mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
merge from lctt.
This commit is contained in:
commit
79b9756115
179
published/19951001 Writing man Pages Using groff.md
Normal file
179
published/19951001 Writing man Pages Using groff.md
Normal file
@ -0,0 +1,179 @@
|
||||
使用 groff 编写 man 手册页
|
||||
===================
|
||||
|
||||
`groff` 是大多数 Unix 系统上所提供的流行的文本格式化工具 nroff/troff 的 GNU 版本。它一般用于编写手册页,即命令、编程接口等的在线文档。在本文中,我们将给你展示如何使用 `groff` 编写你自己的 man 手册页。
|
||||
|
||||
在 Unix 系统上最初有两个文本处理系统:troff 和 nroff,它们是由贝尔实验室为初始的 Unix 所开发的(事实上,开发 Unix 系统的部分原因就是为了支持这样的一个文本处理系统)。这个文本处理器的第一个版本被称作 roff(意为 “runoff”——径流);稍后出现了 troff,在那时用于为特定的<ruby>排字机<rt>Typesetter</rt></ruby>生成输出。nroff 是更晚一些的版本,它成为了各种 Unix 系统的标准文本处理器。groff 是 nroff 和 troff 的 GNU 实现,用在 Linux 系统上。它包括了几个扩展功能和一些打印设备的驱动程序。
|
||||
|
||||
`groff` 能够生成文档、文章和书籍,很多时候它就像是其它的文本格式化系统(如 TeX)的血管一样。然而,`groff`(以及原来的 nroff)有一个固有的功能是 TeX 及其变体所缺乏的:生成普通 ASCII 输出。其它的系统在生成打印的文档方面做得很好,而 `groff` 却能够生成可以在线浏览的普通 ASCII(甚至可以在最简单的打印机上直接以普通文本打印)。如果要生成在线浏览的文档以及打印的表单,`groff` 也许是你所需要的(虽然也有替代品,如 Texinfo、Lametex 等等)。
|
||||
|
||||
`groff` 还有一个好处是它比 TeX 小很多;它所需要的支持文件和可执行程序甚至比最小化的 TeX 版本都少。
|
||||
|
||||
`groff` 一个特定的用途是用于格式化 Unix 的 man 手册页。如果你是一个 Unix 程序员,你肯定需要编写和生成各种 man 手册页。在本文中,我们将通过编写一个简短的 man 手册页来介绍 `groff` 的使用。
|
||||
|
||||
像 TeX 一样,`groff` 使用特定的文本格式化语言来描述如何处理文本。这种语言比 TeX 之类的系统更加神秘一些,但是更加简洁。此外,`groff` 在基本的格式化器之上提供了几个宏软件包;这些宏软件包是为一些特定类型的文档所定制的。举个例子, mgs 宏对于写作文章或论文很适合,而 man 宏可用于 man 手册页。
|
||||
|
||||
### 编写 man 手册页
|
||||
|
||||
用 `groff` 编写 man 手册页十分简单。要让你的 man 手册页看起来和其它的一样,你需要从源头上遵循几个惯例,如下所示。在这个例子中,我们将为一个虚构的命令 `coffee` 编写 man 手册页,它用于以各种方式控制你的联网咖啡机。
|
||||
|
||||
使用任意文本编辑器,输入如下代码,并保存为 `coffee.man`。不要输入每行的行号,它们仅用于本文中的说明。
|
||||
|
||||
```
|
||||
.TH COFFEE 1 "23 March 94"
|
||||
.SH NAME
|
||||
coffee \- Control remote coffee machine
|
||||
.SH SYNOPSIS
|
||||
\fBcoffee\fP [ -h | -b ] [ -t \fItype\fP ]
|
||||
\fIamount\fP
|
||||
.SH DESCRIPTION
|
||||
\fBcoffee\fP queues a request to the remote
|
||||
coffee machine at the device \fB/dev/cf0\fR.
|
||||
The required \fIamount\fP argument specifies
|
||||
the number of cups, generally between 0 and
|
||||
12 on ISO standard coffee machines.
|
||||
.SS Options
|
||||
.TP
|
||||
\fB-h\fP
|
||||
Brew hot coffee. Cold is the default.
|
||||
.TP
|
||||
\fB-b\fP
|
||||
Burn coffee. Especially useful when executing
|
||||
\fBcoffee\fP on behalf of your boss.
|
||||
.TP
|
||||
\fB-t \fItype\fR
|
||||
Specify the type of coffee to brew, where
|
||||
\fItype\fP is one of \fBcolumbian\fP,
|
||||
\fBregular\fP, or \fBdecaf\fP.
|
||||
.SH FILES
|
||||
.TP
|
||||
\fC/dev/cf0\fR
|
||||
The remote coffee machine device
|
||||
.SH "SEE ALSO"
|
||||
milk(5), sugar(5)
|
||||
.SH BUGS
|
||||
May require human intervention if coffee
|
||||
supply is exhausted.
|
||||
```
|
||||
|
||||
*清单 1:示例 man 手册页源文件*
|
||||
|
||||
不要让这些晦涩的代码吓坏了你。字符串序列 `\fB`、`\fI` 和 `\fR` 分别用来改变字体为粗体、斜体和正体(罗马字体)。`\fP` 设置字体为前一个选择的字体。
|
||||
|
||||
其它的 `groff` <ruby>请求<rt>request</rt></ruby>以点(`.`)开头出现在行首。第 1 行中,我们看到的 `.TH` 请求用于设置该 man 手册页的标题为 `COFFEE`、man 的部分为 `1`、以及该 man 手册页的最新版本的日期。(说明,man 手册的第 1 部分用于用户命令、第 2 部分用于系统调用等等。使用 `man man` 命令了解各个部分)。
|
||||
|
||||
在第 2 行,`.SH` 请求用于标记一个<ruby>节<rt>section</rt></ruby>的开始,并给该节名称为 `NAME`。注意,大部分的 Unix man 手册页依次使用 `NAME`、 `SYNOPSIS`、`DESCRIPTION`、`FILES`、`SEE ALSO`、`NOTES`、`AUTHOR` 和 `BUGS` 等节,个别情况下也需要一些额外的可选节。这只是编写 man 手册页的惯例,并不强制所有软件都如此。
|
||||
|
||||
第 3 行给出命令的名称,并在一个横线(`-`)后给出简短描述。在 `NAME` 节使用这个格式以便你的 man 手册页可以加到 whatis 数据库中——它可以用于 `man -k` 或 `apropos` 命令。
|
||||
|
||||
第 4-6 行我们给出了 `coffee` 命令格式的大纲。注意,斜体 `\fI...\fP` 用于表示命令行的参数,可选参数用方括号扩起来。
|
||||
|
||||
第 7-12 行给出了该命令的摘要介绍。粗体通常用于表示程序或文件的名称。
|
||||
|
||||
在 13 行,使用 `.SS` 开始了一个名为 `Options` 的子节。
|
||||
|
||||
接着第 14-25 行是选项列表,会使用参数列表样式表示。参数列表中的每一项以 `.TP` 请求来标记;`.TP` 后的行是参数,再之后是该项的文本。例如,第 14-16 行:
|
||||
|
||||
```
|
||||
.TP
|
||||
\fB-h\P
|
||||
Brew hot coffee. Cold is the default.
|
||||
```
|
||||
|
||||
将会显示如下:
|
||||
|
||||
```
|
||||
-h Brew hot coffee. Cold is the default.
|
||||
```
|
||||
|
||||
第 26-29 行创建该 man 手册页的 `FILES` 节,它用于描述该命令可能使用的文件。可以使用 `.TP` 请求来表示文件列表。
|
||||
|
||||
第 30-31 行,给出了 `SEE ALSO` 节,它提供了其它可以参考的 man 手册页。注意,第 30 行的 `.SH` 请求中 `"SEE ALSO"` 使用括号扩起来,这是因为 `.SH` 使用第一个空格来分隔该节的标题。任何超过一个单词的标题都需要使用引号扩起来成为一个单一参数。
|
||||
|
||||
最后,第 32-34 行,是 `BUGS` 节。
|
||||
|
||||
### 格式化和安装 man 手册页
|
||||
|
||||
为了在你的屏幕上查看这个手册页格式化的样式,你可以使用如下命令:
|
||||
|
||||
|
||||
```
|
||||
$ groff -Tascii -man coffee.man | more
|
||||
```
|
||||
|
||||
`-Tascii` 选项告诉 `groff` 生成普通 ASCII 输出;`-man` 告诉 `groff` 使用 man 手册页宏集合。如果一切正常,这个 man 手册页显示应该如下。
|
||||
|
||||
```
|
||||
COFFEE(1) COFFEE(1)
|
||||
NAME
|
||||
coffee - Control remote coffee machine
|
||||
SYNOPSIS
|
||||
coffee [ -h | -b ] [ -t type ] amount
|
||||
DESCRIPTION
|
||||
coffee queues a request to the remote coffee machine at
|
||||
the device /dev/cf0\. The required amount argument speci-
|
||||
fies the number of cups, generally between 0 and 12 on ISO
|
||||
standard coffee machines.
|
||||
Options
|
||||
-h Brew hot coffee. Cold is the default.
|
||||
-b Burn coffee. Especially useful when executing cof-
|
||||
fee on behalf of your boss.
|
||||
-t type
|
||||
Specify the type of coffee to brew, where type is
|
||||
one of columbian, regular, or decaf.
|
||||
FILES
|
||||
/dev/cf0
|
||||
The remote coffee machine device
|
||||
SEE ALSO
|
||||
milk(5), sugar(5)
|
||||
BUGS
|
||||
May require human intervention if coffee supply is
|
||||
exhausted.
|
||||
```
|
||||
|
||||
*格式化的 man 手册页*
|
||||
|
||||
如之前提到过的,`groff` 能够生成其它类型的输出。使用 `-Tps` 选项替代 `-Tascii` 将会生成 PostScript 输出,你可以将其保存为文件,用 GhostView 查看,或用一个 PostScript 打印机打印出来。`-Tdvi` 会生成设备无关的 .dvi 输出,类似于 TeX 的输出。
|
||||
|
||||
如果你希望让别人在你的系统上也可以查看这个 man 手册页,你需要安装这个 groff 源文件到其它用户的 `%MANPATH` 目录里面。标准的 man 手册页放在 `/usr/man`。第一部分的 man 手册页应该放在 `/usr/man/man1` 下,因此,使用命令:
|
||||
|
||||
```
|
||||
$ cp coffee.man /usr/man/man1/coffee.1
|
||||
```
|
||||
|
||||
这将安装该 man 手册页到 `/usr/man` 中供所有人使用(注意使用 `.1` 扩展名而不是 `.man`)。当接下来执行 `man coffee` 命令时,该 man 手册页会被自动重新格式化,并且可查看的文本会被保存到 `/usr/man/cat1/coffee.1.Z` 中。
|
||||
|
||||
如果你不能直接复制 man 手册页的源文件到 `/usr/man`(比如说你不是系统管理员),你可创建你自己的 man 手册页目录树,并将其加入到你的 `%MANPATH`。`%MANPATH` 环境变量的格式同 `%PATH` 一样,举个例子,要添加目录 `/home/mdw/man` 到 `%MANPATH` ,只需要:
|
||||
|
||||
```
|
||||
$ export MANPATH=/home/mdw/man:$MANPATH
|
||||
```
|
||||
|
||||
`groff` 和 man 手册页宏还有许多其它的选项和格式化命令。找到它们的最好办法是查看 `/usr/lib/groff` 中的文件; `tmac` 目录包含了宏文件,自身通常会包含其所提供的命令的文档。要让 `groff` 使用特定的宏集合,只需要使用 `-m macro` (或 `-macro`) 选项。例如,要使用 mgs 宏,使用命令:
|
||||
|
||||
```
|
||||
groff -Tascii -mgs files...
|
||||
```
|
||||
|
||||
`groff` 的 man 手册页对这个选项描述了更多细节。
|
||||
|
||||
不幸的是,随同 `groff` 提供的宏集合没有完善的文档。第 7 部分的 man 手册页提供了一些,例如,`man 7 groff_mm` 会给你 mm 宏集合的信息。然而,该文档通常只覆盖了在 `groff` 实现中不同和新功能,而假设你已经了解过原来的 nroff/troff 宏集合(称作 DWB:the Documentor's Work Bench)。最佳的信息来源或许是一本覆盖了那些经典宏集合细节的书。要了解更多的编写 man 手册页的信息,你可以看看 man 手册页源文件(`/usr/man` 中),并通过它们来比较源文件的输出。
|
||||
|
||||
这篇文章是《Running Linux》 中的一章,由 Matt Welsh 和 Lar Kaufman 著,奥莱理出版(ISBN 1-56592-100-3)。在本书中,还包括了 Linux 下使用的各种文本格式化系统的教程。这期的《Linux Journal》中的内容及《Running Linux》应该可以给你提供在 Linux 上使用各种文本工具的良好开端。
|
||||
|
||||
### 祝好,撰写快乐!
|
||||
|
||||
Matt Welsh ([mdw@cs.cornell.edu][1])是康奈尔大学的一名学生和系统程序员,在机器人和视觉实验室从事于时时机器视觉研究。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/article/1158
|
||||
|
||||
作者:[Matt Welsh][a]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/800006
|
||||
[1]:mailto:mdw@cs.cornell.edu
|
||||
@ -1,41 +1,27 @@
|
||||
如何在 Linux 系统里用 Scrot 截屏
|
||||
============================================================
|
||||
|
||||
### 文章主要内容
|
||||
|
||||
1. [关于 Scrot][12]
|
||||
2. [安装 Scrot][13]
|
||||
3. [Scrot 的使用和特点][14]
|
||||
1. [获取程序版本][1]
|
||||
2. [抓取当前窗口][2]
|
||||
3. [抓取选定窗口][3]
|
||||
4. [在截屏时包含窗口边框][4]
|
||||
5. [延时截屏][5]
|
||||
6. [截屏前倒数][6]
|
||||
7. [图片质量][7]
|
||||
8. [生成缩略图][8]
|
||||
9. [拼接多显示器截屏][9]
|
||||
10. [在保存截图后执行操作][10]
|
||||
11. [特殊字符串][11]
|
||||
4. [结论][15]
|
||||
|
||||
最近,我们介绍过 [gnome-screenshot][17] 工具,这是一个很优秀的屏幕抓取工具。但如果你想找一个在命令行运行的更好用的截屏工具,你一定要试试 Scrot。这个工具有一些 gnome-screenshot 没有的独特功能。在这片文章里,我们会通过简单易懂的例子来详细介绍 Scrot。
|
||||
最近,我们介绍过 [gnome-screenshot][17] 工具,这是一个很优秀的屏幕抓取工具。但如果你想找一个在命令行运行的更好用的截屏工具,你一定要试试 Scrot。这个工具有一些 gnome-screenshot 没有的独特功能。在这篇文章里,我们会通过简单易懂的例子来详细介绍 Scrot。
|
||||
|
||||
请注意一下,这篇文章里的所有例子都在 Ubuntu 16.04 LTS 上测试过,我们用的 scrot 版本是 0.8。
|
||||
|
||||
### 关于 Scrot
|
||||
|
||||
[Scrot][18] (**SCR**eensh**OT**) 是一个屏幕抓取工具,使用 imlib2 库来获取和保存图片。由 Tom Gilbert 用 C 语言开发完成,通过 BSD 协议授权。
|
||||
[Scrot][18] (**SCR**eensh**OT**) 是一个屏幕抓取工具,使用 imlib2 库来获取和保存图片。由 Tom Gilbert 用 C 语言开发完成,通过 BSD 协议授权。
|
||||
|
||||
### 安装 Scrot
|
||||
|
||||
scort 工具可能在你的 Ubuntu 系统里预装了,不过如果没有的话,你可以用下面的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-get install scrot
|
||||
```
|
||||
|
||||
安装完成后,你可以通过下面的命令来使用:
|
||||
|
||||
```
|
||||
scrot [options] [filename]
|
||||
```
|
||||
|
||||
**注意**:方括号里的参数是可选的。
|
||||
|
||||
@ -51,13 +37,17 @@ scrot [options] [filename]
|
||||
|
||||
默认情况下,抓取的截图会用带时间戳的文件名保存到当前目录下,不过你也可以在运行命令时指定截图文件名。比如:
|
||||
|
||||
```
|
||||
scrot [image-name].png
|
||||
```
|
||||
|
||||
### 获取程序版本
|
||||
|
||||
你想的话,可以用 -v 选项来查看 scrot 的版本。
|
||||
你想的话,可以用 `-v` 选项来查看 scrot 的版本。
|
||||
|
||||
```
|
||||
scrot -v
|
||||
```
|
||||
|
||||
这是例子:
|
||||
|
||||
@ -67,10 +57,11 @@ scrot -v
|
||||
|
||||
### 抓取当前窗口
|
||||
|
||||
这个工具可以限制抓取当前的焦点窗口。这个功能可以通过 -u 选项打开。
|
||||
这个工具可以限制抓取当前的焦点窗口。这个功能可以通过 `-u` 选项打开。
|
||||
|
||||
```
|
||||
scrot -u
|
||||
|
||||
```
|
||||
例如,这是我在命令行执行上边命令时的桌面:
|
||||
|
||||
[
|
||||
@ -85,9 +76,11 @@ scrot -u
|
||||
|
||||
### 抓取选定窗口
|
||||
|
||||
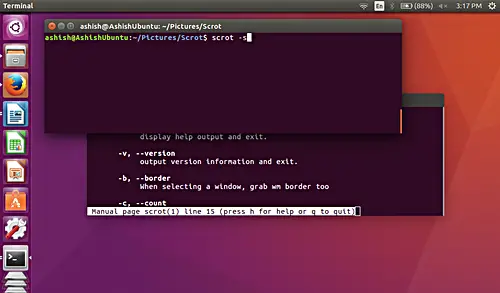
这个工具还可以让你抓取任意用鼠标点击的窗口。这个功能可以用 -s 选项打开。
|
||||
这个工具还可以让你抓取任意用鼠标点击的窗口。这个功能可以用 `-s` 选项打开。
|
||||
|
||||
```
|
||||
scrot -s
|
||||
```
|
||||
|
||||
例如,在下面的截图里你可以看到,我有两个互相重叠的终端窗口。我在上层的窗口里执行上面的命令。
|
||||
|
||||
@ -95,7 +88,7 @@ scrot -s
|
||||
|
||||
][23]
|
||||
|
||||
现在假如我想抓取下层的终端窗口。这样我只要在执行命令后点击窗口就可以了 - 在你用鼠标点击之前,命令的执行不会结束。
|
||||
现在假如我想抓取下层的终端窗口。这样我只要在执行命令后点击窗口就可以了 —— 在你用鼠标点击之前,命令的执行不会结束。
|
||||
|
||||
这是我点击了下层终端窗口后的截图:
|
||||
|
||||
@ -107,9 +100,11 @@ scrot -s
|
||||
|
||||
### 在截屏时包含窗口边框
|
||||
|
||||
我们之前介绍的 -u 选项在截屏时不会包含窗口边框。不过,需要的话你也可以在截屏时包含窗口边框。这个功能可以通过 -b 选项打开(当然要和 -u 选项一起)。
|
||||
我们之前介绍的 `-u` 选项在截屏时不会包含窗口边框。不过,需要的话你也可以在截屏时包含窗口边框。这个功能可以通过 `-b` 选项打开(当然要和 `-u` 选项一起)。
|
||||
|
||||
```
|
||||
scrot -ub
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -121,11 +116,13 @@ scrot -ub
|
||||
|
||||
### 延时截屏
|
||||
|
||||
你可以在开始截屏时增加一点延时。需要在 --delay 或 -d 选项后设定一个时间值参数。
|
||||
你可以在开始截屏时增加一点延时。需要在 `--delay` 或 `-d` 选项后设定一个时间值参数。
|
||||
|
||||
```
|
||||
scrot --delay [NUM]
|
||||
|
||||
scrot --delay 5
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
@ -137,11 +134,13 @@ scrot --delay 5
|
||||
|
||||
### 截屏前倒数
|
||||
|
||||
这个工具也可以在你使用延时功能后显示一个倒计时。这个功能可以通过 -c 选项打开。
|
||||
这个工具也可以在你使用延时功能后显示一个倒计时。这个功能可以通过 `-c` 选项打开。
|
||||
|
||||
```
|
||||
scrot –delay [NUM] -c
|
||||
|
||||
scrot -d 5 -c
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -153,11 +152,13 @@ scrot -d 5 -c
|
||||
|
||||
你可以使用这个工具来调整截图的图片质量,范围是 1-100 之间。较大的值意味着更大的文件大小以及更低的压缩率。默认值是 75,不过最终效果根据选择的文件类型也会有一些差异。
|
||||
|
||||
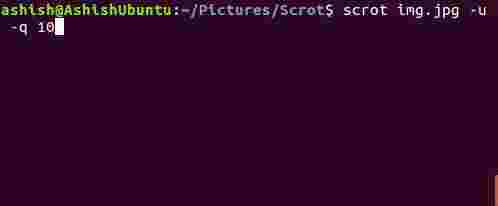
这个功能可以通过 --quality 或 -q 选项打开,但是你必须提供一个 1-100 之间的数值作为参数。
|
||||
这个功能可以通过 `--quality` 或 `-q` 选项打开,但是你必须提供一个 1 - 100 之间的数值作为参数。
|
||||
|
||||
```
|
||||
scrot –quality [NUM]
|
||||
|
||||
scrot –quality 10
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -165,17 +166,19 @@ scrot –quality 10
|
||||
|
||||
][28]
|
||||
|
||||
你可以看到,-q 选项的参数更靠近 1 让图片质量下降了很多。
|
||||
你可以看到,`-q` 选项的参数更靠近 1 让图片质量下降了很多。
|
||||
|
||||
### 生成缩略图
|
||||
|
||||
scort 工具还可以生成截屏的缩略图。这个功能可以通过 --thumb 选项打开。这个选项也需要一个 NUM 数值作为参数,基本上是指定原图大小的百分比。
|
||||
scort 工具还可以生成截屏的缩略图。这个功能可以通过 `--thumb` 选项打开。这个选项也需要一个 NUM 数值作为参数,基本上是指定原图大小的百分比。
|
||||
|
||||
```
|
||||
scrot --thumb NUM
|
||||
|
||||
scrot --thumb 50
|
||||
```
|
||||
|
||||
**注意**:加上 --thumb 选项也会同时保存原始截图文件。
|
||||
**注意**:加上 `--thumb` 选项也会同时保存原始截图文件。
|
||||
|
||||
例如,下面是我测试的原始截图:
|
||||
|
||||
@ -191,9 +194,11 @@ scrot --thumb 50
|
||||
|
||||
### 拼接多显示器截屏
|
||||
|
||||
如果你的电脑接了多个显示设备,你可以用 scort 抓取并拼接这些显示设备的截图。这个功能可以通过 -m 选项打开。
|
||||
如果你的电脑接了多个显示设备,你可以用 scort 抓取并拼接这些显示设备的截图。这个功能可以通过 `-m` 选项打开。
|
||||
|
||||
```
|
||||
scrot -m
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -203,9 +208,11 @@ scrot -m
|
||||
|
||||
### 在保存截图后执行操作
|
||||
|
||||
使用这个工具,你可以在保存截图后执行各种操作 - 例如,用像 gThumb 这样的图片编辑器打开截图。这个功能可以通过 -e 选项打开。下面是例子:
|
||||
使用这个工具,你可以在保存截图后执行各种操作 —— 例如,用像 gThumb 这样的图片编辑器打开截图。这个功能可以通过 `-e` 选项打开。下面是例子:
|
||||
|
||||
scrot abc.png -e ‘gthumb abc.png’
|
||||
```
|
||||
scrot abc.png -e 'gthumb abc.png'
|
||||
```
|
||||
|
||||
这个命令里的 gthumb 是一个图片编辑器,上面的命令在执行后会自动打开。
|
||||
|
||||
@ -223,29 +230,33 @@ scrot abc.png -e ‘gthumb abc.png’
|
||||
|
||||
你可以看到 scrot 抓取了屏幕截图,然后再启动了 gThumb 图片编辑器打开刚才保存的截图图片。
|
||||
|
||||
如果你截图时没有指定文件名,截图将会用带有时间戳的文件名保存到当前目录 - 这是 scrot 的默认设定,我们前面已经说过。
|
||||
如果你截图时没有指定文件名,截图将会用带有时间戳的文件名保存到当前目录 —— 这是 scrot 的默认设定,我们前面已经说过。
|
||||
|
||||
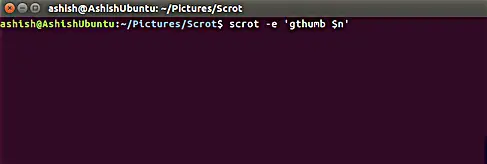
下面是一个使用默认名字并且加上 -e 选项来截图的例子:
|
||||
下面是一个使用默认名字并且加上 `-e` 选项来截图的例子:
|
||||
|
||||
scrot -e ‘gthumb $n’
|
||||
```
|
||||
scrot -e 'gthumb $n'
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][34]
|
||||
|
||||
有个地方要注意的是 $n 是一个特殊字符串,用来获取当前截图的文件名。关于特殊字符串的更多细节,请继续看下个小节。
|
||||
有个地方要注意的是 `$n` 是一个特殊字符串,用来获取当前截图的文件名。关于特殊字符串的更多细节,请继续看下个小节。
|
||||
|
||||
### 特殊字符串
|
||||
|
||||
scrot 的 -e(或 --exec)选项和文件名参数可以使用格式说明符。有两种类型格式。第一种是以 '%' 加字母组成,用来表示日期和时间,第二种以 '$' 开头,scrot 内部使用。
|
||||
scrot 的 `-e`(或 `--exec`)选项和文件名参数可以使用格式说明符。有两种类型格式。第一种是以 `%` 加字母组成,用来表示日期和时间,第二种以 `$` 开头,scrot 内部使用。
|
||||
|
||||
下面介绍几个 --exec 和文件名参数接受的说明符。
|
||||
下面介绍几个 `--exec` 和文件名参数接受的说明符。
|
||||
|
||||
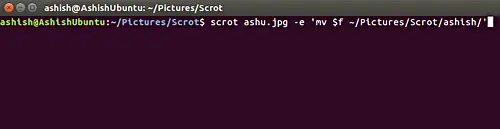
**$f** – 让你可以使用截图的全路径(包括文件名)。
|
||||
`$f` – 让你可以使用截图的全路径(包括文件名)。
|
||||
|
||||
例如
|
||||
例如:
|
||||
|
||||
```
|
||||
scrot ashu.jpg -e ‘mv $f ~/Pictures/Scrot/ashish/’
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -253,17 +264,19 @@ scrot ashu.jpg -e ‘mv $f ~/Pictures/Scrot/ashish/’
|
||||
|
||||
][35]
|
||||
|
||||
如果你没有指定文件名,scrot 默认会用日期格式的文件名保存截图。这个是 scrot 的默认文件名格式:%yy-%mm-%dd-%hhmmss_$wx$h_scrot.png。
|
||||
如果你没有指定文件名,scrot 默认会用日期格式的文件名保存截图。这个是 scrot 的默认文件名格式:`%yy-%mm-%dd-%hhmmss_$wx$h_scrot.png`。
|
||||
|
||||
**$n** – 提供截图文件名。下面是示例截图:
|
||||
`$n` – 提供截图文件名。下面是示例截图:
|
||||
|
||||
[
|
||||
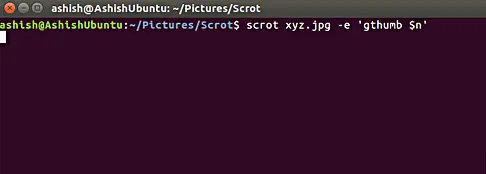
|
||||
][36]
|
||||
|
||||
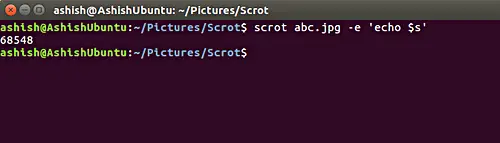
**$s** – 获取截图的文件大小。这个功能可以像下面这样使用。
|
||||
`$s` – 获取截图的文件大小。这个功能可以像下面这样使用。
|
||||
|
||||
```
|
||||
scrot abc.jpg -e ‘echo $s’
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -271,22 +284,19 @@ scrot abc.jpg -e ‘echo $s’
|
||||
|
||||
][37]
|
||||
|
||||
类似的,你也可以使用其他格式字符串 **$p**, **$w**, **$h**, **$t**, **$$** 以及 **\n** 来分别获取图片像素大小,图像宽度,图像高度,图像格式,输入 $ 字符,以及换行。你可以像上面介绍的 **$s** 格式那样使用这些字符串。
|
||||
类似的,你也可以使用其他格式字符串 `$p`、`$w`、 `$h`、`$t`、`$$` 以及 `\n` 来分别获取图片像素大小、图像宽度、图像高度、图像格式、输入 `$` 字符、以及换行。你可以像上面介绍的 `$s` 格式那样使用这些字符串。
|
||||
|
||||
### 结论
|
||||
|
||||
这个应用能轻松地安装在 Ubuntu 系统上,对初学者比较友好。scrot 也提供了一些高级功能,比如支持格式化字符串,方便专业用户用脚本处理。当然,如果你想用起来的话有一点轻微的学习曲线。
|
||||
|
||||

|
||||
[vie][16]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-take-screenshots-in-linux-with-scrot/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
vim 的酷功能:会话!
|
||||
============================================================•
|
||||
============================================================
|
||||
|
||||
昨天我在编写我的[vimrc][5]的时候了解到一个很酷的 vim 功能!(主要为了添加 fzf 和 ripgrep 插件)。这是一个内置功能,不需要特别的插件。
|
||||
|
||||
@ -17,9 +17,7 @@ vim 的酷功能:会话!
|
||||
一些 vim 插件给 vim 会话添加了额外的功能:
|
||||
|
||||
* [https://github.com/tpope/vim-obsession][1]
|
||||
|
||||
* [https://github.com/mhinz/vim-startify][2]
|
||||
|
||||
* [https://github.com/xolox/vim-session][3]
|
||||
|
||||
这是漫画:
|
||||
@ -30,9 +28,9 @@ vim 的酷功能:会话!
|
||||
|
||||
via: https://jvns.ca/blog/2017/09/10/vim-sessions/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
作者:[Julia Evans][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
并发服务器(3) —— 事件驱动
|
||||
并发服务器(三):事件驱动
|
||||
============================================================
|
||||
|
||||
这是《并发服务器》系列的第三节。[第一节][26] 介绍了阻塞式编程,[第二节 —— 线程][27] 探讨了多线程,将其作为一种可行的方法来实现服务器并发编程。
|
||||
这是并发服务器系列的第三节。[第一节][26] 介绍了阻塞式编程,[第二节:线程][27] 探讨了多线程,将其作为一种可行的方法来实现服务器并发编程。
|
||||
|
||||
另一种常见的实现并发的方法叫做 _事件驱动编程_,也可以叫做 _异步_ 编程 [^注1][28]。这种方法变化万千,因此我们会从最基本的开始,使用一些基本的 APIs 而非从封装好的高级方法开始。本系列以后的文章会讲高层次抽象,还有各种混合的方法。
|
||||
另一种常见的实现并发的方法叫做 _事件驱动编程_,也可以叫做 _异步_ 编程 ^注1 。这种方法变化万千,因此我们会从最基本的开始,使用一些基本的 API 而非从封装好的高级方法开始。本系列以后的文章会讲高层次抽象,还有各种混合的方法。
|
||||
|
||||
本系列的所有文章:
|
||||
|
||||
@ -13,13 +13,13 @@
|
||||
|
||||
### 阻塞式 vs. 非阻塞式 I/O
|
||||
|
||||
要介绍这个标题,我们先讲讲阻塞和非阻塞 I/O 的区别。阻塞式 I/O 更好理解,因为这是我们使用 I/O 相关 API 时的“标准”方式。从套接字接收数据的时候,调用 `recv` 函数会发生 _阻塞_,直到它从端口上接收到了来自另一端套接字的数据。这恰恰是第一部分讲到的顺序服务器的问题。
|
||||
作为本篇的介绍,我们先讲讲阻塞和非阻塞 I/O 的区别。阻塞式 I/O 更好理解,因为这是我们使用 I/O 相关 API 时的“标准”方式。从套接字接收数据的时候,调用 `recv` 函数会发生 _阻塞_,直到它从端口上接收到了来自另一端套接字的数据。这恰恰是第一部分讲到的顺序服务器的问题。
|
||||
|
||||
因此阻塞式 I/O 存在着固有的性能问题。第二节里我们讲过一种解决方法,就是用多线程。哪怕一个线程的 I/O 阻塞了,别的线程仍然可以使用 CPU 资源。实际上,阻塞 I/O 通常在利用资源方面非常高效,因为线程就等待着 —— 操作系统将线程变成休眠状态,只有满足了线程需要的条件才会被唤醒。
|
||||
|
||||
_非阻塞式_ I/O 是另一种思路。把套接字设成非阻塞模式时,调用 `recv` 时(还有 `send`,但是我们现在只考虑接收),函数返回地会很快,哪怕没有数据要接收。这时,就会返回一个特殊的错误状态 ^[注2][15] 来通知调用者,此时没有数据传进来。调用者可以去做其他的事情,或者尝试再次调用 `recv` 函数。
|
||||
_非阻塞式_ I/O 是另一种思路。把套接字设成非阻塞模式时,调用 `recv` 时(还有 `send`,但是我们现在只考虑接收),函数返回的会很快,哪怕没有接收到数据。这时,就会返回一个特殊的错误状态 ^注2 来通知调用者,此时没有数据传进来。调用者可以去做其他的事情,或者尝试再次调用 `recv` 函数。
|
||||
|
||||
证明阻塞式和非阻塞式的 `recv` 区别的最好方式就是贴一段示例代码。这里有个监听套接字的小程序,一直在 `recv` 这里阻塞着;当 `recv` 返回了数据,程序就报告接收到了多少个字节 ^[注3][16]:
|
||||
示范阻塞式和非阻塞式的 `recv` 区别的最好方式就是贴一段示例代码。这里有个监听套接字的小程序,一直在 `recv` 这里阻塞着;当 `recv` 返回了数据,程序就报告接收到了多少个字节 ^注3 :
|
||||
|
||||
```
|
||||
int main(int argc, const char** argv) {
|
||||
@ -69,8 +69,7 @@ hello # wait for 2 seconds after typing this
|
||||
socket world
|
||||
^D # to end the connection>
|
||||
```
|
||||
|
||||
The listening program will print the following:
|
||||
|
||||
监听程序会输出以下内容:
|
||||
|
||||
```
|
||||
@ -144,7 +143,6 @@ int main(int argc, const char** argv) {
|
||||
这里与阻塞版本有些差异,值得注意:
|
||||
|
||||
1. `accept` 函数返回的 `newsocktfd` 套接字因调用了 `fcntl`, 被设置成非阻塞的模式。
|
||||
|
||||
2. 检查 `recv` 的返回状态时,我们对 `errno` 进行了检查,判断它是否被设置成表示没有可供接收的数据的状态。这时,我们仅仅是休眠了 200 毫秒然后进入到下一轮循环。
|
||||
|
||||
同样用 `nc` 进行测试,以下是非阻塞监听器的输出:
|
||||
@ -183,19 +181,19 @@ Peer disconnected; I'm done.
|
||||
|
||||
作为练习,给输出添加一个时间戳,确认调用 `recv` 得到结果之间花费的时间是比输入到 `nc` 中所用的多还是少(每一轮是 200 ms)。
|
||||
|
||||
这里就实现了使用非阻塞的 `recv` 让监听者检查套接字变为可能,并且在没有数据的时候重新获得控制权。换句话说,这就是 _polling(轮询)_ —— 主程序周期性的查询套接字以便读取数据。
|
||||
这里就实现了使用非阻塞的 `recv` 让监听者检查套接字变为可能,并且在没有数据的时候重新获得控制权。换句话说,用编程的语言说这就是 <ruby>轮询<rt>polling</rt></ruby> —— 主程序周期性的查询套接字以便读取数据。
|
||||
|
||||
对于顺序响应的问题,这似乎是个可行的方法。非阻塞的 `recv` 让同时与多个套接字通信变成可能,轮询这些套接字,仅当有新数据到来时才处理。就是这样,这种方式 _可以_ 用来写并发服务器;但实际上一般不这么做,因为轮询的方式很难扩展。
|
||||
|
||||
首先,我在代码中引入的 200 ms 延迟对于记录非常好(监听器在我输入 `nc` 之间只打印几行 “Calling recv...”,但实际上应该有上千行)。但它也增加了多达 200 ms 的服务器响应时间,这几乎是意料不到的。实际的程序中,延迟会低得多,休眠时间越短,进程占用的 CPU 资源就越多。有些时钟周期只是浪费在等待,这并不好,尤其是在移动设备上,这些设备的电量往往有限。
|
||||
首先,我在代码中引入的 200ms 延迟对于演示非常好(监听器在我输入 `nc` 之间只打印几行 “Calling recv...”,但实际上应该有上千行)。但它也增加了多达 200ms 的服务器响应时间,这无意是不必要的。实际的程序中,延迟会低得多,休眠时间越短,进程占用的 CPU 资源就越多。有些时钟周期只是浪费在等待,这并不好,尤其是在移动设备上,这些设备的电量往往有限。
|
||||
|
||||
但是当我们实际这样来使用多个套接字的时候,更严重的问题出现了。想像下监听器正在同时处理 1000 个 客户端。这意味着每一个循环迭代里面,它都得为 _这 1000 个套接字中的每一个_ 执行一遍非阻塞的 `recv`,找到其中准备好了数据的那一个。这非常低效,并且极大的限制了服务器能够并发处理的客户端数。这里有个准则:每次轮询之间等待的间隔越久,服务器响应性越差;而等待的时间越少,CPU 在无用的轮询上耗费的资源越多。
|
||||
但是当我们实际这样来使用多个套接字的时候,更严重的问题出现了。想像下监听器正在同时处理 1000 个客户端。这意味着每一个循环迭代里面,它都得为 _这 1000 个套接字中的每一个_ 执行一遍非阻塞的 `recv`,找到其中准备好了数据的那一个。这非常低效,并且极大的限制了服务器能够并发处理的客户端数。这里有个准则:每次轮询之间等待的间隔越久,服务器响应性越差;而等待的时间越少,CPU 在无用的轮询上耗费的资源越多。
|
||||
|
||||
讲真,所有的轮询都像是无用功。当然操作系统应该是知道哪个套接字是准备好了数据的,因此没必要逐个扫描。事实上,就是这样,接下来就会讲一些API,让我们可以更优雅地处理多个客户端。
|
||||
讲真,所有的轮询都像是无用功。当然操作系统应该是知道哪个套接字是准备好了数据的,因此没必要逐个扫描。事实上,就是这样,接下来就会讲一些 API,让我们可以更优雅地处理多个客户端。
|
||||
|
||||
### select
|
||||
|
||||
`select` 的系统调用是轻便的(POSIX),标准 Unix API 中常有的部分。它是为上一节最后一部分描述的问题而设计的 —— 允许一个线程可以监视许多文件描述符 ^[注4][17] 的变化,不用在轮询中执行不必要的代码。我并不打算在这里引入一个关于 `select` 的理解性的教程,有很多网站和书籍讲这个,但是在涉及到问题的相关内容时,我会介绍一下它的 API,然后再展示一个非常复杂的例子。
|
||||
`select` 的系统调用是可移植的(POSIX),是标准 Unix API 中常有的部分。它是为上一节最后一部分描述的问题而设计的 —— 允许一个线程可以监视许多文件描述符 ^注4 的变化,而不用在轮询中执行不必要的代码。我并不打算在这里引入一个关于 `select` 的全面教程,有很多网站和书籍讲这个,但是在涉及到问题的相关内容时,我会介绍一下它的 API,然后再展示一个非常复杂的例子。
|
||||
|
||||
`select` 允许 _多路 I/O_,监视多个文件描述符,查看其中任何一个的 I/O 是否可用。
|
||||
|
||||
@ -209,30 +207,25 @@ int select(int nfds, fd_set *readfds, fd_set *writefds,
|
||||
`select` 的调用过程如下:
|
||||
|
||||
1. 在调用之前,用户先要为所有不同种类的要监视的文件描述符创建 `fd_set` 实例。如果想要同时监视读取和写入事件,`readfds` 和 `writefds` 都要被创建并且引用。
|
||||
|
||||
2. 用户可以使用 `FD_SET` 来设置集合中想要监视的特殊描述符。例如,如果想要监视描述符 2、7 和 10 的读取事件,在 `readfds` 这里调用三次 `FD_SET`,分别设置 2、7 和 10。
|
||||
|
||||
3. `select` 被调用。
|
||||
|
||||
4. 当 `select` 返回时(现在先不管超时),就是说集合中有多少个文件描述符已经就绪了。它也修改 `readfds` 和 `writefds` 集合,来标记这些准备好的描述符。其它所有的描述符都会被清空。
|
||||
|
||||
5. 这时用户需要遍历 `readfds` 和 `writefds`,找到哪个描述符就绪了(使用 `FD_ISSET`)。
|
||||
|
||||
作为完整的例子,我在并发的服务器程序上使用 `select`,重新实现了我们之前的协议。[完整的代码在这里][18];接下来的是代码中的高亮,还有注释。警告:示例代码非常复杂,因此第一次看的时候,如果没有足够的时间,快速浏览也没有关系。
|
||||
作为完整的例子,我在并发的服务器程序上使用 `select`,重新实现了我们之前的协议。[完整的代码在这里][18];接下来的是代码中的重点部分及注释。警告:示例代码非常复杂,因此第一次看的时候,如果没有足够的时间,快速浏览也没有关系。
|
||||
|
||||
### 使用 select 的并发服务器
|
||||
|
||||
使用 I/O 的多发 API 诸如 `select` 会给我们服务器的设计带来一些限制;这不会马上显现出来,但这值得探讨,因为它们是理解事件驱动编程到底是什么的关键。
|
||||
|
||||
最重要的是,要记住这种方法本质上是单线程的 ^[注5][19]。服务器实际上在 _同一时刻只能做一件事_。因为我们想要同时处理多个客户端请求,我们需要换一种方式重构代码。
|
||||
最重要的是,要记住这种方法本质上是单线程的 ^注5 。服务器实际上在 _同一时刻只能做一件事_。因为我们想要同时处理多个客户端请求,我们需要换一种方式重构代码。
|
||||
|
||||
首先,让我们谈谈主循环。它看起来是什么样的呢?先让我们想象一下服务器有一堆任务,它应该监视哪些东西呢?两种类型的套接字活动:
|
||||
|
||||
1. 新客户端尝试连接。这些客户端应该被 `accept`。
|
||||
|
||||
2. 已连接的客户端发送数据。这个数据要用 [第一节][11] 中所讲到的协议进行传输,有可能会有一些数据要被回送给客户端。
|
||||
|
||||
尽管这两种活动在本质上有所区别,我们还是要把他们放在一个循环里,因为只能有一个主循环。循环会包含 `select` 的调用。这个 `select` 的调用会监视上述的两种活动。
|
||||
尽管这两种活动在本质上有所区别,我们还是要把它们放在一个循环里,因为只能有一个主循环。循环会包含 `select` 的调用。这个 `select` 的调用会监视上述的两种活动。
|
||||
|
||||
这里是部分代码,设置了文件描述符集合,并在主循环里转到被调用的 `select` 部分。
|
||||
|
||||
@ -264,9 +257,7 @@ while (1) {
|
||||
这里的一些要点:
|
||||
|
||||
1. 由于每次调用 `select` 都会重写传递给函数的集合,调用器就得维护一个 “master” 集合,在循环迭代中,保持对所监视的所有活跃的套接字的追踪。
|
||||
|
||||
2. 注意我们所关心的,最开始的唯一那个套接字是怎么变成 `listener_sockfd` 的,这就是最开始的套接字,服务器借此来接收新客户端的连接。
|
||||
|
||||
3. `select` 的返回值,是在作为参数传递的集合中,那些已经就绪的描述符的个数。`select` 修改这个集合,用来标记就绪的描述符。下一步是在这些描述符中进行迭代。
|
||||
|
||||
```
|
||||
@ -298,7 +289,7 @@ for (int fd = 0; fd <= fdset_max && nready > 0; fd++) {
|
||||
}
|
||||
```
|
||||
|
||||
这部分循环检查 _可读的_ 描述符。让我们跳过监听器套接字(要浏览所有内容,[看这个代码][20]) 然后看看当其中一个客户端准备好了之后会发生什么。出现了这种情况后,我们调用一个叫做 `on_peer_ready_recv` 的 _回调_ 函数,传入相应的文件描述符。这个调用意味着客户端连接到套接字上,发送某些数据,并且对套接字上 `recv` 的调用不会被阻塞 ^[注6][21]。这个回调函数返回结构体 `fd_status_t`。
|
||||
这部分循环检查 _可读的_ 描述符。让我们跳过监听器套接字(要浏览所有内容,[看这个代码][20]) 然后看看当其中一个客户端准备好了之后会发生什么。出现了这种情况后,我们调用一个叫做 `on_peer_ready_recv` 的 _回调_ 函数,传入相应的文件描述符。这个调用意味着客户端连接到套接字上,发送某些数据,并且对套接字上 `recv` 的调用不会被阻塞 ^注6 。这个回调函数返回结构体 `fd_status_t`。
|
||||
|
||||
```
|
||||
typedef struct {
|
||||
@ -307,7 +298,7 @@ typedef struct {
|
||||
} fd_status_t;
|
||||
```
|
||||
|
||||
这个结构体告诉主循环,是否应该监视套接字的读取事件,写入事件,或者两者都监视。上述代码展示了 `FD_SET` 和 `FD_CLR` 是怎么在合适的描述符集合中被调用的。对于主循环中某个准备好了写入数据的描述符,代码是类似的,除了它所调用的回调函数,这个回调函数叫做 `on_peer_ready_send`。
|
||||
这个结构体告诉主循环,是否应该监视套接字的读取事件、写入事件,或者两者都监视。上述代码展示了 `FD_SET` 和 `FD_CLR` 是怎么在合适的描述符集合中被调用的。对于主循环中某个准备好了写入数据的描述符,代码是类似的,除了它所调用的回调函数,这个回调函数叫做 `on_peer_ready_send`。
|
||||
|
||||
现在来花点时间看看这个回调:
|
||||
|
||||
@ -464,37 +455,36 @@ INFO:2017-09-26 05:29:18,070:conn0 disconnecting
|
||||
INFO:2017-09-26 05:29:18,070:conn2 disconnecting
|
||||
```
|
||||
|
||||
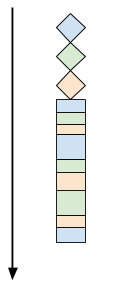
和线程的情况相似,客户端之间没有延迟,他们被同时处理。而且在 `select-server` 也没有用线程!主循环 _多路_ 处理所有的客户端,通过高效使用 `select` 轮询多个套接字。回想下 [第二节中][22] 顺序的 vs 多线程的客户端处理过程的图片。对于我们的 `select-server`,三个客户端的处理流程像这样:
|
||||
和线程的情况相似,客户端之间没有延迟,它们被同时处理。而且在 `select-server` 也没有用线程!主循环 _多路_ 处理所有的客户端,通过高效使用 `select` 轮询多个套接字。回想下 [第二节中][22] 顺序的 vs 多线程的客户端处理过程的图片。对于我们的 `select-server`,三个客户端的处理流程像这样:
|
||||
|
||||
|
||||
|
||||
所有的客户端在同一个线程中同时被处理,通过乘积,做一点这个客户端的任务,然后切换到另一个,再切换到下一个,最后切换回到最开始的那个客户端。注意,这里没有什么循环调度,客户端在它们发送数据的时候被客户端处理,这实际上是受客户端左右的。
|
||||
|
||||
### 同步,异步,事件驱动,回调
|
||||
### 同步、异步、事件驱动、回调
|
||||
|
||||
`select-server` 示例代码为讨论什么是异步编程,它和事件驱动及基于回调的编程有何联系,提供了一个良好的背景。因为这些词汇在并发服务器的(非常矛盾的)讨论中很常见。
|
||||
`select-server` 示例代码为讨论什么是异步编程、它和事件驱动及基于回调的编程有何联系,提供了一个良好的背景。因为这些词汇在并发服务器的(非常矛盾的)讨论中很常见。
|
||||
|
||||
让我们从一段 `select` 的手册页面中引用的一句好开始:
|
||||
让我们从一段 `select` 的手册页面中引用的一句话开始:
|
||||
|
||||
> select,pselect,FD_CLR,FD_ISSET,FD_SET,FD_ZERO - 同步 I/O 处理
|
||||
> select,pselect,FD\_CLR,FD\_ISSET,FD\_SET,FD\_ZERO - 同步 I/O 处理
|
||||
|
||||
因此 `select` 是 _同步_ 处理。但我刚刚演示了大量代码的例子,使用 `select` 作为 _异步_ 处理服务器的例子。有哪些东西?
|
||||
|
||||
答案是:这取决于你的观查角度。同步常用作阻塞处理,并且对 `select` 的调用实际上是阻塞的。和第 1、2 节中讲到的顺序的、多线程的服务器中对 `send` 和 `recv` 是一样的。因此说 `select` 是 _同步的_ API 是有道理的。可是,服务器的设计却可以是 _异步的_,或是 _基于回调的_,或是 _事件驱动的_,尽管其中有对 `select` 的使用。注意这里的 `on_peer_*` 函数是回调函数;它们永远不会阻塞,并且只有网络事件触发的时候才会被调用。它们可以获得部分数据,并能够在调用过程中保持稳定的状态。
|
||||
答案是:这取决于你的观察角度。同步常用作阻塞处理,并且对 `select` 的调用实际上是阻塞的。和第 1、2 节中讲到的顺序的、多线程的服务器中对 `send` 和 `recv` 是一样的。因此说 `select` 是 _同步的_ API 是有道理的。可是,服务器的设计却可以是 _异步的_,或是 _基于回调的_,或是 _事件驱动的_,尽管其中有对 `select` 的使用。注意这里的 `on_peer_*` 函数是回调函数;它们永远不会阻塞,并且只有网络事件触发的时候才会被调用。它们可以获得部分数据,并能够在调用过程中保持稳定的状态。
|
||||
|
||||
如果你曾经做过一些 GUI 编程,这些东西对你来说应该很亲切。有个 “事件循环”,常常完全隐藏在框架里,应用的 “业务逻辑” 建立在回调上,这些回调会在各种事件触发后被调用,用户点击鼠标,选择菜单,定时器到时间,数据到达套接字,等等。曾经最常见的编程模型是客户端的 JavaScript,这里面有一堆回调函数,它们在浏览网页时用户的行为被触发。
|
||||
如果你曾经做过一些 GUI 编程,这些东西对你来说应该很亲切。有个 “事件循环”,常常完全隐藏在框架里,应用的 “业务逻辑” 建立在回调上,这些回调会在各种事件触发后被调用,用户点击鼠标、选择菜单、定时器触发、数据到达套接字等等。曾经最常见的编程模型是客户端的 JavaScript,这里面有一堆回调函数,它们在浏览网页时用户的行为被触发。
|
||||
|
||||
### select 的局限
|
||||
|
||||
使用 `select` 作为第一个异步服务器的例子对于说明这个概念很有用,而且由于 `select` 是很常见,可移植的 API。但是它也有一些严重的缺陷,在监视的文件描述符非常大的时候就会出现。
|
||||
使用 `select` 作为第一个异步服务器的例子对于说明这个概念很有用,而且由于 `select` 是很常见、可移植的 API。但是它也有一些严重的缺陷,在监视的文件描述符非常大的时候就会出现。
|
||||
|
||||
1. 有限的文件描述符的集合大小。
|
||||
|
||||
2. 糟糕的性能。
|
||||
|
||||
从文件描述符的大小开始。`FD_SETSIZE` 是一个编译期常数,在如今的操作系统中,它的值通常是 1024。它被硬编码在 `glibc` 的头文件里,并且不容易修改。它把 `select` 能够监视的文件描述符的数量限制在 1024 以内。曾有些分支想要写出能够处理上万个并发访问的客户端请求的服务器,这个问题很有现实意义。有一些方法,但是不可移植,也很难用。
|
||||
从文件描述符的大小开始。`FD_SETSIZE` 是一个编译期常数,在如今的操作系统中,它的值通常是 1024。它被硬编码在 `glibc` 的头文件里,并且不容易修改。它把 `select` 能够监视的文件描述符的数量限制在 1024 以内。曾有些人想要写出能够处理上万个并发访问的客户端请求的服务器,所以这个问题很有现实意义。有一些方法,但是不可移植,也很难用。
|
||||
|
||||
糟糕的性能问题就好解决的多,但是依然非常严重。注意当 `select` 返回的时候,它向调用者提供的信息是 “就绪的” 描述符的个数,还有被修改过的描述符集合。描述符集映射着描述符 就绪/未就绪”,但是并没有提供什么有效的方法去遍历所有就绪的描述符。如果只有一个描述符是就绪的,最坏的情况是调用者需要遍历 _整个集合_ 来找到那个描述符。这在监视的描述符数量比较少的时候还行,但是如果数量变的很大的时候,这种方法弊端就凸显出了 ^[注7][23]。
|
||||
糟糕的性能问题就好解决的多,但是依然非常严重。注意当 `select` 返回的时候,它向调用者提供的信息是 “就绪的” 描述符的个数,还有被修改过的描述符集合。描述符集映射着描述符“就绪/未就绪”,但是并没有提供什么有效的方法去遍历所有就绪的描述符。如果只有一个描述符是就绪的,最坏的情况是调用者需要遍历 _整个集合_ 来找到那个描述符。这在监视的描述符数量比较少的时候还行,但是如果数量变的很大的时候,这种方法弊端就凸显出了 ^注7 。
|
||||
|
||||
由于这些原因,为了写出高性能的并发服务器, `select` 已经不怎么用了。每一个流行的操作系统有独特的不可移植的 API,允许用户写出非常高效的事件循环;像框架这样的高级结构还有高级语言通常在一个可移植的接口中包含这些 API。
|
||||
|
||||
@ -541,30 +531,23 @@ while (1) {
|
||||
}
|
||||
```
|
||||
|
||||
通过调用 `epoll_ctl` 来配置 `epoll`。这时,配置监听的套接字数量,也就是 `epoll` 监听的描述符的数量。然后分配一个缓冲区,把就绪的事件传给 `epoll` 以供修改。在主循环里对 `epoll_wait` 的调用是魅力所在。它阻塞着,直到某个描述符就绪了(或者超时),返回就绪的描述符数量。但这时,不少盲目地迭代所有监视的集合,我们知道 `epoll_write` 会修改传给它的 `events` 缓冲区,缓冲区中有就绪的事件,从 0 到 `nready-1`,因此我们只需迭代必要的次数。
|
||||
通过调用 `epoll_ctl` 来配置 `epoll`。这时,配置监听的套接字数量,也就是 `epoll` 监听的描述符的数量。然后分配一个缓冲区,把就绪的事件传给 `epoll` 以供修改。在主循环里对 `epoll_wait` 的调用是魅力所在。它阻塞着,直到某个描述符就绪了(或者超时),返回就绪的描述符数量。但这时,不要盲目地迭代所有监视的集合,我们知道 `epoll_write` 会修改传给它的 `events` 缓冲区,缓冲区中有就绪的事件,从 0 到 `nready-1`,因此我们只需迭代必要的次数。
|
||||
|
||||
要在 `select` 里面重新遍历,有明显的差异:如果在监视着 1000 个描述符,只有两个就绪, `epoll_waits` 返回的是 `nready=2`,然后修改 `events` 缓冲区最前面的两个元素,因此我们只需要“遍历”两个描述符。用 `select` 我们就需要遍历 1000 个描述符,找出哪个是就绪的。因此,在繁忙的服务器上,有许多活跃的套接字时 `epoll` 比 `select` 更加容易扩展。
|
||||
|
||||
剩下的代码很直观,因为我们已经很熟悉 `select 服务器` 了。实际上,`epoll 服务器` 中的所有“业务逻辑”和 `select 服务器` 是一样的,回调构成相同的代码。
|
||||
剩下的代码很直观,因为我们已经很熟悉 “select 服务器” 了。实际上,“epoll 服务器” 中的所有“业务逻辑”和 “select 服务器” 是一样的,回调构成相同的代码。
|
||||
|
||||
这种相似是通过将事件循环抽象分离到一个库/框架中。我将会详述这些内容,因为很多优秀的程序员曾经也是这样做的。相反,下一篇文章里我们会了解 `libuv`,一个最近出现的更加受欢迎的时间循环抽象层。像 `libuv` 这样的库让我们能够写出并发的异步服务器,并且不用考虑系统调用下繁琐的细节。
|
||||
这种相似是通过将事件循环抽象分离到一个库/框架中。我将会详述这些内容,因为很多优秀的程序员曾经也是这样做的。相反,下一篇文章里我们会了解 libuv,一个最近出现的更加受欢迎的时间循环抽象层。像 libuv 这样的库让我们能够写出并发的异步服务器,并且不用考虑系统调用下繁琐的细节。
|
||||
|
||||
* * *
|
||||
|
||||
|
||||
[注1][1] 我试着在两件事的实际差别中突显自己,一件是做一些网络浏览和阅读,但经常做得头疼。有很多不同的选项,从“他们是一样的东西”到“一个是另一个的子集”,再到“他们是完全不同的东西”。在面临这样主观的观点时,最好是完全放弃这个问题,专注特殊的例子和用例。
|
||||
|
||||
[注2][2] POSIX 表示这可以是 `EAGAIN`,也可以是 `EWOULDBLOCK`,可移植应用应该对这两个都进行检查。
|
||||
|
||||
[注3][3] 和这个系列所有的 C 示例类似,代码中用到了某些助手工具来设置监听套接字。这些工具的完整代码在这个 [仓库][4] 的 `utils` 模块里。
|
||||
|
||||
[注4][5] `select` 不是网络/套接字专用的函数,它可以监视任意的文件描述符,有可能是硬盘文件,管道,终端,套接字或者 Unix 系统中用到的任何文件描述符。这篇文章里,我们主要关注它在套接字方面的应用。
|
||||
|
||||
[注5][6] 有多种方式用多线程来实现事件驱动,我会把它放在稍后的文章中进行讨论。
|
||||
|
||||
[注6][7] 由于各种非实验因素,它 _仍然_ 可以阻塞,即使是在 `select` 说它就绪了之后。因此服务器上打开的所有套接字都被设置成非阻塞模式,如果对 `recv` 或 `send` 的调用返回了 `EAGAIN` 或者 `EWOULDBLOCK`,回调函数就装作没有事件发生。阅读示例代码的注释可以了解更多细节。
|
||||
|
||||
[注7][8] 注意这比该文章前面所讲的异步 polling 例子要稍好一点。polling 需要 _一直_ 发生,而 `select` 实际上会阻塞到有一个或多个套接字准备好读取/写入;`select` 会比一直询问浪费少得多的 CPU 时间。
|
||||
- 注1:我试着在做网络浏览和阅读这两件事的实际差别中突显自己,但经常做得头疼。有很多不同的选项,从“它们是一样的东西”到“一个是另一个的子集”,再到“它们是完全不同的东西”。在面临这样主观的观点时,最好是完全放弃这个问题,专注特殊的例子和用例。
|
||||
- 注2:POSIX 表示这可以是 `EAGAIN`,也可以是 `EWOULDBLOCK`,可移植应用应该对这两个都进行检查。
|
||||
- 注3:和这个系列所有的 C 示例类似,代码中用到了某些助手工具来设置监听套接字。这些工具的完整代码在这个 [仓库][4] 的 `utils` 模块里。
|
||||
- 注4:`select` 不是网络/套接字专用的函数,它可以监视任意的文件描述符,有可能是硬盘文件、管道、终端、套接字或者 Unix 系统中用到的任何文件描述符。这篇文章里,我们主要关注它在套接字方面的应用。
|
||||
- 注5:有多种方式用多线程来实现事件驱动,我会把它放在稍后的文章中进行讨论。
|
||||
- 注6:由于各种非实验因素,它 _仍然_ 可以阻塞,即使是在 `select` 说它就绪了之后。因此服务器上打开的所有套接字都被设置成非阻塞模式,如果对 `recv` 或 `send` 的调用返回了 `EAGAIN` 或者 `EWOULDBLOCK`,回调函数就装作没有事件发生。阅读示例代码的注释可以了解更多细节。
|
||||
- 注7:注意这比该文章前面所讲的异步轮询的例子要稍好一点。轮询需要 _一直_ 发生,而 `select` 实际上会阻塞到有一个或多个套接字准备好读取/写入;`select` 会比一直询问浪费少得多的 CPU 时间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -572,7 +555,7 @@ via: https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -587,9 +570,9 @@ via: https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[8]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id9
|
||||
[9]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[10]:https://eli.thegreenplace.net/tag/c-c
|
||||
[11]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[12]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[13]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[11]:https://linux.cn/article-8993-1.html
|
||||
[12]:https://linux.cn/article-8993-1.html
|
||||
[13]:https://linux.cn/article-9002-1.html
|
||||
[14]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[15]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id11
|
||||
[16]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id12
|
||||
@ -598,10 +581,10 @@ via: https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[19]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id14
|
||||
[20]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/select-server.c
|
||||
[21]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id15
|
||||
[22]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[22]:https://linux.cn/article-9002-1.html
|
||||
[23]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id16
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/epoll-server.c
|
||||
[25]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[26]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[27]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[26]:https://linux.cn/article-8993-1.html
|
||||
[27]:https://linux.cn/article-9002-1.html
|
||||
[28]:https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/#id10
|
||||
@ -0,0 +1,80 @@
|
||||
面向初学者的 Linux 网络硬件:软件思维
|
||||
===========================================================
|
||||
|
||||

|
||||
|
||||
> 没有路由和桥接,我们将会成为孤独的小岛,你将会在这个网络教程中学到更多知识。
|
||||
|
||||
[Commons Zero][3]Pixabay
|
||||
|
||||
上周,我们学习了本地网络硬件知识,本周,我们将学习网络互联技术和在移动网络中的一些很酷的黑客技术。
|
||||
|
||||
### 路由器
|
||||
|
||||
网络路由器就是计算机网络中的一切,因为路由器连接着网络,没有路由器,我们就会成为孤岛。图一展示了一个简单的有线本地网络和一个无线接入点,所有设备都接入到互联网上,本地局域网的计算机连接到一个连接着防火墙或者路由器的以太网交换机上,防火墙或者路由器连接到网络服务供应商(ISP)提供的电缆箱、调制调节器、卫星上行系统……好像一切都在计算中,就像是一个带着不停闪烁的的小灯的盒子。当你的网络数据包离开你的局域网,进入广阔的互联网,它们穿过一个又一个路由器直到到达自己的目的地。
|
||||
|
||||

|
||||
|
||||
*图一:一个简单的有线局域网和一个无线接入点。*
|
||||
|
||||
路由器可以是各种样式:一个只专注于路由的小巧特殊的小盒子,一个将会提供路由、防火墙、域名服务,以及 VPN 网关功能的大点的盒子,一台重新设计的台式电脑或者笔记本,一个树莓派计算机或者一个 Arduino,体积臃肿矮小的像 PC Engines 这样的单板计算机,除了苛刻的用途以外,普通的商品硬件都能良好的工作运行。高端的路由器使用特殊设计的硬件每秒能够传输最大量的数据包。它们有多路数据总线,多个中央处理器和极快的存储。(可以通过了解 Juniper 和思科的路由器来感受一下高端路由器书什么样子的,而且能看看里面是什么样的构造。)
|
||||
|
||||
接入你的局域网的无线接入点要么作为一个以太网网桥,要么作为一个路由器。桥接器扩展了这个网络,所以在这个桥接器上的任意一端口上的主机都连接在同一个网络中。一台路由器连接的是两个不同的网络。
|
||||
|
||||
### 网络拓扑
|
||||
|
||||
有多种设置你的局域网的方式,你可以把所有主机接入到一个单独的<ruby>平面网络<rt>flat network</rt></ruby>,也可以把它们划分为不同的子网。如果你的交换机支持 VLAN 的话,你也可以把它们分配到不同的 VLAN 中。
|
||||
|
||||
平面网络是最简单的网络,只需把每一台设备接入到同一个交换机上即可,如果一台交换上的端口不够使用,你可以将更多的交换机连接在一起。有些交换机有特殊的上行端口,有些是没有这种特殊限制的上行端口,你可以连接其中的任意端口,你可能需要使用交叉类型的以太网线,所以你要查阅你的交换机的说明文档来设置。
|
||||
|
||||
平面网络是最容易管理的,你不需要路由器也不需要计算子网,但它也有一些缺点。它们的伸缩性不好,所以当网络规模变得越来越大的时候就会被广播网络所阻塞。将你的局域网进行分段将会提升安全保障, 把局域网分成可管理的不同网段将有助于管理更大的网络。图二展示了一个分成两个子网的局域网络:内部的有线和无线主机,和一个托管公开服务的主机。包含面向公共的服务器的子网称作非军事区域 DMZ,(你有没有注意到那些都是主要在电脑上打字的男人们的术语?)因为它被阻挡了所有的内部网络的访问。
|
||||
|
||||

|
||||
|
||||
*图二:一个分成两个子网的简单局域网。*
|
||||
|
||||
即使像图二那样的小型网络也可以有不同的配置方法。你可以将防火墙和路由器放置在一台单独的设备上。你可以为你的非军事区域设置一个专用的网络连接,把它完全从你的内部网络隔离,这将引导我们进入下一个主题:一切基于软件。
|
||||
|
||||
### 软件思维
|
||||
|
||||
你可能已经注意到在这个简短的系列中我们所讨论的硬件,只有网络接口、交换机,和线缆是特殊用途的硬件。
|
||||
其它的都是通用的商用硬件,而且都是软件来定义它的用途。Linux 是一个真实的网络操作系统,它支持大量的网络操作:网关、虚拟专用网关、以太网桥、网页、邮箱以及文件等等服务器、负载均衡、代理、服务质量、多种认证、中继、故障转移……你可以在运行着 Linux 系统的标准硬件上运行你的整个网络。你甚至可以使用 Linux 交换应用(LISA)和VDE2 协议来模拟以太网交换机。
|
||||
|
||||
有一些用于小型硬件的特殊发行版,如 DD-WRT、OpenWRT,以及树莓派发行版,也不要忘记 BSD 们和它们的特殊衍生用途如 pfSense 防火墙/路由器,和 FreeNAS 网络存储服务器。
|
||||
|
||||
你知道有些人坚持认为硬件防火墙和软件防火墙有区别?其实是没有区别的,就像说硬件计算机和软件计算机一样。
|
||||
|
||||
### 端口聚合和以太网绑定
|
||||
|
||||
聚合和绑定,也称链路聚合,是把两条以太网通道绑定在一起成为一条通道。一些交换机支持端口聚合,就是把两个交换机端口绑定在一起,成为一个是它们原来带宽之和的一条新的连接。对于一台承载很多业务的服务器来说这是一个增加通道带宽的有效的方式。
|
||||
|
||||
你也可以在以太网口进行同样的配置,而且绑定汇聚的驱动是内置在 Linux 内核中的,所以不需要任何其他的专门的硬件。
|
||||
|
||||
### 随心所欲选择你的移动宽带
|
||||
|
||||
我期望移动宽带能够迅速增长来替代 DSL 和有线网络。我居住在一个有 25 万人口的靠近一个城市的地方,但是在城市以外,要想接入互联网就要靠运气了,即使那里有很大的用户上网需求。我居住的小角落离城镇有 20 分钟的距离,但对于网络服务供应商来说他们几乎不会考虑到为这个地方提供网络。 我唯一的选择就是移动宽带;这里没有拨号网络、卫星网络(即使它很糟糕)或者是 DSL、电缆、光纤,但却没有阻止网络供应商把那些我在这个区域从没看到过的 Xfinity 和其它高速网络服务的传单塞进我的邮箱。
|
||||
|
||||
我试用了 AT&T、Version 和 T-Mobile。Version 的信号覆盖范围最广,但是 Version 和 AT&T 是最昂贵的。
|
||||
我居住的地方在 T-Mobile 信号覆盖的边缘,但迄今为止他们给了最大的优惠,为了能够能够有效的使用,我必须购买一个 WeBoost 信号放大器和一台中兴的移动热点设备。当然你也可以使用一部手机作为热点,但是专用的热点设备有着最强的信号。如果你正在考虑购买一台信号放大器,最好的选择就是 WeBoost,因为他们的服务支持最棒,而且他们会尽最大努力去帮助你。在一个小小的 APP [SignalCheck Pro][8] 的协助下设置将会精准的增强你的网络信号,他们有一个功能较少的免费的版本,但你将一点都不会后悔去花两美元使用专业版。
|
||||
|
||||
那个小巧的中兴热点设备能够支持 15 台主机,而且还有拥有基本的防火墙功能。 但你如果你使用像 Linksys WRT54GL这样的设备,可以使用 Tomato、OpenWRT,或者 DD-WRT 来替代普通的固件,这样你就能完全控制你的防护墙规则、路由配置,以及任何其它你想要设置的服务。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-think-software
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[4]:https://www.linux.com/files/images/fig-1png-7
|
||||
[5]:https://www.linux.com/files/images/fig-2png-4
|
||||
[6]:https://www.linux.com/files/images/soderskar-islandjpg
|
||||
[7]:https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-lan-hardware
|
||||
[8]:http://www.bluelinepc.com/signalcheck/
|
||||
@ -0,0 +1,135 @@
|
||||
如何使用 GPG 加解密文件
|
||||
=================
|
||||
|
||||
目标:使用 GPG 加密文件
|
||||
|
||||
发行版:适用于任何发行版
|
||||
|
||||
要求:安装了 GPG 的 Linux 或者拥有 root 权限来安装它。
|
||||
|
||||
难度:简单
|
||||
|
||||
约定:
|
||||
|
||||
* `#` - 需要使用 root 权限来执行指定命令,可以直接使用 root 用户来执行,也可以使用 `sudo` 命令
|
||||
* `$` - 可以使用普通用户来执行指定命令
|
||||
|
||||
### 介绍
|
||||
|
||||
加密非常重要。它对于保护敏感信息来说是必不可少的。你的私人文件应该要被加密,而 GPG 提供了很好的解决方案。
|
||||
|
||||
### 安装 GPG
|
||||
|
||||
GPG 的使用非常广泛。你在几乎每个发行版的仓库中都能找到它。如果你还没有安装它,那现在就来安装一下吧。
|
||||
|
||||
**Debian/Ubuntu**
|
||||
|
||||
```
|
||||
$ sudo apt install gnupg
|
||||
```
|
||||
|
||||
**Fedora**
|
||||
|
||||
```
|
||||
# dnf install gnupg2
|
||||
```
|
||||
|
||||
**Arch**
|
||||
|
||||
```
|
||||
# pacman -S gnupg
|
||||
```
|
||||
|
||||
**Gentoo**
|
||||
|
||||
```
|
||||
# emerge --ask app-crypt/gnupg
|
||||
```
|
||||
|
||||
### 创建密钥
|
||||
|
||||
你需要一个密钥对来加解密文件。如果你为 SSH 已经生成过了密钥对,那么你可以直接使用它。如果没有,GPG 包含工具来生成密钥对。
|
||||
|
||||
```
|
||||
$ gpg --full-generate-key
|
||||
```
|
||||
|
||||
GPG 有一个命令行程序可以帮你一步一步的生成密钥。它还有一个简单得多的工具,但是这个工具不能让你设置密钥类型,密钥的长度以及过期时间,因此不推荐使用这个工具。
|
||||
|
||||
GPG 首先会询问你密钥的类型。没什么特别的话选择默认值就好。
|
||||
|
||||
下一步需要设置密钥长度。`4096` 是一个不错的选择。
|
||||
|
||||
之后,可以设置过期的日期。 如果希望密钥永不过期则设置为 `0`。
|
||||
|
||||
然后,输入你的名称。
|
||||
|
||||
最后,输入电子邮件地址。
|
||||
|
||||
如果你需要的话,还能添加一个注释。
|
||||
|
||||
所有这些都完成后,GPG 会让你校验一下这些信息。
|
||||
|
||||
GPG 还会问你是否需要为密钥设置密码。这一步是可选的, 但是会增加保护的程度。若需要设置密码,则 GPG 会收集你的操作信息来增加密钥的健壮性。 所有这些都完成后, GPG 会显示密钥相关的信息。
|
||||
|
||||
### 加密的基本方法
|
||||
|
||||
现在你拥有了自己的密钥,加密文件非常简单。 使用下面的命令在 `/tmp` 目录中创建一个空白文本文件。
|
||||
|
||||
```
|
||||
$ touch /tmp/test.txt
|
||||
```
|
||||
|
||||
然后用 GPG 来加密它。这里 `-e` 标志告诉 GPG 你想要加密文件, `-r` 标志指定接收者。
|
||||
|
||||
```
|
||||
$ gpg -e -r "Your Name" /tmp/test.txt
|
||||
```
|
||||
|
||||
GPG 需要知道这个文件的接收者和发送者。由于这个文件给是你的,因此无需指定发送者,而接收者就是你自己。
|
||||
|
||||
### 解密的基本方法
|
||||
|
||||
你收到加密文件后,就需要对它进行解密。 你无需指定解密用的密钥。 这个信息被编码在文件中。 GPG 会尝试用其中的密钥进行解密。
|
||||
|
||||
```
|
||||
$ gpg -d /tmp/test.txt.gpg
|
||||
```
|
||||
|
||||
### 发送文件
|
||||
|
||||
假设你需要发送文件给别人。你需要有接收者的公钥。 具体怎么获得密钥由你自己决定。 你可以让他们直接把公钥发送给你, 也可以通过密钥服务器来获取。
|
||||
|
||||
收到对方公钥后,导入公钥到 GPG 中。
|
||||
|
||||
```
|
||||
$ gpg --import yourfriends.key
|
||||
```
|
||||
|
||||
这些公钥与你自己创建的密钥一样,自带了名称和电子邮件地址的信息。 记住,为了让别人能解密你的文件,别人也需要你的公钥。 因此导出公钥并将之发送出去。
|
||||
|
||||
```
|
||||
gpg --export -a "Your Name" > your.key
|
||||
```
|
||||
|
||||
现在可以开始加密要发送的文件了。它跟之前的步骤差不多, 只是需要指定你自己为发送人。
|
||||
|
||||
```
|
||||
$ gpg -e -u "Your Name" -r "Their Name" /tmp/test.txt
|
||||
```
|
||||
|
||||
### 结语
|
||||
|
||||
就这样了。GPG 还有一些高级选项, 不过你在 99% 的时间内都不会用到这些高级选项。 GPG 就是这么易于使用。你也可以使用创建的密钥对来发送和接受加密邮件,其步骤跟上面演示的差不多, 不过大多数的电子邮件客户端在拥有密钥的情况下会自动帮你做这个动作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-encrypt-and-decrypt-individual-files-with-gpg
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
74
published/20171120 Mark McIntyre How Do You Fedora.md
Normal file
74
published/20171120 Mark McIntyre How Do You Fedora.md
Normal file
@ -0,0 +1,74 @@
|
||||
Mark McIntyre:与 Fedora 的那些事
|
||||
===========================
|
||||
|
||||

|
||||
|
||||
最近我们采访了 Mark McIntyre,谈了他是如何使用 Fedora 系统的。这也是 Fedora 杂志上[系列文章的一部分][2]。该系列简要介绍了 Fedora 用户,以及他们是如何用 Fedora 把事情做好的。如果你想成为采访对象,请通过[反馈表][3]与我们联系。
|
||||
|
||||
### Mark McIntyre 是谁?
|
||||
|
||||
Mark McIntyre 为极客而生,以 Linux 为乐趣。他说:“我在 13 岁开始编程,当时自学 BASIC 语言,我体会到其中的乐趣,并在乐趣的引导下,一步步成为专业的码农。” Mark 和他的侄女都是披萨饼的死忠粉。“去年秋天,我和我的侄女开始了一个任务,去尝试诺克斯维尔的许多披萨饼连锁店。点击[这里][4]可以了解我们的进展情况。”Mark 也是一名业余的摄影爱好者,并且在 Flickr 上 [发布自己的作品][5]。
|
||||
|
||||

|
||||
|
||||
作为一名开发者,Mark 有着丰富的工作背景。他用过 Visual Basic 编写应用程序,用过 LotusScript、 PL/SQL(Oracle)、 Tcl/TK 编写代码,也用过基于 Python 的 Django 框架。他的强项是 Python。这也是目前他作为系统工程师的工作语言。“我经常使用 Python。由于我的工作变得更像是自动化工程师, Python 用得就更频繁了。”
|
||||
|
||||
McIntyre 自称是个书呆子,喜欢科幻电影,但他最喜欢的一部电影却不是科幻片。“尽管我是个书呆子,喜欢看《<ruby>星际迷航<rt>Star Trek</rt></ruby>》、《<ruby>星球大战<rt>Star Wars</rt></ruby>》之类的影片,但《<ruby>光荣战役<rt>Glory</rt></ruby>》或许才是我最喜欢的电影。”他还提到,电影《<ruby>冲出宁静号<rt>Serenity</rt></ruby>》是一个著名电视剧的精彩后续(指《萤火虫》)。
|
||||
|
||||
Mark 比较看重他人的谦逊、知识与和气。他欣赏能够设身处地为他人着想的人。“如果你决定为另一个人服务,那么你会选择自己愿意亲近的人,而不是让自己备受折磨的人。”
|
||||
|
||||
McIntyre 目前在 [Scripps Networks Interactive][6] 工作,这家公司是 HGTV、Food Network、Travel Channel、DIY、GAC 以及其他几个有线电视频道的母公司。“我现在是一名系统工程师,负责非线性视频内容,这是所有媒体要开展线上消费所需要的。”他为一些开发团队提供支持,他们编写应用程序,将线性视频从有线电视发布到线上平台,比如亚马逊、葫芦。这些系统既包含预置系统,也包含云系统。Mark 还开发了一些自动化工具,将这些应用程序主要部署到云基础结构中。
|
||||
|
||||
### Fedora 社区
|
||||
|
||||
Mark 形容 Fedora 社区是一个富有活力的社区,充满着像 Fedora 用户一样热爱生活的人。“从设计师到封包人,这个团体依然非常活跃,生机勃勃。” 他继续说道:“这使我对该操作系统抱有一种信心。”
|
||||
|
||||
2002 年左右,Mark 开始经常使用 IRC 上的 #fedora 频道:“那时候,Wi-Fi 在启用适配器和配置模块功能时,有许多还是靠手工实现的。”为了让他的 Wi-Fi 能够工作,他不得不重新去编译 Fedora 内核。
|
||||
|
||||
McIntyre 鼓励他人参与 Fedora 社区。“这里有许多来自不同领域的机会。前端设计、测试部署、开发、应用程序打包以及新技术实现。”他建议选择一个感兴趣的领域,然后向那个团体提出疑问。“这里有许多机会去奉献自己。”
|
||||
|
||||
对于帮助他起步的社区成员,Mark 赞道:“Ben Williams 非常乐于助人。在我第一次接触 Fedora 时,他帮我搞定了一些 #fedora 支持频道中的安装补丁。” Ben 也鼓励 Mark 去做 Fedora [大使][7]。
|
||||
|
||||
### 什么样的硬件和软件?
|
||||
|
||||
McIntyre 将 Fedora Linux 系统用在他的笔记本和台式机上。在服务器上他选择了 CentOS,因为它有更长的生命周期支持。他现在的台式机是自己组装的,配有 Intel 酷睿 i5 处理器,32GB 的内存和2TB 的硬盘。“我装了个 4K 的显示屏,有足够大的地方来同时查看所有的应用。”他目前工作用的笔记本是戴尔灵越二合一,配备 13 英寸的屏,16 GB 的内存和 525 GB 的 m.2 固态硬盘。
|
||||
|
||||
|
||||
|
||||
Mark 现在将 Fedora 26 运行在他过去几个月装配的所有机器中。当一个新版本正式发布的时候,他倾向于避开这个高峰期。“除非在它即将发行的时候,我的工作站中有个正在运行下一代测试版本,通常情况下,一旦它发展成熟,我都会试着去获取最新的版本。”他经常采取就地更新:“这种就地更新方法利用 dnf 系统升级插件,目前表现得非常好。”
|
||||
|
||||
为了搞摄影,McIntyre 用上了 [GIMP][8]、[Darktable][9],以及其他一些照片查看包和快速编辑包。当不用 Web 电子邮件时,Mark 会使用 [Geary][10],还有[GNOME Calendar][11]。Mark 选用 HexChat 作为 IRC 客户端,[HexChat][12] 与在 Fedora 服务器实例上运行的 [ZNC bouncer][13] 联机。他的部门通过 Slave 进行沟通交流。
|
||||
|
||||
“我从来都不是 IDE 粉,所以大多数的编辑任务都是在 [vim][14] 上完成的。”Mark 偶尔也会打开一个简单的文本编辑器,如 [gedit][15],或者 [xed][16]。他用 [GPaste][17] 做复制和粘贴工作。“对于终端的选择,我已经变成 [Tilix][18] 的忠粉。”McIntyre 通过 [Rhythmbox][19] 来管理他喜欢的播客,并用 [Epiphany][20] 实现快速网络查询。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/mark-mcintyre-fedora/
|
||||
|
||||
作者:[Charles Profitt][a]
|
||||
译者:[zrszrszrs](https://github.com/zrszrszrs)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/cprofitt/
|
||||
[1]:https://fedoramagazine.org/mark-mcintyre-fedora/
|
||||
[2]:https://fedoramagazine.org/tag/how-do-you-fedora/
|
||||
[3]:https://fedoramagazine.org/submit-an-idea-or-tip/
|
||||
[4]:https://knox-pizza-quest.blogspot.com/
|
||||
[5]:https://www.flickr.com/photos/mockgeek/
|
||||
[6]:http://www.scrippsnetworksinteractive.com/
|
||||
[7]:https://fedoraproject.org/wiki/Ambassadors
|
||||
[8]:https://www.gimp.org/
|
||||
[9]:http://www.darktable.org/
|
||||
[10]:https://wiki.gnome.org/Apps/Geary
|
||||
[11]:https://wiki.gnome.org/Apps/Calendar
|
||||
[12]:https://hexchat.github.io/
|
||||
[13]:https://wiki.znc.in/ZNC
|
||||
[14]:http://www.vim.org/
|
||||
[15]:https://wiki.gnome.org/Apps/Gedit
|
||||
[16]:https://github.com/linuxmint/xed
|
||||
[17]:https://github.com/Keruspe/GPaste
|
||||
[18]:https://fedoramagazine.org/try-tilix-new-terminal-emulator-fedora/
|
||||
[19]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[20]:https://wiki.gnome.org/Apps/Web
|
||||
@ -0,0 +1,149 @@
|
||||
如何判断 Linux 服务器是否被入侵?
|
||||
=========================
|
||||
|
||||
本指南中所谓的服务器被入侵或者说被黑了的意思,是指未经授权的人或程序为了自己的目的登录到服务器上去并使用其计算资源,通常会产生不好的影响。
|
||||
|
||||
免责声明:若你的服务器被类似 NSA 这样的国家机关或者某个犯罪集团入侵,那么你并不会注意到有任何问题,这些技术也无法发觉他们的存在。
|
||||
|
||||
然而,大多数被攻破的服务器都是被类似自动攻击程序这样的程序或者类似“脚本小子”这样的廉价攻击者,以及蠢蛋罪犯所入侵的。
|
||||
|
||||
这类攻击者会在访问服务器的同时滥用服务器资源,并且不怎么会采取措施来隐藏他们正在做的事情。
|
||||
|
||||
### 被入侵服务器的症状
|
||||
|
||||
当服务器被没有经验攻击者或者自动攻击程序入侵了的话,他们往往会消耗 100% 的资源。他们可能消耗 CPU 资源来进行数字货币的采矿或者发送垃圾邮件,也可能消耗带宽来发动 DoS 攻击。
|
||||
|
||||
因此出现问题的第一个表现就是服务器 “变慢了”。这可能表现在网站的页面打开的很慢,或者电子邮件要花很长时间才能发送出去。
|
||||
|
||||
那么你应该查看那些东西呢?
|
||||
|
||||
#### 检查 1 - 当前都有谁在登录?
|
||||
|
||||
你首先要查看当前都有谁登录在服务器上。发现攻击者登录到服务器上进行操作并不复杂。
|
||||
|
||||
其对应的命令是 `w`。运行 `w` 会输出如下结果:
|
||||
|
||||
```
|
||||
08:32:55 up 98 days, 5:43, 2 users, load average: 0.05, 0.03, 0.00
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
root pts/0 113.174.161.1 08:26 0.00s 0.03s 0.02s ssh root@coopeaa12
|
||||
root pts/1 78.31.109.1 08:26 0.00s 0.01s 0.00s w
|
||||
```
|
||||
|
||||
第一个 IP 是英国 IP,而第二个 IP 是越南 IP。这个不是个好兆头。
|
||||
|
||||
停下来做个深呼吸, 不要恐慌之下只是干掉他们的 SSH 连接。除非你能够防止他们再次进入服务器,否则他们会很快进来并踢掉你,以防你再次回去。
|
||||
|
||||
请参阅本文最后的“被入侵之后怎么办”这一章节来看找到了被入侵的证据后应该怎么办。
|
||||
|
||||
`whois` 命令可以接一个 IP 地址然后告诉你该 IP 所注册的组织的所有信息,当然就包括所在国家的信息。
|
||||
|
||||
#### 检查 2 - 谁曾经登录过?
|
||||
|
||||
Linux 服务器会记录下哪些用户,从哪个 IP,在什么时候登录的以及登录了多长时间这些信息。使用 `last` 命令可以查看这些信息。
|
||||
|
||||
输出类似这样:
|
||||
|
||||
```
|
||||
root pts/1 78.31.109.1 Thu Nov 30 08:26 still logged in
|
||||
root pts/0 113.174.161.1 Thu Nov 30 08:26 still logged in
|
||||
root pts/1 78.31.109.1 Thu Nov 30 08:24 - 08:26 (00:01)
|
||||
root pts/0 113.174.161.1 Wed Nov 29 12:34 - 12:52 (00:18)
|
||||
root pts/0 14.176.196.1 Mon Nov 27 13:32 - 13:53 (00:21)
|
||||
```
|
||||
|
||||
这里可以看到英国 IP 和越南 IP 交替出现,而且最上面两个 IP 现在还处于登录状态。如果你看到任何未经授权的 IP,那么请参阅最后章节。
|
||||
|
||||
登录后的历史记录会记录到二进制的 `/var/log/wtmp` 文件中(LCTT 译注:这里作者应该写错了,根据实际情况修改),因此很容易被删除。通常攻击者会直接把这个文件删掉,以掩盖他们的攻击行为。 因此, 若你运行了 `last` 命令却只看得见你的当前登录,那么这就是个不妙的信号。
|
||||
|
||||
如果没有登录历史的话,请一定小心,继续留意入侵的其他线索。
|
||||
|
||||
#### 检查 3 - 回顾命令历史
|
||||
|
||||
这个层次的攻击者通常不会注意掩盖命令的历史记录,因此运行 `history` 命令会显示出他们曾经做过的所有事情。
|
||||
一定留意有没有用 `wget` 或 `curl` 命令来下载类似垃圾邮件机器人或者挖矿程序之类的非常规软件。
|
||||
|
||||
命令历史存储在 `~/.bash_history` 文件中,因此有些攻击者会删除该文件以掩盖他们的所作所为。跟登录历史一样,若你运行 `history` 命令却没有输出任何东西那就表示历史文件被删掉了。这也是个不妙的信号,你需要很小心地检查一下服务器了。(LCTT 译注,如果没有命令历史,也有可能是你的配置错误。)
|
||||
|
||||
#### 检查 4 - 哪些进程在消耗 CPU?
|
||||
|
||||
你常遇到的这类攻击者通常不怎么会去掩盖他们做的事情。他们会运行一些特别消耗 CPU 的进程。这就很容易发现这些进程了。只需要运行 `top` 然后看最前的那几个进程就行了。
|
||||
|
||||
这也能显示出那些未登录进来的攻击者。比如,可能有人在用未受保护的邮件脚本来发送垃圾邮件。
|
||||
|
||||
如果你最上面的进程对不了解,那么你可以 Google 一下进程名称,或者通过 `losf` 和 `strace` 来看看它做的事情是什么。
|
||||
|
||||
使用这些工具,第一步从 `top` 中拷贝出进程的 PID,然后运行:
|
||||
|
||||
```
|
||||
strace -p PID
|
||||
```
|
||||
|
||||
这会显示出该进程调用的所有系统调用。它产生的内容会很多,但这些信息能告诉你这个进程在做什么。
|
||||
|
||||
```
|
||||
lsof -p PID
|
||||
```
|
||||
|
||||
这个程序会列出该进程打开的文件。通过查看它访问的文件可以很好的理解它在做的事情。
|
||||
|
||||
#### 检查 5 - 检查所有的系统进程
|
||||
|
||||
消耗 CPU 不严重的未授权进程可能不会在 `top` 中显露出来,不过它依然可以通过 `ps` 列出来。命令 `ps auxf` 就能显示足够清晰的信息了。
|
||||
|
||||
你需要检查一下每个不认识的进程。经常运行 `ps` (这是个好习惯)能帮助你发现奇怪的进程。
|
||||
|
||||
#### 检查 6 - 检查进程的网络使用情况
|
||||
|
||||
`iftop` 的功能类似 `top`,它会排列显示收发网络数据的进程以及它们的源地址和目的地址。类似 DoS 攻击或垃圾机器人这样的进程很容易显示在列表的最顶端。
|
||||
|
||||
#### 检查 7 - 哪些进程在监听网络连接?
|
||||
|
||||
通常攻击者会安装一个后门程序专门监听网络端口接受指令。该进程等待期间是不会消耗 CPU 和带宽的,因此也就不容易通过 `top` 之类的命令发现。
|
||||
|
||||
`lsof` 和 `netstat` 命令都会列出所有的联网进程。我通常会让它们带上下面这些参数:
|
||||
|
||||
```
|
||||
lsof -i
|
||||
```
|
||||
|
||||
```
|
||||
netstat -plunt
|
||||
```
|
||||
|
||||
你需要留意那些处于 `LISTEN` 和 `ESTABLISHED` 状态的进程,这些进程要么正在等待连接(LISTEN),要么已经连接(ESTABLISHED)。如果遇到不认识的进程,使用 `strace` 和 `lsof` 来看看它们在做什么东西。
|
||||
|
||||
### 被入侵之后该怎么办呢?
|
||||
|
||||
首先,不要紧张,尤其当攻击者正处于登录状态时更不能紧张。**你需要在攻击者警觉到你已经发现他之前夺回机器的控制权。**如果他发现你已经发觉到他了,那么他可能会锁死你不让你登陆服务器,然后开始毁尸灭迹。
|
||||
|
||||
如果你技术不太好那么就直接关机吧。你可以在服务器上运行 `shutdown -h now` 或者 `systemctl poweroff` 这两条命令之一。也可以登录主机提供商的控制面板中关闭服务器。关机后,你就可以开始配置防火墙或者咨询一下供应商的意见。
|
||||
|
||||
如果你对自己颇有自信,而你的主机提供商也有提供上游防火墙,那么你只需要以此创建并启用下面两条规则就行了:
|
||||
|
||||
1. 只允许从你的 IP 地址登录 SSH。
|
||||
2. 封禁除此之外的任何东西,不仅仅是 SSH,还包括任何端口上的任何协议。
|
||||
|
||||
这样会立即关闭攻击者的 SSH 会话,而只留下你可以访问服务器。
|
||||
|
||||
如果你无法访问上游防火墙,那么你就需要在服务器本身创建并启用这些防火墙策略,然后在防火墙规则起效后使用 `kill` 命令关闭攻击者的 SSH 会话。(LCTT 译注:本地防火墙规则 有可能不会阻止已经建立的 SSH 会话,所以保险起见,你需要手工杀死该会话。)
|
||||
|
||||
最后还有一种方法,如果支持的话,就是通过诸如串行控制台之类的带外连接登录服务器,然后通过 `systemctl stop network.service` 停止网络功能。这会关闭所有服务器上的网络连接,这样你就可以慢慢的配置那些防火墙规则了。
|
||||
|
||||
重夺服务器的控制权后,也不要以为就万事大吉了。
|
||||
|
||||
不要试着修复这台服务器,然后接着用。你永远不知道攻击者做过什么,因此你也永远无法保证这台服务器还是安全的。
|
||||
|
||||
最好的方法就是拷贝出所有的数据,然后重装系统。(LCTT 译注:你的程序这时已经不可信了,但是数据一般来说没问题。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/server-hacked/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
132
published/20171130 Wake up and Shut Down Linux Automatically.md
Normal file
132
published/20171130 Wake up and Shut Down Linux Automatically.md
Normal file
@ -0,0 +1,132 @@
|
||||
如何自动唤醒和关闭 Linux
|
||||
=====================
|
||||
|
||||

|
||||
|
||||
> 了解如何通过配置 Linux 计算机来根据时间自动唤醒和关闭。
|
||||
|
||||
|
||||
不要成为一个电能浪费者。如果你的电脑不需要开机就请把它们关机。出于方便和计算机宅的考虑,你可以通过配置你的 Linux 计算机实现自动唤醒和关闭。
|
||||
|
||||
### 宝贵的系统运行时间
|
||||
|
||||
有时候有些电脑需要一直处在开机状态,在不超过电脑运行时间的限制下这种情况是被允许的。有些人为他们的计算机可以长时间的正常运行而感到自豪,且现在我们有内核热补丁能够实现只有在硬件发生故障时才需要机器关机。我认为比较实际可行的是,像减少移动部件磨损一样节省电能,且在不需要机器运行的情况下将其关机。比如,你可以在规定的时间内唤醒备份服务器,执行备份,然后关闭它直到它要进行下一次备份。或者,你可以设置你的互联网网关只在特定的时间运行。任何不需要一直运行的东西都可以将其配置成在其需要工作的时候打开,待其完成工作后将其关闭。
|
||||
|
||||
### 系统休眠
|
||||
|
||||
对于不需要一直运行的电脑,使用 root 的 cron 定时任务(即 `/etc/crontab`)可以可靠地关闭电脑。这个例子创建一个 root 定时任务实现每天晚上 11 点 15 分定时关机。
|
||||
|
||||
```
|
||||
# crontab -e -u root
|
||||
# m h dom mon dow command
|
||||
15 23 * * * /sbin/shutdown -h now
|
||||
```
|
||||
|
||||
以下示例仅在周一至周五运行:
|
||||
|
||||
```
|
||||
15 23 * * 1-5 /sbin/shutdown -h now
|
||||
```
|
||||
|
||||
您可以为不同的日期和时间创建多个 cron 作业。 通过命令 `man 5 crontab` 可以了解所有时间和日期的字段。
|
||||
|
||||
一个快速、容易的方式是,使用 `/etc/crontab` 文件。但这样你必须指定用户:
|
||||
|
||||
```
|
||||
15 23 * * 1-5 root shutdown -h now
|
||||
```
|
||||
|
||||
### 自动唤醒
|
||||
|
||||
实现自动唤醒是一件很酷的事情;我大多数 SUSE (SUSE Linux)的同事都在纽伦堡,因此,因此为了跟同事能有几小时一起工作的时间,我不得不需要在凌晨五点起床。我的计算机早上 5 点半自动开始工作,而我只需要将自己和咖啡拖到我的桌子上就可以开始工作了。按下电源按钮看起来好像并不是什么大事,但是在每天的那个时候每件小事都会变得很大。
|
||||
|
||||
唤醒 Linux 计算机可能不如关闭它可靠,因此你可能需要尝试不同的办法。你可以使用远程唤醒(Wake-On-LAN)、RTC 唤醒或者个人电脑的 BIOS 设置预定的唤醒这些方式。这些方式可行的原因是,当你关闭电脑时,这并不是真正关闭了计算机;此时计算机处在极低功耗状态且还可以接受和响应信号。只有在你拔掉电源开关时其才彻底关闭。
|
||||
|
||||
### BIOS 唤醒
|
||||
|
||||
BIOS 唤醒是最可靠的。我的系统主板 BIOS 有一个易于使用的唤醒调度程序 (图 1)。对你来说也是一样的容易。
|
||||
|
||||

|
||||
|
||||
*图 1:我的系统 BIOS 有个易用的唤醒定时器。*
|
||||
|
||||
### 主机远程唤醒(Wake-On-LAN)
|
||||
|
||||
远程唤醒是仅次于 BIOS 唤醒的又一种可靠的唤醒方法。这需要你从第二台计算机发送信号到所要打开的计算机。可以使用 Arduino 或<ruby>树莓派<rt>Raspberry Pi</rt></ruby>发送给基于 Linux 的路由器或者任何 Linux 计算机的唤醒信号。首先,查看系统主板 BIOS 是否支持 Wake-On-LAN ,要是支持的话,必须先启动它,因为它被默认为禁用。
|
||||
|
||||
然后,需要一个支持 Wake-On-LAN 的网卡;无线网卡并不支持。你需要运行 `ethtool` 命令查看网卡是否支持 Wake-On-LAN :
|
||||
|
||||
```
|
||||
# ethtool eth0 | grep -i wake-on
|
||||
Supports Wake-on: pumbg
|
||||
Wake-on: g
|
||||
```
|
||||
|
||||
这条命令输出的 “Supports Wake-on” 字段会告诉你你的网卡现在开启了哪些功能:
|
||||
|
||||
* d -- 禁用
|
||||
* p -- 物理活动唤醒
|
||||
* u -- 单播消息唤醒
|
||||
* m -- 多播(组播)消息唤醒
|
||||
* b -- 广播消息唤醒
|
||||
* a -- ARP 唤醒
|
||||
* g -- <ruby>特定数据包<rt>magic packet</rt></ruby>唤醒
|
||||
* s -- 设有密码的<ruby>特定数据包<rt>magic packet</rt></ruby>唤醒
|
||||
|
||||
`ethtool` 命令的 man 手册并没说清楚 `p` 选项的作用;这表明任何信号都会导致唤醒。然而,在我的测试中它并没有这么做。想要实现远程唤醒主机,必须支持的功能是 `g` —— <ruby>特定数据包<rt>magic packet</rt></ruby>唤醒,而且下面的“Wake-on” 行显示这个功能已经在启用了。如果它没有被启用,你可以通过 `ethtool` 命令来启用它。
|
||||
|
||||
```
|
||||
# ethtool -s eth0 wol g
|
||||
```
|
||||
|
||||
这条命令可能会在重启后失效,所以为了确保万无一失,你可以创建个 root 用户的定时任务(cron)在每次重启的时候来执行这条命令。
|
||||
|
||||
```
|
||||
@reboot /usr/bin/ethtool -s eth0 wol g
|
||||
```
|
||||
|
||||
另一个选择是最近的<ruby>网络管理器<rt>Network Manager</rt></ruby>版本有一个很好的小复选框来启用 Wake-On-LAN(图 2)。
|
||||
|
||||

|
||||
|
||||
*图 2:启用 Wake on LAN*
|
||||
|
||||
这里有一个可以用于设置密码的地方,但是如果你的网络接口不支持<ruby>安全开机<rt>Secure On</rt></ruby>密码,它就不起作用。
|
||||
|
||||
现在你需要配置第二台计算机来发送唤醒信号。你并不需要 root 权限,所以你可以为你的普通用户创建 cron 任务。你需要用到的是想要唤醒的机器的网络接口和MAC地址信息。
|
||||
|
||||
```
|
||||
30 08 * * * /usr/bin/wakeonlan D0:50:99:82:E7:2B
|
||||
```
|
||||
|
||||
### RTC 唤醒
|
||||
|
||||
通过使用实时闹钟来唤醒计算机是最不可靠的方法。对于这个方法,可以参看 [Wake Up Linux With an RTC Alarm Clock][4] ;对于现在的大多数发行版来说这种方法已经有点过时了。
|
||||
|
||||
下周继续了解更多关于使用 RTC 唤醒的方法。
|
||||
|
||||
通过 Linux 基金会和 edX 可以学习更多关于 Linux 的免费 [Linux 入门][5]教程。
|
||||
|
||||
(题图:[The Observatory at Delhi][7])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://www.linux.com/learn/intro-to-linux/2017/11/wake-and-shut-down-linux-automatically
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/files/images/bannerjpg
|
||||
[2]:https://www.linux.com/files/images/fig-1png-11
|
||||
[3]:https://www.linux.com/files/images/fig-2png-7
|
||||
[4]:https://www.linux.com/learn/wake-linux-rtc-alarm-clock
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[7]:http://www.columbia.edu/itc/mealac/pritchett/00routesdata/1700_1799/jaipur/delhijantarearly/delhijantarearly.html
|
||||
[8]:https://www.linux.com/licenses/category/used-permission
|
||||
[9]:https://www.linux.com/licenses/category/used-permission
|
||||
|
||||
@ -1,13 +1,9 @@
|
||||
如何在 Linux 系统中用用户组来管理用户
|
||||
如何在 Linux 系统中通过用户组来管理用户
|
||||
============================================================
|
||||
|
||||
### [group-of-people-1645356_1920.jpg][1]
|
||||
|
||||

|
||||
|
||||
本教程可以了解如何通过用户组和访问控制表(ACL)来管理用户。
|
||||
|
||||
[创意共享协议][4]
|
||||
> 本教程可以了解如何通过用户组和访问控制表(ACL)来管理用户。
|
||||
|
||||
当你需要管理一台容纳多个用户的 Linux 机器时,比起一些基本的用户管理工具所提供的方法,有时候你需要对这些用户采取更多的用户权限管理方式。特别是当你要管理某些用户的权限时,这个想法尤为重要。比如说,你有一个目录,某个用户组中的用户可以通过读和写的权限访问这个目录,而其他用户组中的用户对这个目录只有读的权限。在 Linux 中,这是完全可以实现的。但前提是你必须先了解如何通过用户组和访问控制表(ACL)来管理用户。
|
||||
|
||||
@ -18,36 +14,32 @@
|
||||
你需要用下面两个用户名新建两个用户:
|
||||
|
||||
* olivia
|
||||
|
||||
* nathan
|
||||
|
||||
你需要新建以下两个用户组:
|
||||
|
||||
* readers
|
||||
|
||||
* editors
|
||||
|
||||
olivia 属于 editors 用户组,而 nathan 属于 readers 用户组。reader 用户组对 ``/DATA`` 目录只有读的权限,而 editors 用户组则对 ``/DATA`` 目录同时有读和写的权限。当然,这是个非常小的任务,但它会给你基本的信息·。你可以扩展这个任务以适应你其他更大的需求。
|
||||
olivia 属于 editors 用户组,而 nathan 属于 readers 用户组。reader 用户组对 `/DATA` 目录只有读的权限,而 editors 用户组则对 `/DATA` 目录同时有读和写的权限。当然,这是个非常小的任务,但它会给你基本的信息,你可以扩展这个任务以适应你其他更大的需求。
|
||||
|
||||
我将在 Ubuntu 16.04 Server 平台上进行演示。这些命令都是通用的,唯一不同的是,要是在你的发行版中不使用 sudo 命令,你必须切换到 root 用户来执行这些命令。
|
||||
我将在 Ubuntu 16.04 Server 平台上进行演示。这些命令都是通用的,唯一不同的是,要是在你的发行版中不使用 `sudo` 命令,你必须切换到 root 用户来执行这些命令。
|
||||
|
||||
### 创建用户
|
||||
|
||||
我们需要做的第一件事是为我们的实验创建两个用户。可以用 ``useradd`` 命令来创建用户,我们不只是简单地创建一个用户,而需要同时创建用户和属于他们的家目录,然后给他们设置密码。
|
||||
我们需要做的第一件事是为我们的实验创建两个用户。可以用 `useradd` 命令来创建用户,我们不只是简单地创建一个用户,而需要同时创建用户和属于他们的家目录,然后给他们设置密码。
|
||||
|
||||
```
|
||||
sudo useradd -m olivia
|
||||
|
||||
sudo useradd -m nathan
|
||||
```
|
||||
|
||||
我们现在创建了两个用户,如果你看看 ``/home`` 目录,你可以发现他们的家目录(因为我们用了 -m 选项,可以帮在创建用户的同时创建他们的家目录。
|
||||
我们现在创建了两个用户,如果你看看 `/home` 目录,你可以发现他们的家目录(因为我们用了 `-m` 选项,可以在创建用户的同时创建他们的家目录。
|
||||
|
||||
之后,我们可以用以下命令给他们设置密码:
|
||||
|
||||
```
|
||||
sudo passwd olivia
|
||||
|
||||
sudo passwd nathan
|
||||
```
|
||||
|
||||
@ -59,26 +51,21 @@ sudo passwd nathan
|
||||
|
||||
```
|
||||
addgroup readers
|
||||
|
||||
addgroup editors
|
||||
```
|
||||
|
||||
(译者注:当你使用 CentOS 等一些 Linux 发行版时,可能系统没有 addgroup 这个命令,推荐使用 groupadd 命令来替换 addgroup 命令以达到同样的效果)
|
||||
|
||||
|
||||
### [groups_1.jpg][2]
|
||||
(LCTT 译注:当你使用 CentOS 等一些 Linux 发行版时,可能系统没有 `addgroup` 这个命令,推荐使用 `groupadd` 命令来替换 `addgroup` 命令以达到同样的效果)
|
||||
|
||||

|
||||
|
||||
图一:我们可以使用刚创建的新用户组了。
|
||||
|
||||
[Used with permission][5]
|
||||
*图一:我们可以使用刚创建的新用户组了。*
|
||||
|
||||
创建用户组后,我们需要添加我们的用户到这两个用户组。我们用以下命令来将 nathan 用户添加到 readers 用户组:
|
||||
|
||||
```
|
||||
sudo usermod -a -G readers nathan
|
||||
```
|
||||
|
||||
用以下命令将 olivia 添加到 editors 用户组:
|
||||
|
||||
```
|
||||
@ -89,7 +76,7 @@ sudo usermod -a -G editors olivia
|
||||
|
||||
### 给用户组授予目录的权限
|
||||
|
||||
假设你有个目录 ``/READERS`` 且允许 readers 用户组的所有成员访问这个目录。首先,我们执行以下命令来更改目录所属用户组:
|
||||
假设你有个目录 `/READERS` 且允许 readers 用户组的所有成员访问这个目录。首先,我们执行以下命令来更改目录所属用户组:
|
||||
|
||||
```
|
||||
sudo chown -R :readers /READERS
|
||||
@ -107,26 +94,23 @@ sudo chmod -R g-w /READERS
|
||||
sudo chmod -R o-x /READERS
|
||||
```
|
||||
|
||||
这时候,只有目录的所有者(root)和用户组 reader 中的用户可以访问 ``/READES`` 中的文件。
|
||||
这时候,只有目录的所有者(root)和用户组 reader 中的用户可以访问 `/READES` 中的文件。
|
||||
|
||||
假设你有个目录 ``/EDITORS`` ,你需要给用户组 editors 里的成员这个目录的读和写的权限。为了达到这个目的,执行下面的这些命令是必要的:
|
||||
假设你有个目录 `/EDITORS` ,你需要给用户组 editors 里的成员这个目录的读和写的权限。为了达到这个目的,执行下面的这些命令是必要的:
|
||||
|
||||
```
|
||||
sudo chown -R :editors /EDITORS
|
||||
|
||||
sudo chmod -R g+w /EDITORS
|
||||
|
||||
sudo chmod -R o-x /EDITORS
|
||||
```
|
||||
|
||||
此时 editors 用户组的所有成员都可以访问和修改其中的文件。除此之外其他用户(除了 root 之外)无法访问 ``/EDITORS`` 中的任何文件。
|
||||
此时 editors 用户组的所有成员都可以访问和修改其中的文件。除此之外其他用户(除了 root 之外)无法访问 `/EDITORS` 中的任何文件。
|
||||
|
||||
使用这个方法的问题在于,你一次只能操作一个组和一个目录而已。这时候访问控制表(ACL)就可以派得上用场了。
|
||||
|
||||
|
||||
### 使用访问控制表(ACL)
|
||||
|
||||
现在,让我们把这个问题变得棘手一点。假设你有一个目录 ``/DATA`` 并且你想给 readers 用户组的成员读取权限并同时给 editors 用户组的成员读和写的权限。为此,你必须要用到 setfacl 命令。setfacl 命令可以为文件或文件夹设置一个访问控制表(ACL)。
|
||||
现在,让我们把这个问题变得棘手一点。假设你有一个目录 `/DATA` 并且你想给 readers 用户组的成员读取权限,并同时给 editors 用户组的成员读和写的权限。为此,你必须要用到 `setfacl` 命令。`setfacl` 命令可以为文件或文件夹设置一个访问控制表(ACL)。
|
||||
|
||||
这个命令的结构如下:
|
||||
|
||||
@ -134,45 +118,41 @@ sudo chmod -R o-x /EDITORS
|
||||
setfacl OPTION X:NAME:Y /DIRECTORY
|
||||
```
|
||||
|
||||
其中 OPTION 是可选选项,X 可以是 u(用户)或者是 g (用户组),NAME 是用户或者用户组的名字,/DIRECTORY 是要用到的目录。我们将使用 -m 选项进行修改(modify)。因此,我们给 readers 用户组添加读取权限的命令是:
|
||||
其中 OPTION 是可选选项,X 可以是 `u`(用户)或者是 `g` (用户组),NAME 是用户或者用户组的名字,/DIRECTORY 是要用到的目录。我们将使用 `-m` 选项进行修改。因此,我们给 readers 用户组添加读取权限的命令是:
|
||||
|
||||
```
|
||||
sudo setfacl -m g:readers:rx -R /DATA
|
||||
```
|
||||
|
||||
现在 readers 用户组里面的每一个用户都可以读取 /DATA 目录里的文件了,但是他们不能修改里面的内容。
|
||||
现在 readers 用户组里面的每一个用户都可以读取 `/DATA` 目录里的文件了,但是他们不能修改里面的内容。
|
||||
|
||||
为了给 editors 用户组里面的用户读写权限,我们执行了以下命令:
|
||||
|
||||
```
|
||||
sudo setfacl -m g:editors:rwx -R /DATA
|
||||
```
|
||||
|
||||
上述命令将赋予 editors 用户组中的任何成员读取权限,同时保留 readers 用户组的只读权限。
|
||||
|
||||
### 更多的权限控制
|
||||
|
||||
使用访问控制表(ACL),你可以实现你所需的权限控制。你可以添加用户到用户组,并且灵活地控制这些用户组对每个目录的权限以达到你的需求。如果想了解上述工具的更多信息,可以执行下列的命令:
|
||||
|
||||
* man usradd
|
||||
|
||||
* man addgroup
|
||||
|
||||
* man usermod
|
||||
|
||||
* man sefacl
|
||||
|
||||
* man chown
|
||||
|
||||
* man chmod
|
||||
* `man usradd`
|
||||
* `man addgroup`
|
||||
* `man usermod`
|
||||
* `man sefacl`
|
||||
* `man chown`
|
||||
* `man chmod`
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/how-manage-users-groups-linux
|
||||
|
||||
作者:[Jack Wallen ]
|
||||
作者:[Jack Wallen]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,298 @@
|
||||
2017 年 30 款最好的支持 Linux 的 Steam 游戏
|
||||
============================================================
|
||||
|
||||
说到游戏,人们一般都会推荐使用 Windows 系统。Windows 能提供更好的显卡支持和硬件兼容性,所以对于游戏爱好者来说的确是个更好的选择。但你是否想过[在 Linux 系统上玩游戏][9]?这的确是可以的,也许你以前还曾经考虑过。但在几年之前, [Steam for Linux][10] 上可玩的游戏并不是很吸引人。
|
||||
|
||||
但现在情况完全不一样了。Steam 商店里现在有许多支持 Linux 平台的游戏(包括很多主流大作)。我们在本文中将介绍 Steam 上最好的一些 Linux 游戏。
|
||||
|
||||
在进入正题之前,先介绍一个省钱小窍门。如果你是个狂热的游戏爱好者,在游戏上花费很多时间和金钱的话,我建议你订阅 [<ruby>Humble 每月包<rt>Humble Monthly</rt></ruby>][11]。这是个每月收费的订阅服务,每月只用 12 美元就能获得价值 100 美元的游戏。
|
||||
|
||||
这个游戏包中可能有些游戏不支持 Linux,但除了 Steam 游戏之外,它还会让 [Humble Bundle 网站][12]上所有的游戏和书籍都打九折,所以这依然是个不错的优惠。
|
||||
|
||||
更棒的是,你在 Humble Bundle 上所有的消费都会捐出一部分给慈善机构。所以你在享受游戏的同时还在帮助改变世界。
|
||||
|
||||
### Steam 上最好的 Linux 游戏
|
||||
|
||||
以下排名无先后顺序。
|
||||
|
||||
额外提示:虽然在 Steam 上有很多支持 Linux 的游戏,但你在 Linux 上玩游戏时依然可能会遇到各种问题。你可以阅读我们之前的文章:[每个 Linux 游戏玩家都会遇到的烦人问题][14]
|
||||
|
||||
可以点击以下链接跳转到你喜欢的游戏类型:
|
||||
|
||||
* [动作类游戏][3]
|
||||
* [角色扮演类游戏][4]
|
||||
* [赛车/运动/模拟类游戏][5]
|
||||
* [冒险类游戏][6]
|
||||
* [独立游戏][7]
|
||||
* [策略类游戏][8]
|
||||
|
||||
### Steam 上最佳 Linux 动作类游戏
|
||||
|
||||
#### 1、 《<ruby>反恐精英:全球攻势<rt>Counter-Strike: Global Offensive</rt></ruby>》(多人)
|
||||
|
||||
《CS:GO》毫无疑问是 Steam 上支持 Linux 的最好的 FPS 游戏之一。我觉得这款游戏无需介绍,但如果你没有听说过它,我要告诉你这将会是你玩过的最好玩的多人 FPS 游戏之一。《CS:GO》还是电子竞技中的一个主流项目。想要提升等级的话,你需要在天梯上和其他玩家同台竞技。但你也可以选择更加轻松的休闲模式。
|
||||
|
||||
我本想写《彩虹六号:围攻行动》,但它目前还不支持 Linux 或 Steam OS。
|
||||
|
||||
- [购买《CS: GO》][15]
|
||||
|
||||
#### 2、 《<ruby>求生之路 2<rt>Left 4 Dead 2</rt></ruby>》(多人/单机)
|
||||
|
||||
这是最受欢迎的僵尸主题多人 FPS 游戏之一。在 Steam 优惠时,价格可以低至 1.3 美元。这是个有趣的游戏,能让你体会到你在僵尸游戏中期待的战栗和刺激。游戏中的环境包括了沼泽、城市、墓地等等,让游戏既有趣又吓人。游戏中的枪械并不是非常先进,但作为一个老游戏来说,它已经提供了足够真实的体验。
|
||||
|
||||
- [购买《求生之路 2》][16]
|
||||
|
||||
#### 3、 《<ruby>无主之地 2<rt>Borderlands 2</rt></ruby>》(单机/协作)
|
||||
|
||||
《无主之地 2》是个很有意思的 FPS 游戏。它和你以前玩过的游戏完全不同。画风看上去有些诡异和卡通化,如果你正在寻找一个第一视角的射击游戏,我可以保证,游戏体验可一点也不逊色!
|
||||
|
||||
如果你在寻找一个好玩而且有很多 DLC 的 Linux 游戏,《无主之地 2》绝对是个不错的选择。
|
||||
|
||||
- [购买《无主之地 2》][17]
|
||||
|
||||
#### 4、 《<ruby>叛乱<rt>Insurgency</rt></ruby>》(多人)
|
||||
|
||||
《叛乱》是 Steam 上又一款支持 Linux 的优秀的 FPS 游戏。它剑走偏锋,从屏幕上去掉了 HUD 和弹药数量指示。如同许多评论者所说,这是款注重武器和团队战术的纯粹的射击游戏。这也许不是最好的 FPS 游戏,但如果你想玩和《三角洲部队》类似的多人游戏的话,这绝对是最好的游戏之一。
|
||||
|
||||
- [购买《叛乱》][18]
|
||||
|
||||
#### 5、 《<ruby>生化奇兵:无限<rt>Bioshock: Infinite</rt></ruby>》(单机)
|
||||
|
||||
《生化奇兵:无限》毫无疑问将会作为 PC 平台最好的单机 FPS 游戏之一而载入史册。你可以利用很多强大的能力来杀死你的敌人。同时你的敌人也各个身怀绝技。游戏的剧情也非常丰富。你不容错过!
|
||||
|
||||
- [购买《生化奇兵:无限》][19]
|
||||
|
||||
#### 6、 《<ruby>杀手(年度版)<rt>HITMAN - Game of the Year Edition</rt></ruby>》(单机)
|
||||
|
||||
《杀手》系列无疑是 PC 游戏爱好者们的最爱之一。本系列的最新作开始按章节发布,让很多玩家觉得不满。但现在 Square Enix 撤出了开发,而最新的年度版带着新的内容重返舞台。在游戏中发挥你的想象力暗杀你的目标吧,杀手47!
|
||||
|
||||
- [购买(杀手(年度版))][20]
|
||||
|
||||
#### 7、 《<ruby>传送门 2<rt>Portal 2</rt></ruby>》
|
||||
|
||||
《传送门 2》完美地结合了动作与冒险。这是款解谜类游戏,你可以与其他玩家协作,并开发有趣的谜题。协作模式提供了和单机模式截然不同的游戏内容。
|
||||
|
||||
- [购买《传送门2》][21]
|
||||
|
||||
#### 8、 《<ruby>杀出重围:人类分裂<rt>Deux Ex: Mankind Divided</rt></ruby>》
|
||||
|
||||
如果你在寻找隐蔽类的射击游戏,《杀出重围》是个填充你的 Steam 游戏库的完美选择。这是个非常华丽的游戏,有着最先进的武器和超乎寻常的战斗机制。
|
||||
|
||||
- [购买《杀出重围:人类分裂》][22]
|
||||
|
||||
#### 9、 《<ruby>地铁 2033 重置版<rt>Metro 2033 Redux</rt></ruby>》 / 《<ruby>地铁:最后曙光 重置版<rt>Metro Last Light Redux</rt></ruby>》
|
||||
|
||||
《地铁 2033 重置版》和《地铁:最后曙光 重置版》是经典的《地铁 2033》和《地铁:最后曙光》的最终版本。故事发生在世界末日之后。你需要消灭所有的变种人来保证人类的生存。剩下的就交给你自己去探索了!
|
||||
|
||||
- [购买《地铁 2033 重置版》][23]
|
||||
- [购买《地铁:最后曙光 重置版》][24]
|
||||
|
||||
#### 10、 《<ruby>坦能堡<rt>Tannenberg</rt></ruby>》(多人)
|
||||
|
||||
《坦能堡》是个全新的游戏 - 在本文发表一个月前刚刚发售。游戏背景是第一次世界大战的东线战场(1914-1918)。这款游戏只有多人模式。如果你想要在游戏中体验第一次世界大战,不要错过这款游戏!
|
||||
|
||||
- [购买《坦能堡》][25]
|
||||
|
||||
### Steam 上最佳 Linux 角色扮演类游戏
|
||||
|
||||
#### 11、 《<ruby>中土世界:暗影魔多<rt>Shadow of Mordor</rt></ruby>》
|
||||
|
||||
《中土世界:暗影魔多》 是 Steam 上支持 Linux 的最好的开放式角色扮演类游戏之一。你将扮演一个游侠(塔里昂),和光明领主(凯勒布理鹏)并肩作战击败索隆的军队(并最终和他直接交手)。战斗机制非常出色。这是款不得不玩的游戏!
|
||||
|
||||
- [购买《中土世界:暗影魔多》][26]
|
||||
|
||||
#### 12、 《<ruby>神界:原罪加强版<rt>Divinity: Original Sin – Enhanced Edition</rt></ruby>》
|
||||
|
||||
《神界:原罪》是一款极其优秀的角色扮演类独立游戏。它非常独特而又引人入胜。这或许是评分最高的带有冒险和策略元素的角色扮演游戏。加强版添加了新的游戏模式,并且完全重做了配音、手柄支持、协作任务等等。
|
||||
|
||||
- [购买《神界:原罪加强版》][27]
|
||||
|
||||
#### 13、 《<ruby>废土 2:导演剪辑版<rt>Wasteland 2: Director’s Cut</rt></ruby>》
|
||||
|
||||
《废土 2》是一款出色的 CRPG 游戏。如果《辐射 4》被移植成 CRPG 游戏,大概就是这种感觉。导演剪辑版完全重做了画面,并且增加了一百多名新人物。
|
||||
|
||||
- [购买《废土 2》][28]
|
||||
|
||||
#### 14、 《<ruby>阴暗森林<rt>Darkwood</rt></ruby>》
|
||||
|
||||
一个充满恐怖的俯视角角色扮演类游戏。你将探索世界、搜集材料、制作武器来生存下去。
|
||||
|
||||
- [购买《阴暗森林》][29]
|
||||
|
||||
### 最佳赛车 / 运动 / 模拟类游戏
|
||||
|
||||
#### 15、 《<ruby>火箭联盟<rt>Rocket League</rt></ruby>》
|
||||
|
||||
《火箭联盟》是一款充满刺激的足球游戏。游戏中你将驾驶用火箭助推的战斗赛车。你不仅是要驾车把球带进对方球门,你甚至还可以让你的对手化为灰烬!
|
||||
|
||||
这是款超棒的体育动作类游戏,每个游戏爱好者都值得拥有!
|
||||
|
||||
- [购买《火箭联盟》][30]
|
||||
|
||||
#### 16、 《<ruby>公路救赎<rt>Road Redemption</rt></ruby>》
|
||||
|
||||
想念《暴力摩托》了?作为它精神上的续作,《公路救赎》可以缓解你的饥渴。当然,这并不是真正的《暴力摩托 2》,但它一样有趣。如果你喜欢《暴力摩托》,你也会喜欢这款游戏。
|
||||
|
||||
- [购买《公路救赎》][31]
|
||||
|
||||
#### 17、 《<ruby>尘埃拉力赛<rt>Dirt Rally</rt></ruby>》
|
||||
|
||||
《尘埃拉力赛》是为想要体验公路和越野赛车的玩家准备的。画面非常有魄力,驾驶手感也近乎完美。
|
||||
|
||||
- [购买《尘埃拉力赛》][32]
|
||||
|
||||
#### 18、 《F1 2017》
|
||||
|
||||
《F1 2017》是另一款令人印象深刻的赛车游戏。由《尘埃拉力赛》的开发者 Codemasters & Feral Interactive 制作。游戏中包含了所有标志性的 F1 赛车,值得你去体验。
|
||||
|
||||
- [购买《F1 2017》][33]
|
||||
|
||||
#### 19、 《<ruby>超级房车赛:汽车运动<rt>GRID Autosport</rt></ruby>》
|
||||
|
||||
《超级房车赛》是最被低估的赛车游戏之一。《超级房车赛:汽车运动》是《超级房车赛》的续作。这款游戏的可玩性令人惊艳。游戏中的赛车也比前作更好。推荐所有的 PC 游戏玩家尝试这款赛车游戏。游戏还支持多人模式,你可以和你的朋友组队参赛。
|
||||
|
||||
- [购买《超级房车赛:汽车运动》][34]
|
||||
|
||||
### 最好的冒险游戏
|
||||
|
||||
#### 20、 《<ruby>方舟:生存进化<rt>ARK: Survival Evolved</rt></ruby>》
|
||||
|
||||
《方舟:生存进化》是一款不错的生存游戏,里面有着激动人心的冒险。你发现自己身处一个未知孤岛(方舟岛),为了生存下去并逃离这个孤岛,你必须去驯服恐龙、与其他玩家合作、猎杀其他人来抢夺资源、以及制作物品。
|
||||
|
||||
- [购买《方舟:生存进化》][35]
|
||||
|
||||
#### 21、 《<ruby>这是我的战争<rt>This War of Mine</rt></ruby>》
|
||||
|
||||
一款独特的战争游戏。你不是扮演士兵,而是要作为一个平民来面对战争带来的艰难。你需要在身经百战的敌人手下逃生,并帮助其他的幸存者。
|
||||
|
||||
- [购买《这是我的战争》][36]
|
||||
|
||||
#### 22、 《<ruby>疯狂的麦克斯<rt>Mad Max</rt></ruby>》
|
||||
|
||||
生存和暴力概括了《疯狂的麦克斯》的全部内容。游戏中有性能强大的汽车,开放性的世界,各种武器,以及徒手肉搏。你要不断地探索世界,并注意升级你的汽车来防患于未然。在做决定之前,你要仔细思考并设计好策略。
|
||||
|
||||
- [购买《疯狂的麦克斯》][37]
|
||||
|
||||
### 最佳独立游戏
|
||||
|
||||
#### 23、 《<ruby>泰拉瑞亚<rt>Terraria</rt></ruby>》
|
||||
|
||||
这是款在 Steam 上广受好评的 2D 游戏。你在旅途中需要去挖掘、战斗、探索、建造。游戏地图是自动生成的,而不是固定不变的。也许你刚刚遇到的东西,你的朋友过一会儿才会遇到。你还将体验到富有新意的 2D 动作场景。
|
||||
|
||||
- [购买《泰拉瑞亚》][38]
|
||||
|
||||
#### 24、 《<ruby>王国与城堡<rt>Kingdoms and Castles</rt></ruby>》
|
||||
|
||||
在《王国与城堡》中,你将建造你自己的王国。在管理你的王国的过程中,你需要收税、保护森林、规划城市,并且发展国防来防止别人入侵你的王国。
|
||||
|
||||
这是款比较新的游戏,但在独立游戏中已经相对获得了比较高的人气。
|
||||
|
||||
- [购买《王国与城堡》][39]
|
||||
|
||||
### Steam 上最佳 Linux 策略类游戏
|
||||
|
||||
#### 25、 《<ruby>文明 5<rt>Sid Meier’s Civilization V</rt></ruby>》
|
||||
|
||||
《文明 5》是 PC 上评价最高的策略游戏之一。如果你想的话,你可以去玩《文明 6》。但是依然有许多玩家喜欢《文明 5》,觉得它更有独创性,游戏细节也更富有创造力。
|
||||
|
||||
- [购买《文明 5》][40]
|
||||
|
||||
#### 26、 《<ruby>全面战争:战锤<rt>Total War: Warhammer</rt></ruby>》
|
||||
|
||||
《全面战争:战锤》是 PC 平台上一款非常出色的回合制策略游戏。可惜的是,新作《战锤 2》依然不支持 Linux。但如果你喜欢使用飞龙和魔法来建造与毁灭帝国的话,2016 年的《战锤》依然是个不错的选择。
|
||||
|
||||
- [购买《全面战争:战锤》][41]
|
||||
|
||||
#### 27、 《<ruby>轰炸小队<rt>Bomber Crew</rt></ruby>》
|
||||
|
||||
想要一款充满乐趣的策略游戏?《轰炸小队》就是为你准备的。你需要选择合适的队员并且让你的队伍稳定运转来取得最终的胜利。
|
||||
|
||||
- [购买《轰炸小队》][42]
|
||||
|
||||
#### 28、 《<ruby>奇迹时代 3<rt>Age of Wonders III</rt></ruby>》
|
||||
|
||||
非常流行的策略游戏,包含帝国建造、角色扮演、以及战争元素。这是款精致的回合制策略游戏,请一定要试试!
|
||||
|
||||
- [购买《奇迹时代 3》][43]
|
||||
|
||||
#### 29、 《<ruby>城市:天际线<rt>Cities: Skylines</rt></ruby>》
|
||||
|
||||
一款非常简洁的策略游戏。你要从零开始建造一座城市,并且管理它的全部运作。你将体验建造和管理城市带来的愉悦与困难。我不觉得每个玩家都会喜欢这款游戏——它的用户群体非常明确。
|
||||
|
||||
- [购买《城市:天际线》][44]
|
||||
|
||||
#### 30、 《<ruby>幽浮 2<rt>XCOM 2</rt></ruby>》
|
||||
|
||||
《幽浮 2》是 PC 上最好的回合制策略游戏之一。我在想如果《幽浮 2》能够被制作成 FPS 游戏的话该有多棒。不过它现在已经是一款好评如潮的杰作了。如果你有多余的预算能花在这款游戏上,建议你购买“<ruby>天选之战<rt>War of the Chosen</rt></ruby>“ DLC。
|
||||
|
||||
- [购买《幽浮 2》][45]
|
||||
|
||||
### 总结
|
||||
|
||||
我们从所有支持 Linux 的游戏中挑选了大部分的主流大作以及一些评价很高的新作。
|
||||
|
||||
你觉得我们遗漏了你最喜欢的支持 Linux 的 Steam 游戏么?另外,你还希望哪些 Steam 游戏开始支持 Linux 平台?
|
||||
|
||||
请在下面的回复中告诉我们你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-linux-games-steam/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
译者:[yixunx](https://github.com/yixunx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://itsfoss.com/author/ankush/
|
||||
[2]:https://itsfoss.com/best-linux-games-steam/#comments
|
||||
[3]:https://itsfoss.com/best-linux-games-steam/#action
|
||||
[4]:https://itsfoss.com/best-linux-games-steam/#rpg
|
||||
[5]:https://itsfoss.com/best-linux-games-steam/#racing
|
||||
[6]:https://itsfoss.com/best-linux-games-steam/#adv
|
||||
[7]:https://itsfoss.com/best-linux-games-steam/#indie
|
||||
[8]:https://itsfoss.com/best-linux-games-steam/#strategy
|
||||
[9]:https://linux.cn/article-7316-1.html
|
||||
[10]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[11]:https://www.humblebundle.com/?partner=itsfoss
|
||||
[12]:https://www.humblebundle.com/store?partner=itsfoss
|
||||
[13]:https://www.humblebundle.com/monthly?partner=itsfoss
|
||||
[14]:https://itsfoss.com/linux-gaming-problems/
|
||||
[15]:http://store.steampowered.com/app/730/CounterStrike_Global_Offensive/
|
||||
[16]:http://store.steampowered.com/app/550/Left_4_Dead_2/
|
||||
[17]:http://store.steampowered.com/app/49520/?snr=1_5_9__205
|
||||
[18]:http://store.steampowered.com/app/222880/?snr=1_5_9__205
|
||||
[19]:http://store.steampowered.com/agecheck/app/8870/
|
||||
[20]:http://store.steampowered.com/app/236870/?snr=1_5_9__205
|
||||
[21]:http://store.steampowered.com/app/620/?snr=1_5_9__205
|
||||
[22]:http://store.steampowered.com/app/337000/?snr=1_5_9__205
|
||||
[23]:http://store.steampowered.com/app/286690/?snr=1_5_9__205
|
||||
[24]:http://store.steampowered.com/app/287390/?snr=1_5_9__205
|
||||
[25]:http://store.steampowered.com/app/633460/?snr=1_5_9__205
|
||||
[26]:http://store.steampowered.com/app/241930/?snr=1_5_9__205
|
||||
[27]:http://store.steampowered.com/app/373420/?snr=1_5_9__205
|
||||
[28]:http://store.steampowered.com/app/240760/?snr=1_5_9__205
|
||||
[29]:http://store.steampowered.com/app/274520/?snr=1_5_9__205
|
||||
[30]:http://store.steampowered.com/app/252950/?snr=1_5_9__205
|
||||
[31]:http://store.steampowered.com/app/300380/?snr=1_5_9__205
|
||||
[32]:http://store.steampowered.com/app/310560/?snr=1_5_9__205
|
||||
[33]:http://store.steampowered.com/app/515220/?snr=1_5_9__205
|
||||
[34]:http://store.steampowered.com/app/255220/?snr=1_5_9__205
|
||||
[35]:http://store.steampowered.com/app/346110/?snr=1_5_9__205
|
||||
[36]:http://store.steampowered.com/app/282070/?snr=1_5_9__205
|
||||
[37]:http://store.steampowered.com/app/234140/?snr=1_5_9__205
|
||||
[38]:http://store.steampowered.com/app/105600/?snr=1_5_9__205
|
||||
[39]:http://store.steampowered.com/app/569480/?snr=1_5_9__205
|
||||
[40]:http://store.steampowered.com/app/8930/?snr=1_5_9__205
|
||||
[41]:http://store.steampowered.com/app/364360/?snr=1_5_9__205
|
||||
[42]:http://store.steampowered.com/app/537800/?snr=1_5_9__205
|
||||
[43]:http://store.steampowered.com/app/226840/?snr=1_5_9__205
|
||||
[44]:http://store.steampowered.com/app/255710/?snr=1_5_9__205
|
||||
[45]:http://store.steampowered.com/app/268500/?snr=1_5_9__205
|
||||
[46]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fbest-linux-games-steam%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[47]:https://twitter.com/share?original_referer=/&text=30+Best+Linux+Games+On+Steam+You+Should+Play+in+2017&url=https://itsfoss.com/best-linux-games-steam/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=ankushdas9
|
||||
[48]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fbest-linux-games-steam%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[49]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fbest-linux-games-steam%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[50]:https://www.reddit.com/submit?url=https://itsfoss.com/best-linux-games-steam/&title=30+Best+Linux+Games+On+Steam+You+Should+Play+in+2017
|
||||
@ -1,233 +0,0 @@
|
||||
A Linux user's guide to Logical Volume Management
|
||||
============================================================
|
||||
|
||||
")
|
||||
Image by : opensource.com
|
||||
|
||||
Managing disk space has always been a significant task for sysadmins. Running out of disk space used to be the start of a long and complex series of tasks to increase the space available to a disk partition. It also required taking the system off-line. This usually involved installing a new hard drive, booting to recovery or single-user mode, creating a partition and a filesystem on the new hard drive, using temporary mount points to move the data from the too-small filesystem to the new, larger one, changing the content of the /etc/fstab file to reflect the correct device name for the new partition, and rebooting to remount the new filesystem on the correct mount point.
|
||||
|
||||
I have to tell you that, when LVM (Logical Volume Manager) first made its appearance in Fedora Linux, I resisted it rather strongly. My initial reaction was that I did not need this additional layer of abstraction between me and the hard drives. It turns out that I was wrong, and that logical volume management is very useful.
|
||||
|
||||
LVM allows for very flexible disk space management. It provides features like the ability to add disk space to a logical volume and its filesystem while that filesystem is mounted and active and it allows for the collection of multiple physical hard drives and partitions into a single volume group which can then be divided into logical volumes.
|
||||
|
||||
The volume manager also allows reducing the amount of disk space allocated to a logical volume, but there are a couple requirements. First, the volume must be unmounted. Second, the filesystem itself must be reduced in size before the volume on which it resides can be reduced.
|
||||
|
||||
It is important to note that the filesystem itself must allow resizing for this feature to work. The EXT2, 3, and 4 filesystems all allow both offline (unmounted) and online (mounted) resizing when increasing the size of a filesystem, and offline resizing when reducing the size. You should check the details of the filesystems you intend to use in order to verify whether they can be resized at all and especially whether they can be resized while online.
|
||||
|
||||
### Expanding a filesystem on the fly
|
||||
|
||||
I always like to run new distributions in a VirtualBox virtual machine for a few days or weeks to ensure that I will not run into any devastating problems when I start installing it on my production machines. One morning a couple years ago I started installing a newly released version of Fedora in a virtual machine on my primary workstation. I thought that I had enough disk space allocated to the host filesystem in which the VM was being installed. I did not. About a third of the way through the installation I ran out of space on that filesystem. Fortunately, VirtualBox detected the out-of-space condition and paused the virtual machine, and even displayed an error message indicating the exact cause of the problem.
|
||||
|
||||
Note that this problem was not due to the fact that the virtual disk was too small, it was rather the logical volume on the host computer that was running out of space so that the virtual disk belonging to the virtual machine did not have enough space to expand on the host's logical volume.
|
||||
|
||||
Since most modern distributions use Logical Volume Management by default, and I had some free space available on the volume group, I was able to assign additional disk space to the appropriate logical volume and then expand filesystem of the host on the fly. This means that I did not have to reformat the entire hard drive and reinstall the operating system or even reboot. I simply assigned some of the available space to the appropriate logical volume and resized the filesystem—all while the filesystem was on-line and the running program, The virtual machine was still using the host filesystem. After resizing the logical volume and the filesystem I resumed running the virtual machine and the installation continued as if no problems had occurred.
|
||||
|
||||
Although this type of problem may never have happened to you, running out of disk space while a critical program is running has happened to many people. And while many programs, especially Windows programs, are not as well written and resilient as VirtualBox, Linux Logical Volume Management made it possible to recover without losing any data and without having to restart the time-consuming installation.
|
||||
|
||||
### LVM Structure
|
||||
|
||||
The structure of a Logical Volume Manager disk environment is illustrated by Figure 1, below. Logical Volume Management enables the combining of multiple individual hard drives and/or disk partitions into a single volume group (VG). That volume group can then be subdivided into logical volumes (LV) or used as a single large volume. Regular file systems, such as EXT3 or EXT4, can then be created on a logical volume.
|
||||
|
||||
In Figure 1, two complete physical hard drives and one partition from a third hard drive have been combined into a single volume group. Two logical volumes have been created from the space in the volume group, and a filesystem, such as an EXT3 or EXT4 filesystem has been created on each of the two logical volumes.
|
||||
|
||||

|
||||
|
||||
_Figure 1: LVM allows combining partitions and entire hard drives into Volume Groups._
|
||||
|
||||
Adding disk space to a host is fairly straightforward but, in my experience, is done relatively infrequently. The basic steps needed are listed below. You can either create an entirely new volume group or you can add the new space to an existing volume group and either expand an existing logical volume or create a new one.
|
||||
|
||||
### Adding a new logical volume
|
||||
|
||||
There are times when it is necessary to add a new logical volume to a host. For example, after noticing that the directory containing virtual disks for my VirtualBox virtual machines was filling up the /home filesystem, I decided to create a new logical volume in which to store the virtual machine data, including the virtual disks. This would free up a great deal of space in my /home filesystem and also allow me to manage the disk space for the VMs independently.
|
||||
|
||||
The basic steps for adding a new logical volume are as follows.
|
||||
|
||||
1. If necessary, install a new hard drive.
|
||||
|
||||
2. Optional: Create a partition on the hard drive.
|
||||
|
||||
3. Create a physical volume (PV) of the complete hard drive or a partition on the hard drive.
|
||||
|
||||
4. Assign the new physical volume to an existing volume group (VG) or create a new volume group.
|
||||
|
||||
5. Create a new logical volumes (LV) from the space in the volume group.
|
||||
|
||||
6. Create a filesystem on the new logical volume.
|
||||
|
||||
7. Add appropriate entries to /etc/fstab for mounting the filesystem.
|
||||
|
||||
8. Mount the filesystem.
|
||||
|
||||
Now for the details. The following sequence is taken from an example I used as a lab project when teaching about Linux filesystems.
|
||||
|
||||
### Example
|
||||
|
||||
This example shows how to use the CLI to extend an existing volume group to add more space to it, create a new logical volume in that space, and create a filesystem on the logical volume. This procedure can be performed on a running, mounted filesystem.
|
||||
|
||||
WARNING: Only the EXT3 and EXT4 filesystems can be resized on the fly on a running, mounted filesystem. Many other filesystems including BTRFS and ZFS cannot be resized.
|
||||
|
||||
### Install hard drive
|
||||
|
||||
If there is not enough space in the volume group on the existing hard drive(s) in the system to add the desired amount of space it may be necessary to add a new hard drive and create the space to add to the Logical Volume. First, install the physical hard drive, and then perform the following steps.
|
||||
|
||||
### Create Physical Volume from hard drive
|
||||
|
||||
It is first necessary to create a new Physical Volume (PV). Use the command below, which assumes that the new hard drive is assigned as /dev/hdd.
|
||||
|
||||
```
|
||||
pvcreate /dev/hdd
|
||||
```
|
||||
|
||||
It is not necessary to create a partition of any kind on the new hard drive. This creation of the Physical Volume which will be recognized by the Logical Volume Manager can be performed on a newly installed raw disk or on a Linux partition of type 83\. If you are going to use the entire hard drive, creating a partition first does not offer any particular advantages and uses disk space for metadata that could otherwise be used as part of the PV.
|
||||
|
||||
### Extend the existing Volume Group
|
||||
|
||||
In this example we will extend an existing volume group rather than creating a new one; you can choose to do it either way. After the Physical Volume has been created, extend the existing Volume Group (VG) to include the space on the new PV. In this example the existing Volume Group is named MyVG01.
|
||||
|
||||
```
|
||||
vgextend /dev/MyVG01 /dev/hdd
|
||||
```
|
||||
|
||||
### Create the Logical Volume
|
||||
|
||||
First create the Logical Volume (LV) from existing free space within the Volume Group. The command below creates a LV with a size of 50GB. The Volume Group name is MyVG01 and the Logical Volume Name is Stuff.
|
||||
|
||||
```
|
||||
lvcreate -L +50G --name Stuff MyVG01
|
||||
```
|
||||
|
||||
### Create the filesystem
|
||||
|
||||
Creating the Logical Volume does not create the filesystem. That task must be performed separately. The command below creates an EXT4 filesystem that fits the newly created Logical Volume.
|
||||
|
||||
```
|
||||
mkfs -t ext4 /dev/MyVG01/Stuff
|
||||
```
|
||||
|
||||
### Add a filesystem label
|
||||
|
||||
Adding a filesystem label makes it easy to identify the filesystem later in case of a crash or other disk related problems.
|
||||
|
||||
```
|
||||
e2label /dev/MyVG01/Stuff Stuff
|
||||
```
|
||||
|
||||
### Mount the filesystem
|
||||
|
||||
At this point you can create a mount point, add an appropriate entry to the /etc/fstab file, and mount the filesystem.
|
||||
|
||||
You should also check to verify the volume has been created correctly. You can use the **df**, **lvs,** and **vgs** commands to do this.
|
||||
|
||||
### Resizing a logical volume in an LVM filesystem
|
||||
|
||||
The need to resize a filesystem has been around since the beginning of the first versions of Unix and has not gone away with Linux. It has gotten easier, however, with Logical Volume Management.
|
||||
|
||||
1. If necessary, install a new hard drive.
|
||||
|
||||
2. Optional: Create a partition on the hard drive.
|
||||
|
||||
3. Create a physical volume (PV) of the complete hard drive or a partition on the hard drive.
|
||||
|
||||
4. Assign the new physical volume to an existing volume group (VG) or create a new volume group.
|
||||
|
||||
5. Create one or more logical volumes (LV) from the space in the volume group, or expand an existing logical volume with some or all of the new space in the volume group.
|
||||
|
||||
6. If you created a new logical volume, create a filesystem on it. If adding space to an existing logical volume, use the resize2fs command to enlarge the filesystem to fill the space in the logical volume.
|
||||
|
||||
7. Add appropriate entries to /etc/fstab for mounting the filesystem.
|
||||
|
||||
8. Mount the filesystem.
|
||||
|
||||
### Example
|
||||
|
||||
This example describes how to resize an existing Logical Volume in an LVM environment using the CLI. It adds about 50GB of space to the /Stuff filesystem. This procedure can be used on a mounted, live filesystem only with the Linux 2.6 Kernel (and higher) and EXT3 and EXT4 filesystems. I do not recommend that you do so on any critical system, but it can be done and I have done so many times; even on the root (/) filesystem. Use your judgment.
|
||||
|
||||
WARNING: Only the EXT3 and EXT4 filesystems can be resized on the fly on a running, mounted filesystem. Many other filesystems including BTRFS and ZFS cannot be resized.
|
||||
|
||||
### Install the hard drive
|
||||
|
||||
If there is not enough space on the existing hard drive(s) in the system to add the desired amount of space it may be necessary to add a new hard drive and create the space to add to the Logical Volume. First, install the physical hard drive and then perform the following steps.
|
||||
|
||||
### Create a Physical Volume from the hard drive
|
||||
|
||||
It is first necessary to create a new Physical Volume (PV). Use the command below, which assumes that the new hard drive is assigned as /dev/hdd.
|
||||
|
||||
```
|
||||
pvcreate /dev/hdd
|
||||
```
|
||||
|
||||
It is not necessary to create a partition of any kind on the new hard drive. This creation of the Physical Volume which will be recognized by the Logical Volume Manager can be performed on a newly installed raw disk or on a Linux partition of type 83\. If you are going to use the entire hard drive, creating a partition first does not offer any particular advantages and uses disk space for metadata that could otherwise be used as part of the PV.
|
||||
|
||||
### Add PV to existing Volume Group
|
||||
|
||||
For this example, we will use the new PV to extend an existing Volume Group. After the Physical Volume has been created, extend the existing Volume Group (VG) to include the space on the new PV. In this example, the existing Volume Group is named MyVG01.
|
||||
|
||||
```
|
||||
vgextend /dev/MyVG01 /dev/hdd
|
||||
```
|
||||
|
||||
### Extend the Logical Volume
|
||||
|
||||
Extend the Logical Volume (LV) from existing free space within the Volume Group. The command below expands the LV by 50GB. The Volume Group name is MyVG01 and the Logical Volume Name is Stuff.
|
||||
|
||||
```
|
||||
lvextend -L +50G /dev/MyVG01/Stuff
|
||||
```
|
||||
|
||||
### Expand the filesystem
|
||||
|
||||
Extending the Logical Volume will also expand the filesystem if you use the -r option. If you do not use the -r option, that task must be performed separately. The command below resizes the filesystem to fit the newly resized Logical Volume.
|
||||
|
||||
```
|
||||
resize2fs /dev/MyVG01/Stuff
|
||||
```
|
||||
|
||||
You should check to verify the resizing has been performed correctly. You can use the **df**, **lvs,** and **vgs** commands to do this.
|
||||
|
||||
### Tips
|
||||
|
||||
Over the years I have learned a few things that can make logical volume management even easier than it already is. Hopefully these tips can prove of some value to you.
|
||||
|
||||
* Use the Extended file systems unless you have a clear reason to use another filesystem. Not all filesystems support resizing but EXT2, 3, and 4 do. The EXT filesystems are also very fast and efficient. In any event, they can be tuned by a knowledgeable sysadmin to meet the needs of most environments if the defaults tuning parameters do not.
|
||||
|
||||
* Use meaningful volume and volume group names.
|
||||
|
||||
* Use EXT filesystem labels.
|
||||
|
||||
I know that, like me, many sysadmins have resisted the change to Logical Volume Management. I hope that this article will encourage you to at least try LVM. I am really glad that I did; my disk management tasks are much easier since I made the switch.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][10]
|
||||
|
||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981\. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years. David has written articles for... [more about David Both][7][More about me][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/9/linux-users-guide-lvm
|
||||
|
||||
作者:[ David Both][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/business/16/9/linux-users-guide-lvm?rate=79vf1js7A7rlp-I96YFneopUQqsa2SuB-g-og7eiF1U
|
||||
[7]:https://opensource.com/users/dboth
|
||||
[8]:https://opensource.com/users/dboth
|
||||
[9]:https://opensource.com/user/14106/feed
|
||||
[10]:https://opensource.com/users/dboth
|
||||
[11]:https://opensource.com/users/dboth
|
||||
[12]:https://opensource.com/users/dboth
|
||||
[13]:https://opensource.com/business/16/9/linux-users-guide-lvm#comments
|
||||
[14]:https://opensource.com/tags/business
|
||||
[15]:https://opensource.com/tags/linux
|
||||
[16]:https://opensource.com/tags/how-tos-and-tutorials
|
||||
[17]:https://opensource.com/tags/sysadmin
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by XiatianSummer
|
||||
|
||||
Why Car Companies Are Hiring Computer Security Experts
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,172 +0,0 @@
|
||||
How to answer questions in a helpful way
|
||||
============================================================
|
||||
|
||||
Your coworker asks you a slightly unclear question. How do you answer? I think asking questions is a skill (see [How to ask good questions][1]) and that answering questions in a helpful way is also a skill! Both of them are super useful.
|
||||
|
||||
To start out with – sometimes the people asking you questions don’t respect your time, and that sucks. I’m assuming here throughout that that’s not what happening – we’re going to assume that the person asking you questions is a reasonable person who is trying their best to figure something out and that you want to help them out. Everyone I work with is like that and so that’s the world I live in :)
|
||||
|
||||
Here are a few strategies for answering questions in a helpful way!
|
||||
|
||||
### If they’re not asking clearly, help them clarify
|
||||
|
||||
Often beginners don’t ask clear questions, or ask questions that don’t have the necessary information to answer the questions. Here are some strategies you can use to help them clarify.
|
||||
|
||||
* **Rephrase a more specific question** back at them (“Are you asking X?”)
|
||||
|
||||
* **Ask them for more specific information** they didn’t provide (“are you using IPv6?”)
|
||||
|
||||
* **Ask what prompted their question**. For example, sometimes people come into my team’s channel with questions about how our service discovery works. Usually this is because they’re trying to set up/reconfigure a service. In that case it’s helpful to ask “which service are you working with? Can I see the pull request you’re working on?”
|
||||
|
||||
A lot of these strategies come from the [how to ask good questions][2] post. (though I would never say to someone “oh you need to read this Document On How To Ask Good Questions before asking me a question”)
|
||||
|
||||
### Figure out what they know already
|
||||
|
||||
Before answering a question, it’s very useful to know what the person knows already!
|
||||
|
||||
Harold Treen gave me a great example of this:
|
||||
|
||||
> Someone asked me the other day to explain “Redux Sagas”. Rather than dive in and say “They are like worker threads that listen for actions and let you update the store!”
|
||||
> I started figuring out how much they knew about Redux, actions, the store and all these other fundamental concepts. From there it was easier to explain the concept that ties those other concepts together.
|
||||
|
||||
Figuring out what your question-asker knows already is important because they may be confused about fundamental concepts (“What’s Redux?”), or they may be an expert who’s getting at a subtle corner case. An answer building on concepts they don’t know is confusing, and an answer that recaps things they know is tedious.
|
||||
|
||||
One useful trick for asking what people know – instead of “Do you know X?”, maybe try “How familiar are you with X?”.
|
||||
|
||||
### Point them to the documentation
|
||||
|
||||
“RTFM” is the classic unhelpful answer to a question, but pointing someone to a specific piece of documentation can actually be really helpful! When I’m asking a question, I’d honestly rather be pointed to documentation that actually answers my question, because it’s likely to answer other questions I have too.
|
||||
|
||||
I think it’s important here to make sure you’re linking to documentation that actually answers the question, or at least check in afterwards to make sure it helped. Otherwise you can end up with this (pretty common) situation:
|
||||
|
||||
* Ali: How do I do X?
|
||||
|
||||
* Jada: <link to documentation>
|
||||
|
||||
* Ali: That doesn’t actually explain how to X, it only explains Y!
|
||||
|
||||
If the documentation I’m linking to is very long, I like to point out the specific part of the documentation I’m talking about. The [bash man page][3] is 44,000 words (really!), so just saying “it’s in the bash man page” is not that helpful :)
|
||||
|
||||
### Point them to a useful search
|
||||
|
||||
Often I find things at work by searching for some Specific Keyword that I know will find me the answer. That keyword might not be obvious to a beginner! So saying “this is the search I’d use to find the answer to that question” can be useful. Again, check in afterwards to make sure the search actually gets them the answer they need :)
|
||||
|
||||
### Write new documentation
|
||||
|
||||
People often come and ask my team the same questions over and over again. This is obviously not the fault of the people (how should _they_ know that 10 people have asked this already, or what the answer is?). So we’re trying to, instead of answering the questions directly,
|
||||
|
||||
1. Immediately write documentation
|
||||
|
||||
2. Point the person to the new documentation we just wrote
|
||||
|
||||
3. Celebrate!
|
||||
|
||||
Writing documentation sometimes takes more time than just answering the question, but it’s often worth it! Writing documentation is especially worth it if:
|
||||
|
||||
a. It’s a question which is being asked again and again b. The answer doesn’t change too much over time (if the answer changes every week or month, the documentation will just get out of date and be frustrating)
|
||||
|
||||
### Explain what you did
|
||||
|
||||
As a beginner to a subject, it’s really frustrating to have an exchange like this:
|
||||
|
||||
* New person: “hey how do you do X?”
|
||||
|
||||
* More Experienced Person: “I did it, it is done.”
|
||||
|
||||
* New person: ….. but what did you DO?!
|
||||
|
||||
If the person asking you is trying to learn how things work, it’s helpful to:
|
||||
|
||||
* Walk them through how to accomplish a task instead of doing it yourself
|
||||
|
||||
* Tell them the steps for how you got the answer you gave them!
|
||||
|
||||
This might take longer than doing it yourself, but it’s a learning opportunity for the person who asked, so that they’ll be better equipped to solve such problems in the future.
|
||||
|
||||
Then you can have WAY better exchanges, like this:
|
||||
|
||||
* New person: “I’m seeing errors on the site, what’s happening?”
|
||||
|
||||
* More Experienced Person: (2 minutes later) “oh that’s because there’s a database failover happening”
|
||||
|
||||
* New person: how did you know that??!?!?
|
||||
|
||||
* More Experienced Person: “Here’s what I did!”:
|
||||
1. Often these errors are due to Service Y being down. I looked at $PLACE and it said Service Y was up. So that wasn’t it.
|
||||
|
||||
2. Then I looked at dashboard X, and this part of that dashboard showed there was a database failover happening.
|
||||
|
||||
3. Then I looked in the logs for the service and it showed errors connecting to the database, here’s what those errors look like.
|
||||
|
||||
If you’re explaining how you debugged a problem, it’s useful both to explain how you found out what the problem was, and how you found out what the problem wasn’t. While it might feel good to look like you knew the answer right off the top of your head, it feels even better to help someone improve at learning and diagnosis, and understand the resources available.
|
||||
|
||||
### Solve the underlying problem
|
||||
|
||||
This one is a bit tricky. Sometimes people think they’ve got the right path to a solution, and they just need one more piece of information to implement that solution. But they might not be quite on the right path! For example:
|
||||
|
||||
* George: I’m doing X, and I got this error, how do I fix it
|
||||
|
||||
* Jasminda: Are you actually trying to do Y? If so, you shouldn’t do X, you should do Z instead
|
||||
|
||||
* George: Oh, you’re right!!! Thank you! I will do Z instead.
|
||||
|
||||
Jasminda didn’t answer George’s question at all! Instead she guessed that George didn’t actually want to be doing X, and she was right. That is helpful!
|
||||
|
||||
It’s possible to come off as condescending here though, like
|
||||
|
||||
* George: I’m doing X, and I got this error, how do I fix it?
|
||||
|
||||
* Jasminda: Don’t do that, you’re trying to do Y and you should do Z to accomplish that instead.
|
||||
|
||||
* George: Well, I am not trying to do Y, I actually want to do X because REASONS. How do I do X?
|
||||
|
||||
So don’t be condescending, and keep in mind that some questioners might be attached to the steps they’ve taken so far! It might be appropriate to answer both the question they asked and the one they should have asked: “Well, if you want to do X then you might try this, but if you’re trying to solve problem Y with that, you might have better luck doing this other thing, and here’s why that’ll work better”.
|
||||
|
||||
### Ask “Did that answer your question?”
|
||||
|
||||
I always like to check in after I _think_ I’ve answered the question and ask “did that answer your question? Do you have more questions?”.
|
||||
|
||||
It’s good to pause and wait after asking this because often people need a minute or two to know whether or not they’ve figured out the answer. I especially find this extra “did this answer your questions?” step helpful after writing documentation! Often when writing documentation about something I know well I’ll leave out something very important without realizing it.
|
||||
|
||||
### Offer to pair program/chat in real life
|
||||
|
||||
I work remote, so many of my conversations at work are text-based. I think of that as the default mode of communication.
|
||||
|
||||
Today, we live in a world of easy video conferencing & screensharing! At work I can at any time click a button and immediately be in a video call/screensharing session with someone. Some problems are easier to talk about using your voices!
|
||||
|
||||
For example, recently someone was asking about capacity planning/autoscaling for their service. I could tell there were a few things we needed to clear up but I wasn’t exactly sure what they were yet. We got on a quick video call and 5 minutes later we’d answered all their questions.
|
||||
|
||||
I think especially if someone is really stuck on how to get started on a task, pair programming for a few minutes can really help, and it can be a lot more efficient than email/instant messaging.
|
||||
|
||||
### Don’t act surprised
|
||||
|
||||
This one’s a rule from the Recurse Center: [no feigning surprise][4]. Here’s a relatively common scenario
|
||||
|
||||
* Human 1: “what’s the Linux kernel?”
|
||||
|
||||
* Human 2: “you don’t know what the LINUX KERNEL is?!!!!?!!!???”
|
||||
|
||||
Human 2’s reaction (regardless of whether they’re _actually_ surprised or not) is not very helpful. It mostly just serves to make Human 1 feel bad that they don’t know what the Linux kernel is.
|
||||
|
||||
I’ve worked on actually pretending not to be surprised even when I actually am a bit surprised the person doesn’t know the thing and it’s awesome.
|
||||
|
||||
### Answering questions well is awesome
|
||||
|
||||
Obviously not all these strategies are appropriate all the time, but hopefully you will find some of them helpful! I find taking the time to answer questions and teach people can be really rewarding.
|
||||
|
||||
Special thanks to Josh Triplett for suggesting this post and making many helpful additions, and to Harold Treen, Vaibhav Sagar, Peter Bhat Harkins, Wesley Aptekar-Cassels, and Paul Gowder for reading/commenting.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/answer-questions-well/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://jvns.ca/blog/good-questions/
|
||||
[2]:https://jvns.ca/blog/good-questions/
|
||||
[3]:https://linux.die.net/man/1/bash
|
||||
[4]:https://jvns.ca/blog/2017/04/27/no-feigning-surprise/
|
||||
59
sources/tech/20170922 How to disable USB storage on Linux.md
Normal file
59
sources/tech/20170922 How to disable USB storage on Linux.md
Normal file
@ -0,0 +1,59 @@
|
||||
translating by lujun9972
|
||||
How to disable USB storage on Linux
|
||||
======
|
||||
To secure our infrastructure of data breaches, we use software & hardware firewalls to restrict unauthorized access from outside but data breaches can occur from inside as well. To remove such a possibility, organizations limit & monitor the access to internet & also disable usb storage devices.
|
||||
|
||||
In this tutorial, we are going to discuss three different ways to disable USB storage devices on Linux machines. All the three methods have been tested on CentOS 6 & 7 machine & are working as they are supposed to . So let’s discuss all the three methods one by one,
|
||||
|
||||
( Also Read : [Ultimate guide to securing SSH sessions][1] )
|
||||
|
||||
### Method 1 – Fake install
|
||||
|
||||
In this method, we add a line ‘install usb-storage /bin/true’ which causes the ‘/bin/true’ to run instead of installing usb-storage module & that’s why it’s also called ‘Fake Install’ . To do this, create and open a file named ‘block_usb.conf’ (it can be something as well) in the folder ‘/etc/modprobe.d’,
|
||||
|
||||
$ sudo vim /etc/modprobe.d/block_usb.conf
|
||||
|
||||
& add the below mentioned line,
|
||||
|
||||
install usb-storage /bin/true
|
||||
|
||||
Now save the file and exit.
|
||||
|
||||
### Method 2 – Removing the USB driver
|
||||
|
||||
Using this method, we can remove/move the drive for usb-storage (usb_storage.ko) from our machines, thus making it impossible to access a usb-storage device from the mahcine. To move the driver from it’s default location, execute the following command,
|
||||
|
||||
$ sudo mv /lib/modules/$(uname -r)/kernel/drivers/usb/storage/usb-storage.ko /home/user1
|
||||
|
||||
Now the driver is not available on its default location & thus would not be loaded when a usb-storage device is attached to the system & device would not be able to work. But this method has one little issue, that is when the kernel of the system is updated the usb-storage module would again show up in it’s default location.
|
||||
|
||||
### Method 3- Blacklisting USB-storage
|
||||
|
||||
We can also blacklist usb-storage using the file ‘/etc/modprobe.d/blacklist.conf’. This file is available on RHEL/CentOS 6 but might need to be created on 7\. To blacklist usb-storage, open/create the above mentioned file using vim,
|
||||
|
||||
$ sudo vim /etc/modprobe.d/blacklist.conf
|
||||
|
||||
& enter the following line to blacklist the usb,
|
||||
|
||||
blacklist usb-storage
|
||||
|
||||
Save file & exit. USB-storage will now be blocked on the system but this method has one major downside i.e. any privileged user can load the usb-storage module by executing the following command,
|
||||
|
||||
$ sudo modprobe usb-storage
|
||||
|
||||
This issue makes this method somewhat not desirable but it works well for non-privileged users.
|
||||
|
||||
Reboot your system after the changes have been made to implement the changes made for all the above mentioned methods. Do check these methods to disable usb storage & let us know if you face any issue or have a query using the comment box below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/disable-usb-storage-linux/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/ultimate-guide-to-securing-ssh-sessions/
|
||||
@ -1,114 +0,0 @@
|
||||
How to manage Linux containers with Ansible Container
|
||||
============================================================
|
||||
|
||||
### Ansible Container addresses Dockerfile shortcomings and offers complete management for containerized projects.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
I love containers and use the technology every day. Even so, containers aren't perfect. Over the past couple of months, however, a set of projects has emerged that addresses some of the problems I've experienced.
|
||||
|
||||
I started using containers with [Docker][11], since this project made the technology so popular. Aside from using the container engine, I learned how to use **[docker-compose][6]** and started managing my projects with it. My productivity skyrocketed! One command to run my project, no matter how complex it was. I was so happy.
|
||||
|
||||
After some time, I started noticing issues. The most apparent were related to the process of creating container images. The Docker tool uses a custom file format as a recipe to produce container images—Dockerfiles. This format is easy to learn, and after a short time you are ready to produce container images on your own. The problems arise once you want to master best practices or have complex scenarios in mind.
|
||||
|
||||
More on Ansible
|
||||
|
||||
* [How Ansible works][1]
|
||||
|
||||
* [Free Ansible eBooks][2]
|
||||
|
||||
* [Ansible quick start video][3]
|
||||
|
||||
* [Download and install Ansible][4]
|
||||
|
||||
Let's take a break and travel to a different land: the world of [Ansible][22]. You know it? It's awesome, right? You don't? Well, it's time to learn something new. Ansible is a project that allows you to manage your infrastructure by writing tasks and executing them inside environments of your choice. No need to install and set up any services; everything can easily run from your laptop. Many people already embrace Ansible.
|
||||
|
||||
Imagine this scenario: You invested in Ansible, you wrote plenty of Ansible roles and playbooks that you use to manage your infrastructure, and you are thinking about investing in containers. What should you do? Start writing container image definitions via shell scripts and Dockerfiles? That doesn't sound right.
|
||||
|
||||
Some people from the Ansible development team asked this question and realized that those same Ansible roles and playbooks that people wrote and use daily can also be used to produce container images. But not just that—they can be used to manage the complete lifecycle of containerized projects. From these ideas, the [Ansible Container][12] project was born. It utilizes existing Ansible roles that can be turned into container images and can even be used for the complete application lifecycle, from build to deploy in production.
|
||||
|
||||
Let's talk about the problems I mentioned regarding best practices in context of Dockerfiles. A word of warning: This is going to be very specific and technical. Here are the top three issues I have:
|
||||
|
||||
### 1\. Shell scripts embedded in Dockerfiles.
|
||||
|
||||
When writing Dockerfiles, you can specify a script that will be interpreted via **/bin/sh -c**. It can be something like:
|
||||
|
||||
```
|
||||
RUN dnf install -y nginx
|
||||
```
|
||||
|
||||
where RUN is a Dockerfile instruction and the rest are its arguments (which are passed to shell). But imagine a more complex scenario:
|
||||
|
||||
```
|
||||
RUN set -eux; \
|
||||
\
|
||||
# this "case" statement is generated via "update.sh"
|
||||
%%ARCH-CASE%%; \
|
||||
\
|
||||
url="https://golang.org/dl/go${GOLANG_VERSION}.${goRelArch}.tar.gz"; \
|
||||
wget -O go.tgz "$url"; \
|
||||
echo "${goRelSha256} *go.tgz" | sha256sum -c -; \
|
||||
```
|
||||
|
||||
This one is taken from [the official golang image][13]. It doesn't look pretty, right?
|
||||
|
||||
### 2\. You can't parse Dockerfiles easily.
|
||||
|
||||
Dockerfiles are a new format without a formal specification. This is tricky if you need to process Dockerfiles in your infrastructure (e.g., automate the build process a bit). The only specification is [the code][14] that is part of **dockerd**. The problem is that you can't use it as a library. The easiest solution is to write a parser on your own and hope for the best. Wouldn't it be better to use some well-known markup language, such as YAML or JSON?
|
||||
|
||||
### 3\. It's hard to control.
|
||||
|
||||
If you are familiar with the internals of container images, you may know that every image is composed of layers. Once the container is created, the layers are stacked onto each other (like pancakes) using union filesystem technology. The problem is, that you cannot explicitly control this layering—you can't say, "here starts a new layer." You are forced to change your Dockerfile in a way that may hurt readability. The bigger problem is that a set of best practices has to be followed to achieve optimal results—newcomers have a really hard time here.
|
||||
|
||||
### Comparing Ansible language and Dockerfiles
|
||||
|
||||
The biggest shortcoming of Dockerfiles in comparison to Ansible is that Ansible, as a language, is much more powerful. For example, Dockerfiles have no direct concept of variables, whereas Ansible has a complete templating system (variables are just one of its features). Ansible contains a large number of modules that can be easily utilized, such as [**wait_for**][15], which can be used for service readiness checks—e.g., wait until a service is ready before proceeding. With Dockerfiles, everything is a shell script. So if you need to figure out service readiness, it has to be done with shell (or installed separately). The other problem with shell scripts is that, with growing complexity, maintenance becomes a burden. Plenty of people have already figured this out and turned those shell scripts into Ansible.
|
||||
|
||||
If you are interested in this topic and would like to know more, please come to [Open Source Summit][16] in Prague to see [my presentation][17] on Monday, Oct. 23, at 4:20 p.m. in Palmovka room.
|
||||
|
||||
_Learn more in Tomas Tomecek's talk, [From Dockerfiles to Ansible Container][7], at [Open Source Summit EU][8], which will be held October 23-26 in Prague._
|
||||
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][18] Tomas Tomecek - Engineer. Hacker. Speaker. Tinker. Red Hatter. Likes containers, linux, open source, python 3, rust, zsh, tmux.[More about me][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/dockerfiles-ansible-container
|
||||
|
||||
作者:[Tomas Tomecek ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tomastomecek
|
||||
[1]:https://www.ansible.com/how-ansible-works?intcmp=701f2000000h4RcAAI
|
||||
[2]:https://www.ansible.com/ebooks?intcmp=701f2000000h4RcAAI
|
||||
[3]:https://www.ansible.com/quick-start-video?intcmp=701f2000000h4RcAAI
|
||||
[4]:https://docs.ansible.com/ansible/latest/intro_installation.html?intcmp=701f2000000h4RcAAI
|
||||
[5]:https://opensource.com/article/17/10/dockerfiles-ansible-container?imm_mid=0f9013&cmp=em-webops-na-na-newsltr_20171201&rate=Wiw_0D6PK_CAjqatYu_YQH0t1sNHEF6q09_9u3sYkCY
|
||||
[6]:https://github.com/docker/compose
|
||||
[7]:http://sched.co/BxIW
|
||||
[8]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[9]:https://opensource.com/users/tomastomecek
|
||||
[10]:https://opensource.com/user/175651/feed
|
||||
[11]:https://opensource.com/tags/docker
|
||||
[12]:https://www.ansible.com/ansible-container
|
||||
[13]:https://github.com/docker-library/golang/blob/master/Dockerfile-debian.template#L14
|
||||
[14]:https://github.com/moby/moby/tree/master/builder/dockerfile
|
||||
[15]:http://docs.ansible.com/wait_for_module.html
|
||||
[16]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[17]:http://events.linuxfoundation.org/events/open-source-summit-europe/program/schedule
|
||||
[18]:https://opensource.com/users/tomastomecek
|
||||
[19]:https://opensource.com/users/tomastomecek
|
||||
[20]:https://opensource.com/users/tomastomecek
|
||||
[21]:https://opensource.com/article/17/10/dockerfiles-ansible-container?imm_mid=0f9013&cmp=em-webops-na-na-newsltr_20171201#comments
|
||||
[22]:https://opensource.com/tags/ansible
|
||||
[23]:https://opensource.com/tags/containers
|
||||
[24]:https://opensource.com/tags/ansible
|
||||
[25]:https://opensource.com/tags/docker
|
||||
[26]:https://opensource.com/tags/open-source-summit
|
||||
@ -1,148 +0,0 @@
|
||||
Reasons Kubernetes is cool
|
||||
============================================================
|
||||
|
||||
When I first learned about Kubernetes (a year and a half ago?) I really didn’t understand why I should care about it.
|
||||
|
||||
I’ve been working full time with Kubernetes for 3 months or so and now have some thoughts about why I think it’s useful. (I’m still very far from being a Kubernetes expert!) Hopefully this will help a little in your journey to understand what even is going on with Kubernetes!
|
||||
|
||||
I will try to explain some reason I think Kubenetes is interesting without using the words “cloud native”, “orchestration”, “container”, or any Kubernetes-specific terminology :). I’m going to explain this mostly from the perspective of a kubernetes operator / infrastructure engineer, since my job right now is to set up Kubernetes and make it work well.
|
||||
|
||||
I’m not going to try to address the question of “should you use kubernetes for your production systems?” at all, that is a very complicated question. (not least because “in production” has totally different requirements depending on what you’re doing)
|
||||
|
||||
### Kubernetes lets you run code in production without setting up new servers
|
||||
|
||||
The first pitch I got for Kubernetes was the following conversation with my partner Kamal:
|
||||
|
||||
Here’s an approximate transcript:
|
||||
|
||||
* Kamal: With Kubernetes you can set up a new service with a single command
|
||||
|
||||
* Julia: I don’t understand how that’s possible.
|
||||
|
||||
* Kamal: Like, you just write 1 configuration file, apply it, and then you have a HTTP service running in production
|
||||
|
||||
* Julia: But today I need to create new AWS instances, write a puppet manifest, set up service discovery, configure my load balancers, configure our deployment software, and make sure DNS is working, it takes at least 4 hours if nothing goes wrong.
|
||||
|
||||
* Kamal: Yeah. With Kubernetes you don’t have to do any of that, you can set up a new HTTP service in 5 minutes and it’ll just automatically run. As long as you have spare capacity in your cluster it just works!
|
||||
|
||||
* Julia: There must be a trap
|
||||
|
||||
There kind of is a trap, setting up a production Kubernetes cluster is (in my experience) is definitely not easy. (see [Kubernetes The Hard Way][3] for what’s involved to get started). But we’re not going to go into that right now!
|
||||
|
||||
So the first cool thing about Kubernetes is that it has the potential to make life way easier for developers who want to deploy new software into production. That’s cool, and it’s actually true, once you have a working Kubernetes cluster you really can set up a production HTTP service (“run 5 of this application, set up a load balancer, give it this DNS name, done”) with just one configuration file. It’s really fun to see.
|
||||
|
||||
### Kubernetes gives you easy visibility & control of what code you have running in production
|
||||
|
||||
IMO you can’t understand Kubernetes without understanding etcd. So let’s talk about etcd!
|
||||
|
||||
Imagine that I asked you today “hey, tell me every application you have running in production, what host it’s running on, whether it’s healthy or not, and whether or not it has a DNS name attached to it”. I don’t know about you but I would need to go look in a bunch of different places to answer this question and it would take me quite a while to figure out. I definitely can’t query just one API.
|
||||
|
||||
In Kubernetes, all the state in your cluster – applications running (“pods”), nodes, DNS names, cron jobs, and more – is stored in a single database (etcd). Every Kubernetes component is stateless, and basically works by
|
||||
|
||||
* Reading state from etcd (eg “the list of pods assigned to node 1”)
|
||||
|
||||
* Making changes (eg “actually start running pod A on node 1”)
|
||||
|
||||
* Updating the state in etcd (eg “set the state of pod A to ‘running’”)
|
||||
|
||||
This means that if you want to answer a question like “hey, how many nginx pods do I have running right now in that availabliity zone?” you can answer it by querying a single unified API (the Kubernetes API!). And you have exactly the same access to that API that every other Kubernetes component does.
|
||||
|
||||
This also means that you have easy control of everything running in Kubernetes. If you want to, say,
|
||||
|
||||
* Implement a complicated custom rollout strategy for deployments (deploy 1 thing, wait 2 minutes, deploy 5 more, wait 3.7 minutes, etc)
|
||||
|
||||
* Automatically [start a new webserver][1] every time a branch is pushed to github
|
||||
|
||||
* Monitor all your running applications to make sure all of them have a reasonable cgroups memory limit
|
||||
|
||||
all you need to do is to write a program that talks to the Kubernetes API. (a “controller”)
|
||||
|
||||
Another very exciting thing about the Kubernetes API is that you’re not limited to just functionality that Kubernetes provides! If you decide that you have your own opinions about how your software should be deployed / created / monitored, then you can write code that uses the Kubernetes API to do it! It lets you do everything you need.
|
||||
|
||||
### If every Kubernetes component dies, your code will still keep running
|
||||
|
||||
One thing I was originally promised (by various blog posts :)) about Kubernetes was “hey, if the Kubernetes apiserver and everything else dies, it’s ok, your code will just keep running”. I thought this sounded cool in theory but I wasn’t sure if it was actually true.
|
||||
|
||||
So far it seems to be actually true!
|
||||
|
||||
I’ve been through some etcd outages now, and what happens is
|
||||
|
||||
1. All the code that was running keeps running
|
||||
|
||||
2. Nothing _new_ happens (you can’t deploy new code or make changes, cron jobs will stop working)
|
||||
|
||||
3. When everything comes back, the cluster will catch up on whatever it missed
|
||||
|
||||
This does mean that if etcd goes down and one of your applications crashes or something, it can’t come back up until etcd returns.
|
||||
|
||||
### Kubernetes’ design is pretty resilient to bugs
|
||||
|
||||
Like any piece of software, Kubernetes has bugs. For example right now in our cluster the controller manager has a memory leak, and the scheduler crashes pretty regularly. Bugs obviously aren’t good but so far I’ve found that Kubernetes’ design helps mitigate a lot of the bugs in its core components really well.
|
||||
|
||||
If you restart any component, what happens is:
|
||||
|
||||
* It reads all its relevant state from etcd
|
||||
|
||||
* It starts doing the necessary things it’s supposed to be doing based on that state (scheduling pods, garbage collecting completed pods, scheduling cronjobs, deploying daemonsets, whatever)
|
||||
|
||||
Because all the components don’t keep any state in memory, you can just restart them at any time and that can help mitigate a variety of bugs.
|
||||
|
||||
For example! Let’s say you have a memory leak in your controller manager. Because the controller manager is stateless, you can just periodically restart it every hour or something and feel confident that you won’t cause any consistency issues. Or we ran into a bug in the scheduler where it would sometimes just forget about pods and never schedule them. You can sort of mitigate this just by restarting the scheduler every 10 minutes. (we didn’t do that, we fixed the bug instead, but you _could_ :) )
|
||||
|
||||
So I feel like I can trust Kubernetes’ design to help make sure the state in the cluster is consistent even when there are bugs in its core components. And in general I think the software is generally improving over time. The only stateful thing you have to operate is etcd
|
||||
|
||||
Not to harp on this “state” thing too much but – I think it’s cool that in Kubernetes the only thing you have to come up with backup/restore plans for is etcd (unless you use persistent volumes for your pods). I think it makes kubernetes operations a lot easier to think about.
|
||||
|
||||
### Implementing new distributed systems on top of Kubernetes is relatively easy
|
||||
|
||||
Suppose you want to implement a distributed cron job scheduling system! Doing that from scratch is a ton of work. But implementing a distributed cron job scheduling system inside Kubernetes is much easier! (still not trivial, it’s still a distributed system)
|
||||
|
||||
The first time I read the code for the Kubernetes cronjob controller I was really delighted by how simple it was. Here, go read it! The main logic is like 400 lines of Go. Go ahead, read it! => [cronjob_controller.go][4] <=
|
||||
|
||||
Basically what the cronjob controller does is:
|
||||
|
||||
* Every 10 seconds:
|
||||
* Lists all the cronjobs that exist
|
||||
|
||||
* Checks if any of them need to run right now
|
||||
|
||||
* If so, creates a new Job object to be scheduled & actually run by other Kubernetes controllers
|
||||
|
||||
* Clean up finished jobs
|
||||
|
||||
* Repeat
|
||||
|
||||
The Kubernetes model is pretty constrained (it has this pattern of resources are defined in etcd, controllers read those resources and update etcd), and I think having this relatively opinionated/constrained model makes it easier to develop your own distributed systems inside the Kubernetes framework.
|
||||
|
||||
Kamal introduced me to this idea of “Kubernetes is a good platform for writing your own distributed systems” instead of just “Kubernetes is a distributed system you can use” and I think it’s really interesting. He has a prototype of a [system to run an HTTP service for every branch you push to github][5]. It took him a weekend and is like 800 lines of Go, which I thought was impressive!
|
||||
|
||||
### Kubernetes lets you do some amazing things (but isn’t easy)
|
||||
|
||||
I started out by saying “kubernetes lets you do these magical things, you can just spin up so much infrastructure with a single configuration file, it’s amazing”. And that’s true!
|
||||
|
||||
What I mean by “Kubernetes isn’t easy” is that Kubernetes has a lot of moving parts learning how to successfully operate a highly available Kubernetes cluster is a lot of work. Like I find that with a lot of the abstractions it gives me, I need to understand what is underneath those abstractions in order to debug issues and configure things properly. I love learning new things so this doesn’t make me angry or anything, I just think it’s important to know :)
|
||||
|
||||
One specific example of “I can’t just rely on the abstractions” that I’ve struggled with is that I needed to learn a LOT [about how networking works on Linux][6] to feel confident with setting up Kubernetes networking, way more than I’d ever had to learn about networking before. This was very fun but pretty time consuming. I might write more about what is hard/interesting about setting up Kubernetes networking at some point.
|
||||
|
||||
Or I wrote a [2000 word blog post][7] about everything I had to learn about Kubernetes’ different options for certificate authorities to be able to set up my Kubernetes CAs successfully.
|
||||
|
||||
I think some of these managed Kubernetes systems like GKE (google’s kubernetes product) may be simpler since they make a lot of decisions for you but I haven’t tried any of them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/10/05/reasons-kubernetes-is-cool/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://github.com/kamalmarhubi/kubereview
|
||||
[2]:https://jvns.ca/categories/kubernetes
|
||||
[3]:https://github.com/kelseyhightower/kubernetes-the-hard-way
|
||||
[4]:https://github.com/kubernetes/kubernetes/blob/e4551d50e57c089aab6f67333412d3ca64bc09ae/pkg/controller/cronjob/cronjob_controller.go
|
||||
[5]:https://github.com/kamalmarhubi/kubereview
|
||||
[6]:https://jvns.ca/blog/2016/12/22/container-networking/
|
||||
[7]:https://jvns.ca/blog/2017/08/05/how-kubernetes-certificates-work/
|
||||
@ -1,3 +1,4 @@
|
||||
**translating by [erlinux](https://github.com/erlinux)**
|
||||
Operating a Kubernetes network
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Dive into BPF: a list of reading material
|
||||
Translating by qhwdw Dive into BPF: a list of reading material
|
||||
============================================================
|
||||
|
||||
* [What is BPF?][143]
|
||||
@ -709,3 +709,5 @@ via: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
|
||||
[190]:https://github.com/torvalds/linux
|
||||
[191]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[192]:https://qmonnet.github.io/whirl-offload/categories/#BPF
|
||||
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
yixunx translating
|
||||
|
||||
Love Your Bugs
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,76 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Glitch: write fun small web projects instantly
|
||||
============================================================
|
||||
|
||||
I just wrote about Jupyter Notebooks which are a fun interactive way to write Python code. That reminded me I learned about Glitch recently, which I also love!! I built a small app to [turn of twitter retweets][2] with it. So!
|
||||
|
||||
[Glitch][3] is an easy way to make Javascript webapps. (javascript backend, javascript frontend)
|
||||
|
||||
The fun thing about glitch is:
|
||||
|
||||
1. you start typing Javascript code into their web interface
|
||||
|
||||
2. as soon as you type something, it automagically reloads the backend of your website with the new code. You don’t even have to save!! It autosaves.
|
||||
|
||||
So it’s like Heroku, but even more magical!! Coding like this (you type, and the code runs on the public internet immediately) just feels really **fun** to me.
|
||||
|
||||
It’s kind of like sshing into a server and editing PHP/HTML code on your server and having it instantly available, which I kind of also loved. Now we have “better deployment practices” than “just edit the code and it is instantly on the internet” but we are not talking about Serious Development Practices, we are talking about writing tiny programs for fun.
|
||||
|
||||
### glitch has awesome example apps
|
||||
|
||||
Glitch seems like fun nice way to learn programming!
|
||||
|
||||
For example, there’s a space invaders game (code by [Mary Rose Cook][4]) at [https://space-invaders.glitch.me/][5]. The thing I love about this is that in just a few clicks I can
|
||||
|
||||
1. click “remix this”
|
||||
|
||||
2. start editing the code to make the boxes orange instead of black
|
||||
|
||||
3. have my own space invaders game!! Mine is at [http://julias-space-invaders.glitch.me/][1]. (i just made very tiny edits to make it orange, nothing fancy)
|
||||
|
||||
They have tons of example apps that you can start from – for instance [bots][6], [games][7], and more.
|
||||
|
||||
### awesome actually useful app: tweetstorms
|
||||
|
||||
The way I learned about Glitch was from this app which shows you tweetstorms from a given user: [https://tweetstorms.glitch.me/][8].
|
||||
|
||||
For example, you can see [@sarahmei][9]’s tweetstorms at [https://tweetstorms.glitch.me/sarahmei][10] (she tweets a lot of good tweetstorms!).
|
||||
|
||||
### my glitch app: turn off retweets
|
||||
|
||||
When I learned about Glitch I wanted to turn off retweets for everyone I follow on Twitter (I know you can do it in Tweetdeck!) and doing it manually was a pain – I had to do it one person at a time. So I wrote a tiny Glitch app to do it for me!
|
||||
|
||||
I liked that I didn’t have to set up a local development environment, I could just start typing and go!
|
||||
|
||||
Glitch only supports Javascript and I don’t really know Javascript that well (I think I’ve never written a Node program before), so the code isn’t awesome. But I had a really good time writing it – being able to type and just see my code running instantly was delightful. Here it is: [https://turn-off-retweets.glitch.me/][11].
|
||||
|
||||
### that’s all!
|
||||
|
||||
Using Glitch feels really fun and democratic. Usually if I want to fork someone’s web project and make changes I wouldn’t do it – I’d have to fork it, figure out hosting, set up a local dev environment or Heroku or whatever, install the dependencies, etc. I think tasks like installing node.js dependencies used to be interesting, like “cool i am learning something new” and now I just find them tedious.
|
||||
|
||||
So I love being able to just click “remix this!” and have my version on the internet instantly.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/13/glitch--write-small-web-projects-easily/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://julias-space-invaders.glitch.me/
|
||||
[2]:https://turn-off-retweets.glitch.me/
|
||||
[3]:https://glitch.com/
|
||||
[4]:https://maryrosecook.com/
|
||||
[5]:https://space-invaders.glitch.me/
|
||||
[6]:https://glitch.com/handy-bots
|
||||
[7]:https://glitch.com/games
|
||||
[8]:https://tweetstorms.glitch.me/
|
||||
[9]:https://twitter.com/sarahmei
|
||||
[10]:https://tweetstorms.glitch.me/sarahmei
|
||||
[11]:https://turn-off-retweets.glitch.me/
|
||||
@ -1,60 +0,0 @@
|
||||
Translating by ValoniaKim
|
||||
Language engineering for great justice
|
||||
============================================================
|
||||
|
||||
Whole-systems engineering, when you get good at it, goes beyond being entirely or even mostly about technical optimizations. Every artifact we make is situated in a context of human action that widens out to the economics of its use, the sociology of its users, and the entirety of what Austrian economists call “praxeology”, the science of purposeful human behavior in its widest scope.
|
||||
|
||||
This isn’t just abstract theory for me. When I wrote my papers on open-source development, they were exactly praxeology – they weren’t about any specific software technology or objective but about the context of human action within which technology is worked. An increase in praxeological understanding of technology can reframe it, leading to tremendous increases in human productivity and satisfaction, not so much because of changes in our tools but because of changes in the way we grasp them.
|
||||
|
||||
In this, the third of my unplanned series of posts about the twilight of C and the huge changes coming as we actually begin to see forward into a new era of systems programming, I’m going to try to cash that general insight out into some more specific and generative ideas about the design of computer languages, why they succeed, and why they fail.
|
||||
|
||||
In my last post I noted that every computer language is an embodiment of a relative-value claim, an assertion about the optimal tradeoff between spending machine resources and spending programmer time, all of this in a context where the cost of computing power steadily falls over time while programmer-time costs remain relatively stable or may even rise. I also highlighted the additional role of transition costs in pinning old tradeoff assertions into place. I described what language designers do as seeking a new optimum for present and near-future conditions.
|
||||
|
||||
Now I’m going to focus on that last concept. A language designer has lots of possible moves in language-design space from where the state of the art is now. What kind of type system? GC or manual allocation? What mix of imperative, functional, or OO approaches? But in praxeological terms his choice is, I think, usually much simpler: attack a near problem or a far problem?
|
||||
|
||||
“Near” and “far” are measured along the curves of falling hardware costs, rising software complexity, and increasing transition costs from existing languages. A near problem is one the designer can see right in front of him; a far problem is a set of conditions that can be seen coming but won’t necessarily arrive for some time. A near solution can be deployed immediately, to great practical effect, but may age badly as conditions change. A far solution is a bold bet that may smother under the weight of its own overhead before its future arrives, or never be adopted at all because moving to it is too expensive.
|
||||
|
||||
Back at the dawn of computing, FORTRAN was a near-problem design, LISP a far-problem one. Assemblers are near solutions. Illustrating that the categories apply to non-general-purpose languages, also roff markup. Later in the game, PHP and Javascript. Far solutions? Oberon. Ocaml. ML. XML-Docbook. Academic languages tend to be far because the incentive structure around them rewards originality and intellectual boldness (note that this is a praxeological cause, not a technical one!). The failure mode of academic languages is predictable; high inward transition costs, nobody goes there, failure to achieve community critical mass sufficient for mainstream adoption, isolation, and stagnation. (That’s a potted history of LISP in one sentence, and I say that as an old LISP-head with a deep love for the language…)
|
||||
|
||||
The failure modes of near designs are uglier. The best outcome to hope for is a graceful death and transition to a newer design. If they hang on (most likely to happen when transition costs out are high) features often get piled on them to keep them relevant, increasing complexity until they become teetering piles of cruft. Yes, C++, I’m looking at you. You too, Javascript. And (alas) Perl, though Larry Wall’s good taste mitigated the problem for many years – but that same good taste eventually moved him to blow up the whole thing for Perl 6.
|
||||
|
||||
This way of thinking about language design encourages reframing the designer’s task in terms of two objectives. (1) Picking a sweet spot on the near-far axis away from you into the projected future; and (2) Minimizing inward transition costs from one or more existing languages so you co-opt their userbases. And now let’s talk about about how C took over the world.
|
||||
|
||||
There is no more more breathtaking example than C than of nailing the near-far sweet spot in the entire history of computing. All I need to do to prove this is point at its extreme longevity as a practical, mainstream language that successfully saw off many competitors for its roles over much of its range. That timespan has now passed about 35 years (counting from when it swamped its early competitors) and is not yet with certainty ended.
|
||||
|
||||
OK, you can attribute some of C’s persistence to inertia if you want, but what are you really adding to the explanation if you use the word “inertia”? What it means is exactly that nobody made an offer that actually covered the transition costs out of the language!
|
||||
|
||||
Conversely, an underappreciated strength of the language was the low inward transition costs. C is an almost uniquely protean tool that, even at the beginning of its long reign, could readily accommodate programming habits acquired from languages as diverse as FORTRAN, Pascal, assemblers and LISP. I noticed back in the 1980s that I could often spot a new C programmer’s last language by his coding style, which was just the flip side of saying that C was damn good at gathering all those tribes unto itself.
|
||||
|
||||
C++ also benefited from having low transition costs in. Later, most new languages at least partly copied C syntax in order to minimize them.Notice what this does to the context of future language designs: it raises the value of being a C-like as possible in order to minimize inward transition costs from anywhere.
|
||||
|
||||
Another way to minimize inward transition costs is to simply be ridiculously easy to learn, even to people with no prior programming experience. This, however, is remarkably hard to pull off. I evaluate that only one language – Python – has made the major leagues by relying on this quality. I mention it only in passing because it’s not a strategy I expect to see a _systems_ language execute successfully, though I’d be delighted to be wrong about that.
|
||||
|
||||
So here we are in late 2017, and…the next part is going to sound to some easily-annoyed people like Go advocacy, but it isn’t. Go, itself, could turn out to fail in several easily imaginable ways. It’s troubling that the Go team is so impervious to some changes their user community is near-unanimously and rightly (I think) insisting it needs. Worst-case GC latency, or the throughput sacrifices made to lower it, could still turn out to drastically narrow the language’s application range.
|
||||
|
||||
That said, there is a grand strategy expressed in the Go design that I think is right. To understand it, we need to review what the near problem for a C replacement is. As I noted in the prequels, it is rising defect rates as systems projects scale up – and specifically memory-management bugs because that category so dominates crash bugs and security exploits.
|
||||
|
||||
We’ve now identified two really powerful imperatives for a C replacement: (1) solve the memory-management problem, and (2) minimize inward-transition costs from C. And the history – the praxeological context – of programming languages tells us that if a C successor candidate don’t address the transition-cost problem effectively enough, it almost doesn’t matter how good a job it does on anything else. Conversely, a C successor that _does_ address transition costs well buys itself a lot of slack for not being perfect in other ways.
|
||||
|
||||
This is what Go does. It’s not a theoretical jewel; it has annoying limitations; GC latency presently limits how far down the stack it can be pushed. But what it is doing is replicating the Unix/C infective strategy of being easy-entry and _good enough_ to propagate faster than alternatives that, if it didn’t exist, would look like better far bets.
|
||||
|
||||
Of course, the proboscid in the room when I say that is Rust. Which is, in fact, positioning itself as the better far bet. I’ve explained in previous installments why I don’t think it’s really ready to compete yet. The TIOBE and PYPL indices agree; it’s never made the TIOBE top 20 and on both indices does quite poorly against Go.
|
||||
|
||||
Where Rust will be in five years is a different question, of course. My advice to the Rust community, if they care, is to pay some serious attention to the transition-cost problem. My personal experience says the C to Rust energy barrier is _[nasty][2]_ . Code-lifting tools like Corrode won’t solve it if all they do is map C to unsafe Rust, and if there were an easy way to automate ownership/lifetime annotations they wouldn’t be needed at all – the compiler would just do that for you. I don’t know what a solution would look like, here, but I think they better find one.
|
||||
|
||||
I will finally note that Ken Thompson has a history of designs that look like minimal solutions to near problems but turn out to have an amazing quality of openness to the future, the capability to _be improved_ . Unix is like this, of course. It makes me very cautious about supposing that any of the obvious annoyances in Go that look like future-blockers to me (like, say, the lack of generics) actually are. Because for that to be true, I’d have to be smarter than Ken, which is not an easy thing to believe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7745
|
||||
|
||||
作者:[Eric Raymond ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7711&cpage=1#comment-1913931
|
||||
[3]:http://esr.ibiblio.org/?p=7745
|
||||
@ -1,3 +1,5 @@
|
||||
translating by aiwhj
|
||||
|
||||
Adopting Kubernetes step by step
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
translating by zrszrszrs
|
||||
# [Mark McIntyre: How Do You Fedora?][1]
|
||||
|
||||
|
||||

|
||||
|
||||
We recently interviewed Mark McIntyre on how he uses Fedora. This is [part of a series][2] on the Fedora Magazine. The series profiles Fedora users and how they use Fedora to get things done. Contact us on the [feedback form][3] to express your interest in becoming a interviewee.
|
||||
|
||||
### Who is Mark McIntyre?
|
||||
|
||||
Mark McIntyre is a geek by birth and Linux by choice. “I started coding at the early age of 13 learning BASIC on my own and finding the excitement of programming which led me down a path of becoming a professional coder,” he says. McIntyre and his niece are big fans of pizza. “My niece and I started a quest last fall to try as many of the pizza joints in Knoxville. You can read about our progress at [https://knox-pizza-quest.blogspot.com/][4]” Mark is also an amateur photographer and [publishes his images][5] on Flickr.
|
||||
|
||||

|
||||
|
||||
Mark has a diverse background as a developer. He has worked with Visual Basic for Applications, LotusScript, Oracle’s PL/SQL, Tcl/Tk and Python with Django as the framework. His strongest skill is Python which he uses in his current job as a systems engineer. “I am using Python on a regular basis. As my job is morphing into more of an automation engineer, that became more frequent.”
|
||||
|
||||
McIntyre is a self-described nerd and loves sci-fi movies, but his favorite movie falls out of that genre. “As much as I am a nerd and love the Star Trek and Star Wars and related movies, the movie Glory is probably my favorite of all time.” He also mentioned that Serenity was a fantastic follow-up to a great TV series.
|
||||
|
||||
Mark values humility, knowledge and graciousness in others. He appreciates people who act based on understanding the situation that other people are in. “If you add a decision to serve another, you have the basis for someone you’d want to be around instead of someone who you have to tolerate.”
|
||||
|
||||
McIntyre works for [Scripps Networks Interactive][6], which is the parent company for HGTV, Food Network, Travel Channel, DIY, GAC, and several other cable channels. “Currently, I function as a systems engineer for the non-linear video content, which is all the media purposed for online consumption.” He supports a few development teams who write applications to publish the linear video from cable TV into the online formats such as Amazon and Hulu. The systems include both on-premise and cloud systems. Mark also develops automation tools for deploying these applications primarily to a cloud infrastructure.
|
||||
|
||||
### The Fedora community
|
||||
|
||||
Mark describes the Fedora community as an active community filled with people who enjoy life as Fedora users. “From designers to packagers, this group is still very active and feels alive.” McIntyre continues, “That gives me a sense of confidence in the operating system.”
|
||||
|
||||
He started frequenting the #fedora channel on IRC around 2002: “Back then, Wi-Fi functionality was still done a lot by hand in starting the adapter and configuring the modules.” In order to get his Wi-Fi working he had to recompile the Fedora kernel. Shortly after, he started helping others in the #fedora channel.
|
||||
|
||||
McIntyre encourages others to get involved in the Fedora Community. “There are many different areas of opportunity in which to be involved. Front-end design, testing deployments, development, packaging of applications, and new technology implementation.” He recommends picking an area of interest and asking questions of that group. “There are many opportunities available to jump in to contribute.”
|
||||
|
||||
He credits a fellow community member with helping him get started: “Ben Williams was very helpful in my first encounters with Fedora, helping me with some of my first installation rough patches in the #fedora support channel.” Ben also encouraged Mark to become an [Ambassador][7].
|
||||
|
||||
### What hardware and software?
|
||||
|
||||
McIntyre uses Fedora Linux on all his laptops and desktops. On servers he chooses CentOS, due to the longer support lifecycle. His current desktop is self-built and equipped with an Intel Core i5 processor, 32 GB of RAM and 2 TB of disk space. “I have a 4K monitor attached which gives me plenty of room for viewing all my applications at once.” His current work laptop is a Dell Inspiron 2-in-1 13-inch laptop with 16 GB RAM and a 525 GB m.2 SSD.
|
||||
|
||||

|
||||
|
||||
Mark currently runs Fedora 26 on any box he setup in the past few months. When it comes to new versions he likes to avoid the rush when the version is officially released. “I usually try to get the latest version as soon as it goes gold, with the exception of one of my workstations running the next version’s beta when it is closer to release.” He usually upgrades in place: “The in-place upgrade using _dnf system-upgrade_ works very well these days.”
|
||||
|
||||
To handle his photography, McIntyre uses [GIMP][8] and [Darktable][9], along with a few other photo viewing and quick editing packages. When not using web-based email, he uses [Geary][10] along with [GNOME Calendar][11]. Mark’s IRC client of choice is [HexChat][12] connecting to a [ZNC bouncer][13]running on a Fedora Server instance. His department’s communication is handled via Slack.
|
||||
|
||||
“I have never really been a big IDE fan, so I spend time in [vim][14] for most of my editing.” Occasionally, he opens up a simple text editor like [gedit][15] or [xed][16]. Mark uses [GPaste][17] for copying and pasting. “I have become a big fan of [Tilix][18] for my terminal choice.” McIntyre manages the podcasts he likes with [Rhythmbox][19], and uses [Epiphany][20] for quick web lookups.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/mark-mcintyre-fedora/
|
||||
|
||||
作者:[Charles Profitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/cprofitt/
|
||||
[1]:https://fedoramagazine.org/mark-mcintyre-fedora/
|
||||
[2]:https://fedoramagazine.org/tag/how-do-you-fedora/
|
||||
[3]:https://fedoramagazine.org/submit-an-idea-or-tip/
|
||||
[4]:https://knox-pizza-quest.blogspot.com/
|
||||
[5]:https://www.flickr.com/photos/mockgeek/
|
||||
[6]:http://www.scrippsnetworksinteractive.com/
|
||||
[7]:https://fedoraproject.org/wiki/Ambassadors
|
||||
[8]:https://www.gimp.org/
|
||||
[9]:http://www.darktable.org/
|
||||
[10]:https://wiki.gnome.org/Apps/Geary
|
||||
[11]:https://wiki.gnome.org/Apps/Calendar
|
||||
[12]:https://hexchat.github.io/
|
||||
[13]:https://wiki.znc.in/ZNC
|
||||
[14]:http://www.vim.org/
|
||||
[15]:https://wiki.gnome.org/Apps/Gedit
|
||||
[16]:https://github.com/linuxmint/xed
|
||||
[17]:https://github.com/Keruspe/GPaste
|
||||
[18]:https://fedoramagazine.org/try-tilix-new-terminal-emulator-fedora/
|
||||
[19]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[20]:https://wiki.gnome.org/Apps/Web
|
||||
@ -1,3 +1,5 @@
|
||||
**translating by [erlinux](https://github.com/erlinux)**
|
||||
|
||||
Why microservices are a security issue
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,78 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
AWS to Help Build ONNX Open Source AI Platform
|
||||
============================================================
|
||||

|
||||
|
||||
|
||||
Amazon Web Services has become the latest tech firm to join the deep learning community's collaboration on the Open Neural Network Exchange, recently launched to advance artificial intelligence in a frictionless and interoperable environment. Facebook and Microsoft led the effort.
|
||||
|
||||
As part of that collaboration, AWS made its open source Python package, ONNX-MxNet, available as a deep learning framework that offers application programming interfaces across multiple languages including Python, Scala and open source statistics software R.
|
||||
|
||||
The ONNX format will help developers build and train models for other frameworks, including PyTorch, Microsoft Cognitive Toolkit or Caffe2, AWS Deep Learning Engineering Manager Hagay Lupesko and Software Developer Roshani Nagmote wrote in an online post last week. It will let developers import those models into MXNet, and run them for inference.
|
||||
|
||||
### Help for Developers
|
||||
|
||||
Facebook and Microsoft this summer launched ONNX to support a shared model of interoperability for the advancement of AI. Microsoft committed its Cognitive Toolkit, Caffe2 and PyTorch to support ONNX.
|
||||
|
||||
Cognitive Toolkit and other frameworks make it easier for developers to construct and run computational graphs that represent neural networks, Microsoft said.
|
||||
|
||||
Initial versions of [ONNX code and documentation][4] were made available on Github.
|
||||
|
||||
AWS and Microsoft last month announced plans for Gluon, a new interface in Apache MXNet that allows developers to build and train deep learning models.
|
||||
|
||||
Gluon "is an extension of their partnership where they are trying to compete with Google's Tensorflow," observed Aditya Kaul, research director at [Tractica][5].
|
||||
|
||||
"Google's omission from this is quite telling but also speaks to their dominance in the market," he told LinuxInsider.
|
||||
|
||||
"Even Tensorflow is open source, and so open source is not the big catch here -- but the rest of the ecosystem teaming up to compete with Google is what this boils down to," Kaul said.
|
||||
|
||||
The Apache MXNet community earlier this month introduced version 0.12 of MXNet, which extends Gluon functionality to allow for new, cutting-edge research, according to AWS. Among its new features are variational dropout, which allows developers to apply the dropout technique for mitigating overfitting to recurrent neural networks.
|
||||
|
||||
Convolutional RNN, Long Short-Term Memory and gated recurrent unit cells allow datasets to be modeled using time-based sequence and spatial dimensions, AWS noted.
|
||||
|
||||
### Framework-Neutral Method
|
||||
|
||||
"This looks like a great way to deliver inference regardless of which framework generated a model," said Paul Teich, principal analyst at [Tirias Research][6].
|
||||
|
||||
"This is basically a framework-neutral way to deliver inference," he told LinuxInsider.
|
||||
|
||||
Cloud providers like AWS, Microsoft and others are under pressure from customers to be able to train on one network while delivering on another, in order to advance AI, Teich pointed out.
|
||||
|
||||
"I see this as kind of a baseline way for these vendors to check the interoperability box," he remarked.
|
||||
|
||||
"Framework interoperability is a good thing, and this will only help developers in making sure that models that they build on MXNet or Caffe or CNTK are interoperable," Tractica's Kaul pointed out.
|
||||
|
||||
As to how this interoperability might apply in the real world, Teich noted that technologies such as natural language translation or speech recognition would require that Alexa's voice recognition technology be packaged and delivered to another developer's embedded environment.
|
||||
|
||||
### Thanks, Open Source
|
||||
|
||||
"Despite their competitive differences, these companies all recognize they owe a significant amount of their success to the software development advancements generated by the open source movement," said Jeff Kaplan, managing director of [ThinkStrategies][7].
|
||||
|
||||
"The Open Neural Network Exchange is committed to producing similar benefits and innovations in AI," he told LinuxInsider.
|
||||
|
||||
A growing number of major technology companies have announced plans to use open source to speed the development of AI collaboration, in order to create more uniform platforms for development and research.
|
||||
|
||||
AT&T just a few weeks ago announced plans [to launch the Acumos Project][8] with TechMahindra and The Linux Foundation. The platform is designed to open up efforts for collaboration in telecommunications, media and technology.
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
|
||||
作者:[ David Jones ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html#searchbyline
|
||||
[1]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html#
|
||||
[2]:https://www.linuxinsider.com/perl/mailit/?id=84971
|
||||
[3]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
[4]:https://github.com/onnx/onnx
|
||||
[5]:https://www.tractica.com/
|
||||
[6]:http://www.tiriasresearch.com/
|
||||
[7]:http://www.thinkstrategies.com/
|
||||
[8]:https://www.linuxinsider.com/story/84926.html
|
||||
[9]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
@ -1,156 +0,0 @@
|
||||
translating by lujun9972
|
||||
How To Tell If Your Linux Server Has Been Compromised
|
||||
--------------
|
||||
|
||||
A server being compromised or hacked for the purpose of this guide is an unauthorized person or bot logging into the server in order to use it for their own, usually negative ends.
|
||||
|
||||
Disclaimer: If your server has been compromised by a state organization like the NSA or a serious criminal group then you will not notice any problems and the following techniques will not register their presence.
|
||||
|
||||
However, the majority of compromised servers are carried out by bots i.e. automated attack programs, in-experienced attackers e.g. “script kiddies”, or dumb criminals.
|
||||
|
||||
These sorts of attackers will abuse the server for all it’s worth whilst they have access to it and take few precautions to hide what they are doing.
|
||||
|
||||
### Symptoms of a compromised server
|
||||
|
||||
When a server has been compromised by an in-experienced or automated attacker they will usually do something with it that consumes 100% of a resource. This resource will usually be either the CPU for something like crypt-currency mining or email spamming, or bandwidth for launching a DOS attack.
|
||||
|
||||
This means that the first indication that something is amiss is that the server is “going slow”. This could manifest in the website serving pages much slower than usual, or email taking many minutes to deliver or send.
|
||||
|
||||
So what should you look for?
|
||||
|
||||
### Check 1 - Who’s currently logged in?
|
||||
|
||||
The first thing you should look for is who is currently logged into the server. It is not uncommon to find the attacker actually logged into the server and working on it.
|
||||
|
||||
The shell command to do this is w. Running w gives the following output:
|
||||
|
||||
```
|
||||
08:32:55 up 98 days, 5:43, 2 users, load average: 0.05, 0.03, 0.00
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
root pts/0 113.174.161.1 08:26 0.00s 0.03s 0.02s ssh root@coopeaa12
|
||||
root pts/1 78.31.109.1 08:26 0.00s 0.01s 0.00s w
|
||||
|
||||
```
|
||||
|
||||
One of those IP’s is a UK IP and the second is Vietnamese. That’s probably not a good thing.
|
||||
|
||||
Stop and take a breath, don’t panic and simply kill their SSH connection. Unless you can stop then re-entering the server they will do so quickly and quite likely kick you off and stop you getting back in.
|
||||
|
||||
Please see the What should I do if I’ve been compromised section at the end of this guide no how to proceed if you do find evidence of compromise.
|
||||
|
||||
The whois command can be run on IP addresses and will tell you what all the information about the organization that the IP is registered to, including the country.
|
||||
|
||||
### Check 2 - Who has logged in?
|
||||
|
||||
Linux servers keep a record of which users logged in, from what IP, when and for how long. This information is accessed with the last command.
|
||||
|
||||
The output looks like this:
|
||||
|
||||
```
|
||||
root pts/1 78.31.109.1 Thu Nov 30 08:26 still logged in
|
||||
root pts/0 113.174.161.1 Thu Nov 30 08:26 still logged in
|
||||
root pts/1 78.31.109.1 Thu Nov 30 08:24 - 08:26 (00:01)
|
||||
root pts/0 113.174.161.1 Wed Nov 29 12:34 - 12:52 (00:18)
|
||||
root pts/0 14.176.196.1 Mon Nov 27 13:32 - 13:53 (00:21)
|
||||
|
||||
```
|
||||
|
||||
There is a mix of my UK IP’s and some Vietnamese ones, with the top two still logged in. If you see any IP’s that are not authorized then refer to the final section.
|
||||
|
||||
The login history is contained in a text file at ~/.bash_history and is therefore easily removable. Often, attackers will simply delete this file to try to cover their tracks. Consequently, if you run last and only see your current login, this is a Bad Sign.
|
||||
|
||||
If there is no login history be very, very suspicious and continue looking for indications of compromise.
|
||||
|
||||
### Check 3 - Review the command history
|
||||
|
||||
This level of attacker will frequently take no precautions to leave no command history so running the history command will show you everything they have done. Be on the lookout for wget or curl commands to download out-of-repo software such as spam bots or crypto miners.
|
||||
|
||||
The command history is contained in the ~/.bash_history file so some attackers will delete this file to cover what they have done. Just as with the login history, if you run history and don’t see anything then the history file has been deleted. Again this is a Bad Sign and you should review the server very carefully.
|
||||
|
||||
### Check 4 - What’s using all the CPU?
|
||||
|
||||
The sorts of attackers that you will encounter usually don’t take too many precautions to hide what they are doing. So they will run processes that consume all the CPU. This generally makes it pretty easy to spot them. Simply run top and look at the highest process.
|
||||
|
||||
This will also show people exploiting your server without having logged in. This could be, for example, someone using an unprotected form-mail script to relay spam.
|
||||
|
||||
If you don’t recognize the top process then either Google its name or investigate what it’s doing with losf or strace.
|
||||
|
||||
To use these tools first copy its PID from top and run:
|
||||
|
||||
```
|
||||
strace -p PID
|
||||
|
||||
```
|
||||
|
||||
This will display all the system calls the process is making. It’s a lot of information but looking through it will give you a good idea what’s going on.
|
||||
|
||||
```
|
||||
lsof -p PID
|
||||
|
||||
```
|
||||
|
||||
This program will list the open files that the process has. Again, this will give you a good idea what it’s doing by showing you what files it is accessing.
|
||||
|
||||
### Check 5 - Review the all the system processes
|
||||
|
||||
If an unauthorized process is not consuming enough CPU to get listed noticeably on top it will still get displayed in a full process listing with ps. My proffered command is ps auxf for providing the most information clearly.
|
||||
|
||||
You should be looking for any processes that you don’t recognize. The more times you run ps on your servers (which is a good habit to get into) the more obvious an alien process will stand out.
|
||||
|
||||
### Check 6 - Review network usage by process
|
||||
|
||||
The command iftop functions like top to show a ranked list of processes that are sending and receiving network data along with their source and destination. A process like a DOS attack or spam bot will immediately show itself at the top of the list.
|
||||
|
||||
### Check 7 - What processes are listening for network connections?
|
||||
|
||||
Often an attacker will install a program that doesn’t do anything except listen on the network port for instructions. This does not consume CPU or bandwidth whilst it is waiting so can get overlooked in the top type commands.
|
||||
|
||||
The commands lsof and netstat will both list all networked processes. I use them with the following options:
|
||||
|
||||
```
|
||||
lsof -i
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
netstat -plunt
|
||||
|
||||
```
|
||||
|
||||
You should look for any process that is listed as in the LISTEN or ESTABLISHED status as these processes are either waiting for a connection (LISTEN) or have a connection open (ESTABLISHED). If you don’t recognize these processes use strace or lsof to try to see what they are doing.
|
||||
|
||||
### What should I do if I’ve been compromised?
|
||||
|
||||
The first thing to do is not to panic, especially if the attacker is currently logged in. You need to be able to take back control of the machine before the attacker is aware that you know about them. If they realize you know about them they may well lock you out of your server and start destroying any assets out of spite.
|
||||
|
||||
If you are not very technical then simply shut down the server. Either from the server itself with shutdown -h now or systemctl poweroff. Or log into your hosting provider’s control panel and shut down the server. Once it’s powered off you can work on the needed firewall rules and consult with your provider in your own time.
|
||||
|
||||
If you’re feeling a bit more confident and your hosting provider has an upstream firewall then create and enable the following two rules in this order:
|
||||
|
||||
1. Allow SSH traffic from only your IP address.
|
||||
|
||||
2. Block everything else, not just SSH but every protocol on every port.
|
||||
|
||||
This will immediately kill their SSH session and give only you access to the server.
|
||||
|
||||
If you don’t have access to an upstream firewall then you will have to create and enable these firewall rules on the server itself and then, when they are in place kill the attacker’s ssh session with the kill command.
|
||||
|
||||
A final method, where available, is to log into the server via an out-of-band connection such as the serial console and stop networking with systemctl stop network.service. This will completely stop any network access so you can now enable the firewall rules in your own time.
|
||||
|
||||
Once you have regained control of the server do not trust it.
|
||||
|
||||
Do not attempt to fix things up and continue using the server. You can never be sure what the attacker did and so you can never sure the server is secure.
|
||||
|
||||
The only sensible course of action is to copy off all the data that you need and start again from a fresh install.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/server-hacked/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
@ -1,95 +0,0 @@
|
||||
translating---aiwhj
|
||||
5 best practices for getting started with DevOps
|
||||
============================================================
|
||||
|
||||
### Are you ready to implement DevOps, but don't know where to begin? Try these five best practices.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Andrew Magill][8]. Modified by Opensource.com. [CC BY 4.0][9]
|
||||
|
||||
DevOps often stymies early adopters with its ambiguity, not to mention its depth and breadth. By the time someone buys into the idea of DevOps, their first questions usually are: "How do I get started?" and "How do I measure success?" These five best practices are a great road map to starting your DevOps journey.
|
||||
|
||||
### 1\. Measure all the things
|
||||
|
||||
You don't know for sure that your efforts are even making things better unless you can quantify the outcomes. Are my features getting out to customers more rapidly? Are fewer defects escaping to them? Are we responding to and recovering more quickly from failure?
|
||||
|
||||
Before you change anything, think about what kinds of outcomes you expect from your DevOps transformation. When you're further into your DevOps journey, you'll enjoy a rich array of near-real-time reports on everything about your service. But consider starting with these two metrics:
|
||||
|
||||
* **Time to market** measures the end-to-end, often customer-facing, business experience. It usually begins when a feature is formally conceived and ends when the customer can consume the feature in production. Time to market is not mainly an engineering team metric; more importantly it shows your business' complete end-to-end efficiency in bringing valuable new features to market and isolates opportunities for system-wide improvement.
|
||||
|
||||
* **Cycle time** measures the engineering team process. Once work on a new feature starts, when does it become available in production? This metric is very useful for understanding the efficiency of the engineering team and isolating opportunities for team-level improvement.
|
||||
|
||||
### 2\. Get your process off the ground
|
||||
|
||||
DevOps success requires an organization to put a regular (and hopefully effective) process in place and relentlessly improve upon it. It doesn't have to start out being effective, but it must be a regular process. Usually that it's some flavor of agile methodology like Scrum or Scrumban; sometimes it's a Lean derivative. Whichever way you go, pick a formal process, start using it, and get the basics right.
|
||||
|
||||
Regular inspect-and-adapt behaviors are key to your DevOps success. Make good use of opportunities like the stakeholder demo, team retrospectives, and daily standups to find opportunities to improve your process.
|
||||
|
||||
A lot of your DevOps success hinges on people working effectively together. People on a team need to work from a common process that they are empowered to improve upon. They also need regular opportunities to share what they are learning with other stakeholders, both upstream and downstream, in the process.
|
||||
|
||||
Good process discipline will help your organization consume the other benefits of DevOps at the great speed that comes as your success builds.
|
||||
|
||||
Although it's common for more development-oriented teams to successfully adopt processes like Scrum, operations-focused teams (or others that are more interrupt-driven) may opt for a process with a more near-term commitment horizon, such as Kanban.
|
||||
|
||||
### 3\. Visualize your end-to-end workflow
|
||||
|
||||
There is tremendous power in being able to see who's working on what part of your service at any given time. Visualizing your workflow will help people know what they need to work on next, how much work is in progress, and where the bottlenecks are in the process.
|
||||
|
||||
You can't effectively limit work in process until you can see it and quantify it. Likewise, you can't effectively eliminate bottlenecks until you can clearly see them.
|
||||
|
||||
Visualizing the entire workflow will help people in all parts of the organization understand how their work contributes to the success of the whole. It can catalyze relationship-building across organizational boundaries to help your teams collaborate more effectively towards a shared sense of success.
|
||||
|
||||
### 4\. Continuous all the things
|
||||
|
||||
DevOps promises a dizzying array of compelling automation. But Rome wasn't built in a day. One of the first areas you can focus your efforts on is [continuous integration][10] (CI). But don't stop there; you'll want to follow quickly with [continuous delivery][11] (CD) and eventually continuous deployment.
|
||||
|
||||
Your CD pipeline is your opportunity to inject all manner of automated quality testing into your process. The moment new code is committed, your CD pipeline should run a battery of tests against the code and the successfully built artifact. The artifact that comes out at the end of this gauntlet is what progresses along your process until eventually it's seen by customers in production.
|
||||
|
||||
Another "continuous" that doesn't get enough attention is continuous improvement. That's as simple as setting some time aside each day to ask your colleagues: "What small thing can we do today to get better at how we do our work?" These small, daily changes compound over time into more profound results. You'll be pleasantly surprised! But it also gets people thinking all the time about how to improve things.
|
||||
|
||||
### 5\. Gherkinize
|
||||
|
||||
Fostering more effective communication across your organization is crucial to fostering the sort of systems thinking prevalent in successful DevOps journeys. One way to help that along is to use a shared language between the business and the engineers to express the desired acceptance criteria for new features. A good product manager can learn [Gherkin][12] in a day and begin using it to express acceptance criteria in an unambiguous, structured form of plain English. Engineers can use this Gherkinized acceptance criteria to write acceptance tests against the criteria, and then develop their feature code until the tests pass. This is a simplification of [acceptance test-driven development][13](ATDD) that can also help kick start your DevOps culture and engineering practice.
|
||||
|
||||
### Start on your journey
|
||||
|
||||
Don't be discouraged by getting started with your DevOps practice. It's a journey. And hopefully these five ideas give you solid ways to get started.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][14]
|
||||
|
||||
Magnus Hedemark - Magnus has been in the IT industry for over 20 years, and a technology enthusiast for most of his life. He's presently Manager of DevOps Engineering at UnitedHealth Group. In his spare time, Magnus enjoys photography and paddling canoes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/5-keys-get-started-devops
|
||||
|
||||
作者:[Magnus Hedemark ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/magnus919
|
||||
[1]:https://opensource.com/tags/devops?src=devops_resource_menu1
|
||||
[2]:https://opensource.com/resources/devops?src=devops_resource_menu2
|
||||
[3]:https://www.openshift.com/promotions/devops-with-openshift.html?intcmp=7016000000127cYAAQ&src=devops_resource_menu3
|
||||
[4]:https://enterprisersproject.com/article/2017/5/9-key-phrases-devops?intcmp=7016000000127cYAAQ&src=devops_resource_menu4
|
||||
[5]:https://www.redhat.com/en/insights/devops?intcmp=7016000000127cYAAQ&src=devops_resource_menu5
|
||||
[6]:https://opensource.com/article/17/11/5-keys-get-started-devops?rate=oEOzMXx1ghbkfl2a5ae6AnvO88iZ3wzkk53K2CzbDWI
|
||||
[7]:https://opensource.com/user/25739/feed
|
||||
[8]:https://ccsearch.creativecommons.org/image/detail/7qRx_yrcN5isTMS0u9iKMA==
|
||||
[9]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[10]:https://martinfowler.com/articles/continuousIntegration.html
|
||||
[11]:https://martinfowler.com/bliki/ContinuousDelivery.html
|
||||
[12]:https://cucumber.io/docs/reference
|
||||
[13]:https://en.wikipedia.org/wiki/Acceptance_test%E2%80%93driven_development
|
||||
[14]:https://opensource.com/users/magnus919
|
||||
[15]:https://opensource.com/users/magnus919
|
||||
[16]:https://opensource.com/users/magnus919
|
||||
[17]:https://opensource.com/tags/devops
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Someone Tries to Bring Back Ubuntu's Unity from the Dead as an Official Spin
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,153 @@
|
||||
translating---geekpi
|
||||
|
||||
Suplemon - Modern CLI Text Editor with Multi Cursor Support
|
||||
======
|
||||
Suplemon is a modern text editor for CLI that emulates the multi cursor behavior and other features of [Sublime Text][1]. It's lightweight and really easy to use, just as Nano is.
|
||||
|
||||
One of the benefits of using a CLI editor is that you can use it whether the Linux distribution that you're using has a GUI or not. This type of text editors also stands out as being simple, fast and powerful.
|
||||
|
||||
You can find useful information and the source code in the [official repository][2].
|
||||
|
||||
### Features
|
||||
|
||||
These are some of its interesting features:
|
||||
|
||||
* Multi cursor support
|
||||
|
||||
* Undo / Redo
|
||||
|
||||
* Copy and Paste, with multi line support
|
||||
|
||||
* Mouse support
|
||||
|
||||
* Extensions
|
||||
|
||||
* Find, find all, find next
|
||||
|
||||
* Syntax highlighting
|
||||
|
||||
* Autocomplete
|
||||
|
||||
* Custom keyboard shortcuts
|
||||
|
||||
### Installation
|
||||
|
||||
First, make sure you have the latest version of python3 and pip3 installed.
|
||||
|
||||
Then type in a terminal:
|
||||
|
||||
```
|
||||
$ sudo pip3 install suplemon
|
||||
```
|
||||
|
||||
Create a new file in the current directory
|
||||
|
||||
Open a terminal and type:
|
||||
|
||||
```
|
||||
$ suplemon
|
||||
```
|
||||
|
||||

|
||||
|
||||
Open one or multiple files
|
||||
|
||||
Open a terminal and type:
|
||||
|
||||
```
|
||||
$ suplemon ...
|
||||
```
|
||||
|
||||
```
|
||||
$ suplemon example1.c example2.c
|
||||
```
|
||||
|
||||
Main configuration
|
||||
|
||||
You can find the configuration file at ~/.config/suplemon/suplemon-config.json.
|
||||
|
||||
Editing this file is easy, you just have to enter command mode (once you are inside suplemon) and run the config command. You can view the default configuration by running config defaults.
|
||||
|
||||
Keymap configuration
|
||||
|
||||
I'll show you the default key mappings for suplemon. If you want to edit them, just run keymap command. Run keymap default to view the default keymap file.
|
||||
|
||||
* Exit: Ctrl + Q
|
||||
|
||||
* Copy line(s) to buffer: Ctrl + C
|
||||
|
||||
* Cut line(s) to buffer: Ctrl + X
|
||||
|
||||
* Insert buffer: Ctrl + V
|
||||
|
||||
* Duplicate line: Ctrl + K
|
||||
|
||||
* Goto: Ctrl + G. You can go to a line or to a file (just type the beginning of a file name). Also, it is possible to type something like 'exam:50' to go to the line 50 of the file example.c at line 50.
|
||||
|
||||
* Search for string or regular expression: Ctrl + F
|
||||
|
||||
* Search next: Ctrl + D
|
||||
|
||||
* Trim whitespace: Ctrl + T
|
||||
|
||||
* Add new cursor in arrow direction: Alt + Arrow key
|
||||
|
||||
* Jump to previous or next word or line: Ctrl + Left / Right
|
||||
|
||||
* Revert to single cursor / Cancel input prompt: Esc
|
||||
|
||||
* Move line(s) up / down: Page Up / Page Down
|
||||
|
||||
* Save file: Ctrl + S
|
||||
|
||||
* Save file with new name: F1
|
||||
|
||||
* Reload current file: F2
|
||||
|
||||
* Open file: Ctrl + O
|
||||
|
||||
* Close file: Ctrl + W
|
||||
|
||||
* Switch to next/previous file: Ctrl + Page Up / Ctrl + Page Down
|
||||
|
||||
* Run a command: Ctrl + E
|
||||
|
||||
* Undo: Ctrl + Z
|
||||
|
||||
* Redo: Ctrl + Y
|
||||
|
||||
* Toggle visible whitespace: F7
|
||||
|
||||
* Toggle mouse mode: F8
|
||||
|
||||
* Toggle line numbers: F9
|
||||
|
||||
* Toggle Full screen: F11
|
||||
|
||||
Mouse shortcuts
|
||||
|
||||
* Set cursor at pointer position: Left Click
|
||||
|
||||
* Add a cursor at pointer position: Right Click
|
||||
|
||||
* Scroll vertically: Scroll Wheel Up / Down
|
||||
|
||||
### Wrapping up
|
||||
|
||||
After trying Suplemon for some time, I have changed my opinion about CLI text editors. I had tried Nano before, and yes, I liked its simplicity, but its modern-feature lack made it non-practical for my everyday use.
|
||||
|
||||
This tool has the best of both CLI and GUI worlds... Simplicity and feature-richness! So I suggest you give it a try, and write your thoughts in the comments :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/tools/suplemon-cli-text-editor-multi-cursor/
|
||||
|
||||
作者:[Ivo Ursino][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/ursinov/
|
||||
[1]:https://linoxide.com/tools/install-sublime-text-editor-linux/
|
||||
[2]:https://github.com/richrd/suplemon/
|
||||
@ -1,156 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Undistract-me : Get Notification When Long Running Terminal Commands Complete
|
||||
============================================================
|
||||
|
||||
by [sk][2] · November 30, 2017
|
||||
|
||||
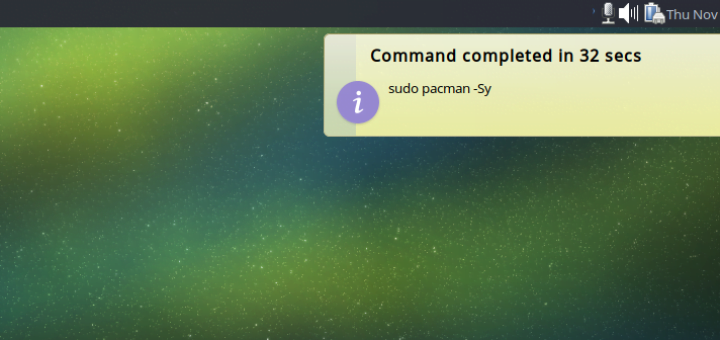
|
||||
|
||||
A while ago, we published how to [get notification when a Terminal activity is done][3]. Today, I found out a similar utility called “undistract-me” that notifies you when long running terminal commands complete. Picture this scenario. You run a command that takes a while to finish. In the mean time, you check your facebook and get so involved in it. After a while, you remembered that you ran a command few minutes ago. You go back to the Terminal and notice that the command has already finished. But you have no idea when the command is completed. Have you ever been in this situation? I bet most of you were in this situation many times. This is where “undistract-me” comes in help. You don’t need to constantly check the terminal to see if a command is completed or not. Undistract-me utility will notify you when a long running command is completed. It will work on Arch Linux, Debian, Ubuntu and other Ubuntu-derivatives.
|
||||
|
||||
#### Installing Undistract-me
|
||||
|
||||
Undistract-me is available in the default repositories of Debian and its variants such as Ubuntu. All you have to do is to run the following command to install it.
|
||||
|
||||
```
|
||||
sudo apt-get install undistract-me
|
||||
```
|
||||
|
||||
The Arch Linux users can install it from AUR using any helper programs.
|
||||
|
||||
Using [Pacaur][4]:
|
||||
|
||||
```
|
||||
pacaur -S undistract-me-git
|
||||
```
|
||||
|
||||
Using [Packer][5]:
|
||||
|
||||
```
|
||||
packer -S undistract-me-git
|
||||
```
|
||||
|
||||
Using [Yaourt][6]:
|
||||
|
||||
```
|
||||
yaourt -S undistract-me-git
|
||||
```
|
||||
|
||||
Then, run the following command to add “undistract-me” to your Bash.
|
||||
|
||||
```
|
||||
echo 'source /etc/profile.d/undistract-me.sh' >> ~/.bashrc
|
||||
```
|
||||
|
||||
Alternatively you can run this command to add it to your Bash:
|
||||
|
||||
```
|
||||
echo "source /usr/share/undistract-me/long-running.bash\nnotify_when_long_running_commands_finish_install" >> .bashrc
|
||||
```
|
||||
|
||||
If you are in Zsh shell, run this command:
|
||||
|
||||
```
|
||||
echo "source /usr/share/undistract-me/long-running.bash\nnotify_when_long_running_commands_finish_install" >> .zshrc
|
||||
```
|
||||
|
||||
Finally update the changes:
|
||||
|
||||
For Bash:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
For Zsh:
|
||||
|
||||
```
|
||||
source ~/.zshrc
|
||||
```
|
||||
|
||||
#### Configure Undistract-me
|
||||
|
||||
By default, Undistract-me will consider any command that takes more than 10 seconds to complete as a long-running command. You can change this time interval by editing /usr/share/undistract-me/long-running.bash file.
|
||||
|
||||
```
|
||||
sudo nano /usr/share/undistract-me/long-running.bash
|
||||
```
|
||||
|
||||
Find “LONG_RUNNING_COMMAND_TIMEOUT” variable and change the default value (10 seconds) to something else of your choice.
|
||||
|
||||
[][7]
|
||||
|
||||
Save and close the file. Do not forget to update the changes:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
Also, you can disable notifications for particular commands. To do so, find the “LONG_RUNNING_IGNORE_LIST” variable and add the commands space-separated like below.
|
||||
|
||||
By default, the notification will only show if the active window is not the window the command is running in. That means, it will notify you only if the command is running in the background Terminal window. If the command is running in active window Terminal, you will not be notified. If you want undistract-me to send notifications either the Terminal window is visible or in the background, you can set IGNORE_WINDOW_CHECK to 1 to skip the window check.
|
||||
|
||||
The other cool feature of Undistract-me is you can set audio notification along with visual notification when a command is done. By default, it will only send a visual notification. You can change this behavior by setting the variable UDM_PLAY_SOUND to a non-zero integer on the command line. However, your Ubuntu system should have pulseaudio-utils and sound-theme-freedesktop utilities installed to enable this functionality.
|
||||
|
||||
Please remember that you need to run the following command to update the changes made.
|
||||
|
||||
For Bash:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
For Zsh:
|
||||
|
||||
```
|
||||
source ~/.zshrc
|
||||
```
|
||||
|
||||
It is time to verify if this really works.
|
||||
|
||||
#### Get Notification When Long Running Terminal Commands Complete
|
||||
|
||||
Now, run any command that takes longer than 10 seconds or the time duration you defined in Undistract-me script.
|
||||
|
||||
I ran the following command on my Arch Linux desktop.
|
||||
|
||||
```
|
||||
sudo pacman -Sy
|
||||
```
|
||||
|
||||
This command took 32 seconds to complete. After the completion of the above command, I got the following notification.
|
||||
|
||||
[][8]
|
||||
|
||||
Please remember Undistract-me script notifies you only if the given command took more than 10 seconds to complete. If the command is completed in less than 10 seconds, you will not be notified. Of course, you can change this time interval settings as I described in the Configuration section above.
|
||||
|
||||
I find this tool very useful. It helped me to get back to the business after I completely lost in some other tasks. I hope this tool will be helpful to you too.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
Resource:
|
||||
|
||||
* [Undistract-me GitHub Repository][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/undistract-get-notification-long-running-terminal-commands-complete/
|
||||
|
||||
作者:[sk][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/jml/undistract-me
|
||||
[2]:https://www.ostechnix.com/author/sk/
|
||||
[3]:https://www.ostechnix.com/get-notification-terminal-task-done/
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/11/undistract-me-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/11/undistract-me-2.png
|
||||
@ -1,135 +0,0 @@
|
||||
|
||||
translating by HardworkFish
|
||||
|
||||
Wake up and Shut Down Linux Automatically
|
||||
============================================================
|
||||
|
||||
### [banner.jpg][1]
|
||||
|
||||

|
||||
|
||||
Learn how to configure your Linux computers to watch the time for you, then wake up and shut down automatically.
|
||||
|
||||
[Creative Commons Attribution][6][The Observatory at Delhi][7]
|
||||
|
||||
Don't be a watt-waster. If your computers don't need to be on then shut them down. For convenience and nerd creds, you can configure your Linux computers to wake up and shut down automatically.
|
||||
|
||||
### Precious Uptimes
|
||||
|
||||
Some computers need to be on all the time, which is fine as long as it's not about satisfying an uptime compulsion. Some people are very proud of their lengthy uptimes, and now that we have kernel hot-patching that leaves only hardware failures requiring shutdowns. I think it's better to be practical. Save electricity as well as wear on your moving parts, and shut them down when they're not needed. For example, you can wake up a backup server at a scheduled time, run your backups, and then shut it down until it's time for the next backup. Or, you can configure your Internet gateway to be on only at certain times. Anything that doesn't need to be on all the time can be configured to turn on, do a job, and then shut down.
|
||||
|
||||
### Sleepies
|
||||
|
||||
For computers that don't need to be on all the time, good old cron will shut them down reliably. Use either root's cron, or /etc/crontab. This example creates a root cron job to shut down every night at 11:15 p.m.
|
||||
|
||||
```
|
||||
# crontab -e -u root
|
||||
# m h dom mon dow command
|
||||
15 23 * * * /sbin/shutdown -h now
|
||||
```
|
||||
|
||||
```
|
||||
15 23 * * 1-5 /sbin/shutdown -h now
|
||||
```
|
||||
|
||||
You may also use /etc/crontab, which is fast and easy, and everything is in one file. You have to specify the user:
|
||||
|
||||
```
|
||||
15 23 * * 1-5 root shutdown -h now
|
||||
```
|
||||
|
||||
Auto-wakeups are very cool; most of my SUSE colleagues are in Nuremberg, so I am crawling out of bed at 5 a.m. to have a few hours of overlap with their schedules. My work computer turns itself on at 5:30 a.m., and then all I have to do is drag my coffee and myself to my desk to start work. It might not seem like pressing a power button is a big deal, but at that time of day every little thing looms large.
|
||||
|
||||
Waking up your Linux PC can be less reliable than shutting it down, so you may want to try different methods. You can use wakeonlan, RTC wakeups, or your PC's BIOS to set scheduled wakeups. These all work because, when you power off your computer, it's not really all the way off; it is in an extremely low-power state and can receive and respond to signals. You need to use the power supply switch to turn it off completely.
|
||||
|
||||
### BIOS Wakeup
|
||||
|
||||
A BIOS wakeup is the most reliable. My system BIOS has an easy-to-use wakeup scheduler (Figure 1). Chances are yours does, too. Easy peasy.
|
||||
|
||||
### [fig-1.png][2]
|
||||
|
||||

|
||||
|
||||
Figure 1: My system BIOS has an easy-to-use wakeup scheduler.
|
||||
|
||||
[Used with permission][8]
|
||||
|
||||
### wakeonlan
|
||||
|
||||
wakeonlan is the next most reliable method. This requires sending a signal from a second computer to the computer you want to power on. You could use an Arduino or Raspberry Pi to send the wakeup signal, a Linux-based router, or any Linux PC. First, look in your system BIOS to see if wakeonlan is supported -- which it should be -- and then enable it, as it should be disabled by default.
|
||||
|
||||
Then, you'll need an Ethernet network adapter that supports wakeonlan; wireless adapters won't work. You'll need to verify that your Ethernet card supports wakeonlan:
|
||||
|
||||
```
|
||||
# ethtool eth0 | grep -i wake-on
|
||||
Supports Wake-on: pumbg
|
||||
Wake-on: g
|
||||
```
|
||||
|
||||
* d -- all wake ups disabled
|
||||
|
||||
* p -- wake up on physical activity
|
||||
|
||||
* u -- wake up on unicast messages
|
||||
|
||||
* m -- wake up on multicast messages
|
||||
|
||||
* b -- wake up on broadcast messages
|
||||
|
||||
* a -- wake up on ARP messages
|
||||
|
||||
* g -- wake up on magic packet
|
||||
|
||||
* s -- set the Secure On password for the magic packet
|
||||
|
||||
man ethtool is not clear on what the p switch does; it suggests that any signal will cause a wake up. In my testing, however, it doesn't do that. The one that must be enabled is g -- wake up on magic packet, and the Wake-on line shows that it is already enabled. If it is not enabled, you can use ethtool to enable it, using your own device name, of course:
|
||||
|
||||
```
|
||||
# ethtool -s eth0 wol g
|
||||
```
|
||||
|
||||
```
|
||||
@reboot /usr/bin/ethtool -s eth0 wol g
|
||||
```
|
||||
|
||||
### [fig-2.png][3]
|
||||
|
||||

|
||||
|
||||
Figure 2: Enable Wake on LAN.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
Another option is recent Network Manager versions have a nice little checkbox to enable wakeonlan (Figure 2).
|
||||
|
||||
There is a field for setting a password, but if your network interface doesn't support the Secure On password, it won't work.
|
||||
|
||||
Now you need to configure a second PC to send the wakeup signal. You don't need root privileges, so create a cron job for your user. You need the MAC address of the network interface on the machine you're waking up:
|
||||
|
||||
```
|
||||
30 08 * * * /usr/bin/wakeonlan D0:50:99:82:E7:2B
|
||||
```
|
||||
|
||||
Using the real-time clock for wakeups is the least reliable method. Check out [Wake Up Linux With an RTC Alarm Clock][4]; this is a bit outdated as most distros use systemd now. Come back next week to learn more about updated ways to use RTC wakeups.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/11/wake-and-shut-down-linux-automatically
|
||||
|
||||
作者:[Carla Schroder]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.linux.com/files/images/bannerjpg
|
||||
[2]:https://www.linux.com/files/images/fig-1png-11
|
||||
[3]:https://www.linux.com/files/images/fig-2png-7
|
||||
[4]:https://www.linux.com/learn/wake-linux-rtc-alarm-clock
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[7]:http://www.columbia.edu/itc/mealac/pritchett/00routesdata/1700_1799/jaipur/delhijantarearly/delhijantarearly.html
|
||||
[8]:https://www.linux.com/licenses/category/used-permission
|
||||
[9]:https://www.linux.com/licenses/category/used-permission
|
||||
@ -1,71 +0,0 @@
|
||||
### [Fedora Classroom Session: Ansible 101][2]
|
||||
|
||||
### By Sachin S Kamath
|
||||
|
||||

|
||||
|
||||
Fedora Classroom sessions continue this week with an Ansible session. The general schedule for sessions appears [on the wiki][3]. You can also find [resources and recordings from previous sessions][4] there. Here are details about this week’s session on [Thursday, 30th November at 1600 UTC][5]. That link allows you to convert the time to your timezone.
|
||||
|
||||
### Topic: Ansible 101
|
||||
|
||||
As the Ansible [documentation][6] explains, Ansible is an IT automation tool. It’s primarily used to configure systems, deploy software, and orchestrate more advanced IT tasks. Examples include continuous deployments or zero downtime rolling updates.
|
||||
|
||||
This Classroom session covers the topics listed below:
|
||||
|
||||
1. Introduction to SSH
|
||||
|
||||
2. Understanding different terminologies
|
||||
|
||||
3. Introduction to Ansible
|
||||
|
||||
4. Ansible installation and setup
|
||||
|
||||
5. Establishing password-less connection
|
||||
|
||||
6. Ad-hoc commands
|
||||
|
||||
7. Managing inventory
|
||||
|
||||
8. Playbooks examples
|
||||
|
||||
There will also be a follow-up Ansible 102 session later. That session will cover complex playbooks, roles, dynamic inventory files, control flow and Galaxy.
|
||||
|
||||
### Instructors
|
||||
|
||||
We have two experienced instructors handling this session.
|
||||
|
||||
[Geoffrey Marr][7], also known by his IRC name as “coremodule,” is a Red Hat employee and Fedora contributor with a background in Linux and cloud technologies. While working, he spends his time lurking in the [Fedora QA][8] wiki and test pages. Away from work, he enjoys RaspberryPi projects, especially those focusing on software-defined radio.
|
||||
|
||||
[Vipul Siddharth][9] is an intern at Red Hat who also works on Fedora. He loves to contribute to open source and seeks opportunities to spread the word of free and open source software.
|
||||
|
||||
### Joining the session
|
||||
|
||||
This session takes place on [BlueJeans][10]. The following information will help you join the session:
|
||||
|
||||
* URL: [https://bluejeans.com/3466040121][1]
|
||||
|
||||
* Meeting ID (for Desktop App): 3466040121
|
||||
|
||||
We hope you attend, learn from, and enjoy this session! If you have any feedback about the sessions, have ideas for a new one or want to host a session, please feel free to comment on this post or edit the [Classroom wiki page][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-classroom-session-ansible-101/
|
||||
|
||||
作者:[Sachin S Kamath]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://bluejeans.com/3466040121
|
||||
[2]:https://fedoramagazine.org/fedora-classroom-session-ansible-101/
|
||||
[3]:https://fedoraproject.org/wiki/Classroom
|
||||
[4]:https://fedoraproject.org/wiki/Classroom#Previous_Sessions
|
||||
[5]:https://www.timeanddate.com/worldclock/fixedtime.html?msg=Fedora+Classroom+-+Ansible+101&iso=20171130T16&p1=%3A
|
||||
[6]:http://docs.ansible.com/ansible/latest/index.html
|
||||
[7]:https://fedoraproject.org/wiki/User:Coremodule
|
||||
[8]:https://fedoraproject.org/wiki/QA
|
||||
[9]:https://fedoraproject.org/wiki/User:Siddharthvipul1
|
||||
[10]:https://www.bluejeans.com/downloads
|
||||
[11]:https://fedoraproject.org/wiki/Classroom
|
||||
@ -1,3 +1,5 @@
|
||||
|
||||
Translating by FelixYFZ
|
||||
How to find a publisher for your tech book
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by wenwensnow
|
||||
Randomize your WiFi MAC address on Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,145 @@
|
||||
translating by imquanquan
|
||||
|
||||
How To Know What A Command Or Program Will Exactly Do Before Executing It
|
||||
======
|
||||
Ever wondered what a Unix command will do before executing it? Not everyone knows what a particular command or program will do. Of course, you can check it with [Explainshell][2]. You need to copy/paste the command in Explainshell website and it let you know what each part of a Linux command does. However, it is not necessary. Now, we can easily know what a command or program will exactly do before executing it, right from the Terminal. Say hello to “maybe”, a simple tool that allows you to run a command and see what it does to your files without actually doing it! After reviewing the output listed, you can then decide whether you really want to run it or not.
|
||||
|
||||
#### How “maybe” works?
|
||||
|
||||
According to the developer,
|
||||
|
||||
> “maybe” runs processes under the control of ptrace with the help of python-ptrace library. When it intercepts a system call that is about to make changes to the file system, it logs that call, and then modifies CPU registers to both redirect the call to an invalid syscall ID (effectively turning it into a no-op) and set the return value of that no-op call to one indicating success of the original call. As a result, the process believes that everything it is trying to do is actually happening, when in reality nothing is.
|
||||
|
||||
Warning: You should be very very careful when using this utility in a production system or in any systems you care about. It can still do serious damages, because it will block only a handful of syscalls.
|
||||
|
||||
#### Installing “maybe”
|
||||
|
||||
Make sure you have installed pip in your Linux system. If not, install it as shown below depending upon the distribution you use.
|
||||
|
||||
On Arch Linux and its derivatives like Antergos, Manjaro Linux, install pip using the following command:
|
||||
|
||||
```
|
||||
sudo pacman -S python-pip
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
|
||||
```
|
||||
sudo yum install python-pip
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
sudo dnf install epel-release
|
||||
```
|
||||
|
||||
```
|
||||
sudo dnf install python-pip
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
sudo apt-get install python-pip
|
||||
```
|
||||
|
||||
On SUSE, openSUSE:
|
||||
|
||||
```
|
||||
sudo zypper install python-pip
|
||||
```
|
||||
|
||||
Once pip installed, run the following command to install “maybe”.
|
||||
|
||||
```
|
||||
sudo pip install maybe
|
||||
```
|
||||
|
||||
#### Know What A Command Or Program Will Exactly Do Before Executing It
|
||||
|
||||
Usage is absolutely easy! Just add “maybe” in front of a command that you want to execute.
|
||||
|
||||
Allow me to show you an example.
|
||||
|
||||
```
|
||||
$ maybe rm -r ostechnix/
|
||||
```
|
||||
|
||||
As you can see, I am going to delete a folder called “ostechnix” from my system. Here is the sample output.
|
||||
|
||||
```
|
||||
maybe has prevented rm -r ostechnix/ from performing 5 file system operations:
|
||||
|
||||
delete /home/sk/inboxer-0.4.0-x86_64.AppImage
|
||||
delete /home/sk/Docker.pdf
|
||||
delete /home/sk/Idhayathai Oru Nodi.mp3
|
||||
delete /home/sk/dThmLbB334_1398236878432.jpg
|
||||
delete /home/sk/ostechnix
|
||||
|
||||
Do you want to rerun rm -r ostechnix/ and permit these operations? [y/N] y
|
||||
```
|
||||
|
||||
[][3]
|
||||
|
||||
The “maybe” tool performs 5 file system operations and shows me what this command (rm -r ostechnix/) will exactly do. Now I can decide whether I should perform this operation or not. Cool, yeah? Indeed!
|
||||
|
||||
Here is another example. I am going to install [Inboxer][4] desktop client for Gmail. This is what I got.
|
||||
|
||||
```
|
||||
$ maybe ./inboxer-0.4.0-x86_64.AppImage
|
||||
fuse: bad mount point `/tmp/.mount_inboxemDzuGV': No such file or directory
|
||||
squashfuse 0.1.100 (c) 2012 Dave Vasilevsky
|
||||
|
||||
Usage: /home/sk/Downloads/inboxer-0.4.0-x86_64.AppImage [options] ARCHIVE MOUNTPOINT
|
||||
|
||||
FUSE options:
|
||||
-d -o debug enable debug output (implies -f)
|
||||
-f foreground operation
|
||||
-s disable multi-threaded operation
|
||||
|
||||
open dir error: No such file or directory
|
||||
maybe has prevented ./inboxer-0.4.0-x86_64.AppImage from performing 1 file system operations:
|
||||
|
||||
create directory /tmp/.mount_inboxemDzuGV
|
||||
|
||||
Do you want to rerun ./inboxer-0.4.0-x86_64.AppImage and permit these operations? [y/N]
|
||||
```
|
||||
|
||||
If it not detects any file system operations, then it will simply display a result something like below.
|
||||
|
||||
For instance, I run this command to update my Arch Linux.
|
||||
|
||||
```
|
||||
$ maybe sudo pacman -Syu
|
||||
sudo: effective uid is not 0, is /usr/bin/sudo on a file system with the 'nosuid' option set or an NFS file system without root privileges?
|
||||
maybe has not detected any file system operations from sudo pacman -Syu.
|
||||
```
|
||||
|
||||
See? It didn’t detect any file system operations, so there were no warnings. This is absolutely brilliant and exactly what I was looking for. From now on, I can easily know what a command or a program will do even before executing it. I hope this will be useful to you too. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
Resource:
|
||||
|
||||
* [“maybe” GitHub page][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/know-command-program-will-exactly-executing/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/p-e-w/maybe
|
||||
[2]:https://www.ostechnix.com/explainshell-find-part-linux-command/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/12/maybe-1.png
|
||||
[4]:https://www.ostechnix.com/inboxer-unofficial-google-inbox-desktop-client/
|
||||
@ -0,0 +1,95 @@
|
||||
Getting started with Turtl, an open source alternative to Evernote
|
||||
======
|
||||

|
||||
|
||||
Just about everyone I know takes notes, and many people use an online note-taking application like Evernote, Simplenote, or Google Keep. Those are all good tools, but you have to wonder about the security and privacy of your information—especially in light of [Evernote's privacy flip-flop of 2016][1]. If you want more control over your notes and your data, you really need to turn to an open source tool.
|
||||
|
||||
Whatever your reasons for moving away from Evernote, there are open source alternatives out there. Let's look at one of those alternatives: Turtl.
|
||||
|
||||
### Getting started
|
||||
|
||||
The developers behind [Turtl][2] want you to think of it as "Evernote with ultimate privacy." To be honest, I can't vouch for the level of privacy that Turtl offers, but it is a quite a good note-taking tool.
|
||||
|
||||
To get started with Turtl, [download][3] a desktop client for Linux, Mac OS, or Windows, or grab the [Android app][4]. Install it, then fire up the client or app. You'll be asked for a username and passphrase. Turtl uses the passphrase to generate a cryptographic key that, according to the developers, encrypts your notes before storing them anywhere on your device or on their servers.
|
||||
|
||||
### Using Turtl
|
||||
|
||||
You can create the following types of notes with Turtl:
|
||||
|
||||
* Password
|
||||
|
||||
* File
|
||||
|
||||
* Image
|
||||
|
||||
* Bookmark
|
||||
|
||||
* Text note
|
||||
|
||||
No matter what type of note you choose, you create it in a window that's similar for all types of notes:
|
||||
|
||||
### [turtl-new-note-520.png][5]
|
||||
|
||||
|
||||
|
||||
Creating a new text note in Turtl
|
||||
|
||||
Add information like the title of the note, some text, and (if you're creating a File or Image note) attach a file or an image. Then click Save.
|
||||
|
||||
You can add formatting to your notes via [Markdown][6]. You need to add the formatting by hand—there are no toolbar shortcuts.
|
||||
|
||||
If you need to organize your notes, you can add them to Boards. Boards are just like notebooks in Evernote. To create a new board, click on the Boards tab, then click the Create a board button. Type a title for the board, then click Create.
|
||||
|
||||
### [turtl-boards-520.png][7]
|
||||
|
||||
|
||||
|
||||
Creating a new board in Turtl
|
||||
|
||||
To add a note to a board, create or edit the note, then click the This note is not in any boards link at the bottom of the note. Select one or more boards, then click Done.
|
||||
|
||||
To add tags to a note, click the Tags icon at the bottom of a note, enter one or more keywords separated by commas, and click Done.
|
||||
|
||||
### Syncing your notes across your devices
|
||||
|
||||
If you use Turtl across several computers and an Android device, for example, Turtl will sync your notes whenever you're online. However, I've encountered a small problem with syncing: Every so often, a note I've created on my phone doesn't sync to my laptop. I tried to sync manually by clicking the icon in the top left of the window and then clicking Sync Now, but that doesn't always work. I found that I occasionally need to click that icon, click Your settings, and then click Clear local data. I then need to log back into Turtl, but all the data syncs properly.
|
||||
|
||||
### A question, and a couple of problems
|
||||
|
||||
When I started using Turtl, I was dogged by one question: Where are my notes kept online? It turns out that the developers behind Turtl are based in the U.S., and that's also where their servers are. Although the encryption that Turtl uses is [quite strong][8] and your notes are encrypted on the server, the paranoid part of me says that you shouldn't save anything sensitive in Turtl (or any online note-taking tool, for that matter).
|
||||
|
||||
Turtl displays notes in a tiled view, reminiscent of Google Keep:
|
||||
|
||||
### [turtl-notes-520.png][9]
|
||||
|
||||
|
||||
|
||||
A collection of notes in Turtl
|
||||
|
||||
There's no way to change that to a list view, either on the desktop or on the Android app. This isn't a problem for me, but I've heard some people pan Turtl because it lacks a list view.
|
||||
|
||||
Speaking of the Android app, it's not bad; however, it doesn't integrate with the Android Share menu. If you want to add a note to Turtl based on something you've seen or read in another app, you need to copy and paste it manually.
|
||||
|
||||
I've been using a Turtl for several months on a Linux-powered laptop, my [Chromebook running GalliumOS][10], and an Android-powered phone. It's been a pretty seamless experience across all those devices. Although it's not my favorite open source note-taking tool, Turtl does a pretty good job. Give it a try; it might be the simple note-taking tool you're looking for.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/using-turtl-open-source-alternative-evernote
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://blog.evernote.com/blog/2016/12/15/evernote-revisits-privacy-policy/
|
||||
[2]:https://turtlapp.com/
|
||||
[3]:https://turtlapp.com/download/
|
||||
[4]:https://turtlapp.com/download/
|
||||
[5]:https://opensource.com/file/378346
|
||||
[6]:https://en.wikipedia.org/wiki/Markdown
|
||||
[7]:https://opensource.com/file/378351
|
||||
[8]:https://turtlapp.com/docs/security/encryption-specifics/
|
||||
[9]:https://opensource.com/file/378356
|
||||
[10]:https://opensource.com/article/17/4/linux-chromebook-gallium-os
|
||||
@ -0,0 +1,402 @@
|
||||
translating by yongshouzhang
|
||||
|
||||
7 tools for analyzing performance in Linux with bcc/BPF
|
||||
============================================================
|
||||
|
||||
### Look deeply into your Linux code with these Berkeley Packet Filter (BPF) Compiler Collection (bcc) tools.
|
||||
|
||||
[][7] 21 Nov 2017 [Brendan Gregg][8] [Feed][9]
|
||||
|
||||
43[up][10]
|
||||
|
||||
[4 comments][11]
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
A new technology has arrived in Linux that can provide sysadmins and developers with a large number of new tools and dashboards for performance analysis and troubleshooting. It's called the enhanced Berkeley Packet Filter (eBPF, or just BPF), although these enhancements weren't developed in Berkeley, they operate on much more than just packets, and they do much more than just filtering. I'll discuss one way to use BPF on the Fedora and Red Hat family of Linux distributions, demonstrating on Fedora 26.
|
||||
|
||||
BPF can run user-defined sandboxed programs in the kernel to add new custom capabilities instantly. It's like adding superpowers to Linux, on demand. Examples of what you can use it for include:
|
||||
|
||||
* Advanced performance tracing tools: programmatic low-overhead instrumentation of filesystem operations, TCP events, user-level events, etc.
|
||||
|
||||
* Network performance: dropping packets early on to improve DDOS resilience, or redirecting packets in-kernel to improve performance
|
||||
|
||||
* Security monitoring: 24x7 custom monitoring and logging of suspicious kernel and userspace events
|
||||
|
||||
BPF programs must pass an in-kernel verifier to ensure they are safe to run, making it a safer option, where possible, than writing custom kernel modules. I suspect most people won't write BPF programs themselves, but will use other people's. I've published many on GitHub as open source in the [BPF Compiler Collection (bcc)][12] project. bcc provides different frontends for BPF development, including Python and Lua, and is currently the most active project for BPF tooling.
|
||||
|
||||
### 7 useful new bcc/BPF tools
|
||||
|
||||
To understand the bcc/BPF tools and what they instrument, I created the following diagram and added it to the bcc project:
|
||||
|
||||
### [bcc_tracing_tools.png][13]
|
||||
|
||||
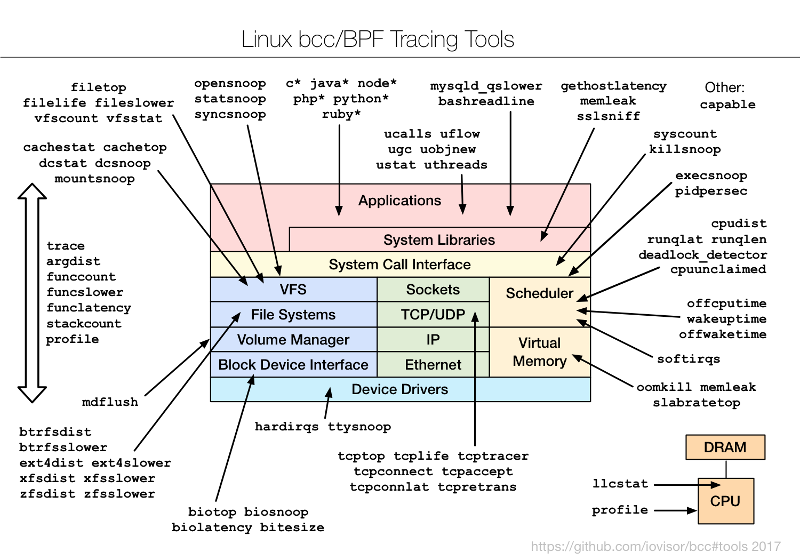
|
||||
|
||||
Brendan Gregg, [CC BY-SA 4.0][14]
|
||||
|
||||
These are command-line interface (CLI) tools you can use over SSH (secure shell). Much analysis nowadays, including at my employer, is conducted using GUIs and dashboards. SSH is a last resort. But these CLI tools are still a good way to preview BPF capabilities, even if you ultimately intend to use them only through a GUI when available. I've began adding BPF capabilities to an open source GUI, but that's a topic for another article. Right now I'd like to share the CLI tools, which you can use today.
|
||||
|
||||
### 1\. execsnoop
|
||||
|
||||
Where to start? How about watching new processes. These can consume system resources, but be so short-lived they don't show up in top(1) or other tools. They can be instrumented (or, using the industry jargon for this, they can be traced) using [execsnoop][15]. While tracing, I'll log in over SSH in another window:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/execsnoop
|
||||
PCOMM PID PPID RET ARGS
|
||||
sshd 12234 727 0 /usr/sbin/sshd -D -R
|
||||
unix_chkpwd 12236 12234 0 /usr/sbin/unix_chkpwd root nonull
|
||||
unix_chkpwd 12237 12234 0 /usr/sbin/unix_chkpwd root chkexpiry
|
||||
bash 12239 12238 0 /bin/bash
|
||||
id 12241 12240 0 /usr/bin/id -un
|
||||
hostname 12243 12242 0 /usr/bin/hostname
|
||||
pkg-config 12245 12244 0 /usr/bin/pkg-config --variable=completionsdir bash-completion
|
||||
grepconf.sh 12246 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12247 12246 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
tty 12249 12248 0 /usr/bin/tty -s
|
||||
tput 12250 12248 0 /usr/bin/tput colors
|
||||
dircolors 12252 12251 0 /usr/bin/dircolors --sh /etc/DIR_COLORS
|
||||
grep 12253 12239 0 /usr/bin/grep -qi ^COLOR.*none /etc/DIR_COLORS
|
||||
grepconf.sh 12254 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12255 12254 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
grepconf.sh 12256 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12257 12256 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
```
|
||||
|
||||
Welcome to the fun of system tracing. You can learn a lot about how the system is really working (or not working, as the case may be) and discover some easy optimizations along the way. execsnoop works by tracing the exec() system call, which is usually used to load different program code in new processes.
|
||||
|
||||
### 2\. opensnoop
|
||||
|
||||
Continuing from above, so, grepconf.sh is likely a shell script, right? I'll run file(1) to check, and also use the [opensnoop][16] bcc tool to see what file is opening:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
PID COMM FD ERR PATH
|
||||
12420 file 3 0 /etc/ld.so.cache
|
||||
12420 file 3 0 /lib64/libmagic.so.1
|
||||
12420 file 3 0 /lib64/libz.so.1
|
||||
12420 file 3 0 /lib64/libc.so.6
|
||||
12420 file 3 0 /usr/lib/locale/locale-archive
|
||||
12420 file -1 2 /etc/magic.mgc
|
||||
12420 file 3 0 /etc/magic
|
||||
12420 file 3 0 /usr/share/misc/magic.mgc
|
||||
12420 file 3 0 /usr/lib64/gconv/gconv-modules.cache
|
||||
12420 file 3 0 /usr/libexec/grepconf.sh
|
||||
1 systemd 16 0 /proc/565/cgroup
|
||||
1 systemd 16 0 /proc/536/cgroup
|
||||
```
|
||||
|
||||
```
|
||||
# file /usr/share/misc/magic.mgc /etc/magic
|
||||
/usr/share/misc/magic.mgc: magic binary file for file(1) cmd (version 14) (little endian)
|
||||
/etc/magic: magic text file for file(1) cmd, ASCII text
|
||||
```
|
||||
|
||||
### 3\. xfsslower
|
||||
|
||||
bcc/BPF can analyze much more than just syscalls. The [xfsslower][17] tool traces common XFS filesystem operations that have a latency of greater than 1 millisecond (the argument):
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/xfsslower 1
|
||||
Tracing XFS operations slower than 1 ms
|
||||
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
14:17:34 systemd-journa 530 S 0 0 1.69 system.journal
|
||||
14:17:35 auditd 651 S 0 0 2.43 audit.log
|
||||
14:17:42 cksum 4167 R 52976 0 1.04 at
|
||||
14:17:45 cksum 4168 R 53264 0 1.62 [
|
||||
14:17:45 cksum 4168 R 65536 0 1.01 certutil
|
||||
14:17:45 cksum 4168 R 65536 0 1.01 dir
|
||||
14:17:45 cksum 4168 R 65536 0 1.17 dirmngr-client
|
||||
14:17:46 cksum 4168 R 65536 0 1.06 grub2-file
|
||||
14:17:46 cksum 4168 R 65536 128 1.01 grub2-fstest
|
||||
[...]
|
||||
```
|
||||
|
||||
This is a useful tool and an important example of BPF tracing. Traditional analysis of filesystem performance focuses on block I/O statistics—what you commonly see printed by the iostat(1) tool and plotted by many performance-monitoring GUIs. Those statistics show how the disks are performing, but not really the filesystem. Often you care more about the filesystem's performance than the disks, since it's the filesystem that applications make requests to and wait for. And the performance of filesystems can be quite different from that of disks! Filesystems may serve reads entirely from memory cache and also populate that cache via a read-ahead algorithm and for write-back caching. xfsslower shows filesystem performance—what the applications directly experience. This is often useful for exonerating the entire storage subsystem; if there is really no filesystem latency, then performance issues are likely to be elsewhere.
|
||||
|
||||
### 4\. biolatency
|
||||
|
||||
Although filesystem performance is important to study for understanding application performance, studying disk performance has merit as well. Poor disk performance will affect the application eventually, when various caching tricks can no longer hide its latency. Disk performance is also a target of study for capacity planning.
|
||||
|
||||
The iostat(1) tool shows the average disk I/O latency, but averages can be misleading. It can be useful to study the distribution of I/O latency as a histogram, which can be done using [biolatency][18]:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency
|
||||
Tracing block device I/O... Hit Ctrl-C to end.
|
||||
^C
|
||||
usecs : count distribution
|
||||
0 -> 1 : 0 | |
|
||||
2 -> 3 : 0 | |
|
||||
4 -> 7 : 0 | |
|
||||
8 -> 15 : 0 | |
|
||||
16 -> 31 : 0 | |
|
||||
32 -> 63 : 1 | |
|
||||
64 -> 127 : 63 |**** |
|
||||
128 -> 255 : 121 |********* |
|
||||
256 -> 511 : 483 |************************************ |
|
||||
512 -> 1023 : 532 |****************************************|
|
||||
1024 -> 2047 : 117 |******** |
|
||||
2048 -> 4095 : 8 | |
|
||||
```
|
||||
|
||||
It's worth noting that many of these tools support CLI options and arguments as shown by their USAGE message:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency -h
|
||||
usage: biolatency [-h] [-T] [-Q] [-m] [-D] [interval] [count]
|
||||
|
||||
Summarize block device I/O latency as a histogram
|
||||
|
||||
positional arguments:
|
||||
interval output interval, in seconds
|
||||
count number of outputs
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-T, --timestamp include timestamp on output
|
||||
-Q, --queued include OS queued time in I/O time
|
||||
-m, --milliseconds millisecond histogram
|
||||
-D, --disks print a histogram per disk device
|
||||
|
||||
examples:
|
||||
./biolatency # summarize block I/O latency as a histogram
|
||||
./biolatency 1 10 # print 1 second summaries, 10 times
|
||||
./biolatency -mT 1 # 1s summaries, milliseconds, and timestamps
|
||||
./biolatency -Q # include OS queued time in I/O time
|
||||
./biolatency -D # show each disk device separately
|
||||
```
|
||||
|
||||
### 5\. tcplife
|
||||
|
||||
Another useful tool and example, this time showing lifespan and throughput statistics of TCP sessions, is [tcplife][19]:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/tcplife
|
||||
PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS
|
||||
12759 sshd 192.168.56.101 22 192.168.56.1 60639 2 3 1863.82
|
||||
12783 sshd 192.168.56.101 22 192.168.56.1 60640 3 3 9174.53
|
||||
12844 wget 10.0.2.15 34250 54.204.39.132 443 11 1870 5712.26
|
||||
12851 curl 10.0.2.15 34252 54.204.39.132 443 0 74 505.90
|
||||
```
|
||||
|
||||
### 6\. gethostlatency
|
||||
|
||||
Every previous example involves kernel tracing, so I need at least one user-level tracing example. Here is [gethostlatency][20], which instruments gethostbyname(3) and related library calls for name resolution:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/gethostlatency
|
||||
TIME PID COMM LATms HOST
|
||||
06:43:33 12903 curl 188.98 opensource.com
|
||||
06:43:36 12905 curl 8.45 opensource.com
|
||||
06:43:40 12907 curl 6.55 opensource.com
|
||||
06:43:44 12911 curl 9.67 opensource.com
|
||||
06:45:02 12948 curl 19.66 opensource.cats
|
||||
06:45:06 12950 curl 18.37 opensource.cats
|
||||
06:45:07 12952 curl 13.64 opensource.cats
|
||||
06:45:19 13139 curl 13.10 opensource.cats
|
||||
```
|
||||
|
||||
### 7\. trace
|
||||
|
||||
Okay, one more example. The [trace][21] tool was contributed by Sasha Goldshtein and provides some basic printf(1) functionality with custom probes. For example:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/trace 'pam:pam_start "%s: %s", arg1, arg2'
|
||||
PID TID COMM FUNC -
|
||||
13266 13266 sshd pam_start sshd: root
|
||||
```
|
||||
|
||||
### Install bcc via packages
|
||||
|
||||
The best way to install bcc is from an iovisor repository, following the instructions from the bcc [INSTALL.md][22]. [IO Visor][23] is the Linux Foundation project that includes bcc. The BPF enhancements these tools use were added in the 4.x series Linux kernels, up to 4.9\. This means that Fedora 25, with its 4.8 kernel, can run most of these tools; and Fedora 26, with its 4.11 kernel, can run them all (at least currently).
|
||||
|
||||
If you are on Fedora 25 (or Fedora 26, and this post was published many months ago—hello from the distant past!), then this package approach should just work. If you are on Fedora 26, then skip to the [Install via Source][24] section, which avoids a [known][25] and [fixed][26] bug. That bug fix hasn't made its way into the Fedora 26 package dependencies at the moment. The system I'm using is:
|
||||
|
||||
```
|
||||
# uname -a
|
||||
Linux localhost.localdomain 4.11.8-300.fc26.x86_64 #1 SMP Thu Jun 29 20:09:48 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
|
||||
# cat /etc/fedora-release
|
||||
Fedora release 26 (Twenty Six)
|
||||
```
|
||||
|
||||
```
|
||||
# echo -e '[iovisor]\nbaseurl=https://repo.iovisor.org/yum/nightly/f25/$basearch\nenabled=1\ngpgcheck=0' | sudo tee /etc/yum.repos.d/iovisor.repo
|
||||
# dnf install bcc-tools
|
||||
[...]
|
||||
Total download size: 37 M
|
||||
Installed size: 143 M
|
||||
Is this ok [y/N]: y
|
||||
```
|
||||
|
||||
```
|
||||
# ls /usr/share/bcc/tools/
|
||||
argdist dcsnoop killsnoop softirqs trace
|
||||
bashreadline dcstat llcstat solisten ttysnoop
|
||||
[...]
|
||||
```
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
chdir(/lib/modules/4.11.8-300.fc26.x86_64/build): No such file or directory
|
||||
Traceback (most recent call last):
|
||||
File "/usr/share/bcc/tools/opensnoop", line 126, in
|
||||
b = BPF(text=bpf_text)
|
||||
File "/usr/lib/python3.6/site-packages/bcc/__init__.py", line 284, in __init__
|
||||
raise Exception("Failed to compile BPF module %s" % src_file)
|
||||
Exception: Failed to compile BPF module
|
||||
```
|
||||
|
||||
```
|
||||
# dnf install kernel-devel-4.11.8-300.fc26.x86_64
|
||||
[...]
|
||||
Total download size: 20 M
|
||||
Installed size: 63 M
|
||||
Is this ok [y/N]: y
|
||||
[...]
|
||||
```
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
PID COMM FD ERR PATH
|
||||
11792 ls 3 0 /etc/ld.so.cache
|
||||
11792 ls 3 0 /lib64/libselinux.so.1
|
||||
11792 ls 3 0 /lib64/libcap.so.2
|
||||
11792 ls 3 0 /lib64/libc.so.6
|
||||
[...]
|
||||
```
|
||||
|
||||
### Install via source
|
||||
|
||||
If you need to install from source, you can also find documentation and updated instructions in [INSTALL.md][27]. I did the following on Fedora 26:
|
||||
|
||||
```
|
||||
sudo dnf install -y bison cmake ethtool flex git iperf libstdc++-static \
|
||||
python-netaddr python-pip gcc gcc-c++ make zlib-devel \
|
||||
elfutils-libelf-devel
|
||||
sudo dnf install -y luajit luajit-devel # for Lua support
|
||||
sudo dnf install -y \
|
||||
http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm
|
||||
sudo pip install pyroute2
|
||||
sudo dnf install -y clang clang-devel llvm llvm-devel llvm-static ncurses-devel
|
||||
```
|
||||
|
||||
```
|
||||
Curl error (28): Timeout was reached for http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm [Connection timed out after 120002 milliseconds]
|
||||
```
|
||||
|
||||
Here are the remaining bcc compilation and install steps:
|
||||
|
||||
```
|
||||
git clone https://github.com/iovisor/bcc.git
|
||||
mkdir bcc/build; cd bcc/build
|
||||
cmake .. -DCMAKE_INSTALL_PREFIX=/usr
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
PID COMM FD ERR PATH
|
||||
4131 date 3 0 /etc/ld.so.cache
|
||||
4131 date 3 0 /lib64/libc.so.6
|
||||
4131 date 3 0 /usr/lib/locale/locale-archive
|
||||
4131 date 3 0 /etc/localtime
|
||||
[...]
|
||||
```
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
This was a quick tour of the new BPF performance analysis superpowers that you can use on the Fedora and Red Hat family of operating systems. I demonstrated the popular
|
||||
|
||||
[bcc][28]
|
||||
|
||||
frontend to BPF and included install instructions for Fedora. bcc comes with more than 60 new tools for performance analysis, which will help you get the most out of your Linux systems. Perhaps you will use these tools directly over SSH, or perhaps you will use the same functionality via monitoring GUIs once they support BPF.
|
||||
|
||||
Also, bcc is not the only frontend in development. There are [ply][29] and [bpftrace][30], which aim to provide higher-level language for quickly writing custom tools. In addition, [SystemTap][31] just released [version 3.2][32], including an early, experimental eBPF backend. Should this continue to be developed, it will provide a production-safe and efficient engine for running the many SystemTap scripts and tapsets (libraries) that have been developed over the years. (Using SystemTap with eBPF would be good topic for another post.)
|
||||
|
||||
If you need to develop custom tools, you can do that with bcc as well, although the language is currently much more verbose than SystemTap, ply, or bpftrace. My bcc tools can serve as code examples, plus I contributed a [tutorial][33] for developing bcc tools in Python. I'd recommend learning the bcc multi-tools first, as you may get a lot of mileage from them before needing to write new tools. You can study the multi-tools from their example files in the bcc repository: [funccount][34], [funclatency][35], [funcslower][36], [stackcount][37], [trace][38], and [argdist][39].
|
||||
|
||||
Thanks to [Opensource.com][40] for edits.
|
||||
|
||||
### Topics
|
||||
|
||||
[Linux][41][SysAdmin][42]
|
||||
|
||||
### About the author
|
||||
|
||||
[][43] Brendan Gregg
|
||||
|
||||
-
|
||||
|
||||
Brendan Gregg is a senior performance architect at Netflix, where he does large scale computer performance design, analysis, and tuning.[More about me][44]
|
||||
|
||||
* [Learn how you can contribute][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://opensource.com/article/17/11/bccbpf-performance
|
||||
|
||||
作者:[Brendan Gregg ][a]
|
||||
译者:[yongshouzhang](https://github.com/yongshouzhang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/participate
|
||||
[7]:https://opensource.com/users/brendang
|
||||
[8]:https://opensource.com/users/brendang
|
||||
[9]:https://opensource.com/user/77626/feed
|
||||
[10]:https://opensource.com/article/17/11/bccbpf-performance?rate=r9hnbg3mvjFUC9FiBk9eL_ZLkioSC21SvICoaoJjaSM
|
||||
[11]:https://opensource.com/article/17/11/bccbpf-performance#comments
|
||||
[12]:https://github.com/iovisor/bcc
|
||||
[13]:https://opensource.com/file/376856
|
||||
[14]:https://opensource.com/usr/share/bcc/tools/trace
|
||||
[15]:https://github.com/brendangregg/perf-tools/blob/master/execsnoop
|
||||
[16]:https://github.com/brendangregg/perf-tools/blob/master/opensnoop
|
||||
[17]:https://github.com/iovisor/bcc/blob/master/tools/xfsslower.py
|
||||
[18]:https://github.com/iovisor/bcc/blob/master/tools/biolatency.py
|
||||
[19]:https://github.com/iovisor/bcc/blob/master/tools/tcplife.py
|
||||
[20]:https://github.com/iovisor/bcc/blob/master/tools/gethostlatency.py
|
||||
[21]:https://github.com/iovisor/bcc/blob/master/tools/trace.py
|
||||
[22]:https://github.com/iovisor/bcc/blob/master/INSTALL.md#fedora---binary
|
||||
[23]:https://www.iovisor.org/
|
||||
[24]:https://opensource.com/article/17/11/bccbpf-performance#InstallViaSource
|
||||
[25]:https://github.com/iovisor/bcc/issues/1221
|
||||
[26]:https://reviews.llvm.org/rL302055
|
||||
[27]:https://github.com/iovisor/bcc/blob/master/INSTALL.md#fedora---source
|
||||
[28]:https://github.com/iovisor/bcc
|
||||
[29]:https://github.com/iovisor/ply
|
||||
[30]:https://github.com/ajor/bpftrace
|
||||
[31]:https://sourceware.org/systemtap/
|
||||
[32]:https://sourceware.org/ml/systemtap/2017-q4/msg00096.html
|
||||
[33]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[34]:https://github.com/iovisor/bcc/blob/master/tools/funccount_example.txt
|
||||
[35]:https://github.com/iovisor/bcc/blob/master/tools/funclatency_example.txt
|
||||
[36]:https://github.com/iovisor/bcc/blob/master/tools/funcslower_example.txt
|
||||
[37]:https://github.com/iovisor/bcc/blob/master/tools/stackcount_example.txt
|
||||
[38]:https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt
|
||||
[39]:https://github.com/iovisor/bcc/blob/master/tools/argdist_example.txt
|
||||
[40]:http://opensource.com/
|
||||
[41]:https://opensource.com/tags/linux
|
||||
[42]:https://opensource.com/tags/sysadmin
|
||||
[43]:https://opensource.com/users/brendang
|
||||
[44]:https://opensource.com/users/brendang
|
||||
@ -0,0 +1,167 @@
|
||||
Linux 用户的逻辑卷管理指南
|
||||
============================================================
|
||||
|
||||
")
|
||||
Image by : opensource.com
|
||||
|
||||
管理磁盘空间对系统管理员来说是一件重要的日常工作。因为磁盘空间耗尽而去启动一系列的耗时而又复杂的任务,来提升磁盘分区中可用的磁盘空间。它会要求系统离线。通常会涉及到安装一个新的硬盘、引导至恢复模式或者单用户模式、在新硬盘上创建一个分区和一个文件系统、挂载到临时挂载点去从一个太小的文件系统中移动数据到较大的新位置、修改 /etc/fstab 文件内容去反映出新分区的正确设备名、以及重新引导去重新挂载新的文件系统到正确的挂载点。
|
||||
|
||||
我想告诉你的是,当 LVM (逻辑卷管理)首次出现在 Fedora Linux 中时,我是非常抗拒它的。我最初的反应是,我并不需要在我和我的设备之间有这种额外的抽象层。结果是我错了,逻辑卷管理是非常有用的。
|
||||
|
||||
LVM 让磁盘空间管理非常灵活。它提供的功能诸如在文件系统已挂载和活动时,很可靠地增加磁盘空间到一个逻辑卷和它的文件系统中,并且,它允许你将多个物理磁盘和分区融合进一个可以分割成逻辑卷的单个卷组中。
|
||||
|
||||
卷管理也允许你去减少分配给一个逻辑卷的磁盘空间数量,但是,这里有两个要求,第一,卷必须是未挂载的。第二,在卷空间调整之前,文件系统本身的空间大小必须被减少。
|
||||
|
||||
有一个重要的提示是,文件系统本身必须允许重新调整大小的操作。当重新提升文件系统大小的时候,EXT2、3、和 4 文件系统都允许离线(未挂载状态)或者在线(挂载状态)重新调整大小。你应该去认真了解你打算去调整的文件系统的详细情况,去验证它们是否可以完全调整大小,尤其是否可以在线调整大小。
|
||||
|
||||
### 在使用中扩展一个文件系统
|
||||
|
||||
在我安装一个新的发行版到我的生产用机器中之前,我总是喜欢在一个 VirtualBox 虚拟机中运行这个新的发行版一段时间,以确保它没有任何的致命的问题存在。在几年前的一个早晨,我在我的主要使用的工作站上的虚拟机中安装一个新发行的 Fedora 版本。我认为我有足够的磁盘空间分配给安装虚拟机的主文件系统。但是,我错了,大约在第三个安装时,我耗尽了我的文件系统的空间。幸运的是,VirtualBox 检测到了磁盘空间不足的状态,并且暂停了虚拟机,然后显示了一个明确指出问题所在的错误信息。
|
||||
|
||||
请注意,这个问题并不是虚拟机磁盘太小造成的,而是由于宿主机上空间不足,导致虚拟机上的虚拟磁盘在宿主机上的逻辑卷中没有足够的空间去扩展。
|
||||
|
||||
因为许多现在的发行版都缺省使用了逻辑卷管理,并且在我的卷组中有一些可用的空余空间,我可以分配额外的磁盘空间到适当的逻辑卷,然后在使用中扩展宿主机的文件系统。这意味着我不需要去重新格式化整个硬盘,以及重新安装操作系统或者甚至是重启机器。我不过是分配了一些可用空间到适当的逻辑卷中,并且重新调整了文件系统的大小 — 所有的这些操作都在文件系统在线并且运行着程序的状态下进行的,虚拟机也一直使用着宿主机文件系统。在调整完逻辑卷和文件系统的大小之后,我恢复了虚拟机的运行,并且继续进行安装过程,就像什么问题都没有发生过一样。
|
||||
|
||||
虽然这种问题你可能从来也没有遇到过,但是,许多人都遇到过重要程序在运行过程中发生磁盘空间不足的问题。而且,虽然许多程序,尤其是 Windows 程序,并不像 VirtualBox 一样写的很好,且富有弹性,Linux 逻辑卷管理可以使它在不丢失数据的情况下去恢复,也不需要去进行耗时的安装过程。
|
||||
|
||||
### LVM 结构
|
||||
|
||||
逻辑卷管理的磁盘环境结构如下面的图 1 所示。逻辑卷管理允许多个单独的硬盘和/或磁盘分区组合成一个单个的卷组(VG)。卷组然后可以再划分为逻辑卷(LV)或者被用于分配成一个大的单一的卷。普通的文件系统,如EXT3 或者 EXT4,可以创建在一个逻辑卷上。
|
||||
|
||||
在图 1 中,两个完整的物理硬盘和一个第三块硬盘的一个分区组合成一个单个的卷组。在这个卷组中创建了两个逻辑卷,和一个文件系统,比如,可以在每个逻辑卷上创建一个 EXT3 或者 EXT4 的文件系统。
|
||||
|
||||

|
||||
|
||||
_图 1: LVM 允许组合分区和整个硬盘到卷组中_
|
||||
|
||||
在一个主机上增加磁盘空间是非常简单的,在我的经历中,这种事情是很少的。下面列出了基本的步骤。你也可以创建一个完整的新卷组或者增加新的空间到一个已存在的逻辑卷中,或者创建一个新的逻辑卷。
|
||||
|
||||
### 增加一个新的逻辑卷
|
||||
|
||||
有时候需要在主机上增加一个新的逻辑卷。例如,在被提示包含我的 VirtualBox 虚拟机的虚拟磁盘的 /home 文件系统被填满时,我决定去创建一个新的逻辑卷,用于去存储虚拟机数据,包含虚拟磁盘。这将在我的 /home 文件系统中释放大量的空间,并且也允许我去独立地管理虚拟机的磁盘空间。
|
||||
|
||||
增加一个新的逻辑卷的基本步骤如下:
|
||||
|
||||
1. 如有需要,安装一个新硬盘。
|
||||
|
||||
2. 可选 1: 在硬盘上创建一个分区
|
||||
|
||||
3. 在硬盘上创建一个完整的物理卷(PV)或者一个分区。
|
||||
|
||||
4. 分配新的物理卷到一个已存在的卷组(VG)中,或者创建一个新的卷组。
|
||||
|
||||
5. 从卷空间中创建一个新的逻辑卷(LV)。
|
||||
|
||||
6. 在新的逻辑卷中创建一个文件系统。
|
||||
|
||||
7. 在 /etc/fstab 中增加适当的条目以挂载文件系统。
|
||||
|
||||
8. 挂载文件系统。
|
||||
|
||||
为了更详细的介绍,接下来将使用一个示例作为一个实验去教授关于 Linux 文件系统的知识。
|
||||
|
||||
### 示例
|
||||
|
||||
这个示例展示了怎么用命令行去扩展一个已存在的卷组,并给它增加更多的空间,在那个空间上创建一个新的逻辑卷,然后在逻辑卷上创建一个文件系统。这个过程一直在运行和挂载的文件系统上执行。
|
||||
|
||||
警告:仅 EXT3 和 EXT4 文件系统可以在运行和挂载状态下调整大小。许多其它的文件系统,包括 BTRFS 和 ZFS 是不能这样做的。
|
||||
|
||||
### 安装硬盘
|
||||
|
||||
如果在系统中现有硬盘上的卷组中没有足够的空间去增加,那么可能需要去增加一块新的硬盘,然后去创建空间增加到逻辑卷中。首先,安装物理硬盘,然后,接着执行后面的步骤。
|
||||
|
||||
### 从硬盘上创建物理卷
|
||||
|
||||
首先需要去创建一个新的物理卷(PV)。使用下面的命令,它假设新硬盘已经分配为 /dev/hdd。
|
||||
|
||||
```
|
||||
pvcreate /dev/hdd
|
||||
```
|
||||
|
||||
在新硬盘上创建一个任意分区并不是必需的。创建的物理卷将被逻辑卷管理器识别为一个新安装的未处理的磁盘或者一个类型为 83 的Linux 分区。如果你想去使用整个硬盘,创建一个分区并没有什么特别的好处,以及另外的物理卷部分的元数据所使用的磁盘空间。
|
||||
|
||||
### 扩展已存在的卷组
|
||||
|
||||
在这个示例中,我将扩展一个已存在的卷组,而不是创建一个新的;你可以选择其它的方式。在物理磁盘已经创建之后,扩展已存在的卷组(VG)去包含新 PV 的空间。在这个示例中,已存在的卷组命名为:MyVG01。
|
||||
|
||||
```
|
||||
vgextend /dev/MyVG01 /dev/hdd
|
||||
```
|
||||
|
||||
### 创建一个逻辑卷
|
||||
|
||||
首先,在卷组中从已存在的空余空间中创建逻辑卷。下面的命令创建了一个 50 GB 大小的 LV。这个卷组的名字为 MyVG01,然后,逻辑卷的名字为 Stuff。
|
||||
|
||||
```
|
||||
lvcreate -L +50G --name Stuff MyVG01
|
||||
```
|
||||
|
||||
### 创建文件系统
|
||||
|
||||
创建逻辑卷并不会创建文件系统。这个任务必须被单独执行。下面的命令在新创建的逻辑卷中创建了一个 EXT4 文件系统。
|
||||
|
||||
```
|
||||
mkfs -t ext4 /dev/MyVG01/Stuff
|
||||
```
|
||||
|
||||
### 增加一个文件系统卷标
|
||||
|
||||
增加一个文件系统卷标,更易于在文件系统以后出现问题时识别它。
|
||||
|
||||
```
|
||||
e2label /dev/MyVG01/Stuff Stuff
|
||||
```
|
||||
|
||||
### 挂载文件系统
|
||||
|
||||
在这个时候,你可以创建一个挂载点,并在 /etc/fstab 文件系统中添加合适的条目,以挂载文件系统。
|
||||
|
||||
你也可以去检查并校验创建的卷是否正确。你可以使用 **df**、**lvs**、和 **vgs** 命令去做这些工作。
|
||||
|
||||
### 提示
|
||||
|
||||
过去几年来,我学习了怎么去做让逻辑卷管理更加容易的一些知识,希望这些提示对你有价值。
|
||||
|
||||
* 除非你有一个明确的原因去使用其它的文件系统外,推荐使用可扩展的文件系统。除了 EXT2、3、和 4 外,并不是所有的文件系统都支持调整大小。EXT 文件系统不但速度快,而且它很高效。在任何情况下,如果默认的参数不能满足你的需要,它们(指的是文件系统参数)可以通过一位知识丰富的系统管理员来调优它。
|
||||
|
||||
* 使用有意义的卷和卷组名字。
|
||||
|
||||
* 使用 EXT 文件系统标签
|
||||
|
||||
我知道,像我一样,大多数的系统管理员都抗拒逻辑卷管理。我希望这篇文章能够鼓励你至少去尝试一个 LVM。如果你能那样做,我很高兴;因为,自从我使用它之后,我的硬盘管理任务变得如此的简单。
|
||||
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][10]
|
||||
|
||||
David Both - 是一位 Linux 和开源软件的倡导者,住在 Raleigh, North Carolina。他在 IT 行业工作了 40 多年,在 IBM 工作了 20 多年。在 IBM 期间,他在 1981 年为最初的 IBM PC 编写了第一个培训课程。他曾教授红帽的 RHCE 课程,并在 MCI Worldcom、Cisco和 North Carolina 工作。他已经使用 Linux 和开源软件工作了将近 20 年。... [more about David Both][7][More about me][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/9/linux-users-guide-lvm
|
||||
|
||||
作者:[David Both](a)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/business/16/9/linux-users-guide-lvm?rate=79vf1js7A7rlp-I96YFneopUQqsa2SuB-g-og7eiF1U
|
||||
[7]:https://opensource.com/users/dboth
|
||||
[8]:https://opensource.com/users/dboth
|
||||
[9]:https://opensource.com/user/14106/feed
|
||||
[10]:https://opensource.com/users/dboth
|
||||
[11]:https://opensource.com/users/dboth
|
||||
[12]:https://opensource.com/users/dboth
|
||||
[13]:https://opensource.com/business/16/9/linux-users-guide-lvm#comments
|
||||
[14]:https://opensource.com/tags/business
|
||||
[15]:https://opensource.com/tags/linux
|
||||
[16]:https://opensource.com/tags/how-tos-and-tutorials
|
||||
[17]:https://opensource.com/tags/sysadmin
|
||||
@ -0,0 +1,197 @@
|
||||
|
||||
如何提供有帮助的回答
|
||||
=============================
|
||||
|
||||
如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题][1]) 同时,合理地回答问题也是一种技巧。他们都是非常实用的。
|
||||
|
||||
一开始 - 有时向你提问的人不尊重你的时间,这很糟糕。
|
||||
|
||||
理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
|
||||
|
||||
下面是有助于回答问题的一些方法!
|
||||
|
||||
|
||||
### 如果他们提问不清楚,帮他们澄清
|
||||
|
||||
通常初学者不会提出很清晰的问题,或者问一些对回答问题没有必要信息的问题。你可以尝试以下方法 澄清问题:
|
||||
|
||||
* ** 重述为一个更明确的问题 ** 来回复他们(”你是想问 X 吗?“)
|
||||
|
||||
* ** 向他们了解更具体的他们并没有提供的信息 ** (”你使用 IPv6 ?”)
|
||||
|
||||
* ** 问是什么导致了他们的问题 ** 例如,有时有些人会进入我的团队频道,询问我们的服务发现(service discovery )如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的 pull requests 吗?”是有帮助的。
|
||||
|
||||
这些方法很多来自 [如何提出有意义的问题][2]中的要点。(尽管我永远不会对某人说“噢,你得先看完 “如何提出有意义的问题”这篇文章后再来像我提问)
|
||||
|
||||
|
||||
### 弄清楚他们已经知道了什么
|
||||
|
||||
在回答问题之前,知道对方已经知道什么是非常有用的!
|
||||
|
||||
Harold Treen 给了我一个很好的例子:
|
||||
|
||||
> 前几天,有人请我解释“ Redux-Sagas ”。与其深入解释不如说“ 他们就像 worker threads 监听行为(actions),让你更新 Redux store 。
|
||||
|
||||
> 我开始搞清楚他们对 Redux 、行为(actions)、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
|
||||
|
||||
弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“ Redux 是什么?“),或者他们可能是专家但是恰巧遇到了微妙的极端情况(corner case)。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
|
||||
|
||||
这里有一个很实用的技巧来了解他们已经知道什么 - 比如可以尝试用“你对 X 了解多少?”而不是问“你知道 X 吗?”。
|
||||
|
||||
|
||||
### 给他们一个文档
|
||||
|
||||
“RTFM” (“去读那些他妈的手册”(Read The Fucking Manual))是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
|
||||
|
||||
我认为明确你所给的文档的确能够解决问题是非常重要的,或者至少经过查阅后确认它对解决问题有帮助。否则,你可能将以下面这种情形结束对话(非常常见):
|
||||
|
||||
* Ali:我应该如何处理 X ?
|
||||
|
||||
* Jada:<文档链接>
|
||||
|
||||
* Ali: 这个并有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
|
||||
|
||||
如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册][3] 有44000个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的:)
|
||||
|
||||
|
||||
### 告诉他们一个有用的搜索
|
||||
|
||||
在工作中,我经常发现我可以利用我所知道的关键字进行搜索找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案:)
|
||||
|
||||
|
||||
### 写新文档
|
||||
|
||||
人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有10个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
|
||||
|
||||
1. 马上写新文档
|
||||
|
||||
2. 给他们我们刚刚写好的新文档
|
||||
|
||||
3. 公示
|
||||
|
||||
写文档有时往往比回答问题需要花很多时间,但这是值得的。写文档尤其重要,如果:
|
||||
|
||||
a. 这个问题被问了一遍又一遍
|
||||
|
||||
b. 随着时间的推移,这个答案不会变化太大(如果这个答案每一个星期或者一个月就会变化,文档就会过时并且令人受挫)
|
||||
|
||||
|
||||
### 解释你做了什么
|
||||
|
||||
对于一个话题,作为初学者来说,这样的交流会真让人沮丧:
|
||||
|
||||
* 新人:“嗨!你如何处理 X ?”
|
||||
|
||||
* 有经验的人:“我已经处理过了,而且它已经完美解决了”
|
||||
|
||||
* 新人:”...... 但是你做了什么?!“
|
||||
|
||||
如果问你问题的人想知道事情是如何进行的,这样是有帮助的:
|
||||
|
||||
* 让他们去完成任务而不是自己做
|
||||
|
||||
* 告诉他们你是如何得到你给他们的答案的。
|
||||
|
||||
这可能比你自己做的时间还要长,但对于被问的人来说这是一个学习机会,因为那样做使得他们将来能够更好地解决问题。
|
||||
|
||||
这样,你可以进行更好的交流,像这:
|
||||
|
||||
* 新人:“这个网站出现了错误,发生了什么?”
|
||||
|
||||
* 有经验的人:(2分钟后)”oh 这是因为发生了数据库故障转移“
|
||||
|
||||
* 新人: ”你是怎么知道的??!?!?“
|
||||
|
||||
* 有经验的人:“以下是我所做的!“:
|
||||
|
||||
1. 通常这些错误是因为服务器 Y 被关闭了。我查看了一下 `$PLACE` 但它表明服务器 Y 开着。所以,并不是这个原因导致的。
|
||||
|
||||
2. 然后我查看 X 的仪表盘 ,仪表盘的这个部分显示这里发生了数据库故障转移。
|
||||
|
||||
3. 然后我在日志中找到了相应服务器,并且它显示连接数据库错误,看起来错误就是这里。
|
||||
|
||||
如果你正在解释你是如何调试一个问题,解释你是如何发现问题,以及如何找出问题的。尽管看起来你好像已经得到正确答案,但感觉更好的是能够帮助他们提高学习和诊断能力,并了解可用的资源。
|
||||
|
||||
|
||||
### 解决根本问题
|
||||
|
||||
这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
|
||||
|
||||
* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
|
||||
|
||||
* Jasminda:”你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。“
|
||||
|
||||
* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。“
|
||||
|
||||
Jasminda 一点都没有回答 George 的问题!反而,她猜测 George 并不想处理 X ,并且她是猜对了。这是非常有用的!
|
||||
|
||||
如果你这样做可能会产生高高在上的感觉:
|
||||
|
||||
* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
|
||||
|
||||
* Jasminda:不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。
|
||||
|
||||
* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。
|
||||
|
||||
所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。
|
||||
|
||||
|
||||
### 询问”那个回答可以解决您的问题吗?”
|
||||
|
||||
我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:”这个回答解决了您的问题吗?您还有其他问题吗?“在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
|
||||
|
||||
我发现尤其是问“这个回答解决了您的问题吗”这个额外的步骤在写完文档后是非常有用的。通常,在写关于我熟悉的东西的文档时,我会忽略掉重要的东西而不会意识到它。
|
||||
|
||||
|
||||
### 结对编程和面对面交谈
|
||||
|
||||
我是远程工作的,所以我的很多对话都是基于文本的。我认为这是沟通的默认方式。
|
||||
|
||||
今天,我们生活在一个方便进行小视频会议和屏幕共享的世界!在工作时候,在任何时间我都可以点击一个按钮并快速加入与他人的视频对话或者屏幕共享的对话中!
|
||||
|
||||
例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视屏会话并在5分钟后,我们解决了他们问题。
|
||||
|
||||
我认为,特别是如果有人真的被困在该如何开始一项任务时,开启视频进行结对编程几分钟真的比电子邮件或者一些即时通信更有效。
|
||||
|
||||
|
||||
### 不要表现得过于惊讶
|
||||
|
||||
这是源自 Recurse Center 的一则法则:[不要故作惊讶][4]。这里有一个常见的情景:
|
||||
|
||||
* 某人1:“什么是 Linux 内核”
|
||||
|
||||
* 某人2:“你竟然不知道什么是 Linux 内核(LINUX KERNEL)?!!!!?!!!????”
|
||||
|
||||
某人2表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某人1不好受,因为他们确实不知道什么是 Linux 内核。
|
||||
|
||||
我一直在假装不惊讶即使我事实上确实有点惊讶那个人不知道这种东西但它是令人敬畏的。
|
||||
|
||||
### 回答问题是令人敬畏的
|
||||
|
||||
显然并不是所有方法都是合适的,但希望你能够发现这里有些是有帮助的!我发现花时间去回答问题并教导人们是其实是很有收获的。
|
||||
|
||||
特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder的阅读或评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/answer-questions-well/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://jvns.ca/blog/good-questions/
|
||||
[2]:https://jvns.ca/blog/good-questions/
|
||||
[3]:https://linux.die.net/man/1/bash
|
||||
[4]:https://jvns.ca/blog/2017/04/27/no-feigning-surprise/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,116 @@
|
||||
怎么去使用 Ansible Container 去管理 Linux 容器
|
||||
============================================================
|
||||
|
||||
### Ansible Container 处理 Dockerfile 的不足和对容器化项目提供完整的管理。
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
我喜欢容器,并且每天都使用这个技术。在过去几个月,在一组项目中已经解决了我遇到的问题,即便如此,容器并不完美。
|
||||
|
||||
我刚开始时,用 [Docker][11] 使用容器,因为这个项目使这个技术非常流行。除此之外,使用这个容器引擎,我学到了怎么去使用 **[docker-compose][6]** 以及怎么去用它管理我的项目。使用它使我的生产力猛增!一个命令去运行我的项目,而不管它有多复杂。因此,我太高兴了。
|
||||
|
||||
使用一段时间之后,我发现了一些问题。最明显的问题是创建窗口镜像的过程。Docker 工具使用一个定制的文件格式作为一个 Recipe 去制作容器镜像 — Dockerfiles。这个格式很容易学会,并且很短的一段时间之后,你就可以为你自己制作容器镜像了。但是,一旦你希望去掌握最佳实践或者有复杂场景的想法,问题就会出现。
|
||||
|
||||
Ansible 的更多资源
|
||||
|
||||
* [Ansible 是怎么工作的][1]
|
||||
|
||||
* [免费的 Ansible 电子书][2]
|
||||
|
||||
* [Ansible 快速上手视频][3]
|
||||
|
||||
* [下载和安装 Ansible][4]
|
||||
|
||||
让我们先休息一会儿,先去了解一个不同的东西:[Ansible][22] 的世界。你知道它吗?它棒极了,是吗?你不这么认为?好吧,是时候去学习一些新事物了。Ansible 是一个项目,它允许你通过写一些任务去管理你的基础设施,并在你选择的环境中运行它们。不需要去安装和设置任何的服务;你可以从你的笔记本电脑中去很很容易地做任何事情。许多人已经接受 Ansible 了。
|
||||
|
||||
想像一下这样的场景:你在 Ansible 中,你写了很多的 Ansible 角色和 playbooks,你可以用它们去管理你的基础设施,并且想把它们运用到容器中。你应该怎么做?开始通过 shell 脚本和 Dockerfiles 去写容器镜像定义?听起来好像不对。
|
||||
|
||||
来自 Ansible 开发团队的一些人问到这个问题,并且它们意识到,人们每天使用那些同样的 Ansible 角色和 playbooks 也可以用来制作容器镜像。但是 Ansible 能做到的不止这些 — 它可以被用于去管理容器化项目的完整的生命周期。从这些想法中,[Ansible Container][12] 项目诞生了。它使用已有的可以变成容器镜像的 Ansible 角色,甚至可以被用于应用程序在生产系统中从构建到部署的完整生命周期。
|
||||
|
||||
现在让我们讨论一下,在 Dockerfiles 环境中关于最佳实践时可能存在的问题。这里有一个警告:这将是非常具体且技术性的。出现最多的三个问题有:
|
||||
|
||||
### 1\. 在 Dockerfiles 中内嵌的 Shell 脚本。
|
||||
|
||||
当写 Dockerfiles 时,你可以通过 **/bin/sh -c** 解释指定的脚本。它可以做类似这样的事情:
|
||||
|
||||
```
|
||||
RUN dnf install -y nginx
|
||||
```
|
||||
|
||||
RUN 处是一个 Dockerfile 指令并且其它的都是参数(它传递给 shell)。但是,想像一个更复杂的场景:
|
||||
|
||||
```
|
||||
RUN set -eux; \
|
||||
\
|
||||
# this "case" statement is generated via "update.sh"
|
||||
%%ARCH-CASE%%; \
|
||||
\
|
||||
url="https://golang.org/dl/go${GOLANG_VERSION}.${goRelArch}.tar.gz"; \
|
||||
wget -O go.tgz "$url"; \
|
||||
echo "${goRelSha256} *go.tgz" | sha256sum -c -; \
|
||||
```
|
||||
|
||||
这仅是从 [the official golang image][13] 中拿来的一个。它看起来并不好看,是不是?
|
||||
|
||||
### 2\. 你解析 Dockerfiles 并不容易。
|
||||
|
||||
Dockerfiles 是一个没有正式规范的新格式。如果你需要在你的基础设施(比如,让构建过程自动化一点)中去处理 Dockerfiles 将会很复杂。仅有的规划是 [这个代码][14],它是 **dockerd** 的一部分。问题是你不能使用它作为一个库(library)。最容易的解决方案是你自己写一个解析器,然后祈祷它运行的很好。使用一些众所周知的标记语言不是更好吗?比如,YAML 或者 JSON。
|
||||
|
||||
### 3\. 管理困难。
|
||||
|
||||
如果你熟悉容器镜像的内部结构,你可能知道每个镜像是由层(layers)构成的。一旦容器被创建,这些层就使用联合文件系统技术堆叠在一起(像煎饼一样)。问题是,你并不能显式地管理这些层 — 你不能说,“这儿开始一个新层”,你被迫使用一种可读性不好的方法去改变你的 Dockerfile。最大的问题是,必须遵循一套最佳实践以去达到最优结果 — 新来的人在这个地方可能很困难。
|
||||
|
||||
### Ansible 语言和 Dockerfiles 比较
|
||||
|
||||
相比 Ansible,Dockerfiles 的最大缺点,也是 Ansible 的优点,作为一个语言,Ansible 更强大。例如,Dockerfiles 没有直接的变量概念,而 Ansible 有一个完整的模板系统(变量只是它其中的一个特性)。Ansible 包含了很多更易于使用的模块,比如,[**wait_for**][15],它可以被用于服务就绪检查,比如,在处理之前等待服务准备就绪。在 Dockerfiles 中,做任何事情都通过一个 shell 脚本。因此,如果你想去找出已准备好的服务,它必须使用 shell(或者独立安装)去做。使用 shell 脚本的其它问题是,它会变得很复杂,维护成为一种负担。很多人已经找到了这个问题,并将这些 shell 脚本转到 Ansible。
|
||||
|
||||
如果你对这个主题感兴趣,并且想去了解更多内容,请访问 [Open Source Summit][16],在 Prague 去看 [我的演讲][17],时间是 10 月 23 日,星期一,4:20 p.m. 在 Palmovka room 中。
|
||||
|
||||
_看更多的 Tomas Tomecek 演讲,[从 Dockerfiles 到 Ansible Container][7],在 [Open Source Summit EU][8],它将在 10 月 23-26 日在 Prague 召开。_
|
||||
|
||||
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][18] Tomas Tomecek - 工程师、Hacker、演讲者、Tinker、Red Hatter。喜欢容器、linux、开源软件、python 3、rust、zsh、tmux。[More about me][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/dockerfiles-ansible-container
|
||||
|
||||
作者:[Tomas Tomecek][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tomastomecek
|
||||
[1]:https://www.ansible.com/how-ansible-works?intcmp=701f2000000h4RcAAI
|
||||
[2]:https://www.ansible.com/ebooks?intcmp=701f2000000h4RcAAI
|
||||
[3]:https://www.ansible.com/quick-start-video?intcmp=701f2000000h4RcAAI
|
||||
[4]:https://docs.ansible.com/ansible/latest/intro_installation.html?intcmp=701f2000000h4RcAAI
|
||||
[5]:https://opensource.com/article/17/10/dockerfiles-ansible-container?imm_mid=0f9013&cmp=em-webops-na-na-newsltr_20171201&rate=Wiw_0D6PK_CAjqatYu_YQH0t1sNHEF6q09_9u3sYkCY
|
||||
[6]:https://github.com/docker/compose
|
||||
[7]:http://sched.co/BxIW
|
||||
[8]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[9]:https://opensource.com/users/tomastomecek
|
||||
[10]:https://opensource.com/user/175651/feed
|
||||
[11]:https://opensource.com/tags/docker
|
||||
[12]:https://www.ansible.com/ansible-container
|
||||
[13]:https://github.com/docker-library/golang/blob/master/Dockerfile-debian.template#L14
|
||||
[14]:https://github.com/moby/moby/tree/master/builder/dockerfile
|
||||
[15]:http://docs.ansible.com/wait_for_module.html
|
||||
[16]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[17]:http://events.linuxfoundation.org/events/open-source-summit-europe/program/schedule
|
||||
[18]:https://opensource.com/users/tomastomecek
|
||||
[19]:https://opensource.com/users/tomastomecek
|
||||
[20]:https://opensource.com/users/tomastomecek
|
||||
[21]:https://opensource.com/article/17/10/dockerfiles-ansible-container?imm_mid=0f9013&cmp=em-webops-na-na-newsltr_20171201#comments
|
||||
[22]:https://opensource.com/tags/ansible
|
||||
[23]:https://opensource.com/tags/containers
|
||||
[24]:https://opensource.com/tags/ansible
|
||||
[25]:https://opensource.com/tags/docker
|
||||
[26]:https://opensource.com/tags/open-source-summit
|
||||
|
||||
|
||||
150
translated/tech/20171005 Reasons Kubernetes is cool.md
Normal file
150
translated/tech/20171005 Reasons Kubernetes is cool.md
Normal file
@ -0,0 +1,150 @@
|
||||
为什么 Kubernetes 很酷
|
||||
============================================================
|
||||
|
||||
在我刚开始学习 Kubernetes(大约是一年半以前吧?)时,我真的不明白为什么应该去关注它。
|
||||
|
||||
在我使用 Kubernetes 全职工作了三个多月后,我才有了一些想法为什么我应该考虑使用它了。(我距离成为一个 Kubernetes 专家还很远!)希望这篇文章对你理解 Kubernetes 能做什么会有帮助!
|
||||
|
||||
我将尝试去解释我认为的对 Kubernetes 感兴趣的一些原因,而不去使用 “原生云(cloud native)”、“编排系统(orchestration)"、”容器(container)“、或者任何 Kubernetes 专用的术语 :)。我去解释的这些主要来自 Kubernetes 操作者/基础设施工程师的观点,因为,我现在的工作就是去配置 Kubernetes 和让它工作的更好。
|
||||
|
||||
我根本就不去尝试解决一些如 “你应该在你的生产系统中使用 Kubernetes 吗?”这样的问题。那是非常复杂的问题。(不仅是因为“生产系统”根据你的用途而总是有不同的要求“)
|
||||
|
||||
### Kubernetes 可以让你在生产系统中运行代码而不需要去设置一台新的服务器
|
||||
|
||||
我首次被说教使用 Kubernetes 是与我的伙伴 Kamal 的下面的谈话:
|
||||
|
||||
大致是这样的:
|
||||
|
||||
* Kamal: 使用 Kubernetes 你可以通过几个简单的命令就能设置一台新的服务器。
|
||||
|
||||
* Julia: 我觉得不太可能吧。
|
||||
|
||||
* Kamal: 像这样,你写一个配置文件,然后应用它,这时候,你就在生产系统中运行了一个 HTTP 服务。
|
||||
|
||||
* Julia: 但是,现在我需要去创建一个新的 AWS 实例,明确地写一个 Puppet,设置服务发现,配置负载均衡,配置开发软件,并且确保 DNS 正常工作,如果没有什么问题的话,至少在 4 小时后才能投入使用。
|
||||
|
||||
* Kamal: 是的,使用 Kubernetes 你不需要做那么多事情,你可以在 5 分钟内设置一台新的 HTTP 服务,并且它将自动运行。只要你的集群中有空闲的资源它就能正常工作!
|
||||
|
||||
* Julia: 这儿一定是一个”坑“
|
||||
|
||||
这里有一种陷阱,设置一个生产用 Kubernetes 集群(在我的经险中)确实并不容易。(查看 [Kubernetes The Hard Way][3] 中去开始使用时有哪些复杂的东西)但是,我们现在并不深入讨论它。
|
||||
|
||||
因此,Kubernetes 第一个很酷的事情是,它可能使那些想在生产系统中部署新开发的软件的方式变得更容易。那是很酷的事,而且它真的是这样,因此,一旦你使用一个 Kubernetes 集群工作,你真的可以仅使用一个配置文件在生产系统中设置一台 HTTP 服务(在 5 分钟内运行这个应用程序,设置一个负载均衡,给它一个 DNS 名字,等等)。看起来真的很有趣。
|
||||
|
||||
### 对于运行在生产系统中的你的代码,Kubernetes 可以提供更好的可见性和可管理性
|
||||
|
||||
在我看来,在理解 etcd 之前,你可能不会理解 Kubernetes 的。因此,让我们先讨论 etcd!
|
||||
|
||||
想像一下,如果现在我这样问你,”告诉我你运行在生产系统中的每个应用程序,它运行在哪台主机上?它是否状态很好?是否为它分配了一个 DNS 名字?”我并不知道这些,但是,我可能需要到很多不同的地方去查询来回答这些问题,并且,我需要花很长的时间才能搞定。我现在可以很确定地说不需要查询,仅一个 API 就可以搞定它们。
|
||||
|
||||
在 Kubernetes 中,你的集群的所有状态 – 应用程序运行 (“pods”)、节点、DNS 名字、 cron 任务、 等等 – 都保存在一个单一的数据库中(etcd)。每个 Kubernetes 组件是无状态的,并且基本是通过下列来工作的。
|
||||
|
||||
* 从 etcd 中读取状态(比如,“分配给节点 1 的 pods 列表“)
|
||||
|
||||
* 产生变化(比如,”在节点 1 上运行 pod A")
|
||||
|
||||
* 更新 etcd 中的状态(比如,“设置 pod A 的状态为 ‘running’”)
|
||||
|
||||
这意味着,如果你想去回答诸如 “在那个可用区域中有多少台运行 nginx 的 pods?” 这样的问题时,你可以通过查询一个统一的 API(Kubernetes API)去回答它。并且,你可以在每个其它 Kubernetes 组件上运行那个 API 去进行同样的访问。
|
||||
|
||||
这也意味着,你可以很容易地去管理每个运行在 Kubernetes 中的任何东西。如果你想这样做,你可以:
|
||||
|
||||
* 为部署实现一个复杂的定制的部署策略(部署一个东西,等待 2 分钟,部署 5 个以上,等待 3.7 分钟,等等)
|
||||
|
||||
* 每当推送到 github 上一个分支,自动化 [启动一个新的 web 服务器][1]
|
||||
|
||||
* 监视所有你的运行的应用程序,确保它们有一个合理的内存使用限制。
|
||||
|
||||
所有你需要做的这些事情,只需要写一个告诉 Kubernetes API(“controller”)的程序就可以了。
|
||||
|
||||
关于 Kubernetes API 的其它的令人激动的事情是,你不会被局限为 Kubernetes 提供的现有功能!如果对于你想去部署/创建/监视的软件有你自己的想法,那么,你可以使用 Kubernetes API 去写一些代码去达到你的目的!它可以让你做到你想做的任何事情。
|
||||
|
||||
### 如果每个 Kubernetes 组件都“挂了”,你的代码将仍然保持运行
|
||||
|
||||
关于 Kubernetes 我承诺的(通过各种博客文章:))一件事情是,“如果 Kubernetes API 服务和其它组件”挂了“,你的代码将一直保持运行状态”。从理论上说,这是它第二件很酷的事情,但是,我不确定它是否真是这样的。
|
||||
|
||||
到目前为止,这似乎是真的!
|
||||
|
||||
我已经断开了一些正在运行的 etcd,它会发生的事情是
|
||||
|
||||
1. 所有的代码继续保持运行状态
|
||||
|
||||
2. 不能做 _新的_ 事情(你不能部署新的代码或者生成变更,cron 作业将停止工作)
|
||||
|
||||
3. 当它恢复时,集群将赶上这期间它错过的内容
|
||||
|
||||
这样做,意味着如果 etcd 宕掉,并且你的应用程序的其中之一崩溃或者发生其它事情,在 etcd 恢复之前,它并不能返回(come back up)。
|
||||
|
||||
### Kubernetes 的设计对 bugs 很有弹性
|
||||
|
||||
与任何软件一样,Kubernetes 有 bugs。例如,到目前为止,我们的集群控制管理器有内存泄漏,并且,调度器经常崩溃。Bugs 当然不好,但是,我发现 Kubernetes 的设计,帮助减少了许多在它的内核中的错误。
|
||||
|
||||
如果你重启动任何组件,将发生:
|
||||
|
||||
* 从 etcd 中读取所有的与它相关的状态
|
||||
|
||||
* 基于那些状态(调度 pods、全部 pods 的垃圾回收、调度 cronjobs、按需部署、等等),它启动去做它认为必须要做的事情。
|
||||
|
||||
因为,所有的组件并不会在内存中保持状态,你在任何时候都可以重启它们,它可以帮助你减少各种 bugs。
|
||||
|
||||
例如,假如说,在你的控制管理器中有内存泄露。因为,控制管理器是无状态的,你可以每小时定期去启动它,或者,感觉到可能导致任何不一致的问题发生时。或者 ,在我们运行的调度器中有一个 bug,它有时仅仅是忘记了 pods 或者从来没有调度它们。你可以每隔 10 分钟来重启调度器来缓减这种情况。(我们并不这么做,而是去修复这个 bug,但是,你_可以吗_:))
|
||||
|
||||
因此,我觉得即使在它的内核组件中有 bug,我仍然可以信任 Kubernetes 的设计去帮助我确保集群状态的一致性。并且,总在来说,随着时间的推移软件将会提高。你去操作的仅有的有状态的东西是 etcd。
|
||||
|
||||
不用过多地讨论“状态”这个东西 – 但是,我认为在 Kubernetes 中很酷的一件事情是,唯一需要去做备份/恢复计划的事情是 etcd (除非为你的 pods 使用了持久化存储的卷)。我认为这样可以使 kubernetes 对关于你考虑的事情的操作更容易一些。
|
||||
|
||||
### 在 Kubernetes 之上实现新的分发系统是非常容易的
|
||||
|
||||
假设你想去实现一个分发 cron 作业调度系统!从零开始做工作量非常大。但是,在 Kubernetes 里面实现一个分发 cron 作业调度系统是非常容易的!(它仍然是一个分布式系统)
|
||||
|
||||
我第一次读到 Kubernetes 的 cronjob 作业控制器的代码时,它是如此的简单,我真的特别高兴。它在这里,去读它吧,主要的逻辑大约是 400 行。去读它吧! => [cronjob_controller.go][4] <=
|
||||
|
||||
从本质上来看,cronjob 控制器做了:
|
||||
|
||||
* 每 10 秒钟:
|
||||
* 列出所有已存在的 cronjobs
|
||||
|
||||
* 检查是否有需要现在去运行的任务
|
||||
|
||||
* 如果有,创建一个新的作业对象去被调度并通过其它的 Kubernetes 控制器去真正地去运行它
|
||||
|
||||
* 清理已完成的作业
|
||||
|
||||
* 重复以上工作
|
||||
|
||||
Kubernetes 模型是很受限制的(它有定义在 etcd 中的资源模式,控制器读取这个资源和更新 etcd),我认为这种相关的固有的/受限制的模型,可以使它更容易地在 Kubernetes 框架中开发你自己的分布式系统。
|
||||
|
||||
Kamal 介绍给我的 “ Kubernetes 是一个写你自己的分布式系统的很好的平台” 这一想法,而不是“ Kubernetes 是一个你可以使用的分布式系统”,并且,我想我对它真的有兴趣。他有一个 [system to run an HTTP service for every branch you push to github][5] 的雏型。他花了一个周末的时候,大约有了 800 行,我觉得它真的很不错!
|
||||
|
||||
### Kubernetes 可以使你做一些非常神奇的事情(但并不容易)
|
||||
|
||||
我一开始就说 “kubernetes 可以让你做一些很神奇的事情,你可以用一个配置文件来做这么多的基础设施,它太神奇了”,而且这是真的!
|
||||
|
||||
为什么说“Kubernetes 并不容易”呢?,是因为 Kubernetes 有很多的课件去学习怎么去成功地运营一个高可用的 Kubernetes 集群要做很多的工作。就像我发现它给我了许多抽象的东西,我需要去理解这些抽象的东西,为了去调试问题和正确地配置它们。我喜欢学习新东西,因此,它并不会使我发狂或者生气,我只是觉得理解它很重要:)
|
||||
|
||||
对于 “我不能仅依靠抽象概念” 的一个具体的例子是,我一直在努力学习需要的更多的 [Linux 上的关于网络的工作][6],去对设置 Kubernetes 网络有信心,这比我以前学过的关于网络的知识要多很多。这种方式很有意思但是非常费时间。在以后的某个时间,我可以写更多的关于设置 Kubernetes 网络的困难的/有趣的事情。
|
||||
|
||||
或者,我写一个关于学习 Kubernetes 的不同选项所做事情的 [2000 字的博客文章][7],才能够成功去设置我的 Kubernetes CAs。
|
||||
|
||||
我觉得,像 GKE (google 的 Kubernetes 生产系统) 这样的一些管理 Kubernetes 的系统可能更简单,因为,他们为你做了许多的决定,但是,我没有尝试过它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/10/05/reasons-kubernetes-is-cool/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://github.com/kamalmarhubi/kubereview
|
||||
[2]:https://jvns.ca/categories/kubernetes
|
||||
[3]:https://github.com/kelseyhightower/kubernetes-the-hard-way
|
||||
[4]:https://github.com/kubernetes/kubernetes/blob/e4551d50e57c089aab6f67333412d3ca64bc09ae/pkg/controller/cronjob/cronjob_controller.go
|
||||
[5]:https://github.com/kamalmarhubi/kubereview
|
||||
[6]:https://jvns.ca/blog/2016/12/22/container-networking/
|
||||
[7]:https://jvns.ca/blog/2017/08/05/how-kubernetes-certificates-work/
|
||||
|
||||
|
||||
@ -1,89 +0,0 @@
|
||||
Translating by FelixYFZ
|
||||
|
||||
面向初学者的Linux网络硬件: 软件工程思想
|
||||
============================================================
|
||||
|
||||

|
||||
没有路由和桥接,我们将会成为孤独的小岛,你将会在这个网络教程中学到更多知识。
|
||||
Commons Zero][3]Pixabay
|
||||
|
||||
上周,我们学习了本地网络硬件知识,本周,我们将学习网络互联技术和在移动网络中的一些很酷的黑客技术。
|
||||
### Routers:路由器
|
||||
|
||||
|
||||
网络路由器就是计算机网络中的一切,因为路由器连接着网络,没有路由器,我们就会成为孤岛,
|
||||
|
||||
图一展示了一个简单的有线本地网络和一个无线接入点,所有设备都接入到Internet上,本地局域网的计算机连接到一个连接着防火墙或者路由器的以太网交换机上,防火墙或者路由器连接到网络服务供应商提供的电缆箱,调制调节器,卫星上行系统...好像一切都在计算中,就像是一个带着不停闪烁的的小灯的盒子,当你的网络数据包离开你的局域网,进入广阔的互联网,它们穿过一个又一个路由器直到到达自己的目的地。
|
||||
|
||||
|
||||
### [fig-1.png][4]
|
||||
|
||||

|
||||
|
||||
图一:一个简单的有线局域网和一个无线接入点。
|
||||
|
||||
一台路由器能连接一切,一个小巧特殊的小盒子只专注于路由,一个大点的盒子将会提供路由,防火墙,域名服务,以及VPN网关功能,一台重新设计的台式电脑或者笔记本,一个树莓派计算机或者一个小模块,体积臃肿矮小的像PC这样的单板计算机,除了苛刻的用途以外,普通的商品硬件都能良好的工作运行。高端的路由器使用特殊设计的硬件每秒能够传输最大量的数据包。 它们有多路数据总线,多个中央处理器和极快的存储。
|
||||
可以通过查阅Juniper和思科的路由器来感受一下高端路由器书什么样子的,而且能看看里面是什么样的构造。
|
||||
一个接入你的局域网的无线接入点要么作为一个以太网网桥要么作为一个路由器。一个桥接器扩展了这个网络,所以在这个桥接器上的任意一端口上的主机都连接在同一个网络中。
|
||||
一台路由器连接的是两个不同的网络。
|
||||
### Network Topology:网络拓扑
|
||||
|
||||
|
||||
有多种设置你的局域网的方式,你可以把所有主机接入到一个单独的平面网络,如果你的交换机支持的话,你也可以把它们分配到不同的子网中。
|
||||
平面网络是最简单的网络,只需把每一台设备接入到同一个交换机上即可,如果一台交换上的端口不够使用,你可以将更多的交换机连接在一起。
|
||||
有些交换机有特殊的上行端口,有些是没有这种特殊限制的上行端口,你可以连接其中的任意端口,你可能需要使用交叉类型的以太网线,所以你要查阅你的交换机的说明文档来设置。平面网络是最容易管理的,你不需要路由器也不需要计算子网,但它也有一些缺点。他们的伸缩性不好,所以当网络规模变得越来越大的时候就会被广播网络所阻塞。
|
||||
将你的局域网进行分段将会提升安全保障, 把局域网分成可管理的不同网段将有助于管理更大的网络。
|
||||
图2展示了一个分成两个子网的局域网络:内部的有线和无线主机,和非军事区域(从来不知道所所有的工作上的男性术语都是在计算机上键入的?)因为他被阻挡了所有的内部网络的访问。
|
||||
|
||||
|
||||
### [fig-2.png][5]
|
||||
|
||||

|
||||
|
||||
图2:一个分成两个子网的简单局域网。
|
||||
即使像图2那样的小型网络也可以有不同的配置方法。你可以将防火墙和路由器放置在一台单独的设备上。
|
||||
你可以为你的非军事区域设置一个专用的网络连接,把它完全从你的内部网络隔离,这将引导我们进入下一个主题:一切基于软件。
|
||||
|
||||
|
||||
### Think Software软件思维
|
||||
|
||||
|
||||
你可能已经注意到在这个简短的系列中我们所讨论的硬件,只有网络接口,交换机,和线缆是特殊用途的硬件。
|
||||
其它的都是通用的商用硬件,而且都是软件来定义它的用途。
|
||||
网关,虚拟专用网关,以太网桥,网页,邮箱以及文件等等。
|
||||
服务器,负载均衡,代理,大量的服务,各种各样的认证,中继,故障转移...你可以在运行着Linux系统的标准硬件上运行你的整个网络。
|
||||
你甚至可以使用Linux交换应用和VDE2协议来模拟以太网交换机,像DD-WRT,openWRT 和Rashpberry Pi distros,这些小型的硬件都是有专业的分类的,要记住BSDS和它们的特殊衍生用途如防火墙,路由器,和网络附件存储。
|
||||
你知道有些人坚持认为硬件防火墙和软件防火墙有区别?其实是没有区别的,就像说有一台硬件计算机和一台软件计算机。
|
||||
### Port Trunking and Ethernet Bonding
|
||||
端口聚合和以太网绑定
|
||||
聚合和绑定,也称链路聚合,是把两条以太网通道绑定在一起成为一条通道。一些交换机支持端口聚合,就是把两个交换机端口绑定在一起成为一个是他们原来带宽之和的一条新的连接。对于一台承载很多业务的服务器来说这是一个增加通道带宽的有效的方式。
|
||||
你也可以在以太网口进行同样的配置,而且绑定汇聚的驱动是内置在Linux内核中的,所以不需要任何其他的专门的硬件。
|
||||
|
||||
|
||||
### Bending Mobile Broadband to your Will随心所欲选择你的移动带宽
|
||||
|
||||
我期望移动带宽能够迅速增长来替代DSL和有线网络。我居住在一个有250,000人口的靠近一个城市的地方,但是在城市以外,要想接入互联网就要靠运气了,即使那里有很大的用户上网需求。我居住的小角落离城镇有20分钟的距离,但对于网络服务供应商来说他们几乎不会考虑到为这个地方提供网络。 我唯一的选择就是移动带宽; 这里没有拨号网络,卫星网络(即使它很糟糕)或者是DSL,电缆,光纤,但却没有阻止网络供应商把那些在我这个区域从没看到过的无限制通信个其他高速网络服务的传单塞进我的邮箱。
|
||||
我试用了AT&T,Version,和T-Mobile。Version的信号覆盖范围最广,但是Version和AT&T是最昂贵的。
|
||||
我居住的地方在T-Mobile信号覆盖的边缘,但迄今为止他们给了最大的优惠,为了能够能够有效的使用,我必须购买一个WeBoostDe信号放大器和
|
||||
一台中兴的移动热点设备。当然你也可以使用一部手机作为热点,但是专用的热点设备有着最强的信号。如果你正在考虑购买一台信号放大器,最好的选择就是WeBoost因为他们的服务支持最棒,而且他们会尽最大努力去帮助你。在一个小小的APP的协助下去设置将会精准的增强 你的网络信号,他们有一个功能较少的免费的版本,但你将一点都不会后悔去花两美元使用专业版。
|
||||
那个小巧的中兴热点设备能够支持15台主机而且还有拥有基本的防火墙功能。 但你如果你使用像 Linksys WRT54GL这样的设备,使用Tomato,openWRT,或者DD-WRT来替代普通的固件,这样你就能完全控制你的防护墙规则,路由配置,以及任何其他你想要设置的服务。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-think-software
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[4]:https://www.linux.com/files/images/fig-1png-7
|
||||
[5]:https://www.linux.com/files/images/fig-2png-4
|
||||
[6]:https://www.linux.com/files/images/soderskar-islandjpg
|
||||
[7]:https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-lan-hardware
|
||||
[8]:http://www.bluelinepc.com/signalcheck/
|
||||
@ -0,0 +1,73 @@
|
||||
Glitch:立即写出有趣的小型网站项目
|
||||
============================================================
|
||||
|
||||
我刚写了一篇关于 Jupyter Notebooks 是一个有趣的交互式写 Python 代码的方式。这让我想起我最近学习了 Glitch,这个我同样喜爱!我构建了一个小的程序来用于[关闭转发 twitter][2]。因此有了这篇文章!
|
||||
|
||||
[Glitch][3] 是一个简单的构建 Javascript web 程序的方式(javascript 后端、javascript 前端)
|
||||
|
||||
关于 glitch 有趣的事有:
|
||||
|
||||
1. 你在他们的网站输入 Javascript 代码
|
||||
|
||||
2. 只要输入了任何代码,它会自动用你的新代码重载你的网站。你甚至不必保存!它会自动保存。
|
||||
|
||||
所以这就像 Heroku,但更神奇!像这样的编码(你输入代码,代码立即在公共网络上运行)对我而言感觉很**有趣**。
|
||||
|
||||
这有点像 ssh 登录服务器,编辑服务器上的 PHP/HTML 代码,并让它立即可用,这也是我所喜爱的。现在我们有了“更好的部署实践”,而不是“编辑代码,它立即出现在互联网上”,但我们并不是在谈论严肃的开发实践,而是在讨论编写微型程序的乐趣。
|
||||
|
||||
### Glitch 有很棒的示例应用程序
|
||||
|
||||
Glitch 似乎是学习编程的好方式!
|
||||
|
||||
比如,这有一个太空侵略者游戏(由 [Mary Rose Cook][4] 编写):[https://space-invaders.glitch.me/][5]。我喜欢的是我只需要点击几下。
|
||||
|
||||
1. 点击 “remix this”
|
||||
|
||||
2. 开始编辑代码使箱子变成橘色而不是黑色
|
||||
|
||||
3. 制作我自己太空侵略者游戏!我的在这:[http://julias-space-invaders.glitch.me/][1]。(我只做了很小的更改使其变成橘色,没什么神奇的)
|
||||
|
||||
他们有大量的示例程序,你可以从中启动 - 例如[机器人][6]、[游戏][7]等等。
|
||||
|
||||
### 实际有用的非常好的程序:tweetstorms
|
||||
|
||||
我学习 Glitch 的方式是从这个程序:[https://tweetstorms.glitch.me/][8],它会向你展示给定用户的 tweetstorm。
|
||||
|
||||
比如,你可以在 [https://tweetstorms.glitch.me/sarahmei][10] 看到 [@sarahmei][9] 的 tweetstorm(她发布了很多好的 tweetstorm!)。
|
||||
|
||||
### 我的 Glitch 程序: 关闭转推
|
||||
|
||||
当我了解到 Glitch 的时候,我想关闭在 Twitter 上关注的所有人的转推(我知道可以在 Tweetdeck 中做这件事),而且手动做这件事是一件很痛苦的事 - 我一次只能设置一个人。所以我写了一个 Glitch 程序来为我做!
|
||||
|
||||
我喜欢我不必设置一个本地开发环境,我可以直接开始输入然后开始!
|
||||
|
||||
Glitch 只支持 Javascript,我不非常了解 Javascript(我之前从没写过一个 Node 程序),所以代码不是很好。但是编写它很愉快 - 能够输入并立即看到我的代码运行是令人愉快的。这是我的项目:[https://turn-off-retweets.glitch.me/][11]。
|
||||
|
||||
### 就是这些!
|
||||
|
||||
使用 Glitch 感觉真的很有趣和民主。通常情况下,如果我想 fork 某人的 Web 项目,并做出更改,我不会这样做 - 我必须 fork,找一个托管,设置本地开发环境或者 Heroku 或其他,安装依赖项等。我认为像安装 node.js 依赖关系这样的任务过去很有趣,就像“我正在学习新东西很酷”,现在我觉得它们很乏味。
|
||||
|
||||
所以我喜欢只需点击 “remix this!” 并立即在互联网上能有我的版本。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/13/glitch--write-small-web-projects-easily/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://julias-space-invaders.glitch.me/
|
||||
[2]:https://turn-off-retweets.glitch.me/
|
||||
[3]:https://glitch.com/
|
||||
[4]:https://maryrosecook.com/
|
||||
[5]:https://space-invaders.glitch.me/
|
||||
[6]:https://glitch.com/handy-bots
|
||||
[7]:https://glitch.com/games
|
||||
[8]:https://tweetstorms.glitch.me/
|
||||
[9]:https://twitter.com/sarahmei
|
||||
[10]:https://tweetstorms.glitch.me/sarahmei
|
||||
[11]:https://turn-off-retweets.glitch.me/
|
||||
@ -0,0 +1,59 @@
|
||||
ESR:最合理的语言工程模式
|
||||
============================================================
|
||||
|
||||
当你熟练掌握一体化工程技术时,你就会发现它逐渐超过了技术优化的层面。我们制作的每件手工艺品都在一个大环境背景下,在这个环境中,人类的行为逐渐突破了经济意义、社会学意义,达到了奥地利经济学家所称的“<ruby>人类行为学<rt>praxeology</rt></ruby>”,这是目的明确的人类行为所能达到的最大范围。
|
||||
|
||||
对我来说这并不只是抽象理论。当我在开源开发项目中编写论文时,我的行为就十分符合人类行为学的理论,这行为不是针对任何特定的软件技术或某个客观事物,它指的是在开发科技的过程中人类行为的背景环境。从人类行为学角度对科技进行的解读不断增加,大量的这种解读可以重塑科技框架,带来人类生产力和满足感的极大幅度增长,而这并不是由于我们换了工具,而是在于我们改变了掌握它们的方式。
|
||||
|
||||
在这个背景下,我的计划之外的文章系列的第三篇中谈到了 C 语言的衰退和正在到来的巨大改变,而我们也确实能够感受到系统编程的新时代的到来,在这个时刻,我决定把我之前有的大体的预感具象化为更加具体的、更实用的想法,它们主要是关于计算机语言设计的分析,例如为什么它们会成功,或为什么它们会失败。
|
||||
|
||||
在我最近的一篇文章中,我写道:所有计算机语言都是对机器资源的成本和程序员工作成本的相对权衡的结果,和对其相对价值的体现。这些都是在一个计算能力成本不断下降但程序员工作成本不减反增的背景下产生的。我还强调了转化成本在使原有交易主张适用于当下环境中的新增角色。在文中我将编程人员描述为一个寻找今后最适方案的探索者。
|
||||
|
||||
现在我要讲一讲最后一点。以现有水平为起点,一个语言工程师有极大可能通过多种方式推动语言设计的发展。通过什么系统呢? GC 还是人工分配?使用何种配置,命令式语言、函数程式语言或是面向对象语言?但是从人类行为学的角度来说,我认为它的形式会更简洁,也许只是选择解决长期问题还是短期问题?
|
||||
|
||||
所谓的“远”、“近”之分,是指硬件成本的逐渐降低,软件复杂程度的上升和由现有语言向其他语言转化的成本的增加,根据它们的变化曲线所做出的判断。短期问题指编程人员眼下发现的问题,长期问题指可预见的一系列情况,但它们一段时间内不会到来。针对近期问题所做出的部署需要非常及时且有效,但随着情况的变化,短期解决方案有可能很快就不适用了。而长期的解决方案可能因其过于超前而夭折,或因其代价过高无法被接受。
|
||||
|
||||
在计算机刚刚面世的时候, FORTRAN 是近期亟待解决的问题, LISP 是远期问题,汇编语言是短期解决方案。说明这种分类适用于非通用语言,还有 roff 标记语言。随着计算机技术的发展,PHP 和 Javascript 逐渐参与到这场游戏中。至于长期的解决方案? Oberon、Ocaml、ML、XML-Docbook 都可以。 它们形成的激励机制带来了大量具有突破性和原创性的想法,事态蓬勃但未形成体系,那个时候距离专业语言的面世还很远,(值得注意的是这些想法的出现都是人类行为学中的因果,并非由于某种技术)。专业语言会失败,这是显而易见的,它的转入成本高昂,让大部分人望而却步,因此不能达到能够让主流群体接受的水平,被孤立,被搁置。这也是 LISP 不为人知的的过去,作为前 LISP 管理层人员,出于对它深深的爱,我为你们讲述了这段历史。
|
||||
|
||||
如果短期解决方案出现故障,它的后果更加惨不忍睹,最好的结果是期待一个相对体面的失败,好转换到另一个设计方案。(通常在转化成本较高时)如果他们执意继续,通常造成众多方案相互之间藕断丝连,形成一个不断扩张的复合体,一直维持到不能运转下去,变成一堆摇摇欲坠的杂物。是的,我说的就是 C++ 语言,还有 Java 描述语言,(唉)还有 Perl,虽然 Larry Wall 的好品味成功地让他维持了很多年,问题一直没有爆发,但在 Perl 6 发行时,他的好品味最终引爆了整个问题。
|
||||
|
||||
这种思考角度激励了编程人员向着两个不同的目的重新塑造语言设计: (1)以远近为轴,在自身和预计的未来之间选取一个最适点,然后(2)降低由一种或多种语言转化为自身语言的转入成本,这样你就可以吸纳他们的用户群。接下来我会讲讲 C 语言是怎样占领全世界的。
|
||||
|
||||
在整个计算机发展史中,没有谁能比 C 语言完美地把握最适点的选取了,我要做的只是证明这一点,作为一种实用的主流语言, C 语言有着更长的寿命,它目睹了无数个竞争者的兴衰,但它的地位仍旧不可取代。从淘汰它的第一个竞争者到现在已经过了 35 年,但看起来C语言的终结仍旧不会到来。
|
||||
|
||||
当然,如果你愿意的话,可以把 C 语言的持久存在归功于人类的文化惰性,但那是对“文化惰性”这个词的曲解, C 语言一直得以延续的真正原因是没有人提供足够的转化费用!
|
||||
|
||||
相反的, C 语言低廉的内部转化成本未得到应有的重视,C 语言是如此的千变万化,从它漫长统治时期的初期开始,它就可以适用于多种语言如 FORTRAN、Pascal 、汇编语言和 LISP 的编程习惯。在二十世纪八十年代我就注意到,我可以根据编程人员的编码风格判断出他的母语是什么,这也从另一方面证明了C 语言的魅力能够吸引全世界的人使用它。
|
||||
|
||||
C++ 语言同样胜在它低廉的转化成本。很快,大部分新兴的语言为了降低自身转化成本,纷纷参考 C 语言语法。请注意这给未来的语言设计环境带来了什么影响:它尽可能地提高了类 C 语言的价值,以此来降低其他语言转化为 C 语言的转化成本。
|
||||
|
||||
另一种降低转入成本的方法十分简单,即使没接触过编程的人都能学会,但这种方法很难完成。我认为唯一使用了这种方法的 Python 就是靠这种方法进入了职业比赛。对这个方法我一带而过,是因为它并不是我希望看到的,顺利执行的系统语言战略,虽然我很希望它不是那样的。
|
||||
|
||||
今天我们在 2017 年底聚集在这里,下一项我们应该为某些暴躁的团体发声,如 Go 团队,但事实并非如此。 Go 这个项目漏洞百出,我甚至可以想象出它失败的各种可能,Go 团队太过固执独断,即使几乎整个用户群体都认为 Go 需要做出改变了,Go 团队也无动于衷,这是个大问题。 一旦发生故障, GC 发生延迟或者用牺牲生产量来弥补延迟,但无论如何,它都会严重影响到这种语言的应用,大幅缩小这种语言的适用范围。
|
||||
|
||||
即便如此,在 Go 的设计中,还是有一个我颇为认同的远大战略目标,想要理解这个目标,我们需要回想一下如果想要取代 C 语言,要面临的短期问题是什么。同我之前提到的,随着项目计划的不断扩张,故障率也在持续上升,这其中内存管理方面的故障尤其多,而内存管理一直是崩溃漏洞和安全漏洞的高发领域。
|
||||
|
||||
我们现在已经知道了两件十分重要的紧急任务,要想取代 C 语言,首先要先做到这两点:(1)解决内存管理问题;(2)降低由 C 语言向本语言转化时所需的转入成本。纵观编程语言的历史——从人类行为学的角度来看,作为 C 语言的准替代者,如果不能有效解决转入成本过高这个问题,那他们所做的其他部分做得再好都不算数。相反的,如果他们把转入成本过高这个问题解决地很好,即使他们其他部分做的不是最好的,人们也不会对他们吹毛求疵。
|
||||
|
||||
这正是 Go 的做法,但这个理论并不是完美无瑕的,它也有局限性。目前 GC 延迟限制了它的发展,但 Go 现在选择照搬 Unix 下 C 语言的传染战略,让自身语言变成易于转入,便于传播的语言,其繁殖速度甚至快于替代品。但从长远角度看,这并不是个好办法。
|
||||
|
||||
当然, Rust 语言的不足是个十分明显的问题,我们不应当回避它。而它,正将自己定位为适用于长远计划的选择。在之前的部分中我已经谈到了为什么我觉得它还不完美,Rust 语言在 TIBOE 和PYPL 指数上的成就也证明了我的说法,在 TIBOE 上 Rust 从来没有进过前 20 名,在 PYPL 指数上它的成就也比 Go 差很多。
|
||||
|
||||
五年后 Rust 能发展的怎样还是个问题,如果他们愿意改变,我建议他们重视转入成本问题。以我个人经历来说,由 C 语言转入 Rust 语言的能量壁垒使人望而却步。如果编码提升工具比如 Corrode 只能把 C 语言映射为不稳定的 Rust 语言,但不能解决能量壁垒的问题;或者如果有更简单的方法能够自动注释所有权或试用期,人们也不再需要它们了——这些问题编译器就能够解决。目前我不知道怎样解决这个问题,但我觉得他们最好找出解决方案。
|
||||
|
||||
在最后我想强调一下,虽然在 Ken Thompson 的设计经历中,他看起来很少解决短期问题,但他对未来有着极大的包容性,并且这种包容性还在不断提升。当然 Unix 也是这样的, 它让我不禁暗自揣测,让我认为 Go 语言中令人不快的地方都其实是他们未来事业的基石(例如缺乏泛型)。如果要确认这件事是真假,我需要比 Ken 还要聪明,但这并不是一件容易让人相信的事情。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7745
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7711&cpage=1#comment-1913931
|
||||
[3]:http://esr.ibiblio.org/?p=7745
|
||||
@ -0,0 +1,76 @@
|
||||
AWS 帮助构建 ONNX 开源 AI 平台
|
||||
============================================================
|
||||

|
||||
|
||||
|
||||
AWS 已经成为最近加入深度学习社区的开放神经网络交换(ONNX)协作的最新技术公司,最近在无摩擦和可互操作的环境中推出了高级人工智能。由 Facebook 和微软领头。
|
||||
|
||||
作为该合作的一部分,AWS 将其开源 Python 软件包 ONNX-MxNet 作为一个深度学习框架提供,该框架提供跨多种语言的编程接口,包括 Python、Scala 和开源统计软件 R。
|
||||
|
||||
AWS 深度学习工程经理 Hagay Lupesko 和软件开发人员 Roshani Nagmote 上周在一篇帖子中写道:ONNX 格式将帮助开发人员构建和训练其他框架的模型,包括 PyTorch、Microsoft Cognitive Toolkit 或 Caffe2。它可以让开发人员将这些模型导入 MXNet,并运行它们进行推理。
|
||||
|
||||
### 对开发者的帮助
|
||||
|
||||
今年夏天,Facebook 和微软推出了 ONNX,以支持共享模式的互操作性,来促进 AI 的发展。微软提交了其 Cognitive Toolkit、Caffe2 和 PyTorch 来支持 ONNX。
|
||||
|
||||
微软表示:Cognitive Toolkit 和其他框架使开发人员更容易构建和运行代表神经网络的计算图。
|
||||
|
||||
Github 上提供了[ ONNX 代码和文档][4]的初始版本。
|
||||
|
||||
AWS 和微软上个月宣布了在 Apache MXNet 上的一个新 Gluon 接口计划,该计划允许开发人员构建和训练深度学习模型。
|
||||
|
||||
[Tractica][5] 的研究总监 Aditya Kaul 观察到:“Gluon 是他们与 Google 的 Tensorflow 竞争的合作伙伴关系的延伸”。
|
||||
|
||||
他告诉 LinuxInsider,“谷歌在这点上的疏忽是非常明显的,但也说明了他们在市场上的主导地位。
|
||||
|
||||
Kaul 说:“甚至 Tensorflow 是开源的,所以开源在这里并不是什么大事,但这归结到底是其他生态系统联手与谷歌竞争。”
|
||||
|
||||
根据 AWS 的说法,本月早些时候,Apache MXNet 社区推出了 MXNet 的 0.12 版本,它扩展了 Gluon 的功能,以便进行新的尖端研究。它的新功能之一是变分 dropout,它允许开发人员使用 dropout 技术来缓解递归神经网络中的过拟合。
|
||||
|
||||
AWS 指出:卷积 RNN、LSTM 网络和门控循环单元(GRU)允许使用基于时间的序列和空间维度对数据集进行建模。
|
||||
|
||||
### 框架中立方式
|
||||
|
||||
[Tirias Research][6] 的首席分析师 Paul Teich 说:“这看起来像是一个提供推理的好方法,而不管是什么框架生成的模型。”
|
||||
|
||||
他告诉 LinuxInsider:“这基本上是一种框架中立的推理方式。”
|
||||
|
||||
Teich 指出,像 AWS、微软等云提供商在客户的压力下可以在一个网络上进行训练,同时提供另一个网络,以推进人工智能。
|
||||
|
||||
他说:“我认为这是这些供应商检查互操作性的一种基本方式。”
|
||||
|
||||
Tractica 的 Kaul 指出:“框架互操作性是一件好事,这会帮助开发人员确保他们建立在 MXNet 或 Caffe 或 CNTK 上的模型可以互操作。”
|
||||
|
||||
至于这种互操作性如何适用于现实世界,Teich 指出,诸如自然语言翻译或语音识别等技术将要求将 Alexa 的语音识别技术打包并交付给另一个开发人员的嵌入式环境。
|
||||
|
||||
### 感谢开源
|
||||
|
||||
[ThinkStrategies][7] 的总经理 Jeff Kaplan 表示:“尽管存在竞争差异,但这些公司都认识到他们在开源运动所带来的软件开发进步方面所取得的巨大成功。”
|
||||
|
||||
他告诉 LinuxInsider:“开放式神经网络交换(ONNX)致力于在人工智能方面产生类似的优势和创新。”
|
||||
|
||||
越来越多的大型科技公司已经宣布使用开源技术来加快 AI 协作开发的计划,以便创建更加统一的开发和研究平台。
|
||||
|
||||
AT&T 几周前宣布了与 TechMahindra 和 Linux 基金会合作[推出 Acumos 项目][8]的计划。该平台旨在开拓电信、媒体和技术方面的合作。
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
|
||||
作者:[ David Jones ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html#searchbyline
|
||||
[1]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html#
|
||||
[2]:https://www.linuxinsider.com/perl/mailit/?id=84971
|
||||
[3]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
[4]:https://github.com/onnx/onnx
|
||||
[5]:https://www.tractica.com/
|
||||
[6]:http://www.tiriasresearch.com/
|
||||
[7]:http://www.thinkstrategies.com/
|
||||
[8]:https://www.linuxinsider.com/story/84926.html
|
||||
[9]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
@ -0,0 +1,92 @@
|
||||
5 个最佳实践开始你的 DevOps 之旅
|
||||
============================================================
|
||||
|
||||
### 想要实现 DevOps 但是不知道如何开始吗?试试这 5 个最佳实践吧。
|
||||
|
||||
|
||||

|
||||
|
||||
Image by : [Andrew Magill][8]. Modified by Opensource.com. [CC BY 4.0][9]
|
||||
|
||||
想要采用 DevOps 的人通常会过早的被它的歧义性给吓跑,更不要说更加深入的使用了。当一些人开始使用 DevOps 的时候都会问:“如何开始使用呢?”,”怎么才算使用了呢?“。这 5 个最佳实践是很好的路线图来指导你的 DevOps 之旅。
|
||||
|
||||
### 1\. 衡量所有的事情
|
||||
|
||||
除非你能量化输出结果,否则你并不能确认你的努力能否使事情变得更好。新功能能否快速的输出给客户?有更少的漏洞泄漏给他们吗?出错了能快速应对和恢复吗?
|
||||
|
||||
在你开始做任何修改之前,思考一下你切换到 DevOps 之后想要一些什么样的输出。随着你的 DevOps 之旅,将享受到服务的所有内容的丰富的实时报告,从这两个指标考虑一下:
|
||||
|
||||
* **上架时间** 衡量端到端,通常是面向客户的业务经验。这通常从一个功能被正式提出而开始,客户在产品中开始使用这个功能而结束。上架时间不是团队的主要指标;更加重要的是,当开发出一个有价值的新功能时,它表明了你完成业务的效率,为系统改进提供了一个机会。
|
||||
|
||||
* **时间周期** 衡量工程团队的进度。从开始开发一个新功能开始,到在产品中运行需要多久?这个指标对于你理解团队的效率是非常有用的,为团队等级的提升提供了一个机会。
|
||||
|
||||
### 2\. 放飞你的流程
|
||||
|
||||
DevOps 的成功需要团队布置一个定期流程并且持续提升它。这不总是有效的,但是必须是一个定期(希望有效)的流程。通常它有一些敏捷开发的味道,就像 Scrum 或者 Scrumban 一样;一些时候它也像精益开发。不论你用的什么方法,挑选一个正式的流程,开始使用它,并且做好这些基础。
|
||||
|
||||
定期检查和调整流程是 DevOps 成功的关键,抓住相关演示,团队回顾,每日会议的机会来提升你的流程。
|
||||
|
||||
DevOps 的成功取决于大家一起有效的工作。团队的成员需要在一个有权改进的公共流程中工作。他们也需要定期找机会分享从这个流程中上游或下游的其他人那里学到的东西。
|
||||
|
||||
随着你构建成功。好的流程规范能帮助你的团队以很快的速度体会到 DevOps 其他的好处
|
||||
|
||||
尽管更多面向开发的团队采用 Scrum 是常见的,但是以运营为中心的团队(或者其他中断驱动的团队)可能选用一个更短期的流程,例如 Kanban。
|
||||
|
||||
### 3\. 可视化工作流程
|
||||
这是很强大的,能够看到哪个人在给定的时间做哪一部分工作,可视化你的工作流程能帮助大家知道接下来应该做什么,流程中有多少工作以及流程中的瓶颈在哪里。
|
||||
|
||||
在你看到和衡量之前你并不能有效的限制流程中的工作。同样的,你也不能有效的排除瓶颈直到你清楚的看到它。
|
||||
|
||||
全部工作可视化能帮助团队中的成员了解他们在整个工作中的贡献。这样可以促进跨组织边界的关系建设,帮助您的团队更有效地协作,实现共同的成就感。
|
||||
|
||||
### 4\. 持续化所有的事情
|
||||
|
||||
DevOps 应该是强制自动化的。然而罗马不是一日建成的。你应该注意的第一个事情应该是努力的持续集成(CI),但是不要停留到这里;紧接着的是持续交付(CD)以及最终的持续部署。
|
||||
|
||||
持续部署的过程中是个注入自动测试的好时机。这个时候新代码刚被提交,你的持续部署应该运行测试代码来测试你的代码和构建成功的加工品。这个加工品经受流程的考验被产出直到最终被客户看到。
|
||||
|
||||
另一个“持续”是不太引人注意的持续改进。一个简单的场景是每天询问你旁边的同事:“今天做些什么能使工作变得更好?”,随着时间的推移,这些日常的小改进融合到一起会引起很大的结果,你将很惊喜!但是这也会让人一直思考着如何改进。
|
||||
|
||||
### 5\. Gherkinize
|
||||
|
||||
促进组织间更有效的沟通对于成功的 DevOps 的系统思想至关重要。在程序员和业务员之间直接使用共享语言来描述新功能的需求文档对于沟通是个好办法。一个好的产品经理能在一天内学会 [Gherkin][12] 然后使用它构造出明确的英语来描述需求文档,工程师会使用 Gherkin 描述的需求文档来写功能测试,之后开发功能代码直到代码通过测试。这是一个简化的 [验收测试驱动开发][13](ATDD),这样就开始了你的 DevOps 文化和开发实践。
|
||||
|
||||
### 开始你旅程
|
||||
|
||||
不要自馁哦。希望这五个想法给你坚实的入门方法。
|
||||
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][14]
|
||||
|
||||
Magnus Hedemark - Magnus 在IT行业已有20多年,并且一直热衷于技术。他目前是 nitedHealth Group 的 DevOps 工程师。在业余时间,Magnus 喜欢摄影和划独木舟。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/5-keys-get-started-devops
|
||||
|
||||
作者:[Magnus Hedemark ][a]
|
||||
译者:[aiwhj](https://github.com/aiwhj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/magnus919
|
||||
[1]:https://opensource.com/tags/devops?src=devops_resource_menu1
|
||||
[2]:https://opensource.com/resources/devops?src=devops_resource_menu2
|
||||
[3]:https://www.openshift.com/promotions/devops-with-openshift.html?intcmp=7016000000127cYAAQ&src=devops_resource_menu3
|
||||
[4]:https://enterprisersproject.com/article/2017/5/9-key-phrases-devops?intcmp=7016000000127cYAAQ&src=devops_resource_menu4
|
||||
[5]:https://www.redhat.com/en/insights/devops?intcmp=7016000000127cYAAQ&src=devops_resource_menu5
|
||||
[6]:https://opensource.com/article/17/11/5-keys-get-started-devops?rate=oEOzMXx1ghbkfl2a5ae6AnvO88iZ3wzkk53K2CzbDWI
|
||||
[7]:https://opensource.com/user/25739/feed
|
||||
[8]:https://ccsearch.creativecommons.org/image/detail/7qRx_yrcN5isTMS0u9iKMA==
|
||||
[9]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[10]:https://martinfowler.com/articles/continuousIntegration.html
|
||||
[11]:https://martinfowler.com/bliki/ContinuousDelivery.html
|
||||
[12]:https://cucumber.io/docs/reference
|
||||
[13]:https://en.wikipedia.org/wiki/Acceptance_test%E2%80%93driven_development
|
||||
[14]:https://opensource.com/users/magnus919
|
||||
[15]:https://opensource.com/users/magnus919
|
||||
[16]:https://opensource.com/users/magnus919
|
||||
[17]:https://opensource.com/tags/devops
|
||||
@ -0,0 +1,185 @@
|
||||
如何在 Linux shell 中找出所有包含指定文本的文件
|
||||
------
|
||||
### 目标
|
||||
|
||||
本文提供一些关于如何搜索出指定目录或整个文件系统中那些包含指定单词或字符串的文件。
|
||||
|
||||
### 难度
|
||||
|
||||
容易
|
||||
|
||||
### 约定
|
||||
|
||||
* \# - 需要使用 root 权限来执行指定命令,可以直接使用 root 用户来执行也可以使用 sudo 命令
|
||||
|
||||
* \$ - 可以使用普通用户来执行指定命令
|
||||
|
||||
### 案例
|
||||
|
||||
#### 非递归搜索包含指定字符串的文件
|
||||
|
||||
第一个例子让我们来搜索 `/etc/` 目录下所有包含 `stretch` 字符串的文件,但不去搜索其中的子目录:
|
||||
|
||||
```shell
|
||||
# grep -s stretch /etc/*
|
||||
/etc/os-release:PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
|
||||
/etc/os-release:VERSION="9 (stretch)"
|
||||
```
|
||||
grep 的 `-s` 选项会在发现不能存在或者不能读取的文件时抑制报错信息。结果现实除了文件名外还有包含请求字符串的行也被一起输出了。
|
||||
|
||||
#### 递归地搜索包含指定字符串的文件
|
||||
|
||||
上面案例中忽略了所有的子目录。所谓递归搜索就是指同时搜索所有的子目录。
|
||||
下面的命令会在 `/etc/` 及其子目录中搜索包含 `stretch` 字符串的文件:
|
||||
|
||||
```shell
|
||||
# grep -R stretch /etc/*
|
||||
/etc/apt/sources.list:# deb cdrom:[Debian GNU/Linux testing _Stretch_ - Official Snapshot amd64 NETINST Binary-1 20170109-05:56]/ stretch main
|
||||
/etc/apt/sources.list:#deb cdrom:[Debian GNU/Linux testing _Stretch_ - Official Snapshot amd64 NETINST Binary-1 20170109-05:56]/ stretch main
|
||||
/etc/apt/sources.list:deb http://ftp.au.debian.org/debian/ stretch main
|
||||
/etc/apt/sources.list:deb-src http://ftp.au.debian.org/debian/ stretch main
|
||||
/etc/apt/sources.list:deb http://security.debian.org/debian-security stretch/updates main
|
||||
/etc/apt/sources.list:deb-src http://security.debian.org/debian-security stretch/updates main
|
||||
/etc/dictionaries-common/words:backstretch
|
||||
/etc/dictionaries-common/words:backstretch's
|
||||
/etc/dictionaries-common/words:backstretches
|
||||
/etc/dictionaries-common/words:homestretch
|
||||
/etc/dictionaries-common/words:homestretch's
|
||||
/etc/dictionaries-common/words:homestretches
|
||||
/etc/dictionaries-common/words:outstretch
|
||||
/etc/dictionaries-common/words:outstretched
|
||||
/etc/dictionaries-common/words:outstretches
|
||||
/etc/dictionaries-common/words:outstretching
|
||||
/etc/dictionaries-common/words:stretch
|
||||
/etc/dictionaries-common/words:stretch's
|
||||
/etc/dictionaries-common/words:stretched
|
||||
/etc/dictionaries-common/words:stretcher
|
||||
/etc/dictionaries-common/words:stretcher's
|
||||
/etc/dictionaries-common/words:stretchers
|
||||
/etc/dictionaries-common/words:stretches
|
||||
/etc/dictionaries-common/words:stretchier
|
||||
/etc/dictionaries-common/words:stretchiest
|
||||
/etc/dictionaries-common/words:stretching
|
||||
/etc/dictionaries-common/words:stretchy
|
||||
/etc/grub.d/00_header:background_image -m stretch `make_system_path_relative_to_its_root "$GRUB_BACKGROUND"`
|
||||
/etc/os-release:PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
|
||||
/etc/os-release:VERSION="9 (stretch)"
|
||||
```
|
||||
|
||||
#### 搜索所有包含特定单词的文件
|
||||
上面 `grep` 命令的案例中列出的是所有包含字符串 `stretch` 的文件。也就是说包含 `stretches` , `stretched` 等内容的行也会被显示。 使用 grep 的 `-w` 选项会只显示包含特定单词的行:
|
||||
|
||||
```shell
|
||||
# grep -Rw stretch /etc/*
|
||||
/etc/apt/sources.list:# deb cdrom:[Debian GNU/Linux testing _Stretch_ - Official Snapshot amd64 NETINST Binary-1 20170109-05:56]/ stretch main
|
||||
/etc/apt/sources.list:#deb cdrom:[Debian GNU/Linux testing _Stretch_ - Official Snapshot amd64 NETINST Binary-1 20170109-05:56]/ stretch main
|
||||
/etc/apt/sources.list:deb http://ftp.au.debian.org/debian/ stretch main
|
||||
/etc/apt/sources.list:deb-src http://ftp.au.debian.org/debian/ stretch main
|
||||
/etc/apt/sources.list:deb http://security.debian.org/debian-security stretch/updates main
|
||||
/etc/apt/sources.list:deb-src http://security.debian.org/debian-security stretch/updates main
|
||||
/etc/dictionaries-common/words:stretch
|
||||
/etc/dictionaries-common/words:stretch's
|
||||
/etc/grub.d/00_header:background_image -m stretch `make_system_path_relative_to_its_root "$GRUB_BACKGROUND"`
|
||||
/etc/os-release:PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
|
||||
/etc/os-release:VERSION="9 (stretch)"
|
||||
```
|
||||
|
||||
#### 显示包含特定文本文件的文件名
|
||||
上面的命令都会产生多余的输出。下一个案例则会递归地搜索 `etc` 目录中包含 `stretch` 的文件并只输出文件名:
|
||||
|
||||
```shell
|
||||
# grep -Rl stretch /etc/*
|
||||
/etc/apt/sources.list
|
||||
/etc/dictionaries-common/words
|
||||
/etc/grub.d/00_header
|
||||
/etc/os-release
|
||||
```
|
||||
|
||||
#### 大小写不敏感的搜索
|
||||
默认情况下搜索 hi 大小写敏感的,也就是说当搜索字符串 `stretch` 时只会包含大小写一致内容的文件。
|
||||
通过使用 grep 的 `-i` 选项,grep 命令还会列出所有包含 `Stretch` , `STRETCH` , `StReTcH` 等内容的文件,也就是说进行的是大小写不敏感的搜索。
|
||||
|
||||
```shell
|
||||
# grep -Ril stretch /etc/*
|
||||
/etc/apt/sources.list
|
||||
/etc/dictionaries-common/default.hash
|
||||
/etc/dictionaries-common/words
|
||||
/etc/grub.d/00_header
|
||||
/etc/os-release
|
||||
```
|
||||
|
||||
#### 搜索是包含/排除指定文件
|
||||
`grep` 命令也可以只在指定文件中进行搜索。比如,我们可以只在配置文件(扩展名为`.conf`)中搜索指定的文本/字符串。 下面这个例子就会在 `/etc` 目录中搜索带字符串 `bash` 且所有扩展名为 `.conf` 的文件:
|
||||
|
||||
```shell
|
||||
# grep -Ril bash /etc/*.conf
|
||||
OR
|
||||
# grep -Ril --include=\*.conf bash /etc/*
|
||||
/etc/adduser.conf
|
||||
```
|
||||
|
||||
类似的,也可以使用 `--exclude` 来排除特定的文件:
|
||||
|
||||
```shell
|
||||
# grep -Ril --exclude=\*.conf bash /etc/*
|
||||
/etc/alternatives/view
|
||||
/etc/alternatives/vim
|
||||
/etc/alternatives/vi
|
||||
/etc/alternatives/vimdiff
|
||||
/etc/alternatives/rvim
|
||||
/etc/alternatives/ex
|
||||
/etc/alternatives/rview
|
||||
/etc/bash.bashrc
|
||||
/etc/bash_completion.d/grub
|
||||
/etc/cron.daily/apt-compat
|
||||
/etc/cron.daily/exim4-base
|
||||
/etc/dictionaries-common/default.hash
|
||||
/etc/dictionaries-common/words
|
||||
/etc/inputrc
|
||||
/etc/passwd
|
||||
/etc/passwd-
|
||||
/etc/profile
|
||||
/etc/shells
|
||||
/etc/skel/.profile
|
||||
/etc/skel/.bashrc
|
||||
/etc/skel/.bash_logout
|
||||
```
|
||||
|
||||
#### 搜索时排除指定目录
|
||||
跟文件一样,grep 也能在搜索时排除指定目录。 使用 `--exclude-dir` 选项就行。
|
||||
下面这个例子会搜索 `/etc` 目录中搜有包含字符串 `stretch` 的文件,但不包括 `/etc/grub.d` 目录下的文件:
|
||||
|
||||
```shell
|
||||
# grep --exclude-dir=/etc/grub.d -Rwl stretch /etc/*
|
||||
/etc/apt/sources.list
|
||||
/etc/dictionaries-common/words
|
||||
/etc/os-release
|
||||
```
|
||||
|
||||
#### 显示包含搜索字符串的行号
|
||||
`-n` 选项还会显示指定字符串所在行的行号:
|
||||
|
||||
```shell
|
||||
# grep -Rni bash /etc/*.conf
|
||||
/etc/adduser.conf:6:DSHELL=/bin/bash
|
||||
```
|
||||
|
||||
#### 寻找不包含指定字符串的文件
|
||||
最后这个例子使用 `-v` 来列出所有 *不* 包含指定字符串的文件。
|
||||
例如下面命令会搜索 `/etc` 目录中不包含 `stretch` 的所有文件:
|
||||
|
||||
```shell
|
||||
# grep -Rlv stretch /etc/*
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-find-all-files-with-a-specific-text-using-linux-shell
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者 ID](https://github.com/校对者 ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -0,0 +1,154 @@
|
||||
Undistract-me:当长时间运行的终端命令完成时获取通知
|
||||
============================================================
|
||||
|
||||
作者:[sk][2],时间:2017.11.30
|
||||
|
||||

|
||||
|
||||
前一段时间,我们发表了如何[在终端活动完成时获取通知][3]。今天,我发现了一个叫做 “undistract-me” 的类似工具,它可以在长时间运行的终端命令完成时通知你。想象这个场景。你运行着一个需要一段时间才能完成的命令。与此同时,你查看你的 Facebook,并参与其中。过了一会儿,你记得你几分钟前执行了一个命令。你回到终端,注意到这个命令已经完成了。但是你不知道命令何时完成。你有没有遇到这种情况?我敢打赌,你们大多数人遇到过许多次这种情况。这就是 “undistract-me” 能帮助的了。你不需要经常检查终端,查看命令是否完成。长时间运行的命令完成后,undistract-me 会通知你。它能在 Arch Linux、Debian、Ubuntu 和其他 Ubuntu 衍生版上运行。
|
||||
|
||||
#### 安装 Undistract-me
|
||||
|
||||
Undistract-me 可以在 Debian 及其衍生版(如 Ubuntu)的默认仓库中使用。你要做的就是运行下面的命令来安装它。
|
||||
|
||||
```
|
||||
sudo apt-get install undistract-me
|
||||
```
|
||||
|
||||
Arch Linux 用户可以使用任何帮助程序从 AUR 安装它。
|
||||
|
||||
使用 [Pacaur][4]:
|
||||
|
||||
```
|
||||
pacaur -S undistract-me-git
|
||||
```
|
||||
|
||||
使用 [Packer][5]:
|
||||
|
||||
```
|
||||
packer -S undistract-me-git
|
||||
```
|
||||
|
||||
使用 [Yaourt][6]:
|
||||
|
||||
```
|
||||
yaourt -S undistract-me-git
|
||||
```
|
||||
|
||||
然后,运行以下命令将 “undistract-me” 添加到 Bash 中。
|
||||
|
||||
```
|
||||
echo 'source /etc/profile.d/undistract-me.sh' >> ~/.bashrc
|
||||
```
|
||||
|
||||
或者,你可以运行此命令将其添加到你的 Bash:
|
||||
|
||||
```
|
||||
echo "source /usr/share/undistract-me/long-running.bash\nnotify_when_long_running_commands_finish_install" >> .bashrc
|
||||
```
|
||||
|
||||
如果你在 Zsh shell 中,请运行以下命令:
|
||||
|
||||
```
|
||||
echo "source /usr/share/undistract-me/long-running.bash\nnotify_when_long_running_commands_finish_install" >> .zshrc
|
||||
```
|
||||
|
||||
最后更新更改:
|
||||
|
||||
对于 Bash:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
对于 Zsh:
|
||||
|
||||
```
|
||||
source ~/.zshrc
|
||||
```
|
||||
|
||||
#### 配置 Undistract-me
|
||||
|
||||
默认情况下,Undistract-me 会将任何超过 10 秒的命令视为长时间运行的命令。你可以通过编辑 /usr/share/undistract-me/long-running.bash 来更改此时间间隔。
|
||||
|
||||
```
|
||||
sudo nano /usr/share/undistract-me/long-running.bash
|
||||
```
|
||||
|
||||
找到 “LONG_RUNNING_COMMAND_TIMEOUT” 变量并将默认值(10 秒)更改为你所选择的其他值。
|
||||
|
||||
[][7]
|
||||
|
||||
保存并关闭文件。不要忘记更新更改:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
此外,你可以禁用特定命令的通知。为此,找到 “LONG_RUNNING_IGNORE_LIST” 变量并像下面那样用空格分隔命令。
|
||||
|
||||
默认情况下,只有当活动窗口不是命令运行的窗口时才会显示通知。也就是说,只有当命令在后台“终端”窗口中运行时,它才会通知你。如果该命令在活动窗口终端中运行,则不会收到通知。如果你希望无论终端窗口可见还是在后台都发送通知,你可以将 IGNORE_WINDOW_CHECK 设置为 1 以跳过窗口检查。
|
||||
|
||||
Undistract-me 的另一个很酷的功能是当命令完成时,你可以设置音频通知和可视通知。默认情况下,它只会发送一个可视通知。你可以通过在命令行上将变量 UDM_PLAY_SOUND 设置为非零整数来更改此行为。但是,你的 Ubuntu 系统应该安装 pulseaudio-utils 和 sound-theme-freedesktop 程序来启用此功能。
|
||||
|
||||
请记住,你需要运行以下命令来更新所做的更改。
|
||||
|
||||
对于 Bash:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
对于 Zsh:
|
||||
|
||||
```
|
||||
source ~/.zshrc
|
||||
```
|
||||
|
||||
现在是时候来验证这是否真的有效。
|
||||
|
||||
#### 在长时间运行的终端命令完成时获取通知
|
||||
|
||||
现在,运行任何需要超过 10 秒或者你在 Undistract-me 脚本中定义的时间的命令
|
||||
|
||||
我在 Arch Linux 桌面上运行以下命令。
|
||||
|
||||
```
|
||||
sudo pacman -Sy
|
||||
```
|
||||
|
||||
这个命令花了 32 秒完成。上述命令完成后,我收到以下通知。
|
||||
|
||||
[][8]
|
||||
|
||||
请记住,只有当给定的命令花了超过 10 秒才能完成,Undistract-me 脚本才会通知你。如果命令在 10 秒内完成,你将不会收到通知。当然,你可以按照上面的“配置”部分所述更改此时间间隔设置。
|
||||
|
||||
我发现这个工具非常有用。在我迷失在其他任务上时,它帮助我回到正事。我希望这个工具也能对你有帮助。
|
||||
|
||||
还有更多的工具。保持耐心!
|
||||
|
||||
干杯!
|
||||
|
||||
资源:
|
||||
|
||||
* [Undistract-me GitHub 仓库][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/undistract-get-notification-long-running-terminal-commands-complete/
|
||||
|
||||
作者:[sk][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/jml/undistract-me
|
||||
[2]:https://www.ostechnix.com/author/sk/
|
||||
[3]:https://www.ostechnix.com/get-notification-terminal-task-done/
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/11/undistract-me-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/11/undistract-me-2.png
|
||||
@ -0,0 +1,71 @@
|
||||
### [Fedora 课堂会议: Ansible 101][2]
|
||||
|
||||
### By Sachin S Kamath
|
||||
|
||||

|
||||
|
||||
Fedora 课堂会议本周继续进行,本周的主题是 Ansible。 会议的时间安排表发布在 [wiki][3] 上。你还可以从那里找到[之前会议的资源和录像][4]。以下是会议的具体时间 [11月30日本周星期四 1600 UTC][5]。该链接可以将这个时间转换为您的时区上的时间。
|
||||
|
||||
### 主题: Ansible 101
|
||||
|
||||
正如 Ansible [文档][6] 所说,Ansible 是一个 IT 自动化工具。它主要用于配置系统,部署软件和编排更高级的 IT 任务。示例包括持续交付与零停机滚动升级。
|
||||
|
||||
本课堂课程涵盖以下主题:
|
||||
|
||||
1. SSH 简介
|
||||
|
||||
2. 了解不同的术语
|
||||
|
||||
3. Ansible 简介
|
||||
|
||||
4. Ansible 安装和设置
|
||||
|
||||
5. 建立无密码连接
|
||||
|
||||
6. Ad-hoc 命令
|
||||
|
||||
7. 管理 inventory
|
||||
|
||||
8. Playbooks 示例
|
||||
|
||||
之后还将有 Ansible 102 的后续会议。该会议将涵盖复杂的 playbooks,playbooks 角色(roles),动态 inventory 文件,流程控制和 Ansible Galaxy 命令行工具.
|
||||
|
||||
### 讲师
|
||||
|
||||
我们有两位经验丰富的讲师进行这次会议。
|
||||
|
||||
[Geoffrey Marr][7],IRC 聊天室中名字叫 coremodule,是 Red Hat 的一名员工和 Fedora 的贡献者,拥有 Linux 和云技术的背景。工作时,他潜心于 [Fedora QA][8] wiki 和测试页面中。业余时间, 他热衷于 RaspberryPi 项目,尤其是专注于那些软件无线电(Software-defined radio)项目。
|
||||
|
||||
[Vipul Siddharth][9] 是Red Hat的实习生,他也在Fedora上工作。他喜欢贡献开源,借此机会传播自由开源软件。
|
||||
|
||||
### 加入会议
|
||||
|
||||
本次会议将在 [BlueJeans][10] 上进行。下面的信息可以帮你加入到会议:
|
||||
|
||||
* 网址: [https://bluejeans.com/3466040121][1]
|
||||
|
||||
* 会议 ID (桌面版): 3466040121
|
||||
|
||||
我们希望您可以参加,学习,并享受这个会议!如果您对会议有任何反馈意见,有什么新的想法或者想要主持一个会议, 可以随时在这篇文章发表评论或者查看[课堂 wiki 页面][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-classroom-session-ansible-101/
|
||||
|
||||
作者:[Sachin S Kamath]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://bluejeans.com/3466040121
|
||||
[2]:https://fedoramagazine.org/fedora-classroom-session-ansible-101/
|
||||
[3]:https://fedoraproject.org/wiki/Classroom
|
||||
[4]:https://fedoraproject.org/wiki/Classroom#Previous_Sessions
|
||||
[5]:https://www.timeanddate.com/worldclock/fixedtime.html?msg=Fedora+Classroom+-+Ansible+101&iso=20171130T16&p1=%3A
|
||||
[6]:http://docs.ansible.com/ansible/latest/index.html
|
||||
[7]:https://fedoraproject.org/wiki/User:Coremodule
|
||||
[8]:https://fedoraproject.org/wiki/QA
|
||||
[9]:https://fedoraproject.org/wiki/User:Siddharthvipul1
|
||||
[10]:https://www.bluejeans.com/downloads
|
||||
[11]:https://fedoraproject.org/wiki/Classroom
|
||||
@ -0,0 +1,127 @@
|
||||
Linux 中最佳的网络监视工具
|
||||
===============================
|
||||
|
||||
保持对我们的网络的管理,防止任何程序过度使用网络、导致整个系统操作变慢,对管理员来说是至关重要的。对不同的系统操作,这是有几个网络监视工具。在这篇文章中,我们将讨论从 Linux 终端中运行的 10 个网络监视工具。它对不使用 GUI 而希望通过 SSH 来保持对网络管理的用户来说是非常理想的。
|
||||
|
||||
### Iftop
|
||||
|
||||
[][2]
|
||||
|
||||
与 Linux 用户经常使用的 Top 是非常类似的。这是一个系统监视工具,它允许我们知道在我们的系统中实时运行的进程,并可以很容易地管理它们。Iftop 与 Top 应用程序类似,但它是专门监视网络的,通过它可以知道更多的关于网络的详细情况和使用网络的所有进程。
|
||||
|
||||
我们可以从 [这个链接][3] 获取关于这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Vnstat
|
||||
|
||||
[][4]
|
||||
|
||||
**Vnstat** 是一个缺省包含在大多数 Linux 发行版中的网络监视工具。它允许我们在一个用户选择的时间周期内获取一个实时管理的发送和接收的流量。
|
||||
|
||||
我们可以从 [这个链接][5] 获取关于这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Iptraf
|
||||
|
||||
[][6]
|
||||
|
||||
**IPTraf** 是一个 Linux 的、基于控制台的、实时网络监视程序。(IP LAN) - 收集经过这个网络的各种各样的信息作为一个 IP 流量监视器,包括 TCP 标志信息、ICMP 详细情况、TCP / UDP 流量故障、TCP 连接包和 Byne 报告。它也收集接口上全部的 TCP、UDP、…… 校验和错误、接口活动等等的详细情况。
|
||||
|
||||
我们可以从 [这个链接][7] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Monitorix - 系统和网络监视
|
||||
|
||||
[][8]
|
||||
|
||||
Monitorix 是一个轻量级的免费应用程序,它设计用于去监视尽可能多的 Linux / Unix 服务器的系统和网络资源。一个 HTTP web 服务器可以被添加到它里面,定期去收集系统和网络信息,并且在一个图表中显示它们。它跟踪平均的系统负载、内存分配、磁盘健康状态、系统服务、网络端口、邮件统计信息(Sendmail、Postfix、Dovecot、等等)、MySQL 统计信息以及其它的更多内容。它设计用于去管理系统的整体性能,以及帮助检测故障、瓶颈、异常活动、等等。
|
||||
|
||||
下载及更多 [信息在这里][9]。
|
||||
|
||||
### Dstat
|
||||
|
||||
[][10]
|
||||
|
||||
这个监视器相比前面的几个知名度低一些,但是,在一些发行版中已经缺省包含了。
|
||||
|
||||
我们可以从 [这个链接][11] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Bwm-ng
|
||||
|
||||
[][12]
|
||||
|
||||
这是最简化的工具中的一个。它允许你去从交互式连接中取得数据,并且,为了便于其它设备使用,在取得数据的同时,能以某些格式导出它们。
|
||||
|
||||
我们可以从 [这个链接][13] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Ibmonitor
|
||||
|
||||
[][14]
|
||||
|
||||
与上面的类似,它显示连接接口上过滤后的网络流量,并且,从接收到的流量中明确地区分区开发送流量。
|
||||
|
||||
我们可以从 [这个链接][15] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Htop - Linux 进程跟踪
|
||||
|
||||
[][16]
|
||||
|
||||
Htop 是一个更高级的、交互式的、实时的 Linux 进程跟踪工具。它类似于 Linux 的 top 命令,但是有一些更高级的特性,比如,一个更易于使用的进程管理接口、快捷键、水平和垂直的进程视图、等更多特性。Htop 是一个第三方工具,它不包含在 Linux 系统中,你必须使用 **YUM** 或者 **APT-GET** 或者其它的包管理工具去安装它。关于安装它的更多信息,读[这篇文章][17]。
|
||||
|
||||
我们可以从 [这个链接][18] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Arpwatch - 以太网活动监视器
|
||||
|
||||
[][19]
|
||||
|
||||
Arpwatch 是一个设计用于在 Linux 网络中去管理以太网通讯的地址解析的程序。它持续监视以太网通讯并记录 IP 地址和 MAC 地址的变化。在一个网络中,它们的变化同时伴随记录一个时间戳。它也有一个功能是当一对 IP 和 MAC 地址被添加或者发生变化时,发送一封邮件给系统管理员。在一个网络中发生 ARP 攻击时,这个功能非常有用。
|
||||
|
||||
我们可以从 [这个链接][20] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Wireshark - 网络监视工具
|
||||
|
||||
[][21]
|
||||
|
||||
**[Wireshark][1]** 是一个免费的应用程序,它允许你去捕获和查看前往你的系统和从你的系统中返回的信息,它可以去深入到通讯包中并查看每个包的内容 – 分开它们来满足你的特殊需要。它一般用于去研究协议问题和去创建和测试程序的特别情况。这个开源分析器是一个被公认的分析器商业标准,它的流行是因为纪念那些年的荣誉。
|
||||
|
||||
最初它被认识是因为 Ethereal,Wireshark 有轻量化的、易于去理解的界面,它能分类显示来自不同的真实系统上的协议信息。
|
||||
|
||||
### 结论
|
||||
|
||||
在这篇文章中,我们看了几个开源的网络监视工具。由于我们从这些工具中挑选出来的认为是“最佳的”,并不意味着它们都是最适合你的需要的。例如,现在有很多的开源监视工具,比如,OpenNMS、Cacti、和 Zennos,并且,你需要去从你的个体情况考虑它们的每个工具的优势。
|
||||
|
||||
另外,还有不同的、更适合你的需要的不开源的工具。
|
||||
|
||||
你知道的或者使用的在 Linux 终端中的更多网络监视工具还有哪些?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-network-monitoring-tools-for-linux
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:https://www.wireshark.org/
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/iftop_orig.png
|
||||
[3]:http://www.ex-parrot.com/pdw/iftop/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/vnstat.png
|
||||
[5]:http://humdi.net/vnstat/
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/iptraf_orig.gif
|
||||
[7]:http://iptraf.seul.org/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/monitorix_orig.png
|
||||
[9]:http://www.monitorix.org
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/dstat_orig.png
|
||||
[11]:http://dag.wiee.rs/home-made/dstat/
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/bwm-ng_orig.png
|
||||
[13]:http://sourceforge.net/projects/bwmng/
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ibmonitor_orig.jpg
|
||||
[15]:http://ibmonitor.sourceforge.net/
|
||||
[16]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/htop_orig.png
|
||||
[17]:http://wesharethis.com/knowledgebase/htop-and-atop/
|
||||
[18]:http://hisham.hm/htop/
|
||||
[19]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/arpwatch_orig.png
|
||||
[20]:http://linux.softpedia.com/get/System/Monitoring/arpwatch-NG-7612.shtml
|
||||
[21]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/how-to-use-wireshark_1_orig.jpg
|
||||
|
||||
|
||||
163
translated/tech/20171205 How to Use the Date Command in Linux.md
Normal file
163
translated/tech/20171205 How to Use the Date Command in Linux.md
Normal file
@ -0,0 +1,163 @@
|
||||
如何使用 Date 命令
|
||||
======
|
||||
在本文中, 我们会通过一些案例来演示如何使用 linux 中的 date 命令. date 命令可以用户输出/设置系统日期和时间. Date 命令很简单, 请参见下面的例子和语法.
|
||||
|
||||
默认情况下,当不带任何参数运行 date 命令时,它会输出当前系统日期和时间:
|
||||
|
||||
```shell
|
||||
date
|
||||
```
|
||||
|
||||
```
|
||||
Sat 2 Dec 12:34:12 CST 2017
|
||||
```
|
||||
|
||||
#### 语法
|
||||
|
||||
```
|
||||
Usage: date [OPTION]... [+FORMAT]
|
||||
or: date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
|
||||
Display the current time in the given FORMAT, or set the system date.
|
||||
|
||||
```
|
||||
|
||||
### 案例
|
||||
|
||||
下面这些案例会向你演示如何使用 date 命令来查看前后一段时间的日期时间.
|
||||
|
||||
#### 1\. 查找5周后的日期
|
||||
|
||||
```shell
|
||||
date -d "5 weeks"
|
||||
Sun Jan 7 19:53:50 CST 2018
|
||||
|
||||
```
|
||||
|
||||
#### 2\. 查找5周后又过4天的日期
|
||||
|
||||
```shell
|
||||
date -d "5 weeks 4 days"
|
||||
Thu Jan 11 19:55:35 CST 2018
|
||||
|
||||
```
|
||||
|
||||
#### 3\. 获取下个月的日期
|
||||
|
||||
```shell
|
||||
date -d "next month"
|
||||
Wed Jan 3 19:57:43 CST 2018
|
||||
```
|
||||
|
||||
#### 4\. 获取下周日的日期
|
||||
|
||||
```shell
|
||||
date -d last-sunday
|
||||
Sun Nov 26 00:00:00 CST 2017
|
||||
```
|
||||
|
||||
date 命令还有很多格式化相关的选项, 下面的例子向你演示如何格式化 date 命令的输出.
|
||||
|
||||
#### 5\. 以 yyyy-mm-dd 的格式显示日期
|
||||
|
||||
```shell
|
||||
date +"%F"
|
||||
2017-12-03
|
||||
```
|
||||
|
||||
#### 6\. 以 mm/dd/yyyy 的格式显示日期
|
||||
|
||||
```shell
|
||||
date +"%m/%d/%Y"
|
||||
12/03/2017
|
||||
|
||||
```
|
||||
|
||||
#### 7\. 只显示时间
|
||||
|
||||
```shell
|
||||
date +"%T"
|
||||
20:07:04
|
||||
|
||||
```
|
||||
|
||||
#### 8\. 显示今天是一年中的第几天
|
||||
|
||||
```shell
|
||||
date +"%j"
|
||||
337
|
||||
|
||||
```
|
||||
|
||||
#### 9\. 与格式化相关的选项
|
||||
|
||||
| **%%** | 百分号 (“**%**“). |
|
||||
| **%a** | 星期的缩写形式 (像这样, **Sun**). |
|
||||
| **%A** | 星期的完整形式 (像这样, **Sunday**). |
|
||||
| **%b** | 缩写的月份 (像这样, **Jan**). |
|
||||
| **%B** | 当前区域的月份全称 (像这样, **January**). |
|
||||
| **%c** | 日期以及时间 (像这样, **Thu Mar 3 23:05:25 2005**). |
|
||||
| **%C** | 本世纪; 类似 **%Y**, 但是会省略最后两位 (像这样, **20**). |
|
||||
| **%d** | 月中的第几日 (像这样, **01**). |
|
||||
| **%D** | 日期; 效果与 **%m/%d/%y** 一样. |
|
||||
| **%e** | 月中的第几日, 会填充空格; 与 **%_d** 一样. |
|
||||
| **%F** | 完整的日期; 跟 **%Y-%m-%d** 一样. |
|
||||
| **%g** | 年份的后两位 (参见 **%G**). |
|
||||
| **%G** | 年份 (参见 **%V**); 通常跟 **%V** 连用. |
|
||||
| **%h** | 同 **%b**. |
|
||||
| **%H** | 小时 (**00**..**23**). |
|
||||
| **%I** | 小时 (**01**..**12**). |
|
||||
| **%j** | 一年中的第几天 (**001**..**366**). |
|
||||
| **%k** | 小时, 用空格填充 ( **0**..**23**); same as **%_H**. |
|
||||
| **%l** | 小时, 用空格填充 ( **1**..**12**); same as **%_I**. |
|
||||
| **%m** | 月份 (**01**..**12**). |
|
||||
| **%M** | 分钟 (**00**..**59**). |
|
||||
| **%n** | 换行. |
|
||||
| **%N** | 纳秒 (**000000000**..**999999999**). |
|
||||
| **%p** | 当前区域时间是上午 **AM** 还是下午 **PM**; 未知则为空哦. |
|
||||
| **%P** | 类似 **%p**, 但是用小写字母现实. |
|
||||
| **%r** | 当前区域的12小时制现实时间 (像这样, **11:11:04 PM**). |
|
||||
| **%R** | 24-小时制的小时和分钟; 同 **%H:%M**. |
|
||||
| **%s** | 从 1970-01-01 00:00:00 UTC 到现在经历的秒数. |
|
||||
| **%S** | 秒数 (**00**..**60**). |
|
||||
| **%t** | tab 制表符. |
|
||||
| **%T** | 时间; 同 **%H:%M:%S**. |
|
||||
| **%u** | 星期 (**1**..**7**); 1 表示 **星期一**. |
|
||||
| **%U** | 一年中的第几个星期, 以周日为一周的开始 (**00**..**53**). |
|
||||
| **%V** | 一年中的第几个星期,以周一为一周的开始 (**01**..**53**). |
|
||||
| **%w** | 用数字表示周几 (**0**..**6**); 0 表示 **周日**. |
|
||||
| **%W** | 一年中的第几个星期, 周一为一周的开始 (**00**..**53**). |
|
||||
| **%x** | Locale’s date representation (像这样, **12/31/99**). |
|
||||
| **%X** | Locale’s time representation (像这样, **23:13:48**). |
|
||||
| **%y** | 年份的后面两位 (**00**..**99**). |
|
||||
| **%Y** | 年. |
|
||||
| **%z** | +hhmm 指定数字时区 (像这样, **-0400**). |
|
||||
| **%:z** | +hh:mm 指定数字时区 (像这样, **-04:00**). |
|
||||
| **%::z** | +hh:mm:ss 指定数字时区 (像这样, **-04:00:00**). |
|
||||
| **%:::z** | 指定数字时区, 其中 “**:**” 的个数由你需要的精度来决定 (例如, **-04**, **+05:30**). |
|
||||
| **%Z** | 时区的字符缩写(例如, EDT). |
|
||||
|
||||
#### 10\. 设置系统时间
|
||||
|
||||
你也可以使用 date 来手工设置系统时间,方法是使用 `--set` 选项, 下面的例子会将系统时间设置成2017年8月30日下午4点22分
|
||||
|
||||
```shell
|
||||
date --set="20170830 16:22"
|
||||
|
||||
```
|
||||
|
||||
当然, 如果你使用的是我们的 [VPS Hosting services][1], 你总是可以联系并咨询我们的Linux专家管理员 (通过客服电话或者下工单的方式) 关于 date 命令的任何东西. 他们是 24×7 在线的,会立即向您提供帮助.
|
||||
|
||||
PS. 如果你喜欢这篇帖子,请点击下面的按钮分享或者留言. 谢谢.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/use-the-date-command-in-linux/
|
||||
|
||||
作者:[][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/hosting-services.html
|
||||
@ -0,0 +1,138 @@
|
||||
NETSTAT 命令: 通过案例学习使用 netstate
|
||||
======
|
||||
Netstat 是一个告诉我们系统中所有 tcp/udp/unix socket 连接状态的命令行工具。它会列出所有已经连接或者等待连接状态的连接。 该工具在识别某个应用监听哪个端口时特别有用,我们也能用它来判断某个应用是否正常的在监听某个端口。
|
||||
|
||||
Netstat 命令还能显示其他各种各样的网络相关信息,例如路由表, 网卡统计信息, 虚假连接以及多播成员等。
|
||||
|
||||
本文中,我们会通过几个例子来学习 Netstat。
|
||||
|
||||
(推荐阅读: [Learn to use CURL command with examples][1] )
|
||||
|
||||
Netstat with examples
|
||||
============================================================
|
||||
|
||||
### 1- 检查所有的连接
|
||||
|
||||
使用 `a` 选项可以列出系统中的所有连接,
|
||||
```shell
|
||||
$ netstat -a
|
||||
```
|
||||
|
||||
这会显示系统所有的 tcp,udp 以及 unix 连接。
|
||||
|
||||
### 2- 检查所有的 tcp/udp/unix socket 连接
|
||||
|
||||
使用 `t` 选项只列出 tcp 连接,
|
||||
|
||||
```shell
|
||||
$ netstat -at
|
||||
```
|
||||
|
||||
类似的,使用 `u` 选项只列出 udp 连接 to list out only the udp connections on our system, we can use ‘u’ option with netstat,
|
||||
|
||||
```shell
|
||||
$ netstat -au
|
||||
```
|
||||
|
||||
使用 `x` 选项只列出 Unix socket 连接,we can use ‘x’ options,
|
||||
|
||||
```shell
|
||||
$ netstat -ax
|
||||
```
|
||||
|
||||
### 3- 同时列出进程 ID/进程名称
|
||||
|
||||
使用 `p` 选项可以在列出连接的同时也显示 PID 或者进程名称,而且它还能与其他选项连用,
|
||||
|
||||
```shell
|
||||
$ netstat -ap
|
||||
```
|
||||
|
||||
### 4- 列出端口号而不是服务名
|
||||
|
||||
使用 `n` 选项可以加快输出,它不会执行任何反向查询(译者注:这里原文说的是 "it will perform any reverse lookup",应该是写错了),而是直接输出数字。 由于无需查询,因此结果输出会快很多。
|
||||
|
||||
```shell
|
||||
$ netstat -an
|
||||
```
|
||||
|
||||
### 5- 只输出监听端口
|
||||
|
||||
使用 `l` 选项只输出监听端口。它不能与 `a` 选项连用,因为 `a` 会输出所有端口,
|
||||
|
||||
```shell
|
||||
$ netstat -l
|
||||
```
|
||||
|
||||
### 6- 输出网络状态
|
||||
|
||||
使用 `s` 选项输出每个协议的统计信息,包括接收/发送的包数量
|
||||
|
||||
```shell
|
||||
$ netstat -s
|
||||
```
|
||||
|
||||
### 7- 输出网卡状态
|
||||
|
||||
使用 `I` 选项只显示网卡的统计信息,
|
||||
|
||||
```shell
|
||||
$ netstat -i
|
||||
```
|
||||
|
||||
### 8- 显示多播组(multicast group)信息
|
||||
|
||||
使用 `g` 选项输出 IPV4 以及 IPV6 的多播组信息,
|
||||
|
||||
```shell
|
||||
$ netstat -g
|
||||
```
|
||||
|
||||
### 9- 显示网络路由信息
|
||||
|
||||
使用 `r` 输出网络路由信息,
|
||||
|
||||
```shell
|
||||
$ netstat -r
|
||||
```
|
||||
|
||||
### 10- 持续输出
|
||||
|
||||
使用 `c` 选项持续输出结果
|
||||
|
||||
```shell
|
||||
$ netstat -c
|
||||
```
|
||||
|
||||
### 11- 过滤出某个端口
|
||||
|
||||
与 `grep` 连用来过滤出某个端口的连接,
|
||||
|
||||
```shell
|
||||
$ netstat -anp | grep 3306
|
||||
```
|
||||
|
||||
### 12- 统计连接个数
|
||||
|
||||
通过与 wc 和 grep 命令连用,可以统计指定端口的连接数量
|
||||
|
||||
```shell
|
||||
$ netstat -anp | grep 3306 | wc -l
|
||||
```
|
||||
|
||||
这回输出 mysql 服务端口(即 3306)的连接数。
|
||||
|
||||
这就是我们间断的案例指南了,希望它带给你的信息量足够。 有任何疑问欢迎提出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/learn-use-netstat-with-examples/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/learn-use-curl-command-examples/
|
||||
@ -0,0 +1,229 @@
|
||||
Linux下使用sudo进行赋权
|
||||
======
|
||||
我最近写了一个简短的 Bash 程序来将 MP3 文件从一台网络主机的 UBS 盘中拷贝到另一台网络主机上去。拷贝出来的文件存放在一台志愿者组织所属服务器的特定目录下, 在那里,这些文件可以被下载和播放。
|
||||
|
||||
我的程序还会做些其他事情,比如为了自动在网页上根据日期排序,在拷贝文件之前会先对这些文件重命名。 在验证拷贝完成后,还会删掉 USB 盘中的所有文件。 这个小程序还有一些其他选项,比如 `-h` 会显示帮助, `-t` 进入测试模式等等。
|
||||
|
||||
我的程序需要以 root 运行才能发挥作用。然而, 这个组织中之后很少的人对管理音频和计算机系统有兴趣的,这使得我不得不找那些半吊子的科技人员来,并培训他们登陆用于传输的计算机,运行这个小程序。
|
||||
|
||||
倒不是说我不能亲自运行这个程序,但由于外出和疾病等等各种原因, 我不是时常在场的。 即使我在场, 作为一名 "懒惰的系统管理员", 我也希望别人能替我把事情给做了。 因此我写了一些脚本来自动完成这些人物并通过 sudo 来指定某些人来运行这些脚本。 很多 Linux 命令都需要用户以 root 身份来运行。 sudo 能够保护系统免遭一时糊涂造成的意外损坏以及恶意用户的故意破坏。
|
||||
|
||||
### Do that sudo that you do so well
|
||||
|
||||
sudo 是一个很方便的工具,它让我一个 root 管理员可以分配所有或者部分管理性的任务给其他用户, 而且还无需告诉他们 root 密码, 从而保证主机的高安全性。
|
||||
|
||||
假设,我给了普通用户 "ruser" 访问我 Bash 程序 "myprog" 的权限, 而这个程序的部分功能需要 root 权限。 那么该用户可以以 ruser 的身份登陆,然后通过以下命令运行 myprog。
|
||||
|
||||
```shell
|
||||
sudo myprog
|
||||
```
|
||||
|
||||
我发现在训练时记录下每个用 sudo 执行的命令会很有帮助。我可以看到谁执行了哪些命令,他们是否输对了。
|
||||
|
||||
我委派了权限给自己和另一个人来运行那个程序; 然而,sudo 可以做更多的事情。 它允许系统管理员委派网络管理或特定的服务器权限给某个人或某组人,以此来保护 root 密码的安全性。
|
||||
|
||||
### 配置 sudoers 文件
|
||||
|
||||
作为一名系统管理员,我使用 `/etc/sudoers` 文件来设置某些用户或某些用户组可以访问某个命令,或某组命令,或所有命令。 这种灵活性是使用 sudo 进行委派时能兼顾功能与简易性的关键。
|
||||
|
||||
我一开始对 `sudoers` 文件感到很困惑,因此下面我会拷贝并分解我所使用主机上的完整 `sudoers` 文件。 希望在分析的过程中不会让你感到困惑。 我意外地发现, 基于 Red Hat 的发行版中默认的配置文件都会很多注释以及例子来指导你如何做出修改,这使得修改配置文件变得简单了很多,也不需要在互联网上搜索那么多东西了。
|
||||
|
||||
不要直接用编辑起来修改 sudoers 文件,而应该用 `visudo` 命令,因为该命令会在你保存并退出编辑器后就立即生效这些变更。 visudo 也可以使用除了 `Vi` 之外的其他编辑器。
|
||||
|
||||
让我们首先来分析一下文件中的各种别名。
|
||||
|
||||
#### Host aliases(主机别名)
|
||||
|
||||
host aliases 用于创建主机分组,在不同主机上可以设置允许访问不同的命令或命令别名 (command aliases)。 它的基本思想是,该文件由组织中的所有主机共同维护,然后拷贝到每台主机中的 `/etc` 中。 其中有些主机, 例如各种服务器, 可以配置成一个组来赋予用户访问特定命令的权限, 比如可以启停类似 HTTPD, DNS, 以及网络服务; 可以挂载文件系统等等。
|
||||
|
||||
在设置主机别名时也可以用 IP 地址替代主机名。
|
||||
|
||||
```
|
||||
## Sudoers allows particular users to run various commands as
|
||||
## the root user,without needing the root password。
|
||||
##
|
||||
## Examples are provided at the bottom of the file for collections
|
||||
## of related commands,which can then be delegated out to particular
|
||||
## users or groups。
|
||||
##
|
||||
## This file must be edited with the 'visudo' command。
|
||||
|
||||
## Host Aliases
|
||||
## Groups of machines。You may prefer to use hostnames (perhaps using
|
||||
## wildcards for entire domains) or IP addresses instead。
|
||||
# Host_Alias FILESERVERS = fs1,fs2
|
||||
# Host_Alias MAILSERVERS = smtp,smtp2
|
||||
|
||||
## User Aliases
|
||||
## These aren't often necessary,as you can use regular groups
|
||||
## (ie,from files, LDAP, NIS, etc) in this file - just use %groupname
|
||||
## rather than USERALIAS
|
||||
# User_Alias ADMINS = jsmith,mikem
|
||||
User_Alias AUDIO = dboth,ruser
|
||||
|
||||
## Command Aliases
|
||||
## These are groups of related commands。.。
|
||||
|
||||
## Networking
|
||||
# Cmnd_Alias NETWORKING = /sbin/route,/sbin/ifconfig,
|
||||
/bin/ping,/sbin/dhclient, /usr/bin/net, /sbin/iptables,
|
||||
/usr/bin/rfcomm,/usr/bin/wvdial, /sbin/iwconfig, /sbin/mii-tool
|
||||
|
||||
## Installation and management of software
|
||||
# Cmnd_Alias SOFTWARE = /bin/rpm,/usr/bin/up2date, /usr/bin/yum
|
||||
|
||||
## Services
|
||||
# Cmnd_Alias SERVICES = /sbin/service,/sbin/chkconfig
|
||||
|
||||
## Updating the locate database
|
||||
# Cmnd_Alias LOCATE = /usr/bin/updatedb
|
||||
|
||||
## Storage
|
||||
# Cmnd_Alias STORAGE = /sbin/fdisk,/sbin/sfdisk, /sbin/parted, /sbin/partprobe, /bin/mount, /bin/umount
|
||||
|
||||
## Delegating permissions
|
||||
# Cmnd_Alias DELEGATING = /usr/sbin/visudo,/bin/chown, /bin/chmod, /bin/chgrp
|
||||
|
||||
## Processes
|
||||
# Cmnd_Alias PROCESSES = /bin/nice,/bin/kill, /usr/bin/kill, /usr/bin/killall
|
||||
|
||||
## Drivers
|
||||
# Cmnd_Alias DRIVERS = /sbin/modprobe
|
||||
|
||||
# Defaults specification
|
||||
|
||||
#
|
||||
# Refuse to run if unable to disable echo on the tty。
|
||||
#
|
||||
Defaults!visiblepw
|
||||
|
||||
Defaults env_reset
|
||||
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
|
||||
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
|
||||
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
|
||||
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
|
||||
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
|
||||
|
||||
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
|
||||
|
||||
## Next comes the main part: which users can run what software on
|
||||
## which machines (the sudoers file can be shared between multiple
|
||||
## systems)。
|
||||
## Syntax:
|
||||
##
|
||||
## user MACHINE=COMMANDS
|
||||
##
|
||||
## The COMMANDS section may have other options added to it。
|
||||
##
|
||||
## Allow root to run any commands anywhere
|
||||
root ALL=(ALL) ALL
|
||||
|
||||
## Allows members of the 'sys' group to run networking,software,
|
||||
## service management apps and more。
|
||||
# %sys ALL = NETWORKING,SOFTWARE, SERVICES, STORAGE, DELEGATING, PROCESSES, LOCATE, DRIVERS
|
||||
|
||||
## Allows people in group wheel to run all commands
|
||||
%wheel ALL=(ALL) ALL
|
||||
|
||||
## Same thing without a password
|
||||
# %wheel ALL=(ALL) NOPASSWD: ALL
|
||||
|
||||
## Allows members of the users group to mount and unmount the
|
||||
## cdrom as root
|
||||
# %users ALL=/sbin/mount /mnt/cdrom,/sbin/umount /mnt/cdrom
|
||||
|
||||
## Allows members of the users group to shutdown this system
|
||||
# %users localhost=/sbin/shutdown -h now
|
||||
|
||||
## Read drop-in files from /etc/sudoers.d (the # here does not mean a comment)
|
||||
#includedir /etc/sudoers.d
|
||||
|
||||
################################################################################
|
||||
# Added by David Both,11/04/2017 to provide limited access to myprog #
|
||||
################################################################################
|
||||
#
|
||||
AUDIO guest1=/usr/local/bin/myprog
|
||||
```
|
||||
|
||||
#### User aliases(用户别名)
|
||||
|
||||
user alias 允许 root 将用户整理成组并按组来分配权限。在这部分内容中我加了一行 `User_Alias AUDIO = dboth, ruser`,他定义了一个别名 `AUDIO` 用来指代了两个用户。
|
||||
|
||||
正如 `sudoers` 文件中所阐明的,也可以直接使用 `/etc/groups` 中定义的组而不用自己设置别名。 如果你定义好的组(假设组名为 "audio")已经能满足要求了, 那么在后面分配命令时只需要在组名前加上 `%` 号,像这样: %audio。
|
||||
|
||||
#### Command aliases(命令别名)
|
||||
|
||||
再后面是 command aliases 部分。这些别名表示的是一系列相关的命令, 比如网络相关命令,或者 RPM 包管理命令。 这些别名允许系统管理员方便地为一组命令分配权限。
|
||||
|
||||
该部分内容已经设置好了许多别名,这使得分配权限给某类命令变得方便很多。
|
||||
|
||||
#### Environment defaults(环境默认值)
|
||||
|
||||
下部分内容设置默认的环境变量。这部分最值得关注的是 `!visiblepw` 这一行, 它表示当用户环境设置成显示密码时禁止 `sudo` 的运行。 这个安全措施不应该被修改掉。
|
||||
|
||||
#### Command section(命令部分)
|
||||
|
||||
command 部分是 `sudoers` 文件的主体。不使用别名并不会影响你完成要实现 的效果。 它只是让整个配置工作大幅简化而已。
|
||||
|
||||
这部分使用之前定义的别名来告诉 `sudo` 哪些人可以在哪些机器上执行哪些操作。一旦你理解了这部分内容的语法,你会发现这些例子都非常的直观。 下面我们来看看它的语法。
|
||||
|
||||
```
|
||||
ruser ALL=(ALL) ALL
|
||||
```
|
||||
|
||||
这是一条为用户 ruser 做出的配置。行中第一个 `ALL` 表示该条规则在所有主机上生效。 第二个 `ALL` 允许 ruser 以其他用户的身份运行命令。 默认情况下, 命令以 root 用户的身份运行, 但 ruser 可以在 sudo 命令行指定程序以其他用户的身份运行。 最后这个 ALL 表示 ruser 可以运行所有命令而不受限制。 这让 ruser 实际上就变成了 root。
|
||||
|
||||
注意到下面还有一条针对 root 的配置。这允许 root 能通过 sudo 在任何主机上运行任何命令。
|
||||
|
||||
```
|
||||
root ALL=(ALL) ALL
|
||||
```
|
||||
|
||||
为了实验一下效果,我注释掉了这行, 然后以 root 的身份, 试着直接运行 chown。 出乎意料的是这样是能成功的。 然后我试了下 sudo chown,结果失败了,提示信息 "Root is not in the sudoers file。 This incident will be reported"。 也就是说 root 可以直接运行任何命令, 但当加上 sudo 时则不行。 这会阻止 root 像其他用户一样使用 sudo 命令来运行其他命令, 但是 root 有太多中方法可以绕过这个约束了。
|
||||
|
||||
下面这行是我新增来控制访问 myprog 的。它指定了只有上面定义的 AUDIO 组中的用户才能在 guest1 这台主机上使用 myprog 这个命令。
|
||||
|
||||
```
|
||||
AUDIO guest1=/usr/local/bin/myprog
|
||||
```
|
||||
|
||||
注意,上面这一行只指定了允许访问的主机名和程序, 而没有说用户可以以其他用户的身份来运行该程序。
|
||||
|
||||
#### 省略密码
|
||||
|
||||
你也可以通过 NOPASSWORD 来让 AUDIO 组中的用户无需密码就能运行 myprog。像这样 Here's how:
|
||||
|
||||
```
|
||||
AUDIO guest1=NOPASSWORD : /usr/local/bin/myprog
|
||||
```
|
||||
|
||||
我并没有这样做,因为哦我觉得使用 sudo 的用户必须要停下来想清楚他们正在做的事情,这对他们有好处。 我这里只是举个例子。
|
||||
|
||||
#### wheel
|
||||
|
||||
`sudoers` 文件中命令部分的 `wheel` 说明(如下所示)允许所有在 "wheel" 组中的用户在任何机器上运行任何命令。wheel 组在 `/etc/group` 文件中定义, 用户必须加入该组后才能工作。 组名前面的 % 符号表示 sudo 应该去 `/etc/group` 文件中查找该组。
|
||||
|
||||
```
|
||||
%wheel ALL = (ALL) ALL
|
||||
```
|
||||
|
||||
这种方法很好的实现了为多个用户赋予完全的 root 权限而不用提供 root 密码。只需要把哦嗯虎加入 wheel 组中就能给他们提供完整的 root 的能力。 它也提供了一个种通过 sudo 创建的日志来监控他们行为的途径。 有些 Linux 发行版, 比如 Ubuntu, 会自动将用户的 ID 加入 `/etc/group` 中的 wheel 组中, 这使得他们能够用 sudo 命令运行所有的特权命令。
|
||||
|
||||
### 结语
|
||||
|
||||
我这里只是小试了一把 sudo — 我只是给一到两个用户以 root 权限运行单个命令的权限。完成这些只添加了两行配置(不考虑注释)。 将某项任务的权限委派给其他非 root 用户非常简单,而且可以节省你大量的时间。 同时它还会产生日志来帮你发现问题。
|
||||
|
||||
`sudoers` 文件还有许多其他的配置和能力。查看 sudo 和 sudoers 的 man 手册可以深入了解详细信息。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/using-sudo-delegate
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
@ -0,0 +1,338 @@
|
||||
如何在 Linux 上安装友好的交互式 shell,Fish
|
||||
======
|
||||
Fish,友好的交互式 shell 的缩写,它是一个适用于类 Unix 系统的装备良好,智能而且用户友好的 shell。Fish 有着很多重要的功能,比如自动建议,语法高亮,可搜索的历史记录(像在 bash 中 CTRL+r),智能搜索功能,极好的 VGA 颜色支持,基本的 web 设置,完善的手册页和许多开箱即用的功能。尽管安装并立即使用它吧。无需更多其他配置,你也不需要安装任何额外的附加组件/插件!
|
||||
|
||||
在这篇教程中,我们讨论如何在 linux 中安装和使用 fish shell。
|
||||
|
||||
#### 安装 Fish
|
||||
|
||||
尽管 fish 是一个非常用户友好的并且功能丰富的 shell,但在大多数 Linux 发行版的默认仓库中它并没有被包括。它只能在少数 Linux 发行版中的官方仓库中找到,如 Arch Linux,Gentoo,NixOS,和 Ubuntu 等。然而,安装 fish 并不难。
|
||||
|
||||
在 Arch Linux 和它的衍生版上,运行以下命令来安装它。
|
||||
|
||||
```
|
||||
sudo pacman -S fish
|
||||
```
|
||||
|
||||
在 CentOS 7 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
cd /etc/yum.repos.d/
|
||||
```
|
||||
|
||||
```
|
||||
wget https://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
在 CentOS 6 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
cd /etc/yum.repos.d/
|
||||
```
|
||||
|
||||
```
|
||||
wget https://download.opensuse.org/repositories/shells:fish:release:2/CentOS_6/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
在 Debian 9 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
wget -nv https://download.opensuse.org/repositories/shells:fish:release:2/Debian_9.0/Release.key -O Release.key
|
||||
```
|
||||
|
||||
```
|
||||
apt-key add - < Release.key
|
||||
```
|
||||
|
||||
```
|
||||
echo 'deb http://download.opensuse.org/repositories/shells:/fish:/release:/2/Debian_9.0/ /' > /etc/apt/sources.list.d/fish.list
|
||||
```
|
||||
|
||||
```
|
||||
apt-get update
|
||||
```
|
||||
|
||||
```
|
||||
apt-get install fish
|
||||
```
|
||||
|
||||
在 Debian 8 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
wget -nv https://download.opensuse.org/repositories/shells:fish:release:2/Debian_8.0/Release.key -O Release.key
|
||||
```
|
||||
|
||||
```
|
||||
apt-key add - < Release.key
|
||||
```
|
||||
|
||||
```
|
||||
echo 'deb http://download.opensuse.org/repositories/shells:/fish:/release:/2/Debian_8.0/ /' > /etc/apt/sources.list.d/fish.list
|
||||
```
|
||||
|
||||
```
|
||||
apt-get update
|
||||
```
|
||||
|
||||
```
|
||||
apt-get install fish
|
||||
```
|
||||
|
||||
在 Fedora 26 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/Fedora_26/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
dnf install fish
|
||||
```
|
||||
|
||||
在 Fedora 25 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/Fedora_25/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
dnf install fish
|
||||
```
|
||||
|
||||
在 Fedora 24 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/Fedora_24/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
dnf install fish
|
||||
```
|
||||
|
||||
在 Fedora 23 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/Fedora_23/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
dnf install fish
|
||||
```
|
||||
|
||||
在 openSUSE 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
zypper install fish
|
||||
```
|
||||
|
||||
在 RHEL 7 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
cd /etc/yum.repos.d/
|
||||
```
|
||||
|
||||
```
|
||||
wget https://download.opensuse.org/repositories/shells:fish:release:2/RHEL_7/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
在 RHEL-6 上以 root 运行以下命令:
|
||||
|
||||
```
|
||||
cd /etc/yum.repos.d/
|
||||
```
|
||||
|
||||
```
|
||||
wget https://download.opensuse.org/repositories/shells:fish:release:2/RedHat_RHEL-6/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
在 Ubuntu 和它的衍生版上:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
```
|
||||
sudo apt-get install fish
|
||||
```
|
||||
|
||||
就这样了。是时候探索 fish shell 了。
|
||||
|
||||
### 用法
|
||||
|
||||
要从你默认的 shell 切换到 fish,请执行以下操作:
|
||||
|
||||
```
|
||||
$ fish
|
||||
Welcome to fish, the friendly interactive shell
|
||||
```
|
||||
|
||||
你可以在 ~/.config/fish/config.fish 上找到默认的 fish 配置(类似于 .bashrc)。如果它不存在,就创建它吧。
|
||||
|
||||
#### 自动建议
|
||||
|
||||
当我输入一个命令,它自动建议一个浅灰色的命令。所以,我需要输入一个 Linux 命令的前几个字母,然后按下 tab 键来完成这个命令。
|
||||
|
||||
[][2]
|
||||
|
||||
如果有更多的可能性,它将会列出它们。你可以使用上/下箭头键从列表中选择列出的命令。在选择你想运行的命令后,只需按下右箭头键,然后按下 ENTER 运行它。
|
||||
|
||||
[][3]
|
||||
|
||||
无需 CTRL+r 了!正如你已知道的,我们通过按 ctrl+r 来反向搜索 Bash shell 中的历史命令。但在 fish shell 中是没有必要的。由于它有自动建议功能,只需输入命令的前几个字母,然后从历史记录中选择已经执行的命令。Cool,是吗?
|
||||
|
||||
#### 智能搜索
|
||||
|
||||
我们也可以使用智能搜索来查找一个特定的命令,文件或者目录。例如,我输入一个命令的子串,然后按向下箭头键进行智能搜索,再次输入一个字母来从列表中选择所需的命令。
|
||||
|
||||
[][4]
|
||||
|
||||
#### 语法高亮
|
||||
|
||||
|
||||
当你输入一个命令时,你将注意到语法高亮。请看下面当我在 Bash shell 和 fish shell 中输入相同的命令时截图的区别。
|
||||
|
||||
Bash:
|
||||
|
||||
[][5]
|
||||
|
||||
Fish:
|
||||
|
||||
[][6]
|
||||
|
||||
正如你所看到的,“sudo” 在 fish shell 中已经被高亮显示。此外,默认情况下它将以红色显示无效命令。
|
||||
|
||||
#### 基于 web 的配置
|
||||
|
||||
这是 fish shell 另一个很酷的功能。我们可以设置我们的颜色,更改 fish 提示,并从网页上查看所有功能,变量,历史记录,键绑定。
|
||||
|
||||
启动 web 配置接口,只需输入:
|
||||
|
||||
```
|
||||
fish_config
|
||||
```
|
||||
|
||||
[][7]
|
||||
|
||||
#### 手册页完成
|
||||
|
||||
Bash 和 其它 shells 支持可编程完成,但只有 fish 会通过解析已安装的手册自动生成他们。
|
||||
|
||||
为此,请运行:
|
||||
|
||||
```
|
||||
fish_update_completions
|
||||
```
|
||||
|
||||
实例输出将是:
|
||||
|
||||
```
|
||||
Parsing man pages and writing completions to /home/sk/.local/share/fish/generated_completions/
|
||||
3435 / 3435 : zramctl.8.gz
|
||||
```
|
||||
|
||||
#### 禁用问候
|
||||
|
||||
默认情况下,fish 在启动时问候你(Welcome to fish, the friendly interactive shell)。如果你不想要这个问候消息,可以禁用它。为此,编辑 fish 配置文件:
|
||||
|
||||
```
|
||||
vi ~/.config/fish/config.fish
|
||||
```
|
||||
|
||||
添加以下行:
|
||||
|
||||
```
|
||||
set -g -x fish_greeting ''
|
||||
```
|
||||
|
||||
你也可以设置任意自定义的问候语,而不是禁用 fish 问候。
|
||||
Instead of disabling fish greeting, you can also set any custom greeting message.
|
||||
|
||||
```
|
||||
set -g -x fish_greeting 'Welcome to OSTechNix'
|
||||
```
|
||||
|
||||
#### 获得帮助
|
||||
|
||||
这是另一个引人注目的令人印象深刻的功能。要在终端的默认 web 浏览器中打开 fish 文档页面,只需输入:
|
||||
|
||||
```
|
||||
help
|
||||
```
|
||||
|
||||
官方文档将会在你的默认浏览器中打开。另外,你可以使用手册页来显示任何命令的帮助部分。
|
||||
|
||||
```
|
||||
man fish
|
||||
```
|
||||
|
||||
#### 设置 fish 为默认 shell
|
||||
|
||||
非常喜欢它?太好了!设置它作为默认 shell 吧。为此,请使用命令 chsh:
|
||||
|
||||
```
|
||||
chsh -s /usr/bin/fish
|
||||
```
|
||||
|
||||
在这里,/usr/bin/fish 是 fish shell 的路径。如果你不知道正确的路径,以下命令将会帮助你:
|
||||
|
||||
```
|
||||
which fish
|
||||
```
|
||||
|
||||
注销并且重新登录以使用新的默认 shell。
|
||||
|
||||
请记住,为 Bash 编写的许多 shell 脚本可能不完全兼容 fish。
|
||||
|
||||
要切换会 Bash,只需运行:
|
||||
|
||||
```
|
||||
bash
|
||||
```
|
||||
|
||||
如果你想 Bash 作为你的永久默认 shell,运行:
|
||||
|
||||
```
|
||||
chsh -s /bin/bash
|
||||
```
|
||||
|
||||
对目前的各位,这就是全部了。在这个阶段,你可能会得到一个有关 fish shell 使用的基本概念。 如果你正在寻找一个Bash的替代品,fish 可能是一个不错的选择。
|
||||
|
||||
Cheers!
|
||||
|
||||
资源:
|
||||
|
||||
* [fish shell website][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[kimii](https://github.com/kimii)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://fishshell.com/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/12/fish-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/12/fish-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/12/fish-6.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/12/fish-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/12/fish-4.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/12/fish-5.png
|
||||
Loading…
Reference in New Issue
Block a user