mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
7826602c01
@ -1,21 +1,24 @@
|
||||
如何在 Git 中重置、恢复、和返回到以前的状态
|
||||
如何在 Git 中重置、恢复,返回到以前的状态
|
||||
======
|
||||
|
||||
> 用简洁而优雅的 Git 命令撤销仓库中的改变。
|
||||
|
||||

|
||||
|
||||
使用 Git 工作时其中一个鲜为人知(和没有意识到)的方面就是,如何很容易地返回到你以前的位置 —— 也就是说,在仓库中如何很容易地去撤销那怕是重大的变更。在本文中,我们将带你了解如何去重置、恢复、和完全回到以前的状态,做到这些只需要几个简单而优雅的 Git 命令。
|
||||
使用 Git 工作时其中一个鲜为人知(和没有意识到)的方面就是,如何轻松地返回到你以前的位置 —— 也就是说,在仓库中如何很容易地去撤销那怕是重大的变更。在本文中,我们将带你了解如何去重置、恢复和完全回到以前的状态,做到这些只需要几个简单而优雅的 Git 命令。
|
||||
|
||||
### reset
|
||||
### 重置
|
||||
|
||||
我们从 Git 的 `reset` 命令开始。确实,你应该能够想到它就是一个 "回滚" — 它将你本地环境返回到前面的提交。这里的 "本地环境" 一词,我们指的是你的本地仓库、暂存区、以及工作目录。
|
||||
我们从 Git 的 `reset` 命令开始。确实,你应该能够认为它就是一个 “回滚” —— 它将你本地环境返回到之前的提交。这里的 “本地环境” 一词,我们指的是你的本地仓库、暂存区以及工作目录。
|
||||
|
||||
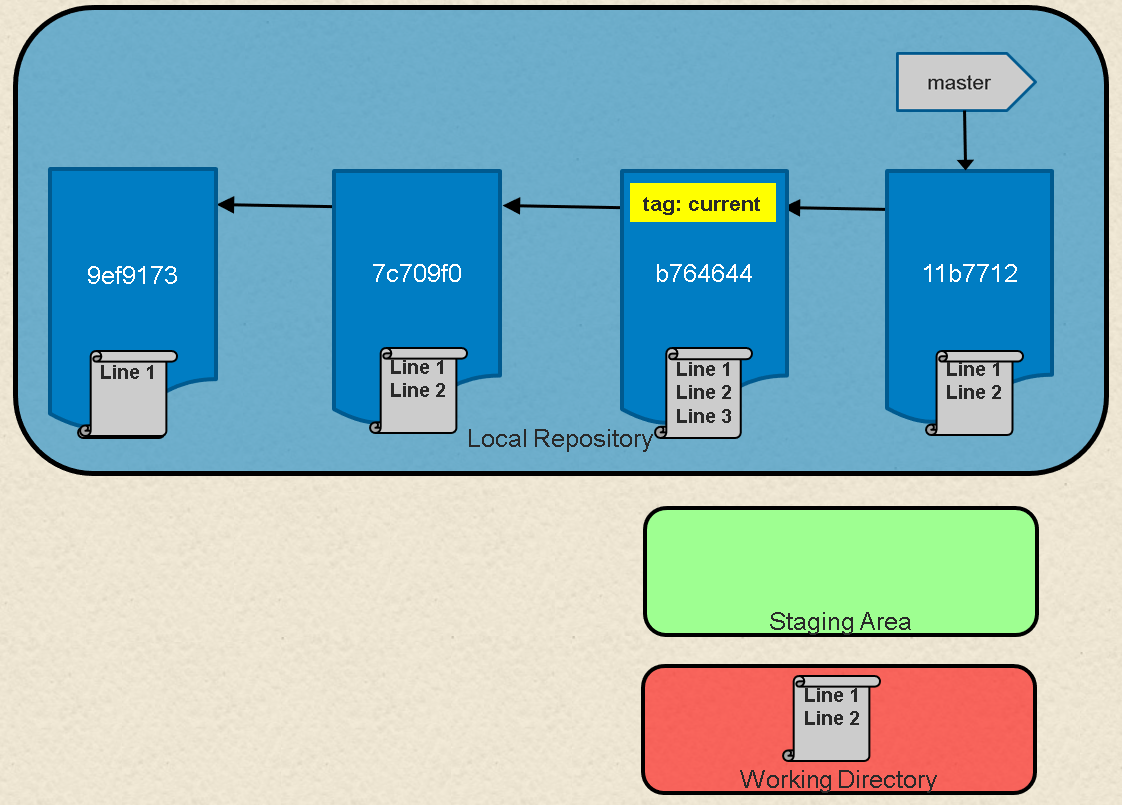
先看一下图 1。在这里我们有一个在 Git 中表示一系列状态的提交。在 Git 中一个分支就是简单的一个命名的、可移动指针到一个特定的提交。在这种情况下,我们的 master 分支是链中指向最新提交的一个指针。
|
||||
先看一下图 1。在这里我们有一个在 Git 中表示一系列提交的示意图。在 Git 中一个分支简单来说就是一个命名的、指向一个特定的提交的可移动指针。在这里,我们的 master 分支是指向链中最新提交的一个指针。
|
||||
|
||||
![Local Git environment with repository, staging area, and working directory][2]
|
||||
|
||||
图 1:有仓库、暂存区、和工作目录的本地环境
|
||||
*图 1:有仓库、暂存区、和工作目录的本地环境*
|
||||
|
||||
如果看一下我们的 master 分支是什么,可以看一下到目前为止我们产生的提交链。
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
b764644 File with three lines
|
||||
@ -23,41 +26,49 @@ b764644 File with three lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
如果我们想回滚到前一个提交会发生什么呢?很简单 —— 我们只需要移动分支指针即可。Git 提供了为我们做这个动作的命令。例如,如果我们重置 master 为当前提交回退两个提交的位置,我们可以使用如下之一的方法:
|
||||
如果我们想回滚到前一个提交会发生什么呢?很简单 —— 我们只需要移动分支指针即可。Git 提供了为我们做这个动作的 `reset` 命令。例如,如果我们重置 master 为当前提交回退两个提交的位置,我们可以使用如下之一的方法:
|
||||
|
||||
`$ git reset 9ef9173`(使用一个绝对的提交 SHA1 值 9ef9173)
|
||||
```
|
||||
$ git reset 9ef9173
|
||||
```
|
||||
|
||||
或
|
||||
(使用一个绝对的提交 SHA1 值 `9ef9173`)
|
||||
|
||||
`$ git reset current~2`(在 “current” 标签之前,使用一个相对值 -2)
|
||||
或:
|
||||
|
||||
```
|
||||
$ git reset current~2
|
||||
```
|
||||
(在 “current” 标签之前,使用一个相对值 -2)
|
||||
|
||||
图 2 展示了操作的结果。在这之后,如果我们在当前分支(master)上运行一个 `git log` 命令,我们将看到只有一个提交。
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
|
||||
9ef9173 File with one line
|
||||
|
||||
```
|
||||
|
||||
![After reset][4]
|
||||
|
||||
图 2:在 `reset` 之后
|
||||
*图 2:在 `reset` 之后*
|
||||
|
||||
`git reset` 命令也包含使用一个你最终满意的提交内容去更新本地环境的其它部分的选项。这些选项包括:`hard` 在仓库中去重置指向的提交,用提交的内容去填充工作目录,并重置暂存区;`soft` 仅重置仓库中的指针;而 `mixed`(默认值)将重置指针和暂存区。
|
||||
`git reset` 命令也包含使用一些选项,可以让你最终满意的提交内容去更新本地环境的其它部分。这些选项包括:`hard` 在仓库中去重置指向的提交,用提交的内容去填充工作目录,并重置暂存区;`soft` 仅重置仓库中的指针;而 `mixed`(默认值)将重置指针和暂存区。
|
||||
|
||||
这些选项在特定情况下非常有用,比如,`git reset --hard <commit sha1 | reference>` 这个命令将覆盖本地任何未提交的更改。实际上,它重置了(清除掉)暂存区,并用你重置的提交内容去覆盖了工作区中的内容。在你使用 `hard` 选项之前,一定要确保这是你真正地想要做的操作,因为这个命令会覆盖掉任何未提交的更改。
|
||||
|
||||
### revert
|
||||
### 恢复
|
||||
|
||||
`git revert` 命令的实际结果类似于 `reset`,但它的方法不同。`reset` 命令是在(默认)链中向后移动分支的指针去“撤销”更改,`revert` 命令是在链中添加一个新的提交去“取消”更改。再次查看图 1 可以非常轻松地看到这种影响。如果我们在链中的每个提交中向文件添加一行,一种方法是使用 `reset` 使那个提交返回到仅有两行的那个版本,如:`git reset HEAD~1`。
|
||||
`git revert` 命令的实际结果类似于 `reset`,但它的方法不同。`reset` 命令(默认)是在链中向后移动分支的指针去“撤销”更改,`revert` 命令是在链中添加一个新的提交去“取消”更改。再次查看图 1 可以非常轻松地看到这种影响。如果我们在链中的每个提交中向文件添加一行,一种方法是使用 `reset` 使那个提交返回到仅有两行的那个版本,如:`git reset HEAD~1`。
|
||||
|
||||
另一个方法是添加一个新的提交去删除第三行,以使最终结束变成两行的版本 —— 实际效果也是取消了那个更改。使用一个 `git revert` 命令可以实现上述目的,比如:
|
||||
|
||||
另一个方法是添加一个新的提交去删除第三行,以使最终结束变成两行的版本 — 实际效果也是取消了那个更改。使用一个 `git revert` 命令可以实现上述目的,比如:
|
||||
```
|
||||
$ git revert HEAD
|
||||
|
||||
```
|
||||
|
||||
因为它添加了一个新的提交,Git 将提示如下的提交信息:
|
||||
|
||||
```
|
||||
Revert "File with three lines"
|
||||
|
||||
@ -74,6 +85,7 @@ This reverts commit b764644bad524b804577684bf74e7bca3117f554.
|
||||
图 3(在下面)展示了 `revert` 操作完成后的结果。
|
||||
|
||||
如果我们现在运行一个 `git log` 命令,我们将看到前面的提交之前的一个新提交。
|
||||
|
||||
```
|
||||
$ git log --oneline
|
||||
11b7712 Revert "File with three lines"
|
||||
@ -83,6 +95,7 @@ b764644 File with three lines
|
||||
```
|
||||
|
||||
这里是工作目录中这个文件当前的内容:
|
||||
|
||||
```
|
||||
$ cat <filename>
|
||||
Line 1
|
||||
@ -91,31 +104,34 @@ Line 2
|
||||
|
||||
|
||||
|
||||
#### Revert 或 reset 如何选择?
|
||||
*图 3 `revert` 操作之后*
|
||||
|
||||
#### 恢复或重置如何选择?
|
||||
|
||||
为什么要优先选择 `revert` 而不是 `reset` 操作?如果你已经将你的提交链推送到远程仓库(其它人可以已经拉取了你的代码并开始工作),一个 `revert` 操作是让他们去获得更改的非常友好的方式。这是因为 Git 工作流可以非常好地在分支的末端添加提交,但是当有人 `reset` 分支指针之后,一组提交将再也看不见了,这可能会是一个挑战。
|
||||
|
||||
当我们以这种方式使用 Git 工作时,我们的基本规则之一是:在你的本地仓库中使用这种方式去更改还没有推送的代码是可以的。如果提交已经推送到了远程仓库,并且可能其它人已经使用它来工作了,那么应该避免这些重写提交历史的更改。
|
||||
|
||||
总之,如果你想回滚、撤销、或者重写其它人已经在使用的一个提交链的历史,当你的同事试图将他们的更改合并到他们拉取的原始链上时,他们可能需要做更多的工作。如果你必须对已经推送并被其他人正在使用的代码做更改,在你做更改之前必须要与他们沟通,让他们先合并他们的更改。然后在没有需要去合并的侵入操作之后,他们再拉取最新的副本。
|
||||
总之,如果你想回滚、撤销或者重写其它人已经在使用的一个提交链的历史,当你的同事试图将他们的更改合并到他们拉取的原始链上时,他们可能需要做更多的工作。如果你必须对已经推送并被其他人正在使用的代码做更改,在你做更改之前必须要与他们沟通,让他们先合并他们的更改。然后在这个侵入操作没有需要合并的内容之后,他们再拉取最新的副本。
|
||||
|
||||
你可能注意到了,在我们做了 `reset` 操作之后,原始的提交链仍然在那个位置。我们移动了指针,然后 `reset` 代码回到前一个提交,但它并没有删除任何提交。换句话说就是,只要我们知道我们所指向的原始提交,我们能够通过简单的返回到分支的原始链的头部来“恢复”指针到前面的位置:
|
||||
|
||||
你可能注意到了,在我们做了 `reset` 操作之后,原始的链仍然在那个位置。我们移动了指针,然后 `reset` 代码回到前一个提交,但它并没有删除任何提交。换句话说就是,只要我们知道我们所指向的原始提交,我们能够通过简单的返回到分支的原始头部来“恢复”指针到前面的位置:
|
||||
```
|
||||
git reset <sha1 of commit>
|
||||
|
||||
```
|
||||
|
||||
当提交被替换之后,我们在 Git 中做的大量其它操作也会发生类似的事情。新提交被创建,有关的指针被移动到一个新的链,但是老的提交链仍然存在。
|
||||
|
||||
### Rebase
|
||||
### 变基
|
||||
|
||||
现在我们来看一个分支变基。假设我们有两个分支 — master 和 feature — 提交链如下图 4 所示。Master 的提交链是 `C4->C2->C1->C0` 和 feature 的提交链是 `C5->C3->C2->C1->C0`.
|
||||
现在我们来看一个分支变基。假设我们有两个分支:master 和 feature,提交链如下图 4 所示。master 的提交链是 `C4->C2->C1->C0` 和 feature 的提交链是 `C5->C3->C2->C1->C0`。
|
||||
|
||||
![Chain of commits for branches master and feature][6]
|
||||
|
||||
图 4:master 和 feature 分支的提交链
|
||||
*图 4:master 和 feature 分支的提交链*
|
||||
|
||||
如果我们在分支中看它的提交记录,它们看起来应该像下面的这样。(为了易于理解,`C` 表示提交信息)
|
||||
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
@ -131,9 +147,10 @@ f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
我给人讲,在 Git 中,可以将 `rebase` 认为是 “将历史合并”。从本质上来说,Git 将一个分支中的每个不同提交尝试“重放”到另一个分支中。
|
||||
我告诉人们在 Git 中,可以将 `rebase` 认为是 “将历史合并”。从本质上来说,Git 将一个分支中的每个不同提交尝试“重放”到另一个分支中。
|
||||
|
||||
因此,我们使用基本的 Git 命令,可以变基一个 feature 分支进入到 master 中,并将它拼入到 `C4` 中(比如,将它插入到 feature 的链中)。操作命令如下:
|
||||
|
||||
因此,我们使用基本的 Git 命令,可以 rebase 一个 feature 分支进入到 master 中,并将它拼入到 `C4` 中(比如,将它插入到 feature 的链中)。操作命令如下:
|
||||
```
|
||||
$ git checkout feature
|
||||
$ git rebase master
|
||||
@ -147,9 +164,10 @@ Applying: C5
|
||||
|
||||
![Chain of commits after the rebase command][8]
|
||||
|
||||
图 5:`rebase` 命令完成后的提交链
|
||||
*图 5:`rebase` 命令完成后的提交链*
|
||||
|
||||
接着,我们看一下提交历史,它应该变成如下的样子。
|
||||
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
@ -168,25 +186,27 @@ f33ae68 C1
|
||||
|
||||
注意那个 `C3'` 和 `C5'`— 在 master 分支上已处于提交链的“顶部”,由于产生了更改而创建了新提交。但是也要注意的是,rebase 后“原始的” `C3` 和 `C5` 仍然在那里 — 只是再没有一个分支指向它们而已。
|
||||
|
||||
如果我们做了这个 rebase,然后确定这不是我们想要的结果,希望去撤销它,我们可以做下面示例所做的操作:
|
||||
如果我们做了这个变基,然后确定这不是我们想要的结果,希望去撤销它,我们可以做下面示例所做的操作:
|
||||
|
||||
```
|
||||
$ git reset 79768b8
|
||||
|
||||
```
|
||||
|
||||
由于这个简单的变更,现在我们的分支将重新指向到做 `rebase` 操作之前一模一样的位置 —— 完全等效于撤销操作(图 6)。
|
||||
|
||||
![After undoing rebase][10]
|
||||
|
||||
图 6:撤销 `rebase` 操作之后
|
||||
*图 6:撤销 `rebase` 操作之后*
|
||||
|
||||
如果你想不起来之前一个操作指向的一个分支上提交了什么内容怎么办?幸运的是,Git 命令依然可以帮助你。用这种方式可以修改大多数操作的指针,Git 会记住你的原始提交。事实上,它是在 `.git` 仓库目录下,将它保存为一个特定的名为 `ORIG_HEAD ` 的文件中。在它被修改之前,那个路径是一个包含了大多数最新引用的文件。如果我们 `cat` 这个文件,我们可以看到它的内容。
|
||||
|
||||
```
|
||||
$ cat .git/ORIG_HEAD
|
||||
79768b891f47ce06f13456a7e222536ee47ad2fe
|
||||
```
|
||||
|
||||
我们可以使用 `reset` 命令,正如前面所述,它返回指向到原始的链。然后它的历史将是如下的这样:
|
||||
|
||||
```
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
@ -196,7 +216,8 @@ f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
在 reflog 中是获取这些信息的另外一个地方。这个 reflog 是你本地仓库中相关切换或更改的详细描述清单。你可以使用 `git reflog` 命令去查看它的内容:
|
||||
在 reflog 中是获取这些信息的另外一个地方。reflog 是你本地仓库中相关切换或更改的详细描述清单。你可以使用 `git reflog` 命令去查看它的内容:
|
||||
|
||||
```
|
||||
$ git reflog
|
||||
79768b8 HEAD@{0}: reset: moving to 79768b
|
||||
@ -216,10 +237,10 @@ f33ae68 HEAD@{13}: commit: C1
|
||||
5043e79 HEAD@{14}: commit (initial): C0
|
||||
```
|
||||
|
||||
你可以使用日志中列出的、你看到的相关命名格式,去 reset 任何一个东西:
|
||||
你可以使用日志中列出的、你看到的相关命名格式,去重置任何一个东西:
|
||||
|
||||
```
|
||||
$ git reset HEAD@{1}
|
||||
|
||||
```
|
||||
|
||||
一旦你理解了当“修改”链的操作发生后,Git 是如何跟踪原始提交链的基本原理,那么在 Git 中做一些更改将不再是那么可怕的事。这就是强大的 Git 的核心能力之一:能够很快速、很容易地尝试任何事情,并且如果不成功就撤销它们。
|
||||
@ -233,7 +254,7 @@ via: https://opensource.com/article/18/6/git-reset-revert-rebase-commands
|
||||
作者:[Brent Laster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,29 +1,28 @@
|
||||
跨站请求伪造
|
||||
CSRF(跨站请求伪造)简介
|
||||
======
|
||||

|
||||
设计 Web 程序时,安全性是一个主要问题。我不是在谈论 DDOS 保护,使用强密码或两步验证。我在谈论对网络程序的最大威胁。它被称为**CSRF**, 是 **Cross Site Resource Forgery** (跨站请求伪造)的缩写。
|
||||
|
||||
设计 Web 程序时,安全性是一个主要问题。我不是在谈论 DDoS 保护、使用强密码或两步验证。我说的是对网络程序的最大威胁。它被称为**CSRF**, 是 **Cross Site Resource Forgery** (跨站请求伪造)的缩写。
|
||||
|
||||
### 什么是 CSRF?
|
||||
|
||||
[][1]
|
||||
|
||||
首先,**CSRF** 是 Cross Site Resource Forgery 的缩写。它通常发音为 “sea-surf”,也经常被称为XSRF。CSRF 是一种攻击类型,在受害者不知情的情况下,在受害者登录的 Web 程序上执行各种操作。这些行为可以是任何事情,从简单地喜欢或评论社交媒体帖子到向人们发送垃圾消息,甚至从受害者的银行账户转移资金。
|
||||
|
||||
首先,**CSRF** 是 Cross Site Resource Forgery 的缩写。它通常发音为 “sea-surf”,也经常被称为 XSRF。CSRF 是一种攻击类型,在受害者不知情的情况下,在受害者登录的 Web 程序上执行各种操作。这些行为可以是任何事情,从简单地点赞或评论社交媒体帖子到向人们发送垃圾消息,甚至从受害者的银行账户转移资金。
|
||||
|
||||
### CSRF 如何工作?
|
||||
|
||||
**CSRF** 攻击尝试利用在所有浏览器一个简单的常见漏洞。每次我们对网站进行身份验证或登录时,会话 cookie 都会存储在浏览器中。因此,每当我们向网站提出请求时,这些 cookie 就会自动发送到服务器,服务器通过匹配与服务器记录一起发送的 cookie 来识别我们。这样就知道是我们了。
|
||||
**CSRF** 攻击尝试利用所有浏览器上的一个简单的常见漏洞。每次我们对网站进行身份验证或登录时,会话 cookie 都会存储在浏览器中。因此,每当我们向网站提出请求时,这些 cookie 就会自动发送到服务器,服务器通过匹配与服务器记录一起发送的 cookie 来识别我们。这样就知道是我们了。
|
||||
|
||||
[][2]
|
||||
|
||||
这意味着我将在知情或不知情的情况下发出关请求。由于 cookie 被发送并且它们将匹配服务器上的记录,服务器认为我在发出该请求。
|
||||
这意味着我将在知情或不知情的情况下发出请求。由于 cookie 也被发送并且它们将匹配服务器上的记录,服务器认为我在发出该请求。
|
||||
|
||||
|
||||
CSRF 攻击通常以链接的形式出现。我们可以在其他网站上点击它们或通过电子邮件接收它们。单击这些链接时,会向服务器发出不需要的请求。正如我之前所说,服务器认为我们发出了请求并对其进行了身份验证。
|
||||
|
||||
#### 一个真实世界的例子
|
||||
|
||||
为了把事情看得更深入,想象一下你已登录银行的网站。并在 **yourbank.com/transfer** 上填写表格。你将接收者的帐号填写为 1234,填入金额 5,000 并单击提交按钮。现在,我们将有一个 **yourbank.com/transfer/send?to=1234&amount=5000** 的请求。因此服务器将根据请求进行操作并转账。现在想象一下你在另一个网站上,然后点击一个链接,用黑客的帐号打开上面的 URL。这笔钱现在会转账给黑客,服务器认为你做了交易。即使你没有。
|
||||
为了把事情看得更深入,想象一下你已登录银行的网站。并在 **yourbank.com/transfer** 上填写表格。你将接收者的帐号填写为 1234,填入金额 5,000 并单击提交按钮。现在,我们将有一个 **yourbank.com/transfer/send?to=1234&amount=5000** 的请求。因此服务器将根据请求进行操作并转账。现在想象一下你在另一个网站上,然后点击一个链接,用黑客的帐号作为参数打开上面的 URL。这笔钱现在会转账给黑客,服务器认为你做了交易。即使你没有。
|
||||
|
||||
[][3]
|
||||
|
||||
@ -43,7 +42,7 @@ via: http://www.linuxandubuntu.com/home/understanding-csrf-cross-site-request-fo
|
||||
作者:[linuxandubuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,603 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
A Collection Of Useful BASH Scripts For Heavy Commandline Users
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, I have stumbled upon a collection of useful BASH scripts for heavy commandline users. These scripts, known as **Bash-Snippets** , might be quite helpful for those who live in Terminal all day. Want to check the weather of a place where you live? This script will do that for you. Wondering what is the Stock price? You can run the script that displays the current details of a stock. Feel bored? You can watch some youtube videos. All from commandline. You don’t need to install any heavy memory consumable GUI applications.
|
||||
|
||||
As of writing this, Bash-Snippets provides the following 19 useful tools:
|
||||
|
||||
1. **Cheat** – Linux Commands cheat sheet.
|
||||
2. **Cloudup** – A tool to backup your GitHub repositories to bitbucket.
|
||||
3. **Crypt** – Encrypt and decrypt files.
|
||||
4. **Cryptocurrency** – Converts Cryptocurrency based on realtime exchange rates of the top 10 cryptos.
|
||||
5. **Currency** – Currency converter.
|
||||
6. **Geo** – Provides the details of wan, lan, router, dns, mac, and ip.
|
||||
7. **Lyrics** – Grab lyrics for a given song quickly from the command line.
|
||||
8. **Meme** – Command line meme creator.
|
||||
9. **Movies** – Search and display a movie details.
|
||||
10. **Newton** – Performs numerical calculations all the way up to symbolic math parsing.
|
||||
11. **Qrify** – Turns the given string into a qr code.
|
||||
12. **Short** – URL Shortner
|
||||
13. **Siteciphers** – Check which ciphers are enabled / disabled for a given https site.
|
||||
14. **Stocks** – Provides certain Stock details.
|
||||
15. **Taste** – Recommendation engine that provides three similar items like the supplied item (The items can be books, music, artists, movies, and games etc).
|
||||
16. **Todo** – Command line todo manager.
|
||||
17. **Transfer** – Quickly transfer files from the command line.
|
||||
18. **Weather** – Displays weather details of your place.
|
||||
19. **Youtube-Viewer** – Watch YouTube from Terminal.
|
||||
|
||||
|
||||
|
||||
The author might add more utilities and/or features in future, so I recommend you to keep an eye on the project’s website or GitHub page for future updates.
|
||||
|
||||
### Bash-Snippets – A Collection Of Useful BASH Scripts For Heavy Commandline Users
|
||||
|
||||
#### Installation
|
||||
|
||||
You can install these scripts on any OS that supports BASH.
|
||||
|
||||
First, clone the GIT repository using command:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
Go to the cloned directory:
|
||||
```
|
||||
$ cd Bash-Snippets/
|
||||
|
||||
```
|
||||
|
||||
Git checkout to the latest stable release:
|
||||
```
|
||||
$ git checkout v1.22.0
|
||||
|
||||
```
|
||||
|
||||
Finally, install the Bash-Snippets using command:
|
||||
```
|
||||
$ sudo ./install.sh
|
||||
|
||||
```
|
||||
|
||||
This will ask you which scripts to install. Just type **Y** and press ENTER key to install the respective script. If you don’t want to install a particular script, type **N** and hit ENTER.
|
||||
```
|
||||
Do you wish to install currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
To install all scripts, run:
|
||||
```
|
||||
$ sudo ./install.sh all
|
||||
|
||||
```
|
||||
|
||||
To install a specific script, say currency, run:
|
||||
```
|
||||
$ sudo ./install.sh currency
|
||||
|
||||
```
|
||||
|
||||
You can also install it using [**Linuxbrew**][1] package manager.
|
||||
|
||||
To installs all tools, run:
|
||||
```
|
||||
$ brew install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
To install specific tools:
|
||||
```
|
||||
$ brew install bash-snippets --without-all-tools --with-newton --with-weather
|
||||
|
||||
```
|
||||
|
||||
Also, there is a PPA for Debian-based systems such as Ubuntu, Linux Mint.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:navanchauhan/bash-snippets
|
||||
$ sudo apt update
|
||||
$ sudo apt install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
**An active Internet connection is required** to use these tools. The usage is fairly simple. Let us see how to use some of these scripts. I assume you have installed all scripts.
|
||||
|
||||
**1\. Currency – Currency Converter**
|
||||
|
||||
This script converts the currency based on realtime exchange rates. Enter the base currency code and the currency to exchange to, and the amount being exchanged one by one as shown below.
|
||||
```
|
||||
$ currency
|
||||
What is the base currency: INR
|
||||
What currency to exchange to: USD
|
||||
What is the amount being exchanged: 10
|
||||
|
||||
=========================
|
||||
| INR to USD
|
||||
| Rate: 0.015495
|
||||
| INR: 10
|
||||
| USD: .154950
|
||||
=========================
|
||||
|
||||
```
|
||||
|
||||
You can also pass all arguments in a single command as shown below.
|
||||
```
|
||||
$ currency INR USD 10
|
||||
|
||||
```
|
||||
|
||||
Refer the following screenshot.
|
||||
|
||||
[![Bash-Snippets][2]][3]
|
||||
|
||||
**2\. Stocks – Display stock price details**
|
||||
|
||||
If you want to check a stock price details, mention the stock item as shown below.
|
||||
```
|
||||
$ stocks Intel
|
||||
|
||||
INTC stock info
|
||||
=============================================
|
||||
| Exchange Name: NASDAQ
|
||||
| Latest Price: 34.2500
|
||||
| Close (Previous Trading Day): 34.2500
|
||||
| Price Change: 0.0000
|
||||
| Price Change Percentage: 0.00%
|
||||
| Last Updated: Jul 12, 4:00PM EDT
|
||||
=============================================
|
||||
|
||||
```
|
||||
|
||||
The above output the **Intel stock** details.
|
||||
|
||||
**3\. Weather – Display Weather details**
|
||||
|
||||
Let us check the Weather details by running the following command:
|
||||
```
|
||||
$ weather
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
![][4]
|
||||
|
||||
As you see in the above screenshot, it provides the 3 day weather forecast. Without any arguments, it will display the weather details based on your IP address. You can also bring the weather details of a particular city or country like below.
|
||||
```
|
||||
$ weather Chennai
|
||||
|
||||
```
|
||||
|
||||
Also, you can view the moon phase by entering the following command:
|
||||
```
|
||||
$ weather moon
|
||||
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
|
||||
![][5]
|
||||
|
||||
**4\. Crypt – Encrypt and Decrypt files**
|
||||
|
||||
This script is a wrapper for openssl that allows you to encrypt and decrypt files quickly and easily.
|
||||
|
||||
To encrypt a file, use the following command:
|
||||
```
|
||||
$ crypt -e [original file] [encrypted file]
|
||||
|
||||
```
|
||||
|
||||
For example, the following command will encrypt a file called **ostechnix.txt** , and save it as **encrypt_ostechnix.txt **in the current working directory.
|
||||
```
|
||||
$ crypt -e ostechnix.txt encrypt_ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
Enter the password for the file twice.
|
||||
```
|
||||
Encrypting ostechnix.txt...
|
||||
enter aes-256-cbc encryption password:
|
||||
Verifying - enter aes-256-cbc encryption password:
|
||||
Successfully encrypted
|
||||
|
||||
```
|
||||
|
||||
The above command will encrypt the given file using **AES 256 level encryption**. The password will not be saved in plain text. You can encrypt .pdf, .txt, .docx, .doc, .png, .jpeg type files.
|
||||
|
||||
To decrypt the file, use the following command:
|
||||
```
|
||||
$ crypt -d [encrypted file] [output file]
|
||||
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
$ crypt -d encrypt_ostechnix.txt ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
Enter the password to decrypt.
|
||||
```
|
||||
Decrypting encrypt_ostechnix.txt...
|
||||
enter aes-256-cbc decryption password:
|
||||
Successfully decrypted
|
||||
|
||||
```
|
||||
|
||||
**5\. Movies – Find Movie details**
|
||||
|
||||
Using this script, you can find a movie details.
|
||||
|
||||
The following command displays the details of a movie called “mother”.
|
||||
```
|
||||
$ movies mother
|
||||
|
||||
==================================================
|
||||
| Title: Mother
|
||||
| Year: 2009
|
||||
| Tomato: 95%
|
||||
| Rated: R
|
||||
| Genre: Crime, Drama, Mystery
|
||||
| Director: Bong Joon Ho
|
||||
| Actors: Hye-ja Kim, Bin Won, Goo Jin, Je-mun Yun
|
||||
| Plot: A mother desperately searches for the killer who framed her son for a girl's horrific murder.
|
||||
==================================================
|
||||
|
||||
```
|
||||
|
||||
**6\. Display similar items like the supplied item**
|
||||
|
||||
To use this script, you need to get the API key **[here][6]**. No worries, it is completely FREE! Once the you got the API, add the following line to your **~/.bash_profile** : **export TASTE_API_KEY=”yourAPIKeyGoesHere”**``
|
||||
|
||||
Now, you can view the similar item like the supplied item as shown below:
|
||||
```
|
||||
$ taste -i Red Hot Chilli Peppers
|
||||
|
||||
```
|
||||
|
||||
**7\. Short – Shorten URLs**
|
||||
|
||||
This script shortens the given URL.
|
||||
```
|
||||
$ short <URL>
|
||||
|
||||
```
|
||||
|
||||
**8\. Geo – Display the details of your network**
|
||||
|
||||
This script helps you to find out the details of your network, such as wan, lan, router, dns, mac, and ip geolocation.
|
||||
|
||||
For example, to find out your LAN ip, run:
|
||||
```
|
||||
$ geo -l
|
||||
|
||||
```
|
||||
|
||||
Sample output from my system:
|
||||
```
|
||||
192.168.43.192
|
||||
|
||||
```
|
||||
|
||||
To find your Wan IP:
|
||||
```
|
||||
$ geo -w
|
||||
|
||||
```
|
||||
|
||||
For more details, just type ‘geo’ in the Terminal.
|
||||
```
|
||||
$ geo
|
||||
Geo
|
||||
Description: Provides quick access for wan, lan, router, dns, mac, and ip geolocation data
|
||||
Usage: geo [flag]
|
||||
-w Returns WAN IP
|
||||
-l Returns LAN IP(s)
|
||||
-r Returns Router IP
|
||||
-d Returns DNS Nameserver
|
||||
-m Returns MAC address for interface. Ex. eth0
|
||||
-g Returns Current IP Geodata
|
||||
Examples:
|
||||
geo -g
|
||||
geo -wlrdgm eth0
|
||||
Custom Geo Output =>
|
||||
[all] [query] [city] [region] [country] [zip] [isp]
|
||||
Example: geo -a 8.8.8.8 -o city,zip,isp
|
||||
-o [options] Returns Specific Geodata
|
||||
-a [address] For specific ip in -s
|
||||
-v Returns Version
|
||||
-h Returns Help Screen
|
||||
-u Updates Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
**9\. Cheat – Display cheatsheets of Linux commands**
|
||||
|
||||
Want to refer the cheatsheet of Linux command? Well, it is also possible. The following command will display the cheatsheet of **curl** command:
|
||||
```
|
||||
$ cheat curl
|
||||
|
||||
```
|
||||
|
||||
Just replace **curl** with the command of your choice to display its cheatsheet. This can be very useful for the quick reference to any command you want to use.
|
||||
|
||||
**10\. Youtube-Viewer – Watch YouTube videos**
|
||||
|
||||
Using this script, you can search or watch youtube videos right from the Terminal.
|
||||
|
||||
Let us watch some **Ed Sheeran** videos.
|
||||
```
|
||||
$ ytview Ed Sheeran
|
||||
|
||||
```
|
||||
|
||||
Choose the video you want to play from the list. The selected will play in your default media player.
|
||||
|
||||
![][7]
|
||||
|
||||
To view recent videos by an artist, you can use:
|
||||
```
|
||||
$ ytview -c [channel name]
|
||||
|
||||
```
|
||||
|
||||
To search for videos, just enter:
|
||||
```
|
||||
$ ytview -s [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
or just,
|
||||
```
|
||||
$ ytview [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
**11\. cloudup – Backup GitHub repositories to bitbucket**
|
||||
|
||||
Have you hosted any project on GitHub? Great! You can backup the GitHub repositories to **bitbucket** , a web-based hosting service used for source code and development projects, at any time.
|
||||
|
||||
You can either backup all github repositories of the designated user at once with the **-a** option. Or run it with no flags and backup individual repositories.
|
||||
|
||||
To backup GitHub repository, run:
|
||||
```
|
||||
$ cloudup
|
||||
|
||||
```
|
||||
|
||||
You will be asked to enter your GitHub username, name of the repository to backup, and bitbucket username and password etc.
|
||||
|
||||
**12\. Qrify – Convert Strings into QR code**
|
||||
|
||||
This script converts any given string of text into a QR code. This is useful for sending links or saving a string of commands to your phone
|
||||
```
|
||||
$ qrify convert this text into qr code
|
||||
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
|
||||
![][8]
|
||||
|
||||
Cool, isn’t it?
|
||||
|
||||
**13\. Cryptocurrency**
|
||||
|
||||
It displays the top ten cryptocurrencies realtime exchange rates.
|
||||
|
||||
Type the following command and hit ENTER to run it:
|
||||
```
|
||||
$ cryptocurrency
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
**14\. Lyrics**
|
||||
|
||||
This script grabs the lyrics for a given song quickly from the command line.
|
||||
|
||||
Say for example, I am going to fetch the lyrics of **“who is it”** song, a popular song sung by **Michael Jackson**.
|
||||
```
|
||||
$ lyrics -a michael jackson -s who is it
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
**15\. Meme**
|
||||
|
||||
This script allows you to create simple memes from command line. It is quite faster than GUI-based meme generators.
|
||||
|
||||
To create a meme, just type:
|
||||
```
|
||||
$ meme -f mymeme
|
||||
Enter the name for the meme's background (Ex. buzz, doge, blb ): buzz
|
||||
Enter the text for the first line: THIS IS A
|
||||
Enter the text for the second line: MEME
|
||||
|
||||
```
|
||||
|
||||
This will create jpg file in your current working directory.
|
||||
|
||||
**16\. Newton**
|
||||
|
||||
Tired of solving complex Maths problems? Here you go. The Newton script will perform numerical calculations all the way up to symbolic math parsing.
|
||||
|
||||
![][11]
|
||||
|
||||
**17\. Siteciphers**
|
||||
|
||||
This script helps you to check which ciphers are enabled / disabled for a given https site.
|
||||
```
|
||||
$ siteciphers google.com
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
**18\. Todo**
|
||||
|
||||
It allows you to create everyday tasks directly from the Terminal.
|
||||
|
||||
Let us create some tasks.
|
||||
```
|
||||
$ todo -a The first task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
To add another task, simply re-run the above command with the task name.
|
||||
```
|
||||
$ todo -a The second task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). The second task Tue Jun 26 14:52:29 IST 2018
|
||||
|
||||
```
|
||||
|
||||
To view the list of tasks, run:
|
||||
```
|
||||
$ todo -g
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). A The second task Tue Jun 26 14:51:46 IST 2018
|
||||
|
||||
```
|
||||
|
||||
Once you completed a task, remove it from the list as shown below.
|
||||
```
|
||||
$ todo -r 2
|
||||
Sucessfully removed task number 2
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
To clear all tasks, run:
|
||||
```
|
||||
$ todo -c
|
||||
Tasks cleared.
|
||||
|
||||
```
|
||||
|
||||
**19\. Transfer**
|
||||
|
||||
The transfer script allows you to quickly and easily transfer files and directories over Internet.
|
||||
|
||||
Let us upload a file.
|
||||
```
|
||||
$ transfer test.txt
|
||||
Uploading test.txt
|
||||
################################################################################################################################################ 100.0%
|
||||
Success!
|
||||
Transfer Download Command: transfer -d desiredOutputDirectory ivmfj test.txt
|
||||
Transfer File URL: https://transfer.sh/ivmfj/test.txt
|
||||
|
||||
```
|
||||
|
||||
The file will be uploaded to transfer.sh site. Transfer.sh allows you to upload files up to **10 GB** in one go. All shared files automatically expire after **14 days**. As you can see, anyone can download the file either by visiting the second URL via a web browser or using the transfer command (it is installed in his/her system, of course).
|
||||
|
||||
Now remove the file from your system.
|
||||
```
|
||||
$ rm -fr test.txt
|
||||
|
||||
```
|
||||
|
||||
Now, you can download the file from transfer.sh site at any time (within 14 days) like below.
|
||||
```
|
||||
$ transfer -d Downloads ivmfj test.txt
|
||||
|
||||
```
|
||||
|
||||
For more details about this utility, refer our following guide.
|
||||
|
||||
##### Getting help
|
||||
|
||||
If you don’t know how to use a particular script, just type that script’s name and press ENTER. You will see the usage details. The following example displays the help section of **Qrify** script.
|
||||
```
|
||||
$ qrify
|
||||
Qrify
|
||||
Usage: qrify [stringtoturnintoqrcode]
|
||||
Description: Converts strings or urls into a qr code.
|
||||
-u Update Bash-Snippet Tools
|
||||
-m Enable multiline support (feature not working yet)
|
||||
-h Show the help
|
||||
-v Get the tool version
|
||||
Examples:
|
||||
qrify this is a test string
|
||||
qrify -m two\\nlines
|
||||
qrify github.com # notice no http:// or https:// this will fail
|
||||
|
||||
```
|
||||
|
||||
#### Updating scripts
|
||||
|
||||
You can update the installed tools at any time suing -u option. The following command updates “weather” tool.
|
||||
```
|
||||
$ weather -u
|
||||
|
||||
```
|
||||
|
||||
#### Uninstall
|
||||
|
||||
You can uninstall these tools as shown below.
|
||||
|
||||
Git clone the repository:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
Go to the Bash-Snippets directory:
|
||||
```
|
||||
$ cd Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
And uninstall the scripts by running the following command:
|
||||
```
|
||||
$ sudo ./uninstall.sh
|
||||
|
||||
```
|
||||
|
||||
Type **y** and hit ENTER to remove each script.
|
||||
```
|
||||
Do you wish to uninstall currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
**Also read: **
|
||||
|
||||
And, that’s all for now folks. I must admit that I’m very impressed when testing this scripts. I really liked the idea of combing all useful scripts into a single package. Kudos to the developer. Give it a try, you won’t be disappointed.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/collection-useful-bash-scripts-heavy-commandline-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_001.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_002-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_003.png
|
||||
[6]:https://tastedive.com/account/api_access
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/07/ytview-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_005.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/07/cryptocurrency.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/07/lyrics.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/07/newton.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/07/siteciphers.png
|
||||
@ -1,151 +0,0 @@
|
||||
fuowang 翻译中
|
||||
|
||||
Arch Linux Applications Automatic Installation Script
|
||||
======
|
||||
|
||||

|
||||
|
||||
Howdy Archers! Today, I have stumbled upon an useful utility called **“ArchI0”** , a CLI menu-based Arch Linux applications automatic installation script. This script provides an easiest way to install all essential applications for your Arch-based distribution. Please note that **this script is meant for noobs only**. Intermediate and advanced users can easily figure out [**how to use pacman**][1] to get things done. If you want to learn how Arch Linux works, I suggest you to manually install all software one by one. For those who are still noobs and wanted an easy and quick way to install all essential applications for their Arch-based systems, make use of this script.
|
||||
|
||||
### ArchI0 – Arch Linux Applications Automatic Installation Script
|
||||
|
||||
The developer of this script has created two scripts namely **ArchI0live** and **ArchI0**. You can use ArchI0live script to test without installing it. This might be helpful to know what actually is in this script before installing it on your system.
|
||||
|
||||
### Install ArchI0
|
||||
|
||||
To install this script, Git cone the ArchI0 script repository using command:
|
||||
```
|
||||
$ git clone https://github.com/SifoHamlaoui/ArchI0.git
|
||||
|
||||
```
|
||||
|
||||
The above command will clone the ArchI0 GtiHub repository contents in a folder called ArchI0 in your current directory. Go to the directory using command:
|
||||
```
|
||||
$ cd ArchI0/
|
||||
|
||||
```
|
||||
|
||||
Make the script executable using command:
|
||||
```
|
||||
$ chmod +x ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
Run the script with command:
|
||||
```
|
||||
$ sudo ./ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
We need to run this script as root or sudo user, because installing applications requires root privileges.
|
||||
|
||||
> **Note:** For those wondering what all are those commands for at the beginning of the script, the first command downloads **figlet** , because the script logo is shown using figlet. The 2nd command install **Leafpad** which is used to open and read the license file. The 3rd command install **wget** to download files from sourceforge. The 4th and 5th commands are to download and open the License File on leafpad. And, the final and 6th command is used to close the license file after reading it.
|
||||
|
||||
Type your Arch Linux system’s architecture and hit ENTER key. When it asks to install the script, type y and hit ENTER.
|
||||
|
||||
![][3]
|
||||
|
||||
Once it is installed, you will be redirected to the main menu.
|
||||
|
||||
![][4]
|
||||
|
||||
As you see in the above screenshot, ArchI0 has 13 categories and contains 90 easy-to-install programs under those categories. These 90 programs are just enough to setup a full-fledged Arch Linux desktop to perform day-to-day activities. To know about this script, type **a** and to exit this script type **q**.
|
||||
|
||||
After installing it, you don’t need to run the ArchI0live script. You can directly launch it using the following command:
|
||||
```
|
||||
$ sudo ArchI0
|
||||
|
||||
```
|
||||
|
||||
It will ask you each time to choose your Arch Linux distribution architecture.
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
Preparing To Run Script
|
||||
Checking For ROOT: PASSED
|
||||
What Is Your OS Architecture? {32/64} 64
|
||||
|
||||
```
|
||||
|
||||
From now on, you can install the program of your choice from the categories listed in the main menu. To view the list of available programs under a specific category, enter the category number. Say for example, to view the list of available programs under **Text Editors** category, type **1** and hit ENTER.
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ R00T MENU ]
|
||||
Make A Choice
|
||||
1) Text Editors
|
||||
2) FTP/Torrent Applications
|
||||
3) Download Managers
|
||||
4) Network managers
|
||||
5) VPN clients
|
||||
6) Chat Applications
|
||||
7) Image Editors
|
||||
8) Video editors/Record
|
||||
9) Archive Handlers
|
||||
10) Audio Applications
|
||||
11) Other Applications
|
||||
12) Development Environments
|
||||
13) Browser/Web Plugins
|
||||
14) Dotfiles
|
||||
15) Usefull Links
|
||||
------------------------
|
||||
a) About ArchI0 Script
|
||||
q) Leave ArchI0 Script
|
||||
|
||||
Choose An Option: 1
|
||||
|
||||
```
|
||||
|
||||
Next, choose the application you want to install. To return to main menu, type **q** and hit ENTER.
|
||||
|
||||
I want to install Emacs, so I type **3**.
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ TEXT EDITORS ]
|
||||
[ Option ] [ Description ]
|
||||
1) GEdit
|
||||
2) Geany
|
||||
3) Emacs
|
||||
4) VIM
|
||||
5) Kate
|
||||
---------------------------
|
||||
q) Return To Main Menu
|
||||
|
||||
Choose An Option: 3
|
||||
|
||||
```
|
||||
|
||||
Now, Emacs will be installed on your Arch Linux system.
|
||||
|
||||
![][5]
|
||||
|
||||
Press ENTER key to return to main menu after installing the applications of your choice.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Undoubtedly, this script makes the Arch Linux user’s life easier, particularly the beginner’s. If you are looking for a fast and easy way to install applications without using pacman, then this script might be a good choice. Give it a try and let us know what you think about this script in the comment section below.
|
||||
|
||||
And, that’s all. Hope this tool helps. We will be posting useful guides every day. If you find our guides useful, please share them on your social, professional networks and support OSTechNix.
|
||||
|
||||
Cheers!!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/archi0-arch-linux-applications-automatic-installation-script/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://www.ostechnix.com/getting-started-pacman/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_003.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_004-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/pacman-as-superuser_005.png
|
||||
@ -1,141 +0,0 @@
|
||||
# A gentle introduction to FreeDOS
|
||||
|
||||

|
||||
|
||||
Image credits :
|
||||
|
||||
Jim Hall, CC BY
|
||||
|
||||
## Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
FreeDOS is an old operating system, but it is new to many people. In 1994, several developers and I came together to [create FreeDOS][1]—a complete, free, DOS-compatible operating system you can use to play classic DOS games, run legacy business software, or develop embedded systems. Any program that works on MS-DOS should also run on FreeDOS.
|
||||
|
||||
In 1994, FreeDOS was immediately familiar to anyone who had used Microsoft's proprietary MS-DOS. And that was by design; FreeDOS intended to mimic MS-DOS as much as possible. As a result, DOS users in the 1990s were able to jump right into FreeDOS. But times have changed. Today, open source developers are more familiar with the Linux command line or they may prefer a graphical desktop like [GNOME][2], making the FreeDOS command line seem alien at first.
|
||||
|
||||
New users often ask, "I [installed FreeDOS][3], but how do I use it?" If you haven't used DOS before, the blinking C:\> DOS prompt can seem a little unfriendly. And maybe scary. This gentle introduction to FreeDOS should get you started. It offers just the basics: how to get around and how to look at files. If you want to learn more than what's offered here, visit the [FreeDOS wiki][4].
|
||||
|
||||
## The DOS prompt
|
||||
|
||||
First, let's look at the empty prompt and what it means.
|
||||
|
||||

|
||||
|
||||
DOS is a "disk operating system" created when personal computers ran from floppy disks. Even when computers supported hard drives, it was common in the 1980s and 1990s to switch frequently between the different drives. For example, you might make a backup copy of your most important files to a floppy disk.
|
||||
|
||||
DOS referenced each drive by a letter. Early PCs could have only two floppy drives, which were assigned as the A: and B: drives. The first partition on the first hard drive was the C: drive, and so on for other drives. The C: in the prompt means you are using the first partition on the first hard drive.
|
||||
|
||||
Starting with PC-DOS 2.0 in 1983, DOS also supported directories and subdirectories, much like the directories and subdirectories on Linux filesystems. But unlike Linux, DOS directory names are delimited by \ instead of /. Putting that together with the drive letter, the C:\ in the prompt means you are in the top, or "root," directory of the C: drive.
|
||||
|
||||
The > is the literal prompt where you type your DOS commands, like the $ prompt on many Linux shells. The part before the > tells you the current working directory, and you type commands at the > prompt.
|
||||
|
||||
## Finding your way around in DOS
|
||||
|
||||
The basics of navigating through directories in DOS are very similar to the steps you'd use on the Linux command line. You need to remember only a few commands.
|
||||
|
||||
### Displaying a directory
|
||||
|
||||
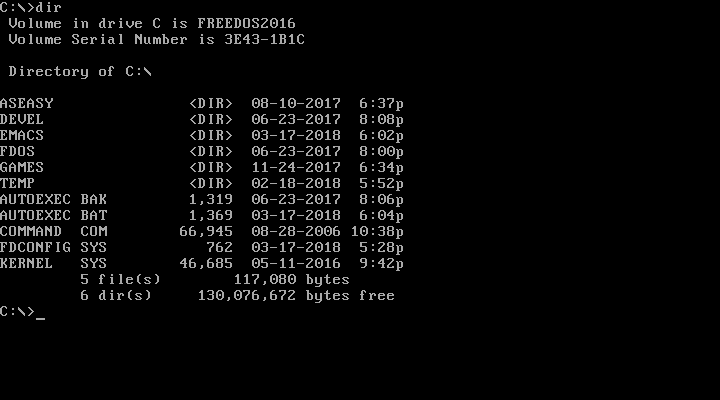
When you want to see the contents of the current directory, use the DIR command. Since DOS commands are not case-sensitive, you could also type dir. By default, DOS displays the details of every file and subdirectory, including the name, extension, size, and last modified date and time.
|
||||
|
||||
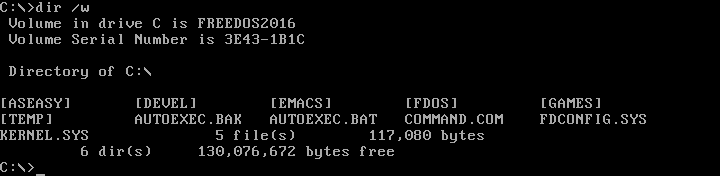
|
||||
|
||||
If you don't want the extra details about individual file sizes, you can display a "wide" directory by using the /w option with the DIR command. Note that Linux uses the hyphen (-) or double-hyphen (--) to start command-line options, but DOS uses the slash character (/).
|
||||
|
||||
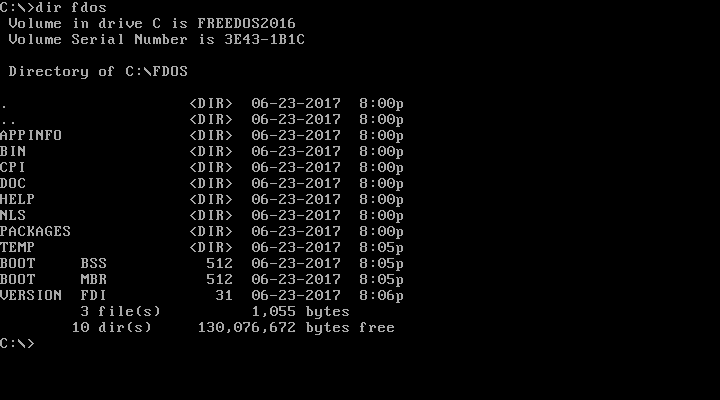
|
||||
|
||||
You can look inside a specific subdirectory by passing the pathname as a parameter to DIR. Again, another difference from Linux is that Linux files and directories are case-sensitive, but DOS names are case-insensitive. DOS will usually display files and directories in all uppercase, but you can equally reference them in lowercase.
|
||||
|
||||
|
||||
|
||||
### Changing the working directory
|
||||
|
||||
Once you can see the contents of a directory, you can "move into" any other directory. On DOS, you change your working directory with the CHDIR command, also abbreviated as CD. You can change into a subdirectory with a command like CD CHOICE or into a new path with CD \FDOS\DOC\CHOICE.
|
||||
|
||||
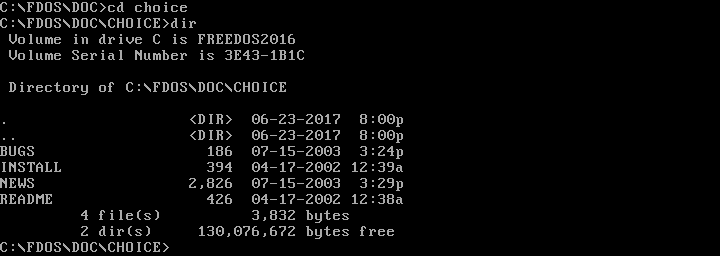
|
||||
|
||||
Just like on the Linux command line, DOS uses . to represent the current directory, and .. for the parent directory (one level "up" from the current directory). You can combine these. For example, CD .. changes to the parent directory, and CD ..\.. moves you two levels "up" from the current directory.
|
||||
|
||||
FreeDOS also borrows a feature from Linux: You can use CD - to jump back to your previous working directory. That is handy after you change into a new path to do one thing and want to go back to your previous work.
|
||||
|
||||
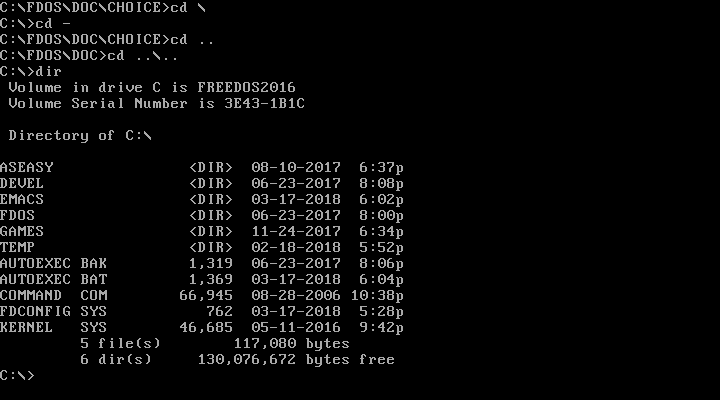
|
||||
|
||||
### Changing the working drive
|
||||
|
||||
Under Linux, the concept of a "drive" is hidden. In Linux and other Unix systems, you "mount" a drive to a directory path, such as /backup, or the system does it for you automatically, such as /var/run/media/user/flashdrive. But DOS is a much simpler system. With DOS, you must change the working drive by yourself.
|
||||
|
||||
Remember that DOS assigns the first partition on the first hard drive as the C: drive, and so on for other drive letters. On modern systems, people rarely divide a hard drive with multiple DOS partitions; they simply use the whole disk—or as much of it as they can assign to DOS. Today, C: is usually the first hard drive, and D: is usually another hard drive or the CD-ROM drive. Other network drives can be mapped to other letters, such as E: or Z: or however you want to organize them.
|
||||
|
||||
Changing drives is easy under DOS. Just type the drive letter followed by a colon (:) on the command line, and DOS will change to that working drive. For example, on my [QEMU][5] system, I set my D: drive to a shared directory in my Linux home directory, where I keep installers for various DOS applications and games I want to test.
|
||||
|
||||
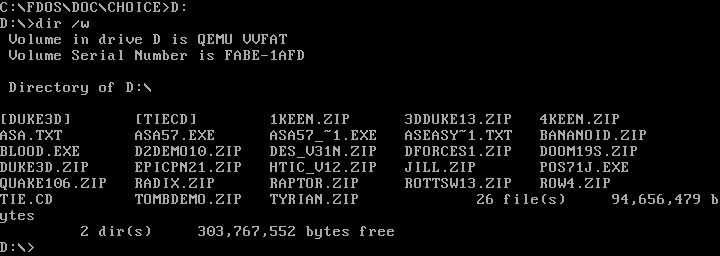
|
||||
|
||||
Be careful that you don't try to change to a drive that doesn't exist. DOS may set the working drive, but if you try to do anything there you'll get the somewhat infamous "Abort, Retry, Fail" DOS error message.
|
||||
|
||||

|
||||
|
||||
## Other things to try
|
||||
|
||||
With the CD and DIR commands, you have the basics of DOS navigation. These commands allow you to find your way around DOS directories and see what other subdirectories and files exist. Once you are comfortable with basic navigation, you might also try these other basic DOS commands:
|
||||
|
||||
* MKDIR or MD to create new directories
|
||||
* RMDIR or RD to remove directories
|
||||
* TREE to view a list of directories and subdirectories in a tree-like format
|
||||
* TYPE and MORE to display file contents
|
||||
* RENAME or REN to rename files
|
||||
* DEL or ERASE to delete files
|
||||
* EDIT to edit files
|
||||
* CLS to clear the screen
|
||||
|
||||
If those aren't enough, you can find a list of [all DOS commands][6] on the FreeDOS wiki.
|
||||
|
||||
In FreeDOS, you can use the /? parameter to get brief instructions to use each command. For example, EDIT /? will show you the usage and options for the editor. Or you can type HELP to use an interactive help system.
|
||||
|
||||
Like any DOS, FreeDOS is meant to be a simple operating system. The DOS filesystem is pretty simple to navigate with only a few basic commands. So fire up a QEMU session, install FreeDOS, and experiment with the DOS command line. Maybe now it won't seem so scary.
|
||||
|
||||
## Related stories:
|
||||
|
||||
* [How to install FreeDOS in QEMU][7]
|
||||
* [How to install FreeDOS on Raspberry Pi][8]
|
||||
* [The origin and evolution of FreeDOS][9]
|
||||
* [Four cool facts about FreeDOS][10]
|
||||
|
||||
## About the author
|
||||
|
||||
[][11]
|
||||
|
||||
Jim Hall \- Jim Hall is an open source software developer and advocate, probably best known as the founder and project coordinator for FreeDOS. Jim is also very active in the usability of open source software, as a mentor for usability testing in GNOME Outreachy, and as an occasional adjunct professor teaching a course on the Usability of Open Source Software. From 2016 to 2017, Jim served as a director on the GNOME Foundation Board of Directors. At work, Jim is Chief Information Officer in local... [more about Jim Hall][12]
|
||||
|
||||
[More about me][13]
|
||||
|
||||
* [Learn how you can contribute][14]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/gentle-introduction-freedos][15]
|
||||
|
||||
作者: [undefined][16] 选题者: [@lujun9972][17] 译者: [译者ID][18] 校对: [校对者ID][19]
|
||||
|
||||
本文由 [LCTT][20] 原创编译,[Linux中国][21] 荣誉推出
|
||||
|
||||
[1]: https://opensource.com/article/17/10/freedos
|
||||
[2]: https://opensource.com/article/17/8/gnome-20-anniversary
|
||||
[3]: http://www.freedos.org/
|
||||
[4]: http://wiki.freedos.org/
|
||||
[5]: https://www.qemu.org/
|
||||
[6]: http://wiki.freedos.org/wiki/index.php/Dos_commands
|
||||
[7]: https://opensource.com/article/17/10/run-dos-applications-linux
|
||||
[8]: https://opensource.com/article/18/3/can-you-run-dos-raspberry-pi
|
||||
[9]: https://opensource.com/article/17/10/freedos
|
||||
[10]: https://opensource.com/article/17/6/freedos-still-cool-today
|
||||
[11]: https://opensource.com/users/jim-hall
|
||||
[12]: https://opensource.com/users/jim-hall
|
||||
[13]: https://opensource.com/users/jim-hall
|
||||
[14]: https://opensource.com/participate
|
||||
[15]: https://opensource.com/article/18/4/gentle-introduction-freedos
|
||||
[16]: undefined
|
||||
[17]: https://github.com/lujun9972
|
||||
[18]: https://github.com/译者ID
|
||||
[19]: https://github.com/校对者ID
|
||||
[20]: https://github.com/LCTT/TranslateProject
|
||||
[21]: https://linux.cn/
|
||||
@ -1,489 +0,0 @@
|
||||
Translating by qhwdw
|
||||
# Understanding metrics and monitoring with Python
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
## Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
My reaction when I first came across the terms counter and gauge and the graphs with colors and numbers labeled "mean" and "upper 90" was one of avoidance. It's like I saw them, but I didn't care because I didn't understand them or how they might be useful. Since my job didn't require me to pay attention to them, they remained ignored.
|
||||
|
||||
That was about two years ago. As I progressed in my career, I wanted to understand more about our network applications, and that is when I started learning about metrics.
|
||||
|
||||
The three stages of my journey to understanding monitoring (so far) are:
|
||||
|
||||
* Stage 1: What? (Looks elsewhere)
|
||||
* Stage 2: Without metrics, we are really flying blind.
|
||||
* Stage 3: How do we keep from doing metrics wrong?
|
||||
|
||||
I am currently in Stage 2 and will share what I have learned so far. I'm moving gradually toward Stage 3, and I will offer some of my resources on that part of the journey at the end of this article.
|
||||
|
||||
Let's get started!
|
||||
|
||||
## Software prerequisites
|
||||
|
||||
More Python Resources
|
||||
|
||||
* [What is Python?][1]
|
||||
* [Top Python IDEs][2]
|
||||
* [Top Python GUI frameworks][3]
|
||||
* [Latest Python content][4]
|
||||
* [More developer resources][5]
|
||||
|
||||
All the demos discussed in this article are available on [my GitHub repo][6]. You will need to have docker and docker-compose installed to play with them.
|
||||
|
||||
## Why should I monitor?
|
||||
|
||||
The top reasons for monitoring are:
|
||||
|
||||
* Understanding _normal_ and _abnormal_ system and service behavior
|
||||
* Doing capacity planning, scaling up or down
|
||||
* Assisting in performance troubleshooting
|
||||
* Understanding the effect of software/hardware changes
|
||||
* Changing system behavior in response to a measurement
|
||||
* Alerting when a system exhibits unexpected behavior
|
||||
|
||||
## Metrics and metric types
|
||||
|
||||
For our purposes, a **metric** is an _observed_ value of a certain quantity at a given point in _time_. The total of number hits on a blog post, the total number of people attending a talk, the number of times the data was not found in the caching system, the number of logged-in users on your website—all are examples of metrics.
|
||||
|
||||
They broadly fall into three categories:
|
||||
|
||||
### Counters
|
||||
|
||||
Consider your personal blog. You just published a post and want to keep an eye on how many hits it gets over time, a number that can only increase. This is an example of a **counter** metric. Its value starts at 0 and increases during the lifetime of your blog post. Graphically, a counter looks like this:
|
||||
|
||||
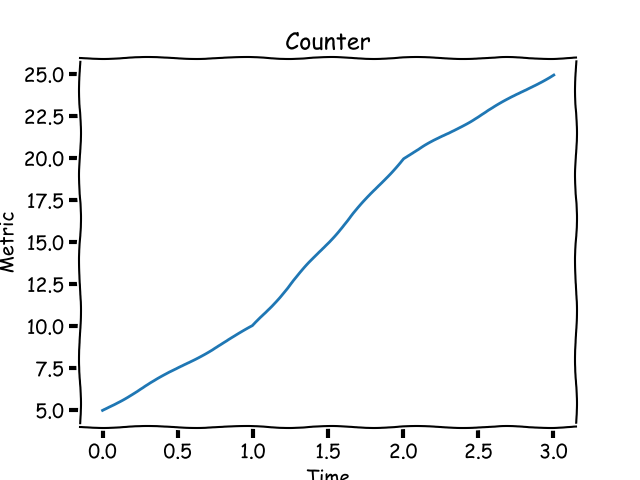
|
||||
|
||||
A counter metric always increases.
|
||||
|
||||
### Gauges
|
||||
|
||||
Instead of the total number of hits on your blog post over time, let's say you want to track the number of hits per day or per week. This metric is called a **gauge** and its value can go up or down. Graphically, a gauge looks like this:
|
||||
|
||||
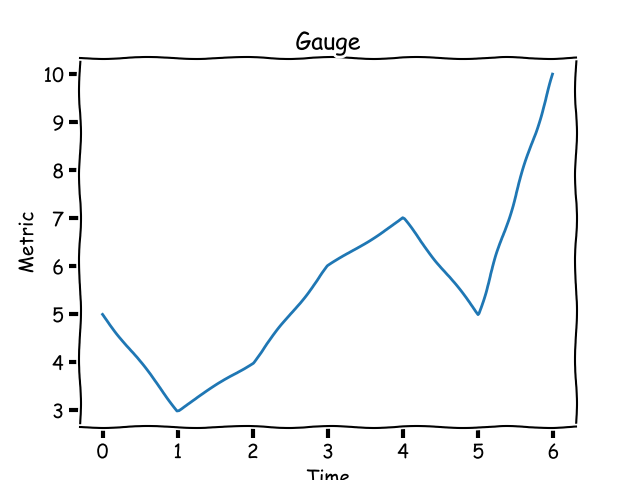
|
||||
|
||||
A gauge metric can increase or decrease.
|
||||
|
||||
A gauge's value usually has a _ceiling_ and a _floor_ in a certain time window.
|
||||
|
||||
### Histograms and timers
|
||||
|
||||
A **histogram** (as Prometheus calls it) or a **timer** (as StatsD calls it) is a metric to track _sampled observations_. Unlike a counter or a gauge, the value of a histogram metric doesn't necessarily show an up or down pattern. I know that doesn't make a lot of sense and may not seem different from a gauge. What's different is what you expect to _do_ with histogram data compared to a gauge. Therefore, the monitoring system needs to know that a metric is a histogram type to allow you to do those things.
|
||||
|
||||
|
||||
|
||||
A histogram metric can increase or decrease.
|
||||
|
||||
## Demo 1: Calculating and reporting metrics
|
||||
|
||||
[Demo 1][7] is a basic web application written using the [Flask][8] framework. It demonstrates how we can _calculate_ and _report_ metrics.
|
||||
|
||||
The src directory has the application in app.py with the src/helpers/middleware.py containing the following:
|
||||
|
||||
```
|
||||
from flask import request
|
||||
import csv
|
||||
import time
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([str(int(time.time())), str(resp_time)])
|
||||
|
||||
return response
|
||||
|
||||
|
||||
def setup_metrics(app):
|
||||
app.before_request(start_timer)
|
||||
app.after_request(stop_timer)
|
||||
```
|
||||
|
||||
When setup_metrics() is called from the application, it configures the start_timer() function to be called before a request is processed and the stop_timer() function to be called after a request is processed but before the response has been sent. In the above function, we write the timestamp and the time it took (in milliseconds) for the request to be processed.
|
||||
|
||||
When we run docker-compose up in the demo1 directory, it starts the web application, then a client container that makes a number of requests to the web application. You will see a src/metrics.csv file that has been created with two columns: timestamp and request_latency.
|
||||
|
||||
Looking at this file, we can infer two things:
|
||||
|
||||
* There is a lot of data that has been generated
|
||||
* No observation of the metric has any characteristic associated with it
|
||||
|
||||
Without a characteristic associated with a metric observation, we cannot say which HTTP endpoint this metric was associated with or which node of the application this metric was generated from. Hence, we need to qualify each metric observation with the appropriate metadata.
|
||||
|
||||
## Statistics 101
|
||||
|
||||
If we think back to high school mathematics, there are a few statistics terms we should all recall, even if vaguely, including mean, median, percentile, and histogram. Let's briefly recap them without judging their usefulness, just like in high school.
|
||||
|
||||
### Mean
|
||||
|
||||
The **mean**, or the average of a list of numbers, is the sum of the numbers divided by the cardinality of the list. The mean of 3, 2, and 10 is (3+2+10)/3 = 5.
|
||||
|
||||
### Median
|
||||
|
||||
The **median** is another type of average, but it is calculated differently; it is the center numeral in a list of numbers ordered from smallest to largest (or vice versa). In our list above (2, 3, 10), the median is 3. The calculation is not very straightforward; it depends on the number of items in the list.
|
||||
|
||||
### Percentile
|
||||
|
||||
The **percentile** is a measure that gives us a measure below which a certain (k) percentage of the numbers lie. In some sense, it gives us an _idea_ of how this measure is doing relative to the k percentage of our data. For example, the 95th percentile score of the above list is 9.29999. The percentile measure varies from 0 to 100 (non-inclusive). The _zeroth_ percentile is the minimum score in a set of numbers. Some of you may recall that the median is the 50th percentile, which turns out to be 3.
|
||||
|
||||
Some monitoring systems refer to the percentile measure as upper_X where _X_ is the percentile; _upper 90_ refers to the value at the 90th percentile.
|
||||
|
||||
### Quantile
|
||||
|
||||
The **q-Quantile** is a measure that ranks q_N_ in a set of _N_ numbers. The value of **q** ranges between 0 and 1 (both inclusive). When **q** is 0.5, the value is the median. The relationship between the quantile and percentile is that the measure at **q** quantile is equivalent to the measure at **100_q_** percentile.
|
||||
|
||||
### Histogram
|
||||
|
||||
The metric **histogram**, which we learned about earlier, is an _implementation detail_ of monitoring systems. In statistics, a histogram is a graph that groups data into _buckets_. Let's consider a different, contrived example: the ages of people reading your blog. If you got a handful of this data and wanted a rough idea of your readers' ages by group, plotting a histogram would show you a graph like this:
|
||||
|
||||
|
||||
|
||||
### Cumulative histogram
|
||||
|
||||
A **cumulative histogram** is a histogram where each bucket's count includes the count of the previous bucket, hence the name _cumulative_. A cumulative histogram for the above dataset would look like this:
|
||||
|
||||
|
||||
|
||||
### Why do we need statistics?
|
||||
|
||||
In Demo 1 above, we observed that there is a lot of data that is generated when we report metrics. We need statistics when working with metrics because there are just too many of them. We don't care about individual values, rather overall behavior. We expect the behavior the values exhibit is a proxy of the behavior of the system under observation.
|
||||
|
||||
## Demo 2: Adding characteristics to metrics
|
||||
|
||||
In our Demo 1 application above, when we calculate and report a request latency, it refers to a specific request uniquely identified by few _characteristics_. Some of these are:
|
||||
|
||||
* The HTTP endpoint
|
||||
* The HTTP method
|
||||
* The identifier of the host/node where it's running
|
||||
|
||||
If we attach these characteristics to a metric observation, we have more context around each metric. Let's explore adding characteristics to our metrics in [Demo 2][9].
|
||||
|
||||
The src/helpers/middleware.py file now writes multiple columns to the CSV file when writing metrics:
|
||||
|
||||
```
|
||||
node_ids = ['10.0.1.1', '10.1.3.4']
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
node_id = node_ids[random.choice(range(len(node_ids)))]
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([
|
||||
str(int(time.time())), 'webapp1', node_id,
|
||||
request.endpoint, request.method, str(response.status_code),
|
||||
str(resp_time)
|
||||
])
|
||||
|
||||
return response
|
||||
```
|
||||
|
||||
Since this is a demo, I have taken the liberty of reporting random IPs as the node IDs when reporting the metric. When we run docker-compose up in the demo2 directory, it will result in a CSV file with multiple columns.
|
||||
|
||||
### Analyzing metrics with pandas
|
||||
|
||||
We'll now analyze this CSV file with [pandas][10]. Running docker-compose up will print a URL that we will use to open a [Jupyter][11] session. Once we upload the Analysis.ipynb notebook into the session, we can read the CSV file into a pandas DataFrame:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
metrics = pd.read_csv('/data/metrics.csv', index_col=0)
|
||||
```
|
||||
|
||||
The index_col specifies that we want to use the timestamp as the index.
|
||||
|
||||
Since each characteristic we add is a column in the DataFrame, we can perform grouping and aggregation based on these columns:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
metrics.groupby(['node_id', 'http_status']).latency.aggregate(np.percentile, 99.999)
|
||||
```
|
||||
|
||||
Please refer to the Jupyter notebook for more example analysis on the data.
|
||||
|
||||
## What should I monitor?
|
||||
|
||||
A software system has a number of variables whose values change during its lifetime. The software is running in some sort of an operating system, and operating system variables change as well. In my opinion, the more data you have, the better it is when something goes wrong.
|
||||
|
||||
Key operating system metrics I recommend monitoring are:
|
||||
|
||||
* CPU usage
|
||||
* System memory usage
|
||||
* File descriptor usage
|
||||
* Disk usage
|
||||
|
||||
Other key metrics to monitor will vary depending on your software application.
|
||||
|
||||
### Network applications
|
||||
|
||||
If your software is a network application that listens to and serves client requests, the key metrics to measure are:
|
||||
|
||||
* Number of requests coming in (counter)
|
||||
* Unhandled errors (counter)
|
||||
* Request latency (histogram/timer)
|
||||
* Queued time, if there is a queue in your application (histogram/timer)
|
||||
* Queue size, if there is a queue in your application (gauge)
|
||||
* Worker processes/threads usage (gauge)
|
||||
|
||||
If your network application makes requests to other services in the context of fulfilling a client request, it should have metrics to record the behavior of communications with those services. Key metrics to monitor include number of requests, request latency, and response status.
|
||||
|
||||
### HTTP web application backends
|
||||
|
||||
HTTP applications should monitor all the above. In addition, they should keep granular data about the count of non-200 HTTP statuses grouped by all the other HTTP status codes. If your web application has user signup and login functionality, it should have metrics for those as well.
|
||||
|
||||
### Long-running processes
|
||||
|
||||
Long-running processes such as Rabbit MQ consumer or task-queue workers, although not network servers, work on the model of picking up a task and processing it. Hence, we should monitor the number of requests processed and the request latency for those processes.
|
||||
|
||||
No matter the application type, each metric should have appropriate **metadata** associated with it.
|
||||
|
||||
## Integrating monitoring in a Python application
|
||||
|
||||
There are two components involved in integrating monitoring into Python applications:
|
||||
|
||||
* Updating your application to calculate and report metrics
|
||||
* Setting up a monitoring infrastructure to house the application's metrics and allow queries to be made against them
|
||||
|
||||
The basic idea of recording and reporting a metric is:
|
||||
|
||||
```
|
||||
def work():
|
||||
requests += 1
|
||||
# report counter
|
||||
start_time = time.time()
|
||||
|
||||
# < do the work >
|
||||
|
||||
# calculate and report latency
|
||||
work_latency = time.time() - start_time
|
||||
...
|
||||
```
|
||||
|
||||
Considering the above pattern, we often take advantage of _decorators_, _context managers_, and _middleware_ (for network applications) to calculate and report metrics. In Demo 1 and Demo 2, we used decorators in a Flask application.
|
||||
|
||||
### Pull and push models for metric reporting
|
||||
|
||||
Essentially, there are two patterns for reporting metrics from a Python application. In the _pull_ model, the monitoring system "scrapes" the application at a predefined HTTP endpoint. In the _push_ model, the application sends the data to the monitoring system.
|
||||
|
||||

|
||||
|
||||
An example of a monitoring system working in the _pull_ model is [Prometheus][12]. [StatsD][13] is an example of a monitoring system where the application _pushes_ the metrics to the system.
|
||||
|
||||
### Integrating StatsD
|
||||
|
||||
To integrate StatsD into a Python application, we would use the [StatsD Python client][14], then update our metric-reporting code to push data into StatsD using the appropriate library calls.
|
||||
|
||||
First, we need to create a client instance:
|
||||
|
||||
```
|
||||
statsd = statsd.StatsClient(host='statsd', port=8125, prefix='webapp1')
|
||||
```
|
||||
|
||||
The prefix keyword argument will add the specified prefix to all the metrics reported via this client.
|
||||
|
||||
Once we have the client, we can report a value for a timer using:
|
||||
|
||||
```
|
||||
statsd.timing(key, resp_time)
|
||||
```
|
||||
|
||||
To increment a counter:
|
||||
|
||||
```
|
||||
statsd.incr(key)
|
||||
```
|
||||
|
||||
To associate metadata with a metric, a key is defined as metadata1.metadata2.metric, where each metadataX is a field that allows aggregation and grouping.
|
||||
|
||||
The demo application [StatsD][15] is a complete example of integrating a Python Flask application with statsd.
|
||||
|
||||
### Integrating Prometheus
|
||||
|
||||
To use the Prometheus monitoring system, we will use the [Promethius Python client][16]. We will first create objects of the appropriate metric class:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY = Histogram('request_latency_seconds', 'Request latency',
|
||||
['app_name', 'endpoint']
|
||||
)
|
||||
```
|
||||
|
||||
The third argument in the above statement is the labels associated with the metric. These labels are what defines the metadata associated with a single metric value.
|
||||
|
||||
To record a specific metric observation:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY.labels('webapp', request.path).observe(resp_time)
|
||||
```
|
||||
|
||||
The next step is to define an HTTP endpoint in our application that Prometheus can scrape. This is usually an endpoint called /metrics:
|
||||
|
||||
```
|
||||
@app.route('/metrics')
|
||||
def metrics():
|
||||
return Response(prometheus_client.generate_latest(), mimetype=CONTENT_TYPE_LATEST)
|
||||
```
|
||||
|
||||
The demo application [Prometheus][17] is a complete example of integrating a Python Flask application with prometheus.
|
||||
|
||||
### Which is better: StatsD or Prometheus?
|
||||
|
||||
The natural next question is: Should I use StatsD or Prometheus? I have written a few articles on this topic, and you may find them useful:
|
||||
|
||||
* [Your options for monitoring multi-process Python applications with Prometheus][18]
|
||||
* [Monitoring your synchronous Python web applications using Prometheus][19]
|
||||
* [Monitoring your asynchronous Python web applications using Prometheus][20]
|
||||
|
||||
## Ways to use metrics
|
||||
|
||||
We've learned a bit about why we want to set up monitoring in our applications, but now let's look deeper into two of them: alerting and autoscaling.
|
||||
|
||||
### Using metrics for alerting
|
||||
|
||||
A key use of metrics is creating alerts. For example, you may want to send an email or pager notification to relevant people if the number of HTTP 500s over the past five minutes increases. What we use for setting up alerts depends on our monitoring setup. For Prometheus we can use [Alertmanager][21] and for StatsD, we use [Nagios][22].
|
||||
|
||||
### Using metrics for autoscaling
|
||||
|
||||
Not only can metrics allow us to understand if our current infrastructure is over- or under-provisioned, they can also help implement autoscaling policies in a cloud infrastructure. For example, if worker process usage on our servers routinely hits 90% over the past five minutes, we may need to horizontally scale. How we would implement scaling depends on the cloud infrastructure. AWS Auto Scaling, by default, allows scaling policies based on system CPU usage, network traffic, and other factors. However, to use application metrics for scaling up or down, we must publish [custom CloudWatch metrics][23].
|
||||
|
||||
## Application monitoring in a multi-service architecture
|
||||
|
||||
When we go beyond a single application architecture, such that a client request can trigger calls to multiple services before a response is sent back, we need more from our metrics. We need a unified view of latency metrics so we can see how much time each service took to respond to the request. This is enabled with [distributed tracing][24].
|
||||
|
||||
You can see an example of distributed tracing in Python in my blog post [Introducing distributed tracing in your Python application via Zipkin][25].
|
||||
|
||||
## Points to remember
|
||||
|
||||
In summary, make sure to keep the following things in mind:
|
||||
|
||||
* Understand what a metric type means in your monitoring system
|
||||
* Know in what unit of measurement the monitoring system wants your data
|
||||
* Monitor the most critical components of your application
|
||||
* Monitor the behavior of your application in its most critical stages
|
||||
|
||||
The above assumes you don't have to manage your monitoring systems. If that's part of your job, you have a lot more to think about!
|
||||
|
||||
## Other resources
|
||||
|
||||
Following are some of the resources I found very useful along my monitoring education journey:
|
||||
|
||||
### General
|
||||
|
||||
* [Monitoring distributed systems][26]
|
||||
* [Observability and monitoring best practices][27]
|
||||
* [Who wants seconds?][28]
|
||||
|
||||
### StatsD/Graphite
|
||||
|
||||
* [StatsD metric types][29]
|
||||
|
||||
### Prometheus
|
||||
|
||||
* [Prometheus metric types][30]
|
||||
* [How does a Prometheus gauge work?][31]
|
||||
* [Why are Prometheus histograms cumulative?][32]
|
||||
* [Monitoring batch jobs in Python][33]
|
||||
* [Prometheus: Monitoring at SoundCloud][34]
|
||||
|
||||
## Avoiding mistakes (i.e., Stage 3 learnings)
|
||||
|
||||
As we learn the basics of monitoring, it's important to keep an eye on the mistakes we don't want to make. Here are some insightful resources I have come across:
|
||||
|
||||
* [How not to measure latency][35]
|
||||
* [Histograms with Prometheus: A tale of woe][36]
|
||||
* [Why averages suck and percentiles are great][37]
|
||||
* [Everything you know about latency is wrong][38]
|
||||
* [Who moved my 99th percentile latency?][39]
|
||||
* [Logs and metrics and graphs][40]
|
||||
* [HdrHistogram: A better latency capture method][41]
|
||||
|
||||
---
|
||||
|
||||
To learn more, attend Amit Saha's talk, [Counter, gauge, upper 90—Oh my!][42], at [PyCon Cleveland 2018][43].
|
||||
|
||||
## About the author
|
||||
|
||||
[][44]
|
||||
|
||||
Amit Saha \- I am a software engineer interested in infrastructure, monitoring and tooling. I am the author of "Doing Math with Python" and creator and the maintainer of Fedora Scientific Spin.
|
||||
|
||||
[More about me][45]
|
||||
|
||||
* [Learn how you can contribute][46]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/metrics-monitoring-and-python][47]
|
||||
|
||||
作者: [Amit Saha][48] 选题者: [@lujun9972][49] 译者: [译者ID][50] 校对: [校对者ID][51]
|
||||
|
||||
本文由 [LCTT][52] 原创编译,[Linux中国][53] 荣誉推出
|
||||
|
||||
[1]: https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[2]: https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[3]: https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[4]: https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[5]: https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[6]: https://github.com/amitsaha/python-monitoring-talk
|
||||
[7]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo1
|
||||
[8]: http://flask.pocoo.org/
|
||||
[9]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo2
|
||||
[10]: https://pandas.pydata.org/
|
||||
[11]: http://jupyter.org/
|
||||
[12]: https://prometheus.io/
|
||||
[13]: https://github.com/etsy/statsd
|
||||
[14]: https://pypi.python.org/pypi/statsd
|
||||
[15]: https://github.com/amitsaha/python-monitoring-talk/tree/master/statsd
|
||||
[16]: https://pypi.python.org/pypi/prometheus_client
|
||||
[17]: https://github.com/amitsaha/python-monitoring-talk/tree/master/prometheus
|
||||
[18]: http://echorand.me/your-options-for-monitoring-multi-process-python-applications-with-prometheus.html
|
||||
[19]: https://blog.codeship.com/monitoring-your-synchronous-python-web-applications-using-prometheus/
|
||||
[20]: https://blog.codeship.com/monitoring-your-asynchronous-python-web-applications-using-prometheus/
|
||||
[21]: https://github.com/prometheus/alertmanager
|
||||
[22]: https://www.nagios.org/about/overview/
|
||||
[23]: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
|
||||
[24]: http://opentracing.io/documentation/
|
||||
[25]: http://echorand.me/introducing-distributed-tracing-in-your-python-application-via-zipkin.html
|
||||
[26]: https://landing.google.com/sre/book/chapters/monitoring-distributed-systems.html
|
||||
[27]: http://www.integralist.co.uk/posts/monitoring-best-practices/?imm_mid=0fbebf&cmp=em-webops-na-na-newsltr_20180309
|
||||
[28]: https://www.robustperception.io/who-wants-seconds/
|
||||
[29]: https://github.com/etsy/statsd/blob/master/docs/metric_types.md
|
||||
[30]: https://prometheus.io/docs/concepts/metric_types/
|
||||
[31]: https://www.robustperception.io/how-does-a-prometheus-gauge-work/
|
||||
[32]: https://www.robustperception.io/why-are-prometheus-histograms-cumulative/
|
||||
[33]: https://www.robustperception.io/monitoring-batch-jobs-in-python/
|
||||
[34]: https://developers.soundcloud.com/blog/prometheus-monitoring-at-soundcloud
|
||||
[35]: https://www.youtube.com/watch?v=lJ8ydIuPFeU&feature=youtu.be
|
||||
[36]: http://linuxczar.net/blog/2017/06/15/prometheus-histogram-2/
|
||||
[37]: https://www.dynatrace.com/news/blog/why-averages-suck-and-percentiles-are-great/
|
||||
[38]: https://bravenewgeek.com/everything-you-know-about-latency-is-wrong/
|
||||
[39]: https://engineering.linkedin.com/performance/who-moved-my-99th-percentile-latency
|
||||
[40]: https://grafana.com/blog/2016/01/05/logs-and-metrics-and-graphs-oh-my/
|
||||
[41]: http://psy-lob-saw.blogspot.com.au/2015/02/hdrhistogram-better-latency-capture.html
|
||||
[42]: https://us.pycon.org/2018/schedule/presentation/133/
|
||||
[43]: https://us.pycon.org/2018/
|
||||
[44]: https://opensource.com/users/amitsaha
|
||||
[45]: https://opensource.com/users/amitsaha
|
||||
[46]: https://opensource.com/participate
|
||||
[47]: https://opensource.com/article/18/4/metrics-monitoring-and-python
|
||||
[48]: https://opensource.com/users/amitsaha
|
||||
[49]: https://github.com/lujun9972
|
||||
[50]: https://github.com/译者ID
|
||||
[51]: https://github.com/校对者ID
|
||||
[52]: https://github.com/LCTT/TranslateProject
|
||||
[53]: https://linux.cn/
|
||||
@ -1,288 +0,0 @@
|
||||
translating by Flowsnow
|
||||
Getting started with the Python debugger
|
||||
======
|
||||
|
||||

|
||||
|
||||
The Python ecosystem is rich with many tools and libraries that improve developers’ lives. For example, the Magazine has previously covered how to [enhance your Python with a interactive shell][1]. This article focuses on another tool that saves you time and improves your Python skills: the Python debugger.
|
||||
|
||||
### Python Debugger
|
||||
|
||||
The Python standard library provides a debugger called pdb. This debugger provides most features needed for debugging such as breakpoints, single line stepping, inspection of stack frames, and so on.
|
||||
|
||||
A basic knowledge of pdb is useful since it’s part of the standard library. You can use it in environments where you can’t install another enhanced debugger.
|
||||
|
||||
#### Running pdb
|
||||
|
||||
The easiest way to run pdb is from the command line, passing the program to debug as an argument. Considering the following script:
|
||||
```
|
||||
# pdb_test.py
|
||||
#!/usr/bin/python3
|
||||
|
||||
from time import sleep
|
||||
|
||||
def countdown(number):
|
||||
for i in range(number, 0, -1):
|
||||
print(i)
|
||||
sleep(1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
seconds = 10
|
||||
countdown(seconds)
|
||||
|
||||
```
|
||||
|
||||
You can run pdb from the command line like this:
|
||||
```
|
||||
$ python3 -m pdb pdb_test.py
|
||||
> /tmp/pdb_test.py(1)<module>()
|
||||
-> from time import sleep
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
Another way to use pdb is to set a breakpoint in the program. To do this, import the pdb module and use the set_trace function:
|
||||
```
|
||||
1 # pdb_test.py
|
||||
2 #!/usr/bin/python3
|
||||
3
|
||||
4 from time import sleep
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
16 countdown(seconds)
|
||||
|
||||
$ python3 pdb_test.py
|
||||
> /tmp/pdb_test.py(6)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
The script stops at the breakpoint, and pdb displays the next line in the script. You can also execute the debugger after a failure. This is known as postmortem debugging.
|
||||
|
||||
#### Navigate the execution stack
|
||||
|
||||
A common use case in debugging is to navigate the execution stack. Once the Python debugger is running, the following commands are useful :
|
||||
|
||||
+ w(here) : Shows which line is currently executed and where the execution stack is.
|
||||
|
||||
|
||||
```
|
||||
$ python3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) w
|
||||
/tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
+ l(ist) : Shows more context (code) around the current the location.
|
||||
|
||||
|
||||
```
|
||||
$ python3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) l
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 -> print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
+ u(p)/d(own) : Navigate the call stack up or down.
|
||||
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) up
|
||||
> /tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
(Pdb) down
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
#### Stepping through a program
|
||||
|
||||
pdb provides the following commands to execute and step through code:
|
||||
|
||||
+ n(ext): Continue execution until the next line in the current function is reached, or it returns
|
||||
+ s(tep): Execute the current line and stop at the first possible occasion (either in a function that is called or in the current function)
|
||||
+ c(ontinue): Continue execution, only stopping at a breakpoint.
|
||||
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) n
|
||||
10
|
||||
> /tmp/test_pdb.py(11)countdown()
|
||||
-> sleep(1)
|
||||
(Pdb) n
|
||||
> /tmp/test_pdb.py(8)countdown()
|
||||
-> for i in range(number, 0, -1):
|
||||
(Pdb) n
|
||||
> /tmp/test_pdb.py(9)countdown()
|
||||
-> import pdb; pdb.set_trace()
|
||||
(Pdb) s
|
||||
--Call--
|
||||
> /usr/lib64/python3.6/pdb.py(1584)set_trace()
|
||||
-> def set_trace():
|
||||
(Pdb) c
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) c
|
||||
9
|
||||
> /tmp/test_pdb.py(9)countdown()
|
||||
-> import pdb; pdb.set_trace()
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
The example shows the difference between next and step. Indeed, when using step the debugger stepped into the pdb module source code, whereas next would have just executed the set_trace function.
|
||||
|
||||
#### Examine variables content
|
||||
|
||||
Where pdb is really useful is examining the content of variables stored in the execution stack. For example, the a(rgs) command prints the variables of the current function, as shown below:
|
||||
```
|
||||
py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) where
|
||||
/tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) args
|
||||
number = 10
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
pdb prints the value of the variable number, in this case 10.
|
||||
|
||||
Another command that can be used to print variables value is p(rint).
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) list
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 -> print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
(Pdb) print(seconds)
|
||||
10
|
||||
(Pdb) p i
|
||||
10
|
||||
(Pdb) p number - i
|
||||
0
|
||||
(Pdb)
|
||||
|
||||
```
|
||||
|
||||
As shown in the example’s last command, print can evaluate an expression before displaying the result.
|
||||
|
||||
The [Python documentation][2] contains the reference and examples for each of the pdb commands. This is a useful read for someone starting with the Python debugger.
|
||||
|
||||
### Enhanced debugger
|
||||
|
||||
Some enhanced debuggers provide a better user experience. Most add useful extra features to pdb, such as syntax highlighting, better tracebacks, and introspection. Popular choices of enhanced debuggers include [IPython’s ipdb][3] and [pdb++][4].
|
||||
|
||||
These examples show you how to install these two debuggers in a virtual environment. These examples use a new virtual environment, but in the case of debugging an application, the application’s virtual environment should be used.
|
||||
|
||||
#### Install IPython’s ipdb
|
||||
|
||||
To install the IPython ipdb, use pip in the virtual environment:
|
||||
```
|
||||
$ python3 -m venv .test_pdb
|
||||
$ source .test_pdb/bin/activate
|
||||
(test_pdb)$ pip install ipdb
|
||||
|
||||
```
|
||||
|
||||
To call ipdb inside a script, you must use the following command. Note that the module is called ipdb instead of pdb:
|
||||
```
|
||||
import ipdb; ipdb.set_trace()
|
||||
|
||||
```
|
||||
|
||||
IPython’s ipdb is also available in Fedora packages, so you can install it using Fedora’s package manager dnf:
|
||||
```
|
||||
$ sudo dnf install python3-ipdb
|
||||
|
||||
```
|
||||
|
||||
#### Install pdb++
|
||||
|
||||
You can install pdb++ similarly:
|
||||
```
|
||||
$ python3 -m venv .test_pdb
|
||||
$ source .test_pdb/bin/activate
|
||||
(test_pdb)$ pip install pdbp
|
||||
|
||||
```
|
||||
|
||||
pdb++ overrides the pdb module, and therefore you can use the same syntax to add a breakpoint inside a program:
|
||||
```
|
||||
import pdb; pdb.set_trace()
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
Learning how to use the Python debugger saves you time when investigating problems with an application. It can also be useful to understand how a complex part of an application or some libraries work, and thereby improve your Python developer skills.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/getting-started-python-debugger/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://fedoramagazine.org/enhance-python-interactive-shell
|
||||
[2]:https://docs.python.org/3/library/pdb.html
|
||||
[3]:https://github.com/gotcha/ipdb
|
||||
[4]:https://github.com/antocuni/pdb
|
||||
@ -1,198 +0,0 @@
|
||||
translating by Flowsnow
|
||||
A sysadmin's guide to Bash
|
||||
======
|
||||
|
||||

|
||||
|
||||
Each trade has a tool that masters in that trade wield most often. For many sysadmins, that tool is their [shell][1]. On the majority of Linux and other Unix-like systems out there, the default shell is Bash.
|
||||
|
||||
Bash is a fairly old program—it originated in the late 1980s—but it builds on much, much older shells, like the C shell ([csh][2]), which is easily 10 years its senior. Because the concept of a shell is that old, there is an enormous amount of arcane knowledge out there waiting to be consumed to make any sysadmin guy's or gal's life a lot easier.
|
||||
|
||||
Let's take a look at some of the basics.
|
||||
|
||||
Who has, at some point, unintentionally ran a command as root and caused some kind of issue? raises hand
|
||||
|
||||
I'm pretty sure a lot of us have been that guy or gal at one point. Very painful. Here are some very simple tricks to prevent you from hitting that stone a second time.
|
||||
|
||||
### Use aliases
|
||||
|
||||
First, set up aliases for commands like **`mv`** and **`rm`** that point to `mv -I` and `rm -I`. This will make sure that running `rm -f /boot` at least asks you for confirmation. In Red Hat Enterprise Linux, these aliases are set up by default if you use the root account.
|
||||
|
||||
If you want to set those aliases for your normal user account as well, just drop these two lines into a file called .bashrc in your home directory (these will also work with sudo):
|
||||
```
|
||||
alias mv='mv -i'
|
||||
|
||||
alias rm='rm -i'
|
||||
|
||||
```
|
||||
|
||||
### Make your root prompt stand out
|
||||
|
||||
Another thing you can do to prevent mishaps is to make sure you are aware when you are using the root account. I usually do that by making the root prompt stand out really well from the prompt I use for my normal, everyday work.
|
||||
|
||||
If you drop the following into the .bashrc file in root's home directory, you will have a root prompt that is red on black, making it crystal clear that you (or anyone else) should tread carefully.
|
||||
```
|
||||
export PS1="\[$(tput bold)$(tput setab 0)$(tput setaf 1)\]\u@\h:\w # \[$(tput sgr0)\]"
|
||||
|
||||
```
|
||||
|
||||
In fact, you should refrain from logging in as root as much as possible and instead run the majority of your sysadmin commands through sudo, but that's a different story.
|
||||
|
||||
Having implemented a couple of minor tricks to help prevent "unintentional side-effects" of using the root account, let's look at a couple of nice things Bash can help you do in your daily work.
|
||||
|
||||
### Control your history
|
||||
|
||||
You probably know that when you press the Up arrow key in Bash, you can see and reuse all (well, many) of your previous commands. That is because those commands have been saved to a file called .bash_history in your home directory. That history file comes with a bunch of settings and commands that can be very useful.
|
||||
|
||||
First, you can view your entire recent command history by typing **`history`** , or you can limit it to your last 30 commands by typing **`history 30`**. But that's pretty vanilla. You have more control over what Bash saves and how it saves it.
|
||||
|
||||
For example, if you add the following to your .bashrc, any commands that start with a space will not be saved to the history list:
|
||||
```
|
||||
HISTCONTROL=ignorespace
|
||||
|
||||
```
|
||||
|
||||
This can be useful if you need to pass a password to a command in plaintext. (Yes, that is horrible, but it still happens.)
|
||||
|
||||
If you don't want a frequently executed command to show up in your history, use:
|
||||
```
|
||||
HISTCONTROL=ignorespace:erasedups
|
||||
|
||||
```
|
||||
|
||||
With this, every time you use a command, all its previous occurrences are removed from the history file, and only the last invocation is saved to your history list.
|
||||
|
||||
A history setting I particularly like is the **`HISTTIMEFORMAT`** setting. This will prepend all entries in your history file with a timestamp. For example, I use:
|
||||
```
|
||||
HISTTIMEFORMAT="%F %T "
|
||||
|
||||
```
|
||||
|
||||
When I type **`history 5`** , I get nice, complete information, like this:
|
||||
```
|
||||
1009 2018-06-11 22:34:38 cat /etc/hosts
|
||||
|
||||
1010 2018-06-11 22:34:40 echo $foo
|
||||
|
||||
1011 2018-06-11 22:34:42 echo $bar
|
||||
|
||||
1012 2018-06-11 22:34:44 ssh myhost
|
||||
|
||||
1013 2018-06-11 22:34:55 vim .bashrc
|
||||
|
||||
```
|
||||
|
||||
That makes it a lot easier to browse my command history and find the one I used two days ago to set up an SSH tunnel to my home lab (which I forget again, and again, and again…).
|
||||
|
||||
### Best Bash practices
|
||||
|
||||
I'll wrap this up with my top 11 list of the best (or good, at least; I don't claim omniscience) practices when writing Bash scripts.
|
||||
|
||||
11. Bash scripts can become complicated and comments are cheap. If you wonder whether to add a comment, add a comment. If you return after the weekend and have to spend time figuring out what you were trying to do last Friday, you forgot to add a comment.
|
||||
|
||||
|
||||
10. Wrap all your variable names in curly braces, like **`${myvariable}`**. Making this a habit makes things like `${variable}_suffix` possible and improves consistency throughout your scripts.
|
||||
|
||||
|
||||
9. Do not use backticks when evaluating an expression; use the **`$()`** syntax instead. So use:
|
||||
```
|
||||
for file in $(ls); do
|
||||
```
|
||||
|
||||
|
||||
not
|
||||
```
|
||||
for file in `ls`; do
|
||||
|
||||
```
|
||||
|
||||
The former option is nestable, more easily readable, and keeps the general sysadmin population happy. Do not use backticks.
|
||||
|
||||
|
||||
|
||||
8. Consistency is good. Pick one style of doing things and stick with it throughout your script. Obviously, I would prefer if people picked the **`$()`** syntax over backticks and wrapped their variables in curly braces. I would prefer it if people used two or four spaces—not tabs—to indent, but even if you choose to do it wrong, do it wrong consistently.
|
||||
|
||||
|
||||
7. Use the proper shebang for a Bash script. As I'm writing Bash scripts with the intention of only executing them with Bash, I most often use **`#!/usr/bin/bash`** as my shebang. Do not use **`#!/bin/sh`** or **`#!/usr/bin/sh`**. Your script will execute, but it'll run in compatibility mode—potentially with lots of unintended side effects. (Unless, of course, compatibility mode is what you want.)
|
||||
|
||||
|
||||
6. When comparing strings, it's a good idea to quote your variables in if-statements, because if your variable is empty, Bash will throw an error for lines like these:
|
||||
```
|
||||
if [ ${myvar} == "foo" ]; then
|
||||
|
||||
echo "bar"
|
||||
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
And will evaluate to false for a line like this:
|
||||
```
|
||||
if [ "${myvar}" == "foo" ]; then
|
||||
|
||||
echo "bar"
|
||||
|
||||
fi
|
||||
```
|
||||
|
||||
Also, if you are unsure about the contents of a variable (e.g., when you are parsing user input), quote your variables to prevent interpretation of some special characters and make sure the variable is considered a single word, even if it contains whitespace.
|
||||
|
||||
|
||||
|
||||
5. This is a matter of taste, I guess, but I prefer using the double equals sign ( **`==`** ) even when comparing strings in Bash. It's a matter of consistency, and even though—for string comparisons only—a single equals sign will work, my mind immediately goes "single equals is an assignment operator!"
|
||||
|
||||
|
||||
4. Use proper exit codes. Make sure that if your script fails to do something, you present the user with a written failure message (preferably with a way to fix the problem) and send a non-zero exit code:
|
||||
```
|
||||
# we have failed
|
||||
|
||||
echo "Process has failed to complete, you need to manually restart the whatchamacallit"
|
||||
|
||||
exit 1
|
||||
|
||||
```
|
||||
|
||||
This makes it easier to programmatically call your script from yet another script and verify its successful completion.
|
||||
|
||||
|
||||
|
||||
3. Use Bash's built-in mechanisms to provide sane defaults for your variables or throw errors if variables you expect to be defined are not defined:
|
||||
```
|
||||
# this sets the value of $myvar to redhat, and prints 'redhat'
|
||||
|
||||
echo ${myvar:=redhat}
|
||||
|
||||
# this throws an error reading 'The variable myvar is undefined, dear reader' if $myvar is undefined
|
||||
|
||||
${myvar:?The variable myvar is undefined, dear reader}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. Especially if you are writing a large script, and especially if you work on that large script with others, consider using the **`local`** keyword when defining variables inside functions. The **`local`** keyword will create a local variable, that is one that's visible only within that function. This limits the possibility of clashing variables.
|
||||
|
||||
|
||||
1. Every sysadmin must do it sometimes: debug something on a console, either a real one in a data center or a virtual one through a virtualization platform. If you have to debug a script that way, you will thank yourself for remembering this: Do not make the lines in your scripts too long!
|
||||
|
||||
On many systems, the default width of a console is still 80 characters. If you need to debug a script on a console and that script has very long lines, you'll be a sad panda. Besides, a script with shorter lines—the default is still 80 characters—is a lot easier to read and understand in a normal editor, too!
|
||||
|
||||
|
||||
|
||||
|
||||
I truly love Bash. I can spend hours writing about it or exchanging nice tricks with fellow enthusiasts. Make sure you drop your favorites in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/admin-guide-bash
|
||||
|
||||
作者:[Maxim Burgerhout][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/wzzrd
|
||||
[1]:http://www.catb.org/jargon/html/S/shell.html
|
||||
[2]:https://en.wikipedia.org/wiki/C_shell
|
||||
@ -1,138 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Use Pbcopy And Pbpaste Commands On Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Since Linux and Mac OS X are *Nix based systems, many commands would work on both platforms. However, some commands may not available in on both platforms, for example **pbcopy** and **pbpaste**. These commands are exclusively available only on Mac OS X platform. The Pbcopy command will copy the standard input into clipboard. You can then paste the clipboard contents using Pbpaste command wherever you want. Of course, there could be some Linux alternatives to the above commands, for example **Xclip**. The Xclip will do exactly same as Pbcopy. But, the distro-hoppers who switched to Linux from Mac OS would miss this command-pair and still prefer to use them. No worries! This brief tutorial describes how to use Pbcopy and Pbpaste commands on Linux.
|
||||
|
||||
### Install Xclip / Xsel
|
||||
|
||||
Like I already said, Pbcopy and Pbpaste commands are not available in Linux. However, we can replicate the functionality of pbcopy and pbpaste commands using Xclip and/or Xsel commands via shell aliasing. Both Xclip and Xsel packages available in the default repositories of most Linux distributions. Please note that you need not to install both utilities. Just install any one of the above utilities.
|
||||
|
||||
To install them on Arch Linux and its derivatives, run:
|
||||
```
|
||||
$ sudo pacman xclip xsel
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
```
|
||||
$ sudo dnf xclip xsel
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt install xclip xsel
|
||||
|
||||
```
|
||||
|
||||
Once installed, you need create aliases for pbcopy and pbpaste commands. To do so, edit your **~/.bashrc** file:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
If you want to use Xclip, paste the following lines:
|
||||
```
|
||||
alias pbcopy='xclip -selection clipboard'
|
||||
alias pbpaste='xclip -selection clipboard -o'
|
||||
|
||||
```
|
||||
|
||||
If you want to use xsel, paste the following lines in your ~/.bashrc file.
|
||||
```
|
||||
alias pbcopy='xsel --clipboard --input'
|
||||
alias pbpaste='xsel --clipboard --output'
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Next, run the following command to update the changes in ~/.bashrc file.
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
The ZSH users paste the above lines in **~/.zshrc** file.
|
||||
|
||||
### Use Pbcopy And Pbpaste Commands On Linux
|
||||
|
||||
Let us see some examples.
|
||||
|
||||
The pbcopy command will copy the text from stdin into clipboard buffer. For example, have a look at the following example.
|
||||
```
|
||||
$ echo "Welcome To OSTechNix!" | pbcopy
|
||||
|
||||
```
|
||||
|
||||
The above command will copy the text “Welcome To OSTechNix” into clipboard. You can access this content later and paste them anywhere you want using Pbpaste command like below.
|
||||
```
|
||||
$ echo `pbpaste`
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
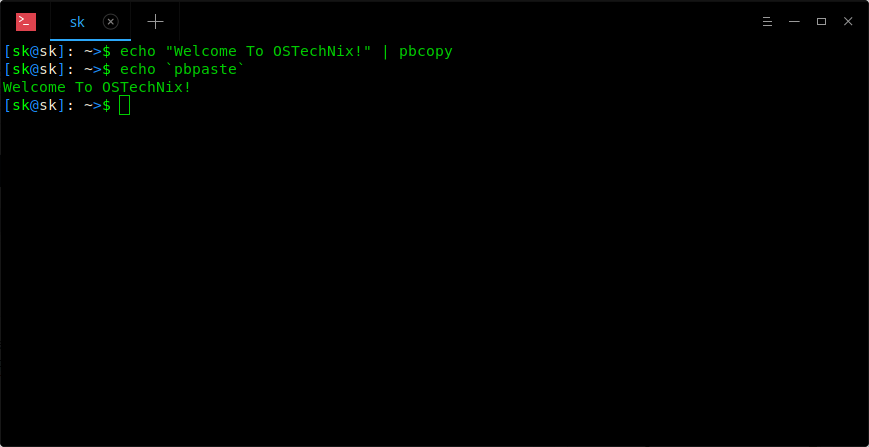
|
||||
|
||||
Here are some other use cases.
|
||||
|
||||
I have a file named **file.txt** with the following contents.
|
||||
```
|
||||
$ cat file.txt
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
You can directly copy the contents of a file into a clipboard as shown below.
|
||||
```
|
||||
$ pbcopy < file.txt
|
||||
|
||||
```
|
||||
|
||||
Now, the contents of the file is available in the clipboard as long as you updated with another file’s contents.
|
||||
|
||||
To retrieve the contents from clipboard, simply type:
|
||||
```
|
||||
$ pbpaste
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
You can also send the output of any Linux command to clip board using pipeline character. Have a look at the following example.
|
||||
```
|
||||
$ ps aux | pbcopy
|
||||
|
||||
```
|
||||
|
||||
Now, type “pbpaste” command at any time to display the output of “ps aux” command from the clipboard.
|
||||
```
|
||||
$ pbpaste
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
There is much more you can do with Pbcopy and Pbpaste commands. I hope you now got a basic idea about these commands.
|
||||
|
||||
And, that’s all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-use-pbcopy-and-pbpaste-commands-on-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,71 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
Getting started with Mu, a Python editor for beginners
|
||||
======
|
||||
|
||||

|
||||
|
||||
Mu is a Python editor for beginning programmers, designed to make the learning experience more pleasant. It gives students the ability to experience success early on, which is important anytime you're learning something new.
|
||||
|
||||
If you have ever tried to teach young people how to program, you will immediately grasp the importance of [Mu][1]. Most programming tools are written by developers for developers and aren't well-suited for beginning programmers, regardless of their age. Mu, however, was written by a teacher for students.
|
||||
|
||||
### Mu's origins
|
||||
|
||||
Mu is the brainchild of [Nicholas Tollervey][2] (who I heard speak at PyCon2018 in May). Nicholas is a classically trained musician who became interested in Python and development early in his career while working as a music teacher. He also wrote [Python in Education][3], a free book you can download from O'Reilly.
|
||||
|
||||
Nicholas was looking for a simpler interface for Python programming. He wanted something without the complexity of other editors—even the IDLE3 editor that comes with Python—so he worked with [Carrie Ann Philbin][4] , director of education at the Raspberry Pi Foundation (which sponsored his work), to develop Mu.
|
||||
|
||||
Mu is an open source application (licensed under [GNU GPLv3][5]) written in Python. It was originally developed to work with the [Micro:bit][6] mini-computer, but feedback and requests from other teachers spurred him to rewrite Mu into a generic Python editor.
|
||||
|
||||
### Inspired by music
|
||||
|
||||
Nicholas' inspiration for Mu came from his approach to teaching music. He wondered what would happen if we taught programming the way we teach music and immediately saw the disconnect. Unlike with programming, we don't have music boot camps and we don't learn to play an instrument from a book on, say, how to play the flute.
|
||||
|
||||
Nicholas says, Mu "aims to be the real thing," because no one can learn Python in 30 minutes. As he developed Mu, he worked with teachers, observed coding clubs, and watched secondary school students as they worked with Python. He found that less is more and keeping things simple improves the finished product's functionality. Mu is only about 3,000 lines of code, Nicholas says.
|
||||
|
||||
### Using Mu
|
||||
|
||||
To try it out, [download][7] Mu and follow the easy installation instructions for [Linux, Windows, and Mac OS][8]. If, like me, you want to [install it on Raspberry Pi][9], enter the following in the terminal:
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install mu
|
||||
|
||||
```
|
||||
|
||||
Launch Mu from the Programming menu. Then you'll have a choice about how you will use Mu.
|
||||
|
||||
|
||||
|
||||
I chose Python 3, which launches an environment to write code; the Python shell is directly below, which allows you to see the code execution.
|
||||
|
||||
|
||||
|
||||
The menu is very simple to use and understand, which achieves Mu's purpose—making coding easy for beginning programmers.
|
||||
|
||||
[Tutorials][10] and other resources are available on the Mu users' website. On the site, you can also see names of some of the [volunteers][11] who helped develop Mu. If you would like to become one of them and [contribute to Mu's development][12], you are most welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://codewith.mu
|
||||
[2]:https://us.pycon.org/2018/speaker/profile/194/
|
||||
[3]:https://www.oreilly.com/programming/free/python-in-education.csp
|
||||
[4]:https://uk.linkedin.com/in/carrie-anne-philbin-a20649b7
|
||||
[5]:https://mu.readthedocs.io/en/latest/license.html
|
||||
[6]:http://microbit.org/
|
||||
[7]:https://codewith.mu/en/download
|
||||
[8]:https://codewith.mu/en/howto/install_with_python
|
||||
[9]:https://codewith.mu/en/howto/install_raspberry_pi
|
||||
[10]:https://codewith.mu/en/tutorials/
|
||||
[11]:https://codewith.mu/en/thanks
|
||||
[12]:https://mu.readthedocs.io/en/latest/contributing.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Switch Between Multiple PHP Versions In Ubuntu
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Automatically Switch To Light / Dark Gtk Themes Based On Sunrise And Sunset Times With AutomaThemely
|
||||
======
|
||||
If you're looking for an easy way of automatically changing the Gtk theme based on sunrise and sunset times, give [AutomaThemely][3] a try.
|
||||
|
||||
@ -0,0 +1,599 @@
|
||||
献给命令行重度用户的一组实用 BASH 脚本
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天,我偶然发现了一组用于命令行重度用户的实用 BASH 脚本,这些脚本被称为 **Bash-Snippets**,它们对于那些整天都与终端打交道的人来说可能会很有帮助。想要查看你居住地的天气情况?它为你做了。想知道股票价格?你可以运行显示股票当前详细信息的脚本。觉得无聊?你可以看一些 YouTube 视频。这些全部在命令行中完成,你无需安装任何严重消耗内存的 GUI 应用程序。
|
||||
|
||||
在撰写本文时,Bash-Snippets 提供以下 19 个实用工具:
|
||||
|
||||
1. **Cheat** – Linux 命令备忘单。
|
||||
2. **Cloudup** – 一个将 GitHub 仓库备份到 bitbucket 的工具。
|
||||
3. **Crypt** – 加解密文件。
|
||||
4. **Cryptocurrency** – 前 10 大加密货币的实时汇率转换。
|
||||
5. **Currency** – 货币转换器。
|
||||
6. **Geo** – 提供 wan、lan、router、dns、mac 和 ip 的详细信息。
|
||||
7. **Lyrics** – 从命令行快速获取给定歌曲的歌词。
|
||||
8. **Meme** – 创造命令行表情包。
|
||||
9. **Movies** – 搜索并显示电影详情。
|
||||
10. **Newton** – 执行数值计算一直到符号数学解析。(to 校正:这里不理解)
|
||||
11. **Qrify** – 将给定的字符串转换为二维码。
|
||||
12. **Short** – 缩短 URL
|
||||
13. **Siteciphers** – 检查给定 https 站点启用或禁用的密码。
|
||||
14. **Stocks** – 提供某些股票的详细信息。
|
||||
15. **Taste** – 推荐引擎提供三个类似的项目,如提供物品(如书籍、音乐、艺术家、电影和游戏等。)
|
||||
16. **Todo** – 命令行待办事项管理。
|
||||
17. **Transfer** – 从命令行快速传输文件。
|
||||
18. **Weather** – 显示你所在地的天气详情。
|
||||
19. **Youtube-Viewer** – 从终端观看 YouTube 视频。
|
||||
|
||||
作者可能会在将来添加更多实用程序和/或功能,因此我建议你密切关注该项目的网站或 GitHub 页面以供将来更新。
|
||||
|
||||
### Bash-Snippets – 一组实用 BASH 脚本献给命令行重度用户
|
||||
|
||||
#### 安装
|
||||
|
||||
你可以在任何支持 BASH 的操作系统上安装这些脚本。
|
||||
|
||||
首先,克隆 git 仓库,使用以下命令:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
进入目录:
|
||||
```
|
||||
$ cd Bash-Snippets/
|
||||
|
||||
```
|
||||
|
||||
切换到最新的稳定版本:
|
||||
```
|
||||
$ git checkout v1.22.0
|
||||
|
||||
```
|
||||
|
||||
最后,使用以下命令安装 Bash-Snippets:
|
||||
```
|
||||
$ sudo ./install.sh
|
||||
|
||||
```
|
||||
|
||||
这将询问你要安装哪些脚本。只需输入**Y** 并按 ENTER 键即可安装相应的脚本。如果你不想安装某些特定脚本,输入 **N** 并按 Enter 键。
|
||||
```
|
||||
Do you wish to install currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
要安装所有脚本,运行:
|
||||
```
|
||||
$ sudo ./install.sh all
|
||||
|
||||
```
|
||||
|
||||
要安装特定的脚本,比如 currency,运行:
|
||||
```
|
||||
$ sudo ./install.sh currency
|
||||
|
||||
```
|
||||
|
||||
你也可以使用 [**Linuxbrew**][1] 包管理器来安装它。
|
||||
|
||||
安装所有的工具,运行:
|
||||
```
|
||||
$ brew install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
安装特定的工具:
|
||||
```
|
||||
$ brew install bash-snippets --without-all-tools --with-newton --with-weather
|
||||
|
||||
```
|
||||
|
||||
另外,对于那些基于 Debian 系统的,例如 Ubuntu, Linux Mint,可以添加 PPA 源:
|
||||
```
|
||||
$ sudo add-apt-repository ppa:navanchauhan/bash-snippets
|
||||
$ sudo apt update
|
||||
$ sudo apt install bash-snippets
|
||||
|
||||
```
|
||||
|
||||
#### 用法
|
||||
|
||||
**需要网络连接**才能使用这些工具。用法很简单。让我们来看看如何使用其中的一些脚本,我假设你已经安装了所有脚本。
|
||||
|
||||
**1\. Currency – 货币转换器**
|
||||
|
||||
这个脚本根据实时汇率转换货币。输入当前货币代码和要交换的货币,以及交换的金额,如下所示:
|
||||
```
|
||||
$ currency
|
||||
What is the base currency: INR
|
||||
What currency to exchange to: USD
|
||||
What is the amount being exchanged: 10
|
||||
|
||||
=========================
|
||||
| INR to USD
|
||||
| Rate: 0.015495
|
||||
| INR: 10
|
||||
| USD: .154950
|
||||
=========================
|
||||
|
||||
```
|
||||
|
||||
你也可以在单条命令中传递所有参数,如下所示:
|
||||
```
|
||||
$ currency INR USD 10
|
||||
|
||||
```
|
||||
|
||||
参考以下屏幕截图:
|
||||
|
||||
[![Bash-Snippets][2]][3]
|
||||
|
||||
**2\. Stocks – 显示股票价格详细信息**
|
||||
|
||||
如果你想查看一只股票价格的详细信息,输入股票即可,如下所示:
|
||||
```
|
||||
$ stocks Intel
|
||||
|
||||
INTC stock info
|
||||
=============================================
|
||||
| Exchange Name: NASDAQ
|
||||
| Latest Price: 34.2500
|
||||
| Close (Previous Trading Day): 34.2500
|
||||
| Price Change: 0.0000
|
||||
| Price Change Percentage: 0.00%
|
||||
| Last Updated: Jul 12, 4:00PM EDT
|
||||
=============================================
|
||||
|
||||
```
|
||||
|
||||
上面输出了 **Intel 股票** 的详情。
|
||||
|
||||
**3\. Weather – 显示天气详细信息**
|
||||
|
||||
让我们查看以下天气详细信息,运行以下命令:
|
||||
```
|
||||
$ weather
|
||||
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
![][4]
|
||||
|
||||
正如你在上面屏幕截图中看到的那样,它提供了 3 天的天气预报。不使用任何参数的话,它将根据你的 IP 地址显示天气详细信息。你还可以显示特定城市或国家/地区的天气详情,如下所示:
|
||||
```
|
||||
$ weather Chennai
|
||||
|
||||
```
|
||||
|
||||
同样,你可以查看输入以下命令来从查看月相(月亮的形态):
|
||||
```
|
||||
$ weather moon
|
||||
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][5]
|
||||
|
||||
**4\. Crypt – 加解密文件**
|
||||
|
||||
此脚本对 openssl 做了一层包装,允许你快速轻松地加密和解密文件。
|
||||
|
||||
要加密文件,使用以下命令:
|
||||
```
|
||||
$ crypt -e [original file] [encrypted file]
|
||||
|
||||
```
|
||||
|
||||
例如,以下命令将加密 **ostechnix.txt**,并将其保存在当前工作目录下,名为 **encrypt_ostechnix.txt**。
|
||||
```
|
||||
$ crypt -e ostechnix.txt encrypt_ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
输入两次文件密码:
|
||||
```
|
||||
Encrypting ostechnix.txt...
|
||||
enter aes-256-cbc encryption password:
|
||||
Verifying - enter aes-256-cbc encryption password:
|
||||
Successfully encrypted
|
||||
|
||||
```
|
||||
|
||||
上面命令将使用 **AES 256 位密钥**加密给定文件。密码不会以纯文本格式保存。你可以加密 .pdf, .txt, .docx, .doc, .png, .jpeg 类型的文件。
|
||||
|
||||
要解密文件,使用以下命令:
|
||||
```
|
||||
$ crypt -d [encrypted file] [output file]
|
||||
|
||||
```
|
||||
|
||||
例如:
|
||||
```
|
||||
$ crypt -d encrypt_ostechnix.txt ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
输入密码解密:
|
||||
```
|
||||
Decrypting encrypt_ostechnix.txt...
|
||||
enter aes-256-cbc decryption password:
|
||||
Successfully decrypted
|
||||
|
||||
```
|
||||
|
||||
**5\. Movies – 查看电影详情**
|
||||
|
||||
使用这个脚本,你可以查看电影详情。
|
||||
|
||||
以下命令显示了一部名为 “mother” 的电影的详情:
|
||||
```
|
||||
$ movies mother
|
||||
|
||||
==================================================
|
||||
| Title: Mother
|
||||
| Year: 2009
|
||||
| Tomato: 95%
|
||||
| Rated: R
|
||||
| Genre: Crime, Drama, Mystery
|
||||
| Director: Bong Joon Ho
|
||||
| Actors: Hye-ja Kim, Bin Won, Goo Jin, Je-mun Yun
|
||||
| Plot: A mother desperately searches for the killer who framed her son for a girl's horrific murder.
|
||||
==================================================
|
||||
|
||||
```
|
||||
|
||||
**6\. 显示类似条目**
|
||||
|
||||
要使用这个脚本,你需要从**[这里][6]** 获取 API 密钥。不过不用担心,它完全是免费的。一旦你获得 API 密钥后,将以下行添加到 **~/.bash_profile**:**export TASTE_API_KEY=”你的 API 密钥放在这里”**
|
||||
|
||||
现在你可以查看类似的项目,如提供的项目,如下所示:(to 校正者:不理解这个脚本的意思肿么办)
|
||||
```
|
||||
$ taste -i Red Hot Chilli Peppers
|
||||
|
||||
```
|
||||
|
||||
**7\. Short – 缩短 URL**
|
||||
|
||||
这个脚本会缩短给定的 URL。
|
||||
```
|
||||
$ short <URL>
|
||||
|
||||
```
|
||||
|
||||
**8\. Geo – 显示网络的详情**
|
||||
|
||||
|
||||
这个脚本会帮助你查找网络的详细信息,例如 wan, lan, router, dns, mac 和 ip 地址。
|
||||
|
||||
例如,要查找你的局域网 ip,运行:
|
||||
```
|
||||
$ geo -l
|
||||
|
||||
```
|
||||
|
||||
我系统上的输出:
|
||||
```
|
||||
192.168.43.192
|
||||
|
||||
```
|
||||
|
||||
查看广域网 ip:
|
||||
```
|
||||
$ geo -w
|
||||
|
||||
```
|
||||
|
||||
在终端中输入 `geo` 来查看更多详细信息。
|
||||
```
|
||||
$ geo
|
||||
Geo
|
||||
Description: Provides quick access for wan, lan, router, dns, mac, and ip geolocation data
|
||||
Usage: geo [flag]
|
||||
-w Returns WAN IP
|
||||
-l Returns LAN IP(s)
|
||||
-r Returns Router IP
|
||||
-d Returns DNS Nameserver
|
||||
-m Returns MAC address for interface. Ex. eth0
|
||||
-g Returns Current IP Geodata
|
||||
Examples:
|
||||
geo -g
|
||||
geo -wlrdgm eth0
|
||||
Custom Geo Output =>
|
||||
[all] [query] [city] [region] [country] [zip] [isp]
|
||||
Example: geo -a 8.8.8.8 -o city,zip,isp
|
||||
-o [options] Returns Specific Geodata
|
||||
-a [address] For specific ip in -s
|
||||
-v Returns Version
|
||||
-h Returns Help Screen
|
||||
-u Updates Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
**9\. Cheat – 显示 Linux 命令的备忘单**
|
||||
|
||||
想参考 Linux 命令的备忘单吗?这是可能的。以下命令将显示 **curl** 命令的备忘单:
|
||||
```
|
||||
$ cheat curl
|
||||
|
||||
```
|
||||
|
||||
只需用你选择的命令替换 **curl** 即可显示其备忘单。这对于快速参考你要使用的任何命令非常有用。
|
||||
|
||||
**10\. Youtube-Viewer – 观看 YouTube 视频**
|
||||
|
||||
使用此脚本,你可以直接在终端上搜索或观看 YouTube 视频。
|
||||
|
||||
让我们来看一些有关 **Ed Sheeran** 的视频。
|
||||
```
|
||||
$ ytview Ed Sheeran
|
||||
|
||||
```
|
||||
|
||||
从列表中选择要播放的视频。所选内容将在你的默认媒体播放器中播放。
|
||||
|
||||
![][7]
|
||||
|
||||
要查看艺术家的近期视频,你可以使用:
|
||||
```
|
||||
$ ytview -c [channel name]
|
||||
|
||||
```
|
||||
|
||||
要寻找视频,只需输入:
|
||||
```
|
||||
$ ytview -s [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
或者:
|
||||
```
|
||||
$ ytview [videoToSearch]
|
||||
|
||||
```
|
||||
|
||||
**11\. cloudup – 备份p GitHub 仓库到 bitbucket**
|
||||
|
||||
你在 GitHub 上托管过任何项目吗?如果托管过,那么你可以随时间 GitHub 仓库备份到 **bitbucket**,它是一种用于源代码和开发项目的基于 Web 的托管服务。
|
||||
|
||||
你可以使用 **-a** 选项一次性备份指定用户的所有 GitHub 仓库,或者不使用它来备份单个仓库。
|
||||
|
||||
要备份 GitHub 仓库,运行:
|
||||
```
|
||||
$ cloudup
|
||||
|
||||
```
|
||||
|
||||
系统将要求你输入 GitHub 用户名, 要备份的仓库名称以及 bitbucket 用户名和密码等。
|
||||
|
||||
**12\. Qrify – 将字符串转换为二维码**
|
||||
|
||||
这个脚本将任何给定的文本字符串转换为二维码。这对于发送链接或者保存一串命令到手机非常有用。
|
||||
```
|
||||
$ qrify convert this text into qr code
|
||||
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][8]
|
||||
|
||||
很酷,不是吗?
|
||||
|
||||
**13\. Cryptocurrency**
|
||||
|
||||
它将显示十大加密货币实时汇率。
|
||||
|
||||
输入以下命令,然后单击 ENTER 来运行:
|
||||
```
|
||||
$ cryptocurrency
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
|
||||
**14\. Lyrics**
|
||||
|
||||
这个脚本从命令行快速获取一首歌曲的歌词。
|
||||
|
||||
例如,我将获取 **“who is it”** 歌曲的歌词,这是一首由 **Michael Jackson(迈克尔·杰克逊)** 演唱的流行歌曲。
|
||||
```
|
||||
$ lyrics -a michael jackson -s who is it
|
||||
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
**15\. Meme**
|
||||
这个脚本允许你从命令行创建简单的表情包。它比基于 GUI 的表情包生成器快得多。
|
||||
|
||||
要创建一个表情包,只需输入:
|
||||
```
|
||||
$ meme -f mymeme
|
||||
Enter the name for the meme's background (Ex. buzz, doge, blb ): buzz
|
||||
Enter the text for the first line: THIS IS A
|
||||
Enter the text for the second line: MEME
|
||||
|
||||
```
|
||||
|
||||
这将在你当前的工作目录创建 jpg 文件。
|
||||
|
||||
**16\. Newton**
|
||||
|
||||
厌倦了解决复杂的数学问题?你来对了。Newton 脚本将执行数值计算,直到符号数学解析。(to 校正者:这里不太理解)
|
||||
|
||||
![][11]
|
||||
|
||||
**17\. Siteciphers**
|
||||
|
||||
这个脚本可以帮助你检查在给定的 https 站点上启用/禁用哪些密码。
|
||||
```
|
||||
$ siteciphers google.com
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
**18\. Todo**
|
||||
|
||||
它允许你直接从终端创建日常任务。
|
||||
|
||||
让我们来创建一些任务。
|
||||
```
|
||||
$ todo -a The first task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
要添加其它任务,只需添加任务名称重新运行上述命令即可。
|
||||
```
|
||||
$ todo -a The second task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). The second task Tue Jun 26 14:52:29 IST 2018
|
||||
|
||||
```
|
||||
|
||||
要查看任务列表,运行:
|
||||
```
|
||||
$ todo -g
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). A The second task Tue Jun 26 14:51:46 IST 2018
|
||||
|
||||
```
|
||||
|
||||
一旦你完成了任务,就可以将其从列表中删除,如下所示:
|
||||
```
|
||||
$ todo -r 2
|
||||
Sucessfully removed task number 2
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
|
||||
```
|
||||
|
||||
要清除所有任务,运行:
|
||||
```
|
||||
$ todo -c
|
||||
Tasks cleared.
|
||||
|
||||
```
|
||||
|
||||
**19\. Transfer**
|
||||
|
||||
Transfer 脚本允许你通过 Internet 快速轻松地传输文件和目录。
|
||||
|
||||
让我们上传一个文件:
|
||||
```
|
||||
$ transfer test.txt
|
||||
Uploading test.txt
|
||||
################################################################################################################################################ 100.0%
|
||||
Success!
|
||||
Transfer Download Command: transfer -d desiredOutputDirectory ivmfj test.txt
|
||||
Transfer File URL: https://transfer.sh/ivmfj/test.txt
|
||||
|
||||
```
|
||||
|
||||
该文件将上传到 transfer.sh 站点。Transfer.sh 允许你一次上传最大 **10 GB** 的文件。所有共享文件在 **14 天**后自动过期。如你所见,任何人都可以通过 Web 浏览器访问 URL 或使用 transfer 目录来下载文件,当然,transfer 必须安装在他/她的系统中。
|
||||
|
||||
现在从你的系统中移除文件。
|
||||
```
|
||||
$ rm -fr test.txt
|
||||
|
||||
```
|
||||
|
||||
现在,你可以随时(14 天内)从 transfer.sh 站点下载该文件,如下所示:
|
||||
```
|
||||
$ transfer -d Downloads ivmfj test.txt
|
||||
|
||||
```
|
||||
|
||||
获取关于此实用脚本的更多详情,参考以下指南。
|
||||
* [从命令行在 Internet 上共享文件的一个简单快捷方法](https://www.ostechnix.com/easy-fast-way-share-files-internet-command-line/)
|
||||
|
||||
##### 获得帮助
|
||||
|
||||
如果你不知道如何使用特定脚本,只需输入该脚本的名称,然后按下 ENTER 键,你将会看到使用细节。以下示例显示 **Qrify** 脚本的帮助信息。
|
||||
```
|
||||
$ qrify
|
||||
Qrify
|
||||
Usage: qrify [stringtoturnintoqrcode]
|
||||
Description: Converts strings or urls into a qr code.
|
||||
-u Update Bash-Snippet Tools
|
||||
-m Enable multiline support (feature not working yet)
|
||||
-h Show the help
|
||||
-v Get the tool version
|
||||
Examples:
|
||||
qrify this is a test string
|
||||
qrify -m two\\nlines
|
||||
qrify github.com # notice no http:// or https:// this will fail
|
||||
|
||||
```
|
||||
|
||||
#### 更新脚本
|
||||
|
||||
你可以随时使用 -u 选项更新已安装的工具。以下命令更新 “weather” 工具。
|
||||
```
|
||||
$ weather -u
|
||||
|
||||
```
|
||||
|
||||
#### 卸载
|
||||
|
||||
你可以使用以下命令来卸载这些工具。
|
||||
|
||||
克隆仓库:
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
进入 Bash-Snippets 目录:
|
||||
```
|
||||
$ cd Bash-Snippets
|
||||
|
||||
```
|
||||
|
||||
运行以下命令来卸载脚本:
|
||||
```
|
||||
$ sudo ./uninstall.sh
|
||||
|
||||
```
|
||||
|
||||
输入 **y**,并按下 ENTER 键来移除每个脚本。
|
||||
```
|
||||
Do you wish to uninstall currency [Y/n]: y
|
||||
|
||||
```
|
||||
|
||||
**另请阅读:**
|
||||
|
||||
好了,这就是全部了。我必须承认,在测试这些脚本时我印象很深刻。我真的很喜欢将所有有用的脚本组合到一个包中的想法。感谢开发者。试一试,你不会失望的。
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/collection-useful-bash-scripts-heavy-commandline-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_001.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_002-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_003.png
|
||||
[6]:https://tastedive.com/account/api_access
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/07/ytview-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_005.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/07/cryptocurrency.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/07/lyrics.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/07/newton.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/07/siteciphers.png
|
||||
@ -0,0 +1,149 @@
|
||||
Arch Linux 应用自动安装脚本
|
||||
======
|
||||
|
||||

|
||||
|
||||
Arch 用户你们好!今天,我偶然发现了一个叫做“**ArchI0**”的实用工具,它是基于命令行菜单的 Arch Linux 应用自动安装脚本。使用此脚本是安装基于 Arch 的发行版所有必要应用最简易的方式。请注意**此脚本仅适用于菜鸟级使用者**。中高级使用者可以轻松掌握[**如何使用 pacman **][1]来完成这件事。如果你想学习如何使用 Arch Linux,我建议你一个个手动安装所有的软件。对那些仍是菜鸟并且希望为自己基于 Arch 的系统快速安装所有必要应用的用户,可以使用此脚本。
|
||||
|
||||
### ArchI0 – Arch Linux 应用自动安装脚本
|
||||
|
||||
此脚本的开发者已经制作了 **ArchI0live** 和 **ArchI0** 两个脚本。你可以通过 ArchI0live 测试,无需安装。这可能有助于在将脚本安装到系统之前了解其实际内容。
|
||||
|
||||
### 安装 ArchI0
|
||||
|
||||
要安装此脚本,使用如下命令通过 Git 克隆 ArchI0 脚本仓库:
|
||||
```
|
||||
$ git clone https://github.com/SifoHamlaoui/ArchI0.git
|
||||
|
||||
```
|
||||
|
||||
上面的命令会克隆 ArchI0 的 Github 仓库内容,在你当前目录的一个名为 ArchI0 的文件夹里。使用如下命令进入此目录:
|
||||
```
|
||||
$ cd ArchI0/
|
||||
|
||||
```
|
||||
|
||||
使用如下命令赋予脚本可执行权限:
|
||||
```
|
||||
$ chmod +x ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
使用如下命令执行脚本:
|
||||
```
|
||||
$ sudo ./ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
此脚本需要以 root 或 sudo 用户身份执行,因为安装应用需要 root 权限。
|
||||
|
||||
> **注意:** 有些人想知道此脚本中所有命令的开头部分,第一个命令是下载 **figlet**,因为此脚本的 logo 是使用 figlet 显示的。第二个命令是安装用来打开并查看许可协议文件的 **Leafpad**。第三个命令是安装从 sourceforge 下载文件的 **wget**。第四和第五个命令是下载许可协议文件并用 leafpad 打开。此外,最后的第6条命令是在阅读许可协议文件之后关闭它。
|
||||
|
||||
输入你的 Arch Linux 系统架构然后按回车键。当其请求安装此脚本时,键入 y 然后按回车键。
|
||||
|
||||
![][3]
|
||||
|
||||
一旦开始安装,将会重定向至主菜单。
|
||||
|
||||
![][4]
|
||||
|
||||
正如前面的截图, ArchI0 有13个目录,包含90个容易安装的程序。这90个程序刚好足够配置一个完整的 Arch Linux 桌面,可执行日常活动。键入 **a** 可查看关于此脚本的信息,键入 **q** 可退出此脚本。
|
||||
|
||||
安装后无需执行 ArchI0live 脚本。可以直接使用如下命令启动:
|
||||
```
|
||||
$ sudo ArchI0
|
||||
|
||||
```
|
||||
|
||||
它会每次询问你选择 Arch Linux 发行版的架构。
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
Preparing To Run Script
|
||||
Checking For ROOT: PASSED
|
||||
What Is Your OS Architecture? {32/64} 64
|
||||
|
||||
```
|
||||
|
||||
从现在开始,你可以从主菜单列出的类别选择要安装的程序。要查看特定类别下的可用程序列表,输入类别号即可。举个例子,要查看**文本编辑器**分类下的可用程序列表,输入 **1** 然后按回车键。
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ R00T MENU ]
|
||||
Make A Choice
|
||||
1) Text Editors
|
||||
2) FTP/Torrent Applications
|
||||
3) Download Managers
|
||||
4) Network managers
|
||||
5) VPN clients
|
||||
6) Chat Applications
|
||||
7) Image Editors
|
||||
8) Video editors/Record
|
||||
9) Archive Handlers
|
||||
10) Audio Applications
|
||||
11) Other Applications
|
||||
12) Development Environments
|
||||
13) Browser/Web Plugins
|
||||
14) Dotfiles
|
||||
15) Usefull Links
|
||||
------------------------
|
||||
a) About ArchI0 Script
|
||||
q) Leave ArchI0 Script
|
||||
|
||||
Choose An Option: 1
|
||||
|
||||
```
|
||||
|
||||
接下来,选择你想安装的程序。要返回至主菜单,输入 **q** 然后按回车键。
|
||||
|
||||
我想安装 Emacs,所以我输入 **3**。
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ TEXT EDITORS ]
|
||||
[ Option ] [ Description ]
|
||||
1) GEdit
|
||||
2) Geany
|
||||
3) Emacs
|
||||
4) VIM
|
||||
5) Kate
|
||||
---------------------------
|
||||
q) Return To Main Menu
|
||||
|
||||
Choose An Option: 3
|
||||
|
||||
```
|
||||
|
||||
现在,Emacs 将会安装至你的 Arch Linux 系统。
|
||||
|
||||
![][5]
|
||||
|
||||
所选择的应用安装完成后,你可以按回车键返回主菜单。
|
||||
|
||||
### 结论
|
||||
|
||||
毫无疑问,此脚本让 Arch Linux 用户使用起来更加容易,特别是刚开始使用的人。如果你正寻找快速简单无需 pacman 的安装应用的方法,此脚本是一个不错的选择。试用一下并在下面的评论区让我们知道你对此脚本的看法。
|
||||
|
||||
就这些。希望这个工具能帮到你。我们每天都会推送实用的指南。如果你觉得我们的指南挺实用,请分享至你的社交网络,专业圈子并支持 OSTechNix。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/archi0-arch-linux-applications-automatic-installation-script/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://www.ostechnix.com/getting-started-pacman/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_003.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_004-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/pacman-as-superuser_005.png
|
||||
@ -0,0 +1,488 @@
|
||||
# 理解指标和使用 Python 去监视
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
## 获取订阅
|
||||
|
||||
加入我们吧,我们有 85,000 位开源支持者,加入后会定期接收到我们免费提供的提示和文章摘要。
|
||||
|
||||
当我第一次看到术语“计数器”和“计量器”和使用颜色及标记着“意思”和“最大 90”的数字图表时,我的反应之一是逃避。就像我看到它们一样,我并不感兴趣,因为我不理解它们是干什么的或如何去使用。因为我的工作不需要我去注意它们,它们被我完全无视。
|
||||
|
||||
这都是在两年以前的事了。随着我的职业发展,我希望去了解更多关于我们的网络应用程序的知识,而那个时候就是我开始去学习指标的时候。
|
||||
|
||||
我的理解监视的学习之旅共有三个阶段(到目前为止),它们是:
|
||||
|
||||
* 阶段 1:什么?(看别处)
|
||||
* 阶段 2:没有指标,我们真的是瞎撞。
|
||||
* 阶段 3:出现不合理的指标我们该如何做?
|
||||
|
||||
我现在处于阶段 2,我将分享到目前为止我学到了些什么。我正在向阶段 3 进发,在本文结束的位置我提供了一些我正在使用的学习资源。
|
||||
|
||||
我们开始吧!
|
||||
|
||||
## 需要的软件
|
||||
|
||||
更多关于 Python 的资源
|
||||
|
||||
* [Python 是什么?][1]
|
||||
* [Python IDE 排行榜][2]
|
||||
* [Python GUI 框架排行榜][3]
|
||||
* [最新的 Python 主题][4]
|
||||
* [更多开发者资源][5]
|
||||
|
||||
在文章中讨论时用到的 demo 都可以在 [我的 GitHub 仓库][6] 中找到。你需要安装 docker 和 docker-compose 才能使用它们。
|
||||
|
||||
## 为什么要监视?
|
||||
|
||||
关于监视的主要原因是:
|
||||
|
||||
* 理解 _正常的_ 和 _不正常的_ 系统和服务的特征
|
||||
* 做容量规划、弹性伸缩
|
||||
* 有助于排错
|
||||
* 了解软件/硬件改变的效果
|
||||
* 测量响应中的系统行为变化
|
||||
* 当系统出现意外行为时发出警报
|
||||
|
||||
## 指标和指标类型
|
||||
|
||||
从我们的用途来看,一个**指标**就是在一个给定时间点上的某些数量的 _测量_ 值。博客文章的总点击次数、参与讨论的总人数、在缓存系统中数据没有被找到的次数、你的网站上的已登录用户数 —— 这些都是指标的例子。
|
||||
|
||||
它们总体上可以分为三类:
|
||||
|
||||
### 计数器
|
||||
|
||||
以你的个人博客为例。你发布一篇文章后,过一段时间后,你希望去了解有多少点击量,数字只会增加。这就是一个**计数器**指标。在你的博客文章的生命周期中,它的值从 0 开始增加。用图表来表示,一个计数器看起来应该像下面的这样:
|
||||
|
||||

|
||||
|
||||
一个计数器指标总是在增加的。
|
||||
|
||||
### 计量器
|
||||
|
||||
如果你想去跟踪你的博客每天或每周的点击量,而不是基于时间的总点击量。这种指标被称为一个**计量器**,它的值可上可下。用图表来表示,一个计量器看起来应该像下面的样子:
|
||||
|
||||

|
||||
|
||||
一个计量器指标可以增加或减少。
|
||||
|
||||
一个计量器的值在某些时间窗口内通常有一个_最大值_ 和 _最小值_ 。
|
||||
|
||||
### 柱状图和计时器
|
||||
|
||||
一个**柱状图**(在 Prometheus 中这么叫它)或一个**计时器**(在 StatsD 中这么叫它)是跟踪已采样的_观测结果_ 的指标。不像一个计数器类或计量器类指标,柱状图指标的值并不是显示为上或下的样式。我知道这可能并没有太多的意义,并且可能和一个计量器图看上去没有什么不同。它们的这同之处在于,你期望使用柱状图数据来做什么,而不是与一个计量器图做比较。因此,监视系统需要知道那个指标是一个柱状图类型,它允许你去做哪些事情。
|
||||
|
||||

|
||||
|
||||
一个柱状图指标可以增加或减少。
|
||||
|
||||
## Demo 1:计算和报告指标
|
||||
|
||||
[Demo 1][7] 是使用 [Flask][8] 框架写的一个基本的 web 应用程序。它演示了我们如何去 _计算_ 和 _报告_ 指标。
|
||||
|
||||
在 src 目录中有 `app.py` 和 `src/helpers/middleware.py` 应用程序,包含以下内容:
|
||||
|
||||
```
|
||||
from flask import request
|
||||
import csv
|
||||
import time
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([str(int(time.time())), str(resp_time)])
|
||||
|
||||
return response
|
||||
|
||||
|
||||
def setup_metrics(app):
|
||||
app.before_request(start_timer)
|
||||
app.after_request(stop_timer)
|
||||
```
|
||||
|
||||
当在应用程序中调用 `setup_metrics()` 时,它在请求处理之前被配置为调用 `start_timer()` 函数,然后在请求处理之后、响应发送之前调用 `stop_timer()` 函数。在上面的函数中,我们写了时间戳并用它来计算处理请求所花费的时间。
|
||||
|
||||
当我们在 demo1 目录中的 docker-compose 上开始去启动 web 应用程序,然后在一个客户端容器中生成一些对 web 应用程序的请求。你将会看到创建了一个 `src/metrics.csv` 文件,它有两个字段:timestamp 和 request_latency。
|
||||
|
||||
通过查看这个文件,我们可以推断出两件事情:
|
||||
|
||||
* 生成了很多数据
|
||||
* 没有观测到任何与指标相关的特征
|
||||
|
||||
没有观测到与指标相关的特征,我们就不能说这个指标与哪个 HTTP 端点有关联,或这个指标是由哪个应用程序的节点所生成的。因此,我们需要使用合适的元数据去限定每个观测指标。
|
||||
|
||||
## Statistics 101~~(译者注:这是一本统计学入门教材的名字)~~
|
||||
|
||||
假如我们回到高中数学,我们应该回忆起一些统计术语,虽然不太确定,但应该包括平均数、中位数、百分位、和柱状图。我们来简要地回顾一下它们,不用去管他们的用法,就像是在上高中一样。
|
||||
|
||||
### 平均数
|
||||
|
||||
**平均数**,或一系列数字的平均值,是将数字汇总然后除以列表的个数。3、2、和 10 的平均数是 (3+2+10)/3 = 5。
|
||||
|
||||
### 中位数
|
||||
|
||||
**中位数**是另一种类型的平均,但它的计算方式不同;它是列表从小到大排序(反之亦然)后取列表的中间数字。以我们上面的列表中(2、3、10),中位数是 3。计算并不简单,它取决于列表中数字的个数。
|
||||
|
||||
### 百分位
|
||||
|
||||
**百分位**是指那个百(千)分比数字低于我们给定的百分数的程度。在一些场景中,百分位是指这个测量值低于我们数据的百(千)分比数字的程度。比如,上面列表中 95% 是 9.29999。百分位的测量范围是 0 到 100(不包括)。0% 是一组数字的最小分数。你可能会想到它的中位数是 50%,它的结果是 3。
|
||||
|
||||
一些监视系统将百分位称为 `upper_X`,其中 _X_ 就是百分位;`_upper 90_` 指的是值在 90%的位置。
|
||||
|
||||
### 分位数
|
||||
|
||||
**q-Quantile** 是将有 _N_ 个数的集合等分为 q_N_ 个集合。**q** 的取值范围为 0 到 1(全部都包括)。当 **q** 取值为 0.5 时,值就是中位数。分位数和百分位数的关系是,分位数值 **q** 等于 **100_q_** 百分位值。
|
||||
|
||||
### 柱状图
|
||||
|
||||
**柱状图**这个指标,我们早期学习过,它是监视系统中一个_详细的实现_。在统计学中,一个柱状图是一个将数据分组为 _桶_ 的图表。我们来考虑一个人为的、不同的示例:阅读你的博客的人的年龄。如果你有一些这样的数据,并想将它进行大致的分组,绘制成的柱状图将看起来像下面的这样:
|
||||
|
||||

|
||||
|
||||
### 累积柱状图
|
||||
|
||||
一个**累积柱状图**也是一个柱状图,它的每个桶的数包含前一个桶的数,因此命名为_累积_。将上面的数据集做成累积柱状图后,看起来应该是这样的:
|
||||
|
||||

|
||||
|
||||
### 我们为什么需要做统计?
|
||||
|
||||
在上面的 Demo 1 中,我们注意到在我们报告指标时,这里生成了许多数据。当我们将它用于指标时我们需要做统计,因为它们实在是太多了。我们需要的是整体行为,我们没法去处理单个值。我们预期展现出来的值的行为应该是代表我们观察的系统的行为。
|
||||
|
||||
## Demo 2:指标上增加特征
|
||||
|
||||
在我们上面的的 Demo 1 应用程序中,当我们计算和报告一个请求的延迟时,它指向了一个由一些_特征_ 唯一标识的特定请求。下面是其中一些:
|
||||
|
||||
* HTTP 端点
|
||||
* HTTP 方法
|
||||
* 运行它的主机/节点的标识符
|
||||
|
||||
如果我们将这些特征附加到要观察的指标上,每个指标将有更多的内容。我们来解释一下 [Demo 2][9] 中添加到我们的指标上的特征。
|
||||
|
||||
在写入指标时,src/helpers/middleware.py 文件将在 CSV 文件中写入多个列:
|
||||
|
||||
```
|
||||
node_ids = ['10.0.1.1', '10.1.3.4']
|
||||
|
||||
|
||||
def start_timer():
|
||||
request.start_time = time.time()
|
||||
|
||||
|
||||
def stop_timer(response):
|
||||
# convert this into milliseconds for statsd
|
||||
resp_time = (time.time() - request.start_time)*1000
|
||||
node_id = node_ids[random.choice(range(len(node_ids)))]
|
||||
with open('metrics.csv', 'a', newline='') as f:
|
||||
csvwriter = csv.writer(f)
|
||||
csvwriter.writerow([
|
||||
str(int(time.time())), 'webapp1', node_id,
|
||||
request.endpoint, request.method, str(response.status_code),
|
||||
str(resp_time)
|
||||
])
|
||||
|
||||
return response
|
||||
```
|
||||
|
||||
因为这只是一个演示,在报告指标时,我们将随意的报告一些随机 IP 作为节点的 ID。当我们在 demo2 目录下运行 docker-compose 时,我们的结果将是一个有多个列的 CSV 文件。
|
||||
|
||||
### 用 pandas 分析指标
|
||||
|
||||
我们将使用 [pandas][10] 去分析这个 CSV 文件。运行中的 docker-compose 将打印出一个 URL,我们将使用它来打开一个 [Jupyter][11] 会话。一旦我们上传 `Analysis.ipynb notebook` 到会话中,我们就可以将 CSV 文件读入到一个 pandas 数据帧中:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
metrics = pd.read_csv('/data/metrics.csv', index_col=0)
|
||||
```
|
||||
|
||||
index_col 指定时间戳作为索引。
|
||||
|
||||
因为每个特征我们都在数据帧中添加一个列,因此我们可以基于这些列进行分组和聚合:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
metrics.groupby(['node_id', 'http_status']).latency.aggregate(np.percentile, 99.999)
|
||||
```
|
||||
|
||||
更多内容请参考 Jupyter notebook 在数据上的分析示例。
|
||||
|
||||
## 我应该监视什么?
|
||||
|
||||
一个软件系统有许多的变量,这些变量的值在它的生命周期中不停地发生变化。软件是运行在某种操作系统上的,而操作系统同时也在不停地变化。在我看来,当某些东西出错时,你所拥有的数据越多越好。
|
||||
|
||||
我建议去监视的关键操作系统指标有:
|
||||
|
||||
* CPU 使用
|
||||
* 系统内存使用
|
||||
* 文件描述符使用
|
||||
* 磁盘使用
|
||||
|
||||
还需要监视的其它关键指标根据你的软件应用程序不同而不同。
|
||||
|
||||
### 网络应用程序
|
||||
|
||||
如果你的软件是一个监听客户端请求和为它提供服务的网络应用程序,需要测量的关键指标还有:
|
||||
|
||||
* 入站请求数(计数器)
|
||||
* 未处理的错误(计数器)
|
||||
* 请求延迟(柱状图/计时器)
|
||||
* 队列时间,如果在你的应用程序中有队列(柱状图/计时器)
|
||||
* 队列大小,如果在你的应用程序中有队列(计量器)
|
||||
* 工作进程/线程使用(计量器)
|
||||
|
||||
如果你的网络应用程序在一个客户端请求的环境中向其它服务发送请求,那么它应该有一个指标去记录它与那个服务之间的通讯行为。需要监视的关键指标包括请求数、请求延迟、和响应状态。
|
||||
|
||||
### HTTP web 应用程序后端
|
||||
|
||||
HTTP 应用程序应该监视上面所列出的全部指标。除此之外,还应该按 HTTP 状态代码分组监视所有非 200 的 HTTP 状态代码的大致数据。如果你的 web 应用程序有用户注册和登录功能,同时也应该为这个功能设置指标。
|
||||
|
||||
### 长周期运行的进程
|
||||
|
||||
长周期运行的进程如 Rabbit MQ 消费者或 task-queue 工作进程,虽然它们不是网络服务,它们以选取一个任务并处理它的工作模型来运行。因此,我们应该监视请求的进程数和这些进程的请求延迟。
|
||||
|
||||
不管是什么类型的应用程序,都有指标与合适的**元数据**相关联。
|
||||
|
||||
## 将监视集成到一个 Python 应用程序中
|
||||
|
||||
将监视集成到 Python 应用程序中需要涉及到两个组件:
|
||||
|
||||
* 更新你的应用程序去计算和报告指标
|
||||
* 配置一个监视基础设施来容纳应用程序的指标,并允许去查询它们
|
||||
|
||||
下面是记录和报告指标的基本思路:
|
||||
|
||||
```
|
||||
def work():
|
||||
requests += 1
|
||||
# report counter
|
||||
start_time = time.time()
|
||||
|
||||
# < do the work >
|
||||
|
||||
# calculate and report latency
|
||||
work_latency = time.time() - start_time
|
||||
...
|
||||
```
|
||||
|
||||
考虑到上面的模式,我们经常使用修饰符、内容管理器、中间件(对于网络应用程序)所带来的好处去计算和报告指标。在 Demo 1 和 Demo 2 中,我们在一个 Flask 应用程序中使用修饰符。
|
||||
|
||||
### 指标报告时的拉取和推送模型
|
||||
|
||||
大体来说,在一个 Python 应用程序中报告指标有两种模式。在 _拉取_ 模型中,监视系统在一个预定义的 HTTP 端点上“刮取”应用程序。在_推送_ 模型中,应用程序发送数据到监视系统。
|
||||
|
||||

|
||||
|
||||
工作在 _拉取_ 模型中的监视系统的一个例子是 [Prometheus][12]。而 [StatsD][13] 是 _推送_ 模型的一个例子。
|
||||
|
||||
### 集成 StatsD
|
||||
|
||||
将 StatsD 集成到一个 Python 应用程序中,我们将使用 [StatsD Python 客户端][14],然后更新我们的指标报告部分的代码,调用合适的库去推送数据到 StatsD 中。
|
||||
|
||||
首先,我们需要去创建一个客户端实例:
|
||||
|
||||
```
|
||||
statsd = statsd.StatsClient(host='statsd', port=8125, prefix='webapp1')
|
||||
```
|
||||
|
||||
`prefix` 关键字参数将为通过这个客户端报告的所有指标添加一个指定的前缀。
|
||||
|
||||
一旦我们有了客户端,我们可以使用如下的代码为一个计时器报告值:
|
||||
|
||||
```
|
||||
statsd.timing(key, resp_time)
|
||||
```
|
||||
|
||||
增加计数器:
|
||||
|
||||
```
|
||||
statsd.incr(key)
|
||||
```
|
||||
|
||||
将指标关联到元数据上,一个键的定义为:metadata1.metadata2.metric,其中每个 metadataX 是一个可以进行聚合和分组的字段。
|
||||
|
||||
这个演示应用程序 [StatsD][15] 是将 statsd 与 Python Flask 应用程序集成的一个完整示例。
|
||||
|
||||
### 集成 Prometheus
|
||||
|
||||
去使用 Prometheus 监视系统,我们使用 [Promethius Python 客户端][16]。我们将首先去创建有关的指标类对象:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY = Histogram('request_latency_seconds', 'Request latency',
|
||||
['app_name', 'endpoint']
|
||||
)
|
||||
```
|
||||
|
||||
在上面的语句中的第三个参数是与这个指标相关的标识符。这些标识符是由与单个指标值相关联的元数据定义的。
|
||||
|
||||
去记录一个特定的观测指标:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY.labels('webapp', request.path).observe(resp_time)
|
||||
```
|
||||
|
||||
下一步是在我们的应用程序中定义一个 Prometheus 能够刮取的 HTTP 端点。这通常是一个被称为 `/metrics` 的端点:
|
||||
|
||||
```
|
||||
@app.route('/metrics')
|
||||
def metrics():
|
||||
return Response(prometheus_client.generate_latest(), mimetype=CONTENT_TYPE_LATEST)
|
||||
```
|
||||
|
||||
这个演示应用程序 [Prometheus][17] 是将 prometheus 与 Python Flask 应用程序集成的一个完整示例。
|
||||
|
||||
### 哪个更好:StatsD 还是 Prometheus?
|
||||
|
||||
本能地想到的下一个问题便是:我应该使用 StatsD 还是 Prometheus?关于这个主题我写了几篇文章,你可能发现它们对你很有帮助:
|
||||
|
||||
* [Your options for monitoring multi-process Python applications with Prometheus][18]
|
||||
* [Monitoring your synchronous Python web applications using Prometheus][19]
|
||||
* [Monitoring your asynchronous Python web applications using Prometheus][20]
|
||||
|
||||
## 指标的使用方式
|
||||
|
||||
我们已经学习了一些关于为什么要在我们的应用程序上配置监视的原因,而现在我们来更深入地研究其中的两个用法:报警和自动扩展。
|
||||
|
||||
### 使用指标进行报警
|
||||
|
||||
指标的一个关键用途是创建警报。例如,假如过去的五分钟,你的 HTTP 500 的数量持续增加,你可能希望给相关的人发送一封电子邮件或页面提示。对于配置警报做什么取决于我们的监视设置。对于 Prometheus 我们可以使用 [Alertmanager][21],而对于 StatsD,我们使用 [Nagios][22]。
|
||||
|
||||
### 使用指标进行自动扩展
|
||||
|
||||
在一个云基础设施中,如果我们当前的基础设施供应过量或供应不足,通过指标不仅可以让我们知道,还可以帮我们实现一个自动伸缩的策略。例如,如果在过去的五分钟里,在我们服务器上的工作进程使用率达到 90%,我们可以水平扩展。我们如何去扩展取决于云基础设施。AWS 的自动扩展,缺省情况下,扩展策略是基于系统的 CPU 使用率、网络流量、以及其它因素。然而,让基础设施伸缩的应用程序指标,我们必须发布 [自定义的 CloudWatch 指标][23]。
|
||||
|
||||
## 在多服务架构中的应用程序监视
|
||||
|
||||
当我们超越一个单应用程序架构时,比如当客户端的请求在响应被发回之前,能够触发调用多个服务,就需要从我们的指标中获取更多的信息。我们需要一个统一的延迟视图指标,这样我们就能够知道响应这个请求时每个服务花费了多少时间。这可以用 [distributed tracing][24] 来实现。
|
||||
|
||||
你可以在我的博客文章 [在你的 Python 应用程序中通过 Zipkin 引入分布式跟踪][25] 中看到在 Python 中进行分布式跟踪的示例。
|
||||
|
||||
## 划重点
|
||||
|
||||
总之,你需要记住以下几点:
|
||||
|
||||
* 理解你的监视系统中指标类型的含义
|
||||
* 知道监视系统需要的你的数据的测量单位
|
||||
* 监视你的应用程序中的大多数关键组件
|
||||
* 监视你的应用程序在它的大多数关键阶段的行为
|
||||
|
||||
以上要点是假设你不去管理你的监视系统。如果管理你的监视系统是你的工作的一部分,那么你还要考虑更多的问题!
|
||||
|
||||
## 其它资源
|
||||
|
||||
以下是我在我的监视学习过程中找到的一些非常有用的资源:
|
||||
|
||||
### 综合的
|
||||
|
||||
* [监视分布式系统][26]
|
||||
* [观测和监视最佳实践][27]
|
||||
* [谁想使用秒?][28]
|
||||
|
||||
### StatsD/Graphite
|
||||
|
||||
* [StatsD 指标类型][29]
|
||||
|
||||
### Prometheus
|
||||
|
||||
* [Prometheus 指标类型][30]
|
||||
* [How does a Prometheus gauge work?][31]
|
||||
* [Why are Prometheus histograms cumulative?][32]
|
||||
* [在 Python 中监视批作业][33]
|
||||
* [Prometheus:监视 SoundCloud][34]
|
||||
|
||||
## 避免犯错(即第 3 阶段的学习)
|
||||
|
||||
在我们学习监视的基本知识时,时刻注意不要犯错误是很重要的。以下是我偶然发现的一些很有见解的资源:
|
||||
|
||||
* [How not to measure latency][35]
|
||||
* [Histograms with Prometheus: A tale of woe][36]
|
||||
* [Why averages suck and percentiles are great][37]
|
||||
* [Everything you know about latency is wrong][38]
|
||||
* [Who moved my 99th percentile latency?][39]
|
||||
* [Logs and metrics and graphs][40]
|
||||
* [HdrHistogram: A better latency capture method][41]
|
||||
|
||||
---
|
||||
|
||||
想学习更多内容,参与到 [PyCon Cleveland 2018][43] 上的 Amit Saha 的讨论,[Counter, gauge, upper 90—Oh my!][42]
|
||||
|
||||
## 关于作者
|
||||
|
||||
[][44]
|
||||
|
||||
Amit Saha — 我是一名对基础设施、监视、和工具感兴趣的软件工程师。我是“用 Python 做数学”的作者和创始人,以及 Fedora Scientific Spin 维护者。
|
||||
|
||||
[关于我的更多信息][45]
|
||||
|
||||
* [Learn how you can contribute][46]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/metrics-monitoring-and-python][47]
|
||||
|
||||
作者: [Amit Saha][48] 选题者: [@lujun9972][49] 译者: [qhwdw][50] 校对: [校对者ID][51]
|
||||
|
||||
本文由 [LCTT][52] 原创编译,[Linux中国][53] 荣誉推出
|
||||
|
||||
[1]: https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[2]: https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[3]: https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[4]: https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[5]: https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[6]: https://github.com/amitsaha/python-monitoring-talk
|
||||
[7]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo1
|
||||
[8]: http://flask.pocoo.org/
|
||||
[9]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo2
|
||||
[10]: https://pandas.pydata.org/
|
||||
[11]: http://jupyter.org/
|
||||
[12]: https://prometheus.io/
|
||||
[13]: https://github.com/etsy/statsd
|
||||
[14]: https://pypi.python.org/pypi/statsd
|
||||
[15]: https://github.com/amitsaha/python-monitoring-talk/tree/master/statsd
|
||||
[16]: https://pypi.python.org/pypi/prometheus_client
|
||||
[17]: https://github.com/amitsaha/python-monitoring-talk/tree/master/prometheus
|
||||
[18]: http://echorand.me/your-options-for-monitoring-multi-process-python-applications-with-prometheus.html
|
||||
[19]: https://blog.codeship.com/monitoring-your-synchronous-python-web-applications-using-prometheus/
|
||||
[20]: https://blog.codeship.com/monitoring-your-asynchronous-python-web-applications-using-prometheus/
|
||||
[21]: https://github.com/prometheus/alertmanager
|
||||
[22]: https://www.nagios.org/about/overview/
|
||||
[23]: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
|
||||
[24]: http://opentracing.io/documentation/
|
||||
[25]: http://echorand.me/introducing-distributed-tracing-in-your-python-application-via-zipkin.html
|
||||
[26]: https://landing.google.com/sre/book/chapters/monitoring-distributed-systems.html
|
||||
[27]: http://www.integralist.co.uk/posts/monitoring-best-practices/?imm_mid=0fbebf&cmp=em-webops-na-na-newsltr_20180309
|
||||
[28]: https://www.robustperception.io/who-wants-seconds/
|
||||
[29]: https://github.com/etsy/statsd/blob/master/docs/metric_types.md
|
||||
[30]: https://prometheus.io/docs/concepts/metric_types/
|
||||
[31]: https://www.robustperception.io/how-does-a-prometheus-gauge-work/
|
||||
[32]: https://www.robustperception.io/why-are-prometheus-histograms-cumulative/
|
||||
[33]: https://www.robustperception.io/monitoring-batch-jobs-in-python/
|
||||
[34]: https://developers.soundcloud.com/blog/prometheus-monitoring-at-soundcloud
|
||||
[35]: https://www.youtube.com/watch?v=lJ8ydIuPFeU&feature=youtu.be
|
||||
[36]: http://linuxczar.net/blog/2017/06/15/prometheus-histogram-2/
|
||||
[37]: https://www.dynatrace.com/news/blog/why-averages-suck-and-percentiles-are-great/
|
||||
[38]: https://bravenewgeek.com/everything-you-know-about-latency-is-wrong/
|
||||
[39]: https://engineering.linkedin.com/performance/who-moved-my-99th-percentile-latency
|
||||
[40]: https://grafana.com/blog/2016/01/05/logs-and-metrics-and-graphs-oh-my/
|
||||
[41]: http://psy-lob-saw.blogspot.com.au/2015/02/hdrhistogram-better-latency-capture.html
|
||||
[42]: https://us.pycon.org/2018/schedule/presentation/133/
|
||||
[43]: https://us.pycon.org/2018/
|
||||
[44]: https://opensource.com/users/amitsaha
|
||||
[45]: https://opensource.com/users/amitsaha
|
||||
[46]: https://opensource.com/participate
|
||||
[47]: https://opensource.com/article/18/4/metrics-monitoring-and-python
|
||||
[48]: https://opensource.com/users/amitsaha
|
||||
[49]: https://github.com/lujun9972
|
||||
[50]: https://github.com/qhwdw
|
||||
[51]: https://github.com/校对者ID
|
||||
[52]: https://github.com/LCTT/TranslateProject
|
||||
[53]: https://linux.cn/
|
||||
@ -0,0 +1,281 @@
|
||||
开始使用Python调试器
|
||||
======
|
||||
|
||||

|
||||
|
||||
Python生态系统包含丰富的工具和库,可以改善开发人员的生活。 例如,杂志之前已经介绍了如何[使用交互式shell增强Python][1]。 本文重点介绍另一种可以节省时间并提高Python技能的工具:Python调试器。
|
||||
|
||||
### Python调试器
|
||||
|
||||
Python标准库提供了一个名为pdb的调试器。 此调试器提供了调试所需的大多数功能,如断点,单行步进,堆栈帧的检查等等。
|
||||
|
||||
pdb的基本知识很有用,因为它是标准库的一部分。 你可以在无法安装其他增强的调试器的环境中使用它。
|
||||
|
||||
#### 运行pdb
|
||||
|
||||
运行pdb的最简单方法是从命令行,将程序作为参数传递给debug。 考虑以下脚本:
|
||||
|
||||
```
|
||||
# pdb_test.py
|
||||
#!/usr/bin/python3
|
||||
|
||||
from time import sleep
|
||||
|
||||
def countdown(number):
|
||||
for i in range(number, 0, -1):
|
||||
print(i)
|
||||
sleep(1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
seconds = 10
|
||||
countdown(seconds)
|
||||
```
|
||||
|
||||
你可以从命令行运行pdb,如下所示:
|
||||
|
||||
```
|
||||
$ python3 -m pdb pdb_test.py
|
||||
> /tmp/pdb_test.py(1)<module>()
|
||||
-> from time import sleep
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
使用pdb的另一种方法是在程序中设置断点。 为此,请导入pdb模块并使用set_trace函数:
|
||||
|
||||
```
|
||||
# pdb_test.py
|
||||
#!/usr/bin/python3
|
||||
|
||||
from time import sleep
|
||||
|
||||
|
||||
def countdown(number):
|
||||
for i in range(number, 0, -1):
|
||||
import pdb; pdb.set_trace()
|
||||
print(i)
|
||||
sleep(1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
seconds = 10
|
||||
countdown(seconds)
|
||||
|
||||
$ python3 pdb_test.py
|
||||
> /tmp/pdb_test.py(6)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
脚本在断点处停止,pdb显示脚本中的下一行。 你也可以在失败后执行调试器。 这称为*事后调试(postmortem debugging)*。
|
||||
|
||||
#### 导航执行堆栈
|
||||
|
||||
调试中的一个常见用例是导航执行堆栈。 Python调试器运行后,以下命令很有用:
|
||||
|
||||
+ w(here) : 显示当前执行的行以及执行堆栈的位置。
|
||||
|
||||
|
||||
```
|
||||
$ python3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) w
|
||||
/tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
+ l(ist) : 显示当前位置周围更多的上下文(代码)。
|
||||
|
||||
|
||||
```
|
||||
$ python3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) l
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 -> print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
```
|
||||
|
||||
+ u(p)/d(own) : 向上或向下导航调用堆栈。
|
||||
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) up
|
||||
> /tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
(Pdb) down
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
#### 单步执行程序
|
||||
|
||||
pdb提供以下命令来执行和单步执行代码:
|
||||
|
||||
+ n(ext): 继续执行,直到达到当前函数中的下一行,否则返回
|
||||
+ s(tep): 执行当前行并在第一个可能的场合停止(在被调用的函数或当前函数中)
|
||||
+ c(ontinue): 继续执行,仅在断点处停止。
|
||||
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) n
|
||||
10
|
||||
> /tmp/test_pdb.py(11)countdown()
|
||||
-> sleep(1)
|
||||
(Pdb) n
|
||||
> /tmp/test_pdb.py(8)countdown()
|
||||
-> for i in range(number, 0, -1):
|
||||
(Pdb) n
|
||||
> /tmp/test_pdb.py(9)countdown()
|
||||
-> import pdb; pdb.set_trace()
|
||||
(Pdb) s
|
||||
--Call--
|
||||
> /usr/lib64/python3.6/pdb.py(1584)set_trace()
|
||||
-> def set_trace():
|
||||
(Pdb) c
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) c
|
||||
9
|
||||
> /tmp/test_pdb.py(9)countdown()
|
||||
-> import pdb; pdb.set_trace()
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
该示例显示了next和step之间的区别。 实际上,当使用step时,调试器会进入pdb模块源代码,而接下来就会执行set_trace函数。
|
||||
|
||||
#### 检查变量内容
|
||||
|
||||
pdb非常有用的地方是检查执行堆栈中存储的变量的内容。 例如,a(rgs)命令打印当前函数的变量,如下所示:
|
||||
|
||||
```
|
||||
py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) where
|
||||
/tmp/test_pdb.py(16)<module>()
|
||||
-> countdown(seconds)
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) args
|
||||
number = 10
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
pdb打印变量的值,在本例中是10。
|
||||
|
||||
可用于打印变量值的另一个命令是p(rint)。
|
||||
|
||||
```
|
||||
$ py3 test_pdb.py
|
||||
> /tmp/test_pdb.py(10)countdown()
|
||||
-> print(i)
|
||||
(Pdb) list
|
||||
5
|
||||
6
|
||||
7 def countdown(number):
|
||||
8 for i in range(number, 0, -1):
|
||||
9 import pdb; pdb.set_trace()
|
||||
10 -> print(i)
|
||||
11 sleep(1)
|
||||
12
|
||||
13
|
||||
14 if __name__ == "__main__":
|
||||
15 seconds = 10
|
||||
(Pdb) print(seconds)
|
||||
10
|
||||
(Pdb) p i
|
||||
10
|
||||
(Pdb) p number - i
|
||||
0
|
||||
(Pdb)
|
||||
```
|
||||
|
||||
如示例中最后的命令所示,print可以在显示结果之前计算表达式。
|
||||
|
||||
[Python文档][2]包含每个pdb命令的参考和示例。 对于开始使用Python调试器人来说,这是一个有用的读物。
|
||||
|
||||
### 增强的调试器
|
||||
|
||||
一些增强的调试器提供了更好的用户体验。 大多数为pdb添加了有用的额外功能,例如语法突出高亮,更好的回溯和自我检查。 流行的增强调试器包括[IPython的ipdb][3]和[pdb ++][4]。
|
||||
|
||||
这些示例显示如何在虚拟环境中安装这两个调试器。 这些示例使用新的虚拟环境,但在调试应用程序的情况下,应使用应用程序的虚拟环境。
|
||||
|
||||
#### 安装IPython的ipdb
|
||||
|
||||
要安装IPython ipdb,请在虚拟环境中使用pip:
|
||||
|
||||
```
|
||||
$ python3 -m venv .test_pdb
|
||||
$ source .test_pdb/bin/activate
|
||||
(test_pdb)$ pip install ipdb
|
||||
```
|
||||
|
||||
要在脚本中调用ipdb,必须使用以下命令。 请注意,该模块称为ipdb而不是pdb:
|
||||
|
||||
```
|
||||
import ipdb; ipdb.set_trace()
|
||||
```
|
||||
|
||||
IPython的ipdb也可以在Fedora包中使用,所以你可以使用Fedora的包管理器dnf来安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-ipdb
|
||||
```
|
||||
|
||||
#### 安装pdb++
|
||||
|
||||
你可以类似地安装pdb++:
|
||||
|
||||
```
|
||||
$ python3 -m venv .test_pdb
|
||||
$ source .test_pdb/bin/activate
|
||||
(test_pdb)$ pip install pdbp
|
||||
```
|
||||
|
||||
pdb++重写了pdb模块,因此你可以使用相同的语法在程序中添加断点:
|
||||
|
||||
```
|
||||
import pdb; pdb.set_trace()
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
学习如何使用Python调试器可以节省你在排查应用程序问题时的时间。 对于了解应用程序或某些库的复杂部分如何工作也是有用的,从而提高Python开发人员的技能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/getting-started-python-debugger/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://fedoramagazine.org/enhance-python-interactive-shell
|
||||
[2]:https://docs.python.org/3/library/pdb.html
|
||||
[3]:https://github.com/gotcha/ipdb
|
||||
[4]:https://github.com/antocuni/pdb
|
||||
173
translated/tech/20180731 A sysadmin-s guide to Bash.md
Normal file
173
translated/tech/20180731 A sysadmin-s guide to Bash.md
Normal file
@ -0,0 +1,173 @@
|
||||
系统管理员的Bash指南
|
||||
======
|
||||
|
||||

|
||||
|
||||
每种交易都有一个掌握该交易最常用的工具。 对于许多系统管理员来说,这个工具就是他们的[shell][1]。 在大多数Linux和其他类Unix系统上,默认的shell是Bash。
|
||||
|
||||
Bash是一个相当古老的程序——它起源于20世纪80年代后期——但它建立在更多更老的shell上,比如C shell(csh),作为前辈,csh很轻松经历了10年。 因为shell的概念是那么古老,所以有大量的神秘知识等待着系统管理员去吸收,从而让他们的生活更容易。
|
||||
|
||||
我们来看看一些基础知识。
|
||||
|
||||
在某些时候,谁曾经无意中以root身份运行命令并导致某种问题? *举手*
|
||||
|
||||
我很确定我们很多人一度都是那个人。 这很痛苦。 这里有一些非常简单的技巧可以防止你再次碰上这类问题。
|
||||
|
||||
### 使用别名
|
||||
|
||||
首先,为**`mv`**和**`rm`**等命令设置别名,指向`mv -i`和`rm -i`。 这将确保在运行`rm -f / boot`时至少需要你确认。 在Red Hat企业版Linux中,如果你使用root帐户,则默认设置这些别名。
|
||||
|
||||
如果你还要为普通用户帐户设置这些别名,只需将这两行放入家目录下名为.bashrc的文件中(这些也适用于sudo):
|
||||
|
||||
```
|
||||
alias mv='mv -i'
|
||||
alias rm='rm -i'
|
||||
```
|
||||
|
||||
### 让你的root提示脱颖而出
|
||||
|
||||
你可以采取的防止意外发生的另一项措施是确保你很清楚在使用root帐户。 在日常工作中,我通常会让root提示从使用的提示中脱颖而出。
|
||||
|
||||
如果将以下内容放入root的家目录中的.bashrc文件中,你将看到一个黑色背景上的红色根root示符,清楚地表明你(或其他任何人)应该谨慎行事。
|
||||
|
||||
```
|
||||
export PS1="\[$(tput bold)$(tput setab 0)$(tput setaf 1)\]\u@\h:\w # \[$(tput sgr0)\]"
|
||||
```
|
||||
|
||||
实际上,你应该尽可能避免以root用户身份登录,而是通过sudo运行大多数sysadmin命令,但这是另一回事。
|
||||
|
||||
使用了一些小技巧用于防止使用root帐户时的“不小心的副作用”之后,让我们看看Bash可以帮助你在日常工作中做的一些好事。
|
||||
|
||||
### 控制你的历史
|
||||
|
||||
你可能知道在bash中你按向上的箭头时能看见能使用所有的(好吧,大多数)你之前的命令。这是因为这些命令已经保存到了你家目录下的名为.bash_history的文件中。这个历史文件附带了一组有用的设置和命令。
|
||||
|
||||
首先,你可以通过键入 **`history`**来查看整个最近的命令历史记录,或者你可以通过键入**`history 30`**将其限制为最近30个命令。但这是非常标准的(vanilla原为香草,后引申没拓展的,标准的,比如vanilla C++ compiler意为标准C++编译器)。 你可以更好地控制Bash保存的内容以及保存方式。
|
||||
|
||||
例如,如果将以下内容添加到.bashrc,那么任何以空格开头的命令都不会保存到历史记录列表中:
|
||||
|
||||
```
|
||||
HISTCONTROL=ignorespace
|
||||
```
|
||||
|
||||
如果你需要以明文形式将密码传递给一个命令,这就非常有用。 (是的,这太可怕了,但它仍然会发生。)
|
||||
|
||||
如果你不希望在历史记录中显示经常执行的命令,请使用:
|
||||
|
||||
```
|
||||
HISTCONTROL=ignorespace:erasedups
|
||||
```
|
||||
|
||||
这样,每次使用一个命令时,都会从历史记录文件中删除之前出现的所有相同命令,并且只将最后一次调用保存到历史记录列表中。
|
||||
|
||||
我特别喜欢的历史记录设置是**`HISTTIMEFORMAT`**设置。 这将在历史记录文件中在所有的条目前面添加上时间戳。 例如,我使用:
|
||||
|
||||
```
|
||||
HISTTIMEFORMAT="%F %T "
|
||||
```
|
||||
|
||||
当我输入**`history 5`**时,我得到了很好的完整信息,如下所示:
|
||||
|
||||
```
|
||||
1009 2018-06-11 22:34:38 cat /etc/hosts
|
||||
1010 2018-06-11 22:34:40 echo $foo
|
||||
1011 2018-06-11 22:34:42 echo $bar
|
||||
1012 2018-06-11 22:34:44 ssh myhost
|
||||
1013 2018-06-11 22:34:55 vim .bashrc
|
||||
```
|
||||
|
||||
这使我更容易浏览我的命令历史记录并找到我两天前用来建立到我家实验室的SSH连接(我再次忘记,再次,再次......)。
|
||||
|
||||
### Bash最佳实践
|
||||
|
||||
I'll wrap this up with my top 11 list of the best (or good, at least; I don't claim omniscience) practices when writing Bash scripts.
|
||||
|
||||
在编写Bash脚本时,我将用最好的(或者至少是好的,我不要求无所不知)11项列表列出来。
|
||||
|
||||
11. Bash脚本可能变得复杂,注释也很方便。 如果你想知道是否要添加注释,那么就添加一个注释。 如果你在周末之后回来并且不得不花时间搞清楚你上周五想要做什么,那你是忘了添加注释。
|
||||
|
||||
|
||||
10. 用花括号括起所有变量名,比如**`${myvariable}`**。 养成这个习惯可以使`${variable}_suffix`成为可能,还能提高整个脚本的一致性。
|
||||
|
||||
|
||||
9. 计算表达式时不要使用反引号; 请改用**`$()`**语法。 所以使用:
|
||||
```
|
||||
for file in $(ls); do
|
||||
```
|
||||
|
||||
|
||||
而不使用
|
||||
```
|
||||
for file in `ls`; do
|
||||
```
|
||||
|
||||
前一个选项是可嵌套的,更易于阅读的,还能让一般的系统管理员群体感到满意。 不要使用反引号。
|
||||
|
||||
8. 一致性是好的。 选择一种风格并在整个脚本中坚持下去。 显然,我喜欢人们在反引号中选择**`$()`** 语法并将其变量包在花括号中。 我更喜欢人们使用两个或四个空格而不是制表符来缩进,但即使你选择了错误的方式,也要一贯地错下去。
|
||||
|
||||
|
||||
7. 使用适当的shebang(LCTT译者注:**Shebang**,也称为 **Hashbang** ,是一个由井号和叹号构成的字符序列 *#!* ,其出现在文本文件的第一行的前两个字符。 在文件中存在 Shebang 的情况下,类 Unix 操作系统的程序载入器会分析 Shebang 后的内容,将这些内容作为解释器指令,并调用该指令,并将载有 Shebang 的文件路径作为该解释器的参数)作为Bash脚本。 因为我正在编写Bash脚本,只打算用Bash执行它们,所以我经常使用**`#!/usr/bin/bash`**作为我的shebang。 不要使用**`#!/bin/sh`**或**`#!/usr/bin/sh`**。 你的脚本会被执行,但它会以兼容模式运行——可能会产生许多意外的副作用。 (当然,除非你想要兼容模式。)
|
||||
|
||||
|
||||
6. 比较字符串时,在if语句中给变量加上引号是个好主意,因为如果你的变量是空的,Bash会为这样的行抛出一个错误:
|
||||
```
|
||||
if [ ${myvar} == "foo" ]; then
|
||||
echo "bar"
|
||||
fi
|
||||
```
|
||||
|
||||
对于这样的行,将判定为false:
|
||||
```
|
||||
if [ "${myvar}" == "foo" ]; then
|
||||
echo "bar"
|
||||
fi
|
||||
```
|
||||
|
||||
此外,如果你不确定变量的内容(例如,在解析用户输入时),请给变量加引号以防止解释某些特殊字符,并确保该变量被视为单个单词,即使它包含空格。
|
||||
|
||||
5. 我想这是一个品味问题,但我更喜欢使用双等号(**`==`**),即使是比较Bash中的字符串。 这是一致性的问题,尽管对于字符串比较,只有一个等号会起作用,我的思维立即变为“单个等于是一个赋值运算符!”
|
||||
|
||||
|
||||
4. 使用适当的退出代码。 确保如果你的脚本无法执行某些操作,则会向用户显示已写好的失败消息(最好通过解决问题的方法)并发送非零退出代码:
|
||||
```
|
||||
# we have failed
|
||||
echo "Process has failed to complete, you need to manually restart the whatchamacallit"
|
||||
exit 1
|
||||
```
|
||||
|
||||
这样可以更容易地以编程方式从另一个脚本调用你的脚本并验证其成功完成。
|
||||
|
||||
3. 使用Bash的内置机制为变量提供合理的默认值,或者如果未定义你希望定义的变量,则抛出错误:
|
||||
```
|
||||
# this sets the value of $myvar to redhat, and prints 'redhat'
|
||||
echo ${myvar:=redhat}
|
||||
```
|
||||
|
||||
```
|
||||
# this throws an error reading 'The variable myvar is undefined, dear reader' if $myvar is undefined
|
||||
${myvar:?The variable myvar is undefined, dear reader}
|
||||
```
|
||||
|
||||
2. 特别是如果你正在编写大型脚本,或者是如果你与其他脚本一起处理该大型脚本,请考虑在函数内部定义变量时使用**`local`**关键字。 **`local`**关键字将创建一个局部变量,该变量只在该函数中可见。 这限制了变量冲突的可能性。
|
||||
|
||||
|
||||
1. 每个系统管理员有时必须这样做:在控制台上调试一些东西,可以是数据中心的真实服务器,也可以是虚拟化平台的虚拟服务器。 如果你必须以这种方式调试脚本,你会感谢你自己记住了这个:不要让你的脚本中的行太长!
|
||||
|
||||
在许多系统上,控制台的默认宽度仍为80个字符。 如果你需要在控制台上调试脚本并且该脚本有很长的行,那么你将成为一个悲伤的熊猫。 此外,具有较短行的脚本—— 默认值仍为80个字符——在普通编辑器中也更容易阅读和理解!
|
||||
|
||||
我真的很喜欢Bash。 我可以花几个小时写这篇文章或与其他爱好者交流优秀的技巧。 就希望你们能在评论中留下赞美
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/admin-guide-bash
|
||||
|
||||
作者:[Maxim Burgerhout][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/wzzrd
|
||||
[1]:http://www.catb.org/jargon/html/S/shell.html
|
||||
[2]:https://en.wikipedia.org/wiki/C_shell
|
||||
@ -0,0 +1,138 @@
|
||||
如何在 Linux 上使用 Pbcopy 和 Pbpaste 命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
由于 Linux 和 Mac OS X 是基于 *Nix 的系统,因此许多命令可以在两个平台上运行。但是,某些命令可能在两个平台上都没有,比如 **pbcopy** 和 **pbpast**。这些命令仅在 Mac OS X 平台上可用。Pbcopy 命令将标准输入复制到剪贴板。然后,你可以在任何地方使用 Pbpaste 命令粘贴剪贴板内容。当然,上述命令可能有一些 Linux 替代品,例如 **Xclip**。 Xclip 与 Pbcopy 完全相同。但是,从 Mac OS 切换到 Linux 的发行版的人将会错过这两个命令,但仍然更喜欢使用它们。别担心!这个简短的教程描述了如何在 Linux 上使用 Pbcopy 和 Pbpaste 命令。
|
||||
|
||||
### 安装 Xclip / Xsel
|
||||
|
||||
就像我已经说过的那样,Linux 中没有 Pbcopy 和 Pbpaste 命令。但是,我们可以通过 shell 别名使用 Xclip 和/或 Xsel 命令复制 pbcopy 和 pbpaste 命令的功能。Xclip 和 Xsel 包存在于大多数 Linux 发行版的默认存储库中。请注意,你无需安装这两个程序。只需安装上述任何一个程序即可。
|
||||
|
||||
要在 Arch Linux 及其衍生产版上安装它们,请运行:
|
||||
```
|
||||
$ sudo pacman xclip xsel
|
||||
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
```
|
||||
$ sudo dnf xclip xsel
|
||||
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
```
|
||||
$ sudo apt install xclip xsel
|
||||
|
||||
```
|
||||
|
||||
Once installed, you need create aliases for pbcopy and pbpaste commands. To do so, edit your **~/.bashrc** file:
|
||||
安装后,你需要为 pbcopy 和 pbpaste 命令创建别名。为此,请编辑 **~/.bashrc**:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
如果要使用 Xclip,请粘贴以下行:
|
||||
```
|
||||
alias pbcopy='xclip -selection clipboard'
|
||||
alias pbpaste='xclip -selection clipboard -o'
|
||||
|
||||
```
|
||||
|
||||
如果要使用 xsel,请在 ~/.bashrc 中粘贴以下行。
|
||||
```
|
||||
alias pbcopy='xsel --clipboard --input'
|
||||
alias pbpaste='xsel --clipboard --output'
|
||||
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
接下来,运行以下命令以更新 ~/.bashrc 中的更改。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
ZSH 用户将上述行粘贴到 **~/.zshrc** 中。
|
||||
|
||||
### 在 Linux 上使用 Pbcopy 和 Pbpaste 命令
|
||||
|
||||
让我们看一些例子。
|
||||
|
||||
pbcopy 命令将文本从 stdin 复制到剪贴板缓冲区。例如,看看下面的例子。
|
||||
```
|
||||
$ echo "Welcome To OSTechNix!" | pbcopy
|
||||
|
||||
```
|
||||
|
||||
上面的命令会将文本 “Welcome to OSTechNix” 复制到剪贴板中。你可以稍后访问此内容并使用如下所示的 Pbpaste 命令将其粘贴到任何位置。
|
||||
```
|
||||
$ echo `pbpaste`
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
以下是一些其他例子。
|
||||
|
||||
我有一个名为 **file.txt*** 的文件,其中包含以下内容。
|
||||
```
|
||||
$ cat file.txt
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
你可以直接将文件内容复制到剪贴板中,如下所示。
|
||||
```
|
||||
$ pbcopy < file.txt
|
||||
|
||||
```
|
||||
|
||||
现在,只要你用其他文件的内容更新了剪切板,那么剪切板中的内容就可用了。
|
||||
|
||||
要从剪贴板检索内容,只需输入:
|
||||
```
|
||||
$ pbpaste
|
||||
Welcome To OSTechNix!
|
||||
|
||||
```
|
||||
|
||||
你还可以使用管道字符将任何 Linux 命令的输出发送到剪贴板。看看下面的例子。
|
||||
```
|
||||
$ ps aux | pbcopy
|
||||
|
||||
```
|
||||
|
||||
现在,输入 “pbpaste” 命令以显示剪贴板中 “ps aux” 命令的输出。
|
||||
```
|
||||
$ pbpaste
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
使用 Pbcopy 和 Pbpaste 命令可以做更多的事情。我希望你现在对这些命令有一个基本的想法。
|
||||
|
||||
就是这些了。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-use-pbcopy-and-pbpaste-commands-on-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,69 @@
|
||||
入门 Mu,一个面向初学者的 Python 编辑器
|
||||
======
|
||||
|
||||

|
||||
|
||||
Mu 是一个给初学 Python 的编辑器,它旨在使学习体验更加愉快。它使学生能够在早期体验成功,这在你学习任何新知识的时候都很重要。
|
||||
|
||||
如果你曾试图教年轻人如何编程,你会立即掌握 [Mu][1] 的重要性。大多数编程工具都是由开发人员为开发人员编写的,不管他们的年龄如何,它们并不适合初学者。然而,Mu 是由老师为学生写的。
|
||||
|
||||
### Mu 的起源
|
||||
|
||||
Mu 是 [Nicholas Tollervey][2] 的心血结晶(我听说他 5 月在 PyCon2018 上发言)。Nicholas 斯是一位受过古典音乐训练的音乐家,在担任音乐老师期间,他在职业生涯早期就开始对 Python 和开发感兴趣。他还写了 [Python in Education][3],这是一本可以从 O'Reilly 下载的免费书。
|
||||
|
||||
Nicholas 过去在寻找一个更简单的 Python 编程接口。他想要一些没有其他编辑器复杂性的东西 - 甚至是 Python 附带的 IDLE3 编辑器 - 所以他与 Raspberry Pi 基金会(赞助他的工作)的教育总监 [Carrie Ann Philbin][4] 合作开发 Mu 。
|
||||
|
||||
Mu 是一个用 Python 编写的开源程序(在 [GNU GPLv3][5] 许可证下)。它最初是为 [Micro:bit][6] 迷你计算机开发的,但是其他老师的反馈和请求促使他将 Mu 重写为通用的 Python 编辑器。
|
||||
|
||||
### 受音乐启发
|
||||
|
||||
Nicholas 对 Mu 的启发来自于他教授音乐的方法。他想知道如果我们按照教授音乐的方式教授编程并立即看到断开会发生什么。与编程不同,我们没有音乐训练营,我们也没有学习如何在书上演奏乐器,比如说如何演奏长笛。
|
||||
|
||||
Nicholas 说,Mu “旨在成为真实的东西”,因为没有人可以在 30 分钟内学习 Python。当他开发 Mu 时,他与老师一起工作,观察编程俱乐部,并观看中学生使用 Python。他发现少即多,保持简单可以改善成品的功能。Nicholas 说,Mu 只有大约 3,000 行代码。
|
||||
|
||||
### 使用 Mu
|
||||
|
||||
要尝试它,[下载][7] Mu 并按照 [Linux、Windows 和 Mac OS] [8]的简易安装说明进行操作。如果像我一样,你想[在 Raspberry Pi 上安装] [9],请在终端中输入以下内容:
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install mu
|
||||
|
||||
```
|
||||
|
||||
从编程菜单启动 Mu。然后你就可以选择如何使用 Mu。
|
||||
|
||||

|
||||
|
||||
我选择了Python 3,它启动了编写代码的环境。Python shell 直接在下面,它允许你查看代码执行。
|
||||
|
||||

|
||||
|
||||
菜单使用和理解非常简单,这实现了 Mu 的目标-让编写代码对初学者简单。
|
||||
|
||||
[教程][10]和其他资源可在 Mu 用户的网站上找到。在网站上,你还可以看到一些帮助开发 Mu 的[志愿者][11]的名字。如果你想成为其中之一并[为 Mu 的发展做出贡献][12],我们非常欢迎您。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://codewith.mu
|
||||
[2]:https://us.pycon.org/2018/speaker/profile/194/
|
||||
[3]:https://www.oreilly.com/programming/free/python-in-education.csp
|
||||
[4]:https://uk.linkedin.com/in/carrie-anne-philbin-a20649b7
|
||||
[5]:https://mu.readthedocs.io/en/latest/license.html
|
||||
[6]:http://microbit.org/
|
||||
[7]:https://codewith.mu/en/download
|
||||
[8]:https://codewith.mu/en/howto/install_with_python
|
||||
[9]:https://codewith.mu/en/howto/install_raspberry_pi
|
||||
[10]:https://codewith.mu/en/tutorials/
|
||||
[11]:https://codewith.mu/en/thanks
|
||||
[12]:https://mu.readthedocs.io/en/latest/contributing.html
|
||||
Loading…
Reference in New Issue
Block a user