mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
Merge branch 'LCTT/master'
This commit is contained in:
commit
77875d24bf
@ -0,0 +1,42 @@
|
||||
Debian 8 "Jessie" 将把GNOME作为默认桌面环境
|
||||
================================================================================
|
||||
> Debian的GNOME团队已经取得了实质进展
|
||||
|
||||
<center></center>
|
||||
|
||||
<center>*GNOME 3.14桌面*</center>
|
||||
|
||||
**Debian项目开发者花了很长一段时间来决定将Xfce,GNOME或一些其他桌面环境中的哪个作为默认环境,不过目前看起来像是GNOME赢了。**
|
||||
|
||||
[我们两天前提到了][1],GNOME 3.14的软件包被上传到 Debian Testing(Debian 8 “Jessie”)的软件仓库中,这是一个令人惊喜的事情。通常情况下,GNOME的维护者对任何类型的软件包都不会这么快地决定添加,更别说桌面环境。
|
||||
|
||||
事实证明,关于即将到来的Debian 8的发行版中所用的默认桌面的争论已经尘埃落定,尽管这个词可能有点过于武断。无论什么情况下,总是有些开发者想要Xfce,另外一些则是喜欢 GNOME,看起来 MATE 也是不少人的备选。
|
||||
|
||||
### 最有可能的是,GNOME将Debian 8“Jessie” 的默认桌面环境###
|
||||
|
||||
我们之所以说“最有可能”是因为协议尚未达成一致,但它看起来GNOME已经遥遥领先了。Debian的维护者和开发者乔伊·赫斯解释了为什么会这样。
|
||||
|
||||
“根据从 https://wiki.debian.org/DebianDesktop/Requalification/Jessie 初步结果看,一些所需数据尚不可用,但在这一点上,我百分之八十地确定GNOME已经领先了。特别是,由于“辅助功能”和某些“systemd”整合的进度。在辅助功能方面:Gnome和Mate都领先了一大截。其他一些桌面的辅助功能改善了在Debian上的支持,部分原因是这一过程推动的,但仍需要上游大力支持。“
|
||||
|
||||
“Systemd /etc 整合方面:Xfce,Mate等尽力追赶在这一领域正在发生的变化,当技术团队停止了修改之后,希望有时间能在冻结期间解决这些问题。所以这并不是完全否决这些桌面,但要从目前的状态看,GNOME是未来的选择,“乔伊·赫斯[补充说][2]。
|
||||
|
||||
开发者在邮件中表示,在Debian的GNOME团队对他们所维护的项目[充满了激情][3],而Debian的Xfce的团队是决定默认桌面的实际阻碍。
|
||||
|
||||
无论如何,Debian 8“Jessie”没有一个具体发布时间,并没有迹象显示何时可能会被发布。在另一方面,GNOME 3.14已经发布了(也许你已经看到新闻了),它将很快应对好进行Debian的测试。
|
||||
|
||||
我们也应该感谢Jordi Mallach,在Debian中的GNOME包的维护者之一,他为我们指引了正确的讯息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Debian-8-quot-Jessie-quot-to-Have-GNOME-as-the-Default-Desktop-459665.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[fbigun](https://github.com/fbigun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://news.softpedia.com/news/Debian-8-quot-Jessie-quot-to-Get-GNOME-3-14-459470.shtml
|
||||
[2]:http://anonscm.debian.org/cgit/tasksel/tasksel.git/commit/?id=dce99f5f8d84e4c885e6beb4cc1bb5bb1d9ee6d7
|
||||
[3]:http://news.softpedia.com/news/Debian-Maintainer-Says-that-Xfce-on-Debian-Will-Not-Meet-Quality-Standards-GNOME-Is-Needed-454962.shtml
|
||||
@ -0,0 +1,29 @@
|
||||
Red Hat Enterprise Linux 5产品线终结
|
||||
================================================================================
|
||||
2007年3月,红帽公司首次宣布它的[Red Hat Enterprise Linux 5][1](RHEL)平台。虽然如今看来很普通,RHEL 5特别显著的一点是它是红帽公司第一个强调虚拟化的主要发行版本,而这点是如今现代发行版所广泛接受的特性。
|
||||
|
||||
最初的计划是为RHEL 5提供七年的寿命,但在2012年该计划改变了,红帽为RHEL 5[扩展][2]至10年的标准支持。
|
||||
|
||||
刚刚过去的这个星期,Red Hat发布的RHEL 5.11是RHEL 5.X系列的最后的、次要里程碑版本。红帽现在进入了将持续三年的名为“production 3”的支持周期。在这阶段将没有新的功能被添加到平台中,并且红帽公司将只提供有重大影响的安全修复程序和紧急优先级的bug修复。
|
||||
|
||||
平台事业部副总裁兼总经理Jim Totton在红帽公司在一份声明中说:“红帽公司致力于建立一个长期,稳定的产品生命周期,这将给那些依赖Red Hat Enterprise Linux为他们的关键应用服务的企业客户提供关键的益处。虽然RHEL 5.11是RHEL 5平台的最终次要版本,但它提供了安全性和可靠性方面的增强功能,以保持该平台接下来几年的活力。”
|
||||
|
||||
新的增强功能包括安全性和稳定性更新,包括改进了红帽帮助用户调试系统的方式。
|
||||
|
||||
还有一些新的存储的驱动程序,以支持新的存储适配器和改进在VMware ESXi上运行RHEL的支持。
|
||||
|
||||
在安全方面的巨大改进是OpenSCAP更新到版本1.0.8。红帽在2011年五月的[RHEL5.7的里程碑更新][3]中第一次支持了OpenSCAP。 OpenSCAP是安全内容自动化协议(SCAP)框架的开源实现,用于创建一个标准化方法来维护安全系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxplanet.com/news/end-of-the-line-for-red-hat-enterprise-linux-5.html
|
||||
|
||||
作者:Sean Michael Kerner
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.internetnews.com/ent-news/article.php/3665641
|
||||
[2]:http://www.serverwatch.com/server-news/red-hat-extends-linux-support.html
|
||||
[3]:http://www.internetnews.com/skerner/2011/05/red-hat-enterprise-linux-57-ad.html
|
||||
@ -0,0 +1,39 @@
|
||||
KDE Plasma 5的第二个bug修复版本发布,带来了很多的改变
|
||||
================================================================================
|
||||
> 新的Plasma 5发布了,带来了新的外观
|
||||
|
||||
<center></center>
|
||||
|
||||
<center>*KDE Plasma 5*</center>
|
||||
|
||||
### Plasma 5的第二个bug修复版本发布,已可下载###
|
||||
|
||||
KDE Plasma 5的bug修复版本不断来到,它新的桌面体验将会是KDE的生态系统的一个组成部分。
|
||||
|
||||
[公告][1]称:“plasma-5.0.2这个版本,新增了一个月以来来自KDE的贡献者新的翻译和修订。Bug修复通常是很小但是很重要,如修正未翻译的文字,使用正确的图标和修正KDELibs 4软件的文件重复现象。它还增加了一个月以来辛勤的翻译成果,使其支持其他更多的语言”
|
||||
|
||||
这个桌面还没有在任何Linux发行版中默认安装,这将持续一段时间,直到我们测试完成。
|
||||
|
||||
开发者还解释说,更新的软件包可以在Kubuntu Plasma 5的开发版本中进行审查。
|
||||
|
||||
如果你个人需要它们,你也可以下载源码包。
|
||||
|
||||
- [KDE Plasma Packages][2]
|
||||
- [KDE Plasma Sources][3]
|
||||
|
||||
如果你决定去编译它,你必须需要知道 KDE Plasma 5.0.2是一组复杂的软件,可能你需要解决不少问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Second-Bugfix-Release-for-KDE-Plasma-5-Arrives-with-Lots-of-Changes-459688.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://kde.org/announcements/plasma-5.0.2.php
|
||||
[2]:https://community.kde.org/Plasma/Packages
|
||||
[3]:http://kde.org/info/plasma-5.0.2.php
|
||||
@ -1,36 +0,0 @@
|
||||
Canonical Closes nginx Exploit in Ubuntu 14.04 LTS
|
||||
================================================================================
|
||||
> Users have to upgrade their systems to fix the issue
|
||||
|
||||
|
||||
|
||||
Ubuntu 14.04 LTS
|
||||
|
||||
**Canonical has published details in a security notice about an nginx vulnerability that affected Ubuntu 14.04 LTS (Trusty Tahr). The problem has been identified and fixed.**
|
||||
|
||||
The Ubuntu developers have fixed a small nginx exploit. They explain that nginx could have been made to expose sensitive information over the network.
|
||||
|
||||
According to the security notice, “Antoine Delignat-Lavaud and Karthikeyan Bhargavan discovered that nginx incorrectly reused cached SSL sessions. An attacker could possibly use this issue in certain configurations to obtain access to information from a different virtual host.”
|
||||
|
||||
For a more detailed description of the problems, you can see Canonical's security [notification][1]. Users should upgrade their Linux distribution in order to correct this issue.
|
||||
|
||||
The problem can be repaired by upgrading the system to the latest nginx package (and dependencies). To apply the patch, you can simply run the Update Manager application.
|
||||
|
||||
If you don't want to use the Software Updater, you can open a terminal and enter the following commands (you will need to be root):
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
In general, a standard system update will make all the necessary changes. You don't have to restart the PC in order to implement this fix.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Canonical-Closes-Nginx-Exploit-in-Ubuntu-14-04-LTS-459677.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://www.ubuntu.com/usn/usn-2351-1/
|
||||
@ -1,29 +0,0 @@
|
||||
End of the Line for Red Hat Enterprise Linux 5
|
||||
================================================================================
|
||||
In March of 2007, Red Hat first announced its [Red Hat Enterprise Linux 5][1]( RHEL) platform. Though it might seem quant today, RHEL 5 was particularly notable in that it was the first major release for Red Hat to emphasize virtualization, which is a feature all modern distros now take for granted.
|
||||
|
||||
Originally the plan was for RHEL 5 to have seven years of life, but that plan changed in 2012 when when Red Hat [extended][2] its standard support for RHEL 5 to 10 years.
|
||||
|
||||
This past week, Red Hat released RHEL 5.11 which is the final minor milestone release for RHEL 5.X. RHEL now enters what Red Hat calls it production 3 support which will last for another three years. During the production three phase no new functionality is added to the platform and Red Hat will only provide critical impact security fixes and urgent priority bug fixes.
|
||||
|
||||
"Red Hat’s commitment to a long, stable product lifecycle is a key benefit for enterprise customers who rely on Red Hat Enterprise Linux for their critical applications," Jim Totton, vice president and general manager, Platform Business Unit, Red Hat said in a statement. " While Red Hat Enterprise Linux 5.11 is the final minor release of the Red Hat Enterprise Linux 5 platform, the enhancements it offers in terms of security and reliability are designed to maintain the platform’s viability for years to come."
|
||||
|
||||
The new enhancements include security and stability updates including improvements to the way that Red Hat can help users to debug a system.
|
||||
|
||||
There are also new storage drivers to support newer storage adapters and improved support for RHEL running on VMware ESXi.
|
||||
|
||||
On the security front the big improvement is an update to OpenSCAP version 1.0.8. Red Hat first provided support for OpenSCAP in May of 2011 with the [RHEL 5.7 milestone update][3]. OpenSCAP is an open source implementation of the Security Content Automation Protocol (SCAP) framework for creating a standardized approach for maintaining secure systems.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxplanet.com/news/end-of-the-line-for-red-hat-enterprise-linux-5.html
|
||||
|
||||
作者:Sean Michael Kerner
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.internetnews.com/ent-news/article.php/3665641
|
||||
[2]:http://www.serverwatch.com/server-news/red-hat-extends-linux-support.html
|
||||
[3]:http://www.internetnews.com/skerner/2011/05/red-hat-enterprise-linux-57-ad.html
|
||||
@ -1,38 +0,0 @@
|
||||
Second Bugfix Release for KDE Plasma 5 Arrives with Lots of Changes
|
||||
================================================================================
|
||||
> The new Plasma 5 desktop is out with a new version
|
||||
|
||||

|
||||
|
||||
KDE Plasma 5
|
||||
|
||||
### The KDE Community has announced that the second bugfix release for Plasma 5 is now out and available for download. ###
|
||||
|
||||
Bugfix releases for the KDE Plasma 5, the new desktop experience that will be an integral part of the KDE ecosystem, have started to arrive very often.
|
||||
|
||||
"This release, versioned plasma-5.0.2, adds a month's worth of new translations and fixes from KDE's contributors. The bugfixes are typically small but important such as fixing text which couldn't be translated, using the correct icons and fixing overlapping files with KDELibs 4 software. It also adds a month's hard work of translations to make support in other languages even more complete," reads the [announcement][1].
|
||||
|
||||
This particular desktop is not yet implemented by default in any Linux distro and it will be a while until we are able to test it properly.
|
||||
|
||||
The developers also explain that the updated packages can be reviewed in the development versions of Kubuntu Plasma 5.
|
||||
|
||||
You can also download the source packages, if you need them individually.
|
||||
|
||||
- [KDE Plasma Packages][2]
|
||||
- [KDE Plasma Sources][3]
|
||||
|
||||
You also have to keep in mind that KDE Plasma 5.0.2 is a sophisticated piece of software and you really need to know what you are doing if you decide to compile it.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Second-Bugfix-Release-for-KDE-Plasma-5-Arrives-with-Lots-of-Changes-459688.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://kde.org/announcements/plasma-5.0.2.php
|
||||
[2]:https://community.kde.org/Plasma/Packages
|
||||
[3]:http://kde.org/info/plasma-5.0.2.php
|
||||
@ -0,0 +1,36 @@
|
||||
Wal Commander GitHub Edition 0.17 released
|
||||
================================================================================
|
||||

|
||||
|
||||
> ### Description ###
|
||||
>
|
||||
> Wal Commander GitHub Edition is a multi-platform open source file manager for Windows, Linux, FreeBSD and OS X.
|
||||
>
|
||||
> The purpose of this project is to create a portable file manager mimicking the look-n-feel of Far Manager.
|
||||
|
||||
The next stable version of our Wal Commander GitHub Edition 0.17 is out. Major features include command line autocomplete using the commands history; file associations to bind custom commands to different actions on files; and experimental support of OS X using XQuartz. A lot of new hotkeys were added in this release. Precompiled binaries are available for Windows x64. Linux, FreeBSD and OS X versions can be built directly from the [GitHub source code][1].
|
||||
|
||||
### Major features ###
|
||||
|
||||
- command line autocomplete (use Del key to erase a command)
|
||||
- file associations (Main menu -> Commands -> File associations)
|
||||
- experimental OS X support on top of XQuartz ([https://github.com/corporateshark/WalCommander/issues/5][2])
|
||||
|
||||
### [Downloads][3] ###.
|
||||
|
||||
Source code: [https://github.com/corporateshark/WalCommander][4]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://wcm.linderdaum.com/release-0-17-0/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://github.com/corporateshark/WalCommander/releases
|
||||
[2]:https://github.com/corporateshark/WalCommander/issues/5
|
||||
[3]:http://wcm.linderdaum.com/downloads/
|
||||
[4]:https://github.com/corporateshark/WalCommander
|
||||
@ -1,92 +0,0 @@
|
||||
Making MySQL Better at GitHub
|
||||
================================================================================
|
||||
> At GitHub we say, "it's not fully shipped until it's fast." We've talked before about some of the ways we keep our [frontend experience speedy][1], but that's only part of the story. Our MySQL database infrastructure dramatically affects the performance of GitHub.com. Here's a look at how our infrastructure team seamlessly conducted a major MySQL improvement last August and made GitHub even faster.
|
||||
|
||||
### The mission ###
|
||||
|
||||
Last year we moved the bulk of GitHub.com's infrastructure into a new datacenter with world-class hardware and networking. Since MySQL forms the foundation of our backend systems, we expected database performance to benefit tremendously from an improved setup. But creating a brand-new cluster with brand-new hardware in a new datacenter is no small task, so we had to plan and test carefully to ensure a smooth transition.
|
||||
|
||||
### Preparation ###
|
||||
|
||||
A major infrastructure change like this requires measurement and metrics gathering every step of the way. After installing base operating systems on our new machines, it was time to test out our new setup with various configurations. To get a realistic test workload, we used tcpdump to extract SELECT queries from the old cluster that was serving production and replayed them onto the new cluster.
|
||||
|
||||
MySQL tuning is very workload specific, and well-known configuration settings like innodb_buffer_pool_size often make the most difference in MySQL's performance. But on a major change like this, we wanted to make sure we covered everything, so we took a look at settings like innodb_thread_concurrency, innodb_io_capacity, and innodb_buffer_pool_instances, among others.
|
||||
|
||||
We were careful to only make one test configuration change at a time, and to run tests for at least 12 hours. We looked for query response time changes, stalls in queries per second, and signs of reduced concurrency. We observed the output of SHOW ENGINE INNODB STATUS, particularly the SEMAPHORES section, which provides information on work load contention.
|
||||
|
||||
Once we were relatively comfortable with configuration settings, we started migrating one of our largest tables onto an isolated cluster. This served as an early test of the process, gave us more space in the buffer pools of our core cluster and provided greater flexibility for failover and storage. This initial migration introduced an interesting application challenge, as we had to make sure we could maintain multiple connections and direct queries to the correct cluster.
|
||||
|
||||
In addition to all our raw hardware improvements, we also made process and topology improvements: we added delayed replicas, faster and more frequent backups, and more read replica capacity. These were all built out and ready for go-live day.
|
||||
|
||||
### Making a list; checking it twice ###
|
||||
|
||||
With millions of people using GitHub.com on a daily basis, we did not want to take any chances with the actual switchover. We came up with a thorough [checklist][2] before the transition:
|
||||
|
||||

|
||||
|
||||
We also planned a maintenance window and [announced it on our blog][3] to give our users plenty of notice.
|
||||
|
||||
### Migration day ###
|
||||
|
||||
At 5am Pacific Time on a Saturday, the migration team assembled online in chat and the process began:
|
||||
|
||||

|
||||
|
||||
We put the site in maintenance mode, made an announcement on Twitter, and set out to work through the list above:
|
||||
|
||||

|
||||
|
||||
**13 minutes** later, we were able to confirm operations of the new cluster:
|
||||
|
||||

|
||||
|
||||
Then we flipped GitHub.com out of maintenance mode, and let the world know that we were in the clear.
|
||||
|
||||

|
||||
|
||||
Lots of up front testing and preparation meant that we kept the work we needed on go-live day to a minimum.
|
||||
|
||||
### Measuring the final results ###
|
||||
|
||||
In the weeks following the migration, we closely monitored performance and response times on GitHub.com. We found that our cluster migration cut the average GitHub.com page load time by half and the 99th percentile by *two-thirds*:
|
||||
|
||||

|
||||
|
||||
### What we learned ###
|
||||
|
||||
#### Functional partitioning ####
|
||||
|
||||
During this process we decided that moving larger tables that mostly store historic data to separate cluster was a good way to free up disk and buffer pool space. This allowed us to leave more resources for our "hot" data, splitting some connection logic to enable the application to query multiple clusters. This proved to be a big win for us and we are working to reuse this pattern.
|
||||
|
||||
#### Always be testing ####
|
||||
|
||||
You can never do too much acceptance and regression testing for your application. Replicating data from the old cluster to the new cluster while running acceptance tests and replaying queries were invaluable for tracing out issues and preventing surprises during the migration.
|
||||
|
||||
#### The power of collaboration ####
|
||||
|
||||
Large changes to infrastructure like this mean a lot of people need to be involved, so pull requests functioned as our primary point of coordination as a team. We had people all over the world jumping in to help.
|
||||
|
||||
Deploy day team map:
|
||||
|
||||
<iframe width="620" height="420" frameborder="0" src="https://render.githubusercontent.com/view/geojson?url=https://gist.githubusercontent.com/anonymous/5fa29a7ccbd0101630da/raw/map.geojson"></iframe>
|
||||
|
||||
This created a workflow where we could open a pull request to try out changes, get real-time feedback, and see commits that fixed regressions or errors -- all without phone calls or face-to-face meetings. When everything has a URL that can provide context, it's easy to involve a diverse range of people and make it simple for them give feedback.
|
||||
|
||||
### One year later.. ###
|
||||
|
||||
A full year later, we are happy to call this migration a success — MySQL performance and reliability continue to meet our expectations. And as an added bonus, the new cluster enabled us to make further improvements towards greater availability and query response times. I'll be writing more about those improvements here soon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/1880-making-mysql-better-at-github
|
||||
|
||||
作者:[samlambert][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/samlambert
|
||||
[1]:https://github.com/blog/1756-optimizing-large-selector-sets
|
||||
[2]:https://help.github.com/articles/writing-on-github#task-lists
|
||||
[3]:https://github.com/blog/1603-site-maintenance-august-31st-2013
|
||||
@ -0,0 +1,82 @@
|
||||
ChromeOS vs Linux: The Good, the Bad and the Ugly
|
||||
================================================================================
|
||||
> In the battle between ChromeOS and Linux, both desktop environments have strengths and weaknesses.
|
||||
|
||||
Anyone who believes Google isn't "making a play" for desktop users isn't paying attention. In recent years, I've seen [ChromeOS][1] making quite a splash on the [Google Chromebook][2]. Exploding with popularity on sites such as Amazon.com, it looks as if ChromeOS could be unstoppable.
|
||||
|
||||
In this article, I'm going to look at ChromeOS as a concept to market, how it's affecting Linux adoption and whether or not it's a good/bad thing for the Linux community as a whole. Plus, I'll talk about the biggest issue of all and how no one is doing anything about it.
|
||||
|
||||
### ChromeOS isn't really Linux ###
|
||||
|
||||
When folks ask me if ChromeOS is a Linux distribution, I usually reply that ChromeOS is to Linux what OS X is to BSD. In other words, I consider ChromeOS to be a forked operating system that uses the Linux kernel under the hood. Much of the operating system is made up of Google's own proprietary blend of code and software.
|
||||
|
||||
So while the ChromeOS is using the Linux kernel under its hood, it's still very different from what we might find with today's modern Linux distributions.
|
||||
|
||||
Where ChromeOS's difference becomes most apparent, however, is in the apps it offers the end user: Web applications. With everything being launched from a browser window, Linux users might find using ChromeOS to be a bit vanilla. But for non-Linux users, the experience is not all that different than what they may have used on their old PCs.
|
||||
|
||||
For example: Anyone who is living a Google-centric lifestyle on Windows will feel right at home on ChromeOS. Odds are this individual is already relying on the Chrome browser, Google Drive and Gmail. By extension, moving over to ChromeOS feels fairly natural for these folks, as they're simply using the browser they're already used to.
|
||||
|
||||
Linux enthusiasts, however, tend to feel constrained almost immediately. Software choices feel limited and boxed in, plus games and VoIP are totally out of the question. Sorry, but [GooglePlus Hangouts][3] isn't a replacement for [VoIP][4] software. Not even by a long shot.
|
||||
|
||||
### ChromeOS or Linux on the desktop ###
|
||||
|
||||
Anyone making the claim that ChromeOS hurts Linux adoption on the desktop needs to come up for air and meet non-technical users sometime.
|
||||
|
||||
Yes, desktop Linux is absolutely fine for most casual computer users. However it helps to have someone to install the OS and offer "maintenance" services like we see in the Windows and OS X camps. Sadly Linux lacks this here in the States, which is where I see ChromeOS coming into play.
|
||||
|
||||
I've found the Linux desktop is best suited for environments where on-site tech support can manage things on the down-low. Examples include: Homes where advanced users can drop by and handle updates, governments and schools with IT departments. These are environments where Linux on the desktop is set up to be used by users of any skill level or background.
|
||||
|
||||
By contrast, ChromeOS is built to be completely maintenance free, thus not requiring any third part assistance short of turning it on and allowing updates to do the magic behind the scenes. This is partly made possible due to the ChromeOS being designed for specific hardware builds, in a similar spirit to how Apple develops their own computers. Because Google has a pulse on the hardware ChromeOS is bundled with, it allows for a generally error free experience. And for some individuals, this is fantastic!
|
||||
|
||||
Comically, the folks who exclaim that there's a problem here are not even remotely the target market for ChromeOS. In short, these are passionate Linux enthusiasts looking for something to gripe about. My advice? Stop inventing problems where none exist.
|
||||
|
||||
The point is: the market share for ChromeOS and Linux on the desktop are not even remotely the same. This could change in the future, but at this time, these two groups are largely separate.
|
||||
|
||||
### ChromeOS use is growing ###
|
||||
|
||||
No matter what your view of ChromeOS happens to be, the fact remains that its adoption is growing. New computers built for ChromeOS are being released all the time. One of the most recent ChromeOS computer releases is from Dell. Appropriately named the [Dell Chromebox][5], this desktop ChromeOS appliance is yet another shot at traditional computing. It has zero software DVDs, no anti-malware software, and offfers completely seamless updates behind the scenes. For casual users, Chromeboxes and Chromebooks are becoming a viable option for those who do most of their work from within a web browser.
|
||||
|
||||
Despite this growth, ChromeOS appliances face one huge downside – storage. Bound by limited hard drive size and a heavy reliance on cloud storage, ChromeOS isn't going to cut it for anyone who uses their computers outside of basic web browser functionality.
|
||||
|
||||
### ChromeOS and Linux crossing streams ###
|
||||
|
||||
Previously, I mentioned that ChromeOS and Linux on the desktop are in two completely separate markets. The reason why this is the case stems from the fact that the Linux community has done a horrid job at promoting Linux on the desktop offline.
|
||||
|
||||
Yes, there are occasional events where casual folks might discover this "Linux thing" for the first time. But there isn't a single entity to then follow up with these folks, making sure they’re getting their questions answered and that they're getting the most out of Linux.
|
||||
|
||||
In reality, the likely offline discovery breakdown goes something like this:
|
||||
|
||||
- Casual user finds out Linux from their local Linux event.
|
||||
- They bring the DVD/USB device home and attempt to install the OS.
|
||||
- While some folks very well may have success with the install process, I've been contacted by a number of folks with the opposite experience.
|
||||
- Frustrated, these folks are then expected to "search" online forums for help. Difficult to do on a primary computer experiencing network or video issues.
|
||||
- Completely fed up, some of the above frustrated bring their computers back into a Windows shop for "repair." In addition to Windows being re-installed, they also receive an earful about how "Linux isn't for them" and should be avoided.
|
||||
|
||||
Some of you might charge that the above example is exaggerated. I would respond with this: It's happened to people I know personally and it happens often. Wake up Linux community, our adoption model is broken and tired.
|
||||
|
||||
### Great platforms, horrible marketing and closing thoughts ###
|
||||
|
||||
If there is one thing that I feel ChromeOS and Linux on the desktop have in common...besides the Linux kernel, it's that they both happen to be great products with rotten marketing. The advantage however, goes to Google with this one, due to their ability to spend big money online and reserve shelf space at big box stores.
|
||||
|
||||
Google believes that because they have the "online advantage" that offline efforts aren't really that important. This is incredibly short-sighted and reflects one of Google's biggest missteps. The belief that if you're not exposed to their online efforts, you're not worth bothering with, is only countered by local shelf-space at select big box stores.
|
||||
|
||||
My suggestion is this – offer Linux on the desktop to the ChromeOS market through offline efforts. This means Linux User Groups need to start raising funds to be present at county fairs, mall kiosks during the holiday season and teaching free classes at community centers. This will immediately put Linux on the desktop in front of the same audience that might otherwise end up with a ChromeOS powered appliance.
|
||||
|
||||
If local offline efforts like this don't happen, not to worry. Linux on the desktop will continue to grow as will the ChromeOS market. Sadly though, it will absolutely keep the two markets separate as they are now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/chromeos-vs-linux-the-good-the-bad-and-the-ugly-1.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://en.wikipedia.org/wiki/Chrome_OS
|
||||
[2]:http://www.google.com/chrome/devices/features/
|
||||
[3]:https://plus.google.com/hangouts
|
||||
[4]:http://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]:http://www.pcworld.com/article/2602845/dell-brings-googles-chrome-os-to-desktops.html
|
||||
@ -1,74 +0,0 @@
|
||||
Translating by GOLinux!
|
||||
How to install Arch Linux the easy way with Evo/Lution
|
||||
================================================================================
|
||||
The one who ventures into an install of Arch Linux and has only experienced installing Linux with Ubuntu or Mint is in for a steep learning curve. The number of people giving up halfway is probably higher than the ones that pull it through. Arch Linux is somewhat cult in the way that you may call yourself a weathered Linux user if you succeed in setting it up and configuring it in a useful way.
|
||||
|
||||
Even though there is a [helpful wiki][1] to guide newcomers, the requirements are still too high for some who set out to conquer Arch. You need to be at least familiar with commands like fdisk or mkfs in a terminal and have heard of mc, nano or chroot to make it through this endeavour. It reminds me of a Debian install 10 years ago.
|
||||
|
||||
For those ambitious souls that still lack some knowledge, there is an installer in the form of an ISO image called [Evo/Lution Live ISO][2] to the rescue. Even though it is booted like a distribution of its own, it does nothing but assist with installing a barebone Arch Linux. Evo/Lution is a project that aims to diversify the user base of Arch by providing a simple way of installing Arch as well as a community that provides comprehensive help and documentation to that group of users. In this mix, Evo is the (non-installable) live CD and Lution is the installer itself. The project's founders see a widening gap between Arch developers and users of Arch and its derivative distributions, and want to build a community with equal roles between all participants.
|
||||
|
||||

|
||||
|
||||
The software part of the project is the CLI installer Lution-AIS which explains every step of what happens during the installation of a pure vanilla Arch. The resulting installation will have all the latest software that Arch has to offer without adding anything from AUR or any other custom packages.
|
||||
|
||||
After booting up the ISO image, which weighs in at 422 MB, we are presented with a workspace consisting of a Conky display on the right with shortcuts to the options and a LX-Terminal on the left waiting to run the installer.
|
||||
|
||||

|
||||
|
||||
After setting off the actual installer by either right-clicking on the desktop or using ALT-i, you are presented with a list of 16 jobs to be run. It makes sense to run them all unless you know better. You can either run them one by one or make a selection like 1 3 6 or 1-4 or do them all at once by entering 1-16. Most steps need to be confirmed with a 'y' for yes, and the next task waits for you to hit Enter. This will allow time to read the installation guide which is hidden behind ALT-g or even walking away from it.
|
||||
|
||||
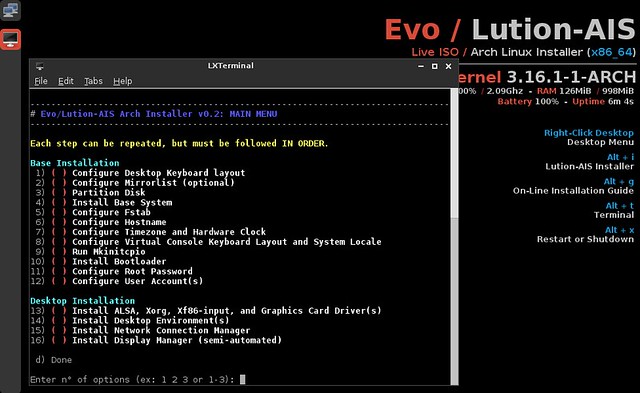
|
||||
|
||||
The 16 steps are divided in "Base Install" and "Desktop Install". The first group takes care of localization, partitioning, and installing a bootloader.
|
||||
|
||||
The installer leads you through partitioning with gparted, gdisk, and cfdisk as options.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
After you have created partitions (e.g., /dev/sda1 for root and /dev/sda2 for swap using gparted as shown in the screenshot), you can choose 1 out of 10 file systems. In the next step, you can choose your kernel (latest or LTS) and base system.
|
||||
|
||||

|
||||
|
||||
After installing the bootloader of your choice, the first part of the install is done, which takes approximately 12 minutes. This is the point where in plain Arch Linux you reboot into your system for the first time.
|
||||
|
||||
With Lution you just move on to the second part which installs Xorg, sound and graphics drivers, and then moves on to desktop environments.
|
||||
|
||||

|
||||
|
||||
The installer detects if an install is done in VirtualBox, and will automatically install and load the right generic drivers for the VM and sets up **systemd** accordingly.
|
||||
|
||||
In the next step, you can choose between the desktop environments KDE, Gnome, Cinnamon, LXDE, Enlightenment, Mate or XFCE. Should you not be friends with the big ships, you can also go with a Window manager like Awesome, Fluxbox, i3, IceWM, Openbox or PekWM.
|
||||
|
||||

|
||||
|
||||
Part two of the installer will take under 10 minutes with Cinnamon as the desktop environment; however, KDE will take longer due to a much larger download.
|
||||
|
||||
Lution-AIS worked like a charm on two tries with Cinnamon and Awesome. After the installer was done and prompted me to reboot, it took me to the desired environments.
|
||||
|
||||

|
||||
|
||||
I have only two points to criticize: when the installer offered me to choose a mirror list and when it created the fstab file. In both cases it opened a second terminal, prompting me with an informational text. It took me a while to figure out I had to close the terminals before the installer would move on. When it prompts you after creating fstab, you need to close the terminal, and answer 'yes' when asked if you want to save the file.
|
||||
|
||||

|
||||
|
||||
The second of my issues probably has to do with VirtualBox. When starting up, you may see a message that no network has been detected. Clicking on the top icon on the left will open wicd, the network manager that is used here. Clicking on "Disconnect" and then "Connect" and restarting the installer will get it automatically detected.
|
||||
|
||||
Evo/Lution seems a worthwhile project, where Lution works fine. Not much can be said on the community part yet. They started a brand new website, forum, and wiki that need to be filled with content first. So if you like the idea, join [their forum][3] and let them know. The ISO image can be downloaded from [the website][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/install-arch-linux-easy-way-evolution.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/ferdinand
|
||||
[1]:https://wiki.archlinux.org/
|
||||
[2]:http://www.evolutionlinux.com/
|
||||
[3]:http://www.evolutionlinux.com/forums/
|
||||
[4]:http://www.evolutionlinux.com/downloads.html
|
||||
@ -1,72 +0,0 @@
|
||||
How to use CloudFlare as a ddclient provider under Ubuntu
|
||||
================================================================================
|
||||
DDclient is a Perl client used to update dynamic DNS entries for accounts on Dynamic DNS Network Service Provider. It was originally written by Paul Burry and is now mostly by wimpunk. It has the capability to update more than just dyndns and it can fetch your WAN-ipaddress in a few different ways.
|
||||
|
||||
CloudFlare, however, has a little known feature that will allow you to update your DNS records via API or a command line script called ddclient. This will give you the same result, and it's also free.
|
||||
|
||||
Unfortunately, ddclient does not work with CloudFlare out of the box. There is a patch available and here is how to hack it up on Debian or Ubuntu, also works in Raspbian with Raspberry Pi.
|
||||
|
||||
### Requirements ###
|
||||
|
||||
Make sure you have a domain name that you own and Sign up to CloudFlare ,add your domain name. Follow the instructions, the default values it gives should be fine.You'll be letting CloudFlare host your domain so you need to adjust the settings at your registrar.If you'd like to use a subdomain, add an ‘A' record for it. Any IP address will do for now.
|
||||
|
||||
### Install ddclient on ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install ddclient
|
||||
|
||||
Now you need to install the patch using the following commands
|
||||
|
||||
sudo apt-get install curl sendmail libjson-any-perl libio-socket-ssl-perl
|
||||
|
||||
curl -O http://blog.peter-r.co.uk/uploads/ddclient-3.8.0-cloudflare-22-6-2014.patch
|
||||
|
||||
sudo patch /usr/sbin/ddclient < ddclient-3.8.0-cloudflare-22-6-2014.patch
|
||||
|
||||
The above commands completes the ddclient and patch
|
||||
|
||||
### Configuring ddclient ###
|
||||
|
||||
You need to edit the ddclient.conf file using the following command
|
||||
|
||||
sudo vi /etc/ddclient.conf
|
||||
|
||||
Add the following information
|
||||
|
||||
##
|
||||
### CloudFlare (cloudflare.com)
|
||||
###
|
||||
ssl=yes
|
||||
use=web, web=dyndns
|
||||
protocol=cloudflare, \
|
||||
server=www.cloudflare.com, \
|
||||
zone=domain.com, \
|
||||
login=you@email.com, \
|
||||
password=api-key \
|
||||
host.domain.com
|
||||
|
||||
Comment out:
|
||||
|
||||
#daemon=300
|
||||
|
||||
Your api-key comes from the cloudflare account page
|
||||
|
||||
ssl=yes might already be in that file
|
||||
|
||||
use=web, web=dyndns will use dyndns to check IP (useful for NAT)
|
||||
|
||||
You're done. Log in to https://www.cloudflare.com and check that the IP listed for your domain matches http://checkip.dyndns.com
|
||||
|
||||
To verify your settings using the following command
|
||||
|
||||
sudo ddclient -daemon=0 -debug -verbose -noquiet
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/how-to-use-cloudflare-as-a-ddclient-provider-under-ubuntu.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,84 @@
|
||||
Linux FAQs with Answers--How to build a RPM or DEB package from the source with CheckInstall
|
||||
================================================================================
|
||||
> **Question**: I would like to install a software program by building it from the source. Is there a way to build and install a package from the source, instead of running "make install"? That way, I could uninstall the program easily later if I want to.
|
||||
|
||||
If you have installed a Linux program from its source by running "make install", it becomes really tricky to remove it completely, unless the author of the program provides an uninstall target in the Makefile. You will have to compare the complete list of files in your system before and after installing the program from source, and manually remove all the files that were added during the installation.
|
||||
|
||||
That is when CheckInstall can come in handy. CheckInstall keeps track of all the files created or modified by an install command line (e.g., "make install" "make install_modules", etc.), and builds a standard binary package, giving you the ability to install or uninstall it with your distribution's standard package management system (e.g., yum for Red Hat or apt-get for Debian). It has been also known to work with Slackware, SuSe, Mandrake and Gentoo as well, as per the [official documentation][1].
|
||||
|
||||
In this post, we will only focus on Red Hat and Debian based distributions, and show how to build a RPM or DEB package from the source using CheckInstall.
|
||||
|
||||
### Installing CheckInstall on Linux ###
|
||||
|
||||
To install CheckInstall on Debian derivatives:
|
||||
|
||||
# aptitude install checkinstall
|
||||
|
||||
To install CheckInstall on Red Hat-based distributions, you will need to download a pre-built .rpm of CheckInstall (e.g., searchable from [http://rpm.pbone.net][2]), as it has been removed from the Repoforge repository. The .rpm package for CentOS 6 works in CentOS 7 as well.
|
||||
|
||||
# wget ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/ikoinoba/CentOS_CentOS-6/x86_64/checkinstall-1.6.2-3.el6.1.x86_64.rpm
|
||||
# yum install checkinstall-1.6.2-3.el6.1.x86_64.rpm
|
||||
|
||||
Once checkinstall is installed, you can use the following format to build a package for particular software.
|
||||
|
||||
# checkinstall <install-command>
|
||||
|
||||
Without <install-command> argument, the default install command "make install" will be used.
|
||||
|
||||
### Build a RPM or DEB Pacakge with CheckInstall ###
|
||||
|
||||
In this example, we will build a package for [htop][3], an interactive text-mode process viewer for Linux (like top on steroids).
|
||||
|
||||
First, let's download the source code from the official website of the project. As a best practice, we will store the tarball in /usr/local/src, and untar it.
|
||||
|
||||
# cd /usr/local/src
|
||||
# wget http://hisham.hm/htop/releases/1.0.3/htop-1.0.3.tar.gz
|
||||
# tar xzf htop-1.0.3.tar.gz
|
||||
# cd htop-1.0.3
|
||||
|
||||
Let's find out the install command for htop, so that we can invoke checkinstall with the command. As shown below, htop is installed with 'make install' command.
|
||||
|
||||
# ./configure
|
||||
# make install
|
||||
|
||||
Therefore, to build a htop package, we can invoke checkinstall without any argument, which will then use 'make install' command to build a package. Along the process, the checkinstall command will ask you a series of questions.
|
||||
|
||||
In short, here are the commands to build a package for **htop**:
|
||||
|
||||
# ./configure
|
||||
# checkinstall
|
||||
|
||||
Answer 'y' to "Should I create a default set of package docs?":
|
||||
|
||||

|
||||
|
||||
You can enter a brief description of the package, then press Enter twice:
|
||||
|
||||

|
||||
|
||||
Enter a number to modify any of the following values or Enter to proceed:
|
||||
|
||||
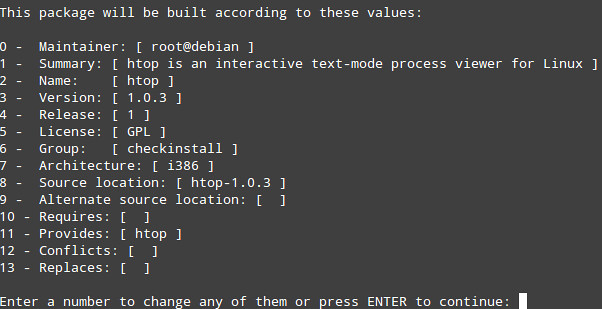
|
||||
|
||||
Then checkinstall will create a .rpm or a .deb package automatically, depending on what your Linux system is:
|
||||
|
||||
On CentOS 7:
|
||||
|
||||
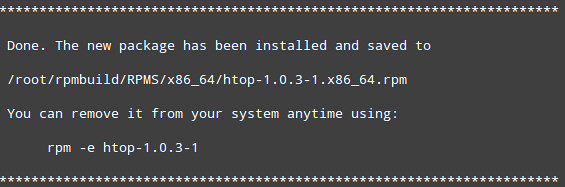
|
||||
|
||||
On Debian 7:
|
||||
|
||||
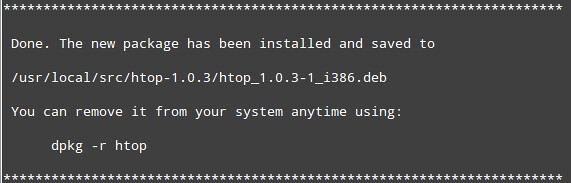
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/build-rpm-deb-package-source-checkinstall.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://checkinstall.izto.org/docs/README
|
||||
[2]:http://rpm.pbone.net/
|
||||
[3]:http://ask.xmodulo.com/install-htop-centos-rhel.html
|
||||
@ -0,0 +1,30 @@
|
||||
Linux FAQs with Answers--How to catch and handle a signal in Perl
|
||||
================================================================================
|
||||
> **Question**: I need to handle an interrupt signal by using a custom signal handler in Perl. In general, how can I catch and handle various signals (e.g., INT, TERM) in a Perl program?
|
||||
|
||||
As an asynchronous notification mechanism in the POSIX standard, a signal is sent by an operating system to a process to notify it of a certain event. When a signal is generated, the target process's execution is interrupted by an operating system, and the signal is delivered to the process's signal handler routine. One can define and register a custom signal handler or rely on the default signal handler.
|
||||
|
||||
In Perl, signals can be caught and handled by using a global %SIG hash variable. This %SIG hash variable is keyed by signal numbers, and contains references to corresponding signal handlers. Therefore, if you want to define a custom signal handler for a particular signal, you can simply update the hash value of %SIG for the signal.
|
||||
|
||||
Here is a code snippet to handle interrupt (INT) and termination (TERM) signals using a custom signal handler.
|
||||
|
||||
$SIG{INT} = \&signal_handler;
|
||||
$SIG{TERM} = \&signal_handler;
|
||||
|
||||
sub signal_handler {
|
||||
print "This is a custom signal handler\n";
|
||||
die "Caught a signal $!";
|
||||
}
|
||||
|
||||

|
||||
|
||||
Other valid hash values for %SIG are 'IGNORE' and 'DEFAULT'. When an assigned hash value is 'IGNORE' (e.g., $SIG{CHLD}='IGNORE'), the corresponding signal will be ignored. Assigning 'DEFAULT' hash value (e.g., $SIG{HUP}='DEFAULT') means that we will be using a default signal handler.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/catch-handle-interrupt-signal-perl.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,69 @@
|
||||
Linux FAQs with Answers--How to change a network interface name on CentOS 7
|
||||
================================================================================
|
||||
> **Question**: On CentOS 7, I would like to change the assigned name of a network interface to something else. What is a proper way to rename a network interface on CentOS or RHEL 7?
|
||||
|
||||
Traditionally, network interfaces in Linux are enumerated as eth[0123...], but these names do not necessarily correspond to actual hardware slots, PCI geography, USB port number, etc. This introduces a unpredictable naming problem (e.g., due to undeterministic device probing behavior) which can cause various network misconfigurations (e.g., disabled interface or firewall bypass resulting from unintentional interface renaming). MAC address based udev rules are not so much helpful in a virtualized environment where MAC addresses are as euphemeral as port numbers.
|
||||
|
||||
CentOS/RHEL 6 has introduced a method for [consistent and predictable network device naming][1] for network interfaces. These features uniquely determine the name of network interfaces in order to make locating and differentiating the interfaces easier and in such a way that it is persistent across later boots, time, and hardware changes. However, this naming rule is not turned on by default on CentOS/RHEL 6.
|
||||
|
||||
Starting with CentOS/RHEL 7, the predictable naming rule is adopted by default. Under this rule, interface names are automatically determined based on firmware, topology, and location information. Now interface names stay fixed even if NIC hardware is added or removed without re-enumeration, and broken hardware can be replaced seamlessly.
|
||||
|
||||
* Two character prefixes based on the type of interface:
|
||||
* en -- ethernet
|
||||
* sl -- serial line IP (slip)
|
||||
* wl -- wlan
|
||||
* ww -- wwan
|
||||
*
|
||||
* Type of names:
|
||||
* b<number> -- BCMA bus core number
|
||||
* ccw<name> -- CCW bus group name
|
||||
* o<index> -- on-board device index number
|
||||
* s<slot>[f<function>][d<dev_port>] -- hotplug slot index number
|
||||
* x<MAC> -- MAC address
|
||||
* [P<domain>]p<bus>s<slot>[f<function>][d<dev_port>]
|
||||
* -- PCI geographical location
|
||||
* [P<domain>]p<bus>s<slot>[f<function>][u<port>][..]1[i<interface>]
|
||||
* -- USB port number chain
|
||||
|
||||
A minor disadvantage of this new naming scheme is that the interface names are somewhat harder to read than the traditional names. For example, you may find names like enp0s3. Besides, you no longer have any control over such interface names.
|
||||
|
||||
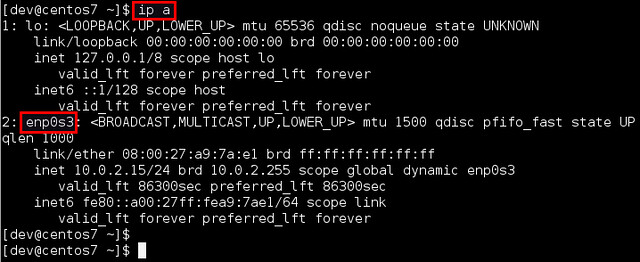
|
||||
|
||||
If, for some reason, you prefer the old way, and want to be able to assign any arbitrary name of your choice to an interface on CentOS/RHEL 7, you need to override the default predictable naming rule, and define a MAC address based udev rule.
|
||||
|
||||
**Here is how to rename a network interface on CentOS or RHEL 7.**
|
||||
|
||||
First, let's disable the predictable naming rule. For that, you can pass "net.ifnames=0" kernel parameter during boot. This is achieved by editing /etc/default/grub and adding "net.ifnames=0" to GRUB_CMDLINE_LINUX variable.
|
||||
|
||||
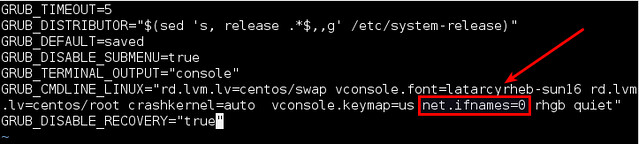
|
||||
|
||||
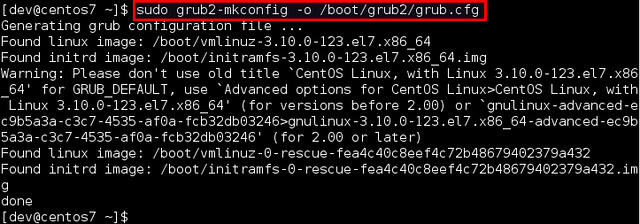
Then run this command to regenerate GRUB configuration with updated kernel parameters.
|
||||
|
||||
$ sudo grub2-mkconfig -o /boot/grub2/grub.cfg
|
||||
|
||||
|
||||
|
||||
Next, edit (or create) a udev network naming rule file (/etc/udev/rules.d/70-persistent-net.rules), and add the following line. Replace MAC address and interface with your own.
|
||||
|
||||
$ sudo vi /etc/udev/rules.d/70-persistent-net.rules
|
||||
|
||||
----------
|
||||
|
||||
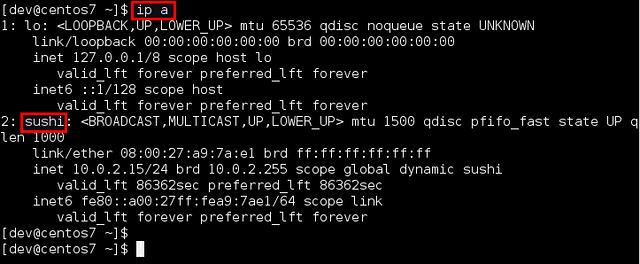
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="08:00:27:a9:7a:e1", ATTR{type}=="1", KERNEL=="eth*", NAME="sushi"
|
||||
|
||||
Finally, reboot the machine, and verify the new interface name.
|
||||
|
||||
|
||||
|
||||
Note that it is still your responsibility to configure the renamed interface. If the network configuration (e.g., IPv4 settings, firewall rules) is based on the old name (before change), you need to update network configuration to reflect the name change.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-network-interface-name-centos7.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Deployment_Guide/appe-Consistent_Network_Device_Naming.html
|
||||
@ -0,0 +1,78 @@
|
||||
Linux FAQs with Answers--How to configure a static IP address on CentOS 7
|
||||
================================================================================
|
||||
> **Question**: On CentOS 7, I want to switch from DHCP to static IP address configuration with one of my network interfaces. What is a proper way to assign a static IP address to a network interface permanently on CentOS or RHEL 7?
|
||||
|
||||
If you want to set up a static IP address on a network interface in CentOS 7, there are several different ways to do it, varying depending on whether or not you want to use Network Manager for that.
|
||||
|
||||
Network Manager is a dynamic network control and configuration system that attempts to keep network devices and connections up and active when they are available). CentOS/RHEL 7 comes with Network Manager service installed and enabled by default.
|
||||
|
||||
To verify the status of Network Manager service:
|
||||
|
||||
$ systemctl status NetworkManager.service
|
||||
|
||||
To check which network interface is managed by Network Manager, run:
|
||||
|
||||
$ nmcli dev status
|
||||
|
||||
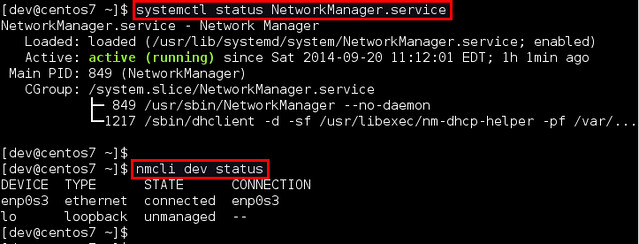
|
||||
|
||||
If the output of nmcli shows "connected" for a particular interface (e.g., enp0s3 in the example), it means that the interface is managed by Network Manager. You can easily disable Network Manager for a particular interface, so that you can configure it on your own for a static IP address.
|
||||
|
||||
Here are **two different ways to assign a static IP address to a network interface on CentOS 7**. We will be configuring a network interface named enp0s3.
|
||||
|
||||
### Configure a Static IP Address without Network Manager ###
|
||||
|
||||
Go to the /etc/sysconfig/network-scripts directory, and locate its configuration file (ifcfg-enp0s3). Create it if not found.
|
||||
|
||||

|
||||
|
||||
Open the configuration file and edit the following variables:
|
||||
|
||||
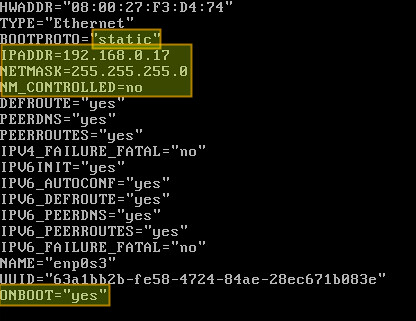
|
||||
|
||||
In the above, "NM_CONTROLLED=no" indicates that this interface will be set up using this configuration file, instead of being managed by Network Manager service. "ONBOOT=yes" tells the system to bring up the interface during boot.
|
||||
|
||||
Save changes and restart the network service using the following command:
|
||||
|
||||
# systemctl restart network.service
|
||||
|
||||
Now verify that the interface has been properly configured:
|
||||
|
||||
# ip add
|
||||
|
||||
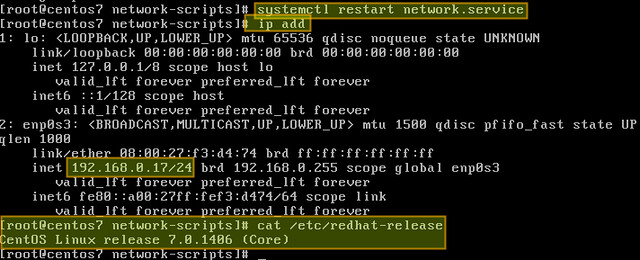
|
||||
|
||||
### Configure a Static IP Address with Network Manager ###
|
||||
|
||||
If you want to use Network Manager to manage the interface, you can use nmtui (Network Manager Text User Interface) which provides a way to configure Network Manager in a terminal environment.
|
||||
|
||||
Before using nmtui, first set "NM_CONTROLLED=yes" in /etc/sysconfig/network-scripts/ifcfg-enp0s3.
|
||||
|
||||
Now let's install nmtui as follows.
|
||||
|
||||
# yum install NetworkManager-tui
|
||||
|
||||
Then go ahead and edit the Network Manager configuration of enp0s3 interface:
|
||||
|
||||
# nmtui edit enp0s3
|
||||
|
||||
The following screen will allow us to manually enter the same information that is contained in /etc/sysconfig/network-scripts/ifcfg-enp0s3.
|
||||
|
||||
Use the arrow keys to navigate this screen, press Enter to select from a list of values (or fill in the desired values), and finally click OK at the bottom right:
|
||||
|
||||

|
||||
|
||||
Finally, restart the network service.
|
||||
|
||||
# systemctl restart network.service
|
||||
|
||||
and you're ready to go.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/configure-static-ip-address-centos7.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,53 @@
|
||||
Linux FAQs with Answers--How to detect a Linux distribution in Perl
|
||||
================================================================================
|
||||
> **Question**: I need to write a Perl program which contains Linux distro-dependent code. For that, the Perl program needs to be able to automatically detect what Linux distribution (e.g., Ubuntu, CentOS, Debian, Fedora, etc) it is running on, and what version number it is. How can I identify Linux distribution in Perl?
|
||||
|
||||
If you want to detect Linux distribution within a Perl script, you can use a Perl module named [Linux::Distribution][1]. This module guesses the underlying Linux operating system by examining /etc/lsb-release, and other distro-specific files under /etc directory. It supports detecting all major Linux distributions, including Fedora, CentOS, Arch Linux, Debian, Ubuntu, SuSe, Red Hat, Gentoo, Slackware, Knoppix, and Mandrake.
|
||||
|
||||
To use this module in a Perl program, you need to install it first.
|
||||
|
||||
### Install Linux::Distribution on Debian or Ubuntu ###
|
||||
|
||||
Installation on Debian-based system is straightforward with apt-get:
|
||||
|
||||
$ sudo apt-get install liblinux-distribution-packages-perl
|
||||
|
||||
### Install Linux::Distribution on Fedora, CentOS or RHEL ###
|
||||
|
||||
If Linux::Distribution module is not available as a package in your Linux (such as on Red Hat based systems), you can use CPAN to build it.
|
||||
|
||||
First, make sure that you have CPAN installed on your Linux system:
|
||||
|
||||
$ sudo yum -y install perl-CPAN
|
||||
|
||||
Then use this command to build and install the module:
|
||||
|
||||
$ sudo perl -MCPAN -e 'install Linux::Distribution'
|
||||
|
||||
### Identify a Linux Distribution in Perl ###
|
||||
|
||||
Once Linux::Distribution module is installed, you can use the following code snippet to identify on which Linux distribution you are running.
|
||||
|
||||
use Linux::Distribution qw(distribution_name distribution_version);
|
||||
|
||||
my $linux = Linux::Distribution->new;
|
||||
|
||||
if ($linux) {
|
||||
my $distro = $linux->distribution_name();
|
||||
my $version = $linux->distribution_version();
|
||||
print "Distro: $distro $version\n";
|
||||
}
|
||||
else {
|
||||
print "Distro: unknown\n";
|
||||
}
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/detect-linux-distribution-in-perl.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://metacpan.org/pod/Linux::Distribution
|
||||
@ -0,0 +1,39 @@
|
||||
Linux FAQs with Answers--How to embed all fonts in a PDF document generated with LaTex
|
||||
================================================================================
|
||||
> **Question**: I generated a PDF document by compiling LaTex source files. However, I noticed that not all fonts used are embedded in the PDF document. How can I make sure that all fonts are embedded in a PDF document generated from LaTex?
|
||||
|
||||
When you create a PDF file, it is a good idea to embed fonts in the PDF file. If you don't embed fonts, a PDF viewer can replace a font with something else if the font is not available on the computer. This will cause the document to be rendered differently across different PDF viewers or OS platforms. Missing fonts can also be an issue when you print out the document.
|
||||
|
||||
When you generate a PDF document from LaTex (for example with pdflatex or dvipdfm), it's possible that not all fonts are embedded in the PDF document. For example, the following output of [pdffonts][1] says that there are missing fonts (e.g., Helvetica) in a PDF document.
|
||||
|
||||

|
||||
|
||||
To avoid this kind of problems, here is how to embed all fonts at LaTex compile time.
|
||||
|
||||
$ latex document.tex
|
||||
$ dvips -Ppdf -G0 -t letter -o document.ps document.dvi
|
||||
$ ps2pdf -dPDFSETTINGS=/prepress \
|
||||
-dCompatibilityLevel=1.4 \
|
||||
-dAutoFilterColorImages=false \
|
||||
-dAutoFilterGrayImages=false \
|
||||
-dColorImageFilter=/FlateEncode \
|
||||
-dGrayImageFilter=/FlateEncode \
|
||||
-dMonoImageFilter=/FlateEncode \
|
||||
-dDownsampleColorImages=false \
|
||||
-dDownsampleGrayImages=false \
|
||||
document.ps document.pdf
|
||||
|
||||
Now you will see that all fonts are properly embedded in the PDF file.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/embed-all-fonts-pdf-document-latex.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://ask.xmodulo.com/check-which-fonts-are-used-pdf-document.html
|
||||
@ -0,0 +1,51 @@
|
||||
How To Reset Root Password On CentOS 7
|
||||
================================================================================
|
||||
The way to reset the root password on centos7 is totally different to Centos 6. Let me show you how to reset root password in CentOS 7.
|
||||
|
||||
1 – In the boot grub menu select option to edit.
|
||||
|
||||

|
||||
|
||||
2 – Select Option to edit (e).
|
||||
|
||||

|
||||
|
||||
3 – Go to the line of Linux 16 and change ro with rw init=/sysroot/bin/sh.
|
||||
|
||||

|
||||
|
||||
4 – Now press Control+x to start on single user mode.
|
||||
|
||||

|
||||
|
||||
5 – Now access the system with this command.
|
||||
|
||||
chroot /sysroot
|
||||
|
||||
6 – Reset the password.
|
||||
|
||||
passwd root
|
||||
|
||||
7 – Update selinux information
|
||||
|
||||
touch /.autorelabel
|
||||
|
||||
8 – Exit chroot
|
||||
|
||||
exit
|
||||
|
||||
9 – Reboot your system
|
||||
|
||||
reboot
|
||||
|
||||
That’s it. Enjoy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/reset-root-password-centos-7/
|
||||
|
||||
作者:M.el Khamlichi
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,151 @@
|
||||
How to manage configurations in Linux with Puppet and Augeas
|
||||
================================================================================
|
||||
Although [Puppet][1](注:此文原文原文中曾今做过,文件名:“20140808 How to install Puppet server and client on CentOS and RHEL.md”,如果翻译发布过,可修改此链接为发布地址) is a really unique and useful tool, there are situations where you could use a bit of a different approach. Situations like modification of configuration files which are already present on several of your servers and are unique on each one of them at the same time. Folks from Puppet labs realized this as well, and integrated a great tool called [Augeas][2] that is designed exactly for this usage.
|
||||
|
||||
Augeas can be best thought of as filling for the gaps in Puppet's capabilities where an objectspecific resource type (such as the host resource to manipulate /etc/hosts entries) is not yet available. In this howto, you will learn how to use Augeas to ease your configuration file management.
|
||||
|
||||
### What is Augeas? ###
|
||||
|
||||
Augeas is basically a configuration editing tool. It parses configuration files in their native formats and transforms them into a tree. Configuration changes are made by manipulating this tree and saving it back into native config files.
|
||||
|
||||
### What are we going to achieve in this tutorial? ###
|
||||
|
||||
We will install and configure the Augeas tool for use with our previously built Puppet server. We will create and test several different configurations with this tool, and learn how to properly use it to manage our system configurations.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
We will need a working Puppet server and client setup. If you don't have it, please follow my previous tutorial.
|
||||
|
||||
Augeas package can be found in our standard CentOS/RHEL repositories. Unfortunately, Puppet uses Augeas ruby wrapper which is only available in the puppetlabs repository (or [EPEL][4]). If you don't have this repository in your system already, add it using following command:
|
||||
|
||||
On CentOS/RHEL 6.5:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/6.5/products/x86_64/puppetlabsrelease610.noarch.rpm
|
||||
|
||||
On CentOS/RHEL 7:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/7/products/x86_64/puppetlabsrelease710.noarch.rpm
|
||||
|
||||
After you have successfully added this repository, install RubyAugeas in your system:
|
||||
|
||||
# yum install rubyaugeas
|
||||
|
||||
Or if you are continuing from my last tutorial, install this package using the Puppet way. Modify your custom_utils class inside of your /etc/puppet/manifests/site.pp to contain "rubyaugeas" inside of the packages array:
|
||||
|
||||
class custom_utils {
|
||||
package { ["nmap","telnet","vimenhanced","traceroute","rubyaugeas"]:
|
||||
ensure => latest,
|
||||
allow_virtual => false,
|
||||
}
|
||||
}
|
||||
|
||||
### Augeas without Puppet ###
|
||||
|
||||
As it was said in the beginning, Augeas is not originally from Puppet Labs, which means we can still use it even without Puppet itself. This approach can be useful for verifying your modifications and ideas before applying them in your Puppet environment. To make this possible, you need to install one additional package in your system. To do so, please execute following command:
|
||||
|
||||
# yum install augeas
|
||||
|
||||
### Puppet Augeas Examples ###
|
||||
|
||||
For demonstration, here are a few example Augeas use cases.
|
||||
|
||||
#### Management of /etc/sudoers file ####
|
||||
|
||||
1. Add sudo rights to wheel group
|
||||
|
||||
This example will show you how to add simple sudo rights for group %wheel in your GNU/Linux system.
|
||||
|
||||
# Install sudo package
|
||||
package { 'sudo':
|
||||
ensure => installed, # ensure sudo package installed
|
||||
}
|
||||
|
||||
# Allow users belonging to wheel group to use sudo
|
||||
augeas { 'sudo_wheel':
|
||||
context => '/files/etc/sudoers', # The target file is /etc/sudoers
|
||||
changes => [
|
||||
# allow wheel users to use sudo
|
||||
'set spec[user = "%wheel"]/user %wheel',
|
||||
'set spec[user = "%wheel"]/host_group/host ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command/runas_user ALL',
|
||||
]
|
||||
}
|
||||
|
||||
Now let's explain what the code does: **spec** defines the user section in /etc/sudoers, **[user]** defines given user from the array, and all definitions behind slash ( / ) are subparts of this user. So in typical configuration this would be represented as:
|
||||
|
||||
user host_group/host host_group/command host_group/command/runas_user
|
||||
|
||||
Which is translated into this line of /etc/sudoers:
|
||||
|
||||
%wheel ALL = (ALL) ALL
|
||||
|
||||
2. Add command alias
|
||||
|
||||
The following part will show you how to define command alias which you can use inside your sudoers file.
|
||||
|
||||
# Create new alias SERVICES which contains some basic privileged commands
|
||||
augeas { 'sudo_cmdalias':
|
||||
context => '/files/etc/sudoers', # The target file is /etc/sudoers
|
||||
changes => [
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/name SERVICES",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[1] /sbin/service",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[2] /sbin/chkconfig",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[3] /bin/hostname",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[4] /sbin/shutdown",
|
||||
]
|
||||
}
|
||||
|
||||
Syntax of sudo command aliases is pretty simple: **Cmnd_Alias** defines the section of command aliases, **[alias/name]** binds all to given alias name, /alias/name **SERVICES** defines the actual alias name and alias/command is the array of all the commands that should be part of this alias. The output of this command will be following:
|
||||
|
||||
Cmnd_Alias SERVICES = /sbin/service , /sbin/chkconfig , /bin/hostname , /sbin/shutdown
|
||||
|
||||
For more information about /etc/sudoers, visit the [official documentation][5].
|
||||
|
||||
#### Adding users to a group ####
|
||||
|
||||
To add users to groups using Augeas, you might want to add the new user either after the gid field or after the last user. We'll use group SVN for the sake of this example. This can be achieved by using the following command:
|
||||
|
||||
In Puppet:
|
||||
|
||||
augeas { 'augeas_mod_group:
|
||||
context => '/files/etc/group', # The target file is /etc/group
|
||||
changes => [
|
||||
"ins user after svn/*[self::gid or self::user][last()]",
|
||||
"set svn/user[last()] john",
|
||||
]
|
||||
}
|
||||
|
||||
Using augtool:
|
||||
|
||||
augtool> ins user after /files/etc/group/svn/*[self::gid or self::user][last()] augtool> set /files/etc/group/svn/user[last()] john
|
||||
|
||||
### Summary ###
|
||||
|
||||
By now, you should have a good idea on how to use Augeas in your Puppet projects. Feel free to experiment with it and definitely go through the official Augeas documentation. It will help you get the idea how to use Augeas properly in your own projects, and it will show you how much time you can actually save by using it.
|
||||
|
||||
If you have any questions feel free to post them in the comments and I will do my best to answer them and advise you.
|
||||
|
||||
### Useful Links ###
|
||||
|
||||
- [http://www.watzmann.net/categories/augeas.html][6]: contains a lot of tutorials focused on Augeas usage.
|
||||
- [http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas][7]: Puppet wiki with a lot of practical examples.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/manage-configurations-linux-puppet-augeas.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
[2]:http://augeas.net/
|
||||
[3]:http://xmodulo.com/manage-configurations-linux-puppet-augeas.html
|
||||
[4]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://augeas.net/docs/references/lenses/files/sudoers-aug.html
|
||||
[6]:http://www.watzmann.net/categories/augeas.html
|
||||
[7]:http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas
|
||||
@ -0,0 +1,120 @@
|
||||
How to monitor user login history on CentOS with utmpdump
|
||||
================================================================================
|
||||
Keeping, maintaining and analyzing logs (i.e., accounts of events that have happened during a certain period of time or are currently happening) are among the most basic and essential tasks of a Linux system administrator. In case of user management, examining user logon and logout logs (both failed and successful) can alert us about any potential security breaches or unauthorized use of our system. For example, remote logins from unknown IP addresses or accounts being used outside working hours or during vacation leave should raise a red flag.
|
||||
|
||||
On a CentOS system, user login history is stored in the following binary files:
|
||||
|
||||
- /var/run/utmp (which logs currently open sessions) is used by who and w tools to show who is currently logged on and what they are doing, and also by uptime to display system up time.
|
||||
- /var/log/wtmp (which stores the history of connections to the system) is used by last tool to show the listing of last logged-in users.
|
||||
- /var/log/btmp (which logs failed login attempts) is used by lastb utility to show the listing of last failed login attempts. `
|
||||
|
||||
|
||||
|
||||
In this post I'll show you how to use utmpdump, a simple program from the sysvinit-tools package that can be used to dump these binary log files in text format for inspection. This tool is available by default on stock CentOS 6 and 7. The information gleaned from utmpdump is more comprehensive than the output of the tools mentioned earlier, and that's what makes it a nice utility for the job. Besides, utmpdump can be used to modify utmp or wtmp, which can be useful if you want to fix any corrupted entries in the binary logs.
|
||||
|
||||
### How to Use Utmpdump and Interpret its Output ###
|
||||
|
||||
As we mentioned earlier, these log files, as opposed to other logs most of us are familiar with (e.g., /var/log/messages, /var/log/cron, /var/log/maillog), are saved in binary file format, and thus we cannot use pagers such as less or more to view their contents. That is where utmpdump saves the day.
|
||||
|
||||
In order to display the contents of /var/run/utmp, run the following command:
|
||||
|
||||
# utmpdump /var/run/utmp
|
||||
|
||||
|
||||
|
||||
To do the same with /var/log/wtmp:
|
||||
|
||||
# utmpdump /var/log/wtmp
|
||||
|
||||
|
||||
|
||||
and finally with /var/log/btmp:
|
||||
|
||||
# utmpdump /var/log/btmp
|
||||
|
||||

|
||||
|
||||
As you can see, the output formats of three cases are identical, except for the fact that the records in the utmp and btmp are arranged chronologically, while in the wtmp, the order is reversed.
|
||||
|
||||
Each log line is formatted in multiple columns described as follows. The first field shows a session identifier, while the second holds PID. The third field can hold one of the following values: ~~ (indicating a runlevel change or a system reboot), bw (meaning a bootwait process), a digit (indicates a TTY number), or a character and a digit (meaning a pseudo-terminal). The fourth field can be either empty or hold the user name, reboot, or runlevel. The fifth field holds the main TTY or PTY (pseudo-terminal), if that information is available. The sixth field holds the name of the remote host (if the login is performed from the local host, this field is blank, except for run-level messages, which will return the kernel version). The seventh field holds the IP address of the remote system (if the login is performed from the local host, this field will show 0.0.0.0). If DNS resolution is not provided, the sixth and seventh fields will show identical information (the IP address of the remote system). The last (eighth) field indicates the date and time when the record was created.
|
||||
|
||||
### Usage Examples of Utmpdump ###
|
||||
|
||||
Here are a few simple use cases of utmpdump.
|
||||
|
||||
1. Check how many times (and at what times) a particular user (e.g., gacanepa) logged on to the system between August 18 and September 17.
|
||||
|
||||
# utmpdump /var/log/wtmp | grep gacanepa
|
||||
|
||||
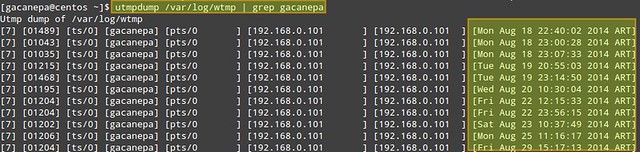
|
||||
|
||||
If you need to review login information from prior dates, you can check the wtmp-YYYYMMDD (or wtmp.[1...N]) and btmp-YYYYMMDD (or btmp.[1...N]) files in /var/log, which are the old archives of wtmp and btmp files, generated by [logrotate][1].
|
||||
|
||||
2. Count the number of logins from IP address 192.168.0.101.
|
||||
|
||||
# utmpdump /var/log/wtmp | grep 192.168.0.101
|
||||
|
||||
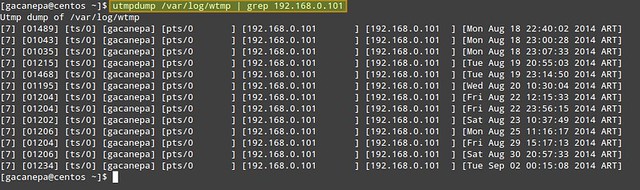
|
||||
|
||||
3. Display failed login attempts.
|
||||
|
||||
# utmpdump /var/log/btmp
|
||||
|
||||
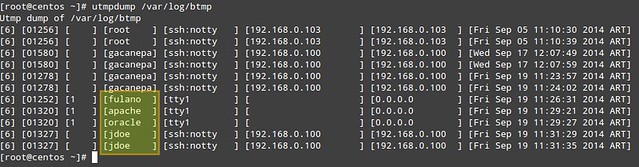
|
||||
|
||||
In the output of /var/log/btmp, every log line corresponds to a failed login attempt (e.g., using incorrect password or a non-existing user ID). Logon using non-existing user IDs are highlighted in the above impage, which can alert you that someone is attempting to break into your system by guessing commonly-used account names. This is particularly serious in the cases when the tty1 was used, since it means that someone had access to a terminal on your machine (time to check who has keys to your datacenter, maybe?).
|
||||
|
||||
4. Display login and logout information per user session.
|
||||
|
||||
# utmpdump /var/log/wtmp
|
||||
|
||||

|
||||
|
||||
In /var/log/wtmp, a new login event is characterized by '7' in the first field, a terminal number (or pseudo-terminal id) in the third field, and username in the fourth. The corresponding logout event will be represented by '8' in the first field, the same PID as the login in the second field, and a blank terminal number field. For example, take a close look at PID 1463 in the above image.
|
||||
|
||||
- On [Fri Sep 19 11:57:40 2014 ART] the login prompt appeared in tty1.
|
||||
- On [Fri Sep 19 12:04:21 2014 ART], user root logged on.
|
||||
- On [Fri Sep 19 12:07:24 2014 ART], root logged out.
|
||||
|
||||
On a side note, the word LOGIN in the fourth field means that a login prompt is present in the terminal specified in the fifth field.
|
||||
|
||||
So far I covered somewhat trivial examples. You can combine utmpdump with other text sculpting tools such as awk, sed, grep or cut to produce filtered and enhanced output.
|
||||
|
||||
For example, you can use the following command to list all login events of a particular user (e.g., gacanepa) and send the output to a .csv file that can be viewed with a pager or a workbook application, such as LibreOffice's Calc or Microsoft Excel. Let's display PID, username, IP address and timestamp only:
|
||||
|
||||
# utmpdump /var/log/wtmp | grep -E "\[7].*gacanepa" | awk -v OFS="," 'BEGIN {FS="] "}; {print $2,$4,$7,$8}' | sed -e 's/\[//g' -e 's/\]//g'
|
||||
|
||||
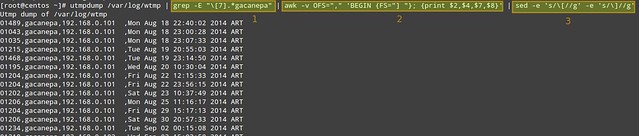
|
||||
|
||||
As represented with three blocks in the image, the filtering logic is composed of three pipelined steps. The first step is used to look for login events ([7]) triggered by user gacanepa. The second and third steps are used to select desired fields, remove square brackets in the output of utmpdump, and set the output field separator to a comma.
|
||||
|
||||
Of course, you need to redirect the output of the above command to a file if you want to open it later (append "> [name_of_file].csv" to the command).
|
||||
|
||||
|
||||
|
||||
In more complex examples, if you want to know what users (as listed in /etc/passwd) have not logged on during the period of time, you could extract user names from /etc/passwd, and then run grep the utmpdump output of /var/log/wtmp against user list. As you see, possibility is limitless.
|
||||
|
||||
Before concluding, let's briefly show yet another use case of utmpdump: modify utmp or wtmp. As these are binary log files, you cannot edit them as is. Instead, you can export their content to text format, modify the text output, and then import the modified content back to the binary logs. That is:
|
||||
|
||||
# utmpdump /var/log/utmp > tmp_output
|
||||
<modify tmp_output using a text editor>
|
||||
# utmpdump -r tmp_output > /var/log/utmp
|
||||
|
||||
This can be useful when you want to remove or fix any bogus entry in the binary logs.
|
||||
|
||||
To sum up, utmpdump complements standard utilities such as who, w, uptime, last, lastb by dumping detailed login events stored in utmp, wtmp and btmp log files, as well as in their rotated old archives, and that certainly makes it a great utility.
|
||||
|
||||
Feel free to enhance this post with your comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/monitor-user-login-history-centos-utmpdump.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/2014/09/logrotate-manage-log-files-linux.html
|
||||
@ -0,0 +1,37 @@
|
||||
Canonical在Ubuntu 14.04 LTS中关闭了一个nginx漏洞
|
||||
================================================================================
|
||||
> 用户不得不升级他们的系统来修复这个漏洞
|
||||
|
||||

|
||||
|
||||
Ubuntu 14.04 LTS
|
||||
|
||||
**Canonical已经在安全公告中公布了这个影响到Ubuntu 14.04 LTS (Trusty Tahr)的nginx漏洞的细节。这个问题已经被确定并被修复了**
|
||||
|
||||
Ubuntu的开发者已经修复了nginx的一个小漏洞。他们解释nginx可能已经被用来暴露网络上的敏感信息。
|
||||
|
||||
|
||||
根据安全公告,“Antoine Delignat-Lavaud和Karthikeyan Bhargavan发现nginx错误地重复使用了缓存的SSL会话。攻击者可能利用此问题,在特定的配置下,可以从不同的虚拟主机获得信息“。
|
||||
|
||||
对于这些问题的更详细的描述,可以看到Canonical的安全[公告][1]。用户应该升级自己的Linux发行版以解决此问题。
|
||||
|
||||
这个问题可以通过在系统升级到最新nginx包(和依赖v包)进行修复。要应用该补丁,你可以直接运行升级管理程序。
|
||||
|
||||
如果你不想使用软件更新器,您可以打开终端,输入以下命令(需要root权限):
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
在一般情况下,一个标准的系统更新将会进行必要的更改。要应用此修补程序您不必重新启动计算机。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Canonical-Closes-Nginx-Exploit-in-Ubuntu-14-04-LTS-459677.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://www.ubuntu.com/usn/usn-2351-1/
|
||||
@ -1,43 +0,0 @@
|
||||
|
||||
Debian 8 "Jessie" 可能将使用GNOME作为默认桌面
|
||||
================================================== ==============================
|
||||
> Debian的GNOME团队已经取得了一定的进展
|
||||
|
||||

|
||||
|
||||
GNOME 3.14桌面
|
||||
|
||||
**从Debian项目开发者在相当长一段时间试图决定是否执行的Xfce,GNOME或一些其他桌面环境在默认情况下,但至少暂时看起来像是GNOME赢了。**
|
||||
|
||||
[我们写在两天以前][1]关于 GNOME 3.14的包都被上传到 Debian Testing 或 Debian 8“Jessie” 的仓库中,这是一个惊喜。通常情况下,GNOME的维护者是不会对任何类型的软件快速补充最新的软件包,更别说桌面环境。
|
||||
|
||||
事实证明,关于即将到来的Debian 8的发行版中实现的默认桌面的争论已经肆虐,尽管这个词可能有点过于强烈。在任何情况下,一些开发者想的Xfce,有些则是 GNOME 和它看起来像 MATE 也是在备选牌上。
|
||||
|
||||
### GNOME将成为默认的Debian 8“Jessie”,最有可能的###
|
||||
|
||||
我们说,很可能是因为协议尚未达成一致,但它看起来像GNOME是遥遥领先其他人的。Debian的维护者和开发者乔伊·赫斯解释了为什么会这样。
|
||||
|
||||
“根据从https://wiki.debian.org/DebianDesktop/Requalification/Jessie初步结果的所需数据尚未公布,但在这一点上我是在80%左右确定GNOME是未来出人头地的过程中。这是特别基于可获得性和一定程度systemd整合。辅助功能:Gnome和Mate都领先了一大截。其他一些桌面有他们前往的整合Debian的改善,部分原因是这一过程驱动的,但仍需要上游大力支持。“
|
||||
|
||||
“Systemd /etc 整合:Xfce,Mate等尽力追赶在这一领域正在发生的变化。将有时间来熨平希望这些问题出在冻结期间,一旦技术堆栈停止从下他们改变了,所以这不是一个完全的否决这些桌面,但要由目前的状态,GNOME是未来,“乔伊·赫斯[补充说][2]。
|
||||
|
||||
开发者表示,在Debian的GNOME团队已经取得了[一个真正充满激情的情况下][3],为他们保留的项目,而Debian的Xfce的团队实际上是矛盾的关于其桌面成为默认桌面。
|
||||
|
||||
在任何情况下,Debian 8“Jessie”没有一个具体推出时间,并没有迹象显示何时可能会被释放。在另一方面,GNOME 3.14是出于今日(也许它会已经被你看新闻的时候推出),它会很快将准备好进行Debian的测试。
|
||||
|
||||
我们也应该感谢Jordi Mallach,在Debian中的GNOME包的维护者之一,伸手指点我们正确的讯息。
|
||||
|
||||
-------------------------------------------------- ------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Debian-8-quot-Jessie-quot-to-Have-GNOME-as-the-Default-Desktop-459665.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[fbigun](https://github.com/fbigun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://news.softpedia.com/news/Debian-8-quot-Jessie-quot-to-Get-GNOME-3-14-459470.shtml
|
||||
[2]:http://anonscm.debian.org/cgit/tasksel/tasksel.git/commit/?id=dce99f5f8d84e4c885e6beb4cc1bb5bb1d9ee6d7
|
||||
[3]:http://news.softpedia.com/news/Debian-Maintainer-Says-that-Xfce-on-Debian-Will-Not-Meet-Quality-Standards-GNOME-Is-Needed-454962.shtml
|
||||
92
translated/talk/20140904 Making MySQL Better at GitHub.md
Normal file
92
translated/talk/20140904 Making MySQL Better at GitHub.md
Normal file
@ -0,0 +1,92 @@
|
||||
优化 GitHub 服务器上的 MySQL 数据库性能
|
||||
================================================================================
|
||||
> 在 GitHub 我们总是说“如果网站响应速度不够快,说明我们的工作没完成”。我们之前在[前端的体验速度][1]这篇文章中介绍了一些提高网站响应速率的方法,但这只是故事的一部分。真正影响到 GitHub.com 性能的因素是 MySQL 数据库架构。让我们来瞧瞧我们的基础架构团队是如何无缝升级了 MySQL 架构吧,这事儿发生在去年8月份,成果就是大大提高了 GitHub 网站的速度。
|
||||
|
||||
### 任务 ###
|
||||
|
||||
去年我们把 GitHub 上的大部分数据移到了新的数据中心,这个中心有世界顶级的硬件资源和网络平台。自从使用了 MySQL 作为我们的后端基本存储系统,我们一直期望着一些改进来大大提高数据库性能,但是在数据中心使用全新的硬件来部署一套全新的集群环境并不是一件简单的工作,所以我们制定了一套计划和测试工作,以便数据能平滑过渡到新环境。
|
||||
|
||||
### 准备工作 ###
|
||||
|
||||
像我们这种关于架构上的巨大改变,在执行的每一步都需要收集数据指标。新机器上安装好了基础操作系统,接下来就是测试新配置下的各种性能。为了模拟真实的工作负载环境,我们使用 tcpdump 工具从老集群那里复制正在发生的 SELECT 请求,并在新集群上重新响应一遍。
|
||||
|
||||
MySQL 微调是个繁琐的细致活,像众所周知的 innodb_buffer_pool_size 这个参数往往能对 MySQL 性能产生巨大的影响。对于这类参数,我们必须考虑在内,所以我们列了一份参数清单,包括 innodb_thread_concurrency,innodb_io_capacity,和 innodb_buffer_pool_instances,还有其它的。
|
||||
|
||||
在每次测试中,我们都很小心地只改变一个参数,并且让一次测试至少运行12小时。我们会观察响应时间的变化曲线,每秒的响应次数,以及有可能会导致并发性降低的参数。我们使用 “SHOW ENGINE INNODB STATUS” 命令打印 InnoDB 性能信息,特别观察了 “SEMAPHORES” 一节的内容,它为我们提供了工作负载的状态信息。
|
||||
|
||||
当我们在设置参数后对运行结果感到满意,然后就开始将我们最大的一个数据表格迁移到一套独立的集群上,这个步骤作为整个迁移过程的早期测试,保证我们的核心集群空出更多的缓存池空间,并且为故障切换和存储功能提供更强的灵活性。这步初始迁移方案也引入了一个有趣的挑战:我们必须维持多条客户连接,并且要将这些连接重定向到正确的集群上。
|
||||
|
||||
除了硬件性能的提升,还需要补充一点,我们同时也对处理进程和拓扑结构进行了改进:我们添加了延时拷贝技术,更快、更高频地备份数据,以及更多的读拷贝空间。这些功能已经准备上线。
|
||||
|
||||
### 列出任务清单,三思后行 ###
|
||||
|
||||
每天有上百万用户的使用 GitHub.com,我们不可能有机会进行实际意义上的数据切换。我们有一个详细的[任务清单][2]来执行迁移:
|
||||
|
||||

|
||||
|
||||
我们还规划了一个维护期,并且[在我们的博客中通知了大家][3],让用户注意到这件事情。
|
||||
|
||||
### 迁移时间到 ###
|
||||
|
||||
太平洋时间星期六上午5点,我们的迁移团队上线集合聊天,同时数据迁移正式开始:
|
||||
|
||||

|
||||
|
||||
我们将 GitHub 网站设置为维护模式,并在 Twitter 上发表声明,然后开始按上述任务清单的步骤开始工作:
|
||||
|
||||

|
||||
|
||||
**13 分钟**后,我们确保新的集群能正常工作:
|
||||
|
||||

|
||||
|
||||
然后我们让 GitHub.com 脱离维护期,并且让全世界的用户都知道我们的最新状态:
|
||||
|
||||

|
||||
|
||||
大量前期的测试工作与准备工作,让我们将维护期缩到最短。
|
||||
|
||||
### 检验最终的成果 ###
|
||||
|
||||
在接下来的几周时间里,我们密切监视着 GitHub.com 的性能和响应时间。我们发现迁移后网站的平均加载时间减少一半,并且在99%的时间里,能减少*三分之二*:
|
||||
|
||||

|
||||
|
||||
### 我们学到了什么 ###
|
||||
|
||||
#### 功能划分 ####
|
||||
|
||||
在迁移过程中,我们采用了一个比较好的方法是:将大的数据表(主要记录了一些历史数据)先迁移过去,空出旧集群的磁盘空间和缓存池空间。这一步给我们留下了更过的资源用户维护“热”数据,将一些连接请求分离到多套集群里面。这步为我们之后的胜利奠定了基础,我们以后还会使用这种模式来进行迁移工作。
|
||||
|
||||
#### 测试测试测试 ####
|
||||
|
||||
为你的应用做验收测试和回归测试,越多越好,多多益善,不要嫌多。从老集群复制数据到新集群的过程中,如果进行验收测试和响应状态测试,得到的数据是不准的,如果数据不理想,这是正常的,不要惊讶,不要试图拿这些数据去分析原因。
|
||||
|
||||
#### 合作的力量 ####
|
||||
|
||||
对基础架构进行大的改变,通常需要涉及到很多人,我们要像一个团队一样为共同的目标而合作。我们的团队成员来自全球各地。
|
||||
|
||||
团队成员地图:
|
||||
|
||||

|
||||
|
||||
本次合作新创了一种工作流程:我们提交更改(pull request),获取实时反馈,查看修改了错误的 commit —— 全程没有电话交流或面对面的会议。当所有东西都可以通过 URL 提供信息,不同区域的人群之间的交流和反馈会变得非常简单。
|
||||
|
||||
### 一年后。。。 ###
|
||||
|
||||
整整一年时间过去了,我们很高兴地宣布这次数据迁移是很成功的 —— MySQL 性能和可靠性一直处于我们期望的状态。另外,新的集群还能让我们进一步去升级,提供更好的可靠性和响应时间。我将继续记录这些优化过程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/1880-making-mysql-better-at-github
|
||||
|
||||
作者:[samlambert][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/samlambert
|
||||
[1]:https://github.com/blog/1756-optimizing-large-selector-sets
|
||||
[2]:https://help.github.com/articles/writing-on-github#task-lists
|
||||
[3]:https://github.com/blog/1603-site-maintenance-august-31st-2013
|
||||
@ -6,84 +6,82 @@
|
||||
|
||||
这是初学者经常会问的一个问题,在这里,我会告诉你们10个我最喜欢的博客,这些博客可以帮助我们解决问题,能让我们及时了解所有 Ubuntu 版本的更新消息。不,我谈论的不是通常的 Linux 和 shell 脚本一类的东东。我是在说一个流畅的 Linux 桌面系统和一个普通的用户所要的关于 Ubuntu 的经验。
|
||||
|
||||
这些网站帮助你解决你正遇到的问题,提醒你关注各种应用和提供给你来自 Ubuntu 世界的最新消息。这个网站可以让你对 Ubuntu 更了解,所以,下面列出的10个我最喜欢的网站覆盖 Ubuntu 的方方面面。
|
||||
这些网站帮助你解决你正遇到的问题,提醒你关注各种应用和提供给你来自 Ubuntu 世界的最新消息。这个网站可以让你对 Ubuntu 更了解,所以,下面列出的是10个我最喜欢的博客,它们包括了 Ubuntu 的方方面面。
|
||||
|
||||
###10个Ubutun用户一定要知道的博客###
|
||||
|
||||
从我开始在 itsfoss 网站上写作开始,我特意把他排除在外,没有列入名单。我也并没有把[Planet Ubuntu][1]列入名单,因为他不适合初学的同学。废话不多说,让我们一起来看下**最好的乌邦图(ubuntu)博客**(排名不分先后):
|
||||
从我开始在 itsfoss 网站上写作开始,我特意把它排除在外,没有列入名单。我也并没有把[Planet Ubuntu][1]列入名单,因为它不适合初学者。废话不多说,让我们一起来看下**最好的乌邦图(ubuntu)博客**(排名不分先后):
|
||||
|
||||
### [OMG! Ubuntu!][2] ###
|
||||
|
||||
这是一个只针对 ubuntu 爱好者的网站。任何和乌邦图有关系的想法,不管成不成熟,OMG!Ubuntu上都会有收集!他主要包括新闻和应用。你也可以再这里找到一些关于 Ubuntu 的教程,但是不是很多。
|
||||
这是一个只针对 ubuntu 爱好者的网站。无论多小,只要是和乌邦图有关系的,OMG!Ubuntu 都会收入站内!博客主要包括新闻和应用。你也可以再这里找到一些关于 Ubuntu 的教程,但不是很多。
|
||||
|
||||
这个博客会让你知道 Ubuntu 的世界是怎么样的。
|
||||
这个博客会让你知道 Ubuntu 世界发生的各种事情。
|
||||
|
||||
### [Web Upd8][3] ###
|
||||
|
||||
Web Upd8 是我最喜欢的博客。除了涵盖新闻,他有很多容易理解的教程。Web Upd8 还维护了几个PPAs。博主[Andrei][4]有时会在评论里回答你的问题,这对你来说也会是很有帮助的。
|
||||
Web Upd8 是我最喜欢的博客。除了涵盖新闻,它有很多容易理解的教程。Web Upd8 还维护了几个PPAs。博主[Andrei][4]有时会在评论里回答你的问题,这对你来说也会是很有帮助的。
|
||||
|
||||
一个你可以追新闻资讯和教程的网站。
|
||||
这是一个你可以了解新闻资讯,学习教程的网站。
|
||||
|
||||
### [Noobs Lab][5] ###
|
||||
|
||||
和Web Upd8一样,Noobs Lab上也有很多教程,新闻,并且它可能是PPA里最大的主题和图标集。
|
||||
和Web Upd8一样,Noobs Lab上也有很多教程,新闻,并且它可能是PPA里最大的主题和图标集。
|
||||
|
||||
如果你是个小白,跟着Noobs Lab。
|
||||
如果你是个新手,去Noobs Lab看看吧。
|
||||
|
||||
### [Linux Scoop][6] ###
|
||||
|
||||
这里,大多数的博客都是“文字博客”。你通过看说明和截图来学习教程。而 Linux Scoop 上有很多录像来帮助初学者来学习,是一个实实在在的录像博客。
|
||||
大多数的博客都是“文字博客”。你通过看说明和截图来学习教程。而 Linux Scoop 上有很多录像来帮助初学者来学习,完全是一个视频博客。
|
||||
|
||||
如果你更喜欢看,而不是阅读的话,Linux Scoop应该是最适合你的。
|
||||
比起阅读来,如果你更喜欢视频,Linux Scoop应该是最适合你的。
|
||||
|
||||
### [Ubuntu Geek][7] ###
|
||||
|
||||
这是一个相对比较老的博客。覆盖面很广,并且有很多快速安装的教程和说明。虽然,有时我发现其中的一些教程文章缺乏深度,当然这也许只是我个人的观点。
|
||||
|
||||
想要快速的小贴士,去Ubuntu Geek。
|
||||
想要快速小贴士,去Ubuntu Geek。
|
||||
|
||||
### [Tech Drive-in][8] ###
|
||||
|
||||
这个网站的更新好像没有以前那么勤快了,可能是 Manuel 在忙于他的工作,但是仍然给我们提供了很多的东西。新闻,教程,应用评论是这个博客的重点。
|
||||
这个网站的更新频率好像没有以前那么快了,可能是 Manuel 在忙于他的工作,但是仍然给我们提供了很多的东西。新闻,教程,应用评论是这个博客的亮点。
|
||||
|
||||
博客经常被收入到[Ubuntu的新闻邮件请求][9],Tech Drive-in肯定是一个很值得你去追的网站。
|
||||
博客经常被收入到[Ubuntu的新闻邀请邮件中][9],Tech Drive-in肯定是一个很值得你去学习的网站。
|
||||
|
||||
### [UbuntuHandbook][10] ###
|
||||
|
||||
快速小贴士,新闻和教程是UbuntuHandbook的USP。[Ji m][11]最近也在参与维护一些PPAS。我必须很认真的说,这个站界面其实可以做得更好看点,纯属个人观点。
|
||||
快速小贴士,新闻和教程是UbuntuHandbook的USP。[Ji m][11]最近也在参与维护一些PPAS。我必须很认真的说,这个博客的页面其实可以做得更好看点,纯属个人观点。
|
||||
|
||||
UbuntuHandbook 真的很方便。
|
||||
|
||||
### [Unixmen][12] ###
|
||||
|
||||
这个网站是由很多人一起维护的,而且并不仅仅局限于Ubuntu,它也覆盖了很多的其他的Linux发行版。他用他自己的方式来帮助用户。
|
||||
这个网站是由很多人一起维护的,而且并不仅仅局限于Ubuntu,它也覆盖了很多的其他的Linux发行版。它有自己的论坛来帮助用户。
|
||||
|
||||
紧跟着 Unixmen 的步伐。。
|
||||
|
||||
### [The Mukt][13] ###
|
||||
|
||||
The Mukt是Muktware新的代表。Muktware是一个逐渐消亡的Linux组织,并以Mukt重生。Muktware是一个很严谨的Linux开源的博客,The Mukt涉及很多广泛的主题,包括,科技新闻,古怪的新闻,有时还有娱乐新闻(听起来是否有一种混搭风的感觉?)The Mukt也包括很多Ubuntu的新闻,有些可能是你感兴趣的。
|
||||
The Mukt是Muktware新的代表。Muktware是一个逐渐消亡的Linux组织,并以Mukt重生。Muktware是一个很严谨的Linux开源的博客,The Mukt涉及很多广泛的主题,包括,科技新闻,极客新闻,有时还有娱乐新闻(听起来是否有一种混搭风的感觉?)The Mukt也包括很多你感兴趣的Ubuntu新闻。
|
||||
|
||||
The Mukt 不仅仅是一个博客,它是一种文化潮流。
|
||||
|
||||
### [LinuxG][14] ###
|
||||
|
||||
LinuxG是一个你可以找到所有关于“怎样安装”文章的站点。几乎所有的文章都开始于一句话“你好,Linux geeksters,正如你所知道的。。。”,博客可以在不同的主题上做得更好。我经常发现有些是文章缺乏深度,并且是急急忙忙写出来的,但是它仍然是一个关注应用更新的好地方。
|
||||
LinuxG是一个你可以找到所有关于“怎样安装”类型文章的站点。几乎所有的文章都开始于一句话“你好,Linux geeksters,正如你所知道的……”,博客可以在不同的主题上做得更好。我经常发现有些是文章缺乏深度,并且是急急忙忙写出来的,但是它仍然是一个关注应用最新版本的好地方。
|
||||
|
||||
它很好的平衡了新的应用和他们最新的版本。
|
||||
这是个快速浏览新的应用和它们最新的版本好地方。
|
||||
|
||||
### 你还有什么好的站点吗? ###
|
||||
|
||||
This was my list of best Ubuntu blogs which I regularly follow. I know there are plenty more out there, perhaps better than some of those listed here. So why don’t you mention your favorite Ubuntu blog in the comment section below?
|
||||
|
||||
这些就是我平时经常浏览的 Ubuntu 博客。我知道还有很多我不知道的站点,可能会比我列出来的这些更好。所以,欢迎把你最喜爱的 Ubuntu 博客在下面评论的位置写出来。
|
||||
这些就是我平时经常浏览的 Ubuntu 博客。我知道还有很多我不知道的站点,可能会比我列出来的这些更好。所以,欢迎把你最喜爱的 Ubuntu 博客写在下面评论区。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/ten-blogs-every-ubuntu-user-must-follow/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
Arch Linux安装捷径:Evo/Lution
|
||||
================================================================================
|
||||
有些人只体验过Ubuntu或Mint的安装,却鼓起勇气想要安装Arch Linux,他们的学习道路是那样的陡峭和严峻,安装过程中半途而废的人数可能要比顺利过关的人多。如果你成功以有用的方式跑起并配置了Arch Linux,那么它已经把你培养成了一个饱经风霜的Linux用户。
|
||||
|
||||
即使有[有帮助的维基][1]可以为新手提供指南,对于那些想要征服Arch的人而言要求仍然太高。你需要至少熟悉诸如fdisk或mkfs之类的终端命令,并且听过mc、nano或chroot这些,并努力掌握它们。这让我回想起了10年前的Debian安装。
|
||||
|
||||
对于那些满怀抱负而又缺乏知识的生灵,有一个叫[Evo/Lution Live ISO][2]的ISO镜像格式安装器可以拯救他们。即便它貌似和自有发行版一样启动,但它也什么都没干,除了辅助安装Arch Linux准系统。Evo/Lution是一个项目,它旨在通过提供Arch的简单安装方式让Arch的用户基础多样化,就像为那些用户提供全面帮助和文档的社区一样。在这样一个组合中,Evo是Live CD(不可安装),而Lution是个安装器。项目创立者看到了Arch开发者和用户之间的巨大鸿沟及其衍生发行版,而想要在所有参与者之间构筑一个平等身份的社区。
|
||||
|
||||

|
||||
|
||||
项目的软件部分是命令行安装器Lution-AIS,它解释了一个普通的纯净的Arch安装过程中的每一步。安装完毕后,你将获得Arch提供的没有从AUR添加任何东西的最新软件或其它任何自定义的包。
|
||||
|
||||
启动这个422MB大小的ISO镜像后,一个由显示在右边的带有选项快捷方式的Conky和一个左边等待运行安装器的LX-Terminal组成的工作区便呈现在我们眼前。
|
||||
|
||||

|
||||
|
||||
在通过右击桌面或使用ALT-i启动实际的安装器后,一个写满了16个等待运行的任务的列表就出现在你面前了。除非你有一个更好的了解,否则将这些命令全部运行一遍。你可以一次运行,也可以进行选择,如1 3 6,或者1-4,也可以一次将它们全部运行,输入1-16。大多数步骤需要‘y’,即yes,来确认,而下一个任务则等着你敲击回车来执行。在此期间,你有足够的时间来阅读安装指南,它可以通过ALT-g来打开。当然,你也可以出去溜达一圈再回来。
|
||||
|
||||

|
||||
|
||||
这16个步骤分成“基础安装”和“桌面安装”两组。第一个组安装主要关注本地化、分区,以及安装启动器。
|
||||
|
||||
安装器带领你穿越分区世界,你可以选择使用gparted、gdisk,以及cfdisk。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
创建完分区后(如,像截图中所示,用gparted划分/dev/sda1用于root,/dev/sda2用于swap),你可以在10个文件系统中选择其中之一。在下一步中,你可以选择内核(最新或长期支持LTS)和基础系统。
|
||||
|
||||

|
||||
|
||||
安装完你喜爱的启动加载器后,第一部分安装就完成了,这大约需要花费12分钟。这是在普通的Arch Linux中你第一次重启进入系统所处之处。
|
||||
|
||||
在Lution的帮助下,继续进入第二部分,在这一部分中将安装Xorg、声音和图形驱动,然后进入桌面环境。
|
||||
|
||||

|
||||
|
||||
安装器会检测是否在VirtualBox中安装,并且会自动为VM安装并加载正确的通用驱动,然后相应地设置**systemd**。
|
||||
|
||||
在下一步中,你可以选择KDE、Gnome、Cinnamon、LXDE、Englightenment、Mate或XFCE作为你的桌面环境。如果你不喜欢臃肿的桌面,你也可以试试这些窗口管理器:Awesome、Fluxbox、i3、IceWM、Openbox或PekWM。
|
||||
|
||||

|
||||
|
||||
在使用Cinnamon作为桌面环境的情况下,第二部分安装将花费不到10分钟的时间;而选择KDE的话,因为要下载的东西多得多,所以花费的时间也会更长。
|
||||
|
||||
Lution-AIS在Cinnamon和Awesome上像个妩媚的小妖精。在安装完成并提示重启后,它就带我进入了我所渴望的环境。
|
||||
|
||||

|
||||
|
||||
我要提出两点非议:一是在安装器要我选择一个镜像列表时,另外一个是在创建fstab文件时。在这两种情况下,它都另外开了一个终端,给出了一些文本信息提示。这让我花了点时间才搞清楚,原来我得把它关了,安装器才会继续。在创建fstab后,它又会提示你,而你需要关闭终端,并在问你是否想要保存文件时回答‘是’。
|
||||
|
||||

|
||||
|
||||
我碰到的第二个问题,可能与VirtualBox有关了。在启动的时候,你可以看到没有网络被检测到的提示信息。点击顶部左边的图标,将会打开wicd,这里所使用的网络管理器。点击“断开”,然后再点击“连接”并重启安装器,就可以让它自动检测到了。
|
||||
|
||||
Evo/Lution我以为是个有价值的项目,在这里Lution工作一切顺利,目前还没有什么可告诉社区的。他们开启了一个全新的网站、论坛和维基,需要填充内容进去啊。所以,如果你喜欢这主意,加入[他们的论坛][3]并告诉他们吧。本文中的ISO镜像可以从[此网站][4]下载。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/install-arch-linux-easy-way-evolution.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/ferdinand
|
||||
[1]:https://wiki.archlinux.org/
|
||||
[2]:http://www.evolutionlinux.com/
|
||||
[3]:http://www.evolutionlinux.com/forums/
|
||||
[4]:http://www.evolutionlinux.com/downloads.html
|
||||
@ -0,0 +1,72 @@
|
||||
Ubuntu下使用CloudFlare作为ddclient提供商
|
||||
================================================================================
|
||||
DDclient是一个Perl客户端,用于更新动态DNS网络服务提供商帐号下的动态DNS条目。它最初是由保罗·巴利编写的,现在大多数是由维姆潘科在做。它能做的不仅仅是动态DNS,也可以通过几种不同的方式获取你的WAN口IP地址。
|
||||
|
||||
CloudFlare有一点已知的功能,它允许你通过API或叫做ddclient的命令行脚本更新你的DNS记录。不管哪一个,结果都一样,而且它是个免费软件。
|
||||
|
||||
不幸的是,ddclient并不能在CloudFlare中即开即用。它需要打补丁,这里就是要介绍怎样在Debian或Ubuntu上破解它,它也能在带有Raspberry Pi的Raspbian上工作。
|
||||
|
||||
### 需求 ###
|
||||
|
||||
首先保证你有一个自有域名,然后登录到CloudFlare,添加你的域名。遵循指令操作,使用它给出的默认值就行了。你将让CloudFlare来托管你的域,所以你需要调整你的注册机构的设置。如果你想要使用子域名,请为它添加一条‘A’记录。目前,任何IP地址都可以。
|
||||
|
||||
### 在Ubuntu上安装ddclient ###
|
||||
|
||||
打开终端,并运行以下命令
|
||||
|
||||
sudo apt-get install ddclient
|
||||
|
||||
现在,你需要使用以下命令来安装补丁
|
||||
|
||||
sudo apt-get install curl sendmail libjson-any-perl libio-socket-ssl-perl
|
||||
|
||||
curl -O http://blog.peter-r.co.uk/uploads/ddclient-3.8.0-cloudflare-22-6-2014.patch
|
||||
|
||||
sudo patch /usr/sbin/ddclient < ddclient-3.8.0-cloudflare-22-6-2014.patch
|
||||
|
||||
以上命令用来完成ddclient的安装和打补丁
|
||||
|
||||
### 配置ddclient ###
|
||||
|
||||
你需要使用以下命令来编辑ddclient.conf文件
|
||||
|
||||
sudo vi /etc/ddclient.conf
|
||||
|
||||
添加以下信息
|
||||
|
||||
##
|
||||
### CloudFlare (cloudflare.com)
|
||||
###
|
||||
ssl=yes
|
||||
use=web, web=dyndns
|
||||
protocol=cloudflare, \
|
||||
server=www.cloudflare.com, \
|
||||
zone=domain.com, \
|
||||
login=you@email.com, \
|
||||
password=api-key \
|
||||
host.domain.com
|
||||
|
||||
Comment out:
|
||||
|
||||
#daemon=300
|
||||
|
||||
来自CloudFlare帐号页面的api密钥
|
||||
|
||||
ssl=yes might already be in that file
|
||||
|
||||
use=web, web=dyndns will use dyndns to check IP (useful for NAT)
|
||||
|
||||
你已经搞定了。登录到https://www.cloudflare.com并检查列出的与你域名对应的IP地址是否匹配到了http://checkip.dyndns.com。
|
||||
|
||||
使用以下命令来验证你的设置
|
||||
|
||||
sudo ddclient -daemon=0 -debug -verbose -noquiet
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/how-to-use-cloudflare-as-a-ddclient-provider-under-ubuntu.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,20 +1,18 @@
|
||||
translating by cvsher
|
||||
20 Useful Commands of ‘Sysstat’ Utilities (mpstat, pidstat, iostat and sar) for Linux Performance Monitoring
|
||||
================================================================================
|
||||
In our last article, we have learned about installing and upgrading the **sysstat** package and understanding briefly about the utilities which comes with the package.
|
||||
‘Sysstat’工具包中20个实用的Linux性能监控工具(包括mpstat, pidstat, iostat 和sar)
|
||||
===============================================================
|
||||
在我们上一篇文章中,我们已经学习了如何去安装和更新**sysstat**,并且了解了包中的一些实用工具。
|
||||
|
||||
注:此文一并附上,在同一个原文更新中
|
||||
注:此文一并附上,在同一个原文中更新
|
||||
- [Sysstat – Performance and Usage Activity Monitoring Tool For Linux][1]
|
||||
|
||||

|
||||
|
||||
20 Sysstat Commands for Linux Monitoring
|
||||
Linux系统监控的20个Sysstat命令
|
||||
今天,我们将会通过一些有趣的实例来学习**mpstat**, **pidstat**, **iostat**和**sar**等工具,这些工具可以帮组我们找出系统中的问题。这些工具都包含了不同的选项,这意味着你可以根据不同的工作使用不同的选项,或者根据你的需求来自定义脚本。我们都知道,系统管理员都会有点懒,他们经常去寻找一些更简单的方法来完成他们的工作。
|
||||
|
||||
Today, we are going to work with some interesting practical examples of **mpstat, pidstat, iostat** and **sar** utilities, which can help us to identify the issues. We have different options to use these utilities, I mean you can fire the commands manually with different options for different kind of work or you can create your customized scripts according to your requirements. You know Sysadmins are always bit Lazy, and always tried to find out the easy way to do the things with minimum efforts.
|
||||
### mpstat - 处理器统计信息 ###
|
||||
|
||||
### mpstat – Processors Statistics ###
|
||||
|
||||
1.Using mpstat command without any option, will display the Global Average Activities by All CPUs.
|
||||
1.不带任何参数的使用mpstat命令将会输出所有CPU的平均统计信息
|
||||
|
||||
tecmint@tecmint ~ $ mpstat
|
||||
|
||||
@ -23,7 +21,7 @@ Today, we are going to work with some interesting practical examples of **mpstat
|
||||
12:23:57 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
12:23:57 IST all 37.35 0.01 4.72 2.96 0.00 0.07 0.00 0.00 0.00 54.88
|
||||
|
||||
2.Using mpstat with option ‘**-P**‘ (Indicate Processor Number) and ‘ALL’, will display statistics about all CPUs one by one starting from 0. 0 will the first one.
|
||||
2.使用‘**-p**’(处理器编码)和‘ALL’参数将会从0开始独立的输出每个CPU的统计信息,0表示第一个cpu。
|
||||
|
||||
tecmint@tecmint ~ $ mpstat -P ALL
|
||||
|
||||
@ -34,7 +32,7 @@ Today, we are going to work with some interesting practical examples of **mpstat
|
||||
12:29:26 IST 0 37.90 0.01 4.96 2.62 0.00 0.03 0.00 0.00 0.00 54.48
|
||||
12:29:26 IST 1 36.75 0.01 4.19 2.54 0.00 0.11 0.00 0.00 0.00 56.40
|
||||
|
||||
3.To display the statistics for **N** number of iterations after n seconds interval with average of each cpu use the following command.
|
||||
3.要进行‘**N**’次,平均每次间隔n秒的输出CPU统计信息,如下所示。
|
||||
|
||||
tecmint@tecmint ~ $ mpstat -P ALL 2 5
|
||||
|
||||
@ -55,11 +53,13 @@ Today, we are going to work with some interesting practical examples of **mpstat
|
||||
12:36:27 IST 0 34.34 0.00 4.04 0.00 0.00 0.00 0.00 0.00 0.00 61.62
|
||||
12:36:27 IST 1 32.82 0.00 6.15 0.51 0.00 0.00 0.00 0.00 0.00 60.51
|
||||
|
||||
4.The option ‘**I**‘ will print total number of interrupt statistics about per processor.
|
||||
(LCTT译注: 上面命令中‘2’ 表示每2秒执行一次‘mpstat -P ALL’命令, ‘5’表示共执行5次)
|
||||
|
||||
4.使用‘**I**’参数将会输出每个处理器的中断统计信息
|
||||
|
||||
tecmint@tecmint ~ $ mpstat -I
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
12:39:56 IST CPU intr/s
|
||||
12:39:56 IST all 651.04
|
||||
@ -72,11 +72,11 @@ Today, we are going to work with some interesting practical examples of **mpstat
|
||||
12:39:56 IST 0 0.00 116.49 0.05 0.27 7.33 0.00 1.22 10.44 0.13 37.47
|
||||
12:39:56 IST 1 0.00 111.65 0.05 0.41 7.07 0.00 56.36 9.97 0.13 41.38
|
||||
|
||||
5.Get all the above information in one command i.e. equivalent to “**-u -I ALL -p ALL**“.
|
||||
5.使用‘**A**’参数将会输出上面提到的所有信息,等同于‘**-u -I All -p ALL**’。
|
||||
|
||||
tecmint@tecmint ~ $ mpstat -A
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
12:41:39 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
|
||||
12:41:39 IST all 38.70 0.01 4.47 2.01 0.00 0.06 0.00 0.00 0.00 54.76
|
||||
@ -96,19 +96,19 @@ Today, we are going to work with some interesting practical examples of **mpstat
|
||||
12:41:39 IST 0 0.00 116.96 0.05 0.26 7.12 0.00 1.24 10.42 0.12 36.99
|
||||
12:41:39 IST 1 0.00 112.25 0.05 0.40 6.88 0.00 55.05 9.93 0.13 41.20
|
||||
|
||||
### pidstat – Process and Kernel Threads Statistics ###
|
||||
###pidstat - 进程和内核线程的统计信息###
|
||||
|
||||
This is used for process monitoring and current threads, which are being managed by kernel. pidstat can also check the status about child processes and threads.
|
||||
该命令是用于监控进程和当前受内核管理的线程。pidstat还可以检查子进程和线程的状态。
|
||||
|
||||
#### Syntax ####
|
||||
#### 语法 ####
|
||||
|
||||
# pidstat <OPTIONS> [INTERVAL] [COUNT]
|
||||
|
||||
6.Using pidstat command without any argument, will display all active tasks.
|
||||
6.不带任何参数使用pidstat将会输出所有活跃的任务。
|
||||
|
||||
tecmint@tecmint ~ $ pidstat
|
||||
tecmint@tecmint ~ $ pidstat
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
12:47:24 IST UID PID %usr %system %guest %CPU CPU Command
|
||||
12:47:24 IST 0 1 0.01 0.12 0.00 0.13 1 init
|
||||
@ -126,11 +126,11 @@ This is used for process monitoring and current threads, which are being managed
|
||||
12:47:24 IST 0 365 0.01 0.00 0.00 0.01 0 systemd-udevd
|
||||
12:47:24 IST 0 476 0.00 0.00 0.00 0.00 0 kworker/u9:1
|
||||
|
||||
7.To print all active and non-active tasks use the option ‘**-p**‘ (processes).
|
||||
7.使用‘**-p**’(进程)参数输出所有活跃和非活跃的任务。
|
||||
|
||||
tecmint@tecmint ~ $ pidstat -p ALL
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
12:51:55 IST UID PID %usr %system %guest %CPU CPU Command
|
||||
12:51:55 IST 0 1 0.01 0.11 0.00 0.12 1 init
|
||||
@ -151,11 +151,11 @@ This is used for process monitoring and current threads, which are being managed
|
||||
12:51:55 IST 0 19 0.00 0.00 0.00 0.00 0 writeback
|
||||
12:51:55 IST 0 20 0.00 0.00 0.00 0.00 1 kintegrityd
|
||||
|
||||
8.Using pidstat command with ‘**-d 2**‘ option, we can get I/O statistics and 2 is interval in seconds to get refreshed statistics. This option can be handy in situation, where your system is undergoing heavy I/O and you want to get clues about the processes consuming high resources.
|
||||
8.使用‘**-d 2**’参数,我们可以看到I/O统计信息,2表示以秒为单位对统计信息进行刷新。这个参数可以方便的知道当系统在进行繁重的I/O时,那些进行占用大量的资源。
|
||||
|
||||
tecmint@tecmint ~ $ pidstat -d 2
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
03:26:53 EDT PID kB_rd/s kB_wr/s kB_ccwr/s Command
|
||||
|
||||
@ -169,11 +169,12 @@ This is used for process monitoring and current threads, which are being managed
|
||||
03:27:03 EDT 25100 0.00 6.00 0.00 sendmail
|
||||
03:27:03 EDT 30829 0.00 6.00 0.00 java
|
||||
|
||||
9.To know the cpu statistics along with all threads about the process id **4164** at interval of **2** sec for **3** times use the following command with option ‘-t‘ (display statistics of selected process).
|
||||
9.想要每间隔**2**秒对进程**4164**的cpu统计信息输出**3**次,则使用如下带参数‘**-t**’(输出某个选定进程的统计信息)的命令。
|
||||
|
||||
|
||||
tecmint@tecmint ~ $ pidstat -t -p 4164 2 3
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
01:09:06 IST UID TGID TID %usr %system %guest %CPU CPU Command
|
||||
01:09:08 IST 1000 4164 - 22.00 1.00 0.00 23.00 1 firefox
|
||||
@ -186,11 +187,11 @@ This is used for process monitoring and current threads, which are being managed
|
||||
01:09:08 IST 1000 - 4176 0.00 0.00 0.00 0.00 1 |__gdbus
|
||||
01:09:08 IST 1000 - 4177 0.00 0.00 0.00 0.00 1 |__gmain
|
||||
|
||||
10.Use the ‘**-rh**‘ option, to know the about memory utilization of processes which are frequently varying their utilization in **2** second interval.
|
||||
10.使用‘**-rh**’参数,将会输出进程的内存使用情况。如下命令每隔2秒刷新经常的内存使用情况。
|
||||
|
||||
tecmint@tecmint ~ $ pidstat -rh 2 3
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
# Time UID PID minflt/s majflt/s VSZ RSS %MEM Command
|
||||
1409816695 1000 3958 3378.22 0.00 707420 215972 5.32 cinnamon
|
||||
@ -209,21 +210,21 @@ This is used for process monitoring and current threads, which are being managed
|
||||
1409816699 1000 4164 599.00 0.00 1261944 476664 11.74 firefox
|
||||
1409816699 1000 6676 168.00 0.00 4436 1020 0.03 pidstat
|
||||
|
||||
11.To print all the process of containing string “**VB**“, use ‘**-t**‘ option to see threads as well.
|
||||
11.要使用‘**-G**’参数可以输出包含某个特定字符串的进程信息。如下命令输出所有包含‘**VB**’字符串的进程的统计信息,使用‘**-t**’参数将线程的信息也进行输出。
|
||||
|
||||
tecmint@tecmint ~ $ pidstat -G VB
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
01:09:06 IST UID PID %usr %system %guest %CPU CPU Command
|
||||
01:09:08 IST 1000 1492 22.00 1.00 0.00 23.00 1 VBoxService
|
||||
01:09:08 IST 1000 1902 4164 20.00 0.50 0.00 20.50 VBoxClient
|
||||
01:09:08 IST 1000 1922 4171 0.00 0.00 0.00 0.00 VBoxClient
|
||||
01:09:06 IST UID PID %usr %system %guest %CPU CPU Command
|
||||
01:09:08 IST 1000 1492 22.00 1.00 0.00 23.00 1 VBoxService
|
||||
01:09:08 IST 1000 1902 4164 20.00 0.50 0.00 20.50 VBoxClient
|
||||
01:09:08 IST 1000 1922 4171 0.00 0.00 0.00 0.00 VBoxClient
|
||||
|
||||
----------
|
||||
|
||||
tecmint@tecmint ~ $ pidstat -t -G VB
|
||||
Linux 2.6.32-431.el6.i686 (tecmint) 09/04/2014 _i686_ (2 CPU)
|
||||
Linux 2.6.32-431.el6.i686 (tecmint) 09/04/2014 _i686_ (2 CPU)
|
||||
|
||||
03:19:52 PM UID TGID TID %usr %system %guest %CPU CPU Command
|
||||
03:19:52 PM 0 1479 - 0.01 0.12 0.00 0.13 1 VBoxService
|
||||
@ -238,32 +239,32 @@ This is used for process monitoring and current threads, which are being managed
|
||||
03:19:52 PM 0 1933 - 0.04 0.89 0.00 0.93 0 VBoxClient
|
||||
03:19:52 PM 0 - 1936 0.04 0.89 0.00 0.93 1 |__X11-NOTIFY
|
||||
|
||||
12.To get realtime priority and scheduling information use option ‘**-R**‘ .
|
||||
12.使用‘**-R**’参数输出实时的进程优先级和调度信息。
|
||||
|
||||
tecmint@tecmint ~ $ pidstat -R
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
01:09:06 IST UID PID prio policy Command
|
||||
01:09:08 IST 1000 3 99 FIFO migration/0
|
||||
01:09:08 IST 1000 5 99 FIFO migration/0
|
||||
01:09:08 IST 1000 6 99 FIFO watchdog/0
|
||||
01:09:06 IST UID PID prio policy Command
|
||||
01:09:08 IST 1000 3 99 FIFO migration/0
|
||||
01:09:08 IST 1000 5 99 FIFO migration/0
|
||||
01:09:08 IST 1000 6 99 FIFO watchdog/0
|
||||
|
||||
Here, I am not going to cover about Iostat utility, as we are already covered it. Please have a look on “[Linux Performance Monitoring with Vmstat and Iostat][2]注:此文也一并附上在同一个原文更新中” to get all details about iostat.
|
||||
因为我们已经学习过Iostat命令了,因此在本文中不在对其进行赘述。若想查看Iostat命令的详细信息,请参看“[使用Iostat和Vmstat进行Linux性能监控][2]注:此文也一并附上在同一个原文更新中”
|
||||
|
||||
### sar – System Activity Reporter ###
|
||||
###sar - 系统活动报告###
|
||||
|
||||
Using “**sar**” command, we can get the reports about whole system’s performance. This can help us to locate the system bottleneck and provide the help to find out the solutions to these annoying performance issues.
|
||||
我们可以使用‘**sar**’命令来获得整个系统性能的报告。这有助于我们定位系统性能的瓶颈,并且有助于我们找出这些烦人的性能问题的解决方法。
|
||||
|
||||
The Linux Kernel maintains some counter internally, which keeps track of all requests, their completion time and I/O block counts etc. From all these information, sar calculates rates and ratio of these request to find out about bottleneck areas.
|
||||
Linux内核维护者一些内部计数器,这些计数器包含了所有的请求及其完成时间和I/O块数等信息,sar命令从所有的这些信息中计算出请求的利用率和比例,以便找出瓶颈所在。
|
||||
|
||||
The main thing about the sar is that, it reports all activities over a period if time. So, make sure that sar collect data on appropriate time (not on Lunch time or on weekend.:)
|
||||
sar命令主要的用途是生成某段时间内所有活动的报告,因此,必需确保sar命令在适当的时间进行数据采集(而不是在午餐时间或者周末。)
|
||||
|
||||
13.Following is a basic command to invoke sar. It will create one file named “**sarfile**” in your current directory. The options ‘**-u**‘ is for CPU details and will collect **5** reports at an interval of **2** seconds.
|
||||
13.下面是执行sar命令的基本用法。它将会在当前目录下创建一个名为‘**sarfile**’的文件。‘**-u**’参数表示CPU详细信息,**5**表示生产5次报告,**2**表示每次报告的时间间隔为2秒。
|
||||
|
||||
tecmint@tecmint ~ $ sar -u -o sarfile 2 5
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
01:42:28 IST CPU %user %nice %system %iowait %steal %idle
|
||||
01:42:30 IST all 36.52 0.00 3.02 0.00 0.00 60.45
|
||||
@ -273,26 +274,26 @@ The main thing about the sar is that, it reports all activities over a period if
|
||||
01:42:38 IST all 50.75 0.00 3.75 0.00 0.00 45.50
|
||||
Average: all 46.30 0.00 3.93 0.00 0.00 49.77
|
||||
|
||||
14.In the above example, we have invoked sar interactively. We also have an option to invoke it non-interactively via cron using scripts **/usr/local/lib/sa1** and **/usr/local/lib/sa2** (If you have used **/usr/local** as prefix during installation time).
|
||||
14.在上面的例子中,我们交互的执行sar命令。sar命令提供了使用cron进行非交互的执行sar命令的方法,使用**/usr/local/lib/sa1**和**/usr/local/lib/sa2**脚本(如果你在安装时使用了**/usr/local**作为前缀)
|
||||
|
||||
- **/usr/local/lib/sa1** is a shell script that we can use for scheduling cron which will create daily binary log file.
|
||||
- **/usr/local/lib/sa2** is a shell script will change binary log file to human-readable form.
|
||||
- **/usr/local/lib/sa1**是一个可以使用cron进行调度生成二进制日志文件的shell脚本。
|
||||
- **/usr/local/lib/sa2**是一个可以将二进制日志文件转换为用户可读的编码方式。
|
||||
|
||||
Use the following Cron entries for making this non-interactive:
|
||||
使用如下Cron项目来将sar命令非交互化。
|
||||
|
||||
# Run sa1 shell script every 10 minutes for collecting data
|
||||
# 每10分钟运行sa1脚本来采集数据
|
||||
*/2 * * * * /usr/local/lib/sa/sa1 2 10
|
||||
|
||||
# Generate a daily report in human readable format at 23:53
|
||||
#在每天23:53时生成一个用户可读的日常报告
|
||||
53 23 * * * /usr/local/lib/sa/sa2 -A
|
||||
|
||||
At the back-end sa1 script will call **sadc** (System Activity Data Collector) utility for fetching the data at a particular interval. **sa2** will call sar for changing binary log file to human readable form.
|
||||
在sa1脚本执行后期,sa1脚本会调用**sabc**(系统活动数据收集器,System Activity Data Collector)工具采集特定时间间隔内的数据。**sa2**脚本会调用sar来将二进制日志文件转换为用户可读的形式。
|
||||
|
||||
15.Check run queue length, total number of processes and load average using ‘**-q**‘ option.
|
||||
15.使用‘**-q**’参数来检查运行队列的长度,所有进程的数量和平均负载
|
||||
|
||||
tecmint@tecmint ~ $ sar -q 2 5
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
02:00:44 IST runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked
|
||||
02:00:46 IST 1 431 1.67 1.22 0.97 0
|
||||
@ -302,11 +303,11 @@ At the back-end sa1 script will call **sadc** (System Activity Data Collector) u
|
||||
02:00:54 IST 0 431 1.64 1.23 0.97 0
|
||||
Average: 2 431 1.68 1.23 0.97 0
|
||||
|
||||
16.Check statistics about the mounted file systems using ‘**-F**‘.
|
||||
|
||||
16.使用‘**-F**’参数查看当前挂载的文件系统统计信息
|
||||
|
||||
tecmint@tecmint ~ $ sar -F 2 4
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
02:02:31 IST MBfsfree MBfsused %fsused %ufsused Ifree Iused %Iused FILESYSTEM
|
||||
02:02:33 IST 1001 449 30.95 1213790475088.85 18919505 364463 1.89 /dev/sda1
|
||||
@ -323,11 +324,11 @@ At the back-end sa1 script will call **sadc** (System Activity Data Collector) u
|
||||
Summary MBfsfree MBfsused %fsused %ufsused Ifree Iused %Iused FILESYSTEM
|
||||
Summary 1001 449 30.95 1213790475088.86 18919505 364463 1.89 /dev/sda1
|
||||
|
||||
17.View network statistics using ‘**-n DEV**‘.
|
||||
17.使用‘**-n DEV**’参数查看网络统计信息
|
||||
|
||||
tecmint@tecmint ~ $ sar -n DEV 1 3 | egrep -v lo
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
02:11:59 IST IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
|
||||
02:12:00 IST wlan0 8.00 10.00 1.23 0.92 0.00 0.00 0.00
|
||||
@ -335,11 +336,11 @@ At the back-end sa1 script will call **sadc** (System Activity Data Collector) u
|
||||
02:12:00 IST eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
|
||||
02:12:00 IST vmnet1 0.00 0.00 0.00 0.00 0.00 0.00 0.00
|
||||
|
||||
18.View block device statistics like iostat using ‘**-d**‘.
|
||||
18.使用‘**-d**’参数查看块设备统计信息(与iostat类似)。
|
||||
|
||||
tecmint@tecmint ~ $ sar -d 1 3
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
02:13:17 IST DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
|
||||
02:13:18 IST dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
|
||||
@ -350,11 +351,11 @@ At the back-end sa1 script will call **sadc** (System Activity Data Collector) u
|
||||
02:13:19 IST DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
|
||||
02:13:20 IST dev8-0 7.00 32.00 80.00 16.00 0.11 15.43 15.43 10.80
|
||||
|
||||
19.To print memory statistics use ‘**-r**‘ option.
|
||||
19.使用‘**-r**’参数输出内存统计信息。
|
||||
|
||||
tecmint@tecmint ~ $ sar -r 1 3
|
||||
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
Linux 3.11.0-23-generic (tecmint.com) Thursday 04 September 2014 _i686_ (2 CPU)
|
||||
|
||||
02:14:29 IST kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
|
||||
02:14:30 IST 1465660 2594840 63.90 133052 1549644 3710800 45.35 1133148 1359792 392
|
||||
@ -362,7 +363,7 @@ At the back-end sa1 script will call **sadc** (System Activity Data Collector) u
|
||||
02:14:32 IST 1469112 2591388 63.82 133060 1550036 3705288 45.28 1130252 1360168 804
|
||||
Average: 1469165 2591335 63.82 133057 1549824 3710531 45.34 1129739 1359987 677
|
||||
|
||||
20.Using ‘**sadf -d**‘, we can extract data in format which can be processed using databases.
|
||||
20.使用‘**sadf -d**’参数可以将数据导出为数据库可以使用的格式。
|
||||
|
||||
tecmint@tecmint ~ $ safd -d /var/log/sa/sa20140903 -- -n DEV | grep -v lo
|
||||
|
||||
@ -382,20 +383,20 @@ At the back-end sa1 script will call **sadc** (System Activity Data Collector) u
|
||||
tecmint;2;2014-09-03 12:00:10 UTC;eth0;0.50;0.50;0.03;0.04;0.00;0.00;0.00;0.00
|
||||
tecmint;2;2014-09-03 12:00:12 UTC;eth0;1.00;0.50;0.12;0.04;0.00;0.00;0.00;0.00
|
||||
|
||||
You can also save this to a csv and then can draw chart for presentation kind of stuff as below.
|
||||
你也可以将这些数据存储在一个csv文档中,然后绘制成图表展示方式,如下所示
|
||||
|
||||

|
||||
|
||||
Network Graph
|
||||
网络信息图表
|
||||
|
||||
That’s it for now, you can refer man pages for more information about each option and don’t forget to tell about article with your valuable comments.
|
||||
现在,你可以参考man手册来后去每个参数的更多详细信息,并且请在文章下留下你宝贵的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sysstat-commands-to-monitor-linux/
|
||||
|
||||
作者:[Kuldeep Sharma][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user