mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
76fd134c4f
@ -1,43 +1,41 @@
|
||||
关于安全,开发人员需要知道的
|
||||
======
|
||||
(to 校正:有些长句子理解得不好,望见谅)
|
||||
> 开发人员不需要成为安全专家, 但他们确实需要摆脱将安全视为一些不幸障碍的心态。
|
||||
|
||||

|
||||
|
||||
DevOps 并不意味着每个人都需要成为开发和运维方面的专家。尤其在大型组织中,其中角色往往更加专业化。相反,DevOps 思想在某种程度上更多地是关注问题的分离。在某种程度上,运维团队可以为开发人员(无论是在本地云还是在公共云中)部署平台,并且不受影响,这对两个团队来说都是好消息。开发人员可以获得高效的开发环境和自助服务,运维人员可以专注于保持基础管道运行和维护平台。
|
||||
|
||||
这是一种约定。开发者期望从运维人员那里得到一个稳定和实用的平台,运维人员希望开发者能够自己处理与开发应用相关的大部分任务。
|
||||
|
||||
也就是说,DevOps 还涉及更好的沟通、合作和透明度。如果它不仅仅是一种介于开发和运维之间的新型壁垒,它的效果会更好。运维人员需要对开发者想要和需要的工具类型以及他们通过监视和日志记录来编写更好应用程序所需的可见性保持敏感。相反,开发人员需要了解如何才能使底层基础设施更有效地使用,以及什么能够在夜间(字面上)保持操作。(to 校正:这里意思是不是在无人时候操作)
|
||||
也就是说,DevOps 还涉及更好的沟通、合作和透明度。如果它不仅仅是一种介于开发和运维之间的新型壁垒,它的效果会更好。运维人员需要对开发者想要和需要的工具类型以及他们通过监视和日志记录来编写更好应用程序所需的可见性保持敏感。另一方面,开发人员需要了解如何才能更有效地使用底层基础设施,以及什么能够使运维在夜间(字面上)保持运行。
|
||||
|
||||
同样的原则也适用于更广泛的 DevSecOps,这个术语明确地提醒我们,安全需要嵌入到整个 DevOps 管道中,从获取内容到编写应用程序、构建应用程序、测试应用程序以及在生产环境中运行它们。开发人员(和运维人员)不需要突然成为安全专家,除了他们的其它角色。但是,他们通常可以从对安全最佳实践(这可能不同于他们已经习惯的)的更高认识中获益,并从将安全视为一些不幸障碍的心态中转变出来。
|
||||
同样的原则也适用于更广泛的 DevSecOps,这个术语明确地提醒我们,安全需要嵌入到整个 DevOps 管道中,从获取内容到编写应用程序、构建应用程序、测试应用程序以及在生产环境中运行它们。开发人员(和运维人员)除了他们已有的角色不需要突然成为安全专家。但是,他们通常可以从对安全最佳实践(这可能不同于他们已经习惯的)的更高认识中获益,并从将安全视为一些不幸障碍的心态中转变出来。
|
||||
|
||||
以下是一些观察结果。
|
||||
|
||||
开放式 Web 应用程序安全项目(Open Web Application Security Project)([OWASP][1])[Top 10 列表]提供了一个窗口,可以了解 Web 应用程序中的主要漏洞。列表中的许多条目对 Web 程序员来说都很熟悉。跨站脚本(XSS)和注入漏洞是最常见的。但令人震惊的是,2007 年列表中的许多漏洞仍在 2017 年的列表中([PDF][3])。无论是培训还是工具,都有问题,许多相同的编码漏洞在不断出现。(to 校正:这句话不清楚)
|
||||
<ruby>开放式 Web 应用程序安全项目<rt>Open Web Application Security Project</rt></ruby>([OWASP][1])[Top 10 列表]提供了一个窗口,可以了解 Web 应用程序中的主要漏洞。列表中的许多条目对 Web 程序员来说都很熟悉。跨站脚本(XSS)和注入漏洞是最常见的。但令人震惊的是,2007 年列表中的许多漏洞仍在 2017 年的列表中([PDF][3])。无论是培训还是工具,都有问题,许多同样的编码漏洞一再出现。
|
||||
|
||||
新平台技术加剧了这种情况。例如,虽然容器不一定要求应用程序以不同的方式编写,但是它们与新模式(例如[微服务][4])相吻合,并且可以放大某些对于安全实践的影响。例如,我的同事 [Dan Walsh][5]([@rhatdan][6])写道:“计算机领域最大的误解是需要 root 权限来运行应用程序,问题是并不是所有开发者都认为他们需要 root,而是他们将这种假设构建到他们建设的服务中,即服务无法在非 root 情况下运行,而这降低了安全性。”
|
||||
新的平台技术加剧了这种情况。例如,虽然容器不一定要求应用程序以不同的方式编写,但是它们与新模式(例如[微服务][4])相吻合,并且可以放大某些对于安全实践的影响。例如,我的同事 [Dan Walsh][5]([@rhatdan][6])写道:“计算机领域最大的误解是需要 root 权限来运行应用程序,问题是并不是所有开发者都认为他们需要 root,而是他们将这种假设构建到他们建设的服务中,即服务无法在非 root 情况下运行,而这降低了安全性。”
|
||||
|
||||
默认使用 root 访问是一个好的实践吗?并不是。但它可能(也许)是一个可以防御的应用程序和系统,否则就会被其它方法完全隔离。但是,由于所有东西都连接在一起,没有真正的边界,多用户工作负载,拥有许多不同级别访问权限的用户,更不用说更加危险的环境了,那么快捷方式的回旋余地就更小了。
|
||||
|
||||
[自动化][7]应该是 DevOps 不可分割的一部分。自动化需要覆盖整个过程中,包括安全和合规性测试。代码是从哪里来的?是否涉及第三方技术、产品或容器映像?是否有已知的安全勘误表?是否有已知的常见代码缺陷?秘密和个人身份信息是否被隔离?如何进行身份认证?谁被授权部署服务和应用程序?
|
||||
[自动化][7]应该是 DevOps 不可分割的一部分。自动化需要覆盖整个过程中,包括安全和合规性测试。代码是从哪里来的?是否涉及第三方技术、产品或容器镜像?是否有已知的安全勘误表?是否有已知的常见代码缺陷?机密信息和个人身份信息是否被隔离?如何进行身份认证?谁被授权部署服务和应用程序?
|
||||
|
||||
你不是在写你自己的加密代码吧?
|
||||
你不是自己在写你的加密代码吧?
|
||||
|
||||
尽可能地自动化渗透测试。我提到过自动化没?它是使安全性持续的一个重要部分,而不是偶尔做一次的检查清单。
|
||||
|
||||
这听起来很难吗?可能有点。至少它是不同的。但是,作一名 [DevOpsDays OpenSpaces][8] 伦敦论坛的一名参与者对我说:“这只是技术测试。它既不神奇也不神秘。”他接着说,将安全作为一种更广泛地了解整个软件生命周期(这是一种不错的技能)的方法来参与进来并不难。他还建议参加事件响应练习或[捕获国旗练习][9]。你会发现它们很有趣。
|
||||
|
||||
本文基于作者将于 5 月 8 日至 10 日在旧金山举行的 [Red Hat Summit 2018][11] 上发表的演讲。_[5 月 7 日前注册][11]以节省 500 美元的注册。使用折扣代码**OPEN18**在支付页面应用折扣_
|
||||
|
||||
这听起来很难吗?可能有点。至少它是不同的。但是,一名 [DevOpsDays OpenSpaces][8] 伦敦论坛的参与者对我说:“这只是技术测试。它既不神奇也不神秘。”他接着说,将安全作为一种更广泛地了解整个软件生命周期的方法(这是一种不错的技能)来参与进来并不难。他还建议参加事件响应练习或[夺旗练习][9]。你会发现它们很有趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/what-developers-need-know-about-security
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,67 @@
|
||||
一个用于家庭项目的单用户、轻量级操作系统
|
||||
======
|
||||
> 业余爱好者应该了解一下 RISC OS 的五个原因。
|
||||
|
||||

|
||||
|
||||
究竟什么是 RISC OS?嗯,它不是一种新的 Linux。它也不是有些人认为的 Windows。事实上,它发布于 1987 年,它比它们任何一个都要古老。但你看到它时不一定会意识到这一点。
|
||||
|
||||
其点击式图形用户界面在底部为活动的程序提供一个固定面板和一个图标栏。因此,它看起来像 Windows 95,并且比它早了 8 年。
|
||||
|
||||
这个操作系统最初是为 [Acorn Archimedes][1] 编写的。这台机器中的 Acorn RISC Machines CPU 是全新的硬件,因此需要在其上运行全新的软件。这是最早的 ARM 芯片上的系统,早于任何人想到的 Android 或 [Armbian][2] 之前。
|
||||
|
||||
虽然 Acorn 桌面最终消失了,但 ARM 芯片继续征服世界。在这里,RISC OS 一直有一个优点 —— 通常在嵌入式设备中,你从来没有真正地意识到它。RISC OS 过去长期以来一直是一个完全专有的操作系统。但近年来,该抄系统的所有者已经开始将源代码发布到一个名为 [RISC OS Open][3] 的项目中。
|
||||
|
||||
### 1、你可以将它安装在树莓派上
|
||||
|
||||
树莓派的官方操作系统 [Raspbian][4] 实际上非常棒(如果你对摆弄不同技术上新奇的东西不感兴趣,那么你可能最初也不会选择树莓派)。由于 RISC OS 是专门为 ARM 编写的,因此它可以在各种小型计算机上运行,包括树莓派的各个型号。
|
||||
|
||||
### 2、它超轻量级
|
||||
|
||||
我的树莓派上安装的 RISC 系统占用了几百兆 —— 这是在我加载了数十个程序和游戏之后。它们大多数时候不超过 1 兆。
|
||||
|
||||
如果你真的节俭,RISC OS Pico 可用在 16MB SD 卡上。如果你要在嵌入式系统或物联网项目中鼓捣某些东西,这是很完美的。当然,16MB 实际上比压缩到 512KB 的老 Archimedes 的 ROM 要多得多。但我想 30 年间内存技术的发展,我们可以稍微放宽一下了。
|
||||
|
||||
### 3、它非常适合复古游戏
|
||||
|
||||
当 Archimedes 处于鼎盛时期时,ARM CPU 的速度比 Apple Macintosh 和 Commodore Amiga 中的 Motorola 68000 要快几倍,它也完全吸了新的 386 技术。这使得它成为对游戏开发者有吸引力的一个平台,他们希望用这个星球上最强大的桌面计算机来支撑他们的东西。
|
||||
|
||||
那些游戏的许多拥有者都非常慷慨,允许业余爱好者免费下载他们的老作品。虽然 RISC OS 和硬件已经发展了,但只需要进行少量的调整就可以让它们运行起来。
|
||||
|
||||
如果你有兴趣探索这个,[这里有一个指南][5]让这些游戏在你的树莓派上运行。
|
||||
|
||||
### 4、它有 BBC BASIC
|
||||
|
||||
就像过去一样,按下 `F12` 进入命令行,输入 `*BASIC`,就可以看到一个完整的 BBC BASIC 解释器。
|
||||
|
||||
对于那些在 80 年代没有接触过它的人,请让我解释一下:BBC BASIC 是当时我们很多人的第一个编程语言,因为它专门教孩子如何编码。当时有大量的书籍和杂志文章教我们编写自己的简单但高度可玩的游戏。
|
||||
|
||||
几十年后,对于一个想要在学校假期做点什么的有技术头脑的孩子而言,在 BBC BASIC 上编写自己的游戏仍然是一个很棒的项目。但很少有孩子在家里有 BBC micro。那么他们应该怎么做呢?
|
||||
|
||||
当然,你可以在每台家用电脑上运行解释器,但是当别人需要使用它时就不能用了。那么为什么不使用装有 RISC OS 的树莓派呢?
|
||||
|
||||
### 5、它是一个简单的单用户操作系统
|
||||
|
||||
RISC OS 不像 Linux 一样有自己的用户和超级用户访问权限。它有一个用户并可以完全访问整个机器。因此,它可能不是跨企业部署的最佳日常驱动,甚至不适合给老人家做银行业务。但是,如果你正在寻找可以用来修改和鼓捣的东西,那绝对是太棒了。你和机器之间没有那么多障碍,所以你可以直接闯进去。
|
||||
|
||||
### 扩展阅读
|
||||
|
||||
如果你想了解有关此操作系统的更多信息,请查看 [RISC OS Open][3],或者将镜像烧到闪存到卡上并开始使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/gentle-intro-risc-os
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dxmjames
|
||||
[1]:https://en.wikipedia.org/wiki/Acorn_Archimedes
|
||||
[2]:https://www.armbian.com/
|
||||
[3]:https://www.riscosopen.org/content/
|
||||
[4]:https://www.raspbian.org/
|
||||
[5]:https://www.riscosopen.org/wiki/documentation/show/Introduction%20to%20RISC%20OS
|
||||
@ -1,67 +1,64 @@
|
||||
**全文共三处“译注”,麻烦校对大大**
|
||||
|
||||
2018 年 5 款最好的 Linux 游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux 可能不会很快成为游戏玩家选择的平台——Valve Steam Machines 的失败似乎是对这一点的深刻提醒——但这并不意味着该平台没有稳定增长,并且拥有相当多的优秀游戏。
|
||||
Linux 可能不会很快成为游戏玩家选择的平台 —— Valve Steam Machines 的失败似乎是对这一点的深刻提醒 —— 但这并不意味着该平台没有稳定增长,并且拥有相当多的优秀游戏。
|
||||
|
||||
从独立打击到辉煌的 RPG(角色扮演),2018 年已经可以称得上是 Linux 游戏的丰收年,在这里,我们将列出迄今为止最喜欢的五款。
|
||||
从独立单机到辉煌的 RPG(角色扮演),2018 年已经可以称得上是 Linux 游戏的丰收年,在这里,我们将列出迄今为止最喜欢的五款。
|
||||
|
||||
你是否在寻找优秀的 Linux 游戏却又不想挥霍金钱?来看看我们的最佳 [免费 Linux 游戏][1] 名单吧!
|
||||
|
||||
### 1. 永恒之柱2:死亡之火(Pillars of Eternity II: Deadfire)
|
||||
### 1、<ruby>永恒之柱 2:死亡之火<rt>Pillars of Eternity II: Deadfire</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-pillars-of-eternity-2-deadfire][2]
|
||||
|
||||
其中一款最能代表近年来 cRPG 的复兴,它让传统的 Bethesda RPG 看起来更像是轻松的动作冒险游戏。在《永恒之柱》系列的最新作品中,当你和船员在充满冒险和危机的岛屿周围航行时,你会发现自己更像是一个海盗。
|
||||
其中一款最能代表近年来 cRPG 的复兴,它让传统的 Bethesda RPG 看起来更像是轻松的动作冒险游戏。在磅礴的《<ruby>永恒之柱<rt>Pillars of Eternity</rt></ruby>》系列的最新作品中,当你和船员在充满冒险和危机的岛屿周围航行时,你会发现自己更像是一个海盗。
|
||||
|
||||
在混合了海战元素的基础上,《死亡之火》延续了前作丰富的游戏剧情和出色的写作,同时在美丽的画面和手绘背景的基础上更进一步。
|
||||
在混合了海战元素的基础上,《死亡之火》延续了前作丰富的游戏剧情和出色的文笔,同时在美丽的画面和手绘背景的基础上更进一步。
|
||||
|
||||
这是一款毫无疑问的深度的硬核 RPG ,可能会让一些人对它产生抵触情绪,不过那些接受它的人会投入几个月的时间沉迷其中。
|
||||
这是一款毫无疑问的令人印象深刻的硬核 RPG ,可能会让一些人对它产生抵触情绪,不过那些接受它的人会投入几个月的时间沉迷其中。
|
||||
|
||||
|
||||
### 2. 杀戮尖塔(Slay the Spire)
|
||||
### 2、<ruby>杀戮尖塔<rt>Slay the Spire</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-slay-the-spire][3]
|
||||
|
||||
《杀戮尖塔》仍处于早期阶段,却已经成为年度最佳游戏之一,它是一款采用 deck-building 玩法的卡牌游戏,由充满活力的视觉风格和流氓般的机制加以点缀,在每次令人愤怒的(但可能是应受的)死亡之后,你还会回来尝试更多次。(译注:翻译出来有点生硬)
|
||||
《杀戮尖塔》仍处于早期阶段,却已经成为年度最佳游戏之一,它是一款采用 deck-building 玩法的卡牌游戏,由充满活力的视觉风格和 rogue-like 机制加以点缀,即便在一次次令人愤怒的(但可能是应受的)死亡之后,你还会再次投入其中。
|
||||
|
||||
每次游戏都有无尽的卡牌组合和不同的布局,《杀戮尖塔》就像是近年来所有震撼独立场景的最佳实现——卡牌游戏和永久死亡冒险合二为一。
|
||||
每次游戏都有无尽的卡牌组合和不同的布局,《杀戮尖塔》就像是近年来所有令人震撼的独立游戏的最佳具现 —— 卡牌游戏和永久死亡冒险模式合二为一。
|
||||
|
||||
再强调一次,它仍处于早期阶段,所以它只会变得越来越好!
|
||||
|
||||
### 3. 战斗机甲(Battletech)
|
||||
### 3、<ruby>战斗机甲<rt>Battletech</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-battletech][4]
|
||||
|
||||
正如我们在这个名单上看到的“重磅”游戏一样(译注:这句翻译出来前后逻辑感觉有问题),《战斗机甲》是一款星际战争游戏(基于桌面游戏),你将装载一个机甲战队并引导它们进行丰富的回合制战斗。
|
||||
这是我们榜单上像“大片”一样的游戏,《战斗机甲》是一款星际战争游戏(基于桌面游戏),你将装载一个机甲战队并引导它们进行丰富的回合制战斗。
|
||||
|
||||
战斗发生在一系列的地形上——从寒冷的荒地到阳光普照的地带——你将用巨大的热武器装备你的四人小队,与对手小队作战。如果你觉得这听起来有点“机械战士”的味道,那么你正是在正确的思考路线上,只不过这次更注重战术安排而不是直接行动。
|
||||
战斗发生在一系列的地形上,从寒冷的荒地到阳光普照的地带,你将用巨大的热武器装备你的四人小队,与对手小队作战。如果你觉得这听起来有点“机械战士”的味道,那么你想的没错,只不过这次更注重战术安排而不是直接行动。
|
||||
|
||||
除了让你在宇宙冲突中指挥的战役外,多人模式也可能会耗费你数不清的时间。
|
||||
|
||||
### 4. 死亡细胞(Dead Cells)
|
||||
### 4、<ruby>死亡细胞<rt>Dead Cells</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-dead-cells][5]
|
||||
|
||||
这款游戏称得上是年度最佳平台动作游戏。"Roguelite" 类游戏《死亡细胞》将你带入一个黑暗(却色彩绚丽)的世界,在那里进行攻击和躲避以通过程序生成的关卡。它有点像 2D 的《黑暗之魂(Dark Souls)》,如果黑暗之魂被五彩缤纷的颜色浸透的话。
|
||||
这款游戏称得上是年度最佳平台动作游戏。Roguelike 游戏《死亡细胞》将你带入一个黑暗(却色彩绚丽)的世界,在那里进行攻击和躲避以通过程序生成的关卡。它有点像 2D 的《<ruby>黑暗之魂<rt>Dark Souls</rt></ruby>》,如果《黑暗之魂》也充满五彩缤纷的颜色的话。
|
||||
|
||||
死亡细胞很残忍,不过精确而灵敏的控制系统一定会让你为死亡付出代价,而在两次运行期间的升级系统又会确保你总是有一些进步的成就感。
|
||||
《死亡细胞》是无情的,只有精确而灵敏的控制才会让你避开死亡,而在两次运行期间的升级系统又会确保你总是有一些进步的成就感。
|
||||
|
||||
《死亡细胞》的像素风、动画效果和游戏机制都达到了巅峰,它及时地提醒我们,在没有 3D 图形的过度使用下游戏可以制作成什么样子。
|
||||
|
||||
|
||||
### 5. 叛逆机械师(Iconoclasts)
|
||||
### 5、<ruby>叛逆机械师<rt>Iconoclasts</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-iconoclasts][6]
|
||||
|
||||
这款游戏不像上面提到的几款那样为人所知,它是一款可爱风格的游戏,可以看作是《死亡细胞》不那么惊悚、更可爱的替代品(译注:形容词生硬)。玩家将扮演成罗宾,发现自己处于政治扭曲的外星世界后开始了逃亡。
|
||||
这款游戏不像上面提到的几款那样为人所知,它是一款可爱风格的游戏,可以看作是《死亡细胞》不那么惊悚、更可爱的替代品。玩家将扮演成罗宾,一个发现自己处于政治扭曲的外星世界后开始了逃亡的女孩。
|
||||
|
||||
尽管你的角色将在非线性的关卡中行动,游戏却有着扣人心弦的游戏剧情,罗宾会获得各种各样充满想象力的提升,其中最重要的是她的扳手,从发射炮弹到解决巧妙的环境问题,你几乎可以用它来做任何事。
|
||||
|
||||
《叛逆机械师》是一个充满快乐与活力的平台游戏,融合了《洛克人(Megaman)》的战斗和《银河战士(Metroid)》的探索。如果你借鉴了那两部伟大的作品,可能不会比它做得更好。
|
||||
《叛逆机械师》是一个充满快乐与活力的平台游戏,融合了《<ruby>洛克人<rt>Megaman</rt></ruby>》的战斗和《<ruby>银河战士<rt>Metroid</rt></ruby>》的探索。如果你借鉴了那两部伟大的作品,可能不会比它做得更好。
|
||||
|
||||
### 总结
|
||||
|
||||
@ -74,7 +71,7 @@ via: https://www.maketecheasier.com/best-linux-games/
|
||||
作者:[Robert Zak][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[seriouszyx](https://github.com/seriouszyx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,247 @@
|
||||
如何使用 chkconfig 和 systemctl 命令启用或禁用 Linux 服务
|
||||
======
|
||||
|
||||
对于 Linux 管理员来说这是一个重要(美妙)的话题,所以每个人都必须知道,并练习怎样才能更高效的使用它们。
|
||||
|
||||
在 Linux 中,无论何时当你安装任何带有服务和守护进程的包,系统默认会把这些服务的初始化及 systemd 脚本添加进去,不过此时它们并没有被启用。
|
||||
|
||||
我们需要手动的开启或者关闭那些服务。Linux 中有三个著名的且一直在被使用的初始化系统。
|
||||
|
||||
### 什么是初始化系统?
|
||||
|
||||
在以 Linux/Unix 为基础的操作系统上,`init` (初始化的简称) 是内核引导系统启动过程中第一个启动的进程。
|
||||
|
||||
`init` 的进程 id (pid)是 1,除非系统关机否则它将会一直在后台运行。
|
||||
|
||||
`init` 首先根据 `/etc/inittab` 文件决定 Linux 运行的级别,然后根据运行级别在后台启动所有其他进程和应用程序。
|
||||
|
||||
BIOS、MBR、GRUB 和内核程序在启动 `init` 之前就作为 Linux 的引导程序的一部分开始工作了。
|
||||
|
||||
下面是 Linux 中可以使用的运行级别(从 0~6 总共七个运行级别):
|
||||
|
||||
* `0`:关机
|
||||
* `1`:单用户模式
|
||||
* `2`:多用户模式(没有NFS)
|
||||
* `3`:完全的多用户模式
|
||||
* `4`:系统未使用
|
||||
* `5`:图形界面模式
|
||||
* `6`:重启
|
||||
|
||||
下面是 Linux 系统中最常用的三个初始化系统:
|
||||
|
||||
* System V(Sys V)
|
||||
* Upstart
|
||||
* systemd
|
||||
|
||||
### 什么是 System V(Sys V)?
|
||||
|
||||
System V(Sys V)是类 Unix 系统第一个也是传统的初始化系统。`init` 是内核引导系统启动过程中第一支启动的程序,它是所有程序的父进程。
|
||||
|
||||
大部分 Linux 发行版最开始使用的是叫作 System V(Sys V)的传统的初始化系统。在过去的几年中,已经发布了好几个初始化系统以解决标准版本中的设计限制,例如:launchd、Service Management Facility、systemd 和 Upstart。
|
||||
|
||||
但是 systemd 已经被几个主要的 Linux 发行版所采用,以取代传统的 SysV 初始化系统。
|
||||
|
||||
### 什么是 Upstart?
|
||||
|
||||
Upstart 是一个基于事件的 `/sbin/init` 守护进程的替代品,它在系统启动过程中处理任务和服务的启动,在系统运行期间监视它们,在系统关机的时候关闭它们。
|
||||
|
||||
它最初是为 Ubuntu 而设计,但是它也能够完美的部署在其他所有 Linux系统中,用来代替古老的 System-V。
|
||||
|
||||
Upstart 被用于 Ubuntu 从 9.10 到 Ubuntu 14.10 和基于 RHEL 6 的系统,之后它被 systemd 取代。
|
||||
|
||||
### 什么是 systemd?
|
||||
|
||||
systemd 是一个新的初始化系统和系统管理器,它被用于所有主要的 Linux 发行版,以取代传统的 SysV 初始化系统。
|
||||
|
||||
systemd 兼容 SysV 和 LSB 初始化脚本。它可以直接替代 SysV 初始化系统。systemd 是被内核启动的第一个程序,它的 PID 是 1。
|
||||
|
||||
systemd 是所有程序的父进程,Fedora 15 是第一个用 systemd 取代 upstart 的发行版。`systemctl` 用于命令行,它是管理 systemd 的守护进程/服务的主要工具,例如:(开启、重启、关闭、启用、禁用、重载和状态)
|
||||
|
||||
systemd 使用 .service 文件而不是 bash 脚本(SysVinit 使用的)。systemd 将所有守护进程添加到 cgroups 中排序,你可以通过浏览 `/cgroup/systemd` 文件查看系统等级。
|
||||
|
||||
### 如何使用 chkconfig 命令启用或禁用引导服务?
|
||||
|
||||
`chkconfig` 实用程序是一个命令行工具,允许你在指定运行级别下启动所选服务,以及列出所有可用服务及其当前设置。
|
||||
|
||||
此外,它还允许我们从启动中启用或禁用服务。前提是你有超级管理员权限(root 或者 `sudo`)运行这个命令。
|
||||
|
||||
所有的服务脚本位于 `/etc/rd.d/init.d`文件中
|
||||
|
||||
### 如何列出运行级别中所有的服务
|
||||
|
||||
`--list` 参数会展示所有的服务及其当前状态(启用或禁用服务的运行级别):
|
||||
|
||||
```
|
||||
# chkconfig --list
|
||||
NetworkManager 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
abrt-ccpp 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||
abrtd 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||
acpid 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
|
||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
.
|
||||
.
|
||||
```
|
||||
|
||||
### 如何查看指定服务的状态
|
||||
|
||||
如果你想查看运行级别下某个服务的状态,你可以使用下面的格式匹配出需要的服务。
|
||||
|
||||
比如说我想查看运行级别中 `auditd` 服务的状态
|
||||
|
||||
```
|
||||
# chkconfig --list| grep auditd
|
||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
```
|
||||
|
||||
### 如何在指定运行级别中启用服务
|
||||
|
||||
使用 `--level` 参数启用指定运行级别下的某个服务,下面展示如何在运行级别 3 和运行级别 5 下启用 `httpd` 服务。
|
||||
|
||||
|
||||
```
|
||||
# chkconfig --level 35 httpd on
|
||||
```
|
||||
|
||||
### 如何在指定运行级别下禁用服务
|
||||
|
||||
同样使用 `--level` 参数禁用指定运行级别下的服务,下面展示的是在运行级别 3 和运行级别 5 中禁用 `httpd` 服务。
|
||||
|
||||
```
|
||||
# chkconfig --level 35 httpd off
|
||||
```
|
||||
|
||||
### 如何将一个新服务添加到启动列表中
|
||||
|
||||
`-–add` 参数允许我们添加任何新的服务到启动列表中,默认情况下,新添加的服务会在运行级别 2、3、4、5 下自动开启。
|
||||
|
||||
```
|
||||
# chkconfig --add nagios
|
||||
```
|
||||
|
||||
### 如何从启动列表中删除服务
|
||||
|
||||
可以使用 `--del` 参数从启动列表中删除服务,下面展示的是如何从启动列表中删除 Nagios 服务。
|
||||
|
||||
```
|
||||
# chkconfig --del nagios
|
||||
```
|
||||
|
||||
### 如何使用 systemctl 命令启用或禁用开机自启服务?
|
||||
|
||||
`systemctl` 用于命令行,它是一个用来管理 systemd 的守护进程/服务的基础工具,例如:(开启、重启、关闭、启用、禁用、重载和状态)。
|
||||
|
||||
所有服务创建的 unit 文件位与 `/etc/systemd/system/`。
|
||||
|
||||
### 如何列出全部的服务
|
||||
|
||||
使用下面的命令列出全部的服务(包括启用的和禁用的)。
|
||||
|
||||
```
|
||||
# systemctl list-unit-files --type=service
|
||||
UNIT FILE STATE
|
||||
arp-ethers.service disabled
|
||||
auditd.service enabled
|
||||
autovt@.service enabled
|
||||
blk-availability.service disabled
|
||||
brandbot.service static
|
||||
chrony-dnssrv@.service static
|
||||
chrony-wait.service disabled
|
||||
chronyd.service enabled
|
||||
cloud-config.service enabled
|
||||
cloud-final.service enabled
|
||||
cloud-init-local.service enabled
|
||||
cloud-init.service enabled
|
||||
console-getty.service disabled
|
||||
console-shell.service disabled
|
||||
container-getty@.service static
|
||||
cpupower.service disabled
|
||||
crond.service enabled
|
||||
.
|
||||
.
|
||||
150 unit files listed.
|
||||
```
|
||||
|
||||
使用下面的格式通过正则表达式匹配出你想要查看的服务的当前状态。下面是使用 `systemctl` 命令查看 `httpd` 服务的状态。
|
||||
|
||||
```
|
||||
# systemctl list-unit-files --type=service | grep httpd
|
||||
httpd.service disabled
|
||||
```
|
||||
|
||||
### 如何让指定的服务开机自启
|
||||
|
||||
使用下面格式的 `systemctl` 命令启用一个指定的服务。启用服务将会创建一个符号链接,如下可见:
|
||||
|
||||
```
|
||||
# systemctl enable httpd
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
|
||||
```
|
||||
|
||||
运行下列命令再次确认服务是否被启用。
|
||||
|
||||
```
|
||||
# systemctl is-enabled httpd
|
||||
enabled
|
||||
```
|
||||
|
||||
### 如何禁用指定的服务
|
||||
|
||||
运行下面的命令禁用服务将会移除你启用服务时所创建的符号链接。
|
||||
|
||||
```
|
||||
# systemctl disable httpd
|
||||
Removed symlink /etc/systemd/system/multi-user.target.wants/httpd.service.
|
||||
```
|
||||
|
||||
运行下面的命令再次确认服务是否被禁用。
|
||||
|
||||
```
|
||||
# systemctl is-enabled httpd
|
||||
disabled
|
||||
```
|
||||
|
||||
### 如何查看系统当前的运行级别
|
||||
|
||||
使用 `systemctl` 命令确认你系统当前的运行级别,`runlevel` 命令仍然可在 systemd 下工作,不过,运行级别对于 systemd 来说是一个历史遗留的概念。所以我建议你全部使用 `systemctl` 命令。
|
||||
|
||||
我们当前处于运行级别 3, 它等同于下面显示的 `multi-user.target`。
|
||||
|
||||
```
|
||||
# systemctl list-units --type=target
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
basic.target loaded active active Basic System
|
||||
cloud-config.target loaded active active Cloud-config availability
|
||||
cryptsetup.target loaded active active Local Encrypted Volumes
|
||||
getty.target loaded active active Login Prompts
|
||||
local-fs-pre.target loaded active active Local File Systems (Pre)
|
||||
local-fs.target loaded active active Local File Systems
|
||||
multi-user.target loaded active active Multi-User System
|
||||
network-online.target loaded active active Network is Online
|
||||
network-pre.target loaded active active Network (Pre)
|
||||
network.target loaded active active Network
|
||||
paths.target loaded active active Paths
|
||||
remote-fs.target loaded active active Remote File Systems
|
||||
slices.target loaded active active Slices
|
||||
sockets.target loaded active active Sockets
|
||||
swap.target loaded active active Swap
|
||||
sysinit.target loaded active active System Initialization
|
||||
timers.target loaded active active Timers
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.2daygeek.com/how-to-enable-or-disable-services-on-boot-in-linux-using-chkconfig-and-systemctl-command/
|
||||
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,11 +1,11 @@
|
||||
使用 Calcurse 在 Linux 命令行中组织任务
|
||||
======
|
||||
|
||||
使用 Calcurse 了解你的日历和待办事项列表。
|
||||
> 使用 Calcurse 了解你的日历和待办事项列表。
|
||||
|
||||

|
||||
|
||||
你是否需要复杂,功能丰富的图形或 Web 程序才能保持井井有条?我不这么认为。正确的命令行工具可以完成工作并且做得很好。
|
||||
你是否需要复杂、功能丰富的图形或 Web 程序才能保持井井有条?我不这么认为。合适的命令行工具可以完成工作并且做得很好。
|
||||
|
||||
当然,说出命令行这个词可能会让一些 Linux 用户感到害怕。对他们来说,命令行是未知领域。
|
||||
|
||||
@ -15,54 +15,51 @@
|
||||
|
||||
### 获取软件
|
||||
|
||||
如果你喜欢编译代码(我通常不喜欢),你可以从[Calcurse 网站][1]获取源码。否则,根据你的 Linux 发行版获取[二进制安装程序][2]。你甚至可以从 Linux 发行版的软件包管理器中获取 Calcurse。检查一下不会有错的。
|
||||
如果你喜欢编译代码(我通常不喜欢),你可以从 [Calcurse 网站][1]获取源码。否则,根据你的 Linux 发行版获取[二进制安装程序][2]。你甚至可以从 Linux 发行版的软件包管理器中获取 Calcurse。检查一下不会有错的。
|
||||
|
||||
编译或安装 Calcurse 后(两者都不用太长时间),你就可以开始使用了。
|
||||
|
||||
### 使用 Calcurse
|
||||
|
||||
打开终端并输入 **calcurse**。
|
||||
打开终端并输入 `calcurse`。
|
||||
|
||||
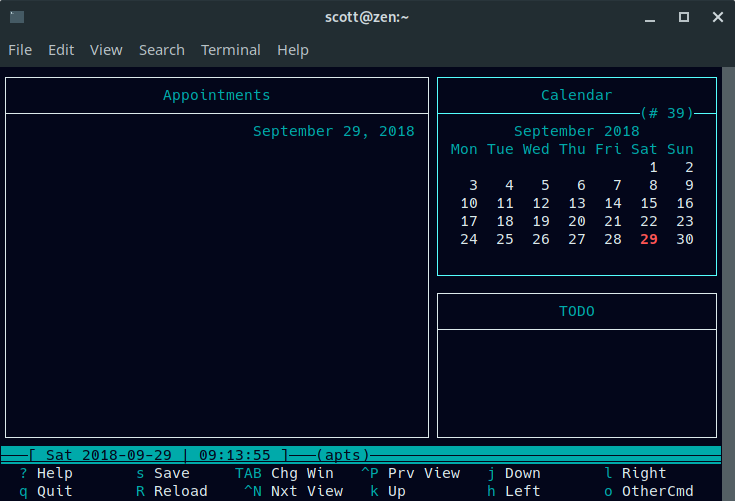
|
||||
|
||||
Calcurse 的界面由三个面板组成:
|
||||
|
||||
* 预约(屏幕左侧)
|
||||
* 日历(右上角)
|
||||
* 待办事项清单(右下角)
|
||||
* <ruby>预约<rt>Appointments</rt></ruby>(屏幕左侧)
|
||||
* <ruby>日历<rt>Calendar</rt></ruby>(右上角)
|
||||
* <ruby>待办事项清单<rt>TODO</rt></ruby>(右下角)
|
||||
|
||||
按键盘上的 `Tab` 键在面板之间移动。要在面板添加新项目,请按下 `a`。Calcurse 将指导你完成添加项目所需的操作。
|
||||
|
||||
一个有趣的地方地是预约和日历面板配合工作。你选中日历面板并添加一个预约。在那里,你选择一个预约的日期。完成后,你回到预约面板,你就看到了。
|
||||
|
||||
|
||||
按键盘上的 Tab 键在面板之间移动。要在面板添加新项目,请按下 **a**。Calcurse 将指导你完成添加项目所需的操作。
|
||||
|
||||
一个有趣的地方地预约和日历面板一起生效。你选中日历面板并添加一个预约。在那里,你选择一个预约的日期。完成后,你回到预约面板。我知道。。。
|
||||
|
||||
按下 **a** 设置开始时间,持续时间(以分钟为单位)和预约说明。开始时间和持续时间是可选的。Calcurse 在它们到期的那天显示预约。
|
||||
按下 `a` 设置开始时间、持续时间(以分钟为单位)和预约说明。开始时间和持续时间是可选的。Calcurse 在它们到期的那天显示预约。
|
||||
|
||||
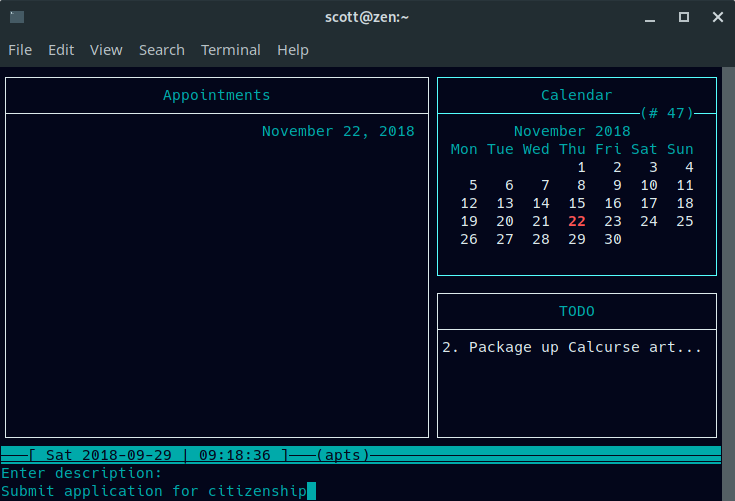
|
||||
|
||||
一天的预约看起来像:
|
||||
一天的预约看起来像这样:
|
||||
|
||||
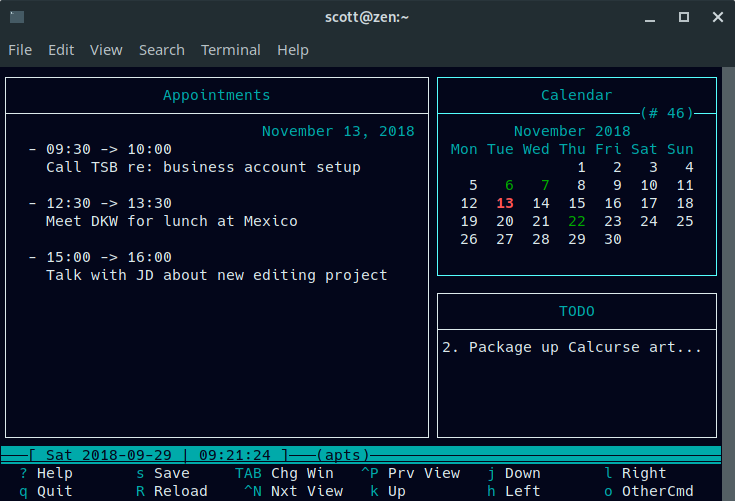
|
||||
|
||||
待办事项列表独立运作。选中待办面板并(再次)按下 **a**。输入任务的描述,然后设置优先级(1 表示最高,9 表示最低)。Calcurse 会在待办事项面板中列出未完成的任务。
|
||||
待办事项列表独立运作。选中待办面板并(再次)按下 `a`。输入任务的描述,然后设置优先级(1 表示最高,9 表示最低)。Calcurse 会在待办事项面板中列出未完成的任务。
|
||||
|
||||
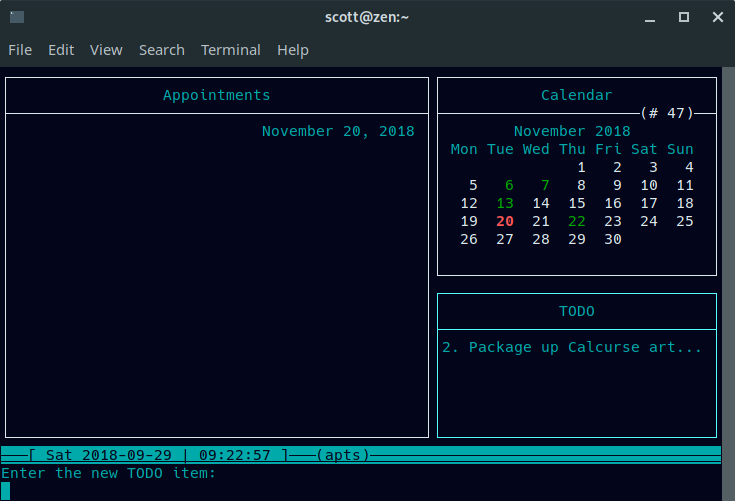
|
||||
|
||||
如果你的任务有很长的描述,那么 Calcurse 会截断它。你可以使用键盘上的向上或向下箭头键浏览任务,然后按下 **v** 查看描述。
|
||||
如果你的任务有很长的描述,那么 Calcurse 会截断它。你可以使用键盘上的向上或向下箭头键浏览任务,然后按下 `v` 查看描述。
|
||||
|
||||
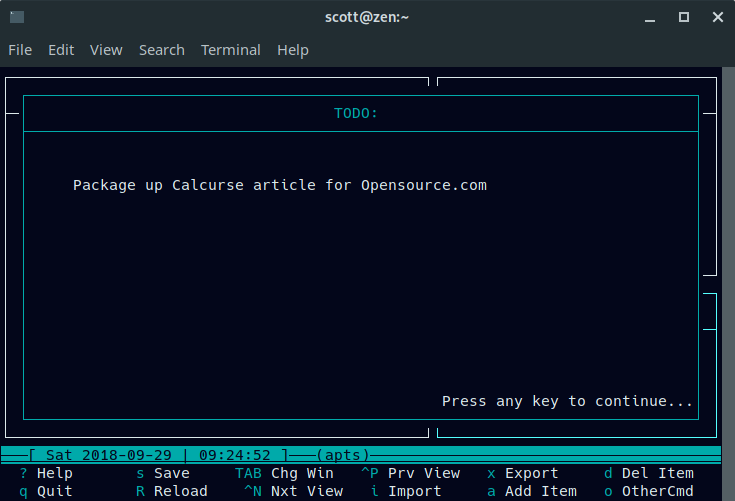
|
||||
|
||||
Calcurse 将其信息以文本形式保存在你的主目录下名为 **.calcurse** 的隐藏文件夹中,例如 **/home/scott/.calcurse**。如果 Calcurse 停止工作,那也很容易找到你的信息。
|
||||
Calcurse 将其信息以文本形式保存在你的主目录下名为 `.calcurse` 的隐藏文件夹中,例如 `/home/scott/.calcurse`。如果 Calcurse 停止工作,那也很容易找到你的信息。
|
||||
|
||||
### 其他有用的功能
|
||||
|
||||
Calcurse 其他的功能包括设置重复预约的功能。要执行此操作,找出要重复的预约,然后在预约面板中按下 **r**。系统会要求你设置频率(例如,每天或每周)以及你希望重复预约的时间。
|
||||
Calcurse 其他的功能包括设置重复预约的功能。要执行此操作,找出要重复的预约,然后在预约面板中按下 `r`。系统会要求你设置频率(例如,每天或每周)以及你希望重复预约的时间。
|
||||
|
||||
你还可以导入 [ICAL][3] 格式的日历或以 ICAL 或 [PCAL][4] 格式导出数据。使用 ICAL,你可以与其他日历程序共享数据。使用 PCAL,你可以生成日历的 Postscript 版本。
|
||||
|
||||
你还可以将许多命令行参数传递给 Calcurse。你可以[在文档中][5]阅读它们。
|
||||
你还可以将许多命令行参数传递给 Calcurse。你可以[在文档中][5]了解它们。
|
||||
|
||||
虽然很简单,但 Calcurse 可以帮助你保持井井有条。你需要更加关注自己的任务和预约,但是你将能够更好地关注你需要做什么以及你需要做的方向。
|
||||
|
||||
@ -73,7 +70,7 @@ via: https://opensource.com/article/18/10/calcurse
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
pydbgen:一个数据库随机生成器
|
||||
======
|
||||
> 用这个简单的工具生成大型数据库,让你更好地研究数据科学。
|
||||
|
||||
> 用这个简单的工具生成带有多表的大型数据库,让你更好地用 SQL 研究数据科学。
|
||||
|
||||

|
||||
|
||||
@ -38,7 +39,6 @@ from pydbgen import pydbgen
|
||||
myDB=pydbgen.pydb()
|
||||
```
|
||||
|
||||
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
||||
随后就可以调用 `pydb` 对象公开的各种内部函数了。可以按照下面的例子,输出随机的美国城市和车牌号码:
|
||||
|
||||
```
|
||||
@ -58,7 +58,7 @@ for _ in range(10):
|
||||
SZL-0934
|
||||
```
|
||||
|
||||
另外,如果你输入的是 city 而不是 city_real,返回的将会是虚构的城市名。
|
||||
另外,如果你输入的是 `city()` 而不是 `city_real()`,返回的将会是虚构的城市名。
|
||||
|
||||
```
|
||||
print(myDB.gen_data_series(num=8,data_type='city'))
|
||||
@ -97,11 +97,12 @@ fields=['name','city','street_address','email'])
|
||||
```
|
||||
|
||||
上面的例子种生成了一个能被 MySQL 和 SQLite 支持的 `.db` 文件。下图则显示了这个文件中的数据表在 SQLite 可视化客户端中打开的画面。
|
||||
|
||||
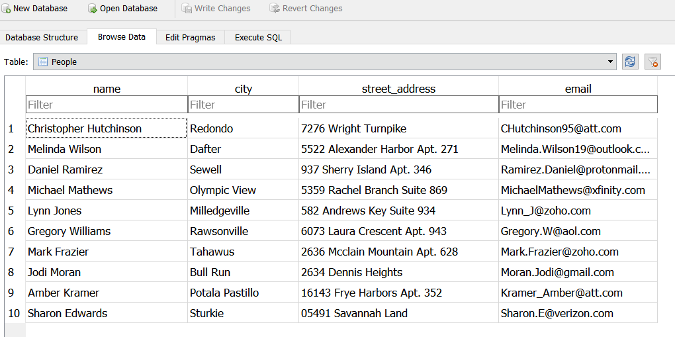
|
||||
|
||||
### 生成 Excel 文件
|
||||
|
||||
和上面的其它示例类似,下面的代码可以生成一个具有随机数据的 Excel 文件。值得一提的是,通过将`phone_simple` 参数设为 `False` ,可以生成较长较复杂的电话号码。如果你想要提高自己在数据提取方面的能力,不妨尝试一下这个功能。
|
||||
和上面的其它示例类似,下面的代码可以生成一个具有随机数据的 Excel 文件。值得一提的是,通过将 `phone_simple` 参数设为 `False` ,可以生成较长较复杂的电话号码。如果你想要提高自己在数据提取方面的能力,不妨尝试一下这个功能。
|
||||
|
||||
```
|
||||
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
||||
@ -109,6 +110,7 @@ phone_simple=False,filename='TestExcel.xlsx')
|
||||
```
|
||||
|
||||
最终的结果类似下图所示:
|
||||
|
||||
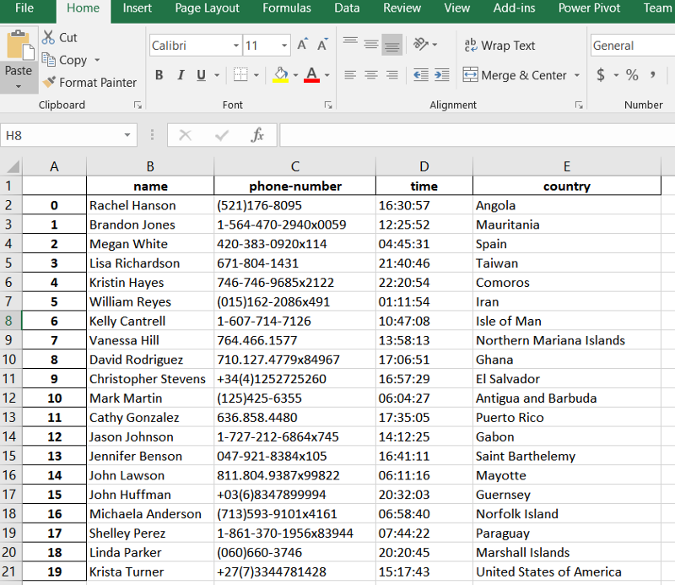
|
||||
|
||||
### 生成随机电子邮箱地址
|
||||
@ -133,7 +135,7 @@ Tirtha.S@comcast.net
|
||||
|
||||
### 未来的改进和用户贡献
|
||||
|
||||
目前的版本中并不完美。如果你发现了 pydbgen 的 bug 导致 pydbgen 在运行期间发生崩溃,请向我反馈。如果你打算对这个项目贡献代码,[也随时欢迎你][1]。当然现在也还有很多改进的方向:
|
||||
目前的版本中并不完美。如果你发现了 pydbgen 的 bug 导致它在运行期间发生崩溃,请向我反馈。如果你打算对这个项目贡献代码,[也随时欢迎你][1]。当然现在也还有很多改进的方向:
|
||||
|
||||
* pydbgen 作为随机数据生成器,可以集成一些机器学习或统计建模的功能吗?
|
||||
* pydbgen 是否会添加可视化功能?
|
||||
@ -151,7 +153,7 @@ via: https://opensource.com/article/18/11/pydbgen-random-database-table-generato
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -11,9 +11,9 @@
|
||||
|
||||
### tin-summer
|
||||
|
||||
`tin-summer` 是使用 Rust 语言编写的免费开源工具,它可以用于查找占用磁盘空间的文件,它也是 `du` 命令的另一个替代品。由于使用了多线程,因此 `tin-summer` 在计算大目录的大小时会比 `du` 命令快得多。`tin-summer` 与 `du` 命令之间的区别是前者读取文件的大小,而后者则读取磁盘使用情况。
|
||||
tin-summer 是使用 Rust 语言编写的自由开源工具,它可以用于查找占用磁盘空间的文件,它也是 `du` 命令的另一个替代品。由于使用了多线程,因此 tin-summer 在计算大目录的大小时会比 `du` 命令快得多。tin-summer 与 `du` 命令之间的区别是前者读取文件的大小,而后者则读取磁盘使用情况。
|
||||
|
||||
`tin-summer` 的开发者认为它可以替代 `du`,因为它具有以下优势:
|
||||
tin-summer 的开发者认为它可以替代 `du`,因为它具有以下优势:
|
||||
|
||||
* 在大目录的操作速度上比 `du` 更快;
|
||||
* 在显示结果上默认采用易读格式;
|
||||
@ -21,26 +21,26 @@
|
||||
* 可以对输出进行排序和着色处理;
|
||||
* 可扩展,等等。
|
||||
|
||||
|
||||
|
||||
**安装 tin-summer**
|
||||
|
||||
要安装 `tin-summer`,只需要在终端中执行以下命令:
|
||||
要安装 tin-summer,只需要在终端中执行以下命令:
|
||||
|
||||
```
|
||||
$ curl -LSfs https://japaric.github.io/trust/install.sh | sh -s -- --git vmchale/tin-summer
|
||||
```
|
||||
|
||||
你也可以使用 `cargo` 软件包管理器安装 `tin-summer`,但你需要在系统上先安装 Rust。在 Rust 已经安装好的情况下,执行以下命令:
|
||||
你也可以使用 `cargo` 软件包管理器安装 tin-summer,但你需要在系统上先安装 Rust。在 Rust 已经安装好的情况下,执行以下命令:
|
||||
|
||||
```
|
||||
$ cargo install tin-summer
|
||||
```
|
||||
|
||||
如果上面提到的这两种方法都不能成功安装 `tin-summer`,还可以从它的[软件发布页][1]下载最新版本的二进制文件编译,进行手动安装。
|
||||
如果上面提到的这两种方法都不能成功安装 tin-summer,还可以从它的[软件发布页][1]下载最新版本的二进制文件编译,进行手动安装。
|
||||
|
||||
**用法**
|
||||
|
||||
(LCTT 译注:tin-summer 的命令名为 `sn`)
|
||||
|
||||
如果需要查看当前工作目录的文件大小,可以执行以下命令:
|
||||
|
||||
```
|
||||
@ -80,13 +80,13 @@ $ sn sort /home/sk/ -n5
|
||||
$ sn ar
|
||||
```
|
||||
|
||||
`tin-summer` 同样支持查找指定大小的带有构建工程的目录。例如执行以下命令可以查找到大小在 100 MB 以上的带有构建工程的目录:
|
||||
tin-summer 同样支持查找指定大小的带有构建工程的目录。例如执行以下命令可以查找到大小在 100 MB 以上的带有构建工程的目录:
|
||||
|
||||
```
|
||||
$ sn ar -t100M
|
||||
```
|
||||
|
||||
如上文所说,`tin-summer` 在操作大目录的时候速度比较快,因此在操作小目录的时候,速度会相对比较慢一些。不过它的开发者已经表示,将会在以后的版本中优化这个缺陷。
|
||||
如上文所说,tin-summer 在操作大目录的时候速度比较快,因此在操作小目录的时候,速度会相对比较慢一些。不过它的开发者已经表示,将会在以后的版本中优化这个缺陷。
|
||||
|
||||
要获取相关的帮助,可以执行以下命令:
|
||||
|
||||
@ -98,7 +98,7 @@ $ sn --help
|
||||
|
||||
### dust
|
||||
|
||||
`dust` (含义是 `du` + `rust` = `dust`)使用 Rust 编写,是一个免费、开源的更直观的 `du` 工具。它可以在不需要 `head` 或`sort` 命令的情况下即时显示目录占用的磁盘空间。与 `tin-summer` 一样,它会默认情况以易读的格式显示每个目录的大小。
|
||||
`dust` (含义是 `du` + `rust` = `dust`)使用 Rust 编写,是一个免费、开源的更直观的 `du` 工具。它可以在不需要 `head` 或`sort` 命令的情况下即时显示目录占用的磁盘空间。与 tin-summer 一样,它会默认情况以易读的格式显示每个目录的大小。
|
||||
|
||||
**安装 dust**
|
||||
|
||||
@ -114,7 +114,7 @@ $ cargo install du-dust
|
||||
$ wget https://github.com/bootandy/dust/releases/download/v0.3.1/dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
|
||||
```
|
||||
|
||||
抽取文件:
|
||||
抽取文件:
|
||||
|
||||
```
|
||||
$ tar -xvf dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
|
||||
@ -283,7 +283,7 @@ via: https://www.ostechnix.com/some-good-alternatives-to-du-command/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
plutoid Translating!
|
||||
|
||||
Write Dumb Code
|
||||
======
|
||||
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
|
||||
|
||||
As students we attempt increasingly challenging problems with increasingly sophisticated technologies. We first learn loops, then functions, then classes, etc.. We are praised as we ascend this hierarchy, writing longer programs with more advanced technology. We learn that experienced programmers use monads while new programmers use for loops.
|
||||
|
||||
Then we graduate and find a job or open source project to work on with others. We search for something that we can add, and implement a solution pridefully, using the all the tricks that we learned in school.
|
||||
|
||||
Ah ha! I can extend this project to do X! And I can use inheritance here! Excellent!
|
||||
|
||||
We implement this feature and feel accomplished, and with good reason. Programming in real systems is no small accomplishment. This was certainly my experience. I was excited to write code and proud that I could show off all of the things that I knew how to do to the world. As evidence of my historical love of programming technology, here is a [linear algebra language][1] built with a another meta-programming language. Notice that no one has touched this code in several years.
|
||||
|
||||
However after maintaining code a bit more I now think somewhat differently.
|
||||
|
||||
1. We should not seek to build software. Software is the currency that we pay to solve problems, which is our actual goal. We should endeavor to build as little software as possible to solve our problems.
|
||||
2. We should use technologies that are as simple as possible, so that as many people as possible can use and extend them without needing to understand our advanced techniques. We should use advanced techniques only when we are not smart enough to figure out how to use more common techniques.
|
||||
|
||||
|
||||
|
||||
Neither of these points are novel. Most people I meet agree with them to some extent, but somehow we forget them when we go to contribute to a new project. The instinct to contribute by building and to demonstrate sophistication often take over.
|
||||
|
||||
### Software is a cost
|
||||
|
||||
Every line that you write costs people time. It costs you time to write it of course, but you are willing to make this personal sacrifice. However this code also costs the reviewers their time to understand it. It costs future maintainers and developers their time as they fix and modify your code. They could be spending this time outside in the sunshine or with their family.
|
||||
|
||||
So when you add code to a project you should feel meek. It should feel as though you are eating with your family and there isn't enough food on the table. You should take only what you need and no more. The people with you will respect you for your efforts to restrict yourself. Solving problems with less code is a hard, but it is a burden that you take on yourself to lighten the burdens of others.
|
||||
|
||||
### Complex technologies are harder to maintain
|
||||
|
||||
As students, we demonstrate merit by using increasingly advanced technologies. Our measure of worth depends on our ability to use functions, then classes, then higher order functions, then monads, etc. in public projects. We show off our solutions to our peers and feel pride or shame according to our sophistication.
|
||||
|
||||
However when working with a team to solve problems in the world the situation is reversed. Now we strive to solve problems with code that is as simple as possible. When we solve a problem simply we enable junior programmers to extend our solution to solve other problems. Simple code enables others and boosts our impact. We demonstrate our value by solving hard problems with only basic techniques.
|
||||
|
||||
Look! I replaced this recursive function with a for loop and it still does everything that we need it to. I know it's not as clever, but I noticed that the interns were having trouble with it and I thought that this change might help.
|
||||
|
||||
If you are a good programmer then you don't need to demonstrate that you know cool tricks. Instead, you can demonstrate your value by solving a problem in a simple way that enables everyone on your team to contribute in the future.
|
||||
|
||||
### But moderation, of course
|
||||
|
||||
That being said, over-adherence to the "build things with simple tools" dogma can be counter productive. Often a recursive solution can be much simpler than a for-loop solution and often times using a Class or a Monad is the right approach. But we should be mindful when using these technologies that we are building for ourselves our own system; a system with which others have had no experience.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://matthewrocklin.com/blog/work/2018/01/27/write-dumb-code
|
||||
|
||||
作者:[Matthew Rocklin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://matthewrocklin.com
|
||||
[1]:https://github.com/mrocklin/matrix-algebra
|
||||
@ -1,3 +1,5 @@
|
||||
HankChow translating
|
||||
|
||||
What you need to know about the GPL Cooperation Commitment
|
||||
======
|
||||
|
||||
|
||||
158
sources/talk/20181114 Analyzing the DNA of DevOps.md
Normal file
158
sources/talk/20181114 Analyzing the DNA of DevOps.md
Normal file
@ -0,0 +1,158 @@
|
||||
Analyzing the DNA of DevOps
|
||||
======
|
||||
How have waterfall, agile, and other development frameworks shaped the evolution of DevOps? Here's what we discovered.
|
||||

|
||||
|
||||
If you were to analyze the DNA of DevOps, what would you find in its ancestry report?
|
||||
|
||||
This article is not a methodology bake-off, so if you are looking for advice or a debate on the best approach to software engineering, you can stop reading here. Rather, we are going to explore the genetic sequences that have brought DevOps to the forefront of today's digital transformations.
|
||||
|
||||
Much of DevOps has evolved through trial and error, as companies have struggled to be responsive to customers’ demands while improving quality and standing out in an increasingly competitive marketplace. Adding to the challenge is the transition from a product-driven to a service-driven global economy that connects people in new ways. The software development lifecycle is becoming an increasingly complex system of services and microservices, both interconnected and instrumented. As DevOps is pushed further and faster than ever, the speed of change is wiping out slower traditional methodologies like waterfall.
|
||||
|
||||
We are not slamming the waterfall approach—many organizations have valid reasons to continue using it. However, mature organizations should aim to move away from wasteful processes, and indeed, many startups have a competitive edge over companies that use more traditional approaches in their day-to-day operations.
|
||||
|
||||
Ironically, lean, [Kanban][1], continuous, and agile principles and processes trace back to the early 1940's, so DevOps cannot claim to be a completely new idea.
|
||||
|
||||
Let's start by stepping back a few years and looking at the waterfall, lean, and agile software development approaches. The figure below shows a “haplogroup” of the software development lifecycle. (Remember, we are not looking for the best approach but trying to understand which approach has positively influenced our combined 67 years of software engineering and the evolution to a DevOps mindset.)
|
||||
|
||||

|
||||
|
||||
> “A fool with a tool is still a fool.” -Mathew Mathai
|
||||
|
||||
### The traditional waterfall method
|
||||
|
||||
From our perspective, the oldest genetic material comes from the [waterfall][2] model, first introduced by Dr. Winston W. Royce in a paper published in the 1970's.
|
||||
|
||||

|
||||
|
||||
Like a waterfall, this approach emphasizes a logical and sequential progression through requirements, analysis, coding, testing, and operations in a single pass. You must complete each sequence, meet criteria, and obtain a signoff before you can begin the next one. The waterfall approach benefits projects that need stringent sequences and that have a detailed and predictable scope and milestone-based development. Contrary to popular belief, it also allows teams to experiment and make early design changes during the requirements, analysis, and design stages.
|
||||
|
||||
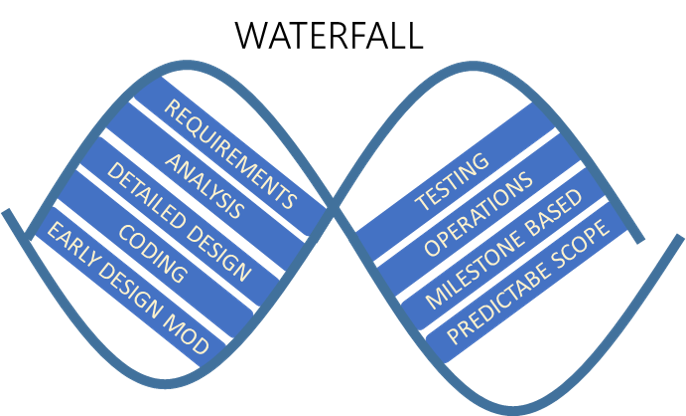
|
||||
|
||||
### Lean thinking
|
||||
|
||||
Although lean thinking dates to the Venetian Arsenal in the 1450s, we start the clock when Toyota created the [Toyota Production System][3], developed by Japanese engineers between 1948 and 1972. Toyota published an official description of the system in 1992.
|
||||
|
||||

|
||||
|
||||
Lean thinking is based on [five principles][4]: value, value stream, flow, pull, and perfection. The core of this approach is to understand and support an effective value stream, eliminate waste, and deliver continuous value to the user. It is about delighting your users without interruption.
|
||||
|
||||

|
||||
|
||||
### Kaizen
|
||||
|
||||
Kaizen is based on incremental improvements; the **Plan- >Do->Check->Act** lifecycle moved companies toward a continuous improvement mindset. Originally developed to improve the flow and processes of the assembly line, the Kaizen concept also adds value across the supply chain. The Toyota Production system was one of the early implementors of Kaizen and continuous improvement. Kaizen and DevOps work well together in environments where workflow goes from design to production. Kaizen focuses on two areas:
|
||||
|
||||
* Flow
|
||||
* Process
|
||||
|
||||
|
||||
|
||||
### Continuous delivery
|
||||
|
||||
Kaizen inspired the development of processes and tools to automate production. Companies were able to speed up production and improve the quality, design, build, test, and delivery phases by removing waste (including culture and mindset) and automating as much as possible using machines, software, and robotics. Much of the Kaizen philosophy also applies to lean business and software practices and continuous delivery deployment for DevOps principles and goals.
|
||||
|
||||
### Agile
|
||||
|
||||
The [Manifesto for Agile Software Development][5] appeared in 2001, authored by Alistair Cockburn, Bob Martin, Jeff Sutherland, Jim Highsmith, Ken Schwaber, Kent Beck, Ward Cunningham, and others.
|
||||
|
||||

|
||||
|
||||
[Agile][6] is not about throwing caution to the wind, ditching design, or building software in the Wild West. It is about being able to create and respond to change. Agile development is [based on twelve principles][7] and a manifesto that values individuals and collaboration, working software, customer collaboration, and responding to change.
|
||||
|
||||

|
||||
|
||||
### Disciplined agile
|
||||
|
||||
Since the Agile Manifesto has remained static for 20 years, many agile practitioners have looked for ways to add choice and subjectivity to the approach. Additionally, the Agile Manifesto focuses heavily on development, so a tweak toward solutions rather than code or software is especially needed in today's fast-paced development environment. Scott Ambler and Mark Lines co-authored [Disciplined Agile Delivery][8] and [The Disciplined Agile Framework][9], based on their experiences at Rational, IBM, and organizations in which teams needed more choice or were not mature enough to implement lean practices, or where context didn't fit the lifecycle.
|
||||
|
||||
The significance of DAD and DA is that it is a [process-decision framework][10] that enables simplified process decisions around incremental and iterative solution delivery. DAD builds on the many practices of agile software development, including scrum, agile modeling, lean software development, and others. The extensive use of agile modeling and refactoring, including encouraging automation through test-driven development (TDD), lean thinking such as Kanban, [XP][11], [scrum][12], and [RUP][13] through a choice of five agile lifecycles, and the introduction of the architect owner, gives agile practitioners added mindsets, processes, and tools to successfully implement DevOps.
|
||||
|
||||
### DevOps
|
||||
|
||||
As far as we can gather, DevOps emerged during a series of DevOpsDays in Belgium in 2009, going on to become the foundation for numerous digital transformations. Microsoft principal DevOps manager [Donovan Brown][14] defines DevOps as “the union of people, process, and products to enable continuous delivery of value to our end users.”
|
||||
|
||||

|
||||
|
||||
Let's go back to our original question: What would you find in the ancestry report of DevOps if you analyzed its DNA?
|
||||
|
||||

|
||||
|
||||
We are looking at history dating back 80, 48, 26, and 17 years—an eternity in today’s fast-paced and often turbulent environment. By nature, we humans continuously experiment, learn, and adapt, inheriting strengths and resolving weaknesses from our genetic strands.
|
||||
|
||||
Under the microscope, we will find traces of waterfall, lean thinking, agile, scrum, Kanban, and other genetic material. For example, there are traces of waterfall for detailed and predictable scope, traces of lean for cutting waste, and traces of agile for promoting increments of shippable code. The genetic strands that define when and how to ship the code are where DevOps lights up in our DNA exploration.
|
||||
|
||||

|
||||
|
||||
You use the telemetry you collect from watching your solution in production to drive experiments, confirm hypotheses, and prioritize your product backlog. In other words, DevOps inherits from a variety of proven and evolving frameworks and enables you to transform your culture, use products as enablers, and most importantly, delight your customers.
|
||||
|
||||
If you are comfortable with lean thinking and agile, you will enjoy the full benefits of DevOps. If you come from a waterfall environment, you will receive help from a DevOps mindset, but your lean and agile counterparts will outperform you.
|
||||
|
||||
### eDevOps
|
||||
|
||||

|
||||
|
||||
In 2016, Brent Reed coined the term eDevOps (no Google or Wikipedia references exist to date), defining it as “a way of working (WoW) that brings continuous improvement across the enterprise seamlessly, through people, processes and tools.”
|
||||
|
||||
Brent found that agile was failing in IT: Businesses that had adopted lean thinking were not achieving the value, focus, and velocity they expected from their trusted IT experts. Frustrated at seeing an "ivory tower" in which siloed IT services were disconnected from architecture, development, operations, and help desk support teams, he applied his practical knowledge of disciplined agile delivery and added some goals and practical applications to the DAD toolset, including:
|
||||
|
||||
* Focus and drive of culture through a continuous improvement (Kaizen) mindset, bringing people together even when they are across the cubicle
|
||||
* Velocity through automation (TDD + refactoring everything possible), removing waste and adopting a [TOGAF][15], JBGE (just barely good enough) approach to documentation
|
||||
* Value through modeling (architecture modeling) and shifting left to enable right through exposing anti-patterns while sharing through collaboration patterns in a more versatile and strategic modern digital repository
|
||||
|
||||
|
||||
|
||||
Using his experience with AI at IBM, Brent designed a maturity model for eDevOps that incrementally automates dashboards for measuring and decision-making purposes so that continuous improvement through a continuous deployment (automating from development to production) is a real possibility for any organization. eDevOps in an effective transformation program based on disciplined DevOps that enables:
|
||||
|
||||
* Business to DevOps (BizDevOps),
|
||||
* Security to DevOps (SecDevOps)
|
||||
* Information to DevOps (DataDevOps)
|
||||
* Loosely coupled technical services while bringing together and delighting all stakeholders
|
||||
* Building potentially consumable solutions every two weeks or faster
|
||||
* Collecting, measuring, analyzing, displaying, and automating actionable insight through the DevOps processes from concept through live production use
|
||||
* Continuous improvement following a Kaizen and disciplined agile approach
|
||||
|
||||
|
||||
|
||||
### The next stage in the development of DevOps
|
||||
|
||||

|
||||
|
||||
Will DevOps ultimately be considered hype—a collection of more tech thrown at corporations and added to the already extensive list of buzzwords? Time, of course, will tell how DevOps will progress. However, DevOps' DNA must continue to mature and be refined, and developers must understand that it is neither a silver bullet nor a remedy to cure all ailments and solve all problems.
|
||||
|
||||
```
|
||||
DevOps != Agile != Lean Thinking != Waterfall
|
||||
|
||||
DevOps != Tools !=Technology
|
||||
|
||||
DevOps Ì Agile Ì Lean Thinking Ì Waterfall
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/analyzing-devops
|
||||
|
||||
作者:[Willy-Peter Schaub][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/wpschaub
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Kanban
|
||||
[2]: https://airbrake.io/blog/sdlc/waterfall-model
|
||||
[3]: https://en.wikipedia.org/wiki/Toyota_Production_System
|
||||
[4]: https://www.lean.org/WhatsLean/Principles.cfm
|
||||
[5]: http://agilemanifesto.org/
|
||||
[6]: https://www.agilealliance.org/agile101
|
||||
[7]: http://agilemanifesto.org/principles.html
|
||||
[8]: https://books.google.com/books?id=CwvBEKsCY2gC
|
||||
[9]: http://www.disciplinedagiledelivery.com/books/
|
||||
[10]: https://en.wikipedia.org/wiki/Disciplined_agile_delivery
|
||||
[11]: https://en.wikipedia.org/wiki/Extreme_programming
|
||||
[12]: https://www.scrum.org/resources/what-is-scrum
|
||||
[13]: https://en.wikipedia.org/wiki/Rational_Unified_Process
|
||||
[14]: http://donovanbrown.com/
|
||||
[15]: http://www.opengroup.org/togaf
|
||||
@ -0,0 +1,76 @@
|
||||
Is your startup built on open source? 9 tips for getting started
|
||||
======
|
||||
Are open source businesses all that different from normal businesses?
|
||||

|
||||
|
||||
When I started [Gluu][1] in 2009, I had no idea how difficult it would be to start an open source software company. Using the open source development methodology seemed like a good idea, especially for infrastructure software based on protocols defined by open standards. By nature, entrepreneurs are optimistic—we underestimate the difficulty of starting a business. However, Gluu was my fourth business, so I thought I knew what I was in for. But I was in for a surprise!
|
||||
|
||||
Every business is unique. One of the challenges of serial entrepreneurship is that a truth that was core to the success of a previous business may be incorrect in your next business. Building a business around open source forced me to change my plan. How to find the right team members, how to price our offering, how to market our product—all of these aspects of starting a business (and more) were impacted by the open source mission and required an adjustment from my previous experience.
|
||||
|
||||
A few years ago, we started to question whether Gluu was pursuing the right business model. The business was growing, but not as fast as we would have liked.
|
||||
|
||||
One of the things we did at Gluu was to prepare a "business model canvas," an approach detailed in the book [Business Model Generation: A Handbook for Visionaries, Game Changers, and Challengers][2] by Yves Pigneur and Alexander Osterwalder. This is a thought-provoking exercise for any business at any stage. It helped us consider our business more holistically. A business is more than a stream of revenue. You need to think about how you segment the market, how to interact with customers, what are your sales channels, what are your key activities, what is your value proposition, what are your expenses, partnerships, and key resources. We've done this a few times over the years because a business model naturally evolves over time.
|
||||
|
||||
In 2016, I started to wonder how other open source businesses were structuring their business models. Business Model Generation talks about three types of companies: product innovation, customer relationship, and infrastructure.
|
||||
|
||||
* Product innovation companies are first to market with new products and can get a lot of market share because they are first.
|
||||
* Customer relationship companies have a wider offering and need to get "wallet share" not market share.
|
||||
* Infrastructure companies are very scalable but need established operating procedures and lots of capital.
|
||||
|
||||
|
||||
|
||||
![Open Source Underdogs podcast][4]
|
||||
|
||||
Mike Swartz, CC BY
|
||||
|
||||
It's hard to figure out what models and types of business other open source software companies are pursuing by just looking at their website. And most open source companies are private—so there are no SEC filings to examine.
|
||||
|
||||
To find out more, I went to the web. I found a [great talk][5] from Mike Olson, Founder and Chief Strategy Officer at Cloudera, about open source business models. It was recorded as part of a Stanford business lecture series. I wanted more of these kinds of talks! But I couldn't find any. That's when I got the idea to start a podcast where I interview founders of open source companies and ask them to describe what business model they are pursuing.
|
||||
|
||||
In 2018, this idea became a reality when we started a podcast called [Open Source Underdogs][6]. So far, we have recorded nine episodes. There is a lot of great content in all the episodes, but I thought it would be fun to share one piece of advice from each.
|
||||
|
||||
### Advice from 9 open source businesses
|
||||
|
||||
**Peter Wang, CTO of Anaconda: **"Investors coming in to help put more gas in your gas tank want to understand what road you're on and how far you want to go. If you can't communicate to investors on a basis that they understand about your business model and revenue model, then you have no business asking them for their money. Don't get mad at them!"
|
||||
|
||||
**Jim Thompson, Founder of Netgate: **"Businesses survive at the whim of their customers. Solving customer problems and providing value to the business is literally why you have a business!"
|
||||
|
||||
**Michael Howard, CEO of MariaDB: **"My advice to open source software startups? It depends what part of the stack you're in. If you're infrastructure, you have no choice but to be open source."
|
||||
|
||||
**Ian Tien, CEO of** **Mattermost: ** "You want to build something that people love. So start with roles that open source can play in your vision for the product, the distribution model, the community you want to build, and the business you want to build."
|
||||
|
||||
**Mike Olson, Founder and Chief Strategy Officer at Cloudera: **"A business model is a complex construct. Open source is a really important component of strategic thinking. It's a great distributed development model. It's a genius, low-cost distribution model—and those have a bunch of advantages. But you need to think about how you're going to get paid."
|
||||
|
||||
**Elliot Horowitz, Founder of MongoDB: **"The most important thing, whether it's open source or not open source, is to get incredibly close to your users."
|
||||
|
||||
**Tom Hatch, CEO of SaltStack: **"Being able to build an internal culture and a management mindset that deals with open source, and profits from open source, and functions in a stable and responsible way with regard to open source is one of the big challenges you're going to face. It's one thing to make a piece of open source software and get people to use it. It's another to build a company on top of that open source."
|
||||
|
||||
**Matt Mullenweg, CEO of Automattic: **"Open source businesses aren't that different from normal businesses. A mistake that we made, that others can avoid, is not incorporating the best leaders and team members in functions like marketing and sales."
|
||||
|
||||
**Gabriel Engel, CEO of RocketChat: **"Moving from a five-person company, where you are the center of the company, and it's easy to know what everyone is doing, and everyone relies on you for decisions, to a 40-person company—that transition is harder than expected."
|
||||
|
||||
### What we've learned
|
||||
|
||||
After recording these podcasts, we've tweaked Gluu's business model a little. It's become clearer that we need to embrace open core—we've been over-reliant on support revenue. It's a direction we had been going, but listening to our podcast's guests supported our decision.
|
||||
|
||||
We have many new episodes lined up for 2018 and 2019, including conversations with the founders of Liferay, Couchbase, TimescaleDB, Canonical, Redis, and more, who are sure to offer even more great insights about the open source software business. You can find all the podcast episodes by searching for "Open Source Underdogs" on iTunes and Google podcasts or by visiting our [website][6]. We want to hear your opinions and ideas you have to help us improve the podcast, so after you listen, please leave us a review.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/tips-open-source-entrepreneurs
|
||||
|
||||
作者:[Mike Schwartz][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gluufederation
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gluu.org/
|
||||
[2]: https://www.wiley.com/en-us/Business+Model+Generation%3A+A+Handbook+for+Visionaries%2C+Game+Changers%2C+and+Challengers-p-9780470876411
|
||||
[3]: /file/414706
|
||||
[4]: https://opensource.com/sites/default/files/uploads/underdogs_logo.jpg (Open Source Underdogs podcast)
|
||||
[5]: https://youtu.be/T_UM5PYk9NA
|
||||
[6]: https://opensourceunderdogs.com/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Publishing Markdown to HTML with MDwiki
|
||||
======
|
||||
|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
Translating by qhwdw
|
||||
|
||||
|
||||
Greg Kroah-Hartman Explains How the Kernel Community Is Securing Linux
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Kernel maintainer Greg Kroah-Hartman talks about how the kernel community is hardening Linux against vulnerabilities.[Creative Commons Zero][2]
|
||||
|
||||
As Linux adoption expands, it’s increasingly important for the kernel community to improve the security of the world’s most widely used technology. Security is vital not only for enterprise customers, it’s also important for consumers, as 80 percent of mobile devices are powered by Linux. In this article, Linux kernel maintainer Greg Kroah-Hartman provides a glimpse into how the kernel community deals with vulnerabilities.
|
||||
|
||||
### There will be bugs
|
||||
|
||||
|
||||

|
||||
|
||||
Greg Kroah-Hartman[The Linux Foundation][1]
|
||||
|
||||
As Linus Torvalds once said, most security holes are bugs, and bugs are part of the software development process. As long as the software is being written, there will be bugs.
|
||||
|
||||
“A bug is a bug. We don’t know if a bug is a security bug or not. There is a famous bug that I fixed and then three years later Red Hat realized it was a security hole,” said Kroah-Hartman.
|
||||
|
||||
There is not much the kernel community can do to eliminate bugs, but it can do more testing to find them. The kernel community now has its own security team that’s made up of kernel developers who know the core of the kernel.
|
||||
|
||||
“When we get a report, we involve the domain owner to fix the issue. In some cases it’s the same people, so we made them part of the security team to speed things up,” Kroah Hartman said. But he also stressed that all parts of the kernel have to be aware of these security issues because kernel is a trusted environment and they have to protect it.
|
||||
|
||||
“Once we fix things, we can put them in our stack analysis rules so that they are never reintroduced,” he said.
|
||||
|
||||
Besides fixing bugs, the community also continues to add hardening to the kernel. “We have realized that we need to have mitigations. We need hardening,” said Kroah-Hartman.
|
||||
|
||||
Huge efforts have been made by Kees Cook and others to take the hardening features that have been traditionally outside of the kernel and merge or adapt them for the kernel. With every kernel released, Cook provides a summary of all the new hardening features. But hardening the kernel is not enough, vendors have to enable the new features and take advantage of them. That’s not happening.
|
||||
|
||||
Kroah-Hartman [releases a stable kernel every week][5], and companies pick one to support for a longer period so that device manufacturers can take advantage of it. However, Kroah-Hartman has observed that, aside from the Google Pixel, most Android phones don’t include the additional hardening features, meaning all those phones are vulnerable. “People need to enable this stuff,” he said.
|
||||
|
||||
“I went out and bought all the top of the line phones based on kernel 4.4 to see which one actually updated. I found only one company that updated their kernel,” he said. “I'm working through the whole supply chain trying to solve that problem because it's a tough problem. There are many different groups involved -- the SoC manufacturers, the carriers, and so on. The point is that they have to push the kernel that we create out to people.”
|
||||
|
||||
The good news is that unlike with consumer electronics, the big vendors like Red Hat and SUSE keep the kernel updated even in the enterprise environment. Modern systems with containers, pods, and virtualization make this even easier. It’s effortless to update and reboot with no downtime. It is, in fact, easier to keep things secure than it used to be.
|
||||
|
||||
### Meltdown and Spectre
|
||||
|
||||
No security discussion is complete without the mention of Meltdown and Spectre. The kernel community is still working on fixes as new flaws are discovered. However, Intel has changed its approach in light of these events.
|
||||
|
||||
“They are reworking on how they approach security bugs and how they work with the community because they know they did it wrong,” Kroah-Hartman said. “The kernel has fixes for almost all of the big Spectre issues, but there is going to be a long tail of minor things.”
|
||||
|
||||
The good news is that these Intel vulnerabilities proved that things are getting better for the kernel community. “We are doing more testing. With the latest round of security patches, we worked on our own for four months before releasing them to the world because we were embargoed. But once they hit the real world, it made us realize how much we rely on the infrastructure we have built over the years to do this kind of testing, which ensures that we don’t have bugs before they hit other people,” he said. “So things are certainly getting better.”
|
||||
|
||||
The increasing focus on security is also creating more job opportunities for talented people. Since security is an area that gets eyeballs, those who want to build a career in kernel space, security is a good place to get started with.
|
||||
|
||||
“If there are people who want a job to do this type of work, we have plenty of companies who would love to hire them. I know some people who have started off fixing bugs and then got hired,” Kroah-Hartman said.
|
||||
|
||||
You can hear more in the video below:
|
||||
|
||||
[视频](https://youtu.be/jkGVabyMh1I)
|
||||
|
||||
_Check out the schedule of talks for Open Source Summit Europe and sign up to receive updates:_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-community-securing-linux-0
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
选题:[oska874][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/greg-k-hpng
|
||||
[4]:https://www.linux.com/files/images/kernel-securityjpg-0
|
||||
[5]:https://www.kernel.org/category/releases.html
|
||||
@ -1,82 +0,0 @@
|
||||
Monitoring database health and behavior: Which metrics matter?
|
||||
======
|
||||
Monitoring your database can be overwhelming or seem not important. Here's how to do it right.
|
||||

|
||||
|
||||
We don’t talk about our databases enough. In this age of instrumentation, we monitor our applications, our infrastructure, and even our users, but we sometimes forget that our database deserves monitoring, too. That’s largely because most databases do their job so well that we simply trust them to do it. Trust is great, but confirmation of our assumptions is even better.
|
||||
|
||||

|
||||
|
||||
### Why monitor your databases?
|
||||
|
||||
There are plenty of reasons to monitor your databases, most of which are the same reasons you'd monitor any other part of your systems: Knowing what’s going on in the various components of your applications makes you a better-informed developer who makes smarter decisions.
|
||||
|
||||

|
||||
|
||||
More specifically, databases are great indicators of system health and behavior. Odd behavior in the database can point to problem areas in your applications. Alternately, when there’s odd behavior in your application, you can use database metrics to help expedite the debugging process.
|
||||
|
||||
### The problem
|
||||
|
||||
The slightest investigation reveals one problem with monitoring databases: Databases have a lot of metrics. "A lot" is an understatement—if you were Scrooge McDuck, you could swim through all of the metrics available. If this were Wrestlemania, the metrics would be folding chairs. Monitoring them all doesn’t seem practical, so how do you decide which metrics to monitor?
|
||||
|
||||

|
||||
|
||||
### The solution
|
||||
|
||||
The best way to start monitoring databases is to identify some foundational, database-agnostic metrics. These metrics create a great start to understanding the lives of your databases.
|
||||
|
||||
### Throughput: How much is the database doing?
|
||||
|
||||
The easiest way to start monitoring a database is to track the number of requests the database receives. We have high expectations for our databases; we expect them to store data reliably and handle all of the queries we throw at them, which could be one massive query a day or millions of queries from users all day long. Throughput can tell you which of those is true.
|
||||
|
||||
You can also group requests by type (reads, writes, server-side, client-side, etc.) to begin analyzing the traffic.
|
||||
|
||||
### Execution time: How long does it take the database to do its job?
|
||||
|
||||
This metric seems obvious, but it often gets overlooked. You don’t just want to know how many requests the database received, but also how long the database spent on each request. It’s important to approach execution time with context, though: What's slow for a time-series database like InfluxDB isn’t the same as what's slow for a relational database like MySQL. Slow in InfluxDB might mean milliseconds, whereas MySQL’s default value for its `SLOW_QUERY` variable is ten seconds.
|
||||
|
||||

|
||||
|
||||
Monitoring execution time is not the same thing as improving execution time, so beware of the temptation to spend time on optimizations if you have other problems in your app to fix.
|
||||
|
||||
### Concurrency: How many jobs is the database doing at the same time?
|
||||
|
||||
Once you know how many requests the database is handling and how long each one takes, you need to add a layer of complexity to start getting real value from these metrics.
|
||||
|
||||
If the database receives ten requests and each one takes ten seconds to complete, is the database busy for 100 seconds, ten seconds—or somewhere in between? The number of concurrent tasks changes the way the database’s resources are used. When you consider things like the number of connections and threads, you’ll start to get a fuller picture of your database metrics.
|
||||
|
||||
Concurrency can also affect latency, which includes not only the time it takes for the task to be completed (execution time) but also the time the task needs to wait before it’s handled.
|
||||
|
||||
### Utilization: What percentage of the time was the database busy?
|
||||
|
||||
Utilization is a culmination of throughput, execution time, and concurrency to determine how often the database was available—or alternatively, how often the database was too busy to respond to a request.
|
||||
|
||||

|
||||
|
||||
This metric is particularly useful for determining the overall health and performance of your database. If it’s available to respond to requests only 80% of the time, you can reallocate resources, work on optimization, or otherwise make changes to get closer to high availability.
|
||||
|
||||
### The good news
|
||||
|
||||
It can seem overwhelming to monitor and analyze, especially because most of us aren’t database experts and we may not have time to devote to understanding these metrics. But the good news is that most of this work is already done for us. Many databases have an internal performance database (Postgres: pg_stats, CouchDB: Runtime_Statistics, InfluxDB: _internal, etc.), which is designed by database engineers to monitor the metrics that matter for that particular database. You can see things as broad as the number of slow queries or as detailed as the average microseconds each event in the database takes.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Databases create enough metrics to keep us all busy for a long time, and while the internal performance databases are full of useful information, it’s not always clear which metrics you should care about. Start with throughput, execution time, concurrency, and utilization, which provide enough information for you to start understanding the patterns in your database.
|
||||
|
||||

|
||||
|
||||
Are you monitoring your databases? Which metrics have you found to be useful? Tell me about it!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/database-metrics-matter
|
||||
|
||||
作者:[Katy Farmer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thekatertot
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,218 +0,0 @@
|
||||
Translating by Jamkr
|
||||
|
||||
How to partition and format a drive on Linux
|
||||
======
|
||||
Everything you wanted to know about setting up storage but were afraid to ask.
|
||||

|
||||
|
||||
On most computer systems, Linux or otherwise, when you plug a USB thumb drive in, you're alerted that the drive exists. If the drive is already partitioned and formatted to your liking, you just need your computer to list the drive somewhere in your file manager window or on your desktop. It's a simple requirement and one that the computer generally fulfills.
|
||||
|
||||
Sometimes, however, a drive isn't set up the way you want. For those times, you need to know how to find and prepare a storage device connected to your machine.
|
||||
|
||||
### What are block devices?
|
||||
|
||||
A hard drive is generically referred to as a "block device" because hard drives read and write data in fixed-size blocks. This differentiates a hard drive from anything else you might plug into your computer, like a printer, gamepad, microphone, or camera. The easy way to list the block devices attached to your Linux system is to use the **lsblk** (list block devices) command:
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
sda 8:0 0 238.5G 0 disk
|
||||
├─sda1 8:1 0 1G 0 part /boot
|
||||
└─sda2 8:2 0 237.5G 0 part
|
||||
└─luks-e2bb...e9f8 253:0 0 237.5G 0 crypt
|
||||
├─fedora-root 253:1 0 50G 0 lvm /
|
||||
├─fedora-swap 253:2 0 5.8G 0 lvm [SWAP]
|
||||
└─fedora-home 253:3 0 181.7G 0 lvm /home
|
||||
sdb 8:16 1 14.6G 0 disk
|
||||
└─sdb1 8:17 1 14.6G 0 part
|
||||
```
|
||||
|
||||
The device identifiers are listed in the left column, each beginning with **sd** , and ending with a letter, starting with **a**. Each partition of each drive is assigned a number, starting with **1**. For example, the second partition of the first drive is **sda2**. If you're not sure what a partition is, that's OK—just keep reading.
|
||||
|
||||
The **lsblk** command is nondestructive and used only for probing, so you can run it without any fear of ruining data on a drive.
|
||||
|
||||
### Testing with dmesg
|
||||
|
||||
If in doubt, you can test device label assignments by looking at the tail end of the **dmesg** command, which displays recent system log entries including kernel events (such as attaching and detaching a drive). For instance, if you want to make sure a thumb drive is really **/dev/sdc** , plug the drive into your computer and run this **dmesg** command:
|
||||
|
||||
```
|
||||
$ sudo dmesg | tail
|
||||
```
|
||||
|
||||
The most recent drive listed is the one you just plugged in. If you unplug it and run that command again, you'll see the device has been removed. If you plug it in again and run the command, the device will be there. In other words, you can monitor the kernel's awareness of your drive.
|
||||
|
||||
### Understanding filesystems
|
||||
|
||||
If all you need is the device label, your work is done. But if your goal is to create a usable drive, you must give the drive a filesystem.
|
||||
|
||||
If you're not sure what a filesystem is, it's probably easier to understand the concept by learning what happens when you have no filesystem at all. If you have a spare drive that has no important data on it whatsoever, you can follow along with this example. Otherwise, do not attempt this exercise, because it will DEFINITELY ERASE DATA, by design.
|
||||
|
||||
It is possible to utilize a drive without a filesystem. Once you have definitely, correctly identified a drive, and you have absolutely verified there is nothing important on it, plug it into your computer—but do not mount it. If it auto-mounts, then unmount it manually.
|
||||
|
||||
```
|
||||
$ su -
|
||||
# umount /dev/sdx{,1}
|
||||
```
|
||||
|
||||
To safeguard against disastrous copy-paste errors, these examples use the unlikely **sdx** label for the drive.
|
||||
|
||||
Now that the drive is unmounted, try this:
|
||||
|
||||
```
|
||||
# echo 'hello world' > /dev/sdx
|
||||
```
|
||||
|
||||
You have just written data to the block device without it being mounted on your system or having a filesystem.
|
||||
|
||||
To retrieve the data you just wrote, you can view the raw data on the drive:
|
||||
|
||||
```
|
||||
# head -n 1 /dev/sdx
|
||||
hello world
|
||||
```
|
||||
|
||||
That seemed to work pretty well, but imagine that the phrase "hello world" is one file. If you want to write a new "file" using this method, you must:
|
||||
|
||||
1. Know there's already an existing "file" on line 1
|
||||
2. Know that the existing "file" takes up only 1 line
|
||||
3. Derive a way to append new data, or else rewrite line 1 while writing line 2
|
||||
|
||||
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
# echo 'hello world
|
||||
> this is a second file' >> /dev/sdx
|
||||
```
|
||||
|
||||
To get the first file, nothing changes.
|
||||
|
||||
```
|
||||
# head -n 1 /dev/sdx
|
||||
hello world
|
||||
```
|
||||
|
||||
But it's more complex to get the second file.
|
||||
|
||||
```
|
||||
# head -n 2 /dev/sdx | tail -n 1
|
||||
this is a second file
|
||||
```
|
||||
|
||||
Obviously, this method of writing and reading data is not practical, so developers have created systems to keep track of what constitutes a file, where one file begins and ends, and so on.
|
||||
|
||||
Most filesystems require a partition.
|
||||
|
||||
### Creating partitions
|
||||
|
||||
A partition on a hard drive is a sort of boundary on the device telling each filesystem what space it can occupy. For instance, if you have a 4GB thumb drive, you can have a partition on that device taking up the entire drive (4GB), two partitions that each take 2GB (or 1 and 3, if you prefer), three of some variation of sizes, and so on. The combinations are nearly endless.
|
||||
|
||||
Assuming your drive is 4GB, you can create one big partition from a terminal with the GNU **parted** command:
|
||||
|
||||
```
|
||||
# parted /dev/sdx --align opt mklabel msdos 0 4G
|
||||
```
|
||||
|
||||
This command specifies the device path first, as required by **parted**.
|
||||
|
||||
The **\--align** option lets **parted** find the partition's optimal starting and stopping point.
|
||||
|
||||
The **mklabel** command creates a partition table (called a disk label) on the device. This example uses the **msdos** label because it's a very compatible and popular label, although **gpt** is becoming more common.
|
||||
|
||||
The desired start and end points of the partition are defined last. Since the **\--align opt** flag is used, **parted** will adjust the size as needed to optimize drive performance, but these numbers serve as a guideline.
|
||||
|
||||
Next, create the actual partition. If your start and end choices are not optimal, **parted** warns you and asks if you want to make adjustments.
|
||||
|
||||
```
|
||||
# parted /dev/sdx -a opt mkpart primary 0 4G
|
||||
|
||||
Warning: The resulting partition is not properly aligned for best performance: 1s % 2048s != 0s
|
||||
Ignore/Cancel? C
|
||||
# parted /dev/sdx -a opt mkpart primary 2048s 4G
|
||||
```
|
||||
|
||||
If you run **lsblk** again (you may have to unplug the drive and plug it back in), you'll see that your drive now has one partition on it.
|
||||
|
||||
### Manually creating a filesystem
|
||||
|
||||
There are many filesystems available. Some are free and open source, while others are not. Some companies decline to support open source filesystems, so their users can't read from open filesystems, while open source users can't read from closed ones without reverse-engineering them.
|
||||
|
||||
This disconnect notwithstanding, there are lots of filesystems you can use, and the one you choose depends on the drive's purpose. If you want a drive to be compatible across many systems, then your only choice right now is the exFAT filesystem. Microsoft has not submitted exFAT code to any open source kernel, so you may have to install exFAT support with your package manager, but support for exFAT is included in both Windows and MacOS.
|
||||
|
||||
Once you have exFAT support installed, you can create an exFAT filesystem on your drive in the partition you created.
|
||||
|
||||
```
|
||||
# mkfs.exfat -n myExFatDrive /dev/sdx1
|
||||
```
|
||||
|
||||
Now your drive is readable and writable by closed systems and by open source systems utilizing additional (and as-yet unsanctioned by Microsoft) kernel modules.
|
||||
|
||||
A common filesystem native to Linux is [ext4][1]. It's arguably a troublesome filesystem for portable drives since it retains user permissions, which are often different from one computer to another, but it's generally a reliable and flexible filesystem. As long as you're comfortable managing permissions, ext4 is a great, journaled filesystem for portable drives.
|
||||
|
||||
```
|
||||
# mkfs.ext4 -L myExt4Drive /dev/sdx1
|
||||
```
|
||||
|
||||
Unplug your drive and plug it back in. For ext4 portable drives, use **sudo** to create a directory and grant permission to that directory to a user and a group common across your systems. If you're not sure what user and group to use, you can either modify read/write permissions with **sudo** or root on the system that's having trouble with the drive.
|
||||
|
||||
### Using desktop tools
|
||||
|
||||
It's great to know how to deal with drives with nothing but a Linux shell standing between you and the block device, but sometimes you just want to get a drive ready to use without so much insightful probing. Excellent tools from both the GNOME and KDE developers can make your drive prep easy.
|
||||
|
||||
[GNOME Disks][2] and [KDE Partition Manager][3] are graphical interfaces providing an all-in-one solution for everything this article has explained so far. Launch either of these applications to see a list of attached devices (in the left column), create or resize partitions, and create a filesystem.
|
||||
|
||||
![KDE Partition Manager][5]
|
||||
|
||||
KDE Partition Manager
|
||||
|
||||
The GNOME version is, predictably, simpler than the KDE version, so I'll demo the more complex one—it's easy to figure out GNOME Disks if that's what you have handy.
|
||||
|
||||
Launch KDE Partition Manager and enter your root password.
|
||||
|
||||
From the left column, select the disk you want to format. If your drive isn't listed, make sure it's plugged in, then select **Tools** > **Refresh devices** (or **F5** on your keyboard).
|
||||
|
||||
Don't continue unless you're ready to destroy the drive's existing partition table. With the drive selected, click **New Partition Table** in the top toolbar. You'll be prompted to select the label you want to give the partition table: either **gpt** or **msdos**. The former is more flexible and can handle larger drives, while the latter is, like many Microsoft technologies, the de-facto standard by force of market share.
|
||||
|
||||
Now that you have a fresh partition table, right-click on your device in the right panel and select **New** to create a new partition. Follow the prompts to set the type and size of your partition. This action combines the partitioning step with creating a filesystem.
|
||||
|
||||
![Create a new partition][7]
|
||||
|
||||
Creating a new partition
|
||||
|
||||
To apply your changes to the drive, click the **Apply** button in the top-left corner of the window.
|
||||
|
||||
### Hard drives, easy drives
|
||||
|
||||
Dealing with hard drives is easy on Linux, and it's even easier if you understand the language of hard drives. Since switching to Linux, I've been better equipped to prepare drives in whatever way I want them to work for me. It's also been easier for me to recover lost data because of the transparency Linux provides when dealing with storage.
|
||||
|
||||
Here are a final few tips, if you want to experiment and learn more about hard drives:
|
||||
|
||||
1. Back up your data, and not just the data on the drive you're experimenting with. All it takes is one wrong move to destroy the partition of an important drive (which is a great way to learn about recreating lost partitions, but not much fun).
|
||||
2. Verify and then re-verify that the drive you are targeting is the correct drive. I frequently use **lsblk** to make sure I haven't moved drives around on myself. (It's easy to remove two drives from two separate USB ports, then mindlessly reattach them in a different order, causing them to get new drive labels.)
|
||||
3. Take the time to "destroy" a test drive and see if you can recover the data. It's a good learning experience to recreate a partition table or try to get data back after a filesystem has been removed.
|
||||
|
||||
|
||||
|
||||
For extra fun, if you have a closed operating system lying around, try getting an open source filesystem working on it. There are a few projects working toward this kind of compatibility, and trying to get them working in a stable and reliable way is a good weekend project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/partition-format-drive-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/5/introduction-ext4-filesystem
|
||||
[2]: https://wiki.gnome.org/Apps/Disks
|
||||
[3]: https://www.kde.org/applications/system/kdepartitionmanager/
|
||||
[4]: /file/413586
|
||||
[5]: https://opensource.com/sites/default/files/uploads/blockdevices_kdepartition.jpeg (KDE Partition Manager)
|
||||
[6]: /file/413591
|
||||
[7]: https://opensource.com/sites/default/files/uploads/blockdevices_newpartition.jpeg (Create a new partition)
|
||||
@ -1,95 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
Gitbase: Exploring git repos with SQL
|
||||
======
|
||||
Gitbase is a Go-powered open source project that allows SQL queries to be run on Git repositories.
|
||||

|
||||
|
||||
Git has become the de-facto standard for code versioning, but its popularity didn't remove the complexity of performing deep analyses of the history and contents of source code repositories.
|
||||
|
||||
SQL, on the other hand, is a battle-tested language to query large codebases as its adoption by projects like Spark and BigQuery shows.
|
||||
|
||||
So it is just logical that at source{d} we chose these two technologies to create gitbase: the code-as-data solution for large-scale analysis of git repositories with SQL.
|
||||
|
||||
[Gitbase][1] is a fully open source project that stands on the shoulders of a series of giants which made its development possible, this article aims to point out the main ones.
|
||||
|
||||
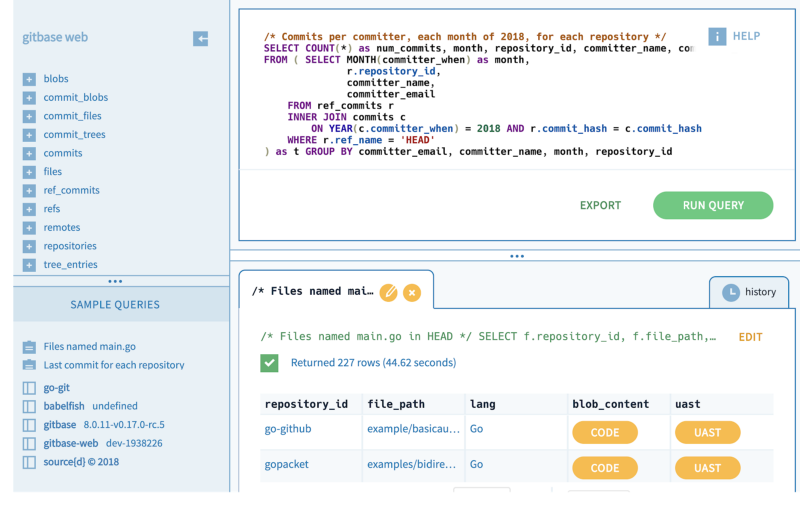
|
||||
|
||||
The [gitbase][2] [playground][2] provides a visual way to use gitbase.
|
||||
|
||||
### Parsing SQL with Vitess
|
||||
|
||||
Gitbase's user interface is SQL. This means we need to be able to parse and understand the SQL requests that arrive through the network following the MySQL protocol. Fortunately for us, this was already implemented by our friends at YouTube and their [Vitess][3] project. Vitess is a database clustering system for horizontal scaling of MySQL.
|
||||
|
||||
We simply grabbed the pieces of code that mattered to us and made it into an [open source project][4] that allows anyone to write a MySQL server in minutes (as I showed in my [justforfunc][5] episode [CSVQL—serving CSV with SQL][6]).
|
||||
|
||||
### Reading git repositories with go-git
|
||||
|
||||
Once we've parsed a request we still need to find how to answer it by reading the git repositories in our dataset. For this, we integrated source{d}'s most successful repository [go-git][7]. Go-git is a* *highly extensible Git implementation in pure Go.
|
||||
|
||||
This allowed us to easily analyze repositories stored on disk as [siva][8] files (again an open source project by source{d}) or simply cloned with git clone.
|
||||
|
||||
### Detecting languages with enry and parsing files with babelfish
|
||||
|
||||
Gitbase does not stop its analytic power at the git history. By integrating language detection with our (obviously) open source project [enry][9] and program parsing with [babelfish][10]. Babelfish is a self-hosted server for universal source code parsing, turning code files into Universal Abstract Syntax Trees (UASTs)
|
||||
|
||||
These two features are exposed in gitbase as the user functions LANGUAGE and UAST. Together they make requests like "find the name of the function that was most often modified during the last month" possible.
|
||||
|
||||
### Making it go fast
|
||||
|
||||
Gitbase analyzes really large datasets—e.g. Public Git Archive, with 3TB of source code from GitHub ([announcement][11]) and in order to do so every CPU cycle counts.
|
||||
|
||||
This is why we integrated two more projects into the mix: Rubex and Pilosa.
|
||||
|
||||
#### Speeding up regular expressions with Rubex and Oniguruma
|
||||
|
||||
[Rubex][12] is a quasi-drop-in replacement for Go's regexp standard library package. I say quasi because they do not implement the LiteralPrefix method on the regexp.Regexp type, but I also had never heard about that method until right now.
|
||||
|
||||
#### Speeding up queries with Pilosa indexes
|
||||
|
||||
Rubex gets its performance from the highly optimized C library [Oniguruma][13] which it calls using [cgo][14]
|
||||
|
||||
Indexes are a well-known feature of basically every relational database, but Vitess does not implement them since it doesn't really need to.
|
||||
|
||||
But again open source came to the rescue with [Pilosa][15], a distributed bitmap index implemented in Go which made gitbase usable on massive datasets. Pilosa is an open source, distributed bitmap index that dramatically accelerates queries across multiple, massive datasets.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I'd like to use this blog post to personally thank the open source community that made it possible for us to create gitbase in such a shorter period that anyone would have expected. At source{d} we are firm believers in open source and every single line of code under github.com/src-d (including our OKRs and investor board) is a testament to that.
|
||||
|
||||
Would you like to give gitbase a try? The fastest and easiest way is with source{d} Engine. Download it from sourced.tech/engine and get gitbase running with a single command!
|
||||
|
||||
Want to know more? Check out the recording of my talk at the [Go SF meetup][16].
|
||||
|
||||
The article was [originally published][17] on Medium and is republished here with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/gitbase
|
||||
|
||||
作者:[Francesc Campoy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/francesc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/src-d/gitbase
|
||||
[2]: https://github.com/src-d/gitbase-web
|
||||
[3]: https://github.com/vitessio/vitess
|
||||
[4]: https://github.com/src-d/go-mysql-server
|
||||
[5]: http://justforfunc.com/
|
||||
[6]: https://youtu.be/bcRDXAraprk
|
||||
[7]: https://github.com/src-d/go-git
|
||||
[8]: https://github.com/src-d/siva
|
||||
[9]: https://github.com/src-d/enry
|
||||
[10]: https://github.com/bblfsh/bblfshd
|
||||
[11]: https://blog.sourced.tech/post/announcing-pga/
|
||||
[12]: https://github.com/moovweb/rubex
|
||||
[13]: https://github.com/kkos/oniguruma
|
||||
[14]: https://golang.org/cmd/cgo/
|
||||
[15]: https://github.com/pilosa/pilosa
|
||||
[16]: https://www.meetup.com/golangsf/events/251690574/
|
||||
[17]: https://medium.com/sourcedtech/gitbase-exploring-git-repos-with-sql-95ec0986386c
|
||||
@ -1,186 +0,0 @@
|
||||
translating by caixiangyue
|
||||
How To Find The Execution Time Of A Command Or Process In Linux
|
||||
======
|
||||

|
||||
|
||||
You probably know the start time of a command/process and [**how long a process is running**][1] in Unix-like systems. But, how do you when did it end and/or what is the total time taken by the command/process to complete? Well, It’s easy! On Unix-like systems, there is a utility named **‘GNU time’** that is specifically designed for this purpose. Using Time utility, we can easily measure the total execution time of a command or program in Linux operating systems. Good thing is ‘time’ command comes preinstalled in most Linux distributions, so you don’t have to bother with installation.
|
||||
|
||||
### Find The Execution Time Of A Command Or Process In Linux
|
||||
|
||||
To measure the execution time of a command/program, just run.
|
||||
|
||||
```
|
||||
$ /usr/bin/time -p ls
|
||||
```
|
||||
|
||||
Or,
|
||||
|
||||
```
|
||||
$ time ls
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
|
||||
real 0m0.007s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
|
||||
$ time ls -a
|
||||
. .bash_logout dir1 file2 mcelog .sudo_as_admin_successful
|
||||
.. .bashrc dir2 .gnupg .profile .wget-hsts
|
||||
.bash_history .cache file1 .local .stack
|
||||
|
||||
real 0m0.008s
|
||||
user 0m0.001s
|
||||
sys 0m0.005s
|
||||
```
|
||||
|
||||
The above commands displays the total execution time of **‘ls’** command. Replace “ls” with any command/process of your choice to find the total execution time.
|
||||
|
||||
Here,
|
||||
|
||||
1. **real** -refers the total time taken by command/program,
|
||||
2. **user** – refers the time taken by the program in user mode,
|
||||
3. **sys** – refers the time taken by the program in kernel mode.
|
||||
|
||||
|
||||
|
||||
We can also limit the command to run only for a certain time as well. Refer the following guide for more details.
|
||||
|
||||
### time vs /usr/bin/time
|
||||
|
||||
As you may noticed, we used two commands **‘time’** and **‘/usr/bin/time’** in the above examples. So, you might wonder what is the difference between them.
|
||||
|
||||
First, let us see what actually ‘time’ is using ‘type’ command. For those who don’t know, the **Type** command is used to find out the information about a Linux command. For more details, refer [**this guide**][2].
|
||||
|
||||
```
|
||||
$ type -a time
|
||||
time is a shell keyword
|
||||
time is /usr/bin/time
|
||||
```
|
||||
|
||||
As you see in the above output, time is both,
|
||||
|
||||
* A keyword built into the BASH shell
|
||||
* An executable file i.e **/usr/bin/time**
|
||||
|
||||
|
||||
|
||||
Since shell keywords take precedence over executable files, when you just run`time`command without full path, you run a built-in shell command. But, When you run `/usr/bin/time`, you run a real **GNU time** program. So, in order to access the real command, you may need to specify its explicit path. Clear, good?
|
||||
|
||||
The built-in ‘time’ shell keyword is available in most shells like BASH, ZSH, CSH, KSH, TCSH etc. The ‘time’ shell keyword has less options than the executables. The only option you can use in ‘time’ keyword is **-p**.
|
||||
|
||||
You know now how to find the total execution time of a given command/process using ‘time’ command. Want to know little bit more about ‘GNU time’ utility? Read on!
|
||||
|
||||
### A brief introduction about ‘GNU time’ program
|
||||
|
||||
The GNU time program runs a command/program with given arguments and summarizes the system resource usage as standard output after the command is completed. Unlike the ‘time’ keyword, the GNU time program not just displays the time used by the command/process, but also other resources like memory, I/O and IPC calls.
|
||||
|
||||
The typical syntax of the Time command is:
|
||||
|
||||
```
|
||||
/usr/bin/time [options] command [arguments...]
|
||||
```
|
||||
|
||||
The ‘options’ in the above syntax refers a set of flags that can be used with time command to perform a particular functionality. The list of available options are given below.
|
||||
|
||||
* **-f, –format** – Use this option to specify the format of output as you wish.
|
||||
* **-p, –portability** – Use the portable output format.
|
||||
* **-o file, –output=FILE** – Writes the output to **FILE** instead of displaying as standard output.
|
||||
* **-a, –append** – Append the output to the FILE instead of overwriting it.
|
||||
* **-v, –verbose** – This option displays the detailed description of the output of the ‘time’ utility.
|
||||
* **–quiet** – This option prevents the time ‘time’ utility to report the status of the program.
|
||||
|
||||
|
||||
|
||||
When using ‘GNU time’ program without any options, you will see output something like below.
|
||||
|
||||
```
|
||||
$ /usr/bin/time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2024maxresident)k
|
||||
0inputs+0outputs (0major+73minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
If you run the same command with the shell built-in keyword ‘time’, the output would be bit different:
|
||||
|
||||
```
|
||||
$ time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
|
||||
real 0m0.006s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
```
|
||||
|
||||
Some times, you might want to write the system resource usage output to a file rather than displaying in the Terminal. To do so, use **-o** flag like below.
|
||||
|
||||
```
|
||||
$ /usr/bin/time -o file.txt ls
|
||||
dir1 dir2 file1 file2 file.txt mcelog
|
||||
```
|
||||
|
||||
As you can see in the output, Time utility doesn’t display the output. Because, we write the output to a file named file.txt. Let us have a look at this file:
|
||||
|
||||
```
|
||||
$ cat file.txt
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2512maxresident)k
|
||||
0inputs+0outputs (0major+106minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
When you use **-o** flag, if there is no file named ‘file.txt’, it will create and write the output in it. If the file.txt is already present, it will overwrite its content.
|
||||
|
||||
You can also append output to the file instead of overwriting it using **-a** flag.
|
||||
|
||||
```
|
||||
$ /usr/bin/time -a file.txt ls
|
||||
```
|
||||
|
||||
The **-f** flag allows the users to control the format of the output as per his/her liking. Say for example, the following command displays output of ‘ls’ command and shows just the user, system, and total time.
|
||||
|
||||
```
|
||||
$ /usr/bin/time -f "\t%E real,\t%U user,\t%S sys" ls
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
0:00.00 real, 0.00 user, 0.00 sys
|
||||
```
|
||||
|
||||
Please be mindful that the built-in shell command ‘time’ doesn’t support all features of GNU time program.
|
||||
|
||||
For more details about GNU time utility, refer the man pages.
|
||||
|
||||
```
|
||||
$ man time
|
||||
```
|
||||
|
||||
To know more about Bash built-in ‘Time’ keyword, run:
|
||||
|
||||
```
|
||||
$ help time
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this useful.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-the-execution-time-of-a-command-or-process-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/find-long-process-running-linux/
|
||||
[2]: https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/
|
||||
@ -1,75 +0,0 @@
|
||||
4 tips for learning Golang
|
||||
======
|
||||
Arriving in Golang land: A senior developer's journey.
|
||||

|
||||
|
||||
In the summer of 2014...
|
||||
|
||||
> IBM: "We need you to go figure out this Docker thing."
|
||||
> Me: "OK."
|
||||
> IBM: "Start contributing and just get involved."
|
||||
> Me: "OK." (internal voice): "This is written in Go. What's that?" (Googles) "Oh, a programming language. I've learned a few of those in my career. Can't be that hard."
|
||||
|
||||
My university's freshman programming class was taught using VAX assembler. In data structures class, we used Pascal—loaded via diskette on tired, old PCs in the library's computer center. In one upper-level course, I had a professor that loved to show all examples in ADA. I learned a bit of C via playing with various Unix utilities' source code on our Sun workstations. At IBM we used C—and some x86 assembler—for the OS/2 source code, and we heavily used C++'s object-oriented features for a joint project with Apple. I learned shell scripting soon after, starting with csh, but moving to Bash after finding Linux in the mid-'90s. I was thrust into learning m4 (arguably more of a macro-processor than a programming language) while working on the just-in-time (JIT) compiler in IBM's custom JVM code when porting it to Linux in the late '90s.
|
||||
|
||||
Fast-forward 20 years... I'd never been nervous about learning a new programming language. But [Go][1] felt different. I was going to contribute publicly, upstream on GitHub, visible to anyone interested enough to look! I didn't want to be the laughingstock, the Go newbie as a 40-something-year-old senior developer! We all know that programmer pride that doesn't like to get bruised, no matter your experience level.
|
||||
|
||||
My early investigations revealed that Go seemed more committed to its "idiomatic-ness" than some languages. It wasn't just about getting the code to compile; I needed to be able to write code "the Go way."
|
||||
|
||||
Now that I'm four years and several hundred pull requests into my personal Go journey, I don't claim to be an expert, but I do feel a lot more comfortable contributing and writing Go code than I did in 2014. So, how do you teach an old guy new tricks—or at least a new programming language? Here are four steps that were valuable in my own journey to Golang land.
|
||||
|
||||
### 1. Don't skip the fundamentals
|
||||
|
||||
While you might be able to get by with copying code and hunting and pecking your way through early learnings (who has time to read the manual?!?), Go has a very readable [language spec][2] that was clearly written to be read and understood, even if you don't have a master's in language or compiler theory. Given that Go made some unique decisions about the order of the **parameter:type** constructs and has interesting language features like channels and goroutines, it is important to get grounded in these new concepts. Reading this document alongside [Effective Go][3], another great resource from the Golang creators, will give you a huge boost in readiness to use the language effectively and properly.
|
||||
|
||||
### 2. Learn from the best
|
||||
|
||||
There are many valuable resources for digging in and taking your Go knowledge to the next level. All the talks from any recent [GopherCon][4] can be found online, like this exhaustive list from [GopherCon US in 2018][5]. Talks range in expertise and skill level, but you can easily find something you didn't know about Go by watching the talks. [Francesc Campoy][6] created a Go programming video series called [JustForFunc][7] that has an ever-increasing number of episodes to expand your Go knowledge and understanding. A quick search on "Golang" reveals many other video and online resources for those who want to learn more.
|
||||
|
||||
Want to look at code? Many of the most popular cloud-native projects on GitHub are written in Go: [Docker/Moby][8], [Kubernetes][9], [Istio][10], [containerd][11], [CoreDNS][12], and many others. Language purists might rate some projects better than others regarding idiomatic-ness, but these are all good starting points to see how large codebases are using Go in highly active projects.
|
||||
|
||||
### 3. Use good language tools
|
||||
|
||||
You will learn quickly about the value of [gofmt][13]. One of the beautiful aspects of Go is that there is no arguing about code formatting guidelines per project— **gofmt** is built into the language runtime, and it formats Go code according to a set of stable, well-understood language rules. I don't know of any Golang-based project that doesn't insist on checking with **gofmt** for pull requests as part of continuous integration.
|
||||
|
||||
Beyond the wide, valuable array of useful tools built directly into the runtime/SDK, I strongly recommend using an editor or IDE with good Golang support features. Since I find myself much more often at a command line, I rely on Vim plus the great [vim-go][14] plugin. I also like what Microsoft has offered with [VS Code][15], especially with its [Go language][16] plugins.
|
||||
|
||||
Looking for a debugger? The [Delve][17] project has been improving and maturing and is a strong contender for doing [gdb][18]-like debugging on Go binaries.
|
||||
|
||||
### 4. Jump in and write some Go!
|
||||
|
||||
You'll never get better at writing Go unless you start trying. Find a project that has some "help needed" issues flagged and make a contribution. If you are already using an open source project written in Go, find out if there are some bugs that have beginner-level solutions and make your first pull request. As with most things in life, the only real way to improve is through practice, so get going.
|
||||
|
||||
And, as it turns out, apparently you can teach an old senior developer new tricks—or languages at least.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/learning-golang
|
||||
|
||||
作者:[Phill Estes][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/estesp
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://golang.org/
|
||||
[2]: https://golang.org/ref/spec
|
||||
[3]: https://golang.org/doc/effective_go.html
|
||||
[4]: https://www.gophercon.com/
|
||||
[5]: https://tqdev.com/2018-gophercon-2018-videos-online
|
||||
[6]: https://twitter.com/francesc
|
||||
[7]: https://www.youtube.com/channel/UC_BzFbxG2za3bp5NRRRXJSw
|
||||
[8]: https://github.com/moby/moby
|
||||
[9]: https://github.com/kubernetes/kubernetes
|
||||
[10]: https://github.com/istio/istio
|
||||
[11]: https://github.com/containerd/containerd
|
||||
[12]: https://github.com/coredns/coredns
|
||||
[13]: https://blog.golang.org/go-fmt-your-code
|
||||
[14]: https://github.com/fatih/vim-go
|
||||
[15]: https://code.visualstudio.com/
|
||||
[16]: https://code.visualstudio.com/docs/languages/go
|
||||
[17]: https://github.com/derekparker/delve
|
||||
[18]: https://www.gnu.org/software/gdb/
|
||||
@ -0,0 +1,148 @@
|
||||
How to use systemd-nspawn for Linux system recovery
|
||||
======
|
||||
Tap into systemd's ability to launch containers to repair a damaged system's root filesystem.
|
||||

|
||||
|
||||
For as long as GNU/Linux systems have existed, system administrators have needed to recover from root filesystem corruption, accidental configuration changes, or other situations that kept the system from booting into a "normal" state.
|
||||
|
||||
Linux distributions typically offer one or more menu options at boot time (for example, in the GRUB menu) that can be used for rescuing a broken system; typically they boot the system into a single-user mode with most system services disabled. In the worst case, the user could modify the kernel command line in the bootloader to use the standard shell as the init (PID 1) process. This method is the most complex and fraught with complications, which can lead to frustration and lost time when a system needs rescuing.
|
||||
|
||||
Most importantly, these methods all assume that the damaged system has a physical console of some sort, but this is no longer a given in the age of cloud computing. Without a physical console, there are few (if any) options to influence the boot process this way. Even physical machines may be small, embedded devices that don't offer an easy-to-use console, and finding the proper serial port cables and adapters and setting up a serial terminal emulator, all to use a serial console port while dealing with an emergency, is often complicated.
|
||||
|
||||
When another system (of the same architecture and generally similar configuration) is available, a common technique to simplify the repair process is to extract the storage device(s) from the damaged system and connect them to the working system as secondary devices. With physical systems, this is usually straightforward, but most cloud computing platforms can also support this since they allow the root storage volume of the damaged instance to be mounted on another instance.
|
||||
|
||||
Once the root filesystem is attached to another system, addressing filesystem corruption is straightforward using **fsck** and other tools. Addressing configuration mistakes, broken packages, or other issues can be more complex since they require mounting the filesystem and locating and changing the correct configuration files or databases.
|
||||
|
||||
### Using systemd
|
||||
|
||||
Before **[**systemd**][1]** , editing configuration files with a text editor was a practical way to correct a configuration. Locating the necessary files and understanding their contents may be a separate challenge, which is beyond the scope of this article.
|
||||
|
||||
When the GNU/Linux system uses **systemd** though, many configuration changes are best made using the tools it provides—enabling and disabling services, for example, requires the creation or removal of symbolic links in various locations. The **systemctl** tool is used to make these changes, but using it requires a **systemd** instance to be running and listening (on D-Bus) for requests. When the root filesystem is mounted as an additional filesystem on another machine, the running **systemd** instance can't be used to make these changes.
|
||||
|
||||
Manually launching the target system's **systemd** is not practical either, since it is designed to be the PID 1 process on a system and manage all other processes, which would conflict with the already-running instance on the system used for the repairs.
|
||||
|
||||
Thankfully, **systemd** has the ability to launch containers, fully encapsulated GNU/Linux systems with their own PID 1 and environment that utilize various namespace features offered by the Linux kernel. Unlike tools like Docker and Rocket, **systemd** doen't require a container image to launch a container; it can launch one rooted at any point in the existing filesystem. This is done using the **systemd-nspawn** tool, which will create the necessary system namespaces and launch the initial process in the container, then provide a console in the container. In contrast to **chroot** , which only changes the apparent root of the filesystem, this type of container will have a separate filesystem namespace, suitable filesystems mounted on **/dev** , **/run** , and **/proc** , and a separate process namespace and IPC namespaces. Consult the **systemd-nspawn** [man page][2] to learn more about its capabilities.
|
||||
|
||||
### An example to show how it works
|
||||
|
||||
In this example, the storage device containing the damaged system's root filesystem has been attached to a running system, where it appears as **/dev/vdc**. The device name will vary based on the number of existing storage devices, the type of device, and the method used to connect it to the system. The root filesystem could use the entire storage device or be in a partition within the device; since the most common (simple) configuration places the root filesystem in the device's first partition, this example will use **/dev/vdc1.** Make sure to replace the device name in the commands below with your system's correct device name.
|
||||
|
||||
The damaged root filesystem may also be more complex than a single filesystem on a device; it may be a volume in an LVM volume set or on a set of devices combined into a software RAID device. In these cases, the necessary steps to compose and activate the logical device holding the filesystem must be performed before it will be available for mounting. Again, those steps are beyond the scope of this article.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
First, ensure the **systemd-nspawn** tool is installed—most GNU/Linux distributions don't install it by default. It's provided by the **systemd-container** package on most distributions, so use your distribution's package manager to install that package. The instructions in this example were tested using Debian 9 but should work similarly on any modern GNU/Linux distribution.
|
||||
|
||||
Using the commands below will almost certainly require root permissions, so you'll either need to log in as root, use **sudo** to obtain a shell with root permissions, or prefix each of the commands with **sudo**.
|
||||
|
||||
#### Verify and mount the fileystem
|
||||
|
||||
First, use **fsck** to verify the target filesystem's structures and content:
|
||||
|
||||
```
|
||||
$ fsck /dev/vdc1
|
||||
```
|
||||
|
||||
If it finds any problems with the filesystem, answer the questions appropriately to correct them. If the filesystem is sufficiently damaged, it may not be repairable, in which case you'll have to find other ways to extract its contents.
|
||||
|
||||
Now, create a temporary directory and mount the target filesystem onto that directory:
|
||||
|
||||
```
|
||||
$ mkdir /tmp/target-rescue
|
||||
$ mount /dev/vdc1 /tmp/target-rescue
|
||||
```
|
||||
|
||||
With the filesystem mounted, launch a container with that filesystem as its root filesystem:
|
||||
|
||||
```
|
||||
$ systemd-nspawn --directory /tmp/target-rescue --boot -- --unit rescue.target
|
||||
```
|
||||
|
||||
The command-line arguments for launching the container are:
|
||||
|
||||
* **\--directory /tmp/target-rescue** provides the path of the container's root filesystem.
|
||||
* **\--boot** searches for a suitable init program in the container's root filesystem and launches it, passing parameters from the command line to it. In this example, the target system also uses **systemd** as its PID 1 process, so the remaining parameters are intended for it. If the target system you are repairing uses any other tool as its PID 1 process, you'll need to adjust the parameters accordingly.
|
||||
* **\--** separates parameters for **systemd-nspawn** from those intended for the container's PID 1 process.
|
||||
* **\--unit rescue.target** tells **systemd** in the container the name of the target it should try to reach during the boot process. In order to simplify the rescue operations in the target system, boot it into "rescue" mode rather than into its normal multi-user mode.
|
||||
|
||||
|
||||
|
||||
If all goes well, you should see output that looks similar to this:
|
||||
|
||||
```
|
||||
Spawning container target-rescue on /tmp/target-rescue.
|
||||
Press ^] three times within 1s to kill container.
|
||||
systemd 232 running in system mode. (+PAM +AUDIT +SELINUX +IMA +APPARMOR +SMACK +SYSVINIT +UTMP +LIBCRYPTSETUP +GCRYPT +GNUTLS +ACL +XZ +LZ4 +SECCOMP +BLKID +ELFUTILS +KMOD +IDN)
|
||||
Detected virtualization systemd-nspawn.
|
||||
Detected architecture arm.
|
||||
|
||||
Welcome to Debian GNU/Linux 9 (Stretch)!
|
||||
|
||||
Set hostname to <test>.
|
||||
Failed to install release agent, ignoring: No such file or directory
|
||||
[ OK ] Reached target Swap.
|
||||
[ OK ] Listening on Journal Socket (/dev/log).
|
||||
[ OK ] Started Dispatch Password Requests to Console Directory Watch.
|
||||
[ OK ] Reached target Encrypted Volumes.
|
||||
[ OK ] Created slice System Slice.
|
||||
Mounting POSIX Message Queue File System...
|
||||
[ OK ] Listening on Journal Socket.
|
||||
Starting Set the console keyboard layout...
|
||||
Starting Restore / save the current clock...
|
||||
Starting Journal Service...
|
||||
Starting Remount Root and Kernel File Systems...
|
||||
[ OK ] Mounted POSIX Message Queue File System.
|
||||
[ OK ] Started Journal Service.
|
||||
[ OK ] Started Remount Root and Kernel File Systems.
|
||||
Starting Flush Journal to Persistent Storage...
|
||||
[ OK ] Started Restore / save the current clock.
|
||||
[ OK ] Started Flush Journal to Persistent Storage.
|
||||
[ OK ] Started Set the console keyboard layout.
|
||||
[ OK ] Reached target Local File Systems (Pre).
|
||||
[ OK ] Reached target Local File Systems.
|
||||
Starting Create Volatile Files and Directories...
|
||||
[ OK ] Started Create Volatile Files and Directories.
|
||||
[ OK ] Reached target System Time Synchronized.
|
||||
Starting Update UTMP about System Boot/Shutdown...
|
||||
[ OK ] Started Update UTMP about System Boot/Shutdown.
|
||||
[ OK ] Reached target System Initialization.
|
||||
[ OK ] Started Rescue Shell.
|
||||
[ OK ] Reached target Rescue Mode.
|
||||
Starting Update UTMP about System Runlevel Changes...
|
||||
[ OK ] Started Update UTMP about System Runlevel Changes.
|
||||
You are in rescue mode. After logging in, type "journalctl -xb" to view
|
||||
system logs, "systemctl reboot" to reboot, "systemctl default" or ^D to
|
||||
boot into default mode.
|
||||
Give root password for maintenance
|
||||
(or press Control-D to continue):
|
||||
```
|
||||
|
||||
In this output, you can see **systemd** launching as the init process in the container and detecting that it is being run inside a container so it can adjust its behavior appropriately. Various unit files are started to bring the container to a usable state, then the target system's root password is requested. You can enter the root password here if you want a shell prompt with root permissions, or you can press **Ctrl+D** to allow the startup process to continue, which will display a normal console login prompt.
|
||||
|
||||
When you have completed the necessary changes to the target system, press **Ctrl+]** three times in rapid succession; this will terminate the container and return you to your original shell. From there, you can clean up by unmounting the target system's filesystem and removing the temporary directory:
|
||||
|
||||
```
|
||||
$ umount /tmp/target-rescue
|
||||
$ rmdir /tmp/target-rescue
|
||||
```
|
||||
|
||||
That's it! You can now remove the target system's storage device(s) and return them to the target system.
|
||||
|
||||
The idea to use **systemd-nspawn** this way, especially the **\--boot parameter** , came from [a question][3] posted on StackExchange. Thanks to Shibumi and kirbyfan64sos for providing useful answers to this question!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/systemd-nspawn-system-recovery
|
||||
|
||||
作者:[Kevin P.Fleming][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kpfleming
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[2]: https://www.freedesktop.org/software/systemd/man/systemd-nspawn.html
|
||||
[3]: https://unix.stackexchange.com/questions/457819/running-systemd-utilities-like-systemctl-under-an-nspawn
|
||||
@ -1,85 +0,0 @@
|
||||
ProtectedText – A Free Encrypted Notepad To Save Your Notes Online
|
||||
======
|
||||

|
||||
Note taking is an important skill to have for all of us. It will help us to remember and maintain permanent record of what we have read, learned and listened to. There are so many apps, tools and utilities available out there for note taking purpose. Today I am going to talk about one such application. Say hello to **ProtectedText** , a free, encrypted notepad to save the notes online. It is a free web service where you can write down your texts, encrypt them and access them from anywhere from any device. It is that simple. All you need is a web browser in an Internet-enabled device.
|
||||
|
||||
ProtectedText site doesn’t require any personal information and doesn’t store the passwords. There is no ads, no cookies, no user tracking and no registration. No one can view the notes except those who have the password to decrypt the text. Since there is no user registration required, you don’t need to create any accounts on this site. Once you done typing the notes, just close the web browser and you’re good to go!
|
||||
|
||||
### Let us save the notes in the encrypted notepad
|
||||
|
||||
Open ProtectedText site by clicking on the following button:
|
||||
|
||||
You will be landed in the home page where you can type your “site name” in the white box given at the center of the page. Alternatively, just write the site name directly in the address bar. Site name is just a custom name (E.g **<https://www.protectedtext.com/mysite>** ) you choose to access your private portal where you keep your notes.
|
||||
|
||||
|
||||
|
||||
If the site you chosen doesn’t exist, you will see the following message. Click on the button says **“Create”** to create your notepad page.
|
||||
|
||||
|
||||
|
||||
That’s it. A dedicated private page has been created for you. Now, start typing the notes. The current maximum length is a bit more then 750,000 chars per page.
|
||||
|
||||
ProtectedText site uses **AES algorithm** to encrypt and decrypt your content and **SHA512 algorithm** for hashing.
|
||||
|
||||
Once you’re done, click **Save** button on the top.
|
||||
|
||||
|
||||
|
||||
After you hit the Save button, you will be prompted to enter a password to protect your site. Enter the password twice and click **Save**.
|
||||
|
||||
|
||||
|
||||
You can use any password of your choice. However, it is recommended to use a long and complex password (inclusive of numbers, special characters) to prevent brute-force attacks. The longer the password, the better! Since ProtectedText servers won’t save your password, **there is no way to recover the lost password**. So, please remember the password or use any password managers like [**Buttercup**][3] and [**KeeWeb**][4] to store your credentials.
|
||||
|
||||
You can access your notepad at anytime by visiting its URL from any device. When you access the URL, you will see the following message. Just type your password and start adding and/or updating the notes.
|
||||
|
||||
|
||||
|
||||
The site can be accessed only by you and others who know the password. If you want to make your site public, just add the password of your site like this: **ProtectedText.com/yourSite?yourPassword** which will automatically decrypt **yourSite** with **yourPassword**.
|
||||
|
||||
There is also an [**Android app**][6] available, which allows you to sync notes across all your devices, work offline, backup notes and lock/unlock your site.
|
||||
|
||||
**Pros**
|
||||
|
||||
* Simple, easy to use, fast and free!
|
||||
* ProtectedText.com client side code is freely available [**here**][7]. You can analyze and check the code yourself to understand what is under the hood.
|
||||
* There is no expiration date to your stored content. You can just leave them there as long as you want.
|
||||
* It is possible to make your data both private (only you can view the data) and public (Data can be viewed by all).
|
||||
|
||||
|
||||
|
||||
**Cons**
|
||||
|
||||
* The client side code is open to everyone, however the server side code is not. So, you **can’t self-host the service yourself**. You got to trust them. If you don’t trust them, it is better to stay away from this site.
|
||||
* Since the site doesn’t store anything about yourself including the password, there is no way to recover your data if you forget the password. They claims that they don’t even know who owns which data. So, don’t lose the password.
|
||||
|
||||
|
||||
|
||||
If you ever wanted a simple way to store your notes online and access them wherever you go without installing any additional tools, ProtectedText service might be a good choice. If you know any similar services and applications, let me know them in the comment section below. I will check them out as well.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/protectedtext-a-free-encrypted-notepad-to-save-your-notes-online/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2018/11/Protected-Text-4.png
|
||||
[3]: https://www.ostechnix.com/buttercup-a-free-secure-and-cross-platform-password-manager/
|
||||
[4]: https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2018/11/Protected-Text-5.png
|
||||
[6]: https://play.google.com/store/apps/details?id=com.protectedtext.android
|
||||
[7]: https://www.protectedtext.com/js/main.js
|
||||
@ -0,0 +1,260 @@
|
||||
11 Things To Do After Installing elementary OS 5 Juno
|
||||
======
|
||||
I’ve been using [elementary OS 5 Juno][1] for over a month and it has been an amazing experience. It is easily the [best Mac OS inspired Linux distribution][2] and one of the [best Linux distribution for beginners][3].
|
||||
|
||||
However, you will need to take care of a couple of things after installing it.
|
||||
In this article, we will discuss the most important things that you need to do after installing [elementary OS][4] 5 Juno.
|
||||
|
||||
### Things to do after installing elementary OS 5 Juno
|
||||
|
||||
![Things to do after installing elementary OS Juno][5]
|
||||
|
||||
Things I mentioned in this list are from my personal experience and preference. Of course, you are not restricted to these few things. You can explore and tweak the system as much as you like. However, if you follow (some of) these recommendations, things might be smoother for you.
|
||||
|
||||
#### 1.Run a System Update
|
||||
|
||||
![terminal showing system updates in elementary os 5 Juno][6]
|
||||
|
||||
Even when you download the latest version of a distribution – it is always recommended to check for the latest System updates. You might have a quick fix for an annoying bug, or, maybe there’s an important security patch that you shouldn’t ignore. So, no matter what – you should always ensure that you have everything up-to-date.
|
||||
|
||||
To do that, you need to type in the following command in the terminal:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
#### 2\. Set Window Hotcorner
|
||||
|
||||
![][7]
|
||||
|
||||
You wouldn’t notice the minimize button for a window. So, how do you do it?
|
||||
|
||||
Well, you can just bring up the dock and click the app icon again to minimize it or press **Windows key + H** as a shortcut to minimize the active window.
|
||||
|
||||
But, I’ll recommend something way more easy and intuitive. Maybe you already knew it, but for the users who were unaware of the “ **hotcorners** ” feature, here’s what it does:
|
||||
|
||||
Whenever you hover the cursor to any of the 4 corners of the window, you can set a preset action to happen when you do that. For example, when you move your cursor to the **left corner** of the screen you get the **multi-tasking view** to switch between apps – which acts like a “gesture“.
|
||||
|
||||
In order to utilize the functionality, you can follow the steps below:
|
||||
|
||||
1. Head to the System Settings.
|
||||
2. Click on the “ **Desktop** ” option (as shown in the image above).
|
||||
3. Next, select the “ **Hot Corner** ” section (as shown in the image below).
|
||||
4. Depending on what corner you prefer, choose an appropriate action (refer to the image below – that’s what I personally prefer as my settings)
|
||||
|
||||
|
||||
|
||||
#### 3\. Install Multimedia codecs
|
||||
|
||||
I’ve tried playing MP3/MP4 files – it just works fine. However, there are a lot of file formats when it comes to multimedia.
|
||||
|
||||
So, just to be able to play almost every format of multimedia, you should install the codecs. Here’s what you need to enter in the terminal:
|
||||
|
||||
To get certain proprietary codecs:
|
||||
|
||||
```
|
||||
sudo apt install ubuntu-restricted-extras
|
||||
```
|
||||
|
||||
To specifically install [Libav][8]:
|
||||
|
||||
```
|
||||
sudo apt install libavcodec-extra
|
||||
```
|
||||
|
||||
To install a codec in order to facilitate playing video DVDs:
|
||||
|
||||
```
|
||||
sudo apt install libdvd-pkg
|
||||
```
|
||||
|
||||
#### 4\. Install GDebi
|
||||
|
||||
You don’t get to install .deb files by just double-clicking it on elementary OS 5 Juno. It just does not let you do that.
|
||||
|
||||
So, you need an additional tool to help you install .deb files.
|
||||
|
||||
We’ll recommend you to use **GDebi**. I prefer it because it lets you know about the dependencies even before trying to install it – that way – you can be sure about what you need in order to correctly install an application.
|
||||
|
||||
Simply install GDebi and open any .deb files by performing a right-click on them **open in GDebi Package Installer.**
|
||||
|
||||
To install it, type in the following command:
|
||||
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
#### 5\. Add a PPA for your Favorite App
|
||||
|
||||
Yes, elementary OS 5 Juno now supports PPA (unlike its previous version). So, you no longer need to enable the support for PPAs explicitly.
|
||||
|
||||
Just grab a PPA and add it via terminal to install something you like.
|
||||
|
||||
#### 6\. Install Essential Applications
|
||||
|
||||
If you’re a Linux power user, you already know what you want and where to get it, but if you’re new to this Linux distro and looking out for some applications to have installed, I have a few recommendations:
|
||||
|
||||
**Steam app** : If you’re a gamer, this is a must-have app. You just need to type in a single command to install it:
|
||||
|
||||
```
|
||||
sudo apt install steam
|
||||
```
|
||||
|
||||
**GIMP** : It is the best photoshop alternative across every platform. Get it installed for every type of image manipulation:
|
||||
|
||||
```
|
||||
sudo apt install gimp
|
||||
```
|
||||
|
||||
**Wine** : If you want to install an application that only runs on Windows, you can try using Wine to run such Windows apps here on Linux. To install, follow the command:
|
||||
|
||||
```
|
||||
sudo apt install wine-stable
|
||||
```
|
||||
|
||||
**qBittorrent** : If you prefer downloading Torrent files, you should have this installed as your Torrent client. To install it, enter the following command:
|
||||
|
||||
```
|
||||
sudo apt install qbittorrent
|
||||
```
|
||||
|
||||
**Flameshot** : You can obviously utilize the default screenshot tool to take screenshots. But, if you want to instantly share your screenshots and the ability to annotate – install flameshot. Here’s how you can do that:
|
||||
|
||||
```
|
||||
sudo apt install flameshot
|
||||
```
|
||||
|
||||
**Chrome/Firefox: **The default browser isn’t much useful. So, you should install Chrome/Firefox – as per your choice.
|
||||
|
||||
To install chrome, enter the command:
|
||||
|
||||
```
|
||||
sudo apt install chromium-browser
|
||||
```
|
||||
|
||||
To install Firefox, enter:
|
||||
|
||||
```
|
||||
sudo apt install firefox
|
||||
```
|
||||
|
||||
These are some of the most common applications you should definitely have installed. For the rest, you should browse through the App Center or the Flathub to install your favorite applications.
|
||||
|
||||
#### 7\. Install Flatpak (Optional)
|
||||
|
||||
It’s just my personal recommendation – I find flatpak to be the preferred way to install apps on any Linux distro I use.
|
||||
|
||||
You can try it and learn more about it at its [official website][9].
|
||||
|
||||
To install flatpak, type in:
|
||||
|
||||
```
|
||||
sudo apt install flatpak
|
||||
```
|
||||
|
||||
After you are done installing flatpak, you can directly head to [Flathub][10] to install some of your favorite apps and you will also find the command/instruction to install it via the terminal.
|
||||
|
||||
In case you do not want to launch the browser, you can search for your app by typing in (example – finding Discord and installing it):
|
||||
|
||||
```
|
||||
flatpak search discord flathub
|
||||
```
|
||||
|
||||
After gettting the application ID, you can proceed installing it by typing in:
|
||||
|
||||
```
|
||||
flatpak install flathub com.discordapp.Discord
|
||||
```
|
||||
|
||||
#### 8\. Enable the Night Light
|
||||
|
||||
![Night Light in elementary OS Juno][11]
|
||||
|
||||
You might have installed Redshift as per our recommendation for [elemantary OS 0.4 Loki][12] to filter the blue light to avoid straining our eyes- but you do not need any 3rd party tool anymore.
|
||||
|
||||
It comes baked in as the “ **Night Light** ” feature.
|
||||
|
||||
You just head to System Settings and click on “ **Displays** ” (as shown in the image above).
|
||||
|
||||
Select the **Night Light** section and activate it with your preferred settings.
|
||||
|
||||
#### 9\. Install NVIDIA driver metapackage (for NVIDIA GPUs)
|
||||
|
||||
![Nvidia drivers in elementary OS juno][13]
|
||||
|
||||
The NVIDIA driver metapackage should be listed right at the App Center – so you can easily the NVIDIA driver.
|
||||
|
||||
However, it’s not the latest driver version – I have version **390.77** installed and it’s performing just fine.
|
||||
|
||||
If you want the latest version for Linux, you should check out NVIDIA’s [official download page][14].
|
||||
|
||||
Also, if you’re curious about the version installed, just type in the following command:
|
||||
|
||||
```
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
#### 10\. Install TLP for Advanced Power Management
|
||||
|
||||
We’ve said it before. And, we’ll still recommend it.
|
||||
|
||||
If you want to manage your background tasks/activity and prevent overheating of your system – you should install TLP.
|
||||
|
||||
It does not offer a GUI, but you don’t have to bother. You just install it and let it manage whatever it takes to prevent overheating.
|
||||
|
||||
It’s very helpful for laptop users.
|
||||
|
||||
To install, type in:
|
||||
|
||||
```
|
||||
supo apt install tlp tlp-rdw
|
||||
```
|
||||
|
||||
#### 11\. Perform visual customizations
|
||||
|
||||
![][15]
|
||||
|
||||
If you need to change the look of your Linux distro, you can install GNOME tweaks tool to get the options. In order to install the tweak tool, type in:
|
||||
|
||||
```
|
||||
sudo apt install gnome-tweaks
|
||||
```
|
||||
|
||||
Once you install it, head to the application launcher and search for “Tweaks”, you’ll find something like this:
|
||||
|
||||
Here, you can select the icon, theme, wallpaper, and you’ll also be able to tweak a couple more options that’s not limited to the visual elements.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
It’s the least you should do after installing elementary OS 5 Juno. However, considering that elementary OS 5 Juno comes with numerous new features – you can explore a lot more new things as well.
|
||||
|
||||
Let us know what you did first after installing elementary OS 5 Juno and how’s your experience with it so far?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/things-to-do-after-installing-elementary-os-5-juno/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/elementary-os-juno-features/
|
||||
[2]: https://itsfoss.com/macos-like-linux-distros/
|
||||
[3]: https://itsfoss.com/best-linux-beginners/
|
||||
[4]: https://elementary.io/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/things-to-do-after-installing-elementary-os-juno.jpeg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-system-update.jpg?ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-hotcorners.jpg?ssl=1
|
||||
[8]: https://libav.org/
|
||||
[9]: https://flatpak.org/
|
||||
[10]: https://flathub.org/home
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-night-light.jpg?ssl=1
|
||||
[12]: https://itsfoss.com/things-to-do-after-installing-elementary-os-loki/
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-nvidia-metapackage.jpg?ssl=1
|
||||
[14]: https://www.nvidia.com/Download/index.aspx
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-gnome-tweaks.jpg?ssl=1
|
||||
147
sources/tech/20181115 How to install a device driver on Linux.md
Normal file
147
sources/tech/20181115 How to install a device driver on Linux.md
Normal file
@ -0,0 +1,147 @@
|
||||
Translating by Jamskr
|
||||
|
||||
How to install a device driver on Linux
|
||||
======
|
||||
Learn how Linux drivers work and how to use them.
|
||||

|
||||
|
||||
One of the most daunting challenges for people switching from a familiar Windows or MacOS system to Linux is installing and configuring a driver. This is understandable, as Windows and MacOS have mechanisms that make this process user-friendly. For example, when you plug in a new piece of hardware, Windows automatically detects it and shows a pop-up window asking if you want to continue with the driver's installation. You can also download a driver from the internet, then just double-click it to run a wizard or import the driver through Device Manager.
|
||||
|
||||
This process isn't as easy on a Linux operating system. For one reason, Linux is an open source operating system, so there are [hundreds of Linux distribution variations][1] . This means it's impossible to create one how-to guide that works for all Linux distros. Each Linux operating system handles the driver installation process a different way.
|
||||
|
||||
Second, most default Linux drivers are open source and integrated into the system, which makes installing any drivers that are not included quite complicated, even though most hardware devices can be automatically detected. Third, license policies vary among the different Linux distributions. For example, [Fedora prohibits][2] including drivers that are proprietary, legally encumbered, or that violate US laws. And Ubuntu asks users to [avoid using proprietary or closed hardware][3].
|
||||
|
||||
To learn more about how Linux drivers work, I recommend reading [An Introduction to Device Drivers][4] in the book Linux Device Drivers.
|
||||
|
||||
### Two approaches to finding drivers
|
||||
|
||||
#### 1\. User interfaces
|
||||
|
||||
If you are new to Linux and coming from the Windows or MacOS world, you'll be glad to know that Linux offers ways to see whether a driver is available through wizard-like programs. Ubuntu offers the [Additional Drivers][5] option. Other Linux distributions provide helper programs, like [Package Manager for GNOME][6], that you can check for available drivers.
|
||||
|
||||
#### 2\. Command line
|
||||
|
||||
What if you can't find a driver through your nice user interface application? Or you only have access through the shell with no graphic interface whatsoever? Maybe you've even decided to expand your skills by using a console. You have two options:
|
||||
|
||||
A. **Use a repository**
|
||||
This is similar to the [**homebrew**][7] command in MacOS.** ** By using **yum** , **dnf** , **apt-get** , etc., you're basically adding a repository and updating the package cache.
|
||||
|
||||
|
||||
B. **Download, compile, and build it yourself**
|
||||
This usually involves downloading a package directly from a website or using the **wget** command and running the configuration file and Makefile to install it. This is beyond the scope of this article, but you should be able to find online guides if you choose to go this route.
|
||||
|
||||
|
||||
|
||||
### Check if a driver is already installed
|
||||
|
||||
Before jumping further into installing a driver in Linux, let's look at some commands that will determine whether the driver is already available on your system.
|
||||
|
||||
The [**lspci**][8] command shows detailed information about all PCI buses and devices on the system:
|
||||
|
||||
```
|
||||
$ lscpci
|
||||
```
|
||||
|
||||
Or with **grep** :
|
||||
|
||||
```
|
||||
$ lscpci | grep SOME_DRIVER_KEYWORD
|
||||
```
|
||||
|
||||
For example, you can type **lspci | grep SAMSUNG** if you want to know if a Samsung driver is installed.
|
||||
|
||||
The [**dmesg**][9] command shows all device drivers recognized by the kernel:
|
||||
|
||||
```
|
||||
$ dmesg
|
||||
```
|
||||
|
||||
Or with **grep** :
|
||||
|
||||
```
|
||||
$ dmesg | grep SOME_DRIVER_KEYWORD
|
||||
```
|
||||
|
||||
Any driver that's recognized will show in the results.
|
||||
|
||||
If nothing is recognized by the **dmesg** or **lscpi** commands, try these two commands to see if the driver is at least loaded on the disk:
|
||||
|
||||
```
|
||||
$ /sbin/lsmod
|
||||
```
|
||||
|
||||
and
|
||||
|
||||
```
|
||||
$ find /lib/modules
|
||||
```
|
||||
|
||||
Tip: As with **lspci** or **dmesg** , append **| grep** to either command above to filter the results.
|
||||
|
||||
If a driver is recognized by those commands but not by **lscpi** or **dmesg** , it means the driver is on the disk but not in the kernel. In this case, load the module with the **modprobe** command:
|
||||
|
||||
```
|
||||
$ sudo modprobe MODULE_NAME
|
||||
```
|
||||
|
||||
Run as this command as **sudo** since this module must be installed as a root user.
|
||||
|
||||
### Add the repository and install
|
||||
|
||||
There are different ways to add the repository through **yum** , **dnf** , and **apt-get** ; describing them all is beyond the scope of this article. To make it simple, this example will use **apt-get** , but the idea is similar for the other options.
|
||||
|
||||
**1\. Delete the existing repository, if it exists.**
|
||||
|
||||
```
|
||||
$ sudo apt-get purge NAME_OF_DRIVER*
|
||||
```
|
||||
|
||||
where **NAME_OF_DRIVER** is the probable name of your driver. You can also add pattern match to your regular expression to filter further.
|
||||
|
||||
**2\. Add the repository to the repolist, which should be specified in the driver guide.**
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository REPOLIST_OF_DRIVER
|
||||
```
|
||||
|
||||
where **REPOLIST_OF_DRIVER** should be specified from the driver documentation (e.g., **epel-list** ).
|
||||
|
||||
**3\. Update the repository list.**
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
```
|
||||
|
||||
**4\. Install the package.**
|
||||
|
||||
```
|
||||
$ sudo apt-get install NAME_OF_DRIVER
|
||||
```
|
||||
|
||||
**5\. Check the installation.**
|
||||
|
||||
Run the **lscpi** command (as above) to check that the driver was installed successfully.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/how-install-device-driver-linux
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/List_of_Linux_distributions
|
||||
[2]: https://fedoraproject.org/wiki/Forbidden_items?rd=ForbiddenItems
|
||||
[3]: https://www.ubuntu.com/licensing
|
||||
[4]: https://www.xml.com/ldd/chapter/book/ch01.html
|
||||
[5]: https://askubuntu.com/questions/47506/how-do-i-install-additional-drivers
|
||||
[6]: https://help.gnome.org/users/gnome-packagekit/stable/add-remove.html.en
|
||||
[7]: https://brew.sh/
|
||||
[8]: https://en.wikipedia.org/wiki/Lspci
|
||||
[9]: https://en.wikipedia.org/wiki/Dmesg
|
||||
54
translated/talk/20180127 Write Dumb Code.md
Normal file
54
translated/talk/20180127 Write Dumb Code.md
Normal file
@ -0,0 +1,54 @@
|
||||
写直白的代码
|
||||
====
|
||||
|
||||
为开源项目作贡献最好的方式是为它减少代码,我们应致力于写出让新手程序员无需注释就容易理解的代码,让维护者也无需花费太多精力就能着手维护。
|
||||
|
||||
在学生时代,我们会更多地用复杂巧妙的技术去挑战新的难题。首先我们会学习循环,然后是函数啊,类啊,等等。 当我们到达一定高的程度,能用更高级的技术写更长的程序,我们会因此受到称赞。 此刻我们发现老司机们用 monads 而新手们用 loop 作循环。
|
||||
|
||||
之后我们毕业找了工作,或者和他人合作开源项目。我们用在学校里学到的各种炫技寻求并骄傲地给出解决方案的代码实现。
|
||||
|
||||
哈哈, 我能扩展这个项目,并实现某牛X功能啦, 我这里能用继承啦, 我太聪明啦!
|
||||
|
||||
我们实现了某个小的功能,并以充分的理由觉得自己做到了。现实项目中的编程却不是针对某某部分的功能而言。以我个人的经验而言,以前我很开心的去写代码,并骄傲地向世界展示我所知道的事情。 有例为证,作为对某种编程技术的偏爱,这是和另一段元语言代码混合在一起的 [一行 algebra 代码][1],我注意到多年以后一直没人愿意碰它。
|
||||
|
||||
在维护了更多的代码后,我的观点发生了变化。
|
||||
|
||||
1. 我们不应去刻意探求如何构建软件。 软件是我们为解决问题所付出的代价, 那才是我们真实的目的。 我们应努力为了解决问题而构建较小的软件。
|
||||
|
||||
2. 我们应使用尽可能简单的技术,那么更多的人就越可能会使用,并且无需理解我们所知的高级技术就能扩展软件的功能。当然,在我们不知道如何使用简单技术去实现时,我们也可以使用高级技术。
|
||||
|
||||
所有的这些例子都不是听来的故事。我遇到的大部分人会认同某些部分,但不知为什么,当我们向一个新项目贡献代码时又会忘掉这个初衷。直觉里用复杂技术去构建的念头往往会占据上风。
|
||||
|
||||
### 软件是种投入
|
||||
|
||||
你写的每行代码都要花费人力。写代码当然是需要时间的,也许你会认为只是你个人在奉献,然而这些代码在被审阅的时候也需要花时间理解,对于未来维护和开发人员来说,他们在维护和修改代码时同样要花费时间。否则他们完全可以用这时间出去晒晒太阳,或者陪伴家人。
|
||||
|
||||
所以,当你向某个项目贡献代码时,请心怀谦恭。就像是,你正和你的家人进餐时,餐桌上却没有足够的食物,你索取你所需的部分,别人对你的自我约束将肃然起敬。以更少的代码去解决问题是很难的,你肩负重任的同时自然减轻了别人的重负。
|
||||
|
||||
### 技术越复杂越难维护
|
||||
|
||||
作为学生,逐渐使用高端技术证明了自己的价值。这体现在,首先我们有能力在开源项目中使用函数,接着是类,然后是高阶函数,monads 等等。我们向同行显示自己的解决方案时,常因自己所用技术高低而感到自豪或卑微。
|
||||
|
||||
而在现实中,和团队去解决问题时,情况发生了逆转。现在,我们致力于尽可能使用简单的代码去解决问题。简单方式解决问题使新手程序员能够以此扩展并解决其他问题。简单的代码让别人容易上手,效果立竿见影。我们藉以只用简单的技术去解决难题,从而展示自己的价值。
|
||||
|
||||
看, 我用循环替代了递归函数并且一样达到了我们的需求。 当然我明白这是不够聪明的做法, 不过我注意到新手同事之前在这里会遇上麻烦,我觉得这改变将有所帮助吧。
|
||||
|
||||
如果你是个好的程序员,你不需要证明你知道很多炫技。相应的,你可以通过用一个简单的方法解决一个问题来显示你的价值,并激发你的团队在未来的时间里去完善它。
|
||||
|
||||
### 当然,也请保持节制
|
||||
|
||||
话虽如此, 过于遵循 “用简单的工具去构建” 的教条也会降低生产力。经常地,用递归会比用循环解决问题更简单,用类或 monad 才是正确的途径。还有两种情况另当别论,一是只是只为满足自我而创建的系统,或者是别人毫无构建经验的系统。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://matthewrocklin.com/blog/work/2018/01/27/write-dumb-code
|
||||
|
||||
作者:[Matthew Rocklin][a]
|
||||
译者:[plutoid](https://github.com/plutoid)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://matthewrocklin.com
|
||||
[1]:https://github.com/mrocklin/matrix-algebra
|
||||
@ -1,98 +1,160 @@
|
||||
Lisp 是怎么成为上帝的编程语言的
|
||||
======
|
||||
|
||||
当程序员们谈论各类编程语言的相对优势时,他们通常会采用相当平淡的词措,就好像这些语言是一条工具带上的各种工具似的——有适合写操作系统的,也有适合把其它程序黏在一起来完成特殊工作的。这种讨论方式非常合理;不同语言的能力不同。不声明特定用途就声称某门语言比其他语言更优秀只能导致侮辱性的无用争论。
|
||||
当程序员们谈论各类编程语言的相对优势时,他们通常会采用相当平淡的措词,就好像这些语言是一条工具带上的各种工具似的 —— 有适合写操作系统的,也有适合把其它程序黏在一起来完成特殊工作的。这种讨论方式非常合理;不同语言的能力不同。不声明特定用途就声称某门语言比其他语言更优秀只能导致侮辱性的无用争论。
|
||||
|
||||
但有一门语言似乎受到和用途无关的特殊尊敬:那就是 Lisp。即使是恨不得给每个说出形如“某某语言比其他所有语言都好”这类话的人都来一拳的键盘远征军们,也会承认Lisp处于另一个层次。 Lisp 超越了用于评判其他语言的实用主义标准,因为普通程序员并不使用 Lisp 编写实用的程序 —— 而且,多半他们永远也不会这么做。然而,人们对 Lisp 的敬意是如此深厚,甚至于到了这门语言会时而被加上神话属性的程度。大家都喜欢的网络漫画合集 xkcd 就至少在两组漫画中如此描绘过 Lisp:[其中一组漫画][1]中,一个人物得到了某种 Lisp 启示,而这好像使他理解了宇宙的基本构架。在[另一组漫画][2]中,一个穿着长袍的老程序员给他的徒弟递了一沓圆括号,说这是“文明时代的优雅武器”,暗示着 Lisp 就像原力那样拥有各式各样的神秘力量。
|
||||
但有一门语言似乎受到和用途无关的特殊尊敬:那就是 Lisp。即使是恨不得给每个说出形如“某某语言比其他所有语言都好”这类话的人都来一拳的键盘远征军们,也会承认 Lisp 处于另一个层次。 Lisp 超越了用于评判其他语言的实用主义标准,因为普通程序员并不使用 Lisp 编写实用的程序 —— 而且,多半他们永远也不会这么做。然而,人们对 Lisp 的敬意是如此深厚,甚至于到了这门语言会时而被加上神话属性的程度。
|
||||
|
||||
大家都喜欢的网络漫画合集 xkcd 就至少在两组漫画中如此描绘过 Lisp:[其中一组漫画][1]中,某人得到了某种 Lisp 启示,而这好像使他理解了宇宙的基本构架。
|
||||
|
||||

|
||||
|
||||
在[另一组漫画][2]中,一个穿着长袍的老程序员给他的徒弟递了一沓圆括号,说这是“文明时代的优雅武器”,暗示着 Lisp 就像原力那样拥有各式各样的神秘力量。
|
||||
|
||||

|
||||
|
||||
另一个绝佳例子是 Bob Kanefsky 的滑稽剧插曲,《上帝就在人间》。这部剧叫做《永恒之火》,编写于 1990 年代中期;剧中描述了上帝必然是使用 Lisp 创造世界的种种原因。完整的歌词可以在 [GNU 幽默合集][3]中找到,如下是一段摘抄:
|
||||
|
||||
> 因为上帝用祂的 Lisp 代码
|
||||
另一个绝佳例子是 Bob Kanefsky 的滑稽剧插曲,《上帝就在人间》。这部剧叫做《永恒之火》,撰写于 1990 年代中期;剧中描述了上帝必然是使用 Lisp 创造世界的种种原因。完整的歌词可以在 [GNU 幽默合集][3]中找到,如下是一段摘抄:
|
||||
|
||||
> 因为上帝用祂的 Lisp 代码
|
||||
|
||||
> 让树叶充满绿意。
|
||||
|
||||
|
||||
> 分形的花儿和递归的根:
|
||||
|
||||
> 我见过的奇技淫巧(hack)之中没什么比这更可爱。
|
||||
|
||||
|
||||
> 我见过的奇技淫巧之中没什么比这更可爱。
|
||||
|
||||
> 当我对着雪花深思时,
|
||||
|
||||
|
||||
> 从未见过两片相同的,
|
||||
|
||||
|
||||
> 我知道,上帝偏爱那一门
|
||||
|
||||
|
||||
> 名字是四个字母的语言。
|
||||
|
||||
以下这句话我实在不好在人前说;不过,我还是觉得,这样一种“ Lisp 是奥术魔法”的文化模因实在是有史以来最奇异、最迷人的东西。 Lisp 是象牙塔的产物,是人工智能研究的工具;因此,它对于编程界的俗人而言总是陌生的,甚至是带有神秘色彩的。然而,当今的程序员们开始怂恿彼此,[“在你死掉之前至少试一试 Lisp ”][4],就像这是一种令人恍惚入迷的致幻剂似的。尽管 Lisp 是广泛使用的编程语言中第二古老的(只比 Fortran 年轻一岁),程序员们也仍旧在互相怂恿。想象一下,如果你的工作是为某种组织或者团队推广一门新的编程语言的话,忽悠大家让他们相信你的新语言拥有神力难道不是绝佳的策略吗?——但你如何能够做到这一点呢?或者,换句话说,一门编程语言究竟是如何变成人们口中“隐晦知识的载体”的呢?
|
||||
以下这句话我实在不好在人前说;不过,我还是觉得,这样一种 “Lisp 是奥术魔法”的文化模因实在是有史以来最奇异、最迷人的东西。Lisp 是象牙塔的产物,是人工智能研究的工具;因此,它对于编程界的俗人而言总是陌生的,甚至是带有神秘色彩的。然而,当今的程序员们[开始怂恿彼此,“在你死掉之前至少试一试 Lisp”][4],就像这是一种令人恍惚入迷的致幻剂似的。尽管 Lisp 是广泛使用的编程语言中第二古老的(只比 Fortran 年轻一岁)[^1] ,程序员们也仍旧在互相怂恿。想象一下,如果你的工作是为某种组织或者团队推广一门新的编程语言的话,忽悠大家让他们相信你的新语言拥有神力难道不是绝佳的策略吗?—— 但你如何能够做到这一点呢?或者,换句话说,一门编程语言究竟是如何变成人们口中“隐晦知识的载体”的呢?
|
||||
|
||||
Lisp 究竟是怎么成为这样的?
|
||||
|
||||
![Byte 杂志封面,1979年八月。][5] Byte 杂志封面,1979年八月。
|
||||
![Byte 杂志封面,1979年八月。][5]
|
||||
|
||||
*Byte 杂志封面,1979年八月。*
|
||||
|
||||
### 理论 A :公理般的语言
|
||||
|
||||
Lisp 的创造者 John McCarthy 最初并没有想过把 Lisp 做成优雅、精炼的计算法则结晶。然而,在一两次运气使然的深谋远虑和一系列优化之后, Lisp 的确变成了那样的东西。 Paul Graham —— 我们一会儿之后才会聊到他 —— 曾经这么写,说, McCarthy 通过 Lisp “为编程作出的贡献就像是欧几里得对几何学所做的贡献一般”。人们可能会在 Lisp 中看出更加隐晦的含义——因为 McCarthy 创造 Lisp 时使用的要素实在是过于基础,基础到连弄明白他到底是创造了这门语言、还是发现了这门语言,都是一件难事。
|
||||
Lisp 的创造者<ruby>约翰·麦卡锡<rt>John McCarthy</rt></ruby>最初并没有想过把 Lisp 做成优雅、精炼的计算法则结晶。然而,在一两次运气使然的深谋远虑和一系列优化之后,Lisp 的确变成了那样的东西。 <ruby>保罗·格雷厄姆<rt>Paul Graham</rt></ruby>(我们一会儿之后才会聊到他)曾经这么写道, 麦卡锡通过 Lisp “为编程作出的贡献就像是欧几里得对几何学所做的贡献一般” [^2]。人们可能会在 Lisp 中看出更加隐晦的含义 —— 因为麦卡锡创造 Lisp 时使用的要素实在是过于基础,基础到连弄明白他到底是创造了这门语言、还是发现了这门语言,都是一件难事。
|
||||
|
||||
最初, McCarthy 产生要造一门语言的想法,是在 1956 年的达特茅斯人工智能夏季研究项目(Darthmouth Summer Research Project on Artificial Intelligence)上。夏季研究项目是个持续数周的学术会议,直到现在也仍旧在举行;它是此类会议之中最早开始举办的会议之一。 McCarthy 当初还是个达特茅斯的数学助教,而“人工智能”这个词事实上就是他建议举办会议时发明的。在整个会议期间大概有十人参加。他们之中包括了 Allen Newell 和 Herbert Simon ,两名隶属于兰德公司和卡内基梅隆大学的学者。这两人不久之前设计了一门语言,叫做IPL。
|
||||
最初, 麦卡锡产生要造一门语言的想法,是在 1956 年的<ruby>达特茅斯人工智能夏季研究项目<rt>Darthmouth Summer Research Project on Artificial Intelligence</rt></ruby>上。夏季研究项目是个持续数周的学术会议,直到现在也仍旧在举行;它是此类会议之中最早开始举办的会议之一。 麦卡锡当初还是个达特茅斯的数学助教,而“<ruby>人工智能<rt>artificial intelligence</rt></ruby>(AI)”这个词事实上就是他建议举办该会议时发明的 [^3]。在整个会议期间大概有十人参加 [^4]。他们之中包括了<ruby>艾伦·纽厄尔<rt>Allen Newell</rt></ruby>和<ruby>赫伯特·西蒙<rt>Herbert Simon</rt></ruby>,两名隶属于<ruby>兰德公司<rt>RAND Corporation</rt></ruby>和<ruby>卡内基梅隆大学<rt>Carnegie Mellon</rt></ruby>的学者。这两人不久之前设计了一门语言,叫做 IPL。
|
||||
|
||||
当时,Newell 和 Simon 正试图制作一套能够在命题演算中生成证明的系统。两人意识到,用电脑的原生指令集编写这套系统会非常困难;于是他们决定创造一门语言——原话是“伪代码”,这样,他们就能更加轻松自然地表达这台“逻辑理论机器”的底层逻辑了。这门语言叫做IPL,即“信息处理语言” (Information Processing Language) ;比起我们现在认知中的编程语言,它更像是一种汇编语言的方言。 Newell 和 Simon 提到,当时人们开发的其它“伪代码”都抓着标准数学符号不放——也许他们指的是 Fortran;与此不同的是,他们的语言使用成组的符号方程来表示命题演算中的语句。通常,用 IPL 写出来的程序会调用一系列的汇编语言宏,以此在这些符号方程列表中对表达式进行变换和求值。
|
||||
当时,纽厄尔和西蒙正试图制作一套能够在命题演算中生成证明的系统。两人意识到,用电脑的原生指令集编写这套系统会非常困难;于是他们决定创造一门语言——他们的原话是“<ruby>伪代码<rt>pseudo-code</rt></ruby>”,这样,他们就能更加轻松自然地表达这台“<ruby>逻辑理论机器<rt>Logic Theory Machine</rt></ruby>”的底层逻辑了 [^5]。这门语言叫做 IPL,即“<ruby>信息处理语言<rt>Information Processing Language</rt></ruby>”;比起我们现在认知中的编程语言,它更像是一种高层次的汇编语言方言。 纽厄尔和西蒙提到,当时人们开发的其它“伪代码”都抓着标准数学符号不放 —— 也许他们指的是 Fortran [^6];与此不同的是,他们的语言使用成组的符号方程来表示命题演算中的语句。通常,用 IPL 写出来的程序会调用一系列的汇编语言宏,以此在这些符号方程列表中对表达式进行变换和求值。
|
||||
|
||||
McCarthy 认为,一门实用的编程语言应该像 Fortran 那样使用代数表达式;因此,他并不怎么喜欢 IPL 。然而,他也认为,在给人工智能领域的一些问题建模时,符号列表会是非常好用的工具——而且在那些涉及演绎的问题上尤其有用。 McCarthy 的渴望最终被诉诸行动;他要创造一门代数的列表处理语言——这门语言会像 Fortran 一样使用代数表达式,但拥有和 IPL 一样的符号列表处理能力。
|
||||
麦卡锡认为,一门实用的编程语言应该像 Fortran 那样使用代数表达式;因此,他并不怎么喜欢 IPL [^7]。然而,他也认为,在给人工智能领域的一些问题建模时,符号列表会是非常好用的工具 —— 而且在那些涉及演绎的问题上尤其有用。麦卡锡的渴望最终被诉诸行动;他要创造一门代数的列表处理语言 —— 这门语言会像 Fortran 一样使用代数表达式,但拥有和 IPL 一样的符号列表处理能力。
|
||||
|
||||
当然,今日的 Lisp 可不像 Fortran。在会议之后的几年中, McCarthy 关于“理想的列表处理语言”的见解似乎在逐渐演化。到 1957 年,他的想法发生了改变。他那时候正在用 Fortran 编写一个能下象棋的程序;越是长时间地使用 Fortran , McCarthy 就越确信其设计中存在不当之处,而最大的问题就是尴尬的“ IF ”声明。为此,他发明了一个替代品,即条件表达式“ true ”;这个表达式会在给定的测试通过时返回子表达式 A ,而在测试未通过时返回子表达式 B ,而且,它只会对返回的子表达式进行求值。在 1958 年夏天,当 McCarthy 设计一个能够求导的程序时,他意识到,他发明的“true”表达式让编写递归函数这件事变得更加简单自然了。也是这个求导问题让 McCarthy 创造了 maplist 函数;这个函数会将其它函数作为参数并将之作用于指定列表的所有元素。在给项数多得叫人抓狂的多项式求导时,它尤其有用。
|
||||
当然,今日的 Lisp 可不像 Fortran。在会议之后的几年中,麦卡锡关于“理想的列表处理语言”的见解似乎在逐渐演化。到 1957 年,他的想法发生了改变。他那时候正在用 Fortran 编写一个能下国际象棋的程序;越是长时间地使用 Fortran ,麦卡锡就越确信其设计中存在不当之处,而最大的问题就是尴尬的 `IF` 声明 [^8]。为此,他发明了一个替代品,即条件表达式 `true`;这个表达式会在给定的测试通过时返回子表达式 `A` ,而在测试未通过时返回子表达式 `B` ,*而且*,它只会对返回的子表达式进行求值。在 1958 年夏天,当麦卡锡设计一个能够求导的程序时,他意识到,他发明的 `true` 条件表达式让编写递归函数这件事变得更加简单自然了 [^9]。也是这个求导问题让麦卡锡创造了 `maplist` 函数;这个函数会将其它函数作为参数并将之作用于指定列表的所有元素 [^10]。在给项数多得叫人抓狂的多项式求导时,它尤其有用。
|
||||
|
||||
然而,以上的所有这些,在 Fortran 中都是没有的;因此,在1958年的秋天,McCarthy 请来了一群学生来实现 Lisp。因为他那时已经成了一名麻省理工助教,所以,这些学生可都是麻省理工的学生。当 McCarthy 和学生们最终将他的主意变为能运行的代码时,这门语言得到了进一步的简化。这之中最大的改变涉及了 Lisp 的语法本身。最初,McCarthy 在设计语言时,曾经试图加入所谓的“M 表达式”;这是一层语法糖,能让 Lisp 的语法变得类似于 Fortran。虽然 M 表达式可以被翻译为 S 表达式 —— 基础的、“用圆括号括起来的列表”,也就是 Lisp 最著名的特征 —— 但 S 表达式事实上是一种给机器看的低阶表达方法。唯一的问题是,McCarthy 用方括号标记 M 表达式,但他的团队在麻省理工使用的 IBM 026 键盘打孔机的键盘上根本没有方括号。于是 Lisp 团队坚定不移地使用着 S 表达式,不仅用它们表示数据列表,也拿它们来表达函数的应用。McCarthy 和他的学生们还作了另外几样改进,包括将数学符号前置;他们也修改了内存模型,这样 Lisp 实质上就只有一种数据类型了。
|
||||
然而,以上的所有这些,在 Fortran 中都是没有的;因此,在 1958 年的秋天,麦卡锡请来了一群学生来实现 Lisp。因为他那时已经成了一名麻省理工助教,所以,这些学生可都是麻省理工的学生。当麦卡锡和学生们最终将他的主意变为能运行的代码时,这门语言得到了进一步的简化。这之中最大的改变涉及了 Lisp 的语法本身。最初,麦卡锡在设计语言时,曾经试图加入所谓的 “M 表达式”;这是一层语法糖,能让 Lisp 的语法变得类似于 Fortran。虽然 M 表达式可以被翻译为 S 表达式 —— 基础的、“用圆括号括起来的列表”,也就是 Lisp 最著名的特征 —— 但 S 表达式事实上是一种给机器看的低阶表达方法。唯一的问题是,麦卡锡用方括号标记 M 表达式,但他的团队在麻省理工使用的 IBM 026 键盘打孔机的键盘上根本没有方括号 [^11]。于是 Lisp 团队坚定不移地使用着 S 表达式,不仅用它们表示数据列表,也拿它们来表达函数的应用。麦卡锡和他的学生们还作了另外几样改进,包括将数学符号前置;他们也修改了内存模型,这样 Lisp 实质上就只有一种数据类型了 [^12]。
|
||||
|
||||
到 1960 年,McCarthy 发表了他关于 Lisp 的著名论文,《用符号方程表示的递归函数及它们的机器计算》。那时候,Lisp 已经被极大地精简,而这让 McCarthy 意识到,他的作品其实是“一套优雅的数学系统”,而非普通的编程语言。他之后这么写道,对 Lisp 的许多简化使其“成了一种描述可计算函数的方式,而且它比图灵机或者一般情况下用于递归函数理论的递归定义更加简洁”。在他的论文中,他不仅使用 Lisp 作为编程语言,也将它当作一套用于研究递归函数行为方式的表达方法。
|
||||
到 1960 年,麦卡锡发表了他关于 Lisp 的著名论文,《用符号方程表示的递归函数及它们的机器计算》。那时候,Lisp 已经被极大地精简,而这让麦卡锡意识到,他的作品其实是“一套优雅的数学系统”,而非普通的编程语言 [^13]。他后来这么写道,对 Lisp 的许多简化使其“成了一种描述可计算函数的方式,而且它比图灵机或者一般情况下用于递归函数理论的递归定义更加简洁” [^14]。在他的论文中,他不仅使用 Lisp 作为编程语言,也将它当作一套用于研究递归函数行为方式的表达方法。
|
||||
|
||||
通过“从一小撮规则中逐步实现出 Lisp”的方式,McCarthy 将这门语言介绍给了他的读者。不久之后,Paul Graham 换用更加易读的写法,在短文[《Lisp 之根》][6](The Roots of Lisp)中再次进行了介绍。在 Graham 的介绍中,他只用了七种基本的运算符、两种函数写法,和几个稍微高级一点的函数(也都使用基本运算符进行定义)。毫无疑问,Lisp 的这种只需使用极少量的基本规则就能完整说明的特点加深了其神秘色彩。Graham 称 McCarthy 的论文为“使计算公理化”的一种尝试。我认为,在思考 Lisp 的魅力从何而来时,这是一个极好的切入点。其它编程语言都有明显的人工构造痕迹,表现为“While”,“typedef”,“public static void”这样的关键词;而 Lisp 的设计却简直像是纯粹计算逻辑的鬼斧神工。Lisp 的这一性质,以及它和晦涩难懂的“递归函数理论”的密切关系,使它具备了获得如今声望的充分理由。
|
||||
通过“从一小撮规则中逐步实现出 Lisp”的方式,麦卡锡将这门语言介绍给了他的读者。后来,保罗·格雷厄姆在短文《<ruby>[Lisp 之根][6]<rt>The Roots of Lisp</rt></ruby>》中用更易读的语言回顾了麦卡锡的步骤。格雷厄姆只用了七种原始运算符、两种函数写法,以及使用原始运算符定义的六个稍微高级一点的函数来解释 Lisp。毫无疑问,Lisp 的这种只需使用极少量的基本规则就能完整说明的特点加深了其神秘色彩。格雷厄姆称麦卡锡的论文为“使计算公理化”的一种尝试 [^15]。我认为,在思考 Lisp 的魅力从何而来时,这是一个极好的切入点。其它编程语言都有明显的人工构造痕迹,表现为 `While`,`typedef`,`public static void` 这样的关键词;而 Lisp 的设计却简直像是纯粹计算逻辑的鬼斧神工。Lisp 的这一性质,以及它和晦涩难懂的“递归函数理论”的密切关系,使它具备了获得如今声望的充分理由。
|
||||
|
||||
### 理论 B:属于未来的机器
|
||||
|
||||
Lisp 诞生二十年后,它成了著名的《黑客词典》中所说的,人工智能研究的“母语”。Lisp 在此之前传播迅速,多半是托了语法规律的福 —— 不管在怎么样的电脑上,实现 Lisp 都是一件相对简单直白的事。而学者们之后坚持使用它乃是因为 Lisp 在处理符号表达式这方面有巨大的优势;在那个时代,人工智能很大程度上就意味着符号,于是这一点就显得十分重要。在许多重要的人工智能项目中都能见到 Lisp 的身影。这些项目包括了 [SHRDLU 自然语言程序][8](the SHRDLU natural language program),[Macsyma 代数系统][9](the Macsyma algebra system),和 [ACL2 逻辑系统][10](the ACL2 logic system)。
|
||||
Lisp 诞生二十年后,它成了著名的《<ruby>[黑客词典][7]<rt>Hacker’s Dictionary</rt></ruby>》中所说的,人工智能研究的“母语”。Lisp 在此之前传播迅速,多半是托了语法规律的福 —— 不管在怎么样的电脑上,实现 Lisp 都是一件相对简单直白的事。而学者们之后坚持使用它乃是因为 Lisp 在处理符号表达式这方面有巨大的优势;在那个时代,人工智能很大程度上就意味着符号,于是这一点就显得十分重要。在许多重要的人工智能项目中都能见到 Lisp 的身影。这些项目包括了 [SHRDLU 自然语言程序][8]、[Macsyma 代数系统][9] 和 [ACL2 逻辑系统][10]。
|
||||
|
||||
然而,在 1970 年代中期,人工智能研究者们的电脑算力开始不够用了。PDP-10 就是一个典型。这个型号在人工智能学界曾经极受欢迎;但面对这些用 Lisp 写的 AI 程序,它的 18 位内存空间一天比一天显得吃紧。许多的 AI 程序在设计上可以与人互动。要让这些既极度要求硬件性能、又有互动功能的程序在分时系统上优秀发挥,是很有挑战性的。麻省理工的 Peter Deutsch 给出了解决方案:那就是针对 Lisp 程序来特别设计电脑。就像是我那[关于 Chaosnet 的上一篇文章][11]所说的那样,这些 Lisp 计算机(Lisp machines)会给每个用户都专门分配一个为 Lisp 特别优化的处理器。到后来,考虑到硬核 Lisp 程序员的需求,这些计算机甚至还配备上了完全由 Lisp 编写的开发环境。在当时那样一个小型机时代已至尾声而微型机的繁盛尚未完全到来的尴尬时期,Lisp 计算机就是编程精英们的“高性能个人电脑”。
|
||||
然而,在 1970 年代中期,人工智能研究者们的电脑算力开始不够用了。PDP-10 就是一个典型。这个型号在人工智能学界曾经极受欢迎;但面对这些用 Lisp 写的 AI 程序,它的 18 位地址空间一天比一天显得吃紧 [^16]。许多的 AI 程序在设计上可以与人互动。要让这些既极度要求硬件性能、又有互动功能的程序在分时系统上优秀发挥,是很有挑战性的。麻省理工的<ruby>彼得·杜奇<rt>Peter Deutsch</rt></ruby>给出了解决方案:那就是针对 Lisp 程序来特别设计电脑。就像是我那[关于 Chaosnet 的上一篇文章][11]所说的那样,这些<ruby>Lisp 计算机<rt>Lisp machines</rt></ruby>会给每个用户都专门分配一个为 Lisp 特别优化的处理器。到后来,考虑到硬核 Lisp 程序员的需求,这些计算机甚至还配备上了完全由 Lisp 编写的开发环境。在当时那样一个小型机时代已至尾声而微型机的繁盛尚未完全到来的尴尬时期,Lisp 计算机就是编程精英们的“高性能个人电脑”。
|
||||
|
||||
有那么一会儿,Lisp 计算机被当成是未来趋势。好几家公司无中生有地出现,追着赶着要把这项技术商业化。其中最成功的一家叫做 Symbolics,由麻省理工 AI 实验室的前成员创立。上世纪八十年代,这家公司生产了所谓的 3600 系列计算机,它们当时在 AI 领域和需要高性能计算的产业中应用极广。3600 系列配备了大屏幕、位图显示、鼠标接口,以及[强大的图形与动画软件][12]。它们都是惊人的机器,能让惊人的程序运行起来。例如,之前在推特上跟我聊过的机器人研究者 Bob Culley,就能用一台 1985 年生产的 Symbolics 3650 写出带有图形演示的寻路算法。他向我解释说,在 1980 年代,位图显示和面向对象编程(能够通过 [Flavors 扩展][13]在 Lisp 计算机上使用)都刚刚出现。Symbolics 站在时代的最前沿。
|
||||
有那么一会儿,Lisp 计算机被当成是未来趋势。好几家公司雨后春笋般出现,追着赶着要把这项技术商业化。其中最成功的一家叫做 Symbolics,由麻省理工 AI 实验室的前成员创立。上世纪八十年代,这家公司生产了所谓的 3600 系列计算机,它们当时在 AI 领域和需要高性能计算的产业中应用极广。3600 系列配备了大屏幕、位图显示、鼠标接口,以及[强大的图形与动画软件][12]。它们都是惊人的机器,能让惊人的程序运行起来。例如,之前在推特上跟我聊过的机器人研究者 Bob Culley,就能用一台 1985 年生产的 Symbolics 3650 写出带有图形演示的寻路算法。他向我解释说,在 1980 年代,位图显示和面向对象编程(能够通过 [Flavors 扩展][13]在 Lisp 计算机上使用)都刚刚出现。Symbolics 站在时代的最前沿。
|
||||
|
||||
![Bob Culley 的寻路程序。][14] Bob Culley 的寻路程序。
|
||||
![Bob Culley 的寻路程序。][14]
|
||||
|
||||
*Bob Culley 的寻路程序。*
|
||||
|
||||
而以上这一切导致 Symbolics 的计算机奇贵无比。在 1983 年,一台 Symbolics 3600 能卖 111,000 美金。所以,绝大部分人只可能远远地赞叹 Lisp 计算机的威力,和操作员们用 Lisp 编写程序的奇妙技术 —— 但他们的确发出了赞叹。从 1979 年到 1980 年代末,Byte 杂志曾经多次提到过 Lisp 和 Lisp 计算机。在 1979 年八月发行的、关于 Lisp 的一期特别杂志中,杂志编辑激情洋溢地写道,麻省理工正在开发的计算机配备了“大坨大坨的内存”和“先进的操作系统”;他觉得,这些 Lisp 计算机的前途是如此光明,以至于它们的面世会让 1978 和 1977 年 —— 诞生了 Apple II, Commodore PET,和TRS-80 的两年 —— 显得黯淡无光。五年之后,在1985年,一名 Byte 杂志撰稿人描述了为“复杂精巧、性能强悍的 Symbolics 3670”编写 Lisp 程序的体验,并力劝读者学习 Lisp,称其为“绝大数人工智能工作者的语言选择”,和将来的通用编程语言。
|
||||
而以上这一切导致 Symbolics 的计算机奇贵无比。在 1983 年,一台 Symbolics 3600 能卖 111,000 美金 [^16]。所以,绝大部分人只可能远远地赞叹 Lisp 计算机的威力,和它们那些用 Lisp 编写的操作符的巫术。不止他们赞叹,从 1979 年到 1980 年代末,Byte 杂志曾经多次提到过 Lisp 和 Lisp 计算机。在 1979 年八月发行的、关于 Lisp 的一期特别杂志中,杂志编辑激情洋溢地写道,麻省理工正在开发的计算机配备了“大坨大坨的内存”和“先进的操作系统” [^17];他觉得,这些 Lisp 计算机的前途是如此光明,以至于它们的面世会让 1978 和 1977 年 —— 诞生了 Apple II、Commodore PET 和 TRS-80 的两年 —— 显得黯淡无光。五年之后,在 1985 年,一名 Byte 杂志撰稿人描述了为“复杂精巧、性能强悍的 Symbolics 3670”编写 Lisp 程序的体验,并力劝读者学习 Lisp,称其为“绝大数人工智能工作者的语言选择”,和将来的通用编程语言 [^18]。
|
||||
|
||||
我问过 Paul McJones [他在山景(Mountain View)的计算机历史博物馆做了许多 Lisp 的[保存工作][15]],人们是什么时候开始将 Lisp 当作高维生物的赠礼一样谈论的呢?他说,这门语言自有的性质毋庸置疑地促进了这种现象的产生;然而,他也说,Lisp 上世纪六七十年代在人工智能领域得到的广泛应用,很有可能也起到了作用。当 1980 年代到来、Lisp 计算机进入市场时,象牙塔外的某些人由此接触到了 Lisp 的能力,于是传说开始滋生。时至今日,很少有人还记得 Lisp 计算机和 Symbolics 公司;但 Lisp 得以在八十年代一直保持神秘,很大程度上要归功于它们。
|
||||
我问过<ruby>保罗·麦克琼斯<rt>Paul McJones</rt></ruby>(他在<ruby>山景城<rt>Mountain View<rt></ruby>的<ruby>计算机历史博物馆<rt>Computer History Museum</rt></ruby>做了许多 Lisp 的[保护工作][15]),人们是什么时候开始将 Lisp 当作高维生物的赠礼一样谈论的呢?他说,这门语言自有的性质毋庸置疑地促进了这种现象的产生;然而,他也说,Lisp 上世纪六七十年代在人工智能领域得到的广泛应用,很有可能也起到了作用。当 1980 年代到来、Lisp 计算机进入市场时,象牙塔外的某些人由此接触到了 Lisp 的能力,于是传说开始滋生。时至今日,很少有人还记得 Lisp 计算机和 Symbolics 公司;但 Lisp 得以在八十年代一直保持神秘,很大程度上要归功于它们。
|
||||
|
||||
### 理论 C:学习编程
|
||||
|
||||
1985 年,两位麻省理工的教授,Harold Abelson 和 Gerald Sussman,外加 Sussman 的妻子,出版了一本叫做《计算机程序的构造和解释》(Structure and Interpretation of Computer Programs)的教科书。这本书用 Scheme(一种 Lisp 方言)向读者们示范如何编程。它被用于教授麻省理工入门编程课程长达二十年之久。出于直觉,我认为 SICP(这是通常而言的标题缩写)倍增了 Lisp 的“神秘要素”。SICP 使用 Lisp 描绘了深邃得几乎可以称之为哲学的编程理念。这些理念非常普适,可以用任意一种编程语言展现;但 SICP 的作者们选择了 Lisp。结果,这本阴阳怪气、卓越不凡、吸引了好几代程序员(还成了一种[奇特的模因][16])的著作臭名远扬之后,Lisp 的声望也顺带被提升了。Lisp 已不仅仅是一如既往的“McCarthy 的优雅表达方式”;它现在还成了“向你传授编程的不传之秘的语言”。
|
||||
1985 年,两位麻省理工的教授,<ruby>哈尔·阿伯尔森<rt>Harold "Hal" Abelson</rt></ruby>和<ruby>杰拉尔德·瑟斯曼<rt>Gerald Sussman</rt></ruby>,外加瑟斯曼的妻子<ruby>朱莉·瑟斯曼<rt>Julie Sussman</rt></ruby>,出版了一本叫做《<ruby>计算机程序的构造和解释<rt>Structure and Interpretation of Computer Programs</rt></ruby>》的教科书。这本书用 Scheme(一种 Lisp 方言)向读者们示范了如何编程。它被用于教授麻省理工入门编程课程长达二十年之久。出于直觉,我认为 SICP(这本书的名字通常缩写为 SICP)倍增了 Lisp 的“神秘要素”。SICP 使用 Lisp 描绘了深邃得几乎可以称之为哲学的编程理念。这些理念非常普适,可以用任意一种编程语言展现;但 SICP 的作者们选择了 Lisp。结果,这本阴阳怪气、卓越不凡、吸引了好几代程序员(还成了一种[奇特的模因][16])的著作臭名远扬之后,Lisp 的声望也顺带被提升了。Lisp 已不仅仅是一如既往的“麦卡锡的优雅表达方式”;它现在还成了“向你传授编程的不传之秘的语言”。
|
||||
|
||||
SICP 究竟有多奇怪这一点值得好好说;因为我认为,时至今日,这本书的古怪之处和 Lisp 的古怪之处是相辅相成的。书的封面就透着一股古怪。那上面画着一位朝着桌子走去,准备要施法的巫师或者炼金术士。他的一只手里抓着一副测径仪 —— 或者圆规,另一只手上拿着个球,上书“eval”和“apply”。他对面的女人指着桌子;在背景中,希腊字母λ漂浮在半空,释放出光芒。
|
||||
SICP 究竟有多奇怪这一点值得好好说;因为我认为,时至今日,这本书的古怪之处和 Lisp 的古怪之处是相辅相成的。书的封面就透着一股古怪。那上面画着一位朝着桌子走去,准备要施法的巫师或者炼金术士。他的一只手里抓着一副测径仪 —— 或者圆规,另一只手上拿着个球,上书“eval”和“apply”。他对面的女人指着桌子;在背景中,希腊字母 λ (lambda)漂浮在半空,释放出光芒。
|
||||
|
||||
![SICP 封面上的画作][17] SICP 封面上的画作。
|
||||
![SICP 封面上的画作][17]
|
||||
|
||||
*SICP 封面上的画作。*
|
||||
|
||||
说真的,这上面画的究竟是怎么一回事?为什么桌子会长着动物的腿?为什么这个女人指着桌子?墨水瓶又是干什么用的?我们是不是该说,这位巫师已经破译了宇宙的隐藏奥秘,而所有这些奥秘就蕴含在 eval/apply 循环和 Lambda 微积分之中?看似就是如此。单单是这张图片,就一定对人们如今谈论 Lisp 的方式产生了难以计量的影响。
|
||||
|
||||
然而,这本书的内容通常并不比封面正常多少。SICP 跟你读过的所有计算机科学教科书都不同。在引言中,作者们表示,这本书不只教你怎么用 Lisp 编程 —— 它是关于“现象的三个焦点:人的心智,复数的计算机程序,和计算机”的作品。在之后,他们对此进行了解释,描述了他们对如下观点的坚信:编程不该被当作是一种计算机科学的训练,而应该是“程序性认识论”的一种新表达方式。程序是将那些偶然被送入计算机的思想组织起来的全新方法。这本书的第一章简明地介绍了 Lisp,但是之后的绝大部分都在讲述更加抽象的概念。其中包括了对不同编程范式的讨论,对于面向对象系统中“时间”和“一致性”的讨论;在书中的某一处,还有关于通信的基本限制可能会如何带来同步问题的讨论 —— 而这些基本限制在通信中就像是光速不变在相对中一样关键。都是些高深难懂的东西。
|
||||
然而,这本书的内容通常并不比封面正常多少。SICP 跟你读过的所有计算机科学教科书都不同。在引言中,作者们表示,这本书不只教你怎么用 Lisp 编程 —— 它是关于“现象的三个焦点:人的心智、复数的计算机程序,和计算机”的作品 [^19]。在之后,他们对此进行了解释,描述了他们对如下观点的坚信:编程不该被当作是一种计算机科学的训练,而应该是“<ruby>程序性认识论<rt>procedural epistemology</rt></ruby>”的一种新表达方式 [^20]。程序是将那些偶然被送入计算机的思想组织起来的全新方法。这本书的第一章简明地介绍了 Lisp,但是之后的绝大部分都在讲述更加抽象的概念。其中包括了对不同编程范式的讨论,对于面向对象系统中“时间”和“一致性”的讨论;在书中的某一处,还有关于通信的基本限制可能会如何带来同步问题的讨论 —— 而这些基本限制在通信中就像是光速不变在相对中一样关键 [^21]。都是些高深难懂的东西。
|
||||
|
||||
以上这些并不是说这是本糟糕的书;这本书其实棒极了。在我读过的所有作品中,这本书对于重要的编程理念的讨论是最为深刻的;那些理念我琢磨了很久,却一直无力用文字去表达。一本入门编程教科书能如此迅速地开始描述面向对象编程的根本缺陷,和函数式语言“将可变状态降到最少”的优点,实在是一件让人印象深刻的事。而这种描述之后变为了另一种震撼人心的讨论:某种(可能类似于今日的 [RxJS][18] 的)流范式能如何同时具备两者的优秀特性。SICP 用和当初 McCarthy 的 Lisp 论文相似的方式提纯出了高级程序设计的精华。你读完这本书之后,会立即想要将它推荐给你的程序员朋友们;如果他们找到这本书,看到了封面,但最终没有阅读的话,他们就只会记住长着动物腿的桌子上方那神秘的、根本的、给予魔法师特殊能力的、写着 eval/apply 的东西。话说回来,书上这两人的鞋子也让我印象颇深。
|
||||
以上这些并不是说这是本糟糕的书;这本书其实棒极了。在我读过的所有作品中,这本书对于重要的编程理念的讨论是最为深刻的;那些理念我琢磨了很久,却一直无力用文字去表达。一本入门编程教科书能如此迅速地开始描述面向对象编程的根本缺陷,和函数式语言“将可变状态降到最少”的优点,实在是一件让人印象深刻的事。而这种描述之后变为了另一种震撼人心的讨论:某种(可能类似于今日的 [RxJS][18] 的)流范式能如何同时具备两者的优秀特性。SICP 用和当初麦卡锡的 Lisp 论文相似的方式提纯出了高级程序设计的精华。你读完这本书之后,会立即想要将它推荐给你的程序员朋友们;如果他们找到这本书,看到了封面,但最终没有阅读的话,他们就只会记住长着动物腿的桌子上方那神秘的、根本的、给予魔法师特殊能力的、写着 eval/apply 的东西。话说回来,书上这两人的鞋子也让我印象颇深。
|
||||
|
||||
然而,SICP 最重要的影响恐怕是,它将 Lisp 由一门怪语言提升成了必要教学工具。在 SICP 面世之前,人们互相推荐 Lisp,以学习这门语言为提升编程技巧的途径。1979 年的 Byte 杂志 Lisp 特刊印证了这一事实。之前提到的那位编辑不仅就麻省理工的新计算机大书特书,还说,Lisp 这门语言值得一学,因为它“代表了分析问题的另一种视角”。但 SICP 并未只把 Lisp 作为其它语言的陪衬来使用;SICP 将其作为入门语言。这就暗含了一种论点,那就是,Lisp 是最能把握计算机编程基础的语言。可以认为,如今的程序员们彼此怂恿“在死掉之前至少试试 Lisp”的时候,他们很大程度上是因为 SICP 才这么说的。毕竟,编程语言 [Brainfuck][19] 想必同样也提供了“分析问题的另一种视角”;但人们学习 Lisp 而非学习 Brainfuck,那是因为他们知道,前者的那种视角在二十年中都被看作是极其有用的,有用到麻省理工在给他们的本科生教其它语言之前,必然会先教 Lisp。
|
||||
然而,SICP 最重要的影响恐怕是,它将 Lisp 由一门怪语言提升成了必要的教学工具。在 SICP 面世之前,人们互相推荐 Lisp,以学习这门语言为提升编程技巧的途径。1979 年的 Byte 杂志 Lisp 特刊印证了这一事实。之前提到的那位编辑不仅就麻省理工的新 Lisp 计算机大书特书,还说,Lisp 这门语言值得一学,因为它“代表了分析问题的另一种视角” [^22]。但 SICP 并未只把 Lisp 作为其它语言的陪衬来使用;SICP 将其作为*入门*语言。这就暗含了一种论点,那就是,Lisp 是最能把握计算机编程基础的语言。可以认为,如今的程序员们彼此怂恿“在死掉之前至少试试 Lisp”的时候,他们很大程度上是因为 SICP 才这么说的。毕竟,编程语言 [Brainfuck][19] 想必同样也提供了“分析问题的另一种视角”;但人们学习 Lisp 而非学习 Brainfuck,那是因为他们知道,前者的那种 Lisp 视角在二十年中都被看作是极其有用的,有用到麻省理工在给他们的本科生教其它语言之前,必然会先教 Lisp。
|
||||
|
||||
### Lisp 的回归
|
||||
|
||||
在 SICP 出版的同一年,Bjarne Stroustrup 公布了 C++ 语言的首个版本,它将面向对象编程带到了大众面前。几年之后,Lisp 计算机市场崩盘,AI 寒冬开始了。在下一个十年的变革中, C++ 和后来的 Java 成了前途无量的语言,而 Lisp 被冷落,无人问津。
|
||||
在 SICP 出版的同一年,<ruby>本贾尼·斯特劳斯特卢普<rt>Bjarne Stroustrup</rt></ruby>发布了 C++ 语言的首个版本,它将面向对象编程带到了大众面前。几年之后,Lisp 计算机的市场崩盘,AI 寒冬开始了。在下一个十年的变革中, C++ 和后来的 Java 成了前途无量的语言,而 Lisp 被冷落,无人问津。
|
||||
|
||||
理所当然地,确定人们对 Lisp 重新燃起热情的具体时间并不可能;但这多半是 Paul Graham 发表他那几篇声称 Lisp 是首选入门语言的短文之后的事了。Paul Graham 是 Y-Combinator 的联合创始人和《黑客新闻》(Hacker News)的创始者,他这几篇短文有很大的影响力。例如,在短文[《胜于平庸》][20](Beating the Averages)中,他声称 Lisp 宏使 Lisp 比其它语言更强。他说,因为他在自己创办的公司 Viaweb 中使用 Lisp,他得以比竞争对手更快地推出新功能。至少,[一部分程序员][21]被说服了。然而,庞大的主流程序员群体并未换用 Lisp。
|
||||
理所当然地,确定人们对 Lisp 重新燃起热情的具体时间并不可能;但这多半是保罗·格雷厄姆发表他那几篇声称 Lisp 是首选入门语言的短文之后的事了。保罗·格雷厄姆是 Y-Combinator 的联合创始人和《Hacker News》的创始者,他这几篇短文有很大的影响力。例如,在短文《<ruby>[胜于平庸][20]<rt>Beating the Averages</rt></ruby>》中,他声称 Lisp 宏使 Lisp 比其它语言更强。他说,因为他在自己创办的公司 Viaweb 中使用 Lisp,他得以比竞争对手更快地推出新功能。至少,[一部分程序员][21]被说服了。然而,庞大的主流程序员群体并未换用 Lisp。
|
||||
|
||||
实际上出现的情况是,Lisp 并未流行,但越来越多 Lisp 式的特性被加入到广受欢迎的语言中。Python 有了列表理解。C# 有了 Linq。Ruby……嗯,[Ruby 是 Lisp 的一种][22]。就如 Graham 在2002年提到的那样,“在一系列常用语言中所体现出的‘默认语言’正越发朝着 Lisp 的方向演化”。尽管其它语言变得越来越像 Lisp,Lisp 本身仍然保留了其作为“很少人了解但是大家都该学的神秘语言”的特殊声望。在 1980 年,Lisp 的诞生二十周年纪念日上,McCarthy写道,Lisp 之所以能够存活这么久,是因为它具备“编程语言领域中的某种近似局部最优”。这句话并未充分地表明 Lisp 的真正影响力。Lisp 能够存活超过半个世纪之久,并非因为程序员们一年年地勉强承认它就是最好的编程工具;事实上,即使绝大多数程序员根本不用它,它还是存活了下来。多亏了它的起源和它的人工智能研究用途,说不定还要多亏 SICP 的遗产,Lisp 一直都那么让人着迷。在我们能够想象上帝用其它新的编程语言创造世界之前,Lisp 都不会走下神坛。
|
||||
实际上出现的情况是,Lisp 并未流行,但越来越多 Lisp 式的特性被加入到广受欢迎的语言中。Python 有了列表理解。C# 有了 Linq。Ruby……嗯,[Ruby 是 Lisp 的一种][22]。就如格雷厄姆之前在 2001 年提到的那样,“在一系列常用语言中所体现出的‘默认语言’正越发朝着 Lisp 的方向演化” [^23]。尽管其它语言变得越来越像 Lisp,Lisp 本身仍然保留了其作为“很少人了解但是大家都该学的神秘语言”的特殊声望。在 1980 年,Lisp 的诞生二十周年纪念日上,麦卡锡写道,Lisp 之所以能够存活这么久,是因为它具备“编程语言领域中的某种近似局部最优” [^24]。这句话并未充分地表明 Lisp 的真正影响力。Lisp 能够存活超过半个世纪之久,并非因为程序员们一年年地勉强承认它就是最好的编程工具;事实上,即使绝大多数程序员根本不用它,它还是存活了下来。多亏了它的起源和它的人工智能研究用途,说不定还要多亏 SICP 的遗产,Lisp 一直都那么让人着迷。在我们能够想象上帝用其它新的编程语言创造世界之前,Lisp 都不会走下神坛。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
[^1]: John McCarthy, “History of Lisp”, 14, Stanford University, February 12, 1979, accessed October 14, 2018, http://jmc.stanford.edu/articles/lisp/lisp.pdf
|
||||
|
||||
[^2]: Paul Graham, “The Roots of Lisp”, 1, January 18, 2002, accessed October 14, 2018, http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf.
|
||||
|
||||
[^3]: Martin Childs, “John McCarthy: Computer scientist known as the father of AI”, The Independent, November 1, 2011, accessed on October 14, 2018, https://www.independent.co.uk/news/obituaries/john-mccarthy-computer-scientist-known-as-the-father-of-ai-6255307.html.
|
||||
|
||||
[^4]: Lisp Bulletin History. http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf
|
||||
|
||||
[^5]: Allen Newell and Herbert Simon, “Current Developments in Complex Information Processing,” 19, May 1, 1956, accessed on October 14, 2018, http://bitsavers.org/pdf/rand/ipl/P-850_Current_Developments_In_Complex_Information_Processing_May56.pdf.
|
||||
|
||||
[^6]: ibid.
|
||||
|
||||
[^7]: Herbert Stoyan, “Lisp History”, 43, Lisp Bulletin #3, December 1979, accessed on October 14, 2018, http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf
|
||||
|
||||
[^8]: McCarthy, “History of Lisp”, 5.
|
||||
|
||||
[^9]: ibid.
|
||||
|
||||
[^10]: McCarthy “History of Lisp”, 6.
|
||||
|
||||
[^11]: Stoyan, “Lisp History”, 45
|
||||
|
||||
[^12]: McCarthy, “History of Lisp”, 8.
|
||||
|
||||
[^13]: McCarthy, “History of Lisp”, 2.
|
||||
|
||||
[^14]: McCarthy, “History of Lisp”, 8.
|
||||
|
||||
[^15]: Graham, “The Roots of Lisp”, 11.
|
||||
|
||||
[^16]: Guy Steele and Richard Gabriel, “The Evolution of Lisp”, 22, History of Programming Languages 2, 1993, accessed on October 14, 2018, http://www.dreamsongs.com/Files/HOPL2-Uncut.pdf. 2
|
||||
|
||||
[^17]: Carl Helmers, “Editorial”, Byte Magazine, 154, August 1979, accessed on October 14, 2018, https://archive.org/details/byte-magazine-1979-08/page/n153.
|
||||
|
||||
[^18]: Patrick Winston, “The Lisp Revolution”, 209, April 1985, accessed on October 14, 2018, https://archive.org/details/byte-magazine-1985-04/page/n207.
|
||||
|
||||
[^19]: Harold Abelson, Gerald Jay. Sussman, and Julie Sussman, Structure and Interpretation of Computer Programs (Cambridge, Mass: MIT Press, 2010), xiii.
|
||||
|
||||
[^20]: Abelson, xxiii.
|
||||
|
||||
[^21]: Abelson, 428.
|
||||
|
||||
[^22]: Helmers, 7.
|
||||
|
||||
[^23]: Paul Graham, “What Made Lisp Different”, December 2001, accessed on October 14, 2018, http://www.paulgraham.com/diff.html.
|
||||
|
||||
[^24]: John McCarthy, “Lisp—Notes on its past and future”, 3, Stanford University, 1980, accessed on October 14, 2018, http://jmc.stanford.edu/articles/lisp20th/lisp20th.pdf.
|
||||
|
||||
via: https://twobithistory.org/2018/10/14/lisp.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Northurland](https://github.com/Northurland)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,65 +0,0 @@
|
||||
适用于你下一个家庭项目的单用户轻量级操作系统| Opensource.com
|
||||
======
|
||||

|
||||
|
||||
究竟什么是 RISC OS?嗯,它不是一种新的 Linux。它也不是有些人认为的 Windows。事实上,在 1987 年发布,它比其中任何一个都要老。但你看到它不一定会意识到这一点。
|
||||
|
||||
点击式图形用户界面在活动程序的底部有一个固定板和一个图标栏。因此,它看起来像 Windows 95,并且比它早了 8 年。
|
||||
|
||||
这个操作系统最初是为 [Acorn Archimedes][1] 编写的。这台机器中的 Acorn RISC Machines CPU 是全新的硬件,因此需要在其上运行全新的软件。这是最早的 ARM 芯片上的系统,早于任何人想到的 Android 或 [Armbian][2] 之前。
|
||||
|
||||
虽然 Acorn 桌面最终消失了,但 ARM 芯片继续征服世界。在这里,RISC OS 一直有一个优点 - 通常在嵌入式设备中,你从来没有真正地意识到它。RISC OS 过去长期以来一直是一个完全专有的操作系统。但近年来,所有人已经开始将源代码发布到一个名为 [RISC OS Open][3] 的项目中。
|
||||
|
||||
### 1\. 你可以将它安装在树莓派上
|
||||
|
||||
树莓派的官方操作系统 [Raspbian][4] 实际上非常棒(但如果你对摆弄不同技术上新奇的东西不敢兴趣,那么你可能最初也不会选择树莓派)。由于 RISC OS 是专门为 ARM 编写的,因此它可以在各种小型计算机上运行,包括树莓派的各个型号。
|
||||
|
||||
### 2\. 它超轻量级
|
||||
|
||||
我的树莓派上安装的 RISC 系统占用了几百兆 - 就是在我加载了数十个程序和游戏之后。其中大多数时候不大于 1 兆。
|
||||
|
||||
如果你真的节俭,RISC OS Pico 可用在 16MB SD 卡上。如果你在嵌入式系统或物联网项目中 hack 某些东西,这是很完美的。当然,16MB 实际上比压缩到 512KB 的老 Archimedes 的 ROM 要多得多。但我想 30 年间内存的发展,我们可以稍微放宽一下了。
|
||||
|
||||
### 3\. 它非常适合复古游戏
|
||||
|
||||
当 Archimedes 处于鼎盛时期时,ARM CPU 的速度比 Apple Macintosh 和 Commodore Amiga 中的 Motorola 68000 要快几倍,它也完全吸了新的 386。这使得它成为对游戏开发者有吸引力的一个平台,他们希望用这个星球上最强大的桌面计算机来支撑他们的东西。
|
||||
|
||||
这些游戏的许多拥有者都非常慷慨,允许业余爱好者免费下载他们的老作品。虽然 RISC OS 和硬件已经发展了,但只需要进行少量的调整就可以让它们运行起来。
|
||||
|
||||
如果你有兴趣探索这个,[这里有一个指南][5]让这些游戏在你的树莓派上运行。
|
||||
|
||||
### 4\. 它有 BBC BASIC
|
||||
|
||||
就像过去一样,按下 F12 进入命令行,输入 `*BASIC`,就可以看到一个完整的 BBC BASIC 解释器。
|
||||
|
||||
对于那些在 80 年代没有接触过的人,请让我解释一下:BBC BASIC 是当时我们很多人的第一个编程语言,因为它专门教孩子如何编码。当时有大量的书籍和杂志文章教我们编写自己的简单但高度可玩的游戏。
|
||||
|
||||
几十年后,对于一个想要在学校假期做点什么的有技术头脑的孩子而言,在 BBC BASIC 上编写自己的游戏仍然是一个很棒的项目。但很少有孩子在家里有 BBC micro。那么他们应该怎么做呢?
|
||||
|
||||
没问题,你可以在每台家用电脑上运行解释器,但是当别人需要使用它时就不能用了。那么为什么不使用装有 RISC OS 的树莓派呢?
|
||||
|
||||
### 5\. 它是一个简单的单用户操作系统
|
||||
|
||||
RISC OS 不像 Linux 一样有自己的用户和超级用户访问权限。它有一个用户并可以完全访问整个机器。因此,它可能不是跨企业部署的最佳日常驱动,甚至不适合给爷爷做银行业务。但是,如果你正在寻找可以用来修改和 hack 的东西,那绝对是太棒了。你和机器之间没有那么多,所以你可以直接进去。
|
||||
|
||||
### 扩展阅读
|
||||
|
||||
如果你想了解有关此操作系统的更多信息,请查看 [RISC OS Open][3],或者将镜像烧到闪存到卡上并开始使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/gentle-intro-risc-os
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dxmjames
|
||||
[1]:https://en.wikipedia.org/wiki/Acorn_Archimedes
|
||||
[2]:https://www.armbian.com/
|
||||
[3]:https://www.riscosopen.org/content/
|
||||
[4]:https://www.raspbian.org/
|
||||
[5]:https://www.riscosopen.org/wiki/documentation/show/Introduction%20to%20RISC%20OS
|
||||
@ -0,0 +1,70 @@
|
||||
|
||||
Greg Kroah-Hartman 解释内核社区如何保护 Linux
|
||||
============================================================
|
||||
|
||||

|
||||
内核维护者 Greg Kroah-Hartman 谈论内核社区如何保护 Linux 不遭受损害。[Creative Commons Zero][2]
|
||||
|
||||
由于 Linux 使用量持续扩大,内核社区去提高全世界最广泛使用的技术 — Linux 内核的安全性的重要程序越来越高。安全不仅对企业客户很重要,它对消费者也很重要,因为 80% 的移动设备都使用了 Linux。在本文中,Linux 内核维护者 Greg Kroah-Hartman 带我们了解内核社区如何应对威胁。
|
||||
|
||||
### bug 不可避免
|
||||
|
||||
|
||||

|
||||
|
||||
Greg Kroah-Hartman [Linux 基金会][1]
|
||||
|
||||
正如 Linus Torvalds 曾经说过,大多数安全问题都是 bug 造成的,而 bug 又是软件开发过程的一部分。是个软件就有 bug。
|
||||
|
||||
Kroah-Hartman 说:“就算是 bug ,我们也不知道它是安全的 bug 还是不安全的 bug。我修复的一个著名 bug,在三年后才被 Red Hat 认定为安全漏洞“。
|
||||
|
||||
在消除 bug 方面,内核社区没有太多的办法,只能做更多的测试来寻找 bug。内核社区现在已经有了自己的安全团队,它们是由熟悉内核核心的内核开发者组成。
|
||||
|
||||
Kroah Hartman 说:”当我们收到一个报告时,我们就让参与这个领域的核心开发者去修复它。在一些情况下,他们可能是同一个人,让他们进入安全团队可以更快地解决问题“。但他也强调,内核所有部分的开发者都必须清楚地了解这些问题,因为内核是一个可信环境,它必须被保护起来。
|
||||
|
||||
Kroah Hartman 说:”一旦我们修复了它,我们就将它放到我们的栈分析规则中,以便于以后不再重新出现这个 bug。“
|
||||
|
||||
除修复 bug 之外,内核社区也不断加固内核。Kroah Hartman 说:“我们意识到,我们需要一些主动的缓减措施。因此我们需要加固内核。”
|
||||
|
||||
Kees Cook 和其他一些人付出了巨大的努力,带来了一直在内核之外的加固特性,并将它们合并或适配到内核中。在每个内核发行后,Cook 都对所有新的加固特性做一个总结。但是只加固内核是不够的,供应商必须要启用这些新特性来让它们充分发挥作用。但他们并没有这么做。
|
||||
|
||||
Kroah-Hartman [每周发布一个稳定版内核][5],而为了长周期的支持,公司只从中挑选一个,以便于设备制造商能够利用它。但是,Kroah-Hartman 注意到,除了 Google Pixel 之外,大多数 Android 手机并不包含这些额外的安全加固特性,这就意味着,所有的这些手机都是有漏洞的。他说:“人们应该去启用这些加固特性”。
|
||||
|
||||
Kroah-Hartman 说:“我购买了基于 Linux 内核 4.4 的所有旗舰级手机,去查看它们中哪些确实升级了新特性。结果我发现只有一家公司升级了它们的内核”。“我在整个供应链中努力去解决这个问题,因为这是一个很棘手的问题。它涉及许多不同的组织 — SoC 制造商、运营商、等等。关键点是,需要他们把我们辛辛苦苦设计的内核去推送给大家。
|
||||
|
||||
好消息是,与消息电子产品不一样,像 Red Hat 和 SUSE 这样的大供应商,在企业环境中持续对内核进行更新。使用容器、pod、和虚拟化的现代系统做到这一点更容易了。无需停机就可以毫不费力地更新和重启。事实上,现在来保证系统安全相比过去容易多了。
|
||||
|
||||
### Meltdown 和 Spectre
|
||||
|
||||
没有任何一个关于安全的讨论能够避免提及 Meltdown 和 Spectre。内核社区一直致力于修改新发现的和已查明的安全漏洞。不管怎样,Intel 已经因为这些事情改变了它们的策略。
|
||||
|
||||
Kroah-Hartman 说:“他们已经重新研究如何处理安全 bug,以及如何与社区合作,因为他们知道他们做错了。内核已经修复了几乎所有大的 Spectre 问题,但是还有一些小问题仍在处理中”。
|
||||
|
||||
好消息是,这些 Intel 漏洞使得内核社区正在变得更好。Kroah-Hartman 说:“我们需要做更多的测试。对于最新一轮的安全补丁,在它们被发布之前,我们自己花了四个月时间来测试它们,因为我们要防止这个安全问题在全世界扩散。而一旦这些漏洞在真实的世界中被利用,将让我们认识到我们所依赖的基础设施是多么的脆弱,我们多年来一直在做这种测试,这确保了其它人不会遭到这些 bug 的伤害。所以说,Intel 的这些漏洞在某种程度上让内核社区变得更好了”。
|
||||
|
||||
对安全的日渐关注也为那些有才华的人创造了更多的工作机会。由于安全是个极具吸引力的领域,那些希望在内核空间中有所建树的人,安全将是他们一个很好的起点。
|
||||
|
||||
Kroah-Hartman 说:“如果有人想从事这方面的工作,我们有大量的公司愿意雇佣他们。我知道一些开始去修复 bug 的人已经被他们雇佣了。”
|
||||
|
||||
你可以在下面链接的视频上查看更多的内容:
|
||||
|
||||
[视频](https://youtu.be/jkGVabyMh1I)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-community-securing-linux-0
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
选题:[oska874][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/greg-k-hpng
|
||||
[4]:https://www.linux.com/files/images/kernel-securityjpg-0
|
||||
[5]:https://www.kernel.org/category/releases.html
|
||||
@ -1,485 +0,0 @@
|
||||
如何使用chkconfig和systemctl命令启用或禁用linux服务
|
||||
======
|
||||
|
||||
对于Linux管理员来说这是一个重要(美妙)的话题,所以每个人都必须知道并练习怎样才能更高效的使用它们。
|
||||
|
||||
|
||||
|
||||
在Linux中,无论何时当你安装任何带有服务和守护进程的包,系统默认会把这些进程添加到 “init & systemd” 脚本中,不过此时它们并没有被启动 。
|
||||
|
||||
|
||||
|
||||
我们需要手动的开启或者关闭那些服务。Linux中有三个著名的且一直在被使用的init系统。
|
||||
|
||||
|
||||
|
||||
### 什么是init系统?
|
||||
|
||||
|
||||
|
||||
在以Linux/Unix 为基础的操作系统上,init (初始化的简称) 是内核引导系统启动过程中第一个启动的进程。
|
||||
|
||||
|
||||
|
||||
init的进程id(pid)是1,除非系统关机否则它将会一直在后台运行。
|
||||
|
||||
|
||||
|
||||
Init 首先根据 `/etc/inittab` 文件决定Linux运行的级别,然后根据运行级别在后台启动所有其他进程和应用程序。
|
||||
|
||||
|
||||
|
||||
BIOS, MBR, GRUB 和内核程序在启动init之前就作为linux的引导程序的一部分开始工作了。
|
||||
|
||||
|
||||
|
||||
下面是Linux中可以使用的运行级别(从0~6总共七个运行级别)
|
||||
|
||||
|
||||
|
||||
* **`0:`** 关机
|
||||
|
||||
* **`1:`** 单用户模式
|
||||
|
||||
* **`2:`** 多用户模式(没有NFS)
|
||||
|
||||
* **`3:`** 完全的多用户模式
|
||||
|
||||
* **`4:`** 系统未使用
|
||||
|
||||
* **`5:`** 图形界面模式
|
||||
|
||||
* **`:`** 重启
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
下面是Linux系统中最常用的三个init系统
|
||||
|
||||
|
||||
|
||||
* System V (Sys V)
|
||||
|
||||
* Upstart
|
||||
|
||||
* systemd
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 什么是 System V (Sys V)?
|
||||
|
||||
|
||||
|
||||
System V (Sys V)是类Unix系统第一个传统的init系统之一。init是内核引导系统启动过程中第一支启动的程序 ,它是所有程序的父进程。
|
||||
|
||||
|
||||
|
||||
大部分Linux发行版最开始使用的是叫作System V(Sys V)的传统的init系统。在过去的几年中,已经有好几个init系统被发布用来解决标准版本中的设计限制,例如:launchd, the Service Management Facility, systemd 和 Upstart。
|
||||
|
||||
|
||||
|
||||
与传统的 SysV init系统相比,systemd已经被几个主要的Linux发行版所采用。
|
||||
|
||||
|
||||
|
||||
### 什么是 Upstart?
|
||||
|
||||
|
||||
|
||||
Upstart 是一个基于事件的/sbin/init守护进程的替代品,它在系统启动过程中处理任务和服务的启动,在系统运行期间监视它们,在系统关机的时候关闭它们。
|
||||
|
||||
|
||||
|
||||
它最初是为Ubuntu而设计,但是它也能够完美的部署在其他所有Linux系统中,用来代替古老的System-V。
|
||||
|
||||
|
||||
|
||||
Upstart被用于Ubuntu 从 9.10 到 Ubuntu 14.10和基于RHEL 6的系统,之后它被systemd取代。
|
||||
|
||||
|
||||
|
||||
### 什么是 systemd?
|
||||
|
||||
|
||||
|
||||
Systemd是一个新的init系统和系统管理器, 和传统的SysV相比,它可以用于所有主要的Linux发行版。
|
||||
|
||||
|
||||
|
||||
systemd 兼容 SysV 和 LSB init脚本。 它可以直接替代Sys V init系统。systemd是被内核启动的第一支程序,它的PID 是1。
|
||||
|
||||
|
||||
|
||||
systemd是所有程序的父进程,Fedora 15 是第一个用systemd取代upstart的发行版。systemctl用于命令行,它是管理systemd的守护进程/服务的主要工具,例如:(开启,重启,关闭,启用,禁用,重载和状态)
|
||||
|
||||
|
||||
|
||||
systemd 使用.service 文件而不是bash脚本 (SysVinit 使用的). systemd将所有守护进程添加到cgroups中排序,你可以通过浏览`/cgroup/systemd` 文件查看系统等级。
|
||||
|
||||
|
||||
|
||||
### 如何使用chkconfig命令启用或禁用引导服务?
|
||||
|
||||
|
||||
|
||||
chkconfig实用程序是一个命令行工具,允许你在指定运行级别下启动所选服务,以及列出所有可用服务及其当前设置。
|
||||
|
||||
|
||||
|
||||
此外,它还允许我们从启动中启用或禁用服务。前提是你有超级管理员权限(root或者sudo)运行这个命令。
|
||||
|
||||
|
||||
|
||||
所有的服务脚本位于 `/etc/rd.d/init.d`文件中
|
||||
|
||||
|
||||
|
||||
### 如何列出运行级别中所有的服务
|
||||
|
||||
|
||||
|
||||
`--list` 参数会展示所有的服务及其当前状态 (启用或禁用服务的运行级别)
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# chkconfig --list
|
||||
|
||||
NetworkManager 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
|
||||
abrt-ccpp 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||
|
||||
abrtd 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||
|
||||
acpid 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
|
||||
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
|
||||
|
||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
|
||||
.
|
||||
|
||||
.
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何查看指定服务的状态
|
||||
|
||||
|
||||
|
||||
如果你想查看运行级别下某个服务的状态,你可以使用下面的格式匹配出需要的服务。
|
||||
|
||||
|
||||
|
||||
比如说我想查看运行级别中`auditd`服务的状态
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# chkconfig --list| grep auditd
|
||||
|
||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何在指定运行级别中启用服务
|
||||
|
||||
|
||||
|
||||
使用`--level`参数启用指定运行级别下的某个服务,下面展示如何在运行级别3和运行级别5下启用 `httpd` 服务。
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# chkconfig --level 35 httpd on
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何在指定运行级别下禁用服务
|
||||
|
||||
|
||||
|
||||
同样使用 `--level`参数禁用指定运行级别下的服务,下面展示的是在运行级别3和运行级别5中禁用`httpd`服务。
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# chkconfig --level 35 httpd off
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何将一个新服务添加到启动列表中
|
||||
|
||||
|
||||
|
||||
`-–add`参数允许我们添加任何信服务到启动列表中, 默认情况下,新添加的服务会在运行级别2,3,4,5下自动开启。
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# chkconfig --add nagios
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何从启动列表中删除服务
|
||||
|
||||
|
||||
|
||||
可以使用 `--del` 参数从启动列表中删除服务,下面展示的事如何从启动列表中删除Nagios服务。
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# chkconfig --del nagios
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何使用systemctl命令启用或禁用开机自启服务?
|
||||
|
||||
|
||||
|
||||
systemctl用于命令行,它是一个基础工具用来管理systemd的守护进程/服务,例如:(开启,重启,关闭,启用,禁用,重载和状态)
|
||||
|
||||
|
||||
|
||||
所有服务创建的unit文件位与`/etc/systemd/system/`.
|
||||
|
||||
|
||||
|
||||
### 如何列出全部的服务
|
||||
|
||||
|
||||
|
||||
使用下面的命令列出全部的服务(包括启用的和禁用的)
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# systemctl list-unit-files --type=service
|
||||
|
||||
UNIT FILE STATE
|
||||
|
||||
arp-ethers.service disabled
|
||||
|
||||
auditd.service enabled
|
||||
|
||||
[email protected] enabled
|
||||
|
||||
blk-availability.service disabled
|
||||
|
||||
brandbot.service static
|
||||
|
||||
[email protected] static
|
||||
|
||||
chrony-wait.service disabled
|
||||
|
||||
chronyd.service enabled
|
||||
|
||||
cloud-config.service enabled
|
||||
|
||||
cloud-final.service enabled
|
||||
|
||||
cloud-init-local.service enabled
|
||||
|
||||
cloud-init.service enabled
|
||||
|
||||
console-getty.service disabled
|
||||
|
||||
console-shell.service disabled
|
||||
|
||||
[email protected] static
|
||||
|
||||
cpupower.service disabled
|
||||
|
||||
crond.service enabled
|
||||
|
||||
.
|
||||
|
||||
.
|
||||
|
||||
150 unit files listed.
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
使用下面的格式通过正则表达式匹配出你想要查看的服务的当前状态。下面是使用systemctl命令查看`httpd` 服务的状态。
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# systemctl list-unit-files --type=service | grep httpd
|
||||
|
||||
httpd.service disabled
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何让指定的服务开机自启
|
||||
|
||||
|
||||
|
||||
使用下面格式的systemctl命令启用一个指定的服务。启用服务将会创建一个符号链接,如下可见
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# systemctl enable httpd
|
||||
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
运行下列命令再次确认服务是否被启用。
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# systemctl is-enabled httpd
|
||||
|
||||
enabled
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何禁用指定的服务
|
||||
|
||||
|
||||
|
||||
运行下面的命令禁用服务将会移除你启用服务时所创建的
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# systemctl disable httpd
|
||||
|
||||
Removed symlink /etc/systemd/system/multi-user.target.wants/httpd.service.
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
运行下面的命令再次确认服务是否被禁用
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# systemctl is-enabled httpd
|
||||
|
||||
disabled
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 如何查看系统当前的运行级别
|
||||
|
||||
|
||||
|
||||
使用systemctl命令确认你系统当前的运行级别,'运行级'别仍然由systemd管理,不过,运行级别对于systemd来说是一个历史遗留的概念。所以我建议你全部使用systemctl命令。
|
||||
|
||||
|
||||
|
||||
我们当前处于`运行级别3`, 下面显示的是`multi-user.target`。
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
# systemctl list-units --type=target
|
||||
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
|
||||
basic.target loaded active active Basic System
|
||||
|
||||
cloud-config.target loaded active active Cloud-config availability
|
||||
|
||||
cryptsetup.target loaded active active Local Encrypted Volumes
|
||||
|
||||
getty.target loaded active active Login Prompts
|
||||
|
||||
local-fs-pre.target loaded active active Local File Systems (Pre)
|
||||
|
||||
local-fs.target loaded active active Local File Systems
|
||||
|
||||
multi-user.target loaded active active Multi-User System
|
||||
|
||||
network-online.target loaded active active Network is Online
|
||||
|
||||
network-pre.target loaded active active Network (Pre)
|
||||
|
||||
network.target loaded active active Network
|
||||
|
||||
paths.target loaded active active Paths
|
||||
|
||||
remote-fs.target loaded active active Remote File Systems
|
||||
|
||||
slices.target loaded active active Slices
|
||||
|
||||
sockets.target loaded active active Sockets
|
||||
|
||||
swap.target loaded active active Swap
|
||||
|
||||
sysinit.target loaded active active System Initialization
|
||||
|
||||
timers.target loaded active active Timers
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
|
||||
via: https://www.2daygeek.com/how-to-enable-or-disable-services-on-boot-in-linux-using-chkconfig-and-systemctl-command/
|
||||
|
||||
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
|
||||
选题:[lujun9972][b]
|
||||
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
|
||||
[b]: https://github.com/lujun9972
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
监测数据库的健康和行为: 有哪些重要指标?
|
||||
======
|
||||
对数据库的监测可能过于困难或者没有监测到关键点。本文将讲述如何正确的监测数据库。
|
||||

|
||||
|
||||
我们没有足够的讨论数据库。在这个充满监测仪器的时代,我们监测我们的应用程序、基础设施、甚至我们的用户,但有时忘记我们的数据库也值得被监测。这很大程度是因为数据库表现的很好,以至于我们单纯地信任它能把任务完成的很好。信任固然重要,但能够证明它的表现确实如我们所期待的那样就更好了。
|
||||
|
||||

|
||||
|
||||
### 为什么监测你的数据库?
|
||||
|
||||
监测数据库的原因有很多,其中大多数原因与监测系统的任何其他部分的原因相同:了解应用程序的各个组件中发生的什么,会让你成为更了解情况的,能够做出明智决策的开发人员。
|
||||
|
||||

|
||||
|
||||
更具体地说,数据库是系统健康和行为的重要标志。数据库中的异常行为能够指出应用程序中出现问题的区域。另外,当应用程序中有异常行为时,你可以利用数据库的指标来迅速完成排除故障的过程。
|
||||
|
||||
### 问题
|
||||
|
||||
最轻微的调查揭示了监测数据库的一个问题:数据库有很多指标。说“很多”只是轻描淡写,如果你是Scrooge McDuck,你可以浏览所有可用的指标。如果这是Wrestlemania,那么指标就是折叠椅。监测所有指标似乎并不实用,那么你如何决定要监测哪些指标?
|
||||
|
||||

|
||||
|
||||
### 解决方案
|
||||
|
||||
开始监测数据库的最好方式是认识一些基础的数据库指标。这些指标为理解数据库的行为创造了良好的开端。
|
||||
|
||||
### 吞吐量:数据库做了多少?
|
||||
|
||||
开始检测数据库的最好方法是跟踪它所接到请求的数量。我们对数据库有较高期望;期望它能稳定的存储数据,并处理我们抛给它的所有查询,这些查询可能是一天一次大规模查询,或者是来自用户一天到晚的数百万次查询。吞吐量可以告诉我们数据库是否如我们期望的那样工作。
|
||||
|
||||
你也可以将请求安照类型(读,写,服务器端,客户端等)分组,以开始分析流量。
|
||||
|
||||
### 执行时间:数据库完成工作需要多长时间?
|
||||
|
||||
这个指标看起来很明显,但往往被忽视了。 你不仅想知道数据库收到了多少请求,还想知道数据库在每个请求上花费了多长时间。 然而,参考上下文来讨论执行时间非常重要:像InfluxDB这样的时间序列数据库中的慢与像MySQL这样的关系型数据库中的慢不一样。InfluxDB中的慢可能意味着毫秒,而MySQL的“SLOW_QUERY”变量的默认值是10秒。
|
||||
|
||||

|
||||
|
||||
监测执行时间和提高执行时间不一样,所以如果你的应用程序中有其他问题需要修复,那么请注意在优化上花费时间的诱惑。
|
||||
|
||||
### 并发性:数据库同时做了多少工作?
|
||||
|
||||
一旦你知道数据库正在处理多少请求以及每个请求需要多长时间,你就需要添加一层复杂性以开始从这些指标中获得实际值。
|
||||
|
||||
如果数据库接收到十个请求,并且每个请求需要十秒钟来完成,那么数据库是否忙碌了100秒、10秒,或者介于两者之间?并发任务的数量改变了数据库资源的使用方式。当你考虑连接和线程的数量等问题时,你将开始对数据库指标有更全面的了解。
|
||||
|
||||
并发性还能影响延迟,这不仅包括任务完成所需的时间(执行时间),还包括任务在处理之前需要等待的时间。
|
||||
|
||||
### 利用率:数据库繁忙的时间百分比是多少?
|
||||
|
||||
利用率是由吞吐量、执行时间和并发性的峰值所确定的数据库可用的频率,或者数据库太忙而不能响应请求的频率。
|
||||
|
||||

|
||||
|
||||
该指标对于确定数据库的整体健康和性能特别有用。如果只能在80%的时间内响应请求,则可以重新分配资源、进行优化工作,或者进行更改以更接近高可用性。
|
||||
|
||||
### 好消息
|
||||
|
||||
监测和分析似乎非常困难,特别是因为我们大多数人不是数据库专家,我们可能没有时间去理解这些指标。但好消息是,大部分的工作已经为我们做好了。许多数据库都有一个内部性能数据库(Postgres:pg_stats、CouchDB:Runtime_.、InfluxDB:_internal等),数据库工程师设计该数据库来监测与该特定数据库有关的指标。你可以看到像慢速查询的数量一样广泛的内容,或者像数据库中每个事件的平均微秒一样详细的内容。
|
||||
|
||||
### 结论
|
||||
|
||||
数据库创建了足够的指标以使我们需要长时间研究,虽然内部性能数据库充满了有用的信息,但并不总是使你清楚应该关注哪些指标。 从吞吐量,执行时间,并发性和利用率开始,它们为你提供了足够的信息,使你可以开始了解你的数据库中的情况。
|
||||
|
||||

|
||||
|
||||
你在监视你的数据库吗?你发现哪些指标有用?告诉我吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/database-metrics-matter
|
||||
|
||||
作者:[Katy Farmer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ChiZelin](https://github.com/ChiZelin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thekatertot
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,213 @@
|
||||
如何在 Linux 上对驱动器进行分区和格式化
|
||||
======
|
||||
这里有所有你想知道的关于设置存储器而又不敢问的一切。
|
||||
|
||||

|
||||
|
||||
在大多数的计算机系统上,Linux 或者是其它,当你插入一个 USB 设备时,你会注意到一个提示驱动器存在的警告。如果该驱动器已经按你想要的进行分区和格式化,你只需要你的计算机在文件管理器或桌面上的某个地方列出驱动器。这是一个简单的要求,而且通常计算机都能满足。
|
||||
|
||||
然而,有时候,驱动器并没有按你想要的方式进行格式化。对于这些,你必须知道如何查找准备连接到您计算机上的存储设备。
|
||||
|
||||
### 什么是块设备?
|
||||
|
||||
硬盘驱动器通常被称为“块设备”,因为硬盘驱动器以固定大小的块进行读写。这就可以区分硬盘驱动器和其它可能插入到您计算机的一些设备,如打印机,游戏手柄,麦克风,或相机。一个简单的方法用来列出连接到你 Linux 系统上的块设备就是使用 `lsblk` (list block devices)命令:
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
sda 8:0 0 238.5G 0 disk
|
||||
├─sda1 8:1 0 1G 0 part /boot
|
||||
└─sda2 8:2 0 237.5G 0 part
|
||||
└─luks-e2bb...e9f8 253:0 0 237.5G 0 crypt
|
||||
├─fedora-root 253:1 0 50G 0 lvm /
|
||||
├─fedora-swap 253:2 0 5.8G 0 lvm [SWAP]
|
||||
└─fedora-home 253:3 0 181.7G 0 lvm /home
|
||||
sdb 8:16 1 14.6G 0 disk
|
||||
└─sdb1 8:17 1 14.6G 0 part
|
||||
```
|
||||
|
||||
最左列是设备标识符,每个都是以 `sd` 开头,并以一个字母结尾,字母从 `a` 开始。每个块设备上的分区分配一个数字,从 1 开始。例如,第一个设备上的第二个分区用 `sda2` 表示。如果你不确定到底是哪个分区,那也不要紧,只需接着往下读。
|
||||
|
||||
`lsblk` 命令是无损的,仅仅用于检测,所以你可以放心的使用而不用担心破坏你驱动器上的数据。
|
||||
|
||||
### 使用 `dmesg` 进行测试
|
||||
|
||||
如果你有疑问,你可以通过在 `dmesg` 命令的最后几行查看驱动器的卷标,这个命令显示了操作系统最近的日志(比如说插入或移除一个驱动器)。一句话,如果你想确认你插入的设备是不是 `/dev/sdc` ,那么,把设备插到你的计算机上,然后运行这个 `dmesg` 命令:
|
||||
|
||||
```
|
||||
$ sudo dmesg | tail
|
||||
```
|
||||
|
||||
显示中列出的最新的驱动器就是你刚刚插入的那个。如果你拔掉它,并再运行这个命令一次,你可以看到,这个设备已经被移除。如果你再插上它再运行命令,这个设备又会出现在那里。换句话说,你可以监控内核对驱动器的识别。
|
||||
|
||||
### 解理文件系统
|
||||
|
||||
如果你只需要设备卷标,那么你的工作就完成了。但是如果你的目的是想创建一个可用的驱动器,那你还必须给这个驱动器做一个文件系统。
|
||||
|
||||
如果你还不知道什么是文件系统,那么通过了解当没有文件系统时会发生什么,可能会更容易理解这个概念。如果你有多余的设备驱动器,并且上面没有什么重要的数据资料,你可以跟着做一下下面的这个实验。否则,请不要尝试,因为根据设计,这个肯定会删除您的资料。
|
||||
|
||||
当一个驱动器没有文件系统时也是可以使用的。一旦你已经肯定,正解识别了一个驱动器,并且已经确定上面没有任何重要的资料,那就可以把它插到你的计算机上——但是不要挂载它,如果它被自动挂载上了,那就请手动卸载掉它。
|
||||
|
||||
```
|
||||
$ su -
|
||||
# umount /dev/sdx{,1}
|
||||
```
|
||||
|
||||
为了防止灾难性的复制-粘贴错误,下面的例子将使用不太可能出现的 `sdx` 来作为驱动器的卷标。
|
||||
|
||||
现在,这个驱动器已经被卸载了,尝试使用下面的命令:
|
||||
|
||||
```
|
||||
# echo 'hello world' > /dev/sdx
|
||||
```
|
||||
|
||||
你已经可以将数据写入到块设备中,而无需将其挂载到你的操作系统上,也不需要一个文件系统。
|
||||
|
||||
再把刚写入的数据取出来,你可以看到驱动器上的原始数据:
|
||||
|
||||
```
|
||||
# head -n 1 /dev/sdx
|
||||
hello world
|
||||
```
|
||||
|
||||
这看起来工作得很好,但是想象一下如果 "hello world" 这个短语是一个文件,如果你想要用这种方法写入一个新的文件,则必须:
|
||||
|
||||
1. 知道第 1 行已经存在一个文件了
|
||||
2. 知道已经存在的文件只占用了 1 行
|
||||
3. 创建一种新的方法来在后面添加数据,或者在写第 2 行的时候重写第 1 行
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
# echo 'hello world
|
||||
> this is a second file' >> /dev/sdx
|
||||
```
|
||||
|
||||
获取第 1 个文件,没有任何改变。
|
||||
|
||||
```
|
||||
# head -n 1 /dev/sdx
|
||||
hello world
|
||||
```
|
||||
|
||||
但是,获取第 2 个文件的时候就显得有点复杂了。
|
||||
|
||||
```
|
||||
# head -n 2 /dev/sdx | tail -n 1
|
||||
this is a second file
|
||||
```
|
||||
|
||||
显然,通过这种方式读写数据并不实用,因此,开发人员创建了一个系统来跟踪文件的组成,并标识一个文件的开始和结束,等等。
|
||||
|
||||
大多数的文件系统都需要一个分区。
|
||||
|
||||
### 创建分区
|
||||
|
||||
分区是硬盘驱动器的一种边界,用来告诉文件系统它可以占用哪些空间。举例来说,你有一个 4GB 的 USB 驱动器,你可以只分一个分区占用一个驱动器 (4GB),或两个分区,每个 2GB (又或者是一个 1GB,一个 3GB,只要你愿意),或者三个不同的尺寸大小,等等。这种组合将是无穷无尽的。
|
||||
|
||||
假设你的驱动器是 4GB,你可以 GNU `parted` 命令来创建一个大的分区。
|
||||
|
||||
```
|
||||
# parted /dev/sdx --align opt mklabel msdos 0 4G
|
||||
```
|
||||
|
||||
按 `parted` 命令的要求,首先指定了驱动器的路径。
|
||||
|
||||
`\--align` 选项让 `parted` 命令自动选择一个最佳的开始点和结束点。
|
||||
|
||||
`mklabel` 命令在驱动器上创建了一个分区表 (称为磁盘卷标)。这个例子使用了 msdos 磁盘卷标,因为它是一个非常兼容和流行的卷标,虽然 gpt 正变得越来越普遍。
|
||||
|
||||
最后定义了分区所需的起点和终点。因为使用了 `\--align opt` 标志,所以 `parted` 将根据需要调整大小以优化驱动器的性能,但这些数字仍然可以做为参考。
|
||||
|
||||
接下来,创建实际的分区。如果你开始点和结束点的选择并不是最优的, `parted` 会向您发出警告并让您做出调整。
|
||||
|
||||
```
|
||||
# parted /dev/sdx -a opt mkpart primary 0 4G
|
||||
|
||||
Warning: The resulting partition is not properly aligned for best performance: 1s % 2048s != 0s
|
||||
Ignore/Cancel? C
|
||||
# parted /dev/sdx -a opt mkpart primary 2048s 4G
|
||||
```
|
||||
|
||||
如果你再次运行 `lsblk` 命令,(你可能必须要拔掉驱动器,并把它再插回去),你就可以看到你的驱动器上现在已经有一个分区了。
|
||||
|
||||
### 手动创建一个文件系统
|
||||
|
||||
我们有很多文件系统可以使用。有些是开源和免费的,另外的一些并不是。一些公司拒绝支持开源文件系统,所以他们的用户无法使用开源的文件系统读取,而开源的用户也无法在不对其进行逆向工程的情况下从封闭的文件系统中读取。
|
||||
|
||||
尽管有这种特殊的情况存在,还是仍然有很多操作系统可以使用,选择哪个取决于驱动器的用途。如果你希望你的驱动器兼容多个系统,那么你唯一的选择是 exFAT 文件系统。然而微软尚未向任何开源内核提交 exFAT 的代码,因此你可能必须在软件包管理器中安装 exFAT 支持,但是 Windows 和 MacOS 都支持 exFAT 文件系统。
|
||||
|
||||
一旦你安装了 exFAT 支持,你可以在驱动器上你创建好的分区中创建一个 exFAT 文件系统。
|
||||
|
||||
```
|
||||
# mkfs.exfat -n myExFatDrive /dev/sdx1
|
||||
```
|
||||
|
||||
现在你的驱动器可由封闭系统和其它开源的系统(尚未经过微软批准)内核模块进行读写了。
|
||||
|
||||
Linux 中常见的文件系统是 [ext4][1]。但对于便携式的设备来说,这可能是一个麻烦的文件系统,因为它保留了用户的权限,这些权限通常因为计算机而异,但是它通常是一个可靠而灵活的文件系统。只要你熟悉管理权限,那 ext4 对于便携式的设备来说就是一个很棒的文件系统。
|
||||
|
||||
```
|
||||
# mkfs.ext4 -L myExt4Drive /dev/sdx1
|
||||
```
|
||||
|
||||
拔掉你的驱动器,再把它插回去。对于 ext4 文件系统的便携设备来说,使用 `sudo` 创建一个目录,并将该目录的权限授予用户和系统中通用的组。如果你不确定使用哪个用户和组,也可以使用 `sudo` 或 `root` 来修改出现问题的设备的读写权限。
|
||||
|
||||
### 使用桌面工具
|
||||
|
||||
很高兴知道了在只有一个 Linux shell的时候,如何操作和处理你的块设备,但是,有时候你仅仅是想让一个驱动器可用,而不需要进行那么多的检测。 GNOME 的 KDE 的开发者们提供了这样的一些优秀的工具让这个过程变得简单。
|
||||
|
||||
[GNOME 磁盘][2] 和 [KDE 分区管理器][3] 是一个图形化的工具,为本文到目前为止提到的一切提供了一个一体化的解决方案。启动其中的任何一个,来查看所有连接的设备(在左侧列表中),创建和调整分区大小,和创建文件系统。
|
||||
|
||||
![KDE 分区管理器][5]
|
||||
|
||||
KDE 分区管理器
|
||||
|
||||
可以预见的是,GNOME 版本会比 KDE 版本更加简单,因此,我将使用复杂的版本进行演示——如果你愿意动手的话,很容易弄清楚 GNOME 磁盘工具的使用。
|
||||
|
||||
启动 KDE 分区管理工具,然后输入你的 root 密码。
|
||||
|
||||
在最左边的一列,选择你想要格式化的驱动器。如果你的驱动器并没有列出来,确认下是否已经插好,然后选择 Tools > Refresh devices (或使用键盘上的 F5 键)。
|
||||
|
||||
除非你想销毁驱动器已经存在的分区表,否则请勿继续。选择好驱动器后,单击顶部工具栏中的 New Partition Table 。系统会提示你为该分区选择一个卷标: gpt 或 msdos 。前者更加灵活可以处理更大的驱动器,而后者像很多微软的技术一样,是占据大量市场份额的事实上的标准。
|
||||
|
||||
现在您有了一个新的分区表,在右侧的面板中右键单击你的设备,然后选择 New 来创建新的分区,按照提示设置分区的类型和大小。此操作包括了分区步骤和创建文件系统。
|
||||
|
||||
![创建一个新分区][7]
|
||||
|
||||
创建一个新分区
|
||||
|
||||
要将更改应用于你的驱动器,单击窗口左上角的 Apply 按钮。
|
||||
|
||||
### 硬盘驱动器, 容易驱动
|
||||
|
||||
在 Linux 上处理硬盘驱动器很容易,甚至如果你理解硬盘驱动器的语言就更容易了。自从切换到 Linux 系统以来,我已经能够以任何我想要的方式来处理我的硬盘驱动器了。由于 Linux 在处理存储提供的透明性,因此恢复数据也变得更加容易了。
|
||||
|
||||
如果你想实验并了解有关硬盘驱动器的更多的信息,请参考下面的几个提示:
|
||||
|
||||
1. 备份您的数据,而不仅仅是你在实验的驱动器上。仅仅需要一个小小的错误操作来破坏一个重要驱动器的分区。(这是一个用来学习重建丢失分区的很好的方法,但并不是很有趣)。
|
||||
2. 反复确认你所定位的驱动器是正确的驱动器。我经常使用 `lsblk` 来确定我并没有移动驱动器。(因为从两个独立的 USB 端口移除两个驱动器很容易,然后以不同的顺序重新连接它们,就会很容易导致它们获得了新的驱动器标签。)
|
||||
3. 花点时间“销毁”你测试的驱动器,看看你是否可以把数据恢复。在删除文件系统后,重新创建分区表或尝试恢复数据是一个很好的学习体验。
|
||||
|
||||
还有一些更好玩的东西,如果你身边有一个封闭的操作系统,在上面尝试使用一个开源的文件系统。有一些项目致力于解决这种兼容性,并且尝试让它们以一种可靠稳定的方式工作是一个很好的业余项目。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/partition-format-drive-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Jamskr](https://github.com/Jamskr)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/5/introduction-ext4-filesystem
|
||||
[2]: https://wiki.gnome.org/Apps/Disks
|
||||
[3]: https://www.kde.org/applications/system/kdepartitionmanager/
|
||||
[4]: /file/413586
|
||||
[5]: https://opensource.com/sites/default/files/uploads/blockdevices_kdepartition.jpeg (KDE Partition Manager)
|
||||
[6]: /file/413591
|
||||
[7]: https://opensource.com/sites/default/files/uploads/blockdevices_newpartition.jpeg (Create a new partition)
|
||||
@ -0,0 +1,91 @@
|
||||
使用 gitbase 在 git 仓库进行 SQL 查询
|
||||
======
|
||||
gitbase 是一个使用 go 开发的的开源项目,它实现了在 git 仓库上执行 SQL 查询。
|
||||
|
||||

|
||||
|
||||
git 已经成为了代码版本控制的事实标准,但尽管 git 相当普及,对代码仓库的深入分析的工作难度却没有因此而下降;而 SQL 在大型代码库的查询方面则已经是一种久经考验的语言,因此诸如 Spark 和 BigQuery 这样的项目都采用了它。
|
||||
|
||||
所以,source{d} 很顺理成章地将这两种技术结合起来,就产生了 gitbase。gitbase 是一个<ruby>代码即数据<rt>code-as-data</rt></ruby>的解决方案,可以使用 SQL 对 git 仓库进行大规模分析。
|
||||
|
||||
[gitbase][1] 是一个完全开源的项目。它站在了很多巨人的肩上,因此得到了足够的发展竞争力。下面就来介绍一下其中的一些“巨人”。
|
||||
|
||||

|
||||
|
||||
[gitbase playground][2] 为 gitbase 提供了一个可视化的操作环境。
|
||||
|
||||
### 用 Vitess 解析 SQL
|
||||
|
||||
gitbase 通过 SQL 与用户进行交互,因此需要能够遵循 MySQL 协议来对传入的 SQL 请求作出解析和理解,万幸由 YouTube 建立的 [Vitess][3] 项目已经在这一方面给出了解决方案。Vitess 是一个横向扩展的 MySQL数据库集群系统。
|
||||
|
||||
我们只是使用了这个项目中的部分重要代码,并将其转化为一个可以让任何人在数分钟以内编写出一个 MySQL 服务器的[开源程序][4],就像我在 [justforfunc][5] 视频系列中展示的 [CSVQL][6] 一样,它可以使用 SQL 操作 CSV 文件。
|
||||
|
||||
### 用 go-git 读取 git 仓库
|
||||
|
||||
在成功解析 SQL 请求之后,还需要对数据集中的 git 仓库进行查询才能返回结果。因此,我们还结合使用了 source{d} 最成功的 [go-git][7] 仓库。go-git 是使用纯 go 语言编写的具有高度可扩展性的 git 实现。
|
||||
|
||||
借此我们就可以很方便地将存储在磁盘上的代码仓库保存为 [siva][8] 文件格式(这同样是 source{d} 的一个开源项目),也可以通过 `git clone` 来对代码仓库进行复制。
|
||||
|
||||
### 使用 enry 检测语言、使用 babelfish 解析文件
|
||||
|
||||
gitbase 集成了我们的语言检测开源项目 [enry][9] 以及代码解析项目 [babelfish][10],因此在分析 git 仓库历史代码的能力也相当强大。babelfish 是一个自托管服务,普适于各种源代码解析,并将代码文件转换为<ruby>通用抽象语法树<rt>Universal Abstract Syntax Tree</rt></ruby>(UAST)。
|
||||
|
||||
这两个功能在 gitbase 中可以被用户以函数 LANGUAGE 和 UAST 调用,诸如“查找上个月最常被修改的函数的名称”这样的请求就需要通过这两个功能实现。
|
||||
|
||||
### 提高性能
|
||||
|
||||
gitbase 可以对非常大的数据集进行分析,例如源代码大小达 3 TB 的 Public Git Archive。面临的工作量如此巨大,因此每一点性能都必须运用到极致。于是,我们也使用到了 Rubex 和 Pilosa 这两个项目。
|
||||
|
||||
#### 使用 Rubex 和 Oniguruma 优化正则表达式速度
|
||||
|
||||
[Rubex][12] 是 go 的正则表达式标准库包的一个准替代品。之所以说它是准替代品,是因为它没有在 regexp.Regexp 类中实现 LiteralPrefix 方法,直到现在都还没有。
|
||||
|
||||
Rubex 的高性能是由于使用 [cgo][14] 调用了 [Oniguruma][13],它是一个高度优化的 C 代码库。
|
||||
|
||||
#### 使用 Pilosa 索引优化查询速度
|
||||
|
||||
索引几乎是每个关系型数据库都拥有的特性,但 Vitess 由于不需要用到索引,因此并没有进行实现。
|
||||
|
||||
于是我们引入了 [Pilosa][15] 这个开源项目。Pilosa 是一个使用 go 实现的分布式位图索引,可以显著提升跨多个大型数据集的查询的速度。通过 Pilosa,gitbase 才得以在巨大的数据集中进行查询。
|
||||
|
||||
### 总结
|
||||
|
||||
我想用这一篇文章来对开源社区表达我衷心的感谢,让我们能够不负众望的在短时间内完成 gitbase 的开发。我们 source{d} 的每一位成员都是开源的拥护者,github.com/src-d 下的每一行代码都是见证。
|
||||
|
||||
你想使用 gitbase 吗?最简单快捷的方式是从 sourced.tech/engine 下载 source{d} 引擎,就可以通过单个命令运行 gitbase 了。
|
||||
|
||||
想要了解更多,可以听听我在 [Go SF 大会][16]上的演讲录音。
|
||||
|
||||
本文在 [Medium][17] 首发,并经许可在此发布。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/gitbase
|
||||
|
||||
作者:[Francesc Campoy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/francesc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/src-d/gitbase
|
||||
[2]: https://github.com/src-d/gitbase-web
|
||||
[3]: https://github.com/vitessio/vitess
|
||||
[4]: https://github.com/src-d/go-mysql-server
|
||||
[5]: http://justforfunc.com/
|
||||
[6]: https://youtu.be/bcRDXAraprk
|
||||
[7]: https://github.com/src-d/go-git
|
||||
[8]: https://github.com/src-d/siva
|
||||
[9]: https://github.com/src-d/enry
|
||||
[10]: https://github.com/bblfsh/bblfshd
|
||||
[11]: https://blog.sourced.tech/post/announcing-pga/
|
||||
[12]: https://github.com/moovweb/rubex
|
||||
[13]: https://github.com/kkos/oniguruma
|
||||
[14]: https://golang.org/cmd/cgo/
|
||||
[15]: https://github.com/pilosa/pilosa
|
||||
[16]: https://www.meetup.com/golangsf/events/251690574/
|
||||
[17]: https://medium.com/sourcedtech/gitbase-exploring-git-repos-with-sql-95ec0986386c
|
||||
|
||||
@ -0,0 +1,185 @@
|
||||
在linux中如何查找一个命令或进程的执行时间
|
||||
======
|
||||

|
||||
|
||||
你可能知道一个命令或进程开始执行的时间和在类Unix系统中[**一个命令运行了多久**][1]。 但是,你如何知道这个命令或进程何时结束或者它完成运行所花费的总时间呢? 在类Unix系统中,这是非常容易的! 有一个程序专门为此设计名叫 **‘GNU time’**。 使用time程序, 我们可以轻松地测量Linux操作系统中命令或程序的总执行时间。 ‘time’命令在大多数Linux发行版中都有预装, 所以你不必去安装它。
|
||||
|
||||
### 在Linux中查找一个命令或进程的执行时间
|
||||
|
||||
要测量一个命令或程序的执行时间,运行。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -p ls
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ time ls
|
||||
```
|
||||
|
||||
输出样例:
|
||||
|
||||
```
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
|
||||
real 0m0.007s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
|
||||
$ time ls -a
|
||||
. .bash_logout dir1 file2 mcelog .sudo_as_admin_successful
|
||||
.. .bashrc dir2 .gnupg .profile .wget-hsts
|
||||
.bash_history .cache file1 .local .stack
|
||||
|
||||
real 0m0.008s
|
||||
user 0m0.001s
|
||||
sys 0m0.005s
|
||||
```
|
||||
|
||||
以上命令显示出了 **‘ls’** 命令的总执行时间。 你可以将 “ls” 替换为任何命令或进程,以查找总的执行时间。
|
||||
|
||||
输出详解:
|
||||
|
||||
1. **real** -指的是命令或程序所花费的总时间
|
||||
2. **user** – 指的是在用户模式下程序所花费的时间,
|
||||
3. **sys** – 指的是在内核模式下程序所花费的时间。
|
||||
|
||||
|
||||
|
||||
我们也可以将命令限制为仅运行一段时间。
|
||||
|
||||
### time vs /usr/bin/time
|
||||
|
||||
你可能注意到了, 我们在上面的例子中使用了两个命令 **‘time’** and **‘/usr/bin/time’** 。 所以,你可能会想知道他们的不同。
|
||||
|
||||
首先, 让我们使用 ‘type’ 命令看看 ‘time’ 命令到底是什么。对于那些我们不知道的Linux命令, **Type** 命令用于查找相关命令的信息。 更多详细信息, [**请参阅本指南**][2]。
|
||||
|
||||
```
|
||||
$ type -a time
|
||||
time is a shell keyword
|
||||
time is /usr/bin/time
|
||||
```
|
||||
|
||||
正如你在上面的输出中看到的一样, 这两个都是time,
|
||||
|
||||
* 一个是BASH shell中内建的关键字
|
||||
* 一个是可执行文件 如 **/usr/bin/time**
|
||||
|
||||
|
||||
|
||||
由于shell关键字的优先级高于可执行文件, 当你没有给出完整路径只运行`time`命令时, 你运行的是shell内建的命令。 但是,当你运行 `/usr/bin/time`时, 你运行的是真正的 **GNU time** 命令。 因此,为了执行真正的命令你可能需要给出完整路径。
|
||||
|
||||
在大多数shell中如 BASH, ZSH, CSH, KSH, TCSH 等,内建的关键字‘time’是可用的。 ‘time’ 关键字的选项少于可执行文件. 你可以使用的唯一选项是 **-p**。
|
||||
|
||||
你现在知道如何使用 ‘time’ 命令查找给定命令或进程的总执行时间。 想进一步了解 ‘GNU time’ 工具吗? 继续阅读吧!
|
||||
|
||||
### 关于 ‘GNU time’ 程序的简要介绍
|
||||
|
||||
Gnu time程序运行带有给定参数的命令或程序,并在命令完成后将系统资源使用情况汇总到标准输出。 与 ‘time’ 关键字不同, Gnu time程序不仅显示命令或进程的执行时间,还显示内存,I/O和IPC调用等其他资源。
|
||||
|
||||
time 命令的语法是:
|
||||
|
||||
```
|
||||
/usr/bin/time [options] command [arguments...]
|
||||
```
|
||||
|
||||
语法中的‘options’是指一组可以与time命令一起使用去执行特定功能的选项。 下面给出了可用的‘options’。
|
||||
|
||||
* **-f, –format** – 使用此选项可以根据需求指定输出格式。
|
||||
* **-p, –portability** – 使用简要的输出格式。
|
||||
* **-o file, –output=FILE** – 将输出写到指定文件中而不是到标准输出。
|
||||
* **-a, –append** – 将输出追加到文件中而不是覆盖它。
|
||||
* **-v, –verbose** – 此选项显示 ‘time’ 命令输出的详细信息。
|
||||
* **–quiet** – 此选项可以防止 ‘time’ 命令报告程序的状态.
|
||||
|
||||
|
||||
|
||||
当不带任何选项使用 ‘GNU time’ 命令时, 你将看到以下输出。
|
||||
|
||||
```
|
||||
$ /usr/bin/time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2024maxresident)k
|
||||
0inputs+0outputs (0major+73minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
如果你用shell关键字 ‘time’ 运行相同的命令, 输出会有一点儿不同:
|
||||
|
||||
```
|
||||
$ time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
|
||||
real 0m0.006s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
```
|
||||
|
||||
有时,你可能希望将系统资源使用情况输出到文件中而不是终端上。 为此, 你可以使用 **-o** 选项,如下所示。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -o file.txt ls
|
||||
dir1 dir2 file1 file2 file.txt mcelog
|
||||
```
|
||||
|
||||
正如你看到的, time命令不会显示到终端上. 因为我们将输出写到了file.txt的文件中。 让我们看一下这个文件的内容:
|
||||
|
||||
```
|
||||
$ cat file.txt
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2512maxresident)k
|
||||
0inputs+0outputs (0major+106minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
当你使用 **-o** 选项时, 如果你没有一个文件名叫 ‘file.txt’, 它会创建一个并把输出写进去。 如果文件存在, 它会覆盖文件原来的内容。
|
||||
|
||||
你可以使用 **-a** 选项将输出追加到文件后面,而不是覆盖它的内容。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -a file.txt ls
|
||||
```
|
||||
|
||||
**-f** 选项允许用户根据自己的喜好控制输出格式。 比如说, 以下命令的输出仅显示用户,系统和总时间。
|
||||
|
||||
```
|
||||
$ /usr/bin/time -f "\t%E real,\t%U user,\t%S sys" ls
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
0:00.00 real, 0.00 user, 0.00 sys
|
||||
```
|
||||
|
||||
请注意shell中内建的 ‘time’ 命令并不具有Gnu time程序的所有功能。
|
||||
|
||||
有关Gnu time程序的详细说明可以使用man命令来查看。
|
||||
|
||||
```
|
||||
$ man time
|
||||
```
|
||||
|
||||
想要了解有关Bash 内建 ‘Time’ 关键字的更多信息, 请运行:
|
||||
|
||||
```
|
||||
$ help time
|
||||
```
|
||||
|
||||
就到这里吧。 希望对你有所帮助。
|
||||
|
||||
会有更多好东西分享哦。 请关注我们!
|
||||
|
||||
加油哦!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-the-execution-time-of-a-command-or-process-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[caixiangyue](https://github.com/caixiangyue)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/find-long-process-running-linux/
|
||||
[2]: https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/
|
||||
76
translated/tech/20181113 4 tips for learning Golang.md
Normal file
76
translated/tech/20181113 4 tips for learning Golang.md
Normal file
@ -0,0 +1,76 @@
|
||||
学习 Golang 的 4 个技巧
|
||||
======
|
||||
到达 Golang 大陆:一个高级开发者的日记。
|
||||

|
||||
|
||||
2014 年夏天...
|
||||
|
||||
> IBM:“我们需要你弄清楚这个 Docker。”
|
||||
> Me:“没问题。”
|
||||
> IBM:“那就开始吧。”
|
||||
> Me:“好的。”(内心声音):”Docker 是用 Go 编写的。是吗?“(Googles)“哦,一门编程语言。我在我的岗位上已经学习了很多了。这不会太难。”
|
||||
|
||||
|
||||
我的大学新生编程课是使用 VAX 汇编程序教授的。在数据结构课上,我们在图书馆计算机中心的旧电脑上使用 Pascal 加载的软盘。在一门更上一级的课程中,我有一个教授喜欢用 ADA 去展示所有的例子。我在我们的 Sun 工作站上通过各种的 UNIX 的实用源代码学到了一点 C。在 IBM,我们使用 C 和一些 x86 汇编程序来获取 OS/2 源代码,我们大量使用 C++ 的面向对象功能与 Apple 合作。不久后我学到了 shell 脚本,并开始使用 csh,但是在 90 年代中期发现 Linux 后就转到了 Bash。在 90 年代后期将其移植到 Linux 时,我正在研究 IBM 的自定义 JVM 代码中的即时(JIT)编译器,因此我开始学习 m4(可以说是宏编程器而不是编程语言)。
|
||||
|
||||
快进 20 年... 我从未因为学习一门新的编程语言而焦灼。但是 [Go][1] 感觉有些不同。我打算在 GitHub 上游公开贡献,让任何有兴趣的人都可以看到!作为一个 40 多岁高级开发者的 Go 新手,我不想成为一个笑话。我们都知道程序员的骄傲是不想受伤,不论你的经验水平如何。
|
||||
|
||||
我早期的调查显示,Go 似乎比某些语言更倾向于 “惯用语”。它不仅仅是编译代码; 我需要能够用 “Go 的方式” 写代码。
|
||||
|
||||
现在在我的私人 Go 日志上,四年有上百个 pull requests,我不是致力于成为一个专家,但是我觉得贡献和编写代码比我在 2014 年的时候更舒服了。所以,你该怎么教一个老人新的技能或者至少一门编程语言?以下是我自己在前往 Golang 大陆的四个步骤。
|
||||
|
||||
### 1. 不要跳过基础
|
||||
|
||||
虽然你可以通过复制代码来进行你早期的学习(还有谁有时间阅读手册!?),Go 有一个非常易读的 [语言规范][2],它写的很清楚,即便你在语言或者编译理论方面没有硕士学位。鉴于 Go 在 **参数:类型** 的顺序做的独特决定,在使用有趣的语言功能,例如 通道和 goroutines 时,搞定这些新概念是非常重要的是事情。阅读文档 [高效 Go 编程][3],这是 Golang 创作者的另一个重要资源,它将为你提供有效和正确使用语言的准备。
|
||||
|
||||
### 2. 从最好的中学习
|
||||
|
||||
有许多宝贵的资源可供挖掘,并将你的 Go 知识提升到下一个等级。最近在 [GopherCon][4] 上的所有谈话都可以在网上找到,就像 [GopherCon US 在 2018][5] 中的详尽列表一样。谈话的专业知识和技术水平各不相同,但是你可以通过谈话轻松地找到一些你不了解的事情。[Francesc Campoy][6] 创建了一个名叫 [JustForFunc][7] 的 Go 编程视频系列,其中有越来越多的剧集来拓宽你的 Go 知识和理解。快速搜索 “Golang" 可以为那些想要了解更多信息的人们展示许多其他视频和在线资源。
|
||||
|
||||
想要看代码?在 GitHub 上许多受欢迎的云原生项目都是用 Go 写的:[Docker/Moby][8],[Kubernetes][9],[Istio][10],[containerd][11],[CoreDNS][12],以及许多其他的。语言纯粹者可能会评价一些项目的惯用语优于其他的,但是这些都是在了解大型代码在高度活跃的项目中开始使用 Go 的大好起点。
|
||||
|
||||
### 3. 使用优秀的语言工具
|
||||
|
||||
你将要快速了解有关 [gofmt][13] 的宝贵之处。Go 最漂亮的一个地方就在于没有关于每个项目代码格式的争论 —— **gofmt** 内置在语言的运行库中,并且根据一系列稳固、易于理解的语言规则对 Go 代码进行格式化。我不理解任何基于 Golang 不坚持使用 **gofmt** 检查 pull requests 作为持续集成一部分的项目。
|
||||
|
||||
除了直接构建在 runtime/SDK 有价值的工具之外,我强烈建议使用一个对 Golang 的特性有良好支持的编辑器或者 IDE。由于我经常在命令行中进行工作,我依赖于 Vim 加上强大的 [vim-go][14] 插件。我也喜欢微软提供的 [VS Code][15],特别是它的 [Go language][16] 插件。
|
||||
|
||||
想要一个调试器?[Delve][17] 项目在不断的改进和成熟,而且是在 Go 二进制文件上进行 [gdb][18] 式调试的强有力的竞争者。
|
||||
|
||||
### 4. 写一些代码
|
||||
|
||||
你要是不开始尝试使用 Go 写代码,你永远不知道它有什么好的地方。找一个有 “需要帮助” 问题标签的项目,然后开始贡献代码。如果你已经使用了一个用 Go 编写的开源项目,找出它是否有一些用初学者方式解决的 Bugs,然后开始你的第一个 pull request。与生活中的大多数事情一样,唯一真正的改进方法就是通过实践,所以开始吧。
|
||||
|
||||
事实证明,你似乎可以教一个老高级开发者至少一门新的技能或者编程语言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/learning-golang
|
||||
|
||||
作者:[Phill Estes][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/estesp
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://golang.org/
|
||||
[2]: https://golang.org/ref/spec
|
||||
[3]: https://golang.org/doc/effective_go.html
|
||||
[4]: https://www.gophercon.com/
|
||||
[5]: https://tqdev.com/2018-gophercon-2018-videos-online
|
||||
[6]: https://twitter.com/francesc
|
||||
[7]: https://www.youtube.com/channel/UC_BzFbxG2za3bp5NRRRXJSw
|
||||
[8]: https://github.com/moby/moby
|
||||
[9]: https://github.com/kubernetes/kubernetes
|
||||
[10]: https://github.com/istio/istio
|
||||
[11]: https://github.com/containerd/containerd
|
||||
[12]: https://github.com/coredns/coredns
|
||||
[13]: https://blog.golang.org/go-fmt-your-code
|
||||
[14]: https://github.com/fatih/vim-go
|
||||
[15]: https://code.visualstudio.com/
|
||||
[16]: https://code.visualstudio.com/docs/languages/go
|
||||
[17]: https://github.com/derekparker/delve
|
||||
[18]: https://www.gnu.org/software/gdb/
|
||||
@ -0,0 +1,81 @@
|
||||
ProtectedText:一个免费的在线加密笔记
|
||||
======
|
||||

|
||||
|
||||
记录笔记是我们每个人必备的重要技能,它可以帮助我们把自己听到、读到、学到的内容长期地保留下来,也有很多的应用和工具都能让我们更好地记录笔记。下面我要介绍一个叫做 **ProtectedText** 的应用,一个可以将你的笔记在线上保存起来的免费的加密笔记。它是一个免费的 web 服务,在上面记录文本以后,它将会对文本进行加密,只需要一台支持连接到互联网并且拥有 web 浏览器的设备,就可以访问到记录的内容。
|
||||
|
||||
ProtectedText 不会向你询问任何个人信息,也不会保存任何密码,没有广告,没有 Cookies,更没有用户跟踪和注册流程。除了拥有密码能够解密文本的人,任何人都无法查看到笔记的内容。而且,使用前不需要在网站上注册账号,写完笔记之后,直接关闭浏览器,你的笔记也就保存好了。
|
||||
|
||||
### 在加密笔记本上记录笔记
|
||||
|
||||
访问 <https://www.protectedtext.com/> 这个链接,就可以打开 ProtectedText 页面了。这个时候你将进入网站主页,接下来需要在页面上的输入框输入一个你想用的名称,或者在地址栏后面直接加上想用的名称。这个名称是一个自定义的名称(例如 <https://www.protectedtext.com/mysite>),是你查看自己保存的笔记的专有入口。
|
||||
|
||||

|
||||
|
||||
如果你选用的名称还没有被占用,你就会看到下图中的提示信息。点击“Create”键就可以创建你的个人笔记页了。
|
||||
|
||||

|
||||
|
||||
至此你已经创建好了你自己的笔记页面,可以开始记录笔记了。目前每个笔记页的最大容量是每页 750000+ 个字符。
|
||||
|
||||
ProtectedText 使用 AES 算法对你的笔记内容进行加密和解密,而计算散列则使用了 SHA512 算法。
|
||||
|
||||
笔记记录完毕以后,点击顶部的“Save”键保存。
|
||||
|
||||

|
||||
|
||||
按下保存键之后,ProtectedText 会提示你输入密码以加密你的笔记内容。按照它的要求输入两次密码,然后点击“Save”键。
|
||||
|
||||

|
||||
|
||||
尽管 ProtectedText 对你使用的密码没有太多要求,但毕竟密码总是一寸长一寸强,所以还是最好使用长且复杂的密码(用到数字和特殊字符)以避免暴力破解。由于 ProtectedText 不会保存你的密码,一旦密码丢失,密码和笔记内容就都找不回来了。因此,请牢记你的密码,或者使用诸如 [Buttercup][3]、[KeeWeb][4] 这样的密码管理器来存储你的密码。
|
||||
|
||||
在使用其它设备时,可以通过访问之前创建的 URL 就可以访问你的笔记了。届时会出现如下的提示信息,只需要输入正确的密码,就可以查看和编辑你的笔记。
|
||||
|
||||

|
||||
|
||||
一般情况下,只有知道密码的人才能正常访问笔记的内容。如果你希望将自己的笔记公开,只需要以 <https://www.protectedtext.com/yourSite?yourPassword> 的形式访问就可以了,ProtectedText 将会自动使用 `yourPassword` 字符串解密你的笔记。
|
||||
|
||||
ProtectedText 还有配套的 [Android 应用][6] 可以让你在移动设备上进行同步笔记、离线工作、备份笔记、锁定/解锁笔记等等操作。
|
||||
|
||||
**优点**
|
||||
|
||||
* 简单、易用、快速、免费
|
||||
* ProtectedText.com 的客户端代码可以在[这里][7]免费获取,如果你想了解它的底层实现,可以自行学习它的源代码
|
||||
* 存储的内容没有到期时间,只要你愿意,笔记内容可以一直保存在服务器上
|
||||
* 可以让你的数据限制为私有或公开开放
|
||||
|
||||
|
||||
|
||||
**缺点**
|
||||
|
||||
* 尽管客户端代码是公开的,但服务端代码并没有公开,因此你无法自行搭建一个类似的服务。如果你不信任这个网站,请不要使用。
|
||||
* 由于网站不存储你的任何个人信息,包括你的密码,因此如果你丢失了密码,数据将永远无法恢复。网站方还声称他们并不清楚谁拥有了哪些数据,所以一定要牢记密码。
|
||||
|
||||
|
||||
|
||||
如果你想通过一种简单的方式将笔记保存到线上,并且需要在不需要安装任何工具的情况下访问,那么 ProtectedText 会是一个好的选择。如果你还知道其它类似的应用程序,欢迎在评论区留言!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/protectedtext-a-free-encrypted-notepad-to-save-your-notes-online/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2018/11/Protected-Text-4.png
|
||||
[3]: https://www.ostechnix.com/buttercup-a-free-secure-and-cross-platform-password-manager/
|
||||
[4]: https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2018/11/Protected-Text-5.png
|
||||
[6]: https://play.google.com/store/apps/details?id=com.protectedtext.android
|
||||
[7]: https://www.protectedtext.com/js/main.js
|
||||
|
||||
Loading…
Reference in New Issue
Block a user