mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge pull request #1 from LCTT/master
This commit is contained in:
commit
7573323847
@ -1,12 +1,13 @@
|
||||
# 如何在 Ubuntu 上使用 Grafana 监控 Docker
|
||||
如何在 Ubuntu 上使用 Grafana 监控 Docker
|
||||
=========
|
||||
|
||||
Grafana 是一个有着丰富指标的开源控制面板。在进行大型的测量数据的可视化时是非常有用的。根据不同的丰富指标,它提供了一个强大、优雅的方式来创建、浏览数据的方式。
|
||||
Grafana 是一个有着丰富指标的开源控制面板。在可视化大规模测量数据的时候是非常有用的。根据不同的指标数据,它提供了一个强大、优雅的来创建、分享和浏览数据的方式。
|
||||
|
||||
它提供了丰富多样、灵活的图形选项。此外,针对数据源,它支持许多不同的存储后端。每个数据源都有针对特定数据源公开的特性和功能定制的查询编辑器。下述数据源 Grafana 提供了正式的支持:Graphite, InfluxDB, OpenTSDB, Prometheus, Elasticsearch 和 Cloudwatch。
|
||||
它提供了丰富多样、灵活的图形选项。此外,针对数据源(Data Source),它支持许多不同的存储后端。每个数据源都有针对特定数据源的特性和功能所定制的查询编辑器。Grafana 提供了对下述数据源的正式支持:Graphite、InfluxDB、OpenTSDB、 Prometheus、Elasticsearch 和 Cloudwatch。
|
||||
|
||||
查询语言和每个数据源的能力显然是不同的,你可以将来自多个数据源的数据混合到一个单一的仪表盘上,但每个小组被绑定到属于一个特定组织的特点数据源。它支持验证登陆和基于角色的访问控制的实现。它是作为一个独立软件部署的,使用 Go 和 JavaScript 编写的。
|
||||
每个数据源的查询语言和能力显然是不同的,你可以将来自多个数据源的数据混合到一个单一的仪表盘上,但每个面板(Panel)被绑定到属于一个特定组织(Organization)的特定数据源上。它支持验证登录和基于角色的访问控制方案。它是作为一个独立软件部署,使用 Go 和 JavaScript 编写的。
|
||||
|
||||
在这篇文章,我将讲解如何在 Ubuntu 16.04 上安装 Grafana 并使用这个软件配置 Docker 监控
|
||||
在这篇文章,我将讲解如何在 Ubuntu 16.04 上安装 Grafana 并使用这个软件配置 Docker 监控。
|
||||
|
||||
### 先决条件
|
||||
|
||||
@ -14,7 +15,7 @@ Grafana 是一个有着丰富指标的开源控制面板。在进行大型的测
|
||||
|
||||
### 安装 Grafana
|
||||
|
||||
我们可以在 Docker 中构建我们的 Grafana。 这里有一个官方的 Grafana Docker 镜像.请运行下述命令来构建Grafana 容器。
|
||||
我们可以在 Docker 中构建我们的 Grafana。 有一个官方提供的 Grafana Docker 镜像。请运行下述命令来构建Grafana 容器。
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -i -p 3000:3000 grafana/grafana
|
||||
@ -48,115 +49,66 @@ t=2016-07-27T15:20:20+0000 lvl=info msg="Starting plugin search" logger=plugins
|
||||
t=2016-07-27T15:20:20+0000 lvl=info msg="Server Listening" logger=server address=0.0.0.0:3000 protocol=http subUrl=
|
||||
```
|
||||
|
||||
我们可以通过运行此命令确认 Grafana 容器的工作状态 `docker ps -a` 或通过这个URL访问 `http://Docker IP:3000`
|
||||
我们可以通过运行此命令确认 Grafana 容器的工作状态 `docker ps -a` 或通过这个URL访问 `http://Docker IP:3000`。
|
||||
|
||||
所有的 Grafana 配置设置都使用环境变量定义,在使用容器技术时这个是非常有用的。Grafana 配置文件路径为 /etc/grafana/grafana.ini.
|
||||
所有的 Grafana 配置设置都使用环境变量定义,在使用容器技术时这个是非常有用的。Grafana 配置文件路径为 `/etc/grafana/grafana.ini`。
|
||||
|
||||
### 理解配置项
|
||||
|
||||
Grafana 有多个 ini 文件作为被指定的配置文件,或可以指定使用前面提到的环境变量。
|
||||
Grafana 可以在它的 ini 配置文件中指定几个配置选项,或可以使用前面提到的环境变量来指定。
|
||||
|
||||
#### 配置文件位置
|
||||
|
||||
通常配置文件路径:
|
||||
|
||||
- 默认配置文件路径 : $WORKING_DIR/conf/defaults.ini
|
||||
- 自定义配置文件路径 : $WORKING_DIR/conf/custom.ini
|
||||
- 默认配置文件路径 : `$WORKING_DIR/conf/defaults.ini`
|
||||
- 自定义配置文件路径 : `$WORKING_DIR/conf/custom.ini`
|
||||
|
||||
PS:当你使用 deb、rpm 或 docker 镜像安装 Grafana ,你的配置文件在 /etc/grafana/grafana.ini
|
||||
PS:当你使用 deb、rpm 或 docker 镜像安装 Grafana 时,你的配置文件在 `/etc/grafana/grafana.ini`。
|
||||
|
||||
#### 理解配置变量
|
||||
|
||||
现在我们看一些配置文件中的变量:
|
||||
|
||||
`instance_name` : 这是 Grafana 服务器实例的名字。默认值从 ${HOSTNAME} 获取,将会被环境变量 HOSTNAME替换,如果为空或不存在,Grafana 将会尝试使用系统调用来获取机器名。
|
||||
|
||||
`[paths]`
|
||||
|
||||
`data` : 这个是 Grafana 存储 sqlite3 数据库(如果使用),基于文件的 Sessions(如果使用),和其他数据的路径
|
||||
|
||||
`logs` : 这个是 Grafana 存储日志的路径
|
||||
|
||||
这些路径通常都是在 init.d 脚本或 systemd service文件通过命令行指定。
|
||||
|
||||
`[server]`
|
||||
|
||||
`http_addr` : 应用监听的 IP 地址,如果为空,则监听所有的IP。
|
||||
|
||||
`http_port` : 应用监听的端口,默认是 3000,你可以使用下面的命令在 80 端口重定向到 3000 端口。
|
||||
|
||||
```
|
||||
$iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 3000
|
||||
```
|
||||
|
||||
`root_url` : 这个 URL 用于从浏览器访问 Grafana 。
|
||||
|
||||
`cert_file` : 证书文件的路径(如果协议是 HTTPS)
|
||||
|
||||
`cert_key` : 证书密钥文件的路径(如果协议是 HTTPS)
|
||||
|
||||
`[database]`
|
||||
|
||||
Grafana 使用数据库来存储用户和仪表盘以及其他信息,默认配置为使用嵌入在 Grafana 主要的二进制文件中传的 SQLite3
|
||||
|
||||
`type`
|
||||
你可以根据你的需求选择 MySQL、Postgres、SQLite3。
|
||||
|
||||
`path`
|
||||
|
||||
它只在选择 SQLite3 数据库时被应用,这个是数据库将要被存储的路径。
|
||||
|
||||
`host`
|
||||
仅适用 MySQL 或者 Postgres。它包括 IP 地址或主机名以及端口。例如,Grafana 和 MySQL 运行在同一台主机上设置如: host = 127.0.0.1:3306
|
||||
|
||||
`name`
|
||||
Grafana 数据库的名称,把它设置为 Grafana 或其它名称。
|
||||
|
||||
`user`
|
||||
数据库用户(不适用于 SQLite3)
|
||||
|
||||
`password`
|
||||
数据库用户密码(不适用于 SQLite3)
|
||||
|
||||
`ssl_mode`
|
||||
对于Postgres,使用 disable,require,或 verify-full.对于 MySQL,使用 true,false,或 skip-verify
|
||||
|
||||
`ca_cert_path`
|
||||
|
||||
(只适用于MySQL)CA 证书文件路径,在多数 Linux 系统中,证书可以在 /etc/ssl/certs 找到
|
||||
|
||||
`client_key_path`
|
||||
(只适用于MySQL)客户端密钥的路径,只在服务端需要用户端验证时使用。
|
||||
|
||||
`client_cert_path`
|
||||
(只适用于MySQL)客户端证书的路径,只在服务端需要用户端验证时使用。
|
||||
|
||||
`server_cert_name`
|
||||
(只适用于MySQL) MySQL 服务端使用的证书的通用名称字段。如果 ssl_mode 设置为 skip-verify 时可以不设置
|
||||
|
||||
`[security]`
|
||||
|
||||
`admin_user` : 这个是 Grafana 默认的管理员用户的用户名,默认设置为 admin.
|
||||
|
||||
`admin_password` : 这个是 Grafana 默认的管理员用户的密码,在第一次运行时设置,默认为 admin
|
||||
|
||||
`login_remember_days` : 保持登陆/记住我 的持续天数
|
||||
|
||||
`secret_key` : 用于保持登陆/记住我的 cookies 的签名
|
||||
- `instance_name`:这是 Grafana 服务器实例的名字。默认值从 `${HOSTNAME}` 获取,其值是环境变量` HOSTNAME`,如果该变量为空或不存在,Grafana 将会尝试使用系统调用来获取机器名。
|
||||
- `[paths]`:这些路径通常都是在 init.d 脚本或 systemd service 文件中通过命令行指定。
|
||||
- `data`:这个是 Grafana 存储 sqlite3 数据库(如果使用)、基于文件的会话(如果使用),和其他数据的路径。
|
||||
- `logs`:这个是 Grafana 存储日志的路径。
|
||||
- `[server]`
|
||||
- `http_addr`:应用监听的 IP 地址,如果为空,则监听所有的接口。
|
||||
- `http_port`:应用监听的端口,默认是 3000,你可以使用下面的命令将你的 80 端口重定向到 3000 端口:`$iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 3000`
|
||||
- `root_url` : 这个 URL 用于从浏览器访问 Grafana 。
|
||||
- `cert_file` : 证书文件的路径(如果协议是 HTTPS)。
|
||||
- `cert_key` : 证书密钥文件的路径(如果协议是 HTTPS)。
|
||||
- `[database]`:Grafana 使用数据库来存储用户和仪表盘以及其他信息,默认配置为使用内嵌在 Grafana 主二进制文件中的 SQLite3。
|
||||
- `type`:你可以根据你的需求选择 MySQL、Postgres、SQLite3。
|
||||
- `path`:仅用于选择 SQLite3 数据库时,这个是数据库所存储的路径。
|
||||
- `host`:仅适用 MySQL 或者 Postgres。它包括 IP 地址或主机名以及端口。例如,Grafana 和 MySQL 运行在同一台主机上设置如: `host = 127.0.0.1:3306`。
|
||||
- `name`:Grafana 数据库的名称,把它设置为 Grafana 或其它名称。
|
||||
- `user`:数据库用户(不适用于 SQLite3)。
|
||||
- `password`:数据库用户密码(不适用于 SQLite3)。
|
||||
- `ssl_mode`:对于 Postgres,使用 `disable`,`require`,或 `verify-full` 等值。对于 MySQL,使用 `true`,`false`,或 `skip-verify`。
|
||||
- `ca_cert_path`:(只适用于 MySQL)CA 证书文件路径,在多数 Linux 系统中,证书可以在 `/etc/ssl/certs` 找到。
|
||||
- `client_key_path`:(只适用于 MySQL)客户端密钥的路径,只在服务端需要用户端验证时使用。
|
||||
- `client_cert_path`:(只适用于 MySQL)客户端证书的路径,只在服务端需要用户端验证时使用。
|
||||
- `server_cert_name`:(只适用于 MySQL)MySQL 服务端使用的证书的通用名称字段。如果 `ssl_mode` 设置为 `skip-verify` 时可以不设置。
|
||||
- `[security]`
|
||||
- `admin_user`:这个是 Grafana 默认的管理员用户的用户名,默认设置为 admin。
|
||||
- `admin_password`:这个是 Grafana 默认的管理员用户的密码,在第一次运行时设置,默认为 admin。
|
||||
- `login_remember_days`:保持登录/记住我的持续天数。
|
||||
- `secret_key`:用于保持登录/记住我的 cookies 的签名。
|
||||
|
||||
### 设置监控的重要组件
|
||||
|
||||
我们可以使用下面的组件来创建我们的 Docker 监控系统
|
||||
我们可以使用下面的组件来创建我们的 Docker 监控系统。
|
||||
|
||||
`cAdvisor` : 他被称为 Container Advisor。它提供了对用户的资源利用和性能特征的解读。它收集、合并、处理、导出运行中的容器的信息。你可以通过文档了解更多关于这个。
|
||||
- `cAdvisor`:它被称为 Container Advisor。它给用户提供了一个资源利用和性能特征的解读。它会收集、聚合、处理、导出运行中的容器的信息。你可以通过[这个文档](https://github.com/google/cadvisor)了解更多。
|
||||
- `InfluxDB`:这是一个包含了时间序列、度量和分析数据库。我们使用这个数据源来设置我们的监控。cAdvisor 只展示实时信息,并不保存这些度量信息。Influx Db 帮助保存 cAdvisor 提供的监控数据,以展示非某一时段的数据。
|
||||
- `Grafana Dashboard`:它可以帮助我们在视觉上整合所有的信息。这个强大的仪表盘使我们能够针对 InfluxDB 数据存储进行查询并将他们放在一个布局合理好看的图表中。
|
||||
|
||||
`InfluxDB` : 这是一个时间排序、度量和分析数据库。我们使用这个数据源来设置我们的监控。cAdvisor 只展示时间信息,不保存度量信息。Influx Db帮助保存 cAdvisor 提供的监控数据,以展示非实时数据。
|
||||
### Docker 监控的安装
|
||||
|
||||
`Grafana Dashboard` : 它可以帮助我们在视觉上整合所有的信息。这个强大的仪表盘使我们能够针对数据存储 InfluxDB 进行查询并将他们放在一个布局合理好看的图表中。
|
||||
|
||||
### Docker监控的安装
|
||||
|
||||
我们需要一步一步的安装每一个下面的组件在我们的 Docker 系统中。
|
||||
我们需要一步一步的在我们的 Docker 系统中安装以下每一个组件:
|
||||
|
||||
#### 安装 InfluxDB
|
||||
|
||||
@ -185,11 +137,11 @@ d3b6f7789e0d1d01fa4e0aacdb636c221421107d1df96808ecbe8e241ceb1823
|
||||
--name influxsrv : container have name influxsrv, use to cAdvisor link it.
|
||||
```
|
||||
|
||||
你可以测试 InfluxDB 是否安装好,通过访问这个 URL>>http://45.79.148.234:8083 (译者注,应当访问你自己的服务器的IP:8083),并且使用 root 用户的帐号和密码登陆
|
||||
你可以测试 InfluxDB 是否安装好,通过访问这个 URL `http://你的 IP 地址:8083`,用户名和密码都是 ”root“。
|
||||
|
||||

|
||||
|
||||
我们可以在这个界面上创建我们需要的数据库.
|
||||
我们可以在这个界面上创建我们所需的数据库。
|
||||
|
||||

|
||||
|
||||
@ -217,39 +169,39 @@ root@ubuntu:~#
|
||||
-storage_driver_db=cadvisor: database name. Uses db ‘cadvisor’ by default
|
||||
```
|
||||
|
||||
你可以通过访问这个地址来测试安装 cAdvisor 是否正常 >>http://45.79.148.234:8080. 这将为你的 Docker 主机和容器提供统计信息。
|
||||
你可以通过访问这个地址来测试安装 cAdvisor 是否正常 `http://你的 IP 地址:8080`。 这将为你的 Docker 主机和容器提供统计信息。
|
||||
|
||||

|
||||
|
||||
#### 安装 Grafana 控制面板
|
||||
|
||||
首先我们需要安装 Grafana 仪表板并链接到 InfluxDB,你可以执行下面的命令来设置他
|
||||
最后,我们需要安装 Grafana 仪表板并连接到 InfluxDB,你可以执行下面的命令来设置它。
|
||||
|
||||
```
|
||||
root@ubuntu:~# docker run -d -p 3000:3000 -e INFLUXDB_HOST=localhost -e INFLUXDB_PORT=8086 -e INFLUXDB_NAME=cadvisor -e INFLUXDB_USER=root -e INFLUXDB_PASS=root --link influxsrv:influxsrv --name grafana grafana/grafana
|
||||
f3b7598529202b110e4e6b998dca6b6e60e8608d75dcfe0d2b09ae408f43684a
|
||||
```
|
||||
|
||||
现在我们可以登陆 Grafana 来配置数据源. 访问 http://45.79.148.234:3000 或 http://45.79.148.234:
|
||||
现在我们可以登录 Grafana 来配置数据源. 访问 `http://你的 IP 地址:3000` 或 `http://你的 IP 地址`(如果你在前面做了端口映射的话):
|
||||
|
||||
用户名- admin
|
||||
密码- admin
|
||||
- 用户名 - admin
|
||||
- 密码 - admin
|
||||
|
||||
一旦我们安装好了 Grafana,我们可以链接 InfluxDB。登陆到控制台并且点击面板左上方角落的 Grafana 图标(火球)。点击数据源(Data Sources)来配置。
|
||||
一旦我们安装好了 Grafana,我们可以连接 InfluxDB。登录到仪表盘并且点击面板左上方角落的 Grafana 图标(那个火球)。点击数据源(Data Sources)来配置。
|
||||
|
||||

|
||||
|
||||
现在你可以添加我们新的图像到我们默认的数据源 InfluxDB.
|
||||
现在你可以添加新的图形(Graph)到我们默认的数据源 InfluxDB。
|
||||
|
||||

|
||||
|
||||
我们可以通过在测量页面调整我们的图像可以编辑和调整我们的查询
|
||||
我们可以通过在测量(Metric)页面编辑和调整我们的查询以调整我们的图形。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
你可以在 [更多信息][1]看到更多关于Docker监控的小心。 感谢你的阅读。我希望你可以留下有价值的建议和评论。希望你有个美好的一天
|
||||
关于 Docker 监控,你可用[从此了解][1]更多信息。 感谢你的阅读。我希望你可以留下有价值的建议和评论。希望你有个美好的一天。
|
||||
|
||||
------
|
||||
|
||||
@ -257,7 +209,7 @@ via: http://linoxide.com/linux-how-to/monitor-docker-containers-grafana-ubuntu/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
410
published/20160820 Protocol Buffer Basics C++.md
Normal file
410
published/20160820 Protocol Buffer Basics C++.md
Normal file
@ -0,0 +1,410 @@
|
||||
C++ 程序员 Protocol Buffers 基础指南
|
||||
============================
|
||||
|
||||
这篇教程提供了一个面向 C++ 程序员关于 protocol buffers 的基础介绍。通过创建一个简单的示例应用程序,它将向我们展示:
|
||||
|
||||
* 在 `.proto` 文件中定义消息格式
|
||||
* 使用 protocol buffer 编译器
|
||||
* 使用 C++ protocol buffer API 读写消息
|
||||
|
||||
这不是一个关于在 C++ 中使用 protocol buffers 的全面指南。要获取更详细的信息,请参考 [Protocol Buffer Language Guide][1] 和 [Encoding Reference][2]。
|
||||
|
||||
### 为什么使用 Protocol Buffers
|
||||
|
||||
我们接下来要使用的例子是一个非常简单的"地址簿"应用程序,它能从文件中读取联系人详细信息。地址簿中的每一个人都有一个名字、ID、邮件地址和联系电话。
|
||||
|
||||
如何序列化和获取结构化的数据?这里有几种解决方案:
|
||||
|
||||
* 以二进制形式发送/接收原生的内存数据结构。通常,这是一种脆弱的方法,因为接收/读取代码必须基于完全相同的内存布局、大小端等环境进行编译。同时,当文件增加时,原始格式数据会随着与该格式相关的软件而迅速扩散,这将导致很难扩展文件格式。
|
||||
* 你可以创造一种 ad-hoc 方法,将数据项编码为一个字符串——比如将 4 个整数编码为 `12:3:-23:67`。虽然它需要编写一次性的编码和解码代码且解码需要耗费一点运行时成本,但这是一种简单灵活的方法。这最适合编码非常简单的数据。
|
||||
* 序列化数据为 XML。这种方法是非常吸引人的,因为 XML 是一种适合人阅读的格式,并且有为许多语言开发的库。如果你想与其他程序和项目共享数据,这可能是一种不错的选择。然而,众所周知,XML 是空间密集型的,且在编码和解码时,它对程序会造成巨大的性能损失。同时,使用 XML DOM 树被认为比操作一个类的简单字段更加复杂。
|
||||
|
||||
Protocol buffers 是针对这个问题的一种灵活、高效、自动化的解决方案。使用 Protocol buffers,你需要写一个 `.proto` 说明,用于描述你所希望存储的数据结构。利用 `.proto` 文件,protocol buffer 编译器可以创建一个类,用于实现对高效的二进制格式的 protocol buffer 数据的自动化编码和解码。产生的类提供了构造 protocol buffer 的字段的 getters 和 setters,并且作为一个单元来处理读写 protocol buffer 的细节。重要的是,protocol buffer 格式支持格式的扩展,代码仍然可以读取以旧格式编码的数据。
|
||||
|
||||
### 在哪可以找到示例代码
|
||||
|
||||
示例代码被包含于源代码包,位于“examples”文件夹。可在[这里][4]下载代码。
|
||||
|
||||
### 定义你的协议格式
|
||||
|
||||
为了创建自己的地址簿应用程序,你需要从 `.proto` 开始。`.proto` 文件中的定义很简单:为你所需要序列化的每个数据结构添加一个消息(message),然后为消息中的每一个字段指定一个名字和类型。这里是定义你消息的 `.proto` 文件 `addressbook.proto`。
|
||||
|
||||
```
|
||||
package tutorial;
|
||||
|
||||
message Person {
|
||||
required string name = 1;
|
||||
required int32 id = 2;
|
||||
optional string email = 3;
|
||||
|
||||
enum PhoneType {
|
||||
MOBILE = 0;
|
||||
HOME = 1;
|
||||
WORK = 2;
|
||||
}
|
||||
|
||||
message PhoneNumber {
|
||||
required string number = 1;
|
||||
optional PhoneType type = 2 [default = HOME];
|
||||
}
|
||||
|
||||
repeated PhoneNumber phone = 4;
|
||||
}
|
||||
|
||||
message AddressBook {
|
||||
repeated Person person = 1;
|
||||
}
|
||||
```
|
||||
|
||||
如你所见,其语法类似于 C++ 或 Java。我们开始看看文件的每一部分内容做了什么。
|
||||
|
||||
`.proto` 文件以一个 package 声明开始,这可以避免不同项目的命名冲突。在 C++,你生成的类会被置于与 package 名字一样的命名空间。
|
||||
|
||||
下一步,你需要定义消息(message)。消息只是一个包含一系列类型字段的集合。大多标准的简单数据类型是可以作为字段类型的,包括 `bool`、`int32`、`float`、`double` 和 `string`。你也可以通过使用其他消息类型作为字段类型,将更多的数据结构添加到你的消息中——在以上的示例,`Person` 消息包含了 `PhoneNumber` 消息,同时 `AddressBook` 消息包含 `Person` 消息。你甚至可以定义嵌套在其他消息内的消息类型——如你所见,`PhoneNumber` 类型定义于 `Person` 内部。如果你想要其中某一个字段的值是预定义值列表中的某个值,你也可以定义 `enum` 类型——这儿你可以指定一个电话号码是 `MOBILE`、`HOME` 或 `WORK` 中的某一个。
|
||||
|
||||
每一个元素上的 `= 1`、`= 2` 标记确定了用于二进制编码的唯一“标签”(tag)。标签数字 1-15 的编码比更大的数字少需要一个字节,因此作为一种优化,你可以将这些标签用于经常使用的元素或 repeated 元素,剩下 16 以及更高的标签用于非经常使用的元素或 `optional` 元素。每一个 `repeated` 字段的元素需要重新编码标签数字,因此 `repeated` 字段适合于使用这种优化手段。
|
||||
|
||||
每一个字段必须使用下面的修饰符加以标注:
|
||||
|
||||
* `required`:必须提供该字段的值,否则消息会被认为是 “未初始化的”(uninitialized)。如果 `libprotobuf` 以调试模式编译,序列化未初始化的消息将引起一个断言失败。以优化形式构建,将会跳过检查,并且无论如何都会写入该消息。然而,解析未初始化的消息总是会失败(通过 parse 方法返回 `false`)。除此之外,一个 `required` 字段的表现与 `optional` 字段完全一样。
|
||||
* `optional`:字段可能会被设置,也可能不会。如果一个 `optional` 字段没被设置,它将使用默认值。对于简单类型,你可以指定你自己的默认值,正如例子中我们对电话号码的 `type` 一样,否则使用系统默认值:数字类型为 0、字符串为空字符串、布尔值为 false。对于嵌套消息,默认值总为消息的“默认实例”或“原型”,它的所有字段都没被设置。调用 accessor 来获取一个没有显式设置的 `optional`(或 `required`) 字段的值总是返回字段的默认值。
|
||||
* `repeated`:字段可以重复任意次数(包括 0 次)。`repeated` 值的顺序会被保存于 protocol buffer。可以将 repeated 字段想象为动态大小的数组。
|
||||
|
||||
你可以查找关于编写 `.proto` 文件的完整指导——包括所有可能的字段类型——在 [Protocol Buffer Language Guide][6] 里面。不要在这里面查找与类继承相似的特性,因为 protocol buffers 不会做这些。
|
||||
|
||||
> **`required` 是永久性的**
|
||||
|
||||
>在把一个字段标识为 `required` 的时候,你应该特别小心。如果在某些情况下你不想写入或者发送一个 `required` 的字段,那么将该字段更改为 `optional` 可能会遇到问题——旧版本的读者(LCTT 译注:即读取、解析旧版本 Protocol Buffer 消息的一方)会认为不含该字段的消息是不完整的,从而有可能会拒绝解析。在这种情况下,你应该考虑编写特别针对于应用程序的、自定义的消息校验函数。Google 的一些工程师得出了一个结论:使用 `required` 弊多于利;他们更愿意使用 `optional` 和 `repeated` 而不是 `required`。当然,这个观点并不具有普遍性。
|
||||
|
||||
### 编译你的 Protocol Buffers
|
||||
|
||||
既然你有了一个 `.proto`,那你需要做的下一件事就是生成一个将用于读写 `AddressBook` 消息的类(从而包括 `Person` 和 `PhoneNumber`)。为了做到这样,你需要在你的 `.proto` 上运行 protocol buffer 编译器 `protoc`:
|
||||
|
||||
1. 如果你没有安装编译器,请[下载这个包][4],并按照 README 中的指令进行安装。
|
||||
2. 现在运行编译器,指定源目录(你的应用程序源代码位于哪里——如果你没有提供任何值,将使用当前目录)、目标目录(你想要生成的代码放在哪里;常与 `$SRC_DIR` 相同),以及你的 `.proto` 路径。在此示例中:
|
||||
|
||||
```
|
||||
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/addressbook.proto
|
||||
```
|
||||
|
||||
因为你想要 C++ 的类,所以你使用了 `--cpp_out` 选项——也为其他支持的语言提供了类似选项。
|
||||
|
||||
在你指定的目标文件夹,将生成以下的文件:
|
||||
|
||||
* `addressbook.pb.h`,声明你生成类的头文件。
|
||||
* `addressbook.pb.cc`,包含你的类的实现。
|
||||
|
||||
### Protocol Buffer API
|
||||
|
||||
让我们看看生成的一些代码,了解一下编译器为你创建了什么类和函数。如果你查看 `addressbook.pb.h`,你可以看到有一个在 `addressbook.proto` 中指定所有消息的类。关注 `Person` 类,可以看到编译器为每个字段生成了读写函数(accessors)。例如,对于 `name`、`id`、`email` 和 `phone` 字段,有下面这些方法:(LCTT 译注:此处原文所指文件名有误,径该之。)
|
||||
|
||||
```c++
|
||||
// name
|
||||
inline bool has_name() const;
|
||||
inline void clear_name();
|
||||
inline const ::std::string& name() const;
|
||||
inline void set_name(const ::std::string& value);
|
||||
inline void set_name(const char* value);
|
||||
inline ::std::string* mutable_name();
|
||||
|
||||
// id
|
||||
inline bool has_id() const;
|
||||
inline void clear_id();
|
||||
inline int32_t id() const;
|
||||
inline void set_id(int32_t value);
|
||||
|
||||
// email
|
||||
inline bool has_email() const;
|
||||
inline void clear_email();
|
||||
inline const ::std::string& email() const;
|
||||
inline void set_email(const ::std::string& value);
|
||||
inline void set_email(const char* value);
|
||||
inline ::std::string* mutable_email();
|
||||
|
||||
// phone
|
||||
inline int phone_size() const;
|
||||
inline void clear_phone();
|
||||
inline const ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >& phone() const;
|
||||
inline ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >* mutable_phone();
|
||||
inline const ::tutorial::Person_PhoneNumber& phone(int index) const;
|
||||
inline ::tutorial::Person_PhoneNumber* mutable_phone(int index);
|
||||
inline ::tutorial::Person_PhoneNumber* add_phone();
|
||||
```
|
||||
|
||||
正如你所见到,getters 的名字与字段的小写名字完全一样,并且 setter 方法以 set_ 开头。同时每个单一(singular)(`required` 或 `optional`)字段都有 `has_` 方法,该方法在字段被设置了值的情况下返回 true。最后,所有字段都有一个 `clear_` 方法,用以清除字段到空(empty)状态。
|
||||
|
||||
数字型的 `id` 字段仅有上述的基本读写函数集合(accessors),而 `name` 和 `email` 字段有两个额外的方法,因为它们是字符串——一个是可以获得字符串直接指针的`mutable_` 的 getter ,另一个为额外的 setter。注意,尽管 `email` 还没被设置(set),你也可以调用 `mutable_email`;因为 `email` 会被自动地初始化为空字符串。在本例中,如果你有一个单一的(`required` 或 `optional`)消息字段,它会有一个 `mutable_` 方法,而没有 `set_` 方法。
|
||||
|
||||
`repeated` 字段也有一些特殊的方法——如果你看看 `repeated` 的 `phone` 字段的方法,你可以看到:
|
||||
|
||||
* 检查 `repeated` 字段的 `_size`(也就是说,与 `Person` 相关的电话号码的个数)
|
||||
* 使用下标取得特定的电话号码
|
||||
* 更新特定下标的电话号码
|
||||
* 添加新的电话号码到消息中,之后你便可以编辑。(`repeated` 标量类型有一个 `add_` 方法,用于传入新的值)
|
||||
|
||||
为了获取 protocol 编译器为所有字段定义生成的方法的信息,可以查看 [C++ generated code reference][5]。
|
||||
|
||||
#### 枚举和嵌套类
|
||||
|
||||
与 `.proto` 的枚举相对应,生成的代码包含了一个 `PhoneType` 枚举。你可以通过 `Person::PhoneType` 引用这个类型,通过 `Person::MOBILE`、`Person::HOME` 和 `Person::WORK` 引用它的值。(实现细节有点复杂,但是你无须了解它们而可以直接使用)
|
||||
|
||||
编译器也生成了一个 `Person::PhoneNumber` 的嵌套类。如果你查看代码,你可以发现真正的类型为 `Person_PhoneNumber`,但它通过在 `Person` 内部使用 `typedef` 定义,使你可以把 `Person_PhoneNumber` 当成嵌套类。唯一产生影响的一个例子是,如果你想要在其他文件前置声明该类——在 C++ 中你不能前置声明嵌套类,但是你可以前置声明 `Person_PhoneNumber`。
|
||||
|
||||
#### 标准的消息方法
|
||||
|
||||
所有的消息方法都包含了许多别的方法,用于检查和操作整个消息,包括:
|
||||
|
||||
* `bool IsInitialized() const;` :检查是否所有 `required` 字段已经被设置。
|
||||
* `string DebugString() const;` :返回人类可读的消息表示,对调试特别有用。
|
||||
* `void CopyFrom(const Person& from);`:使用给定的值重写消息。
|
||||
* `void Clear();`:清除所有元素为空(empty)的状态。
|
||||
|
||||
上面这些方法以及下一节要讲的 I/O 方法实现了被所有 C++ protocol buffer 类共享的消息(Message)接口。为了获取更多信息,请查看 [complete API documentation for Message][7]。
|
||||
|
||||
#### 解析和序列化
|
||||
|
||||
最后,所有 protocol buffer 类都有读写你选定类型消息的方法,这些方法使用了特定的 protocol buffer [二进制格式][8]。这些方法包括:
|
||||
|
||||
* `bool SerializeToString(string* output) const;`:序列化消息并将消息字节数据存储在给定的字符串中。注意,字节数据是二进制格式的,而不是文本格式;我们只使用 `string` 类作为合适的容器。
|
||||
* `bool ParseFromString(const string& data);`:从给定的字符创解析消息。
|
||||
* `bool SerializeToOstream(ostream* output) const;`:将消息写到给定的 C++ `ostream`。
|
||||
* `bool ParseFromIstream(istream* input);`:从给定的 C++ `istream` 解析消息。
|
||||
|
||||
这些只是两个用于解析和序列化的选择。再次说明,可以查看 `Message API reference` 完整的列表。
|
||||
|
||||
> **Protocol Buffers 和面向对象设计**
|
||||
|
||||
> Protocol buffer 类通常只是纯粹的数据存储器(像 C++ 中的结构体);它们在对象模型中并不是一等公民。如果你想向生成的 protocol buffer 类中添加更丰富的行为,最好的方法就是在应用程序中对它进行封装。如果你无权控制 `.proto` 文件的设计的话,封装 protocol buffers 也是一个好主意(例如,你从另一个项目中重用一个 `.proto` 文件)。在那种情况下,你可以用封装类来设计接口,以更好地适应你的应用程序的特定环境:隐藏一些数据和方法,暴露一些便于使用的函数,等等。**但是你绝对不要通过继承生成的类来添加行为。**这样做的话,会破坏其内部机制,并且不是一个好的面向对象的实践。
|
||||
|
||||
### 写消息
|
||||
|
||||
现在我们尝试使用 protocol buffer 类。你的地址簿程序想要做的第一件事是将个人详细信息写入到地址簿文件。为了做到这一点,你需要创建、填充 protocol buffer 类实例,并且将它们写入到一个输出流(output stream)。
|
||||
|
||||
这里的程序可以从文件读取 `AddressBook`,根据用户输入,将新 `Person` 添加到 `AddressBook`,并且再次将新的 `AddressBook` 写回文件。这部分直接调用或引用 protocol buffer 类的代码会以“// pb”标出。
|
||||
|
||||
```c++
|
||||
#include <iostream>
|
||||
#include <fstream>
|
||||
#include <string>
|
||||
#include "addressbook.pb.h" // pb
|
||||
using namespace std;
|
||||
|
||||
// This function fills in a Person message based on user input.
|
||||
void PromptForAddress(tutorial::Person* person) {
|
||||
cout << "Enter person ID number: ";
|
||||
int id;
|
||||
cin >> id;
|
||||
person->set_id(id); // pb
|
||||
cin.ignore(256, '\n');
|
||||
|
||||
cout << "Enter name: ";
|
||||
getline(cin, *person->mutable_name()); // pb
|
||||
|
||||
cout << "Enter email address (blank for none): ";
|
||||
string email;
|
||||
getline(cin, email);
|
||||
if (!email.empty()) { // pb
|
||||
person->set_email(email); // pb
|
||||
}
|
||||
|
||||
while (true) {
|
||||
cout << "Enter a phone number (or leave blank to finish): ";
|
||||
string number;
|
||||
getline(cin, number);
|
||||
if (number.empty()) {
|
||||
break;
|
||||
}
|
||||
|
||||
tutorial::Person::PhoneNumber* phone_number = person->add_phone(); //pb
|
||||
phone_number->set_number(number); // pb
|
||||
|
||||
cout << "Is this a mobile, home, or work phone? ";
|
||||
string type;
|
||||
getline(cin, type);
|
||||
if (type == "mobile") {
|
||||
phone_number->set_type(tutorial::Person::MOBILE); // pb
|
||||
} else if (type == "home") {
|
||||
phone_number->set_type(tutorial::Person::HOME); // pb
|
||||
} else if (type == "work") {
|
||||
phone_number->set_type(tutorial::Person::WORK); // pb
|
||||
} else {
|
||||
cout << "Unknown phone type. Using default." << endl;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Main function: Reads the entire address book from a file,
|
||||
// adds one person based on user input, then writes it back out to the same
|
||||
// file.
|
||||
int main(int argc, char* argv[]) {
|
||||
// Verify that the version of the library that we linked against is
|
||||
// compatible with the version of the headers we compiled against.
|
||||
GOOGLE_PROTOBUF_VERIFY_VERSION; // pb
|
||||
|
||||
if (argc != 2) {
|
||||
cerr << "Usage: " << argv[0] << " ADDRESS_BOOK_FILE" << endl;
|
||||
return -1;
|
||||
}
|
||||
|
||||
tutorial::AddressBook address_book; // pb
|
||||
|
||||
{
|
||||
// Read the existing address book.
|
||||
fstream input(argv[1], ios::in | ios::binary);
|
||||
if (!input) {
|
||||
cout << argv[1] << ": File not found. Creating a new file." << endl;
|
||||
} else if (!address_book.ParseFromIstream(&input)) { // pb
|
||||
cerr << "Failed to parse address book." << endl;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
// Add an address.
|
||||
PromptForAddress(address_book.add_person()); // pb
|
||||
|
||||
{
|
||||
// Write the new address book back to disk.
|
||||
fstream output(argv[1], ios::out | ios::trunc | ios::binary);
|
||||
if (!address_book.SerializeToOstream(&output)) { // pb
|
||||
cerr << "Failed to write address book." << endl;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
// Optional: Delete all global objects allocated by libprotobuf.
|
||||
google::protobuf::ShutdownProtobufLibrary(); // pb
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
注意 `GOOGLE_PROTOBUF_VERIFY_VERSION` 宏。它是一种好的实践——虽然不是严格必须的——在使用 C++ Protocol Buffer 库之前执行该宏。它可以保证避免不小心链接到一个与编译的头文件版本不兼容的库版本。如果被检查出来版本不匹配,程序将会终止。注意,每个 `.pb.cc` 文件在初始化时会自动调用这个宏。
|
||||
|
||||
同时注意在程序最后调用 `ShutdownProtobufLibrary()`。它用于释放 Protocol Buffer 库申请的所有全局对象。对大部分程序,这不是必须的,因为虽然程序只是简单退出,但是 OS 会处理释放程序的所有内存。然而,如果你使用了内存泄漏检测工具,工具要求全部对象都要释放,或者你正在写一个 Protocol Buffer 库,该库可能会被一个进程多次加载和卸载,那么你可能需要强制 Protocol Buffer 清除所有东西。
|
||||
|
||||
### 读取消息
|
||||
|
||||
当然,如果你无法从它获取任何信息,那么这个地址簿没多大用处!这个示例读取上面例子创建的文件,并打印文件里的所有内容。
|
||||
|
||||
```c++
|
||||
#include <iostream>
|
||||
#include <fstream>
|
||||
#include <string>
|
||||
#include "addressbook.pb.h" // pb
|
||||
using namespace std;
|
||||
|
||||
// Iterates though all people in the AddressBook and prints info about them.
|
||||
void ListPeople(const tutorial::AddressBook& address_book) { // pb
|
||||
for (int i = 0; i < address_book.person_size(); i++) { // pb
|
||||
const tutorial::Person& person = address_book.person(i); // pb
|
||||
|
||||
cout << "Person ID: " << person.id() << endl; // pb
|
||||
cout << " Name: " << person.name() << endl; // pb
|
||||
if (person.has_email()) { // pb
|
||||
cout << " E-mail address: " << person.email() << endl; // pb
|
||||
}
|
||||
|
||||
for (int j = 0; j < person.phone_size(); j++) { // pb
|
||||
const tutorial::Person::PhoneNumber& phone_number = person.phone(j); // pb
|
||||
|
||||
switch (phone_number.type()) { // pb
|
||||
case tutorial::Person::MOBILE: // pb
|
||||
cout << " Mobile phone #: ";
|
||||
break;
|
||||
case tutorial::Person::HOME: // pb
|
||||
cout << " Home phone #: ";
|
||||
break;
|
||||
case tutorial::Person::WORK: // pb
|
||||
cout << " Work phone #: ";
|
||||
break;
|
||||
}
|
||||
cout << phone_number.number() << endl; // ob
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Main function: Reads the entire address book from a file and prints all
|
||||
// the information inside.
|
||||
int main(int argc, char* argv[]) {
|
||||
// Verify that the version of the library that we linked against is
|
||||
// compatible with the version of the headers we compiled against.
|
||||
GOOGLE_PROTOBUF_VERIFY_VERSION; // pb
|
||||
|
||||
if (argc != 2) {
|
||||
cerr << "Usage: " << argv[0] << " ADDRESS_BOOK_FILE" << endl;
|
||||
return -1;
|
||||
}
|
||||
|
||||
tutorial::AddressBook address_book; // pb
|
||||
|
||||
{
|
||||
// Read the existing address book.
|
||||
fstream input(argv[1], ios::in | ios::binary);
|
||||
if (!address_book.ParseFromIstream(&input)) { // pb
|
||||
cerr << "Failed to parse address book." << endl;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
ListPeople(address_book);
|
||||
|
||||
// Optional: Delete all global objects allocated by libprotobuf.
|
||||
google::protobuf::ShutdownProtobufLibrary(); // pb
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
### 扩展 Protocol Buffer
|
||||
|
||||
或早或晚在你发布了使用 protocol buffer 的代码之后,毫无疑问,你会想要 "改善"
|
||||
protocol buffer 的定义。如果你想要新的 buffers 向后兼容,并且老的 buffers 向前兼容——几乎可以肯定你很渴望这个——这里有一些规则,你需要遵守。在新的 protocol buffer 版本:
|
||||
|
||||
* 你绝不可以修改任何已存在字段的标签数字
|
||||
* 你绝不可以添加或删除任何 `required` 字段
|
||||
* 你可以删除 `optional` 或 `repeated` 字段
|
||||
* 你可以添加新的 `optional` 或 `repeated` 字段,但是你必须使用新的标签数字(也就是说,标签数字在 protocol buffer 中从未使用过,甚至不能是已删除字段的标签数字)。
|
||||
|
||||
(对于上面规则有一些[例外情况][9],但它们很少用到。)
|
||||
|
||||
如果你能遵守这些规则,旧代码则可以欢快地读取新的消息,并且简单地忽略所有新的字段。对于旧代码来说,被删除的 `optional` 字段将会简单地赋予默认值,被删除的 `repeated` 字段会为空。新代码显然可以读取旧消息。然而,请记住新的 `optional` 字段不会呈现在旧消息中,因此你需要显式地使用 `has_` 检查它们是否被设置或者在 `.proto` 文件在标签数字后使用 `[default = value]` 提供一个合理的默认值。如果一个 `optional` 元素没有指定默认值,它将会使用类型特定的默认值:对于字符串,默认值为空字符串;对于布尔值,默认值为 false;对于数字类型,默认类型为 0。注意,如果你添加一个新的 `repeated` 字段,新代码将无法辨别它被留空(left empty)(被新代码)或者从没被设置(被旧代码),因为 `repeated` 字段没有 `has_` 标志。
|
||||
|
||||
### 优化技巧
|
||||
|
||||
C++ Protocol Buffer 库已极度优化过了。但是,恰当的用法能够更多地提高性能。这里是一些技巧,可以帮你从库中挤压出最后一点速度:
|
||||
|
||||
* 尽可能复用消息对象。即使它们被清除掉,消息也会尽量保存所有被分配来重用的内存。因此,如果我们正在处理许多相同类型或一系列相似结构的消息,一个好的办法是重用相同的消息对象,从而减少内存分配的负担。但是,随着时间的流逝,对象可能会膨胀变大,尤其是当你的消息尺寸(LCTT 译注:各消息内容不同,有些消息内容多一些,有些消息内容少一些)不同的时候,或者你偶尔创建了一个比平常大很多的消息的时候。你应该自己通过调用 [SpaceUsed][10] 方法监测消息对象的大小,并在它太大的时候删除它。
|
||||
* 对于在多线程中分配大量小对象的情况,你的操作系统内存分配器可能优化得不够好。你可以尝试使用 google 的 [tcmalloc][11]。
|
||||
|
||||
### 高级用法
|
||||
|
||||
Protocol Buffers 绝不仅用于简单的数据存取以及序列化。请阅读 [C++ API reference][12] 来看看你还能用它来做什么。
|
||||
|
||||
protocol 消息类所提供的一个关键特性就是反射(reflection)。你不需要针对一个特殊的消息类型编写代码,就可以遍历一个消息的字段并操作它们的值。一个使用反射的有用方法是 protocol 消息与其他编码互相转换,比如 XML 或 JSON。反射的一个更高级的用法可能就是可以找出两个相同类型的消息之间的区别,或者开发某种“协议消息的正则表达式”,利用正则表达式,你可以对某种消息内容进行匹配。只要你发挥你的想像力,就有可能将 Protocol Buffers 应用到一个更广泛的、你可能一开始就期望解决的问题范围上。
|
||||
|
||||
反射是由 [Message::Reflection interface][13] 提供的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://developers.google.com/protocol-buffers/docs/cpptutorial
|
||||
|
||||
作者:[Google][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://developers.google.com/protocol-buffers/docs/cpptutorial
|
||||
[1]: https://developers.google.com/protocol-buffers/docs/proto
|
||||
[2]: https://developers.google.com/protocol-buffers/docs/encoding
|
||||
[3]: https://developers.google.com/protocol-buffers/docs/downloads
|
||||
[4]: https://developers.google.com/protocol-buffers/docs/downloads.html
|
||||
[5]: https://developers.google.com/protocol-buffers/docs/reference/cpp-generated
|
||||
[6]: https://developers.google.com/protocol-buffers/docs/proto
|
||||
[7]: https://developers.google.com/protocol-buffers/docs/reference/cpp/google.protobuf.message.html#Message
|
||||
[8]: https://developers.google.com/protocol-buffers/docs/encoding
|
||||
[9]: https://developers.google.com/protocol-buffers/docs/proto#updating
|
||||
[10]: https://developers.google.com/protocol-buffers/docs/reference/cpp/google.protobuf.message.html#Message.SpaceUsed.details
|
||||
[11]: http://code.google.com/p/google-perftools/
|
||||
[12]: https://developers.google.com/protocol-buffers/docs/reference/cpp/index.html
|
||||
[13]: https://developers.google.com/protocol-buffers/docs/reference/cpp/google.protobuf.message.html#Message.Reflection
|
||||
64
published/20161026 2 free desktop recording tools to try.md
Normal file
64
published/20161026 2 free desktop recording tools to try.md
Normal file
@ -0,0 +1,64 @@
|
||||
两款免费的 Linux 桌面录制工具:SimpleScreenRecorder 和 Kazam
|
||||
====
|
||||
|
||||
> 桌面录制工具可以帮做我们快速高效的制作教学视频和在线示范。
|
||||
|
||||

|
||||
|
||||
一图胜千言,但一段视频演示则可以让你不用大费口舌。我是一个“视觉学习者”,亲眼目睹一件事情的发生对我的学习大有裨益。我也曾观察发现,如果学生实际看到应用程序的设置流程或者代码的编写过程,他们就能从中受益良多。所以,录屏工具是制作教学视频的绝佳工具。在本文中我将介绍一下两款开源桌面录制工具: [SimpleScreenRecorder][4] 和 [Kazam][3]。
|
||||
|
||||
### SimpleScreenRecorder
|
||||
|
||||
使用 SimpleScreenRecorder 能够轻松录制桌面动作,它拥有直观的用户界面以及多样的编码方式,如 MP4、OGG、[Matroska][2] 或 [WebM][1] 格式。 SimpleScreenRecorder 遵从 GPL 协议发行,运行在 Linux 上。
|
||||
|
||||
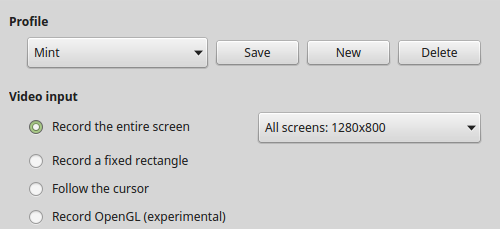
在安装运行 SimpleScreenRecorder 后,你可以轻松选择录制整个桌面、指定窗口或者一个自定义的区域。我比较偏爱最后这种方式,因为这样我可以使我的学生把注意力集中在我想让他们注意的地方。你还可以在设置中选择是否隐藏光标、调整录制帧率(默认帧率为 30fps)、视频压缩比例或者调整音频后端(如 ALSA、JACK 或 PusleAudio)。
|
||||
|
||||
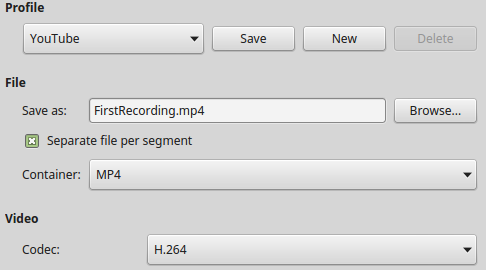
由于 SimpleScreenRecorder 使用了 libav/ffmpeg 库进行编码,故而支持多种文件格式和视频编码方式。可以使用不同的配置文件(编码更快的配置文件意味着更大的体积),包括 YouTube 和 1000kbps – 3000kbps 的 LiveStream。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
配置完毕后,单击“开始录制”按钮或者使用自定义的快捷键就可以轻松开始录制屏幕啦~
|
||||
|
||||
|
||||
|
||||
你还能在设置中开启提示音功能,它会开始录制和录制结束时给你声音的提示。屏幕录制完成后,你可以对视频文件进行编辑或者直接上传到 YouTube、Vimeo 等视频网站上。
|
||||
|
||||
SimpleScreenRecorder 的[官方网站][4]上还有大量说明文档,其中包括设置、录制、上传等方面的帮助手册和针对多种Linux发行版的安装说明。
|
||||
|
||||
### Kazam
|
||||
|
||||
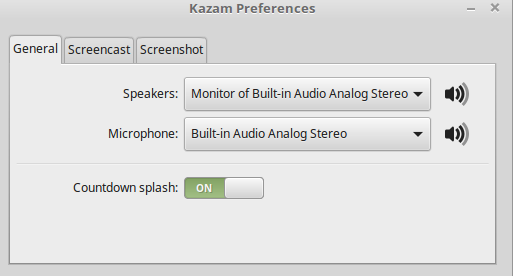
Kazam 桌面录制工具同样是遵循 GPL 协议的软件。同时和 SimpleScreenRecorder 一样,Kazam 易于上手,界面直观。安装运行 Kazam 之后,你可以设置选择录制整个桌面、指定窗口或是一个自定义的区域。(LCTT 译注:关于自定义区域录制一部分的内容与 SimpleScreenRecorder 介绍中的内容基本相似,略过) ,你还可以选择记录鼠标的移动轨迹。我最中意 Kazam 的一点是延时录制的功能,这在制作视频教程的时候必不可少。
|
||||
|
||||
在“文件|设置”菜单下可以轻松对 Kazam 进行个性化设置,比如可以选择扬声器或是麦克风中的音源、关闭倒计时提示等等。
|
||||
|
||||
|
||||
|
||||
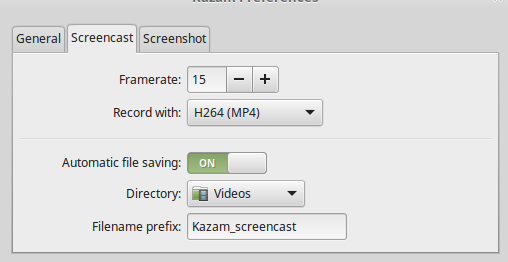
在设置页的第二个选项卡中可以进行视频录制设置。Kazam 默认录制帧率为 15fps,编码格式为 H264(MP4)。其它可供选择的格式有 VP8(WEBM)、HUFFYUV、Lossless JPEG 以及 RAW AVI。录制好的文件会以附加一个预设的前缀来命名,并自动保存在默认目录下,你可以随时修改这些设置。
|
||||
|
||||
|
||||
|
||||
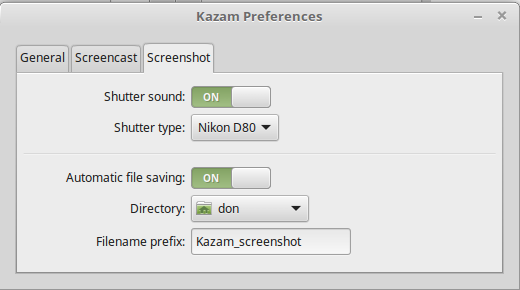
设置屏幕截图同样很简单。你可以选择 Nikon D80 或 Canon 7D 的快门音效,也可以干脆关掉他们。截图文件是自动存放的。除非你关闭这一功能。
|
||||
|
||||
|
||||
|
||||
录制好的视频将会存储在你选定的目录下,随时可以上传到你喜欢的视频分享网站或是教程网站上。
|
||||
|
||||
是时候利用 Linux 和录屏工具让你的课堂焕然一新了!如果你还有其他的屏幕录制工具或是使用技巧,记得在评论里与我交流哦~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/education/16/10/simplescreenrecorder-and-kazam
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[HaohongWANG](https://github.com/HaohongWANG)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[1]:https://www.webmproject.org/
|
||||
[2]:https://www.matroska.org/technical/whatis/index.html
|
||||
[3]:https://launchpad.net/kazam
|
||||
[4]:http://www.maartenbaert.be/simplescreenrecorder/
|
||||
@ -1,3 +1,5 @@
|
||||
OneNewLife translating
|
||||
|
||||
# How to Encrypt and Decrypt Files and Directories Using Tar and OpenSSL
|
||||
|
||||
When you have important sensitive data, then its crucial to have an extra layer of security to your files and directories, specially when you need to transmit the data with others over a network.
|
||||
|
||||
@ -1,156 +0,0 @@
|
||||
OneNewLife translating.
|
||||
|
||||
How to Install Git and Setup Git Account in RHEL, CentOS and Fedora
|
||||
=========
|
||||
|
||||
For newbies, Git is a free and open source, fast and distributed version control system (VCS), which by design is based on speed, efficient performance and data integrity to support small-scale to extensive software development projects.
|
||||
|
||||
Git is a software repository that allows you to keep a track of your software changes, revert to previous version and create another versions of files and directories.
|
||||
|
||||
Git is written in C, with a mix of Perl and a variety of shell scripts, it’s primarily intended to run on the Linux kernel and has a number of remarkable features as listed below:
|
||||
|
||||
1. Easy to learn
|
||||
2. It is fast and most of its operations are carried out locally, in addition, this offers it a tremendous speed on centralized systems that need to communicate with remote servers.
|
||||
3. Highly efficient
|
||||
4. Supports data integrity checks
|
||||
5. Enables cheap local branching
|
||||
6. Offers a convenient staging area
|
||||
7. It also maintains multiple work-flows together with many others
|
||||
|
||||
In this how-to guide, we shall move through the necessary steps of installing Git on CentOS/RHEL 7/6 and Fedora 20-24 Linux distributions along with how to configure Git so that you can start participating right away..
|
||||
|
||||
### Install Git Using Yum
|
||||
|
||||
We shall install Git from the system default repositories, and make sure that your system is up-to-date with the latest version of packages by running the [YUM package manager][8] update command below:
|
||||
|
||||
```
|
||||
# yum update
|
||||
|
||||
```
|
||||
|
||||
Next, install Git by typing the following command:
|
||||
|
||||
```
|
||||
# yum install git
|
||||
|
||||
```
|
||||
|
||||
After git successfully installed, you can issue the following command to display the version of Git installed:
|
||||
|
||||
```
|
||||
# git --version
|
||||
|
||||
```
|
||||
|
||||
[][7]
|
||||
|
||||
Check Git Installed Version
|
||||
|
||||
Important: Installing Git from default repositories will give you older version. If you looking to have a most recent version of Git, consider compiling from source using following instructions.
|
||||
|
||||
### Install Git from Source
|
||||
|
||||
Before you begin, first you need to install required software dependencies from the default repositories, along with the utilities that needed to build a binary from source:
|
||||
|
||||
```
|
||||
# yum groupinstall "Development Tools"
|
||||
# yum install gettext-devel openssl-devel perl-CPAN perl-devel zlib-devel
|
||||
|
||||
```
|
||||
|
||||
After you have installed required software dependencies, go to the official [Git release page][6] and grab the latest version and compile it from source using following series of command:
|
||||
|
||||
```
|
||||
# wget https://github.com/git/git/archive/v2.10.1.tar.gz -O git.tar.gz
|
||||
# tar -zxf git.tar.gz
|
||||
# cd git-2.10.1/
|
||||
# make configure
|
||||
# ./configure --prefix=/usr/local
|
||||
# make install
|
||||
# git --version
|
||||
|
||||
```
|
||||
|
||||
[][5]
|
||||
|
||||
Check Installed Git Version
|
||||
|
||||
**Suggested Read:** [11 Best Git Clients and Git Repository Viewers for Linux][4]
|
||||
|
||||
### Set Up Git Account in Linux
|
||||
|
||||
In this section, we shall cover how to set up a Git account with correct user information such as name and email address to avoid any commit errors, and the `git config` command is used to do that.
|
||||
|
||||
Important: Make sure to replace username with the actual name for the Git user to be created and used on your system.
|
||||
|
||||
You can start by creating a Git user with the [useradd command][3] as below, where the `-m` flag used to create the user’s home directory under `/home` and `-s` specifies the user’s default shell.
|
||||
|
||||
```
|
||||
# useradd -m -s /bin/bash username
|
||||
# passwd username
|
||||
|
||||
```
|
||||
|
||||
Now, add the new user to the wheel group to enable the account to use the `sudo` command:
|
||||
|
||||
```
|
||||
# usermod username -aG wheel
|
||||
|
||||
```
|
||||
|
||||
[][2]
|
||||
|
||||
Create Git User Account
|
||||
|
||||
Then configure Git with the new user as follows:
|
||||
|
||||
```
|
||||
# su username
|
||||
$ sudo git config --global user.name "Your Name"
|
||||
$ sudo git config --global user.email "you@example.com"
|
||||
|
||||
```
|
||||
|
||||
Now verify Git configuration using following command.
|
||||
|
||||
```
|
||||
$ sudo git config --list
|
||||
|
||||
```
|
||||
|
||||
If there are no errors with the configurations, you should be able to view an output with the following details:
|
||||
|
||||
```
|
||||
user.name=username
|
||||
user.email= username@some-domian.com
|
||||
|
||||
```
|
||||
|
||||
[][1]
|
||||
>Setup Git Account in Linux
|
||||
|
||||
##### Conclusion
|
||||
|
||||
In this simple tutorial, we have looked at how to install Git on your Linux system as well as configuring it. I believe the instructions are easy to follow, however, to get in touch with us for any questions or suggestions you can make use of the reaction section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-git-centos-fedora-redhat/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2016/10/Setup-Git-Account.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/10/Create-Git-User-Account.png
|
||||
[3]:http://www.tecmint.com/add-users-in-linux/
|
||||
[4]:http://www.tecmint.com/best-gui-git-clients-git-repository-viewers-for-linux/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/10/Check-Git-Source-Version.png
|
||||
[6]:https://github.com/git/git/releases
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/10/Check-Git-Version.png
|
||||
[8]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
@ -1,68 +0,0 @@
|
||||
Translating by Haohong WANG
|
||||
|
||||
2 free desktop recording tools to try: SimpleScreenRecorder and Kazam
|
||||
====
|
||||
|
||||
>Desktop recording tools can help you whip up tutorials for the classroom or online demonstrations.
|
||||
|
||||

|
||||
|
||||
A picture might be worth a thousand words, but a video demonstration can save a lot of talking. I'm a visual learner, so seeing how to do something has been very helpful in my education. I've found that students benefit from seeing exactly how an application is configured or how a code snippet is written. Desktop screen recorders are great tools for creating instructional videos. In this article, I'll look at two free, open source desktop screen recorders: [SimpleScreenRecorder][4] and [Kazam][3].
|
||||
|
||||
### SimpleScreenRecorder
|
||||
|
||||
SimpleScreenRecorder lets you easily record desktop action. It has an untuitive interface and the ability to record in MP4, OGG, [Matroska][2], or [WebM][1] format. SimpleScreenRecorder is released under the Gnu Public License and runs on Linux.
|
||||
|
||||
After installing and launching the program, you can easily configure it to capture the whole desktop, a specific window, or a select area. The latter is my personal favorite because it focuses the learner's attention on exactly where I want them to look. You can record the cursor or not, adjust the frame rate, scale the video, and adjust the audio backend, which includes three options: ALSA, JACK, and PulseAudio. Video frame rate defaults to 30fps.
|
||||
|
||||
Because SimpleScreenRecorder uses libav/ffmpeg libraries for encoding, it supports a variety of file formats and video codecs. Different profiles can be used (faster profiles mean bigger file sizes), including YouTube, LiveStream (1000kbps), LiveStream (2000kbps), LiveStream (3000 kbps), and high-quality intermediate.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
After you've configured your system, recording is easy. You can either click on the Start recording button or use a selection hot key.
|
||||
|
||||

|
||||
|
||||
Sound notification can also be enabled, which is a nice feature that lets you know when the recording begins and ends. Once the recording is completed, the file can edited or uploaded to YouTube, Vimeo, or an educational learning management system.
|
||||
|
||||
SimpleScreenRecorder has great documentation on its website, which includes tips for configuration, recording, and uploading, as well as installation instructions for various Linux distributions.
|
||||
|
||||
### Kazam
|
||||
|
||||
The Kazam desktop screen recorder is also released under the Gnu Public License and, like SimpleScreenRecorder, it is easy to use and offers an intuitive interface. After you install and launch the program, you can configure it to capture the whole desktop, a specific window, or a select area. Recording a select area of a screen can come in handy because it focuses the learner's attention on exactly where you want them to look. You can capture the mouse pointer movement, too. I like that Kazam also has the ability to delay the capture, which can come in useful when recording tutorials.
|
||||
|
||||
Configuring preferences is easy under the File | Preferencesmenu, and audio capture sources can be selected to include speakers and microphone. Countdown splash can be turned off, too.
|
||||
|
||||

|
||||
|
||||
The second tab of preferences is for selecting video preferences. Frame rate defaults to 15fps. The default recording is set to H264(MP4), but there are other formats available, such as VP8(WEBM), HUFFYUV, LosslessJPEG, and RAW AVI. Automatic file saving is enabled by default, along with the self-selected directory where videos are saved and a default file-name prefix, which is user-configurable.
|
||||
|
||||

|
||||
|
||||
Configuring the screenshot is easy. The shutter sound is on by default, and the shutter type can be self-selected and includes the default Nikon D80 or Canon 7D. File saving is automatic unless otherwise selected.
|
||||
|
||||

|
||||
|
||||
Screencasts are easily saved to a directory of your choice, and the file is ready to upload to your favorite sharing site or your learning management system.
|
||||
|
||||
Here's to flipping your classroom and instruction using a Linux computer and either of these great desktop screen recorders! What other screen recording tools and tricks are useful in your classroom? Let me know about them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/education/16/10/simplescreenrecorder-and-kazam
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[1]:https://www.webmproject.org/
|
||||
[2]:https://www.matroska.org/technical/whatis/index.html
|
||||
[3]:https://launchpad.net/kazam
|
||||
[4]:http://www.maartenbaert.be/simplescreenrecorder/
|
||||
453
sources/tech/20161027 DTrace for Linux 2016.md
Normal file
453
sources/tech/20161027 DTrace for Linux 2016.md
Normal file
@ -0,0 +1,453 @@
|
||||
DTrace for Linux 2016
|
||||
===========
|
||||
|
||||
|
||||
|
||||
With the final major capability for BPF tracing (timed sampling) merging in Linux 4.9-rc1, the Linux kernel now has raw capabilities similar to those provided by DTrace, the advanced tracer from Solaris. As a long time DTrace user and expert, this is an exciting milestone! On Linux, you can now analyze the performance of applications and the kernel using production-safe low-overhead custom tracing, with latency histograms, frequency counts, and more.
|
||||
|
||||
There have been many tracing projects for Linux, but the technology that finally merged didn’t start out as a tracing project at all: it began as enhancements to Berkeley Packet Filter (BPF). At first, these enhancements allowed BPF to redirect packets to create software-defined networks. Later on, support for tracing events was added, enabling programmatic tracing in Linux.
|
||||
|
||||
While BPF currently lacks a high-level language like DTrace, the front-ends available have been enough for me to create many BPF tools, some based on my older [DTraceToolkit][37]. In this post I'll describe how you can use these tools, the front-ends available, and discuss where the technology is going next.
|
||||
|
||||
### Screenshots
|
||||
|
||||
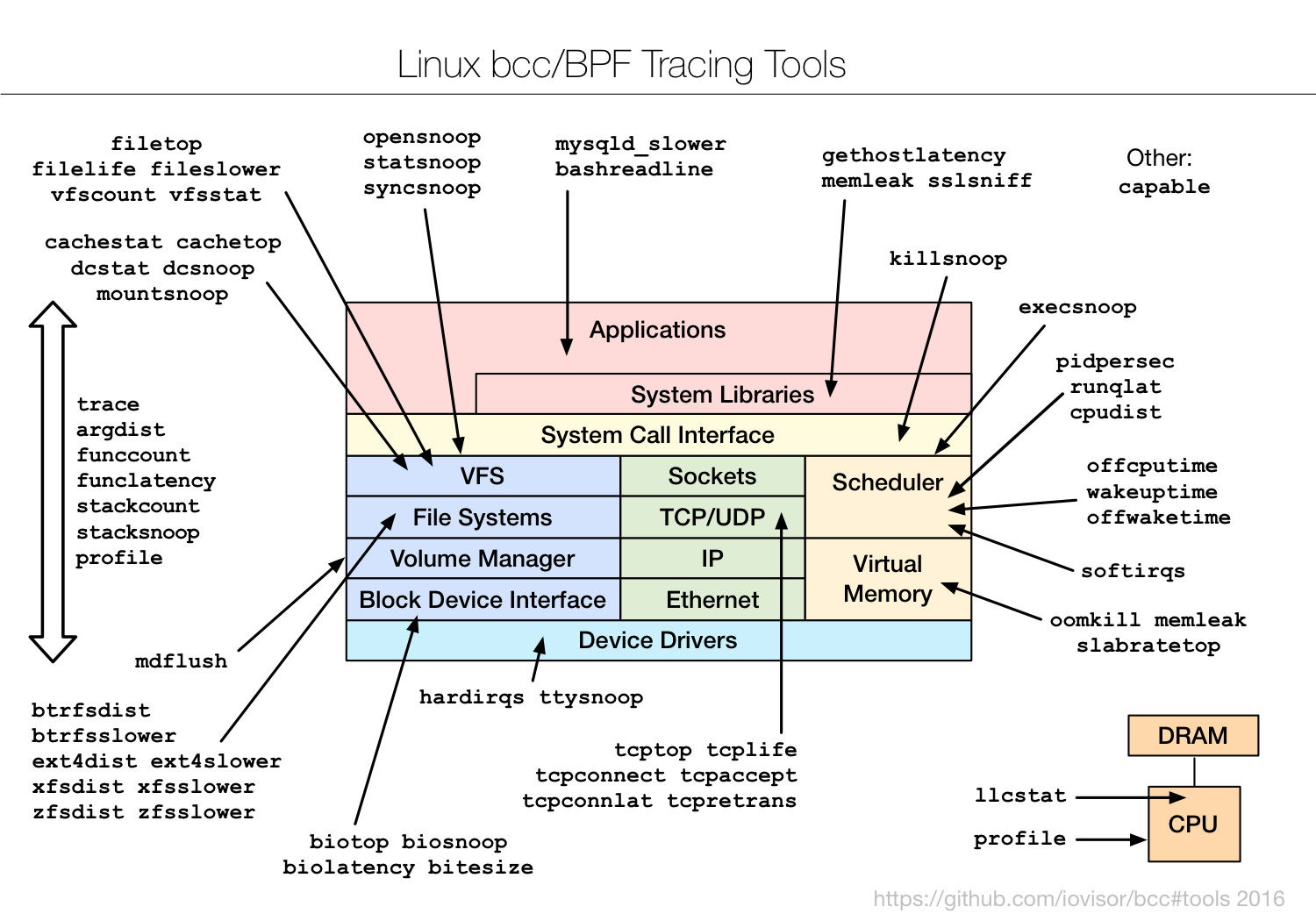
I've been adding BPF-based tracing tools to the open source [bcc][36] project (thanks to Brenden Blanco, of PLUMgrid, for leading bcc development). See the [bcc install][35] instructions. It will add a collection of tools under /usr/share/bcc/tools, including the following.
|
||||
|
||||
Tracing new processes:
|
||||
|
||||
```
|
||||
# **execsnoop**
|
||||
PCOMM PID RET ARGS
|
||||
bash 15887 0 /usr/bin/man ls
|
||||
preconv 15894 0 /usr/bin/preconv -e UTF-8
|
||||
man 15896 0 /usr/bin/tbl
|
||||
man 15897 0 /usr/bin/nroff -mandoc -rLL=169n -rLT=169n -Tutf8
|
||||
man 15898 0 /usr/bin/pager -s
|
||||
nroff 15900 0 /usr/bin/locale charmap
|
||||
nroff 15901 0 /usr/bin/groff -mtty-char -Tutf8 -mandoc -rLL=169n -rLT=169n
|
||||
groff 15902 0 /usr/bin/troff -mtty-char -mandoc -rLL=169n -rLT=169n -Tutf8
|
||||
groff 15903 0 /usr/bin/grotty
|
||||
|
||||
```
|
||||
|
||||
Histogram of disk I/O latency:
|
||||
|
||||
```
|
||||
# **biolatency -m**
|
||||
Tracing block device I/O... Hit Ctrl-C to end.
|
||||
^C
|
||||
msecs : count distribution
|
||||
0 -> 1 : 96 |************************************ |
|
||||
2 -> 3 : 25 |********* |
|
||||
4 -> 7 : 29 |*********** |
|
||||
8 -> 15 : 62 |*********************** |
|
||||
16 -> 31 : 100 |**************************************|
|
||||
32 -> 63 : 62 |*********************** |
|
||||
64 -> 127 : 18 |****** |
|
||||
|
||||
```
|
||||
|
||||
Tracing common ext4 operations slower than 5 milliseconds:
|
||||
|
||||
```
|
||||
# **ext4slower 5**
|
||||
Tracing ext4 operations slower than 5 ms
|
||||
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
21:49:45 supervise 3570 W 18 0 5.48 status.new
|
||||
21:49:48 supervise 12770 R 128 0 7.55 run
|
||||
21:49:48 run 12770 R 497 0 16.46 nsswitch.conf
|
||||
21:49:48 run 12770 R 1680 0 17.42 netflix_environment.sh
|
||||
21:49:48 run 12770 R 1079 0 9.53 service_functions.sh
|
||||
21:49:48 run 12772 R 128 0 17.74 svstat
|
||||
21:49:48 svstat 12772 R 18 0 8.67 status
|
||||
21:49:48 run 12774 R 128 0 15.76 stat
|
||||
21:49:48 run 12777 R 128 0 7.89 grep
|
||||
21:49:48 run 12776 R 128 0 8.25 ps
|
||||
21:49:48 run 12780 R 128 0 11.07 xargs
|
||||
21:49:48 ps 12776 R 832 0 12.02 libprocps.so.4.0.0
|
||||
21:49:48 run 12779 R 128 0 13.21 cut
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
Tracing new active TCP connections (connect()):
|
||||
|
||||
```
|
||||
# **tcpconnect**
|
||||
PID COMM IP SADDR DADDR DPORT
|
||||
1479 telnet 4 127.0.0.1 127.0.0.1 23
|
||||
1469 curl 4 10.201.219.236 54.245.105.25 80
|
||||
1469 curl 4 10.201.219.236 54.67.101.145 80
|
||||
1991 telnet 6 ::1 ::1 23
|
||||
2015 ssh 6 fe80::2000:bff:fe82:3ac fe80::2000:bff:fe82:3ac 22
|
||||
|
||||
```
|
||||
|
||||
Tracing DNS latency by tracing getaddrinfo()/gethostbyname() library calls:
|
||||
|
||||
```
|
||||
# **gethostlatency**
|
||||
TIME PID COMM LATms HOST
|
||||
06:10:24 28011 wget 90.00 www.iovisor.org
|
||||
06:10:28 28127 wget 0.00 www.iovisor.org
|
||||
06:10:41 28404 wget 9.00 www.netflix.com
|
||||
06:10:48 28544 curl 35.00 www.netflix.com.au
|
||||
06:11:10 29054 curl 31.00 www.plumgrid.com
|
||||
06:11:16 29195 curl 3.00 www.facebook.com
|
||||
06:11:25 29404 curl 72.00 foo
|
||||
06:11:28 29475 curl 1.00 foo
|
||||
|
||||
```
|
||||
|
||||
Interval summaries of VFS operations by type:
|
||||
|
||||
```
|
||||
# **vfsstat**
|
||||
TIME READ/s WRITE/s CREATE/s OPEN/s FSYNC/s
|
||||
18:35:32: 231 12 4 98 0
|
||||
18:35:33: 274 13 4 106 0
|
||||
18:35:34: 586 86 4 251 0
|
||||
18:35:35: 241 15 4 99 0
|
||||
|
||||
```
|
||||
|
||||
Tracing off-CPU time with kernel and user stack traces (summarized in kernel), for a given PID:
|
||||
|
||||
```
|
||||
# **offcputime -d -p 24347**
|
||||
Tracing off-CPU time (us) of PID 24347 by user + kernel stack... Hit Ctrl-C to end.
|
||||
^C
|
||||
[...]
|
||||
ffffffff810a9581 finish_task_switch
|
||||
ffffffff8185d385 schedule
|
||||
ffffffff81085672 do_wait
|
||||
ffffffff8108687b sys_wait4
|
||||
ffffffff81861bf6 entry_SYSCALL_64_fastpath
|
||||
--
|
||||
00007f6733a6b64a waitpid
|
||||
- bash (24347)
|
||||
4952
|
||||
|
||||
ffffffff810a9581 finish_task_switch
|
||||
ffffffff8185d385 schedule
|
||||
ffffffff81860c48 schedule_timeout
|
||||
ffffffff810c5672 wait_woken
|
||||
ffffffff8150715a n_tty_read
|
||||
ffffffff815010f2 tty_read
|
||||
ffffffff8122cd67 __vfs_read
|
||||
ffffffff8122df65 vfs_read
|
||||
ffffffff8122f465 sys_read
|
||||
ffffffff81861bf6 entry_SYSCALL_64_fastpath
|
||||
--
|
||||
00007f6733a969b0 read
|
||||
- bash (24347)
|
||||
1450908
|
||||
|
||||
```
|
||||
|
||||
Tracing MySQL query latency (via a USDT probe):
|
||||
|
||||
```
|
||||
# **mysqld_qslower `pgrep -n mysqld`**
|
||||
Tracing MySQL server queries for PID 14371 slower than 1 ms...
|
||||
TIME(s) PID MS QUERY
|
||||
0.000000 18608 130.751 SELECT * FROM words WHERE word REGEXP '^bre.*n$'
|
||||
2.921535 18608 130.590 SELECT * FROM words WHERE word REGEXP '^alex.*$'
|
||||
4.603549 18608 24.164 SELECT COUNT(*) FROM words
|
||||
9.733847 18608 130.936 SELECT count(*) AS count FROM words WHERE word REGEXP '^bre.*n$'
|
||||
17.864776 18608 130.298 SELECT * FROM words WHERE word REGEXP '^bre.*n$' ORDER BY word
|
||||
|
||||
```
|
||||
|
||||
Using the trace multi-tool to watch login requests, by instrumenting the pam library:
|
||||
|
||||
```
|
||||
# **trace 'pam:pam_start "%s: %s", arg1, arg2'**
|
||||
TIME PID COMM FUNC -
|
||||
17:49:45 5558 sshd pam_start sshd: root
|
||||
17:49:47 5662 sudo pam_start sudo: root
|
||||
17:49:49 5727 login pam_start login: bgregg
|
||||
|
||||
```
|
||||
|
||||
Many tools have usage messages (-h), and all should have man pages and text files of example output in the bcc project.
|
||||
|
||||
### Out of necessity
|
||||
|
||||
In 2014, Linux tracing had some kernel summary features (from ftrace and perf_events), but outside those we still had to dump-and-post-process data – a decades old technique that has high overhead at scale. You couldn't frequency count process names, function names, stack traces, or other arbitrary data in the kernel. You couldn't save variables in one probe event, and then retrieve them in another, which meant that you couldn't measure latency (or time deltas) in custom places, and you couldn't create in-kernel latency histograms. You couldn't trace USDT probes. You couldn't even write custom programs. DTrace could do all these, but only on Solaris or BSD. On Linux, some out-of-tree tracers like SystemTap could serve these needs, but brought their own challenges. (For the sake of completeness: yes, you _could_ write kprobe-based kernel modules – but practically no one did.)
|
||||
|
||||
In 2014 I joined the Netflix cloud performance team. Having spent years as a DTrace expert, it might have seemed crazy for me to move to Linux. But I had some motivations, in particular seeking a greater challenge: performance tuning the Netflix cloud, with its rapid application changes, microservice architecture, and distributed systems. Sometimes this job involves systems tracing, for which I'd previously used DTrace. Without DTrace on Linux, I began by using what was built in to the Linux kernel, ftrace and perf_events, and from them made a toolkit of tracing tools ([perf-tools][34]). They have been invaluable. But I couldn't do some tasks, particularly latency histograms and stack trace counting. We needed kernel tracing to be programmatic.
|
||||
|
||||
### What happened?
|
||||
|
||||
BPF adds programmatic capabilities to the existing kernel tracing facilities (tracepoints, kprobes, uprobes). It has been enhanced rapidly in the Linux 4.x series.
|
||||
|
||||
Timed sampling was the final major piece, and it landed in Linux 4.9-rc1 ([patchset][33]). Many thanks to Alexei Starovoitov (now working on BPF at Facebook), the lead developer behind these BPF enhancements.
|
||||
|
||||
The Linux kernel now has the following features built in (added between 2.6 and 4.9):
|
||||
|
||||
* Dynamic tracing, kernel-level (BPF support for kprobes)
|
||||
* Dynamic tracing, user-level (BPF support for uprobes)
|
||||
* Static tracing, kernel-level (BPF support for tracepoints)
|
||||
* Timed sampling events (BPF with perf_event_open)
|
||||
* PMC events (BPF with perf_event_open)
|
||||
* Filtering (via BPF programs)
|
||||
* Debug output (bpf_trace_printk())
|
||||
* Per-event output (bpf_perf_event_output())
|
||||
* Basic variables (global & per-thread variables, via BPF maps)
|
||||
* Associative arrays (via BPF maps)
|
||||
* Frequency counting (via BPF maps)
|
||||
* Histograms (power-of-2, linear, and custom, via BPF maps)
|
||||
* Timestamps and time deltas (bpf_ktime_get_ns(), and BPF programs)
|
||||
* Stack traces, kernel (BPF stackmap)
|
||||
* Stack traces, user (BPF stackmap)
|
||||
* Overwrite ring buffers (perf_event_attr.write_backward)
|
||||
|
||||
The front-end we are using is bcc, which provides both Python and lua interfaces. bcc adds:
|
||||
|
||||
* Static tracing, user-level (USDT probes via uprobes)
|
||||
* Debug output (Python with BPF.trace_pipe() and BPF.trace_fields())
|
||||
* Per-event output (BPF_PERF_OUTPUT macro and BPF.open_perf_buffer())
|
||||
* Interval output (BPF.get_table() and table.clear())
|
||||
* Histogram printing (table.print_log2_hist())
|
||||
* C struct navigation, kernel-level (bcc rewriter maps to bpf_probe_read())
|
||||
* Symbol resolution, kernel-level (ksym(), ksymaddr())
|
||||
* Symbol resolution, user-level (usymaddr())
|
||||
* BPF tracepoint support (via TRACEPOINT_PROBE)
|
||||
* BPF stack trace support (incl. walk method for stack frames)
|
||||
* Various other helper macros and functions
|
||||
* Examples (under /examples)
|
||||
* Many tools (under /tools)
|
||||
* Tutorials (/docs/tutorial*.md)
|
||||
* Reference guide (/docs/reference_guide.md)
|
||||
|
||||
I'd been holding off on this post until the last major feature was integrated, and now it has been in 4.9-rc1\. There are still some minor missing things we have workarounds for, and additional things we might do, but what we have right now is worth celebrating. Linux now has advanced tracing capabilities built in.
|
||||
|
||||
### Safety
|
||||
|
||||
BPF and its enhancements are designed to be production safe, and it is used today in large scale production environments. But if you're determined, you may be able to still find a way to hang the kernel. That experience should be the exception rather than the rule, and such bugs will be fixed fast, especially since BPF is part of Linux. All eyes are on Linux.
|
||||
|
||||
We did hit a couple of non-BPF bugs during development that needed to be fixed: rcu not reentrant, which could cause kernel hangs for funccount and was fixed by the "bpf: map pre-alloc" patchset in 4.6, and with a workaround in bcc for older kernels. And a uprobe memory accounting issue, which failed uprobe allocations, and was fixed by the "uprobes: Fix the memcg accounting" patch in 4.8 and backported to earlier kernels (eg, it's in the current 4.4.27 and 4.4.0-45.66).
|
||||
|
||||
### Why did Linux tracing take so long?
|
||||
|
||||
Prior work had been split among several other tracers: there was never a consolidated effort on any single one. For more about this and other issues, see my 2014 [tracing summit talk][32]. One thing I didn't note there was the counter effect of partial solutions: some companies had found another tracer (SystemTap or LTTng) was sufficient for their specific needs, and while they have been happy to hear about BPF, contributing to its development wasn't a priority given their existing solution.
|
||||
|
||||
BPF has only been enhanced to do tracing in the last two years. This process could have gone faster, but early on there were zero full-time engineers working on BPF tracing. Alexei Starovoitov (BPF lead), Brenden Blanco (bcc lead), myself, and others, all had other priorities. I tracked my hours on this at Netflix (voluntarily), and I've spent around 7% of my time on BPF/bcc. It wasn't that much of a priority, in part because we had our own workarounds (including my perf-tools, which work on older kernels).
|
||||
|
||||
Now that BPF tracing has arrived, there's already tech companies on the lookout for BPF skills. I can still highly recommend [Netflix][31]. (If you're trying to hire _me_ for BPF skills, then I'm still very happy at Netflix!.)
|
||||
|
||||
### Ease of use
|
||||
|
||||
What might appear to be the largest remaining difference between DTrace and bcc/BPF is ease of use. But it depends on what you're doing with BPF tracing. Either you are:
|
||||
|
||||
* **Using BPF tools/metrics**: There should be no difference. Tools behave the same, GUIs can access similar metrics. Most people will use BPF in this way.
|
||||
* **Developing tools/metrics**: bcc right now is much harder. DTrace has its own concise language, D, similar to awk, whereas bcc uses existing languages (C and Python or lua) with libraries. A bcc tool in C+Python may be a _lot_ more code than a D-only tool: 10x the lines, or more. However, many DTrace tools used shell wrapping to provide arguments and error checking, inflating the code to a much bigger size. The coding difficulty is also different: the rewriter in bcc can get fiddly, which makes some scripts much more complicated to develop (extra bpf_probe_read()s, requiring more knowledge of BPF internals). This situation should improve over time as improvements are planned.
|
||||
* **Running common one-liners**: Fairly similar. DTrace could do many with the "dtrace" command, whereas bcc has a variety of multitools: trace, argdist, funccount, funclatency, etc.
|
||||
* **Writing custom ad hoc one-liners**: With DTrace this was trivial, and accelerated advanced analysis by allowing rapid custom questions to be posed and answered by the system. bcc is currently limited by its multitools and their scope.
|
||||
|
||||
In short, if you're an end user of BPF tools, you shouldn't notice these differences. If you're an advanced user and tool developer (like me), bcc is a lot more difficult right now.
|
||||
|
||||
To show a current example of the bcc Python front-end, here's the code for tracing disk I/O and printing I/O size as a histogram:
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
from time import sleep
|
||||
|
||||
# load BPF program
|
||||
b = BPF(text="""
|
||||
#include <uapi/linux/ptrace.h>
|
||||
#include <linux/blkdev.h>
|
||||
|
||||
BPF_HISTOGRAM(dist);
|
||||
|
||||
int kprobe__blk_account_io_completion(struct pt_regs *ctx, struct request *req)
|
||||
{
|
||||
dist.increment(bpf_log2l(req->__data_len / 1024));
|
||||
return 0;
|
||||
}
|
||||
""")
|
||||
|
||||
# header
|
||||
print("Tracing... Hit Ctrl-C to end.")
|
||||
|
||||
# trace until Ctrl-C
|
||||
try:
|
||||
sleep(99999999)
|
||||
except KeyboardInterrupt:
|
||||
print
|
||||
|
||||
# output
|
||||
b["dist"].print_log2_hist("kbytes")
|
||||
|
||||
```
|
||||
|
||||
Note the embedded C (text=) in the Python code.
|
||||
|
||||
This gets the job done, but there's also room for improvement. Fortunately, we have time to do so: it will take many months before people are on Linux 4.9 and can use BPF, so we have time to create tools and front-ends.
|
||||
|
||||
### A higher-level language
|
||||
|
||||
An easier front-end, such as a higher-level language, may not improve adoption as much as you might imagine. Most people will use the canned tools (and GUIs), and only some of us will actually write them. But I'm not opposed to a higher-level language either, and some already exist, like SystemTap:
|
||||
|
||||
```
|
||||
#!/usr/bin/stap
|
||||
/*
|
||||
* opensnoop.stp Trace file open()s. Basic version of opensnoop.
|
||||
*/
|
||||
|
||||
probe begin
|
||||
{
|
||||
printf("\n%6s %6s %16s %s\n", "UID", "PID", "COMM", "PATH");
|
||||
}
|
||||
|
||||
probe syscall.open
|
||||
{
|
||||
printf("%6d %6d %16s %s\n", uid(), pid(), execname(), filename);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Wouldn't it be nice if we could have the SystemTap front-end with all its language integration and tapsets, with the high-performance kernel built in BPF back-end? Richard Henderson of Red Hat has already begun work on this, and has released an [initial version][30]!
|
||||
|
||||
There's also [ply][29], an entirely new higher-level language for BPF:
|
||||
|
||||
```
|
||||
#!/usr/bin/env ply
|
||||
|
||||
kprobe:SyS_*
|
||||
{
|
||||
$syscalls[func].count()
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This is also promising.
|
||||
|
||||
Although, I think the real challenge for tool developers won't be the language: it will be knowing what to do with these new superpowers.
|
||||
|
||||
### How you can contribute
|
||||
|
||||
* **Promotion**: There are currently no marketing efforts for BPF tracing. Some companies know it and are using it (Facebook, Netflix, Github, and more), but it'll take years to become widely known. You can help by sharing articles and resources with others in the industry.
|
||||
* **Education**: You can write articles, give meetup talks, and contribute to bcc documentation. Share case studies of how BPF has solved real issues, and provided value to your company.
|
||||
* **Fix bcc issues**: See the [bcc issue list][19], which includes bugs and feature requests.
|
||||
* **File bugs**: Use bcc/BPF, and file bugs as you find them.
|
||||
* **New tools**: There are more observability tools to develop, but please don't be hasty: people are going to spend hours learning and using your tool, so make it as intuitive and excellent as possible (see my [docs][18]). As Mike Muuss has said about his [ping][17] program: "If I'd known then that it would be my most famous accomplishment in life, I might have worked on it another day or two and added some more options."
|
||||
* **High-level language**: If the existing bcc front-end languages really bother you, maybe you can come up with something much better. If you build it in bcc you can leverage libbcc. Or, you could help the SystemTap BPF or ply efforts.
|
||||
* **GUI integration**: Apart from the bcc CLI observability tools, how can this new information be visualized? Latency heat maps, flame graphs, and more.
|
||||
|
||||
### Other Tracers
|
||||
|
||||
What about SystemTap, ktap, sysdig, LTTng, etc? It's possible that they all have a future, either by using BPF, or by becoming better at what they specifically do. Explaining each will be a blog post by itself.
|
||||
|
||||
And DTrace itself? We're still using it at Netflix, on our FreeBSD-based CDN.
|
||||
|
||||
### Further bcc/BPF Reading
|
||||
|
||||
I've written a [bcc/BPF Tool End-User Tutorial][28], a [bcc Python Developer's Tutorial][27], a [bcc/BPF Reference Guide][26], and contributed useful [/tools][25], each with an [example.txt][24] file and [man page][23]. My prior posts about bcc & BPF include:
|
||||
|
||||
* [eBPF: One Small Step][16] (we later just called it BPF)
|
||||
* [bcc: Taming Linux 4.3+ Tracing Superpowers][15]
|
||||
* [Linux eBPF Stack Trace Hack][14] (stack traces are now officially supported)
|
||||
* [Linux eBPF Off-CPU Flame Graph][13] (" " ")
|
||||
* [Linux Wakeup and Off-Wake Profiling][12] (" " ")
|
||||
* [Linux Chain Graph Prototype][11] (" " ")
|
||||
* [Linux eBPF/bcc uprobes][10]
|
||||
* [Linux BPF Superpowers][9]
|
||||
* [Ubuntu Xenial bcc/BPF][8]
|
||||
* [Linux bcc Tracing Security Capabilities][7]
|
||||
* [Linux MySQL Slow Query Tracing with bcc/BPF][6]
|
||||
* [Linux bcc ext4 Latency Tracing][5]
|
||||
* [Linux bcc/BPF Run Queue (Scheduler) Latency][4]
|
||||
* [Linux bcc/BPF Node.js USDT Tracing][3]
|
||||
* [Linux bcc tcptop][2]
|
||||
* [Linux 4.9's Efficient BPF-based Profiler][1]
|
||||
|
||||
I've also given a talk about bcc/BPF, at Facebook's Performance@Scale event: [Linux BPF Superpowers][22]. In December, I'm giving a tutorial and talk on BPF/bcc at [USENIX LISA][21] in Boston.
|
||||
|
||||
### Acknowledgements
|
||||
|
||||
* Van Jacobson and Steve McCanne, who created the original BPF as a packet filter.
|
||||
* Barton P. Miller, Jeffrey K. Hollingsworth, and Jon Cargille, for inventing dynamic tracing, and publishing the paper: "Dynamic Program Instrumentation for Scalable Performance Tools", Scalable High-performance Conputing Conference (SHPCC), Knoxville, Tennessee, May 1994.
|
||||
* kerninst (ParaDyn, UW-Madison), an early dynamic tracing tool that showed the value of dynamic tracing (late 1990's).
|
||||
* Mathieu Desnoyers (of LTTng), the lead developer of kernel markers that led to tracepoints.
|
||||
* IBM developed kprobes as part of DProbes. DProbes was combined with LTT to provide Linux dynamic tracing in 2000, but wasn't integrated.
|
||||
* Bryan Cantrill, Mike Shapiro, and Adam Leventhal (Sun Microsystems), the core developers of DTrace, an awesome tool which proved that dynamic tracing could be production safe and easy to use (2004). Given the mechanics of dynamic tracing, this was a crucial turning point for the technology: that it became safe enough to be shipped _by default in Solaris_, an OS known for reliability.
|
||||
* The many Sun Microsystems staff in marketing, sales, training, and other roles, for promoting DTrace and creating the awareness and desire for advanced system tracing.
|
||||
* Roland McGrath (at Red Hat), the lead developer of utrace, which became uprobes.
|
||||
* Alexei Starovoitov (PLUMgrid, then Facebook), the lead developer of enhanced BPF: the programmatic kernel components necessary.
|
||||
* Many other Linux kernel engineers who contributed feedback, code, testing, and their own patchsets for the development of enhanced BPF (search lkml for BPF): Wang Nan, Daniel Borkmann, David S. Miller, Peter Zijlstra, and many others.
|
||||
* Brenden Blanco (PLUMgrid), the lead developer of bcc.
|
||||
* Sasha Goldshtein (Sela) developed tracepoint support in bcc, developed the most powerful bcc multitools trace and argdist, and contributed to USDT support.
|
||||
* Vicent Martí and others at Github engineering, for developing the lua front-end for bcc, and contributing parts of USDT.
|
||||
* Allan McAleavy, Mark Drayton, and other bcc contributors for various improvements.
|
||||
|
||||
Thanks to Netflix for providing the environment and support where I've been able to contribute to BPF and bcc tracing, and help get them done. I've also contributed to tracing in general over the years by developing tracing tools (using TNF/prex, DTrace, SystemTap, ktap, ftrace, perf, and now bcc/BPF), and books, blogs, and talks.
|
||||
|
||||
Finally, thanks to [Deirdré][20] for editing another post.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Linux doesn't have DTrace (the language), but it now does, in a way, have the DTraceToolkit (the tools).
|
||||
|
||||
The Linux 4.9 kernel has the final capabilities needed to support modern tracing, via enhancments to its built-in BPF engine. The hardest part is now done: kernel support. Future work now includes more performance CLI tools, alternate higher-level languages, and GUIs.
|
||||
|
||||
For customers of performance analysis products, this is also good news: you can now ask for latency histograms and heatmaps, CPU and off-CPU flame graphs, better latency breakdowns, and lower-cost instrumentation. Per-packet tracing and processing in user space is now the old inefficient way.
|
||||
|
||||
So when are you going to upgrade to Linux 4.9? Once it is officially released, new performance tools await: apt-get install bcc-tools.
|
||||
|
||||
Enjoy!
|
||||
|
||||
Brendan
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2016-10-27/dtrace-for-linux-2016.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com/
|
||||
[1]:http://www.brendangregg.com/blog/2016-10-21/linux-efficient-profiler.html
|
||||
[2]:http://www.brendangregg.com/blog/2016-10-15/linux-bcc-tcptop.html
|
||||
[3]:http://www.brendangregg.com/blog/2016-10-12/linux-bcc-nodejs-usdt.html
|
||||
[4]:http://www.brendangregg.com/blog/2016-10-08/linux-bcc-runqlat.html
|
||||
[5]:http://www.brendangregg.com/blog/2016-10-06/linux-bcc-ext4dist-ext4slower.html
|
||||
[6]:http://www.brendangregg.com/blog/2016-10-04/linux-bcc-mysqld-qslower.html
|
||||
[7]:http://www.brendangregg.com/blog/2016-10-01/linux-bcc-security-capabilities.html
|
||||
[8]:http://www.brendangregg.com/blog/2016-06-14/ubuntu-xenial-bcc-bpf.html
|
||||
[9]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[10]:http://www.brendangregg.com/blog/2016-02-08/linux-ebpf-bcc-uprobes.html
|
||||
[11]:http://www.brendangregg.com/blog/2016-02-05/ebpf-chaingraph-prototype.html
|
||||
[12]:http://www.brendangregg.com/blog/2016-02-01/linux-wakeup-offwake-profiling.html
|
||||
[13]:http://www.brendangregg.com/blog/2016-01-20/ebpf-offcpu-flame-graph.html
|
||||
[14]:http://www.brendangregg.com/blog/2016-01-18/ebpf-stack-trace-hack.html
|
||||
[15]:http://www.brendangregg.com/blog/2015-09-22/bcc-linux-4.3-tracing.html
|
||||
[16]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[17]:http://ftp.arl.army.mil/~mike/ping.html
|
||||
[18]:https://github.com/iovisor/bcc/blob/master/CONTRIBUTING-SCRIPTS.md
|
||||
[19]:https://github.com/iovisor/bcc/issues
|
||||
[20]:http://www.brendangregg.com/blog/2016-07-23/deirdre.html
|
||||
[21]:https://www.usenix.org/conference/lisa16
|
||||
[22]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[23]:https://github.com/iovisor/bcc/tree/master/man/man8
|
||||
[24]:https://github.com/iovisor/bcc/tree/master/tools
|
||||
[25]:https://github.com/iovisor/bcc/tree/master/tools
|
||||
[26]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[27]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[28]:https://github.com/iovisor/bcc/blob/master/docs/tutorial.md
|
||||
[29]:https://wkz.github.io/ply/
|
||||
[30]:https://lkml.org/lkml/2016/6/14/749
|
||||
[31]:http://www.brendangregg.com/blog/2016-03-30/working-at-netflix-2016.html
|
||||
[32]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux
|
||||
[33]:https://lkml.org/lkml/2016/9/1/831
|
||||
[34]:https://github.com/brendangregg/perf-tools
|
||||
[35]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[36]:https://github.com/iovisor/bcc
|
||||
[37]:https://github.com/opendtrace/toolkit
|
||||
[38]:https://raw.githubusercontent.com/brendangregg/bcc/master/images/bcc_tracing_tools_2016.png
|
||||
@ -1,411 +0,0 @@
|
||||
Protocol Buffer Basics: C++
|
||||
============================
|
||||
|
||||
这篇教程提供了一个面向 C++ 程序员、关于 `protocol buffers` 的基础介绍。通过创建一个简单的示例应用程序,它将向我们展示:
|
||||
|
||||
* 在 `.proto` 文件中定义消息格式
|
||||
* 使用 `protocol buffer` 编译器
|
||||
* 使用 `C++ protocol buffer API` 读写消息
|
||||
|
||||
这不是一个关于使用 C++ protocol buffers 的全面指南。要获取更详细的信息,请参考 [Protocol Buffer Language Guide][1] 和 [Encoding Reference][2]。
|
||||
|
||||
### 为什么使用 Protocol Buffers
|
||||
|
||||
我们接下来要使用的例子是一个非常简单的"地址簿"应用程序,它能从文件中读取联系人详细信息。地址簿中的每一个人都有一个名字,ID,邮件地址和联系电话。
|
||||
|
||||
如何序列化和获取结构化的数据?这里有几种解决方案:
|
||||
|
||||
* 以二进制形式发送/接收原生的内存数据结构。通常,这是一种脆弱的方法,因为接收/读取代码的编译必须基于完全相同的内存布局、大小端等等。同时,当文件增加时,原始格式数据会随着与该格式相连的软件拷贝而迅速扩散,这将很难扩展文件格式。
|
||||
|
||||
* 你可以创造一种 `ad-hoc` 方法,将数据项编码为一个字符串——比如将 4 个整数编码为 "12:3:-23:67"。虽然它需要编写一次性的编码和解码代码且解码需要耗费小的运行时成本,但这是一种简单灵活的方法。这最适合编码非常简单的数据。
|
||||
|
||||
* 序列化数据为 `XML`。这种方法是非常吸引人的,因为 `XML` 是一种适合人阅读的格式,并且有为许多语言开发的库。如果你想与其他程序和项目共享数据,这可能是一种不错的选择。然而,众所周知,`XML` 是空间密集型的,且在编码和解码时,它对程序会造成巨大的性能损失。同时,使用 XML DOM 树被认为比操作一个类的简单字段更加复杂。
|
||||
|
||||
`Protocol buffers` 是针对这个问题的一种灵活、高效、自动化的解决方案。使用 `Protocol buffers`,你需要写一个 `.proto` 说明,用于描述你所希望存储的数据结构。利用 `.proto` 文件,protocol buffer 编译器可以创建一个类,用于实现自动化编码和解码高效的二进制格式的 protocol buffer 数据。产生的类提供了构造 `protocol buffer` 的字段的 getters 和 setters,并且作为一个单元,关注读写 `protocol buffer` 的细节。重要的是,`protocol buffer` 格式支持扩展格式,代码仍然可以读取以旧格式编码的数据。
|
||||
|
||||
### 在哪可以找到示例代码
|
||||
|
||||
示例代码被包含于源代码包,位于 "examples" 文件夹。在[这][4]下载代码。
|
||||
|
||||
### 定义你的协议格式
|
||||
|
||||
为了创建自己的地址簿应用程序,你需要从 `.proto` 开始。`.proto` 文件中的定义很简单:为你所需要序列化的数据结构添加一个消息(message),然后为消息中的每一个字段指定一个名字和类型。这里是定义你消息的 `.proto` 文件,`addressbook.proto`。
|
||||
|
||||
```
|
||||
package tutorial;
|
||||
|
||||
message Person {
|
||||
required string name = 1;
|
||||
required int32 id = 2;
|
||||
optional string email = 3;
|
||||
|
||||
enum PhoneType {
|
||||
MOBILE = 0;
|
||||
HOME = 1;
|
||||
WORK = 2;
|
||||
}
|
||||
|
||||
message PhoneNumber {
|
||||
required string number = 1;
|
||||
optional PhoneType type = 2 [default = HOME];
|
||||
}
|
||||
|
||||
repeated PhoneNumber phone = 4;
|
||||
}
|
||||
|
||||
message AddressBook {
|
||||
repeated Person person = 1;
|
||||
}
|
||||
```
|
||||
|
||||
如你所见,其语法类似于 C++ 或 Java。我们开始看看文件的每一部分内容做了什么。
|
||||
|
||||
`.proto` 文件以一个 package 声明开始,这可以避免不同项目的命名冲突。在 C++,你生成的类会被置于与 package 名字一样的命名空间。
|
||||
|
||||
下一步,你需要定义消息(message)。消息只是一个包含一系列类型字段的集合。大多标准简单数据类型是可以作为字段类型的,包括 `bool`、`int32`、`float`、`double` 和 `string`。你也可以通过使用其他消息类型作为字段类型,将更多的数据结构添加到你的消息中——在以上的示例,`Person` 消息包含了 `PhoneNumber` 消息,同时 `AddressBook` 消息包含 `Person` 消息。你甚至可以定义嵌套在其他消息内的消息类型——如你所见,`PhoneNumber` 类型定义于 `Person` 内部。如果你想要其中某一个字段拥有预定义值列表中的某个值,你也可以定义 `enum` 类型——这儿你想指定一个电话号码可以是 `MOBILE`、`HOME` 或 `WORK` 中的某一个。
|
||||
|
||||
每一个元素上的 “=1”、"=2" 标记确定了用于二进制编码的唯一"标签"(tag)。标签数字 1-15 的编码比更大的数字少需要一个字节,因此作为一种优化,你可以将这些标签用于经常使用或 repeated 元素,剩下 16 以及更高的标签用于非经常使用或 optional 元素。每一个 repeated 字段的元素需要重新编码标签数字,因此 repeated 字段对于这优化是一个特别好的候选者。
|
||||
|
||||
每一个字段必须使用下面的修饰符加以标注:
|
||||
|
||||
* required:必须提供字段的值,否则消息会被认为是 "未初始化的"(uninitialized)。如果 `libprotobuf` 以 debug 模式编译,序列化未初始化的消息将引起一个断言失败。以优化形式构建,将会跳过检查,并且无论如何都会写入消息。然而,解析未初始化的消息总是会失败(通过 parse 方法返回 `false`)。除此之外,一个 required 字段的表现与 optional 字段完全一样。
|
||||
|
||||
* optional:字段可能会被设置,也可能不会。如果一个 optional 字段没被设置,它将使用默认值。对于简单类型,你可以指定你自己的默认值,正如例子中我们对电话号码的 `type` 一样,否则使用系统默认值:数字类型为 0、字符串为空字符串、布尔值为 false。对于嵌套消息,默认值总为消息的"默认实例"或"原型",它的所有字段都没被设置。调用 accessor 来获取一个没有显式设置的 optional(或 required) 字段的值总是返回字段的默认值。
|
||||
|
||||
* repeated:字段可以重复任意次数(包括 0)。repeated 值的顺序会被保存于 protocol buffer。可以将 repeated 字段想象为动态大小的数组。
|
||||
|
||||
你可以查找关于编写 `.proto` 文件的完整指导——包括所有可能的字段类型——在 [Protocol Buffer Language Guide][6]。不要在这里面查找与类继承相似的特性,因为 protocol buffers 不会做这些。
|
||||
|
||||
> required 是永久性的,在把一个字段标识为 required 的时候,你应该特别小心。如果在某些情况下你不想写入或者发送一个 required 的字段,那么将该字段更改为 optional 可能会遇到问题——旧版本的读者(译者注:即读取、解析旧版本 Protocol Buffer 消息的一方)会认为不含该字段的消息是不完整的,从而有可能会拒绝解析。在这种情况下,你应该考虑编写特别针对于应用程序的、自定义的消息校验函数。Google 的一些工程师得出了一个结论:使用 required 弊多于利;他们更愿意使用 optional 和 repeated 而不是 required。当然,这个观点并不具有普遍性。
|
||||
|
||||
### 编译你的 Protocol Buffers
|
||||
|
||||
既然你有了一个 `.proto`,那你需要做的下一件事就是生成一个将用于读写 `AddressBook` 消息的类(从而包括 `Person` 和 `PhoneNumber`)。为了做到这样,你需要在你的 `.proto` 上运行 protocol buffer 编译器 `protoc`:
|
||||
|
||||
1. 如果你没有安装编译器,请[下载这个包][4],并按照 README 中的指令进行安装。
|
||||
2. 现在运行编译器,知道源目录(你的应用程序源代码位于哪里——如果你没有提供任何值,将使用当前目录),目标目录(你想要生成的代码放在哪里;常与 `$SRC_DIR` 相同),并且你的 `.proto` 路径。在此示例,你...:
|
||||
|
||||
```
|
||||
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/addressbook.proto
|
||||
```
|
||||
|
||||
因为你想要 C++ 的类,所以你使用了 `--cpp_out` 选项——也为其他支持的语言提供了类似选项。
|
||||
|
||||
在你指定的目标文件夹,将生成以下的文件:
|
||||
|
||||
* `addressbook.pb.h`,声明你生成类的头文件。
|
||||
* `addressbook.pb.cc`,包含你的类的实现。
|
||||
|
||||
### Protocol Buffer API
|
||||
|
||||
让我们看看生成的一些代码,了解一下编译器为你创建了什么类和函数。如果你查看 `tutorial.pb.h`,你可以看到有一个在 `tutorial.proto` 中指定所有消息的类。关注 `Person` 类,可以看到编译器为每个字段生成了读写函数(accessors)。例如,对于 `name`、`id`、`email` 和 `phone` 字段,有下面这些方法:
|
||||
|
||||
```c++
|
||||
// name
|
||||
inline bool has_name() const;
|
||||
inline void clear_name();
|
||||
inline const ::std::string& name() const;
|
||||
inline void set_name(const ::std::string& value);
|
||||
inline void set_name(const char* value);
|
||||
inline ::std::string* mutable_name();
|
||||
|
||||
// id
|
||||
inline bool has_id() const;
|
||||
inline void clear_id();
|
||||
inline int32_t id() const;
|
||||
inline void set_id(int32_t value);
|
||||
|
||||
// email
|
||||
inline bool has_email() const;
|
||||
inline void clear_email();
|
||||
inline const ::std::string& email() const;
|
||||
inline void set_email(const ::std::string& value);
|
||||
inline void set_email(const char* value);
|
||||
inline ::std::string* mutable_email();
|
||||
|
||||
// phone
|
||||
inline int phone_size() const;
|
||||
inline void clear_phone();
|
||||
inline const ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >& phone() const;
|
||||
inline ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >* mutable_phone();
|
||||
inline const ::tutorial::Person_PhoneNumber& phone(int index) const;
|
||||
inline ::tutorial::Person_PhoneNumber* mutable_phone(int index);
|
||||
inline ::tutorial::Person_PhoneNumber* add_phone();
|
||||
```
|
||||
|
||||
正如你所见到,getters 的名字与字段的小写名字完全一样,并且 setter 方法以 set_ 开头。同时每个单一(singular)(required 或 optional)字段都有 `has_` 方法,该方法在字段被设置了值的情况下返回 true。最后,所有字段都有一个 `clear_` 方法,用以清除字段到空(empty)状态。
|
||||
|
||||
数字 `id` 字段仅有上述的基本读写函数集合(accessors),而 `name` 和 `email` 字段有两个额外的方法,因为它们是字符串——一个是可以获得字符串直接指针的`mutable_` getter ,另一个为额外的 setter。注意,尽管 `email` 还没被设置(set),你也可以调用 `mutable_email`;因为 `email` 会被自动地初始化为空字符串。在本例中,如果你有一个单一的(required 或 optional)消息字段,它会有一个 `mutable_` 方法,而没有 `set_` 方法。
|
||||
|
||||
repeated 字段也有一些特殊的方法——如果你看看 repeated `phone` 字段的方法,你可以看到:
|
||||
|
||||
* 检查 repeated 字段的 `_size`(也就是说,与 `Person` 相关的电话号码的个数)
|
||||
* 使用下标取得特定的电话号码
|
||||
* 更新特定下标的电话号码
|
||||
* 添加新的电话号码到消息中,之后你便可以编辑。(repeated 标量类型有一个 `add_` 方法,用于传入新的值)
|
||||
|
||||
为了获取 protocol 编译器为所有字段定义生成的方法的信息,可以查看 [C++ generated code reference][5]。
|
||||
|
||||
#### 枚举和嵌套类(Enums and Nested Classes)
|
||||
|
||||
与 `.proto` 的枚举相对应,生成的代码包含了一个 `PhoneType` 枚举。你可以通过 `Person::PhoneType` 引用这个类型,通过 `Person::MOBILE`、`Person::HOME` 和 `Person::WORK` 引用它的值。(实现细节有点复杂,但是你无须了解它们而可以直接使用)
|
||||
|
||||
编译器也生成了一个 `Person::PhoneNumber` 的嵌套类。如果你查看代码,你可以发现真正的类型为 `Person_PhoneNumber`,但它通过在 `Person` 内部使用 typedef 定义,使你可以把 `Person_PhoneNumber` 当成嵌套类。唯一产生影响的一个例子是,如果你想要在其他文件前置声明该类——在 C++ 中你不能前置声明嵌套类,但是你可以前置声明 `Person_PhoneNumber`。
|
||||
|
||||
#### 标准的消息方法
|
||||
|
||||
所有的消息方法都包含了许多别的方法,用于检查和操作整个消息,包括:
|
||||
|
||||
* `bool IsInitialized() const;` :检查是否所有 `required` 字段已经被设置。
|
||||
* `string DebugString() const;`:返回人类可读的消息表示,对 debug 特别有用。
|
||||
* `void CopyFrom(const Person& from);`:使用给定的值重写消息。
|
||||
* `void Clear();`:清除所有元素为空(empty)的状态。
|
||||
|
||||
上面这些方法以及下一节要讲的 I/O 方法实现了被所有 C++ protocol buffer 类共享的消息(Message)接口。为了获取更多信息,请查看 [complete API documentation for Message][7]。
|
||||
|
||||
#### 解析和序列化(Parsing and Serialization)
|
||||
|
||||
最后,所有 protocol buffer 类都有读写你选定类型消息的方法,这些方法使用了特定的 protocol buffer [二进制格式][8]。这些方法包括:
|
||||
|
||||
* `bool SerializeToString(string* output) const;`:序列化消息以及将消息字节数据存储在给定的字符串。注意,字节数据是二进制格式的,而不是文本格式;我们只使用 `string` 类作为合适的容器。
|
||||
* `bool ParseFromString(const string& data);`:从给定的字符创解析消息。
|
||||
* `bool SerializeToOstream(ostream* output) const;`:将消息写到给定的 C++ `ostream`。
|
||||
* `bool ParseFromIstream(istream* input);`:从给定的 C++ `istream` 解析消息。
|
||||
|
||||
这些只是两个用于解析和序列化的选择。再次说明,可以查看 `Message API reference` 完整的列表。
|
||||
|
||||
> Protocol Buffers 和 面向对象设计的 Protocol buffer 类通常只是纯粹的数据存储器(像 C++ 中的结构体);它们在对象模型中并不是一等公民。如果你想向生成的 protocol buffer 类中添加更丰富的行为,最好的方法就是在应用程序中对它进行封装。如果你无权控制 .proto 文件的设计的话,封装 protocol buffers 也是一个好主意(例如,你从另一个项目中重用一个 .proto 文件)。在那种情况下,你可以用封装类来设计接口,以更好地适应你的应用程序的特定环境:隐藏一些数据和方法,暴露一些便于使用的函数,等等。但是你绝对不要通过继承生成的类来添加行为。这样做的话,会破坏其内部机制,并且不是一个好的面向对象的实践。
|
||||
|
||||
### 写消息(Writing A Message)
|
||||
|
||||
现在我们尝试使用 protocol buffer 类。你的地址簿程序想要做的第一件事是将个人详细信息写入到地址簿文件。为了做到这一点,你需要创建、填充 protocol buffer 类实例,并且将它们写入到一个输出流(output stream)。
|
||||
|
||||
这里的程序可以从文件读取 `AddressBook`,根据用户输入,将新 `Person` 添加到 `AddressBook`,并且再次将新的 `AddressBook` 写回文件。这部分直接调用或引用 protocol buffer 类的代码会高亮显示。
|
||||
|
||||
```c++
|
||||
#include <iostream>
|
||||
#include <fstream>
|
||||
#include <string>
|
||||
#include "addressbook.pb.h"
|
||||
using namespace std;
|
||||
|
||||
// This function fills in a Person message based on user input.
|
||||
void PromptForAddress(tutorial::Person* person) {
|
||||
cout << "Enter person ID number: ";
|
||||
int id;
|
||||
cin >> id;
|
||||
person->set_id(id);
|
||||
cin.ignore(256, '\n');
|
||||
|
||||
cout << "Enter name: ";
|
||||
getline(cin, *person->mutable_name());
|
||||
|
||||
cout << "Enter email address (blank for none): ";
|
||||
string email;
|
||||
getline(cin, email);
|
||||
if (!email.empty()) {
|
||||
person->set_email(email);
|
||||
}
|
||||
|
||||
while (true) {
|
||||
cout << "Enter a phone number (or leave blank to finish): ";
|
||||
string number;
|
||||
getline(cin, number);
|
||||
if (number.empty()) {
|
||||
break;
|
||||
}
|
||||
|
||||
tutorial::Person::PhoneNumber* phone_number = person->add_phone();
|
||||
phone_number->set_number(number);
|
||||
|
||||
cout << "Is this a mobile, home, or work phone? ";
|
||||
string type;
|
||||
getline(cin, type);
|
||||
if (type == "mobile") {
|
||||
phone_number->set_type(tutorial::Person::MOBILE);
|
||||
} else if (type == "home") {
|
||||
phone_number->set_type(tutorial::Person::HOME);
|
||||
} else if (type == "work") {
|
||||
phone_number->set_type(tutorial::Person::WORK);
|
||||
} else {
|
||||
cout << "Unknown phone type. Using default." << endl;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Main function: Reads the entire address book from a file,
|
||||
// adds one person based on user input, then writes it back out to the same
|
||||
// file.
|
||||
int main(int argc, char* argv[]) {
|
||||
// Verify that the version of the library that we linked against is
|
||||
// compatible with the version of the headers we compiled against.
|
||||
GOOGLE_PROTOBUF_VERIFY_VERSION;
|
||||
|
||||
if (argc != 2) {
|
||||
cerr << "Usage: " << argv[0] << " ADDRESS_BOOK_FILE" << endl;
|
||||
return -1;
|
||||
}
|
||||
|
||||
tutorial::AddressBook address_book;
|
||||
|
||||
{
|
||||
// Read the existing address book.
|
||||
fstream input(argv[1], ios::in | ios::binary);
|
||||
if (!input) {
|
||||
cout << argv[1] << ": File not found. Creating a new file." << endl;
|
||||
} else if (!address_book.ParseFromIstream(&input)) {
|
||||
cerr << "Failed to parse address book." << endl;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
// Add an address.
|
||||
PromptForAddress(address_book.add_person());
|
||||
|
||||
{
|
||||
// Write the new address book back to disk.
|
||||
fstream output(argv[1], ios::out | ios::trunc | ios::binary);
|
||||
if (!address_book.SerializeToOstream(&output)) {
|
||||
cerr << "Failed to write address book." << endl;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
// Optional: Delete all global objects allocated by libprotobuf.
|
||||
google::protobuf::ShutdownProtobufLibrary();
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
注意 `GOOGLE_PROTOBUF_VERIFY_VERSION` 宏。它是一种好的实践——虽然不是严格必须的——在使用 C++ Protocol Buffer 库之前执行该宏。它可以保证避免不小心链接到一个与编译的头文件版本不兼容的库版本。如果被检查出来版本不匹配,程序将会终止。注意,每个 `.pb.cc` 文件在初始化时会自动调用这个宏。
|
||||
|
||||
同时注意在程序最后调用 `ShutdownProtobufLibrary()`。它用于释放 Protocol Buffer 库申请的所有全局对象。对大部分程序,这不是必须的,因为虽然程序只是简单退出,但是 OS 会处理释放程序的所有内存。然而,如果你使用了内存泄漏检测工具,工具要求全部对象都要释放,或者你正在写一个库,该库可能会被一个进程多次加载和卸载,那么你可能需要强制 Protocol Buffer 清除所有东西。
|
||||
|
||||
### 读取消息
|
||||
|
||||
当然,如果你无法从它获取任何信息,那么这个地址簿没多大用处!这个示例读取上面例子创建的文件,并打印文件里的所有内容。
|
||||
|
||||
```c++
|
||||
#include <iostream>
|
||||
#include <fstream>
|
||||
#include <string>
|
||||
#include "addressbook.pb.h"
|
||||
using namespace std;
|
||||
|
||||
// Iterates though all people in the AddressBook and prints info about them.
|
||||
void ListPeople(const tutorial::AddressBook& address_book) {
|
||||
for (int i = 0; i < address_book.person_size(); i++) {
|
||||
const tutorial::Person& person = address_book.person(i);
|
||||
|
||||
cout << "Person ID: " << person.id() << endl;
|
||||
cout << " Name: " << person.name() << endl;
|
||||
if (person.has_email()) {
|
||||
cout << " E-mail address: " << person.email() << endl;
|
||||
}
|
||||
|
||||
for (int j = 0; j < person.phone_size(); j++) {
|
||||
const tutorial::Person::PhoneNumber& phone_number = person.phone(j);
|
||||
|
||||
switch (phone_number.type()) {
|
||||
case tutorial::Person::MOBILE:
|
||||
cout << " Mobile phone #: ";
|
||||
break;
|
||||
case tutorial::Person::HOME:
|
||||
cout << " Home phone #: ";
|
||||
break;
|
||||
case tutorial::Person::WORK:
|
||||
cout << " Work phone #: ";
|
||||
break;
|
||||
}
|
||||
cout << phone_number.number() << endl;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Main function: Reads the entire address book from a file and prints all
|
||||
// the information inside.
|
||||
int main(int argc, char* argv[]) {
|
||||
// Verify that the version of the library that we linked against is
|
||||
// compatible with the version of the headers we compiled against.
|
||||
GOOGLE_PROTOBUF_VERIFY_VERSION;
|
||||
|
||||
if (argc != 2) {
|
||||
cerr << "Usage: " << argv[0] << " ADDRESS_BOOK_FILE" << endl;
|
||||
return -1;
|
||||
}
|
||||
|
||||
tutorial::AddressBook address_book;
|
||||
|
||||
{
|
||||
// Read the existing address book.
|
||||
fstream input(argv[1], ios::in | ios::binary);
|
||||
if (!address_book.ParseFromIstream(&input)) {
|
||||
cerr << "Failed to parse address book." << endl;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
ListPeople(address_book);
|
||||
|
||||
// Optional: Delete all global objects allocated by libprotobuf.
|
||||
google::protobuf::ShutdownProtobufLibrary();
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
### 扩展 Protocol Buffer
|
||||
|
||||
早晚在你发布了使用 protocol buffer 的代码之后,毫无疑问,你会想要 "改善"
|
||||
protocol buffer 的定义。如果你想要新的 buffers 向后兼容,并且老的 buffers 向前兼容——几乎可以肯定你很渴望这个——这里有一些规则,你需要遵守。在新的 protocol buffer 版本:
|
||||
|
||||
* 你绝不可以修改任何已存在字段的标签数字
|
||||
* 你绝不可以添加或删除任何 required 字段
|
||||
* 你可以删除 optional 或 repeated 字段
|
||||
* 你可以添加新的 optional 或 repeated 字段,但是你必须使用新的标签数字(也就是说,标签数字在 protocol buffer 中从未使用过,甚至不能是已删除字段的标签数字)。
|
||||
|
||||
(这是对于上面规则的一些[异常情况][9],但它们很少用到。)
|
||||
|
||||
如果你能遵守这些规则,旧代码则可以欢快地读取新的消息,并且简单地忽略所有新的字段。对于旧代码来说,被删除的 optional 字段将会简单地赋予默认值,被删除的 `repeated` 字段会为空。新代码显然可以读取旧消息。然而,请记住新的 optional 字段不会呈现在旧消息中,因此你需要显式地使用 `has_` 检查它们是否被设置或者在 `.proto` 文件在标签数字后使用 `[default = value]` 提供一个合理的默认值。如果一个 optional 元素没有指定默认值,它将会使用类型特定的默认值:对于字符串,默认值为空字符串;对于布尔值,默认值为 false;对于数字类型,默认类型为 0。注意,如果你添加一个新的 repeated 字段,新代码将无法辨别它被留空(left empty)(被新代码)或者从没被设置(被旧代码),因为 repeated 字段没有 `has_` 标志。
|
||||
|
||||
### 优化技巧
|
||||
|
||||
C++ Protocol Buffer 库已极度优化过了。但是,恰当的用法能够更多地提高性能。这里是一些技巧,可以帮你从库中挤压出最后一点速度:
|
||||
|
||||
* 尽可能复用消息对象。即使它们被清除掉,消息也会尽量保存所有被分配来重用的内存。因此,如果我们正在处理许多相同类型或一系列相似结构的消息,一个好的办法是重用相同的消息对象,从而减少内存分配的负担。但是,随着时间的流逝,对象可能会膨胀变大,尤其是当你的消息尺寸(译者注:各消息内容不同,有些消息内容多一些,有些消息内容少一些)不同的时候,或者你偶尔创建了一个比平常大很多的消息的时候。你应该自己通过调用 [SpaceUsed][10] 方法监测消息对象的大小,并在它太大的时候删除它。
|
||||
|
||||
* 对于在多线程中分配大量小对象的情况,你的操作系统内存分配器可能优化得不够好。你可以尝试使用 google 的 [tcmalloc][11]。
|
||||
|
||||
### 高级用法
|
||||
|
||||
Protocol Buffers 绝不仅用于简单的数据存取以及序列化。请阅读 [C++ API reference][12] 来看看你还能用它来做什么。
|
||||
|
||||
protocol 消息类所提供的一个关键特性就是反射。你不需要编写针对一个特殊的消息类型的代码,就可以遍历一个消息的字段并操作它们的值。一个使用反射的有用方法是 protocol 消息与其他编码互相转换,比如 XML 或 JSON。反射的一个更高级的用法可能就是可以找出两个相同类型的消息之间的区别,或者开发某种 "协议消息的正则表达式",利用正则表达式,你可以对某种消息内容进行匹配。只要你发挥你的想像力,就有可能将 Protocol Buffers 应用到一个更广泛的、你可能一开始就期望解决的问题范围上。
|
||||
|
||||
反射是由 [Message::Reflection interface][13] 提供的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://developers.google.com/protocol-buffers/docs/cpptutorial
|
||||
|
||||
作者:[Google][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://developers.google.com/protocol-buffers/docs/cpptutorial
|
||||
[1]: https://developers.google.com/protocol-buffers/docs/proto
|
||||
[2]: https://developers.google.com/protocol-buffers/docs/encoding
|
||||
[3]: https://developers.google.com/protocol-buffers/docs/downloads
|
||||
[4]: https://developers.google.com/protocol-buffers/docs/downloads.html
|
||||
[5]: https://developers.google.com/protocol-buffers/docs/reference/cpp-generated
|
||||
[6]: https://developers.google.com/protocol-buffers/docs/proto
|
||||
[7]: https://developers.google.com/protocol-buffers/docs/reference/cpp/google.protobuf.message.html#Message
|
||||
[8]: https://developers.google.com/protocol-buffers/docs/encoding
|
||||
[9]: https://developers.google.com/protocol-buffers/docs/proto#updating
|
||||
[10]: https://developers.google.com/protocol-buffers/docs/reference/cpp/google.protobuf.message.html#Message.SpaceUsed.details
|
||||
[11]: http://code.google.com/p/google-perftools/
|
||||
[12]: https://developers.google.com/protocol-buffers/docs/reference/cpp/index.html
|
||||
[13]: https://developers.google.com/protocol-buffers/docs/reference/cpp/google.protobuf.message.html#Message.Reflection
|
||||
@ -0,0 +1,156 @@
|
||||
OneNewLife translated
|
||||
|
||||
怎样在 RHEL,CentOS 和 Fedora 上安装 Git 并设置 Git 账号
|
||||
=========
|
||||
|
||||
对于新手来说,Git 是一个免费、开源、高效的分布式版本控制系统(VCS),它是为了给广泛的小规模软件开发项目提供速度、高性能以及数据一致性而设计的。
|
||||
|
||||
Git 是一个软件仓库,它可以让你追踪你的软件改动,回滚到之前的版本以及创建新版本的目录和文件。
|
||||
|
||||
Git 主要是用 C 语言来写的,当中还混入了 Perl 和各种各样的 shell 脚本。它主要在 Linux 内核上运行,并且有以下列举的卓越的性能:
|
||||
|
||||
1. 容易上手
|
||||
2. 运行速度飞快且大部分操作在本地进行,因此,它为需要与远程服务器通信的集中式系统提供了巨大的速度。
|
||||
3. 高性能
|
||||
4. 提供数据一致性检查
|
||||
5. 启用低开销的本地分支
|
||||
6. 提供非常便利的暂存区
|
||||
7. 可以集成其它工具来维持大量工作流
|
||||
|
||||
在这篇操作指南中,我们将介绍在 CentOS/RHEL 7/6 和 Fedora 20-24 Linux 发行版上安装 Git 的必要步骤以及怎么配置 Git,以便于你可以快速开始参与工作。
|
||||
|
||||
### 使用 Yum 安装 Git
|
||||
|
||||
我们应该从系统默认的仓库安装 Git,并通过运行以下 [YUM 包管理器][8] 的更新命令来确保你系统的软件包都是最新的:
|
||||
|
||||
```
|
||||
# yum update
|
||||
|
||||
```
|
||||
|
||||
接着,通过以下命令来安装 Git:
|
||||
|
||||
```
|
||||
# yum install git
|
||||
|
||||
```
|
||||
|
||||
在 Git 成功安装之后,你可以通过以下命令来显示 Git 安装的版本:
|
||||
|
||||
```
|
||||
# git --version
|
||||
|
||||
```
|
||||
|
||||
[][7]
|
||||
|
||||
检查 Git 安装的版本
|
||||
|
||||
注意:从系统默认仓库安装的 Git 会是比较旧的版本。如果你想拥有最新版的 Git,请考虑使用以下说明来编译源代码进行安装。
|
||||
|
||||
### 从源代码安装 Git
|
||||
|
||||
开始之前,你首先需要从系统默认仓库安装所需的软件依赖包,以及从源代码构建二进制文件所需的实用工具:
|
||||
|
||||
```
|
||||
# yum groupinstall "Development Tools"
|
||||
# yum install gettext-devel openssl-devel perl-CPAN perl-devel zlib-devel
|
||||
|
||||
```
|
||||
|
||||
安装所需的软件依赖包之后,转到官方的 [Git 发布页面][6],抓取最新版的 Git 并使用下列命令编译它的源代码:
|
||||
|
||||
```
|
||||
# wget https://github.com/git/git/archive/v2.10.1.tar.gz -O git.tar.gz
|
||||
# tar -zxf git.tar.gz
|
||||
# cd git-2.10.1/
|
||||
# make configure
|
||||
# ./configure --prefix=/usr/local
|
||||
# make install
|
||||
# git --version
|
||||
|
||||
```
|
||||
|
||||
[][5]
|
||||
|
||||
检查 Git 的安装版本
|
||||
|
||||
**推荐阅读:** [Linux 下 11 个最好用的 Git 客户端和 Git 仓库查看器][4]
|
||||
|
||||
### 在 Linux 设置 Git 账户
|
||||
|
||||
在这个环节中,我们将介绍如何使用正确的用户信息(如:姓名、邮件地址)和 `git config` 命令来设置 Git 账户,以避免出现提交错误。
|
||||
|
||||
注意:确保将用户名替换为在你的系统上创建和使用的 Git 用户的真实名称。
|
||||
|
||||
你可以使用下面的 [useradd 命令][3] 创建一个 Git 用户,其中 `-m` 选项用于在 `/home` 目录下创建用户主目录,`-s` 选项用于指定用户默认的 shell。
|
||||
|
||||
```
|
||||
# useradd -m -s /bin/bash username
|
||||
# passwd username
|
||||
|
||||
```
|
||||
|
||||
现在,将新用户添加到 `wheel` 用户组以启用其使用 `sudo` 命令的权限:
|
||||
|
||||
```
|
||||
# usermod username -aG wheel
|
||||
|
||||
```
|
||||
|
||||
[][2]
|
||||
|
||||
创建 Git 用户账号
|
||||
|
||||
然后通过以下命令使用新用户配置 Git:
|
||||
|
||||
```
|
||||
# su username
|
||||
$ sudo git config --global user.name "Your Name"
|
||||
$ sudo git config --global user.email "you@example.com"
|
||||
|
||||
```
|
||||
|
||||
现在通过下面的命令校验 Git 的配置。
|
||||
|
||||
```
|
||||
$ sudo git config --list
|
||||
|
||||
```
|
||||
|
||||
如果配置没有错误的话,你应该能够查看具有以下详细信息的输出:
|
||||
|
||||
```
|
||||
user.name=username
|
||||
user.email= username@some-domian.com
|
||||
|
||||
```
|
||||
|
||||
[][1]
|
||||
>在 Linux 设置 Git 用户
|
||||
|
||||
##### 总结
|
||||
|
||||
在这个简单的教程中,我们已经了解怎么在你的 Linux 系统上安装 Git 以及配置它。我相信你应该可以驾轻就熟。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
编译自: http://www.tecmint.com/install-git-centos-fedora-redhat/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
|
||||
译者:[OneNewLife](https://github.com/OneNewLife)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2016/10/Setup-Git-Account.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/10/Create-Git-User-Account.png
|
||||
[3]:http://www.tecmint.com/add-users-in-linux/
|
||||
[4]:http://www.tecmint.com/best-gui-git-clients-git-repository-viewers-for-linux/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/10/Check-Git-Source-Version.png
|
||||
[6]:https://github.com/git/git/releases
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2016/10/Check-Git-Version.png
|
||||
[8]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
@ -1,40 +1,39 @@
|
||||
翻译认领
|
||||
How To Download A RPM Package With All Dependencies In CentOS
|
||||
在CentOS下根据依赖性来下载RPM软件包
|
||||
===
|
||||
|
||||

|
||||

|
||||
|
||||
The other day I was trying to create a local repository with packages only we use often in CentOS 7\. Of course we can download any package using _curl_ or _wget_ commands. These commands however won’t download the required dependencies. You have to spend some time and manually search and download the dependencies required by the package to install. Well, not anymore. In this brief tutorial, I will walk you through how to download a RPM package with all dependencies in two methods. I tested this guide on CentOS 7, although the same steps may work on other RPM based systems such as RHEL, Fedora and Scientific Linux.
|
||||
前几天我尝试去创建一个我们在CentOS 7下经常使用的软件的本地的仓库。当然我们可以使用 curl 或者 wget 下载任何软件包。然而这些命令并不能下载要求的依赖软件包。你必须去花一些时间而且手动的去寻找和下载被安装的软件所依赖的软件包。然而,这并不是我们必须要做的事情。在这个简短的教程中,我将会带领你学习如何根据依赖性来下载软件包的两种方法。我已经在CentOS 7 下进行了测试,尽管这些相同的步骤或许在其他基于 RPM 管理系统的发行版上也可以工作,例如 RHEL,Fedora 和 Scientific Linux。
|
||||
|
||||
### Method 1 – Download A RPM Package With All Dependencies Using “Downloadonly” plugin
|
||||
### 方法 1-利用“Downloadonly”插件来根据依赖性来下载RPM软件包
|
||||
|
||||
We can easily download any RPM package with all dependencies using “Downloadonly” plugin for yum command.
|
||||
我们可以通过 yum 命令的“Downloadonly”插件来很容易地根据依赖性来下载RPM软件包。
|
||||
|
||||
To install Downloadonly plugin, run the following command as root user.
|
||||
为了安装 Downloadonly 插件,以 root 身份运行以下命令。
|
||||
|
||||
```
|
||||
yum install yum-plugin-downloadonly
|
||||
```
|
||||
|
||||
Now, run the following command to download a RPM package.
|
||||
现在,运行以下命令去下载一个 RPM 软件包
|
||||
|
||||
```
|
||||
yum install --downloadonly <package-name>
|
||||
```
|
||||
|
||||
By default, this command will download and save the packages in /var/cache/yum/ in rhel-{arch}-channel/packageslocation. However, you can download and save the packages in any location of your choice using _“–downloaddir”_ option.
|
||||
默认情况下,这个命令将会下载并把软件包保存到 /var/cache/yum/ 在 rhel-{arch}-channel/packageslocation,然而,你可以下载和保存软件包到任何位置,你可以通过 “–downloaddir” 选项来指定。
|
||||
|
||||
```
|
||||
yum install --downloadonly --downloaddir=<directory> <package-name>
|
||||
```
|
||||
|
||||
Example:
|
||||
例子:
|
||||
|
||||
```
|
||||
yum install --downloadonly --downloaddir=/root/mypackages/ httpd
|
||||
```
|
||||
|
||||
Sample output:
|
||||
终端输出:
|
||||
|
||||
```
|
||||
Loaded plugins: fastestmirror
|
||||
@ -89,15 +88,15 @@ exiting because "Download Only" specified
|
||||
|
||||
[][6]
|
||||
|
||||
Now go the location that you specified in the above command. You will see there the downloaded package with all dependencies. In my case, I have downloaded the packages in _/root/mypackages/_ directory.
|
||||
现在去你指定的目录位置下。你将会看到那里有下载好的软件包和依赖的软件。在我这种情况下,我已经把软件包下载到/root/mypackages/ 目录下。
|
||||
|
||||
Let us verify the contents.
|
||||
让我们来查看一下内容。
|
||||
|
||||
```
|
||||
ls /root/mypackages/
|
||||
```
|
||||
|
||||
Sample output:
|
||||
样本输出:
|
||||
|
||||
```
|
||||
apr-1.4.8-3.el7.x86_64.rpm
|
||||
@ -109,11 +108,12 @@ mailcap-2.1.41-2.el7.noarch.rpm
|
||||
|
||||
[][5]
|
||||
|
||||
As you see in the above output, the package httpd has been downloaded with all dependencies.
|
||||
正如你在上面输出所看到的, httpd软件包已经被依据所有依赖性下载完成了.
|
||||
|
||||
Please note that this plugin is applicable for “yum install/yum update” and not for “yum groupinstall”. By default this plugin will download the latest available packages in the repository. You can however download a particular version by specifying the version.
|
||||
|
||||
Example:
|
||||
请注意,这个插件适用于 “yum install/yum update” 而且并不适用于 “yum groupinstall”。默认情况下,这个插件将会下载仓库中最新可用的软件包。然而你可以通过指定版本号来下载某个特定的软件版本。
|
||||
|
||||
例子:
|
||||
|
||||
```
|
||||
yum install --downloadonly --downloaddir=/root/mypackages/ httpd-2.2.6-40.el7
|
||||
@ -125,44 +125,42 @@ Also, you can download multiple packages at once as shown below.
|
||||
yum install --downloadonly --downloaddir=/root/mypackages/ httpd vsftpd
|
||||
```
|
||||
|
||||
### Method 2 – Download A RPM Package With All Dependencies Using “Yumdownloader” utility
|
||||
### 方法 2-使用 Yumdownloader 工具来根据依赖性下载 RPM 软件包,
|
||||
|
||||
|
||||
Yumdownloader is a simple, yet useful command-line utility that downloads any RPM package along with all required dependencies in one go.
|
||||
|
||||
Install Yumdownloader using the following command as root user.
|
||||
Yumdownloader是一款简单,但是却十分有用的命令行工具,它可以一次性根据依赖性下载任何 RPM 软件包
|
||||
|
||||
以 root 身份运行如下命令安装 Yumdownloader 工具
|
||||
|
||||
```
|
||||
yum install yum-utils
|
||||
```
|
||||
|
||||
Once installed, run the following command to download a package, for example httpd.
|
||||
一旦安装完成,运行如下命令去下载一个软件包,例如 httpd
|
||||
|
||||
```
|
||||
yumdownloader httpd
|
||||
```
|
||||
|
||||
To download packages with all dependencies, use _–resolve_ option:
|
||||
为了根据所有依赖性下载软件包,我们使用 _–resolve 参数:
|
||||
|
||||
```
|
||||
yumdownloader --resolve httpd
|
||||
```
|
||||
|
||||
By default, Yumdownloader will download the packages in the current working directory.
|
||||
|
||||
To download packages along with all dependencies to a specific location, use _–destdir_ option:
|
||||
默认情况下,Yumdownloader 将会下载软件包到当前工作目录下。
|
||||
|
||||
为了将软件下载到一个特定的目录下,我们使用 _–destdir 参数:
|
||||
```
|
||||
yumdownloader --resolve --destdir=/root/mypackages/ httpd
|
||||
```
|
||||
|
||||
Or
|
||||
或者
|
||||
|
||||
```
|
||||
yumdownloader --resolve --destdir /root/mypackages/ httpd
|
||||
```
|
||||
|
||||
Sample output:
|
||||
终端输出:
|
||||
|
||||
```
|
||||
Loaded plugins: fastestmirror
|
||||
@ -192,13 +190,12 @@ Loading mirror speeds from cached hostfile
|
||||
|
||||
[][3]
|
||||
|
||||
Let us verify whether packages have been downloaded in the specified location.
|
||||
|
||||
让我们确认一下软件包是否被下载到我们指定的目录下。
|
||||
```
|
||||
ls /root/mypackages/
|
||||
```
|
||||
|
||||
Sample output:
|
||||
终端输出:
|
||||
|
||||
```
|
||||
apr-1.4.8-3.el7.x86_64.rpm
|
||||
@ -210,17 +207,17 @@ mailcap-2.1.41-2.el7.noarch.rpm
|
||||
|
||||
[][2]
|
||||
|
||||
Unlike “Downloadonly” plugin, Yumdownload can download the packages related to a particular group.
|
||||
不像 Downloadonly 插件,Yumdownload 可以下载一组相关的软件包。
|
||||
|
||||
```
|
||||
yumdownloader "@Development Tools" --resolve --destdir /root/mypackages/
|
||||
```
|
||||
|
||||
Personally, I prefer Yumdownloader over “Downloadonly” plugin for yum. But, both are extremely easy and handy and does the same job.
|
||||
在我看来,我更喜欢 Yumdownloader 应用在 Yum 上面。但是,两者都是十分简单易懂而且可以完成相同的工作。
|
||||
|
||||
That’s all for today. If you find this guide helpful, please share it on your social networks and let others to benefit.
|
||||
这就是今天所有的内容,如果你觉得这份引导教程有用,清在你的社交媒体上面分享一下去让更多的人知道。
|
||||
|
||||
Cheers!
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -228,7 +225,7 @@ via: https://www.ostechnix.com/download-rpm-package-dependencies-centos/
|
||||
|
||||
作者:[SK][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[LinuxBars](https://github.com/LinuxBars)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
Loading…
Reference in New Issue
Block a user