||||
|
||||
My full setup includes all the stuff discussed in this article and even more. Check it out: [https://github.com/sobolevn/dotfiles][9]
|
||||
|
||||
### Shell
|
||||
|
||||
Using a good, helping, and the stable shell is the key to your command line productivity. While there are many choices, I prefer `zsh` coupled with `oh-my-zsh`. It is amazing for several reasons:
|
||||
|
||||
* Autocomplete nearly everything
|
||||
|
||||
* Tons of plugins
|
||||
|
||||
* Really helping and customizable `PROMPT`
|
||||
|
||||
You can follow these steps to install this setup:
|
||||
|
||||
1. Install `zsh`: [https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH][1]
|
||||
|
||||
2. Install `oh-my-zsh`: [http://ohmyz.sh/][2]
|
||||
|
||||
3. Choose plugins that might be useful for you: [https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins][3]
|
||||
|
||||
You may also want to tweak your settings to [turn off case sensitive autocomplete][10]. Or change how your [history works][11].
|
||||
|
||||
That's it. You will gain instant +50% productivity. Now hit tab as much as you can!
|
||||
|
||||
### Theme
|
||||
|
||||
Choosing theme is quite important as well since you see it all the time. It has to be functional and pretty. I also prefer minimalistic themes, since it does not contain a lot of visual noise and unused information.
|
||||
|
||||
Your theme should show you:
|
||||
|
||||
* current folder
|
||||
|
||||
* current branch
|
||||
|
||||
* current repository status: clean or dirty
|
||||
|
||||
* error codes if any
|
||||
|
||||
I also prefer my theme to have new commands on a new line, so there is enough space to read and write it.
|
||||
|
||||
I personally use [`sobole`][12]. It looks pretty awesome. It has two modes.
|
||||
|
||||
Light:
|
||||
|
||||
[][13]
|
||||
|
||||
And dark:
|
||||
|
||||
[][14]
|
||||
|
||||
Get your another +15% boost. And an awesome-looking theme.
|
||||
|
||||
### Syntax highlighting
|
||||
|
||||
For me, it is very important to have enough visual information from my shell to make right decisions. Like "does this command have any typos in its name" or "do I have paired scopes in this command"? And I really make tpyos all the time.
|
||||
|
||||
So, [`zsh-syntax-highlighting`][15] was a big finding for me. It comes with reasonable defaults, but you can [change anything you want][16].
|
||||
|
||||
These steps brings us extra +5%.
|
||||
|
||||
### Working with files
|
||||
|
||||
I travel inside my directories a lot. Like _a lot_ . And I do all the things there:
|
||||
|
||||
* navigating back and forwards
|
||||
|
||||
* listing files and directories
|
||||
|
||||
* printing files' contents
|
||||
|
||||
I prefer to use [`z`][17] to navigate to the folders I have already been to. This tool is awesome. It uses 'frecency' method to turn your `.dot TAB` into `~/dev/shell/config/.dotfiles`. Really nice!
|
||||
|
||||
When printing files you want usually to know several things:
|
||||
|
||||
* file names
|
||||
|
||||
* permissions
|
||||
|
||||
* owner
|
||||
|
||||
* git status of the file
|
||||
|
||||
* modified date
|
||||
|
||||
* size in human readable form
|
||||
|
||||
You also probably what to show hidden files to show up by default as well. So, I use [`exa`][18] as the replacement for standard `ls`. Why? Because it has a lot of stuff enabled by default:
|
||||
|
||||
[][19]
|
||||
|
||||
To print the file contents I use standard `cat` or if I want to see to proper syntax highlighting I use a custom alias:
|
||||
|
||||
```
|
||||
# exa:
|
||||
alias la="exa -abghl --git --color=automatic"
|
||||
|
||||
# `cat` with beautiful colors. requires: pip install -U Pygments
|
||||
alias c='pygmentize -O style=borland -f console256 -g'
|
||||
```
|
||||
|
||||
Now you have mastered the navigation. Get your +15% productivity boost.
|
||||
|
||||
### Searching
|
||||
|
||||
When searching in a source code of your applications you don't want to include folders like `node_modules` or `bower_components` into your results by default. You also want your search to be fast and smooth.
|
||||
|
||||
Here's a good replacement for the built in search methods: [`the_silver_searcher`][20].
|
||||
|
||||
It is written in pure `C` and uses a lot of smart logic to work fast.
|
||||
|
||||
Using `ctrl` + `R` for [reverse search][21] in `history` is very useful. But have you ever found yourself in a situation when I can quite remember a command? What if there were a tool that makes this search even greater enabling fuzzy searching and a nice UI?
|
||||
|
||||
There is such a tool, actually. It is called `fzf`:
|
||||
|
||||
[][22]
|
||||
|
||||
It can be used to fuzzy-find anything, not just history. But it requires [some configuration][23].
|
||||
|
||||
You are now a search ninja with +15% productivity bonus.
|
||||
|
||||
### Further reading
|
||||
|
||||
Using better CLIs: [https://dev.to/sobolevn/using-better-clis-6o8][24]
|
||||
|
||||
### Conclusion
|
||||
|
||||
Following these simple steps, you can dramatically increase your command line productivity, like +100% (numbers are approximate).
|
||||
|
||||
There are other tools and hacks I will cover in the next articles.
|
||||
|
||||
Do you like reading about the latest trends in software development? Subscribe to our blog on Medium: [https://medium.com/wemake-services][25]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dev.to/sobolevn/instant-100-command-line-productivity-boost
|
||||
|
||||
作者:[Nikita Sobolev ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dev.to/sobolevn
|
||||
[1]:https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH
|
||||
[2]:http://ohmyz.sh/
|
||||
[3]:https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins
|
||||
[4]:https://dev.to/sobolevn
|
||||
[5]:http://github.com/sobolevn
|
||||
[6]:https://dev.to/t/commandline
|
||||
[7]:https://dev.to/t/dotfiles
|
||||
[8]:https://dev.to/t/productivity
|
||||
[9]:https://github.com/sobolevn/dotfiles
|
||||
[10]:https://github.com/sobolevn/dotfiles/blob/master/zshrc#L12
|
||||
[11]:https://github.com/sobolevn/dotfiles/blob/master/zshrc#L24
|
||||
[12]:https://github.com/sobolevn/sobole-zsh-theme
|
||||
[13]:https://res.cloudinary.com/practicaldev/image/fetch/s--Lz_uthoR--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/env-and-user.png
|
||||
[14]:https://res.cloudinary.com/practicaldev/image/fetch/s--4o6hZwL9--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/dark-mode.png
|
||||
[15]:https://github.com/zsh-users/zsh-syntax-highlighting
|
||||
[16]:https://github.com/zsh-users/zsh-syntax-highlighting/blob/master/docs/highlighters.md
|
||||
[17]:https://github.com/rupa/z
|
||||
[18]:https://github.com/ogham/exa
|
||||
[19]:https://res.cloudinary.com/practicaldev/image/fetch/s--n_YCO9Hj--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/ogham/exa/master/screenshots.png
|
||||
[20]:https://github.com/ggreer/the_silver_searcher
|
||||
[21]:https://unix.stackexchange.com/questions/73498/how-to-cycle-through-reverse-i-search-in-bash
|
||||
[22]:https://res.cloudinary.com/practicaldev/image/fetch/s--hykHvwjq--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://thepracticaldev.s3.amazonaws.com/i/erts5tffgo5i0rpi8q3r.png
|
||||
[23]:https://github.com/sobolevn/dotfiles/blob/master/shell/.external#L19
|
||||
[24]:https://dev.to/sobolevn/using-better-clis-6o8
|
||||
[25]:https://medium.com/wemake-services
|
||||
@ -1,283 +0,0 @@
|
||||
[Considering Python's Target Audience][40]
|
||||
============================================================
|
||||
|
||||
Who is Python being designed for?
|
||||
|
||||
* [Use cases for Python's reference interpreter][8]
|
||||
|
||||
* [Which audience does CPython primarily serve?][9]
|
||||
|
||||
* [Why is this relevant to anything?][10]
|
||||
|
||||
* [Where does PyPI fit into the picture?][11]
|
||||
|
||||
* [Why are some APIs changed when adding them to the standard library?][12]
|
||||
|
||||
* [Why are some APIs added in provisional form?][13]
|
||||
|
||||
* [Why are only some standard library APIs upgraded?][14]
|
||||
|
||||
* [Will any parts of the standard library ever be independently versioned?][15]
|
||||
|
||||
* [Why do these considerations matter?][16]
|
||||
|
||||
Several years ago, I [highlighted][38] "CPython moves both too fast and too slowly" as one of the more common causes of conflict both within the python-dev mailing list, as well as between the active CPython core developers and folks that decide that participating in that process wouldn't be an effective use of their personal time and energy.
|
||||
|
||||
I still consider that to be the case, but it's also a point I've spent a lot of time reflecting on in the intervening years, as I wrote that original article while I was still working for Boeing Defence Australia. The following month, I left Boeing for Red Hat Asia-Pacific, and started gaining a redistributor level perspective on [open source supply chain management][39] in large enterprises.
|
||||
|
||||
### [Use cases for Python's reference interpreter][17]
|
||||
|
||||
While it's a gross oversimplification, I tend to break down CPython's use cases as follows (note that these categories aren't fully distinct, they're just aimed at focusing my thinking on different factors influencing the rollout of new software features and versions):
|
||||
|
||||
* Education: educator's main interest is in teaching ways of modelling and manipulating the world computationally, _not_ writing or maintaining production software). Examples:
|
||||
* Australia's [Digital Curriculum][1]
|
||||
|
||||
* Lorena A. Barba's [AeroPython][2]
|
||||
|
||||
* Personal automation & hobby projects: software where the main, and often only, user is the individual that wrote it. Examples:
|
||||
* my Digital Blasphemy [image download notebook][3]
|
||||
|
||||
* Paul Fenwick's (Inter)National [Rick Astley Hotline][4]
|
||||
|
||||
* Organisational process automation: software where the main, and often only, user is the organisation it was originally written to benefit. Examples:
|
||||
* CPython's [core workflow tools][5]
|
||||
|
||||
* Development, build & release management tooling for Linux distros
|
||||
|
||||
* Set-and-forget infrastructure: software where, for sometimes debatable reasons, in-life upgrades to the software itself are nigh impossible, but upgrades to the underlying platform may be feasible. Examples:
|
||||
* most self-managed corporate and institutional infrastructure (where properly funded sustaining engineering plans are disturbingly rare)
|
||||
|
||||
* grant funded software (where maintenance typically ends when the initial grant runs out)
|
||||
|
||||
* software with strict certification requirements (where recertification is too expensive for routine updates to be economically viable unless absolutely essential)
|
||||
|
||||
* Embedded software systems without auto-upgrade capabilities
|
||||
|
||||
* Continuously upgraded infrastructure: software with a robust sustaining engineering model, where dependency and platform upgrades are considered routine, and no more concerning than any other code change. Examples:
|
||||
* Facebook's Python service infrastructure
|
||||
|
||||
* Rolling release Linux distributions
|
||||
|
||||
* most public PaaS and serverless environments (Heroku, OpenShift, AWS Lambda, Google Cloud Functions, Azure Cloud Functions, etc)
|
||||
|
||||
* Intermittently upgraded standard operating environments: environments that do carry out routine upgrades to their core components, but those upgrades occur on a cycle measured in years, rather than weeks or months. Examples:
|
||||
* [VFX Platform][6]
|
||||
|
||||
* LTS Linux distributions
|
||||
|
||||
* CPython and the Python standard library
|
||||
|
||||
* Infrastructure management & orchestration tools (e.g. OpenStack, Ansible)
|
||||
|
||||
* Hardware control systems
|
||||
|
||||
* Ephemeral software: software that tends to be used once and then discarded or ignored, rather than being subsequently upgraded in place. Examples:
|
||||
* Ad hoc automation scripts
|
||||
|
||||
* Single-player games with a defined "end" (once you've finished them, even if you forget to uninstall them, you probably won't reinstall them on a new device)
|
||||
|
||||
* Single-player games with little or no persistent state (if you uninstall and reinstall them, it doesn't change much about your play experience)
|
||||
|
||||
* Event-specific applications (the application was tied to a specific physical event, and once the event is over, that app doesn't matter any more)
|
||||
|
||||
* Regular use applications: software that tends to be regularly upgraded after deployment. Examples:
|
||||
* Business management software
|
||||
|
||||
* Personal & professional productivity applications (e.g. Blender)
|
||||
|
||||
* Developer tools & services (e.g. Mercurial, Buildbot, Roundup)
|
||||
|
||||
* Multi-player games, and other games with significant persistent state, but no real defined "end"
|
||||
|
||||
* Embedded software systems with auto-upgrade capabilities
|
||||
|
||||
* Shared abstraction layers: software components that are designed to make it possible to work effectively in a particular problem domain even if you don't personally grasp all the intricacies of that domain yet. Examples:
|
||||
* most runtime libraries and frameworks fall into this category (e.g. Django, Flask, Pyramid, SQL Alchemy, NumPy, SciPy, requests)
|
||||
|
||||
* many testing and type inference tools also fit here (e.g. pytest, Hypothesis, vcrpy, behave, mypy)
|
||||
|
||||
* plugins for other applications (e.g. Blender plugins, OpenStack hardware adapters)
|
||||
|
||||
* the standard library itself represents the baseline "world according to Python" (and that's an [incredibly complex][7] world view)
|
||||
|
||||
### [Which audience does CPython primarily serve?][18]
|
||||
|
||||
Ultimately, the main audiences that CPython and the standard library specifically serve are those that, for whatever reason, aren't adequately served by the combination of a more limited standard library and the installation of explicitly declared third party dependencies from PyPI.
|
||||
|
||||
To oversimplify the above review of different usage and deployment models even further, it's possible to summarise the single largest split in Python's user base as the one between those that are using Python as a _scripting language_ for some environment of interest, and those that are using it as an _application development language_ , where the eventual artifact that will be distributed is something other than the script that they're working on.
|
||||
|
||||
Typical developer behaviours when using Python as a scripting language include:
|
||||
|
||||
* the main working unit consists of a single Python file (or Jupyter notebook!), rather than a directory of Python and metadata files
|
||||
|
||||
* there's no separate build step of any kind - the script is distributed _as_ a script, similar to the way standalone shell scripts are distributed
|
||||
|
||||
* there's no separate install step (other than downloading the file to an appropriate location), as it is expected that the required runtime environment will be preconfigured on the destination system
|
||||
|
||||
* no explicit dependencies stated, except perhaps a minimum Python version, or else a statement of the expected execution environment. If dependencies outside the standard library are needed, they're expected to be provided by the environment being scripted (whether that's an operating system, a data analysis platform, or an application that embeds a Python runtime)
|
||||
|
||||
* no separate test suite, with the main test of correctness being "Did the script do what you wanted it to do with the input that you gave it?"
|
||||
|
||||
* if testing prior to live execution is needed, it will be in the form of a "dry run" or "preview" mode that conveys to the user what the software _would_ do if run that way
|
||||
|
||||
* if static code analysis tools are used at all, it's via integration into the user's software development environment, rather than being set up separately for each individual script
|
||||
|
||||
By contrast, typical developer behaviours when using Python as an application development language include:
|
||||
|
||||
* the main working unit consists of a directory of Python and metadata files, rather than a single Python file
|
||||
|
||||
* these is a separate build step to prepare the application for publication, even if it's just bundling the files together into a Python sdist, wheel or zipapp archive
|
||||
|
||||
* whether there's a separate install step to prepare the application for use will depend on how the application is packaged, and what the supported target environments are
|
||||
|
||||
* external dependencies are expressed in a metadata file, either directly in the project directory (e.g. `pyproject.toml`, `requirements.txt`, `Pipfile`), or as part of the generated publication archive (e.g. `setup.py`, `flit.ini`)
|
||||
|
||||
* a separate test suite exists, either as unit tests for the Python API, integration tests for the functional interfaces, or a combination of the two
|
||||
|
||||
* usage of static analysis tools is configured at the project level as part of its testing regime, rather than being dependent on
|
||||
|
||||
As a result of that split, the main purpose that CPython and the standard library end up serving is to define the redistributor independent baseline of assumed functionality for educational and ad hoc Python scripting environments 3-5 years after the corresponding CPython feature release.
|
||||
|
||||
For ad hoc scripting use cases, that 3-5 year latency stems from a combination of delays in redistributors making new releases available to their users, and users of those redistributed versions taking time to revise their standard operating environments.
|
||||
|
||||
In the case of educational environments, educators need that kind of time to review the new features and decide whether or not to incorporate them into the courses they offer their students.
|
||||
|
||||
### [Why is this relevant to anything?][19]
|
||||
|
||||
This post was largely inspired by the Twitter discussion following on from [this comment of mine][20] citing the Provisional API status defined in [PEP 411][21] as an example of an open source project issuing a de facto invitation to users to participate more actively in the design & development process as co-creators, rather than only passively consuming already final designs.
|
||||
|
||||
The responses included several expressions of frustration regarding the difficulty of supporting provisional APIs in higher level libraries, without those libraries making the provisional status transitive, and hence limiting support for any related features to only the latest version of the provisional API, and not any of the earlier iterations.
|
||||
|
||||
My [main reaction][22] was to suggest that open source publishers should impose whatever support limitations they need to impose to make their ongoing maintenance efforts personally sustainable. That means that if supporting older iterations of provisional APIs is a pain, then they should only be supported if the project developers themselves need that, or if somebody is paying them for the inconvenience. This is similar to my view on whether or not volunteer-driven projects should support older commercial LTS Python releases for free when it's a hassle for them to do: I [don't think they should][23], as I expect most such demands to be stemming from poorly managed institutional inertia, rather than from genuine need (and if the need _is_ genuine, then it should instead be possible to find some means of paying to have it addressed).
|
||||
|
||||
However, my [second reaction][24], was to realise that even though I've touched on this topic over the years (e.g. in the original 2011 article linked above, as well as in Python 3 Q & A answers [here][25], [here][26], and [here][27], and to a lesser degree in last year's article on the [Python Packaging Ecosystem][28]), I've never really attempted to directly explain the impact it has on the standard library design process.
|
||||
|
||||
And without that background, some aspects of the design process, such as the introduction of provisional APIs, or the introduction of inspired-by-but-not-the-same-as, seem completely nonsensical, as they appear to be an attempt to standardise APIs without actually standardising them.
|
||||
|
||||
### [Where does PyPI fit into the picture?][29]
|
||||
|
||||
The first hurdle that _any_ proposal sent to python-ideas or python-dev has to clear is answering the question "Why isn't a module on PyPI good enough?". The vast majority of proposals fail at this step, but there are several common themes for getting past it:
|
||||
|
||||
* rather than downloading a suitable third party library, novices may be prone to copying & pasting bad advice from the internet at large (e.g. this is why the `secrets` library now exists: to make it less likely people will use the `random` module, which is intended for games and statistical simulations, for security-sensitive purposes)
|
||||
|
||||
* the module is intended to provide a reference implementation and to enable interoperability between otherwise competing implementations, rather than necessarily being all things to all people (e.g. `asyncio`, `wsgiref`, `unittest``, and `logging` all fall into this category)
|
||||
|
||||
* the module is intended for use in other parts of the standard library (e.g. `enum` falls into this category, as does `unittest`)
|
||||
|
||||
* the module is designed to support a syntactic addition to the language (e.g. the `contextlib`, `asyncio` and `typing` modules fall into this category)
|
||||
|
||||
* the module is just plain useful for ad hoc scripting purposes (e.g. `pathlib`, and `ipaddress` fall into this category)
|
||||
|
||||
* the module is useful in an educational context (e.g. the `statistics` module allows for interactive exploration of statistic concepts, even if you wouldn't necessarily want to use it for full-fledged statistical analysis)
|
||||
|
||||
Passing this initial "Is PyPI obviously good enough?" check isn't enough to ensure that a module will be accepted for inclusion into the standard library, but it's enough to shift the question to become "Would including the proposed library result in a net improvement to the typical introductory Python software developer experience over the next few years?"
|
||||
|
||||
The introduction of `ensurepip` and `venv` modules into the standard library also makes it clear to redistributors that we expect Python level packaging and installation tools to be supported in addition to any platform specific distribution mechanisms.
|
||||
|
||||
### [Why are some APIs changed when adding them to the standard library?][30]
|
||||
|
||||
While existing third party modules are sometimes adopted wholesale into the standard library, in other cases, what actually gets added is a redesigned and reimplemented API that draws on the user experience of the existing API, but drops or revises some details based on the additional design considerations and privileges that go with being part of the language's reference implementation.
|
||||
|
||||
For example, unlike its popular third party predecessor, `path.py`, ``pathlib` does _not_ define string subclasses, but instead independent types. Solving the resulting interoperability challenges led to the definition of the filesystem path protocol, allowing a wider range of objects to be used with interfaces that work with filesystem paths.
|
||||
|
||||
The API design for the `ipaddress` module was adjusted to explicitly separate host interface definitions (IP addresses associated with particular IP networks) from the definitions of addresses and networks in order to serve as a better tool for teaching IP addressing concepts, whereas the original `ipaddr` module is less strict in the way it uses networking terminology.
|
||||
|
||||
In other cases, standard library modules are constructed as a synthesis of multiple existing approaches, and may also rely on syntactic features that didn't exist when the APIs for pre-existing libraries were defined. Both of these considerations apply for the `asyncio` and `typing` modules, while the latter consideration applies for the `dataclasses` API being considered in PEP 557 (which can be summarised as "like attrs, but using variable annotations for field declarations").
|
||||
|
||||
The working theory for these kinds of changes is that the existing libraries aren't going away, and their maintainers often aren't all that interested in putitng up with the constraints associated with standard library maintenance (in particular, the relatively slow release cadence). In such cases, it's fairly common for the documentation of the standard library version to feature a "See Also" link pointing to the original module, especially if the third party version offers additional features and flexibility that were omitted from the standard library module.
|
||||
|
||||
### [Why are some APIs added in provisional form?][31]
|
||||
|
||||
While CPython does maintain an API deprecation policy, we generally prefer not to use it without a compelling justification (this is especially the case while other projects are attempting to maintain compatibility with Python 2.7).
|
||||
|
||||
However, when adding new APIs that are inspired by existing third party ones without being exact copies of them, there's a higher than usual risk that some of the design decisions may turn out to be problematic in practice.
|
||||
|
||||
When we consider the risk of such changes to be higher than usual, we'll mark the related APIs as provisional, indicating that conservative end users may want to avoid relying on them at all, and that developers of shared abstraction layers may want to consider imposing stricter than usual constraints on which versions of the provisional API they're prepared to support.
|
||||
|
||||
### [Why are only some standard library APIs upgraded?][32]
|
||||
|
||||
The short answer here is that the main APIs that get upgraded are those where:
|
||||
|
||||
* there isn't likely to be a lot of external churn driving additional updates
|
||||
|
||||
* there are clear benefits for either ad hoc scripting use cases or else in encouraging future interoperability between multiple third party solutions
|
||||
|
||||
* a credible proposal is submitted by folks interested in doing the work
|
||||
|
||||
If the limitations of an existing module are mainly noticeable when using the module for application development purposes (e.g. `datetime`), if redistributors already tend to make an improved alternative third party option readily available (e.g. `requests`), or if there's a genuine conflict between the release cadence of the standard library and the needs of the package in question (e.g. `certifi`), then the incentives to propose a change to the standard library version tend to be significantly reduced.
|
||||
|
||||
This is essentially the inverse to the question about PyPI above: since PyPI usually _is_ a sufficiently good distribution mechanism for application developer experience enhancements, it makes sense for such enhancements to be distributed that way, allowing redistributors and platform providers to make their own decisions about what they want to include as part of their default offering.
|
||||
|
||||
Changing CPython and the standard library only comes into play when there is perceived value in changing the capabilities that can be assumed to be present by default in 3-5 years time.
|
||||
|
||||
### [Will any parts of the standard library ever be independently versioned?][33]
|
||||
|
||||
Yes, it's likely the bundling model used for `ensurepip` (where CPython releases bundle a recent version of `pip` without actually making it part of the standard library) may be applied to other modules in the future.
|
||||
|
||||
The most probable first candidate for that treatment would be the `distutils` build system, as switching to such a model would allow the build system to be more readily kept consistent across multiple releases.
|
||||
|
||||
Other potential candidates for this kind of treatment would be the Tcl/Tk graphics bindings, and the IDLE editor, which are already unbundled and turned into an optional addon installations by a number of redistributors.
|
||||
|
||||
### [Why do these considerations matter?][34]
|
||||
|
||||
By the very nature of things, the folks that tend to be most actively involved in open source development are those folks working on open source applications and shared abstraction layers.
|
||||
|
||||
The folks writing ad hoc scripts or designing educational exercises for their students often won't even think of themselves as software developers - they're teachers, system administrators, data analysts, quants, epidemiologists, physicists, biologists, business analysts, market researchers, animators, graphical designers, etc.
|
||||
|
||||
When all we have to worry about for a language is the application developer experience, then we can make a lot of simplifying assumptions around what people know, the kinds of tools they're using, the kinds of development processes they're following, and the ways they're going to be building and deploying their software.
|
||||
|
||||
Things get significantly more complicated when an application runtime _also_ enjoys broad popularity as a scripting engine. Doing either job well is already difficult, and balancing the needs of both audiences as part of a single project leads to frequent incomprehension and disbelief on both sides.
|
||||
|
||||
This post isn't intended to claim that we never make incorrect decisions as part of the CPython development process - it's merely pointing out that the most reasonable reaction to seemingly nonsensical feature additions to the Python standard library is going to be "I'm not part of the intended target audience for that addition" rather than "I have no interest in that, so it must be a useless and pointless addition of no value to anyone, added purely to annoy me".
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html
|
||||
|
||||
作者:[Nick Coghlan ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.curiousefficiency.org/pages/about.html
|
||||
[1]:https://aca.edu.au/#home-unpack
|
||||
[2]:https://github.com/barbagroup/AeroPython
|
||||
[3]:https://nbviewer.jupyter.org/urls/bitbucket.org/ncoghlan/misc/raw/default/notebooks/Digital%20Blasphemy.ipynb
|
||||
[4]:https://github.com/pjf/rickastley
|
||||
[5]:https://github.com/python/core-workflow
|
||||
[6]:http://www.vfxplatform.com/
|
||||
[7]:http://www.curiousefficiency.org/posts/2015/10/languages-to-improve-your-python.html#broadening-our-horizons
|
||||
[8]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#use-cases-for-python-s-reference-interpreter
|
||||
[9]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#which-audience-does-cpython-primarily-serve
|
||||
[10]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-is-this-relevant-to-anything
|
||||
[11]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#where-does-pypi-fit-into-the-picture
|
||||
[12]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-changed-when-adding-them-to-the-standard-library
|
||||
[13]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-added-in-provisional-form
|
||||
[14]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-only-some-standard-library-apis-upgraded
|
||||
[15]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#will-any-parts-of-the-standard-library-ever-be-independently-versioned
|
||||
[16]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-do-these-considerations-matter
|
||||
[17]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id1
|
||||
[18]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id2
|
||||
[19]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id3
|
||||
[20]:https://twitter.com/ncoghlan_dev/status/916994106819088384
|
||||
[21]:https://www.python.org/dev/peps/pep-0411/
|
||||
[22]:https://twitter.com/ncoghlan_dev/status/917092464355241984
|
||||
[23]:http://www.curiousefficiency.org/posts/2015/04/stop-supporting-python26.html
|
||||
[24]:https://twitter.com/ncoghlan_dev/status/917088410162012160
|
||||
[25]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#wouldn-t-a-python-2-8-release-help-ease-the-transition
|
||||
[26]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#doesn-t-this-make-python-look-like-an-immature-and-unstable-platform
|
||||
[27]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#what-about-insert-other-shiny-new-feature-here
|
||||
[28]:http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html
|
||||
[29]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id4
|
||||
[30]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id5
|
||||
[31]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id6
|
||||
[32]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id7
|
||||
[33]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id8
|
||||
[34]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id9
|
||||
[35]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
|
||||
[36]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#disqus_thread
|
||||
[37]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.rst
|
||||
[38]:http://www.curiousefficiency.org/posts/2011/04/musings-on-culture-of-python-dev.html
|
||||
[39]:http://community.redhat.com/blog/2015/02/the-quid-pro-quo-of-open-infrastructure/
|
||||
[40]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
|
||||
@ -1,4 +1,5 @@
|
||||
translating by firmianay
|
||||
translating---geekpi
|
||||
|
||||
|
||||
Examining network connections on Linux systems
|
||||
============================================================
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by sugarfillet
|
||||
Linux Networking Hardware for Beginners: Think Software
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
translating by 2ephaniah
|
||||
translating---geekpi
|
||||
|
||||
|
||||
Proxy Models in Container Environments
|
||||
============================================================
|
||||
|
||||
@ -1,128 +0,0 @@
|
||||
How to implement cloud-native computing with Kubernetes
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Kubernetes and containers can speed up the development process while minimizing programmer and system administration costs, say representatives of the Open Container Initiative and the Cloud Native Computing Foundation. To take advantage of Kubernetes and its related tools to run a cloud-native architecture, start with unappreciated Kubernetes features like namespaces.
|
||||
|
||||
[Kubernetes][2] is far more than a cloud-container manager. As Steve Pousty, [Red Hat's][3] lead developer advocate for [OpenShift][4], explained in a presentation at [the Linux Foundation's][5] [Open Source Summit][6], Kubernetes serves as a "common operating plane for cloud-native computing using containers."
|
||||
|
||||
What does Pousty mean by that? Let's review the basics.
|
||||
|
||||
“Cloud-native computing uses an open source software stack to deploy applications as microservices, package each part into its own container, and dynamically orchestrate those containers to optimize resource utilization,” explains Chris Aniszczyk, executive director of the [Open Container Initiative][7] (OCI) and the [Cloud Native Computing Foundation][8] (CNCF). [Kubernetes takes care of that last element][9] of cloud-native computing. The result is part of a larger transition in IT, moving from servers to virtual machines to buildpacks—and now to [containers][10].
|
||||
|
||||
This data center evolution has netted significant cost savings, in part because it requires fewer dedicated staff, conference presenters say. For example, by using Kubernetes, Google needs only one site reliability engineer per 10,000 machines, according to Aniszczyk.
|
||||
|
||||
Practically speaking, however, system administrators can take advantage of new Kubernetes-related tools and exploit under-appreciated features.
|
||||
|
||||
### Building a native cloud platform
|
||||
|
||||
Pousty explained, "For Red Hat, Kubernetes is the cloud Linux kernel. It's this infrastructure that everybody's going to build on."
|
||||
|
||||
For an example, let's say you have an application within a container image. How do you know it's safe? Red Hat and other companies use [OpenSCAP][11], which is based on the [Security Content Automation Protocol][12] (SCAP), a specification for expressing and manipulating security data in standardized ways. The OpenSCAP project provides open source hardening guides and configuration baselines. You select an appropriate security policy, then use OpenSCAP-approved security tools to make certain the programs within your Kubernetes-controlled containers comply with those customized security standards.
|
||||
|
||||
Unsure how to get started with containers? Yes, we have a guide for that.
|
||||
|
||||
[Get Containers for Dummies][1]
|
||||
|
||||
Red Hat automated this process further using [Atomic Scan][13]; it works with any OpenSCAP provider to scan container images for known security vulnerabilities and policy configuration problems. Atomic Scan mounts read-only file systems. These are passed to the scanning container, along with a writeable directory for the scanner's output.
|
||||
|
||||
This approach has several advantages, Pousty pointed out, primarily, "You can scan a container image without having to actually run it." So, if there is bad code or a flawed security policy within the container, it can't do anything to your system.
|
||||
|
||||
Atomic Scan works much faster than running OpenSCAP manually. Since containers tend to be spun up and destroyed in minutes or hours, Atomic Scan enables Kubernetes users to keep containers secure in container time rather than the much-slower sysadmin time.
|
||||
|
||||
### Tool time
|
||||
|
||||
Another tool that help sysadmins and DevOps make the most of Kubernetes is [CRI-O][14]. This is an OCI-based implementation of the [Kubernetes Container Runtime Interface][15]. CRI-O is a daemon that Kubernetes can use for running container images stored on Docker registries, explains Dan Walsh, a Red Hat consulting engineer and [SELinux][16] project lead. It enables you to launch container images directly from Kubernetes instead of spending time and CPU cycles on launching the [Docker Engine][17]. And it’s image format agnostic.
|
||||
|
||||
In Kubernetes, [kubelets][18] manage pods, or containers’ clusters. With CRI-O, Kubernetes and its kubelets can manage the entire container lifecycle. The tool also isn't wedded to Docker images; you can also use the new [OCI Image Format][19] and [CoreOS's rkt][20] container images.
|
||||
|
||||
Together, these tools are becoming a Kubernetes stack: the orchestrator, the [Container Runtime Interface][21] (CRI), and CRI-O. Lead Kubernetes engineer Kelsey Hightower says, "We don’t really need much from any container runtime—whether it’s Docker or [rkt][22]. Just give us an API to the kernel." The result, promise these techies, is the power to spin containers faster than ever.
|
||||
|
||||
Kubernetes is also speeding up building container images. Until recently, there were [three ways to build containers][23]. The first way is to build container images in place via a Docker or CoreOS. The second approach is to inject custom code into a prebuilt image. Finally, Asset Generation Pipelines use containers to compile assets that are then included during a subsequent image build using Docker's [Multi-Stage Builds][24].
|
||||
|
||||
Now, there's a Kubernetes-native method: Red Hat's [Buildah][25], [a scriptable shell tool][26] for efficiently and quickly building OCI-compliant images and containers. Buildah simplifies creating, building, and updating images while decreasing the learning curve of the container environment, Pousty said. You can use it with Kubernetes to create and spin up containers automatically based on an application's calls. Buildah also saves system resources, because it does not require a container runtime daemon.
|
||||
|
||||
So, rather than actually booting a container and doing all sorts of steps in the container itself, Pousty said, “you mount the file system, do normal operations on your machine as if it were your normal file system, and then commit at the end."
|
||||
|
||||
What this means is that you can pull down an image from a registry, create its matching container, and customize it. Then you can use Buildah within Kubernetes to create new running images as you need them. The end result, he said, is even more speed for running Kubernetes-managed containerized applications, requiring fewer resources.
|
||||
|
||||
### Kubernetes features you didn’t know you had
|
||||
|
||||
You don’t necessarily need to look for outside tools. Kubernetes has several underappreciated features.
|
||||
|
||||
One of them, according to Allan Naim, a Google Cloud global product lead, is [Kubernetes namespaces][27]. In his Open Source Summit speech on Kubernetes best practices, Naim said, "Few people use namespaces—and that's a mistake."
|
||||
|
||||
“Namespaces are the way to partition a single Kubernetes cluster into multiple virtual clusters," said Naim. For example, "you can think of namespaces as family names." So, if "Smith" identifies a family, one member, say, Steve Smith, is just “Steve,” but outside the confines of the family, he's "Steve Smith" or perhaps "Steve Smith from Chicago.”
|
||||
|
||||
More technically, "namespaces are a logical partitioning capability that enable one Kubernetes cluster to be used by multiple users, teams of users, or a single user with multiple applications without confusion,” Naim explained. “Each user, team of users, or application may exist within its namespace, isolated from every other user of the cluster and operating as if it were the sole user of the cluster.”
|
||||
|
||||
Practically speaking, you can use namespaces to mold an enterprise's multiple business/technology entities onto Kubernetes. For example, cloud architects can define the corporate namespace strategy by mapping product, location, team, and cost-center namespaces.
|
||||
|
||||
Another approach Naim suggested is to use namespaces to partition software development pipelines into discrete namespaces. These could be such familiar units as testing, quality assurance, staging, and production. Or namespaces can be used to manage separate customers. For instance, you could create a separate namespace for each customer, customer project, or customer business unit. That makes it easier to distinguish between projects and avoid reusing the same names for resources.
|
||||
|
||||
However, Kubernetes doesn't currently provide a mechanism to enforce access controls across namespaces. Therefore, Naim recommended you don't externally expose programs using this approach. Also keep in mind that namespaces aren't a management cure-all. For example, you can't nest namespaces within one other. In addition, there's no mechanism to enforce security across namespaces.
|
||||
|
||||
Still, used with care, namespaces can be quite useful.
|
||||
|
||||
### Human-centered tips
|
||||
|
||||
Moving from deep technology to project management, Pousty suggested that, in the move to a cloud-native and microservice architecture, you put an operations person on your microservice team. “If you're going to do microservices, your team will end up doing Ops-y work. And, it's kind of foolish not to bring in someone who already knows operations,” he said. “You need the right core competencies on that team. I don't want developers to reinvent the operations wheel."
|
||||
|
||||
Instead, reinvent your work process into one that enables you to make the most from containers and clouds. For that, Kubernetes is great.
|
||||
|
||||
### Cloud-native computing with Kubernetes: Lessons for leaders
|
||||
|
||||
* The cloud-native ecosystem is expanding rapidly. Look for tools that can extend the ways you use containers.
|
||||
|
||||
* Explore less well-known Kubernetes features such as namespaces. They can improve your organization and automation.
|
||||
|
||||
* Make sure development teams deploying to containers have an Ops person involved. Otherwise strife will ensue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Steven J. Vaughan-Nichols, CEO, Vaughan-Nichols & Associates
|
||||
|
||||
Steven J. Vaughan-Nichols, aka sjvn, has been writing about technology and the business of technology since CP/M-80 was the cutting edge, PC operating system; 300bps was a fast Internet connection; WordStar was the state of the art word processor; and we liked it. His work has been published in everything from highly technical publications (IEEE Computer, ACM NetWorker, Byte) to business publications (eWEEK, InformationWeek, ZDNet) to popular technology (Computer Shopper, PC Magazine, PC World) to the mainstream press (Washington Post, San Francisco Chronicle, BusinessWeek).
|
||||
|
||||
---------------------
|
||||
|
||||
|
||||
via: https://insights.hpe.com/articles/how-to-implement-cloud-native-computing-with-kubernetes-1710.html
|
||||
|
||||
作者:[ Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.hpe.com/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_insights~510287587~Containers_Dummies~sjvn_Kubernetes
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.redhat.com/en
|
||||
[4]:https://www.openshift.com/
|
||||
[5]:https://www.linuxfoundation.org/
|
||||
[6]:http://events.linuxfoundation.org/events/open-source-summit-north-america
|
||||
[7]:https://www.opencontainers.org/
|
||||
[8]:https://www.cncf.io/
|
||||
[9]:https://insights.hpe.com/articles/the-basics-explaining-kubernetes-mesosphere-and-docker-swarm-1702.html
|
||||
[10]:https://insights.hpe.com/articles/when-to-use-containers-and-when-not-to-1705.html
|
||||
[11]:https://www.open-scap.org/
|
||||
[12]:https://scap.nist.gov/
|
||||
[13]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||
[14]:http://cri-o.io/
|
||||
[15]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[16]:https://wiki.centos.org/HowTos/SELinux
|
||||
[17]:https://docs.docker.com/engine/
|
||||
[18]:https://kubernetes.io/docs/admin/kubelet/
|
||||
[19]:http://www.zdnet.com/article/containers-consolidation-open-container-initiative-1-0-released/
|
||||
[20]:https://coreos.com/rkt/docs/latest/
|
||||
[21]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[22]:https://coreos.com/rkt/
|
||||
[23]:http://chris.collins.is/2017/02/24/three-docker-build-strategies/
|
||||
[24]:https://docs.docker.com/engine/userguide/eng-image/multistage-build/#use-multi-stage-builds
|
||||
[25]:https://github.com/projectatomic/buildah
|
||||
[26]:https://www.projectatomic.io/blog/2017/06/introducing-buildah/
|
||||
[27]:https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||
@ -1,98 +0,0 @@
|
||||
XYenChi is translating
|
||||
Image Processing on Linux
|
||||
============================================================
|
||||
|
||||
|
||||
I've covered several scientific packages in this space that generate nice graphical representations of your data and work, but I've not gone in the other direction much. So in this article, I cover a popular image processing package called ImageJ. Specifically, I am looking at [Fiji][4], an instance of ImageJ bundled with a set of plugins that are useful for scientific image processing.
|
||||
|
||||
The name Fiji is a recursive acronym, much like GNU. It stands for "Fiji Is Just ImageJ". ImageJ is a useful tool for analyzing images in scientific research—for example, you may use it for classifying tree types in a landscape from aerial photography. ImageJ can do that type categorization. It's built with a plugin architecture, and a very extensive collection of plugins is available to increase the available functionality.
|
||||
|
||||
The first step is to install ImageJ (or Fiji). Most distributions will have a package available for ImageJ. If you wish, you can install it that way and then install the individual plugins you need for your research. The other option is to install Fiji and get the most commonly used plugins at the same time. Unfortunately, most Linux distributions will not have a package available within their package repositories for Fiji. Luckily, however, an easy installation file is available from the main website. It's a simple zip file, containing a directory with all of the files required to run Fiji. When you first start it, you get only a small toolbar with a list of menu items (Figure 1).
|
||||
|
||||

|
||||
|
||||
Figure 1\. You get a very minimal interface when you first start Fiji.
|
||||
|
||||
If you don't already have some images to use as you are learning to work with ImageJ, the Fiji installation includes several sample images. Click the File→Open Samples menu item for a dropdown list of sample images (Figure 2). These samples cover many of the potential tasks you might be interested in working on.
|
||||
|
||||

|
||||
|
||||
Figure 2\. Several sample images are available that you can use as you learn how to work with ImageJ.
|
||||
|
||||
If you installed Fiji, rather than ImageJ alone, a large set of plugins already will be installed. The first one of note is the autoupdater plugin. This plugin checks the internet for updates to ImageJ, as well as the installed plugins, each time ImageJ is started.
|
||||
|
||||
All of the installed plugins are available under the Plugins menu item. Once you have installed a number of plugins, this list can become a bit unwieldy, so you may want to be judicious in your plugin selection. If you want to trigger the updates manually, click the Help→Update Fiji menu item to force the check and get a list of available updates (Figure 3).
|
||||
|
||||

|
||||
|
||||
Figure 3\. You can force a manual check of what updates are available.
|
||||
|
||||
Now, what kind of work can you do with Fiji/ImageJ? One example is doing counts of objects within an image. You can load a sample by clicking File→Open Samples→Embryos.
|
||||
|
||||

|
||||
|
||||
Figure 4\. With ImageJ, you can count objects within an image.
|
||||
|
||||
The first step is to set a scale to the image so you can tell ImageJ how to identify objects. First, select the line button on the toolbar and draw a line over the length of the scale legend on the image. You then can select Analyze→Set Scale, and it will set the number of pixels that the scale legend occupies (Figure 5). You can set the known distance to be 100 and the units to be "um".
|
||||
|
||||

|
||||
|
||||
Figure 5\. For many image analysis tasks, you need to set a scale to the image.
|
||||
|
||||
The next step is to simplify the information within the image. Click Image→Type→8-bit to reduce the information to an 8-bit gray-scale image. To isolate the individual objects, click Process→Binary→Make Binary to threshold the image automatically (Figure 6).
|
||||
|
||||

|
||||
|
||||
Figure 6\. There are tools to do automatic tasks like thresholding.
|
||||
|
||||
Before you can count the objects within the image, you need to remove artifacts like the scale legend. You can do that by using the rectangular selection tool to select it and then click Edit→Clear. Now you can analyze the image and see what objects are there.
|
||||
|
||||
Making sure that there are no areas selected in the image, click Analyze→Analyze Particles to pop up a window where you can select the minimum size, what results to display and what to show in the final image (Figure 7).
|
||||
|
||||

|
||||
|
||||
Figure 7\. You can generate a reduced image with identified particles.
|
||||
|
||||
Figure 8 shows an overall look at what was discovered in the summary results window. There is also a detailed results window for each individual particle.
|
||||
|
||||

|
||||
|
||||
Figure 8\. One of the output results includes a summary list of the particles identified.
|
||||
|
||||
Once you have an analysis worked out for a given image type, you often need to apply the exact same analysis to a series of images. This series may number into the thousands, so it's typically not something you will want to repeat manually for each image. In such cases, you can collect the required steps together into a macro so that they can be reapplied multiple times. Clicking Plugins→Macros→Record pops up a new window where all of your subsequent commands will be recorded. Once all of the steps are finished, you can save them as a macro file and rerun them on other images by clicking Plugins→Macros→Run.
|
||||
|
||||
If you have a very specific set of steps for your workflow, you simply can open the macro file and edit it by hand, as it is a simple text file. There is actually a complete macro language available to you to control the process that is being applied to your images more fully.
|
||||
|
||||
If you have a really large set of images that needs to be processed, however, this still might be too tedious for your workflow. In that case, go to Process→Batch→Macro to pop up a new window where you can set up your batch processing workflow (Figure 9).
|
||||
|
||||

|
||||
|
||||
Figure 9\. You can run a macro on a batch of input image files with a single command.
|
||||
|
||||
From this window, you can select which macro file to apply, the source directory where the input images are located and the output directory where you want the output images to be written. You also can set the output file format and filter the list of images being used as input based on what the filename contains. Once everything is done, start the batch run by clicking the Process button at the bottom of the window.
|
||||
|
||||
If this is a workflow that will be repeated over time, you can save the batch process to a text file by clicking the Save button at the bottom of the window. You then can reload the same workflow by clicking the Open button, also at the bottom of the window. All of this functionality allows you to automate the most tedious parts of your research so you can focus on the actual science.
|
||||
|
||||
Considering that there are more than 500 plugins and more than 300 macros available from the main ImageJ website alone, it is an understatement that I've been able to touch on only the most basic of topics in this short article. Luckily, many domain-specific tutorials are available, along with the very good documentation for the core of ImageJ from the main project website. If you think this tool could be of use to your research, there is a wealth of information to guide you in your particular area of study.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Joey Bernard has a background in both physics and computer science. This serves him well in his day job as a computational research consultant at the University of New Brunswick. He also teaches computational physics and parallel programming.
|
||||
|
||||
--------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/image-processing-linux
|
||||
|
||||
作者:[Joey Bernard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxjournal.com/users/joey-bernard
|
||||
[1]:https://www.linuxjournal.com/tag/science
|
||||
[2]:https://www.linuxjournal.com/tag/statistics
|
||||
[3]:https://www.linuxjournal.com/users/joey-bernard
|
||||
[4]:https://imagej.net/Fiji
|
||||
@ -1,82 +0,0 @@
|
||||
How containers and microservices change security
|
||||
============================================================
|
||||
|
||||
### Cloud-native applications and infrastructure require a radically different approach to security. Keep these best practices in mind
|
||||
|
||||

|
||||
>thinkstock
|
||||
|
||||
|
||||
|
||||
Today organizations large and small are exploring the adoption of cloud-native software technologies. “Cloud-native” refers to an approach that packages software within standardized units called containers, arranges those units into microservices that interface with each other to form applications, and ensures that running applications are fully automated for greater speed, agility, and scalability.
|
||||
|
||||
Because this approach fundamentally changes how software is built, deployed, and run, it also fundamentally changes how software needs to be protected. Cloud-native applications and infrastructure create several new challenges for security professionals, who will need to establish new security programs that support their organization’s use of cloud-native technologies.
|
||||
|
||||
Let’s take a look at those challenges, and then we’ll discuss a number of best practices security teams should adopt to address them. First the challenges:
|
||||
|
||||
* **Traditional security infrastructure lacks container visibility. **Most existing host-based and network security tools do not have the ability to monitor or capture container activity. These tools were built to secure single operating systems or the traffic between host machines rather than the applications running above, resulting in a loss of visibility into container events, system interactions, and inter-container traffic.
|
||||
|
||||
* **Attack surfaces can change rapidly.** Cloud-native applications are made up of many smaller components called microservices that are highly distributed, each of which must be individually audited and secured. Because these applications are designed to be provisioned and scaled by orchestration systems, their attack surfaces change constantly—and far faster than traditional monolithic applications.
|
||||
|
||||
* **Distributed data flows require continuous monitoring.**Containers and microservices are designed to be lightweight and to interconnect programmatically with each other or external cloud services. This generates large volumes of fast-moving data across the environment to be continuously monitored for indicators of attack and compromise as well as unauthorized data access or exfiltration.
|
||||
|
||||
* **Detection, prevention, and response must be automated. **The speed and volume of events generated by containers overwhelms current security operations workflows. The ephemeral life spans of containers also make it difficult to capture, analyze, and determine the root cause of incidents. Effective threat protection means automating data collection, filtering, correlation, and analysis to be able to react fast enough to new incidents.
|
||||
|
||||
Faced with these new challenges, security professionals will need to establish new security programs that support their organization’s use of cloud-native technologies. Naturally, your security program should address the entire lifecycle of cloud-native applications, which can be split into two distinct phases: the build and deploy phase, and the runtime phase. Each of these phases has a different set of security considerations that must be addressed to form a comprehensive security program.
|
||||
|
||||
|
||||
### Securing container builds and deployment
|
||||
|
||||
Security for the build and deploy phase focuses on applying controls to developer workflows and continuous integration and deployment pipelines to mitigate the risk of security issues that may arise after containers have been launched. These controls can incorporate the following guidelines and best practices:
|
||||
|
||||
* **Keep images as small as possible. **A container image is a lightweight executable that packages application code and its dependencies. Restricting each image to only what is essential for software to run minimizes the attack surface for every container launched from the image. Starting with minimal operating system base images such as Alpine Linux can reduce image sizes and make images easier to manage.
|
||||
|
||||
* **Scan images for known issues. **As images get built, they should be checked for known vulnerabilities and exposures. Each file system layer that makes up an image can be scanned and the results compared to a Common Vulnerabilities and Exposures (CVE) database that is regularly updated. Development and security teams can then address discovered vulnerabilities before the images are used to launch containers.
|
||||
|
||||
* **Digitally sign images. **Once images have been built, their integrity should be verified prior to deployment. Some image formats utilize unique identifiers called digests that can be used to detect when image contents have changed. Signing images with private keys provides cryptographic assurances that each image used to launch containers was created by a trusted party.
|
||||
|
||||
* **Harden and restrict access to the host OS. **Since containers running on a host share the same OS, it is important to ensure that they start with an appropriately restricted set of capabilities. This can be achieved using kernel security features and modules such as Seccomp, AppArmor, and SELinux.
|
||||
|
||||
* **Specify application-level segmentation policies. **Network traffic between microservices can be segmented to limit how they connect to each other. However, this needs to be configured based on application-level attributes such as labels and selectors, abstracting away the complexity of dealing with traditional network details such as IP addresses. The challenge with segmentation is having to define policies upfront that restrict communications without impacting the ability of containers to communicate within and across environments as part of their normal activity.
|
||||
|
||||
* **Protect secrets to be used by containers. **Microservices interfacing with each other frequently exchange sensitive data such as passwords, tokens, and keys, referred to as secrets. These secrets can be accidentally exposed if they are stored in images or environment variables. As a result, several orchestration platforms such as Docker and Kubernetes have integrated secrets management, ensuring that secrets are only distributed to the containers that use them, when they need them.
|
||||
|
||||
Several leading container platforms and tools from companies such as Docker, Red Hat, and CoreOS provide some or all of these capabilities. Getting started with one of these options is the easiest way to ensure robust security during the build and deploy phase.
|
||||
|
||||
However, build and deployment phase controls are still insufficient to ensuring a comprehensive security program. Preempting all security incidents before containers start running is not possible for the following reasons. First, vulnerabilities will never be fully eliminated and new ones are exploited all the time. Second, declarative container metadata and network segmentation policies cannot fully anticipate all legitimate application activity in a highly distributed environment. And third, runtime controls are complex to use and often misconfigured, leaving applications susceptible to threats.
|
||||
|
||||
### Securing containers at runtime
|
||||
|
||||
Runtime phase security encompasses all the functions—visibility, detection, response, and prevention—required to discover and stop attacks and policy violations that occur once containers are running. Security teams need to triage, investigate, and identify the root causes of security incidents in order to fully remediate them. Here are the key aspects of successful runtime phase security:
|
||||
|
||||
|
||||
* **Instrument the entire environment for continuous visibility. **Being able to detect attacks and policy violations starts with being able to capture all activity from running containers in real time to provide an actionable “source of truth.” Various instrumentation frameworks exist to capture different types of container-relevant data. Selecting one that can handle the volume and speed of containers is critical.
|
||||
|
||||
* **Correlate distributed threat indicators. **Containers are designed to be distributed across compute infrastructure based on resource availability. Given that an application may be comprised of hundreds or thousands of containers, indicators of compromise may be spread out across large numbers of hosts, making it harder to pinpoint those that are related as part of an active threat. Large-scale, fast correlation is needed to determine which indicators form the basis for particular attacks.
|
||||
|
||||
* **Analyze container and microservices behavior. **Microservices and containers enable applications to be broken down into minimal components that perform specific functions and are designed to be immutable. This makes it easier to understand normal patterns of expected behavior than in traditional application environments. Deviations from these behavioral baselines may reflect malicious activity and can be used to detect threats with greater accuracy.
|
||||
|
||||
* **Augment threat detection with machine learning.** The volume and speed of data generated in container environments overwhelms conventional detection techniques. Automation and machine learning can enable far more effective behavioral modeling, pattern recognition, and classification to detect threats with increased fidelity and fewer false positives. Beware solutions that use machine learning simply to generate static whitelists used to alert on anomalies, which can result in substantial alert noise and fatigue.
|
||||
|
||||
* **Intercept and block unauthorized container engine commands. **Commands issued to the container engine, e.g., Docker, are used to create, launch, and kill containers as well as run commands inside of running containers. These commands can reflect attempts to compromise containers, meaning it is essential to disallow any unauthorized ones.
|
||||
|
||||
* **Automate actions for response and forensics. **The ephemeral life spans of containers mean that they often leave very little information available for incident response and forensics. Further, cloud-native architectures typically treat infrastructure as immutable, automatically replacing impacted systems with new ones, meaning containers may be gone by the time of investigation. Automation can ensure information is captured, analyzed, and escalated quickly enough to mitigate the impact of attacks and violations.
|
||||
|
||||
Cloud-native software built on container technologies and microservices architectures is rapidly modernizing applications and infrastructure. This paradigm shift forces security professionals to rethink the programs required to effectively protect their organizations. A comprehensive security program for cloud-native software addresses the entire application lifecycle as containers are built, deployed, and run. By implementing a program using the guidelines above, organizations can build a secure foundation for container infrastructures and the applications and services that run on them.
|
||||
|
||||
_Wei Lien Dang is VP of product at StackRox, a security company that provides adaptive threat protection for containers. Previously, he was head of product at CoreOS and held senior product management roles for security and cloud infrastructure at Amazon Web Services, Splunk, and Bracket Computing._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3233139/cloud-computing/how-cloud-native-applications-change-security.html
|
||||
|
||||
作者:[ Wei Lien Dang][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/blog/new-tech-forum/
|
||||
[1]:https://www.stackrox.com/
|
||||
[2]:https://www.infoworld.com/article/3204171/what-is-docker-linux-containers-explained.html#tk.ifw-infsb
|
||||
[3]:https://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker.html#tk.ifw-infsb
|
||||
@ -1,386 +0,0 @@
|
||||
Translating by qhwdw Learn how to program in Python by building a simple dice game
|
||||
============================================================
|
||||
|
||||
### Python is a good language for young and old, with or without any programming experience.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
[Python][9] is an all-purpose programming language that can be used to create desktop applications, 3D graphics, video games, and even websites. It's a great first programming language because it can be easy to learn and it's simpler than complex languages like C, C++, or Java. Even so, Python is powerful and robust enough to create advanced applications, and it's used in just about every industry that uses computers. This makes Python a good language for young and old, with or without any programming experience.
|
||||
|
||||
### Installing Python
|
||||
|
||||
Before learning Python, you may need to install it.
|
||||
|
||||
**Linux: **If you use Linux, Python is already included, but make sure that you have Python 3 specifically. To check which version is installed, open a terminal window and type:
|
||||
|
||||
```
|
||||
python3 -V
|
||||
```
|
||||
|
||||
If that command is not found, you'll need to install Python 3 from your package manager.
|
||||
|
||||
**MacOS:** If you're on a Mac, follow the instructions for Linux above to see if you have Python 3 installed. MacOS does not have a built-in package manager, so if Python 3 is not found, install it from [python.org/downloads/mac-osx][10]. Although macOS does have Python 2 installed, you should learn Python 3.
|
||||
|
||||
**Windows:** Microsoft Windows doesn't currently ship with Python. Install it from [python.org/downloads/windows][11]. Be sure to select **Add Python to PATH** in the install wizard.
|
||||
|
||||
### Running an IDE
|
||||
|
||||
To write programs in Python, all you really need is a text editor, but it's convenient to have an integrated development environment (IDE). An IDE integrates a text editor with some friendly and helpful Python features. IDLE 3 and NINJA-IDE are two options to consider.
|
||||
|
||||
### IDLE 3
|
||||
|
||||
Python comes with a basic IDE called IDLE.
|
||||
|
||||
### [idle3.png][2]
|
||||
|
||||

|
||||
|
||||
IDLE
|
||||
|
||||
It has keyword highlighting to help detect typos and a Run button to test code quickly and easily. To use it:
|
||||
|
||||
* On Linux or macOS, launch a terminal window and type **idle3**.
|
||||
|
||||
* On Windows, launch Python 3 from the Start menu.
|
||||
* If you don't see Python in the Start menu, launch the Windows command prompt by typing **cmd** in the Start menu, and type **C:\Windows\py.exe**.
|
||||
|
||||
* If that doesn't work, try reinstalling Python. Be sure to select **Add Python to PATH** in the install wizard. Refer to [docs.python.org/3/using/windows.html][1] for detailed instructions.
|
||||
|
||||
* If that still doesn't work, just use Linux. It's free and, as long as you save your Python files to a USB thumb drive, you don't even have to install it to use it.
|
||||
|
||||
### Ninja-IDE
|
||||
|
||||
[Ninja-IDE][12] is an excellent Python IDE. It has keyword highlighting to help detect typos, quotation and parenthesis completion to avoid syntax errors, line numbers (helpful when debugging), indentation markers, and a Run button to test code quickly and easily.
|
||||
|
||||
### [ninja.png][3]
|
||||
|
||||

|
||||
|
||||
Ninja-IDE
|
||||
|
||||
To use it:
|
||||
|
||||
1. Install Ninja-IDE. if you're using Linux, it's easiest to use your package manager; otherwise [download][7] the correct installer version from NINJA-IDE's website.
|
||||
|
||||
2. Launch Ninja-IDE.
|
||||
|
||||
3. Go to the Edit menu and select Preferences.
|
||||
|
||||
4. In the Preferences window, click the Execution tab.
|
||||
|
||||
5. In the Execution tab, change **python** to **python3**.
|
||||
|
||||
### [pref.png][4]
|
||||
|
||||

|
||||
|
||||
Python3 in Ninja-IDE
|
||||
|
||||
### Telling Python what to do
|
||||
|
||||
Keywords tell Python what you want it to do. In either IDLE or Ninja, go to the File menu and create a new file. Ninja users: Do not create a new project, just a new file.
|
||||
|
||||
In your new, empty file, type this into IDLE or Ninja:
|
||||
|
||||
```
|
||||
print("Hello world.")
|
||||
```
|
||||
|
||||
* If you are using IDLE, go to the Run menu and select Run module option.
|
||||
|
||||
* If you are using Ninja, click the Run File button in the left button bar.
|
||||
|
||||
### [ninja_run.png][5]
|
||||
|
||||

|
||||
|
||||
Run file in Ninja
|
||||
|
||||
The keyword **print** tells Python to print out whatever text you give it in parentheses and quotes.
|
||||
|
||||
That's not very exciting, though. At its core, Python has access to only basic keywords, like **print**, **help**, basic math functions, and so on.
|
||||
|
||||
Use the **import** keyword to load more keywords. Start a new file in IDLE or Ninja and name it **pen.py**.
|
||||
|
||||
**Warning**: Do not call your file **turtle.py**, because **turtle.py** is the name of the file that contains the turtle program you are controlling. Naming your file **turtle.py** will confuse Python, because it will think you want to import your own file.
|
||||
|
||||
Type this code into your file, and then run it:
|
||||
|
||||
```
|
||||
import turtle
|
||||
```
|
||||
|
||||
Turtle is a fun module to use. Try this:
|
||||
|
||||
```
|
||||
turtle.begin_fill()
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.end_fill()
|
||||
```
|
||||
|
||||
See what shapes you can draw with the turtle module.
|
||||
|
||||
To clear your turtle drawing area, use the **turtle.clear()** keyword. What do you think the keyword **turtle.color("blue")** does?
|
||||
|
||||
Try more complex code:
|
||||
|
||||
```
|
||||
import turtle as t
|
||||
import time
|
||||
|
||||
t.color("blue")
|
||||
t.begin_fill()
|
||||
|
||||
counter=0
|
||||
|
||||
while counter < 4:
|
||||
t.forward(100)
|
||||
t.left(90)
|
||||
counter = counter+1
|
||||
|
||||
t.end_fill()
|
||||
time.sleep(5)
|
||||
```
|
||||
|
||||
Once you have run your script, it's time to explore an even better module.
|
||||
|
||||
### Learning Python by making a game
|
||||
|
||||
To learn more about how Python works and prepare for more advanced programming with graphics, let's focus on game logic. In this tutorial, we'll also learn a bit about how computer programs are structured by making a text-based game in which the computer and the player roll a virtual die, and the one with the highest roll wins.
|
||||
|
||||
### Planning your game
|
||||
|
||||
Before writing code, it's important to think about what you intend to write. Many programmers [write simple documentation][13] _before_ they begin writing code, so they have a goal to program toward. Here's how the dice program might look if you shipped documentation along with the game:
|
||||
|
||||
1. Start the dice game and press Return or Enter to roll.
|
||||
|
||||
2. The results are printed out to your screen.
|
||||
|
||||
3. You are prompted to roll again or to quit.
|
||||
|
||||
It's a simple game, but the documentation tells you a lot about what you need to do. For example, it tells you that you need the following components to write this game:
|
||||
|
||||
* Player: You need a human to play the game.
|
||||
|
||||
* AI: The computer must roll a die, too, or else the player has no one to win or lose to.
|
||||
|
||||
* Random number: A common six-sided die renders a random number between 1 and 6.
|
||||
|
||||
* Operator: Simple math can compare one number to another to see which is higher.
|
||||
|
||||
* A win or lose message.
|
||||
|
||||
* A prompt to play again or quit.
|
||||
|
||||
### Making dice game alpha
|
||||
|
||||
Few programs start with all of their features, so the first version will only implement the basics. First a couple of definitions:
|
||||
|
||||
A **variable **is a value that is subject to change, and they are used a lot in Python. Whenever you need your program to "remember" something, you use a variable. In fact, almost all the information that code works with is stored in variables. For example, in the math equation **x + 5 = 20**, the variable is _x_ , because the letter _x_ is a placeholder for a value.
|
||||
|
||||
An **integer **is a number; it can be positive or negative. For example, 1 and -1 are both integers. So are 14, 21, and even 10,947.
|
||||
|
||||
Variables in Python are easy to create and easy to work with. This initial version of the dice game uses two variables: **player** and **ai**.
|
||||
|
||||
Type the following code into a new text file called **dice_alpha.py**:
|
||||
|
||||
```
|
||||
import random
|
||||
|
||||
player = random.randint(1,6)
|
||||
ai = random.randint(1,6)
|
||||
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
else:
|
||||
print("You lose")
|
||||
```
|
||||
|
||||
Launch your game to make sure it works.
|
||||
|
||||
This basic version of your dice game works pretty well. It accomplishes the basic goals of the game, but it doesn't feel much like a game. The player never knows what they rolled or what the computer rolled, and the game ends even if the player would like to play again.
|
||||
|
||||
This is common in the first version of software (called an alpha version). Now that you are confident that you can accomplish the main part (rolling a die), it's time to add to the program.
|
||||
|
||||
### Improving the game
|
||||
|
||||
In this second version (called a beta) of your game, a few improvements will make it feel more like a game.
|
||||
|
||||
#### 1\. Describe the results
|
||||
|
||||
Instead of just telling players whether they did or didn't win, it's more interesting if they know what they rolled. Try making these changes to your code:
|
||||
|
||||
```
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + player)
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolled " + ai)
|
||||
```
|
||||
|
||||
If you run the game now, it will crash because Python thinks you're trying to do math. It thinks you're trying to add the letters "You rolled" and whatever number is currently stored in the player variable.
|
||||
|
||||
You must tell Python to treat the numbers in the player and ai variables as if they were a word in a sentence (a string) rather than a number in a math equation (an integer).
|
||||
|
||||
Make these changes to your code:
|
||||
|
||||
```
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + str(player) )
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolled " + str(ai) )
|
||||
```
|
||||
|
||||
Run your game now to see the result.
|
||||
|
||||
#### 2\. Slow it down
|
||||
|
||||
Computers are fast. Humans sometimes can be fast, but in games, it's often better to build suspense. You can use Python's **time** function to slow your game down during the suspenseful parts.
|
||||
|
||||
```
|
||||
import random
|
||||
import time
|
||||
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + str(player) )
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolls...." )
|
||||
time.sleep(2)
|
||||
print("The computer has rolled a " + str(player) )
|
||||
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
else:
|
||||
print("You lose")
|
||||
```
|
||||
|
||||
Launch your game to test your changes.
|
||||
|
||||
#### 3\. Detect ties
|
||||
|
||||
If you play your game enough, you'll discover that even though your game appears to be working correctly, it actually has a bug in it: It doesn't know what to do when the player and the computer roll the same number.
|
||||
|
||||
To check whether a value is equal to another value, Python uses **==**. That's _two_ equal signs, not just one. If you use only one, Python thinks you're trying to create a new variable, but you're actually trying to do math.
|
||||
|
||||
When you want to have more than just two options (i.e., win or lose), you can using Python's keyword **elif**, which means _else if_ . This allows your code to check to see whether any one of _some _ results are true, rather than just checking whether _one_ thing is true.
|
||||
|
||||
Modify your code like this:
|
||||
|
||||
```
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
elif player == ai:
|
||||
print("Tie game.")
|
||||
else:
|
||||
print("You lose")
|
||||
```
|
||||
|
||||
Launch your game a few times to see if you can tie the computer's roll.
|
||||
|
||||
### Programming the final release
|
||||
|
||||
The beta release of your dice game is functional and feels more like a game than the alpha. For the final release, create your first Python **function**.
|
||||
|
||||
A function is a collection of code that you can call upon as a distinct unit. Functions are important because most applications have a lot of code in them, but not all of that code has to run at once. Functions make it possible to start an application and control what happens and when.
|
||||
|
||||
Change your code to this:
|
||||
|
||||
```
|
||||
import random
|
||||
import time
|
||||
|
||||
def dice():
|
||||
player = random.randint(1,6)
|
||||
print("You rolled " + str(player) )
|
||||
|
||||
ai = random.randint(1,6)
|
||||
print("The computer rolls...." )
|
||||
time.sleep(2)
|
||||
print("The computer has rolled a " + str(player) )
|
||||
|
||||
if player > ai :
|
||||
print("You win") # notice indentation
|
||||
else:
|
||||
print("You lose")
|
||||
|
||||
print("Quit? Y/N")
|
||||
cont = input()
|
||||
|
||||
if cont == "Y" or cont == "y":
|
||||
exit()
|
||||
elif cont == "N" or cont == "n":
|
||||
pass
|
||||
else:
|
||||
print("I did not understand that. Playing again.")
|
||||
```
|
||||
|
||||
This version of the game asks the player whether they want to quit the game after they play. If they respond with a **Y** or **y**, Python's **exit** function is called and the game quits.
|
||||
|
||||
More importantly, you've created your own function called **dice**. The dice function doesn't run right away. In fact, if you try your game at this stage, it won't crash, but it doesn't exactly run, either. To make the **dice** function actually do something, you have to **call it** in your code.
|
||||
|
||||
Add this loop to the bottom of your existing code. The first two lines are only for context and to emphasize what gets indented and what does not. Pay close attention to indentation.
|
||||
|
||||
```
|
||||
else:
|
||||
print("I did not understand that. Playing again.")
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
print("Press return to roll your die.")
|
||||
roll = input()
|
||||
dice()
|
||||
```
|
||||
|
||||
The **while True** code block runs first. Because **True** is always true by definition, this code block always runs until Python tells it to quit.
|
||||
|
||||
The **while True** code block is a loop. It first prompts the user to start the game, then it calls your **dice** function. That's how the game starts. When the dice function is over, your loop either runs again or it exits, depending on how the player answered the prompt.
|
||||
|
||||
Using a loop to run a program is the most common way to code an application. The loop ensures that the application stays open long enough for the computer user to use functions within the application.
|
||||
|
||||
### Next steps
|
||||
|
||||
Now you know the basics of Python programming. The next article in this series will describe how to write a video game with [PyGame][14], a module that has more features than turtle, but is also a lot more complex.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Seth Kenlon - Seth Kenlon is an independent multimedia artist, free culture advocate, and UNIX geek. He has worked in the film and computing industry, often at the same time. He is one of the maintainers of the Slackware-based multimedia production project, http://slackermedia.info
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/python-101
|
||||
|
||||
作者:[Seth Kenlon ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:https://docs.python.org/3/using/windows.html
|
||||
[2]:https://opensource.com/file/374606
|
||||
[3]:https://opensource.com/file/374611
|
||||
[4]:https://opensource.com/file/374621
|
||||
[5]:https://opensource.com/file/374616
|
||||
[6]:https://opensource.com/article/17/10/python-101?rate=XlcW6PAHGbAEBboJ3z6P_4Sx-hyMDMlga9NfoauUA0w
|
||||
[7]:http://ninja-ide.org/downloads/
|
||||
[8]:https://opensource.com/user/15261/feed
|
||||
[9]:https://www.python.org/
|
||||
[10]:https://www.python.org/downloads/mac-osx/
|
||||
[11]:https://www.python.org/downloads/windows
|
||||
[12]:http://ninja-ide.org/
|
||||
[13]:https://opensource.com/article/17/8/doc-driven-development
|
||||
[14]:https://www.pygame.org/news
|
||||
[15]:https://opensource.com/users/seth
|
||||
[16]:https://opensource.com/users/seth
|
||||
[17]:https://opensource.com/article/17/10/python-101#comments
|
||||
@ -1,338 +0,0 @@
|
||||
How to manage Docker containers in Kubernetes with Java
|
||||
==========================
|
||||
|
||||
|
||||
>Orchestrate production-ready systems at enterprise scale.
|
||||
|
||||
Learn basic Kubernetes concepts and mechanisms for automating the deployment, maintenance, and scaling of your Java applications with “Kubernetes for Java Developers.” [Download your free copy][3].
|
||||
|
||||
|
||||
In [_Containerizing Continuous Delivery in Java_][23] we explored the fundamentals of packaging and deploying Java applications within Docker containers. This was only the first step in creating production-ready, container-based systems. Running containers at any real-world scale requires a container orchestration and scheduling platform, and although many exist (i.e., Docker Swarm, Apache Mesos, and AWS ECS), the most popular is [Kubernetes][24]. Kubernetes is used in production at many organizations, and is now hosted by the [Cloud Native Computing Foundation (CNCF)][25]. In this article, we will take the previous simple Java-based, e-commerce shop that we packaged within Docker containers and run this on Kubernetes.
|
||||
|
||||
### The “Docker Java Shopfront” application
|
||||
|
||||
The architecture of the “Docker Java Shopfront” application that we will package into containers and deploy onto Kubernetes can be seen below:
|
||||
|
||||
|
||||

|
||||
|
||||
Before we start creating the required Kubernetes deployment configuration files let’s first learn about core concepts within this container orchestration platform.
|
||||
|
||||
### Kubernetes 101
|
||||
|
||||
Kubernetes is an open source orchestrator for deploying containerized applications that was originally developed by Google. Google has been running containerized applications for many years, and this led to the creation of the [Borg container orchestrator][26] that is used internally within Google, and was the source of inspiration for Kubernetes. If you are not familiar with this technology then a number of core concepts may appear alien at first glance, but they actually hide great power. The first is that Kubernetes embraces the principles of immutable infrastructure. Once a container is deployed the contents (i.e., the application) are not updated by logging into the container and making changes. Instead a new version is deployed. Second, everything in Kubernetes is declaratively configured. The developer or operator specifies the desired state of the system through deployment descriptors and configuration files, and Kubernetes is responsible for making this happen - you don’t need to provide imperative, step-by-step instructions.
|
||||
|
||||
These principles of immutable infrastructure and declarative configuration have a number of benefits: it is easier to prevent configuration drift, or “snowflake” application instances; declarative deployment configuration can be stored within version control, alongside the code; and Kubernetes can be largely self-healing, as if the system experiences failure like an underlying compute node failure, the system can rebuild and rebalance the applications according to the state specified in the declarative configuration.
|
||||
|
||||
Kubernetes provides several abstractions and APIs that make it easier to build these distributed applications, such as those based on the microservice architectural style:
|
||||
|
||||
* [Pods][5] - This is the lowest unit of deployment within Kubernetes, and is essentially a groups of containers. A pod allows a microservice application container to be grouped with other “sidecar” containers that may provide system services like logging, monitoring or communication management. Containers within a pod share a filesystem and network namespace. Note that a single container can be deployed, but it is always deployed within a pod
|
||||
|
||||
* [Services][6] - Kubernetes Services provide load balancing, naming, and discovery to isolate one microservice from another. Services are backed by [Replication Controllers][7], which in turn are responsible for details associated with maintaining the desired number of instances of a pod to be running within the system. Services, Replication Controllers and Pods are connected together in Kubernetes through the use of “[labels][8]”, both for naming and selecting.
|
||||
|
||||
Let’s now create a service for one of our Java-based microservice applications.
|
||||
|
||||
|
||||
### Building Java applications and container images
|
||||
|
||||
Before we first create a container and the associated Kubernetes deployment configuration, we must first ensure that we have installed the following prerequisites:
|
||||
|
||||
* Docker for [Mac][11] / [Windows][12] / [Linux][13] - This allows us to build, run and test Docker containers outside of Kubernetes on our local development machine.
|
||||
|
||||
* [Minikube][14] - This is a tool that makes it easy to run a single-node Kubernetes test cluster on our local development machine via a virtual machine.
|
||||
|
||||
* A [GitHub][15] account, and [Git][16] installed locally - The code examples are stored on GitHub, and by using Git locally you can fork the repository and commit changes to your own personal copy of the application.
|
||||
|
||||
* [Docker Hub][17] account - If you would like to follow along with this tutorial, you will need a Docker Hub account in order to push and store your copies of the container images that we will build below.
|
||||
|
||||
* [Java 8][18] (or 9) SDK and [Maven][19] - We will be building code with the Maven build and dependency tool that uses Java 8 features.
|
||||
|
||||
Clone the project repository from GitHub (optionally you can fork this repository and clone your personal copy), and locate the “shopfront” microservice application: [https://github.com/danielbryantuk/oreilly-docker-java-shopping/][27]
|
||||
|
||||
```
|
||||
$ git clone git@github.com:danielbryantuk/oreilly-docker-java-shopping.git
|
||||
$ cd oreilly-docker-java-shopping/shopfront
|
||||
|
||||
```
|
||||
|
||||
Feel free to load the shopfront code into your editor of choice, such as IntelliJ IDE or Eclipse, and have a look around. Let’s build the application using Maven. The resulting runnable JAR file that contains the application will be located in the ./target directory.
|
||||
|
||||
```
|
||||
$ mvn clean install
|
||||
…
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] BUILD SUCCESS
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] Total time: 17.210 s
|
||||
[INFO] Finished at: 2017-09-30T11:28:37+01:00
|
||||
[INFO] Final Memory: 41M/328M
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
Now we will build the Docker container image. The operating system choice, configuration and build steps for a Docker image are typically specified via a Dockerfile. Let’s look at our example Dockerfile that is located in the shopfront directory:
|
||||
|
||||
```
|
||||
FROM openjdk:8-jre
|
||||
ADD target/shopfront-0.0.1-SNAPSHOT.jar app.jar
|
||||
EXPOSE 8010
|
||||
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
|
||||
|
||||
```
|
||||
|
||||
The first line specifies that our container image should be created “from” the openjdk:8-jre base image. The [openjdk:8-jre][28] image is maintained by the OpenJDK team, and contains everything we need to run a Java 8 application within a Docker container (such as an operating system with the OpenJDK 8 JRE installed and configured). The second line takes the runnable JAR we built above and “adds” this to the image. The third line specifies that port 8010, which our application will listen on, must be “exposed” as externally accessible, and the fourth line specifies the “entrypoint” or command to run when the container is initialized. Let’s build our container:
|
||||
|
||||
|
||||
```
|
||||
$ docker build -t danielbryantuk/djshopfront:1.0 .
|
||||
Successfully built 87b8c5aa5260
|
||||
Successfully tagged danielbryantuk/djshopfront:1.0
|
||||
|
||||
```
|
||||
|
||||
Now let’s push this to Docker Hub. If you haven’t logged into the Docker Hub via your command line, you must do this now, and enter your username and password:
|
||||
|
||||
```
|
||||
$ docker login
|
||||
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
|
||||
Username:
|
||||
Password:
|
||||
Login Succeeded
|
||||
$
|
||||
$ docker push danielbryantuk/djshopfront:1.0
|
||||
The push refers to a repository [docker.io/danielbryantuk/djshopfront]
|
||||
9b19f75e8748: Pushed
|
||||
...
|
||||
cf4ecb492384: Pushed
|
||||
1.0: digest: sha256:8a6b459b0210409e67bee29d25bb512344045bd84a262ede80777edfcff3d9a0 size: 2210
|
||||
|
||||
```
|
||||
|
||||
### Deploying onto Kubernetes
|
||||
|
||||
Now let’s run this container within Kubernetes. First, change the “kubernetes” directory in the root of the project:
|
||||
|
||||
```
|
||||
$ cd ../kubernetes
|
||||
|
||||
```
|
||||
|
||||
Open the shopfront-service.yaml Kubernetes deployment file and have a look at the contents:
|
||||
|
||||
```
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: shopfront
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
type: NodePort
|
||||
selector:
|
||||
app: shopfront
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 8010
|
||||
name: http
|
||||
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ReplicationController
|
||||
metadata:
|
||||
name: shopfront
|
||||
spec:
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
containers:
|
||||
- name: shopfront
|
||||
image: danielbryantuk/djshopfront:latest
|
||||
ports:
|
||||
- containerPort: 8010
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /health
|
||||
port: 8010
|
||||
initialDelaySeconds: 30
|
||||
timeoutSeconds: 1
|
||||
|
||||
```
|
||||
|
||||
The first section of the yaml file creates a Service named “shopfront” that will route TCP traffic targeting this service on port 8010 to pods with the label “app: shopfront”. The second section of the configuration file creates a `ReplicationController` that specifies Kubernetes should run one replica (instance) of our shopfront container, which we have declared as part of the “spec” (specification) labelled as “app: shopfront”. We have also specified that the 8010 application traffic port we exposed in our Docker container is open, and declared a “livenessProbe” or healthcheck that Kubernetes can use to determine if our containerized application is running correctly and ready to accept traffic. Let’s start `minikube` and deploy this service (note that you may need to change the specified `minikube` CPU and Memory requirements depending on the resources available on your development machine):
|
||||
|
||||
```
|
||||
$ minikube start --cpus 2 --memory 4096
|
||||
Starting local Kubernetes v1.7.5 cluster...
|
||||
Starting VM...
|
||||
Getting VM IP address...
|
||||
Moving files into cluster...
|
||||
Setting up certs...
|
||||
Connecting to cluster...
|
||||
Setting up kubeconfig...
|
||||
Starting cluster components...
|
||||
Kubectl is now configured to use the cluster.
|
||||
$ kubectl apply -f shopfront-service.yaml
|
||||
service "shopfront" created
|
||||
replicationcontroller "shopfront" created
|
||||
|
||||
```
|
||||
|
||||
You can view all Services within Kubernetes by using the “kubectl get svc” command. You can also view all associated pods by using the “kubectl get pods” command (note that the first time you issue the get pods command, the container may not have finished creating, and is marked as not yet ready):
|
||||
|
||||
```
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 18h
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 12s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 0/1 ContainerCreating 0 18s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 1/1 Running 0 2m
|
||||
|
||||
```
|
||||
|
||||
We have now successfully deployed our first Service into Kubernetes!
|
||||
|
||||
### Time for a smoke test
|
||||
|
||||
Let’s use curl to see if we can get data from the shopfront application’s healthcheck endpoint:
|
||||
|
||||
```
|
||||
$ curl $(minikube service shopfront --url)/health
|
||||
{"status":"UP"}
|
||||
|
||||
```
|
||||
|
||||
You can see from the results of the curl against the application/health endpoint that the application is up and running, but we need to deploy the remaining microservice application containers before the application will function as we expect it to.
|
||||
|
||||
### Building the remaining applications
|
||||
|
||||
Now that we have one container up and running let’s build the remaining two supporting microservice applications and containers:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd productcatalogue/
|
||||
$ mvn clean install
|
||||
…
|
||||
$ docker build -t danielbryantuk/djproductcatalogue:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djproductcatalogue:1.0
|
||||
...
|
||||
$ cd ..
|
||||
$ cd stockmanager/
|
||||
$ mvn clean install
|
||||
...
|
||||
$ docker build -t danielbryantuk/djstockmanager:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djstockmanager:1.0
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
At this point we have built all of our microservices and the associated Docker images, and also pushed the images to Docker Hub. Let’s now deploy the `productcatalogue` and `stockmanager` services to Kubernetes.
|
||||
|
||||
### Deploying the entire Java application in Kubernetes
|
||||
|
||||
In a similar fashion to the process we used above to deploy the shopfront service, we can now deploy the remaining two microservices within our application to Kubernetes:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd kubernetes/
|
||||
$ kubectl apply -f productcatalogue-service.yaml
|
||||
service "productcatalogue" created
|
||||
replicationcontroller "productcatalogue" created
|
||||
$ kubectl apply -f stockmanager-service.yaml
|
||||
service "stockmanager" created
|
||||
replicationcontroller "stockmanager" created
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 19h
|
||||
productcatalogue 10.0.0.37 <nodes> 8020:31803/TCP 42s
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 13m
|
||||
stockmanager 10.0.0.149 <nodes> 8030:30723/TCP 16s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
productcatalogue-79qn4 1/1 Running 0 55s
|
||||
shopfront-0w1js 1/1 Running 0 13m
|
||||
stockmanager-lmgj9 1/1 Running 0 29s
|
||||
|
||||
```
|
||||
|
||||
Depending on how quickly you issue the “kubectl get pods” command, you may see that all of the pods are not yet running. Before moving on to the next section of this article wait until the command shows that all of the pods are running (maybe this is a good time to brew a cup of tea!)
|
||||
|
||||
### Viewing the complete application
|
||||
|
||||
With all services deployed and all associated pods running, we now should be able to access our completed application via the shopfront service GUI. We can open the service in our default browser by issuing the following command in `minikube`:
|
||||
|
||||
```
|
||||
$ minikube service shopfront
|
||||
|
||||
```
|
||||
|
||||
If everything is working correctly, you should see the following page in your browser:
|
||||
|
||||

|
||||
|
||||
### Conclusion
|
||||
|
||||
In this article, we have taken our application that consisted of three Java Spring Boot and Dropwizard microservices, and deployed it onto Kubernetes. There are many more things we need to think about in the future, such as debugging services (perhaps through the use of tools like [Telepresence][29] and [Sysdig][30]), testing and deploying via a continuous delivery pipeline like [Jenkins][31] or [Spinnaker][32], and observing our running system.
|
||||
|
||||
* * *
|
||||
|
||||
_This article was created in collaboration with NGINX. [See our statement of editorial independence][22]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel Bryant works as an Independent Technical Consultant, and is the CTO at SpectoLabs. He currently specialises in enabling continuous delivery within organisations through the identification of value streams, creation of build pipelines, and implementation of effective testing strategies. Daniel’s technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms, and microservice implementations. He also contributes to several open source projects, writes for InfoQ, O’Reilly, and Voxxed, and regularly presents at internatio...
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java
|
||||
|
||||
作者:[ Daniel Bryant ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/d3f4d647-482d-4dce-a0e5-a09773b77150
|
||||
[1]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[2]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[3]:https://www.nginx.com/resources/library/kubernetes-for-java-developers/
|
||||
[4]:https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021
|
||||
[5]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[6]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[7]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[9]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[10]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[11]:https://docs.docker.com/docker-for-mac/install/
|
||||
[12]:https://docs.docker.com/docker-for-windows/install/
|
||||
[13]:https://docs.docker.com/engine/installation/linux/ubuntu/
|
||||
[14]:https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||
[15]:https://github.com/
|
||||
[16]:https://git-scm.com/
|
||||
[17]:https://hub.docker.com/
|
||||
[18]:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
|
||||
[19]:https://maven.apache.org/
|
||||
[20]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[21]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[22]:http://www.oreilly.com/about/editorial_independence.html
|
||||
[23]:https://www.nginx.com/resources/library/containerizing-continuous-delivery-java/
|
||||
[24]:https://kubernetes.io/
|
||||
[25]:https://www.cncf.io/
|
||||
[26]:https://research.google.com/pubs/pub44843.html
|
||||
[27]:https://github.com/danielbryantuk/oreilly-docker-java-shopping/
|
||||
[28]:https://hub.docker.com/_/openjdk/
|
||||
[29]:https://telepresence.io/
|
||||
[30]:https://www.sysdig.org/
|
||||
[31]:https://wiki.jenkins.io/display/JENKINS/Kubernetes+Plugin
|
||||
[32]:https://www.spinnaker.io/
|
||||
@ -1,143 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
# Why Did Ubuntu Drop Unity? Mark Shuttleworth Explains
|
||||
|
||||
[][6]
|
||||
|
||||
Mark Shuttleworth, found of Ubuntu
|
||||
|
||||
Ubuntu’s decision to ditch Unity took all of us — even me — by surprise when announced [back in April.][4]
|
||||
|
||||
Now Ubuntu founder [Mark Shuttleworth ][7]shares more details about why Ubuntu chose to drop Unity.
|
||||
|
||||
And the answer might surprise…
|
||||
|
||||
Actually, no; the answer probably _won’t_ surprise you.
|
||||
|
||||
Like, at all.
|
||||
|
||||
### Why Did Ubuntu Drop Unity?
|
||||
|
||||
Last week saw the [release of Ubuntu 17.10][8], the first release of Ubuntu to ship without the Unity desktop since it was [introduced back in 2011][9].
|
||||
|
||||
‘We couldn’t have on our books very substantial projects which have no commercial angle to them’
|
||||
|
||||
Naturally the mainstream press is curious about where Unity has gone. And so Mark Shuttleworth has [spoke to eWeek][10] to detail his decision to jettison Unity from the Ubuntu roadmap.
|
||||
|
||||
The _tl;dr_ he ejected Unity as part of a cost-saving pivot designed to put Canonical on the path toward an [initial public offering][11] (known as an “IPO”).
|
||||
|
||||
Yup: investors are coming.
|
||||
|
||||
But the full interview provides more context on the decision, and reveals just how difficult it was to let go of the desktop he helped nurture.
|
||||
|
||||
### “Ubuntu Has Moved In To The Mainstream”
|
||||
|
||||
Mark Shuttleworth, speaking to [Sean Michael Kerner,][12] starts by reminding us all how great Ubuntu is:
|
||||
|
||||
_“The beautiful thing about Ubuntu is that we created the possibility of a platform that is free of charge to its end users, with commercial services around it, in the dream that that might define the future in all sorts of different ways._
|
||||
|
||||
_We really have seen that Ubuntu has moved in to the mainstream in a bunch of areas.”_
|
||||
|
||||
‘We created a platform that is free of charge to its end users, with commercial services around it’
|
||||
|
||||
But being popular isn’t the same as being profitable, as Mark notes:
|
||||
|
||||
_“Some of the things that we were doing were clearly never going to be commercially sustainable, other things clearly will be commercially sustainable, or already are commercially sustainable. _
|
||||
|
||||
_As long as we stay a purely private company we have complete discretion whether we carry things that are not commercially sustainable.”_
|
||||
|
||||
Shuttleworth says he, along with the other ‘leads’ at Canonical, came to a consensual view that they should put the company on the path to becoming a public company.
|
||||
|
||||
‘In the last 7 years Ubuntu itself became completely sustainable’
|
||||
|
||||
And to appear attractive to potential investors the company has to focus on its areas of profitability — something Unity, Ubuntu phone, Unity 8 and convergence were not part of:
|
||||
|
||||
_“[The decision] meant that we couldn’t have on our books (effectively) very substantial projects which clearly have no commercial angle to them at all._
|
||||
|
||||
_It doesn’t mean that we would consider changing the terms of Ubuntu for example, because it’s foundational to everything we do. And we don’t have to, effectively.”_
|
||||
|
||||
‘I could get hit by a bus tomorrow and Ubuntu could continue’
|
||||
|
||||
#### ‘Ubuntu itself is now completely sustainable’
|
||||
|
||||
Money may have meant Unity’s demise but the wider Ubuntu project is in rude health. as Shuttleworth explains:
|
||||
|
||||
_“One of the things I’m most proud of is in the last 7 years is that Ubuntu itself became completely sustainable. _ _I could get hit by a bus tomorrow and Ubuntu could continue._
|
||||
|
||||
_It’s kind of magical, right? Here’s a platform that is a world class enterprise platform, that’s completely freely available, and yet it is sustainable._
|
||||
|
||||
_Jane Silber is largely to thank for that.”_
|
||||
|
||||
While it’s all-too-easy for desktop users to focus on, well, the desktop, there is far more to Canonical (the company) than the 6-monthly releases we look forward to.
|
||||
|
||||
Losing Unity may have been a big blow for desktop users but it helped to balance other parts of the company:
|
||||
|
||||
_“There are huge possibilities for us in the enterprise beyond that, in terms of really defining how cloud infrastructure is built, how cloud applications are operated, and so on. And, in IoT, looking at that next wave of possibility, innovators creating stuff on IoT._
|
||||
|
||||
_And all of that is ample for us to essentially put ourselves on course to IPO around that.”_
|
||||
|
||||
Dropping Unity wasn’t easy for Mark, though:
|
||||
|
||||
_“We had this big chunk of work, which was Unity, which I really loved._
|
||||
|
||||
_I think the engineering of Unity 8 was pretty spectacularly good, and the deep ideas of how you bring these different form factors together was pretty beautiful._
|
||||
|
||||
“I couldn’t make an argument for [Unity] to sit on Canonical’s books any longer”
|
||||
|
||||
_“But I couldn’t make an argument for that to sit on Canonical’s books any longer, if we were gonna go on a path to an IPO._
|
||||
|
||||
_So what you should see at some stage, and I think fairly soon, I think we’ll announce that we have broken even on all of the pieces that we do commercially, effectively, without Unity.“_
|
||||
|
||||
Soon after this he says the company will likely take its first round investment for growth, ahead of transitioning to a formal public company at a later date.
|
||||
|
||||
But Mark doesn’t want anyone to think that investors will ‘ruin the party’:
|
||||
|
||||
_“We’re not in a situation where we need to kind of flip flop based on what VCs might tell us to do. We’ve a pretty clear view of what our customers like, we’ve found good market traction and product fit both on cloud and on IoT.”_
|
||||
|
||||
Mark adds that the team at Canonical is ‘justifiably excited’ at this decision.
|
||||
|
||||
‘Emotionally I never want to go through a process like that again,’ Mark says
|
||||
|
||||
_“Emotionally I never want to go through a process like that again. I made some miscalculations around Unity. I really thought industry would rally to the idea of having a free platform that was independent._
|
||||
|
||||
_But then I also don’t regret having the will to go do that. Lots of people will complain about the options that they have and don’t go and create other options._
|
||||
|
||||
_It takes a bit of spine and, as it turns out, quite a lot of money to go and try and create those options.”_
|
||||
|
||||
#### OMG! IPO? NO!
|
||||
|
||||
Before anyone splits too many hairs over the notion of Canonical (possibly) becoming a public company let’s remember that Redhat has been a public company for 20 years. Both the GNOME desktop and Fedora are tickling along nicely, free of any ‘money making’ interventions.
|
||||
|
||||
If Canonical IPOs there is unlikely to be any sudden, dramatic change to Ubuntu because, as Shuttleworth himself has said, it’s the foundation on which everything else is built.
|
||||
|
||||
Ubuntu is established. It’s the number one OS on cloud. It’s the world’s most popular Linux distribution (in the world beyond [Distrowatch’s rankings][13]). And it’s apparently seeing great adoption in the Internet of Things space.
|
||||
|
||||
And Mark says Ubuntu is now totally sustainable.
|
||||
|
||||
With a [warm reception greeting the arrival of Ubuntu 17.10][14], and a new LTS on the horizon, things are looking pretty good…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/10/why-did-ubuntu-drop-unity-mark-shuttleworth-explains
|
||||
|
||||
作者:[ JOEY SNEDDON ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://trw.431.night8.win/yy.php/H5aIh_2F/ywcKfGz_/2BKS471c/l3mPrAOp/L1WrIpnn/GpPc4TFY/yHh6t5Cu/gk7ZPrW2/omFcT6ao/A9I_3D/b0/
|
||||
[2]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU38e9i0/RMyYqikJ/lzgv8Nfz/0gk_3D/b0/
|
||||
[3]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU38e9i0/RMyYqikO/nDs5/b0/
|
||||
[4]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJPe_2FH/MCjCI_2B/94yrj1PG/NeqgpjVN/F7WuA815/jIj6rCNO/KcNXKJ1Y/cEP_2BUn/_2Fb/b0/
|
||||
[5]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJLa_2FH/EIgGEu68/W3whyDb7/Om4zhPVa/LtGc511Z/WysilILZ/4JLodYKV/r1TGTQPz/vy99PlQJ/jKI1w_3D/b0/
|
||||
[6]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU3oaoGy/TM2etmgU/1jk67s77/0w3ZM_2F/fi_2BnMN/DP2NDdJ3/jL_2F3qj/xOKtYNKY/BYNRj6S2/w_3D/b0/
|
||||
[7]:https://trw.431.night8.win/yy.php/H5aIh_2B/myK6OBw_/2BSN4bVQ/2DSPs0u3/aQv0c4Oc/QtGBjFUI/jDg_2B7s/Tt2AyCaQ/_3D_3D/b0/
|
||||
[8]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJLa_2FH/MCjCI_2B/94yrgFPH/MeqhqzBY/W6GlQcZ5/wJjqrS1J/b0/
|
||||
[9]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3h/DJLa_2FH/MCjCI_2B/94yrhlPG/NeqmoDVJ/Q_2F_2Bk/CcZ91IDr/8ixfNdgO/KYI_3D/b0/
|
||||
[10]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7Gfze/iWqrJW1D/WFr1j9bB/Ltc9_2B0/DsKao3VP/mi0k7c_2/Fz1B_2Ba/LKi94yxc/TrrtGM8x/yJzw8ilJ/a8YYM5xY/KBvlVWLW/Mn6z_2B8/XgVNTHKF/zugKBoCH/NJcQJTvL/37D4mgxw/_3D_3D/b0/
|
||||
[11]:https://trw.431.night8.win/yy.php/H5aIh_2B/myK6OBw_/2BSN4bVQ/2DSPs0u3/aQv0c4OY/TcqeumcM/pjw_2F4M/3z1CGZZ6/G2vDVTXQ/_3D_3D/b0/
|
||||
[12]:https://trw.431.night8.win/yy.php/H5aIh_2F/irbKCczf/_2FT575U/lk6FokTS/cRftdM29/StCe/b0/
|
||||
[13]:https://trw.431.night8.win/yy.php/VoOIzOWv/caaH3_2B/yJ57kX2n/WN7lj5fA/76NNy5U5/yOunUUiy/Uo99Xz2B/DLdKWmoC/hI/b0/
|
||||
[14]:https://trw.431.night8.win/yy.php/VoOI3_2F/urK7uFz_/2Fif8b9N/zDSDrgLt/dU2tKp3m/DJLa_2FH/MCjCI_2B/94yrgFPH/MeqhqypU/X6XtHs9p/z4jqrw_3/D_3D/b0/
|
||||
@ -1,229 +0,0 @@
|
||||
How to roll your own backup solution with BorgBackup, Rclone, and Wasabi cloud storage
|
||||
============================================================
|
||||
|
||||
### Protect your data with an automated backup solution built on open source software and inexpensive cloud storage.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
For several years, I used CrashPlan to back up my family's computers, including machines belonging to my wife and siblings. The fact that CrashPlan was essentially "always on" and doing frequent backups without ever having to think about it was fantastic. Additionally, the ability to do point-in-time restores came in handy on several occasions. Because I'm generally the IT person for the family, I loved that the user interface was so easy to use that family members could recover their data without my help.
|
||||
|
||||
Recently [CrashPlan announced][5] that it was dropping its consumer subscriptions to focus on its enterprise customers. It makes sense, I suppose, as it wasn't making a lot of money off folks like me, and our family plan was using a whole lot of storage on its system.
|
||||
|
||||
I decided that the features I would need in a suitable replacement included:
|
||||
|
||||
* Cross-platform support for Linux and Mac
|
||||
|
||||
* Automation (so there's no need to remember to click "backup")
|
||||
|
||||
* Point-in-time recovery (or something close) so if you accidentally delete a file but don't notice until later, it's still recoverable
|
||||
|
||||
* Low cost
|
||||
|
||||
* Replicated data store for backup sets, so data exists in more than one place (i.e., not just backing up to a local USB drive)
|
||||
|
||||
* Encryption in case the backup files fall into the wrong hands
|
||||
|
||||
I searched around and asked my friends about services similar to CrashPlan. One was really happy with [Arq][6], but no Linux support meant it was no good for me. [Carbonite][7] is similar to CrashPlan but would be expensive, because I have multiple machines to back up. [Backblaze][8] offers unlimited backups at a good price (US$ 5/month), but its backup client doesn't support Linux. [BackupPC][9] was a strong contender, but I had already started testing my solution before I remembered it. None of the other options I looked at matched everything I was looking for. That meant I had to figure out a way to replicate what CrashPlan delivered for me and my family.
|
||||
|
||||
I knew there were lots of good options for backing up files on Linux systems. In fact, I've been using [rdiff-backup][10] for at least 10 years, usually for saving snapshots of remote filesystems locally. I had hopes of finding something that would do a better job of deduplicating backup data though, because I knew there were going to be some things (like music libraries and photos) that were stored on multiple computers.
|
||||
|
||||
I think what I worked out came pretty close to meeting my goals.
|
||||
|
||||
### My backup solution
|
||||
|
||||
### [backup-diagram.png][1]
|
||||
|
||||

|
||||
|
||||
Ultimately, I landed on a combination of [BorgBackup][11], [Rclone][12], and [Wasabi cloud storage][13], and I couldn't be happier with my decision. Borg fits all my criteria and has a pretty healthy [community of users and contributors][14]. It offers deduplication and compression, and works great on PC, Mac, and Linux. I use Rclone to synchronize the backup repositories from the Borg host to S3-compatible storage on Wasabi. Any S3-compatible storage will work, but I chose Wasabi because its price can't be beat and it outperforms Amazon's S3\. With this setup, I can restore files from the local Borg host or from Wasabi.
|
||||
|
||||
Installing Borg on my machine was as simple as **sudo apt install borgbackup**. My backup host is a Linux machine that's always on with a 1.5TB USB drive attached to it. This backup host could be something as lightweight as a Raspberry Pi if you don't have a machine available. Just make sure all the client machines can reach this server over SSH and you are good to go.
|
||||
|
||||
On the backup host, initialize a new backup repository with:
|
||||
|
||||
```
|
||||
$ borg init /mnt/backup/repo1
|
||||
```
|
||||
|
||||
Depending on what you're backing up, you might choose to make multiple repositories per machine, or possibly one big repository for all your machines. Because Borg deduplicates, if you have identical data on many computers, sending backups from all those machines to the same repository might make sense.
|
||||
|
||||
Installing Borg on the Linux client machines was straightforward. On Mac OS X I needed to install XCode and Homebrew first. I followed a [how-to][15] to install the command-line tools, then used **pip3 install borgbackup**.
|
||||
|
||||
### Backing up
|
||||
|
||||
Each machine has a **backup.sh** script (see below) that is kicked off by **cron** at regular intervals; it will make only one backup set per day, but it doesn't hurt to try a few times in the same day. The laptops are set to try every two hours, because there's no guarantee they will be on at a certain time, but it's very likely they'll be on during one of those times. This could be improved by writing a daemon that's always running and triggers a backup attempt anytime the laptop wakes up. For now, I'm happy with the way things are working.
|
||||
|
||||
I could skip the cron job and provide a relatively easy way for each user to trigger a backup using [BorgWeb][16], but I really don't want anyone to have to remember to back things up. I tend to forget to click that backup button until I'm in dire need of a restoration (at which point it's way too late!).
|
||||
|
||||
The backup script I'm using came from the Borg [quick start][17] docs, plus I added a little check at the top to see if Borg is already running, which will exit the script if the previous backup run is still in progress. This script makes a new backup set and labels it with the hostname and current date. It then prunes old backup sets with an easy retention schedule.
|
||||
|
||||
Here is my **backup.sh** script:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
REPOSITORY=borg@borgserver:/mnt/backup/repo1
|
||||
|
||||
#Bail if borg is already running, maybe previous run didn't finish
|
||||
if pidof -x borg >/dev/null; then
|
||||
echo "Backup already running"
|
||||
exit
|
||||
fi
|
||||
|
||||
# Setting this, so you won't be asked for your repository passphrase:
|
||||
export BORG_PASSPHRASE='thisisnotreallymypassphrase'
|
||||
# or this to ask an external program to supply the passphrase:
|
||||
export BORG_PASSCOMMAND='pass show backup'
|
||||
|
||||
# Backup all of /home and /var/www except a few
|
||||
# excluded directories
|
||||
borg create -v --stats \
|
||||
$REPOSITORY::'{hostname}-{now:%Y-%m-%d}' \
|
||||
/home/doc \
|
||||
--exclude '/home/doc/.cache' \
|
||||
--exclude '/home/doc/.minikube' \
|
||||
--exclude '/home/doc/Downloads' \
|
||||
--exclude '/home/doc/Videos' \
|
||||
--exclude '/home/doc/Music' \
|
||||
|
||||
# Use the `prune` subcommand to maintain 7 daily, 4 weekly and 6 monthly
|
||||
# archives of THIS machine. The '{hostname}-' prefix is very important to
|
||||
# limit prune's operation to this machine's archives and not apply to
|
||||
# other machine's archives also.
|
||||
borg prune -v --list $REPOSITORY --prefix '{hostname}-' \
|
||||
--keep-daily=7 --keep-weekly=4 --keep-monthly=6
|
||||
```
|
||||
|
||||
The output from a backup run looks like this:
|
||||
|
||||
```
|
||||
------------------------------------------------------------------------------
|
||||
Archive name: x250-2017-10-05
|
||||
Archive fingerprint: xxxxxxxxxxxxxxxxxxx
|
||||
Time (start): Thu, 2017-10-05 03:09:03
|
||||
Time (end): Thu, 2017-10-05 03:12:11
|
||||
Duration: 3 minutes 8.12 seconds
|
||||
Number of files: 171150
|
||||
------------------------------------------------------------------------------
|
||||
Original size Compressed size Deduplicated size
|
||||
This archive: 27.75 GB 27.76 GB 323.76 MB
|
||||
All archives: 3.08 TB 3.08 TB 262.76 GB
|
||||
|
||||
Unique chunks Total chunks
|
||||
Chunk index: 1682989 24007828
|
||||
------------------------------------------------------------------------------
|
||||
[...]
|
||||
Keeping archive: x250-2017-09-17 Sun, 2017-09-17 03:09:02
|
||||
Pruning archive: x250-2017-09-28 Thu, 2017-09-28 03:09:02
|
||||
```
|
||||
|
||||
Once I had all the machines backing up to the host, I followed [the instructions for installing a precompiled Rclone binary][18] and set it up to access my Wasabi account.
|
||||
|
||||
This script runs each night to synchronize any changes to the backup sets:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
repos=( repo1 repo2 repo3 )
|
||||
|
||||
#Bail if rclone is already running, maybe previous run didn't finish
|
||||
if pidof -x rclone >/dev/null; then
|
||||
echo "Process already running"
|
||||
exit
|
||||
fi
|
||||
|
||||
for i in "${repos[@]}"
|
||||
do
|
||||
#Lets see how much space is used by directory to back up
|
||||
#if directory is gone, or has gotten small, we will exit
|
||||
space=`du -s /mnt/backup/$i|awk '{print $1}'`
|
||||
|
||||
if (( $space < 34500000 )); then
|
||||
echo "EXITING - not enough space used in $i"
|
||||
exit
|
||||
fi
|
||||
|
||||
/usr/bin/rclone -v sync /mnt/backup/$i wasabi:$i >> /home/borg/wasabi-sync.log 2>&1
|
||||
done
|
||||
```
|
||||
|
||||
The first synchronization of the backup set to Wasabi with Rclone took several days, but it was around 400GB of new data, and my outbound connection is not super-fast. But the daily delta is very small and completes in just a few minutes.
|
||||
|
||||
### Restoring files
|
||||
|
||||
Restoring files is not as easy as it was with CrashPlan, but it is relatively straightforward. The fastest approach is to restore from the backup stored on the Borg backup server. Here are some example commands used to restore:
|
||||
|
||||
```
|
||||
#List which backup sets are in the repo
|
||||
$ borg list borg@borgserver:/mnt/backup/repo1
|
||||
Remote: Authenticated with partial success.
|
||||
Enter passphrase for key ssh://borg@borgserver/mnt/backup/repo1:
|
||||
x250-2017-09-17 Sun, 2017-09-17 03:09:02
|
||||
#List contents of a backup set
|
||||
$ borg list borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 | less
|
||||
#Restore one file from the repo
|
||||
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc/somefile.jpg
|
||||
#Restore a whole directory
|
||||
$ borg extract borg@borgserver:/mnt/backup/repo1::x250-2017-09-17 home/doc
|
||||
```
|
||||
|
||||
If something happens to the local Borg server or the USB drive holding all the backup repositories, I can also easily restore directly from Wasabi. If the machine has Rclone installed, using **[rclone mount][3]** I can mount the remote storage bucket as though it were a local filesystem:
|
||||
|
||||
```
|
||||
#Mount the S3 store and run in the background
|
||||
$ rclone mount wasabi:repo1 /mnt/repo1 &
|
||||
#List archive contents
|
||||
$ borg list /mnt/repo1
|
||||
#Extract a file
|
||||
$ borg extract /mnt/repo1::x250-2017-09-17 home/doc/somefile.jpg
|
||||
```
|
||||
|
||||
### How it's working
|
||||
|
||||
Now that I've been using this backup approach for a few weeks, I can say I'm really happy with it. Setting everything up and getting it running was a lot more complicated than just installing CrashPlan of course, but that's the difference between rolling your own solution and using a service. I will have to watch closely to be sure backups continue to run and the data is properly synchronized to Wasabi.
|
||||
|
||||
But, overall, replacing CrashPlan with something offering comparable backup coverage at a really reasonable price turned out to be a little easier than I expected. If you see room for improvement please let me know.
|
||||
|
||||
_This was originally published on _ [_Local Conspiracy_][19] _ and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Christopher Aedo - Christopher Aedo has been working with and contributing to open source software since his college days. Most recently he can be found leading an amazing team of upstream developers at IBM who are also developer advocates. When he’s not at work or speaking at a conference, he’s probably using a RaspberryPi to brew and ferment a tasty homebrew in Portland OR.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/backing-your-machines-borg
|
||||
|
||||
作者:[ Christopher Aedo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/docaedo
|
||||
[1]:https://opensource.com/file/375066
|
||||
[2]:https://opensource.com/article/17/10/backing-your-machines-borg?rate=Aa1IjkXuXy95tnvPGLWcPQJCKBih4Wo9hNPxhDs-mbQ
|
||||
[3]:https://rclone.org/commands/rclone_mount/
|
||||
[4]:https://opensource.com/user/145976/feed
|
||||
[5]:https://www.crashplan.com/en-us/consumer/nextsteps/
|
||||
[6]:https://www.arqbackup.com/
|
||||
[7]:https://www.carbonite.com/
|
||||
[8]:https://www.backblaze.com/
|
||||
[9]:http://backuppc.sourceforge.net/BackupPCServerStatus.html
|
||||
[10]:http://www.nongnu.org/rdiff-backup/
|
||||
[11]:https://www.borgbackup.org/
|
||||
[12]:https://rclone.org/
|
||||
[13]:https://wasabi.com/
|
||||
[14]:https://github.com/borgbackup/borg/
|
||||
[15]:http://osxdaily.com/2014/02/12/install-command-line-tools-mac-os-x/
|
||||
[16]:https://github.com/borgbackup/borgweb
|
||||
[17]:https://borgbackup.readthedocs.io/en/stable/quickstart.html
|
||||
[18]:https://rclone.org/install/
|
||||
[19]:http://localconspiracy.com/2017/10/backup-everything.html
|
||||
[20]:https://opensource.com/users/docaedo
|
||||
[21]:https://opensource.com/users/docaedo
|
||||
[22]:https://opensource.com/article/17/10/backing-your-machines-borg#comments
|
||||
@ -1,104 +0,0 @@
|
||||
jrglinux is translating!!!
|
||||
|
||||
But I don't know what a container is
|
||||
============================================================
|
||||
|
||||
### Here's how containers are both very much like — and very much unlike — virtual machines.
|
||||
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
I've been speaking about security in DevOps—also known as "DevSecOps"[*][9]—at a few conferences and seminars recently, and I've started to preface the discussion with a quick question: "Who here understands what a container is?" Usually I don't see many hands going up,[**][10] so I've started briefly explaining what containers[***][11] are before going much further.
|
||||
|
||||
To be clear: You _can_ do DevOps without containers, and you _can_ do DevSecOps without containers. But containers lend themselves so well to the DevOps approach—and to DevSecOps, it turns out—that even though it's possible to do DevOps without them, I'm going to assume that most people will use containers.
|
||||
|
||||
### What is a container?
|
||||
|
||||
Linux Containers
|
||||
|
||||
* [What are Linux containers?][1]
|
||||
|
||||
* [What is Docker?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [An introduction to container terminology][4]
|
||||
|
||||
I was in a meeting with colleagues a few months ago, and one of them was presenting on containers. Not everybody around the table was an expert on the technology, so he started simply. He said something like, "There's no mention of containers in the Linux kernel source code." This, it turned out, was a dangerous statement to make in this particular group, and within a few seconds, both my boss (sitting next to me) and I were downloading the recent kernel source tarballs and performing a count of the exact number of times that the word "container" occurred. It turned out that his statement wasn't entirely correct. To give you an idea, I just tried it on an old version (4.9.2) I have on a laptop—it turns out 15,273 lines in that version include the word "container."[****][16] My boss and I had a bit of a smirk and ensured we corrected him at the next break.
|
||||
|
||||
What my colleague meant to say—and clarified later—is that the concept of a container doesn't really exist as a clear element within the Linux kernel. In other words, containers use a number of abstractions, components, tools, and mechanisms from the Linux kernel, but there's nothing very special about these; they can also be used for other purposes. So, there's "no such thing as a container, according to the Linux kernel."
|
||||
|
||||
What, then, is a container? Well, I come from a virtualization—hypervisor and virtual machine (VM)—background, and, in my mind, containers are both very much like and very much unlike VMs. I realize that this may not sound very helpful, but let me explain.
|
||||
|
||||
### How is a container like a VM?
|
||||
|
||||
The main way in which a container is like a VM is that it's a unit of execution. You bundle something up—an image—which you can then run on a suitably equipped host platform. Like a VM, it's a workload on a host, and like a VM, it runs at the mercy of that host. Beyond providing workloads with the resources they need to do their job (CPU cycles, networking, storage access, etc.), the host has a couple of jobs that it needs to do:
|
||||
|
||||
1. Protect workloads from each other, and make sure that a malicious, compromised, or poorly written workload cannot affect the operation of any others.
|
||||
|
||||
2. Protect itself (the host) from workloads, and make sure that a malicious, compromised, or poorly written workload cannot affect the operation of the host.
|
||||
|
||||
The ways VMs and containers achieve this isolation are fundamentally different, with VMs isolated by hypervisors making use of hardware capabilities, and containers isolated via software controls provided by the Linux kernel.[******][12]These controls revolve around various "namespaces" that ensure one container can't see other containers' files, users, network connections, etc.—nor those of the host. These can be supplemented by tools such as SELinux, which provide capabilities controls for further isolation of containers.
|
||||
|
||||
### How is a container unlike a VM?
|
||||
|
||||
The problem with the description above is that if you're even vaguely hypervisor-aware, you probably think that a container is just like a VM, and it _really_ isn't.
|
||||
|
||||
A container, first and foremost,[*******][6] is a packaging format. "WHAT?" you say, "but you just said it was something that was executed." Well, yes, but the main reason containers are so interesting is that it's very easy to create the images from which they're instantiated, and those images are typically much, _much_ smaller than for VMs. For this reason, they take up very little memory and can be spun up and spun down very, very quickly. Having a container that sits around for just a few minutes or even seconds (OK, milliseconds, if you like) is an entirely sensible and feasible idea. For VMs, not so much.
|
||||
|
||||
Given that containers are so lightweight and easy to replace, people are using them to create microservices—minimal components split out of an application that can be used by one or many other microservices to build into whatever you want. Given that you plan to put only what you need for a particular function or service within a container, you're now free to make it very small, which means that writing new ones and throwing away the old ones becomes very practicable. I'll follow up on this and some of the impacts this might have on security, and hence DevSecOps, in a future article.
|
||||
|
||||
Hopefully this has been a useful intro to containers, and you're motivated to learn more about DevSecOps. (And if you aren't, just pretend.)
|
||||
|
||||
* * *
|
||||
|
||||
* I think SecDevOps reads oddly, and DevOpsSec tends to get pluralized, and then you're on an entirely different topic.
|
||||
|
||||
** I should note that this isn't just with British audiences, who are reserved and don't like drawing attention to themselves. This also happens with Canadian and U.S. audiences who, well … are different in that regard.
|
||||
|
||||
*** I'm going to be talking about Linux containers. I'm aware there's history here, so it's worth noting. In case of pedantry.
|
||||
|
||||
**** I used **grep -ir container linux-4.9.2 | wc -l** in case you're interested.[*****][13]
|
||||
|
||||
***** To be fair, at a quick glance, a number of those uses have nothing to do with containers in the way we're discussing them as "Linux containers," but refer to abstractions, which can be said to contain other elements, and are, therefore, logically referred to as containers.
|
||||
|
||||
****** There are clever ways to combine VMs and containers to benefit from the strengths of each. I'm not going into those today.
|
||||
|
||||
_*******_Well, apart from the execution bit that we just covered, obviously.
|
||||
|
||||
_This article originally appeared on [Alice, Eve, and Bob—a security blog][7] and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Mike Bursell - I've been in and around Open Source since around 1997, and have been running (GNU) Linux as my main desktop at home and work since then: not always easy... I'm a security bod and architect, and am currently employed as Chief Security Architect for Red Hat. I have a blog - "Alice, Eve & Bob" - where I write (sometimes rather parenthetically) about security. I live in the UK and like single malts.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/what-are-containers
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[2]:https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[4]:https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[5]:https://opensource.com/article/17/10/what-are-containers?rate=sPHuhiD4Z3D3vJ6ZqDT-wGp8wQjcQDv-iHf2OBG_oGQ
|
||||
[6]:https://opensource.com/article/17/10/what-are-containers#*******
|
||||
[7]:https://aliceevebob.wordpress.com/2017/07/04/but-i-dont-know-what-a-container-is/
|
||||
[8]:https://opensource.com/user/105961/feed
|
||||
[9]:https://opensource.com/article/17/10/what-are-containers#*
|
||||
[10]:https://opensource.com/article/17/10/what-are-containers#**
|
||||
[11]:https://opensource.com/article/17/10/what-are-containers#***
|
||||
[12]:https://opensource.com/article/17/10/what-are-containers#******
|
||||
[13]:https://opensource.com/article/17/10/what-are-containers#*****
|
||||
[14]:https://opensource.com/users/mikecamel
|
||||
[15]:https://opensource.com/users/mikecamel
|
||||
[16]:https://opensource.com/article/17/10/what-are-containers#****
|
||||
278
sources/tech/20171111 A CEOs Guide to Emacs.md
Normal file
278
sources/tech/20171111 A CEOs Guide to Emacs.md
Normal file
@ -0,0 +1,278 @@
|
||||
# mandeler translating A CEO's Guide to Emacs
|
||||
============================================================
|
||||
|
||||
Years—no, decades—ago, I lived in Emacs. I wrote code and documents, managed email and calendar, and shelled all in the editor/OS. I was quite happy. Years went by and I moved to newer, shinier things. As a result, I forgot how to do tasks as basic as efficiently navigating files without a mouse. About three months ago, noticing just how much of my time was spent switching between applications and computers, I decided to give Emacs another try. It was a good decision for several reasons that will be covered in this post. Covered too are `.emacs` and Dropbox tips so that you can set up a good, movable environment.
|
||||
|
||||
For those who haven't used Emacs, it's something you'll likely hate, but may love. It's sort of a Rube Goldberg machine the size of a house that, at first glance, performs all the functions of a toaster. That hardly sounds like an endorsement, but the key phrase is "at first glance." Once you grok Emacs, you realize that it's a thermonuclear toaster that can also serve as the engine for... well, just about anything you want to do with text. When you think about how much your computing life revolves around text, this is a rather bold statement. Bold, but true.
|
||||
|
||||
Perhaps more importantly to me though, it's the one application I've ever used that makes me feel like I really own it instead of casting me as an anonymous "user" whose wallet is cleverly targeted by product marketing departments in fancy offices somewhere near [Soma][30] or Redmond. Modern productivity and authoring applications (e.g., Pages or IDEs) are like carbon fiber racing bikes. They come kitted out very nicely and fully assembled. Emacs is like a box of classic [Campagnolo][31] parts and a beautiful lugged steel frame that's missing one crank arm and a brake lever that you have to find in some tiny subculture on the Internet. The first one is faster and complete. The second is a source of endless joy or annoyance depending on your personality—and will last until your dying day. I'm the sort of person who feels equal joy at finding an old stash of Campy parts or tweaking my editor with eLisp. YMMV.
|
||||
|
||||

|
||||
A 1933 steel bicycle that I still ride. Check out this comparison of frame tubes: [https://www.youtube.com/watch?v=khJQgRLKMU0][6].
|
||||
|
||||
This may give the impression that Emacs is anachronistic or old-fashioned. It's not. It's powerful and timeless, but demands that you patiently understand it on its terms. The terms are pretty far off the beaten path and seem odd, but there is a logic to them that is both compelling and charming. To me, Emacs feels like the future rather than the past. Just as the lugged steel frame will be useful and comfortable in decades to come and the carbon fiber wunderbike will be in a landfill, having shattered on impact, so will Emacs persist as a useful tool when the latest trendy app is long forgotten.
|
||||
|
||||
If the notion of building your own personal working environment by editing Lisp code and having that fits-like-a-glove environment follow you to any computer is appealing to you, you may really like Emacs. If you like the new and shiny and want to get straight to work without much investment of time and mental cycles, it's likely not for you. I don't write code any more (other than Ludwig and Emacs Lisp), but many of the engineers at Fugue use Emacs to good effect. I'd say our engineers are about 30% Emacs, 40% IDEs, and 30% Vim users. But, this post is about Emacs for CEOs and other [Pointy-Haired Bosses][32] (PHB)[1][7] (and, hey, anyone who’s curious), so I'm going to explain and/or rationalize why I love it and how I use it. I also hope to provide you with enough detail that you can have a successful experience with it, without hours of Googling.
|
||||
|
||||
### Lasting Advantages
|
||||
|
||||
The long-term advantages that come with using Emacs just make life easier. The net gain makes the initial lift entirely worthwhile. Consider these:
|
||||
|
||||
### No More Context Switching
|
||||
|
||||
Org Mode alone is worth investing some serious time in, but if you are like me, you are usually working on a dozen or so documents—from blog posts to lists of what you need to do for a conference to employee reviews. In the modern world of computing, this generally means using several applications, all of which have distracting user interfaces and different ways to store, sort, and search. The result is that you need to constantly switch mental contexts and remember minutiae. I hate context switching because it is an imposition put on me due to a broken interface model[2][8] and I hate having to remember things my computer should remember for me in any rational world. In providing a single environment, Emacs is even more powerful for the PHB than the programmer, since programmers tend to spend a greater percentage of their day in a single application. Switching mental contexts has a higher cost than is often apparent. OS and application vendors have tarted up interfaces to distract us from this reality. If you’re technical, having access to a powerful [language interpreter][33] in a single keyboard shortcut (`M-:`) is especially useful.[3][9]
|
||||
|
||||
Many applications can be full screened all day and used to edit text. Emacs is singular because it is both an editor and a Lisp interpreter. In essence, you have a Turing complete machine a keystroke or two away at all times, while you go about your business. If you know a little or a lot about programming, you'll recognize that this means you can do _anything_ in Emacs. The full power of your computer is available to you in near real time while you work, once you have the commands in memory. You won't want to re-create Excel in eLisp, but most things you might do in Excel are smaller in scope and easy to accomplish in a line or two of code. If I need to crunch numbers, I'm more likely to jump over to the scratch buffer and write a little code than open a spreadsheet. Even if I have an email to write that isn't a one-liner, I'll usually just write it in Emacs and paste it into my email client. Why context switch when you can just flow? You might start with a simple calculation or two, but, over time, anything you need computed can be added with relative ease to Emacs. This is perhaps unique in applications that also provide rich features for creating things for other humans. Remember those magical terminals in Isaac Asimov's books? Emacs is the closest thing I've encountered to them.[4][10] I no longer decide what app to use for this or that thing. Instead, I just work. There is real power and efficiency to having a great tool and committing to it.
|
||||
|
||||
### Creating Things in Peace and Quiet
|
||||
|
||||
What’s the end result of having the best text editing features I've ever found? Having a community of people making all manner of useful additions? Having the full power of Lisp a keychord away? It’s that I use Emacs for all my creative work, aside from making music or images.
|
||||
|
||||
I have a dual monitor set up at my desk. One of them is in portrait mode with Emacs full screened all day long. The other one has web browsers for researching and reading; it usually has a terminal open as well. I keep my calendar, email, etc., on another desktop in OS X, which is hidden while I'm in Emacs, and I keep all notifications turned off. This allows me to actually concentrate on what I'm doing. I've found eliminating distractions to be almost impossible in the more modern UI applications due to their efforts to be helpful and easy to use. I don't need to be constantly reminded how to do operations I've done tens of thousands of times, but I do need a nice, clean white sheet of paper to be thoughtful. Maybe I'm just bad at living in noisy environments due to age and abuse, but I’d suggest it’s worth a try for anyone. See what it's like to have some actual peace and quiet in your computing environment. Of course, lots of apps now have modes that hide the interface and, thankfully, both Apple and Microsoft now have meaningful full-screen modes. But, no other application is powerful enough to “live in” for most things. Unless you are writing code all day or perhaps working on a very long document like a book, you're still going to face the noise of other apps. Also, most modern applications seem simultaneously patronizing and lacking in functionality and usability.[5][11] The only applications I dislike more than office apps are the online versions.
|
||||
|
||||

|
||||
My desktop arrangement. Emacs on the left.
|
||||
|
||||
But what about communicating? The difference between creating and communicating is substantial. I'm much more productive at both when I set aside distinct time for each. We use Slack at Fugue, which is both wonderful and hellish. I keep it on a messaging desktop alongside my calendar and email, so that, while I'm actually making things, I'm blissfully unaware of all the chatter in the world. It takes just one Slackstorm or an email from a VC or Board Director to immediately throw me out of my work. But, most things can usually wait an hour or two.
|
||||
|
||||
### Taking Everything with You and Keeping It Forever
|
||||
|
||||
The third reason I find Emacs more advantageous than other environments is that it's easy to take all your stuff with you. By this, I mean that, rather than having a plethora of apps interacting and syncing in their own ways, all you need is one or two directories syncing via Dropbox or the like. Then, you can have all your work follow you anywhere in the environment you have crafted to suit your purposes. I do this across OS X, Windows, and sometimes Linux. It's dead simple and reliable. I've found this capability to be so useful that I dread dealing with Pages, GDocs, Office, or other kinds of files and applications that force me back into finding stuff somewhere on the filesystem or in the cloud.
|
||||
|
||||
The limiting factor in keeping things forever on a computer is file format. Assuming that humans have now solved the problem of storage [6][12] for good, the issue we face over time is whether we can continue to access the information we've created. Text files are the most long-lived format for computing. You easily can open a text file from 1970 in Emacs. That’s not so true for Office applications. Text files are also nice and small—radically smaller than Office application data files. As a digital pack rat and as someone who makes lots of little notes as things pop into my head, having a simple, light, permanent collection of stuff that is always available is important to me.
|
||||
|
||||
If you’re feeling ready to give Emacs a try, read on! The sections that follow don’t take the place of a full tutorial, but will have you operational by the time you finish reading.
|
||||
|
||||
### Learning To Ride Emacs - A Technical Setup
|
||||
|
||||
The price of all this power and mental peace and quiet is that you have a steep learning curve with Emacs and it does everything differently than you're used to. At first, this will make you feel like you’re wasting time on an archaic and strange application that the modern world passed by. It’s a bit like learning to ride a bicycle[7][13]if you've only driven cars.
|
||||
|
||||
### Which Emacs?
|
||||
|
||||
I use the plain vanilla Emacs from GNU for OS X and Windows. You can get the OS X version at [][34][http://emacsformacosx.com/][35] and the Windows version at [][36][http://www.gnu.org/software/emacs/][37]. There are a bunch of other versions out there, especially for the Mac, but I've found the learning curve for doing powerful stuff (which involves Lisp and lots of modes) to be much lower with the real deal. So download it, and we can get started![8][14]
|
||||
|
||||
### First, You'll Need To Learn How To Navigate
|
||||
|
||||
I use the Emacs conventions for keys and combinations in this document. These are 'C' for control, 'M' for meta (which is usually mapped to Alt or Option), and the hyphen for holding down the keys in combination. So `C-h t` means to hold down control and type h, then release control and type t. This is the command for bringing up the tutorial, which you should go ahead and do.
|
||||
|
||||
Don't use the arrow keys or the mouse. They work, but you should give yourself a week of using the native navigation commands in Emacs. Once you have them committed to muscle memory, you'll likely enjoy them and miss them badly everywhere else you go. The Emacs tutorial does a pretty good job of walking you through them, but I'll summarize so you don't need to read the whole thing. The boring stuff is that, instead of arrows, you use `C-b` for back, `C-f` for forward, `C-p` for previous (up), and `C-n` for next (down). You may be thinking "why in the world would I do that, when I have perfectly good arrow keys?" There are several reasons. First, you don't have to move your hands from the typing position, and the forward and back keys used with Alt (or Meta in Emacspeak) navigate a word at a time. This is more handy than is obvious. The third good reason is that, if you want to repeat a command, you can precede it with a number. I often use this when editing documents by estimating how many words I need to go back or lines up or down and doing something like `C-9 C-p` or `M-5 M-b`. The other really important navigation commands are based on `a` for the beginning of a thing and `e` for the end of a thing. Using `C-a|e` are on lines, and using `M-a|e`, are on sentences. For the sentence commands to work properly, you'll need to double space after periods, which simultaneously provides a useful feature and takes a shibboleth of [opinion][38] off the mental table. If you need to export the document to a single space [publication environment][39], you can write a macro in moments to do so.
|
||||
|
||||
It genuinely is worth going through the tutorial that ships with Emacs. I'll cover a few important commands for the truly impatient, but the tutorial is gold. Reminder: `C-h t` for the tutorial.
|
||||
|
||||
### Learn To Copy and Paste
|
||||
|
||||
You can put Emacs into `CUA` mode, which will work in familiar ways, but the native Emacs way is pretty great and plenty easy once you learn it. You mark regions (like selecting) by using Shift with the navigation commands. So `C-F` selects one character forward from the cursor, etc. You copy with `M-w`, you cut with `C-w`, and you paste with `C-y`. These are actually called killing and yanking, but it's very similar to cut and paste. There is magic under the hood here in the kill ring, but for now, just worry about cut, copy, and paste. If you start fumbling around at this point, `C-x u` is undo...
|
||||
|
||||
### Next, Learn Ido Mode
|
||||
|
||||
Trust me. Ido makes working with files much easier. You don't generally use a separate Finder|Explorer window to work with files in Emacs. Instead you use the editor's commands to create, open, and save files. This is a bit of a pain without Ido, so I recommend installing it before learning the other way. Ido comes with Emacs beginning with version 22, but you'll want to make some tweaks to your `.emacs` file so that it is always used. This is a good excuse to get your environment set up.
|
||||
|
||||
Most features in Emacs come in modes. To install any given mode, you'll need to do two things. Well, at first you'll need to do a few extra things, but these only need to be done once, and thereafter only two things. So the extra things are that you'll need a single place to put all your eLisp files and you'll need to tell Emacs where that place is. I suggest you make a single directory in, say, Dropbox that is your Emacs home. Inside this, you'll want to create an `.emacs` file and an `.emacs.d` directory. Inside the `.emacs.d`, make a directory called `lisp`. So you should have:
|
||||
|
||||
```
|
||||
home
|
||||
|
|
||||
+.emacs
|
||||
|
|
||||
-.emacs.d
|
||||
|
|
||||
-lisp
|
||||
```
|
||||
|
||||
You'll put the `.el` files for things like modes into the `home/.emacs.d/lisp`directory, and you'll point to that in your `.emacs` like so:
|
||||
|
||||
`(add-to-list 'load-path "~/.emacs.d/lisp/")`
|
||||
|
||||
Ido Mode comes with Emacs, so you won't need to put an `.el` file into your Lisp directory for this, but you'll be adding other stuff soon that will go in there.
|
||||
|
||||
### Symlinks are Your Friend
|
||||
|
||||
But wait, that says that `.emacs` and `.emacs.d` are in your home directory, and we put them in some dumb folder in Dropbox! Correct. This is how you make it easy to have your environment anywhere you go. Keep everything in Dropbox and make symbolic links to `.emacs`, `.emacs.d`, and your main document directories in `~`. On OS X, this is super easy with the `ln -s` command, but on Windows this is a pain. Fortunately, Emacs provides an easy alternative to symlinking on Windows, the HOME environment variable. Go into Environment Variables in Windows (as of Windows 10, you can just hit the Windows key and type "Environment Variables" to find this with search, which is the best part of Windows 10), and make a HOME environment variable in your account that points to the Dropbox folder you made for Emacs. If you want to make it easy to navigate to local files that aren't in Dropbox, you may instead want to make a symbolic link to the Dropbox Emacs home in your actual home directory.
|
||||
|
||||
So now you've done all the jiggery-pokery needed to get any machine pointed to your Emacs setup and files. If you get a new computer or use someone else's for an hour or a day, you get your entire work environment. This seems a little difficult the first time you do it, but it's about a ten minute (at most) operation once you know what you're doing.
|
||||
|
||||
But we were configuring Ido...
|
||||
|
||||
`C-x` `C-f` and type `~/.emacs RET RET` to create your `.emacs` file. Add these lines to it:
|
||||
|
||||
```
|
||||
;; set up ido mode
|
||||
(require `ido)
|
||||
(setq ido-enable-flex-matching t)
|
||||
(setq ido-everywhere t)
|
||||
(ido-mode 1)
|
||||
```
|
||||
|
||||
With the `.emacs` buffer open, do an `M-x evaluate-buffer` command, and you'll either get an error if you munged something or you'll get Ido. Ido changes how the minibuffer works when doing file operations. There is great documentation on it, but I'll point out a few tips. Use the `~/` effectively; you can just type `~/` at any point in the minibuffer and it'll jump back to home. Implicit in this is that you should have most of your stuff a short hop off your home. I use `~/org` for all my non-code stuff and `~/code` for code. Once you’re in the right directory, you'll often have a collection of files with different extensions, especially if you use Org Mode and publish from it. You can type period and the extension you want no matter where you are in the file name and Ido will limit the choices to files with that extension. For example, I'm writing this blog post in Org Mode, so the main file is:
|
||||
|
||||
`~/org/blog/emacs.org`
|
||||
|
||||
I also occasionally push it out to HTML using Org Mode publishing, so I've got an `emacs.html` file in the same directory. When I want to open the Org file, I will type:
|
||||
|
||||
`C-x C-f ~/o[RET]/bl[RET].or[RET]`
|
||||
|
||||
The [RET]s are me hitting return for auto completion for Ido Mode. So, that’s 12 characters typed and, if you're used to it, a _lot_ less time than opening Finder|Explorer and clicking around. Ido Mode is plenty useful, but really is a utility mode for operating Emacs. Let's explore some modes that are useful for getting work done.
|
||||
|
||||
### Fonts and Styles
|
||||
|
||||
I recommend getting the excellent input family of typefaces for use in Emacs. They are customizable with different braces, zeroes, and other characters. You can build in extra line spacing into the font files themselves. I recommend a 1.5X line spacing and using their excellent proportional fonts for code and data. I use Input Serif for my writing, which has a funky but modern feel. You can find them on [http://input.fontbureau.com/][40] where you can customize to your preferences. You can manually set the fonts using menus in Emacs, but this puts code into your `.emacs`file and, if you use multiple devices, you may find you want some different settings. I've set up my `.emacs` to look for the machine I'm using by name and configure the screen appropriately. The code for this is:
|
||||
|
||||
```
|
||||
;; set up fonts for different OSes. OSX toggles to full screen.
|
||||
(setq myfont "InputSerif")
|
||||
(cond
|
||||
((string-equal system-name "Sampo.local")
|
||||
(set-face-attribute 'default nil :font myfont :height 144)
|
||||
(toggle-frame-fullscreen))
|
||||
((string-equal system-name "Morpheus.local")
|
||||
(set-face-attribute 'default nil :font myfont :height 144))
|
||||
((string-equal system-name "ILMARINEN")
|
||||
(set-face-attribute 'default nil :font myfont :height 106))
|
||||
((string-equal system-name "UKKO")
|
||||
(set-face-attribute 'default nil :font myfont :height 104)))
|
||||
```
|
||||
|
||||
You should replace the `system-name` values with what you get when you evaluate `(system-name)` in your copy of Emacs. Note that on Sampo (my MacBook), I also set Emacs to full screen. I'd like to do this on Windows as well, but Windows and Emacs don't really love each other and it always ends up in some wonky state when I try this. Instead, I just fullscreen it manually after launch.
|
||||
|
||||
I also recommend getting rid of the awful toolbar that Emacs got sometime in the 90s when the cool thing to do was to have toolbars in your application. I also got rid of some other "chrome" so that I have a simple, productive interface. Add these to your `.emacs` file to get rid of the toolbar and scroll bars, but to keep your menu available (on OS X, it'll be hidden unless you mouse to the top of the screen anyway):
|
||||
|
||||
```
|
||||
(if (fboundp 'scroll-bar-mode) (scroll-bar-mode -1))
|
||||
(if (fboundp 'tool-bar-mode) (tool-bar-mode -1))
|
||||
(if (fboundp 'menu-bar-mode) (menu-bar-mode 1))
|
||||
```
|
||||
|
||||
### Org Mode
|
||||
|
||||
I pretty much live in Org Mode. It is my go-to environment for authoring documents, keeping notes, making to-do lists and 90% of everything else I do. Org was originally conceived as a combination note-taking and to-do list utility by a fellow who is a laptop-in-meetings sort. I am against use of laptops in meetings and don't do it myself, so my use cases are a little different than his. For me, Org is primarily a way to handle all manner of content within a structure. There are heads and subheads, etc., in Org Mode, and they function like an outline. Org allows you to expand or hide the contents of the tree and also to rearrange the tree. This fits how I think very nicely and I find it to be just a pleasure to use in this way.
|
||||
|
||||
Org Mode also has a lot of little things that make life pleasant. For example, the footnote handling is excellent and the LaTeX/PDF output is great. Org has the ability to generate agendas based on the to-do's in all your documents and a nice way to relate them to dates/times. I don't use this for any sort of external commitments, which are handled on a shared calendar, but for creating things and keeping track of what I need to create in the future, it's invaluable. Installing it is as easy as adding the `org-mode.el` to your Lisp directory and adding these lines to your `.emacs`, if you want it to indent based on tree location and to open documents fully expanded:
|
||||
|
||||
```
|
||||
;; set up org mode
|
||||
(setq org-startup-indented t)
|
||||
(setq org-startup-folded "showall")
|
||||
(setq org-directory "~/org")
|
||||
```
|
||||
|
||||
The last line is there so that Org knows where to look for files to include in agendas and some other things. I keep Org right in my home directory, i.e., a symlink to the directory that lives in Dropbox, as described earlier.
|
||||
|
||||
I have a `stuff.org` file that is always open in a buffer. I use it like a notepad. Org makes it easy to extract things like TODOs and stuff with deadlines. It's especially useful when you can inline Lisp code and evaluate it whenever you need. Having code with content is super handy. Again, you have access to the actual computer with Emacs, and this is a liberation.
|
||||
|
||||
#### Publishing with Org Mode
|
||||
|
||||
I care about the appearance and formatting of my documents. I started my career as a designer, and I think information can and should be presented clearly and beautifully. Org has great support for generating PDFs via LaTeX, which has a bit of its own learning curve, but doing simple things is pretty easy.
|
||||
|
||||
If you want to use fonts and styles other than the typical LaTeX ones, you've got a few things to do. First, you'll want XeLaTeX so you can use normal system fonts rather than LaTeX specific fonts. Next, you'll want to add this to `.emacs`:
|
||||
|
||||
```
|
||||
(setq org-latex-pdf-process
|
||||
'("xelatex -interaction nonstopmode %f"
|
||||
"xelatex -interaction nonstopmode %f"))
|
||||
```
|
||||
|
||||
I put this right at the end of my Org section of `.emacs` to keep things tidy. This will allow you to use more formatting options when publishing from Org. For example, I often use:
|
||||
|
||||
```
|
||||
#+LaTeX_HEADER: \usepackage{fontspec}
|
||||
#+LATEX_HEADER: \setmonofont[Scale=0.9]{Input Mono}
|
||||
#+LATEX_HEADER: \setromanfont{Maison Neue}
|
||||
#+LATEX_HEADER: \linespread{1.5}
|
||||
#+LATEX_HEADER: \usepackage[margin=1.25in]{geometry}
|
||||
|
||||
#+TITLE: Document Title Here
|
||||
```
|
||||
|
||||
These simply go somewhere in your `.org` file. Our corporate font for body copy is Maison Neue, but you can put whatever is appropriate here. I strongly discourage the use of Maison Neue. It’s a terrible font and no one should ever use it.
|
||||
|
||||
This file is an example of PDF output using these settings. This is what out-of-the-box LaTeX always looks like. It's fine I suppose, but the fonts are boring and a little odd. Also, if you use the standard format, people will assume they are reading something that is or pretends to be an academic paper. You've been warned.
|
||||
|
||||
### Ace Jump Mode
|
||||
|
||||
This is more of a gem than a major feature, but you want it. It works a bit like Jef Raskin's Leap feature from days gone by.[9][15] The way it works is you type `C-c` `C-SPC`and then type the first letter of the word you want to jump to. It highlights all occurrences of words with that initial character, replacing it with a letter of the alphabet. You simply type the letter of the alphabet for the location you want and your cursor jumps to it. I find myself using this as often as the more typical nav keys or search. Download the `.el` to your Lisp directory and put this in your `.emacs`:
|
||||
|
||||
```
|
||||
;; set up ace-jump-mode
|
||||
(add-to-list 'load-path "which-folder-ace-jump-mode-file-in/")
|
||||
(require 'ace-jump-mode)
|
||||
(define-key global-map (kbd "C-c C-SPC" ) 'ace-jump-mode)
|
||||
```
|
||||
|
||||
### More Later
|
||||
|
||||
That's enough for one post—this may get you somewhere you'd like to be. I'd love to hear about your uses for Emacs aside from programming (or for programming!) and whether this was useful at all. There are likely some boneheaded PHBisms in how I use Emacs, and if you want to point them out, I'd appreciate it. I'll probably write some updates over time to introduce additional features or modes. I'll certainly show you how to use Fugue with Emacs and Ludwig-mode as we evolve it into something more useful than code highlighting. Send your thoughts to [@fugueHQ][41] on Twitter.
|
||||
|
||||
* * *
|
||||
|
||||
#### Footnotes
|
||||
|
||||
1. [^][16] If you are now a PHB of some sort, but were never technical, Emacs likely isn’t for you. There may be a handful of folks for whom Emacs will form a path into the more technical aspects of computing, but this is probably a small population. It’s helpful to know how to use a Unix or Windows terminal, to have edited a dotfile or two, and to have written some code at some point in your life for Emacs to make much sense.
|
||||
|
||||
2. [^][17] [][18][http://archive.wired.com/wired/archive/2.08/tufte.html][19]
|
||||
|
||||
3. [^][20] I mainly use this to perform calculations while writing. For example, I was writing an offer letter to a new employee and wanted to calculate how many options to include in the offer. Since I have a variable defined in my `.emacs` for outstanding-shares, I can simply type `M-: (* .001 outstanding-shares)`and get a tenth of a point without opening a calculator or spreadsheet. I keep _lots_ of numbers in variables like this so I can avoid context switching.
|
||||
|
||||
4. [^][21] The missing piece of this is the web. There is an Emacs web browser called eww that will allow you to browse in Emacs. I actually use this, as it is both a great ad-blocker and removes most of the poor choices in readability from the web designer's hands. It's a bit like Reading Mode in Safari. Unfortunately, most websites have lots of annoying cruft and navigation that translates poorly into text.
|
||||
|
||||
5. [^][22] Usability is often confused with learnability. Learnability is how difficult it is to learn a tool. Usability is how useful the tool is. Often, these are at odds, such as with the mouse and menus. Menus are highly learnable, but have poor usability, so there have been keyboard shortcuts from the earliest days. Raskin was right on many points where he was ignored about GUIs in general. Now, OSes are putting things like decent search onto a keyboard shortcut. On OS X and Windows, my default method of navigation is search. Ubuntu's search is badly broken, as is the rest of its GUI.
|
||||
|
||||
6. [^][23] AWS S3 has effectively solved file storage for as long as we have the Internet. Trillions of objects are stored in S3 and they've never lost one of them. Most every service out there that offers cloud storage is built on S3 or imitates it. No one has the scale of S3, so I keep important stuff there, via Dropbox.
|
||||
|
||||
7. [^][24] By now, you might be thinking "what is it with this guy and bicycles?" ... I love them on every level. They are the most mechanically efficient form of transportation ever invented. They can be objects of real beauty. And, with some care, they can last a lifetime. I had Rivendell Bicycle Works build a frame for me back in 2001 and it still makes me happy every time I look at it. Bicycles and UNIX are the two best inventions I've interacted with. Well, they and Emacs.
|
||||
|
||||
8. [^][25] This is not a tutorial for Emacs. It comes with one and it's excellent. I do walk through some of the things that I find most important to getting a useful Emacs setup, but this is not a replacement in any way.
|
||||
|
||||
9. [^][26] Jef Raskin designed the Canon Cat computer in the 1980s after falling out with Steve Jobs on the Macintosh project, which he originally led. The Cat had a document-centric interface (as all computers should) and used the keyboard in innovative ways that you can now imitate with Emacs. If I could have a modern, powerful Cat with a giant high-res screen and Unix underneath, I'd trade my Mac for it right away. [][27][https://youtu.be/o_TlE_U_X3c?t=19s][28]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.fugue.co/2015-11-11-guide-to-emacs.html
|
||||
|
||||
作者:[Josh Stella ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.fugue.co/authors/josh.html
|
||||
[1]:https://blog.fugue.co/2013-10-16-vpc-on-aws-part3.html
|
||||
[2]:https://blog.fugue.co/2013-10-02-vpc-on-aws-part2.html
|
||||
[3]:http://ww2.fugue.co/2017-05-25_OS_AR_GartnerCoolVendor2017_01-LP-Registration.html
|
||||
[4]:https://blog.fugue.co/authors/josh.html
|
||||
[5]:https://twitter.com/joshstella
|
||||
[6]:https://www.youtube.com/watch?v=khJQgRLKMU0
|
||||
[7]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#phb
|
||||
[8]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#tufte
|
||||
[9]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#interpreter
|
||||
[10]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#eww
|
||||
[11]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#usability
|
||||
[12]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#s3
|
||||
[13]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#bicycles
|
||||
[14]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#nottutorial
|
||||
[15]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#canoncat
|
||||
[16]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#phbOrigin
|
||||
[17]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#tufteOrigin
|
||||
[18]:http://archive.wired.com/wired/archive/2.08/tufte.html
|
||||
[19]:http://archive.wired.com/wired/archive/2.08/tufte.html
|
||||
[20]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#interpreterOrigin
|
||||
[21]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#ewwOrigin
|
||||
[22]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#usabilityOrigin
|
||||
[23]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#s3Origin
|
||||
[24]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#bicyclesOrigin
|
||||
[25]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#nottutorialOrigin
|
||||
[26]:https://blog.fugue.co/2015-11-11-guide-to-emacs.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#canoncatOrigin
|
||||
[27]:https://youtu.be/o_TlE_U_X3c?t=19s
|
||||
[28]:https://youtu.be/o_TlE_U_X3c?t=19s
|
||||
[29]:https://blog.fugue.co/authors/josh.html
|
||||
[30]:http://www.huffingtonpost.com/zachary-ehren/soma-isnt-a-drug-san-fran_b_987841.html
|
||||
[31]:http://www.campagnolo.com/US/en
|
||||
[32]:http://www.businessinsider.com/best-pointy-haired-boss-moments-from-dilbert-2013-10
|
||||
[33]:http://www.webopedia.com/TERM/I/interpreter.html
|
||||
[34]:http://emacsformacosx.com/
|
||||
[35]:http://emacsformacosx.com/
|
||||
[36]:http://www.gnu.org/software/emacs/
|
||||
[37]:http://www.gnu.org/software/emacs/
|
||||
[38]:http://www.huffingtonpost.com/2015/05/29/two-spaces-after-period-debate_n_7455660.html
|
||||
[39]:http://practicaltypography.com/one-space-between-sentences.html
|
||||
[40]:http://input.fontbureau.com/
|
||||
[41]:https://twitter.com/fugueHQ
|
||||
93
sources/tech/20171113 The big break in computer languages.md
Normal file
93
sources/tech/20171113 The big break in computer languages.md
Normal file
@ -0,0 +1,93 @@
|
||||
Translated by name1e5s
|
||||
|
||||
The big break in computer languages
|
||||
============================================================
|
||||
|
||||
|
||||
My last post ([The long goodbye to C][3]) elicited a comment from a C++ expert I was friends with long ago, recommending C++ as the language to replace C. Which ain’t gonna happen; if that were a viable future, Go and Rust would never have been conceived.
|
||||
|
||||
But my readers deserve more than a bald assertion. So here, for the record, is the story of why I don’t touch C++ any more. This is a launch point for a disquisition on the economics of computer-language design, why some truly unfortunate choices got made and baked into our infrastructure, and how we’re probably going to fix them.
|
||||
|
||||
Along the way I will draw aside the veil from a rather basic mistake that people trying to see into the future of programming languages (including me) have been making since the 1980s. Only very recently do we have the field evidence to notice where we went wrong.
|
||||
|
||||
I think I first picked up C++ because I needed GNU eqn to be able to output MathXML, and eqn was written in C++. That project succeeded. Then I was a senior dev on Battle For Wesnoth for a number of years in the 2000s and got comfortable with the language.
|
||||
|
||||
Then came the day we discovered that a person we incautiously gave commit privileges to had fucked up the games’s AI core. It became apparent that I was the only dev on the team not too frightened of that code to go in. And I fixed it all right – took me two weeks of struggle. After which I swore a mighty oath never to go near C++ again.
|
||||
|
||||
My problem with the language, starkly revealed by that adventure, is that it piles complexity on complexity upon chrome upon gingerbread in an attempt to address problems that cannot actually be solved because the foundational abstractions are leaky. It’s all very well to say “well, don’t do that” about things like bare pointers, and for small-scale single-developer projects (like my eqn upgrade) it is realistic to expect the discipline can be enforced.
|
||||
|
||||
Not so on projects with larger scale or multiple devs at varying skill levels (the case I normally deal with). With probability asymptotically approaching one over time and increasing LOC, someone is inadvertently going to poke through one of the leaks. At which point you have a bug which, because of over-layers of gnarly complexity such as STL, is much more difficult to characterize and fix than the equivalent defect in C. My Battle For Wesnoth experience rubbed my nose in this problem pretty hard.
|
||||
|
||||
What works for a Steve Heller (my old friend and C++ advocate) doesn’t scale up when I’m dealing with multiple non-Steve-Hellers and might end up having to clean up their mess. So I just don’t go there any more. Not worth the aggravation. C is flawed, but it does have one immensely valuable property that C++ didn’t keep – if you can mentally model the hardware it’s running on, you can easily see all the way down. If C++ had actually eliminated C’s flaws (that it, been type-safe and memory-safe) giving away that transparency might be a trade worth making. As it is, nope.
|
||||
|
||||
One way we can tell that C++ is not sufficient is to imagine an alternate world in which it is. In that world, older C projects would routinely up-migrate to C++. Major OS kernels would be written in C++, and existing kernel implementations like Linux would be upgrading to it. In the real world, this ain’t happening. Not only has C++ failed to present enough of a value proposition to keep language designers uninterested in imagining languages like D, Go, and Rust, it has failed to displace its own ancestor. There’s no path forward from C++ without breaching its core assumptions; thus, the abstraction leaks won’t go away.
|
||||
|
||||
Since I’ve mentioned D, I suppose this is also the point at which I should explain why I don’t see it as a serious contender to replace C. Yes, it was spun up eight years before Rust and nine years before Go – props to Walter Bright for having the vision. But in 2001 the example of Perl and Python had already been set – the window when a proprietary language could compete seriously with open source was already closing. The wrestling match between the official D library/runtime and Tango hurt it, too. It has never recovered from those mistakes.
|
||||
|
||||
So now there’s Go (I’d say “…and Rust”, but for reasons I’ve discussed before I think it will be years before Rust is fully competitive). It _is_ type-safe and memory-safe (well, almost; you can partway escape using interfaces, but it’s not normal to have to go to the unsafe places). One of my regulars, Mark Atwood, has correctly pointed out that Go is a language made of grumpy-old-man rage, specifically rage by _one of the designers of C_ (Ken Thompson) at the bloated mess that C++ became.
|
||||
|
||||
I can relate to Ken’s grumpiness; I’ve been muttering for decades that C++ attacked the wrong problem. There were two directions a successor language to C might have gone. One was to do what C++ did – accept C’s leaky abstractions, bare pointers and all, for backward compatibility, than try to build a state-of-the-art language on top of them. The other would have been to attack C’s problems at their root – _fix_ the leaky abstractions. That would break backward compatibility, but it would foreclose the class of problems that dominate C/C++ defects.
|
||||
|
||||
The first serious attempt at the second path was Java in 1995\. It wasn’t a bad try, but the choice to build it over a j-code interpreter mode it unsuitable for systems programming. That left a huge hole in the options for systems programming that wouldn’t be properly addressed for another 15 years, until Rust and Go. In particular, it’s why software like my GPSD and NTPsec projects is still predominantly written in C in 2017 despite C’s manifest problems.
|
||||
|
||||
This is in many ways a bad situation. It was hard to really see this because of the lack of viable alternatives, but C/C++ has not scaled well. Most of us take for granted the escalating rate of defects and security compromises in infrastructure software without really thinking about how much of that is due to really fundamental language problems like buffer-overrun vulnerabilities.
|
||||
|
||||
So, why did it take so long to address that? It was 37 years from C (1972) to Go (2009); Rust only launched a year sooner. I think the underlying reasons are economic.
|
||||
|
||||
Ever since the very earliest computer languages it’s been understood that every language design embodies an assertion about the relative value of programmer time vs. machine resources. At one end of that spectrum you have languages like assembler and (later) C that are designed to extract maximum performance at the cost of also pessimizing developer time and costs; at the other, languages like Lisp and (later) Python that try to automate away as much housekeeping detail as possible, at the cost of pessimizing machine performance.
|
||||
|
||||
In broadest terms, the most important discriminator between the ends of this spectrum is the presence or absence of automatic memory management. This corresponds exactly to the empirical observation that memory-management bugs are by far the most common class of defects in machine-centric languages that require programmers to manage that resource by hand.
|
||||
|
||||
A language becomes economically viable where and when its relative-value assertion matches the actual cost drivers of some particular area of software development. Language designers respond to the conditions around them by inventing languages that are a better fit for present or near-future conditions than the languages they have available to use.
|
||||
|
||||
Over time, there’s been a gradual shift from languages that require manual memory management to languages with automatic memory management and garbage collection (GC). This shift corresponds to the Moore’s Law effect of decreasing hardware costs making programmer time relatively more expensive. But there are at least two other relevant dimensions.
|
||||
|
||||
One is distance from the bare metal. Inefficiency low in the software stack (kernels and service code) ripples multiplicatively up the stack. This, we see machine-centric languages down low and programmer-centric languages higher up, most often in user-facing software that only has to respond at human speed (time scale 0.1 sec).
|
||||
|
||||
Another is project scale. Every language also has an expected rate of induced defects per thousand lines of code due to programmers tripping over leaks and flaws in its abstractions. This rate runs higher in machine-centric languages, much lower in programmer-centric ones with GC. As project scale goes up, therefore, languages with GC become more and more important as a strategy against unacceptable defect rates.
|
||||
|
||||
When we view language deployments along these three dimensions, the observed pattern today – C down below, an increasing gallimaufry of languages with GC above – almost makes sense. Almost. But there is something else going on. C is stickier than it ought to be, and used way further up the stack than actually makes sense.
|
||||
|
||||
Why do I say this? Consider the classic Unix command-line utilities. These are generally pretty small programs that would run acceptably fast implemented in a scripting language with a full POSIX binding. Re-coded that way they would be vastly easier to debug, maintain and extend.
|
||||
|
||||
Why are these still in C (or, in unusual exceptions like eqn, in C++)? Transition costs. It’s difficult to translate even small, simple programs between languages and verify that you have faithfully preserved all non-error behaviors. More generally, any area of applications or systems programming can stay stuck to a language well after the tradeoff that language embodies is actually obsolete.
|
||||
|
||||
Here’s where I get to the big mistake I and other prognosticators made. We thought falling machine-resource costs – increasing the relative cost of programmer-hours – would be enough by themselves to displace C (and non-GC languages generally). In this we were not entirely or even mostly wrong – the rise of scripting languages, Java, and things like Node.js since the early 1990s was pretty obviously driven that way.
|
||||
|
||||
Not so the new wave of contending systems-programming languages, though. Rust and Go are both explicitly responses to _increasing project scale_ . Where scripting languages got started as an effective way to write small programs and gradually scaled up, Rust and Go were positioned from the start as ways to reduce defect rates in _really large_ projects. Like, Google’s search service and Facebook’s real-time-chat multiplexer.
|
||||
|
||||
I think this is the answer to the “why not sooner” question. Rust and Go aren’t actually late at all, they’re relatively prompt responses to a cost driver that was underweighted until recently.
|
||||
|
||||
OK, so much for theory. What predictions does this one generate? What does it tell us about what comes after C?
|
||||
|
||||
Here’s the big one. The largest trend driving development towards GC languages haven’t reversed, and there’s no reason to expect it will. Therefore: eventually we _will_ have GC techniques with low enough latency overhead to be usable in kernels and low-level firmware, and those will ship in language implementations. Those are the languages that will truly end C’s long reign.
|
||||
|
||||
There are broad hints in the working papers from the Go development group that they’re headed in this direction – references to academic work on concurrent garbage collectors that never have stop-the-world pauses. If Go itself doesn’t pick up this option, other language designers will. But I think they will – the business case for Google to push them there is obvious (can you say “Android development”?).
|
||||
|
||||
Well before we get to GC that good, I’m putting my bet on Go to replace C anywhere that the GC it has now is affordable – which means not just applications but most systems work outside of kernels and embedded. The reason is simple: there is no path out of C’s defect rates with lower transition costs.
|
||||
|
||||
I’ve been experimenting with moving C code to Go over the last week, and I’m noticing two things. One is that it’s easy to do – C’s idioms map over pretty well. The other is that the resulting code is much simpler. One would expect that, with GC in the language and maps as a first-class data type, but I’m seeing larger reductions in code volume than initially expected – about 2:1, similar to what I see when moving C code to Python.
|
||||
|
||||
Sorry, Rustaceans – you’ve got a plausible future in kernels and deep firmware, but too many strikes against you to beat Go over most of C’s range. No GC, plus Rust is a harder transition from C because of the borrow checker, plus the standardized part of the API is still seriously incomplete (where’s my select(2), again?).
|
||||
|
||||
The only consolation you get, if it is one, is that the C++ fans are screwed worse than you are. At least Rust has a real prospect of dramatically lowering downstream defect rates relative to C anywhere it’s not crowded out by Go; C++ doesn’t have that.
|
||||
|
||||
This entry was posted in [Software][4] by [Eric Raymond][5]. Bookmark the [permalink][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7724
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7724
|
||||
[3]:http://esr.ibiblio.org/?p=7711
|
||||
[4]:http://esr.ibiblio.org/?cat=13
|
||||
[5]:http://esr.ibiblio.org/?author=2
|
||||
[6]:http://esr.ibiblio.org/?p=7724
|
||||
@ -0,0 +1,60 @@
|
||||
Translating by ValoniaKim
|
||||
Language engineering for great justice
|
||||
============================================================
|
||||
|
||||
Whole-systems engineering, when you get good at it, goes beyond being entirely or even mostly about technical optimizations. Every artifact we make is situated in a context of human action that widens out to the economics of its use, the sociology of its users, and the entirety of what Austrian economists call “praxeology”, the science of purposeful human behavior in its widest scope.
|
||||
|
||||
This isn’t just abstract theory for me. When I wrote my papers on open-source development, they were exactly praxeology – they weren’t about any specific software technology or objective but about the context of human action within which technology is worked. An increase in praxeological understanding of technology can reframe it, leading to tremendous increases in human productivity and satisfaction, not so much because of changes in our tools but because of changes in the way we grasp them.
|
||||
|
||||
In this, the third of my unplanned series of posts about the twilight of C and the huge changes coming as we actually begin to see forward into a new era of systems programming, I’m going to try to cash that general insight out into some more specific and generative ideas about the design of computer languages, why they succeed, and why they fail.
|
||||
|
||||
In my last post I noted that every computer language is an embodiment of a relative-value claim, an assertion about the optimal tradeoff between spending machine resources and spending programmer time, all of this in a context where the cost of computing power steadily falls over time while programmer-time costs remain relatively stable or may even rise. I also highlighted the additional role of transition costs in pinning old tradeoff assertions into place. I described what language designers do as seeking a new optimum for present and near-future conditions.
|
||||
|
||||
Now I’m going to focus on that last concept. A language designer has lots of possible moves in language-design space from where the state of the art is now. What kind of type system? GC or manual allocation? What mix of imperative, functional, or OO approaches? But in praxeological terms his choice is, I think, usually much simpler: attack a near problem or a far problem?
|
||||
|
||||
“Near” and “far” are measured along the curves of falling hardware costs, rising software complexity, and increasing transition costs from existing languages. A near problem is one the designer can see right in front of him; a far problem is a set of conditions that can be seen coming but won’t necessarily arrive for some time. A near solution can be deployed immediately, to great practical effect, but may age badly as conditions change. A far solution is a bold bet that may smother under the weight of its own overhead before its future arrives, or never be adopted at all because moving to it is too expensive.
|
||||
|
||||
Back at the dawn of computing, FORTRAN was a near-problem design, LISP a far-problem one. Assemblers are near solutions. Illustrating that the categories apply to non-general-purpose languages, also roff markup. Later in the game, PHP and Javascript. Far solutions? Oberon. Ocaml. ML. XML-Docbook. Academic languages tend to be far because the incentive structure around them rewards originality and intellectual boldness (note that this is a praxeological cause, not a technical one!). The failure mode of academic languages is predictable; high inward transition costs, nobody goes there, failure to achieve community critical mass sufficient for mainstream adoption, isolation, and stagnation. (That’s a potted history of LISP in one sentence, and I say that as an old LISP-head with a deep love for the language…)
|
||||
|
||||
The failure modes of near designs are uglier. The best outcome to hope for is a graceful death and transition to a newer design. If they hang on (most likely to happen when transition costs out are high) features often get piled on them to keep them relevant, increasing complexity until they become teetering piles of cruft. Yes, C++, I’m looking at you. You too, Javascript. And (alas) Perl, though Larry Wall’s good taste mitigated the problem for many years – but that same good taste eventually moved him to blow up the whole thing for Perl 6.
|
||||
|
||||
This way of thinking about language design encourages reframing the designer’s task in terms of two objectives. (1) Picking a sweet spot on the near-far axis away from you into the projected future; and (2) Minimizing inward transition costs from one or more existing languages so you co-opt their userbases. And now let’s talk about about how C took over the world.
|
||||
|
||||
There is no more more breathtaking example than C than of nailing the near-far sweet spot in the entire history of computing. All I need to do to prove this is point at its extreme longevity as a practical, mainstream language that successfully saw off many competitors for its roles over much of its range. That timespan has now passed about 35 years (counting from when it swamped its early competitors) and is not yet with certainty ended.
|
||||
|
||||
OK, you can attribute some of C’s persistence to inertia if you want, but what are you really adding to the explanation if you use the word “inertia”? What it means is exactly that nobody made an offer that actually covered the transition costs out of the language!
|
||||
|
||||
Conversely, an underappreciated strength of the language was the low inward transition costs. C is an almost uniquely protean tool that, even at the beginning of its long reign, could readily accommodate programming habits acquired from languages as diverse as FORTRAN, Pascal, assemblers and LISP. I noticed back in the 1980s that I could often spot a new C programmer’s last language by his coding style, which was just the flip side of saying that C was damn good at gathering all those tribes unto itself.
|
||||
|
||||
C++ also benefited from having low transition costs in. Later, most new languages at least partly copied C syntax in order to minimize them.Notice what this does to the context of future language designs: it raises the value of being a C-like as possible in order to minimize inward transition costs from anywhere.
|
||||
|
||||
Another way to minimize inward transition costs is to simply be ridiculously easy to learn, even to people with no prior programming experience. This, however, is remarkably hard to pull off. I evaluate that only one language – Python – has made the major leagues by relying on this quality. I mention it only in passing because it’s not a strategy I expect to see a _systems_ language execute successfully, though I’d be delighted to be wrong about that.
|
||||
|
||||
So here we are in late 2017, and…the next part is going to sound to some easily-annoyed people like Go advocacy, but it isn’t. Go, itself, could turn out to fail in several easily imaginable ways. It’s troubling that the Go team is so impervious to some changes their user community is near-unanimously and rightly (I think) insisting it needs. Worst-case GC latency, or the throughput sacrifices made to lower it, could still turn out to drastically narrow the language’s application range.
|
||||
|
||||
That said, there is a grand strategy expressed in the Go design that I think is right. To understand it, we need to review what the near problem for a C replacement is. As I noted in the prequels, it is rising defect rates as systems projects scale up – and specifically memory-management bugs because that category so dominates crash bugs and security exploits.
|
||||
|
||||
We’ve now identified two really powerful imperatives for a C replacement: (1) solve the memory-management problem, and (2) minimize inward-transition costs from C. And the history – the praxeological context – of programming languages tells us that if a C successor candidate don’t address the transition-cost problem effectively enough, it almost doesn’t matter how good a job it does on anything else. Conversely, a C successor that _does_ address transition costs well buys itself a lot of slack for not being perfect in other ways.
|
||||
|
||||
This is what Go does. It’s not a theoretical jewel; it has annoying limitations; GC latency presently limits how far down the stack it can be pushed. But what it is doing is replicating the Unix/C infective strategy of being easy-entry and _good enough_ to propagate faster than alternatives that, if it didn’t exist, would look like better far bets.
|
||||
|
||||
Of course, the proboscid in the room when I say that is Rust. Which is, in fact, positioning itself as the better far bet. I’ve explained in previous installments why I don’t think it’s really ready to compete yet. The TIOBE and PYPL indices agree; it’s never made the TIOBE top 20 and on both indices does quite poorly against Go.
|
||||
|
||||
Where Rust will be in five years is a different question, of course. My advice to the Rust community, if they care, is to pay some serious attention to the transition-cost problem. My personal experience says the C to Rust energy barrier is _[nasty][2]_ . Code-lifting tools like Corrode won’t solve it if all they do is map C to unsafe Rust, and if there were an easy way to automate ownership/lifetime annotations they wouldn’t be needed at all – the compiler would just do that for you. I don’t know what a solution would look like, here, but I think they better find one.
|
||||
|
||||
I will finally note that Ken Thompson has a history of designs that look like minimal solutions to near problems but turn out to have an amazing quality of openness to the future, the capability to _be improved_ . Unix is like this, of course. It makes me very cautious about supposing that any of the obvious annoyances in Go that look like future-blockers to me (like, say, the lack of generics) actually are. Because for that to be true, I’d have to be smarter than Ken, which is not an easy thing to believe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7745
|
||||
|
||||
作者:[Eric Raymond ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7711&cpage=1#comment-1913931
|
||||
[3]:http://esr.ibiblio.org/?p=7745
|
||||
86
translated/talk/20171107 The long goodbye to C.md
Normal file
86
translated/talk/20171107 The long goodbye to C.md
Normal file
@ -0,0 +1,86 @@
|
||||
对 C 的漫长的告别
|
||||
==========================================
|
||||
|
||||
|
||||
这几天来,我就在思考那些能够挑战 C 语言作为系统编程语言堆中的根节点的地位的新潮语言,尤其是 Go 和 Rust。我发现了一个让我震惊的事实 —— 我有着 35 年的 C 语言经验。每周我都要写很多 C 代码,但是我已经忘了我上一次是在什么时候 _创建新的 C 语言项目_ 了。
|
||||
|
||||
如果你认为这件事情不够震惊,那你可能不是一个系统程序员。我知道有很多程序员使用更高级的语言工作。但是我把大部分时间都花在了深入打磨像 NTPsec , GPSD 以及 giflib 这些东西上。熟练使用 C 语言在这几十年里一直就是我的专长。但是,现在我不仅是不再使用 C 语言写新的项目,而且我都记不清我什么时候开始这样做的了。而且...回望历史,我不认为这是本世纪发生的事情。
|
||||
|
||||
当你问到我我的五个核心软件开发技能,“C 语言专家” 一定是你最有可能听到的,这件事情对我来说很好。这也激起了我的思考。C 的未来会怎样 ?C 是否正像当年的 COBOL 一样,在辉煌之后,走向落幕?
|
||||
|
||||
我恰好是在 C 语言迅猛发展并把汇编语言以及其他许多编译型语言挤出主流存在的前几年开始编程的。那场过渡大约是在 1982 到 1985 年之间。在那之前,有很多编译型语言来争相吸引程序员的注意力,那些语言中还没有明确的领导者;但是在那之后,小众的语言直接毫无声息的退出舞台。主流的(FORTRAN,Pascal,COBOL)语言则要么只限于老代码,要么就是固守单一领域,再就是在 C 语言的边缘领域顶着愈来愈大的压力苟延残喘。
|
||||
|
||||
在那以后,这种情形持续了近 30 年。尽管在应用程序开发上出现了新的动向: Java, Perl, Python, 以及许许多多不是很成功的竞争者。起初我很少关注这些语言,这很大一部是是因为在它们的运行时的开销对于当时的实际硬件来说太大。因此,这就使得 C 的成功无可撼动;为了使用之前存在的 C 语言代码,你得使用 C 语言写新代码(一部分脚本语言尝试过大伯这个限制,但是只有 Python 做到了)
|
||||
|
||||
回想起来,我在 1997 年使用脚本语言写应用时本应该注意到这些语言的更重要的意义的。当时我写的是一个帮助图书管理员使用一款叫做 SunSITE 的源码分发式软件,我使用的那个语言,叫做 Perl。
|
||||
|
||||
这个应用完全是基于文本的,而且只需要以人类能反应过来的速度运行(大概 0.1 秒),因此使用 C 或者别的没有动态内存分配以及字符串类型的语言来写就会显得很傻。但是在当时,我仅仅是把其视为一个试验,我在那时没想到我几乎再也不会在一个新项目的第一个文件里敲下 “int main(int argc, char **argv)” 了。
|
||||
|
||||
我说“几乎”,主要是因为 1999 年的 [SNG][3].我像那是我最后一个从头开始写的项目。在那之后我的所有新的 C 代码都是为我贡献代码,或者成为维护者的项目而写 —— 比如 GPSD 以及 NTPsec。
|
||||
|
||||
当年我本不应该使用 C 语言写 SNG 的。因为在那个年代,摩尔定律的快速循环使得硬件愈加便宜,像 Perl 这样的语言的运行也不再是问题。仅仅三年以后,我可能就会毫不犹豫地使用 Python 而不是 C 语言来写 SNG。
|
||||
|
||||
在 1997 年学习了 Python 这件事对我来说是一道分水岭。这个语言很完美 —— 就像我早年使用的 Lisp 一样,而且 Python 还有很酷的库!还完全绑定了 POSIX!还有一个绝不完犊子的对象系统!Python 没有把 C 语言挤出我的工具箱,但是我很快就习惯了在只要能用 Python 时就写 Python ,而只在必须使用 C 时写 C .
|
||||
|
||||
(在此之后,我开始在我的访谈中指出我所谓的 “Perl 的教训” ,也就是任何一个没有和 C 语言语义等价的 POSIX 绑定的语言_都得失败_。在计算机科学的发展史上,作者没有意识到这一点的学术语言的骨骸俯拾皆是。)
|
||||
|
||||
显然,对我来说,,Python 的主要优势之一就是它很简单,当我写 Python 时,我不再需要担心内存管理问题或者会导致吐核的程序崩溃 —— 对于 C 程序员来说,处理这些问题烦的要命。而不那么明显的优势恰好在我更改语言时显现,我在 90 年代末写应用程序和非核心系统服务的代码时为了平衡成本与风险都会倾向于选择具有自动内存管理但是开销更大的语言,以抵消之前提到的 C 语言的缺陷。而在仅仅几年之前(甚至是 1990 年),那些语言的开销还是大到无法承受的;那时摩尔定律还没让硬件产业迅猛发展。
|
||||
|
||||
与 C 相比更喜欢 Python —— 然后只要是能的话我就会从 C 语言转移到 Python ,这让我的工作的复杂程度降了不少。我开始在 GPSD 以及 NTPsec 里面加入 Python。这就是我们能把 NTP 的代码库大小削减四分之一的原因。
|
||||
|
||||
但是今天我不是来讲 Python 的。尽管我觉得它在竞争中脱颖而出,Python 也不是在 2000 年之前彻底结束我在新项目上使用 C 语言的原因,在当时任何一个新的学院派的动态语言都可以让我不写 C 语言代码。那件事可能是在我写了很多 Java 之后发生的,这就是另一段时间线了。
|
||||
|
||||
我写这个回忆录部分原因是我觉得我不特殊,我像在世纪之交,同样的事件也改变了不少 C 语言老手的编码习惯。他们也会和我之前一样,没有发现这一转变。
|
||||
|
||||
在 2000 年以后,尽管我还在使用 C/C++ 写之前的项目,比如 GPSD ,游戏韦诺之战以及 NTPsec,但是我的所有新项目都是使用 Python 的。
|
||||
|
||||
有很多程序是在完全无法在 C 语言下写出来的,尤其是 [reposurgeon][4] 以及 [doclifter][5] 这样的项目。由于 C 语言的有限的数据本体以及其脆弱的底层管理,尝试用 C 写的话可能会很恐怖,并注定失败。
|
||||
|
||||
甚至是对于更小的项目 —— 那些可以在 C 中实现的东西 —— 我也使用 Python 写,因为我不想花不必要的时间以及精力去处理内核转储问题。这种情况一直持续到去年年底,持续到我创建我的第一个 Rust 项目,以及成功写出第一个[使用 Go 语言的项目][6]。
|
||||
|
||||
如前文所述,尽管我是在讨论我的个人经历,但是我想我的经历体现了时代的趋势。我期待新潮流的出现,而不是仅仅跟随潮流。在 98 年,我是 Python 的早期使用者。来自 [TIOBE][7] 的数据让我在 Go 语言脱胎于公司的实验项目从小众语言火爆的几个月内开始写自己的第一个 Go 语言项目。
|
||||
|
||||
总而言之:直到现在第一批有可能挑战 C 语言的传统地位的语言才出现。我判断这个的标砖很简单 —— 只要这个语言能让我等 C 语言老手接受不再写 C 的 事实,这个语言才 “有可能” 挑战到 C 语言的地位 —— 来看啊,这有个新编译器,能把 C 转换到新语言,现在你可以让他完成你的_全部工作_了 —— 这样 C 语言的老手就会开心起来。
|
||||
|
||||
Python 以及和其类似的语言对此做的并不够好。使用 Python 实现 NTPsec(以此举例)可能是个灾难,最终会由于过高的运行时开销以及由于垃圾回收机制导致的延迟变化而烂尾。当写单用户且只需要以人类能接受的速度运行的程序时,使用 Python 很好,但是对于以 _机器的速度_ 运行的程序来说就不总是如此了 —— 尤其是在很高的多用户负载之下。这不只是我自己的判断,起初 Go 存在的主要原因就是 Google ,然后 Python 的众多支持者也来支持这款语言 ——— 他们遭遇了同样的痛点。
|
||||
|
||||
Go 语言就是为了处理 Python 处理不了的类 C 语言工作而设计的。尽管没有一个全自动语言转换软件让我很是不爽,但是使用 Go 语言来写系统程序对我来说不算麻烦,我发现我写 Go 写的还挺开心的。我的 很多 C 编码技能还可以继续使用,我还收获了垃圾回收机制以及并发编程机制,这何乐而不为?
|
||||
|
||||
([这里][8]有关于我第一次写 Go 的经验的更多信息)
|
||||
|
||||
本来我像把 Rust 也视为 “C 语言要过时了” 的例子,但是在学习这们语言并尝试使用这门语言编程之后,我觉得[这语言现在还不行][9]。也许 5 年以后,它才会成为 C 语言的对手。
|
||||
|
||||
随着 2017 的临近,我们已经发现了一个相对成熟的语言,其和 C 类似,能够胜任 C 语言的大部分工作场景(我在下面会准确描述),在几年以后,这个语言届的新星可能就会取得成功。
|
||||
|
||||
这件事意义重大。如果你不长远地回顾历史,你可能看不出来这件事情的伟大性。_三十年了_ —— 这几乎就是我写代码的时间,我们都没有等到 C 语言的继任者。也无法体验在前 C 语言时代的系统编程是什么模样。但是现在我们可以使用两种视角来看待系统编程...
|
||||
|
||||
...另一个视角就是下面这个语言。我的一个朋友正在开发一个他称之为 "Cx" 的语言,这个语言在 C 语言上做了很少的改动,使得其能够支持类型安全;他的项目的目的就是要创建一个能够在最少人力参与的情况下把古典 C 语言修改为新语言的程序。我不会指出这位朋友的名字,免得给他太多压力,让他给我做出不切实际的保证,他的实现方法真的很是有意思,我会尽量给他募集资金。
|
||||
|
||||
现在,除了 C 语言之外,我看到了三种不同的道路。在两年之前,我一种都不会发现。我重复一遍:这件事情意义重大。
|
||||
|
||||
我是说 C 语言将要灭绝吗?没有,在可预见的未来里,C 语言还会在操作系统的内核以及设备固件的编程的主流语言,在那里,尽力压榨硬件性能的古老命令还在奏效,尽管它可能不是那么安全。
|
||||
|
||||
现在被攻破的领域就是我之前提到的我经常出没的领域 —— 比如 GPSD 以及 NTPsec ,系统服务以及那些因为历史原因而使用 C 语言写的进程。还有就是以 DNS 服务器以及邮箱 —— 那些得以机器而不是人类的速度运行的系统程序。
|
||||
|
||||
现在我们可以预见,未来大多数代码都是由具有强大内存安全特性的 C 语言的替代者实现。Go , Rust 或者 Cx ,无论是哪个, C 的存在都将被弱化。如果我现在来实现 NTP ,我可能就会毫不犹豫的使用 Go 语言来实现。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7711
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7711
|
||||
[3]:http://sng.sourceforge.net/
|
||||
[4]:http://www.catb.org/esr/reposurgeon/
|
||||
[5]:http://www.catb.org/esr/doclifter/
|
||||
[6]:http://www.catb.org/esr/loccount/
|
||||
[7]:https://www.tiobe.com/tiobe-index/
|
||||
[8]:https://blog.ntpsec.org/2017/02/07/grappling-with-go.html
|
||||
[9]:http://esr.ibiblio.org/?p=7303
|
||||
@ -0,0 +1,73 @@
|
||||
介绍 MOBY 项目:推进软件容器化运动的一个新的开源项目
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
自从 Docker 四年前将软件容器推向民主化以来,整个生态系统都围绕着容器化而发展,在这段压缩的时期,它经历了两个不同的增长阶段。在这每一个阶段,生产容器系统的模式已经演变成适应用户群体以及项目的规模和需求和不断增长的贡献者生态系统。
|
||||
|
||||
Moby 是一个新的开源项目,旨在推进软件容器化运动,帮助生态系统将容器作为主流。它提供了一个组件库,一个将它们组装到定制的基于容器的系统的框架,以及所有容器爱好者进行实验和交换想法的地方。
|
||||
|
||||
让我们来回顾一下我们如何走到今天。在 2013-2014 年,开拓者开始使用容器,并在一个单一的开源代码库,Docker 和其他一些项目中进行协作,以帮助工具成熟。
|
||||
|
||||

|
||||
|
||||
然后在 2015-2016 年,云原生应用中大量采用容器用于生产环境。在这个阶段,用户社区已经发展到支持成千上万个部署,由数百个生态系统项目和成千上万的贡献者支持。正是在这个阶段,Docker 将其生产模式演变为基于开放式组件的方法。这样,它使我们能够增加创新和合作的方面。
|
||||
|
||||
涌现出来的新独立的 Docker 组件项目帮助刺激了合作伙伴生态系统和用户社区的发展。在此期间,我们从 Docker 代码库中提取并快速创新组件,以便系统制造商可以在构建自己的容器系统时独立重用它们:[runc][7]、[HyperKit][8]、[VPNKit][9]、[SwarmKit][10]、[InfraKit][11]、[containerd][12] 等。
|
||||
|
||||

|
||||
|
||||
站在容器浪潮的最前沿,我们看到 2017 年出现的一个趋势是容器将成为主流,传播到计算、服务器、数据中心、云、桌面、物联网和移动的各个领域。每个行业和垂直市场、金融、医疗、政府、旅游、制造。以及每一个使用案例,现代网络应用、传统服务器应用、机器学习、工业控制系统、机器人技术。容器生态系统中许多新进入者的共同点是,它们建立专门的系统,针对特定的基础设施、行业或使用案例。
|
||||
|
||||
作为一家公司,Docker 使用开源作为我们的创新实验室,而与整个生态系统合作。Docker 的成功取决于容器生态系统的成功:如果生态系统成功,我们就成功了。因此,我们一直在计划下一阶段的容器生态系统增长:什么样的生产模式将帮助我们扩大集容器生态系统,实现容器成为主流的承诺?
|
||||
|
||||
去年,我们的客户开始在 Linux 以外的许多平台上要求有 Docker:Mac 和 Windows 桌面、Windows Server、云平台(如亚马逊网络服务(AWS)、Microsoft Azure 或 Google 云平台),并且我们专门为这些平台创建了[许多 Docker 版本][13]。为了在一个相对较短的时间与更小的团队,以可扩展的方式构建和发布这些专业版本,而不必重新发明轮子,很明显,我们需要一个新的方法。我们需要我们的团队不仅在组件上进行协作,而且还在组件组合上进行协作,这借用[来自汽车行业的想法][14],其中组件被重用于构建完全不同的汽车。
|
||||
|
||||

|
||||
|
||||
我们认为将容器生态系统提升到一个新的水平以让容器成为主流的最佳方式是在生态系统层面上进行协作。
|
||||
|
||||

|
||||
|
||||
为了实现这种新的合作高度,今天我们宣布推出软件容器化运动的新开源项目 Moby。它是提供了数十个组件的“乐高集”,一个将它们组合成定制容器系统的框架,以及所有容器爱好者进行试验和交换意见的场所。可以把 Moby 认为是容器系统的“乐高俱乐部”。
|
||||
|
||||
Moby包括:
|
||||
|
||||
1. 容器化后端组件**库**(例如,底层构建器、日志记录设备、卷管理、网络、镜像管理、containerd、SwarmKit 等)
|
||||
|
||||
2. 将组件组合到独立容器平台中的**框架**,以及为这些组件构建、测试和部署构件的工具。
|
||||
|
||||
3. 一个名为 **Moby Origin** 的引用组件,它是 Docker 容器平台的开放基础,以及使用 Moby 库或其他项目的各种组件的容器系统示例。
|
||||
|
||||
Moby 专为系统构建者而设计,他们想要构建自己的基于容器的系统,而不是可以使用 Docker 或其他容器平台的应用程序开发人员。Moby 的参与者可以从源自 Docker 的组件库中进行选择,或者可以选择将“自己的组件”(BYOC)打包为容器,以便在所有组件之间进行混合和匹配以创建定制的容器系统。
|
||||
|
||||
Docker 将 Moby 作为一个开放的研发实验室来试验、开发新的组件,并与容器技术的未来生态系统进行协作。我们所有的开源协作都将转向 Moby。Docker 现在并且将来仍然是一个开源产品,可以让你创建、发布和运行容器。从用户的角度来看,它是完全一样的。用户可以继续从 docker.com 下载 Docker。请在 Moby 网站上参阅[有关 Docker 和 Moby 各自角色的更多信息][15]。
|
||||
|
||||
请加入我们,帮助软件容器成为主流,并通过在组件和组合上进行协作,将我们的生态系统和用户社区发展到下一个高度。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/04/introducing-the-moby-project/
|
||||
|
||||
作者:[Solomon Hykes ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/solomon/
|
||||
[1]:https://blog.docker.com/author/solomon/
|
||||
[2]:https://blog.docker.com/tag/containerization/
|
||||
[3]:https://blog.docker.com/tag/moby-library/
|
||||
[4]:https://blog.docker.com/tag/moby-origin/
|
||||
[5]:https://blog.docker.com/tag/moby-project/
|
||||
[6]:https://blog.docker.com/tag/open-source/
|
||||
[7]:https://github.com/opencontainers/runc
|
||||
[8]:https://github.com/docker/hyperkit
|
||||
[9]:https://github.com/docker/vpnkit
|
||||
[10]:https://github.com/docker/swarmkit
|
||||
[11]:https://github.com/docker/infrakit
|
||||
[12]:https://github.com/containerd/containerd
|
||||
[13]:https://blog.docker.com/2017/03/docker-enterprise-edition/
|
||||
[14]:https://en.wikipedia.org/wiki/List_of_Volkswagen_Group_platforms
|
||||
[15]:https://mobyproject.org/#moby-and-docker
|
||||
91
translated/tech/20170524 View Counting at Reddit.md
Normal file
91
translated/tech/20170524 View Counting at Reddit.md
Normal file
@ -0,0 +1,91 @@
|
||||
Reddit 的浏览计数
|
||||
======================
|
||||
|
||||

|
||||
|
||||
|
||||
我们希望更好地将 Reddit 的规模传达给我们的用户。到目前为止,投票得分和评论数量是特定文章活动的主要指标。然而,Reddit 有许多访问者在没有投票或评论的情况下阅读内容。我们希望建立一个能够捕捉到帖子阅读数量的系统。然后将数量展示给内容创建者和版主,以便他们更好地了解特定帖子上的活动。
|
||||
|
||||

|
||||
|
||||
在这篇文章中,我们将讨论我们如何伸缩地实现计数。
|
||||
|
||||
### 计数方法
|
||||
|
||||
对浏览计数有四个主要要求:
|
||||
|
||||
* 计数必须是实时的或接近实时的。不是每天或每小时的总量。
|
||||
* 每个用户在短时间内只能计数一次。
|
||||
* 显示的数量与实际的误差在百分之几。
|
||||
* 系统必须能够在生产环境运行,并在事件发生后几秒内处理事件。
|
||||
|
||||
满足这四项要求比听起来要复杂得多。为了实时保持准确的计数,我们需要知道某个特定的用户是否曾经访问过这个帖子。要知道这些信息,我们需要存储先前访问过每个帖子的用户组,然后在每次处理新帖子时查看该组。这个解决方案的一个原始实现是将唯一的用户集作为散列表存储在内存中,并且以发布 ID 作为关键字。
|
||||
|
||||
这种方法适用于较少浏览量的文章,但一旦文章流行,阅读人数迅速增加,这种方法很难扩展。几个热门的帖子有超过一百万的唯一读者!对于这种帖子,对于内存和 CPU 来说影响都很大,因为要存储所有的 ID,并频繁地查找集合,看看是否有人已经访问过。
|
||||
|
||||
由于我们不能提供精确的计数, 我们研究了几个不同的[基数估计][1] 算法。我们考虑了两个非常符合我们期望的选择:
|
||||
|
||||
1. 线性概率计数方法,非常准确,但要计数的集合越大,则线性地需要更多的内存。
|
||||
2. 基于 [HyperLogLog][2](HLL)的计数方法。HLL 随集合大小次线性增长,但不能提供与线性计数器相同的准确度。
|
||||
|
||||
要了解 HLL 真正节省的空间大小,考虑到右侧图片包括顶部的文章。它有超过 100 万的唯一用户。如果我们存储 100 万个唯一用户 ID,并且每个用户 ID 是 8 个字节长,那么我们需要 8 兆内存来计算单个帖子的唯一用户数!相比之下,使用 HLL 进行计数会占用更少的内存。每个实现的内存量是不一样的,但是对于[这个实现][3],我们可以使用仅仅 12 千字节的空间计算超过一百万个 ID,这将是原始空间使用量的 0.15%!
|
||||
|
||||
([这篇关于高可伸缩性的文章][5]很好地概述了上述两种算法。)
|
||||
|
||||
许多 HLL 实现使用了上述两种方法的组合,即对于小集合以线性计数开始并且一旦大小达到特定点就切换到 HLL。前者通常被称为 “稀疏” HLL 表达,而后者被称为“密集” HLL 表达。混合的方法是非常有利的,因为它可以提供准确的结果,同时保留适度的内存占用量。这个方法在[Google 的 HyperLogLog++ 论文][6]中有更详细的描述。
|
||||
|
||||
虽然 HLL 算法是相当标准的,但在我们的实现中我们考虑使用三种变体。请注意,对于内存中的 HLL 实现,我们只关注 Java 和 Scala 实现,因为我们主要在数据工程团队中使用 Java 和 Scala。
|
||||
|
||||
1. Twitter 的 Algebird 库,用 Scala 实现。Algebird 有很好的使用文档,但是稀疏和密集的 HLL 表达的实现细节不容易理解。
|
||||
2. 在 stream-lib 中的 HyperLogLog++ 的实现,用 Java 实现。stream-lib 中的代码有很好的文档,但是要理解如何正确使用这个库并且调整它以满足我们的需求是有些困难的。
|
||||
3. Redis 的 HLL 实现(我们选择的)。我们认为,Redis 的 HLL 实施方案有很好的文档并且易于配置,所提供的 HLL 相关的 API 易于集成。作为一个额外的好处,使用 Redis 通过将计数应用程序(HLL 计算)的 CPU 和内存密集型部分移出并将其移至专用服务器上,从而缓解了我们的许多性能问题。
|
||||
|
||||

|
||||
|
||||
Reddit 的数据管道主要围绕 [Apache Kafka][7]。当用户查看帖子时,事件被激发并发送到事件收集器服务器,该服务器批量处理事件并将其保存到 Kafka 中。
|
||||
|
||||
从这里,浏览计数系统有两个按顺序运行的组件。我们的计数架构的第一部分是一个名为 [Nazar][8] 的 Kafka 消费者,它将读取来自 Kafka 的每个事件,并通过我们编制的一组规则来确定是否应该计算一个事件。我们给它起了这个名字是因为 Nazar 是一个保护你免受邪恶的眼形护身符,Nazar 系统是一个“眼睛”,它可以保护我们免受不良因素的影响。Nazar 使用 Redis 保持状态,并跟踪不应计算浏览的潜在原因。我们可能无法统计事件的一个原因是,由于同一用户在短时间内重复浏览的结果。Nazar 接着将改变事件,添加一个布尔标志表明是否应该被计数,然后再发回 Kafka 事件。
|
||||
|
||||
这是这个项目要说的第二部分。我们有第二个叫做 [Abacus][9] 的 Kafka 消费者,它实际上对视浏览进行计数,并使计数在网站和客户端可见。Abacus 读取 Nazar 输出的 Kafka 事件。接着,根据 Nazar 的决定,它将计算或跳过本次浏览。如果事件被标记为计数,那么 Abacus 首先检查 Redis 中是否存在已经存在与事件对应的帖子的 HLL 计数器。如果计数器已经在 Redis 中,那么 Abacus 向 Redis 发出一个 [PFADD][10] 的请求。如果计数器还没有在 Redis 中,那么 Abacus 向 Cassandra 集群发出请求,我们用这个集群来持久化 HLL 计数器和原始计数,并向 Redis 发出一个 [SET][11] 请求来添加过滤器。这种情况通常发生在人们查看已经被 Redis 删除的旧帖的时候。
|
||||
|
||||
为了保持对可能从 Redis 删除的旧帖子的维护,Abacus 定期将 Redis 的完整 HLL 过滤器以及每个帖子的计数记录到 Cassandra 集群中。 Cassandra 的写入以 10 秒一组分批写入,以避免超载。下面是一个高层的事件流程图。
|
||||
|
||||

|
||||
|
||||
### 总结
|
||||
|
||||
我们希望浏览量计数器能够更好地帮助内容创作者了解每篇文章的情况,并帮助版主快速确定哪些帖子在其社区拥有大量流量。未来,我们计划利用数据管道的实时潜力向更多的人提供更多有用的反馈。
|
||||
|
||||
如果你有兴趣解决这样的问题,[请查看我们的职位页面][12]。
|
||||
|
||||
|
||||
----------------------
|
||||
|
||||
via: https://redditblog.com/2017/05/24/view-counting-at-reddit/
|
||||
|
||||
作者:[Krishnan Chandra ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://redditblog.com/topic/technology/
|
||||
[1]:https://en.wikipedia.org/wiki/Count-distinct_problem
|
||||
[2]:http://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf
|
||||
[3]:http://antirez.com/news/75
|
||||
[5]:http://highscalability.com/blog/2012/4/5/big-data-counting-how-to-count-a-billion-distinct-objects-us.html
|
||||
[6]:https://stefanheule.com/papers/edbt13-hyperloglog.pdf
|
||||
[7]:https://kafka.apache.org/
|
||||
[8]:https://en.wikipedia.org/wiki/Nazar_(amulet)
|
||||
[9]:https://en.wikipedia.org/wiki/Abacus
|
||||
[10]:https://redis.io/commands/pfadd
|
||||
[11]:https://redis.io/commands/set
|
||||
[12]:https://about.reddit.com/careers/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,393 @@
|
||||
LinchPin:一个使用 Ansible 的简化的编排工具
|
||||
============================================================
|
||||
|
||||
### 2016年开始的 LinchPin,现在已经拥有一个 Python API 和一个成长中的社区。
|
||||
|
||||
|
||||

|
||||
>Image by : [Internet Archive Book Images][10]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
过去的一年里,[我的团队公布了][11] [LinchPin][12],一个使用 Ansible 的混合[云][13]编排工具。准备云资源从来没有这么容易或更快。Ansible 强力支持的 LinchPin,专注于简化,在用户指尖下,将有更多的可用云资源。在这篇文章中,我将介绍 LinchPin,并且去看看过去的 10 个月,有多少成熟的项目。
|
||||
|
||||
LinchPin 刚被引入的时候,使用 **ansible-playbook** 命令去运行 LinchPin ,虽然可以完成,但是还是很复杂的,LinchPin 现在有一个前端命令行用户界面(CLI),它是在 [Click][14] 中写的,而且它使 LinchPin 比以前更简单。
|
||||
|
||||
探索开源云
|
||||
|
||||
* [云是什么?][1]
|
||||
|
||||
* [OpenStack 是什么?][2]
|
||||
|
||||
* [Kubernetes 是什么?][3]
|
||||
|
||||
* [为什么操作系统对容器很重要?][4]
|
||||
|
||||
* [保持 Linux 容器的安全][5]
|
||||
|
||||
为了不落后于 CLI,LinchPin 现在也有一个 [Python][15] API,它可以被用于管理资源,比如,Amazon EC2 和 OpenStack 实例、网络、存储、安全组、等等。这个 API [文档][16] 可以在你想去尝试 LinchPin 的 Python API 时帮助你。
|
||||
|
||||
### Playbooks 作为一个库
|
||||
|
||||
因为 LinchPin 的核心 bits 是 [Ansible playbooks][17]、角色、模块、过滤器,以及任何被称为 Ansible 模块的东西都被移进 LinchPin 库中,这意味着我们可以直接调用 playbooks,但它不是资源管理的首选机制。**linchpin** 可执行文件已经成为命令行的事实上的前端。
|
||||
|
||||
### 深入了解命令行
|
||||
|
||||
让我们深入了解**linchpin**命令行:
|
||||
|
||||
```
|
||||
$ linchpin
|
||||
Usage: linchpin [OPTIONS] COMMAND [ARGS]...
|
||||
|
||||
linchpin: hybrid cloud orchestration
|
||||
|
||||
Options:
|
||||
-c, --config PATH Path to config file
|
||||
-w, --workspace PATH Use the specified workspace if the familiar Jenkins
|
||||
$WORKSPACE environment variable is not set
|
||||
-v, --verbose Enable verbose output
|
||||
--version Prints the version and exits
|
||||
--creds-path PATH Use the specified credentials path if WORKSPACE
|
||||
environment variable is not set
|
||||
-h, --help Show this message and exit.
|
||||
|
||||
Commands:
|
||||
init Initializes a linchpin project.
|
||||
up Provisions nodes from the given target(s) in...
|
||||
destroy Destroys nodes from the given target(s) in...
|
||||
```
|
||||
|
||||
你可以立即看到一个简单的描述,以及命令的选项和参数。这个帮助的最下面的三个命令是本文的重点内容。
|
||||
|
||||
### 配置
|
||||
|
||||
以前,有个名为 **linchpin_config.yml** 的文件。现在这个文件没有了,替换它的是一个 ini 形式的配置文件,称为 **linchpin.conf**。虽然这个文件可以被修改或放到别的地方,它可以放置在配置文件容易找到的库的路径中。在多数情况下,**linchpin.conf** 文件是不需要去修改的。
|
||||
|
||||
### 工作空间
|
||||
|
||||
工作空间是一个定义的文件系统路径,它是一个逻辑上的资源组。一个工作空间可以认为是一个特定环境、服务组、或其它逻辑组的一个单个点。它也可以是一个所有可管理资源的大的存储容器。
|
||||
|
||||
工作空间在命令行上使用 **--workspace (-w)** 选项去指定,随后是工作空间路径。它也可以使用环境变量(比如,bash 中的 **$WORKSPACE**)指定。默认工作空间是当前目录。
|
||||
|
||||
### 初始化 (init)
|
||||
|
||||
运行 **linchpin init** 将生成一个需要的目录结构,以及一个 **PinFile**、**topology**、和 **layout** 文件的示例:
|
||||
|
||||
```
|
||||
$ export WORKSPACE=/tmp/workspace
|
||||
$ linchpin init
|
||||
PinFile and file structure created at /tmp/workspace
|
||||
$ cd /tmp/workspace/
|
||||
$ tree
|
||||
.
|
||||
├── credentials
|
||||
├── hooks
|
||||
├── inventories
|
||||
├── layouts
|
||||
│ └── example-layout.yml
|
||||
├── PinFile
|
||||
├── resources
|
||||
└── topologies
|
||||
└── example-topology.yml
|
||||
```
|
||||
|
||||
在这个时候,一个可执行的 **linchpin up** 并且提供一个 **libvirt** 虚拟机,和一个名为 **linchpin-centos71** 的网络。一个库存(inventory)将被生成,并被放在 **inventories/libvirt.inventory** 目录中。它可以通过读取 **topologies/example-topology.yml** 和收集 **topology_name** 的值了解它。
|
||||
|
||||
### 做好准备 (linchpin up)
|
||||
|
||||
一旦有了一个 PinFile、拓扑、和一个可选的布局,它已经做好了准备。
|
||||
|
||||
我们使用 dummy 工具,因为用它去配置非常简单;它不需要任何额外的东西(认证、网络、等等)。dummy 提供创建一个临时文件,它表示配置的主机。如果临时文件没有任何数据,说明主机没有被配置,或者它已经被销毁了。
|
||||
|
||||
dummy 提供的树像这样:
|
||||
|
||||
```
|
||||
$ tree
|
||||
.
|
||||
├── hooks
|
||||
├── inventories
|
||||
├── layouts
|
||||
│ └── dummy-layout.yml
|
||||
├── PinFile
|
||||
├── resources
|
||||
└── topologies
|
||||
└── dummy-cluster.yml
|
||||
```
|
||||
|
||||
PinFile 也很简单;它指定了它的拓扑,并且可以为 **dummy1** 目标提供一个可选的布局:
|
||||
|
||||
```
|
||||
---
|
||||
dummy1:
|
||||
topology: dummy-cluster.yml
|
||||
layout: dummy-layout.yml
|
||||
```
|
||||
|
||||
**dummy-cluster.yml** 拓扑文件是一个引用到提供的三个 **dummy_node** 类型的资源:
|
||||
|
||||
```
|
||||
---
|
||||
topology_name: "dummy_cluster" # topology name
|
||||
resource_groups:
|
||||
-
|
||||
resource_group_name: "dummy"
|
||||
resource_group_type: "dummy"
|
||||
resource_definitions:
|
||||
-
|
||||
name: "web"
|
||||
type: "dummy_node"
|
||||
count: 3
|
||||
```
|
||||
|
||||
执行命令 **linchpin up** 将基于上面的 **topology_name**(在这个案例中是 **dummy_cluster**)生成 **resources** 和 **inventory** 文件。
|
||||
|
||||
```
|
||||
$ linchpin up
|
||||
target: dummy1, action: up
|
||||
|
||||
$ ls {resources,inventories}/dummy*
|
||||
inventories/dummy_cluster.inventory resources/dummy_cluster.output
|
||||
```
|
||||
|
||||
去验证 dummy 集群的资源,检查 **/tmp/dummy.hosts**:
|
||||
|
||||
```
|
||||
$ cat /tmp/dummy.hosts
|
||||
web-0.example.net
|
||||
web-1.example.net
|
||||
web-2.example.net
|
||||
```
|
||||
|
||||
Dummy 模块为假定的(或 dummy)供应提供了一个基本工具。OpenStack、AWS EC2、Google Cloud、和更多的关于 LinchPin 的详细情况,可以去看[示例][18]。
|
||||
|
||||
### 库存(Inventory)生成
|
||||
|
||||
作为上面提到的 PinFile 的一部分,可以指定一个 **layout**。如果这个文件被指定,并且放在一个正确的位置上,一个用于提供资源的 Ansible 的静态库存(inventory)文件将被自动生成:
|
||||
|
||||
```
|
||||
---
|
||||
inventory_layout:
|
||||
vars:
|
||||
hostname: __IP__
|
||||
hosts:
|
||||
example-node:
|
||||
count: 3
|
||||
host_groups:
|
||||
- example
|
||||
```
|
||||
|
||||
当 **linchpin up** 运行完成,资源文件将提供一个很有用的详细信息。特别是,插入到静态库存(inventory)的 IP 地址或主机名:
|
||||
|
||||
```
|
||||
[example]
|
||||
web-2.example.net hostname=web-2.example.net
|
||||
web-1.example.net hostname=web-1.example.net
|
||||
web-0.example.net hostname=web-0.example.net
|
||||
|
||||
[all]
|
||||
web-2.example.net hostname=web-2.example.net
|
||||
web-1.example.net hostname=web-1.example.net
|
||||
web-0.example.net hostname=web-0.example.net
|
||||
```
|
||||
|
||||
### 卸载 (linchpin destroy)
|
||||
|
||||
LinchPin 也可以执行一个资源卸载。一个卸载动作一般认为资源是已经配置好的;然而,因为 Ansible 是幂等的(idempotent),**linchpin destroy** 将仅去检查确认资源是启用的。如果这个资源已经是启用的,它将去卸载它。
|
||||
|
||||
命令 **linchpin destroy** 也将使用资源和/或拓扑文件去决定合适的卸载过程。
|
||||
|
||||
**dummy** Ansible 角色不使用资源,卸载期间仅有拓扑:
|
||||
|
||||
```
|
||||
$ linchpin destroy
|
||||
target: dummy1, action: destroy
|
||||
|
||||
$ cat /tmp/dummy.hosts
|
||||
-- EMPTY FILE --
|
||||
```
|
||||
|
||||
在暂时的资源上,卸载功能有一些限制,像网络、存储、等等。网络资源被用于多个云实例是可能的。在这种情况下,执行一个 **linchpin destroy** 不能卸载某些资源。这取决于每个供应商的实现。查看每个[供应商][19]的具体实现。
|
||||
|
||||
### LinchPin 的 Python API
|
||||
|
||||
在 **linchpin** 命令行中实现的功能大多数已经被写成了 Python API。这个 API,虽然不完整,但它已经成为 LinchPin 工具的至关重要的组件。
|
||||
|
||||
这个 API 由下面的三个包组成:
|
||||
|
||||
* **linchpin**
|
||||
|
||||
* **linchpin.cli**
|
||||
|
||||
* **linchpin.api**
|
||||
|
||||
这个命令行工具是基于 **linchpin** 包来管理的。它导入了 **linchpin.cli** 模块和类,它是 **linchpin.api** 的子类。它的目的是为了允许使用 **linchpin.api** 的 LinchPin 的可能的其它实现,比如像计划的 RESTful API。
|
||||
|
||||
更多信息,去查看 [Python API library documentation on Read the Docs][20]。
|
||||
|
||||
### Hooks
|
||||
|
||||
LinchPin 1.0 的其中一个大的变化是转向 hooks。hooks 的目标是在 **linchpin** 运行期间,允许配置使用外部资源。目前情况如下:
|
||||
|
||||
* **preup**: 在准备拓扑资源之前运行
|
||||
|
||||
* **postup**: 在准备拓扑资源之后运行,并且生成可选的库存(inventory)
|
||||
|
||||
* **predestroy**: 卸载拓扑资源之前运行
|
||||
|
||||
* **postdestroy**: 卸载拓扑资源之后运行
|
||||
|
||||
在每种情况下,这些 hooks 允许去运行外部脚本。存在几种类型的 hooks,包括一个定制的叫做 _Action Managers_。这是一个内置的动作管理的列表:
|
||||
|
||||
* **shell**: 允许任何的内联(inline)shell 命令,或者一个可运行的 shell 脚本
|
||||
|
||||
* **python**: 运行一个 Python 脚本
|
||||
|
||||
* **ansible**: 运行一个 Ansible playbook,允许通过一个 **vars_file** 和 **extra_vars** 表示为一个 Python 字典
|
||||
|
||||
* **nodejs**: 运行一个 Node.js 脚本
|
||||
|
||||
* **ruby**: 运行一个 Ruby 脚本
|
||||
|
||||
一个 hook 是绑定到一个特定的目标,并且每个目标使用时必须重新声明。将来,hooks 将可能是全局的,然后它们在每个目标的 **hooks** 节更简单地进行命名。
|
||||
|
||||
### 使用 hooks
|
||||
|
||||
描述 hooks 是非常简单的,理解它们强大的功能却并不简单。这个特性的存在是为了给用户提供灵活的功能,而这些功能开发着可能并不会去考虑。对于实例,在运行其它的 hook 之前,这个概念可能会带来一个简单的方式去 ping 一套系统。
|
||||
|
||||
更仔细地去研究 _工作空间_ ,你可能会注意到 **hooks** 目录,让我们看一下这个目录的结构:
|
||||
|
||||
```
|
||||
$ tree hooks/
|
||||
hooks/
|
||||
├── ansible
|
||||
│ ├── ping
|
||||
│ │ └── dummy_ping.yaml
|
||||
└── shell
|
||||
└── database
|
||||
├── init_db.sh
|
||||
└── setup_db.sh
|
||||
```
|
||||
|
||||
在任何情况下,hooks 都可以在 **PinFile** 中使用,展示如下:
|
||||
|
||||
```
|
||||
---
|
||||
dummy1:
|
||||
topology: dummy-cluster.yml
|
||||
layout: dummy-layout.yml
|
||||
hooks:
|
||||
postup:
|
||||
- name: ping
|
||||
type: ansible
|
||||
actions:
|
||||
- dummy_ping.yaml
|
||||
- name: database
|
||||
type: shell
|
||||
actions:
|
||||
- setup_db.sh
|
||||
- init_db.sh
|
||||
```
|
||||
|
||||
那是基本概念,这里有三个 postup 动作去完成。Hooks 是从上到下运行的,因此,Ansible **ping** 任务将首先运行,紧接着是两个 shell 任务, **setup_db.sh** 和 **init_db.sh**。假设 hooks 运行成功。将发生一个系统的 ping,然后,一个数据库被安装和初始化。
|
||||
|
||||
### 认证的驱动程序
|
||||
|
||||
在 LinchPin 的最初设计中,开发者决定去在 Ansible playbooks 中管理认证;然而,移到更多的 API 和命令行驱动的工具后,意味着认证将被置于 playbooks 库之外,并且还可以根据需要去传递认证值。
|
||||
|
||||
### 配置
|
||||
|
||||
让用户使用驱动程序提供的认证方法去完成这个任务。对于实例,如果对于 OpenStack 调用的拓扑,标准方法是可以使用一个 yaml 文件,或者类似于 **OS_** 前缀的环境变量。一个 clouds.yaml 文件是一个 profile 文件的组成部分,它有一个 **auth** 节:
|
||||
|
||||
```
|
||||
clouds:
|
||||
default:
|
||||
auth:
|
||||
auth_url: http://stack.example.com:5000/v2.0/
|
||||
project_name: factory2
|
||||
username: factory-user
|
||||
password: password-is-not-a-good-password
|
||||
```
|
||||
|
||||
更多详细信息在 [OpenStack documentation][21]。
|
||||
|
||||
这个 clouds.yaml 或者在位于 **default_credentials_path** (比如,~/.config/linchpin)中和拓扑中引用的任何其它认证文件:
|
||||
|
||||
```
|
||||
---
|
||||
topology_name: openstack-test
|
||||
resource_groups:
|
||||
-
|
||||
resource_group_name: linchpin
|
||||
resource_group_type: openstack
|
||||
resource_definitions:
|
||||
- name: resource
|
||||
type: os_server
|
||||
flavor: m1.small
|
||||
image: rhel-7.2-server-x86_64-released
|
||||
count: 1
|
||||
keypair: test-key
|
||||
networks:
|
||||
- test-net2
|
||||
fip_pool: 10.0.72.0/24
|
||||
credentials:
|
||||
filename: clouds.yaml
|
||||
profile: default
|
||||
```
|
||||
|
||||
**default_credentials_path** 可以通过修改 **linchpin.conf** 被改变。
|
||||
|
||||
拓扑在底部包含一个新的 **credentials** 节。使用 **openstack**、**ec2**、和 **gcloud** 模块,也可以去指定类似的凭据。认证驱动程序将查看给定的 _名为_ **clouds.yaml** 的文件,并搜索名为 **default** 的 _配置_。
|
||||
|
||||
假设认证被找到并被加载,准备将正常继续。
|
||||
|
||||
### 简化
|
||||
|
||||
虽然 LinchPin 可以完成复杂的拓扑、库存布局、hooks、和认证管理,但是,终极目标是简化。通过使用一个命令行界面的简化,除了提升已经完成的 1.0 版的开发者体验外,LinchPin 将持续去展示复杂的配置可以很简单地去管理。
|
||||
|
||||
### 社区的成长
|
||||
|
||||
在过去的一年中,LinchPin 的社区现在已经有了 [邮件列表][22]和一个 IRC 频道(#linchpin on chat.freenode.net,而且在 [GitHub][23] 中我们很努力地管理它。
|
||||
|
||||
在过去的一年里,社区成员已经从 2 位核心开发者增加到大约 10 位贡献者。更多的人持续参与到项目中。如果你对 LinchPin 感兴趣,可以给我们写信、在 GitHub 上提问,加入 IRC,或者给我们发邮件。
|
||||
|
||||
_这篇文章是基于 Clint Savage 在 OpenWest 上的演讲 [Introducing LinchPin: Hybrid cloud provisioning using Ansible][7] 整理的。[OpenWest][8] 将在 2017 年 7 月 12-15 日在盐城湖市举行。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Clint Savage - 工作于 Red Hat 是一位负责原子项目(Project Atomic)的高级软件工程师。他的工作是为 Fedora、CentOS、和 Red Hat Enterprise Linux(RHEL)提供自动原子服务器构建。
|
||||
|
||||
-------------
|
||||
|
||||
via: https://opensource.com/article/17/6/linchpin
|
||||
|
||||
作者:[Clint Savage][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/herlo
|
||||
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||
[6]:https://opensource.com/article/17/6/linchpin?rate=yx4feHOc5Kf9gaZe5S4MoVAmf9mgtociUimJKAYgwZs
|
||||
[7]:https://www.openwest.org/custom/description.php?id=166
|
||||
[8]:https://www.openwest.org/
|
||||
[9]:https://opensource.com/user/145261/feed
|
||||
[10]:https://www.flickr.com/photos/internetarchivebookimages/14587478927/in/photolist-oe2Gwy-otuvuy-otus3U-otuuh3-ovwtoH-oe2AXD-otutEw-ovwpd8-oe2Me9-ovf688-oxhaVa-oe2mNh-oe3AN6-ovuyL7-ovf9Kt-oe2m4G-ovwqsH-ovjfJY-ovjfrU-oe2rAU-otuuBw-oe3Dgn-oe2JHY-ovfcrF-oe2Ns1-ovjh2N-oe3AmK-otuwP7-ovwrHt-ovwmpH-ovf892-ovfbsr-ovuAzN-ovf3qp-ovuFcJ-oe2T3U-ovwn8r-oe2L3T-oe3ELr-oe2Dmr-ovuyB9-ovuA9s-otuvPG-oturHA-ovuDAh-ovwkV6-ovf5Yv-ovuCC5-ovfc2x-oxhf1V
|
||||
[11]:http://sexysexypenguins.com/posts/introducing-linch-pin/
|
||||
[12]:http://linch-pin.readthedocs.io/en/develop/
|
||||
[13]:https://opensource.com/resources/cloud
|
||||
[14]:http://click.pocoo.org/
|
||||
[15]:https://opensource.com/resources/python
|
||||
[16]:http://linchpin.readthedocs.io/en/develop/libdocs.html
|
||||
[17]:http://docs.ansible.com/ansible/playbooks.html
|
||||
[18]:https://github.com/CentOS-PaaS-SIG/linchpin/tree/develop/linchpin/examples/topologies
|
||||
[19]:https://github.com/CentOS-PaaS-SIG/linch-pin/tree/develop/linchpin/provision/roles
|
||||
[20]:http://linchpin.readthedocs.io/en/develop/libdocs.html
|
||||
[21]:https://docs.openstack.org/developer/python-openstackclient/configuration.html
|
||||
[22]:https://www.redhat.com/mailman/listinfo/linchpin
|
||||
[23]:https://github.com/CentOS-PaaS-SIG/linch-pin/projects/4
|
||||
[24]:https://opensource.com/users/herlo
|
||||
@ -1,255 +0,0 @@
|
||||
扩展 GitLab 数据库
|
||||
============================================================
|
||||
|
||||
在扩展 GitLab 数据库和我们应用的解决方案,去帮助解决我们的数据库设置中的问题时,我们深入分析了所面临的挑战。
|
||||
|
||||
很长时间以来 GitLab.com 使用了一个单个的 PostgreSQL 数据库服务器和一个用于灾难恢复的单个复制。在 GitLab.com 最初的几年,它工作的还是很好的,但是,随着时间的推移,我们看到这种设置的很多问题,在这篇文章中,我们将带你了解我们在帮助解决 GitLab.com 和 GitLab 实例所在的主机时都做了些什么。
|
||||
|
||||
例如,数据库在正常负载下, CPU 使用率几乎所有时间都处于 70% 左右。并不是因为我们以最好的方式使用了全部的可用资源,而是因为我们使用了太多的(未经优化的)查询去“冲击”服务器。我们意识到需要去优化设置,这样我们就可以平衡负载,使 GitLab.com 能够更灵活地应对可能出现在主数据库服务器上的任何问题。
|
||||
|
||||
在我们使用 PostgreSQL 去跟踪这些问题时,使用了以下的四种技术:
|
||||
|
||||
1. 优化你的应用程序代码,以使查询更加高效(并且理论上使用了很少的资源)。
|
||||
|
||||
2. 使用一个连接池去减少必需的数据库连接数量(和相关的资源)。
|
||||
|
||||
3. 跨多个服务器去平衡负载。
|
||||
|
||||
4. 分片你的数据库
|
||||
|
||||
在过去的两年里,我们一直在积极地优化应用程序代码,但它不是一个完美的解决方案,甚至,如果你改善了性能,当流量也增加时,你还需要去应用其它的两种技术。为了这篇文章,我们将跳过特定主题,而专注于其它技术。
|
||||
|
||||
### 连接池
|
||||
|
||||
在 PostgreSQL 中一个连接是通过启动一个操作系统进程来处理的,这反过来又需要大量的资源,更多的连接(和这些进程),将使用你的数据库上的更多的资源。 PostgreSQL 也在 [max_connections][5] 设置中定义了一个强制执行的最大连接数量。一旦达到这个限制,PostgreSQL 将拒绝新的连接, 比如,下面的图表示的设置:
|
||||
|
||||

|
||||
|
||||
这里我们的客户端直接连接到 PostgreSQL,这样每个客户端请求一个连接。
|
||||
|
||||
通过连接池,我们可以有多个客户端侧连接重复使用一个 PostgreSQL 连接。例如,没有连接池时,我们需要 100 个 PostgreSQL 连接去处理 100 个客户端连接;使用连接池后,我们仅需要 10 个,或者依据我们配置的 PostgreSQL 连接。这意味着我们的连接图表将变成下面看到的那样:
|
||||
|
||||

|
||||
|
||||
这里我们展示了一个示例,四个客户端连接到 pgbouncer,但不是使用了四个 PostgreSQL 连接,而是仅需要两个。
|
||||
|
||||
对于 PostgreSQL 这里我们使用了两个最常用的连接池:
|
||||
|
||||
* [pgbouncer][1]
|
||||
|
||||
* [pgpool-II][2]
|
||||
|
||||
pgpool 有一点特殊,因为它不仅仅是连接池:它有一个内置的查询缓存机制,可以跨多个数据库负载均衡、管理复制等等。
|
||||
|
||||
另一个 pgbouncer 是很简单的:它就是一个连接池。
|
||||
|
||||
### 数据库负载均衡
|
||||
|
||||
数据库级的负载均衡一般是使用 PostgreSQL 的 "[热备机][6]" 特性来实现的。 一个热备机是允许你去运行只读 SQL 查询的 PostgreSQL 复制,与不允许运行任何 SQL 查询的普通备用机相反。去使用负载均衡,你需要设置一个或多个热备服务器,并且以某些方式去平衡这些跨主机的只读查询,同时将其它操作发送到主服务器上。扩展这样一个设置是很容易的:简单地增加多个热备机(如果需要的话)以增加只读流量。
|
||||
|
||||
这种方法的另一个好处是拥有一个更具弹性的数据库集群。即使主服务器出现问题,仅使用次级服务器也可以继续处理 Web 请求;当然,如果这些请求最终使用主服务器,你可能仍然会遇到错误。
|
||||
|
||||
然而,这种方法很难实现。例如,一旦它们包含写操作,事务显然需要在主服务器上运行。此外,在写操作完成之后,我们希望继续使用主服务器,因为在使用异步复制的时候,热备机服务器上可能还没有这些更改。
|
||||
|
||||
### 分片
|
||||
|
||||
分片是水平分割你的数据的行为。这意味着数据保存在特定的服务器上并且使用一个分片键检索。例如,你可以按项目分片数据并且使用项目 ID 做为分片键。当你有一个很高的写负载时(除了一个多主设置外,没有一个其它的简单方法来平衡写操作),分片数据库是很有用的。或者当你有_大量_的数据并且不你再使用传统方式保存它。(比如,你可以简单地把它放进一个单个磁盘中)。
|
||||
|
||||
不幸的是,设置分片数据库是一个任务量很大的过程,甚至,在我们使用软件如 [Citus][7] 时。你不仅需要设置基础设施 (不同的复杂程序取决于是你运行在你自己的数据中心还是托管主机的解决方案),你还得需要调整你的应用程序中很大的一部分去支持分片。
|
||||
|
||||
### 反对分片的案例
|
||||
|
||||
在 GitLab.com 上一般情况下写负载是非常低的,同时大多数的查询都是只读查询。在极端情况下,尖峰值达到每秒 1500 元组写入,但是,在大多数情况下不超过每秒 200 元组写入。另一方面,我们可以在任何给定的次级服务器上轻松达到每秒 1000 万元组读取。
|
||||
|
||||
明智的存储,我们也不使用太多的数据:大约 800 GB。这些数据中的很大一部分是被迁移到后台的,这些数据一经迁移后,我们的数据库收缩的相当多。
|
||||
|
||||
接下来的工作量就是调整应用程序,以便于所有查询都可以正确地使用分片键。 直到大量的查询都包含了一个项目 ID,它是我们使用的分片键,也有许多的查询不是这种情况。分片也会影响贡献者的改变过程,作为每个贡献者,现在必须确保它们的查询中包含分片键。
|
||||
|
||||
最后,是完成这些工作所需要的基础设施。服务器已经完成设置,并添加监视、完成对工程师们的培训,以便于他们熟悉上面列出的这些新的设置。虽然托管解决方案可能不需要你自己管理服务器,但它不能解决所有问题。工程师们仍然需要去培训(很可能非常昂贵)并需要为此支付账单。在 GitLab 上,我们也非常乐意提供我们需要的这些工具,这样社区就可以使用它们。这意味着如果我们去分片数据库, 我们将在我们的 Omnibus 包中提供它(或至少是其中的一部分)。确保你提供的服务的唯一方法就是你自己去管理它,这意味着我们不能使用主机托管的解决方案。
|
||||
|
||||
最终,我们决定不使用数据库分片,因为它是昂贵的、费时的、复杂的解决方案。
|
||||
|
||||
### GitLab 的连接池
|
||||
|
||||
对于连接池我们有两个主要的诉求:
|
||||
|
||||
1. 它必须工作的很好(很显然这是必需的)。
|
||||
|
||||
2. 它必须易于在我们的 Omnibus 包中运用,以便于我们的用户也可以从连接池中得到好处。
|
||||
|
||||
用下面两步去评估这两个解决方案(pgpool 和 pgbouncer):
|
||||
|
||||
1. 执行各种技术测试(是否有效,配置是否容易,等等)。
|
||||
|
||||
2. 找出使用这个解决方案的其它用户的经验,他们遇到了什么问题?怎么去解决的?等等。
|
||||
|
||||
pgpool 是我们考察的第一个解决方案,主要是因为它提供的很多特性看起来很有吸引力。我们的其中一些测试数据可以在 [这里][8] 找到。
|
||||
|
||||
最终,基于多个因素,我们决定不使用 pgpool 。例如, pgpool 不支持粘连接。 当执行一个写入并(尝试)立即显示结果时,它会出现问题。想像一下,创建一个资料(issue)并立即重定向到这个页面, 没有想到会出现 HTTP 404,这是因为任何用于只读查询的服务器还没有收到数据。针对这种情况的一种解决办法是使用同步复制,但这会给表带来更多的其它问题,而我们希望去避免问题。
|
||||
|
||||
另一个问题是, pgpool 的负载均衡逻辑与你的应用程序是不相干的,是通过解析 SQL 查询并将它们发送到正确的服务器。因为这发生在你的应用程序之外,你几乎无法控制查询运行在哪里。这实际上对某些人也可能是有好处的, 因为你不需要额外的应用程序逻辑。但是,它也妨碍了你在需要的情况下调整路由逻辑。
|
||||
|
||||
由于配置选项非常多,配置 pgpool 也是很困难的。从过去使用过它的那些人中得到的反馈,可能促使我们最终决定不使用它了。即使是大多数的案例都不是很详细的情况下,我们收到的反馈对 pgpool 通常都持有负面的观点。虽然出现的报怨大多数都与早期版本的 pgpool 有关,但仍然让我们怀疑使用它是否是个正确的选择。
|
||||
|
||||
结合上面描述的问题和反馈,最终我们决定不使用 pgpool 而是使用 pgbouncer 。我们用 pgbouncer 执行了一个类似的测试,并且对它的结果是非常满意的。它非常容易配置(而且一开始不需要很多的配置),运用相对容易,仅专注于连接池(而且它真的很好), 而且没有明显的开销(如果有的话)。也许我唯一的报怨是,pgbouncer 的网站有点难以导航。
|
||||
|
||||
使用 pgbouncer 后,通过使用事务池我们可以将活动的 PostgreSQL 连接数从几百降到仅 10 - 20 个。我们选择事务池是因为 Rails 数据库连接是持久的。这个设置中,使用会话池可以防止我们降低 PostgreSQL 连接数,这样会有一些好处(如果有的话)。通过使用事务池,我们可以去降低 PostgreSQL 的 `max_connections` 的设置值,从 3000 (这个特定值的原因我们也不清楚) 到 300 。这样配置的 pgbouncer ,即使在尖峰时,我们也仅需要 200 个连接,这为我们提供了一些额外连接的空间,如 `psql` 控制台和维护任务。
|
||||
|
||||
对于使用事务池的影响方面,你不能使用预处理语句,因为 `PREPARE` 和 `EXECUTE` 命令可以在不同的连接中运行,产生错误的结果。 幸运的是,当我们禁用了预处理语句时,并没有测量到任何响应时间的增加,但是我们 _确定_ 测量到在我们的服务器上内存使用减少了大约 20 GB。
|
||||
|
||||
为确保我们的 web 请求和后台作业都有可用连接,我们设置了两个独立的池: 一个有 150 个连接的后台进程连接池,和一个有 50 个连接的 web 请求连接池。对于 web 连接需要的请求,我们很少超过 20 个,但是,对于后台进程,由于在 GitLab.com 上后台运行着大量的进程,我们的尖峰值可以很容易达到 100 个连接。
|
||||
|
||||
今天,我们提供 pgbouncer 作为 GitLab EE 高可用包的一部分。对于更多的信息,你可以参考 ["Omnibus GitLab PostgreSQL High Availability."][9]。
|
||||
|
||||
### GitLab 上的数据库负载均衡
|
||||
|
||||
使用 pgpool 和它的负载均衡特性,我们需要一些其它的东西去分发负载到多个热备服务器上。
|
||||
|
||||
对于(但不限于) Rails 应用程序,它有一个叫 [Makara][10] 的库,它实现了负载均衡的逻辑并包含缺省实现的活动记录。然而,Makara 也有一些我们认为是有些遗憾的问题。例如,它支持的粘连接是非常有限的:当你使用一个 cookie 和一个固定的 TTL 去执行一个写操作时,连接将粘到主服务器。这意味着,如果复制极大地滞后于 TTL,最终你可能会发现,你的查询运行在一个没有你需要的数据的主机上。
|
||||
|
||||
Makara 也需要你做很多配置,如所有的数据库主机和它们的规则,没有服务发现机制(我们当前的解决方案也不支持它们,即使它是将来计划的)。 Makara 也 [似乎不是线程安全的][11],这是有问题的,因为 Sidekiq (我们使用的后台进程)是多线程的。 最终,我们希望尽可能地去控制负载均衡的逻辑。
|
||||
|
||||
除了 Makara 之外 ,这也有 [Octopus][12] ,它也是内置的负载均衡机制。但是 Octopus 是面向分片数据库的,而不仅是均衡只读查询的。因此,最终我们不考虑使用 Octopus。
|
||||
|
||||
最终,我们构建了自己的解决方案,直接进入 GitLab EE。 合并需求并增加到初始实现,可以在 [这里][13]找到,尽管一些更改、提升在以后去应用。
|
||||
|
||||
我们的解决方案本质上是通过用一个处理查询路由的代理对象替换 `ActiveRecord::Base.connection` 。它可以让我们尽可能去均衡负载,甚至,不是直接从我们所有的代码中来的查询。这个代理对象基于调用方式去决定将查询转发到哪个主机, 消除了解析 SQL 查询的需要。
|
||||
|
||||
### 粘连接
|
||||
|
||||
粘连接是通过在执行写入时,将当前 PostgreSQL WAL 位置存储到一个指针中实现支持的。对于一个短的请求,在请求即将结束时,指针是保存在 Redis 中,每个用户提供他自己的 key,因此,一个用户的动作不会导致其他的用户受到影响。下次请求时,我们取得指针,并且与所有的次级服务器进行比较。如果所有的次级服务器都有一个数量超过我们的指针的 WAL 指针,因为我们知道它们是同步的,我们可以为我们的只读查询安全地使用次级服务器。如果一个或多个次级服务器没有同步,我们将继续使用主服务器直到它们同步。如果执行的写入操作在 30 秒内没有完成,并且所有的次级服务器还没有同步,我们将恢复使用次级服务器,这是为了防止有些人的查询永远运行在主服务器上。
|
||||
|
||||
检查一个次级服务器是否在 `Gitlab::Database::LoadBalancing::Host#caught_up?` 中被捕获是很简单的, 如下:
|
||||
|
||||
```
|
||||
def caught_up?(location)
|
||||
string = connection.quote(location)
|
||||
|
||||
query = "SELECT NOT pg_is_in_recovery() OR " \
|
||||
"pg_xlog_location_diff(pg_last_xlog_replay_location(), #{string}) >= 0 AS result"
|
||||
|
||||
row = connection.select_all(query).first
|
||||
|
||||
row && row['result'] == 't'
|
||||
ensure
|
||||
release_connection
|
||||
end
|
||||
|
||||
```
|
||||
这里的大部分代码是标准的 Rails 代码,去运行原生查询(raw queries)和获取结果,查询的最有趣的部分如下:
|
||||
|
||||
```
|
||||
SELECT NOT pg_is_in_recovery()
|
||||
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER) >= 0 AS result"
|
||||
|
||||
```
|
||||
|
||||
这里 `WAL-POINTER` 是 WAL 指针,通过 PostgreSQL 函数 `pg_current_xlog_insert_location()`返回的,它是在主服务器上执行的。在上面的代码片断中,指针是传递给一个数组的,然后它被引入或传出给查询。
|
||||
|
||||
使用函数 `pg_last_xlog_replay_location()` 我们可以取得次级服务器的 WAL 指针,然后,我们可以通过函数 `pg_xlog_location_diff()` 与我们的主服务器上的指针进行比较。如果结果大于 0 ,我们就可以知道次级服务器是同步的。
|
||||
|
||||
当一个次级服务器被提升为主服务器,并且我们的 GitLab 进程还不知道这一点的时候,检查 `NOT pg_is_in_recovery()` 是添加的,以确保查询不会失败。在这个案例中,主服务器与它自己是同步的,所以它简单返回一个 `true`.
|
||||
|
||||
### 后台进程
|
||||
|
||||
我们的后台进程代码 _总是_ 使用主服务器,因为在后台执行的大部分工作都是写入。此外,我们不能可靠地使用一个热备机,因为我们无法知道作业是否在主服务器执行,因为许多作业并没有直接绑定到用户上。
|
||||
|
||||
### 连接错误
|
||||
|
||||
去解决负载均衡器不使用一个如果被认为是离线的次级服务器的连接错误,加上,任何主机上(包括主服务器)的连接错误将导致负载均衡器多次重试,这是确保,在遇到偶发的小问题或数据库失败事件时,不会立即显示一个错误页面。当我们在负载均衡器级别上处理 [热备机冲突][14] 的问题时,我们最终在次级服务器上启用了 `hot_standby_feedback` ,这样就解决了热备机冲突的所有问题,而不会对表膨胀造成任何负面影响。
|
||||
|
||||
我们使用的过程很简单:对于次级服务器,我们在它们之间用无延迟试了几次。对于主服务器,我们通过使用指数回退来尝试几次。
|
||||
|
||||
更多信息你可以查看 GitLab EE 上的源代码:
|
||||
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb][3]
|
||||
|
||||
* [https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing][4]
|
||||
|
||||
数据库负载均衡第一次介绍在 GitLab 9.0 中并且 _仅_ 支持 PostgreSQL。更多信息可以在 [9.0 release post][15] 和 [documentation][16] 中找到。
|
||||
|
||||
### Crunchy Data
|
||||
|
||||
在部署连接池和负载均衡的同时,我们与 [Crunchy Data][17] 一起工作。直到最近我还是唯一的 [数据库专家][18],它意味着我有很多工作要做。此外,我知道的 PostgreSQL 的内部的和它大量的设置是有限的 (或者至少现在是),这意味着我能做的有限。因为这些原因,我们雇用了 Crunchy 去帮我们找出问题、研究慢查询、建议模式优化、优化 PostgreSQL 设置等等。
|
||||
|
||||
在合作期间,大部分工作都是在相互信任的基础上完成的,因此,我们共享私人数据,比如日志。在合作结束时,我们从一些资料和公开的内容中删除了敏感数据,主要的资料在 [gitlab-com/infrastructure#1448][19], 这又反过来导致许多问题被产生和解决。
|
||||
|
||||
这次合作的好处是巨大的,他帮助我们发现并解决了许多的问题,如果必须我们自己来做的话,我们可能需要花上几个月的时间来识别和解决它。
|
||||
|
||||
幸运的是,最近我们成功地雇佣了我们的 [第二个数据库专家][20] 并且我们希望以后我们的团队能够发展壮大。
|
||||
|
||||
### 整合连接池和数据库负载均衡
|
||||
|
||||
整合连接池和数据库负载均衡允许我们去大幅减少运行数据库集群所需要的资源和在热备机上分发的负载。例如,以前我们的主服务器 CPU 使用率一直徘徊在 70%,现在它一般在 10% 到 20% 之间,而我们的两台热备机服务器则大部分时间在 20% 左右:
|
||||
|
||||

|
||||
|
||||
在这里, `db3.cluster.gitlab.com` 是我们的主服务器,而其它的两台是我们的次级服务器。
|
||||
|
||||
其它的负载相关的因素,如平均负载、磁盘使用、内存使用也大为改善。例如,主服务器现在的平均负载几乎不会超过 10,而不像以前它一直徘徊在 20 左右:
|
||||
|
||||

|
||||
|
||||
在业务繁忙期间,我们的次级服务器每秒事务数在 12000 左右(大约为每分钟 740000),而主服务器每秒事务数在 6000 左右(大约每分钟 340000):
|
||||
|
||||

|
||||
|
||||
可惜的是,在部署 pgbouncer 和我们的数据库负载均衡器之前,我们没有关于事务速率的任何数据。
|
||||
|
||||
我们的 PostgreSQL 的最新统计数据的摘要可以在我们的 [public Grafana dashboard][21] 上找到。
|
||||
|
||||
我们的其中一些 pgbouncer 的设置如下:
|
||||
|
||||
| Setting | Value |
|
||||
| --- | --- |
|
||||
| default_pool_size | 100 |
|
||||
| reserve_pool_size | 5 |
|
||||
| reserve_pool_timeout | 3 |
|
||||
| max_client_conn | 2048 |
|
||||
| pool_mode | transaction |
|
||||
| server_idle_timeout | 30 |
|
||||
|
||||
除了前面所说的这些外,还有一些工作要作,比如: 部署服务发现([#2042][22]), 持续改善如何检查次级服务器是否可用([#2866][23]),和忽略落后于主服务器太多的次级服务器 ([#2197][24])。
|
||||
|
||||
值得一提的是,到目前为止,我们还没有任何计划将我们的负载均衡解决方案,独立打包成一个你可以在 GitLab 之外使用的库,相反,我们的重点是为 GitLab EE 提供一个可靠的负载均衡解决方案。
|
||||
|
||||
如果你对它感兴趣,并喜欢使用数据库,改善应用程序性能,给 GitLab上增加数据库相关的特性(比如: [服务发现][25]),你一定要去查看一下 [招聘职位][26] 和 [数据库专家手册][27] 去获取更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/
|
||||
|
||||
作者:[Yorick Peterse ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://about.gitlab.com/team/#yorickpeterse
|
||||
[1]:https://pgbouncer.github.io/
|
||||
[2]:http://pgpool.net/mediawiki/index.php/Main_Page
|
||||
[3]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb
|
||||
[4]:https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing
|
||||
[5]:https://www.postgresql.org/docs/9.6/static/runtime-config-connection.html#GUC-MAX-CONNECTIONS
|
||||
[6]:https://www.postgresql.org/docs/9.6/static/hot-standby.html
|
||||
[7]:https://www.citusdata.com/
|
||||
[8]:https://gitlab.com/gitlab-com/infrastructure/issues/259#note_23464570
|
||||
[9]:https://docs.gitlab.com/ee/administration/high_availability/alpha_database.html
|
||||
[10]:https://github.com/taskrabbit/makara
|
||||
[11]:https://github.com/taskrabbit/makara/issues/151
|
||||
[12]:https://github.com/thiagopradi/octopus
|
||||
[13]:https://gitlab.com/gitlab-org/gitlab-ee/merge_requests/1283
|
||||
[14]:https://www.postgresql.org/docs/current/static/hot-standby.html#HOT-STANDBY-CONFLICT
|
||||
[15]:https://about.gitlab.com/2017/03/22/gitlab-9-0-released/
|
||||
[16]:https://docs.gitlab.com/ee/administration/database_load_balancing.html
|
||||
[17]:https://www.crunchydata.com/
|
||||
[18]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
[19]:https://gitlab.com/gitlab-com/infrastructure/issues/1448
|
||||
[20]:https://gitlab.com/_stark
|
||||
[21]:http://monitor.gitlab.net/dashboard/db/postgres-stats?refresh=5m&orgId=1
|
||||
[22]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[23]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2866
|
||||
[24]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2197
|
||||
[25]:https://gitlab.com/gitlab-org/gitlab-ee/issues/2042
|
||||
[26]:https://about.gitlab.com/jobs/specialist/database/
|
||||
[27]:https://about.gitlab.com/handbook/infrastructure/database/
|
||||
@ -1,66 +0,0 @@
|
||||
不!Linux 桌面版并没有流行起来
|
||||
============================================================
|
||||
|
||||
一直流传着这样一个说法,Linux 桌面版已经流行起来了,并且使用者超过了 macOS,其实,它并不是这样的。
|
||||
|
||||
有很多“故事”说,Linux 桌面版的市场占有率比通常的 1.5% - 3% 增加了一倍,达到5%。这些报告是基于 [NetMarketShare][4] 的桌面操作系统分析,它显示,在七月份,Linux 桌面版的市场占有率从 2.5% 飙升,在九月份几乎达到 5%。但对 Linux 迷来说,很不幸,它并不是真的。
|
||||
|
||||
它也不是谷歌推出的 Chrome OS,它在 NetMarketShare 和 [StatCounter][5] 的桌面操作系统的数据中被低估,它被认为是 Linux,请注意,那是公平的,因为 [Chrome OS 是基于 Linux 的][6]。
|
||||
|
||||
真正的解释要简单的多。这似乎只是一个错误。NetMarketShare 的市场营销高管 Vince Vizzaccaro 告诉我,“Linux 份额是不正确的。我们意识到这个问题,目前正在调查此事”。
|
||||
|
||||
如果这听起来很奇怪,那是因为你可能认为,NetMarketShare 和 StatCounter 只是计算用户数量。他们没有。相反,他们都使用自己的秘密的方法去统计这些操作系统的数据。
|
||||
|
||||
NetMarketShare 的方法是对 “[从网站访问者的浏览器中收集数据][7]到我们专用的请求式 HitsLink 分析网络中和 SharePost 客户端。该网络包括超过4万个网站,遍布全球。我们“计数”到我们的网络站点的唯一并且每天只对每个网络站点进行一次唯一访问的访客。”
|
||||
|
||||
然后,公司按国家对数据进行加权。“ 我们将我们的流量与 CIA 的网络流量进行比较,并相应地对我们的数据进行加权。” 例如,如果我们的全球数据显示巴西占我们网络流量的 2%,而 CIA 的数据显示巴西占全球互联网流量的4%,我们将统计每一个来自巴西的唯一访问者两次。
|
||||
|
||||
他们究竟如何 “权衡” 每天访问一个站点的数据?我们不知道。
|
||||
|
||||
StatCounter 也有自己的方法。它使用 “[在全球超过 200 万个站点上安装的跟踪代码][8]。这些网站涵盖了各种活动和地理位置。每个月,我们都会在这些站点上记录数十亿页的页面查看。对于每个页面查看,我们分析使用的浏览器/操作系统/屏幕分辨率,如果页面查看来自移动设备。 ... 我们总结了所有这些数据以获取我们的全球统计信息。
|
||||
|
||||
我们为互联网使用趋势提供独立的、公正的统计数据。我们不与任何其他信息源核对我们的统计数据,也 [没有使用人为加权][9]。
|
||||
|
||||
他们如何汇总他们的数据?你猜猜看?其它我们也不知道。
|
||||
|
||||
因此,无论何时,从他们这些经常被引用的操作系统或浏览器的数字中,通常是“加盐”处理过的。
|
||||
|
||||
对于更精确的,以美国为对象的操作系统和浏览器数量,我更喜欢使用联邦政府的 [数字分析程序 (DAP)][10]。
|
||||
|
||||
与其它的不同, DAP 的数量来自在过去的 90 天访问过 [400 个美国政府行政机构域名][11] 的数十亿访问者。那里有 [大概 5000 个网站][12],并且包含每个秘密部门。 DAP 从一个谷歌分析帐户中得到原始数据。 DAP 有 [开源的代码,它显示在这个网站上][13] 和它的 [数据收集代码][14]。最重要的是,与其它的不同,你可以从 [JavaScript Object Notation (JSON)][15] 上下载它的数据,这样你就可以自己分析原始数据了。
|
||||
|
||||
在 [分析美国][16] 网站上,它汇总了 DAP 的数据,你可以找到 Linux 桌面版,和往常一样,它挂在 “其它” 中,占 1.5%。Windows 仍然是高达 45.9%,接下来是 Apple iOS,占 25.5%,Android 占 18.6%,而 macOS 占 8.5%。
|
||||
|
||||
对不起,伙计们,我也我希望它更高,真的,我相信它是。没有人,甚至是 DAP,看上起做的更好,基于 Linux 的 Chrome OS 数据。直到现在,Linux 桌面版仅为 Linux 高手、软件开发者、系统管理员和工程师使用。Linux 迷们必须保留着所有计算机设备 -- 服务器、云、超级计算机等等上最高级的操作系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/no-the-linux-desktop-hasnt-jumped-in-popularity/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[2]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[3]:http://www.zdnet.com/article/the-tension-between-iot-and-erp/
|
||||
[4]:https://www.netmarketshare.com/
|
||||
[5]:https://statcounter.com/
|
||||
[6]:http://www.zdnet.com/article/the-secret-origins-of-googles-chrome-os/
|
||||
[7]:http://www.netmarketshare.com/faq.aspx#Methodology
|
||||
[8]:http://gs.statcounter.com/faq#methodology
|
||||
[9]:http://gs.statcounter.com/faq#no-weighting
|
||||
[10]:https://www.digitalgov.gov/services/dap/
|
||||
[11]:https://analytics.usa.gov/data/live/second-level-domains.csv
|
||||
[12]:https://analytics.usa.gov/data/live/sites.csv
|
||||
[13]:https://github.com/GSA/analytics.usa.gov
|
||||
[14]:https://github.com/18F/analytics-reporter
|
||||
[15]:http://json.org/
|
||||
[16]:https://analytics.usa.gov/
|
||||
[17]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[18]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[19]:http://www.zdnet.com/blog/open-source/
|
||||
[20]:http://www.zdnet.com/topic/enterprise-software/
|
||||
@ -0,0 +1,607 @@
|
||||
并发服务器(3) —— 事件驱动
|
||||
============================================================
|
||||
|
||||
这是《并发服务器》系列的第三节。[第一节][26] 介绍了阻塞式编程,[第二节 —— 线程][27] 探讨了多线程,将其作为一种可行的方法来实现服务器并发编程。
|
||||
|
||||
另一种常见的实现并发的方法叫做 _事件驱动编程_,也可以叫做 _异步_ 编程 [^注1][28]。这种方法变化万千,因此我们会从最基本的开始,使用一些基本的 APIs 而非从封装好的高级方法开始。本系列以后的文章会讲高层次抽象,还有各种混合的方法。
|
||||
|
||||
本系列的所有文章:
|
||||
|
||||
* [第一节 - 简介][12]
|
||||
* [第二节 - 线程][13]
|
||||
* [第三节 - 事件驱动][14]
|
||||
|
||||
### 阻塞式 vs. 非阻塞式 I/O
|
||||
|
||||
要介绍这个标题,我们先讲讲阻塞和非阻塞 I/O 的区别。阻塞式 I/O 更好理解,因为这是我们使用 I/O 相关 API 时的“标准”方式。从套接字接收数据的时候,调用 `recv` 函数会发生 _阻塞_,直到它从端口上接收到了来自另一端套接字的数据。这恰恰是第一部分讲到的顺序服务器的问题。
|
||||
|
||||
因此阻塞式 I/O 存在着固有的性能问题。第二节里我们讲过一种解决方法,就是用多线程。哪怕一个线程的 I/O 阻塞了,别的线程仍然可以使用 CPU 资源。实际上,阻塞 I/O 通常在利用资源方面非常高效,因为线程就等待着 —— 操作系统将线程变成休眠状态,只有满足了线程需要的条件才会被唤醒。
|
||||
|
||||
_非阻塞式_ I/O 是另一种思路。把套接字设成非阻塞模式时,调用 `recv` 时(还有 `send`,但是我们现在只考虑接收),函数返回地会很快,哪怕没有数据要接收。这时,就会返回一个特殊的错误状态 ^[注2][15] 来通知调用者,此时没有数据传进来。调用者可以去做其他的事情,或者尝试再次调用 `recv` 函数。
|
||||
|
||||
证明阻塞式和非阻塞式的 `recv` 区别的最好方式就是贴一段示例代码。这里有个监听套接字的小程序,一直在 `recv` 这里阻塞着;当 `recv` 返回了数据,程序就报告接收到了多少个字节 ^[注3][16]:
|
||||
|
||||
```
|
||||
int main(int argc, const char** argv) {
|
||||
setvbuf(stdout, NULL, _IONBF, 0);
|
||||
|
||||
int portnum = 9988;
|
||||
if (argc >= 2) {
|
||||
portnum = atoi(argv[1]);
|
||||
}
|
||||
printf("Listening on port %d\n", portnum);
|
||||
|
||||
int sockfd = listen_inet_socket(portnum);
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd = accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
|
||||
while (1) {
|
||||
uint8_t buf[1024];
|
||||
printf("Calling recv...\n");
|
||||
int len = recv(newsockfd, buf, sizeof buf, 0);
|
||||
if (len < 0) {
|
||||
perror_die("recv");
|
||||
} else if (len == 0) {
|
||||
printf("Peer disconnected; I'm done.\n");
|
||||
break;
|
||||
}
|
||||
printf("recv returned %d bytes\n", len);
|
||||
}
|
||||
|
||||
close(newsockfd);
|
||||
close(sockfd);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
主循环重复调用 `recv` 并且报告它返回的字节数(记住 `recv` 返回 0 时,就是客户端断开连接了)。试着运行它,我们会在一个终端里运行这个程序,然后在另一个终端里用 `nc` 进行连接,发送一些字符,每次发送之间间隔几秒钟:
|
||||
|
||||
```
|
||||
$ nc localhost 9988
|
||||
hello # wait for 2 seconds after typing this
|
||||
socket world
|
||||
^D # to end the connection>
|
||||
```
|
||||
|
||||
The listening program will print the following:
|
||||
监听程序会输出以下内容:
|
||||
|
||||
```
|
||||
$ ./blocking-listener 9988
|
||||
Listening on port 9988
|
||||
peer (localhost, 37284) connected
|
||||
Calling recv...
|
||||
recv returned 6 bytes
|
||||
Calling recv...
|
||||
recv returned 13 bytes
|
||||
Calling recv...
|
||||
Peer disconnected; I'm done.
|
||||
```
|
||||
|
||||
现在试试非阻塞的监听程序的版本。这是代码:
|
||||
|
||||
```
|
||||
int main(int argc, const char** argv) {
|
||||
setvbuf(stdout, NULL, _IONBF, 0);
|
||||
|
||||
int portnum = 9988;
|
||||
if (argc >= 2) {
|
||||
portnum = atoi(argv[1]);
|
||||
}
|
||||
printf("Listening on port %d\n", portnum);
|
||||
|
||||
int sockfd = listen_inet_socket(portnum);
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd = accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
|
||||
// 把套接字设成非阻塞模式
|
||||
int flags = fcntl(newsockfd, F_GETFL, 0);
|
||||
if (flags == -1) {
|
||||
perror_die("fcntl F_GETFL");
|
||||
}
|
||||
|
||||
if (fcntl(newsockfd, F_SETFL, flags | O_NONBLOCK) == -1) {
|
||||
perror_die("fcntl F_SETFL O_NONBLOCK");
|
||||
}
|
||||
|
||||
while (1) {
|
||||
uint8_t buf[1024];
|
||||
printf("Calling recv...\n");
|
||||
int len = recv(newsockfd, buf, sizeof buf, 0);
|
||||
if (len < 0) {
|
||||
if (errno == EAGAIN || errno == EWOULDBLOCK) {
|
||||
usleep(200 * 1000);
|
||||
continue;
|
||||
}
|
||||
perror_die("recv");
|
||||
} else if (len == 0) {
|
||||
printf("Peer disconnected; I'm done.\n");
|
||||
break;
|
||||
}
|
||||
printf("recv returned %d bytes\n", len);
|
||||
}
|
||||
|
||||
close(newsockfd);
|
||||
close(sockfd);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
这里与阻塞版本有些差异,值得注意:
|
||||
|
||||
1. `accept` 函数返回的 `newsocktfd` 套接字因调用了 `fcntl`, 被设置成非阻塞的模式。
|
||||
|
||||
2. 检查 `recv` 的返回状态时,我们对 `errno` 进行了检查,判断它是否被设置成表示没有可供接收的数据的状态。这时,我们仅仅是休眠了 200 毫秒然后进入到下一轮循环。
|
||||
|
||||
同样用 `nc` 进行测试,以下是非阻塞监听器的输出:
|
||||
|
||||
```
|
||||
$ ./nonblocking-listener 9988
|
||||
Listening on port 9988
|
||||
peer (localhost, 37288) connected
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
recv returned 6 bytes
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
recv returned 13 bytes
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Calling recv...
|
||||
Peer disconnected; I'm done.
|
||||
```
|
||||
|
||||
作为练习,给输出添加一个时间戳,确认调用 `recv` 得到结果之间花费的时间是比输入到 `nc` 中所用的多还是少(每一轮是 200 ms)。
|
||||
|
||||
这里就实现了使用非阻塞的 `recv` 让监听者检查套接字变为可能,并且在没有数据的时候重新获得控制权。换句话说,这就是 _polling(轮询)_ —— 主程序周期性的查询套接字以便读取数据。
|
||||
|
||||
对于顺序响应的问题,这似乎是个可行的方法。非阻塞的 `recv` 让同时与多个套接字通信变成可能,轮询这些套接字,仅当有新数据到来时才处理。就是这样,这种方式 _可以_ 用来写并发服务器;但实际上一般不这么做,因为轮询的方式很难扩展。
|
||||
|
||||
首先,我在代码中引入的 200 ms 延迟对于记录非常好(监听器在我输入 `nc` 之间只打印几行 “Calling recv...”,但实际上应该有上千行)。但它也增加了多达 200 ms 的服务器响应时间,这几乎是意料不到的。实际的程序中,延迟会低得多,休眠时间越短,进程占用的 CPU 资源就越多。有些时钟周期只是浪费在等待,这并不好,尤其是在移动设备上,这些设备的电量往往有限。
|
||||
|
||||
但是当我们实际这样来使用多个套接字的时候,更严重的问题出现了。想像下监听器正在同时处理 1000 个 客户端。这意味着每一个循环迭代里面,它都得为 _这 1000 个套接字中的每一个_ 执行一遍非阻塞的 `recv`,找到其中准备好了数据的那一个。这非常低效,并且极大的限制了服务器能够并发处理的客户端数。这里有个准则:每次轮询之间等待的间隔越久,服务器响应性越差;而等待的时间越少,CPU 在无用的轮询上耗费的资源越多。
|
||||
|
||||
讲真,所有的轮询都像是无用功。当然操作系统应该是知道哪个套接字是准备好了数据的,因此没必要逐个扫描。事实上,就是这样,接下来就会讲一些API,让我们可以更优雅地处理多个客户端。
|
||||
|
||||
### select
|
||||
|
||||
`select` 的系统调用是轻便的(POSIX),标准 Unix API 中常有的部分。它是为上一节最后一部分描述的问题而设计的 —— 允许一个线程可以监视许多文件描述符 ^[注4][17] 的变化,不用在轮询中执行不必要的代码。我并不打算在这里引入一个关于 `select` 的理解性的教程,有很多网站和书籍讲这个,但是在涉及到问题的相关内容时,我会介绍一下它的 API,然后再展示一个非常复杂的例子。
|
||||
|
||||
`select` 允许 _多路 I/O_,监视多个文件描述符,查看其中任何一个的 I/O 是否可用。
|
||||
|
||||
```
|
||||
int select(int nfds, fd_set *readfds, fd_set *writefds,
|
||||
fd_set *exceptfds, struct timeval *timeout);
|
||||
```
|
||||
|
||||
`readfds` 指向文件描述符的缓冲区,这个缓冲区被监视是否有读取事件;`fd_set` 是一个特殊的数据结构,用户使用 `FD_*` 宏进行操作。`writefds` 是针对写事件的。`nfds` 是监视的缓冲中最大的文件描述符数字(文件描述符就是整数)。`timeout` 可以让用户指定 `select` 应该阻塞多久,直到某个文件描述符准备好了(`timeout == NULL` 就是说一直阻塞着)。现在先跳过 `exceptfds`。
|
||||
|
||||
`select` 的调用过程如下:
|
||||
|
||||
1. 在调用之前,用户先要为所有不同种类的要监视的文件描述符创建 `fd_set` 实例。如果想要同时监视读取和写入事件,`readfds` 和 `writefds` 都要被创建并且引用。
|
||||
|
||||
2. 用户可以使用 `FD_SET` 来设置集合中想要监视的特殊描述符。例如,如果想要监视描述符 2、7 和 10 的读取事件,在 `readfds` 这里调用三次 `FD_SET`,分别设置 2、7 和 10。
|
||||
|
||||
3. `select` 被调用。
|
||||
|
||||
4. 当 `select` 返回时(现在先不管超时),就是说集合中有多少个文件描述符已经就绪了。它也修改 `readfds` 和 `writefds` 集合,来标记这些准备好的描述符。其它所有的描述符都会被清空。
|
||||
|
||||
5. 这时用户需要遍历 `readfds` 和 `writefds`,找到哪个描述符就绪了(使用 `FD_ISSET`)。
|
||||
|
||||
作为完整的例子,我在并发的服务器程序上使用 `select`,重新实现了我们之前的协议。[完整的代码在这里][18];接下来的是代码中的高亮,还有注释。警告:示例代码非常复杂,因此第一次看的时候,如果没有足够的时间,快速浏览也没有关系。
|
||||
|
||||
### 使用 select 的并发服务器
|
||||
|
||||
使用 I/O 的多发 API 诸如 `select` 会给我们服务器的设计带来一些限制;这不会马上显现出来,但这值得探讨,因为它们是理解事件驱动编程到底是什么的关键。
|
||||
|
||||
最重要的是,要记住这种方法本质上是单线程的 ^[注5][19]。服务器实际上在 _同一时刻只能做一件事_。因为我们想要同时处理多个客户端请求,我们需要换一种方式重构代码。
|
||||
|
||||
首先,让我们谈谈主循环。它看起来是什么样的呢?先让我们想象一下服务器有一堆任务,它应该监视哪些东西呢?两种类型的套接字活动:
|
||||
|
||||
1. 新客户端尝试连接。这些客户端应该被 `accept`。
|
||||
|
||||
2. 已连接的客户端发送数据。这个数据要用 [第一节][11] 中所讲到的协议进行传输,有可能会有一些数据要被回送给客户端。
|
||||
|
||||
尽管这两种活动在本质上有所区别,我们还是要把他们放在一个循环里,因为只能有一个主循环。循环会包含 `select` 的调用。这个 `select` 的调用会监视上述的两种活动。
|
||||
|
||||
这里是部分代码,设置了文件描述符集合,并在主循环里转到被调用的 `select` 部分。
|
||||
|
||||
```
|
||||
// “master” 集合存活在该循环中,跟踪我们想要监视的读取事件或写入事件的文件描述符(FD)。
|
||||
fd_set readfds_master;
|
||||
FD_ZERO(&readfds_master);
|
||||
fd_set writefds_master;
|
||||
FD_ZERO(&writefds_master);
|
||||
|
||||
// 监听的套接字一直被监视,用于读取数据,并监测到来的新的端点连接。
|
||||
FD_SET(listener_sockfd, &readfds_master);
|
||||
|
||||
// 要想更加高效,fdset_max 追踪当前已知最大的 FD;这使得每次调用时对 FD_SETSIZE 的迭代选择不是那么重要了。
|
||||
int fdset_max = listener_sockfd;
|
||||
|
||||
while (1) {
|
||||
// select() 会修改传递给它的 fd_sets,因此进行拷贝一下再传值。
|
||||
fd_set readfds = readfds_master;
|
||||
fd_set writefds = writefds_master;
|
||||
|
||||
int nready = select(fdset_max + 1, &readfds, &writefds, NULL, NULL);
|
||||
if (nready < 0) {
|
||||
perror_die("select");
|
||||
}
|
||||
...
|
||||
```
|
||||
|
||||
这里的一些要点:
|
||||
|
||||
1. 由于每次调用 `select` 都会重写传递给函数的集合,调用器就得维护一个 “master” 集合,在循环迭代中,保持对所监视的所有活跃的套接字的追踪。
|
||||
|
||||
2. 注意我们所关心的,最开始的唯一那个套接字是怎么变成 `listener_sockfd` 的,这就是最开始的套接字,服务器借此来接收新客户端的连接。
|
||||
|
||||
3. `select` 的返回值,是在作为参数传递的集合中,那些已经就绪的描述符的个数。`select` 修改这个集合,用来标记就绪的描述符。下一步是在这些描述符中进行迭代。
|
||||
|
||||
```
|
||||
...
|
||||
for (int fd = 0; fd <= fdset_max && nready > 0; fd++) {
|
||||
// 检查 fd 是否变成可读的
|
||||
if (FD_ISSET(fd, &readfds)) {
|
||||
nready--;
|
||||
|
||||
if (fd == listener_sockfd) {
|
||||
// 监听的套接字就绪了;这意味着有个新的客户端连接正在联系
|
||||
...
|
||||
} else {
|
||||
fd_status_t status = on_peer_ready_recv(fd);
|
||||
if (status.want_read) {
|
||||
FD_SET(fd, &readfds_master);
|
||||
} else {
|
||||
FD_CLR(fd, &readfds_master);
|
||||
}
|
||||
if (status.want_write) {
|
||||
FD_SET(fd, &writefds_master);
|
||||
} else {
|
||||
FD_CLR(fd, &writefds_master);
|
||||
}
|
||||
if (!status.want_read && !status.want_write) {
|
||||
printf("socket %d closing\n", fd);
|
||||
close(fd);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这部分循环检查 _可读的_ 描述符。让我们跳过监听器套接字(要浏览所有内容,[看这个代码][20]) 然后看看当其中一个客户端准备好了之后会发生什么。出现了这种情况后,我们调用一个叫做 `on_peer_ready_recv` 的 _回调_ 函数,传入相应的文件描述符。这个调用意味着客户端连接到套接字上,发送某些数据,并且对套接字上 `recv` 的调用不会被阻塞 ^[注6][21]。这个回调函数返回结构体 `fd_status_t`。
|
||||
|
||||
```
|
||||
typedef struct {
|
||||
bool want_read;
|
||||
bool want_write;
|
||||
} fd_status_t;
|
||||
```
|
||||
|
||||
这个结构体告诉主循环,是否应该监视套接字的读取事件,写入事件,或者两者都监视。上述代码展示了 `FD_SET` 和 `FD_CLR` 是怎么在合适的描述符集合中被调用的。对于主循环中某个准备好了写入数据的描述符,代码是类似的,除了它所调用的回调函数,这个回调函数叫做 `on_peer_ready_send`。
|
||||
|
||||
现在来花点时间看看这个回调:
|
||||
|
||||
```
|
||||
typedef enum { INITIAL_ACK, WAIT_FOR_MSG, IN_MSG } ProcessingState;
|
||||
|
||||
#define SENDBUF_SIZE 1024
|
||||
|
||||
typedef struct {
|
||||
ProcessingState state;
|
||||
|
||||
// sendbuf 包含了服务器要返回给客户端的数据。on_peer_ready_recv 句柄填充这个缓冲,
|
||||
// on_peer_read_send 进行消耗。sendbuf_end 指向缓冲区的最后一个有效字节,
|
||||
// sendptr 指向下个字节
|
||||
uint8_t sendbuf[SENDBUF_SIZE];
|
||||
int sendbuf_end;
|
||||
int sendptr;
|
||||
} peer_state_t;
|
||||
|
||||
// 每一端都是通过它连接的文件描述符(fd)进行区分。只要客户端连接上了,fd 就是唯一的。
|
||||
// 当客户端断开连接,另一个客户端连接上就会获得相同的 fd。on_peer_connected 应该
|
||||
// 进行初始化,以便移除旧客户端在同一个 fd 上留下的东西。
|
||||
peer_state_t global_state[MAXFDS];
|
||||
|
||||
fd_status_t on_peer_ready_recv(int sockfd) {
|
||||
assert(sockfd < MAXFDs);
|
||||
peer_state_t* peerstate = &global_state[sockfd];
|
||||
|
||||
if (peerstate->state == INITIAL_ACK ||
|
||||
peerstate->sendptr < peerstate->sendbuf_end) {
|
||||
// 在初始的 ACK 被送到了客户端,就没有什么要接收的了。
|
||||
// 等所有待发送的数据都被发送之后接收更多的数据。
|
||||
return fd_status_W;
|
||||
}
|
||||
|
||||
uint8_t buf[1024];
|
||||
int nbytes = recv(sockfd, buf, sizeof buf, 0);
|
||||
if (nbytes == 0) {
|
||||
// 客户端断开连接
|
||||
return fd_status_NORW;
|
||||
} else if (nbytes < 0) {
|
||||
if (errno == EAGAIN || errno == EWOULDBLOCK) {
|
||||
// 套接字 *实际* 并没有准备好接收,等到它就绪。
|
||||
return fd_status_R;
|
||||
} else {
|
||||
perror_die("recv");
|
||||
}
|
||||
}
|
||||
bool ready_to_send = false;
|
||||
for (int i = 0; i < nbytes; ++i) {
|
||||
switch (peerstate->state) {
|
||||
case INITIAL_ACK:
|
||||
assert(0 && "can't reach here");
|
||||
break;
|
||||
case WAIT_FOR_MSG:
|
||||
if (buf[i] == '^') {
|
||||
peerstate->state = IN_MSG;
|
||||
}
|
||||
break;
|
||||
case IN_MSG:
|
||||
if (buf[i] == '$') {
|
||||
peerstate->state = WAIT_FOR_MSG;
|
||||
} else {
|
||||
assert(peerstate->sendbuf_end < SENDBUF_SIZE);
|
||||
peerstate->sendbuf[peerstate->sendbuf_end++] = buf[i] + 1;
|
||||
ready_to_send = true;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
// 如果没有数据要发送给客户端,报告读取状态作为最后接收的结果。
|
||||
return (fd_status_t){.want_read = !ready_to_send,
|
||||
.want_write = ready_to_send};
|
||||
}
|
||||
```
|
||||
|
||||
`peer_state_t` 是全状态对象,用来表示在主循环中两次回调函数调用之间的客户端的连接。因为回调函数在客户端发送的某些数据时被调用,不能假设它能够不停地与客户端通信,并且它得运行得很快,不能被阻塞。因为套接字被设置成非阻塞模式,`recv` 会快速的返回。除了调用 `recv`, 这个句柄做的是处理状态,没有其它的调用,从而不会发生阻塞。
|
||||
|
||||
举个例子,你知道为什么这个代码需要一个额外的状态吗?这个系列中,我们的服务器目前只用到了两个状态,但是这个服务器程序需要三个状态。
|
||||
|
||||
来看看 “套接字准备好发送” 的回调函数:
|
||||
|
||||
```
|
||||
fd_status_t on_peer_ready_send(int sockfd) {
|
||||
assert(sockfd < MAXFDs);
|
||||
peer_state_t* peerstate = &global_state[sockfd];
|
||||
|
||||
if (peerstate->sendptr >= peerstate->sendbuf_end) {
|
||||
// 没有要发送的。
|
||||
return fd_status_RW;
|
||||
}
|
||||
int sendlen = peerstate->sendbuf_end - peerstate->sendptr;
|
||||
int nsent = send(sockfd, peerstate->sendbuf, sendlen, 0);
|
||||
if (nsent == -1) {
|
||||
if (errno == EAGAIN || errno == EWOULDBLOCK) {
|
||||
return fd_status_W;
|
||||
} else {
|
||||
perror_die("send");
|
||||
}
|
||||
}
|
||||
if (nsent < sendlen) {
|
||||
peerstate->sendptr += nsent;
|
||||
return fd_status_W;
|
||||
} else {
|
||||
// 所有东西都成功发送;重置发送队列。
|
||||
peerstate->sendptr = 0;
|
||||
peerstate->sendbuf_end = 0;
|
||||
|
||||
// 如果我们现在是处于特殊的 INITIAL_ACK 状态,就转变到其他状态。
|
||||
if (peerstate->state == INITIAL_ACK) {
|
||||
peerstate->state = WAIT_FOR_MSG;
|
||||
}
|
||||
|
||||
return fd_status_R;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里也一样,回调函数调用了一个非阻塞的 `send`,演示了状态管理。在异步代码中,回调函数执行的很快是受争议的,任何延迟都会阻塞主循环进行处理,因此也阻塞了整个服务器程序去处理其他的客户端。
|
||||
|
||||
用脚步再来运行这个服务器,同时连接 3 个客户端。在一个终端中我们运行下面的命令:
|
||||
|
||||
```
|
||||
$ ./select-server
|
||||
```
|
||||
|
||||
在另一个终端中:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-26 05:29:15,864:conn1 connected...
|
||||
INFO:2017-09-26 05:29:15,864:conn2 connected...
|
||||
INFO:2017-09-26 05:29:15,864:conn0 connected...
|
||||
INFO:2017-09-26 05:29:15,865:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-26 05:29:15,865:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-26 05:29:15,865:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-26 05:29:15,865:conn1 received b'bcdbcuf'
|
||||
INFO:2017-09-26 05:29:15,865:conn2 received b'bcdbcuf'
|
||||
INFO:2017-09-26 05:29:15,865:conn0 received b'bcdbcuf'
|
||||
INFO:2017-09-26 05:29:16,866:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-26 05:29:16,867:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-26 05:29:16,867:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-26 05:29:16,867:conn1 received b'234'
|
||||
INFO:2017-09-26 05:29:16,868:conn0 received b'234'
|
||||
INFO:2017-09-26 05:29:16,868:conn2 received b'234'
|
||||
INFO:2017-09-26 05:29:17,868:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-26 05:29:17,869:conn1 received b'36bc1111'
|
||||
INFO:2017-09-26 05:29:17,869:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-26 05:29:17,870:conn0 received b'36bc1111'
|
||||
INFO:2017-09-26 05:29:17,870:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-26 05:29:17,870:conn2 received b'36bc1111'
|
||||
INFO:2017-09-26 05:29:18,069:conn1 disconnecting
|
||||
INFO:2017-09-26 05:29:18,070:conn0 disconnecting
|
||||
INFO:2017-09-26 05:29:18,070:conn2 disconnecting
|
||||
```
|
||||
|
||||
和线程的情况相似,客户端之间没有延迟,他们被同时处理。而且在 `select-server` 也没有用线程!主循环 _多路_ 处理所有的客户端,通过高效使用 `select` 轮询多个套接字。回想下 [第二节中][22] 顺序的 vs 多线程的客户端处理过程的图片。对于我们的 `select-server`,三个客户端的处理流程像这样:
|
||||
|
||||

|
||||
|
||||
所有的客户端在同一个线程中同时被处理,通过乘积,做一点这个客户端的任务,然后切换到另一个,再切换到下一个,最后切换回到最开始的那个客户端。注意,这里没有什么循环调度,客户端在它们发送数据的时候被客户端处理,这实际上是受客户端左右的。
|
||||
|
||||
### 同步,异步,事件驱动,回调
|
||||
|
||||
`select-server` 示例代码为讨论什么是异步编程,它和事件驱动及基于回调的编程有何联系,提供了一个良好的背景。因为这些词汇在并发服务器的(非常矛盾的)讨论中很常见。
|
||||
|
||||
让我们从一段 `select` 的手册页面中引用的一句好开始:
|
||||
|
||||
> select,pselect,FD_CLR,FD_ISSET,FD_SET,FD_ZERO - 同步 I/O 处理
|
||||
|
||||
因此 `select` 是 _同步_ 处理。但我刚刚演示了大量代码的例子,使用 `select` 作为 _异步_ 处理服务器的例子。有哪些东西?
|
||||
|
||||
答案是:这取决于你的观查角度。同步常用作阻塞处理,并且对 `select` 的调用实际上是阻塞的。和第 1、2 节中讲到的顺序的、多线程的服务器中对 `send` 和 `recv` 是一样的。因此说 `select` 是 _同步的_ API 是有道理的。可是,服务器的设计却可以是 _异步的_,或是 _基于回调的_,或是 _事件驱动的_,尽管其中有对 `select` 的使用。注意这里的 `on_peer_*` 函数是回调函数;它们永远不会阻塞,并且只有网络事件触发的时候才会被调用。它们可以获得部分数据,并能够在调用过程中保持稳定的状态。
|
||||
|
||||
如果你曾经做过一些 GUI 编程,这些东西对你来说应该很亲切。有个 “事件循环”,常常完全隐藏在框架里,应用的 “业务逻辑” 建立在回调上,这些回调会在各种事件触发后被调用,用户点击鼠标,选择菜单,定时器到时间,数据到达套接字,等等。曾经最常见的编程模型是客户端的 JavaScript,这里面有一堆回调函数,它们在浏览网页时用户的行为被触发。
|
||||
|
||||
### select 的局限
|
||||
|
||||
使用 `select` 作为第一个异步服务器的例子对于说明这个概念很有用,而且由于 `select` 是很常见,可移植的 API。但是它也有一些严重的缺陷,在监视的文件描述符非常大的时候就会出现。
|
||||
|
||||
1. 有限的文件描述符的集合大小。
|
||||
|
||||
2. 糟糕的性能。
|
||||
|
||||
从文件描述符的大小开始。`FD_SETSIZE` 是一个编译期常数,在如今的操作系统中,它的值通常是 1024。它被硬编码在 `glibc` 的头文件里,并且不容易修改。它把 `select` 能够监视的文件描述符的数量限制在 1024 以内。曾有些分支想要写出能够处理上万个并发访问的客户端请求的服务器,这个问题很有现实意义。有一些方法,但是不可移植,也很难用。
|
||||
|
||||
糟糕的性能问题就好解决的多,但是依然非常严重。注意当 `select` 返回的时候,它向调用者提供的信息是 “就绪的” 描述符的个数,还有被修改过的描述符集合。描述符集映射着描述符 就绪/未就绪”,但是并没有提供什么有效的方法去遍历所有就绪的描述符。如果只有一个描述符是就绪的,最坏的情况是调用者需要遍历 _整个集合_ 来找到那个描述符。这在监视的描述符数量比较少的时候还行,但是如果数量变的很大的时候,这种方法弊端就凸显出了 ^[注7][23]。
|
||||
|
||||
由于这些原因,为了写出高性能的并发服务器, `select` 已经不怎么用了。每一个流行的操作系统有独特的不可移植的 API,允许用户写出非常高效的事件循环;像框架这样的高级结构还有高级语言通常在一个可移植的接口中包含这些 API。
|
||||
|
||||
### epoll
|
||||
|
||||
举个例子,来看看 `epoll`,Linux 上的关于高容量 I/O 事件通知问题的解决方案。`epoll` 高效的关键之处在于它与内核更好的协作。不是使用文件描述符,`epoll_wait` 用当前准备好的事件填满一个缓冲区。只有准备好的事件添加到了缓冲区,因此没有必要遍历客户端中当前 _所有_ 监视的文件描述符。这简化了查找就绪的描述符的过程,把空间复杂度从 `select` 中的 O(N) 变为了 O(1)。
|
||||
|
||||
关于 `epoll` API 的完整展示不是这里的目的,网上有很多相关资源。虽然你可能猜到了,我还要写一个不同的并发服务器,这次是用 `epool` 而不是 `select`。完整的示例代码 [在这里][24]。实际上,由于大部分代码和 `用 select 的服务器`相同,所以我只会讲要点,在主循环里使用 `epoll`:
|
||||
|
||||
```
|
||||
struct epoll_event accept_event;
|
||||
accept_event.data.fd = listener_sockfd;
|
||||
accept_event.events = EPOLLIN;
|
||||
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listener_sockfd, &accept_event) < 0) {
|
||||
perror_die("epoll_ctl EPOLL_CTL_ADD");
|
||||
}
|
||||
|
||||
struct epoll_event* events = calloc(MAXFDS, sizeof(struct epoll_event));
|
||||
if (events == NULL) {
|
||||
die("Unable to allocate memory for epoll_events");
|
||||
}
|
||||
|
||||
while (1) {
|
||||
int nready = epoll_wait(epollfd, events, MAXFDS, -1);
|
||||
for (int i = 0; i < nready; i++) {
|
||||
if (events[i].events & EPOLLERR) {
|
||||
perror_die("epoll_wait returned EPOLLERR");
|
||||
}
|
||||
|
||||
if (events[i].data.fd == listener_sockfd) {
|
||||
// 监听的套接字就绪了;意味着新客户端正在连接。
|
||||
...
|
||||
} else {
|
||||
// A peer socket is ready.
|
||||
if (events[i].events & EPOLLIN) {
|
||||
// 准备好了读取
|
||||
...
|
||||
} else if (events[i].events & EPOLLOUT) {
|
||||
// 准备好了写入
|
||||
...
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
通过调用 `epoll_ctl` 来配置 `epoll`。这时,配置监听的套接字数量,也就是 `epoll` 监听的描述符的数量。然后分配一个缓冲区,把就绪的事件传给 `epoll` 以供修改。在主循环里对 `epoll_wait` 的调用是魅力所在。它阻塞着,直到某个描述符就绪了(或者超时),返回就绪的描述符数量。但这时,不少盲目地迭代所有监视的集合,我们知道 `epoll_write` 会修改传给它的 `events` 缓冲区,缓冲区中有就绪的事件,从 0 到 `nready-1`,因此我们只需迭代必要的次数。
|
||||
|
||||
要在 `select` 里面重新遍历,有明显的差异:如果在监视着 1000 个描述符,只有两个就绪, `epoll_waits` 返回的是 `nready=2`,然后修改 `events` 缓冲区最前面的两个元素,因此我们只需要“遍历”两个描述符。用 `select` 我们就需要遍历 1000 个描述符,找出哪个是就绪的。因此,在繁忙的服务器上,有许多活跃的套接字时 `epoll` 比 `select` 更加容易扩展。
|
||||
|
||||
剩下的代码很直观,因为我们已经很熟悉 `select 服务器` 了。实际上,`epoll 服务器` 中的所有“业务逻辑”和 `select 服务器` 是一样的,回调构成相同的代码。
|
||||
|
||||
这种相似是通过将事件循环抽象分离到一个库/框架中。我将会详述这些内容,因为很多优秀的程序员曾经也是这样做的。相反,下一篇文章里我们会了解 `libuv`,一个最近出现的更加受欢迎的时间循环抽象层。像 `libuv` 这样的库让我们能够写出并发的异步服务器,并且不用考虑系统调用下繁琐的细节。
|
||||
|
||||
* * *
|
||||
|
||||
|
||||
[注1][1] 我试着在两件事的实际差别中突显自己,一件是做一些网络浏览和阅读,但经常做得头疼。有很多不同的选项,从“他们是一样的东西”到“一个是另一个的子集”,再到“他们是完全不同的东西”。在面临这样主观的观点时,最好是完全放弃这个问题,专注特殊的例子和用例。
|
||||
|
||||
[注2][2] POSIX 表示这可以是 `EAGAIN`,也可以是 `EWOULDBLOCK`,可移植应用应该对这两个都进行检查。
|
||||
|
||||
[注3][3] 和这个系列所有的 C 示例类似,代码中用到了某些助手工具来设置监听套接字。这些工具的完整代码在这个 [仓库][4] 的 `utils` 模块里。
|
||||
|
||||
[注4][5] `select` 不是网络/套接字专用的函数,它可以监视任意的文件描述符,有可能是硬盘文件,管道,终端,套接字或者 Unix 系统中用到的任何文件描述符。这篇文章里,我们主要关注它在套接字方面的应用。
|
||||
|
||||
[注5][6] 有多种方式用多线程来实现事件驱动,我会把它放在稍后的文章中进行讨论。
|
||||
|
||||
[注6][7] 由于各种非实验因素,它 _仍然_ 可以阻塞,即使是在 `select` 说它就绪了之后。因此服务器上打开的所有套接字都被设置成非阻塞模式,如果对 `recv` 或 `send` 的调用返回了 `EAGAIN` 或者 `EWOULDBLOCK`,回调函数就装作没有事件发生。阅读示例代码的注释可以了解更多细节。
|
||||
|
||||
[注7][8] 注意这比该文章前面所讲的异步 polling 例子要稍好一点。polling 需要 _一直_ 发生,而 `select` 实际上会阻塞到有一个或多个套接字准备好读取/写入;`select` 会比一直询问浪费少得多的 CPU 时间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id3
|
||||
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id4
|
||||
[4]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/utils.h
|
||||
[5]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id5
|
||||
[6]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id6
|
||||
[7]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id8
|
||||
[8]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id9
|
||||
[9]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[10]:https://eli.thegreenplace.net/tag/c-c
|
||||
[11]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[12]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[13]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[14]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[15]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id11
|
||||
[16]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id12
|
||||
[17]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id13
|
||||
[18]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/select-server.c
|
||||
[19]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id14
|
||||
[20]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/select-server.c
|
||||
[21]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id15
|
||||
[22]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[23]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id16
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/epoll-server.c
|
||||
[25]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[26]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[27]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[28]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id10
|
||||
283
translated/tech/20171009 Considering Pythons Target Audience.md
Normal file
283
translated/tech/20171009 Considering Pythons Target Audience.md
Normal file
@ -0,0 +1,283 @@
|
||||
[谁是 Python 的目标受众?][40]
|
||||
============================================================
|
||||
|
||||
Python 是为谁设计的?
|
||||
|
||||
* [Python 使用情况的参考][8]
|
||||
|
||||
* [CPython 主要服务于哪些受众?][9]
|
||||
|
||||
* [这些相关问题的原因是什么?][10]
|
||||
|
||||
* [适合进入 PyPI 规划的方面有哪些?][11]
|
||||
|
||||
* [当增加它到标准库中时,为什么一些 APIs 会被改变?][12]
|
||||
|
||||
* [为什么一些 API 是以临时(provisional)的形式被增加的?][13]
|
||||
|
||||
* [为什么只有一些标准库 APIs 被升级?][14]
|
||||
|
||||
* [标准库任何部分都有独立的版本吗?][15]
|
||||
|
||||
* [这些注意事项为什么很重要?][16]
|
||||
|
||||
几年前, 我在 python-dev 邮件列表中、活跃的 CPython 核心开发人员、以及决定参与该过程的人员中[强调][38]说,“CPython 的动作太快了也太慢了”,作为这种冲突的一个主要原因是,它们不能有效地使用他们的个人时间和精力。
|
||||
|
||||
我一直在考虑这种情况,在参与的这几年,我也花费了一些时间去思考这一点,在我写那篇文章的时候,我还在波音防务澳大利亚公司(Boeing Defence Australia)工作。下个月,我将离开波音进入红帽亚太(Red Hat Asia-Pacific),并且开始在大企业的[开源供应链管理][39]上获得重分发者(redistributor)级别的观点。
|
||||
|
||||
### [Python 使用情况的参考][17]
|
||||
|
||||
我将分解 CPython 的使用情况如下,它虽然有些过于简化(注意,这些分类并不是很清晰,他们仅关注影响新软件特性和版本的部署不同因素):
|
||||
|
||||
* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,_不_ 写或维护软件产品。例如:
|
||||
* 澳大利亚的 [数字课程][1]
|
||||
|
||||
* Lorena A. Barba 的 [AeroPython][2]
|
||||
|
||||
* 个人的自动化爱好者的项目:主要的是软件,经常是只有软件,而且用户通常是写它的人。例如:
|
||||
* my Digital Blasphemy [image download notebook][3]
|
||||
|
||||
* Paul Fenwick's (Inter)National [Rick Astley Hotline][4]
|
||||
|
||||
* 组织(organisational)过程的自动化:主要是软件,经常是只有软件,用户是为了利益而编写它的组织。例如:
|
||||
* CPython 的 [核发工作流工具][5]
|
||||
|
||||
* Linux 发行版的开发、构建&发行工具
|
||||
|
||||
* “一劳永逸(Set-and-forget)” 的基础设施中:这里是软件,(这种说法有时候有些争议),在生命周期中软件几乎不会升级,但是,在底层平台可能会升级。例如:
|
||||
* 大多数的自我管理的企业或机构的基础设施(在那些资金充足的可持续工程计划中,这是让人非常不安的)
|
||||
|
||||
* 拨款资助的软件(当最初的拨款耗尽时,维护通常会终止)
|
||||
|
||||
* 有严格认证要求的软件(如果没有绝对必要的话,从经济性考虑,重新认证比常规更新来说要昂贵很多)
|
||||
|
||||
* 没有自动升级功能的嵌入式软件系统
|
||||
|
||||
* 持续升级的基础设施:具有健壮的持续工程化模型的软件,对于依赖和平台升级被认为是例行的,而不去关心其它的代码改变。例如:
|
||||
* Facebook 的 Python 服务基础设施
|
||||
|
||||
* 滚动发布的 Linux 分发版
|
||||
|
||||
* 大多数的公共 PaaS 无服务器环境(Heroku、OpenShift、AWS Lambda、Google Cloud Functions、Azure Cloud Functions等等)
|
||||
|
||||
* 间歇性升级的标准的操作环境:对其核心组件进行常规升级,但这些升级以年为单位进行,而不是周或月。例如:
|
||||
* [VFX 平台][6]
|
||||
|
||||
* 长周期支持的 Linux 分发版
|
||||
|
||||
* CPython 和 Python 标准库
|
||||
|
||||
* 基础设施管理 & 业务流程工具(比如 OpenStack、 Ansible)
|
||||
|
||||
* 硬件控制系统
|
||||
|
||||
* 短生命周期的软件:软件仅被使用一次,然后就丢弃或忽略,而不是随后接着升级。例如:
|
||||
* 临时(Ad hoc)自动脚本
|
||||
|
||||
* 被确定为 “终止” 的单用户游戏(你玩它们一次后,甚至都忘了去卸载它,或许在一个新的设备上都不打算再去安装它)
|
||||
|
||||
* 短暂的或非持久状态的单用户游戏(如果你卸载并重安装它们,你的游戏体验也不会有什么大的变化)
|
||||
|
||||
* 特定事件的应用程序(这些应用程序与特定的物理事件捆绑,一旦事件结束,这些应用程序就不再有用了)
|
||||
|
||||
* 定期使用的应用程序:部署后定期升级的软件。例如:
|
||||
* 业务管理软件
|
||||
|
||||
* 个人 & 专业的生产力应用程序(比如,Blender)
|
||||
|
||||
* 开发工具 & 服务(比如,Mercurial、 Buildbot、 Roundup)
|
||||
|
||||
* 多用户游戏,和其它明显的处于持续状态的还没有被定义为 “终止” 的游戏
|
||||
|
||||
* 有自动升级功能的嵌入式软件系统
|
||||
|
||||
* 共享的抽象层:软件组件的设计使它能够在特定的问题域有效地工作,即使你没有亲自掌握该领域的所有错综复杂的东西。例如:
|
||||
* 大多数的运行时库和归入这一类的框架(比如,Django、Flask、Pyramid、SQL Alchemy、NumPy、SciPy、requests)
|
||||
|
||||
* 也适合归入这里的许多测试和类型引用工具(比如,pytest、Hypothesis、vcrpy、behave、mypy)
|
||||
|
||||
* 其它应用程序的插件(比如,Blender plugins、OpenStack hardware adapters)
|
||||
|
||||
* 本身就代表了 “Python 世界” 的基准的标准库(那是一个 [难以置信的复杂][7] 的世界观)
|
||||
|
||||
### [CPython 主要服务于哪些受众?][18]
|
||||
|
||||
最终,CPython 和标准库的主要受众是哪些,不论什么原因,一个更多的有限的标准库和从 PyPI 安装的显式声明的第三方库的组合,提供的服务是不够的。
|
||||
|
||||
为了更一步简化上面回顾的不同用法和部署模式,为了尽可能的总结,将最大的 Python 用户群体分开来看,一种是,在一些环境中将 Python 作为一种_脚本语言_使用的,另外一种是将它用作一个_应用程序开发语言_,最终发布的是一种产品而不是他们的脚本。
|
||||
|
||||
当把 Python 作为一种脚本语言来使用时,它们典型的开发者特性包括:
|
||||
|
||||
* 主要的处理单元是由一个 Python 文件组成的(或 Jupyter notebook !),而不是一个 Python 目录和元数据文件
|
||||
|
||||
* 没有任何形式的单独的构建步骤 - 是_作为_一个脚本分发的,类似于分发一个单独的 shell 脚本的方法。
|
||||
|
||||
* 没有单独的安装步骤(除了下载这个文件到一个合适的位置),除了在目标系统上要求预配置运行时环境
|
||||
|
||||
* 没有显式的规定依赖关系,除了最低的 Python 版本,或一个预期的运行环境声明。如果需要一个标准库以外的依赖项,他们会通过一个环境脚本去提供(无论是操作系统、数据分析平台、还是嵌入 Python 运行时的应用程序)
|
||||
|
||||
* 没有单独的测试套件,使用 "通过你给定的输入,这个脚本是否给出了你期望的结果?" 这种方式来进行测试
|
||||
|
||||
* 如果在执行前需要测试,它将以 “dry run” 和 “预览” 模式来向用户展示软件_将_怎样运行
|
||||
|
||||
* 如果可以完全使用静态代码分析工具,它是通过集成进用户的软件开发环境的,而不是为个别的脚本单独设置的。
|
||||
|
||||
相比之下,使用 Python 作为一个应用程序开发语言的开发者特征包括:
|
||||
|
||||
* 主要的工作单元是由 Python 的目录和元数据文件组成的,而不是单个 Python 文件
|
||||
|
||||
* 在发布之前有一个单独的构建步骤去预处理应用程序,即使是把它的这些文件一起打包进一个 Python sdist、wheel 或 zipapp 文档
|
||||
|
||||
* 是否有独立的安装步骤去预处理将要使用的应用程序,取决于应用程序是如何打包的,和支持的目标环境
|
||||
|
||||
* 外部的依赖直接在项目目录中的一个元数据文件中表示(比如,`pyproject.toml`、`requirements.txt`、`Pipfile`),或作为生成的发行包的一部分(比如,`setup.py`、`flit.ini`)
|
||||
|
||||
* 存在一个独立的测试套件,或者作为一个 Python API 的一个测试单元、功能接口的集成测试、或者是两者的一个结合
|
||||
|
||||
* 静态分析工具的使用是在项目级配置的,作为测试管理的一部分,而不是依赖
|
||||
|
||||
作为以上分类的一个结果,CPython 和标准库最终提供的主要用途是,在合适的 CPython 特性发布后3 - 5年,为教育和临时(ad hoc)的 Python 脚本环境的呈现的功能,定义重新分发的独立基准。
|
||||
|
||||
对于临时(ad hoc)脚本使用的情况,这个 3-5 年的延迟是由于新版本重分发给用户的延迟组成的,以及那些重分发版的用户花在修改他们的标准操作环境上的时间。
|
||||
|
||||
在教育环境中的情况,教育工作者需要一些时间去评估新特性,和决定是否将它们包含进提供给他们的学生的课程中。
|
||||
|
||||
### [这些相关问题的原因是什么?][19]
|
||||
|
||||
这篇文章很大程序上是受 Twitter 上 [我的评论][20] 的讨论鼓舞的,定义在 [PEP 411][21] 中引用临时(Provisional)的 API 的情形,作为一个开源项目发行的例子,一个真实的被邀请用户,作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
|
||||
|
||||
这些回复包括一些在更高级别的库中支持的临时(Provisional) API 的一些相关的沮丧的表述,这些库没有临时(Provisional)状态的传递,以及因此而被限制为只有最新版本的临时(Provisional) API 支持这些相关特性,而不是任何的早期迭代版本。
|
||||
|
||||
我的 [主要反应][22] 是去建议,开源提供者应该努力加强他们需要的有限支持,以加强他们的维护工作的可持续性。这意味着,如果支持老版本的临时(Provisional) API 是非常痛苦的,然后,只有项目开发人员自己需要时,或者,有人为此支付费用时,他们才会去提供支持。这类似于我的观点,志愿者提供的项目是否应该免费支持老的商业的长周期支持的 Python 发行版,这对他们来说是非常麻烦的事,我[不认他们应该去做][23],正如我所期望的那样,大多数这样的需求都来自于管理差劲的习以为常的惯性,而不是真正的需求(真正的需求,它应该去支付费用来解决问题)
|
||||
|
||||
然而,我的[第二个反应][24]是,去认识到这一点,尽管多年来一直在讨论这个问题(比如,在上面链接中 2011 的一篇年的文章中,以及在 Python 3 问答的回答中 [在这里][25]、[这里][26]、和[这里][27],和在去年的 [Python 包生态系统][28]上的一篇文章中的一小部分),我从来没有真实尝试直接去解释过它对标准库设计过程中的影响。
|
||||
|
||||
如果没有这些背景,设计过程中的一些方面,如临时(Provisional) API 的介绍,或者是受到不同的启发(inspired-by-not-the-same-as)的介绍,看起来似乎是很荒谬的,因为它们似乎是在试图标准化 API,而实际上并没有对 API 进行标准化。
|
||||
|
||||
### [适合进入 PyPI 规划的方面有哪些?][29]
|
||||
|
||||
提交给 python-ideas 或 python-dev 的_任何_建议的第一个门槛就是,清楚地回答这个问题,“为什么 PyPI 上的一个模块不够好?”。绝大多数的建议都在这一步失败了,但通过他们得到了几个共同的主题:
|
||||
|
||||
* 大多数新手可能经常是从互联网上去 “复制粘贴” 错误的建议,而不是去下载一个合适的第三方库。(比如,这就是为什么存在 `secrets` 库的原因:使得很少的人去使用 `random` 模块,因为安全敏感的原因,这是用于游戏和统计模拟的)
|
||||
|
||||
* 这个模块是用于提供一个实现的参考,并去允许与其它的相互竞争的实现之间提供互操作性,而不是对所有人的所有事物都是必要的。(比如,`asyncio`、`wsgiref`、`unittest`、和 `logging` 全部都是这种情况)
|
||||
|
||||
* 这个模块是用于标准库的其它部分(比如,`enum` 就是这种情况,像`unittest`一样)
|
||||
|
||||
* 这个模块是被设计去支持语言之外的一些语法(比如,`contextlib`、`asyncio` 和 `typing` 模块,就是这种情况)
|
||||
|
||||
* 这个模块只是普通的临时(ad hoc)脚本用途(比如,`pathlib` 和 `ipaddress` 就是这种情况)
|
||||
|
||||
* 这个模块被用于一个教育环境(比如,`statistics` 模块允许进行交互式地探索统计的概念,尽管你不会用它来做全部的统计分析)
|
||||
|
||||
通过前面的 “PyPI 是不是明显不够好” 的检查,一个模块还不足以确保被接收到标准库中,但它已经足够转变问题为 “在接下来的几年中,你所推荐的要包含的库能否对一般的 Python 开发人员的经验有所改提升?”
|
||||
|
||||
标准库中的 `ensurepip` 和 `venv` 模块的介绍也明确地告诉分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
|
||||
|
||||
### [当增加它到标准库中时,为什么一些 APIs 会被改变?][30]
|
||||
|
||||
现在已经存在的第三方模块有时候会被批量地采用到标准库中,在其它情况下,实际上增加进行的是重新设计和重新实现的 API,只是它参照了现有 API 的用户体验,但是,根据另外的设计参考,删除或修改了一些细节,和附属于语言参考实现部分的权限。
|
||||
|
||||
例如,不像广受欢迎的第三方库的前身 `path.py`,`pathlib` 并_不_规定字符串子类,而是独立的类型。作为解决文件互操作性问题的结果,是定义了文件系统路径协议,它允许与文件系统路径一起使用的接口,去使用更大范围的对象。
|
||||
|
||||
为 `ipaddress` 模块设计的 API 是为教学 IP 地址概念,从定义的地址和网络中,为显式的单独主机接口调整的(IP 地址关联到特定的 IP 网络),为了提供一个最佳的教学工具,而最原始的 “ipaddr” 模块中,使用网络术语的方式不那么严谨。
|
||||
|
||||
在其它情况下,标准库被构建为多种现有方法的一个综合,而且,还有可能依赖于定义现有库的 API 时不存在的特性。应用于 `asyncio` 和 `typing` 模块的所有的这些考虑,虽然后来考虑适用于 `dataclasses` 的 API 被认为是 PEP 557 (它可以被总结为 “像属性一样,但是使用变量注释作为字段声明”)。
|
||||
|
||||
这类改变的工作原理是,这类库不会消失,而且,它们的维护者经常并不关心与标准库相关的限制(特别是,相对缓慢的发行节奏)。在这种情况下,对于标准库版本的文档来说,使用 “See Also” 链接指向原始模块是很常见的,特别是,如果第三方版本提供了标准库模块中忽略的其他特性和灵活性时。
|
||||
|
||||
### [为什么一些 API 是以临时(provisional)的形式被增加的?][31]
|
||||
|
||||
虽然 CPython 确实设置了 API 的弃用策略,但我们通常不希望在没有令人信服的理由的情况下去使用它(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
|
||||
|
||||
然而,当增加一个受已有的第三方启发去设计的而不是去拷贝的新的 API 时,在设计实践中,有些设计实践可能会出现问题,这比平常的风险要高。
|
||||
|
||||
当我们考虑这种改变的风险比平常要高,我们将相关的 API 标记为临时(provisional),表示保守的终端用户可以希望避免完全依赖他们,并且,共享抽象层的开发者可能希望考虑,对他们准备支持的临时(provisional) API 的版本实施比平时更严格的限制。
|
||||
|
||||
### [为什么只有一些标准库 APIs 被升级?][32]
|
||||
|
||||
这里简短的回答升级的主要 APIs 有哪些?:
|
||||
|
||||
* 不适合外部因素驱动的补充更新
|
||||
|
||||
* 无论是临时(ad hoc)脚本使用情况,还是为促进将来的多个第三方解决方案之间的互操作性,都有明显好外的
|
||||
|
||||
* 对这方面感兴趣的人提交了一个可接受的建议
|
||||
|
||||
如果一个用于应用程序开发的模块存在一个非常明显的限制(limitations),比如,`datetime`,如果重分发版通过替代一个现成的第三方模块有所改善,比如,`requests`,或者,如果标准库的发布节奏与需要的有问题的包之间有真正的冲突,比如,`certifi`,那么,计划对标准库版本进行改变的因素将显著减少。
|
||||
|
||||
从本质上说,这和关于 PyPI 上面的问题是相反的:因为,PyPI 分发机制对增强应用程序开发人员经验来说,通常_是_足够好的,这样的改进是有意义的,允许重分发者和平台提供者自行决定将哪些内容作为缺省提供的一部分。
|
||||
|
||||
当改变后的能力(capabilities)假设在 3-5 年内缺省出现时被认为是有价值的,才会将这些改变进入到 CPython 和标准库中。
|
||||
|
||||
### [标准库任何部分都有独立的版本吗?][33]
|
||||
|
||||
是的,它就像是 `ensurepip` 使用的捆绑模式( CPython 发行了一个 `pip` 的最新捆绑版本,而并没有把它放进标准库中),将来可能被应用到其它模块中。
|
||||
|
||||
最有可能的第一个候选者是 `distutils` 构建系统,因为切换到这种模式将允许构建系统在多个发行版本之间保持一致。
|
||||
|
||||
这种处理方式的其它可能的候选对象是 Tcl/Tk graphics 捆绑和 IDLE 编辑器,它们已经被拆分,并且通过一些重分发程序转换成安装可选项。
|
||||
|
||||
### [这些注意事项为什么很重要?][34]
|
||||
|
||||
从本质上说,那些积极参与开源开发的人就是那些致力于开源应用程序和共享抽象层的人。
|
||||
|
||||
写一些临时(ad hoc)脚本和为学生设计一些教学习题的人,通常不会认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、商业分析师、动画师、架构设计师、等等。
|
||||
|
||||
当所有我们的担心是,语言是开发人员的经验时,那么,我们可以简单假设人们知道一些什么,他们使用的工具,所遵循的开发流程,以及构建和部署他们软件的方法。
|
||||
|
||||
当一个应用程序运行时(runtime),_也_作为一个脚本引擎广为流行时,事情将变的更加复杂。在一个项目中去平衡两种需求,就会导致双方的不理解和怀疑,做任何一件事都将变得很困难。
|
||||
|
||||
这篇文章不是为了说,我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是指出添加到 Python 标准库中的看上去很荒谬的特性的最合理的反应(reaction),它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此,它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html
|
||||
|
||||
作者:[Nick Coghlan ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.curiousefficiency.org/pages/about.html
|
||||
[1]:https://aca.edu.au/#home-unpack
|
||||
[2]:https://github.com/barbagroup/AeroPython
|
||||
[3]:https://nbviewer.jupyter.org/urls/bitbucket.org/ncoghlan/misc/raw/default/notebooks/Digital%20Blasphemy.ipynb
|
||||
[4]:https://github.com/pjf/rickastley
|
||||
[5]:https://github.com/python/core-workflow
|
||||
[6]:http://www.vfxplatform.com/
|
||||
[7]:http://www.curiousefficiency.org/posts/2015/10/languages-to-improve-your-python.html#broadening-our-horizons
|
||||
[8]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#use-cases-for-python-s-reference-interpreter
|
||||
[9]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#which-audience-does-cpython-primarily-serve
|
||||
[10]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-is-this-relevant-to-anything
|
||||
[11]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#where-does-pypi-fit-into-the-picture
|
||||
[12]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-changed-when-adding-them-to-the-standard-library
|
||||
[13]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-some-apis-added-in-provisional-form
|
||||
[14]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-are-only-some-standard-library-apis-upgraded
|
||||
[15]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#will-any-parts-of-the-standard-library-ever-be-independently-versioned
|
||||
[16]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#why-do-these-considerations-matter
|
||||
[17]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id1
|
||||
[18]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id2
|
||||
[19]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id3
|
||||
[20]:https://twitter.com/ncoghlan_dev/status/916994106819088384
|
||||
[21]:https://www.python.org/dev/peps/pep-0411/
|
||||
[22]:https://twitter.com/ncoghlan_dev/status/917092464355241984
|
||||
[23]:http://www.curiousefficiency.org/posts/2015/04/stop-supporting-python26.html
|
||||
[24]:https://twitter.com/ncoghlan_dev/status/917088410162012160
|
||||
[25]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#wouldn-t-a-python-2-8-release-help-ease-the-transition
|
||||
[26]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#doesn-t-this-make-python-look-like-an-immature-and-unstable-platform
|
||||
[27]:http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#what-about-insert-other-shiny-new-feature-here
|
||||
[28]:http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html
|
||||
[29]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id4
|
||||
[30]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id5
|
||||
[31]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id6
|
||||
[32]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id7
|
||||
[33]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id8
|
||||
[34]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#id9
|
||||
[35]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
|
||||
[36]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#disqus_thread
|
||||
[37]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.rst
|
||||
[38]:http://www.curiousefficiency.org/posts/2011/04/musings-on-culture-of-python-dev.html
|
||||
[39]:http://community.redhat.com/blog/2015/02/the-quid-pro-quo-of-open-infrastructure/
|
||||
[40]:http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html#
|
||||
@ -1,57 +0,0 @@
|
||||
CyberShaolin:教授下一代网络安全专家
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
CyberShaolin 联合创始人 Reuben Paul 将在布拉格的开源峰会上发表演讲,强调网络安全意识对于孩子们的重要性。
|
||||
|
||||
Reuben Paul 并不是唯一一个玩电子游戏的孩子,但是他对游戏和电脑的痴迷使他走上了一段独特的好奇之旅,引起了他对网络安全教育和宣传的早期兴趣,并创立了 CyberShaolin,一个帮助孩子理解网络攻击的威胁。现年 11 岁的 Paul 将在[布拉格开源峰会]上发表主题演讲,分享他的经验,并强调玩具、设备和日常使用的其他技术的不安全性。
|
||||
|
||||

|
||||
|
||||
CyberShaolin 联合创始人 Reuben Paul
|
||||
|
||||
我们采访了 Paul 听取了他的故事,并讨论 CyberShaolin 及其教育、赋予孩子(及其父母)的网络安全危险和防御知识。Linux.com:你对电脑的迷恋是什么时候开始的?Reuben Paul:我对电脑的迷恋始于电子游戏。我喜欢手机游戏以及视频游戏。当我大约 5 岁时(我想),我通过 Gameloft 在手机上玩 “Asphalt” 赛车游戏。这是一个简单而有趣的游戏。我得触摸手机右侧加快速度,触摸手机左侧减慢速度。我问我爸,“游戏怎么知道我触摸了哪里?”
|
||||
|
||||
他研究发现,手机屏幕是一个 xy 坐标系统,所以他告诉我,如果 x 值大于手机屏幕宽度的一半,那么它是右侧的触摸。否则,这是左侧接触。为了帮助我更好地理解这是如何工作的,他给了我一个线性的方程,它是 y = mx + b,并问:“你能找每个 x 值 对应的 y 值吗?”大约 30 分钟后,我计算出了所有他给我的 x 对应的 y 值。
|
||||
|
||||
当我父亲意识到我能够学习编程的一些基本逻辑时,他给我介绍了 Scratch,并且使用鼠标指针的 x 和 y 值编写了我的第一个游戏 - 名为 “Big Fish eats Small Fish”。然后,我爱上了电脑。现年 11 岁的 Paul 将在[布拉格的开源峰会]上发表主题演讲,分享他的经验,强调玩具、设备和其他技术在日常使用中的不安全性。
|
||||
|
||||
Linux.com:你对网络安全感兴趣吗?Paul:我的父亲 Mano Paul 曾经在网络安全方面培训他的商业客户。每当他在家里工作,我都会听到他的电话交谈。到了我 6 岁的时候,我就知道互联网、防火墙和云计算等东西。当我的父亲意识到我有兴趣和学习的潜力,他开始教我安全方面,如社会工程技术、克隆网站、中间人攻击技术、hack 移动程序,等等。当我第一次从目标测试机器上获得一个 meterpreter shell 时,我的感觉就像 Peter Parker 刚刚发现他的蜘蛛侠的能力一样。
|
||||
|
||||
Linux.com:你如何以及为什么创建 CyberShaolin 的?Paul:当我 8 岁的时候,我首先在 DerbyCon 上做了主题为“来自孩子(或者是 8 岁)之口的安全信息”的演讲。那是在 2014 年 9 月。那次会议之后,我收到了几个邀请函,2014 年底之前,我还在其他三个会议上做了主题演讲。
|
||||
|
||||
所以,当孩子们开始听到我在这些不同的会议上发言时,他们开始写信给我,要我教他们。我告诉我的父母,我想教别的孩子,他们问我如何。我说:“也许我可以制作一些视频,并在像 YouTube 这样的频道上发布。”他们问我是否要收费,而我说“不”。我希望我的视频可以免费供在世界上任何地方的任何孩子使用。CyberShaolin 就是这样创建的。
|
||||
|
||||
Linux.com:CyberShaolin 的目标是什么? Paul:CyberShaolin 是我父母帮助我创立的非营利组织。它的任务是教育、赋予孩子(和他们的父母)掌握网络安全的危险和防范知识,我在学校、功夫、体操、游泳、曲棍球、钢琴和鼓的其他时间开发了这些视频和其他训练材料。迄今为止,我已经在 www.CyberShaolin.org 网站上发布了大量的视频,并计划开发更多的视频。我也想制作游戏和漫画来支持安全学习。
|
||||
|
||||
CyberShaolin 来自两个词:网络和少林。网络这个词当然是来自技术。少林来自功夫武术形式,我和我的父亲都是黑带 2 段。在功夫方面,我们有显示知识进步的缎带,你可以想像 CyberShaolin 像数码功夫,在我们的网站上学习和考试后,孩子们可以成为网络黑带。
|
||||
|
||||
Linux.com:你认为孩子对网络安全的理解有多重要?Paul:我们生活在一个技术和设备不仅存在我们家里,还在我们学校和几乎任何你去的地方的时代。世界也正在与物联网联系起来,这些物联网很容易成为威胁网。儿童是这些技术和设备的主要用户之一。不幸的是,这些设备和设备上的应用程序不是很安全,可能会给儿童和家庭带来严重的问题。例如,最近(2017 年 5 月),我演示了如何才能闯入智能玩具泰迪熊,并将其变成远程侦察设备。孩子也是下一代。如果他们对网络安全没有意识和训练,那么未来(我们的未来)将不会很好。
|
||||
|
||||
Linux.com:该项目如何帮助孩子?Paul:正如我之前提到的,CyberShaolin 的使命是教育、赋予孩子(和他们的父母)网络安全的危险和防御知识。
|
||||
|
||||
当孩子们受到网络欺凌、中间人、钓鱼、隐私、在线威胁、移动威胁等网络安全危害的教育时,他们将具备知识和技能,从而使他们能够在网络空间做出明智的决定并保持安全。而且,正如我永远不会用我的功夫技能去伤害某个人一样,我希望所有的 CyberShaolin 毕业生都能利用他们的网络功夫技能为人类的利益创造一个安全的未来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Swapnil Bhartiya 是一名记者和作家,专注在 Linux 和 Open Source 上 10 多年。
|
||||
|
||||
-------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/cybershaolin-teaching-next-generation-cybersecurity-experts/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/sbhartiya/
|
||||
[1]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[2]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[3]:https://www.linuxfoundation.org/author/sbhartiya/
|
||||
[4]:https://www.linuxfoundation.org/category/blog/
|
||||
[5]:https://www.linuxfoundation.org/category/campaigns/events-campaigns/
|
||||
[6]:https://www.linuxfoundation.org/category/blog/qa/
|
||||
@ -1,77 +0,0 @@
|
||||
商业软件开源的六个好处
|
||||
============================================================
|
||||
|
||||
### 为什么商业软件应该开源
|
||||
|
||||

|
||||
图片来源 : opensource.com
|
||||
|
||||
在相同的基础上,开源软件要优于不开源的软件。想知道为什么?这里有六个商业机构及政府部门可以从开源软件获得好处的原因
|
||||
### 1\. 让运营商审核更简单
|
||||
|
||||
在你将工程和金融资源整合成一个产品加入你的基础设施之前,你需要知道你选择了一个正确的版本。你想要一个在活跃发展的产品,它有定期的安全更新和漏洞修复,同时在你有需求时,产品能有相应的更新。这最后一点也许比你想的还要重要:是的,一个满足你需求的解决方案。但是产品的需求随着市场的成熟以及你商业的发展在变化。如果这个产品不能满足这些需求,在未来你需要花费很大的代价来进行迁移。
|
||||
|
||||
你要怎么知道你没有正在把你的时间和资金投入到一个正在灭亡的产品?在开源的世界里,你可以不选择一个只有卖家有话语权的运营商。你可以通过考虑[发展速度以及社区发展的健康程度][3] 来比较运营商. 一到两年之后,一个更活跃、多样性和健康的社区将开发出一个更好的产品,这是一个重要的考虑因素。当然,就像这篇 [关于企业开源软件的博文][4] 指出的, 运营商必须有能力处理由于项目发展革新带来的不稳定性。寻找一个有长支持周期的运营商来避免混乱的更新。
|
||||
|
||||
### 2\. 来自独立性的长寿
|
||||
|
||||
福布斯杂志指出[90%的初创公司是失败的][5] ,而他们中不超过一半的中小型公司存活超过五年。当你不得不迁移到一个新的运营商时,你花费的代价是昂贵的。所以最好避免一些只有一个运营商支持的产品。
|
||||
|
||||
开源使得社区成员能够一起编写软件。例如 OpenStack [是由许多公司以及志愿者一起编写的][6]。这给客户提供了一个保证,不管任何一个独立运营商发生问题,也总会有一个运营商能提供支持。随着软件的开源,企业对开发团队实施产品的努力进行长期的投资。有权使用开源代码确保你总是能从贡献者中雇佣到人来保持你的发展活跃期和你需要它的时间一样长。当然,没有一个大的活跃的社区,也就只有少量的贡献者能被雇佣。所以活跃贡献者的数量是重要的。
|
||||
|
||||
### 3\. 安全性
|
||||
|
||||
安全是一件复杂的事情。这就是为什么开源发展是构建安全解决方案的关键因素和先决条件。同时安全每一天都在变得更重要。当发展在公开的环境下进行,你能直接的校验运营商是否积极的在追求安全,以及看到运营商是如何对待安全问题的。研究代码和执行独立代码审计的能力让运营商尽可能早的发现和修复漏洞。一些运营商给社区提供上千万的美金的[漏洞奖金][7] 作为额外的奖励来刺激开发者发现他们产品的安全漏洞,同时也展示了运营商对于自己产品的信任。
|
||||
|
||||
除了代码,开源发展同样意味着开源过程,所以你能检查和看到供应商是否遵循ISO27001、 [云安全准则][8] 及其他标准所推荐的工业标准发展过程。当然,一个可信组织额外的检查提供了额外的保障,例如在 Nextcloud 与我们合作的[NCC小组][9]。
|
||||
|
||||
### 4\. 更多的顾客导向
|
||||
|
||||
由于用户和顾客能直接看到和参与到产品的发展中,开源项目比那些只关注于营销团队回应的闭源软件更加的贴合用户的需求。你可以注意到开源软件项目趋向于横向发展。一个社区有许多迫切需要解决的事情以及致力于发展更多的功能,然而一个以营利为目的的运营商更关注于一个能够给他们带来利益的个体或小型团队。这导致更少的易于销售的版本,因为相比混合且匹配的多样性改进,它只关注于一件事情。但是它创造了许多对用户更有价值的产品。
|
||||
|
||||
### 5\. 更好的支持
|
||||
一个私人的运营商总能在你遇到问题时给你提供帮助。如果他们不提供你所需要的服务或者对调整你的商务需求收取额外昂贵的费用,那真是不好运。对私人软件提供的支持是一个典型的 "[柠檬市场][10]." 随着软件的开源,运营商将提供巨大的支持或者其他的一些东西来填补间隙,来确保你能得到最好的服务支持,这是自由市场的最佳选择。
|
||||
|
||||
### 6\. 更佳的许可
|
||||
|
||||
典型的软件许可证[充斥着令人不愉快的条款][11], ,通常是在强制套利的情况下,这样你就不会有机会起诉运营商的不当行为。其中一个问题是你仅仅被授予了软件的使用权,这通常完全由供应商自行决定。如果软件不运行或者停止运行或者如果运营商要求支付更多的费用,你得不到软件的所有权或其他的权利。像 GPL 一类的开源许可证是为保护客户专门设计的。它确保软件能够在没有专制限制的情况下满足你所需要时间内的任意需求。
|
||||
|
||||
由于它们的广泛使用,GPL 的含义及其衍生出来的其他许可被广泛的理解。例如,你能确保许可证允许你现存的基础设施(开源或闭源)通过设定好的 API 去进行连接。其没有时间或者是用户人数上的限制,同时也不会强迫你公开软件架构或者是知识产权(例如公司商标)。
|
||||
|
||||
这也让遵循规定变得更加的容易。专利软件意味着你有可以罚款的严厉的法规。更糟糕的是一些开源代码产品在 GPL 和专利软件的混合规定下运行。这[违反了许可规定][12]以及将顾客置于风险中。同时Gartner指出,一个开源代码模型意味着你 [不能从开源中获利][13]。一个纯净的开源许可产品避免了这些问题。相反,你只有一个服从的规定:如果你对代码做出了修改(不包括配置、商标或其他类似的东西),你必须将这些与使用你软件的人分享,如果他们要求
|
||||
Clearly open sou
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
一个善于与人打交道的技术爱好者和开源传播者。Nextcloud 的销售主管,曾是 ownCloud 和 SUSE 的社区经理,同时还是一个有多年经验的 KDE 销售人员。喜欢骑自行车穿越柏林和为家人朋友做饭。[点击这里找到我的博客][16].
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/10/6-reasons-choose-open-source-software
|
||||
|
||||
作者:[Jos Poortvliet Feed ][a]
|
||||
译者:[ZH1122](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jospoortvliet
|
||||
[1]:https://opensource.com/article/17/10/6-reasons-choose-open-source-software?rate=um7KfpRlV5lROQDtqJVlU4y8lBa9rsZ0-yr2aUd8fXY
|
||||
[2]:https://opensource.com/user/27446/feed
|
||||
[3]:https://nextcloud.com/blog/nextcloud-the-most-active-open-source-file-sync-and-share-project/
|
||||
[4]:http://www.redhat-cloudstrategy.com/open-source-for-business-people/
|
||||
[5]:http://www.forbes.com/sites/neilpatel/2015/01/16/90-of-startups-will-fail-heres-what-you-need-to-know-about-the-10/
|
||||
[6]:http://stackalytics.com/
|
||||
[7]:https://hackerone.com/nextcloud
|
||||
[8]:https://www.ncsc.gov.uk/guidance/implementing-cloud-security-principles
|
||||
[9]:https://nextcloud.com/secure
|
||||
[10]:https://en.wikipedia.org/wiki/The_Market_for_Lemons
|
||||
[11]:http://boingboing.net/2016/11/01/why-are-license-agreements.html
|
||||
[12]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPluginsInNF
|
||||
[13]:http://blogs.gartner.com/brian_prentice/2010/03/31/open-core-the-emperors-new-clothes/
|
||||
[14]:https://opensource.com/users/jospoortvliet
|
||||
[15]:https://opensource.com/users/jospoortvliet
|
||||
[16]:http://blog.jospoortvliet.com/
|
||||
|
||||
94
translated/tech/20171017 Image Processing on Linux.md
Normal file
94
translated/tech/20171017 Image Processing on Linux.md
Normal file
@ -0,0 +1,94 @@
|
||||
Linux上的图像处理
|
||||
============================================================
|
||||
|
||||
|
||||
我发现了很多生成图像表示你的数据和工作的系统软件,但是我不能写太多其他东西。因此在这篇文章中,包含了一款叫 ImageJ 的热门图像处理软件。特别的,我注意到了 [Fiji][4], 一例绑定了科学性图像处理的系列插件的 ImageJ 版本。
|
||||
|
||||
Fiji这个名字是一个循环缩略词,很像 GNU 。代表着 "Fiji Is Just ImageJ"。 ImageJ 是科学研究领域进行图像分析的实用工具——例如你可以用它来辨认航拍风景图中树的种类。 ImageJ 能划分物品种类。它以插件架构制成,海量插件供选择以提升使用灵活度。
|
||||
|
||||
首先是安装 ImageJ (或 Fiji). 大多数的 ImageJ 发行版都可使用软件包。你愿意的话,可以以这种方式安装它然后为你的研究安装所需的独立插件。另一种选择是安装 Fiji 的同时获取最常用的插件。不幸的是,大多数 Linux 发行版的软件中心不会有可用的 Fiji 安装包。幸而,官网上的简单安装文件是可以使用的。包含了运行 Fiji 需要的所有文件目录。第一次启动时,会给一个有菜单项列表的工具栏。(图1)
|
||||
|
||||

|
||||
|
||||
图 1\.第一次打开 Fiji 有一个最小化的界面。
|
||||
|
||||
如果你没有备好图片来练习使用 ImageJ ,Fiji 安装包包含了一些示例图片。点击文件->打开示例图片的下拉菜单选项(图2)。这些案例包含了许多你可能有兴趣做的任务。
|
||||
|
||||

|
||||
|
||||
图 2\. 案例图片可供学习使用 ImageJ。
|
||||
|
||||
安装了 Fiji,而不是单纯的 ImageJ ,大量插件也会被安装。首先要注意的是自动更新插件。每次打开 ImageJ ,该插件联网检验 ImageJ 和已安装插件的更新。所有已安装的插件都在插件菜单项中可选。一旦你安装了很多插件,列表会变得冗杂,所以需要精简你的插件选项。你想手动更新的话,点击帮助->更新 Fiji 菜单项强制检测获取可用更新列表(图3)。
|
||||
|
||||

|
||||
|
||||
图 3\. 强制手动检测可用更新。
|
||||
|
||||
那么,Now,用 Fiji/ImageJ 可以做什么呢?举一例,图片中的物品数。你可以通过点击文件->打开示例->胚芽来载入一例。
|
||||
|
||||

|
||||
|
||||
图 4\. 用 ImageJ算出图中的物品数。
|
||||
|
||||
第一步设定图片的范围这样你可以告诉 ImageJ 如何判别物品。首先,选择在工具栏选择线条按钮。然后选择分析->设定范围,然后就会设置范围内包含的像素点个数(图 5)。你可以设置已知距离为100,单元为“um”。
|
||||
|
||||

|
||||
|
||||
图 5\. 很多图片分析任务需要对图片设定一个范围。
|
||||
|
||||
接下来的步骤是简化图片内的信息。点击图片->类型->8比特来减少信息量到8比特灰度图片。点击处理->二进制->图片定界, 以分隔独立物体。点击处理->二进制->设置二进制来自动给图片定界(图 6)。
|
||||
|
||||

|
||||
|
||||
图 6\. 有些像开关一样完成自动任务的工具。
|
||||
|
||||
图片内的物品计数前,你需要移除像范围轮廓之类的人工操作。可以用三角选择工具来选中它并点击编辑->清空来完成这项操作。现在你可以分析图片看看这里是啥物体。
|
||||
|
||||
确保图中没有区域被选中,点击分析->分析最小粒子弹出窗口来选择最小尺寸,这决定了最后的图片会展示什么(图7)。
|
||||
|
||||

|
||||
|
||||
图 7\.你可以通过确定最小尺寸生成一个缩减过的图片。
|
||||
|
||||
图 8 在总结窗口展示了一个概览。每个最小点也有独立的细节窗口。
|
||||
|
||||

|
||||
|
||||
图 8\. 包含了已知最小点总览清单的输出结果。
|
||||
|
||||
只要你有一个分析程序来给定图片类型,相同的程序往往需要被应用到一系列图片当中。可能数以千计,你当然不会想对每张图片手动重复操作。这时候,你可以集中必要步骤到宏这样它们可以被应用多次。点击插件->宏- >记录弹出一个新的窗口记录你随后的所有命令。所有步骤一完成,你可以将之保存为一个宏文件并且通过点击插件->宏->运行来在其他图片上重复运行。
|
||||
|
||||
如果你有特定的工作步骤,你可以轻易打开宏文件并手动编辑它,因为它是一个简单的文本文件。事实上有一套完整的宏语言可供你更加充分地控制图片处理过程。
|
||||
|
||||
然而,如果你有真的非常多的系列图片需要处理,这也将是冗长乏味的工作。这种情况下,前往过程->批量->宏弹出一个新窗口你可以批量处理工作(图9)。
|
||||
|
||||

|
||||
|
||||
图 9\. 在批量输出图片时用简单命令运行宏。
|
||||
|
||||
这个窗口中,你能选择应用哪个宏文件,输入图片所在的源目录和你想写入输出图片的输出目录。也可以设置输出文件格式及通过文件名筛选输入图片中需要使用的。万事具备,点击窗口下方的的处理按钮开始批量操作。
|
||||
|
||||
若这是会重复多次的工作,你可以点击窗口底部的保存按钮保存批量处理到一个文本文件。点击也在窗口底部的开始按钮重载相同的工作。所有的应用都使得研究中最冗余部分自动化,这样你就可以在重点放在实际的科学研究中。
|
||||
考虑到单单是 ImageJ 主页就有超过500个插件和超过300种宏可供使用,简短起见,我只能在这篇短文中提出最基本的话题。幸运的是,有很多专业领域的教程可供使用,项目主页上还有关于 ImageJ 核心的非常棒的文档。如果觉得这个工具对研究有用,你研究的专业领域也会有很多信息指引你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Joey Bernard 有物理学和计算机科学的相关背景。这对他在新不伦瑞克大学当计算研究顾问的日常工作大有裨益。他也教计算物理和并行程序规划。
|
||||
|
||||
--------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/image-processing-linux
|
||||
|
||||
作者:[Joey Bernard][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxjournal.com/users/joey-bernard
|
||||
[1]:https://www.linuxjournal.com/tag/science
|
||||
[2]:https://www.linuxjournal.com/tag/statistics
|
||||
[3]:https://www.linuxjournal.com/users/joey-bernard
|
||||
[4]:https://imagej.net/Fiji
|
||||
@ -1,104 +0,0 @@
|
||||
由 KRACK 攻击想到的确保网络安全的小贴士
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
最近的 KRACK (密钥重装攻击,一个安全漏洞名称或该漏洞利用攻击行为的名称)漏洞攻击的目标是,在你的设备和 Wi-Fi 访问点之间的链路,它或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器,这些提示能帮你提升你的连接的安全性。[Creative Commons Zero][1]Pixabay
|
||||
|
||||
[KRACK 漏洞攻击][4] 现在已经超过 48 小时,并且已经在 [相关技术网站][5] 上有很多详细的讨论,因此,我将不在这里重复攻击的技术细节。攻击方式的总结如下:
|
||||
|
||||
* 在 WPA2 无线握手协议中的一个缺陷允许攻击者在你的设备和 wi-fi 访问点之间嗅探或操纵通讯。
|
||||
|
||||
* 它在 Linux 和 Android 设备上尤其严重,由于在 WPA2 标准中的措施含糊不清,也或许是在实现它时的错误理解,事实上,直到操作系统底层打完补丁以前,该漏洞一直可以强制实现无线之间的无加密通讯。
|
||||
|
||||
* 这个漏洞可以在客户端上修补,因此,天并没有塌下来,而且,WPA2 加密标准并没有像 WEP 标准那样被淘汰(不能通过切换到 WEP 加密的方式去“修复”这个问题)。
|
||||
|
||||
* 大多数流行的 Linux 分发版都已经通过升级修复了这个客户端上的漏洞,因此,老老实实地去更新它吧。
|
||||
|
||||
* Android 也很快修复了这个漏洞。如果你的设备接收到了 Android 安全补丁,你将修复这个漏洞。如果你的设备不再接收这些更新,那么,这个特别的漏洞将是你停止使用你的旧设备的一个理由。
|
||||
|
||||
即使如此,从我的观点来看, Wi-Fi 是不受信任的基础设施链中的另一个环节,并且,我们应该完全避免将其视为可信任的通信通道。
|
||||
|
||||
### 作为不受信任的基础设备的 Wi-Fi
|
||||
|
||||
如果从你的笔记本电脑或移动设备中读到这篇文章,那么,你的通信链路看起来应该是这样:
|
||||
|
||||

|
||||
|
||||
KRACK 攻击目标是在你的设备和 Wi-Fi 访问点之间的链接,它或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器。
|
||||
|
||||

|
||||
|
||||
实际上,这个图示应该看起来像这样:
|
||||
|
||||

|
||||
|
||||
Wi-Fi 仅仅是在我们不信任的信道的长通信链的第一个链路。如果我去假设,你使用的 Wi-Fi 路由器没有使用一个安全更新,并且,更严重的是,它或许使用了一个从未被更改过的、缺省的,易猜出的管理凭据(用户名和密码)。除非你自己安装并配置你的路由器,并且你可以记得你上次更新的它的固件,否则,你应该假设现在它已经被一些人控制并不受信任的。
|
||||
|
||||
说完 Wi-Fi 路由器,我们的通讯进入一般意义上的常见不信任区域 -- 根据你的猜疑水平,这里有上游的 ISPs 和提供商,其中的很多已经被监视、更改、分析和销售我们的流量数据,试图从我们的浏览习惯中赠更多的钱。通常他们的安全补丁计划还留下许多期望改进的地方,最终让我们的流量暴露在一些恶意者眼中。
|
||||
|
||||
一般来说,在因特网上,我们必须担心强大的国家级的参与者能够操纵核心网络协议,以执行大规模的网络监视和状态级的流量过滤。
|
||||
|
||||
### HTTPS 协议
|
||||
|
||||
值的庆幸的是,我们有一个基于不信任的介质进行安全通讯的解决方案,并且,我们可以每天都能使用它 -- HTTPS 协议,它加密你的点对点的因特网通讯,并且确信我们可以信任,站点与我们之间的通讯。
|
||||
|
||||
Linux 基金会的一些措施,比如像 [让我们加密吧][7] 使世界各地的网站所有者都可以很容易地提供端到端的加密,这有助于确保我们的个人设备与我们试图访问的网站之间的任何有安全隐患的设备不再重要。
|
||||
|
||||

|
||||
|
||||
是的... 几乎无关紧要。
|
||||
|
||||
### DNS —— 剩下的一个问题
|
||||
|
||||
虽然,我们可以尽职尽责使用 HTTPS 去创建一个可信的通信信道,但是,这里仍然有一个攻击者可以访问我们的路由器或修改我们的 Wi-Fi 流量的机会 -- 在使用 KRACK 的这个案例中 -- 可以欺骗我们的通讯进入一个错误的网站。他们可以利用我们仍然非常依赖 DNS 的这一事实 -- 一个未加密的、易受欺骗的 [诞生自1980年代的协议][8]。
|
||||
|
||||

|
||||
|
||||
DNS 是一个将人类友好的域名像 “linux.com” 这样的,转换成计算机可以用于和其它计算机通讯的 IP 地址的一个系统。去转换一个域名到一个 IP 地址,计算机将查询解析软件 -- 通常运行在 Wi-Fi 路由器或一个系统上。解析软件将查询一个分布式的 “root” 域名服务器网络,去找到在因特网上哪个系统有 “linux.com” 域名所对应的 IP 地址的“权威”信息。、
|
||||
|
||||
麻烦的是,所有发生的这些通讯都是未经认证的、[易于欺骗的][9]、明文协议、并且响应可以很容易地被攻击者修改,去返回一个不正确的数据。如果有人去欺骗一个 DNS 查询并且返回错误的 IP 地址,他们可以操纵我们的系统最终发送 HTTP 请求到那里。
|
||||
|
||||
幸运的是,HTTPS 有一些内置的保护措施去确保它不会很容易地被其它人诱导至其它假冒站点。恶意服务器上的 TLS 凭据必须与你请求的 DNS 名字匹配 -- 并且它必须通过你的浏览器由一个公认的、可信任的 [认证机构][10] 发布。如果不是这种情况,你的浏览器将在你试图去与他们告诉你的地址进行通讯时出现一个很大的警告。如果你看到这样的警告,在选择不理会警告之前,请你格外小心,因为,它有可能会把你的秘密泄露给那些可能会对付你的人。
|
||||
|
||||
如果攻击者完全控制了路由器,他们在一开始时,通过拦截来自服务器的指示你建立一个安全连接的响应,可以阻止你使用 HTTPS 连接(这被称为 “[SSL 脱衣攻击][11]”)。 为帮助你保护这种类型的攻击,站点可以增加一个 [特殊响应头][12] 去告诉你的浏览器以后与它通讯时使用 HTTPS 协议,但是,这仅仅是在你首次访问之后的事。对于一些非常流行的站点,浏览器现在包含一个 [域名硬编码列表][13],即使是首次连接,它也将总是使用 HTTPS 协议访问。
|
||||
|
||||
现在已经有了 DNS 欺骗的解决方案,它被称为 [DNSSEC][14],由于有重大的障碍 -- 真实和可感知的(译者注,指的是要求实名认证),它看起来接受程序很慢。直到 DNSSEC 被普遍使用之前,我们必须假设,我们接收到的 DNS 信息是不能完全信任的。
|
||||
|
||||
### 使用 VPN 去解决“最后一公里”的安全问题
|
||||
|
||||
因此,如果你不能信任固件太旧的 Wi-Fi -- 和/或无线路由器 -- 我们能做些什么来确保,发生在你的设备与一般说的因特网之间的“最后一公里”通讯的完整性呢?
|
||||
|
||||
一个可接受的解决方案是去使用信誉好的 VPN 供应商的 VPN 服务,它将在你的系统和他们的基础设施之间建立一条安全的通讯链路。这里有一个期望,就是它比你的路由器提供者和你的当前因特网供应商更注重安全,因为,他们处于一个更好的位置去确保你的流量不会受到恶意的攻击或欺骗。在你的工作站和移动设备之间使用 VPN,可以确保免受像 KRACK 这样的漏洞攻击,或不安全的路由器不会影响你与外界通讯的完整性。
|
||||
|
||||

|
||||
|
||||
这有一个很重要的警告是,当你选择一个 VPN 供应商时,你必须确信他们的信用;否则,你将被另外的一拨恶意的“演员”交易。远离任何人提供的所谓“免费 VPN”,因为,它们可以通过监视你和向市场营销公司销售你的流量来赚钱。 [这个网站][2] 是一个很好的资源,你可以去比较他们提供的各种 VPN,去看他们是怎么互相竞争的。
|
||||
|
||||
注意,你所有的设备都应该在它上面安装 VPN,那些你每天使用的网站,你的私人信息,尤其是任何与你的钱和你的身份(政府、银行网站、社交网络、等等)有关的东西都必须得到保护。VPN 并不是对付所有网络级漏洞的万能药,但是,当你在机场使用无法保证的 Wi-Fi 时,或者下次发现类似 KRACK 的漏洞时,它肯定会保护你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2017/10/tips-secure-your-network-wake-krack
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.vpnmentor.com/bestvpns/overall/
|
||||
[3]:https://www.linux.com/files/images/krack-securityjpg
|
||||
[4]:https://www.krackattacks.com/
|
||||
[5]:https://blog.cryptographyengineering.com/2017/10/16/falling-through-the-kracks/
|
||||
[6]:https://en.wikipedia.org/wiki/BGP_hijacking
|
||||
[7]:https://letsencrypt.org/
|
||||
[8]:https://en.wikipedia.org/wiki/Domain_Name_System#History
|
||||
[9]:https://en.wikipedia.org/wiki/DNS_spoofing
|
||||
[10]:https://en.wikipedia.org/wiki/Certificate_authority
|
||||
[11]:https://en.wikipedia.org/wiki/Moxie_Marlinspike#Notable_research
|
||||
[12]:https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security
|
||||
[13]:https://hstspreload.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions
|
||||
@ -0,0 +1,97 @@
|
||||
# [用 coredumpctl 更好地记录 bug][1]
|
||||
|
||||

|
||||
|
||||
一个不幸的事实是,所有的软件都有 bug,一些 bug 会导致系统崩溃。当它出现的时候,它经常会在磁盘上留下一个名为 _core dump_ 的数据文件。该文件包含有关系统崩溃时的相关数据,可能有助于确定发生崩溃的原因。通常开发者要求有显示导致崩溃的指令流的 _backtrace_ 形式的数据。开发人员可以使用它来修复 bug 并改进系统。如果系统崩溃,以下是如何轻松生成 backtrace 的方法。
|
||||
|
||||
### 开始使用 coredumpctl
|
||||
|
||||
大多数 Fedora 系统使用[自动错误报告工具 (ABRT)][2]来自动捕获崩溃文件并记录 bug。但是,如果你禁用了此服务或删除了该软件包,则此方法可能会有所帮助。
|
||||
|
||||
如果你遇到系统崩溃,请首先确保你运行的是最新的软件。更新通常包含修复程序,这些更新通常含有已经发现的会导致严重错误和崩溃的错误的修复。当你更新后,请尝试重新创建导致错误的情况。
|
||||
|
||||
如果崩溃仍然发生,或者你已经在运行最新的软件,那么可以使用有用的 _coredumpctl_。此程序可帮助查找和处理崩溃。要查看系统上所有核心转储列表,请运行以下命令:
|
||||
|
||||
```
|
||||
coredumpctl list
|
||||
```
|
||||
|
||||
如果你看到比预期长的列表,请不要感到惊讶。有时系统组件在后台默默地崩溃,并自行恢复。现在快速查找转储的简单方法是使用 _-since_ 选项:
|
||||
|
||||
```
|
||||
coredumpctl list --since=today
|
||||
```
|
||||
|
||||
_PID_ 列包含用于标识转储的进程 ID。请注意这个数字,因为你会之后再用到它。或者,如果你不想记住它,使用下面的命令将它赋值给一个变量:
|
||||
|
||||
```
|
||||
MYPID=<PID>
|
||||
```
|
||||
|
||||
要查看关于核心转储的信息,请使用此命令(使用 _$MYPID_ 变量或替换 PID 编号):
|
||||
|
||||
```
|
||||
coredumpctl info $MYPID
|
||||
```
|
||||
|
||||
### 安装 debuginfo 包
|
||||
|
||||
在核心转储中的数据以及原始代码中的指令之间调试符号转义。这个符号数据可能相当大。因此,符号以 _debuginfo_ 软件包的形式与大多数用户使用的 Fedora 系统分开安装。要确定你必须安装哪些 debuginfo 包,请先运行以下命令:
|
||||
|
||||
```
|
||||
coredumpctl gdb $MYPID
|
||||
```
|
||||
|
||||
这可能会在屏幕上显示大量信息。最后一行可能会告诉你使用 _dnf_ 安装更多的 debuginfo 软件包。[用 sudo ][3]运行该命令:
|
||||
|
||||
```
|
||||
sudo dnf debuginfo-install <packages...>
|
||||
```
|
||||
|
||||
然后再次尝试 _coredumpctl gdb $MYPID_ 命令。**你可能需要重复执行此操作**,因为其他符号会在 trace 中展开。
|
||||
|
||||
### 捕获 backtrace
|
||||
|
||||
运行以下命令以在调试器中记录信息:
|
||||
|
||||
```
|
||||
set logging file mybacktrace.txt
|
||||
set logging on
|
||||
```
|
||||
|
||||
你可能会发现关闭分页有帮助。对于长的 backtrace,这可以节省时间。
|
||||
|
||||
```
|
||||
set pagination off
|
||||
```
|
||||
|
||||
现在运行 backtrace:
|
||||
|
||||
```
|
||||
thread apply all bt full
|
||||
```
|
||||
|
||||
现在你可以输入 _quit_ 来退出调试器。_mybacktrace.txt_ 包含可附加到 bug 或问题的追踪信息。或者,如果你正在与某人实时合作,则可以将文本上传到 pastebin。无论哪种方式,你现在可以向开发人员提供更多的帮助来解决问题。
|
||||
|
||||
---------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Paul W. Frields
|
||||
|
||||
Paul W. Frields 自 1997 年以来一直是 Linux 用户和爱好者,并于 2003 年在 Fedora 发布不久后加入 Fedora。他是 Fedora 项目委员会的创始成员之一,从事文档、网站发布、宣传、工具链开发和维护软件。他于 2008 年 2 月至 2010 年 7 月加入 Red Hat,担任 Fedora 项目负责人,现任红帽公司工程部经理。他目前和妻子和两个孩子住在弗吉尼亚州。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/file-better-bugs-coredumpctl/
|
||||
|
||||
作者:[Paul W. Frields ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/file-better-bugs-coredumpctl/
|
||||
[2]:https://github.com/abrt/abrt
|
||||
[3]:https://fedoramagazine.org/howto-use-sudo/
|
||||
Loading…
Reference in New Issue
Block a user