mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
74aab89fe5
@ -1,15 +1,15 @@
|
||||
Streams:一个新的 Redis 通用数据结构
|
||||
======
|
||||
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,<ruby>流<rt>streams</rt></ruby>只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息[1],也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,<ruby>流<rt>streams</rt></ruby>只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息(LCTT 译注:参见 [CAP 定理][1]) ,也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
|
||||
|
||||
然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis <ruby>列表<rt>list</rt></ruby>、<ruby>有序集合<rt>sorted list</rt></ruby>、<ruby>发布/订阅<rt>Pub/Sub</rt></ruby>功能之间有某些缺陷。你可以权衡使用这些工具对一个消息或事件建模。
|
||||
然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis <ruby>列表<rt>list</rt></ruby>、<ruby>有序集<rt>sorted list</rt></ruby>、<ruby>发布/订阅<rt>Pub/Sub</rt></ruby>功能之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件建模。
|
||||
|
||||
排序集合是内存消耗大户,那自然就不能对投递相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集合并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
|
||||
有序集是内存消耗大户,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
|
||||
|
||||
列表有另外的问题,它在某些特定的用例中产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
|
||||
列表有另外的问题,它在某些特定的用例中会产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
|
||||
|
||||
对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想<ruby>“即发即弃”<rt>fire-and-forget</rt></ruby>的东西:保留一个历史是很重要的,不只是因为是断开之后重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:在这 10 秒范围内温度读数是多少?
|
||||
对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想<ruby>“即发即弃”<rt>fire-and-forget</rt></ruby>的东西:保留一个历史是很重要的,不只是因为是断开之后会重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:比如在这 10 秒范围内温度读数是多少?
|
||||
|
||||
我试图解决上述问题,我想规划一个通用的有序集合,并列入一个独特的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而告终。Redis 有个好处,它的数据结构导出更像自然的计算机科学的数据结构,而不是 “Salvatore 发明的 API”。因此,我最终停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许我会为发布/订阅增加一些历史信息,或者为列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说 “你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
|
||||
|
||||
@ -22,7 +22,7 @@ Streams:一个新的 Redis 通用数据结构
|
||||
|
||||
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的契机。我需要去重新构思 “日志” 的概念是什么。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移应该怎么办?我们有范围查询可用。同样,日志通常很难进行垃圾回收:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然可以用<ruby>对数时间<rt>logarithmic time</rt></ruby>来访问范围。同时,我开始去读关于 Kafka 流以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka <ruby>消费群体<rt>consumer groups</rt></ruby>的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在<ruby>对数时间<rt>logarithmic time</rt></ruby>内访问范围。同时,我开始去读关于 Kafka 的流相关的内容以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka <ruby>消费组<rt>consumer groups</rt></ruby>的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
|
||||
|
||||
### 让我们写一些代码吧
|
||||
|
||||
@ -159,7 +159,7 @@ QUEUED
|
||||
|
||||
### 内存使用和节省加载时间
|
||||
|
||||
因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
|
||||
因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,该格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
|
||||
|
||||
我还计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识条目为已删除,并且,当已删除条目占全部条目的比例达到指定值时,这个块将被回收重写,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
@ -175,7 +175,7 @@ via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
校对:[wxy](https://github.com/wxy), [pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,40 +1,41 @@
|
||||
通过构建一个区块链来学习区块链技术
|
||||
想学习区块链?那就用 Python 构建一个
|
||||
======
|
||||
|
||||
> 了解区块链是如何工作的最快的方法是构建一个。
|
||||
|
||||

|
||||
你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术是什么。
|
||||
|
||||
你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术基础是什么。
|
||||
|
||||
但是理解区块链并不容易 —— 至少对我来说是这样。我徜徉在各种难懂的视频中,并且因为示例太少而陷入深深的挫败感中。
|
||||
|
||||
我喜欢在实践中学习。这迫使我去处理被卡在代码级别上的难题。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
|
||||
我喜欢在实践中学习。这会使得我在代码层面上处理主要问题,从而可以让我坚持到底。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
|
||||
|
||||
### 开始之前 …
|
||||
|
||||
记住,区块链是一个 _不可更改的、有序的_ 被称为区块的记录链。它们可以包括事务~~(交易???校对确认一下,下同)~~、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
|
||||
记住,区块链是一个 _不可更改的、有序的_ 记录(被称为区块)的链。它们可以包括<ruby>交易<rt>transaction</rt></ruby>、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
|
||||
|
||||
如果你不知道哈希是什么,[这里有解释][1]。
|
||||
|
||||
**_本指南的目标读者是谁?_** 你应该能很容易地读和写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
|
||||
**_本指南的目标读者是谁?_** 你应该能轻松地读、写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
|
||||
|
||||
**_我需要做什么?_** 确保安装了 [Python 3.6][2]+(以及 `pip`),还需要去安装 Flask 和非常好用的 Requests 库:
|
||||
|
||||
```
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
```
|
||||
|
||||
当然,你也需要一个 HTTP 客户端,像 [Postman][3] 或者 cURL。哪个都行。
|
||||
|
||||
**_最终的代码在哪里可以找到?_** 源代码在 [这里][4]。
|
||||
|
||||
* * *
|
||||
|
||||
### 第 1 步:构建一个区块链
|
||||
|
||||
打开你喜欢的文本编辑器或者 IDE,我个人 ❤️ [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将使用一个单个的文件,如果你看晕了,可以去参考 [源代码][6]。
|
||||
打开你喜欢的文本编辑器或者 IDE,我个人喜欢 [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将仅使用一个文件,如果你看晕了,可以去参考 [源代码][6]。
|
||||
|
||||
#### 描述一个区块链
|
||||
|
||||
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存事务。下面是我们的类规划:
|
||||
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存交易。下面是我们的类规划:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -58,15 +59,16 @@ class Blockchain(object):
|
||||
@property
|
||||
def last_block(self):
|
||||
# Returns the last Block in the chain
|
||||
pass
|
||||
pass
|
||||
```
|
||||
|
||||
*我们的 Blockchain 类的原型*
|
||||
|
||||
我们的区块链类负责管理链。它将存储事务并且有一些为链中增加新区块的助理性质的方法。现在我们开始去充实一些类的方法。
|
||||
我们的 `Blockchain` 类负责管理链。它将存储交易并且有一些为链中增加新区块的辅助性质的方法。现在我们开始去充实一些类的方法。
|
||||
|
||||
#### 一个区块是什么样子的?
|
||||
#### 区块是什么样子的?
|
||||
|
||||
每个区块有一个索引、一个时间戳(Unix 时间)、一个事务的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
|
||||
每个区块有一个索引、一个时间戳(Unix 时间)、一个交易的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
|
||||
|
||||
单个区块的示例应该是下面的样子:
|
||||
|
||||
@ -86,13 +88,15 @@ block = {
|
||||
}
|
||||
```
|
||||
|
||||
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。这一点非常重要,因为这就是区块链不可更改的原因:如果攻击者修改了一个早期的区块,那么所有的后续区块将包含错误的哈希。
|
||||
*我们的区块链中的块示例*
|
||||
|
||||
这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。
|
||||
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。**这一点非常重要,因为这就是区块链不可更改的原因**:如果攻击者修改了一个早期的区块,那么**所有**的后续区块将包含错误的哈希。
|
||||
|
||||
#### 添加事务到一个区块
|
||||
*这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。*
|
||||
|
||||
我们将需要一种区块中添加事务的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
|
||||
#### 添加交易到一个区块
|
||||
|
||||
我们将需要一种区块中添加交易的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -113,14 +117,14 @@ class Blockchain(object):
|
||||
'amount': amount,
|
||||
})
|
||||
|
||||
return self.last_block['index'] + 1
|
||||
return self.last_block['index'] + 1
|
||||
```
|
||||
|
||||
在 `new_transaction()` 运行后将在列表中添加一个事务,它返回添加事务后的那个区块的索引 —— 那个区块接下来将被挖矿。提交事务的用户后面会用到这些。
|
||||
在 `new_transaction()` 运行后将在列表中添加一个交易,它返回添加交易后的那个区块的索引 —— 那个区块接下来将被挖矿。提交交易的用户后面会用到这些。
|
||||
|
||||
#### 创建新区块
|
||||
|
||||
当我们的区块链被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
|
||||
当我们的 `Blockchain` 被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
|
||||
|
||||
除了在我们的构造函数中创建创世区块之外,我们还需要写一些方法,如 `new_block()`、`new_transaction()` 以及 `hash()`:
|
||||
|
||||
@ -190,18 +194,18 @@ class Blockchain(object):
|
||||
|
||||
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
|
||||
block_string = json.dumps(block, sort_keys=True).encode()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
```
|
||||
|
||||
上面的内容简单明了 —— 我添加了一些注释和文档字符串,以使代码清晰可读。到此为止,表示我们的区块链基本上要完成了。但是,你肯定想知道新区块是如何被创建、打造或者挖矿的。
|
||||
|
||||
#### 理解工作量证明
|
||||
|
||||
一个工作量证明(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
|
||||
<ruby>工作量证明<rt>Proof of Work</rt></ruby>(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
|
||||
|
||||
我们来看一个非常简单的示例来帮助你了解它。
|
||||
|
||||
我们来解决一个问题,一些整数 x 乘以另外一个整数 y 的结果的哈希值必须以 0 结束。因此,hash(x * y) = ac23dc…0。为简单起见,我们先把 x = 5 固定下来。在 Python 中的实现如下:
|
||||
我们来解决一个问题,一些整数 `x` 乘以另外一个整数 `y` 的结果的哈希值必须以 `0` 结束。因此,`hash(x * y) = ac23dc…0`。为简单起见,我们先把 `x = 5` 固定下来。在 Python 中的实现如下:
|
||||
|
||||
```
|
||||
from hashlib import sha256
|
||||
@ -215,19 +219,21 @@ while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
|
||||
print(f'The solution is y = {y}')
|
||||
```
|
||||
|
||||
在这里的答案是 y = 21。因为它产生的哈希值是以 0 结尾的:
|
||||
在这里的答案是 `y = 21`。因为它产生的哈希值是以 0 结尾的:
|
||||
|
||||
```
|
||||
hash(5 * 21) = 1253e9373e...5e3600155e860
|
||||
```
|
||||
|
||||
在比特币中,工作量证明算法被称之为 [Hashcash][10]。与我们上面的例子没有太大的差别。这就是矿工们进行竞赛以决定谁来创建新块的算法。一般来说,其难度取决于在一个字符串中所查找的字符数量。然后矿工会因其做出的求解而得到奖励的币——在一个交易当中。
|
||||
|
||||
网络上的任何人都可以很容易地去核验它的答案。
|
||||
|
||||
#### 实现基本的 PoW
|
||||
|
||||
为我们的区块链来实现一个简单的算法。我们的规则与上面的示例类似:
|
||||
|
||||
> 找出一个数字 p,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 0 组成。
|
||||
> 找出一个数字 `p`,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 `0` 组成。
|
||||
|
||||
```
|
||||
import hashlib
|
||||
@ -266,25 +272,21 @@ class Blockchain(object):
|
||||
|
||||
guess = f'{last_proof}{proof}'.encode()
|
||||
guess_hash = hashlib.sha256(guess).hexdigest()
|
||||
return guess_hash[:4] == "0000"
|
||||
return guess_hash[:4] == "0000"
|
||||
```
|
||||
|
||||
为了调整算法的难度,我们可以修改前导 0 的数量。但是 4 个零已经足够难了。你会发现,将前导 0 的数量每增加一,那么找到正确答案所需要的时间难度将大幅增加。
|
||||
|
||||
我们的类基本完成了,现在我们开始去使用 HTTP 请求与它交互。
|
||||
|
||||
* * *
|
||||
|
||||
### 第 2 步:以 API 方式去访问我们的区块链
|
||||
|
||||
我们将去使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
|
||||
我们将使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
|
||||
|
||||
我们将创建三个方法:
|
||||
|
||||
* `/transactions/new` 在一个区块上创建一个新事务
|
||||
|
||||
* `/transactions/new` 在一个区块上创建一个新交易
|
||||
* `/mine` 告诉我们的服务器去挖矿一个新区块
|
||||
|
||||
* `/chain` 返回完整的区块链
|
||||
|
||||
#### 配置 Flask
|
||||
@ -332,33 +334,33 @@ def full_chain():
|
||||
return jsonify(response), 200
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
```
|
||||
|
||||
对上面的代码,我们做添加一些详细的解释:
|
||||
|
||||
* Line 15:实例化我们的节点。更多关于 Flask 的知识读 [这里][7]。
|
||||
|
||||
* Line 18:为我们的节点创建一个随机的名字。
|
||||
|
||||
* Line 21:实例化我们的区块链类。
|
||||
|
||||
* Line 24–26:创建 /mine 端点,这是一个 GET 请求。
|
||||
|
||||
* Line 28–30:创建 /transactions/new 端点,这是一个 POST 请求,因为我们要发送数据给它。
|
||||
|
||||
* Line 32–38:创建 /chain 端点,它返回全部区块链。
|
||||
|
||||
* Line 24–26:创建 `/mine` 端点,这是一个 GET 请求。
|
||||
* Line 28–30:创建 `/transactions/new` 端点,这是一个 POST 请求,因为我们要发送数据给它。
|
||||
* Line 32–38:创建 `/chain` 端点,它返回全部区块链。
|
||||
* Line 40–41:在 5000 端口上运行服务器。
|
||||
|
||||
#### 事务端点
|
||||
#### 交易端点
|
||||
|
||||
这就是对一个事务的请求,它是用户发送给服务器的:
|
||||
这就是对一个交易的请求,它是用户发送给服务器的:
|
||||
|
||||
```
|
||||
{ "sender": "my address", "recipient": "someone else's address", "amount": 5}
|
||||
{
|
||||
"sender": "my address",
|
||||
"recipient": "someone else's address",
|
||||
"amount": 5
|
||||
}
|
||||
```
|
||||
|
||||
因为我们已经有了添加交易到块中的类方法,剩下的就很容易了。让我们写个函数来添加交易:
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
@ -383,18 +385,17 @@ def new_transaction():
|
||||
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
|
||||
|
||||
response = {'message': f'Transaction will be added to Block {index}'}
|
||||
return jsonify(response), 201
|
||||
return jsonify(response), 201
|
||||
```
|
||||
创建事务的方法
|
||||
|
||||
*创建交易的方法*
|
||||
|
||||
#### 挖矿端点
|
||||
|
||||
我们的挖矿端点是见证奇迹的地方,它实现起来很容易。它要做三件事情:
|
||||
|
||||
1. 计算工作量证明
|
||||
|
||||
2. 因为矿工(我们)添加一个事务而获得报酬,奖励矿工(我们) 1 个硬币
|
||||
|
||||
2. 因为矿工(我们)添加一个交易而获得报酬,奖励矿工(我们) 1 个币
|
||||
3. 通过将它添加到链上而打造一个新区块
|
||||
|
||||
```
|
||||
@ -434,10 +435,10 @@ def mine():
|
||||
'proof': block['proof'],
|
||||
'previous_hash': block['previous_hash'],
|
||||
}
|
||||
return jsonify(response), 200
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的区块链类的方法进行交互的。到目前为止,我们已经做到了,现在开始与我们的区块链去交互。
|
||||
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的 `Blockchain` 类的方法进行交互的。到目前为止,我们已经做完了,现在开始与我们的区块链去交互。
|
||||
|
||||
### 第 3 步:与我们的区块链去交互
|
||||
|
||||
@ -447,24 +448,33 @@ return jsonify(response), 200
|
||||
|
||||
```
|
||||
$ python blockchain.py
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
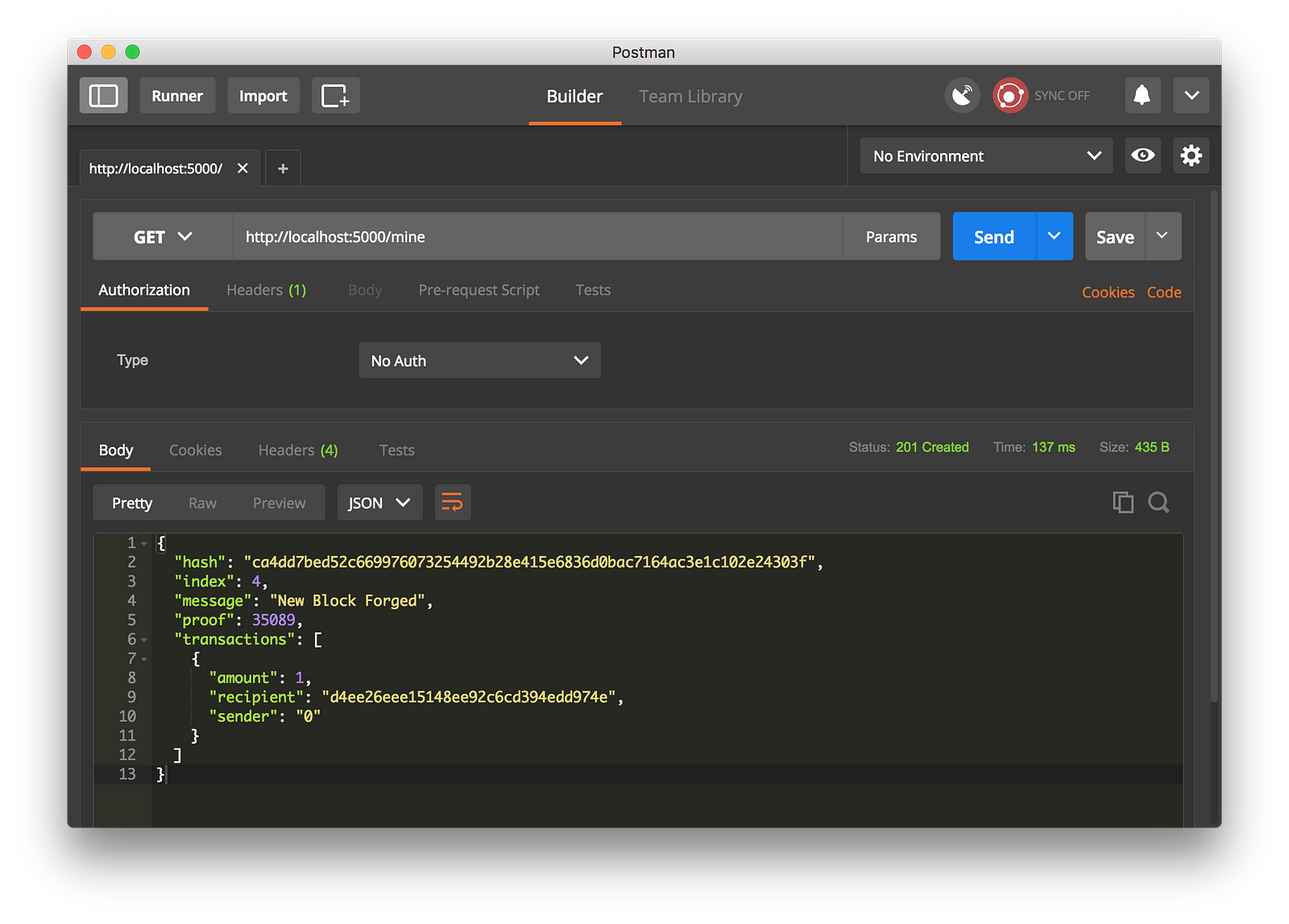
我们通过生成一个 GET 请求到 http://localhost:5000/mine 去尝试挖一个区块:
|
||||
我们通过生成一个 `GET` 请求到 `http://localhost:5000/mine` 去尝试挖一个区块:
|
||||
|
||||
|
||||
使用 Postman 去生成一个 GET 请求
|
||||
|
||||
我们通过生成一个 POST 请求到 http://localhost:5000/transactions/new 去创建一个区块,它带有一个包含我们的事务结构的 `Body`:
|
||||
*使用 Postman 去生成一个 GET 请求*
|
||||
|
||||
我们通过生成一个 `POST` 请求到 `http://localhost:5000/transactions/new` 去创建一个区块,请求数据包含我们的交易结构:
|
||||
|
||||
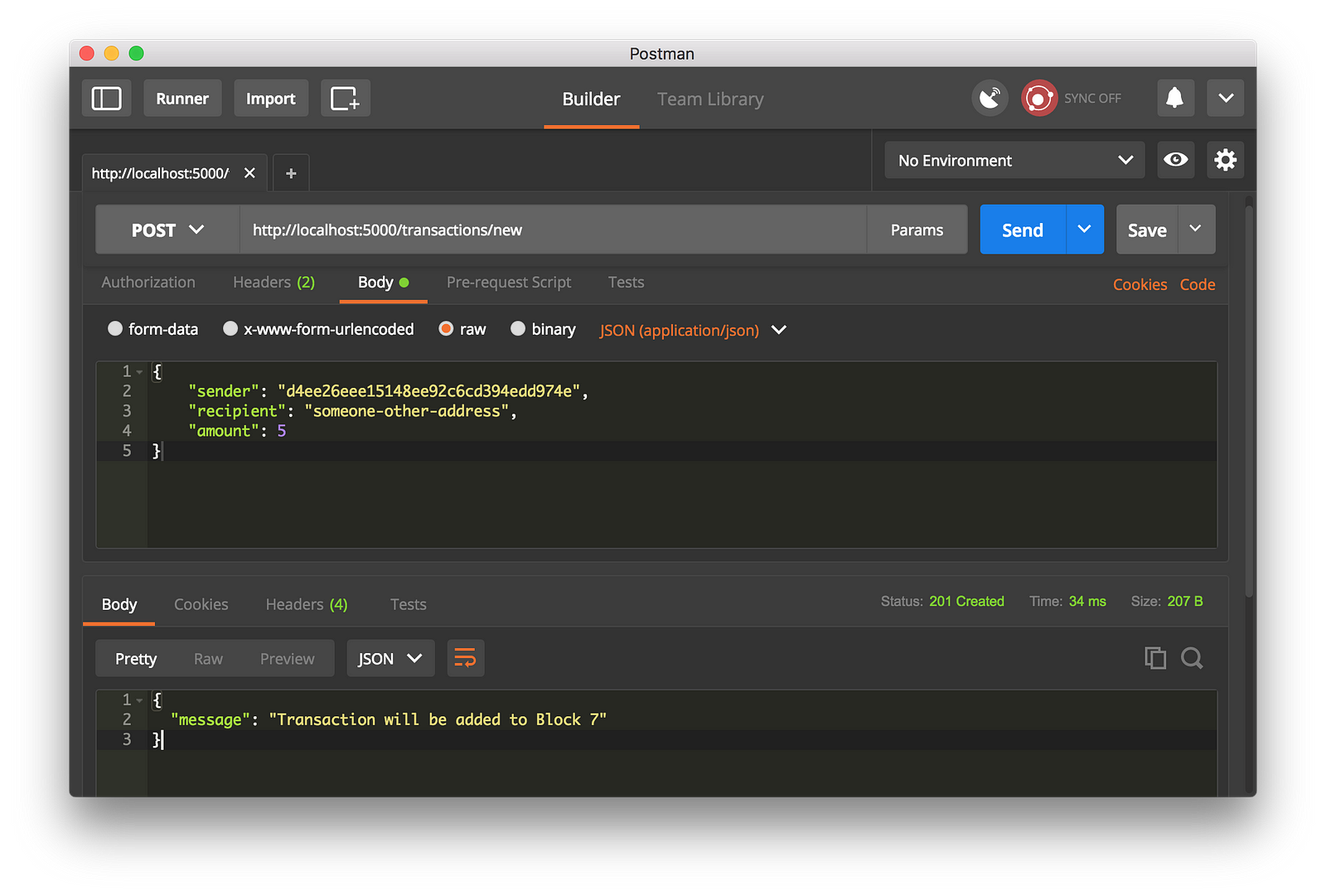
|
||||
使用 Postman 去生成一个 POST 请求
|
||||
|
||||
*使用 Postman 去生成一个 POST 请求*
|
||||
|
||||
如果你不使用 Postman,也可以使用 cURL 去生成一个等价的请求:
|
||||
|
||||
```
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee15148ee92c6cd394edd974e", "recipient": "someone-other-address", "amount": 5}' "http://localhost:5000/transactions/new"
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{
|
||||
"sender": "d4ee26eee15148ee92c6cd394edd974e",
|
||||
"recipient": "someone-other-address",
|
||||
"amount": 5
|
||||
}' "http://localhost:5000/transactions/new"
|
||||
```
|
||||
我重启动我的服务器,然后我挖到了两个区块,这样总共有了3 个区块。我们通过请求 http://localhost:5000/chain 来检查整个区块链:
|
||||
|
||||
我重启动我的服务器,然后我挖到了两个区块,这样总共有了 3 个区块。我们通过请求 `http://localhost:5000/chain` 来检查整个区块链:
|
||||
|
||||
```
|
||||
{
|
||||
"chain": [
|
||||
@ -503,18 +513,18 @@ $ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee151
|
||||
}
|
||||
],
|
||||
"length": 3
|
||||
}
|
||||
```
|
||||
### 第 4 步:共识
|
||||
|
||||
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收事务并允许我们去挖掘出新区块。但是区块链的整个重点在于它是去中心化的。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是共识问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
|
||||
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收交易并允许我们去挖掘出新区块。但是区块链的整个重点在于它是<ruby>去中心化的<rt>decentralized</rt></ruby>。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是<ruby>共识<rt>Consensus</rt></ruby>问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
|
||||
|
||||
#### 注册新节点
|
||||
|
||||
在我们能实现一个共识算法之前,我们需要一个办法去让一个节点知道网络上的邻居节点。我们网络上的每个节点都保留有一个该网络上其它节点的注册信息。因此,我们需要更多的端点:
|
||||
|
||||
1. /nodes/register 以 URLs 的形式去接受一个新节点列表
|
||||
|
||||
2. /nodes/resolve 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
|
||||
1. `/nodes/register` 以 URL 的形式去接受一个新节点列表
|
||||
2. `/nodes/resolve` 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
|
||||
|
||||
我们需要去修改我们的区块链的构造函数,来提供一个注册节点的方法:
|
||||
|
||||
@ -538,11 +548,12 @@ class Blockchain(object):
|
||||
"""
|
||||
|
||||
parsed_url = urlparse(address)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
```
|
||||
一个添加邻居节点到我们的网络的方法
|
||||
|
||||
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的内容是幂等的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
|
||||
*一个添加邻居节点到我们的网络的方法*
|
||||
|
||||
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的节点是<ruby>幂等<rt>idempotent</rt></ruby>的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
|
||||
|
||||
#### 实现共识算法
|
||||
|
||||
@ -615,12 +626,12 @@ class Blockchain(object)
|
||||
self.chain = new_chain
|
||||
return True
|
||||
|
||||
return False
|
||||
return False
|
||||
```
|
||||
|
||||
第一个方法 `valid_chain()` 是负责来检查链是否有效,它通过遍历区块链上的每个区块并验证它们的哈希和工作量证明来检查这个区块链是否有效。
|
||||
|
||||
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。
|
||||
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。**如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。**
|
||||
|
||||
在我们的 API 上来注册两个端点,一个用于添加邻居节点,另一个用于解决冲突:
|
||||
|
||||
@ -658,18 +669,20 @@ def consensus():
|
||||
'chain': blockchain.chain
|
||||
}
|
||||
|
||||
return jsonify(response), 200
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
这种情况下,如果你愿意可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:[http://localhost:5000][9] 和 http://localhost:5001。
|
||||
这种情况下,如果你愿意,可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:`http://localhost:5000` 和 `http://localhost:5001`。
|
||||
|
||||
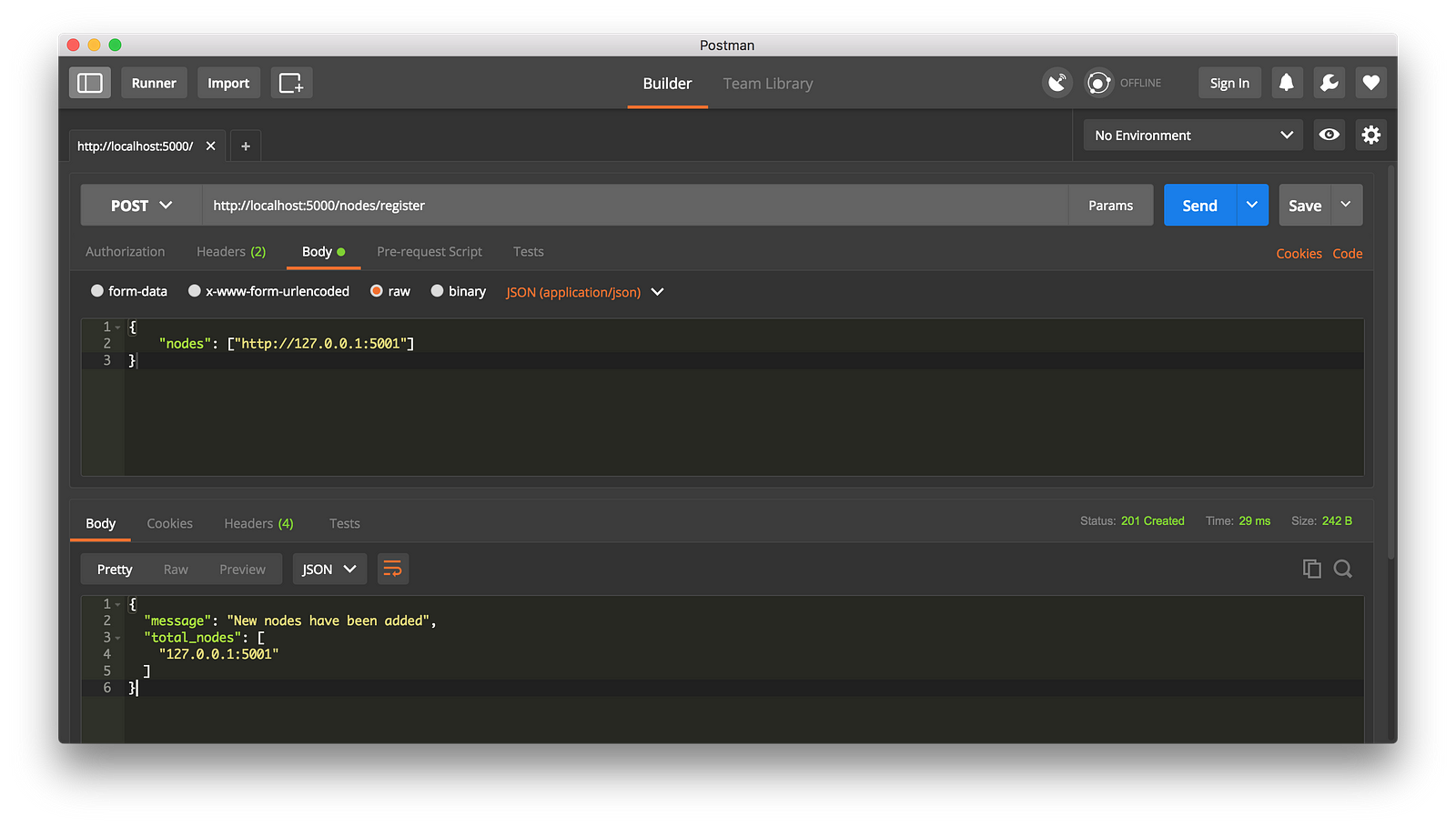
|
||||
注册一个新节点
|
||||
|
||||
*注册一个新节点*
|
||||
|
||||
我接着在节点 2 上挖出一些新区块,以确保这个链是最长的。之后我在节点 1 上以 `GET` 方式调用了 `/nodes/resolve`,这时,节点 1 上的链被共识算法替换成节点 2 上的链了:
|
||||
|
||||
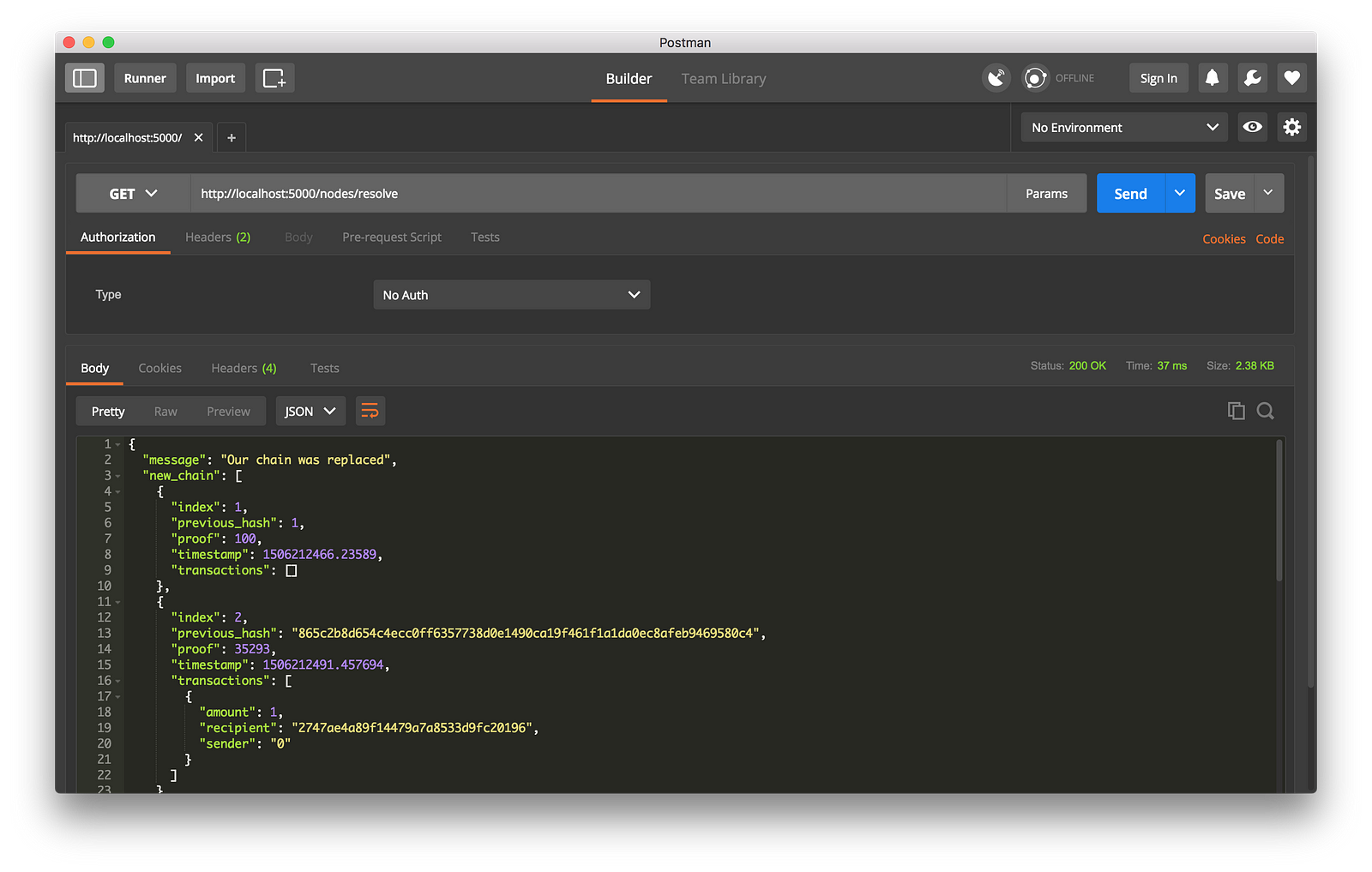
|
||||
工作中的共识算法
|
||||
|
||||
*工作中的共识算法*
|
||||
|
||||
然后将它们封装起来 … 找一些朋友来帮你一起测试你的区块链。
|
||||
|
||||
@ -677,7 +690,7 @@ return jsonify(response), 200
|
||||
|
||||
我希望以上内容能够鼓舞你去创建一些新的东西。我是加密货币的狂热拥护者,因此我相信区块链将迅速改变我们对经济、政府和记录保存的看法。
|
||||
|
||||
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备事务验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。
|
||||
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备交易验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。(LCTT 译注:第二篇并没有~!)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -685,7 +698,7 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
|
||||
作者:[Daniel van Flymen][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -699,3 +712,4 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
[7]:http://flask.pocoo.org/docs/0.12/quickstart/#a-minimal-application
|
||||
[8]:http://localhost:5000/transactions/new
|
||||
[9]:http://localhost:5000
|
||||
[10]:https://en.wikipedia.org/wiki/Hashcash
|
||||
87
published/20180115 Why DevSecOps matters to IT leaders.md
Normal file
87
published/20180115 Why DevSecOps matters to IT leaders.md
Normal file
@ -0,0 +1,87 @@
|
||||
为什么 DevSecOps 对 IT 领导来说如此重要
|
||||
======
|
||||
|
||||
> DevSecOps 也许不是一个优雅的词汇,但是其结果很吸引人:更强的安全、提前出现在开发周期中。来看看一个 IT 领导与 Meltdown 的拼搏。
|
||||
|
||||

|
||||
|
||||
如果 [DevOps][1] 最终是关于创造更好的软件,那也就意味着是更安全的软件。
|
||||
|
||||
而到了术语 “DevSecOps”,就像任何其他 IT 术语一样,DevSecOps —— 一个更成熟的 DevOps 的后代 ——可能容易受到炒作和盗用。但这个术语对那些拥抱了 DevOps 文化的领导者们来说具有重要的意义,并且其实践和工具可以帮助他们实现其承诺。
|
||||
|
||||
说道这里:“DevSecOps”是什么意思?
|
||||
|
||||
“DevSecOps 是开发、安全、运营的混合,”来自 [Datical][2] 的首席技术官和联合创始人 Robert 说。“这提醒我们,对我们的应用程序来说安全和创建并部署应用到生产中一样重要。”
|
||||
|
||||
**[想阅读其他首席技术官的 DevOps 文章吗?查阅我们丰富的资源,[DevOps:IT 领导者指南][3]]**
|
||||
|
||||
向非技术人员解释 DevSecOps 的一个简单的方法是:它是指将安全有意并提前加入到开发过程中。
|
||||
|
||||
“安全团队从历史上一直都被孤立于开发团队——每个团队在 IT 的不同领域都发展了很强的专业能力”,来自红帽安全策的专家 Kirsten 最近告诉我们。“不需要这样,非常关注安全也关注他们通过软件来兑现商业价值的能力的企业正在寻找能够在应用开发生命周期中加入安全的方法。他们通过在整个 CI/CD 管道中集成安全实践、工具和自动化来采用 DevSecOps。”
|
||||
|
||||
“为了能够做的更好,他们正在整合他们的团队——专业的安全人员从开始设计到部署到生产中都融入到了开发团队中了,”她说,“双方都收获了价值——每个团队都拓展了他们的技能和基础知识,使他们自己都成更有价值的技术人员。 DevOps 做的很正确——或者说 DevSecOps——提高了 IT 的安全性。”
|
||||
|
||||
IT 团队比任何以往都要求要快速频繁的交付服务。DevOps 在某种程度上可以成为一个很棒的推动者,因为它能够消除开发和运营之间通常遇到的一些摩擦,运营一直被排挤在整个过程之外直到要部署的时候,开发者把代码随便一放之后就不再去管理,他们承担更少的基础架构的责任。那种孤立的方法引起了很多问题,委婉的说,在数字时代,如果将安全孤立起来同样的情况也会发生。
|
||||
|
||||
“我们已经采用了 DevOps,因为它已经被证明通过移除开发和运营之间的阻碍来提高 IT 的绩效,”Reevess 说,“就像我们不应该在开发周期要结束时才加入运营,我们不应该在快要结束时才加入安全。”
|
||||
|
||||
### 为什么 DevSecOps 必然出现
|
||||
|
||||
或许会把 DevSecOps 看作是另一个时髦词,但对于安全意识很强的IT领导者来说,它是一个实质性的术语:在软件开发管道中安全必须是第一层面的要素,而不是部署前的最后一步的螺栓,或者更糟的是,作为一个团队只有当一个实际的事故发生的时候安全人员才会被重用争抢。
|
||||
|
||||
“DevSecOps 不只是一个时髦的术语——因为多种原因它是现在和未来 IT 将呈现的状态”,来自 [Sumo Logic] 的安全和合规副总裁 George 说道,“最重要的好处是将安全融入到开发和运营当中开提供保护的能力”
|
||||
|
||||
此外,DevSecOps 的出现可能是 DevOps 自身逐渐成熟并扎根于 IT 之中的一个征兆。
|
||||
|
||||
“企业中的 DevOps 文化已成定局,而且那意味着开发者们正以不断增长的速度交付功能和更新,特别是自我管理的组织会对合作和衡量的结果更加满意”,来自 [CYBRIC] 的首席技术官和联合创始人 Mike 说道。
|
||||
|
||||
在实施 DevOps 的同时继续保留原有安全措施的团队和公司,随着他们继续部署的更快更频繁可能正在经历越来越多的安全管理风险上的痛苦。
|
||||
|
||||
“现在的手工的安全测试方法会继续远远被甩在后面。”
|
||||
|
||||
“如今,手动的安全测试方法正被甩得越来越远,利用自动化和协作将安全测试转移到软件开发生命周期中,因此推动 DevSecOps 的文化是 IT 领导者们为增加整体的灵活性提供安全保证的唯一途径”,Kail 说。
|
||||
|
||||
转移安全测试也使开发者受益:他们能够在开放的较早的阶段验证并解决潜在的问题——这样很少需要或者甚至不需要安全人员的介入,而不是在一个新的服务或者更新部署之前在他们的代码中发现一个明显的漏洞。
|
||||
|
||||
“做的正确,DevSecOps 能够将安全融入到开发生命周期中,允许开发者们在没有安全中断的情况下更加快速容易的保证他们应用的安全”,来自 [SAS][8] 的首席信息安全员 Wilson 说道。
|
||||
|
||||
Wilson 指出静态(SAST)和源组合分析(SCA)工具,集成到团队的持续交付管道中,作为有用的技术通过给予开发者关于他们的代码中的潜在问题和第三方依赖中的漏洞的反馈来使之逐渐成为可能。
|
||||
|
||||
“因此,开发者们能够主动和迭代的缓解应用安全的问题,然后在不需要安全人员介入的情况下重新进行安全扫描。” Wilson 说。他同时指出 DevSecOps 能够帮助开发者简化更新和打补丁。
|
||||
|
||||
DevSecOps 并不意味着你不再需要安全组的意见了,就如同 DevOps 并不意味着你不再需要基础架构专家;它只是帮助你减少在生产中发现缺陷的可能性,或者减少导致降低部署速度的阻碍,因为缺陷已经在开发周期中被发现解决了。
|
||||
|
||||
“如果他们有问题或者需要帮助,我们就在这儿,但是因为已经给了开发者他们需要的保护他们应用安全的工具,我们很少在一个深入的测试中发现一个导致中断的问题,”Wilson 说道。
|
||||
|
||||
### DevSecOps 遇到 Meltdown
|
||||
|
||||
Sumo Locic 的 Gerchow 向我们分享了一个在运转中的 DevSecOps 文化的一个及时案例:当最近 [Meltdown 和 Spectre] 的消息传来的时候,团队的 DevSecOps 方法使得有了一个快速的响应来减轻风险,没有任何的通知去打扰内部或者外部的顾客,Gerchow 所说的这点对原生云、高监管的公司来说特别的重要。
|
||||
|
||||
第一步:Gerchow 的小型安全团队都具有一定的开发能力,能够通过 Slack 和它的主要云供应商协同工作来确保它的基础架构能够在 24 小时之内完成修复。
|
||||
|
||||
“接着我的团队立即开始进行系统级的修复,实现终端客户的零停机时间,不需要去开工单给工程师,如果那样那意味着你需要等待很长的变更过程。所有的变更都是通过 Slack 的自动 jira 票据进行,通过我们的日志监控和分析解决方案”,Gerchow 解释道。
|
||||
|
||||
在本质上,它听起来非常像 DevOps 文化,匹配正确的人员、过程和工具,但它明确的将安全作为文化中的一部分进行了混合。
|
||||
|
||||
“在传统的环境中,这将花费数周或数月的停机时间来处理,因为开发、运维和安全三者是相互独立的”,Gerchow 说道,“通过一个 DevSecOps 的过程和习惯,终端用户可以通过简单的沟通和当日修复获得无缝的体验。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.datical.com/
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
[4]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[5]:https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
|
||||
[6]:https://www.sumologic.com/
|
||||
[7]:https://www.cybric.io/
|
||||
[8]:https://www.sas.com/en_us/home.html
|
||||
[9]:https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-heres-what-you-need-know?intcmp=701f2000000tjyaAAA
|
||||
@ -1,9 +1,11 @@
|
||||
Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
|
||||
Kubernetes 分布式应用部署实战:以人脸识别应用为例
|
||||
============================================================
|
||||
|
||||
# 简介
|
||||

|
||||
|
||||
伙计们,请做好准备,下面将是一段漫长的旅程,期望你能够乐在其中。
|
||||
## 简介
|
||||
|
||||
伙计们,请搬好小板凳坐好,下面将是一段漫长的旅程,期望你能够乐在其中。
|
||||
|
||||
我将基于 [Kubernetes][5] 部署一个分布式应用。我曾试图编写一个尽可能真实的应用,但由于时间和精力有限,最终砍掉了很多细节。
|
||||
|
||||
@ -11,17 +13,17 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
# 应用
|
||||
## 应用
|
||||
|
||||
### TL;DR
|
||||
|
||||
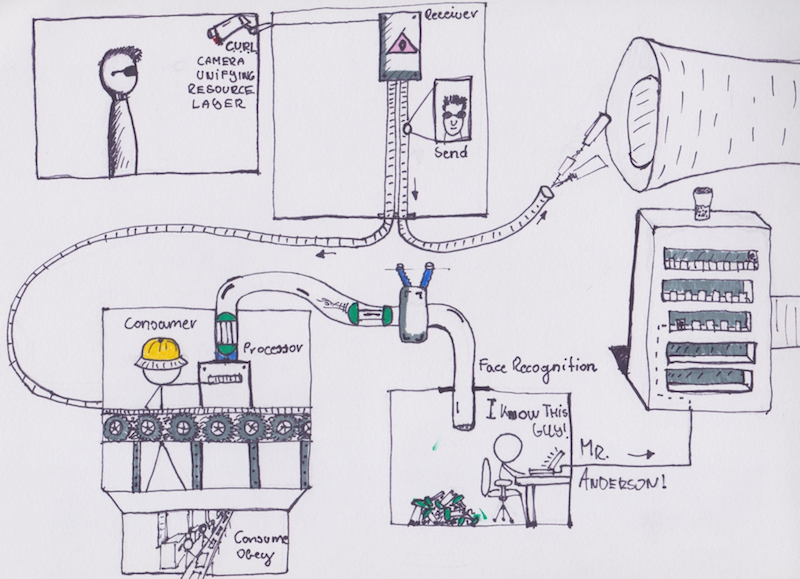
|
||||
|
||||
应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
|
||||
该应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
|
||||
|
||||
这是一个人脸识别服务,通过比较已知个人的图片,识别给定图片对应的个人。前端页面用表格形式简要的展示图片及对应的个人。具体而言,向 [接收器][6] 发送请求,请求包含指向一个图片的链接。图片可以位于任何位置。接受器将图片地址存储到数据库 (MySQL) 中,然后向队列发送处理请求,请求中包含已保存图片的 ID。这里我们使用 [NSQ][8] 建立队列。
|
||||
|
||||
[图片处理][9]服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的[人脸识别][10]后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
|
||||
[图片处理][9] 服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的 [人脸识别][10] 后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
|
||||
|
||||
标记为失败的图片可以通过计划任务等方式进行重试。
|
||||
|
||||
@ -33,39 +35,31 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
|
||||
|
||||
```
|
||||
curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image/post
|
||||
|
||||
```
|
||||
|
||||
此时,接收器将<ruby>路径<rt>path</rt></ruby>存储到共享数据库集群中,对应的条目包括数据库服务提供的 ID。本应用采用”持久层提供条目对象唯一标识“的模型。获得条目 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
|
||||
此时,接收器将<ruby>路径<rt>path</rt></ruby>存储到共享数据库集群中,该实体存储后将从数据库服务收到对应的 ID。本应用采用“<ruby>实体对象<rt>Entity Object</rt></ruby>的唯一标识由持久层提供”的模型。获得实体 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
|
||||
|
||||
### 图片处理器
|
||||
|
||||
从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go routines,具体为:
|
||||
从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go <ruby>协程<rt>routine</rt></ruby>,具体为:
|
||||
|
||||
### Consume
|
||||
|
||||
这是一个 NSQ 消费者,需要完成三项任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个 routine 处理。最后,告知第二个 routine 处理新任务,方法为 [sync.Condition][12]。
|
||||
这是一个 NSQ 消费者,需要完成三项必需的任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个协程处理。最后,告知第二个协程处理新任务,方法为 [sync.Condition][12]。
|
||||
|
||||
### ProcessImages
|
||||
|
||||
该 routine 会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该 routine 并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
|
||||
该协程会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该协程并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
|
||||
|
||||
* 与人脸识别服务建立 gRPC 连接,其中人脸识别服务会在人脸识别部分进行介绍
|
||||
|
||||
* 从数据库获取图片对应的条目
|
||||
|
||||
* 从数据库获取图片对应的实体
|
||||
* 为 [断路器][1] 准备两个函数
|
||||
* 函数 1: 用于 RPC 方法调用的主函数
|
||||
|
||||
* 函数 2: 基于 ping 的断路器健康检查
|
||||
|
||||
* 调用函数 1 将图片路径发送至人脸识别服务,其中路径应该是人脸识别服务可以访问的,最好是共享的,例如 NFS
|
||||
|
||||
* 如果调用失败,将图片条目状态更新为 FAILEDPROCESSING
|
||||
|
||||
* 如果调用失败,将图片实体状态更新为 FAILEDPROCESSING
|
||||
* 如果调用成功,返回值是一个图片的名字,对应数据库中的一个个人。通过联合 SQL 查询,获取对应个人的 ID
|
||||
|
||||
* 将数据库中的图片条目状态更新为 PROCESSED,更新图片被识别成的个人的 ID
|
||||
* 将数据库中的图片实体状态更新为 PROCESSED,更新图片被识别成的个人的 ID
|
||||
|
||||
这个服务可以复制多份同时运行。
|
||||
|
||||
@ -89,7 +83,7 @@ curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image
|
||||
|
||||
注意:我曾经试图使用 [GoCV][14],这是一个极好的 Go 库,但欠缺所需的 C 绑定。推荐马上了解一下这个库,它会让你大吃一惊,例如编写若干行代码即可实现实时摄像处理。
|
||||
|
||||
这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg, hannibal_2.jpg, gergely_1.jpg, john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person, person_images`,具体如下:
|
||||
这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg`、 `hannibal_2.jpg`、 `gergely_1.jpg`、 `john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person`、 `person_images`,具体如下:
|
||||
|
||||
```
|
||||
+----+----------+
|
||||
@ -126,13 +120,13 @@ NSQ 是 Go 编写的小规模队列,可扩展且占用系统内存较少。NSQ
|
||||
|
||||
### 配置
|
||||
|
||||
为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 .env 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
|
||||
为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 `.env` 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
|
||||
|
||||
### 应用小结
|
||||
|
||||
这就是待部署应用的全部架构信息。应用的各个组件都是可变更的,他们之间仅通过数据库、消息队列和 gRPC 进行耦合。考虑到更新机制的原理,这是部署分布式应用所必须的;在部署部分我会继续分析。
|
||||
|
||||
# 使用 Kubernetes 部署应用
|
||||
## 使用 Kubernetes 部署应用
|
||||
|
||||
### 基础知识
|
||||
|
||||
@ -144,55 +138,51 @@ Kubernetes 是容器化服务及应用的管理器。它易于扩展,可以管
|
||||
|
||||
在 Kubernetes 中,你给出期望的应用状态,Kubernetes 会尽其所能达到对应的状态。状态可以是已部署、已暂停,有 2 个副本等,以此类推。
|
||||
|
||||
Kubernetes 使用标签和注释标记组件,包括服务,部署,副本组,守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与 应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
|
||||
Kubernetes 使用标签和注释标记组件,包括服务、部署、副本组、守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
|
||||
|
||||
### Kubernetes 集群
|
||||
|
||||
要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求 Nodes 并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
|
||||
要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求节点并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
|
||||
|
||||
### 节点 (Nodes)
|
||||
### 节点
|
||||
|
||||
节点是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
|
||||
<ruby>节点<rt>node</rt></ruby>是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
|
||||
|
||||
### Pods
|
||||
### Pod
|
||||
|
||||
Pods 是本地容器组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和 虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
|
||||
Pod 是本地容器逻辑上组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
|
||||
|
||||
### 部署 (Deployments)
|
||||
### 部署
|
||||
|
||||
在 Kubernetes 中创建任何类型的资源时,后台使用一个部署,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
|
||||
在 Kubernetes 中创建任何类型的资源时,后台使用一个<ruby>部署<rt>deployment</rt></ruby>组件,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
|
||||
|
||||
### 服务 (Services)
|
||||
### 服务
|
||||
|
||||
默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,mysql,内部 API 或前端,都需要长期运行并使用保持不变的 IP 或 更佳的 DNS 记录。
|
||||
默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,MySQL、内部 API 或前端,都需要长期运行并使用保持不变的 IP 或更好的 DNS 记录。
|
||||
|
||||
为解决这个问题,Kubernetes 提供了服务组件,可以定义访问模式,支持的模式包括负载均衡,简单 IP 或 内部 DNS。
|
||||
为解决这个问题,Kubernetes 提供了<ruby>服务<rt>service</rt></ruby>组件,可以定义访问模式,支持的模式包括负载均衡、简单 IP 或内部 DNS。
|
||||
|
||||
Kubernetes 如何获知服务运行正常呢?你可以配置健康性检查和可用性检查。健康性检查是指检查容器是否处于运行状态,但容器处于运行状态并不意味着服务运行正常。对此,你应该使用可用性检查,即请求应用的一个特别<ruby>接口<rt>endpoint</rt></ruby>。
|
||||
|
||||
由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络,服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
|
||||
由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络、服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
|
||||
|
||||
### DNS / 服务发现
|
||||
|
||||
在 Kubernetes 集群中创建服务后,该服务会从名为 kube-proxy 和 kube-dns 的特殊 Kubernetes 部署中获取一个 DNS 记录。他们两个用于提供集群内的服务发现。如果你有一个正在运行的 mysql 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
|
||||
在 Kubernetes 集群中创建服务后,该服务会从名为 `kube-proxy` 和 `kube-dns` 的特殊 Kubernetes 部署中获取一个 DNS 记录。它们两个用于提供集群内的服务发现。如果你有一个正在运行的 MySQL 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
|
||||
|
||||
* `mysql` – 服务的名称
|
||||
|
||||
* `default` – 命名空间的名称
|
||||
|
||||
* `svc` – 对应服务分类
|
||||
|
||||
* `cluster.local` – 本地集群的域名
|
||||
|
||||
可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 提供程序并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
|
||||
可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 服务,并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
|
||||
|
||||
* 节点端口方式 – `kubectl get -o jsonpath="{.spec.ports[0].nodePort}" services mysql`
|
||||
|
||||
* 负载均衡方式 – `kubectl get -o jsonpath="{.spec.ports[0].LoadBalancer}" services mysql`
|
||||
|
||||
### 模板文件
|
||||
|
||||
类似 Docker Compose, TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
|
||||
类似 Docker Compose、TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
|
||||
|
||||
以 Nginx 部署为例,查看下面的 yaml 模板:
|
||||
|
||||
@ -218,26 +208,26 @@ spec: #(4)
|
||||
image: nginx:1.7.9
|
||||
ports:
|
||||
- containerPort: 80
|
||||
|
||||
```
|
||||
|
||||
在这个示例部署中,我们做了如下操作:
|
||||
|
||||
* (1) 使用 kind 关键字定义模板类型
|
||||
* (2) 使用 metadata 关键字,增加该部署的识别信息,使用 labels 标记每个需要创建的资源 (3)
|
||||
* (4) 然后使用 spec 关键字描述所需的状态
|
||||
* (5) nginx 应用需要 3 个副本
|
||||
* (6) Pod 中容器的模板定义部分
|
||||
* 容器名称为 nginx
|
||||
* 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
|
||||
* (1) 使用 `kind` 关键字定义模板类型
|
||||
* (2) 使用 `metadata` 关键字,增加该部署的识别信息
|
||||
* (3) 使用 `labels` 标记每个需要创建的资源
|
||||
* (4) 然后使用 `spec` 关键字描述所需的状态
|
||||
* (5) nginx 应用需要 3 个副本
|
||||
* (6) Pod 中容器的模板定义部分
|
||||
* 容器名称为 nginx
|
||||
* 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
|
||||
|
||||
### 副本组 (ReplicaSet)
|
||||
### 副本组
|
||||
|
||||
副本组是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
|
||||
<ruby>副本组<rt>ReplicaSet</rt></ruby>是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
|
||||
|
||||
### 守护进程组 (DaemonSet)
|
||||
### 守护进程组
|
||||
|
||||
上面提到 Kubernetes 始终使用标签,还有印象吗?守护进程组是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
|
||||
上面提到 Kubernetes 始终使用标签,还有印象吗?<ruby>守护进程组<rt>DaemonSet</rt></ruby>是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
|
||||
|
||||
例如,你将所有节点增加 `logger` 或 `mission_critical` 的标签,以便运行日志 / 审计服务的守护进程。接着,你创建一个守护进程组并使用 `logger` 或 `mission_critical` 节点选择器。Kubernetes 会查找具有该标签的节点,确保守护进程的实例一直运行在这些节点中。因而,节点中运行的所有进程都可以在节点内访问对应的守护进程。
|
||||
|
||||
@ -253,7 +243,7 @@ spec: #(4)
|
||||
|
||||
### Kubernetes 部分小结
|
||||
|
||||
Kubernetes 是容器编排的便捷工具,工作单元为 Pods,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
|
||||
Kubernetes 是容器编排的便捷工具,工作单元为 Pod,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
|
||||
|
||||
截至目前,Kubernetes 原生支持所有主流云服务供应商,而且完全开源。如果你愿意,可以贡献代码;如果你希望对工作原理有深入了解,可以查阅代码:[GitHub 上的 Kubernetes 项目][22]。
|
||||
|
||||
@ -272,7 +262,7 @@ kubectl get nodes -o yaml
|
||||
|
||||
### 构建容器
|
||||
|
||||
Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python,NSQ 和 MySQL 使用对应的容器。
|
||||
Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python、NSQ 和 MySQL 使用对应的容器。
|
||||
|
||||
### 上下文
|
||||
|
||||
@ -293,9 +283,9 @@ Switched to context "kube-face-cluster".
|
||||
```
|
||||
此后,所有 `kubectl` 命令都会使用 `face` 命名空间。
|
||||
|
||||
(译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
|
||||
(LCTT 译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
|
||||
|
||||
### 应用部署
|
||||
## 应用部署
|
||||
|
||||
Pods 和 服务概览:
|
||||
|
||||
@ -318,7 +308,6 @@ type: Opaque
|
||||
data:
|
||||
mysql_password: base64codehere
|
||||
mysql_userpassword: base64codehere
|
||||
|
||||
```
|
||||
|
||||
其中 base64 编码通过如下命令生成:
|
||||
@ -326,10 +315,9 @@ data:
|
||||
```
|
||||
echo -n "ubersecurepassword" | base64
|
||||
echo -n "root:ubersecurepassword" | base64
|
||||
|
||||
```
|
||||
|
||||
(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 mysql_password, 仅包含密码;另一条对应 mysql_userpassword,包含用户和密码。后文会用到 mysql_userpassword,但没有提及相应的生成)
|
||||
(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 `mysql_password`,仅包含密码;另一条对应 `mysql_userpassword`,包含用户和密码。后文会用到 `mysql_userpassword`,但没有提及相应的生成)
|
||||
|
||||
我的部署 yaml 对应部分如下:
|
||||
|
||||
@ -362,13 +350,12 @@ echo -n "root:ubersecurepassword" | base64
|
||||
|
||||
其中 `presistentVolumeClain` 是关键,告知 Kubernetes 当前资源需要持久化存储。持久化存储的提供方式对用户透明。类似 Pods,如果想了解更多细节,参考文档:[Kubernetes 持久化存储][27]。
|
||||
|
||||
(LCTT 译注:使用 presistentVolumeClain 之前需要创建 presistentVolume,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
|
||||
(LCTT 译注:使用 `presistentVolumeClain` 之前需要创建 `presistentVolume`,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
|
||||
|
||||
使用如下命令部署 MySQL 服务:
|
||||
|
||||
```
|
||||
kubectl apply -f mysql.yaml
|
||||
|
||||
```
|
||||
|
||||
这里比较一下 `create` 和 `apply`。`apply` 是一种<ruby>宣告式<rt>declarative</rt></ruby>的对象配置命令,而 `create` 是<ruby>命令式<rt>imperative</rt>的命令。当下我们需要知道的是,`create` 通常对应一项任务,例如运行某个组件或创建一个部署;相比而言,当我们使用 `apply` 的时候,用户并没有指定具体操作,Kubernetes 会根据集群目前的状态定义需要执行的操作。故如果不存在名为 `mysql` 的服务,当我执行 `apply -f mysql.yaml` 时,Kubernetes 会创建该服务。如果再次执行这个命令,Kubernetes 会忽略该命令。但如果我再次运行 `create`,Kubernetes 会报错,告知服务已经创建。
|
||||
@ -460,7 +447,7 @@ volumes:
|
||||
|
||||
```
|
||||
|
||||
(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,person_images 表中的 person_id 列数字都小 1,作者默认 id 从 0 开始,但应该是从 1 开始)
|
||||
(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,`person_images` 表中的 `person_id` 列数字都小 1,作者默认 `id` 从 0 开始,但应该是从 1 开始)
|
||||
|
||||
运行如下命令查看引导脚本是否正确执行:
|
||||
|
||||
@ -489,7 +476,6 @@ mysql>
|
||||
|
||||
```
|
||||
kubectl logs deployment/mysql -f
|
||||
|
||||
```
|
||||
|
||||
### NSQ 查询
|
||||
@ -505,7 +491,7 @@ NSQ 查询将以内部服务的形式运行。由于不需要外部访问,这
|
||||
|
||||
```
|
||||
|
||||
那么,内部 DNS 对应的条目类似于:`nsqlookup.default.svc.cluster.local`。
|
||||
那么,内部 DNS 对应的实体类似于:`nsqlookup.default.svc.cluster.local`。
|
||||
|
||||
无头服务的更多细节,可以参考:[无头服务][32]。
|
||||
|
||||
@ -517,7 +503,7 @@ args: ["--broadcast-address=nsqlookup.default.svc.cluster.local"]
|
||||
|
||||
```
|
||||
|
||||
你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,nsqlookup 使用 `hostname` (LCTT 译注:这里是指容器的主机名,而不是 hostname 字符串本身)作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
|
||||
你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,`nsqlookup` 使用容器的主机名作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
|
||||
|
||||
NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsqd 守护进程的回调。在 Dockerfile 中暴露相应端口,在 Kubernetes 模板中使用它们,类似如下:
|
||||
|
||||
@ -533,6 +519,7 @@ NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsq
|
||||
```
|
||||
|
||||
服务模板:
|
||||
|
||||
```
|
||||
spec:
|
||||
ports:
|
||||
@ -592,13 +579,13 @@ NSQ 守护进程也需要一些调整的参数配置:
|
||||
|
||||
```
|
||||
|
||||
其中我们配置了 lookup-tcp-address 和 broadcast-address 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
|
||||
其中我们配置了 `lookup-tcp-address` 和 `broadcast-address` 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
|
||||
|
||||
#### 对外公开
|
||||
|
||||
下面即将创建第一个对外公开的服务。有两种方式可供选择。考虑到该 API 负载较高,可以使用负载均衡的方式。另外,如果希望将其部署到生产环境中的任选节点,也应该使用负载均衡方式。
|
||||
|
||||
但由于我使用的本地集群只有一个节点,那么使用 `节点端口` 的方式就足够了。`节点端口` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `<NodeIP>:<NodePort>` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
|
||||
但由于我使用的本地集群只有一个节点,那么使用 `NodePort` 的方式就足够了。`NodePort` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `<NodeIP>:<NodePort>` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
|
||||
|
||||
更多信息,请参考文档:[服务发布][33]。
|
||||
|
||||
@ -643,7 +630,7 @@ spec:
|
||||
|
||||
### 图片处理器
|
||||
|
||||
图片处理器用于将图片传送至识别组件。它需要访问 nslookupd, mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
|
||||
图片处理器用于将图片传送至识别组件。它需要访问 nslookupd、 mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
|
||||
|
||||
```
|
||||
---
|
||||
@ -781,7 +768,7 @@ curl -d '{"path":"/unknown_people/unknown220.jpg"}' http://192.168.99.100:30251/
|
||||
|
||||
```
|
||||
|
||||
图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 known_foler 文件中找到 unknown220.jpg 对应个人的图片,最后返回匹配图片的名称。
|
||||
图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 `known_folder` 文件中找到 `unknown220.jpg` 对应个人的图片,最后返回匹配图片的名称。
|
||||
|
||||
查看日志,大致信息如下:
|
||||
|
||||
@ -861,9 +848,9 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
|
||||
|
||||
```
|
||||
|
||||
### 滚动更新 (Rolling Update)
|
||||
## 滚动更新
|
||||
|
||||
滚动更新过程中会发生什么呢?
|
||||
<ruby>滚动更新<rt>Rolling Update</rt></ruby>过程中会发生什么呢?
|
||||
|
||||
|
||||
|
||||
@ -871,7 +858,7 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
|
||||
|
||||
目前的 API 一次只能处理一个图片,不能批量处理,对此我并不满意。
|
||||
|
||||
#### 代码
|
||||
### 代码
|
||||
|
||||
目前,我们使用下面的代码段处理单个图片的情形:
|
||||
|
||||
@ -900,7 +887,7 @@ func main() {
|
||||
|
||||
这里,你可能会说你并不需要保留旧代码;某些情况下,确实如此。因此,我们打算直接修改旧代码,让其通过少量参数调用新代码。这样操作操作相当于移除了旧代码。当所有客户端迁移完毕后,这部分代码也可以安全地删除。
|
||||
|
||||
#### 新的 Endpoint
|
||||
### 新的接口
|
||||
|
||||
让我们添加新的路由方法:
|
||||
|
||||
@ -941,7 +928,7 @@ func PostImage(w http.ResponseWriter, r *http.Request) {
|
||||
|
||||
```
|
||||
|
||||
当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片 PR][34] 中可以找到更多的修改方式。
|
||||
当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片的 PR][34] 中可以找到更多的修改方式。
|
||||
|
||||
至此,我们使用两种方法调用接收器:
|
||||
|
||||
@ -958,7 +945,7 @@ curl -d '{"paths":[{"path":"unknown4456.jpg"}]}' http://127.0.0.1:8000/images/po
|
||||
|
||||
为了简洁,我不打算为 NSQ 和其它组件增加批量图片处理的能力。这些组件仍然是一次处理一个图片。这部分修改将留给你作为扩展内容。 :)
|
||||
|
||||
#### 新镜像
|
||||
### 新镜像
|
||||
|
||||
为实现滚动更新,我首先需要为接收器服务创建一个新的镜像。新镜像使用新标签,告诉大家版本号为 v1.1。
|
||||
|
||||
@ -969,11 +956,11 @@ docker build -t skarlso/kube-receiver-alpine:v1.1 .
|
||||
|
||||
新镜像创建后,我们可以开始滚动更新了。
|
||||
|
||||
#### 滚动更新
|
||||
### 滚动更新
|
||||
|
||||
在 Kubernetes 中,可以使用多种方式完成滚动更新。
|
||||
|
||||
##### 手动更新
|
||||
#### 手动更新
|
||||
|
||||
不妨假设在我配置文件中使用的容器版本为 `v1.0`,那么实现滚动更新只需运行如下命令:
|
||||
|
||||
@ -991,7 +978,7 @@ kubectl rolling-update receiver --rollback
|
||||
|
||||
容器将回滚到使用上一个版本镜像,操作简捷无烦恼。
|
||||
|
||||
##### 应用新的配置文件
|
||||
#### 应用新的配置文件
|
||||
|
||||
手动更新的不足在于无法版本管理。
|
||||
|
||||
@ -1051,7 +1038,7 @@ kubectl delete services -all
|
||||
|
||||
```
|
||||
|
||||
# 写在最后的话
|
||||
## 写在最后的话
|
||||
|
||||
各位看官,本文就写到这里了。我们在 Kubernetes 上编写、部署、更新和扩展(老实说,并没有实现)了一个分布式应用。
|
||||
|
||||
@ -1065,9 +1052,9 @@ Gergely 感谢你阅读本文。
|
||||
|
||||
via: https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/
|
||||
|
||||
作者:[hannibal ][a]
|
||||
作者:[hannibal][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
215
published/20180708 Getting Started with Debian Packaging.md
Normal file
215
published/20180708 Getting Started with Debian Packaging.md
Normal file
@ -0,0 +1,215 @@
|
||||
Debian 打包入门
|
||||
======
|
||||
|
||||
> 创建 CardBook 软件包、本地 Debian 仓库,并修复错误。
|
||||
|
||||

|
||||
|
||||
我在 GSoC(LCTT 译注:Google Summer Of Code,一项针对学生进行的开源项目训练营,一般在夏季进行。)的任务中有一项是为用户构建 Thunderbird <ruby>扩展<rt>add-ons</rt></ruby>。一些非常流行的扩展,比如 [Lightning][1] (日历行事历)已经拥有了 deb 包。
|
||||
|
||||
另外一个重要的用于管理基于 CardDav 和 vCard 标准的联系人的扩展 [Cardbook][2] ,还没有一个 deb 包。
|
||||
|
||||
我的导师, [Daniel][3] 鼓励我去为它制作一个包,并上传到 [mentors.debian.net][4]。因为这样就可以使用 `apt-get` 来安装,简化了安装流程。这篇博客描述了我是如何从头开始学习为 CardBook 创建一个 Debian 包的。
|
||||
|
||||
首先,我是第一次接触打包,我在从源码构建包的基础上进行了大量研究,并检查它的协议是是否与 [DFSG][5] 兼容。
|
||||
|
||||
我从多个 Debian Wiki 中的指南中进行学习,比如 [打包介绍][6]、 [构建一个包][7],以及一些博客。
|
||||
|
||||
我还研究了包含在 [Lightning 扩展包][8]的 amd64 文件。
|
||||
|
||||
我创建的包可以在[这里][9]找到。
|
||||
|
||||
![Debian Package!][10]
|
||||
|
||||
*Debian 包*
|
||||
|
||||
### 创建一个空的包
|
||||
|
||||
我从使用 `dh_make` 来创建一个 `debian` 目录开始。
|
||||
|
||||
```
|
||||
# Empty project folder
|
||||
$ mkdir -p Debian/cardbook
|
||||
```
|
||||
|
||||
```
|
||||
# create files
|
||||
$ dh_make\
|
||||
> --native \
|
||||
> --single \
|
||||
> --packagename cardbook_1.0.0 \
|
||||
> --email minkush@example.com
|
||||
```
|
||||
|
||||
一些重要的文件,比如 `control`、`rules`、`changelog`、`copyright` 等文件被初始化其中。
|
||||
|
||||
所创建的文件的完整列表如下:
|
||||
|
||||
```
|
||||
$ find /debian
|
||||
debian/
|
||||
debian/rules
|
||||
debian/preinst.ex
|
||||
debian/cardbook-docs.docs
|
||||
debian/manpage.1.ex
|
||||
debian/install
|
||||
debian/source
|
||||
debian/source/format
|
||||
debian/cardbook.debhelper.lo
|
||||
debian/manpage.xml.ex
|
||||
debian/README.Debian
|
||||
debian/postrm.ex
|
||||
debian/prerm.ex
|
||||
debian/copyright
|
||||
debian/changelog
|
||||
debian/manpage.sgml.ex
|
||||
debian/cardbook.default.ex
|
||||
debian/README
|
||||
debian/cardbook.doc-base.EX
|
||||
debian/README.source
|
||||
debian/compat
|
||||
debian/control
|
||||
debian/debhelper-build-stamp
|
||||
debian/menu.ex
|
||||
debian/postinst.ex
|
||||
debian/cardbook.substvars
|
||||
debian/files
|
||||
```
|
||||
|
||||
我了解了 Debian 系统中 [Dpkg][11] 包管理器及如何用它安装、删除和管理包。
|
||||
|
||||
我使用 `dpkg` 命令创建了一个空的包。这个命令创建一个空的包文件以及四个名为 `.changes`、`.deb`、 `.dsc`、 `.tar.gz` 的文件。
|
||||
|
||||
- `.dsc` 文件包含了所发生的修改和签名
|
||||
- `.deb` 文件是用于安装的主要包文件。
|
||||
- `.tar.gz` (tarball)包含了源代码
|
||||
|
||||
这个过程也在 `/usr/share` 目录下创建了 `README` 和 `changelog` 文件。它们包含了关于这个包的基本信息比如描述、作者、版本。
|
||||
|
||||
我安装这个包,并检查这个包安装的内容。我的新包中包含了版本、架构和描述。
|
||||
|
||||
```
|
||||
$ dpkg -L cardbook
|
||||
/usr
|
||||
/usr/share
|
||||
/usr/share/doc
|
||||
/usr/share/doc/cardbook
|
||||
/usr/share/doc/cardbook/README.Debian
|
||||
/usr/share/doc/cardbook/changelog.gz
|
||||
/usr/share/doc/cardbook/copyright
|
||||
```
|
||||
|
||||
### 包含 CardBook 源代码
|
||||
|
||||
在成功的创建了一个空包以后,我在包中添加了实际的 CardBook 扩展文件。 CardBook 的源代码托管在 [Gitlab][12] 上。我将所有的源码文件包含在另外一个目录,并告诉打包命令哪些文件需要包含在这个包中。
|
||||
|
||||
我使用 `vi` 编辑器创建一个 `debian/install` 文件并列举了需要被安装的文件。在这个过程中,我花费了一些时间去学习基于 Linux 终端的文本编辑器,比如 `vi` 。这让我熟悉如何在 `vi` 中编辑、创建文件和快捷方式。
|
||||
|
||||
当这些完成后,我在变更日志中更新了包的版本并记录了我所做的改变。
|
||||
|
||||
```
|
||||
$ dpkg -l | grep cardbook
|
||||
ii cardbook 1.1.0 amd64 Thunderbird add-on for address book
|
||||
```
|
||||
|
||||
![Changelog][13]
|
||||
|
||||
*更新完包的变更日志*
|
||||
|
||||
在重新构建完成后,重要的依赖和描述信息可以被加入到包中。 Debian 的 `control` 文件可以用来添加额外的必须项目和依赖。
|
||||
|
||||
### 本地 Debian 仓库
|
||||
|
||||
在不创建本地存储库的情况下,CardBook 可以使用如下的命令来安装:
|
||||
|
||||
```
|
||||
$ sudo dpkg -i cardbook_1.1.0.deb
|
||||
```
|
||||
|
||||
为了实际测试包的安装,我决定构建一个本地 Debian 存储库。没有它,`apt-get` 命令将无法定位包,因为它没有在 Debian 的包软件列表中。
|
||||
|
||||
为了配置本地 Debian 存储库,我复制我的包 (.deb)为放在 `/tmp` 目录中的 `Packages.gz` 文件。
|
||||
|
||||
![Packages-gz][14]
|
||||
|
||||
*本地 Debian 仓库*
|
||||
|
||||
为了使它工作,我了解了 `apt` 的配置和它查找文件的路径。
|
||||
|
||||
我研究了一种在 `apt-config` 中添加文件位置的方法。最后,我通过在 APT 中添加 `*.list` 文件来添加包的路径,并使用 `apt-cache` 更新APT缓存来完成我的任务。
|
||||
|
||||
因此,最新的 CardBook 版本可以成功的通过 `apt-get install cardbook` 来安装了。
|
||||
|
||||
![Package installation!][15]
|
||||
|
||||
*使用 apt-get 安装 CardBook*
|
||||
|
||||
### 修复打包错误和 Bugs
|
||||
|
||||
我的导师 Daniel 在这个过程中帮了我很多忙,并指导我如何进一步进行打包。他告诉我使用 [Lintian][16] 来修复打包过程中出现的常见错误和最终使用 [dput][17] 来上传 CardBook 包。
|
||||
|
||||
> Lintian 是一个用于发现策略问题和 Bug 的包检查器。它是 Debian 维护者们在上传包之前广泛使用的自动化检查 Debian 策略的工具。
|
||||
|
||||
我上传了该软件包的第二个更新版本到 Debian 目录中的 [Salsa 仓库][18] 的一个独立分支中。
|
||||
|
||||
我从 Debian backports 上安装 Lintian 并学习在一个包上用它来修复错误。我研究了它用在其错误信息中的缩写,和如何查看 Lintian 命令返回的详细内容。
|
||||
|
||||
```
|
||||
$ lintian -i -I --show-overrides cardbook_1.2.0.changes
|
||||
```
|
||||
|
||||
最初,在 `.changes` 文件上运行命令时,我惊讶地看到显示出来了大量错误、警告和注释!
|
||||
|
||||
![Package Error Brief!][19]
|
||||
|
||||
*在包上运行 Lintian 时看到的大量报错*
|
||||
|
||||
![Lintian error1!][20]
|
||||
|
||||
*详细的 Lintian 报错*
|
||||
|
||||
![Lintian error2!][23]
|
||||
|
||||
*详细的 Lintian 报错 (2) 以及更多*
|
||||
|
||||
我花了几天时间修复与 Debian 包策略违例相关的一些错误。为了消除一个简单的错误,我必须仔细研究每一项策略和 Debian 的规则。为此,我参考了 [Debian 策略手册][21] 以及 [Debian 开发者参考][22]。
|
||||
|
||||
我仍然在努力使它变得完美无暇,并希望很快可以将它上传到 mentors.debian.net!
|
||||
|
||||
如果 Debian 社区中使用 Thunderbird 的人可以帮助修复这些报错就太感谢了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://minkush.me/cardbook-debian-package/
|
||||
|
||||
作者:[Minkush Jain][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://minkush.me/cardbook-debian-package/#
|
||||
[1]:https://addons.mozilla.org/en-US/thunderbird/addon/lightning/
|
||||
[2]:https://addons.mozilla.org/nn-NO/thunderbird/addon/cardbook/?src=hp-dl-featured
|
||||
[3]:https://danielpocock.com/
|
||||
[4]:https://mentors.debian.net/
|
||||
[5]:https://wiki.debian.org/DFSGLicenses
|
||||
[6]:https://wiki.debian.org/Packaging/Intro
|
||||
[7]:https://wiki.debian.org/BuildingAPackage
|
||||
[8]:https://packages.debian.org/stretch/amd64/lightning/filelist
|
||||
[9]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package/Debian
|
||||
[10]:http://minkush.me/img/posts/13.png
|
||||
[11]:https://packages.debian.org/stretch/dpkg
|
||||
[12]:https://gitlab.com/CardBook/CardBook
|
||||
[13]:http://minkush.me/img/posts/15.png
|
||||
[14]:http://minkush.me/img/posts/14.png
|
||||
[15]:http://minkush.me/img/posts/11.png
|
||||
[16]:https://packages.debian.org/stretch/lintian
|
||||
[17]:https://packages.debian.org/stretch/dput
|
||||
[18]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package
|
||||
[19]:http://minkush.me/img/posts/16.png (Running Lintian on package)
|
||||
[20]:http://minkush.me/img/posts/10.png
|
||||
[21]:https://www.debian.org/doc/debian-policy/
|
||||
[22]:https://www.debian.org/doc/manuals/developers-reference/
|
||||
[23]:http://minkush.me/img/posts/17.png
|
||||
@ -1,38 +1,38 @@
|
||||
15 个适用于 MacOS 的开源应用程序
|
||||
======
|
||||
|
||||
> 钟爱开源的用户不会觉得在非 Linux 操作系统上使用他们喜爱的应用有多难。
|
||||
|
||||

|
||||
|
||||
只要有可能的情况下,我都会去选择使用开源工具。不久之前,我回到大学去攻读教育领导学硕士学位。即便是我将喜欢的 Linux 笔记本电脑换成了一台 MacBook Pro(因为我不能确定校园里能够接受 Linux),我还是决定继续使用我喜欢的工具,哪怕是在 MacOS 上也是如此。
|
||||
|
||||
幸运的是,它很容易,并且没有哪个教授质疑过我用的是什么软件。即然如此,我就不能保守秘密。
|
||||
幸运的是,它很容易,并且没有哪个教授质疑过我用的是什么软件。即然如此,我就不能秘而不宣。
|
||||
|
||||
我知道,我的一些同学最终会在学区担任领导职务,因此,我与我的那些使用 MacOS 或 Windows 的同学分享了关于下面描述的这些开源软件。毕竟,开源软件是真正地自由和友好的。我也希望他们去了解它,并且愿意以很少的一些成本去提供给他们的学生去使用这些世界级的应用程序。他们中的大多数人都感到很惊讶,因为,众所周知,开源软件除了有像你和我这样的用户之外,压根就没有销售团队。
|
||||
|
||||
### 我的 MacOS 学习曲线
|
||||
|
||||
虽然大多数的开源工具都能像以前我在 Linux 上使用的那样工作,只是需要不同的安装方法。但是,经过这个过程,我学习了这些工具在 MacOS 上的一些细微差别。像 [yum][1]、[DNF][2]、和 [APT][3] 在 MacOS 的世界中压根不存在 — 我真的很怀念它们。
|
||||
虽然大多数的开源工具都能像以前我在 Linux 上使用的那样工作,只是需要不同的安装方法。但是,经过这个过程,我学习了这些工具在 MacOS 上的一些细微差别。像 [yum][1]、[DNF][2]、和 [APT][3] 在 MacOS 的世界中压根不存在 —— 我真的很怀念它们。
|
||||
|
||||
一些 MacOS 应用程序要求依赖项,并且安装它们要比我在 Linux 上习惯的方法困难很多。尽管如此,我仍然没有放弃。在这个过程中,我学会了如何在我的新平台上保留最好的软件。即便是 MacOS 大部分的核心也是 [开源的][4]。
|
||||
|
||||
此外,我的 Linux 的知识背景让我使用 MacOS 的命令行很轻松很舒适。我仍然使用命令行去创建和拷贝文件、添加用户、以及使用其它的像 cat、tac、more、less、和 tail 这样的 [实用工具][5]。
|
||||
此外,我的 Linux 的知识背景让我使用 MacOS 的命令行很轻松很舒适。我仍然使用命令行去创建和拷贝文件、添加用户、以及使用其它的像 `cat`、`tac`、`more`、`less` 和 `tail` 这样的 [实用工具][5]。
|
||||
|
||||
### 15 个适用于 MacOS 的非常好的开源应用程序
|
||||
|
||||
* 在大学里,要求我使用 DOCX 的电子版格式来提交我的工作,而这其实很容易,最初我使用的是 [OpenOffice][6],而后来我使用的是 [LibreOffice][7] 去完成我的论文。
|
||||
* 当我因为演示需要去做一些图像时,我使用的是我最喜欢的图像应用程序 [GIMP][8] 和 [Inkscape][9]。
|
||||
* 我喜欢的播客创建工具是 [Audacity][10]。它比起 Mac 上搭载的专有的应用程序更加简单。我使用它去录制访谈和为视频演示创建配乐。
|
||||
* 我喜欢的播客创建工具是 [Audacity][10]。它比起 Mac 上搭载的专有应用程序更加简单。我使用它去录制访谈和为视频演示创建配乐。
|
||||
* 在 MacOS 上我最早发现的多媒体播放器是 [VideoLan][11] (VLC)。
|
||||
* MacOS 的内置专有视频创建工具是一个非常好的产品,但是你也可以很轻松地去安装和使用 [OpenShot][12],它是一个非常好的内容创建工具。
|
||||
* MacOS 内置的专有视频创建工具是一个非常好的产品,但是你也可以很轻松地去安装和使用 [OpenShot][12],它是一个非常好的内容创建工具。
|
||||
* 当我需要在我的客户端上分析网络时,我在我的 Mac 上使用了易于安装的 [Nmap][13] (Network Mapper) 和 [Wireshark][14] 工具。
|
||||
* 当我为图书管理员和其它教育工作者提供培训时,我在 MacOS 上使用 [VirtualBox][15] 去做 Raspbian、Fedora、Ubuntu、和其它 Linux 发行版的示范操作。
|
||||
* 当我为图书管理员和其它教育工作者提供培训时,我在 MacOS 上使用 [VirtualBox][15] 去做 Raspbian、Fedora、Ubuntu 和其它 Linux 发行版的示范操作。
|
||||
* 我使用 [Etcher.io][16] 在我的 MacBook 上制作了一个引导盘,下载 ISO 文件,将它刻录到一个 U 盘上。
|
||||
* 我认为 [Firefox][17] 比起 MacBook Pro 自带的专有浏览器更易用更安全,并且它允许我跨操作系统去同步我的书签。
|
||||
* 当我使用电子书阅读器时,[Calibre][18] 是当之无愧的选择。它很容易去下载和安装,你甚至只需要几次点击就能将它配置为一台 [教室中使用的电子书服务器][19]。
|
||||
* 最近我给中学的学习教 Python 课程,我发现它可以很容易地从 [Python.org][20] 上下载和安装 Python 3 及 IDLE3 编辑器。我也喜欢学习数据科学,并与学生分享。不论你是对 Python 还是 R 感兴趣,我都建议你下载和 [安装][21] [Anaconda 发行版][22]。它包含了非常好的 iPython 编辑器、RStudio、Jupyter Notebooks、和 JupyterLab,以及其它一些应用程序。
|
||||
* [HandBrake][23] 是一个将你家里的旧的视频 DVD 转成 MP4 的工具,这样你就可以将它们共享到 YouTube、Vimeo、或者你的 MacOS 上的 [Kodi][24] 服务器上。
|
||||
|
||||
|
||||
* 最近我给中学的学生教 Python 课程,我发现它可以很容易地从 [Python.org][20] 上下载和安装 Python 3 及 IDLE3 编辑器。我也喜欢学习数据科学,并与学生分享。不论你是对 Python 还是 R 感兴趣,我都建议你下载和 [安装][21] [Anaconda 发行版][22]。它包含了非常好的 iPython 编辑器、RStudio、Jupyter Notebooks、和 JupyterLab,以及其它一些应用程序。
|
||||
* [HandBrake][23] 是一个将你家里的旧的视频 DVD 转成 MP4 的工具,这样你就可以将它们共享到 YouTube、Vimeo、或者你的 MacOS 上的 [Kodi][24] 服务器上。
|
||||
|
||||
现在轮到你了:你在 MacOS(或 Windows)上都使用什么样的开源软件?在下面的评论区共享出来吧。
|
||||
|
||||
@ -43,7 +43,7 @@ via: https://opensource.com/article/18/7/open-source-tools-macos
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,101 +1,93 @@
|
||||
使用 Wttr.in 在你的终端中显示天气预报
|
||||
======
|
||||
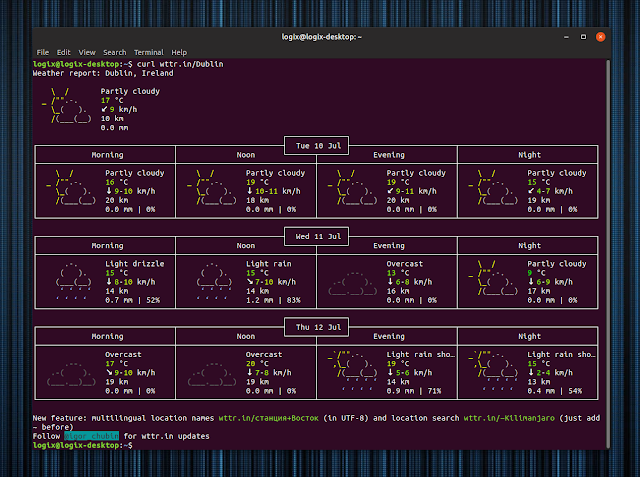
**[wttr.in][1] 是一个功能丰富的天气预报服务,它支持在命令行显示天气**。它可以自动检测你的位置(根据你的 IP 地址),支持指定位置或搜索地理位置(如城市、山区等)等。哦,另外**你不需要安装它 - 你只需要使用 cURL 或 Wget**(见下文)。
|
||||
|
||||
|
||||
|
||||
[wttr.in][1] 是一个功能丰富的天气预报服务,它支持在命令行显示天气。它可以(根据你的 IP 地址)自动检测你的位置,也支持指定位置或搜索地理位置(如城市、山区等)等。哦,另外**你不需要安装它 —— 你只需要使用 cURL 或 Wget**(见下文)。
|
||||
|
||||
wttr.in 功能包括:
|
||||
|
||||
* **显示当前天气以及 3 天天气预报,分为早晨、中午、傍晚和夜晚**(包括温度范围、风速和风向、可见度、降水量和概率)
|
||||
|
||||
* **显示当前天气以及 3 天内的天气预报,分为早晨、中午、傍晚和夜晚**(包括温度范围、风速和风向、可见度、降水量和概率)
|
||||
* **可以显示月相**
|
||||
|
||||
* **基于你的 IP 地址自动检测位置**
|
||||
|
||||
* **允许指定城市名称、3 字母的机场代码、区域代码、GPS 坐标、IP 地址或域名**。你还可以指定地理位置,如湖泊、山脉、地标等)
|
||||
|
||||
* **支持多语言位置名称**(查询字符串必须以 Unicode 指定)
|
||||
|
||||
* **支持指定**天气预报显示的语言(它支持超过 50 种语言)
|
||||
|
||||
* **it uses USCS units for queries from the USA and the metric system for the rest of the world** , but you can change this by appending `?u` for USCS, and `?m` for the metric system (SI)
|
||||
* **来自美国的查询使用 USCS 单位用于,世界其他地方使用公制系统**,但你可以通过附加 `?u` 使用 USCS,附加 `?m` 使用公制系统。 )
|
||||
* **3 种输出格式:终端的 ANSI,浏览器的 HTML 和 PNG**
|
||||
|
||||
* **3 种输出格式:终端的 ANSI,浏览器的 HTML 和 PNG**。
|
||||
|
||||
|
||||
|
||||
|
||||
就像我在文章开头提到的那样,使用 wttr.in,你只需要 cURL 或 Wget,但你也可以
|
||||
就像我在文章开头提到的那样,使用 wttr.in,你只需要 cURL 或 Wget,但你也可以在你的服务器上[安装它][3]。 或者你可以安装 [wego][4],这是一个使用 wtter.in 的终端气候应用,虽然 wego 要求注册一个 API 密钥来安装。
|
||||
|
||||
**在使用 wttr.in 之前,请确保已安装 cURL。**在 Debian、Ubuntu 或 Linux Mint(以及其他基于 Debian 或 Ubuntu 的 Linux 发行版)中,使用以下命令安装 cURL:
|
||||
|
||||
```
|
||||
sudo apt install curl
|
||||
|
||||
```
|
||||
|
||||
### wttr.in 命令行示例
|
||||
|
||||
获取你所在位置的天气(wttr.in 会根据你的 IP 地址猜测你的位置):
|
||||
|
||||
```
|
||||
curl wttr.in
|
||||
|
||||
```
|
||||
|
||||
通过在 `curl` 之后添加 `-4`,强制 cURL 将名称解析为 IPv4 地址(如果你遇到 IPv6 和 wttr.in 问题):
|
||||
通过在 `curl` 之后添加 `-4`,强制 cURL 将名称解析为 IPv4 地址(如果你用 IPv6 访问 wttr.in 有问题):
|
||||
|
||||
```
|
||||
curl -4 wttr.in
|
||||
|
||||
```
|
||||
|
||||
如果你想检索天气预报保存为 png,**还可以使用 Wget**(而不是 cURL),或者你想这样使用它:
|
||||
|
||||
```
|
||||
wget -O- -q wttr.in
|
||||
|
||||
```
|
||||
|
||||
如果相对 cURL 你更喜欢 Wget ,可以在下面的所有命令中用 `wget -O- -q` 替换 `curl`。
|
||||
|
||||
指定位置:
|
||||
|
||||
```
|
||||
curl wttr.in/Dublin
|
||||
|
||||
```
|
||||
|
||||
显示地标的天气信息(本例中为艾菲尔铁塔):
|
||||
|
||||
```
|
||||
curl wttr.in/~Eiffel+Tower
|
||||
|
||||
```
|
||||
|
||||
获取 IP 地址位置的天气信息(以下 IP 属于 GitHub):
|
||||
|
||||
```
|
||||
curl wttr.in/@192.30.253.113
|
||||
|
||||
```
|
||||
|
||||
使用 USCS 单位检索天气:
|
||||
|
||||
```
|
||||
curl wttr.in/Paris?u
|
||||
|
||||
```
|
||||
|
||||
如果你在美国,强制 wttr.in 使用公制系统(SI):
|
||||
|
||||
```
|
||||
curl wttr.in/New+York?m
|
||||
|
||||
```
|
||||
|
||||
使用 Wget 将当前天气和 3 天预报下载为 PNG 图像:
|
||||
|
||||
```
|
||||
wget wttr.in/Istanbul.png
|
||||
|
||||
```
|
||||
|
||||
你可以指定 PNG 名称
|
||||
你可以指定 PNG 的[透明度][5],这在你要使用一个脚本自动添加天气信息到某些图片(比如墙纸)上有用。
|
||||
|
||||
**对于其他示例,请查看 wttr.in [项目页面][2]或在终端中输入:**
|
||||
|
||||
```
|
||||
curl wttr.in/:help
|
||||
|
||||
```
|
||||
|
||||
|
||||
@ -106,7 +98,7 @@ via: https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,13 @@
|
||||
Python 集合是什么,为什么应该使用以及如何使用?
|
||||
=====
|
||||
|
||||
[wilfredinni][5] 在 07/10/2018 发表
|
||||
|
||||

|
||||
|
||||
Python 配备了几种内置数据类型来帮我们组织数据。这些结构包括列表,字典,元组和集合。
|
||||
Python 配备了几种内置数据类型来帮我们组织数据。这些结构包括列表、字典、元组和集合。
|
||||
|
||||
根据 Python 3 文档:
|
||||
|
||||
> 集合是一个*无序*集合,没有*重复元素*。基本用途包括*成员测试*和*消除重复的条目*。集合对象还支持数学运算,如*并集*,*交集*,*差集*和*对等差分*。
|
||||
> 集合是一个*无序*集合,没有*重复元素*。基本用途包括*成员测试*和*消除重复的条目*。集合对象还支持数学运算,如*并集*、*交集*、*差集*和*对等差分*。
|
||||
|
||||
在本文中,我们将回顾并查看上述定义中列出的每个要素的示例。让我们马上开始,看看如何创建它。
|
||||
|
||||
@ -25,7 +23,6 @@ Python 配备了几种内置数据类型来帮我们组织数据。这些结构
|
||||
{1, 2, 3}
|
||||
>>> type(s1)
|
||||
<class 'set'>
|
||||
|
||||
```
|
||||
|
||||
使用 `{}`:
|
||||
@ -38,7 +35,6 @@ Python 配备了几种内置数据类型来帮我们组织数据。这些结构
|
||||
>>> type(s2)
|
||||
<class 'set'>
|
||||
>>>
|
||||
|
||||
```
|
||||
|
||||
如你所见,这两种方法都是有效的。但问题是,如果我们想要一个空的集合呢?
|
||||
@ -47,34 +43,32 @@ Python 配备了几种内置数据类型来帮我们组织数据。这些结构
|
||||
>>> s = {}
|
||||
>>> type(s)
|
||||
<class 'dict'>
|
||||
|
||||
```
|
||||
|
||||
没错,如果我们使用空花括号,我们将得到一个字典而不是一个集合。
|
||||
没错,如果我们使用空花括号,我们将得到一个字典而不是一个集合。=)
|
||||
|
||||
值得一提的是,为了简单起见,本文中提供的所有示例都将使用整数集合,但集合可以包含 Python 支持的所有 [hashable(可哈希)][6] 数据类型。换句话说,即整数,字符串和元组,而不是*列表*或*字典*这样的可变类型。
|
||||
值得一提的是,为了简单起见,本文中提供的所有示例都将使用整数集合,但集合可以包含 Python 支持的所有 <ruby>[可哈希的][6]<rt>hashable</rt></ruby> 数据类型。换句话说,即整数、字符串和元组,而不是*列表*或*字典*这样的可变类型。
|
||||
|
||||
```
|
||||
>>> s = {1, 'coffee', [4, 'python']}
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
TypeError: unhashable type: 'list'
|
||||
|
||||
```
|
||||
|
||||
既然你知道如何创建一个集合以及它可以包含哪些类型的元素,那么让我们继续看看*为什么*我们总是应该把它放在我们的工具箱中。
|
||||
既然你知道了如何创建一个集合以及它可以包含哪些类型的元素,那么让我们继续看看*为什么*我们总是应该把它放在我们的工具箱中。
|
||||
|
||||
### 为什么你需要使用它
|
||||
|
||||
写代码时,你可以用不止一种方法来完成它。有些被认为是相当糟糕的,另一些则是清晰的,简介的和可维护的,或者是 "[_pythonic_][7]" 的。
|
||||
写代码时,你可以用不止一种方法来完成它。有些被认为是相当糟糕的,另一些则是清晰的、简洁的和可维护的,或者是 “<ruby>[Python 式的][7]<rt>pythonic</rt></ruby>”。
|
||||
|
||||
根据 [Hitchhiker 对 Python 的建议][8]:
|
||||
|
||||
> 当一个经验丰富的 Python 开发人员(Pythonista)调用一些不够 “Pythonic” 的代码时,他们通常认为着这些代码不遵循通用指南,并且无法被认为是以一种好的方式(可读性)来表达意图。
|
||||
> 当一个经验丰富的 Python 开发人员(<ruby>Python 人<rt>Pythonista</rt></ruby>)调用一些不够 “<ruby>Python 式的<rt>pythonic</rt></ruby>” 的代码时,他们通常认为着这些代码不遵循通用指南,并且无法被认为是以一种好的方式(可读性)来表达意图。
|
||||
|
||||
让我们开始探索 Python 集合那些不仅可以帮助我们提高可读性,还可以加快程序执行时间的方式。
|
||||
|
||||
### 无序的集合元素
|
||||
#### 无序的集合元素
|
||||
|
||||
首先你需要明白的是:你无法使用索引访问集合中的元素。
|
||||
|
||||
@ -84,8 +78,8 @@ TypeError: unhashable type: 'list'
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
TypeError: 'set' object does not support indexing
|
||||
|
||||
```
|
||||
|
||||
或者使用切片修改它们:
|
||||
|
||||
```
|
||||
@ -93,7 +87,6 @@ TypeError: 'set' object does not support indexing
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
TypeError: 'set' object is not subscriptable
|
||||
|
||||
```
|
||||
|
||||
但是,如果我们需要删除重复项,或者进行组合列表(与)之类的数学运算,那么我们可以,并且*应该*始终使用集合。
|
||||
@ -101,16 +94,13 @@ TypeError: 'set' object is not subscriptable
|
||||
我不得不提一下,在迭代时,集合的表现优于列表。所以,如果你需要它,那就加深对它的喜爱吧。为什么?好吧,这篇文章并不打算解释集合的内部工作原理,但是如果你感兴趣的话,这里有几个链接,你可以阅读它:
|
||||
|
||||
* [时间复杂度][1]
|
||||
|
||||
* [set() 是如何实现的?][2]
|
||||
|
||||
* [Python 集合 vs 列表][3]
|
||||
|
||||
* [在列表中使用集合是否有任何优势或劣势,以确保独一无二的列表条目?][4]
|
||||
|
||||
### 没有重复项
|
||||
#### 没有重复项
|
||||
|
||||
写这篇文章的时候,我总是不停地思考,我经常使用 *for* 循环和 *if* 语句检查并删除列表中的重复元素。记得那时我的脸红了,而且不止一次,我写了类似这样的代码:
|
||||
写这篇文章的时候,我总是不停地思考,我经常使用 `for` 循环和 `if` 语句检查并删除列表中的重复元素。记得那时我的脸红了,而且不止一次,我写了类似这样的代码:
|
||||
|
||||
```
|
||||
>>> my_list = [1, 2, 3, 2, 3, 4]
|
||||
@ -121,7 +111,6 @@ TypeError: 'set' object is not subscriptable
|
||||
...
|
||||
>>> no_duplicate_list
|
||||
[1, 2, 3, 4]
|
||||
|
||||
```
|
||||
|
||||
或者使用列表解析:
|
||||
@ -133,7 +122,6 @@ TypeError: 'set' object is not subscriptable
|
||||
[None, None, None, None]
|
||||
>>> no_duplicate_list
|
||||
[1, 2, 3, 4]
|
||||
|
||||
```
|
||||
|
||||
但没关系,因为我们现在有了武器装备,没有什么比这更重要的了:
|
||||
@ -144,10 +132,9 @@ TypeError: 'set' object is not subscriptable
|
||||
>>> no_duplicate_list
|
||||
[1, 2, 3, 4]
|
||||
>>>
|
||||
|
||||
```
|
||||
|
||||
现在让我们使用 *timeit* 模块,查看列表和集合在删除重复项时的执行时间:
|
||||
现在让我们使用 `timeit` 模块,查看列表和集合在删除重复项时的执行时间:
|
||||
|
||||
```
|
||||
>>> from timeit import timeit
|
||||
@ -159,7 +146,6 @@ TypeError: 'set' object is not subscriptable
|
||||
>>> # 首先,让我们看看列表的执行情况:
|
||||
>>> print(timeit('no_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=1000))
|
||||
0.0018683355819786227
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
@ -168,25 +154,27 @@ TypeError: 'set' object is not subscriptable
|
||||
>>> print(timeit('list(set([1, 2, 3, 1, 2, 3, 4]))', number=1000))
|
||||
0.0010220493243764395
|
||||
>>> # 快速而且干净 =)
|
||||
|
||||
```
|
||||
|
||||
使用集合而不是列表推导不仅让我们编写*更少的代码*,而且还能让我们获得*更具可读性*和*高性能*的代码。
|
||||
|
||||
注意:请记住集合是无序的,因此无法保证在将它们转换回列表时,元素的顺序不变。
|
||||
|
||||
[Python 之禅][9]:
|
||||
(to 校正者:建议英文保留)
|
||||
> Beautiful is better than ugly. 优美胜于丑陋。
|
||||
> Explicit is better than implicit.明了胜于晦涩。
|
||||
> Simple is better than complex.简洁胜于复杂。
|
||||
> Flat is better than nested. 扁平胜于嵌套。
|
||||
[Python 之禅][9]:
|
||||
|
||||
集合不正是这样美丽,明了,简单且扁平吗?
|
||||
> <ruby>优美胜于丑陋<rt>Beautiful is better than ugly.</rt></ruby>
|
||||
|
||||
### 成员测试
|
||||
> <ruby>明了胜于晦涩<rt>Explicit is better than implicit.</rt></ruby>
|
||||
|
||||
每次我们使用 *if* 语句来检查一个元素,例如,它是否在列表中时,意味着你正在进行成员测试:
|
||||
> <ruby>简洁胜于复杂<rt>Simple is better than complex.</rt></ruby>
|
||||
|
||||
> <ruby>扁平胜于嵌套<rt>Flat is better than nested.</rt></ruby>
|
||||
|
||||
集合不正是这样美丽、明了、简单且扁平吗?
|
||||
|
||||
#### 成员测试
|
||||
|
||||
每次我们使用 `if` 语句来检查一个元素,例如,它是否在列表中时,意味着你正在进行成员测试:
|
||||
|
||||
```
|
||||
my_list = [1, 2, 3]
|
||||
@ -194,7 +182,6 @@ my_list = [1, 2, 3]
|
||||
... print('Yes, this is a membership test!')
|
||||
...
|
||||
Yes, this is a membership test!
|
||||
|
||||
```
|
||||
|
||||
在执行这些操作时,集合比列表更高效:
|
||||
@ -210,7 +197,6 @@ Yes, this is a membership test!
|
||||
... setup="from __main__ import in_test; iterable = list(range(1000))",
|
||||
... number=1000)
|
||||
12.459663048726043
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
@ -224,11 +210,9 @@ Yes, this is a membership test!
|
||||
... setup="from __main__ import in_test; iterable = set(range(1000))",
|
||||
... number=1000)
|
||||
.12354438152988223
|
||||
|
||||
>>>
|
||||
|
||||
```
|
||||
注意:上面的测试来自于[这里][10] StackOverflow thread。
|
||||
|
||||
注意:上面的测试来自于[这个][10] StackOverflow 话题。
|
||||
|
||||
因此,如果你在巨大的列表中进行这样的比较,尝试将该列表转换为集合,它应该可以加快你的速度。
|
||||
|
||||
@ -236,7 +220,7 @@ Yes, this is a membership test!
|
||||
|
||||
现在你已经了解了集合是什么以及为什么你应该使用它,现在让我们快速浏览一下,看看我们如何修改和操作它。
|
||||
|
||||
### 添加元素
|
||||
#### 添加元素
|
||||
|
||||
根据要添加的元素数量,我们要在 `add()` 和 `update()` 方法之间进行选择。
|
||||
|
||||
@ -247,7 +231,6 @@ Yes, this is a membership test!
|
||||
>>> s.add(4)
|
||||
>>> s
|
||||
{1, 2, 3, 4}
|
||||
|
||||
```
|
||||
|
||||
`update()` 适用于添加多个元素:
|
||||
@ -257,12 +240,11 @@ Yes, this is a membership test!
|
||||
>>> s.update([2, 3, 4, 5, 6])
|
||||
>>> s
|
||||
{1, 2, 3, 4, 5, 6}
|
||||
|
||||
```
|
||||
|
||||
请记住,集合会移除重复项。
|
||||
|
||||
### 移除元素
|
||||
#### 移除元素
|
||||
|
||||
如果你希望在代码中尝试删除不在集合中的元素时收到警报,请使用 `remove()`。否则,`discard()` 提供了一个很好的选择:
|
||||
|
||||
@ -275,7 +257,6 @@ Yes, this is a membership test!
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
KeyError: 3
|
||||
|
||||
```
|
||||
|
||||
`discard()` 不会引起任何错误:
|
||||
@ -287,7 +268,6 @@ KeyError: 3
|
||||
{1, 2}
|
||||
>>> s.discard(3)
|
||||
>>> # 什么都不会发生
|
||||
|
||||
```
|
||||
|
||||
我们也可以使用 `pop()` 来随机丢弃一个元素:
|
||||
@ -298,7 +278,6 @@ KeyError: 3
|
||||
1
|
||||
>>> s
|
||||
{2, 3, 4, 5}
|
||||
|
||||
```
|
||||
|
||||
或者 `clear()` 方法来清空一个集合:
|
||||
@ -308,10 +287,9 @@ KeyError: 3
|
||||
>>> s.clear() # 清空集合
|
||||
>>> s
|
||||
set()
|
||||
|
||||
```
|
||||
|
||||
### union()
|
||||
#### union()
|
||||
|
||||
`union()` 或者 `|` 将创建一个新集合,其中包含我们提供集合中的所有元素:
|
||||
|
||||
@ -320,10 +298,9 @@ set()
|
||||
>>> s2 = {3, 4, 5}
|
||||
>>> s1.union(s2) # 或者 's1 | s2'
|
||||
{1, 2, 3, 4, 5}
|
||||
|
||||
```
|
||||
|
||||
### intersection()
|
||||
#### intersection()
|
||||
|
||||
`intersection` 或 `&` 将返回一个由集合共同元素组成的集合:
|
||||
|
||||
@ -333,10 +310,9 @@ set()
|
||||
>>> s3 = {3, 4, 5}
|
||||
>>> s1.intersection(s2, s3) # 或者 's1 & s2 & s3'
|
||||
{3}
|
||||
|
||||
```
|
||||
|
||||
### difference()
|
||||
#### difference()
|
||||
|
||||
使用 `diference()` 或 `-` 创建一个新集合,其值在 “s1” 中但不在 “s2” 中:
|
||||
|
||||
@ -345,10 +321,9 @@ set()
|
||||
>>> s2 = {2, 3, 4}
|
||||
>>> s1.difference(s2) # 或者 's1 - s2'
|
||||
{1}
|
||||
|
||||
```
|
||||
|
||||
### symmetric_diference()
|
||||
#### symmetric_diference()
|
||||
|
||||
`symetric_difference` 或 `^` 将返回集合之间的不同元素。
|
||||
|
||||
@ -357,7 +332,6 @@ set()
|
||||
>>> s2 = {2, 3, 4}
|
||||
>>> s1.symmetric_difference(s2) # 或者 's1 ^ s2'
|
||||
{1, 4}
|
||||
|
||||
```
|
||||
|
||||
### 结论
|
||||
@ -372,7 +346,7 @@ via: https://www.pythoncheatsheet.org/blog/python-sets-what-why-how
|
||||
|
||||
作者:[wilfredinni][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
Tech jargon: The good, the bad, and the ugly
|
||||
======
|
||||
|
||||
|
||||
One enduring and complex piece of jargon is the use of "free" in relation to software. In fact, the term is so ambiguous that different terms have evolved to describe some of the variants—open source, FOSS, and even phrases such as "free as in speech, not as in beer." But surely this is a good thing, right? We know what we mean; we're sharing shorthand by using a particular word in a particular way. Some people might not understand, and there's some ambiguity. But does that matter?
|
||||
|
||||
### A couple of definitions
|
||||
|
||||
I was involved in an interesting discussion with colleagues recently about the joys (or otherwise) of jargon. It stemmed from a section I wrote in a recent article, [How to talk to security people: a guide for the rest of us][1], where I said:
|
||||
|
||||
> "Jargon has at least two uses:
|
||||
>
|
||||
> 1. as an exclusionary mechanism for groups to keep non-members in the dark;
|
||||
> 2. as a short-hand to exchange information between 'in-the-know' people so that they don't need to explain everything in exhaustive detail every time."
|
||||
>
|
||||
|
||||
|
||||
Given the discussion that arose, I thought it was worth delving more deeply into this question. It's more than an idle interest, as I think there are important lessons around our use of jargon that impact how we interact with our colleagues and peers that deserve some careful thought. These lessons apply particularly to my chosen field, security.
|
||||
|
||||
Before we start, we should define "jargon". It's always nice to have two conflicting versions, so here we go:
|
||||
|
||||
* "Special words or expressions used by a profession or group that are difficult for others to understand." ([Oxford Living Dictionaries][2])
|
||||
* "Without a qualifier, denotes informal 'slangy' language peculiar to or predominantly found among hackers." ([The Jargon File][3])
|
||||
|
||||
|
||||
|
||||
I should start by pointing out that The Jargon File, which was published in paper form in at least [two versions][4] as The Hacker's Dictionary (ed. Steele) and The New Hacker's Dictionary (ed. Raymond), has a pretty special place in my heart. When I decided that I wanted to properly "take up" geekery,1,2 I read The New Hacker's Dictionary from cover to cover, several times, and when a new edition came out, I bought that and did the same.
|
||||
|
||||
In fact, for more technical readers, I suspect that a fair amount of your cultural background is expressed within its covers (paper or virtual), even if you're not aware of it. If you're interested in delving deeper and like the feel of paper in your hands, I encourage you to purchase a copy—but be careful to get the right one. There are some expensive versions that seem just to be printouts of The Jargon File, rather than properly typeset and edited versions.3
|
||||
|
||||
But let's get onto the meat of this article: is jargon a force for good or ill?
|
||||
|
||||
### First: Why jargon is good
|
||||
|
||||
The case for jargon is quite simple. We need jargon to enable us to discuss concepts and the use of terms in normal language—like scheduling—as jargon leads to some interesting metaphors that guide us in our practice.4 We absolutely need shared practice, and for that we need shared language—and some of that language is bound to become jargon over time. But consider a lexicon, or an FAQ, or other ways to allow your colleagues to participate: be inclusive, not exclusive. That's the good. The problem, however, is the bad.
|
||||
|
||||
### The case against jargon: Ambiguity
|
||||
|
||||
You would think jargon would serve to provide agreed terms within a particular discipline and help prevent ambiguity around contexts. It may be a surprise, then, that the first problem we often run into with jargon is namespace clashes. Consider the following. There's an old joke about how to distinguish an electrical engineer from a humanities5 graduate: ask them how many syllables are in the word "coax." The point here, of course, is that they come from different disciplines. But there are lots of words—and particularly abbreviations—that have different meanings or expansions depending on context and where disciplines and contexts may collide.
|
||||
|
||||
What do these words mean to you?6
|
||||
|
||||
* Scheduling: kernel-level CPU allocation to processes OR placement of workloads by an orchestration component
|
||||
* Comms: I/O in a computer system OR marketing/analyst communications
|
||||
* Layer: OSI model OR IP suite layer OR another architectural abstraction layer such as host or workload
|
||||
* SME: subject matter expert OR small/medium enterprise
|
||||
* SMB: small/medium business OR small message block
|
||||
* TLS: transport layer security OR Times Literary Supplement
|
||||
* IP: internet protocol OR intellectual property OR intellectual property as expressed as a silicon component block
|
||||
* FFS for further study OR …7
|
||||
|
||||
|
||||
|
||||
One of the interesting things is that quite a lot of my background is betrayed by the various options that present themselves to me. I wonder how many readers will have thought of the Times Literary Supplement, for example. I'm also more likely to think of SME as the term relating to organisations, because that's the favoured form in Europe, whereas I believe that the US tends to SMB. I'm sure your experiences will all be different—which rather makes my point for me.
|
||||
|
||||
That's the first problem. In a context where jargon is often praised as a way of shortcutting lengthy explanations, it can actually be a significant ambiguating force.
|
||||
|
||||
### The case against jargon: Exclusion
|
||||
|
||||
Intentionally or not—and sometimes it is intentional—groups define themselves through the use of specific terminology. Once this terminology becomes opaque to those outside the group, it becomes "jargon," as per our first definition above. "Good" use of jargon generally allows those within the group to converse using shared context around concepts that do not need to be explained in detail every time they are used.
|
||||
|
||||
An example would be a "smoke test"—a quick test to check that basic functionality is performing correctly (see the Jargon File's [definition][5] for more). If everyone in the group understands what this means, then why go into more detail? But if you are joined at a stand-up meeting8 by a member of marketing who wants to know whether a particular build is ready for release, and you say "well, no—it's only been smoke-tested so far," then it's likely you'll need to explain.
|
||||
|
||||
The problem is that there are occasions when jargon can exclude others, whether that usage is intended or not. There have been times for most of us, I'm sure, when we want to show we're part of a group, so we use terms that we know another person won't understand. On other occasions, the term may be so ingrained in our practice that we use it without thinking, and the other person is unintentionally excluded. I would argue that we need to be careful to avoid both of these uses.
|
||||
|
||||
Intentional exclusion is rarely helpful, but unintentional exclusion can be just as damaging—in some ways more so, as it is typically unremarked and therefore difficult to remedy.
|
||||
|
||||
### What to do?
|
||||
|
||||
First, be aware when you're using jargon, and try to foster an environment where people feel happy to query what you mean. If you see people's eyes glazing over, take a step back and explain the context and the term. Second, be on the lookout for ambiguity: if you're on a project where something can mean more than one thing, disambiguate somewhere in a file or diagram that everyone can access and is easily discoverable. And last, don't use jargon to exclude. We need all the people we can get, so let's bring them in, not push them out.
|
||||
|
||||
1\. "Properly"—really? Although I'm not sure "improperly" is any better.
|
||||
|
||||
2\. I studied English Literature and Theology at university, so this was a conscious decision to embrace a rather different culture.
|
||||
|
||||
3\. The most recent "real" edition of which I'm aware is Raymond, Eric S., 1996, [The New Hacker's Dictionary][6], 3rd ed., MIT University Press, Cambridge, Mass.
|
||||
|
||||
4\. Although metaphors can themselves be constraining as they tend to push us to think in a particular way, even if that way isn't entirely applicable in this context.
|
||||
|
||||
5\. Or "liberal arts".
|
||||
|
||||
6\. I've added the first options that spring to mind when I come across them—I'm aware there are almost certainly others.
|
||||
|
||||
7\. Believe me, when I saw this abbreviation in a research paper for the first time, I was most confused and had to look it up.
|
||||
|
||||
8\. Oh, look: jargon…
|
||||
|
||||
This article originally appeared on [Alice, Eve, and Bob – a security blog][7] and is republished with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/tech-jargon
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:http://aliceevebob.com/2018/05/08/how-to-talk-to-security-people-a-guide-for-the-rest-of-us/
|
||||
[2]:https://en.oxforddictionaries.com/definition/jargon
|
||||
[3]:http://catb.org/jargon/html/distinctions.html
|
||||
[4]:https://en.wikipedia.org/wiki/Jargon_File
|
||||
[5]:http://catb.org/jargon/html/S/smoke-test.html
|
||||
[6]:https://www.amazon.com/New-Hackers-Dictionary-3rd/dp/0262680920
|
||||
[7]:https://aliceevebob.com/2018/06/26/jargon-a-force-for-good-or-ill/
|
||||
@ -1,79 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
GitLab’s Ultimate & Gold Plans Are Now Free For Open-Source Projects
|
||||
======
|
||||
A lot has happened in the open-source community recently. First, [Microsoft acquired GitHub][1] and then people started to look for [GitHub alternatives][2] without even taking a second to think about it while Linus Torvalds released the [Linux Kernel 4.17][3]. Well, if you’ve been following us, I assume that you know all that.
|
||||
|
||||
But, today, GitLab made a smart move by making some of its high-tier plans free for educational institutes and open-source projects. There couldn’t be a better time to offer something like this when a lot of developers are interested in migrating their open-source projects to GitLab.
|
||||
|
||||
### GitLab’s premium plans are now free for open source projects and educational institutes
|
||||
|
||||
![GitLab Logo][4]
|
||||
|
||||
In a [blog post][5] today, GitLab announced that the **Ultimate** and Gold plans are now free for educational institutes and open-source projects. While we already know why GitLab made this move (a darn perfect timing!), they did explain their motive to make it free:
|
||||
|
||||
> We make GitLab free for education because we want students to use our most advanced features. Many universities already run GitLab. If the students use the advanced features of GitLab Ultimate and Gold they will take their experiences with these advanced features to their workplaces.
|
||||
>
|
||||
> We would love to have more open source projects use GitLab. Public projects on GitLab.com already have all the features of GitLab Ultimate. And projects like [Gnome][6] and [Debian][7] already run their own server with the open source version of GitLab. With today’s announcement, open source projects that are comfortable running on proprietary software can use all the features GitLab has to offer while allowing us to have a sustainable business model by charging non-open-source organizations.
|
||||
|
||||
### What are these ‘free’ plans offered by GitLab?
|
||||
|
||||
![GitLab Pricing][8]
|
||||
|
||||
GitLab has two categories of offerings. One is the software that you could host on your own cloud hosting service like [Digital Ocean][9]. The other is providing GitLab software as a service where the hosting is managed by GitLab itself and you get an account on GitLab.com.
|
||||
|
||||
![GitLab Pricing for hosted service][10]
|
||||
|
||||
Gold is the highest offering in the hosted category while Ultimate is the highest offering in the self-hosted category.
|
||||
|
||||
You can get more details about their features on GitLab pricing page. Do note that the support is not included in this offer. You have to purchase it separately.
|
||||
|
||||
### You have to match certain criteria to avail this offer
|
||||
|
||||
GitLab also mentioned – to whom the offer will be valid for. Here’s what they wrote in their blog post:
|
||||
|
||||
> 1. **Educational institutions:** any institution whose purposes directly relate to learning, teaching, and/or training by a qualified educational institution, faculty, or student. Educational purposes do not include commercial, professional, or any other for-profit purposes.
|
||||
>
|
||||
> 2. **Open source projects:** any project that uses a [standard open source license][11] and is non-commercial. It should not have paid support or paid contributors.
|
||||
>
|
||||
>
|
||||
|
||||
|
||||
Although the free plan does not include support, you can still pay an additional fee of 4.95 USD per user per month – which is a very fair price, when you are in the dire need of an expert to help resolve an issue.
|
||||
|
||||
GitLab also added a note for the students:
|
||||
|
||||
> To reduce the administrative burden for GitLab, only educational institutions can apply on behalf of their students. If you’re a student and your educational institution does not apply, you can use public projects on GitLab.com with all functionality, use private projects with the free functionality, or pay yourself.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Now that GitLab is stepping up its game, what do you think about it?
|
||||
|
||||
Do you have a project hosted on [GitHub][12]? Will you be switching over? Or, luckily, you already happen to use GitLab from the start?
|
||||
|
||||
Let us know your thoughts in the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/gitlab-free-open-source/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://itsfoss.com/microsoft-github/
|
||||
[2]:https://itsfoss.com/github-alternatives/
|
||||
[3]:https://itsfoss.com/linux-kernel-4-17/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/GitLab-logo-800x450.png
|
||||
[5]:https://about.gitlab.com/2018/06/05/gitlab-ultimate-and-gold-free-for-education-and-open-source/
|
||||
[6]:https://www.gnome.org/news/2018/05/gnome-moves-to-gitlab-2/
|
||||
[7]:https://salsa.debian.org/public
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-pricing.jpeg
|
||||
[9]:https://m.do.co/c/d58840562553
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-hosted-service-800x273.jpeg
|
||||
[11]:https://itsfoss.com/open-source-licenses-explained/
|
||||
[12]:https://github.com/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating...by SunWave
|
||||
|
||||
How to Check Disk Space on Linux from the Command Line
|
||||
======
|
||||
|
||||
|
||||
@ -1,214 +0,0 @@
|
||||
translating by bestony
|
||||
|
||||
Getting Started with Debian Packaging
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of my tasks in GSoC involved set up of Thunderbird extensions for the user. Some of the more popular add-ons like [‘Lightning’][1] (calendar organiser) already has a Debian package.
|
||||
|
||||
Another important add on is ‘[Cardbook][2]’ which is used to manage contacts for the user based on CardDAV and vCard standards. But it doesn’t have a package yet.
|
||||
|
||||
My mentor, [Daniel][3] motivated me to create a package for it and upload it to [mentors.debian.net][4]. It would ease the installation process as it could get installed through `apt-get`. This blog describes how I learned and created a Debian package for CardBook from scratch.
|
||||
|
||||
Since, I was new to packaging, I did extensive research on basics of building a package from the source code and checked if the license was [DFSG][5] compatible.
|
||||
|
||||
I learned from various Debian wiki guides like ‘[Packaging Intro][6]’, ‘[Building a Package][7]’ and blogs.
|
||||
|
||||
I also studied the amd64 files included in [Lightning extension package][8].
|
||||
|
||||
The package I created could be found [here][9].
|
||||
|
||||
![Debian Package!][10]
|
||||
|
||||
Debian Package
|
||||
|
||||
### Creating an empty package
|
||||
|
||||
I started by creating a `debian` directory by using `dh_make` command
|
||||
```
|
||||
# Empty project folder
|
||||
$ mkdir -p Debian/cardbook
|
||||
|
||||
```
|
||||
```
|
||||
# create files
|
||||
$ dh_make\
|
||||
> --native \
|
||||
> --single \
|
||||
> --packagename cardbook_1.0.0 \
|
||||
> --email minkush@example.com
|
||||
|
||||
```
|
||||
|
||||
Some important files like control, rules, changelog, copyright are initialized with it.
|
||||
|
||||
The list of all the files created:
|
||||
```
|
||||
$ find /debian
|
||||
debian/
|
||||
debian/rules
|
||||
debian/preinst.ex
|
||||
debian/cardbook-docs.docs
|
||||
debian/manpage.1.ex
|
||||
debian/install
|
||||
debian/source
|
||||
debian/source/format
|
||||
debian/cardbook.debhelper.lo
|
||||
debian/manpage.xml.ex
|
||||
debian/README.Debian
|
||||
debian/postrm.ex
|
||||
debian/prerm.ex
|
||||
debian/copyright
|
||||
debian/changelog
|
||||
debian/manpage.sgml.ex
|
||||
debian/cardbook.default.ex
|
||||
debian/README
|
||||
debian/cardbook.doc-base.EX
|
||||
debian/README.source
|
||||
debian/compat
|
||||
debian/control
|
||||
debian/debhelper-build-stamp
|
||||
debian/menu.ex
|
||||
debian/postinst.ex
|
||||
debian/cardbook.substvars
|
||||
debian/files
|
||||
|
||||
```
|
||||
|
||||
I gained an understanding of [Dpkg][11] package management program in Debian and its use to install, remove and manage packages.
|
||||
|
||||
I build an empty package with `dpkg` commands. This created an empty package with four files namely `.changes`, `.deb`, `.dsc`, `.tar.gz`
|
||||
|
||||
`.dsc` file contains the changes made and signature
|
||||
|
||||
`.deb` is the main package file which can be installed
|
||||
|
||||
`.tar.gz` (tarball) contains the source package
|
||||
|
||||
The process also created the README and changelog files in `/usr/share`. They contain the essential notes about the package like description, author and version.
|
||||
|
||||
I installed the package and checked the installed package contents. My new package mentions the version, architecture and description!
|
||||
```
|
||||
$ dpkg -L cardbook
|
||||
/usr
|
||||
/usr/share
|
||||
/usr/share/doc
|
||||
/usr/share/doc/cardbook
|
||||
/usr/share/doc/cardbook/README.Debian
|
||||
/usr/share/doc/cardbook/changelog.gz
|
||||
/usr/share/doc/cardbook/copyright
|
||||
|
||||
```
|
||||
|
||||
### Including CardBook source files
|
||||
|
||||
After successfully creating an empty package, I added the actual CardBook add-on files inside the package. The CardBook’s codebase is hosted [here][12] on Gitlab. I included all the source files inside another directory and told the build package command which files to include in the package.
|
||||
|
||||
I did this by creating a file `debian/install` using vi editor and listed the directories that should be installed. In this process I spent some time learning to use Linux terminal based text editors like vi. It helped me become familiar with editing, creating new files and shortcuts in vi.
|
||||
|
||||
Once, this was done, I updated the package version in the changelog file to document the changes that I have made.
|
||||
```
|
||||
$ dpkg -l | grep cardbook
|
||||
ii cardbook 1.1.0 amd64 Thunderbird add-on for address book
|
||||
|
||||
```
|
||||
|
||||
![Changelog][13]
|
||||
|
||||
Changelog file after updating Package
|
||||
|
||||
After rebuilding it, dependencies and detailed description can be added if necessary. The Debian control file can be edited to add the additional package requirements and dependencies.
|
||||
|
||||
### Local Debian Repository
|
||||
|
||||
Without creating a local repository, CardBook could be installed with:
|
||||
```
|
||||
$ sudo dpkg -i cardbook_1.1.0.deb
|
||||
|
||||
```
|
||||
|
||||
To actually test the installation for the package, I decided to build a local Debian repository. Without it, the `apt-get` command would not locate the package, as it is not in uploaded in Debian packages on net.
|
||||
|
||||
For configuring a local Debian repository, I copied my packages (.deb) to `Packages.gz` file placed in a `/tmp` location.
|
||||
|
||||
![Packages-gz][14]
|
||||
|
||||
Local Debian Repo
|
||||
|
||||
To make it work, I learned about the apt configuration and where it looks for files.
|
||||
|
||||
I researched for a way to add my file location in apt-config. Finally I could accomplish the task by adding `*.list` file with package’s path in APT and updating ‘apt-cache’ afterwards.
|
||||
|
||||
Hence, the latest CardBook version could be successfully installed by `apt-get install cardbook`
|
||||
|
||||
![Package installation!][15]
|
||||
|
||||
CardBook Installation through apt-get
|
||||
|
||||
### Fixing Packaging errors and bugs
|
||||
|
||||
My mentor, Daniel helped me a lot during this process and guided me how to proceed further with the package. He told me to use [Lintian][16] for fixing common packaging error and then using [dput][17] to finally upload the CardBook package.
|
||||
|
||||
> Lintian is a Debian package checker which finds policy violations and bugs. It is one of the most widely used tool by Debian Maintainers to automate checks for Debian policies before uploading the package.
|
||||
|
||||
I have uploaded the second updated version of the package in a separate branch of the repository on Salsa [here][18] inside Debian directory.
|
||||
|
||||
I installed Lintian from backports and learned to use it on a package to fix errors. I researched on the abbreviations used in its errors and how to show detailed response from lintian commands
|
||||
```
|
||||
$ lintian -i -I --show-overrides cardbook_1.2.0.changes
|
||||
|
||||
```
|
||||
|
||||
Initially on running the command on the `.changes` file, I was surprised to see that a large number of errors, warnings and notes were displayed!
|
||||
|
||||
![Package Error Brief!][19]
|
||||
|
||||
Brief errors after running Lintian on Package
|
||||
|
||||
![Lintian error1!][20]
|
||||
|
||||
Detailed Lintian errors
|
||||
|
||||
Detailed Lintian errostyle=”width:200px;”rs
|
||||
|
||||
I spend some days to fix some errors related to Debian package policy violations. I had to dig into every policy and Debian rules carefully to eradicate a simple error. For this I referred various sections on [Debian Policy Manual][21] and [Debian Developer’s Reference][22].
|
||||
|
||||
I am still working on making it flawless and hope to upload it on mentors.debian.net soon!
|
||||
|
||||
It would be grateful if people from the Debian community who use Thunderbird could help fix these errors.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://minkush.me/cardbook-debian-package/
|
||||
|
||||
作者:[Minkush Jain][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://minkush.me/cardbook-debian-package/#
|
||||
[1]:https://addons.mozilla.org/en-US/thunderbird/addon/lightning/
|
||||
[2]:https://addons.mozilla.org/nn-NO/thunderbird/addon/cardbook/?src=hp-dl-featured
|
||||
[3]:https://danielpocock.com/
|
||||
[4]:https://mentors.debian.net/
|
||||
[5]:https://wiki.debian.org/DFSGLicenses
|
||||
[6]:https://wiki.debian.org/Packaging/Intro
|
||||
[7]:https://wiki.debian.org/BuildingAPackage
|
||||
[8]:https://packages.debian.org/stretch/amd64/lightning/filelist
|
||||
[9]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package/Debian
|
||||
[10]:/img/posts/13.png
|
||||
[11]:https://packages.debian.org/stretch/dpkg
|
||||
[12]:https://gitlab.com/CardBook/CardBook
|
||||
[13]:/img/posts/15.png
|
||||
[14]:/img/posts/14.png
|
||||
[15]:/img/posts/11.png
|
||||
[16]:https://packages.debian.org/stretch/lintian
|
||||
[17]:https://packages.debian.org/stretch/dput
|
||||
[18]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package
|
||||
[19]:/img/posts/16.png (Running Lintian on package)
|
||||
[20]:/img/posts/10.png
|
||||
[21]:https://www.debian.org/doc/debian-policy/
|
||||
[22]:https://www.debian.org/doc/manuals/developers-reference/
|
||||
@ -1,3 +1,7 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
|
||||
|
||||
How To View Detailed Information About A Package In Linux
|
||||
======
|
||||
This is know topic and we can write so many articles because most of the time we would stick with package managers for many reasons.
|
||||
|
||||
@ -1,263 +0,0 @@
|
||||
name1e5s is translating
|
||||
|
||||
|
||||
Slices from the ground up
|
||||
============================================================
|
||||
|
||||
This blog post was inspired by a conversation with a co-worker about using a slice as a stack. The conversation turned into a wider discussion on the way slices work in Go, so I thought it would be useful to write it up.
|
||||
|
||||
### Arrays
|
||||
|
||||
Every discussion of Go’s slice type starts by talking about something that isn’t a slice, namely, Go’s array type. Arrays in Go have two relevant properties:
|
||||
|
||||
1. They have a fixed size; `[5]int` is both an array of 5 `int`s and is distinct from `[3]int`.
|
||||
|
||||
2. They are value types. Consider this example:
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
var a [5]int
|
||||
b := a
|
||||
b[2] = 7
|
||||
fmt.Println(a, b) // prints [0 0 0 0 0] [0 0 7 0 0]
|
||||
}
|
||||
```
|
||||
|
||||
The statement `b := a` declares a new variable, `b`, of type `[5]int`, and _copies _ the contents of `a` to `b`. Updating `b` has no effect on the contents of `a` because `a` and `b` are independent values.[1][1]
|
||||
|
||||
### Slices
|
||||
|
||||
Go’s slice type differs from its array counterpart in two important ways:
|
||||
|
||||
1. Slices do not have a fixed length. A slice’s length is not declared as part of its type, rather it is held within the slice itself and is recoverable with the built-in function `len`.[2][2]
|
||||
|
||||
2. Assigning one slice variable to another _does not_ make a copy of the slices contents. This is because a slice does not directly hold its contents. Instead a slice holds a pointer to its _underlying_ array[3][3] which holds the contents of the slice.
|
||||
|
||||
As a result of the second property, two slices can share the same underlying array. Consider these examples:
|
||||
|
||||
1. Slicing a slice:
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
var a = []int{1,2,3,4,5}
|
||||
b := a[2:]
|
||||
b[0] = 0
|
||||
fmt.Println(a, b) // prints [1 2 0 4 5] [0 4 5]
|
||||
}
|
||||
```
|
||||
|
||||
In this example `a` and `b` share the same underlying array–even though `b` starts at a different offset in that array, and has a different length. Changes to the underlying array via `b` are thus visible to `a`.
|
||||
|
||||
2. Passing a slice to a function:
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func negate(s []int) {
|
||||
for i := range s {
|
||||
s[i] = -s[i]
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
var a = []int{1, 2, 3, 4, 5}
|
||||
negate(a)
|
||||
fmt.Println(a) // prints [-1 -2 -3 -4 -5]
|
||||
}
|
||||
```
|
||||
|
||||
In this example `a` is passed to `negate`as the formal parameter `s.` `negate` iterates over the elements of `s`, negating their sign. Even though `negate` does not return a value, or have any way to access the declaration of `a` in `main`, the contents of `a` are modified when passed to `negate`.
|
||||
|
||||
Most programmers have an intuitive understanding of how a Go slice’s underlying array works because it matches how array-like concepts in other languages tend to work. For example, here’s the first example of this section rewritten in Python:
|
||||
|
||||
```
|
||||
Python 2.7.10 (default, Feb 7 2017, 00:08:15)
|
||||
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.34)] on darwin
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> a = [1,2,3,4,5]
|
||||
>>> b = a
|
||||
>>> b[2] = 0
|
||||
>>> a
|
||||
[1, 2, 0, 4, 5]
|
||||
```
|
||||
|
||||
And also in Ruby:
|
||||
|
||||
```
|
||||
irb(main):001:0> a = [1,2,3,4,5]
|
||||
=> [1, 2, 3, 4, 5]
|
||||
irb(main):002:0> b = a
|
||||
=> [1, 2, 3, 4, 5]
|
||||
irb(main):003:0> b[2] = 0
|
||||
=> 0
|
||||
irb(main):004:0> a
|
||||
=> [1, 2, 0, 4, 5]
|
||||
```
|
||||
|
||||
The same applies to most languages that treat arrays as objects or reference types.[4][8]
|
||||
|
||||
### The slice header value
|
||||
|
||||
The magic that makes a slice behave both as a value and a pointer is to understand that a slice is actually a struct type. This is commonly referred to as a _slice header_ after its [counterpart in the reflect package][20]. The definition of a slice header looks something like this:
|
||||
|
||||
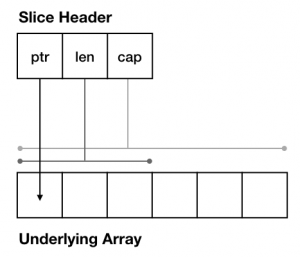
|
||||
|
||||
```
|
||||
package runtime
|
||||
|
||||
type slice struct {
|
||||
ptr unsafe.Pointer
|
||||
len int
|
||||
cap int
|
||||
}
|
||||
```
|
||||
|
||||
This is important because [_unlike_ `map` and `chan`types][21] slices are value types and are _copied_ when assigned or passed as arguments to functions.
|
||||
|
||||
To illustrate this, programmers instinctively understand that `square`‘s formal parameter `v` is an independent copy of the `v` declared in `main`.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func square(v int) {
|
||||
v = v * v
|
||||
}
|
||||
|
||||
func main() {
|
||||
v := 3
|
||||
square(v)
|
||||
fmt.Println(v) // prints 3, not 9
|
||||
}
|
||||
```
|
||||
|
||||
So the operation of `square` on its `v` has no effect on `main`‘s `v`. So too the formal parameter `s` of `double` is an independent copy of the slice `s` declared in `main`, _not_ a pointer to `main`‘s `s` value.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func double(s []int) {
|
||||
s = append(s, s...)
|
||||
}
|
||||
|
||||
func main() {
|
||||
s := []int{1, 2, 3}
|
||||
double(s)
|
||||
fmt.Println(s, len(s)) // prints [1 2 3] 3
|
||||
}
|
||||
```
|
||||
|
||||
The slightly unusual nature of a Go slice variable is it’s passed around as a value, not than a pointer. 90% of the time when you declare a struct in Go, you will pass around a pointer to values of that struct.[5][9] This is quite uncommon, the only other example of passing a struct around as a value I can think of off hand is `time.Time`.
|
||||
|
||||
It is this exceptional behaviour of slices as values, rather than pointers to values, that can confuses Go programmer’s understanding of how slices work. Just remember that any time you assign, subslice, or pass or return, a slice, you’re making a copy of the three fields in the slice header; the pointer to the underlying array, and the current length and capacity.
|
||||
|
||||
### Putting it all together
|
||||
|
||||
I’m going to conclude this post on the example of a slice as a stack that I opened this post with:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func f(s []string, level int) {
|
||||
if level > 5 {
|
||||
return
|
||||
}
|
||||
s = append(s, fmt.Sprint(level))
|
||||
f(s, level+1)
|
||||
fmt.Println("level:", level, "slice:", s)
|
||||
}
|
||||
|
||||
func main() {
|
||||
f(nil, 0)
|
||||
}
|
||||
```
|
||||
|
||||
Starting from `main` we pass a `nil` slice into `f` as `level` 0\. Inside `f` we append to `s` the current `level`before incrementing `level` and recursing. Once `level` exceeds 5, the calls to `f` return, printing their current level and the contents of their copy of `s`.
|
||||
|
||||
```
|
||||
level: 5 slice: [0 1 2 3 4 5]
|
||||
level: 4 slice: [0 1 2 3 4]
|
||||
level: 3 slice: [0 1 2 3]
|
||||
level: 2 slice: [0 1 2]
|
||||
level: 1 slice: [0 1]
|
||||
level: 0 slice: [0]
|
||||
```
|
||||
|
||||
You can see that at each level the value of `s` was unaffected by the operation of other callers of `f`, and that while four underlying arrays were created [6][10] higher levels of `f` in the call stack are unaffected by the copy and reallocation of new underlying arrays as a by-product of `append`.
|
||||
|
||||
### Further reading
|
||||
|
||||
If you want to find out more about how slices work in Go, I recommend these posts from the Go blog:
|
||||
|
||||
* [Go Slices: usage and internals][11] (blog.golang.org)
|
||||
|
||||
* [Arrays, slices (and strings): The mechanics of ‘append’][12] (blog.golang.org)
|
||||
|
||||
### Notes
|
||||
|
||||
1. This is not a unique property of arrays. In Go _every_ assignment is a copy.[][13]
|
||||
|
||||
2. You can also use `len` on array values, but the result is a forgone conclusion.[][14]
|
||||
|
||||
3. This is also known as the backing array or sometimes, less correctly, as the backing slice[][15]
|
||||
|
||||
4. In Go we tend to say value type and pointer type because of the confusion caused by C++’s _reference_ type, but in this case I think calling arrays as objects reference types is appropriate.[][16]
|
||||
|
||||
5. I’d argue if that struct has a [method defined on it and/or is used to satisfy an interface][17]then the percentage that you will pass around a pointer to your struct raises to near 100%.[][18]
|
||||
|
||||
6. Proof of this is left as an exercise to the reader.[][19]
|
||||
|
||||
### Related Posts:
|
||||
|
||||
1. [If a map isn’t a reference variable, what is it?][4]
|
||||
|
||||
2. [What is the zero value, and why is it useful ?][5]
|
||||
|
||||
3. [The empty struct][6]
|
||||
|
||||
4. [Should methods be declared on T or *T][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dave.cheney.net/2018/07/12/slices-from-the-ground-up
|
||||
|
||||
作者:[Dave Cheney][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dave.cheney.net/
|
||||
[1]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-1-3265
|
||||
[2]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-2-3265
|
||||
[3]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-3-3265
|
||||
[4]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
[5]:https://dave.cheney.net/2013/01/19/what-is-the-zero-value-and-why-is-it-useful
|
||||
[6]:https://dave.cheney.net/2014/03/25/the-empty-struct
|
||||
[7]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
|
||||
[8]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-4-3265
|
||||
[9]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-5-3265
|
||||
[10]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-6-3265
|
||||
[11]:https://blog.golang.org/go-slices-usage-and-internals
|
||||
[12]:https://blog.golang.org/slices
|
||||
[13]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-1-3265
|
||||
[14]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-2-3265
|
||||
[15]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-3-3265
|
||||
[16]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-4-3265
|
||||
[17]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
|
||||
[18]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-5-3265
|
||||
[19]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-6-3265
|
||||
[20]:https://golang.org/pkg/reflect/#SliceHeader
|
||||
[21]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
@ -1,3 +1,5 @@
|
||||
Translating... by SunWave
|
||||
|
||||
3 Methods to List All The Users in Linux System
|
||||
======
|
||||
Everyone knows user information was residing in `/etc/passwd` file.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
4 cool new projects to try in COPR for July 2018
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,165 @@
|
||||
Setting Up a Timer with systemd in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Previously, we saw how to enable and disable systemd services [by hand][1], [at boot time and on power down][2], [when a certain device is activated][3], and [when something changes in the filesystem][4].
|
||||
|
||||
Timers add yet another way of starting services, based on... well, time. Although similar to cron jobs, systemd timers are slightly more flexible. Let's see how they work.
|
||||
|
||||
### "Run when"
|
||||
|
||||
Let's expand the [Minetest][5] [service you set up][1] in [the first two articles of this series][2] as our first example on how to use timer units. If you haven't read those articles yet, you may want to go and give them a look now.
|
||||
|
||||
So you will "improve" your Minetest set up by creating a timer that will run the game's server 1 minute after boot up has finished instead of right away. The reason for this could be that, as you want your service to do other stuff, like send emails to the players telling them the game is available, you will want to make sure other services (like the network) are fully up and running before doing anything fancy.
|
||||
|
||||
Jumping in at the deep end, your _minetest.timer_ unit will look like this:
|
||||
```
|
||||
# minetest.timer
|
||||
[Unit]
|
||||
Description=Runs the minetest.service 1 minute after boot up
|
||||
|
||||
[Timer]
|
||||
OnBootSec=1 m
|
||||
Unit=minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
Not hard at all.
|
||||
|
||||
As usual, you have a `[Unit]` section with a description of what the unit does. Nothing new there. The `[Timer]` section is new, but it is pretty self-explanatory: it contains information on when the service will be triggered and the service to trigger. In this case, the `OnBootSec` is the directive you need to tell systemd to run the service after boot has finished.
|
||||
|
||||
Other directives you could use are:
|
||||
|
||||
* `OnActiveSec=`, which tells systemd how long to wait after the timer itself is activated before starting the service.
|
||||
* `OnStartupSec=`, on the other hand, tells systemd how long to wait after systemd was started before starting the service.
|
||||
* `OnUnitActiveSec=` tells systemd how long to wait after the service the timer is activating was last activated.
|
||||
* `OnUnitInactiveSec=` tells systemd how long to wait after the service the timer is activating was last deactivated.
|
||||
|
||||
|
||||
|
||||
Continuing down the _minetest.timer_ unit, the `basic.target` is usually used as a synchronization point for late boot services. This means it makes _minetest.timer_ wait until local mount points and swap devices are mounted, sockets, timers, path units and other basic initialization processes are running before letting _minetest.timer_ start. As we explained in [the second article on systemd units][2], _targets_ are like the old run levels and can be used to put your machine into one state or another, or, like here, to tell your service to wait until a certain state has been reached.
|
||||
|
||||
The _minetest.service_ you developed in the first two articles [ended up][2] looking like this:
|
||||
```
|
||||
# minetest.service
|
||||
[Unit]
|
||||
Description= Minetest server
|
||||
Documentation= https://wiki.minetest.net/Main_Page
|
||||
|
||||
[Service]
|
||||
Type= simple
|
||||
User=
|
||||
|
||||
ExecStart= /usr/games/minetest --server
|
||||
ExecStartPost= /home//bin/mtsendmail.sh "Ready to rumble?" "Minetest Starting up"
|
||||
|
||||
TimeoutStopSec= 180
|
||||
ExecStop= /home//bin/mtsendmail.sh "Off to bed. Nightie night!" "Minetest Stopping in 2 minutes"
|
||||
ExecStop= /bin/sleep 120
|
||||
ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.target
|
||||
|
||||
```
|
||||
|
||||
There’s nothing you need to change here. But you do have to change _mtsendmail.sh_ (your email sending script) from this:
|
||||
```
|
||||
#!/bin/bash
|
||||
# mtsendmail
|
||||
sleep 20
|
||||
echo $1 | mutt -F /home/<username>/.muttrc -s "$2" my_minetest@mailing_list.com
|
||||
sleep 10
|
||||
|
||||
```
|
||||
|
||||
to this:
|
||||
```
|
||||
#!/bin/bash
|
||||
# mtsendmail.sh
|
||||
echo $1 | mutt -F /home/paul/.muttrc -s "$2" pbrown@mykolab.com
|
||||
|
||||
```
|
||||
|
||||
What you are doing is stripping out those hacky pauses in the Bash script. Systemd does the waiting now.
|
||||
|
||||
### Making it work
|
||||
|
||||
To make sure things work, disable _minetest.service_ :
|
||||
```
|
||||
sudo systemctl disable minetest
|
||||
|
||||
```
|
||||
|
||||
so it doesn't get started when the system starts; and, instead, enable _minetest.timer_ :
|
||||
```
|
||||
sudo systemctl enable minetest.timer
|
||||
|
||||
```
|
||||
|
||||
Now you can reboot you server machine and, when you run `sudo journalctl -u minetest.*` you will see how, first the _minetest.timer_ unit gets executed and then the _minetest.service_ starts up after a minute... more or less.
|
||||
|
||||
![minetest timer][7]
|
||||
|
||||
Figure 1: The minetest.service gets started one minute after the minetest.timer... more or less.
|
||||
|
||||
[Used with permission][8]
|
||||
|
||||
### A Matter of Time
|
||||
|
||||
A couple of clarifications about why the _minetest.timer_ entry in the systemd's Journal shows its start time as 09:08:33, while the _minetest.service_ starts at 09:09:18, that is less than a minute later: First, remember we said that the `OnBootSec=` directive calculates when to start a service from when boot is complete. By the time _minetest.timer_ comes along, boot has finished a few seconds ago.
|
||||
|
||||
The other thing is that systemd gives itself a margin of error (by default, 1 minute) to run stuff. This helps distribute the load when several resource-intensive processes are running at the same time: by giving itself a minute, systemd can wait for some processes to power down. This also means that _minetest.service_ will start somewhere between the 1 minute and 2 minute mark after boot is completed, but when exactly within that range is anybody's guess.
|
||||
|
||||
For the record, [you can change the margin of error with `AccuracySec=` directive][9].
|
||||
|
||||
Another thing you can do is check when all the timers on your system are scheduled to run or the last time the ran:
|
||||
```
|
||||
systemctl list-timers --all
|
||||
|
||||
```
|
||||
|
||||
![check timer][11]
|
||||
|
||||
Figure 2: Check when your timers are scheduled to fire or when they fired last.
|
||||
|
||||
[Used with permission][8]
|
||||
|
||||
The final thing to take into consideration is the format you should use to express the periods of time. Systemd is very flexible in that respect: `2 h`, `2 hours` or `2hr` will all work to express a 2 hour delay. For seconds, you can use `seconds`, `second`, `sec`, and `s`, the same way as for minutes you can use `minutes`, `minute`, `min`, and `m`. You can see a full list of time units systemd understands by checking `man systemd.time`.
|
||||
|
||||
### Next Time
|
||||
|
||||
You'll see how to use calendar dates and times to run services at regular intervals and how to combine timers and device units to run services at defined point in time after you plug in some hardware.
|
||||
|
||||
See you then!
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][12]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit
|
||||
[2]:https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
[5]:https://www.minetest.net/
|
||||
[6]:/files/images/minetest-timer-1png
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-1.png?itok=TG0xJvYM (minetest timer)
|
||||
[8]:/licenses/category/used-permission
|
||||
[9]:https://www.freedesktop.org/software/systemd/man/systemd.timer.html#AccuracySec=
|
||||
[10]:/files/images/minetest-timer-2png
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minetest-timer-2.png?itok=pYxyVx8- (check timer)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,4 +1,4 @@
|
||||
translating---geelkpi
|
||||
translating---geekpi
|
||||
|
||||
Textricator: Data extraction made simple
|
||||
======
|
||||
|
||||
@ -0,0 +1,212 @@
|
||||
Best Online Linux Terminals and Online Bash Editors
|
||||
======
|
||||
No matter whether you want to practice Linux commands or just analyze/test your shell scripts online, there’s always a couple of online Linux terminals and online bash compilers available.
|
||||
|
||||
This is particularly helpful when you are using the Windows operating system. Though you can [install Linux inside Windows using Windows Subsystem for Linux][1], using online Linux terminals are often more convenient for a quick test.
|
||||
|
||||
![Websites that allow to use Linux Terminal online][2]
|
||||
|
||||
But where can you find free Linux console? Which online Linux shell should you use?
|
||||
|
||||
Fret not, to save you the hassle, here, we have compiled a list of the best online Linux terminals and a separate list of best online bash compilers for you to look at.
|
||||
|
||||
**Note:** All of the online terminals support several browsers that include Google Chrome, Mozilla Firefox, Opera and Microsoft Edge.
|
||||
|
||||
### Best Online Linux Terminals To Practice Linux Commands
|
||||
|
||||
In the first part, I’ll list the online Linux terminals. These websites allow you to run the regular Linux commands in a web browser so that you can practice or test them. Some websites may require you to register and login to save your sessions.
|
||||
|
||||
#### 1. JSLinux
|
||||
|
||||
![online linux terminal - jslinux][3]
|
||||
|
||||
JSLinux is more like a complete Linux emulator instead of just offering you the terminal. As the name suggests, it has been entirely written in JavaScript. You get to choose a console-based system or a GUI-based online Linux system. However, in this case, you would want to launch the console-based system to practice Linux commands. To be able to connect your account, you need to sign up first.
|
||||
|
||||
JSLinux also lets you upload files to the virtual machine. At its core, it utilizes [Buildroot][4] (a tool that helps you to build a complete Linux system for an embedded system).
|
||||
|
||||
[Try JSLinux Terminal][5]
|
||||
|
||||
#### 2. Copy.sh
|
||||
|
||||
![copysh online linux terminal][6]
|
||||
|
||||
Copy.sh offers one of the best online Linux terminals which is fast and reliable to test and run Linux commands.
|
||||
|
||||
Copy.sh is also on [GitHub][7] – and it is being actively maintained, which is a good thing. It also supports other Operating Systems, which includes:
|
||||
|
||||
* Windows 98
|
||||
* KolibriOS
|
||||
* FreeDOS
|
||||
* Windows 1.01
|
||||
* Archlinux
|
||||
|
||||
|
||||
|
||||
[Try Copy.sh Terminal][8]
|
||||
|
||||
#### 3. Webminal
|
||||
|
||||
![webminal online linux terminal][9]
|
||||
|
||||
Webminal is an impressive online Linux terminal – and my personal favorite when it comes to a recommendation for beginners to practice Linux commands online.
|
||||
|
||||
The website offers several lessons to learn from while you type in the commands in the same window. So, you do not need to refer to another site for the lessons and then switch back or split the screen in order to practice commands. It’s all right there – in a single tab on the browser.
|
||||
|
||||
[Try Webminal Terminal][10]
|
||||
|
||||
#### 4. Tutorialspoint Unix Terminal
|
||||
|
||||
![tutorialspoint linux terminal][11]
|
||||
|
||||
You might be aware of Tutorialspoint – which happens to be one of the most popular websites with high quality (yet free) online tutorials for just about any programming language (and more).
|
||||
|
||||
So, for obvious reasons, they provide a free online Linux console for you to practice commands while referring to their site as a resource at the same time. You also get the ability to upload files. It is quite simple but an effective online terminal. Also, it doesn’t stop there, it offers a lot of different online terminals as well in its [Coding Ground][12] page.
|
||||
|
||||
[Try Unix Terminal Online][13]
|
||||
|
||||
#### 5. JS/UIX
|
||||
|
||||
![js uix online linux terminal][14]
|
||||
|
||||
JS/UIX is yet another online Linux terminal which is written entirely in JavaScript without any plug-ins. It contains an online Linux virtual machine, virtual file-system, shell, and so on.
|
||||
|
||||
You can go through its manual page for the list of commands implemented.
|
||||
|
||||
[Try JS/UX Terminal][15]
|
||||
|
||||
#### 6. CB.VU
|
||||
|
||||
![online linux terminal][16]
|
||||
|
||||
If you are in for a treat with FreeBSD 7.1 stable version, cb.vu is a quite simple solution for that.
|
||||
|
||||
Nothing fancy, just try out the Linux commands you want and get the output. Unfortunately, you do not get the ability to upload files here.
|
||||
|
||||
[Try CB.VU Terminal][17]
|
||||
|
||||
#### 7. Linux Containers
|
||||
|
||||
![online linux terminal][18]
|
||||
|
||||
Linux Containers lets you run a demo server with a 30-minute countdown on which acts as one of the best online Linux terminals. In fact, it’s a project sponsored by Canonical.
|
||||
|
||||
[Try Linux LXD][19]
|
||||
|
||||
#### 8. Codeanywhere
|
||||
|
||||
![online linux terminal][20]
|
||||
|
||||
Codeanywhere is a service which offers cross-platform cloud IDEs. However, in order to run a free Linux virtual machine, you just need to sign up and choose the free plan. And, then, proceed to create a new connection while setting up a container with an OS of your choice. Finally, you will have a free Linux console at your disposal.
|
||||
|
||||
[Try Codeanywhere Editor][21]
|
||||
|
||||
### Best Online Bash Editors
|
||||
|
||||
Wait a sec! Are the online Linux terminals not good enough for Bash scripting? They are. But creating bash scripts in terminal editors and then executing them is not as convinient as using an online Bash editor.
|
||||
|
||||
These bash editors allow you to easily write shell scripts online and you can run them to check if it works or not.
|
||||
|
||||
Let’s see here can you run shell scripts online.
|
||||
|
||||
#### Tutorialspoint Bash Compiler
|
||||
|
||||
![online bash compiler][22]
|
||||
|
||||
As mentioned above, Tutorialspoint also offers an online Bash compiler. It is a very simple bash compiler to execute bash shell online.
|
||||
|
||||
[Try Tutorialspoint Bash Compiler][23]
|
||||
|
||||
#### JDOODLE
|
||||
|
||||
![online bash compiler][24]
|
||||
|
||||
Yet another useful online bash editor to test Bash scripts is JDOODLE. It also offers other IDEs, but we’ll focus on bash script execution here. You get to set the command line arguments and the stdin inputs, and would normally get the result of your code.
|
||||
|
||||
[Try JDOODLE Bash Script Online Tester][25]
|
||||
|
||||
#### Paizo.io
|
||||
|
||||
![paizo online bash editor][26]
|
||||
|
||||
Paizo.io is a good bash online editor that you can try for free. To utilize some of its advanced features like task scheduling, you need to first sign up. It also supports real-time collaboration, but that’s still in the experimental phase.
|
||||
|
||||
[Try Paizo.io Bash Editor][27]
|
||||
|
||||
#### ShellCheck
|
||||
|
||||
![shell check bash check][28]
|
||||
|
||||
An interesting Bash editor which lets you find bugs in your shell script. It is available on [GitHub][29] as well. In addition, you can install ShellCheck locally on [supported platforms][30].
|
||||
|
||||
[Try ShellCheck][31]
|
||||
|
||||
#### Rextester
|
||||
|
||||
![rextester bash editor][32]
|
||||
|
||||
If you only want a dead simple online bash compiler, Rextester should be your choice. It also supports other programming languages.
|
||||
|
||||
[Try Rextester][33]
|
||||
|
||||
#### Learn Shell
|
||||
|
||||
![online bash shell editor][34]
|
||||
|
||||
Just like [Webminal][35], Learnshell provides you with the content (or resource) to learn shell programming and you could also run/try your code at the same time. It covers the basics and a few advanced topics as well.
|
||||
|
||||
[Try Learn Shell Programming][36]
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Now that you know of the most reliable and fast online Linux terminals & online bash editors, learn, experiment, and play with the code!
|
||||
|
||||
We might have missed any of your favorite online Linux terminals or maybe the best online bash compiler which you happen to use? Let us know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/online-linux-terminals/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://itsfoss.com/install-bash-on-windows/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/online-linux-terminals.jpeg
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/jslinux-online-linux-terminal.jpg
|
||||
[4]:https://buildroot.org/
|
||||
[5]:https://bellard.org/jslinux/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/copy-sh-online-linux-terminal.jpg
|
||||
[7]:https://github.com/copy/v86
|
||||
[8]:https://copy.sh/v86/?profile=linux26
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/webminal.jpg
|
||||
[10]:http://www.webminal.org/terminal/
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/coding-ground-tutorialspoint-online-linux-terminal.jpg
|
||||
[12]:https://www.tutorialspoint.com/codingground.htm
|
||||
[13]:https://www.tutorialspoint.com/unix_terminal_online.php
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/JS-UIX-online-linux-terminal.jpg
|
||||
[15]:http://www.masswerk.at/jsuix/index.html
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/cb-vu-online-linux-terminal.jpg
|
||||
[17]:http://cb.vu/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/linux-containers-terminal.jpg
|
||||
[19]:https://linuxcontainers.org/lxd/try-it/
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/codeanywhere-terminal.jpg
|
||||
[21]:https://codeanywhere.com/editor/
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/tutorialspoint-bash-compiler.jpg
|
||||
[23]:https://www.tutorialspoint.com/execute_bash_online.php
|
||||
[24]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/jdoodle-online-bash-editor.jpg
|
||||
[25]:https://www.jdoodle.com/test-bash-shell-script-online
|
||||
[26]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/paizo-io-bash-editor.jpg
|
||||
[27]:https://paiza.io/en/projects/new?language=bash
|
||||
[28]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/shell-check-bash-analyzer.jpg
|
||||
[29]:https://github.com/koalaman/shellcheck
|
||||
[30]:https://github.com/koalaman/shellcheck#user-content-installing
|
||||
[31]:https://www.shellcheck.net/#
|
||||
[32]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/rextester-bash-editor.jpg
|
||||
[33]:http://rextester.com/l/bash_online_compiler
|
||||
[34]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/learnshell-online-bash-shell.jpg
|
||||
[35]:http://www.webminal.org/
|
||||
[36]:http://www.learnshell.org/
|
||||
531
sources/tech/20180725 Build an interactive CLI with Node.js.md
Normal file
531
sources/tech/20180725 Build an interactive CLI with Node.js.md
Normal file
@ -0,0 +1,531 @@
|
||||
Build an interactive CLI with Node.js
|
||||
======
|
||||
|
||||

|
||||
|
||||
Node.js can be very useful when it comes to building command-line interfaces (CLIs). In this post, I'll teach you how to use [Node.js][1] to build a CLI that asks some questions and creates a file based on the answers.
|
||||
|
||||
### Get started
|
||||
|
||||
Let's start by creating a brand new [npm][2] package. (Npm is the JavaScript package manager.)
|
||||
```
|
||||
mkdir my-script
|
||||
|
||||
cd my-script
|
||||
|
||||
npm init
|
||||
|
||||
```
|
||||
|
||||
Npm will ask some questions. After that, we need to install some packages.
|
||||
```
|
||||
npm install --save chalk figlet inquirer shelljs
|
||||
|
||||
```
|
||||
|
||||
Here's what these packages do:
|
||||
|
||||
* **Chalk:** Terminal string styling done right
|
||||
* **Figlet:** A program for making large letters out of ordinary text
|
||||
* **Inquirer:** A collection of common interactive command-line user interfaces
|
||||
* **ShellJS:** Portable Unix shell commands for Node.js
|
||||
|
||||
|
||||
|
||||
### Make an index.js file
|
||||
|
||||
Now we'll create an `index.js` file with the following content:
|
||||
```
|
||||
#!/usr/bin/env node
|
||||
|
||||
|
||||
|
||||
const inquirer = require("inquirer");
|
||||
|
||||
const chalk = require("chalk");
|
||||
|
||||
const figlet = require("figlet");
|
||||
|
||||
const shell = require("shelljs");
|
||||
|
||||
```
|
||||
|
||||
### Plan the CLI
|
||||
|
||||
It's always good to plan what a CLI needs to do before writing any code. This CLI will do just one thing: **create a file**.
|
||||
|
||||
The CLI will ask two questions—what is the filename and what is the extension?—then create the file, and show a success message with the created file path.
|
||||
```
|
||||
// index.js
|
||||
|
||||
|
||||
|
||||
const run = async () => {
|
||||
|
||||
// show script introduction
|
||||
|
||||
// ask questions
|
||||
|
||||
// create the file
|
||||
|
||||
// show success message
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
run();
|
||||
|
||||
```
|
||||
|
||||
The first function is the script introduction. Let's use `chalk` and `figlet` to get the job done.
|
||||
```
|
||||
const init = () => {
|
||||
|
||||
console.log(
|
||||
|
||||
chalk.green(
|
||||
|
||||
figlet.textSync("Node JS CLI", {
|
||||
|
||||
font: "Ghost",
|
||||
|
||||
horizontalLayout: "default",
|
||||
|
||||
verticalLayout: "default"
|
||||
|
||||
})
|
||||
|
||||
)
|
||||
|
||||
);
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
const run = async () => {
|
||||
|
||||
// show script introduction
|
||||
|
||||
init();
|
||||
|
||||
|
||||
|
||||
// ask questions
|
||||
|
||||
// create the file
|
||||
|
||||
// show success message
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
run();
|
||||
|
||||
```
|
||||
|
||||
Second, we'll write a function that asks the questions.
|
||||
```
|
||||
const askQuestions = () => {
|
||||
|
||||
const questions = [
|
||||
|
||||
{
|
||||
|
||||
name: "FILENAME",
|
||||
|
||||
type: "input",
|
||||
|
||||
message: "What is the name of the file without extension?"
|
||||
|
||||
},
|
||||
|
||||
{
|
||||
|
||||
type: "list",
|
||||
|
||||
name: "EXTENSION",
|
||||
|
||||
message: "What is the file extension?",
|
||||
|
||||
choices: [".rb", ".js", ".php", ".css"],
|
||||
|
||||
filter: function(val) {
|
||||
|
||||
return val.split(".")[1];
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
];
|
||||
|
||||
return inquirer.prompt(questions);
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
// ...
|
||||
|
||||
|
||||
|
||||
const run = async () => {
|
||||
|
||||
// show script introduction
|
||||
|
||||
init();
|
||||
|
||||
|
||||
|
||||
// ask questions
|
||||
|
||||
const answers = await askQuestions();
|
||||
|
||||
const { FILENAME, EXTENSION } = answers;
|
||||
|
||||
|
||||
|
||||
// create the file
|
||||
|
||||
// show success message
|
||||
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
Notice the constants FILENAME and EXTENSIONS that came from `inquirer`.
|
||||
|
||||
The next step will create the file.
|
||||
```
|
||||
const createFile = (filename, extension) => {
|
||||
|
||||
const filePath = `${process.cwd()}/${filename}.${extension}`
|
||||
|
||||
shell.touch(filePath);
|
||||
|
||||
return filePath;
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
// ...
|
||||
|
||||
|
||||
|
||||
const run = async () => {
|
||||
|
||||
// show script introduction
|
||||
|
||||
init();
|
||||
|
||||
|
||||
|
||||
// ask questions
|
||||
|
||||
const answers = await askQuestions();
|
||||
|
||||
const { FILENAME, EXTENSION } = answers;
|
||||
|
||||
|
||||
|
||||
// create the file
|
||||
|
||||
const filePath = createFile(FILENAME, EXTENSION);
|
||||
|
||||
|
||||
|
||||
// show success message
|
||||
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
And last but not least, we'll show the success message along with the file path.
|
||||
```
|
||||
const success = (filepath) => {
|
||||
|
||||
console.log(
|
||||
|
||||
chalk.white.bgGreen.bold(`Done! File created at ${filepath}`)
|
||||
|
||||
);
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
// ...
|
||||
|
||||
|
||||
|
||||
const run = async () => {
|
||||
|
||||
// show script introduction
|
||||
|
||||
init();
|
||||
|
||||
|
||||
|
||||
// ask questions
|
||||
|
||||
const answers = await askQuestions();
|
||||
|
||||
const { FILENAME, EXTENSION } = answers;
|
||||
|
||||
|
||||
|
||||
// create the file
|
||||
|
||||
const filePath = createFile(FILENAME, EXTENSION);
|
||||
|
||||
|
||||
|
||||
// show success message
|
||||
|
||||
success(filePath);
|
||||
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
Let's test the script by running `node index.js`. Here's what we get:
|
||||
|
||||
### The full code
|
||||
|
||||
Here is the final code:
|
||||
```
|
||||
#!/usr/bin/env node
|
||||
|
||||
|
||||
|
||||
const inquirer = require("inquirer");
|
||||
|
||||
const chalk = require("chalk");
|
||||
|
||||
const figlet = require("figlet");
|
||||
|
||||
const shell = require("shelljs");
|
||||
|
||||
|
||||
|
||||
const init = () => {
|
||||
|
||||
console.log(
|
||||
|
||||
chalk.green(
|
||||
|
||||
figlet.textSync("Node JS CLI", {
|
||||
|
||||
font: "Ghost",
|
||||
|
||||
horizontalLayout: "default",
|
||||
|
||||
verticalLayout: "default"
|
||||
|
||||
})
|
||||
|
||||
)
|
||||
|
||||
);
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
const askQuestions = () => {
|
||||
|
||||
const questions = [
|
||||
|
||||
{
|
||||
|
||||
name: "FILENAME",
|
||||
|
||||
type: "input",
|
||||
|
||||
message: "What is the name of the file without extension?"
|
||||
|
||||
},
|
||||
|
||||
{
|
||||
|
||||
type: "list",
|
||||
|
||||
name: "EXTENSION",
|
||||
|
||||
message: "What is the file extension?",
|
||||
|
||||
choices: [".rb", ".js", ".php", ".css"],
|
||||
|
||||
filter: function(val) {
|
||||
|
||||
return val.split(".")[1];
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
];
|
||||
|
||||
return inquirer.prompt(questions);
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
const createFile = (filename, extension) => {
|
||||
|
||||
const filePath = `${process.cwd()}/${filename}.${extension}`
|
||||
|
||||
shell.touch(filePath);
|
||||
|
||||
return filePath;
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
const success = filepath => {
|
||||
|
||||
console.log(
|
||||
|
||||
chalk.white.bgGreen.bold(`Done! File created at ${filepath}`)
|
||||
|
||||
);
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
const run = async () => {
|
||||
|
||||
// show script introduction
|
||||
|
||||
init();
|
||||
|
||||
|
||||
|
||||
// ask questions
|
||||
|
||||
const answers = await askQuestions();
|
||||
|
||||
const { FILENAME, EXTENSION } = answers;
|
||||
|
||||
|
||||
|
||||
// create the file
|
||||
|
||||
const filePath = createFile(FILENAME, EXTENSION);
|
||||
|
||||
|
||||
|
||||
// show success message
|
||||
|
||||
success(filePath);
|
||||
|
||||
};
|
||||
|
||||
|
||||
|
||||
run();
|
||||
|
||||
```
|
||||
|
||||
### Use the script anywhere
|
||||
|
||||
To execute this script anywhere, add a `bin` section in your `package.json` file and run `npm link`.
|
||||
```
|
||||
{
|
||||
|
||||
"name": "creator",
|
||||
|
||||
"version": "1.0.0",
|
||||
|
||||
"description": "",
|
||||
|
||||
"main": "index.js",
|
||||
|
||||
"scripts": {
|
||||
|
||||
"test": "echo \"Error: no test specified\" && exit 1",
|
||||
|
||||
"start": "node index.js"
|
||||
|
||||
},
|
||||
|
||||
"author": "",
|
||||
|
||||
"license": "ISC",
|
||||
|
||||
"dependencies": {
|
||||
|
||||
"chalk": "^2.4.1",
|
||||
|
||||
"figlet": "^1.2.0",
|
||||
|
||||
"inquirer": "^6.0.0",
|
||||
|
||||
"shelljs": "^0.8.2"
|
||||
|
||||
},
|
||||
|
||||
"bin": {
|
||||
|
||||
"creator": "./index.js"
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Running `npm link` makes this script available anywhere.
|
||||
|
||||
That's what happens when you run this command:
|
||||
```
|
||||
/usr/bin/creator -> /usr/lib/node_modules/creator/index.js
|
||||
|
||||
/usr/lib/node_modules/creator -> /home/hugo/code/creator
|
||||
|
||||
```
|
||||
|
||||
It links the `index.js` file as an executable. This is only possible because of the first line of the CLI script: `#!/usr/bin/env node`.
|
||||
|
||||
Now we can run this script by calling:
|
||||
```
|
||||
$ creator
|
||||
|
||||
```
|
||||
|
||||
### Wrapping up
|
||||
|
||||
As you can see, Node.js makes it very easy to build nice command-line tools! If you want to go even further, check this other packages:
|
||||
|
||||
* [meow][3] – a simple command-line helper
|
||||
* [yargs][4] – a command-line opt-string parser
|
||||
* [pkg][5] – package your Node.js project into an executable
|
||||
|
||||
|
||||
|
||||
Tell us about your experience building a CLI in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/node-js-interactive-cli
|
||||
|
||||
作者:[Hugo Dias][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hugodias
|
||||
[1]:https://nodejs.org/en/
|
||||
[2]:https://www.npmjs.com/
|
||||
[3]:https://github.com/sindresorhus/meow
|
||||
[4]:https://github.com/yargs/yargs
|
||||
[5]:https://github.com/zeit/pkg
|
||||
@ -0,0 +1,101 @@
|
||||
How do private keys work in PKI and cryptography?
|
||||
======
|
||||
|
||||

|
||||
|
||||
In [a previous article][1], I gave an overview of cryptography and discussed the core concepts of confidentiality (keeping data secret), integrity (protecting data from tampering), and authentication (knowing the identity of the data's source). Since authentication relates so closely to all the messiness of identity in the real world, a complex technological ecosystem has evolved around establishing that someone is who they claim to be. In this article, I'll describe in broad strokes how these systems work.
|
||||
|
||||
### A quick review of public key cryptography and digital signatures
|
||||
|
||||
Authentication in the online world relies on public key cryptography where a key has two parts: a private key kept secret by the owner and a public key shared with the world. After the public key encrypts data, only the private key can decrypt it. This feature is useful if a whistleblower wanted to establish contact with a [journalist][2], for example. More importantly for this article, a private key can be combined with a message to create a digital signature that provides integrity and authentication.
|
||||
|
||||
In practice, what is signed is not the actual message, but a digest of a message attained by sending the message through a cryptographic hash function. Instead of signing an entire zip file of source code, the sender signs the 256-bit [SHA-256][3] digest of that zip file and sends the zip file in the clear. Recipients independently calculate the SHA-256 digest of the file they received. They input their digest, the signature they received, and the sender's public key into a signature verification algorithm. The verification process varies depending on the encryption algorithm, and there are enough subtleties that signature verification [vulnerabilities][4] still [pop up][5] . If the verification succeeds, the file has not been modified in transit and must have originated from the sender since only the sender has the private key that created the signature.
|
||||
|
||||
### The missing piece of the puzzle
|
||||
|
||||
There's one major detail missing from this scenario. Where do we get the sender's public key? The sender could send the public key along with a message, but then we have no proof of their identity beyond their own assertion. Imagine being a bank teller and a customer walks up and says, "Hello, I'm Jane Doe, and I'd like to make a withdrawal." When you ask for identification, she points to a name tag sticker on her shirt that says "Jane Doe." Personally, I would politely turn "Jane" away.
|
||||
|
||||
If you already know the sender, you could meet in person and exchange public keys. If you don't, you could meet in person, examine their passport, and once you are satisfied it is authentic, accept their public key. To make the process more efficient, you could throw a [party][6], invite a bunch of people, examine all their passports, and accept all their public keys. Building off that, if you know Jane Doe and trust her (despite her unusual banking practices), Jane could go to the party, get the public keys, and give them to you. In fact, Jane could just sign the other public keys using her own private key, and then you could use [an online repository][7] of public keys, trusting the ones signed by Jane. If a person's public key is signed by multiple people you trust, then you might decide to trust that person as well (even though you don't know them). In this fashion, you can build a [web of trust][8].
|
||||
|
||||
But now things have gotten complicated: We need to decide on a standard way to encode a key and the identity associated with that key into a digital bundle we can sign. More properly, these digital bundles are called certificates. We'll also need tooling that can create, use, and manage these certificates. The way we solve these and other requirements is what constitutes a public key infrastructure (PKI).
|
||||
|
||||
### Beyond the web of trust
|
||||
|
||||
You can think of the web of trust as a network of people. A network with many interconnections between the people makes it easy to find a short path of trust: a social circle, for example. [GPG][9]-encrypted email relies on a web of trust, and it functions ([in theory][10]) since most of us communicate primarily with a relatively small group of friends, family, and co-workers.
|
||||
|
||||
In practice, the web of trust has some [significant problems][11], many of them around scaling. When the network starts to get larger and there are few connections between people, the web of trust starts to break down. If the path of trust is attenuated across a long chain of people, you face a higher chance of encountering someone who carelessly or maliciously signed a key. And if there is no path at all, you have to create one by contacting the other party and verifying their key to your satisfaction. Imagine going to an online store that you and your friends have never used. Before you establish a secure communications channel to place an order, you'd need to verify the site's public key belongs to the company and not an impostor. That vetting would entail going to a physical store, making telephone calls, or some other laborious process. Online shopping would be a lot less convenient (or a lot less secure since many people would cut corners and accept the key without verifying it).
|
||||
|
||||
What if the world had some exceptionally trustworthy people constantly verifying and signing keys for websites? You could just trust them, and browsing the internet would be much smoother. At a high level, that's how things work today. These "exceptionally trustworthy people" are companies called certificate authorities (CAs). When a website wants to get its public key signed, it submits a certificate signing request (CSR) to the CA.
|
||||
|
||||
CSRs are like stub certificates that contain a public key and an identity (in this case, the hostname of the server), but are not signed by a CA. Before signing, the CA performs some verification steps. In some cases, the CA merely verifies that the requester controls the domain for the hostname listed in the CSR (via a challenge-and-response email exchange with the address in the WHOIS entry, for example). [In other cases][12], the CA inspects legal documents, like business licenses. Once the CA is satisfied (and usually after the requester has paid a fee), it takes the data from the CSR and signs it with its own private key to create a certificate. The CA then sends the certificate to the requester. The requester installs the certificate on their site's web server, and the certificate is delivered to users when they connect over HTTPS (or any other protocol secured with [TLS][13]).
|
||||
|
||||
When users connect to the site, their browser looks at the certificate, checks that the hostname in the certificate is the same as the hostname it is connected to (more on this in a moment), and verifies the CA's signature. If any of these steps fail, the browser will show a warning and break off the connection. Otherwise, the browser uses the public key in the certificate to verify some signed information sent from the server to ensure that the server possesses the certificate's private key. These messages also serve as steps in one of several algorithms used to establish a shared secret key that will encrypt subsequent messages. Key exchange algorithms are beyond the scope of this article, but there's a good discussion of one of them in [this video][14].
|
||||
|
||||
### Creating trust
|
||||
|
||||
You're probably wondering, "If the CA's private key signs a certificate, that means to verify a certificate we need the CA's public key. Where does it come from and who signs it?" The answer is the CA signs for itself! A certificate can be signed using the private key associated with the same certificate's public key. These certificates are said to be self-signed; they are the PKI equivalent of saying, "Trust me." (People often say, as a form of shorthand, that a certificate has signed something even though it's the private key—which isn't in the certificate at all—doing the actual signing.)
|
||||
|
||||
By adhering to policies established by [web browser][15] and [operating system][16] vendors, CAs demonstrate they are trustworthy enough to be placed into a group of self-signed certificates built into the browser or operating system. These certificates are called trust anchors or root CA certificates, and they are placed in a root certificate store where they are trusted implicitly.
|
||||
|
||||
A CA can also issue a certificate endowed with the ability to act as a CA itself. In this way, they can create a chain of certificates. To verify the chain, a program starts at the trust anchor and verifies (among other things) the signature on the next certificate using the public key of the current certificate. It continues down the chain, verifying each link until it reaches the end. If there are no problems along the way, a chain of trust is established. When a website pays a CA to sign a certificate for it, they are paying for the privilege of being placed at the end of that chain. CAs mark certificates sold to websites as not being allowed to sign subsequent certificates; this is so they can terminate the chain of trust at the appropriate place.
|
||||
|
||||
Why would a chain ever be more than two links long? After all, a site just needs its certificate signed by a CA's root certificate. In practice, CAs create intermediate CA certificates for convenience (among other reasons). The private keys for a CA's root certificates are so valuable that they reside in a specialized device, a [hardware security module][17] (HSM), that requires multiple people to unlock it, is completely offline, and is kept inside a [vault][18] wired with alarms and cameras.
|
||||
|
||||
CAB Forum, the association that governs CAs, [requires][19] any interaction with a CA's root certificate to be performed directly by a human. Issuing certificates for dozens of websites a day would be tedious if every certificate request required an employee to place the request on secure media, enter a vault, unlock the HSM with a coworker, sign the certificate, exit the vault, and then copy the signed certificate off the media. Instead, CAs create internal, intermediate CAs used to sign certificates automatically.
|
||||
|
||||
You can see this chain in Firefox by clicking the lock icon in the URL bar, opening up the page information, and clicking the "View Certificate" button on the "Security" tab. As of this writing, [opensource.com][20] had the following chain:
|
||||
```
|
||||
DigiCert High Assurance EV Root CA
|
||||
|
||||
DigiCert SHA2 High Assurance Server CA
|
||||
|
||||
opensource.com
|
||||
|
||||
```
|
||||
|
||||
### The man in the middle
|
||||
|
||||
I mentioned earlier that a browser needs to check that the hostname in the certificate is the same as the hostname it connected to. Why? The answer has to do with what's called a [man-in-the-middle (MITM) attack][21]. These are [network attacks][22] that allow an attacker to insert itself between a client and a server, masquerading as the server to the client and vice versa. If the traffic is over HTTPS, it's encrypted and eavesdropping is fruitless. Instead, the attacker can create a proxy that will accept HTTPS connections from the victim, decrypt the information, and then form an HTTPS connection with the original destination. To create the phony HTTPS connection, the proxy must return a certificate that our attacker has the private key for. Our attacker could generate self-signed certificates, but the victim's browser won't trust anything not signed by a CA's root certificate in the browser's root certificate store. What if instead, the attacker uses a certificate signed by a trusted CA for a domain it owns?
|
||||
|
||||
Imagine we're back to our job in the bank. A man walks in and asks to withdraw money from Jane Doe's account. When asked for identification, the man hands us a valid driver's license for Joe Smith. We would be rightfully fired if we allowed the transaction to continue. If a browser detects a mismatch between the certificate hostname and the connection hostname, it will show a warning that says something like "Your connection is not secure" and an option to show additional details. In Firefox, this error is called SSL_ERROR_BAD_CERT_DOMAIN.
|
||||
|
||||
If there's one lesson I want you to remember from this article, it's: If you see these warnings, **do not disregard them**! They signal that the site is either configured so erroneously that you shouldn't use it or that you're the potential victim of a MITM attack.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
I've only scratched the surface of the PKI world in this article, but I hope that I've given you a map that you can use to guide your further explorations. Cryptography and PKI are fractal-like in their beauty and complexity. The further you dive in, the more there is to discover.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/private-keys
|
||||
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/awood
|
||||
[1]:https://opensource.com/article/18/5/cryptography-pki
|
||||
[2]:https://theintercept.com/2014/10/28/smuggling-snowden-secrets/
|
||||
[3]:https://en.wikipedia.org/wiki/SHA-2
|
||||
[4]:https://www.ietf.org/mail-archive/web/openpgp/current/msg00999.html
|
||||
[5]:https://www.imperialviolet.org/2014/09/26/pkcs1.html
|
||||
[6]:https://en.wikipedia.org/wiki/Key_signing_party
|
||||
[7]:https://en.wikipedia.org/wiki/Key_server_(cryptographic)
|
||||
[8]:https://en.wikipedia.org/wiki/Web_of_trust
|
||||
[9]:https://www.gnupg.org/gph/en/manual/x547.html
|
||||
[10]:https://blog.cryptographyengineering.com/2014/08/13/whats-matter-with-pgp/
|
||||
[11]:https://lists.torproject.org/pipermail/tor-talk/2013-September/030235.html
|
||||
[12]:https://en.wikipedia.org/wiki/Extended_Validation_Certificate
|
||||
[13]:https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[14]:https://www.youtube.com/watch?v=YEBfamv-_do
|
||||
[15]:https://www.mozilla.org/en-US/about/governance/policies/security-group/certs/policy/
|
||||
[16]:https://technet.microsoft.com/en-us/library/cc751157.aspx
|
||||
[17]:https://en.wikipedia.org/wiki/Hardware_security_module
|
||||
[18]:https://arstechnica.com/information-technology/2012/11/inside-symantecs-ssl-certificate-vault/
|
||||
[19]:https://cabforum.org/baseline-requirements-documents/
|
||||
[20]:http://opensource.com
|
||||
[21]:https://en.wikipedia.org/wiki/Man-in-the-middle_attack
|
||||
[22]:http://www.shortestpathfirst.net/2010/11/18/man-in-the-middle-mitm-attacks-explained-arp-poisoining/
|
||||
121
sources/tech/20180726 4 cool apps for your terminal.md
Normal file
121
sources/tech/20180726 4 cool apps for your terminal.md
Normal file
@ -0,0 +1,121 @@
|
||||
4 cool apps for your terminal
|
||||
======
|
||||
|
||||

|
||||
|
||||
Many Linux users think that working in a terminal is either too complex or boring, and try to escape it. Here is a fix, though — four great open source apps for your terminal. They’re fun and easy to use, and may even brighten up your life when you need to spend a time in the command line.
|
||||
|
||||
### No More Secrets
|
||||
|
||||
This is a simple command line tool that recreates the famous data decryption effect seen in the 1992 movie [Sneakers][1]. The project lets you compile the nms command, which works with piped data and prints the output in the form of messed characters. Once it does so, you can press any key, and see the live “deciphering” of the output with a cool Hollywood-style effect.
|
||||
|
||||
![][2]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
A fresh Fedora Workstation system already includes everything you need to build No More Secrets from source. Just enter the following command in your terminal:
|
||||
```
|
||||
git clone https://github.com/bartobri/no-more-secrets.git
|
||||
cd ./no-more-secrets
|
||||
make nms
|
||||
make sneakers ## Optional
|
||||
sudo make install
|
||||
|
||||
```
|
||||
|
||||
The sneakers command is a little bonus for those who remember the original movie, but the main hero is nms. Use a pipe to redirect any Linux command to nms, like this:
|
||||
```
|
||||
systemctl list-units --type=target | nms
|
||||
|
||||
```
|
||||
|
||||
Once the text stops flickering, hit any key to “decrypt” it. The systemctl command above is only an example — you can replace it with virtually anything!
|
||||
|
||||
### Lolcat
|
||||
|
||||
Here’s a command that colorizes the terminal output with rainbows. Nothing can be more useless, but boy, it looks awesome!
|
||||
|
||||
![][3]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
Lolcat is a Ruby package available from the official Ruby Gems hosting. So, you’ll need the gem client first:
|
||||
```
|
||||
sudo dnf install -y rubygems
|
||||
|
||||
```
|
||||
|
||||
And then install Lolcat itself:
|
||||
```
|
||||
gem install lolcat
|
||||
|
||||
```
|
||||
|
||||
Again, use the lolcat command in for piping any other command and enjoy rainbows (and unicorns!) right in your Fedora terminal.
|
||||
|
||||
### Chafa
|
||||
|
||||
![][4]
|
||||
|
||||
Chafa is a [command line image converter and viewer][5]. It helps you enjoy your images without leaving your lovely terminal. The syntax is very straightforward:
|
||||
```
|
||||
chafa /path/to/your/image
|
||||
|
||||
```
|
||||
|
||||
You can throw almost any sort of image to Chafa, including JPG, PNG, TIFF, BMP or virtually anything that ImageMagick supports — this is the engine that Chafa uses for parsing input files. The coolest part is that Chafa can also show very smooth and fluid GIF animations right inside your terminal!
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
Chafa isn’t packaged for Fedora yet, but it’s quite easy to build it from source. First, get the necessary build dependencies:
|
||||
```
|
||||
sudo dnf install -y autoconf automake libtool gtk-doc glib2-devel ImageMagick-devel
|
||||
|
||||
```
|
||||
|
||||
Next, clone the code or download a snapshot from the project’s Github page and cd to the Chafa directory. After that, you’re ready to go:
|
||||
```
|
||||
git clone https://github.com/hpjansson/chafa
|
||||
./autogen.sh
|
||||
make
|
||||
sudo make install
|
||||
|
||||
```
|
||||
|
||||
Large images can take a while to process at the first run, but Chafa caches everything you load with it. Next runs will be nearly instantaneous.
|
||||
|
||||
### Browsh
|
||||
|
||||
Browsh is a fully-fledged web browser for the terminal. It’s more powerful than Lynx and certainly more eye-catching. Browsh launches the Firefox web browser in a headless mode (so that you can’t see it) and connects it with your terminal with the help of special web extension. Therefore, Browsh renders all rich media content just like Firefox, only in a bit pixelated style.
|
||||
|
||||
![][6]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The project provides packages for various Linux distributions, including Fedora. Install it this way:
|
||||
```
|
||||
sudo dnf install -y https://github.com/browsh-org/browsh/releases/download/v1.4.6/browsh_1.4.6_linux_amd64.rpm
|
||||
|
||||
```
|
||||
|
||||
After that, launch the browsh command and give it a couple of seconds to load up. Press Ctrl+L to switch focus to the address bar and start browsing the Web like you never did before! Use Ctrl+Q to get back to your terminal.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-apps-for-your-terminal/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://www.imdb.com/title/tt0105435/
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/nms.gif
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/lolcat.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/sir.gif
|
||||
[5]:https://hpjansson.org/chafa/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/browsh.png
|
||||
599
sources/tech/20180726 The evolution of package managers.md
Normal file
599
sources/tech/20180726 The evolution of package managers.md
Normal file
@ -0,0 +1,599 @@
|
||||
The evolution of package managers
|
||||
======
|
||||
|
||||

|
||||
|
||||
Every computerized device uses some form of software to perform its intended tasks. In the early days of software, products were stringently tested for bugs and other defects. For the last decade or so, software has been released via the internet with the intent that any bugs would be fixed by applying new versions of the software. In some cases, each individual application has its own updater. In others, it is left up to the user to figure out how to obtain and upgrade software.
|
||||
|
||||
Linux adopted early the practice of maintaining a centralized location where users could find and install software. In this article, I'll discuss the history of software installation on Linux and how modern operating systems are kept up to date against the never-ending torrent of [CVEs][1].
|
||||
|
||||
### How was software on Linux installed before package managers?
|
||||
|
||||
Historically, software was provided either via FTP or mailing lists (eventually this distribution would grow to include basic websites). Only a few small files contained the instructions to create a binary (normally in a tarfile). You would untar the files, read the readme, and as long as you had GCC or some other form of C compiler, you would then typically run a `./configure` script with some list of attributes, such as pathing to library files, location to create new binaries, etc. In addition, the `configure` process would check your system for application dependencies. If any major requirements were missing, the configure script would exit and you could not proceed with the installation until all the dependencies were met. If the configure script completed successfully, a `Makefile` would be created.
|
||||
|
||||
Once a `Makefile` existed, you would then proceed to run the `make` command (this command is provided by whichever compiler you were using). The `make` command has a number of options called make flags, which help optimize the resulting binaries for your system. In the earlier days of computing, this was very important because hardware struggled to keep up with modern software demands. Today, compilation options can be much more generic as most hardware is more than adequate for modern software.
|
||||
|
||||
Finally, after the `make` process had been completed, you would need to run `make install` (or `sudo make install`) in order to actually install the software. As you can imagine, doing this for every single piece of software was time-consuming and tedious—not to mention the fact that updating software was a complicated and potentially very involved process.
|
||||
|
||||
### What is a package?
|
||||
|
||||
Packages were invented to combat this complexity. Packages collect multiple data files together into a single archive file for easier portability and storage, or simply compress files to reduce storage space. The binaries included in a package are precompiled with according to the sane defaults the developer chosen. Packages also contain metadata, such as the software's name, a description of its purpose, a version number, and a list of dependencies necessary for the software to run properly.
|
||||
|
||||
Several flavors of Linux have created their own package formats. Some of the most commonly used package formats include:
|
||||
|
||||
* .deb: This package format is used by Debian, Ubuntu, Linux Mint, and several other derivatives. It was the first package type to be created.
|
||||
* .rpm: This package format was originally called Red Hat Package Manager. It is used by Red Hat, Fedora, SUSE, and several other smaller distributions.
|
||||
* .tar.xz: While it is just a compressed tarball, this is the format that Arch Linux uses.
|
||||
|
||||
|
||||
|
||||
While packages themselves don't manage dependencies directly, they represented a huge step forward in Linux software management.
|
||||
|
||||
### What is a software repository?
|
||||
|
||||
A few years ago, before the proliferation of smartphones, the idea of a software repository was difficult for many users to grasp if they were not involved in the Linux ecosystem. To this day, most Windows users still seem to be hardwired to open a web browser to search for and install new software. However, those with smartphones have gotten used to the idea of a software "store." The way smartphone users obtain software and the way package managers work are not dissimilar. While there have been several attempts at making an attractive UI for software repositories, the vast majority of Linux users still use the command line to install packages. Software repositories are a centralized listing of all of the available software for any repository the system has been configured to use. Below are some examples of searching a repository for a specifc package (note that these have been truncated for brevity):
|
||||
|
||||
Arch Linux with aurman
|
||||
```
|
||||
user@arch ~ $ aurman -Ss kate
|
||||
|
||||
extra/kate 18.04.2-2 (kde-applications kdebase)
|
||||
Advanced Text Editor
|
||||
aur/kate-root 18.04.0-1 (11, 1.139399)
|
||||
Advanced Text Editor, patched to be able to run as root
|
||||
aur/kate-git r15288.15d26a7-1 (1, 1e-06)
|
||||
An advanced editor component which is used in numerous KDE applications requiring a text editing component
|
||||
```
|
||||
|
||||
CentOS 7 using YUM
|
||||
```
|
||||
[user@centos ~]$ yum search kate
|
||||
|
||||
kate-devel.x86_64 : Development files for kate
|
||||
kate-libs.x86_64 : Runtime files for kate
|
||||
kate-part.x86_64 : Kate kpart plugin
|
||||
```
|
||||
|
||||
Ubuntu using APT
|
||||
```
|
||||
user@ubuntu ~ $ apt search kate
|
||||
Sorting... Done
|
||||
Full Text Search... Done
|
||||
|
||||
kate/xenial 4:15.12.3-0ubuntu2 amd64
|
||||
powerful text editor
|
||||
|
||||
kate-data/xenial,xenial 4:4.14.3-0ubuntu4 all
|
||||
shared data files for Kate text editor
|
||||
|
||||
kate-dbg/xenial 4:15.12.3-0ubuntu2 amd64
|
||||
debugging symbols for Kate
|
||||
|
||||
kate5-data/xenial,xenial 4:15.12.3-0ubuntu2 all
|
||||
shared data files for Kate text editor
|
||||
```
|
||||
|
||||
### What are the most prominent package managers?
|
||||
|
||||
As suggested in the above output, package managers are used to interact with software repositories. The following is a brief overview of some of the most prominent package managers.
|
||||
|
||||
#### RPM-based package managers
|
||||
|
||||
Updating RPM-based systems, particularly those based on Red Hat technologies, has a very interesting and detailed history. In fact, the current versions of [yum][2] (for enterprise distributions) and [DNF][3] (for community) combine several open source projects to provide their current functionality.
|
||||
|
||||
Initially, Red Hat used a package manager called [RPM][4] (Red Hat Package Manager), which is still in use today. However, its primary use is to install RPMs, which you have locally, not to search software repositories. The package manager named `up2date` was created to inform users of updates to packages and enable them to search remote repositories and easily install dependencies. While it served its purpose, some community members felt that `up2date` had some significant shortcomings.
|
||||
|
||||
The current incantation of yum came from several different community efforts. Yellowdog Updater (YUP) was developed in 1999-2001 by folks at Terra Soft Solutions as a back-end engine for a graphical installer of [Yellow Dog Linux][5]. Duke University liked the idea of YUP and decided to improve upon it. They created [Yellowdog Updater, Modified (yum)][6] which was eventually adapted to help manage the university's Red Hat Linux systems. Yum grew in popularity, and by 2005 it was estimated to be used by more than half of the Linux market. Today, almost every distribution of Linux that uses RPMs uses yum for package management (with a few notable exceptions).
|
||||
|
||||
#### Working with yum
|
||||
|
||||
In order for yum to download and install packages out of an internet repository, files must be located in `/etc/yum.repos.d/` and they must have the extension `.repo`. Here is an example repo file:
|
||||
```
|
||||
[local_base]
|
||||
name=Base CentOS (local)
|
||||
baseurl=http://7-repo.apps.home.local/yum-repo/7/
|
||||
enabled=1
|
||||
gpgcheck=0
|
||||
```
|
||||
|
||||
This is for one of my local repositories, which explains why the GPG check is off. If this check was on, each package would need to be signed with a cryptographic key and a corresponding key would need to be imported into the system receiving the updates. Because I maintain this repository myself, I trust the packages and do not bother signing them.
|
||||
|
||||
Once a repository file is in place, you can start installing packages from the remote repository. The most basic command is `yum update`, which will update every package currently installed. This does not require a specific step to refresh the information about repositories; this is done automatically. A sample of the command is shown below:
|
||||
```
|
||||
[user@centos ~]$ sudo yum update
|
||||
Loaded plugins: fastestmirror, product-id, search-disabled-repos, subscription-manager
|
||||
local_base | 3.6 kB 00:00:00
|
||||
local_epel | 2.9 kB 00:00:00
|
||||
local_rpm_forge | 1.9 kB 00:00:00
|
||||
local_updates | 3.4 kB 00:00:00
|
||||
spideroak-one-stable | 2.9 kB 00:00:00
|
||||
zfs | 2.9 kB 00:00:00
|
||||
(1/6): local_base/group_gz | 166 kB 00:00:00
|
||||
(2/6): local_updates/primary_db | 2.7 MB 00:00:00
|
||||
(3/6): local_base/primary_db | 5.9 MB 00:00:00
|
||||
(4/6): spideroak-one-stable/primary_db | 12 kB 00:00:00
|
||||
(5/6): local_epel/primary_db | 6.3 MB 00:00:00
|
||||
(6/6): zfs/x86_64/primary_db | 78 kB 00:00:00
|
||||
local_rpm_forge/primary_db | 125 kB 00:00:00
|
||||
Determining fastest mirrors
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
```
|
||||
|
||||
If you are sure you want yum to execute any command without stopping for input, you can put the `-y` flag in the command, such as `yum update -y`.
|
||||
|
||||
Installing a new package is just as easy. First, search for the name of the package with `yum search`:
|
||||
```
|
||||
[user@centos ~]$ yum search kate
|
||||
|
||||
artwiz-aleczapka-kates-fonts.noarch : Kates font in Artwiz family
|
||||
ghc-highlighting-kate-devel.x86_64 : Haskell highlighting-kate library development files
|
||||
kate-devel.i686 : Development files for kate
|
||||
kate-devel.x86_64 : Development files for kate
|
||||
kate-libs.i686 : Runtime files for kate
|
||||
kate-libs.x86_64 : Runtime files for kate
|
||||
kate-part.i686 : Kate kpart plugin
|
||||
```
|
||||
|
||||
Once you have the name of the package, you can simply install the package with `sudo yum install kate-devel -y`. If you installed a package you no longer need, you can remove it with `sudo yum remove kate-devel -y`. By default, yum will remove the package plus its dependencies.
|
||||
|
||||
There may be times when you do not know the name of the package, but you know the name of the utility. For example, suppose you are looking for the utility `updatedb`, which creates/updates the database used by the `locate` command. Attempting to install `updatedb` returns the following results:
|
||||
```
|
||||
[user@centos ~]$ sudo yum install updatedb
|
||||
Loaded plugins: fastestmirror, langpacks
|
||||
Loading mirror speeds from cached hostfile
|
||||
No package updatedb available.
|
||||
Error: Nothing to do
|
||||
```
|
||||
|
||||
You can find out what package the utility comes from by running:
|
||||
```
|
||||
[user@centos ~]$ yum whatprovides *updatedb
|
||||
Loaded plugins: fastestmirror, langpacks
|
||||
Loading mirror speeds from cached hostfile
|
||||
|
||||
bacula-director-5.2.13-23.1.el7.x86_64 : Bacula Director files
|
||||
Repo : local_base
|
||||
Matched from:
|
||||
Filename : /usr/share/doc/bacula-director-5.2.13/updatedb
|
||||
|
||||
mlocate-0.26-8.el7.x86_64 : An utility for finding files by name
|
||||
Repo : local_base
|
||||
Matched from:
|
||||
Filename : /usr/bin/updatedb
|
||||
```
|
||||
|
||||
The reason I have used an asterisk `*` in front of the command is because `yum whatprovides` uses the path to the file in order to make a match. Since I was not sure where the file was located, I used an asterisk to indicate any path.
|
||||
|
||||
There are, of course, many more options available to yum. I encourage you to view the man page for yum for additional options.
|
||||
|
||||
[Dandified Yum (DNF)][7] is a newer iteration on yum. Introduced in Fedora 18, it has not yet been adopted in the enterprise distributions, and as such is predominantly used in Fedora (and derivatives). Its usage is almost exactly the same as that of yum, but it was built to address poor performance, undocumented APIs, slow/broken dependency resolution, and occasional high memory usage. DNF is meant as a drop-in replacement for yum, and therefore I won't repeat the commands—wherever you would use `yum`, simply substitute `dnf`.
|
||||
|
||||
#### Working with Zypper
|
||||
|
||||
[Zypper][8] is another package manager meant to help manage RPMs. This package manager is most commonly associated with [SUSE][9] (and [openSUSE][10]) but has also seen adoption by [MeeGo][11], [Sailfish OS][12], and [Tizen][13]. It was originally introduced in 2006 and has been iterated upon ever since. There is not a whole lot to say other than Zypper is used as the back end for the system administration tool [YaST][14] and some users find it to be faster than yum.
|
||||
|
||||
Zypper's usage is very similar to that of yum. To search for, update, install or remove a package, simply use the following:
|
||||
```
|
||||
zypper search kate
|
||||
zypper update
|
||||
zypper install kate
|
||||
zypper remove kate
|
||||
```
|
||||
Some major differences come into play in how repositories are added to the system with `zypper`. Unlike the package managers discussed above, `zypper` adds repositories using the package manager itself. The most common way is via a URL, but `zypper` also supports importing from repo files.
|
||||
```
|
||||
suse:~ # zypper addrepo http://download.videolan.org/pub/vlc/SuSE/15.0 vlc
|
||||
Adding repository 'vlc' [done]
|
||||
Repository 'vlc' successfully added
|
||||
|
||||
Enabled : Yes
|
||||
Autorefresh : No
|
||||
GPG Check : Yes
|
||||
URI : http://download.videolan.org/pub/vlc/SuSE/15.0
|
||||
Priority : 99
|
||||
```
|
||||
|
||||
You remove repositories in a similar manner:
|
||||
```
|
||||
suse:~ # zypper removerepo vlc
|
||||
Removing repository 'vlc' ...................................[done]
|
||||
Repository 'vlc' has been removed.
|
||||
```
|
||||
|
||||
Use the `zypper repos` command to see what the status of repositories are on your system:
|
||||
```
|
||||
suse:~ # zypper repos
|
||||
Repository priorities are without effect. All enabled repositories share the same priority.
|
||||
|
||||
# | Alias | Name | Enabled | GPG Check | Refresh
|
||||
---|---------------------------|-----------------------------------------|---------|-----------|--------
|
||||
1 | repo-debug | openSUSE-Leap-15.0-Debug | No | ---- | ----
|
||||
2 | repo-debug-non-oss | openSUSE-Leap-15.0-Debug-Non-Oss | No | ---- | ----
|
||||
3 | repo-debug-update | openSUSE-Leap-15.0-Update-Debug | No | ---- | ----
|
||||
4 | repo-debug-update-non-oss | openSUSE-Leap-15.0-Update-Debug-Non-Oss | No | ---- | ----
|
||||
5 | repo-non-oss | openSUSE-Leap-15.0-Non-Oss | Yes | ( p) Yes | Yes
|
||||
6 | repo-oss | openSUSE-Leap-15.0-Oss | Yes | ( p) Yes | Yes
|
||||
```
|
||||
|
||||
`zypper` even has a similar ability to determine what package name contains files or binaries. Unlike YUM, it uses a hyphen in the command (although this method of searching is deprecated):
|
||||
```
|
||||
localhost:~ # zypper what-provides kate
|
||||
Command 'what-provides' is replaced by 'search --provides --match-exact'.
|
||||
See 'help search' for all available options.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
S | Name | Summary | Type
|
||||
---|------|----------------------|------------
|
||||
i+ | Kate | Advanced Text Editor | application
|
||||
i | kate | Advanced Text Editor | package
|
||||
```
|
||||
|
||||
As with YUM and DNF, Zypper has a much richer feature set than covered here. Please consult with the official documentation for more in-depth information.
|
||||
|
||||
#### Debian-based package managers
|
||||
|
||||
One of the oldest Linux distributions currently maintained, Debian's system is very similar to RPM-based systems. They use `.deb` packages, which can be managed by a tool called dpkg. dpkg is very similar to rpm in that it was designed to manage packages that are available locally. It does no dependency resolution (although it does dependency checking), and has no reliable way to interact with remote repositories. In order to improve the user experience and ease of use, the Debian project commissioned a project called Deity. This codename was eventually abandoned and changed to [Advanced Package Tool (APT)][15].
|
||||
|
||||
Released as test builds in 1998 (before making an appearance in Debian 2.1 in 1999), many users consider APT one of the defining features of Debian-based systems. It makes use of repositories in a similar fashion to RPM-based systems, but instead of individual `.repo` files that `yum` uses, `apt` has historically used `/etc/apt/sources.list` to manage repositories. More recently, it also ingests files from `/etc/apt/sources.d/`. Following the examples in the RPM-based package managers, to accomplish the same thing on Debian-based distributions you have a few options. You can edit/create the files manually in the aforementioned locations from the terminal, or in some cases, you can use a UI front end (such as `Software & Updates` provided by Ubuntu et al.). To provide the same treatment to all distributions, I will cover only the command-line options. To add a repository without directly editing a file, you can do something like this:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-add-repository "deb http://APT.spideroak.com/ubuntu-spideroak-hardy/ release restricted"
|
||||
|
||||
```
|
||||
|
||||
This will create a `spideroakone.list` file in `/etc/apt/sources.list.d`. Obviously, these lines change depending on the repository being added. If you are adding a Personal Package Archive (PPA), you can do this:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-add-repository ppa:gnome-desktop
|
||||
|
||||
```
|
||||
|
||||
NOTE: Debian does not support PPAs natively.
|
||||
|
||||
After a repository has been added, Debian-based systems need to be made aware that there is a new location to search for packages. This is done via the `apt-get update` command:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get update
|
||||
Get:1 http://security.ubuntu.com/ubuntu xenial-security InRelease [107 kB]
|
||||
Hit:2 http://APT.spideroak.com/ubuntu-spideroak-hardy release InRelease
|
||||
Hit:3 http://ca.archive.ubuntu.com/ubuntu xenial InRelease
|
||||
Get:4 http://ca.archive.ubuntu.com/ubuntu xenial-updates InRelease [109 kB]
|
||||
Get:5 http://security.ubuntu.com/ubuntu xenial-security/main amd64 Packages [517 kB]
|
||||
Get:6 http://security.ubuntu.com/ubuntu xenial-security/main i386 Packages [455 kB]
|
||||
Get:7 http://security.ubuntu.com/ubuntu xenial-security/main Translation-en [221 kB]
|
||||
...
|
||||
|
||||
Fetched 6,399 kB in 3s (2,017 kB/s)
|
||||
Reading package lists... Done
|
||||
```
|
||||
|
||||
Now that the new repository is added and updated, you can search for a package using the `apt-cache` command:
|
||||
```
|
||||
user@ubuntu:~$ apt-cache search kate
|
||||
aterm-ml - Afterstep XVT - a VT102 emulator for the X window system
|
||||
frescobaldi - Qt4 LilyPond sheet music editor
|
||||
gitit - Wiki engine backed by a git or darcs filestore
|
||||
jedit - Plugin-based editor for programmers
|
||||
kate - powerful text editor
|
||||
kate-data - shared data files for Kate text editor
|
||||
kate-dbg - debugging symbols for Kate
|
||||
katepart - embeddable text editor component
|
||||
```
|
||||
|
||||
To install `kate`, simply run the corresponding install command:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get install kate
|
||||
|
||||
```
|
||||
|
||||
To remove a package, use `apt-get remove`:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get remove kate
|
||||
|
||||
```
|
||||
|
||||
When it comes to package discovery, APT does not provide any functionality that is similar to `yum whatprovides`. There are a few ways to get this information if you are trying to find where a specific file on disk has come from.
|
||||
|
||||
Using dpkg
|
||||
```
|
||||
user@ubuntu:~$ dpkg -S /bin/ls
|
||||
coreutils: /bin/ls
|
||||
```
|
||||
|
||||
Using apt-file
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get install apt-file -y
|
||||
|
||||
user@ubuntu:~$ sudo apt-file update
|
||||
|
||||
user@ubuntu:~$ apt-file search kate
|
||||
```
|
||||
|
||||
The problem with `apt-file search` is that it, unlike `yum whatprovides`, it is overly verbose unless you know the exact path, and it automatically adds a wildcard search so that you end up with results for anything with the word kate in it:
|
||||
```
|
||||
kate: /usr/bin/kate
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katebacktracebrowserplugin.so
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katebuildplugin.so
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katecloseexceptplugin.so
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katectagsplugin.so
|
||||
```
|
||||
|
||||
Most of these examples have used `apt-get`. Note that most of the current tutorials for Ubuntu specifically have taken to simply using `apt`. The single `apt` command was designed to implement only the most commonly used commands in the APT arsenal. Since functionality is split between `apt-get`, `apt-cache`, and other commands, `apt` looks to unify these into a single command. It also adds some niceties such as colorization, progress bars, and other odds and ends. Most of the commands noted above can be replaced with `apt`, but not all Debian-based distributions currently receiving security patches support using `apt` by default, so you may need to install additional packages.
|
||||
|
||||
#### Arch-based package managers
|
||||
|
||||
[Arch Linux][16] uses a package manager called [pacman][17]. Unlike `.deb` or `.rpm` files, pacman uses a more traditional tarball with the LZMA2 compression (`.tar.xz`). This enables Arch Linux packages to be much smaller than other forms of compressed archives (such as gzip). Initially released in 2002, pacman has been steadily iterated and improved. One of the major benefits of pacman is that it supports the [Arch Build System][18], a system for building packages from source. The build system ingests a file called a PKGBUILD, which contains metadata (such as version numbers, revisions, dependencies, etc.) as well as a shell script with the required flags for compiling a package conforming to the Arch Linux requirements. The resulting binaries are then packaged into the aforementioned `.tar.xz` file for consumption by pacman.
|
||||
|
||||
This system led to the creation of the [Arch User Repository][19] (AUR) which is a community-driven repository containing PKGBUILD files and supporting patches or scripts. This allows for a virtually endless amount of software to be available in Arch. The obvious advantage of this system is that if a user (or maintainer) wishes to make software available to the public, they do not have to go through official channels to get it accepted in the main repositories. The downside is that it relies on community curation similar to [Docker Hub][20], Canonical's Snap packages, or other similar mechanisms. There are numerous AUR-specific package managers that can be used to download, compile, and install from the PKGBUILD files in the AUR (we will look at this later).
|
||||
|
||||
#### Working with pacman and official repositories
|
||||
|
||||
Arch's main package manager, pacman, uses flags instead of command words like `yum` and `apt`. For example, to search for a package, you would use `pacman -Ss`. As with most commands on Linux, you can find both a `manpage` and inline help. Most of the commands for `pacman `use the sync (-S) flag. For example:
|
||||
```
|
||||
user@arch ~ $ pacman -Ss kate
|
||||
|
||||
extra/kate 18.04.2-2 (kde-applications kdebase)
|
||||
Advanced Text Editor
|
||||
extra/libkate 0.4.1-6 [installed]
|
||||
A karaoke and text codec for embedding in ogg
|
||||
extra/libtiger 0.3.4-5 [installed]
|
||||
A rendering library for Kate streams using Pango and Cairo
|
||||
extra/ttf-cheapskate 2.0-12
|
||||
TTFonts collection from dustimo.com
|
||||
community/haskell-cheapskate 0.1.1-100
|
||||
Experimental markdown processor.
|
||||
```
|
||||
|
||||
Arch also uses repositories similar to other package managers. In the output above, search results are prefixed with the repository they are found in (`extra/` and `community/` in this case). Similar to both Red Hat and Debian-based systems, Arch relies on the user to add the repository information into a specific file. The location for these repositories is `/etc/pacman.conf`. The example below is fairly close to a stock system. I have enabled the `[multilib]` repository for Steam support:
|
||||
```
|
||||
[options]
|
||||
Architecture = auto
|
||||
|
||||
Color
|
||||
CheckSpace
|
||||
|
||||
SigLevel = Required DatabaseOptional
|
||||
LocalFileSigLevel = Optional
|
||||
|
||||
[core]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
|
||||
[extra]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
|
||||
[community]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
|
||||
[multilib]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
```
|
||||
|
||||
It is possible to specify a specific URL in `pacman.conf`. This functionality can be used to make sure all packages come from a specific point in time. If, for example, a package has a bug that affects you severely and it has several dependencies, you can roll back to a specific point in time by adding a specific URL into your `pacman.conf` and then running the commands to downgrade the system:
|
||||
```
|
||||
[core]
|
||||
Server=https://archive.archlinux.org/repos/2017/12/22/$repo/os/$arch
|
||||
```
|
||||
|
||||
Like Debian-based systems, Arch does not update its local repository information until you tell it to do so. You can refresh the package database by issuing the following command:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Sy
|
||||
|
||||
:: Synchronizing package databases...
|
||||
core 130.2 KiB 851K/s 00:00 [##########################################################] 100%
|
||||
extra 1645.3 KiB 2.69M/s 00:01 [##########################################################] 100%
|
||||
community 4.5 MiB 2.27M/s 00:02 [##########################################################] 100%
|
||||
multilib is up to date
|
||||
```
|
||||
|
||||
As you can see in the above output, `pacman` thinks that the multilib package database is up to date. You can force a refresh if you think this is incorrect by running `pacman -Syy`. If you want to update your entire system (excluding packages installed from the AUR), you can run `pacman -Syu`:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Syu
|
||||
|
||||
:: Synchronizing package databases...
|
||||
core is up to date
|
||||
extra is up to date
|
||||
community is up to date
|
||||
multilib is up to date
|
||||
:: Starting full system upgrade...
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (45) ceph-13.2.0-2 ceph-libs-13.2.0-2 debootstrap-1.0.105-1 guile-2.2.4-1 harfbuzz-1.8.2-1 harfbuzz-icu-1.8.2-1 haskell-aeson-1.3.1.1-20
|
||||
haskell-attoparsec-0.13.2.2-24 haskell-tagged-0.8.6-1 imagemagick-7.0.8.4-1 lib32-harfbuzz-1.8.2-1 lib32-libgusb-0.3.0-1 lib32-systemd-239.0-1
|
||||
libgit2-1:0.27.2-1 libinput-1.11.2-1 libmagick-7.0.8.4-1 libmagick6-6.9.10.4-1 libopenshot-0.2.0-1 libopenshot-audio-0.1.6-1 libosinfo-1.2.0-1
|
||||
libxfce4util-4.13.2-1 minetest-0.4.17.1-1 minetest-common-0.4.17.1-1 mlt-6.10.0-1 mlt-python-bindings-6.10.0-1 ndctl-61.1-1 netctl-1.17-1
|
||||
nodejs-10.6.0-1
|
||||
|
||||
Total Download Size: 2.66 MiB
|
||||
Total Installed Size: 879.15 MiB
|
||||
Net Upgrade Size: -365.27 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
```
|
||||
|
||||
In the scenario mentioned earlier regarding downgrading a system, you can force a downgrade by issuing `pacman -Syyuu`. It is important to note that this should not be undertaken lightly. This should not cause a problem in most cases; however, there is a chance that downgrading of a package or several packages will cause a cascading failure and leave your system in an inconsistent state. USE WITH CAUTION!
|
||||
|
||||
To install a package, simply use `pacman -S kate`:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -S kate
|
||||
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (7) editorconfig-core-c-0.12.2-1 kactivities-5.47.0-1 kparts-5.47.0-1 ktexteditor-5.47.0-2 syntax-highlighting-5.47.0-1 threadweaver-5.47.0-1
|
||||
kate-18.04.2-2
|
||||
|
||||
Total Download Size: 10.94 MiB
|
||||
Total Installed Size: 38.91 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
```
|
||||
|
||||
To remove a package, you can run `pacman -R kate`. This removes only the package and not its dependencies:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -S kate
|
||||
|
||||
checking dependencies...
|
||||
|
||||
Packages (1) kate-18.04.2-2
|
||||
|
||||
Total Removed Size: 20.30 MiB
|
||||
|
||||
:: Do you want to remove these packages? [Y/n]
|
||||
```
|
||||
|
||||
If you want to remove the dependencies that are not required by other packages, you can run `pacman -Rs:`
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Rs kate
|
||||
|
||||
checking dependencies...
|
||||
|
||||
Packages (7) editorconfig-core-c-0.12.2-1 kactivities-5.47.0-1 kparts-5.47.0-1 ktexteditor-5.47.0-2 syntax-highlighting-5.47.0-1 threadweaver-5.47.0-1
|
||||
kate-18.04.2-2
|
||||
|
||||
Total Removed Size: 38.91 MiB
|
||||
|
||||
:: Do you want to remove these packages? [Y/n]
|
||||
```
|
||||
|
||||
Pacman, in my opinion, offers the most succinct way of searching for the name of a package for a given utility. As shown above, `yum` and `apt` both rely on pathing in order to find useful results. Pacman makes some intelligent guesses as to which package you are most likely looking for:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Fs updatedb
|
||||
core/mlocate 0.26.git.20170220-1
|
||||
usr/bin/updatedb
|
||||
|
||||
user@arch ~ $ sudo pacman -Fs kate
|
||||
extra/kate 18.04.2-2
|
||||
usr/bin/kate
|
||||
```
|
||||
|
||||
#### Working with the AUR
|
||||
|
||||
There are several popular AUR package manager helpers. Of these, `yaourt` and `pacaur` are fairly prolific. However, both projects are listed as discontinued or problematic on the [Arch Wiki][21]. For that reason, I will discuss `aurman`. It works almost exactly like `pacman,` except it searches the AUR and includes some helpful, albeit potentially dangerous, options. Installing a package from the AUR will initiate use of the package maintainer's build scripts. You will be prompted several times for permission to continue (I have truncated the output for brevity):
|
||||
```
|
||||
aurman -S telegram-desktop-bin
|
||||
~~ initializing aurman...
|
||||
~~ the following packages are neither in known repos nor in the aur
|
||||
...
|
||||
~~ calculating solutions...
|
||||
|
||||
:: The following 1 package(s) are getting updated:
|
||||
aur/telegram-desktop-bin 1.3.0-1 -> 1.3.9-1
|
||||
|
||||
?? Do you want to continue? Y/n: Y
|
||||
|
||||
~~ looking for new pkgbuilds and fetching them...
|
||||
Cloning into 'telegram-desktop-bin'...
|
||||
|
||||
remote: Counting objects: 301, done.
|
||||
remote: Compressing objects: 100% (152/152), done.
|
||||
remote: Total 301 (delta 161), reused 286 (delta 147)
|
||||
Receiving objects: 100% (301/301), 76.17 KiB | 639.00 KiB/s, done.
|
||||
Resolving deltas: 100% (161/161), done.
|
||||
?? Do you want to see the changes of telegram-desktop-bin? N/y: N
|
||||
|
||||
[sudo] password for user:
|
||||
|
||||
...
|
||||
==> Leaving fakeroot environment.
|
||||
==> Finished making: telegram-desktop-bin 1.3.9-1 (Thu 05 Jul 2018 11:22:02 AM EDT)
|
||||
==> Cleaning up...
|
||||
loading packages...
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (1) telegram-desktop-bin-1.3.9-1
|
||||
|
||||
Total Installed Size: 88.81 MiB
|
||||
Net Upgrade Size: 5.33 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
```
|
||||
|
||||
Sometimes you will be prompted for more input, depending on the complexity of the package you are installing. To avoid this tedium, `aurman` allows you to pass both the `--noconfirm` and `--noedit` options. This is equivalent to saying "accept all of the defaults, and trust that the package maintainers scripts will not be malicious." **USE THIS OPTION WITH EXTREME CAUTION!** While these options are unlikely to break your system on their own, you should never blindly accept someone else's scripts.
|
||||
|
||||
### Conclusion
|
||||
|
||||
This article, of course, only scratches the surface of what package managers can do. There are also many other package managers available that I could not cover in this space. Some distributions, such as Ubuntu or Elementary OS, have gone to great lengths to provide a graphical approach to package management.
|
||||
|
||||
If you are interested in some of the more advanced functions of package managers, please post your questions or comments below and I would be glad to write a follow-up article.
|
||||
|
||||
### Appendix
|
||||
```
|
||||
# search for packages
|
||||
yum search <package>
|
||||
dnf search <package>
|
||||
zypper search <package>
|
||||
apt-cache search <package>
|
||||
apt search <package>
|
||||
pacman -Ss <package>
|
||||
|
||||
# install packages
|
||||
yum install <package>
|
||||
dnf install <package>
|
||||
zypper install <package>
|
||||
apt-get install <package>
|
||||
apt install <package>
|
||||
pacman -Ss <package>
|
||||
|
||||
# update package database, not required by yum, dnf and zypper
|
||||
apt-get update
|
||||
apt update
|
||||
pacman -Sy
|
||||
|
||||
# update all system packages
|
||||
yum update
|
||||
dnf update
|
||||
zypper update
|
||||
apt-get upgrade
|
||||
apt upgrade
|
||||
pacman -Su
|
||||
|
||||
# remove an installed package
|
||||
yum remove <package>
|
||||
dnf remove <package>
|
||||
apt-get remove <package>
|
||||
apt remove <package>
|
||||
pacman -R <package>
|
||||
pacman -Rs <package>
|
||||
|
||||
# search for the package name containing specific file or folder
|
||||
yum whatprovides *<binary>
|
||||
dnf whatprovides *<binary>
|
||||
zypper what-provides <binary>
|
||||
zypper search --provides <binary>
|
||||
apt-file search <binary>
|
||||
pacman -Sf <binary>
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/evolution-package-managers
|
||||
|
||||
作者:[Steve Ovens][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/stratusss
|
||||
[1]:https://en.wikipedia.org/wiki/Common_Vulnerabilities_and_Exposures
|
||||
[2]:https://en.wikipedia.org/wiki/Yum_(software)
|
||||
[3]:https://fedoraproject.org/wiki/DNF
|
||||
[4]:https://en.wikipedia.org/wiki/Rpm_(software)
|
||||
[5]:https://en.wikipedia.org/wiki/Yellow_Dog_Linux
|
||||
[6]:https://searchdatacenter.techtarget.com/definition/Yellowdog-Updater-Modified-YUM
|
||||
[7]:https://en.wikipedia.org/wiki/DNF_(software)
|
||||
[8]:https://en.opensuse.org/Portal:Zypper
|
||||
[9]:https://www.suse.com/
|
||||
[10]:https://www.opensuse.org/
|
||||
[11]:https://en.wikipedia.org/wiki/MeeGo
|
||||
[12]:https://sailfishos.org/
|
||||
[13]:https://www.tizen.org/
|
||||
[14]:https://en.wikipedia.org/wiki/YaST
|
||||
[15]:https://en.wikipedia.org/wiki/APT_(Debian)
|
||||
[16]:https://www.archlinux.org/
|
||||
[17]:https://wiki.archlinux.org/index.php/pacman
|
||||
[18]:https://wiki.archlinux.org/index.php/Arch_Build_System
|
||||
[19]:https://aur.archlinux.org/
|
||||
[20]:https://hub.docker.com/
|
||||
[21]:https://wiki.archlinux.org/index.php/AUR_helpers#Discontinued_or_problematic
|
||||
@ -0,0 +1,145 @@
|
||||
4 Ways to Customize Xfce and Give it a Modern Look
|
||||
======
|
||||
**Brief: Xfce is a great lightweight desktop environment with one drawback. It looks sort of old. But you don’t have to stick with the default looks. Let’s see various ways you can customize Xfce to give it a modern and beautiful look.**
|
||||
|
||||
![Customize Xfce desktop envirnment][1]
|
||||
|
||||
To start with, Xfce is one of the most [popular desktop environments][2]. Being a lightweight DE, you can run Xfce on very low resource and it still works great. This is one of the reasons why many [lightweight Linux distributions][3] use Xfce by default.
|
||||
|
||||
Some people prefer it even on a high-end device stating its simplicity, easy of use and non-resource hungry nature as the main reasons.
|
||||
|
||||
[Xfce][4] is in itself minimal and provides just what you need. The one thing that bothers is its look and feel which feel old. However, you can easily customize Xfce to look modern and beautiful without reaching the limit where a Unity/GNOME session eats up system resources.
|
||||
|
||||
### 4 ways to Customize Xfce desktop
|
||||
|
||||
Let’s see some of the ways by which we can improve the look and feel of your Xfce desktop environment.
|
||||
|
||||
The default Xfce desktop environment looks something like this :
|
||||
|
||||
![Xfce default screen][5]
|
||||
|
||||
As you can see, the default Xfce desktop is kinda boring. We will use some themes, icon packs and change the default dock to make it look fresh and a bit revealing.
|
||||
|
||||
#### 1. Change themes in Xfce
|
||||
|
||||
The first thing we will do is pick up a theme from [xfce-look.org][6]. My favorite Xfce theme is [XFCE-D-PRO][7].
|
||||
|
||||
You can download the theme from [here][8] and extract it somewhere.
|
||||
|
||||
You can copy this extracted file to **.theme** folder in your home directory. If the folder is not present by default, you can create one and the same goes for icons which needs a **.icons** folder in the home directory.
|
||||
|
||||
Open **Settings > Appearance > Style** to select the theme, log out and login to see the change. Adwaita-dark from default is also a nice one.
|
||||
|
||||
![Appearance Xfce][9]
|
||||
|
||||
You can use any [good GTK theme][10] on Xfce.
|
||||
|
||||
#### 2. Change icons in Xfce
|
||||
|
||||
Xfce-look.org also provides icon themes which you can download, extract and put it in your home directory under **.icons** directory. Once you have added the icon theme in the .icons directory, go to **Settings > Appearance > Icons** to select that icon theme.
|
||||
|
||||
![Moka icon theme][11]
|
||||
|
||||
I have installed [Moka icon set][12] that looks awesome.
|
||||
|
||||
![Moka theme][13]
|
||||
|
||||
You can also refer to our list of [awesome icon themes][14].
|
||||
|
||||
##### **Optional: Installing themes through Synaptic**
|
||||
|
||||
If you want to avoid the manual search and copying of the files, install Synaptic Manager in your system. You can look for some best themes over web and icon sets, and using synaptic manager you can search and install it.
|
||||
```
|
||||
sudo apt-get install synaptic
|
||||
|
||||
```
|
||||
|
||||
**Searching and installing theme/icons through Synaptic**
|
||||
|
||||
Open synaptic and click on **Search**. Enter your desired theme, and it will display the list of matching items. Mark all the additional required changes and click on **Apply**. This will download the theme and then install it.
|
||||
|
||||
![Arc Theme][15]
|
||||
|
||||
Once done, you can open the **Appearance** option to select the desired theme.
|
||||
|
||||
In my opinion, this is not the best way to install themes in Xfce.
|
||||
|
||||
#### 3. Change wallpapers in Xfce
|
||||
|
||||
Again, the default Xfce wallpaper is not bad at all. But you can change the wallpaper to something that matches with your icons and themes.
|
||||
|
||||
To change wallpapers in Xfce, right click on the desktop and click on Desktop Settings. You can change the desktop background from your custom collection or the defaults one given.
|
||||
|
||||
Right click on the desktop and click on **Desktop Settings**. Choose **Background** from the folder option, and choose any one of the default backgrounds or a custom one.
|
||||
|
||||
![Changing desktop wallpapers][16]
|
||||
|
||||
#### 4. Change the dock in Xfce
|
||||
|
||||
The default dock is nice and pretty much does what it is for. But again, it looks a bit boring.
|
||||
|
||||
![Docky][17]
|
||||
|
||||
However, if you want your dock to be better and with a little more customization options, you can install another dock.
|
||||
|
||||
Plank is one of the simplest and lightweight docks and is highly configurable.
|
||||
|
||||
To install Plank use the command below:
|
||||
|
||||
`sudo apt-get install plank`
|
||||
|
||||
If Plank is not available in the default repository, you can install it from this PPA.
|
||||
```
|
||||
sudo add-apt-repository ppa:ricotz/docky
|
||||
sudo apt-get update
|
||||
sudo apt-get install plank
|
||||
|
||||
```
|
||||
|
||||
Before you use Plank, you should remove the default dock by right-clicking in it and under Panel Settings, clicking on delete.
|
||||
|
||||
Once done, go to **Accessory > Plank** to launch Plank dock.
|
||||
|
||||
![Plank][18]
|
||||
|
||||
Plank picks up icons from the one you are using. So if you change the icon themes, you’ll see the change is reflected in the dock also.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
XFCE is a lightweight, fast and highly customizable. If you are limited on system resource, it serves good and you can easily customize it to look better. Here’s how my screen looks after applying these steps.
|
||||
|
||||
![XFCE desktop][19]
|
||||
|
||||
This is just with half an hour of effort. You can make it look much better with different themes/icons customization. Feel free to share your customized XFCE desktop screen in the comments and the combination of themes and icons you are using.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/customize-xfce/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/xfce-customization.jpeg
|
||||
[2]:https://itsfoss.com/best-linux-desktop-environments/
|
||||
[3]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[4]:https://xfce.org/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/1-1-800x410.jpg
|
||||
[6]:http://xfce-look.org
|
||||
[7]:https://www.xfce-look.org/p/1207818/XFCE-D-PRO
|
||||
[8]:https://www.xfce-look.org/p/1207818/startdownload?file_id=1523730502&file_name=XFCE-D-PRO-1.6.tar.xz&file_type=application/x-xz&file_size=105328&url=https%3A%2F%2Fdl.opendesktop.org%2Fapi%2Ffiles%2Fdownloadfile%2Fid%2F1523730502%2Fs%2F6019b2b57a1452471eac6403ae1522da%2Ft%2F1529360682%2Fu%2F%2FXFCE-D-PRO-1.6.tar.xz
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/4.jpg
|
||||
[10]:https://itsfoss.com/best-gtk-themes/
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/6.jpg
|
||||
[12]:https://snwh.org/moka
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/11-800x547.jpg
|
||||
[14]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/5-800x531.jpg
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/7-800x546.jpg
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/8.jpg
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/9.jpg
|
||||
[19]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/10-800x447.jpg
|
||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,134 @@
|
||||
Three Graphical Clients for Git on Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Those that develop on Linux are likely familiar with [Git][1]. With good reason. Git is one of the most widely used and recognized version control systems on the planet. And for most, Git use tends to lean heavily on the terminal. After all, much of your development probably occurs at the command line, so why not interact with Git in the same manner?
|
||||
|
||||
In some instances, however, having a GUI tool to work with can make your workflow slightly more efficient (at least for those that tend to depend upon a GUI). To that end, what options do you have for Git GUI tools? Fortunately, we found some that are worthy of your time and (in some cases) money. I want to highlight three such Git clients that run on the Linux operating system. Out of these three, you should be able to find one that meets all of your needs.
|
||||
I am going to assume you understand how Git and repositories like GitHub function, [which I covered previously][2], so I won’t be taking the time for any how-tos with these tools. Instead, this will be an introduction, so you (the developer) know these tools are available for your development tasks.
|
||||
|
||||
A word of warning: Not all of these tools are free, and some are released under proprietary licenses. However, they all work quite well on the Linux platform and make interacting with GitHub a breeze.
|
||||
|
||||
With that said, let’s look at some outstanding Git GUIs.
|
||||
|
||||
### SmartGit
|
||||
|
||||
[SmartGit][3] is a proprietary tool that’s free for non-commercial usage. If you plan on employing SmartGit in a commercial environment, the license cost is $99 USD per year for one license or $5.99 per month. There are other upgrades (such as Distributed Reviews and SmartSynchronize), which are both $15 USD per licence. You can download either the source or a .deb package for installation. I tested SmartGit on Ubuntu 18.04 and it worked without issue.
|
||||
|
||||
But why would you want to use SmartGit? There are plenty of reasons. First and foremost, SmartGit makes it incredibly easy to integrate with the likes of GitHub and Subversion servers. Instead of spending your valuable time attempting to configure the GUI to work with your remote accounts, SmartGit takes the pain out of that task. The SmartGit GUI (Figure 1) is also very well designed to be uncluttered and intuitive.
|
||||
|
||||
|
||||
![SmartGit][5]
|
||||
|
||||
Figure 1: The SmartGit UI helps to simplify your workflow.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
After installing SmartGit, I had it connected with my personal GitHub account in seconds. The default toolbar makes working with a repository, incredibly simple. Push, pull, check out, merge, add branches, cherry pick, revert, rebase, reset — all of Git’s most popular features are there to use. Outside of supporting most of the standard Git and GitHub functions/features, SmartGit is very stable. At least when using the tool on the Ubuntu desktop, you feel like you’re working with an application that was specifically designed and built for Linux.
|
||||
|
||||
SmartGit is probably one of the best tools that makes working with even advanced Git features easy enough for any level of user. To learn more about SmartGit, take a look at the [extensive documentation][7].
|
||||
|
||||
### GitKraken
|
||||
|
||||
[GitKraken][8] is another proprietary GUI tool that makes working with both Git and GitHub an experience you won’t regret. Where SmartGit has a very simplified UI, GitKraken has a beautifully designed interface that offers a bit more feature-wise at the ready. There is a free version of GitKraken available (and you can test the full-blown paid version with a 15 day trial period). After the the trial period ends, you can continue using the free version, but for non-commercial use only.
|
||||
|
||||
For those who want to get the most out of their development workflow, GitKraken might be the tool to choose. This particular take on the Git GUI features the likes of visual interactions, resizable commit graphs, drag and drop, seamless integration (with GitHub, GitLab, and BitBucket), easy in-app tasks, in-app merge tools, fuzzy finder, gitflow support, 1-click undo & redo, keyboard shortcuts, file history & blame, submodules, light & dark themes, git hooks support, git LFS, and much more. But the one feature that many users will appreciate the most is the incredibly well-designed interface (Figure 2).
|
||||
|
||||
|
||||
![GitKraken][10]
|
||||
|
||||
Figure 2: The GitKraken interface is tops.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
Outside of the amazing interface, one of the things that sets GitKraken above the rest of the competition is how easy it makes working with multiple remote repositories and multiple profiles. The one caveat to using GitKraken (besides it being proprietary) is the cost. If you’re looking at using GitKraken for commercial use, the license costs are:
|
||||
|
||||
* $49 per user per year for individual
|
||||
|
||||
* $39 per user per year for 10+ users
|
||||
|
||||
* $29 per user per year for 100+ users
|
||||
|
||||
|
||||
|
||||
|
||||
The Pro accounts allow you to use both the Git Client and the Glo Boards (which is the GitKraken project management tool) commercially. The Glo Boards are an especially interesting feature as they allow you to sync your Glo Board to GitHub Issues. Glo Boards are sharable and include search & filters, issue tracking, markdown support, file attachments, @mentions, card checklists, and more. All of this can be accessed from within the GitKraken GUI.
|
||||
GitKraken is available for Linux as either an installable .deb file, or source.
|
||||
|
||||
### Git Cola
|
||||
|
||||
[Git Cola][11] is our free, open source entry in the list. Unlike both GitKraken and Smart Git, Git Cola is a pretty bare bones, no-nonsense Git client. Git Cola is written in Python with a GTK interface, so no matter what distribution and desktop combination you use, it should integrate seamlessly. And because it’s open source, you should find it in your distribution's package manager. So installation is nothing more than a matter of opening your distribution’s app store, searching for “Git Cola” and installing. You can also install from the command line like so:
|
||||
```
|
||||
sudo apt install git-cola
|
||||
|
||||
```
|
||||
|
||||
Or:
|
||||
```
|
||||
sudo dnf install git-cola
|
||||
|
||||
```
|
||||
|
||||
The Git Cola interface is pretty simple (Figure 3). In fact, you won’t find much in the way of too many bells and whistles, as Git Cola is all about the basics.
|
||||
|
||||
|
||||
![Git Cola][13]
|
||||
|
||||
Figure 3: The Git Cola interface is a much simpler affair.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
Because of Git Cola’s return to basics, there will be times when you must interface with the terminal. However, for many Linux users this won’t be a deal breaker (as most are developing within the terminal anyway). Git Cola does include features like:
|
||||
|
||||
* Multiple subcommands
|
||||
|
||||
* Custom window settings
|
||||
|
||||
* Configurable and environment variables
|
||||
|
||||
* Language settings
|
||||
|
||||
* Supports custom GUI settings
|
||||
|
||||
* Keyboard shortcuts
|
||||
|
||||
|
||||
|
||||
|
||||
Although Git Cola does support connecting to remote repositories, the integration to the likes of Github isn’t nearly as intuitive as it is on either GitKraken or SmartGit. But if you’re doing most of your work locally, Git Cola is an outstanding tool that won’t get in between you and Git.
|
||||
|
||||
Git Cola also comes with an advanced (Directed Acyclic Graph) DAG visualizer, called Git Dag. This tool allows you to get a visual representation of your branches. You start Git Dag either separately from Git Cola or within Git Cola from the View > DAG menu entry. Git DAG is a very powerful tool, which helps to make Git Cola one of the top open source Git GUIs on the market.
|
||||
|
||||
### There’s more where that came from
|
||||
|
||||
There are plenty more Git GUI tools available. However, from these three tools you can do some serious work. Whether you’re looking for a tool with all the bells and whistles (regardless of license) or if you’re a strict GPL user, one of these should fit the bill.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][14]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/7/three-graphical-clients-git-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://git-scm.com/
|
||||
[2]:https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git
|
||||
[3]:https://www.syntevo.com/smartgit/
|
||||
[4]:/files/images/gitgui1jpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_1.jpg?itok=LEZ_PYIf (SmartGit)
|
||||
[6]:/licenses/category/used-permission
|
||||
[7]:http://www.syntevo.com/doc/display/SG/Manual
|
||||
[8]:https://www.gitkraken.com/
|
||||
[9]:/files/images/gitgui2jpg
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_2.jpg?itok=Y8crSLhf (GitKraken)
|
||||
[11]:https://git-cola.github.io/
|
||||
[12]:/files/images/gitgui3jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gitgui_3.jpg?itok=bS9OYPQo (Git Cola)
|
||||
[14]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,86 +0,0 @@
|
||||
为什么DevSecOps对领导来说如此重要
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果[DevOps][1] 最终是关于创造更好的软件,那也就意味着是更安全的软件。
|
||||
|
||||
输入术语“DevSecOps.”像任何其他IT术语一样,DevSecOps - 一个整容后的DevOps的后代 -可能容易被炒作和盗用。但这个术语对那些拥抱DevOps文化的领导者们,帮助他们实现其承诺的实践和工具来说具有重要的意义。
|
||||
|
||||
说道这里:“DevSecOps”是什么意思?
|
||||
|
||||
“DevSecOps是开发、安全、运营的混合,”来自[Datical][2]的首席技术官和联合创始人罗伯特说。“这提醒我们安全对我们的应用程序来说和创建并部署应用到生产中一样重要。”
|
||||
**[想阅读其他首席技术官的DevOps文章吗?查阅我们广泛的资源,[DevOps:IT领导者的指南][3].]**
|
||||
|
||||
向非技术人员解释DevSecOps的一个简单的方法是:它是指将安全有意并提前加入到开发过程中。
|
||||
|
||||
”安全团队从历史上一直都被从开发团队中所孤立-每个团队在IT的不同领域都开发了很强的专业能力,”来自红帽安全策的专家Kirsten最近告诉我们。“它不需要这样,非常关注安全也关注他们通过软件来兑现商业价值的能力的企业正在寻找能够在应用开发生命周期中加入安全的方法。他们通过在整个CI/CD管道中集成安全实践,工具和自动化来采用DevSecOps.”
|
||||
|
||||
"为了能够做的更好,他们正在整合他们的团队-专业的安全人员从开始设计到部署到生产中都嵌入到了应开发团队中了,"她说。“双方都收获了价值-每个团队都拓展了他们的技能和基础知识,使他们自己都成更有价值的技术人员。DevOps做的很正确-或者说DevSecOps-提高了IT的安全性。”
|
||||
|
||||
IT团队比任何以往都要求要快速频繁的交付服务。DevOps在某种程度上可以成为一个很棒的推动者,因为它能够消除开发和运营之间通常遇到的一些摩擦,运营一直被排挤在整个过程之外直到要部署的时候,开发者把代码随便一放之后就不再去管理,他们承担更少的基础架构的责任。那种孤立的方法引起了很多问题,委婉的说,在数字时代,如果将安全孤立起来同样的情况也会发生。
|
||||
|
||||
“我们已经采用了DevOps因为它已经被证明通过移除开发和运营之间的阻碍来提高IT的绩效,”Reevess说。“就像我们不应该在开发周期要结束时才加入运营,我们不应该在快要结束时才加入安全。”
|
||||
|
||||
### 为什么DevSecOps在此停留
|
||||
或许会把DevSecOps看作是另一个时髦词,但对于安全意识很强的IT领导者来说,它是一个实质性的术语:在软件开发管道中安全必须是第一流的公民,而不是部署前的最后一步的螺栓,或者更糟的是,作为一个团队只有当一个实际的事故发生的时候安全人员才会被重用争抢。
|
||||
|
||||
“DevSecOps不只是一个时髦的术语-因为多种原因它是现在和未来IT将呈现的状态,”来自[Sumo Logic]的安全和合规副总裁George说道,“最重要的好处是将安全融入到开发和运营当中开提供保护的能力”
|
||||
|
||||
此外,DevSecOps的出现可能是DevOps自身逐渐成熟并扎根于IT之中的一个征兆。
|
||||
|
||||
“企业中的DevOps文化就在这里,而且那意味着开发者们正以不断增长的速度交付功能和更新,特别是自我管理的组织对合作和衡量的结果更加满意时,”来自[CYBRIC]
|
||||
的首席技术官和联合创始人Mike说道。
|
||||
|
||||
在实施DevOps的同时继续保留原有安全措施的团队和公司,随着他们继续部署的更快更频繁可能正在经历越来越多的安全管理风险上的痛苦。
|
||||
|
||||
“现在的手工的安全测试方法会继续远远被甩在后面。”
|
||||
|
||||
“如今,手动的安全测试方法正被甩得越来越远,利用自动化和协作将安全测试转移到软件开发生命周期中,因此推动DevSecOps的文化是IT领导者们增加整体的灵活性提供安全保证的唯一途径,”Kail说。
|
||||
|
||||
转移安全测试也使开发者受益:而不是在一个新的服务或者更新部署之前在他们的代码中发现一个明显的漏洞,他们能够在开放的较早的阶段验证并解决潜在的问题-经常
|
||||
是很少需要或者甚至不需要安全人员的介入。
|
||||
|
||||
“做的正确,DevSecOps能够将安全融入到开发生命周期中,允许开发者们在没有安全中断的情况下更加快速容易的保证他们应用的安全,”来自[SAS][8]的首席信息安全员Wilson说道。
|
||||
|
||||
Wilson指出静态(SAST)和源组合工具(SCA),集成到团队的持续交付管道中,作为有用的技术通过给予开发者关于他们的代码中的潜在问题和第三方依赖中的漏洞的反馈
|
||||
来使之逐渐成为可能。
|
||||
|
||||
“因此,开发者们能够主动和迭代的缓解应用安全的问题,然后在不需要安全人员介入的情况下重新进行安全扫描。”Wilson说。他同时指出DevSecOps能够帮助开发者简化更新和打补丁。
|
||||
|
||||
DevSecOps并不意味着你不再需要安全组的意见了,就如同DevOps并不意味着你不再需要基础架构专家;它只是帮助减少在生产中发现缺陷的可能性,或者减少导致是降低部署的速度的阻碍,因为缺陷已经在开放周期中被发现解决了。
|
||||
|
||||
“如果他们有问题或者需要帮助,我们就在这儿,但是因为已经给了开发者他们需要的保护他们应用安全的工具,我们很少在一个深入的测试中发现一个导致中断的问题,”Wilson说道。
|
||||
|
||||
### DevSecOps 遇到危机
|
||||
|
||||
Sumo Locic's的Gerchow向我们分享了一个在运转中的DevSecOps文化的一个及时的案列:当最近[危机和幽灵]的消息传来的时候,团队的DevSecOps方法使得有了一个快速的响应来减轻风险,没有任何的通知去打扰内部或者外部的顾客,Gerchow所说的这点对原生云高监管的公司来说特别的重要。
|
||||
|
||||
第一步:Gerchow的小的安全团队,都具有一定的开发能力,能够通过Slack和它的主要云供应商协同工作来确保它的基础架构能够在24小时之内完成修复。
|
||||
|
||||
“接着我的团队立即开始进行系统级的修复,实现终端客户的零停机时间,不需要去开单给工程师,如果那样那意味着你需要等待很长的变更过程。所有的变更都是通过Slack自动jira票据进行,通过我们的日志监控和分析解决方案,”Gerchow解释道。
|
||||
|
||||
在本质上,它听起来非常像DevOps的文化,匹配正确的人员,进程和工具,但它明确的包括了安全作为文化中的一部分进行混合。
|
||||
|
||||
“在传统的环境中,这将花费数周或数月的停机时间来处理,因为开发,运维和安全三者是相互独立的,”Gerchow说道."通过一个DevSecOps的过程和习惯,终端用户可以通过简单的沟通和当日修复获得无缝的体验。"
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.datical.com/
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
[4]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[5]:https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
|
||||
[6]:https://www.sumologic.com/
|
||||
[7]:https://www.cybric.io/
|
||||
[8]:https://www.sas.com/en_us/home.html
|
||||
[9]:https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-heres-what-you-need-know?intcmp=701f2000000tjyaAAA
|
||||
@ -1,30 +1,32 @@
|
||||
如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 探索如何将 Android Things 与 Tensorflow 集成起来,以及如何应用机器学习到物联网系统上。学习如何在装有 Android Things 的树莓派上使用 Tensorflow 进行图片分类。
|
||||
|
||||
这个项目探索了如何将机器学习应用到物联网上。具体来说,物联网平台我们将使用 **Android Things**,而机器学习引擎我们将使用 **Google TensorFlow**。
|
||||
|
||||

|
||||
现如今,Android Things 处于名为 Android Things 1.0 的稳定版本,已经可以用在生产系统中了。如你可能已经知道的,树莓派是一个可以支持 Android Things 1.0 做开发和原型设计的平台。本教程将使用 Android Things 1.0 和树莓派,当然,你可以无需修改代码就能换到其它所支持的平台上。这个教程是关于如何将机器学习应用到物联网的,这个物联网平台就是 Android Things Raspberry Pi。
|
||||
|
||||
现如今,机器学习是物联网上使用的最热门的主题之一。给机器学习的最简单的定义,可能就是 [维基百科上的定义][13]:机器学习是计算机科学中,让计算机不需要显式编程就能去“学习”(即,逐步提升在特定任务上的性能)使用数据的一个领域。
|
||||
物联网上的机器学习是最热门的话题之一。要给机器学习一个最简单的定义,可能就是 [维基百科上的定义][13]:
|
||||
|
||||
换句话说就是,经过训练之后,那怕是它没有针对它们进行特定的编程,这个系统也能够预测结果。另一方面,我们都知道物联网和联网设备的概念。其中一个前景看好的领域就是如何在物联网上应用机器学习,构建专业的系统,这样就能够去开发一个能够“学习”的系统。此外,还可以使用这些知识去控制和管理物理对象。
|
||||
> 机器学习是计算机科学中,让计算机不需要显式编程就能去“学习”(即,逐步提升在特定任务上的性能)使用数据的一个领域。
|
||||
|
||||
这里有几个应用机器学习和物联网产生重要价值的领域,以下仅提到了几个感兴趣的领域,它们是:
|
||||
换句话说就是,经过训练之后,那怕是它没有针对它们进行特定的编程,这个系统也能够预测结果。另一方面,我们都知道物联网和联网设备的概念。其中前景最看好的领域之一就是如何在物联网上应用机器学习,构建专家系统,这样就能够去开发一个能够“学习”的系统。此外,还可以使用这些知识去控制和管理物理对象。在深入了解 Android Things 的细节之前,你应该先将其安装在你的设备上。如果你是第一次使用 Android Things,你可以阅读一下这篇[如何在你的设备上安装 Android Things][14] 的教程。
|
||||
|
||||
这里有几个应用机器学习和物联网产生重要价值的领域,以下仅提到了几个有趣的领域,它们是:
|
||||
|
||||
* 在工业物联网(IIoT)中的预见性维护
|
||||
|
||||
* 消费物联网中,机器学习可以让设备更智能,它通过调整使设备更适应我们的习惯
|
||||
|
||||
在本教程中,我们希望去探索如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。这个 Adnroid Things 物联网项目的基本想法是,探索如何去*构建一个能够识别前方道路上基本形状(比如箭头)的无人驾驶汽车*。我们已经介绍了 [如何使用 Android Things 去构建一个无人驾驶汽车][5],因此,在开始这个项目之前,我们建议你去阅读那个教程。
|
||||
在本教程中,我们希望去探索如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。这个 Adnroid Things 物联网项目的基本想法是,探索如何去*构建一个能够识别前方道路上基本形状(比如箭头)并控制其道路方向的无人驾驶汽车*。我们已经介绍了 [如何使用 Android Things 去构建一个无人驾驶汽车][5],因此,在开始这个项目之前,我们建议你去阅读那个教程。
|
||||
|
||||
这个机器学习和物联网项目包含如下的主题:
|
||||
|
||||
* 如何使用 Docker 配置 TensorFlow 环境
|
||||
|
||||
* 如何训练 TensorFlow 系统
|
||||
|
||||
* 如何使用 Android Things 去集成 TensorFlow
|
||||
|
||||
* 如何使用 TensorFlow 的成果去控制无人驾驶汽车
|
||||
|
||||
这个项目起源于 [Android Things TensorFlow 图像分类器][6]。
|
||||
@ -33,59 +35,55 @@
|
||||
|
||||
### 如何使用 Tensorflow 图像识别
|
||||
|
||||
在开始之前,需要安装和配置 TensorFlow 环境。我不是机器学习方面的专家,因此,我需要快速找到并且准备去使用一些东西,因此,我们可以构建 TensorFlow 图像识别器。为此,我们使用 Docker 去运行一个 TensorFlow 镜像。以下是操作步骤:
|
||||
在开始之前,需要安装和配置 TensorFlow 环境。我不是机器学习方面的专家,因此,我需要找到一些快速而能用的东西,以便我们可以构建 TensorFlow 图像识别器。为此,我们使用 Docker 去运行一个 TensorFlow 镜像。以下是操作步骤:
|
||||
|
||||
1. 克隆 TensorFlow 仓库:
|
||||
```
|
||||
git clone https://github.com/tensorflow/tensorflow.git
|
||||
cd /tensorflow
|
||||
git checkout v1.5.0
|
||||
```
|
||||
1、 克隆 TensorFlow 仓库:
|
||||
|
||||
2. 创建一个目录(`/tf-data`),它将用于保存这个项目中使用的所有文件。
|
||||
```
|
||||
git clone https://github.com/tensorflow/tensorflow.git
|
||||
cd /tensorflow
|
||||
git checkout v1.5.0
|
||||
```
|
||||
|
||||
3. 运行 Docker:
|
||||
```
|
||||
docker run -it \
|
||||
--volume /tf-data:/tf-data \
|
||||
--volume /tensorflow:/tensorflow \
|
||||
--workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
|
||||
```
|
||||
2、 创建一个目录(`/tf-data`),它将用于保存这个项目中使用的所有文件。
|
||||
|
||||
使用这个命令,我们运行一个交互式 TensorFlow 环境,可以在使用项目期间挂载一些目录。
|
||||
3、 运行 Docker:
|
||||
|
||||
```
|
||||
docker run -it \
|
||||
--volume /tf-data:/tf-data \
|
||||
--volume /tensorflow:/tensorflow \
|
||||
--workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
|
||||
```
|
||||
|
||||
使用这个命令,我们运行一个交互式 TensorFlow 环境,可以挂载一些在使用项目期间使用的目录。
|
||||
|
||||
### 如何训练 TensorFlow 去识别图像
|
||||
|
||||
在 Android Things 系统能够识别图像之前,我们需要去训练 TensorFlow 引擎,以使它能够构建它的模型。为此,我们需要去收集一些图像。正如前面所言,我们需要使用箭头来控制 Android Things 无人驾驶汽车,因此,我们至少要收集四种类型的箭头:
|
||||
|
||||
* 向上的箭头
|
||||
|
||||
* 向下的箭头
|
||||
|
||||
* 向左的箭头
|
||||
|
||||
* 向右的箭头
|
||||
|
||||
为训练这个系统,需要使用这四类不同的图像去创建一个“知识库”。在 `/tf-data` 目录下创建一个名为 `images` 的目录,然后在它下面创建如下名字的四个子目录:
|
||||
|
||||
* up-arrow
|
||||
|
||||
* down-arrow
|
||||
|
||||
* left-arrow
|
||||
|
||||
* right-arrow
|
||||
* `up-arrow`
|
||||
* `down-arrow`
|
||||
* `left-arrow`
|
||||
* `right-arrow`
|
||||
|
||||
现在,我们去找图片。我使用的是 Google 图片搜索,你也可以使用其它的方法。为了简化图片下载过程,你可以安装一个 Chrome 下载插件,这样你只需要点击就可以下载选定的图片。别忘了多下载一些图片,这样训练效果更好,当然,这样创建模型的时间也会相应增加。
|
||||
|
||||
**扩展阅读**
|
||||
[如何使用 API 去集成 Android Things][2]
|
||||
[如何与 Firebase 一起使用 Android Things][3]
|
||||
|
||||
- [如何使用 API 去集成 Android Things][2]
|
||||
- [如何与 Firebase 一起使用 Android Things][3]
|
||||
|
||||
打开浏览器,开始去查找四种箭头的图片:
|
||||
|
||||

|
||||
[Save][7]
|
||||
|
||||
每个类别我下载了 80 张图片。不用管图片文件的扩展名。
|
||||
|
||||
@ -102,9 +100,8 @@ python /tensorflow/examples/image_retraining/retrain.py \
|
||||
|
||||
这个过程你需要耐心等待,它需要花费很长时间。结束之后,你将在 `/tf-data` 目录下发现如下的两个文件:
|
||||
|
||||
1. retrained_graph.pb
|
||||
|
||||
2. retrained_labels.txt
|
||||
1. `retrained_graph.pb`
|
||||
2. `retrained_labels.txt`
|
||||
|
||||
第一个文件包含了 TensorFlow 训练过程产生的结果模型,而第二个文件包含了我们的四个图片类相关的标签。
|
||||
|
||||
@ -139,7 +136,6 @@ python /tensorflow/python/tools/optimize_for_inference.py \
|
||||
TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将 Android Things 与 TensorFlow 集成到一起。为此,我们将这个任务分为两步来完成:
|
||||
|
||||
1. 硬件部分,我们将把电机和其它部件连接到 Android Things 开发板上
|
||||
|
||||
2. 实现这个应用程序
|
||||
|
||||
### Android Things 示意图
|
||||
@ -147,13 +143,9 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
|
||||
在深入到如何连接外围部件之前,先列出在这个 Android Things 项目中使用到的组件清单:
|
||||
|
||||
1. Android Things 开发板(树莓派 3)
|
||||
|
||||
2. 树莓派摄像头
|
||||
|
||||
3. 一个 LED 灯
|
||||
|
||||
4. LN298N 双 H 桥电机驱动模块(连接控制电机)
|
||||
|
||||
5. 一个带两个轮子的无人驾驶汽车底盘
|
||||
|
||||
我不再重复 [如何使用 Android Things 去控制电机][9] 了,因为在以前的文章中已经讲过了。
|
||||
@ -161,12 +153,10 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
|
||||
下面是示意图:
|
||||
|
||||

|
||||
[Save][10]
|
||||
|
||||
上图中没有展示摄像头。最终成果如下图:
|
||||
|
||||

|
||||
[Save][11]
|
||||
|
||||
### 使用 TensorFlow 实现 Android Things 应用程序
|
||||
|
||||
@ -175,11 +165,8 @@ TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将
|
||||
这个 Android Things 应用程序与原始的应用程序是不一样的,因为:
|
||||
|
||||
1. 它不使用按钮去开启摄像头图像捕获
|
||||
|
||||
2. 它使用了不同的模型
|
||||
|
||||
3. 它使用一个闪烁的 LED 灯来提示,摄像头将在 LED 停止闪烁后拍照
|
||||
|
||||
4. 当 TensorFlow 检测到图像时(箭头)它将控制电机。此外,在第 3 步的循环开始之前,它将打开电机 5 秒钟。
|
||||
|
||||
为了让 LED 闪烁,使用如下的代码:
|
||||
@ -264,7 +251,7 @@ public void onImageAvailable(ImageReader reader) {
|
||||
|
||||
在这个方法中,当 TensorFlow 返回捕获的图片匹配到的可能的标签之后,应用程序将比较这个结果与可能的方向,并因此来控制电机。
|
||||
|
||||
最后,将去使用前面创建的模型了。拷贝 _assets_ 文件夹下的 `opt_graph.pb` 和 `reatrained_labels.txt` 去替换现在的文件。
|
||||
最后,将去使用前面创建的模型了。拷贝 `assets` 文件夹下的 `opt_graph.pb` 和 `reatrained_labels.txt` 去替换现在的文件。
|
||||
|
||||
打开 `Helper.java` 并修改如下的行:
|
||||
|
||||
@ -289,9 +276,9 @@ public static final String OUTPUT_NAME = "final_result";
|
||||
|
||||
via: https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html
|
||||
|
||||
作者:[Francesco Azzola ][a]
|
||||
作者:[Francesco Azzola][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -309,3 +296,4 @@ via: https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-usi
|
||||
[11]:http://pinterest.com/pin/create/bookmarklet/?media=data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=&url=https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html&is_video=false&description=Integrating%20Android%20Things%20with%20TensorFlow
|
||||
[12]:https://github.com/androidthings/sample-tensorflow-imageclassifier
|
||||
[13]:https://en.wikipedia.org/wiki/Machine_learning
|
||||
[14]:https://www.survivingwithandroid.com/2017/01/android-things-android-internet-of-things.html
|
||||
@ -0,0 +1,78 @@
|
||||
GitLab 的旗舰和黄金计划现在可以免费用于开源项目
|
||||
======
|
||||
最近在开源社区发生了很多事情。首先,[微软收购了GitHub][1],然后人们开始寻找[ GitHub 替代方案][2],甚至在 Linus Torvalds 发布 [Linux Kernel 4.17][3] 时没有花一点时间考虑它。好吧,如果你一直关注我们,我认为你知道这一切。
|
||||
|
||||
但是,今天,GitLab 做出了一个明智的举措,为教育机构和开源项目免费提供高级计划。当许多开发人员有兴趣将他们的开源项目迁移到 GitLab 时,没有更好的时机来提供这些了。
|
||||
|
||||
### GitLab 的高级计划现在对开源项目和教育机构免费
|
||||
|
||||
![GitLab Logo][4]
|
||||
|
||||
在今天[发布的博客][5]中,GitLab 宣布**旗舰**和黄金计划现在对教育机构和开源项目免费。虽然我们已经知道为什么 GitLab 做出这个举动(一个完美的时机!),但他们还是解释了他们让它免费的动机:
|
||||
|
||||
>我们让 GitLab 对教育免费,因为我们希望学生使用我们最先进的功能。许多大学已经运行了 GitLab。如果学生使用 GitLab Ultimate 和 Gold 的高级功能,他们将把这些高级功能的经验带到他们的工作场所。
|
||||
>
|
||||
>我们希望有更多的开源项目使用GitLab。GitLab.com 上的公共项目已经拥有 GitLab Ultimate 的所有功能。像 [Gnome][6] 和 [Debian][7] 这样的项目已经在自己的服务器运行开源版 GitLab 。随着今天的宣布,在专有软件上运行的开源项目可以使用 GitLab 提供的所有功能,同时我们通过向非开源组织收费来建立可持续的业务模式。
|
||||
|
||||
### GitLab 提供的这些“免费”计划是什么?
|
||||
|
||||
![GitLab Pricing][8]
|
||||
|
||||
GitLab 有两类产品。一个是你可以在自己的云托管服务如 [Digital Ocean][9] 上运行的软件。另一个是 Gitlab 软件既服务,其中托管由 GitLab 本身管理,你在 GitLab.com 上获得一个帐户。
|
||||
|
||||
![GitLab Pricing for hosted service][10]
|
||||
|
||||
Gold 是托管类别中最高的产品,而 Ultimate 是自托管类别中的最高产品。
|
||||
|
||||
You can get more details about their features on GitLab pricing page. Do note that the support is not included in this offer. You have to purchase it separately.
|
||||
你可以在 GitLab 定价页面上获得有关其功能的更多详细信息。请注意,支持不在计划中。你必须单独购买。
|
||||
|
||||
### 你必须符合某些条件才能使用此优惠
|
||||
|
||||
GitLab 还提到 - 该优惠对谁有效。以下是他们在博客文章中写的内容:
|
||||
|
||||
> 1. **教育机构:**任何为了学习、教育的机构,并且/或者由合格的教育机构、教职人员、学生训练。教育目的不包括商业,专业或任何其他营利目的。
|
||||
>
|
||||
> 2. **开源项目:**任何使用[标准开源许可证][11]且非商业性的项目。它不应该有付费支持或付费贡献者。
|
||||
>
|
||||
>
|
||||
|
||||
|
||||
虽然免费计划不包括支持,但是当你迫切需要专家帮助解决问题时,你仍然可以支付每用户每月 4.95 美元的额外费用 - 当你特别需要一个专家来解决问题时,这是一个非常合理的价格。
|
||||
|
||||
GitLab 还为学生们添加了一条说明:
|
||||
|
||||
>为减轻 GitLab 的管理负担,只有教育机构才能代表学生申请。如果你是学生并且你的教育机构不申请,你可以在 GitLab.com 上使用公共项目的所有功能,使用私人项目的免费功能,或者自己付费。
|
||||
|
||||
### 总结
|
||||
|
||||
现在 GitLab 正在加快脚步,你如何看待它?
|
||||
|
||||
你有 [GitHub][12] 上的项目吗?你会切换么?或者,幸运的是,你从一开始就碰巧使用 GitLab?
|
||||
|
||||
请在下面的评论栏告诉我们你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/gitlab-free-open-source/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://itsfoss.com/microsoft-github/
|
||||
[2]:https://itsfoss.com/github-alternatives/
|
||||
[3]:https://itsfoss.com/linux-kernel-4-17/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/GitLab-logo-800x450.png
|
||||
[5]:https://about.gitlab.com/2018/06/05/gitlab-ultimate-and-gold-free-for-education-and-open-source/
|
||||
[6]:https://www.gnome.org/news/2018/05/gnome-moves-to-gitlab-2/
|
||||
[7]:https://salsa.debian.org/public
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-pricing.jpeg
|
||||
[9]:https://m.do.co/c/d58840562553
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-hosted-service-800x273.jpeg
|
||||
[11]:https://itsfoss.com/open-source-licenses-explained/
|
||||
[12]:https://github.com/
|
||||
@ -0,0 +1,214 @@
|
||||
Javascript 框架对比及案例(React、Vue 及 Hyperapp)
|
||||
============================================================
|
||||
在[我的上一片文章中][5],我试图解释为什么我认为[Hyperapp][6]是一个可用的 [React][7] 或 [Vue][8] 的替代品,我发现当我开始用它时,会容易的找到这个原因。许多人批评这篇文章,认为它自以为是,并没有给其他框架一个展示自己的机会。因此,在这篇文章中,我将尽可能客观的通过提供一些最小化的例子来比较这三个框架,以展示他们的能力。
|
||||
|
||||
#### 臭名昭著计时器例子
|
||||
|
||||
计时器可能是响应式编程中最常用最容易理解的例子之一:
|
||||
|
||||
* 你需要一个变量 `count` 保持对计数器的追踪。
|
||||
|
||||
* 你需要两个方法来增加或减少 `count` 变量的值。
|
||||
|
||||
* 你需要一种方法来渲染 `count` 变量,并将其呈现给用户。
|
||||
|
||||
* 你需要两个挂载到两个方法上的按钮,以便在用户和它们产生交互时变更 `count` 变量。
|
||||
|
||||
下述代码是上述所有三个框架的实现:
|
||||
|
||||
|
||||
|
||||
使用 React、Vue 和 Hyperapp 实现的计数器
|
||||
|
||||
|
||||
这里或许会有很多要做的事情,特别是当你并不熟悉其中的一个或多个的时候,因此,我们来一步一步解构这些代码:
|
||||
|
||||
* 这三个框架的顶部都有一些 `import` 语句
|
||||
|
||||
* React 更推崇面向对象的范式,就是创建一个 `Counter` 组件的 `class`,Vue 遵循类似的范式,并通过创建一个新的 `Vue` 类的实例并将信息传递给它来实现。 最后,Hyperapp 坚持函数范式,同时完全分离 `view`、`state`和`action` 。
|
||||
|
||||
* 就 `count` 变量而言, React 在组件的构造函数内对其进行实例化,而 Vue 和 Hyperapp 则分别是在它们的 `data` 和 `state` 中设置这些属性。
|
||||
|
||||
* 继续看,你可能注意到 React 和 Vue 有相同的方法来于 `count` 变量进行交互。 React 使用继承自 `React.Component` 的 `setState` 方法来修改它的状态,而 Vue 直接修改 `this.count`。 Hyperapp 使用 ES6 的双箭头语法来实现这个方法,并且,据我所知,这是唯一一个更推荐使用这种语法的框架,React 和 Vue 需要在它们的方法内使用 `this`。另一方面,Hyperapp 的方法需要将状态作为参数,这意味着可以在不同的上下文中重用它们。
|
||||
|
||||
* 这三个框架的渲染部分实际上是相同的。唯一的细微差别是 Vue 需要一个函数 `h` 作为参数传递给渲染器,事实上 Hyperapp 使用 `onclick` 替代 `onClick` 以及基于每个框架中实现状态的方式引用 `count` 变量的方式。
|
||||
|
||||
* 最后,所有的三个框架都被挂载到了 `#app` 元素上。每个框架都有稍微不同的语法,Vue 则使用了最直接的语法,通过使用元素选择器而不是使用元素来提供最大的通用性。
|
||||
|
||||
#### 计数器案例对比意见
|
||||
|
||||
|
||||
同时比较所有的三个框架,Hyperapp 需要最少的代码来实现计数器,并且他是唯一一个使用函数范式的框架。然而,Vue 的代码在绝对长度上似乎更短一些,元素选择器的安装是一个很好的补充。React 的代码看起来最多,但是并不意味着代码不好理解。
|
||||
|
||||
* * *
|
||||
|
||||
#### 使用异步代码
|
||||
|
||||
偶尔你可能要不得不处理异步代码。最常见的异步操作之一是发送请求给一个 API。为了这个例子的目的,我将使用一个[占位 API]以及一些假数据来渲染一个文章的列表。必须做的事情如下:
|
||||
|
||||
* 在状态里保存一个 `posts` 的数组
|
||||
|
||||
* 使用一个方法和正确的 URL 来调用 `fetch()` ,等待返回数据,转化为 JSON,最终使用接收到的数据更新 `posts` 变量。
|
||||
|
||||
* 渲染一个按钮,这个按钮将调用抓取文章的方法。
|
||||
|
||||
* 渲染有主键的 `posts` 列表。
|
||||
|
||||
|
||||
|
||||
从一个 RESTFul API 抓取数据
|
||||
|
||||
让我们分解上面的代码,并比较三个框架:
|
||||
|
||||
* 与上面的技术里例子类似,这三个框架之间的存储状态、渲染试图和挂载非常相似。这些差异与上面的讨论相同。
|
||||
|
||||
* 在三个框架中使用 `fetch()` 抓取数据都非常简单并且可以像预期一样工作。然而其中的关键在于, Hyperapp 处理异步操作和其他两种框架有些不同。当数据被接收到并转换为JSON 时,该操作将调用不同的同步动作以取代直接在异步操作中修改状态。
|
||||
|
||||
* 就代码长度而言, Hyperapp 依然需要最少的代码行数来实现相同的结果,但是 Vue 的代码看起来不那么的冗长,同时拥有最少的绝对字符长度。
|
||||
|
||||
#### 异步代码对比意见
|
||||
|
||||
无论你选择哪种框架,异步操作都非常简单。在应用异步操作时, Hyperapp 可能会迫使你去遵循编写更加函数化和模块化的代码的路径。但是另外两个框架也确实可以做到这一点,并且在这一方面给你提供更多的选择。
|
||||
|
||||
* * *
|
||||
|
||||
#### To-Do List 组件案例
|
||||
|
||||
在响应式编程中,最出名的例子可能是使用每一个框架里来实现 To-Do List。我不打算在这里实现整个部分,我只实现一个无状态的组件,来展示三个框架如何帮助创建更小的可复用的块来协助构建应用程序。
|
||||
|
||||
|
||||
演示 TodoItem 实现
|
||||
|
||||
上面的图片展示了每一个框架一个例子,并为 React 提供了一个额外的例子。接下来是我们从它们四个中看到的:
|
||||
|
||||
* React 在编程范式上最为灵活。它支持函数组件以及类组件。它还支持你在右下角看到的 Hyperapp 组件,无需任何修改。
|
||||
|
||||
* Hyperapp 还支持 React 的函数组件实现,这意味着两个框架之间还有实验的空间。
|
||||
|
||||
* 最后出现的 Vue 有着其合理而又奇怪的语法,即使是对另外两个很有经验的人,也不能马上理解其含义。
|
||||
|
||||
* 在长度方面,所有的案例代码长度非常相似,在 React 的一些方法中稍微冗长一些。
|
||||
|
||||
#### To-Do List 项目对比意见
|
||||
|
||||
Vue 需要花费一些时间来熟悉,因为它的模板和其他两个框架有一些不同。React 非常的灵活,支持多种不同的方法来创建组件,而 HyperApp 保持一切简单,并提供与 React 的兼容性,以免你希望在某些时刻进行切换。
|
||||
|
||||
* * *
|
||||
|
||||
#### 生命周期方法比较
|
||||
|
||||
|
||||
另一个关键对比是组件的生命周期事件,每一个框架允许你根据你的需要来订阅和处理这些时间。下面是我根据各框架的 API 参考手册创建的表格:
|
||||
|
||||

|
||||
Lifecycle method comparison
|
||||
|
||||
* Vue 提供了最多的生命周期钩子,提供了处理生命周期时间之前或之后发生任何时间的机会。这能有效帮助管理复杂的组件。
|
||||
|
||||
* React 和 Hyperapp 的生命周期钩子非常类似,React 将 `unmount` 和 `destory` 绑定在了一切,而 Hyperapp 则将 `create` 和 `mount` 绑定在了一起。两者在处理生命周期事件方面都提供了相当数量的控制。
|
||||
|
||||
* Vue 根本没有处理 `unmount` (据我所理解),而是依赖于 `destroy` 事件在组件稍后的生命周期进行处理。 React 不处理 `destory` 事件,而是选择只处理 `unmount` 事件。最终,HyperApp 不处理 `create` 事件,取而代之的是只依赖 `mount` 事件。
|
||||
|
||||
#### 生命周期对比意见
|
||||
|
||||
总的来说,每个框架都提供了生命周期组件,它们帮助你处理组件生命周期中的许多事情。这三个框架都为它们的生命周期提供了钩子,其之间的细微差别,可能源自于实现和方案上的根本差异。通过提供更细粒度的时间处理,Vue 可以更进一步的允许你在开始或结束之后处理生命周期事件。
|
||||
|
||||
* * *
|
||||
|
||||
#### 性能比较
|
||||
|
||||
除了易用性和编码技术以外,性能也是大多数开发人员考虑的关键因素,尤其是在进行更复杂的应用程序时。[js-framework-benchmark][10]是一个很好的用于比较框架的工具,所以让我们看看每一组测评数据数组都说了些什么:
|
||||
|
||||
|
||||
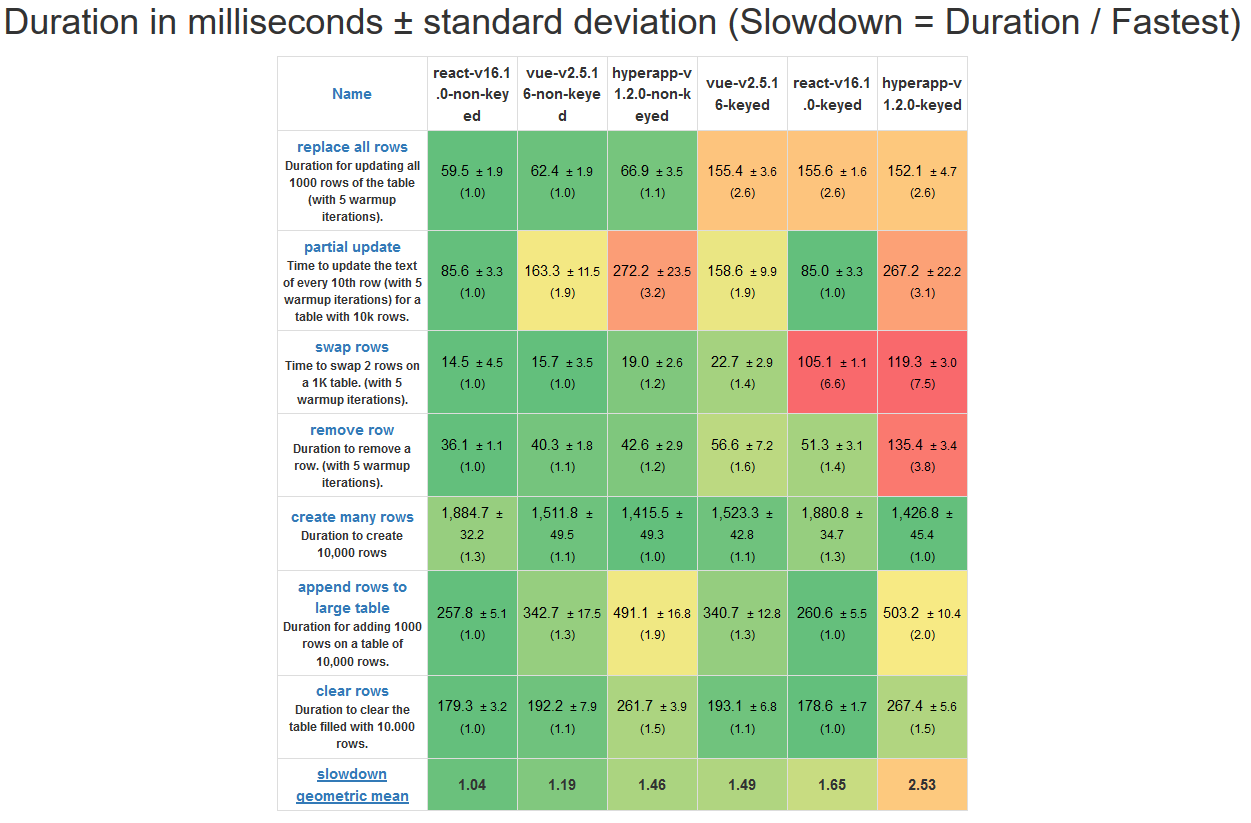
|
||||
测评操作表
|
||||
|
||||
* 与三个框架的有主键操作相比,无主键操作更快。
|
||||
|
||||
* 无主键的 React 在所有六种对比中拥有最强的性能,他在所有测试上都有令人深刻的表现。
|
||||
|
||||
* 有主键的 Vue 只比有主键的 React 性能稍强,而无主键的 Vue 要比无主键的 React 性能差。
|
||||
|
||||
* Vue 和 Hyperapp 在进行局部更新性能测试时遇见了一些问题,与此同时,React 似乎对该问题进行很好的优化。
|
||||
|
||||
|
||||
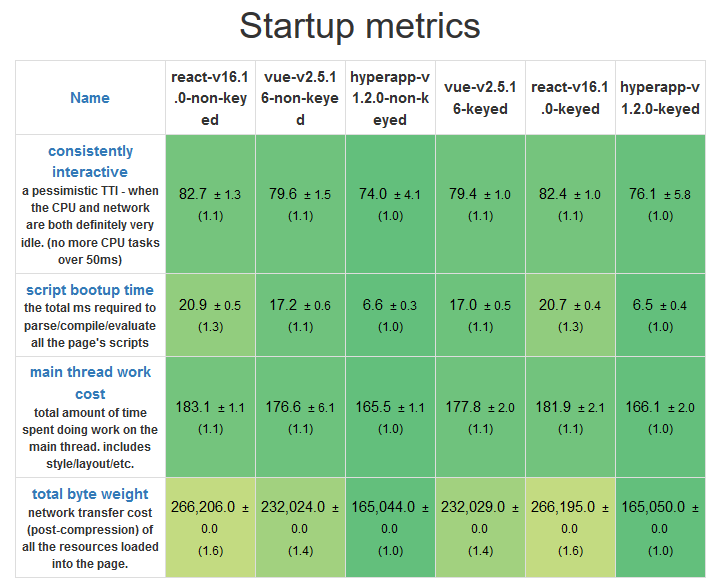
|
||||
|
||||
启动测试
|
||||
|
||||
* Hyperapp 是三个框架中最轻量的,而 React 和 Vue 有非常小尺度的差异。
|
||||
|
||||
* Hyperapp 具有最快的启动时间,这得益于他极小的大小和极简的API
|
||||
|
||||
* Vue 在启动上比 React 好一些,但是非常小。
|
||||
|
||||
|
||||

|
||||
内存分配测试
|
||||
|
||||
* Hyperapp 是三者中对资源依赖最小的一个,与其他两者相比,任何一个操作都需要更少的内存。
|
||||
|
||||
* 资源消耗不是跟高,三者应该在现代硬件上进行类似的操作。
|
||||
|
||||
#### 性能对比意见
|
||||
|
||||
如果性能是一个问题,你应该考虑你正在使用什么样的应用程序以及你的需求是什么。看起来 Vue 和 React 用于更复杂的应用程序更好,而 Hyperapp 更适合于更小的应用程序、更少的数据处理和需要快速启动的应用程序,以及需要在低端硬件上工作的应用程序。
|
||||
|
||||
但是,要记住,这些测试远不能代表一般用例,所以在现实场景中可能会看到不同的结果。
|
||||
|
||||
* * *
|
||||
|
||||
#### 额外备注
|
||||
|
||||
Comparing React, Vue and Hyperapp might feel like comparing apples and oranges in many ways. There are some additional considerations concerning these frameworks that could very well help you decide on one over the other two:
|
||||
|
||||
比较 React、Vue 和 Hyperapp 可能像在许多方面比较苹果、橘子。关于这些框架还有一些其他的考虑,它们可以帮助你决定使用另一个框架。
|
||||
|
||||
* React 通过引入片段,避免了相邻的JSX元素必须封装在父元素中的问题,这些元素允许你将子元素列表分组,而无需向DOM添加额外的节点。
|
||||
|
||||
* Read还为你提供更高级别的组件,而VUE为你提供重用组件功能的MIXIN。
|
||||
|
||||
* Vue 允许使用[模板][4]来分离结构和功能,从而更好的分离关注点。
|
||||
|
||||
* 与其他两个相比,Hyperapp 感觉像是一个较低级别的API,它的代码短得多,如果你愿意调整它并学习它的工作原理,那么它可以提供更多的通用性。
|
||||
|
||||
* * *
|
||||
|
||||
#### 结论
|
||||
|
||||
我认为如果你已经阅读了这么多,你已经知道哪种工具更适合你的需求。毕竟,这不是讨论哪一个更好,而是讨论哪一个更适合每种情况。总而言之:
|
||||
|
||||
|
||||
* React 是一个非常强大的工具,他的周围有大量的开发者,可能会帮助你找到一个工作。入门并不难,但是掌握它肯定需要很多时间。然而,这是非常值得去花费你的时间全面掌握的。
|
||||
|
||||
* 如果你过去曾使用过另外一个 JavaScript 框架,Vue 可能看起来有点奇怪,但它也是一个非常有趣的工具。如果 React 不是你所喜欢的 ,那么它可能是一个可行的值得学习的选择。
|
||||
|
||||
* 最后,Hyperapp 是一个为小型项目而生的很酷的小框架,也是初学者入门的好地方。它提供比 React 或 Vue 更少的工具,但是它能帮助你快速构建原型并理解许多基本原理。你编写的许多代码都和其他两个框架兼容,或者是稍做更改,你可以在对它们中另外一个有信心时切换框架。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Web developer who loves to code, creator of 30 seconds of code (https://30secondsofcode.org/) and the mini.css framework (http://minicss.org).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/javascript-framework-comparison-with-examples-react-vue-hyperapp-97f064fb468d
|
||||
|
||||
作者:[Angelos Chalaris ][a]
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@chalarangelo?source=post_header_lockup
|
||||
[1]:https://reactjs.org/docs/fragments.html
|
||||
[2]:https://reactjs.org/docs/higher-order-components.html
|
||||
[3]:https://vuejs.org/v2/guide/mixins.html
|
||||
[4]:https://vuejs.org/v2/guide/syntax.html
|
||||
[5]:https://hackernoon.com/i-abandonded-react-in-favor-of-hyperapp-heres-why-df65638f8a79
|
||||
[6]:https://hyperapp.js.org/
|
||||
[7]:https://reactjs.org/
|
||||
[8]:https://vuejs.org/
|
||||
[9]:https://jsonplaceholder.typicode.com/
|
||||
[10]:https://github.com/krausest/js-framework-benchmark
|
||||
260
translated/tech/20180712 Slices from the ground up.md
Normal file
260
translated/tech/20180712 Slices from the ground up.md
Normal file
@ -0,0 +1,260 @@
|
||||
Slices from the ground up
|
||||
============================================================
|
||||
|
||||
这篇文章最初的灵感来源于我与一个使用切片作栈的同事的一次聊天。那次聊天,话题最后拓展到了 Go 语言中的切片是如何工作的。我认为把这些知识记录下来会帮到别人。
|
||||
|
||||
### 数组
|
||||
|
||||
任何关于 Go 语言的切片的讨论都要从另一个数据结构,也就是 Go 语言的数组开始。Go 语言的数组有两个特性:
|
||||
|
||||
1. 数组的长度是固定的;`[5]int` 是由 5 个 `unt` 构成的数组,和`[3]int` 不同。
|
||||
|
||||
2. 数组是值类型。考虑如下示例:
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
var a [5]int
|
||||
b := a
|
||||
b[2] = 7
|
||||
fmt.Println(a, b) // prints [0 0 0 0 0] [0 0 7 0 0]
|
||||
}
|
||||
```
|
||||
|
||||
语句 `b := a` 定义了一个新的变量 `b`,类型是 `[5]int`,然后把 `a` 中的内容_复制_到 `b` 中。改变 `b` 中的值对 `a` 中的内容没有影响,因为 `a` 和 `b` 是相互独立的值。 [1][1]
|
||||
|
||||
### 切片
|
||||
|
||||
Go 语言的切片和数组的主要有如下两个区别:
|
||||
|
||||
1. 切片没有一个固定的长度。切片的长度不是它类型定义的一部分,而是由切片内部自己维护的。我们可以使用内置的 `len` 函数知道他的长度。
|
||||
|
||||
2. 将一个切片赋值给另一个切片时 _不会_ 将切片进行复制操作。这是因为切片没有直接保存它的内部数据,而是保留了一个指向 _底层数组_ [3][3]的指针。数据都保留在底层数组里。
|
||||
|
||||
基于第二个特性,两个切片可以享有共同的底层数组。考虑如下示例:
|
||||
|
||||
1. 对切片取切片
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
var a = []int{1,2,3,4,5}
|
||||
b := a[2:]
|
||||
b[0] = 0
|
||||
fmt.Println(a, b) // prints [1 2 0 4 5] [0 4 5]
|
||||
}
|
||||
```
|
||||
|
||||
在这个例子里,`a` 和 `b` 享有共同的底层数组 —— 尽管 `b` 的起始值在数组里的偏移不同,两者的长度也不同。通过 `b` 修改底层数组的值也会导致 `a` 里的值的改变。
|
||||
|
||||
2. 将切片传进函数
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func negate(s []int) {
|
||||
for i := range s {
|
||||
s[i] = -s[i]
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
var a = []int{1, 2, 3, 4, 5}
|
||||
negate(a)
|
||||
fmt.Println(a) // prints [-1 -2 -3 -4 -5]
|
||||
}
|
||||
```
|
||||
|
||||
在这个例子里,`a` 作为形参 `s` 的实参传进了 `negate` 函数,这个函数遍历 `s` 内的元素并改变其符号。尽管 `nagate` 没有返回值,且没有接触到 `main` 函数里的 `a`。但是当将之传进 `negate` 函数内时,`a` 里面的值却被改变了。
|
||||
|
||||
大多数程序员都能直观地了解 Go 语言切片的底层数组是如何工作的,因为它与其他语言中类似数组的工作方式类似。比如下面就是使用 Python 重写的这一小节的第一个示例:
|
||||
|
||||
```
|
||||
Python 2.7.10 (default, Feb 7 2017, 00:08:15)
|
||||
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.34)] on darwin
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> a = [1,2,3,4,5]
|
||||
>>> b = a
|
||||
>>> b[2] = 0
|
||||
>>> a
|
||||
[1, 2, 0, 4, 5]
|
||||
```
|
||||
|
||||
以及使用 Ruby 重写的版本:
|
||||
|
||||
```
|
||||
irb(main):001:0> a = [1,2,3,4,5]
|
||||
=> [1, 2, 3, 4, 5]
|
||||
irb(main):002:0> b = a
|
||||
=> [1, 2, 3, 4, 5]
|
||||
irb(main):003:0> b[2] = 0
|
||||
=> 0
|
||||
irb(main):004:0> a
|
||||
=> [1, 2, 0, 4, 5]
|
||||
```
|
||||
|
||||
在大多数将数组视为对象或者是引用类型的语言也是如此。[4][8]
|
||||
|
||||
### 切片头
|
||||
|
||||
让切片得以同时拥有值和指针的特性的魔法来源于切片实际上是一个结构体类型。这个结构体通常叫做 _切片头_,这里是 [反射包内的相关定义][20]。且片头的定义大致如下:
|
||||
|
||||

|
||||
|
||||
```
|
||||
package runtime
|
||||
|
||||
type slice struct {
|
||||
ptr unsafe.Pointer
|
||||
len int
|
||||
cap int
|
||||
}
|
||||
```
|
||||
|
||||
这个头很重要,因为和[ `map` 以及 `chan` 这两个类型不同][21],切片是值类型,当被赋值或者被作为函数的参数时候会被复制过去。
|
||||
|
||||
程序员们都能理解 `square` 的形参 `v` 和 `main` 中声明的 `v` 的是相互独立的,我们一次为例。
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func square(v int) {
|
||||
v = v * v
|
||||
}
|
||||
|
||||
func main() {
|
||||
v := 3
|
||||
square(v)
|
||||
fmt.Println(v) // prints 3, not 9
|
||||
}
|
||||
```
|
||||
|
||||
因此 `square` 对自己的形参 `v` 的操作没有影响到 `main` 中的 `v`。下面这个示例中的 `s` 也是 `main` 中声明的切片 `s` 的独立副本,_而不是_指向 `main` 的 `s` 的指针。
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func double(s []int) {
|
||||
s = append(s, s...)
|
||||
}
|
||||
|
||||
func main() {
|
||||
s := []int{1, 2, 3}
|
||||
double(s)
|
||||
fmt.Println(s, len(s)) // prints [1 2 3] 3
|
||||
}
|
||||
```
|
||||
|
||||
Go 语言的切片是作为值传递的这一点很是不寻常。当你在 Go 语言内定义一个结构体时,90% 的时间里传递的都是这个结构体的指针。[5][9] 切片的传递方式真的很不寻常,我能想到的唯一与之相同的例子只有 `time.Time`。
|
||||
|
||||
切片作为值传递而不是作为指针传递这一点会让很多想要理解切片的工作原理的 Go 程序员感到困惑,这是可以理解的。你只需要记住,当你对切片进行赋值,取切片,传参或者作为返回值等操作时,你是在复制结构体内的三个位域:指针,长度,以及容量。
|
||||
|
||||
### 总结
|
||||
|
||||
我们来用我们引出这一话题的切片作为栈的例子来总结下本文的内容:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func f(s []string, level int) {
|
||||
if level > 5 {
|
||||
return
|
||||
}
|
||||
s = append(s, fmt.Sprint(level))
|
||||
f(s, level+1)
|
||||
fmt.Println("level:", level, "slice:", s)
|
||||
}
|
||||
|
||||
func main() {
|
||||
f(nil, 0)
|
||||
}
|
||||
```
|
||||
|
||||
在 `main` 函数的最开始我们把一个 `nil` 切片以及 `level` 0传给了函数 `f`。在函数 `f` 里我们把当前的 `level` 添加到切片的后面,之后增加 `level` 的值并进行递归。一旦 `level` 大于 5,函数返回,打印出当前的 `level` 以及他们复制到的 `s` 的内容。
|
||||
|
||||
```
|
||||
level: 5 slice: [0 1 2 3 4 5]
|
||||
level: 4 slice: [0 1 2 3 4]
|
||||
level: 3 slice: [0 1 2 3]
|
||||
level: 2 slice: [0 1 2]
|
||||
level: 1 slice: [0 1]
|
||||
level: 0 slice: [0]
|
||||
```
|
||||
|
||||
你可以注意到在每一个 `level` 内 `s` 的值没有被别的 `f` 的调用影响,尽管当计算更高阶的 `level` 时作为 `append` 的副产品,调用栈内的四个 `f` 函数创建了四个底层数组,但是没有影响到当前各自的切片。
|
||||
|
||||
### 了解更多
|
||||
|
||||
如果你想要了解更多 Go 语言内切片运行的原理,我建议看看 Go 博客里的这些文章:
|
||||
|
||||
* [Go Slices: usage and internals][11] (blog.golang.org)
|
||||
|
||||
* [Arrays, slices (and strings): The mechanics of ‘append’][12] (blog.golang.org)
|
||||
|
||||
### 注释
|
||||
|
||||
1. 这不是数组才有的特性,在 Go 语言里,_一切_ 赋值都是复制过去的,
|
||||
|
||||
2. 你可以在对数组使用 `len` 函数,但是得到的结果是多少人尽皆知。[][14]
|
||||
|
||||
3. 也叫做后台数组,以及更不严谨的说法是后台切片。[][15]
|
||||
|
||||
4. Go 语言里我们倾向于说值类型以及指针类型,因为 C++ 的引用会使使用引用类型这个词产生误会。但是在这里我说引用类型是没有问题的。[][16]
|
||||
|
||||
5. 如果你的结构体有[定义在其上的方法或者实现了什么接口][17],那么这个比率可以飙升到接近 100%。[][18]
|
||||
|
||||
6. 证明留做习题。
|
||||
|
||||
### 相关文章:
|
||||
|
||||
1. [If a map isn’t a reference variable, what is it?][4]
|
||||
|
||||
2. [What is the zero value, and why is it useful ?][5]
|
||||
|
||||
3. [The empty struct][6]
|
||||
|
||||
4. [Should methods be declared on T or *T][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dave.cheney.net/2018/07/12/slices-from-the-ground-up
|
||||
|
||||
作者:[Dave Cheney][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dave.cheney.net/
|
||||
[1]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-1-3265
|
||||
[2]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-2-3265
|
||||
[3]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-3-3265
|
||||
[4]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
[5]:https://dave.cheney.net/2013/01/19/what-is-the-zero-value-and-why-is-it-useful
|
||||
[6]:https://dave.cheney.net/2014/03/25/the-empty-struct
|
||||
[7]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
|
||||
[8]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-4-3265
|
||||
[9]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-5-3265
|
||||
[10]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-6-3265
|
||||
[11]:https://blog.golang.org/go-slices-usage-and-internals
|
||||
[12]:https://blog.golang.org/slices
|
||||
[13]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-1-3265
|
||||
[14]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-2-3265
|
||||
[15]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-3-3265
|
||||
[16]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-4-3265
|
||||
[17]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
|
||||
[18]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-5-3265
|
||||
[19]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-6-3265
|
||||
[20]:https://golang.org/pkg/reflect/#SliceHeader
|
||||
[21]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
Loading…
Reference in New Issue
Block a user