mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
20180202 选题
This commit is contained in:
parent
c1ba624d39
commit
7981f922a3
@ -0,0 +1,161 @@
|
||||
Learn your tools: Navigating your Git History
|
||||
============================================================
|
||||
|
||||
Starting a greenfield application everyday is nearly impossible, especially in your daily job. In fact, most of us are facing (somewhat) legacy codebases on a daily basis, and regaining the context of why some feature, or line of code exists in the codebase is very important. This is where `git`, the distributed version control system, is invaluable. Let’s dive in and see how we can use our `git` history and easily navigate through it.
|
||||
|
||||
### Git history
|
||||
|
||||
First and foremost, what is `git` history? As the name says, it is the commit history of a `git` repo. It contains a bunch of commit messages, with their authors’ name, the commit hash and the date of the commit. The easiest way to see the history of a `git`repo, is the `git log` command.
|
||||
|
||||
Sidenote: For the purpose of this post, we will use Ruby on Rails’ repo, the `master`branch. The reason behind this is because Rails has a very good `git` history, with nice commit messages, references and explanations behind every change. Given the size of the codebase, the age and the number of maintainers, it’s certainly one of the best repositories that I have seen. Of course, I am not saying there are no other repositories built with good `git` practices, but this is one that has caught my eye.
|
||||
|
||||
So back to Rails’ repo. If you run `git log` in the Rails’ repo, you will see something like this:
|
||||
|
||||
```
|
||||
commit 66ebbc4952f6cfb37d719f63036441ef98149418Author: Arthur Neves <foo@bar.com>Date: Fri Jun 3 17:17:38 2016 -0400 Dont re-define class SQLite3Adapter on test We were declaring in a few tests, which depending of the order load will cause an error, as the super class could change. see https://github.com/rails/rails/commit/ac1c4e141b20c1067af2c2703db6e1b463b985da#commitcomment-17731383commit 755f6bf3d3d568bc0af2c636be2f6df16c651eb1Merge: 4e85538 f7b850eAuthor: Eileen M. Uchitelle <foo@bar.com>Date: Fri Jun 3 10:21:49 2016 -0400 Merge pull request #25263 from abhishekjain16/doc_accessor_thread [skip ci] Fix grammarcommit f7b850ec9f6036802339e965c8ce74494f731b4aAuthor: Abhishek Jain <foo@bar.com>Date: Fri Jun 3 16:49:21 2016 +0530 [skip ci] Fix grammarcommit 4e85538dddf47877cacc65cea6c050e349af0405Merge: 082a515 cf2158cAuthor: Vijay Dev <foo@bar.com>Date: Fri Jun 3 14:00:47 2016 +0000 Merge branch 'master' of github.com:rails/docrails Conflicts: guides/source/action_cable_overview.mdcommit 082a5158251c6578714132e5c4f71bd39f462d71Merge: 4bd11d4 3bd30d9Author: Yves Senn <foo@bar.com>Date: Fri Jun 3 11:30:19 2016 +0200 Merge pull request #25243 from sukesan1984/add_i18n_validation_test Add i18n_validation_testcommit 4bd11d46de892676830bca51d3040f29200abbfaMerge: 99d8d45 e98caf8Author: Arthur Nogueira Neves <foo@bar.com>Date: Thu Jun 2 22:55:52 2016 -0400 Merge pull request #25258 from alexcameron89/master [skip ci] Make header bullets consistent in engines.mdcommit e98caf81fef54746126d31076c6d346c48ae8e1bAuthor: Alex Kitchens <foo@bar.com>Date: Thu Jun 2 21:26:53 2016 -0500 [skip ci] Make header bullets consistent in engines.md
|
||||
```
|
||||
|
||||
As you can see, the `git log` shows the commit hash, the author and his email and the date of when the commit was created. Of course, `git` being super customisable, it allows you to customise the output format of the `git log` command. Let’s say, we want to just see the first line of the commit message, we could run `git log --oneline`, which will produce a more compact log:
|
||||
|
||||
```
|
||||
66ebbc4 Dont re-define class SQLite3Adapter on test755f6bf Merge pull request #25263 from abhishekjain16/doc_accessor_threadf7b850e [skip ci] Fix grammar4e85538 Merge branch 'master' of github.com:rails/docrails082a515 Merge pull request #25243 from sukesan1984/add_i18n_validation_test4bd11d4 Merge pull request #25258 from alexcameron89/mastere98caf8 [skip ci] Make header bullets consistent in engines.md99d8d45 Merge pull request #25254 from kamipo/fix_debug_helper_test818397c Merge pull request #25240 from matthewd/reloadable-channels2c5a8ba Don't blank pad day of the month when formatting dates14ff8e7 Fix debug helper test
|
||||
```
|
||||
|
||||
To see all of the `git log` options, I recommend checking out manpage of `git log`, available in your terminal via `man git-log` or `git help log`. A tip: if `git log` is a bit scarse or complicated to use, or maybe you are just bored, I recommend checking out various `git` GUIs and command line tools. In the past I’ve used [GitX][1] which was very good, but since the command line feels like home to me, after trying [tig][2] I’ve never looked back.
|
||||
|
||||
### Finding Nemo
|
||||
|
||||
So now, since we know the bare minimum of the `git log` command, let’s see how we can explore the history more effectively in our everyday work.
|
||||
|
||||
Let’s say, hypothetically, we are suspecting an unexpected behaviour in the`String#classify` method and we want to find how and where it has been implemented.
|
||||
|
||||
One of the first commands that you can use, to see where the method is defined, is `git grep`. Simply said, this command prints out lines that match a certain pattern. Now, to find the definition of the method, it’s pretty simple - we can grep for `def classify` and see what we get:
|
||||
|
||||
```
|
||||
➜ git grep 'def classify'activesupport/lib/active_support/core_ext/string/inflections.rb: def classifyactivesupport/lib/active_support/inflector/methods.rb: def classify(table_name)tools/profile: def classify
|
||||
```
|
||||
|
||||
Now, although we can already see where our method is created, we are not sure on which line it is. If we add the `-n` flag to our `git grep` command, `git` will provide the line numbers of the match:
|
||||
|
||||
```
|
||||
➜ git grep -n 'def classify'activesupport/lib/active_support/core_ext/string/inflections.rb:205: def classifyactivesupport/lib/active_support/inflector/methods.rb:186: def classify(table_name)tools/profile:112: def classify
|
||||
```
|
||||
|
||||
Much better, right? Having the context in mind, we can easily figure out that the method that we are looking for lives in `activesupport/lib/active_support/core_ext/string/inflections.rb`, on line 205\. The `classify` method, in all of it’s glory looks like this:
|
||||
|
||||
```
|
||||
# Creates a class name from a plural table name like Rails does for table names to models.# Note that this returns a string and not a class. (To convert to an actual class# follow +classify+ with +constantize+.)## 'ham_and_eggs'.classify # => "HamAndEgg"# 'posts'.classify # => "Post"def classify ActiveSupport::Inflector.classify(self)end
|
||||
```
|
||||
|
||||
Although the method we found is the one we usually call on `String`s, it invokes another method on the `ActiveSupport::Inflector`, with the same name. Having our `git grep` result available, we can easily navigate there, since we can see the second line of the result being`activesupport/lib/active_support/inflector/methods.rb` on line 186\. The method that we are are looking for is:
|
||||
|
||||
```
|
||||
# Creates a class name from a plural table name like Rails does for table# names to models. Note that this returns a string and not a Class (To# convert to an actual class follow +classify+ with #constantize).## classify('ham_and_eggs') # => "HamAndEgg"# classify('posts') # => "Post"## Singular names are not handled correctly:## classify('calculus') # => "Calculus"def classify(table_name) # strip out any leading schema name camelize(singularize(table_name.to_s.sub(/.*\./, ''.freeze)))end
|
||||
```
|
||||
|
||||
Boom! Given the size of Rails, finding this should not take us more than 30 seconds with the help of `git grep`.
|
||||
|
||||
### So, what changed last?
|
||||
|
||||
Now, since we have the method available, we need to figure out what were the changes that this file has gone through. The since we know the correct file name and line number, we can use `git blame`. This command shows what revision and author last modified each line of a file. Let’s see what were the latest changes made to this file:
|
||||
|
||||
```
|
||||
git blame activesupport/lib/active_support/inflector/methods.rb
|
||||
```
|
||||
|
||||
Whoa! Although we get the last change of every line in the file, we are more interested in the specific method (lines 176 to 189). Let’s add a flag to the `git blame` command, that will show the blame of just those lines. Also, we will add the `-s` (suppress) option to the command, to skip the author names and the timestamp of the revision (commit) that changed the line:
|
||||
|
||||
```
|
||||
git blame -L 176,189 -s activesupport/lib/active_support/inflector/methods.rb9fe8e19a 176) # Creates a class name from a plural table name like Rails does for table5ea3f284 177) # names to models. Note that this returns a string and not a Class (To9fe8e19a 178) # convert to an actual class follow +classify+ with #constantize).51cd6bb8 179) #6d077205 180) # classify('ham_and_eggs') # => "HamAndEgg"9fe8e19a 181) # classify('posts') # => "Post"51cd6bb8 182) #51cd6bb8 183) # Singular names are not handled correctly:5ea3f284 184) #66d6e7be 185) # classify('calculus') # => "Calculus"51cd6bb8 186) def classify(table_name)51cd6bb8 187) # strip out any leading schema name5bb1d4d2 188) camelize(singularize(table_name.to_s.sub(/.*\./, ''.freeze)))51cd6bb8 189) end
|
||||
```
|
||||
|
||||
The output of the `git blame` command now shows all of the file lines and their respective revisions. Now, to see a specific revision, or in other words, what each of those revisions changed, we can use the `git show` command. When supplied a revision hash (like `66d6e7be`) as an argument, it will show you the full revision, with the author name, timestamp and the whole revision in it’s glory. Let’s see what actually changed at the latest revision that changed line 188:
|
||||
|
||||
```
|
||||
git show 5bb1d4d2
|
||||
```
|
||||
|
||||
Whoa! Did you test that? If you didn’t, it’s an awesome [commit][3] by [Schneems][4] that made a very interesting performance optimization by using frozen strings, which makes sense in our current context. But, since we are on this hypothetical debugging session, this doesn’t tell much about our current problem. So, how can we see what changes has our method under investigation gone through?
|
||||
|
||||
### Searching the logs
|
||||
|
||||
Now, we are back to the `git` log. The question is, how can we see all the revisions that the `classify` method went under?
|
||||
|
||||
The `git log` command is quite powerful, because it has a rich list of options to apply to it. We can try to see what the `git` log has stored for this file, using the `-p`options, which means show me the patch for this entry in the `git` log:
|
||||
|
||||
```
|
||||
git log -p activesupport/lib/active_support/inflector/methods.rb
|
||||
```
|
||||
|
||||
This will show us a big list of revisions, for every revision of this file. But, just like before, we are interested in the specific file lines. Let’s modify the command a bit, to show us what we need:
|
||||
|
||||
```
|
||||
git log -L 176,189:activesupport/lib/active_support/inflector/methods.rb
|
||||
```
|
||||
|
||||
The `git log` command accepts the `-L` option, which takes the lines range and the filename as arguments. The format might be a bit weird for you, but it translates to:
|
||||
|
||||
```
|
||||
git log -L <start-line>,<end-line>:<path-to-file>
|
||||
```
|
||||
|
||||
When we run this command, we can see the list of revisions for these lines, which will lead us to the first revision that created the method:
|
||||
|
||||
```
|
||||
commit 51xd6bb829c418c5fbf75de1dfbb177233b1b154Author: Foo Bar <foo@bar.com>Date: Tue Jun 7 19:05:09 2011 -0700 Refactordiff --git a/activesupport/lib/active_support/inflector/methods.rb b/activesupport/lib/active_support/inflector/methods.rb--- a/activesupport/lib/active_support/inflector/methods.rb+++ b/activesupport/lib/active_support/inflector/methods.rb@@ -58,0 +135,14 @@+ # Create a class name from a plural table name like Rails does for table names to models.+ # Note that this returns a string and not a Class. (To convert to an actual class+ # follow +classify+ with +constantize+.)+ #+ # Examples:+ # "egg_and_hams".classify # => "EggAndHam"+ # "posts".classify # => "Post"+ #+ # Singular names are not handled correctly:+ # "business".classify # => "Busines"+ def classify(table_name)+ # strip out any leading schema name+ camelize(singularize(table_name.to_s.sub(/.*\./, '')))+ end
|
||||
```
|
||||
|
||||
Now, look at that - it’s a commit from 2011\. Practically, `git` allows us to travel back in time. This is a very good example of why a proper commit message is paramount to regain context, because from the commit message we cannot really regain context of how this method came to be. But, on the flip side, you should **never ever** get frustrated about it, because you are looking at someone that basically gives away his time and energy for free, doing open source work.
|
||||
|
||||
Coming back from that tangent, we are not sure how the initial implementation of the `classify` method came to be, given that the first commit is just a refactor. Now, if you are thinking something within the lines of “but maybe, just maybe, the method was not on the line range 176 to 189, and we should look more broadly in the file”, you are very correct. The revision that we saw said “Refactor” in it’s commit message, which means that the method was actually there, but after that refactor it started to exist on that line range.
|
||||
|
||||
So, how can we confirm this? Well, believe it or not, `git` comes to the rescue again. The `git log` command accepts the `-S` option, which looks for the code change (additions or deletions) for the specified string as an argument to the command. This means that, if we call `git log -S classify`, we can see all of the commits that changed a line that contains that string.
|
||||
|
||||
If you call this command in the Rails repo, you will first see `git` slowing down a bit. But, when you realise that `git` actually parses all of the revisions in the repo to match the string, it’s actually super fast. Again, the power of `git` at your fingertips. So, to find the first version of the `classify` method, we can run:
|
||||
|
||||
```
|
||||
git log -S 'def classify'
|
||||
```
|
||||
|
||||
This will return all of the revisions where this method has been introduced or changed. If you were following along, the last commit in the log that you will see is:
|
||||
|
||||
```
|
||||
commit db045dbbf60b53dbe013ef25554fd013baf88134Author: David Heinemeier Hansson <foo@bar.com>Date: Wed Nov 24 01:04:44 2004 +0000 Initial git-svn-id: http://svn-commit.rubyonrails.org/rails/trunk@4 5ecf4fe2-1ee6-0310-87b1-e25e094e27de
|
||||
```
|
||||
|
||||
How cool is that? It’s the initial commit to Rails, made on a `svn` repo by DHH! This means that `classify` has been around since the beginning of (Rails) time. Now, to see the commit with all of it’s changes, we can run:
|
||||
|
||||
```
|
||||
git show db045dbbf60b53dbe013ef25554fd013baf88134
|
||||
```
|
||||
|
||||
Great, we got to the bottom of it. Now, by using the output from `git log -S 'def classify'` you can track the changes that have happened to this method, combined with the power of the `git log -L` command.
|
||||
|
||||
### Until next time
|
||||
|
||||
Sure, we didn’t really fix any bugs, because we were trying some `git` commands and following along the evolution of the `classify` method. But, nevertheless, `git` is a very powerful tool that we all must learn to use and to embrace. I hope this article gave you a little bit more knowledge of how useful `git` is.
|
||||
|
||||
What are your favourite (or, most effective) ways of navigating through the `git`history?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Backend engineer, interested in Ruby, Go, microservices, building resilient architectures and solving challenges at scale. I coach at Rails Girls in Amsterdam, maintain a list of small gems and often contribute to Open Source.
|
||||
This is where I write about software development, programming languages and everything else that interests me.
|
||||
|
||||
------
|
||||
|
||||
via: https://ieftimov.com/learn-your-tools-navigating-git-history
|
||||
|
||||
作者:[Ilija Eftimov ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ieftimov.com/
|
||||
[1]:http://gitx.frim.nl/
|
||||
[2]:https://github.com/jonas/tig
|
||||
[3]:https://github.com/rails/rails/commit/5bb1d4d288d019e276335465d0389fd2f5246bfd
|
||||
[4]:https://twitter.com/schneems
|
||||
@ -0,0 +1,305 @@
|
||||
Create and manage MacOS LaunchAgents using Go
|
||||
============================================================
|
||||
|
||||
If you have ever tried writing a daemon for MacOS you have met with `launchd`. For those that don’t have the experience, think of it as a framework for starting, stopping and managing daemons, applications, processes, and scripts. If you have any *nix experience the word daemon should not be too alien to you.
|
||||
|
||||
For those unfamiliar, a daemon is a program running in the background without requiring user input. A typical daemon might, for instance, perform daily maintenance tasks or scan a device for malware when connected.
|
||||
|
||||
This post is aimed at folks that know a little bit about what daemons are, what is the common way of using them and know a bit about Go. Also, if you have ever written a daemon for any other *nix system, you will have a good idea of what we are going to talk here. If you are an absolute beginner in Go or systems this might prove to be an overwhelming article. Still, feel free to give it a shot and let me know how it goes.
|
||||
|
||||
If you ever find yourself wanting to write a MacOS daemon with Go you would like to know most of the stuff we are going to talk about in this article. Without further ado, let’s dive in.
|
||||
|
||||
### What is `launchd` and how it works?
|
||||
|
||||
`launchd` is a unified service-management framework, that starts, stops and manages daemons, applications, processes, and scripts in MacOS.
|
||||
|
||||
One of its key features is that it differentiates between agents and daemons. In `launchd` land, an agent runs on behalf of the logged in user while a daemon runs on behalf of the root user or any specified user.
|
||||
|
||||
### Defining agents and daemons
|
||||
|
||||
An agent/daemon is defined in an XML file, which states the properties of the program that will execute, among a list of other properties. Another aspect to keep in mind is that `launchd` decides if a program will be treated as a daemon or an agent by where the program XML is located.
|
||||
|
||||
Over at [launchd.info][3], there’s a simple table that shows where you would (or not) place your program’s XML:
|
||||
|
||||
```
|
||||
+----------------+-------------------------------+----------------------------------------------------+| Type | Location | Run on behalf of |+----------------+-------------------------------+----------------------------------------------------+| User Agents | ~/Library/LaunchAgents | Currently logged in user || Global Agents | /Library/LaunchAgents | Currently logged in user || Global Daemons | /Library/LaunchDaemons | root or the user specified with the key 'UserName' || System Agents | /System/Library/LaunchAgents | Currently logged in user || System Daemons | /System/Library/LaunchDaemons | root or the user specified with the key 'UserName' |+----------------+-------------------------------+----------------------------------------------------+
|
||||
```
|
||||
|
||||
This means that when we set our XML file in, for example, the `/Library/LaunchAgents` path our process will be treated as a global agent. The main difference between the daemons and agents is that LaunchDaemons will run as root, and are generally background processes. On the other hand, LaunchAgents are jobs that will run as a user or in the context of userland. These may be scripts or other foreground items and they also have access to the MacOS UI (e.g. you can send notifications, control the windows, etc.)
|
||||
|
||||
So, how do we define an agent? Let’s take a look at a simple XML file that `launchd`understands:
|
||||
|
||||
```
|
||||
<!--- Example blatantly ripped off from http://www.launchd.info/ --><?xml version="1.0" encoding="UTF-8"?><!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"><plist version="1.0"> <dict> <key>Label</key> <string>com.example.app</string> <key>Program</key> <string>/Users/Me/Scripts/cleanup.sh</string> <key>RunAtLoad</key> <true/> </dict></plist>
|
||||
```
|
||||
|
||||
The XML is quite self-explanatory, unless it’s the first time you are seeing an XML file. The file has three main properties, with values. In fact, if you take a better look you will see the `dict` keyword which means `dictionary`. This actually means that the XML represents a key-value structure, so in Go it would look like:
|
||||
|
||||
```
|
||||
map[string]string{ "Label": "com.example.app", "Program": "/Users/Me/Scripts/cleanup.sh", "RunAtLoad": "true",}
|
||||
```
|
||||
|
||||
Let’s look at each of the keys:
|
||||
|
||||
1. `Label` - The job definition or the name of the job. This is the unique identifier for the job within the `launchd` instance. Usually, the label (and hence the name) is written in [Reverse domain name notation][1].
|
||||
|
||||
2. `Program` - This key defines what the job should start, in our case a script with the path `/Users/Me/Scripts/cleanup.sh`.
|
||||
|
||||
3. `RunAtLoad` - This key specifies when the job should be run, in this case right after it’s loaded.
|
||||
|
||||
As you can see, the keys used in this XML file are quite self-explanatory. This is the case for the remaining 30-40 keys that `launchd` supports. Last but not least these files although have an XML syntax, in fact, they have a `.plist` extension (which means `Property List`). Makes a lot of sense, right?
|
||||
|
||||
### `launchd` v.s. `launchctl`
|
||||
|
||||
Before we continue with our little exercise of creating daemons/agents with Go, let’s first see how `launchd` allows us to control these jobs. While `launchd`’s job is to boot the system and to load and maintain services, there is a different command used for jobs management - `launchctl`. With `launchd` facilitating jobs, the control of services is centralized in the `launchctl` command.
|
||||
|
||||
`launchctl` has a long list of subcommands that we can use. For example, loading or unloading a job is done via:
|
||||
|
||||
```
|
||||
launchctl unload/load ~/Library/LaunchAgents/com.example.app.plist
|
||||
```
|
||||
|
||||
Or, starting/stopping a job is done via:
|
||||
|
||||
```
|
||||
launchctl start/stop ~/Library/LaunchAgents/com.example.app.plist
|
||||
```
|
||||
|
||||
To get any confusion out of the way, `load` and `start` are different. While `start`only starts the agent/daemon, `load` loads the job and it might also start it if the job is configured to run on load. This is achieved by setting the `RunAtLoad` property in the property list XML of the job:
|
||||
|
||||
```
|
||||
<!--- Example blatantly ripped off from http://www.launchd.info/ --><?xml version="1.0" encoding="UTF-8"?><!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"><plist version="1.0"> <dict> <key>Label</key> <string>com.example.app</string> <key>Program</key> <string>/Users/Me/Scripts/cleanup.sh</string> <key>RunAtLoad</key><true/> </dict></plist>
|
||||
```
|
||||
|
||||
If you would like to see what other commands `launchctl` supports, you can run`man launchctl` in your terminal and see the options in detail.
|
||||
|
||||
### Automating with Go
|
||||
|
||||
After getting the basics of `launchd` and `launctl` out of the way, why don’t we see how we can add an agent to any Go package? For our example, we are going to write a simple way of plugging in a `launchd` agent for any of your Go packages.
|
||||
|
||||
As we already established before, `launchd` speaks in XML. Or, rather, it understands XML files, called _property lists_ (or `.plist`). This means, for our Go package to have an agent running on MacOS, it will need to tell `launchd` “hey, `launchd`, run this thing!”. And since `launch` speaks only in `.plist`, that means our package needs to be capable of generating XML files.
|
||||
|
||||
### Templates in Go
|
||||
|
||||
While one could have a hardcoded `.plist` file in their project and copy it across to the `~/Library/LaunchAgents` path, a more programmatical way to do this would be to use a template to generate these XML files. The good thing is Go’s standard library has us covered - the `text/template` package ([docs][4]) does exactly what we need.
|
||||
|
||||
In a nutshell, `text/template` implements data-driven templates for generating textual output. Or in other words, you give it a template and a data structure, it will mash them up together and produce a nice and clean text file. Perfect.
|
||||
|
||||
Let’s say the `.plist` we need to generate in our case is the following:
|
||||
|
||||
```
|
||||
<?xml version='1.0' encoding='UTF-8'?><!DOCTYPE plist PUBLIC \"-//Apple Computer//DTD PLIST 1.0//EN\" \"http://www.apple.com/DTDs/PropertyList-1.0.dtd\" ><plist version='1.0'> <dict> <key>Label</key><string>Ticker</string> <key>Program</key><string>/usr/local/bin/ticker</string> <key>StandardOutPath</key><string>/tmp/ticker.out.log</string> <key>StandardErrorPath</key><string>/tmp/ticker.err.log</string> <key>KeepAlive</key><true/> <key>RunAtLoad</key><true/> </dict></plist>
|
||||
```
|
||||
|
||||
We want to keep it quite simple in our little exercise. It will contain only six properties: `Label`, `Program`, `StandardOutPath`, `StandardErrorPath`, `KeepAlive` and `RunAtLoad`. To generate such a XML, its template would look something like this:
|
||||
|
||||
```
|
||||
<?xml version='1.0' encoding='UTF-8'?>
|
||||
<!DOCTYPE plist PUBLIC \"-//Apple Computer//DTD PLIST 1.0//EN\" \"http://www.apple.com/DTDs/PropertyList-1.0.dtd\" >
|
||||
<plist version='1.0'>
|
||||
<dict>
|
||||
<key>Label</key><string>{{.Label}}</string>
|
||||
<key>Program</key><string>{{.Program}}</string>
|
||||
<key>StandardOutPath</key><string>/tmp/{{.Label}}.out.log</string>
|
||||
<key>StandardErrorPath</key><string>/tmp/{{.Label}}.err.log</string>
|
||||
<key>KeepAlive</key><{{.KeepAlive}}/>
|
||||
<key>RunAtLoad</key><{{.RunAtLoad}}/>
|
||||
</dict>
|
||||
</plist>
|
||||
|
||||
```
|
||||
|
||||
As you can see, the difference between the two XMLs is that the second one has the double curly braces with expressions in them in places where the first XML has some sort of a value. These are called “actions”, which can be data evaluations or control structures and are delimited by “ and “. Any of the text outside actions is copied to the output untouched.
|
||||
|
||||
### Injecting your data
|
||||
|
||||
Now that we have our template with its glorious XML and curly braces (or actions), let’s see how we can inject our data into it. Since things are generally simple in Go, especially when it comes to its standard library, you should not worry - this will be easy!
|
||||
|
||||
To keep thing simple, we will store the whole XML template in a plain old string. Yes, weird, I know. The best way would be to store it in a file and read it from there, or embed it in the binary itself, but in our little example let’s keep it simple:
|
||||
|
||||
```
|
||||
// template.go
|
||||
package main
|
||||
|
||||
func Template() string {
|
||||
return `
|
||||
<?xml version='1.0' encoding='UTF-8'?>
|
||||
<!DOCTYPE plist PUBLIC \"-//Apple Computer//DTD PLIST 1.0//EN\" \"http://www.apple.com/DTDs/PropertyList-1.0.dtd\" >
|
||||
<plist version='1.0'>
|
||||
<dict>
|
||||
<key>Label</key><string>{{.Label}}</string>
|
||||
<key>Program</key><string>{{.Program}}</string>
|
||||
<key>StandardOutPath</key><string>/tmp/{{.Label}}.out.log</string>
|
||||
<key>StandardErrorPath</key><string>/tmp/{{.Label}}.err.log</string>
|
||||
<key>KeepAlive</key><{{.KeepAlive}}/>
|
||||
<key>RunAtLoad</key><{{.RunAtLoad}}/>
|
||||
</dict>
|
||||
</plist>
|
||||
`
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
And the program that will use our little template function:
|
||||
|
||||
```
|
||||
// main.gopackage mainimport ( "log" "os" "text/template")func main() { data := struct { Label string Program string KeepAlive bool RunAtLoad bool }{ Label: "ticker", Program: "/usr/local/bin/ticker", KeepAlive: true, RunAtLoad: true, } t := template.Must(template.New("launchdConfig").Parse(Template())) err := t.Execute(os.Stdout, data) if err != nil { log.Fatalf("Template generation failed: %s", err) }}
|
||||
```
|
||||
|
||||
So, what happens there, in the `main` function? It’s actually quite simple:
|
||||
|
||||
1. We declare a small `struct`, which has only the properties that will be needed in the template, and we immediately initialize it with the values for our program.
|
||||
|
||||
2. We build a new template, using the `template.New` function, with the name`launchdConfig`. Then, we invoke the `Parse` function on it, which takes the XML template as an argument.
|
||||
|
||||
3. We invoke the `template.Must` function, which takes our built template as argument. From the documentation, `template.Must` is a helper that wraps a call to a function returning `(*Template, error)` and panics if the error is non-`nil`. Actually, `template.Must` is built to, in a way, validate if the template can be understood by the `text/template` package.
|
||||
|
||||
4. Finally, we invoke `Execute` on our built template, which takes a data structure and applies its attributes to the actions in the template. Then it sends the output to `os.Stdout`, which does the trick for our example. Of course, the output can be sent to any struct that implements the `io.Writer` interface, like a file (`os.File`).
|
||||
|
||||
### Make and load my `.plist`
|
||||
|
||||
Instead of sending all this nice XML to standard out, let’s throw in an open file descriptor to the `Execute` function and finally save our `.plist` file in`~/Library/LaunchAgents`. There are a couple of main points we need to change.
|
||||
|
||||
First, getting the location of the binary. Since it’s a Go binary, and we will install it via `go install`, we can assume that the path will be at `$GOPATH/bin`. Second, since we don’t know the actual `$HOME` of the current user, we will have to get it through the environment. Both of these can be done via `os.Getenv` ([docs][5]) which takes a variable name and returns its value.
|
||||
|
||||
```
|
||||
// main.gopackage mainimport ( "log" "os" "text/template")func main() { data := struct { Label string Program string KeepAlive bool RunAtLoad bool }{ Label: "com.ieftimov.ticker", // Reverse-DNS naming convention Program: fmt.Sprintf("%s/bin/ticker", os.Getenv("GOPATH")), KeepAlive: true, RunAtLoad: true, } plistPath := fmt.Sprintf("%s/Library/LaunchAgents/%s.plist", os.Getenv("HOME"), data.Label) f, err := os.Open(plistPath) t := template.Must(template.New("launchdConfig").Parse(Template())) err := t.Execute(f, data) if err != nil { log.Fatalf("Template generation failed: %s", err) }}
|
||||
```
|
||||
|
||||
That’s about it. The first part, about setting the correct `Program` property, is done by concatenating the name of the program and `$GOPATH`:
|
||||
|
||||
```
|
||||
fmt.Sprintf("%s/bin/ticker", os.Getenv("GOPATH"))// Output: /Users/<username>/go/bin/ticker
|
||||
```
|
||||
|
||||
The second part is slightly more complex, and it’s done by concatenating three strings, the `$HOME` environment variable, the `Label` property of the program and the `/Library/LaunchAgents` string:
|
||||
|
||||
```
|
||||
fmt.Sprintf("%s/Library/LaunchAgents/%s.plist", os.Getenv("HOME"), data.Label)// Output: /Users/<username>/Library/LaunchAgents/com.ieftimov.ticker.plist
|
||||
```
|
||||
|
||||
By having these two paths, opening the file and writing to it is very trivial - we open the file via `os.Open` and we pass in the `os.File` structure to `t.Execute` which writes to the file descriptor.
|
||||
|
||||
### What about the Launch Agent?
|
||||
|
||||
We will keep this one simple as well. Let’s throw in a command to our package, make it installable via `go install` (not that there’s much to it) and make it runnable by our `.plist` file:
|
||||
|
||||
```
|
||||
// cmd/ticker/main.gopackage tickerimport ( "time" "fmt")func main() { for range time.Tick(30 * time.Second) { fmt.Println("tick!") }}
|
||||
```
|
||||
|
||||
This the `ticker` program will use `time.Tick`, to execute an action every 30 seconds. Since this will be an infinite loop, `launchd` will kick off the program on boot (because `RunAtLoad` is set to `true` in the `.plist` file) and will keep it running. But, to make the program controllable from the operating system, we need to make the program react to some OS signals, like `SIGINT` or `SIGTERM`.
|
||||
|
||||
### Understanding and handling OS signals
|
||||
|
||||
While there’s quite a bit to be learned about OS signals, in our example we will scratch a bit off the surface. (If you know a lot about inter-process communication this might be too much of an oversimplification to you - and I apologize up front. Feel free to drop some links on the topic in the comments so others can learn more!)
|
||||
|
||||
The best way to think about a signal is that it’s a message from the operating system or another process, to a process. It is an asynchronous notification sent to a process or to a specific thread within the same process to notify it of an event that occurred.
|
||||
|
||||
There are quite a bit of various signals that can be sent to a process (or a thread), like `SIGKILL` (which kills a process), `SIGSTOP` (stop), `SIGTERM` (termination), `SIGILL`and so on and so forth. There’s an exhaustive list of signal types on [Wikipedia’s page][6]on signals.
|
||||
|
||||
To get back to `launchd`, if we look at its documentation about stopping a job we will notice the following:
|
||||
|
||||
> Stopping a job will send the signal `SIGTERM` to the process. Should this not stop the process launchd will wait `ExitTimeOut` seconds (20 seconds by default) before sending `SIGKILL`.
|
||||
|
||||
Pretty self-explanatory, right? We need to handle one signal - `SIGTERM`. Why not `SIGKILL`? Because `SIGKILL` is a special signal that cannot be caught - it kills the process without any chance for a graceful shutdown, no questions asked. That’s why there’s a termination signal and a “kill” signal.
|
||||
|
||||
Let’s throw in a bit of signal handling in our code, so our program knows that it needs to exit when it gets told to do so:
|
||||
|
||||
```
|
||||
package mainimport ( "fmt" "os" "os/signal" "syscall" "time")func main() { sigs := make(chan os.Signal, 1) signal.Notify(sigs, syscall.SIGINT, syscall.SIGTERM) go func() { <-sigs os.Exit(0) }() for range time.Tick(30 * time.Second) { fmt.Println("tick!") }}
|
||||
```
|
||||
|
||||
In the new version, the agent program has two new packages imported: `os/signal`and `syscall`. `os/signal` implements access to incoming signals, that are primarily used on Unix-like systems. Since in this article we are specifically interested in MacOS, this is exactly what we need.
|
||||
|
||||
Package `syscall` contains an interface to the low-level operating system primitives. An important note about `syscall` is that it is locked down since Go v1.4\. This means that any code outside of the standard library that uses the `syscall` package should be migrated to use the new `golang.org/x/sys` [package][7]. Since we are using **only**the signals constants of `syscall` we can get away with this.
|
||||
|
||||
(If you want to read more about the package lockdown, you can see [the rationale on locking it down][8] by the Go team and the new [golang.org/s/sys][9] package.)
|
||||
|
||||
Having the basics of the packages out of the way, let’s go step by step through the new lines of code added:
|
||||
|
||||
1. We make a buffered channel of type `os.Signal`, with a size of `1`. `os.Signal`is a type that represents an operating system signal.
|
||||
|
||||
2. We call `signal.Notify` with the new channel as an argument, plus`syscall.SIGINT` and `syscall.SIGTERM`. This function states “when the OS sends a `SIGINT` or a `SIGTERM` signal to this program, send the signal to the channel”. This allows us to somehow handle the sent OS signal.
|
||||
|
||||
3. The new goroutine that we spawn waits for any of the signals to arrive through the channel. Since we know that any of the signals that will arrive are about shutting down the program, after receiving any signal we use `os.Exit(0)`([docs][2]) to gracefully stop the program. One caveat here is that if we had any `defer`red calls they would not be run.
|
||||
|
||||
Now `launchd` can run the agent program and we can `load` and `unload`, `start`and `stop` it using `launchctl`.
|
||||
|
||||
### Putting it all together
|
||||
|
||||
Now that we have all the pieces ready, we need to put them together to a good use. Our application will consist of two binaries - a CLI tool and an agent (daemon). Both of the programs will be stored in separate subdirectories of the `cmd` directory.
|
||||
|
||||
The CLI tool:
|
||||
|
||||
```
|
||||
// cmd/cli/main.gopackage mainimport ( "log" "os" "text/template")func main() { data := struct { Label string Program string KeepAlive bool RunAtLoad bool }{ Label: "com.ieftimov.ticker", // Reverse-DNS naming convention Program: fmt.Sprintf("%s/bin/ticker", os.Getenv("GOPATH")), KeepAlive: true, RunAtLoad: true, } plistPath := fmt.Sprintf("%s/Library/LaunchAgents/%s.plist", os.Getenv("HOME"), data.Label) f, err := os.Open(plistPath) t := template.Must(template.New("launchdConfig").Parse(Template())) err := t.Execute(f, data) if err != nil { log.Fatalf("Template generation failed: %s", err) }}
|
||||
```
|
||||
|
||||
And the ticker program:
|
||||
|
||||
```
|
||||
// cmd/ticker/main.gopackage mainimport ( "fmt" "os" "os/signal" "syscall" "time")func main() { sigs := make(chan os.Signal, 1) signal.Notify(sigs, syscall.SIGINT, syscall.SIGTERM) go func() { <-sigs os.Exit(0) }() for range time.Tick(30 * time.Second) { fmt.Println("tick!") }}
|
||||
```
|
||||
|
||||
To install them both, we need to run `go install ./...` in the project root. The command will install all the sub-packages that are located within the project. This will leave us with two available binaries, installed in the `$GOPATH/bin` path.
|
||||
|
||||
To install our launch agent, we need to run only the CLI tool, via the `cli` command. This will generate the `.plist` file and place it in the `~/Library/LaunchAgents`path. We don’t need to touch the `ticker` binary - that one will be managed by `launchd`.
|
||||
|
||||
To load the newly created `.plist` file, we need to run:
|
||||
|
||||
```
|
||||
launchctl load ~/Library/LaunchAgents/com.ieftimov.ticker.plist
|
||||
```
|
||||
|
||||
When we run it, we will not see anything immediately, but after 30 seconds the ticker will add a `tick!` line in `/tmp/ticker.out.log`. We can `tail` the file to see the new lines being added. If we want to unload the agent, we can use:
|
||||
|
||||
```
|
||||
launchctl unload ~/Library/LaunchAgents/com.ieftimov.ticker.plist
|
||||
```
|
||||
|
||||
This will unload the launch agent and will stop the ticker from running. Remember the signal handling we added? This is the case where it’s being used! Also, we could have automated the (un)loading of the file via the CLI tool but for simplicity, we left it out. You can try to improve the CLI tool by making it a bit smarter with subcommands and flags, as a follow-up exercise from this tutorial.
|
||||
|
||||
Finally, if you decide to completely delete the launch agent, you can remove the`.plist` file:
|
||||
|
||||
```
|
||||
rm ~/Library/LaunchAgents/com.ieftimov.ticker.plist
|
||||
```
|
||||
|
||||
### In closing
|
||||
|
||||
As part of this (quite long!) article, we saw how we can work with `launchd` and Golang. We took a detour, like learning about `launchd` and `launchctl`, generating XML files using the `text/template` package, we took a look at OS signals and how we can gracefully shutdown a Go program by handling the `SIGINT` and `SIGTERM`signals. There was quite a bit to learn and see, but we got to the end.
|
||||
|
||||
Of course, we only scratched the surface with this article. For example, `launchd` is quite an interesting tool. You can use it also like `crontab` because it allows running programs at explicit time/date combinations or on specific days. Or, for example, the XML template can be embedded in the program binary using tools like [`go-bindata`][10], instead of hardcoding it in a function. Also, you explore more about signals, how they work and how Go implements these low-level primitives so you can use them with ease in your programs. The options are plenty, feel free to explore!
|
||||
|
||||
If you have found any mistakes in the article, feel free to drop a comment below - I will appreciate it a ton. I find learning through teaching (blogging) a very pleasant experience and would like to have all the details fully correct in my posts.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Backend engineer, interested in Ruby, Go, microservices, building resilient architectures and solving challenges at scale. I coach at Rails Girls in Amsterdam, maintain a list of small gems and often contribute to Open Source.
|
||||
This is where I write about software development, programming languages and everything else that interests me.
|
||||
|
||||
---------------------
|
||||
|
||||
|
||||
via: https://ieftimov.com/create-manage-macos-launchd-agents-golang
|
||||
|
||||
作者:[Ilija Eftimov ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ieftimov.com/about
|
||||
[1]:https://ieftimov.com/en.wikipedia.org/wiki/Reverse_domain_name_notation
|
||||
[2]:https://godoc.org/os#Exit
|
||||
[3]:https://launchd.info/
|
||||
[4]:https://godoc.org/text/template
|
||||
[5]:https://godoc.org/os#Getenv
|
||||
[6]:https://en.wikipedia.org/wiki/Signal_(IPC)
|
||||
[7]:https://golang.org/x/sys
|
||||
[8]:https://docs.google.com/document/d/1QXzI9I1pOfZPujQzxhyRy6EeHYTQitKKjHfpq0zpxZs/edit
|
||||
[9]:https://golang.org/x/sys
|
||||
[10]:https://github.com/jteeuwen/go-bindata
|
||||
112
sources/tech/20180130 Trying Other Go Versions.md
Normal file
112
sources/tech/20180130 Trying Other Go Versions.md
Normal file
@ -0,0 +1,112 @@
|
||||
Trying Other Go Versions
|
||||
============================================================
|
||||
|
||||
While I generally use the current release of Go, sometimes I need to try a different version. For example, I need to check that all the examples in my [Guide to JSON][2] work with [both the supported releases of Go][3](1.8.6 and 1.9.3 at time of writing) along with go1.10rc1.
|
||||
|
||||
I primarily use the current version of Go, updating it when new versions are released. I try out other versions as needed following the methods described in this article.
|
||||
|
||||
### Trying Betas and Release Candidates[¶][4]
|
||||
|
||||
When [go1.8beta2 was released][5], a new tool for trying the beta and release candidates was also released that allowed you to `go get` the beta. It allowed you to easily run the beta alongside your Go installation by getting the beta with:
|
||||
|
||||
```
|
||||
go get golang.org/x/build/version/go1.8beta2
|
||||
```
|
||||
|
||||
This downloads and builds a small program that will act like the `go` tool for that specific version. The full release can then be downloaded and installed with:
|
||||
|
||||
```
|
||||
go1.8beta2 download
|
||||
```
|
||||
|
||||
This downloads the release from [https://golang.org/dl][6] and installs it into `$HOME/sdk` or `%USERPROFILE%\sdk`.
|
||||
|
||||
Now you can use `go1.8beta2` as if it were the normal Go command.
|
||||
|
||||
This method works for [all the beta and release candidates][7] released after go1.8beta2.
|
||||
|
||||
### Trying a Specific Release[¶][8]
|
||||
|
||||
While only beta and release candidates are provided, they can easily be adapted to work with any released version. For example, to use go1.9.2:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"golang.org/x/build/version"
|
||||
)
|
||||
|
||||
func main() {
|
||||
version.Run("go1.9.2")
|
||||
}
|
||||
```
|
||||
|
||||
Replace `go1.9.2` with the release you want to run and build/install as usual.
|
||||
|
||||
Since the program I use to build my [Guide to JSON][9] calls `go` itself (for each example), I build this as `go` and prepend the directory to my `PATH` so it will use this one instead of my normal version.
|
||||
|
||||
### Trying Any Release[¶][10]
|
||||
|
||||
This small program can be extended so you can specify the release to use instead of having to maintain binaries for each version.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
|
||||
"golang.org/x/build/version"
|
||||
)
|
||||
|
||||
func main() {
|
||||
if len(os.Args) < 2 {
|
||||
fmt.Printf("USAGE: %v <version> [commands as normal]\n",
|
||||
os.Args[0])
|
||||
os.Exit(1)
|
||||
}
|
||||
|
||||
v := os.Args[1]
|
||||
os.Args = append(os.Args[0:1], os.Args[2:]...)
|
||||
|
||||
version.Run("go" + v)
|
||||
}
|
||||
```
|
||||
|
||||
I have this installed as `gov` and run it like `gov 1.8.6 version`, using the version I want to run.
|
||||
|
||||
### Trying a Source Build (e.g., tip)[¶][11]
|
||||
|
||||
I also use this same infrastructure to manage source builds of Go, such as tip. There’s just a little trick to it:
|
||||
|
||||
* use the directory `$HOME/sdk/go<version>` (e.g., `$HOME/sdk/gotip`)
|
||||
|
||||
* [build as normal][1]
|
||||
|
||||
* `touch $HOME/sdk/go<version>/.unpacked-success` This is an empty file used as a sentinel to indicate the download and unpacking was successful.
|
||||
|
||||
(On Windows, replace `$HOME/sdk` with `%USERPROFILE%\sdk`)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pocketgophers.com/trying-other-versions/
|
||||
|
||||
作者:[Nathan Kerr ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:nathan@pocketgophers.com
|
||||
[1]:https://golang.org/doc/install/source
|
||||
[2]:https://pocketgophers.com/guide-to-json/
|
||||
[3]:https://pocketgophers.com/when-should-you-upgrade-go/
|
||||
[4]:https://pocketgophers.com/trying-other-versions/#trying-betas-and-release-candidates
|
||||
[5]:https://groups.google.com/forum/#!topic/golang-announce/LvfYP-Wk1s0
|
||||
[6]:https://golang.org/dl
|
||||
[7]:https://godoc.org/golang.org/x/build/version#pkg-subdirectories
|
||||
[8]:https://pocketgophers.com/trying-other-versions/#trying-a-specific-release
|
||||
[9]:https://pocketgophers.com/guide-to-json/
|
||||
[10]:https://pocketgophers.com/trying-other-versions/#trying-any-release
|
||||
[11]:https://pocketgophers.com/trying-other-versions/#trying-a-source-build-e-g-tip
|
||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,222 @@
|
||||
How to test Webhooks when you’re developing locally
|
||||
============================================================
|
||||
|
||||

|
||||
Photo by [Fernando Venzano][1] on [Unsplash][2]
|
||||
|
||||
[Webhooks][10] can be used by an external system for notifying your system about a certain event or update. Probably the most well known type is the one where a Payment Service Provider (PSP) informs your system about status updates of payments.
|
||||
|
||||
Often they come in the form where you listen on a predefined URL. For example [http://example.com/webhooks/payment-update][11]. Meanwhile the other system sends a POST request with a certain payload to that URL (for example a payment ID). As soon as the request comes in, you fetch the payment ID, ask the PSP for the latest status via their API, and update your database afterward.
|
||||
|
||||
Other examples can be found in this excellent explanation about Webhooks. [https://sendgrid.com/blog/whats-webhook/][12].
|
||||
|
||||
Testing these webhooks goes fairly smoothly as long as the system is publicly accessible over the internet. This might be your production environment or a publicly accessible staging environment. It becomes harder when you are developing locally on your laptop or inside a Virtual Machine (VM, for example, a Vagrant box). In those cases, the local URL’s are not publicly accessible by the party sending the webhook. Also, monitoring the requests being sent around is be difficult, which might make development and debugging hard.
|
||||
|
||||
What will this example solve:
|
||||
|
||||
* Testing webhooks from a local development environment, which is not accessible over the internet. It cannot be accessed by the service sending the data to the webhook from their servers.
|
||||
|
||||
* Monitor the requests and data being sent around, but also the response your application generates. This will allow easier debugging, and therefore a shorter development cycle.
|
||||
|
||||
Prerequisites:
|
||||
|
||||
* _Optional_ : in case you are developing using a Virtual Machine (VM), make sure it’s running and make sure the next steps are done in the VM.
|
||||
|
||||
* For this tutorial, we assume you have a vhost defined at `webhook.example.vagrant`. I used a Vagrant VM for this tutorial, but you are free in choosing the name of your vhost.
|
||||
|
||||
* Install `ngrok`by following the [installation instructions][3]. Inside a VM, I find the Node version of it also useful: [https://www.npmjs.com/package/ngrok][4], but feel free to use other methods.
|
||||
|
||||
I assume you don’t have SSL running in your environment, but if you do, feel free to replace port 80 with port 433 and `_http://_` with `_https://_` in the examples below.
|
||||
|
||||
#### Make the webhook testable
|
||||
|
||||
Let’s assume the following example code. I’ll be using PHP, but read it as pseudo-code as I left some crucial parts out (for example API keys, input validation, etc.)
|
||||
|
||||
The first file: _payment.php_ . This file creates a payment object and then registers it with the PSP. It then fetches the URL the customer needs to visit in order to pay and redirects the user to the customer in there.
|
||||
|
||||
Note that the `webhook.example.vagrant` in this example is the local vhost we’ve defined for our development set-up. It’s not accessible from the outside world.
|
||||
|
||||
```
|
||||
<?php
|
||||
/*
|
||||
* This file creates a payment and tells the PSP what webhook URL to use for updates
|
||||
* After creating the payment, we get a URL to send the customer to in order to pay at the PSP
|
||||
*/
|
||||
$payment = [
|
||||
'order_id' => 123,
|
||||
'amount' => 25.00,
|
||||
'description' => 'Test payment',
|
||||
'redirect_url' => 'http://webhook.example.vagrant/redirect.php',
|
||||
'webhook_url' => 'http://webhook.example.vagrant/webhook.php',
|
||||
];
|
||||
```
|
||||
|
||||
```
|
||||
$payment = $paymentProvider->createPayment($payment);
|
||||
header("Location: " . $payment->getPaymentUrl());
|
||||
```
|
||||
|
||||
Second file: _webhook.php_ . This file waits to be called by the PSP to get notified about updates.
|
||||
|
||||
```
|
||||
<?php
|
||||
/*
|
||||
* This file gets called by the PSP and in the $_POST they submit an 'id'
|
||||
* We can use this ID to get the latest status from the PSP and update our internal systems afterward
|
||||
*/
|
||||
```
|
||||
|
||||
```
|
||||
$paymentId = $_POST['id'];
|
||||
$paymentInfo = $paymentProvider->getPayment($paymentId);
|
||||
$status = $paymentInfo->getStatus();
|
||||
```
|
||||
|
||||
```
|
||||
// Perform actions in here to update your system
|
||||
if ($status === 'paid') {
|
||||
..
|
||||
}
|
||||
elseif ($status === 'cancelled') {
|
||||
..
|
||||
}
|
||||
```
|
||||
|
||||
Our webhook URL is not accessible over the internet (remember: `webhook.example.vagrant`). Thus, the file _webhook.php_ will never be called by the PSP. Your system will never get to know about the payment status. This ultimately leads to orders never being shipped to customers.
|
||||
|
||||
Luckily, _ngrok_ can in solving this problem. [_ngrok_][13] describes itself as:
|
||||
|
||||
> ngrok exposes local servers behind NATs and firewalls to the public internet over secure tunnels.
|
||||
|
||||
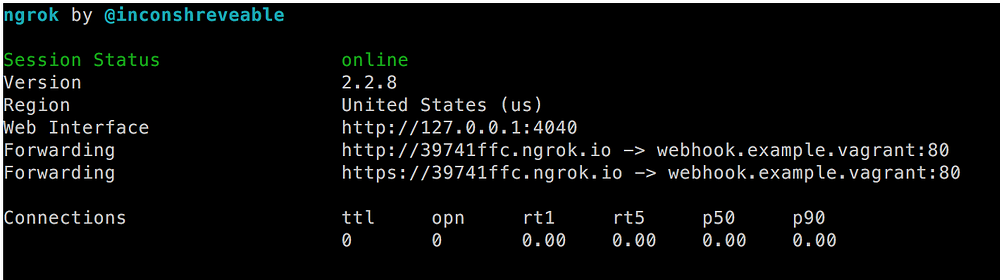
Let’s start a basic tunnel for our project. On your environment (either on your system or on the VM) run the following command:
|
||||
|
||||
`ngrok http -host-header=rewrite webhook.example.vagrant:80`
|
||||
|
||||
Read about more configuration options in their documentation: [https://ngrok.com/docs][14].
|
||||
|
||||
A screen like this will come up:
|
||||
|
||||
|
||||
|
||||
ngrok output
|
||||
|
||||
What did we just start? Basically, we instructed `ngrok` to start a tunnel to `[http://webhook.example.vagr][5]ant` at port 80\. This same URL can now be reached via `[http://39741ffc.ngrok.i][6]o` or `[https://39741ffc.ngrok.io][7]`[,][15] They are publicly accessible over the internet by anyone that knows this URL.
|
||||
|
||||
Note that you get both HTTP and HTTPS available out of the box. The documentation gives examples of how to restrict this to HTTPS only: [https://ngrok.com/docs#bind-tls][16].
|
||||
|
||||
So, how do we make our webhook work now? Update _payment.php_ to the following code:
|
||||
|
||||
```
|
||||
<?php
|
||||
/*
|
||||
* This file creates a payment and tells the PSP what webhook URL to use for updates
|
||||
* After creating the payment, we get a URL to send the customer to in order to pay at the PSP
|
||||
*/
|
||||
$payment = [
|
||||
'order_id' => 123,
|
||||
'amount' => 25.00,
|
||||
'description' => 'Test payment',
|
||||
'redirect_url' => 'http://webhook.example.vagrant/redirect.php',
|
||||
'webhook_url' => 'https://39741ffc.ngrok.io/webhook.php',
|
||||
];
|
||||
```
|
||||
|
||||
```
|
||||
$payment = $paymentProvider->createPayment($payment);
|
||||
header("Location: " . $payment->getPaymentUrl());
|
||||
```
|
||||
|
||||
Now, we told the PSP to call the tunnel URL over HTTPS. _ngrok_ will make sure your internal URL get’s called with an unmodified payload, as soon as the PSP calls the webhook via the tunnel.
|
||||
|
||||
#### How to monitor calls to the webhook?
|
||||
|
||||
The screenshot you’ve seen above gives an overview of the calls being made to the tunnel host. This data is rather limited. Fortunately, `ngrok` offers a very nice dashboard, which allows you to inspect all calls:
|
||||
|
||||
|
||||
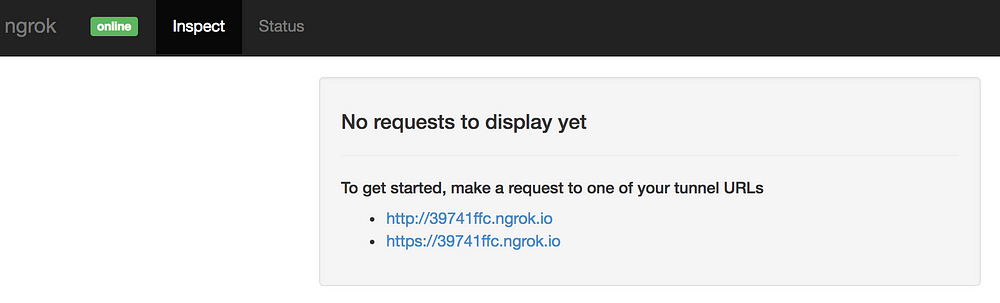
|
||||
|
||||
I won’t go into this very deep because it’s self-explanatory as soon as you have it running. Therefore I will explain how to access it on the Vagrant box as it doesn’t work out of the box.
|
||||
|
||||
The dashboard will allow you to see all the calls, their status codes, the headers and data being sent around. You will also see the response your application generated.
|
||||
|
||||
Another neat feature of the dashboard is that it allows you to replay a certain call. Let’s say your webhook code ran into a fatal error, it would be tedious to start a new payment and wait for the webhook to be called. Replaying the previous call makes your development process way faster.
|
||||
|
||||
The dashboard by default is accessible at [http://localhost:4040.][17]
|
||||
|
||||
#### Dashboard in a VM
|
||||
|
||||
In order to make this work inside a VM, you have to perform some additional steps:
|
||||
|
||||
First, make sure the VM can be accessed on port 4040\. Then, create a file inside the VM holding this configuration:
|
||||
|
||||
`web_addr: 0.0.0.0:4040`
|
||||
|
||||
Now, kill the `ngrok` process that’s still running and start it with this slightly adjusted command:
|
||||
|
||||
`ngrok http -config=/path/to/config/ngrok.conf -host-header=rewrite webhook.example.vagrant:80`
|
||||
|
||||
You will get a screen looking similar to the previous screenshot though the ID’s have changed. The previous URL doesn’t work anymore, but you got a new URL. Also, the `Web Interface` URL got changed:
|
||||
|
||||
|
||||
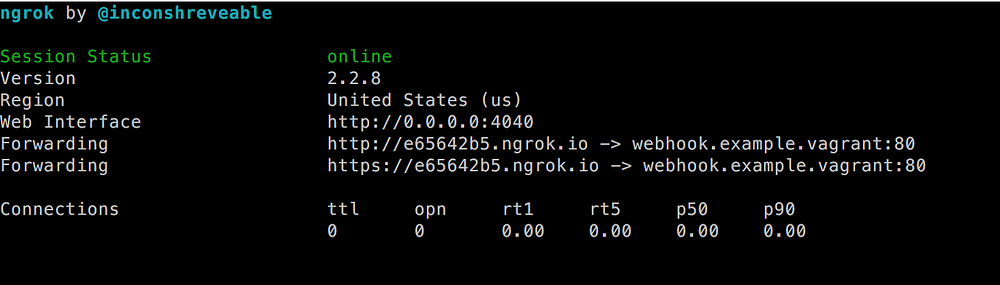
|
||||
|
||||
Now direct your browser to `[http://webhook.example.vagrant:4040][8]` to access the dashboard. Also, make a call to `[https://e65642b5.ngrok.io/webhook.php][9]`[.][18]This will probably result in an error in your browser, but the dashboard should show the request being made.
|
||||
|
||||
#### Final remarks
|
||||
|
||||
The examples above are pseudo-code. The reason is that every external system uses webhooks in a different way. I tried to give an example based on a fictive PSP implementation, as probably many developers have to deal with payments at some moment.
|
||||
|
||||
Please be aware that your webhook URL can also be used by others with bad intentions. Make sure to validate any input being sent to it.
|
||||
|
||||
Preferably also add a token to the URL which is unique for each payment. This token must only be known by your system and the system sending the webhook.
|
||||
|
||||
Good luck testing and debugging your webhooks!
|
||||
|
||||
Note: I haven’t tested this tutorial on Docker. However, this Docker container looks like a good starting point and includes clear instructions. [https://github.com/wernight/docker-ngrok][19].
|
||||
|
||||
Stefan Doorn
|
||||
|
||||
[https://github.com/stefandoorn][20]
|
||||
[https://twitter.com/stefan_doorn][21]
|
||||
[https://www.linkedin.com/in/stefandoorn][22]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Backend Developer (PHP/Node/Laravel/Symfony/Sylius)
|
||||
|
||||
|
||||
--------
|
||||
|
||||
via: https://medium.freecodecamp.org/testing-webhooks-while-using-vagrant-for-development-98b5f3bedb1d
|
||||
|
||||
作者:[Stefan Doorn ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@stefandoorn
|
||||
[1]:https://unsplash.com/photos/MYTyXb7fgG0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://ngrok.com/download
|
||||
[4]:https://www.npmjs.com/package/ngrok
|
||||
[5]:http://webhook.example.vagrnat/
|
||||
[6]:http://39741ffc.ngrok.io/
|
||||
[7]:http://39741ffc.ngrok.io/
|
||||
[8]:http://webhook.example.vagrant:4040/
|
||||
[9]:https://e65642b5.ngrok.io/webhook.php.
|
||||
[10]:https://sendgrid.com/blog/whats-webhook/
|
||||
[11]:http://example.com/webhooks/payment-update%29
|
||||
[12]:https://sendgrid.com/blog/whats-webhook/
|
||||
[13]:https://ngrok.com/
|
||||
[14]:https://ngrok.com/docs
|
||||
[15]:http://39741ffc.ngrok.io%2C/
|
||||
[16]:https://ngrok.com/docs#bind-tls
|
||||
[17]:http://localhost:4040./
|
||||
[18]:https://e65642b5.ngrok.io/webhook.php.
|
||||
[19]:https://github.com/wernight/docker-ngrok
|
||||
[20]:https://github.com/stefandoorn
|
||||
[21]:https://twitter.com/stefan_doorn
|
||||
[22]:https://www.linkedin.com/in/stefandoorn
|
||||
@ -0,0 +1,395 @@
|
||||
How to write a really great resume that actually gets you hired
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
This is a data-driven guide to writing a resume that actually gets you hired. I’ve spent the past four years analyzing which resume advice works regardless of experience, role, or industry. The tactics laid out below are the result of what I’ve learned. They helped me land offers at Google, Microsoft, and Twitter and have helped my students systematically land jobs at Amazon, Apple, Google, Microsoft, Facebook, and more.
|
||||
|
||||
### Writing Resumes Sucks.
|
||||
|
||||
It’s a vicious cycle.
|
||||
|
||||
We start by sifting through dozens of articles by career “gurus,” forced to compare conflicting advice and make our own decisions on what to follow.
|
||||
|
||||
The first article says “one page MAX” while the second says “take two or three and include all of your experience.”
|
||||
|
||||
The next says “write a quick summary highlighting your personality and experience” while another says “summaries are a waste of space.”
|
||||
|
||||
You scrape together your best effort and hit “Submit,” sending your resume into the ether. When you don’t hear back, you wonder what went wrong:
|
||||
|
||||
_“Was it the single page or the lack of a summary? Honestly, who gives a s**t at this point. I’m sick of sending out 10 resumes every day and hearing nothing but crickets.”_
|
||||
|
||||
|
||||

|
||||
How it feels to try and get your resume read in today’s world.
|
||||
|
||||
Writing resumes sucks but it’s not your fault.
|
||||
|
||||
The real reason it’s so tough to write a resume is because most of the advice out there hasn’t been proven against the actual end goal of getting a job. If you don’t know what consistently works, you can’t lay out a system to get there.
|
||||
|
||||
It’s easy to say “one page works best” when you’ve seen it happen a few times. But how does it hold up when we look at 100 resumes across different industries, experience levels, and job titles?
|
||||
|
||||
That’s what this article aims to answer.
|
||||
|
||||
Over the past four years, I’ve personally applied to hundreds of companies and coached hundreds of people through the job search process. This has given me a huge opportunity to measure, analyze, and test the effectiveness of different resume strategies at scale.
|
||||
|
||||
This article is going to walk through everything I’ve learned about resumes over the past 4 years, including:
|
||||
|
||||
* Mistakes that more than 95% of people make, causing their resumes to get tossed immediately
|
||||
|
||||
* Three things that consistently appear in the resumes of highly effective job searchers (who go on to land jobs at the world’s best companies)
|
||||
|
||||
* A quick hack that will help you stand out from the competition and instantly build relationships with whomever is reading your resume (increasing your chances of hearing back and getting hired)
|
||||
|
||||
* The exact resume template that got me interviews and offers at Google, Microsoft, Twitter, Uber, and more
|
||||
|
||||
Before we get to the unconventional strategies that will help set you apart, we need to make sure our foundational bases are covered. That starts with understanding the mistakes most job seekers make so we can make our resume bulletproof.
|
||||
|
||||
### Resume Mistakes That 95% Of People Make
|
||||
|
||||
Most resumes that come through an online portal or across a recruiter’s desk are tossed out because they violate a simple rule.
|
||||
|
||||
When recruiters scan a resume, the first thing they look for is mistakes. Your resume could be fantastic, but if you violate a rule like using an unprofessional email address or improper grammar, it’s going to get tossed out.
|
||||
|
||||
Our goal is to fully understand the triggers that cause recruiters/ATS systems to make the snap decisions on who stays and who goes.
|
||||
|
||||
In order to get inside the heads of these decision makers, I collected data from dozens of recruiters and hiring mangers across industries. These people have several hundred years of hiring experience under their belts and they’ve reviewed 100,000+ resumes across industries.
|
||||
|
||||
They broke down the five most common mistakes that cause them to cut resumes from the pile:
|
||||
|
||||
|
||||

|
||||
|
||||
### The Five Most Common Resume Mistakes (According To Recruiters & Hiring Managers)
|
||||
|
||||
Issue #1: Sloppiness (typos, spelling errors, & grammatical mistakes). Close to 60% of resumes have some sort of typo or grammatical issue.
|
||||
|
||||
Solution: Have your resume reviewed by three separate sources — spell checking software, a friend, and a professional. Spell check should be covered if you’re using Microsoft Word or Google Docs to create your resume.
|
||||
|
||||
A friend or family member can cover the second base, but make sure you trust them with reviewing the whole thing. You can always include an obvious mistake to see if they catch it.
|
||||
|
||||
Finally, you can hire a professional editor on [Upwork][1]. It shouldn’t take them more than 15–20 minutes to review so it’s worth paying a bit more for someone with high ratings and lots of hours logged.
|
||||
|
||||
Issue #2: Summaries are too long and formal. Many resumes include summaries that consist of paragraphs explaining why they are a “driven, results oriented team player.” When hiring managers see a block of text at the top of the resume, you can bet they aren’t going to read the whole thing. If they do give it a shot and read something similar to the sentence above, they’re going to give up on the spot.
|
||||
|
||||
Solution: Summaries are highly effective, but they should be in bullet form and showcase your most relevant experience for the role. For example, if I’m applying for a new business sales role my first bullet might read “Responsible for driving $11M of new business in 2018, achieved 168% attainment (#1 on my team).”
|
||||
|
||||
Issue #3: Too many buzz words. Remember our driven team player from the last paragraph? Phrasing like that makes hiring managers cringe because your attempt to stand out actually makes you sound like everyone else.
|
||||
|
||||
Solution: Instead of using buzzwords, write naturally, use bullets, and include quantitative results whenever possible. Would you rather hire a salesperson who “is responsible for driving new business across the healthcare vertical to help companies achieve their goals” or “drove $15M of new business last quarter, including the largest deal in company history”? Skip the buzzwords and focus on results.
|
||||
|
||||
Issue #4: Having a resume that is more than one page. The average employer spends six seconds reviewing your resume — if it’s more than one page, it probably isn’t going to be read. When asked, recruiters from Google and Barclay’s both said multiple page resumes “are the bane of their existence.”
|
||||
|
||||
Solution: Increase your margins, decrease your font, and cut down your experience to highlight the most relevant pieces for the role. It may seem impossible but it’s worth the effort. When you’re dealing with recruiters who see hundreds of resumes every day, you want to make their lives as easy as possible.
|
||||
|
||||
### More Common Mistakes & Facts (Backed By Industry Research)
|
||||
|
||||
In addition to personal feedback, I combed through dozens of recruitment survey results to fill any gaps my contacts might have missed. Here are a few more items you may want to consider when writing your resume:
|
||||
|
||||
* The average interviewer spends 6 seconds scanning your resume
|
||||
|
||||
* The majority of interviewers have not looked at your resume until
|
||||
you walk into the room
|
||||
|
||||
* 76% of resumes are discarded for an unprofessional email address
|
||||
|
||||
* Resumes with a photo have an 88% rejection rate
|
||||
|
||||
* 58% of resumes have typos
|
||||
|
||||
* Applicant tracking software typically eliminates 75% of resumes due to a lack of keywords and phrases being present
|
||||
|
||||
Now that you know every mistake you need to avoid, the first item on your to-do list is to comb through your current resume and make sure it doesn’t violate anything mentioned above.
|
||||
|
||||
Once you have a clean resume, you can start to focus on more advanced tactics that will really make you stand out. There are a few unique elements you can use to push your application over the edge and finally get your dream company to notice you.
|
||||
|
||||
|
||||

|
||||
|
||||
### The 3 Elements Of A Resume That Will Get You Hired
|
||||
|
||||
My analysis showed that highly effective resumes typically include three specific elements: quantitative results, a simple design, and a quirky interests section. This section breaks down all three elements and shows you how to maximize their impact.
|
||||
|
||||
### Quantitative Results
|
||||
|
||||
Most resumes lack them.
|
||||
|
||||
Which is a shame because my data shows that they make the biggest difference between resumes that land interviews and resumes that end up in the trash.
|
||||
|
||||
Here’s an example from a recent resume that was emailed to me:
|
||||
|
||||
> Experience
|
||||
|
||||
> + Identified gaps in policies and processes and made recommendations for solutions at the department and institution level
|
||||
|
||||
> + Streamlined processes to increase efficiency and enhance quality
|
||||
|
||||
> + Directly supervised three managers and indirectly managed up to 15 staff on multiple projects
|
||||
|
||||
> + Oversaw execution of in-house advertising strategy
|
||||
|
||||
> + Implemented comprehensive social media plan
|
||||
|
||||
As an employer, that tells me absolutely nothing about what to expect if I hire this person.
|
||||
|
||||
They executed an in-house marketing strategy. Did it work? How did they measure it? What was the ROI?
|
||||
|
||||
They also also identified gaps in processes and recommended solutions. What was the result? Did they save time and operating expenses? Did it streamline a process resulting in more output?
|
||||
|
||||
Finally, they managed a team of three supervisors and 15 staffers. How did that team do? Was it better than the other teams at the company? What results did they get and how did those improve under this person’s management?
|
||||
|
||||
See what I’m getting at here?
|
||||
|
||||
These types of bullets talk about daily activities, but companies don’t care about what you do every day. They care about results. By including measurable metrics and achievements in your resume, you’re showcasing the value that the employer can expect to get if they hire you.
|
||||
|
||||
Let’s take a look at revised versions of those same bullets:
|
||||
|
||||
> Experience
|
||||
|
||||
> + Managed a team of 20 that consistently outperformed other departments in lead generation, deal size, and overall satisfaction (based on our culture survey)
|
||||
|
||||
> + Executed in-house marketing strategy that resulted in a 15% increase in monthly leads along with a 5% drop in the cost per lead
|
||||
|
||||
> + Implemented targeted social media campaign across Instagram & Pintrest, which drove an additional 50,000 monthly website visits and generated 750 qualified leads in 3 months
|
||||
|
||||
If you were in the hiring manager’s shoes, which resume would you choose?
|
||||
|
||||
That’s the power of including quantitative results.
|
||||
|
||||
### Simple, Aesthetic Design That Hooks The Reader
|
||||
|
||||
These days, it’s easy to get carried away with our mission to “stand out.” I’ve seen resume overhauls from graphic designers, video resumes, and even resumes [hidden in a box of donuts.][2]
|
||||
|
||||
While those can work in very specific situations, we want to aim for a strategy that consistently gets results. The format I saw the most success with was a black and white Word template with sections in this order:
|
||||
|
||||
* Summary
|
||||
|
||||
* Interests
|
||||
|
||||
* Experience
|
||||
|
||||
* Education
|
||||
|
||||
* Volunteer Work (if you have it)
|
||||
|
||||
This template is effective because it’s familiar and easy for the reader to digest.
|
||||
|
||||
As I mentioned earlier, hiring managers scan resumes for an average of 6 seconds. If your resume is in an unfamiliar format, those 6 seconds won’t be very comfortable for the hiring manager. Our brains prefer things we can easily recognize. You want to make sure that a hiring manager can actually catch a glimpse of who you are during their quick scan of your resume.
|
||||
|
||||
If we’re not relying on design, this hook needs to come from the _Summary_ section at the top of your resume.
|
||||
|
||||
This section should be done in bullets (not paragraph form) and it should contain 3–4 highlights of the most relevant experience you have for the role. For example, if I was applying for a New Business Sales position, my summary could look like this:
|
||||
|
||||
> Summary
|
||||
|
||||
> Drove quarterly average of $11M in new business with a quota attainment of 128% (#1 on my team)
|
||||
|
||||
> Received award for largest sales deal of the year
|
||||
|
||||
> Developed and trained sales team on new lead generation process that increased total leads by 17% in 3 months, resulting in 4 new deals worth $7M
|
||||
|
||||
Those bullets speak directly to the value I can add to the company if I was hired for the role.
|
||||
|
||||
### An “Interests” Section That’s Quirky, Unique, & Relatable
|
||||
|
||||
This is a little “hack” you can use to instantly build personal connections and positive associations with whomever is reading your resume.
|
||||
|
||||
Most resumes have a skills/interests section, but it’s usually parked at the bottom and offers little to no value. It’s time to change things up.
|
||||
|
||||
[Research shows][3] that people rely on emotions, not information, to make decisions. Big brands use this principle all the time — emotional responses to advertisements are more influential on a person’s intent to buy than the content of an ad.
|
||||
|
||||
You probably remember Apple’s famous “Get A Mac” campaign:
|
||||
|
||||
|
||||
When it came to specs and performance, Macs didn’t blow every single PC out of the water. But these ads solidified who was “cool” and who wasn’t, which was worth a few extra bucks to a few million people.
|
||||
|
||||
By tugging at our need to feel “cool,” Apple’s campaign led to a [42% increase in market share][4] and a record sales year for Macbooks.
|
||||
|
||||
Now we’re going to take that same tactic and apply it to your resume.
|
||||
|
||||
If you can invoke an emotional response from your recruiter, you can influence the mental association they assign to you. This gives you a major competitive advantage.
|
||||
|
||||
Let’s start with a question — what could you talk about for hours?
|
||||
|
||||
It could be cryptocurrency, cooking, World War 2, World of Warcraft, or how Google’s bet on segmenting their company under the Alphabet is going to impact the technology sector over the next 5 years.
|
||||
|
||||
Did a topic (or two) pop into year head? Great.
|
||||
|
||||
Now think about what it would be like to have a conversation with someone who was just as passionate and knew just as much as you did on the topic. It’d be pretty awesome, right? _Finally, _ someone who gets it!
|
||||
|
||||
That’s exactly the kind of emotional response we’re aiming to get from a hiring manager.
|
||||
|
||||
There are five “neutral” topics out there that people enjoy talking about:
|
||||
|
||||
1. Food/Drink
|
||||
|
||||
2. Sports
|
||||
|
||||
3. College
|
||||
|
||||
4. Hobbies
|
||||
|
||||
5. Geography (travel, where people are from, etc.)
|
||||
|
||||
These topics are present in plenty of interest sections but we want to take them one step further.
|
||||
|
||||
Let’s say you had the best night of your life at the Full Moon Party in Thailand. Which of the following two options would you be more excited to read:
|
||||
|
||||
* Traveling
|
||||
|
||||
* Ko Pha Ngan beaches (where the full moon party is held)
|
||||
|
||||
Or, let’s say that you went to Duke (an ACC school) and still follow their basketball team. Which would you be more pumped about:
|
||||
|
||||
* College Sports
|
||||
|
||||
* ACC Basketball (Go Blue Devils!)
|
||||
|
||||
In both cases, the second answer would probably invoke a larger emotional response because it is tied directly to your experience.
|
||||
|
||||
I want you to think about your interests that fit into the five categories I mentioned above.
|
||||
|
||||
Now I want you to write a specific favorite associated with each category in parentheses next to your original list. For example, if you wrote travel you can add (ask me about the time I was chased by an elephant in India) or (specifically meditation in a Tibetan monastery).
|
||||
|
||||
Here is the [exact set of interests][5] I used on my resume when I interviewed at Google, Microsoft, and Twitter:
|
||||
|
||||
_ABC Kitchen’s Atmosphere, Stumptown Coffee (primarily cold brew), Michael Lewis (Liar’s Poker), Fishing (especially fly), Foods That Are Vehicles For Hot Sauce, ACC Sports (Go Deacs!) & The New York Giants_
|
||||
|
||||
|
||||

|
||||
|
||||
If you want to cheat here, my experience shows that anything about hot sauce is an instant conversation starter.
|
||||
|
||||
### The Proven Plug & Play Resume Template
|
||||
|
||||
Now that we have our strategies down, it’s time to apply these tactics to a real resume. Our goal is to write something that increases your chances of hearing back from companies, enhances your relationships with hiring managers, and ultimately helps you score the job offer.
|
||||
|
||||
The example below is the exact resume that I used to land interviews and offers at Microsoft, Google, and Twitter. I was targeting roles in Account Management and Sales, so this sample is tailored towards those positions. We’ll break down each section below:
|
||||
|
||||
|
||||

|
||||
|
||||
First, I want you to notice how clean this is. Each section is clearly labeled and separated and flows nicely from top to bottom.
|
||||
|
||||
My summary speaks directly to the value I’ve created in the past around company culture and its bottom line:
|
||||
|
||||
* I consistently exceeded expectations
|
||||
|
||||
* I started my own business in the space (and saw real results)
|
||||
|
||||
* I’m a team player who prioritizes culture
|
||||
|
||||
I purposefully include my Interests section right below my Summary. If my hiring manager’s six second scan focused on the summary, I know they’ll be interested. Those bullets cover all the subconscious criteria for qualification in sales. They’re going to be curious to read more in my Experience section.
|
||||
|
||||
By sandwiching my Interests in the middle, I’m upping their visibility and increasing the chance of creating that personal connection.
|
||||
|
||||
You never know — the person reading my resume may also be a hot sauce connoisseur and I don’t want that to be overlooked because my interests were sitting at the bottom.
|
||||
|
||||
Next, my Experience section aims to flesh out the points made in my Summary. I mentioned exceeding my quota up top, so I included two specific initiatives that led to that attainment, including measurable results:
|
||||
|
||||
* A partnership leveraging display advertising to drive users to a gamified experience. The campaign resulted in over 3000 acquisitions and laid the groundwork for the 2nd largest deal in company history.
|
||||
|
||||
* A partnership with a top tier agency aimed at increasing conversions for a client by improving user experience and upgrading tracking during a company-wide website overhaul (the client has ~20 brand sites). Our efforts over 6 months resulted in a contract extension worth 316% more than their original deal.
|
||||
|
||||
Finally, I included my education at the very bottom starting with the most relevant coursework.
|
||||
|
||||
Download My Resume Templates For Free
|
||||
|
||||
You can download a copy of the resume sample above as well as a plug and play template here:
|
||||
|
||||
Austin’s Resume: [Click To Download][6]
|
||||
|
||||
Plug & Play Resume Template: [Click To Download][7]
|
||||
|
||||
### Bonus Tip: An Unconventional Resume “Hack” To Help You Beat Applicant Tracking Software
|
||||
|
||||
If you’re not already familiar, Applicant Tracking Systems are pieces of software that companies use to help “automate” the hiring process.
|
||||
|
||||
After you hit submit on your online application, the ATS software scans your resume looking for specific keywords and phrases (if you want more details, [this article][8] does a good job of explaining ATS).
|
||||
|
||||
If the language in your resume matches up, the software sees it as a good fit for the role and will pass it on to the recruiter. However, even if you’re highly qualified for the role but you don’t use the right wording, your resume can end up sitting in a black hole.
|
||||
|
||||
I’m going to teach you a little hack to help improve your chances of beating the system and getting your resume in the hands of a human:
|
||||
|
||||
Step 1: Highlight and select the entire job description page and copy it to your clipboard.
|
||||
|
||||
Step 2: Head over to [WordClouds.com][9] and click on the “Word List” button at the top. Towards the top of the pop up box, you should see a link for Paste/Type Text. Go ahead and click that.
|
||||
|
||||
Step 3: Now paste the entire job description into the box, then hit “Apply.”
|
||||
|
||||
WordClouds is going to spit out an image that showcases every word in the job description. The larger words are the ones that appear most frequently (and the ones you want to make sure to include when writing your resume). Here’s an example for a data a science role:
|
||||
|
||||
|
||||

|
||||
|
||||
You can also get a quantitative view by clicking “Word List” again after creating your cloud. That will show you the number of times each word appeared in the job description:
|
||||
|
||||
9 data
|
||||
|
||||
6 models
|
||||
|
||||
4 experience
|
||||
|
||||
4 learning
|
||||
|
||||
3 Experience
|
||||
|
||||
3 develop
|
||||
|
||||
3 team
|
||||
|
||||
2 Qualifications
|
||||
|
||||
2 statistics
|
||||
|
||||
2 techniques
|
||||
|
||||
2 libraries
|
||||
|
||||
2 preferred
|
||||
|
||||
2 research
|
||||
|
||||
2 business
|
||||
|
||||
When writing your resume, your goal is to include those words in the same proportions as the job description.
|
||||
|
||||
It’s not a guaranteed way to beat the online application process, but it will definitely help improve your chances of getting your foot in the door!
|
||||
|
||||
* * *
|
||||
|
||||
### Want The Inside Info On Landing A Dream Job Without Connections, Without “Experience,” & Without Applying Online?
|
||||
|
||||
[Click here to get the 5 free strategies that my students have used to land jobs at Google, Microsoft, Amazon, and more without applying online.][10]
|
||||
|
||||
_Originally published at _ [_cultivatedculture.com_][11] _._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I help people land jobs they love and salaries they deserve at CultivatedCulture.com
|
||||
|
||||
----------
|
||||
|
||||
via: https://medium.freecodecamp.org/how-to-write-a-really-great-resume-that-actually-gets-you-hired-e18533cd8d17
|
||||
|
||||
作者:[Austin Belcak ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@austin.belcak
|
||||
[1]:http://www.upwork.com/
|
||||
[2]:https://www.thrillist.com/news/nation/this-guy-hides-his-resume-in-boxes-of-donuts-to-score-job-interviews
|
||||
[3]:https://www.psychologytoday.com/blog/inside-the-consumer-mind/201302/how-emotions-influence-what-we-buy
|
||||
[4]:https://www.businesswire.com/news/home/20070608005253/en/Apple-Mac-Named-Successful-Marketing-Campaign-2007
|
||||
[5]:http://cultivatedculture.com/resume-skills-section/
|
||||
[6]:https://drive.google.com/file/d/182gN6Kt1kBCo1LgMjtsGHOQW2lzATpZr/view?usp=sharing
|
||||
[7]:https://drive.google.com/open?id=0B3WIcEDrxeYYdXFPVlcyQlJIbWc
|
||||
[8]:https://www.jobscan.co/blog/8-things-you-need-to-know-about-applicant-tracking-systems/
|
||||
[9]:https://www.wordclouds.com/
|
||||
[10]:https://cultivatedculture.com/dreamjob/
|
||||
[11]:https://cultivatedculture.com/write-a-resume/
|
||||
@ -0,0 +1,140 @@
|
||||
What I Learned from Programming Interviews
|
||||
============================================================
|
||||
|
||||

|
||||
Whiteboard programming interviews
|
||||
|
||||
In 2017, I went to the [Grace Hopper Celebration][1] of women in computing. It’s the largest gathering of this kind, with 17,000 women attending last year.
|
||||
|
||||
This conference has a huge career fair where companies interview attendees. Some even get offers. Walking around the area, I noticed that some people looked stressed and worried. I overheard conversations, and some talked about how they didn’t do well in the interview.
|
||||
|
||||
I approached a group of people that I overheard and gave them advice. I considered some of the advice I gave to be basic, such as “it’s okay to think of the naive solution first.” But people were surprised by most of the advice I gave them.
|
||||
|
||||
I wanted to help more people with this. I gathered a list of tips that worked for me and published a [podcast episode][2] about them. They’re also the topic of this post.
|
||||
|
||||
I’ve had many programming interviews both for internships and full-time jobs. When I was in college studying Computer Science, there was a career fair every fall semester where the first round of interviews took place. I have failed at the first and final rounds of interviews. After each interview, I reflected on what I could’ve done better and had mock up interviews with friends who gave me feedback.
|
||||
|
||||
Whether we find a job through a job portal, networking, or university recruiting, part of the process involves doing a technical interview.
|
||||
|
||||
In recent years we’ve seen different interview formats emerge:
|
||||
|
||||
* Pair programming with an engineer
|
||||
|
||||
* Online quiz and online coding
|
||||
|
||||
* Whiteboard interviews
|
||||
|
||||
I’ll focus on the whiteboard interview because it’s the one that I have experienced. I’ve had many interviews. Some of them have gone well, while others haven’t.
|
||||
|
||||
### What I did wrong
|
||||
|
||||
First, I want to go over the things I did wrong in my interviews. This helps see the problems and what to improve.
|
||||
|
||||
When an interviewer gave me a technical problem, I immediately went to the whiteboard and started trying to solve it. _Without saying a word._
|
||||
|
||||
I made two mistakes here:
|
||||
|
||||
#### Not clarifying information that is crucial to solve a problem
|
||||
|
||||
For example, are we only working with numbers or also strings? Are we supporting multiple data types? If you don’t ask questions before you start working on a question, your interviewer can get the impression that you won’t ask questions before you start working on a project at their company. This is an important skill to have in the workplace. It is not like school anymore. You don’t get an assignment with all the steps detailed for you. You have to find out what those are and define them.
|
||||
|
||||
#### Thinking without writing or communicating
|
||||
|
||||
Often times I stood there thinking without writing. When I was doing a mock interview with a friend, he told me that he knew I was thinking because we had worked together. To a stranger, it can seem that I’m clueless, or that I’m thinking. It is also important not to rush on a solution right away. Take some time to brainstorm ideas. Sometimes the interviewer will gladly participate in this. After all, that’s how it is at work meetings.
|
||||
|
||||
### Coming up with a solution
|
||||
|
||||
Before you begin writing code, it helps if you come up with the algorithm first. Don’t start writing code and hope that you’ll solve the problem as you write.
|
||||
|
||||
This is what has worked for me:
|
||||
|
||||
1. Brainstorm
|
||||
|
||||
2. Coding
|
||||
|
||||
3. Error handling
|
||||
|
||||
4. Testing
|
||||
|
||||
#### 1\. Brainstorm
|
||||
|
||||
For me, it helps to visualize first what the problem is through a series of examples. If it’s a problem related to trees, I would start with the null case, one node, two nodes, three nodes. This can help you generalize a solution.
|
||||
|
||||
On the whiteboard, write down a list of the things the algorithm needs to do. This way, you can find bugs and issues before writing any code. Just keep track of the time. I made a mistake once where I spent too much time asking clarifying questions and brainstorming, and I barely had time to write the code. The downside of this is that your interviewer doesn’t get to see how you code. You can also come off as if you’re trying to avoid the coding portion. It helps to wear a wrist watch, or if there’s a clock in the room, look at it occasionally. Sometimes the interviewer will tell you, “I think we have the necessary information, let’s start coding it.”
|
||||
|
||||
#### 2\. Coding and code walkthrough
|
||||
|
||||
If you don’t have the solution right away, it always helps to point out the obvious naive solution. While you’re explaining this, you should be thinking of how to improve it. When you state the obvious, indicate why it is not the best solution. For this it helps to be familiar with big O notation. It is okay to go over 2–3 solutions first. The interviewer sometimes guides you by saying, “Can we do better?” This can sometimes mean they are looking for a more efficient solution.
|
||||
|
||||
#### 3\. Error handling
|
||||
|
||||
While you’re coding, point out that you’re leaving a code comment for error handling. Once an interviewer said, “That’s a good point. How would you handle it? Would you throw an exception? Or return a specific value?” This can make for a good short discussion about code quality. Mention a few error cases. Other times, the interviewer might say that you can assume that the parameters you’re getting already passed a validation. However, it is still important to bring this up to show that you are aware of error cases and quality.
|
||||
|
||||
#### 4\. Testing
|
||||
|
||||
After you have finished coding the solution, re-use the examples from brainstorming to walk through your code and make sure it works. For example you can say, “Let’s go over the example of a tree with one node, two nodes.”
|
||||
|
||||
After you finish this, the interviewer sometimes asks you how you would test your code, and what your test cases would be. I recommend that you organize your test cases in different categories.
|
||||
|
||||
Some examples are:
|
||||
|
||||
1. Performance
|
||||
|
||||
2. Error cases
|
||||
|
||||
3. Positive expected cases
|
||||
|
||||
For performance, think about extreme quantities. For example, if the problem is about lists, mention that you would have a case with a large list and a really small list. If it’s about numbers, you’ll test the maximum integer number and the smallest. I recommend reading about testing software to get more ideas. My favorite book on this is [How We Test Software at Microsoft][3].
|
||||
|
||||
For error cases, think about what is expected to fail and list those.
|
||||
|
||||
For positive expected cases, it helps to think of what the user requirements are. What are the cases that this solution is meant to solve? Those are the positive test cases.
|
||||
|
||||
### “Do you have any questions for me?”
|
||||
|
||||
Almost always there will be a few minutes dedicated at the end for you to ask questions. I recommend that you write down the questions you would ask your interviewer before the interview. Don’t say, “I don’t have any questions.” Even if you feel the interview didn’t go well, or you’re not super passionate about the company, there’s always something you can ask. It can be about what the person likes and hates most about his or her job. Or it can be something related to the person’s work, or technologies and practices used at the company. Don’t feel discouraged to ask something even if you feel you didn’t do well.
|
||||
|
||||
### Applying for a job
|
||||
|
||||
As for searching and applying for a job, I’ve been told that you should only apply to a place that you would be truly passionate to work for. They say pick a company that you love, or a product that you enjoy using, and see if you can work there.
|
||||
|
||||
I don’t recommend that you always do this. You can rule out many good options this way, especially if you’re looking for an internship or an entry-level job.
|
||||
|
||||
You can focus on other goals instead. What do I want to get more experience in? Is it cloud computing, web development, or artificial intelligence? When you talk to companies at the career fair, find out if their job openings are in this area. You might find a really good position at a company or a non-profit that wasn’t in your list.
|
||||
|
||||
#### Switching teams
|
||||
|
||||
After a year and a half at my first team, I decided that it was time to explore something different. I found a team I liked and had 4 rounds of interviews. I didn’t do well.
|
||||
|
||||
I didn’t practice anything, not even simply writing on a whiteboard. My logic had been, if I have been working at the company for almost 2 years, why would I need to practice? I was wrong about this. I struggled to write a solution on the whiteboard. Things like my writing being too small and running out of space by not starting at the top left all contributed to not passing.
|
||||
|
||||
I hadn’t brushed up on data structures and algorithms. If I had, I would’ve been more confident. Even if you’ve been working at a company as a Software Engineer, before you do a round of interviews with another team, I strongly recommend you go through practice problems on a whiteboard.
|
||||
|
||||
As for finding a team, if you are looking to switch teams at your company, it helps to talk informally with members of that team. For this, I found that almost everyone is willing to have lunch with you. People are mostly available at noon too, so there is low risk of lack of availability and meeting conflicts. This is an informal way to find out what the team is working on, and see what the personalities of your potential team members are like. You can learn many things from lunch meetings that can help you in the formal interviews.
|
||||
|
||||
It is important to know that at the end of the day, you are interviewing for a specific team. Even if you do really well, you might not get an offer because you are not a culture fit. That’s part of why I try to meet different people in the team first, but this is not always possible. Don’t get discouraged by a rejection, keep your options open, and practice.
|
||||
|
||||
This content is from the [“Programming interviews”][4] episode on [The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Software Engineer II at Microsoft Research, opinions are my own, host of www.thewomenintechshow.com
|
||||
|
||||
------------
|
||||
|
||||
via: https://medium.freecodecamp.org/what-i-learned-from-programming-interviews-29ba49c9b851
|
||||
|
||||
作者:[Edaena Salinas ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@edaenas
|
||||
[1]:https://anitab.org/event/2017-grace-hopper-celebration-women-computing/
|
||||
[2]:https://thewomenintechshow.com/2017/12/18/programming-interviews/
|
||||
[3]:https://www.amazon.com/How-We-Test-Software-Microsoft/dp/0735624259
|
||||
[4]:https://thewomenintechshow.com/2017/12/18/programming-interviews/
|
||||
[5]:https://thewomenintechshow.com/
|
||||
@ -0,0 +1,206 @@
|
||||
Conditional Rendering in React using Ternaries and Logical AND
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Photo by [Brendan Church][1] on [Unsplash][2]
|
||||
|
||||
There are several ways that your React component can decide what to render. You can use the traditional `if` statement or the `switch` statement. In this article, we’ll explore a few alternatives. But be warned that some come with their own gotchas, if you’re not careful.
|
||||
|
||||
### Ternary vs if/else
|
||||
|
||||
Let’s say we have a component that is passed a `name` prop. If the string is non-empty, we display a greeting. Otherwise we tell the user they need to sign in.
|
||||
|
||||
Here’s a Stateless Function Component (SFC) that does just that.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => {
|
||||
if (name) {
|
||||
return (
|
||||
<div className="hello">
|
||||
Hello {name}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
return (
|
||||
<div className="hello">
|
||||
Please sign in
|
||||
</div>
|
||||
);
|
||||
};
|
||||
```
|
||||
|
||||
Pretty straightforward. But we can do better. Here’s the same component written using a conditional ternary operator.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name }) => (
|
||||
<div className="hello">
|
||||
{name ? `Hello ${name}` : 'Please sign in'}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
Notice how concise this code is compared to the example above.
|
||||
|
||||
A few things to note. Because we are using the single statement form of the arrow function, the `return` statement is implied. Also, using a ternary allowed us to DRY up the duplicate `<div className="hello">` markup. 🎉
|
||||
|
||||
### Ternary vs Logical AND
|
||||
|
||||
As you can see, ternaries are wonderful for `if/else` conditions. But what about simple `if` conditions?
|
||||
|
||||
Let’s look at another example. If `isPro` (a boolean) is `true`, we are to display a trophy emoji. We are also to render the number of stars (if not zero). We could go about it like this.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro ? '🏆' : null}
|
||||
</div>
|
||||
{stars ? (
|
||||
<div>
|
||||
Stars:{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
) : null}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
But notice the “else” conditions return `null`. This is becasue a ternary expects an else condition.
|
||||
|
||||
For simple `if` conditions, we could use something a little more fitting: the logical AND operator. Here’s the same code written using a logical AND.
|
||||
|
||||
```
|
||||
const MyComponent = ({ name, isPro, stars}) => (
|
||||
<div className="hello">
|
||||
<div>
|
||||
Hello {name}
|
||||
{isPro && '🏆'}
|
||||
</div>
|
||||
{stars && (
|
||||
<div>
|
||||
Stars:{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
Not too different, but notice how we eliminated the `: null` (i.e. else condition) at the end of each ternary. Everything should render just like it did before.
|
||||
|
||||
|
||||
Hey! What gives with John? There is a `0` when nothing should be rendered. That’s the gotcha that I was referring to above. Here’s why.
|
||||
|
||||
[According to MDN][3], a Logical AND (i.e. `&&`):
|
||||
|
||||
> `expr1 && expr2`
|
||||
|
||||
> Returns `expr1` if it can be converted to `false`; otherwise, returns `expr2`. Thus, when used with Boolean values, `&&` returns `true` if both operands are true; otherwise, returns `false`.
|
||||
|
||||
OK, before you start pulling your hair out, let me break it down for you.
|
||||
|
||||
In our case, `expr1` is the variable `stars`, which has a value of `0`. Because zero is falsey, `0` is returned and rendered. See, that wasn’t too bad.
|
||||
|
||||
I would write this simply.
|
||||
|
||||
> If `expr1` is falsey, returns `expr1`, else returns `expr2`.
|
||||
|
||||
So, when using a logical AND with non-boolean values, we must make the falsey value return something that React won’t render. Say, like a value of `false`.
|
||||
|
||||
There are a few ways that we can accomplish this. Let’s try this instead.
|
||||
|
||||
```
|
||||
{!!stars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
```
|
||||
|
||||
Notice the double bang operator (i.e. `!!`) in front of `stars`. (Well, actually there is no “double bang operator”. We’re just using the bang operator twice.)
|
||||
|
||||
The first bang operator will coerce the value of `stars` into a boolean and then perform a NOT operation. If `stars` is `0`, then `!stars` will produce `true`.
|
||||
|
||||
Then we perform a second NOT operation, so if `stars` is 0, `!!stars` would produce `false`. Exactly what we want.
|
||||
|
||||
If you’re not a fan of `!!`, you can also force a boolean like this (which I find a little wordy).
|
||||
|
||||
```
|
||||
{Boolean(stars) && (
|
||||
```
|
||||
|
||||
Or simply give a comparator that results in a boolean value (which some might say is even more semantic).
|
||||
|
||||
```
|
||||
{stars > 0 && (
|
||||
```
|
||||
|
||||
#### A word on strings
|
||||
|
||||
Empty string values suffer the same issue as numbers. But because a rendered empty string is invisible, it’s not a problem that you will likely have to deal with, or will even notice. However, if you are a perfectionist and don’t want an empty string on your DOM, you should take similar precautions as we did for numbers above.
|
||||
|
||||
### Another solution
|
||||
|
||||
A possible solution, and one that scales to other variables in the future, would be to create a separate `shouldRenderStars` variable. Then you are dealing with boolean values in your logical AND.
|
||||
|
||||
```
|
||||
const shouldRenderStars = stars > 0;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
Then, if in the future, the business rule is that you also need to be logged in, own a dog, and drink light beer, you could change how `shouldRenderStars` is computed, and what is returned would remain unchanged. You could also place this logic elsewhere where it’s testable and keep the rendering explicit.
|
||||
|
||||
```
|
||||
const shouldRenderStars =
|
||||
stars > 0 && loggedIn && pet === 'dog' && beerPref === 'light`;
|
||||
```
|
||||
|
||||
```
|
||||
return (
|
||||
<div>
|
||||
{shouldRenderStars && (
|
||||
<div>
|
||||
{'⭐️'.repeat(stars)}
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
);
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
I’m of the opinion that you should make best use of the language. And for JavaScript, this means using conditional ternary operators for `if/else`conditions and logical AND operators for simple `if` conditions.
|
||||
|
||||
While we could just retreat back to our safe comfy place where we use the ternary operator everywhere, you now possess the knowledge and power to go forth AND prosper.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Managing Editor at the American Express Engineering Blog http://aexp.io and Director of Engineering @AmericanExpress. MyViews !== ThoseOfMyEmployer.
|
||||
|
||||
----------------
|
||||
|
||||
via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternaries-and-logical-and-7807f53b6935
|
||||
|
||||
作者:[Donavon West][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@donavon
|
||||
[1]:https://unsplash.com/photos/pKeF6Tt3c08?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/search/photos/road-sign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
|
||||
@ -0,0 +1,223 @@
|
||||
Here are some amazing advantages of Go that you don’t hear much about
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Artwork from [https://github.com/ashleymcnamara/gophers][1]
|
||||
|
||||
In this article, I discuss why you should give Go a chance and where to start.
|
||||
|
||||
Golang is a programming language you might have heard about a lot during the last couple years. Even though it was created back in 2009, it has started to gain popularity only in recent years.
|
||||
|
||||
|
||||
|
||||
Golang popularity according to Google Trends
|
||||
|
||||
This article is not about the main selling points of Go that you usually see.
|
||||
|
||||
Instead, I would like to present to you some rather small but still significant features that you only get to know after you’ve decided to give Go a try.
|
||||
|
||||
These are amazing features that are not laid out on the surface, but they can save you weeks or months of work. They can also make software development more enjoyable.
|
||||
|
||||
Don’t worry if Go is something new for you. This article does not require any prior experience with the language. I have included a few extra links at the bottom, in case you would like to learn a bit more.
|
||||
|
||||
We will go through such topics as:
|
||||
|
||||
* GoDoc
|
||||
|
||||
* Static code analysis
|
||||
|
||||
* Built-in testing and profiling framework
|
||||
|
||||
* Race condition detection
|
||||
|
||||
* Learning curve
|
||||
|
||||
* Reflection
|
||||
|
||||
* Opinionatedness
|
||||
|
||||
* Culture
|
||||
|
||||
Please, note that the list doesn’t follow any particular order. It is also opinionated as hell.
|
||||
|
||||
### GoDoc
|
||||
|
||||
Documentation in code is taken very seriously in Go. So is simplicity.
|
||||
|
||||
[GoDoc][4] is a static code analyzing tool that creates beautiful documentation pages straight out of your code. A remarkable thing about GoDoc is that it doesn’t use any extra languages, like JavaDoc, PHPDoc, or JSDoc to annotate constructions in your code. Just English.
|
||||
|
||||
It uses as much information as it can get from the code to outline, structure, and format the documentation. And it has all the bells and whistles, such as cross-references, code samples, and direct links to your version control system repository.
|
||||
|
||||
All you can do is to add a good old `// MyFunc transforms Foo into Bar` kind of comment which would be reflected in the documentation, too. You can even add [code examples][5] which are actually runnable via the web interface or locally.
|
||||
|
||||
GoDoc is the only documentation engine for Go that is used by the whole community. This means that every library or application written in Go has the same format of documentation. In the long run, it saves you tons of time while browsing those docs.
|
||||
|
||||
Here, for example, is the GoDoc page for my recent pet project: [pullkee — GoDoc][6].
|
||||
|
||||
### Static code analysis
|
||||
|
||||
Go heavily relies on static code analysis. Examples include [godoc][7] for documentation, [gofmt][8] for code formatting, [golint][9] for code style linting, and many others.
|
||||
|
||||
There are so many of them that there’s even an everything-included-kind-of project called [gometalinter][10] to compose them all into a single utility.
|
||||
|
||||
Those tools are commonly implemented as stand-alone command line applications and integrate easily with any coding environment.
|
||||
|
||||
Static code analysis isn’t actually something new to modern programming, but Go sort of brings it to the absolute. I can’t overestimate how much time it saved me. Also, it gives you a feeling of safety, as though someone is covering your back.
|
||||
|
||||
It’s very easy to create your own analyzers, as Go has dedicated built-in packages for parsing and working with Go sources.
|
||||
|
||||
You can learn more from this talk: [GothamGo Kickoff Meetup: Go Static Analysis Tools by Alan Donovan][11].
|
||||
|
||||
### Built-in testing and profiling framework
|
||||
|
||||
Have you ever tried to pick a testing framework for a Javascript project you are starting from scratch? If so, you might understand that struggle of going through such an analysis paralysis. You might have also realized that you were not using like 80% of the framework you have chosen.
|
||||
|
||||
The issue repeats over again once you need to do some reliable profiling.
|
||||
|
||||
Go comes with a built-in testing tool designed for simplicity and efficiency. It provides you the simplest API possible, and makes minimum assumptions. You can use it for different kinds of testing, profiling, and even to provide executable code examples.
|
||||
|
||||
It produces CI-friendly output out-of-box, and the usage is usually as easy as running `go test`. Of course, it also supports advanced features like running tests in parallel, marking them skipped, and many more.
|
||||
|
||||
### Race condition detection
|
||||
|
||||
You might already know about Goroutines, which are used in Go to achieve concurrent code execution. If you don’t, [here’s][12] a really brief explanation.
|
||||
|
||||
Concurrent programming in complex applications is never easy regardless of the specific technique, partly due to the possibility of race conditions.
|
||||
|
||||
Simply put, race conditions happen when several concurrent operations finish in an unpredicted order. It might lead to a huge number of bugs, which are particularly hard to chase down. Ever spent a day debugging an integration test which only worked in about 80% of executions? It probably was a race condition.
|
||||
|
||||
All that said, concurrent programming is taken very seriously in Go and, luckily, we have quite a powerful tool to hunt those race conditions down. It is fully integrated into Go’s toolchain.
|
||||
|
||||
You can read more about it and learn how to use it here: [Introducing the Go Race Detector — The Go Blog][13].
|
||||
|
||||
### Learning curve
|
||||
|
||||
You can learn ALL Go’s language features in one evening. I mean it. Of course, there are also the standard library, and the best practices in different, more specific areas. But two hours would totally be enough time to get you confidently writing a simple HTTP server, or a command-line app.
|
||||
|
||||
The project has [marvelous documentation][14], and most of the advanced topics have already been covered on their blog: [The Go Programming Language Blog][15].
|
||||
|
||||
Go is much easier to bring to your team than Java (and the family), Javascript, Ruby, Python, or even PHP. The environment is easy to setup, and the investment your team needs to make is much smaller before they can complete your first production code.
|
||||
|
||||
### Reflection
|
||||
|
||||
Code reflection is essentially an ability to sneak under the hood and access different kinds of meta-information about your language constructs, such as variables or functions.
|
||||
|
||||
Given that Go is a statically typed language, it’s exposed to a number of various limitations when it comes to more loosely typed abstract programming. Especially compared to languages like Javascript or Python.
|
||||
|
||||
Moreover, Go [doesn’t implement a concept called Generics][16] which makes it even more challenging to work with multiple types in an abstract way. Nevertheless, many people think it’s actually beneficial for the language because of the amount of complexity Generics bring along. And I totally agree.
|
||||
|
||||
According to Go’s philosophy (which is a separate topic itself), you should try hard to not over-engineer your solutions. And this also applies to dynamically-typed programming. Stick to static types as much as possible, and use interfaces when you know exactly what sort of types you’re dealing with. Interfaces are very powerful and ubiquitous in Go.
|
||||
|
||||
However, there are still cases in which you can’t possibly know what sort of data you are facing. A great example is JSON. You convert all the kinds of data back and forth in your applications. Strings, buffers, all sorts of numbers, nested structs and more.
|
||||
|
||||
In order to pull that off, you need a tool to examine all the data in runtime that acts differently depending on its type and structure. Reflection to rescue! Go has a first-class [reflect][17] package to enable your code to be as dynamic as it would be in a language like Javascript.
|
||||
|
||||
An important caveat is to know what price you pay for using it — and only use it when there is no simpler way.
|
||||
|
||||
You can read more about it here: [The Laws of Reflection — The Go Blog][18].
|
||||
|
||||
You can also read some real code from the JSON package sources here: [src/encoding/json/encode.go — Source Code][19]
|
||||
|
||||
### Opinionatedness
|
||||
|
||||
Is there such a word, by the way?
|
||||
|
||||
Coming from the Javascript world, one of the most daunting processes I faced was deciding which conventions and tools I needed to use. How should I style my code? What testing library should I use? How should I go about structure? What programming paradigms and approaches should I rely on?
|
||||
|
||||
Which sometimes basically got me stuck. I was doing this instead of writing the code and satisfying the users.
|
||||
|
||||
To begin with, I should note that I totally get where those conventions should come from. It’s always you and your team. Anyway, even a group of experienced Javascript developers can easily find themselves having most of the experience with entirely different tools and paradigms to achieve kind of the same results.
|
||||
|
||||
This makes the analysis paralysis cloud explode over the whole team, and also makes it harder for the individuals to integrate with each other.
|
||||
|
||||
Well, Go is different. You have only one style guide that everyone follows. You have only one testing framework which is built into the basic toolchain. You have a lot of strong opinions on how to structure and maintain your code. How to pick names. What structuring patterns to follow. How to do concurrency better.
|
||||
|
||||
While this might seem too restrictive, it saves tons of time for you and your team. Being somewhat limited is actually a great thing when you are coding. It gives you a more straightforward way to go when architecting new code, and makes it easier to reason about the existing one.
|
||||
|
||||
As a result, most of the Go projects look pretty alike code-wise.
|
||||
|
||||
### Culture
|
||||
|
||||
People say that every time you learn a new spoken language, you also soak in some part of the culture of the people who speak that language. Thus, the more languages you learn, more personal changes you might experience.
|
||||
|
||||
It’s the same with programming languages. Regardless of how you are going to apply a new programming language in the future, it always gives you a new perspective on programming in general, or on some specific techniques.
|
||||
|
||||
Be it functional programming, pattern matching, or prototypal inheritance. Once you’ve learned it, you carry these approaches with you which broadens the problem-solving toolset that you have as a software developer. It also changes the way you see high-quality programming in general.
|
||||
|
||||
And Go is a terrific investment here. The main pillar of Go’s culture is keeping simple, down-to-earth code without creating many redundant abstractions and putting the maintainability at the top. It’s also a part of the culture to spend the most time actually working on the codebase, instead of tinkering with the tools and the environment. Or choosing between different variations of those.
|
||||
|
||||
Go is also all about “there should be only one way of doing a thing.”
|
||||
|
||||
A little side note. It’s also partially true that Go usually gets in your way when you need to build relatively complex abstractions. Well, I’d say that’s the tradeoff for its simplicity.
|
||||
|
||||
If you really need to write a lot of abstract code with complex relationships, you’d be better off using languages like Java or Python. However, even when it’s not obvious, it’s very rarely the case.
|
||||
|
||||
Always use the best tool for the job!
|
||||
|
||||
### Conclusion
|
||||
|
||||
You might have heard of Go before. Or maybe it’s something that has been staying out of your radar for a while. Either way, chances are, Go can be a very decent choice for you or your team when starting a new project or improving the existing one.
|
||||
|
||||
This is not a complete list of all the amazing things about Go. Just the undervalued ones.
|
||||
|
||||
Please, give Go a try with [A Tour of Go][20] which is an incredible place to start.
|
||||
|
||||
If you wish to learn more about Go’s benefits, you can check out these links:
|
||||
|
||||
* [Why should you learn Go? — Keval Patel — Medium][2]
|
||||
|
||||
* [Farewell Node.js — TJ Holowaychuk — Medium][3]
|
||||
|
||||
Share your observations down in the comments!
|
||||
|
||||
Even if you are not specifically looking for a new language to use, it’s worth it to spend an hour or two getting the feel of it. And maybe it can become quite useful for you in the future.
|
||||
|
||||
Always be looking for the best tools for your craft!
|
||||
|
||||
* * *
|
||||
|
||||
If you like this article, please consider following me for more, and clicking on those funny green little hands right below this text for sharing. 👏👏👏
|
||||
|
||||
Check out my [Github][21] and follow me on [Twitter][22]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Software Engineer and Traveler. Coding for fun. Javascript enthusiast. Tinkering with Golang. A lot into SOA and Docker. Architect at Velvica.
|
||||
|
||||
------------
|
||||
|
||||
|
||||
via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that-you-dont-hear-much-about-1af99de3b23a
|
||||
|
||||
作者:[Kirill Rogovoy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://github.com/ashleymcnamara/gophers
|
||||
[2]:https://medium.com/@kevalpatel2106/why-should-you-learn-go-f607681fad65
|
||||
[3]:https://medium.com/@tjholowaychuk/farewell-node-js-4ba9e7f3e52b
|
||||
[4]:https://godoc.org/
|
||||
[5]:https://blog.golang.org/examples
|
||||
[6]:https://godoc.org/github.com/kirillrogovoy/pullkee
|
||||
[7]:https://godoc.org/
|
||||
[8]:https://golang.org/cmd/gofmt/
|
||||
[9]:https://github.com/golang/lint
|
||||
[10]:https://github.com/alecthomas/gometalinter#supported-linters
|
||||
[11]:https://vimeo.com/114736889
|
||||
[12]:https://gobyexample.com/goroutines
|
||||
[13]:https://blog.golang.org/race-detector
|
||||
[14]:https://golang.org/doc/
|
||||
[15]:https://blog.golang.org/
|
||||
[16]:https://golang.org/doc/faq#generics
|
||||
[17]:https://golang.org/pkg/reflect/
|
||||
[18]:https://blog.golang.org/laws-of-reflection
|
||||
[19]:https://golang.org/src/encoding/json/encode.go
|
||||
[20]:https://tour.golang.org/
|
||||
[21]:https://github.com/kirillrogovoy/
|
||||
[22]:https://twitter.com/krogovoy
|
||||
@ -0,0 +1,199 @@
|
||||
I Built This - Now What? How to deploy a React App on a DigitalOcean Droplet.
|
||||
============================================================
|
||||
|
||||

|
||||
Photo by [Thomas Kvistholt][1]
|
||||
|
||||
Most aspiring developers have uploaded static HTML sites before. The process isn’t too daunting, as you’re essentially just moving files from one computer to another, and then BAM! Website.
|
||||
|
||||
But those who have tackled learning React often pour hundreds or even thousands of hours into learning about components, props, and state, only to be left with the question “How do I host this?” Fear not, fellow developer. Deploying your latest masterpiece is a little more in-depth, but not overly difficult. Here’s how:
|
||||
|
||||
### Preparing For Production
|
||||
|
||||
There are a few things you’ll want to do to get your app ready for deployment.
|
||||
|
||||
#### Turn off service workers
|
||||
|
||||
If you’ve used something like create-react-app to bootstrap your project, you’ll want to turn off the built-in service worker if you haven’t specifically integrated it to work with your app. While usually harmless, it can cause some issues, so it’s best to just get rid of it up front. Find these lines in your `src/index.js` file and delete them:`registerServiceWorker();` `import registerServiceWorker from ‘register-service-worker’`
|
||||
|
||||
#### Get your server ready
|
||||
|
||||
To get the most bang for your buck, a production build will minify the code and remove extra white-space and comments so that it’s as fast to download as possible. It creates a new directory called `/build`, and we need to make sure we’re telling Express to use it. On your server page, add this line: `app.use( express.static( `${__dirname}/../build` ) );`
|
||||
|
||||
Next, you’ll need to make sure your routes know how to get to your index.html file. To do this, we need to create an endpoint and place it below all other endpoints in your server file. It should look like this:
|
||||
|
||||
```
|
||||
const path = require('path')app.get('*', (req, res)=>{ res.sendFile(path.join(__dirname, '../build/index.html'));})
|
||||
```
|
||||
|
||||
#### Create the production build
|
||||
|
||||
Now that Express knows to use the `/build` directory, it’s time to create it. Open up your terminal, make sure you’re in your project directory, and use the command `npm run build`
|
||||
|
||||
#### Keep your secrets safe
|
||||
|
||||
If you’re using API keys or a database connection string, hopefully you’ve already hidden them in a `.env` file. All the configuration that is different between deployed and local should go into this file as well. Tags cannot be proxied, so we have to hard code in the backend address when using the React dev server, but we want to use relative paths in production. Your resulting `.env` file might look something like this:
|
||||
|
||||
```
|
||||
REACT_APP_LOGIN="http://localhost:3030/api/auth/login"REACT_APP_LOGOUT="http://localhost:3030/api/auth/logout"DOMAIN="user4234.auth0.com"ID="46NxlCzM0XDE7T2upOn2jlgvoS"SECRET="0xbTbFK2y3DIMp2TdOgK1MKQ2vH2WRg2rv6jVrMhSX0T39e5_Kd4lmsFz"SUCCESS_REDIRECT="http://localhost:3030/"FAILURE_REDIRECT="http://localhost:3030/api/auth/login"
|
||||
```
|
||||
|
||||
```
|
||||
AWS_ACCESS_KEY_ID=AKSFDI4KL343K55L3
|
||||
AWS_SECRET_ACCESS_KEY=EkjfDzVrG1cw6QFDK4kjKFUa2yEDmPOVzN553kAANcy
|
||||
```
|
||||
|
||||
```
|
||||
CONNECTION_STRING="postgres://vuigx:k8Io13cePdUorndJAB2ijk_u0r4@stampy.db.elephantsql.com:5432/vuigx"NODE_ENV=development
|
||||
```
|
||||
|
||||
#### Push your code
|
||||
|
||||
Test out your app locally by going to `[http://localhost:3030][2]` and replacing 3030 with your server port to make sure everything still runs smoothly. Remember to start your local server with node or nodemon so it’s up and running when you check it. Once everything looks good, we can push it to Github (or Bit Bucket, etc).
|
||||
|
||||
IMPORTANT! Before you do so, double check that your `.gitignore` file contains `.env` and `/build` so you’re not publishing sensitive information or needless files.
|
||||
|
||||
### Setting Up DigitalOcean
|
||||
|
||||
[DigitalOcean][8] is a leading hosting platform, and makes it relatively easy and cost-effective to deploy React sites. They utilize Droplets, which is the term they use for their servers. Before we create our Droplet, we still have a little work to do.
|
||||
|
||||
#### Creating SSH Keys
|
||||
|
||||
Servers are computers that have public IP addresses. Because of this, we need a way to tell the server who we are, so that we can do things we wouldn’t want anyone else doing, like making changes to our files. Your everyday password won’t be secure enough, and a password long and complex enough to protect your Droplet would be nearly impossible to remember. Instead, we’ll use an SSH key.
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
Photo by [Brenda Clarke][3]
|
||||
|
||||
To create your SSH key, enter this command in your terminal: `ssh-keygen -t rsa`
|
||||
|
||||
This starts the process of SSH key generation. First, you’ll be asked to specify where to save the new key. Unless you already have a key you need to keep, you can keep the default location and simply press enter to continue.
|
||||
|
||||
As an added layer of security in case someone gets ahold of your computer, you’ll have to enter a password to secure your key. Your terminal will not show your keystrokes as you type this password, but it is keeping track of it. Once you hit enter, you’ll have to type it in once more to confirm. If successful, you should now see something like this:
|
||||
|
||||
```
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/Users/username/.ssh/id_rsa):
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in demo_rsa.
|
||||
Your public key has been saved in demo_rsa.pub.
|
||||
The key fingerprint is:
|
||||
cc:28:30:44:01:41:98:cf:ae:b6:65:2a:f2:32:57:b5 user@user.local
|
||||
The key's randomart image is:
|
||||
+--[ RSA 2048]----+
|
||||
|=*+. |
|
||||
|o. |
|
||||
| oo |
|
||||
| oo .+ |
|
||||
| . ....S |
|
||||
| . ..E |
|
||||
| . + |
|
||||
|*.= |
|
||||
|+Bo |
|
||||
+-----------------+
|
||||
```
|
||||
|
||||
#### What happened?
|
||||
|
||||
Two files have been created on your computer — `id_rsa` and `id_rsa.pub`. The `id_rsa` file is your private key and is used to verify your signature when you use the `id_rsa.pub` file, or public key. We need to give our public key to DigitalOcean. To get it, enter `cat ~/.ssh/id_rsa.pub`. You should now be looking at a long string of characters, which is the contents of your `id_rsa.pub` file. It looks something like this:
|
||||
|
||||
```
|
||||
ssh-rsaAABC3NzaC1yc2EAAAADAQABAAABAQDR5ehyadT9unUcxftJOitl5yOXgSi2Wj/s6ZBudUS5Cex56LrndfP5Uxb8+Qpx1D7gYNFacTIcrNDFjdmsjdDEIcz0WTV+mvMRU1G9kKQC01YeMDlwYCopuENaas5+cZ7DP/qiqqTt5QDuxFgJRTNEDGEebjyr9wYk+mveV/acBjgaUCI4sahij98BAGQPvNS1xvZcLlhYssJSZrSoRyWOHZ/hXkLtq9CvTaqkpaIeqvvmNxQNtzKu7ZwaYWLydEKCKTAe4ndObEfXexQHOOKwwDSyesjaNc6modkZZC+anGLlfwml4IUwGv10nogVg9DTNQQLSPVmnEN3Z User@Computer.local
|
||||
```
|
||||
|
||||
Now _that’s_ a password! Copy the string manually, or use the command `pbcopy < ~/.ssh/id_rsa.pub` to have the terminal copy it for you.
|
||||
|
||||
#### Adding your SSH Key to DigitalOcean
|
||||
|
||||
Login to your DigitalOcean account or sign up if you haven’t already. Go to your [Security Settings][9] and click on Add SSH. Paste in the key you copied and give it a name. You can name it whatever you like, but it’s good idea to reference the computer the key is saved on, especially if you use multiple computers regularly.
|
||||
|
||||
#### Creating a Droplet
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
Photo by [M. Maddo][4]
|
||||
|
||||
With the key in place, we can finally create our Droplet. To get started, click Create Droplet. You’ll be asked to choose an OS, but for our purposes, the default Ubuntu will work just fine.
|
||||
|
||||
You’ll need to select which size Droplet you want to use. In many cases, the smallest Droplet will do. However, review the available options and choose the one that will work best for your project.
|
||||
|
||||
Next, select a data center for your Droplet. Choose a location central to your expected visitor base. New features are rolled out by DigitalOcean in different data centers at different times, but unless you know you want to use a special feature that’s only available in specific locations, this won’t matter.
|
||||
|
||||
If you want to add additional services to your Droplet such as backups or private networking, you have that option here. Be aware, there is an associated cost for these services.
|
||||
|
||||
Finally, make sure your SSH key is selected and give your Droplet a name. It is possible to host multiple projects on a single Droplet, so you may not want to give it a project-specific name. Submit your settings by clicking the Create button at the bottom of the page.
|
||||
|
||||
#### Connecting to your Droplet
|
||||
|
||||
With our Droplet created, we can now connect to it via SSH. Copy the IP address for your Droplet and go back to your terminal. Enter ssh followed by root@youripaddress, where youripaddress is the IP address for your Droplet. It should look something like this: `ssh root@123.45.67.8`. This tells your computer that you want to connect to your IP address as the root user. Alternatively, you can [set up user accounts][10] if you don’t want to login as root, but it’s not necessary.
|
||||
|
||||
#### Installing Node
|
||||
|
||||
|
||||

|
||||
|
||||
To run React, we’ll need an updated version of Node. First we want to run `apt-get update && apt-get dist-upgrade` to update the Linux software list. Next, enter `apt-get install nodejs -y`, `apt-get install npm -y`, and `npm i -g n` to install Nodejs and npm.
|
||||
|
||||
Your React app dependencies might require a specific version of Node, so check the version that your project is using by running `node -v` in your projects directory. You’ll probably want to do this in a different terminal tab so you don’t have to log in through SSH again.
|
||||
|
||||
Once you know what version you need, go back to your SSH connection and run `n 6.11.2`, replacing 6.11.2 with your specific version number. This ensures your Droplet’s version of Node matches your project and minimizes potential issues.
|
||||
|
||||
### Install your app to the Droplet
|
||||
|
||||
All the groundwork has been laid, and it’s finally time to install our React app! While still connected through SSH, make sure you’re in your home directory. You can enter `cd ~` to take you there if you’re not sure.
|
||||
|
||||
To get the files to your Droplet, you’re going to clone them from your Github repo. Grab the HTTP clone link from Github and in your terminal enter `git clone [https://github.com/username/my-react-project.git][5]`. Just like with your local project, cd into your project folder using `cd my-react-project` and then run `npm install`.
|
||||
|
||||
#### Don’t ignore your ignored files
|
||||
|
||||
Remember that we told Git to ignore the `.env` file, so it won’t be included in the code we just pulled down. We need to add it manually now. `touch .env`will create an empty `.env` file that we can then open in the nano editor using `nano .env`. Copy the contents of your local `.env` file and paste them into the nano editor.
|
||||
|
||||
We also told Git to ignore the build directory. That’s because we were just testing the production build, but now we’re going to build it again on our Droplet. Use `npm run build` to run this process again. If you get an error, check to make sure you have all of your dependencies listed in your `package.json` file. If there are any missing, npm install those packages.
|
||||
|
||||
#### Start it up!
|
||||
|
||||
Run your server with `node server/index.js` (or whatever your server file is named) to make sure everything is working. If it throws an error, check again for any missing dependencies that might not have been caught in the build process. If everything starts up, you should now be able to go to ipaddress:serverport to see your site: `123.45.67.8:3232`. If your server is running on port 80, this is a default port and you can just use the IP address without specifying a port number: `123.45.67.8`
|
||||
|
||||
|
||||

|
||||
Photo by [John Baker][6] on [Unsplash][7]
|
||||
|
||||
You now have a space on the internet to call your own! If you have purchased a domain name you’d like to use in place of the IP address, you can follow [DigitalOcean’s instructions][11] on how to set this up.
|
||||
|
||||
#### Keep it running
|
||||
|
||||
Your site is live, but once you close the terminal, your server will stop. This is a problem, so we’ll want to install some more software that will tell the server not to stop once the connection is terminated. There are some options for this, but let’s use Program Manager 2 for the sake of this article.
|
||||
|
||||
Kill your server if you haven’t already and run `npm install -g pm2`. Once installed, we can tell it to run our server using `pm2 start server/index.js`
|
||||
|
||||
### Updating your code
|
||||
|
||||
At some point, you’ll probably want to update your project, but luckily uploading changes is quick and easy. Once you push your code to Github, ssh into your Droplet and cd into your project directory. Because we cloned from Github initially, we don’t need to provide any links this time. You can pull down the new code simply by running `git pull`.
|
||||
|
||||
To incorporate frontend changes, you will need to run the build process again with `npm run build`. If you’ve made changes to the server file, restart PM2 by running `pm2 restart all`. That’s it! Your updates should be live now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/i-built-this-now-what-how-to-deploy-a-react-app-on-a-digitalocean-droplet-662de0fe3f48
|
||||
|
||||
作者:[Andrea Stringham ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@astringham
|
||||
[1]:https://unsplash.com/photos/oZPwn40zCK4?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:http://localhost:3030/
|
||||
[3]:https://www.flickr.com/photos/37753256@N08/
|
||||
[4]:https://www.flickr.com/photos/14141796@N05/
|
||||
[5]:https://github.com/username/my-react-project.git
|
||||
[6]:https://unsplash.com/photos/3To9V42K0Ag?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[7]:https://unsplash.com/search/photos/key?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]:https://www.digitalocean.com/
|
||||
[9]:https://cloud.digitalocean.com/settings/security
|
||||
[10]:https://www.digitalocean.com/community/tutorials/initial-server-setup-with-ubuntu-14-04
|
||||
[11]:https://www.digitalocean.com/community/tutorials/how-to-point-to-digitalocean-nameservers-from-common-domain-registrars
|
||||
@ -0,0 +1,292 @@
|
||||
Rock Solid React.js Foundations: A Beginner’s Guide
|
||||
============================================================
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
React.js crash course
|
||||
|
||||
I’ve been working with React and React-Native for the last couple of months. I have already released two apps in production, [Kiven Aa][1] (React) and [Pollen Chat][2] (React Native). When I started learning React, I was searching for something (a blog, a video, a course, whatever) that didn’t only teach me how to write apps in React. I also wanted it to prepare me for interviews.
|
||||
|
||||
Most of the material I found, concentrated on one or the other. So, this post is aimed towards the audience who is looking for a perfect mix of theory and hands-on. I will give you a little bit of theory so that you understand what is happening under the hood and then I will show you how to write some React.js code.
|
||||
|
||||
If you prefer video, I have this entire course up on YouTube as well. Please check that out.
|
||||
|
||||
|
||||
Let’s dive in…
|
||||
|
||||
> React.js is a JavaScript library for building user interfaces
|
||||
|
||||
You can build all sorts of single page applications. For example, chat messengers and e-commerce portals where you want to show changes on the user interface in real-time.
|
||||
|
||||
### Everything’s a component
|
||||
|
||||
A React app is comprised of components, _a lot of them_ , nested into one another. _But what are components, you may ask?_
|
||||
|
||||
A component is a reusable piece of code, which defines how certain features should look and behave on the UI. For example, a button is a component.
|
||||
|
||||
Let’s look at the following calculator, which you see on Google when you try to calculate something like 2+2 = 4 –1 = 3 (quick maths!)
|
||||
|
||||
|
||||

|
||||
Red markers denote components
|
||||
|
||||
As you can see in the image above, the calculator has many areas — like the _result display window_ and the _numpad_ . All of these can be separate components or one giant component. It depends on how comfortable one is in breaking down and abstracting away things in React
|
||||
|
||||
You write code for all such components separately. Then combine those under one container, which in turn is a React component itself. This way you can create reusable components and your final app will be a collection of separate components working together.
|
||||
|
||||
The following is one such way you can write the calculator, shown above, in React.
|
||||
|
||||
```
|
||||
<Calculator>
|
||||
<DisplayWindow />
|
||||
<NumPad>
|
||||
<Key number={1}/>
|
||||
<Key number={2}/>
|
||||
.
|
||||
.
|
||||
.
|
||||
<Key number={9}/>
|
||||
</NumPad>
|
||||
</Calculator>
|
||||
|
||||
```
|
||||
|
||||
Yes! It looks like HTML code, but it isn’t. We will explore more about it in the later sections.
|
||||
|
||||
### Setting up our Playground
|
||||
|
||||
This tutorial focuses on React’s fundamentals. It is not primarily geared towards React for Web or [React Native][3] (for building mobile apps). So, we will use an online editor so as to avoid web or native specific configurations before even learning what React can do.
|
||||
|
||||
I’ve already set up an environment for you on [codepen.io][4]. Just follow the link and read all the comments in HTML and JavaScript (JS) tabs.
|
||||
|
||||
### Controlling Components
|
||||
|
||||
We’ve learned that a React app is a collection of various components, structured as a nested tree. Thus, we require some sort of mechanism to pass data from one component to other.
|
||||
|
||||
#### Enter “props”
|
||||
|
||||
We can pass arbitrary data to our component using a `props` object. Every component in React gets this `props` object.
|
||||
|
||||
Before learning how to use this `props` object, let’s learn about functional components.
|
||||
|
||||
#### a) Functional component
|
||||
|
||||
A functional component in React consumes arbitrary data that you pass to it using `props` object. It returns an object which describes what UI React should render. Functional components are also known as Stateless components.
|
||||
|
||||
Let’s write our first functional component.
|
||||
|
||||
```
|
||||
function Hello(props) {
|
||||
return <div>{props.name}</div>
|
||||
}
|
||||
```
|
||||
|
||||
It’s that simple. We just passed `props` as an argument to a plain JavaScript function and returned, _umm, well, what was that? That _ `_<div>{props.name}</div>_` _thing!_ It’s JSX (JavaScript Extended). We will learn more about it in a later section.
|
||||
|
||||
This above function will render the following HTML in the browser.
|
||||
|
||||
```
|
||||
<!-- If the "props" object is: {name: 'rajat'} -->
|
||||
<div>
|
||||
rajat
|
||||
</div>
|
||||
```
|
||||
|
||||
|
||||
> Read the section below about JSX, where I have explained how did we get this HTML from our JSX code.
|
||||
|
||||
How can you use this functional component in your React app? Glad you asked! It’s as simple as the following.
|
||||
|
||||
```
|
||||
<Hello name='rajat' age={26}/>
|
||||
```
|
||||
|
||||
The attribute `name` in the above code becomes `props.name` inside our `Hello`component. The attribute `age` becomes `props.age` and so on.
|
||||
|
||||
> Remember! You can nest one React component inside other React components.
|
||||
|
||||
Let’s use this `Hello` component in our codepen playground. Replace the `div`inside `ReactDOM.render()` with our `Hello` component, as follows, and see the changes in the bottom window.
|
||||
|
||||
```
|
||||
function Hello(props) {
|
||||
return <div>{props.name}</div>
|
||||
}
|
||||
|
||||
ReactDOM.render(<Hello name="rajat"/>, document.getElementById('root'));
|
||||
```
|
||||
|
||||
|
||||
> But what if your component has some internal state. For instance, like the following counter component, which has an internal count variable, which changes on + and — key presses.
|
||||
|
||||
A React component with an internal state
|
||||
|
||||
#### b) Class-based component
|
||||
|
||||
The class-based component has an additional property `state` , which you can use to hold a component’s private data. We can rewrite our `Hello` component using class notation as follows. Since these components have a state, these are also known as Stateful components.
|
||||
|
||||
```
|
||||
class Counter extends React.Component {
|
||||
// this method should be present in your component
|
||||
render() {
|
||||
return (
|
||||
<div>
|
||||
{this.props.name}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We extend `React.Component` class of React library to make class-based components in React. Learn more about JavaScript classes [here][5].
|
||||
|
||||
The `render()` method must be present in your class as React looks for this method in order to know what UI it should render on screen.
|
||||
|
||||
To use this sort of internal state, we first have to initialize the `state` object in the constructor of the component class, in the following way.
|
||||
|
||||
```
|
||||
class Counter extends React.Component {
|
||||
constructor() {
|
||||
super();
|
||||
|
||||
// define the internal state of the component
|
||||
this.state = {name: 'rajat'}
|
||||
}
|
||||
|
||||
render() {
|
||||
return (
|
||||
<div>
|
||||
{this.state.name}
|
||||
</div>
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
// Usage:
|
||||
// In your react app: <Counter />
|
||||
```
|
||||
|
||||
Similarly, the `props` can be accessed inside our class-based component using `this.props` object.
|
||||
|
||||
To set the state, you use `React.Component`'s `setState()`. We will see an example of this, in the last part of this tutorial.
|
||||
|
||||
> Tip: Never call `setState()` inside `render()` function, as `setState()` causes component to re-render and this will result in endless loop.
|
||||
|
||||
|
||||
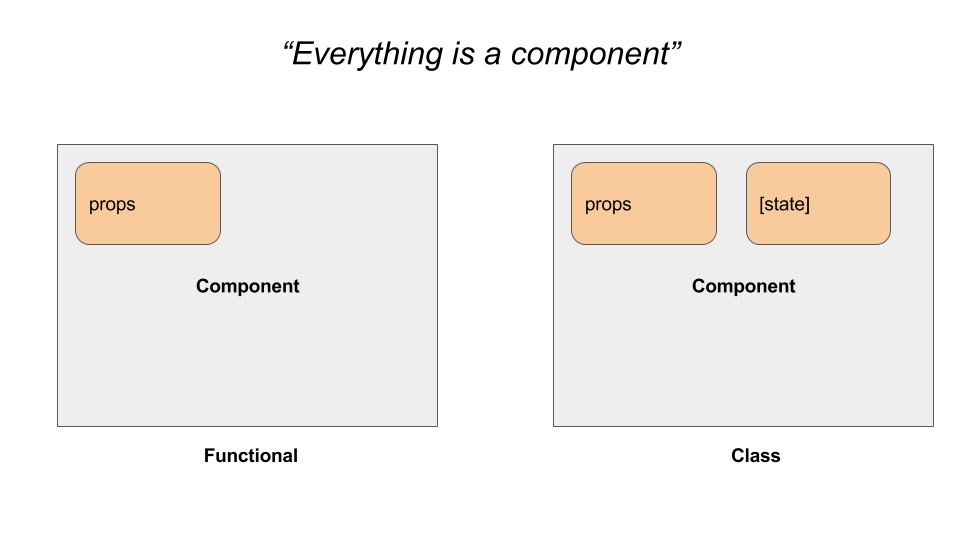
|
||||
A class-based component has an optional property “state”.
|
||||
|
||||
_Apart from _ `_state_` _, a class-based component has some life-cycle methods like _ `_componentWillMount()._` _ These you can use to do stuff, like initializing the _ `_state_` _and all but that is out of the scope of this post._
|
||||
|
||||
### JSX
|
||||
|
||||
JSX is a short form of _JavaScript Extended_ and it is a way to write `React`components. Using JSX, you get the full power of JavaScript inside XML like tags.
|
||||
|
||||
You put JavaScript expressions inside `{}`. The following are some valid JSX examples.
|
||||
|
||||
```
|
||||
<button disabled={true}>Press me!</button>
|
||||
|
||||
<button disabled={true}>Press me {3+1} times!</button>;
|
||||
|
||||
<div className='container'><Hello /></div>
|
||||
|
||||
```
|
||||
|
||||
The way it works is you write JSX to describe what your UI should look like. A [transpiler][6] like `Babel` converts that code into a bunch of `React.createElement()` calls. The React library then uses those `React.createElement()` calls to construct a tree-like structure of DOM elements. In case of React for Web or Native views in case of React Native. It keeps it in the memory.
|
||||
|
||||
React then calculates how it can effectively mimic this tree in the memory of the UI displayed to the user. This process is known as [reconciliation][7]. After that calculation is done, React makes the changes to the actual UI on the screen.
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
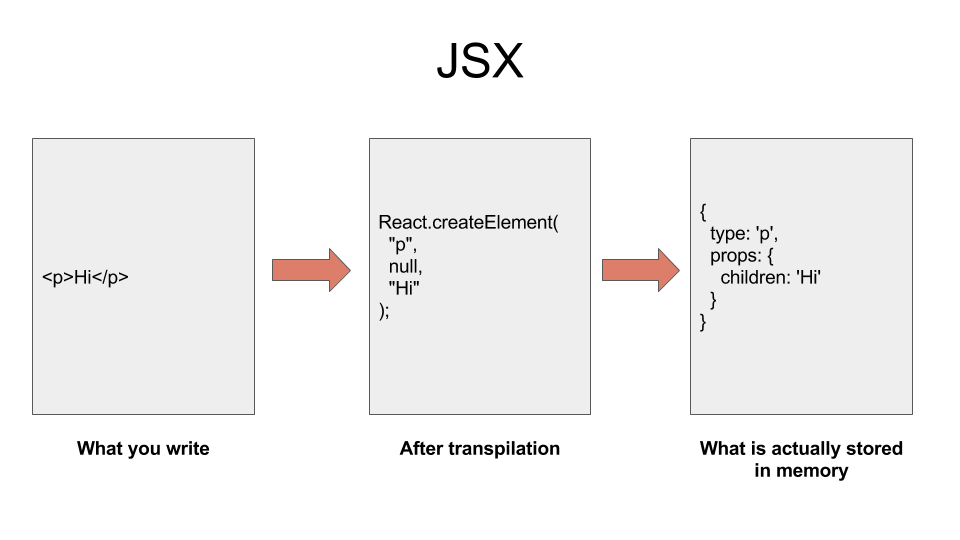
|
||||
How React converts your JSX into a tree which describes your app’s UI
|
||||
|
||||
You can use [Babel’s online REPL][8] to see what React actually outputs when you write some JSX.
|
||||
|
||||
|
||||
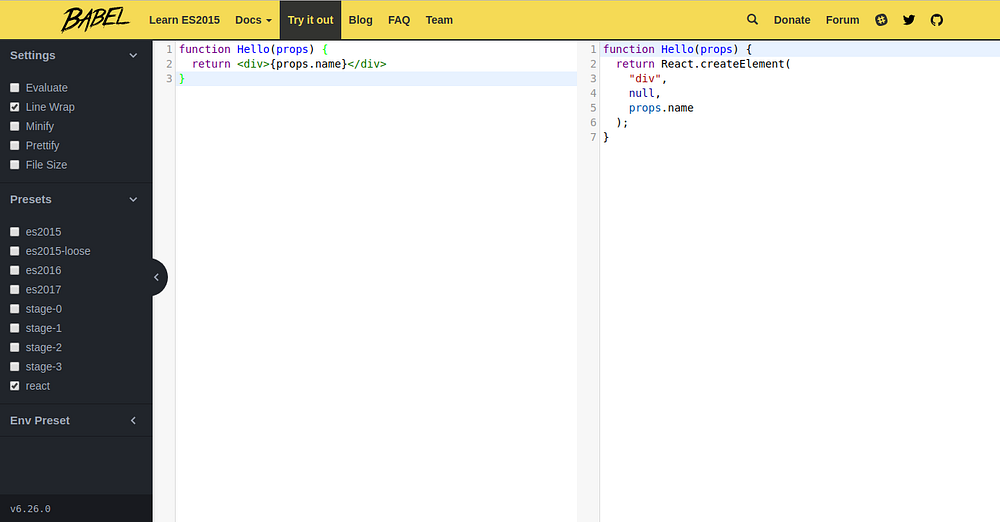
|
||||
Use Babel REPL to transform JSX into plain JavaScript
|
||||
|
||||
> Since JSX is just a syntactic sugar over plain `React.createElement()` calls, React can be used without JSX.
|
||||
|
||||
Now we have every concept in place, so we are well positioned to write a `counter` component that we saw earlier as a GIF.
|
||||
|
||||
The code is as follows and I hope that you already know how to render that in our playground.
|
||||
|
||||
```
|
||||
class Counter extends React.Component {
|
||||
constructor(props) {
|
||||
super(props);
|
||||
|
||||
this.state = {count: this.props.start || 0}
|
||||
|
||||
// the following bindings are necessary to make `this` work in the callback
|
||||
this.inc = this.inc.bind(this);
|
||||
this.dec = this.dec.bind(this);
|
||||
}
|
||||
|
||||
inc() {
|
||||
this.setState({
|
||||
count: this.state.count + 1
|
||||
});
|
||||
}
|
||||
|
||||
dec() {
|
||||
this.setState({
|
||||
count: this.state.count - 1
|
||||
});
|
||||
}
|
||||
|
||||
render() {
|
||||
return (
|
||||
<div>
|
||||
<button onClick={this.inc}>+</button>
|
||||
<button onClick={this.dec}>-</button>
|
||||
<div>{this.state.count}</div>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The following are some salient points about the above code.
|
||||
|
||||
1. JSX uses `camelCasing` hence `button`'s attribute is `onClick`, not `onclick`, as we use in HTML.
|
||||
|
||||
2. Binding is necessary for `this` to work on callbacks. See line #8 and 9 in the code above.
|
||||
|
||||
The final interactive code is located [here][9].
|
||||
|
||||
With that, we’ve reached the conclusion of our React crash course. I hope I have shed some light on how React works and how you can use React to build bigger apps, using smaller and reusable components.
|
||||
|
||||
* * *
|
||||
|
||||
If you have any queries or doubts, hit me up on Twitter [@rajat1saxena][10] or write to me at [rajat@raynstudios.com][11].
|
||||
|
||||
* * *
|
||||
|
||||
#### Please recommend this post, if you liked it and share it with your network. Follow me for more tech related posts and consider subscribing to my channel [Rayn Studios][12] on YouTube. Thanks a lot.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/rock-solid-react-js-foundations-a-beginners-guide-c45c93f5a923
|
||||
|
||||
作者:[Rajat Saxena ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@rajat1saxena
|
||||
[1]:https://kivenaa.com/
|
||||
[2]:https://play.google.com/store/apps/details?id=com.pollenchat.android
|
||||
[3]:https://facebook.github.io/react-native/
|
||||
[4]:https://codepen.io/raynesax/pen/MrNmBM
|
||||
[5]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes
|
||||
[6]:https://en.wikipedia.org/wiki/Source-to-source_compiler
|
||||
[7]:https://reactjs.org/docs/reconciliation.html
|
||||
[8]:https://babeljs.io/repl
|
||||
[9]:https://codepen.io/raynesax/pen/QaROqK
|
||||
[10]:https://twitter.com/rajat1saxena
|
||||
[11]:mailto:rajat@raynstudios.com
|
||||
[12]:https://www.youtube.com/channel/UCUmQhjjF9bsIaVDJUHSIIKw
|
||||
Loading…
Reference in New Issue
Block a user