mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
7a368797c9
@ -1,28 +1,28 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10608-1.html)
|
||||
[#]: subject: (Akira: The Linux Design Tool We’ve Always Wanted?)
|
||||
[#]: via: (https://itsfoss.com/akira-design-tool)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Akira:我们一直想要的 Linux 设计工具?
|
||||
Akira 是我们一直想要的 Linux 设计工具吗?
|
||||
======
|
||||
|
||||
先说一下,我不是一个专业的设计师 - 但我在 Windows 上使用了某些工具(如 Photoshop、Illustrator 等)和 [Figma] [1](这是一个基于浏览器的界面设计工具)。我相信 Mac 和 Windows 上还有更多的设计工具。
|
||||
先说一下,我不是一个专业的设计师,但我在 Windows 上使用过某些工具(如 Photoshop、Illustrator 等)和 [Figma] [1](这是一个基于浏览器的界面设计工具)。我相信 Mac 和 Windows 上还有更多的设计工具。
|
||||
|
||||
即使在 Linux 上,也只有有限的专用[图形设计工具][2]。其中一些工具如 [GIMP][3] 和 [Inkscape][4] 也被专业人士使用。但不幸的是,它们中的大多数都不被视为专业级。
|
||||
即使在 Linux 上,也有数量有限的专用[图形设计工具][2]。其中一些工具如 [GIMP][3] 和 [Inkscape][4] 也被专业人士使用。但不幸的是,它们中的大多数都不被视为专业级。
|
||||
|
||||
即使有更多解决方案 - 我也从未遇到过可以取代 [Sketch][5]、Figma 或 Adobe XD 的原生 Linux 应用。任何专业设计师都同意这点,不是吗?
|
||||
即使有更多解决方案,我也从未遇到过可以取代 [Sketch][5]、Figma 或 Adobe XD 的原生 Linux 应用。任何专业设计师都同意这点,不是吗?
|
||||
|
||||
### Akira 是否会在 Linux 上取代 Sketch、Figma 和 Adobe XD?
|
||||
|
||||
所以,为了开发一些能够取代那些专有工具的应用 - [Alessandro Castellani][6] 发起了一个 [Kickstarter 活动][7],并与几位经验丰富的开发人员 [Alberto Fanjul][8]、[Bilal Elmoussaoui][9] 和 [Felipe Escoto][10] 组队合作。
|
||||
所以,为了开发一些能够取代那些专有工具的应用,[Alessandro Castellani][6] 发起了一个 [Kickstarter 活动][7],并与几位经验丰富的开发人员 [Alberto Fanjul][8]、[Bilal Elmoussaoui][9] 和 [Felipe Escoto][10] 组队合作。
|
||||
|
||||
是的,Akira 仍然只是一个想法,只有一个界面原型(正如我最近在 Kickstarter 的[直播流][11]中看到的那样)。
|
||||
|
||||
### 如果它还没有,为什么会发起 Kickstarter 活动?
|
||||
### 如果它还不存在,为什么会发起 Kickstarter 活动?
|
||||
|
||||
![][12]
|
||||
|
||||
@ -30,37 +30,38 @@ Kickstarter 活动的目的是收集资金,以便雇用开发人员,并花
|
||||
|
||||
尽管如此,如果你想支持这个项目,你应该知道一些细节,对吧?
|
||||
|
||||
不用担心,我们在他们的直播中问了几个问题 - 让我们看下
|
||||
不用担心,我们在他们的直播中问了几个问题 - 让我们看下:
|
||||
|
||||
### Akira:更多细节
|
||||
|
||||
![Akira prototype interface][13]
|
||||
图片来源:Kickstarter
|
||||
|
||||
*图片来源:Kickstarter*
|
||||
|
||||
如 Kickstarter 活动描述的那样:
|
||||
|
||||
> Akira 的主要目的是提供一个快速而直观的工具来**创建 Web 和移动界面**,更像是 **Sketch**、**Figma** 或 **Adobe XD**,并且是 Linux 原生体验。
|
||||
> Akira 的主要目的是提供一个快速而直观的工具来**创建 Web 和移动端界面**,更像是 **Sketch**、**Figma** 或 **Adobe XD**,并且是 Linux 原生体验。
|
||||
|
||||
他们还详细描述了该工具与 Inkscape、Glade 或 QML Editor 的不同之处。当然,如果你想要所有的技术细节,请查看 [Kickstarter][7]。但是,在此之前,让我们看一看当我询问有关 Akira 的一些问题时他们说了些什么。
|
||||
他们还详细描述了该工具与 Inkscape、Glade 或 QML Editor 的不同之处。当然,如果你想要了解所有的技术细节,请查看 [Kickstarter][7]。但是,在此之前,让我们看一看当我询问有关 Akira 的一些问题时他们说了些什么。
|
||||
|
||||
问:如果你认为你的项目类似于 Figma - 人们为什么要考虑安装 Akira 而不是使用基于网络的工具?它是否只是这些工具的克隆 - 提供原生 Linux 体验,还是有一些非常有趣的东西可以鼓励用户切换(除了是开源解决方案之外)?
|
||||
**问:**如果你认为你的项目类似于 Figma,人们为什么要考虑安装 Akira 而不是使用基于网络的工具?它是否只是这些工具的克隆 —— 提供原生 Linux 体验,还是有一些非常有趣的东西可以鼓励用户切换(除了是开源解决方案之外)?
|
||||
|
||||
** Akira:** 与基于网络的 electron 应用相比,Linux 原生体验总是更好、更快。此外,如果你选择使用 Figma,硬件配置也很重要 - 但 Akira 将会占用很少的系统资源,并且你可以在不需要上网的情况下完成类似工作。
|
||||
**Akira:** 与基于网络的 electron 应用相比,Linux 原生体验总是更好、更快。此外,如果你选择使用 Figma,硬件配置也很重要,但 Akira 将会占用很少的系统资源,并且你可以在不需要上网的情况下完成类似工作。
|
||||
|
||||
问:假设它成为了 Linux用户一直在等待的开源方案(拥有专有工具的类似功能)。你有什么维护计划?你是否计划引入定价 - 或依赖捐赠?
|
||||
**问:**假设它成为了 Linux 用户一直在等待的开源方案(拥有专有工具的类似功能)。你有什么维护计划?你是否计划引入定价方案,或依赖捐赠?
|
||||
|
||||
**Akira:**该项目主要依靠捐赠(类似于 [Krita 基金会][14] 这样的想法)。但是,不会有“专业版”计划 - 它将免费提供,它将是一个开源项目。
|
||||
**Akira:**该项目主要依靠捐赠(类似于 [Krita 基金会][14] 这样的想法)。但是,不会有“专业版”计划,它将免费提供,它将是一个开源项目。
|
||||
|
||||
根据我得到的回答,它看起来似乎很有希望,我们应该支持。
|
||||
|
||||
- [查看该 Kickstarter 活动](https://www.kickstarter.com/projects/alecaddd/akira-the-linux-design-tool/description)
|
||||
|
||||
### 总结
|
||||
|
||||
你怎么认为 Akira?它只是一个概念吗?或者你希望看到进展?
|
||||
你怎么看 Akira?它只是一个概念吗?或者你希望看到进展?
|
||||
|
||||
请在下面的评论中告诉我们你的想法。
|
||||
|
||||
![][15]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/akira-design-tool
|
||||
@ -68,7 +69,7 @@ via: https://itsfoss.com/akira-design-tool
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,35 +1,38 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (alim0x)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10607-1.html)
|
||||
[#]: subject: (Booting Linux faster)
|
||||
[#]: via: (https://opensource.com/article/19/1/booting-linux-faster)
|
||||
[#]: author: (Stewart Smith https://opensource.com/users/stewart-ibm)
|
||||
|
||||
更快启动 Linux
|
||||
让 Linux 启动更快
|
||||
======
|
||||
进行 Linux 内核与固件开发的时候,往往需要多次的重启,会浪费大把的时间。
|
||||
|
||||
> 进行 Linux 内核与固件开发的时候,往往需要多次的重启,会浪费大把的时间。
|
||||
|
||||

|
||||
|
||||
在所有我拥有或使用过的电脑中,启动最快的那台是 20 世纪 80 年代的电脑。在你把手从电源键移到键盘上的时候,BASIC 解释器已经在等待你输入命令了。对于现代的电脑,启动时间从笔记本电脑的 15 秒到小型家庭服务器的数分钟不等。为什么它们的启动时间有差别?
|
||||
|
||||
那台直接启动到 BASIC 命令行提示符的 20 世纪 80 年代微电脑,有着一颗非常简单的 CPU,它在通电的时候就立即开始从一个存储地址中获取和执行指令。因为这些系统在 ROM 里面有 BASIC,基本不需要载入的时间——你很快就进到 BASIC 命令提示符中了。同时代更加复杂的系统,比如 IBM PC 或 Macintosh,需要一段可观的时间来启动(大约 30 秒),尽管这主要是因为需要从软盘上读取操作系统的缘故。在可以加载操作系统之前,只有很小一部分时间是花在固件上的。
|
||||
那台直接启动到 BASIC 命令行提示符的 20 世纪 80 年代微电脑,有着一颗非常简单的 CPU,它在通电的时候就立即开始从一个内存地址中获取和执行指令。因为这些系统的 BASIC 在 ROM 里面,基本不需要载入的时间——你很快就进到 BASIC 命令提示符中了。同时代更加复杂的系统,比如 IBM PC 或 Macintosh,需要一段可观的时间来启动(大约 30 秒),尽管这主要是因为需要从软盘上读取操作系统的缘故。在可以加载操作系统之前,只有很小一部分时间是花费在固件上的。
|
||||
|
||||
现代服务器往往在从磁盘上读取操作系统之前,在固件上花费了数分钟而不是数秒。这主要是因为现代系统日益增加的复杂性。CPU 不再能够只是起来就开始全速执行指令,我们已经习惯于 CPU 频率变化,节省能源的待机状态以及 CPU 多核。实际上,在现代 CPU 内部有惊人数量的更简单的处理器,它们协助主 CPU 核心启动并提供运行时服务,比如在过热的时候压制频率。在绝大多数 CPU 架构中,在你的 CPU 内的这些核心上运行的代码都以不透明的二进制 blob 形式提供。
|
||||
现代服务器往往在从磁盘上读取操作系统之前,在固件上花费了数分钟而不是数秒。这主要是因为现代系统日益增加的复杂性。CPU 不再能够只是运行起来就开始全速执行指令,我们已经习惯于 CPU 频率变化、节省能源的待机状态以及 CPU 多核。实际上,在现代 CPU 内部有数量惊人的更简单的处理器,它们协助主 CPU 核心启动并提供运行时服务,比如在过热的时候压制频率。在绝大多数 CPU 架构中,在你的 CPU 内的这些核心上运行的代码都以不透明的二进制 blob 形式提供。
|
||||
|
||||
在 OpenPOWER 系统上,所有运行在 CPU 内部每个核心的指令都是开源的。在有 [OpenBMC][1](比如 IBM 的 AC922 系统和 Raptor 的 TALOS II 以及 Blackbird 系统)的机器上,这还延伸到了运行在基板管理控制器上的代码。这就意味着我们可以一探究竟,到底为什么从接入电源线到显示出熟悉的登陆界面花了这么长时间。
|
||||
在 OpenPOWER 系统上,所有运行在 CPU 内部每个核心的指令都是开源的。在有 [OpenBMC][1](比如 IBM 的 AC922 系统和 Raptor 的 TALOS II 以及 Blackbird 系统)的机器上,这还延伸到了运行在<ruby>基板管理控制器<rt>Baseboard Management Controller</rt></ruby>上的代码。这就意味着我们可以一探究竟,到底为什么从接入电源线到显示出熟悉的登录界面花了这么长时间。
|
||||
|
||||
如果你是内核相关团队的一员,你可能启动过许多内核。如果你是固件相关团队的一员,你可能要启动许多不同的固件映像,接着是一个操作系统,来确保你的固件仍能工作。如果我们可以减少硬件的启动时间,这些团队可以更有生产力,并且终端用户在搭建系统或重启安装固件或系统更新的时候会对此表示感激。
|
||||
|
||||
过去的几年,Linux 发行版的启动时间已经做了很多改善。现代 init 系统在处理并行和按需任务上做得很好。在一个现代系统上,一旦内核开始执行,它可以在短短数秒内进入登陆提示符界面。这里短短的数秒不是优化启动时间的下手之处,我们得到更早的地方:在我们到达操作系统之前。
|
||||
过去的几年,Linux 发行版的启动时间已经做了很多改善。现代的初始化系统在处理并行和按需任务上做得很好。在一个现代系统上,一旦内核开始执行,它可以在短短数秒内进入登录提示符界面。这里短短的数秒不是优化启动时间的下手之处,我们要到更早的地方:在我们到达操作系统之前。
|
||||
|
||||
在 OpenPOWER 系统上,固件通过启动一个存储在固件闪存芯片上的 Linux 内核来加载操作系统,它运行一个叫做 [Petitboot][2] 的用户态程序去寻找用户想要启动的系统所在磁盘,并通过 [kexec][3] 启动它。有了这些优化,启动 Petitboot 环境只占了启动时间的个位数百分比,所以我们还得从其他地方寻找优化项。
|
||||
在 OpenPOWER 系统上,固件通过启动一个存储在固件闪存芯片上的 Linux 内核来加载操作系统,它运行一个叫做 [Petitboot][2] 的用户态程序去寻找用户想要启动的系统所在磁盘,并通过 [kexec][3] 启动它。有了这些优化,启动 Petitboot 环境只占了启动时间的百分之几,所以我们还得从其他地方寻找优化项。
|
||||
|
||||
在 Petitboot 环境启动前,有一个先导固件,叫做 [Skiboot][4],在它之前有个 [Hostboot][5]。在 Hostboot 之前是 [Self-Boot Engine][6],一个 die 上的单独核心,它启动单个 CPU 核心并执行来自 Level 3 缓存的指令。这些组件是我们可以在减少启动时间上取得进展的主要部分,因为它们花费了启动的绝大部分时间。或许这些组件中的一部分没有进行足够的优化或尽可能做到并行?
|
||||
在 Petitboot 环境启动前,有一个先导固件,叫做 [Skiboot][4],在它之前有个 [Hostboot][5]。在 Hostboot 之前是 [Self-Boot Engine][6],一个晶圆切片(die)上的单独核心,它启动单个 CPU 核心并执行来自 Level 3 缓存的指令。这些组件是我们可以在减少启动时间上取得进展的主要部分,因为它们花费了启动的绝大部分时间。或许这些组件中的一部分没有进行足够的优化或尽可能做到并行?
|
||||
|
||||
另一个研究路径是重启时间而不是启动时间。在重启的时候,我们真的需要对所有硬件重新初始化吗?
|
||||
|
||||
正如任何现代系统那样,改善启动(或重启)时间的方案已经变成了更多并行、解决遗留问题、(可以认为)作弊的结合体。
|
||||
正如任何现代系统那样,改善启动(或重启)时间的方案已经变成了更多的并行执行、解决遗留问题、(可以认为)作弊的结合体。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -38,7 +41,7 @@ via: https://opensource.com/article/19/1/booting-linux-faster
|
||||
作者:[Stewart Smith][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,65 +0,0 @@
|
||||
Translating by wwhio
|
||||
|
||||
Pi Day: 12 fun facts and ways to celebrate
|
||||
======
|
||||
|
||||

|
||||
Today, tech teams around the world will celebrate a number. March 14 (written 3/14 in the United States) is known as Pi Day, a holiday that people ring in with pie eating contests, pizza parties, and math puns. If the most important number in mathematics wasn’t enough of a reason to reach for a slice of pie, March 14 also happens to be Albert Einstein’s birthday, the release anniversary of Linux kernel 1.0.0, and the day Eli Whitney patented the cotton gin.
|
||||
|
||||
In honor of this special day, we’ve rounded up a dozen fun facts and interesting pi-related projects. Master you team’s Pi Day trivia, or borrow an idea or two for a team-building exercise. Do a project with a budding technologist. And let us know in the comments if you are doing anything unique to celebrate everyone’s favorite never-ending number.
|
||||
|
||||
### Pi Day celebrations:
|
||||
|
||||
* Today is the 30th anniversary of Pi Day. The first was held in 1988 in San Francisco at the Exploratorium by physicist Larry Shaw. “On [the first Pi Day][1], staff brought in fruit pies and a tea urn for the celebration. At 1:59 – the pi numbers that follow 3.14 – Shaw led a circular parade around the museum with his boombox blaring the digits of pi to the music of ‘Pomp and Circumstance.’” It wasn’t until 21 years later, March 2009, that Pi Day became an official national holiday in the U.S.
|
||||
* Although it started in San Francisco, one of the biggest Pi Day celebrations can be found in Princeton. The town holds a [number of events][2] over the course of five days, including an Einstein look-alike contest, a pie-throwing event, and a pi recitation competition. Some of the activities even offer a cash prize of $314.15 for the winner.
|
||||
* MIT Sloan School of Management (on Twitter as [@MITSloan][3]) is celebrating Pi Day with fun facts about pi – and pie. Follow along with the Twitter hashtag #PiVersusPie
|
||||
|
||||
|
||||
|
||||
### Pi-related projects and activities:
|
||||
|
||||
* If you want to keep your math skills sharpened, NASA Jet Propulsion Lab has posted a [new set of math problems][4] that illustrate how pi can be used to unlock the mysteries of space. This marks the fifth year of NASA’s Pi Day Challenge, geared toward students.
|
||||
* There's no better way to get into the spirit of Pi Day than to take on a [Raspberry Pi][5] project. Whether you are looking for a project to do with your kids or with your team, there’s no shortage of ideas out there. Since its launch in 2012, millions of the basic computer boards have been sold. In fact, it’s the [third best-selling general purpose computer][6] of all time. Here are a few Raspberry Pi projects and activities that caught our eye:
|
||||
* Grab an AIY (AI-Yourself) kit from Google. You can create a [voice-controlled digital assistant][7] or an [image-recognition device][8].
|
||||
* [Run Kubernetes][9] on a Raspberry Pi.
|
||||
* Save Princess Peach by building a [retro gaming system][10].
|
||||
* Host a [Raspberry Jam][11] with your team. The Raspberry Pi Foundation has released a [Guidebook][12] to make hosting easy. According to the website, Raspberry Jams provide, “a support network for people of all ages in digital making. All around the world, like-minded people meet up to discuss and share their latest projects, give workshops, and chat about all things Pi.”
|
||||
|
||||
|
||||
|
||||
### Other fun Pi facts:
|
||||
|
||||
* The current [world record holder][13] for reciting pi is Suresh Kumar Sharma, who in October 2015 recited 70,030 digits. It took him 17 hours and 14 minutes to do so. However, the [unofficial record][14] goes to Akira Haraguchi, who claims he can recite up to 111,700 digits.
|
||||
* And, there’s more to remember than ever before. In November 2016, R&D scientist Peter Trueb calculated 22,459,157,718,361 digits of pi – [9 trillion more digits][15] than the previous world record set in 2013. According to New Scientist, “The final file containing the 22 trillion digits of pi is nearly 9 terabytes in size. If printed out, it would fill a library of several million books containing a thousand pages each."
|
||||
|
||||
|
||||
|
||||
Happy Pi Day!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate
|
||||
|
||||
作者:[Carla Rudder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/crudder
|
||||
[1]:https://www.exploratorium.edu/pi/pi-day-history
|
||||
[2]:https://princetontourcompany.com/activities/pi-day/
|
||||
[3]:https://twitter.com/MITSloan
|
||||
[4]:https://www.jpl.nasa.gov/news/news.php?feature=7074
|
||||
[5]:https://opensource.com/resources/raspberry-pi
|
||||
[6]:https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64
|
||||
[7]:http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/
|
||||
[8]:http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/
|
||||
[9]:https://opensource.com/article/17/3/kubernetes-raspberry-pi
|
||||
[10]:https://opensource.com/article/18/1/retro-gaming
|
||||
[11]:https://opensource.com/article/17/5/how-run-raspberry-pi-meetup
|
||||
[12]:https://www.raspberrypi.org/blog/support-raspberry-jam-community/
|
||||
[13]:http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi
|
||||
[14]:https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi
|
||||
[15]:https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071
|
||||
@ -1,277 +0,0 @@
|
||||
Translating by cycoe
|
||||
Cycoe 翻译中
|
||||
What's a hero without a villain? How to add one to your Python game
|
||||
======
|
||||

|
||||
|
||||
In the previous articles in this series (see [part 1][1], [part 2][2], [part 3][3], and [part 4][4]), you learned how to use Pygame and Python to spawn a playable character in an as-yet empty video game world. But, what's a hero without a villain?
|
||||
|
||||
It would make for a pretty boring game if you had no enemies, so in this article, you'll add an enemy to your game and construct a framework for building levels.
|
||||
|
||||
It might seem strange to jump ahead to enemies when there's still more to be done to make the player sprite fully functional, but you've learned a lot already, and creating villains is very similar to creating a player sprite. So relax, use the knowledge you already have, and see what it takes to stir up some trouble.
|
||||
|
||||
For this exercise, you can download some pre-built assets from [Open Game Art][5]. Here are some of the assets I use:
|
||||
|
||||
|
||||
+ Inca tileset
|
||||
+ Some invaders
|
||||
+ Sprites, characters, objects, and effects
|
||||
|
||||
|
||||
### Creating the enemy sprite
|
||||
|
||||
Yes, whether you realize it or not, you basically already know how to implement enemies. The process is very similar to creating a player sprite:
|
||||
|
||||
1. Make a class so enemies can spawn.
|
||||
2. Create an `update` function so enemies can detect collisions.
|
||||
3. Create a `move` function so your enemy can roam around.
|
||||
|
||||
|
||||
|
||||
Start with the class. Conceptually, it's mostly the same as your Player class. You set an image or series of images, and you set the sprite's starting position.
|
||||
|
||||
Before continuing, make sure you have a graphic for your enemy, even if it's just a temporary one. Place the graphic in your game project's `images` directory (the same directory where you placed your player image).
|
||||
|
||||
A game looks a lot better if everything alive is animated. Animating an enemy sprite is done the same way as animating a player sprite. For now, though, keep it simple, and use a non-animated sprite.
|
||||
|
||||
At the top of the `objects` section of your code, create a class called Enemy with this code:
|
||||
```
|
||||
class Enemy(pygame.sprite.Sprite):
|
||||
|
||||
'''
|
||||
|
||||
Spawn an enemy
|
||||
|
||||
'''
|
||||
|
||||
def __init__(self,x,y,img):
|
||||
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
|
||||
self.image = pygame.image.load(os.path.join('images',img))
|
||||
|
||||
self.image.convert_alpha()
|
||||
|
||||
self.image.set_colorkey(ALPHA)
|
||||
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
self.rect.x = x
|
||||
|
||||
self.rect.y = y
|
||||
|
||||
```
|
||||
|
||||
If you want to animate your enemy, do it the [same way][4] you animated your player.
|
||||
|
||||
### Spawning an enemy
|
||||
|
||||
You can make the class useful for spawning more than just one enemy by allowing yourself to tell the class which image to use for the sprite and where in the world the sprite should appear. This means you can use this same enemy class to generate any number of enemy sprites anywhere in the game world. All you have to do is make a call to the class, and tell it which image to use and the X and Y coordinates of your desired spawn point.
|
||||
|
||||
Again, this is similar in principle to spawning a player sprite. In the `setup` section of your script, add this code:
|
||||
```
|
||||
enemy = Enemy(20,200,'yeti.png')# spawn enemy
|
||||
|
||||
enemy_list = pygame.sprite.Group() # create enemy group
|
||||
|
||||
enemy_list.add(enemy) # add enemy to group
|
||||
|
||||
```
|
||||
|
||||
In that sample code, `20` is the X position and `200` is the Y position. You might need to adjust these numbers, depending on how big your enemy sprite is, but try to get it to spawn in a place so that you can reach it with your player sprite. `Yeti.png` is the image used for the enemy.
|
||||
|
||||
Next, draw all enemies in the enemy group to the screen. Right now, you have only one enemy, but you can add more later if you want. As long as you add an enemy to the enemies group, it will be drawn to the screen during the main loop. The middle line is the new line you need to add:
|
||||
```
|
||||
player_list.draw(world)
|
||||
|
||||
enemy_list.draw(world) # refresh enemies
|
||||
|
||||
pygame.display.flip()
|
||||
|
||||
```
|
||||
|
||||
Launch your game. Your enemy appears in the game world at whatever X and Y coordinate you chose.
|
||||
|
||||
### Level one
|
||||
|
||||
Your game is in its infancy, but you will probably want to add another level. It's important to plan ahead when you program so your game can grow as you learn more about programming. Even though you don't even have one complete level yet, you should code as if you plan on having many levels.
|
||||
|
||||
Think about what a "level" is. How do you know you are at a certain level in a game?
|
||||
|
||||
You can think of a level as a collection of items. In a platformer, such as the one you are building here, a level consists of a specific arrangement of platforms, placement of enemies and loot, and so on. You can build a class that builds a level around your player. Eventually, when you create more than one level, you can use this class to generate the next level when your player reaches a specific goal.
|
||||
|
||||
Move the code you wrote to create an enemy and its group into a new function that will be called along with each new level. It requires some modification so that each time you create a new level, you can create several enemies:
|
||||
```
|
||||
class Level():
|
||||
|
||||
def bad(lvl,eloc):
|
||||
|
||||
if lvl == 1:
|
||||
|
||||
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
|
||||
|
||||
enemy_list = pygame.sprite.Group() # create enemy group
|
||||
|
||||
enemy_list.add(enemy) # add enemy to group
|
||||
|
||||
if lvl == 2:
|
||||
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
|
||||
|
||||
return enemy_list
|
||||
|
||||
```
|
||||
|
||||
The `return` statement ensures that when you use the `Level.bad` function, you're left with an `enemy_list` containing each enemy you defined.
|
||||
|
||||
Since you are creating enemies as part of each level now, your `setup` section needs to change, too. Instead of creating an enemy, you must define where the enemy will spawn and what level it belongs to.
|
||||
```
|
||||
eloc = []
|
||||
|
||||
eloc = [200,20]
|
||||
|
||||
enemy_list = Level.bad( 1, eloc )
|
||||
|
||||
```
|
||||
|
||||
Run the game again to confirm your level is generating correctly. You should see your player, as usual, and the enemy you added in this chapter.
|
||||
|
||||
### Hitting the enemy
|
||||
|
||||
An enemy isn't much of an enemy if it has no effect on the player. It's common for enemies to cause damage when a player collides with them.
|
||||
|
||||
Since you probably want to track the player's health, the collision check happens in the Player class rather than in the Enemy class. You can track the enemy's health, too, if you want. The logic and code are pretty much the same, but, for now, just track the player's health.
|
||||
|
||||
To track player health, you must first establish a variable for the player's health. The first line in this code sample is for context, so add the second line to your Player class:
|
||||
```
|
||||
self.frame = 0
|
||||
|
||||
self.health = 10
|
||||
|
||||
```
|
||||
|
||||
In the `update` function of your Player class, add this code block:
|
||||
```
|
||||
hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
|
||||
|
||||
for enemy in hit_list:
|
||||
|
||||
self.health -= 1
|
||||
|
||||
print(self.health)
|
||||
|
||||
```
|
||||
|
||||
This code establishes a collision detector using the Pygame function `sprite.spritecollide`, called `enemy_hit`. This collision detector sends out a signal any time the hitbox of its parent sprite (the player sprite, where this detector has been created) touches the hitbox of any sprite in `enemy_list`. The `for` loop is triggered when such a signal is received and deducts a point from the player's health.
|
||||
|
||||
Since this code appears in the `update` function of your player class and `update` is called in your main loop, Pygame checks for this collision once every clock tick.
|
||||
|
||||
### Moving the enemy
|
||||
|
||||
An enemy that stands still is useful if you want, for instance, spikes or traps that can harm your player, but the game is more of a challenge if the enemies move around a little.
|
||||
|
||||
Unlike a player sprite, the enemy sprite is not controlled by the user. Its movements must be automated.
|
||||
|
||||
Eventually, your game world will scroll, so how do you get an enemy to move back and forth within the game world when the game world itself is moving?
|
||||
|
||||
You tell your enemy sprite to take, for example, 10 paces to the right, then 10 paces to the left. An enemy sprite can't count, so you have to create a variable to keep track of how many paces your enemy has moved and program your enemy to move either right or left depending on the value of your counting variable.
|
||||
|
||||
First, create the counter variable in your Enemy class. Add the last line in this code sample:
|
||||
```
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
self.rect.x = x
|
||||
|
||||
self.rect.y = y
|
||||
|
||||
self.counter = 0 # counter variable
|
||||
|
||||
```
|
||||
|
||||
Next, create a `move` function in your Enemy class. Use an if-else loop to create what is called an infinite loop:
|
||||
|
||||
* Move right if the counter is on any number from 0 to 100.
|
||||
* Move left if the counter is on any number from 100 to 200.
|
||||
* Reset the counter back to 0 if the counter is greater than 200.
|
||||
|
||||
|
||||
|
||||
An infinite loop has no end; it loops forever because nothing in the loop is ever untrue. The counter, in this case, is always either between 0 and 100 or 100 and 200, so the enemy sprite walks right to left and right to left forever.
|
||||
|
||||
The actual numbers you use for how far the enemy will move in either direction depending on your screen size, and possibly, eventually, the size of the platform your enemy is walking on. Start small and work your way up as you get used to the results. Try this first:
|
||||
```
|
||||
def move(self):
|
||||
|
||||
'''
|
||||
|
||||
enemy movement
|
||||
|
||||
'''
|
||||
|
||||
distance = 80
|
||||
|
||||
speed = 8
|
||||
|
||||
|
||||
|
||||
if self.counter >= 0 and self.counter <= distance:
|
||||
|
||||
self.rect.x += speed
|
||||
|
||||
elif self.counter >= distance and self.counter <= distance*2:
|
||||
|
||||
self.rect.x -= speed
|
||||
|
||||
else:
|
||||
|
||||
self.counter = 0
|
||||
|
||||
|
||||
|
||||
self.counter += 1
|
||||
|
||||
```
|
||||
|
||||
You can adjust the distance and speed as needed.
|
||||
|
||||
Will this code work if you launch your game now?
|
||||
|
||||
Of course not, and you probably know why. You must call the `move` function in your main loop. The first line in this sample code is for context, so add the last two lines:
|
||||
```
|
||||
enemy_list.draw(world) #refresh enemy
|
||||
|
||||
for e in enemy_list:
|
||||
|
||||
e.move()
|
||||
|
||||
```
|
||||
|
||||
Launch your game and see what happens when you hit your enemy. You might have to adjust where the sprites spawn so that your player and your enemy sprite can collide. When they do collide, look in the console of [IDLE][6] or [Ninja-IDE][7] to see the health points being deducted.
|
||||
|
||||
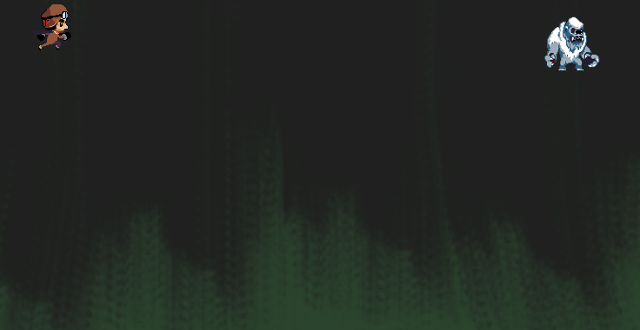
|
||||
|
||||
You may notice that health is deducted for every moment your player and enemy are touching. That's a problem, but it's a problem you'll solve later, after you've had more practice with Python.
|
||||
|
||||
For now, try adding some more enemies. Remember to add each enemy to the `enemy_list`. As an exercise, see if you can think of how you can change how far different enemy sprites move.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/pygame-enemy
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:https://opensource.com/article/17/10/python-101
|
||||
[2]:https://opensource.com/article/17/12/game-framework-python
|
||||
[3]:https://opensource.com/article/17/12/game-python-add-a-player
|
||||
[4]:https://opensource.com/article/17/12/game-python-moving-player
|
||||
[5]:https://opengameart.org
|
||||
[6]:https://docs.python.org/3/library/idle.html
|
||||
[7]:http://ninja-ide.org/
|
||||
@ -1,286 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (HTTP: Brief History of HTTP)
|
||||
[#]: via: (https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol)
|
||||
[#]: author: (Ilya Grigorik https://www.igvita.com/)
|
||||
|
||||
HTTP: Brief History of HTTP
|
||||
======
|
||||
|
||||
### Introduction
|
||||
|
||||
The Hypertext Transfer Protocol (HTTP) is one of the most ubiquitous and widely adopted application protocols on the Internet: it is the common language between clients and servers, enabling the modern web. From its simple beginnings as a single keyword and document path, it has become the protocol of choice not just for browsers, but for virtually every Internet-connected software and hardware application.
|
||||
|
||||
In this chapter, we will take a brief historical tour of the evolution of the HTTP protocol. A full discussion of the varying HTTP semantics is outside the scope of this book, but an understanding of the key design changes of HTTP, and the motivations behind each, will give us the necessary background for our discussions on HTTP performance, especially in the context of the many upcoming improvements in HTTP/2.
|
||||
|
||||
### §HTTP 0.9: The One-Line Protocol
|
||||
|
||||
The original HTTP proposal by Tim Berners-Lee was designed with simplicity in mind as to help with the adoption of his other nascent idea: the World Wide Web. The strategy appears to have worked: aspiring protocol designers, take note.
|
||||
|
||||
In 1991, Berners-Lee outlined the motivation for the new protocol and listed several high-level design goals: file transfer functionality, ability to request an index search of a hypertext archive, format negotiation, and an ability to refer the client to another server. To prove the theory in action, a simple prototype was built, which implemented a small subset of the proposed functionality:
|
||||
|
||||
* Client request is a single ASCII character string.
|
||||
|
||||
* Client request is terminated by a carriage return (CRLF).
|
||||
|
||||
* Server response is an ASCII character stream.
|
||||
|
||||
|
||||
|
||||
* Server response is a hypertext markup language (HTML).
|
||||
|
||||
* Connection is terminated after the document transfer is complete.
|
||||
|
||||
|
||||
|
||||
|
||||
However, even that sounds a lot more complicated than it really is. What these rules enable is an extremely simple, Telnet-friendly protocol, which some web servers support to this very day:
|
||||
|
||||
```
|
||||
$> telnet google.com 80
|
||||
|
||||
Connected to 74.125.xxx.xxx
|
||||
|
||||
GET /about/
|
||||
|
||||
(hypertext response)
|
||||
(connection closed)
|
||||
```
|
||||
|
||||
The request consists of a single line: `GET` method and the path of the requested document. The response is a single hypertext document—no headers or any other metadata, just the HTML. It really couldn’t get any simpler. Further, since the previous interaction is a subset of the intended protocol, it unofficially acquired the HTTP 0.9 label. The rest, as they say, is history.
|
||||
|
||||
From these humble beginnings in 1991, HTTP took on a life of its own and evolved rapidly over the coming years. Let us quickly recap the features of HTTP 0.9:
|
||||
|
||||
* Client-server, request-response protocol.
|
||||
|
||||
* ASCII protocol, running over a TCP/IP link.
|
||||
|
||||
* Designed to transfer hypertext documents (HTML).
|
||||
|
||||
* The connection between server and client is closed after every request.
|
||||
|
||||
|
||||
```
|
||||
Popular web servers, such as Apache and Nginx, still support the HTTP 0.9 protocol—in part, because there is not much to it! If you are curious, open up a Telnet session and try accessing google.com, or your own favorite site, via HTTP 0.9 and inspect the behavior and the limitations of this early protocol.
|
||||
```
|
||||
|
||||
### §HTTP/1.0: Rapid Growth and Informational RFC
|
||||
|
||||
The period from 1991 to 1995 is one of rapid coevolution of the HTML specification, a new breed of software known as a "web browser," and the emergence and quick growth of the consumer-oriented public Internet infrastructure.
|
||||
|
||||
```
|
||||
##### §The Perfect Storm: Internet Boom of the Early 1990s
|
||||
|
||||
Building on Tim Berner-Lee’s initial browser prototype, a team at the National Center of Supercomputing Applications (NCSA) decided to implement their own version. With that, the first popular browser was born: NCSA Mosaic. One of the programmers on the NCSA team, Marc Andreessen, partnered with Jim Clark to found Mosaic Communications in October 1994. The company was later renamed Netscape, and it shipped Netscape Navigator 1.0 in December 1994. By this point, it was already clear that the World Wide Web was bound to be much more than just an academic curiosity.
|
||||
|
||||
In fact, that same year the first World Wide Web conference was organized in Geneva, Switzerland, which led to the creation of the World Wide Web Consortium (W3C) to help guide the evolution of HTML. Similarly, a parallel HTTP Working Group (HTTP-WG) was established within the IETF to focus on improving the HTTP protocol. Both of these groups continue to be instrumental to the evolution of the Web.
|
||||
|
||||
Finally, to create the perfect storm, CompuServe, AOL, and Prodigy began providing dial-up Internet access to the public within the same 1994–1995 time frame. Riding on this wave of rapid adoption, Netscape made history with a wildly successful IPO on August 9, 1995—the Internet boom had arrived, and everyone wanted a piece of it!
|
||||
```
|
||||
|
||||
The growing list of desired capabilities of the nascent Web and their use cases on the public Web quickly exposed many of the fundamental limitations of HTTP 0.9: we needed a protocol that could serve more than just hypertext documents, provide richer metadata about the request and the response, enable content negotiation, and more. In turn, the nascent community of web developers responded by producing a large number of experimental HTTP server and client implementations through an ad hoc process: implement, deploy, and see if other people adopt it.
|
||||
|
||||
From this period of rapid experimentation, a set of best practices and common patterns began to emerge, and in May 1996 the HTTP Working Group (HTTP-WG) published RFC 1945, which documented the "common usage" of the many HTTP/1.0 implementations found in the wild. Note that this was only an informational RFC: HTTP/1.0 as we know it is not a formal specification or an Internet standard!
|
||||
|
||||
Having said that, an example HTTP/1.0 request should look very familiar:
|
||||
|
||||
```
|
||||
$> telnet website.org 80
|
||||
|
||||
Connected to xxx.xxx.xxx.xxx
|
||||
|
||||
GET /rfc/rfc1945.txt HTTP/1.0
|
||||
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
|
||||
Accept: */*
|
||||
|
||||
HTTP/1.0 200 OK
|
||||
Content-Type: text/plain
|
||||
Content-Length: 137582
|
||||
Expires: Thu, 01 Dec 1997 16:00:00 GMT
|
||||
Last-Modified: Wed, 1 May 1996 12:45:26 GMT
|
||||
Server: Apache 0.84
|
||||
|
||||
(plain-text response)
|
||||
(connection closed)
|
||||
```
|
||||
|
||||
1. Request line with HTTP version number, followed by request headers
|
||||
|
||||
2. Response status, followed by response headers
|
||||
|
||||
|
||||
|
||||
|
||||
The preceding exchange is not an exhaustive list of HTTP/1.0 capabilities, but it does illustrate some of the key protocol changes:
|
||||
|
||||
* Request may consist of multiple newline separated header fields.
|
||||
|
||||
* Response object is prefixed with a response status line.
|
||||
|
||||
* Response object has its own set of newline separated header fields.
|
||||
|
||||
* Response object is not limited to hypertext.
|
||||
|
||||
* The connection between server and client is closed after every request.
|
||||
|
||||
|
||||
|
||||
|
||||
Both the request and response headers were kept as ASCII encoded, but the response object itself could be of any type: an HTML file, a plain text file, an image, or any other content type. Hence, the "hypertext transfer" part of HTTP became a misnomer not long after its introduction. In reality, HTTP has quickly evolved to become a hypermedia transport, but the original name stuck.
|
||||
|
||||
In addition to media type negotiation, the RFC also documented a number of other commonly implemented capabilities: content encoding, character set support, multi-part types, authorization, caching, proxy behaviors, date formats, and more.
|
||||
|
||||
```
|
||||
Almost every server on the Web today can and will still speak HTTP/1.0. Except that, by now, you should know better! Requiring a new TCP connection per request imposes a significant performance penalty on HTTP/1.0; see [Three-Way Handshake][1], followed by [Slow-Start][2].
|
||||
```
|
||||
|
||||
### §HTTP/1.1: Internet Standard
|
||||
|
||||
The work on turning HTTP into an official IETF Internet standard proceeded in parallel with the documentation effort around HTTP/1.0 and happened over a period of roughly four years: between 1995 and 1999. In fact, the first official HTTP/1.1 standard is defined in RFC 2068, which was officially released in January 1997, roughly six months after the publication of HTTP/1.0. Then, two and a half years later, in June of 1999, a number of improvements and updates were incorporated into the standard and were released as RFC 2616.
|
||||
|
||||
The HTTP/1.1 standard resolved a lot of the protocol ambiguities found in earlier versions and introduced a number of critical performance optimizations: keepalive connections, chunked encoding transfers, byte-range requests, additional caching mechanisms, transfer encodings, and request pipelining.
|
||||
|
||||
With these capabilities in place, we can now inspect a typical HTTP/1.1 session as performed by any modern HTTP browser and client:
|
||||
|
||||
```
|
||||
$> telnet website.org 80
|
||||
Connected to xxx.xxx.xxx.xxx
|
||||
|
||||
GET /index.html HTTP/1.1
|
||||
Host: website.org
|
||||
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
|
||||
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
|
||||
Accept-Encoding: gzip,deflate,sdch
|
||||
Accept-Language: en-US,en;q=0.8
|
||||
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
|
||||
Cookie: __qca=P0-800083390... (snip)
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Server: nginx/1.0.11
|
||||
Connection: keep-alive
|
||||
Content-Type: text/html; charset=utf-8
|
||||
Via: HTTP/1.1 GWA
|
||||
Date: Wed, 25 Jul 2012 20:23:35 GMT
|
||||
Expires: Wed, 25 Jul 2012 20:23:35 GMT
|
||||
Cache-Control: max-age=0, no-cache
|
||||
Transfer-Encoding: chunked
|
||||
|
||||
100
|
||||
<!doctype html>
|
||||
(snip)
|
||||
|
||||
100
|
||||
(snip)
|
||||
|
||||
0
|
||||
|
||||
GET /favicon.ico HTTP/1.1
|
||||
Host: www.website.org
|
||||
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
|
||||
Accept: */*
|
||||
Referer: http://website.org/
|
||||
Connection: close
|
||||
Accept-Encoding: gzip,deflate,sdch
|
||||
Accept-Language: en-US,en;q=0.8
|
||||
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
|
||||
Cookie: __qca=P0-800083390... (snip)
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Server: nginx/1.0.11
|
||||
Content-Type: image/x-icon
|
||||
Content-Length: 3638
|
||||
Connection: close
|
||||
Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT
|
||||
Cache-Control: max-age=315360000
|
||||
Accept-Ranges: bytes
|
||||
Via: HTTP/1.1 GWA
|
||||
Date: Sat, 21 Jul 2012 21:35:22 GMT
|
||||
Expires: Thu, 31 Dec 2037 23:55:55 GMT
|
||||
Etag: W/PSA-GAu26oXbDi
|
||||
|
||||
(icon data)
|
||||
(connection closed)
|
||||
```
|
||||
|
||||
1. Request for HTML file, with encoding, charset, and cookie metadata
|
||||
|
||||
2. Chunked response for original HTML request
|
||||
|
||||
3. Number of octets in the chunk expressed as an ASCII hexadecimal number (256 bytes)
|
||||
|
||||
4. End of chunked stream response
|
||||
|
||||
5. Request for an icon file made on same TCP connection
|
||||
|
||||
6. Inform server that the connection will not be reused
|
||||
|
||||
7. Icon response, followed by connection close
|
||||
|
||||
|
||||
|
||||
|
||||
Phew, there is a lot going on in there! The first and most obvious difference is that we have two object requests, one for an HTML page and one for an image, both delivered over a single connection. This is connection keepalive in action, which allows us to reuse the existing TCP connection for multiple requests to the same host and deliver a much faster end-user experience; see [Optimizing for TCP][3].
|
||||
|
||||
To terminate the persistent connection, notice that the second client request sends an explicit `close` token to the server via the `Connection` header. Similarly, the server can notify the client of the intent to close the current TCP connection once the response is transferred. Technically, either side can terminate the TCP connection without such signal at any point, but clients and servers should provide it whenever possible to enable better connection reuse strategies on both sides.
|
||||
|
||||
```
|
||||
HTTP/1.1 changed the semantics of the HTTP protocol to use connection keepalive by default. Meaning, unless told otherwise (via `Connection: close` header), the server should keep the connection open by default.
|
||||
|
||||
However, this same functionality was also backported to HTTP/1.0 and enabled via the `Connection: Keep-Alive` header. Hence, if you are using HTTP/1.1, technically you don’t need the `Connection: Keep-Alive` header, but many clients choose to provide it nonetheless.
|
||||
```
|
||||
|
||||
Additionally, the HTTP/1.1 protocol added content, encoding, character set, and even language negotiation, transfer encoding, caching directives, client cookies, plus a dozen other capabilities that can be negotiated on each request.
|
||||
|
||||
We are not going to dwell on the semantics of every HTTP/1.1 feature. This is a subject for a dedicated book, and many great ones have been written already. Instead, the previous example serves as a good illustration of both the quick progress and evolution of HTTP, as well as the intricate and complicated dance of every client-server exchange. There is a lot going on in there!
|
||||
|
||||
```
|
||||
For a good reference on all the inner workings of the HTTP protocol, check out O’Reilly’s HTTP: The Definitive Guide by David Gourley and Brian Totty.
|
||||
```
|
||||
|
||||
### §HTTP/2: Improving Transport Performance
|
||||
|
||||
Since its publication, RFC 2616 has served as a foundation for the unprecedented growth of the Internet: billions of devices of all shapes and sizes, from desktop computers to the tiny web devices in our pockets, speak HTTP every day to deliver news, video, and millions of other web applications we have all come to depend on in our lives.
|
||||
|
||||
What began as a simple, one-line protocol for retrieving hypertext quickly evolved into a generic hypermedia transport, and now a decade later can be used to power just about any use case you can imagine. Both the ubiquity of servers that can speak the protocol and the wide availability of clients to consume it means that many applications are now designed and deployed exclusively on top of HTTP.
|
||||
|
||||
Need a protocol to control your coffee pot? RFC 2324 has you covered with the Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0)—originally an April Fools’ Day joke by IETF, and increasingly anything but a joke in our new hyper-connected world.
|
||||
|
||||
> The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. It is a generic, stateless, protocol that can be used for many tasks beyond its use for hypertext, such as name servers and distributed object management systems, through extension of its request methods, error codes and headers. A feature of HTTP is the typing and negotiation of data representation, allowing systems to be built independently of the data being transferred.
|
||||
>
|
||||
> RFC 2616: HTTP/1.1, June 1999
|
||||
|
||||
The simplicity of the HTTP protocol is what enabled its original adoption and rapid growth. In fact, it is now not unusual to find embedded devices—sensors, actuators, and coffee pots alike—using HTTP as their primary control and data protocols. But under the weight of its own success and as we increasingly continue to migrate our everyday interactions to the Web—social, email, news, and video, and increasingly our entire personal and job workspaces—it has also begun to show signs of stress. Users and web developers alike are now demanding near real-time responsiveness and protocol performance from HTTP/1.1, which it simply cannot meet without some modifications.
|
||||
|
||||
To meet these new challenges, HTTP must continue to evolve, and hence the HTTPbis working group announced a new initiative for HTTP/2 in early 2012:
|
||||
|
||||
> There is emerging implementation experience and interest in a protocol that retains the semantics of HTTP without the legacy of HTTP/1.x message framing and syntax, which have been identified as hampering performance and encouraging misuse of the underlying transport.
|
||||
>
|
||||
> The working group will produce a specification of a new expression of HTTP’s current semantics in ordered, bi-directional streams. As with HTTP/1.x, the primary target transport is TCP, but it should be possible to use other transports.
|
||||
>
|
||||
> HTTP/2 charter, January 2012
|
||||
|
||||
The primary focus of HTTP/2 is on improving transport performance and enabling both lower latency and higher throughput. The major version increment sounds like a big step, which it is and will be as far as performance is concerned, but it is important to note that none of the high-level protocol semantics are affected: all HTTP headers, values, and use cases are the same.
|
||||
|
||||
Any existing website or application can and will be delivered over HTTP/2 without modification: you do not need to modify your application markup to take advantage of HTTP/2. The HTTP servers will have to speak HTTP/2, but that should be a transparent upgrade for the majority of users. The only difference if the working group meets its goal, should be that our applications are delivered with lower latency and better utilization of the network link!
|
||||
|
||||
Having said that, let’s not get ahead of ourselves. Before we get to the new HTTP/2 protocol features, it is worth taking a step back and examining our existing deployment and performance best practices for HTTP/1.1. The HTTP/2 working group is making fast progress on the new specification, but even if the final standard was already done and ready, we would still have to support older HTTP/1.1 clients for the foreseeable future—realistically, a decade or more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol
|
||||
|
||||
作者:[Ilya Grigorik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.igvita.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://hpbn.co/building-blocks-of-tcp/#three-way-handshake
|
||||
[2]: https://hpbn.co/building-blocks-of-tcp/#slow-start
|
||||
[3]: https://hpbn.co/building-blocks-of-tcp/#optimizing-for-tcp
|
||||
@ -1,533 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (SPEED TEST: x86 vs. ARM for Web Crawling in Python)
|
||||
[#]: via: (https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/)
|
||||
[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
|
||||
|
||||
SPEED TEST: x86 vs. ARM for Web Crawling in Python
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Can you imagine if your job was to trawl competitor websites and jot prices down by hand, again and again and again? You’d burn your whole office down by lunchtime.
|
||||
|
||||
So, little wonder web crawlers are huge these days. They can keep track of customer sentiment and trending topics, monitor job openings, real estate transactions, UFC results, all sorts of stuff.
|
||||
|
||||
For those of a certain bent, this is fascinating stuff. Which is how I found myself playing around with [Scrapy][2], an open source web crawling framework written in Python.
|
||||
|
||||
Being wary of the potential to do something catastrophic to my computer while poking with things I didn’t understand, I decided to install it on my main machine but a Raspberry Pi.
|
||||
|
||||
And wouldn’t you know it? It actually didn’t run too shabby on the little tacker. Maybe this is a good use case for an ARM server?
|
||||
|
||||
Google had no solid answer. The nearest thing I found was [this Drupal hosting drag race][3], which showed an ARM server outperforming a much more expensive x86 based account.
|
||||
|
||||
That was definitely interesting. I mean, isn’t a web server kind of like a crawler in reverse? But with one operating on a LAMP stack and the other on a Python interpreter, it’s hardly the exact same thing.
|
||||
|
||||
So what could I do? Only one thing. Get some VPS accounts and make them race each other.
|
||||
|
||||
### What’s the Deal With ARM Processors?
|
||||
|
||||
ARM is now the most popular CPU architecture in the world.
|
||||
|
||||
But it’s generally seen as something you’d opt for to save money and battery life, rather than a serious workhorse.
|
||||
|
||||
It wasn’t always that way: this CPU was designed in Cambridge, England to power the fiendishly expensive [Acorn Archimedes][4]. This was the most powerful desktop computer in the world, and by a long way too: it was multiple times the speed of the fastest 386.
|
||||
|
||||
Acorn, like Commodore and Atari, somewhat ignorantly believed that the making of a great computer company was in the making of great computers. Bill Gates had a better idea. He got DOS on as many x86 machines – of the most widely varying quality and expense – as he could.
|
||||
|
||||
Having the best user base made you the obvious platform for third party developers to write software for; having all the software support made yours the most useful computer.
|
||||
|
||||
Even Apple nearly bit the dust. All the $$$$ were in building a better x86 chip, this was the architecture that ended up being developed for serious computing.
|
||||
|
||||
That wasn’t the end for ARM though. Their chips weren’t just fast, they could run well without drawing much power or emitting much heat. That made them a preferred technology in set top boxes, PDAs, digital cameras, MP3 players, and basically anything that either used a battery or where you’d just rather avoid the noise of a large fan.
|
||||
|
||||
So it was that Acorn spun off ARM, who began an idiosyncratic business model that continues to today: ARM doesn’t actually manufacture any chips, they license their intellectual property to others who do.
|
||||
|
||||
Which is more or less how they ended up in so many phones and tablets. When Linux was ported to the architecture, the door opened to other open source technologies, which is how we can run a web crawler on these chips today.
|
||||
|
||||
#### ARM in the Server Room
|
||||
|
||||
Some big names, like [Microsoft][5] and [Cloudflare][6], have placed heavy bets on the British Bulldog for their infrastructure. But for those of us with more modest budgets, the options are fairly sparse.
|
||||
|
||||
In fact, when it comes to cheap and cheerful VPS accounts that you can stick on the credit card for a few bucks a month, for years the only option was [Scaleway][7].
|
||||
|
||||
This changed a few months ago when public cloud heavyweight [AWS][8] launched its own ARM processor: the [AWS Graviton][9].
|
||||
|
||||
I decided to grab one of each, and race them against the most similar Intel offering from the same provider.
|
||||
|
||||
### Looking Under the Hood
|
||||
|
||||
So what are we actually racing here? Let’s jump right in.
|
||||
|
||||
#### Scaleway
|
||||
|
||||
Scaleway positions itself as “designed for developers”. And you know what? I think that’s fair enough: it’s definitely been a good little sandbox for developing and prototyping.
|
||||
|
||||
The dirt simple product offering and clean, easy dashboard guides you from home page to bash shell in minutes. That makes it a strong option for small businesses, freelancers and consultants who just want to get straight into a good VPS at a great price to run some crawls.
|
||||
|
||||
The ARM account we will be using is their [ARM64-2GB][10], which costs 3 euros a month and has 4 Cavium ThunderX cores. This launched in 2014 as the first server-class ARMv8 processor, but is now looking a bit middle-aged, having been superseded by the younger, prettier ThunderX2.
|
||||
|
||||
The x86 account we will be comparing it to is the [1-S][11], which costs a more princely 4 euros a month and has 2 Intel Atom C3995 cores. Intel’s Atom range is a low power single-threaded system on chip design, first built for laptops and then adapted for server use.
|
||||
|
||||
These accounts are otherwise fairly similar: they each have 2 gigabytes of memory, 50 gigabytes of SSD storage and 200 Mbit/s bandwidth. The disk drives possibly differ, but with the crawls we’re going to run here, this won’t come into play, we’re going to be doing everything in memory.
|
||||
|
||||
When I can’t use a package manager I’m familiar with, I become angry and confused, a bit like an autistic toddler without his security blanket, entirely beyond reasoning or consolation, it’s quite horrendous really, so both of these accounts will use Debian Stretch.
|
||||
|
||||
#### Amazon Web Services
|
||||
|
||||
In the same length of time as it takes you to give Scaleway your credit card details, launch a VPS, add a sudo user and start installing dependencies, you won’t even have gotten as far as registering your AWS account. You’ll still be reading through the product pages trying to figure out what’s going on.
|
||||
|
||||
There’s a serious breadth and depth here aimed at enterprises and others with complicated or specialised needs.
|
||||
|
||||
The AWS Graviton we wanna drag race is part of AWS’s “Elastic Compute Cloud” or EC2 range. I’ll be running it as an on-demand instance, which is the most convenient and expensive way to use EC2. AWS also operates a [spot market][12], where you get the server much cheaper if you can be flexible about when it runs. There’s also a [mid-priced option][13] if you want to run it 24/7.
|
||||
|
||||
Did I mention that AWS is complicated? Anyhoo..
|
||||
|
||||
The two accounts we’re comparing are [a1.medium][14] and [t2.small][15]. They both offer 2GB of RAM. Which begs the question: WTF is a vCPU? Confusingly, it’s a different thing on each account.
|
||||
|
||||
On the a1.medium account, a vCPU is a single core of the new AWS Graviton chip. This was built by Annapurna Labs, an Israeli chip maker bought by Amazon in 2015. This is a single-threaded 64-bit ARMv8 core exclusive to AWS. This has an on-demand price of 0.0255 US dollars per hour.
|
||||
|
||||
Our t2.small account runs on an Intel Xeon – though exactly which Xeon chip it is, I couldn’t really figure out. This has two threads per core – though we’re not really getting the whole core, or even the whole thread.
|
||||
|
||||
Instead we’re getting a “baseline performance of 20%, with the ability to burst above that baseline using CPU credits”. Which makes sense in principle, though it’s completely unclear to me what to actually expect from this. The on-demand price for this account is 0.023 US dollars per hour.
|
||||
|
||||
I couldn’t find Debian in the image library here, so both of these accounts will run Ubuntu 18.04.
|
||||
|
||||
### Beavis and Butthead Do Moz’s Top 500
|
||||
|
||||
To test these VPS accounts, I need a crawler to run – one that will let the CPU stretch its legs a bit. One way to do this would be to just hammer a few websites with as many requests as fast as possible, but that’s not very polite. What we’ll do instead is a broad crawl of many websites at once.
|
||||
|
||||
So it’s in tribute to my favourite physicist turned filmmaker, Mike Judge, that I wrote beavis.py. This crawls Moz’s Top 500 Websites to a depth of 3 pages to count how many times the words “wood” and “ass” occur anywhere within the HTML source.
|
||||
|
||||
Not all 500 websites will actually get crawled here – some will be excluded by robots.txt and others will require javascript to follow links and so on. But it’s a wide enough crawl to keep the CPU busy.
|
||||
|
||||
Python’s [global interpreter lock][16] means that beavis.py can only make use of a single CPU thread. To test multi-threaded we’re going to have to launch multiple spiders as seperate processes.
|
||||
|
||||
This is why I wrote butthead.py. Any true fan of the show knows that, as crude as Butthead was, he was always slightly more sophisticated than Beavis.
|
||||
|
||||
Splitting the crawl into multiple lists of start pages and allowed domains might slightly impact what gets crawled – fewer external links to other websites in the top 500 will get followed. But every crawl will be different anyway, so we will count how many pages are scraped as well as how long they take.
|
||||
|
||||
### Installing Scrapy on an ARM Server
|
||||
|
||||
Installing Scrapy is basically the same on each architecture. You install pip and various other dependencies, then install Scrapy from pip.
|
||||
|
||||
Installing Scrapy from pip to an ARM device does take noticeably longer though. I’m guessing this is because it has to compile the binary parts from source.
|
||||
|
||||
Once Scrapy is installed, I ran it from the shell to check that it’s fetching pages.
|
||||
|
||||
On Scaleway’s ARM account, there seemed to be a hitch with the service_identity module: it was installed but not working. This issue had come up on the Raspberry Pi as well, but not the AWS Graviton.
|
||||
|
||||
Not to worry, this was easily fixed with the following command:
|
||||
|
||||
```
|
||||
sudo pip3 install service_identity --force --upgrade
|
||||
```
|
||||
|
||||
Then we were off and racing!
|
||||
|
||||
### Single Threaded Crawls
|
||||
|
||||
The Scrapy docs say to try to [keep your crawls running between 80-90% CPU usage][17]. In practice, it’s hard – at least it is with the script I’ve written. What tends to happen is that the CPU gets very busy early in the crawl, drops a little bit and then rallies again.
|
||||
|
||||
The last part of the crawl, where most of the domains have been finished, can go on for quite a few minutes, which is frustrating, because at that point it feels like more a measure of how big the last website is than anything to do with the processor.
|
||||
|
||||
So please take this for what it is: not a state of the art benchmarking tool, but a short and slightly balding Australian in his underpants running some scripts and watching what happens.
|
||||
|
||||
So let’s get down to brass tacks. We’ll start with the Scaleway crawls.
|
||||
|
||||
| VPS | Account | Time | Pages | Scraped | Pages/Hour | €/million | pages |
|
||||
| --------- | ------- | ------- | ------ | ---------- | ---------- | --------- | ----- |
|
||||
| Scaleway | | | | | | | |
|
||||
| ARM64-2GB | 108m | 59.27s | 38,205 | 21,032.623 | 0.28527 | | |
|
||||
| --------- | ------- | ------- | ------ | ---------- | ---------- | --------- | ----- |
|
||||
| Scaleway | | | | | | | |
|
||||
| 1-S | 97m | 44.067s | 39,476 | 24,324.648 | 0.33011 | | |
|
||||
|
||||
I kept an eye on the CPU use of both of these crawls using [top][18]. Both crawls hit 100% CPU use at the beginning, but the ThunderX chip was definitely redlining a lot more. That means these figures understate how much faster the Atom core crawls than the ThunderX.
|
||||
|
||||
While I was watching CPU use in top, I could also see how much RAM was in use – this increased as the crawl continued. The ARM account used 14.7% at the end of the crawl, while the x86 was at 15%.
|
||||
|
||||
Watching the logs of these crawls, I also noticed a lot more pages timing out and going missing when the processor was maxed out. That makes sense – if the CPU’s too busy to respond to everything then something’s gonna go missing.
|
||||
|
||||
That’s not such a big deal when you’re just racing the things to see which is fastest. But in a real-world situation, with business outcomes at stake in the quality of your data, it’s probably worth having a little bit of headroom.
|
||||
|
||||
And what about AWS?
|
||||
|
||||
| VPS Account | Time | Pages Scraped | Pages / Hour | $ / Million Pages |
|
||||
| ----------- | ---- | ------------- | ------------ | ----------------- |
|
||||
| a1.medium | 100m 39.900s | 41,294 | 24,612.725 | 1.03605 |
|
||||
| t2.small | 78m 53.171s | 41,200 | 31,336.286 | 0.73397 |
|
||||
|
||||
I’ve included these results for sake of comparison with the Scaleway crawls, but these crawls were kind of a bust. Monitoring the CPU use – this time through the AWS dashboard rather than through top – showed that the script wasn’t making good use of the available processing power on either account.
|
||||
|
||||
This was clearest with the a1.medium account – it hardly even got out of bed. It peaked at about 45% near the beginning and then bounced around between 20% and 30% for the rest.
|
||||
|
||||
What’s intriguing to me about this is that the exact same script ran much slower on the ARM processor – and that’s not because it hit a limit of the Graviton’s CPU power. It had oodles of headroom left. Even the Intel Atom core managed to finish, and that was maxing out for some of the crawl. The settings were the same in the code, the way they were being handled differently on the different architecture.
|
||||
|
||||
It’s a bit of a black box to me whether that’s something inherent to the processor itself, the way the binaries were compiled, or some interaction between the two. I’m going to speculate that we might have seen the same thing on the Scaleway ARM VPS, if we hadn’t hit the limit of the CPU core’s processing power first.
|
||||
|
||||
It was harder to know how the t2.small account was doing. The crawl sat at about 20%, sometimes going as high as 35%. Was that it meant by “baseline performance of 20%, with the ability to burst to a higher level”? I had no idea. But I could see on the dashboard I wasn’t burning through any CPU credits.
|
||||
|
||||
Just to make extra sure, I installed [stress][19] and ran it for a few minutes; sure enough, this thing could do 100% if you pushed it.
|
||||
|
||||
Clearly, I was going to need to crank the settings up on both these processors to make them sweat a bit, so I set CONCURRENT_REQUESTS to 5000 and REACTOR_THREADPOOL_MAXSIZE to 120 and ran some more crawls.
|
||||
|
||||
| VPS Account | Time | Pages Scraped | Pages/hr | $/10000 Pages |
|
||||
| ----------- | ---- | ------------- | -------- | ------------- |
|
||||
| a1.medium | 46m 13.619s | 40,283 | 52,285.047 | 0.48771 |
|
||||
| t2.small | 41m7.619s | 36,241 | 52,871.857 | 0.43501 |
|
||||
| t2.small (No CPU credits) | 73m 8.133s | 34,298 | 28,137.8891 | 0.81740 |
|
||||
|
||||
The a1 instance hit 100% usage about 5 minutes into the crawl, before dropping back to 80% use for another 20 minutes, climbing up to 96% again and then dropping down again as it was wrapping things up. That was probably about as well-tuned as I was going to get it.
|
||||
|
||||
The t2 instance hit 50% early in the crawl and stayed there for until it was nearly done. With 2 threads per core, 50% CPU use is one thread maxed out.
|
||||
|
||||
Here we see both accounts produce similar speeds. But the Xeon thread was redlining for most of the crawl, and the Graviton was not. I’m going to chalk this up as a slight win for the Graviton.
|
||||
|
||||
But what about once you’ve burnt through all your CPU credits? That’s probably the fairer comparison – to only use them as you earn them. I wanted to test that as well. So I ran stress until all the CPU credits were exhausted and ran the crawl again.
|
||||
|
||||
With no credits in the bank, the CPU usage maxed out at 27% and stayed there. So many pages ended up going missing that it actually performed worse than when on the lower settings.
|
||||
|
||||
### Multi Threaded Crawls
|
||||
|
||||
Dividing our crawl up between multiple spiders in separate processes offers a few more options to make use of the available cores.
|
||||
|
||||
I first tried dividing everything up between 10 processes and launching them all at once. This turned out to be slower than just dividing them up into 1 process per core.
|
||||
|
||||
I got the best result by combining these methods – dividing the crawl up into 10 processes and then launching 1 process per core at the start and then the rest as these crawls began to wind down.
|
||||
|
||||
To make this even better, you could try to minimise the problem of the last lingering crawler by making sure the longest crawls start first. I actually attempted to do this.
|
||||
|
||||
Figuring that the number of links on the home page might be a rough proxy for how large the crawl would be, I built a second spider to count them and then sort them in descending order of number of outgoing links. This preprocessing worked well and added a little over a minute.
|
||||
|
||||
It turned out though that blew the crawling time out beyond two hours! Putting all the most link heavy websites together in the same process wasn’t a great idea after all.
|
||||
|
||||
You might effectively deal with this by tweaking the number of domains per process as well – or by shuffling the list after it’s ordered. That’s a bit much for Beavis and Butthead though.
|
||||
|
||||
So I went back to my earlier method that had worked somewhat well:
|
||||
|
||||
| VPS Account | Time | Pages Scraped | Pages/hr | €/10,000 pages |
|
||||
| ----------- | ---- | ------------- | -------- | -------------- |
|
||||
| Scaleway ARM64-2GB | 62m 10.078s | 36,158 | 34,897.0719 | 0.17193 |
|
||||
| Scaleway 1-S | 60m 56.902s | 36,725 | 36,153.5529 | 0.22128 |
|
||||
|
||||
After all that, using more cores did speed up the crawl. But it’s hardly a matter of just halving or quartering the time taken.
|
||||
|
||||
I’m certain that a more experienced coder could better optimise this to take advantage of all the cores. But, as far as “out of the box” Scrapy performance goes, it seems to be a lot easier to speed up a crawl by using faster threads rather than by throwing more cores at it.
|
||||
|
||||
As it is, the Atom has scraped slightly more pages in slightly less time. On a value for money metric, you could possibly say that the ThunderX is ahead. Either way, there’s not a lot of difference here.
|
||||
|
||||
### Everything You Always Wanted to Know About Ass and Wood (But Were Afraid to Ask)
|
||||
|
||||
After scraping 38,205 pages, our crawler found 24,170,435 mentions of ass and 54,368 mentions of wood.
|
||||
|
||||
![][20]
|
||||
|
||||
Considered on its own, this is a respectable amount of wood.
|
||||
|
||||
But when you set it against the sheer quantity of ass we’re dealing with here, the wood looks miniscule.
|
||||
|
||||
### The Verdict
|
||||
|
||||
From what’s visible to me at the moment, it looks like the CPU architecture you use is actually less important than how old the processor is. The AWS Graviton from 2018 was the winner here in single-threaded performance.
|
||||
|
||||
You could of course argue that the Xeon still wins, core for core. But then you’re not really going dollar for dollar anymore, or even thread for thread.
|
||||
|
||||
The Atom from 2017, on the other hand, comfortably bested the ThunderX from 2014. Though, on the value for money metric, the ThunderX might be the clear winner. Then again, if you can run your crawls on Amazon’s spot market, the Graviton is still ahead.
|
||||
|
||||
All in all, I think this shows that, yes, you can crawl the web with an ARM device, and it can compete on both performance and price.
|
||||
|
||||
Whether the difference is significant enough for you to turn what you’re doing upside down is a whole other question of course. Certainly, if you’re already on the AWS cloud – and your code is portable enough – then it might be worthwhile testing out their a1 instances.
|
||||
|
||||
Hopefully we will see more ARM options on the public cloud in near future.
|
||||
|
||||
### The Scripts
|
||||
|
||||
This is my first real go at doing anything in either Python or Scrapy. So this might not be great code to learn from. Some of what I’ve done here – such as using global variables – is definitely a bit kludgey.
|
||||
|
||||
Still, I want to be transparent about my methods, so here are my scripts.
|
||||
|
||||
To run them, you’ll need Scrapy installed and you will need the CSV file of [Moz’s top 500 domains][21]. To run butthead.py you will also need [psutil][22].
|
||||
|
||||
##### beavis.py
|
||||
|
||||
```
|
||||
import scrapy
|
||||
from scrapy.spiders import CrawlSpider, Rule
|
||||
from scrapy.linkextractors import LinkExtractor
|
||||
from scrapy.crawler import CrawlerProcess
|
||||
|
||||
ass = 0
|
||||
wood = 0
|
||||
totalpages = 0
|
||||
|
||||
def getdomains():
|
||||
|
||||
moz500file = open('top500.domains.05.18.csv')
|
||||
|
||||
domains = []
|
||||
moz500csv = moz500file.readlines()
|
||||
|
||||
del moz500csv[0]
|
||||
|
||||
for csvline in moz500csv:
|
||||
leftquote = csvline.find('"')
|
||||
rightquote = leftquote + csvline[leftquote + 1:].find('"')
|
||||
domains.append(csvline[leftquote + 1:rightquote])
|
||||
|
||||
return domains
|
||||
|
||||
def getstartpages(domains):
|
||||
|
||||
startpages = []
|
||||
|
||||
for domain in domains:
|
||||
startpages.append('http://' + domain)
|
||||
|
||||
return startpages
|
||||
|
||||
class AssWoodItem(scrapy.Item):
|
||||
ass = scrapy.Field()
|
||||
wood = scrapy.Field()
|
||||
url = scrapy.Field()
|
||||
|
||||
class AssWoodPipeline(object):
|
||||
def __init__(self):
|
||||
self.asswoodstats = []
|
||||
|
||||
def process_item(self, item, spider):
|
||||
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
|
||||
|
||||
def close_spider(self, spider):
|
||||
asstally, woodtally = 0, 0
|
||||
|
||||
for asswoodcount in self.asswoodstats:
|
||||
asstally += asswoodcount[1]
|
||||
woodtally += asswoodcount[2]
|
||||
|
||||
global ass, wood, totalpages
|
||||
ass = asstally
|
||||
wood = woodtally
|
||||
totalpages = len(self.asswoodstats)
|
||||
|
||||
class BeavisSpider(CrawlSpider):
|
||||
name = "Beavis"
|
||||
allowed_domains = getdomains()
|
||||
start_urls = getstartpages(allowed_domains)
|
||||
#start_urls = [ 'http://medium.com' ]
|
||||
custom_settings = {
|
||||
'DEPTH_LIMIT': 3,
|
||||
'DOWNLOAD_DELAY': 3,
|
||||
'CONCURRENT_REQUESTS': 1500,
|
||||
'REACTOR_THREADPOOL_MAXSIZE': 60,
|
||||
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
|
||||
'LOG_LEVEL': 'INFO',
|
||||
'RETRY_ENABLED': False,
|
||||
'DOWNLOAD_TIMEOUT': 30,
|
||||
'COOKIES_ENABLED': False,
|
||||
'AJAXCRAWL_ENABLED': True
|
||||
}
|
||||
|
||||
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
|
||||
|
||||
def parse_asswood(self, response):
|
||||
if isinstance(response, scrapy.http.TextResponse):
|
||||
item = AssWoodItem()
|
||||
item['ass'] = response.text.casefold().count('ass')
|
||||
item['wood'] = response.text.casefold().count('wood')
|
||||
item['url'] = response.url
|
||||
yield item
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
process = CrawlerProcess({
|
||||
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
|
||||
})
|
||||
|
||||
process.crawl(BeavisSpider)
|
||||
process.start()
|
||||
|
||||
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
|
||||
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
|
||||
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
|
||||
```
|
||||
|
||||
##### butthead.py
|
||||
|
||||
```
|
||||
import scrapy, time, psutil
|
||||
from scrapy.spiders import CrawlSpider, Rule, Spider
|
||||
from scrapy.linkextractors import LinkExtractor
|
||||
from scrapy.crawler import CrawlerProcess
|
||||
from multiprocessing import Process, Queue, cpu_count
|
||||
|
||||
ass = 0
|
||||
wood = 0
|
||||
totalpages = 0
|
||||
linkcounttuples =[]
|
||||
|
||||
def getdomains():
|
||||
|
||||
moz500file = open('top500.domains.05.18.csv')
|
||||
|
||||
domains = []
|
||||
moz500csv = moz500file.readlines()
|
||||
|
||||
del moz500csv[0]
|
||||
|
||||
for csvline in moz500csv:
|
||||
leftquote = csvline.find('"')
|
||||
rightquote = leftquote + csvline[leftquote + 1:].find('"')
|
||||
domains.append(csvline[leftquote + 1:rightquote])
|
||||
|
||||
return domains
|
||||
|
||||
def getstartpages(domains):
|
||||
|
||||
startpages = []
|
||||
|
||||
for domain in domains:
|
||||
startpages.append('http://' + domain)
|
||||
|
||||
return startpages
|
||||
|
||||
class AssWoodItem(scrapy.Item):
|
||||
ass = scrapy.Field()
|
||||
wood = scrapy.Field()
|
||||
url = scrapy.Field()
|
||||
|
||||
class AssWoodPipeline(object):
|
||||
def __init__(self):
|
||||
self.asswoodstats = []
|
||||
|
||||
def process_item(self, item, spider):
|
||||
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
|
||||
|
||||
def close_spider(self, spider):
|
||||
asstally, woodtally = 0, 0
|
||||
|
||||
for asswoodcount in self.asswoodstats:
|
||||
asstally += asswoodcount[1]
|
||||
woodtally += asswoodcount[2]
|
||||
|
||||
global ass, wood, totalpages
|
||||
ass = asstally
|
||||
wood = woodtally
|
||||
totalpages = len(self.asswoodstats)
|
||||
|
||||
|
||||
class ButtheadSpider(CrawlSpider):
|
||||
name = "Butthead"
|
||||
custom_settings = {
|
||||
'DEPTH_LIMIT': 3,
|
||||
'DOWNLOAD_DELAY': 3,
|
||||
'CONCURRENT_REQUESTS': 250,
|
||||
'REACTOR_THREADPOOL_MAXSIZE': 30,
|
||||
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
|
||||
'LOG_LEVEL': 'INFO',
|
||||
'RETRY_ENABLED': False,
|
||||
'DOWNLOAD_TIMEOUT': 30,
|
||||
'COOKIES_ENABLED': False,
|
||||
'AJAXCRAWL_ENABLED': True
|
||||
}
|
||||
|
||||
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
|
||||
|
||||
|
||||
def parse_asswood(self, response):
|
||||
if isinstance(response, scrapy.http.TextResponse):
|
||||
item = AssWoodItem()
|
||||
item['ass'] = response.text.casefold().count('ass')
|
||||
item['wood'] = response.text.casefold().count('wood')
|
||||
item['url'] = response.url
|
||||
yield item
|
||||
|
||||
def startButthead(domainslist, urlslist, asswoodqueue):
|
||||
crawlprocess = CrawlerProcess({
|
||||
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
|
||||
})
|
||||
|
||||
crawlprocess.crawl(ButtheadSpider, allowed_domains = domainslist, start_urls = urlslist)
|
||||
crawlprocess.start()
|
||||
asswoodqueue.put( (ass, wood, totalpages) )
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
asswoodqueue = Queue()
|
||||
domains=getdomains()
|
||||
startpages=getstartpages(domains)
|
||||
processlist =[]
|
||||
cores = cpu_count()
|
||||
|
||||
for i in range(10):
|
||||
domainsublist = domains[i * 50:(i + 1) * 50]
|
||||
pagesublist = startpages[i * 50:(i + 1) * 50]
|
||||
p = Process(target = startButthead, args = (domainsublist, pagesublist, asswoodqueue))
|
||||
processlist.append(p)
|
||||
|
||||
for i in range(cores):
|
||||
processlist[i].start()
|
||||
|
||||
time.sleep(180)
|
||||
|
||||
i = cores
|
||||
|
||||
while i != 10:
|
||||
time.sleep(60)
|
||||
if psutil.cpu_percent() < 66.7:
|
||||
processlist[i].start()
|
||||
i += 1
|
||||
|
||||
for i in range(10):
|
||||
processlist[i].join()
|
||||
|
||||
for i in range(10):
|
||||
asswoodtuple = asswoodqueue.get()
|
||||
ass += asswoodtuple[0]
|
||||
wood += asswoodtuple[1]
|
||||
totalpages += asswoodtuple[2]
|
||||
|
||||
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
|
||||
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
|
||||
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/quadbike-1024x683.jpg
|
||||
[2]: https://scrapy.org/
|
||||
[3]: https://www.info2007.net/blog/2018/review-scaleway-arm-based-cloud-server.html
|
||||
[4]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
|
||||
[5]: https://www.computerworld.com/article/3178544/microsoft-windows/microsoft-and-arm-look-to-topple-intel-in-servers.html
|
||||
[6]: https://www.datacenterknowledge.com/design/cloudflare-bets-arm-servers-it-expands-its-data-center-network
|
||||
[7]: https://www.scaleway.com/
|
||||
[8]: https://aws.amazon.com/
|
||||
[9]: https://www.theregister.co.uk/2018/11/27/amazon_aws_graviton_specs/
|
||||
[10]: https://www.scaleway.com/virtual-cloud-servers/#anchor_arm
|
||||
[11]: https://www.scaleway.com/virtual-cloud-servers/#anchor_starter
|
||||
[12]: https://aws.amazon.com/ec2/spot/pricing/
|
||||
[13]: https://aws.amazon.com/ec2/pricing/reserved-instances/
|
||||
[14]: https://aws.amazon.com/ec2/instance-types/a1/
|
||||
[15]: https://aws.amazon.com/ec2/instance-types/t2/
|
||||
[16]: https://wiki.python.org/moin/GlobalInterpreterLock
|
||||
[17]: https://docs.scrapy.org/en/latest/topics/broad-crawls.html
|
||||
[18]: https://linux.die.net/man/1/top
|
||||
[19]: https://linux.die.net/man/1/stress
|
||||
[20]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/Screenshot-from-2019-02-16-17-01-08.png
|
||||
[21]: https://moz.com/top500
|
||||
[22]: https://pypi.org/project/psutil/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
关于圆周率日:12个有趣的事实与庆祝方式
|
||||
======
|
||||
|
||||

|
||||
今天,全世界的技术团队都会为一个数字庆祝。3 月 14 日是圆周率日,人们会在这一天举行吃派比赛、披萨舞会,玩<ruby>数学梗<rt>math puns</rt></ruby>。如果数学领域中重要的常数不足以让 3 月 14 日成为一个节日的话,加上爱因斯坦的生日、Linux 内核 1.0.0 发布的周年纪念日,莱伊·惠特尼在这一天申请了轧花机的专利这些原因,应该足够了吧。
|
||||
|
||||
(LCTT译注:[轧花机](https://zh.wikipedia.org/wiki/%E8%BB%8B%E6%A3%89%E6%A9%9F)是一种快速而且简单地分开棉花纤维和种子的机器,生产力比人手分离高得多。)
|
||||
|
||||
很荣幸,我门能在这一天一起了解有关它的有趣的事实和与π相关的活动。来吧,和你的团队一起庆祝圆周率日:找一两个点子来进行团队建设,用新兴技术做一个项目。如果你有庆祝为被大家所喜爱的无限小数的独特方式,请在评论区与大家分享。
|
||||
|
||||
### 圆周率日的庆祝方法:
|
||||
|
||||
* 今天是圆周率日的第 30 次周年纪念。第一次为它庆祝是在旧金山的<ruby>探索博物馆<rt>Exploratorium</rt></ruby>由物理学家Larry Shaw 举行。“在第 1 次周年纪念日当天,工作人员带来了水果派和茶壶来庆祝它。在 1 点 59 分,圆周率中紧接着 3.14,Shaw 在博物馆外领着队伍环馆一周。队伍中用扩音器播放着‘Pomp and Circumstance’。” 直到 21 年后,在 2009 年 3 月,圆周率正式成为了美国的法定假日。
|
||||
* 虽然它起源于旧金山,可规模最大的庆祝活动是在普林斯顿举行的,小镇举办了为期五天的[数字活动][2],包括爱因斯坦模仿比赛、投掷派比赛,圆周率背诵比赛等等。其中的某些活动甚至会给获胜者提供高达 314.5 美元的奖金。
|
||||
* <ruby>麻省理工的斯隆管理学院<rt>MIT Sloan School of Management</rt></ruby>正在庆祝圆周率日。他们在 Twitter 上分享着关于圆周率日有趣的事实,详情请关注<ruby>推特话题<rt>Twitter hashtag</rt></ruby> #PiVersusPie 。
|
||||
|
||||
(LCTT译注:本文写于 2018 年的圆周率日,故在细节上存在出入。例如今天(2019 年 3 月 14 日)是圆周率日的第 31 次周年纪念。)
|
||||
|
||||
### 与圆周率有关的项目与活动:
|
||||
|
||||
* 如果你像锻炼你的数学技能,<ruby>美国国家航空航天局<rt>NASA, National Aeronautics and Space Administration</rt></ruby>的<ruby>喷气推进实验室<rt>JPL, Jet Propulsion Lab</rt></ruby>发布了[一系列数学问题][4],希望通过这些问题展现如何把圆周率用于空间探索。这也是美国国家航天局面向学生举办的第五届圆周率日挑战。
|
||||
* 想要领略圆周率日的精神,最好的方法也许就是开展一个[树莓派][5]项目了,无论是和你的孩子还是和你的团队一起完成,都没有什么明显的缺点。树莓派作为一项从 2012 年开启的项目,现在已经有数百万块的基本电脑板被出售。事实上,它已经在[通用计算机畅销榜上排名第三][6]了。这里列举一些可能会吸引你的树莓派项目或活动:
|
||||
* 来自谷歌的<ruby>自己做AI<rt>AIY (AI-Yourself)</rt></ruby>项目让你自己创造一个[语音控制的数字助手][7]或者[一个图像识别设备][8]。
|
||||
* 在树莓派上[使用 Kubernets][9]。
|
||||
* 目标:拯救桃子公主!组装一台[怀旧游戏系统][10]。
|
||||
* 和你的团队举办一场[树莓派 Jam][11]。树莓派基金会发布了[GitBook][12]来帮助大家顺利举办。根据网页内容,树莓派 Jam 旨在“给所有年龄的人在数字创作中提供支持,全世界的有着相同想法的人集中起来讨论并分享他们的项目,举办讲习班,讨论和圆周率相关的一切。”
|
||||
|
||||
### 其他有关圆周率的事实:
|
||||
|
||||
* 当前背诵圆周率的[世界纪录保持者][13]是 Suresh Kumar Sharma,他在 2015 年 10 月花了 17 小时零 14 分钟背出了 70,030 位数字。然而,[非官方记录][14]的保持者 Akira Haraguchi 声称他可以背出 111,700 位数字。
|
||||
* 现在,已知的圆周率数字的长度比以往都要多。在 2016 年 11 月,R&D 科学家 Peter Trueb 计算出了 22,459,157,718,361 位圆周率数字,比 2013 年的世界记录多了 [9 万亿数字][15]。据<ruby>新科学家<rt>New Scientist</rt></ruby>所述,“最终文件包含了圆周率的 22 万亿位数字,大小接近 9 TB。如果将其打印出来,能用数百万本 1000 页的书装满一整个图书馆。”
|
||||
|
||||
祝你圆周率日快乐!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate
|
||||
|
||||
作者:[Carla Rudder][a]
|
||||
译者:[wwhio](https://github.com/wwhio)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/crudder
|
||||
[1]:https://www.exploratorium.edu/pi/pi-day-history
|
||||
[2]:https://princetontourcompany.com/activities/pi-day/
|
||||
[3]:https://twitter.com/MITSloan
|
||||
[4]:https://www.jpl.nasa.gov/news/news.php?feature=7074
|
||||
[5]:https://opensource.com/resources/raspberry-pi
|
||||
[6]:https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64
|
||||
[7]:http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/
|
||||
[8]:http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/
|
||||
[9]:https://opensource.com/article/17/3/kubernetes-raspberry-pi
|
||||
[10]:https://opensource.com/article/18/1/retro-gaming
|
||||
[11]:https://opensource.com/article/17/5/how-run-raspberry-pi-meetup
|
||||
[12]:https://www.raspberrypi.org/blog/support-raspberry-jam-community/
|
||||
[13]:http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi
|
||||
[14]:https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi
|
||||
[15]:https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071
|
||||
@ -0,0 +1,275 @@
|
||||
没有恶棍,英雄又将如何?如何向你的 Python 游戏中添加一个敌人
|
||||
======
|
||||

|
||||
|
||||
在本系列的前几篇文章中(参见 [第一部分][1]、[第二部分][2]、[第三部分][3] 以及 [第四部分][4]),你已经学习了如何使用 Pygame 和 Python 在一个空白的视频游戏世界中生成一个可玩的角色。但没有恶棍,英雄又将如何?
|
||||
|
||||
如果你没有敌人,那将会是一个非常无聊的游戏。所以在此篇文章中,你将为你的游戏添加一个敌人并构建一个用于创建关卡的框架。
|
||||
|
||||
在对玩家妖精实现全部功能仍有许多事情可做之前,跳向敌人似乎就很奇怪。但你已经学到了很多东西,创造恶棍与与创造玩家妖精非常相似。所以放轻松,使用你已经掌握的知识,看看能挑起怎样一些麻烦。
|
||||
|
||||
针对本次训练,你能够从 [Open Game Art][5] 下载一些预创建的素材。此处是我使用的一些素材:
|
||||
|
||||
|
||||
+ 印加花砖(译注:游戏中使用的花砖贴图)
|
||||
+ 一些侵略者
|
||||
+ 妖精、角色、物体以及特效
|
||||
|
||||
|
||||
### 创造敌方妖精
|
||||
|
||||
是的,不管你意识到与否,你其实已经知道如何去实现敌人。这个过程与创造一个玩家妖精非常相似:
|
||||
|
||||
1. 创建一个类用于敌人生成
|
||||
2. 创建 `update` 方法使得敌人能够检测碰撞
|
||||
3. 创建 `move` 方法使得敌人能够四处游荡
|
||||
|
||||
|
||||
|
||||
从类入手。从概念上看,它与你的 Player 类大体相同。你设置一张或者一组图片,然后设置妖精的初始位置。
|
||||
|
||||
在继续下一步之前,确保你有一张你的敌人的图像,即使只是一张临时图像。将图像放在你的游戏项目的 `images` 目录(你放置你的玩家图像的相同目录)。
|
||||
|
||||
如果所有的活物都拥有动画,那么游戏看起来会好得多。为敌方妖精设置动画与为玩家妖精设置动画具有相同的方式。但现在,为了保持简单,我们使用一个没有动画的妖精。
|
||||
|
||||
在你代码 `objects` 节的顶部,使用以下代码创建一个叫做 `Enemy` 的类:
|
||||
```
|
||||
class Enemy(pygame.sprite.Sprite):
|
||||
|
||||
'''
|
||||
|
||||
生成一个敌人
|
||||
|
||||
'''
|
||||
|
||||
def __init__(self,x,y,img):
|
||||
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
|
||||
self.image = pygame.image.load(os.path.join('images',img))
|
||||
|
||||
self.image.convert_alpha()
|
||||
|
||||
self.image.set_colorkey(ALPHA)
|
||||
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
self.rect.x = x
|
||||
|
||||
self.rect.y = y
|
||||
|
||||
```
|
||||
|
||||
如果你想让你的敌人动起来,使用让你的玩家拥有动画的 [相同方式][4]。
|
||||
|
||||
### 生成一个敌人
|
||||
|
||||
你能够通过告诉类,妖精应使用哪张图像,应出现在世界上的什么地方,来生成不只一个敌人。这意味着,你能够使用相同的敌人类,在游戏世界的任意地方生成任意数量的敌方妖精。你需要做的仅仅是调用这个类,并告诉它应使用哪张图像,以及你期望生成点的 X 和 Y 坐标。
|
||||
|
||||
再次,这从原则上与生成一个玩家精灵相似。在你脚本的 `setup` 节添加如下代码:
|
||||
```
|
||||
enemy = Enemy(20,200,'yeti.png') # 生成敌人
|
||||
|
||||
enemy_list = pygame.sprite.Group() # 创建敌人组
|
||||
|
||||
enemy_list.add(enemy) # 将敌人加入敌人组
|
||||
|
||||
```
|
||||
|
||||
在示例代码中,X 坐标为 20,Y 坐标为 200。你可能需要根据你的敌方妖精的大小,来调整这些数字,但尽量生成在一个地方,使得你的玩家妖精能够到它。`Yeti.png` 是用于敌人的图像。
|
||||
|
||||
接下来,将敌人组的所有敌人绘制在屏幕上。现在,你只有一个敌人,如果你想要更多你可以稍后添加。一但你将一个敌人加入敌人组,它就会在主循环中被绘制在屏幕上。中间这一行是你需要添加的新行:
|
||||
```
|
||||
player_list.draw(world)
|
||||
|
||||
enemy_list.draw(world) # 刷新敌人
|
||||
|
||||
pygame.display.flip()
|
||||
|
||||
```
|
||||
|
||||
启动你的游戏,你的敌人会出现在游戏世界中你选择的 X 和 Y 坐标处。
|
||||
|
||||
### 关卡一
|
||||
|
||||
你的游戏仍处在襁褓期,但你可能想要为它添加另一个关卡。为你的程序做好未来规划非常重要,因为随着你学会更多的编程技巧,你的程序也会随之成长。即使你现在仍没有一个完整的关卡,你也应该按照假设会有很多关卡来编程。
|
||||
|
||||
思考一下“关卡”是什么。你如何知道你是在游戏中的一个特定关卡中呢?
|
||||
|
||||
你可以把关卡想成一系列项目的集合。就像你刚刚创建的这个平台中,一个关卡,包含了平台、敌人放置、赃物等的一个特定排列。你可以创建一个类,用来在你的玩家附近创建关卡。最终,当你创建了超过一个关卡,你就可以在你的玩家达到特定目标时,使用这个类生成下一个关卡。
|
||||
|
||||
将你写的用于生成敌人及其群组的代码,移动到一个每次生成新关卡时都会被调用的新函数中。你需要做一些修改,使得每次你创建新关卡时,你都能够创建一些敌人。
|
||||
```
|
||||
class Level():
|
||||
|
||||
def bad(lvl,eloc):
|
||||
|
||||
if lvl == 1:
|
||||
|
||||
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # 生成敌人
|
||||
|
||||
enemy_list = pygame.sprite.Group() # 生成敌人组
|
||||
|
||||
enemy_list.add(enemy) # 将敌人加入敌人组
|
||||
|
||||
if lvl == 2:
|
||||
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
|
||||
|
||||
return enemy_list
|
||||
|
||||
```
|
||||
|
||||
`return` 语句确保了当你调用 `Level.bad` 方法时,你将会得到一个 `enemy_list` 变量包含了所有你定义的敌人。
|
||||
|
||||
因为你现在将创造敌人作为每个关卡的一部分,你的 `setup` 部分也需要做些更改。不同于创造一个敌人,取而代之的是你必须去定义敌人在那里生成,以及敌人属于哪个关卡。
|
||||
```
|
||||
eloc = []
|
||||
|
||||
eloc = [200,20]
|
||||
|
||||
enemy_list = Level.bad( 1, eloc )
|
||||
|
||||
```
|
||||
|
||||
再次运行游戏来确认你的关卡生成正确。与往常一样,你应该会看到你的玩家,并且能看到你在本章节中添加的敌人。
|
||||
|
||||
### 痛击敌人
|
||||
|
||||
一个敌人如果对玩家没有效果,那么它不太算得上是一个敌人。当玩家与敌人发生碰撞时,他们通常会对玩家造成伤害。
|
||||
|
||||
因为你可能想要去跟踪玩家的生命值,因此碰撞检测发生在 Player 类,而不是 Enemy 类中。当然如果你想,你也可以跟踪敌人的生命值。它们之间的逻辑与代码大体相似,现在,我们只需要跟踪玩家的生命值。
|
||||
|
||||
为了跟踪玩家的生命值,你必须为它确定一个变量。代码示例中的第一行是上下文提示,那么将第二行代码添加到你的 Player 类中:
|
||||
```
|
||||
self.frame = 0
|
||||
|
||||
self.health = 10
|
||||
|
||||
```
|
||||
|
||||
在你 Player 类的 `update` 方法中,添加如下代码块:
|
||||
```
|
||||
hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
|
||||
|
||||
for enemy in hit_list:
|
||||
|
||||
self.health -= 1
|
||||
|
||||
print(self.health)
|
||||
|
||||
```
|
||||
|
||||
这段代码使用 Pygame 的 `sprite.spritecollide` 方法,建立了一个碰撞检测器,称作 `enemy_hit`。每当它的父类妖精(生成检测器的玩家妖精)的碰撞区触碰到 `enemy_list` 中的任一妖精的碰撞区时,碰撞检测器都会发出一个信号。当这个信号被接收,`for` 循环就会被触发,同时扣除一点玩家生命值。
|
||||
|
||||
一旦这段代码出现在你 Player 类的 `update` 方法,并且 `update` 方法在你的主循环中被调用,Pygame 会在每个时钟 tick 检测一次碰撞。
|
||||
|
||||
### 移动敌人
|
||||
|
||||
如果你愿意,静止不动的敌人也可以很有用,比如能够对你的玩家造成伤害的尖刺和陷阱。但如果敌人能够四处徘徊,那么游戏将更富有挑战。
|
||||
|
||||
与玩家妖精不同,敌方妖精不是由玩家控制,因此它必须自动移动。
|
||||
|
||||
最终,你的游戏世界将会滚动。那么,如何在游戏世界自身滚动的情况下,使游戏世界中的敌人前后移动呢?
|
||||
|
||||
举个例子,你告诉你的敌方妖精向右移动 10 步,向左移动 10 步。但敌方妖精不会计数,因此你需要创建一个变量来跟踪你的敌人已经移动了多少步,并根据计数变量的值来向左或向右移动你的敌人。
|
||||
|
||||
首先,在你的 Enemy 类中创建计数变量。添加以下代码示例中的最后一行代码:
|
||||
```
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
self.rect.x = x
|
||||
|
||||
self.rect.y = y
|
||||
|
||||
self.counter = 0 # 计数变量
|
||||
|
||||
```
|
||||
|
||||
然后,在你的 Enemy 类中创建一个 `move` 方法。使用 if-else 循环来创建一个所谓的死循环:
|
||||
|
||||
* 如果计数在 0 到 100 之间,向右移动;
|
||||
* 如果计数在 100 到 200 之间,向左移动;
|
||||
* 如果计数大于 200,则将计数重置为 0。
|
||||
|
||||
|
||||
|
||||
死循环没有终点,因为循环判断条件永远为真,所以它将永远循环下去。在此情况下,计数器总是介于 0 到 100 或 100 到 200 之间,因此敌人会永远地从左向右再从右向左移动。
|
||||
|
||||
你用于敌人在每个方向上移动距离的具体值,取决于你的屏幕尺寸,更确切地说,取决于你的敌人移动的平台大小。从较小的值开始,依据习惯逐步提高数值。首先进行如下尝试:
|
||||
```
|
||||
def move(self):
|
||||
|
||||
'''
|
||||
|
||||
敌人移动
|
||||
|
||||
'''
|
||||
|
||||
distance = 80
|
||||
|
||||
speed = 8
|
||||
|
||||
|
||||
|
||||
if self.counter >= 0 and self.counter <= distance:
|
||||
|
||||
self.rect.x += speed
|
||||
|
||||
elif self.counter >= distance and self.counter <= distance*2:
|
||||
|
||||
self.rect.x -= speed
|
||||
|
||||
else:
|
||||
|
||||
self.counter = 0
|
||||
|
||||
|
||||
|
||||
self.counter += 1
|
||||
|
||||
```
|
||||
|
||||
你可以根据需要调整距离和速度。
|
||||
|
||||
当你现在启动游戏,这段代码有效果吗?
|
||||
|
||||
当然不,你应该也知道原因。你必须在主循环中调用 `move` 方法。如下示例代码中的第一行是上下文提示,那么添加最后两行代码:
|
||||
```
|
||||
enemy_list.draw(world) #refresh enemy
|
||||
|
||||
for e in enemy_list:
|
||||
|
||||
e.move()
|
||||
|
||||
```
|
||||
|
||||
启动你的游戏看看当你打击敌人时发生了什么。你可能需要调整妖精的生成地点,使得你的玩家和敌人能够碰撞。当他们发生碰撞时,查看 [IDLE][6] 或 [Ninja-IDE][7] 的控制台,你可以看到生命值正在被扣除。
|
||||
|
||||

|
||||
|
||||
你应该已经注意到,在你的玩家和敌人接触时,生命值在时刻被扣除。这是一个问题,但你将在对 Python 进行更多练习以后解决它。
|
||||
|
||||
现在,尝试添加更多敌人。记得将每个敌人加入 `enemy_list`。作为一个练习,看看你能否想到如何改变不同敌方妖精的移动距离。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/pygame-enemy
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:https://opensource.com/article/17/10/python-101
|
||||
[2]:https://opensource.com/article/17/12/game-framework-python
|
||||
[3]:https://opensource.com/article/17/12/game-python-add-a-player
|
||||
[4]:https://opensource.com/article/17/12/game-python-moving-player
|
||||
[5]:https://opengameart.org
|
||||
[6]:https://docs.python.org/3/library/idle.html
|
||||
[7]:http://ninja-ide.org/
|
||||
274
translated/tech/20180926 HTTP- Brief History of HTTP.md
Normal file
274
translated/tech/20180926 HTTP- Brief History of HTTP.md
Normal file
@ -0,0 +1,274 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (HTTP: Brief History of HTTP)
|
||||
[#]: via: (https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol)
|
||||
[#]: author: (Ilya Grigorik https://www.igvita.com/)
|
||||
|
||||
HTTP: HTTP 历史简介
|
||||
======
|
||||
<to 校正:这篇可能得费费心了。。。>
|
||||
### 介绍
|
||||
|
||||
超文本传输协议(HTTP)是 Internet 上最普遍和广泛采用的应用程序协议之一。它是客户端和服务器之间的通用语言,支持现代 Web。从最初作为一个简单的关键字和文档路径开始,它已成为不仅仅是浏览器的首选协议,而且几乎是所有连接互联网硬件和软件应用程序的首选协议。
|
||||
|
||||
在本文中,我们将简要回顾 HTTP 协议的发展历史。对 HTTP 不同语义的完整讨论超出了本文的范围,但理解 HTTP 的关键设计变更以及每个变更背后的动机将为我们讨论 HTTP 性能提供必要的背景,特别是在 HTTP/2 中即将进行的许多改进。
|
||||
|
||||
### §HTTP 0.9: 单向协议
|
||||
|
||||
Tim Berners-Lee 最初的 HTTP 提案在设计时考虑到了简单性,以帮助他采用他的另一个新想法:万维网(World Wide Web)。这个策略看起来奏效了:注意,他是一个有抱负的协议设计者。
|
||||
|
||||
1991 年,Berners-Lee 概述了新协议的动机,并列出了几个高级设计目标:文件传输功能,请求超文档存档索引搜索的能力,格式协商以及将客户端引用到另一个服务器的能力。为了证明该理论的实际应用,我们构建了一个简单原型,它实现了所提议功能的一小部分。
|
||||
|
||||
* 客户端请求是一个 ASCII 字符串。
|
||||
|
||||
* 客户端请求以回车符(CRLF)终止。
|
||||
|
||||
* 服务器响应是 ASCII 字符流。
|
||||
|
||||
* 服务器响应是一种超文本标记语言(HTML)。
|
||||
|
||||
* 文档传输完成后连接终止。
|
||||
|
||||
这些听起来就挺复杂,而实际情况比这复杂得多。这些规则支持的是一种非常简单的,对 Telnet 友好的协议,一些 Web 服务器至今仍然支持这种协议:
|
||||
|
||||
```
|
||||
$> telnet google.com 80
|
||||
|
||||
Connected to 74.125.xxx.xxx
|
||||
|
||||
GET /about/
|
||||
|
||||
(hypertext response)
|
||||
(connection closed)
|
||||
```
|
||||
|
||||
请求包含这样一行:`GET` 方法和请求文档的路径。响应是一个超文本文档-没有标题或任何其他元数据,只有 HTML。真的是再简单不过了。此外,由于之前的交互是预期协议的子集,因此它获得了一个非官方的 HTTP 0.9 标签。其余的,就像他们所说的,都是历史。
|
||||
|
||||
从 1991 年这些不起眼的开始,HTTP 就有了自己的生命,并在接下来几年里迅速发展。让我们快速回顾一下 HTTP 0.9 的特性:
|
||||
|
||||
* 采用客户端-服务器架构,是一种请求-响应协议。
|
||||
|
||||
* 采用 ASCII 协议,运行在 TCP/IP 链路上。
|
||||
|
||||
* 旨在传输超文本文档(HTML)。
|
||||
|
||||
* 每次请求后,服务器和客户端之间的连接都将关闭。
|
||||
|
||||
```
|
||||
流行的 Web 服务器,如 Apache 和 Nginx,仍然支持 HTTP 0.9 协议,部分原因是因为它没有太多功能!如果你感兴趣,打开 Telnet 会话并尝试通过 HTTP 0.9 访问 google.com 或你最喜欢的网站,并检查早期协议的行为和限制。
|
||||
|
||||
```
|
||||
### §HTTP/1.0: 快速增长和 Informational RFC
|
||||
|
||||
1991 年至 1995 年期间, HTML 规范和一种称为 “web 浏览器”的新型软件快速发展,面向消费者的公共互联网基础设施也开始出现并快速增长。
|
||||
|
||||
```
|
||||
##### §完美风暴: 1990 年代初的互联网热潮
|
||||
|
||||
基于 Tim Berner-Lee 最初的浏览器原型,美国国家超级计算机应用中心(NCSA)的一个团队决定实现他们自己的版本。就这样,第一个流行的浏览器诞生了:NCSA Mosaic。1994 年 10 月,NCSA 团队的一名程序员 Marc Andreessen 与 Jim Clark 合作创建了 Mosaic Communications,该公司后来改名为 Netscape(网景),并于 1994 年 12 月发布了 Netscape Navigator 1.0。从这一点来说,已经很清楚了,万维网已经不仅仅是学术上的好奇心了。
|
||||
|
||||
实际上,同年在瑞士日内网组织了第一次万维网会议,这导致万维网联盟(W3C)的成立,以帮助指导 HTML 的发展。同样,在 IETF 内部建立了一个并行的 HTTP 工作组(HTTP-WG),专注于改进 HTTP 协议。后来这两个团体一直对 Web 的发展起着重要作用。
|
||||
|
||||
最后,完美的风暴来临,CompuServe,AOL 和 Prodigy 在 1994-1995 年的同一时间开始向公众提供拨号上网服务。凭借这股迅速的浪潮,Netscape 在 1995 年 8 月 9 日凭借其成功的 IPO 创造了历史。这预示着互联网热潮已经到来,人人都想分一杯羹!
|
||||
```
|
||||
|
||||
不断增长的新 Web 所需功能及其在公共网站上的用例很快暴露了 HTTP 0.9 的许多基础限制:我们需要一种能够提供超文本文档、提供关于请求和响应的更丰富的元数据,支持内容协商等等的协议。相应地,新兴的 Web 开发人员社区通过一个特殊的过程生成了大量实验性的 HTTP 服务器和客户端实现来回应:实现,部署,并查看其他人是否采用它。
|
||||
|
||||
从这些急速增长的实验开始,一系列最佳实践和常见模式开始出现。1996 年 5 月,HTTP 工作组(HTTP-WG)发布了 RFC 1945,它记录了许多被广泛使用的 HTTP/1.0 实现的“常见用法”。请注意,这只是一个信息 RFC:HTTP/1.0,因为我们知道它不是一个正式规范或 Internet 标准!
|
||||
|
||||
话虽如此,HTTP/1.0 请求看起来应该是:
|
||||
|
||||
```
|
||||
$> telnet website.org 80
|
||||
|
||||
Connected to xxx.xxx.xxx.xxx
|
||||
|
||||
GET /rfc/rfc1945.txt HTTP/1.0
|
||||
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
|
||||
Accept: */*
|
||||
|
||||
HTTP/1.0 200 OK
|
||||
Content-Type: text/plain
|
||||
Content-Length: 137582
|
||||
Expires: Thu, 01 Dec 1997 16:00:00 GMT
|
||||
Last-Modified: Wed, 1 May 1996 12:45:26 GMT
|
||||
Server: Apache 0.84
|
||||
|
||||
(plain-text response)
|
||||
(connection closed)
|
||||
```
|
||||
|
||||
1. 请求行有 HTTP 版本号,后面跟请求头
|
||||
|
||||
2. 响应状态,后跟响应头
|
||||
|
||||
|
||||
前面交换的并不是 HTTP/1.0 功能的详尽列表,但它确实说明了一些关键的协议更改:
|
||||
|
||||
* 请求可能多个由换行符分隔的请求头字段组成。
|
||||
|
||||
* 响应对象的前缀是响应状态行。
|
||||
|
||||
* 响应对象有自己的一组由换行符分隔的响应头字段。
|
||||
|
||||
* 响应对象不限于超文本。
|
||||
|
||||
* 每次请求后,服务器和客户端之间的连接都将关闭。
|
||||
|
||||
请求头和响应头都保留为 ASCII 编码,但响应对象本身可以是任何类型:一个 HTML 文件,一个纯文本文件,一个图像或任何其他内容类型。因此,HTTP 的“超文本传输”部分在引入后不久就变成了用词不当。实际上,HTTP 已经迅速发展成为一种超媒体传输,但最初的名称没有改变。
|
||||
|
||||
除了媒体类型协商之外,RFC 还记录了许多其他常用功能:内容编码,字符集支持,多部分类型,授权,缓存,代理行为,日期格式等。
|
||||
|
||||
```
|
||||
今天,几乎所有 Web 上的服务器都可以并且仍将使用 HTTP/1.0。不过,现在你应该更加清楚了!每个请求都需要一个新的 TCP 连接,这会对 HTTP/1.0 造成严重的性能损失。参见[三次握手][1],接着会[慢启动][2]。
|
||||
```
|
||||
|
||||
### §HTTP/1.1: Internet 标准
|
||||
|
||||
将 HTTP 转变为官方 IETF 互联网标准的工作与围绕 HTTP/1.0 的文档工作并行进行,并计划从 1995 年至 1999 年完成。事实上,第一个正式的 HTTP/1.1 标准定义于 RFC 2068,它在 HTTP/1.0 发布大约六个月后,即 1997 年 1 月正式发布。两年半后,即 1999 年 6 月,一些新的改进和更新被纳入标准,并作为 RFC 2616 发布。
|
||||
|
||||
HTTP/1.1 标准解决了早期版本中发现的许多协议歧义,并引入了一些关键的性能优化:保持连接,分块编码传输,字节范围请求,附加缓存机制,传输编码和请求管道。
|
||||
|
||||
有了这些功能,我们现在可以审视一下由任何现代 HTTP 浏览器和客户端执行的典型 HTTP/1.1 会话:
|
||||
|
||||
```
|
||||
$> telnet website.org 80
|
||||
Connected to xxx.xxx.xxx.xxx
|
||||
|
||||
GET /index.html HTTP/1.1
|
||||
Host: website.org
|
||||
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
|
||||
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
|
||||
Accept-Encoding: gzip,deflate,sdch
|
||||
Accept-Language: en-US,en;q=0.8
|
||||
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
|
||||
Cookie: __qca=P0-800083390... (snip)
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Server: nginx/1.0.11
|
||||
Connection: keep-alive
|
||||
Content-Type: text/html; charset=utf-8
|
||||
Via: HTTP/1.1 GWA
|
||||
Date: Wed, 25 Jul 2012 20:23:35 GMT
|
||||
Expires: Wed, 25 Jul 2012 20:23:35 GMT
|
||||
Cache-Control: max-age=0, no-cache
|
||||
Transfer-Encoding: chunked
|
||||
|
||||
100
|
||||
<!doctype html>
|
||||
(snip)
|
||||
|
||||
100
|
||||
(snip)
|
||||
|
||||
0
|
||||
|
||||
GET /favicon.ico HTTP/1.1
|
||||
Host: www.website.org
|
||||
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
|
||||
Accept: */*
|
||||
Referer: http://website.org/
|
||||
Connection: close
|
||||
Accept-Encoding: gzip,deflate,sdch
|
||||
Accept-Language: en-US,en;q=0.8
|
||||
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
|
||||
Cookie: __qca=P0-800083390... (snip)
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Server: nginx/1.0.11
|
||||
Content-Type: image/x-icon
|
||||
Content-Length: 3638
|
||||
Connection: close
|
||||
Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT
|
||||
Cache-Control: max-age=315360000
|
||||
Accept-Ranges: bytes
|
||||
Via: HTTP/1.1 GWA
|
||||
Date: Sat, 21 Jul 2012 21:35:22 GMT
|
||||
Expires: Thu, 31 Dec 2037 23:55:55 GMT
|
||||
Etag: W/PSA-GAu26oXbDi
|
||||
|
||||
(icon data)
|
||||
(connection closed)
|
||||
```
|
||||
|
||||
1. 请求的 HTML 文件,包括编码,字符集和 cookie 元数据
|
||||
|
||||
2. 原始 HTML 请求的分块响应
|
||||
|
||||
3. 以 ASCII 十六进制数字(256 字节)表示块中的八位元数
|
||||
|
||||
4. 分块流响应结束
|
||||
|
||||
5. 在相同的 TCP 连接上请求一个图标文件
|
||||
|
||||
6. 通知服务器不再重用连接
|
||||
|
||||
7. 图标响应后,然后关闭连接
|
||||
|
||||
|
||||
哇,这里发生了很多事情!第一个也是最明显的区别是我们有两个对象请求,一个用于 HTML 页面,另一个用于图像,它们都通过一个连接完成。这就是保持连接的实际应用,它允许我们重用现有的 TCP 连接到同一个主机的多个请求,提供一个更快的最终用户体验。参见[TCP 优化][3]。
|
||||
|
||||
要终止持久连接,注意第二个客户端请求通过 `Connection` 请求头向服务器发送显示的 `close`。类似地,一旦传输响应,服务器就可以通知客户端关闭当前 TCP 连接。从技术上讲,任何一方都可以在没有此类信号的情况下终止 TCP 连接,但客户端和服务器应尽可能提供此类信号,以便双方都启用更好的连接重用策略。
|
||||
|
||||
```
|
||||
HTTP/1.1 改变了 HTTP 协议的语义,默认情况下使用保持连接。这意味着,除非另有说明(通过 `Connection:close` 头),否则服务器应默认保持连接打开。
|
||||
|
||||
但是,同样的功能也被反向移植到 HTTP/1.0 上,通过 `Connection:keep-Alive` 头启用。因此,如果你使用 HTTP/1.1,从技术上讲,你不需要 `Connection:keep-Alive` 头,但许多客户端仍然选择提供它。
|
||||
```
|
||||
|
||||
此外,HTTP/1.1 协议还添加了内容、编码、字符集,甚至语言协商、传输编码、缓存指令、客户端 cookie,以及可以针对每个请求协商的十几个其他功能。
|
||||
|
||||
我们不打算详细讨论每个 HTTP/1.1 特性的语义。这个主题可以写一本专门的书了,已经有了很多很棒的书。相反,前面的示例很好地说明了 HTTP 的快速进展和演变,以及每个客户端-服务器交换的错综复杂的过程,里面发生了很多事情!
|
||||
|
||||
```
|
||||
要了解 HTTP 协议所有内部工作原理,参考 David Gourley 和 Brian Totty 共同撰写的权威指南: The Definitive Guide。(to 校正:这里翻译的不准确)
|
||||
```
|
||||
|
||||
### §HTTP/2: 提高传输性能
|
||||
|
||||
RFC 2616 自发布以来,已经成为互联网空前增长的基础:数十亿各种形状和大小的设备,从台式电脑到我们口袋里的小型网络设备,每天都在使用 HTTP 来传送新闻,视频,在我们生活中的数百万的其他网络应用程序都在依靠它。
|
||||
|
||||
一开始是一个简单的,用于检索超文本的简单协议,很快演变成了一种通用的超媒体传输,现在十年过去了,它几乎可以为你所能想象到的任何用例提供支持。可以使用协议的服务器无处不在,客户端也可以使用协议,这意味着现在许多应用程序都是专门在 HTTP 之上设计和部署的。
|
||||
|
||||
需要一个协议来控制你的咖啡壶?RFC 2324 已经涵盖了超文本咖啡壶控制协议(HTCPCP/1.0)- 它原本是 IETF 在愚人节开的一个玩笑,但在我们这个超链接的新世界中,它不仅仅意味着一个玩笑。
|
||||
|
||||
> 超文本传输协议(HTTP)是一个应用程序级的协议,用于分布式、协作、超媒体信息系统。它是一种通用的、无状态的协议,可以通过扩展请求方法、错误码和头,用于超出超文本之外的许多任务,比如名称服务器和分布式对象管理系统。HTTP 的一个特性是数据表示的类型和协商,允许独立于传输的数据构建系统。
|
||||
>
|
||||
> RFC 2616: HTTP/1.1, June 1999
|
||||
|
||||
HTTP 协议的简单性是它最初被采用和快速增长的原因。事实上,现在使用 HTTP 作为主要控制和数据协议的嵌入式设备(传感器,执行器和咖啡壶)并不罕见。但在其自身成功的重压下,随着我们越来越多地继续将日常互动转移到网络-社交、电子邮件、新闻和视频,以及越来越多的个人和工作空间,它也开始显示出压力的迹象。用户和 Web 开发人员现在都要求 HTTP/1.1 提供近乎实时的响应能力和协议
|
||||
性能,如果不进行一些修改,就无法满足这些要求。
|
||||
|
||||
为了应对这些新挑战,HTTP 必须继续发展,因此 HTTPbis 工作组在 2012 年初宣布了一项针对 HTTP/2 的新计划:
|
||||
|
||||
> 已经有一个协议中出现了新的实现经验和兴趣,该协议保留了 HTTP 的语义,但是没有保留 HTTP/1.x 的消息框架和语法,这些问题已经被确定为妨碍性能和鼓励滥用底层传输。
|
||||
>
|
||||
> 工作组将使用有序的双向流中生成 HTTP 当前语义的新表达式的规范。与 HTTP/1.x 一样,主要传输目标是 TCP,但是应该可以使用其他方式传输。
|
||||
>
|
||||
> HTTP/2 charter, January 2012
|
||||
|
||||
HTTP/2 的主要重点是提高传输性能并支持更低的延迟和更高的吞吐量。主要的版本增量听起来像是一个很大的步骤,但就性能而言,它将是一个重大的步骤,但重要的是要注意,没有任何高级协议语义收到影响:所有的 HTTP 头,值和用例是相同的。
|
||||
|
||||
任何现有的网站或应用程序都可以并且将通过 HTTP/2 传送而无需修改。你无需修改应用程序标记来利用 HTTP/2。HTTP 服务器必须使用 HTTP/2,但这对大多数用户来说应该是透明的升级。如果工作组实现目标,唯一的区别应该是我们的应用程序以更低的延迟和更好的网络连接利用率来传送数据。
|
||||
|
||||
话虽如此,但我们不要走的太远了。在讨论新的 HTTP/2 协议功能之前,有必要回顾一下我们现有的 HTTP/1.1 部署和性能最佳实践。HTTP/2 工作组正在新规范上取得快速的进展,但即使最终标准已经完成并准备就绪,在可预见的未来,我们仍然必须支持旧的 HTTP/1.1 客户端,实际上,这得十年或更长时间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol
|
||||
|
||||
作者:[Ilya Grigorik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.igvita.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://hpbn.co/building-blocks-of-tcp/#three-way-handshake
|
||||
[2]: https://hpbn.co/building-blocks-of-tcp/#slow-start
|
||||
[3]: https://hpbn.co/building-blocks-of-tcp/#optimizing-for-tcp
|
||||
@ -0,0 +1,525 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (SPEED TEST: x86 vs. ARM for Web Crawling in Python)
|
||||
[#]: via: (https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/)
|
||||
[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
|
||||
|
||||
x86 和 ARM 的 Python 爬虫速度对比
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
如果你的老板给你的任务是不断地访问竞争对手的网站,把对方商品的价格记录下来,而且要纯手工操作,恐怕你会想要把整个办公室都烧掉。
|
||||
|
||||
之所以现在网络爬虫的影响力如此巨大,就是因为网络爬虫可以被用于追踪客户的情绪和趋向、搜寻空缺的职位、监控房地产的交易,甚至是获取 UFC 的比赛结果。除此以外,还有很多意想不到的用途。
|
||||
|
||||
对于有这方面爱好的人来说,爬虫无疑是一个很好的工具。因此,我使用了 [Scrapy][2] 这个基于 Python 编写的开源网络爬虫框架。
|
||||
|
||||
鉴于我不太了解这个工具是否会对我的计算机造成伤害,我并没有将它搭建在我的主力机器上,而是搭建在了一台树莓派上面。
|
||||
|
||||
令人感到意外的是,Scrapy 在树莓派上面的性能并不差,或许这是 ARM 架构服务器的又一个成功例子?
|
||||
|
||||
我尝试 Google 了一下,但并没有得到令我满意的结果,仅仅找到了一篇相关的《[Drupal 建站对比][3]》。这篇文章的结论是,ARM 架构服务器性能比昂贵的 x86 架构服务器要更好。
|
||||
|
||||
从另一个角度来看,这种 web 服务可以看作是一个“被爬虫”服务,但和 Scrapy 对比起来,前者是基于 LAMP 技术栈,而后者则依赖于 Python,这就导致两者之间没有太多的可比性。
|
||||
|
||||
那我们该怎样做呢?只能在一些 VPS 上搭建服务来对比一下了。
|
||||
|
||||
### 什么是 ARM 架构处理器?
|
||||
|
||||
ARM 是目前世界上最流行的 CPU 架构。
|
||||
|
||||
但 ARM 架构处理器在很多人眼中的地位只是作为一个节省成本的选择,而不是跑在生产环境中的处理器的首选。
|
||||
|
||||
然而,诞生于英国剑桥的 ARM CPU,最初是用于昂贵的 [Acorn Archimedes][4] 计算机上的,这是当时世界上最强大的计算机,它的运算速度甚至比最快的 386 还要快好几倍。
|
||||
|
||||
Acorn 公司和 Commodore、Atari 的理念类似,他们认为一家伟大的计算机公司就应该制造出伟大的计算机,让人感觉有点目光短浅。而比尔盖茨的想法则有所不同,他力图在更多不同种类和价格的 x86 机器上使用他的 DOS 系统。
|
||||
|
||||
拥有大量用户基础的平台会让更多开发者开发出众多适应平台的软件,而软件资源丰富又让计算机更受用户欢迎。
|
||||
|
||||
即使是苹果公司也在这上面吃到了苦头,不得不在 x86 芯片上投入大量的财力。最终,这些芯片不再仅仅用于专业的计算任务,走进了人们的日常生活中。
|
||||
|
||||
ARM 架构也并没有消失。基于 ARM 架构的芯片不仅运算速度快,同时也非常节能。因此诸如机顶盒、PDA、数码相机、MP3 播放器这些电子产品多数都会采用 ARM 架构的芯片,甚至在很多需要用电池、不配备大散热风扇的电子产品上,都可以见到 ARM 芯片的身影。
|
||||
|
||||
而 ARM 则脱离 Acorn 成为了一种独立的商业模式,他们不生产实物芯片,仅仅是向芯片生产厂商出售相关的知识产权。
|
||||
|
||||
因此,ARM 芯片被应用于很多手机和平板电脑上。当 Linux 被移植到这种架构的芯片上时,开源技术的大门就已经向它打开了,这才让我们今天得以在这些芯片上运行 web 爬虫程序。
|
||||
|
||||
#### 服务器端的 ARM
|
||||
|
||||
诸如[微软][5]和 [Cloudflare][6] 这些大厂都在基础设施建设上花了重金,所以对于我们这些预算不高的用户来说,可以选择的余地并不多。
|
||||
|
||||
实际上,如果你的信用卡只够付每月数美元的 VPS 费用,一直以来只能考虑 [Scaleway][7] 这个高性价比的厂商。
|
||||
|
||||
但自从数个月前公有云巨头 [AWS][8] 推出了他们自研的 ARM 处理器 [AWS Graviton][9] 之后,选择似乎就丰富了一些。
|
||||
|
||||
我决定在其中选择一款 VPS 厂商,将它提供的 ARM 处理器和 x86 处理器作出对比。
|
||||
|
||||
### 深入了解
|
||||
|
||||
所以我们要对比的是什么指标呢?
|
||||
|
||||
#### Scaleway
|
||||
|
||||
Scaleway 自身的定位是“专为开发者设计”。我觉得这个定位很准确,对于开发原型来说,Scaleway 提供的产品确实可以作为一个很好的沙盒环境。
|
||||
|
||||
Scaleway 提供了一个简洁的页面,让用户可以快速地从主页进入 bash shell 界面。对于很多小企业、自由职业者或者技术顾问,如果想要运行 web 爬虫,这个产品毫无疑问是一个物美价廉的选择。
|
||||
|
||||
ARM 方面我们选择 [ARM64-2GB][10] 这一款服务器,每月只需要 3 欧元。它带有 4 个 Cavium ThunderX 核心,是在 2014 年推出的第一款服务器级的 ARMv8 处理器。但现在看来它已经显得有点落后了,并逐渐被更新的 ThunderX2 取代。
|
||||
|
||||
x86 方面我们选择 [1-S][11],每月的费用是 4 欧元。它拥有 2 个英特尔 Atom C3995 核心。英特尔的 Atom 系列处理器的特点是低功耗、单线程,最初是用在笔记本电脑上的,后来也被服务器所采用。
|
||||
|
||||
两者在处理器以外的条件都大致相同,都使用 2 GB 的内存、50 GB 的 SSD 存储以及 200 Mbit/s 的带宽。磁盘驱动器可能会有所不同,但由于我们运行的是 web 爬虫,基本都是在内存中完成操作,因此这方面的差异可以忽略不计。
|
||||
|
||||
为了避免我不能熟练使用包管理器的尴尬局面,两方的操作系统我都会选择使用 Debian 9。
|
||||
|
||||
#### Amazon Web Services
|
||||
|
||||
当你还在注册 AWS 账号的时候,使用 Scaleway 的用户可能已经把提交信用卡信息、启动 VPS 实例、添加sudoer、安装依赖包这一系列流程都完成了。AWS 的操作相对来说比较繁琐,甚至需要详细阅读手册才能知道你正在做什么。
|
||||
|
||||
当然这也是合理的,对于一些需求复杂或者特殊的企业用户,确实需要通过详细的配置来定制合适的使用方案。
|
||||
|
||||
我们所采用的 AWS Graviton 处理器是 AWS EC2(Elastic Compute Cloud)的一部分,我会以按需实例的方式来运行,这也是最贵但最简捷的方式。AWS 同时也提供[竞价实例][12],这样可以用较低的价格运行实例,但实例的运行时间并不固定。如果实例需要长时间持续运行,还可以选择[预留实例][13]。
|
||||
|
||||
看,AWS 就是这么复杂……
|
||||
|
||||
我们分别选择 [a1.medium][14] 和 [t2.small][15] 两种型号的实例进行对比,两者都带有 2GB 内存。这个时候问题来了,手册中提到的 vCPU 又是什么?两种型号的不同之处就在于此。
|
||||
|
||||
对于 a1.medium 型号的实例,vCPU 是 AWS Graviton 芯片提供的单个计算核心。这个芯片由被亚马逊在 2015 收购的以色列厂商 Annapurna Labs 研发,是 AWS 独有的单线程 64 位 ARMv8 内核。它的按需价格为每小时 0.0255 美元。
|
||||
|
||||
而 t2.small 型号实例使用英特尔至强系列芯片,但我不确定具体是其中的哪一款。它每个核心有两个线程,但我们并不能用到整个核心,甚至整个线程。我们能用到的只是“20% 的基准性能,可以使用 CPU 积分突破这个基准”。这可能有一定的原因,但我没有弄懂。它的按需价格是每小时 0.023 美元。
|
||||
|
||||
在镜像库中没有 Debian 发行版的镜像,因此我选择了 Ubuntu 18.04。
|
||||
|
||||
### Beavis and Butthead Do Moz’s Top 500
|
||||
|
||||
要测试这些 VPS 的 CPU 性能,就该使用爬虫了。一般来说都是对几个网站在尽可能短的时间里发出尽可能多的请求,但这种操作太暴力了,我的做法是只向大量网站发出少数几个请求。
|
||||
|
||||
为此,我编写了 `beavs.py` 这个爬虫程序(致敬我最喜欢的物理学家和制片人 Mike Judge)。这个程序会将 Moz 上排行前 500 的网站都爬取 3 层的深度,并计算 “wood” 和 “ass” 这两个单词在 HTML 文件中出现的次数。
|
||||
|
||||
但我实际爬取的网站可能不足 500 个,因为我需要遵循网站的 `robot.txt` 协定,另外还有些网站需要提交 javascript 请求,也不一定会计算在内。但这已经是一个足以让 CPU 保持繁忙的爬虫任务了。
|
||||
|
||||
Python 的[全局解释器锁][16]机制会让我的程序只能用到一个 CPU 线程。为了测试多线程的性能,我需要启动多个独立的爬虫程序进程。
|
||||
|
||||
因此我还编写了 `butthead.py`,尽管 Butthead 很粗鲁,它也比 Beavis 要略胜一筹(译者注:beavis 和 butt-head 都是 Mike Judge 的动画片《Beavis and Butt-head》中的角色)。
|
||||
|
||||
我将整个爬虫任务拆分为多个部分,这可能会对爬取到的链接数量有一点轻微的影响。但无论如何,每次爬取都会有所不同,我们要关注的是爬取了多少个页面,以及耗时多长。
|
||||
|
||||
### 在 ARM 服务器上安装 Scrapy
|
||||
|
||||
安装 Scrapy 的过程与芯片的不同架构没有太大的关系,都是安装 pip 和相关的依赖包之后,再使用 pip 来安装Scrapy。
|
||||
|
||||
据我观察,在使用 ARM 的机器上使用 pip 安装 Scrapy 确实耗时要长一点,我估计是由于需要从源码编译为二进制文件。
|
||||
|
||||
在 Scrapy 安装结束后,就可以通过 shell 来查看它的工作状态了。
|
||||
|
||||
在 Scaleway 的 ARM 机器上,Scrapy 安装完成后会无法正常运行,这似乎和 `service_identity` 模块有关。这个现象也会在树莓派上出现,但在 AWS Graviton 上不会出现。
|
||||
|
||||
对于这个问题,可以用这个命令来解决:
|
||||
|
||||
```
|
||||
sudo pip3 install service_identity --force --upgrade
|
||||
```
|
||||
|
||||
接下来就可以开始对比了。
|
||||
|
||||
### 单线程爬虫
|
||||
|
||||
Scrapy 的官方文档建议[将爬虫程序的 CPU 使用率控制在 80% 到 90% 之间][17],在真实操作中并不容易,尤其是对于我自己写的代码。根据我的观察,实际的 CPU 使用率变动情况是一开始非常繁忙,随后稍微下降,接着又再次升高。
|
||||
|
||||
在爬取任务的最后,也就是大部分目标网站都已经被爬取了的这个阶段,会持续数分钟的时间。这让人有点失望,因为在这个阶段当中,任务的运行时长只和网站的大小有比较直接的关系,并不能以之衡量 CPU 的性能。
|
||||
|
||||
所以这并不是一次严谨的基准测试,只是我通过自己写的爬虫程序来观察实际的现象。
|
||||
|
||||
下面我们来看看最终的结果。首先是 Scaleway 的机器:
|
||||
|
||||
| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每百万页面费用(欧元) |
|
||||
| ------------------ | ----------- | ---------- | ---------------- | ---------------------- |
|
||||
| Scaleway ARM64-2GB | 108m 59.27s | 38,205 | 21,032.623 | 0.28527 |
|
||||
| Scaleway 1-S | 97m 44.067s | 39,476 | 24,324.648 | 0.33011 |
|
||||
|
||||
我使用了 [top][18] 工具来查看爬虫程序运行期间的 CPU 使用率。在任务刚开始的时候,两者的 CPU 使用率都达到了 100%,但 ThunderX 大部分时间都达到了 CPU 的极限,无法看出来 Atom 的性能会比 ThunderX 超出多少。
|
||||
|
||||
通过 top 工具,我还观察了它们的内存使用情况。随着爬取任务的进行,ARM 机器的内存使用率最终达到了 14.7%,而 x86 则最终是 15%。
|
||||
|
||||
从运行日志还可以看出来,当 CPU 使用率到达极限时,会有大量的超时页面产生,最终导致页面丢失。这也是合理出现的现象,因为 CPU 过于繁忙会无法完整地记录所有爬取到的页面。
|
||||
|
||||
如果仅仅是为了对比爬虫的速度,页面丢失并不是什么大问题。但在实际中,业务成果和爬虫数据的质量是息息相关的,因此必须为 CPU 留出一些用量,以防出现这种现象。
|
||||
|
||||
再来看看 AWS 这边:
|
||||
|
||||
| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每百万页面费用(美元) |
|
||||
| --------- | ------------ | ---------- | ---------------- | ---------------------- |
|
||||
| a1.medium | 100m 39.900s | 41,294 | 24,612.725 | 1.03605 |
|
||||
| t2.small | 78m 53.171s | 41,200 | 31,336.286 | 0.73397 |
|
||||
|
||||
为了方便比较,对于在 AWS 上跑的爬虫,我记录的指标和 Scaleway 上一致,但似乎没有达到预期的效果。这里我没有使用 top,而是使用了 AWS 提供的控制台来监控 CPU 的使用情况,从监控结果来看,我的爬虫程序并没有完全用到这两款服务器所提供的所有性能。
|
||||
|
||||
a1.medium 型号的机器尤为如此,在任务开始阶段,它的 CPU 使用率达到了峰值 45%,但随后一直在 20% 到 30% 之间。
|
||||
|
||||
让我有点感到意外的是,这个程序在 ARM 处理器上的运行速度相当慢,但却远未达到 Graviton CPU 能力的极限,而在 Inter 处理器上则可以在某些时候达到 CPU 能力的极限。它们运行的代码是完全相同的,处理器的不同架构可能导致了对代码的不同处理方式。
|
||||
|
||||
个中原因无论是由于处理器本身的特性,还是而今是文件的编译,又或者是两者皆有,对我来说都是一个黑盒般的存在。我认为,既然在 AWS 机器上没有达到 CPU 处理能力的极限,那么只有在 Scaleway 机器上跑出来的性能数据是可以作为参考的。
|
||||
|
||||
t2.small 型号的机器性能让人费解。CPU 利用率大概 20%,最高才达到 35%,是因为手册中说的“20% 的基准性能,可以使用 CPU 积分突破这个基准”吗?但在控制台中可以看到 CPU 积分并没有被消耗。
|
||||
|
||||
为了确认这一点,我安装了 [stress][19] 这个软件,然后运行了一段时间,这个时候发现居然可以把 CPU 使用率提高到 100% 了。
|
||||
|
||||
显然,我需要调整一下它们的配置文件。我将 CONCURRENT_REQUESTS 参数设置为 5000,将 REACTOR_THREADPOOL_MAXSIZE 参数设置为 120,将爬虫任务的负载调得更大。
|
||||
|
||||
| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每万页面费用(美元) |
|
||||
| ----------------------- | ----------- | ---------- | ---------------- | -------------------- |
|
||||
| a1.medium | 46m 13.619s | 40,283 | 52,285.047 | 0.48771 |
|
||||
| t2.small | 41m7.619s | 36,241 | 52,871.857 | 0.43501 |
|
||||
| t2.small(无 CPU 积分) | 73m 8.133s | 34,298 | 28,137.8891 | 0.81740 |
|
||||
|
||||
a1.medium 型号机器的 CPU 使用率在爬虫任务开始后 5 分钟飙升到了 100%,随后下降到 80% 并持续了 20 分钟,然后再次攀升到 96%,直到任务接近结束时再次下降。这大概就是我想要的效果了。
|
||||
|
||||
而 t2.small 型号机器在爬虫任务的前期就达到了 50%,并一直保持在这个水平直到任务接近结束。如果每个核心都有两个线程,那么 50% 的 CPU 使用率确实是单个线程可以达到的极限了。
|
||||
|
||||
现在我们看到它们的性能都差不多了。但至强处理器的线程持续跑满了 CPU,Graviton 处理器则只是有一段时间如此。可以认为 Graviton 略胜一筹。
|
||||
|
||||
然而,如果 CPU 积分耗尽了呢?这种情况下的对比可能更为公平。为了测试这种情况,我使用 stress 把所有的 CPU 积分用完,然后再次启动了爬虫任务。
|
||||
|
||||
在没有 CPU 积分的情况下,CPU 使用率在 27% 就到达极限不再上升了,同时又出现了丢失页面的现象。这么看来,它的性能比负载较低的时候更差。
|
||||
|
||||
### 多线程爬虫
|
||||
|
||||
将爬虫任务分散到不同的进程中,可以有效利用机器所提供的多个核心。
|
||||
|
||||
一开始,我将爬虫任务分布在 10 个不同的进程中并同时启动,结果发现比仅使用 1 个进程的时候还要慢。
|
||||
|
||||
经过尝试,我得到了一个比较好的方案。把爬虫任务分布在 10 个进程中,但每个核心只启动 1 个进程,在每个进程接近结束的时候,再从剩余的进程中选出 1 个进程启动起来。
|
||||
|
||||
如果还需要优化,还可以让运行时间越长的爬虫进程在启动顺序中排得越靠前,我也在尝试实现这个方法。
|
||||
|
||||
想要预估某个域名的页面量,一定程度上可以参考这个域名主页的链接数量。我用另一个程序来对这个数量进行了统计,然后按照降序排序。经过这样的预处理之后,只会额外增加 1 分钟左右的时间。
|
||||
|
||||
结果,爬虫运行的总耗时找过了两个小时!毕竟把链接最多的域名都堆在同一个进程中也存在一定的弊端。
|
||||
|
||||
针对这个问题,也可以通过调整各个进程爬取的域名数量来进行优化,又或者在排序之后再作一定的修改。不过这种优化可能有点复杂了。
|
||||
|
||||
因此,我还是用回了最初的方法,它的效果还是相当不错的:
|
||||
|
||||
| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每万页面费用(欧元) |
|
||||
| ------------------ | ----------- | ---------- | ---------------- | -------------------- |
|
||||
| Scaleway ARM64-2GB | 62m 10.078s | 36,158 | 34,897.0719 | 0.17193 |
|
||||
| Scaleway 1-S | 60m 56.902s | 36,725 | 36,153.5529 | 0.22128 |
|
||||
|
||||
毕竟,使用多个核心能够大大加快爬虫的速度。
|
||||
|
||||
我认为,如果让一个经验丰富的程序员来优化的话,一定能够更好地利用所有的计算核心。但对于开箱即用的 Scrapy 来说,想要提高性能,使用更快的线程似乎比使用更多核心要简单得多。
|
||||
|
||||
从数量来看,Atom 处理器在更短的时间内爬取到了更多的页面。但如果从性价比角度来看,ThunderX 又是稍稍领先的。不过总的来说差距不大。
|
||||
|
||||
### 爬取结果分析
|
||||
|
||||
在爬取了 38205 个页面之后,我们可以统计到在这些页面中 “ass” 出现了 24170435 次,而 “wood” 出现了 54368 次。
|
||||
|
||||
![][20]
|
||||
|
||||
“wood” 的出现次数不少,但和 “ass” 比起来简直微不足道。
|
||||
|
||||
### 结论
|
||||
|
||||
从上面的数据来看,不同架构的 CPU 性能和它们的问世时间没有直接的联系,AWS Graviton 是单线程情况下性能最佳的。
|
||||
|
||||
另外在性能方面 2017 年生产的 Atom 轻松击败了 2014 年生产的 ThunderX,而 ThunderX 则在性价比方面占优。当然,如果你使用 AWS 的机器的话,还是使用 Graviton 吧。
|
||||
|
||||
总之,ARM 架构的硬件是可以用来运行爬虫程序的,而且在性能和费用方面也相当有竞争力。
|
||||
|
||||
而这种差异是否足以让你将整个技术架构迁移到 ARM 上?这就是另一回事了。当然,如果你已经是 AWS 用户,并且你的代码有很强的可移植性,那么不妨尝试一下 a1 型号的实例。
|
||||
|
||||
希望 ARM 设备在不久的将来能够在公有云上大放异彩。
|
||||
|
||||
### 源代码
|
||||
|
||||
这是我第一次使用 Python 和 Scrapy 来做一个项目,所以我的代码写得可能不是很好,例如代码中使用全局变量就有点力不从心。
|
||||
|
||||
不过我仍然会在下面开源我的代码。
|
||||
|
||||
要运行这些代码,需要预先安装 Scrapy,并且需要 [Moz 上排名前 500 的网站][21]的 csv 文件。如果要运行 `butthead.py`,还需要安装 [psutil][22] 这个库。
|
||||
|
||||
##### beavis.py
|
||||
|
||||
```
|
||||
import scrapy
|
||||
from scrapy.spiders import CrawlSpider, Rule
|
||||
from scrapy.linkextractors import LinkExtractor
|
||||
from scrapy.crawler import CrawlerProcess
|
||||
|
||||
ass = 0
|
||||
wood = 0
|
||||
totalpages = 0
|
||||
|
||||
def getdomains():
|
||||
|
||||
moz500file = open('top500.domains.05.18.csv')
|
||||
|
||||
domains = []
|
||||
moz500csv = moz500file.readlines()
|
||||
|
||||
del moz500csv[0]
|
||||
|
||||
for csvline in moz500csv:
|
||||
leftquote = csvline.find('"')
|
||||
rightquote = leftquote + csvline[leftquote + 1:].find('"')
|
||||
domains.append(csvline[leftquote + 1:rightquote])
|
||||
|
||||
return domains
|
||||
|
||||
def getstartpages(domains):
|
||||
|
||||
startpages = []
|
||||
|
||||
for domain in domains:
|
||||
startpages.append('http://' + domain)
|
||||
|
||||
return startpages
|
||||
|
||||
class AssWoodItem(scrapy.Item):
|
||||
ass = scrapy.Field()
|
||||
wood = scrapy.Field()
|
||||
url = scrapy.Field()
|
||||
|
||||
class AssWoodPipeline(object):
|
||||
def __init__(self):
|
||||
self.asswoodstats = []
|
||||
|
||||
def process_item(self, item, spider):
|
||||
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
|
||||
|
||||
def close_spider(self, spider):
|
||||
asstally, woodtally = 0, 0
|
||||
|
||||
for asswoodcount in self.asswoodstats:
|
||||
asstally += asswoodcount[1]
|
||||
woodtally += asswoodcount[2]
|
||||
|
||||
global ass, wood, totalpages
|
||||
ass = asstally
|
||||
wood = woodtally
|
||||
totalpages = len(self.asswoodstats)
|
||||
|
||||
class BeavisSpider(CrawlSpider):
|
||||
name = "Beavis"
|
||||
allowed_domains = getdomains()
|
||||
start_urls = getstartpages(allowed_domains)
|
||||
#start_urls = [ 'http://medium.com' ]
|
||||
custom_settings = {
|
||||
'DEPTH_LIMIT': 3,
|
||||
'DOWNLOAD_DELAY': 3,
|
||||
'CONCURRENT_REQUESTS': 1500,
|
||||
'REACTOR_THREADPOOL_MAXSIZE': 60,
|
||||
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
|
||||
'LOG_LEVEL': 'INFO',
|
||||
'RETRY_ENABLED': False,
|
||||
'DOWNLOAD_TIMEOUT': 30,
|
||||
'COOKIES_ENABLED': False,
|
||||
'AJAXCRAWL_ENABLED': True
|
||||
}
|
||||
|
||||
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
|
||||
|
||||
def parse_asswood(self, response):
|
||||
if isinstance(response, scrapy.http.TextResponse):
|
||||
item = AssWoodItem()
|
||||
item['ass'] = response.text.casefold().count('ass')
|
||||
item['wood'] = response.text.casefold().count('wood')
|
||||
item['url'] = response.url
|
||||
yield item
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
process = CrawlerProcess({
|
||||
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
|
||||
})
|
||||
|
||||
process.crawl(BeavisSpider)
|
||||
process.start()
|
||||
|
||||
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
|
||||
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
|
||||
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
|
||||
```
|
||||
|
||||
##### butthead.py
|
||||
|
||||
```
|
||||
import scrapy, time, psutil
|
||||
from scrapy.spiders import CrawlSpider, Rule, Spider
|
||||
from scrapy.linkextractors import LinkExtractor
|
||||
from scrapy.crawler import CrawlerProcess
|
||||
from multiprocessing import Process, Queue, cpu_count
|
||||
|
||||
ass = 0
|
||||
wood = 0
|
||||
totalpages = 0
|
||||
linkcounttuples =[]
|
||||
|
||||
def getdomains():
|
||||
|
||||
moz500file = open('top500.domains.05.18.csv')
|
||||
|
||||
domains = []
|
||||
moz500csv = moz500file.readlines()
|
||||
|
||||
del moz500csv[0]
|
||||
|
||||
for csvline in moz500csv:
|
||||
leftquote = csvline.find('"')
|
||||
rightquote = leftquote + csvline[leftquote + 1:].find('"')
|
||||
domains.append(csvline[leftquote + 1:rightquote])
|
||||
|
||||
return domains
|
||||
|
||||
def getstartpages(domains):
|
||||
|
||||
startpages = []
|
||||
|
||||
for domain in domains:
|
||||
startpages.append('http://' + domain)
|
||||
|
||||
return startpages
|
||||
|
||||
class AssWoodItem(scrapy.Item):
|
||||
ass = scrapy.Field()
|
||||
wood = scrapy.Field()
|
||||
url = scrapy.Field()
|
||||
|
||||
class AssWoodPipeline(object):
|
||||
def __init__(self):
|
||||
self.asswoodstats = []
|
||||
|
||||
def process_item(self, item, spider):
|
||||
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
|
||||
|
||||
def close_spider(self, spider):
|
||||
asstally, woodtally = 0, 0
|
||||
|
||||
for asswoodcount in self.asswoodstats:
|
||||
asstally += asswoodcount[1]
|
||||
woodtally += asswoodcount[2]
|
||||
|
||||
global ass, wood, totalpages
|
||||
ass = asstally
|
||||
wood = woodtally
|
||||
totalpages = len(self.asswoodstats)
|
||||
|
||||
|
||||
class ButtheadSpider(CrawlSpider):
|
||||
name = "Butthead"
|
||||
custom_settings = {
|
||||
'DEPTH_LIMIT': 3,
|
||||
'DOWNLOAD_DELAY': 3,
|
||||
'CONCURRENT_REQUESTS': 250,
|
||||
'REACTOR_THREADPOOL_MAXSIZE': 30,
|
||||
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
|
||||
'LOG_LEVEL': 'INFO',
|
||||
'RETRY_ENABLED': False,
|
||||
'DOWNLOAD_TIMEOUT': 30,
|
||||
'COOKIES_ENABLED': False,
|
||||
'AJAXCRAWL_ENABLED': True
|
||||
}
|
||||
|
||||
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
|
||||
|
||||
|
||||
def parse_asswood(self, response):
|
||||
if isinstance(response, scrapy.http.TextResponse):
|
||||
item = AssWoodItem()
|
||||
item['ass'] = response.text.casefold().count('ass')
|
||||
item['wood'] = response.text.casefold().count('wood')
|
||||
item['url'] = response.url
|
||||
yield item
|
||||
|
||||
def startButthead(domainslist, urlslist, asswoodqueue):
|
||||
crawlprocess = CrawlerProcess({
|
||||
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
|
||||
})
|
||||
|
||||
crawlprocess.crawl(ButtheadSpider, allowed_domains = domainslist, start_urls = urlslist)
|
||||
crawlprocess.start()
|
||||
asswoodqueue.put( (ass, wood, totalpages) )
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
asswoodqueue = Queue()
|
||||
domains=getdomains()
|
||||
startpages=getstartpages(domains)
|
||||
processlist =[]
|
||||
cores = cpu_count()
|
||||
|
||||
for i in range(10):
|
||||
domainsublist = domains[i * 50:(i + 1) * 50]
|
||||
pagesublist = startpages[i * 50:(i + 1) * 50]
|
||||
p = Process(target = startButthead, args = (domainsublist, pagesublist, asswoodqueue))
|
||||
processlist.append(p)
|
||||
|
||||
for i in range(cores):
|
||||
processlist[i].start()
|
||||
|
||||
time.sleep(180)
|
||||
|
||||
i = cores
|
||||
|
||||
while i != 10:
|
||||
time.sleep(60)
|
||||
if psutil.cpu_percent() < 66.7:
|
||||
processlist[i].start()
|
||||
i += 1
|
||||
|
||||
for i in range(10):
|
||||
processlist[i].join()
|
||||
|
||||
for i in range(10):
|
||||
asswoodtuple = asswoodqueue.get()
|
||||
ass += asswoodtuple[0]
|
||||
wood += asswoodtuple[1]
|
||||
totalpages += asswoodtuple[2]
|
||||
|
||||
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
|
||||
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
|
||||
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/quadbike-1024x683.jpg
|
||||
[2]: https://scrapy.org/
|
||||
[3]: https://www.info2007.net/blog/2018/review-scaleway-arm-based-cloud-server.html
|
||||
[4]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
|
||||
[5]: https://www.computerworld.com/article/3178544/microsoft-windows/microsoft-and-arm-look-to-topple-intel-in-servers.html
|
||||
[6]: https://www.datacenterknowledge.com/design/cloudflare-bets-arm-servers-it-expands-its-data-center-network
|
||||
[7]: https://www.scaleway.com/
|
||||
[8]: https://aws.amazon.com/
|
||||
[9]: https://www.theregister.co.uk/2018/11/27/amazon_aws_graviton_specs/
|
||||
[10]: https://www.scaleway.com/virtual-cloud-servers/#anchor_arm
|
||||
[11]: https://www.scaleway.com/virtual-cloud-servers/#anchor_starter
|
||||
[12]: https://aws.amazon.com/ec2/spot/pricing/
|
||||
[13]: https://aws.amazon.com/ec2/pricing/reserved-instances/
|
||||
[14]: https://aws.amazon.com/ec2/instance-types/a1/
|
||||
[15]: https://aws.amazon.com/ec2/instance-types/t2/
|
||||
[16]: https://wiki.python.org/moin/GlobalInterpreterLock
|
||||
[17]: https://docs.scrapy.org/en/latest/topics/broad-crawls.html
|
||||
[18]: https://linux.die.net/man/1/top
|
||||
[19]: https://linux.die.net/man/1/stress
|
||||
[20]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/Screenshot-from-2019-02-16-17-01-08.png
|
||||
[21]: https://moz.com/top500
|
||||
[22]: https://pypi.org/project/psutil/
|
||||
|
||||
@ -7,41 +7,41 @@
|
||||
[#]: via: (https://kerneltalks.com/tools/how-to-use-sudo-access-in-winscp/)
|
||||
[#]: author: (kerneltalks https://kerneltalks.com)
|
||||
|
||||
How to use sudo access in winSCP
|
||||
如何在 winSCP 中使用 sudo
|
||||
======
|
||||
|
||||
Learn how to use sudo access in winSCP with screenshots.
|
||||
用截图了解如何在 winSCP 中使用 sudo
|
||||
|
||||
![How to use sudo access in winSCP][1]sudo access in winSCP
|
||||
|
||||
First of all you need to check where is your SFTP server binary located on server you are trying to connect with winSCP.
|
||||
首先你需要检查你尝试使用 winSCP 连接的 sftp 服务器的二进制文件的位置。
|
||||
|
||||
You can check SFTP server binary location with below command –
|
||||
你可以使用以下命令检查 SFTP 服务器二进制文件位置:
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# cat /etc/ssh/sshd_config |grep -i sftp-server
|
||||
Subsystem sftp /usr/libexec/openssh/sftp-server
|
||||
```
|
||||
|
||||
Here you can see sftp server binary is located at `/usr/libexec/openssh/sftp-server`
|
||||
你可以看到 sftp 服务器的二进制文件位于 `/usr/libexec/openssh/sftp-server`。
|
||||
|
||||
Now open winSCP and click `Advanced` button to open up advanced settings.
|
||||
打开 winSCP 并单击“高级”按钮打开高级设置。
|
||||
|
||||
![winSCP advance settings][2]
|
||||
winSCP advance settings
|
||||
winSCP 高级设置
|
||||
|
||||
It will open up advanced setting window like one below. Here select `SFTP `under `Environment` on left hand side panel. You will be presented with option on right hand side.
|
||||
它将打开如下高级设置窗口。在左侧面板上选择`环境`下的 `SFTP`。你会在右侧看到选项。
|
||||
|
||||
Now, add SFTP server value here with command `sudo su -c` here as displayed in screenshot below –
|
||||
现在,使用命令 `sudo su -c` 在这里添加 SFTP 服务器值,如下截图所示:
|
||||
|
||||
![SFTP server setting in winSCP][3]
|
||||
SFTP server setting in winSCP
|
||||
winSCP 中的 SFTP 服务器设置
|
||||
|
||||
So we added `sudo su -c /usr/libexec/openssh/sftp-server` in settings here. Now click Ok and connect to server as you normally do.
|
||||
所以我们在设置中添加了 `sudo su -c /usr/libexec/openssh/sftp-server`。单击“确定”并像平常一样连接到服务器。
|
||||
|
||||
After connection you will be able to transfer files from directory where you normally need sudo permission to access.
|
||||
连接之后,你将可以从需要 sudo 权限的目录传输文件了。
|
||||
|
||||
That’s it! You logged to server using winSCP and sudo access.
|
||||
完成了!你已经使用 winSCP 使用 sudo 登录服务器了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -49,7 +49,7 @@ via: https://kerneltalks.com/tools/how-to-use-sudo-access-in-winscp/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user