mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
7680a83b63
@ -1,13 +1,13 @@
|
||||
IT 灾备:系统管理员对抗自然灾害 | HPE
|
||||
IT 灾备:系统管理员对抗自然灾害
|
||||
======
|
||||
|
||||

|
||||
|
||||
面对倾泻的洪水或地震时业务需要继续运转。在飓风卡特里娜、桑迪和其他灾难中幸存下来的系统管理员向在紧急状况下负责 IT 的人们分享真实世界中的建议。
|
||||
> 面对倾泻的洪水或地震时业务需要继续运转。在飓风卡特里娜、桑迪和其他灾难中幸存下来的系统管理员向在紧急状况下负责 IT 的人们分享真实世界中的建议。
|
||||
|
||||
说到自然灾害,2017 年可算是多灾多难。飓风哈维,厄玛和玛莉亚给休斯顿,波多黎各,弗罗里达和加勒比造成了严重破坏。此外,西部的野火将多处住宅和商业建筑付之一炬。
|
||||
说到自然灾害,2017 年可算是多灾多难。(LCTT 译注:本文发表于 2017 年)飓风哈维、厄玛和玛莉亚给休斯顿、波多黎各、弗罗里达和加勒比造成了严重破坏。此外,西部的野火将多处住宅和商业建筑付之一炬。
|
||||
|
||||
再来一篇关于[有备无患][1]的警示文章——当然其中都是好的建议——是很简单的,但这无法帮助网络管理员应对湿漉漉的烂摊子。那些善意的建议中大多数都假定掌权的人乐于投入资金来实施这些建议。
|
||||
再来一篇关于[有备无患][1]的警示文章 —— 当然其中都是好的建议 —— 是很简单的,但这无法帮助网络管理员应对湿漉漉的烂摊子。那些善意的建议中大多数都假定掌权的人乐于投入资金来实施这些建议。
|
||||
|
||||
我们对真实世界更感兴趣。不如让我们来充分利用这些坏消息。
|
||||
|
||||
@ -23,21 +23,21 @@ IT 灾备:系统管理员对抗自然灾害 | HPE
|
||||
|
||||
当灯光忽明忽暗,狂风象火车机车一样怒号时,就该启动你的业务持续计划和灾备计划了。
|
||||
|
||||
有太多的系统管理员报告当暴风雨来临时这两个计划中一个也没有。这并不令人惊讶。2014 年[<ruby>灾备预备状态委员会<rt>Disaster Recovery Preparedness Council</rt></ruby>][6]发现[世界范围内被调查的公司中有 73% 没有足够的灾备计划][7]。
|
||||
有太多的系统管理员报告当暴风雨来临时这两个计划中一个也没有。这并不令人惊讶。2014 年<ruby>[灾备预备状态委员会][6]<rt>Disaster Recovery Preparedness Council</rt></ruby>发现[世界范围内被调查的公司中有 73% 没有足够的灾备计划][7]。
|
||||
|
||||
“足够”是关键词。正如一个系统管理员2016年在 Reddit 上写的那样,“[我们的灾备计划就是一场灾难。][8]我们所有的数据都备份在离这里大约 30 英里的一个<ruby>存储区域网络<rt>SAN</rt></ruby>。我们没有将数据重新上线的硬件,甚至好几天过去了都没能让核心服务器启动运行起来。我们是个年营收 40 亿美元的公司,却不愿为适当的设备投入几十万美元,或是在数据中心添置几台服务器。当添置硬件的提案被提出的时候,我们的管理层说,‘嗐,碰到这种事情的机会能有多大呢’。”
|
||||
“**足够**”是关键词。正如一个系统管理员 2016 年在 Reddit 上写的那样,“[我们的灾备计划就是一场灾难。][8]我们所有的数据都备份在离这里大约 30 英里的一个<ruby>存储区域网络<rt>SAN</rt></ruby>。我们没有将数据重新上线的硬件,甚至好几天过去了都没能让核心服务器启动运行起来。我们是个年营收 40 亿美元的公司,却不愿为适当的设备投入几十万美元,或是在数据中心添置几台服务器。当添置硬件的提案被提出的时候,我们的管理层说,‘嗐,碰到这种事情的机会能有多大呢’。”
|
||||
|
||||
同一个帖子中另一个人说得更简洁:“眼下我的灾备计划只能在黑暗潮湿的角落里哭泣,但愿没人在乎损失的任何东西。”
|
||||
|
||||
如果你在哭泣,但愿你至少不是独自流泪。任何灾备计划,即便是 IT 部门制订的灾备计划,必须确定[你能跟别人通讯][10],如同系统管理员 Jim Thompson 从卡特里娜飓风中得到的教训:“确保你有一个与人们通讯的计划。在一场严重的区域性灾难期间,你将无法给身处灾区的任何人打电话。”
|
||||
|
||||
有一个选择可能会让有技术头脑的人感兴趣:[<ruby>业余电台<rt>ham radio</rt></ruby>][11]。[它在波多黎各发挥了巨大作用][12]。
|
||||
有一个选择可能会让有技术头脑的人感兴趣:<ruby>[业余电台][11]<rt>ham radio</rt></ruby>。[它在波多黎各发挥了巨大作用][12]。
|
||||
|
||||
### 列一个愿望清单
|
||||
|
||||
第一步是承认问题。“许多公司实际上对灾备计划不感兴趣,或是消极对待”,[Micro Focus][14] 的首席架构师 [Joshua Focus][13] 说。“将灾备看作业务持续性的一个方面是种不同的视角。所有公司都要应对业务持续性,所以灾备应被视为业务持续性的一部分。”
|
||||
|
||||
IT 部门需要将其需求书面化以确保适当的灾备和业务持续性计划。即使是你不知道如何着手,或尤其是这种时候,也是如此。正如一个系统管理员所言,“我喜欢有一个‘想法转储’,让所有计划,点子,改进措施毫无保留地提出来。[这][对一类情况尤其有帮助,即当你提议变更][15],并付诸实施,接着 6 个月之后你警告过的状况就要来临。”现在你做好了一切准备并且可以开始讨论:“如同我们之前在 4 月讨论过的那样……”
|
||||
IT 部门需要将其需求书面化以确保适当的灾备和业务持续性计划。即使是你不知道如何着手,或尤其是这种时候,也是如此。正如一个系统管理员所言,“我喜欢有一个‘想法转储’,让所有计划、点子、改进措施毫无保留地提出来。(这)[对一类情况尤其有帮助,即当你提议变更][15],并付诸实施,接着 6 个月之后你警告过的状况就要来临。”现在你做好了一切准备并且可以开始讨论:“如同我们之前在 4 月讨论过的那样……”
|
||||
|
||||
因此,当你的管理层对业务持续性计划回应道“嗐,碰到这种事的机会能有多大呢?”的时候你能做些什么呢?有个系统管理员称这也完全是管理层的正常行为。在这种糟糕的处境下,老练的系统管理员建议用书面形式把这些事情记录下来。记录应清楚表明你告知管理层需要采取的措施,且[他们拒绝采纳建议][16]。“总的来说就是有足够的书面材料能让他们搓成一根绳子上吊,”该系统管理员补充道。
|
||||
|
||||
@ -47,13 +47,13 @@ IT 部门需要将其需求书面化以确保适当的灾备和业务持续性
|
||||
|
||||
“[我们的办公室是幢摇摇欲坠的建筑][18],”飓风哈维重创休斯顿之后有个系统管理员提到。“我们盲目地进入那幢建筑,现场的基础设施糟透了。正是我们给那幢建筑里带去了最不想要的一滴水,现在基础设施整个都沉在水下了。”
|
||||
|
||||
尽管如此,如果你想让数据中心继续运转——或在暴风雨过后恢复运转——你需要确保该场所不仅能经受住你所在地区那些意料中的灾难,而且能经受住那些意料之外的灾难。一个旧金山的系统管理员知道为什么重要的是确保公司的服务器安置在可以承受里氏 7 级地震的建筑内。一家圣路易斯的公司知道如何应对龙卷风。但你应当为所有可能发生的事情做好准备:加州的龙卷风,密苏里州的地震,或[僵尸末日][19](给你在 IT 预算里增加一把链锯提供了充分理由)。
|
||||
尽管如此,如果你想让数据中心继续运转——或在暴风雨过后恢复运转 —— 你需要确保该场所不仅能经受住你所在地区那些意料中的灾难,而且能经受住那些意料之外的灾难。一个旧金山的系统管理员知道为什么重要的是确保公司的服务器安置在可以承受里氏 7 级地震的建筑内。一家圣路易斯的公司知道如何应对龙卷风。但你应当为所有可能发生的事情做好准备:加州的龙卷风、密苏里州的地震,或[僵尸末日][19](给你在 IT 预算里增加一把链锯提供了充分理由)。
|
||||
|
||||
在休斯顿的情况下,[多数数据中心保持运转][20],因为它们是按照抵御暴风雨和洪水的标准建造的。[Data Foundry][21] 的首席技术官 Edward Henigin 说他们公司的数据中心之一,“专门建造的休斯顿 2 号的设计能抵御 5 级飓风的风速。这个场所的公共供电没有中断,我们得以避免切换到后备发电机。”
|
||||
|
||||
那是好消息。坏消息是伴随着超级飓风桑迪于2012年登场,如果[你的数据中心没准备好应对洪水][22],你会陷入一个麻烦不断的世界。一个不能正常运转的数据中心 [Datagram][23] 服务的客户包括 Gawker,Gizmodo 和 Buzzfeed 等知名网站。
|
||||
那是好消息。坏消息是伴随着超级飓风桑迪于 2012 年登场,如果[你的数据中心没准备好应对洪水][22],你会陷入一个麻烦不断的世界。一个不能正常运转的数据中心 [Datagram][23] 服务的客户包括 Gawker、Gizmodo 和 Buzzfeed 等知名网站。
|
||||
|
||||
当然,有时候你什么也做不了。正如某个波多黎各圣胡安的系统管理员在飓风厄玛扫过后悲伤地写到,“发电机没油了。服务器机房靠电池在运转但是没有[空调]。[永别了,服务器][24]。”由于 <ruby>MPLS<rt>Multiprotocol Lable Switching</rt></ruby> 线路亦中断,该系统管理员没法切换到灾备措施:“多么充实的一天。”
|
||||
当然,有时候你什么也做不了。正如某个波多黎各圣胡安的系统管理员在飓风厄玛扫过后悲伤地写到,“发电机没油了。服务器机房靠电池在运转但是没有(空调)。[永别了,服务器][24]。”由于 <ruby>MPLS<rt>Multiprotocol Lable Switching</rt></ruby> 线路亦中断,该系统管理员没法切换到灾备措施:“多么充实的一天。”
|
||||
|
||||
总而言之,IT 专业人士需要了解他们所处的地区,了解他们面临的风险并将他们的服务器安置在能抵御当地自然灾害的数据中心内。
|
||||
|
||||
@ -73,37 +73,37 @@ IT 部门需要将其需求书面化以确保适当的灾备和业务持续性
|
||||
|
||||
某个系统管理员挖苦式的计划是什么呢?“趁 UPS 完蛋之前把你能关的机器关掉,不能关的就让它崩溃咯。然后,[喝个痛快直到供电恢复][28]。”
|
||||
|
||||
在 2016 年德尔塔和西南航空停电事故之后,IT 员工驱动的一个更加严肃的计划是由一个有管理的服务供应商为其客户[部署不间断电源][29]:“对于至关重要的部分,在供电中断时我们结合使用<ruby>简单网络管理协议<rt>SNMP</rt></ruby>信令和 <ruby>PowerChute 网络关机<rt>PowerChute Nrework Shutdown</rt></ruby>客户端来关闭设备。至于重新开机,那取决于客户。有些是自动启动,有些则需要人工干预。”
|
||||
在 2016 年德尔塔和西南航空停电事故之后,IT 员工推动的一个更加严肃的计划是由一个有管理的服务供应商为其客户[部署不间断电源][29]:“对于至关重要的部分,在供电中断时我们结合使用<ruby>简单网络管理协议<rt>SNMP</rt></ruby>信令和 <ruby>PowerChute 网络关机<rt>PowerChute Nrework Shutdown</rt></ruby>客户端来关闭设备。至于重新开机,那取决于客户。有些是自动启动,有些则需要人工干预。”
|
||||
|
||||
另一种做法是用来自两个供电所的供电线路支持数据中心。例如,[西雅图威斯汀大厦数据中心][30]有来自不同供电所的多路 13.4 千伏供电线路,以及多个 480 伏三相变电箱。
|
||||
|
||||
预防严重断电的系统不是“通用的”设备。系统管理员应当[为数据中心请求一台定制的柴油发电机][31]。除了按你特定的需求调整,发电机必须能迅速跳至全速运转并承载全部电力负荷而不致影响系统负载性能。”
|
||||
|
||||
这些发电机也必须加以保护。例如,将你的发电机安置在泛洪区的一楼就不是个聪明的主意。位于纽约<ruby>百老街<rt>Broad street</rt></ruby>的数据中心在超级飓风桑迪期间就是类似情形,备用发电机的燃料油桶在地下室——并且被水淹了。尽管一场[“人力接龙”用容量 5 加仑的水桶将柴油输送到 17 段楼梯之上的发电机][32]使 [Peer 1 Hosting][33] 得以继续运营,这不是一个切实可行的业务持续计划。
|
||||
这些发电机也必须加以保护。例如,将你的发电机安置在泛洪区的一楼就不是个聪明的主意。位于纽约<ruby>百老街<rt>Broad street</rt></ruby>的数据中心在超级飓风桑迪期间就是类似情形,备用发电机的燃料油桶在地下室 —— 并且被水淹了。尽管一场[“人力接龙”用容量 5 加仑的水桶将柴油输送到 17 段楼梯之上的发电机][32]使 [Peer 1 Hosting][33] 得以继续运营,但这不是一个切实可行的业务持续计划。
|
||||
|
||||
正如多数数据中心专家所知那样,如果你有时间——假设一个飓风离你有一天的距离——确保你的发电机正常工作,加满油,准备好当供电线路被刮断时立即开启,不管怎样你之前应当每月测试你的发电机。你之前是那么做的,是吧?是就好!
|
||||
正如多数数据中心专家所知那样,如果你有时间 —— 假设一个飓风离你有一天的距离 —— 确保你的发电机正常工作,加满油,准备好当供电线路被刮断时立即开启,不管怎样你之前应当每月测试你的发电机。你之前是那么做的,是吧?是就好!
|
||||
|
||||
### 测试你对备份的信心
|
||||
|
||||
普通用户几乎从不备份,检查备份是否实际完好的就更少了。系统管理员对此更加了解。
|
||||
|
||||
有些 [IT 部门在寻求将他们的备份迁移到云端][34]。但有些系统管理员仍对此不买账——他们有很好的理由。最近有人报告,“在用了整整 5 天[从亚马逊 Glacier 恢复了 [400 GB] 数据][35]之后,我欠了亚马逊将近 200 美元的传输费,并且[我还是]处于未完全恢复状态,还差大约 100 GB 文件。
|
||||
有些 [IT 部门在寻求将他们的备份迁移到云端][34]。但有些系统管理员仍对此不买账 —— 他们有很好的理由。最近有人报告,“在用了整整 5 天[从亚马逊 Glacier 恢复了(400 GB)数据][35]之后,我欠了亚马逊将近 200 美元的传输费,并且(我还是)处于未完全恢复状态,还差大约 100 GB 文件。”
|
||||
|
||||
结果是有些系统管理员依然喜欢磁带备份。磁带肯定不够时髦,但正如操作系统专家 Andrew S. Tanenbaum 说的那样,“[永远不要低估一辆装满磁带在高速上飞驰的旅行车的带宽][36]。”
|
||||
|
||||
目前每盘磁带可以存储 10 TB 数据;有的进行中的实验可在磁带上存储高达 200 TB 数据。诸如[<ruby>线性磁带文件系统<rt>Linear Tape File System</rt></ruby>][37]之类的技术允许你象访问网络硬盘一样读取磁带数据。
|
||||
目前每盘磁带可以存储 10 TB 数据;有的进行中的实验可在磁带上存储高达 200 TB 数据。诸如<ruby>[线性磁带文件系统][37]<rt>Linear Tape File System</rt></ruby>之类的技术允许你象访问网络硬盘一样读取磁带数据。
|
||||
|
||||
然而对许多人而言,磁带[绝对是最后选择的手段][38]。没关系,因为备份应该有大量的可选方案。在这种情况下,一个系统管理员说到,“故障时我们会用这些方法(恢复备份):[Windows] 服务器层面的 VSS [Volume Shadow Storage] 快照,<ruby>存储区域网络<rt>SAN</rt></ruby>层面的卷快照,以及存储区域网络层面的异地归档快照。但是万一有什么事情发生并摧毁了我们的虚拟机,存储区域网络和备份存储区域网络,我们还是可以取回磁带并恢复数据。”
|
||||
然而对许多人而言,磁带[绝对是最后选择的手段][38]。没关系,因为备份应该有大量的可选方案。在这种情况下,一个系统管理员说到,“故障时我们会用这些方法(恢复备份):(Windows)服务器层面的 VSS (Volume Shadow Storage)快照,<ruby>存储区域网络<rt>SAN</rt></ruby>层面的卷快照,以及存储区域网络层面的异地归档快照。但是万一有什么事情发生并摧毁了我们的虚拟机,存储区域网络和备份存储区域网络,我们还是可以取回磁带并恢复数据。”
|
||||
|
||||
当麻烦即将到来时,可使用副本工具如 [Veeam][39],它会为你的服务器创建一个虚拟机副本。若出现故障,副本会自动启动。没有麻烦,没有手忙脚乱,正如某个系统管理员在这个流行的系统管理员帖子中所说,“[我爱你 Veeam][40]。”
|
||||
|
||||
### 网络?什么网络?
|
||||
|
||||
当然,如果员工们无法触及他们的服务,没有任何云,colo 和远程数据中心能帮到你。你不需要一场自然灾害来证明冗余互联网连接的正确性。只需要一台挖断线路的挖掘机或断掉的光缆就能让你在工作中渡过糟糕的一天。
|
||||
当然,如果员工们无法触及他们的服务,没有任何云、colo 和远程数据中心能帮到你。你不需要一场自然灾害来证明冗余互联网连接的正确性。只需要一台挖断线路的挖掘机或断掉的光缆就能让你在工作中渡过糟糕的一天。
|
||||
|
||||
“理想状态下”,某个系统管理员明智地观察到,“你应该有[两路互联网接入线路连接到有独立基础设施的两个 ISP][41]。例如,你不希望两个 ISP 都依赖于同一根光缆。你也不希望采用两家本地 ISP,并发现他们的上行带宽都依赖于同一家骨干网运营商。”
|
||||
|
||||
聪明的系统管理员知道他们公司的互联网接入线路[必须是商业级别的,带有<ruby>服务等级协议<rt>service-level agreement(SLA)</rt></ruby>][43],其中包含“修复时间”条款。或者更好的是采用<ruby>互联网接入专线<rt></rt>dedicated Internet access</ruby>。技术上这与任何其他互联网接入方式没有区别。区别在于互联网接入专线不是一种“尽力而为”的接入方式,而是你会得到明确规定的专供你使用的带宽并附有服务等级协议。这种专线不便宜,但正如一句格言所说的那样,“速度,可靠性,便宜,只能挑两个。”当你的业务跑在这条线路上并且一场暴风雨即将来袭,“可靠性”必须是你挑的两个之一。
|
||||
聪明的系统管理员知道他们公司的互联网接入线路[必须是商业级别的][43],带有<ruby>服务等级协议<rt>service-level agreement(SLA)</rt></ruby>,其中包含“修复时间”条款。或者更好的是采用<ruby>互联网接入专线<rt></rt>dedicated Internet access</ruby>。技术上这与任何其他互联网接入方式没有区别。区别在于互联网接入专线不是一种“尽力而为”的接入方式,而是你会得到明确规定的专供你使用的带宽并附有服务等级协议。这种专线不便宜,但正如一句格言所说的那样,“速度、可靠性、便宜,只能挑两个。”当你的业务跑在这条线路上并且一场暴风雨即将来袭,“可靠性”必须是你挑的两个之一。
|
||||
|
||||
### 晴空重现之时
|
||||
|
||||
@ -113,7 +113,7 @@ IT 部门需要将其需求书面化以确保适当的灾备和业务持续性
|
||||
|
||||
* 你的 IT 员工得说多少次:不要仅仅备份,还得测试备份?
|
||||
* 没电就没公司。确保你的服务器有足够的应急电源来满足业务需要,并确保它们能正常工作。
|
||||
* 如果你的公司在一场自然灾害中幸存下来——或者避开了灾害——明智的系统管理员知道这就是向管理层申请被他们推迟的灾备预算的时候了。因为下次你就未必有这么幸运了。
|
||||
* 如果你的公司在一场自然灾害中幸存下来,或者避开了灾害,明智的系统管理员知道这就是向管理层申请被他们推迟的灾备预算的时候了。因为下次你就未必有这么幸运了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -121,8 +121,8 @@ IT 部门需要将其需求书面化以确保适当的灾备和业务持续性
|
||||
via: https://www.hpe.com/us/en/insights/articles/it-disaster-recovery-sysadmins-vs-natural-disasters-1711.html
|
||||
|
||||
作者:[Steven-J-Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/0x996)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[0x996](https://github.com/0x996)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,137 @@
|
||||
两种 cp 命令的绝佳用法的快捷方式
|
||||
===================
|
||||
|
||||
> 这篇文章是关于如何在使用 cp 命令进行备份以及同步时提高效率。
|
||||
|
||||

|
||||
|
||||
去年七月,我写了一篇[关于 cp 命令的两种绝佳用法][7]的文章:备份一个文件,以及同步一个文件夹的备份。
|
||||
|
||||
虽然这些工具确实很好用,但同时,输入这些命令太过于累赘了。为了解决这个问题,我在我的 Bash 启动文件里创建了一些 Bash 快捷方式。现在,我想把这些捷径分享给你们,以便于你们在需要的时候可以拿来用,或者是给那些还不知道怎么使用 Bash 的别名以及函数的用户提供一些思路。
|
||||
|
||||
### 使用 Bash 别名来更新一个文件夹的副本
|
||||
|
||||
如果要使用 `cp` 来更新一个文件夹的副本,通常会使用到的命令是:
|
||||
|
||||
```
|
||||
cp -r -u -v SOURCE-FOLDER DESTINATION-DIRECTORY
|
||||
```
|
||||
|
||||
其中 `-r` 代表“向下递归访问文件夹中的所有文件”,`-u` 代表“更新目标”,`-v` 代表“详细模式”,`SOURCE-FOLDER` 是包含最新文件的文件夹的名称,`DESTINATION-DIRECTORY` 是包含必须同步的`SOURCE-FOLDER` 副本的目录。
|
||||
|
||||
因为我经常使用 `cp` 命令来复制文件夹,我会很自然地想起使用 `-r` 选项。也许再想地更深入一些,我还可以想起用 `-v` 选项,如果再想得再深一层,我会想起用选项 `-u`(不知道这个选项是代表“更新”还是“同步”还是一些什么其它的)。
|
||||
|
||||
或者,还可以使用[Bash 的别名功能][8]来将 `cp` 命令以及其后的选项转换成一个更容易记忆的单词,就像这样:
|
||||
|
||||
```
|
||||
alias sync='cp -r -u -v'
|
||||
```
|
||||
|
||||
如果我将其保存在我的主目录中的 `.bash_aliases` 文件中,然后启动一个新的终端会话,我可以使用该别名了,例如:
|
||||
|
||||
```
|
||||
sync Pictures /media/me/4388-E5FE
|
||||
```
|
||||
|
||||
可以将我的主目录中的图片文件夹与我的 USB 驱动器中的相同版本同步。
|
||||
|
||||
不清楚 `sync` 是否已经定义了?你可以在终端里输入 `alias` 这个单词来列出所有正在使用的命令别名。
|
||||
|
||||
喜欢吗?想要现在就立即使用吗?那就现在打开终端,输入:
|
||||
|
||||
```
|
||||
echo "alias sync='cp -r -u -v'" >> ~/.bash_aliases
|
||||
```
|
||||
|
||||
然后启动一个新的终端窗口并在命令提示符下键入 `alias`。你应该看到这样的东西:
|
||||
|
||||
```
|
||||
me@mymachine~$ alias
|
||||
|
||||
alias alert='notify-send --urgency=low -i "$([ $? = 0 ] && echo terminal || echo error)" "$(history|tail -n1|sed -e '\''s/^\s*[0-9]\+\s*//;s/[;&|]\s*alert$//'\'')"'
|
||||
alias egrep='egrep --color=auto'
|
||||
alias fgrep='fgrep --color=auto'
|
||||
alias grep='grep --color=auto'
|
||||
alias gvm='sdk'
|
||||
alias l='ls -CF'
|
||||
alias la='ls -A'
|
||||
alias ll='ls -alF'
|
||||
alias ls='ls --color=auto'
|
||||
alias sync='cp -r -u -v'
|
||||
me@mymachine:~$
|
||||
```
|
||||
|
||||
这里你能看到 `sync` 已经定义了。
|
||||
|
||||
### 使用 Bash 函数来为备份编号
|
||||
|
||||
若要使用 `cp` 来备份一个文件,通常使用的命令是:
|
||||
|
||||
```
|
||||
cp --force --backup=numbered WORKING-FILE BACKED-UP-FILE
|
||||
```
|
||||
|
||||
其中 `--force` 代表“强制制作副本”,`--backup= numbered` 代表“使用数字表示备份的生成”,`WORKING-FILE` 是我们希望保留的当前文件,`BACKED-UP-FILE` 与 `WORKING-FILE` 的名称相同,并附加生成信息。
|
||||
|
||||
我们不仅需要记得所有 `cp` 的选项,我们还需要记得去重复输入 `WORKING-FILE` 的名字。但当[Bash 的函数功能][9]已经可以帮我们做这一切,为什么我们还要不断地重复这个过程呢?就像这样:
|
||||
|
||||
再一次提醒,你可将下列内容保存入你在家目录下的 `.bash_aliases` 文件里:
|
||||
|
||||
```
|
||||
function backup {
|
||||
if [ $# -ne 1 ]; then
|
||||
echo "Usage: $0 filename"
|
||||
elif [ -f $1 ] ; then
|
||||
echo "cp --force --backup=numbered $1 $1"
|
||||
cp --force --backup=numbered $1 $1
|
||||
else
|
||||
echo "$0: $1 is not a file"
|
||||
fi
|
||||
}
|
||||
```
|
||||
|
||||
我将此函数称之为 `backup`,因为我的系统上没有任何其他名为 `backup` 的命令,但你可以选择适合的任何名称。
|
||||
|
||||
第一个 `if` 语句是用于检查是否提供有且只有一个参数,否则,它会用 `echo` 命令来打印出正确的用法。
|
||||
|
||||
`elif` 语句是用于检查提供的参数所指向的是一个文件,如果是的话,它会用第二个 `echo` 命令来打印所需的 `cp` 的命令(所有的选项都是用全称来表示)并且执行它。
|
||||
|
||||
如果所提供的参数不是一个文件,文件中的第三个 `echo` 用于打印错误信息。
|
||||
|
||||
在我的家目录下,如果我执行 `backup` 这个命令,我可以发现目录下多了一个文件名为`checkCounts.sql.~1~` 的文件,如果我再执行一次,便又多了另一个名为 `checkCounts.sql.~2~` 的文件。
|
||||
|
||||
成功了!就像所想的一样,我可以继续编辑 `checkCounts.sql`,但如果我可以经常地用这个命令来为文件制作快照的话,我可以在我遇到问题的时候回退到最近的版本。
|
||||
|
||||
也许在未来的某个时间,使用 `git` 作为版本控制系统会是一个好主意。但像上文所介绍的 `backup` 这个简单而又好用的工具,是你在需要使用快照的功能时却还未准备好使用 `git` 的最好工具。
|
||||
|
||||
### 结论
|
||||
|
||||
在我的上一篇文章里,我保证我会通过使用脚本,shell 里的函数以及别名功能来简化一些机械性的动作来提高生产效率。
|
||||
|
||||
在这篇文章里,我已经展示了如何在使用 `cp` 命令同步或者备份文件时运用 shell 函数以及别名功能来简化操作。如果你想要了解更多,可以读一下这两篇文章:[怎样通过使用命令别名功能来减少敲击键盘的次数][10] 以及由我的同事 Greg 和 Seth 写的 [Shell 编程:shift 方法和自定义函数介绍][11]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/two-great-uses-cp-command-update
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
译者:[zyk2290](https://github.com/zyk2290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clhermansen
|
||||
[1]:https://opensource.com/users/clhermansen
|
||||
[2]:https://opensource.com/users/clhermansen
|
||||
[3]:https://opensource.com/user/37806/feed
|
||||
[4]:https://opensource.com/article/18/1/two-great-uses-cp-command-update?rate=J_7R7wSPbukG9y8jrqZt3EqANfYtVAwZzzpopYiH3C8
|
||||
[5]:https://opensource.com/article/18/1/two-great-uses-cp-command-update#comments
|
||||
[6]:https://www.flickr.com/photos/internetarchivebookimages/14803082483/in/photolist-oy6EG4-pZR3NZ-i6r3NW-e1tJSX-boBtf7-oeYc7U-o6jFKK-9jNtc3-idt2G9-i7NG1m-ouKjXe-owqviF-92xFBg-ow9e4s-gVVXJN-i1K8Pw-4jybMo-i1rsBr-ouo58Y-ouPRzz-8cGJHK-85Evdk-cru4Ly-rcDWiP-gnaC5B-pAFsuf-hRFPcZ-odvBMz-hRCE7b-mZN3Kt-odHU5a-73dpPp-hUaaAi-owvUMK-otbp7Q-ouySkB-hYAgmJ-owo4UZ-giHgqu-giHpNc-idd9uQ-osAhcf-7vxk63-7vwN65-fQejmk-pTcLgA-otZcmj-fj1aSX-hRzHQk-oyeZfR
|
||||
[7]:https://opensource.com/article/17/7/two-great-uses-cp-command
|
||||
[8]:https://opensource.com/article/17/5/introduction-alias-command-line-tool
|
||||
[9]:https://opensource.com/article/17/1/shell-scripting-shift-method-custom-functions
|
||||
[10]:https://opensource.com/article/17/5/introduction-alias-command-line-tool
|
||||
[11]:https://opensource.com/article/17/1/shell-scripting-shift-method-custom-functions
|
||||
[12]:https://opensource.com/tags/linux
|
||||
[13]:https://opensource.com/users/clhermansen
|
||||
[14]:https://opensource.com/users/clhermansen
|
||||
@ -0,0 +1,201 @@
|
||||
本地开发如何测试 Webhook
|
||||
===================
|
||||
|
||||

|
||||
|
||||
[Webhook][10] 可用于外部系统通知你的系统发生了某个事件或更新。可能最知名的 [Webhook][10] 类型是支付服务提供商(PSP)通知你的系统支付状态有了更新。
|
||||
|
||||
它们通常以监听的预定义 URL 的形式出现,例如 `http://example.com/webhooks/payment-update`。同时,另一个系统向该 URL 发送具有特定有效载荷的 POST 请求(例如支付 ID)。一旦请求进入,你就会获得支付 ID,可以通过 PSP 的 API 用这个支付 ID 向它们询问最新状态,然后更新你的数据库。
|
||||
|
||||
其他例子可以在这个对 Webhook 的出色的解释中找到:[https://sendgrid.com/blog/whats-webhook/][12]。
|
||||
|
||||
只要系统可通过互联网公开访问(这可能是你的生产环境或可公开访问的临时环境),测试这些 webhook 就相当顺利。而当你在笔记本电脑上或虚拟机内部(例如,Vagrant 虚拟机)进行本地开发时,它就变得困难了。在这些情况下,发送 webhook 的一方无法公开访问你的本地 URL。此外,监视发送的请求也很困难,这可能使开发和调试变得困难。
|
||||
|
||||
因此,这个例子将解决:
|
||||
|
||||
* 测试来自本地开发环境的 webhook,该环境无法通过互联网访问。从服务器向 webhook 发送数据的服务无法访问它。
|
||||
* 监控发送的请求和数据,以及应用程序生成的响应。这样可以更轻松地进行调试,从而缩短开发周期。
|
||||
|
||||
前置需求:
|
||||
|
||||
* *可选*:如果你使用虚拟机(VM)进行开发,请确保它正在运行,并确保在 VM 中完成后续步骤。
|
||||
* 对于本教程,我们假设你定义了一个 vhost:`webhook.example.vagrant`。我在本教程中使用了 Vagrant VM,但你可以自由选择 vhost。
|
||||
* 按照这个[安装说明][3]安装 `ngrok`。在 VM 中,我发现它的 Node 版本也很有用:[https://www.npmjs.com/package/ngrok][4],但你可以随意使用其他方法。
|
||||
|
||||
我假设你没有在你的环境中运行 SSL,但如果你使用了,请将在下面的示例中的端口 80 替换为端口 433,`http://` 替换为 `https://`。
|
||||
|
||||
### 使 webhook 可测试
|
||||
|
||||
我们假设以下示例代码。我将使用 PHP,但请将其视作伪代码,因为我留下了一些关键部分(例如 API 密钥、输入验证等)没有编写。
|
||||
|
||||
第一个文件:`payment.php`。此文件创建一个 `$payment` 对象,将其注册到 PSP。然后它获取客户需要访问的 URL,以便支付并将用户重定向到客户那里。
|
||||
|
||||
请注意,此示例中的 `webhook.example.vagrant` 是我们为开发设置定义的本地虚拟主机。它无法从外部世界进入。
|
||||
|
||||
```
|
||||
<?php
|
||||
/*
|
||||
* This file creates a payment and tells the PSP what webhook URL to use for updates
|
||||
* After creating the payment, we get a URL to send the customer to in order to pay at the PSP
|
||||
*/
|
||||
$payment = [
|
||||
'order_id' => 123,
|
||||
'amount' => 25.00,
|
||||
'description' => 'Test payment',
|
||||
'redirect_url' => 'http://webhook.example.vagrant/redirect.php',
|
||||
'webhook_url' => 'http://webhook.example.vagrant/webhook.php',
|
||||
];
|
||||
|
||||
$payment = $paymentProvider->createPayment($payment);
|
||||
header("Location: " . $payment->getPaymentUrl());
|
||||
```
|
||||
|
||||
第二个文件:`webhook.php`。此文件等待 PSP 调用以获得有关更新的通知。
|
||||
|
||||
```
|
||||
<?php
|
||||
/*
|
||||
* This file gets called by the PSP and in the $_POST they submit an 'id'
|
||||
* We can use this ID to get the latest status from the PSP and update our internal systems afterward
|
||||
*/
|
||||
|
||||
$paymentId = $_POST['id'];
|
||||
$paymentInfo = $paymentProvider->getPayment($paymentId);
|
||||
$status = $paymentInfo->getStatus();
|
||||
|
||||
// Perform actions in here to update your system
|
||||
if ($status === 'paid') {
|
||||
..
|
||||
}
|
||||
elseif ($status === 'cancelled') {
|
||||
..
|
||||
}
|
||||
```
|
||||
|
||||
我们的 webhook URL 无法通过互联网访问(请记住它:`webhook.example.vagrant`)。因此,PSP 永远不可能调用文件 `webhook.php`,你的系统将永远不会知道付款状态,这最终导致订单永远不会被运送给客户。
|
||||
|
||||
幸运的是,`ngrok` 可以解决这个问题。 [ngrok][13] 将自己描述为:
|
||||
|
||||
> ngrok 通过安全隧道将 NAT 和防火墙后面的本地服务器暴露给公共互联网。
|
||||
|
||||
让我们为我们的项目启动一个基本的隧道。在你的环境中(在你的系统上或在 VM 上)运行以下命令:
|
||||
|
||||
```
|
||||
ngrok http -host-header=rewrite webhook.example.vagrant:80
|
||||
```
|
||||
|
||||
> 阅读其文档可以了解更多配置选项:[https://ngrok.com/docs][14]。
|
||||
|
||||
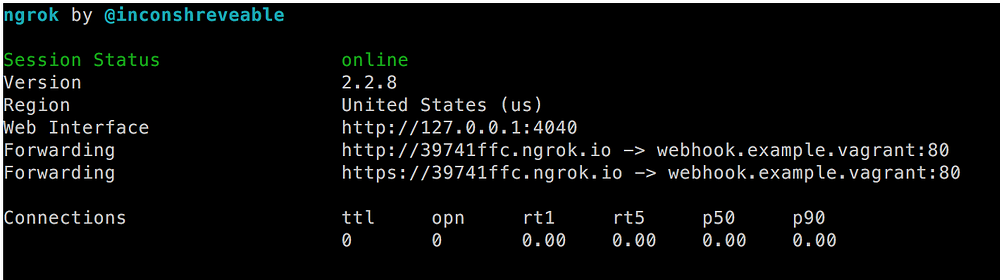
会出现这样的屏幕:
|
||||
|
||||
|
||||
|
||||
*ngrok 输出*
|
||||
|
||||
我们刚刚做了什么?基本上,我们指示 `ngrok` 在端口 80 建立了一个到 `http://webhook.example.vagrant` 的隧道。同一个 URL 也可以通过 `http://39741ffc.ngrok.io` 或 `https://39741ffc.ngrok.io` 访问,它们能被任何知道此 URL 的人通过互联网公开访问。
|
||||
|
||||
请注意,你可以同时获得 HTTP 和 HTTPS 两个服务。这个文档提供了如何将此限制为 HTTPS 的示例:[https://ngrok.com/docs#bind-tls][16]。
|
||||
|
||||
那么,我们如何让我们的 webhook 现在工作起来?将 `payment.php` 更新为以下代码:
|
||||
|
||||
```
|
||||
<?php
|
||||
/*
|
||||
* This file creates a payment and tells the PSP what webhook URL to use for updates
|
||||
* After creating the payment, we get a URL to send the customer to in order to pay at the PSP
|
||||
*/
|
||||
$payment = [
|
||||
'order_id' => 123,
|
||||
'amount' => 25.00,
|
||||
'description' => 'Test payment',
|
||||
'redirect_url' => 'http://webhook.example.vagrant/redirect.php',
|
||||
'webhook_url' => 'https://39741ffc.ngrok.io/webhook.php',
|
||||
];
|
||||
|
||||
$payment = $paymentProvider->createPayment($payment);
|
||||
header("Location: " . $payment->getPaymentUrl());
|
||||
```
|
||||
|
||||
现在,我们告诉 PSP 通过 HTTPS 调用此隧道 URL。只要 PSP 通过隧道调用 webhook,`ngrok` 将确保使用未修改的有效负载调用内部 URL。
|
||||
|
||||
### 如何监控对 webhook 的调用?
|
||||
|
||||
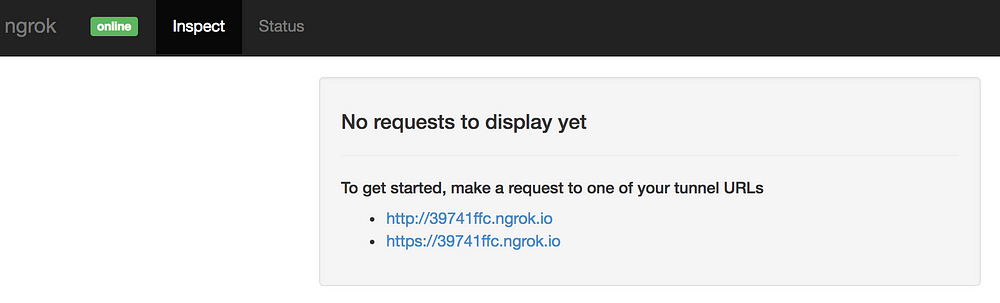
你在上面看到的屏幕截图概述了对隧道主机的调用,这些数据相当有限。幸运的是,`ngrok` 提供了一个非常好的仪表板,允许你检查所有调用:
|
||||
|
||||
|
||||
|
||||
我不会深入研究这个问题,因为它是不言自明的,你只要运行它就行了。因此,我将解释如何在 Vagrant 虚拟机上访问它,因为它不是开箱即用的。
|
||||
|
||||
仪表板将允许你查看所有调用、其状态代码、标头和发送的数据。你将看到应用程序生成的响应。
|
||||
|
||||
仪表板的另一个优点是它允许你重放某个调用。假设你的 webhook 代码遇到了致命的错误,开始新的付款并等待 webhook 被调用将会很繁琐。重放上一个调用可以使你的开发过程更快。
|
||||
|
||||
默认情况下,仪表板可在 `http://localhost:4040` 访问。
|
||||
|
||||
### 虚拟机中的仪表盘
|
||||
|
||||
为了在 VM 中完成此工作,你必须执行一些额外的步骤:
|
||||
|
||||
首先,确保可以在端口 4040 上访问 VM。然后,在 VM 内创建一个文件已存放此配置:
|
||||
|
||||
```
|
||||
web_addr: 0.0.0.0:4040
|
||||
```
|
||||
|
||||
现在,杀死仍在运行的 `ngrok` 进程,并使用稍微调整过的命令启动它:
|
||||
|
||||
```
|
||||
ngrok http -config=/path/to/config/ngrok.conf -host-header=rewrite webhook.example.vagrant:80
|
||||
```
|
||||
|
||||
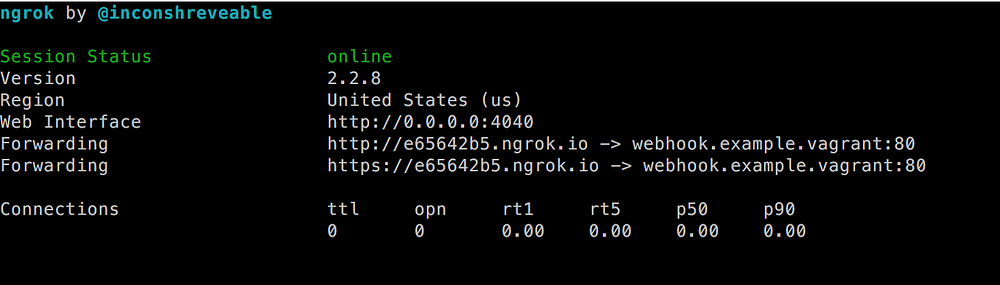
尽管 ID 已经更改,但你将看到类似于上一屏幕截图的屏幕。之前的网址不再有效,但你有了一个新网址。 此外,`Web Interface` URL 已更改:
|
||||
|
||||
|
||||
|
||||
现在将浏览器指向 `http://webhook.example.vagrant:4040` 以访问仪表板。另外,对 `https://e65642b5.ngrok.io/webhook.php` 做个调用。这可能会导致你的浏览器出错,但仪表板应显示正有一个请求。
|
||||
|
||||
### 最后的备注
|
||||
|
||||
上面的例子是伪代码。原因是每个外部系统都以不同的方式使用 webhook。我试图基于一个虚构的 PSP 实现给出一个例子,因为可能很多开发人员在某个时刻肯定会处理付款。
|
||||
|
||||
请注意,你的 webhook 网址也可能被意图不好的其他人使用。确保验证发送给它的任何输入。
|
||||
|
||||
更好的的,可以向 URL 添加令牌,该令牌对于每个支付是唯一的。只有你的系统和发送 webhook 的系统才能知道此令牌。
|
||||
|
||||
祝你测试和调试你的 webhook 顺利!
|
||||
|
||||
注意:我没有在 Docker 上测试过本教程。但是,这个 Docker 容器看起来是一个很好的起点,并包含了明确的说明:[https://github.com/wernight/docker-ngrok][19] 。
|
||||
|
||||
--------
|
||||
|
||||
via: https://medium.freecodecamp.org/testing-webhooks-while-using-vagrant-for-development-98b5f3bedb1d
|
||||
|
||||
作者:[Stefan Doorn][a]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@stefandoorn
|
||||
[1]:https://unsplash.com/photos/MYTyXb7fgG0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://ngrok.com/download
|
||||
[4]:https://www.npmjs.com/package/ngrok
|
||||
[5]:http://webhook.example.vagrnat/
|
||||
[6]:http://39741ffc.ngrok.io/
|
||||
[7]:http://39741ffc.ngrok.io/
|
||||
[8]:http://webhook.example.vagrant:4040/
|
||||
[9]:https://e65642b5.ngrok.io/webhook.php.
|
||||
[10]:https://sendgrid.com/blog/whats-webhook/
|
||||
[11]:http://example.com/webhooks/payment-update%29
|
||||
[12]:https://sendgrid.com/blog/whats-webhook/
|
||||
[13]:https://ngrok.com/
|
||||
[14]:https://ngrok.com/docs
|
||||
[15]:http://39741ffc.ngrok.io%2C/
|
||||
[16]:https://ngrok.com/docs#bind-tls
|
||||
[17]:http://localhost:4040./
|
||||
[18]:https://e65642b5.ngrok.io/webhook.php.
|
||||
[19]:https://github.com/wernight/docker-ngrok
|
||||
[20]:https://github.com/stefandoorn
|
||||
[21]:https://twitter.com/stefan_doorn
|
||||
[22]:https://www.linkedin.com/in/stefandoorn
|
||||
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11200-1.html)
|
||||
[#]: subject: (How to detect automatically generated emails)
|
||||
[#]: via: (https://arp242.net/weblog/autoreply.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
如何检测自动生成的电子邮件
|
||||
======
|
||||
|
||||

|
||||
|
||||
当你用电子邮件系统发送自动回复时,你需要注意不要向自动生成的电子邮件发送回复。最好的情况下,你将获得无用的投递失败消息。更可能的是,你会得到一个无限的电子邮件循环和一个混乱的世界。
|
||||
|
||||
事实证明,可靠地检测自动生成的电子邮件并不总是那么容易。以下是基于为此编写的检测器并使用它扫描大约 100,000 封电子邮件(大量的个人存档和公司存档)的观察结果。
|
||||
|
||||
### Auto-submitted 信头
|
||||
|
||||
由 [RFC 3834][1] 定义。
|
||||
|
||||
这是表示你的邮件是自动回复的“官方”标准。如果存在 `Auto-Submitted` 信头,并且其值不是 `no`,你应该**不**发送回复。
|
||||
|
||||
### X-Auto-Response-Suppress 信头
|
||||
|
||||
[由微软][2]定义。
|
||||
|
||||
此信头由微软 Exchange、Outlook 和其他一些产品使用。许多新闻订阅等都设定了这个。如果 `X-Auto-Response-Suppress` 包含 `DR`(“抑制投递报告”)、`AutoReply`(“禁止 OOF 通知以外的自动回复消息”)或 `All`,你应该**不**发送回复。
|
||||
|
||||
### List-Id 和 List-Unsubscribe 信头
|
||||
|
||||
由 [RFC 2919][3] 定义。
|
||||
|
||||
你通常不希望给邮件列表或新闻订阅发送自动回复。几乎所有的邮件列表和大多数新闻订阅都至少设置了其中一个信头。如果存在这些信头中的任何一个,你应该**不**发送回复。这个信头的值不重要。
|
||||
|
||||
### Feedback-ID 信头
|
||||
|
||||
[由谷歌][4]定义。
|
||||
|
||||
Gmail 使用此信头识别邮件是否是新闻订阅,并使用它为这些新闻订阅的所有者生成统计信息或报告。如果此信头存在,你应该**不**发送回复。这个信头的值不重要。
|
||||
|
||||
### 非标准方式
|
||||
|
||||
上述方法定义明确(即使有些是非标准的)。不幸的是,有些电子邮件系统不使用它们中的任何一个 :-( 这里有一些额外的措施。
|
||||
|
||||
#### Precedence 信头
|
||||
|
||||
在 [RFC 2076][5] 中没有真正定义,不鼓励使用它(但通常会遇到此信头)。
|
||||
|
||||
请注意,不建议检查是否存在此信头,因为某些邮件使用 `normal` 和其他一些(少见的)值(尽管这不常见)。
|
||||
|
||||
我的建议是如果其值不区分大小写地匹配 `bulk`、`auto_reply` 或 `list`,则**不**发送回复。
|
||||
|
||||
#### 其他不常见的信头
|
||||
|
||||
这是我遇到的另外的一些(不常见的)信头。如果设置了其中一个,我建议**不**发送自动回复。大多数邮件也设置了上述信头之一,但有些没有(这并不常见)。
|
||||
|
||||
* `X-MSFBL`:无法真正找到定义(Microsoft 信头?),但我只有自动生成的邮件带有此信头。
|
||||
* `X-Loop`:在任何地方都没有真正定义过,有点罕见,但有时有。它通常设置为不应该收到电子邮件的地址,但也会遇到 `X-Loop: yes`。
|
||||
* `X-Autoreply`:相当罕见,并且似乎总是具有 `yes` 的值。
|
||||
|
||||
#### Email 地址
|
||||
|
||||
检查 `From` 或 `Reply-To` 信头是否包含 `noreply`、`no-reply` 或 `no_reply`(正则表达式:`^no.?reply@`)。
|
||||
|
||||
#### 只有 HTML 部分
|
||||
|
||||
如果电子邮件只有 HTML 部分,而没有文本部分,则表明这是一个自动生成的邮件或新闻订阅。几乎所有邮件客户端都设置了文本部分。
|
||||
|
||||
#### 投递失败消息
|
||||
|
||||
许多传递失败消息并不能真正表明它们是失败的。一些检查方法:
|
||||
|
||||
* `From` 包含 `mailer-daemon` 或 `Mail Delivery Subsystem`
|
||||
|
||||
#### 特定的邮件库特征
|
||||
|
||||
许多邮件类库留下了某种痕迹,大多数常规邮件客户端使用自己的数据覆盖它。检查这个似乎工作得相当可靠。
|
||||
|
||||
* `X-Mailer: Microsoft CDO for Windows 2000`:由某些微软软件设置;我只能在自动生成的邮件中找到它。是的,在 2015 年它仍然在使用。
|
||||
* `Message-ID` 信头包含 `.JavaMail.`:我发现了一些(5 个 50k 大小的)常规消息,但不是很多;绝大多数(数千封)邮件是新闻订阅、订单确认等。
|
||||
* `^X-Mailer` 以 `PHP` 开头。这应该会同时看到 `X-Mailer: PHP/5.5.0` 和 `X-Mailer: PHPmailer XXX XXX`。与 “JavaMail” 相同。
|
||||
* 出现了 `X-Library`;似乎只有 [Indy][6] 设定了这个。
|
||||
* `X-Mailer` 以 `wdcollect` 开头。由一些 Plesk 邮件设置。
|
||||
* `X-Mailer` 以 `MIME-tools` 开头。
|
||||
|
||||
### 最后的预防措施:限制回复的数量
|
||||
|
||||
即使遵循上述所有建议,你仍可能会遇到一个避开所有这些检测的电子邮件程序。这可能非常危险,因为电子邮件系统只是“如果有电子邮件那么发送”,就有可能导致无限的电子邮件循环。
|
||||
|
||||
出于这个原因,我建议你记录你自动发送的电子邮件,并将此速率限制为在几分钟内最多几封电子邮件。这将打破循环链条。
|
||||
|
||||
我们使用每五分钟一封电子邮件的设置,但没这么严格的设置可能也会运作良好。
|
||||
|
||||
### 你需要为自动回复设置什么信头
|
||||
|
||||
具体细节取决于你发送的邮件类型。这是我们用于自动回复邮件的内容:
|
||||
|
||||
```
|
||||
Auto-Submitted: auto-replied
|
||||
X-Auto-Response-Suppress: All
|
||||
Precedence: auto_reply
|
||||
```
|
||||
|
||||
### 反馈
|
||||
|
||||
你可以发送电子邮件至 [martin@arp242.net][7] 或 [创建 GitHub 议题][8]以提交反馈、问题等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/autoreply.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://tools.ietf.org/html/rfc3834
|
||||
[2]: https://msdn.microsoft.com/en-us/library/ee219609(v=EXCHG.80).aspx
|
||||
[3]: https://tools.ietf.org/html/rfc2919)
|
||||
[4]: https://support.google.com/mail/answer/6254652?hl=en
|
||||
[5]: http://www.faqs.org/rfcs/rfc2076.html
|
||||
[6]: http://www.indyproject.org/index.en.aspx
|
||||
[7]: mailto:martin@arp242.net
|
||||
[8]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
@ -0,0 +1,228 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "wxy"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-11198-1.html"
|
||||
[#]: subject: "How To Parse And Pretty Print JSON With Linux Commandline Tools"
|
||||
[#]: via: "https://www.ostechnix.com/how-to-parse-and-pretty-print-json-with-linux-commandline-tools/"
|
||||
[#]: author: "EDITOR https://www.ostechnix.com/author/editor/"
|
||||
|
||||
如何用 Linux 命令行工具解析和格式化输出 JSON
|
||||
======
|
||||
|
||||

|
||||
|
||||
JSON 是一种轻量级且与语言无关的数据存储格式,易于与大多数编程语言集成,也易于人类理解 —— 当然,如果格式正确的话。JSON 这个词代表 **J**ava **S**cript **O**bject **N**otation,虽然它以 JavaScript 开头,而且主要用于在服务器和浏览器之间交换数据,但现在正在用于许多领域,包括嵌入式系统。在这里,我们将使用 Linux 上的命令行工具解析并格式化打印 JSON。它对于在 shell 脚本中处理大型 JSON 数据或在 shell 脚本中处理 JSON 数据非常有用。
|
||||
|
||||
### 什么是格式化输出?
|
||||
|
||||
JSON 数据的结构更具人性化。但是在大多数情况下,JSON 数据会存储在一行中,甚至没有行结束字符。
|
||||
|
||||
显然,这对于手动阅读和编辑不太方便。
|
||||
|
||||
这是<ruby>格式化输出<rt>pretty print</rt></ruby>就很有用。这个该名称不言自明:重新格式化 JSON 文本,使人们读起来更清晰。这被称为 **JSON 格式化输出**。
|
||||
|
||||
### 用 Linux 命令行工具解析和格式化输出 JSON
|
||||
|
||||
可以使用命令行文本处理器解析 JSON 数据,例如 `awk`、`sed` 和 `gerp`。实际上 `JSON.awk` 是一个来做这个的 awk 脚本。但是,也有一些专用工具可用于同一目的。
|
||||
|
||||
1. `jq` 或 `jshon`,shell 下的 JSON 解析器,它们都非常有用。
|
||||
2. Shell 脚本,如 `JSON.sh` 或 `jsonv.sh`,用于在 bash、zsh 或 dash shell 中解析JSON。
|
||||
3. `JSON.awk`,JSON 解析器 awk 脚本。
|
||||
4. 像 `json.tool` 这样的 Python 模块。
|
||||
5. `undercore-cli`,基于 Node.js 和 javascript。
|
||||
|
||||
在本教程中,我只关注 `jq`,这是一个 shell 下的非常强大的 JSON 解析器,具有高级过滤和脚本编程功能。
|
||||
|
||||
### JSON 格式化输出
|
||||
|
||||
JSON 数据可能放在一行上使人难以解读,因此为了使其具有一定的可读性,JSON 格式化输出就可用于此目的的。
|
||||
|
||||
**示例:**来自 `jsonip.com` 的数据,使用 `curl` 或 `wget` 工具获得 JSON 格式的外部 IP 地址,如下所示。
|
||||
|
||||
```
|
||||
$ wget -cq http://jsonip.com/ -O -
|
||||
```
|
||||
|
||||
实际数据看起来类似这样:
|
||||
|
||||
```
|
||||
{"ip":"111.222.333.444","about":"/about","Pro!":"http://getjsonip.com"}
|
||||
```
|
||||
|
||||
现在使用 `jq` 格式化输出它:
|
||||
|
||||
```
|
||||
$ wget -cq http://jsonip.com/ -O - | jq '.'
|
||||
```
|
||||
|
||||
通过 `jq` 过滤了该结果之后,它应该看起来类似这样:
|
||||
|
||||
```
|
||||
{
|
||||
"ip": "111.222.333.444",
|
||||
"about": "/about",
|
||||
"Pro!": "http://getjsonip.com"
|
||||
}
|
||||
```
|
||||
|
||||
同样也可以通过 Python `json.tool` 模块做到。示例如下:
|
||||
|
||||
```
|
||||
$ cat anything.json | python -m json.tool
|
||||
```
|
||||
|
||||
这种基于 Python 的解决方案对于大多数用户来说应该没问题,但是如果没有预安装或无法安装 Python 则不行,比如在嵌入式系统上。
|
||||
|
||||
然而,`json.tool` Python 模块具有明显的优势,它是跨平台的。因此,你可以在 Windows、Linux 或 Mac OS 上无缝使用它。
|
||||
|
||||
### 如何用 jq 解析 JSON
|
||||
|
||||
首先,你需要安装 `jq`,它已被大多数 GNU/Linux 发行版选中,并使用各自的软件包安装程序命令进行安装。
|
||||
|
||||
在 Arch Linux 上:
|
||||
|
||||
```
|
||||
$ sudo pacman -S jq
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install jq
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install jq
|
||||
```
|
||||
|
||||
在 openSUSE 上:
|
||||
|
||||
```
|
||||
$ sudo zypper install jq
|
||||
```
|
||||
|
||||
对于其它操作系统或平台参见[官方的安装指导][1]。
|
||||
|
||||
#### jq 的基本过滤和标识符功能
|
||||
|
||||
`jq` 可以从 `STDIN` 或文件中读取 JSON 数据。你可以根据情况使用。
|
||||
|
||||
单个符号 `.` 是最基本的过滤器。这些过滤器也称为**对象标识符-索引**。`jq` 使用单个 `.` 过滤器基本上相当将输入的 JSON 文件格式化输出。
|
||||
|
||||
- **单引号**:不必始终使用单引号。但是如果你在一行中组合几个过滤器,那么你必须使用它们。
|
||||
- **双引号**:你必须用两个双引号括起任何特殊字符,如 `@`、`#`、`$`,例如 `jq .foo.”@bar”`。
|
||||
- **原始数据打印**:不管出于任何原因,如果你只需要最终解析的数据(不包含在双引号内),请使用带有 `-r` 标志的 `jq` 命令,如下所示:`jq -r .foo.bar`。
|
||||
|
||||
#### 解析特定数据
|
||||
|
||||
要过滤出 JSON 的特定部分,你需要了解格式化输出的 JSON 文件的数据层次结构。
|
||||
|
||||
来自维基百科的 JSON 数据示例:
|
||||
|
||||
```
|
||||
{
|
||||
"firstName": "John",
|
||||
"lastName": "Smith",
|
||||
"age": 25,
|
||||
"address": {
|
||||
"streetAddress": "21 2nd Street",
|
||||
"city": "New York",
|
||||
"state": "NY",
|
||||
"postalCode": "10021"
|
||||
},
|
||||
"phoneNumber": [
|
||||
{
|
||||
"type": "home",
|
||||
"number": "212 555-1234"
|
||||
},
|
||||
{
|
||||
"type": "fax",
|
||||
"number": "646 555-4567"
|
||||
}
|
||||
],
|
||||
"gender": {
|
||||
"type": "male"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我将在本教程中将此 JSON 数据用作示例,将其保存为 `sample.json`。
|
||||
|
||||
假设我想从 `sample.json` 文件中过滤出地址。所以命令应该是这样的:
|
||||
|
||||
```
|
||||
$ jq .address sample.json
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
{
|
||||
"streetAddress": "21 2nd Street",
|
||||
"city": "New York",
|
||||
"state": "NY",
|
||||
"postalCode": "10021"
|
||||
}
|
||||
```
|
||||
|
||||
再次,我想要邮政编码,然后我要添加另一个**对象标识符-索引**,即另一个过滤器。
|
||||
|
||||
```
|
||||
$ cat sample.json | jq .address.postalCode
|
||||
```
|
||||
|
||||
另请注意,**过滤器区分大小写**,并且你必须使用完全相同的字符串来获取有意义的输出,否则就是 null。
|
||||
|
||||
#### 从 JSON 数组中解析元素
|
||||
|
||||
JSON 数组的元素包含在方括号内,这无疑是非常通用的。
|
||||
|
||||
要解析数组中的元素,你必须使用 `[]` 标识符以及其他对象标识符索引。
|
||||
|
||||
在此示例 JSON 数据中,电话号码存储在数组中,要从此数组中获取所有内容,你只需使用括号,像这个示例:
|
||||
|
||||
```
|
||||
$ jq .phoneNumber[] sample.json
|
||||
```
|
||||
|
||||
假设你只想要数组的第一个元素,然后使用从 `0` 开始的数组对象编号,对于第一个项目,使用 `[0]`,对于下一个项目,它应该每步增加 1。
|
||||
|
||||
```
|
||||
$ jq .phoneNumber[0] sample.json
|
||||
```
|
||||
|
||||
#### 脚本编程示例
|
||||
|
||||
假设我只想要家庭电话,而不是整个 JSON 数组数据。这就是用 `jq` 命令脚本编写的方便之处。
|
||||
|
||||
```
|
||||
$ cat sample.json | jq -r '.phoneNumber[] | select(.type == "home") | .number'
|
||||
```
|
||||
|
||||
首先,我将一个过滤器的结果传递给另一个,然后使用 `select` 属性选择特定类型的数据,再次将结果传递给另一个过滤器。
|
||||
|
||||
解释每种类型的 `jq` 过滤器和脚本编程超出了本教程的范围和目的。强烈建议你阅读 `jq` 手册,以便更好地理解下面的内容。
|
||||
|
||||
资源:
|
||||
|
||||
- https://stedolan.github.io/jq/manual/
|
||||
- http://www.compciv.org/recipes/cli/jq-for-parsing-json/
|
||||
- https://lzone.de/cheat-sheet/jq
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-parse-and-pretty-print-json-with-linux-commandline-tools/
|
||||
|
||||
作者:[ostechnix][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://stedolan.github.io/jq/download/
|
||||
@ -1,74 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11195-1.html)
|
||||
[#]: subject: (Check storage performance with dd)
|
||||
[#]: via: (https://fedoramagazine.org/check-storage-performance-with-dd/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
Check storage performance with dd
|
||||
使用 dd 检查存储性能
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
This article includes some example commands to show you how to get a _rough_ estimate of hard drive and RAID array performance using the _dd_ command. Accurate measurements would have to take into account things like [write amplification][2] and [system call overhead][3], which this guide does not. For a tool that might give more accurate results, you might want to consider using [hdparm][4].
|
||||
本文包含一些示例命令,向你展示如何使用 `dd` 命令*粗略*估计硬盘驱动器和 RAID 阵列的性能。准确的测量必须考虑诸如[写入放大][2]和[系统调用开销][3]之类的事情,本指南不会考虑这些。对于可能提供更准确结果的工具,你可能需要考虑使用 [hdparm][4]。
|
||||
|
||||
To factor out performance issues related to the file system, these examples show how to test the performance of your drives and arrays at the block level by reading and writing directly to/from their block devices. **WARNING** : The _write_ tests will destroy any data on the block devices against which they are run. **Do not run them against any device that contains data you want to keep!**
|
||||
为了分解与文件系统相关的性能问题,这些示例显示了如何通过直接读取和写入块设备来在块级测试驱动器和阵列的性能。**警告**:*写入*测试将会销毁用来运行测试的块设备上的所有数据。**不要对包含你想要保留的数据的任何设备运行这些测试!**
|
||||
|
||||
### Four tests
|
||||
### 四个测试
|
||||
|
||||
Below are four example dd commands that can be used to test the performance of a block device:
|
||||
下面是四个示例 `dd` 命令,可用于测试块设备的性能:
|
||||
|
||||
1. One process reading from $MY_DISK:
|
||||
1、 从 `$MY_DISK` 读取的一个进程:
|
||||
|
||||
```
|
||||
# dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache
|
||||
```
|
||||
|
||||
2. One process writing to $MY_DISK:
|
||||
2、写入到 `$MY_DISK` 的一个进程:
|
||||
|
||||
```
|
||||
# dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct
|
||||
```
|
||||
|
||||
3. Two processes reading concurrently from $MY_DISK:
|
||||
3、从 `$MY_DISK` 并发读取的两个进程:
|
||||
|
||||
```
|
||||
# (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache &); (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache skip=200 &)
|
||||
```
|
||||
|
||||
4. Two processes writing concurrently to $MY_DISK:
|
||||
4、 并发写入到 `$MY_DISK` 的两个进程:
|
||||
|
||||
```
|
||||
# (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct &); (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct skip=200 &)
|
||||
```
|
||||
|
||||
- 执行读写测试时,相应的 `iflag=nocache` 和 `oflag=direct` 参数非常重要,因为没有它们,`dd` 命令有时会显示从[内存][5]中传输数据的结果速度,而不是从硬盘。
|
||||
- `bs` 和 `count` 参数的值有些随意,我选择的值应足够大,以便在大多数情况下为当前硬件提供合适的平均值。
|
||||
- `null` 和 `zero` 设备在读写测试中分别用于目标和源,因为它们足够快,不会成为性能测试中的限制因素。
|
||||
- 并发读写测试中第二个 `dd` 命令的 `skip=200` 参数是为了确保 `dd` 的两个副本在硬盘驱动器的不同区域上运行。
|
||||
|
||||
### 16 个示例
|
||||
|
||||
下面是演示,显示针对以下四个块设备中之一运行上述四个测试中的各个结果:
|
||||
|
||||
– The _iflag=nocache_ and _oflag=direct_ parameters are important when performing the read and write tests (respectively) because without them the dd command will sometimes show the resulting speed of transferring the data to/from [RAM][5] rather than the hard drive.
|
||||
1. `MY_DISK=/dev/sda2`(用在示例 1-X 中)
|
||||
2. `MY_DISK=/dev/sdb2`(用在示例 2-X 中)
|
||||
3. `MY_DISK=/dev/md/stripped`(用在示例 3-X 中)
|
||||
4. `MY_DISK=/dev/md/mirrored`(用在示例 4-X 中)
|
||||
|
||||
– The values for the _bs_ and _count_ parameters are somewhat arbitrary and what I have chosen should be large enough to provide a decent average in most cases for current hardware.
|
||||
|
||||
– The _null_ and _zero_ devices are used for the destination and source (respectively) in the read and write tests because they are fast enough that they will not be the limiting factor in the performance tests.
|
||||
|
||||
– The _skip=200_ parameter on the second dd command in the concurrent read and write tests is to ensure that the two copies of dd are operating on different areas of the hard drive.
|
||||
|
||||
### 16 examples
|
||||
|
||||
Below are demonstrations showing the results of running each of the above four tests against each of the following four block devices:
|
||||
|
||||
1. MY_DISK=/dev/sda2 (used in examples 1-X)
|
||||
2. MY_DISK=/dev/sdb2 (used in examples 2-X)
|
||||
3. MY_DISK=/dev/md/stripped (used in examples 3-X)
|
||||
4. MY_DISK=/dev/md/mirrored (used in examples 4-X)
|
||||
|
||||
|
||||
|
||||
A video demonstration of the these tests being run on a PC is provided at the end of this guide.
|
||||
|
||||
Begin by putting your computer into _rescue_ mode to reduce the chances that disk I/O from background services might randomly affect your test results. **WARNING** : This will shutdown all non-essential programs and services. Be sure to save your work before running these commands. You will need to know your _root_ password to get into rescue mode. The _passwd_ command, when run as the root user, will prompt you to (re)set your root account password.
|
||||
首先将计算机置于*救援*模式,以减少后台服务的磁盘 I/O 随机影响测试结果的可能性。**警告**:这将关闭所有非必要的程序和服务。在运行这些命令之前,请务必保存你的工作。你需要知道 `root` 密码才能进入救援模式。`passwd` 命令以 `root` 用户身份运行时,将提示你(重新)设置 `root` 帐户密码。
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
@ -77,14 +67,14 @@ $ sudo -i
|
||||
# systemctl rescue
|
||||
```
|
||||
|
||||
You might also want to temporarily disable logging to disk:
|
||||
你可能还想暂时禁止将日志记录到磁盘:
|
||||
|
||||
```
|
||||
# sed -r -i.bak 's/^#?Storage=.*/Storage=none/' /etc/systemd/journald.conf
|
||||
# systemctl restart systemd-journald.service
|
||||
```
|
||||
|
||||
If you have a swap device, it can be temporarily disabled and used to perform the following tests:
|
||||
如果你有交换设备,可以暂时禁用它并用于执行后面的测试:
|
||||
|
||||
```
|
||||
# swapoff -a
|
||||
@ -93,7 +83,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
# mdadm --zero-superblock $MY_DEVS
|
||||
```
|
||||
|
||||
#### Example 1-1 (reading from sda)
|
||||
#### 示例 1-1 (从 sda 读取)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||
@ -106,7 +96,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.7003 s, 123 MB/s
|
||||
```
|
||||
|
||||
#### Example 1-2 (writing to sda)
|
||||
#### 示例 1-2 (写入到 sda)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||
@ -119,7 +109,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67117 s, 125 MB/s
|
||||
```
|
||||
|
||||
#### Example 1-3 (reading concurrently from sda)
|
||||
#### 示例 1-3 (从 sda 并发读取)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||
@ -135,7 +125,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.52614 s, 59.5 MB/s
|
||||
```
|
||||
|
||||
#### Example 1-4 (writing concurrently to sda)
|
||||
#### 示例 1-4 (并发写入到 sda)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||
@ -150,7 +140,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.60872 s, 58.1 MB/s
|
||||
```
|
||||
|
||||
#### Example 2-1 (reading from sdb)
|
||||
#### 示例 2-1 (从 sdb 读取)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||
@ -163,7 +153,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67285 s, 125 MB/s
|
||||
```
|
||||
|
||||
#### Example 2-2 (writing to sdb)
|
||||
#### 示例 2-2 (写入到 sdb)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||
@ -176,7 +166,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67198 s, 125 MB/s
|
||||
```
|
||||
|
||||
#### Example 2-3 (reading concurrently from sdb)
|
||||
#### 示例 2-3 (从 sdb 并发读取)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||
@ -192,7 +182,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.57736 s, 58.6 MB/s
|
||||
```
|
||||
|
||||
#### Example 2-4 (writing concurrently to sdb)
|
||||
#### 示例 2-4 (并发写入到 sdb)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||
@ -208,7 +198,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.81475 s, 55.0 MB/s
|
||||
```
|
||||
|
||||
#### Example 3-1 (reading from RAID0)
|
||||
#### 示例 3-1 (从 RAID0 读取)
|
||||
|
||||
```
|
||||
# mdadm --create /dev/md/stripped --homehost=any --metadata=1.0 --level=0 --raid-devices=2 $MY_DEVS
|
||||
@ -222,7 +212,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 0.837419 s, 250 MB/s
|
||||
```
|
||||
|
||||
#### Example 3-2 (writing to RAID0)
|
||||
#### 示例 3-2 (写入到 RAID0)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/stripped
|
||||
@ -235,7 +225,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 0.823648 s, 255 MB/s
|
||||
```
|
||||
|
||||
#### Example 3-3 (reading concurrently from RAID0)
|
||||
#### 示例 3-3 (从 RAID0 并发读取)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/stripped
|
||||
@ -251,7 +241,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.80016 s, 116 MB/s
|
||||
```
|
||||
|
||||
#### Example 3-4 (writing concurrently to RAID0)
|
||||
#### 示例 3-4 (并发写入到 RAID0)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/stripped
|
||||
@ -267,7 +257,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.81323 s, 116 MB/s
|
||||
```
|
||||
|
||||
#### Example 4-1 (reading from RAID1)
|
||||
#### 示例 4-1 (从 RAID1 读取)
|
||||
|
||||
```
|
||||
# mdadm --stop /dev/md/stripped
|
||||
@ -282,7 +272,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.74963 s, 120 MB/s
|
||||
```
|
||||
|
||||
#### Example 4-2 (writing to RAID1)
|
||||
#### 示例 4-2 (写入到 RAID1)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/mirrored
|
||||
@ -295,7 +285,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.74625 s, 120 MB/s
|
||||
```
|
||||
|
||||
#### Example 4-3 (reading concurrently from RAID1)
|
||||
#### 示例 4-3 (从 RAID1 并发读取)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/mirrored
|
||||
@ -311,7 +301,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67685 s, 125 MB/s
|
||||
```
|
||||
|
||||
#### Example 4-4 (writing concurrently to RAID1)
|
||||
#### 示例 4-4 (并发写入到 RAID1)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/mirrored
|
||||
@ -327,7 +317,7 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 4.1067 s, 51.1 MB/s
|
||||
```
|
||||
|
||||
#### Restore your swap device and journald configuration
|
||||
#### 恢复交换设备和日志配置
|
||||
|
||||
```
|
||||
# mdadm --stop /dev/md/stripped /dev/md/mirrored
|
||||
@ -339,23 +329,19 @@ If you have a swap device, it can be temporarily disabled and used to perform th
|
||||
# reboot
|
||||
```
|
||||
|
||||
### Interpreting the results
|
||||
### 结果解读
|
||||
|
||||
Examples 1-1, 1-2, 2-1, and 2-2 show that each of my drives read and write at about 125 MB/s.
|
||||
示例 1-1、1-2、2-1 和 2-2 表明我的每个驱动器以大约 125 MB/s 的速度读写。
|
||||
|
||||
Examples 1-3, 1-4, 2-3, and 2-4 show that when two reads or two writes are done in parallel on the same drive, each process gets at about half the drive’s bandwidth (60 MB/s).
|
||||
示例 1-3、1-4、2-3 和 2-4 表明,当在同一驱动器上并行完成两次读取或写入时,每个进程的驱动器带宽大约为一半(60 MB/s)。
|
||||
|
||||
The 3-x examples show the performance benefit of putting the two drives together in a RAID0 (data stripping) array. The numbers, in all cases, show that the RAID0 array performs about twice as fast as either drive is able to perform on its own. The trade-off is that you are twice as likely to lose everything because each drive only contains half the data. A three-drive array would perform three times as fast as a single drive (all drives being equal) but it would be thrice as likely to suffer a [catastrophic failure][6].
|
||||
3-X 示例显示了将两个驱动器放在 RAID0(数据条带化)阵列中的性能优势。在所有情况下,这些数字表明 RAID0 阵列的执行速度是任何一个驱动器能够独立提供的速度的两倍。相应的是,丢失所有内容的可能性也是两倍,因为每个驱动器只包含一半的数据。一个三个驱动器阵列的执行速度是单个驱动器的三倍(所有驱动器规格都相同),但遭受[灾难性故障][6]的可能也是三倍。
|
||||
|
||||
The 4-x examples show that the performance of the RAID1 (data mirroring) array is similar to that of a single disk except for the case where multiple processes are concurrently reading (example 4-3). In the case of multiple processes reading, the performance of the RAID1 array is similar to that of the RAID0 array. This means that you will see a performance benefit with RAID1, but only when processes are reading concurrently. For example, if a process tries to access a large number of files in the background while you are trying to use a web browser or email client in the foreground. The main benefit of RAID1 is that your data is unlikely to be lost [if a drive fails][7].
|
||||
4-X 示例显示 RAID1(数据镜像)阵列的性能类似于单个磁盘的性能,除了多个进程同时读取的情况(示例4-3)。在多个进程读取的情况下,RAID1 阵列的性能类似于 RAID0 阵列的性能。这意味着你将看到 RAID1 的性能优势,但仅限于进程同时读取时。例如,当你在前台使用 Web 浏览器或电子邮件客户端时,进程会尝试访问后台中的大量文件。RAID1 的主要好处是,[如果驱动器出现故障][7],你的数据不太可能丢失。
|
||||
|
||||
### Video demo
|
||||
### 故障排除
|
||||
|
||||
Testing storage throughput using dd
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
If the above tests aren’t performing as you expect, you might have a bad or failing drive. Most modern hard drives have built-in Self-Monitoring, Analysis and Reporting Technology ([SMART][8]). If your drive supports it, the _smartctl_ command can be used to query your hard drive for its internal statistics:
|
||||
如果上述测试未按预期执行,则可能是驱动器坏了或出现故障。大多数现代硬盘都内置了自我监控、分析和报告技术([SMART][8])。如果你的驱动器支持它,`smartctl` 命令可用于查询你的硬盘驱动器的内部统计信息:
|
||||
|
||||
```
|
||||
# smartctl --health /dev/sda
|
||||
@ -363,21 +349,21 @@ If the above tests aren’t performing as you expect, you might have a bad or fa
|
||||
# smartctl -x /dev/sda
|
||||
```
|
||||
|
||||
Another way that you might be able to tune your PC for better performance is by changing your [I/O scheduler][9]. Linux systems support several I/O schedulers and the current default for Fedora systems is the [multiqueue][10] variant of the [deadline][11] scheduler. The default performs very well overall and scales extremely well for large servers with many processors and large disk arrays. There are, however, a few more specialized schedulers that might perform better under certain conditions.
|
||||
另一种可以调整 PC 以获得更好性能的方法是更改 [I/O 调度程序][9]。Linux 系统支持多个 I/O 调度程序,Fedora 系统的当前默认值是 [deadline][11] 调度程序的 [multiqueue][10] 变体。默认情况下它的整体性能非常好,并且对于具有许多处理器和大型磁盘阵列的大型服务器,其扩展性极为出色。但是,有一些更专业的调度程序在某些条件下可能表现更好。
|
||||
|
||||
To view which I/O scheduler your drives are using, issue the following command:
|
||||
要查看驱动器正在使用的 I/O 调度程序,请运行以下命令:
|
||||
|
||||
```
|
||||
$ for i in /sys/block/sd?/queue/scheduler; do echo "$i: $(<$i)"; done
|
||||
```
|
||||
|
||||
You can change the scheduler for a drive by writing the name of the desired scheduler to the /sys/block/<device name>/queue/scheduler file:
|
||||
你可以通过将所需调度程序的名称写入 `/sys/block/<device name>/queue/scheduler` 文件来更改驱动器的调度程序:
|
||||
|
||||
```
|
||||
# echo bfq > /sys/block/sda/queue/scheduler
|
||||
```
|
||||
|
||||
You can make your changes permanent by creating a [udev rule][12] for your drive. The following example shows how to create a udev rule that will set all [rotational drives][13] to use the [BFQ][14] I/O scheduler:
|
||||
你可以通过为驱动器创建 [udev 规则][12]来永久更改它。以下示例显示了如何创建将所有的[旋转式驱动器][13]设置为使用 [BFQ][14] I/O 调度程序的 udev 规则:
|
||||
|
||||
```
|
||||
# cat << END > /etc/udev/rules.d/60-ioscheduler-rotational.rules
|
||||
@ -385,7 +371,7 @@ ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="1", ATTR{queue
|
||||
END
|
||||
```
|
||||
|
||||
Here is another example that sets all [solid-state drives][15] to use the [NOOP][16] I/O scheduler:
|
||||
这是另一个设置所有的[固态驱动器][15]使用 [NOOP][16] I/O 调度程序的示例:
|
||||
|
||||
```
|
||||
# cat << END > /etc/udev/rules.d/60-ioscheduler-solid-state.rules
|
||||
@ -393,11 +379,7 @@ ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue
|
||||
END
|
||||
```
|
||||
|
||||
Changing your I/O scheduler won’t affect the raw throughput of your devices, but it might make your PC seem more responsive by prioritizing the bandwidth for the foreground tasks over the background tasks or by eliminating unnecessary block reordering.
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[ _James Donovan_][17]_ on _[_Unsplash_][18]_._
|
||||
更改 I/O 调度程序不会影响设备的原始吞吐量,但通过优先考虑后台任务的带宽或消除不必要的块重新排序,可能会使你的 PC 看起来响应更快。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -405,8 +387,8 @@ via: https://fedoramagazine.org/check-storage-performance-with-dd/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,183 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11221-1.html)
|
||||
[#]: subject: (How to install Elasticsearch and Kibana on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/7/install-elasticsearch-and-kibana-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何在 Linux 上安装 Elasticsearch 和 Kibana
|
||||
======
|
||||
|
||||
> 获取我们关于安装两者的简化说明。
|
||||
|
||||
![5 pengiuns floating on iceburg][1]
|
||||
|
||||
如果你渴望学习基于开源 Lucene 库的著名开源搜索引擎 Elasticsearch,那么没有比在本地安装它更好的方法了。这个过程在 [Elasticsearch 网站][2]中有详细介绍,但如果你是初学者,官方说明就比必要的信息多得多。本文采用一种简化的方法。
|
||||
|
||||
### 添加 Elasticsearch 仓库
|
||||
|
||||
首先,将 Elasticsearch 仓库添加到你的系统,以便你可以根据需要安装它并接收更新。如何做取决于你的发行版。在基于 RPM 的系统上,例如 [Fedora][3]、[CentOS] [4]、[Red Hat Enterprise Linux(RHEL)][5] 或 [openSUSE][6],(本文任何地方引用 Fedora 或 RHEL 的也适用于 CentOS 和 openSUSE)在 `/etc/yum.repos.d/` 中创建一个名为 `elasticsearch.repo` 的仓库描述文件:
|
||||
|
||||
```
|
||||
$ cat << EOF | sudo tee /etc/yum.repos.d/elasticsearch.repo
|
||||
[elasticsearch-7.x]
|
||||
name=Elasticsearch repository for 7.x packages
|
||||
baseurl=https://artifacts.elastic.co/packages/oss-7.x/yum
|
||||
gpgcheck=1
|
||||
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
enabled=1
|
||||
autorefresh=1
|
||||
type=rpm-md
|
||||
EOF
|
||||
```
|
||||
|
||||
在 Ubuntu 或 Debian 上,不要使用 `add-apt-repository` 工具。由于它自身默认的和 Elasticsearch 仓库提供的不匹配而导致错误。相反,设置这个:
|
||||
|
||||
```
|
||||
$ echo "deb https://artifacts.elastic.co/packages/oss-7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
|
||||
```
|
||||
|
||||
在你从该仓库安装之前,导入 GPG 公钥,然后更新:
|
||||
|
||||
```
|
||||
$ sudo apt-key adv --keyserver \
|
||||
hkp://keyserver.ubuntu.com:80 \
|
||||
--recv D27D666CD88E42B4
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
此存储库仅包含 Elasticsearch 的开源功能,在 [Apache 许可证][7]下发布,没有提供订阅版本的额外功能。如果你需要仅限订阅的功能(这些功能是**并不**开源),那么 `baseurl` 必须设置为:
|
||||
|
||||
```
|
||||
baseurl=https://artifacts.elastic.co/packages/7.x/yum
|
||||
```
|
||||
|
||||
### 安装 Elasticsearch
|
||||
|
||||
你需要安装的软件包的名称取决于你使用的是开源版本还是订阅版本。本文使用开源版本,包名最后有 `-oss` 后缀。如果包名后没有 `-oss`,那么表示你请求的是仅限订阅版本。
|
||||
|
||||
如果你创建了订阅版本的仓库却尝试安装开源版本,那么就会收到“非指定”的错误。如果你创建了一个开源版本仓库却没有将 `-oss` 添加到包名后,那么你也会收到错误。
|
||||
|
||||
使用包管理器安装 Elasticsearch。例如,在 Fedora、CentOS 或 RHEL 上运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install elasticsearch-oss
|
||||
```
|
||||
|
||||
在 Ubuntu 或 Debian 上,运行:
|
||||
|
||||
```
|
||||
$ sudo apt install elasticsearch-oss
|
||||
```
|
||||
|
||||
如果你在安装 Elasticsearch 时遇到错误,那么你可能安装的是错误的软件包。如果你想如本文这样使用开源包,那么请确保使用正确的 apt 仓库或在 Yum 配置正确的 `baseurl`。
|
||||
|
||||
### 启动并启用 Elasticsearch
|
||||
|
||||
安装 Elasticsearch 后,你必须启动并启用它:
|
||||
|
||||
```
|
||||
$ sudo systemctl daemon-reload
|
||||
$ sudo systemctl enable --now elasticsearch.service
|
||||
```
|
||||
|
||||
要确认 Elasticsearch 在其默认端口 9200 上运行,请在 Web 浏览器中打开 `localhost:9200`。你可以使用 GUI 浏览器,也可以在终端中执行此操作:
|
||||
|
||||
|
||||
```
|
||||
$ curl localhost:9200
|
||||
{
|
||||
|
||||
"name" : "fedora30",
|
||||
"cluster_name" : "elasticsearch",
|
||||
"cluster_uuid" : "OqSbb16NQB2M0ysynnX1hA",
|
||||
"version" : {
|
||||
"number" : "7.2.0",
|
||||
"build_flavor" : "oss",
|
||||
"build_type" : "rpm",
|
||||
"build_hash" : "508c38a",
|
||||
"build_date" : "2019-06-20T15:54:18.811730Z",
|
||||
"build_snapshot" : false,
|
||||
"lucene_version" : "8.0.0",
|
||||
"minimum_wire_compatibility_version" : "6.8.0",
|
||||
"minimum_index_compatibility_version" : "6.0.0-beta1"
|
||||
},
|
||||
"tagline" : "You Know, for Search"
|
||||
}
|
||||
```
|
||||
|
||||
### 安装 Kibana
|
||||
|
||||
Kibana 是 Elasticsearch 数据可视化的图形界面。它包含在 Elasticsearch 仓库,因此你可以使用包管理器进行安装。与 Elasticsearch 本身一样,如果你使用的是 Elasticsearch 的开源版本,那么必须将 `-oss` 放到包名最后,订阅版本则不用(两者安装需要匹配):
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install kibana-oss
|
||||
```
|
||||
|
||||
在 Ubuntu 或 Debian 上:
|
||||
|
||||
```
|
||||
$ sudo apt install kibana-oss
|
||||
```
|
||||
|
||||
Kibana 在端口 5601 上运行,因此打开图形化 Web 浏览器并进入 `localhost:5601` 来开始使用 Kibana,如下所示:
|
||||
|
||||
![Kibana running in Firefox.][8]
|
||||
|
||||
### 故障排除
|
||||
|
||||
如果在安装 Elasticsearch 时出现错误,请尝试手动安装 Java 环境。在 Fedora、CentOS 和 RHEL 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install java-openjdk-devel java-openjdk
|
||||
```
|
||||
|
||||
在 Ubuntu 上:
|
||||
|
||||
```
|
||||
$ sudo apt install default-jdk
|
||||
```
|
||||
|
||||
如果所有其他方法都失败,请尝试直接从 Elasticsearch 服务器安装 Elasticsearch RPM:
|
||||
|
||||
```
|
||||
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-oss-7.2.0-x86_64.rpm{,.sha512}
|
||||
$ shasum -a 512 -c elasticsearch-oss-7.2.0-x86_64.rpm.sha512 && sudo rpm --install elasticsearch-oss-7.2.0-x86_64.rpm
|
||||
```
|
||||
|
||||
在 Ubuntu 或 Debian 上,请使用 DEB 包。
|
||||
|
||||
如果你无法使用 Web 浏览器访问 Elasticsearch 或 Kibana,那么可能是你的防火墙阻止了这些端口。你可以通过调整防火墙设置来允许这些端口上的流量。例如,如果你运行的是 `firewalld`(Fedora 和 RHEL 上的默认防火墙,并且可以在 Debian 和 Ubuntu 上安装),那么你可以使用 `firewall-cmd`:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --add-port=9200/tcp --permanent
|
||||
$ sudo firewall-cmd --add-port=5601/tcp --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
设置完成了,你可以关注我们接下来的 Elasticsearch 和 Kibana 安装文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/install-elasticsearch-and-kibana-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux31x_cc.png?itok=Pvim4U-B (5 pengiuns floating on iceburg)
|
||||
[2]: https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html
|
||||
[3]: https://getfedora.org
|
||||
[4]: https://www.centos.org
|
||||
[5]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[6]: https://www.opensuse.org
|
||||
[7]: http://www.apache.org/licenses/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/kibana.jpg (Kibana running in Firefox.)
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11202-1.html)
|
||||
[#]: subject: (What is a golden image?)
|
||||
[#]: via: (https://opensource.com/article/19/7/what-golden-image)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
@ -12,27 +12,27 @@
|
||||
|
||||
> 正在开发一个将广泛分发的项目吗?了解一下黄金镜像吧,以便在出现问题时轻松恢复到“完美”状态。
|
||||
|
||||
![Gold star][1]
|
||||

|
||||
|
||||
如果你正在进行质量保证、系统管理或媒体制作(没想到吧),你可能听说过<ruby>正式版<rt>gold master</rt></ruby>、<ruby>黄金镜像<rt>golden image</rt></ruby>或<ruby>母片<rt>master image</rt></ruby>等等这一术语的某些变体。这个术语已经进入了每个参与创建一个**完美**模具的人的集体意识,然后从该模具中产生许多复制品。母片或黄金镜像就是:一种虚拟模具,你可以从中打造可分发的模型。
|
||||
如果你正在从事于质量保证、系统管理或媒体制作(没想到吧),你可能听说过<ruby>正式版<rt>gold master</rt></ruby>这一术语的某些变体,如<ruby>黄金镜像<rt>golden image</rt></ruby>或<ruby>母片<rt>master image</rt></ruby>等等。这个术语已经进入了每个参与创建**完美**模具的人的集体意识,然后从该模具中产生许多复制品。母片或黄金镜像就是:一种虚拟模具,你可以从中打造可分发的模型。
|
||||
|
||||
在媒体制作中,这就是全体人员努力开发母片的过程。这个最终产品是独一无二的。它看起来和听起来像是能够看和听的最好的电影或专辑(或其他任何东西)。可以制作和压缩该母片的副本并发送给急切的公众。
|
||||
在媒体制作中,这就是所有人努力开发母片的过程。这个最终产品是独一无二的。它看起来和听起来像是可以看和听的最好的电影或专辑(或其他任何东西)。可以制作和压缩该母片的副本并发送给急切的公众。
|
||||
|
||||
在软件中,与该术语相关联的也是类似的思路。一旦软件经过编译和一再测试,完美的构建就会被声明为**黄金版本**。不允许对它进一步更改,并且所有可分发的副本都是从此母片生成的(当软件是用 CD 或 DVD 分发时,这实际上意味着母盘)。
|
||||
在软件中,与该术语相关联的也是类似的意思。一旦软件经过编译和一再测试,完美的构建成果就会被声明为**黄金版本**,不允许对它进一步更改,并且所有可分发的副本都是从此母片生成的(当软件是用 CD 或 DVD 分发时,这实际上就是母盘)。
|
||||
|
||||
在系统管理中,你可能会遇到你的机构所选的操作系统的黄金镜像,其中的重要设置已经就绪,如安装好的虚拟专用网络(VPN)证书、设置好的电子邮件收件服务器的邮件客户端,等等。同样,你可能也会在虚拟机(VM)的世界中听到这个术语,其中精心配置的虚拟驱动器的黄金镜像是所有克隆的新虚拟机的源头。
|
||||
在系统管理中,你可能会遇到你的机构所选的操作系统的黄金镜像,其中的重要设置已经就绪,如安装好的虚拟专用网络(VPN)证书、设置好的电子邮件收件服务器的邮件客户端等等。同样,你可能也会在虚拟机(VM)的世界中听到这个术语,其中精心配置了虚拟驱动器的黄金镜像是所有克隆的新虚拟机的源头。
|
||||
|
||||
### GNOME Boxes
|
||||
|
||||
正式版的概念很简单,但往往忽视将其付诸实践。有时,你的团队很高兴能够达成他们的目标,但没有人停下来考虑将这些成就指定为权威版本。在其他时候,没有简单的机制来做到这一点。
|
||||
|
||||
黄金镜像等同于部分历史保存和提前备份计划。一旦你制作了一个完美的模型,无论你正在努力做什么,你都应该为自己保留这项工作,因为它不仅标志着你的进步,而且如果你继续工作时遇到问题,它就会成为一个后备。
|
||||
黄金镜像等同于部分历史的保存和提前备份计划。一旦你制作了一个完美的模型,无论你正在努力做什么,你都应该为自己保留这项工作,因为它不仅标志着你的进步,而且如果你继续工作时遇到问题,它就会成为一个后备。
|
||||
|
||||
[GNOME Boxes][2],是随 GNOME 桌面一起提供的虚拟化平台,可以提供简单的演示。如果你从未使用过GNOME Boxes,你可以在 Alan Formy-Duval 的文章 [GNOME Boxes 入门][3]中学习它的基础知识。
|
||||
[GNOME Boxes][2],是随 GNOME 桌面一起提供的虚拟化平台,可以用作简单的演示用途。如果你从未使用过 GNOME Boxes,你可以在 Alan Formy-Duval 的文章 [GNOME Boxes 入门][3]中学习它的基础知识。
|
||||
|
||||
想象一下,你使用 GNOME Boxes 创建虚拟机,然后将操作系统安装到该 VM 中。现在,你想要制作一个黄金镜像。GNOME Boxes 已经率先摄取了你的安装快照,可以作为库存的操作系统安装的黄金镜像。
|
||||
想象一下,你使用 GNOME Boxes 创建虚拟机,然后将操作系统安装到该 VM 中。现在,你想要制作一个黄金镜像。GNOME Boxes 已经率先摄取了你的安装快照,可以作为更多的操作系统安装的黄金镜像。
|
||||
|
||||
打开 GNOME Boxes 并在仪表板视图中,右键单击任何虚拟机,然后选择**属性**。 在**属性**窗口中,选择**快照**选项卡。由 GNOME Boxes 自动创建的第一个快照是“Just Installed”。顾名思义,这是你最初安装到虚拟机上的操作系统。
|
||||
打开 GNOME Boxes 并在仪表板视图中,右键单击任何虚拟机,然后选择**属性**。在**属性**窗口中,选择**快照**选项卡。由 GNOME Boxes 自动创建的第一个快照是“Just Installed”。顾名思义,这是你最初安装到虚拟机上的操作系统。
|
||||
|
||||
![The Just Installed snapshot, or initial golden image, in GNOME Boxes.][4]
|
||||
|
||||
@ -52,7 +52,7 @@
|
||||
|
||||
### 黄金镜像
|
||||
|
||||
很少有学科无法从黄金镜像中受益。无论你是在 [Git][8] 中标记版本、在 Boxes 中拍摄快照、出版原型黑胶唱片、打印书籍以进行审核、设计用于批量生产的丝网印刷、还是制作文字模具,到处都是各种原型。这只是现代技术让我们人类更聪明而不是更努力的另一种方式,因此为你的项目制作一个黄金镜像,并根据需要随时生成克隆。
|
||||
很少有学科无法从黄金镜像中受益。无论你是在 [Git][8] 中标记版本、在 Boxes 中拍摄快照、出版原型黑胶唱片、打印书籍以进行审核、设计用于批量生产的丝网印刷、还是制作文字模具,到处都是各种原型。这只是现代技术让我们人类更聪明而不是更努力的另一种方式,因此为你的项目制作一个黄金镜像,并根据需要随时生成克隆吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -61,7 +61,7 @@ via: https://opensource.com/article/19/7/what-golden-image
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,74 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (arrowfeng)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11208-1.html)
|
||||
[#]: subject: (Understanding software design patterns)
|
||||
[#]: via: (https://opensource.com/article/19/7/understanding-software-design-patterns)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brsonhttps://opensource.com/users/erezhttps://opensource.com/users/brson)
|
||||
|
||||
理解软件设计模式
|
||||
======
|
||||
设计模式可以帮助消除冗余代码。学习如何利用Java使用单例模式、工厂模式和观察者模式。
|
||||
![clouds in the sky with blue pattern][1]
|
||||
> 设计模式可以帮助消除冗余代码。学习如何利用 Java 使用单例模式、工厂模式和观察者模式。
|
||||
|
||||
如果你是一名正在致力于计算机科学或者相关学科的程序员或者学生,很快,你将会遇到一条术语 “软件设计模式。” 根据维基百科,_" [软件设计模式][2]是在平常的软件设计工作中所遭遇的问题是一种通用的, 可重复使用的解决方案。“_ 这里是我对定义的理解:当你在编码项目上的同时,你经常会思考,“呵呵,这里貌似是冗余代码,我想是否我能改变代码使得更灵活并且这个改变是可接受的?”因此,你将开始思考怎样分割那些保持不变的内容和需要经常改变的内容。
|
||||

|
||||
|
||||
如果你是一名正在致力于计算机科学或者相关学科的程序员或者学生,很快,你将会遇到一条术语 “<ruby>软件设计模式<rt>software design pattern</rt></ruby>”。根据维基百科,“*[软件设计模式][2]是在平常的软件设计工作中所遭遇的问题的一种通用的、可重复使用的解决方案*”。我对该定义的理解是:当在从事于一个编码项目时,你经常会思考,“嗯,这里貌似是冗余代码,我觉得是否能改变这些代码使之更灵活和便于修改?”因此,你会开始考虑怎样分割那些保持不变的内容和需要经常改变的内容。
|
||||
|
||||
> 设计模式是一种通过分割那些保持不变的部分和经常变化的部分,让你的代码更容易修改的方法。
|
||||
> **设计模式**是一种通过分割那些保持不变的部分和经常变化的部分,让你的代码更容易修改的方法。
|
||||
|
||||
不出意外的话,每个从事编码工程的人都可能会有同样的思考。特别是那些工业级别的工程,在那里通常工作着数十甚至数百名开发者;协作过程表明必须有一些标准和规则来使代码更加优雅并适应变化。 这就是为什么我们有 [面向对象编程][3](OOP)和 [软件框架工具][4]。设计模式有点类似于OOP,但它通过将变化视为自然开发过程的一部分而进一步发展。基本上,设计模式利用了一些OOP的思想,比如抽象和接口,但是专注于改变的过程。
|
||||
不出意外的话,每个从事编程项目的人都可能会有同样的思考。特别是那些工业级别的项目,在那里通常工作着数十甚至数百名开发者;协作过程表明必须有一些标准和规则来使代码更加优雅并适应变化。这就是为什么我们有了 [面向对象编程][3](OOP)和 [软件框架工具][4]。设计模式有点类似于 OOP,但它通过将变化视为自然开发过程的一部分而进一步发展。基本上,设计模式利用了一些 OOP 的思想,比如抽象和接口,但是专注于改变的过程。
|
||||
|
||||
当你开始开发项目时,你经常会听到这样一个术语*重构*,它意味着*通过改变代码使它变得更优雅和可复用*;这就是设计模式耀眼的地方。当你处理现有代码时(无论是由其他人构建还是你自己过去构建的),了解设计模式可以帮助你以不同的方式看待事物,你将发现问题以及改进代码的方法。
|
||||
|
||||
当你开始开发项目时, 你经常会听到这样一个术语 _重构_,_意味着通过改变代码使它变得更优雅和可复用;_ 这就是设计模式耀眼的地方。 无论什么时候你处理现有代码时(无论是由其他人构建还是你自己过去构建的),了解设计模式可以帮助你以不同的方式看待事物,你将发现问题以及改进代码的方法。
|
||||
|
||||
那里有很多种设计模式,其中单例模式,工厂模式,和观察者模式三种最受欢迎,在这篇文章中我将会一一介绍它们。
|
||||
有很多种设计模式,其中单例模式、工厂模式和观察者模式三种最受欢迎,在这篇文章中我将会一一介绍它们。
|
||||
|
||||
### 如何遵循本指南
|
||||
|
||||
无论你是一位有经验的编程工作者还是一名刚刚接触的新手,我想让这篇教程很容易让每个人都可以理解。设计模式概念并不容易理解,减少开始旅程时的学习曲线始终是首要任务。因此,除了这篇带有图表和代码片段的文章外,我还创建了一个 [GitHub仓库][5],你可以克隆和在你的电脑上运行代码去实现这三种设计模式。你也可以观看我创建的 [YouTube视频][6]。
|
||||
|
||||
无论你是一位有经验的编程工作者还是一名刚刚接触的新手,我想让这篇教程让每个人都很容易理解。设计模式概念并不容易理解,减少开始旅程时的学习曲线始终是首要任务。因此,除了这篇带有图表和代码片段的文章外,我还创建了一个 [GitHub 仓库][5],你可以克隆仓库并在你的电脑上运行这些代码来实现这三种设计模式。你也可以观看我创建的 [YouTube视频][6]。
|
||||
|
||||
#### 必要条件
|
||||
|
||||
如果你只是想了解一般的设计模式思想,则无需克隆示例项目或安装任何工具。但是,如果要运行示例代码,你需要安装以下工具:
|
||||
|
||||
* **Java 开发套件(JDK)**:我强烈建议使用 [OpenJDK][7]。
|
||||
* **Apache Maven**:这个简单的项目使用 [Apache Maven][8] 构建;好的是许多 IDE 自带了Maven。
|
||||
* **交互式开发编辑器(IDE)**:我使用 [社区版 IntelliJ][9],但是你也可以使用 [Eclipse IDE][10] 或者其他你喜欢的 Java IDE。
|
||||
* **Git**:如果你想克隆这个工程,你需要 [Git][11] 客户端。
|
||||
|
||||
* **Java Development Kit (JDK):** 我强烈建议 [OpenJDK][7]。
|
||||
* **Apache Maven:** 这个简单的工程使用 [Apache Maven][8] 构建; 幸好许多IDEs自带了Maven。
|
||||
* **Interactive development editor (IDE):** 我使用 [IntelliJ Community Edition][9], 但是你也可以使用 [Eclipse IDE][10] 或者其他你喜欢的 Java IDE。
|
||||
* **Git:** 如果你想克隆这个工程,你需要 [Git][11]客户端。
|
||||
|
||||
|
||||
安装好Git后运行下列命令克隆这个工程:
|
||||
安装好 Git 后运行下列命令克隆这个工程:
|
||||
|
||||
```
|
||||
`git clone https://github.com/bryantson/OpensourceDotComDemos.git`
|
||||
git clone https://github.com/bryantson/OpensourceDotComDemos.git
|
||||
```
|
||||
|
||||
然后在你喜欢的IDE中,你可以将TopDesignPatterns仓库中的代码作为Apache Maven项目导入。
|
||||
然后在你喜欢的 IDE 中,你可以将 TopDesignPatterns 仓库中的代码作为 Apache Maven 项目导入。
|
||||
|
||||
我正在使用Java,但你也可以使用支持 [抽象原理][12]的任何编程语言来实现设计模式。
|
||||
我使用的是 Java,但你也可以使用支持[抽象原则][12]的任何编程语言来实现设计模式。
|
||||
|
||||
### 单例模式:避免每次创建一个对象
|
||||
|
||||
[单例模式][13]是非常受欢迎的设计模式,它的实现相对来说很简单,因为你只需要一个类。然而,许多开发人员争论单例设计模式的是否利大于弊,因为它缺乏明显的好处并且容易被滥用。很少有开发人员直接实现单例;相反,像Spring Framework和Google Guice等编程框架内置了单例设计模式的特性。
|
||||
<ruby>[单例模式][13]<rt>singleton pattern</rt></ruby>是非常流行的设计模式,它的实现相对来说很简单,因为你只需要一个类。然而,许多开发人员争论单例设计模式的是否利大于弊,因为它缺乏明显的好处并且容易被滥用。很少有开发人员直接实现单例;相反,像 Spring Framework 和 Google Guice 等编程框架内置了单例设计模式的特性。
|
||||
|
||||
但是了解单例模式仍然有巨大的用处。单例模式确保一个类仅创建一次且提供了一个对他的全局访问点。
|
||||
但是了解单例模式仍然有巨大的用处。单例模式确保一个类仅创建一次且提供了一个对它的全局访问点。
|
||||
|
||||
> **Singleton pattern:** 确保仅有一个实例被创建且避免在同样的工程中创建多个实例。
|
||||
> **单例模式**:确保仅创建一个实例且避免在同一个项目中创建多个实例。
|
||||
|
||||
下面这幅图展示了经典的类对象创建过程。当客户端请求创建一个对象时,构造函数会创建或者实例化一个对象并调用方法返回这个类。但是每次请求一个对象都会发生这样的情况——构造函数被调用,一个新的对象被创建并且它返回一个唯一的对象。我猜面向对象语言的创建者有每次都创建一个新对象的原因,但是单例过程的支持者说这是冗余的且浪费资源。
|
||||
下面这幅图展示了典型的类对象创建过程。当客户端请求创建一个对象时,构造函数会创建或者实例化一个对象并调用方法返回这个类给调用者。但是每次请求一个对象都会发生这样的情况:构造函数被调用,一个新的对象被创建并且它返回了一个独一无二的对象。我猜面向对象语言的创建者有每次都创建一个新对象的理由,但是单例过程的支持者说这是冗余的且浪费资源。
|
||||
|
||||
![Normal class instantiation][14]
|
||||
|
||||
下面这幅图使用单例模式创建对象。这里,构造函数仅当对象首次通过调用预先设计好的 getInstance() 方法时才会被调用。这通常通过检查值是否为 null 来完成,并且这个对象被作为私有变量保存在单例类的内部。下次 getInstance() 被调用时,这个类会返回第一次被创建的对象。没有新的对象产生;它只是返回旧的那一个。
|
||||
下面这幅图使用单例模式创建对象。这里,构造函数仅当对象首次通过调用预先设计好的 `getInstance()` 方法时才会被调用。这通常通过检查该值是否为 `null` 来完成,并且这个对象被作为私有变量保存在单例类的内部。下次 `getInstance()` 被调用时,这个类会返回第一次被创建的对象。而没有新的对象产生;它只是返回旧的那一个。
|
||||
|
||||
![Singleton pattern instantiation][15]
|
||||
|
||||
下面这段代码展示了创建单例模式最简单的方法:
|
||||
|
||||
|
||||
```
|
||||
package org.opensource.demo.singleton;
|
||||
|
||||
@ -89,7 +84,7 @@ public class OpensourceSingleton {
|
||||
}
|
||||
```
|
||||
|
||||
在调用方, 这里展示了如何调用单例类来获取对象:
|
||||
在调用方,这里展示了如何调用单例类来获取对象:
|
||||
|
||||
```
|
||||
Opensource newObject = Opensource.getInstance();
|
||||
@ -97,11 +92,10 @@ Opensource newObject = Opensource.getInstance();
|
||||
|
||||
这段代码很好的验证了单例模式的思想:
|
||||
|
||||
1. 当 getInstance() 被调用时,它通过检查 null 值来见检查对象是否已经被创建。
|
||||
2. 如果值为空,它会创建一个新对象并把它保存到私有域,返回这个对象给调用者。否则直接返回之前被创建的对象。
|
||||
1. 当 `getInstance()` 被调用时,它通过检查 `null` 值来检查对象是否已经被创建。
|
||||
2. 如果值为 `null`,它会创建一个新对象并把它保存到私有域,返回这个对象给调用者。否则直接返回之前被创建的对象。
|
||||
|
||||
|
||||
单例模式实现的主要问题是它忽略了并行进程。当多个进程使用线程同时访问资源时,这个问题就产生了。对于这种情况有对应的解决方案,它被称为 _双重检查锁_ 用于多线程安全,如下所示:
|
||||
单例模式实现的主要问题是它忽略了并行进程。当多个进程使用线程同时访问资源时,这个问题就产生了。对于这种情况有对应的解决方案,它被称为*双重检查锁*,用于多线程安全,如下所示:
|
||||
|
||||
```
|
||||
package org.opensource.demo.singleton;
|
||||
@ -126,21 +120,21 @@ public class ImprovedOpensourceSingleton {
|
||||
}
|
||||
```
|
||||
|
||||
只是为了强调前一点,确保只有在你认为这是一个安全的选项时才能直接实现你的单例模式。最好的方法是通过使用一个制作精良的编程框架来利用单例功能。
|
||||
再强调一下前面的观点,确保只有在你认为这是一个安全的选择时才直接实现你的单例模式。最好的方法是通过使用一个制作精良的编程框架来利用单例功能。
|
||||
|
||||
### 工厂模式:将对象创建委派给工厂类以隐藏创建逻辑
|
||||
|
||||
[工厂模式][16] 是另一种众所周知的设计模式,但是有一小点复杂。实现工厂模式的方法有很多,而下列的代码示例为最简单的实现方式。为了创建对象,工厂模式定义了一个接口,让它的子类去决定哪一个子类实例化。
|
||||
<ruby>[工厂模式][16]<rt>factory pattern</rt></ruby>是另一种众所周知的设计模式,但是有一小点复杂。实现工厂模式的方法有很多,而下列的代码示例为最简单的实现方式。为了创建对象,工厂模式定义了一个接口,让它的子类去决定实例化哪一个类。
|
||||
|
||||
> **Factory pattern:** 将对象创建委派给工厂类,因此它能隐藏创建逻辑。
|
||||
> **工厂模式**:将对象创建委派给工厂类,因此它能隐藏创建逻辑。
|
||||
|
||||
下列的图片展示了最简单的工厂模式是如何实现的?
|
||||
下列的图片展示了最简单的工厂模式是如何实现的。
|
||||
|
||||
![Factory pattern][17]
|
||||
|
||||
客户端请求工厂类创建某个对象,类型 x,而不是客户端直接调用对象创建。根据类型,工厂模式决定要创建和返回的对象。
|
||||
客户端请求工厂类创建类型为 x 的某个对象,而不是客户端直接调用对象创建。根据其类型,工厂模式决定要创建和返回的对象。
|
||||
|
||||
在下列代码示例中,OpensourceFactory 是工厂类实现,它从调用者那里获取 _类型_ 并根据该输入值决定要创建和返回的对象:
|
||||
在下列代码示例中,`OpensourceFactory` 是工厂类实现,它从调用者那里获取*类型*并根据该输入值决定要创建和返回的对象:
|
||||
|
||||
```
|
||||
package org.opensource.demo.factory;
|
||||
@ -164,8 +158,7 @@ public class OpensourceFactory {
|
||||
}
|
||||
```
|
||||
|
||||
OpenSourceJVMServer 是一个100%的抽象类(或者一个接口类),它指示要实现的是什么,而不是怎样实现:
|
||||
|
||||
`OpenSourceJVMServer` 是一个 100% 的抽象类(即接口类),它指示要实现的是什么,而不是怎样实现:
|
||||
|
||||
```
|
||||
package org.opensource.demo.factory;
|
||||
@ -177,8 +170,7 @@ public interface OpensourceJVMServers {
|
||||
}
|
||||
```
|
||||
|
||||
这是一个 OpensourceJVMServers 实现类示例。当 “RedHat” 被作为类型传递给工厂类,WildFly 服务器将被创建:
|
||||
|
||||
这是一个 `OpensourceJVMServers` 类的实现示例。当 `RedHat` 被作为类型传递给工厂类,`WildFly` 服务器将被创建:
|
||||
|
||||
```
|
||||
package org.opensource.demo.factory;
|
||||
@ -200,18 +192,17 @@ public class WildFly implements OpensourceJVMServers {
|
||||
|
||||
### 观察者模式:订阅主题并获取相关更新的通知
|
||||
|
||||
最后是[观察者模式][20]。像单例模式那样,很少有专业的程序员直接实现观察者模式。但是,许多消息队列和数据服务实现都借用了观察者模式的概念。观察者模式在对象之间定义了一对多的依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都将被自动地通知和更新。
|
||||
最后是<ruby>[观察者模式][20]<rt>observer pattern</rt></ruby>。像单例模式那样,很少有专业的程序员直接实现观察者模式。但是,许多消息队列和数据服务实现都借用了观察者模式的概念。观察者模式在对象之间定义了一对多的依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都将被自动地通知和更新。
|
||||
|
||||
> **Observer pattern:** 如果有更新,那么订阅了该话题/主题的客户端将被通知。
|
||||
> **观察者模式**:如果有更新,那么订阅了该话题/主题的客户端将被通知。
|
||||
|
||||
思考观察者模式的最简单方法是想象一个邮件列表,你可以在其中订阅任何主题,无论是开源,技术,名人,烹饪还是您感兴趣的任何其他内容。每个主题维护者一个它的订阅者列表,在观察者模式中它们相当于观察者。当某一个主题更新时,它所有的订阅者(观察者)都将被通知这次改变。并且订阅者总是能取消某一个主题的订阅。
|
||||
理解观察者模式的最简单方法是想象一个邮件列表,你可以在其中订阅任何主题,无论是开源、技术、名人、烹饪还是您感兴趣的任何其他内容。每个主题维护者一个它的订阅者列表,在观察者模式中它们相当于观察者。当某一个主题更新时,它所有的订阅者(观察者)都将被通知这次改变。并且订阅者总是能取消某一个主题的订阅。
|
||||
|
||||
如下图所示,客户端可以订阅不同的主题并添加观察者以获得最新信息的通知。因为观察者不断的监听着这个主题,这个观察者会通知客户端任何发生的改变。
|
||||
|
||||
![Observer pattern][21]
|
||||
|
||||
让我们呢来看看观察者模式的代码示例,从主题/话题类开始:
|
||||
|
||||
让我们来看看观察者模式的代码示例,从主题/话题类开始:
|
||||
|
||||
```
|
||||
package org.opensource.demo.observer;
|
||||
@ -223,7 +214,8 @@ public interface Topic {
|
||||
public void notifyObservers();
|
||||
}
|
||||
```
|
||||
这段代码描述了一个接口为不同的主题去实现已定义的方法。注意一个观察者如何被添加、移除和通知。
|
||||
|
||||
这段代码描述了一个为不同的主题去实现已定义方法的接口。注意一个观察者如何被添加、移除和通知的。
|
||||
|
||||
这是一个主题的实现示例:
|
||||
|
||||
@ -270,7 +262,7 @@ public class Conference implements Topic {
|
||||
}
|
||||
```
|
||||
|
||||
这段代码定义了一个特定主题的实现。当发生改变时,这个实现调用它自己的方法。 注意这将获取存储为列表的观察者的数量,并且可以通知和维护观察者。
|
||||
这段代码定义了一个特定主题的实现。当发生改变时,这个实现调用它自己的方法。注意这将获取观察者的数量,它以列表方式存储,并且可以通知和维护观察者。
|
||||
|
||||
这是一个观察者类:
|
||||
|
||||
@ -286,7 +278,6 @@ public interface [Observer][22] {
|
||||
|
||||
例如,实现了该接口的观察者可以在会议上打印出与会者和发言人的数量:
|
||||
|
||||
|
||||
```
|
||||
package org.opensource.demo.observer;
|
||||
|
||||
@ -314,13 +305,11 @@ public class MonitorConferenceAttendees implements [Observer][22] {
|
||||
}
|
||||
```
|
||||
|
||||
### 之后去哪?
|
||||
### 接下来
|
||||
|
||||
现在你已经阅读了这篇对于设计模式的介绍引导,你应该去一个好地方寻求其他设计模式,例如外观模式,模版模式和装饰器模式。也有一些并发和分布式系统的设计模式如断路器模式和锚定模式。
|
||||
现在你已经阅读了这篇对于设计模式的介绍引导,你还可以去寻求了解其他设计模式,例如外观模式,模版模式和装饰器模式。也有一些并发和分布式系统的设计模式如断路器模式和锚定模式。
|
||||
|
||||
可是,我相信最好的磨砺你的技能首先是通过在你的边缘工程或者练习中实现这些设计模式。你甚至可以开始考虑如何在实际项目中应用这些设计模式。接下来,我强烈建议您查看OOP的 [SOLID原则][23]。之后,你将准备好了解其他设计模式。
|
||||
|
||||
However, I believe it's best to hone your skills first by implementing these design patterns in your side projects or just as practice. You can even begin to contemplate how you can apply these design patterns in your real projects. Next, I highly recommend checking out the [SOLID principles][23] of OOP. After that, you will be ready to look into the other design patterns.
|
||||
可是,我相信最好的磨砺你的技能的方式首先是通过在你的业余项目或者练习中实现这些设计模式。你甚至可以开始考虑如何在实际项目中应用这些设计模式。接下来,我强烈建议你查看 OOP 的 [SOLID 原则][23]。之后,你就准备好了解其他设计模式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -329,7 +318,7 @@ via: https://opensource.com/article/19/7/understanding-software-design-patterns
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
245
published/20190725 Introduction to GNU Autotools.md
Normal file
245
published/20190725 Introduction to GNU Autotools.md
Normal file
@ -0,0 +1,245 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11218-1.html)
|
||||
[#]: subject: (Introduction to GNU Autotools)
|
||||
[#]: via: (https://opensource.com/article/19/7/introduction-gnu-autotools)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
GNU Autotools 介绍
|
||||
======
|
||||
|
||||
> 如果你仍未使用过 Autotools,那么这篇文章将改变你递交代码的方式。
|
||||
|
||||

|
||||
|
||||
你有没有下载过流行的软件项目的源代码,要求你输入几乎是仪式般的 `./configure; make && make install` 命令序列来构建和安装它?如果是这样,你已经使用过 [GNU Autotools][2] 了。如果你曾经研究过这样的项目所附带的一些文件,你可能会对这种构建系统的显而易见的复杂性感到害怕。
|
||||
|
||||
好的消息是,GNU Autotools 的设置要比你想象的要简单得多,GNU Autotools 本身可以为你生成这些上千行的配置文件。是的,你可以编写 20 或 30 行安装代码,并免费获得其他 4,000 行。
|
||||
|
||||
### Autotools 工作方式
|
||||
|
||||
如果你是初次使用 Linux 的用户,正在寻找有关如何安装应用程序的信息,那么你不必阅读本文!如果你想研究如何构建软件,欢迎阅读它;但如果你只是要安装一个新应用程序,请阅读我在[在 Linux 上安装应用程序][3]的文章。
|
||||
|
||||
对于开发人员来说,Autotools 是一种管理和打包源代码的快捷方式,以便用户可以编译和安装软件。 Autotools 也得到了主要打包格式(如 DEB 和 RPM)的良好支持,因此软件存储库的维护者可以轻松管理使用 Autotools 构建的项目。
|
||||
|
||||
Autotools 工作步骤:
|
||||
|
||||
1. 首先,在 `./configure` 步骤中,Autotools 扫描宿主机系统(即当前正在运行的计算机)以发现默认设置。默认设置包括支持库所在的位置,以及新软件应放在系统上的位置。
|
||||
2. 接下来,在 `make` 步骤中,Autotools 通常通过将人类可读的源代码转换为机器语言来构建应用程序。
|
||||
3. 最后,在 `make install` 步骤中,Autotools 将其构建好的文件复制到计算机上(在配置阶段检测到)的相应位置。
|
||||
|
||||
这个过程看起来很简单,和你使用 Autotools 的步骤一样。
|
||||
|
||||
### Autotools 的优势
|
||||
|
||||
GNU Autotools 是我们大多数人认为理所当然的重要软件。与 [GCC(GNU 编译器集合)][4]一起,Autotools 是支持将自由软件构建和安装到正在运行的系统的脚手架。如果你正在运行 [POSIX][5] 系统,可以毫不保守地说,你的计算机上的操作系统里大多数可运行软件都是这些这样构建的。
|
||||
|
||||
即使是你的项目是个玩具项目不是操作系统,你可能会认为 Autotools 对你的需求来说太过分了。但是,尽管它的名气很大,Autotools 有许多可能对你有益的小功能,即使你的项目只是一个相对简单的应用程序或一系列脚本。
|
||||
|
||||
#### 可移植性
|
||||
|
||||
首先,Autotools 考虑到了可移植性。虽然它无法使你的项目在所有 POSIX 平台上工作(这取决于你,编码的人),但 Autotools 可以确保你标记为要安装的文件安装到已知平台上最合理的位置。而且由于 Autotools,高级用户可以轻松地根据他们自己的系统情况定制和覆盖任何非最佳设定。
|
||||
|
||||
使用 Autotools,你只要知道需要将文件安装到哪个常规位置就行了。它会处理其他一切。不需要可能破坏未经测试的操作系统的定制安装脚本。
|
||||
|
||||
#### 打包
|
||||
|
||||
Autotools 也得到了很好的支持。将一个带有 Autotools 的项目交给一个发行版打包者,无论他们是打包成 RPM、DEB、TGZ 还是其他任何东西,都很简单。打包工具知道 Autotools,因此可能不需要修补、魔改或调整。在许多情况下,将 Autotools 项目结合到流程中甚至可以实现自动化。
|
||||
|
||||
### 如何使用 Autotools
|
||||
|
||||
要使用 Autotools,必须先安装它。你的发行版可能提供一个单个的软件包来帮助开发人员构建项目,或者它可能为每个组件提供了单独的软件包,因此你可能需要在你的平台上进行一些研究以发现需要安装的软件包。
|
||||
|
||||
Autotools 的组件是:
|
||||
|
||||
* `automake`
|
||||
* `autoconf`
|
||||
* `automake`
|
||||
* `make`
|
||||
|
||||
虽然你可能需要安装项目所需的编译器(例如 GCC),但 Autotools 可以很好地处理不需要编译的脚本或二进制文件。实际上,Autotools 对于此类项目非常有用,因为它提供了一个 `make uninstall` 脚本,以便于删除。
|
||||
|
||||
安装了所有组件之后,现在让我们了解一下你的项目文件的组成结构。
|
||||
|
||||
#### Autotools 项目结构
|
||||
|
||||
GNU Autotools 有非常具体的预期规范,如果你经常下载和构建源代码,可能大多数都很熟悉。首先,源代码本身应该位于一个名为 `src` 的子目录中。
|
||||
|
||||
你的项目不必遵循所有这些预期规范,但如果你将文件放在非标准位置(从 Autotools 的角度来看),那么你将不得不稍后在 `Makefile` 中对其进行调整。
|
||||
|
||||
此外,这些文件是必需的:
|
||||
|
||||
* `NEWS`
|
||||
* `README`
|
||||
* `AUTHORS`
|
||||
* `ChangeLog`
|
||||
|
||||
你不必主动使用这些文件,它们可以是包含所有信息的单个汇总文档(如 `README.md`)的符号链接,但它们必须存在。
|
||||
|
||||
#### Autotools 配置
|
||||
|
||||
在你的项目根目录下创建一个名为 `configure.ac` 的文件。`autoconf` 使用此文件来创建用户在构建之前运行的 `configure` shell 脚本。该文件必须至少包含 `AC_INIT` 和 `AC_OUTPUT` [M4 宏][6]。你不需要了解有关 M4 语言的任何信息就可以使用这些宏;它们已经为你编写好了,并且所有与 Autotools 相关的内容都在该文档中定义好了。
|
||||
|
||||
在你喜欢的文本编辑器中打开该文件。`AC_INIT` 宏可以包括包名称、版本、报告错误的电子邮件地址、项目 URL 以及可选的源 TAR 文件名称等参数。
|
||||
|
||||
[AC_OUTPUT][7] 宏更简单,不用任何参数。
|
||||
|
||||
```
|
||||
AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
|
||||
AC_OUTPUT
|
||||
```
|
||||
|
||||
如果你此刻运行 `autoconf`,会依据你的 `configure.ac` 文件生成一个 `configure` 脚本,它是可以运行的。但是,也就是能运行而已,因为到目前为止你所做的就是定义项目的元数据,并要求创建一个配置脚本。
|
||||
|
||||
你必须在 `configure.ac` 文件中调用的下一个宏是创建 [Makefile][9] 的函数。 `Makefile` 会告诉 `make` 命令做什么(通常是如何编译和链接程序)。
|
||||
|
||||
创建 `Makefile` 的宏是 `AM_INIT_AUTOMAKE`,它不接受任何参数,而 `AC_CONFIG_FILES` 接受的参数是你要输出的文件的名称。
|
||||
|
||||
最后,你必须添加一个宏来考虑你的项目所需的编译器。你使用的宏显然取决于你的项目。如果你的项目是用 C++ 编写的,那么适当的宏是 `AC_PROG_CXX`,而用 C 编写的项目需要 `AC_PROG_CC`,依此类推,详见 Autoconf 文档中的 [Building Programs and Libraries][10] 部分。
|
||||
|
||||
例如,我可能会为我的 C++ 程序添加以下内容:
|
||||
|
||||
```
|
||||
AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
|
||||
AC_OUTPUT
|
||||
AM_INIT_AUTOMAKE
|
||||
AC_CONFIG_FILES([Makefile])
|
||||
AC_PROG_CXX
|
||||
```
|
||||
|
||||
保存该文件。现在让我们将目光转到 `Makefile`。
|
||||
|
||||
#### 生成 Autotools Makefile
|
||||
|
||||
`Makefile` 并不难手写,但 Autotools 可以为你编写一个,而它生成的那个将使用在 `./configure` 步骤中检测到的配置选项,并且它将包含比你考虑要包括或想要自己写的还要多得多的选项。然而,Autotools 并不能检测你的项目构建所需的所有内容,因此你必须在文件 `Makefile.am` 中添加一些细节,然后在构造 `Makefile` 时由 `automake` 使用。
|
||||
|
||||
`Makefile.am` 使用与 `Makefile` 相同的语法,所以如果你曾经从头开始编写过 `Makefile`,那么这个过程将是熟悉和简单的。通常,`Makefile.am` 文件只需要几个变量定义来指示要构建的文件以及它们的安装位置即可。
|
||||
|
||||
以 `_PROGRAMS` 结尾的变量标识了要构建的代码(这通常被认为是<ruby>原语<rt>primary</rt></ruby>目标;这是 `Makefile` 存在的主要意义)。Automake 也会识别其他原语,如 `_SCRIPTS`、`_ DATA`、`_LIBRARIES`,以及构成软件项目的其他常见部分。
|
||||
|
||||
如果你的应用程序在构建过程中需要实际编译,那么你可以用 `bin_PROGRAMS` 变量将其标记为二进制程序,然后使用该程序名称作为变量前缀引用构建它所需的源代码的任何部分(这些部分可能是将被编译和链接在一起的一个或多个文件):
|
||||
|
||||
```
|
||||
bin_PROGRAMS = penguin
|
||||
penguin_SOURCES = penguin.cpp
|
||||
```
|
||||
|
||||
`bin_PROGRAMS` 的目标被安装在 `bindir` 中,它在编译期间可由用户配置。
|
||||
|
||||
如果你的应用程序不需要实际编译,那么你的项目根本不需要 `bin_PROGRAMS` 变量。例如,如果你的项目是用 Bash、Perl 或类似的解释语言编写的脚本,那么定义一个 `_SCRIPTS` 变量来替代:
|
||||
|
||||
```
|
||||
bin_SCRIPTS = bin/penguin
|
||||
```
|
||||
|
||||
Automake 期望源代码位于名为 `src` 的目录中,因此如果你的项目使用替代目录结构进行布局,则必须告知 Automake 接受来自外部源的代码:
|
||||
|
||||
```
|
||||
AUTOMAKE_OPTIONS = foreign subdir-objects
|
||||
```
|
||||
|
||||
最后,你可以在 `Makefile.am` 中创建任何自定义的 `Makefile` 规则,它们将逐字复制到生成的 `Makefile` 中。例如,如果你知道一些源代码中的临时值需要在安装前替换,则可以为该过程创建自定义规则:
|
||||
|
||||
```
|
||||
all-am: penguin
|
||||
touch bin/penguin.sh
|
||||
|
||||
penguin: bin/penguin.sh
|
||||
@sed "s|__datadir__|@datadir@|" $< >bin/$@
|
||||
```
|
||||
|
||||
一个特别有用的技巧是扩展现有的 `clean` 目标,至少在开发期间是这样的。`make clean` 命令通常会删除除了 Automake 基础结构之外的所有生成的构建文件。它是这样设计的,因为大多数用户很少想要 `make clean` 来删除那些便于构建代码的文件。
|
||||
|
||||
但是,在开发期间,你可能需要一种方法可靠地将项目返回到相对不受 Autotools 影响的状态。在这种情况下,你可能想要添加:
|
||||
|
||||
```
|
||||
clean-local:
|
||||
@rm config.status configure config.log
|
||||
@rm Makefile
|
||||
@rm -r autom4te.cache/
|
||||
@rm aclocal.m4
|
||||
@rm compile install-sh missing Makefile.in
|
||||
```
|
||||
|
||||
这里有很多灵活性,如果你还不熟悉 `Makefile`,那么很难知道你的 `Makefile.am` 需要什么。最基本需要的是原语目标,无论是二进制程序还是脚本,以及源代码所在位置的指示(无论是通过 `_SOURCES` 变量还是使用 `AUTOMAKE_OPTIONS` 告诉 Automake 在哪里查找源代码)。
|
||||
|
||||
一旦定义了这些变量和设置,如下一节所示,你就可以尝试生成构建脚本,并调整缺少的任何内容。
|
||||
|
||||
#### 生成 Autotools 构建脚本
|
||||
|
||||
你已经构建了基础结构,现在是时候让 Autotools 做它最擅长的事情:自动化你的项目工具。对于开发人员(你),Autotools 的接口与构建代码的用户的不同。
|
||||
|
||||
构建者通常使用这个众所周知的顺序:
|
||||
|
||||
```
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
但是,要使这种咒语起作用,你作为开发人员必须引导构建这些基础结构。首先,运行 `autoreconf` 以生成用户在运行 `make` 之前调用的 `configure` 脚本。使用 `-install` 选项将辅助文件(例如符号链接)引入到 `depcomp`(这是在编译过程中生成依赖项的脚本),以及 `compile` 脚本的副本(一个编译器的包装器,用于说明语法,等等)。
|
||||
|
||||
```
|
||||
$ autoreconf --install
|
||||
configure.ac:3: installing './compile'
|
||||
configure.ac:2: installing './install-sh'
|
||||
configure.ac:2: installing './missing'
|
||||
```
|
||||
|
||||
使用此开发构建环境,你可以创建源代码分发包:
|
||||
|
||||
```
|
||||
$ make dist
|
||||
```
|
||||
|
||||
`dist` 目标是从 Autotools “免费”获得的规则。这是一个内置于 `Makefile` 中的功能,它是通过简单的 `Makefile.am` 配置生成的。该目标可以生成一个 `tar.gz` 存档,其中包含了所有源代码和所有必要的 Autotools 基础设施,以便下载程序包的人员可以构建项目。
|
||||
|
||||
此时,你应该仔细查看存档文件的内容,以确保它包含你要发送给用户的所有内容。当然,你也应该尝试自己构建:
|
||||
|
||||
```
|
||||
$ tar --extract --file penguin-0.0.1.tar.gz
|
||||
$ cd penguin-0.0.1
|
||||
$ ./configure
|
||||
$ make
|
||||
$ DESTDIR=/tmp/penguin-test-build make install
|
||||
```
|
||||
|
||||
如果你的构建成功,你将找到由 `DESTDIR` 指定的已编译应用程序的本地副本(在此示例的情况下为 `/tmp/penguin-test-build`)。
|
||||
|
||||
```
|
||||
$ /tmp/example-test-build/usr/local/bin/example
|
||||
hello world from GNU Autotools
|
||||
```
|
||||
|
||||
### 去使用 Autotools
|
||||
|
||||
Autotools 是一个很好的脚本集合,可用于可预测的自动发布过程。如果你习惯使用 Python 或 Bash 构建器,这个工具集对你来说可能是新的,但它为你的项目提供的结构和适应性可能值得学习。
|
||||
|
||||
而 Autotools 也不只是用于代码。Autotools 可用于构建 [Docbook][11] 项目,保持媒体有序(我使用 Autotools 进行音乐发布),文档项目以及其他任何可以从可自定义安装目标中受益的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/introduction-gnu-autotools
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_kernel_clang_vscode.jpg?itok=fozZ4zrr (Linux kernel source code (C) in Visual Studio Code)
|
||||
[2]: https://www.gnu.org/software/automake/faq/autotools-faq.html
|
||||
[3]: https://linux.cn/article-9486-1.html
|
||||
[4]: https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[5]: https://en.wikipedia.org/wiki/POSIX
|
||||
[6]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Initializing-configure.html
|
||||
[7]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Output.html#Output
|
||||
[8]: mailto:seth@example.com
|
||||
[9]: https://www.gnu.org/software/make/manual/html_node/Introduction.html
|
||||
[10]: https://www.gnu.org/software/automake/manual/html_node/Programs.html#Programs
|
||||
[11]: https://opensource.com/article/17/9/docbook
|
||||
131
published/20190730 How to create a pull request in GitHub.md
Executable file
131
published/20190730 How to create a pull request in GitHub.md
Executable file
@ -0,0 +1,131 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "furrybear"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-11215-1.html"
|
||||
[#]: subject: "How to create a pull request in GitHub"
|
||||
[#]: via: "https://opensource.com/article/19/7/create-pull-request-github"
|
||||
[#]: author: "Kedar Vijay Kulkarni https://opensource.com/users/kkulkarn"
|
||||
|
||||
如何在 Github 上创建一个拉取请求
|
||||
======
|
||||
|
||||
> 学习如何复刻一个仓库,进行更改,并要求维护人员审查并合并它。
|
||||
|
||||
![a checklist for a team][1]
|
||||
|
||||
你知道如何使用 git 了,你有一个 [GitHub][2] 仓库并且可以向它推送。这一切都很好。但是你如何为他人的 GitHub 项目做出贡献? 这是我在学习 git 和 GitHub 之后想知道的。在本文中,我将解释如何<ruby>复刻<rt>fork</rt></ruby>一个 git 仓库、进行更改并提交一个<ruby>拉取请求<rt>pull request</rt></ruby>。
|
||||
|
||||
当你想要在一个 GitHub 项目上工作时,第一步是复刻一个仓库。
|
||||
|
||||
![Forking a GitHub repo][3]
|
||||
|
||||
你可以使用[我的演示仓库][4]试一试。
|
||||
|
||||
当你在这个页面时,单击右上角的 “Fork”(复刻)按钮。这将在你的 GitHub 用户账户下创建我的演示仓库的一个新副本,其 URL 如下:
|
||||
|
||||
```
|
||||
https://github.com/<你的用户名>/demo
|
||||
```
|
||||
|
||||
这个副本包含了原始仓库中的所有代码、分支和提交。
|
||||
|
||||
接下来,打开你计算机上的终端并运行命令来<ruby>克隆<rt>clone</rt></ruby>仓库:
|
||||
|
||||
```
|
||||
git clone https://github.com/<你的用户名>/demo
|
||||
```
|
||||
|
||||
一旦仓库被克隆后,你需要做两件事:
|
||||
|
||||
1、通过发出命令创建一个新分支 `new_branch` :
|
||||
|
||||
```
|
||||
git checkout -b new_branch
|
||||
```
|
||||
|
||||
2、使用以下命令为上游仓库创建一个新的<ruby>远程<rt>remote</rt></ruby>:
|
||||
|
||||
```
|
||||
git remote add upstream https://github.com/kedark3/demo
|
||||
```
|
||||
|
||||
在这种情况下,“上游仓库”指的是你创建复刻来自的原始仓库。
|
||||
|
||||
现在你可以更改代码了。以下代码创建一个新分支,进行任意更改,并将其推送到 `new_branch` 分支:
|
||||
|
||||
```
|
||||
$ git checkout -b new_branch
|
||||
Switched to a new branch ‘new_branch’
|
||||
$ echo “some test file” > test
|
||||
$ cat test
|
||||
Some test file
|
||||
$ git status
|
||||
On branch new_branch
|
||||
No commits yet
|
||||
Untracked files:
|
||||
(use "git add <file>..." to include in what will be committed)
|
||||
test
|
||||
nothing added to commit but untracked files present (use "git add" to track)
|
||||
$ git add test
|
||||
$ git commit -S -m "Adding a test file to new_branch"
|
||||
[new_branch (root-commit) 4265ec8] Adding a test file to new_branch
|
||||
1 file changed, 1 insertion(+)
|
||||
create mode 100644 test
|
||||
$ git push -u origin new_branch
|
||||
Enumerating objects: 3, done.
|
||||
Counting objects: 100% (3/3), done.
|
||||
Writing objects: 100% (3/3), 918 bytes | 918.00 KiB/s, done.
|
||||
Total 3 (delta 0), reused 0 (delta 0)
|
||||
Remote: Create a pull request for ‘new_branch’ on GitHub by visiting:
|
||||
Remote: <http://github.com/example/Demo/pull/new/new\_branch>
|
||||
Remote:
|
||||
* [new branch] new_branch -> new_branch
|
||||
```
|
||||
|
||||
一旦你将更改推送到您的仓库后, “Compare & pull request”(比较和拉取请求)按钮将出现在GitHub。
|
||||
|
||||
![GitHub's Compare & Pull Request button][5]
|
||||
|
||||
单击它,你将进入此屏幕:
|
||||
|
||||
![GitHub's Open pull request button][6]
|
||||
|
||||
单击 “Create pull request”(创建拉取请求)按钮打开一个拉取请求。这将允许仓库的维护者们审查你的贡献。然后,如果你的贡献是没问题的,他们可以合并它,或者他们可能会要求你做一些改变。
|
||||
|
||||
### 精简版
|
||||
|
||||
总之,如果您想为一个项目做出贡献,最简单的方法是:
|
||||
|
||||
1. 找到您想要贡献的项目
|
||||
2. 复刻它
|
||||
3. 将其克隆到你的本地系统
|
||||
4. 建立一个新的分支
|
||||
5. 进行你的更改
|
||||
6. 将其推送回你的仓库
|
||||
7. 单击 “Compare & pull request”(比较和拉取请求)按钮
|
||||
8. 单击 “Create pull request”(创建拉取请求)以打开一个新的拉取请求
|
||||
|
||||
如果审阅者要求更改,请重复步骤 5 和 6,为你的拉取请求添加更多提交。
|
||||
|
||||
快乐编码!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/create-pull-request-github
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[furrybear](https://github.com/furrybear)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kkulkarnhttps://opensource.com/users/fontanahttps://opensource.com/users/mhanwellhttps://opensource.com/users/mysentimentshttps://opensource.com/users/greg-p
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_hands_team_collaboration.png?itok=u82QepPk "a checklist for a team"
|
||||
[2]: https://github.com/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/forkrepo.png "Forking a GitHub repo"
|
||||
[4]: https://github.com/kedark3/demo
|
||||
[5]: https://opensource.com/sites/default/files/uploads/compare-and-pull-request-button.png "GitHub's Compare & Pull Request button"
|
||||
[6]: https://opensource.com/sites/default/files/uploads/open-a-pull-request_crop.png "GitHub's Open pull request button"
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11196-1.html)
|
||||
[#]: subject: (5 Free Partition Managers for Linux)
|
||||
[#]: via: (https://itsfoss.com/partition-managers-linux/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
@ -10,16 +10,17 @@
|
||||
5 个免费的 Linux 分区管理器
|
||||
======
|
||||
|
||||
_ **以下是我们推荐的 Linux 分区工具。它们能让你删除、添加、微调 Linux 系统上的磁盘分区或分区大小。** _
|
||||
> 以下是我们推荐的 Linux 分区工具。它们能让你删除、添加、调整或缩放 Linux 系统上的磁盘分区。
|
||||
|
||||
通常,你在安装操作系统时决定磁盘分区。但是,如果你需要在安装后的某个时间修改分区,该怎么办?你无法会到系统安装页面。因此,这就需要分区管理器(或准确地说是磁盘分区管理器)上场了。
|
||||
通常,你在安装操作系统时决定磁盘分区。但是,如果你需要在安装后的某个时间修改分区,该怎么办?你无法回到系统安装阶段。因此,这就需要分区管理器(或准确地说是磁盘分区管理器)上场了。
|
||||
|
||||
在大多数情况下,你无需单独安装分区管理器,因为它已预先安装。此外,值得注意的是,你可以选择基于命令行或有 GUI 的分区管理器。
|
||||
|
||||
注意!
|
||||
**注意!**
|
||||
|
||||
磁盘分区是一项有风险的任务。除非绝对必要,否则不要这样做。
|
||||
如果你使用的是基于命令行的分区工具,那么需要学习完成任务的命令。否则,你可能最终会擦除整个磁盘。
|
||||
> 磁盘分区是一项有风险的任务。除非绝对必要,否则不要这样做。
|
||||
>
|
||||
> 如果你使用的是基于命令行的分区工具,那么需要学习完成任务的命令。否则,你可能最终会擦除整个磁盘。
|
||||
|
||||
### Linux 中的 5 个管理磁盘分区的工具
|
||||
|
||||
@ -35,7 +36,7 @@ _ **以下是我们推荐的 Linux 分区工具。它们能让你删除、添加
|
||||
|
||||
它会在启动时直接提示你以 root 用户进行身份验证。所以,你根本不需要在这里使用终端。身份验证后,它会分析设备,然后让你调整磁盘分区。如果发生数据丢失或意外删除文件,你还可以找到“尝试数据救援”的选项。
|
||||
|
||||
[GParted][3]
|
||||
- [GParted][3]
|
||||
|
||||
#### GNOME Disks
|
||||
|
||||
@ -43,36 +44,35 @@ _ **以下是我们推荐的 Linux 分区工具。它们能让你删除、添加
|
||||
|
||||
一个基于 GUI 的分区管理器,随 Ubuntu 或任何基于 Ubuntu 的发行版(如 Zorin OS)一起出现。
|
||||
|
||||
它能让你删除、添加、调整大小和微调分区。如果还有疑问,它甚至可以帮助你[在 Ubuntu 中格式化 USB][6]。
|
||||
它能让你删除、添加、缩放和微调分区。如果你遇到故障,它甚至可以[在 Ubuntu 中格式化 USB][6] 来帮助你救援机器。
|
||||
|
||||
你甚至可以借助此工具尝试修复分区。它的选项还包括编辑文件系统、创建分区镜像、还原镜像以及对分区进行基准测试。
|
||||
|
||||
[GNOME Disks][7]
|
||||
- [GNOME Disks][7]
|
||||
|
||||
#### KDE Partition Manager
|
||||
|
||||
![Kde Partition Manager][8]
|
||||
|
||||
KDE Partition Manager 应该预装在基于 KDE 的 Linux 发行版上。但是,如果没有,你可以在软件中心搜索并轻松安装它。
|
||||
KDE Partition Manager 应该已经预装在基于 KDE 的 Linux 发行版上了。但是,如果没有,你可以在软件中心搜索并轻松安装它。
|
||||
|
||||
|
||||
如果你没有预装它,那么可能会在尝试启动时通知你没有管理权限。没有管理员权限,你无法做任何事情。因此,在这种情况下,请输入以下命令:
|
||||
如果你不是预装的,那么可能会在尝试启动时通知你没有管理权限。没有管理员权限,你无法做任何事情。因此,在这种情况下,请输入以下命令:
|
||||
|
||||
```
|
||||
sudo partitionmanager
|
||||
```
|
||||
|
||||
它将扫描你的设备,然后你就可以创建、移动、复制、删除和调整分区大小。你还可以导入/导出分区表及使用其他许多调整选项。
|
||||
它将扫描你的设备,然后你就可以创建、移动、复制、删除和缩放分区。你还可以导入/导出分区表及使用其他许多调整选项。
|
||||
|
||||
[KDE Partition Manager][9]
|
||||
- [KDE Partition Manager][9]
|
||||
|
||||
#### Fdisk (命令行)
|
||||
#### Fdisk(命令行)
|
||||
|
||||
![Fdisk][10]
|
||||
|
||||
[fdisk][11] 是一个命令行程序,它在每个类 Unix 的系统中都有。不要担心,即使它需要你启动终端并输入命令,但这并不是很困难。但是,如果你在使用基于文本的程序时感到困惑,那么你应该继续使用上面提到的 GUI 程序。它们都做同样的事情。
|
||||
|
||||
要启动 fdisk,你必须是 root 用户并指定管理分区的设备。以下是该命令的示例:
|
||||
要启动 `fdisk`,你必须是 root 用户并指定管理分区的设备。以下是该命令的示例:
|
||||
|
||||
```
|
||||
sudo fdisk /dev/sdc
|
||||
@ -80,17 +80,17 @@ sudo fdisk /dev/sdc
|
||||
|
||||
你可以参考 [Linux 文档项目的维基页面][12]以获取命令列表以及有关其工作原理的更多详细信息。
|
||||
|
||||
#### GNU Parted (命令行)
|
||||
#### GNU Parted(命令行)
|
||||
|
||||
![Gnu Parted][13]
|
||||
|
||||
这是另一个在你 Linux 发行版上预安装的命令行程序。你需要输入下面的命令启动:
|
||||
这是在你 Linux 发行版上预安装的另一个命令行程序。你需要输入下面的命令启动:
|
||||
|
||||
```
|
||||
sudo parted
|
||||
```
|
||||
|
||||
**总结**
|
||||
### 总结
|
||||
|
||||
我不会忘了说 [QtParted][15] 是分区管理器的替代品之一。但它已经几年没有维护,因此我不建议使用它。
|
||||
|
||||
@ -103,7 +103,7 @@ via: https://itsfoss.com/partition-managers-linux/
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11199-1.html)
|
||||
[#]: subject: (Bash Script to Send a Mail When a New User Account is Created in System)
|
||||
[#]: via: (https://www.2daygeek.com/linux-bash-script-to-monitor-user-creation-send-email/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
在系统创建新用户时发送邮件的 Bash 脚本
|
||||
======
|
||||
|
||||

|
||||
|
||||
目前市场上有许多开源监测工具可用于监控 Linux 系统的性能。当系统到达指定的阈值时,它将发送邮件提醒。
|
||||
|
||||
它会监控 CPU 利用率、内存利用率、交换内存利用率、磁盘空间利用率等所有内容。但我不认为它们可以选择监控新用户创建活动,并发送提醒。
|
||||
|
||||
如果没有,这并不重要,因为我们可以编写自己的 bash 脚本来实现这一点。
|
||||
|
||||
我们过去写了许多有用的 shell 脚本。如果要查看它们,请点击以下链接。
|
||||
|
||||
* [如何使用 shell 脚本自动化执行日常任务?][1]
|
||||
|
||||
这个脚本做了什么?它监测 `/var/log/secure` 文件,并在系统创建新帐户时提醒管理员。
|
||||
|
||||
我们不会经常运行此脚本,因为创建用户不经常发生。但是,我打算一天运行一次这个脚本。因此,我们可以获得有关用户创建的综合报告。
|
||||
|
||||
如果在昨天的 `/var/log/secure` 中找到了 “useradd” 字符串,那么该脚本将向指定的邮箱发送邮件提醒,其中包含了新用户的详细信息。
|
||||
|
||||
**注意:**你需要更改邮箱而不是使用我们的邮箱。
|
||||
|
||||
```
|
||||
# vi /opt/scripts/new-user.sh
|
||||
```
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
#Set the variable which equal to zero
|
||||
prev_count=0
|
||||
count=$(grep -i "`date --date='yesterday' '+%b %e'`" /var/log/secure | egrep -wi 'useradd' | wc -l)
|
||||
|
||||
if [ "$prev_count" -lt "$count" ] ; then
|
||||
# Send a mail to given email id when errors found in log
|
||||
SUBJECT="ATTENTION: New User Account is created on server : `date --date='yesterday' '+%b %e'`"
|
||||
# This is a temp file, which is created to store the email message.
|
||||
MESSAGE="/tmp/new-user-logs.txt"
|
||||
TO="2daygeek@gmail.com"
|
||||
echo "Hostname: `hostname`" >> $MESSAGE
|
||||
echo -e "\n" >> $MESSAGE
|
||||
echo "The New User Details are below." >> $MESSAGE
|
||||
echo "+------------------------------+" >> $MESSAGE
|
||||
grep -i "`date --date='yesterday' '+%b %e'`" /var/log/secure | egrep -wi 'useradd' | grep -v 'failed adding'| awk '{print $4,$8}' | uniq | sed 's/,/ /' >> $MESSAGE
|
||||
echo "+------------------------------+" >> $MESSAGE
|
||||
mail -s "$SUBJECT" "$TO" < $MESSAGE
|
||||
rm $MESSAGE
|
||||
fi
|
||||
```
|
||||
|
||||
给 `new-user.sh` 添加可执行权限。
|
||||
|
||||
```
|
||||
$ chmod +x /opt/scripts/new-user.sh
|
||||
```
|
||||
|
||||
最后添加一个 cron 任务来自动化执行它。它会在每天 7 点运行。
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
|
||||
0 7 * * * /bin/bash /opt/scripts/new-user.sh
|
||||
```
|
||||
|
||||
注意:你将在每天 7 点收到一封邮件提醒,但这是昨天的日志。
|
||||
|
||||
你将会看到类似下面的邮件提醒。
|
||||
|
||||
```
|
||||
# cat /tmp/logs.txt
|
||||
|
||||
Hostname: 2g.server10.com
|
||||
|
||||
The New User Details are below.
|
||||
+------------------------------+
|
||||
2g.server10.com name=magesh
|
||||
2g.server10.com name=daygeek
|
||||
+------------------------------+
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-bash-script-to-monitor-user-creation-send-email/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/shell-script/
|
||||
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11206-1.html)
|
||||
[#]: subject: (4 cool new projects to try in COPR for August 2019)
|
||||
[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-august-2019/)
|
||||
[#]: author: (Dominik Turecek https://fedoramagazine.org/author/dturecek/)
|
||||
|
||||
COPR 仓库中 4 个很酷的新项目(2019.8)
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
COPR 是个人软件仓库[集合][2],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准;或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
|
||||
|
||||
这是 COPR 中一组新的有趣项目。
|
||||
|
||||
### Duc
|
||||
|
||||
[duc][3] 是磁盘使用率检查和可视化工具的集合。Duc 使用索引数据库来保存系统上文件的大小。索引完成后,你可以通过命令行界面或 GUI 快速查看磁盘使用情况。
|
||||
|
||||
![][4]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该[仓库][5]目前为 EPEL 7、Fedora 29 和 30 提供 duc。要安装 duc,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable terrywang/duc
|
||||
sudo dnf install duc
|
||||
```
|
||||
|
||||
### MuseScore
|
||||
|
||||
[MuseScore][6] 是一个处理音乐符号的软件。使用 MuseScore,你可以使用鼠标、虚拟键盘或 MIDI 控制器创建乐谱。然后,MuseScore 可以播放创建的音乐或将其导出为 PDF、MIDI 或 MusicXML。此外,它还有一个由 MuseScore 用户创建的含有大量乐谱的数据库。
|
||||
|
||||
![][7]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该[仓库][5]目前为 Fedora 29 和 30 提供 MuseScore。要安装 MuseScore,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable jjames/MuseScore
|
||||
sudo dnf install musescore
|
||||
```
|
||||
|
||||
### 动态墙纸编辑器
|
||||
|
||||
[动态墙纸编辑器][9] 是一个可在 GNOME 中创建和编辑随时间变化的壁纸集合的工具。这可以使用 XML 文件来完成,但是,动态墙纸编辑器通过其图形界面使其变得简单,你可以在其中简单地添加图片、排列图片并设置每张图片的持续时间以及它们之间的过渡。
|
||||
|
||||
![][10]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该[仓库][11]目前为 Fedora 30 和 Rawhide 提供动态墙纸编辑器。要安装它,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable atim/dynamic-wallpaper-editor
|
||||
sudo dnf install dynamic-wallpaper-editor
|
||||
```
|
||||
|
||||
### Manuskript
|
||||
|
||||
[Manuskript][12] 是一个给作者的工具,旨在让创建大型写作项目更容易。它既可以作为编写文本的编辑器,也可以作为组织故事本身、故事人物和单个情节的注释的工具。
|
||||
|
||||
![][13]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该[仓库][14]目前为 Fedora 29、30 和 Rawhide 提供 Manuskript。要安装 Manuskript,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable notsag/manuskript
|
||||
sudo dnf install manuskript
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-august-2019/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/dturecek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2017/08/4-copr-945x400.jpg
|
||||
[2]: https://copr.fedorainfracloud.org/
|
||||
[3]: https://duc.zevv.nl/
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/07/duc.png
|
||||
[5]: https://copr.fedorainfracloud.org/coprs/terrywang/duc/
|
||||
[6]: https://musescore.org/
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/07/musescore-1024x512.png
|
||||
[8]: https://copr.fedorainfracloud.org/coprs/jjames/MuseScore/
|
||||
[9]: https://github.com/maoschanz/dynamic-wallpaper-editor
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/07/dynamic-walppaper-editor.png
|
||||
[11]: https://copr.fedorainfracloud.org/coprs/atim/dynamic-wallpaper-editor/
|
||||
[12]: https://www.theologeek.ch/manuskript/
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2019/07/manuskript-1024x600.png
|
||||
[14]: https://copr.fedorainfracloud.org/coprs/notsag/manuskript/
|
||||
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11211-1.html)
|
||||
[#]: subject: (GameMode – A Tool To Improve Gaming Performance On Linux)
|
||||
[#]: via: (https://www.ostechnix.com/gamemode-a-tool-to-improve-gaming-performance-on-linux/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
GameMode:提高 Linux 游戏性能的工具
|
||||
======
|
||||
|
||||
![Gamemmode improve gaming performance on Linux][1]
|
||||
|
||||
去问一些 Linux 用户为什么他们仍然坚持 Windows 双启动,他们的答案可能是 - “游戏!”。这是真的!幸运的是,开源游戏平台如 [Lutris][2] 和专有游戏平台 Steam 已经为 Linux 平台带来了许多游戏,并且近几年来显著改善了 Linux 的游戏体验。今天,我偶然发现了另一款名为 GameMode 的 Linux 游戏相关开源工具,它能让用户提高 Linux 上的游戏性能。
|
||||
|
||||
GameMode 基本上是一组守护进程/库,它可以按需优化 Linux 系统的游戏性能。我以为 GameMode 是一个杀死在后台运行的对资源消耗大进程的工具。但它并不是。它实际上只是让 CPU **在用户玩游戏时自动运行在高性能模式下**并帮助 Linux 用户从游戏中获得最佳性能。
|
||||
|
||||
在玩游戏时,GameMode 通过对宿主机请求临时应用一组优化来显著提升游戏性能。目前,它支持下面这些优化:
|
||||
|
||||
* CPU 调控器,
|
||||
* I/O 优先级,
|
||||
* 进程 nice 值
|
||||
* 内核调度器(SCHED_ISO),
|
||||
* 禁止屏幕保护,
|
||||
* GPU 高性能模式(NVIDIA 和 AMD),GPU 超频(NVIDIA),
|
||||
* 自定义脚本。
|
||||
|
||||
GameMode 是由世界领先的游戏发行商 [Feral Interactive][3] 开发的自由开源的系统工具。
|
||||
|
||||
### 安装 GameMode
|
||||
|
||||
GameMode 适用于许多 Linux 发行版。
|
||||
|
||||
在 Arch Linux 及其变体上,你可以使用任何 AUR 助手程序,如 [Yay][5] 从 [AUR][4] 安装它。
|
||||
|
||||
```
|
||||
$ yay -S gamemode
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 和其他基于 Deb 的系统上:
|
||||
|
||||
```
|
||||
$ sudo apt install gamemode
|
||||
```
|
||||
|
||||
如果 GameMode 不适用于你的系统,你可以按照它的 Github 页面中开发章节下的描述从源码手动编译和安装它。
|
||||
|
||||
### 激活 GameMode 支持以改善 Linux 上的游戏性能
|
||||
|
||||
以下是集成支持了 GameMode 的游戏列表,因此我们无需进行任何其他配置即可激活 GameMode 支持。
|
||||
|
||||
* 古墓丽影:崛起
|
||||
* 全面战争传奇:不列颠尼亚王座
|
||||
* 全面战争:战锤 2
|
||||
* 尘埃 4
|
||||
* 全面战争:三国
|
||||
|
||||
只需运行这些游戏,就会自动启用 GameMode 支持。
|
||||
|
||||
这里还有将 GameMode 与 GNOME shell 集成的的[扩展][6]。它会在顶部指示 GameMode 何时处于活跃。
|
||||
|
||||
对于其他游戏,你可能需要手动请求 GameMode 支持,如下所示。
|
||||
|
||||
```
|
||||
gamemoderun ./game
|
||||
```
|
||||
|
||||
我不喜欢游戏,并且我已经很多年没玩游戏了。所以,我无法分享一些实际的基准测试。
|
||||
|
||||
但是,我在 Youtube 上找到了一个简短的[视频教程](https://youtu.be/4gyRyYfyGJw),以便为 Lutris 游戏启用 GameMode 支持。对于那些想要第一次尝试 GameMode 的人来说,这是个不错的开始。
|
||||
|
||||
通过浏览视频中的评论,我可以说 GameMode 确实提高了 Linux 上的游戏性能。
|
||||
|
||||
对于更多细节,请参阅 [GameMode 的 GitHub 仓库][7]。
|
||||
|
||||
相关阅读:
|
||||
|
||||
* [GameHub – 将所有游戏集合在一起的仓库][8]
|
||||
* [如何在 Linux 中运行 MS-DOS 游戏和程序][9]
|
||||
|
||||
你用过 GameMode 吗?它真的有改善 Linux 上的游戏性能吗?请在下面的评论栏分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/gamemode-a-tool-to-improve-gaming-performance-on-linux/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Gamemode-720x340.png
|
||||
[2]: https://www.ostechnix.com/manage-games-using-lutris-linux/
|
||||
[3]: http://www.feralinteractive.com/en/
|
||||
[4]: https://aur.archlinux.org/packages/gamemode/
|
||||
[5]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[6]: https://github.com/gicmo/gamemode-extension
|
||||
[7]: https://github.com/FeralInteractive/gamemode
|
||||
[8]: https://www.ostechnix.com/gamehub-an-unified-library-to-put-all-games-under-one-roof/
|
||||
[9]: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
|
||||
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11220-1.html)
|
||||
[#]: subject: (How To Set Up Time Synchronization On Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-set-up-time-synchronization-on-ubuntu/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
如何在 Ubuntu 上设置时间同步
|
||||
======
|
||||
|
||||

|
||||
|
||||
你可能设置过 [cron 任务][2] 来在特定时间备份重要文件或执行系统相关任务。也许你配置了一个日志服务器在特定时间间隔[轮转日志][3]。但如果你的时钟不同步,这些任务将无法按时执行。这就是要在 Linux 系统上设置正确的时区并保持时钟与互联网同步的原因。本指南介绍如何在 Ubuntu Linux 上设置时间同步。下面的步骤已经在 Ubuntu 18.04 上进行了测试,但是对于使用 systemd 的 `timesyncd` 服务的其他基于 Ubuntu 的系统它们是相同的。
|
||||
|
||||
### 在 Ubuntu 上设置时间同步
|
||||
|
||||
通常,我们在安装时设置时区。但是,你可以根据需要更改或设置不同的时区。
|
||||
|
||||
首先,让我们使用 `date` 命令查看 Ubuntu 系统中的当前时区:
|
||||
|
||||
```
|
||||
$ date
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Tue Jul 30 11:47:39 UTC 2019
|
||||
```
|
||||
|
||||
如上所见,`date` 命令显示实际日期和当前时间。这里,我当前的时区是 **UTC**,代表**协调世界时**。
|
||||
|
||||
或者,你可以在 `/etc/timezone` 文件中查找当前时区。
|
||||
|
||||
```
|
||||
$ cat /etc/timezone
|
||||
UTC
|
||||
```
|
||||
|
||||
现在,让我们看看时钟是否与互联网同步。只需运行:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Local time: Tue 2019-07-30 11:53:58 UTC
|
||||
Universal time: Tue 2019-07-30 11:53:58 UTC
|
||||
RTC time: Tue 2019-07-30 11:53:59
|
||||
Time zone: Etc/UTC (UTC, +0000)
|
||||
System clock synchronized: yes
|
||||
systemd-timesyncd.service active: yes
|
||||
RTC in local TZ: no
|
||||
```
|
||||
|
||||
如你所见,`timedatectl` 命令显示本地时间、世界时、时区以及系统时钟是否与互联网服务器同步,以及 `systemd-timesyncd.service` 是处于活动状态还是非活动状态。就我而言,系统时钟已与互联网时间服务器同步。
|
||||
|
||||
如果时钟不同步,你会看到下面截图中显示的 `System clock synchronized: no`。
|
||||
|
||||
![][4]
|
||||
|
||||
*时间同步已禁用。*
|
||||
|
||||
注意:上面的截图是旧截图。这就是你看到不同日期的原因。
|
||||
|
||||
如果你看到 `System clock synchronized:` 值设置为 `no`,那么 `timesyncd` 服务可能处于非活动状态。因此,只需重启服务并看下是否正常。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart systemd-timesyncd.service
|
||||
```
|
||||
|
||||
现在检查 `timesyncd` 服务状态:
|
||||
|
||||
```
|
||||
$ sudo systemctl status systemd-timesyncd.service
|
||||
● systemd-timesyncd.service - Network Time Synchronization
|
||||
Loaded: loaded (/lib/systemd/system/systemd-timesyncd.service; enabled; vendor preset: enabled)
|
||||
Active: active (running) since Tue 2019-07-30 10:50:18 UTC; 1h 11min ago
|
||||
Docs: man:systemd-timesyncd.service(8)
|
||||
Main PID: 498 (systemd-timesyn)
|
||||
Status: "Synchronized to time server [2001:67c:1560:8003::c7]:123 (ntp.ubuntu.com)."
|
||||
Tasks: 2 (limit: 2319)
|
||||
CGroup: /system.slice/systemd-timesyncd.service
|
||||
└─498 /lib/systemd/systemd-timesyncd
|
||||
|
||||
Jul 30 10:50:30 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:31 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:31 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:32 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:32 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:51:06 ubuntuserver systemd-timesyncd[498]: Synchronized to time server [2001:67c:1560:800
|
||||
```
|
||||
|
||||
如果此服务已启用并处于活动状态,那么系统时钟应与互联网时间服务器同步。
|
||||
|
||||
你可以使用命令验证是否启用了时间同步:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
```
|
||||
|
||||
如果仍然不起作用,请运行以下命令以启用时间同步:
|
||||
|
||||
```
|
||||
$ sudo timedatectl set-ntp true
|
||||
```
|
||||
|
||||
现在,你的系统时钟将与互联网时间服务器同步。
|
||||
|
||||
#### 使用 timedatectl 命令更改时区
|
||||
|
||||
如果我想使用 UTC 以外的其他时区怎么办?这很容易!
|
||||
|
||||
首先,使用命令列出可用时区:
|
||||
|
||||
```
|
||||
$ timedatectl list-timezones
|
||||
```
|
||||
|
||||
你将看到类似于下图的输出。
|
||||
|
||||
![][5]
|
||||
|
||||
*使用 timedatectl 命令列出时区*
|
||||
|
||||
你可以使用以下命令设置所需的时区(例如,Asia/Shanghai):
|
||||
|
||||
(LCTT 译注:本文原文使用印度时区作为示例,这里为了便于使用,换为中国标准时区 CST。另外,在时区设置中,要注意 CST 这个缩写会代表四个不同的时区,因此建议使用城市和 UTC+8 来说设置。)
|
||||
|
||||
```
|
||||
$ sudo timedatectl set-timezone Asia/Shanghai
|
||||
```
|
||||
|
||||
使用 `date` 命令再次检查时区是否已真正更改:
|
||||
|
||||
```
|
||||
$ date
|
||||
Tue Jul 30 20:22:33 CST 2019
|
||||
```
|
||||
|
||||
或者,如果需要详细输出,请使用 `timedatectl` 命令:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
Local time: Tue 2019-07-30 20:22:35 CST
|
||||
Universal time: Tue 2019-07-30 12:22:35 UTC
|
||||
RTC time: Tue 2019-07-30 12:22:36
|
||||
Time zone: Asia/Shanghai (CST, +0800)
|
||||
System clock synchronized: yes
|
||||
systemd-timesyncd.service active: yes
|
||||
RTC in local TZ: no
|
||||
```
|
||||
|
||||
如你所见,我已将时区从 UTC 更改为 CST(中国标准时间)。
|
||||
|
||||
要切换回 UTC 时区,只需运行:
|
||||
|
||||
```
|
||||
$ sudo timedatectl set-timezone UTC
|
||||
```
|
||||
|
||||
#### 使用 tzdata 更改时区
|
||||
|
||||
在较旧的 Ubuntu 版本中,没有 `timedatectl` 命令。这种情况下,你可以使用 `tzdata`(Time zone data)来设置时间同步。
|
||||
|
||||
```
|
||||
$ sudo dpkg-reconfigure tzdata
|
||||
```
|
||||
|
||||
选择你居住的地理区域。对我而言,我选择 **Asia**。选择 OK,然后按回车键。
|
||||
|
||||
![][6]
|
||||
|
||||
接下来,选择与你的时区对应的城市或地区。这里,我选择了 **Kolkata**(LCTT 译注:中国用户请相应使用 Shanghai 等城市)。
|
||||
|
||||
![][7]
|
||||
|
||||
最后,你将在终端中看到类似下面的输出。
|
||||
|
||||
```
|
||||
Current default time zone: 'Asia/Shanghai'
|
||||
Local time is now: Tue Jul 30 21:59:25 CST 2019.
|
||||
Universal Time is now: Tue Jul 30 13:59:25 UTC 2019.
|
||||
```
|
||||
|
||||
#### 在图形模式下配置时区
|
||||
|
||||
有些用户可能对命令行方式不太满意。如果你是其中之一,那么你可以轻松地在图形模式的系统设置面板中进行设置。
|
||||
|
||||
点击 Super 键(Windows 键),在 Ubuntu dash 中输入 **settings**,然后点击设置图标。
|
||||
|
||||
![][8]
|
||||
|
||||
*从 Ubuntu dash 启动系统的设置*
|
||||
|
||||
或者,单击位于 Ubuntu 桌面右上角的向下箭头,然后单击左上角的“设置”图标。
|
||||
|
||||
![][9]
|
||||
|
||||
*从顶部面板启动系统的设置*
|
||||
|
||||
在下一个窗口中,选择“细节”,然后单击“日期与时间”选项。打开“自动的日期与时间”和“自动的时区”。
|
||||
|
||||
![][10]
|
||||
|
||||
*在 Ubuntu 中设置自动时区*
|
||||
|
||||
关闭设置窗口就行了!你的系统始终应该与互联网时间服务器同步了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-set-up-time-synchronization-on-ubuntu/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Set-Up-Time-Synchronization-On-Ubuntu-720x340.png
|
||||
[2]: https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
|
||||
[3]: https://www.ostechnix.com/manage-log-files-using-logrotate-linux/
|
||||
[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/timedatectl-command-output-ubuntu.jpeg
|
||||
[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/List-timezones-using-timedatectl-command.png
|
||||
[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/configure-time-zone-using-tzdata-1.png
|
||||
[7]: https://www.ostechnix.com/wp-content/uploads/2019/07/configure-time-zone-using-tzdata-2.png
|
||||
[8]: https://www.ostechnix.com/wp-content/uploads/2019/07/System-settings-Ubuntu-dash.png
|
||||
[9]: https://www.ostechnix.com/wp-content/uploads/2019/07/Ubuntu-system-settings.png
|
||||
[10]: https://www.ostechnix.com/wp-content/uploads/2019/07/Set-automatic-timezone-in-ubuntu.png
|
||||
147
published/20190805 How To Verify ISO Images In Linux.md
Normal file
147
published/20190805 How To Verify ISO Images In Linux.md
Normal file
@ -0,0 +1,147 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "FSSlc"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-11212-1.html"
|
||||
[#]: subject: "How To Verify ISO Images In Linux"
|
||||
[#]: via: "https://www.ostechnix.com/how-to-verify-iso-images-in-linux/"
|
||||
[#]: author: "sk https://www.ostechnix.com/author/sk/"
|
||||
|
||||
如何在 Linux 中验证 ISO 镜像
|
||||
======
|
||||
|
||||
![如何在 Linux 中校验 ISO 镜像][1]
|
||||
|
||||
你从喜爱的 Linux 发行版的官方网站或第三方网站下载了它的 ISO 镜像之后,接下来要做什么呢?是[创建可启动介质][2]并开始安装系统吗?并不是,请稍等一下。在开始使用它之前,强烈建议你检查一下你刚下载到本地系统中的 ISO 文件是否是下载镜像站点中 ISO 文件的一个精确拷贝。因为在前几年 [Linux Mint 的网站被攻破了][3],并且攻击者创建了一个包含后门的经过修改的 Linux Mint ISO 文件。 所以验证下载的 Linux ISO 镜像的可靠性和完整性是非常重要的一件事儿。假如你不知道如何在 Linux 中验证 ISO 镜像,本次的简要介绍将给予你帮助,请接着往下看!
|
||||
|
||||
### 在 Linux 中验证 ISO 镜像
|
||||
|
||||
我们可以使用 ISO 镜像的“校验和”来验证 ISO 镜像。校验和是一系列字母和数字的组合,用来检验下载文件的数据是否有错以及验证其可靠性和完整性。当前存在不同类型的校验和,例如 SHA-0、SHA-1、SHA-2(224、256、384、512)和 MD5。MD5 校验和最为常用,但对于现代的 Linux 发行版,SHA-256 最常被使用。
|
||||
|
||||
我们将使用名为 `gpg` 和 `sha256` 的两个工具来验证 ISO 镜像的可靠性和完整性。
|
||||
|
||||
#### 下载校验和及签名
|
||||
|
||||
针对本篇指南的目的,我将使用 Ubuntu 18.04 LTS 服务器 ISO 镜像来做验证,但对于其他的 Linux 发行版应该也是适用的。
|
||||
|
||||
在靠近 Ubuntu 下载页的最上端,你将看到一些额外的文件(校验和及签名),正如下面展示的图片那样:
|
||||
|
||||
![Ubuntu 18.04 的校验和及签名][4]
|
||||
|
||||
其中名为 `SHA256SUMS` 的文件包含了这里所有可获取镜像的校验和,而 `SHA256SUMS.gpg` 文件则是这个文件的 GnuPG 签名。在下面的步骤中,我们将使用这个签名文件来 **验证** 校验和文件。
|
||||
|
||||
下载 Ubuntu 的 ISO 镜像文件以及刚才提到的那两个文件,然后将它们放到同一目录下,例如这里的 `ISO` 目录:
|
||||
|
||||
```
|
||||
$ ls ISO/
|
||||
SHA256SUMS SHA256SUMS.gpg ubuntu-18.04.2-live-server-amd64.iso
|
||||
```
|
||||
|
||||
如你所见,我已经下载了 Ubuntu 18.04.2 LTS 服务器版本的镜像,以及对应的校验和文件和签名文件。
|
||||
|
||||
#### 下载有效的签名秘钥
|
||||
|
||||
现在,使用下面的命令来下载正确的签名秘钥:
|
||||
|
||||
```
|
||||
$ gpg --keyid-format long --keyserver hkp://keyserver.ubuntu.com --recv-keys 0x46181433FBB75451 0xD94AA3F0EFE21092
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
gpg: key D94AA3F0EFE21092: 57 signatures not checked due to missing keys
|
||||
gpg: key D94AA3F0EFE21092: public key "Ubuntu CD Image Automatic Signing Key (2012) <[email protected]>" imported
|
||||
gpg: key 46181433FBB75451: 105 signatures not checked due to missing keys
|
||||
gpg: key 46181433FBB75451: public key "Ubuntu CD Image Automatic Signing Key <[email protected]>" imported
|
||||
gpg: no ultimately trusted keys found
|
||||
gpg: Total number processed: 2
|
||||
gpg: imported: 2
|
||||
```
|
||||
|
||||
#### 验证 SHA-256 校验和
|
||||
|
||||
接下来我们将使用签名来验证校验和文件:
|
||||
|
||||
```
|
||||
$ gpg --keyid-format long --verify SHA256SUMS.gpg SHA256SUMS
|
||||
```
|
||||
|
||||
下面是示例输出:
|
||||
|
||||
```
|
||||
gpg: Signature made Friday 15 February 2019 04:23:33 AM IST
|
||||
gpg: using DSA key 46181433FBB75451
|
||||
gpg: Good signature from "Ubuntu CD Image Automatic Signing Key <[email protected]>" [unknown]
|
||||
gpg: WARNING: This key is not certified with a trusted signature!
|
||||
gpg: There is no indication that the signature belongs to the owner.
|
||||
Primary key fingerprint: C598 6B4F 1257 FFA8 6632 CBA7 4618 1433 FBB7 5451
|
||||
gpg: Signature made Friday 15 February 2019 04:23:33 AM IST
|
||||
gpg: using RSA key D94AA3F0EFE21092
|
||||
gpg: Good signature from "Ubuntu CD Image Automatic Signing Key (2012) <[email protected]>" [unknown]
|
||||
gpg: WARNING: This key is not certified with a trusted signature!
|
||||
gpg: There is no indication that the signature belongs to the owner.
|
||||
Primary key fingerprint: 8439 38DF 228D 22F7 B374 2BC0 D94A A3F0 EFE2 1092
|
||||
```
|
||||
|
||||
假如你在输出中看到 `Good signature` 字样,那么该校验和文件便是由 Ubuntu 开发者制作的,并且由秘钥文件的所属者签名认证。
|
||||
|
||||
#### 检验下载的 ISO 文件
|
||||
|
||||
下面让我们继续检查下载的 ISO 文件是否和所给的校验和相匹配。为了达到该目的,只需要运行:
|
||||
|
||||
```
|
||||
$ sha256sum -c SHA256SUMS 2>&1 | grep OK
|
||||
ubuntu-18.04.2-live-server-amd64.iso: OK
|
||||
```
|
||||
|
||||
假如校验和是匹配的,你将看到 `OK` 字样,这意味着下载的文件是合法的,没有被改变或篡改过。
|
||||
|
||||
假如你没有获得类似的输出,或者看到不同的输出,则该 ISO 文件可能已经被修改过或者没有被正确地下载。你必须从一个更好的下载源重新下载该文件。
|
||||
|
||||
某些 Linux 发行版已经在它的下载页面中包含了校验和。例如 Pop!_os 的开发者在他们的下载页面中提供了所有 ISO 镜像的 SHA-256 校验和,这样你就可以快速地验证这些 ISO 镜像。
|
||||
|
||||
![Pop os 位于其下载页面中的 SHA256 校验和][5]
|
||||
|
||||
在下载完 ISO 镜像文件后,可以使用下面的命令来验证它们:
|
||||
|
||||
```
|
||||
$ sha256sum Soft_backup/ISOs/pop-os_18.04_amd64_intel_54.iso
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
680e1aa5a76c86843750e8120e2e50c2787973343430956b5cbe275d3ec228a6 Soft_backup/ISOs/pop-os_18.04_amd64_intel_54.iso
|
||||
```
|
||||
|
||||
![Pop os 的 SHA256 校验和的值][6]
|
||||
|
||||
在上面的输出中,以 `680elaa` 开头的部分为 SHA-256 校验和的值。请将该值与位于下载页面中提供的 SHA-256 校验和的值进行比较,如果这两个值相同,那说明这个下载的 ISO 文件是合法的,与它的原有状态相比没有经过更改或者篡改。万事俱备,你可以进行下一步了!
|
||||
|
||||
上面的内容便是我们如何在 Linux 中验证一个 ISO 文件的可靠性和完整性的方法。无论你是从官方站点或者第三方站点下载 ISO 文件,我们总是推荐你在使用它们之前做一次简单的快速验证。希望本篇的内容对你有所帮助。
|
||||
|
||||
参考文献:
|
||||
|
||||
* [https://tutorials.ubuntu.com/tutorial/tutorial-how-to-verify-ubuntu][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-verify-iso-images-in-linux/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Verify-ISO-Images-In-Linux-720x340.png
|
||||
[2]: https://www.ostechnix.com/etcher-beauitiful-app-create-bootable-sd-cards-usb-drives/
|
||||
[3]: https://blog.linuxmint.com/?p=2994
|
||||
[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/Ubuntu-18.04-checksum-and-signature.png
|
||||
[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Pop-os-SHA256-sum.png
|
||||
[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/Pop-os-SHA256-sum-value.png
|
||||
[7]: https://tutorials.ubuntu.com/tutorial/tutorial-how-to-verify-ubuntu
|
||||
@ -0,0 +1,58 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11207-1.html)
|
||||
[#]: subject: (Microsoft finds Russia-backed attacks that exploit IoT devices)
|
||||
[#]: via: (https://www.networkworld.com/article/3430356/microsoft-finds-russia-backed-attacks-that-exploit-iot-devices.html)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
微软发现由俄罗斯背后支持的利用物联网设备进行的攻击
|
||||
======
|
||||
|
||||
> 微软表示,默认密码、未打补丁的设备,物联网设备库存不足是导致俄罗斯的 STRONTIUM 黑客组织发起针对公司的攻击的原因。
|
||||
|
||||
![Zmeel / Getty Images][1]
|
||||
|
||||
在微软安全响应中心周一发布的博客文章中,该公司称,STRONTIUM 黑客组织对未披露名字的微软客户进行了基于 [IoT][2] 的攻击,安全研究人员相信 STRONTIUM 黑客组织和俄罗斯 GRU 军事情报机构有密切的关系。
|
||||
|
||||
微软[在博客中说][3],它在 4 月份发现的攻击针对三种特定的物联网设备:一部 VoIP 电话、一部视频解码器和一台打印机(该公司拒绝说明品牌),并将它们用于获得对不特定的公司网络的访问权限。其中两个设备遭到入侵是因为没有更改过制造商的默认密码,而另一个设备则是因为没有应用最新的安全补丁。
|
||||
|
||||
以这种方式受到攻击的设备成为了安全的网络的后门,允许攻击者自由扫描这些网络以获得进一步的漏洞,并访问其他系统获取更多的信息。攻击者也被发现其在调查受攻击网络上的管理组,试图获得更多访问权限,以及分析本地子网流量以获取其他数据。
|
||||
|
||||
STRONTIUM,也被称为 Fancy Bear、Pawn Storm、Sofacy 和 APT28,被认为是代表俄罗斯政府进行的一系列恶意网络活动的幕后黑手,其中包括 2016 年对民主党全国委员会的攻击,对世界反兴奋剂机构的攻击,针对记者调查马来西亚航空公司 17 号航班在乌克兰上空被击落的情况,向美国军人的妻子发送捏造的死亡威胁等等。
|
||||
|
||||
根据 2018 年 7 月特别顾问罗伯特·穆勒办公室发布的起诉书,STRONTIUM 袭击的指挥者是一群俄罗斯军官,所有这些人都被 FBI 通缉与这些罪行有关。
|
||||
|
||||
微软通知客户发现其遭到了民族国家的攻击,并在过去 12 个月内发送了大约 1,400 条与 STRONTIUM 相关的通知。微软表示,其中大多数(五分之四)是对政府、军队、国防、IT、医药、教育和工程领域的组织的攻击,其余的则是非政府组织、智囊团和其他“政治附属组织”。
|
||||
|
||||
根据微软团队的说法,漏洞的核心是机构缺乏对其网络上运行的所有设备的充分认识。另外,他们建议对在企业环境中运行的所有 IoT 设备进行编目,为每个设备实施自定义安全策略,在可行的情况下在各自独立的网络上屏蔽物联网设备,并对物联网组件执行定期补丁和配置审核。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3430356/microsoft-finds-russia-backed-attacks-that-exploit-iot-devices.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/07/cso_russian_hammer_and_sickle_binary_code_by_zmeel_gettyimages-927363118_2400x1600-100801412-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
|
||||
[3]: https://msrc-blog.microsoft.com/2019/08/05/corporate-iot-a-path-to-intrusion/
|
||||
[4]: https://www.networkworld.com/article/3207535/internet-of-things/what-is-the-iot-how-the-internet-of-things-works.html
|
||||
[5]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html
|
||||
[6]: https://www.networkworld.com/article/3270961/internet-of-things/10-hot-iot-startups-to-watch.html
|
||||
[7]: https://www.networkworld.com/article/3279346/internet-of-things/the-6-ways-to-make-money-in-iot.html
|
||||
[8]: https://www.networkworld.com/article/3280225/internet-of-things/what-is-digital-twin-technology-and-why-it-matters.html
|
||||
[9]: https://www.networkworld.com/article/3276313/internet-of-things/blockchain-service-centric-networking-key-to-iot-success.html
|
||||
[10]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
|
||||
[11]: https://www.networkworld.com/article/3276304/internet-of-things/building-iot-ready-networks-must-become-a-priority.html
|
||||
[12]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
|
||||
[13]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[14]: https://www.facebook.com/NetworkWorld/
|
||||
[15]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,183 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11216-1.html)
|
||||
[#]: subject: (Use a drop-down terminal for fast commands in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/use-a-drop-down-terminal-for-fast-commands-in-fedora/)
|
||||
[#]: author: (Guilherme Schelp https://fedoramagazine.org/author/schelp/)
|
||||
|
||||
在 Fedora 下使用下拉式终端更快输入命令
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
下拉式终端可以一键打开,并快速输入桌面上的任何命令。通常它会以平滑的方式创建终端,有时会带有下拉效果。本文演示了如何使用 Yakuake、Tilda、Guake 和 GNOME 扩展等下拉式终端来改善和加速日常任务。
|
||||
|
||||
### Yakuake
|
||||
|
||||
[Yakuake][2] 是一个基于 KDE Konsole 技术的下拉式终端模拟器。它以 GNU GPLv2 条款分发。它包括以下功能:
|
||||
|
||||
* 从屏幕顶部平滑地滚下
|
||||
* 标签式界面
|
||||
* 尺寸和动画速度可配置
|
||||
* 换肤
|
||||
* 先进的 D-Bus 接口
|
||||
|
||||
要安装 Yakuake,请使用以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y yakuake
|
||||
```
|
||||
|
||||
#### 启动和配置
|
||||
|
||||
如果你运行 KDE,请打开系统设置,然后转到“启动和关闭”。将“yakuake”添加到“自动启动”下的程序列表中,如下所示:
|
||||
|
||||
![][3]
|
||||
|
||||
Yakuake 运行时很容易配置,首先在命令行启动该程序:
|
||||
|
||||
```
|
||||
$ yakuake &
|
||||
```
|
||||
|
||||
随后出现欢迎对话框。如果标准的快捷键和你已经使用的快捷键冲突,你可以设置一个新的。
|
||||
|
||||
![][4]
|
||||
|
||||
点击菜单按钮,出现如下帮助菜单。接着,选择“配置 Yakuake……”访问配置选项。
|
||||
|
||||
![][5]
|
||||
|
||||
你可以自定义外观选项,例如透明度、行为(例如当鼠标指针移过它们时聚焦终端)和窗口(如大小和动画)。在窗口选项中,你会发现当你使用两个或更多监视器时最有用的选项之一:“在鼠标所在的屏幕上打开”。
|
||||
|
||||
#### 使用 Yakuake
|
||||
|
||||
主要的快捷键有:
|
||||
|
||||
* `F12` = 打开/撤回 Yakuake
|
||||
* `Ctrl+F11` = 全屏模式
|
||||
* `Ctrl+)` = 上下分割
|
||||
* `Ctrl+(` = 左右分割
|
||||
* `Ctrl+Shift+T` = 新会话
|
||||
* `Shift+Right` = 下一个会话
|
||||
* `Shift+Left` = 上一个会话
|
||||
* `Ctrl+Alt+S` = 重命名会话
|
||||
|
||||
以下是 Yakuake 像[终端多路复用器][6]一样分割会话的示例。使用此功能,你可以在一个会话中运行多个 shell。
|
||||
|
||||
![][7]
|
||||
|
||||
### Tilda
|
||||
|
||||
[Tilda][8] 是一个下拉式终端,可与其他流行的终端模拟器相媲美,如 GNOME 终端、KDE 的 Konsole、xterm 等等。
|
||||
|
||||
它具有高度可配置的界面。你甚至可以更改终端大小和动画速度等选项。Tilda 还允许你启用热键,以绑定到各种命令和操作。
|
||||
|
||||
要安装 Tilda,请运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y tilda
|
||||
```
|
||||
|
||||
#### 启动和配置
|
||||
|
||||
大多数用户更喜欢在登录时就在后台运行一个下拉式终端。要设置此选项,请首先转到桌面上的应用启动器,搜索 Tilda,然后将其打开。
|
||||
|
||||
接下来,打开 Tilda 配置窗口。 选择“隐藏启动 Tilda”,即启动时不会立即显示终端。
|
||||
|
||||
![][9]
|
||||
|
||||
接下来,你要设置你的桌面自动启动 Tilda。如果你使用的是 KDE,请转到“系统设置 > 启动与关闭 > 自动启动”并“添加一个程序”。
|
||||
|
||||
![][10]
|
||||
|
||||
如果你正在使用 GNOME,则可以在终端中运行此命令:
|
||||
|
||||
```
|
||||
$ ln -s /usr/share/applications/tilda.desktop ~/.config/autostart/
|
||||
```
|
||||
|
||||
当你第一次运行它时,会出现一个向导来设置首选项。如果需要更改设置,请右键单击终端并转到菜单中的“首选项”。
|
||||
|
||||
![][11]
|
||||
|
||||
你还可以创建多个配置文件,并绑定其他快捷键以在屏幕上的不同位置打开新终端。为此,请运行以下命令:
|
||||
|
||||
```
|
||||
$ tilda -C
|
||||
```
|
||||
|
||||
每次使用上述命令时,Tilda 都会在名为 `~/.config/tilda/` 文件夹中创建名为 `config_0`、`config_1` 之类的新配置文件。然后,你可以映射组合键以打开具有一组特定选项的新 Tilda 终端。
|
||||
|
||||
#### 使用 Tilda
|
||||
|
||||
主要快捷键有:
|
||||
|
||||
* `F1` = 拉下终端 Tilda(注意:如果你有多个配置文件,快捷方式是 F1、F2、F3 等)
|
||||
* `F11` = 全屏模式
|
||||
* `F12` = 切换透明模式
|
||||
* `Ctrl+Shift+T` = 添加标签
|
||||
* `Ctrl+Page Up` = 下一个标签
|
||||
* `Ctrl+Page Down` = 上一个标签
|
||||
|
||||
### GNOME 扩展
|
||||
|
||||
Drop-down Terminal [GNOME 扩展][12]允许你在 GNOME Shell 中使用这个有用的工具。它易于安装和配置,使你可以快速访问终端会话。
|
||||
|
||||
#### 安装
|
||||
|
||||
打开浏览器并转到[此 GNOME 扩展的站点][12]。启用扩展设置为“On”,如下所示:
|
||||
|
||||
![][13]
|
||||
|
||||
然后选择“Install”以在系统上安装扩展。
|
||||
|
||||
![][14]
|
||||
|
||||
执行此操作后,无需设置任何自动启动选项。只要你登录 GNOME,扩展程序就会自动运行!
|
||||
|
||||
#### 配置
|
||||
|
||||
安装后,将打开 Drop-down Terminal 配置窗口以设置首选项。例如,可以设置终端大小、动画、透明度和使用滚动条。
|
||||
|
||||
![][15]
|
||||
|
||||
如果你将来需要更改某些首选项,请运行 `gnome-shell-extension-prefs` 命令并选择“Drop Down Terminal”。
|
||||
|
||||
#### 使用该扩展
|
||||
|
||||
快捷键很简单:
|
||||
|
||||
* 反尖号 (通常是 `Tab` 键上面的一个键) = 打开/撤回终端
|
||||
* `F12` (可以定制) = 打开/撤回终端
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-a-drop-down-terminal-for-fast-commands-in-fedora/
|
||||
|
||||
作者:[Guilherme Schelp][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/schelp/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/dropdown-terminals-816x345.jpg
|
||||
[2]: https://kde.org/applications/system/org.kde.yakuake
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/07/auto_start-1024x723.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/07/yakuake_config-1024x419.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/07/yakuake_config_01.png
|
||||
[6]: https://fedoramagazine.org/4-cool-terminal-multiplexers/
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/07/yakuake_usage.gif
|
||||
[8]: https://github.com/lanoxx/tilda
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/07/tilda_startup.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/07/tilda_startup_alt.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/07/tilda_config.png
|
||||
[12]: https://extensions.gnome.org/extension/442/drop-down-terminal/
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2019/07/gnome-shell-install_2-1024x455.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2019/07/gnome-shell-install_3.png
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2019/07/gnome-shell-install_4.png
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Intel pulls the plug on Omni-Path networking fabric architecture)
|
||||
[#]: via: (https://www.networkworld.com/article/3429614/intel-pulls-the-plug-on-omni-path-networking-fabric-architecture.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Intel pulls the plug on Omni-Path networking fabric architecture
|
||||
======
|
||||
Omni-Path Architecture, which Intel had high hopes for in the high-performance computing (HPC) space, has been scrapped after one generation.
|
||||
![Gerd Altmann \(CC0\)][1]
|
||||
|
||||
Intel’s battle to gain ground in the high-performance computing (HPC) market isn’t going so well. The Omni-Path Architecture it had pinned its hopes on has been scrapped after one generation.
|
||||
|
||||
An Intel spokesman confirmed to me that the company will no longer offer Intel OmniPath Architecture 200 (OPA200) products to customers, but it will continue to encourage customers, OEMs, and partners to use OPA100 in new designs.
|
||||
|
||||
“We are continuing to sell, maintain, and support OPA100. We actually announced some new features for OPA100 back at International Supercomputing in June,” the spokesperson said via email.
|
||||
|
||||
**[ Learn [who's developing quantum computers][2]. ]**
|
||||
|
||||
Intel said it continues to invest in connectivity solutions for its customers and that the recent [acquisition of Barefoot Networks][3] is an example of Intel’s strategy of supporting end-to-end cloud networking and infrastructure. It would not say if Barefoot’s technology would be the replacement for OPA.
|
||||
|
||||
While Intel owns the supercomputing market, it has not been so lucky with the HPC fabric, a network that connects CPUs and memory for faster data sharing. Market leader Mellanox with its Enhanced Data Rate (HDR) InfiniBand framework rules the roost, and now [Mellanox is about to be acquired][4] by Intel’s biggest nemesis, Nvidia.
|
||||
|
||||
Technically, Intel was a bit behind Mellanox. OPA100 is 100 Gbits, and OPA200 was intended to be 200 Gbits, but Mellanox was already at 200 Gbits and is set to introduce 400-Gbit products later this year.
|
||||
|
||||
Analyst Jim McGregor isn’t surprised. “They have a history where if they don’t get high uptick on something and don’t think it’s of value, they’ll kill it. A lot of times when they go through management changes, they look at how to optimize. Paul [Otellini] did this extensively. I would expect Bob [Swan, the newly minted CEO] to do that and say these things aren’t worth our investment,” he said.
|
||||
|
||||
The recent [sale of the 5G unit to Apple][5] is another example of Swan cleaning house. McGregor notes Apple was hounding them to invest more in 5G and at the same time tried to hire people away.
|
||||
|
||||
The writing was on the wall for OPA as far back as March when Intel introduced Compute Express Link (CXL), a cache coherent accelerator interconnect that basically does what OPA does. At the time, people were wondering where this left OPA. Now they know.
|
||||
|
||||
The problem once again is that Intel is swimming upstream. CXL competes with Cache Coherent Interconnect for Accelerators (CCIX) and OpenCAPI, the former championed by basically all of its competition and the latter promoted by IBM.
|
||||
|
||||
All are built on PCI Express (PCIe) and bring features such as cache coherence to PCIe, which it does not have natively. Both CXL and CCIX can run on top of PCIe and co-exist with it. The trick is that the host and the accelerator must have matching support. A host with CCIX can only work with a CCIX device; there is no mixing them.
|
||||
|
||||
As I said, CCIX support is basically everybody but Intel: ARM, AMD, IBM, Marvell, Qualcomm, and Xilinx are just a few of its backers. CXL includes Intel, Hewlett Packard Enterprise, and Dell EMC. The sane thing to do would be merge the two standards, take the best of both and make one standard. But anyone who remembers the HD-DVD/Blu-ray battle of last decade knows how likely that is.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3429614/intel-pulls-the-plug-on-omni-path-networking-fabric-architecture.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/07/digital_transformation_finger_tap_causes_waves_of_interconnected_digital_ripples_by_gerd_altmann_cc0_via_pixabay_1200x800-100765086-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3275385/who-s-developing-quantum-computers.html
|
||||
[3]: https://www.idgconnect.com/news/1502086/intel-delves-deeper-network-barefoot-networks
|
||||
[4]: https://www.networkworld.com/article/3356444/nvidia-grabs-mellanox-out-from-under-intels-nose.html
|
||||
[5]: https://www.computerworld.com/article/3411922/what-you-need-to-know-about-apples-1b-intel-5g-modem-investment.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
62
sources/talk/20190806 Is Perl going extinct.md
Normal file
62
sources/talk/20190806 Is Perl going extinct.md
Normal file
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Is Perl going extinct?)
|
||||
[#]: via: (https://opensource.com/article/19/8/command-line-heroes-perl)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/shawnhcoreyhttps://opensource.com/users/sethhttps://opensource.com/users/roger78)
|
||||
|
||||
Is Perl going extinct?
|
||||
======
|
||||
Command Line Heroes explores the meteoric rise of Perl, its fall from
|
||||
the spotlight, and what's next in the programming language's lifecycle.
|
||||
![Listen to the Command Line Heroes Podcast][1]
|
||||
|
||||
Is there an [endangered species][2] list for programming languages? If there is, [Command Line Heroes][3] suggests that Perl is somewhere between vulnerable and critically endangered. The dominant language of the 1990s is the focus of this week's podcast (Season 3, Episode 4) and explores its highs and lows since it was introduced over 30 years ago.
|
||||
|
||||
### The timeline
|
||||
|
||||
1991 was the year that changed everything. Tim Berners-Lee released the World Wide Web. The internet had been connecting computers for 20 years, but the web connected people in brand new ways. An entire new frontier of web-based development opened.
|
||||
|
||||
Last week's episode explored [how JavaScript was born][4] and launched the browser wars. Before that language dominated the web, Perl was incredibly popular. It was open source, general purpose, and ran on nearly every Unix-like platform. Perl allowed a familiar set of practices any sysadmin would appreciate running.
|
||||
|
||||
### What happened?
|
||||
|
||||
So, if Perl was doing so well in the '90s, why did it start to sink? The dot-com bubble burst in 2000, and the first heady rush of web development was about to give way to a slicker, faster, different generation. Python became a favorite for first-time developers, much like Perl used to be an attractive first language that stole newbies away from FORTRAN or C.
|
||||
|
||||
Perl was regarded highly because it allowed developers to solve a problem in many ways, but that feature later became known as a bug. [Python's push toward a single right answer][5] ended up being where many people wanted to go. Conor Myhrvold wrote in _Fast Company_ how Python became more attractive and [what Perl might have done to keep up][6]. For these reasons and myriad others, like the delay of Perl 6, it lost momentum.
|
||||
|
||||
### Lifecycle management
|
||||
|
||||
Overall, I'm comfortable with the idea that some languages don't make it. [BASIC][7] isn't exactly on the software bootcamp hit list these days. But maybe Perl isn't on the same trajectory and could be best-in-class for a more specific type of problem around glue code for system challenges.
|
||||
|
||||
I love how Command Line Heroes host [Saron Yitbarek][8] summarizes it at the end of the podcast episode:
|
||||
|
||||
> "Languages have lifecycles. When new languages emerge, exquisitely adapted to new realities, an option like Perl might occupy a smaller, more niche area. But that's not a bad thing. Our languages should expand and shrink their communities as our needs change. Perl was a crucial player in the early history of web development—and it stays with us in all kinds of ways that become obvious with a little history and a look at the big picture."
|
||||
|
||||
Learning about Perl's rise and search for a new niche makes me wonder which of the new languages we're developing today will still be around in 30 years.
|
||||
|
||||
Command Line Heroes will cover programming languages for all of season 3. [Subscribe so you don't miss a single one][3]. I would love to hear your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/command-line-heroes-perl
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/shawnhcoreyhttps://opensource.com/users/sethhttps://opensource.com/users/roger78
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/command-line-heroes-520x292.png?itok=s_F6YEoS (Listen to the Command Line Heroes Podcast)
|
||||
[2]: https://www.nationalgeographic.org/media/endangered/
|
||||
[3]: https://www.redhat.com/en/command-line-heroes
|
||||
[4]: https://opensource.com/article/19/7/command-line-heroes-javascript
|
||||
[5]: https://opensource.com/article/19/6/command-line-heroes-python
|
||||
[6]: https://www.fastcompany.com/3026446/the-fall-of-perl-the-webs-most-promising-language
|
||||
[7]: https://opensource.com/19/7/command-line-heroes-ruby-basic
|
||||
[8]: https://twitter.com/saronyitbarek
|
||||
@ -0,0 +1,249 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Intro to Corteza, an open source alternative to Salesforce)
|
||||
[#]: via: (https://opensource.com/article/19/8/corteza-open-source-alternative-salesforce)
|
||||
[#]: author: (Denis Arh https://opensource.com/users/darhhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/jason-bakerhttps://opensource.com/users/jason-baker)
|
||||
|
||||
Intro to Corteza, an open source alternative to Salesforce
|
||||
======
|
||||
Learn how to use and get Corteza up and running.
|
||||
![Team communication, chat][1]
|
||||
|
||||
[Corteza][2] is an open source, self-hosted digital work platform for growing an organization's productivity, enabling its relationships, and protecting its work and the privacy of those involved. The project was developed entirely in the public domain by [Crust Technology][3]. It has four core features: customer relationship management, a low-code development platform, messaging, and a unified workspace. This article will also explain how to get started with Corteza on the command line.
|
||||
|
||||
### Customer relationship management
|
||||
|
||||
[Corteza CRM][4] is a feature-rich open source CRM platform that gives organizations a 360-degree overview of leads and accounts. It's flexible, can easily be tailored to any organization, and includes a powerful automation module to automate processes.
|
||||
|
||||
![Corteza CRM screenshot][5]
|
||||
|
||||
### Low-code development platform
|
||||
|
||||
[Corteza Low Code][6] is an open source [low-code development platform][7] and alternative to Salesforce Lightning. It has an intuitive drag-and-drop builder and allows users to create and deploy record-based business applications with ease. Corteza CRM is built on Corteza Low Code.
|
||||
|
||||
![Corteza Low Code screenshot][8]
|
||||
|
||||
### Messaging
|
||||
|
||||
[Corteza Messaging][9] is an alternative to Salesforce Chatter and Slack. It is a secure, high-performance collaboration platform that allows teams to collaborate more efficiently and communicate safely with other organizations or customers. It integrates tightly with Corteza CRM and Corteza Low Code.
|
||||
|
||||
![Corteza Messaging screenshot][10]
|
||||
|
||||
### Unified workspace
|
||||
|
||||
[Corteza One][11] is a unified workspace to access and run third-party web and Corteza applications. Centralized access management from a single console enables administrative control over who can see or access applications.
|
||||
|
||||
![Corteza One screenshot][12]
|
||||
|
||||
## Set up Corteza
|
||||
|
||||
You can set up and run the Corteza platform with a set of simple command-line commands.
|
||||
|
||||
### Set up Docker
|
||||
|
||||
If Docker is already set up on the machine where you want to use Corteza, you can skip this section. (If you are using a Docker version below 18.0, I strongly encourage you to update.)
|
||||
|
||||
If you're not sure whether you have Docker, open your console or terminal and enter:
|
||||
|
||||
|
||||
```
|
||||
`$> docker -v`
|
||||
```
|
||||
|
||||
If the response is "command not found," download and install a Docker community edition for [desktop][13] or [server or cloud][14] that fits your environment.
|
||||
|
||||
### Configure Corteza locally
|
||||
|
||||
By using Docker's command-line interface (CLI) utility **docker-compose** (which simplifies work with containers), Corteza's setup is as effortless as possible.
|
||||
|
||||
The following script provides the absolute minimum configuration to set up a local version of Corteza. If you prefer, you can [open this file on GitHub][15]. Note that this setup does not use persistent storage; you will need to set up container volumes for that.
|
||||
|
||||
|
||||
```
|
||||
version: '2.0'
|
||||
|
||||
services:
|
||||
db:
|
||||
image: percona:8.0
|
||||
environment:
|
||||
MYSQL_DATABASE: corteza
|
||||
MYSQL_USER: corteza
|
||||
MYSQL_PASSWORD: oscom-tutorial
|
||||
MYSQL_ROOT_PASSWORD: supertopsecret
|
||||
|
||||
server:
|
||||
image: cortezaproject/corteza-server:latest
|
||||
|
||||
# Map internal 80 port (where Corteza API is listening)
|
||||
# to external port 10080. If you change this, make sure you change API_BASEURL setting below
|
||||
ports: [ "10080:80" ]
|
||||
|
||||
environment:
|
||||
# Tell corteza-server where can it be reached from the outside
|
||||
VIRTUAL_HOST: localhost:10080
|
||||
|
||||
# Serving the app from the localhost port 20080 is not very usual setup,
|
||||
# this will override settings auto-discovery procedure (provision) and
|
||||
# use custom values for frontend URL base
|
||||
PROVISION_SETTINGS_AUTH_FRONTEND_URL_BASE: <http://localhost:20080>
|
||||
|
||||
# Database connection, make sure username, password, and database matches values in the db service
|
||||
DB_DSN: corteza:oscom-tutorial@tcp(db:3306)/corteza?collation=utf8mb4_general_ci
|
||||
|
||||
webapp:
|
||||
image: cortezaproject/corteza-webapp:latest
|
||||
|
||||
# Map internal 80 port (where we serve the web application)
|
||||
# to external port 20080.
|
||||
ports: [ "20080:80" ]
|
||||
|
||||
environment:
|
||||
# Where API can be found
|
||||
API_BASEURL: localhost:10080
|
||||
|
||||
# We're using one service for the API
|
||||
MONOLITH_API: 1
|
||||
```
|
||||
|
||||
Run the services by entering:
|
||||
|
||||
|
||||
```
|
||||
`docker-compose up`
|
||||
```
|
||||
|
||||
You'll see a stream of log lines announcing the database container initialization. Meanwhile, Corteza server will try (and retry) to connect to the database. If you change the database configuration (i.e., username, database, password), you'll get some errors.
|
||||
|
||||
When Corteza server connects, it initializes "store" (for uploaded files), and the settings-discovery process will try to auto-discover as much as possible. (You can help by setting the **VIRTUAL_HOST** and **PROVISION_SETTINGS_AUTH_FRONTEND_URL_BASE** variables just right for your environment.)
|
||||
|
||||
When you see "Starting HTTP server with REST API," Corteza server is ready for use.
|
||||
|
||||
#### Troubleshooting
|
||||
|
||||
If you misconfigure **VIRTUAL_HOST**, **API_BASEURL**, or **PROVISION_SETTINGS_AUTH_FRONTEND_URL_BASE**, your setup will most likely be unusable. The easiest fix is bringing all services down (**docker-compose down**) and back up (**docker-compose up**) again, but this will delete all data. See "Splitting services" below if you want to make it work without this purge-and-restart approach.
|
||||
|
||||
### Log in and explore
|
||||
|
||||
Open <http://localhost:20080> in your browser, and give Corteza a try.
|
||||
|
||||
First, you'll see the login screen. Follow the sign-up link and register. Corteza auto-promotes the first user to the administrator role. You can explore the administration area and the messaging and low-code tools with the support of the [user][16] and [administrator][17] guides.
|
||||
|
||||
### Run in the background
|
||||
|
||||
If you're not familiar with **docker-compose**, you can bring up the services with the **-d** flag and run them in the background. You can still access service logs with the **docker-container logs** command if you want.
|
||||
|
||||
## Expose Corteza to your internal network and the world
|
||||
|
||||
If you want to use Corteza in production and with other users, take a look at Corteza's [simple][18] and [advanced][19] deployment setup examples.
|
||||
|
||||
### Establish data persistency
|
||||
|
||||
If you use one of the simple or advanced examples, you can persist your data by uncommenting one of the volume line pairs.
|
||||
|
||||
If you want to store data on your local filesystem, you might need to pay special attention to file permissions. Review the logs when starting up the services if there are any related errors.
|
||||
|
||||
### Proxy requests to containers
|
||||
|
||||
Both server and web-app containers listen on port 80 by default. If you want to expose them to the outside world, you need to use a different outside port. Unfortunately, this makes it not very user-friendly. We do not want to have to tell users to access Corteza on (for example) **corteza.example.org:31337** but directly on **corteza.example.org** with an API served from **api.corteza.example.org**.
|
||||
|
||||
The easiest way to do this is with another Docker image: **[jwilder/nginx-proxy][20]**. You can find a [configuration example][21] in Corteza's docs. When you spin-up an **nginx-proxy** container, it listens for Docker events (e.g., when a container starts or stops), reads values from the container's **VIRTUAL_HOST** variable, and creates an [Nginx][22] configuration that proxies requests directed to the domain configured with **VIRTUAL_HOST** to the container using the domain.
|
||||
|
||||
### Secure HTTP
|
||||
|
||||
Corteza server speaks only plain HTTP (and HTTP 2.0). It does not do any SSL termination, so you must set up the (reverse) proxy that handles HTTPS traffic and redirects it to internal HTTP ports.
|
||||
|
||||
If you use **jwilder/nginx-proxy** as your front end, you can use another image—**[jrcs/letsencrypt-nginx-proxy-companion][23]**—to take care of SSL certificates from Let's Encrypt. It listens for Docker events (in a similar way as **nginx-proxy**) and reads the **LETSENCRYPT_HOST** variable.
|
||||
|
||||
### Configuration
|
||||
|
||||
Another ENV file holds configuration values. See the [docs][24] for details. There are two levels of configuration, with ENV variables and settings stored in the database.
|
||||
|
||||
### Authentication
|
||||
|
||||
Along with its internal authentication capabilities (with usernames and encrypted passwords stored in the database), Corteza supports registration and authentication with GitHub, Google, Facebook, Linkedin, or any other [OpenID Connect][25] (OIDC)-compatible identity provider.
|
||||
|
||||
You can add any [external OIDC provider][26] using auto-discovery or by explicitly setting your key and secret. (Note that GitHub, Google, Facebook, and Linkedin require you to register an application and provide a redirection link.)
|
||||
|
||||
### Splitting services
|
||||
|
||||
If you expect more load or want to separate services to fine-tune your containers, follow the [advanced deployment][19] example, which has more of a microservice-type architecture. It still uses a single database, but it can split into three parts.
|
||||
|
||||
### Other types of setup
|
||||
|
||||
In the future, Corteza will be available for different distributions, appliances, container types, and more
|
||||
|
||||
If you have special requirements, you can always build Corteza as a backend service and the web applications [from source][27].
|
||||
|
||||
## Using Corteza
|
||||
|
||||
Once you have Corteza up and running, you can start using all its features. Here is a list of recommended actions.
|
||||
|
||||
### Log in
|
||||
|
||||
Enter Corteza at, for example, your **corteza.example.org** link. You'll see the login screen.
|
||||
|
||||
![Corteza Login screenshot][28]
|
||||
|
||||
As mentioned above, Corteza auto-promotes the first user to the administrator role. If you haven't yet, explore the administration area, messaging, and low-code tools.
|
||||
|
||||
### Other tasks to get started
|
||||
|
||||
Here are some other tasks you'll want to do when you're setting up Corteza for your organization.
|
||||
|
||||
* Share the login link with others who will work in your Corteza instance so that they can sign up.
|
||||
* Create roles, if needed, and assign users to the right roles. By default, only admins can do this.
|
||||
* Corteza CRM has a complete list of modules. You can enter the CRM admin page to fine-tune the CRM to your needs or just start using it with the defaults.
|
||||
* Enter Corteza Low Code and create a new low-code app from scratch.
|
||||
* Create public and private channels in Corteza Messaging for your team. (For example a public "General" or a private "Sales" channel.)
|
||||
|
||||
|
||||
|
||||
## For more information
|
||||
|
||||
If you or your users have any questions—or would like to contribute—please join the [Corteza Community][29]. After you log in, please introduce yourself in the #Welcome channel.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/corteza-open-source-alternative-salesforce
|
||||
|
||||
作者:[Denis Arh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/darhhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/jason-bakerhttps://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://www.cortezaproject.org/
|
||||
[3]: https://www.crust.tech/
|
||||
[4]: https://cortezaproject.org/technology/core/corteza-crm/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/screenshot-corteza-crm-1.png (Corteza CRM screenshot)
|
||||
[6]: https://cortezaproject.org/technology/core/corteza-low-code/
|
||||
[7]: https://en.wikipedia.org/wiki/Low-code_development_platform
|
||||
[8]: https://opensource.com/sites/default/files/uploads/screenshot-corteza-low-code-2.png (Corteza Low Code screenshot)
|
||||
[9]: https://cortezaproject.org/technology/core/corteza-messaging/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/screenshot-corteza-messaging-1.png (Corteza Messaging screenshot)
|
||||
[11]: https://cortezaproject.org/technology/core/corteza-one/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/screenshot-cortezaone-unifiedworkspace.png (Corteza One screenshot)
|
||||
[13]: https://www.docker.com/products/docker-desktop
|
||||
[14]: https://hub.docker.com/search?offering=community&type=edition
|
||||
[15]: https://github.com/cortezaproject/corteza-docs/blob/master/deploy/docker-compose/example-2019-07-os.com/docker-compose.yml
|
||||
[16]: https://cortezaproject.org/documentation/user-guides/
|
||||
[17]: https://cortezaproject.org/documentation/administrator-guides/
|
||||
[18]: https://github.com/cortezaproject/corteza-docs/blob/master/deploy/docker-compose/simple.md
|
||||
[19]: https://github.com/cortezaproject/corteza-docs/blob/master/deploy/docker-compose/advanced.md
|
||||
[20]: https://github.com/jwilder/nginx-proxy
|
||||
[21]: https://github.com/cortezaproject/corteza-docs/blob/master/deploy/docker-compose/nginx-proxy/docker-compose.yml
|
||||
[22]: http://nginx.org/
|
||||
[23]: https://github.com/JrCs/docker-letsencrypt-nginx-proxy-companion
|
||||
[24]: https://github.com/cortezaproject/corteza-docs/tree/master/config
|
||||
[25]: https://en.wikipedia.org/wiki/OpenID_Connect
|
||||
[26]: https://github.com/cortezaproject/corteza-docs/blob/master/config/ExternalAuth.md
|
||||
[27]: https://github.com/cortezaproject
|
||||
[28]: https://opensource.com/sites/default/files/uploads/screenshot-corteza-login.png (Corteza Login screenshot)
|
||||
[29]: https://latest.cortezaproject.org/
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why fear of failure is a silent DevOps virus)
|
||||
[#]: via: (https://opensource.com/article/19/8/why-fear-failure-silent-devops-virus)
|
||||
[#]: author: (Willy-Peter SchaubJustin Kearns https://opensource.com/users/wpschaubhttps://opensource.com/users/bclasterhttps://opensource.com/users/juliegundhttps://opensource.com/users/kearnsjdhttps://opensource.com/users/ophirhttps://opensource.com/users/willkelly)
|
||||
|
||||
Why fear of failure is a silent DevOps virus
|
||||
======
|
||||
In the context of software development, fail fast is innocuous to
|
||||
DevOps.
|
||||
![gears and lightbulb to represent innovation][1]
|
||||
|
||||
Do you recognize the following scenario? I do, because a manager once stifled my passion and innovation to the point I was anxious to make decisions, take risks, and focus on what's important: "_uncovering better ways of developing software by doing it and helping others do it_" ([Agile Manifesto, 2001][2]).
|
||||
|
||||
> **Developer:** "_The UX hypothesis failed. Users did not respond well to the new navigation experience, resulting in 80% of users switching back to the classic navigation._"
|
||||
>
|
||||
> **Manager: **"_This is really bad! How is this possible? We need to fix this because I'm not sure that our stakeholders want to hear about your failure._"
|
||||
|
||||
Here is a different, more powerful response.
|
||||
|
||||
> **Leader:** "What are the probable causes for our hypothesis failing and how can we improve the user experience? Let us analyze and share our remediation plan with our stakeholders."
|
||||
|
||||
It is all about the tone that centers on a constructive and blameless mindset.
|
||||
|
||||
There are various types of fear that paralyze people, who then infect their team. Fearful that nothing is ever enough, pushing themselves to do more and more, viewing feedback as unfavorable, and often burning themselves out. They work hard, not smart—delivering volume, not value.
|
||||
|
||||
Others fear being judged, compare themselves with others, and shy away from accountability. They seldom share their knowledge, passion, or work; instead of vibrant collaboration, they find themselves wandering through a ghost ship filled with skeletons and foul fish.
|
||||
|
||||
> _"The only thing we have to fear is fear itself."_ – Franklin D. Roosevelt
|
||||
|
||||
_Fear of failure_ is rife in many organizations, especially those that have embarked on a digital transformation journey. It's caused by the undesirability of failure, knowledge of repercussions, and lack of appetite for validated learning.
|
||||
|
||||
This is a strange phenomenon because when we look at the Manifesto for Agile Software Development, we notice references to "customer collaboration" and "responding to change." Lean thinking promotes principles such as "optimize the whole," "eliminate waste," "create knowledge," "build quality in," and "respect people." Also, two of the [Kanban principles][3] mention "visualize work" and "continuous improvement."
|
||||
|
||||
I have a hypothesis:
|
||||
|
||||
> "_I believe an organization will embrace failure if we elaborate the benefit of failure in the context of software engineering to all stakeholders._"
|
||||
|
||||
Let's look at a traditional software development lifecycle that strives for quality, is based on strict processes, and is sensitive to failure. We design, develop, and test all features in sequence. The solution is released to the customer when QA and security give us the "thumbs up," followed by a happy user (success) or unhappy user (failure).
|
||||
|
||||
![Traditional software development lifecycle][4]
|
||||
|
||||
With the traditional model, we have one opportunity to fail or succeed. This is probably an effective model if we are building a sensitive product such as a multimillion-dollar rocket or aircraft. Context is important!
|
||||
|
||||
Now let's look at a more modern software development lifecycle that strives for quality and _embraces failure_. We design, build, and test and release a limited release to our users for preview. We get feedback. If the user is happy (success), we move to the next feature. If the user is unhappy (failure), we either improve or scrap the feature based on validated feedback.
|
||||
|
||||
![Modern software development lifecycle][5]
|
||||
|
||||
Note that we have a minimum of one opportunity to fail per feature, giving us a minimum of 10 opportunities to improve our product, based on validated user feedback, before we release the same product. Essentially, this modern approach is a repetition of the traditional approach, but it's broken down into smaller release cycles. We cannot reduce the effort to design, develop, and test our features, but we can learn and improve the process. You can take this software engineering process a few steps further.
|
||||
|
||||
* **Continuous delivery** (CD) aims to deliver software in short cycles and releases features reliably, one at a time, at a click of a button by the business or user.
|
||||
* **Test-driven development** (TDD) is a software engineering approach that creates many debates among stakeholders in business, development, and quality assurance. It relies on short and repetitive development cycles, each one crafting test cases based on requirements, failing, and developing software to pass the test cases.
|
||||
* [**Hypothesis-driven development**][6] (HDD) is based on a series of experiments to validate or disprove a hypothesis in a complex problem domain where we have unknown unknowns. When the hypothesis fails, we pivot. When it passes, we focus on the next experiment. Like TDD, it is based on very short repetitions to explore and react on validated learning.
|
||||
|
||||
|
||||
|
||||
Yes, I am confident that failure is not bad. In fact, it is an enabler for innovation and continuous learning. It is important to emphasize that we need to embrace failure in the form of _fail fast_, which means that we slice our product into small units of work that can be developed and delivered as value, quickly and reliably. When we fail, the waste and impact must be minimized, and the validated learning maximized.
|
||||
|
||||
To avoid the fear of failure among engineers, all stakeholders in an organization need to trust the engineering process and embrace failure. The best antidote is leaders who are supportive and inspiring, along with having a collective blameless mindset to plan, prioritize, build, release, and support. We should not be reckless or oblivious of the impact of failure, especially when it impacts investors or livelihoods.
|
||||
|
||||
We cannot be afraid of failure when we're developing software. Otherwise, we will stifle innovation and evolution, which in turn suffocates the union of people, process, and continuous delivery of value, key ingredients of DevOps as defined by [Donovan Brown][7]:
|
||||
|
||||
> _"DevOps is the union of people, process, and products to enable continuous delivery of value to our end users."_
|
||||
|
||||
* * *
|
||||
|
||||
_Special thanks to Anton Teterine and Alex Bunardzic for sharing their perspectives on fear._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/why-fear-failure-silent-devops-virus
|
||||
|
||||
作者:[Willy-Peter SchaubJustin Kearns][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/wpschaubhttps://opensource.com/users/bclasterhttps://opensource.com/users/juliegundhttps://opensource.com/users/kearnsjdhttps://opensource.com/users/ophirhttps://opensource.com/users/willkelly
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/innovation_lightbulb_gears_devops_ansible.png?itok=TSbmp3_M (gears and lightbulb to represent innovation)
|
||||
[2]: https://agilemanifesto.org/
|
||||
[3]: https://www.agilealliance.org/glossary/kanban
|
||||
[4]: https://opensource.com/sites/default/files/uploads/waterfall.png (Traditional software development lifecycle)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/agile_1.png (Modern software development lifecycle)
|
||||
[6]: https://opensource.com/article/19/6/why-hypothesis-driven-development-devops
|
||||
[7]: http://donovanbrown.com/post/what-is-devops
|
||||
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A data transmission revolution is underway)
|
||||
[#]: via: (https://www.networkworld.com/article/3429610/a-data-transmission-revolution-is-underway.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
A data transmission revolution is underway
|
||||
======
|
||||
Two radical data transmission ideas are being developed. One uses trions instead of electrons to transmit information, and the other replaces the silicon in semiconductors with other compounds.
|
||||
![Getty Images][1]
|
||||
|
||||
Radical data communications technologies are in development in a slew of academic scientific labs around the world. While we’ve already seen, and gotten used, to a shift from data sent being over copper wire to light-based, fiber-optic channels (and the resulting capacity and speed increases), much of the thrust by engineers today is in the area of semiconductor improvements, in part to augment those pipes.
|
||||
|
||||
The work includes [a potential overall shift to photons and light, not wires on chips][2], and even more revolutionary ideas such as the abandonment of not only silicon, but also the traditional electron.
|
||||
|
||||
**[ Also read: [Who's developing quantum computers?][3] ]**
|
||||
|
||||
### Electrons aren’t capacious enough
|
||||
|
||||
“Most electronics today use individual electrons to conduct electricity and transmit information,” writes Iqbal Pittalwala [on the University of California at Riverside news website][4]. Trions, though, are better than electrons for data transmission, the physicists at that university claim.
|
||||
|
||||
Why? Electrons, the incumbents, are subatomic particles that are charged and have a surrounding electrical field. They carry electricity and information. However, gate-tunable trions from the quantum family are a spinning, charged combination of two electrons and one hole, or two holes and one electron, depending on polarity, they explain. More, in other words, and enough to carry greater amounts of information than a single electron.
|
||||
|
||||
A trion contains three interacting particles, allowing it to carry much more information than a single electron, the researchers say.
|
||||
|
||||
“Just like increasing your Wi-Fi bandwidth at home, trion transmission allows more information to come through than individual electrons,” says Erfu Liu in the article. Liu is the first author of the [research paper][5] about the work being done.
|
||||
|
||||
The researchers plan to test dark trions (harder to do than light trions, but with more capacity) to transport quantum information. It could revolutionize information transmission, the group says.
|
||||
|
||||
### Dump silicon
|
||||
|
||||
Separately, scientists at Cardiff University’s Institute for Compound Semiconductors are adopting an alternative approach to speed up and gain capacity at the semiconductor level. They aim to replace silicon with other variants of atom combinations, the team explains in a press release.
|
||||
|
||||
The compound semiconductors they’re working on are like silicon, but they come from elements on either side of silicon on the periodic table, the institute explains in a video presentation of its work. The properties on the wafer are different and thus allow new technologies. Some compound semiconductors are already used in smartphone and other newer technology, but the group says much more can be done in this area.
|
||||
|
||||
“Extremely low excess noise and high-sensitivity avalanche photodiodes [have] the potential to yield a new class of high-performance receivers,” says Diana Huffaker, a professor at Cardiff University’s Institute for Compound Semiconductors, [on the school’s website][6]. That technology is geared towards applications in fast networking and sensing environments.
|
||||
|
||||
The avalanche photodiodes (APDs) that the institute is building create less noise than silicon. APDs are semiconductors that convert light into electricity. Autonomous vehicles’ LIDAR (Light Detection and Ranging) is one use. LIDAR is a way for the vehicle to sense where it is, and it needs very fast communications. “The innovation lies in the advanced materials development to ‘grow’ the compound semiconductor crystal in an atom-by-atom regime,” Huffaker says in the article. Special reactors are needed to do it.
|
||||
|
||||
Players are noticing. Huffaker says Airbus may implement the APD technology in a “future free space optics communication system.” Airbus is behind the design and build-out of OneWeb’s planned internet backbone in space. Space laser systems, coming in due course, will have the advantage of performing a capacious data-send without hinderance of interfering air or other earthly environmental limitations—such as digging trenches, making NIMBY-prone planning applications, or implementing latency-increasing repeaters.
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3429610/a-data-transmission-revolution-is-underway.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/11/3_industrial-iot_solar-power-panels_energy_network_internet-100779353-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3338081/light-based-computers-to-be-5000-times-faster.html
|
||||
[3]: https://www.networkworld.com/article/3275385/who-s-developing-quantum-computers.html
|
||||
[4]: https://news.ucr.edu/articles/2019/07/09/physicists-finding-could-revolutionize-information-transmission
|
||||
[5]: https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.123.027401
|
||||
[6]: https://www.cardiff.ac.uk/news/view/1527841-cardiff-in-world-beating-cs-breakthrough
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Scrum vs. kanban: Which agile methodology is better?)
|
||||
[#]: via: (https://opensource.com/article/19/8/scrum-vs-kanban)
|
||||
[#]: author: (Taz Brown https://opensource.com/users/heronthecli)
|
||||
|
||||
Scrum vs. kanban: Which agile methodology is better?
|
||||
======
|
||||
Learn the differences between scrum and kanban and which may be best for
|
||||
your team.
|
||||
![Team checklist and to dos][1]
|
||||
|
||||
Because scrum and kanban both fall under the agile methodology umbrella, many people confuse them or think they're the same thing. There are differences, however. For one, scrum is more specific to software development teams, while kanban is used by many kinds of teams and focuses on providing a visual representation of an agile team's workflow. Some argue that kanban is about getting things done, and scrum is about talking about getting things done.
|
||||
|
||||
### A history lesson
|
||||
|
||||
Before we get too deep into scrum and kanban, let's talk a little history. Before scrum, kanban, and agile, there was the waterfall model. It was popular in the '80s and '90s, especially in civil and mechanical engineering where changes were rare and design often stayed the same. It was adopted for software development, but it didn't translate well into that arena, with results rarely as anyone expected or desired.
|
||||
|
||||
In 2001, the [Agile Manifesto][2] emerged as an alternative to overcome the problems with waterfall. The Manifesto outlined agile principles and beliefs including shorter lead times, open communication, lighter processes, continuous training, and adaptation to change. These principles took on a life of their own when it came to software development practices and teams. In cases of irregularities, bugs, or dissatisfied customers, agile enabled development teams to make changes quickly, and software was released faster with much higher quality.
|
||||
|
||||
### What is agile?
|
||||
|
||||
An agile framework (or just agile) is an umbrella term for several iterative and incremental software development approaches such as kanban and scrum. Kanban and scrum are also considered to be agile frameworks on their own. As [Mendix explains][3]:
|
||||
|
||||
> "While each agile methodology type has its own unique qualities, they all incorporate elements of iterative development and continuous feedback when creating an application. Any agile development project involves continuous planning, continuous testing, continuous integration, and other forms of continuous development of both the project and the application resulting from the agile framework."
|
||||
|
||||
### What is kanban?
|
||||
|
||||
[Kanban][4] is the Japanese word for "visual signal." It is also an agile framework or work management system and is considered to be a powerful project management tool.
|
||||
|
||||
A kanban board (such as [Wekan][5], an open source kanban application) is a visual method for managing the creation of products through a series of fixed steps. It emphasizes continuous flow and is designed as a list of stages displayed in columns on a board. There is a waiting or backlog stage at the start of the kanban board, and there may be some progress stages, such as testing, development, completed, or abandoned.
|
||||
|
||||
![Wekan kanban board][6]
|
||||
|
||||
Each task or part of a project is represented on a card, and the cards are moved across this board as they progress across the stages. A card's current stage must be completed before it can be moved to the next stage.
|
||||
|
||||
Other features of kanban include color-coding (to identify different stages or types of tasks visually) and Work in Progress ([WIP][7]) limits (to restrict the maximum number of work items allowed in the different stages of the workflow).
|
||||
|
||||
Wekan is [similar to Trello][8] (a proprietary kanban application). It's one of [a variety][9] of digital kanban tools. Teams can also use the traditional kanban approach: a wall, a board, or a large piece of paper with different colored sticky notes for various tasks. Whatever method you use, the idea is to apply agile effectively, efficiently, and continuously.
|
||||
|
||||
Overall, kanban and Wekan offer a simple, graphical way of monitoring progress, sharing responsibility, and mitigating bottlenecks. It is a team effort to ensure that the final product is created with high quality and to the customers' satisfaction.
|
||||
|
||||
### What is scrum?
|
||||
|
||||
[Scrum][10] typically involves daily standups and sprints with sprint planning, sprint reviews, and retrospectives. It establishes specific release days and where cards can move across the board. There are daily scrums and two- to four-week sprints (putting code into production) with the goal to create a shippable product after every sprint.
|
||||
|
||||
![team_meeting_at_board.png][11]
|
||||
|
||||
Daily stand-up meetings allow team members to share progress. (Photo credit: Andrea Truong)
|
||||
|
||||
|
||||
|
||||
Scrum teams are usually comprised of a scrum master, a product owner, and the development team. All must operate in synchronicity to produce high-quality software products in a fast, efficient, cost-effective way that pleases the customer.
|
||||
|
||||
### Which is better: scrum or kanban?
|
||||
|
||||
With all that as background, the important question we are left with is: Which agile methodology is superior, kanban, or scrum? Well, it depends. It is certainly not a straightforward or easy choice, and neither method is inherently superior. The type of team and the project's scope or requirements influence which is likely to be the better choice.
|
||||
|
||||
Software development teams typically use scrum because it has been found to be highly useful in the software lifecycle process.
|
||||
|
||||
Kanban can be used by all kinds of teams—IT, marketing, HR, transformation, manufacturing, healthcare, finance, etc. Its core values are continuous workflow, continuous feedback, continuous change, and stir vigorously until you achieve the desired quality and consistency or create a shippable product. The team works from the backlog until all tasks are completed. Usually, members will pick tasks based on their specialized knowledge or area of expertise, but the team must be careful not to reduce its effectiveness with too much specialization.
|
||||
|
||||
### Conclusion
|
||||
|
||||
There is a place for both scrum and kanban agile frameworks, and their utility is determined by the makeup of the team, the product or service to be delivered, the requirements or scope of the project, and the organizational culture. There will be trial and error, especially for new teams.
|
||||
|
||||
Scrum and kanban are both iterative work systems that rely on process flows and aim to reduce waste. No matter which framework your team chooses, you will be a winner. Both methodologies are valuable now and likely will be for some time to come.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/scrum-vs-kanban
|
||||
|
||||
作者:[Taz Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/heronthecli
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/todo_checklist_team_metrics_report.png?itok=oB5uQbzf (Team checklist and to dos)
|
||||
[2]: https://www.scrumalliance.org/resources/agile-manifesto
|
||||
[3]: https://www.mendix.com/agile-framework/
|
||||
[4]: https://en.wikipedia.org/wiki/Kanban
|
||||
[5]: https://wekan.github.io/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/wekan-board.png (Wekan kanban board)
|
||||
[7]: https://www.atlassian.com/agile/kanban/wip-limits
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-wekan
|
||||
[9]: https://opensource.com/alternatives/trello
|
||||
[10]: https://en.wikipedia.org/wiki/Scrum_(software_development)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/team_meeting_at_board.png (team_meeting_at_board.png)
|
||||
67
sources/talk/20190809 Goodbye, Linux Journal.md
Normal file
67
sources/talk/20190809 Goodbye, Linux Journal.md
Normal file
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Goodbye, Linux Journal)
|
||||
[#]: via: (https://opensource.com/article/19/8/goodbye-linux-journal)
|
||||
[#]: author: (Jim Hall https://opensource.com/users/jim-hallhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/alanfdoss)
|
||||
|
||||
Goodbye, Linux Journal
|
||||
======
|
||||
Linux Journal's coverage from 1994 to 2019 highlighted Linux’s rise to
|
||||
an enterprise platform that runs a majority of the world’s servers and
|
||||
services.
|
||||
![Linux keys on the keyboard for a desktop computer][1]
|
||||
|
||||
I first discovered Linux in 1993, when I was an undergraduate physics student who wanted the power of Big Unix on my home PC. I remember installing my first Linux distribution, SoftLanding Systems (SLS), and exploring the power of Linux on my ‘386 PC. I was immediately impressed. Since then, I’ve run Linux at home—and even at work.
|
||||
|
||||
In those early days, it felt like I was the only person who knew about Linux. Certainly, there was an online community via Usenet, but there weren’t many other ways to get together with other Linux users—unless you had a local Linux User Group in your area. I shared what I knew about Linux with those around me, and we pooled our Linux fu.
|
||||
|
||||
So, it was awesome to learn about a print magazine that was dedicated to all things Linux. In March 1994, Phil Hughes and Red Hat co-founder Bob Young published a new magazine about Linux, named _Linux Journal_. The [first issue][2] featured an "[Interview With Linus, The Author of Linux][3]" by Robert Young, and an article comparing "[Linux Vs. Windows NT and OS/2][4]" by Bernie Thompson.
|
||||
|
||||
From the start, _Linux Journal_ aimed to be a community-driven magazine. Hughes and Young were not the only contributors to the magazine. Instead, they invited others to write about Linux and share what they had learned. In a way, _Linux Journal_ used a model similar to open source software. Anyone could contribute, and the editors acted as "maintainers" to ensure content was top quality and informative.
|
||||
|
||||
_Linux Journal_ also went for a broad audience. The editors realized that a purely technical magazine would lose too many new users, while a magazine written for "newbies" would not attract a more focused audience. In the first issue, [Hughes highlighted][5] both groups of users as the audience _Linux Journal_ was looking for, writing: "We see this part of our audience as being two groups. Lots of the current Linux users have worked professionally with Unix. The other segment is the DOS user who wants to upgrade to a multi-user system. With a combination of tutorials and technical articles, we hope to satisfy the needs of both these groups."
|
||||
|
||||
I was glad to discover _Linux Journal_ in those early days, and I quickly became a subscriber. In time, I contributed my own stories to _Linux Journal_. I’ve written several articles including essays on usability in open source software, Bash shell scripting tricks, and C programming how-tos.
|
||||
|
||||
But my contributions to Linux Journal are meager compared to others. Over the years, I have enjoyed reading many article series from regular contributors. I loved Dave Taylor's "Work the Shell" series about practical and sometimes magical scripts written for the Bash shell. I always turned to Kyle Rankin's "Hack and /" series about cool projects with Linux. And I have enjoyed reading articles from the latest Linux Journal deputy editor Bryan Lunduke, especially a recent geeky article about "[How to Live Entirely in a Terminal][6]" that showed you can still do daily tasks on Linux without a graphical environment.
|
||||
|
||||
Many years later, things took a turn. Linux Journal’s Publisher Carlie Fairchild wrote a seemingly terminal essay [_Linux Journal Ceases Publication_][7] in December 2017 that indicated _Linux Journal_ had "run out of money, and options along with it." But a month later, Carlie updated the news item to report that "*Linux Journal *was saved and brought back to life" by an angel investor. London Trust Media, the parent company of Private Internet Access, injected new funds into Linux Journal to get the magazine back on its feet. _Linux Journal_ resumed regular issues in March 2018.
|
||||
|
||||
But it seems the rescue was not enough. Late in the evening of August 7, 2019, _Linux Journal_ posted a final, sudden goodbye. Kyle Rankin’s essay [_Linux Journal Ceases Publication: An Awkward Goodbye_][8] was preceded with this announcement:
|
||||
|
||||
**IMPORTANT NOTICE FROM LINUX JOURNAL, LLC:**
|
||||
_On August 7, 2019, Linux Journal shut its doors for good. All staff were laid off and the company is left with no operating funds to continue in any capacity. The website will continue to stay up for the next few weeks, hopefully longer for archival purposes if we can make it happen.
|
||||
–Linux Journal, LLC_
|
||||
|
||||
The announcement came as a surprise to readers and staff alike. I reached out to Bryan Lunduke, who commented the shutdown was a "total surprise. Was writing an article the night before for an upcoming issue... No indication that things were preparing to fold." The next morning, on August 7, Lunduke said he "had a series of frantic messages from our Editor (Jill) and Publisher (Carlie). They had just found out, effective the night before... _Linux Journal_ was shut down. So we weren't so much being told that Linux Journal is shutting down... as _Linux Journal_ had already been shut down the day before... and we just didn't know it."
|
||||
|
||||
It's the end of an era. And as we salute the passing of _Linux Journal_, I’d like to recognize the indelible mark the magazine has left on the Linux landscape. _Linux Journal_ was the first publication to highlight Linux as a serious platform, and I think that made people take notice.
|
||||
|
||||
And with that seriousness, that maturity, _Linux Journal_ helped Linux shake its early reputation of being a hobby project. _Linux Journal's_ coverage from 1994 to 2019 highlighted Linux’s rise to an enterprise platform that runs a majority of the world’s servers and services.
|
||||
|
||||
I tip my hat to everyone at _Linux Journal_ and any contributor who was part of its journey. It has been a pleasure to work with you over the years. You kept the spirit alive. This may be a painful experience, but I hope everyone ends up in a good place.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/goodbye-linux-journal
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hallhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_keyboard_desktop.png?itok=I2nGw78_ (Linux keys on the keyboard for a desktop computer)
|
||||
[2]: https://www.linuxjournal.com/issue/1
|
||||
[3]: https://www.linuxjournal.com/article/2736
|
||||
[4]: https://www.linuxjournal.com/article/2734
|
||||
[5]: https://www.linuxjournal.com/article/2735
|
||||
[6]: https://www.linuxjournal.com/content/without-gui-how-live-entirely-terminal
|
||||
[7]: https://www.linuxjournal.com/content/linux-journal-ceases-publication
|
||||
[8]: https://www.linuxjournal.com/content/linux-journal-ceases-publication-awkward-goodbye
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How SD-Branch addresses today’s network security concerns)
|
||||
[#]: via: (https://www.networkworld.com/article/3431166/how-sd-branch-addresses-todays-network-security-concerns.html)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
How SD-Branch addresses today’s network security concerns
|
||||
======
|
||||
New digital technologies such as IoT at remote locations increase the need to identify devices and monitor network activity. That’s where SD-Branch can help, says Fortinet’s John Maddison.
|
||||
![KontekBrothers / Getty Images][1]
|
||||
|
||||
Secure software-defined WAN (SD-WAN) has become one of the hottest new technologies, with some reports claiming that 85% of companies are actively considering [SD-WAN][2] to improve cloud-based application performance, replace expensive and inflexible fixed WAN connections, and increase security.
|
||||
|
||||
But now the industry is shifting to software-defined branch ([SD-Branch][3]), which is broader than SD-WAN but introduced several new things for organizations to consider, including better security for new digital technologies. To understand what's required in this new solution set, I recently sat down with John Maddison, Fortinet’s executive vice president of products and solutions.
|
||||
|
||||
**[ Learn more: [SD-Branch: What it is, and why you'll need it][3] | Get regularly scheduled insights: [Sign up for Network World newsletters][4] ]**
|
||||
|
||||
### Zeus Kerravala: To get started, what exactly is SD-Branch?
|
||||
|
||||
**John Maddison:** To answer that question, let’s step back and look at the need for a secure SD-WAN solution. Organizations need to expand their digital transformation efforts out to their remote locations, such as branch offices, remote school campuses, and retail locations. The challenge is that today’s networks and applications are highly elastic and constantly changing, which means that the traditional fixed and static WAN connections to their remote offices, such as [MPLS][5], can’t support this new digital business model.
|
||||
|
||||
That’s where SD-WAN comes in. It replaces those legacy, and sometimes quite expensive, connections with flexible and intelligent connectivity designed to optimize bandwidth, maximize application performance, secure direct internet connections, and ensure that traffic, applications, workflows, and data are secure.
|
||||
|
||||
However, most branch offices and retail stores have a local LAN behind that connection that is undergoing rapid transformation. Internet of things (IoT) devices, for example, are being adopted at remote locations at an unprecedented rate. Retail shops now include a wide array of connected devices, from cash registers and scanners to refrigeration units and thermostats, to security cameras and inventory control devices. Hotels monitor room access, security and safety devices, elevators, HVAC systems, and even minibar purchases. The same sort of transformation is happening at schools, branch and field offices, and remote production facilities.
|
||||
|
||||
![John Maddison, executive vice president, Fortinet][6]
|
||||
|
||||
The challenge is that many of these environments, especially these new IoT and mobile end-user devices, lack adequate safeguards. SD-Branch extends the benefits of the secure SD-WAN’s security and control functions into the local network by securing wired and wireless access points, monitoring and inspecting internal traffic and applications, and leveraging network access control (NAC) to identify the devices being deployed at the branch and then dynamically assigning them to network segments where they can be more easily controlled.
|
||||
|
||||
### What unique challenges do remote locations, such as branch offices, schools, and retail locations, face?
|
||||
|
||||
Many of the devices being deployed at these remote locations need access to the internal network, to cloud services, or to internet resources to operate. The challenge is that IoT devices, in particular, are notoriously insecure and vulnerable to a host of threats and exploits. In addition, end users are connecting a growing number of unauthorized devices to the office. While these are usually some sort of personal smart device, they can also include anything from a connected coffee maker to a wireless access point.
|
||||
|
||||
**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][7] ]**
|
||||
|
||||
Any of these, if connected to the network and then exploited, not only represent a threat to that remote location, but they can also be used as a door into the larger core network. There are numerous examples of vulnerable point-of-sale devices or HVAC systems being used to tunnel back into the organization’s data center to steal account and financial information.
|
||||
|
||||
Of course, these issues might be solved by adding a number of additional networking and security technologies to the branch, but most IT teams can’t afford to put IT resources onsite to deploy and manage these solutions, even temporarily. What’s needed is a security solution that combines traffic scanning and security enforcement, access control for both wired and wireless connections, device recognition, dynamic segmentation, and integrated management in a single low-touch/no-touch device. That’s where SD-Branch comes in.
|
||||
|
||||
### Why aren't traditional branch solutions, such as integrated routers, solving these challenges?
|
||||
|
||||
Most of the solutions designed for branch and retail locations predate SD-WAN and digital transformation. As a result, most do not provide support for the sort of flexible SD-WAN functionality that today’s remote locations require. In addition, while they may claim to provide low-touch deployment and management, the experience of most organizations tells a different story. Complicating things further, these solutions provide little more than a superficial integration between their various services.
|
||||
|
||||
For example, few if any of these integrated devices can manage or secure the wired and wireless access points deployed as part of the larger branch LAN, provide device recognition and network access control, scan network traffic, or deliver the sort of robust security that today’s networks require. Instead, many of these solutions are little more than a collection of separate limited networking, connectivity, and security elements wrapped in a piece of sheet metal that all require separate management systems, providing little to no control for those extended LAN environments with their own access points and switches – which adds to IT overhead rather than reducing it.
|
||||
|
||||
### What role does security play in an SD-Branch?
|
||||
|
||||
Security is a critical element of any branch or retail location, especially as the ongoing deployment of IoT and end-user devices continues to expand the potential attack surface. As I explained before, IoT devices are a particular concern, as they are generally quite insecure, and as a result, they need to be automatically identified, segmented, and continuously monitored for malware and unusual behaviors.
|
||||
|
||||
But that is just part of the equation. Security tools need to be integrated into the switch and wireless infrastructure so that networking protocols, security policies, and network access controls can work together as a single system. This allows the SD-Branch solution to identify devices and dynamically match them to security policies, inspect applications and workflows, and dynamically assign devices and traffic to their appropriate network segment based on their function and role.
|
||||
|
||||
The challenge is that there is often no IT staff on site to set up, manage, and fine-tune a system like this. SD-Branch provides these advanced security, access control, and network management services in a zero-touch model so they can be deployed across multiple locations and then be remotely managed through a common interface.
|
||||
|
||||
### Security teams often face challenges with a lack of visibility and control at their branch offices. How does SD-Branch address this?
|
||||
|
||||
An SD-Branch solution seamlessly extends an organization's core security into the local branch network. For organizations with multiple branch or retail locations, this enables the creation of an integrated security fabric operating through a single pane of glass management system that can see all devices and orchestrate all security policies and configurations. This approach allows all remote locations to be dynamically coordinated and updated, supports the collection and correlation of threat intelligence from every corner of the network – from the core to the branch to the cloud – and enables a coordinated response to cyber events that can automatically raise defenses everywhere while identifying and eliminating all threads of an attack.
|
||||
|
||||
Combining security with switches, access points, and network access control systems means that every connected device can not only be identified and monitored, but every application and workflow can also be seen and tracked, even if they travel across or between the different branch and cloud environments.
|
||||
|
||||
### How is SD-Branch related to secure SD-WAN?
|
||||
|
||||
SD-Branch is a natural extension of secure SD-WAN. We are finding that once an organization deploys a secure SD-WAN solution, they quickly discover that the infrastructure behind that connection is often not ready to support their digital transformation efforts. Every new threat vector adds additional risk to their organization.
|
||||
|
||||
While secure SD-WAN can see and secure applications running to or between remote locations, the applications and workflows running inside those branch offices, schools, or retail stores are not being recognized or properly inspected. Shadow IT instances are not being identified. Wired and wireless access points are not secured. End-user devices have open access to network resources. And IoT devices are expanding the potential attack surface without corresponding protections in place. That requires an SD-Branch solution.
|
||||
|
||||
Of course, this is about much more than the emergence of the next-gen branch. These new remote network environments are just another example of the new edge model that is extending and replacing the traditional network perimeter. Cloud and multi-cloud, mobile workers, 5G networks, and the next-gen branch – including offices, retail locations, and extended school campuses – are all emerging simultaneously. That means they all need to be addressed by IT and security teams at the same time. However, the traditional model of building a separate security strategy for each edge environment is a recipe for an overwhelmed IT staff. Instead, every edge needs to be seen as part of a larger, integrated security strategy where every component contributes to the overall health of the entire distributed network.
|
||||
|
||||
With that in mind, adding SD-Branch solutions to SD-WAN deployments not only extends security deep into branch office and other remote locations, but they are also a critical component of a broader strategy that ensures consistent security across all edge environments, while providing a mechanism for controlling operational expenses across the entire distributed network through central management, visibility, and control.
|
||||
|
||||
**[ For more on IoT security, see [our corporate guide to addressing IoT security concerns][8]. ]**
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3431166/how-sd-branch-addresses-todays-network-security-concerns.html
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/07/cio_cw_distributed_decentralized_global_network_africa_by_kontekbrothers_gettyimages-1004007018_2400x1600-100802403-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[3]: https://www.networkworld.com/article/3250664/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://www.networkworld.com/article/2297171/network-security-mpls-explained.html
|
||||
[6]: https://images.idgesg.net/images/article/2019/08/john-maddison-_fortinet-square-100808017-small.jpg
|
||||
[7]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[8]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Xilinx launches new FPGA cards that can match GPU performance)
|
||||
[#]: via: (https://www.networkworld.com/article/3430763/xilinx-launches-new-fpga-cards-that-can-match-gpu-performance.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Xilinx launches new FPGA cards that can match GPU performance
|
||||
======
|
||||
Xilinx says its new FPGA card, the Alveo U50, can match the performance of a GPU in areas of artificial intelligence (AI) and machine learning.
|
||||
![Thinkstock][1]
|
||||
|
||||
Xilinx has launched a new FPGA card, the Alveo U50, that it claims can match the performance of a GPU in areas of artificial intelligence (AI) and machine learning.
|
||||
|
||||
The company claims the card is the industry’s first low-profile adaptable accelerator with PCIe Gen 4 support, which offers double the throughput over PCIe Gen3. It was finalized in 2017, but cards and motherboards to support it have been slow to come to market.
|
||||
|
||||
The Alveo U50 provides customers with a programmable low-profile and low-power accelerator platform built for scale-out architectures and domain-specific acceleration of any server deployment, on premises, in the cloud, and at the edge.
|
||||
|
||||
**[ Also read: [What is quantum computing (and why enterprises should care)][2] ]**
|
||||
|
||||
Xilinx claims the Alveo U50 delivers 10 to 20 times improvements in throughput and latency as compared to a CPU. One thing's for sure, it beats the competition on power draw. It has a 75 watt power envelope, which is comparable to a desktop CPU and vastly better than a Xeon or GPU.
|
||||
|
||||
For accelerated networking and storage workloads, the U50 card helps developers identify and eliminate latency and data movement bottlenecks by moving compute closer to the data.
|
||||
|
||||
![Xilinx Alveo U50][3]
|
||||
|
||||
The Alveo U50 card is the first in the Alveo portfolio to be packaged in a half-height, half-length form factor. It runs the Xilinx UltraScale+ FPGA architecture, features high-bandwidth memory (HBM2), 100 gigabits per second (100 Gbps) networking connectivity, and support for the PCIe Gen 4 and CCIX interconnects. Thanks to the 8GB of HBM2 memory, data transfer speeds can reach 400Gbps. It also supports NVMe-over-Fabric for high-speed SSD transfers.
|
||||
|
||||
That’s a lot of performance packed into a small card.
|
||||
|
||||
**[ [Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][4] ]**
|
||||
|
||||
### What the Xilinx Alveo U50 can do
|
||||
|
||||
Xilinx is making some big boasts about Alveo U50's capabilities:
|
||||
|
||||
* Deep learning inference acceleration (speech translation): delivers up to 25x lower latency, 10x higher throughput, and significantly improved power efficiency per node compared to GPU-only for speech translation performance.
|
||||
* Data analytics acceleration (database query): running the TPC-H Query benchmark, Alveo U50 delivers 4x higher throughput per hour and reduced operational costs by 3x compared to in-memory CPU.
|
||||
* Computational storage acceleration (compression): delivers 20x more compression/decompression throughput, faster Hadoop and big data analytics, and over 30% lower cost per node compared to CPU-only nodes.
|
||||
* Network acceleration (electronic trading): delivers 20x lower latency and sub-500ns trading time compared to CPU-only latency of 10us.
|
||||
* Financial modeling (grid computing): running the Monte Carlo simulation, Alveo U50 delivers 7x greater power efficiency compared to GPU-only performance for a faster time to insight, deterministic latency and reduced operational costs.
|
||||
|
||||
|
||||
|
||||
The Alveo U50 is sampling now with OEM system qualifications in process. General availability is slated for fall 2019.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3430763/xilinx-launches-new-fpga-cards-that-can-match-gpu-performance.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2014/04/bolts-of-light-speeding-through-the-acceleration-tunnel-95535268-100264665-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3275367/what-s-quantum-computing-and-why-enterprises-need-to-care.html
|
||||
[3]: https://images.idgesg.net/images/article/2019/08/xilinx-alveo-u50-100808003-medium.jpg
|
||||
[4]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -1,154 +0,0 @@
|
||||
translating by zyk2290
|
||||
|
||||
Two great uses for the cp command: Bash shortcuts
|
||||
============================================================
|
||||
|
||||
### Here's how to streamline the backup and synchronize functions of the cp command.
|
||||
|
||||

|
||||
|
||||
>Image by : [Internet Archive Book Images][6]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
Last July, I wrote about [two great uses for the cp command][7]: making a backup of a file, and synchronizing a secondary copy of a folder.
|
||||
|
||||
Having discovered these great utilities, I find that they are more verbose than necessary, so I created shortcuts to them in my Bash shell startup script. I thought I’d share these shortcuts in case they are useful to others or could offer inspiration to Bash users who haven’t quite taken on aliases or shell functions.
|
||||
|
||||
### Updating a second copy of a folder – Bash alias
|
||||
|
||||
The general pattern for updating a second copy of a folder with cp is:
|
||||
|
||||
```
|
||||
cp -r -u -v SOURCE-FOLDER DESTINATION-DIRECTORY
|
||||
```
|
||||
|
||||
I can easily remember the -r option because I use it often when copying folders around. I can probably, with some more effort, remember -v, and with even more effort, -u (is it “update” or “synchronize” or…).
|
||||
|
||||
Or I can just use the [alias capability in Bash][8] to convert the cp command and options to something more memorable, like this:
|
||||
|
||||
```
|
||||
alias sync='cp -r -u -v'
|
||||
```
|
||||
|
||||
```
|
||||
sync Pictures /media/me/4388-E5FE
|
||||
```
|
||||
|
||||
Not sure if you already have a sync alias defined? You can list all your currently defined aliases by typing the word alias at the command prompt in your terminal window.
|
||||
|
||||
Like this so much you just want to start using it right away? Open a terminal window and type:
|
||||
|
||||
```
|
||||
echo "alias sync='cp -r -u -v'" >> ~/.bash_aliases
|
||||
```
|
||||
|
||||
```
|
||||
me@mymachine~$ alias
|
||||
|
||||
alias alert='notify-send --urgency=low -i "$([ $? = 0 ] && echo terminal || echo error)" "$(history|tail -n1|sed -e '\''s/^\s*[0-9]\+\s*//;s/[;&|]\s*alert$//'\'')"'
|
||||
|
||||
alias egrep='egrep --color=auto'
|
||||
|
||||
alias fgrep='fgrep --color=auto'
|
||||
|
||||
alias grep='grep --color=auto'
|
||||
|
||||
alias gvm='sdk'
|
||||
|
||||
alias l='ls -CF'
|
||||
|
||||
alias la='ls -A'
|
||||
|
||||
alias ll='ls -alF'
|
||||
|
||||
alias ls='ls --color=auto'
|
||||
|
||||
alias sync='cp -r -u -v'
|
||||
|
||||
me@mymachine:~$
|
||||
```
|
||||
|
||||
### Making versioned backups – Bash function
|
||||
|
||||
The general pattern for making a backup of a file with cp is:
|
||||
|
||||
```
|
||||
cp --force --backup=numbered WORKING-FILE BACKED-UP-FILE
|
||||
```
|
||||
|
||||
Besides remembering the options to the cp command, we also need to remember to repeat the WORKING-FILE name a second time. But why repeat ourselves when [a Bash function][9] can take care of that overhead for us, like this:
|
||||
|
||||
Again, you can save this to your .bash_aliases file in your home directory.
|
||||
|
||||
```
|
||||
function backup {
|
||||
|
||||
if [ $# -ne 1 ]; then
|
||||
|
||||
echo "Usage: $0 filename"
|
||||
|
||||
elif [ -f $1 ] ; then
|
||||
|
||||
echo "cp --force --backup=numbered $1 $1"
|
||||
|
||||
cp --force --backup=numbered $1 $1
|
||||
|
||||
else
|
||||
|
||||
echo "$0: $1 is not a file"
|
||||
|
||||
fi
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
The first if statement checks to make sure that only one argument is provided to the function, otherwise printing the correct usage with the echo command.
|
||||
|
||||
The elif statement checks to make sure the argument provided is a file, and if so, it (verbosely) uses the second echo to print the cp command to be used and then executes it.
|
||||
|
||||
If the single argument is not a file, the third echo prints an error message to that effect.
|
||||
|
||||
In my home directory, if I execute the backup command so defined on the file checkCounts.sql, I see that backup creates a file called checkCounts.sql.~1~. If I execute it once more, I see a new file checkCounts.sql.~2~.
|
||||
|
||||
Success! As planned, I can go on editing checkCounts.sql, but if I take a snapshot of it every so often with backup, I can return to the most recent snapshot should I run into trouble.
|
||||
|
||||
At some point, it’s better to start using git for version control, but backup as defined above is a nice cheap tool when you need to create snapshots but you’re not ready for git.
|
||||
|
||||
### Conclusion
|
||||
|
||||
In my last article, I promised you that repetitive tasks can often be easily streamlined through the use of shell scripts, shell functions, and shell aliases.
|
||||
|
||||
Here I’ve shown concrete examples of the use of shell aliases and shell functions to streamline the synchronize and backup functionality of the cp command. If you’d like to learn more about this, check out the two articles cited above: [How to save keystrokes at the command line with alias][10] and [Shell scripting: An introduction to the shift method and custom functions][11], written by my colleagues Greg and Seth, respectively.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][13] Chris Hermansen
|
||||
|
||||
|
||||
Engaged in computing since graduating from the University of British Columbia in 1978, I have been a full-time Linux user since 2005 and a full-time Solaris, SunOS and UNIX System V user before that. On the technical side of things, I have spent a great deal of my career doing data analysis; especially spatial data analysis. I have a substantial amount of programming experience in relation to data analysis, using awk, Python, PostgreSQL, PostGIS and lately Groovy. I have also built a few... [more about Chris Hermansen][14]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/two-great-uses-cp-command-update
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clhermansen
|
||||
[1]:https://opensource.com/users/clhermansen
|
||||
[2]:https://opensource.com/users/clhermansen
|
||||
[3]:https://opensource.com/user/37806/feed
|
||||
[4]:https://opensource.com/article/18/1/two-great-uses-cp-command-update?rate=J_7R7wSPbukG9y8jrqZt3EqANfYtVAwZzzpopYiH3C8
|
||||
[5]:https://opensource.com/article/18/1/two-great-uses-cp-command-update#comments
|
||||
[6]:https://www.flickr.com/photos/internetarchivebookimages/14803082483/in/photolist-oy6EG4-pZR3NZ-i6r3NW-e1tJSX-boBtf7-oeYc7U-o6jFKK-9jNtc3-idt2G9-i7NG1m-ouKjXe-owqviF-92xFBg-ow9e4s-gVVXJN-i1K8Pw-4jybMo-i1rsBr-ouo58Y-ouPRzz-8cGJHK-85Evdk-cru4Ly-rcDWiP-gnaC5B-pAFsuf-hRFPcZ-odvBMz-hRCE7b-mZN3Kt-odHU5a-73dpPp-hUaaAi-owvUMK-otbp7Q-ouySkB-hYAgmJ-owo4UZ-giHgqu-giHpNc-idd9uQ-osAhcf-7vxk63-7vwN65-fQejmk-pTcLgA-otZcmj-fj1aSX-hRzHQk-oyeZfR
|
||||
[7]:https://opensource.com/article/17/7/two-great-uses-cp-command
|
||||
[8]:https://opensource.com/article/17/5/introduction-alias-command-line-tool
|
||||
[9]:https://opensource.com/article/17/1/shell-scripting-shift-method-custom-functions
|
||||
[10]:https://opensource.com/article/17/5/introduction-alias-command-line-tool
|
||||
[11]:https://opensource.com/article/17/1/shell-scripting-shift-method-custom-functions
|
||||
[12]:https://opensource.com/tags/linux
|
||||
[13]:https://opensource.com/users/clhermansen
|
||||
[14]:https://opensource.com/users/clhermansen
|
||||
@ -1,224 +0,0 @@
|
||||
wxy is applied
|
||||
|
||||
How to test Webhooks when you’re developing locally
|
||||
============================================================
|
||||
|
||||

|
||||
Photo by [Fernando Venzano][1] on [Unsplash][2]
|
||||
|
||||
[Webhooks][10] can be used by an external system for notifying your system about a certain event or update. Probably the most well known type is the one where a Payment Service Provider (PSP) informs your system about status updates of payments.
|
||||
|
||||
Often they come in the form where you listen on a predefined URL. For example [http://example.com/webhooks/payment-update][11]. Meanwhile the other system sends a POST request with a certain payload to that URL (for example a payment ID). As soon as the request comes in, you fetch the payment ID, ask the PSP for the latest status via their API, and update your database afterward.
|
||||
|
||||
Other examples can be found in this excellent explanation about Webhooks. [https://sendgrid.com/blog/whats-webhook/][12].
|
||||
|
||||
Testing these webhooks goes fairly smoothly as long as the system is publicly accessible over the internet. This might be your production environment or a publicly accessible staging environment. It becomes harder when you are developing locally on your laptop or inside a Virtual Machine (VM, for example, a Vagrant box). In those cases, the local URL’s are not publicly accessible by the party sending the webhook. Also, monitoring the requests being sent around is be difficult, which might make development and debugging hard.
|
||||
|
||||
What will this example solve:
|
||||
|
||||
* Testing webhooks from a local development environment, which is not accessible over the internet. It cannot be accessed by the service sending the data to the webhook from their servers.
|
||||
|
||||
* Monitor the requests and data being sent around, but also the response your application generates. This will allow easier debugging, and therefore a shorter development cycle.
|
||||
|
||||
Prerequisites:
|
||||
|
||||
* _Optional_ : in case you are developing using a Virtual Machine (VM), make sure it’s running and make sure the next steps are done in the VM.
|
||||
|
||||
* For this tutorial, we assume you have a vhost defined at `webhook.example.vagrant`. I used a Vagrant VM for this tutorial, but you are free in choosing the name of your vhost.
|
||||
|
||||
* Install `ngrok`by following the [installation instructions][3]. Inside a VM, I find the Node version of it also useful: [https://www.npmjs.com/package/ngrok][4], but feel free to use other methods.
|
||||
|
||||
I assume you don’t have SSL running in your environment, but if you do, feel free to replace port 80 with port 433 and `_http://_` with `_https://_` in the examples below.
|
||||
|
||||
#### Make the webhook testable
|
||||
|
||||
Let’s assume the following example code. I’ll be using PHP, but read it as pseudo-code as I left some crucial parts out (for example API keys, input validation, etc.)
|
||||
|
||||
The first file: _payment.php_ . This file creates a payment object and then registers it with the PSP. It then fetches the URL the customer needs to visit in order to pay and redirects the user to the customer in there.
|
||||
|
||||
Note that the `webhook.example.vagrant` in this example is the local vhost we’ve defined for our development set-up. It’s not accessible from the outside world.
|
||||
|
||||
```
|
||||
<?php
|
||||
/*
|
||||
* This file creates a payment and tells the PSP what webhook URL to use for updates
|
||||
* After creating the payment, we get a URL to send the customer to in order to pay at the PSP
|
||||
*/
|
||||
$payment = [
|
||||
'order_id' => 123,
|
||||
'amount' => 25.00,
|
||||
'description' => 'Test payment',
|
||||
'redirect_url' => 'http://webhook.example.vagrant/redirect.php',
|
||||
'webhook_url' => 'http://webhook.example.vagrant/webhook.php',
|
||||
];
|
||||
```
|
||||
|
||||
```
|
||||
$payment = $paymentProvider->createPayment($payment);
|
||||
header("Location: " . $payment->getPaymentUrl());
|
||||
```
|
||||
|
||||
Second file: _webhook.php_ . This file waits to be called by the PSP to get notified about updates.
|
||||
|
||||
```
|
||||
<?php
|
||||
/*
|
||||
* This file gets called by the PSP and in the $_POST they submit an 'id'
|
||||
* We can use this ID to get the latest status from the PSP and update our internal systems afterward
|
||||
*/
|
||||
```
|
||||
|
||||
```
|
||||
$paymentId = $_POST['id'];
|
||||
$paymentInfo = $paymentProvider->getPayment($paymentId);
|
||||
$status = $paymentInfo->getStatus();
|
||||
```
|
||||
|
||||
```
|
||||
// Perform actions in here to update your system
|
||||
if ($status === 'paid') {
|
||||
..
|
||||
}
|
||||
elseif ($status === 'cancelled') {
|
||||
..
|
||||
}
|
||||
```
|
||||
|
||||
Our webhook URL is not accessible over the internet (remember: `webhook.example.vagrant`). Thus, the file _webhook.php_ will never be called by the PSP. Your system will never get to know about the payment status. This ultimately leads to orders never being shipped to customers.
|
||||
|
||||
Luckily, _ngrok_ can in solving this problem. [_ngrok_][13] describes itself as:
|
||||
|
||||
> ngrok exposes local servers behind NATs and firewalls to the public internet over secure tunnels.
|
||||
|
||||
Let’s start a basic tunnel for our project. On your environment (either on your system or on the VM) run the following command:
|
||||
|
||||
`ngrok http -host-header=rewrite webhook.example.vagrant:80`
|
||||
|
||||
Read about more configuration options in their documentation: [https://ngrok.com/docs][14].
|
||||
|
||||
A screen like this will come up:
|
||||
|
||||
|
||||

|
||||
ngrok output
|
||||
|
||||
What did we just start? Basically, we instructed `ngrok` to start a tunnel to `[http://webhook.example.vagr][5]ant` at port 80\. This same URL can now be reached via `[http://39741ffc.ngrok.i][6]o` or `[https://39741ffc.ngrok.io][7]`[,][15] They are publicly accessible over the internet by anyone that knows this URL.
|
||||
|
||||
Note that you get both HTTP and HTTPS available out of the box. The documentation gives examples of how to restrict this to HTTPS only: [https://ngrok.com/docs#bind-tls][16].
|
||||
|
||||
So, how do we make our webhook work now? Update _payment.php_ to the following code:
|
||||
|
||||
```
|
||||
<?php
|
||||
/*
|
||||
* This file creates a payment and tells the PSP what webhook URL to use for updates
|
||||
* After creating the payment, we get a URL to send the customer to in order to pay at the PSP
|
||||
*/
|
||||
$payment = [
|
||||
'order_id' => 123,
|
||||
'amount' => 25.00,
|
||||
'description' => 'Test payment',
|
||||
'redirect_url' => 'http://webhook.example.vagrant/redirect.php',
|
||||
'webhook_url' => 'https://39741ffc.ngrok.io/webhook.php',
|
||||
];
|
||||
```
|
||||
|
||||
```
|
||||
$payment = $paymentProvider->createPayment($payment);
|
||||
header("Location: " . $payment->getPaymentUrl());
|
||||
```
|
||||
|
||||
Now, we told the PSP to call the tunnel URL over HTTPS. _ngrok_ will make sure your internal URL get’s called with an unmodified payload, as soon as the PSP calls the webhook via the tunnel.
|
||||
|
||||
#### How to monitor calls to the webhook?
|
||||
|
||||
The screenshot you’ve seen above gives an overview of the calls being made to the tunnel host. This data is rather limited. Fortunately, `ngrok` offers a very nice dashboard, which allows you to inspect all calls:
|
||||
|
||||
|
||||

|
||||
|
||||
I won’t go into this very deep because it’s self-explanatory as soon as you have it running. Therefore I will explain how to access it on the Vagrant box as it doesn’t work out of the box.
|
||||
|
||||
The dashboard will allow you to see all the calls, their status codes, the headers and data being sent around. You will also see the response your application generated.
|
||||
|
||||
Another neat feature of the dashboard is that it allows you to replay a certain call. Let’s say your webhook code ran into a fatal error, it would be tedious to start a new payment and wait for the webhook to be called. Replaying the previous call makes your development process way faster.
|
||||
|
||||
The dashboard by default is accessible at [http://localhost:4040.][17]
|
||||
|
||||
#### Dashboard in a VM
|
||||
|
||||
In order to make this work inside a VM, you have to perform some additional steps:
|
||||
|
||||
First, make sure the VM can be accessed on port 4040\. Then, create a file inside the VM holding this configuration:
|
||||
|
||||
`web_addr: 0.0.0.0:4040`
|
||||
|
||||
Now, kill the `ngrok` process that’s still running and start it with this slightly adjusted command:
|
||||
|
||||
`ngrok http -config=/path/to/config/ngrok.conf -host-header=rewrite webhook.example.vagrant:80`
|
||||
|
||||
You will get a screen looking similar to the previous screenshot though the ID’s have changed. The previous URL doesn’t work anymore, but you got a new URL. Also, the `Web Interface` URL got changed:
|
||||
|
||||
|
||||

|
||||
|
||||
Now direct your browser to `[http://webhook.example.vagrant:4040][8]` to access the dashboard. Also, make a call to `[https://e65642b5.ngrok.io/webhook.php][9]`[.][18]This will probably result in an error in your browser, but the dashboard should show the request being made.
|
||||
|
||||
#### Final remarks
|
||||
|
||||
The examples above are pseudo-code. The reason is that every external system uses webhooks in a different way. I tried to give an example based on a fictive PSP implementation, as probably many developers have to deal with payments at some moment.
|
||||
|
||||
Please be aware that your webhook URL can also be used by others with bad intentions. Make sure to validate any input being sent to it.
|
||||
|
||||
Preferably also add a token to the URL which is unique for each payment. This token must only be known by your system and the system sending the webhook.
|
||||
|
||||
Good luck testing and debugging your webhooks!
|
||||
|
||||
Note: I haven’t tested this tutorial on Docker. However, this Docker container looks like a good starting point and includes clear instructions. [https://github.com/wernight/docker-ngrok][19].
|
||||
|
||||
Stefan Doorn
|
||||
|
||||
[https://github.com/stefandoorn][20]
|
||||
[https://twitter.com/stefan_doorn][21]
|
||||
[https://www.linkedin.com/in/stefandoorn][22]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Backend Developer (PHP/Node/Laravel/Symfony/Sylius)
|
||||
|
||||
|
||||
--------
|
||||
|
||||
via: https://medium.freecodecamp.org/testing-webhooks-while-using-vagrant-for-development-98b5f3bedb1d
|
||||
|
||||
作者:[Stefan Doorn ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@stefandoorn
|
||||
[1]:https://unsplash.com/photos/MYTyXb7fgG0?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://ngrok.com/download
|
||||
[4]:https://www.npmjs.com/package/ngrok
|
||||
[5]:http://webhook.example.vagrnat/
|
||||
[6]:http://39741ffc.ngrok.io/
|
||||
[7]:http://39741ffc.ngrok.io/
|
||||
[8]:http://webhook.example.vagrant:4040/
|
||||
[9]:https://e65642b5.ngrok.io/webhook.php.
|
||||
[10]:https://sendgrid.com/blog/whats-webhook/
|
||||
[11]:http://example.com/webhooks/payment-update%29
|
||||
[12]:https://sendgrid.com/blog/whats-webhook/
|
||||
[13]:https://ngrok.com/
|
||||
[14]:https://ngrok.com/docs
|
||||
[15]:http://39741ffc.ngrok.io%2C/
|
||||
[16]:https://ngrok.com/docs#bind-tls
|
||||
[17]:http://localhost:4040./
|
||||
[18]:https://e65642b5.ngrok.io/webhook.php.
|
||||
[19]:https://github.com/wernight/docker-ngrok
|
||||
[20]:https://github.com/stefandoorn
|
||||
[21]:https://twitter.com/stefan_doorn
|
||||
[22]:https://www.linkedin.com/in/stefandoorn
|
||||
@ -1,162 +0,0 @@
|
||||
DF-SHOW – A Terminal File Manager Based On An Old DOS Application
|
||||
======
|
||||

|
||||
|
||||
If you have worked on good-old MS-DOS, you might have used or heard about **DF-EDIT**. The DF-EDIT, stands for **D** irectory **F** ile **Edit** or, is an obscure DOS file manager, originally written by **Larry Kroeker** for MS-DOS and PC-DOS systems. It is used to display the contents of a given directory or file in MS-DOS and PC-DOS systems. Today, I stumbled upon a similar utility named **DF-SHOW** ( **D** irectory **F** ile **S** how), a terminal file manager for Unix-like operating systems. It is an Unix rewrite of obscure DF-EDIT file manager and is based on DF-EDIT 2.3d release from 1986. DF-SHOW is completely free, open source and released under GPLv3.
|
||||
|
||||
DF-SHOW can be able to,
|
||||
|
||||
* List contents of a directory,
|
||||
* View files,
|
||||
* Edit files using your default file editor,
|
||||
* Copy files to/from different locations,
|
||||
* Rename files,
|
||||
* Delete files,
|
||||
* Create new directories from within the DF-SHOW interface,
|
||||
* Update file permissions, owners and groups,
|
||||
* Search files matching a search term,
|
||||
* Launch executable files.
|
||||
|
||||
|
||||
|
||||
### DF-SHOW Usage
|
||||
|
||||
DF-SHOW consists of two programs, namely **“show”** and **“sf”**.
|
||||
|
||||
**Show command**
|
||||
|
||||
The “show” program (similar to the `ls` command) is used to display the contents of a directory, create new directories, rename, delete files/folders, update permissions, search files and so on.
|
||||
|
||||
To view the list of contents in a directory, use the following command:
|
||||
|
||||
```
|
||||
$ show <directory path>
|
||||
```
|
||||
|
||||
Example:
|
||||
|
||||
```
|
||||
$ show dfshow
|
||||
```
|
||||
|
||||
Here, dfshow is a directory. If you invoke the “show” command without specifying a directory path, it will display the contents of current directory.
|
||||
|
||||
Here is how DF-SHOW default interface looks like.
|
||||
|
||||
|
||||
|
||||
As you can see, DF-SHOW interface is self-explanatory.
|
||||
|
||||
On the top bar, you see the list of available options such as Copy, Delete, Edit, Modify etc.
|
||||
|
||||
Complete list of available options are given below:
|
||||
|
||||
* **C** opy,
|
||||
* **D** elete,
|
||||
* **E** dit,
|
||||
* **H** idden,
|
||||
* **M** odify,
|
||||
* **Q** uit,
|
||||
* **R** ename,
|
||||
* **S** how,
|
||||
* h **U** nt,
|
||||
* e **X** ec,
|
||||
* **R** un command,
|
||||
* **E** dit file,
|
||||
* **H** elp,
|
||||
* **M** ake dir,
|
||||
* **Q** uit,
|
||||
* **S** how dir
|
||||
|
||||
|
||||
|
||||
In each option, one letter has been capitalized and marked as bold. Just press the capitalized letter to perform the respective operation. For example, to rename a file, just press **R** and type the new name and hit ENTER to rename the selected item.
|
||||
|
||||

|
||||
|
||||
To display all options or cancel an operation, just press **ESC** key.
|
||||
|
||||
Also, you will see a bunch of function keys at the bottom of DF-SHOW interface to navigate through the contents of a directory.
|
||||
|
||||
* **UP/DOWN** arrows or **F1/F2** – Move up and down (one line at time),
|
||||
* **PgUp/Pg/Dn** – Move one page at a time,
|
||||
* **F3/F4** – Instantly go to Top and bottom of the list,
|
||||
* **F5** – Refresh,
|
||||
* **F6** – Mark/Unmark files (Files marked will be indicated with an ***** in front of them),
|
||||
* **F7/F8** – Mark/Unmark all files at once,
|
||||
* **F9** – Sort the list by – Date & time, Name, Size.,
|
||||
|
||||
|
||||
|
||||
Press **h** to learn more details about **show** command and its options.
|
||||
|
||||
To exit DF-SHOW, simply press **q**.
|
||||
|
||||
**SF Command**
|
||||
|
||||
The “sf” (show files) is used to display the contents of a file.
|
||||
|
||||
```
|
||||
$ sf <file>
|
||||
```
|
||||
|
||||

|
||||
|
||||
Press **h** to learn more “sf” command and its options. To quit, press **q**.
|
||||
|
||||
Want to give it a try? Great! Go ahead and install DF-SHOW on your Linux system as described below.
|
||||
|
||||
### Installing DF-SHOW
|
||||
|
||||
DF-SHOW is available in [**AUR**][1], so you can install it on any Arch-based system using AUR programs such as [**Yay**][2].
|
||||
|
||||
```
|
||||
$ yay -S dfshow
|
||||
```
|
||||
|
||||
On Ubuntu and its derivatives:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:ian-hawdon/dfshow
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install dfshow
|
||||
```
|
||||
|
||||
On other Linux distributions, you can compile and build it from the source as shown below.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/roberthawdon/dfshow
|
||||
$ cd dfshow
|
||||
$ ./bootstrap
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
The author of DF-SHOW project has only rewritten some of the applications of DF-EDIT utility. Since the source code is freely available on GitHub, you can add more features, improve the code and submit or fix the bugs (if there are any). It is still in alpha stage, but fully functional.
|
||||
|
||||
Have you tried it already? If so, how’d go? Tell us your experience in the comments section below.
|
||||
|
||||
And, that’s all for now. Hope this was useful.More good stuffs to come.
|
||||
|
||||
Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/df-show-a-terminal-file-manager-based-on-an-old-dos-application/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://aur.archlinux.org/packages/dfshow/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
@ -1,144 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to detect automatically generated emails)
|
||||
[#]: via: (https://arp242.net/weblog/autoreply.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
How to detect automatically generated emails
|
||||
======
|
||||
|
||||
### How to detect automatically generated emails
|
||||
|
||||
|
||||
When you send out an auto-reply from an email system you want to take care to not send replies to automatically generated emails. At best, you will get a useless delivery failure. At words, you will get an infinite email loop and a world of chaos.
|
||||
|
||||
Turns out that reliably detecting automatically generated emails is not always easy. Here are my observations based on writing a detector for this and scanning about 100,000 emails with it (extensive personal archive and company archive).
|
||||
|
||||
### Auto-submitted header
|
||||
|
||||
Defined in [RFC 3834][1].
|
||||
|
||||
This is the ‘official’ standard way to indicate your message is an auto-reply. You should **not** send a reply if `Auto-Submitted` is present and has a value other than `no`.
|
||||
|
||||
### X-Auto-Response-Suppress header
|
||||
|
||||
Defined [by Microsoft][2]
|
||||
|
||||
This header is used by Microsoft Exchange, Outlook, and perhaps some other products. Many newsletters and such also set this. You should **not** send a reply if `X-Auto-Response-Suppress` contains `DR` (“Suppress delivery reports”), `AutoReply` (“Suppress auto-reply messages other than OOF notifications”), or `All`.
|
||||
|
||||
### List-Id and List-Unsubscribe headers
|
||||
|
||||
Defined in [RFC 2919][3]
|
||||
|
||||
You usually don’t want to send auto-replies to mailing lists or news letters. Pretty much all mail lists and most newsletters set at least one of these headers. You should **not** send a reply if either of these headers is present. The value is unimportant.
|
||||
|
||||
### Feedback-ID header
|
||||
|
||||
Defined [by Google][4].
|
||||
|
||||
Gmail uses this header to identify mail newsletters, and uses it to generate statistics/reports for owners of those newsletters. You should **not** send a reply if this headers is present; the value is unimportant.
|
||||
|
||||
### Non-standard ways
|
||||
|
||||
The above methods are well-defined and clear (even though some are non-standard). Unfortunately some email systems do not use any of them :-( Here are some additional measures.
|
||||
|
||||
#### Precedence header
|
||||
|
||||
Not really defined anywhere, mentioned in [RFC 2076][5] where its use is discouraged (but this header is commonly encountered).
|
||||
|
||||
Note that checking for the existence of this field is not recommended, as some ails use `normal` and some other (obscure) values (this is not very common though).
|
||||
|
||||
My recommendation is to **not** send a reply if the value case-insensitively matches `bulk`, `auto_reply`, or `list`.
|
||||
|
||||
#### Other obscure headers
|
||||
|
||||
A collection of other (somewhat obscure) headers I’ve encountered. I would recommend **not** sending an auto-reply if one of these is set. Most mails also set one of the above headers, but some don’t (but it’s not very common).
|
||||
|
||||
* `X-MSFBL`; can’t really find a definition (Microsoft header?), but I only have auto-generated mails with this header.
|
||||
|
||||
* `X-Loop`; not really defined anywhere, and somewhat rare, but sometimes it’s set. It’s most often set to the address that should not get emails, but `X-Loop: yes` is also encountered.
|
||||
|
||||
* `X-Autoreply`; fairly rare, and always seems to have a value of `yes`.
|
||||
|
||||
|
||||
|
||||
|
||||
#### Email address
|
||||
|
||||
Check if the `From` or `Reply-To` headers contains `noreply`, `no-reply`, or `no_reply` (regex: `^no.?reply@`).
|
||||
|
||||
#### HTML only
|
||||
|
||||
If an email only has a HTML part, but no text part it’s a good indication this is an auto-generated mail or newsletter. Pretty much all mail clients also set a text part.
|
||||
|
||||
#### Delivery failures
|
||||
|
||||
Many delivery failure messages don’t really indicate that they’re failures. Some ways to check this:
|
||||
|
||||
* `From` contains `mailer-daemon` or `Mail Delivery Subsystem`
|
||||
|
||||
|
||||
|
||||
Many mail libraries leave some sort of footprint, and most regular mail clients override this with their own data. Checking for this seems to work fairly well.
|
||||
|
||||
* `X-Mailer: Microsoft CDO for Windows 2000` – Set by some MS software; I can only find it on autogenerated mails. Yes, it’s still used in 2015.
|
||||
|
||||
* `Message-ID` header contains `.JavaMail.` – I’ve found a few (5 on 50k) regular messages with this, but not many; the vast majority (thousends) of messages are news-letters, order confirmations, etc.
|
||||
|
||||
* `^X-Mailer` starts with `PHP`. This should catch both `X-Mailer: PHP/5.5.0` and `X-Mailer: PHPmailer blah blah`. The same as `JavaMail` applies.
|
||||
|
||||
* `X-Library` presence; only [Indy][6] seems to set this.
|
||||
|
||||
* `X-Mailer` starts with `wdcollect`. Set by some Plesk mails.
|
||||
|
||||
* `X-Mailer` starts with `MIME-tools`.
|
||||
|
||||
|
||||
|
||||
|
||||
### Final precaution: limit the number of replies
|
||||
|
||||
Even when following all of the above advice, you may still encounter an email program that will slip through. This can very dangerous, as email systems that simply `IF email THEN send_email` have the potential to cause infinite email loops.
|
||||
|
||||
For this reason, I recommend keeping track of which emails you’ve sent an autoreply to and rate limiting this to at most n emails in n minutes. This will break the back-and-forth chain.
|
||||
|
||||
We use one email per five minutes, but something less strict will probably also work well.
|
||||
|
||||
### What you need to set on your auto-response
|
||||
|
||||
The specifics for this will vary depending on what sort of mails you’re sending. This is what we use for auto-reply mails:
|
||||
|
||||
```
|
||||
Auto-Submitted: auto-replied
|
||||
X-Auto-Response-Suppress: All
|
||||
Precedence: auto_reply
|
||||
```
|
||||
|
||||
### Feedback
|
||||
|
||||
You can mail me at [martin@arp242.net][7] or [create a GitHub issue][8] for feedback, questions, etc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/autoreply.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://tools.ietf.org/html/rfc3834
|
||||
[2]: https://msdn.microsoft.com/en-us/library/ee219609(v=EXCHG.80).aspx
|
||||
[3]: https://tools.ietf.org/html/rfc2919)
|
||||
[4]: https://support.google.com/mail/answer/6254652?hl=en
|
||||
[5]: http://www.faqs.org/rfcs/rfc2076.html
|
||||
[6]: http://www.indyproject.org/index.en.aspx
|
||||
[7]: mailto:martin@arp242.net
|
||||
[8]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
@ -1,264 +0,0 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: subject: "How To Parse And Pretty Print JSON With Linux Commandline Tools"
|
||||
[#]: via: "https://www.ostechnix.com/how-to-parse-and-pretty-print-json-with-linux-commandline-tools/"
|
||||
[#]: author: "EDITOR https://www.ostechnix.com/author/editor/"
|
||||
|
||||
How To Parse And Pretty Print JSON With Linux Commandline Tools
|
||||
======
|
||||
|
||||
**JSON** is a lightweight and language independent data storage format, easy to integrate with most programming languages and also easy to understand by humans, of course when properly formatted. The word JSON stands for **J** ava **S** cript **O** bject **N** otation, though it starts with JavaScript, and primarily used to exchange data between server and browser, but now being used in many fields including embedded systems. Here we’re going to parse and pretty print JSON with command line tools on Linux. It’s extremely useful for handling large JSON data in a shell scripts, or manipulating JSON data in a shell script.
|
||||
|
||||
### What is pretty printing?
|
||||
|
||||
The JSON data is structured to be somewhat more human readable. However in most cases, JSON data is stored in a single line, even without a line ending character.
|
||||
|
||||
Obviously that’s not very convenient for reading and editing manually.
|
||||
|
||||
That’s when pretty print is useful. The name is quite self explanatory, re-formatting the JSON text to be more legible by humans. This is known as **JSON pretty printing**.
|
||||
|
||||
### Parse And Pretty Print JSON With Linux Commandline Tools
|
||||
|
||||
JSON data could be parsed with command line text processors like **awk** , **sed** and **gerp**. In fact JSON.awk is an awk script to do that. However there are some dedicated tools for the same purpose.
|
||||
|
||||
1. **jq** or **jshon** , JSON parser for shell, both of them are quite useful.
|
||||
|
||||
2. Shell scripts like **JSON.sh** or **jsonv.sh** to parse JSON in bash, zsh or dash shell.
|
||||
|
||||
3. **JSON.awk** , JSON parser awk script.
|
||||
|
||||
4. Python modules like **json.tool**.
|
||||
|
||||
5. **underscore-cli** , Node.js and javascript based.
|
||||
|
||||
|
||||
|
||||
|
||||
In this tutorial I’m focusing only on **jq** , which is quite powerful JSON parser for shells with advanced filtering and scripting capability.
|
||||
|
||||
### JSON pretty printing
|
||||
|
||||
JSON data could be in one and nearly illegible for humans, so to make it somewhat readable, JSON pretty printing is here.
|
||||
|
||||
**Example:** A data from **jsonip.com** , to get external IP address in JSON format, use **curl** or **wget** tools like below.
|
||||
|
||||
```
|
||||
$ wget -cq http://jsonip.com/ -O -
|
||||
```
|
||||
|
||||
The actual data looks like this:
|
||||
|
||||
```
|
||||
{"ip":"111.222.333.444","about":"/about","Pro!":"http://getjsonip.com"}
|
||||
```
|
||||
|
||||
Now pretty print it with jq:
|
||||
|
||||
```
|
||||
$ wget -cq http://jsonip.com/ -O - | jq '.'
|
||||
```
|
||||
|
||||
This should look like below, after filtering the result with jq.
|
||||
|
||||
```
|
||||
{
|
||||
|
||||
"ip": "111.222.333.444",
|
||||
|
||||
"about": "/about",
|
||||
|
||||
"Pro!": "http://getjsonip.com"
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
The Same thing could be done with python **json.tool** module. Here is an example:
|
||||
|
||||
```
|
||||
$ cat anything.json | python -m json.tool
|
||||
```
|
||||
|
||||
This Python based solution should be fine for most users, but it’s not that useful where Python is not pre-installed or could not be installed, like on embedded systems.
|
||||
|
||||
However the json.tool python module has a distinct advantage, it’s cross platform. So, you can use it seamlessly on Windows, Linux or mac OS.
|
||||
|
||||
|
||||
### How to parse JSON with jq
|
||||
|
||||
First, you need to install jq, it’s already picked up by most GNU/Linux distributions, install it with their respective package installer commands.
|
||||
|
||||
On Arch Linux:
|
||||
|
||||
```
|
||||
$ sudo pacman -S jq
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install jq
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install jq
|
||||
```
|
||||
|
||||
On openSUSE:
|
||||
|
||||
```
|
||||
$ sudo zypper install jq
|
||||
```
|
||||
|
||||
For other OS or platforms, see the [official installation instructions][1].
|
||||
|
||||
**Basic filters and identifiers of jq**
|
||||
|
||||
jq could read the JSON data either from **stdin** or a **file**. You’ve to use both depending on the situation.
|
||||
|
||||
The single symbol of **.** is the most basic filter. These filters are also called as **object identifier-index**. Using a single **.** along with jq basically pretty prints the input JSON file.
|
||||
|
||||
**Single quotes** – You don’t have to use the single quote always. But if you’re combining several filters in a single line, then you must use them.
|
||||
|
||||
**Double quotes** – You’ve to enclose any special character like **@** , **#** , **$** within two double quotes, like this example, **jq .foo.”@bar”**
|
||||
|
||||
**Raw data print** – For any reason, if you need only the final parsed data, not enclosed within a double quote, use the -r flag with the jq command, like this. **– jq -r .foo.bar**.
|
||||
|
||||
**Parsing specific data**
|
||||
|
||||
To filter out a specific part of JSON, you’ve to look into the pretty printed JSON file’s data hierarchy.
|
||||
|
||||
An example of JSON data, from Wikipedia:
|
||||
|
||||
```
|
||||
{
|
||||
|
||||
"firstName": "John",
|
||||
|
||||
"lastName": "Smith",
|
||||
|
||||
"age": 25,
|
||||
|
||||
"address": {
|
||||
|
||||
"streetAddress": "21 2nd Street",
|
||||
|
||||
"city": "New York",
|
||||
|
||||
"state": "NY",
|
||||
|
||||
"postalCode": "10021"
|
||||
|
||||
},
|
||||
|
||||
"phoneNumber": [
|
||||
|
||||
{
|
||||
|
||||
"type": "home",
|
||||
|
||||
"number": "212 555-1234"
|
||||
|
||||
},
|
||||
|
||||
{
|
||||
|
||||
"type": "fax",
|
||||
|
||||
"number": "646 555-4567"
|
||||
|
||||
}
|
||||
|
||||
],
|
||||
|
||||
"gender": {
|
||||
|
||||
"type": "male"
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
I’m going to use this JSON data as an example in this tutorial, saved this as **sample.json**.
|
||||
|
||||
Let’s say I want to filter out the address from sample.json file. So the command should be like:
|
||||
|
||||
```
|
||||
$ jq .address sample.json
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
{
|
||||
|
||||
"streetAddress": "21 2nd Street",
|
||||
|
||||
"city": "New York",
|
||||
|
||||
"state": "NY",
|
||||
|
||||
"postalCode": "10021"
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Again let’s say I want the postal code, then I’ve to add another **object identifier-index** , i.e. another filter.
|
||||
|
||||
```
|
||||
$ cat sample.json | jq .address.postalCode
|
||||
```
|
||||
|
||||
Also note that the **filters are case sensitive** and you’ve to use the exact same string to get something meaningful output instead of null.
|
||||
|
||||
**Parsing elements from JSON array**
|
||||
|
||||
Elements of JSON array are enclosed within square brackets, undoubtedly quite versatile to use.
|
||||
|
||||
To parse elements from a array, you’ve to use the **[]identifier** along with other object identifier-index.
|
||||
|
||||
In this sample JSON data, the phone numbers are stored inside an array, to get all the contents from this array, you’ve to use only the brackets, like this example.
|
||||
|
||||
```
|
||||
$ jq .phoneNumber[] sample.json
|
||||
```
|
||||
|
||||
Let’s say you just want the first element of the array, then use the array object numbers starting for 0, for the first item, use **[0]** , for the next items, it should be incremented by one each step.
|
||||
|
||||
```
|
||||
$ jq .phoneNumber[0] sample.json
|
||||
```
|
||||
|
||||
**Scripting examples**
|
||||
|
||||
Let’s say I want only the the number for home, not entire JSON array data. Here’s when scripting within jq command comes handy.
|
||||
|
||||
```
|
||||
$ cat sample.json | jq -r '.phoneNumber[] | select(.type == "home") | .number'
|
||||
```
|
||||
|
||||
Here first I’m piping the results of one filer to another, then using the select attribute to select a particular type of data, again piping the result to another filter.
|
||||
|
||||
Explaining every type of jq filters and scripting is beyond the scope and purpose of this tutorial. It’s highly suggested to read the JQ manual for better understanding given below.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-parse-and-pretty-print-json-with-linux-commandline-tools/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://stedolan.github.io/jq/download/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (luming)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233 )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is a Linux user?)
|
||||
[#]: via: (https://opensource.com/article/19/6/what-linux-user)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva/users/petercheer/users/ansilva/users/greg-p/users/ansilva/users/ansilva/users/bcotton/users/ansilva/users/seth/users/ansilva/users/don-watkins/users/ansilva/users/seth)
|
||||
|
||||
What is a Linux user?
|
||||
======
|
||||
The definition of who is a "Linux user" has grown to be a bigger tent,
|
||||
and it's a great change.
|
||||
![][1]
|
||||
|
||||
> _Editor's note: this article was updated on Jun 11, 2019, at 1:15:19 PM to more accurately reflect the author's perspective on an open and inclusive community of practice in the Linux community._
|
||||
|
||||
In only two years, the Linux kernel will be 30 years old. Think about that! Where were you in 1991? Were you even born? I was 13! Between 1991 and 1993 a few Linux distributions were created, and at least three of them—Slackware, Debian, and Red Hat–provided the [backbone][2] the Linux movement was built on.
|
||||
|
||||
Getting a copy of a Linux distribution and installing and configuring it on a desktop or server was very different back then than today. It was hard! It was frustrating! It was an accomplishment if you got it running! We had to fight with incompatible hardware, configuration jumpers on devices, BIOS issues, and many other things. Even if the hardware was compatible, many times, you still had to compile the kernel, modules, and drivers to get them to work on your system.
|
||||
|
||||
If you were around during those days, you are probably nodding your head. Some readers might even call them the "good old days," because choosing to use Linux meant you had to learn about operating systems, computer architecture, system administration, networking, and even programming, just to keep the OS functioning. I am not one of them though: Linux being a regular part of everyone's technology experience is one of the most amazing changes in our industry!
|
||||
|
||||
Almost 30 years later, Linux has gone far beyond the desktop and server. You will find Linux in automobiles, airplanes, appliances, smartphones… virtually everywhere! You can even purchase laptops, desktops, and servers with Linux preinstalled. If you consider cloud computing, where corporations and even individuals can deploy Linux virtual machines with the click of a button, it's clear how widespread the availability of Linux has become.
|
||||
|
||||
With all that in mind, my question for you is: **How do you define a "Linux user" today?**
|
||||
|
||||
If you buy your parent or grandparent a Linux laptop from System76 or Dell, log them into their social media and email, and tell them to click "update system" every so often, they are now a Linux user. If you did the same with a Windows or MacOS machine, they would be Windows or MacOS users. It's incredible to me that, unlike the '90s, Linux is now a place for anyone and everyone to compute.
|
||||
|
||||
In many ways, this is due to the web browser becoming the "killer app" on the desktop computer. Now, many users don't care what operating system they are using as long as they can get to their app or service.
|
||||
|
||||
How many people do you know who use their phone, desktop, or laptop regularly but can't manage files, directories, and drivers on their systems? How many can't install a binary that isn't attached to an "app store" of some sort? How about compiling an application from scratch?! For me, it's almost no one. That's the beauty of open source software maturing along with an ecosystem that cares about accessibility.
|
||||
|
||||
Today's Linux user is not required to know, study, or even look up information as the Linux user of the '90s or early 2000s did, and that's not a bad thing. The old imagery of Linux being exclusively for bearded men is long gone, and I say good riddance.
|
||||
|
||||
There will always be room for a Linux user who is interested, curious, _fascinated_ about computers, operating systems, and the idea of creating, using, and collaborating on free software. There is just as much room for creative open source contributors on Windows and MacOS these days as well. Today, being a Linux user is being anyone with a Linux system. And that's a wonderful thing.
|
||||
|
||||
### The change to what it means to be a Linux user
|
||||
|
||||
When I started with Linux, being a user meant knowing how to the operating system functioned in every way, shape, and form. Linux has matured in a way that allows the definition of "Linux users" to encompass a much broader world of possibility and the people who inhabit it. It may be obvious to say, but it is important to say clearly: anyone who uses Linux is an equal Linux user.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/what-linux-user
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva/users/petercheer/users/ansilva/users/greg-p/users/ansilva/users/ansilva/users/bcotton/users/ansilva/users/seth/users/ansilva/users/don-watkins/users/ansilva/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22
|
||||
[2]: https://en.wikipedia.org/wiki/Linux_distribution#/media/File:Linux_Distribution_Timeline.svg
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,311 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Learn object-oriented programming with Python)
|
||||
[#]: via: (https://opensource.com/article/19/7/get-modular-python-classes)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Learn object-oriented programming with Python
|
||||
======
|
||||
Make your code more modular with Python classes.
|
||||
![Developing code.][1]
|
||||
|
||||
In my previous article, I explained how to [make Python modular][2] by using functions, creating modules, or both. Functions are invaluable to avoid repeating code you intend to use several times, and modules ensure that you can use your code across different projects. But there's another component to modularity: the class.
|
||||
|
||||
If you've heard the term _object-oriented programming_, then you may have some notion of the purpose classes serve. Programmers tend to consider a class as a virtual object, sometimes with a direct correlation to something in the physical world, and other times as a manifestation of some programming concept. Either way, the idea is that you can create a class when you want to create "objects" within a program for you or other parts of the program to interact with.
|
||||
|
||||
### Templates without classes
|
||||
|
||||
Assume you're writing a game set in a fantasy world, and you need this application to be able to drum up a variety of baddies to bring some excitement into your players' lives. Knowing quite a lot about functions, you might think this sounds like a textbook case for functions: code that needs to be repeated often but is written once with allowance for variations when called.
|
||||
|
||||
Here's an example of a purely function-based implementation of an enemy generator:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
def enemy(ancestry,gear):
|
||||
enemy=ancestry
|
||||
weapon=gear
|
||||
hp=random.randrange(0,20)
|
||||
ac=random.randrange(0,20)
|
||||
return [enemy,weapon,hp,ac]
|
||||
|
||||
def fight(tgt):
|
||||
print("You take a swing at the " + tgt[0] + ".")
|
||||
hit=random.randrange(0,20)
|
||||
if hit > tgt[3]:
|
||||
print("You hit the " + tgt[0] + " for " + str(hit) + " damage!")
|
||||
tgt[2] = tgt[2] - hit
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
foe=enemy("troll","great axe")
|
||||
print("You meet a " + foe[0] + " wielding a " + foe[1])
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
while True:
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
fight(foe)
|
||||
|
||||
if foe[2] < 1:
|
||||
print("You killed your foe!")
|
||||
else:
|
||||
print("The " + foe[0] + " has " + str(foe[2]) + " HP remaining")
|
||||
```
|
||||
|
||||
The **enemy** function creates an enemy with several attributes, such as ancestry, a weapon, health points, and a defense rating. It returns a list of each attribute, representing the sum total of the enemy.
|
||||
|
||||
In a sense, this code has created an object, even though it's not using a class yet. Programmers call this "enemy" an _object_ because the result (a list of strings and integers, in this case) of the function represents a singular but complex _thing_ in the game. That is, the strings and integers in the list aren't arbitrary: together, they describe a virtual object.
|
||||
|
||||
When writing a collection of descriptors, you use variables so you can use them any time you want to generate an enemy. It's a little like a template.
|
||||
|
||||
In the example code, when an attribute of the object is needed, the corresponding list item is retrieved. For instance, to get the ancestry of an enemy, the code looks at **foe[0]**, for health points, it looks at **foe[2]** for health points, and so on.
|
||||
|
||||
There's nothing necessarily wrong with this approach. The code runs as expected. You could add more enemies of different types, you could create a list of enemy types and randomly select from the list during enemy creation, and so on. It works well enough, and in fact [Lua][3] uses this principle very effectively to approximate an object-oriented model.
|
||||
|
||||
However, there's sometimes more to an object than just a list of attributes.
|
||||
|
||||
### The way of the object
|
||||
|
||||
In Python, everything is an object. Anything you create in Python is an _instance_ of some predefined template. Even basic strings and integers are derivatives of the Python **type** class. You can witness this for yourself an interactive Python shell:
|
||||
|
||||
|
||||
```
|
||||
>>> foo=3
|
||||
>>> type(foo)
|
||||
<class 'int'>
|
||||
>>> foo="bar"
|
||||
>>> type(foo)
|
||||
<class 'str'>
|
||||
```
|
||||
|
||||
When an object is defined by a class, it is more than just a collection of attributes. Python classes have functions all their own. This is convenient, logically, because actions that pertain only to a certain class of objects are contained within that object's class.
|
||||
|
||||
In the example code, the fight code is a function of the main application. That works fine for a simple game, but in a complex one, there would be more than just players and enemies in the game world. There might be townsfolk, livestock, buildings, forests, and so on, and none of them ever need access to a fight function. Placing code for combat in an enemy class means your code is better organized; and in a complex application, that's a significant advantage.
|
||||
|
||||
Furthermore, each class has privileged access to its own local variables. An enemy's health points, for instance, isn't data that should ever change except by some function of the enemy class. A random butterfly in the game should not accidentally reduce an enemy's health to 0. Ideally, even without classes, that would never happen, but in a complex application with lots of moving parts, it's a powerful trick of the trade to ensure that parts that don't need to interact with one another never do.
|
||||
|
||||
Python classes are also subject to garbage collection. When an instance of a class is no longer used, it is moved out of memory. You may never know when this happens, but you tend to notice when it doesn't happen because your application takes up more memory and runs slower than it should. Isolating data sets into classes helps Python track what is in use and what is no longer needed.
|
||||
|
||||
### Classy Python
|
||||
|
||||
Here's the same simple combat game using a class for the enemy:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.ac=random.randrange(12,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
|
||||
# game start
|
||||
foe=Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
This version of the game handles the enemy as an object containing the same attributes (ancestry, weapon, health, and defense), plus a new attribute measuring whether the enemy has been vanquished yet, as well as a function for combat.
|
||||
|
||||
The first function of a class is a special function called (in Python) an _init_, or initialization, function. This is similar to a [constructor][4] in other languages; it creates an instance of the class, which is identifiable to you by its attributes and to whatever variable you use when invoking the class (**foe** in the example code).
|
||||
|
||||
### Self and class instances
|
||||
|
||||
The class' functions accept a new form of input you don't see outside of classes: **self**. If you don't include **self**, then Python has no way of knowing _which_ instance of the class to use when you call a class function. It's like challenging a single orc to a duel by saying "I'll fight the orc" in a room full of orcs; nobody knows which one you're referring to, and so bad things happen.
|
||||
|
||||
![Image of an Orc, CC-BY-SA by Buch on opengameart.org][5]
|
||||
|
||||
CC-BY-SA by Buch on opengameart.org
|
||||
|
||||
Each attribute created within a class is prepended with the **self** notation, which identifies that variable as an attribute of the class. Once an instance of a class is spawned, you swap out the **self** prefix with the variable representing that instance. Using this technique, you could challenge just one orc to a duel in a room full of orcs by saying "I'll fight the gorblar.orc"; when Gorblar the Orc hears **gorblar.orc**, he knows which orc you're referring to (him_self_), and so you get a fair fight instead of a brawl. In Python:
|
||||
|
||||
|
||||
```
|
||||
gorblar=Enemy("orc","sword")
|
||||
print("The " + gorblar.enemy + " has " + str(gorblar.hp) + " remaining.")
|
||||
```
|
||||
|
||||
Instead of looking to **foe[0]** (as in the functional example) or **gorblar[0]** for the enemy type, you retrieve the class attribute (**gorblar.enemy** or **gorblar.hp** or whatever value for whatever object you need).
|
||||
|
||||
### Local variables
|
||||
|
||||
If a variable in a class is not prepended with the **self** keyword, then it is a local variable, just as in any function. For instance, no matter what you do, you cannot access the **hit** variable outside the **Enemy.fight** class:
|
||||
|
||||
|
||||
```
|
||||
>>> print(foe.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.hit)
|
||||
AttributeError: 'Enemy' object has no attribute 'hit'
|
||||
|
||||
>>> print(foe.fight.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.fight.hit)
|
||||
AttributeError: 'function' object has no attribute 'hit'
|
||||
```
|
||||
|
||||
The **hit** variable is contained within the Enemy class, and only "lives" long enough to serve its purpose in combat.
|
||||
|
||||
### More modularity
|
||||
|
||||
This example uses a class in the same text document as your main application. In a complex game, it's easier to treat each class almost as if it were its own self-standing application. You see this when multiple developers work on the same application: one developer works on a class, and the other works on the main program, and as long as they communicate with one another about what attributes the class must have, the two code bases can be developed in parallel.
|
||||
|
||||
To make this example game modular, split it into two files: one for the main application and one for the class. Were it a more complex application, you might have one file per class, or one file per logical groups of classes (for instance, a file for buildings, a file for natural surroundings, a file for enemies and NPCs, and so on).
|
||||
|
||||
Save one file containing just the Enemy class as **enemy.py** and another file containing everything else as **main.py**.
|
||||
|
||||
Here's **enemy.py**:
|
||||
|
||||
|
||||
```
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.stg=random.randrange(0,20)
|
||||
self.ac=random.randrange(0,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
```
|
||||
|
||||
Here's **main.py**:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import enemy as en
|
||||
|
||||
# game start
|
||||
foe=en.Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
Importing the module **enemy.py** is done very specifically with a statement that refers to the file of classes as its name without the **.py** extension, followed by a namespace designator of your choosing (for example, **import enemy as en**). This designator is what you use in the code when invoking a class. Instead of just using **Enemy()**, you preface the class with the designator of what you imported, such as **en.Enemy**.
|
||||
|
||||
All of these file names are entirely arbitrary, although not uncommon in principle. It's a common convention to name the part of the application that serves as the central hub **main.py**, and a file full of classes is often named in lowercase with the classes inside it, each beginning with a capital letter. Whether you follow these conventions doesn't affect how the application runs, but it does make it easier for experienced Python programmers to quickly decipher how your application works.
|
||||
|
||||
There's some flexibility in how you structure your code. For instance, using the code sample, both files must be in the same directory. If you want to package just your classes as a module, then you must create a directory called, for instance, **mybad** and move your classes into it. In **main.py**, your import statement changes a little:
|
||||
|
||||
|
||||
```
|
||||
`from mybad import enemy as en`
|
||||
```
|
||||
|
||||
Both systems produce the same results, but the latter is best if the classes you have created are generic enough that you think other developers could use them in their projects.
|
||||
|
||||
Regardless of which you choose, launch the modular version of the game:
|
||||
|
||||
|
||||
```
|
||||
$ python3 ./main.py
|
||||
You meet a troll wielding a great axe
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You missed.
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 8 damage!
|
||||
The troll has 4 HP remaining
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 11 damage!
|
||||
The troll has -7 HP remaining
|
||||
You have won...this time.
|
||||
```
|
||||
|
||||
The game works. It's modular. And now you know what it means for an application to be object-oriented. But most importantly, you know to be specific when challenging an orc to a duel.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
|
||||
[2]: https://opensource.com/article/19/6/get-modular-python-functions
|
||||
[3]: https://opensource.com/article/17/4/how-program-games-raspberry-pi
|
||||
[4]: https://opensource.com/article/19/6/what-java-constructor
|
||||
[5]: https://opensource.com/sites/default/files/images/orc-buch-opengameart_cc-by-sa.jpg (CC-BY-SA by Buch on opengameart.org)
|
||||
@ -1,185 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (runningwater)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to install Elasticsearch and Kibana on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/7/install-elasticsearch-and-kibana-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
How to install Elasticsearch and Kibana on Linux
|
||||
======
|
||||
Get our simplified instructions for installing both.
|
||||
![5 pengiuns floating on iceburg][1]
|
||||
|
||||
If you're keen to learn Elasticsearch, the famous open source search engine based on the open source Lucene library, then there's no better way than to install it locally. The process is outlined in detail on the [Elasticsearch website][2], but the official instructions have a lot more detail than necessary if you're a beginner. This article takes a simplified approach.
|
||||
|
||||
### Add the Elasticsearch repository
|
||||
|
||||
First, add the Elasticsearch software repository to your system, so you can install it and receive updates as needed. How you do so depends on your distribution. On an RPM-based system, such as [Fedora][3], [CentOS][4], [Red Hat Enterprise Linux (RHEL)][5], or [openSUSE][6], (anywhere in this article that references Fedora or RHEL applies to CentOS and openSUSE as well) create a repository description file in **/etc/yum.repos.d/** called **elasticsearch.repo**:
|
||||
|
||||
|
||||
```
|
||||
$ cat << EOF | sudo tee /etc/yum.repos.d/elasticsearch.repo
|
||||
[elasticsearch-7.x]
|
||||
name=Elasticsearch repository for 7.x packages
|
||||
baseurl=<https://artifacts.elastic.co/packages/oss-7.x/yum>
|
||||
gpgcheck=1
|
||||
gpgkey=<https://artifacts.elastic.co/GPG-KEY-elasticsearch>
|
||||
enabled=1
|
||||
autorefresh=1
|
||||
type=rpm-md
|
||||
EOF
|
||||
```
|
||||
|
||||
On Ubuntu or Debian, do not use the **add-apt-repository** utility. It causes errors due to a mismatch in its defaults and what Elasticsearch’s repository provides. Instead, set up this one:
|
||||
|
||||
|
||||
```
|
||||
$ echo "deb <https://artifacts.elastic.co/packages/oss-7.x/apt> stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
|
||||
```
|
||||
|
||||
This repository contains only Elasticsearch’s open source features, under an [Apache License][7], with none of the extra features provided by a subscription. If you need subscription-only features (these features are _not_ open source), the **baseurl** must be set to:
|
||||
|
||||
|
||||
```
|
||||
`baseurl=https://artifacts.elastic.co/packages/7.x/yum`
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Install Elasticsearch
|
||||
|
||||
The name of the package you need to install depends on whether you use the open source version or the subscription version. This article uses the open source version, which appends **-oss** to the end of the package name. Without **-oss** appended to the package name, you are requesting the subscription-only version.
|
||||
|
||||
If you create a repository pointing to the subscription version but try to install the open source version, you will get a fairly non-specific error in return. If you create a repository for the open source version and fail to append **-oss** to the package name, you will also get an error.
|
||||
|
||||
Install Elasticsearch with your package manager. For instance, on Fedora, CentOS, or RHEL, run the following:
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install elasticsearch-oss
|
||||
```
|
||||
|
||||
On Ubuntu or Debian, run:
|
||||
|
||||
|
||||
```
|
||||
$ sudo apt install elasticsearch-oss
|
||||
```
|
||||
|
||||
If you get errors while installing Elasticsearch, then you may be attempting to install the wrong package. If your intention is to use the open source package, as this article does, then make sure you are using the correct **apt** repository or baseurl in your Yum configuration.
|
||||
|
||||
### Start and enable Elasticsearch
|
||||
|
||||
Once Elasticsearch has been installed, you must start and enable it:
|
||||
|
||||
|
||||
```
|
||||
$ sudo systemctl daemon-reload
|
||||
$ sudo systemctl enable --now elasticsearch.service
|
||||
```
|
||||
|
||||
Then, to confirm that Elasticsearch is running on its default port of 9200, point a web browser to **localhost:9200**. You can use a GUI browser or you can do it in the terminal:
|
||||
|
||||
|
||||
```
|
||||
$ curl localhost:9200
|
||||
{
|
||||
|
||||
"name" : "fedora30",
|
||||
"cluster_name" : "elasticsearch",
|
||||
"cluster_uuid" : "OqSbb16NQB2M0ysynnX1hA",
|
||||
"version" : {
|
||||
"number" : "7.2.0",
|
||||
"build_flavor" : "oss",
|
||||
"build_type" : "rpm",
|
||||
"build_hash" : "508c38a",
|
||||
"build_date" : "2019-06-20T15:54:18.811730Z",
|
||||
"build_snapshot" : false,
|
||||
"lucene_version" : "8.0.0",
|
||||
"minimum_wire_compatibility_version" : "6.8.0",
|
||||
"minimum_index_compatibility_version" : "6.0.0-beta1"
|
||||
},
|
||||
"tagline" : "You Know, for Search"
|
||||
}
|
||||
```
|
||||
|
||||
### Install Kibana
|
||||
|
||||
Kibana is a graphical interface for Elasticsearch data visualization. It’s included in the Elasticsearch repository, so you can install it with your package manager. Just as with Elasticsearch itself, you must append **-oss** to the end of the package name if you are using the open source version of Elasticsearch, and not the subscription version (the two installations need to match):
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install kibana-oss
|
||||
```
|
||||
|
||||
On Ubuntu or Debian:
|
||||
|
||||
|
||||
```
|
||||
$ sudo apt install kibana-oss
|
||||
```
|
||||
|
||||
Kibana runs on port 5601, so launch a graphical web browser and navigate to **localhost:5601** to start using the Kibana interface, which is shown below:
|
||||
|
||||
![Kibana running in Firefox.][8]
|
||||
|
||||
### Troubleshoot
|
||||
|
||||
If you get errors while installing Elasticsearch, try installing a Java environment manually. On Fedora, CentOS, and RHEL:
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install java-openjdk-devel java-openjdk
|
||||
```
|
||||
|
||||
On Ubuntu:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install default-jdk`
|
||||
```
|
||||
|
||||
If all else fails, try installing the Elasticsearch RPM directly from the Elasticsearch servers:
|
||||
|
||||
|
||||
```
|
||||
$ wget <https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-oss-7.2.0-x86\_64.rpm{,.sha512}>
|
||||
$ shasum -a 512 -c elasticsearch-oss-7.2.0-x86_64.rpm.sha512 && sudo rpm --install elasticsearch-oss-7.2.0-x86_64.rpm
|
||||
```
|
||||
|
||||
On Ubuntu or Debian, use the DEB package instead.
|
||||
|
||||
If you cannot access either Elasticsearch or Kibana with a web browser, then your firewall may be blocking those ports. You can allow traffic on those ports by adjusting your firewall settings. For instance, if you are running **firewalld** (the default on Fedora and RHEL, and installable on Debian and Ubuntu), then you can use **firewall-cmd**:
|
||||
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --add-port=9200/tcp --permanent
|
||||
$ sudo firewall-cmd --add-port=5601/tcp --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
You’re now set up and can follow along with our upcoming installation articles for Elasticsearch and Kibana.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/install-elasticsearch-and-kibana-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux31x_cc.png?itok=Pvim4U-B (5 pengiuns floating on iceburg)
|
||||
[2]: https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html
|
||||
[3]: https://getfedora.org
|
||||
[4]: https://www.centos.org
|
||||
[5]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[6]: https://www.opensuse.org
|
||||
[7]: http://www.apache.org/licenses/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/kibana.jpg (Kibana running in Firefox.)
|
||||
@ -1,263 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Introduction to GNU Autotools)
|
||||
[#]: via: (https://opensource.com/article/19/7/introduction-gnu-autotools)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Introduction to GNU Autotools
|
||||
======
|
||||
If you're not using Autotools yet, this tutorial will change the way you
|
||||
deliver your code.
|
||||
![Linux kernel source code \(C\) in Visual Studio Code][1]
|
||||
|
||||
Have you ever downloaded the source code for a popular software project that required you to type the almost ritualistic **./configure; make && make install** command sequence to build and install it? If so, you’ve used [GNU Autotools][2]. If you’ve ever looked into some of the files accompanying such a project, you’ve likely also been terrified at the apparent complexity of such a build system.
|
||||
|
||||
Good news! GNU Autotools is a lot simpler to set up than you think, and it’s GNU Autotools itself that generates those 1,000-line configuration files for you. Yes, you can write 20 or 30 lines of installation code and get the other 4,000 for free.
|
||||
|
||||
### Autotools at work
|
||||
|
||||
If you’re a user new to Linux looking for information on how to install applications, you do not have to read this article! You’re welcome to read it if you want to research how software is built, but if you’re just installing a new application, go read my article about [installing apps on Linux][3].
|
||||
|
||||
For developers, Autotools is a quick and easy way to manage and package source code so users can compile and install software. Autotools is also well-supported by major packaging formats, like DEB and RPM, so maintainers of software repositories can easily prepare a project built with Autotools.
|
||||
|
||||
Autotools works in stages:
|
||||
|
||||
1. First, during the **./configure** step, Autotools scans the host system (the computer it’s being run on) to discover the default settings. Default settings include where support libraries are located, and where new software should be placed on the system.
|
||||
2. Next, during the **make** step, Autotools builds the application, usually by converting human-readable source code into machine language.
|
||||
3. Finally, during the **make install** step, Autotools copies the files it built to the appropriate locations (as detected during the configure stage) on your computer.
|
||||
|
||||
|
||||
|
||||
This process seems simple, and it is, as long as you use Autotools.
|
||||
|
||||
### The Autotools advantage
|
||||
|
||||
GNU Autotools is a big and important piece of software that most of us take for granted. Along with [GCC (the GNU Compiler Collection)][4], Autotools is the scaffolding that allows Free Software to be constructed and installed to a running system. If you’re running a [POSIX][5] system, it’s not an understatement to say that most of your operating system exists as runnable software on your computer because of these projects.
|
||||
|
||||
In the likely event that your pet project isn’t an operating system, you might assume that Autotools is overkill for your needs. But, despite its reputation, Autotools has lots of little features that may benefit you, even if your project is a relatively simple application or series of scripts.
|
||||
|
||||
#### Portability
|
||||
|
||||
First of all, Autotools comes with portability in mind. While it can’t make your project work across all POSIX platforms (that’s up to you, as the coder), Autotools can ensure that the files you’ve marked for installation get installed to the most sensible locations on a known platform. And because of Autotools, it’s trivial for a power user to customize and override any non-optimal value, according to their own system.
|
||||
|
||||
With Autotools, all you need to know is what files need to be installed to what general location. It takes care of everything else. No more custom install scripts that break on any untested OS.
|
||||
|
||||
#### Packaging
|
||||
|
||||
Autotools is also well-supported. Hand a project with Autotools over to a distro packager, whether they’re packaging an RPM, DEB, TGZ, or anything else, and their job is simple. Packaging tools know Autotools, so there’s likely to be no patching, hacking, or adjustments necessary. In many cases, incorporating an Autotools project into a pipeline can even be automated.
|
||||
|
||||
### How to use Autotools
|
||||
|
||||
To use Autotools, you must first have Autotools installed. Your distribution may provide one package meant to help developers build projects, or it may provide separate packages for each component, so you may have to do some research on your platform to discover what packages you need to install.
|
||||
|
||||
The components of Autotools are:
|
||||
|
||||
* **automake**
|
||||
* **autoconf**
|
||||
* **automake**
|
||||
* **make**
|
||||
|
||||
|
||||
|
||||
While you likely need to install the compiler (GCC, for instance) required by your project, Autotools works just fine with scripts or binary assets that don’t need to be compiled. In fact, Autotools can be useful for such projects because it provides a **make uninstall** script for easy removal.
|
||||
|
||||
Once you have all of the components installed, it’s time to look at the structure of your project’s files.
|
||||
|
||||
#### Autotools project structure
|
||||
|
||||
GNU Autotools has very specific expectations, and most of them are probably familiar if you download and build source code often. First, the source code itself is expected to be in a subdirectory called **src**.
|
||||
|
||||
Your project doesn’t have to follow all of these expectations, but if you put files in non-standard locations (from the perspective of Autotools), then you’ll have to make adjustments for that in your Makefile later.
|
||||
|
||||
Additionally, these files are required:
|
||||
|
||||
* **NEWS**
|
||||
* **README**
|
||||
* **AUTHORS**
|
||||
* **ChangeLog**
|
||||
|
||||
|
||||
|
||||
You don’t have to actively use the files, and they can be symlinks to a monolithic document (like **README.md**) that encompasses all of that information, but they must be present.
|
||||
|
||||
#### Autotools configuration
|
||||
|
||||
Create a file called **configure.ac** at your project’s root directory. This file is used by **autoconf** to create the **configure** shell script that users run before building. The file must contain, at the very least, the **AC_INIT** and **AC_OUTPUT** [M4 macros][6]. You don’t need to know anything about the M4 language to use these macros; they’re already written for you, and all of the ones relevant to Autotools are defined in the documentation.
|
||||
|
||||
Open the file in your favorite text editor. The **AC_INIT** macro may consist of the package name, version, an email address for bug reports, the project URL, and optionally the name of the source TAR file.
|
||||
|
||||
The **[AC_OUTPUT][7]** macro is much simpler and accepts no arguments.
|
||||
|
||||
|
||||
```
|
||||
AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
|
||||
AC_OUTPUT
|
||||
```
|
||||
|
||||
If you were to run **autoconf** at this point, a **configure** script would be generated from your **configure.ac** file, and it would run successfully. That’s all it would do, though, because all you have done so far is define your project’s metadata and called for a configuration script to be created.
|
||||
|
||||
The next macros you must invoke in your **configure.ac** file are functions to create a [Makefile][9]. A Makefile tells the **make** command what to do (usually, how to compile and link a program).
|
||||
|
||||
The macros to create a Makefile are **AM_INIT_AUTOMAKE**, which accepts no arguments, and **AC_CONFIG_FILES**, which accepts the name you want to call your output file.
|
||||
|
||||
Finally, you must add a macro to account for the compiler your project needs. The macro you use obviously depends on your project. If your project is written in C++, the appropriate macro is **AC_PROG_CXX**, while a project written in C requires **AC_PROG_CC**, and so on, as detailed in the [Building Programs and Libraries][10] section in the Autoconf documentation.
|
||||
|
||||
For example, I might add the following for my C++ program:
|
||||
|
||||
|
||||
```
|
||||
AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
|
||||
AC_OUTPUT
|
||||
AM_INIT_AUTOMAKE
|
||||
AC_CONFIG_FILES([Makefile])
|
||||
AC_PROG_CXX
|
||||
```
|
||||
|
||||
Save the file. It’s time to move on to the Makefile.
|
||||
|
||||
#### Autotools Makefile generation
|
||||
|
||||
Makefiles aren’t difficult to write manually, but Autotools can write one for you, and the one it generates will use the configuration options detected during the `./configure` step, and it will contain far more options than you would think to include or want to write yourself. However, Autotools can’t detect everything your project requires to build, so you have to add some details in the file **Makefile.am**, which in turn is used by **automake** when constructing a Makefile.
|
||||
|
||||
**Makefile.am** uses the same syntax as a Makefile, so if you’ve ever written a Makefile from scratch, then this process will be familiar and simple. Often, a **Makefile.am** file needs only a few variable definitions to indicate what files are to be built, and where they are to be installed.
|
||||
|
||||
Variables ending in **_PROGRAMS** identify code that is to be built (this is usually considered the _primary_ target; it’s the main reason the Makefile exists). Automake recognizes other primaries, like **_SCRIPTS**, **_DATA**, **_LIBRARIES**, and other common parts that make up a software project.
|
||||
|
||||
If your application is literally compiled during the build process, then you identify it as a binary program with the **bin_PROGRAMS** variable, and then reference any part of the source code required to build it (these parts may be one or more files to be compiled and linked together) using the program name as the variable prefix:
|
||||
|
||||
|
||||
```
|
||||
bin_PROGRAMS = penguin
|
||||
penguin_SOURCES = penguin.cpp
|
||||
```
|
||||
|
||||
The target of **bin_PROGRAMS** is installed into the **bindir**, which is user-configurable during compilation.
|
||||
|
||||
If your application isn’t actually compiled, then your project doesn’t need a **bin_PROGRAMS** variable at all. For instance, if your project is a script written in Bash, Perl, or a similar interpreted language, then define a **_SCRIPTS** variable instead:
|
||||
|
||||
|
||||
```
|
||||
bin_SCRIPTS = bin/penguin
|
||||
```
|
||||
|
||||
Automake expects sources to be located in a directory called **src**, so if your project uses an alternative directory structure for its layout, you must tell Automake to accept code from outside sources:
|
||||
|
||||
|
||||
```
|
||||
AUTOMAKE_OPTIONS = foreign subdir-objects
|
||||
```
|
||||
|
||||
Finally, you can create any custom Makefile rules in **Makefile.am** and they’ll be copied verbatim into the generated Makefile. For instance, if you know that a temporary value needs to be replaced in your source code before the installation proceeds, you could make a custom rule for that process:
|
||||
|
||||
|
||||
```
|
||||
all-am: penguin
|
||||
touch bin/penguin.sh
|
||||
|
||||
penguin: bin/penguin.sh
|
||||
@sed "s|__datadir__|@datadir@|" $< >bin/$@
|
||||
```
|
||||
|
||||
A particularly useful trick is to extend the existing **clean** target, at least during development. The **make clean** command generally removes all generated build files with the exception of the Automake infrastructure. It’s designed this way because most users rarely want **make clean** to obliterate the files that make it easy to build their code.
|
||||
|
||||
However, during development, you might want a method to reliably return your project to a state relatively unaffected by Autotools. In that case, you may want to add this:
|
||||
|
||||
|
||||
```
|
||||
clean-local:
|
||||
@rm config.status configure config.log
|
||||
@rm Makefile
|
||||
@rm -r autom4te.cache/
|
||||
@rm aclocal.m4
|
||||
@rm compile install-sh missing Makefile.in
|
||||
```
|
||||
|
||||
There’s a lot of flexibility here, and if you’re not already familiar with Makefiles, it can be difficult to know what your **Makefile.am** needs. The barest necessity is a primary target, whether that’s a binary program or a script, and an indication of where the source code is located (whether that’s through a **_SOURCES** variable or by using **AUTOMAKE_OPTIONS** to tell Automake where to look for source code).
|
||||
|
||||
Once you have those variables and settings defined, you can try generating your build scripts as you see in the next section, and adjust for anything that’s missing.
|
||||
|
||||
#### Autotools build script generation
|
||||
|
||||
You’ve built the infrastructure, now it’s time to let Autotools do what it does best: automate your project tooling. The way the developer (you) interfaces with Autotools is different from how users building your code do.
|
||||
|
||||
Builders generally use this well-known sequence:
|
||||
|
||||
|
||||
```
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
For that incantation to work, though, you as the developer must bootstrap the build infrastructure. First, run **autoreconf** to generate the configure script that users invoke before running **make**. Use the **–install** option to bring in auxiliary files, such as a symlink to **depcomp**, a script to generate dependencies during the compiling process, and a copy of the **compile** script, a wrapper for compilers to account for syntax variance, and so on.
|
||||
|
||||
|
||||
```
|
||||
$ autoreconf --install
|
||||
configure.ac:3: installing './compile'
|
||||
configure.ac:2: installing './install-sh'
|
||||
configure.ac:2: installing './missing'
|
||||
```
|
||||
|
||||
With this development build environment, you can then create a package for source code distribution:
|
||||
|
||||
|
||||
```
|
||||
$ make dist
|
||||
```
|
||||
|
||||
The **dist** target is a rule you get for "free" from Autotools.
|
||||
It’s a feature that gets built into the Makefile generated from your humble **Makefile.am** configuration. This target produces a **tar.gz** archive containing all of your source code and all of the essential Autotools infrastructure so that people downloading the package can build the project.
|
||||
|
||||
At this point, you should review the contents of the archive carefully to ensure that it contains everything you intend to ship to your users. You should also, of course, try building from it yourself:
|
||||
|
||||
|
||||
```
|
||||
$ tar --extract --file penguin-0.0.1.tar.gz
|
||||
$ cd penguin-0.0.1
|
||||
$ ./configure
|
||||
$ make
|
||||
$ DESTDIR=/tmp/penguin-test-build make install
|
||||
```
|
||||
|
||||
If your build is successful, you find a local copy of your compiled application specified by **DESTDIR** (in the case of this example, **/tmp/penguin-test-build**).
|
||||
|
||||
|
||||
```
|
||||
$ /tmp/example-test-build/usr/local/bin/example
|
||||
hello world from GNU Autotools
|
||||
```
|
||||
|
||||
### Time to use Autotools
|
||||
|
||||
Autotools is a great collection of scripts for a predictable and automated release process. This toolset may be new to you if you’re used to Python or Bash builders, but it’s likely worth learning for the structure and adaptability it provides to your project.
|
||||
|
||||
And Autotools is not just for code, either. Autotools can be used to build [Docbook][11] projects, to keep media organized (I use Autotools for my music releases), documentation projects, and anything else that could benefit from customizable install targets.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/introduction-gnu-autotools
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_kernel_clang_vscode.jpg?itok=fozZ4zrr (Linux kernel source code (C) in Visual Studio Code)
|
||||
[2]: https://www.gnu.org/software/automake/faq/autotools-faq.html
|
||||
[3]: https://opensource.com/article/18/1/how-install-apps-linux
|
||||
[4]: https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[5]: https://en.wikipedia.org/wiki/POSIX
|
||||
[6]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Initializing-configure.html
|
||||
[7]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Output.html#Output
|
||||
[8]: mailto:seth@example.com
|
||||
[9]: https://www.gnu.org/software/make/manual/html_node/Introduction.html
|
||||
[10]: https://www.gnu.org/software/automake/manual/html_node/Programs.html#Programs
|
||||
[11]: https://opensource.com/article/17/9/docbook
|
||||
@ -1,144 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (furrybear)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to create a pull request in GitHub)
|
||||
[#]: via: (https://opensource.com/article/19/7/create-pull-request-github)
|
||||
[#]: author: (Kedar Vijay Kulkarni https://opensource.com/users/kkulkarnhttps://opensource.com/users/fontanahttps://opensource.com/users/mhanwellhttps://opensource.com/users/mysentimentshttps://opensource.com/users/greg-p)
|
||||
|
||||
How to create a pull request in GitHub
|
||||
======
|
||||
Learn how to fork a repo, make changes, and ask the maintainers to
|
||||
review and merge it.
|
||||
![a checklist for a team][1]
|
||||
|
||||
So, you know how to use git. You have a [GitHub][2] repo and can push to it. All is well. But how the heck do you contribute to other people's GitHub projects? That is what I wanted to know after I learned git and GitHub. In this article, I will explain how to fork a git repo, make changes, and submit a pull request.
|
||||
|
||||
When you want to work on a GitHub project, the first step is to fork a repo.
|
||||
|
||||
![Forking a GitHub repo][3]
|
||||
|
||||
Use [my demo repo][4] to try it out.
|
||||
|
||||
Once there, click on the **Fork** button in the top-right corner. This creates a new copy of my demo repo under your GitHub user account with a URL like:
|
||||
|
||||
|
||||
```
|
||||
`https://github.com/<YourUserName>/demo`
|
||||
```
|
||||
|
||||
The copy includes all the code, branches, and commits from the original repo.
|
||||
|
||||
Next, clone the repo by opening the terminal on your computer and running the command:
|
||||
|
||||
|
||||
```
|
||||
`git clone https://github.com/<YourUserName>/demo`
|
||||
```
|
||||
|
||||
Once the repo is cloned, you need to do two things:
|
||||
|
||||
1. Create a new branch by issuing the command:
|
||||
|
||||
|
||||
```
|
||||
`git checkout -b new_branch`
|
||||
```
|
||||
|
||||
2. Create a new remote for the upstream repo with the command:
|
||||
|
||||
|
||||
```
|
||||
`git remote add upstream https://github.com/kedark3/demo`
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
In this case, "upstream repo" refers to the original repo you created your fork from.
|
||||
|
||||
Now you can make changes to the code. The following code creates a new branch, makes an arbitrary change, and pushes it to **new_branch**:
|
||||
|
||||
|
||||
```
|
||||
$ git checkout -b new_branch
|
||||
Switched to a new branch ‘new_branch’
|
||||
$ echo “some test file” > test
|
||||
$ cat test
|
||||
Some test file
|
||||
$ git status
|
||||
On branch new_branch
|
||||
No commits yet
|
||||
Untracked files:
|
||||
(use "git add <file>..." to include in what will be committed)
|
||||
test
|
||||
nothing added to commit but untracked files present (use "git add" to track)
|
||||
$ git add test
|
||||
$ git commit -S -m "Adding a test file to new_branch"
|
||||
[new_branch (root-commit) 4265ec8] Adding a test file to new_branch
|
||||
1 file changed, 1 insertion(+)
|
||||
create mode 100644 test
|
||||
$ git push -u origin new_branch
|
||||
Enumerating objects: 3, done.
|
||||
Counting objects: 100% (3/3), done.
|
||||
Writing objects: 100% (3/3), 918 bytes | 918.00 KiB/s, done.
|
||||
Total 3 (delta 0), reused 0 (delta 0)
|
||||
Remote: Create a pull request for ‘new_branch’ on GitHub by visiting:
|
||||
Remote: <http://github.com/example/Demo/pull/new/new\_branch>
|
||||
Remote:
|
||||
* [new branch] new_branch -> new_branch
|
||||
```
|
||||
|
||||
Once you push the changes to your repo, the **Compare & pull request** button will appear in GitHub.
|
||||
|
||||
![GitHub's Compare & Pull Request button][5]
|
||||
|
||||
Click it and you'll be taken to this screen:
|
||||
|
||||
![GitHub's Open pull request button][6]
|
||||
|
||||
Open a pull request by clicking the **Create pull request** button. This allows the repo's maintainers to review your contribution. From here, they can merge it if it is good, or they may ask you to make some changes.
|
||||
|
||||
### TLDR
|
||||
|
||||
In summary, if you want to contribute to a project, the simplest way is to:
|
||||
|
||||
1. Find a project you want to contribute to
|
||||
2. Fork it
|
||||
3. Clone it to your local system
|
||||
4. Make a new branch
|
||||
5. Make your changes
|
||||
6. Push it back to your repo
|
||||
7. Click the **Compare & pull request** button
|
||||
8. Click **Create pull request** to open a new pull request
|
||||
|
||||
|
||||
|
||||
If the reviewers ask for changes, repeat steps 5 and 6 to add more commits to your pull request.
|
||||
|
||||
Happy coding!
|
||||
|
||||
In a previous article , I discussed the complaints that have been leveled against GitHub during the...
|
||||
|
||||
Arfon Smith works at GitHub and is involved in a number of activities at the intersection of open...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/create-pull-request-github
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kkulkarnhttps://opensource.com/users/fontanahttps://opensource.com/users/mhanwellhttps://opensource.com/users/mysentimentshttps://opensource.com/users/greg-p
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_hands_team_collaboration.png?itok=u82QepPk (a checklist for a team)
|
||||
[2]: https://github.com/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/forkrepo.png (Forking a GitHub repo)
|
||||
[4]: https://github.com/kedark3/demo
|
||||
[5]: https://opensource.com/sites/default/files/uploads/compare-and-pull-request-button.png (GitHub's Compare & Pull Request button)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/open-a-pull-request_crop.png (GitHub's Open pull request button)
|
||||
@ -1,123 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bash Script to Send a Mail When a New User Account is Created in System)
|
||||
[#]: via: (https://www.2daygeek.com/linux-bash-script-to-monitor-user-creation-send-email/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Bash Script to Send a Mail When a New User Account is Created in System
|
||||
======
|
||||
|
||||
There are many open source monitoring tools are currently available in market to monitor Linux systems performance.
|
||||
|
||||
It will send an email alert when the system reaches the specified threshold limit.
|
||||
|
||||
It monitors everything such as CPU utilization, Memory utilization, swap utilization, disk space utilization and much more.
|
||||
|
||||
But i don’t think they have an option to monitor a new user creation activity and alert when it’s happening.
|
||||
|
||||
If not, it doesn’t really matter as we can write our own bash script to achieve this.
|
||||
|
||||
We had added many useful shell scripts in the past. If you want to check those, navigate to the below link.
|
||||
|
||||
* **[How to automate day to day activities using shell scripts?][1]**
|
||||
|
||||
|
||||
|
||||
What the script does? It monitors **`/var/log/secure`**` ` file and alert admin when a new account is created in system.
|
||||
|
||||
We can’t run this script frequently since user creation is not happening very often. However, I’m planning to run this script once in a day.
|
||||
|
||||
So, that we can get a consolidated report about the user creation.
|
||||
|
||||
If useradd string was found in “/var/log/secure” file for yesterday’s date, then the script will send an email alert to given email id with new users details.
|
||||
|
||||
**Note:** You need to change the email id instead of ours.
|
||||
|
||||
```
|
||||
# vi /opt/scripts/new-user.sh
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
#Set the variable which equal to zero
|
||||
prev_count=0
|
||||
|
||||
count=$(grep -i "`date --date='yesterday' '+%b %e'`" /var/log/secure | egrep -wi 'useradd' | wc -l)
|
||||
|
||||
if [ "$prev_count" -lt "$count" ] ; then
|
||||
|
||||
# Send a mail to given email id when errors found in log
|
||||
|
||||
SUBJECT="ATTENTION: New User Account is created on server : `date --date='yesterday' '+%b %e'`"
|
||||
|
||||
# This is a temp file, which is created to store the email message.
|
||||
|
||||
MESSAGE="/tmp/new-user-logs.txt"
|
||||
|
||||
TO="[email protected]"
|
||||
|
||||
echo "Hostname: `hostname`" >> $MESSAGE
|
||||
|
||||
echo -e "\n" >> $MESSAGE
|
||||
|
||||
echo "The New User Details are below." >> $MESSAGE
|
||||
|
||||
echo "+------------------------------+" >> $MESSAGE
|
||||
|
||||
grep -i "`date --date='yesterday' '+%b %e'`" /var/log/secure | egrep -wi 'useradd' | grep -v 'failed adding'| awk '{print $4,$8}' | uniq | sed 's/,/ /' >> $MESSAGE
|
||||
|
||||
echo "+------------------------------+" >> $MESSAGE
|
||||
|
||||
mail -s "$SUBJECT" "$TO" < $MESSAGE
|
||||
|
||||
rm $MESSAGE
|
||||
|
||||
fi
|
||||
```
|
||||
|
||||
Set an executable permission to **`new-user.sh`**` ` file.
|
||||
|
||||
```
|
||||
$ chmod +x /opt/scripts/new-user.sh
|
||||
```
|
||||
|
||||
Finally add a cronjob to automate this. It will run everyday at 7'o clock.
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
|
||||
0 7 * * * /bin/bash /opt/scripts/new-user.sh
|
||||
```
|
||||
|
||||
Note: You will be getting an email alert everyday at 7 o'clock, which is for yesterday's log.
|
||||
|
||||
**`Output:`**` ` You will be getting an email alert similar to below.
|
||||
|
||||
```
|
||||
# cat /tmp/logs.txt
|
||||
|
||||
Hostname: 2g.server10.com
|
||||
|
||||
The New User Details are below.
|
||||
+------------------------------+
|
||||
2g.server10.com name=magesh
|
||||
2g.server10.com name=daygeek
|
||||
+------------------------------+
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-bash-script-to-monitor-user-creation-send-email/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/shell-script/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -157,7 +157,7 @@ via: https://fedoramagazine.org/use-postfix-to-get-email-from-your-fedora-system
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,105 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 cool new projects to try in COPR for August 2019)
|
||||
[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-august-2019/)
|
||||
[#]: author: (Dominik Turecek https://fedoramagazine.org/author/dturecek/)
|
||||
|
||||
4 cool new projects to try in COPR for August 2019
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
COPR is a [collection][2] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
Here’s a set of new and interesting projects in COPR.
|
||||
|
||||
### Duc
|
||||
|
||||
[Duc][3] is a collection of tools for disk usage inspection and visualization. Duc uses an indexed database to store sizes of files on your system. Once the indexing is done, you can then quickly overview your disk usage either by its command-line interface or the GUI.
|
||||
|
||||
![][4]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][5] currently provides duc for EPEL 7, Fedora 29 and 30. To install duc, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable terrywang/duc
|
||||
sudo dnf install duc
|
||||
```
|
||||
|
||||
### MuseScore
|
||||
|
||||
[MuseScore][6] is a software for working with music notation. With MuseScore, you can create sheet music either by using a mouse, virtual keyboard or a MIDI controller. MuseScore can then play the created music or export it as a PDF, MIDI or MusicXML. Additionally, there’s an extensive database of sheet music created by Musescore users.
|
||||
|
||||
![][7]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][8] currently provides MuseScore for Fedora 29 and 30. To install MuseScore, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable jjames/MuseScore
|
||||
sudo dnf install musescore
|
||||
```
|
||||
|
||||
### Dynamic Wallpaper Editor
|
||||
|
||||
[Dynamic Wallpaper Editor][9] is a tool for creating and editing a collection of wallpapers in GNOME that change in time. This can be done using XML files, however, Dynamic Wallpaper Editor makes this easy with its graphical interface, where you can simply add pictures, arrange them and set the duration of each picture and transitions between them.
|
||||
|
||||
![][10]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][11] currently provides dynamic-wallpaper-editor for Fedora 30 and Rawhide. To install dynamic-wallpaper-editor, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable atim/dynamic-wallpaper-editor
|
||||
sudo dnf install dynamic-wallpaper-editor
|
||||
```
|
||||
|
||||
### Manuskript
|
||||
|
||||
[Manuskript][12] is a tool for writers and is aimed to make creating large writing projects easier. It serves as an editor for writing the text itself, as well as a tool for organizing notes about the story itself, characters of the story and individual plots.
|
||||
|
||||
![][13]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The [repo][14] currently provides Manuskript for Fedora 29, 30 and Rawhide. To install Manuskript, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable notsag/manuskript
|
||||
sudo dnf install manuskript
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-august-2019/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/dturecek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2017/08/4-copr-945x400.jpg
|
||||
[2]: https://copr.fedorainfracloud.org/
|
||||
[3]: https://duc.zevv.nl/
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/07/duc.png
|
||||
[5]: https://copr.fedorainfracloud.org/coprs/terrywang/duc/
|
||||
[6]: https://musescore.org/
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/07/musescore-1024x512.png
|
||||
[8]: https://copr.fedorainfracloud.org/coprs/jjames/MuseScore/
|
||||
[9]: https://github.com/maoschanz/dynamic-wallpaper-editor
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/07/dynamic-walppaper-editor.png
|
||||
[11]: https://copr.fedorainfracloud.org/coprs/atim/dynamic-wallpaper-editor/
|
||||
[12]: https://www.theologeek.ch/manuskript/
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2019/07/manuskript-1024x600.png
|
||||
[14]: https://copr.fedorainfracloud.org/coprs/notsag/manuskript/
|
||||
@ -1,117 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (GameMode – A Tool To Improve Gaming Performance On Linux)
|
||||
[#]: via: (https://www.ostechnix.com/gamemode-a-tool-to-improve-gaming-performance-on-linux/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
GameMode – A Tool To Improve Gaming Performance On Linux
|
||||
======
|
||||
|
||||
![Gamemmode improve gaming performance on Linux][1]
|
||||
|
||||
Ask some Linux users why they still sticks with Windows dual boot, probably the answer would be – “Games!”. It was true! Luckily, open source gaming platforms like [**Lutris**][2] and Proprietary gaming platform **Steam** have brought many games to Linux platforms and improved the Linux gaming experience significantly over the years. Today, I stumbled upon yet another Linux gaming-related, open source tool named **GameMode** , which allows the users to improve gaming performance on Linux.
|
||||
|
||||
GameMode is basically a daemon/lib combo that lets the games optimise Linux system performance on demand. I thought GameMode is a kind of tool that would kill some resource-hungry tools running in the background. But it is different. What it does actually is just instruct the CPU to **automatically run in Performance mode when playing games** and helps the Linux users to get best possible performance out of their games.
|
||||
|
||||
GameMode improves the gaming performance significantly by requesting a set of optimisations be temporarily applied to the host OS while playing the games. Currently, It includes support for optimisations including the following:
|
||||
|
||||
* CPU governor,
|
||||
* I/O priority,
|
||||
* Process niceness,
|
||||
* Kernel scheduler (SCHED_ISO),
|
||||
* Screensaver inhibiting,
|
||||
* GPU performance mode (NVIDIA and AMD), GPU overclocking (NVIDIA),
|
||||
* Custom scripts.
|
||||
|
||||
|
||||
|
||||
GameMode is free and open source system tool developed by [**Feral Interactive**][3], a world-leading publisher of games.
|
||||
|
||||
### Install GameMode
|
||||
|
||||
GameMode is available for many Linux distributions.
|
||||
|
||||
On Arch Linux and its variants, you can install it from [**AUR**][4] using any AUR helper programs, for example [**Yay**][5].
|
||||
|
||||
```
|
||||
$ yay -S gamemode
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint and other Deb-based systems:
|
||||
|
||||
```
|
||||
$ sudo apt install gamemode
|
||||
```
|
||||
|
||||
If GameMode is not available for your system, you can manually compile and install it from source as described in its Github page under Development section.
|
||||
|
||||
### Activate GameMode support to improve Gaming Performance on Linux
|
||||
|
||||
Here are the list of games with GameMode integration, so we need not to do any additional configuration to activate GameMode support.
|
||||
|
||||
* Rise of the Tomb Raider
|
||||
* Total War Saga: Thrones of Britannia
|
||||
* Total War: WARHAMMER II
|
||||
* DiRT 4
|
||||
* Total War: Three Kingdoms
|
||||
|
||||
|
||||
|
||||
Simply run these games and GameMode support will be enabled automatically.
|
||||
|
||||
There is also an [**extension**][6] is available to integrate GameMode support with GNOME shell. It indicates when GameMode is active in the top panel.
|
||||
|
||||
For other games, you may need to manually request GameMode support like below.
|
||||
|
||||
```
|
||||
gamemoderun ./game
|
||||
```
|
||||
|
||||
I am not fond of games and I haven’t played any games for years. So, I can’t share any actual benchmarks.
|
||||
|
||||
However, I’ve found a short video tutorial on Youtube to enable GameMode support for Lutris games. It is a good start point for those who wants to try GameMode for the first time.
|
||||
|
||||
<https://youtu.be/4gyRyYfyGJw>
|
||||
|
||||
By looking at the comments in the video, I can say that that GameMode has indeed improved gaming performance on Linux.
|
||||
|
||||
For more details, refer the [**GameMode GitHub repository**][7].
|
||||
|
||||
* * *
|
||||
|
||||
**Related read:**
|
||||
|
||||
* [**GameHub – An Unified Library To Put All Games Under One Roof**][8]
|
||||
* [**How To Run MS-DOS Games And Programs In Linux**][9]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
Have you used GameMode tool? Did it really improve the Gaming performance on your Linux box? Share you thoughts in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/gamemode-a-tool-to-improve-gaming-performance-on-linux/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Gamemode-720x340.png
|
||||
[2]: https://www.ostechnix.com/manage-games-using-lutris-linux/
|
||||
[3]: http://www.feralinteractive.com/en/
|
||||
[4]: https://aur.archlinux.org/packages/gamemode/
|
||||
[5]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[6]: https://github.com/gicmo/gamemode-extension
|
||||
[7]: https://github.com/FeralInteractive/gamemode
|
||||
[8]: https://www.ostechnix.com/gamehub-an-unified-library-to-put-all-games-under-one-roof/
|
||||
[9]: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
|
||||
@ -1,236 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Set Up Time Synchronization On Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-set-up-time-synchronization-on-ubuntu/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Set Up Time Synchronization On Ubuntu
|
||||
======
|
||||
|
||||
![Set Up Time Synchronization On Ubuntu][1]
|
||||
|
||||
You might have set up [**cron jobs**][2] that runs at a specific time to backup important files or perform any system related tasks. Or, you might have configured a [**log server to rotate the logs**][3] out of your system at regular interval time. If your clock is out-of-sync, these jobs will not execute at the desired time. This is why setting up a correct time zone on the Linux systems and keep the clock synchronized with Internet is important. This guide describes how to set up time synchronization on Ubuntu Linux. The steps given below have been tested on Ubuntu 18.04, however they are same for other Ubuntu-based systems that uses systemd’s **timesyncd** service.
|
||||
|
||||
### Set Up Time Synchronization On Ubuntu
|
||||
|
||||
Usually, we set time zone during installation. You can however change it or set different time zone if you want to.
|
||||
|
||||
First, let us see the current time zone in our Ubuntu system using “date” command:
|
||||
|
||||
```
|
||||
$ date
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Tue Jul 30 11:47:39 UTC 2019
|
||||
```
|
||||
|
||||
As you see in the above output, the “date” command shows the actual date as well as the current time. Here, my current time zone is **UTC** which stands for **Coordinated Universal Time**.
|
||||
|
||||
Alternatively, you can look up the **/etc/timezone** file to find the current time zone.
|
||||
|
||||
```
|
||||
$ cat /etc/timezone
|
||||
UTC
|
||||
```
|
||||
|
||||
Now, let us see if the clock is synchronized with Internet. To do so, simply run:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Local time: Tue 2019-07-30 11:53:58 UTC
|
||||
Universal time: Tue 2019-07-30 11:53:58 UTC
|
||||
RTC time: Tue 2019-07-30 11:53:59
|
||||
Time zone: Etc/UTC (UTC, +0000)
|
||||
System clock synchronized: yes
|
||||
systemd-timesyncd.service active: yes
|
||||
RTC in local TZ: no
|
||||
```
|
||||
|
||||
As you can see, the “timedatectl” command displays the local time, universal time, time zone and whether the system clock is synchronized with Internet servers and if the **systemd-timesyncd.service** is active or inactive. In my case, the system clock is synchronizing with Internet time servers.
|
||||
|
||||
If the clock is out-of-sync, you would see **“System clock synchronized: no”** as shown in the below screenshot.
|
||||
|
||||
![][4]
|
||||
|
||||
Time synchronization is disabled.
|
||||
|
||||
Note: The above screenshot is old one. That’s why you see the different date.
|
||||
|
||||
If you see **“System clock synchronized:** value set as **no** , the timesyncd service might be inactive. So, simply restart the service and see if it helps.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart systemd-timesyncd.service
|
||||
```
|
||||
|
||||
Now check the timesyncd service status:
|
||||
|
||||
```
|
||||
$ sudo systemctl status systemd-timesyncd.service
|
||||
● systemd-timesyncd.service - Network Time Synchronization
|
||||
Loaded: loaded (/lib/systemd/system/systemd-timesyncd.service; enabled; vendor preset: enabled)
|
||||
Active: active (running) since Tue 2019-07-30 10:50:18 UTC; 1h 11min ago
|
||||
Docs: man:systemd-timesyncd.service(8)
|
||||
Main PID: 498 (systemd-timesyn)
|
||||
Status: "Synchronized to time server [2001:67c:1560:8003::c7]:123 (ntp.ubuntu.com)."
|
||||
Tasks: 2 (limit: 2319)
|
||||
CGroup: /system.slice/systemd-timesyncd.service
|
||||
└─498 /lib/systemd/systemd-timesyncd
|
||||
|
||||
Jul 30 10:50:30 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:31 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:31 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:32 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:32 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:50:35 ubuntuserver systemd-timesyncd[498]: Network configuration changed, trying to estab
|
||||
Jul 30 10:51:06 ubuntuserver systemd-timesyncd[498]: Synchronized to time server [2001:67c:1560:800
|
||||
```
|
||||
|
||||
If this service is enabled and active, your system clock should sync with Internet time servers.
|
||||
|
||||
You can verify if the time synchronization is enabled or not using command:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
```
|
||||
|
||||
If it still not works, run the following command to enable the time synchronization:
|
||||
|
||||
```
|
||||
$ sudo timedatectl set-ntp true
|
||||
```
|
||||
|
||||
Now your system clock will synchronize with Internet time servers.
|
||||
|
||||
##### Change time zone using Timedatectl command
|
||||
|
||||
What if I want to use different time zone other than UTC? It is easy!
|
||||
|
||||
First, list of available time zones using command:
|
||||
|
||||
```
|
||||
$ timedatectl list-timezones
|
||||
```
|
||||
|
||||
You will see an output similar to below image.
|
||||
|
||||
![][5]
|
||||
|
||||
List time zones using timedatectl command
|
||||
|
||||
You can set the desired time zone(E.g. Asia/Kolkata) using command:
|
||||
|
||||
```
|
||||
$ sudo timedatectl set-timezone Asia/Kolkata
|
||||
```
|
||||
|
||||
Check again if the time zone has been really changed using “date” command:
|
||||
|
||||
**$ date**
|
||||
Tue Jul 30 17:52:33 **IST** 2019
|
||||
|
||||
Or, use timedatectl command if you want the detailed output:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
Local time: Tue 2019-07-30 17:52:35 IST
|
||||
Universal time: Tue 2019-07-30 12:22:35 UTC
|
||||
RTC time: Tue 2019-07-30 12:22:36
|
||||
Time zone: Asia/Kolkata (IST, +0530)
|
||||
System clock synchronized: yes
|
||||
systemd-timesyncd.service active: yes
|
||||
RTC in local TZ: no
|
||||
```
|
||||
|
||||
As you noticed, I have changed the time zone from UTC to IST (Indian standard time).
|
||||
|
||||
To switch back to UTC time zone, simply run:
|
||||
|
||||
```
|
||||
$ sudo timedatectl set-timezone UTC
|
||||
```
|
||||
|
||||
##### Change time zone using Tzdata
|
||||
|
||||
In older Ubuntu versions, the Timedatectl command is not available. In such cases, you can use **Tzdata** (Time zone data) to set up time synchronization.
|
||||
|
||||
```
|
||||
$ sudo dpkg-reconfigure tzdata
|
||||
```
|
||||
|
||||
Choose the geographic area in which you live. In my case, I chose **Asia**. Select OK and hit ENTER key.
|
||||
|
||||
![][6]
|
||||
|
||||
Next, select the city or region corresponding to your time zone. Here I’ve chosen **Kolkata**.
|
||||
|
||||
![][7]
|
||||
|
||||
Finally, you will see an output something like below in the Terminal.
|
||||
|
||||
```
|
||||
Current default time zone: 'Asia/Kolkata'
|
||||
Local time is now: Tue Jul 30 19:29:25 IST 2019.
|
||||
Universal Time is now: Tue Jul 30 13:59:25 UTC 2019.
|
||||
```
|
||||
|
||||
##### Configure time zone in graphical mode
|
||||
|
||||
Some users may not be comfortable with CLI way. If you’re one of them, you can easily change do all this from system settings panel in graphical mode.
|
||||
|
||||
Hit the **Super key** (Windows key), type **settings** in the Ubuntu dash and click on **Settings** icon.
|
||||
|
||||
![][8]
|
||||
|
||||
Launch System’s settings from Ubuntu dash
|
||||
|
||||
Alternatively, click on the down arrow located at the top right corner of your Ubuntu desktop and click the Settings icon in the left corner.
|
||||
|
||||
![][9]
|
||||
|
||||
Launch System’s settings from top panel
|
||||
|
||||
In the next window, choose **Details** and then Click **Date & Time** option. Turn on both **Automatic Date & Time** and **Automatic Time Zone** options.
|
||||
|
||||
![][10]
|
||||
|
||||
Set automatic time zone in Ubuntu
|
||||
|
||||
Close the Settings window an you’re done! Your system clock should now sync with Internet time servers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-set-up-time-synchronization-on-ubuntu/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Set-Up-Time-Synchronization-On-Ubuntu-720x340.png
|
||||
[2]: https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
|
||||
[3]: https://www.ostechnix.com/manage-log-files-using-logrotate-linux/
|
||||
[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/timedatectl-command-output-ubuntu.jpeg
|
||||
[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/List-timezones-using-timedatectl-command.png
|
||||
[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/configure-time-zone-using-tzdata-1.png
|
||||
[7]: https://www.ostechnix.com/wp-content/uploads/2019/07/configure-time-zone-using-tzdata-2.png
|
||||
[8]: https://www.ostechnix.com/wp-content/uploads/2019/07/System-settings-Ubuntu-dash.png
|
||||
[9]: https://www.ostechnix.com/wp-content/uploads/2019/07/Ubuntu-system-settings.png
|
||||
[10]: https://www.ostechnix.com/wp-content/uploads/2019/07/Set-automatic-timezone-in-ubuntu.png
|
||||
@ -1,155 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (FSSlc)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Verify ISO Images In Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-verify-iso-images-in-linux/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Verify ISO Images In Linux
|
||||
======
|
||||
|
||||
![How To Verify ISO Images In Linux][1]
|
||||
|
||||
You just downloaded an ISO image of your favorite Linux distribution from the official site or a third party site, now what? [**Create bootable medium**][2] and start installing the OS? No, wait. Before start using it, It is highly recommended to verify that the downloaded ISO in your local system is the exact copy of the ISO present in the download mirrors. Because, [**Linux Mint’s website is hacked**][3] few years ago and the hackers made a modified Linux Mint ISO, with a backdoor in it. So, It is important to check the authenticity and integrity of your Linux ISO images. If you don’t know how to verify ISO images in Linux, this brief guide will help. Read on!
|
||||
|
||||
### Verify ISO Images In Linux
|
||||
|
||||
We can verify ISO images using the **Checksum** values. Checksum is a sequence of letters and numbers used to check data for errors and verify the authenticity and integrity of the downloaded files. There are different types of checksums, such as SHA-0, SHA-1, SHA-2 (224, 256, 384, 512) and MD5. MD5 sums have been the most popular, but nowadays SHA-256 sums are mostly used by modern Linux distros.
|
||||
|
||||
We are going to use two tools namely **“gpg”** and **“sha256”** to verify authenticity and integrity of the ISO images.
|
||||
|
||||
##### Download checksums and signatures
|
||||
|
||||
For the purpose of this guide, I am going to use Ubuntu 18.04 LTS server ISO image. However, the steps given below should work on other Linux distributions as well.
|
||||
|
||||
Near the top of the Ubuntu download page, you will see a few extra files (checksums and signatures) as shown in the following picture.
|
||||
|
||||
![][4]
|
||||
|
||||
Ubuntu 18.04 checksum and signature
|
||||
|
||||
Here, the **SHA256SUMS** file contains checksums for all the available images and the **SHA256SUMS.gpg** file is the GnuPG signature for that file. We use this signature file to **verify** the checksum file in subsequent steps.
|
||||
|
||||
Download the Ubuntu ISO images and these two files and put them all in a directory, for example **ISO**.
|
||||
|
||||
```
|
||||
$ ls ISO/
|
||||
SHA256SUMS SHA256SUMS.gpg ubuntu-18.04.2-live-server-amd64.iso
|
||||
```
|
||||
|
||||
As you see in the above output, I have downloaded Ubuntu 18.04.2 LTS server image along with checksum and signature values.
|
||||
|
||||
##### Download valid signature key
|
||||
|
||||
Now, download the correct signature key using command:
|
||||
|
||||
```
|
||||
$ gpg --keyid-format long --keyserver hkp://keyserver.ubuntu.com --recv-keys 0x46181433FBB75451 0xD94AA3F0EFE21092
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
gpg: key D94AA3F0EFE21092: 57 signatures not checked due to missing keys
|
||||
gpg: key D94AA3F0EFE21092: public key "Ubuntu CD Image Automatic Signing Key (2012) <[email protected]>" imported
|
||||
gpg: key 46181433FBB75451: 105 signatures not checked due to missing keys
|
||||
gpg: key 46181433FBB75451: public key "Ubuntu CD Image Automatic Signing Key <[email protected]>" imported
|
||||
gpg: no ultimately trusted keys found
|
||||
gpg: Total number processed: 2
|
||||
gpg: imported: 2
|
||||
```
|
||||
|
||||
##### Verify SHA-256 checksum
|
||||
|
||||
Next verify the checksum file using the signature with command:
|
||||
|
||||
```
|
||||
$ gpg --keyid-format long --verify SHA256SUMS.gpg SHA256SUMS
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
gpg: Signature made Friday 15 February 2019 04:23:33 AM IST
|
||||
gpg: using DSA key 46181433FBB75451
|
||||
gpg: Good signature from "Ubuntu CD Image Automatic Signing Key <[email protected]>" [unknown]
|
||||
gpg: WARNING: This key is not certified with a trusted signature!
|
||||
gpg: There is no indication that the signature belongs to the owner.
|
||||
Primary key fingerprint: C598 6B4F 1257 FFA8 6632 CBA7 4618 1433 FBB7 5451
|
||||
gpg: Signature made Friday 15 February 2019 04:23:33 AM IST
|
||||
gpg: using RSA key D94AA3F0EFE21092
|
||||
gpg: Good signature from "Ubuntu CD Image Automatic Signing Key (2012) <[email protected]>" [unknown]
|
||||
gpg: WARNING: This key is not certified with a trusted signature!
|
||||
gpg: There is no indication that the signature belongs to the owner.
|
||||
Primary key fingerprint: 8439 38DF 228D 22F7 B374 2BC0 D94A A3F0 EFE2 1092
|
||||
```
|
||||
|
||||
If you see “Good signature” in the output,the checksum file is created by Ubuntu developer and signed by the owner of the key file.
|
||||
|
||||
##### Check the downloaded ISO file
|
||||
|
||||
Next, let us go ahead and check the downloaded ISO file matches the checksum. To do so, simply run:
|
||||
|
||||
```
|
||||
$ sha256sum -c SHA256SUMS 2>&1 | grep OK
|
||||
ubuntu-18.04.2-live-server-amd64.iso: OK
|
||||
```
|
||||
|
||||
If the checksum values are matched, you will see the **“OK”** message. Meaning – the downloaded file is legitimate and hasn’t altered or tampered.
|
||||
|
||||
If you don’t get any output or different than above output, the ISO file has been modified or incorrectly downloaded. You must re-download the file again from a good source.
|
||||
|
||||
Some Linux distributions have included the checksum value in the download page itself. For example, **Pop!_os** developers have provided the SHA-256 checksum values for all ISO images in the download page itself, so you can quickly verify the ISO images.
|
||||
|
||||
![][5]
|
||||
|
||||
Pop os SHA256 sum value in download page
|
||||
|
||||
After downloading the the ISO image, verify it using command:
|
||||
|
||||
```
|
||||
$ sha256sum Soft_backup/ISOs/pop-os_18.04_amd64_intel_54.iso
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
680e1aa5a76c86843750e8120e2e50c2787973343430956b5cbe275d3ec228a6 Soft_backup/ISOs/pop-os_18.04_amd64_intel_54.iso
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
Pop os SHA256 sum value
|
||||
|
||||
Here, the random string starting with **“680elaa…”** is the SHA-256 checksum value. Compare this value with the SHA-256 sum value provided on the downloads page. If both values are same, you’re good to go! The downloaded ISO file is legitimate and it hasn’t changed or modified from its original state.
|
||||
|
||||
This is how we can verify the authenticity and integrity of an ISO file in Linux. Whether you download ISOs from official or third-party sources, it is always recommended to do a quick verification before using them. Hope this was useful.
|
||||
|
||||
**Reference:**
|
||||
|
||||
* [**https://tutorials.ubuntu.com/tutorial/tutorial-how-to-verify-ubuntu**][7]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-verify-iso-images-in-linux/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Verify-ISO-Images-In-Linux-720x340.png
|
||||
[2]: https://www.ostechnix.com/etcher-beauitiful-app-create-bootable-sd-cards-usb-drives/
|
||||
[3]: https://blog.linuxmint.com/?p=2994
|
||||
[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/Ubuntu-18.04-checksum-and-signature.png
|
||||
[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Pop-os-SHA256-sum.png
|
||||
[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/Pop-os-SHA256-sum-value.png
|
||||
[7]: https://tutorials.ubuntu.com/tutorial/tutorial-how-to-verify-ubuntu
|
||||
@ -0,0 +1,207 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 tools for doing presentations from the command line)
|
||||
[#]: via: (https://opensource.com/article/19/8/command-line-presentation-tools)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitthttps://opensource.com/users/murphhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/scottnesbitt)
|
||||
|
||||
3 tools for doing presentations from the command line
|
||||
======
|
||||
mdp, tpp, and sent may not win you any design awards, but they'll give
|
||||
you basic slides that you can run from a terminal.
|
||||
![Files in a folder][1]
|
||||
|
||||
Tired of creating and displaying presentation slides using [LibreOffice Impress][2] or various slightly geeky [tools][3] and [frameworks][4]? Instead, consider running the slides for your next talk from a terminal window.
|
||||
|
||||
Using the terminal to present slides sounds strange, but it isn't. Maybe you want to embrace your inner geek a bit more. Perhaps you want your audience to focus on your ideas rather than your slides. Maybe you're a devotee of the [Takahashi method][5]. Whatever your reasons for turning to the terminal, there's a (presentation) tool for you.
|
||||
|
||||
Let's take a look at three of them.
|
||||
|
||||
### mdp
|
||||
|
||||
Seeing as how I'm something of a Markdown person, I took [mdp][6] for a spin the moment I heard about it.
|
||||
|
||||
You create your slides in a text editor, prettying the text up with Markdown. mpd recognizes most Markdown formatting—from headings and lists to code blocks to character formatting and URLs.
|
||||
|
||||
You can also add a [Pandoc metadata block][7], which can contain your name, the title of your presentation, and the date you're giving your talk. That adds the title to the top of every slide and your name and the date to the bottom.
|
||||
|
||||
Your slides are in a single text file. To let mdp know where a slide starts, add a line of dashes after each slide.
|
||||
|
||||
Here's a very simple example:
|
||||
|
||||
|
||||
```
|
||||
%title: Presentation Title
|
||||
%author: Your Name
|
||||
%date: YYYY-MM-DD
|
||||
|
||||
-> # Slide 1 <-
|
||||
|
||||
Intro slide
|
||||
|
||||
\--------------------------------------------------
|
||||
-> # Slide 2 <-
|
||||
==============
|
||||
|
||||
* Item 1
|
||||
* Item 2
|
||||
* Item 3
|
||||
|
||||
\-------------------------------------------------
|
||||
-> # Slide 3 <-
|
||||
|
||||
This one with a numbered list
|
||||
|
||||
1\. Item 1
|
||||
2\. Item 2
|
||||
3\. Item 3
|
||||
|
||||
\-------------------------------------------------
|
||||
|
||||
-> # Conclusion <-
|
||||
|
||||
mdp supports *other* **formatting**, too. Give it a try!
|
||||
```
|
||||
|
||||
See the **->** and **<-** surrounding the titles of each slide? Any text between those characters is centered in a terminal window.
|
||||
|
||||
Run your slideshow by typing **mdp slides.md** (or whatever you named your file) in a terminal window. Here's what the example slides I cobbled together look like:
|
||||
|
||||
![Example mdp slide][8]
|
||||
|
||||
Cycle through them by pressing the arrow keys or the spacebar on your keyboard.
|
||||
|
||||
### tpp
|
||||
|
||||
[tpp][9] is another simple, text-based presentation tool. It eschews Markdown for its own formatting. While the formatting is simple, it's very concise and offers a couple of interesting—and useful—surprises.
|
||||
|
||||
You use dashes to indicate most of the formatting. You can add a metadata block at the top of your slide file to create the title slide for your presentation. Denote headings by typing **\--heading** followed by the heading's text. Center text on a slide by typing **\--center** and then the text.
|
||||
|
||||
To create a new slide, type:
|
||||
|
||||
|
||||
```
|
||||
\---
|
||||
\--newpage
|
||||
```
|
||||
|
||||
Here's an example of some basic slides:
|
||||
|
||||
|
||||
```
|
||||
\--title Presentation Title
|
||||
\--date YYYY-MM-DD
|
||||
\--author Your Name
|
||||
|
||||
\---
|
||||
\--newpage
|
||||
|
||||
\--heading Slide 1
|
||||
|
||||
* Item 1
|
||||
|
||||
\---
|
||||
\--newpage
|
||||
|
||||
\--heading Slide 2
|
||||
* Item 1
|
||||
* Item 2
|
||||
|
||||
\---
|
||||
\--newpage
|
||||
|
||||
\--heading Slide 3
|
||||
|
||||
* Item 1
|
||||
* Item 2
|
||||
* Item 3
|
||||
```
|
||||
|
||||
Here's what they look like in a terminal window:
|
||||
|
||||
![tpp slide example][10]
|
||||
|
||||
Move through your slides by pressing the arrow keys on your keyboard.
|
||||
|
||||
What about those interesting and useful surprises I mentioned earlier? You can add a splash of color to the text on a slide by typing **\--color** and then the name of the color you want to use—for example, **red**. Below that, add the text whose color you want to change, like this:
|
||||
|
||||
|
||||
```
|
||||
\--color red
|
||||
Some text
|
||||
```
|
||||
|
||||
If you have a terminal command that you want to include on a slide, wrap it between **\--beginoutput** and **\--endoutput**. Taking that a step further, you can simulate typing the command by putting it between **\--beginshelloutput** and **\--endshelloutput**. Here's an example:
|
||||
|
||||
![Typing a command on a slide with tpp][11]
|
||||
|
||||
### Sent
|
||||
|
||||
[Sent][12] isn't strictly a command-line presentation tool. You run it from the command line, but it opens an X11 window containing your slides.
|
||||
|
||||
Sent is built around the Takahashi method for presenting that I mentioned at the beginning of this article. The core idea behind the Takahashi method is to have one or two keywords in large type on a slide. The keywords distill the idea you're trying to get across at that point in your presentation.
|
||||
|
||||
As with mpd and tpp, you craft your slides in [plain text][13] in a text editor. Sent doesn't use markup, and there are no special characters to indicate where a new slide begins. Sent assumes each new paragraph is a slide.
|
||||
|
||||
You're not limited to using text. Sent also supports images. To add an image to a slide, type **@** followed by the name of the image—for example, **@mySummerVacation.jpg**.
|
||||
|
||||
Here's an excerpt from a slide file:
|
||||
|
||||
|
||||
```
|
||||
On Writing Evergreen Articles
|
||||
|
||||
Evergreen?
|
||||
|
||||
8 Keys to Good Evergreen Articles
|
||||
|
||||
@images/typewriter.jpg
|
||||
|
||||
Be Passionate
|
||||
|
||||
Get Your Hands Dirty
|
||||
|
||||
Focus
|
||||
```
|
||||
|
||||
Fire up your slides by typing **sent filename** in a terminal window. The X11 window that opens goes into full-screen mode and displays text in as large a font as possible. Any images in your slides are centered in the window.
|
||||
|
||||
![Example Sent slide][14]
|
||||
|
||||
### Drawbacks of these tools
|
||||
|
||||
You're not going to win any design awards for the slides you create with mdp, tpp, or sent. They're plain. They're utilitarian. But, as I pointed out at the beginning of this article, the slides you create and present with those tools can help your audience focus on what you're saying rather than your visuals.
|
||||
|
||||
If you use mdp or tpp, you need to do some fiddling with your terminal emulator's settings to get the fonts and sizes right. Out of the box, the fonts might be too small—as you see in the screen captures above. If your terminal emulator supports profiles, create one for presentations with the font you want to use at the size you want. Then go full-screen.
|
||||
|
||||
Neither mdp, tpp, nor sent will appeal to everyone. That's fine. There's no one presentation tool to rule them all, no matter what some people say. But if you need, or just want, to go back to basics, these three tools are good options.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/command-line-presentation-tools
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitthttps://opensource.com/users/murphhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_paper_folder.png?itok=eIJWac15 (Files in a folder)
|
||||
[2]: https://www.libreoffice.org/discover/impress/
|
||||
[3]: https://opensource.com/article/18/5/markdown-slide-generators
|
||||
[4]: https://opensource.com/article/18/2/how-create-slides-emacs-org-mode-and-revealjs
|
||||
[5]: https://presentationzen.blogs.com/presentationzen/2005/09/living_large_ta.html
|
||||
[6]: https://github.com/visit1985/mdp
|
||||
[7]: https://pandoc.org/MANUAL.html#metadata-blocks
|
||||
[8]: https://opensource.com/sites/default/files/uploads/mdp-slides.png (Example mdp slide)
|
||||
[9]: https://synflood.at/tpp.html
|
||||
[10]: https://opensource.com/sites/default/files/uploads/tpp-example.png (tpp slide example)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/tpp-code_1.gif (Typing a command on a slide with tpp)
|
||||
[12]: https://tools.suckless.org/sent/
|
||||
[13]: https://plaintextproject.online
|
||||
[14]: https://opensource.com/sites/default/files/uploads/sent-example.png (Example Sent slide)
|
||||
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Avoiding burnout: 4 considerations for a more energetic organization)
|
||||
[#]: via: (https://opensource.com/open-organization/19/8/energy-fatigue-burnout)
|
||||
[#]: author: (Ron McFarland https://opensource.com/users/ron-mcfarlandhttps://opensource.com/users/jonobaconhttps://opensource.com/users/marcobravohttps://opensource.com/users/ron-mcfarland)
|
||||
|
||||
Avoiding burnout: 4 considerations for a more energetic organization
|
||||
======
|
||||
Being open requires a certain kind of energy—and if you don't take time
|
||||
to replenish that energy, your organization will suffer.
|
||||
![Light bulb][1]
|
||||
|
||||
In both personal and organizational life, energy levels are important. This is no less true of open organizations. Consider this: When you're tired, you'll have trouble _adapting_ when challenges arise. When your energy is low, you'll have trouble _collaborating_ with others. When you're feeling fatigued, building and energizing an open organization _community_ is difficult.
|
||||
|
||||
At a time when [the World Health Organization (WHO) has recently formalized its definition for burnout][2], this issue seems more important than ever. In this article, I'll address the important issue of managing daily energy—both at the personal and organizational levels.
|
||||
|
||||
### Energy management
|
||||
|
||||
Having spent most of my career in overseas sales and sales training, I've learned that both individual and company energy levels are very important. In the early part of the career, I was traveling approximately every two months. Most trips were two to four weeks long. When teaching during those trips, I'd find myself standing six hours every day as I presented selling techniques to salespeople. It was exhausting.
|
||||
|
||||
But I loved the work, and I knew I had to do something to keep my energy up. At a physical level, I knew I had to strengthen my legs and my heart, as well as change my diet to be able to sleep deeper at odd times of the day. Interestingly, I was not alone, as I heard many jet lag and exhaustion complaints in airport business lounges regularly. But I had to think about energy at an emotional level, too. I knew that the outside retail sales people I was training had to take rejection every day; they had to be able to control their levels of emotion and energy to be productive.
|
||||
|
||||
Whether for companies or individuals, exhaustion is counter-productive, resulting in errors, frustration, and poor performance. This could be even more true in open organizations, as many participants are contributing for a wide range of reasons outside of basic monetary rewards. Many organizations emphasize time-management, stress-management, crisis-management, and resource-management—but I've never heard of a company that has adopted and introduced an "energy management" program.
|
||||
|
||||
Why not?
|
||||
|
||||
In my case, in order to keep both myself and the sales people I was training energized and productive, I had to address the issue of energy. So I started studying and reading about the subject. Eventually I found the book [_The Way We're Working Isn't Working_][3] by Tony Schwartz, and still consider it the most helpful. Schwartz went on to develop [The Energy Project][4],"a consulting firm that helps individuals and organizations grow and transform so together they can prosper, add more value in the world, and do less harm." It addresses this issue of fatigue head on.
|
||||
|
||||
Schwartz distinguishes four separate and distinct categories of energy: physical, emotional, mental, and spiritual. Let me explain each and add some comments along the way.
|
||||
|
||||
### Four categories of energy
|
||||
|
||||
#### Physical health
|
||||
|
||||
First, to have adequate energy every day, you've got to take care of your physical health. That means you _must_ address issues like nutrition, posture, sleep, and exercise (I found the book _Farewell to Fatigue_ by Donald Norfolk especially helpful for learning how to get over jet lag quickly.) To use an automotive term: You should always have a good "power to weight ratio." In other words, you must increase the driveline power/efficiency or reduce the overall weight of the vehicle to improve performance.
|
||||
|
||||
I decided to work on both, keeping my legs strong and my weight down. I started jogging four to five times per week and improved my diet, which really helped me get a lot more out of my days and reduce fatigue.
|
||||
|
||||
#### Emotional well-being
|
||||
|
||||
Our energy grows when we feel appreciated by others. When the environment is exciting, we are motivated—which also leads to added energy. Conversely, when we don't feel that others appreciate us—or we find ourselves in a dull, even toxic environment—our energy levels suffer. In [_Every Word Has Power_][5], author Yvonne Oswald writes that the words we use and hear can make a big difference to our energy levels and well-being. She writes that simply reframing our everyday speech can help us boost energy levels. Instead of speaking excessively with the word "not" ("Don't strike out," "Don't double-fault,"), we should form sentences that paint a positive (energy-creating) image or picture in our minds. ("Hit a home run," "Serve an ace"). The former statements _consume_ our energy; the latter _enhance_ it.
|
||||
|
||||
Regarding energy generation in a working environment, the book [_The Progress Principle_ by Teresa Amabile][6] taught me an important insight. Amabile's research shows that generating a feeling of upward progress is the most powerful way to increase energy in an organization. A feeling of progress, learning, developing, and moving upward is extremely important. The opposite is true for declining organizations. I've consulted a lot of companies over the years, and when I'm seeking to get a feeling for an organization's energy level, all I have to do is ask one question: "What is your company's project or product development program and its future prospects?" If I can't get a clear, detailed answer to that question throughout the organization, I know that people are just biding their time and aren't energized.
|
||||
|
||||
#### Mental clarity
|
||||
|
||||
Our minds consume more energy than any other part of our body, just like computers that consume a lot of electricity. That is why we're so tired after studying for many hours or taking long tests. We didn't move around much, but we're tired just the same because we consumed energy through concentration and mental activity. When our mental energy is low, our ability to focus intensely, prioritize, and think creatively suffer. We therefore must know when to relax and re-energize our brains.
|
||||
|
||||
Whether for companies or individuals, exhaustion is counter-productive, resulting in errors, frustration, and poor performance. This could be even more true in open organizations, as many participants are contributing for a wide range of reasons outside of basic monetary rewards.
|
||||
|
||||
Additionally, consider mental energy and the concept of "multi-tasking." Some people proudly report that they're good at multi-tasking—but they shouldn't be, as it wastes mental energy. I am not saying we shouldn't listen to music while driving the car, but when it comes to cognitive mental processing, we can only do one thing at a time. The concept of "multi-tasking" is actually a misnomer in the context of deep thinking. Human brains process information sequentially (one issue at a time). We simply _cannot_ conduct two thinking tasks at the same time. Instead, what we're _really_ doing is task "switching," a back-and-forth movement between tasks that has a significant mental energy cost for the value gained. First and foremost, it is less efficient. Also, it consumes a great deal of energy. Best is to start a task and completely finish it before moving on to the next task, reducing shut-down and recall waste.
|
||||
|
||||
Just like overworking a muscle, mental clarity, strength, and energy can be used up. Therefore, mental recovery is important. Many people have found “power naps” or meditating extremely helpful. Going into a relax mode for only 20 minutes can be very helpful. It is just enough time to build your mental energy, but not long enough to make you groggy.
|
||||
|
||||
#### Spiritual significance
|
||||
|
||||
Spiritual significance creates energy, and it comes from the feeling of serving a mission beyond financial rewards. Put simply, it is doing something we consider important (an internal desire or goal). In the case of my sales training career, for example, I had a purpose of building the _careers_ of salespeople who had very little formal education. Teaching in countless developing countries really offered an inspiring purpose for me. At that time, this dimension of my work provided "spiritual significance". It generated a great deal of energy in me. As I grow older, I'm finding this spiritual significance becoming extremely important while financial rewards start to weaken. I'm sure this is true for many people that are contributing to open organizations. This contribution is where their energy comes from.
|
||||
|
||||
Not just for me, not just for open organization, but for _people in general_, I've found these four types of energy very important—so much so that I've prepared and delivered [presentations][7] on them.
|
||||
|
||||
### Energy across four zones
|
||||
|
||||
In _[The Way We're Working Isn't Working][3],_ Tony Schwartz mentions four zones that people operate in, which I've diagrammed in Figure 1.
|
||||
|
||||
![][8]
|
||||
|
||||
Here we see four quadrants useful in evaluating a working environment. From left to right we see an assessment of the environment, with a negative environment (energy-consuming) on the left and a positive environment (energizing) on the right. From top to bottom, then, is an assessment of the organization's (or individual's) energy level. Obviously, you want to be in the upper-right zone as much as possible and out of the bottom-left zone as much as possible.
|
||||
|
||||
To move from the Survival Zone (left) to the Performance Zone (right), Schwartz suggests you can manage your attitude by looking through three "lenses":
|
||||
|
||||
* **Reflection lens.** Ask two very simple questions: 1. What are the facts? and 2. What assumptions am I making? Stand back, observe the environment, and give yourself a chance to consider other, more positive ways of thinking about the situation.
|
||||
* **Reverse lens.** How do you think other people (particularly the person creating the negative environment) feel about the situation? Try to find ways to see or feel that person's perspective.
|
||||
* **Long lens.** Even after learning and confirming the facts and considering other people's perspectives, if you still feel like you're in the Survival Zone or Burnout Zone, consider the future. Imagine how you can make the best of a bad situation and move above it. No matter how badly you feel right now, how can you learn from this experience and excel in the future? Try to see value in the experience.
|
||||
|
||||
|
||||
|
||||
Do yourself a favor when you wake up in the morning. Evaluate yourself on the four energy types I mentioned in this article. Rate yourself from 1 to 10 on your current "morning physical health energy level." Then, do the same thing for your "emotional well-being energy level," "mental clarity energy level" and "spiritual significance energy level." That will give you some idea of what you'll have to work on to get the most out of both your day and life.
|
||||
|
||||
Jono Bacon shares some quite ridiculous life choices from his early years that illustrate important...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/8/energy-fatigue-burnout
|
||||
|
||||
作者:[Ron McFarland][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ron-mcfarlandhttps://opensource.com/users/jonobaconhttps://opensource.com/users/marcobravohttps://opensource.com/users/ron-mcfarland
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bulb-light-energy-power-idea.png?itok=zTEEmTZB (Light bulb)
|
||||
[2]: https://icd.who.int/browse11/l-m/en#/http://id.who.int/icd/entity/129180281
|
||||
[3]: https://www.simonandschuster.com/books/The-Way-Were-Working-Isnt-Working/Tony-Schwartz/9781451610260
|
||||
[4]: https://theenergyproject.com/team/tony-schwartz/
|
||||
[5]: https://www.simonandschuster.com/books/Every-Word-Has-Power/Yvonne-Oswald/9781582701813
|
||||
[6]: http://progressprinciple.com/books/single/the_progress_principle
|
||||
[7]: https://www.slideshare.net/RonMcFarland1/increasing-company-energy?qid=e3c251fc-be71-4185-b216-3c7e5b48f7b1&v=&b=&from_search=2
|
||||
[8]: https://opensource.com/sites/default/files/images/open-org/energy_zones.png
|
||||
99
sources/tech/20190806 Unboxing the Raspberry Pi 4.md
Normal file
99
sources/tech/20190806 Unboxing the Raspberry Pi 4.md
Normal file
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Unboxing the Raspberry Pi 4)
|
||||
[#]: via: (https://opensource.com/article/19/8/unboxing-raspberry-pi-4)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilvahttps://opensource.com/users/bennuttall)
|
||||
|
||||
Unboxing the Raspberry Pi 4
|
||||
======
|
||||
The Raspberry Pi 4 delivers impressive performance gains over its
|
||||
predecessors, and the Starter Kit makes it easy to get it up and running
|
||||
quickly.
|
||||
![Raspberry Pi 4 board, posterized filter][1]
|
||||
|
||||
When the Raspberry Pi 4 was [announced at the end of June][2], I wasted no time. I ordered two Raspberry Pi 4 Starter Kits the same day from [CanaKit][3]. The 1GB RAM version was available right away, but the 4GB version wouldn't ship until July 19th. Since I wanted to try both, I ordered them to be shipped together.
|
||||
|
||||
![CanaKit's Raspberry Pi 4 Starter Kit and official accessories][4]
|
||||
|
||||
Here's what I found when I unboxed my Raspberry Pi 4.
|
||||
|
||||
### Power supply
|
||||
|
||||
The Raspberry Pi 4 uses a USB-C connector for its power supply. Even though USB-C cables are very common now, your Pi 4 [may not like your USB-C cable][5] (at least with these first editions of the Raspberry Pi 4). So, unless you know exactly what you are doing, I recommend ordering the Starter Kit, which comes with an official Raspberry Pi charger. In case you would rather try whatever you have on hand, the device's input reads 100-240V ~ 50/60Hz 0.5A, and the output says 5.1V --- 3.0A.
|
||||
|
||||
![Raspberry Pi USB-C charger][6]
|
||||
|
||||
### Keyboard and mouse
|
||||
|
||||
The official keyboard and mouse are [sold separately][7] from the Starter Kit, and at $25 total, they aren't really cheap, given you're paying only $35 to $55 for a proper computer. But the Raspberry Pi logo is printed on this keyboard (instead of the Windows logo), and there is something compelling about having an appropriate appearance. The keyboard is also a USB hub, so it allows you to plug in even more devices. I plugged in my [YubiKey][8] security key, and it works very nicely. I would classify the keyboard and mouse as a "nice to have" versus a "must-have." Your regular keyboard and mouse should work fine.
|
||||
|
||||
![Official Raspberry Pi keyboard \(with YubiKey plugged in\) and mouse.][9]
|
||||
|
||||
![Raspberry Pi logo on the keyboard][10]
|
||||
|
||||
### Micro-HDMI cable
|
||||
|
||||
Something that may have caught some folks by surprise is that, unlike the Raspberry Pi Zero that comes with a Mini-HDMI port, the Raspberry Pi 4 comes with a Micro-HDMI. They are not the same thing! So, even though you may have a suitable USB-C cable/power adaptor, mouse, and keyboard on hand, there is a pretty good chance you will need a Micro-HDMI-to-HDMI cable (or an adapter) to plug your new Raspberry Pi into a display.
|
||||
|
||||
### The case
|
||||
|
||||
Cases for the Raspberry Pi have been around for years and are probably one of the very first "official" peripherals the Raspberry Pi Foundation sold. Some people like them; others don't. I think putting a Pi in a case makes it easier to carry it around and avoid static electricity and bent pins.
|
||||
|
||||
On the other hand, keeping your Pi covered can overheat the board. This CanaKit Starter Kit also comes with heatsink for the processor, which might help, as the newer Pis are already [known for running pretty hot][11].
|
||||
|
||||
![Raspberry Pi 4 case][12]
|
||||
|
||||
### Raspbian and NOOBS
|
||||
|
||||
The other item that comes with the Starter Kit is a microSD card with the correct version of the [NOOBS][13] operating system for the Raspberry Pi 4 pre-installed. (I got version 3.1.1, released June 24, 2019). If you're using a Raspberry Pi for the first time and are not sure where to start, this could save you a lot of time. The microSD card in the Starter Kit is 32GB.
|
||||
|
||||
After you insert the microSD card and connect all the cables, just start up the Pi, boot into NOOBS, pick the Raspbian distribution, and wait while it installs.
|
||||
|
||||
![Raspberry Pi 4 with 4GB of RAM][14]
|
||||
|
||||
I noticed a couple of improvements while installing the latest Raspbian. (Forgive me if they've been around for a while—I haven't done a fresh install on a Pi since the 3 came out.) One is that Raspbian will ask you to set up a password for your account at first boot after installation, and the other is that it will run a software update (assuming you have network connectivity). These are great improvements to help keep your Raspberry Pi a little more secure. I would love to see the option to encrypt the microSD card at installation … maybe someday?
|
||||
|
||||
![Running Raspbian updates at first boot][15]
|
||||
|
||||
![Raspberry Pi 4 setup][16]
|
||||
|
||||
It runs very smoothly!
|
||||
|
||||
### Wrapping up
|
||||
|
||||
Although CanaKit isn't the only authorized Raspberry Pi retailer in the US, I found its Starter Kit to provide great value for the price.
|
||||
|
||||
So far, I am very impressed with the performance gains in the Raspberry Pi 4. I'm planning to try spending an entire workday using it as my only computer, and I'll write a follow-up article soon about how far I can go. Stay tuned!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/unboxing-raspberry-pi-4
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilvahttps://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/raspberrypi4_board_hardware.jpg?itok=KnFU7NvR (Raspberry Pi 4 board, posterized filter)
|
||||
[2]: https://opensource.com/article/19/6/raspberry-pi-4
|
||||
[3]: https://www.canakit.com/raspberry-pi-4-starter-kit.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/raspberrypi4_canakit.jpg (CanaKit's Raspberry Pi 4 Starter Kit and official accessories)
|
||||
[5]: https://www.techrepublic.com/article/your-new-raspberry-pi-4-wont-power-on-usb-c-cable-problem-now-officially-confirmed/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/raspberrypi_usb-c_charger.jpg (Raspberry Pi USB-C charger)
|
||||
[7]: https://www.canakit.com/official-raspberry-pi-keyboard-mouse.html?defpid=4476
|
||||
[8]: https://www.yubico.com/products/yubikey-hardware/
|
||||
[9]: https://opensource.com/sites/default/files/uploads/raspberrypi_keyboardmouse.jpg (Official Raspberry Pi keyboard (with YubiKey plugged in) and mouse.)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/raspberrypi_keyboardlogo.jpg (Raspberry Pi logo on the keyboard)
|
||||
[11]: https://www.theregister.co.uk/2019/07/22/raspberry_pi_4_too_hot_to_handle/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/raspberrypi4_case.jpg (Raspberry Pi 4 case)
|
||||
[13]: https://www.raspberrypi.org/downloads/noobs/
|
||||
[14]: https://opensource.com/sites/default/files/uploads/raspberrypi4_ram.jpg (Raspberry Pi 4 with 4GB of RAM)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/raspberrypi4_rasbpianupdate.jpg (Running Raspbian updates at first boot)
|
||||
[16]: https://opensource.com/sites/default/files/uploads/raspberrypi_setup.jpg (Raspberry Pi 4 setup)
|
||||
@ -0,0 +1,203 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Navigating the Bash shell with pushd and popd)
|
||||
[#]: via: (https://opensource.com/article/19/8/navigating-bash-shell-pushd-popd)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/dnearyhttps://opensource.com/users/greg-phttps://opensource.com/users/shishz)
|
||||
|
||||
Navigating the Bash shell with pushd and popd
|
||||
======
|
||||
Pushd and popd are the fastest navigational commands you've never heard
|
||||
of.
|
||||
![bash logo on green background][1]
|
||||
|
||||
The **pushd** and **popd** commands are built-in features of the Bash shell to help you "bookmark" directories for quick navigation between locations on your hard drive. You might already feel that the terminal is an impossibly fast way to navigate your computer; in just a few key presses, you can go anywhere on your hard drive, attached storage, or network share. But that speed can break down when you find yourself going back and forth between directories, or when you get "lost" within your filesystem. Those are precisely the problems **pushd** and **popd** can help you solve.
|
||||
|
||||
### pushd
|
||||
|
||||
At its most basic, **pushd** is a lot like **cd**. It takes you from one directory to another. Assume you have a directory called **one**, which contains a subdirectory called **two**, which contains a subdirectory called **three**, and so on. If your current working directory is **one**, then you can move to **two** or **three** or anywhere with the **cd** command:
|
||||
|
||||
|
||||
```
|
||||
$ pwd
|
||||
one
|
||||
$ cd two/three
|
||||
$ pwd
|
||||
three
|
||||
```
|
||||
|
||||
You can do the same with **pushd**:
|
||||
|
||||
|
||||
```
|
||||
$ pwd
|
||||
one
|
||||
$ pushd two/three
|
||||
~/one/two/three ~/one
|
||||
$ pwd
|
||||
three
|
||||
```
|
||||
|
||||
The end result of **pushd** is the same as **cd**, but there's an additional intermediate result: **pushd** echos your destination directory and your point of origin. This is your _directory stack_, and it is what makes **pushd** unique.
|
||||
|
||||
### Stacks
|
||||
|
||||
A stack, in computer terminology, refers to a collection of elements. In the context of this command, the elements are directories you have recently visited by using the **pushd** command. You can think of it as a history or a breadcrumb trail.
|
||||
|
||||
You can move all over your filesystem with **pushd**; each time, your previous and new locations are added to the stack:
|
||||
|
||||
|
||||
```
|
||||
$ pushd four
|
||||
~/one/two/three/four ~/one/two/three ~/one
|
||||
$ pushd five
|
||||
~/one/two/three/four/five ~/one/two/three/four ~/one/two/three ~/one
|
||||
```
|
||||
|
||||
### Navigating the stack
|
||||
|
||||
Once you've built up a stack, you can use it as a collection of bookmarks or fast-travel waypoints. For instance, assume that during a session you're doing a lot of work within the **~/one/two/three/four/five** directory structure of this example. You know you've been to **one** recently, but you can't remember where it's located in your **pushd** stack. You can view your stack with the **+0** (that's a plus sign followed by a zero) argument, which tells **pushd** not to change to any directory in your stack, but also prompts **pushd** to echo your current stack:
|
||||
|
||||
|
||||
```
|
||||
$ pushd +0
|
||||
~/one/two/three/four ~/one/two/three ~/one ~/one/two/three/four/five
|
||||
```
|
||||
|
||||
The first entry in your stack is your current location. You can confirm that with **pwd** as usual:
|
||||
|
||||
|
||||
```
|
||||
$ pwd
|
||||
~/one/two/three/four
|
||||
```
|
||||
|
||||
Starting at 0 (your current location and the first entry of your stack), the _second_ element in your stack is **~/one**, which is your desired destination. You can move forward in your stack using the **+2** option:
|
||||
|
||||
|
||||
```
|
||||
$ pushd +2
|
||||
~/one ~/one/two/three/four/five ~/one/two/three/four ~/one/two/three
|
||||
$ pwd
|
||||
~/one
|
||||
```
|
||||
|
||||
This changes your working directory to **~/one** and also has shifted the stack so that your new location is at the front.
|
||||
|
||||
You can also move backward in your stack. For instance, to quickly get to **~/one/two/three** given the example output, you can move back by one, keeping in mind that **pushd** starts with 0:
|
||||
|
||||
|
||||
```
|
||||
$ pushd -0
|
||||
~/one/two/three ~/one ~/one/two/three/four/five ~/one/two/three/four
|
||||
```
|
||||
|
||||
### Adding to the stack
|
||||
|
||||
You can continue to navigate your stack in this way, and it will remain a static listing of your recently visited directories. If you want to add a directory, just provide the directory's path. If a directory is new to the stack, it's added to the list just as you'd expect:
|
||||
|
||||
|
||||
```
|
||||
$ pushd /tmp
|
||||
/tmp ~/one/two/three ~/one ~/one/two/three/four/five ~/one/two/three/four
|
||||
```
|
||||
|
||||
But if it already exists in the stack, it's added a second time:
|
||||
|
||||
|
||||
```
|
||||
$ pushd ~/one
|
||||
~/one /tmp ~/one/two/three ~/one ~/one/two/three/four/five ~/one/two/three/four
|
||||
```
|
||||
|
||||
While the stack is often used as a list of directories you want quick access to, it is really a true history of where you've been. If you don't want a directory added redundantly to the stack, you must use the **+N** and **-N** notation.
|
||||
|
||||
### Removing directories from the stack
|
||||
|
||||
Your stack is, obviously, not immutable. You can add to it with **pushd** or remove items from it with **popd**.
|
||||
|
||||
For instance, assume you have just used **pushd** to add **~/one** to your stack, making **~/one** your current working directory. To remove the first (or "zeroeth," if you prefer) element:
|
||||
|
||||
|
||||
```
|
||||
$ pwd
|
||||
~/one
|
||||
$ popd +0
|
||||
/tmp ~/one/two/three ~/one ~/one/two/three/four/five ~/one/two/three/four
|
||||
$ pwd
|
||||
~/one
|
||||
```
|
||||
|
||||
Of course, you can remove any element, starting your count at 0:
|
||||
|
||||
|
||||
```
|
||||
$ pwd ~/one
|
||||
$ popd +2
|
||||
/tmp ~/one/two/three ~/one/two/three/four/five ~/one/two/three/four
|
||||
$ pwd ~/one
|
||||
```
|
||||
|
||||
You can also use **popd** from the back of your stack, again starting with 0. For example, to remove the final directory from your stack:
|
||||
|
||||
|
||||
```
|
||||
$ popd -0
|
||||
/tmp ~/one/two/three ~/one/two/three/four/five
|
||||
```
|
||||
|
||||
When used like this, **popd** does not change your working directory. It only manipulates your stack.
|
||||
|
||||
### Navigating with popd
|
||||
|
||||
The default behavior of **popd**, given no arguments, is to remove the first (zeroeth) item from your stack and make the next item your current working directory.
|
||||
|
||||
This is most useful as a quick-change command, when you are, for instance, working in two different directories and just need to duck away for a moment to some other location. You don't have to think about your directory stack if you don't need an elaborate history:
|
||||
|
||||
|
||||
```
|
||||
$ pwd
|
||||
~/one
|
||||
$ pushd ~/one/two/three/four/five
|
||||
$ popd
|
||||
$ pwd
|
||||
~/one
|
||||
```
|
||||
|
||||
You're also not required to use **pushd** and **popd** in rapid succession. If you use **pushd** to visit a different location, then get distracted for three hours chasing down a bug or doing research, you'll find your directory stack patiently waiting (unless you've ended your terminal session):
|
||||
|
||||
|
||||
```
|
||||
$ pwd ~/one
|
||||
$ pushd /tmp
|
||||
$ cd {/etc,/var,/usr}; sleep 2001
|
||||
[...]
|
||||
$ popd
|
||||
$ pwd
|
||||
~/one
|
||||
```
|
||||
|
||||
### Pushd and popd in the real world
|
||||
|
||||
The **pushd** and **popd** commands are surprisingly useful. Once you learn them, you'll find excuses to put them to good use, and you'll get familiar with the concept of the directory stack. Getting comfortable with **pushd** was what helped me understand **git stash**, which is entirely unrelated to **pushd** but similar in conceptual intangibility.
|
||||
|
||||
Using **pushd** and **popd** in shell scripts can be tempting, but generally, it's probably best to avoid them. They aren't portable outside of Bash and Zsh, and they can be obtuse when you're re-reading a script (**pushd +3** is less clear than **cd $HOME/$DIR/$TMP** or similar).
|
||||
|
||||
Aside from these warnings, if you're a regular Bash or Zsh user, then you can and should try **pushd** and **popd**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/navigating-bash-shell-pushd-popd
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/dnearyhttps://opensource.com/users/greg-phttps://opensource.com/users/shishz
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bash_command_line.png?itok=k4z94W2U (bash logo on green background)
|
||||
210
sources/tech/20190807 Trace code in Fedora with bpftrace.md
Normal file
210
sources/tech/20190807 Trace code in Fedora with bpftrace.md
Normal file
@ -0,0 +1,210 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Trace code in Fedora with bpftrace)
|
||||
[#]: via: (https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/)
|
||||
[#]: author: (Augusto Caringi https://fedoramagazine.org/author/acaringi/)
|
||||
|
||||
Trace code in Fedora with bpftrace
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
bpftrace is [a new eBPF-based tracing tool][2] that was first included in Fedora 28. It was developed by Brendan Gregg, Alastair Robertson and Matheus Marchini with the help of a loosely-knit team of hackers across the Net. A tracing tool lets you analyze what a system is doing behind the curtain. It tells you which functions in code are being called, with which arguments, how many times, and so on.
|
||||
|
||||
This article covers some basics about bpftrace, and how it works. Read on for more information and some useful examples.
|
||||
|
||||
### eBPF (extended Berkeley Packet Filter)
|
||||
|
||||
[eBPF][3] is a tiny virtual machine, or a virtual CPU to be more precise, in the Linux Kernel. The eBPF can load and run small programs in a safe and controlled way in kernel space. This makes it safer to use, even in production systems. This virtual machine has its own instruction set architecture ([ISA][4]) resembling a subset of modern processor architectures. The ISA makes it easy to translate those programs to the real hardware. The kernel performs just-in-time translation to native code for main architectures to improve the performance.
|
||||
|
||||
The eBPF virtual machine allows the kernel to be extended programmatically. Nowadays several kernel subsystems take advantage of this new powerful Linux Kernel capability. Examples include networking, seccomp, tracing, and more. The main idea is to attach eBPF programs into specific code points, and thereby extend the original kernel behavior.
|
||||
|
||||
eBPF machine language is very powerful. But writing code directly in it is extremely painful, because it’s a low level language. This is where bpftrace comes in. It provides a high-level language to write eBPF tracing scripts. The tool then translates these scripts to eBPF with the help of clang/LLVM libraries, and then attached to the specified code points.
|
||||
|
||||
## Installation and quick start
|
||||
|
||||
To install bpftrace, run the following command in a terminal [using][5] _[sudo][5]_:
|
||||
|
||||
```
|
||||
$ sudo dnf install bpftrace
|
||||
```
|
||||
|
||||
Try it out with a “hello world” example:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 'BEGIN { printf("hello world\n"); }'
|
||||
```
|
||||
|
||||
Note that you must run _bpftrace_ as _root_ due to the privileges required. Use the _-e_ option to specify a program, and to construct the so-called “one-liners.” This example only prints _hello world_, and then waits for you to press **Ctrl+C**.
|
||||
|
||||
_BEGIN_ is a special probe name that fires only once at the beginning of execution. Every action inside the curly braces _{ }_ fires whenever the probe is hit — in this case, it’s just a _printf_.
|
||||
|
||||
Let’s jump now to a more useful example:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_enter_execve { printf("%s called %s\n", comm, str(args->filename)); }'
|
||||
```
|
||||
|
||||
This example prints the parent process name _(comm)_ and the name of every new process being created in the system. _t:syscalls:sys_enter_execve_ is a kernel tracepoint. It’s a shorthand for _tracepoint:syscalls:sys_enter_execve_, but both forms can be used. The next section shows you how to list all available tracepoints.
|
||||
|
||||
_comm_ is a bpftrace builtin that represents the process name. _filename_ is a field of the _t:syscalls:sys_enter_execve_ tracepoint. You can access these fields through the _args_ builtin.
|
||||
|
||||
All available fields of the tracepoint can be listed with this command:
|
||||
|
||||
```
|
||||
bpftrace -lv "t:syscalls:sys_enter_execve"
|
||||
```
|
||||
|
||||
## Example usage
|
||||
|
||||
### Listing probes
|
||||
|
||||
A central concept for _bpftrace_ are **probe points**. Probe points are instrumentation points in code (kernel or userspace) where eBPF programs can be attached. They fit into the following categories:
|
||||
|
||||
* _kprobe_ – kernel function start
|
||||
* _kretprobe_ – kernel function return
|
||||
* _uprobe_ – user-level function start
|
||||
* _uretprobe_ – user-level function return
|
||||
* _tracepoint_ – kernel static tracepoints
|
||||
* _usdt_ – user-level static tracepoints
|
||||
* _profile_ – timed sampling
|
||||
* _interval_ – timed output
|
||||
* _software_ – kernel software events
|
||||
* _hardware_ – processor-level events
|
||||
|
||||
|
||||
|
||||
All available _kprobe/kretprobe_, _tracepoints_, _software_ and _hardware_ probes can be listed with this command:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -l
|
||||
```
|
||||
|
||||
The _uprobe/uretprobe_ and _usdt_ probes are userspace probes specific to a given executable. To use them, use the special syntax shown later in this article.
|
||||
|
||||
The _profile_ and _interval_ probes fire at fixed time intervals. Fixed time intervals are not covered in this article.
|
||||
|
||||
### Counting system calls
|
||||
|
||||
**Maps** are special BPF data types that store counts, statistics, and histograms. You can use maps to summarize how many times each syscall is being called:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_enter_* { @[probe] = count(); }'
|
||||
```
|
||||
|
||||
Some probe types allow wildcards to match multiple probes. You can also specify multiple attach points for an action block using a comma separated list. In this example, the action block attaches to all tracepoints whose name starts with _t:syscalls:sys_enter__, which means all available syscalls.
|
||||
|
||||
The bpftrace builtin function _count()_ counts the number of times this function is called. _@[]_ represents a map (an associative array). The key of this map is _probe_, which is another bpftrace builtin that represents the full probe name.
|
||||
|
||||
Here, the same action block is attached to every syscall. Then, each time a syscall is called the map will be updated, and the entry is incremented in the map relative to this same syscall. When the program terminates, it automatically prints out all declared maps.
|
||||
|
||||
This example counts the syscalls called globally, it’s also possible to filter for a specific process by _PID_ using the bpftrace filter syntax:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_enter_* / pid == 1234 / { @[probe] = count(); }'
|
||||
```
|
||||
|
||||
### Write bytes by process
|
||||
|
||||
Using these concepts, let’s analyze how many bytes each process is writing:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_exit_write /args->ret > 0/ { @[comm] = sum(args->ret); }'
|
||||
```
|
||||
|
||||
_bpftrace_ attaches the action block to the write syscall return probe (_t:syscalls:sys_exit_write_). Then, it uses a filter to discard the negative values, which are error codes _(/args->ret > 0/)_.
|
||||
|
||||
The map key _comm_ represents the process name that called the syscall. The _sum()_ builtin function accumulates the number of bytes written for each map entry or process. _args_ is a bpftrace builtin to access tracepoint’s arguments and return values. Finally, if successful, the _write_ syscall returns the number of written bytes. _args->ret_ provides access to the bytes.
|
||||
|
||||
### Read size distribution by process (histogram):
|
||||
|
||||
_bpftrace_ supports the creation of histograms. Let’s analyze one example that creates a histogram of the _read_ size distribution by process:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
|
||||
```
|
||||
|
||||
Histograms are BPF maps, so they must always be attributed to a map (_@_). In this example, the map key is _comm_.
|
||||
|
||||
The example makes _bpftrace_ generate one histogram for every process that calls the _read_ syscall. To generate just one global histogram, attribute the _hist()_ function just to _‘@’_ (without any key).
|
||||
|
||||
bpftrace automatically prints out declared histograms when the program terminates. The value used as base for the histogram creation is the number of read bytes, found through _args->ret_.
|
||||
|
||||
### Tracing userspace programs
|
||||
|
||||
You can also trace userspace programs with _uprobes/uretprobes_ and _USDT_ (User-level Statically Defined Tracing). The next example uses a _uretprobe_, which probes to the end of a user-level function. It gets the command lines issued in every _bash_ running in the system:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 'uretprobe:/bin/bash:readline { printf("readline: \"%s\"\n", str(retval)); }'
|
||||
```
|
||||
|
||||
To list all available _uprobes/uretprobes_ of the _bash_ executable, run this command:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -l "uprobe:/bin/bash"
|
||||
```
|
||||
|
||||
_uprobe_ instruments the beginning of a user-level function’s execution, and _uretprobe_ instruments the end (its return). _readline()_ is a function of _/bin/bash_, and it returns the typed command line. _retval_ is the return value for the instrumented function, and can only be accessed on _uretprobe_.
|
||||
|
||||
When using _uprobes_, you can access arguments with _arg0..argN_. A _str()_ call is necessary to turn the _char *_ pointer to a _string_.
|
||||
|
||||
## Shipped Scripts
|
||||
|
||||
There are many useful scripts shipped with bpftrace package. You can find them in the _/usr/share/bpftrace/tools/_ directory.
|
||||
|
||||
Among them, you can find:
|
||||
|
||||
* _killsnoop.bt_ – Trace signals issued by the kill() syscall.
|
||||
* _tcpconnect.bt_ – Trace all TCP network connections.
|
||||
* _pidpersec.bt_ – Count new procesess (via fork) per second.
|
||||
* _opensnoop.bt_ – Trace open() syscalls.
|
||||
* _vfsstat.bt_ – Count some VFS calls, with per-second summaries.
|
||||
|
||||
|
||||
|
||||
You can directly use the scripts. For example:
|
||||
|
||||
```
|
||||
$ sudo /usr/share/bpftrace/tools/killsnoop.bt
|
||||
```
|
||||
|
||||
You can also study these scripts as you create new tools.
|
||||
|
||||
## Links
|
||||
|
||||
* bpftrace reference guide – <https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md>
|
||||
* bpftrace (DTrace 2.0) for Linux 2018 – <http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html>
|
||||
* BPF: the universal in-kernel virtual machine – <https://lwn.net/Articles/599755/>
|
||||
* Linux Extended BPF (eBPF) Tracing Tools – <http://www.brendangregg.com/ebpf.html>
|
||||
* Dive into BPF: a list of reading material – [https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf][6]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[_Roman Romashov_][7]_ on _[_Unsplash_][8]_._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/
|
||||
|
||||
作者:[Augusto Caringi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/acaringi/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/bpftrace-816x345.jpg
|
||||
[2]: https://github.com/iovisor/bpftrace
|
||||
[3]: https://lwn.net/Articles/740157/
|
||||
[4]: https://github.com/iovisor/bpf-docs/blob/master/eBPF.md
|
||||
[5]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[6]: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
|
||||
[7]: https://unsplash.com/@wehavemegapixels?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]: https://unsplash.com/search/photos/trace?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Find Out How Long Does it Take To Boot Your Linux System)
|
||||
[#]: via: (https://itsfoss.com/check-boot-time-linux/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Find Out How Long Does it Take To Boot Your Linux System
|
||||
======
|
||||
|
||||
When you power on your system, you wait for the manufacturer’s logo to come up, a few messages on the screen perhaps (booting in insecure mode), [Grub][1] screen, operating system loading screen and finally the login screen.
|
||||
|
||||
Did you check how long did it take? Perhaps not. Unless you really need to know, you won’t bother with the boot time details.
|
||||
|
||||
But what if you are curious to know long long your Linux system takes to boot? Running a stopwatch is one way to find that but in Linux, you have better and easier ways to find out your system’s start up time.
|
||||
|
||||
### Checking boot time in Linux with systemd-analyze
|
||||
|
||||
![][2]
|
||||
|
||||
Like it or not, [systemd][3] is running on most of the popular Linux distributions. The systemd has a number of utilities to manage your Linux system. One of those utilities is systemd-analyze.
|
||||
|
||||
The systemd-analyze command gives you a detail of how many services ran at the last start up and how long they took.
|
||||
|
||||
If you run the following command in the terminal:
|
||||
|
||||
```
|
||||
systemd-analyze
|
||||
```
|
||||
|
||||
You’ll get the total boot time along with the time taken by firmware, boot loader, kernel and the userspace:
|
||||
|
||||
```
|
||||
Startup finished in 7.275s (firmware) + 13.136s (loader) + 2.803s (kernel) + 12.488s (userspace) = 35.704s
|
||||
|
||||
graphical.target reached after 12.408s in userspace
|
||||
```
|
||||
|
||||
As you can see in the output above, it took about 35 seconds for my system to reach the screen where I could enter my password. I am using Dell XPS Ubuntu edition. It uses SSD storage and despite of that it takes this much time to start.
|
||||
|
||||
Not that impressive, is it? Why don’t you share your system’s boot time? Let’s compare.
|
||||
|
||||
You can further breakdown the boot time into each unit with the following command:
|
||||
|
||||
```
|
||||
systemd-analyze blame
|
||||
```
|
||||
|
||||
This will produce a huge output with all the services listed in the descending order of the time taken.
|
||||
|
||||
```
|
||||
7.347s plymouth-quit-wait.service
|
||||
6.198s NetworkManager-wait-online.service
|
||||
3.602s plymouth-start.service
|
||||
3.271s plymouth-read-write.service
|
||||
2.120s apparmor.service
|
||||
1.503s [email protected]
|
||||
1.213s motd-news.service
|
||||
908ms snapd.service
|
||||
861ms keyboard-setup.service
|
||||
739ms fwupd.service
|
||||
702ms bolt.service
|
||||
672ms dev-nvme0n1p3.device
|
||||
608ms [email protected]:intel_backlight.service
|
||||
539ms snap-core-7270.mount
|
||||
504ms snap-midori-451.mount
|
||||
463ms snap-screencloud-1.mount
|
||||
446ms snapd.seeded.service
|
||||
440ms snap-gtk\x2dcommon\x2dthemes-1313.mount
|
||||
420ms snap-core18-1066.mount
|
||||
416ms snap-scrcpy-133.mount
|
||||
412ms snap-gnome\x2dcharacters-296.mount
|
||||
```
|
||||
|
||||
#### Bonus Tip: Improving boot time
|
||||
|
||||
If you look at this output, you can see that both network manager and [plymouth][4] take a huge bunch of boot time.
|
||||
|
||||
[][5]
|
||||
|
||||
Suggested read How To Fix: No Unity, No Launcher, No Dash In Ubuntu Linux
|
||||
|
||||
Plymouth is responsible for that boot splash screen you see before the login screen in Ubuntu and other distributions. Network manager is responsible for the internet connection and may be turned off to speed up boot time. Don’t worry, once you log in, you’ll have wifi working normally.
|
||||
|
||||
```
|
||||
sudo systemctl disable NetworkManager-wait-online.service
|
||||
```
|
||||
|
||||
If you want to revert the change, you can use this command:
|
||||
|
||||
```
|
||||
sudo systemctl enable NetworkManager-wait-online.service
|
||||
```
|
||||
|
||||
Now, please don’t go disabling various services on your own without knowing what it is used for. It may have dangerous consequences.
|
||||
|
||||
_**Now that you know how to check the boot time of your Linux system, why not share your system’s boot time in the comment section?**_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/check-boot-time-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gnu.org/software/grub/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-boot-time.jpg?resize=800%2C450&ssl=1
|
||||
[3]: https://en.wikipedia.org/wiki/Systemd
|
||||
[4]: https://wiki.archlinux.org/index.php/Plymouth
|
||||
[5]: https://itsfoss.com/how-to-fix-no-unity-no-launcher-no-dash-in-ubuntu-12-10-quick-tip/
|
||||
93
sources/tech/20190808 How to manipulate PDFs on Linux.md
Normal file
93
sources/tech/20190808 How to manipulate PDFs on Linux.md
Normal file
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to manipulate PDFs on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3430781/how-to-manipulate-pdfs-on-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How to manipulate PDFs on Linux
|
||||
======
|
||||
The pdftk command provides many options for working with PDFs, including merging pages, encrypting files, applying watermarks, compressing files, and even repairing PDFs -- easily and on the command line.
|
||||
![Toshiyuki IMAI \(CC BY-SA 2.0\)][1]
|
||||
|
||||
While PDFs are generally regarded as fairly stable files, there’s a lot you can do with them on both Linux and other systems. This includes merging, splitting, rotating, breaking into single pages, encrypting and decrypting, applying watermarks, compressing and uncompressing, and even repairing. The **pdftk** command does all this and more.
|
||||
|
||||
The name “pdftk” stands for “PDF tool kit,” and the command is surprisingly easy to use and does a good job of manipulating PDFs. For example, to pull separate files into a single PDF file, you would use a command like this:
|
||||
|
||||
```
|
||||
$ pdftk pg1.pdf pg2.pdf pg3.pdf pg4.pdf pg5.pdf cat output OneDoc.pdf
|
||||
```
|
||||
|
||||
That OneDoc.pdf file will contain all five of the documents shown and the command will run in a matter of seconds. Note that the **cat** option directs the files to be joined together and the **output** option specifies the name of the new file.
|
||||
|
||||
**[ Two-Minute Linux Tips: [Learn how to master a host of Linux commands in these 2-minute video tutorials][2] ]**
|
||||
|
||||
You can also pull select pages from a PDF to create a separate PDF file. For example, if you wanted to create a new PDF with only pages 1, 2, 3, and 5 of the document created above, you could do this:
|
||||
|
||||
```
|
||||
$ pdftk OneDoc.pdf cat 1-3 5 output 4pgs.pdf
|
||||
```
|
||||
|
||||
If, on the other hand, you wanted pages 1, 3, 4, and 5, we might use this syntax instead:
|
||||
|
||||
```
|
||||
$ pdftk OneDoc.pdf cat 1 3-end output 4pgs.pdf
|
||||
```
|
||||
|
||||
You have the option of specifying all individual pages or using page ranges as shown in the examples above.
|
||||
|
||||
This next command will create a collated document from one that contains the odd pages (1, 3, etc.) and one that contains the even pages (2, 4, etc.):
|
||||
|
||||
```
|
||||
$ pdftk A=odd.pdf B=even.pdf shuffle A B output collated.pdf
|
||||
```
|
||||
|
||||
Notice that the **shuffle** option make this collation possible and dictates the order in which the documents are used. Note also: While the odd/even pages example might suggest otherwise, you are not restricted to using only two input files.
|
||||
|
||||
If you want to create an encrypted PDF that can only be opened by a recipient who knows the password, you could use a command like this one:
|
||||
|
||||
```
|
||||
$ pdftk prep.pdf output report.pdf user_pw AsK4n0thingGeTn0thing
|
||||
```
|
||||
|
||||
The options provide for 40 (**encrypt_40bit**) and 128 (**encrypt_128bit**) bit encryption. The 128 bit encryption is used by default.
|
||||
|
||||
You can also break a PDF file into individual pages using the **burst** option:
|
||||
|
||||
```
|
||||
$ pdftk allpgs.pdf burst
|
||||
$ ls -ltr *.pdf | tail -5
|
||||
-rw-rw-r-- 1 shs shs 22933 Aug 8 08:18 pg_0001.pdf
|
||||
-rw-rw-r-- 1 shs shs 23773 Aug 8 08:18 pg_0002.pdf
|
||||
-rw-rw-r-- 1 shs shs 23260 Aug 8 08:18 pg_0003.pdf
|
||||
-rw-rw-r-- 1 shs shs 23435 Aug 8 08:18 pg_0004.pdf
|
||||
-rw-rw-r-- 1 shs shs 23136 Aug 8 08:18 pg_0005.pdf
|
||||
```
|
||||
|
||||
The **pdftk** command makes pulling together, tearing apart, rebuilding and encrypting PDF files surprisingly easy. To learn more about its many options, I check out the examples page from [PDF Labs][3].
|
||||
|
||||
**[ Also see: [Invaluable tips and tricks for troubleshooting Linux][4] ]**
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3430781/how-to-manipulate-pdfs-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/08/book-pages-100807709-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: https://www.pdflabs.com/docs/pdftk-cli-examples/
|
||||
[4]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
257
sources/tech/20190808 Sending custom emails with Python.md
Normal file
257
sources/tech/20190808 Sending custom emails with Python.md
Normal file
@ -0,0 +1,257 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Sending custom emails with Python)
|
||||
[#]: via: (https://opensource.com/article/19/8/sending-custom-emails-python)
|
||||
[#]: author: (Brian "bex" Exelbierd https://opensource.com/users/bexelbie)
|
||||
|
||||
Sending custom emails with Python
|
||||
======
|
||||
Customize your group emails with Mailmerge, a command-line program that
|
||||
can handle simple and complex emails.
|
||||
![Chat via email][1]
|
||||
|
||||
Email remains a fact of life. Despite all its warts, it's still the best way to send information to most people, especially in automated ways that allow messages to queue for recipients.
|
||||
|
||||
One of the highlights of my work as the [Fedora Community Action and Impact Coordinator][2] is giving people good news about travel funding. I often send this information over email. Here, I'll show you how I send custom messages to groups of people using [Mailmerge][3], a command-line Python program that can handle simple and complex emails.
|
||||
|
||||
### Install Mailmerge
|
||||
|
||||
Mailmerge is packaged and available in Fedora, and you can install it from the command line with **sudo dnf install python3-mailmerge**. You can also install it from PyPI using **pip**, as the project's [README explains][4].
|
||||
|
||||
### Configure your Mailmerge files
|
||||
|
||||
Three files control how Mailmerge works. If you run **mailmerge --sample**, it will create template files for you. The files are:
|
||||
|
||||
* **mailmerge_server.conf:** This contains the configuration details for your SMTP host to send emails. Your password is _not_ stored in this file.
|
||||
* **mailmerge_database.csv:** This holds the custom data for each email, including the recipients' email addresses.
|
||||
* **mailmerge_template.txt:** This is your email's text with placeholder fields that will be replaced using the data from **mailmerge_database.csv**.
|
||||
|
||||
|
||||
|
||||
#### Server.conf
|
||||
|
||||
The sample **mailmerge_server.conf** file includes several examples that should be familiar. If you've ever added email to your phone or set up a desktop email client, you've seen this data before. The big thing to remember is to update your username in the file, especially if you are using one of the example configurations.
|
||||
|
||||
#### Database.csv
|
||||
|
||||
The **mailmerge_database.csv** file is a bit more complicated. It must contain (at minimum) the recipients' email addresses and any other custom details necessary to replace the fields in your email. It is a good idea to write the **mailmerge_template.txt** file at the same time you create the fields list for this file. I find it helpful to use a spreadsheet to capture this data and export it as a CSV file when I am done. This sample file:
|
||||
|
||||
|
||||
```
|
||||
email,name,number
|
||||
[myself@mydomain.com][5],"Myself",17
|
||||
[bob@bobdomain.com][6],"Bob",42
|
||||
```
|
||||
|
||||
allows you to send emails to two people, using their first name and telling them a number. This file, while not terribly interesting, illustrates an important habit: Always make yourself the first recipient in the file. This enables you to send yourself a test email to verify everything works as expected before you email the entire list.
|
||||
|
||||
If any of your values contain commas, you _**must**_ enclose the entire value in double-quotes (**"**). If you need to include a double-quote in a double-quoted field, use two double-quotes in a row. Quoting rules are fun, so read about [CSVs in Python 3][7] for specifics.
|
||||
|
||||
#### Template.txt
|
||||
|
||||
As part of my work, I get to share news about travel-funding decisions for our Fedora contributor conference, [Flock][8]. A simple email tells people they've been selected for travel funding and their specific funding details. One user-specific detail is how much money we can allocate for their airfare. Here is an abbreviated version of my template file (I've snipped out a lot of the text for brevity):
|
||||
|
||||
|
||||
```
|
||||
$ cat mailmerge_template.txt
|
||||
TO: {{Email}}
|
||||
SUBJECT: Flock 2019 Funding Offer
|
||||
FROM: Brian Exelbierd <[bexelbie@redhat.com][9]>
|
||||
|
||||
Hi {{Name}},
|
||||
|
||||
I am writing you on behalf of the Flock funding committee. You requested funding for your attendance at Flock. After careful consideration we are able to offer you the following funding:
|
||||
|
||||
Travel Budget: {{Travel_Budget}}
|
||||
|
||||
<<snip>>
|
||||
```
|
||||
|
||||
The top of the template specifies the recipient, sender, and subject. After the blank line, there's the body of the email. This email needs the recipients' **Email**, **Name**, and **Travel_Budget** from the **database.csv** file. Notice that those fields are surrounded by double curly braces (**{{** and **}}**). The corresponding **mailmerge_database.csv** looks like this:
|
||||
|
||||
|
||||
```
|
||||
$ cat mailmerge_database.csv
|
||||
Name,Email,Travel_Budget
|
||||
Brian,[bexelbie@redhat.com][9],1000
|
||||
PersonA,[persona@fedoraproject.org][10],1500
|
||||
PèrsonB,[personb@fedoraproject.org][11],500
|
||||
```
|
||||
|
||||
Notice that I listed myself first (for testing) and there are two other people in the file. The second person, PèrsonB, has an accented character in their name; Mailmerge will automatically encode it.
|
||||
|
||||
That's the whole template concept: Write your email and put placeholders in double curly braces. Then create a database that provides those values. Now let's test the email.
|
||||
|
||||
### Test and send simple email merges
|
||||
|
||||
#### Do a dry-run
|
||||
|
||||
Start by doing a dry-run that prints the emails, with the placeholder fields completed, to the screen. By default, if you run the command **mailmerge**, it will do a dry-run of the first email:
|
||||
|
||||
|
||||
```
|
||||
$ mailmerge
|
||||
>>> encoding ascii
|
||||
>>> message 0
|
||||
TO: [bexelbie@redhat.com][9]
|
||||
SUBJECT: Flock 2019 Funding Offer
|
||||
FROM: Brian Exelbierd <[bexelbie@redhat.com][9]>
|
||||
MIME-Version: 1.0
|
||||
Content-Type: text/plain; charset="us-ascii"
|
||||
Content-Transfer-Encoding: 7bit
|
||||
Date: Sat, 20 Jul 2019 18:17:15 -0000
|
||||
|
||||
Hi Brian,
|
||||
|
||||
I am writing you on behalf of the Flock funding committee. You requested funding for your attendance at Flock. After careful consideration we are able to offer you the following funding:
|
||||
|
||||
Travel Budget: 1000
|
||||
|
||||
<<snip>>
|
||||
|
||||
>>> sent message 0 DRY RUN
|
||||
>>> No attachments were sent with the emails.
|
||||
>>> Limit was 1 messages. To remove the limit, use the --no-limit option.
|
||||
>>> This was a dry run. To send messages, use the --no-dry-run option.
|
||||
```
|
||||
|
||||
Reviewing the first email (**message 0**, as counting starts from zero, like many things in computer science), you can see my name and travel budget are correct. If you want to review every email, enter **mailmerge --no-limit** to tell Mailmerge not to limit itself to the first email. Here's the dry-run of the third email, which shows the special character encoding:
|
||||
|
||||
|
||||
```
|
||||
>>> message 2
|
||||
TO: [personb@fedoraproject.org][11]
|
||||
SUBJECT: Flock 2019 Funding Offer
|
||||
FROM: Brian Exelbierd <[bexelbie@redhat.com][9]>
|
||||
MIME-Version: 1.0
|
||||
Content-Type: text/plain; charset="iso-8859-1"
|
||||
Content-Transfer-Encoding: quoted-printable
|
||||
Date: Sat, 20 Jul 2019 18:22:48 -0000
|
||||
|
||||
Hi P=E8rsonB,
|
||||
```
|
||||
|
||||
That's not an error; **P=E8rsonB** is the encoded form of **PèrsonB**.
|
||||
|
||||
#### Send a test message
|
||||
|
||||
Now, send a test email with the command **mailmerge --no-dry-run**, which tells Mailmerge to send a message to the first email on the list:
|
||||
|
||||
|
||||
```
|
||||
$ mailmerge --no-dry-run
|
||||
>>> encoding ascii
|
||||
>>> message 0
|
||||
TO: [bexelbie@redhat.com][9]
|
||||
SUBJECT: Flock 2019 Funding Offer
|
||||
FROM: Brian Exelbierd <[bexelbie@redhat.com][9]>
|
||||
MIME-Version: 1.0
|
||||
Content-Type: text/plain; charset="us-ascii"
|
||||
Content-Transfer-Encoding: 7bit
|
||||
Date: Sat, 20 Jul 2019 18:25:45 -0000
|
||||
|
||||
Hi Brian,
|
||||
|
||||
I am writing you on behalf of the Flock funding committee. You requested funding for your attendance at Flock. After careful consideration we are able to offer you the following funding:
|
||||
|
||||
Travel Budget: 1000
|
||||
|
||||
<<snip>>
|
||||
|
||||
>>> Read SMTP server configuration from mailmerge_server.conf
|
||||
>>> host = smtp.gmail.com
|
||||
>>> port = 587
|
||||
>>> username = [bexelbie@redhat.com][9]
|
||||
>>> security = STARTTLS
|
||||
>>> password for [bexelbie@redhat.com][9] on smtp.gmail.com:
|
||||
>>> sent message 0
|
||||
>>> No attachments were sent with the emails.
|
||||
>>> Limit was 1 messages. To remove the limit, use the --no-limit option.
|
||||
```
|
||||
|
||||
On the fourth to last line, you can see it prompts you for your password. If you're using two-factor authentication or domain-managed logins, you will need to create an application password that bypasses these controls. If you're using Gmail and similar systems, you can do it directly from the interface; otherwise, contact your email system administrator. This will not compromise the security of your email system, but you should still keep the password complex and secret.
|
||||
|
||||
When I checked my email account, I received a beautifully formatted test email. If your test email looks ready, send all the emails by entering **mailmerge --no-dry-run --no-limit**.
|
||||
|
||||
### Send complex emails
|
||||
|
||||
You can really see the power of Mailmerge when you take advantage of [Jinja2 templating][12]. I've found it useful for including conditional text and sending attachments. Here is a complex template and the corresponding database:
|
||||
|
||||
|
||||
```
|
||||
$ cat mailmerge_template.txt
|
||||
TO: {{Email}}
|
||||
SUBJECT: Flock 2019 Funding Offer
|
||||
FROM: Brian Exelbierd <[bexelbie@redhat.com][9]>
|
||||
ATTACHMENT: attachments/{{File}}
|
||||
|
||||
Hi {{Name}},
|
||||
|
||||
I am writing you on behalf of the Flock funding committee. You requested funding for your attendance at Flock. After careful consideration we are able to offer you the following funding:
|
||||
|
||||
Travel Budget: {{Travel_Budget}}
|
||||
{% if Hotel == "Yes" -%}
|
||||
Lodging: Lodging in the hotel Wednesday-Sunday (4 nights)
|
||||
{%- endif %}
|
||||
|
||||
<<snip>>
|
||||
|
||||
$ cat mailmerge_database.csv
|
||||
Name,Email,Travel_Budget,Hotel,File
|
||||
Brian,[bexelbie@redhat.com][9],1000,Yes,visa_bex.pdf
|
||||
PersonA,[persona@fedoraproject.org][10],1500,No,visa_person_a.pdf
|
||||
PèrsonB,[personb@fedoraproject.org][11],500,Yes,visa_person_b.pdf
|
||||
```
|
||||
|
||||
There are two new things in this email. First, there's an attachment. I have to send visa invitation letters to international travelers to help them come to Flock, and the **ATTACHMENT** part of the header specifies which file to attach. To keep my directory clean, I put all of them in my Attachments subdirectory. Second, it includes conditional information about a hotel, because some people receive funding for their hotel stay, and I need to include those details for those who do. This is done with the **if** construction:
|
||||
|
||||
|
||||
```
|
||||
{% if Hotel == "Yes" -%}
|
||||
Lodging: Lodging in the hotel Wednesday-Sunday (4 nights)
|
||||
{%- endif %}
|
||||
```
|
||||
|
||||
This works just like an **if** in most programming languages. Jinja2 is very expressive and can do multi-level conditions. Experiment with making your life easier by including database elements that control the contents of the email. Using whitespace is important for email readability. The minus (**-**) symbols in **if** and **endif** are part of how Jinja2 controls [whitespace][13]. There are lots of options, so experiment to see what looks best for you.
|
||||
|
||||
Also note that I extended the database with two fields, **Hotel** and **File**. These are the values that control the inclusion of the hotel text and provide the name of the attachment. In my example, PèrsonB and I got hotel funding, while PersonA didn't.
|
||||
|
||||
Doing a dry-run and sending the emails is the same whether you're using a simple or a complex template. Give it a try!
|
||||
|
||||
You can also experiment with using conditionals (**if** … **endif**) in the header. You can, for example, have an attachment only if one is in the database, or maybe you need to change the sender's name for some emails but not others.
|
||||
|
||||
### Mailmerge's advantages
|
||||
|
||||
The Mailmerge program provides a powerful but simple method of sending lots of customized emails. Everyone gets only the information they need, and extraneous steps and details are omitted.
|
||||
|
||||
Even for simple group emails, I have found this method much more effective than sending one email to a bunch of people using CC or BCC. A lot of people filter their email and delay reading anything not sent directly to them. Using Mailmerge ensures that every person gets their own email. Messages will filter properly for the recipient and no one can accidentally "reply all" to the entire group.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/sending-custom-emails-python
|
||||
|
||||
作者:[Brian "bex" Exelbierd][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bexelbie
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/email_chat_communication_message.png?itok=LKjiLnQu (Chat via email)
|
||||
[2]: https://docs.fedoraproject.org/en-US/council/fcaic/
|
||||
[3]: https://github.com/awdeorio/mailmerge
|
||||
[4]: https://github.com/awdeorio/mailmerge#install
|
||||
[5]: mailto:myself@mydomain.com
|
||||
[6]: mailto:bob@bobdomain.com
|
||||
[7]: https://docs.python.org/3/library/csv.html
|
||||
[8]: https://flocktofedora.org/
|
||||
[9]: mailto:bexelbie@redhat.com
|
||||
[10]: mailto:persona@fedoraproject.org
|
||||
[11]: mailto:personb@fedoraproject.org
|
||||
[12]: http://jinja.pocoo.org/docs/latest/templates/
|
||||
[13]: http://jinja.pocoo.org/docs/2.10/templates/#whitespace-control
|
||||
222
sources/tech/20190809 Copying files in Linux.md
Normal file
222
sources/tech/20190809 Copying files in Linux.md
Normal file
@ -0,0 +1,222 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Copying files in Linux)
|
||||
[#]: via: (https://opensource.com/article/19/8/copying-files-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/greg-p)
|
||||
|
||||
Copying files in Linux
|
||||
======
|
||||
Learn multiple ways to copy files on Linux, and the advantages of each.
|
||||
![Filing papers and documents][1]
|
||||
|
||||
Copying documents used to require a dedicated staff member in offices, and then a dedicated machine. Today, copying is a task computer users do without a second thought. Copying data on a computer is so trivial that copies are made without you realizing it, such as when dragging a file to an external drive.
|
||||
|
||||
The concept that digital entities are trivial to reproduce is pervasive, so most modern computerists don’t think about the options available for duplicating their work. And yet, there are several different ways to copy a file on Linux. Each method has nuanced features that might benefit you, depending on what you need to get done.
|
||||
|
||||
Here are a number of ways to copy files on Linux, BSD, and Mac.
|
||||
|
||||
### Copying in the GUI
|
||||
|
||||
As with most operating systems, you can do all of your file management in the GUI, if that's the way you prefer to work.
|
||||
|
||||
Drag and drop
|
||||
|
||||
The most obvious way to copy a file is the way you’re probably used to copying files on computers: drag and drop. On most Linux desktops, dragging and dropping from one local folder to another local folder _moves_ a file by default. You can change this behavior to a copy operation by holding down the **Ctrl** key after you start dragging the file.
|
||||
|
||||
Your cursor may show an indicator, such as a plus sign, to show that you are in copy mode:
|
||||
|
||||
![Copying a file.][2]
|
||||
|
||||
Note that if the file exists on a remote system, whether it’s a web server or another computer on your own network that you access through a file-sharing protocol, the default action is often to copy, not move, the file.
|
||||
|
||||
#### Right-click
|
||||
|
||||
If you find dragging and dropping files around your desktop imprecise or clumsy, or doing so takes your hands away from your keyboard too much, you can usually copy a file using the right-click menu. This possibility depends on the file manager you use, but generally, a right-click produces a contextual menu containing common actions.
|
||||
|
||||
The contextual menu copy action stores the [file path][3] (where the file exists on your system) in your clipboard so you can then _paste_ the file somewhere else:
|
||||
|
||||
![Copying a file from the context menu.][4]
|
||||
|
||||
In this case, you’re not actually copying the file’s contents to your clipboard. Instead, you're copying the [file path][3]. When you paste, your file manager looks at the path in your clipboard and then runs a copy command, copying the file located at that path to the path you are pasting into.
|
||||
|
||||
### Copying on the command line
|
||||
|
||||
While the GUI is a generally familiar way to copy files, copying in a terminal can be more efficient.
|
||||
|
||||
#### cp
|
||||
|
||||
The obvious terminal-based equivalent to copying and pasting a file on the desktop is the **cp** command. This command copies files and directories and is relatively straightforward. It uses the familiar _source_ and _target_ (strictly in that order) syntax, so to copy a file called **example.txt** into your **Documents** directory:
|
||||
|
||||
|
||||
```
|
||||
$ cp example.txt ~/Documents
|
||||
```
|
||||
|
||||
Just like when you drag and drop a file onto a folder, this action doesn’t replace **Documents** with **example.txt**. Instead, **cp** detects that **Documents** is a folder, and places a copy of **example.txt** into it.
|
||||
|
||||
You can also, conveniently (and efficiently), rename the file as you copy it:
|
||||
|
||||
|
||||
```
|
||||
$ cp example.txt ~/Documents/example_copy.txt
|
||||
```
|
||||
|
||||
That fact is important because it allows you to make a copy of a file in the same directory as the original:
|
||||
|
||||
|
||||
```
|
||||
$ cp example.txt example.txt
|
||||
cp: 'example.txt' and 'example.txt' are the same file.
|
||||
$ cp example.txt example_copy.txt
|
||||
```
|
||||
|
||||
To copy a directory, you must use the **-r** option, which stands for --**recursive**. This option runs **cp** on the directory _inode_, and then on all files within the directory. Without the **-r** option, **cp** doesn’t even recognize a directory as an object that can be copied:
|
||||
|
||||
|
||||
```
|
||||
$ cp notes/ notes-backup
|
||||
cp: -r not specified; omitting directory 'notes/'
|
||||
$ cp -r notes/ notes-backup
|
||||
```
|
||||
|
||||
#### cat
|
||||
|
||||
The **cat** command is one of the most misunderstood commands, but only because it exemplifies the extreme flexibility of a [POSIX][5] system. Among everything else **cat** does (including its intended purpose of con_cat_enating files), it can also copy. For instance, with **cat** you can [create two copies from one file][6] with just a single command. You can’t do that with **cp**.
|
||||
|
||||
The significance of using **cat** to copy a file is the way the system interprets the action. When you use **cp** to copy a file, the file’s attributes are copied along with the file itself. That means that the file permissions of the duplicate are the same as the original:
|
||||
|
||||
|
||||
```
|
||||
$ ls -l -G -g
|
||||
-rw-r--r--. 1 57368 Jul 25 23:57 foo.jpg
|
||||
$ cp foo.jpg bar.jpg
|
||||
-rw-r--r--. 1 57368 Jul 29 13:37 bar.jpg
|
||||
-rw-r--r--. 1 57368 Jul 25 23:57 foo.jpg
|
||||
```
|
||||
|
||||
Using **cat** to read the contents of a file into another file, however, invokes a system call to create a new file. These new files are subject to your default **umask** settings. To learn more about `umask`, read Alex Juarez’s article covering [umask][7] and permissions in general.
|
||||
|
||||
Run **umask** to get the current settings:
|
||||
|
||||
|
||||
```
|
||||
$ umask
|
||||
0002
|
||||
```
|
||||
|
||||
This setting means that new files created in this location are granted **664** (**rw-rw-r--**) permission because nothing is masked by the first digits of the **umask** setting (and the executable bit is not a default bit for file creation), and the write permission is blocked by the final digit.
|
||||
|
||||
When you copy with **cat**, you don’t actually copy the file. You use **cat** to read the contents of the file, and then redirect the output into a new file:
|
||||
|
||||
|
||||
```
|
||||
$ cat foo.jpg > baz.jpg
|
||||
$ ls -l -G -g
|
||||
-rw-r--r--. 1 57368 Jul 29 13:37 bar.jpg
|
||||
-rw-rw-r--. 1 57368 Jul 29 13:42 baz.jpg
|
||||
-rw-r--r--. 1 57368 Jul 25 23:57 foo.jpg
|
||||
```
|
||||
|
||||
As you can see, **cat** created a brand new file with the system’s default umask applied.
|
||||
|
||||
In the end, when all you want to do is copy a file, the technicalities often don’t matter. But sometimes you want to copy a file and end up with a default set of permissions, and with **cat** you can do it all in one command**.**
|
||||
|
||||
#### rsync
|
||||
|
||||
The **rsync** command is a versatile tool for copying files, with the notable ability to synchronize your source and destination. At its most simple, **rsync** can be used similarly to **cp** command:
|
||||
|
||||
|
||||
```
|
||||
$ rsync example.txt example_copy.txt
|
||||
$ ls
|
||||
example.txt example_copy.txt
|
||||
```
|
||||
|
||||
The command’s true power lies in its ability to _not_ copy when it’s not necessary. If you use **rsync** to copy a file into a directory, but that file already exists in that directory, then **rsync** doesn’t bother performing the copy operation. Locally, that fact doesn’t necessarily mean much, but if you’re copying gigabytes of data to a remote server, this feature makes a world of difference.
|
||||
|
||||
What does make a difference even locally, though, is the command’s ability to differentiate files that share the same name but which contain different data. If you’ve ever found yourself faced with two copies of what is meant to be the same directory, then **rsync** can synchronize them into one directory containing the latest changes from each. This setup is a pretty common occurrence in industries that haven’t yet discovered the magic of version control, and for backup solutions in which there is one source of truth to propagate.
|
||||
|
||||
You can emulate this situation intentionally by creating two folders, one called **example** and the other **example_dupe**:
|
||||
|
||||
|
||||
```
|
||||
$ mkdir example example_dupe
|
||||
```
|
||||
|
||||
Create a file in the first folder:
|
||||
|
||||
|
||||
```
|
||||
$ echo "one" > example/foo.txt
|
||||
```
|
||||
|
||||
Use **rsync** to synchronize the two directories. The most common options for this operation are **-a** (for _archive_, which ensures symlinks and other special files are preserved) and **-v** (for _verbose_, providing feedback to you on the command’s progress):
|
||||
|
||||
|
||||
```
|
||||
$ rsync -av example/ example_dupe/
|
||||
```
|
||||
|
||||
The directories now contain the same information:
|
||||
|
||||
|
||||
```
|
||||
$ cat example/foo.txt
|
||||
one
|
||||
$ cat example_dupe/foo.txt
|
||||
one
|
||||
```
|
||||
|
||||
If the file you are treating as the source diverges, then the target is updated to match:
|
||||
|
||||
|
||||
```
|
||||
$ echo "two" >> example/foo.txt
|
||||
$ rsync -av example/ example_dupe/
|
||||
$ cat example_dupe/foo.txt
|
||||
one
|
||||
two
|
||||
```
|
||||
|
||||
Keep in mind that the **rsync** command is meant to copy data, not to act as a version control system. For instance, if a file in the destination somehow gets ahead of a file in the source, that file is still overwritten because **rsync** compares files for divergence and assumes that the destination is always meant to mirror the source:
|
||||
|
||||
|
||||
```
|
||||
$ echo "You will never see this note again" > example_dupe/foo.txt
|
||||
$ rsync -av example/ example_dupe/
|
||||
$ cat example_dupe/foo.txt
|
||||
one
|
||||
two
|
||||
```
|
||||
|
||||
If there is no change, then no copy occurs.
|
||||
|
||||
The **rsync** command has many options not available in **cp**, such as the ability to set target permissions, exclude files, delete outdated files that don’t appear in both directories, and much more. Use **rsync** as a powerful replacement for **cp**, or just as a useful supplement.
|
||||
|
||||
### Many ways to copy
|
||||
|
||||
There are many ways to achieve essentially the same outcome on a POSIX system, so it seems that open source’s reputation for flexibility is well earned. Have I missed a useful way to copy data? Share your copy hacks in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/copying-files-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/greg-p
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/documents_papers_file_storage_work.png?itok=YlXpAqAJ (Filing papers and documents)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/copy-nautilus.jpg (Copying a file.)
|
||||
[3]: https://opensource.com/article/19/7/understanding-file-paths-and-how-use-them
|
||||
[4]: https://opensource.com/sites/default/files/uploads/copy-files-menu.jpg (Copying a file from the context menu.)
|
||||
[5]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[6]: https://opensource.com/article/19/2/getting-started-cat-command
|
||||
[7]: https://opensource.com/article/19/7/linux-permissions-101
|
||||
@ -0,0 +1,285 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Mutation testing is the evolution of TDD)
|
||||
[#]: via: (https://opensource.com/article/19/8/mutation-testing-evolution-tdd)
|
||||
[#]: author: (Alex Bunardzic https://opensource.com/users/alex-bunardzic)
|
||||
|
||||
Mutation testing is the evolution of TDD
|
||||
======
|
||||
Since test-driven development is modeled on how nature works, mutation
|
||||
testing is the natural next step in the evolution of DevOps.
|
||||
![Ants and a leaf making the word "open"][1]
|
||||
|
||||
In "[Failure is a feature in blameless DevOps][2]," I discussed the central role of failure in delivering quality by soliciting feedback. This is the failure agile DevOps teams rely on to guide them and drive development. [Test-driven development (TDD)][3] is the _[conditio sine qua non][4]_ of any agile DevOps value stream delivery. Failure-centric TDD methodology only works if it is paired with measurable tests.
|
||||
|
||||
TDD methodology is modeled on how nature works and how nature produces winners and losers in the evolutionary game.
|
||||
|
||||
### Natural selection
|
||||
|
||||
![Charles Darwin][5]
|
||||
|
||||
In 1859, [Charles Darwin][6] proposed the theory of evolution in his book _[On the Origin of Species][7]_. Darwin's thesis was that natural variability is caused by the combination of spontaneous mutations in individual organisms and environmental pressures. These pressures eliminate less-adapted organisms while favoring other, more fit organisms. Each and every living being mutates its chromosomes, and those spontaneous mutations are carried to the next generation (the offspring). The newly emerged variability is then tested under natural selection—the environmental pressures that exist due to the variability of environmental conditions.
|
||||
|
||||
This simplified diagram illustrates the process of adjusting to environmental conditions.
|
||||
|
||||
![Environmental pressures on fish][8]
|
||||
|
||||
Fig. 1. Different environmental pressures result in different outcomes governed by natural selection. Image screenshot from a [video by Richard Dawkins][9].
|
||||
|
||||
This illustration shows a school of fish in their natural habitat. The habitat varies (darker or lighter gravel at the bottom of the sea or riverbed), as does each fish (darker or lighter body patterns and colors).
|
||||
|
||||
It also shows two situations (i.e., two variations of the environmental pressure):
|
||||
|
||||
1. The predator is present
|
||||
2. The predator is absent
|
||||
|
||||
|
||||
|
||||
In the first situation, fish that are easier to spot against the gravel shade are at higher risk of being picked off by predators. When the gravel is darker, the lighter portion of the fish population is thinned out. And vice versa—when the gravel is a lighter shade, the darker portion of the fish population suffers the thinning out scenario.
|
||||
|
||||
In the second situation, fish are sufficiently relaxed to engage in mating. In the absence of predators and in the presence of the mating ritual, the opposite results can be expected: The fish that stand out against the background have a better chance of being picked for mating and transferring their characteristics to offspring.
|
||||
|
||||
### Selection criteria
|
||||
|
||||
When selecting among variability, the process is never arbitrary, capricious, whimsical, nor random. The decisive factor is always measurable. That decisive factor is usually called a _test_ or a _goal_.
|
||||
|
||||
A simple mathematical example can illustrate this process of decision making. (Only in this case it won't be governed by natural selection, but by artificial selection.) Suppose someone asks you to build a little function that will take a positive number and calculate that number's square root. How would you go about doing that?
|
||||
|
||||
The agile DevOps way is to _fail fast_. Start with humility, admitting upfront that you don't really know how to develop that function. All you know, at this point, is how to _describe_ what you'd like to do. In technical parlance, you are ready to engage in crafting a _unit test_.
|
||||
|
||||
"Unit test" describes your specific expectation. It could simply be formulated as "given the number 16, I expect the square root function to return number 4." You probably know that the square root of 16 is 4. However, you don't know the square root for some larger numbers (such as 533).
|
||||
|
||||
At the very least, you have formulated your selection criteria, your test or goal.
|
||||
|
||||
### Implement the failing test
|
||||
|
||||
The [.NET Core][10] platform can illustrate the implementation. .NET typically uses [xUnit.net][11] as a unit-testing framework. (To follow the coding examples, please install .NET Core and xUnit.net.)
|
||||
|
||||
Open the command line and create a folder where your square root solution will be implemented. For example, type:
|
||||
|
||||
|
||||
```
|
||||
`mkdir square_root`
|
||||
```
|
||||
|
||||
Then type:
|
||||
|
||||
|
||||
```
|
||||
`cd square_root`
|
||||
```
|
||||
|
||||
Create a separate folder for unit tests:
|
||||
|
||||
|
||||
```
|
||||
`mkdir unit_tests`
|
||||
```
|
||||
|
||||
Move into the **unit_tests** folder (**cd unit_tests**) and initiate the xUnit framework:
|
||||
|
||||
|
||||
```
|
||||
`dotnet new xunit`
|
||||
```
|
||||
|
||||
Now, move one folder up to the **square_root** folder, and create the **app** folder:
|
||||
|
||||
|
||||
```
|
||||
mkdir app
|
||||
cd app
|
||||
```
|
||||
|
||||
Create the scaffold necessary for the C# code:
|
||||
|
||||
|
||||
```
|
||||
`dotnet new classlib`
|
||||
```
|
||||
|
||||
Now open your favorite editor and start cracking!
|
||||
|
||||
In your code editor, navigate to the **unit_tests** folder and open **UnitTest1.cs**.
|
||||
|
||||
Replace auto-generated code in **UnitTest1.cs** with:
|
||||
|
||||
|
||||
```
|
||||
using System;
|
||||
using Xunit;
|
||||
using app;
|
||||
|
||||
namespace unit_tests{
|
||||
|
||||
public class UnitTest1{
|
||||
Calculator calculator = new Calculator();
|
||||
|
||||
[Fact]
|
||||
public void GivenPositiveNumberCalculateSquareRoot(){
|
||||
var expected = 4;
|
||||
var actual = calculator.CalculateSquareRoot(16);
|
||||
Assert.Equal(expected, actual);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This unit test describes the expectation that the variable **expected** should be 4. The next line describes the **actual** value. It proposes to calculate the **actual** value by sending a message to the component called **calculator**. This component is described as capable of handling the **CalculateSquareRoot** message by accepting a numeric value. That component hasn't been developed yet. But it doesn't really matter, because this merely describes the expectations.
|
||||
|
||||
Finally, it describes what happens when the message is triggered to be sent. At that point, it asserts whether the **expected** value is equal to the **actual** value. If it is, the test passed and the goal is reached. If the **expected** value isn't equal to the **actual value**, the test fails.
|
||||
|
||||
Next, to implement the component called **calculator**, create a new file in the **app** folder and call it **Calculator.cs**. To implement a function that calculates the square root of a number, add the following code to this new file:
|
||||
|
||||
|
||||
```
|
||||
namespace app {
|
||||
public class Calculator {
|
||||
public double CalculateSquareRoot(double number) {
|
||||
double bestGuess = number;
|
||||
return bestGuess;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Before you can test this implementation, you need to instruct the unit test how to find this new component (**Calculator**). Navigate to the **unit_tests** folder and open the **unit_tests.csproj** file. Add the following line in the **<ItemGroup>** code block:
|
||||
|
||||
|
||||
```
|
||||
`<ProjectReference Include="../app/app.csproj" />`
|
||||
```
|
||||
|
||||
Save the **unit_test.csproj** file. Now you are ready for your first test run.
|
||||
|
||||
Go to the command line and **cd** into the **unit_tests** folder. Run the following command:
|
||||
|
||||
|
||||
```
|
||||
`dotnet test`
|
||||
```
|
||||
|
||||
Running the unit test will produce the following output:
|
||||
|
||||
![xUnit output after the unit test run fails][12]
|
||||
|
||||
Fig. 2. xUnit output after the unit test run fails.
|
||||
|
||||
As you can see, the unit test failed. It expected that sending number 16 to the **calculator** component would result in the number 4 as the output, but the output (the **actual** value) was the number 16.
|
||||
|
||||
Congratulations! You have created your first failure. Your unit test provided strong, immediate feedback urging you to fix the failure.
|
||||
|
||||
### Fix the failure
|
||||
|
||||
To fix the failure, you must improve **bestGuess**. Right now, **bestGuess** merely takes the number the function receives and returns it. Not good enough.
|
||||
|
||||
But how do you figure out a way to calculate the square root value? I have an idea—how about looking at how Mother Nature solves problems.
|
||||
|
||||
### Emulate Mother Nature by iterating
|
||||
|
||||
It is extremely hard (pretty much impossible) to guess the correct value from the first (and only) attempt. You must allow for several attempts at guessing to increase your chances of solving the problem. And one way to allow for multiple attempts is to _iterate_.
|
||||
|
||||
To iterate, store the **bestGuess** value in the **previousGuess** variable, transform the **bestGuess** value, and compare the difference between the two values. If the difference is 0, you solved the problem. Otherwise, keep iterating.
|
||||
|
||||
Here is the body of the function that produces the correct value for the square root of any positive number:
|
||||
|
||||
|
||||
```
|
||||
double bestGuess = number;
|
||||
double previousGuess;
|
||||
|
||||
do {
|
||||
previousGuess = bestGuess;
|
||||
bestGuess = (previousGuess + (number/previousGuess))/2;
|
||||
} while((bestGuess - previousGuess) != 0);
|
||||
|
||||
return bestGuess;
|
||||
```
|
||||
|
||||
This loop (iteration) converges bestGuess values to the desired solution. Now your carefully crafted unit test passes!
|
||||
|
||||
![Unit test successful][13]
|
||||
|
||||
Fig. 3. Unit test successful, 0 tests failed.
|
||||
|
||||
### The iteration solves the problem
|
||||
|
||||
Just like Mother Nature's approach, in this exercise, iteration solves the problem. An incremental approach combined with stepwise refinement is the guaranteed way to arrive at a satisfactory solution. The decisive factor in this game is having a measurable goal and test. Once you have that, you can keep iterating until you hit the mark.
|
||||
|
||||
### Now the punchline!
|
||||
|
||||
OK, this was an amusing experiment, but the more interesting discovery comes from playing with this newly minted solution. Until now, your starting **bestGuess** was always equal to the number the function receives as the input parameter. What happens if you change the initial **bestGuess**?
|
||||
|
||||
To test that, you can run a few scenarios. First, observe the stepwise refinement as the iteration loops through a series of guesses as it tries to calculate the square root of 25:
|
||||
|
||||
![Code iterating for the square root of 25][14]
|
||||
|
||||
Fig. 4. Iterating to calculate the square root of 25.
|
||||
|
||||
Starting with 25 as the **bestGuess**, it takes eight iterations for the function to calculate the square root of 25. But what would happen if you made a comical, ridiculously wrong stab at the **bestGuess**? What if you started with a clueless second guess, that 1 million might be the square root of 25? What would happen in such an obviously erroneous situation? Would your function be able to deal with such idiocy?
|
||||
|
||||
Take a look at the horse's mouth. Rerun the scenario, this time starting from 1 million as the **bestGuess**:
|
||||
|
||||
![Stepwise refinement][15]
|
||||
|
||||
Fig. 5. Stepwise refinement when calculating the square root of 25 by starting with 1 million as the initial **bestGuess**.
|
||||
|
||||
Oh wow! Starting with a ludicrously large number, the number of iterations only tripled (from eight iterations to 23). Not nearly as dramatic an increase as you might intuitively expect.
|
||||
|
||||
### The moral of the story
|
||||
|
||||
The _Aha!_ moment arrives when you realize that, not only is iteration guaranteed to solve the problem, but it doesn't matter whether your search for the solution begins with a good or a terribly botched initial guess. However erroneous your initial understanding, the process of iteration, coupled with a measurable test/goal, puts you on the right track and delivers the solution. Guaranteed.
|
||||
|
||||
Figures 4 and 5 show a steep and dramatic burndown. From a wildly incorrect starting point, the iteration quickly burns down to an absolutely correct solution.
|
||||
|
||||
This amazing methodology, in a nutshell, is the essence of agile DevOps.
|
||||
|
||||
### Back to some high-level observations
|
||||
|
||||
Agile DevOps practice stems from the recognition that we live in a world that is fundamentally based on uncertainty, ambiguity, incompleteness, and a healthy dose of confusion. From the scientific/philosophical point of view, these traits are well documented and supported by [Heisenberg's Uncertainty Principle][16] (covering the uncertainty part), [Wittgenstein's Tractatus Logico-Philosophicus][17] (the ambiguity part), [Gödel's incompleteness theorems][18] (the incompleteness aspect), and the [Second Law of Thermodynamics][19] (the confusion caused by relentless entropy).
|
||||
|
||||
In a nutshell, no matter how hard you try, you can never get complete information when trying to solve any problem. It is, therefore, more profitable to abandon an arrogant stance and adopt a more humble approach to solving problems. Humility pays big dividends in rewarding you—not only with the hoped-for solution but also with the byproduct of a well-structured solution.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Nature works incessantly—it's a continuous flow. Nature has no master plan; everything happens as a response to what happened earlier. The feedback loops are very tight, and apparent progress/regress is piecemeal. Everywhere you look in nature, you see stepwise refinement, in one shape or form or another.
|
||||
|
||||
Agile DevOps is a very interesting outcome of the engineering model's gradual maturation. DevOps is based on the recognition that the information you have available is always incomplete, so you'd better proceed cautiously. Obtain a measurable test (e.g., a hypothesis, a measurable expectation), make a humble attempt at satisfying it, most likely fail, then collect the feedback, fix the failure, and continue. There is no plan other than agreeing that, with each step of the way, there must be a measurable hypothesis/test.
|
||||
|
||||
In the next article in this series, I'll take a closer look at how mutation testing provides much-needed feedback that drives value.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/mutation-testing-evolution-tdd
|
||||
|
||||
作者:[Alex Bunardzic][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alex-bunardzic
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_520X292_openanttrail-2.png?itok=xhD3WmUd (Ants and a leaf making the word "open")
|
||||
[2]: https://opensource.com/article/19/7/failure-feature-blameless-devops
|
||||
[3]: https://en.wikipedia.org/wiki/Test-driven_development
|
||||
[4]: https://www.merriam-webster.com/dictionary/conditio%20sine%20qua%20non
|
||||
[5]: https://opensource.com/sites/default/files/uploads/darwin.png (Charles Darwin)
|
||||
[6]: https://en.wikipedia.org/wiki/Charles_Darwin
|
||||
[7]: https://en.wikipedia.org/wiki/On_the_Origin_of_Species
|
||||
[8]: https://opensource.com/sites/default/files/uploads/environmentalconditions2.png (Environmental pressures on fish)
|
||||
[9]: https://www.youtube.com/watch?v=MgK5Rf7qFaU
|
||||
[10]: https://dotnet.microsoft.com/
|
||||
[11]: https://xunit.net/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/xunit-output.png (xUnit output after the unit test run fails)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/unit-test-success.png (Unit test successful)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/iterating-square-root.png (Code iterating for the square root of 25)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/bestguess.png (Stepwise refinement)
|
||||
[16]: https://en.wikipedia.org/wiki/Uncertainty_principle
|
||||
[17]: https://en.wikipedia.org/wiki/Tractatus_Logico-Philosophicus
|
||||
[18]: https://en.wikipedia.org/wiki/G%C3%B6del%27s_incompleteness_theorems
|
||||
[19]: https://en.wikipedia.org/wiki/Second_law_of_thermodynamics
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (EndeavourOS Aims to Fill the Void Left by Antergos in Arch Linux World)
|
||||
[#]: via: (https://itsfoss.com/endeavouros/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
EndeavourOS Aims to Fill the Void Left by Antergos in Arch Linux World
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
I’m sure that most of our readers are aware of the [end of the Antergos project][2]. In the wake of the announcement, the members of the Antergos community created several successors. Today, we will be looking at one of the ‘spiritual successors’ of Antergos: [EndeavourOS][3].
|
||||
|
||||
### EndeavourOS is not a fork of Antergos
|
||||
|
||||
Before we start, I would like to make it very clear that EndeavourOS is not a fork of Antergos. The developers used Antergos as their inspiration to create a light Arch-based distro.
|
||||
|
||||
![Endeavouros First Boot][4]
|
||||
|
||||
According to the [project’s site][5], EndeavourOS came into existence because people in the Antergos community wanted to keep the spirit of Antergos alive. Their goal was simply to “have Arch installed with an easy to use installer and a friendly, helpful community to fall back on during the journey to master the system”.
|
||||
|
||||
Unlike many Arch-based distros, EndeavourOS is intending to work [like vanilla Arch][5], “so no one-click solutions to install your favorite app or a bunch of preinstalled apps you’ll eventually don’t need”. For most people, especially those new to Linux and Arch, there will be a learning curve, but EndeavourOS aims to have a large friendly community where people are encouraged to ask questions and learn about their systems.
|
||||
|
||||
![Endeavouros Installing][6]
|
||||
|
||||
### A Work in Progress
|
||||
|
||||
EndeavourOS was [first released on July 15th][7] of this year after the project was first announced on [May 23rd][8]. Unfortunately, this means that the developers were unable to incorporate all of the features that they have planned.
|
||||
|
||||
For example, they want to have an online install similar to the one used by Antergos but ran into [issues with the current options][9]. “Cnchi has caused serious problems to be working outside the Antergos eco system and it needs a complete rewrite to work. The Fenix installer by RebornOS is getting more into shape, but needs more time to properly function.” For now, EndeavourOS will ship with the [Calamares installer][10].
|
||||
|
||||
[][11]
|
||||
|
||||
Suggested read Velt/OS: A Material Design-Themed Desktop Environment
|
||||
|
||||
EndeavourOS will also offer [less stuff than Antergos][9]: It’s repo is smaller than Antergos though they ship with some AUR packages. Their goal is to deliver a system that’s close to Arch an not vanilla Arch.
|
||||
|
||||
![Endeavouros Updating With Kalu][12]
|
||||
|
||||
The developers [stated further][13]:
|
||||
|
||||
> “Linux and specifically Arch are all about freedom of choice, we provide a basic install that lets you explore those choices with a small layer of convenience. We will never judge you by installing GUI apps like Pamac or even work with sandbox solutions like Flatpak or Snaps. It’s up to you what you are installing to make EndeavourOS work in your circumstances, that’s the main difference we have with Antergos or Manjaro, but like Antergos we will try to help you if you run into a problem with one of your installed packages.”
|
||||
|
||||
### Experiencing EndeavourOS
|
||||
|
||||
I installed EndeavourOS in [VirtualBox][14] and took a look around. When I first booted from the image, I was greeted by a little box with links to the EndeavourOS site about installing. It also has a button to install and one to manually partition the drive. The Calamares installer worked very smoothly for me.
|
||||
|
||||
After I rebooted into a fresh install of EndeavourOS, I was greeted by a colorful themed XFCE desktop. I was also treated to a bunch of notification balloons. Most Arch-based distros I’ve used come with a GUI tool like [pamac][15] or [octopi][16] to keep the system up-to-date. EndeavourOS comes with [kalu][17]. (kalu stands for “Keeping Arch Linux Up-to-date”.) It checks for updated packages, Arch Linux News, updated AUR packages and more. Once it sees an update for any of those areas, it will create a notification balloon.
|
||||
|
||||
I took a look through the menu to see what was installed by default. The answer is not much, not even an office suite. If they intend for EndeavourOS to be a blank canvas for anyone to create the system they want. they are headed in the right direction.
|
||||
|
||||
![Endeavouros Desktop][18]
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
EndeavourOS is still very young. The first stable release was issued only 3 weeks ago. It is missing some stuff, most importantly an online installer. That being said, it is possible to gauge where EndeavourOS will be heading.
|
||||
|
||||
[][19]
|
||||
|
||||
Suggested read An Overview of Intel's Clear Linux, its Features and Installation Procedure
|
||||
|
||||
While it is not an exact clone of Antergos, EndeavourOS wants to replicate the most important part of Antergos the welcoming, friendly community. All to often, the Linux community can seem to be unwelcoming and downright hostile to the beginner. I’ve seen more and more people trying to combat that negativity and bring more people into Linux. With the EndeavourOS team making that their main focus, a great distro can be the only result.
|
||||
|
||||
If you are currently using Antergos, there is a way for you to [switch to EndeavourOS without performing a clean install.][20]
|
||||
|
||||
If you want an exact clone of Antergos, I would recommend checking out [RebornOS][21]. They are currently working on a replacement of the Cnchi installer named Fenix.
|
||||
|
||||
Have you tried EndeavourOS already? How’s your experience with it?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/endeavouros/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-logo.png?ssl=1
|
||||
[2]: https://itsfoss.com/antergos-linux-discontinued/
|
||||
[3]: https://endeavouros.com/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-first-boot.png?resize=800%2C600&ssl=1
|
||||
[5]: https://endeavouros.com/info-2/
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-installing.png?resize=800%2C600&ssl=1
|
||||
[7]: https://endeavouros.com/endeavouros-first-stable-release-has-arrived/
|
||||
[8]: https://forum.antergos.com/topic/11780/endeavour-antergos-community-s-next-stage
|
||||
[9]: https://endeavouros.com/what-to-expect-on-the-first-release/
|
||||
[10]: https://calamares.io/
|
||||
[11]: https://itsfoss.com/veltos-linux/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-updating-with-kalu.png?resize=800%2C600&ssl=1
|
||||
[13]: https://endeavouros.com/second-week-after-the-stable-release/
|
||||
[14]: https://itsfoss.com/install-virtualbox-ubuntu/
|
||||
[15]: https://aur.archlinux.org/packages/pamac-aur/
|
||||
[16]: https://octopiproject.wordpress.com/
|
||||
[17]: https://github.com/jjk-jacky/kalu
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/endeavouros-desktop.png?resize=800%2C600&ssl=1
|
||||
[19]: https://itsfoss.com/clear-linux/
|
||||
[20]: https://forum.endeavouros.com/t/how-to-switch-from-antergos-to-endevouros/105/2
|
||||
[21]: https://rebornos.org/
|
||||
@ -0,0 +1,245 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?)
|
||||
[#]: via: (https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/)
|
||||
[#]: author: (2daygeek http://www.2daygeek.com/author/2daygeek/)
|
||||
|
||||
How to Upgrade Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?
|
||||
======
|
||||
|
||||
Linux Mint 19.2 “Tina” was released on Aug 02nd 2019, it is a long term support release, which is based on Ubuntu 18.04 LTS (Bionic Beaver).
|
||||
|
||||
It will be supported until 2023. It comes with updated software and brings refinements and many new features to make your desktop even more comfortable to use.
|
||||
|
||||
Linux Mint 19.2 features with Cinnamon 4.2, Linux kernel 4.15, and Ubuntu 18.04 package base.
|
||||
|
||||
**`Note:`**` ` Don’t forget to take backup of your important data. If something goes wrong you can restore the data from the backup after fresh installation.
|
||||
|
||||
Backup can be done either rsnapshot or timeshift.
|
||||
|
||||
Linux Mint 19.2 “Tina” Release notes can be found in the following link.
|
||||
|
||||
* **[Linux Mint 19.2 (Tina) Release Notes][1]**
|
||||
|
||||
|
||||
|
||||
There are three ways that we can upgrade to Linux Mint 19.2 “Tina”.
|
||||
|
||||
* Upgrade Linux Mint 19.2 (Tina) Using Native Method
|
||||
* Upgrade Linux Mint 19.2 (Tina) Using Mintupgrade Utility
|
||||
* Upgrade Linux Mint 19.2 (Tina) Using GUI
|
||||
|
||||
|
||||
|
||||
### How to Perform The Upgrade from Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina)?
|
||||
|
||||
Upgrading the Linux Mint system is an easy and painless task. It can be done three ways.
|
||||
|
||||
### Method-1: Upgrade Linux Mint 19.2 (Tina) Using Native Method
|
||||
|
||||
This is one of the native and standard method to perform the upgrade for Linux Mint system.
|
||||
|
||||
To do so, follow the below procedures.
|
||||
|
||||
Make sure that your current Linux Mint system is up-to-date.
|
||||
|
||||
Update your existing software to latest available version using the following commands.
|
||||
|
||||
### Step-1:
|
||||
|
||||
Refresh the repositories index by running the following command.
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
Run the following command to install the available updates on system.
|
||||
|
||||
```
|
||||
$ sudo apt upgrade
|
||||
```
|
||||
|
||||
Run the following command to perform the available minor upgrade with in version.
|
||||
|
||||
```
|
||||
$ sudo apt full-upgrade
|
||||
```
|
||||
|
||||
By default, it will remove obsolete packages by running the above command. However, i advise you to run the below commands.
|
||||
|
||||
```
|
||||
$ sudo apt autoremove
|
||||
|
||||
$ sudo apt clean
|
||||
```
|
||||
|
||||
You may need to reboot the system, if a new kernel is installed. If so, run the following command.
|
||||
|
||||
```
|
||||
$ sudo shutdown -r now
|
||||
```
|
||||
|
||||
Finally check the currently installed version.
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
|
||||
No LSB modules are available.
|
||||
Distributor ID: Linux Mint
|
||||
Description: Linux Mint 19.1 (Tessa)
|
||||
Release: 19.1
|
||||
Codename: Tessa
|
||||
```
|
||||
|
||||
### Step-2: Update/Modify the /etc/apt/sources.list file
|
||||
|
||||
After reboot, modify the sources.list file and point from Linux Mint 19.1 (Tessa) to Linux Mint 19.2 (Tina).
|
||||
|
||||
First backup the below config files using the cp command.
|
||||
|
||||
```
|
||||
$ sudo cp /etc/apt/sources.list /root
|
||||
$ sudo cp -r /etc/apt/sources.list.d/ /root
|
||||
```
|
||||
|
||||
Modify the “sources.list” file and point to Linux Mint 19.1 (Tina).
|
||||
|
||||
```
|
||||
$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list
|
||||
$ sudo sed -i 's/tessa/tina/g' /etc/apt/sources.list.d/*
|
||||
```
|
||||
|
||||
Refresh the repositories index by running the following command.
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
Run the following command to install the available updates on system. During the upgrade you may need to confirm for service restart and config file replace so, just follow on-screen instructions.
|
||||
|
||||
The upgrade may take some time depending on the number of updates and your Internet speed.
|
||||
|
||||
```
|
||||
$ sudo apt upgrade
|
||||
```
|
||||
|
||||
Run the following command to perform a complete upgrade of the system.
|
||||
|
||||
```
|
||||
$ sudo apt full-upgrade
|
||||
```
|
||||
|
||||
By default, the above command will remove obsolete packages. However, i advise you to run the below commands once again.
|
||||
|
||||
```
|
||||
$ sudo apt autoremove
|
||||
|
||||
$ sudo apt clean
|
||||
```
|
||||
|
||||
Finally reboot the system to boot with Linux Mint 19.2 (Tina).
|
||||
|
||||
```
|
||||
$ sudo shutdown -r now
|
||||
```
|
||||
|
||||
The upgraded Linux Mint version can be verified by running the following command.
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
|
||||
No LSB modules are available.
|
||||
Distributor ID: Linux Mint
|
||||
Description: Linux Mint 19.2 (Tina)
|
||||
Release: 19.2
|
||||
Codename: Tina
|
||||
```
|
||||
|
||||
### Method-2: Upgrade Linux Mint 19.2 (Tina) Using Mintupgrade Utility
|
||||
|
||||
This is Mint official utility that allow us to perform the smooth upgrade for Linux Mint system.
|
||||
|
||||
Use the below command to install mintupgrade package.
|
||||
|
||||
```
|
||||
$ sudo apt install mintupgrade
|
||||
```
|
||||
|
||||
Make sure you have installed the latest version of mintupgrade package.
|
||||
|
||||
```
|
||||
$ apt version mintupgrade
|
||||
```
|
||||
|
||||
Run the below command as a normal user to simulate an upgrade and follow on-screen instructions.
|
||||
|
||||
```
|
||||
$ mintupgrade check
|
||||
```
|
||||
|
||||
Use the below command to download the packages necessary to upgrade to Linux Mint 19.2 (Tina) and follow on screen instructions.
|
||||
|
||||
```
|
||||
$ mintupgrade download
|
||||
```
|
||||
|
||||
Run the following command to apply the upgrades and follow on-screen instructions.
|
||||
|
||||
```
|
||||
$ mintupgrade upgrade
|
||||
```
|
||||
|
||||
Once upgrade done successfully, Reboot the system and check the upgraded version.
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
|
||||
No LSB modules are available.
|
||||
Distributor ID: Linux Mint
|
||||
Description: Linux Mint 19.2 (Tina)
|
||||
Release: 19.2
|
||||
Codename: Tina
|
||||
```
|
||||
|
||||
### Method-3: Upgrade Linux Mint 19.2 (Tina) Using GUI
|
||||
|
||||
Alternatively, we can perform the upgrade through GUI.
|
||||
|
||||
### Step-1:
|
||||
|
||||
Create a system snapshot through Timeshift. If anything goes wrong, you can easily restore your operating system to its previous state.
|
||||
|
||||
### Step-2:
|
||||
|
||||
Open the Update Manager, click on the Refresh button to check for any new version of mintupdate and mint-upgrade-info. If there are updates for these packages, apply them.
|
||||
|
||||
Launch the System Upgrade by clicking on “Edit->Upgrade to Linux Mint 19.2 Tina”.
|
||||
[![][2]![][2]][3]
|
||||
|
||||
Follow the instructions on the screen. If asked whether to keep or replace configuration files, choose to replace them.
|
||||
[![][2]![][2]][4]
|
||||
|
||||
### Step-3:
|
||||
|
||||
Once the upgrade is finished, reboot your computer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/upgrade-linux-mint-19-1-tessa-to-linux-mint-19-2-tina/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.2daygeek.com/author/2daygeek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxtechnews.com/linux-mint-19-2-tina-released-check-what-is-new-feature/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade.png
|
||||
[4]: https://www.2daygeek.com/wp-content/uploads/2019/08/linux-mint-19-2-tina-mintupgrade-1.png
|
||||
@ -0,0 +1,310 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Setup Disk Quota on XFS File System in Linux Servers)
|
||||
[#]: via: (https://www.linuxtechi.com/disk-quota-xfs-file-system-linux-servers/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
How to Setup Disk Quota on XFS File System in Linux Servers
|
||||
======
|
||||
|
||||
Managing Disk quota on file systems is one of the most common day to day operation tasks for Linux admins, in this article we will demonstrate how to setup disk quota on XFS file system / partition on Linux Servers like **CentOS**, **RHEL**, **Ubuntu** and **Debian**. Here Disk quota means implementing limit on disk usage and file or inode usage.
|
||||
|
||||
[![Setup-Disk-Quota-XFS-Linux-Servers][1]][2]
|
||||
|
||||
Disk quota on XFS file system is implemented as followings:
|
||||
|
||||
* User Quota
|
||||
* Group Quota
|
||||
* Project Quota (or Directory Quota)
|
||||
|
||||
|
||||
|
||||
To setup disk quota on XFS file system, first we must enable quota using following mount options:
|
||||
|
||||
* **uquota**: Enable user quota & also enforce usage limits.
|
||||
* **uqnoenforce**: Enable user quota and report usage but don’t enforce usage limits.
|
||||
* **gquota**: Enable group quota & also enforce usage limits.
|
||||
* **gqnoenforce**: Enable group quota and report usage, but don’t enforce usage limits.
|
||||
* **prjquota / pquota**: Enable project quota & enforce usage limits.
|
||||
* **pqnoenforce**: Enable project quota and report usage but don’t enforce usage limits.
|
||||
|
||||
|
||||
|
||||
In article we will implement user & group disk quota on /home partition and apart from this we will also see how to setup inode quota on /home file system and project quota on /var file system.
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# df -Th /home /var
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/mapper/Vol-home xfs 16G 33M 16G 1% /home
|
||||
/dev/mapper/Vol-var xfs 18G 87M 18G 1% /var
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Enable User and Group Quota on /home
|
||||
|
||||
Unmount /home partition and then edit the /etc/fstab file,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# umount /home/
|
||||
```
|
||||
|
||||
Add uquota and gquota after default keyword for /home partition in /etc/fstab file, example is shown below
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/fstab
|
||||
……………………………
|
||||
/dev/mapper/Vol-home /home xfs defaults,uquota,gquota 0 0
|
||||
……………………………
|
||||
```
|
||||
|
||||
![user-group-quota-fstab-file][1]
|
||||
|
||||
Now mount the /home partition using below “**mount -a**” command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# mount -a
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Verify whether quota is enabled on /home or not,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# mount | grep /home
|
||||
/dev/mapper/Vol-home on /home type xfs (rw,relatime,seclabel,attr2,inode64,usrquota,grpquota)
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
**Note :** While umounting /home partition if you get /home is busy then edit the fstab file, add uquota and gquota keywords after default keyword for /home partition and then reboot your system. After reboot we will see that quota is enabled on /home.
|
||||
|
||||
Quota on XFS file system is managed by the command line tool called “**xfs_quota**“. xfs_quota works in two modes:
|
||||
|
||||
* **Basic Mode** – For this mode, simply type xfs_quota then you will enter basic mode there you can print disk usage of all file system and disk quota for users, example is show below
|
||||
|
||||
|
||||
|
||||
![xfs-quota-basic-mode][1]
|
||||
|
||||
* **Expert Mode** – This mode is invoked using “-x” option in “xfs_quota” command, as the name suggests this mode is used to configure disk and file quota for local users on xfs file system.
|
||||
|
||||
|
||||
|
||||
To print disk quota on any file system, let’s say /home, use the following command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'report -h' /home
|
||||
User quota on /home (/dev/mapper/Vol-home)
|
||||
Blocks
|
||||
User ID Used Soft Hard Warn/Grace
|
||||
---------- ---------------------------------
|
||||
root 0 0 0 00 [------]
|
||||
pkumar 12K 0 0 00 [------]
|
||||
|
||||
Group quota on /home (/dev/mapper/Vol-home)
|
||||
Blocks
|
||||
Group ID Used Soft Hard Warn/Grace
|
||||
---------- ---------------------------------
|
||||
root 0 0 0 00 [------]
|
||||
pkumar 12K 0 0 00 [------]
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Configure User Quota
|
||||
|
||||
Let’s assume we have a user named “pkumar”, let’s set disk and file quota on his home directory using “xfs_quota” command
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit bsoft=4250m bhard=4550m pkumar' /home
|
||||
```
|
||||
|
||||
In above command, **bsoft** is block soft limit in MBs and **bhard** is block hard limit in MBs, limit is a keyword to implement disk or file limit on a file system for a specific user.
|
||||
|
||||
Let’s set file or inode limit for user pkumar on his home directory,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit isoft=400 ihard=500 pkumar' /home
|
||||
```
|
||||
|
||||
In above command isoft is inode or file soft limit and ihard is inode or file hard limit.
|
||||
|
||||
Both block (disk) limit and Inode (file) limit can be applied using a single command, example is shown below,
|
||||
|
||||
```
|
||||
root@linuxtechi ~]# xfs_quota -x -c 'limit bsoft=4250m bhard=4550m isoft=400 ihard=500 pkumar' /home
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Now verify whether disk and inode limits are implemented on pkumar user using the following xfs_quota command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c "report -bih" /home
|
||||
```
|
||||
|
||||
![User-Quota-Details-xfs-linux][1]
|
||||
|
||||
In above xfs_quota command, report is a keyword , b is for block report , i is for inode report and h is for to display report in human readable format,
|
||||
|
||||
### Configure Group Quota
|
||||
|
||||
Let’s assume we have a group named called “**engineering**” and two local users (shashi & rakesh) whose secondary group is engineering
|
||||
|
||||
Now set the following quotas:
|
||||
|
||||
* Soft block limit: 6 GB (or 6144 MB),
|
||||
* Hard block limit :8 GB (or 8192 MB),
|
||||
* Soft file limit: 1000
|
||||
* Hard file limit: 1200
|
||||
|
||||
|
||||
|
||||
So to configure disk and file quota on engineering group, use the beneath xfs_quota command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit -g bsoft=6144m bhard=8192m isoft=1000 ihard=1200 engineering' /home
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
**Note:** In xfs_quota we can also specify the block limit size in GB like “bsoft=6g and bhard=8g”
|
||||
|
||||
Now verify the Quota details for group engineering using the following command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c "report -gbih" /home
|
||||
Group quota on /home (/dev/mapper/Vol-home)
|
||||
Blocks Inodes
|
||||
Group ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
|
||||
---------- --------------------------------- ---------------------------------
|
||||
root 0 0 0 00 [------] 3 0 0 00 [------]
|
||||
pkumar 12K 0 0 00 [------] 4 0 0 00 [------]
|
||||
engineering 0 6G 8G 00 [------] 0 1000 1.2k 00 [------]
|
||||
shashi 12K 0 0 00 [------] 4 0 0 00 [------]
|
||||
rakesh 12K 0 0 00 [------] 4 0 0 00 [------]
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
As we can see above command output, disk and file quota is implemented on engineering group and under the engineering group, we have two users.
|
||||
|
||||
### Configure Project (or Directory) Quota
|
||||
|
||||
Let’s assume we want to set project quota or directory Quota on “**/var/log**“, So first enable project quota(**prjquota**) on /var file system, edit the /etc/fstab file, add “**prjquota**” after default keyword for /var file system, example is shown below,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/fstab
|
||||
……………………………….
|
||||
/dev/mapper/Vol-var /var xfs defaults,prjquota 0 0
|
||||
…………………………………
|
||||
```
|
||||
|
||||
Save & exit the file
|
||||
|
||||
To make the above changes into the effect, we must reboot our system,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# init 6
|
||||
```
|
||||
|
||||
After reboot, we can verify whether project quota is enabled or not on /var file system using below mount command
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# mount | grep /var
|
||||
/dev/mapper/Vol-var on /var type xfs (rw,relatime,seclabel,attr2,inode64,prjquota)
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
As we can see in above output, project quota is enabled now, so to configure quota /var/log directory, first we must define directory path and its unique id in the file /etc/projects ( In my case i am taking 151 as unique id for /var/log)
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/projects
|
||||
51:/var/log
|
||||
```
|
||||
|
||||
Save & exit the file
|
||||
|
||||
Now associate the above id “151” to a project called “**Logs**”, create a file **/etc/projid** and add the following content to it,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/projid
|
||||
Logs:151
|
||||
```
|
||||
|
||||
Save & exit the file
|
||||
|
||||
Initialize “Logs” project directory using the xfs_quota command,
|
||||
|
||||
**Syntax: #** xfs_quota -x -c ‘project -s project_name’ project_directory
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'project -s Logs' /var
|
||||
Setting up project Logs (path /var/log)...
|
||||
Processed 1 (/etc/projects and cmdline) paths for project Logs with recursion depth infinite (-1).
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Let’s suppose we want to implement 10 GB hard disk limit and 8 GB soft limit on /var/log directory, run the following xfs_quota command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit -p bsoft=8g bhard=10g Logs' /var
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
In above command we have used “-p” after limit keyword which shows that we want to implement project quota
|
||||
|
||||
Use below xfs_quota command to set file or inode limit on /var/log directory
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit -p isoft=1800 ihard=2000 Logs' /var
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Use below command to print Project quota details
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -xc 'report -pbih' /var
|
||||
Project quota on /var (/dev/mapper/Vol-var)
|
||||
Blocks Inodes
|
||||
Project ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
|
||||
---------- --------------------------------- ---------------------------------
|
||||
#0 137.6M 0 0 00 [------] 1.5k 0 0 00 [------]
|
||||
Logs 3.1M 8G 10G 00 [------] 33 1.8k 2k 00 [------]
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Test Project quota by creating big files under /var/log folder and see whether you can cross 10GB block limit,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# cd /var/log/
|
||||
[root@linuxtechi log]# dd if=/dev/zero of=big_file bs=1G count=9
|
||||
9+0 records in
|
||||
9+0 records out
|
||||
9663676416 bytes (9.7 GB) copied, 37.8915 s, 255 MB/s
|
||||
[root@linuxtechi log]# dd if=/dev/zero of=big_file2 bs=1G count=5
|
||||
dd: error writing ‘big_file2’: No space left on device
|
||||
1+0 records in
|
||||
0+0 records out
|
||||
1069219840 bytes (1.1 GB) copied, 3.90945 s, 273 MB/s
|
||||
[root@linuxtechi log]#
|
||||
```
|
||||
|
||||
Above dd error command confirms that configured project quota is working fine, we can also confirm the same from xfs_quota command,
|
||||
|
||||
![xfs-project-quota-details][1]
|
||||
|
||||
That’s all from this tutorial, I hope these steps helps you to understand about quota on XFS file system, please do share your feedback and comments in the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/disk-quota-xfs-file-system-linux-servers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Setup-Disk-Quota-XFS-Linux-Servers.jpg
|
||||
@ -0,0 +1,202 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to measure the health of an open source community)
|
||||
[#]: via: (https://opensource.com/article/19/8/measure-project)
|
||||
[#]: author: (Jon Lawrence https://opensource.com/users/the3rdlaw)
|
||||
|
||||
How to measure the health of an open source community
|
||||
======
|
||||
It's complicated.
|
||||
![metrics and data shown on a computer screen][1]
|
||||
|
||||
As a person who normally manages software development teams, over the years I’ve come to care about metrics quite a bit. Time after time, I’ve found myself leading teams using one project platform or another (Jira, GitLab, and Rally, for example) generating an awful lot of measurable data. From there, I’ve promptly invested significant amounts of time to pull useful metrics out of the platform-of-record and into a format where we could make sense of them, and then use the metrics to make better choices about many aspects of development.
|
||||
|
||||
Earlier this year, I had the good fortune of coming across a project at the [Linux Foundation][2] called [Community Health Analytics for Open Source Software][3], or CHAOSS. This project focuses on collecting and enriching metrics from a wide range of sources so that stakeholders in open source communities can measure the health of their projects.
|
||||
|
||||
### What is CHAOSS?
|
||||
|
||||
As I grew familiar with the project’s underlying metrics and objectives, one question kept turning over in my head. What is a "healthy" open source project, and by whose definition?
|
||||
|
||||
What’s considered healthy by someone in a particular role may not be viewed that way by someone in another role. It seemed there was an opportunity to back out from the granular data that CHAOSS collects and do a market segmentation exercise, focusing on what might be the most meaningful contextual questions for a given role, and what metrics CHAOSS collects that might help answer those questions.
|
||||
|
||||
This exercise was made possible by the fact that the CHAOSS project creates and maintains a suite of open source applications and metric definitions, including:
|
||||
|
||||
* A number of server-based applications for gathering, aggregating, and enriching metrics (such as Augur and GrimoireLab).
|
||||
* The open source versions of ElasticSearch, Kibana, and Logstash (ELK).
|
||||
* Identity services, data analysis services, and a wide range of integration libraries.
|
||||
|
||||
|
||||
|
||||
In one of my past programs, where half a dozen teams were working on projects of varying complexity, we found a neat tool which allowed us to create any kind of metric we wanted from a simple (or complex) JQL statement, and then develop calculations against and between those metrics. Before we knew it, we were pulling over 400 metrics from Jira alone, and more from manual sources.
|
||||
|
||||
By the end of the project, we decided that out of the 400-ish metrics, most of them didn’t really matter when it came to making decisions _in our roles_. At the end of the day, there were only three that really mattered to us: "Defect Removal Efficiency," "Points completed vs. Points committed," and "Work-in-Progress per Developer." Those three metrics mattered most because they were promises we made to ourselves, to our clients, and to our team members, and were, therefore, the most meaningful.
|
||||
|
||||
Drawing from the lessons learned through that experience and the question of what is a healthy open source project?, I jumped into the CHAOSS community and started building a set of personas to offer a constructive approach to answering that question from a role-based lens.
|
||||
|
||||
CHAOSS is an open source project and we try to operate using democratic consensus. So, I decided that instead of stakeholders, I’d use the word _constituent_, because it aligns better with the responsibility we have as open source contributors to create a more symbiotic value chain.
|
||||
|
||||
While the exercise of creating this constituent model takes a particular goal-question-metric approach, there are many ways to segment. CHAOSS contributors have developed great models that segment by vectors, like project profiles (for example, individual, corporate, or coalition) and "Tolerance to Failure." Every model provides constructive influence when developing metric definitions for CHAOSS.
|
||||
|
||||
Based on all of this, I set out to build a model of who might care about CHAOSS metrics, and what questions each constituent might care about most in each of CHAOSS’ four focus areas:
|
||||
|
||||
* [Diversity and Inclusion][4]
|
||||
* [Evolution][5]
|
||||
* [Risk][6]
|
||||
* [Value][7]
|
||||
|
||||
|
||||
|
||||
Before we dive in, it’s important to note that the CHAOSS project expressly leaves contextual judgments to teams implementing the metrics. What’s "meaningful" and the answer to "What is healthy?" is expected to vary by team and by project. The CHAOSS software’s ready-made dashboards focus on objective metrics as much as possible. In this article, we focus on project founders, project maintainers, and contributors.
|
||||
|
||||
### Project constituents
|
||||
|
||||
While this is by no means an exhaustive list of questions these constituents might feel are important, these choices felt like a good place to start. Each of the Goal-Question-Metric segments below is directly tied to metrics that the CHAOSS project is collecting and aggregating.
|
||||
|
||||
Now, on to Part 1 of the analysis!
|
||||
|
||||
#### Project founders
|
||||
|
||||
As a **project founder**, I care **most** about:
|
||||
|
||||
* Is my project **useful to others?** Measured as a function of:
|
||||
|
||||
* How many forks over time?
|
||||
**Metric:** Repository forks.
|
||||
|
||||
* How many contributors over time?
|
||||
**Metric:** Contributor count.
|
||||
|
||||
* Net quality of contributions.
|
||||
**Metric:** Bugs filed over time.
|
||||
**Metric:** Regressions over time.
|
||||
|
||||
* Financial health of my project.
|
||||
**Metric:** Donations/Revenue over time.
|
||||
**Metric:** Expenses over time.
|
||||
|
||||
* How **visible** is my project to others?
|
||||
|
||||
* Does anyone know about my project? Do others think it’s neat?
|
||||
**Metric:** Social media mentions, shares, likes, and subscriptions.
|
||||
|
||||
* Does anyone with influence know about my project?
|
||||
**Metric:** Social reach of contributors.
|
||||
|
||||
* What are people saying about the project in public spaces? Is it positive or negative?
|
||||
**Metric:** Sentiment (keyword or NLP) analysis across social media channels.
|
||||
|
||||
* How **viable** is my project?
|
||||
|
||||
* Do we have enough maintainers? Is the number rising or falling over time?
|
||||
**Metric:** Number of maintainers.
|
||||
|
||||
* Do we have enough contributors? Is the number rising or falling over time?
|
||||
**Metric:** Number of contributors.
|
||||
|
||||
* How is velocity changing over time?
|
||||
**Metric:** Percent change of code over time.
|
||||
**Metric:** Time between pull request, code review, and merge.
|
||||
|
||||
* How [**diverse & inclusive**][4] is my project?
|
||||
|
||||
* Do we have a valid, public, Code of Conduct (CoC)?
|
||||
**Metric:** CoC repository file check.
|
||||
|
||||
* Are events associated with my project actively inclusive?
|
||||
**Metric:** Manual reporting on event ticketing policies and event inclusion activities.
|
||||
|
||||
* Does our project do a good job of being accessible?
|
||||
**Metric:** Validation of typed meeting minutes being posted.
|
||||
**Metric:** Validation of closed captioning used during meetings.
|
||||
**Metric:** Validation of color-blind-accessible materials in presentations and in project front-end designs.
|
||||
|
||||
* How much [**value**][7] does my project represent?
|
||||
|
||||
* How can I help organizations understand how much time and money using our project would save them (labor investment)
|
||||
**Metric:** Repo count of issues, commits, pull requests, and the estimated labor rate.
|
||||
|
||||
* How can I understand the amount of downstream value my project creates and how vital (or not) it is to the wider community to maintain my project?
|
||||
**Metric:** Repo count of how many other projects rely on my project.
|
||||
|
||||
* How much opportunity is there for those contributing to my project to use what they learn working on it to land good jobs and at what organizations (aka living wage)?
|
||||
**Metric:** Count of organizations using or contributing to this library.
|
||||
**Metric:** Averages of salaries for developers working with this kind of project.
|
||||
**Metric:** Count of job postings with keywords that match this project.
|
||||
|
||||
|
||||
|
||||
|
||||
### Project maintainers
|
||||
|
||||
As a **Project Maintainer,** I care **most** about:
|
||||
|
||||
* Am I an **efficient** maintainer?
|
||||
**Metric:** Time PR’s wait before a code review.
|
||||
**Metric:** Time between code review and subsequent PR’s.
|
||||
**Metric:** How many of my code reviews are approvals?
|
||||
**Metric:** How many of my code reviews are rejections/rework requests?
|
||||
**Metric:** Sentiment analysis of code review comments.
|
||||
|
||||
* How do I get **more people** to help me maintain this thing?
|
||||
**Metric:** Count of social reach of project contributors.
|
||||
|
||||
* Is our **code quality** getting better or worse over time?
|
||||
**Metric:** Count how many regressions are being introduced over time.
|
||||
**Metric:** Count how many bugs are being introduced over time.
|
||||
**Metric:** Time between bug filing, pull request, review, merge, and release.
|
||||
|
||||
|
||||
|
||||
|
||||
### Project developers and contributors
|
||||
|
||||
As a **project developer or contributor**, I care most about:
|
||||
|
||||
* What things of value can I gain from contributing to this project and how long might it take to realize that value?
|
||||
**Metric:** Downstream value.
|
||||
**Metric:** Time between commits, code reviews, and merges.
|
||||
|
||||
* Are there good prospects for using what I learn by contributing to increase my job opportunities?
|
||||
**Metric:** Living wage.
|
||||
|
||||
* How popular is this project?
|
||||
**Metric:** Counts of social media posts, shares, and favorites.
|
||||
|
||||
* Do community influencers know about my project?
|
||||
**Metric:** Social reach of founders, maintainers, and contributors.
|
||||
|
||||
|
||||
|
||||
|
||||
By creating this list, we’ve just begun to put meat on the contextual bones of CHAOSS, and with the first release of metrics in the project this summer, I can’t wait to see what other great ideas the broader open source community may have to contribute and what else we can all learn (and measure!) from those contributions.
|
||||
|
||||
### Other roles
|
||||
|
||||
Next, you need to learn more about goal-question-metric sets for other roles (such as foundations, corporate open source program offices, business risk and legal teams, human resources, and others) as well as end users, who have a distinctly different set of things they care about when it comes to open source.
|
||||
|
||||
If you’re an open source contributor or constituent, we invite you to [come check out the project][8] and get engaged in the community!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/measure-project
|
||||
|
||||
作者:[Jon Lawrence][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/the3rdlaw
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
|
||||
[2]: https://www.linuxfoundation.org/
|
||||
[3]: https://chaoss.community/
|
||||
[4]: https://github.com/chaoss/wg-diversity-inclusion
|
||||
[5]: https://github.com/chaoss/wg-evolution
|
||||
[6]: https://github.com/chaoss/wg-risk
|
||||
[7]: https://github.com/chaoss/wg-value
|
||||
[8]: https://github.com/chaoss/
|
||||
@ -0,0 +1,88 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cloud-native Java, open source security, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/19/8/cloud-native-java-and-more)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
Cloud-native Java, open source security, and more industry trends
|
||||
======
|
||||
A weekly look at open source community and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [Why is modern web development so complicated?][2]
|
||||
|
||||
> Modern frontend web development is a polarizing experience: many love it, others despise it.
|
||||
>
|
||||
> I am a huge fan of modern web development, though I would describe it as "magical"—and magic has its upsides and downsides... Recently I’ve been needing to explain “modern web development workflows” to folks who only have a cursory of vanilla web development workflows and… It is a LOT to explain! Even a hasty explanation ends up being pretty long. So in the effort of writing more of my explanations down, here is the beginning of a long yet hasty explanation of the evolution of web development..
|
||||
|
||||
**The impact:** Specific enough to be useful to (especially new) frontend developers, but simple and well explained enough to help non-developers understand better some of the frontend developer problems. By the end, you'll (kinda) know the difference between Javascript and WebAPIs and how 2019 Javascript is different than 2006 Javascript.
|
||||
|
||||
## [Open sourcing the Kubernetes security audit][3]
|
||||
|
||||
> Last year, the Cloud Native Computing Foundation (CNCF) began the process of performing and open sourcing third-party security audits for its projects in order to improve the overall security of our ecosystem. The idea was to start with a handful of projects and gather feedback from the CNCF community as to whether or not this pilot program was useful. The first projects to undergo this process were [CoreDNS][4], [Envoy][5] and [Prometheus][6]. These first public audits identified security issues from general weaknesses to critical vulnerabilities. With these results, project maintainers for CoreDNS, Envoy and Prometheus have been able to address the identified vulnerabilities and add documentation to help users.
|
||||
>
|
||||
> The main takeaway from these initial audits is that a public security audit is a great way to test the quality of an open source project along with its vulnerability management process and more importantly, how resilient the open source project’s security practices are. With CNCF [graduated projects][7] especially, which are used widely in production by some of the largest companies in the world, it is imperative that they adhere to the highest levels of security best practices.
|
||||
|
||||
**The impact:** A lot of companies are placing big bets on Kubernetes being to the cloud what Linux is to that data center. Seeing 4 of those companies working together to make sure the project is doing what it should be from a security perspective inspires confidence. Sharing that research shows that open source is so much more than code in a repository; it is the capturing and sharing of expert opinions in a way that benefits the community at large rather than the interests of a few.
|
||||
|
||||
## [Quarkus—what's next for the lightweight Java framework?][8]
|
||||
|
||||
> What does “container first” mean? What are the strengths of Quarkus? What’s new in 0.20.0? What features can we look forward to in the future? When will version 1.0.0 be released? We have so many questions about Quarkus and Alex Soto was kind enough to answer them all. _With the release of Quarkus 0.20.0, we decided to get in touch with [JAX London speaker][9], Java Champion, and Director of Developer Experience at Red Hat – Alex Soto. He was kind enough to answer all our questions about the past, present, and future of Quarkus. It seems like we have a lot to look forward to with this exciting lightweight framework!_
|
||||
|
||||
**The impact**: Someone clever recently told me that Quarkus has the potential to make Java "possibly one of the best languages for containers and serverless environments". That made me do a double-take; while Java is one of the most popular programming languages ([if not the most popular][10]) it probably isn't the first one that jumps to mind when you hear the words "cloud native." Quarkus could extend and grow the value of the skills held by a huge chunk of the developer workforce by allowing them to apply their experience to new challenges.
|
||||
|
||||
## [Julia programming language: Users reveal what they love and hate the most about it][11]
|
||||
|
||||
> The most popular technical feature of Julia is speed and performance followed by ease of use, while the most popular non-technical feature is that users don't have to pay to use it.
|
||||
>
|
||||
> Users also report their biggest gripes with the language. The top one is that packages for add-on features aren't sufficiently mature or well maintained to meet their needs.
|
||||
|
||||
**The impact:** The Julia 1.0 release has been out for a year now, and has seen impressive growth in a bunch of relevant metrics (downloads, GitHub stars, etc). It is a language aimed squarely at some of our biggest current and future challenges ("scientific computing, machine learning, data mining, large-scale linear algebra, distributed and parallel computing") so finding out how it's users are feeling about it gives an indirect read on how well those challenges are being addressed.
|
||||
|
||||
## [Multi-cloud by the numbers: 11 interesting stats][12]
|
||||
|
||||
> If you boil our recent dive into [interesting stats about Kubernetes][13] down to its bottom line, it looks something like this: [Kubernetes'][14] popularity will continue for the foreseeable future.
|
||||
>
|
||||
> Spoiler alert: When you dig up recent numbers about [multi-cloud][15] usage, they tell a similar story: Adoption is soaring.
|
||||
>
|
||||
> This congruity makes sense. Perhaps not every organization will use Kubernetes to manage its multi-cloud and/or [hybrid cloud][16] infrastructure, but the two increasingly go hand-in-hand. Even when they don’t, they both reflect a general shift toward more distributed and heterogeneous IT environments, as well as [cloud-native development][17] and other overlapping trends.
|
||||
|
||||
**The impact**: Another explanation of increasing adoption of "multi-cloud strategies" is they retroactively legitimize decisions taken in separate parts of an organization without consultation as "strategic." "Wait, so you bought hours from who? And you bought hours from the other one? Why wasn't that in the meeting minutes? I guess we're a multi-cloud company now!" Of course I'm joking, I'm sure most big companies are a lot better coordinated than that, right?
|
||||
|
||||
_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/cloud-native-java-and-more
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://www.vrk.dev/2019/07/11/why-is-modern-web-development-so-complicated-a-long-yet-hasty-explanation-part-1/
|
||||
[3]: https://www.cncf.io/blog/2019/08/06/open-sourcing-the-kubernetes-security-audit/
|
||||
[4]: https://coredns.io/2018/03/15/cure53-security-assessment/
|
||||
[5]: https://github.com/envoyproxy/envoy/blob/master/docs/SECURITY_AUDIT.pdf
|
||||
[6]: https://cure53.de/pentest-report_prometheus.pdf
|
||||
[7]: https://www.cncf.io/projects/
|
||||
[8]: https://jaxenter.com/quarkus-whats-next-for-the-lightweight-java-framework-160793.html
|
||||
[9]: https://jaxlondon.com/cloud-kubernetes-serverless/java-particle-acceleration-using-quarkus/
|
||||
[10]: https://opensource.com/article/19/8/possibly%20one%20of%20the%20best%20languages%20for%20containers%20and%20serverless%20environments.
|
||||
[11]: https://www.zdnet.com/article/julia-programming-language-users-reveal-what-they-love-and-hate-the-most-about-it/#ftag=RSSbaffb68
|
||||
[12]: https://enterprisersproject.com/article/2019/8/multi-cloud-statistics
|
||||
[13]: https://enterprisersproject.com/article/2019/7/kubernetes-statistics-13-compelling
|
||||
[14]: https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=701f2000000tjyaAAA
|
||||
[15]: https://www.redhat.com/en/topics/cloud-computing/what-is-multicloud?intcmp=701f2000000tjyaAAA
|
||||
[16]: https://enterprisersproject.com/hybrid-cloud
|
||||
[17]: https://enterprisersproject.com/article/2018/10/how-explain-cloud-native-apps-plain-english
|
||||
240
sources/tech/20190812 How Hexdump works.md
Normal file
240
sources/tech/20190812 How Hexdump works.md
Normal file
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How Hexdump works)
|
||||
[#]: via: (https://opensource.com/article/19/8/dig-binary-files-hexdump)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/shishz)
|
||||
|
||||
How Hexdump works
|
||||
======
|
||||
Hexdump helps you investigate the contents of binary files. Learn how
|
||||
hexdump works.
|
||||
![Magnifying glass on code][1]
|
||||
|
||||
Hexdump is a utility that displays the contents of binary files in hexadecimal, decimal, octal, or ASCII. It’s a utility for inspection and can be used for [data recovery][2], reverse engineering, and programming.
|
||||
|
||||
### Learning the basics
|
||||
|
||||
Hexdump provides output with very little effort on your part and depending on the size of the file you’re looking at, there can be a lot of output. For the purpose of this article, create a 1x1 PNG file. You can do this with a graphics application such as [GIMP][3] or [Mtpaint][4], or you can create it in a terminal with [ImageMagick][5].
|
||||
|
||||
Here’s a command to generate a 1x1 pixel PNG with ImageMagick:
|
||||
|
||||
|
||||
```
|
||||
$ convert -size 1x1 canvas:black pixel.png
|
||||
```
|
||||
|
||||
You can confirm that this file is a PNG with the **file** command:
|
||||
|
||||
|
||||
```
|
||||
$ file pixel.png
|
||||
pixel.png: PNG image data, 1 x 1, 1-bit grayscale, non-interlaced
|
||||
```
|
||||
|
||||
You may wonder how the **file** command is able to determine what kind of file it is. Coincidentally, that’s what **hexdump** will reveal. For now, you can view your one-pixel graphic in the image viewer of your choice (it looks like this: **.** ), or you can view what’s inside the file with **hexdump**:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a 0000 0d00 4849 5244
|
||||
0000010 0000 0100 0000 0100 0001 0000 3700 f96e
|
||||
0000020 0024 0000 6704 4d41 0041 b100 0b8f 61fc
|
||||
0000030 0005 0000 6320 5248 004d 7a00 0026 8000
|
||||
0000040 0084 fa00 0000 8000 00e8 7500 0030 ea00
|
||||
0000050 0060 3a00 0098 1700 9c70 51ba 003c 0000
|
||||
0000060 6202 474b 0044 dd01 138a 00a4 0000 7407
|
||||
0000070 4d49 0745 07e3 081a 3539 a487 46b0 0000
|
||||
0000080 0a00 4449 5441 d708 6063 0000 0200 0100
|
||||
0000090 21e2 33bc 0000 2500 4574 7458 6164 6574
|
||||
00000a0 633a 6572 7461 0065 3032 3931 302d 2d37
|
||||
00000b0 3532 3254 3a30 3735 353a 2b33 3231 303a
|
||||
00000c0 ac30 5dcd 00c1 0000 7425 5845 6474 7461
|
||||
00000d0 3a65 6f6d 6964 7966 3200 3130 2d39 3730
|
||||
00000e0 322d 5435 3032 353a 3a37 3335 312b 3a32
|
||||
00000f0 3030 90dd 7de5 0000 0000 4549 444e 42ae
|
||||
0000100 8260
|
||||
0000102
|
||||
```
|
||||
|
||||
What you’re seeing is the contents of the sample PNG file through a lens you may have never used before. It’s the exact same data you see in an image viewer, encoded in a way that’s probably unfamiliar to you.
|
||||
|
||||
### Extracting familiar strings
|
||||
|
||||
Just because the default data dump seems meaningless, that doesn’t mean it’s devoid of valuable information. You can translate this output or at least the parts that actually translate, to a more familiar character set with the **\--canonical** option:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump --canonical foo.png
|
||||
00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
|
||||
00000010 00 00 00 01 00 00 00 01 01 00 00 00 00 37 6e f9 |.............7n.|
|
||||
00000020 24 00 00 00 04 67 41 4d 41 00 00 b1 8f 0b fc 61 |$....gAMA......a|
|
||||
00000030 05 00 00 00 20 63 48 52 4d 00 00 7a 26 00 00 80 |.... cHRM..z&...|
|
||||
00000040 84 00 00 fa 00 00 00 80 e8 00 00 75 30 00 00 ea |...........u0...|
|
||||
00000050 60 00 00 3a 98 00 00 17 70 9c ba 51 3c 00 00 00 |`..:....p..Q<...|
|
||||
00000060 02 62 4b 47 44 00 01 dd 8a 13 a4 00 00 00 07 74 |.bKGD..........t|
|
||||
00000070 49 4d 45 07 e3 07 1a 08 39 35 87 a4 b0 46 00 00 |IME.....95...F..|
|
||||
00000080 00 0a 49 44 41 54 08 d7 63 60 00 00 00 02 00 01 |..IDAT..c`......|
|
||||
00000090 e2 21 bc 33 00 00 00 25 74 45 58 74 64 61 74 65 |.!.3...%tEXtdate|
|
||||
000000a0 3a 63 72 65 61 74 65 00 32 30 31 39 2d 30 37 2d |:create.2019-07-|
|
||||
000000b0 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a 30 |25T20:57:53+12:0|
|
||||
000000c0 30 ac cd 5d c1 00 00 00 25 74 45 58 74 64 61 74 |0..]....%tEXtdat|
|
||||
000000d0 65 3a 6d 6f 64 69 66 79 00 32 30 31 39 2d 30 37 |e:modify.2019-07|
|
||||
000000e0 2d 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a |-25T20:57:53+12:|
|
||||
000000f0 30 30 dd 90 e5 7d 00 00 00 00 49 45 4e 44 ae 42 |00...}....IEND.B|
|
||||
00000100 60 82 |`.|
|
||||
00000102
|
||||
```
|
||||
|
||||
In the right column, you see the same data that’s on the left but presented as ASCII. If you look carefully, you can pick out some useful information, such as the file’s format (PNG) and—toward the bottom—the date and time the file was created and last modified. The dots represent symbols that aren’t present in the ASCII character set, which is to be expected because binary formats aren’t restricted to mundane letters and numbers.
|
||||
|
||||
The **file** command knows from the first 8 bytes what this file is. The [libpng specification][6] alerts programmers what to look for. You can see that within the first 8 bytes of this image file, specifically, is the string **PNG**. That fact is significant because it reveals how the **file** command knows what kind of file to report.
|
||||
|
||||
You can also control how many bytes **hexdump** displays, which is useful with files larger than one pixel:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump --length 8 pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a
|
||||
0000008
|
||||
```
|
||||
|
||||
You don’t have to limit **hexdump** to PNG or graphic files. You can run **hexdump** against binaries you run on a daily basis as well, such as [ls][7], [rsync][8], or any binary format you want to inspect.
|
||||
|
||||
### Implementing cat with hexdump
|
||||
|
||||
If you read the PNG spec, you may notice that the data in the first 8 bytes looks different than what **hexdump** provides. Actually, it’s the same data, but it’s presented using a different conversion. So, the output of **hexdump** is true, but not always directly useful to you, depending on what you’re looking for. For that reason, **hexdump** has options to format and convert the raw data it dumps.
|
||||
|
||||
The conversion options can get complex, so it’s useful to practice with something trivial first. Here’s a gentle introduction to formatting **hexdump** output by reimplementing the [**cat**][9] command. First, run **hexdump** on a text file to see its raw data. You can usually find a copy of the [GNU General Public License (GPL)][10] license somewhere on your hard drive, or you can use any text file you have handy. Your output may differ, but here’s how to find a copy of the GPL on your system (or at least part of it):
|
||||
|
||||
|
||||
```
|
||||
$ find /usr/share/doc/ -type f -name "COPYING" | tail -1
|
||||
/usr/share/doc/libblkid-devel/COPYING
|
||||
```
|
||||
|
||||
Run **hexdump** against it:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump /usr/share/doc/libblkid-devel/COPYING
|
||||
0000000 6854 7369 6c20 6269 6172 7972 6920 2073
|
||||
0000010 7266 6565 7320 666f 7774 7261 3b65 7920
|
||||
0000020 756f 6320 6e61 7220 6465 7369 7274 6269
|
||||
0000030 7475 2065 7469 6120 646e 6f2f 0a72 6f6d
|
||||
0000040 6964 7966 6920 2074 6e75 6564 2072 6874
|
||||
0000050 2065 6574 6d72 2073 666f 7420 6568 4720
|
||||
0000060 554e 4c20 7365 6573 2072 6547 656e 6172
|
||||
0000070 206c 7550 6c62 6369 4c0a 6369 6e65 6573
|
||||
0000080 6120 2073 7570 6c62 7369 6568 2064 7962
|
||||
[...]
|
||||
```
|
||||
|
||||
If the file’s output is very long, use the **\--length** (or **-n** for short) to make it manageable for yourself.
|
||||
|
||||
The raw data probably means nothing to you, but you already know how to convert it to ASCII:
|
||||
|
||||
|
||||
```
|
||||
hexdump --canonical /usr/share/doc/libblkid-devel/COPYING
|
||||
00000000 54 68 69 73 20 6c 69 62 72 61 72 79 20 69 73 20 |This library is |
|
||||
00000010 66 72 65 65 20 73 6f 66 74 77 61 72 65 3b 20 79 |free software; y|
|
||||
00000020 6f 75 20 63 61 6e 20 72 65 64 69 73 74 72 69 62 |ou can redistrib|
|
||||
00000030 75 74 65 20 69 74 20 61 6e 64 2f 6f 72 0a 6d 6f |ute it and/or.mo|
|
||||
00000040 64 69 66 79 20 69 74 20 75 6e 64 65 72 20 74 68 |dify it under th|
|
||||
00000050 65 20 74 65 72 6d 73 20 6f 66 20 74 68 65 20 47 |e terms of the G|
|
||||
00000060 4e 55 20 4c 65 73 73 65 72 20 47 65 6e 65 72 61 |NU Lesser Genera|
|
||||
00000070 6c 20 50 75 62 6c 69 63 0a 4c 69 63 65 6e 73 65 |l Public.License|
|
||||
[...]
|
||||
```
|
||||
|
||||
That output is helpful but unwieldy and difficult to read. To format **hexdump**’s output beyond what’s offered by its own options, use **\--format** (or **-e**) along with specialized formatting codes. The shorthand used for formatting is similar to what the **printf** command uses, so if you are familiar with **printf** statements, you may find **hexdump** formatting easier to learn.
|
||||
|
||||
In **hexdump**, the character sequence **%_p** tells **hexdump** to print a character in your system’s default character set. All formatting notation for the **\--format** option must be enclosed in _single quotes_:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -e'"%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is fre*
|
||||
software; you can redistribute it and/or.modify it under the terms of the GNU Les*
|
||||
er General Public.License as published by the Fre*
|
||||
Software Foundation; either.version 2.1 of the License, or (at your option) any later.version..*
|
||||
The complete text of the license is available in the..*
|
||||
/Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
This output is better, but still inconvenient to read. Traditionally, UNIX text files assume an 80-character output width (because long ago, monitors tended to fit only 80 characters across).
|
||||
|
||||
While this output isn’t bound by formatting, you can force **hexdump** to process 80 bytes at a time with additional options. Specifically, by dividing 80 by one, you can tell **hexdump** to treat 80 bytes as one unit:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is free software; you can redistribute it and/or.modify it under the terms of the GNU Lesser General Public.License as published by the Free Software Foundation; either.version 2.1 of the License, or (at your option) any later.version...The complete text of the license is available in the.../Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
Now the file is processed in 80-byte chunks, but it’s lost any sense of new lines. You can add your own with the **\n** character, which in UNIX represents a new line:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p""\n"'
|
||||
This library is free software; you can redistribute it and/or.modify it under th
|
||||
e terms of the GNU Lesser General Public.License as published by the Free Softwa
|
||||
re Foundation; either.version 2.1 of the License, or (at your option) any later.
|
||||
version...The complete text of the license is available in the.../Documentation/
|
||||
licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
You have now (approximately) implemented the **cat** command with **hexdump** formatting.
|
||||
|
||||
### Controlling the output
|
||||
|
||||
Formatting is, realistically, how you make **hexdump** useful. Now that you’re familiar, in principle at least, with **hexdump** formatting, you can make the output of **hexdump -n 8** match the output of the PNG header as described by the official **libpng** spec.
|
||||
|
||||
First, you know that you want **hexdump** to process the PNG file in 8-byte chunks. Furthermore, you may know by integer recognition that the PNG spec is documented in decimal, which is represented by **%d** according to the **hexdump** documentation:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d""\n"' pixel.png
|
||||
13780787113102610
|
||||
```
|
||||
|
||||
You can make the output perfect by adding a blank space after each integer:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d ""\n"' pixel.png
|
||||
137 80 78 71 13 10 26 10
|
||||
```
|
||||
|
||||
The output is now a perfect match to the PNG specification.
|
||||
|
||||
### Hexdumping for fun and profit
|
||||
|
||||
Hexdump is a fascinating tool that not only teaches you more about how computers process and convert information, but also about how file formats and compiled binaries function. You should try running **hexdump** on files at random throughout the day as you work. You never know what kinds of information you may find, nor when having that insight may be useful.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/dig-binary-files-hexdump
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/shishz
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||
[2]: https://www.redhat.com/sysadmin/find-lost-files-scalpel
|
||||
[3]: http://gimp.org
|
||||
[4]: https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs
|
||||
[5]: https://opensource.com/article/17/8/imagemagick
|
||||
[6]: http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html
|
||||
[7]: https://opensource.com/article/19/7/master-ls-command
|
||||
[8]: https://opensource.com/article/19/5/advanced-rsync
|
||||
[9]: https://opensource.com/article/19/2/getting-started-cat-command
|
||||
[10]: https://en.wikipedia.org/wiki/GNU_General_Public_License
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-hwe-kernel/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS
|
||||
======
|
||||
|
||||
_**The recently released Ubuntu 18.04.3 includes Linux Kernel 5.0 among several new features and improvements but you won’t get it by default. This tutorial demonstrates how to get Linux Kernel 5 in Ubuntu 18.04 LTS.**_
|
||||
|
||||
[Subscribe to It’s FOSS YouTube Channel for More Videos][1]
|
||||
|
||||
The [third point release of Ubuntu 18.04 is here][2] and it brings new stable versions of GNOME component, livepatch desktop integration and kernel 5.0.
|
||||
|
||||
But wait! What is a point release? Let me explain it to you first.
|
||||
|
||||
### Ubuntu LTS point release
|
||||
|
||||
Ubuntu 18.04 was released in April 2018 and since it’s a long term support (LTS) release, it will be supported till 2023. There have been a number of bug fixes, security updates and software upgrades since then. If you download Ubuntu 18.04 today, you’ll have to install all those updates as one of the first [things to do after installing Ubuntu 18.04][3].
|
||||
|
||||
That, of course, is not an ideal situation. This is why Ubuntu provides these “point releases”. A point release consists of all the feature and security updates along with the bug fixes that has been added since the initial release of the LTS version. If you download Ubuntu today, you’ll get Ubuntu 18.04.3 instead of Ubuntu 18.04. This saves the trouble of downloading and installing hundreds of updates on a newly installed Ubuntu system.
|
||||
|
||||
Okay! So now you know the concept of point release. How do you upgrade to these point releases? The answer is simple. Just [update your Ubuntu system][4] like you normally do and you’ll be already on the latest point release.
|
||||
|
||||
You can [check Ubuntu version][5] to see which point release you are using. I did a check and since I was on Ubuntu 18.04.3, I assumed that I would have gotten Linux kernel 5 as well. When I [check the Linux kernel version][6], it was still the base kernel 4.15.
|
||||
|
||||
![Ubuntu Version And Linux Kernel Version Check][7]
|
||||
|
||||
Why is that? If Ubuntu 18.04.3 has Linux kernel 5.0 then why does it still have Linux Kernel 4.15? It’s because you have to manually ask for installing the new kernel in Ubuntu LTS by opting for LTS Enablement Stack popularly known as HWE.
|
||||
|
||||
[][8]
|
||||
|
||||
Suggested read Canonical Announces Ubuntu Edge!
|
||||
|
||||
### Get Linux Kernel 5.0 in Ubuntu 18.04 with Hardware Enablement Stack
|
||||
|
||||
By default, Ubuntu LTS release stay on the same Linux kernel they were released with. The [hardware enablement stack][9] (HWE) provides newer kernel and xorg support for existing Ubuntu LTS release.
|
||||
|
||||
Things have been changed recently. If you downloaded Ubuntu 18.04.2 or newer desktop version, HWE is enabled for you and you’ll get the new kernel along with the regular updates by default.
|
||||
|
||||
For server versions and people who downloaded 18.04 and 18.04.1, you’ll have to install the HWE kernel. Once you do that, you’ll get the newer kernel releases provided by Ubuntu to the LTS version.
|
||||
|
||||
To install HWE kernel in Ubuntu desktop along with newer xorg, you can use this command in the terminal:
|
||||
|
||||
```
|
||||
sudo apt install --install-recommends linux-generic-hwe-18.04 xserver-xorg-hwe-18.04
|
||||
```
|
||||
|
||||
If you are using Ubuntu Server edition, you won’t have the xorg option. So just install the HWE kernel in Ubutnu server:
|
||||
|
||||
```
|
||||
sudo apt-get install --install-recommends linux-generic-hwe-18.04
|
||||
```
|
||||
|
||||
Once you finish installing the HWE kernel, restart your system. Now you should have the newer Linux kernel.
|
||||
|
||||
**Are you getting kernel 5.0 in Ubuntu 18.04?**
|
||||
|
||||
Do note that HWE is enabled for people who downloaded and installed Ubuntu 18.04.2. So these users will get Kernel 5.0 without any trouble.
|
||||
|
||||
Should you go by the trouble of enabling HWE kernel in Ubuntu? It’s entirely up to you. [Linux Kernel 5.0][10] has several performance improvement and better hardware support. You’ll get the benefit of the new kernel.
|
||||
|
||||
What do you think? Will you install kernel 5.0 or will you rather stay on the kernel 4.15?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-hwe-kernel/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/channel/UCEU9D6KIShdLeTRyH3IdSvw
|
||||
[2]: https://ubuntu.com/blog/enhanced-livepatch-desktop-integration-available-with-ubuntu-18-04-3-lts
|
||||
[3]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[4]: https://itsfoss.com/update-ubuntu/
|
||||
[5]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[6]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/ubuntu-version-and-kernel-version-check.png?resize=800%2C300&ssl=1
|
||||
[8]: https://itsfoss.com/canonical-announces-ubuntu-edge/
|
||||
[9]: https://wiki.ubuntu.com/Kernel/LTSEnablementStack
|
||||
[10]: https://itsfoss.com/linux-kernel-5/
|
||||
94
sources/tech/20190812 What open source is not.md
Normal file
94
sources/tech/20190812 What open source is not.md
Normal file
@ -0,0 +1,94 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What open source is not)
|
||||
[#]: via: (https://opensource.com/article/19/8/what-open-source-not)
|
||||
[#]: author: (Gordon Haff https://opensource.com/users/ghaff)
|
||||
|
||||
What open source is not
|
||||
======
|
||||
Here are some things that are not central to what open source is and
|
||||
where it’s going.
|
||||
![Open here.][1]
|
||||
|
||||
From its early days, the availability of source code was one of the defining characteristics of open source software. Indeed, Brian Behlendorf of the Apache web server project, an early open source software success, favored "source code available software."
|
||||
|
||||
Another important aspect related to user rights. Hence, the "free software" terminology that came out of Richard Stallman’s GNU Manifesto and GNU Public License (GPL). As the shorthand went, free was about freedom, not price. [Christine Peterson would later coin "open source"][2] as an alternative that avoided the confusion that regularly arose between these two meanings of free. And that’s the term that’s most widely used today.
|
||||
|
||||
These and other historical contexts still flavor how many think about open source today. Where open source came from should still inform today’s thinking about open source. But it also shouldn’t overly constrain that thinking.
|
||||
|
||||
With that background, here are some things that open source is not, or at least that aren’t central to what open source is and where it’s going.
|
||||
|
||||
### Open source is not licenses
|
||||
|
||||
Licenses as a legal concept remain an important part of open source software’s foundations. But, recent hullabaloo on the topic notwithstanding, licenses are mostly not the central topic that they once were. It’s generally understood that the gamut of licenses from copyleft ones like the GPL family to the various permissionless licenses like the Apache, BSD, and MIT licenses come with various strengths and tradeoffs.
|
||||
|
||||
Today’s projects tend to choose licenses based on practical concerns—with a general overall rise in using permissionless licenses for new projects. The proliferation of new open source licenses has also largely subsided given a broad recognition that the [Open Source Definition (OSD)][3] is well-covered by existing license options.
|
||||
|
||||
(The OSD and the set of approved licenses maintained by the Open Source Initiative (OSI) serve as a generally accepted standard for what constitutes an open source software license. Core principles include free redistribution, providing a means to obtain source code, allowing modifications, and a lack of prohibitions about who can use the software and for what purpose.)
|
||||
|
||||
### Open source is not a buzzword
|
||||
|
||||
Words matter.
|
||||
|
||||
Open source software is popular with users for many reasons. They can acquire the software for free and modify it as needed. They can also purchase commercial products that package up open source projects and support them through a life cycle in ways that are needed for many enterprise production deployments.
|
||||
|
||||
Many users of open source software also view it as a great way to get [access to all of the innovation][4] happening in upstream community projects.
|
||||
|
||||
The term "open source" carries a generally positive vibe in other words.
|
||||
|
||||
But open source also has a specific definition, according to the aforementioned OSD. So you can’t just slap an open source label on your license and software and call it open source if it is not, in fact, open source. Well, no one can stop you, but they can call you out for it. Proprietary software with an open source label doesn’t confer any of the advantages of an open source approach for either you or your users.
|
||||
|
||||
### Open source is not viewing code
|
||||
|
||||
The ability to obtain and view open source code is inherent to open source’s definition. But viewing isn’t the interesting part.
|
||||
|
||||
If I write something and put it up on a public repo under an open source license and call it a day, that’s not a very interesting act. It’s _possible_ that there’s enough value in just the code that someone else will fork the software and do something useful with it.
|
||||
|
||||
However, for the most part, if I don’t invite contributions or otherwise make an effort to form a community around the project and codebase, it’s unlikely to gain traction. And, if no one is around to look at the code, does it really matter that it’s possible to do so?
|
||||
|
||||
### Open source is not a business model
|
||||
|
||||
It’s common to hear people talk about "open source business models." I’m going to be just a bit pedantic and argue that there’s no such thing.
|
||||
|
||||
It’s not that open source doesn’t intersect with and influence business models. Of course, it does. Most obviously, open source tends to preclude business models that depend in whole—or in significant part—on restricting access to software that has not been purchased in some manner.
|
||||
|
||||
Conversely, participation in upstream open source communities can create opportunities that otherwise wouldn’t exist. For example, companies can share the effort of writing common infrastructure software with competitors while focusing on those areas of their business where they think they can add unique value—their secret sauce if you will.
|
||||
|
||||
However, thinking of open source itself as a business model is, I would argue, the wrong framing. It draws attention away from thinking about business models in terms of sustainable company objectives and differentiation.
|
||||
|
||||
### Open source is...
|
||||
|
||||
Which brings us to a key aspect of open source, as it’s developed into such an important part of the software landscape.
|
||||
|
||||
Open source preserves user freedoms and provides users with the strategic flexibility to shift vendors and technologies to a degree that’s rarely possible with proprietary software. That’s a given.
|
||||
|
||||
Open source has also emerged as a great model for collaborative software development.
|
||||
|
||||
But taking full advantage of that model requires embracing it and not just adopting some superficial trappings.
|
||||
|
||||
Are there challenges associated with creating and executing business models that depend in large part on open source software today? Certainly. But those challenges have always existed even if large cloud providers have arguably dialed up the degree of difficulty. And, truly, building sustainable software businesses has never been easy.
|
||||
|
||||
Open source software is increasingly an integral part of most software businesses. That fact introduces some new challenges. But it also opens up new possibilities.
|
||||
|
||||
**Watch: Gordon Haff and Spender Krum discuss this topic IBM Think 2019**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/what-open-source-not
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ghaff
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OPENHERE_green.png?itok=4kTXtbNP (Open here.)
|
||||
[2]: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
[3]: https://opensource.org/osd
|
||||
[4]: https://www.redhat.com/en/enterprise-open-source-report/2019
|
||||
402
sources/tech/20190812 Why const Doesn-t Make C Code Faster.md
Normal file
402
sources/tech/20190812 Why const Doesn-t Make C Code Faster.md
Normal file
@ -0,0 +1,402 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LazyWolfLin)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why const Doesn't Make C Code Faster)
|
||||
[#]: via: (https://theartofmachinery.com/2019/08/12/c_const_isnt_for_performance.html)
|
||||
[#]: author: (Simon Arneaud https://theartofmachinery.com)
|
||||
|
||||
Why const Doesn't Make C Code Faster
|
||||
======
|
||||
|
||||
In a post a few months back I said [it’s a popular myth that `const` is helpful for enabling compiler optimisations in C and C++][1]. I figured I should explain that one, especially because I used to believe it was obviously true, myself. I’ll start off with some theory and artificial examples, then I’ll do some experiments and benchmarks on a real codebase: Sqlite.
|
||||
|
||||
### A simple test
|
||||
|
||||
Let’s start with what I used to think was the simplest and most obvious example of how `const` can make C code faster. First, let’s say we have these two function declarations:
|
||||
|
||||
```
|
||||
void func(int *x);
|
||||
void constFunc(const int *x);
|
||||
```
|
||||
|
||||
And suppose we have these two versions of some code:
|
||||
|
||||
```
|
||||
void byArg(int *x)
|
||||
{
|
||||
printf("%d\n", *x);
|
||||
func(x);
|
||||
printf("%d\n", *x);
|
||||
}
|
||||
|
||||
void constByArg(const int *x)
|
||||
{
|
||||
printf("%d\n", *x);
|
||||
constFunc(x);
|
||||
printf("%d\n", *x);
|
||||
}
|
||||
```
|
||||
|
||||
To do the `printf()`, the CPU has to fetch the value of `*x` from RAM through the pointer. Obviously, `constByArg()` can be made slightly faster because the compiler knows that `*x` is constant, so there’s no need to load its value a second time after `constFunc()` does its thing. It’s just printing the same thing. Right? Let’s see the assembly code generated by GCC with optimisations cranked up:
|
||||
|
||||
```
|
||||
$ gcc -S -Wall -O3 test.c
|
||||
$ view test.s
|
||||
```
|
||||
|
||||
Here’s the full assembly output for `byArg()`:
|
||||
|
||||
```
|
||||
byArg:
|
||||
.LFB23:
|
||||
.cfi_startproc
|
||||
pushq %rbx
|
||||
.cfi_def_cfa_offset 16
|
||||
.cfi_offset 3, -16
|
||||
movl (%rdi), %edx
|
||||
movq %rdi, %rbx
|
||||
leaq .LC0(%rip), %rsi
|
||||
movl $1, %edi
|
||||
xorl %eax, %eax
|
||||
call __printf_chk@PLT
|
||||
movq %rbx, %rdi
|
||||
call func@PLT # The only instruction that's different in constFoo
|
||||
movl (%rbx), %edx
|
||||
leaq .LC0(%rip), %rsi
|
||||
xorl %eax, %eax
|
||||
movl $1, %edi
|
||||
popq %rbx
|
||||
.cfi_def_cfa_offset 8
|
||||
jmp __printf_chk@PLT
|
||||
.cfi_endproc
|
||||
```
|
||||
|
||||
The only difference between the generated assembly code for `byArg()` and `constByArg()` is that `constByArg()` has a `call constFunc@PLT`, just like the source code asked. The `const` itself has literally made zero difference.
|
||||
|
||||
Okay, that’s GCC. Maybe we just need a sufficiently smart compiler. Is Clang any better?
|
||||
|
||||
```
|
||||
$ clang -S -Wall -O3 -emit-llvm test.c
|
||||
$ view test.ll
|
||||
```
|
||||
|
||||
Here’s the IR. It’s more compact than assembly, so I’ll dump both functions so you can see what I mean by “literally zero difference except for the call”:
|
||||
|
||||
```
|
||||
; Function Attrs: nounwind uwtable
|
||||
define dso_local void @byArg(i32*) local_unnamed_addr #0 {
|
||||
%2 = load i32, i32* %0, align 4, !tbaa !2
|
||||
%3 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %2)
|
||||
tail call void @func(i32* %0) #4
|
||||
%4 = load i32, i32* %0, align 4, !tbaa !2
|
||||
%5 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %4)
|
||||
ret void
|
||||
}
|
||||
|
||||
; Function Attrs: nounwind uwtable
|
||||
define dso_local void @constByArg(i32*) local_unnamed_addr #0 {
|
||||
%2 = load i32, i32* %0, align 4, !tbaa !2
|
||||
%3 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %2)
|
||||
tail call void @constFunc(i32* %0) #4
|
||||
%4 = load i32, i32* %0, align 4, !tbaa !2
|
||||
%5 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %4)
|
||||
ret void
|
||||
}
|
||||
```
|
||||
|
||||
### Something that (sort of) works
|
||||
|
||||
Here’s some code where `const` actually does make a difference:
|
||||
|
||||
```
|
||||
void localVar()
|
||||
{
|
||||
int x = 42;
|
||||
printf("%d\n", x);
|
||||
constFunc(&x);
|
||||
printf("%d\n", x);
|
||||
}
|
||||
|
||||
void constLocalVar()
|
||||
{
|
||||
const int x = 42; // const on the local variable
|
||||
printf("%d\n", x);
|
||||
constFunc(&x);
|
||||
printf("%d\n", x);
|
||||
}
|
||||
```
|
||||
|
||||
Here’s the assembly for `localVar()`, which has two instructions that have been optimised out of `constLocalVar()`:
|
||||
|
||||
```
|
||||
localVar:
|
||||
.LFB25:
|
||||
.cfi_startproc
|
||||
subq $24, %rsp
|
||||
.cfi_def_cfa_offset 32
|
||||
movl $42, %edx
|
||||
movl $1, %edi
|
||||
movq %fs:40, %rax
|
||||
movq %rax, 8(%rsp)
|
||||
xorl %eax, %eax
|
||||
leaq .LC0(%rip), %rsi
|
||||
movl $42, 4(%rsp)
|
||||
call __printf_chk@PLT
|
||||
leaq 4(%rsp), %rdi
|
||||
call constFunc@PLT
|
||||
movl 4(%rsp), %edx # not in constLocalVar()
|
||||
xorl %eax, %eax
|
||||
movl $1, %edi
|
||||
leaq .LC0(%rip), %rsi # not in constLocalVar()
|
||||
call __printf_chk@PLT
|
||||
movq 8(%rsp), %rax
|
||||
xorq %fs:40, %rax
|
||||
jne .L9
|
||||
addq $24, %rsp
|
||||
.cfi_remember_state
|
||||
.cfi_def_cfa_offset 8
|
||||
ret
|
||||
.L9:
|
||||
.cfi_restore_state
|
||||
call __stack_chk_fail@PLT
|
||||
.cfi_endproc
|
||||
```
|
||||
|
||||
The LLVM IR is a little clearer. The `load` just before the second `printf()` call has been optimised out of `constLocalVar()`:
|
||||
|
||||
```
|
||||
; Function Attrs: nounwind uwtable
|
||||
define dso_local void @localVar() local_unnamed_addr #0 {
|
||||
%1 = alloca i32, align 4
|
||||
%2 = bitcast i32* %1 to i8*
|
||||
call void @llvm.lifetime.start.p0i8(i64 4, i8* nonnull %2) #4
|
||||
store i32 42, i32* %1, align 4, !tbaa !2
|
||||
%3 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 42)
|
||||
call void @constFunc(i32* nonnull %1) #4
|
||||
%4 = load i32, i32* %1, align 4, !tbaa !2
|
||||
%5 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %4)
|
||||
call void @llvm.lifetime.end.p0i8(i64 4, i8* nonnull %2) #4
|
||||
ret void
|
||||
}
|
||||
```
|
||||
|
||||
Okay, so, `constLocalVar()` has sucessfully elided the reloading of `*x`, but maybe you’ve noticed something a bit confusing: it’s the same `constFunc()` call in the bodies of `localVar()` and `constLocalVar()`. If the compiler can deduce that `constFunc()` didn’t modify `*x` in `constLocalVar()`, why can’t it deduce that the exact same function call didn’t modify `*x` in `localVar()`?
|
||||
|
||||
The explanation gets closer to the heart of why C `const` is impractical as an optimisation aid. C `const` effectively has two meanings: it can mean the variable is a read-only alias to some data that may or may not be constant, or it can mean the variable is actually constant. If you cast away `const` from a pointer to a constant value and then write to it, the result is undefined behaviour. On the other hand, it’s okay if it’s just a `const` pointer to a value that’s not constant.
|
||||
|
||||
This possible implementation of `constFunc()` shows what that means:
|
||||
|
||||
```
|
||||
// x is just a read-only pointer to something that may or may not be a constant
|
||||
void constFunc(const int *x)
|
||||
{
|
||||
// local_var is a true constant
|
||||
const int local_var = 42;
|
||||
|
||||
// Definitely undefined behaviour by C rules
|
||||
doubleIt((int*)&local_var);
|
||||
// Who knows if this is UB?
|
||||
doubleIt((int*)x);
|
||||
}
|
||||
|
||||
void doubleIt(int *x)
|
||||
{
|
||||
*x *= 2;
|
||||
}
|
||||
```
|
||||
|
||||
`localVar()` gave `constFunc()` a `const` pointer to non-`const` variable. Because the variable wasn’t originally `const`, `constFunc()` can be a liar and forcibly modify it without triggering UB. So the compiler can’t assume the variable has the same value after `constFunc()` returns. The variable in `constLocalVar()` really is `const`, though, so the compiler can assume it won’t change — because this time it _would_ be UB for `constFunc()` to cast `const` away and write to it.
|
||||
|
||||
The `byArg()` and `constByArg()` functions in the first example are hopeless because the compiler has no way of knowing if `*x` really is `const`.
|
||||
|
||||
But why the inconsistency? If the compiler can assume that `constFunc()` doesn’t modify its argument when called in `constLocalVar()`, surely it can go ahead an apply the same optimisations to other `constFunc()` calls, right? Nope. The compiler can’t assume `constLocalVar()` is ever run at all. If it isn’t (say, because it’s just some unused extra output of a code generator or macro), `constFunc()` can sneakily modify data without ever triggering UB.
|
||||
|
||||
You might want to read the above explanation and examples a few times, but don’t worry if it sounds absurd: it is. Unfortunately, writing to `const` variables is the worst kind of UB: most of the time the compiler can’t know if it even would be UB. So most of the time the compiler sees `const`, it has to assume that someone, somewhere could cast it away, which means the compiler can’t use it for optimisation. This is true in practice because enough real-world C code has “I know what I’m doing” casting away of `const`.
|
||||
|
||||
In short, a whole lot of things can prevent the compiler from using `const` for optimisation, including receiving data from another scope using a pointer, or allocating data on the heap. Even worse, in most cases where `const` can be used by the compiler, it’s not even necessary. For example, any decent compiler can figure out that `x` is constant in the following code, even without `const`:
|
||||
|
||||
```
|
||||
int x = 42, y = 0;
|
||||
printf("%d %d\n", x, y);
|
||||
y += x;
|
||||
printf("%d %d\n", x, y);
|
||||
```
|
||||
|
||||
TL;DR: `const` is almost useless for optimisation because
|
||||
|
||||
1. Except for special cases, the compiler has to ignore it because other code might legally cast it away
|
||||
2. In most of the exceptions to #1, the compiler can figure out a variable is constant, anyway
|
||||
|
||||
|
||||
|
||||
### C++
|
||||
|
||||
There’s another way `const` can affect code generation if you’re using C++: function overloads. You can have `const` and non-`const` overloads of the same function, and maybe the non-`const` can be optimised (by the programmer, not the compiler) to do less copying or something.
|
||||
|
||||
```
|
||||
void foo(int *p)
|
||||
{
|
||||
// Needs to do more copying of data
|
||||
}
|
||||
|
||||
void foo(const int *p)
|
||||
{
|
||||
// Doesn't need defensive copies
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
const int x = 42;
|
||||
// const-ness affects which overload gets called
|
||||
foo(&x);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
On the one hand, I don’t think this is exploited much in practical C++ code. On the other hand, to make a real difference, the programmer has to make assumptions that the compiler can’t make because they’re not guaranteed by the language.
|
||||
|
||||
### An experiment with Sqlite3
|
||||
|
||||
That’s enough theory and contrived examples. How much effect does `const` have on a real codebase? I thought I’d do a test on the Sqlite database (version 3.30.0) because
|
||||
|
||||
* It actually uses `const`
|
||||
* It’s a non-trivial codebase (over 200KLOC)
|
||||
* As a database, it includes a range of things from string processing to arithmetic to date handling
|
||||
* It can be tested with CPU-bound loads
|
||||
|
||||
|
||||
|
||||
Also, the author and contributors have put years of effort into performance optimisation already, so I can assume they haven’t missed anything obvious.
|
||||
|
||||
#### The setup
|
||||
|
||||
I made two copies of [the source code][2] and compiled one normally. For the other copy, I used this hacky preprocessor snippet to turn `const` into a no-op:
|
||||
|
||||
```
|
||||
#define const
|
||||
```
|
||||
|
||||
(GNU) `sed` can add that to the top of each file with something like `sed -i '1i#define const' *.c *.h`.
|
||||
|
||||
Sqlite makes things slightly more complicated by generating code using scripts at build time. Fortunately, compilers make a lot of noise when `const` and non-`const` code are mixed, so it was easy to detect when this happened, and tweak the scripts to include my anti-`const` snippet.
|
||||
|
||||
Directly diffing the compiled results is a bit pointless because a tiny change can affect the whole memory layout, which can change pointers and function calls throughout the code. Instead I took a fingerprint of the disassembly (`objdump -d libsqlite3.so.0.8.6`), using the binary size and mnemonic for each instruction. For example, this function:
|
||||
|
||||
```
|
||||
000000000005d570 <sqlite3_blob_read>:
|
||||
5d570: 4c 8d 05 59 a2 ff ff lea -0x5da7(%rip),%r8 # 577d0 <sqlite3BtreePayloadChecked>
|
||||
5d577: e9 04 fe ff ff jmpq 5d380 <blobReadWrite>
|
||||
5d57c: 0f 1f 40 00 nopl 0x0(%rax)
|
||||
```
|
||||
|
||||
would turn into something like this:
|
||||
|
||||
```
|
||||
sqlite3_blob_read 7lea 5jmpq 4nopl
|
||||
```
|
||||
|
||||
I left all the Sqlite build settings as-is when compiling anything.
|
||||
|
||||
#### Analysing the compiled code
|
||||
|
||||
The `const` version of libsqlite3.so was 4,740,704 bytes, about 0.1% larger than the 4,736,712 bytes of the non-`const` version. Both had 1374 exported functions (not including low-level helpers like stuff in the PLT), and a total of 13 had any difference in fingerprint.
|
||||
|
||||
A few of the changes were because of the dumb preprocessor hack. For example, here’s one of the changed functions (with some Sqlite-specific definitions edited out):
|
||||
|
||||
```
|
||||
#define LARGEST_INT64 (0xffffffff|(((int64_t)0x7fffffff)<<32))
|
||||
#define SMALLEST_INT64 (((int64_t)-1) - LARGEST_INT64)
|
||||
|
||||
static int64_t doubleToInt64(double r){
|
||||
/*
|
||||
** Many compilers we encounter do not define constants for the
|
||||
** minimum and maximum 64-bit integers, or they define them
|
||||
** inconsistently. And many do not understand the "LL" notation.
|
||||
** So we define our own static constants here using nothing
|
||||
** larger than a 32-bit integer constant.
|
||||
*/
|
||||
static const int64_t maxInt = LARGEST_INT64;
|
||||
static const int64_t minInt = SMALLEST_INT64;
|
||||
|
||||
if( r<=(double)minInt ){
|
||||
return minInt;
|
||||
}else if( r>=(double)maxInt ){
|
||||
return maxInt;
|
||||
}else{
|
||||
return (int64_t)r;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Removing `const` makes those constants into `static` variables. I don’t see why anyone who didn’t care about `const` would make those variables `static`. Removing both `static` and `const` makes GCC recognise them as constants again, and we get the same output. Three of the 13 functions had spurious changes because of local `static const` variables like this, but I didn’t bother fixing any of them.
|
||||
|
||||
Sqlite uses a lot of global variables, and that’s where most of the real `const` optimisations came from. Typically they were things like a comparison with a variable being replaced with a constant comparison, or a loop being partially unrolled a step. (The [Radare toolkit][3] was handy for figuring out what the optimisations did.) A few changes were underwhelming. `sqlite3ParseUri()` is 487 instructions, but the only difference `const` made was taking this pair of comparisons:
|
||||
|
||||
```
|
||||
test %al, %al
|
||||
je <sqlite3ParseUri+0x717>
|
||||
cmp $0x23, %al
|
||||
je <sqlite3ParseUri+0x717>
|
||||
```
|
||||
|
||||
And swapping their order:
|
||||
|
||||
```
|
||||
cmp $0x23, %al
|
||||
je <sqlite3ParseUri+0x717>
|
||||
test %al, %al
|
||||
je <sqlite3ParseUri+0x717>
|
||||
```
|
||||
|
||||
#### Benchmarking
|
||||
|
||||
Sqlite comes with a performance regression test, so I tried running it a hundred times for each version of the code, still using the default Sqlite build settings. Here are the timing results in seconds:
|
||||
|
||||
| const | No const
|
||||
---|---|---
|
||||
Minimum | 10.658s | 10.803s
|
||||
Median | 11.571s | 11.519s
|
||||
Maximum | 11.832s | 11.658s
|
||||
Mean | 11.531s | 11.492s
|
||||
|
||||
Personally, I’m not seeing enough evidence of a difference worth caring about. I mean, I removed `const` from the entire program, so if it made a significant difference, I’d expect it to be easy to see. But maybe you care about any tiny difference because you’re doing something absolutely performance critical. Let’s try some statistical analysis.
|
||||
|
||||
I like using the Mann-Whitney U test for stuff like this. It’s similar to the more-famous t test for detecting differences in groups, but it’s more robust to the kind of complex random variation you get when timing things on computers (thanks to unpredictable context switches, page faults, etc). Here’s the result:
|
||||
|
||||
| const | No const
|
||||
---|---|---
|
||||
N | 100 | 100
|
||||
Mean rank | 121.38 | 79.62
|
||||
Mann-Whitney U | 2912
|
||||
---|---
|
||||
Z | -5.10
|
||||
2-sided p value | <10-6
|
||||
HL median difference | -.056s
|
||||
95% confidence interval | -.077s – -0.038s
|
||||
|
||||
The U test has detected a statistically significant difference in performance. But, surprise, it’s actually the non-`const` version that’s faster — by about 60ms, or 0.5%. It seems like the small number of “optimisations” that `const` enabled weren’t worth the cost of extra code. It’s not like `const` enabled any major optimisations like auto-vectorisation. Of course, your mileage may vary with different compiler flags, or compiler versions, or codebases, or whatever, but I think it’s fair to say that if `const` were effective at improving C performance, we’d have seen it by now.
|
||||
|
||||
### So, what’s `const` for?
|
||||
|
||||
For all its flaws, C/C++ `const` is still useful for type safety. In particular, combined with C++ move semantics and `std::unique_pointer`s, `const` can make pointer ownership explicit. Pointer ownership ambiguity was a huge pain in old C++ codebases over ~100KLOC, so personally I’m grateful for that alone.
|
||||
|
||||
However, I used to go beyond using `const` for meaningful type safety. I’d heard it was best practices to use `const` literally as much as possible for performance reasons. I’d heard that when performance really mattered, it was important to refactor code to add more `const`, even in ways that made it less readable. That made sense at the time, but I’ve since learned that it’s just not true.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://theartofmachinery.com/2019/08/12/c_const_isnt_for_performance.html
|
||||
|
||||
作者:[Simon Arneaud][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LazyWolfLin](https://github.com/LazyWolfLin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://theartofmachinery.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://theartofmachinery.com/2019/04/05/d_as_c_replacement.html#const-and-immutable
|
||||
[2]: https://sqlite.org/src/doc/trunk/README.md
|
||||
[3]: https://rada.re/r/
|
||||
@ -0,0 +1,161 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Install & Use VirtualBox Guest Additions on Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/virtualbox-guest-additions-ubuntu/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
How to Install & Use VirtualBox Guest Additions on Ubuntu
|
||||
======
|
||||
|
||||
_**Brief: Install VirtualBox Guest Additions in Ubuntu and with this you’ll be able to copy-paste, drag and drop between the host and guest system. It makes using Ubuntu in virtual machine a lot easier.**_
|
||||
|
||||
The VirtualBox Guest Additions consist of device drivers and system applications that optimize the operating system for better performance and usability. These drivers provide a tighter integration between the guest and host systems.
|
||||
|
||||
No matter how you are using your Virtual Machine, Guest Additions can be very helpful for you. For example, I test many installations and applications inside a VM and take a lot of screenshots. It comes in very handy to be able to move those screenshots freely between the Host OS and the Guest OS.
|
||||
|
||||
Guest? Host? What’s that?
|
||||
|
||||
If you are not aware already, you should know the terminology first.
|
||||
Host system is your actual operating system installed on your physical system.
|
||||
Guest system is the virtual machine you have installed inside your host operating system.
|
||||
|
||||
Before you see the steps to install VirtualBox Guest Additions in Ubuntu, let’s first talk about its features.
|
||||
|
||||
### Why should you use VirtualBox Guest Additions?
|
||||
|
||||
![][1]
|
||||
|
||||
With VirtualBox Guest Additions enabled, using the virtual machine becomes a lot more comfortable. Don’t believe me? Here are the important features that the Guest Additions offer:
|
||||
|
||||
* **Mouse pointer integration**: You no longer need to press any key to “free” the cursor from the Guest OS.
|
||||
* **Shared clipboard**: With the Guest Additions installed, you can copy-paste between the guest and the host operating systems.
|
||||
* **Drag and drop**: You can also drag and drop files between the host and the guest OS.
|
||||
* **Shared folders**: My favorite feature; this feature allows you to exchange files between the host and the guest. You can tell VirtualBox to treat a certain host directory as a shared folder, and the program will make it available to the guest operating system as a network share, irrespective of whether guest actually has a network.
|
||||
* **Better video support**: The custom video drivers that are installed with the Guest Additions provide you with extra high and non-standard video modes, as well as accelerated video performance. It also allows you to resize the virtual machine’s window. The video resolution in the guest will be automatically adjusted, as if you had manually entered an arbitrary resolution in the guest’s Display settings.
|
||||
* **Seamless windows**: The individual windows that are displayed on the desktop of the virtual machine can be mapped on the host’s desktop, as if the underlying application was actually running on the host.
|
||||
* **Generic host/guest communication channels**: The Guest Additions enable you to control and monitor guest execution. The “guest properties” provide a generic string-based mechanism to exchange data bits between a guest and a host, some of which have special meanings for controlling and monitoring the guest. Applications can be started in the Guest machine from the Host.
|
||||
* **Time synchronization**: The Guest Additions will resynchronize the time with that of the Host machine regularly. The parameters of the time synchronization mechanism can be configured.
|
||||
* **Automated logins**: Basically credentials passing, it can be a useful feature.
|
||||
|
||||
|
||||
|
||||
[][2]
|
||||
|
||||
Suggested read How To Extract Audio From Video In Ubuntu Linux
|
||||
|
||||
Impressed by the features it provides? Let’s see how you can install VirtualBox Guest Additions on Ubuntu Linux.
|
||||
|
||||
### Installing VirtualBox Guest Additions on Ubuntu
|
||||
|
||||
The scenario here is that you have [Ubuntu Linux installed inside VirtualBox][3]. The host system could be any operating system.
|
||||
|
||||
I’ll demonstrate the installation process on a minimal install of a Ubuntu virtual machine. First run your virtual machine:
|
||||
|
||||
![VirtualBox Ubuntu Virtual Machine][4]
|
||||
|
||||
To get started, select **Device > Insert Guest Additions CD image…**:
|
||||
|
||||
![Insert Guest Additions CD Image][5]
|
||||
|
||||
This will provide you with the required installer inside the guest system (i.e. the virtual operating system). It will try auto-running, so just click **Run**:
|
||||
|
||||
![AutoRun Guest Additions Installation][6]
|
||||
|
||||
This should open up the installation in a terminal window. Follow the on-screen instructions and you’ll have the Guest Additions installed in a few minutes at most.
|
||||
|
||||
**Troubleshooting tips:**
|
||||
|
||||
If you get an error like this one, it means you are missing some kernel modules (happens in some cases, such as minimal installs):
|
||||
|
||||
![Error while installing Guest Additions in Ubuntu][7]
|
||||
|
||||
You need to install a few more packages here. Just to clarify, you need to run these commands in the virtual Ubuntu system:
|
||||
|
||||
```
|
||||
sudo apt install build-essential dkms linux-headers-$(uname -r)
|
||||
```
|
||||
|
||||
Now run the Guest Addition setup again:
|
||||
|
||||
```
|
||||
sudo rcvboxadd setup
|
||||
```
|
||||
|
||||
### Using VirtualBox Guest Addition features
|
||||
|
||||
Here are some screenshots for enabling/using helpful features of VirtualBox Guest Additions in use:
|
||||
|
||||
#### Change the Virtual Screen Resolution
|
||||
|
||||
![Change Virtual Screen Resolution][8]
|
||||
|
||||
#### Configure Drag And Drop (any files)
|
||||
|
||||
You can enable drag and drop from the top menu -> Devices ->Drag and Drop -> Bidirectional.
|
||||
|
||||
With Bidirectional, you can drag and drop from guest to host and from host to guest, both.
|
||||
|
||||
![Drag and Drop][9]
|
||||
|
||||
##### Configure Shared Clipboard (for copy-pasting)
|
||||
|
||||
Similarly, you can enable shared clipboard from the top menu -> Devices -> Shared Clipboard -> Bidirectional.
|
||||
|
||||
![Shared Clipboard][10]
|
||||
|
||||
### Uninstalling VirtualBox Guest Additions
|
||||
|
||||
Navigate to the CD image and open it in terminal (**Right Click** inside directory > **Open in Terminal**):
|
||||
|
||||
![Open in Terminal][11]
|
||||
|
||||
Now enter:
|
||||
|
||||
```
|
||||
sh ./VBoxLinuxAdditions.run uninstall
|
||||
```
|
||||
|
||||
However, in some cases you might have to do some more cleanup. Use the command:
|
||||
|
||||
```
|
||||
/opt/VBoxGuestAdditions-version/uninstall.sh
|
||||
```
|
||||
|
||||
**Note:** _Replace **VBoxGuestAdditions-version** with the right version (you can hit **tab** to autocomplete; in my case it is **VBoxGuestAdditions-6.0.4**)._
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Hopefully by now you have learned how to install and use the VirtualBox Guest Additions in Ubuntu. Let us know if you use these Additions, and what feature you find to be the most helpful!
|
||||
|
||||
[][12]
|
||||
|
||||
Suggested read Fix Grub Not Showing For Windows 10 Linux Dual Boot
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/virtualbox-guest-additions-ubuntu/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/virtual-box-guest-additions-ubuntu.png?resize=800%2C450&ssl=1
|
||||
[2]: https://itsfoss.com/extract-audio-video-ubuntu/
|
||||
[3]: https://itsfoss.com/install-linux-in-virtualbox/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/virtualbox_ubuntu_virtual_machine.png?fit=800%2C450&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/install_guest_additions.png?fit=800%2C504&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/autorun_guest_additions_installation.png?fit=800%2C602&ssl=1
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/guest_additions_terminal_output.png?fit=800%2C475&ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/change_virtual_screen_resolution.png?fit=744%2C800&ssl=1
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/drag_and_drop.png?fit=800%2C352&ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/shared_clipboard.png?fit=800%2C331&ssl=1
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/open_in_terminal.png?fit=800%2C537&ssl=1
|
||||
[12]: https://itsfoss.com/no-grub-windows-linux/
|
||||
@ -0,0 +1,150 @@
|
||||
DF-SHOW:一个基于老式 DOS 应用的终端文件管理器
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你曾经使用过老牌的 MS-DOS,你可能已经使用或听说过 DF-EDIT。DF-EDIT,意即 **D**irectory **F**ile **Edit**,它是一个鲜为人知的 DOS 文件管理器,最初由 Larry Kroeker 为 MS-DOS 和 PC-DOS 系统而编写。它用于在 MS-DOS 和 PC-DOS 系统中显示给定目录或文件的内容。今天,我偶然发现了一个名为 DF-SHOW 的类似实用程序(**D**irectory **F**ile **Show**),这是一个类 Unix 操作系统的终端文件管理器。它是鲜为人知的 DF-EDIT 文件管理器的 Unix 重写版本,其基于 1986 年发布的 DF-EDIT 2.3d。DF-SHOW 完全是自由开源的,并在 GPLv3 下发布。
|
||||
|
||||
DF-SHOW 可以:
|
||||
|
||||
* 列出目录的内容,
|
||||
* 查看文件,
|
||||
* 使用你的默认文件编辑器编辑文件,
|
||||
* 将文件复制到不同位置,
|
||||
* 重命名文件,
|
||||
* 删除文件,
|
||||
* 在 DF-SHOW 界面中创建新目录,
|
||||
* 更新文件权限,所有者和组,
|
||||
* 搜索与搜索词匹配的文件,
|
||||
* 启动可执行文件。
|
||||
|
||||
### DF-SHOW 用法
|
||||
|
||||
DF-SHOW 实际上是两个程序的结合,名为 `show` 和 `sf`。
|
||||
|
||||
#### Show 命令
|
||||
|
||||
`show` 程序(类似于 `ls` 命令)用于显示目录的内容、创建新目录、重命名和删除文件/文件夹、更新权限、搜索文件等。
|
||||
|
||||
要查看目录中的内容列表,请使用以下命令:
|
||||
|
||||
```
|
||||
$ show <directory path>
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ show dfshow
|
||||
```
|
||||
|
||||
这里,`dfshow` 是一个目录。如果在未指定目录路径的情况下调用 `show` 命令,它将显示当前目录的内容。
|
||||
|
||||
这是 DF-SHOW 默认界面的样子。
|
||||
|
||||

|
||||
|
||||
如你所见,DF-SHOW 的界面不言自明。
|
||||
|
||||
在顶部栏上,你会看到可用的选项列表,例如复制、删除、编辑、修改等。
|
||||
|
||||
完整的可用选项列表如下:
|
||||
|
||||
* `C` opy(复制)
|
||||
* `D` elete(删除)
|
||||
* `E` dit(编辑)
|
||||
* `H` idden(隐藏)
|
||||
* `M` odify(修改)
|
||||
* `Q` uit(退出)
|
||||
* `R` ename(重命名)
|
||||
* `S` how(显示)
|
||||
* h `U` nt(文件内搜索)
|
||||
* e `X` ec(执行)
|
||||
* `R` un command(运行命令)
|
||||
* `E` dit file(编辑文件)
|
||||
* `H` elp(帮助)
|
||||
* `M` ake dir(创建目录)
|
||||
* `S` how dir(显示目录)
|
||||
|
||||
在每个选项中,有一个字母以大写粗体标记。只需按下该字母即可执行相应的操作。例如,要重命名文件,只需按 `R` 并键入新名称,然后按回车键重命名所选项目。
|
||||
|
||||

|
||||
|
||||
要显示所有选项或取消操作,只需按 `ESC` 键即可。
|
||||
|
||||
此外,你将在 DF-SHOW 界面的底部看到一堆功能键,以浏览目录的内容。
|
||||
|
||||
* `UP` / `DOWN` 箭头或 `F1` / `F2` - 上下移动(一次一行),
|
||||
* `PgUp` / `PgDn` - 一次移动一页,
|
||||
* `F3` / `F4` - 立即转到列表的顶部和底部,
|
||||
* `F5` - 刷新,
|
||||
* `F6` - 标记/取消标记文件(标记的文件将在它们前面用 `*`表示),
|
||||
* `F7` / `F8` - 一次性标记/取消标记所有文件,
|
||||
* `F9` - 按以下顺序对列表排序 - 日期和时间、名称、大小。
|
||||
|
||||
按 `h` 了解有关 `show` 命令及其选项的更多详细信息。
|
||||
|
||||
要退出 DF-SHOW,只需按 `q` 即可。
|
||||
|
||||
#### SF 命令
|
||||
|
||||
`sf` (显示文件)用于显示文件的内容。
|
||||
|
||||
```
|
||||
$ sf <file>
|
||||
```
|
||||
|
||||

|
||||
|
||||
按 `h` 了解更多 `sf` 命令及其选项。要退出,请按 `q`。
|
||||
|
||||
想试试看?很好,让我们继续在 Linux 系统上安装 DF-SHOW,如下所述。
|
||||
|
||||
### 安装 DF-SHOW
|
||||
|
||||
DF-SHOW 在 [AUR][1] 中可用,因此你可以使用 AUR 程序(如 [yay][2])在任何基于 Arch 的系统上安装它。
|
||||
|
||||
```
|
||||
$ yay -S dfshow
|
||||
```
|
||||
|
||||
在 Ubuntu 及其衍生版上:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:ian-hawdon/dfshow
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install dfshow
|
||||
```
|
||||
|
||||
在其他 Linux 发行版上,你可以从源代码编译和构建它,如下所示。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/roberthawdon/dfshow
|
||||
$ cd dfshow
|
||||
$ ./bootstrap
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
DF-SHOW 项目的作者只重写了 DF-EDIT 实用程序的一些应用程序。由于源代码可以在 GitHub 上免费获得,因此你可以添加更多功能、改进代码并提交或修复错误(如果有的话)。它仍处于 beta 阶段,但功能齐全。
|
||||
|
||||
你有没试过吗?如果试过,觉得如何?请在下面的评论部分告诉我们你的体验。
|
||||
|
||||
不管如何,希望这有用。还有更多好东西。敬请关注!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/df-show-a-terminal-file-manager-based-on-an-old-dos-application/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://aur.archlinux.org/packages/dfshow/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
62
translated/tech/20190611 What is a Linux user.md
Normal file
62
translated/tech/20190611 What is a Linux user.md
Normal file
@ -0,0 +1,62 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "qfzy1233 "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: subject: "What is a Linux user?"
|
||||
[#]: via: "https://opensource.com/article/19/6/what-linux-user"
|
||||
[#]: author: "Anderson Silva https://opensource.com/users/ansilva/users/petercheer/users/ansilva/users/greg-p/users/ansilva/users/ansilva/users/bcotton/users/ansilva/users/seth/users/ansilva/users/don-watkins/users/ansilva/users/seth"
|
||||
|
||||
何谓 Linux 用户?
|
||||
======
|
||||
|
||||
“Linux 用户”这一定义已经拓展到了更大的范围,同时也发生了巨大的改变。
|
||||
![][1]
|
||||
|
||||
> _编者按: 本文更新于2019年6月11日下午1:15:19更新,以更准确地反映作者对Linux社区中开放和包容的社区性的看法_
|
||||
|
||||
|
||||
|
||||
再过两年,Linux 内核就要迎来它30岁的生日了。让我们回想一下!1991年的时候你在哪里?你出生了吗?那年我13岁!在1991到1993年间只推出了极少数的 Linux 发行版,且至少有三款—Slackware, Debian, 和 Red Hat–支持[backbone][2] 这也使得 Linux 运动得以发展。
|
||||
|
||||
当年获得Linux发行版的副本,并在笔记本或服务器上进行安装和配置,和今天相比是很不一样的。当时是十分艰难的!也是令人沮丧的!如果你让能让它运行起来,就是一个了不起的成就!我们不得不与不兼容的硬件、设备上的配置跳线、BIOS 问题以及许多其他问题作斗争。即使硬件是兼容的,很多时候,你仍然需要编译内核、模块和驱动程序才能让它们在你的系统上工作。
|
||||
|
||||
如果你当时在场,你可能会点头。有些读者甚至称它们为“美好的过往”,因为选择使用 Linux 意味着仅仅是为了让操作系统继续运行,你就必须学习操作系统、计算机体系架构、系统管理、网络,甚至编程。但我并不赞同他们的说法,窃以为: Linux 在 IT 行业带给我们的最让人惊讶的改变就是,它成为了我们每个人技术能力的基础组成部分!
|
||||
|
||||
将近30年过去了,无论是桌面和服务器领域 Linux 系统都有了脱胎换骨的变换。你可以在汽车上,在飞机上,家用电器上,智能手机上……几乎任何地方发现 Linux 的影子!你甚至可以购买预装 Linux 的笔记本电脑、台式机和服务器。如果你考虑云计算,企业甚至个人都可以一键部署 Linux 虚拟机,由此可见 Linux 的应用已经变得多么普遍了。
|
||||
|
||||
考虑到这些,我想问你的问题是: **这个时代如何定义“Linux用户”**
|
||||
|
||||
如果你从 System76 或 Dell 为你的父母或祖父母购买一台 Linux 笔记本电脑,为其登录好他们的社交媒体和电子邮件,并告诉他们经常单击“系统升级”,那么他们现在就是 Linux 用户了。如果你是在 Windows 或MacOS 机器上进行以上操作,那么他们就是 Windows 或 MacOS 用户。令人难以置信的是,与90年代不同,现在的 Linux 任何人都可以轻易上手。
|
||||
|
||||
由于种种原因,这也归因于web浏览器成为了桌面计算机上的“杀手级应用程序”。现在,许多用户并不关心他们使用的是什么操作系统,只要他们能够访问到他们的应用程序或服务。
|
||||
|
||||
你知道有多少人经常使用他们的电话、桌面或笔记本电脑,但无法管理他们系统上的文件、目录和驱动程序?又有多少人不会通过二进制文件安装“应用程序商店”没有收录的程序?更不要提从头编译应用程序,对我来说,几乎没有人。这正是成熟的开源软件和相应的生态对于易用性的改进的动人之处。
|
||||
|
||||
今天的 Linux 用户不需要像90年代或21世纪初的 Linux 用户那样了解、学习甚至查询信息,这并不是一件坏事。过去那种认为Linux只适合工科男使用的想法已经一去不复返了。
|
||||
|
||||
对于那些对计算机、操作系统以及在自由软件上创建、使用和协作的想法感兴趣、好奇、着迷的Linux用户来说,Liunx 依旧有研究的空间。如今在 Windows 和 MacOS 上也有同样多的空间留给创造性的开源贡献者。今天,成为Linux用户就是成为一名与 Linux 系统同行的人。这是一件很棒的事情。
|
||||
|
||||
|
||||
|
||||
### Linux 用户定义的转变
|
||||
|
||||
当我开始使用Linux时,作为一个 Linux 用户意味着知道操作系统如何以各种方式、形态和形式运行。Linux 在某种程度上已经成熟,这使得“Linux用户”的定义可以包含更广泛的领域及那些领域里的人们。这可能是显而易见的一点,但重要的还是要说清楚:任何Linux 用户皆“生”而平等。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/what-linux-user
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva/users/petercheer/users/ansilva/users/greg-p/users/ansilva/users/ansilva/users/bcotton/users/ansilva/users/seth/users/ansilva/users/don-watkins/users/ansilva/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22
|
||||
[2]: https://en.wikipedia.org/wiki/Linux_distribution#/media/File:Linux_Distribution_Timeline.svg
|
||||
@ -0,0 +1,302 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Learn object-oriented programming with Python)
|
||||
[#]: via: (https://opensource.com/article/19/7/get-modular-python-classes)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 Python 学习面对对象的编程
|
||||
======
|
||||
使用 Python 类使你的代码变得更加模块化。
|
||||
![Developing code.][1]
|
||||
|
||||
在我上一篇文章中,我解释了如何通过使用函数、创建模块或者两者一起来[使 Python 代码更加模块化][2]。函数对于避免重复多次使用的代码非常有用,而模块可以确保你在不同的项目中复用代码。但是模块化还有另一种方法:类。
|
||||
|
||||
如果你已经听过 _面对对象编程_ 这个术语,那么你可能会对类的用途有一些概念。程序员倾向于将类视为一个虚拟对象,有时与物理世界中的某些东西直接相关,有时则作为某种编程概念的表现形式。无论哪种表示,当你想要在程序中为你或程序的其他部分创建“对象”时,你都可以创建一个类来交互。
|
||||
|
||||
### 没有类的模板
|
||||
|
||||
假设你正在编写一个以幻想世界为背景的游戏,并且你需要这个应用程序能够涌现出各种坏蛋来给玩家的生活带来一些刺激。了解了很多关于函数的知识后,你可能会认为这听起来像是函数的一个教科书案例:需要经常重复的代码,但是在调用时可以考虑变量而只编写一次。
|
||||
|
||||
下面一个纯粹基于函数的敌人生成器实现的例子:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
def enemy(ancestry,gear):
|
||||
enemy=ancestry
|
||||
weapon=gear
|
||||
hp=random.randrange(0,20)
|
||||
ac=random.randrange(0,20)
|
||||
return [enemy,weapon,hp,ac]
|
||||
|
||||
def fight(tgt):
|
||||
print("You take a swing at the " + tgt[0] + ".")
|
||||
hit=random.randrange(0,20)
|
||||
if hit > tgt[3]:
|
||||
print("You hit the " + tgt[0] + " for " + str(hit) + " damage!")
|
||||
tgt[2] = tgt[2] - hit
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
foe=enemy("troll","great axe")
|
||||
print("You meet a " + foe[0] + " wielding a " + foe[1])
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
while True:
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
fight(foe)
|
||||
|
||||
if foe[2] < 1:
|
||||
print("You killed your foe!")
|
||||
else:
|
||||
print("The " + foe[0] + " has " + str(foe[2]) + " HP remaining")
|
||||
```
|
||||
|
||||
**enemy** 函数创造了一个具有多个属性的敌人,例如祖先、武器、生命值和防御等级。它返回每个属性的列表,表示敌人全部特征。
|
||||
|
||||
从某种意义上说,这段代码创建了一个对象,即使它还没有使用类。程序员将这个 "enemy" 称为 _对象_,因为该函数的结果(本例中是一个包含字符串和整数的列表)表示游戏中一个单独但复杂的 _东西_。也就是说,列表中字符串和整数不是任意的:它们一起描述了一个虚拟对象。
|
||||
|
||||
在编写描述符集合时,你可以使用变量,以便随时使用它们来生成敌人。这有点像模板。
|
||||
|
||||
在示例代码中,当需要对象的属性时,会检索相应的列表项。例如,要获取敌人的祖先,代码会查询 **foe[0]**,对于生命值,会查询 **foe[2]**,以此类推。
|
||||
|
||||
这种方法没有什么不妥,代码按预期运行。你可以添加更多不同类型的敌人,创建一个敌人类型列表,并在敌人创建期间从列表中随机选择,等等,它工作得很好。实际上,[Lua][3] 非常有效地利用这个原理来近似面对对象模型。
|
||||
|
||||
然而,有时候对象不仅仅是属性列表。
|
||||
|
||||
### 使用对象
|
||||
|
||||
在 Python 中,一切都是对象。你在 Python 中创建的任何东西都是某个预定义模板的 _实例_。甚至基本的字符串和整数都是 Python **type** 类的衍生物。你可以在这个交互式 Python shell 中见证:
|
||||
|
||||
```
|
||||
>>> foo=3
|
||||
>>> type(foo)
|
||||
<class 'int'>
|
||||
>>> foo="bar"
|
||||
>>> type(foo)
|
||||
<class 'str'>
|
||||
```
|
||||
|
||||
当一个对象由一个类定义时,它不仅仅是一个属性的集合,Python 类具有各自的函数。从逻辑上讲,这很方便,因为只涉及某个对象类的操作包含在该对象的类中。
|
||||
|
||||
在示例代码中,fight 代码是主应用程序的功能。这对于一个简单的游戏来说是可行的,但对于一个复杂的游戏来说,世界中不仅仅有玩家和敌人,还可能有城镇居民、牲畜、建筑物、森林等等,他们都不需要使用战斗功能。将战斗代码放在敌人的类中意味着你的代码更有条理,在一个复杂的应用程序中,这是一个重要的优势。
|
||||
|
||||
此外,每个类都有特权访问自己的本地变量。例如,敌人的生命值,除了某些功能之外,是不会改变的数据。游戏中的随机蝴蝶不应该意外地将敌人的生命值降低到 0。理想情况下,即使没有类,也不会发生这种情况。但是在具有大量活动部件的复杂应用程序中,确保不需要相互交互的部件永远不会发生这种情况,这是一个非常有用的技巧。
|
||||
|
||||
Python 类也受垃圾收集的影响。当不再使用类的实例时,它将被移出内存。你可能永远不知道这种情况会什么时候发生,但是你往往知道什么时候它不会发生,因为你的应用程序占用了更多的内存,而且运行速度比较慢。将数据集隔离到类中可以帮助 Python 跟踪哪些数据正在使用,哪些不在需要了。
|
||||
|
||||
### 优雅的 Python
|
||||
|
||||
下面是一个同样简单的战斗游戏,使用了 Enemy 类:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.ac=random.randrange(12,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
|
||||
# 游戏开始
|
||||
foe=Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# 主函数循环
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
这个版本的游戏将敌人作为一个包含相同属性(祖先,武器,生命值和防御)的对象来处理,并添加一个新的属性来衡量敌人时候已被击败,以及一个战斗功能。
|
||||
|
||||
类的第一个函数是一个特殊的函数,在 Python 中称为 \_init\_ 或初始化函数。这类似于其他语言中的[构造器][4],它创建了类的一个实例,你可以通过它的属性和调用类时使用的任何变量来识别它(示例代码中的 **foe**)。
|
||||
|
||||
### Self 和类实例
|
||||
|
||||
类的函数接受一种你在类之外看不到的新形式的输入:**self**。如果不包含 **self**,那么当你调用类函数时,Python 无法知道要使用的类的 _哪个_ 实例。这就像在一间充满兽人的房间里说:“我要和兽人战斗”,向一个兽人发起。没有人知道你指的是谁,所以坏事就发生了。
|
||||
|
||||
![Image of an Orc, CC-BY-SA by Buch on opengameart.org][5]
|
||||
|
||||
CC-BY-SA by Buch on opengameart.org
|
||||
|
||||
类中创建的每个属性都以 **self** 符号作为前缀,该符号将变量标识为类的属性。一旦派生出类的实例,就用表示该实例的变量替换掉 **self** 前缀。使用这个技巧,你可以在一间满是兽人的房间里说:“我要和祖先是 orc 的兽人战斗”,这样来挑战一个兽人。当 orc 听到 "gorblar.orc" 时,它就知道你指的是谁(他自己),所以你得到是一场公平的战斗而不是争吵。在 Python 中:
|
||||
|
||||
```
|
||||
gorblar=Enemy("orc","sword")
|
||||
print("The " + gorblar.enemy + " has " + str(gorblar.hp) + " remaining.")
|
||||
```
|
||||
|
||||
通过检索类属性而不是查询 **foe[0]**(在函数示例中)或 **gorblar[0]** 来寻找敌人(**gorblar.enemy** 或 **gorblar.hp** 或你需要的任何对象的任何值)。
|
||||
|
||||
### 本地变量
|
||||
|
||||
如果类中的变量没有以 **self** 关键字作为前缀,那么它就是一个局部变量,就像在函数中一样。例如,无论你做什么,你都无法访问 **Enemy.fight** 类之外的 **hit** 变量:
|
||||
|
||||
```
|
||||
>>> print(foe.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.hit)
|
||||
AttributeError: 'Enemy' object has no attribute 'hit'
|
||||
|
||||
>>> print(foe.fight.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.fight.hit)
|
||||
AttributeError: 'function' object has no attribute 'hit'
|
||||
```
|
||||
|
||||
**hi** 变量包含在 Enemy 类中,并且只能“存活”到在战斗种发挥作用。
|
||||
|
||||
### 更模块化
|
||||
|
||||
本例使用与主应用程序相同的文本文档中的类。在一个复杂的游戏中,我们更容易将每个类看作是自己独立的应用程序。当多个开发人员处理同一个应用程序时,你会看到这一点:一个开发人员处理一个类,另一个开发主程序,只要他们彼此沟通这个类必须具有什么属性,就可以并行地开发这两个代码块。
|
||||
|
||||
要使这个示例游戏模块化,可以把它拆分为两个文件:一个用于主应用程序,另一个用于类。如果它是一个更复杂的应用程序,你可能每个类都有一个文件,或每个逻辑类组有一个文件(例如,用于建筑物的文件,用于自然环境的文件,用于敌人或 NPC 的文件等)。
|
||||
|
||||
将只包含 Enemy 类的一个文件保存为 **enemy.py**,将另一个包含其他内容的文件保存为 **main.py**。
|
||||
|
||||
以下是 **enemy.py**:
|
||||
|
||||
```
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.stg=random.randrange(0,20)
|
||||
self.ac=random.randrange(0,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
```
|
||||
|
||||
以下是 **main.py**:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import enemy as en
|
||||
|
||||
# game start
|
||||
foe=en.Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
导入模块 **enemy.py** 使用了一条特别的语句,将类文件名称作为引用而不是 **.py** 扩展名,后跟你选择的命名空间指示符(例如,**import enemy as en**)。这个指示符是在你调用类时在代码中使用的。你需要在导入时添加指定符,例如 **en.Enemy**,而不是只使用 **Enemy()**。
|
||||
|
||||
所有这些文件名都是任意的,尽管在原则上并不罕见。将应用程序的中心命名为 **main.py** 是一个常见约定,和一个充满类的文件通常以小写形式命名,其中的类都以大写字母开头。是否遵循这些约定不会影响应用程序的运行方式,但它确实使经验丰富的 Python 程序员更容易快速理解应用程序的工作方式。
|
||||
|
||||
在如何构建代码方面有一些灵活性。例如,使用代码示例,两个文件必须位于同一目录中。如果你只想将类打包为模块,那么必须创建一个名为 **mybad** 的目录,并将你的类移入其中。在 **main.py** 中,你的 import 语句稍有变化:
|
||||
|
||||
```
|
||||
from mybad import enemy as en
|
||||
```
|
||||
|
||||
两种方法都会产生相同的结果,但如果你创建的类足够通用,你认为其他开发人员可以在他们的项目中使用它们,那么后者是更好的。
|
||||
|
||||
无论你选择哪种方式,都可以启动游戏的模块化版本:
|
||||
|
||||
```
|
||||
$ python3 ./main.py
|
||||
You meet a troll wielding a great axe
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You missed.
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 8 damage!
|
||||
The troll has 4 HP remaining
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 11 damage!
|
||||
The troll has -7 HP remaining
|
||||
You have won...this time.
|
||||
```
|
||||
|
||||
游戏启动了,它现在更加模块化了。现在你知道了面对对象的应用程序意味着什么,但最重要的是,当你向兽人发起决斗的时候,你要想清楚。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
|
||||
[2]: https://opensource.com/article/19/6/get-modular-python-functions
|
||||
[3]: https://opensource.com/article/17/4/how-program-games-raspberry-pi
|
||||
[4]: https://opensource.com/article/19/6/what-java-constructor
|
||||
[5]: https://opensource.com/sites/default/files/images/orc-buch-opengameart_cc-by-sa.jpg (CC-BY-SA by Buch on opengameart.org)
|
||||
Loading…
Reference in New Issue
Block a user