mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge pull request #1664 from SPccman/master
How to sniff HTTP traffic from the command line on Linux.md
This commit is contained in:
commit
7a927ff475
@ -1,104 +0,0 @@
|
||||
SPccman is translating
|
||||
How to sniff HTTP traffic from the command line on Linux
|
||||
================================================================================
|
||||
Suppose you want to sniff live HTTP web traffic (i.e., HTTP requests and responses) on the wire for some reason. For example, you may be testing experimental features of a web server. Or you may be debugging a web application or a RESTful service. Or you may be trying to troubleshoot [PAC (proxy auto config)][1] or check for any malware files surreptitiously downloaded from a website. Whatever the reason is, there are cases where HTTP traffic sniffing is helpful, for system admins, developers, or even end users.
|
||||
|
||||
While [packet sniffing tools][2] such as tcpdump are popularly used for live packet dump, you need to set up proper filtering to capture HTTP traffic, and even then, their raw output typically cannot be interpreted on the HTTP protocol level so easily. Real-time web server log parsers such as [ngxtop][3] provide human-readable real-time web traffic traces, but only applicable with a full access to live web server logs.
|
||||
|
||||
What will be nice is to have tcpdump-like traffic sniffing tool, but targeting HTTP traffic only. In fact, [httpry][4] is extactly that: **HTTP packet sniffing tool**. httpry captures live HTTP packets on the wire, and displays their content at the HTTP protocol level in a human-readable format. In this tutorial, let's see how we can sniff HTTP traffic with httpry.
|
||||
|
||||
### Install httpry on Linux ###
|
||||
|
||||
On Debian-based systems (Ubuntu or Linux Mint), httpry is not available in base repositories. So build it from the source:
|
||||
|
||||
$ sudo apt-get install gcc make git libpcap0.8-dev
|
||||
$ git clone https://github.com/jbittel/httpry.git
|
||||
$ cd httpry
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
On Fedora, CentOS or RHEL, you can install httpry with yum as follows. On CentOS/RHEL, enable [EPEL repo][5] before running yum.
|
||||
|
||||
$ sudo yum install httpry
|
||||
|
||||
If you still want to build httpry from the source, you can easily do that by:
|
||||
|
||||
$ sudo yum install gcc make git libpcap-devel
|
||||
$ git clone https://github.com/jbittel/httpry.git
|
||||
$ cd httpry
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
### Basic Usage of httpry ###
|
||||
|
||||
The basic use case of httpry is as follows.
|
||||
|
||||
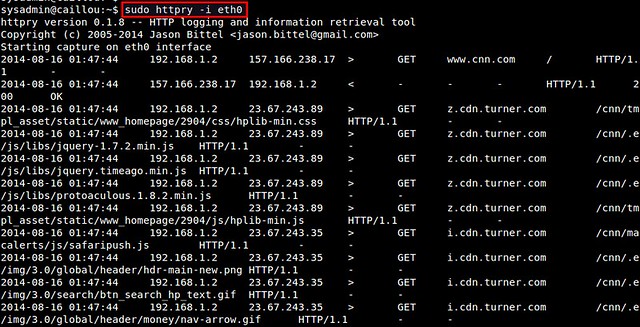
$ sudo httpry -i <network-interface>
|
||||
|
||||
httpry then listens on a specified network interface, and displays captured HTTP requests/responses in real time.
|
||||
|
||||
|
||||
|
||||
In most cases, however, you will be swamped with the fast scrolling output as packets are coming in and out. So you want to save captured HTTP packets for offline analysis. For that, use either '-b' or '-o' options. The '-b' option allows you to save raw HTTP packets into a binary file as is, which then can be replayed with httpry later. On the other hand, '-o' option saves human-readable output of httpry into a text file.
|
||||
|
||||
To save raw HTTP packets into a binary file:
|
||||
|
||||
$ sudo httpry -i eth0 -b output.dump
|
||||
|
||||
To replay saved HTTP packets:
|
||||
|
||||
$ httpry -r output.dump
|
||||
|
||||
Note that when you read a dump file with '-r' option, you don't need root privilege.
|
||||
|
||||
To save httpr's output to a text file:
|
||||
|
||||
$ sudo httpry -i eth0 -o output.txt
|
||||
|
||||
### Advanced Usage of httpry ###
|
||||
|
||||
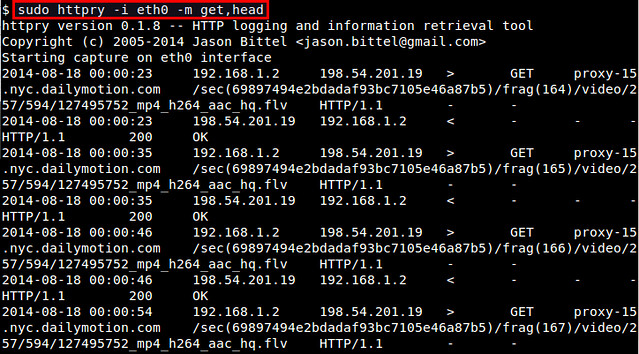
If you want to monitor only specific HTTP methods (e.g., GET, POST, PUT, HEAD, CONNECT, etc), use '-m' option:
|
||||
|
||||
$ sudo httpry -i eth0 -m get,head
|
||||
|
||||
|
||||
|
||||
If you downloaded httpry's source code, you will notice that the source code comes with a collection of Perl scripts which aid in analyzing httpry's output. These scripts are found in httpry/scripts/plugins directory. If you want to write a custom parser for httpry's output, these scripts can be good examples to start from. Some of their capabilities are:
|
||||
|
||||
- **hostnames**: Displays a list of unique host names with counts.
|
||||
- **find_proxies**: Detect web proxies.
|
||||
- **search_terms**: Find and count search terms entered in search services.
|
||||
- **content_analysis**: Find URIs which contain specific keywords.
|
||||
- **xml_output**: Convert output into XML format.
|
||||
- **log_summary**: Generate a summary of log.
|
||||
- **db_dump**: Dump log file data into a database.
|
||||
|
||||
Before using these scripts, first run httpry with '-o' option for some time. Once you obtained the output file, run the scripts on it at once by using this command:
|
||||
|
||||
$ cd httpry/scripts
|
||||
$ perl parse_log.pl -d ./plugins <httpry-output-file>
|
||||
|
||||
You may encounter warnings with several plugins. For example, db_dump plugin may fail if you haven't set up a MySQL database with DBI interface. If a plugin fails to initialize, it will automatically be disabled. So you can ignore those warnings.
|
||||
|
||||
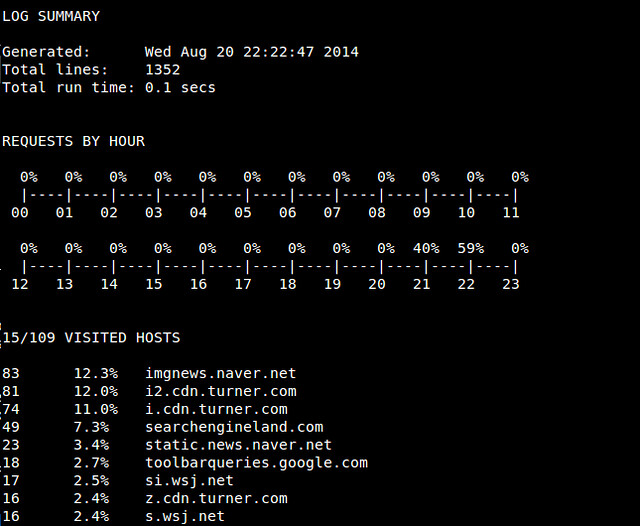
After parse_log.pl is completed, you will see a number of analysis results (*.txt/xml) in httpry/scripts directory. For example, log_summary.txt looks like the following.
|
||||
|
||||
|
||||
|
||||
To conclude, httpry can be a life saver if you are in a situation where you need to interpret live HTTP packets. That might not be so common for average Linux users, but it never hurts to be prepared. What do you think of this tool?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/sniff-http-traffic-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/2012/12/how-to-set-up-proxy-auto-config-on-ubuntu-desktop.html
|
||||
[2]:http://xmodulo.com/2012/11/what-are-popular-packet-sniffers-on-linux.html
|
||||
[3]:http://xmodulo.com/2014/06/monitor-nginx-web-server-command-line-real-time.html
|
||||
[4]:http://dumpsterventures.com/jason/httpry/
|
||||
[5]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -0,0 +1,103 @@
|
||||
使用Linux命令行嗅探HTTP流量
|
||||
================================================================================
|
||||
假设由于某种原因,你需要嗅探HTTP站点的流量(如HTTP请求与响应)。举个例子,你可能在测试一个web服务器的实验性功能,或者 你在为某个web应用或RESTful服务排错,又或者你正在为PAC排错或寻找某个站点下载的恶意软件。不论什么原因,在这些情况下,进行HTTP流量嗅探对于系统管理、开发者、甚至最终用户来说都是很有帮助的。
|
||||
|
||||
数据包嗅工具tcpdump被广泛用于实时数据包的导出,但是你需要设置过滤规则来捕获HTTP流量,甚至它的原始输出通常不能方便的停 在HTTP协议层。实时web服务器日志解析器如[ngxtop][3]提供可读的实时web流量跟踪痕迹,但这仅适用于可完全访问live web服务器日志的情况。
|
||||
|
||||
要是有一个仅用于抓取HTTP流量的类tcpdump的数据包嗅探工具就非常好了。事实上,[httpry][4]就是:**HTTP包嗅探工具**。httpry捕获HTTP数据包,并且将HTTP协议层的数据内容以可读形式列举出来。通过这篇指文章,让我们了解如何使用httpry工具嗅探HTTP流 量。
|
||||
|
||||
###在Linux上安装httpry###
|
||||
|
||||
在基于Debian系统(Ubuntu 或 LinuxMint),基础仓库中没有httpry安装包(译者注:本人ubuntu14.04,仓库中已有包,可直接安装)。所以我们需要通过源码安装:
|
||||
|
||||
$ sudo apt-get install gcc make git libpcap0.8-dev
|
||||
$ git clone https://github.com/jbittel/httpry.git
|
||||
$ cd httpry
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
在Fedora,CentOS 或 RHEL系统,可以使用如下yum命令安装httpry。在CentOS/RHEL系统上,运行yum之前使能[EPEL repo][5]。
|
||||
|
||||
$ sudo yum install httpry
|
||||
|
||||
如果逆向通过源码来构httpry的话,你可以通过这几个步骤实现:
|
||||
|
||||
$ sudo yum install gcc make git libpcap-devel
|
||||
$ git clone https://github.com/jbittel/httpry.git
|
||||
$ cd httpry
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
###httpry的基本用法###
|
||||
|
||||
以下是httpry的基本用法
|
||||
|
||||
$ sudo httpry -i <network-interface>
|
||||
|
||||
httpry就会监听指定的网络接口,并且实时的显示捕获到的HTTP 请求/响。
|
||||
|
||||

|
||||
|
||||
在大多数情况下,由于发送与接到的数据包过多导致刷屏很快,难以分析。这时候你肯定想将捕获到的数据包保存下来以离线分析。可以使用'b'或'-o'选项保存数据包。'-b'选项将数据包以二进制文件的形式保存下来,这样可以使用httpry软件打开文件以浏览。另 一方面,'-o'选项将数据以可读的字符文件形式保存下来。
|
||||
|
||||
以二进制形式保存文件:
|
||||
|
||||
$ sudo httpry -i eth0 -b output.dump
|
||||
|
||||
浏览所保存的HTTP数据包文件:
|
||||
|
||||
$ httpry -r output.dump
|
||||
|
||||
注意,不需要根用户权限就可以使用'-r'选项读取数据文件。
|
||||
|
||||
将httpry数据以字符文件保存:
|
||||
|
||||
$ sudo httpry -i eth0 -o output.txt
|
||||
|
||||
###httpry 的高级应用###
|
||||
|
||||
如果你想监视指定的HTTP方法(如:GET,POST,PUT,HEAD,CONNECT等),使用'-m'选项:
|
||||
|
||||
$ sudo httpry -i eth0 -m get,head
|
||||
|
||||

|
||||
|
||||
如果你下载了httpry的源码,你会发现源码下有一系Perl脚本,这些脚本用于分析httpry输出。脚本位于目录httpry/scripts/plugins。如果你想写一个定制的httpry输出分析器,则这些脚可以作为很好的例子。其中一些有如下的功能:
|
||||
|
||||
- **hostnames**: 显示唯一主机名列表.
|
||||
- **find_proxies**: 探测web代理.
|
||||
- **search_terms**: 查找及计算输入检索服务的检索词。
|
||||
- **content_analysis**: 查找含有指定关键的URL。
|
||||
- **xml_output**: 将输出转换为XML形式。
|
||||
- **log_summary**: 生成日志摘要。
|
||||
- **db_dump**: 将日志文件数据保存数据库。
|
||||
|
||||
在使用这些脚本之前,首先使用'-o'选项运行httpry。当获取到输出文件后,立即使用如下命令执行脚本:
|
||||
|
||||
$ cd httpry/scripts
|
||||
$ perl parse_log.pl -d ./plugins <httpry-output-file>
|
||||
|
||||
你可能在使用插件的时候遇到警告。比如,如果你没有安装带有DBI接口的MySQL数据库那么使用db_dump插件时可能会失败。如果一个 插件初始化失败的话,那么这个插件不能使用。所以你可以忽略那些警告。
|
||||
|
||||
当parse_log.pl完成后,你将在httpry/scripts 目录下看到数个分析结果。例如,log_summary.txt 与如下内容类似。
|
||||
|
||||

|
||||
|
||||
总结,当你要分析HTTP数据包的时候,httpry非常有用。它可能并不被大多Linux使用着所熟知,但会用总是有好处的。你对这个工具有什么看法呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/sniff-http-traffic-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[DoubleC](https://github.com/DoubleC)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/2012/12/how-to-set-up-proxy-auto-config-on-ubuntu-desktop.html
|
||||
[2]:http://xmodulo.com/2012/11/what-are-popular-packet-sniffers-on-linux.html
|
||||
[3]:http://xmodulo.com/2014/06/monitor-nginx-web-server-command-line-real-time.html
|
||||
[4]:http://dumpsterventures.com/jason/httpry/
|
||||
[5]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
Loading…
Reference in New Issue
Block a user