-}
-```
-
-It’s that simple. We just passed `props` as an argument to a plain JavaScript function and returned, _umm, well, what was that? That _ `_
{props.name}
_` _thing!_ It’s JSX (JavaScript Extended). We will learn more about it in a later section.
-
-This above function will render the following HTML in the browser.
-
-```
-
-
- rajat
-
-```
-
-
-> Read the section below about JSX, where I have explained how did we get this HTML from our JSX code.
-
-How can you use this functional component in your React app? Glad you asked! It’s as simple as the following.
-
-```
-
-```
-
-The attribute `name` in the above code becomes `props.name` inside our `Hello`component. The attribute `age` becomes `props.age` and so on.
-
-> Remember! You can nest one React component inside other React components.
-
-Let’s use this `Hello` component in our codepen playground. Replace the `div`inside `ReactDOM.render()` with our `Hello` component, as follows, and see the changes in the bottom window.
-
-```
-function Hello(props) {
- return
{props.name}
-}
-
-ReactDOM.render(, document.getElementById('root'));
-```
-
-
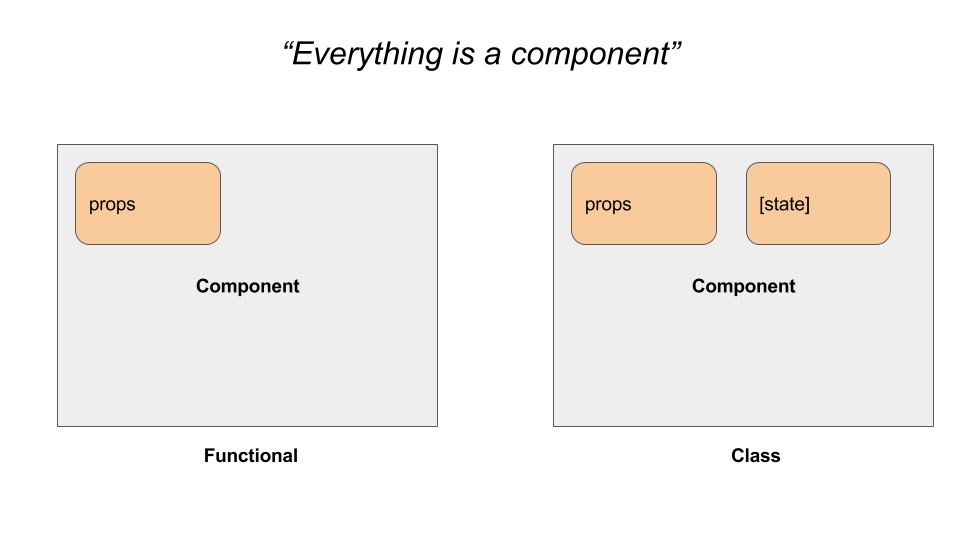
-> But what if your component has some internal state. For instance, like the following counter component, which has an internal count variable, which changes on + and — key presses.
-
-A React component with an internal state
-
-#### b) Class-based component
-
-The class-based component has an additional property `state` , which you can use to hold a component’s private data. We can rewrite our `Hello` component using class notation as follows. Since these components have a state, these are also known as Stateful components.
-
-```
-class Counter extends React.Component {
- // this method should be present in your component
- render() {
- return (
-
- {this.props.name}
-
- );
- }
-}
-```
-
-We extend `React.Component` class of React library to make class-based components in React. Learn more about JavaScript classes [here][5].
-
-The `render()` method must be present in your class as React looks for this method in order to know what UI it should render on screen.
-
-To use this sort of internal state, we first have to initialize the `state` object in the constructor of the component class, in the following way.
-
-```
-class Counter extends React.Component {
- constructor() {
- super();
-
- // define the internal state of the component
- this.state = {name: 'rajat'}
- }
-
- render() {
- return (
-
- {this.state.name}
-
- );
- }
-}
-
-// Usage:
-// In your react app:
-```
-
-Similarly, the `props` can be accessed inside our class-based component using `this.props` object.
-
-To set the state, you use `React.Component`'s `setState()`. We will see an example of this, in the last part of this tutorial.
-
-> Tip: Never call `setState()` inside `render()` function, as `setState()` causes component to re-render and this will result in endless loop.
-
-
-
-A class-based component has an optional property “state”.
-
- _Apart from _ `_state_` _, a class-based component has some life-cycle methods like _ `_componentWillMount()._` _ These you can use to do stuff, like initializing the _ `_state_` _and all but that is out of the scope of this post._
-
-### JSX
-
-JSX is a short form of _JavaScript Extended_ and it is a way to write `React`components. Using JSX, you get the full power of JavaScript inside XML like tags.
-
-You put JavaScript expressions inside `{}`. The following are some valid JSX examples.
-
- ```
-
-
- ;
-
-
-
- ```
-
-The way it works is you write JSX to describe what your UI should look like. A [transpiler][6] like `Babel` converts that code into a bunch of `React.createElement()` calls. The React library then uses those `React.createElement()` calls to construct a tree-like structure of DOM elements. In case of React for Web or Native views in case of React Native. It keeps it in the memory.
-
-React then calculates how it can effectively mimic this tree in the memory of the UI displayed to the user. This process is known as [reconciliation][7]. After that calculation is done, React makes the changes to the actual UI on the screen.
-
- ** 此处有Canvas,请手动处理 **
-
-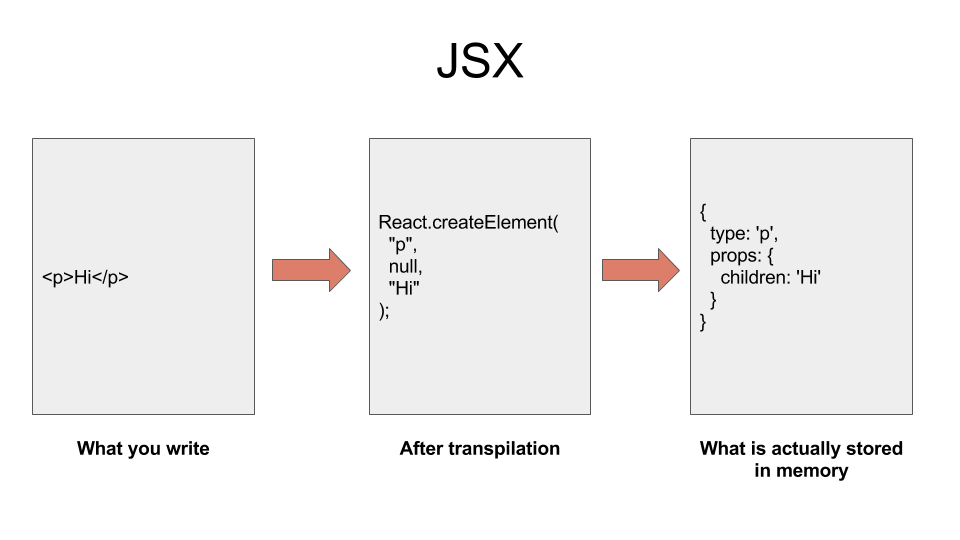
-How React converts your JSX into a tree which describes your app’s UI
-
-You can use [Babel’s online REPL][8] to see what React actually outputs when you write some JSX.
-
-
-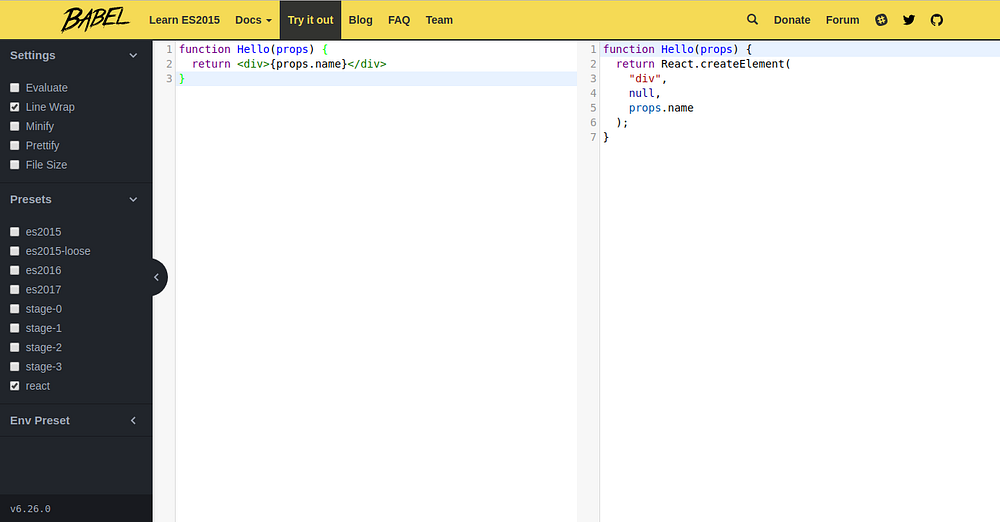
-Use Babel REPL to transform JSX into plain JavaScript
-
-> Since JSX is just a syntactic sugar over plain `React.createElement()` calls, React can be used without JSX.
-
-Now we have every concept in place, so we are well positioned to write a `counter` component that we saw earlier as a GIF.
-
-The code is as follows and I hope that you already know how to render that in our playground.
-
-```
-class Counter extends React.Component {
- constructor(props) {
- super(props);
-
- this.state = {count: this.props.start || 0}
-
- // the following bindings are necessary to make `this` work in the callback
- this.inc = this.inc.bind(this);
- this.dec = this.dec.bind(this);
- }
-
- inc() {
- this.setState({
- count: this.state.count + 1
- });
- }
-
- dec() {
- this.setState({
- count: this.state.count - 1
- });
- }
-
- render() {
- return (
-
-
-
-
{this.state.count}
-
- );
- }
-}
-```
-
-The following are some salient points about the above code.
-
-1. JSX uses `camelCasing` hence `button`'s attribute is `onClick`, not `onclick`, as we use in HTML.
-
-2. Binding is necessary for `this` to work on callbacks. See line #8 and 9 in the code above.
-
-The final interactive code is located [here][9].
-
-With that, we’ve reached the conclusion of our React crash course. I hope I have shed some light on how React works and how you can use React to build bigger apps, using smaller and reusable components.
-
-* * *
-
-If you have any queries or doubts, hit me up on Twitter [@rajat1saxena][10] or write to me at [rajat@raynstudios.com][11].
-
-* * *
-
-#### Please recommend this post, if you liked it and share it with your network. Follow me for more tech related posts and consider subscribing to my channel [Rayn Studios][12] on YouTube. Thanks a lot.
-
---------------------------------------------------------------------------------
-
-via: https://medium.freecodecamp.org/rock-solid-react-js-foundations-a-beginners-guide-c45c93f5a923
-
-作者:[Rajat Saxena ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://medium.freecodecamp.org/@rajat1saxena
-[1]:https://kivenaa.com/
-[2]:https://play.google.com/store/apps/details?id=com.pollenchat.android
-[3]:https://facebook.github.io/react-native/
-[4]:https://codepen.io/raynesax/pen/MrNmBM
-[5]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes
-[6]:https://en.wikipedia.org/wiki/Source-to-source_compiler
-[7]:https://reactjs.org/docs/reconciliation.html
-[8]:https://babeljs.io/repl
-[9]:https://codepen.io/raynesax/pen/QaROqK
-[10]:https://twitter.com/rajat1saxena
-[11]:mailto:rajat@raynstudios.com
-[12]:https://www.youtube.com/channel/UCUmQhjjF9bsIaVDJUHSIIKw
diff --git a/sources/tech/20180412 A Desktop GUI Application For NPM.md b/sources/tech/20180412 A Desktop GUI Application For NPM.md
deleted file mode 100644
index 5c87aad3c0..0000000000
--- a/sources/tech/20180412 A Desktop GUI Application For NPM.md
+++ /dev/null
@@ -1,149 +0,0 @@
-translating---geekpi
-
-A Desktop GUI Application For NPM
-======
-
-
-
-NPM, short for **N** ode **P** ackage **M** anager, is a command line package manager for installing NodeJS packages, or modules. We already have have published a guide that described how to [**manage NodeJS packages using NPM**][1]. As you may noticed, managing NodeJS packages or modules using Npm is not a big deal. However, if you’re not compatible with CLI-way, there is a desktop GUI application named **NDM** which can be used for managing NodeJS applications/modules. NDM, stands for **N** PM **D** esktop **M** anager, is a free, open source graphical front-end for NPM that allows us to install, update, remove NodeJS packages via a simple graphical window.
-
-In this brief tutorial, we are going to learn about Ndm in Linux.
-
-### Install NDM
-
-NDM is available in AUR, so you can install it using any AUR helpers on Arch Linux and its derivatives like Antergos and Manjaro Linux.
-
-Using [**Pacaur**][2]:
-```
-$ pacaur -S ndm
-
-```
-
-Using [**Packer**][3]:
-```
-$ packer -S ndm
-
-```
-
-Using [**Trizen**][4]:
-```
-$ trizen -S ndm
-
-```
-
-Using [**Yay**][5]:
-```
-$ yay -S ndm
-
-```
-
-Using [**Yaourt**][6]:
-```
-$ yaourt -S ndm
-
-```
-
-On RHEL based systems like CentOS, run the following command to install NDM.
-```
-$ echo "[fury] name=ndm repository baseurl=https://repo.fury.io/720kb/ enabled=1 gpgcheck=0" | sudo tee /etc/yum.repos.d/ndm.repo && sudo yum update &&
-
-```
-
-On Debian, Ubuntu, Linux Mint:
-```
-$ echo "deb [trusted=yes] https://apt.fury.io/720kb/ /" | sudo tee /etc/apt/sources.list.d/ndm.list && sudo apt-get update && sudo apt-get install ndm
-
-```
-
-NDM can also be installed using **Linuxbrew**. First, install Linuxbrew as described in the following link.
-
-After installing Linuxbrew, you can install NDM using the following commands:
-```
-$ brew update
-
-$ brew install ndm
-
-```
-
-On other Linux distributions, go to the [**NDM releases page**][7], download the latest version, compile and install it yourself.
-
-### NDM Usage
-
-Launch NDM wither from the Menu or using application launcher. This is how NDM’s default interface looks like.
-
-![][9]
-
-From here, you can install NodeJS packages/modules either locally or globally.
-
-**Install NodeJS packages locally**
-
-To install a package locally, first choose project directory by clicking on the **“Add projects”** button from the Home screen and select the directory where you want to keep your project files. For example, I have chosen a directory named **“demo”** as my project directory.
-
-Click on the project directory (i.e **demo** ) and then, click **Add packages** button.
-
-![][10]
-
-Type the package name you want to install and hit the **Install** button.
-
-![][11]
-
-Once installed, the packages will be listed under the project’s directory. Simply click on the directory to view the list of installed packages locally.
-
-![][12]
-
-Similarly, you can create separate project directories and install NodeJS modules in them. To view the list of installed modules on a project, click on the project directory, and you will the packages on the right side.
-
-**Install NodeJS packages globally**
-
-To install NodeJS packages globally, click on the **Globals** button on the left from the main interface. Then, click “Add packages” button, type the name of the package and hit “Install” button.
-
-**Manage packages**
-
-Click on any installed packages and you will see various options on the top, such as
-
- 1. Version (to view the installed version),
- 2. Latest (to install latest available version),
- 3. Update (to update the currently selected package),
- 4. Uninstall (to remove the selected package) etc.
-
-
-
-![][13]
-
-NDM has two more options namely **“Update npm”** which is used to update the node package manager to latest available version, and **Doctor** that runs a set of checks to ensure that your npm installation has what it needs to manage your packages/modules.
-
-### Conclusion
-
-NDM makes the process of installing, updating, removing NodeJS packages easier! You don’t need to memorize the commands to perform those tasks. NDM lets us to do them all with a few mouse clicks via simple graphical window. For those who are lazy to type commands, NDM is perfect companion to manage NodeJS packages.
-
-Cheers!
-
-**Resource:**
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/ndm-a-desktop-gui-application-for-npm/
-
-作者:[SK][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
-[2]:https://www.ostechnix.com/install-pacaur-arch-linux/
-[3]:https://www.ostechnix.com/install-packer-arch-linux-2/
-[4]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
-[5]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
-[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
-[7]:https://github.com/720kb/ndm/releases
-[8]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[9]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-1.png
-[10]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-5-1.png
-[11]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-6.png
-[12]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-7.png
-[13]:http://www.ostechnix.com/wp-content/uploads/2018/04/ndm-8.png
diff --git a/sources/tech/20180824 What Stable Kernel Should I Use.md b/sources/tech/20180824 What Stable Kernel Should I Use.md
deleted file mode 100644
index 52b77498c5..0000000000
--- a/sources/tech/20180824 What Stable Kernel Should I Use.md
+++ /dev/null
@@ -1,140 +0,0 @@
-Translating by qhwdw
-What Stable Kernel Should I Use?
-======
-I get a lot of questions about people asking me about what stable kernel should they be using for their product/device/laptop/server/etc. all the time. Especially given the now-extended length of time that some kernels are being supported by me and others, this isn’t always a very obvious thing to determine. So this post is an attempt to write down my opinions on the matter. Of course, you are free to use what ever kernel version you want, but here’s what I recommend.
-
-As always, the opinions written here are my own, I speak for no one but myself.
-
-### What kernel to pick
-
-Here’s the my short list of what kernel you should use, raked from best to worst options. I’ll go into the details of all of these below, but if you just want the summary of all of this, here it is:
-
-Hierarchy of what kernel to use, from best solution to worst:
-
- * Supported kernel from your favorite Linux distribution
- * Latest stable release
- * Latest LTS release
- * Older LTS release that is still being maintained
-
-
-
-What kernel to never use:
-
- * Unmaintained kernel release
-
-
-
-To give numbers to the above, today, as of August 24, 2018, the front page of kernel.org looks like this:
-
-![][1]
-
-So, based on the above list that would mean that:
-
- * 4.18.5 is the latest stable release
- * 4.14.67 is the latest LTS release
- * 4.9.124, 4.4.152, and 3.16.57 are the older LTS releases that are still being maintained
- * 4.17.19 and 3.18.119 are “End of Life” kernels that have had a release in the past 60 days, and as such stick around on the kernel.org site for those who still might want to use them.
-
-
-
-Quite easy, right?
-
-Ok, now for some justification for all of this:
-
-### Distribution kernels
-
-The best solution for almost all Linux users is to just use the kernel from your favorite Linux distribution. Personally, I prefer the community based Linux distributions that constantly roll along with the latest updated kernel and it is supported by that developer community. Distributions in this category are Fedora, openSUSE, Arch, Gentoo, CoreOS, and others.
-
-All of these distributions use the latest stable upstream kernel release and make sure that any needed bugfixes are applied on a regular basis. That is the one of the most solid and best kernel that you can use when it comes to having the latest fixes ([remember all fixes are security fixes][2]) in it.
-
-There are some community distributions that take a bit longer to move to a new kernel release, but eventually get there and support the kernel they currently have quite well. Those are also great to use, and examples of these are Debian and Ubuntu.
-
-Just because I did not list your favorite distro here does not mean its kernel is not good. Look on the web site for the distro and make sure that the kernel package is constantly updated with the latest security patches, and all should be well.
-
-Lots of people seem to like the old, “traditional” model of a distribution and use RHEL, SLES, CentOS or the “LTS” Ubuntu release. Those distros pick a specific kernel version and then camp out on it for years, if not decades. They do loads of work backporting the latest bugfixes and sometimes new features to these kernels, all in a Quixote quest to keep the version number from never being changed, despite having many thousands of changes on top of that older kernel version. This work is a truly thankless job, and the developers assigned to these tasks do some wonderful work in order to achieve these goals. If you like never seeing your kernel version number change, then use these distributions. They usually cost some money to use, but the support you get from these companies is worth it when something goes wrong.
-
-So again, the best kernel you can use is one that someone else supports, and you can turn to for help. Use that support, usually you are already paying for it (for the enterprise distributions), and those companies know what they are doing.
-
-But, if you do not want to trust someone else to manage your kernel for you, or you have hardware that a distribution does not support, then you want to run the Latest stable release:
-
-### Latest stable release
-
-This kernel is the latest one from the Linux kernel developer community that they declare as “stable”. About every three months, the community releases a new stable kernel that contains all of the newest hardware support, the latest performance improvements, as well as the latest bugfixes for all parts of the kernel. Over the next 3 months, bugfixes that go into the next kernel release to be made are backported into this stable release, so that any users of this kernel are sure to get them as soon as possible.
-
-This is usually the kernel that most community distributions use as well, so you can be sure it is tested and has a large audience of users. Also, the kernel community (all 4000+ developers) are willing to help support users of this release, as it is the latest one that they made.
-
-After 3 months, a new kernel is released and you should move to it to ensure that you stay up to date, as support for this kernel is usually dropped a few weeks after the newer release happens.
-
-If you have new hardware that is purchased after the last LTS release came out, you almost are guaranteed to have to run this kernel in order to have it supported. So for desktops or new servers, this is usually the recommended kernel to be running.
-
-### Latest LTS release
-
-If your hardware relies on a vendors out-of-tree patch in order to make it work properly (like almost all embedded devices these days), then the next best kernel to be using is the latest LTS release. That release gets all of the latest kernel fixes that goes into the stable releases where applicable, and lots of users test and use it.
-
-Note, no new features and almost no new hardware support is ever added to these kernels, so if you need to use a new device, it is better to use the latest stable release, not this release.
-
-Also this release is common for users that do not like to worry about “major” upgrades happening on them every 3 months. So they stick to this release and upgrade every year instead, which is a fine practice to follow.
-
-The downsides of using this release is that you do not get the performance improvements that happen in newer kernels, except when you update to the next LTS kernel, potentially a year in the future. That could be significant for some workloads, so be very aware of this.
-
-Also, if you have problems with this kernel release, the first thing that any developer whom you report the issue to is going to ask you to do is, “does the latest stable release have this problem?” So you will need to be aware that support might not be as easy to get as with the latest stable releases.
-
-Now if you are stuck with a large patchset and can not update to a new LTS kernel once a year, perhaps you want the older LTS releases:
-
-### Older LTS release
-
-These releases have traditionally been supported by the community for 2 years, sometimes longer for when a major distribution relies on this (like Debian or SLES). However in the past year, thanks to a lot of suport and investment in testing and infrastructure from Google, Linaro, Linaro member companies, [kernelci.org][3], and others, these kernels are starting to be supported for much longer.
-
-Here’s the latest LTS releases and how long they will be supported for, as shown at [kernel.org/category/releases.html][4] on August 24, 2018:
-
-![][5]
-
-The reason that Google and other companies want to have these kernels live longer is due to the crazy (some will say broken) development model of almost all SoC chips these days. Those devices start their development lifecycle a few years before the chip is released, however that code is never merged upstream, resulting in a brand new chip being released based on a 2 year old kernel. These SoC trees usually have over 2 million lines added to them, making them something that I have started calling “Linux-like” kernels.
-
-If the LTS releases stop happening after 2 years, then support from the community instantly stops, and no one ends up doing bugfixes for them. This results in millions of very insecure devices floating around in the world, not something that is good for any ecosystem.
-
-Because of this dependency, these companies now require new devices to constantly update to the latest LTS releases as they happen for their specific release version (i.e. every 4.9.y release that happens). An example of this is the Android kernel requirements for new devices shipping for the “O” and now “P” releases specified the minimum kernel version allowed, and Android security releases might start to require those “.y” releases to happen more frequently on devices.
-
-I will note that some manufacturers are already doing this today. Sony is one great example of this, updating to the latest 4.4.y release on many of their new phones for their quarterly security release. Another good example is the small company Essential which has been tracking the 4.4.y releases faster than anyone that I know of.
-
-There is one huge caveat when using a kernel like this. The number of security fixes that get backported are not as great as with the latest LTS release, because the traditional model of the devices that use these older LTS kernels is a much more reduced user model. These kernels are not to be used in any type of “general computing” model where you have untrusted users or virtual machines, as the ability to do some of the recent Spectre-type fixes for older releases is greatly reduced, if present at all in some branches.
-
-So again, only use older LTS releases in a device that you fully control, or lock down with a very strong security model (like Android enforces using SELinux and application isolation). Never use these releases on a server with untrusted users, programs, or virtual machines.
-
-Also, support from the community for these older LTS releases is greatly reduced even from the normal LTS releases, if available at all. If you use these kernels, you really are on your own, and need to be able to support the kernel yourself, or rely on you SoC vendor to provide that support for you (note that almost none of them do provide that support, so beware…)
-
-### Unmaintained kernel release
-
-Surprisingly, many companies do just grab a random kernel release, slap it into their product and proceed to ship it in hundreds of thousands of units without a second thought. One crazy example of this would be the Lego Mindstorm systems that shipped a random -rc release of a kernel in their device for some unknown reason. A -rc release is a development release that not even the Linux kernel developers feel is ready for everyone to use just yet, let alone millions of users.
-
-You are of course free to do this if you want, but note that you really are on your own here. The community can not support you as no one is watching all kernel versions for specific issues, so you will have to rely on in-house support for everything that could go wrong. Which for some companies and systems, could be just fine, but be aware of the “hidden” cost this might cause if you do not plan for this up front.
-
-### Summary
-
-So, here’s a short list of different types of devices, and what I would recommend for their kernels:
-
- * Laptop / Desktop: Latest stable release
- * Server: Latest stable release or latest LTS release
- * Embedded device: Latest LTS release or older LTS release if the security model used is very strong and tight.
-
-
-
-And as for me, what do I run on my machines? My laptops run the latest development kernel (i.e. Linus’s development tree) plus whatever kernel changes I am currently working on and my servers run the latest stable release. So despite being in charge of the LTS releases, I don’t run them myself, except in testing systems. I rely on the development and latest stable releases to ensure that my machines are running the fastest and most secure releases that we know how to create at this point in time.
-
---------------------------------------------------------------------------------
-
-via: http://kroah.com/log/blog/2018/08/24/what-stable-kernel-should-i-use/
-
-作者:[Greg Kroah-Hartman][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://kroah.com
-[1]:https://s3.amazonaws.com/kroah.com/images/kernel.org_2018_08_24.png
-[2]:http://kroah.com/log/blog/2018/02/05/linux-kernel-release-model/
-[3]:https://kernelci.org/
-[4]:https://www.kernel.org/category/releases.html
-[5]:https://s3.amazonaws.com/kroah.com/images/kernel.org_releases_2018_08_24.png
diff --git a/sources/tech/20180926 3 open source distributed tracing tools.md b/sources/tech/20180926 3 open source distributed tracing tools.md
deleted file mode 100644
index 9879302d38..0000000000
--- a/sources/tech/20180926 3 open source distributed tracing tools.md
+++ /dev/null
@@ -1,90 +0,0 @@
-translating by belitex
-
-3 open source distributed tracing tools
-======
-
-Find performance issues quickly with these tools, which provide a graphical view of what's happening across complex software systems.
-
-
-
-Distributed tracing systems enable users to track a request through a software system that is distributed across multiple applications, services, and databases as well as intermediaries like proxies. This allows for a deeper understanding of what is happening within the software system. These systems produce graphical representations that show how much time the request took on each step and list each known step.
-
-A user reviewing this content can determine where the system is experiencing latencies or blockages. Instead of testing the system like a binary search tree when requests start failing, operators and developers can see exactly where the issues begin. This can also reveal where performance changes might be occurring from deployment to deployment. It’s always better to catch regressions automatically by alerting to the anomalous behavior than to have your customers tell you.
-
-How does this tracing thing work? Well, each request gets a special ID that’s usually injected into the headers. This ID uniquely identifies that transaction. This transaction is normally called a trace. The trace is the overall abstract idea of the entire transaction. Each trace is made up of spans. These spans are the actual work being performed, like a service call or a database request. Each span also has a unique ID. Spans can create subsequent spans called child spans, and child spans can have multiple parents.
-
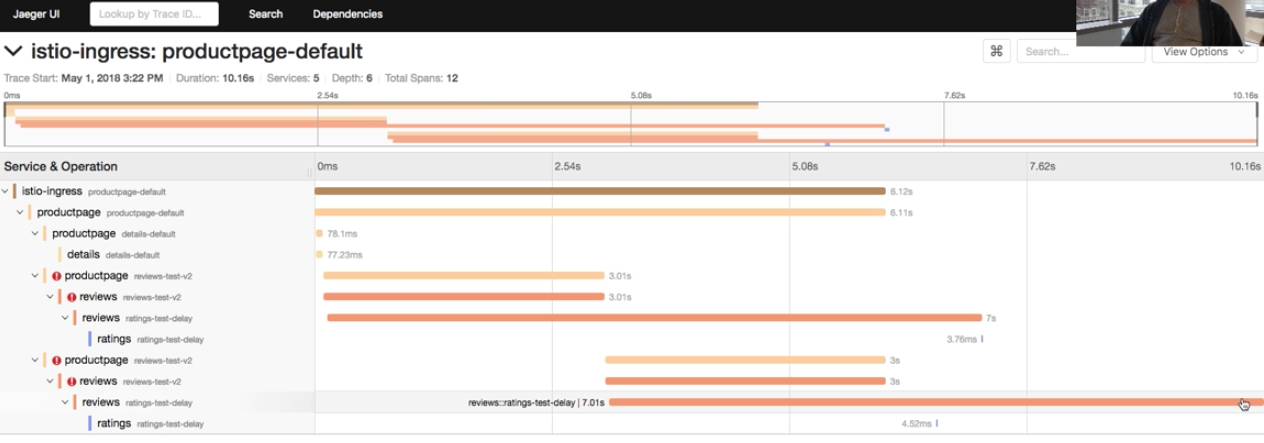
-Once a transaction (or trace) has run its course, it can be searched in a presentation layer. There are several tools in this space that we’ll discuss later, but the picture below shows [Jaeger][1] from my [Istio walkthrough][2]. It shows multiple spans of a single trace. The power of this is immediately clear as you can better understand the transaction’s story at a glance.
-
-
-
-This demo uses Istio’s built-in OpenTracing implementation, so I can get tracing without even modifying my application. It also uses Jaeger, which is OpenTracing-compatible.
-
-So what is OpenTracing? Let’s find out.
-
-### OpenTracing API
-
-[OpenTracing][3] is a spec that grew out of [Zipkin][4] to provide cross-platform compatibility. It offers a vendor-neutral API for adding tracing to applications and delivering that data into distributed tracing systems. A library written for the OpenTracing spec can be used with any system that is OpenTracing-compliant. Zipkin, Jaeger, and Appdash are examples of open source tools that have adopted the open standard, but even proprietary tools like [Datadog][5] and [Instana][6] are adopting it. This is expected to continue as OpenTracing reaches ubiquitous status.
-
-### OpenCensus
-
-Okay, we have OpenTracing, but what is this [OpenCensus][7] thing that keeps popping up in my searches? Is it a competing standard, something completely different, or something complementary?
-
-The answer depends on who you ask. I will do my best to explain the difference (as I understand it): OpenCensus takes a more holistic or all-inclusive approach. OpenTracing is focused on establishing an open API and spec and not on open implementations for each language and tracing system. OpenCensus provides not only the specification but also the language implementations and wire protocol. It also goes beyond tracing by including additional metrics that are normally outside the scope of distributed tracing systems.
-
-OpenCensus allows viewing data on the host where the application is running, but it also has a pluggable exporter system for exporting data to central aggregators. The current exporters produced by the OpenCensus team include Zipkin, Prometheus, Jaeger, Stackdriver, Datadog, and SignalFx, but anyone can create an exporter.
-
-From my perspective, there’s a lot of overlap. One isn’t necessarily better than the other, but it’s important to know what each does and doesn’t do. OpenTracing is primarily a spec, with others doing the implementation and opinionation. OpenCensus provides a holistic approach for the local component with more opinionation but still requires other systems for remote aggregation.
-
-### Tool options
-
-#### Zipkin
-
-Zipkin was one of the first systems of this kind. It was developed by Twitter based on the [Google Dapper paper][8] about the internal system Google uses. Zipkin was written using Java, and it can use Cassandra or ElasticSearch as a scalable backend. Most companies should be satisfied with one of those options. The lowest supported Java version is Java 6. It also uses the [Thrift][9] binary communication protocol, which is popular in the Twitter stack and is hosted as an Apache project.
-
-The system consists of reporters (clients), collectors, a query service, and a web UI. Zipkin is meant to be safe in production by transmitting only a trace ID within the context of a transaction to inform receivers that a trace is in process. The data collected in each reporter is then transmitted asynchronously to the collectors. The collectors store these spans in the database, and the web UI presents this data to the end user in a consumable format. The delivery of data to the collectors can occur in three different methods: HTTP, Kafka, and Scribe.
-
-The [Zipkin community][10] has also created [Brave][11], a Java client implementation compatible with Zipkin. It has no dependencies, so it won’t drag your projects down or clutter them with libraries that are incompatible with your corporate standards. There are many other implementations, and Zipkin is compatible with the OpenTracing standard, so these implementations should also work with other distributed tracing systems. The popular Spring framework has a component called [Spring Cloud Sleuth][12] that is compatible with Zipkin.
-
-#### Jaeger
-
-[Jaeger][1] is a newer project from Uber Technologies that the [CNCF][13] has since adopted as an Incubating project. It is written in Golang, so you don’t have to worry about having dependencies installed on the host or any overhead of interpreters or language virtual machines. Similar to Zipkin, Jaeger also supports Cassandra and ElasticSearch as scalable storage backends. Jaeger is also fully compatible with the OpenTracing standard.
-
-Jaeger’s architecture is similar to Zipkin, with clients (reporters), collectors, a query service, and a web UI, but it also has an agent on each host that locally aggregates the data. The agent receives data over a UDP connection, which it batches and sends to a collector. The collector receives that data in the form of the [Thrift][14] protocol and stores that data in Cassandra or ElasticSearch. The query service can access the data store directly and provide that information to the web UI.
-
-By default, a user won’t get all the traces from the Jaeger clients. The system samples 0.1% (1 in 1,000) of traces that pass through each client. Keeping and transmitting all traces would be a bit overwhelming to most systems. However, this can be increased or decreased by configuring the agents, which the client consults with for its configuration. This sampling isn’t completely random, though, and it’s getting better. Jaeger uses probabilistic sampling, which tries to make an educated guess at whether a new trace should be sampled or not. [Adaptive sampling is on its roadmap][15], which will improve the sampling algorithm by adding additional context for making decisions.
-
-#### Appdash
-
-[Appdash][16] is a distributed tracing system written in Golang, like Jaeger. It was created by [Sourcegraph][17] based on Google’s Dapper and Twitter’s Zipkin. Similar to Jaeger and Zipkin, Appdash supports the OpenTracing standard; this was a later addition and requires a component that is different from the default component. This adds risk and complexity.
-
-At a high level, Appdash’s architecture consists mostly of three components: a client, a local collector, and a remote collector. There’s not a lot of documentation, so this description comes from testing the system and reviewing the code. The client in Appdash gets added to your code. Appdash provides Python, Golang, and Ruby implementations, but OpenTracing libraries can be used with Appdash’s OpenTracing implementation. The client collects the spans and sends them to the local collector. The local collector then sends the data to a centralized Appdash server running its own local collector, which is the remote collector for all other nodes in the system.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/distributed-tracing-tools
-
-作者:[Dan Barker][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/barkerd427
-[1]: https://www.jaegertracing.io/
-[2]: https://www.youtube.com/watch?v=T8BbeqZ0Rls
-[3]: http://opentracing.io/
-[4]: https://zipkin.io/
-[5]: https://www.datadoghq.com/
-[6]: https://www.instana.com/
-[7]: https://opencensus.io/
-[8]: https://research.google.com/archive/papers/dapper-2010-1.pdf
-[9]: https://thrift.apache.org/
-[10]: https://zipkin.io/pages/community.html
-[11]: https://github.com/openzipkin/brave
-[12]: https://cloud.spring.io/spring-cloud-sleuth/
-[13]: https://www.cncf.io/
-[14]: https://en.wikipedia.org/wiki/Apache_Thrift
-[15]: https://www.jaegertracing.io/docs/roadmap/#adaptive-sampling
-[16]: https://github.com/sourcegraph/appdash
-[17]: https://about.sourcegraph.com/
diff --git a/sources/tech/20181002 How to use the SSH and SFTP protocols on your home network.md b/sources/tech/20181002 How to use the SSH and SFTP protocols on your home network.md
index 5c24e87901..a58aa55ffd 100644
--- a/sources/tech/20181002 How to use the SSH and SFTP protocols on your home network.md
+++ b/sources/tech/20181002 How to use the SSH and SFTP protocols on your home network.md
@@ -1,3 +1,5 @@
+translating by singledo
+
How to use the SSH and SFTP protocols on your home network
======
diff --git a/sources/tech/20181003 Tips for listing files with ls at the Linux command line.md b/sources/tech/20181003 Tips for listing files with ls at the Linux command line.md
index d04e94a541..fda48f1622 100644
--- a/sources/tech/20181003 Tips for listing files with ls at the Linux command line.md
+++ b/sources/tech/20181003 Tips for listing files with ls at the Linux command line.md
@@ -1,3 +1,5 @@
+translating---geekpi
+
Tips for listing files with ls at the Linux command line
======
Learn some of the Linux 'ls' command's most useful variations.
diff --git a/sources/tech/20181004 Functional programming in Python- Immutable data structures.md b/sources/tech/20181004 Functional programming in Python- Immutable data structures.md
index b831ff726f..e6050d52f9 100644
--- a/sources/tech/20181004 Functional programming in Python- Immutable data structures.md
+++ b/sources/tech/20181004 Functional programming in Python- Immutable data structures.md
@@ -1,3 +1,4 @@
+Translating by Ryze-Borgia
Functional programming in Python: Immutable data structures
======
Immutability can help us better understand our code. Here's how to achieve it without sacrificing performance.
diff --git a/sources/tech/20181009 6 Commands To Shutdown And Reboot The Linux System From Terminal.md b/sources/tech/20181009 6 Commands To Shutdown And Reboot The Linux System From Terminal.md
new file mode 100644
index 0000000000..15230ecd0b
--- /dev/null
+++ b/sources/tech/20181009 6 Commands To Shutdown And Reboot The Linux System From Terminal.md
@@ -0,0 +1,328 @@
+6 Commands To Shutdown And Reboot The Linux System From Terminal
+======
+Linux administrator performing many tasks in their routine work. The system Shutdown and Reboot task also included in it.
+
+It’s one of the risky task for them because some times it wont come back due to some reasons and they need to spend more time on it to troubleshoot.
+
+These task can be performed through CLI in Linux. Most of the time Linux administrator prefer to perform these kind of tasks via CLI because they are familiar on this.
+
+There are few commands are available in Linux to perform these tasks and user needs to choose appropriate command to perform the task based on the requirement.
+
+All these commands has their own feature and allow Linux admin to use it.
+
+**Suggested Read :**
+**(#)** [11 Methods To Find System/Server Uptime In Linux][1]
+**(#)** [Tuptime – A Tool To Report The Historical And Statistical Running Time Of Linux System][2]
+
+When the system is initiated for Shutdown or Reboot. It will be notified to all logged-in users and processes. Also, it wont allow any new logins if the time argument is used.
+
+I would suggest you to double check before you perform this action because you need to follow few prerequisites to make sure everything is fine.
+
+Those steps are listed below.
+
+ * Make sure you should have a console access to troubleshoot further in case any issues arise. VMWare access for VMs and IPMI/iLO/iDRAC access for physical servers.
+ * You have to create a ticket as per your company procedure either Incident or Change ticket and get approval
+ * Take the important configuration files backup and move to other servers for safety
+ * Verify the log files (Perform the pre-check)
+ * Communicate about your activity with other dependencies teams like DBA, Application, etc
+ * Ask them to bring down their Database service or Application service and get a confirmation from them.
+ * Validate the same from your end using the appropriate command to double confirm this.
+ * Finally reboot the system
+ * Verify the log files (Perform the post-check), If everything is good then move to next step. If you found something is wrong then troubleshoot accordingly.
+ * If it’s back to up and running, ask the dependencies team to bring up their applications.
+ * Monitor for some time, and communicate back to them saying everything is working fine as expected.
+
+
+
+This task can be performed using following commands.
+
+ * **`shutdown Command:`** shutdown command used to halt, power-off or reboot the machine.
+ * **`halt Command:`** halt command used to halt, power-off or reboot the machine.
+ * **`poweroff Command:`** poweroff command used to halt, power-off or reboot the machine.
+ * **`reboot Command:`** reboot command used to halt, power-off or reboot the machine.
+ * **`init Command:`** init (short for initialization) is the first process started during booting of the computer system.
+ * **`systemctl Command:`** systemd is a system and service manager for Linux operating systems.
+
+
+
+### Method-1: How To Shutdown And Reboot The Linux System Using Shutdown Command
+
+shutdown command used to power-off or reboot a Linux remote machine or local host. It’s offering
+multiple options to perform this task effectively. If the time argument is used, 5 minutes before the system goes down the /run/nologin file is created to ensure that further logins shall not be allowed.
+
+The general syntax is
+
+```
+# shutdown [OPTION] [TIME] [MESSAGE]
+
+```
+
+Run the below command to shutdown a Linux machine immediately. It will kill all the processes immediately and will shutdown the system.
+
+```
+# shutdown -h now
+
+```
+
+ * **`-h:`** Equivalent to –poweroff, unless –halt is specified.
+
+
+
+Alternatively we can use the shutdown command with `halt` option to bring down the machine immediately.
+
+```
+# shutdown --halt now
+or
+# shutdown -H now
+
+```
+
+ * **`-H, --halt:`** Halt the machine.
+
+
+
+Alternatively we can use the shutdown command with `poweroff` option to bring down the machine immediately.
+
+```
+# shutdown --poweroff now
+or
+# shutdown -P now
+
+```
+
+ * **`-P, --poweroff:`** Power-off the machine (the default).
+
+
+
+Run the below command to shutdown a Linux machine immediately. It will kill all the processes immediately and will shutdown the system.
+
+```
+# shutdown -h now
+
+```
+
+ * **`-h:`** Equivalent to –poweroff, unless –halt is specified.
+
+
+
+If you run the below commands without time parameter, it will wait for a minute then execute the given command.
+
+```
+# shutdown -h
+Shutdown scheduled for Mon 2018-10-08 06:42:31 EDT, use 'shutdown -c' to cancel.
+
+[email protected]#
+Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
+
+The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
+
+```
+
+All other logged in users can see a broadcast message in their terminal like below.
+
+```
+[[email protected] ~]$
+Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
+
+The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
+
+```
+
+for Halt option.
+
+```
+# shutdown -H
+Shutdown scheduled for Mon 2018-10-08 06:37:53 EDT, use 'shutdown -c' to cancel.
+
+[email protected]#
+Broadcast message from [email protected] (Mon 2018-10-08 06:36:53 EDT):
+
+The system is going down for system halt at Mon 2018-10-08 06:37:53 EDT!
+
+```
+
+for Poweroff option.
+
+```
+# shutdown -P
+Shutdown scheduled for Mon 2018-10-08 06:40:07 EDT, use 'shutdown -c' to cancel.
+
+[email protected]#
+Broadcast message from [email protected] (Mon 2018-10-08 06:39:07 EDT):
+
+The system is going down for power-off at Mon 2018-10-08 06:40:07 EDT!
+
+```
+
+This can be cancelled by hitting `shutdown -c` option on your terminal.
+
+```
+# shutdown -c
+
+Broadcast message from [email protected] (Mon 2018-10-08 06:39:09 EDT):
+
+The system shutdown has been cancelled at Mon 2018-10-08 06:40:09 EDT!
+
+```
+
+All other logged in users can see a broadcast message in their terminal like below.
+
+```
+[[email protected] ~]$
+Broadcast message from [email protected] (Mon 2018-10-08 06:41:35 EDT):
+
+The system shutdown has been cancelled at Mon 2018-10-08 06:42:35 EDT!
+
+```
+
+Add a time parameter, if you want to perform shutdown or reboot in `N` seconds. Here you can add broadcast a custom message to logged-in users. In this example, we are rebooting the machine in another 5 minutes.
+
+```
+# shutdown -r +5 "To activate the latest Kernel"
+Shutdown scheduled for Mon 2018-10-08 07:13:16 EDT, use 'shutdown -c' to cancel.
+
+[[email protected] ~]#
+Broadcast message from [email protected] (Mon 2018-10-08 07:08:16 EDT):
+
+To activate the latest Kernel
+The system is going down for reboot at Mon 2018-10-08 07:13:16 EDT!
+
+```
+
+Run the below command to reboot a Linux machine immediately. It will kill all the processes immediately and will reboot the system.
+
+```
+# shutdown -r now
+
+```
+
+ * **`-r, --reboot:`** Reboot the machine.
+
+
+
+### Method-2: How To Shutdown And Reboot The Linux System Using reboot Command
+
+reboot command used to power-off or reboot a Linux remote machine or local host. Reboot command comes with two useful options.
+
+It will perform a graceful shutdown and restart of the machine (This is similar to your restart option which is available in your system menu).
+
+Run “reboot’ command without any option to reboot Linux machine.
+
+```
+# reboot
+
+```
+
+Run the “reboot” command with `-p` option to power-off or shutdown the Linux machine.
+
+```
+# reboot -p
+
+```
+
+ * **`-p, --poweroff:`** Power-off the machine, either halt or poweroff commands is invoked.
+
+
+
+Run the “reboot” command with `-f` option to forcefully reboot the Linux machine (This is similar to pressing the power button on the CPU).
+
+```
+# reboot -f
+
+```
+
+ * **`-f, --force:`** Force immediate halt, power-off, or reboot.
+
+
+
+### Method-3: How To Shutdown And Reboot The Linux System Using init Command
+
+init (short for initialization) is the first process started during booting of the computer system.
+
+It will check the /etc/inittab file to decide the Linux run level. Also, allow users to perform shutdown and reboot the Linux machine. There are seven runlevels exist, from zero to six.
+
+**Suggested Read :**
+**(#)** [How To Check All Running Services In Linux][3]
+
+Run the below init command to shutdown the system .
+
+```
+# init 0
+
+```
+
+ * **`0:`** Halt – to shutdown the system.
+
+
+
+Run the below init command to reboot the system .
+
+```
+# init 6
+
+```
+
+ * **`6:`** Reboot – to reboot the system.
+
+
+
+### Method-4: How To Shutdown The Linux System Using halt Command
+
+halt command used to power-off or shutdown a Linux remote machine or local host.
+halt terminates all processes and shuts down the cpu.
+
+```
+# halt
+
+```
+
+### Method-5: How To Shutdown The Linux System Using poweroff Command
+
+poweroff command used to power-off or shutdown a Linux remote machine or local host. Poweroff is exactly like halt, but it also turns off the unit itself (lights and everything on a PC). It sends an ACPI command to the board, then to the PSU, to cut the power.
+
+```
+# poweroff
+
+```
+
+### Method-6: How To Shutdown And Reboot The Linux System Using systemctl Command
+
+Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the traditional SysV init systems.
+
+systemd is compatible with SysV and LSB init scripts. It can work as a drop-in replacement for sysvinit system. systemd is the first process get started by kernel and holding PID 1.
+
+**Suggested Read :**
+**(#)** [chkservice – A Tool For Managing Systemd Units From Linux Terminal][4]
+
+It’s a parent process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart.
+
+systemctl is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload & status).
+
+systemd uses .service files Instead of bash scripts (SysVinit uses). systemd sorts all daemons into their own Linux cgroups and you can see the system hierarchy by exploring /cgroup/systemd file.
+
+```
+# systemctl halt
+# systemctl poweroff
+# systemctl reboot
+# systemctl suspend
+# systemctl hibernate
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/6-commands-to-shutdown-halt-poweroff-reboot-the-linux-system/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/prakash/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/
+[2]: https://www.2daygeek.com/tuptime-a-tool-to-report-the-historical-and-statistical-running-time-of-linux-system/
+[3]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
+[4]: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
diff --git a/sources/tech/20181009 Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool.md b/sources/tech/20181009 Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool.md
new file mode 100644
index 0000000000..f2c17ff7c2
--- /dev/null
+++ b/sources/tech/20181009 Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool.md
@@ -0,0 +1,70 @@
+Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool
+======
+**Mathpix is a nifty little tool that allows you to take screenshots of complex mathematical equations and instantly converts it into LaTeX editable text.**
+
+![Mathpix converts math equations images into LaTeX][1]
+
+[LaTeX editors][2] are excellent when it comes to writing academic and scientific documentation.
+
+There is a steep learning curved involved of course. And this learning curve becomes steeper if you have to write complex mathematical equations.
+
+[Mathpix][3] is a nifty little tool that helps you in this regard.
+
+Suppose you are reading a document that has mathematical equations. If you want to use those equations in your [LaTeX document][4], you need to use your ninja LaTeX skills and plenty of time.
+
+But Mathpix solves this problem for you. With Mathpix, you take the screenshot of the mathematical equations, and it will instantly give you the LaTeX code. You can then use this code in your [favorite LaTeX editor][2].
+
+See Mathpix in action in the video below:
+
+
+
+[Video credit][5]: Reddit User [kaitlinmcunningham][6]
+
+Isn’t it super-cool? I guess the hardest part of writing LaTeX documents are those complicated equations. For lazy bums like me, Mathpix is a godsend.
+
+### Getting Mathpix
+
+Mathpix is available for Linux, macOS, Windows and iOS. There is no Android app for the moment.
+
+Note: Mathpix is a free to use tool but it’s not open source.
+
+On Linux, [Mathpix is available as a Snap package][7]. Which means [if you have Snap support enabled on your Linux distribution][8], you can install Mathpix with this simple command:
+
+```
+sudo snap install mathpix-snipping-tool
+
+```
+
+Using Mathpix is simple. Once installed, open the tool. You’ll find it in the top panel. You can start taking the screenshot with Mathpix using the keyboard shortcut Ctrl+Alt+M.
+
+It will instantly translate the image of equation into a LaTeX code. The code will be copied into clipboard and you can then paste it in a LaTeX editor.
+
+Mathpix’s optical character recognition technology is [being used][9] by a number of companies like [WolframAlpha][10], Microsoft, Google, etc. to improve their tools’ image recognition capability while dealing with math symbols.
+
+Altogether, it’s an awesome tool for students and academics. It’s free to use and I so wish that it was an open source tool. We cannot get everything in life, can we?
+
+Do you use Mathpix or some other similar tool while dealing with mathematical symbols in LaTeX? What do you think of Mathpix? Share your views with us in the comment section.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/mathpix/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/mathpix-converts-equations-into-latex.jpeg
+[2]: https://itsfoss.com/latex-editors-linux/
+[3]: https://mathpix.com/
+[4]: https://www.latex-project.org/
+[5]: https://g.redditmedia.com/b-GL1rQwNezQjGvdlov9U_6vDwb1A7kEwGHYcQ1Ogtg.gif?fm=mp4&mp4-fragmented=false&s=39fd1816b43e2b544986d629f75a7a8e
+[6]: https://www.reddit.com/user/kaitlinmcunningham
+[7]: https://snapcraft.io/mathpix-snipping-tool
+[8]: https://itsfoss.com/install-snap-linux/
+[9]: https://mathpix.com/api.html
+[10]: https://www.wolframalpha.com/
diff --git a/sources/tech/20181009 How To Create And Maintain Your Own Man Pages.md b/sources/tech/20181009 How To Create And Maintain Your Own Man Pages.md
new file mode 100644
index 0000000000..6d78d132e2
--- /dev/null
+++ b/sources/tech/20181009 How To Create And Maintain Your Own Man Pages.md
@@ -0,0 +1,198 @@
+How To Create And Maintain Your Own Man Pages
+======
+
+
+
+We already have discussed about a few [**good alternatives to Man pages**][1]. Those alternatives are mainly used for learning concise Linux command examples without having to go through the comprehensive man pages. If you’re looking for a quick and dirty way to easily and quickly learn a Linux command, those alternatives are worth trying. Now, you might be thinking – how can I create my own man-like help pages for a Linux command? This is where **“Um”** comes in handy. Um is a command line utility, used to easily create and maintain your own Man pages that contains only what you’ve learned about a command so far.
+
+By creating your own alternative to man pages, you can avoid lots of unnecessary, comprehensive details in a man page and include only what is necessary to keep in mind. If you ever wanted to created your own set of man-like pages, Um will definitely help. In this brief tutorial, we will see how to install “Um” command line utility and how to create our own man pages.
+
+### Installing Um
+
+Um is available for Linux and Mac OS. At present, it can only be installed using **Linuxbrew** package manager in Linux systems. Refer the following link if you haven’t installed Linuxbrew yet.
+
+Once Linuxbrew installed, run the following command to install Um utility.
+
+```
+$ brew install sinclairtarget/wst/um
+
+```
+
+If you will see an output something like below, congratulations! Um has been installed and ready to use.
+
+```
+[...]
+==> Installing sinclairtarget/wst/um
+==> Downloading https://github.com/sinclairtarget/um/archive/4.0.0.tar.gz
+==> Downloading from https://codeload.github.com/sinclairtarget/um/tar.gz/4.0.0
+-=#=# # #
+==> Downloading https://rubygems.org/gems/kramdown-1.17.0.gem
+######################################################################## 100.0%
+==> gem install /home/sk/.cache/Homebrew/downloads/d0a5d978120a791d9c5965fc103866815189a4e3939
+==> Caveats
+Bash completion has been installed to:
+/home/linuxbrew/.linuxbrew/etc/bash_completion.d
+==> Summary
+🍺 /home/linuxbrew/.linuxbrew/Cellar/um/4.0.0: 714 files, 1.3MB, built in 35 seconds
+==> Caveats
+==> openssl
+A CA file has been bootstrapped using certificates from the SystemRoots
+keychain. To add additional certificates (e.g. the certificates added in
+the System keychain), place .pem files in
+/home/linuxbrew/.linuxbrew/etc/openssl/certs
+
+and run
+/home/linuxbrew/.linuxbrew/opt/openssl/bin/c_rehash
+==> ruby
+Emacs Lisp files have been installed to:
+/home/linuxbrew/.linuxbrew/share/emacs/site-lisp/ruby
+==> um
+Bash completion has been installed to:
+/home/linuxbrew/.linuxbrew/etc/bash_completion.d
+
+```
+
+Before going to use to make your man pages, you need to enable bash completion for Um.
+
+To do so, open your **~/.bash_profile** file:
+
+```
+$ nano ~/.bash_profile
+
+```
+
+And, add the following lines in it:
+
+```
+if [ -f $(brew --prefix)/etc/bash_completion.d/um-completion.sh ]; then
+ . $(brew --prefix)/etc/bash_completion.d/um-completion.sh
+fi
+
+```
+
+Save and close the file. Run the following commands to update the changes.
+
+```
+$ source ~/.bash_profile
+
+```
+
+All done. let us go ahead and create our first man page.
+
+### Create And Maintain Your Own Man Pages
+
+Let us say, you want to create your own man page for “dpkg” command. To do so, run:
+
+```
+$ um edit dpkg
+
+```
+
+The above command will open a markdown template in your default editor:
+
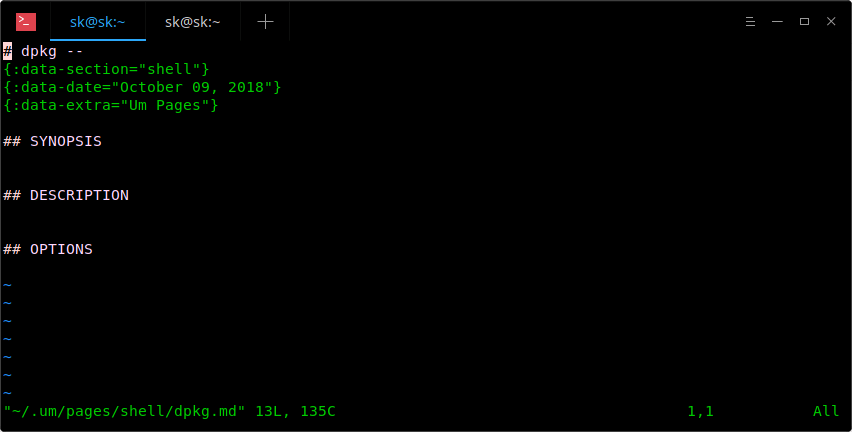
+
+
+My default editor is Vi, so the above commands open it in the Vi editor. Now, start adding everything you want to remember about “dpkg” command in this template.
+
+Here is a sample:
+
+
+
+As you see in the above output, I have added Synopsis, description and two options for dpkg command. You can add as many as sections you want in the man pages. Make sure you have given proper and easily-understandable titles for each section. Once done, save and quit the file (If you use Vi editor, Press **ESC** key and type **:wq** ).
+
+Finally, view your newly created man page using command:
+
+```
+$ um dpkg
+
+```
+
+
+
+As you can see, the the dpkg man page looks exactly like the official man pages. If you want to edit and/or add more details in a man page, again run the same command and add the details.
+
+```
+$ um edit dpkg
+
+```
+
+To view the list of newly created man pages using Um, run:
+
+```
+$ um list
+
+```
+
+All man pages will be saved under a directory named**`.um`**in your home directory
+
+Just in case, if you don’t want a particular page, simply delete it as shown below.
+
+```
+$ um rm dpkg
+
+```
+
+To view the help section and all available general options, run:
+
+```
+$ um --help
+usage: um
+ um [ARGS...]
+
+The first form is equivalent to `um read `.
+
+Subcommands:
+ um (l)ist List the available pages for the current topic.
+ um (r)ead Read the given page under the current topic.
+ um (e)dit Create or edit the given page under the current topic.
+ um rm Remove the given page.
+ um (t)opic [topic] Get or set the current topic.
+ um topics List all topics.
+ um (c)onfig [config key] Display configuration environment.
+ um (h)elp [sub-command] Display this help message, or the help message for a sub-command.
+
+```
+
+### Configure Um
+
+To view the current configuration, run:
+
+```
+$ um config
+Options prefixed by '*' are set in /home/sk/.um/umconfig.
+editor = vi
+pager = less
+pages_directory = /home/sk/.um/pages
+default_topic = shell
+pages_ext = .md
+
+```
+
+In this file, you can edit and change the values for **pager** , **editor** , **default_topic** , **pages_directory** , and **pages_ext** options as you wish. Say for example, if you want to save the newly created Um pages in your **[Dropbox][2]** folder, simply change the value of **pages_directory** directive and point it to the Dropbox folder in **~/.um/umconfig** file.
+
+```
+pages_directory = /Users/myusername/Dropbox/um
+
+```
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-create-and-maintain-your-own-man-pages/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
+[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
diff --git a/sources/tech/20181010 5 alerting and visualization tools for sysadmins.md b/sources/tech/20181010 5 alerting and visualization tools for sysadmins.md
new file mode 100644
index 0000000000..f933449461
--- /dev/null
+++ b/sources/tech/20181010 5 alerting and visualization tools for sysadmins.md
@@ -0,0 +1,163 @@
+5 alerting and visualization tools for sysadmins
+======
+These open source tools help users understand system behavior and output, and provide alerts for potential problems.
+
+
+
+You probably know (or can guess) what alerting and visualization tools are used for. Why would we discuss them as observability tools, especially since some systems include visualization as a feature?
+
+Observability comes from control theory and describes our ability to understand a system based on its inputs and outputs. This article focuses on the output component of observability.
+
+Alerting and visualization tools analyze the outputs of other systems and provide structured representations of these outputs. Alerts are basically a synthesized understanding of negative system outputs, and visualizations are disambiguated structured representations that facilitate user comprehension.
+
+### Common types of alerts and visualizations
+
+#### Alerts
+
+Let’s first cover what alerts are _not_. Alerts should not be sent if the human responder can’t do anything about the problem. This includes alerts that are sent to multiple individuals with only a few who can respond, or situations where every anomaly in the system triggers an alert. This leads to alert fatigue and receivers ignoring all alerts within a specific medium until the system escalates to a medium that isn’t already saturated.
+
+For example, if an operator receives hundreds of emails a day from the alerting system, that operator will soon ignore all emails from the alerting system. The operator will respond to a real incident only when he or she is experiencing the problem, emailed by a customer, or called by the boss. In this case, alerts have lost their meaning and usefulness.
+
+Alerts are not a constant stream of information or a status update. They are meant to convey a problem from which the system can’t automatically recover, and they are sent only to the individual most likely to be able to recover the system. Everything that falls outside this definition isn’t an alert and will only damage your employees and company culture.
+
+Everyone has a different set of alert types, so I won't discuss things like priority levels (P1-P5) or models that use words like "Informational," "Warning," and "Critical." Instead, I’ll describe the generic categories emergent in complex systems’ incident response.
+
+You might have noticed I mentioned an “Informational” alert type right after I wrote that alerts shouldn’t be informational. Well, not everyone agrees, but I don’t consider something an alert if it isn’t sent to anyone. It is a data point that many systems refer to as an alert. It represents some event that should be known but not responded to. It is generally part of the visualization system of the alerting tool and not an event that triggers actual notifications. Mike Julian covers this and other aspects of alerting in his book [Practical Monitoring][1]. It's a must read for work in this area.
+
+Non-informational alerts consist of types that can be responded to or require action. I group these into two categories: internal outage and external outage. (Most companies have more than two levels for prioritizing their response efforts.) Degraded system performance is considered an outage in this model, as the impact to each user is usually unknown.
+
+Internal outages are a lower priority than external outages, but they still need to be responded to quickly. They often include internal systems that company employees use or components of applications that are visible only to company employees.
+
+External outages consist of any system outage that would immediately impact a customer. These don’t include a system outage that prevents releasing updates to the system. They do include customer-facing application failures, database outages, and networking partitions that hurt availability or consistency if either can impact a user. They also include outages of tools that may not have a direct impact on users, as the application continues to run but this transparent dependency impacts performance. This is common when the system uses some external service or data source that isn’t necessary for full functionality but may cause delays as the application performs retries or handles errors from this external dependency.
+
+### Visualizations
+
+There are many visualization types, and I won’t cover them all here. It’s a fascinating area of research. On the data analytics side of my career, learning and applying that knowledge is a constant challenge. We need to provide simple representations of complex system outputs for the widest dissemination of information. [Google Charts][2] and [Tableau][3] have a wide selection of visualization types. We’ll cover the most common visualizations and some innovative solutions for quickly understanding systems.
+
+#### Line chart
+
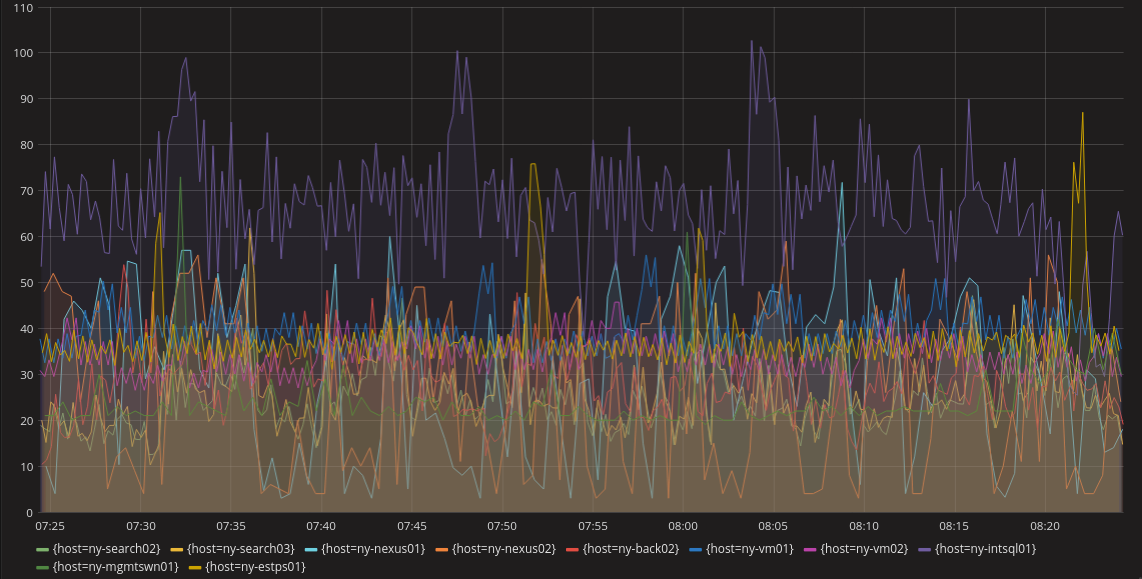
+The line chart is probably the most common visualization. It does a pretty good job of producing an understanding of a system over time. A line chart in a metrics system would have a line for each unique metric or some aggregation of metrics. This can get confusing when there are a lot of metrics in the same dashboard (as shown below), but most systems can select specific metrics to view rather than having all of them visible. Also, anomalous behavior is easy to spot if it’s significant enough to escape the noise of normal operations. Below we can see purple, yellow, and light blue lines that might indicate anomalous behavior.
+
+
+
+Another feature of a line chart is that you can often stack them to show relationships. For example, you might want to look at requests on each server individually, but also in aggregate. This allows you to understand the overall system as well as each instance in the same graph.
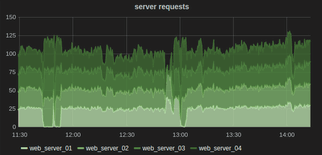
+
+
+
+#### Heatmaps
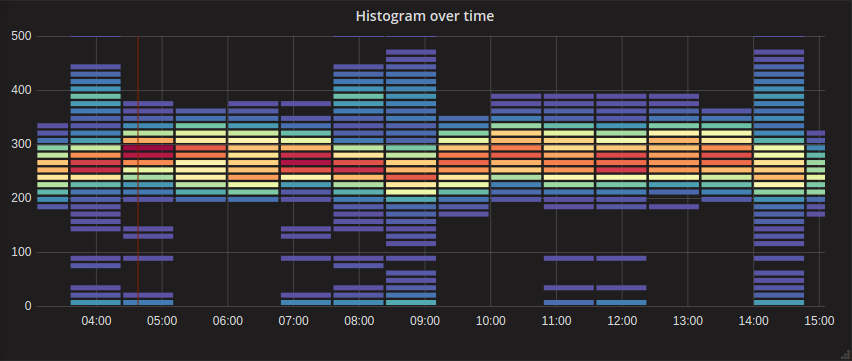
+
+Another common visualization is the heatmap. It is useful when looking at histograms. This type of visualization is similar to a bar chart but can show gradients within the bars representing the different percentiles of the overall metric. For example, suppose you’re looking at request latencies and you want to quickly understand the overall trend as well as the distribution of all requests. A heatmap is great for this, and it can use color to disambiguate the quantity of each section with a quick glance.
+
+The heatmap below shows the higher concentration around the centerline of the graph with an easy-to-understand visualization of the distribution vertically for each time bucket. We might want to review a couple of points in time where the distribution gets wide while the others are fairly tight like at 14:00. This distribution might be a negative performance indicator.
+
+
+
+#### Gauges
+
+The last common visualization I’ll cover here is the gauge, which helps users understand a single metric quickly. Gauges can represent a single metric, like your speedometer represents your driving speed or your gas gauge represents the amount of gas in your car. Similar to the gas gauge, most monitoring gauges clearly indicate what is good and what isn’t. Often (as is shown below), good is represented by green, getting worse by orange, and “everything is breaking” by red. The middle row below shows traditional gauges.
+
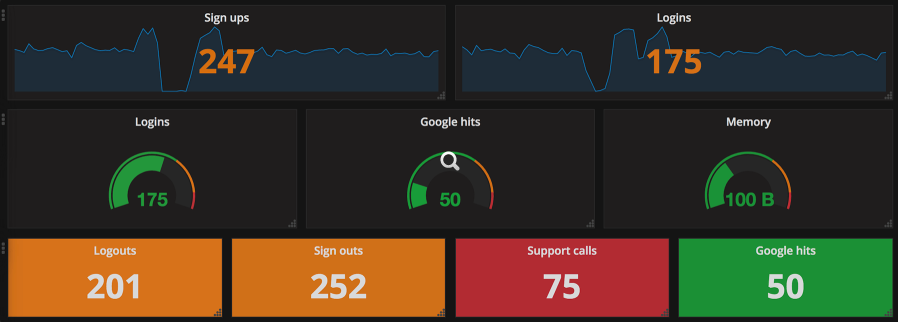
+
+
+This image shows more than just traditional gauges. The other gauges are single stat representations that are similar to the function of the classic gauge. They all use the same color scheme to quickly indicate system health with just a glance. Arguably, the bottom row is probably the best example of a gauge that allows you to glance at a dashboard and know that everything is healthy (or not). This type of visualization is usually what I put on a top-level dashboard. It offers a full, high-level understanding of system health in seconds.
+
+#### Flame graphs
+
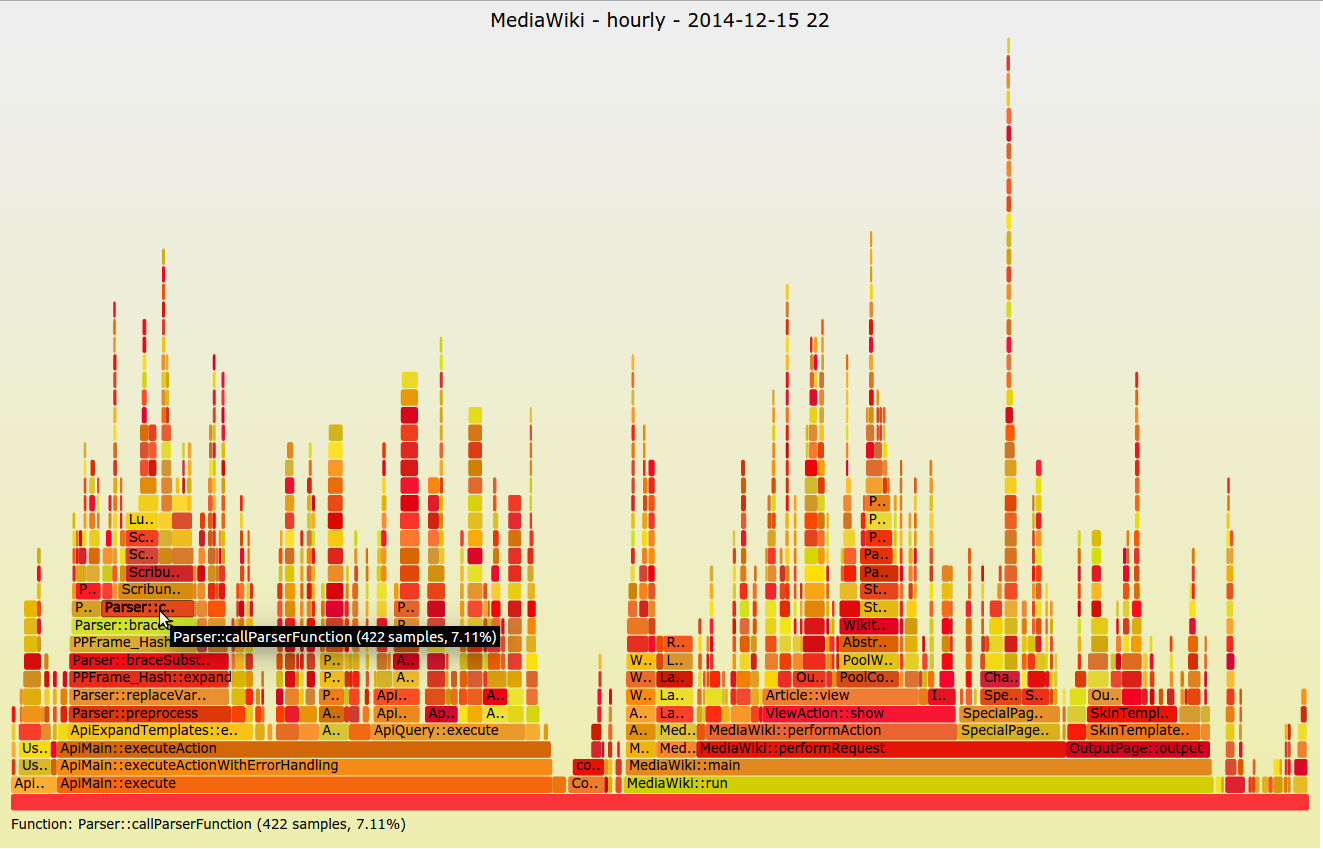
+A less common visualization is the flame graph, introduced by [Netflix’s Brendan Gregg][4] in 2011. It’s not ideal for dashboarding or quickly observing high-level system concerns; it’s normally seen when trying to understand a specific application problem. This visualization focuses on CPU and memory and the associated frames. The X-axis lists the frames alphabetically, and the Y-axis shows stack depth. Each rectangle is a stack frame and includes the function being called. The wider the rectangle, the more it appears in the stack. This method is invaluable when trying to diagnose system performance at the application level and I urge everyone to give it a try.
+
+
+
+### Tool options
+
+There are several commercial options for alerting, but since this is Opensource.com, I’ll cover only systems that are being used at scale by real companies that you can use at no cost. Hopefully, you’ll be able to contribute new and innovative features to make these systems even better.
+
+### Alerting tools
+
+#### Bosun
+
+If you’ve ever done anything with computers and gotten stuck, the help you received was probably thanks to a Stack Exchange system. Stack Exchange runs many different websites around a crowdsourced question-and-answer model. [Stack Overflow][5] is very popular with developers, and [Super User][6] is popular with operations. However, there are now hundreds of sites ranging from parenting to sci-fi and philosophy to bicycles.
+
+Stack Exchange open-sourced its alert management system, [Bosun][7], around the same time Prometheus and its [AlertManager][8] system were released. There were many similarities in the two systems, and that’s a really good thing. Like Prometheus, Bosun is written in Golang. Bosun’s scope is more extensive than Prometheus’ as it can interact with systems beyond metrics aggregation. It can also ingest data from log and event aggregation systems. It supports Graphite, InfluxDB, OpenTSDB, and Elasticsearch.
+
+Bosun’s architecture consists of a single server binary, a backend like OpenTSDB, Redis, and [scollector agents][9]. The scollector agents automatically detect services on a host and report metrics for those processes and other system resources. This data is sent to a metrics backend. The Bosun server binary then queries the backends to determine if any alerts need to be fired. Bosun can also be used by tools like [Grafana][10] to query the underlying backends through one common interface. Redis is used to store state and metadata for Bosun.
+
+A really neat feature of Bosun is that it lets you test your alerts against historical data. This was something I missed in Prometheus several years ago, when I had data for an issue I wanted alerts on but no easy way to test it. To make sure my alerts were working, I had to create and insert dummy data. This system alleviates that very time-consuming process.
+
+Bosun also has the usual features like showing simple graphs and creating alerts. It has a powerful expression language for writing alerting rules. However, it only has email and HTTP notification configurations, which means connecting to Slack and other tools requires a bit more customization ([which its documentation covers][11]). Similar to Prometheus, Bosun can use templates for these notifications, which means they can look as awesome as you want them to. You can use all your HTML and CSS skills to create the baddest email alert anyone has ever seen.
+
+#### Cabot
+
+[Cabot][12] was created by a company called [Arachnys][13]. You may not know who Arachnys is or what it does, but you have probably felt its impact: It built the leading cloud-based solution for fighting financial crimes. That sounds pretty cool, right? At a previous company, I was involved in similar functions around [“know your customer"][14] laws. Most companies would consider it a very bad thing to be linked to a terrorist group, for example, funneling money through their systems. These solutions also help defend against less-atrocious offenders like fraudsters who could also pose a risk to the institution.
+
+So why did Arachnys create Cabot? Well, it is kind of a Christmas present to everyone, as it was a Christmas project built because its developers couldn’t wrap their heads around [Nagios][15]. And really, who can blame them? Cabot was written with Django and Bootstrap, so it should be easy for most to contribute to the project. (Another interesting factoid: The name comes from the creator’s dog.)
+
+The Cabot architecture is similar to Bosun in that it doesn’t collect any data. Instead, it accesses data through the APIs of the tools it is alerting for. Therefore, Cabot uses a pull (rather than a push) model for alerting. It reaches out into each system’s API and retrieves the information it needs to make a decision based on a specific check. Cabot stores the alerting data in a Postgres database and also has a cache using Redis.
+
+Cabot natively supports [Graphite][16], but it also supports [Jenkins][17], which is rare in this area. [Arachnys][13] uses Jenkins like a centralized cron, but I like this idea of treating build failures like outages. Obviously, a build failure isn’t as critical as a production outage, but it could still alert the team and escalate if the failure isn’t resolved. Who actually checks Jenkins every time an email comes in about a build failure? Yeah, me too!
+
+Another interesting feature is that Cabot can integrate with Google Calendar for on-call rotations. Cabot calls this feature Rota, which is a British term for a roster or rotation. This makes a lot of sense, and I wish other systems would take this idea further. Cabot doesn’t support anything more complex than primary and backup personnel, but there is certainly room for additional features. The docs say if you want something more advanced, you should look at a commercial option.
+
+#### StatsAgg
+
+[StatsAgg][18]? How did that make the list? Well, it’s not every day you come across a publishing company that has created an alerting platform. I think that deserves recognition. Of course, [Pearson][19] isn’t just a publishing company anymore; it has several web presences and a joint venture with [O’Reilly Media][20]. However, I still think of it as the company that published my schoolbooks and tests.
+
+StatsAgg isn’t just an alerting platform; it’s also a metrics aggregation platform. And it’s kind of like a proxy for other systems. It supports Graphite, StatsD, InfluxDB, and OpenTSDB as inputs, but it can also forward those metrics to their respective platforms. This is an interesting concept, but potentially risky as loads increase on a central service. However, if the StatsAgg infrastructure is robust enough, it can still produce alerts even when a backend storage platform has an outage.
+
+StatsAgg is written in Java and consists only of the main server and UI, which keeps complexity to a minimum. It can send alerts based on regular expression matching and is focused on alerting by service rather than host or instance. Its goal is to fill a void in the open source observability stack, and I think it does that quite well.
+
+### Visualization tools
+
+#### Grafana
+
+Almost everyone knows about [Grafana][10], and many have used it. I have used it for years whenever I need a simple dashboard. The tool I used before was deprecated, and I was fairly distraught about that until Grafana made it okay. Grafana was gifted to us by Torkel Ödegaard. Like Cabot, Grafana was also created around Christmastime, and released in January 2014. It has come a long way in just a few years. It started life as a Kibana dashboarding system, and Torkel forked it into what became Grafana.
+
+Grafana’s sole focus is presenting monitoring data in a more usable and pleasing way. It can natively gather data from Graphite, Elasticsearch, OpenTSDB, Prometheus, and InfluxDB. There’s an Enterprise version that uses plugins for more data sources, but there’s no reason those other data source plugins couldn’t be created as open source, as the Grafana plugin ecosystem already offers many other data sources.
+
+What does Grafana do for me? It provides a central location for understanding my system. It is web-based, so anyone can access the information, although it can be restricted using different authentication methods. Grafana can provide knowledge at a glance using many different types of visualizations. However, it has started integrating alerting and other features that aren’t traditionally combined with visualizations.
+
+Now you can set alerts visually. That means you can look at a graph, maybe even one showing where an alert should have triggered due to some degradation of the system, click on the graph where you want the alert to trigger, and then tell Grafana where to send the alert. That’s a pretty powerful addition that won’t necessarily replace an alerting platform, but it can certainly help augment it by providing a different perspective on alerting criteria.
+
+Grafana has also introduced more collaboration features. Users have been able to share dashboards for a long time, meaning you don’t have to create your own dashboard for your [Kubernetes][21] cluster because there are several already available—with some maintained by Kubernetes developers and others by Grafana developers.
+
+The most significant addition around collaboration is annotations. Annotations allow a user to add context to part of a graph. Other users can then use this context to understand the system better. This is an invaluable tool when a team is in the middle of an incident and communication and common understanding are critical. Having all the information right where you’re already looking makes it much more likely that knowledge will be shared across the team quickly. It’s also a nice feature to use during blameless postmortems when the team is trying to understand how the failure occurred and learn more about their system.
+
+#### Vizceral
+
+Netflix created [Vizceral][22] to understand its traffic patterns better when performing a traffic failover. Unlike Grafana, which is a more general tool, Vizceral serves a very specific use case. Netflix no longer uses this tool internally and says it is no longer actively maintained, but it still updates the tool periodically. I highlight it here primarily to point out an interesting visualization mechanism and how it can help solve a problem. It’s worth running it in a demo environment just to better grasp the concepts and witness what’s possible with these systems.
+
+### What to read next
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/alerting-and-visualization-tools-sysadmins
+
+作者:[Dan Barker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/barkerd427
+[b]: https://github.com/lujun9972
+[1]: https://www.practicalmonitoring.com/
+[2]: https://developers.google.com/chart/interactive/docs/gallery
+[3]: https://libguides.libraries.claremont.edu/c.php?g=474417&p=3286401
+[4]: http://www.brendangregg.com/flamegraphs.html
+[5]: https://stackoverflow.com/
+[6]: https://superuser.com/
+[7]: http://bosun.org/
+[8]: https://prometheus.io/docs/alerting/alertmanager/
+[9]: https://bosun.org/scollector/
+[10]: https://grafana.com/
+[11]: https://bosun.org/notifications
+[12]: https://cabotapp.com/
+[13]: https://www.arachnys.com/
+[14]: https://en.wikipedia.org/wiki/Know_your_customer
+[15]: https://www.nagios.org/
+[16]: https://graphiteapp.org/
+[17]: https://jenkins.io/
+[18]: https://github.com/PearsonEducation/StatsAgg
+[19]: https://www.pearson.com/us/
+[20]: https://www.oreilly.com/
+[21]: https://opensource.com/resources/what-is-kubernetes
+[22]: https://github.com/Netflix/vizceral
diff --git a/sources/tech/20181010 An introduction to using tcpdump at the Linux command line.md b/sources/tech/20181010 An introduction to using tcpdump at the Linux command line.md
new file mode 100644
index 0000000000..6998661f23
--- /dev/null
+++ b/sources/tech/20181010 An introduction to using tcpdump at the Linux command line.md
@@ -0,0 +1,457 @@
+An introduction to using tcpdump at the Linux command line
+======
+
+This flexible, powerful command-line tool helps ease the pain of troubleshooting network issues.
+
+
+
+In my experience as a sysadmin, I have often found network connectivity issues challenging to troubleshoot. For those situations, tcpdump is a great ally.
+
+Tcpdump is a command line utility that allows you to capture and analyze network traffic going through your system. It is often used to help troubleshoot network issues, as well as a security tool.
+
+A powerful and versatile tool that includes many options and filters, tcpdump can be used in a variety of cases. Since it's a command line tool, it is ideal to run in remote servers or devices for which a GUI is not available, to collect data that can be analyzed later. It can also be launched in the background or as a scheduled job using tools like cron.
+
+In this article, we'll look at some of tcpdump's most common features.
+
+### 1\. Installation on Linux
+
+Tcpdump is included with several Linux distributions, so chances are, you already have it installed. Check if tcpdump is installed on your system with the following command:
+
+```
+$ which tcpdump
+/usr/sbin/tcpdump
+```
+
+If tcpdump is not installed, you can install it but using your distribution's package manager. For example, on CentOS or Red Hat Enterprise Linux, like this:
+
+```
+$ sudo yum install -y tcpdump
+```
+
+Tcpdump requires `libpcap`, which is a library for network packet capture. If it's not installed, it will be automatically added as a dependency.
+
+You're ready to start capturing some packets.
+
+### 2\. Capturing packets with tcpdump
+
+To capture packets for troubleshooting or analysis, tcpdump requires elevated permissions, so in the following examples most commands are prefixed with `sudo`.
+
+To begin, use the command `tcpdump -D` to see which interfaces are available for capture:
+
+```
+$ sudo tcpdump -D
+1.eth0
+2.virbr0
+3.eth1
+4.any (Pseudo-device that captures on all interfaces)
+5.lo [Loopback]
+```
+
+In the example above, you can see all the interfaces available in my machine. The special interface `any` allows capturing in any active interface.
+
+Let's use it to start capturing some packets. Capture all packets in any interface by running this command:
+
+```
+$ sudo tcpdump -i any
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+09:56:18.293641 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3770820720:3770820916, ack 3503648727, win 309, options [nop,nop,TS val 76577898 ecr 510770929], length 196
+09:56:18.293794 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 391, options [nop,nop,TS val 510771017 ecr 76577898], length 0
+09:56:18.295058 IP rhel75.59883 > gateway.domain: 2486+ PTR? 1.64.168.192.in-addr.arpa. (43)
+09:56:18.310225 IP gateway.domain > rhel75.59883: 2486 NXDomain* 0/1/0 (102)
+09:56:18.312482 IP rhel75.49685 > gateway.domain: 34242+ PTR? 28.64.168.192.in-addr.arpa. (44)
+09:56:18.322425 IP gateway.domain > rhel75.49685: 34242 NXDomain* 0/1/0 (103)
+09:56:18.323164 IP rhel75.56631 > gateway.domain: 29904+ PTR? 1.122.168.192.in-addr.arpa. (44)
+09:56:18.323342 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 196:584, ack 1, win 309, options [nop,nop,TS val 76577928 ecr 510771017], length 388
+09:56:18.323563 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 584, win 411, options [nop,nop,TS val 510771047 ecr 76577928], length 0
+09:56:18.335569 IP gateway.domain > rhel75.56631: 29904 NXDomain* 0/1/0 (103)
+09:56:18.336429 IP rhel75.44007 > gateway.domain: 61677+ PTR? 98.122.168.192.in-addr.arpa. (45)
+09:56:18.336655 IP gateway.domain > rhel75.44007: 61677* 1/0/0 PTR rhel75. (65)
+09:56:18.337177 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 584:1644, ack 1, win 309, options [nop,nop,TS val 76577942 ecr 510771047], length 1060
+
+---- SKIPPING LONG OUTPUT -----
+
+09:56:19.342939 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 1752016, win 1444, options [nop,nop,TS val 510772067 ecr 76578948], length 0
+^C
+9003 packets captured
+9010 packets received by filter
+7 packets dropped by kernel
+$
+```
+
+Tcpdump continues to capture packets until it receives an interrupt signal. You can interrupt capturing by pressing `Ctrl+C`. As you can see in this example, `tcpdump` captured more than 9,000 packets. In this case, since I am connected to this server using `ssh`, tcpdump captured all these packages. To limit the number of packets captured and stop `tcpdump`, use the `-c` option:
+
+```
+$ sudo tcpdump -i any -c 5
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+11:21:30.242740 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3772575680:3772575876, ack 3503651743, win 309, options [nop,nop,TS val 81689848 ecr 515883153], length 196
+11:21:30.242906 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 1443, options [nop,nop,TS val 515883235 ecr 81689848], length 0
+11:21:30.244442 IP rhel75.43634 > gateway.domain: 57680+ PTR? 1.64.168.192.in-addr.arpa. (43)
+11:21:30.244829 IP gateway.domain > rhel75.43634: 57680 NXDomain 0/0/0 (43)
+11:21:30.247048 IP rhel75.33696 > gateway.domain: 37429+ PTR? 28.64.168.192.in-addr.arpa. (44)
+5 packets captured
+12 packets received by filter
+0 packets dropped by kernel
+$
+```
+
+In this case, `tcpdump` stopped capturing automatically after capturing five packets. This is useful in different scenarios—for instance, if you're troubleshooting connectivity and capturing a few initial packages is enough. This is even more useful when we apply filters to capture specific packets (shown below).
+
+By default, tcpdump resolves IP addresses and ports into names, as shown in the previous example. When troubleshooting network issues, it is often easier to use the IP addresses and port numbers; disable name resolution by using the option `-n` and port resolution with `-nn`:
+
+```
+$ sudo tcpdump -i any -c5 -nn
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+23:56:24.292206 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 166198580:166198776, ack 2414541257, win 309, options [nop,nop,TS val 615664 ecr 540031155], length 196
+23:56:24.292357 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 196, win 1377, options [nop,nop,TS val 540031229 ecr 615664], length 0
+23:56:24.292570 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 372
+23:56:24.292655 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 568, win 1400, options [nop,nop,TS val 540031229 ecr 615664], length 0
+23:56:24.292752 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 568:908, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 340
+5 packets captured
+6 packets received by filter
+0 packets dropped by kernel
+```
+
+As shown above, the capture output now displays the IP addresses and port numbers. This also prevents tcpdump from issuing DNS lookups, which helps to lower network traffic while troubleshooting network issues.
+
+Now that you're able to capture network packets, let's explore what this output means.
+
+### 3\. Understanding the output format
+
+Tcpdump is capable of capturing and decoding many different protocols, such as TCP, UDP, ICMP, and many more. While we can't cover all of them here, to help you get started, let's explore the TCP packet. You can find more details about the different protocol formats in tcpdump's [manual pages][1]. A typical TCP packet captured by tcpdump looks like this:
+
+```
+08:41:13.729687 IP 192.168.64.28.22 > 192.168.64.1.41916: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 117964079 ecr 816509256], length 372
+```
+
+The fields may vary depending on the type of packet being sent, but this is the general format.
+
+The first field, `08:41:13.729687,` represents the timestamp of the received packet as per the local clock.
+
+Next, `IP` represents the network layer protocol—in this case, `IPv4`. For `IPv6` packets, the value is `IP6`.
+
+The next field, `192.168.64.28.22`, is the source IP address and port. This is followed by the destination IP address and port, represented by `192.168.64.1.41916`.
+
+After the source and destination, you can find the TCP Flags `Flags [P.]`. Typical values for this field include:
+
+| Value | Flag Type | Description |
+|-------| --------- | ----------------- |
+| S | SYN | Connection Start |
+| F | FIN | Connection Finish |
+| P | PUSH | Data push |
+| R | RST | Connection reset |
+| . | ACK | Acknowledgment |
+
+This field can also be a combination of these values, such as `[S.]` for a `SYN-ACK` packet.
+
+Next is the sequence number of the data contained in the packet. For the first packet captured, this is an absolute number. Subsequent packets use a relative number to make it easier to follow. In this example, the sequence is `seq 196:568,` which means this packet contains bytes 196 to 568 of this flow.
+
+This is followed by the Ack Number: `ack 1`. In this case, it is 1 since this is the side sending data. For the side receiving data, this field represents the next expected byte (data) on this flow. For example, the Ack number for the next packet in this flow would be 568.
+
+The next field is the window size `win 309`, which represents the number of bytes available in the receiving buffer, followed by TCP options such as the MSS (Maximum Segment Size) or Window Scale. For details about TCP protocol options, consult [Transmission Control Protocol (TCP) Parameters][2].
+
+Finally, we have the packet length, `length 372`, which represents the length, in bytes, of the payload data. The length is the difference between the last and first bytes in the sequence number.
+
+Now let's learn how to filter packages to narrow down results and make it easier to troubleshoot specific issues.
+
+### 4\. Filtering packets
+
+As mentioned above, tcpdump can capture too many packages, some of which are not even related to the issue you're troubleshooting. For example, if you're troubleshooting a connectivity issue with a web server you're not interested in the SSH traffic, so removing the SSH packets from the output makes it easier to work on the real issue.
+
+One of tcpdump's most powerful features is its ability to filter the captured packets using a variety of parameters, such as source and destination IP addresses, ports, protocols, etc. Let's look at some of the most common ones.
+
+#### Protocol
+
+To filter packets based on protocol, specifying the protocol in the command line. For example, capture ICMP packets only by using this command:
+
+```
+$ sudo tcpdump -i any -c5 icmp
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+```
+
+In a different terminal, try to ping another machine:
+
+```
+$ ping opensource.com
+PING opensource.com (54.204.39.132) 56(84) bytes of data.
+64 bytes from ec2-54-204-39-132.compute-1.amazonaws.com (54.204.39.132): icmp_seq=1 ttl=47 time=39.6 ms
+```
+
+Back in the tcpdump capture, notice that tcpdump captures and displays only the ICMP-related packets. In this case, tcpdump is not displaying name resolution packets that were generated when resolving the name `opensource.com`:
+
+```
+09:34:20.136766 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 1, length 64
+09:34:20.176402 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 1, length 64
+09:34:21.140230 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 2, length 64
+09:34:21.180020 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 2, length 64
+09:34:22.141777 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 3, length 64
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+#### Host
+
+Limit capture to only packets related to a specific host by using the `host` filter:
+
+```
+$ sudo tcpdump -i any -c5 -nn host 54.204.39.132
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+09:54:20.042023 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [S], seq 1375157070, win 29200, options [mss 1460,sackOK,TS val 122350391 ecr 0,nop,wscale 7], length 0
+09:54:20.088127 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [S.], seq 1935542841, ack 1375157071, win 28960, options [mss 1460,sackOK,TS val 522713542 ecr 122350391,nop,wscale 9], length 0
+09:54:20.088204 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122350437 ecr 522713542], length 0
+09:54:20.088734 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122350438 ecr 522713542], length 112: HTTP: GET / HTTP/1.1
+09:54:20.129733 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [.], ack 113, win 57, options [nop,nop,TS val 522713552 ecr 122350438], length 0
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+In this example, tcpdump captures and displays only packets to and from host `54.204.39.132`.
+
+#### Port
+
+To filter packets based on the desired service or port, use the `port` filter. For example, capture packets related to a web (HTTP) service by using this command:
+
+```
+$ sudo tcpdump -i any -c5 -nn port 80
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+09:58:28.790548 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [S], seq 1745665159, win 29200, options [mss 1460,sackOK,TS val 122599140 ecr 0,nop,wscale 7], length 0
+09:58:28.834026 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [S.], seq 4063583040, ack 1745665160, win 28960, options [mss 1460,sackOK,TS val 522775728 ecr 122599140,nop,wscale 9], length 0
+09:58:28.834093 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122599183 ecr 522775728], length 0
+09:58:28.834588 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122599184 ecr 522775728], length 112: HTTP: GET / HTTP/1.1
+09:58:28.878445 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [.], ack 113, win 57, options [nop,nop,TS val 522775739 ecr 122599184], length 0
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+#### Source IP/hostname
+
+You can also filter packets based on the source or destination IP Address or hostname. For example, to capture packets from host `192.168.122.98`:
+
+```
+$ sudo tcpdump -i any -c5 -nn src 192.168.122.98
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10:02:15.220824 IP 192.168.122.98.39436 > 192.168.122.1.53: 59332+ A? opensource.com. (32)
+10:02:15.220862 IP 192.168.122.98.39436 > 192.168.122.1.53: 20749+ AAAA? opensource.com. (32)
+10:02:15.364062 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [S], seq 1108640533, win 29200, options [mss 1460,sackOK,TS val 122825713 ecr 0,nop,wscale 7], length 0
+10:02:15.409229 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [.], ack 669337581, win 229, options [nop,nop,TS val 122825758 ecr 522832372], length 0
+10:02:15.409667 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 122825759 ecr 522832372], length 112: HTTP: GET / HTTP/1.1
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+Notice that tcpdumps captured packets with source IP address `192.168.122.98` for multiple services such as name resolution (port 53) and HTTP (port 80). The response packets are not displayed since their source IP is different.
+
+Conversely, you can use the `dst` filter to filter by destination IP/hostname:
+
+```
+$ sudo tcpdump -i any -c5 -nn dst 192.168.122.98
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10:05:03.572931 IP 192.168.122.1.53 > 192.168.122.98.47049: 2248 1/0/0 A 54.204.39.132 (48)
+10:05:03.572944 IP 192.168.122.1.53 > 192.168.122.98.47049: 33770 0/0/0 (32)
+10:05:03.621833 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [S.], seq 3474204576, ack 3256851264, win 28960, options [mss 1460,sackOK,TS val 522874425 ecr 122993922,nop,wscale 9], length 0
+10:05:03.667767 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [.], ack 113, win 57, options [nop,nop,TS val 522874436 ecr 122993972], length 0
+10:05:03.672221 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 522874437 ecr 122993972], length 642: HTTP: HTTP/1.1 302 Found
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+#### Complex expressions
+
+You can also combine filters by using the logical operators `and` and `or` to create more complex expressions. For example, to filter packets from source IP address `192.168.122.98` and service HTTP only, use this command:
+
+```
+$ sudo tcpdump -i any -c5 -nn src 192.168.122.98 and port 80
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10:08:00.472696 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [S], seq 2712685325, win 29200, options [mss 1460,sackOK,TS val 123170822 ecr 0,nop,wscale 7], length 0
+10:08:00.516118 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 268723504, win 229, options [nop,nop,TS val 123170865 ecr 522918648], length 0
+10:08:00.516583 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 123170866 ecr 522918648], length 112: HTTP: GET / HTTP/1.1
+10:08:00.567044 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 123170916 ecr 522918661], length 0
+10:08:00.788153 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [F.], seq 112, ack 643, win 239, options [nop,nop,TS val 123171137 ecr 522918661], length 0
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+You can create more complex expressions by grouping filter with parentheses. In this case, enclose the entire filter expression with quotation marks to prevent the shell from confusing them with shell expressions:
+
+```
+$ sudo tcpdump -i any -c5 -nn "port 80 and (src 192.168.122.98 or src 54.204.39.132)"
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10:10:37.602214 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [S], seq 871108679, win 29200, options [mss 1460,sackOK,TS val 123327951 ecr 0,nop,wscale 7], length 0
+10:10:37.650651 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [S.], seq 854753193, ack 871108680, win 28960, options [mss 1460,sackOK,TS val 522957932 ecr 123327951,nop,wscale 9], length 0
+10:10:37.650708 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 0
+10:10:37.651097 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 112: HTTP: GET / HTTP/1.1
+10:10:37.692900 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [.], ack 113, win 57, options [nop,nop,TS val 522957942 ecr 123328000], length 0
+5 packets captured
+5 packets received by filter
+0 packets dropped by kernel
+```
+
+In this example, we're filtering packets for HTTP service only (port 80) and source IP addresses `192.168.122.98` or `54.204.39.132`. This is a quick way of examining both sides of the same flow.
+
+### 5\. Checking packet content
+
+In the previous examples, we're checking only the packets' headers for information such as source, destinations, ports, etc. Sometimes this is all we need to troubleshoot network connectivity issues. Sometimes, however, we need to inspect the content of the packet to ensure that the message we're sending contains what we need or that we received the expected response. To see the packet content, tcpdump provides two additional flags: `-X` to print content in hex, and ASCII or `-A` to print the content in ASCII.
+
+For example, inspect the HTTP content of a web request like this:
+
+```
+$ sudo tcpdump -i any -c10 -nn -A port 80
+tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
+listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+13:02:14.871803 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [S], seq 2546602048, win 29200, options [mss 1460,sackOK,TS val 133625221 ecr 0,nop,wscale 7], length 0
+E..<..@.@.....zb6.'....P...@......r............
+............................
+13:02:14.910734 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [S.], seq 1877348646, ack 2546602049, win 28960, options [mss 1460,sackOK,TS val 525532247 ecr 133625221,nop,wscale 9], length 0
+E..<..@./..a6.'...zb.P..o..&...A..q a..........
+.R.W....... ................
+13:02:14.910832 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 133625260 ecr 525532247], length 0
+E..4..@.@.....zb6.'....P...Ao..'...........
+.....R.W................
+13:02:14.911808 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 133625261 ecr 525532247], length 112: HTTP: GET / HTTP/1.1
+E.....@.@..1..zb6.'....P...Ao..'...........
+.....R.WGET / HTTP/1.1
+User-Agent: Wget/1.14 (linux-gnu)
+Accept: */*
+Host: opensource.com
+Connection: Keep-Alive
+
+................
+13:02:14.951199 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [.], ack 113, win 57, options [nop,nop,TS val 525532257 ecr 133625261], length 0
+E..4.F@./.."6.'...zb.P..o..'.......9.2.....
+.R.a....................
+13:02:14.955030 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 525532258 ecr 133625261], length 642: HTTP: HTTP/1.1 302 Found
+E....G@./...6.'...zb.P..o..'.......9.......
+.R.b....HTTP/1.1 302 Found
+Server: nginx
+Date: Sun, 23 Sep 2018 17:02:14 GMT
+Content-Type: text/html; charset=iso-8859-1
+Content-Length: 207
+X-Content-Type-Options: nosniff
+Location: https://opensource.com/
+Cache-Control: max-age=1209600
+Expires: Sun, 07 Oct 2018 17:02:14 GMT
+X-Request-ID: v-6baa3acc-bf52-11e8-9195-22000ab8cf2d
+X-Varnish: 632951979
+Age: 0
+Via: 1.1 varnish (Varnish/5.2)
+X-Cache: MISS
+Connection: keep-alive
+
+
+
+302 Found
+
+
+
+................
+13:02:14.955083 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 133625304 ecr 525532258], length 0
+E..4..@.@.....zb6.'....P....o..............
+.....R.b................
+13:02:15.195524 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 133625545 ecr 525532258], length 0
+E..4..@.@.....zb6.'....P....o..............
+.....R.b................
+13:02:15.236592 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 525532329 ecr 133625545], length 0
+E..4.H@./.. 6.'...zb.P..o..........9.I.....
+.R......................
+13:02:15.236656 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 133625586 ecr 525532329], length 0
+E..4..@.@.....zb6.'....P....o..............
+.....R..................
+10 packets captured
+10 packets received by filter
+0 packets dropped by kernel
+```
+
+This is helpful for troubleshooting issues with API calls, assuming the calls are using plain HTTP. For encrypted connections, this output is less useful.
+
+### 6\. Saving captures to a file
+
+Another useful feature provided by tcpdump is the ability to save the capture to a file so you can analyze the results later. This allows you to capture packets in batch mode overnight, for example, and verify the results in the morning. It also helps when there are too many packets to analyze since real-time capture can occur too fast.
+
+To save packets to a file instead of displaying them on screen, use the option `-w`:
+
+```
+$ sudo tcpdump -i any -c10 -nn -w webserver.pcap port 80
+[sudo] password for ricardo:
+tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
+10 packets captured
+10 packets received by filter
+0 packets dropped by kernel
+```
+
+This command saves the output in a file named `webserver.pcap`. The `.pcap` extension stands for "packet capture" and is the convention for this file format.
+
+As shown in this example, nothing gets displayed on-screen, and the capture finishes after capturing 10 packets, as per the option `-c10`. If you want some feedback to ensure packets are being captured, use the option `-v`.
+
+Tcpdump creates a file in binary format so you cannot simply open it with a text editor. To read the contents of the file, execute tcpdump with the `-r` option:
+
+```
+$ tcpdump -nn -r webserver.pcap
+reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
+13:36:57.679494 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [S], seq 3709732619, win 29200, options [mss 1460,sackOK,TS val 135708029 ecr 0,nop,wscale 7], length 0
+13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
+13:36:57.719005 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 0
+13:36:57.719186 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 112: HTTP: GET / HTTP/1.1
+13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
+13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
+13:36:57.760182 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 135708109 ecr 526052959], length 0
+13:36:57.977602 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 135708327 ecr 526052959], length 0
+13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
+13:36:58.022132 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 135708371 ecr 526053025], length 0
+$
+```
+
+Since you're no longer capturing the packets directly from the network interface, `sudo` is not required to read the file.
+
+You can also use any of the filters we've discussed to filter the content from the file, just as you would with real-time data. For example, inspect the packets in the capture file from source IP address `54.204.39.132` by executing this command:
+
+```
+$ tcpdump -nn -r webserver.pcap src 54.204.39.132
+reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
+13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
+13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
+13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
+13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
+```
+
+### What's next?
+
+These basic features of tcpdump will help you get started with this powerful and versatile tool. To learn more, consult the [tcpdump website][3] and [man pages][4].
+
+The tcpdump command line interface provides great flexibility for capturing and analyzing network traffic. If you need a graphical tool to understand more complex flows, look at [Wireshark][5].
+
+One benefit of Wireshark is that it can read `.pcap` files captured by tcpdump. You can use tcpdump to capture packets in a remote machine that does not have a GUI and analyze the result file with Wireshark, but that is a topic for another day.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/10/introduction-tcpdump
+
+作者:[Ricardo Gerardi][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rgerardi
+[b]: https://github.com/lujun9972
+[1]: http://www.tcpdump.org/manpages/tcpdump.1.html#lbAG
+[2]: https://www.iana.org/assignments/tcp-parameters/tcp-parameters.xhtml
+[3]: http://www.tcpdump.org/#
+[4]: http://www.tcpdump.org/manpages/tcpdump.1.html
+[5]: https://www.wireshark.org/
diff --git a/sources/tech/20181010 Cloc - Count The Lines Of Source Code In Many Programming Languages.md b/sources/tech/20181010 Cloc - Count The Lines Of Source Code In Many Programming Languages.md
new file mode 100644
index 0000000000..1cefdaaa4f
--- /dev/null
+++ b/sources/tech/20181010 Cloc - Count The Lines Of Source Code In Many Programming Languages.md
@@ -0,0 +1,197 @@
+Cloc – Count The Lines Of Source Code In Many Programming Languages
+======
+
+
+
+As a developer, you may need to share the progress and statistics of your code to your boss or colleagues. Your boss might want to analyze the code and give any additional inputs. In such cases, there are few programs, as far as I know, available to analyze the source code. One such program is [**Ohcount**][1]. Today, I came across yet another similar utility namely **“Cloc”**. Using the Cloc, you can easily count the lines of source code in several programming languages. It counts the blank lines, comment lines, and physical lines of source code and displays the result in a neat tabular-column format. Cloc is free, open source and cross-platform utility entirely written in **Perl** programming language.
+
+### Features
+
+Cloc ships with numerous advantages including the following:
+
+ * Easy to install/use. Requires no dependencies.
+ * Portable
+ * It can produce results in a variety of formats, such as plain text, SQL, JSON, XML, YAML, comma separated values.
+ * Can count your git commits.
+ * Count the code in directories and sub-directories.
+ * Count codes count code within compressed archives like tar balls, Zip files, Java .ear files etc.
+ * Open source and cross platform.
+
+
+
+### Installing Cloc
+
+The Cloc utility is available in the default repositories of most Unix-like operating systems. So, you can install it using the default package manager as shown below.
+
+On Arch Linux and its variants:
+
+```
+$ sudo pacman -S cloc
+
+```
+
+On Debian, Ubuntu:
+
+```
+$ sudo apt-get install cloc
+
+```
+
+On CentOS, Red Hat, Scientific Linux:
+
+```
+$ sudo yum install cloc
+
+```
+
+On Fedora:
+
+```
+$ sudo dnf install cloc
+
+```
+
+On FreeBSD:
+
+```
+$ sudo pkg install cloc
+
+```
+
+It can also installed using third-party package manager like [**NPM**][2] as well.
+
+```
+$ npm install -g cloc
+
+```
+
+### Count The Lines Of Source Code In Many Programming Languages
+
+Let us start with a simple example. I have a “hello world” program written in C in my current working directory.
+
+```
+$ cat hello.c
+#include
+int main()
+{
+ // printf() displays the string inside quotation
+ printf("Hello, World!");
+ return 0;
+}
+
+```
+
+To count the lines of code in the hello.c program, simply run:
+
+```
+$ cloc hello.c
+
+```
+
+Sample output:
+
+
+
+The first column specifies the **name of programming languages that the source code consists of**. As you can see in the above output, the source code of “hello world” program is written using **C** programming language.
+
+The second column displays the **number of files in each programming languages**. So, our code contains **1 file** in total.
+
+The third column displays the **total number of blank lines**. We have zero blank files in our code.
+
+The fourth column displays **number of comment lines**.
+
+And the final and fifth column displays **total physical lines of given source code**.
+
+It is just a 6 line code program, so counting the lines in the code is not a big deal. What about the some big source code file? Have a look at the following example:
+
+```
+$ cloc file.tar.gz
+
+```
+
+Sample output:
+
+
+
+As per the above output, it is quite difficult to manually find exact count of code. But, Cloc displays the result in seconds with nice tabular-column format. You can view the gross total of each section at the end which is quite handy when it comes to analyze the source code of a program.
+
+Cloc not only counts the individual source code files, but also files inside directories and sub-directories, archives, and even in specific git commits etc.
+
+**Count the lines of codes in a directory:**
+
+```
+$ cloc dir/
+
+```
+
+![][4]
+
+**Sub-directory:**
+
+```
+$ cloc dir/cloc/tests
+
+```
+
+![][5]
+
+**Count the lines of codes in archive file:**
+
+```
+$ cloc archive.zip
+
+```
+
+![][6]
+
+You can also count lines in a git repository, using a specific commit like below.
+
+```
+$ git clone https://github.com/AlDanial/cloc.git
+
+$ cd cloc
+
+$ cloc 157d706
+
+```
+
+![][7]
+
+Cloc can recognize several programming languages. To view the complete list of recognized languages, run:
+
+```
+$ cloc --show-lang
+
+```
+
+For more details, refer the help section.
+
+```
+$ cloc --help
+
+```
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/cloc-count-the-lines-of-source-code-in-many-programming-languages/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/ohcount-the-source-code-line-counter-and-analyzer/
+[2]: https://www.ostechnix.com/install-node-js-linux/
+[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[4]: http://www.ostechnix.com/wp-content/uploads/2018/10/cloc-2-1.png
+[5]: http://www.ostechnix.com/wp-content/uploads/2018/10/cloc-4.png
+[6]: http://www.ostechnix.com/wp-content/uploads/2018/10/cloc-3.png
+[7]: http://www.ostechnix.com/wp-content/uploads/2018/10/cloc-5.png
diff --git a/translated/tech/20180201 Rock Solid React.js Foundations A Beginners Guide.md b/translated/tech/20180201 Rock Solid React.js Foundations A Beginners Guide.md
new file mode 100644
index 0000000000..bdb2abca36
--- /dev/null
+++ b/translated/tech/20180201 Rock Solid React.js Foundations A Beginners Guide.md
@@ -0,0 +1,281 @@
+坚实的 React 基础:初学者指南
+============================================================
+
+React.js crash course
+
+在过去的几个月里,我一直在使用 React 和 React-Native。我已经发布了两个作为产品的应用, [Kiven Aa][1](React)和 [Pollen Chat][2](React Native)。当我开始学习 React 时,我找了一些不仅仅是教我如何用 React 写应用的东西(一个博客,一个视频,一个课程,等等),我也想让它帮我做好面试准备。
+
+我发现的大部分资料都集中在某一单一方面上。所以,这篇文章针对的是那些希望理论与实践完美结合的观众。我会告诉你一些理论,以便你了解幕后发生的事情,然后我会向你展示如何编写一些 React.js 代码。
+
+如果你更喜欢视频形式,我在YouTube上传了整个课程,请去看看。
+
+
+让我们开始......
+
+> React.js 是一个用于构建用户界面的 JavaScript 库
+
+你可以构建各种单页应用程序。例如,你希望在用户界面上实时显示更改的聊天软件和电子商务门户。
+
+### 一切都是组件
+
+React 应用由组件组成,数量多且互相嵌套。你或许会问:”可什么是组件呢?“
+
+组件是可重用的代码段,它定义了某些功能在 UI 上的外观和行为。 比如,按钮就是一个组件。
+
+让我们看看下面的计算器,当你尝试计算2 + 2 = 4 -1 = 3(简单的数学题)时,你会在Google上看到这个计算器。
+
+
+红色标记表示组件
+
+
+
+如上图所示,这个计算器有很多区域,比如展示窗口和数字键盘。所有这些都可以是许多单独的组件或一个巨大的组件。这取决于在 React 中分解和抽象出事物的程度。你为所有这些组件分别编写代码,然后合并这些组件到一个容器中,而这个容器又是一个 React 组件。这样你就可以创建可重用的组件,最终的应用将是一组协同工作的单独组件。
+
+
+
+以下是一个你践行了以上原则并可以用 React 编写计算器的方法。
+
+```
+
+
+
+
+
+ .
+ .
+ .
+
+
+
+
+```
+
+没错!它看起来像HTML代码,然而并不是。我们将在后面的部分中详细探讨它。
+
+### 设置我们的 Playground
+
+这篇教程专注于 React 的基础部分。它没有偏向 Web 或 React Native(开发移动应用)。所以,我们会用一个在线编辑器,这样可以在学习 React 能做什么之前避免 web 或 native 的具体配置。
+
+我已经为读者在 [codepen.io][4] 设置好了开发环境。只需点开这个链接并且阅读所有 HTML 和 JavaScript 注释。
+
+### 控制组件
+
+我们已经了解到 React 应用是各种组件的集合,结构为嵌套树。因此,我们需要某种机制来将数据从一个组件传递到另一个组件。
+
+#### 进入 “props”
+
+我们可以使用 `props` 对象将任意数据传递给我们的组件。 React 中的每个组件都会获取 `props` 对象。在学习如何使用 `props` 之前,让我们学习函数式组件。
+
+#### a) 函数式组件
+
+在 React 中,一个函数式组件通过 `props` 对象使用你传递给它的任意数据。它返回一个对象,该对象描述了 React 应渲染的 UI。函数式组件也称为无状态组件。
+
+
+
+让我们编写第一个函数式组件。
+
+```
+function Hello(props) {
+ return