mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-10 00:00:29 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
747c7a50c8
@ -0,0 +1,146 @@
|
||||
如何使用命令行检查 Linux 上的磁盘空间
|
||||
========
|
||||
|
||||
> Linux 提供了所有必要的工具来帮助你确切地发现你的驱动器上剩余多少空间。Jack 在这里展示了如何做。
|
||||
|
||||

|
||||
|
||||
快速提问:你的驱动器剩余多少剩余空间?一点点还是很多?接下来的提问是:你知道如何找出这些剩余空间吗?如果你碰巧使用的是 GUI 桌面( 例如 GNOME、KDE、Mate、Pantheon 等 ),则任务可能非常简单。但是,当你要在一个没有 GUI 桌面的服务器上查询剩余空间,你该如何去做呢?你是否要为这个任务安装相应的软件工具?答案是绝对不是。在 Linux 中,具备查找驱动器上的剩余磁盘空间的所有工具。事实上,有两个非常容易使用的工具。
|
||||
|
||||
在本文中,我将演示这些工具。我将使用 [Elementary OS][1](LCTT译注:Elementary OS 是基于 Ubuntu 精心打磨美化的桌面 Linux 发行版 ),它还包括一个 GUI 方式,但我们将限制自己仅使用命令行。好消息是这些命令行工具随时可用于每个 Linux 发行版。在我的测试系统中,连接了许多的驱动器(内部的和外部的)。使用的命令与连接驱动器的位置无关,仅仅与驱动器是否已经挂载好并且对操作系统可见有关。
|
||||
|
||||
言归正传,让我们来试试这些工具。
|
||||
|
||||
### df
|
||||
|
||||
`df` 命令是我第一个用于在 Linux 上查询驱动器空间的工具,时间可以追溯到 20 世纪 90 年代。它的使用和报告结果非常简单。直到今天,`df` 还是我执行此任务的首选命令。此命令有几个选项开关,对于基本的报告,你实际上只需要一个选项。该命令是 `df -H` 。`-H` 选项开关用于将 `df` 的报告结果以人类可读的格式进行显示。`df -H` 的输出包括:已经使用了的空间量、可用空间、空间使用的百分比,以及每个磁盘连接到系统的挂载点(图 1)。
|
||||
|
||||
![df output][3]
|
||||
|
||||
*图 1:Elementary OS 系统上 `df -H` 命令的输出结果*
|
||||
|
||||
如果你的驱动器列表非常长并且你只想查看单个驱动器上使用的空间,该怎么办?对于 `df` 这没问题。我们来看一下位于 `/dev/sda1` 的主驱动器已经使用了多少空间。为此,执行如下命令:
|
||||
|
||||
```
|
||||
df -H /dev/sda1
|
||||
```
|
||||
输出将限于该驱动器(图 2)。
|
||||
|
||||
![disk usage][6]
|
||||
|
||||
*图 2:一个单独驱动器空间情况*
|
||||
|
||||
你还可以限制 `df` 命令结果报告中显示指定的字段。可用的字段包括:
|
||||
|
||||
- `source` — 文件系统的来源(LCTT译注:通常为一个设备,如 `/dev/sda1` )
|
||||
- `size` — 块总数
|
||||
- `used` — 驱动器已使用的空间
|
||||
- `avail` — 可以使用的剩余空间
|
||||
- `pcent` — 驱动器已经使用的空间占驱动器总空间的百分比
|
||||
- `target` —驱动器的挂载点
|
||||
|
||||
让我们显示所有驱动器的输出,仅显示 `size` ,`used` ,`avail` 字段。对此的命令是:
|
||||
|
||||
```
|
||||
df -H --output=size,used,avail
|
||||
```
|
||||
|
||||
该命令的输出非常简单( 图 3 )。
|
||||
|
||||
![output][8]
|
||||
|
||||
*图 3:显示我们驱动器的指定输出*
|
||||
|
||||
这里唯一需要注意的是我们不知道该输出的来源,因此,我们要把 `source` 加入命令中:
|
||||
|
||||
```
|
||||
df -H --output=source,size,used,avail
|
||||
```
|
||||
|
||||
现在输出的信息更加全面有意义(图 4)。
|
||||
|
||||
![source][10]
|
||||
|
||||
*图 4:我们现在知道了磁盘使用情况的来源*
|
||||
|
||||
### du
|
||||
|
||||
我们的下一个命令是 `du` 。 正如您所料,这代表<ruby>磁盘使用情况<rt>disk usage</rt></ruby>。 `du` 命令与 `df` 命令完全不同,因为它报告目录而不是驱动器的空间使用情况。 因此,您需要知道要检查的目录的名称。 假设我的计算机上有一个包含虚拟机文件的目录。 那个目录是 `/media/jack/HALEY/VIRTUALBOX` 。 如果我想知道该特定目录使用了多少空间,我将运行如下命令:
|
||||
|
||||
```
|
||||
du -h /media/jack/HALEY/VIRTUALBOX
|
||||
```
|
||||
|
||||
上面命令的输出将显示目录中每个文件占用的空间(图 5)。
|
||||
|
||||
![du command][12]
|
||||
|
||||
*图 5 在特定目录上运行 `du` 命令的输出*
|
||||
|
||||
到目前为止,这个命令并没有那么有用。如果我们想知道特定目录的总使用量怎么办?幸运的是,`du` 可以处理这项任务。对于同一目录,命令将是:
|
||||
|
||||
```
|
||||
du -sh /media/jack/HALEY/VIRTUALBOX/
|
||||
```
|
||||
|
||||
现在我们知道了上述目录使用存储空间的总和(图 6)。
|
||||
|
||||
![space used][14]
|
||||
|
||||
*图 6:我的虚拟机文件使用存储空间的总和是 559GB*
|
||||
|
||||
您还可以使用此命令查看父项的所有子目录使用了多少空间,如下所示:
|
||||
|
||||
```
|
||||
du -h /media/jack/HALEY
|
||||
```
|
||||
|
||||
此命令的输出见(图 7),是一个用于查看各子目录占用的驱动器空间的好方法。
|
||||
|
||||
![directories][16]
|
||||
|
||||
*图 7:子目录的存储空间使用情况*
|
||||
|
||||
`du` 命令也是一个很好的工具,用于查看使用系统磁盘空间最多的目录列表。执行此任务的方法是将 `du` 命令的输出通过管道传递给另外两个命令:`sort` 和 `head` 。下面的命令用于找出驱动器上占用存储空间最大的前 10 个目录:
|
||||
|
||||
```
|
||||
du -a /media/jack | sort -n -r |head -n 10
|
||||
```
|
||||
|
||||
输出将以从大到小的顺序列出这些目录(图 8)。
|
||||
|
||||
![top users][18]
|
||||
|
||||
*图 8:使用驱动器空间最多的 10 个目录*
|
||||
|
||||
### 没有你想像的那么难
|
||||
|
||||
查看 Linux 系统上挂载的驱动器的空间使用情况非常简单。只要你将你的驱动器挂载在 Linux 系统上,使用 `df` 命令或 `du` 命令在报告必要信息方面都会非常出色。使用 `df` 命令,您可以快速查看磁盘上总的空间使用量,使用 `du` 命令,可以查看特定目录的空间使用情况。对于每一个 Linux 系统的管理员来说,这两个命令的结合使用是必须掌握的。
|
||||
|
||||
而且,如果你没有注意到,我最近介绍了[查看 Linux 上内存使用情况的方法][19]。总之,这些技巧将大力帮助你成功管理 Linux 服务器。
|
||||
|
||||
通过 Linux Foundation 和 edX 免费提供的 “Linux 简介” 课程,了解更多有关 Linux 的信息。
|
||||
|
||||
--------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/6how-check-disk-space-linux-command-line
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[SunWave](https://github.com/SunWave)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://elementary.io/
|
||||
[3]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_1.jpg?itok=aJa8AZAM
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_2.jpg?itok=_PAq3kxC
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_3.jpg?itok=51m8I-Vu
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_4.jpg?itok=SuwgueN3
|
||||
[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_5.jpg?itok=XfS4s7Zq
|
||||
[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_6.jpg?itok=r71qICyG
|
||||
[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_7.jpg?itok=PtDe4q5y
|
||||
[18]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/diskspace_8.jpg?itok=v9E1SFcC
|
||||
[19]:https://www.linux.com/learn/5-commands-checking-memory-usage-linux
|
||||
[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -7,63 +7,59 @@
|
||||
|
||||
我们最新的展示应用,[Winds 2.0][5],是用 Node.js 构建的,很快我们就了解到测试 Go 和 Python 的常规方法并不适合它。而且,创造一个好的测试套件需要用 Node.js 做很多额外的工作,因为我们正在使用的框架没有提供任何内建的测试功能。
|
||||
|
||||
不论你用什么语言,要构建完好的测试框架可能都非常复杂。本文我们会展示在使用 Node.js 测试过程中的困难部分,以及我们在 Winds 2.0 中用到的各种工具,并且在你要编写下一个测试集合时为你指明正确的方向。
|
||||
不论你用什么语言,要构建完好的测试框架可能都非常复杂。本文我们会展示 Node.js 测试过程中的困难部分,以及我们在 Winds 2.0 中用到的各种工具,并且在你要编写下一个测试集合时为你指明正确的方向。
|
||||
|
||||
### 为什么测试如此重要
|
||||
|
||||
我们都向生产环境中推送过糟糕的提交,并且经历过结果。碰到这样的情况不是好事。编写一个稳固的测试套件不仅仅是一个明智的检测,而且它还让你能够自由的重构代码,重构之后的代码仍然正常运行会让你信心倍增。这在你刚刚开始编写代码的时候尤为重要。
|
||||
我们都向生产环境中推送过糟糕的提交,并且遭受了其后果。碰到这样的情况不是好事。编写一个稳固的测试套件不仅仅是一个明智的检测,而且它还让你能够完全地重构代码,并自信重构之后的代码仍然可以正常运行。这在你刚刚开始编写代码的时候尤为重要。
|
||||
|
||||
如果你是与团队共事,达到测试覆盖率极其重要。没有它,团队中的其他开发者几乎不可能知道他们所做的工作是否导致重大变动(ouch)。
|
||||
如果你是与团队共事,达到测试覆盖率极其重要。没有它,团队中的其他开发者几乎不可能知道他们所做的工作是否导致重大变动(或破坏)。
|
||||
|
||||
编写测试同时促进你和你的队友把代码分割成更小的片段。这让别人去理解你的代码和修改 bug 变得容易多了。产品收益变得更大,因为你能更早的发现 bug。
|
||||
编写测试同时会促进你和你的队友把代码分割成更小的片段。这让别人去理解你的代码和修改 bug 变得容易多了。产品收益变得更大,因为你能更早的发现 bug。
|
||||
|
||||
最后,没有测试,你的基本代码还不如一堆纸片。基本不能保证你的代码是稳定的。
|
||||
|
||||
### 困难的部分
|
||||
|
||||
在我看来,我们在 Winds 中遇到的大多数测试问题是 Node.js 中特有的。它的生态系统总是在变大。例如,如果你用的是 macOS,运行 "brew upgrade"(安装了 homebrew),你看到你一个新版本的 Node.js 的概率非常高。由于 Node.js 迭代频繁,相应的库也紧随其后,想要与最新的库保持同步非常困难。
|
||||
在我看来,我们在 Winds 中遇到的大多数测试问题是 Node.js 中特有的。它的生态系统一直在变大。例如,如果你用的是 macOS,运行 `brew upgrade`(安装了 homebrew),你看到你一个新版本的 Node.js 的概率非常高。由于 Node.js 迭代频繁,相应的库也紧随其后,想要与最新的库保持同步非常困难。
|
||||
|
||||
以下是一些要记在心上的痛点:
|
||||
以下是一些马上映入脑海的痛点:
|
||||
|
||||
1. 在 Node.js 中进行测试是固执又不是固执的。人们对于如何构建一个测试架构以及如何检验成功有不同的看法。沮丧的是还没有一个黄金准则规定你应该如何进行测试。
|
||||
|
||||
2. 有一堆框架能够在你的应用里使用。但是它们一般都很精简,没有完好的配置或者启动过程。这会导致非常常见的副作用,而且还很难检测到;所以你们最终会想要从零开始编写自己的测试执行平台。
|
||||
|
||||
3. 几乎能保证你 _需要_ 编写自己的测试执行平台(马上就会讲到这一节)。
|
||||
1. 在 Node.js 中进行测试是非常主观而又不主观的。人们对于如何构建一个测试架构以及如何检验成功有不同的看法。沮丧的是还没有一个黄金准则规定你应该如何进行测试。
|
||||
2. 有一堆框架能够用在你的应用里。但是它们一般都很精简,没有完好的配置或者启动过程。这会导致非常常见的副作用,而且还很难检测到;所以你最终会想要从零开始编写自己的<ruby>测试执行平台<rt>test runner</rt></ruby>测试执行平台。
|
||||
3. 几乎可以保证你 _需要_ 编写自己的测试执行平台(马上就会讲到这一节)。
|
||||
|
||||
以上列出的情况不是理想的,而且这是 Node.js 社区应该尽管处理的事情。如果其他语言解决了这些问题,我认为也是作为广泛使用的语言, Node.js 解决这些问题的时候。
|
||||
|
||||
### 编写你自己的测试执行平台
|
||||
|
||||
所以...你可能会好奇测试执行平台 _是_ 什么,它并不复杂。测试执行平台在测试套件中是最高层的容器。它允许你指定全局配置和环境,还可以导入配置。可能有人觉得做这个很简单,对吧?没那么快呢。
|
||||
所以……你可能会好奇<rt>test runner</rt></ruby>测试执行平台 _是_ 什么,说实话,它并不复杂。测试执行平台是测试套件中最高层的容器。它允许你指定全局配置和环境,还可以导入配置。可能有人觉得做这个很简单,对吧?别那么快下结论。
|
||||
|
||||
我们所学到的是,尽管现在就有足够数量的测试框架了,没有一个关于 Node.js 的测试框架提供标准的方式能构建你的测试执行平台。很难受,这需要开发者来完成。这里有个关于测试执行平台的需求的简单总结:
|
||||
我们所了解到的是,尽管现在就有足够多的测试框架了,但没有一个测试框架为 Node.js 提供了构建你的测试执行平台的标准方式。不幸的是,这需要开发者来完成。这里有个关于测试执行平台的需求的简单总结:
|
||||
|
||||
* 能够加载不同的配置(比如,本地的,测试的,开发的),能够确保你 _永远不会_ 加载一个生产环境的配置 —— 你能想象出那样会出什么问题。
|
||||
* 能够加载不同的配置(比如,本地的、测试的、开发的),并确保你 _永远不会_ 加载一个生产环境的配置 —— 你能想象出那样会出什么问题。
|
||||
* 播种数据库——产生用于测试的数据。必须要支持多种数据库,不论是 MySQL、PostgreSQL、MongoDB 或者其它任何一个数据库。
|
||||
* 能够加载配置(带有用于开发环境测试的播种数据的文件)。
|
||||
|
||||
* 支持数据库,生成种子数据库,产生用于测试的数据。必须要支持多种数据库,不论是 MySQL、PostgreSQL、MongoDB 或者其它任何一个数据库。
|
||||
|
||||
* 能够加载配置(带有用于开发环境的种子数据的文件)。
|
||||
|
||||
做 Winds 的时候,我们选择 Mocha 作为测试执行平台。Mocha 提供了简单并且可编程的方式,通过命令行工具(整合了 Babel)来运行 ES6 代码的测试。
|
||||
开发 Winds 的时候,我们选择 Mocha 作为测试执行平台。Mocha 提供了简单并且可编程的方式,通过命令行工具(整合了 Babel)来运行 ES6 代码的测试。
|
||||
|
||||
为了进行测试,我们注册了自己的 Babel 模块引导器。这为我们提供了更细的粒度,更强大的控制,在 Babel 覆盖掉 Node.js 模块加载过程前,对导入的模块进行控制,让我们有机会在所有测试运行前对模块进行模拟。
|
||||
|
||||
此外,我们还使用了 Mocha 的测试执行平台特性,预先把特定的请求赋给 HTTP 管理器。我们这么做是因为常规的初始化代码在测试中不会运行(服务器交互是用 Chai HTTP 插件模拟的),还要做一些安全性检查来确保我们不会连接到生产环境数据库。
|
||||
|
||||
尽管这不是测试执行平台的一部分,有一个固定加载器也是我们测试套件中的重要的一部分。我们试验过已有的解决方案;然而,我们最终决定编写自己的助手,这样它就能贴合我们的需求。根据我们的解决方案,在生成或手动编写配置时,通过遵循简单专有的协议,我们就能加载数据依赖很复杂的配置。
|
||||
尽管这不是测试执行平台的一部分,有一个<ruby>配置<rt>fixture</rt></ruby>加载器也是我们测试套件中的重要的一部分。我们试验过已有的解决方案;然而,我们最终决定编写自己的助手程序,这样它就能贴合我们的需求。根据我们的解决方案,在生成或手动编写配置时,通过遵循简单专有的协议,我们就能加载数据依赖很复杂的配置。
|
||||
|
||||
### Winds 中用到的工具
|
||||
|
||||
尽管过程很冗长,我们还是能够合理使用框架和工具,使得针对后台 API 进行的适当测试变成现实。这里是我们选择使用的工具:
|
||||
|
||||
### Mocha ☕
|
||||
#### Mocha
|
||||
|
||||
[Mocha][6], 被称为 “在 Node.js 上运行的特性丰富的测试框架”,是我们完成任务的首选。拥有超过 15K 的 stars,很多支持者和贡献者,我们指定这是正确的框架。
|
||||
[Mocha][6],被称为 “运行在 Node.js 上的特性丰富的测试框架”,是我们用于该任务的首选工具。拥有超过 15K 的星标,很多支持者和贡献者,我们知道对于这种任务,这是正确的框架。
|
||||
|
||||
### Chai 🥃
|
||||
#### Chai
|
||||
|
||||
然后是我们的断言库。我们选择使用传统方法,也就是最适合配合 Mocha 使用的 —— [Chai][7]。Chai 是一个用于 Node.js,适合 BDD 和 TDD 模式的断言库。有简单的 API,Chai 很容易整合进我们的应用,让我们能够轻松地断言出我们 _期望_ 从 Winds API 中返回的应该是什么。最棒的地方在于,用 Chai 编写测试让人觉得很自然。这是一个简短的例子:
|
||||
然后是我们的断言库。我们选择使用传统方法,也就是最适合配合 Mocha 使用的 —— [Chai][7]。Chai 是一个用于 Node.js,适合 BDD 和 TDD 模式的断言库。拥有简单的 API,Chai 很容易整合进我们的应用,让我们能够轻松地断言出我们 _期望_ 从 Winds API 中返回的应该是什么。最棒的地方在于,用 Chai 编写测试让人觉得很自然。这是一个简短的例子:
|
||||
|
||||
```
|
||||
describe('retrieve user', () => {
|
||||
@ -113,14 +109,13 @@ describe('retrieve user', () => {
|
||||
});
|
||||
```
|
||||
|
||||
### Sinon 🧙
|
||||
#### Sinon
|
||||
|
||||
拥有与任何测试框架相适应的能力,[Sinon][8] 是模拟库的首选。而且,精简安装带来的超级整洁的整合,让 Sinon 把模拟请求变成简单的过程。它的网站有极其良好的用户体验,并且提供简单的步骤,供你将 Sinon 整合进自己的测试框架中。
|
||||
拥有与任何单元测试框架相适应的能力,[Sinon][8] 是模拟库的首选。而且,精简安装带来的超级整洁的整合,让 Sinon 把模拟请求变成了简单而轻松的过程。它的网站有极其良好的用户体验,并且提供简单的步骤,供你将 Sinon 整合进自己的测试框架中。
|
||||
|
||||
### Nock 🔮
|
||||
#### Nock
|
||||
|
||||
For all external HTTP requests, we use [nock][9], a robust HTTP mocking library that really comes in handy when you have to communicate with a third party API (such as [Stream’s REST API][10]). There’s not much to say about this little library aside from the fact that it is awesome at what it does, and that’s why we like it. Here’s a quick example of us calling our [personalization][11] engine for Stream:
|
||||
对于所有外部的 HTTP 请求,我们使用稳定的 HTTP 模拟库 [nock][9],在你要和第三方 API 交互时非常易用(比如说 [Stream's REST API][10])。它做的事情非常酷炫,这就是我们喜欢它的原因,除此之外关于这个精妙的库没有什么要多说的了。这是我们的速成示例,调用我们在 Stream 引擎中提供的 [personalization][11]:
|
||||
对于所有外部的 HTTP 请求,我们使用健壮的 HTTP 模拟库 [nock][9],在你要和第三方 API 交互时非常易用(比如说 [Stream 的 REST API][10])。它做的事情非常酷炫,这就是我们喜欢它的原因,除此之外关于这个精妙的库没有什么要多说的了。这是我们的速成示例,调用我们在 Stream 引擎中提供的 [personalization][11]:
|
||||
|
||||
```
|
||||
nock(config.stream.baseUrl)
|
||||
@ -128,11 +123,11 @@ nock(config.stream.baseUrl)
|
||||
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
|
||||
```
|
||||
|
||||
### Mock-require 🎩
|
||||
#### Mock-require
|
||||
|
||||
[mock-require][12] 库允许依赖外部代码。用一行代码,你就可以替换一个模块,并且当代码尝试导入这个库时,将会产生模拟请求。这是一个小巧但稳定的库,我们还是它的粉丝。
|
||||
[mock-require][12] 库允许依赖外部代码。用一行代码,你就可以替换一个模块,并且当代码尝试导入这个库时,将会产生模拟请求。这是一个小巧但稳定的库,我们是它的超级粉丝。
|
||||
|
||||
### Istanbul 🔭
|
||||
#### Istanbul
|
||||
|
||||
[Istanbul][13] 是 JavaScript 代码覆盖工具,在运行测试的时候,通过模块钩子自动添加覆盖率,可以计算语句,行数,函数和分支覆盖率。尽管我们有相似功能的 CodeCov(见下一节),进行本地测试时,这仍然是一个很棒的工具。
|
||||
|
||||
@ -210,46 +205,55 @@ describe('Article controller', () => {
|
||||
|
||||
有很多可用的持续集成服务,但我们钟爱 [Travis CI][15],因为他们和我们一样喜爱开源环境。考虑到 Winds 是开源的,它再合适不过了。
|
||||
|
||||
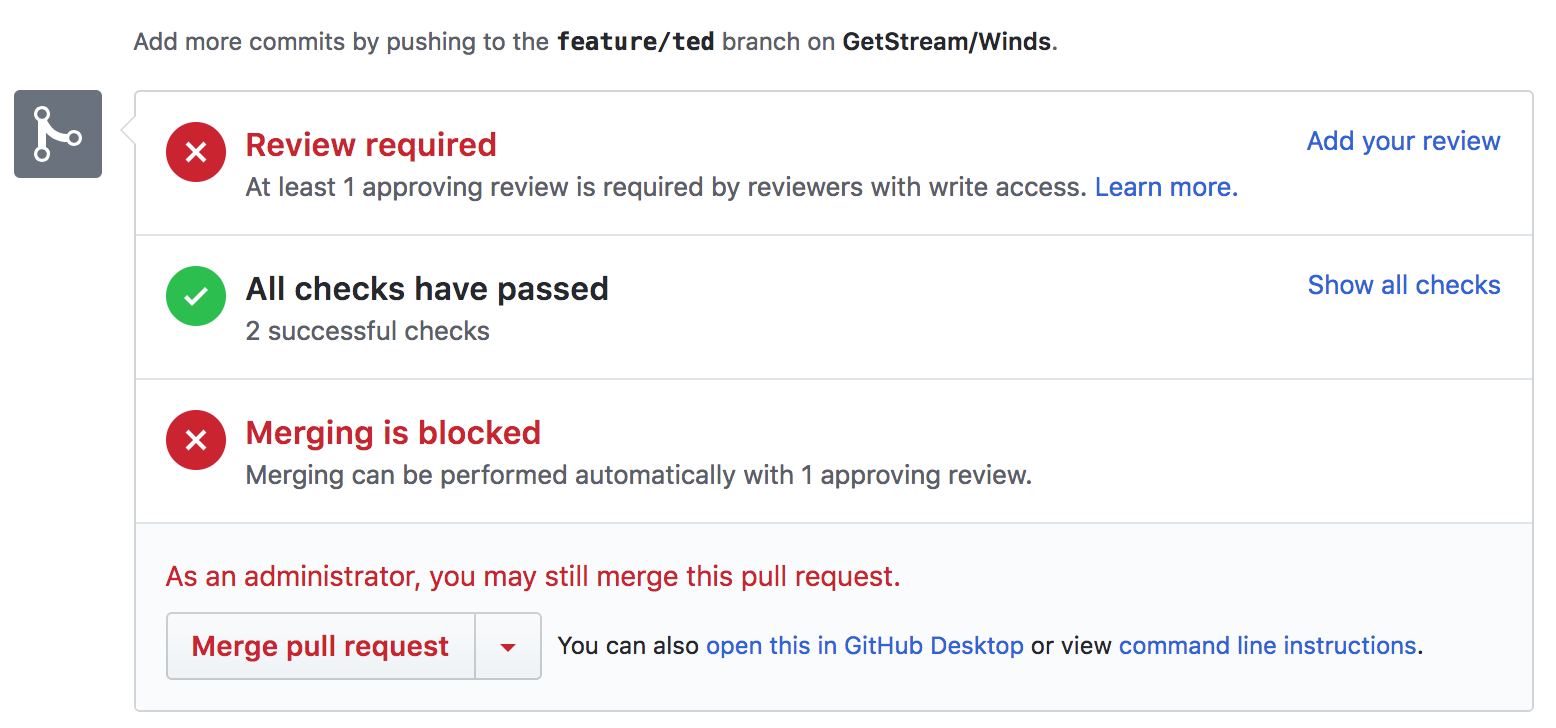
我们的集成非常简单 —— 我们用 [.travis.yml] 文件设置环境,通过简单的 [npm][17] 命令进行测试。测试覆盖率反馈给 Github,在 Github 上我们通过明了的图片能够看出我们最新的代码或者 PR 是不是通过了测试。Github 集成很棒,因为它可以自动查询 Travis CI 获取结果。以下是一个在 Github 上查看 PR (经过测试)的简单截图:
|
||||
我们的集成非常简单 —— 我们用 [.travis.yml] 文件设置环境,通过简单的 [npm][17] 命令进行测试。测试覆盖率反馈给 GitHub,在 GitHub 上我们将清楚地看出我们最新的代码或者 PR 是不是通过了测试。GitHub 集成很棒,因为它可以自动查询 Travis CI 获取结果。以下是一个在 GitHub 上看到 (经过了测试的) PR 的简单截图:
|
||||
|
||||
|
||||
|
||||
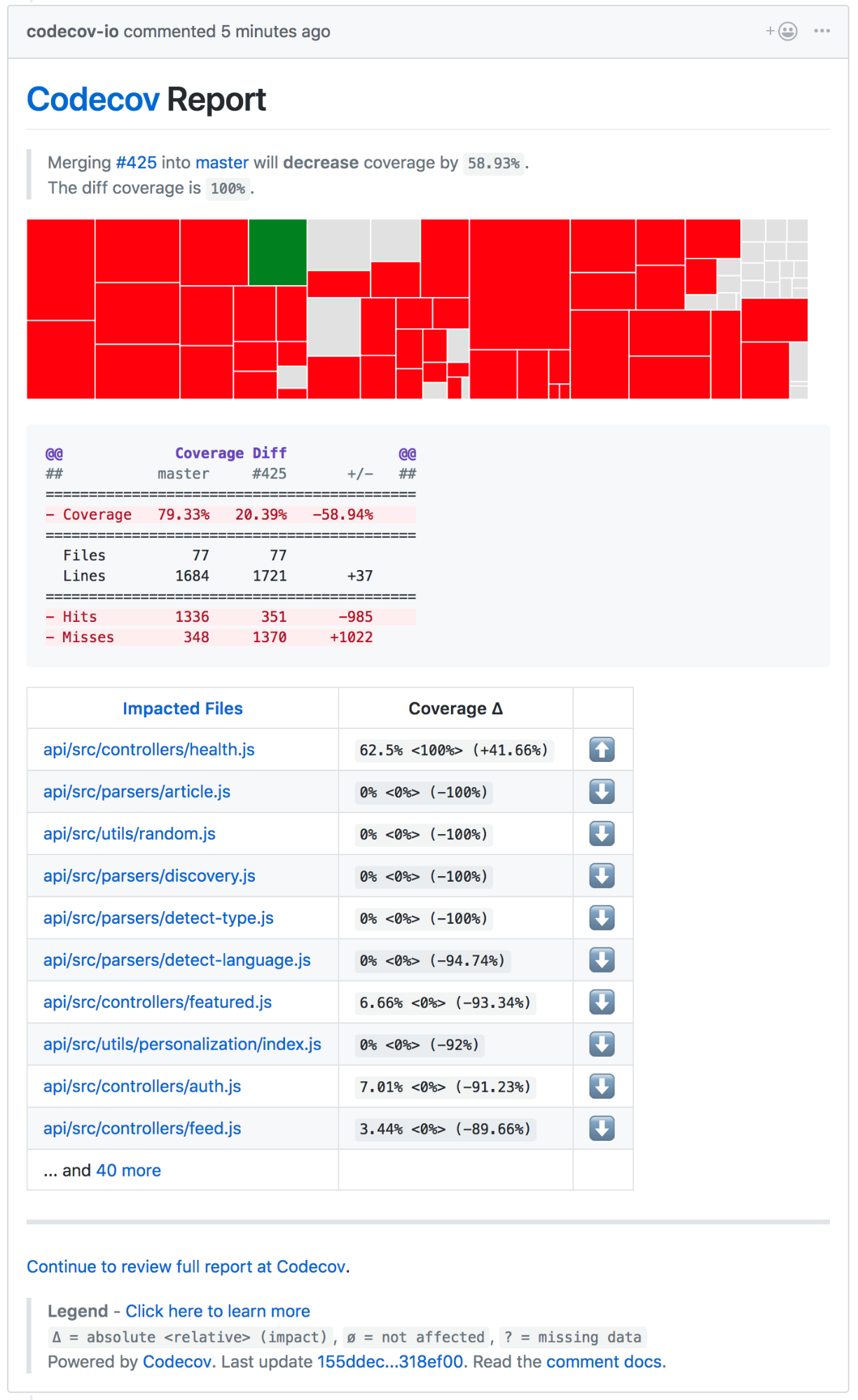
除了 Travis CI,我们还用到了叫做 [CodeCov][18] 的工具。CodeCov 和 [Istanbul] 很像,但它是个可视化的工具,方便我们 查看代码覆盖率,文件变动,行数变化,还有其他各种小玩意儿。尽管不用 CodeCov 也可以可视化数据,但把所有东西囊括在一个地方也很不错。
|
||||
|
||||
### 我们学到了什么
|
||||
除了 Travis CI,我们还用到了叫做 [CodeCov][18] 的工具。CodeCov 和 [Istanbul] 很像,但它是个可视化的工具,方便我们查看代码覆盖率、文件变动、行数变化,还有其他各种小玩意儿。尽管不用 CodeCov 也可以可视化数据,但把所有东西囊括在一个地方也很不错。
|
||||
|
||||
|
||||
|
||||
在开发我们的测试套件的整个过程中,我们学到了很多东西。开发时没有“正确”的方法,我们决定开始创造自己的测试流程,通过理清楚可用的库,找到那些足够有用的东西添加到我们的工具箱中。
|
||||
### 我们学到了什么
|
||||
|
||||
在开发我们的测试套件的整个过程中,我们学到了很多东西。开发时没有所谓“正确”的方法,我们决定开始创造自己的测试流程,通过理清楚可用的库,找到那些足够有用的东西添加到我们的工具箱中。
|
||||
|
||||
最终我们学到的是,在 Node.js 中进行测试不是听上去那么简单。还好,随着 Node.js 持续完善,社区将会聚集力量,构建一个坚固稳健的库,可以用“正确”的方式处理所有和测试相关的东西。
|
||||
|
||||
直到那时,我们还会接着用自己的测试套件,也就是开源的 [Winds Github repository][20]。
|
||||
但在那时到来之前,我们还会接着用自己的测试套件,它开源在 [Winds 的 GitHub 仓库][20]。
|
||||
|
||||
### 局限
|
||||
|
||||
#### 创建配置没有简单的方法
|
||||
|
||||
框架和语言,就如 Python 中的 Django,有简单的方式来创建配置。比如,你可以使用下面这些 Django 命令,把数据导出到文件中来自动化配置的创建过程:
|
||||
有的框架和语言,就如 Python 中的 Django,有简单的方式来创建配置。比如,你可以使用下面这些 Django 命令,把数据导出到文件中来自动化配置的创建过程:
|
||||
|
||||
以下命令会把整个数据库导出到 db.json 文件中:
|
||||
以下命令会把整个数据库导出到 `db.json` 文件中:
|
||||
|
||||
```
|
||||
./manage.py dumpdata > db.json
|
||||
```
|
||||
|
||||
以下命令仅导出 django 中 admin.logentry 表里的内容:
|
||||
以下命令仅导出 django 中 `admin.logentry` 表里的内容:
|
||||
|
||||
```
|
||||
./manage.py dumpdata admin.logentry > logentry.json
|
||||
```
|
||||
|
||||
以下命令会导出 auth.user 表中的内容:
|
||||
以下命令会导出 `auth.user` 表中的内容:
|
||||
|
||||
```
|
||||
./manage.py dumpdata auth.user > user.json
|
||||
```
|
||||
|
||||
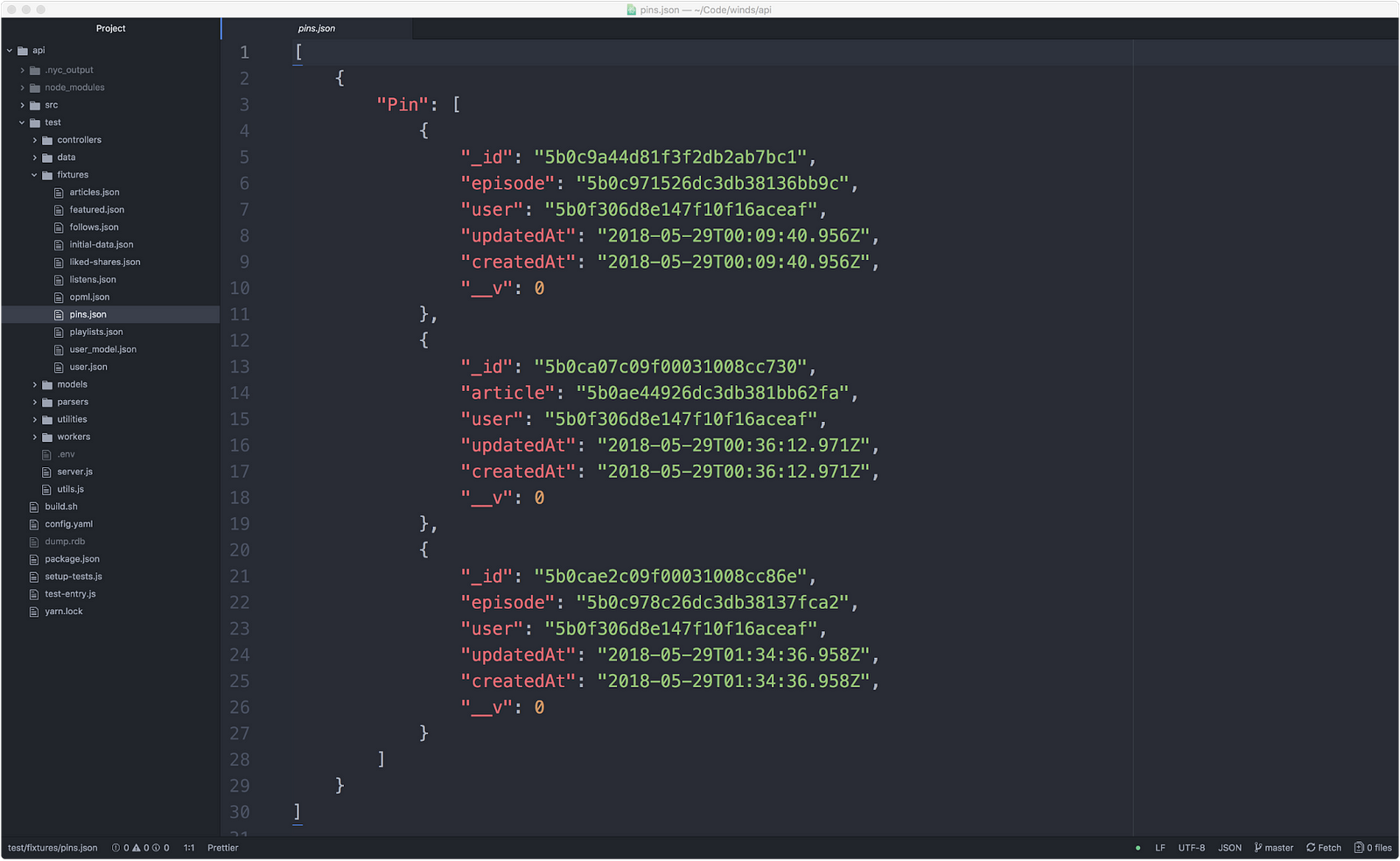
Node.js 里面没有简单的方式来创建配置。我们最后做的事情是用 MongoDB Compass 工具导出数据到 JSON 中。这生成了不错的配置,如下图(但是,这是个乏味的过程,肯定会出错):
|
||||
Node.js 里面没有创建配置的简单方式。我们最后做的事情是用 MongoDB Compass 工具导出数据到 JSON 中。这生成了不错的配置,如下图(但是,这是个乏味的过程,肯定会出错):
|
||||
|
||||
|
||||
|
||||
#### 使用 Babel,模拟模块和 Mocha 测试执行平台时,模块加载不直观
|
||||
|
||||
为了支持多种 node 版本,能够获取 JavaScript 标准的最新附件,我们使用 Babel 把 ES6 代码转换成 ES5。Node.js 模块系统基于 CommonJS 标准,而 ES6 模块系统中有不同的语义。
|
||||
为了支持多种 node 版本,和获取 JavaScript 标准的最新附件,我们使用 Babel 把 ES6 代码转换成 ES5。Node.js 模块系统基于 CommonJS 标准,而 ES6 模块系统中有不同的语义。
|
||||
|
||||
Babel 在 Node.js 模块系统的顶层模拟 ES6 模块语义,但由于我们要使用模拟访问来介入模块的加载,所以我们干的是经历奇怪的模块加载边角情况,这看上去很不直观,而且能导致在整个代码中,导入的、初始化的和使用的模块有不同的版本。这使测试时的模拟过程和全局状态管理复杂化了。
|
||||
Babel 在 Node.js 模块系统的顶层模拟 ES6 模块语义,但由于我们要使用 mock-require 来介入模块的加载,所以我们经历了罕见的怪异的模块加载过程,这看上去很不直观,而且能导致在整个代码中,导入的、初始化的和使用的模块有不同的版本。这使测试时的模拟过程和全局状态管理复杂化了。
|
||||
|
||||
#### 在使用 ES6 模块时声明的函数,模块内部的函数,都无法模拟
|
||||
|
||||
@ -259,14 +263,12 @@ Babel 在 Node.js 模块系统的顶层模拟 ES6 模块语义,但由于我们
|
||||
|
||||
测试 Node.js 应用是复杂的过程,因为它的生态系统总在发展。掌握最新和最好的工具很重要,这样你就不会掉队了。
|
||||
|
||||
如今有很多路径获取 JavaScript 相关的新闻,导致与时俱进很难。关注邮件新闻刊物如 [JavaScript Weekly][21] 和 [Node Weekly][22] 是良好的开始。还有,关注一些子模块如 [/r/node][23] 也不错。如果你喜欢了解最新的趋势,[State of JS][24] 在帮助开发者可视化测试世界的趋势方便就做的很好。
|
||||
如今有很多方式获取 JavaScript 相关的新闻,导致与时俱进很难。关注邮件新闻刊物如 [JavaScript Weekly][21] 和 [Node Weekly][22] 是良好的开始。还有,关注一些 reddit 子模块如 [/r/node][23] 也不错。如果你喜欢了解最新的趋势,[State of JS][24] 在测试领域帮助开发者可视化趋势方面就做的很好。
|
||||
|
||||
最后,这里是一些我喜欢的博客,我经常在这上面发文章:
|
||||
|
||||
* [Hacker Noon][1]
|
||||
|
||||
* [Free Code Camp][2]
|
||||
|
||||
* [Bits and Pieces][3]
|
||||
|
||||
觉得我遗漏了某些重要的东西?在评论区或者 Twitter [@NickParsons][25] 让我知道。
|
||||
@ -287,7 +289,7 @@ via: https://hackernoon.com/testing-node-js-in-2018-10a04dd77391
|
||||
|
||||
作者:[Nick Parsons][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,65 +0,0 @@
|
||||
What data is too risky for the cloud?
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this four-part series, we've been looking at the pitfalls every organization should avoid when transitioning operations to the cloud—specifically into hybrid multi-cloud environments.
|
||||
|
||||
[In part one][1], we covered basic definitions and our views on hybrid cloud and multi-cloud, making sure to show the dividing lines between the two. In [part two][2], we discussed the first of three pitfalls: why cost is not always the obvious motivator for moving to the cloud. And, in [part three][3], we examined the viability of moving all workloads to the cloud.
|
||||
|
||||
Finally, in part four, we're looking at what to do with data in the cloud. Should you move data into the cloud? How much? What data works in the cloud and what creates too much risk to move?
|
||||
|
||||
### Data… data… data
|
||||
|
||||
The crucial factor influencing all your decisions about data in the cloud is determining your bandwidth and storage needs. Gartner projects that "data storage will be a [$173 billion][4] business in 2018" and a lot of that money is wasted on unneeded capacity: "companies globally could save $62 billion in IT costs just by optimizing their workloads." Stunningly, companies are "paying an average of 36% more for cloud services than they actually need to," according to Gartner's research.
|
||||
|
||||
If you've read the first three articles in this series, you shouldn't be surprised by this. What is surprising, however, is Gartner's conclusion that, "only 25% of companies would save money if they transferred their server data directly onto the cloud."
|
||||
|
||||
Wait a minute … workloads can be optimized for the cloud, but only a small percentage of companies would save money by moving data into the cloud? What does this mean?
|
||||
|
||||
If you consider cloud providers typically charge rates based on bandwidth, moving all of your on-premises data to the cloud soon becomes a cost burden. There are three scenarios where companies decide it's worth putting data in the cloud:
|
||||
|
||||
* A single cloud with storage and applications
|
||||
* Applications in the cloud with storage on premises
|
||||
* Applications in the cloud and data cached in the cloud, with storage on premises
|
||||
|
||||
|
||||
|
||||
In the first scenario, bandwidth costs are reduced by keeping everything with a single cloud vendor. However, this creates lock-in, which often is contrary to a CIO's cloud strategy or risk prevention plan.
|
||||
|
||||
The second scenario keeps only the data that applications collect in the cloud and transports out the minimum to on-premises storage. This requires a carefully considered strategy where only applications that use minimal data are deployed in the cloud.
|
||||
|
||||
In the third scenario, data is cached in the cloud with applications and storage of that data, or the "one truth," stored on premises. This means analytics, artificial intelligence, and machine learning can be run on premises without having to upload data to cloud providers and then back again after processing. The cached data is based only on application needs and can even be cached across multi-cloud deployments.
|
||||
|
||||
For more insight, download a Red Hat [case study][5] that describes Amsterdam Airport Schiphol's data, cloud, and deployment strategies across a hybrid multi-cloud environment.
|
||||
|
||||
### Data dangers
|
||||
|
||||
Most companies recognize that their data is their proprietary advantage, their intellectual capacity, in their market. As such, they've thought very carefully about where it will be stored.
|
||||
|
||||
Imagine this scenario: You're a retailer, one of the top 10 worldwide. You've been planning your cloud strategy for some time now and have decided to use Amazon's cloud services. Suddenly, [Amazon buys Whole Foods][6] and is moving into your market.
|
||||
|
||||
Overnight, Amazon has grown to 50% of your retail size. Do you trust its cloud with your retail data? What do you do if your data is already in the Amazon cloud? Did you create your cloud plan with an exit strategy? While Amazon might never leverage your data's potential insights—the company even has protocols against this—can you trust anyone's word in today's world?
|
||||
|
||||
### Pitfalls shared, pitfalls avoided
|
||||
|
||||
Sharing just a few pitfalls we have seen in our experience should help your company plan a safer, more secure, and persistent cloud strategy. Understanding that [cost is not the obvious motivator][2], [not everything should be in the cloud][3], and you must manage your data effectively in the cloud are all keys to your success.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/data-risky-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
[2]:https://opensource.com/article/18/6/reasons-move-to-cloud
|
||||
[3]:https://opensource.com/article/18/7/why-you-cant-move-everything-cloud
|
||||
[4]:http://www.businessinsider.com/companies-waste-62-billion-on-the-cloud-by-paying-for-storage-they-dont-need-according-to-a-report-2017-11
|
||||
[5]:https://www.redhat.com/en/resources/amsterdam-airport-schiphol-case-study
|
||||
[6]:https://www.forbes.com/sites/ciocentral/2017/06/23/amazon-buys-whole-foods-now-what-the-story-behind-the-story/#33e9cc6be898
|
||||
@ -1,175 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Splicing the Cloud Native Stack, One Floor at a Time
|
||||
======
|
||||
At Packet, our value (automated infrastructure) is super fundamental. As such, we spend an enormous amount of time looking up at the players and trends in all the ecosystems above us - as well as the very few below!
|
||||
|
||||
It’s easy to get confused, or simply lose track, when swimming deep in the oceans of any ecosystem. I know this for a fact because when I started at Packet last year, my English degree from Bryn Mawr didn’t quite come with a Kubernetes certification. :)
|
||||
|
||||
Due to its super fast evolution and massive impact, the cloud native ecosystem defies precedent. It seems that every time you blink, entirely new technologies (not to mention all of the associated logos) have become relevant...or at least interesting. Like many others, I’ve relied on the CNCF’s ubiquitous “[Cloud Native Landscape][1]” as a touchstone as I got to know the space. However, if there is one element that defines ecosystems, it is the people that contribute to and steer them.
|
||||
|
||||
That’s why, when we were walking back to the office one cold December afternoon, we hit upon a creative way to explain “cloud native” to an investor, whose eyes were obviously glazing over as we talked about the nuances that distinguished Cilium from Aporeto, and why everything from CoreDNS and Spiffe to Digital Rebar and Fission were interesting in their own right.
|
||||
|
||||
Looking up at our narrow 13 story office building in the shadow of the new World Trade Center, we hit on an idea that took us down an artistic rabbit hole: why not draw it?
|
||||
|
||||
![][2]
|
||||
|
||||
And thus began our journey to splice the Cloud Native Stack, one floor at a time. Let’s walk through it together and we can give you the “guaranteed to be outdated tomorrow” down low.
|
||||
|
||||
[[View a High Resolution JPG][3]] or email us to request a copy.
|
||||
|
||||
### Starting at the Very Bottom
|
||||
|
||||
As we started to put pen to paper, we knew we wanted to shine a light on parts of the stack that we interact with on a daily basis, but that is largely invisible to users further up: hardware. And like any good secret lab investing in the next great (usually proprietary) thing, we thought the basement was the perfect spot.
|
||||
|
||||
From the well established giants of the space like Intel, AMD and Huawei (rumor has it they employ nearly 80,000 engineers!), to more niche players like Mellanox, the hardware ecosystem is on fire. In fact, we may be entering a Golden Age of hardware, as billions of dollars are poured into upstarts hacking on new offloads, GPU’s, custom co-processors.
|
||||
|
||||
The famous software trailblazer Alan Kay said over 25 years ago: “People who are really serious about software should make their own hardware.” Good call Alan!
|
||||
|
||||
### The Cloud is About Capital
|
||||
|
||||
As our CEO Zac Smith has told me many times: it’s all about the money. And not just about making it, but spending it! In the cloud, it takes billions of dollars of capital to make computers show up in data centers so that developers can consume them with software. In other words:
|
||||
|
||||
|
||||
![][4]
|
||||
|
||||
We thought the best place for “The Bank” (e.g. the lenders and investors that make this cloud fly) was the ground floor. So we transformed our lobby into the Banker’s Cafe, complete with a wheel of fortune for all of us out there playing the startup game.
|
||||
|
||||
![][5]
|
||||
|
||||
### The Ping and Power
|
||||
|
||||
If the money is the grease, then the engine that consumes much of the fuel is the datacenter providers and the networks that connect them. We call them “power” and “ping”.
|
||||
|
||||
From top of mind names like Equinix and edge upstarts like Vapor.io, to the “pipes” that Verizon, Crown Castle and others literally put in the ground (or on the ocean floor), this is a part of the stack that we all rely upon but rarely see in person.
|
||||
|
||||
Since we spend a lot of time looking at datacenters and connectivity, one thing to note is that this space is changing quite rapidly, especially as 5G arrives in earnest and certain workloads start to depend on less centralized infrastructure.
|
||||
|
||||
The edge is coming y’all! :-)
|
||||
|
||||
![][6]
|
||||
|
||||
### Hey, It's Infrastructure!
|
||||
|
||||
Sitting on top of “ping” and “power” is the floor we lovingly call “processors”. This is where our magic happens - we turn the innovation and physical investments from down below into something at the end of an API.
|
||||
|
||||
Since this is a NYC building, we kept the cloud providers here fairly NYC centric. That’s why you see Sammy the Shark (of Digital Ocean lineage) and a nod to Google over in the “meet me” room.
|
||||
|
||||
As you’ll see, this scene is pretty physical. Racking and stacking, as it were. While we love our facilities manager in EWR1 (Michael Pedrazzini), we are working hard to remove as much of this manual labor as possible. PhD’s in cabling are hard to come by, after all.
|
||||
|
||||
![][7]
|
||||
|
||||
### Provisioning
|
||||
|
||||
One floor up, layered on top of infrastructure, is provisioning. This is one of our favorite spots, which years ago we might have called “config management.” But now it’s all about immutable infrastructure and automation from the start: Terraform, Ansible, Quay.io and the like. You can tell that software is working its way down the stack, eh?
|
||||
|
||||
Kelsey Hightower noted recently “it’s an exciting time to be in boring infrastructure.” I don’t think he meant the physical part (although we think it’s pretty dope), but as software continues to hack on all layers of the stack, you can guarantee a wild ride.
|
||||
|
||||
![][8]
|
||||
|
||||
### Operating Systems
|
||||
|
||||
With provisioning in place, we move to the operating system layer. This is where we get to start poking fun at some of our favorite folks as well: note Brian Redbeard’s above average yoga pose. :)
|
||||
|
||||
Packet offers eleven major operating systems for our clients to choose from, including some that you see in this illustration: Ubuntu, CoreOS, FreeBSD, Suse, and various Red Hat offerings. More and more, we see folks putting their opinion on this layer: from custom kernels and golden images of their favorite distros for immutable deploys, to projects like NixOS and LinuxKit.
|
||||
|
||||
![][9]
|
||||
|
||||
### Run Time
|
||||
|
||||
We had to have fun with this, so we placed the runtime in the gym, with a championship match between CoreOS-sponsored rkt and Docker’s containerd. Either way the CNCF wins!
|
||||
|
||||
We felt the fast-evolving storage ecosystem deserved some lockers. What’s fun about the storage aspect is the number of new players trying to conquer the challenging issue of persistence, as well as performance and flexibility. As they say: storage is just plain hard.
|
||||
|
||||
![][10]
|
||||
|
||||
### Orchestration
|
||||
|
||||
The orchestration layer has been all about Kubernetes this past year, so we took one of its most famous evangelists (Kelsey Hightower) and featured him in this rather odd meetup scene. We have some major Nomad fans on our team, and there is just no way to consider the cloud native space without the impact of Docker and its toolset.
|
||||
|
||||
While workload orchestration applications are fairly high up our stack, we see all kinds of evidence for these powerful tools are starting to look way down the stack to help users take advantage of GPU’s and other specialty hardware. Stay tuned - we’re in the early days of the container revolution!
|
||||
|
||||
![][11]
|
||||
|
||||
### Platforms
|
||||
|
||||
This is one of our favorite layers of the stack, because there is so much craft in how each platform helps users accomplish what they really want to do (which, by the way, isn’t run containers but run applications!). From Rancher and Kontena, to Tectonic and Redshift to totally different approaches like Cycle.io and Flynn.io - we’re always thrilled to see how each of these projects servers users differently.
|
||||
|
||||
The main takeaway: these platforms are helping to translate all of the various, fast-moving parts of the cloud native ecosystem to users. It’s great watching what they each come up with!
|
||||
|
||||
![][12]
|
||||
|
||||
### Security
|
||||
|
||||
When it comes to security, it’s been a busy year! We tried to represent some of the more famous attacks and illustrate how various tools are trying to help protect us as workloads become highly distributed and portable (while at the same time, attackers become ever more resourceful).
|
||||
|
||||
We see a strong movement towards trustless environments (see Aporeto) and low level security (Cilium), as well as tried and true approaches at the network level like Tigera. No matter your approach, it’s good to remember: This is definitely not fine. :0
|
||||
|
||||
![][13]
|
||||
|
||||
### Apps
|
||||
|
||||
How to represent the huge, vast, limitless ecosystem of applications? In this case, it was easy: stay close to NYC and pick our favorites. ;) From the Postgres “elephant in the room” and the Timescale clock, to the sneaky ScyllaDB trash and the chillin’ Travis dude - we had fun putting this slice together.
|
||||
|
||||
One thing that surprised us: how few people noticed the guy taking a photocopy of his rear end. I guess it’s just not that common to have a photocopy machine anymore?!?
|
||||
|
||||
![][14]
|
||||
|
||||
### Observability
|
||||
|
||||
As our workloads start moving all over the place, and the scale gets gigantic, there is nothing quite as comforting as a really good Grafana dashboard, or that handy Datadog agent. As complexity increases, the “SRE” generation are starting to rely ever more on alerting and other intelligence events to help us make sense of what’s going on, and work towards increasingly self-healing infrastructure and applications.
|
||||
|
||||
It will be interesting to see what kind of logos make their way into this floor over the coming months and years...maybe some AI, blockchain, ML powered dashboards? :-)
|
||||
|
||||
![][15]
|
||||
|
||||
### Traffic Management
|
||||
|
||||
People tend to think that the internet “just works” but in reality, we’re kind of surprised it works at all. I mean, a loose connection of disparate networks at massive scale - you have to be joking!?
|
||||
|
||||
One reason it all sticks together is traffic management, DNS and the like. More and more, these players are helping to make the interest both faster and safer, as well as more resilient. We’re especially excited to see upstarts like Fly.io and NS1 competing against well established players, and watching the entire ecosystem improve as a result. Keep rockin’ it y’all!
|
||||
|
||||
![][16]
|
||||
|
||||
### Users
|
||||
|
||||
What good is a technology stack if you don’t have fantastic users? Granted, they sit on top of a massive stack of innovation, but in the cloud native world they do more than just consume: they create and contribute. From massive contributions like Kubernetes to more incremental (but equally important) aspects, what we’re all a part of is really quite special.
|
||||
|
||||
Many of the users lounging on our rooftop deck, like Ticketmaster and the New York Times, are not mere upstarts: these are organizations that have embraced a new way of deploying and managing their applications, and their own users are reaping the rewards.
|
||||
|
||||
![][17]
|
||||
|
||||
### Last but not Least, the Adult Supervision!
|
||||
|
||||
In previous ecosystems, foundations have played a more passive “behind the scenes” role. Not the CNCF! Their goal of building a robust cloud native ecosystem has been supercharged by the incredible popularity of the movement - and they’ve not only caught up but led the way.
|
||||
|
||||
From rock solid governance and a thoughtful group of projects, to outreach like the CNCF Landscape, CNCF Cross Cloud CI, Kubernetes Certification, and Speakers Bureau - the CNCF is way more than “just” the ever popular KubeCon + CloudNativeCon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.packet.net/blog/splicing-the-cloud-native-stack/
|
||||
|
||||
作者:[Zoe Allen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.packet.net/about/zoe-allen/
|
||||
[1]:https://landscape.cncf.io/landscape=cloud
|
||||
[2]:https://assets.packet.net/media/images/PIFg-30.vesey.street.ny.jpg
|
||||
[3]:https://www.dropbox.com/s/ujxk3mw6qyhmway/Packet_Cloud_Native_Building_Stack.jpg?dl=0
|
||||
[4]:https://assets.packet.net/media/images/3vVx-there.is.no.cloud.jpg
|
||||
[5]:https://assets.packet.net/media/images/X0b9-the.bank.jpg
|
||||
[6]:https://assets.packet.net/media/images/2Etm-ping.and.power.jpg
|
||||
[7]:https://assets.packet.net/media/images/C800-infrastructure.jpg
|
||||
[8]:https://assets.packet.net/media/images/0V4O-provisioning.jpg
|
||||
[9]:https://assets.packet.net/media/images/eMYp-operating.system.jpg
|
||||
[10]:https://assets.packet.net/media/images/9BII-run.time.jpg
|
||||
[11]:https://assets.packet.net/media/images/njak-orchestration.jpg
|
||||
[12]:https://assets.packet.net/media/images/1QUS-platforms.jpg
|
||||
[13]:https://assets.packet.net/media/images/TeS9-security.jpg
|
||||
[14]:https://assets.packet.net/media/images/SFgF-apps.jpg
|
||||
[15]:https://assets.packet.net/media/images/SXoj-observability.jpg
|
||||
[16]:https://assets.packet.net/media/images/tKhf-traffic.management.jpg
|
||||
[17]:https://assets.packet.net/media/images/7cpe-users.jpg
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Auk7F7
|
||||
|
||||
How to Manage Fonts in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,72 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Revisiting wallabag, an open source alternative to Instapaper
|
||||
======
|
||||
|
||||

|
||||
|
||||
Back in 2014, I [wrote about wallabag][1], an open source alternative to read-it-later applications like Instapaper and Pocket. Go take a look at that article if you want to. Don't worry, I'll wait for you.
|
||||
|
||||
Done? Great!
|
||||
|
||||
In the four years since I wrote that article, a lot about [wallabag][2] has changed. It's time to take a peek to see how wallabag has matured.
|
||||
|
||||
### What's new
|
||||
|
||||
The biggest change took place behind the scenes. Wallabag's developer Nicolas Lœuillet and the project's contributors did a lot of tinkering with the code, which improved the application. You see and feel the changes wrought by wallabag's newer codebase every time you use it.
|
||||
|
||||
So what are some of those changes? There are [quite a few][3]. Here are the ones I found most interesting and useful.
|
||||
|
||||
Besides making wallabag a bit snappier and more stable, the application's ability to import and export content has improved. You can import articles from Pocket and Instapaper, as well as articles marked as "To read" in bookmarking service [Pinboard][4]. You can also import Firefox and Chrome bookmarks.
|
||||
|
||||
You can also export your articles in several formats including EPUB, MOBI, PDF, and plaintext. You can do that for individual articles, all your unread articles, or every article—read and unread. The version of wallabag that I used four years ago could export to EPUB and PDF, but that export was balky at times. Now, those exports are quick and smooth.
|
||||
|
||||
Annotations and highlighting in the web interface now work much better and more consistently. Admittedly, I don't use them often—but they don't randomly disappear like they sometimes did with version 1 of wallabag.
|
||||
|
||||

|
||||
|
||||
The look and feel of wallabag have improved, too. That's thanks to a new theme inspired by [Material Design][5]. That might not seem like a big deal, but that theme makes wallabag a bit more visually attractive and makes articles easier to scan and read. Yes, kids, good UX can make a difference.
|
||||
|
||||
|
||||
|
||||
One of the biggest changes was the introduction of [a hosted version][6] of wallabag. More than a few people (yours truly included) don't have a server to run web apps and aren't entirely comfortable doing that. When it comes to anything technical, I have 10 thumbs. I don't mind paying € 9 (just over US$ 10 at the time I wrote this) a year to get a fully working version of the application that I don't need to watch over.
|
||||
|
||||
### What hasn't changed
|
||||
|
||||
Overall, wallabag's core functions are the same. The updated codebase, as I mentioned above, makes those functions run quite a bit smoother and quicker.
|
||||
|
||||
Wallabag's [browser extensions][7] do the same job in the same way. I've found that the extensions work a bit better than they did when I first tried them and when the application was at version 1.
|
||||
|
||||
### What's disappointing
|
||||
|
||||
The mobile app is good, but it's not great. It does a good job of rendering articles and has a few configuration options. But you can't highlight or annotate articles. That said, you can use the app to dip into your stock of archived articles.
|
||||
|
||||
|
||||
|
||||
While wallabag does a great job collecting articles, there are sites whose content you can't save to it. I haven't run into many such sites, but there have been enough for the situation to be annoying. I'm not sure how much that has to do with wallabag. Rather, I suspect it has something to do with the way the sites are coded—I ran into the same problem while looking at a couple of proprietary read-it-later tools.
|
||||
|
||||
Wallabag might not be a feature-for-feature replacement for Pocket or Instapaper, but it does a great job. It has improved noticeably in the four years since I first wrote about it. There's still room for improvement, but does what it says on the tin.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Since 2014, wallabag has evolved. It's gotten better, bit by bit and step by step. While it might not be a feature-for-feature replacement for the likes of Instapaper and Pocket, wallabag is a worthy open source alternative to proprietary read-it-later tools.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/wallabag
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/life/14/4/open-source-read-it-later-app-wallabag
|
||||
[2]:https://wallabag.org/en
|
||||
[3]:https://www.wallabag.org/en/news/wallabag-v2
|
||||
[4]:https://pinboard.in
|
||||
[5]:https://en.wikipedia.org/wiki/Material_Design
|
||||
[6]:https://www.wallabag.it
|
||||
[7]:https://github.com/wallabag/wallabagger
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Use Pbcopy And Pbpaste Commands On Linux
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,51 @@
|
||||
那些数据对于云来说风险太大?
|
||||
======
|
||||
|
||||

|
||||
|
||||
在这个由四部分组成的系列文章中,我们一直在关注每个组织在将操作转换到云时应避免的陷阱 - 特别是混合多云环境。
|
||||
在第一部分中,我们介绍了基本定义以及我们对混合云和多云的看法,确保显示两者之间的分界线。 在第二部分中,我们讨论了三个陷阱中的第一个:为什么成本并不总是成为迁移到云的明显动力。 而且,在第三部分中,我们研究了将所有工作负载迁移到云的可行性。
|
||||
最后,在第四部分中,我们将研究如何处理云中的数据。 您应该将数据移动到云中吗? 多少? 什么数据在云中起作用,是什么造成移动风险太大?
|
||||
|
||||
### 数据... 数据... 数据...
|
||||
影响您对云中数据的所有决策的关键因素是确定您的带宽和存储需求。 Gartner预计“数据存储将在2018年成为[1730亿美元] [4]业务”,其中大部分资金浪费在不必要的容量上:“全球公司只需优化工作量就可以节省620亿美元的IT成本。” 根据Gartner的研究,令人惊讶的是,公司“为云服务平均支付的费用比他们实际需要的多36%”。
|
||||
如果您已经阅读了本系列的前三篇文章,那么您不应该对此感到惊讶。 然而,令人惊讶的是,Gartner的结论是,“如果他们将服务器数据直接转移到云上,只有25%的公司会省钱。”
|
||||
等一下......工作负载可以针对云进行优化,但只有一小部分公司会通过将数据迁移到云来节省资金吗? 这是什么意思?
|
||||
如果您认为云提供商通常会根据带宽收取费率,那么将所有内部部署数据移至云中很快就会成为成本负担。 有三种情况,公司决定将数据放入云中是值得的:
|
||||
|
||||
具有存储和应用程序的单个云
|
||||
|
||||
云中的应用程序,内部存储
|
||||
|
||||
云中的应用程序和缓存在云中的数据,以及内部存储
|
||||
|
||||
|
||||
在第一种情况下,通过将所有内容保留在单个云供应商中来降低带宽成本。 但是,这会产生锁定,这通常与CIO的云战略或风险防范计划相悖。
|
||||
第二种方案仅保留应用程序在云中收集的数据,并将最小值传输到本地存储。 这需要仔细考虑的策略,其中只有使用最少数据的应用程序部署在云中。
|
||||
在第三种情况下,数据缓存在云中,应用程序和存储的数据,或存储在内部的“一个事实”。 这意味着分析,人工智能和机器学习可以在内部运行,而无需将数据上传到云提供商,然后在处理后再返回。 缓存数据仅基于应用程序需求,甚至可以跨多云部署进行缓存。
|
||||
|
||||
要获得更多信息,请下载红帽[案例研究] [5],其中描述了跨混合多云环境的阿姆斯特丹史基浦机场数据,云和部署策略。
|
||||
### 数据危险
|
||||
大多数公司都认识到他们的数据是他们在市场上的专有优势,智能能力。 因此,他们非常仔细地考虑了它的储存地点。
|
||||
想象一下这种情况:你是一个零售商,全球十大零售商之一。 您已经计划了一段时间的云战略,并决定使用亚马逊的云服务。 突然,[亚马逊购买了Whole Foods] [6]并且正在进入你的市场。
|
||||
一夜之间,亚马逊已经增长到零售规模的50%。 您是否信任其零售数据的云? 如果您的数据已经在亚马逊云中,您会怎么做? 您是否使用退出策略创建了云计划? 虽然亚马逊可能永远不会利用您的数据的潜在见解 - 该公司甚至有针对此的协议 - 你能相信今天世界上任何人的话吗?
|
||||
### 陷阱分享,避免陷阱
|
||||
分享我们在经验中看到的一些陷阱应该有助于您的公司规划更安全,更安全,更持久的云战略。 了解[成本不是明显的激励因素] [2],[并非一切都应该在云中] [3],并且您必须在云中有效地管理数据才是您成功的关键。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/data-risky-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekmar](https://github.com/geekmar)
|
||||
校对:[geekmar](https://github.com/geekmar)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
[2]:https://opensource.com/article/18/6/reasons-move-to-cloud
|
||||
[3]:https://opensource.com/article/18/7/why-you-cant-move-everything-cloud
|
||||
[4]:http://www.businessinsider.com/companies-waste-62-billion-on-the-cloud-by-paying-for-storage-they-dont-need-according-to-a-report-2017-11
|
||||
[5]:https://www.redhat.com/en/resources/amsterdam-airport-schiphol-case-study
|
||||
[6]:https://www.forbes.com/sites/ciocentral/2017/06/23/amazon-buys-whole-foods-now-what-the-story-behind-the-story/#33e9cc6be898
|
||||
@ -0,0 +1,174 @@
|
||||
逐层拼接云原生栈
|
||||
======
|
||||
在 Packet,我们的价值(自动化的基础设施)是非常基础的。因此,我们花费大量的时间来研究我们之上所有生态系统中的参与者和趋势 —— 以及之下的极少数!
|
||||
|
||||
当你在任何生态系统的汪洋大海中徜徉时,很容易困惑或迷失方向。我知道这是事实,因为当我去年进入 Packet 工作时,从 Bryn Mawr 获得的英语学位,并没有让我完全得到一个 Kubernetes 的认证。 :)
|
||||
|
||||
由于它超快的演进和巨大的影响,云原生生态系统打破了先例。似乎每眨一次眼睛,之前全新的技术(更不用说所有相关的理念了)就变得有意义 ... 或至少有趣了。和其他许多人一样,我依据无处不在的 CNCF 的 “[云原生蓝图][1]” 作为我去了解这个空间的参考标准。尽管如此,如果有一个定义这个生态系统的元素,那它一定是贡献和控制他们的人。
|
||||
|
||||
所以,在 12 月份一个很冷的下午,当我们走回办公室时,我们偶然发现了一个给投资人解释“云原生”的创新方式,当我们谈到从 Aporeto 中区分 Cilium 的细微差别时,他的眼睛中充满了兴趣,以及为什么从 CoreDNS 和 Spiffe 到 Digital Rebar 和 Fission 的所有这些都这么有趣。
|
||||
|
||||
在新世贸中心的阴影下,看到我们位于 13 层的狭窄办公室,我突然想到一个好主意,把我们带到《兔子洞》的艺术世界中:为什么不把它画出来呢?
|
||||
|
||||
![][2]
|
||||
|
||||
于是,我们开始了把云原生栈逐层拼接起来的旅程。让我们一起探索它,并且我们可以给你一个“仅限今日”的低价。
|
||||
|
||||
[[查看高清大图][3]] 或给我们发邮件索取副本。
|
||||
|
||||
### 从最底层开始
|
||||
|
||||
当我们开始下笔的时候,我们知道,我们希望首先亮出的是每天都与之交互的栈的那一部分,但它对用户却是不可见的:硬件。就像任何投资于下一个伟大的(通常是私有的)东西的秘密实验室一样,我们认为地下室是最好的地点。
|
||||
|
||||
从大家公认的像 Intel、AMD 和华为(传言他们雇佣的工程师接近 80000 名)这样的巨头,到像 Mellanox 这样的细分市场参与者,硬件生态系统现在非常火。事实上,随着数十亿美元投入去攻克新的 offloads、GPU、定制协处理器,我们可能正在进入硬件的黄金时代。
|
||||
|
||||
著名的软件先驱 Alan Kay 在 25 年前说过:“对软件非常认真的人都应该去制造他自己的硬件” ,为 Alan 打 call!
|
||||
|
||||
### 云即资本
|
||||
|
||||
就像我们的 CEO Zac Smith 多次告诉我:所有都是钱的问题。不仅要制造它,还要消费它!在云中,数十亿美元的投入才能让数据中心出现计算机,这样才能让开发者使用软件去消费它。换句话说:
|
||||
|
||||
|
||||
![][4]
|
||||
|
||||
我们认为,对于“银行”(即能让云运转起来的借款人或投资人)来说最好的位置就是一楼。因此我们将大堂改造成银行家的咖啡馆,以便为所有的创业者提供幸运之轮。
|
||||
|
||||
![][5]
|
||||
|
||||
### 连通和动力
|
||||
|
||||
如果金钱是燃料,那么消耗大量燃料的引擎就是数据中心供应商和连接它们的网络。我们称他们为“动力”和“连通”。
|
||||
|
||||
从像 Equinix 这样处于核心的和像 Vapor.io 这样的接入新贵,到 Verizon、Crown Castle 和其它的处于地下(或海底)的“管道”,这是我们所有的栈都依赖但很少有人能看到的一部分。
|
||||
|
||||
因为我们花费大量的时间去研究数据中心和连通性,需要注意的一件事情是,这一部分的变化非常快,尤其是在 5G 正式商用时,某些负载开始不再那么依赖中心化的基础设施了。
|
||||
|
||||
接入即将到来! :-)
|
||||
|
||||
![][6]
|
||||
|
||||
### 嗨,它就是基础设施!
|
||||
|
||||
居于“连接”和“动力”之上的这一层,我们爱称为“处理器们”。这是奇迹发生的地方 —— 我们将来自下层的创新和实物投资转变成一个 API 尽头的某些东西。
|
||||
|
||||
由于这是纽约的一个大楼,我们让在这里的云供应商处于纽约的中心。这就是为什么你会看到(Digital Ocean 系的)鲨鱼 Sammy 和在 Google 之上的 “meet me” 的房间中和我打招呼的原因了。
|
||||
|
||||
正如你所见,这个场景是非常写实的。它就是一垛一垛堆起来的。尽管我们爱 EWR1 的设备经理(Michael Pedrazzini),我们努力去尽可能减少这种体力劳动。毕竟布线专业的博士学位是很难拿到的。
|
||||
|
||||
![][7]
|
||||
|
||||
### 供给
|
||||
|
||||
再上一层,在基础设施层之上是供给层。这是我们最喜欢的地方之一,它以前被我们称为“配置管理”。但是现在到处都是一开始就是不可改变的基础设施和自动化:Terraform、Ansible、Quay.io 等等类似的东西。你可以看出软件是按它的方式来工作的,对吗?
|
||||
|
||||
Kelsey Hightower 最近写道“呆在无聊的基础设施中是一个让人兴奋的时刻”,我不认为它说的是物理部分(虽然我们认为它非常让人兴奋),但是由于软件持续侵入到栈的所有层,可以保证你有一个疯狂的旅程。
|
||||
|
||||
![][8]
|
||||
|
||||
### 操作系统
|
||||
|
||||
供应就绪后,我们来到操作系统层。这就是我们开始取笑我们最喜欢的一个人的地方:注意上面 Brian Redbeard 的瑜珈姿势。:)
|
||||
|
||||
Packet 为我们的客户提供了 11 种主要的操作系统去选择,包括一些你在图中看到的:Ubuntu、CoreOS、FreeBSD、Suse、和各种 Red Hat 的作品。我们看到越来越多的人们在这一层上有了他们自己的看法:从定制的内核和为了不可改变的部署而使用的他们最喜欢的发行版,到像 NixOS 和 LinuxKit 这样的项目。
|
||||
|
||||
![][9]
|
||||
|
||||
### 运行时
|
||||
|
||||
我们玩的很开心,因此我们将运行时放在了体育馆内,并在 CoreOS 赞助的 rkt 和 Docker 的容器化之间进行了一场锦标赛。无论哪种方式赢家都是 CNCF!
|
||||
|
||||
我们认为快速演进的存储生态系统应该得到一些可上锁的储物柜。关于存储部分有趣的地方在于许多的新玩家尝试去解决持久性的挑战问题,以及性能和灵活性问题。就像他们说的:存储很简单。
|
||||
|
||||
![][10]
|
||||
|
||||
### 编排
|
||||
|
||||
在过去的这些年里,编排层所有都是关于 Kubernetes 的,因此我们选取了其中一位著名的布道者(Kelsey Hightower),并在这个古怪的会议场景中给他一个特写。在我们的团队中有一些主要的 Nomad 粉丝,并且如果没有 Docker 和它的工具集的影响,根本就没有办法去考虑云原生空间。
|
||||
|
||||
虽然负载编排应用程序在我们栈中的地位非常高,我们看到的各种各样的证据表明,这些强大的工具开始去深入到栈中,以帮助用户利用 GPU 和其它特定硬件的优势。请继续关注 —— 我们正处于容器化革命的早期阶段!
|
||||
|
||||
![][11]
|
||||
|
||||
### 平台
|
||||
|
||||
这是栈中我们喜欢的层之一,因为每个平台都有很多技能帮助用户去完成他们想要做的事情(顺便说一下,不是去运行容器,而是运行应用程序)。从 Rancher 和 Kontena,到 Tectonic 和 Redshift 都是像 Cycle.io 和 Flynn.io 一样是完全不同的方法 —— 我们看到这些项目如何以不同的方式为用户提供服务,总是激动不已。
|
||||
|
||||
关键点:这些平台是帮助去转化各种各样的云原生生态系统的快速变化部分给用户。很高兴能看到他们每个人带来的东西!
|
||||
|
||||
![][12]
|
||||
|
||||
### 安全
|
||||
|
||||
当说到安全时,今年是很忙的一年!我们尝试去展示一些很著名的攻击,并说明随着工作负载变得更加分散和更加便携(当然,同时攻击也变得更加智能),这些各式各样的工具是如何去帮助保护我们的。
|
||||
|
||||
我们看到一个用于不可信环境(Aporeto)和低级安全(Cilium)的强大动作,以及尝试在网络级别上的像 Tigera 这样的可信方法。不管你的方法如何,记住这一点:关于安全这肯定不够。:0
|
||||
|
||||
![][13]
|
||||
|
||||
### 应用程序
|
||||
|
||||
如何去表示海量的、无限的应用程序生态系统?在这个案例中,很容易:我们在纽约,选我们最喜欢的。;) 从 Postgres “房间里的大象” 和 Timescale 时钟,到鬼鬼崇崇的 ScyllaDB 垃圾桶和 chillin 的《特拉维斯兄弟》—— 我们把这个片子拼到一起很有趣。
|
||||
|
||||
让我们感到很惊奇的一件事情是:很少有人注意到那个复印他的屁股的家伙。我想现在复印机已经不常见了吧?
|
||||
|
||||
![][14]
|
||||
|
||||
### 可观测性
|
||||
|
||||
由于我们的工作负载开始到处移动,规模也越来越大,这里没有一件事情能够像一个非常好用的 Grafana 仪表盘、或方便的 Datadog 代理让人更加欣慰了。由于复杂度的提升,“SRE” 的产生开始越来越多地依赖警报和其它情报事件去帮我们感知发生的事件,以及获得越来越多的自我修复的基础设施和应用程序。
|
||||
|
||||
在未来的几个月或几年中,我们将看到什么样的公司进入这一领域 … 或许是一些人工智能、区块链、机器学习支撑的仪表盘?:-)
|
||||
|
||||
![][15]
|
||||
|
||||
### 流量管理
|
||||
|
||||
人们倾向于认为互联网“只是工作而已”,但事实上,我们很惊讶于它的工作方式。我的意思是,大规模的独立的网络的一个松散连接 —— 你不是在开玩笑吧?
|
||||
|
||||
能够把所有的这些独立的网络拼接到一起的一个原因是流量管理、DNS 和类似的东西。随着规模越来越大,这些参与者帮助让互联网变得更快、更安全、同时更具弹性。我们尤其高兴的是看到像 Fly.io 和 NS1 这样的新贵与优秀的老牌参与者进行竞争,最后的结果是整个生态系统都得以提升。让竞争来的更激烈吧!
|
||||
|
||||
![][16]
|
||||
|
||||
### 用户
|
||||
|
||||
如果没有非常棒的用户,技术栈还有什么用呢?确实,它们位于大量的创新之上,但在云原生的世界里,他们所做的远不止消费这么简单:他们设计和贡献。从像 Kubernetes 这样的大量的贡献者到越来越多的(但同样重要)更多方面,我们都是其中的非常棒的一份子。
|
||||
|
||||
在我们屋顶的客厅上的许多用户,比如 Ticketmaster 和《纽约时报》,而不仅仅是新贵:这些组织采用了一种新的方式去部署和管理他们的应用程序,并且他们自己的用户正在收获回报。
|
||||
|
||||
![][17]
|
||||
|
||||
### 最后的但并非是不重要的,成熟的监管!
|
||||
|
||||
在以前的生态系统中,基金会扮演了一个“在场景背后”的非常被动的角色。而 CNCF 不是!他们的目标(构建一个健壮的云原生生态系统),被美妙的流行动向所推动 —— 他们不仅已迎头赶上还一路领先。
|
||||
|
||||
从坚实的管理和一个经过深思熟虑的项目组,到提出像 CNCF 这样的蓝图,CNCF 横跨云 CI、Kubernetes 认证、和演讲者委员会 —— CNCF 已不再是 “仅仅” 受欢迎的 KubeCon + CloudNativeCon 了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.packet.net/blog/splicing-the-cloud-native-stack/
|
||||
|
||||
作者:[Zoe Allen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.packet.net/about/zoe-allen/
|
||||
[1]:https://landscape.cncf.io/landscape=cloud
|
||||
[2]:https://assets.packet.net/media/images/PIFg-30.vesey.street.ny.jpg
|
||||
[3]:https://www.dropbox.com/s/ujxk3mw6qyhmway/Packet_Cloud_Native_Building_Stack.jpg?dl=0
|
||||
[4]:https://assets.packet.net/media/images/3vVx-there.is.no.cloud.jpg
|
||||
[5]:https://assets.packet.net/media/images/X0b9-the.bank.jpg
|
||||
[6]:https://assets.packet.net/media/images/2Etm-ping.and.power.jpg
|
||||
[7]:https://assets.packet.net/media/images/C800-infrastructure.jpg
|
||||
[8]:https://assets.packet.net/media/images/0V4O-provisioning.jpg
|
||||
[9]:https://assets.packet.net/media/images/eMYp-operating.system.jpg
|
||||
[10]:https://assets.packet.net/media/images/9BII-run.time.jpg
|
||||
[11]:https://assets.packet.net/media/images/njak-orchestration.jpg
|
||||
[12]:https://assets.packet.net/media/images/1QUS-platforms.jpg
|
||||
[13]:https://assets.packet.net/media/images/TeS9-security.jpg
|
||||
[14]:https://assets.packet.net/media/images/SFgF-apps.jpg
|
||||
[15]:https://assets.packet.net/media/images/SXoj-observability.jpg
|
||||
[16]:https://assets.packet.net/media/images/tKhf-traffic.management.jpg
|
||||
[17]:https://assets.packet.net/media/images/7cpe-users.jpg
|
||||
@ -1,138 +0,0 @@
|
||||
如何使用命令行检查 Linux 上的磁盘空间
|
||||
========
|
||||
|
||||
>通过使用 `df` 命令和 `du` 命令查看 Linux 系统上挂载的驱动器的空间使用情况
|
||||
|
||||

|
||||
|
||||
-----------------------------
|
||||
|
||||
*** 快速提问: ***你的驱动器剩余多少剩余空间?一点点还是很多?接下来的提问是:你知道如何找出这些剩余空间吗?如果你使用的是 GUI 桌面( 例如 GNOME,KDE,Mate,Pantheon 等 ),则任务可能非常简单。但是,当你要在一个没有 GUI 桌面的服务器上查询剩余空间,你该如何去做呢?你是否要为这个任务安装相应的软件工具?答案是绝对不是。在 Linux 中,具备查找驱动器上的剩余磁盘空间的所有工具。事实上,有两个非常容易使用的工具。
|
||||
|
||||
在本文中,我将演示这些工具。我将使用 Elementary OS( LCTT译注:Elementary OS 是基于 Ubuntu 精心打磨美化的桌面 Linux 发行版 ),它还包括一个 GUI 选项,但我们将限制自己仅使用命令行。好消息是这些命令行工具随时可用于每个 Linux 发行版。在我的测试系统中,连接了许多的驱动器( 内部的和外部的 )。使用的命令与连接驱动器的位置无关,仅仅与驱动器是否已经挂载好并且对操作系统可见。
|
||||
|
||||
话虽如此,让我们来试试这些工具。
|
||||
|
||||
### df
|
||||
|
||||
`df` 命令是我第一次用于在 Linux 上查询驱动器空间的工具,时间可以追溯到20世纪90年代。它的使用和报告结果非常简单。直到今天,`df` 还是我执行此任务的首选命令。此命令有几个选项开关,对于基本的报告,你实际上只需要一个选项。该命令是 `df -H` 。`-H` 选项开关用于将df的报告结果以人类可读的格式进行显示。`df -H` 的输出包括:已经使用了的空间量,可用空间,空间使用的百分比,以及每个磁盘连接到系统的挂载点( 图 1 )。
|
||||
|
||||

|
||||
|
||||
图 1:Elementary OS 系统上 `df -H` 命令的输出结果
|
||||
|
||||
如果你的驱动器列表非常长并且你只想查看单个驱动器上使用的空间,该怎么办?有了 `df`,就可以做到。我们来看一下位于 `/dev/sda1` 的主驱动器已经使用了多少空间。为此,执行如下命令:
|
||||
```
|
||||
df -H /dev/sda1
|
||||
```
|
||||
输出将限于该驱动器( 图 2 )。
|
||||

|
||||
|
||||
图 2:一个单独驱动器空间情况
|
||||
|
||||
你还可以限制 `df` 命令结果报告中显示指定的字段。可用的字段包括:
|
||||
|
||||
- source — 文件系统的来源( LCTT译注:通常为一个设备,如 `/dev/sda1` )
|
||||
- size — 块总数
|
||||
- used — 驱动器已使用的空间
|
||||
- avail — 可以使用的剩余空间
|
||||
- pcent — 驱动器已经使用的空间占驱动器总空间的百分比
|
||||
- target —驱动器的挂载点
|
||||
|
||||
让我们显示所有驱动器的输出,仅显示 `size` ,`used` ,`avail` 字段。对此的命令是:
|
||||
```
|
||||
df -H --output=size,used,avail
|
||||
```
|
||||
该命令的输出非常简单( 图 3 )。
|
||||

|
||||
|
||||
图 3:显示我们驱动器的指定输出
|
||||
|
||||
这里唯一需要注意的是我们不知道输出的来源,因此,我们要把来源加入命令中:
|
||||
```
|
||||
df -H --output=source,size,used,avail
|
||||
```
|
||||
现在输出的信息更加全面有意义( 图 4 )。
|
||||

|
||||
|
||||
图 4:我们现在知道了磁盘使用情况的来源
|
||||
|
||||
|
||||
### du
|
||||
|
||||
我们的下一个命令是 `du` 。 正如您所料,这代表磁盘使用情况( disk usage )。 `du` 命令与 `df` 命令完全不同,因为它报告目录而不是驱动器的空间使用情况。 因此,您需要知道要检查的目录的名称。 假设我的计算机上有一个包含虚拟机文件的目录。 那个目录是 `/media/jack/HALEY/VIRTUALBOX` 。 如果我想知道该特定目录使用了多少空间,我将运行如下命令:
|
||||
```
|
||||
du -h /media/jack/HALEY/VIRTUALBOX
|
||||
```
|
||||
上面命令的输出将显示目录中每个文件占用的空间( 图 5 )。
|
||||

|
||||
|
||||
图 5 在特定目录上运行 `du` 命令的输出
|
||||
|
||||
到目前为止,这个命令并没有那么有用。如果我们想知道特定目录的总使用量怎么办?幸运的是,`du` 可以处理这项任务。对于同一目录,命令将是:
|
||||
```
|
||||
du -sh /media/jack/HALEY/VIRTUALBOX/
|
||||
```
|
||||
现在我们知道了上述目录使用存储空间的总和( 图 6 )。
|
||||

|
||||
|
||||
图 6:我的虚拟机文件使用存储空间的总和是 559GB
|
||||
|
||||
您还可以使用此命令查看父项的所有子目录使用了多少空间,如下所示:
|
||||
```
|
||||
du -h /media/jack/HALEY
|
||||
```
|
||||
此命令的输出见( 图 7 ),是一个用于查看各子目录占用的驱动器空间的好方法。
|
||||

|
||||
|
||||
图 7:子目录的存储空间使用情况
|
||||
|
||||
`du` 命令也是一个很好的工具,用于查看使用系统磁盘空间最多的目录列表。执行此任务的方法是将 `du` 命令的输出通过管道传递给另外两个命令:`sort` 和 `head` 。下面的命令用于找出驱动器上占用存储空间最大的前10各目录:
|
||||
```
|
||||
du -a /media/jack | sort -n -r |head -n 10
|
||||
```
|
||||
输出将以从大到小的顺序列出这些目录( 图 8 )。
|
||||

|
||||
|
||||
图 8:使用驱动器空间最多的 10 个目录
|
||||
|
||||
### 没有你想像的那么难
|
||||
|
||||
查看 Linux 系统上挂载的驱动器的空间使用情况非常简单。只要你将你的驱动器挂载在 Linux 系统上,使用 `df` 命令或 `du` 命令在报告必要信息方面都会非常出色。使用 `df` 命令,您可以快速查看磁盘上总的空间使用量,使用 `du` 命令,可以查看特定目录的空间使用情况。对于每一个 Linux 系统的管理员来说,这两个命令的结合使用是必须掌握的。
|
||||
|
||||
而且,如果你不需要使用 `du` 或 `df` 命令查看驱动器空间的使用情况,我最近介绍了查看 Linux 上内存使用情况的方法。总之,这些技巧将大力帮助你成功管理 Linux 服务器。
|
||||
|
||||
通过 Linux Foundation 和 edX 免费提供的 “ Linux 简介 ” 课程,了解更多有关 Linux 的信息。
|
||||
|
||||
--------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/6how-check-disk-space-linux-command-line
|
||||
|
||||
作者:Jack Wallen 选题:lujun9972 译者:SunWave 校对:校对者ID
|
||||
|
||||
本文由 LCTT 原创编译,Linux中国 荣誉推出
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,70 @@
|
||||
重温 wallabag,Instapaper 的开源替代品
|
||||
======
|
||||
|
||||

|
||||
|
||||
早在 2014 年,我[写了篇关于 wallabag 的文章][1],它是稍后阅读应用如 Instapaper 和 Pocket 的开源替代品。如果你愿意,去看看那篇文章吧。别担心,我会等你的。
|
||||
|
||||
好了么?很好
|
||||
|
||||
自从我写这篇文章的四年来,[wallabag][2]的很多东西都发生了变化。现在是时候看看 wallabag 是如何成熟的。
|
||||
|
||||
### 有什么新的
|
||||
|
||||
最大的变化发生在幕后。Wallabag 的开发人员 Nicolas Lœuillet 和该项目的贡献者对代码进行了大量修改,从而改进了程序。每次使用时,你都会看到并感受到 wallabag 新代码库所带来的变化。
|
||||
|
||||
那么这些变化有哪些呢?有[很多][3]。以下是我发现最有趣和最有用的内容。
|
||||
|
||||
除了使 wallabag 更加快速和稳定之外,程序的导入和导出内容的能力也得到了提高。你可以从 Pocket 和 Instapaper 导入文章,也可导入书签服务 [Pinboard][4] 中标记为 “To read” 的文章。你还可以导入 Firefox 和 Chrome 书签。
|
||||
|
||||
你还可以以多种格式导出文章,包括 EPUB、MOBI、PDF 和纯文本。你可以为单篇文章、所有未读文章或所有已读和未读执行此操作。我四年前使用的 wallabag 版本可以导出到 EPUB 和 PDF,但有时导出很糟糕。现在,这些导出快速而顺利。
|
||||
|
||||
Web 界面中的注释和高亮显示现在可以更好,更一致地工作。不可否认,我并不经常使用它们 - 但它们不会像 wallabag v1 那样随机消失。
|
||||
|
||||

|
||||
|
||||
wallabag 的外观和感觉也有所改善。这要归功于受 [Material Design][5] 启发的新主题。这似乎不是什么大不了的事,但这个主题使得 wallabag 在视觉上更具吸引力,使文章更容易扫描和阅读。是的,孩子们,良好的用户体验可以有所不同。
|
||||
|
||||

|
||||
|
||||
其中一个最大的变化是引入了 wallabag 的[托管版本][6]。不止一些人(包括你在内)没有服务器来运行网络程序,并且不太愿意这样做。当遇到任何技术问题时,我很窘迫。我不介意每年花 9 欧元(我写这篇文章的时候只要 10 美元),以获得一个我不需要关注的程序的完整工作版本。
|
||||
|
||||
### 没有改变什么
|
||||
|
||||
总的来说,wallabag 的核心功能是相同的。如上所述,更新的代码库使这些函数运行得更顺畅,更快速。
|
||||
|
||||
Wallabag 的[浏览器扩展][7]以同样的方式完成同样的工作。我发现这些扩展比我第一次尝试时和程序的 v1 版本时要好一些。
|
||||
|
||||
### 有什么令人失望的
|
||||
|
||||
移动应用良好,但没有很棒。它在渲染文章方面做得很好,并且有一些配置选项。但是你不能高亮或注释文章。也就是说,你可以使用该程序浏览你的存档文章。
|
||||
|
||||

|
||||
|
||||
虽然 wallabag 在收藏文章方面做得很好,但有些网站的内容却无法保存。我没有碰到很多这样的网站,但已经遇到让人烦恼的情况。我不确定与 wallabag 有多大关系。相反,我怀疑它与网站的编码方式有关 - 我在使用几个专有的稍后阅读工具时遇到了同样的问题。
|
||||
|
||||
Wallabag 可能不是 Pocket 或 Instapaper 的等功能的替代品,但它做得很好。自从我第一次写这篇文章以来的四年里,它已经有了明显的改善。它仍然有改进的余地,但要做好它宣传的。
|
||||
|
||||
### 最后的想法
|
||||
|
||||
自 2014 年以来,wallabag 在一直在演化。它一点一滴,一步一步地变得更好。虽然它可能不是 Instapaper 和 Pocket 等功能的替代品,但 wallabag 有价值的专有稍后阅读工具的开源替代品。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/wallabag
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/life/14/4/open-source-read-it-later-app-wallabag
|
||||
[2]:https://wallabag.org/en
|
||||
[3]:https://www.wallabag.org/en/news/wallabag-v2
|
||||
[4]:https://pinboard.in
|
||||
[5]:https://en.wikipedia.org/wiki/Material_Design
|
||||
[6]:https://www.wallabag.it
|
||||
[7]:https://github.com/wallabag/wallabagger
|
||||
Loading…
Reference in New Issue
Block a user