mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-04 22:00:34 +08:00
commit
72a9268382
@ -1,12 +1,15 @@
|
||||
献给写作者的 Linux 工具
|
||||
======
|
||||
|
||||
> 这些易用的开源应用可以帮助你打磨你的写作技巧、使研究更高效、更具有条理。
|
||||
|
||||

|
||||
如果你已经阅读过[我关于如何切换到 Linux 的文章][1],那么你就知道我是一个超级用户。另外,我不是任何方面的“专家”,这点仍然可以相信。但是在过去几年里我学到了很多有用的东西,我想将这些技巧传给其他新的 Linux 用户。
|
||||
|
||||
如果你已经阅读过[我关于如何切换到 Linux 的文章][1],那么你就知道我是一个超级用户。另外,我不是任何方面的“专家”,目前仍然如此。但是在过去几年里我学到了很多有用的东西,我想将这些技巧传给其他新的 Linux 用户。
|
||||
|
||||
今天,我将讨论我写作时使用的工具,基于三个标准来选择:
|
||||
|
||||
1. 当我提交故事或文章时,我的主要写作工具必须与任何发布者兼容。
|
||||
1. 当我提交作品或文章时,我的主要写作工具必须与任何发布者兼容。
|
||||
2. 该软件使用起来必须简单快捷。
|
||||
3. 免费(自由)是很棒的。
|
||||
|
||||
@ -16,30 +19,29 @@
|
||||
2. [Manuskript][3]
|
||||
3. [oStorybook][4]
|
||||
|
||||
但是,当我试图寻找信息时,我往往会迷失方向并失去思路,所以我选择了适合我需求的多个应用程序。另外,我不想依赖互联网,以免服务下线。我把这些程序放在显示器桌面上,以便我一下全看到它们。
|
||||
|
||||
但是,当我试图寻找信息时,我往往会迷失方向并失去思路,所以我选择了适合我需求的多个应用程序。另外,如果服务停止的话,我不想依赖互联网。我在监视器上设置了这些程序,以便我可以马上看到它们。
|
||||
请考虑以下工具建议 : 每个人的工作方式都不相同,并且你可能会发现一些更适合你工作方式的其他应用程序。以下这些工具是目前的写作工具:
|
||||
|
||||
请考虑以下工具建议 - 每个人的工作方式都不相同,并且你可能会发现一些更适合你工作方式的其他应用程序。这些工具是目前的写作工具:
|
||||
### 文字处理器
|
||||
|
||||
### Word 处理器
|
||||
|
||||
[LibreOffice 6.0.1][5]。直到最近,我使用了 [WPS][6],但由于字体渲染问题(Times New Roman 总是以粗体显示)而否定了它。LibreOffice 的最新版本非常适合 Microsoft Office,事实上它是开源的,这对我来说很重要。
|
||||
[LibreOffice 6.0.1][5]。直到最近,我使用了 [WPS][6],但由于字体渲染问题(Times New Roman 总是以粗体显示)而否定了它。LibreOffice 的最新版本非常适应 Microsoft Office,而且事实上它是开源的,这对我来说很重要。
|
||||
|
||||
### 词库
|
||||
|
||||
[Artha][7] 可以给出同义词,反义词,派生词等等。它外观干净,速度快。例如,输入 “fast” 这个词,你会得到字典定义以及上面列出的其他选项。Artha 是送给开源社区的一个巨大的礼物,更多的人应该尝试它,因为它似乎是一个模糊(to 校正者:这里模糊一次感觉不太恰当,或许是不太出名的)的小程序。如果你使用 Linux,请立即安装此应用程序,你不会后悔的。
|
||||
[Artha][7] 可以给出同义词、反义词、派生词等等。它外观整洁、速度快。例如,输入 “fast” 这个词,你会得到字典定义以及上面列出的其他选项。Artha 是送给开源社区的一个巨大的礼物,人们应该试试它,因为它似乎是一个冷僻的小程序。如果你使用 Linux,请立即安装此应用程序,你不会后悔的。
|
||||
|
||||
### 记笔记
|
||||
|
||||
[Zim][8] 标榜自己是一个桌面维基,但它也是你在任何地方都能找到的最简单的多层笔记应用程序。还有其它更漂亮的笔记程序,但 Zim 正是那种我需要管理角色,地点,情节和次要情节的程序。
|
||||
[Zim][8] 标榜自己是一个桌面维基,但它也是你所能找到的最简单的多层级笔记应用程序。还有其它更漂亮的笔记程序,但 Zim 正是那种我需要管理角色、地点、情节和次要情节的程序。
|
||||
|
||||
### Submission tracking
|
||||
### 投稿跟踪
|
||||
|
||||
我曾经使用过一款名为 [FileMaker Pro][9] 的专有软件,它让我心烦(to 校正者:这句话注意一下)。有很多数据库应用程序,但在我看来,最简单的一个就是 [Glom][10]。它以图形方式满足我的需求,让我以表单形式输入信息而不是表格。在 Glom 中,你可以创建你需要的表单,这样你就可以立即看到相关信息(对于我来说,通过电子表格来查找信息就像将我的眼球拖到玻璃碎片上)。尽管 Glom 不再处于开发阶段,但它仍然是很棒的。
|
||||
我曾经使用过一款名为 [FileMaker Pro][9] 的专有软件,它惯坏了我。有很多数据库应用程序,但在我看来,最容易使用的某过于 [Glom][10] 了。它以图形方式满足我的需求,让我以表单形式输入信息而不是表格。在 Glom 中,你可以创建你需要的表单,这样你就可以立即看到相关信息(对于我来说,通过电子表格来查找信息就像将我的眼球拖到玻璃碎片上)。尽管 Glom 不再处于开发阶段,但它仍然是很棒的。
|
||||
|
||||
### 搜索
|
||||
|
||||
我已经开始使用 [StartPage.com][11] 作为我的默认搜索引擎。当然,当你写作时,[Google][12] 可以成为你最好的朋友之一。但我不喜欢每次我想了解特定人物,地点或事物时,Google 都会跟踪我。所以我使用 StartPage.com 来代替。它速度很快,并且不会跟踪你的搜索。我也使用 [DuckDuckGo.com][13] 作为 Google 的替代品。
|
||||
我已经开始使用 [StartPage.com][11] 作为我的默认搜索引擎。当然,当你写作时,[Google][12] 可以成为你最好的朋友之一。但我不喜欢每次我想了解特定人物、地点或事物时,Google 都会跟踪我。所以我使用 StartPage.com 来代替。它速度很快,并且不会跟踪你的搜索。我也使用 [DuckDuckGo.com][13] 作为 Google 的替代品。
|
||||
|
||||
### 其他的工具
|
||||
|
||||
@ -47,7 +49,7 @@
|
||||
|
||||
尽管来自 [Mozilla][17] 的 [Thunderbird][16] 是一个很棒的程序,但我发现 [Geary][18] 是一个更快更轻的电子邮件应用程序。有关开源电子邮件应用程序的更多信息,请阅读 [Jason Baker][19] 的优秀文章:[6 个开源的桌面电子邮件客户端][20]。
|
||||
|
||||
正如你可能已经注意到,我对应用程序的喜爱趋向于在 Windows,MacOS 都能运行(to 校正者:此处小心)以及此处提到的开源 Linux 替代品。我希望这些建议能帮助你发现有用的新方法来撰写并跟踪你的写作(谢谢你,Artha!)。
|
||||
正如你可能已经注意到,我对应用程序的喜爱趋向于将最好的 Windows、MacOS 都能运行,以及此处提到的开源 Linux 替代品融合在一起。我希望这些建议能帮助你发现有用的新方法来撰写并跟踪你的写作(谢谢你,Artha!)。
|
||||
|
||||
写作愉快!
|
||||
|
||||
@ -57,7 +59,7 @@ via: https://opensource.com/article/18/3/top-Linux-tools-for-writers
|
||||
|
||||
作者:[Adam Worth][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -10,12 +10,13 @@
|
||||
### 在 Linux 中禁用内置摄像头
|
||||
|
||||
首先,使用如下命令找到网络摄像头驱动:
|
||||
|
||||
```
|
||||
$ sudo lsmod | grep uvcvideo
|
||||
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
uvcvideo 114688 1
|
||||
videobuf2_vmalloc 16384 1 uvcvideo
|
||||
@ -24,7 +25,6 @@ videobuf2_common 53248 2 uvcvideo,videobuf2_v4l2
|
||||
videodev 208896 4 uvcvideo,videobuf2_common,videobuf2_v4l2
|
||||
media 45056 2 uvcvideo,videodev
|
||||
usbcore 286720 9 uvcvideo,usbhid,usb_storage,ehci_hcd,ath3k,btusb,uas,ums_realtek,ehci_pci
|
||||
|
||||
```
|
||||
|
||||
这里,**uvcvideo** 是我的网络摄像头驱动。
|
||||
@ -32,45 +32,45 @@ usbcore 286720 9 uvcvideo,usbhid,usb_storage,ehci_hcd,ath3k,btusb,uas,ums_realte
|
||||
现在,让我们禁用网络摄像头。
|
||||
|
||||
为此,请编辑以下文件(如果文件不存在,只需创建它):
|
||||
|
||||
```
|
||||
$ sudo nano /etc/modprobe.d/blacklist.conf
|
||||
|
||||
```
|
||||
|
||||
添加以下行:
|
||||
|
||||
```
|
||||
##Disable webcam.
|
||||
blacklist uvcvideo
|
||||
|
||||
```
|
||||
|
||||
**“##Disable webcam”** 这行不是必需的。为了便于理解,我添加了它。
|
||||
`##Disable webcam` 这行不是必需的。为了便于理解,我添加了它。
|
||||
|
||||
保存并退出文件。重启系统以使更改生效。
|
||||
|
||||
要验证网络摄像头是否真的被禁用,请打开任何即时通讯程序或网络摄像头软件,如 Cheese 或 Guvcview。你会看到如下的空白屏幕。
|
||||
|
||||
**Cheese 输出:**
|
||||
Cheese 输出:
|
||||
|
||||
![][2]
|
||||
|
||||
**Guvcview 输出:**
|
||||
Guvcview 输出:
|
||||
|
||||
![][3]
|
||||
|
||||
看见了么?网络摄像头被禁用而无法使用。
|
||||
|
||||
要启用它,请编辑:
|
||||
|
||||
```
|
||||
$ sudo nano /etc/modprobe.d/blacklist.conf
|
||||
|
||||
```
|
||||
|
||||
注释掉你之前添加的行。
|
||||
|
||||
```
|
||||
##Disable webcam.
|
||||
#blacklist uvcvideo
|
||||
|
||||
```
|
||||
|
||||
保存并关闭文件。然后,重启计算机以启用网络摄像头。
|
||||
@ -90,7 +90,7 @@ via: https://www.ostechnix.com/how-to-disable-built-in-webcam-in-ubuntu/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,124 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
A friendly alternative to the find tool in Linux
|
||||
======
|
||||

|
||||
|
||||
[fd][1] is a super fast, [Rust][2]-based alternative to the Unix/Linux `find` command. It does not mirror all of `find`'s powerful functionality; however, it does provide just enough features to cover 80% of the use cases you might run into. Features like a well thought-out and convenient syntax, colorized output, smart case, regular expressions, and parallel command execution make `fd` a more than capable successor.
|
||||
|
||||
### Installation
|
||||
|
||||
Head over the [fd][1] GitHub page and check out the section on installation. It covers how to install the application on [macOS,][3] [Debian/Ubuntu][4] [Red Hat][5] , and [Arch Linux][6] . Once installed, you can get a complete overview of all available command-line options by runningfor concise help, or `fd -h` for concise help, or `fd --help` for more detailed help.
|
||||
|
||||
### Simple search
|
||||
|
||||
`fd` is designed to help you easily find files and folders in your operating system's filesystem. The simplest search you can perform is to run `fd` with a single argument, that argument being whatever it is that you're searching for. For example, let's assume that you want to find a Markdown document that has the word `services` as part of the filename:
|
||||
```
|
||||
$ fd services
|
||||
|
||||
downloads/services.md
|
||||
|
||||
```
|
||||
|
||||
If called with just a single argument, `fd` searches the current directory recursively for any files and/or directories that match your argument. The equivalent search using the built-in `find` command looks something like this:
|
||||
```
|
||||
$ find . -name 'services'
|
||||
|
||||
downloads/services.md
|
||||
|
||||
```
|
||||
|
||||
As you can see, `fd` is much simpler and requires less typing. Getting more done with less typing is always a win in my book.
|
||||
|
||||
### Files and folders
|
||||
|
||||
You can restrict your search to files or directories by using the `-t` argument, followed by the letter that represents what you want to search for. For example, to find all files in the current directory that have `services` in the filename, you would use:
|
||||
```
|
||||
$ fd -tf services
|
||||
|
||||
downloads/services.md
|
||||
|
||||
```
|
||||
|
||||
And to find all directories in the current directory that have `services` in the filename:
|
||||
```
|
||||
$ fd -td services
|
||||
|
||||
applications/services
|
||||
|
||||
library/services
|
||||
|
||||
```
|
||||
|
||||
How about listing all documents with the `.md` extension in the current folder?
|
||||
```
|
||||
$ fd .md
|
||||
|
||||
administration/administration.md
|
||||
|
||||
development/elixir/elixir_install.md
|
||||
|
||||
readme.md
|
||||
|
||||
sidebar.md
|
||||
|
||||
linux.md
|
||||
|
||||
```
|
||||
|
||||
As you can see from the output, `fd` not only found and listed files from the current folder, but it also found files in subfolders. Pretty neat. You can even search for hidden files using the `-H` argument:
|
||||
```
|
||||
fd -H sessions .
|
||||
|
||||
.bash_sessions
|
||||
|
||||
```
|
||||
|
||||
### Specifying a directory
|
||||
|
||||
If you want to search a specific directory, the name of the directory can be given as a second argument to `fd`:
|
||||
```
|
||||
$ fd passwd /etc
|
||||
|
||||
/etc/default/passwd
|
||||
|
||||
/etc/pam.d/passwd
|
||||
|
||||
/etc/passwd
|
||||
|
||||
```
|
||||
|
||||
In this example, we're telling `fd` that we want to search for all instances of the word `passwd` in the `etc` directory.
|
||||
|
||||
### Global searches
|
||||
|
||||
What if you know part of the filename but not the folder? Let's say you downloaded a book on Linux network administration but you have no idea where it was saved. No problem:
|
||||
```
|
||||
fd Administration /
|
||||
|
||||
/Users/pmullins/Documents/Books/Linux/Mastering Linux Network Administration.epub
|
||||
|
||||
```
|
||||
|
||||
### Wrapping up
|
||||
|
||||
The `fd` utility is an excellent replacement for the `find` command, and I'm sure you'll find it just as useful as I do. To learn more about the command, simply explore the rather extensive man page.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/friendly-alternative-find
|
||||
|
||||
作者:[Patrick H. Mullins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pmullins
|
||||
[1]:https://github.com/sharkdp/fd
|
||||
[2]:https://www.rust-lang.org/en-US/
|
||||
[3]:https://en.wikipedia.org/wiki/MacOS
|
||||
[4]:https://www.ubuntu.com/community/debian
|
||||
[5]:https://www.redhat.com/en
|
||||
[6]:https://www.archlinux.org/
|
||||
@ -0,0 +1,120 @@
|
||||
Write fast apps with Pronghorn, a Java framework
|
||||
======
|
||||
|
||||

|
||||
|
||||
In 1973, [Carl Hewitt][1] had an idea inspired by quantum mechanics. He wanted to develop computing machines that were capable of parallel execution of tasks, communicating with each other seamlessly while containing their own local memory and processors.
|
||||
|
||||
Born was the [actor model][2], and with that, a very simple concept: Everything is an actor. This allows for some great benefits: Separating business and other logic is made vastly easier. Security is easily gained because each core component of your application is separate and independent. Prototyping is accelerated due to the nature of actors and their interconnectivity.
|
||||
|
||||
### What is Pronghorn?
|
||||
|
||||
However, what ties it all together is the ability to pass messages between these actors concurrently. An actor responds based on an input message; it can then send back an acknowledgment, deliver content, and designate behaviors to be used for the next time a message gets received. For example, one actor is loading image files from disk while simultaneously streaming chunks to other actors for further processing; i.e., image analysis or conversion. Another actor then takes these as inputs and writes them back to disk or logs them to the terminal. Independently, these actors alone can’t accomplish much—but together, they form an application.
|
||||
|
||||
Today there are many implementations of this actor model. At [Object Computing][3], we’ve been working on a highly scalable, performant, and completely open source Java framework called [Pronghorn][4], named after one of the world’s fastest land animals.
|
||||
|
||||
Pronghorn, recently released to 1.0, attempts to address a few of the shortcomings of [Akka][5] and [RxJava][6], two popular actor frameworks for Java and Scala.
|
||||
|
||||
As a result, we developed Pronghorn with a comprehensive list of features in mind:
|
||||
|
||||
1. We wanted to produce as little garbage as possible. Without the Garbage Collector kicking in regularly, it is able to reach performance levels never seen before.
|
||||
2. We wanted to make sure that Pronghorn has a minimal memory footprint and is mechanical-sympathetic. Built from the ground up with performance in mind, it leverages CPU prefetch functions and caches for fastest possible throughput. Using zero copy direct access, it loads fields from schemas in nanoseconds and never stall cores, while also being non-blocking and lock-free.
|
||||
3. Pronghorn ensures that you write correct code securely. Through its APIs and contracts, and by using "[software fortresses][7]" and industry-leading encryption, Pronghorn lets you build applications that are secure and that fail safely.
|
||||
4. Debugging and testing can be stressful and annoying, especially when you need to hit a deadline. Pronghorn easily integrates with common testing frameworks and simplifies refactoring and debugging through its automatically generated and live-updating telemetry graph, fuzz testing (in work) based on existing message schemas, and warnings when certain actors are misbehaving or consuming too many resources. This helps you rapidly prototype and spend more time focusing on your business needs.
|
||||
|
||||
|
||||
|
||||
For more details, visit the [Pronghorn Features list][8].
|
||||
|
||||
### Why Pronghorn?
|
||||
|
||||
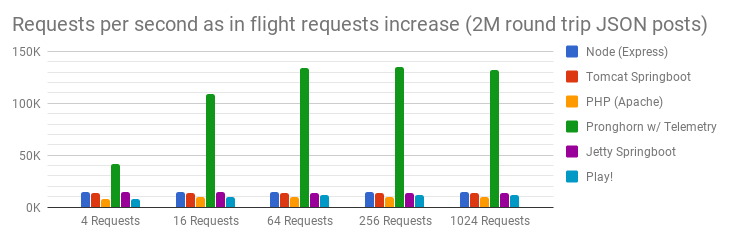
Writing concurrent and performant applications has never been easy, and we don’t promise to solve the problems entirely. However, to give you an idea of the benefits of Pronghorn and the power of its API, we wrote a small HTTP REST server and benchmarked it against common industry standards such as [Node & Express][9] and [Tomcat][10] & [Spring Boot][11]:
|
||||
|
||||
|
||||
|
||||
We encourage you to [run these numbers yourself][12], share your results, and add your own web server.
|
||||
|
||||
As you can see, Pronghorn does exceptionally well in this REST example. While almost being 10x faster than conventional solutions, Pronghorn could help cut server costs (such as EC2 or Azure) in half or more through its garbage-free, statically-typed backend. HTTP requests can be parsed, and responses are generated while actors are working concurrently. The scheduling and threading are automatically handled by Pronghorn's powerful default scheduler.
|
||||
|
||||
As mentioned above, Pronghorn allows you to rapidly prototype and envision your project, generally by following three basic steps:
|
||||
|
||||
1. **Define your data flow graph**
|
||||
|
||||
|
||||
|
||||
This is a crucial first step. Pronghorn takes a data-first approach; processing large volumes of data rapidly. In your application, think about the type of data that should flow through the "pipes"—for example, if you’re building an image analysis tool, you will need actors to read, write, and analyze image files. The format of the data between actors needs also to be established; it could be schemas containing JPG MCUs or raw binary BMP files. Pick the format that works best for your application.
|
||||
|
||||
2. **Define the contracts between each stage**
|
||||
|
||||
|
||||
|
||||
Contracts allow you to easily define your messages using [FAST][13], a proven protocol used by the finance industry for stock trading. These contracts are used in the testing phase to ensure implementation aligns with your message field definitions. This is a contractual approach; it must be respected for actors to communicate with each other.
|
||||
|
||||
3. **Test first development by using generative testing as the graph is implemented**
|
||||
|
||||
|
||||
|
||||
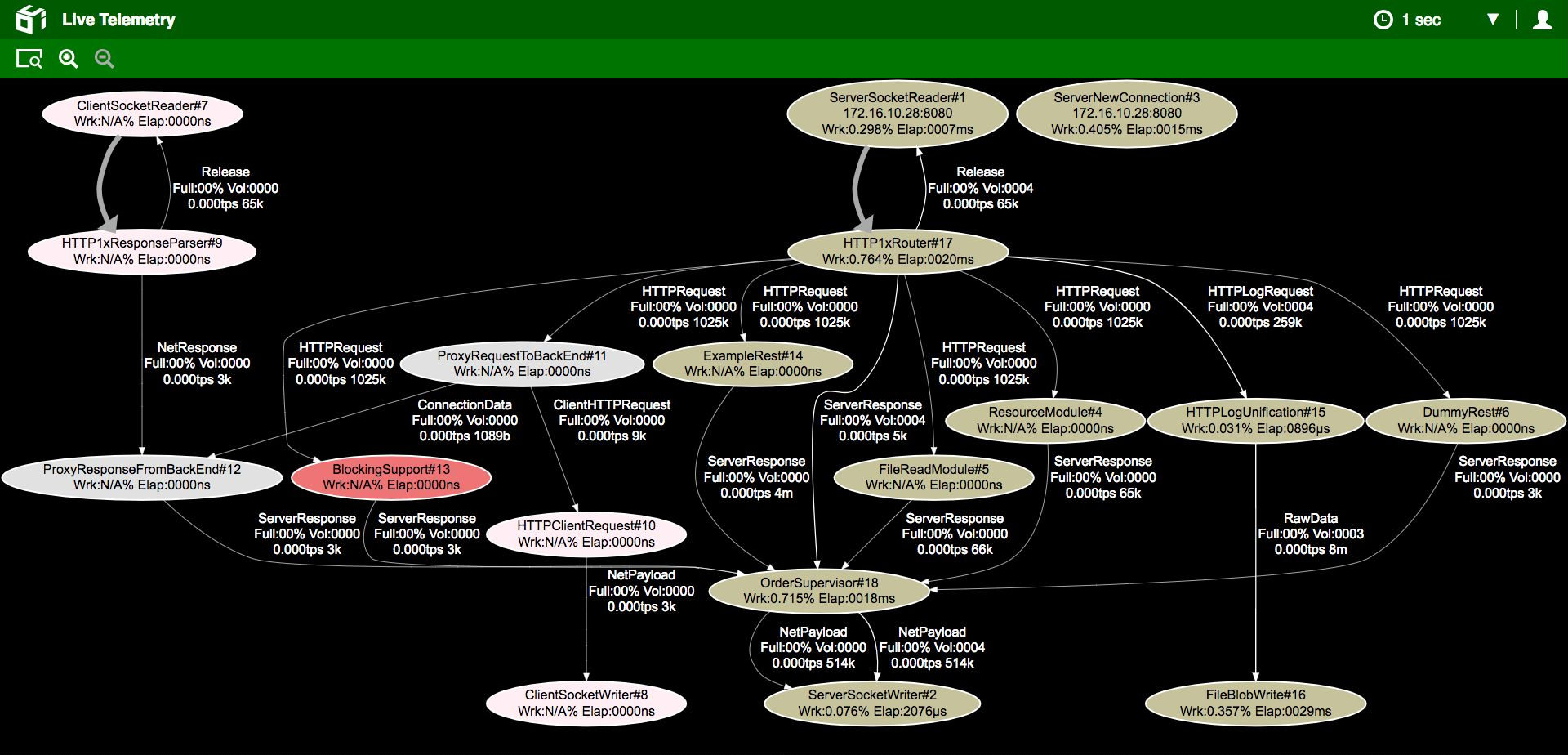
Schemas are code-generated for you as you develop your application. Test-driven development allows for correct and safe code, saving valuable time as you head towards release. As your program grows, the graph grows as well, describing every single interaction between actors and illustrating your message data flow on pipes between stages. Through its automatically telemetry, you can easily keep track of even the most complex applications, as shown below:
|
||||
|
||||
|
||||
|
||||
### What does it look like?
|
||||
|
||||
You may be curious about what Pronghorn code looks like. Below is some sample code for generating the message schemas in our "[Hello World][14]" example.
|
||||
|
||||
To define a message, create a new XML file similar to this:
|
||||
```
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<templates xmlns="http://www.fixprotocol.org/ns/fast/td/1.1">
|
||||
<template name="HelloWorldMessage" id="1">
|
||||
<string name="GreetingName" id="100" charset="unicode"/>
|
||||
</template>
|
||||
</templates>
|
||||
```
|
||||
|
||||
This schema will then be used by the stages described in the Hello World example. Populating a graph in your application using this schema is even easier:
|
||||
```
|
||||
private static void populateGraph(GraphManager gm) {
|
||||
Pipe<HelloWorldSchema> messagePipe =
|
||||
HelloWorldSchema.instance.newPipe(10, 10_000);
|
||||
new GreeterStage(gm, "Jon Snow", messagePipe);
|
||||
new GuestStage(gm, messagePipe);
|
||||
}
|
||||
```
|
||||
|
||||
This uses the stages created in the [Hello World tutorial][14].
|
||||
|
||||
We use a [Maven][15] archetype to provide you with everything you need to start building Pronghorn applications.
|
||||
|
||||
### Start using Pronghorn
|
||||
|
||||
We hope this article has offered a taste of how Pronghorn can help you write performant, efficient, and secure applications in Java using Pronghorn, an alternative to Akka and RXJava. We’d love your feedback on how to make this an ideal platform for developers, managers, CFOs, and others.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/writing-applications-java-pronghorn
|
||||
|
||||
作者:[Tobi Schweiger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tobischw
|
||||
[1]:https://en.wikipedia.org/wiki/Carl_Hewitt
|
||||
[2]:https://en.wikipedia.org/wiki/Actor_model
|
||||
[3]:https://objectcomputing.com/
|
||||
[4]:https://oci-pronghorn.gitbook.io/pronghorn/chapter-0-what-is-pronghorn/home
|
||||
[5]:https://akka.io/
|
||||
[6]:https://github.com/ReactiveX/RxJava
|
||||
[7]:https://www.amazon.com/Software-Fortresses-Modeling-Enterprise-Architectures/dp/0321166086
|
||||
[8]:https://oci-pronghorn.gitbook.io/pronghorn/chapter-0-what-is-pronghorn/features
|
||||
[9]:https://expressjs.com/
|
||||
[10]:http://tomcat.apache.org/
|
||||
[11]:https://spring.io/projects/spring-boot
|
||||
[12]:https://github.com/oci-pronghorn/GreenLoader
|
||||
[13]:https://en.wikipedia.org/wiki/FAST_protocol
|
||||
[14]:https://oci-pronghorn.gitbook.io/pronghorn/chapter-1-getting-started-with-pronghorn/1.-hello-world-introduction/0.-getting-started
|
||||
[15]:https://maven.apache.org/
|
||||
@ -0,0 +1,89 @@
|
||||
Getting started with Open edX to host your course
|
||||
======
|
||||
|
||||

|
||||
|
||||
Now in its [seventh major release][1], the [Open edX platform][2] is a free and open source course management system that is used [all over the world][3] to host Massive Open Online Courses (MOOCs) as well as smaller classes and training modules. To date, Open edX software has powered more than 8,000 original courses and 50 million course enrollments. You can install the platform yourself with on-premise equipment or by leveraging any of the industry-leading cloud infrastructure services providers, but it is also increasingly being made available in a Software-as-a-Service (SaaS) model from several of the project’s growing list of [service providers][4].
|
||||
|
||||
The Open edX platform is used by many of the world’s premier educational institutions as well as private sector companies, public sector institutions, NGOs, non-profits, and educational technology startups, and the project’s global community of service providers continues to make the platform accessible to ever-smaller organizations. If you plan to create and offer educational content to a broad audience, you should consider using the Open edX platform.
|
||||
|
||||
### Installation
|
||||
|
||||
There are multiple ways to install the software, which might be an unwelcome surprise, at least initially. But you get the same application software with the same feature set regardless of how you go about [installing Open edX][5]. The default installation includes a fully functioning learning management system (LMS) for online learners plus a full-featured course management studio (CMS) that your instructor teams can use to author original course content. You can think of the CMS as a “[Wordpress][6]” of course content creation and management, and the LMS as a “[Magento][7]” of course marketing, distribution, and consumption.
|
||||
|
||||
Open edX application software is device-agnostic and fully responsive, and with modest effort, you can also publish native iOS and Android apps that seamlessly integrate to your instance’s backend. The code repositories for the Open edX platform, the native mobile apps, and the installation scripts are all publicly available on [GitHub][8].
|
||||
|
||||
#### What to expect
|
||||
|
||||
The Open edX platform [GitHub repository][9] contains performant, production-ready code that is suitable for organizations of all sizes. Thousands of programmers from hundreds of institutions regularly contribute to the edX repositories, and the platform is a veritable case study on how to build and manage a complex enterprise application the right way. So even though you’re certain to face a multitude of concerns about how to move the platform into production, you should not lose sleep about the general quality and robustness of the Open edX Platform codebase itself.
|
||||
|
||||
With minimal training, your instructors will be able to create good online course content. But bear in mind that Open edX is extensible via its [XBlock][10] component architecture, so your instructors will have the potential to turn good course content into great course content with incremental effort on their parts and yours.
|
||||
|
||||
The platform works well in a single-server environment, and it is highly modular, making it nearly infinitely horizontally scalable. It is theme-able, localizable, and completely open source, providing limitless possibilities to tailor the appearance and functionality of the platform to your needs. The platform runs reliably as an on-premise installation on your own equipment.
|
||||
|
||||
#### Some assembly required
|
||||
|
||||
Bear in mind that a handful of the edX software modules are not included in the default installation and that these modules are often on the requirements lists of organizations. Namely, the Analytics module, the e-commerce module, and the Notes/Annotations course feature are not part of the default platform installation, and each of these individually is a non-trivial installation. Additionally, you’re entirely on your own with regard to data backup-restore and system administration in general. Fortunately, there’s a growing body of community-sourced documentation and how-to articles, all searchable via Google and Bing, to help make your installation production-ready.
|
||||
|
||||
Setting up [oAuth][11] and [SSL/TLS][12] as well as getting the platform’s [REST API][13] up and running can be challenging, depending on your skill level, even though these are all well-documented procedures. Additionally, some organizations require that MySQL and/or MongoDB databases be managed in an existing centralized environment, and if this is your situation, you’ll also need to work through the process of hiving these services out of the default platform installation. The edX design team has done everything possible to simplify this for you, but it’s still a non-trivial change that will likely take some time to implement.
|
||||
|
||||
Not to be discouraged—if you’re facing resource and/or technical headwinds, Open edX community SaaS providers like [appsembler][14] and [eduNEXT][15] offer compelling alternatives to a do-it-yourself installation, particularly if you’re just window shopping.
|
||||
|
||||
### Technology stack
|
||||
|
||||
Poking around in an Open edX platform installation is a real thrill, and architecturally speaking, the project is a masterpiece. The application modules are [Django][16] apps that leverage a plethora of the open source community’s premier projects, including [Ubuntu][17], [MySQL][18], [MongoDB][19], [RabbitMQ][20], [Elasticsearch][21], [Hadoop][22], and others.
|
||||
|
||||
![edx-architecture.png][24]
|
||||
|
||||
The Open edX technology stack (CC BY, by edX)
|
||||
|
||||
Getting all of these components installed and configured is a feat in and of itself, but packaging everything in such a way that organizations of arbitrary size and complexity can tailor installations to their needs without having to perform heart surgery on the codebase would seem impossible—that is, until you see how neatly and intuitively the major platform configuration parameters have been organized and named. Mind you, there’s a learning curve to the platform’s organizational structure, but the upshot is that everything you learn is worth knowing, not just for this project but large IT projects in general.
|
||||
|
||||
One word of caution: The platform's UI is in flux, with the aim of eventually standardizing on [React][25] and [Bootstrap][26]. Meanwhile, you'll find multiple approaches to implementing styling for the base theme, and this can get confusing.
|
||||
|
||||
### Adoption
|
||||
|
||||
The edX project has enjoyed rapid international adoption, due in no small measure to how well the software works. Not surprisingly, the project’s success has attracted a large and growing list of talented participants who contribute to the project as programmers, project consultants, translators, technical writers, and bloggers. The annual [Open edX Conference][27], the [Official edX Google Group][28], and the [Open edX Service Providers List][4] are good starting points for learning more about this diverse and growing ecosystem. As a relative newcomer myself, I’ve found it comparatively easy to engage and to get directly involved with the project in multiple facets.
|
||||
|
||||
Good luck with your journey, and feel free to reach out to me as a sounding board while you’re conceptualizing your project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/getting-started-open-edx
|
||||
|
||||
作者:[Lawrence Mc Daniel][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mcdaniel0073
|
||||
[1]:https://openedx.atlassian.net/wiki/spaces/DOC/pages/11108700/Open+edX+Releases
|
||||
[2]:https://open.edx.org/about-open-edx
|
||||
[3]:https://www.edx.org/schools-partners
|
||||
[4]:https://openedx.atlassian.net/wiki/spaces/COMM/pages/65667081/Open+edX+Service+Providers
|
||||
[5]:https://openedx.atlassian.net/wiki/spaces/OpenOPS/pages/60227779/Open+edX+Installation+Options
|
||||
[6]:https://wordpress.com/
|
||||
[7]:https://magento.com/
|
||||
[8]:https://github.com/edx
|
||||
[9]:https://github.com/edx/edx-platform
|
||||
[10]:https://open.edx.org/xblocks
|
||||
[11]:https://oauth.net/
|
||||
[12]:https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[13]:https://en.wikipedia.org/wiki/Representational_state_transfer
|
||||
[14]:https://www.appsembler.com/
|
||||
[15]:https://www.edunext.co/
|
||||
[16]:https://www.djangoproject.com/
|
||||
[17]:https://www.ubuntu.com/
|
||||
[18]:https://www.mysql.com/
|
||||
[19]:https://www.mongodb.com/
|
||||
[20]:https://www.rabbitmq.com/
|
||||
[21]:https://www.elastic.co/
|
||||
[22]:http://hadoop.apache.org/
|
||||
[23]:/file/400696
|
||||
[24]:https://opensource.com/sites/default/files/uploads/edx-architecture_0.png (edx-architecture.png)
|
||||
[25]:%E2%80%9Chttps://reactjs.org/%E2%80%9C
|
||||
[26]:%E2%80%9Chttps://getbootstrap.com/%E2%80%9C
|
||||
[27]:https://con.openedx.org/
|
||||
[28]:https://groups.google.com/forum/#!forum/openedx-ops
|
||||
@ -0,0 +1,253 @@
|
||||
How to reset, revert, and return to previous states in Git
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of the lesser understood (and appreciated) aspects of working with Git is how easy it is to get back to where you were before—that is, how easy it is to undo even major changes in a repository. In this article, we'll take a quick look at how to reset, revert, and completely return to previous states, all with the simplicity and elegance of individual Git commands.
|
||||
|
||||
### Reset
|
||||
|
||||
Let's start with the Git command `reset`. Practically, you can think of it as a "rollback"—it points your local environment back to a previous commit. By "local environment," we mean your local repository, staging area, and working directory.
|
||||
|
||||
Take a look at Figure 1. Here we have a representation of a series of commits in Git. A branch in Git is simply a named, movable pointer to a specific commit. In this case, our branch master is a pointer to the latest commit in the chain.
|
||||
|
||||
![Local Git environment with repository, staging area, and working directory][2]
|
||||
|
||||
Fig. 1: Local Git environment with repository, staging area, and working directory
|
||||
|
||||
If we look at what's in our master branch now, we can see the chain of commits made so far.
|
||||
```
|
||||
$ git log --oneline
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
`reset` command to do this for us. For example, if we want to reset master to point to the commit two back from the current commit, we could use either of the following methods:
|
||||
|
||||
What happens if we want to roll back to a previous commit. Simple—we can just move the branch pointer. Git supplies thecommand to do this for us. For example, if we want to reset master to point to the commit two back from the current commit, we could use either of the following methods:
|
||||
|
||||
`$ git reset 9ef9173` (using an absolute commit SHA1 value 9ef9173)
|
||||
|
||||
or
|
||||
|
||||
`$ git reset current~2` (using a relative value -2 before the "current" tag)
|
||||
|
||||
Figure 2 shows the results of this operation. After this, if we execute a `git log` command on the current branch (master), we'll see just the one commit.
|
||||
```
|
||||
$ git log --oneline
|
||||
|
||||
9ef9173 File with one line
|
||||
|
||||
```
|
||||
|
||||
![After reset][4]
|
||||
|
||||
Fig. 2: After `reset`
|
||||
|
||||
The `git reset` command also includes options to update the other parts of your local environment with the contents of the commit where you end up. These options include: `hard` to reset the commit being pointed to in the repository, populate the working directory with the contents of the commit, and reset the staging area; `soft` to only reset the pointer in the repository; and `mixed` (the default) to reset the pointer and the staging area.
|
||||
|
||||
Using these options can be useful in targeted circumstances such as `git reset --hard <commit sha1 | reference>``.` This overwrites any local changes you haven't committed. In effect, it resets (clears out) the staging area and overwrites content in the working directory with the content from the commit you reset to. Before you use the `hard` option, be sure that's what you really want to do, since the command overwrites any uncommitted changes.
|
||||
|
||||
### Revert
|
||||
|
||||
The net effect of the `git revert` command is similar to reset, but its approach is different. Where the `reset` command moves the branch pointer back in the chain (typically) to "undo" changes, the `revert` command adds a new commit at the end of the chain to "cancel" changes. The effect is most easily seen by looking at Figure 1 again. If we add a line to a file in each commit in the chain, one way to get back to the version with only two lines is to reset to that commit, i.e., `git reset HEAD~1`.
|
||||
|
||||
Another way to end up with the two-line version is to add a new commit that has the third line removed—effectively canceling out that change. This can be done with a `git revert` command, such as:
|
||||
```
|
||||
$ git revert HEAD
|
||||
|
||||
```
|
||||
|
||||
Because this adds a new commit, Git will prompt for the commit message:
|
||||
```
|
||||
Revert "File with three lines"
|
||||
|
||||
This reverts commit b764644bad524b804577684bf74e7bca3117f554.
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with '#' will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
# Changes to be committed:
|
||||
# modified: file1.txt
|
||||
#
|
||||
```
|
||||
|
||||
Figure 3 (below) shows the result after the `revert` operation is completed.
|
||||
|
||||
If we do a `git log` now, we'll see a new commit that reflects the contents before the previous commit.
|
||||
```
|
||||
$ git log --oneline
|
||||
11b7712 Revert "File with three lines"
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
Here are the current contents of the file in the working directory:
|
||||
```
|
||||
$ cat <filename>
|
||||
Line 1
|
||||
Line 2
|
||||
```
|
||||
|
||||
#### Revert or reset?
|
||||
|
||||
Why would you choose to do a `revert` over a `reset` operation? If you have already pushed your chain of commits to the remote repository (where others may have pulled your code and started working with it), a revert is a nicer way to cancel out changes for them. This is because the Git workflow works well for picking up additional commits at the end of a branch, but it can be challenging if a set of commits is no longer seen in the chain when someone resets the branch pointer back.
|
||||
|
||||
This brings us to one of the fundamental rules when working with Git in this manner: Making these kinds of changes in your local repository to code you haven't pushed yet is fine. But avoid making changes that rewrite history if the commits have already been pushed to the remote repository and others may be working with them.
|
||||
|
||||
In short, if you rollback, undo, or rewrite the history of a commit chain that others are working with, your colleagues may have a lot more work when they try to merge in changes based on the original chain they pulled. If you must make changes against code that has already been pushed and is being used by others, consider communicating before you make the changes and give people the chance to merge their changes first. Then they can pull a fresh copy after the infringing operation without needing to merge.
|
||||
|
||||
You may have noticed that the original chain of commits was still there after we did the reset. We moved the pointer and reset the code back to a previous commit, but it did not delete any commits. This means that, as long as we know the original commit we were pointing to, we can "restore" back to the previous point by simply resetting back to the original head of the branch:
|
||||
```
|
||||
git reset <sha1 of commit>
|
||||
|
||||
```
|
||||
|
||||
A similar thing happens in most other operations we do in Git when commits are replaced. New commits are created, and the appropriate pointer is moved to the new chain. But the old chain of commits still exists.
|
||||
|
||||
### Rebase
|
||||
|
||||
Now let's look at a branch rebase. Consider that we have two branches—master and feature—with the chain of commits shown in Figure 4 below. Master has the chain `C4->C2->C1->C0` and feature has the chain `C5->C3->C2->C1->C0`.
|
||||
|
||||
![Chain of commits for branches master and feature][6]
|
||||
|
||||
Fig. 4: Chain of commits for branches master and feature
|
||||
|
||||
If we look at the log of commits in the branches, they might look like the following. (The `C` designators for the commit messages are used to make this easier to understand.)
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
I tell people to think of a rebase as a "merge with history" in Git. Essentially what Git does is take each different commit in one branch and attempt to "replay" the differences onto the other branch.
|
||||
|
||||
So, we can rebase a feature onto master to pick up `C4` (e.g., insert it into feature's chain). Using the basic Git commands, it might look like this:
|
||||
```
|
||||
$ git checkout feature
|
||||
$ git rebase master
|
||||
|
||||
First, rewinding head to replay your work on top of it...
|
||||
Applying: C3
|
||||
Applying: C5
|
||||
```
|
||||
|
||||
Afterward, our chain of commits would look like Figure 5.
|
||||
|
||||
![Chain of commits after the rebase command][8]
|
||||
|
||||
Fig. 5: Chain of commits after the `rebase` command
|
||||
|
||||
Again, looking at the log of commits, we can see the changes.
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
c4533a5 C5
|
||||
64f2047 C3
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
Notice that we have `C3'` and `C5'`—new commits created as a result of making the changes from the originals "on top of" the existing chain in master. But also notice that the "original" `C3` and `C5` are still there—they just don't have a branch pointing to them anymore.
|
||||
|
||||
If we did this rebase, then decided we didn't like the results and wanted to undo it, it would be as simple as:
|
||||
```
|
||||
$ git reset 79768b8
|
||||
|
||||
```
|
||||
|
||||
With this simple change, our branch would now point back to the same set of commits as before the `rebase` operation—effectively undoing it (Figure 6).
|
||||
|
||||
![After undoing rebase][10]
|
||||
|
||||
Fig. 6: After undoing the `rebase` operation
|
||||
|
||||
What happens if you can't recall what commit a branch pointed to before an operation? Fortunately, Git again helps us out. For most operations that modify pointers in this way, Git remembers the original commit for you. In fact, it stores it in a special reference named `ORIG_HEAD `within the `.git` repository directory. That path is a file containing the most recent reference before it was modified. If we `cat` the file, we can see its contents.
|
||||
```
|
||||
$ cat .git/ORIG_HEAD
|
||||
79768b891f47ce06f13456a7e222536ee47ad2fe
|
||||
```
|
||||
|
||||
We could use the `reset` command, as before, to point back to the original chain. Then the log would show this:
|
||||
```
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
Another place to get this information is in the reflog. The reflog is a play-by-play listing of switches or changes to references in your local repository. To see it, you can use the `git reflog` command:
|
||||
```
|
||||
$ git reflog
|
||||
79768b8 HEAD@{0}: reset: moving to 79768b
|
||||
c4533a5 HEAD@{1}: rebase finished: returning to refs/heads/feature
|
||||
c4533a5 HEAD@{2}: rebase: C5
|
||||
64f2047 HEAD@{3}: rebase: C3
|
||||
6a92e7a HEAD@{4}: rebase: checkout master
|
||||
79768b8 HEAD@{5}: checkout: moving from feature to feature
|
||||
79768b8 HEAD@{6}: commit: C5
|
||||
000f9ae HEAD@{7}: checkout: moving from master to feature
|
||||
6a92e7a HEAD@{8}: commit: C4
|
||||
259bf36 HEAD@{9}: checkout: moving from feature to master
|
||||
000f9ae HEAD@{10}: commit: C3
|
||||
259bf36 HEAD@{11}: checkout: moving from master to feature
|
||||
259bf36 HEAD@{12}: commit: C2
|
||||
f33ae68 HEAD@{13}: commit: C1
|
||||
5043e79 HEAD@{14}: commit (initial): C0
|
||||
```
|
||||
|
||||
You can then reset to any of the items in that list using the special relative naming format you see in the log:
|
||||
```
|
||||
$ git reset HEAD@{1}
|
||||
|
||||
```
|
||||
|
||||
Once you understand that Git keeps the original chain of commits around when operations "modify" the chain, making changes in Git becomes much less scary. This is one of Git's core strengths: being able to quickly and easily try things out and undo them if they don't work.
|
||||
|
||||
Brent Laster will present [Power Git: Rerere, Bisect, Subtrees, Filter Branch, Worktrees, Submodules, and More][11] at the 20th annual [OSCON][12] event, July 16-19 in Portland, Ore. For more tips and explanations about using Git at any level, checkout Brent's book "[Professional Git][13]," available on Amazon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/git-reset-revert-rebase-commands
|
||||
|
||||
作者:[Brent Laster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bclaster
|
||||
[1]:/file/401126
|
||||
[2]:https://opensource.com/sites/default/files/uploads/gitcommands1_local-environment.png (Local Git environment with repository, staging area, and working directory)
|
||||
[3]:/file/401131
|
||||
[4]:https://opensource.com/sites/default/files/uploads/gitcommands2_reset.png (After reset)
|
||||
[5]:/file/401141
|
||||
[6]:https://opensource.com/sites/default/files/uploads/gitcommands4_commits-branches.png (Chain of commits for branches master and feature)
|
||||
[7]:/file/401146
|
||||
[8]:https://opensource.com/sites/default/files/uploads/gitcommands5_commits-rebase.png (Chain of commits after the rebase command)
|
||||
[9]:/file/401151
|
||||
[10]:https://opensource.com/sites/default/files/uploads/gitcommands6_rebase-undo.png (After undoing rebase)
|
||||
[11]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67142
|
||||
[12]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
[13]:https://www.amazon.com/Professional-Git-Brent-Laster/dp/111928497X/ref=la_B01MTGIINQ_1_2?s=books&ie=UTF8&qid=1528826673&sr=1-2
|
||||
@ -0,0 +1,95 @@
|
||||
Use this vi setup to keep and organize your notes
|
||||
======
|
||||
|
||||

|
||||
|
||||
The idea of using vi to manage a wiki for your notes may seem unconventional, but when you're using vi in your daily work, it makes a lot of sense.
|
||||
|
||||
As a software developer, it’s just easier to write my notes in the same tool I use to code. I want my notes to be only an editor command away, available wherever I am, and managed the same way I handle my code. That's why I created a vi-based setup for my personal knowledge base. In a nutshell: I use the vi plugin [Vimwiki][1] to manage my wiki locally on my laptop, I use Git to version it (and keep a central, updated version), and I use GitLab for online editing (for example, on my mobile device).
|
||||
|
||||
### Why it makes sense to use a wiki for note-keeping
|
||||
|
||||
I've tried many different tools to keep track of notes, write down fleeting thoughts, and structure tasks I shouldn’t forget. These include offline notebooks (yes, that involves paper), special note-keeping software, and mind-mapping software.
|
||||
|
||||
All these solutions have positives, but none fit all of my needs. For example, [mind maps][2] are a great way to visualize what’s in your mind (hence the name), but the tools I tried provided poor searching functionality. (The same thing is true for paper notes.) Also, it’s often hard to read mind maps after time passes, so they don’t work very well for long-term note keeping.
|
||||
|
||||
One day while setting up a [DokuWiki][3] for a collaboration project, I found that the wiki structure fits most of my requirements. With a wiki, you can create notes (like you would in any text editor) and create links between your notes. If a link points to a non-existent page (maybe because you wanted a piece of information to be on its own page but haven’t set it up yet), the wiki will create that page for you. These features make a wiki a good fit for quickly writing things as they come to your mind, while still keeping your notes in a page structure that is easy to browse and search for keywords.
|
||||
|
||||
While this sounds promising, and setting up DokuWiki is not difficult, I found it a bit too much work to set up a whole wiki just for keeping track of my notes. After some research, I found Vimwiki, a Vi plugin that does what I want. Since I use Vi every day, keeping notes is very similar to editing code. Also, it’s even easier to create a page in Vimwiki than DokuWiki—all you have to do is press Enter while your cursor hovers over a word. If there isn’t already a page with that name, Vimwiki will create it for you.
|
||||
|
||||
To take my plan to use my everyday tools for note-keeping a step further, I’m not only using my favorite IDE to write notes but also my favorite code management tools—Git and GitLab—to distribute notes across my various machines and be able to access them online. I’m also using Markdown syntax in GitLab's online Markdown editor to write this article.
|
||||
|
||||
### Setting up Vimwiki
|
||||
|
||||
Installing Vimwiki is easy using your existing plugin manager: Just add `vimwiki/vimwiki` to your plugins. In my preferred plugin manager, Vundle, you just add the line `Plugin 'vimwiki/vimwiki'` in your `~/.vimrc` followed by a `:source ~/.vimrc|PluginInstall`.
|
||||
|
||||
Following is a piece of my `~.vimrc` showing a bit of Vimwiki configuration. You can learn more about installing and using this tool on the [Vimwiki page][1].
|
||||
```
|
||||
let wiki_1 = {}
|
||||
let wiki_1.path = '~/vimwiki_work_md/'
|
||||
let wiki_1.syntax = 'markdown'
|
||||
let wiki_1.ext = '.md'
|
||||
|
||||
let wiki_2 = {}
|
||||
let wiki_2.path = '~/vimwiki_personal_md/'
|
||||
let wiki_2.syntax = 'markdown'
|
||||
let wiki_2.ext = '.md'
|
||||
|
||||
let g:vimwiki_list = [wiki_1, wiki_2]
|
||||
let g:vimwiki_ext2syntax = {'.md': 'markdown', '.markdown': 'markdown', '.mdown': 'markdown'}
|
||||
```
|
||||
|
||||
Another advantage of my approach, which you can see in the configuration, is that I can easily divide my personal and work-related notes without switching the note-keeping software. I want my personal notes accessible everywhere, but I don’t want to sync my work-related notes to my private GitLab and computer. This was easier to set up in Vimwiki compared to the other software I tried.
|
||||
|
||||
The configuration tells Vimwiki there are two different wikis and I want to use Markdown syntax in both (again, because I’m used to Markdown from my daily work). It also tells Vimwiki the folders where to store the wiki pages.
|
||||
|
||||
If you navigate to the folders where the wiki pages are stored, you will find your wiki’s flat Markdown pages without any special Vimwiki context. That makes it easy to initialize a Git repository and sync your wiki to a central repository.
|
||||
|
||||
### Synchronizing your wiki to GitLab
|
||||
|
||||
The steps to check out a GitLab project to your local Vimwiki folder are nearly the same as you’d use for any GitHub repository. I just prefer to keep my notes in a private GitLab repository, so I keep a GitLab instance running for my personal projects.
|
||||
|
||||
GitLab has a wiki functionality that allows you to create wiki pages for your projects. Those wikis are Git repositories themselves. And they use Markdown syntax. You get where this is leading.
|
||||
|
||||
Just initialize the wiki you want to synchronize with the wiki of a project you created for your notes:
|
||||
```
|
||||
cd ~/vimwiki_personal_md/
|
||||
git init
|
||||
git remote add origin git@your.gitlab.com:your_user/vimwiki_personal_md.wiki
|
||||
git add .
|
||||
git commit -m "Initial commit"
|
||||
git push -u origin master
|
||||
```
|
||||
|
||||
These steps can be copied from the page where you land after creating a new project on GitLab. The only thing to change is the `.wiki` at the end of the repository URL (instead of `.git`), which tells it to clone the wiki repository instead of the project itself.
|
||||
|
||||
That’s it! Now you can manage your notes with Git and edit them in GitLab’s wiki user interface.
|
||||
|
||||
But maybe (like me) you don’t want to manually create commits for every note you add to your notebook. To solve this problem, I use the Vim plugin [chazy/dirsettings][4]. I added a `.vimdir` file with the following content to `~/vimwiki_personal_md`:
|
||||
```
|
||||
:cd %:p:h
|
||||
silent! !git pull > /dev/null
|
||||
:e!
|
||||
autocmd! BufWritePost * silent! !git add .;git commit -m "vim autocommit" > /dev/null; git push > /dev/null&
|
||||
```
|
||||
|
||||
This pulls the latest version of my wiki every time I open a wiki file and publishes my changes after every `:w` command. Doing this should keep your local copy in sync with the central repo. If you have merge conflicts, you may need to resolve them (as usual).
|
||||
|
||||
For now, this is the way I interact with my knowledge base, and I’m quite happy with it. Please let me know what you think about this approach. And please share in the comments your favorite way to keep track of your notes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/vimwiki-gitlab-notes
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ntlx
|
||||
[1]:http://vimwiki.github.io/
|
||||
[2]:https://opensource.com/article/17/8/mind-maps-creative-dashboard
|
||||
[3]:https://www.dokuwiki.org/dokuwiki
|
||||
[4]:https://github.com/chazy/dirsettings
|
||||
@ -0,0 +1,122 @@
|
||||
Linux 中一种友好的 find 替代工具
|
||||
======
|
||||

|
||||
|
||||
[fd][1] 是一个超快的,基于 [Rust][2] 的 Unix/Linux `find` 命令的替代。它不提供所有 `find` 的强大功能。但是,它确实提供了足够的功能来覆盖可能遇到的 80% 的情况。诸如良好的规划和方便的语法、彩色输出、智能大小写、正则表达式以及并行命令执行等特性使 `fd` 成为一个非常有能力的后继者。
|
||||
|
||||
### 安装
|
||||
|
||||
进入 [fd][1] GitHub 页面,查看安装部分。它涵盖了如何在[macOS][3]、 [Debian/Ubuntu][4] [Red Hat][5] 和 [Arch Linux][6] 上安装程序。安装完成后,你可以通过运行帮助来获得所有可用命令行选项的完整概述,通过 `fd -h` 获取简明帮助,或者通过 `fd --help` 获取更详细的帮助。
|
||||
|
||||
### 简单搜索
|
||||
|
||||
`fd` 旨在帮助你轻松找到文件系统中的文件和文件夹。你可以用 `fd` 带上一个参数执行最简单的搜索,该参数就是你要搜索的任何东西。例如,假设你想要找一个 Markdown 文档,其中包含单词 `services` 作为文件名的一部分:
|
||||
```
|
||||
$ fd services
|
||||
|
||||
downloads/services.md
|
||||
|
||||
```
|
||||
|
||||
如果仅带一个参数调用,那么 `fd` 递归地搜索当前目录以查找与莫的参数匹配的任何文件和/或目录。使用内置的 `find` 命令的等效搜索如下所示:
|
||||
```
|
||||
$ find . -name 'services'
|
||||
|
||||
downloads/services.md
|
||||
|
||||
```
|
||||
|
||||
如你所见,`fd` 要简单得多,并需要更少的输入。在我心中用更少的输入做更多的事情总是胜利的。
|
||||
|
||||
### 文件和文件夹
|
||||
|
||||
您可以使用 `-t` 参数将搜索范围限制为文件或目录,后面跟着代表你要搜索的内容的字母。例如,要查找当前目录中文件名中包含 `services` 的所有文件,可以使用:
|
||||
```
|
||||
$ fd -tf services
|
||||
|
||||
downloads/services.md
|
||||
|
||||
```
|
||||
|
||||
并找到当前目录中文件名中包含 `services` 的所有目录:
|
||||
```
|
||||
$ fd -td services
|
||||
|
||||
applications/services
|
||||
|
||||
library/services
|
||||
|
||||
```
|
||||
|
||||
如何在当前文件夹中列出所有带 `.md` 扩展名的文档?
|
||||
```
|
||||
$ fd .md
|
||||
|
||||
administration/administration.md
|
||||
|
||||
development/elixir/elixir_install.md
|
||||
|
||||
readme.md
|
||||
|
||||
sidebar.md
|
||||
|
||||
linux.md
|
||||
|
||||
```
|
||||
|
||||
从输出中可以看到,`fd` 不仅可以找到并列出当前文件夹中的文件,还可以在子文件夹中找到文件。很简单。你甚至可以使用 `-H` 参数来搜索隐藏文件:
|
||||
```
|
||||
fd -H sessions .
|
||||
|
||||
.bash_sessions
|
||||
|
||||
```
|
||||
|
||||
### 指定目录
|
||||
|
||||
如果你想搜索一个特定的目录,这个目录的名字可以作为第二个参数传给 `fd`
|
||||
```
|
||||
$ fd passwd /etc
|
||||
|
||||
/etc/default/passwd
|
||||
|
||||
/etc/pam.d/passwd
|
||||
|
||||
/etc/passwd
|
||||
|
||||
```
|
||||
|
||||
在这个例子中,我们告诉 `fd` 我们要在 `etc` 目录中搜索 `passwd` 这个单词的所有实例。
|
||||
|
||||
### 全局搜索
|
||||
|
||||
如果你知道文件名的一部分,但不知道文件夹怎么办?假设你下载了一本关于 Linux 网络管理的书,但你不知道它的保存位置。没有问题:
|
||||
```
|
||||
fd Administration /
|
||||
|
||||
/Users/pmullins/Documents/Books/Linux/Mastering Linux Network Administration.epub
|
||||
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
`fd` 是 `find` 命令的极好的替代品,我相信你会和我一样发现它很有用。要了解该命令的更多信息,只需浏览手册页。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/friendly-alternative-find
|
||||
|
||||
作者:[Patrick H. Mullins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pmullins
|
||||
[1]:https://github.com/sharkdp/fd
|
||||
[2]:https://www.rust-lang.org/en-US/
|
||||
[3]:https://en.wikipedia.org/wiki/MacOS
|
||||
[4]:https://www.ubuntu.com/community/debian
|
||||
[5]:https://www.redhat.com/en
|
||||
[6]:https://www.archlinux.org/
|
||||
Loading…
Reference in New Issue
Block a user