mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
commit
71ed0966d3
@ -1,35 +1,33 @@
|
||||
[调试器的工作原理: 第3篇 - 调试信息][25]
|
||||
调试器工作原理(三):调试信息
|
||||
============================================================
|
||||
|
||||
|
||||
这是调试器的工作原理系列文章的第三篇。阅读这篇文章之前应当先阅读[第一篇][26]与[第二篇][27]。
|
||||
|
||||
### 这篇文章的主要内容
|
||||
|
||||
本文将解释调试器是如何在机器码中,查找它将C语言源代码转换成机器语言代码时所需要的C语言函数、变量、与数据。
|
||||
本文将解释调试器是如何在机器码中查找它将 C 语言源代码转换成机器语言代码时所需要的 C 语言函数、变量、与数据。
|
||||
|
||||
### 调试信息
|
||||
|
||||
|
||||
现代编译器能够将有着各种排版或嵌套的程序流程、各种数据类型的变量的高级语言代码转换为一大堆称之为机器码的 0/1 数据,这么做的唯一目的是尽可能快的在目标 CPU 上运行程序。通常来说一行C语言代码能够转换为若干条机器码。变量被分散在机器码中的各个部分,有的在堆栈中,有的在寄存器中,或者直接被优化掉了。数据结构与对象在机器码中甚至不“存在”,它们只是用于将数据按一定的结构编码存储进缓存。
|
||||
现代编译器能够将有着各种缩进或嵌套的程序流程、各种数据类型的变量的高级语言代码转换为一大堆称之为机器码的 0/1 数据,这么做的唯一目的是尽可能快的在目标 CPU 上运行程序。通常来说一行 C 语言代码能够转换为若干条机器码。变量被分散在机器码中的各个部分,有的在堆栈中,有的在寄存器中,或者直接被优化掉了。数据结构与对象在机器码中甚至不“存在”,它们只是用于将数据按一定的结构编码存储进缓存。
|
||||
|
||||
那么调试器怎么知道,当你需要在某个函数入口处暂停时,程序要在哪停下来呢?它怎么知道当你查看某个变量值时,它怎么找到这个值?答案是,调试信息。
|
||||
|
||||
编译器在生成机器码时同时会生成相应的调试信息。调试信息代表了可执行程序与源代码之间的关系,并以一种提前定义好的格式,同机器码存放在一起。过去的数年里,人们针对不同的平台与可执行文件发明了很多种用于存储这些信息的格式。不过我们这篇文章不会讲这些格式的历史,而是将阐述这些调试信息是如何工作的,所以我们将专注于一些事情,比如 `DWARF`。`DWARF` 如今十分广泛的应用在类 `Unix` 平台上的可执行文件的调试。
|
||||
编译器在生成机器码时同时会生成相应的调试信息。调试信息代表了可执行程序与源代码之间的关系,并以一种提前定义好的格式,同机器码存放在一起。过去的数年里,人们针对不同的平台与可执行文件发明了很多种用于存储这些信息的格式。不过我们这篇文章不会讲这些格式的历史,而是将阐述这些调试信息是如何工作的,所以我们将专注于一些事情,比如 `DWARF`。`DWARF` 如今十分广泛的用作 Linux 和类 `Unix` 平台上的可执行文件的调试格式。
|
||||
|
||||
### ELF 中的 DWARF
|
||||
|
||||

|
||||

|
||||
|
||||
根据[它的维基百科][17] 所描述,虽然 `DWARF` 是同 `ELF` 一同设计的(`DWARF` 是由 `DWARF` 标准委员会推出的开放标准。上文中展示的 图标就来自这个网站。),但 `DWARF` 在理论上来说也可以嵌入到其他的可执行文件格式中。
|
||||
根据[它的维基百科][17] 所描述,虽然 `DWARF` 是同 `ELF` 一同设计的(`DWARF` 是由 `DWARF` 标准委员会推出的开放标准。上文中展示的图标就来自这个网站。),但 `DWARF` 在理论上来说也可以嵌入到其他的可执行文件格式中。
|
||||
|
||||
`DWARF` 是一种复杂的格式,它的构建基于过去多年中许多不同的编译器与操作系统。正是因为它解决了一个为任意语言在任何平台与业务系统中产生调试信息的这样棘手的难题,它也必须很复杂。想要透彻的讲解 `DWARF` 仅仅是通过这单薄的一篇文章是远远不够的,说实话我也并没有充分地了解 `DWARF` 到每一个微小的细节,所以我也不能十分透彻的讲解 (如果你感兴趣的话,文末有一些能够帮助你的资源。建议从 `DWARF` 教程开始上手)。这篇文章中我将以浅显易懂的方式展示 `DWARF` 在实际应用中调试信息是如何工作的。
|
||||
`DWARF` 是一种复杂的格式,它吸收了过去许多年各种不同的架构与操作系统的格式的经验。正是因为它解决了一个在任何平台与 ABI (应用二进制接口)上为任意高级语言产生调试信息这样棘手的难题,它也必须很复杂。想要透彻的讲解 `DWARF` 仅仅是通过这单薄的一篇文章是远远不够的,说实话我也并没有充分地了解 `DWARF` 到每一个微小的细节,所以我也不能十分透彻的讲解 (如果你感兴趣的话,文末有一些能够帮助你的资源。建议从 `DWARF` 教程开始上手)。这篇文章中我将以浅显易懂的方式展示 `DWARF`,以说明调试信息是如何实际工作的。
|
||||
|
||||
### ELF文件中的调试部分
|
||||
### ELF 文件中的调试部分
|
||||
|
||||
首先让我们看看 `DWARF` 处在 ELF 文件中的什么位置。`ELF` 定义了每一个生成的目标文件中的每一部分。 _section header table_ 声明并定义了每一部分。不同的工具以不同的方式处理不同的部分,例如连接器会寻找连接器需要的部分,调试器会查找调试器需要的部分。
|
||||
首先让我们看看 `DWARF` 处在 ELF 文件中的什么位置。`ELF` 定义了每一个生成的目标文件中的每一节。 <ruby>节头表<rt>section header table</rt></ruby> 声明并定义了每一节及其名字。不同的工具以不同的方式处理不同的节,例如连接器会寻找连接器需要的部分,调试器会查找调试器需要的部分。
|
||||
|
||||
我们本文的实验会使用从这个C语言源文件构建的可执行文件,编译成 tracedprog2:
|
||||
我们本文的实验会使用从这个 C 语言源文件构建的可执行文件,编译成 `tracedprog2`:
|
||||
|
||||
|
||||
```
|
||||
@ -52,7 +50,7 @@ int main()
|
||||
```
|
||||
|
||||
|
||||
使用 `objdump -h` 命令检查 `ELF` 可执行文件中的段落头,我们会看到几个以 .debug_ 开头的段落,这些就是 `DWARF` 的调试部分。
|
||||
使用 `objdump -h` 命令检查 `ELF` 可执行文件中的<ruby>节头<rt>section header</rt></ruby>,我们会看到几个以 `.debug_` 开头的节,这些就是 `DWARF` 的调试部分。
|
||||
|
||||
```
|
||||
26 .debug_aranges 00000020 00000000 00000000 00001037
|
||||
@ -73,23 +71,23 @@ int main()
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
```
|
||||
|
||||
每个段落的第一个数字代表了这个段落的大小,最后一个数字代表了这个段落开始位置距离 `ELF` 的偏移量。调试器利用这些信息从可执行文件中读取段落。
|
||||
每个节的第一个数字代表了该节的大小,最后一个数字代表了这个节开始位置距离 `ELF` 的偏移量。调试器利用这些信息从可执行文件中读取节。
|
||||
|
||||
现在让我们看看一些在 `DWARF` 中查找有用的调试信息的实际例子。
|
||||
|
||||
### 查找函数
|
||||
|
||||
调试器的基础任务之一,就是当我们在某个函数处设置断点时,调试器需要能够在入口处暂停。为此,必须为函数与函数在机器码地址这两者建立起某种映射关系。
|
||||
调试器的最基础的任务之一,就是当我们在某个函数处设置断点时,调试器需要能够在入口处暂停。为此,必须为高级代码中的函数名称与函数在机器码中指令开始的地址这两者之间建立起某种映射关系。
|
||||
|
||||
为了获取这种映射关系,我们可以查找 `DWARF` 中的 .debug_info 段落。在我们深入之前,需要一点基础知识。`DWARF` 中每一个描述类型被称之为调试信息入口(`DIE`)。每个 `DIE` 都有关于它的属性之类的标签。`DIE` 之间通过兄弟节点或子节点连接,属性的值也可以指向其他的 `DIE`.
|
||||
为了获取这种映射关系,我们可以查找 `DWARF` 中的 `.debug_info` 节。在我们深入之前,需要一点基础知识。`DWARF` 中每一个描述类型被称之为调试信息入口(`DIE`)。每个 `DIE` 都有关于它的类型、属性之类的标签。`DIE` 之间通过兄弟节点或子节点相互连接,属性的值也可以指向其它的 `DIE`。
|
||||
|
||||
运行以下命令
|
||||
运行以下命令:
|
||||
|
||||
```
|
||||
objdump --dwarf=info tracedprog2
|
||||
```
|
||||
|
||||
输出文件相当的长,为了方便举例我们只关注这些行(从这里开始,无用的冗长信息我会以 (...)代替,方便排版。):
|
||||
输出文件相当的长,为了方便举例我们只关注这些行(从这里开始,无用的冗长信息我会以 (...)代替,方便排版):
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
@ -114,7 +112,7 @@ objdump --dwarf=info tracedprog2
|
||||
<c7> DW_AT_frame_base : 0x2c (location list)
|
||||
```
|
||||
|
||||
上面的代码中有两个带有 DW_TAG_subprogram 标签的入口,在 `DWARF` 中这是对函数的指代。注意,这是两个段落入口,其中一个是 do_stuff 函数的入口,另一个是主函数的入口。这些信息中有很多值得关注的属性,但其中最值得注意的是 DW_AT_low_pc。它代表了函数开始处程序指针的值(在x86平台上是 `EIP`)。此处 0x8048604 代表了 do_stuff 函数开始处的程序指针。下面我们将利用 `objdump -d` 命令对可执行文件进行反汇编。来看看这块地址中都有什么:
|
||||
上面的代码中有两个带有 `DW_TAG_subprogram` 标签的入口,在 `DWARF` 中这是对函数的指代。注意,这是两个节的入口,其中一个是 `do_stuff` 函数的入口,另一个是主(`main`)函数的入口。这些信息中有很多值得关注的属性,但其中最值得注意的是 `DW_AT_low_pc`。它代表了函数开始处程序指针的值(在 x86 平台上是 `EIP`)。此处 `0x8048604` 代表了 `do_stuff` 函数开始处的程序指针。下面我们将利用 `objdump -d` 命令对可执行文件进行反汇编。来看看这块地址中都有什么:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
@ -139,13 +137,13 @@ objdump --dwarf=info tracedprog2
|
||||
804863d: c3 ret
|
||||
```
|
||||
|
||||
显然,0x8048604 是 do_stuff 的开始地址,这样一来,调试器就可以建立函数与其在可执行文件中的位置间的映射关系。
|
||||
显然,`0x8048604` 是 `do_stuff` 的开始地址,这样一来,调试器就可以建立函数与其在可执行文件中的位置间的映射关系。
|
||||
|
||||
### 查找变量
|
||||
|
||||
假设我们当前在 do_staff 函数中某个位置上设置断点停了下来。我们想通过调试器取得 my_local 这个变量的值。调试器怎么知道在哪里去找这个值呢?很显然这要比查找函数更为困难。变量可能存储在全局存储区、堆栈、甚至是寄存器中。此外,同名变量在不同的作用域中可能有着不同的值。调试信息必须能够反映所有的这些变化,当然,`DWARF` 就能做到。
|
||||
假设我们当前在 `do_staff` 函数中某个位置上设置断点停了下来。我们想通过调试器取得 `my_local` 这个变量的值。调试器怎么知道在哪里去找这个值呢?很显然这要比查找函数更为困难。变量可能存储在全局存储区、堆栈、甚至是寄存器中。此外,同名变量在不同的作用域中可能有着不同的值。调试信息必须能够反映所有的这些变化,当然,`DWARF` 就能做到。
|
||||
|
||||
我不会逐一去将每一种可能的状况,但我会以调试器在 do_stuff 函数中查找 my_local 变量的过程来举个例子。下面我们再看一遍 .debug_info 中 do_stuff 的每一个入口,这次连它的子入口也要一起看。
|
||||
我不会逐一去将每一种可能的状况,但我会以调试器在 `do_stuff` 函数中查找 `my_local` 变量的过程来举个例子。下面我们再看一遍 `.debug_info` 中 `do_stuff` 的每一个入口,这次连它的子入口也要一起看。
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
@ -178,11 +176,11 @@ objdump --dwarf=info tracedprog2
|
||||
<af> DW_AT_location : (...) (DW_OP_fbreg: -24)
|
||||
```
|
||||
|
||||
看到每个入口处第一对尖括号中的数字了吗?这些是嵌套的等级,在上面的例子中,以 <2> 开头的入口是以 <1> 开头的子入口。因此我们得知 my_local 变量(以 DW_TAG_variable 标签标记)是 do_stuff 函数的局部变量。除此之外,调试器也需要知道变量的数据类型,这样才能正确的使用与显示变量。上面的例子中 my_local 的变量类型指向另一个 `DIE` <0x4b>。如果使用 objdump 命令查看这个 `DIE` 部分的话,我们会发现这部分代表了有符号4字节整型数据。
|
||||
看到每个入口处第一对尖括号中的数字了吗?这些是嵌套的等级,在上面的例子中,以 `<2>` 开头的入口是以 `<1>` 开头的子入口。因此我们得知 `my_local` 变量(以 `DW_TAG_variable` 标签标记)是 `do_stuff` 函数的局部变量。除此之外,调试器也需要知道变量的数据类型,这样才能正确的使用与显示变量。上面的例子中 `my_local` 的变量类型指向另一个 `DIE` `<0x4b>`。如果使用 `objdump` 命令查看这个 `DIE` 的话,我们会发现它是一个有符号 4 字节整型数据。
|
||||
|
||||
而为了在实际运行的程序内存中查找变量的值,调试器需要使用到 DW_AT_location 属性。对于 my_local 而言,是 DW_OP_fbreg: -20。这个代码段的意思是说 my_local 存储在距离它所在函数起始地址偏移量为-20的地方。
|
||||
而为了在实际运行的程序内存中查找变量的值,调试器需要使用到 `DW_AT_location` 属性。对于 `my_local` 而言,是 `DW_OP_fbreg: -20`。这个代码段的意思是说 `my_local` 存储在距离它所在函数起始地址偏移量为 `-20` 的地方。
|
||||
|
||||
do_stuff 函数的 DW_AT_frame_base 属性值为 0x0 (location list)。这意味着这个属性的值需要在 location list 中查找。下面我们来一起看看。
|
||||
`do_stuff` 函数的 `DW_AT_frame_base` 属性值为 `0x0 (location list)`。这意味着这个属性的值需要在 `location list` 中查找。下面我们来一起看看。
|
||||
|
||||
```
|
||||
$ objdump --dwarf=loc tracedprog2
|
||||
@ -202,9 +200,9 @@ Contents of the .debug_loc section:
|
||||
0000002c <End of list>
|
||||
```
|
||||
|
||||
我们需要关注的是第一列(do_stuff 函数的 DW_AT_frame_base 属性包含 location list 中 0x0 的偏移量。而 main 函数的相同属性包含 0x2c 的偏移量,这个偏移量是第二套地址列表的偏移量。)。对于调试器可能定位到的每一个地址,它都会指定当前栈帧到变量间的偏移量,而这个偏移就是通过寄存器来计算的。对于x86平台而言,bpreg4 指向 esp,而 bpreg5 指向 ebp。
|
||||
我们需要关注的是第一列(`do_stuff` 函数的 `DW_AT_frame_base` 属性包含 `location list` 中 `0x0` 的偏移量。而 `main` 函数的相同属性包含 `0x2c` 的偏移量,这个偏移量是第二套地址列表的偏移量)。对于调试器可能定位到的每一个地址,它都会指定当前栈帧到变量间的偏移量,而这个偏移就是通过寄存器来计算的。对于 x86 平台而言,`bpreg4` 指向 `esp`,而 `bpreg5` 指向 `ebp`。
|
||||
|
||||
让我们再看看 do_stuff 函数的头几条指令。
|
||||
让我们再看看 `do_stuff` 函数的头几条指令。
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
@ -216,15 +214,15 @@ Contents of the .debug_loc section:
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
```
|
||||
|
||||
只有当第二条指令执行后,ebp 寄存器才真正存储了有用的值。当然,前两条指令的基址是由上面所列出来的地址信息表计算出来的。一但 ebp 确定了,计算偏移量就十分方便了,因为尽管 esp 在操作堆栈的时候需要移动,但 ebp 作为栈底并不需要移动。
|
||||
只有当第二条指令执行后,`ebp` 寄存器才真正存储了有用的值。当然,前两条指令的基址是由上面所列出来的地址信息表计算出来的。一但 `ebp` 确定了,计算偏移量就十分方便了,因为尽管 `esp` 在操作堆栈的时候需要移动,但 `ebp` 作为栈底并不需要移动。
|
||||
|
||||
究竟我们应该去哪里找 my_local 的值呢?在 0x8048610 这块地址后, my_local 的值经过在 eax 中的计算后被存在了内存中,从这里开始我们才需要关注 my_local 的值。调试器会利用 DW_OP_breg5: 8 这个基址来查找。我们回想下,my_local 的 DW_AT_location 属性值为 DW_OP_fbreg: -20。所以应当从基址中 -20 ,同时由于 ebp 寄存器需要 + 8,所以最终结果为 - 12。现在再次查看反汇编代码,来看看数据从 eax 中被移动到哪里了。当然,这里 my_local 应当被存储在了 ebp - 12 的地址中。
|
||||
究竟我们应该去哪里找 `my_local` 的值呢?在 `0x8048610` 这块地址后, `my_local` 的值经过在 `eax` 中的计算后被存在了内存中,从这里开始我们才需要关注 `my_local` 的值。调试器会利用 `DW_OP_breg5: 8` 这个栈帧来查找。我们回想下,`my_local` 的 `DW_AT_location` 属性值为 `DW_OP_fbreg: -20`。所以应当从基址中 `-20` ,同时由于 `ebp` 寄存器需要 `+8`,所以最终结果为 `ebp - 12`。现在再次查看反汇编代码,来看看数据从 `eax` 中被移动到哪里了。当然,这里 `my_local` 应当被存储在了 `ebp - 12` 的地址中。
|
||||
|
||||
### 查看行号
|
||||
|
||||
当我们谈论调试信息的时候,我们利用了些技巧。当调试C语言源代码并在某个函数出放置断点的时候,我们并不关注第一条“机器码”指令(函数的调用准备工作已经完成而局部变量还没有初始化。)。我们真正关注的是函数的第一行“C代码”。
|
||||
当我们谈到在调试信息寻找函数的时候,我们利用了些技巧。当调试 C 语言源代码并在某个函数出放置断点的时候,我们并不关注第一条“机器码”指令(函数的调用准备工作已经完成而局部变量还没有初始化)。我们真正关注的是函数的第一行“C 代码”。
|
||||
|
||||
这就是 `DWARF` 完全覆盖映射C源代码与可执行文件中机器码地址的原因。下面是 .debug_line 段中所包含的内容,我们将其转换为可读的格式展示如下。
|
||||
这就是 `DWARF` 完全覆盖映射 C 源代码中的行与可执行文件中机器码地址的原因。下面是 `.debug_line` 节中所包含的内容,我们将其转换为可读的格式展示如下。
|
||||
|
||||
```
|
||||
$ objdump --dwarf=decodedline tracedprog2
|
||||
@ -247,27 +245,27 @@ tracedprog2.c 17 0x8048653
|
||||
tracedprog2.c 18 0x8048658
|
||||
```
|
||||
|
||||
很容易就可以看出其中C源代码与反汇编代码之间的对应关系。第5行指向 do_stuff 函数的入口,0x8040604。第6行,指向 0x804860a ,正是调试器在调试 do_stuff 函数时需要停下来的地方。这里已经完成了函数调用的准备工作。上面的这些信息形成了行号与地址间的双向映射关系。
|
||||
很容易就可以看出其中 C 源代码与反汇编代码之间的对应关系。第 5 行指向 `do_stuff` 函数的入口,`0x8040604`。第 6 行,指向 `0x804860a` ,正是调试器在调试 `do_stuff` 函数时需要停下来的地方。这里已经完成了函数调用的准备工作。上面的这些信息形成了行号与地址间的双向映射关系。
|
||||
|
||||
* 当在某一行设置断点的时候,调试器会利用这些信息去查找相应的地址来做断点工作(还记得上篇文章中的 int 3 指令吗?)
|
||||
* 当指令造成代码段错误时,调试器会利用这些信息来查看源代码中发生的状况。
|
||||
* 当在某一行设置断点的时候,调试器会利用这些信息去查找相应的地址来做断点工作(还记得上篇文章中的 `int 3` 指令吗?)
|
||||
* 当指令造成段错误时,调试器会利用这些信息来查看源代码中发生问题的行。
|
||||
|
||||
### libdwarf - 用 DWARF 编程
|
||||
|
||||
尽管使用命令行工具来获得 `DWARF` 很有用,但这仍然不够易用。作为程序员,我们应当知道当我们需要这些调试信息时应当怎么编程来获取这些信息。
|
||||
尽管使用命令行工具来获得 `DWARF` 很有用,但这仍然不够易用。作为程序员,我们希望知道当我们需要这些调试信息时应当怎么编程来获取这些信息。
|
||||
|
||||
自然我们想到的第一种方法就是阅读 `DWARF` 规范并按规范操作阅读使用。有句话说的好,分析 HTML 应当使用库函数,永远不要手工分析。对于 `DWARF` 来说这是如此。`DWARF` 比 HTML 要复杂得多。上面所展示出来的只是冰山一角。更糟糕的是,在实际的目标文件中,大部分信息是以压缩格式存储的,分析起来更加复杂(信息中的某些部分,例如位置信息与行号信息,在某些虚拟机下是以指令的方式编码的。)。
|
||||
自然我们想到的第一种方法就是阅读 `DWARF` 规范并按规范操作阅读使用。有句话说的好,分析 HTML 应当使用库函数,永远不要手工分析。对于 `DWARF` 来说正是如此。`DWARF` 比 HTML 要复杂得多。上面所展示出来的只是冰山一角。更糟糕的是,在实际的目标文件中,大部分信息是以非常紧凑的压缩格式存储的,分析起来更加复杂(信息中的某些部分,例如位置信息与行号信息,在某些虚拟机下是以指令的方式编码的)。
|
||||
|
||||
所以我们要使用库函数来处理 `DWARF`。下面是两种我熟悉的主流库(还有些不完整的库这里没有写)
|
||||
所以我们要使用库来处理 `DWARF`。下面是两种我熟悉的主要的库(还有些不完整的库这里没有写)
|
||||
|
||||
1. `BFD` (libbfd),包含了 `objdump` (对,就是这篇文章中我们一直在用的这货),`ld`(`GNU` 连接器)与 `as`(`GNU` 编译器)。`BFD` 主要用于[GNU binutils][11]。
|
||||
1. `BFD` (libbfd),包含了 `objdump` (对,就是这篇文章中我们一直在用的这货),`ld`(`GNU` 连接器)与 `as`(`GNU` 编译器)。`BFD` 主要用于 [GNU binutils][11]。
|
||||
2. `libdwarf` ,同它的哥哥 `libelf` 一同用于 `Solaris` 与 `FreeBSD` 中的调试信息分析。
|
||||
|
||||
相比较而言我更倾向于使用 `libdwarf`,因为我对它了解的更多,并且 `libdwarf` 的开源协议更开放。
|
||||
相比较而言我更倾向于使用 `libdwarf`,因为我对它了解的更多,并且 `libdwarf` 的开源协议更开放(`LGPL` 对比 `GPL`)。
|
||||
|
||||
因为 `libdwarf` 本身相当复杂,操作起来需要相当多的代码,所以我在这不会展示所有代码。你可以在 [这里][24] 下载代码并运行试试。运行这些代码需要提前安装 `libelfand` 与 `libdwarf` ,同时在使用连接器的时候要使用参数 `-lelf` 与 `-ldwarf`。
|
||||
|
||||
这个示例程序可以接受可执行文件并打印其中的函数名称与函数入口地址。下面是我们整篇文章中使用的C程序经过示例程序处理后的输出。
|
||||
这个示例程序可以接受可执行文件并打印其中的函数名称与函数入口地址。下面是我们整篇文章中使用的 C 程序经过示例程序处理后的输出。
|
||||
|
||||
```
|
||||
$ dwarf_get_func_addr tracedprog2
|
||||
@ -285,17 +283,17 @@ high pc : 0x0804865a
|
||||
|
||||
原理上讲,调试信息是个很简单的概念。尽管实现细节可能比较复杂,但经过了上面的学习我想你应该了解了调试器是如何从可执行文件中获取它需要的源代码信息的了。对于程序员而言,程序只是代码段与数据结构;对可执行文件而言,程序只是一系列存储在内存或寄存器中的指令或数据。但利用调试信息,调试器就可以将这两者连接起来,从而完成调试工作。
|
||||
|
||||
此文与这系列的前两篇,一同介绍了调试器的内部工作过程。利用这里所讲到的知识,再敲些代码,应该可以完成一个 `Linux` 中最简单基础但也有一定功能的调试器。
|
||||
此文与这系列的前两篇,一同介绍了调试器的内部工作过程。利用这里所讲到的知识,再敲些代码,应该可以完成一个 Linux 中最简单、基础但也有一定功能的调试器。
|
||||
|
||||
下一步我并不确定要做什么,这个系列文章可能就此结束,也有可能我要讲些堆栈调用的事情,又或者讲 `Windows` 下的调试。你们有什么好的点子或者相关材料,可以直接评论或者发邮件给我。
|
||||
下一步我并不确定要做什么,这个系列文章可能就此结束,也有可能我要讲些堆栈调用的事情,又或者讲 Windows 下的调试。你们有什么好的点子或者相关材料,可以直接评论或者发邮件给我。
|
||||
|
||||
### 参考
|
||||
|
||||
* objdump 参考手册
|
||||
* [ELF][12] 与 [DWARF][13]的维基百科
|
||||
* [Dwarf Debugging Standard home page][14],这里有很棒的 DWARF 教程与 DWARF 标准,作者是 Michael Eager。第二版基于 GCC 也许更能吸引你。
|
||||
* [libdwarf home page][15],这里可以下载到 libwarf 的完整库与参考手册
|
||||
* [BFD documentation][16]
|
||||
* [ELF][12] 与 [DWARF][13] 的维基百科
|
||||
* [Dwarf Debugging Standard 主页][14],这里有很棒的 DWARF 教程与 DWARF 标准,作者是 Michael Eager。第二版基于 GCC 也许更能吸引你。
|
||||
* [libdwarf 主页][15],这里可以下载到 libwarf 的完整库与参考手册
|
||||
* [BFD 文档][16]
|
||||
|
||||
* * *
|
||||
|
||||
@ -305,7 +303,7 @@ via: http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[YYforymj](https://github.com/YYforymj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -335,5 +333,5 @@ via: http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging
|
||||
[23]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id12
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2011/dwarf_get_func_addr.c
|
||||
[25]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
[26]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
[27]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints/
|
||||
[26]:https://linux.cn/article-8552-1.html
|
||||
[27]:https://linux.cn/article-8418-1.html
|
||||
@ -0,0 +1,101 @@
|
||||
软件定义存储(SDS)的发展:十个你应当知道的项目
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
*凭借 SDS,组织机构可以更好抽象出底层存储的管理功能,并且通过不同策略实现灵活配置。下面将要向你展示一些你应当知道的此类开源项目。Creative Commons Zero,Pixabay *
|
||||
|
||||
纵观 2016 年,SDS(Software-Defined Storage,软件定义存储)方面取得了很多里程碑式的进步,并且日益紧密的与云部署结合在了一起。凭借 SDS ,组织机构可以更好抽象出底层存储的管理功能,并且通过不同策略实现灵活配置。当然,他们也可以选择自由开源的 SDS 解决方案。人们熟知的 Ceph 正是凭借 OpenStack 部署在不断扩大自己的影响力,但是它离成为唯一的 SDS 开源项目还有很长的路要走。
|
||||
|
||||
Gartner 的一份市场调查报告中预测,截至到 2019 年,70% 已有的存储部署解决方案会支持以纯软件的方式来实施。同时 Gartner 还预测截至到 2020 年,70% 到 80% 的非结构化数据会存储在由 SDS 管理的廉价存储设备中。
|
||||
|
||||
最近,Dell EMC 公司加入到了由 Linux 基金会发起的 [OpenSDS][4] 项目中。 OpenSDS 致力于寻求解决 SDS 集成所面临的挑战,并推动企业对开放标准的采用。它由存储客户与厂商组成,包括 Fujitsu,Hitachi Data Systems,Huawei,Oregon State University 以及 Vodafone。同时 OpenSDS 也寻求与其它的上游开源社区进行合作,比如 Cloud Native Computing Foundation、Docker、OpenStack 以及 Open Container Initiative。
|
||||
|
||||
根据 Open SDS 项目的 [主页][5],2017 年会是 SDS 的一个元年:“社区希望在 2017 第二季度完成原型的发布,并且在第三季度中发布一个测试版本。OpenSDS 的最初组织者期望能通过这个项目来影响到一些开源技术,比如来自 Openstack 社区的 Cinder 和 Manila 项目,并且能够支持更广泛的云存储解决方案。”
|
||||
|
||||
与此同时,SDS 相关项目也呈现了爆发式的增长,其范围横跨 Apache Cassandra 到 Cehp。Linux 基金会最近发布了 2016 年度报告“[开放云指南:当前的趋势及开源项目][7]”,报告从整体上分析了开放云计算的现状,其中有一章涵盖了 SDS。你可以[下载][8]这篇报告,需要注意的是,这是一份综合了容器发展趋势、SDS,以及云计算的重新定义等等很多内容。报告中涵盖了当今对于开源云计算最重要的一些项目,并分类给出了描述和链接。
|
||||
|
||||
在这个系列的文章中,我们从该报告中整理了很多项目,并且针对它们是如何发展的提供了一些额外的视角及信息。在下面的内容当中,你会看到现今对 SDS 来说很重要的项目,并且能了解到它们为什么具有这么大的影响力。同时,根据上面的报告,我们提供了相关项目的 GitHub 仓库链接,方便大家查看。
|
||||
|
||||
### 软件定义存储(SDS)
|
||||
|
||||
- [Apache Cassandra][9]
|
||||
|
||||
Apache Cassandra 是一个可扩展的、高可用的,面向任务优先应用的数据库。它可以运行在商业设备或者云架构上,并且能实现跨数据中心的低延迟数据传输,同时具备良好的容错性。[Cassandra 的 GitHub 仓库][10]。
|
||||
|
||||
- [Ceph][11]
|
||||
|
||||
Ceph 是 Red Hat 构建的一个企业级可扩展的块设备、对象,以及文件存储平台,并且可部署在公有云或者私有云之上。Ceph 目前被广泛应用于 OpenStack。[Ceph 的 GitHub 仓库][12]。
|
||||
|
||||
- [CouchDB][13]
|
||||
|
||||
CouchDB 是一个 Apache 软件基金会项目,是一个单节点或者集群数据库管理系统。CouchDB 提供了 RESTful HTTP 接口来读取和更新数据库文件。[CouchDB 的 GitHub 仓库][14]。
|
||||
|
||||
- [Docker 数据卷插件][15]
|
||||
|
||||
Docker Engine 数据卷插件可以使 Engine 与外部的存储系统一起集成部署,并且数据卷的生命周期与单一 Engine 主机相同。目前存在很多第三方的数据卷管理插件,包括 Azure File Storage、NetApp、VMware vSphere 等等。你可以在 GitHub上查找到更多的插件。
|
||||
|
||||
- [GlusterFS][16]
|
||||
|
||||
Gluster 是 Red Hat 的可扩展网络文件系统,同时也是数据管理平台。Gluster 可以部署在公有云,私有云或者混合云之上,可用于 Linux 容器内的流媒体处理任务、数据分析任务,以及其它数据和带宽敏感型任务的执行。[GlusterFS 的 GitHub 仓库][17]。
|
||||
|
||||
- [MongoDB][18]
|
||||
|
||||
MongoDB 是一个高性能的文件数据库,并且部署和扩展都非常简单。[MongoDB 的 GitHub 仓库][19]。
|
||||
|
||||
- [Nexenta][20]
|
||||
|
||||
NexentaStor 是一个可扩展的、统一的软件定义的文件和块设备管理服务,同时支持数据管理功能。它能够与 VMware 集成,并且支持 Docker 和 OpenStack。[Nexenta 的 GitHub 仓库][21]。
|
||||
|
||||
- [Redis][22]
|
||||
|
||||
Redis 是一个基于内存的数据存储,一般被用作数据库、缓存,以及消息代理。它支持多种数据结构,并且本身支持复制、Lua 脚本、LRU 算法、事务,以及多层级的硬盘持久化。
|
||||
|
||||
- [Riak CS][24]
|
||||
|
||||
Riak CS(Cloud Storage)是基于 Basho 的分布式数据库 Riak KV 构建的对象存储软件。它提供了在不同规模的分布式云存储能力,可以用于公有云和私有云,还能为大压力的应用和服务提供基础的存储服务。其 API 兼容 Amazon S3,并且支持租户级别的费用计算和测量能力。[Riak CS 的 GitHub 仓库][25]。
|
||||
|
||||
- [Swift][26]
|
||||
|
||||
Swift 是 OpenStack 项目中的对象存储系统,设计初衷是通过简单 API 存储和获取非结构化数据。Swift 设计之初就是可扩展的,并且针对持久性、可靠性以及并发数据读取做了优化。[Swift 的 GitHub 仓库][27]。
|
||||
|
||||
_了解更多的开源云计算趋势以及更完整的开源云计算项目列表,请[下载 Linux 基金会的“开放云指南”][3]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/guide-open-cloud-software-defined-storage-opens
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[toutoudnf](https://github.com/toutoudnf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/software-definedjpg
|
||||
[3]:http://bit.ly/2eHQOwy
|
||||
[4]:http://ctt.marketwire.com/?release=11G125514-001&id=10559023&type=0&url=https%3A%2F%2Fwww.opensds.io%2F
|
||||
[5]:https://www.opensds.io/
|
||||
[6]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[7]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[8]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[9]:http://cassandra.apache.org/
|
||||
[10]:https://github.com/apache/cassandra
|
||||
[11]:http://ceph.com/
|
||||
[12]:https://github.com/ceph/ceph
|
||||
[13]:http://couchdb.apache.org/
|
||||
[14]:https://github.com/apache/couchdb
|
||||
[15]:https://docs.docker.com/engine/extend/plugins_volume/
|
||||
[16]:https://www.gluster.org/
|
||||
[17]:https://github.com/gluster/glusterfs
|
||||
[18]:https://www.mongodb.com/
|
||||
[19]:https://github.com/mongodb/mongo
|
||||
[20]:https://nexenta.com/
|
||||
[21]:https://github.com/Nexenta
|
||||
[22]:http://redis.io/
|
||||
[23]:https://github.com/antirez/redis
|
||||
[24]:http://docs.basho.com/riak/cs/2.1.1/
|
||||
[25]:https://github.com/basho/riak_cs
|
||||
[26]:https://wiki.openstack.org/wiki/Swift
|
||||
[27]:https://github.com/openstack/swift
|
||||
@ -3,7 +3,7 @@
|
||||
|
||||
在之前的一篇文章里,我们回顾了[ Linux 下 9 个最好的文件比较工具][1],本篇文章中,我们将会描述在 Linux 下怎样找到两个目录之间的不同。
|
||||
|
||||
一般情况下,要在 Linux 下比较两个文件,我们会使用 **diff** (一个简单的源自 Unix 的命令行工具 )来显示两个计算机文件的不同;它一行一行的去比较文件,而且很方便使用,在几乎全部的 Linux 发行版都预装了。
|
||||
一般情况下,要在 Linux 下比较两个文件,我们会使用 `diff` (一个简单的源自 Unix 的命令行工具)来显示两个计算机文件的不同;它一行一行的去比较文件,而且很方便使用,在几乎全部的 Linux 发行版都预装了。
|
||||
|
||||
问题是在 Linux 下我们怎么才能比较两个目录?现在,我们想知道两个目录中哪些文件/子目录是共有的,哪些只存在一个于目录。
|
||||
|
||||
@ -14,7 +14,7 @@ $ diff [OPTION]… FILES
|
||||
$ diff options dir1 dir2
|
||||
```
|
||||
|
||||
默认情况下,输出是按文件/子文件夹的文件名的字母排序的,如下面截图所示,在命令中, `-q` 开关是告诉 diif 只有在文件有差异时报告。
|
||||
默认情况下,输出是按文件/子文件夹的文件名的字母排序的,如下面截图所示,在命令中, `-q` 开关是告诉 `diif` 只有在文件有差异时报告。
|
||||
|
||||
```
|
||||
$ diff -q directory-1/ directory-2/
|
||||
@ -25,7 +25,7 @@ $ diff -q directory-1/ directory-2/
|
||||
|
||||
*两个文件夹之间的差异*
|
||||
|
||||
再次运行 diff 并不能进入子文件夹,但是我们可以使用 `-r` 开关来读子文件夹,如下所示。
|
||||
再次运行 `diff` 并不能进入子文件夹,但是我们可以使用 `-r` 开关来读子文件夹,如下所示。
|
||||
|
||||
```
|
||||
$ diff -qr directory-1/ directory-2/
|
||||
@ -33,7 +33,7 @@ $ diff -qr directory-1/ directory-2/
|
||||
|
||||
### 使用 Meld 可视化比较和合并工具
|
||||
|
||||
meld 是一个很酷的图形化工具(一个 GNOME 桌面下的可视化的比较和合并工具),可供那些喜欢使用鼠标的人使用,可按如下来安装。
|
||||
`meld` 是一个很酷的图形化工具(一个 GNOME 桌面下的可视化的比较和合并工具),可供那些喜欢使用鼠标的人使用,可按如下来安装。
|
||||
|
||||
```
|
||||
$ sudo apt install meld [Debian/Ubuntu systems]
|
||||
@ -51,6 +51,7 @@ $ sudo dnf install meld [Fedora 22+]
|
||||
*Meld 比较工具*
|
||||
|
||||
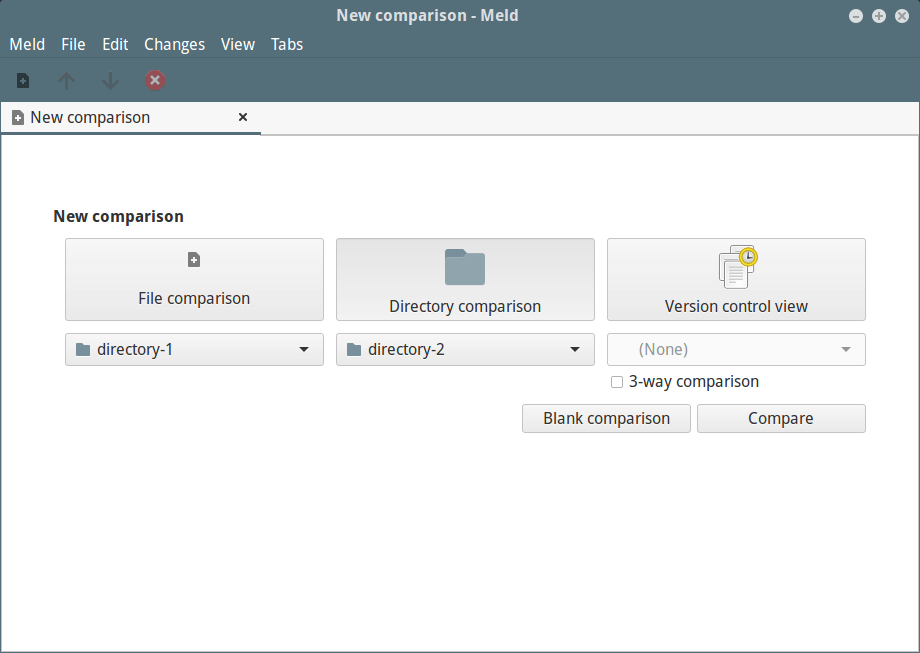
选择你想要比较的文件夹,注意你可以勾选 “**3-way Comparison**” 选项,添加第三个文件夹。
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
@ -76,7 +77,7 @@ Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者,即将成为 Linux 系统管
|
||||
|
||||
via: http://www.tecmint.com/compare-find-difference-between-two-directories-in-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[hkurj](https://github.com/hkurj)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -1,45 +1,40 @@
|
||||
wcnnbdk1 translating
|
||||
ssh_scan – Verifies Your SSH Server Configuration and Policy in Linux
|
||||
ssh_scan:远程验证你 SSH 服务的配置和策略
|
||||
============================================================
|
||||
|
||||
`ssh_scan` 是一个面向 Linux 和 UNIX 服务器的易用的 SSH 服务参数配置和策略的扫描器程序,其思路来自[Mozilla OpenSSH 安全指南][6],这个指南为 SSH 服务参数配置提供了一个可靠的安全策略基线的建议,如加密算法(Ciphers),报文认证信息码算法(MAC),密钥交换算法(KexAlgos)和其它。
|
||||
|
||||
ssh_scan is an easy-to-use prototype SSH configuration and policy scanner for Linux and UNIX servers, inspired by [Mozilla OpenSSH Security Guide][6], which provides a reasonable baseline policy recommendation for SSH configuration parameters such as Ciphers, MACs, and KexAlgos and much more.
|
||||
`ssh_scan` 有如下好处:
|
||||
|
||||
It has some of the following benefits:
|
||||
* 它的依赖是最小化的,`ssh_scan` 只引入了本地 Ruby 和 BinData 来进行它的工作,没有太多的依赖。
|
||||
* 它是可移植的,你可以在其它的项目中使用 `ssh_scan` 或者将它用在[自动化任务][1]上。
|
||||
* 它是易于使用的,只需要简单的将它指向一个 SSH 服务就可以获得一个该服务所支持的选项和策略状态的 JSON 格式报告。
|
||||
* 它同时也是易于配置的,你可以创建适合你策略需求的策略。
|
||||
|
||||
* It has minimal dependencies, ssh_scan only employs native Ruby and BinData to do its work, no heavy dependencies.
|
||||
**建议阅读:** [如何在 Linux 上安装配置 OpenSSH 服务][7]
|
||||
|
||||
* It’s portable, you can use ssh_scan in another project or for [automation of tasks][1].
|
||||
### 如何在 Linux 上安装 ssh_scan
|
||||
|
||||
* It’s easy to use, simply point it at an SSH service and get a JSON report of what it supports and it’s policy status.
|
||||
有如下三种安装 `ssh_scan` 的方式:
|
||||
|
||||
* It’s also configurable, you can create your own custom policies that fit your specific policy requirements.
|
||||
|
||||
**Suggested Read:** [How to Install and Configure OpenSSH Server in Linux][7]
|
||||
|
||||
### How to Install ssh_scan in Linux
|
||||
|
||||
There are three ways you can install ssh_scan and they are:
|
||||
|
||||
To install and run as a gem, type:
|
||||
使用 Ruby gem 来安装运行,如下:
|
||||
|
||||
```
|
||||
----------- On Debian/Ubuntu -----------
|
||||
----------- 在 Debian/Ubuntu -----------
|
||||
$ sudo apt-get install ruby gem
|
||||
$ sudo gem install ssh_scan
|
||||
----------- On CentOS/RHEL -----------
|
||||
----------- 在 CentOS/RHEL -----------
|
||||
# yum install ruby rubygem
|
||||
# gem install ssh_scan
|
||||
```
|
||||
|
||||
To run from a [docker container][8], type:
|
||||
使用[docker 容器][8]来运行,如下:
|
||||
|
||||
```
|
||||
# docker pull mozilla/ssh_scan
|
||||
# docker run -it mozilla/ssh_scan /app/bin/ssh_scan -t github.com
|
||||
```
|
||||
|
||||
To install and run from source, type:
|
||||
使用源码安装运行,如下:
|
||||
|
||||
```
|
||||
# git clone https://github.com/mozilla/ssh_scan.git
|
||||
@ -53,29 +48,29 @@ To install and run from source, type:
|
||||
# ./bin/ssh_scan
|
||||
```
|
||||
|
||||
### How to Use ssh_scan in Linux
|
||||
### 如何在 Linux 上使用 ssh_scan
|
||||
|
||||
The syntax for using ssh_scan is as follows:
|
||||
使用 `ssh_scan` 的语法如下:
|
||||
|
||||
```
|
||||
$ ssh_scan -t ip-address
|
||||
$ ssh_scan -t server-hostname
|
||||
$ ssh_scan -t ip地址
|
||||
$ ssh_scan -t 主机名
|
||||
```
|
||||
|
||||
For example to scan SSH configs and policy of server 92.168.43.198, enter:
|
||||
举个例子来扫描 192.168.43.198 这台服务器的 SSH 配置和策略,键入:
|
||||
|
||||
```
|
||||
$ ssh_scan -t 192.168.43.198
|
||||
```
|
||||
|
||||
Note you can also pass a [IP/Range/Hostname] to the `-t` option as shown in the options below:
|
||||
注意你同时也可以像下方展示的给 `-t` 选项传入一个[IP地址/地址段/主机名]:
|
||||
|
||||
```
|
||||
$ ssh_scan -t 192.168.43.198,200,205
|
||||
$ ssh_scan -t test.tecmint.lan
|
||||
```
|
||||
|
||||
##### Sample Output
|
||||
输出示例:
|
||||
|
||||
```
|
||||
I, [2017-05-09T10:36:17.913644 #7145] INFO -- : You're using the latest version of ssh_scan 0.0.19
|
||||
@ -192,25 +187,25 @@ I, [2017-05-09T10:36:17.913644 #7145] INFO -- : You're using the latest version
|
||||
]
|
||||
```
|
||||
|
||||
You can use `-p` to specify a different port, `-L` to enable the logger and `-V` to define the verbosity level as shown below:
|
||||
你可以使用 `-p` 选项来指定不同的端口,`-L` 选项来开启日志记录配合 `-V` 选项来指定日志级别:
|
||||
|
||||
```
|
||||
$ ssh_scan -t 192.168.43.198 -p 22222 -L ssh-scan.log -V INFO
|
||||
```
|
||||
|
||||
Additionally, use a custom policy file (default is Mozilla Modern) with the `-P` or `--policy [FILE]` like so:
|
||||
另外,可以使用 `-P` 或 `--policy` 选项来指定一个策略文件(默认是 Mozilla Modern)(LCTT 译注:这里的 Modern 可能指的是 https://wiki.mozilla.org/Security/Server_Side_TLS 中提到的 Modern compatibility ):
|
||||
|
||||
```
|
||||
$ ssh_scan -t 192.168.43.198 -L ssh-scan.log -V INFO -P /path/to/custom/policy/file
|
||||
```
|
||||
|
||||
Type this to view all ssh_scan usage options and more examples:
|
||||
ssh_scan 使用帮助与其它示例:
|
||||
|
||||
```
|
||||
$ ssh_scan -h
|
||||
```
|
||||
|
||||
##### Sample Output
|
||||
输出示例:
|
||||
|
||||
```
|
||||
ssh_scan v0.0.17 (https://github.com/mozilla/ssh_scan)
|
||||
@ -245,34 +240,28 @@ ssh_scan -t 192.168.1.1 -P custom_policy.yml
|
||||
ssh_scan -t 192.168.1.1 --unit-test -P custom_policy.yml
|
||||
```
|
||||
|
||||
Check out some useful artilces on SSH Server:
|
||||
SSH 服务器相关参考阅读:
|
||||
|
||||
1. [SSH Passwordless Login Using SSH Keygen in 5 Easy Steps][2]
|
||||
1. [使用 SSH Keygen(ssh-keygen)五步实现 SSH 免密登录][2]
|
||||
2. [安全 SSH 服务器的 5 个最佳实践][3]
|
||||
3. [使用 Chroot 来限制 SSH 用户进入某些目录][4]
|
||||
4. [如何配置 SSH 连接来简化远程登录][5]
|
||||
|
||||
2. [5 Best Practices to Secure SSH Server][3]
|
||||
如果需要更详细的信息可以访问 `ssh_scan` 的 Github 仓库:[https://github.com/mozilla/ssh_scan][9]
|
||||
|
||||
3. [Restrict SSH User Access to Certain Directory Using Chrooted Jail][4]
|
||||
|
||||
4. [How to Configure Custom SSH Connections to Simplify Remote Access][5]
|
||||
|
||||
For more details visit ssh_scan Github repository: [https://github.com/mozilla/ssh_scan][9]
|
||||
|
||||
In this article, we showed you how to set up and use ssh_scan in Linux. Do you know of any similar tools out there? Let us know via the feedback form below, including any other thoughts concerning this guide.
|
||||
|
||||
SHARE[+][10][0][11][20][12][25][13] [][14]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
Aaron Kili 是 Linux 与 F.O.S.S (自由及开源软件)爱好者,一位将来的 Linux 系统管理员,网站开发者,现在是一个热爱与计算机一起工作并且拥有强烈知识分信念的 TecMint 内容贡献者。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -286,11 +275,4 @@ via: https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-l
|
||||
[7]:https://www.tecmint.com/install-openssh-server-in-linux/
|
||||
[8]:https://www.tecmint.com/install-docker-and-learn-containers-in-centos-rhel-7-6/
|
||||
[9]:https://github.com/mozilla/ssh_scan
|
||||
[10]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#
|
||||
[11]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#
|
||||
[12]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#
|
||||
[13]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#
|
||||
[14]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#comments
|
||||
[15]:https://www.tecmint.com/author/aaronkili/
|
||||
[16]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[17]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,90 @@
|
||||
理解 Linux 中的 Shutdown、Poweroff、Halt 和 Reboot 命令
|
||||
============================================================
|
||||
|
||||
在本篇中,我们会向你解释 **shutdown、poweroff、halt 以及 reboot** 命令。我们会解释当使用可选项时,它们实际做了什么。
|
||||
|
||||
如果你想深入管理 Linux 服务器,那么为了有效和可靠的服务器管理,这些[重要的 Linux 命令][1]你需要完全理解。
|
||||
|
||||
通常上,当你想要关闭或者重启你的机器时,你会运行下面之一的命令:
|
||||
|
||||
### Shutdown 命令
|
||||
|
||||
**shutdown** 会给系统计划一个时间关机。它可被用于停止、关机、重启机器。
|
||||
|
||||
你也许会指定一个时间字符串(通常是 “now” 或者 “hh:mm” 用于小时/分钟)作为第一个参数。额外地,你也可以设置一个广播信息在系统关闭前发送给所有已登录的用户。
|
||||
|
||||
重要:如果使用了时间参数,系统关机前 5 分钟,/run/nologin 文件会被创建来确保没有人可以再登录。
|
||||
|
||||
shutdown 命令示例:
|
||||
|
||||
```
|
||||
# shutdown
|
||||
# shutdown now
|
||||
# shutdown 13:20
|
||||
# shutdown -p now #关闭机器
|
||||
# shutdown -H now #停止机器
|
||||
# shutdown -r09:35 #在 09:35am 重启机器
|
||||
```
|
||||
|
||||
要取消即将的关机,只要输入下面的命令:
|
||||
|
||||
```
|
||||
# shutdown -c
|
||||
```
|
||||
|
||||
### Halt 命令
|
||||
|
||||
**halt** 通知硬件来停止所有的 CPU 功能,但是仍然保持通电。你可以用它使系统处于低层维护状态。
|
||||
|
||||
注意在有些情况会它会完全关闭系统。下面是 halt 命令示例:
|
||||
|
||||
```
|
||||
# halt #停止机器
|
||||
# halt -p #关闭机器
|
||||
# halt --reboot #重启机器
|
||||
```
|
||||
|
||||
### poweroff 命令
|
||||
|
||||
**poweroff** 会发送一个 ACPI 信号来通知系统关机。
|
||||
|
||||
下面是 poweroff 命令示例:
|
||||
|
||||
```
|
||||
# poweroff #关闭机器
|
||||
# poweroff --halt #停止机器
|
||||
# poweroff --reboot #重启机器
|
||||
```
|
||||
|
||||
### Reboot 命令
|
||||
|
||||
reboot 通知系统重启。
|
||||
|
||||
```
|
||||
# reboot #重启机器
|
||||
# reboot --halt #停止机器
|
||||
# reboot -p #关闭机器
|
||||
```
|
||||
|
||||
就是这样了!如先前提到的,理解这些命令能够有效并可靠地在多用户环境下管理 Linux 服务器。你有一些额外的想法么?在评论区留言与我们分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一名 Linux 和 F.O.S.S 的爱好者,未来的 Linux 系统管理员、网站开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并乐于分享知识。
|
||||
|
||||
--------------------------
|
||||
|
||||
via: https://www.tecmint.com/shutdown-poweroff-halt-and-reboot-commands-in-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/60-commands-of-linux-a-guide-from-newbies-to-system-administrator/
|
||||
[2]:https://www.tecmint.com/author/aaronkili/
|
||||
|
||||
131
published/20170529 Linux comm command tutorial for beginners.md
Normal file
131
published/20170529 Linux comm command tutorial for beginners.md
Normal file
@ -0,0 +1,131 @@
|
||||
使用 comm 比较两个排序好的文件
|
||||
===========================================================
|
||||
|
||||
Linux 中的 `comm` 命令可以让用户按行比较两个**已经排序好**的文件。在本教程中,我们将使用一些浅显易懂的例子来讨论这个命令行工具。在开始之前,请注意,本教程中提到的所有例子都已经在 Ubuntu 16.04LTS 版本中测试过。
|
||||
|
||||
下面的例子将会告诉你 `comm` 命令是如何工作的。
|
||||
|
||||
### 1、 如何使用 `comm` 比较两个排序好的文件
|
||||
|
||||
要使用 `comm` 命令比较两个排序好的文件,只需要把它们的名字作为 `comm` 命令的参数。下面是通常的语法:
|
||||
|
||||
```
|
||||
comm [name-of-first-file] [name-of-second-file]
|
||||
```
|
||||
|
||||
比如,假设 `file1` 和 `file2` 是这种情况下的两个文件。前者包含下面几行内容:
|
||||
|
||||
```
|
||||
001
|
||||
056
|
||||
127
|
||||
258
|
||||
```
|
||||
|
||||
而后者包含下面几行内容:
|
||||
|
||||
```
|
||||
002
|
||||
056
|
||||
167
|
||||
369
|
||||
```
|
||||
|
||||
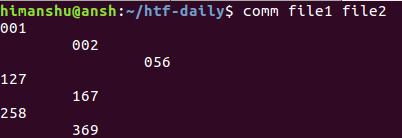
此时,`comm` 命令的输出如下图所示:
|
||||
|
||||
```
|
||||
comm file1 file2
|
||||
```
|
||||
|
||||
[][8]
|
||||
|
||||
你可以看到,输出包含 3 列。第一列是仅包含在 `file1` 中的内容,第二列是仅包含在 `file2` 中的内容,最后,第三列是两个文件中均包含的内容。
|
||||
|
||||
### 2、 如何不输出 `comm` 命令输出中的某些列
|
||||
|
||||
如果你想,你可以不输出 `comm` 命令输出中的某些列。对于该特性,你有三个命令行选项可用:`-1`、`-2` 和 `-3` 。正如你所猜想的,这些数字表示你不想输出的列。
|
||||
|
||||
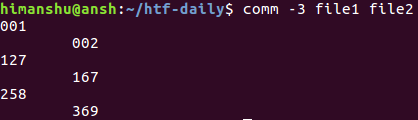
比如,下面这个命令将会不输出上面例子中的第三列:
|
||||
|
||||
```
|
||||
comm -3 file1 file2
|
||||
```
|
||||
[][9]
|
||||
|
||||
|
||||
因此,你可以看到,第三列并没有输出。
|
||||
|
||||
注意,你可以通过一个单一命令同时不输出多列内容。比如:
|
||||
|
||||
```
|
||||
comm -12 file1 file2
|
||||
```
|
||||
|
||||
上面这个命令将会不输出第一、二列。
|
||||
|
||||
### 3、 如何使用 `comm` 命令比较两个未排序好的文件
|
||||
|
||||
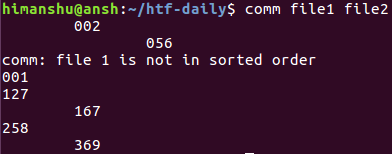
正如我们所知道的,`comm` 只可用于排序好的文件。如果发现其中一个文件未排序好,那么便会在输出中产生一条信息来告诉用户。比如,我们交换 `file1` 的第一行和第二行,然后与 `file2` 进行比较。下面是该命令的输出:
|
||||
|
||||
[][10]
|
||||
|
||||
你可以看到,这个命令产生一个输出告诉我们:`file1` 还没有排序好。此时,如果你不想让这个工具检查输入是否已经排序好,那么你可以使用 `--nocheck-order` 选项:
|
||||
|
||||
```
|
||||
comm --nocheck-order file1 file2
|
||||
```
|
||||
|
||||
[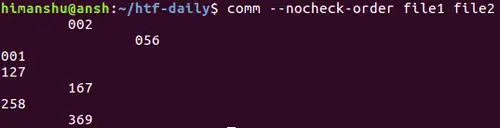][11]
|
||||
|
||||
你可以看到,前面出现的提示信息已经消失了。
|
||||
|
||||
注意,如果你想明确告诉 `comm` 命令来检查输入文件是否排序好,那么你可以使用 `--check-order` 选项。
|
||||
|
||||
### 4、 如何用自定义字符串分隔 `comm` 命令的输出列
|
||||
|
||||
默认情况下,`comm` 命令的输出列之间是以空格分隔的。然而,如何你想使用一个自定义字符串作为分隔符,那么你可以使用 `--output-delimiter` 选项。使用该选项时需要指定你想用来作为分隔符的字符串。
|
||||
|
||||
```
|
||||
comm --output-delimiter=+ file1 file2
|
||||
```
|
||||
|
||||
比如,我们使用加号来作为分隔符:
|
||||
|
||||
[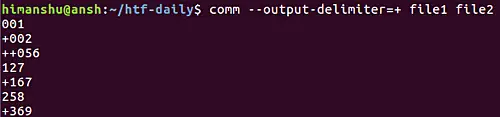][12]
|
||||
|
||||
### 5、 如何使 `comm` 的输出行以 `NUL` 字符终止
|
||||
|
||||
默认情况下,`comm` 命令的输出行以新行终止。然而,如果你想,那么你可以改为以 `NUL` 字符终止,只需要使用 `-z` 选项即可:
|
||||
|
||||
```
|
||||
comm -z file1 file2
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
`comm` 命令并没有特别多的特性性,我们在这儿已经讨论了它的绝大多数命令行选项。只需要理解和练习在这篇教程中讨论的内容,那么你便可以在日常工作中知道如何使用这个工具了。如果你有任何问题或者疑问,请前往该命令的 [man 手册][13],或者在下面评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-comm-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/linux-comm-command/
|
||||
[1]:https://www.howtoforge.com/linux-comm-command/#linux-comm-command
|
||||
[2]:https://www.howtoforge.com/linux-comm-command/#-how-to-compare-two-sorted-files-using-comm
|
||||
[3]:https://www.howtoforge.com/linux-comm-command/#-how-tonbspsuppress-individual-columns-in-comm-command-output
|
||||
[4]:https://www.howtoforge.com/linux-comm-command/#-how-to-make-comm-compare-files-that-are-not-sorted
|
||||
[5]:https://www.howtoforge.com/linux-comm-command/#-how-to-separate-comm-output-columns-with-custom-string
|
||||
[6]:https://www.howtoforge.com/linux-comm-command/#-how-to-make-comm-output-lines-nul-terminated
|
||||
[7]:https://www.howtoforge.com/linux-comm-command/#conclusion
|
||||
[8]:https://www.howtoforge.com/images/linux_comm_command/big/comm-output.png
|
||||
[9]:https://www.howtoforge.com/images/linux_comm_command/big/comm-supress-column.png
|
||||
[10]:https://www.howtoforge.com/images/linux_comm_command/big/comm-not-sorted-message.png
|
||||
[11]:https://www.howtoforge.com/images/linux_comm_command/big/comm-nocheck-order.png
|
||||
[12]:https://www.howtoforge.com/images/linux_comm_command/big/comm-output-delimiter.png
|
||||
[13]:https://linux.cn/man/1/comm
|
||||
@ -0,0 +1,108 @@
|
||||
使用 Python 开始你的机器学习之旅
|
||||
============================================================
|
||||
|
||||
> 机器学习是你的简历中必需的一门技能。我们简要概括一下使用 Python 来进行机器学习的一些步骤。
|
||||
|
||||
|
||||

|
||||
|
||||
>图片来自: opensource.com
|
||||
|
||||
你想知道如何开始机器学习吗?在这篇文章中,我将简要概括一下使用 [Python][16] 来开始机器学习的一些步骤。Python 是一门流行的开源程序设计语言,也是在人工智能及其它相关科学领域中最常用的语言之一。机器学习简称 ML,是人工智能的一个分支,它是利用算法从数据中进行学习,然后作出预测。机器学习有助于帮助我们预测我们周围的世界。
|
||||
|
||||
从无人驾驶汽车到股市预测,再到在线学习,机器学习通过预测来进行自我提高的方法几乎被用在了每一个领域。由于机器学习的实际运用,目前它已经成为就业市场上最有需求的技能之一。另外,使用 Python 来开始机器学习很简单,因为有大量的在线资源,以及许多可用的 [Python 机器学习库][16]。
|
||||
|
||||
你需要如何开始使用 Python 进行机器学习呢?让我们来总结一下这个过程。
|
||||
|
||||
### 提高你的 Python 技能
|
||||
|
||||
由于 Python 在工业界和科学界都非常受欢迎,因此你不难找到 Python 的学习资源。如果你是一个从未接触过 Python 的新手,你可以利用在线资源,比如课程、书籍和视频来学习 Python。比如下面列举的一些资源:
|
||||
|
||||
* [Python 学习之路][5]
|
||||
* [Google 开发者 Python 课程(视频)][6]
|
||||
* [Google 的 Python 课堂][7]
|
||||
|
||||
### 安装 Anaconda
|
||||
|
||||
下一步是安装 [Anacona][2]。有了 Anaconda ,你将可以开始使用 Python 来探索机器学习的世界了。Anaconda 的默认安装库包含了进行机器学习所需要的工具。
|
||||
|
||||
### 基本的机器学习技能
|
||||
|
||||
有了一些基本的 Python 编程技能,你就可以开始学习一些基本的机器学习技能了。一个实用的学习方法是学到一定技能便开始进行练习。然而,如果你想深入学习这个领域,那么你需要准备投入更多的学习时间。
|
||||
|
||||
一个获取技能的有效方法是在线课程。吴恩达的 Coursera [机器学习课程][20] 是一个不错的选择。其它有用的在线训练包括:
|
||||
|
||||
* [Python 机器学习: Scikit-Learn 教程][8]
|
||||
* [Python 实用机器学习教程][9]
|
||||
|
||||
你也可以在 [LiveEdu.tv][21] 上观看机器学习视频,从而进一步了解这个领域。
|
||||
|
||||
### 学习更多的 Python 库
|
||||
|
||||
当你对 Python 和机器学习有一个好的感觉之后,可以开始学习一些[开源的 Python 库][22]。科学的 Python 库将会使完成一些简单的机器学习任务变得很简单。然而,选择什么库是完全主观的,并且在业界内许多人有很大的争论。
|
||||
|
||||
一些实用的 Python 库包括:
|
||||
|
||||
* [Scikit-learn][10] :一个优雅的机器学习算法库,可用于数据挖掘和数据分析任务。
|
||||
* [Tensorflow][11] :一个易于使用的神经网络库。
|
||||
* [Theano][12] : 一个强大的机器学习库,可以帮助你轻松的评估数学表达式。
|
||||
* [Pattern][13] : 可以帮助你进行自然语言处理、数据挖掘以及更多的工作。
|
||||
* [Nilearn][14] :基于 Scikit-learn,它可以帮助你进行简单快速的统计学习。
|
||||
|
||||
### 探索机器学习
|
||||
|
||||
对基本的 Python、机器学习技能和 Python 库有了一定理解之后,就可以开始探索机器学习了。接下来,尝试探索一下 Scikit-learn 库。一个不错的教程是 Jake VanderPlas 写的 [Scikit-learn 简介][23]。
|
||||
|
||||
然后,进入中级主题,比如 [K-均值聚类算法简介][24]、线性回归、[决策树][25]和逻辑回归。
|
||||
|
||||
最后,深入高级机器学习主题,比如向量机和复杂数据转换。
|
||||
|
||||
就像学习任何新技能一样,练习得越多,就会学得越好。你可以通过练习不同的算法,使用不同的数据集来更好的理解机器学习,并提高解决问题的整体能力。
|
||||
|
||||
使用 Python 进行机器学习是对你的技能的一个很好的补充,并且有大量免费和低成本的在线资源可以帮助你。你已经掌握机器学习技能了吗?可以在下面留下你的评论,或者[提交一篇文章][26]来分享你的故事。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Michael J. Garbade 博士是旧金山 LiveEdu Inc(Livecoding.tv)的创始人兼首席执行官。Livecoding.tv 是世界上观看工程师直播编代码最先进的直播平台。你可以通过观看工程师们写网站、移动应用和游戏,来将你的技能提升到一个新的水平。MichaelJ. Garbade 博士拥有金融学博士学位,并且是一名自学成才的工程师,他喜欢 Python、Django、Sencha Touch 和视频流。
|
||||
|
||||
-----------
|
||||
|
||||
via: https://opensource.com/article/17/5/python-machine-learning-introduction
|
||||
|
||||
作者:[Michael J. Garbade][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drmjg
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&amp;amp;amp;src=programming_resource_menu
|
||||
[5]:https://learnpythonthehardway.org/book/
|
||||
[6]:https://www.youtube.com/playlist?list=PLfZeRfzhgQzTMgwFVezQbnpc1ck0I6CQl
|
||||
[7]:https://developers.google.com/edu/python/
|
||||
[8]:https://www.datacamp.com/community/tutorials/machine-learning-python#gs.HfAvLRs
|
||||
[9]:https://pythonprogramming.net/machine-learning-tutorial-python-introduction/
|
||||
[10]:http://scikit-learn.org/stable/
|
||||
[11]:https://opensource.com/article/17/2/machine-learning-projects-tensorflow-raspberry-pi
|
||||
[12]:http://deeplearning.net/software/theano/
|
||||
[13]:https://github.com/clips/pattern
|
||||
[14]:https://github.com/nilearn/nilearn
|
||||
[15]:https://opensource.com/article/17/5/python-machine-learning-introduction?rate=jgAmIV_YqoWTbnSgNjZ0EE5lyhJtzf-ukzhiMmXtfMQ
|
||||
[16]:https://opensource.com/article/17/2/3-top-machine-learning-libraries-python
|
||||
[17]:https://www.liveedu.tv/learn/python/
|
||||
[18]:https://opensource.com/article/17/2/3-top-machine-learning-libraries-python
|
||||
[19]:http://docs.continuum.io/anaconda/install
|
||||
[20]:https://www.coursera.org/learn/machine-learning
|
||||
[21]:https://www.liveedu.tv/
|
||||
[22]:https://opensource.com/article/17/5/4-practical-python-libraries
|
||||
[23]:http://nbviewer.jupyter.org/github/donnemartin/data-science-ipython-notebooks/blob/master/scikit-learn/scikit-learn-intro.ipynb
|
||||
[24]:https://www.datascience.com/blog/introduction-to-k-means-clustering-algorithm-learn-data-science-tutorials
|
||||
[25]:http://machinelearningmastery.com/implement-decision-tree-algorithm-scratch-python/
|
||||
[26]:https://opensource.com/story
|
||||
[27]:https://opensource.com/user/78291/feed
|
||||
[28]:https://opensource.com/users/drmjg
|
||||
@ -0,0 +1,156 @@
|
||||
MyCLI :一个支持自动补全和语法高亮的 MySQL/MariaDB 客户端
|
||||
====
|
||||
|
||||
MyCLI 是一个易于使用的命令行客户端,可用于受欢迎的数据库管理系统 MySQL、MariaDB 和 Percona,支持自动补全和语法高亮。它是使用 `prompt_toolkit` 库写的,需要 Python 2.7、3.3、3.4、3.5 和 3.6 的支持。MyCLI 还支持通过 SSL 安全连接到 MySQL 服务器。
|
||||
|
||||
#### MyCLI 的特性
|
||||
|
||||
* 当你第一次使用它的时候,将会自动创建一个文件 `~/.myclirc`。
|
||||
* 当输入 SQL 的关键词和数据库中的表、视图和列时,支持自动补全。
|
||||
* 默认情况下也支持智能补全,能根据上下文的相关性提供补全建议。
|
||||
|
||||
比如:
|
||||
|
||||
```
|
||||
SELECT * FROM <Tab> - 这将显示出数据库中的表名。
|
||||
SELECT * FROM users WHERE <Tab> - 这将简单的显示出列名称。
|
||||
```
|
||||
|
||||
* 通过使用 `Pygents` 支持语法高亮
|
||||
* 支持 SSL 连接
|
||||
* 提供多行查询支持
|
||||
* 它可以将每一个查询和输出记录到一个文件中(默认情况下禁用)。
|
||||
* 允许保存收藏一个查询(使用 `\fs 别名` 保存一个查询,并可使用 `\f 别名` 运行它)。
|
||||
* 支持 SQL 语句执行和表查询计时
|
||||
* 以更吸引人的方式打印表格数据
|
||||
|
||||
### 如何在 Linux 上为 MySQL 和 MariaDB 安装 MyCLI
|
||||
|
||||
在 Debian/Ubuntu 发行版上,你可以很容易的像下面这样使用 [`apt` 命令][6] 来安装 MyCLI 包:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install mycli
|
||||
```
|
||||
|
||||
同样,在 Fedora 22+ 上也有 MyCLI 的可用包,你可以像下面这样使用 [`dnf` 命令][7] 来安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install mycli
|
||||
```
|
||||
|
||||
对于其他 Linux 发行版,比如 RHEL/CentOS,你需要使用 Python 的 `pip` 工具来安装 MyCLI。首先,使用下面的命令来安装 pip:
|
||||
|
||||
```
|
||||
$ sudo yum install pip
|
||||
```
|
||||
|
||||
安装好 `pip` 以后,你可以像下面这样安装 MyCLI:
|
||||
|
||||
```
|
||||
$ sudo pip install mycli
|
||||
```
|
||||
|
||||
### 在 Linux 中如何使用 MyCLI 连接 MySQL 和 MariaDB
|
||||
|
||||
安装好 MyCLI 以后,你可以像下面这样使用它:
|
||||
|
||||
```
|
||||
$ mycli -u root -h localhost
|
||||
```
|
||||
|
||||
#### 自动补全
|
||||
|
||||
对于关键词和 SQL 函数可以进行简单的自动补全:
|
||||
|
||||
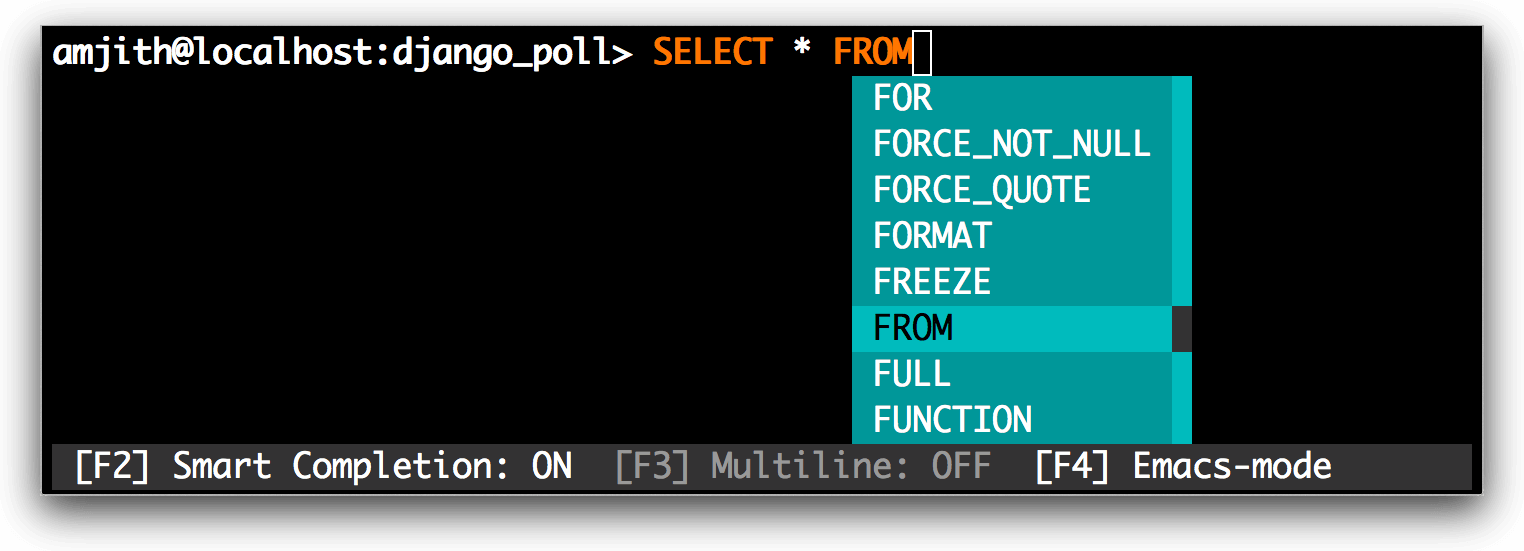
|
||||
|
||||
*MySQL 自动补全*
|
||||
|
||||
#### 智能补全
|
||||
|
||||
当输入 `FROM` 关键词以后会进行表名称的补全:
|
||||
|
||||
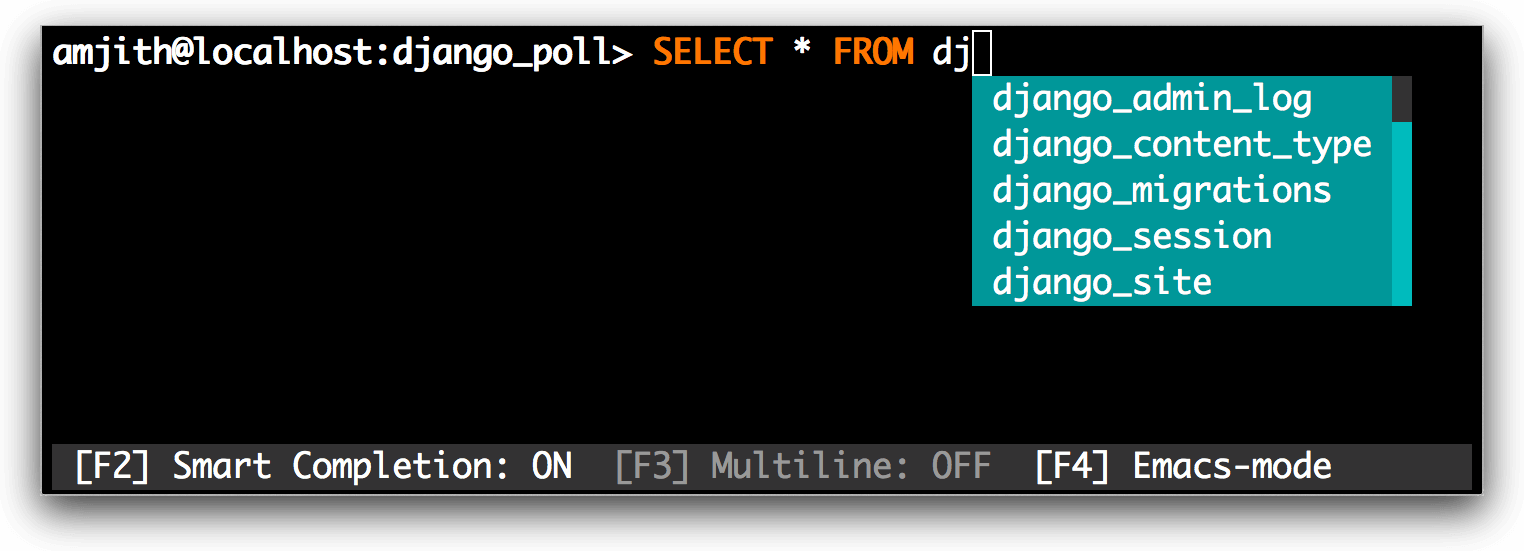
|
||||
|
||||
*MySQL 智能补全*
|
||||
|
||||
#### 别名支持
|
||||
|
||||
当表的名称设置别名以后,也支持列名称的补全:
|
||||
|
||||
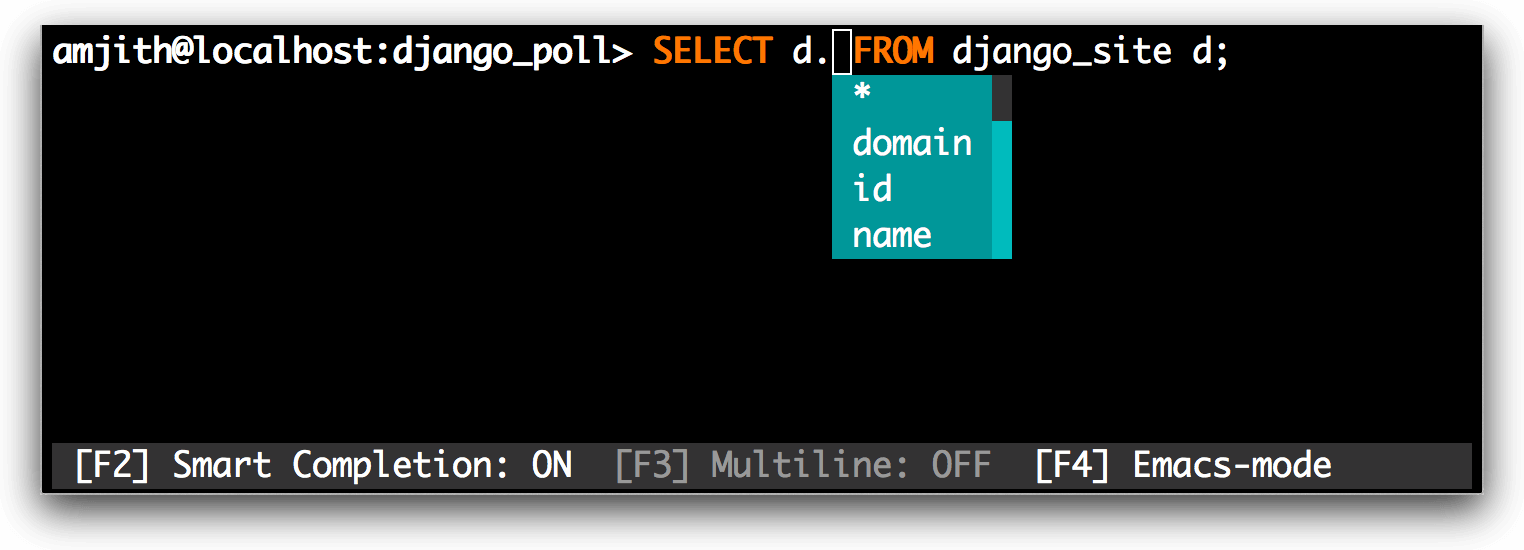
|
||||
|
||||
*MySQL 别名支持*
|
||||
|
||||
#### 语法高亮
|
||||
|
||||
支持 MySQL 语法高亮:
|
||||
|
||||
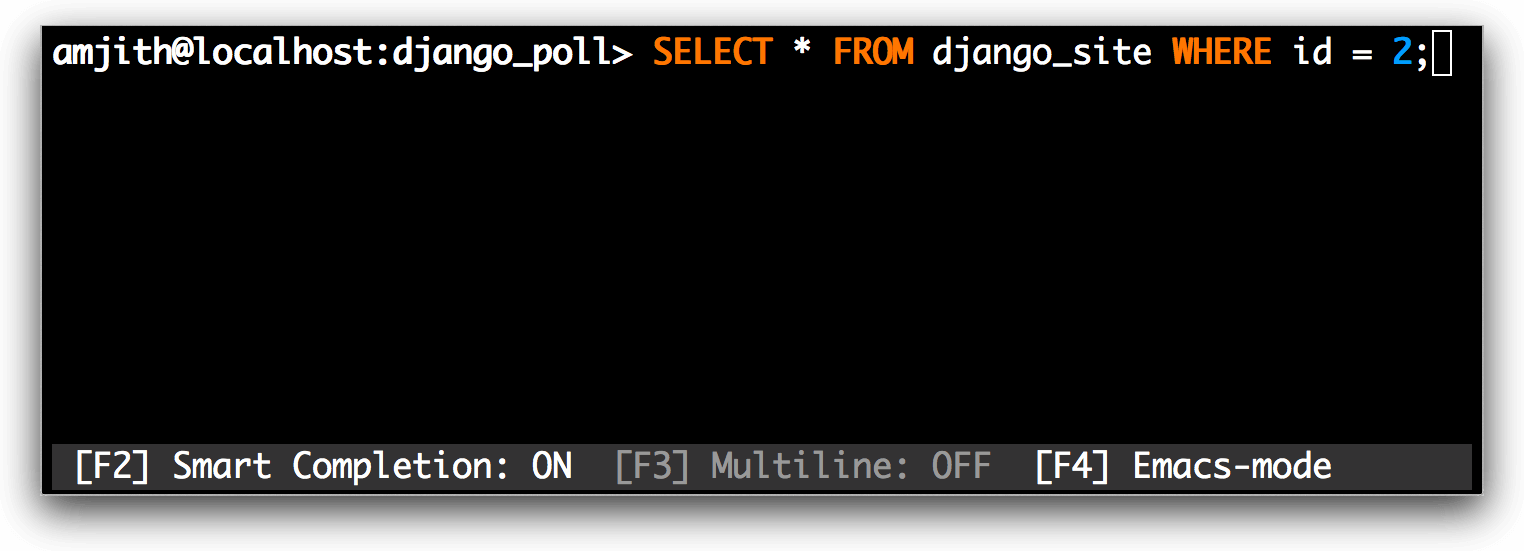
|
||||
|
||||
*MySQL 语法高亮*
|
||||
|
||||
#### 格式化 SQL 的输出
|
||||
|
||||
MySQL 的输出会通过 [`less` 命令][8] 进行格式化输出:
|
||||
|
||||
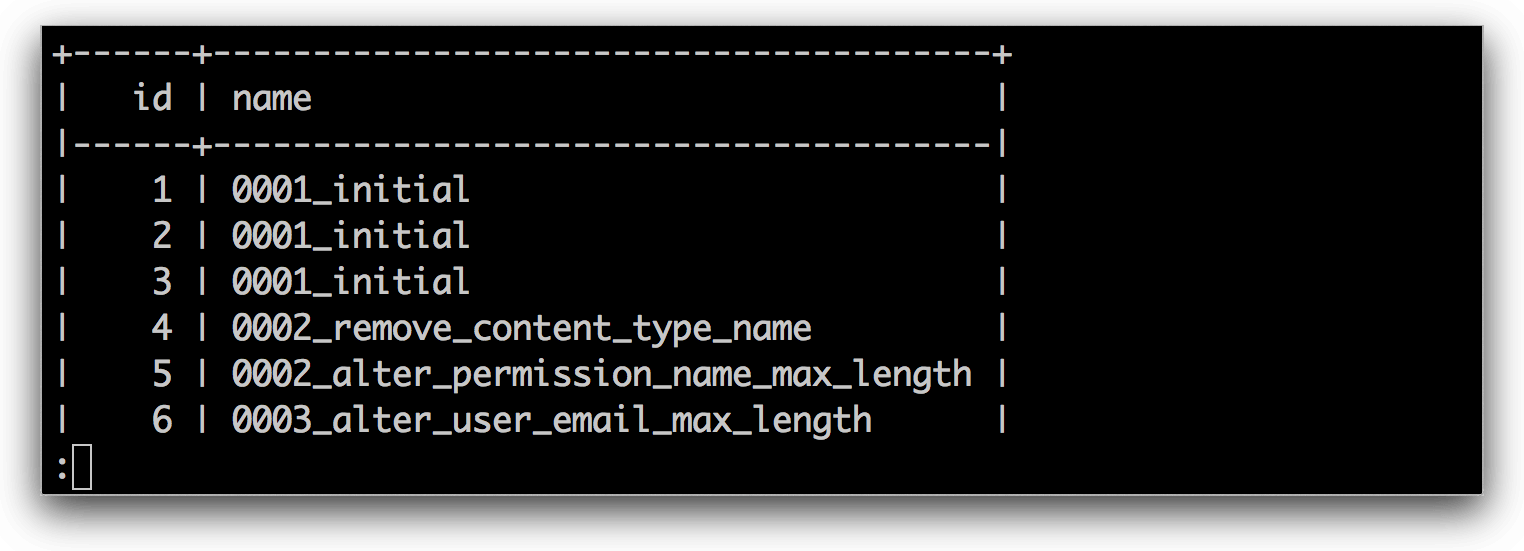
|
||||
|
||||
*MySQL 格式化输出*
|
||||
|
||||
要登录 MySQL 并同时选择数据库,你可以使用和下面类似的命令:
|
||||
|
||||
```
|
||||
$ mycli local_database
|
||||
$ mycli -h localhost -u root app_db
|
||||
$ mycli mysql://amjith@localhost:3306/django_poll
|
||||
```
|
||||
|
||||
更多使用选项,请输入:
|
||||
|
||||
```
|
||||
$ mycli --help
|
||||
```
|
||||
|
||||
MyCLI 主页: [http://mycli.net/index][9]
|
||||
|
||||
记得阅读一些关于 MySQL 管理的有用文章:
|
||||
|
||||
1. [在 Linux 中用于数据库管理的 20 个 MySQL(Mysqladmin)命令][1]
|
||||
2. [如何在 Linux 中更改默认的 MySQL/MariaDB 数据目录][2]
|
||||
3. [在 Linux 中监测 MySQL 性能的 4 个实用命令行工具][3]
|
||||
4. [如何在 Linux 中更改 MySQL 或 MariaDB 的 Root 密码][4]
|
||||
5. [MySQL 备份和恢复数据库管理命令 ][5]
|
||||
|
||||
这就是本文的全部内容了。在这篇指南中,我们展示了如何通过一些简单的命令在 Linux 中安装和使用 MyCLI。记得通过下面的反馈表向我们分享你关于这篇文章的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili是一名 Linux 和 F.O.S.S 的爱好者,未来的 Linux 系统管理员、网站开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并乐于分享知识。
|
||||
|
||||
---------
|
||||
|
||||
via: https://www.tecmint.com/mycli-mysql-client-with-auto-completion-syntax-highlighting/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/mysqladmin-commands-for-database-administration-in-linux/
|
||||
[2]:https://www.tecmint.com/change-default-mysql-mariadb-data-directory-in-linux/
|
||||
[3]:https://www.tecmint.com/mysql-performance-monitoring/
|
||||
[4]:https://www.tecmint.com/change-mysql-mariadb-root-password/
|
||||
[5]:https://www.tecmint.com/mysql-backup-and-restore-commands-for-database-administration/
|
||||
[6]:https://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[7]:https://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[8]:https://www.tecmint.com/linux-more-command-and-less-command-examples/
|
||||
[9]:http://mycli.net/index
|
||||
[10]:https://www.tecmint.com/author/aaronkili/
|
||||
[11]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[12]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,105 @@
|
||||
mimipenguin:从当前 Linux 用户转储登录密码
|
||||
============================================================
|
||||
|
||||
mimipenguin 是一个免费、开源、简单但是强大的 shell/python 脚本,用来从当前 Linux 桌面用户转储登录凭证(用户名和密码),并且已在不同的 Linux 发行版中测试过。
|
||||
|
||||
另外,它还支持如:VSFTPd(活跃的 FTP 客户端连接)、Apache2(活跃的/旧的 HTTP 基础认证会话,但是这需要 Gcore),还有 openssh-server(活跃的 SSH 链接,需用 [sudo 命令][5])。重要的是,它逐渐被移植到其他语言中,以支持所有可想到的以后可以利用的情况。
|
||||
|
||||
### mimipenguin 是如何工作的?
|
||||
|
||||
要理解 mimipenguin 是如何工作的,你需要知道所有或者大多数的 Linux 发行版会在内存中存储大量的重要信息, 如:凭据、加密密钥以及个人数据。
|
||||
|
||||
尤其是用户名和密码是由进程(运行中的程序)保存在内存中,并以明文形式存储较长时间。mimipenguin 在技术上利用这些在内存中的明文凭证 - 它会转储一个进程,并提取可能包含明文凭据的行。
|
||||
|
||||
然后,通过以下内容的哈希值来尝试计算每个单词的出现几率:`/etc/shadow`、内存和 regex 搜索。一旦找到任何内容,它就会在标准输出上打印出来。
|
||||
|
||||
### 在 Linux 中安装 mimipenguin
|
||||
|
||||
我们将使用 git 来克隆 mimipenguin 仓库,因此如果你还没安装,那么首先在系统上安装 git。
|
||||
|
||||
```
|
||||
$ sudo apt install git #Debian/Ubuntu systems
|
||||
$ sudo yum install git #RHEL/CentOS systems
|
||||
$ sudo dnf install git #Fedora 22+
|
||||
```
|
||||
|
||||
接着像这样在你的家目录(或者其他任何地方)克隆 mimipenguin 目录:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/huntergregal/mimipenguin.git
|
||||
```
|
||||
|
||||
下载完成后,进入并如下运行 mimipenguin:
|
||||
|
||||
```
|
||||
$ cd mimipenguin/
|
||||
$ ./mimipenguin.sh
|
||||
```
|
||||
|
||||
注意:如果你遇到下面的错误,那就使用 sudo 命令:
|
||||
|
||||
```
|
||||
Root required - You are dumping memory...
|
||||
Even mimikatz requires administrator
|
||||
```
|
||||
|
||||

|
||||
|
||||
*在 Linux 中转储登录密码*
|
||||
|
||||
从上面的输出中,mimipenguin 向你提供了桌面环境的用户名和密码。
|
||||
|
||||
另外,还可以如下运行 python 版脚本:
|
||||
|
||||
```
|
||||
$ sudo ./mimipenguin.py
|
||||
```
|
||||
|
||||
注意有时 gcore 可能会阻塞脚本(这是 gcore 中一个已知问题)。
|
||||
|
||||
#### 未来更新
|
||||
|
||||
下面是将会被添加到 mimipenguin 的功能:
|
||||
|
||||
* 提升总体效率
|
||||
* 添加更多支持以及其他的凭据位置
|
||||
* 包括支持非桌面环境
|
||||
* 添加 LDAP 的支持
|
||||
|
||||
mimipenguin 的 Github 仓库:[https://github.com/huntergregal/mimipenguin][6]
|
||||
|
||||
同样,请查阅:
|
||||
|
||||
1. [如何在 Linux 中用密码保护一个 vim 文件][1]
|
||||
2. [如何在 Linux 中生成/加密/解密随机密码][2]
|
||||
3. [如何在 RHEL/CentOS/Fedora 中用密码保护 GRUB][3]
|
||||
4. [在 CentOS 7 中重置/恢复忘记的 root 用户账号密码][4]
|
||||
|
||||
在下面的评论栏中分享你关于这个工具的额外想法或者对 Linux 中内存中明文凭据的问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,即将成为 Linux SysAdmin 和网络开发人员,目前是 TecMint 的内容创作者,他喜欢在电脑上工作,并坚信分享知识。
|
||||
|
||||
-------------
|
||||
|
||||
via: https://www.tecmint.com/mimipenguin-hack-login-passwords-of-linux-users/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://linux.cn/article-8547-1.html
|
||||
[2]:https://www.tecmint.com/generate-encrypt-decrypt-random-passwords-in-linux/
|
||||
[3]:https://www.tecmint.com/password-protect-grub-in-linux/
|
||||
[4]:https://linux.cn/article-8212-1.html
|
||||
[5]:https://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[6]:https://github.com/huntergregal/mimipenguin
|
||||
[7]:https://www.tecmint.com/author/aaronkili/
|
||||
[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
101
published/The history of Android/18 - The history of Android.md
Normal file
101
published/The history of Android/18 - The history of Android.md
Normal file
@ -0,0 +1,101 @@
|
||||
安卓编年史(16):安卓 3.0 蜂巢—平板和设计复兴
|
||||
================================================================================
|
||||

|
||||
|
||||
*安卓市场的新设计试水“卡片式”界面,这将成为谷歌的主要风格。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
安卓推向市场已经有两年半时间了,安卓市场放出了它的第四版设计。这个新设计十分重要,因为它已经很接近谷歌的“卡片式”界面了。通过在小方块中显示应用或其他内容,谷歌可以使它的设计在不同尺寸屏幕下无缝过渡而不受影响。内容可以像一个相册应用里的照片一样显示——给布局渲染填充一个内容块列表,加上屏幕包装,就完成了。更大的屏幕一次可以看到更多的内容块,小点的屏幕一次看到的内容就少。内容用了不一样的方式显示,谷歌还在右边新增了一个“分类”板块,顶部还有个巨大的热门应用滚动显示。
|
||||
|
||||
虽然设计上为更容易配置界面准备好准备好了,但功能上还没有。最初发布的市场版本锁定为横屏模式,而且还是蜂巢独占的。
|
||||
|
||||
|
||||
|
||||
*应用详情页和“我的应用”界面。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
新的市场不仅出售应用,还加入了书籍和电影租借。谷歌从 2010 年开始出售图书;之前只通过网站出售。新的市场将谷歌所有的内容销售聚合到了一处,进一步向苹果 iTunes 所的主宰地位展开较量。虽然在“安卓市场”出售这些东西有点品牌混乱,因为大部分内容都不依赖于安卓才能使用。
|
||||
|
||||
|
||||
|
||||
*浏览器看起来非常像 Chrome,联系人使用了双面板界面。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
新浏览器界面顶部添加了标签页栏。尽管这个浏览器并不是 Chrome ,但它模仿了许多 Chrome 的设计和特性。除了这个探索性的顶部标签页界面,浏览器还加入了隐身标签,在浏览网页时不保存历史记录和自动补全记录。它还有个选项可以让你拥有一个 Chrome 风格的新标签页,页面上包含你最经常访问的网页略缩图。
|
||||
|
||||
新浏览器甚至还能和 Chrome 同步。在浏览器登录后,它会下载你的 Chrome 书签并且自动登录你的谷歌账户。收藏一个页面只需点击地址栏的星形标志即可,和谷歌地图一样,浏览器抛弃了缩放按钮,完全改用手势控制。
|
||||
|
||||
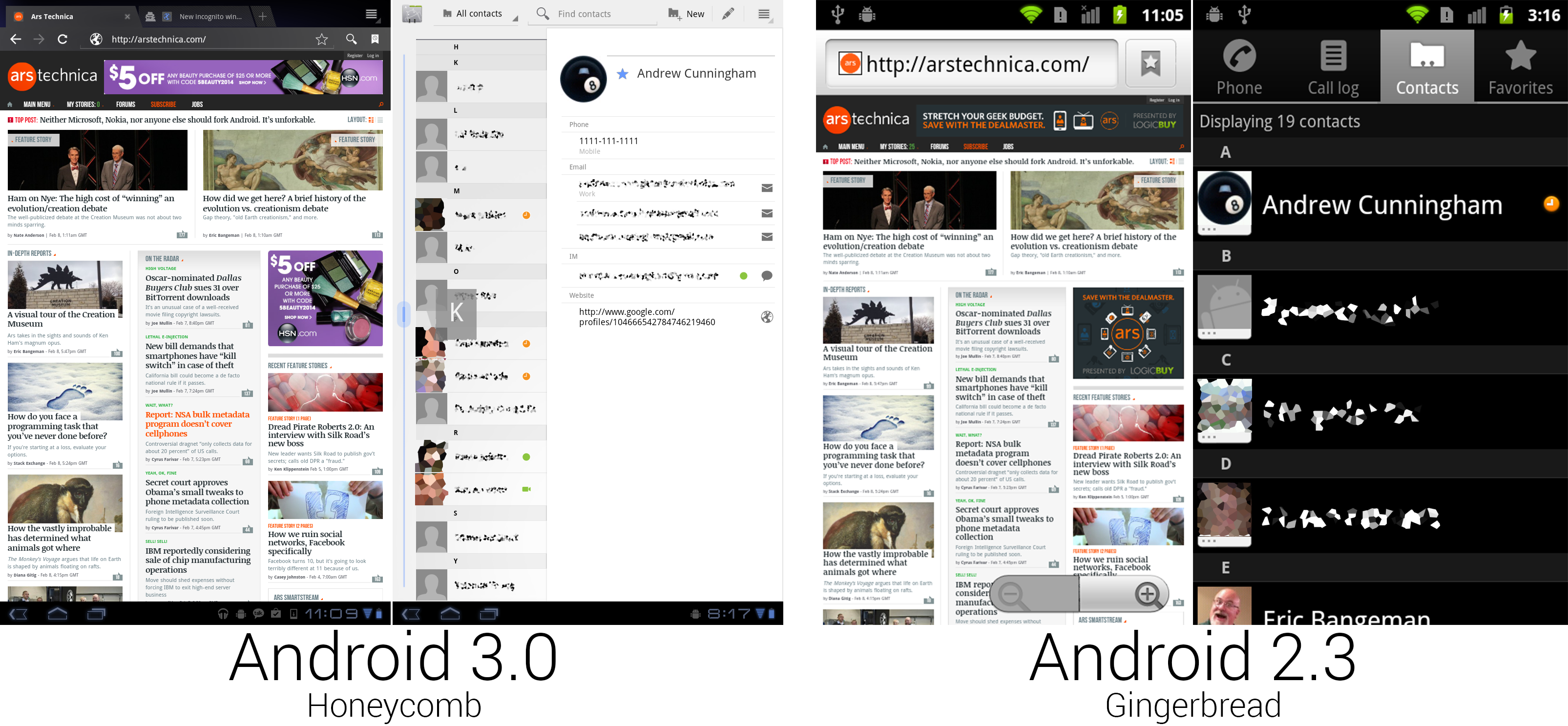
联系人应用最终从电话应用中移除,并且独立为一个应用。之前的联系人/拨号的混合式设计相对于人们使用现代智能手机的方式来说,过于以电话为中心了。联系人中存有电子邮件、IM、短信、地址、生日以及社交网络等信息,所以将它们捆绑在电话应用里的意义和将它们放进谷歌地图里差不多。抛开了电话通讯功能,联系人能够简化成没有标签页的联系人列表。蜂巢采用了双面板视图,在左侧显示完整的联系人列表,右侧是联系人详情。应用利用了 Fragments API,通过它应用可以在同一屏显示多个面板界面。
|
||||
|
||||
蜂巢版本的联系人应用是第一个拥有快速滚动功能的版本。当按住左侧滚动条的时候,你可以快速上下拖动,应用会显示列表当前位置的首字母预览。
|
||||
|
||||
|
||||
|
||||
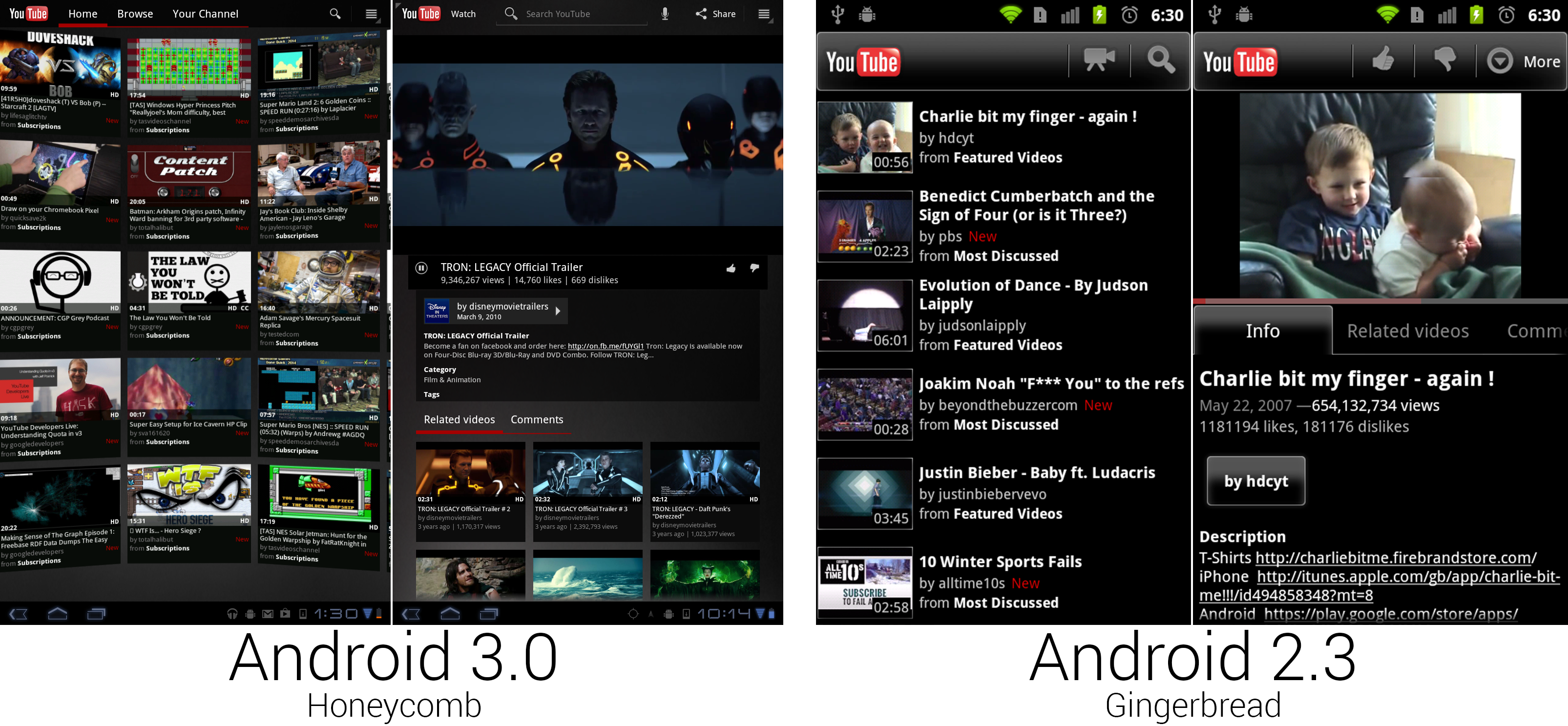
*新 Youtube 应用看起来像是来自黑客帝国。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
谢天谢地 Youtube 终于抛弃了自安卓 2.3 以来的谷歌给予这个视频服务的“独特”设计,新界面设计与系统更加一体化。主界面是一个水平滚动的曲面墙,上面显示着最热门或者(登录之后)个人关注的视频。虽然谷歌从来没有将这个设计带到手机上,但它可以被认为是一个易于重新配置的卡片界面。操作栏在这里是个可配置的工具栏。没有登录时,操作栏由一个搜索栏填满。当你登录后,搜索缩小为一个按钮,“首页”,“浏览”和“你的频道”标签将会显示出来。
|
||||
|
||||
|
||||
|
||||
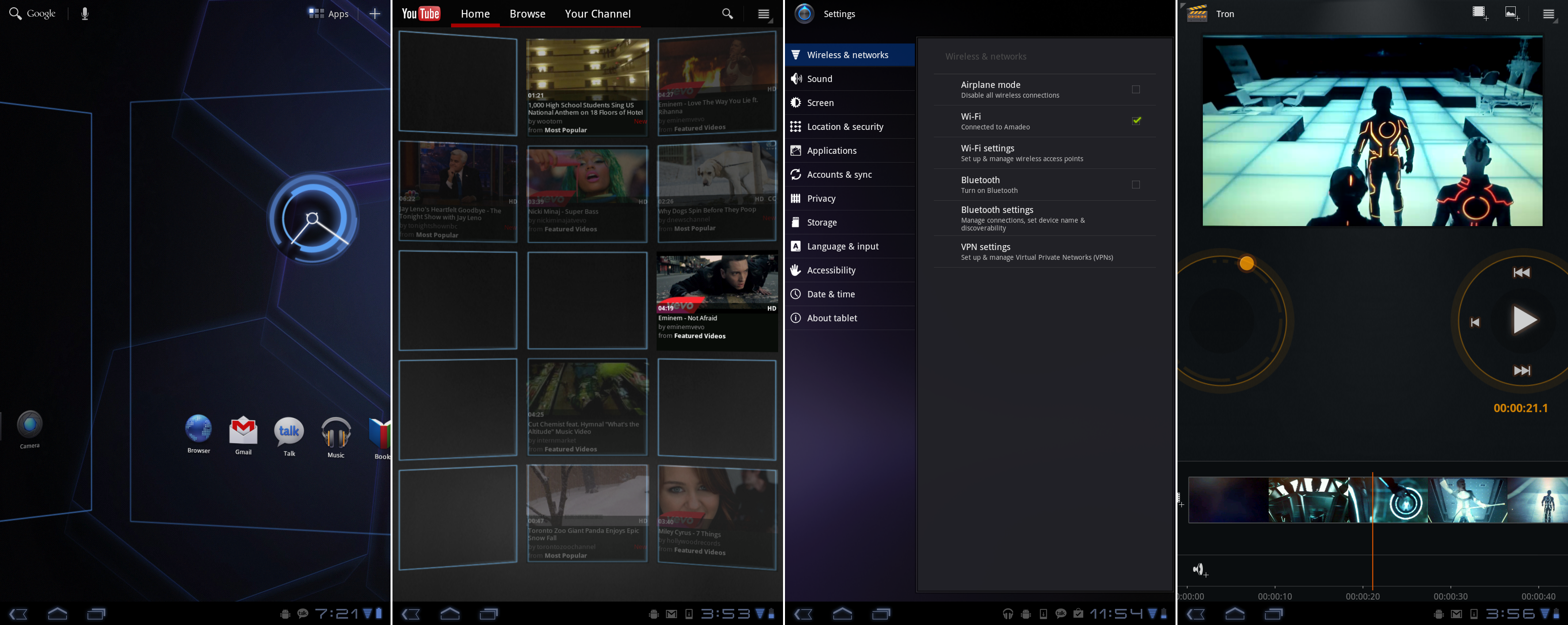
*蜂巢用一个蓝色框架的电脑界面来驱动主屏。电影工作室完全采用橙色电子风格主题。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
蜂巢新增的应用“电影工作室”,这不是一个不言自明的应用,而且没有任何的解释或说明。就我们所知,你可以导入视频,剪切它们,添加文本和场景过渡。编辑视频——电脑上你可以做的最耗时、困难,以及处理器密集型任务之一 —— 在平板上完成感觉有点野心过大了,谷歌在之后的版本里将其完全移除了。电影工作室里我们最喜欢的部分是它完全的电子风格主题。虽然系统的其它部分使用蓝色高亮,在这里是橙色的。(电影工作室是个邪恶的程序!)
|
||||
|
||||
|
||||
*小部件!
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
蜂巢带来了新的部件框架,允许部件滚动,Gmail、Email 以及日历部件都升级了以支持改功能。Youtube 和书籍使用了新的部件,内容卡片可以自动滚动切换。在小部件上轻轻向上或向下滑动可以切换卡片。我们不确定你的书籍中哪些书会被显示出来,但如果你想要的话它就在那儿。尽管所有的这些小部件在 10 英寸屏幕上运行良好,谷歌从未为手机重新设计它们,这让它们在安卓最流行的规格上几乎毫无用处。所有的小部件有个大块的标识标题栏,而且通常占据大半屏幕只显示很少的内容。
|
||||
|
||||
|
||||
|
||||
*安卓 3.1 中可滚动的最近应用以及可自定义大小的小部件。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
蜂巢后续的版本修复了 3.0 早期的一些问题。安卓 3.1 在蜂巢的第一个版本之后三个月放出,并带来了一些改进。小部件自定义大小是添加的最大特性之一。长按小部件之后,一个带有拖拽按钮的蓝色外框会显示出来,拖动按钮可以改变小部件尺寸。最近应用界面现在可以垂直滚动并且承载更多应用。这个版本唯一缺失的功能是滑动关闭应用。
|
||||
|
||||
在今天,一个 0.1 版本的升级是个主要更新,但是在蜂巢,那只是个小更新。除了一些界面调整,3.1 添加了对游戏手柄,键盘,鼠标以及其它 USB 和蓝牙输入设备的支持。它还提供了更多的开发者 API。
|
||||
|
||||
|
||||
|
||||
*安卓 3.2 的兼容性缩放和一个安卓平板上典型的展开视图应用。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
安卓 3.2 在 3.1 发布后两个月放出,添加了七到八英寸的小尺寸平板支持。3.2 终于启用了 SD 卡支持,Xoom 在生命最初的五个月就像是初生儿的柔弱的肢体一样。
|
||||
|
||||
蜂巢匆匆问世是为了成为一个生态系统建设者。如果应用没有平板版本,没人会想要一个安卓平板的,所以谷歌知道需要尽快将东西送到开发者手中。在这个安卓平板生态的早期阶段,应用还没有到齐。这是拥有 Xoom 的人们所面临的最大的问题。
|
||||
|
||||
3.2 添加了“兼容缩放”,给了用户一个新选项,可以将应用拉伸适应屏幕(如右侧图片显示的那样)或缩放成正常的应用布局来适应屏幕。这些选项都不是很理想,由于没有应用生态来支持平板,蜂巢设备销售状况惨淡。但谷歌的平板决策最终还是会得到回报。今天,安卓平板已经[取代 iOS 占据了最大的市场份额][1]。
|
||||
|
||||
|
||||
|
||||
*姜饼上的 Google Music Beta。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
### Google Music Beta —— 取代内容商店的云存储 ###
|
||||
|
||||
尽管蜂巢改进了 Google Music 的界面,但是音乐应用的设计并没有从蜂巢直接进化到冰淇淋三明治。2011 年 5 月,谷歌发布了“[Google Music Beta][1]”,和新的 Google Music 应用一同到来的在线音乐存储。
|
||||
|
||||
新 Google Music 为安卓 2.2 及以上版本设计,借鉴了 Cooliris 相册的设计语言,但也有改变之处,背景使用了模糊处理的图片。几乎所有东西都是透明的:弹出菜单,顶部标签页,还有底部的正在播放栏。可以下载单独的歌曲或整个播放列表到设备上离线播放,这让 Google Music 成为一个让音乐同步到你所有设备的好途径。除了移动应用外,Google Music 还有一个 Web 应用,让它可以在任何一台桌面电脑上使用。
|
||||
|
||||
谷歌和唱片公司关于内容的合约还没有谈妥,音乐商店还没准备好,所以它的权宜之计是允许用户存储音乐到线上并下载到设备上。如今谷歌除了音乐存储服务外,还有单曲购买和订阅模式。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron 是 Ars Technica 的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/18/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://techcrunch.com/2014/03/03/gartner-195m-tablets-sold-in-2013-android-grabs-top-spot-from-ipad-with-62-share/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -0,0 +1,62 @@
|
||||
安卓编年史(18):Android 4.0 冰淇淋三明治—摩登时代
|
||||
================================================================================
|
||||
|
||||
### Android 4.0 冰淇淋三明治 —— 摩登时代 ###
|
||||
|
||||

|
||||
|
||||
*三星 Galaxy Nexus,安卓4.0的首发设备。*
|
||||
|
||||
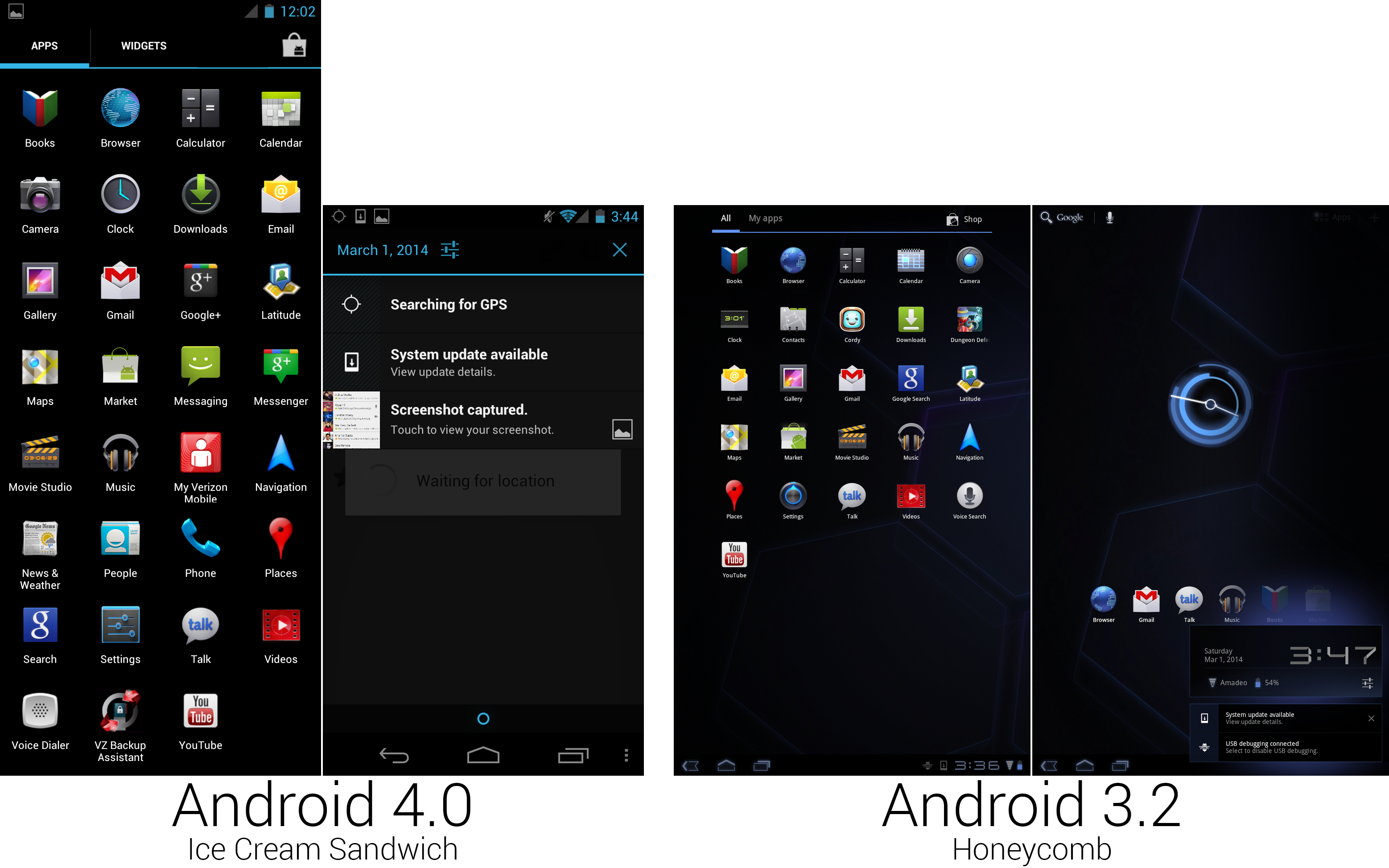
安卓 4.0,冰淇淋三明治,在 2011 年 10 月发布,系统发布回到正轨,带来定期发布的手机和平板,并且安卓再次开源。这是自姜饼以来手机设备的第一个更新,意味着最主要的安卓用户群体近乎一年没有见到更新了。4.0 随处可见缩小版的蜂巢设计,还将虚拟按键,操作栏(Action Bar),全新的设计语言带到了手机上。
|
||||
|
||||
冰淇淋三明治在三星 Galaxy Nexus 上首次亮相,也是最早带有 720p 显示屏的安卓手机之一。随着分辨率的提高,Galaxy Nexus 使用了更大的 4.65 英寸显示屏——几乎比最初的 Nexus One 大了一整英寸。这被许多批评者认为“太大了”,但如今的安卓设备甚至更大。(5 英寸当今是“正常”的。)冰淇淋三明治比姜饼的性能要求更高,Galaxy Nexus 配备了一颗双核,1.2Ghz 德州仪器 OMAP 处理器和 1GB 的内存。
|
||||
|
||||
在美国,Galaxy Nexus 在 Verizon 首发并且支持 LTE。不像之前的 Nexus 设备,最流行的型号——Verizon 版——是在运营商的控制之下,谷歌的软件和更新在手机得到更新之前要经过 Verizon 的核准。这导致了更新的延迟以及 Verizon 不喜欢的应用被移除,即便是 Google Wallet 也不例外。
|
||||
|
||||
多亏了冰淇淋三明治的软件改进,谷歌终于达成了移除手机上按钮的目标。有了虚拟导航键,实体电容按钮就可以移除了,最终 Galaxy Nexus 仅有电源和音量是实体按键。
|
||||
|
||||

|
||||
|
||||
*安卓 4.0 将很多蜂巢的设计缩小了。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
电子质感的审美在蜂巢中显得有点多。于是在冰淇淋三明治中,谷歌开始减少科幻风的设计。科幻风的时钟字体从半透明折叠风格转变成纤细,优雅,看起来更加正常的字体。解锁环的水面波纹效果被去除了,蜂巢中的外星风格时钟小部件也被极简设计所取代。系统按钮也经过了重新设计,原先的蓝色轮廓,偶尔的厚边框变成了细的,设置带有白色轮廓。默认壁纸从蜂巢的蓝色太空船内部变成条纹状,破碎的彩虹,给默认布局增添了不少迟来的色彩。
|
||||
|
||||
蜂巢的系统栏在手机上一分为二。在顶上是传统的状态栏,底部是新的系统栏,放着三个系统按钮:后退、主屏幕、最近应用。一个固定的搜索栏放置在了主屏幕顶部。该栏以和底栏一样的方式固定在屏幕上,所以在五个主屏上,它总共占据了 20 个图标大小的位置。在蜂巢的锁屏上,内部的小圆圈可以向大圆圈外的任意位置滑动来解锁设备。在冰淇淋三明治,你得把小圆圈移动到解锁图标上。这个新准确度要求允许谷歌向锁屏添加新的选项:一个相机快捷方式。将小圆圈拖向相机图标会直接启动相机,跳过了主屏幕。
|
||||
|
||||
|
||||
|
||||
*一个手机系统意味着更多的应用,通知面板重新回到了全屏界面。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
应用抽屉还是标签页式的,但是蜂巢中的“我的应用”标签被“部件”标签页替代,这是个简单的 2×3 部件略缩图视图。像蜂巢里的那样,这个应用抽屉是分页的,需要水平滑动换页。(如今安卓仍在使用这个应用抽屉设计。)应用抽屉里新增的是 Google+ 应用,后来独立存在。还有一个“Messenger”快捷方式,是 Google+ 的私密信息服务。(不要混淆 “Messenger” 和已有的 “Messaging” 短信应用。)
|
||||
|
||||
因为我们现在回到了手机上,所以短信,新闻和天气,电话,以及语音拨号都回来了,以及 Cordy,一个平板的游戏,被移除了。尽管不是 Nexus 设备,我们的截图还是来自 Verizon 版的设备,可以从图上看到有像 “My Verizon Mobile” 和 “VZ Backup Assistant” 这样没用的应用。为了和冰淇淋三明治的去电子风格主题一致,日历和相机图标现在看起来更像是来自地球的东西而不是来自外星球。时钟,下载,电话,以及安卓市场同样得到了新图标,“联系人”获得了新图标,还有新名字 “People”。
|
||||
|
||||
通知面板进行了大改造,特别是和[之前姜饼中的设计][2]相比而言。面板头部有个日期,一个设置的快捷方式,以及“清除所有”按钮。虽然蜂巢的第一个版本就允许用户通过通知右边的“X”消除单个通知,但是冰淇淋三明治的实现更加优雅:只要从左向右滑动通知即可。蜂巢有着蓝色高亮,但是蓝色色调到处都是。冰淇淋三明治几乎把所有地方的蓝色统一成一个(如果你想知道确定的值,hex 码是 `#33B5E5`)。通知面板的背景是透明的,底部的“把手”变为一个简单的小蓝圈,带着不透明的黑色背景。
|
||||
|
||||

|
||||
|
||||
*安卓市场的主页背景变成了黑色。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
市场获得了又一个新设计。它终于再次支持纵向模式,并且添加了音乐到商店中,你可以从中购买音乐。新的市场拓展了从蜂巢中引入的卡片概念,它还是第一个同时使用在手机和平板上的版本。主页上的卡片通常不是链接到应用的,而是指向特别的促销页面,像是“编辑精选”或季度促销。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/19/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2011/05/hands-on-grooving-on-the-go-with-impressive-google-music-beta/
|
||||
[2]:http://cdn.arstechnica.net/wp-content/uploads/2014/02/32.png
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,60 +1,68 @@
|
||||
安卓编年史
|
||||
安卓编年史(19):Android 4.0 冰淇淋三明治—摩登时代
|
||||
================================================================================
|
||||
|
||||

|
||||
和之前完全不同的市场设计。以上是分类,特色,热门应用以及应用详情页面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
*和之前完全不同的市场设计。以上是分类,特色,热门应用以及应用详情页面。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
这些截图给了我们冰淇淋三明治中新版操作栏的第一印象。几乎所有的应用顶部都有一条栏,带有应用图标,当前界面标题,一些功能按钮,右边还有一个菜单按钮。这个右对齐的菜单按钮被称为“更多操作”,因为里面存放着无法放置到主操作栏的项目。不过更多操作菜单并不是固定不变的,它给了操作栏节省了更多的屏幕空间——比如在横屏模式或在平板上时,更多操作菜单的项目会像通常的按钮一样显示在操作栏上。
|
||||
|
||||
冰淇凌三明治中新增了“滑动标签页”设计,替换掉了谷歌之前推行的2×3方阵导航屏幕。一个标签页栏放置在了操作栏下方,位于中间的标签显示的是当前页面,左右侧的两个标签显示的是对应的当前页面的左右侧页面。向左右滑动可以切换标签页,或者你可以点击指定页面的标签跳转过去。
|
||||
冰淇凌三明治中新增了“滑动标签页”设计,替换掉了谷歌之前推行的 2×3 方阵导航屏幕。一个标签页栏放置在了操作栏下方,位于中间的标签显示的是当前页面,左右侧的两个标签显示的是对应的当前页面的左右侧页面。向左右滑动可以切换标签页,或者你可以点击指定页面的标签跳转过去。
|
||||
|
||||
应用详情页面有个很赞的设计,在应用截图后,会根据你关于那个应用的历史动态地重新布局页面。如果你从来没有安装过该应用,应用描述会优先显示。如果你曾安装过这个应用,第一部分将会是评价栏,它会邀请你评价该应用或者提醒你上次你安装该应用时的评价是什么。之前使用过的应用页面第二部分是“新特性”,因为一个老用户最关心的应该是应用有什么变化。
|
||||
|
||||

|
||||
最近应用和浏览器和蜂巢中的类似,但是是小号的。
|
||||
Ron Amadeo 供图
|
||||
|
||||
最近应用的电子风格外观被移除了。略缩图周围的蓝色的轮廓线被去除了,同时去除的还有背景怪异的,不均匀的蓝色光晕。它现在看起来是个中立型的界面,在任何时候看起来都很舒适。
|
||||
*最近应用和浏览器和蜂巢中的类似,但是是小号的。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
最近应用的电子风格外观被移除了。略缩图周围的蓝色的轮廓线被去除了,同时去除的还有背景怪异的、不均匀的蓝色光晕。它现在看起来是个中立型的界面,在任何时候看起来都很舒适。
|
||||
|
||||
浏览器尽了最大的努力把标签页体验带到手机上来。多标签浏览受到了关注,操作栏上引入的一个标签页按钮会打开一个类似最近应用的界面,显示你打开的标签页,而不是浪费宝贵的屏幕空间引入一个标签条。从功能上来说,这个和之前的浏览器中的“窗口”视图没什么差别。浏览器最佳的改进是菜单中的“请求桌面版站点”选项,这让你可以从默认的移动站点视图切换到正常站点。浏览器展示了谷歌的操作栏设计的灵活性,尽管这里没有左上角的应用图标,功能上来说和其他的顶栏设计相似。
|
||||
|
||||

|
||||
Gmail 和 Google Talk —— 它们和蜂巢中的相似,但是更小!
|
||||
Ron Amadeo 供图
|
||||
|
||||
Gmail 和 Google Talk 看起来都像是之前蜂巢中的设计的缩小版,但是有些小调整让它们在小屏幕上表现更佳。Gmail 以双操作栏为特色——一个在屏幕顶部,一个在底部。顶部操作栏显示当前文件夹,账户,以及未读消息数目,点击顶栏可以打开一个导航菜单。底部操作栏有你期望出现在更多操作中的选项。使用双操作栏布局是为了在界面显示更多的按钮,但是在横屏模式下纵向空间有限,双操作栏就是合并成一个顶部操作栏。
|
||||
*Gmail 和 Google Talk —— 它们和蜂巢中的相似,但是更小!
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
在邮件视图下,往下滚动屏幕时蓝色栏有“粘性”。它会固定在屏幕顶部,所以你一直可以看到该邮件是谁写的,回复它,或者给它加星标。一旦处于邮件消息界面,底部细长的,深灰色栏会显示你当前在收件箱(或你所在的某个列表)的位置,并且你可以向左或向右滑动来切换到其他邮件。
|
||||
Gmail 和 Google Talk 看起来都像是之前蜂巢中的设计的缩小版,但是有些小调整让它们在小屏幕上表现更佳。Gmail 以双操作栏为特色——一个在屏幕顶部,一个在底部。顶部操作栏显示当前文件夹、账户,以及未读消息数目,点击顶栏可以打开一个导航菜单。底部操作栏有你期望出现在更多操作中的选项。使用双操作栏布局是为了在界面显示更多的按钮,但是在横屏模式下纵向空间有限,双操作栏就合并成一个顶部操作栏。
|
||||
|
||||
在邮件视图下,往下滚动屏幕时蓝色栏有“粘性”。它会固定在屏幕顶部,所以你一直可以看到该邮件是谁写的,回复它,或者给它加星标。一旦处于邮件消息界面,底部细长的、深灰色栏会显示你当前在收件箱(或你所在的某个列表)的位置,并且你可以向左或向右滑动来切换到其他邮件。
|
||||
|
||||
Google Talk 允许你像在 Gmail 中那样左右滑动来切换聊天窗口,但是这里显示栏是在顶部。
|
||||
|
||||

|
||||
新的拨号和来电界面,都是姜饼以来我们还没见过的。
|
||||
Ron Amadeo 供图
|
||||
|
||||
因为蜂巢只给平板使用,所以一些界面设计直接超前于姜饼。冰淇淋三明治的新拨号界面就是如此,黑色和蓝色相间,并且使用了可滑动切换的小标签。尽管冰淇淋三明治终于做了对的事情并将电话主体和联系人独立开来,但电话应用还是有它自己的联系人标签。现在有两个地方可以看到你的联系人列表——一个有着暗色主题,另一个有着亮色主题。由于实体搜索按钮不再是硬性要求,底部的按钮栏的语音信息快捷方式被替换为了搜索图标。
|
||||
*新的拨号和来电界面,都是姜饼以来我们还没见过的。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
因为蜂巢只给平板使用,所以一些界面设计直接超前于姜饼。冰淇淋三明治的新拨号界面就是如此,黑色和蓝色相间,并且使用了可滑动切换的小标签。尽管冰淇淋三明治终于做对了,将电话主体和联系人独立开来,但电话应用还是有它自己的联系人标签。现在有两个地方可以看到你的联系人列表——一个有着暗色主题,另一个有着亮色主题。由于实体搜索按钮不再是硬性要求,底部的按钮栏的语音信息快捷方式被替换为了搜索图标。
|
||||
|
||||
谷歌几乎就是把来电界面做成了锁屏界面的镜像,这意味着冰淇淋三明治有着一个环状解锁设计。除了通常的接受和挂断选项,圆环的顶部还添加了一个按钮,让你可以挂断来电并给对方发送一条预先定义好的信息。向上滑动并选择一条信息如“现在无法接听,一会回电”,相比于一直响个不停的手机而言这样做的信息交流更加丰富。
|
||||
|
||||

|
||||
蜂巢没有文件夹和信息应用,所以这里是冰淇淋三明治和姜饼的对比。
|
||||
Ron Amadeo 供图
|
||||
|
||||
*蜂巢没有文件夹和信息应用,所以这里是冰淇淋三明治和姜饼的对比。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
现在创建文件夹更加方便了。在姜饼中,你得长按屏幕,选择“文件夹”选项,再点击“新文件夹”。在冰淇淋三明治中,你只要将一个图标拖拽到另一个图标上面,就会自动创建一个文件夹,并包含这两个图标。这简直不能更简单了,比寻找隐藏的长按命令容易多了。
|
||||
|
||||
设计上也有很大的改进。姜饼使用了一个通用的米黄色文件夹图标,但冰淇淋三明治直接显示出了文件夹中的头三个应用,把它们的图标叠在一起,在外侧画一个圆圈,并将其设置为文件夹图标。打开文件夹容器将自动调整大小以适应文件夹中的应用图标数目,而不是显示一个全屏的,大部分都是空的对话框。这看起来好得多得多。
|
||||
|
||||

|
||||
Youtube 转换到一个更加现代的白色主题,使用了列表视图替换疯狂的 3D 滚动视图。
|
||||
Ron Amadeo 供图
|
||||
|
||||
*Youtube 转换到一个更加现代的白色主题,使用了列表视图替换疯狂的 3D 滚动视图。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
Youtube 经过了完全的重新设计,看起来没那么像是来自黑客帝国的产物,更像是,嗯,Youtube。它现在就是一个简单的垂直滚动的白色视频列表,就像网站的那样。在你手机上制作视频受到了重视,操作栏的第一个按钮专用于拍摄视频。奇怪的是,不同的界面左上角使用了不同的 Youtube 标志,在水平的 Youtube 标志和方形标志之间切换。
|
||||
|
||||
Youtube 几乎在所有地方都使用了滑动标签页。它们被放置在主页面以在浏览和账户间切换,放置在视频页面以在评论,介绍和相关视频之间切换。4.0 版本的应用显示出 Google+ Youtube 集成的第一个信号,通常的评分按钮旁边放置了 “+1” 图标。最终 Google+ 会完全占据 Youtube,将评论和作者页面变成 Google+ 活动。
|
||||
|
||||

|
||||
冰淇淋三明治试着让事情对所有人都更加简单。这里是数据使用量追踪,打开许多数据的新开发者选项,以及使用向导。
|
||||
Ron Amadeo 供图
|
||||
|
||||
*冰淇淋三明治试着让事情对所有人都更加简单。这里是数据使用量追踪,打开许多数据的新开发者选项,以及使用向导。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
数据使用量允许用户更轻松地追踪和控制他们的数据使用。主页面显示一个月度使用量图表,用户可以设置数据使用警告值或者硬性使用限制以避免超量使用产生费用。所有的这些只需简单地拖动橙色和红色水平限制线在图表上的位置即可。纵向的白色把手允许用户选择图表上的一段指定时间段。在页面底部,选定时间段内的数据使用量又细分到每个应用,所以用户可以选择一个数据使用高峰并轻松地查看哪个应用在消耗大量流量。当流量紧张的时候,更多操作按钮中有个限制所有后台流量的选项。设置之后只用在前台运行的程序有权连接互联网。
|
||||
|
||||
@ -63,27 +71,42 @@ Ron Amadeo 供图
|
||||
安卓和 iOS 之间最大的区别之一就是应用抽屉界面。在冰淇淋三明治对更加用户友好的追求下,设备第一次初始化启动会启动一个小教程,向用户展示应用抽屉的位置以及如何将应用图标从应用抽屉拖拽到主屏幕。随着实体菜单按键的移除和像这样的改变,安卓 4.0 做了很大的努力变得对新智能手机用户和转换过来的用户更有吸引力。
|
||||
|
||||

|
||||
“触摸分享”NFC 支持,Google Earth,以及应用信息,让你可以禁用垃圾软件。
|
||||
|
||||
冰淇淋三明治内置对 [NFC][1] 的完整支持。尽管之前的设备,比如 Nexus S 也拥有 NFC,得到的支持是有限的并且系统并不能利用芯片做太多事情。4.0 添加了一个“Android Beam”功能,两台拥有 NFC 的安卓 4.0 设备可以借此在设备间来回传输数据。NFC 会传输关于此事屏幕显示的数据,因此在手机显示一个网页的时候使用该功能会将该页面传送给另一部手机。你还可以发送联系人信息,方向导航,以及 Youtube 链接。当两台手机放在一起时,屏幕显示会缩小,点击缩小的界面会发送相关信息。
|
||||
*“触摸分享”NFC 支持,Google Earth,以及应用信息,让你可以禁用垃圾软件。*
|
||||
|
||||
I在安卓中,用户不允许删除系统应用,以保证系统完整性。运营商和 OEM 利用该特性并开始将垃圾软件放入系统分区,经常有一些没用的应用存在系统中。安卓 4.0 允许用户禁用任何不能被卸载的应用,意味着该应用还存在于系统中但是不显示在应用抽屉里并且不能运行。如果用户愿意深究设置项,这给了他们一个简单的途径来拿回手机的控制权。
|
||||
冰淇淋三明治内置对 [NFC][1] 的完整支持。尽管之前的设备,比如 Nexus S 也拥有 NFC,得到的支持是有限的并且系统并不能利用芯片做太多事情。4.0 添加了一个“Android Beam”功能,两台拥有 NFC 的安卓 4.0 设备可以借此在设备间来回传输数据。NFC 会传输关于此时屏幕显示的数据,因此在手机显示一个网页的时候使用该功能会将该页面传送给另一部手机。你还可以发送联系人信息、方向导航,以及 Youtube 链接。当两台手机放在一起时,屏幕显示会缩小,点击缩小的界面会发送相关信息。
|
||||
|
||||
安卓 4.0 可以看做是现代安卓时代的开始。大部分这时发布的谷歌应用只能在安卓 4.0 及以上版本运行。4.0 还有许多谷歌想要好好利用的新 API——至少最初想要——对 4.0 以下的版本的支持就有限了。在冰淇淋三明治和蜂巢之后,谷歌真的开始认真对待软件设计。在2012年1月,谷歌[最终发布了][2] *Android Design*,一个教安卓开发者如何创建符合安卓外观和感觉的应用的设计指南站点。这是 iOS 在有第三方应用支持开始就在做的事情,苹果还严肃地对待应用的设计,不符合指南的应用都被 App Store 拒之门外。安卓三年以来谷歌没有给出任何公共设计规范文档的事实,足以说明事情有多糟糕。但随着在 Duarte 掌控下的安卓设计革命,谷歌终于发布了基本设计需求。
|
||||
在安卓中,用户不允许删除系统应用,以保证系统完整性。运营商和 OEM 利用该特性并开始将垃圾软件放入系统分区,经常有一些没用的应用存在系统中。安卓 4.0 允许用户禁用任何不能被卸载的应用,意味着该应用还存在于系统中但是不显示在应用抽屉里并且不能运行。如果用户愿意深究设置项,这给了他们一个简单的途径来拿回手机的控制权。
|
||||
|
||||
安卓 4.0 可以看做是现代安卓时代的开始。大部分这时发布的谷歌应用只能在安卓 4.0 及以上版本运行。4.0 还有许多谷歌想要好好利用的新 API——至少最初想要——对 4.0 以下的版本的支持就有限了。在冰淇淋三明治和蜂巢之后,谷歌真的开始认真对待软件设计。在 2012 年 1 月,谷歌[最终发布了][2] *Android Design*,一个教安卓开发者如何创建符合安卓外观和感觉的应用的设计指南站点。这是 iOS 在有第三方应用支持开始就在做的事情,苹果还严肃地对待应用的设计,不符合指南的应用都被 App Store 拒之门外。安卓三年以来谷歌没有给出任何公共设计规范文档的事实,足以说明事情有多糟糕。但随着在 Duarte 掌控下的安卓设计革命,谷歌终于发布了基本设计需求。
|
||||
|
||||
### Google Play 和直接面向消费者出售设备的回归 ###
|
||||
|
||||
2012 年 3 月 6 日,谷歌将旗下提供的所有内容统一到 “Google Play”。安卓市场变为了 Google Play 商店,Google Books 变为 Google Play Books,Google Music 变为 Google Play Music,还有 Android Market Movies 变为 Google Play Movies & TV。尽管应用界面的变化不是很大,这四个内容应用都获得了新的名称和图标。在 Play 商店购买的内容会下载到对应的应用中,Play 商店和 Play 内容应用一道给用户提供了易管理的内容体验。
|
||||
|
||||
Google Play 更新是谷歌第一个大的更新周期外更新。四个自带应用都没有通过系统更新获得升级,它们都是直接通过安卓市场/ Play 商店更新的。对单独的应用启用周期外更新是谷歌的重大关注点之一,而能够实现这样的更新,是自姜饼时代开始的工程努力的顶峰。谷歌一直致力于对应用从系统“解耦”,从而让它们能够通过安卓市场/ Play 商店进行分发。
|
||||
|
||||
尽管一两个应用(主要是地图和 Gmail)之前就在安卓市场上,从这里开始你会看到许多更重大的更新,而其和系统发布无关。系统更新需要 OEM 厂商和运营商的合作,所以很难保证推送到每个用户手上。而 Play 商店更新则完全掌握在谷歌手上,给了谷歌一条直接到达用户设备的途径。因为 Google Play 的发布,安卓市场对自身升级到了 Google Play Store,在那之后,图书,音乐以及电影应用都下发了 Google Play 式的更新。
|
||||
|
||||
Google Play 系列应用的设计仍然不尽相同。每个应用的外观和功能各有差异,但暂且来说,一个统一的品牌标识是个好的开始。从品牌标识中去除“安卓”字样是很有必要的,因为很多服务是在浏览器中提供的,不需要安卓设备也能使用。
|
||||
|
||||
2012 年 4 月,谷歌[再次开始通过 Play 商店销售设备][1],恢复在 Nexus One 发布时尝试的直接面向消费者销售的方式。尽管距 Nexus One 销售结束仅有两年,但网上购物现在更加寻常,在接触到物品之前就购买它并不像在 2010 年时听起来那么疯狂。
|
||||
|
||||
谷歌也看到了价格敏感的用户在面对 Nexus One 的 530 美元的价格时的反应。第一部销售的设备是无锁的,GSM 版本的 Galaxy Nexus,价格 399 美元。在那之后,价格变得更低。350 美元成为了最近两台 Nexus 设备的入门价,7 英寸 Nexus 平板的价格更是只有 200 美元到 220 美元。
|
||||
|
||||
今天,Play 商店销售八款不同的安卓设备,四款 Chromebook,一款自动调温器,以及许多配件,设备商店已经是谷歌新产品发布的实际地点了。新产品发布总是如此受欢迎,站点往往无法承载如此大的流量,新 Nexus 手机也在几小时内售空。
|
||||
|
||||
----------
|
||||
|
||||

|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/20/
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/20/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,3 @@
|
||||
/*翻译中 WangYueScream LemonDemo*/
|
||||
|
||||
|
||||
|
||||
What is open source
|
||||
===========================
|
||||
|
||||
|
||||
@ -1,6 +1,3 @@
|
||||
|
||||
translating by ynmlml
|
||||
|
||||
Tips for non-native English speakers working on open source projects
|
||||
============================================================
|
||||

|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by scoutydren
|
||||
|
||||
Be a force for good in your community
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by SysTick
|
||||
|
||||
The decline of GPL?
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,80 +0,0 @@
|
||||
Why AlphaGo Is Not AI
|
||||
============================================================
|
||||
|
||||

|
||||
>Photo: RobotCub
|
||||
>“There is no AI without robotics,” the author argues.
|
||||
|
||||
_This is a guest post. The views expressed here are solely those of the author and do not represent positions of _ IEEE Spectrum _ or the IEEE._
|
||||
|
||||
What is AI and what is not AI is, to some extent, a matter of definition. There is no denying that AlphaGo, the Go-playing artificial intelligence designed by Google DeepMind that [recently beat world champion Lee Sedol][1], and similar [deep learning approaches][2] have managed to solve quite hard computational problems in recent years. But is it going to get us to _full AI_ , in the sense of an artificial general intelligence, or [AGI][3], machine? Not quite, and here is why.
|
||||
|
||||
One of the key issues when building an AGI is that it will have to make sense of the world for itself, to develop its own, internal meaning for everything it will encounter, hear, say, and do. Failing to do this, you end up with today’s AI programs where all the meaning is actually provided by the designer of the application: the AI basically doesn’t understand what is going on and has a narrow domain of expertise.
|
||||
|
||||
The problem of meaning is perhaps the most fundamental problem of AI and has still not been solved today. One of the first to express it was cognitive scientist Stevan Harnad, in his 1990 paper about “The Symbol Grounding Problem.” Even if you don’t believe we are explicitly manipulating symbols, which is indeed questionable, the problem remains: _the grounding of whatever representation exists inside the system into the real world outside_ .
|
||||
|
||||
To be more specific, the problem of meaning leads us to four sub-problems:
|
||||
|
||||
1. How do you structure the information the agent (human or AI) is receiving from the world?
|
||||
2. How do you link this structured information to the world, or, taking the above definition, how do you build “meaning” for the agent?
|
||||
3. How do you synchronize this meaning with other agents? (Otherwise, there is no communication possible and you get an incomprehensible, isolated form of intelligence.)
|
||||
4. Why does the agent do something at all rather than nothing? How to set all this into motion?
|
||||
|
||||
The first problem, about structuring information, is very well addressed by deep learning and similar unsupervised learning algorithms, used for example in the [AlphaGo program][4]. We have made tremendous progress in this area, in part because of the recent gain in computing power and the use of GPUs that are especially good at parallelizing information processing. What these algorithms do is take a signal that is extremely redundant and expressed in a high dimensional space, and reduce it to a low dimensionality signal, minimizing the loss of information in the process. In other words, it “captures” what is important in the signal, from an information processing point of view.
|
||||
|
||||
“There is no AI without robotics . . . This realization is often called the ‘embodiment problem’ and most researchers in AI now agree that intelligence and embodiment are tightly coupled issues. Every different body has a different form of intelligence, and you see that pretty clearly in the animal kingdom.”</aside>
|
||||
|
||||
The second problem, about linking information to the real world, or creating “meaning,” is fundamentally tied to robotics. Because you need a body to interact with the world, and you need to interact with the world to build this link. That’s why I often say that there is no AI without robotics (although there can be pretty good robotics without AI, but that’s another story). This realization is often called the “embodiment problem” and most researchers in AI now agree that intelligence and embodiment are tightly coupled issues. Every different body has a different form of intelligence, and you see that pretty clearly in the animal kingdom.
|
||||
|
||||
It starts with simple things like making sense of your own body parts, and how you can control them to produce desired effects in the observed world around you, how you build your own notion of space, distance, color, etc. This has been studied extensively by researchers like [J. Kevin O’Regan][5] and his “sensorimotor theory.” It is just a first step however, because then you have to build up more and more abstract concepts, on top of those grounded sensorimotor structures. We are not quite there yet, but that’s the current state of research on that matter.
|
||||
|
||||
The third problem is fundamentally the question of the origin of culture. Some animals show some simple form of culture, even transgenerational acquired competencies, but it is very limited and only humans have reached the threshold of exponentially growing acquisition of knowledge that we call culture. Culture is the essential catalyst of intelligence and an AI without the capability to interact culturally would be nothing more than an academic curiosity.
|
||||
|
||||
However, culture can not be hand coded into a machine; it must be the result of a learning process. The best way to start looking to try to understand this process is in developmental psychology, with the work of Jean Piaget and Michael Tomasello, studying how children acquire cultural competencies. This approach gave birth to a new discipline in robotics called “developmental robotics,” which is taking the child as a model (as illustrated by the [iCub robot][6], pictured above).
|
||||
|
||||
“Culture is the essential catalyst of intelligence and an AI without the capability to interact culturally would be nothing more than an academic curiosity. However, culture can not be hand coded into a machine; it must be the result of a learning process.”</aside>
|
||||
|
||||
It is also closely linked to the study of language learning, which is one of the topics that I mostly focused on as a researcher myself. The work of people like [Luc Steels][7] and many others have shown that we can see language acquisition as an evolutionary process: the agent creates new meanings by interacting with the world, use them to communicate with other agents, and select the most successful structures that help to communicate (that is, to achieve joint intentions, mostly). After hundreds of trial and error steps, just like with biological evolution, the system evolves the best meaning and their syntactic/grammatical translation.
|
||||
|
||||
This process has been tested experimentally and shows striking resemblance with how natural languages evolve and grow. Interestingly, it accounts for instantaneous learning, when a concept is acquired in one shot, something that heavily statistical models like deep learning are _not_ capable to explain. Several research labs are now trying to go further into acquiring grammar, gestures, and more complex cultural conventions using this approach, in particular the [AI Lab][8] that I founded at [Aldebaran][9], the French robotics company—now part of the SoftBank Group—that created the robots [Nao][10], [Romeo][11], and [Pepper][12] (pictured below).
|
||||
|
||||

|
||||
>Aldebaran’s humanoid robots: Nao, Romeo, and Pepper.</figcaption>
|
||||
|
||||
Finally, the fourth problem deals with what is called “intrinsic motivation.” Why does the agent do anything at all, rather than nothing. Survival requirements are not enough to explain human behavior. Even perfectly fed and secure, humans don’t just sit idle until hunger comes back. There is more: they explore, they try, and all of that seems to be driven by some kind of intrinsic curiosity. Researchers like [Pierre-Yves Oudeyer][13] have shown that simple mathematical formulations of curiosity, as an expression of the tendency of the agent to maximize its rate of learning, are enough to account for incredibly complex and surprising behaviors (see, for example, [the Playground experiment][14] done at Sony CSL).
|
||||
|
||||
It seems that something similar is needed inside the system to drive its desire to go through the previous three steps: structure the information of the world, connect it to its body and create meaning, and then select the most “communicationally efficient” one to create a joint culture that enables cooperation. This is, in my view, the program of AGI.
|
||||
|
||||
Again, the rapid advances of deep learning and the recent success of this kind of AI at games like Go are very good news because they could lead to lots of really useful applications in medical research, industry, environmental preservation, and many other areas. But this is only one part of the problem, as I’ve tried to show here. I don’t believe deep learning is the silver bullet that will get us to true AI, in the sense of a machine that is able to learn to live in the world, interact naturally with us, understand deeply the complexity of our emotions and cultural biases, and ultimately help us to make a better world.
|
||||
|
||||
**[Jean-Christophe Baillie][15] is founder and president of [Novaquark][16], a Paris-based virtual reality startup developing [Dual Universe][17], a next-generation online world where participants will be able to create entire civilizations through fully emergent gameplay. A graduate from the École Polytechnique in Paris, Baillie received a PhD in AI from Paris IV University and founded the Cognitive Robotics Lab at ENSTA ParisTech and, later, Gostai, a robotics company acquired by the Aldebaran/SoftBank Group in 2012\. This article originally [appeared][18] in LinkedIn.**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/why-alphago-is-not-ai
|
||||
|
||||
作者:[Jean-Christophe Baillie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jcbaillie
|
||||
[1]:http://spectrum.ieee.org/tech-talk/computing/networks/alphago-wins-match-against-top-go-player
|
||||
[2]:http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/facebook-ai-director-yann-lecun-on-deep-learning
|
||||
[3]:https://en.wikipedia.org/wiki/Artificial_general_intelligence
|
||||
[4]:http://spectrum.ieee.org/tech-talk/computing/software/monster-machine-defeats-prominent-pro-player
|
||||
[5]:http://nivea.psycho.univ-paris5.fr/
|
||||
[6]:http://www.icub.org/
|
||||
[7]:https://ai.vub.ac.be/members/steels
|
||||
[8]:http://a-labs.aldebaran.com/labs/ai-lab
|
||||
[9]:https://www.aldebaran.com/en
|
||||
[10]:http://spectrum.ieee.org/automaton/robotics/humanoids/aldebaran-new-nao-robot-demo
|
||||
[11]:http://spectrum.ieee.org/automaton/robotics/humanoids/france-developing-advanced-humanoid-robot-romeo
|
||||
[12]:http://spectrum.ieee.org/robotics/home-robots/how-aldebaran-robotics-built-its-friendly-humanoid-robot-pepper
|
||||
[13]:http://www.pyoudeyer.com/
|
||||
[14]:http://www.pyoudeyer.com/SS305OudeyerP-Y.pdf
|
||||
[15]:https://www.linkedin.com/in/jcbaillie
|
||||
[16]:http://www.dualthegame.com/novaquark
|
||||
[17]:http://www.dualthegame.com/
|
||||
[18]:https://www.linkedin.com/pulse/why-alphago-ai-jean-christophe-baillie
|
||||
@ -1,98 +0,0 @@
|
||||
#rusking translating
|
||||
Why do you use Linux and open source software?
|
||||
============================================================
|
||||
|
||||
>LinuxQuestions.org readers share reasons they use Linux and open source technologies. How will Opensource.com readers respond?
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
As I mentioned when [The Queue][4] launched, although typically I will answer questions from readers, sometimes I'll switch that around and ask readers a question. I haven't done so since that initial column, so it's overdue. I recently asked two related questions at LinuxQuestions.org and the response was overwhelming. Let's see how the Opensource.com community answers both questions, and how those responses compare and contrast to those on LQ.
|
||||
|
||||
### Why do you use Linux?
|
||||
|
||||
The first question I asked the LinuxQuestions.org community is: **[What are the reasons you use Linux?][1]**
|
||||
|
||||
### Answer highlights
|
||||
|
||||
_oldwierdal_ : I use Linux because it is fast, safe, and reliable. With contributors from all over the world, it has become, perhaps, the most advanced and innovative software available. And, here is the icing on the red-velvet cake; It is free!
|
||||
|
||||
_Timothy Miller_ : I started using it because it was free as in beer and I was poor so couldn't afford to keep buying new Windows licenses.
|
||||
|
||||
_ondoho_ : Because it's a global community effort, self-governed grassroot operating system. Because it's free in every sense. Because there's good reason to trust in it.
|
||||
|
||||
_joham34_ : Stable, free, safe, runs in low specs PCs, nice support community, little to no danger for viruses.
|
||||
|
||||
_Ook_ : I use Linux because it just works, something Windows never did well for me. I don't have to waste time and money getting it going and keeping it going.
|
||||
|
||||
_rhamel_ : I am very concerned about the loss of privacy as a whole on the internet. I recognize that compromises have to be made between privacy and convenience. I may be fooling myself but I think Linux gives me at least the possibility of some measure of privacy.
|
||||
|
||||
_educateme_ : I use Linux because of the open-minded, learning-hungry, passionately helpful community. And, it's free.
|
||||
|
||||
_colinetsegers_ : Why I use Linux? There's not only one reason. In short I would say:
|
||||
|
||||
1. The philosophy of free shared knowledge.
|
||||
2. Feeling safe while surfing the web.
|
||||
3. Lots of free and useful software.
|
||||
|
||||
_bamunds_ : Because I love freedom.
|
||||
|
||||
_cecilskinner1989_ : I use linux for two reasons: stability and privacy.
|
||||
|
||||
### Why do you use open source software?
|
||||
|
||||
The second questions is, more broadly: **[What are the reasons you use open source software?][2]** You'll notice that, although there is a fair amount of overlap here, the general tone is different, with some sentiments receiving more emphasis, and others less.
|
||||
|
||||
### Answer highlights
|
||||
|
||||
_robert leleu_ : Warm and cooperative atmosphere is the main reason of my addiction to open source.
|
||||
|
||||
_cjturner_ : Open Source is an answer to the Pareto Principle as applied to Applications; OOTB, a software package ends up meeting 80% of your requirements, and you have to get the other 20% done. Open Source gives you a mechanism and a community to share this burden, putting your own effort (if you have the skills) or money into your high-priority requirements.
|
||||
|
||||
_Timothy Miller_ : I like the knowledge that I _can_ examine the source code to verify that the software is secure if I so choose.
|
||||
|
||||
_teckk_ : There are no burdensome licensing requirements or DRM and it's available to everyone.
|
||||
|
||||
_rokytnji_ : Beer money. Motorcycle parts. Grandkids birthday presents.
|
||||
|
||||
_timl_ : Privacy is impossible without free software
|
||||
|
||||
_hazel_ : I like the philosophy of free software, but I wouldn't use it just for philosophical reasons if Linux was a bad OS. I use Linux because I love Linux, and because you can get it for free as in free beer. The fact that it's also free as in free speech is a bonus, because it makes me feel good about using it. But if I find that a piece of hardware on my machine needs proprietary firmware, I'll use proprietary firmware.
|
||||
|
||||
_lm8_ : I use open source software because I don't have to worry about it going obsolete when a company goes out of business or decides to stop supporting it. I can continue to update and maintain the software myself. I can also customize it if the software does almost everything I want, but it would be nice to have a few more features. I also like open source because I can share my favorite programs with friend and coworkers.
|
||||
|
||||
_donguitar_ : Because it empowers me and enables me to empower others.
|
||||
|
||||
### Your turn
|
||||
|
||||
So, what are the reasons _**you**_ use Linux? What are the reasons _**you**_ use open source software? Let us know in the comments.
|
||||
|
||||
### Fill The Queue
|
||||
|
||||
Lastly, what questions would you like to see answered in a future article? From questions on building and maintaining communities, to what you'd like to know about contributing to an open source project, to questions more technical in nature—[submit your Linux and open source questions][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jeremy Garcia - Jeremy Garcia is the founder of LinuxQuestions.org and an ardent but realistic open source advocate. Follow Jeremy on Twitter: @linuxquestions
|
||||
|
||||
------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software
|
||||
|
||||
作者:[Jeremy Garcia ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jeremy-garcia
|
||||
[1]:http://www.linuxquestions.org/questions/linux-general-1/what-are-the-reasons-you-use-linux-4175600842/
|
||||
[2]:http://www.linuxquestions.org/questions/linux-general-1/what-are-the-reasons-you-use-open-source-software-4175600843/
|
||||
[3]:https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software?rate=lVazcbF6Oern5CpV86PgNrRNZltZ8aJZwrUp7SrZIAw
|
||||
[4]:https://opensource.com/tags/queue-column
|
||||
[5]:https://opensource.com/thequeue-submit-question
|
||||
[6]:https://opensource.com/user/86816/feed
|
||||
[7]:https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software#comments
|
||||
[8]:https://opensource.com/users/jeremy-garcia
|
||||
@ -1,72 +0,0 @@
|
||||
|
||||
朝鲜180局的网络战部门让西方国家忧虑。
|
||||
|
||||
Translating by hwlog
|
||||
North Korea's Unit 180, the cyber warfare cell that worries the West
|
||||
|
||||
============================================================
|
||||
[][13] [**PHOTO:** 脱北者说, 平壤的网络战攻击目的在于一个叫做“180局”的部门来筹集资金。(Reuters: Damir Sagolj, file)][14]
|
||||
据叛逃者,官方和网络安全专家称,朝鲜的情报机关有一个叫做180局的特殊部门, 这个部门已经发起过多起勇敢且成功的网络战。
|
||||
近几年朝鲜被美国,韩国,和周边几个国家指责对多数的金融网络发起过一系列在线袭击。
|
||||
网络安全技术人员称他们找到了这个月感染了150多个国家30多万台计算机的全球想哭勒索病毒"ransomware"和朝鲜网络战有关联的技术证据。
|
||||
平壤称该指控是“荒谬的”。
|
||||
对朝鲜的关键指控是指朝鲜与一个叫做拉撒路的黑客组织有联系,这个组织是在去年在孟加拉国中央银行网络抢劫8000万美元并在2014年攻击了索尼的好莱坞工作室的网路。
|
||||
美国政府指责朝鲜对索尼公司的黑客袭击,同时美国政府对平壤在孟加拉国银行的盗窃行为提起公诉并要求立案。
|
||||
由于没有确凿的证据,没有犯罪指控并不能够立案。朝鲜之后也否认了Sony公司和银行的袭击与其有关。
|
||||
朝鲜是世界上最封闭的国家之一,它秘密行动的一些细节很难获得。
|
||||
但研究这个封闭的国家和流落到韩国和一些西方国家的的叛逃者已经给出了或多或少的提示。
|
||||
|
||||
### 黑客们喜欢用雇员来作为掩护
|
||||
金恒光,朝鲜前计算机教授,2004叛逃到韩国,他仍然有着韩国内部的消息,他说平壤的网络战目的在于通过侦察总局下属的一个叫做180局来筹集资金,这个局主要是负责海外的情报机构。
|
||||
金教授称,“180局负责入侵金融机构通过漏洞从银行账户提取资金”。
|
||||
他之前也说过,他以前的一些学生已经加入了朝鲜的网络战略司令部-朝鲜的网络部队。
|
||||
|
||||
>"黑客们到海外寻找比朝鲜更好的互联网服务的地方,以免留下痕迹," 金教授补充说。
|
||||
他说他们经常用贸易公司,朝鲜的海外分公司和在中国和东南亚合资企业的雇员来作为掩护
|
||||
位于华盛顿的战略与国际研究中心的叫做James Lewis的朝鲜专家称,平壤首先用黑客作为间谍活动的工具然后对韩国和美国的目的进行政治干扰。
|
||||
索尼公司事件之后,他们改变方法,通过用黑客来支持犯罪活动来形成国内坚挺的货币经济政策。
|
||||
“目前为止,网上毒品,假冒伪劣,走私,都是他们惯用的伎俩”。
|
||||
Media player: 空格键播放,“M”键静音,“左击”和“右击”查看。
|
||||
|
||||
[**VIDEO:** 你遇到过勒索病毒吗? (ABC News)][16]
|
||||
|
||||
### 韩国声称拥有大量的“证据”
|
||||
美国国防部称在去年提交给国会的一个报告中显示,朝鲜可能有作为有效成本的,不对称的,可拒绝的工具,它能够应付来自报复性袭击很小的风险,因为它的“网络”大部分是和因特网分离的。
|
||||
|
||||
> 报告中说," 它可能从第三方国家使用互联网基础设施"。
|
||||
韩国政府称,他们拥有朝鲜网络战行动的大量证据。
|
||||
“朝鲜进行网络战通过第三方国家来掩护网络袭击的来源,并且使用他们的信息和通讯技术设施”,Ahn Chong-ghee,韩国外交部副部长,在书面评论中告诉路透社。
|
||||
除了孟加拉银行抢劫案,他说平壤也被怀疑与菲律宾,越南和波兰的银行袭击有关。
|
||||
去年六月,警察称朝鲜袭击了160个韩国公司和政府机构,入侵了大约14万台计算机,暗中在他的对手的计算机中植入恶意代码作为长期计划的一部分来进行大规模网络攻击。
|
||||
朝鲜也被怀疑在2014年对韩国核反应堆操作系统进行阶段性网络攻击,尽管朝鲜否认与其无关。
|
||||
根据在一个韩国首尔的杀毒软件厂商“hauri”的高级安全研究员Simon Choi的说法,网络袭击是来自于他在中国的一个基地。
|
||||
Choi先生,一个有着对朝鲜的黑客能力进行了广泛的研究的人称,“他们在那里行动以至于不论他们做什么样的计划,他们拥有中国的ip地址”。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.abc.net.au/news/2017-05-21/north-koreas-unit-180-cyber-warfare-cell-hacking/8545106
|
||||
|
||||
作者:[www.abc.net.au ][a]
|
||||
译者:[译者ID](https://github.com/hwlog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.abc.net.au
|
||||
[1]:http://www.abc.net.au/news/2017-05-16/wannacry-ransomware-showing-up-in-obscure-places/8527060
|
||||
[2]:http://www.abc.net.au/news/2015-08-05/why-we-should-care-about-cyber-crime/6673274
|
||||
[3]:http://www.abc.net.au/news/2017-05-15/what-to-do-if-youve-been-hacked/8526118
|
||||
[4]:http://www.abc.net.au/news/2017-05-16/researchers-link-wannacry-to-north-korea/8531110
|
||||
[5]:http://www.abc.net.au/news/2017-05-18/adylkuzz-cyberattack-could-be-far-worse-than-wannacry:-expert/8537502
|
||||
[6]:http://www.google.com/maps/place/Korea,%20Democratic%20People%20S%20Republic%20Of/@40,127,5z
|
||||
[7]:http://www.abc.net.au/news/2017-05-16/wannacry-ransomware-showing-up-in-obscure-places/8527060
|
||||
[8]:http://www.abc.net.au/news/2017-05-16/wannacry-ransomware-showing-up-in-obscure-places/8527060
|
||||
[9]:http://www.abc.net.au/news/2015-08-05/why-we-should-care-about-cyber-crime/6673274
|
||||
[10]:http://www.abc.net.au/news/2015-08-05/why-we-should-care-about-cyber-crime/6673274
|
||||
[11]:http://www.abc.net.au/news/2017-05-15/what-to-do-if-youve-been-hacked/8526118
|
||||
[12]:http://www.abc.net.au/news/2017-05-15/what-to-do-if-youve-been-hacked/8526118
|
||||
[13]:http://www.abc.net.au/news/2017-05-21/military-trucks-trhough-pyongyang/8545134
|
||||
[14]:http://www.abc.net.au/news/2017-05-21/military-trucks-trhough-pyongyang/8545134
|
||||
[15]:http://www.abc.net.au/news/2017-05-16/researchers-link-wannacry-to-north-korea/8531110
|
||||
[16]:http://www.abc.net.au/news/2017-05-15/have-you-been-hit-by-ransomware/8527854
|
||||
@ -0,0 +1,120 @@
|
||||
Why working openly is hard when you just want to get stuff done
|
||||
============================================================
|
||||
|
||||
### Learn how to create a book using the Open Decision Framework.
|
||||
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
Three letters guide the way I work: GSD—get stuff done. Over the years, I've managed to blend concepts like feedback loops (from lean methodologies) and iterative improvement (from Agile) into my everyday work habits so I can better GSD (if I can use that as a verb). This means being extremely efficient with my time: outlining clear, discrete goals; checking completed items off a master list; and advancing projects forward iteratively and constantly. But can someone still GSD while defaulting to open? Or is this when getting stuff done comes to a grinding halt? Most would assume the worst, but I found that's not necessarily the case.
|
||||
|
||||
Working in the open and using guidance from the [Open Decision Framework][6] can get projects off to a slower start. But during a recent project, we made the decision—right at the beginning—to work openly and collaborate with our community.
|
||||
|
||||
Open Organization resources
|
||||
|
||||
* [Download the Open Organization Guide to IT Culture Change][1]
|
||||
|
||||
* [Download the Open Organization Leaders Manual][2]
|
||||
|
||||
* [What is an Open Organization?][3]
|
||||
|
||||
* [What is an Open Decision?][4]
|
||||
|
||||
It was the best decision we could have made.
|
||||
|
||||
Let's take a look at a few unexpected consequences from this experience and see how we can incorporate a GSD mentality into the Open Decision Framework.
|
||||
|
||||
### Building community
|
||||
|
||||
In November 2014, I undertook a new project: build a community around the concepts in _The Open Organization_ , a forthcoming (at the time) book by Red Hat CEO Jim Whitehurst. I thought, "Cool, that sounds like a challenge—I'm in!" Then [impostor syndrome][7] set in. I started thinking: "What in the world are we going to do, and what would success look like?"
|
||||
|
||||
_Spoiler alert_ . At the end of the book, Jim recommends that readers visit Opensource.com to continue the conversation about openness and management in the 21st century. So, in May 2015, my team launched a new section of the site dedicated to those ideas. We planned to engage in some storytelling, just like we always do at Opensource.com—this time around the ideas and concepts in the book. Since then, we've published new articles every week, hosted an online book club complete with Twitter chats, and turned _The Open Organization_ into [a book series][8].
|
||||
|
||||
We produced the first three installments of our book series in-house, releasing one every six months. When we finished one, we'd announce it to the community. Then we'd get to work on the next one, and the cycle would continue.
|
||||
|
||||
Working this way, we saw great success. Nearly 3,000 people have registered to receive the [latest book in the series][9], _The Open Organization Leaders Manual_ . And we've maintained our six-month cadence, which means the next book would coincide with the second anniversary of the book.
|
||||
|
||||
Behind the scenes, our process for creating the books is fairly straightforward: We collect our best-of-best stories about particular aspects of working openly, organize them into a compelling narrative, recruit writers to fill some gaps, typeset everything with open tools, collaborate with designers on a cover, and release. Working like this allows us to stay on our own timeline—GSD, full steam ahead. By the [third book][10], we seemed to have perfected the process.
|
||||
|
||||
That all changed when we began planning the latest volume in _Open Organization_ series, one focused on the intersection of open organizations and IT culture. I proposed using the Open Decision Framework because I wanted this book to be proof that working openly produced better results, even though I knew it would completely change our approach to the work. In spite of a fairly aggressive timeline (about two-and-a-half months), we decided to try it.
|
||||
|
||||
### Creating a book with the Open Decision Framework
|
||||
|
||||
The Open Decision Framework lists four phases that constitute the open decision-making process. Here's what we did during each (and how it worked out).
|
||||
|
||||
### 1\. Ideation
|
||||
|
||||
First, we drafted a document outlining a tentative vision for the project. We needed something we could begin sharing with potential "customers" (in our case, potential stakeholders and authors). Then we scheduled interviews with source matter experts we thought would be interested in the project—people who would give us raw, honest feedback about it. Enthusiasm and guidance from those experts validated our idea and gave us the feedback we needed to move forward. If we hadn't gotten that validation, we'd have gone back to our proposal and made a decision on where to pivot and start over.
|
||||
|
||||
### 2\. Planning and research
|
||||
|
||||
With validation after several interviews, we prepared to [announce the project publically on Opensource.com][11]. At the same time, we [launched the project on GitHub][12], offering a description, prospective timeline, and set of constraints. The project announcement was so well-received that all remaining holes in our proposed table of contents were filled within 72 hours. In addition (and more importantly), readers proposed ideas for chapters that _weren't _ already in the table of contents—things they thought might enhance the vision we'd initially sketched.
|
||||
|
||||
We experienced Linus' Law firsthand: "With more eyes, all _typos_ are shallow."
|
||||
|
||||
Looking back, I get the sense that working openly on Phases 1 and 2 really didn't negatively impacted our ability to GSD. In fact, working this way had a huge upside: identifying and filling content gaps. We didn't just fill them; we filled them _rapidly_ and with chapter ideas, we never would have considered on our own. This didn't necessarily involve more work—just work of a different type. We found ourselves asking people in our limited network to write chapters, then managing incoming requests, setting context, and pointing people in the right direction.
|
||||
|
||||
### 3\. Design, development, and testing
|
||||
|
||||
This point in the project was all about project management, cat herding, and maintaining expectations. We were on a deadline, and we communicated that early and often. We also used a tactic of creating a list of contributors and stakeholders and keeping them updated and informed along the entire journey, particularly at milestones we'd identified on GitHub.
|
||||
|
||||
Eventually, our book needed a title. We gathered lots of feedback on what the title should be, and more importantly what it _shouldn't_ be. We [opened an issue][13] as one way of gathering feedback, then openly shared that my team would be making the final decision. When we were ready to announce the final title, my colleague Bryan Behrenshausen did a great job [sharing the context for the decision][14]. People seemed to be happy with it—even if they didn't agree with where we landed with the final title.
|
||||
|
||||
Book "testing" involved extensive [proofreading][15]. The community really stepped up to answer this "help wanted" request. We received approximately 80 comments on the GitHub issue outlining the proofing process (not to mention numerous additional interactions from others via email and other feedback channels).
|
||||
|
||||
With respect to getting things done: In this phase, we experienced [Linus' Law][16] firsthand: "With more eyes, all _typos_ are shallow." Had we used the internalized method we'd used for our three previous book projects, the entire burden of proofing would have fallen on our shoulders (as it did for those books!). Instead, community members graciously helped us carry the burden of proofing, and our work shifted from proofing itself (though we still did plenty of that) to managing all the change requests coming in. This was a much-welcomed change for our team and a chance for the community to participate. We certainly would have finished the proofing faster if we'd done it ourselves, but working on this in the open undeniably allowed us to catch a greater number of errors in advance of our deadline.
|
||||
|
||||
### 4\. Launch
|
||||
|
||||
And here we are, on the cusp of launching the final (or is it just the first?) version of the book.
|
||||
|
||||
Following the Open Decision Framework was key to the success of the Guide to IT Culture Change.
|
||||
|
||||
Our approach to launch consists of two phases. First, in keeping with our public project timeline, we quietly soft-launched the book days ago so our community of contributors could help us test the [download form][17]. The second phase begins right now, with the final, formal announcement of the book's [general availability][18]. Of course, we'll continue accepting additional feedback post-launch, as is the open source way.
|
||||
|
||||
### Achievement unlocked
|
||||
|
||||
Following the Open Decision Framework was key to the success of the _Guide to IT Culture Change_ . By working with our customers and stakeholders, sharing our constraints, and being transparent with the work, we exceeded even our own expectations for the book project.
|
||||
|
||||
I was definitely pleased with the collaboration, feedback, and activity we experienced throughout the entire project. And although the feeling of anxiety about not getting stuff done as quickly as I'd liked loomed over me for a time, I soon realized that opening up the process actually allowed us to get _more_ done than we would have otherwise. That should be evident based on some of the outcomes I outlined above.
|
||||
|
||||
So perhaps I should reconsider my GSD mentality and expand it to GMD: Get **more** done—and, in this case, with better results.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jason Hibbets - Jason Hibbets is a senior community evangelist in Corporate Marketing at Red Hat where he is a community manager for Opensource.com. He has been with Red Hat since 2003 and is the author of The foundation for an open source city. Prior roles include senior marketing specialist, project manager, Red Hat Knowledgebase maintainer, and support engineer. Follow him on Twitter:
|
||||
|
||||
-----------
|
||||
|
||||
via: https://opensource.com/open-organization/17/6/working-open-and-gsd
|
||||
|
||||
作者:[Jason Hibbets ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jhibbets
|
||||
[1]:https://opensource.com/open-organization/resources/culture-change?src=too_resource_menu
|
||||
[2]:https://opensource.com/open-organization/resources/leaders-manual?src=too_resource_menu
|
||||
[3]:https://opensource.com/open-organization/resources/open-org-definition?src=too_resource_menu
|
||||
[4]:https://opensource.com/open-organization/resources/open-decision-framework?src=too_resource_menu
|
||||
[5]:https://opensource.com/open-organization/17/6/working-open-and-gsd?rate=ZgpGc0D07SjGkTOf708lnNqbF_HvkhXTXeSzRKMhvVM
|
||||
[6]:https://opensource.com/open-organization/resources/open-decision-framework
|
||||
[7]:https://opensource.com/open-organization/17/5/team-impostor-syndrome
|
||||
[8]:https://opensource.com/open-organization/resources
|
||||
[9]:https://opensource.com/open-organization/resources/leaders-manual
|
||||
[10]:https://opensource.com/open-organization/resources/leaders-manual
|
||||
[11]:https://opensource.com/open-organization/17/3/announcing-it-culture-book
|
||||
[12]:https://github.com/open-organization-ambassadors/open-org-it-culture
|
||||
[13]:https://github.com/open-organization-ambassadors/open-org-it-culture/issues/20
|
||||
[14]:https://github.com/open-organization-ambassadors/open-org-it-culture/issues/20#issuecomment-297970303
|
||||
[15]:https://github.com/open-organization-ambassadors/open-org-it-culture/issues/29
|
||||
[16]:https://en.wikipedia.org/wiki/Linus%27s_Law
|
||||
[17]:https://opensource.com/open-organization/resources/culture-change
|
||||
[18]:https://opensource.com/open-organization/resources/culture-change
|
||||
[19]:https://opensource.com/user/10530/feed
|
||||
[20]:https://opensource.com/users/jhibbets
|
||||
@ -1,5 +1,3 @@
|
||||
Martin translating...
|
||||
|
||||
Network automation with Ansible
|
||||
================
|
||||
|
||||
|
||||
@ -0,0 +1,176 @@
|
||||
Docker Engine swarm mode - Intro tutorial
|
||||
============================
|
||||
|
||||
Sounds like a punk rock band. But it is the brand new orchestration mechanism, or rather, an improvement of the orchestration available in [Docker][1]. To keep it short and sweet, if you are using an older version of Docker, you will manually need to setup Swarm to create Docker clusters. Starting with [version 1.12][2], the Docker engine comes with a native implementation allowing a seamless clustering setup. The reason why we are here.
|
||||
|
||||
In this tutorial, I will try to give you a taste of what Docker can do when it comes to orchestration. This article is by no means all inclusive (bed & breakfast) or all-knowing, but it has what it takes to embark you on your clustering journey. After me.
|
||||
|
||||

|
||||
|
||||
### Technology overview
|
||||
|
||||
It would be a shame for me to rehash the very detailed and highly useful Docker documentation article, so I will just outline a brief overview of the technology. So we have Docker, right. Now, you want to use more than a single server as a Docker host, but you want them to belong to the same logical entity. Hence, clustering.
|
||||
|
||||
Let's start by a cluster of one. When you initiate swarm on a host, it becomes a manager of the cluster. Technically speaking, it becomes a consensus group of one node. The mathematical logic behind is based on the [Raft][3] algorithm. The manager is responsible for scheduling tasks. The tasks will be delegated to worker nodes, once and if they join the swarm. This is governed by the Node API. I hate the word API, but I must use it here.
|
||||
|
||||
The Service API is the second component of this implementation. It allows manager nodes to create distributed services on all of the nodes in the swarm. The services can be replicated, meaning they are spread across the cluster using balancing mechanisms, or they can be global, meaning an instance of the service will be running on each node.
|
||||
|
||||
There's much more at work here, but this is good enough to get you primed and pumped. Now, let's do some actual hands-on stuff. Our target platform is [CentOS 7.2][4], which is quite interesting, because at the time I wrote this tutorial, it only had Docker 1.10 in the repos, and I had to manually upgrade the framework to use swarm. We will discuss this in a separate tutorial. Then, we will also have a follow-up guide, where we will join new nodes into our cluster, and we will try an asymmetric setup with [Fedora][5]. At this point, please assume the correct setup is in place, and let's get a cluster service up and running.
|
||||
|
||||
### Setup image & service
|
||||
|
||||
I will try to setup a load-balanced [Apache][6] service, with multiple instances serving content via a single IP address. Pretty standard. It also highlights the typical reasons why you would go with a cluster configuration - availability, redundancy, horizontal scaling, and performance. Of course, you also need to take into consideration the [networking][7] piece, as well as [storage][8], but that's something that goes beyond the immediate scope of this guide.
|
||||
|
||||
The actual Dockerfile template is available in the official repository under httpd. You will need a minimal setup to get underway. The details on how to download images, how to create your own and such are available in my intro guide, linked at the beginning of this tutorial.
|
||||
|
||||
docker build -t my-apache2 .
|
||||
Sending build context to Docker daemon 2.048 kB
|
||||
Step 1 : FROM httpd:2.4
|
||||
Trying to pull repository docker.io/library/httpd ...
|
||||
2.4: Pulling from docker.io/library/httpd
|
||||
|
||||
8ad8b3f87b37: Pull complete
|
||||
c95e1f92326d: Pull complete
|
||||
96e8046a7a4e: Pull complete
|
||||
00a0d292c371: Pull complete
|
||||
3f7586acab34: Pull complete
|
||||
Digest: sha256:3ad4d7c4f1815bd1c16788a57f81b413...a915e50a0d3a4
|
||||
Status: Downloaded newer image for docker.io/httpd:2.4
|
||||
---> fe3336dd034d
|
||||
Step 2 : COPY ../public-html/ /usr/local/apache2/htdocs/
|
||||
...
|
||||
|
||||

|
||||
|
||||
Before you go any further, you should start a single instance and see that your container is created without any errors and that you can connect to the Web server. Once we establish that, we will create a distributed service.
|
||||
|
||||
docker run -dit --name my-running-app my-apache2
|
||||
|
||||
Check the IP address, punch into a browser, see what gives.
|
||||
|
||||
### Swarm initiation and setup
|
||||
|
||||
The next step is to get swarm going. Here's the most basic of commands that will get you underway, and it is very similar to the example used in the Docker blog:
|
||||
|
||||
docker service create --name frontend --replicas 5 -p 80:80/tcp my-apache2:latest
|
||||
|
||||
What do we have here? We are creating a service called frontend, with five container instances. We are also binding our hostPort 80 with the containerPort 80. And we are using my freshly created Apache image for this. However, when you do this, you will get the following error:
|
||||
|
||||
docker service create --name frontend --replicas 5 -p 80:80/tcp my-apache2:latest
|
||||
Error response from daemon: This node is not a swarm manager. Use "docker swarm init" or "docker swarm join" to connect this node to swarm and try again.
|
||||
|
||||
This means you have not setup the current host (node) to be a swarm manager. You either need to init the swarm or join an existing one. Since we do not have one yet, we will now initialize it:
|
||||
|
||||
docker swarm init
|
||||
Swarm initialized: current node (dm58mmsczqemiikazbfyfwqpd) is now a manager.
|
||||
|
||||
To add a worker to this swarm, run the following command:
|
||||
|
||||
docker swarm join \
|
||||
--token SWMTKN-1-4ofd46a2nfyvrqwu8w5oeetukrbylyznxla
|
||||
9srf9vxkxysj4p8-eu5d68pu5f1ci66s7w4wjps1u \
|
||||
10.0.2.15:2377
|
||||
|
||||
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
|
||||
|
||||
The output is fairly self explanatory. We have created a swarm. New nodes will need to use the correct token to join the swarm. You also have the IP address and port identified, if you require firewall rules. Moreover, you can add managers to the swarm, too. Now, rerun the service create command:
|
||||
|
||||
docker service create --name frontend --replicas 5 -p 80:80/tcp my-apache2:latest
|
||||
6lrx1vhxsar2i50is8arh4ud1
|
||||
|
||||
### Test connectivity
|
||||
|
||||
Now, let's check that our service actually works. In a way, this is similar to what we did with [Vagrant][9] and [coreOS][10]. After all, the concepts are almost identical. It's just different implementation of the same idea. First, docker ps should show the right output. You should have multiple replicas for the created service.
|
||||
|
||||
docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
|
||||
NAMES
|
||||
cda532f67d55 my-apache2:latest "httpd-foreground"
|
||||
2 minutes ago Up 2 minutes 80/tcp frontend.1.2sobjfchdyucschtu2xw6ms9a
|
||||
75fe6e0aa77b my-apache2:latest "httpd-foreground"
|
||||
2 minutes ago Up 2 minutes 80/tcp frontend.4.ag77qtdeby9fyvif5v6c4zcpc
|
||||
3ce824d3151f my-apache2:latest "httpd-foreground"
|
||||
2 minutes ago Up 2 minutes 80/tcp frontend.2.b6fqg6sf4hkeqs86ps4zjyq65
|
||||
eda01569181d my-apache2:latest "httpd-foreground"
|
||||
2 minutes ago Up 2 minutes 80/tcp frontend.5.0rmei3zeeh8usagg7fn3olsp4
|
||||
497ef904e381 my-apache2:latest "httpd-foreground"
|
||||
2 minutes ago Up 2 minutes 80/tcp frontend.3.7m83qsilli5dk8rncw3u10g5a
|
||||
|
||||
I also tested with different, non-default ports, and it works well. You have a lot of leeway in how you can connect to the server and get the response. You can use localhost or the docker interface IP address with the correct port. The example below shows port 1080:
|
||||
|
||||

|
||||
|
||||
Now, this a very rough, very simple beginning. The real challenge is in creating optimized, scalable services, but they do require a proper technical use case. Moreover, you should also use the docker info and docker service (inspect|ps) commands to learn more about how your cluster is behaving.
|
||||
|
||||
### Possible problems
|
||||
|
||||
You may encounter some small (or not so small) issues while playing with Docker and swarm. For example, SELinux may complain that you are trying to do something illegal. However, the errors and warnings should not impede you too much.
|
||||
|
||||

|
||||
|
||||
### Docker service is not a docker command
|
||||
|
||||
When you try to run the necessary command to start a replicated service, you get an error that says docker: 'service' is not a docker command. This means that you do not have the right version of Docker (check with -v). We will fix this in a follow-up tutorial.
|
||||
|
||||
docker service create --name frontend --replicas 5 -p 80:80/tcp my-apache2:latest
|
||||
docker: 'service' is not a docker command.
|
||||
|
||||
### Docker tag not recognized
|
||||
|
||||
You may also see the following error:
|
||||
|
||||
docker service create -name frontend -replicas 5 -p 80:80/tcp my-apache2:latest
|
||||
Error response from daemon: rpc error: code = 3 desc = ContainerSpec: "-name" is not a valid repository/tag
|
||||
|
||||
There are several [discussions][11] [threads][12] around this. The error may actually be quite innocent. You may have copied the command from a browser, and the hyphens may not be parsed correctly. As simple as that.
|
||||
|
||||
### More reading
|
||||
|
||||
There's a lot more to be said on this topic, including the Swarm implementation prior to Docker 1.12, as well as the current version of the Docker engine. To wit, please do not be lazy and spend some time reading:
|
||||
|
||||
Docker Swarm [overview][13] (for standalone Swarm installations)
|
||||
|
||||
[Build][14] a Swarm cluster for production (standalone setups)
|
||||
|
||||
[Install and create][15] a Docker Swarm (standalone setups)
|
||||
|
||||
Docker engine swarm [overview][16] (for version 1.12)
|
||||
|
||||
Getting started with [swarm][17] mode (for version 1.12)
|
||||
|
||||
### Conclusion
|
||||
|
||||
There you go. Nothing too grand at this point, but I believe you will find the article useful. It covers several key concepts, there's an overview of how the swarm mode works and what it does, and we successfully managed to download and create our own Web server image and then run several clustered instances of it. We did this on a single node for now, but we will expand in the future. Also, we tackled some common problems.
|
||||
|
||||
I hope you find this guide interesting. Combined with my previous work on Docker, this should give you a decent understand of how to work with images, the networking stack, storage, and now clusters. Warming up. Indeed, enjoy and see you soon with fresh new tutorials on Docker. I just can't contain [sic] myself.
|
||||
|
||||
Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dedoimedo.com/computers/docker-swarm-intro.html
|
||||
|
||||
作者:[Dedoimedo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/computers/docker-swarm-intro.html
|
||||
[1]:http://www.dedoimedo.com/computers/docker-guide.html
|
||||
[2]:https://blog.docker.com/2016/06/docker-1-12-built-in-orchestration/
|
||||
[3]:https://en.wikipedia.org/wiki/Raft_%28computer_science%29
|
||||
[4]:http://www.dedoimedo.com/computers/lenovo-g50-centos-xfce.html
|
||||
[5]:http://www.dedoimedo.com/computers/fedora-24-gnome.html
|
||||
[6]:https://hub.docker.com/_/httpd/
|
||||
[7]:http://www.dedoimedo.com/computers/docker-networking.html
|
||||
[8]:http://www.dedoimedo.com/computers/docker-data-volumes.html
|
||||
[9]:http://www.dedoimedo.com/computers/vagrant-intro.html
|
||||
[10]:http://www.dedoimedo.com/computers/vagrant-coreos.html
|
||||
[11]:https://github.com/docker/docker/issues/24192
|
||||
[12]:http://stackoverflow.com/questions/38618609/docker-swarm-1-12-name-option-not-recognized
|
||||
[13]:https://docs.docker.com/swarm/
|
||||
[14]:https://docs.docker.com/swarm/install-manual/
|
||||
[15]:https://docs.docker.com/swarm/install-w-machine/
|
||||
[16]:https://docs.docker.com/engine/swarm/
|
||||
[17]:https://docs.docker.com/engine/swarm/swarm-tutorial/
|
||||
@ -1,5 +1,3 @@
|
||||
translating by flankershen
|
||||
|
||||
# Network management with LXD (2.3+)
|
||||
|
||||

|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
jayjay823 翻译中
|
||||
|
||||
User Editorial: Steam Machines & SteamOS after a year in the wild
|
||||
====
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
翻译中--by zky001
|
||||
Top 8 systems operations and engineering trends for 2017
|
||||
=================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
vim-kakali translating
|
||||
|
||||
3 open source music players: Aqualung, Lollypop, and GogglesMM
|
||||
============================================================
|
||||

|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
translating by cycoe
|
||||
|
||||
10 reasons to use Cinnamon as your Linux desktop environment
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
geekrainy translating
|
||||
A look at 6 iconic open source brands
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,101 +0,0 @@
|
||||
Software-Defined Storage Opens Up: 10 Projects to Know
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
With SDS, organizations can manage policy-based provisioning and management of data storage independent of the underlying hardware. Here's a list of open source projects you should know.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
Throughout 2016, the SDS (Software-Defined Storage) category achieved many new milestones and became increasingly tied to successful cloud deployments. With SDS, organizations can manage policy-based provisioning and management of data storage independent of the underlying hardware. They can also deploy free and open source SDS solutions. Many people are familiar with Ceph and are leveraging it within their OpenStack deployments, but Ceph is far from the only relevant open source SDS project.
|
||||
|
||||
A market research report from Gartner predicted that by 2019, 70 percent of existing storage array solutions will be available as a “software only” version. The research firm also predicted that by 2020, 70 percent to 80 percent of unstructured data will be stored in less expensive storage hardware managed by SDS systems.
|
||||
|
||||
Just recently, Dell EMC joined the[ OpenSDS][4] Project, of which The Linux Foundation is the steward. The OpenSDS community seeks to address software-defined storage integration challenges with the goal of driving enterprise adoption of open standards. It comprises storage users and vendors, including Fujitsu, Hitachi Data Systems, Huawei, Oregon State University and Vodafone. The project also seeks to collaborate with other upstream open source communities such as the Cloud Native Computing Foundation, Docker, OpenStack and Open Container Initiative.
|
||||
|
||||
According to the Open SDS project's[ home][5], 2017 will be a milestone year for SDS: "The community hopes to have an initial prototype available in Q2 2017 with a beta release by Q3 2017\. The initial participants expect OpenSDS will leverage open source technologies, such as Cinder and Manila from the OpenStack community, to best enable support across a wide range of cloud storage solutions."
|
||||
|
||||
Meanwhile, the number of projects in the SDS category is ballooning. They range from Apache Cassandra to Ceph. The Linux Foundation recently[][6]released its 2016 report[ "Guide to the Open Cloud: Current Trends and Open Source Projects,][7]” which provides a comprehensive look at the state of open cloud computing, and includes a section on SDS. You can[ download the report][8] now, and one of the first things to notice is that it aggregates and analyzes research, illustrating how trends in containers, SDS, and more are reshaping cloud computing. The report provides descriptions and links to categorized projects central to today’s open cloud environment.
|
||||
|
||||
In this series of articles, we are calling out many of these projects from the guide, providing extra insights on how the categories are evolving. Below, you’ll find a collection of several important SDS projects and the impact that they are having, along with links to their GitHub repositories, all gathered from the Guide to the Open Cloud:
|
||||
|
||||
### Software-Defined Storage
|
||||
|
||||
[Apache Cassandra][9]
|
||||
|
||||
Apache Cassandra is a scalable, high-availability database for mission-critical applications. It runs on commodity hardware or cloud infrastructure and replicates across multiple data centers for lower latency and fault tolerance. [Cassandra on GitHub][10]
|
||||
|
||||
[Ceph][11]
|
||||
|
||||
Ceph is Red Hat’s distributed, highly scalable block, object, and file storage platform for enterprises deploying public or private clouds. It’s commonly used with OpenStack. [Ceph on GitHub][12]
|
||||
|
||||
[CouchDB][13]
|
||||
|
||||
CouchDB, an Apache Software Foundation project, is a single-node or clustered database management system. It provides a RESTful HTTP API for reading and updating database documents. [CouchDB on GitHub][14]
|
||||
|
||||
[Docker Volume Plugins][15]
|
||||
|
||||
Docker Engine volume plugins enable Engine deployments to be integrated with external storage systems and enable data volumes to persist beyond the lifetime of a single Engine host. Volume plugins exist for multiple external storage systems including Azure File Storage, NetApp, VMware vSphere, and more. You can find individual plugins on GitHub.
|
||||
|
||||
[GlusterFS][16]
|
||||
|
||||
Gluster is Red Hat’s scalable network filesystem and data management platform. It can deploy on-premise, in private, public, or hybrid clouds, and in Linux containers for media streaming, data analysis, and other data- and bandwidth-intensive tasks. [GlusterFS on GitHub][17]
|
||||
|
||||
[MongoDB][18]
|
||||
|
||||
MongoDB is a high performance document database designed for ease of development and scaling. [MongoDB on GitHub][19]
|
||||
|
||||
[Nexenta][20]
|
||||
|
||||
NexentaStor is a scalable, unified software-defined file and block storage service that includes data management functionality. It integrates with VMware and supports Docker and OpenStack. [Nexenta on GitHub][21]
|
||||
|
||||
[Redis][22]
|
||||
|
||||
Redis is an in-memory data structure store, used as database, cache and message broker. It supports multiple data structures and has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence. [Redis on GitHub][23]
|
||||
|
||||
[Riak CS][24]
|
||||
|
||||
Riak CS (Cloud Storage) is object storage software built on top of Riak KV, Basho’s distributed database. It provides distributed cloud storage at any scale, and can be used to build public or private cloud architectures or as storage infrastructure for heavy-duty applications and services. Its API is Amazon S3 compatible and supports per-tenant reporting for use cases involving billing and metering. [Riak CS on GitHub][25]
|
||||
|
||||
[Swift][26]
|
||||
|
||||
Swift is OpenStack’s object storage system designed to store and retrieve unstructured data with a simple API. It’s built for scale and optimized for durability, availability, and concurrency across the entire data set. [Swift on GitHub][27]
|
||||
|
||||
_Learn more about trends in open source cloud computing and see the full list of the top open source cloud computing projects. [Download The Linux Foundation’s Guide to the Open Cloud report today!][3]_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/guide-open-cloud-software-defined-storage-opens
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/software-definedjpg
|
||||
[3]:http://bit.ly/2eHQOwy
|
||||
[4]:http://ctt.marketwire.com/?release=11G125514-001&id=10559023&type=0&url=https%3A%2F%2Fwww.opensds.io%2F
|
||||
[5]:https://www.opensds.io/
|
||||
[6]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[7]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[8]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[9]:http://cassandra.apache.org/
|
||||
[10]:https://github.com/apache/cassandra
|
||||
[11]:http://ceph.com/
|
||||
[12]:https://github.com/ceph/ceph
|
||||
[13]:http://couchdb.apache.org/
|
||||
[14]:https://github.com/apache/couchdb
|
||||
[15]:https://docs.docker.com/engine/extend/plugins_volume/
|
||||
[16]:https://www.gluster.org/
|
||||
[17]:https://github.com/gluster/glusterfs
|
||||
[18]:https://www.mongodb.com/
|
||||
[19]:https://github.com/mongodb/mongo
|
||||
[20]:https://nexenta.com/
|
||||
[21]:https://github.com/Nexenta
|
||||
[22]:http://redis.io/
|
||||
[23]:https://github.com/antirez/redis
|
||||
[24]:http://docs.basho.com/riak/cs/2.1.1/
|
||||
[25]:https://github.com/basho/riak_cs
|
||||
[26]:https://wiki.openstack.org/wiki/Swift
|
||||
[27]:https://github.com/openstack/swift
|
||||
@ -0,0 +1,76 @@
|
||||
cygmris is translating
|
||||
|
||||
# Filtering Packets In Wireshark on Kali Linux
|
||||
|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Introduction][1]
|
||||
|
||||
* [2. Boolean Expressions and Comparison Operators][2]
|
||||
|
||||
* [3. Filtering Capture][3]
|
||||
|
||||
* [4. Filtering Results][4]
|
||||
|
||||
* [5. Closing Thoughts][5]
|
||||
|
||||
### Introduction
|
||||
|
||||
Filtering allows you to focus on the exact sets of data that you are interested in reading. As you have seen, Wireshark collects _everything_ by default. That can get in the way of the specific data that you are looking for. Wireshark provides two powerful filtering tools to make targeting the exact data you need simple and painless.
|
||||
|
||||
There are two way that Wireshark can filter packets. It can filter an only collect certain packets, or the packet results can be filtered after they are collected. Of course, these can be used in conjunction with one another, and their respective usefulness is dependent on which and how much data is being collected.
|
||||
|
||||
### Boolean Expressions and Comparison Operators
|
||||
|
||||
Wireshark has plenty of built-in filters which work just great. Start typing in either of the filter fields, and you will see them autocomplete in. Most correspond to the more common distinctions that a user would make between packets. Filtering only HTTP requests would be a good example.
|
||||
|
||||
For everything else, Wireshark uses Boolean expressions and/or comparison operators. If you've ever done any kind of programming, you should be familiar with Boolean expressions. They are expressions that use "and," "or," and "not" to verify the truthfulness of a statement or expression. Comparison operators are much simpler. They just determine if two or more things are equal, greater, or less than one another.
|
||||
|
||||
### Filtering Capture
|
||||
|
||||
Before diving in to custom capture filters, take a look at the ones Wireshark already has built in. Click on the "Capture" tab on the top menu, and go to "Options." Below the available interfaces is the line where you can write your capture filters. Directly to its left is a button labeled "Capture Filter." Click on it, and you will see a new dialog box with a listing of pre-built capture filters. Look around and see what's there.
|
||||
|
||||

|
||||
|
||||
|
||||
At the bottom of that box, there is a small form for creating and saving hew capture filters. Press the "New" button to the left. It will create a new capture filter populated with filler data. To save the new filter, just replace the filler with the actual name and expression that you want and click "Ok." The filter will be saved and applied. Using this tool, you can write and save multiple different filters and have them ready to use again in the future.
|
||||
|
||||
Capture has it's own syntax for filtering. For comparison, it omits and equals symbol and uses `>` and for greater and less than. For Booleans, it relies on the words "and," "or," and "not."
|
||||
|
||||
If, for example, you only wanted to listen to traffic on port 80, you could use and expressions like this: `port 80`. If you only wanted to listen on port 80 from a specific IP, you would add that on. `port 80 and host 192.168.1.20` As you can see, capture filters have specific keywords. These keywords are used to tell Wireshark how to monitor packets and which ones to look at. For example, `host` is used to look at all traffic from an IP. `src` is used to look at traffic originating from that IP. `dst` in contrast, only watches incoming traffic to an IP. To watch traffic on a set of IPs or a network, use `net`.
|
||||
|
||||
### Filtering Results
|
||||
|
||||
The bottom menu bar on your layout is the one dedicated to filtering results. This filter doesn't change the data that Wireshark has collected, it just allows you to sort through it more easily. There is a text field for entering a new filter expression with a drop down arrow to review previously entered filters. Next to that is a button marked "Expression" and a few others for clearing and saving your current expression.
|
||||
|
||||
Click on the "Expression" button. You will see a small window with several boxes with options in them. To the left is the largest box with a huge list of items, each with additional collapsed sub-lists. These are all of the different protocols, fields, and information that you can filter by. There's no way to go through all of it, so the best thing to do is look around. You should notice some familiar options like HTTP, SSL, and TCP.
|
||||
|
||||

|
||||
|
||||
The sub-lists contain the different parts and methods that you can filter by. This would be where you'd find the methods for filtering HTTP requests by GET and POST.
|
||||
|
||||
You can also see a list of operators in the middle boxes. By selecting items from each column, you can use this window to create filters without memorizing every item that Wireshark can filter by. For filtering results, comparison operators use a specific set of symbols. `==` determines if two things are equal. `>`determines if one thing is greater than another, `<` finds if something is less. `>=` and `<=` are for greater than or equal to and less than or equal to respectively. They can be used to determine if packets contain the right values or filter by size. An example of using `==` to filter only HTTP GET requests like this: `http.request.method == "GET"`.
|
||||
|
||||
Boolean operators can chain smaller expressions together to evaluate based on multiple conditions. Instead of words like with capture, they use three basic symbols to do this. `&&` stands for "and." When used, both statements on either side of `&&` must be true in order for Wireshark to filter those packages. `||`signifies "or." With `||` as long as either expression is true, it will be filtered. If you were looking for all GET and POST requests, you could use `||` like this: `(http.request.method == "GET") || (http.request.method == "POST")`. `!` is the "not" operator. It will look for everything but the thing that is specified. For example, `!http` will give you everything but HTTP requests.
|
||||
|
||||
### Closing Thoughts
|
||||
|
||||
Filtering Wireshark really allows you to efficiently monitor your network traffic. It takes some time to familiarize yourself with the options available and become used to the powerful expressions that you can create with filters. Once you do, though, you will be able to quickly collect and find exactly the network data the you are looking for without having to comb through long lists of packets or do a whole lot of work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
|
||||
作者:[Nick Congleton ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
[1]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h1-introduction
|
||||
[2]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h2-boolean-expressions-and-comparison-operators
|
||||
[3]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h3-filtering-capture
|
||||
[4]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h4-filtering-results
|
||||
[5]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h5-closing-thoughts
|
||||
@ -1,4 +1,3 @@
|
||||
dongdongmian 翻译中
|
||||
How to take screenshots on Linux using Scrot
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
# rusking translating
|
||||
An introduction to the Linux boot and startup processes
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
translating by Flowsnow!
|
||||
|
||||
Many SQL Performance Problems Stem from “Unnecessary, Mandatory Work”
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Yoo-4x Translating
|
||||
|
||||
OpenGL & Go Tutorial Part 1: Hello, OpenGL
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
【翻译中】
|
||||
Getting started with Perl on the Raspberry Pi
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
#rusking translating
|
||||
|
||||
An introduction to GRUB2 configuration for your Linux machine
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,7 +1,3 @@
|
||||
svtter tranlating...
|
||||
|
||||
---
|
||||
|
||||
STUDY RUBY PROGRAMMING WITH OPEN-SOURCE BOOKS
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
trnhoe translating~
|
||||
Introduction to functional programming
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,213 +0,0 @@
|
||||
(翻译中 by runningwater)
|
||||
FreeFileSync – Compare and Synchronize Files in Ubuntu
|
||||
============================================================
|
||||
|
||||
|
||||
FreeFileSync is a free, open source and cross platform folder comparison and synchronization software, which helps you [synchronize files and folders on Linux][2], Windows and Mac OS.
|
||||
|
||||
It is portable and can also be installed locally on a system, it’s feature-rich and is intended to save time in setting up and executing backup operations while having attractive graphical interface as well.
|
||||
|
||||
#### FreeFileSync Features
|
||||
|
||||
Below are it’s key features:
|
||||
|
||||
1. It can synchronize network shares and local disks.
|
||||
2. It can synchronize MTP devices (Android, iPhone, tablet, digital camera).
|
||||
3. It can also synchronize via [SFTP (SSH File Transfer Protocol)][1].
|
||||
4. It can identify moved and renamed files and folders.
|
||||
5. Displays disk space usage with directory trees.
|
||||
6. Supports copying locked files (Volume Shadow Copy Service).
|
||||
7. Identifies conflicts and propagate deletions.
|
||||
8. Supports comparison of files by content.
|
||||
9. It can be configured to handle Symbolic Links.
|
||||
10. Supports automation of sync as a batch job.
|
||||
11. Enables processing of multiple folder pairs.
|
||||
12. Supports in-depth and detailed error reporting.
|
||||
13. Supports copying of NTFS extended attributes such as (compressed, encrypted, sparse).
|
||||
14. Also supports copying of NTFS security permissions and NTFS Alternate Data Streams.
|
||||
15. Support long file paths with more than 260 characters.
|
||||
16. Supports Fail-safe file copy prevents data corruption.
|
||||
17. Allows expanding of environment variables such as %UserProfile%.
|
||||
18. Supports accessing of variable drive letters by volume name (USB sticks).
|
||||
19. Supports managing of versions of deleted/updated files.
|
||||
20. Prevent disc space issues via optimal sync sequence.
|
||||
21. Supports full Unicode.
|
||||
22. Offers a highly optimized run time performance.
|
||||
23. Supports filters to include and exclude files plus lots more.
|
||||
|
||||
### How To Install FreeFileSync in Ubuntu Linux
|
||||
|
||||
We will add official FreeFileSync PPA, which is available for Ubuntu 14.04 and Ubuntu 15.10 only, then update the system repository list and install it like so:
|
||||
|
||||
```
|
||||
-------------- On Ubuntu 14.04 and 15.10 --------------
|
||||
$ sudo apt-add-repository ppa:freefilesync/ffs
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install freefilesync
|
||||
```
|
||||
|
||||
On Ubuntu 16.04 and newer version, go to the [FreeFileSync download page][3] and get the appropriate package file for Ubuntu and Debian Linux.
|
||||
|
||||
Next, move into the Download folder, extract the FreeFileSync_*.tar.gz into the /opt directory as follows:
|
||||
|
||||
```
|
||||
$ cd Downloads/
|
||||
$ sudo tar xvf FreeFileSync_*.tar.gz -C /opt/
|
||||
$ cd /opt/
|
||||
$ ls
|
||||
$ sudo unzip FreeFileSync/Resources.zip -d /opt/FreeFileSync/Resources/
|
||||
```
|
||||
|
||||
Now we will create an application launcher (.desktop file) using Gnome Panel. To view examples of `.desktop`files on your system, list the contents of the directory /usr/share/applications:
|
||||
|
||||
```
|
||||
$ ls /usr/share/applications
|
||||
```
|
||||
|
||||
In case you do not have Gnome Panel installed, type the command below to install it:
|
||||
|
||||
```
|
||||
$ sudo apt-get install --no-install-recommends gnome-panel
|
||||
```
|
||||
|
||||
Next, run the command below to create the application launcher:
|
||||
|
||||
```
|
||||
$ sudo gnome-desktop-item-edit /usr/share/applications/ --create-new
|
||||
```
|
||||
|
||||
And define the values below:
|
||||
|
||||
```
|
||||
Type: Application
|
||||
Name: FreeFileSync
|
||||
Command: /opt/FreeFileSync/FreeFileSync
|
||||
Comment: Folder Comparison and Synchronization
|
||||
```
|
||||
|
||||
To add an icon for the launcher, simply clicking on the spring icon to select it: /opt/FreeFileSync/Resources/FreeFileSync.png.
|
||||
|
||||
When you have set all the above, click OK create it.
|
||||
|
||||
[
|
||||
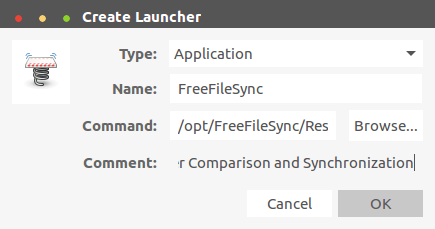
|
||||
][4]
|
||||
|
||||
Create Desktop Launcher
|
||||
|
||||
If you don’t want to create desktop launcher, you can start FreeFileSync from the directory itself.
|
||||
|
||||
```
|
||||
$ ./FreeFileSync
|
||||
```
|
||||
|
||||
### How to Use FreeFileSync in Ubuntu
|
||||
|
||||
In Ubuntu, search for FreeFileSync in the Unity Dash, whereas in Linux Mint, search for it in the System Menu, and click on the FreeFileSync icon to open it.
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
FreeFileSync
|
||||
|
||||
#### Compare Two Folders Using FreeFileSync
|
||||
|
||||
In the example below, we’ll use:
|
||||
|
||||
```
|
||||
Source Folder: /home/aaronkilik/bin
|
||||
Destination Folder: /media/aaronkilik/J_CPRA_X86F/scripts
|
||||
```
|
||||
|
||||
To compare the file time and size of the two folders (default setting), simply click on the Compare button.
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
Compare Two Folders in Linux
|
||||
|
||||
Press `F6` to change what to compare by default, in the two folders: file time and size, content or file size from the interface below. Note that the meaning of the each option you select is included as well.
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
File Comparison Settings
|
||||
|
||||
#### Synchronization Two Folders Using FreeFileSync
|
||||
|
||||
You can start by comparing the two folders, and then click on Synchronize button, to start the synchronization process; click Start from the dialog box the appears thereafter:
|
||||
|
||||
```
|
||||
Source Folder: /home/aaronkilik/Desktop/tecmint-files
|
||||
Destination Folder: /media/aaronkilik/Data/Tecmint
|
||||
```
|
||||
[
|
||||
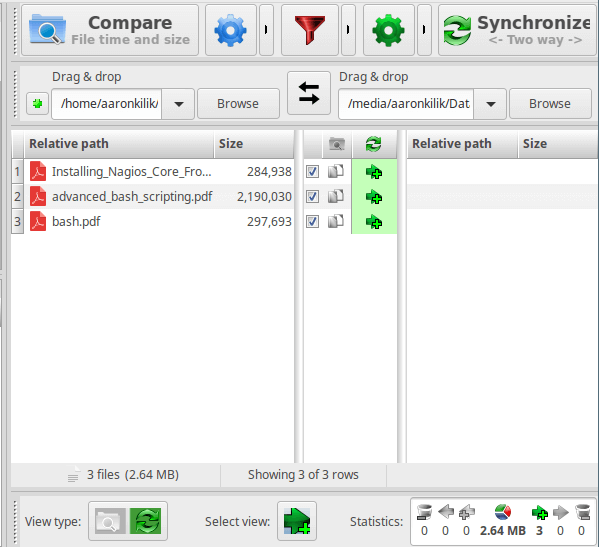
|
||||
][8]
|
||||
|
||||
Compare and Synchronize Two Folders
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
Start File Synchronization
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
File Synchronization Completed
|
||||
|
||||
To set the default synchronization option: two way, mirror, update or custom, from the following interface; press `F8`. The meaning of the each option is included there.
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
File Synchronization Settings
|
||||
|
||||
For more information, visit FreeFileSync homepage at [http://www.freefilesync.org/][12]
|
||||
|
||||
That’s all! In this article, we showed you how to install FreeFileSync in Ubuntu and it’s derivatives such as Linux Mint, Kubuntu and many more. Drop your comments via the feedback section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I am Ravi Saive, creator of TecMint. A Computer Geek and Linux Guru who loves to share tricks and tips on Internet. Most Of My Servers runs on Open Source Platform called Linux. Follow Me: [Twitter][00], [Facebook][01] and [Google+][02]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/freefilesync-compare-synchronize-files-in-ubuntu/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[00]:https://twitter.com/ravisaive
|
||||
[01]:https://www.facebook.com/ravi.saive
|
||||
[02]:https://plus.google.com/u/0/+RaviSaive
|
||||
|
||||
[1]:http://www.tecmint.com/sftp-command-examples/
|
||||
[2]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[3]:http://www.freefilesync.org/download.php
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Create-Desktop-Launcher.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/FreeFileSync-launched.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/compare-two-folders.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/comparison-settings.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/compare-and-sychronize-two-folders.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/start-sychronization.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/synchronization-complete.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/synchronization-setttings.png
|
||||
[12]:http://www.freefilesync.org/
|
||||
[13]:http://www.tecmint.com/author/admin/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
261
sources/tech/20170520 How to master the art of Git.md
Normal file
261
sources/tech/20170520 How to master the art of Git.md
Normal file
@ -0,0 +1,261 @@
|
||||
How to master the art of Git
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
### Step up your software development game with 7 simple Git commands.
|
||||
|
||||
Have you ever wondered how one learns to use Git well? You use Git very poorly for a long time. Eventually, you’ll get the hang of it. That’s why I’m here. I’ll take you on a journey to enlightenment. These are my basic guidelines of how to speed up the process of learning Git significantly. I’ll cover what Git actually is and the 7 Git commands I use the most. This article is mainly aimed towards aspiring developers and college freshmen who are in need of an introductory explanation of what Git is and how to master the basics.
|
||||
|
||||
* * *
|
||||
|
||||
You can go ahead and read the whole article or hurt my feelings significantly by only reading the TLDR;
|
||||
|
||||
#### TLDR;
|
||||
|
||||
When in the process of learning Git, make a habit of following these steps:
|
||||
|
||||
1. `git status` all the time!
|
||||
|
||||
2. Try only to change files you really want to change.
|
||||
|
||||
3. `git add -A` is your friend.
|
||||
|
||||
4. Feel free to `git commit -m "meaningful messages"` .
|
||||
|
||||
5. Always `git pull` before doing any pushing,
|
||||
but after you have committed any changes.
|
||||
|
||||
6. Finally, `git push` the committed changes.
|
||||
|
||||
* * *
|
||||
|
||||
#### Do not go gentle into that good night.
|
||||
|
||||
The universal first step for any developer is to choose a common place to host his or her code base. Voilá, [GitHub][4]! The meeting place for all things regarding code. To be able to understand the concept of GitHub you would first need to understand what Git really is.
|
||||
|
||||
Git is a version control software, based on the command line, with a few desktop apps available for Windows and Mac. Created by Linus Torvalds, the father of Linux and one of the most influential people in computer science, ever. Channeling this merit, Git has become a standard for a vast majority of software developers regarding sharing and maintaining code. Those were a bunch of large words. Let’s break it down. Version control software, means exactly what it says. Git allows you to have a preview of all the versions of your code you have ever written. Literally, ever! Every code base a developer has, will be stored in its respective repository, which can be named anything from _pineapple_ to _express_ . In the process of developing the code within this repository you will make countless changes, up until the first official release. Here lies the core reason why version control software is so important. It enables you, the developer, to have a clear view of all changes, revisions and improvements ever done to the code base. In turn making it much easier to collaborate, download code to make edits, and upload changes to the repository. However, in spite of all this awesomeness, one thing takes the crown as the most incredible. You can download and use the files even thought you have nothing to do with the development process!
|
||||
|
||||
Let’s get back to the GitHub part of the story. It’s just a hub for all repositories, where they can be stored and viewed online. A central meeting point for like minded individuals.
|
||||
|
||||
#### Let’s start using it already!
|
||||
|
||||
Okay, remember, Git is a software, and like any other software you’ll first need to install it:
|
||||
|
||||
[Git - Installing Git
|
||||
If you do want to install Git from source, you need to have the following libraries that Git depends on: autotools…git-scm.com][5][][6]
|
||||
|
||||
*Anchorman voice*
|
||||
_Please click on the link above, and follow the instructions stated…_
|
||||
|
||||
Done installing it, great. Now you will need to punch in [github.com][7] in your browsers address bar. Create an account if you don’t already have one, and you’re set to rock’n’roll! Jump in and create a new repository, name it Steve for no reason at all, just for the fun of having a repository named Steve. Go ahead and check the _Initialize this repository with a README _ checkbox and click the create button. You now have a new repository called Steve. Be proud of yourself, I sure am.
|
||||
|
||||
|
||||
|
||||
|
||||
#### Starting to use Git for real this time.
|
||||
|
||||
Now comes the fun part. You’re ready to clone Steve to your local machine. View this process as simply copying the repository from GitHub to your computer. By clicking the _clone or download_ button you will see a URL which will look something like this:
|
||||
|
||||
```
|
||||
https://github.com/yourGithubAccountName/Steve.git
|
||||
```
|
||||
|
||||
Copy this URL and open up a command prompt. Now write and run this command:
|
||||
|
||||
```
|
||||
git clone https://github.com/yourGithubAccountName/Steve.git
|
||||
```
|
||||
|
||||
Abrakadabra! Steve has automagically been cloned to your computer. Looking in the directory where you cloned the repository, you’ll see a folder named Steve. This local folder is now linked with it’s _origin, _ the original repository on Github.
|
||||
|
||||
Remember this process, you will surely repeat it many times in your career as a software developer. With all this formal stuff done, you are ready to get started with the most common and regularly used Git commands.
|
||||
|
||||
|
||||

|
||||
Lame video game reference
|
||||
|
||||
#### You’re actually just now starting to use Git for real.
|
||||
|
||||
Open up the Steve directory and go ahead and open a command prompt from within the same directory. Run the command:
|
||||
|
||||
```
|
||||
git status
|
||||
```
|
||||
|
||||
This will output the status of your working directory, showing you all the files you have edited. This means it’s showing you the difference between the files on the origin and your local working directory. The status command is designed to be used as a _commit_ template. I’ll come back to talking about commit a bit further down this tutorial. Simply put, `[git status][1]` shows you which files you have edited, in turn giving you an overview of which you wish to upload back to the origin.
|
||||
|
||||
But, before you do any of that, first you need to pick which files you wish to send back to the origin. This is done with:
|
||||
|
||||
```
|
||||
git add
|
||||
```
|
||||
|
||||
Please go ahead and create a new text file in the Steve directory. Name it _pineapple.txt_ just for the fun of it. Write whatever you would want in this file. Switch back to the command prompt, and run `git status` once again. Now, you’ll see the file show up in red under the banner _untracked files._
|
||||
|
||||
```
|
||||
On branch master
|
||||
Your branch is up-to-date with 'origin/master'.
|
||||
Untracked files:
|
||||
(use "git add <file>..." to include in what will be commited)
|
||||
```
|
||||
|
||||
```
|
||||
pineapple.txt
|
||||
```
|
||||
|
||||
The next step is to add a file to staging. Staging can be viewed as a context where all changes you have picked will be bundled into one, when the time comes to commit them. Now you can go ahead and add this file to staging:
|
||||
|
||||
```
|
||||
git add -A
|
||||
```
|
||||
|
||||
The _-A _ flag means that all files that have been changed will be staged for commit. However, `git add` is very flexible and it is perfectly fine to add files one by one. Just like this:
|
||||
|
||||
```
|
||||
git add pineapple.txt
|
||||
```
|
||||
|
||||
This approach gives you power to cherry pick every file you wish to stage, without the added worry that you’ll change something you weren’t supposed to.
|
||||
|
||||
After running `git status` once again you should see something like this:
|
||||
|
||||
```
|
||||
On branch master
|
||||
Your branch is up-to-date with 'origin/master'.
|
||||
Changes to be committed:
|
||||
(use "git reset HEAD <file>..." to unstage)
|
||||
```
|
||||
|
||||
```
|
||||
new file: pineapple.txt
|
||||
```
|
||||
|
||||
Ready to commit the changes? I sure am.
|
||||
|
||||
```
|
||||
git commit -m "Write your message here"
|
||||
```
|
||||
|
||||
The [Git commit][9] command stores the current files in staging in a new commit along with a log message from the user describing the changes. The _-m _ flag includes the message written in double quotes in the commit.
|
||||
|
||||
Checking the status once again will show you:
|
||||
|
||||
```
|
||||
On branch master
|
||||
Your branch is ahead of 'origin/master' by 1 commit.
|
||||
(use "git push" to publish your local commits)
|
||||
nothing to commit, working directory clean
|
||||
```
|
||||
|
||||
All changes have now been bundled into one commit with one dedicated message regarding the work you have done. You’re now ready to `[git push][2]`this commit to the _origin_ . The push command does literally what it means. It will upload your committed changes from your local machine to the repository origin on GitHub. Go back to the command prompt and run:
|
||||
|
||||
```
|
||||
git push
|
||||
```
|
||||
|
||||
It will ask you to enter your GitHub username and password, after which you will see something like this:
|
||||
|
||||
```
|
||||
Counting objects: 3, done.
|
||||
Delta compression using up to 4 threads.
|
||||
Compressing objects: 100% (2/2), done.
|
||||
Writing objects: 100% (3/3), 280 bytes | 0 bytes/s, done.
|
||||
Total 3 (delta 0), reused 0 (delta 0)
|
||||
To https://github.com/yourGithubUserName/Steve.git
|
||||
c77a97c..08bb95a master -> master
|
||||
```
|
||||
|
||||
That’s it. You have uploaded the local changes. Go ahead and look at your repository on GitHub and you’ll see that it now contains a file named _pineapple.txt_ .
|
||||
|
||||
What if you work in a team of developers? Where all of them push commits to the origin. What happens then? This is where Git starts to show it’s real power. You can just as easily [pull][10] the latest version of the code base to your local machine with one simple command.
|
||||
|
||||
```
|
||||
git pull
|
||||
```
|
||||
|
||||
But Git has it’s limitations. You need to have matching versions to be able to push changes to the origin. Meaning the version you have locally needs to be exactly the same as the one on the origin. When pulling from the origin you shouldn’t have files in the working directory, as they will be overwritten in the process. Hence me giving this simple advice. When in the process of learning Git, make a habit of following these steps:
|
||||
|
||||
1. `git status` all the time!
|
||||
|
||||
2. Try only to change files you really want to change.
|
||||
|
||||
3. `git add -A` is your friend.
|
||||
|
||||
4. Feel free to `git commit -m "meaningful messages"` .
|
||||
|
||||
5. Always `git pull` before doing any pushing,
|
||||
but after you have committed any changes.
|
||||
|
||||
6. Finally, `git push` the committed changes.
|
||||
|
||||
* * *
|
||||
|
||||
Phew, are you still with me? You’ve come a long way. Have a break.
|
||||
|
||||
|
||||

|
||||
Lame video-game references, once again…
|
||||
|
||||
Rested up? Great! You’re ready for some error handling. What if you accidentally changed some files your shouldn’t have touched. No need to freak out, just use `[git checkout][3]`. Let’s change something in the _pineapple.txt_ file. Add another line of text in there, let’s say, _“Steve is mega-awesome!”_ . Go ahead, save the changes and check the `git status`.
|
||||
|
||||
```
|
||||
On branch master
|
||||
Your branch is up-to-date with 'origin/master'.
|
||||
Changes not staged for commit:
|
||||
(use "git add <file>..." to update what will be committed)
|
||||
(use "git checkout -- <file>..." to discard changes in working directory)
|
||||
```
|
||||
|
||||
```
|
||||
modified: pineapple.txt
|
||||
```
|
||||
|
||||
```
|
||||
no changes added to commit (use "git add" and/or "git commit -a")
|
||||
```
|
||||
|
||||
As expected it has been registered as a change. But what if Steve really isn’t that mega-awesome? What if Steve is mega-lame? Worry not! The simplest way to revert the changes is to run:
|
||||
|
||||
```
|
||||
git checkout -- pineapple.txt
|
||||
```
|
||||
|
||||
Now you will see the file has been returned to it’s previous state.
|
||||
|
||||
But what if you really mess up. I mean like majorly mess things up, and need to reset everything back to the state the _origin_ is in. No need to worry, during emergencies like this we have this beauty:
|
||||
|
||||
```
|
||||
git reset --hard
|
||||
```
|
||||
|
||||
The [Git reset][11] command with the _--hard_ flag discards all changes since the last commit. Pretty handy sometimes.
|
||||
|
||||
* * *
|
||||
|
||||
To wrap up, I’d like to encourage you to play around with Git as much as possible. It’s by far the best way of learning how to use it with confidence. Apart from that, make a habit of reading the Git documentation. As confusing as it may seem at first, after a few moments of reading you will get the hang of it.
|
||||
|
||||
_Hope you guys and girls had as much fun reading this article as I had writing it._ _Feel free to share if you believe it will be of help to someone, or if you liked it, click the 💚 below so other people will see this here on Medium._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/how-to-master-the-art-of-git-68e1050f3147
|
||||
|
||||
作者:[Adnan Rahić][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@adnanrahic
|
||||
[1]:https://git-scm.com/docs/git-status
|
||||
[2]:https://git-scm.com/docs/git-push
|
||||
[3]:https://git-scm.com/docs/git-checkout
|
||||
[4]:https://github.com/
|
||||
[5]:https://git-scm.com/book/en/v2/Getting-Started-Installing-Git
|
||||
[6]:https://git-scm.com/book/en/v2/Getting-Started-Installing-Git
|
||||
[7]:https://github.com/
|
||||
[8]:https://git-scm.com/docs/git-add
|
||||
[9]:https://git-scm.com/docs/git-commit
|
||||
[10]:https://git-scm.com/docs/git-pull
|
||||
[11]:https://git-scm.com/docs/git-reset
|
||||
@ -0,0 +1,99 @@
|
||||
11 reasons to use the GNOME 3 desktop environment for Linux
|
||||
============================================================
|
||||
|
||||
### The GNOME 3 desktop was designed with the goals of being simple, easy to access, and reliable. GNOME's popularity attests to the achievement of those goals.
|
||||
|
||||
|
||||

|
||||
>Image by : [Gunnar Wortmann][8] via [Pixabay][9]. Modified by Opensource.com. [CC BY-SA 4.0][10].
|
||||
|
||||
Late last year, an upgrade to Fedora 25 caused issues with the new version of [KDE][11] Plasma that made it difficult for me to get any work done. So I decided to try other Linux desktop environments for two reasons. First, I needed to get my work done. Second, having been using KDE exclusively for many years, I thought it might be time to try some different desktops.
|
||||
|
||||
The first alternate desktop I tried for several weeks was [Cinnamon][12] which I wrote about in January, and then I wrote about [LXDE][13] which I used for about eight weeks and I have found many things about it that I like. I have used [GNOME 3][14] for a few weeks to research this article.
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
Like almost everything else in the cyberworld, GNOME is an acronym; it stands for GNU Network Object Model. The GNOME 3 desktop was designed with the goals of being simple, easy to access, and reliable. GNOME's popularity attests to the achievement of those goals.
|
||||
|
||||
GNOME 3 is useful in environments where lots of screen real-estate is needed. That means both large screens with high resolution, and minimizing the amount of space needed by the desktop widgets, panels, and icons to allow access to tasks like launching new programs. The GNOME project has a set of Human Interface Guidelines (HIG) that are used to define the GNOME philosophy for how humans should interface with the computer.
|
||||
|
||||
### My eleven reasons for using GNOME 3
|
||||
|
||||
1. **Choice:** GNOME is available in many forms on some distributions like my personal favorite, Fedora. The login options for your desktop of choice are GNOME Classic, GNOME on Xorg, GNOME, and GNOME (Wayland). On the surface, these all look the same once they are launched but they use different X servers or are built with different toolkits. Wayland provides more functionality for the little niceties of the desktop such as kinetic scrolling, drag-and-drop, and paste with middle click.
|
||||
|
||||
2. **Getting started tutorial:** The getting started tutorial is displayed the first time a user logs into the desktop. It shows how to perform common tasks and provides a link to more extensive help. The tutorial is also easily accessible after it is dismissed on first boot so it can be accessed at any time. It is very simple and straightforward and provides users new to GNOME an easy and obvious starting point. To return to the tutorial later, click on **Activities**, then click on the square of nine dots which displays the applications. Then find and click on the life preserver icon labeled, **Help**.
|
||||
|
||||
3. **Clean deskto****p:** With a minimalist approach to a desktop environment in order to reduce clutter, GNOME is designed to present only the minimum necessary to have a functional environment. You should see only the top bar (yes, that is what it is called) and all else is hidden until needed. The intention is to allow the user to focus on the task at hand and to minimize the distractions caused by other stuff on the desktop.
|
||||
|
||||
4. **The top bar:** The top bar is always the place to start, no matter what you want to do. You can launch applications, log out, power off, start or stop the network, and more. This makes life simple when you want to do anything. Aside from the current application, the top bar is usually the only other object on the desktop.
|
||||
|
||||
5. **The dash:** The dash contains three icons by default, as shown below. As you start using applications, they are added to the dash so that your most frequently used applications are displayed there. You can also add application icons to the dash yourself from the application viewer.
|
||||
|
||||
|
||||
|
||||
6. **A****pplication ****v****iewer:** I really like the application viewer that is accessible from the vertical bar on the left side of the GNOME desktop,, above. The GNOME desktop normally has nothing on it unless there is a running program so you must click on the **Activities** selection on the top bar, click on the square consisting of nine dots at the bottom of the dash, which is the icon for the viewer.
|
||||
|
||||
|
||||
|
||||
The viewer itself is a matrix consisting of the icons of the installed applications as shown above. There is a pair of mutually exclusive buttons below the matrix, **Frequent **and **All**. By default, the application viewer shows all installed applications. Click on the **Frequent** button and it shows only the applications used most frequently. Scroll up and down to locate the application you want to launch. The applications are displayed in alphabetical order by name.
|
||||
|
||||
The [GNOME][6] website and the built-in help have more detail on the viewer.
|
||||
|
||||
7. **Application ready n****otification****s:** GNOME has a neat notifier that appears at top of screen when the window for a newly launched app is open and ready. Simply click on the notification to switch to that window. This saved me some time compared to searching for the newly opened application window on some other desktops.
|
||||
|
||||
8. **A****pplication ****display****:** In order to access a different running application that is not visible you click on the activity menu. This displays all of the running applications in a matrix on the desktop. Click on the desired application to bring it to the foreground. Although the current application is displayed in the Top Bar, other running applications are not.
|
||||
|
||||
9. **Minimal w****indow decorations:** Open windows on the desktop are also quite simple. The only button apparent on the title bar is the "**X**" button to close a window. All other functions such as minimize, maximize, move to another desktop, and so on, are accessible with a right-click on the title bar.
|
||||
|
||||
10. **New d****esktops are automatically created: **New empty desktops created automatically when the next empty one down is used. This means that there will always be one empty desktop and available when needed. All of the other desktops I have used allow you to set the number of desktops while the desktop is active, too, but it must be done manually using the system settings.
|
||||
|
||||
11. **Compatibility:** As with all of the other desktops I have used, applications created for other desktops will work correctly on GNOME. This is one of the features that has made it possible for me to test all of these desktops so that I can write about them.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
GNOME is a desktop unlike any other I have used. Its prime directive is "simplicity." Everything else takes a back seat to simplicity and ease of use. It takes very little time to learn how to use GNOME if you start with the getting started tutorial. That does not mean that GNOME is deficient in any way. It is a powerful and flexible desktop that stays out of the way at all times.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||
|
||||
---------------
|
||||
|
||||
via: https://opensource.com/article/17/5/reasons-gnome
|
||||
|
||||
作者:[David Both ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://www.gnome.org/gnome-3/
|
||||
[7]:https://opensource.com/article/17/5/reasons-gnome?rate=MbGLV210A21ONuGAP8_Qa4REL7cKFvcllqUddib0qMs
|
||||
[8]:https://pixabay.com/en/users/karpartenhund-3077375/
|
||||
[9]:https://pixabay.com/en/garden-gnome-black-and-white-f%C3%B6hr-1584401/
|
||||
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
[12]:https://opensource.com/article/17/1/cinnamon-desktop-environment
|
||||
[13]:https://opensource.com/article/17/3/8-reasons-use-lxde
|
||||
[14]:https://www.gnome.org/gnome-3/
|
||||
[15]:https://opensource.com/user/14106/feed
|
||||
[16]:https://opensource.com/article/17/5/reasons-gnome#comments
|
||||
[17]:https://opensource.com/users/dboth
|
||||
@ -0,0 +1,222 @@
|
||||
How to Fix SambaCry Vulnerability (CVE-2017-7494) in Linux Systems
|
||||
============================================================
|
||||
|
||||
|
||||
Samba has long been the standard for providing shared file and print services to Windows clients on *nix systems. Used by home users, mid-size businesses, and large companies alike, it stands out as the go-to solution in environments where different operating systems coexist.
|
||||
|
||||
As it sadly happens with broadly-used tools, most Samba installations are under risk of an attack that may exploit a known vulnerability, which was not considered to be serious until the WannaCry ransomware attack hit the news not too long ago.
|
||||
|
||||
In this article, we will explain what this Samba vulnerability is and how to protect the systems you are responsible for against it. Depending on your installation type (from repositories or from source), you will need to take a different approach to do it.
|
||||
|
||||
If you are currently using Samba in any environment or know someone who does, read on!
|
||||
|
||||
### The Vulnerability
|
||||
|
||||
Outdated and unpatched systems are vulnerable to a remote code execution vulnerability. In simple terms, this means that a person with access to a writeable share can upload a piece of arbitrary code and execute it with root permissions in the server.
|
||||
|
||||
The issue is described in the Samba website as [CVE-2017-7494][1] and is known to affect Samba versions 3.5 (released in early March 2010) and onwards. Unofficially, it has been named SambaCry due to its similarities with WannaCry: both target the SMB protocol and are potentially wormable – which can cause it to spread from system to system.
|
||||
|
||||
Debian, Ubuntu, CentOS and Red Hat have taken rapid action to protect its users and have released patches for their supported versions. Additionally, security workarounds have also been provided for unsupported ones.
|
||||
|
||||
### Updating Samba
|
||||
|
||||
As mentioned earlier, there are two approaches to follow depending on the previous installation method:
|
||||
|
||||
If you installed Samba from your distribution’s repositories.
|
||||
|
||||
Let’s take a look at what you need to do in this case:
|
||||
|
||||
#### Fix Sambacry in Debian
|
||||
|
||||
Make sure [apt][2] is set to get the latest security updates by adding the following lines to your sources list (/etc/apt/sources.list):
|
||||
|
||||
```
|
||||
deb http://security.debian.org stable/updates main
|
||||
deb-src http://security.debian.org/ stable/updates main
|
||||
```
|
||||
|
||||
Next, update the list of available packages:
|
||||
|
||||
```
|
||||
# aptitude update
|
||||
```
|
||||
|
||||
Finally, make sure the version of the samba package matches the version where the vulnerability has been fixed (see [CVE-2017-7494][3]):
|
||||
|
||||
```
|
||||
# aptitude show samba
|
||||
```
|
||||
|
||||
|
||||
|
||||
Fix Sambacry in Debian
|
||||
|
||||
#### Fix Sambacry in Ubuntu
|
||||
|
||||
To begin, check for new available packages and update the samba package as follows:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install samba
|
||||
```
|
||||
|
||||
The Samba versions where the fix for CVE-2017-7494 has already been applied are the following:
|
||||
|
||||
* 17.04: samba 2:4.5.8+dfsg-0ubuntu0.17.04.2
|
||||
|
||||
* 16.10: samba 2:4.4.5+dfsg-2ubuntu5.6
|
||||
|
||||
* 16.04 LTS: samba 2:4.3.11+dfsg-0ubuntu0.16.04.7
|
||||
|
||||
* 14.04 LTS: samba 2:4.3.11+dfsg-0ubuntu0.14.04.8
|
||||
|
||||
Finally, run the following command to verify that your Ubuntu box now has the right Samba version installed.
|
||||
|
||||
```
|
||||
$ sudo apt-cache show samba
|
||||
```
|
||||
|
||||
#### Fix Sambacry on CentOS/RHEL 7
|
||||
|
||||
The patched Samba version in EL 7 is samba-4.4.4-14.el7_3. To install it, do
|
||||
|
||||
```
|
||||
# yum makecache fast
|
||||
# yum update samba
|
||||
```
|
||||
|
||||
As before, make sure you have now the patched Samba version:
|
||||
|
||||
```
|
||||
# yum info samba
|
||||
```
|
||||
|
||||
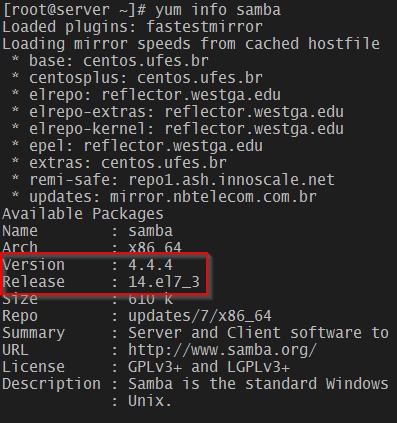
|
||||
|
||||
Fix Sambacry in CentOS
|
||||
|
||||
Older, still supported versions of CentOS and RHEL have available fixes as well. Check [RHSA-2017-1270][4] to find out more.
|
||||
|
||||
##### If you installed Samba from source
|
||||
|
||||
Note: The following procedure assumes that you have previously built Samba from source. You are highly encouraged to try it out extensively in a testing environment BEFORE deploying it to a production server.
|
||||
|
||||
Additionally, make sure you back up the smb.conf file before you start.
|
||||
|
||||
In this case, we will compile and update Samba from source as well. Before we begin, however, we must ensure all the dependencies are previously installed. Note that this may take several minutes.
|
||||
|
||||
#### In Debian and Ubuntu:
|
||||
|
||||
```
|
||||
# aptitude install acl attr autoconf bison build-essential \
|
||||
debhelper dnsutils docbook-xml docbook-xsl flex gdb krb5-user \
|
||||
libacl1-dev libaio-dev libattr1-dev libblkid-dev libbsd-dev \
|
||||
libcap-dev libcups2-dev libgnutls28-dev libjson-perl \
|
||||
libldap2-dev libncurses5-dev libpam0g-dev libparse-yapp-perl \
|
||||
libpopt-dev libreadline-dev perl perl-modules pkg-config \
|
||||
python-all-dev python-dev python-dnspython python-crypto xsltproc \
|
||||
zlib1g-dev libsystemd-dev libgpgme11-dev python-gpgme python-m2crypto
|
||||
```
|
||||
|
||||
#### In CentOS 7 or similar:
|
||||
|
||||
```
|
||||
# yum install attr bind-utils docbook-style-xsl gcc gdb krb5-workstation \
|
||||
libsemanage-python libxslt perl perl-ExtUtils-MakeMaker \
|
||||
perl-Parse-Yapp perl-Test-Base pkgconfig policycoreutils-python \
|
||||
python-crypto gnutls-devel libattr-devel keyutils-libs-devel \
|
||||
libacl-devel libaio-devel libblkid-devel libxml2-devel openldap-devel \
|
||||
pam-devel popt-devel python-devel readline-devel zlib-devel
|
||||
```
|
||||
|
||||
Stop the service:
|
||||
|
||||
```
|
||||
# systemctl stop smbd
|
||||
```
|
||||
|
||||
Download and untar the source (with 4.6.4 being the latest version at the time of this writing):
|
||||
|
||||
```
|
||||
# wget https://www.samba.org/samba/ftp/samba-latest.tar.gz
|
||||
# tar xzf samba-latest.tar.gz
|
||||
# cd samba-4.6.4
|
||||
```
|
||||
|
||||
For informative purposes only, check the available configure options for the current release with.
|
||||
|
||||
```
|
||||
# ./configure --help
|
||||
```
|
||||
|
||||
You may include some of the options returned by the above command if they were used in the previous build, or you may choose to go with the default:
|
||||
|
||||
```
|
||||
# ./configure
|
||||
# make
|
||||
# make install
|
||||
```
|
||||
|
||||
Finally, restart the service.
|
||||
|
||||
```
|
||||
# systemctl restart smbd
|
||||
```
|
||||
|
||||
and verify you’re running the updated version:
|
||||
|
||||
```
|
||||
# smbstatus --version
|
||||
```
|
||||
|
||||
which should return 4.6.4.
|
||||
|
||||
### General Considerations
|
||||
|
||||
If you are running an unsupported version of a given distribution and are unable to upgrade to a more recent one for some reason, you may want to take the following suggestions into account:
|
||||
|
||||
* If SELinux is enabled, you are protected!
|
||||
|
||||
* Make sure Samba shares are mounted with the noexec option. This will prevent the execution of binaries residing on the mounted filesystem.
|
||||
|
||||
Add,
|
||||
|
||||
```
|
||||
nt pipe support = no
|
||||
```
|
||||
|
||||
to the [global] section of your smb.conf file and restart the service. You may want to keep in mind that this “may disable some functionality in Windows clients”, as per the Samba project.
|
||||
|
||||
Important: Be aware that the option “nt pipe support = no” would disable shares listing from Windows clients. Eg: When you type \\10.100.10.2\ from Windows Explorer on a samba server you would get a permission denied. Windows clients would have to manually specify the share as \\10.100.10.2\share_name to access the share.
|
||||
|
||||
##### Summary
|
||||
|
||||
In this article, we have described the vulnerability known as SambaCry and how to mitigate it. We hope that you will be able to use this information to protect the systems you’re responsible for.
|
||||
|
||||
If you have any questions or comments about this article, feel free to use the form below to let us know.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
Gabriel Cánepa is a GNU/Linux sysadmin and web developer from Villa Mercedes, San Luis, Argentina. He works for a worldwide leading consumer product company and takes great pleasure in using FOSS tools to increase productivity in all areas of his daily work.
|
||||
|
||||
--------------
|
||||
|
||||
via: https://www.tecmint.com/fix-sambacry-vulnerability-cve-2017-7494-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://www.samba.org/samba/security/CVE-2017-7494.html
|
||||
[2]:https://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[3]:https://security-tracker.debian.org/tracker/CVE-2017-7494
|
||||
[4]:https://rhn.redhat.com/errata/RHSA-2017-1270.html
|
||||
[5]:https://www.tecmint.com/author/gacanepa/
|
||||
[6]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,210 @@
|
||||
Translating by kylecao
|
||||
|
||||
Understand Linux Load Averages and Monitor Performance of Linux
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
In this article, we will explain one of the critical Linux system administration tasks – performance monitoring in regards to system/CPU load and load averages.
|
||||
|
||||
Before we move any further, let’s understand these two important phrases in all Unix-like systems:
|
||||
|
||||
* System load/CPU Load – is a measurement of CPU over or under-utilization in a Linux system; the number of processes which are being executed by the CPU or in waiting state.
|
||||
|
||||
* Load average – is the average system load calculated over a given period of time of 1, 5 and 15 minutes.
|
||||
|
||||
In Linux, the load-average is technically believed to be a running average of processes in it’s (kernel) execution queue tagged as running or uninterruptible.
|
||||
|
||||
Note that:
|
||||
|
||||
* All if not most systems powered by Linux or other Unix-like systems will possibly show the load average values somewhere for a user.
|
||||
|
||||
* A downright idle Linux system may have a load average of zero, excluding the idle process.
|
||||
|
||||
* Nearly all Unix-like systems count only processes in the running or waiting states. But this is not the case with Linux, it includes processes in uninterruptible sleep states; those waiting for other system resources like disk I/O etc.
|
||||
|
||||
### How to Monitor Linux System Load Average
|
||||
|
||||
There are numerous ways of monitoring system load average including uptime which shows how long the system has been running, number of users together with load averages:
|
||||
|
||||
```
|
||||
$ uptime
|
||||
07:13:53 up 8 days, 19 min, 1 user, load average: 1.98, 2.15, 2.21
|
||||
```
|
||||
|
||||
The numbers are read from left to right, and the output above means that:
|
||||
|
||||
* load average over the last 1 minute is 1.98
|
||||
|
||||
* load average over the last 5 minutes is 2.15
|
||||
|
||||
* load average over the last 15 minutes is 2.21
|
||||
|
||||
High load averages imply that a system is overloaded; many processes are waiting for CPU time.
|
||||
|
||||
We will uncover this in the next section in relation to number of CPU cores. Additionally, we can as well use other well known tools such as [top][5] and [glances][6] which display a real-time state of a running Linux system, plus many other tools:
|
||||
|
||||
#### Top Command
|
||||
|
||||
```
|
||||
$ top
|
||||
```
|
||||
Display Running Linux Processes
|
||||
```
|
||||
top - 12:51:42 up 2:11, 1 user, load average: 1.22, 1.12, 1.26
|
||||
Tasks: 243 total, 1 running, 242 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 17.4 us, 2.9 sy, 0.3 ni, 74.8 id, 4.6 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
KiB Mem : 8069036 total, 388060 free, 4381184 used, 3299792 buff/cache
|
||||
KiB Swap: 3906556 total, 3901876 free, 4680 used. 2807464 avail Mem
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
6265 tecmint 20 0 1244348 170680 83616 S 13.3 2.1 6:47.72 Headset
|
||||
2301 tecmint 9 -11 640332 13344 9932 S 6.7 0.2 2:18.96 pulseaudio
|
||||
2459 tecmint 20 0 1707692 315628 62992 S 6.7 3.9 6:55.45 cinnamon
|
||||
2957 tecmint 20 0 2644644 1.035g 137968 S 6.7 13.5 50:11.13 firefox
|
||||
3208 tecmint 20 0 507060 52136 33152 S 6.7 0.6 0:04.34 gnome-terminal-
|
||||
3272 tecmint 20 0 1521380 391324 178348 S 6.7 4.8 6:21.01 chrome
|
||||
6220 tecmint 20 0 1595392 106964 76836 S 6.7 1.3 3:31.94 Headset
|
||||
1 root 20 0 120056 6204 3964 S 0.0 0.1 0:01.83 systemd
|
||||
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
|
||||
3 root 20 0 0 0 0 S 0.0 0.0 0:00.10 ksoftirqd/0
|
||||
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
|
||||
....
|
||||
```
|
||||
|
||||
#### Glances Tool
|
||||
|
||||
```
|
||||
$ glances
|
||||
```
|
||||
Glances – Linux System Monitoring Tool
|
||||
```
|
||||
TecMint (LinuxMint 18 64bit / Linux 4.4.0-21-generic) Uptime: 2:16:06
|
||||
CPU 16.4% nice: 0.1% LOAD 4-core MEM 60.5% active: 4.90G SWAP 0.1%
|
||||
user: 10.2% irq: 0.0% 1 min: 1.20 total: 7.70G inactive: 2.07G total: 3.73G
|
||||
system: 3.4% iowait: 2.7% 5 min: 1.16 used: 4.66G buffers: 242M used: 4.57M
|
||||
idle: 83.6% steal: 0.0% 15 min: 1.24 free: 3.04G cached: 2.58G free: 3.72G
|
||||
NETWORK Rx/s Tx/s TASKS 253 (883 thr), 1 run, 252 slp, 0 oth sorted automatically by cpu_percent, flat view
|
||||
enp1s0 525Kb 31Kb
|
||||
lo 2Kb 2Kb CPU% MEM% VIRT RES PID USER NI S TIME+ IOR/s IOW/s Command
|
||||
wlp2s0 0b 0b 14.6 13.3 2.53G 1.03G 2957 tecmint 0 S 51:49.10 0 40K /usr/lib/firefox/firefox
|
||||
7.4 2.2 1.16G 176M 6265 tecmint 0 S 7:08.18 0 0 /usr/lib/Headset/Headset --type=renderer --no-sandbox --primordial-pipe-token=879B36514C6BEDB183D3E4142774D1DF --lan
|
||||
DISK I/O R/s W/s 4.9 3.9 1.63G 310M 2459 tecmint 0 R 7:12.18 0 0 cinnamon --replace
|
||||
ram0 0 0 4.2 0.2 625M 13.0M 2301 tecmint -11 S 2:29.72 0 0 /usr/bin/pulseaudio --start --log-target=syslog
|
||||
ram1 0 0 4.2 1.3 1.52G 105M 6220 tecmint 0 S 3:42.64 0 0 /usr/lib/Headset/Headset
|
||||
ram10 0 0 2.9 0.8 409M 66.7M 6240 tecmint 0 S 2:40.44 0 0 /usr/lib/Headset/Headset --type=gpu-process --no-sandbox --supports-dual-gpus=false --gpu-driver-bug-workarounds=7,2
|
||||
ram11 0 0 2.9 1.8 531M 142M 1690 root 0 S 6:03.79 0 0 /usr/lib/xorg/Xorg :0 -audit 0 -auth /var/lib/mdm/:0.Xauth -nolisten tcp vt8
|
||||
ram12 0 0 2.6 0.3 79.3M 23.8M 9651 tecmint 0 R 0:00.71 0 0 /usr/bin/python3 /usr/bin/glances
|
||||
ram13 0 0 1.6 4.8 1.45G 382M 3272 tecmint 0 S 6:25.30 0 4K /opt/google/chrome/chrome
|
||||
...
|
||||
```
|
||||
|
||||
The load averages shown by these tools is read /proc/loadavg file, which you can view using the [cat command][7] as below:
|
||||
|
||||
```
|
||||
$ cat /proc/loadavg
|
||||
2.48 1.69 1.42 5/889 10570
|
||||
```
|
||||
|
||||
To monitor load averages in graph format, check out: [ttyload – Shows a Color-coded Graph of Linux Load Average in Terminal][8]
|
||||
|
||||
On desktop machines, there are graphical user interface tools that we can use to view system load averages.
|
||||
|
||||
### Understanding System Average Load in Relation Number of CPUs
|
||||
|
||||
We can’t possibly explain system load or system performance without shedding light on the impact of the number of CPU cores on performance.
|
||||
|
||||
#### Multi-processor Vs Multi-core
|
||||
|
||||
* Multi-processor – is where two or more physical CPU’s are integrated into a single computer system.
|
||||
|
||||
* Multi-core processor – is a single physical CPU which has at least two or more separate cores (or what we can also refer to as processing units) that work in parallel. Meaning a dual-core has 2 two processing units, a quad-core has 4 processing units and so on.
|
||||
|
||||
Furthermore, there is also a processor technology which was first introduced by Intel to improve parallel computing, referred to as hyper threading.
|
||||
|
||||
Under hyper threading, a single physical CPU core appears as two logical CPUs core to an operating system (but in reality, there is one physical hardware component).
|
||||
|
||||
Note that a single CPU core can only carry out one task at a time, thus technologies such as multiple CPUs/processors, multi-core CPUs and hyper-threading were brought to life.
|
||||
|
||||
With more than one CPU, several programs can be executed simultaneously. Present-day Intel CPUs use a combination of both multiple cores and hyper-threading technology.
|
||||
|
||||
To find the number of processing units available on a system, we may use the [nproc or lscpu commands][9] as follows:
|
||||
|
||||
```
|
||||
$ nproc
|
||||
4
|
||||
OR
|
||||
lscpu
|
||||
```
|
||||
|
||||
Another way to find the number of processing units using [grep command][10] as shown.
|
||||
|
||||
```
|
||||
$ grep 'model name' /proc/cpuinfo | wc -l
|
||||
4
|
||||
```
|
||||
|
||||
Now, to further understand system load, we will take a few assumptions. Let’s say we have load averages below:
|
||||
|
||||
```
|
||||
23:16:49 up 10:49, 5 user, load average: 1.00, 0.40, 3.35
|
||||
```
|
||||
|
||||
###### On a single core system this would mean:
|
||||
|
||||
* The CPU was fully (100%) utilized on average; 1 processes was running on the CPU (1.00) over the last 1 minute.
|
||||
|
||||
* The CPU was idle by 60% on average; no processes were waiting for CPU time (0.40) over the last 5 minutes.
|
||||
|
||||
* The CPU was overloaded by 235% on average; 2.35 processes were waiting for CPU time (3.35) over the last 15 minutes.
|
||||
|
||||
###### On a dual-core system this would mean:
|
||||
|
||||
* The one CPU was 100% idle on average, one CPU was being used; no processes were waiting for CPU time(1.00) over the last 1 minute.
|
||||
|
||||
* The CPUs were idle by 160% on average; no processes were waiting for CPU time. (0.40) over the last 5 minutes.
|
||||
|
||||
* The CPUs were overloaded by 135% on average; 1.35 processes were waiting for CPU time. (3.35) over the last 15 minutes.
|
||||
|
||||
You might also like:
|
||||
|
||||
1. [20 Command Line Tools to Monitor Linux Performance – Part 1][1]
|
||||
|
||||
2. [13 Linux Performance Monitoring Tools – Part 2][2]
|
||||
|
||||
3. [Perf- A Performance Monitoring and Analysis Tool for Linux][3]
|
||||
|
||||
4. [Nmon: Analyze and Monitor Linux System Performance][4]
|
||||
|
||||
In conclusion, if you are a system administrator then high load averages are real to worry about. When they are high, above the number of CPU cores, it signifies high demand for the CPUs, and low load averages below the number of CPU cores tells us that CPUs are underutilized.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
|
||||
|
||||
-----
|
||||
|
||||
via: https://www.tecmint.com/understand-linux-load-averages-and-monitor-performance/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[2]:https://www.tecmint.com/linux-performance-monitoring-tools/
|
||||
[3]:https://www.tecmint.com/perf-performance-monitoring-and-analysis-tool-for-linux/
|
||||
[4]:https://www.tecmint.com/nmon-analyze-and-monitor-linux-system-performance/
|
||||
[5]:https://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[6]:https://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[7]:https://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[8]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/
|
||||
[9]:https://www.tecmint.com/check-linux-cpu-information/
|
||||
[10]:https://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[11]:https://www.tecmint.com/author/aaronkili/
|
||||
[12]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[13]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,128 @@
|
||||
Cron Vs Anacron: How to Schedule Jobs Using Anacron on Linux
|
||||
============================================================
|
||||
|
||||
In this article, we will explain cron and anacron and also shows you how to setup anacron on Linux. We will as well cover a comparison of these two utilities.
|
||||
|
||||
To [schedule a task on given or later time][1], you can use the ‘at’ or ‘batch’ commands and to set up commands to run repeatedly, you can employ the cron and anacron facilities.
|
||||
|
||||
[Cron][2] – is a daemon used to run scheduled tasks such as system backups, updates and many more. It is suitable for running scheduled tasks on machines that will run continuously 24X7 such as servers.
|
||||
|
||||
The commands/tasks are scripted into cron jobs which are scheduled in crontab files. The default system crontab file is /etc/crontab, but each user can also create their own crontab file that can launch commands at times that the user defines.
|
||||
|
||||
To create a personal crontab file, simply type the following:
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
```
|
||||
|
||||
### How to Setup Anacron in Linux
|
||||
|
||||
Anacron is used to run commands periodically with a frequency defined in days. It works a little different from cron; assumes that a machine will not be powered on all the time.
|
||||
|
||||
It is appropriate for running daily, weekly, and monthly scheduled jobs normally run by cron, on machines that will not run 24-7 such as laptops and desktops machines.
|
||||
|
||||
Assuming you have a scheduled task (such as a backup script) to be run using cron every midnight, possibly when your asleep, and your desktop/laptop is off by that time. Your backup script will not be executed.
|
||||
|
||||
However, if you use anacron, you can be assured that the next time you power on the desktop/laptop again, the backup script will be executed.
|
||||
|
||||
### How Anacron Works in Linux
|
||||
|
||||
anacron jobs are listed in /etc/anacrontab and jobs can be scheduled using the format below (comments inside anacrontab file must start with #).
|
||||
|
||||
```
|
||||
period delay job-identifier command
|
||||
```
|
||||
|
||||
From the above format:
|
||||
|
||||
* period – this is the frequency of job execution specified in days or as @daily, @weekly, or @monthly for once per day, week, or month. You can as well use numbers: 1 – daily, 7 – weekly, 30 – monthly and N – number of days.
|
||||
|
||||
* delay – it’s the number of minutes to wait before executing a job.
|
||||
|
||||
* job-id – it’s the distinctive name for the job written in log files.
|
||||
|
||||
To view example files, type:
|
||||
|
||||
```
|
||||
$ ls -l /var/spool/anacron/
|
||||
total 12
|
||||
-rw------- 1 root root 9 Jun 1 10:25 cron.daily
|
||||
-rw------- 1 root root 9 May 27 11:01 cron.monthly
|
||||
-rw------- 1 root root 9 May 30 10:28 cron.weekly
|
||||
```
|
||||
|
||||
* command – it’s the command or shell script to be executed.
|
||||
|
||||
##### This is what practically happens:
|
||||
|
||||
* Anacron will check if a job has been executed within the specified period in the period field. If not, it executes the command specified in the command field after waiting the number of minutes specified in the delay field.
|
||||
|
||||
* Once the job has been executed, it records the date in a timestamp file in the /var/spool/anacrondirectory with the name specified in the job-id (timestamp file name) field.
|
||||
|
||||
Let’s now look at an example. This will run the /home/aaronkilik/bin/backup.sh script everyday:
|
||||
|
||||
```
|
||||
@daily 10 example.daily /bin/bash /home/aaronkilik/bin/backup.sh
|
||||
```
|
||||
|
||||
If the machine is off when the backup.sh job is expected to run, anacron will run it 10 minutes after the machine is powered on without having to wait for another 7 days.
|
||||
|
||||
There are two important variables in the anacrontab file that you should understand:
|
||||
|
||||
* START_HOURS_RANGE – this sets time range in which jobs will be started (i.e execute jobs during the following hours only).
|
||||
|
||||
* RANDOM_DELAY – this defines the maximum random delay added to the user defined delay of a job (by default it’s 45).
|
||||
|
||||
This is how your anacrontab file would possibly look like.
|
||||
|
||||
Anacron – /etc/anacrontab File
|
||||
```
|
||||
# /etc/anacrontab: configuration file for anacron
|
||||
# See anacron(8) and anacrontab(5) for details.
|
||||
SHELL=/bin/sh
|
||||
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
|
||||
HOME=/root
|
||||
LOGNAME=root
|
||||
# These replace cron's entries
|
||||
1 5 cron.daily run-parts --report /etc/cron.daily
|
||||
7 10 cron.weekly run-parts --report /etc/cron.weekly
|
||||
@monthly 15 cron.monthly run-parts --report /etc/cron.monthly
|
||||
@daily 10 example.daily /bin/bash /home/aaronkilik/bin/backup.sh
|
||||
```
|
||||
|
||||
The following is a comparison of cron and anacron to help you understand when to use either of them.
|
||||
|
||||
| Cron | Anacron |
|
||||
| It’s a daemon | It’s not a daemon |
|
||||
| Appropriate for server machines | Appropriate for desktop/laptop machines |
|
||||
| Enables you to run scheduled jobs every minute | Only enables you to run scheduled jobs on daily basis |
|
||||
| Doesn’t executed a scheduled job when the machine if off | If the machine if off when a scheduled job is due, it will execute a scheduled job when the machine is powered on the next time |
|
||||
| Can be used by both normal users and root | Can only be used by root unless otherwise (enabled for normal users with specific configs) |
|
||||
|
||||
The major difference between cron and anacron is that cron works effectively on machines that will run continuously while anacron is intended for machines that will be powered off in a day or week.
|
||||
|
||||
If you know any other way, do share with us using the comment form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: https://www.tecmint.com/cron-vs-anacron-schedule-jobs-using-anacron-on-linux/
|
||||
|
||||
作者:[Aaron Kili | ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/linux-cron-alternative-at-command-to-schedule-tasks/
|
||||
[2]:https://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[3]:https://www.tecmint.com/author/aaronkili/
|
||||
[4]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[5]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,423 @@
|
||||
How to Install and Configure GitLab on Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Step 1 - Install required Ubuntu Packages][1]
|
||||
|
||||
2. [Step 2 - Install Gitlab][2]
|
||||
|
||||
3. [Step 3 - Configure Gitlab Main URL][3]
|
||||
|
||||
4. [Step 4 - Generate SSL Let's encrypt and DHPARAM Certificate][4]
|
||||
|
||||
5. [Step 5 - Enable Nginx HTTPS for GitLab][5]
|
||||
|
||||
6. [Step 6 - Configure UFW Firewall][6]
|
||||
|
||||
7. [Step 7 - Gitlab post-installation][7]
|
||||
|
||||
8. [Step 8 - Testing][8]
|
||||
|
||||
9. [Preferences][9]
|
||||
|
||||
GitLab is an open source GIT repository manager based on Rails and developed by GitLab Inc. It is a web-based GIT repository manager that allows your team to work on code, track bugs and feature requests and to test and deploy applications. GitLab provides features like a wiki, issue tracking, code reviews, activity feeds and merge management. It is capable of hosting multiple projects.
|
||||
|
||||
GitLab is available in four editions:
|
||||
|
||||
1. Gitlab CE (Community Edition) - self-hosted, free and support from the Community forum.
|
||||
|
||||
2. Gitlab EE (Enterprise Edition) - self-hosted, paid app, comes with additional features.
|
||||
|
||||
3. GitLab.com - SaaS, free.
|
||||
|
||||
4. GitLab.io - Private GitLab instance managed by GitLab Inc.
|
||||
|
||||
In this tutorial, I will show you step-by-step how to install GitLab CE (Community Edition) on your own Ubuntu 16.04 Xenial Xerus server. In this tutorial, I will be using the 'omnibus' package provided by GitLab for easy installation.
|
||||
|
||||
**What we will do:**
|
||||
|
||||
1. Install Packages
|
||||
|
||||
2. Install GitLab
|
||||
|
||||
3. Configure GitLab URL
|
||||
|
||||
4. Generate SSL Let's encrypt and DHPARAM Certificate
|
||||
|
||||
5. Enable Nginx HTTPS for GitLab
|
||||
|
||||
6. Configure UFW Firewall
|
||||
|
||||
7. Perform the GitLab Installation
|
||||
|
||||
8. Testing
|
||||
|
||||
**Prerequisites**
|
||||
|
||||
* Ubuntu 16.04 Server - 64bit
|
||||
|
||||
* Min RAM 2GB
|
||||
|
||||
* Root Privileges
|
||||
|
||||
### Step 1 - Install required Ubuntu Packages
|
||||
|
||||
The first step is to install the packages needed for the GitLab installation. Please log in to the server as root user and upddate the Ubuntu repository.
|
||||
|
||||
```
|
||||
ssh root@GitLabServer
|
||||
apt-get update
|
||||
```
|
||||
|
||||
Now install the packages including curl for downloading the GitLab repository, ca-certificates, and postfix for the SMTP configuration.
|
||||
|
||||
Install all packages with the apt command below.
|
||||
|
||||
```
|
||||
sudo apt install curl openssh-server ca-certificates postfix
|
||||
```
|
||||
|
||||
During postfix installation, you will be prompted about the configuration, select 'Internet Site'.
|
||||
|
||||
[][13]
|
||||
|
||||
and then enter the server domain name that shall be used for sending an email.
|
||||
|
||||
[][14]
|
||||
|
||||
### Step 2 - Install Gitlab
|
||||
|
||||
In this step, we will install GitLab using the omnibus packages. Omnibus will install all packages, services, and tools required for running GitLab on your server.
|
||||
|
||||
Add GitLab repository with the curl command.
|
||||
|
||||
```
|
||||
curl -sS https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.deb.sh | sudo bash
|
||||
```
|
||||
|
||||
[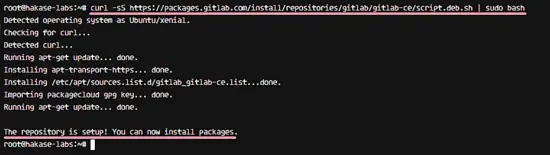][15]
|
||||
|
||||
And then install GitLab CE Community Edition with the apt command.
|
||||
|
||||
```
|
||||
sudo apt install gitlab-ce
|
||||
```
|
||||
|
||||
Wait for the server to download and install the gitlab package. When the installation is complete, you will see the results as below.
|
||||
|
||||
[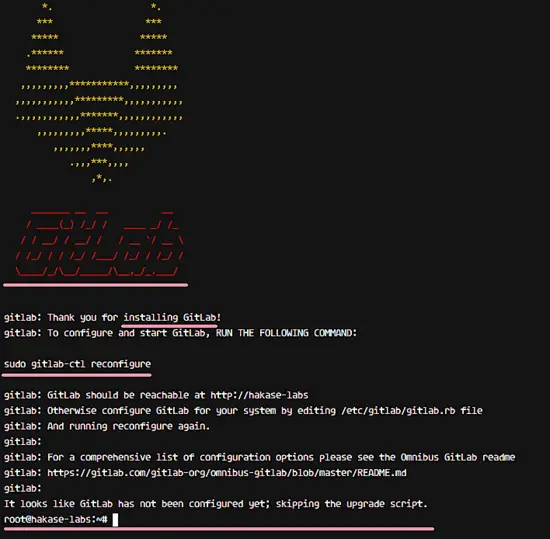][16]
|
||||
|
||||
### Step 3 - Configure Gitlab Main URL
|
||||
|
||||
Now we should configure the URL that will be used to access our GitLab server. I will use the domain name 'gitlab.hakase-labs.co' for the GitLab URL here (please choose your own domain name) and I'll use HTTPS for users access security.
|
||||
|
||||
The main configuration of GitLab is in the '/etc/gitlab' directory. Go to that directory and edit the configuration file 'gitlab.rb' with vim.
|
||||
|
||||
```
|
||||
cd /etc/gitlab
|
||||
vim gitlab.rb
|
||||
```
|
||||
|
||||
In the GitLab configuration go to line 9 'external_url' and change the URL to your URL 'gitlab.hakase-labs.co'.
|
||||
|
||||
external_url 'http://gitlab.hakase-labs.co'
|
||||
|
||||
Save the file and exit the editor. In the next step will enable HTTPS for GitLab.
|
||||
|
||||
[][17]
|
||||
|
||||
### Step 4 - Generate SSL Let's encrypt and DHPARAM Certificate
|
||||
|
||||
In this step, we will enable the HTTPS protocol for GitLab. I will use a free SSL certificates provided by let's encrypt for the gitlab domain name.
|
||||
|
||||
Install letsencrypt command-line tool with apt command.
|
||||
|
||||
```
|
||||
sudo apt install letsencrypt -y
|
||||
```
|
||||
|
||||
When the installation is complete, generate a new certificate for the gitlab domain name with the command below.
|
||||
|
||||
```
|
||||
letsencrypt certonly -d gitlab.hakase-labs.co
|
||||
```
|
||||
|
||||
Enter your email address for the SSL certificate renew notification.
|
||||
|
||||
[][18]
|
||||
|
||||
Choose 'Agree' for the Let's Encrypt Terms of Services and wait.
|
||||
|
||||
[][19]
|
||||
|
||||
When it's done, you will see the result below.
|
||||
|
||||
[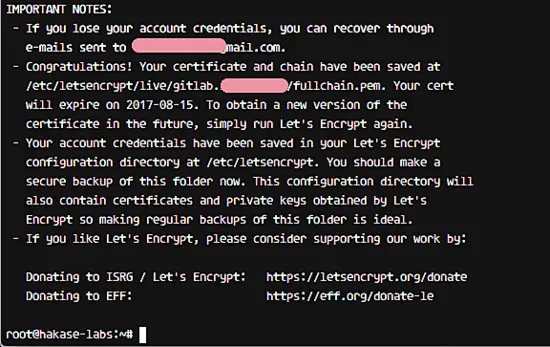][20]
|
||||
|
||||
New Let's encrypt certificate files for GitLab have been generated. You can find the certificate files in the '/etc/letsencrypt/live' directory.
|
||||
|
||||
Next, create a new directory named 'ssl' under the GitLab configuration directory.
|
||||
|
||||
```
|
||||
mkdir -p /etc/gitlab/ssl/
|
||||
```
|
||||
|
||||
And generate dhparam pem files in the ssl directory with the openssl command.
|
||||
|
||||
```
|
||||
sudo openssl dhparam -out /etc/gitlab/ssl/dhparams.pem 2048
|
||||
```
|
||||
|
||||
[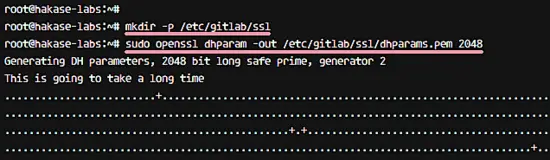][21]
|
||||
|
||||
Now change the permissions of the certificate files to 600.
|
||||
|
||||
```
|
||||
chmod 600 /etc/gitlab/ssl/*
|
||||
```
|
||||
|
||||
The SSL Let's encrypt cert for GitLab and the DHPARAM certificate has been generated.
|
||||
|
||||
### Step 5 - Enable Nginx HTTPS for GitLab
|
||||
|
||||
At this stage, we have the certificate files from Letsencrypt in '/etc/letsencrypt/live' directory and the DHPARAM certificate in the '/etc/gitlab/ssl' directory.
|
||||
|
||||
In this step, we will configure a GitLab to use our certificate files. Go to the '/etc/gitlab' directory, then edit 'gitlab.rb' configuration with vim.
|
||||
|
||||
```
|
||||
cd /etc/gitlab/
|
||||
vim gitlab.rb
|
||||
```
|
||||
|
||||
Change the external url to use 'https' instead of 'http'.
|
||||
|
||||
external_url 'https://gitlab.hakase-labs.co'
|
||||
|
||||
Then add the new SSL configuration for gitlab as below.
|
||||
|
||||
nginx['redirect_http_to_https'] = true
|
||||
nginx['ssl_certificate'] = "/etc/letsencrypt/live/gitlab.hakase-labs.co/fullchain.pem"
|
||||
nginx['ssl_certificate_key'] = "/etc/letsencrypt/live/gitlab.hakase-labs.co/privkey.pem"
|
||||
nginx['ssl_dhparam'] = "/etc/gitlab/ssl/dhparams.pem"
|
||||
|
||||
**Note:**
|
||||
|
||||
We will enable HTTP to HTTPS redirect in gitlab.
|
||||
|
||||
Save the file and exit vim.
|
||||
|
||||
[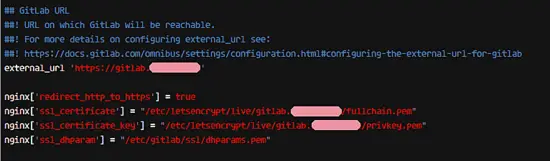][22]
|
||||
|
||||
Now we need to run the command below as root to apply the new gitlab configuration.
|
||||
|
||||
```
|
||||
sudo gitlab-ctl reconfigure
|
||||
```
|
||||
|
||||
You will see the results as below.
|
||||
|
||||
[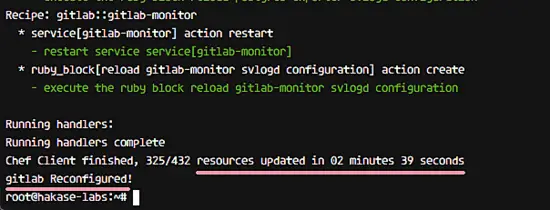][23]
|
||||
|
||||
HTTPS Configuration for GitLab has been completed.
|
||||
|
||||
### Step 6 - Configure UFW Firewall
|
||||
|
||||
In this step, we will enable the UFW firewall. It's already installed on the system, we just need to start the service. We will run GitLab behind the UFW firewall, so we must open the HTTP and HTTPS ports.
|
||||
|
||||
Enable UFW firewall with the command below.
|
||||
|
||||
```
|
||||
ufw enable
|
||||
```
|
||||
|
||||
The command will run ufw service and add it to start automatically at the boot time.
|
||||
|
||||
Next, open new ports ssh, HTTP, and HTTPS.
|
||||
|
||||
```
|
||||
ufw allow ssh
|
||||
ufw allow http
|
||||
ufw allow https
|
||||
```
|
||||
|
||||
[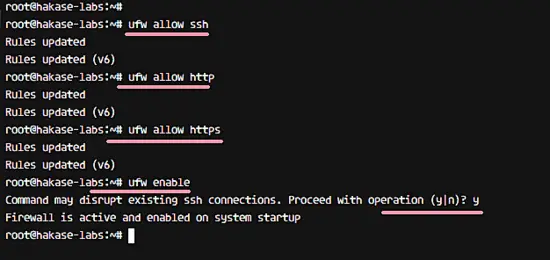][24]
|
||||
|
||||
Now check the firewall status and make sure ssh, http, and https ports is on the list.
|
||||
|
||||
```
|
||||
ufw status
|
||||
```
|
||||
|
||||
HTTP and HTTPS ports are configured.
|
||||
|
||||
[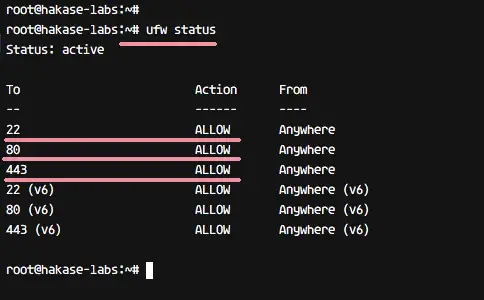][25]
|
||||
|
||||
### Step 7 - Gitlab post-installation
|
||||
|
||||
GitLab has been installed to the system, and it's running behind the UFW firewall. In this step, we will do some quick settings like changing password, username and profile settings.
|
||||
|
||||
Open your web browser and type in the gitlab URL, mine is 'gitlab.hakase-labs.co'. You will be redirected to the HTTPS connection.
|
||||
|
||||
**Reset GitLab root password**
|
||||
|
||||
[][26]
|
||||
|
||||
Now login to GitLab with user 'root' and with your password.
|
||||
|
||||
[][27]
|
||||
|
||||
**Change Username and Profile**
|
||||
|
||||
On the top right corner, click your profile and choose 'Profile Settings'.
|
||||
|
||||
[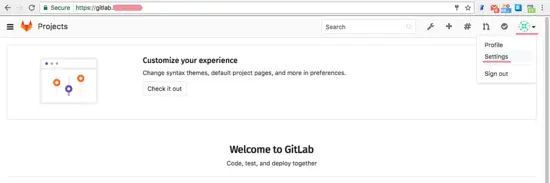][28]
|
||||
|
||||
On the profile tab, exchange the default name with your name and email with your email address. Now click 'Update Profile'.
|
||||
|
||||
[][29]
|
||||
|
||||
Click on the tab 'Account', change username with your own username. Then click 'Update Username'.
|
||||
|
||||
[][30]
|
||||
|
||||
**Add SSH Key**
|
||||
|
||||
Make sure you already have a key, if you do not have an SSH key, you can generate with it with the command below.
|
||||
|
||||
```
|
||||
ssh-keygen
|
||||
```
|
||||
|
||||
And you will get two keys, 'id_rsa' your private key and 'id_rsa.pub' your public key.
|
||||
|
||||
[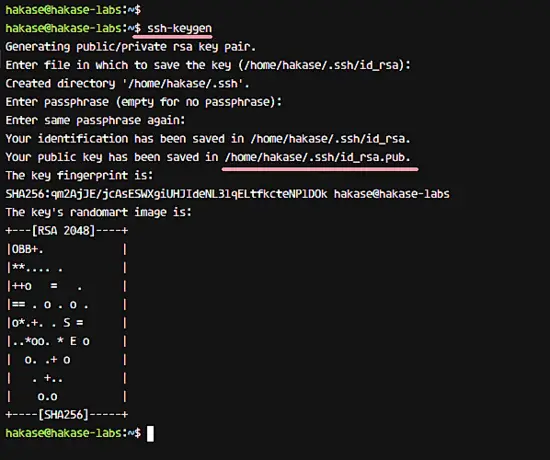][31]
|
||||
|
||||
Next, click on the tab 'SSH Key', copy the content of 'id_rsa.pub' file and paste to the key box, and click 'Add Key'.
|
||||
|
||||
[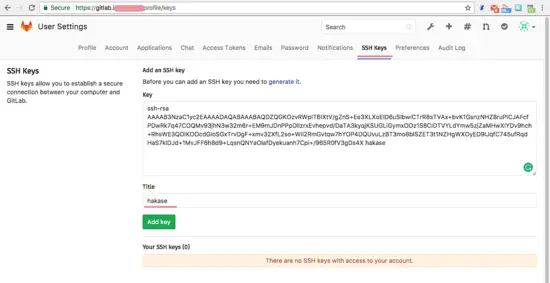][32]
|
||||
|
||||
New SSH Key has been added.
|
||||
|
||||
**Sign up Restrictions and Limit Settings**
|
||||
|
||||
Click on the 'admin area' icon, and then click on the gear icon and choose 'Settings'.
|
||||
|
||||
[][33]
|
||||
|
||||
On the 'Account and Limit Settings' - you can configure max projects per user and the 'Sign-up Restrictions', you can add the domain name of your email to the white-list box.
|
||||
|
||||
And if all is complete, scroll to the bottom and click 'Save'.
|
||||
|
||||
[][34]
|
||||
|
||||
Basic GitLab configuration has been completed.
|
||||
|
||||
### Step 8 - Testing
|
||||
|
||||
Finally, we will do some tests to ensure that our GitLab system is working properly.
|
||||
|
||||
**Create New Project**
|
||||
|
||||
Click the plus icon on the top to create a new project repository. Type in your project name, description, and setup the visibility settings of your project. Then click on the 'Create project' button.
|
||||
|
||||
[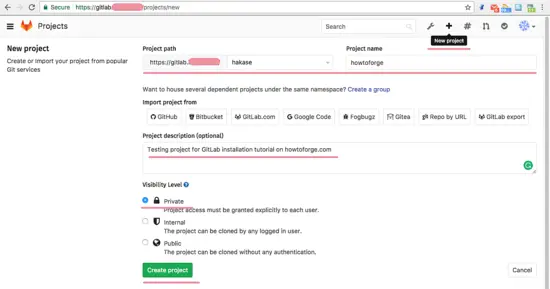][35]
|
||||
|
||||
The new project has been created.
|
||||
|
||||
**Test First Commit and Push**
|
||||
|
||||
After the 'howtoforge' project has been created, you will be redirected to the project page. Now start adding new content to the repository. Make sure Git is installed on your computer and setup the global username and email for git with the command below.
|
||||
|
||||
```
|
||||
git config --global user.name "hakase"
|
||||
git config --global user.email "admin@hakase-labs.co"
|
||||
```
|
||||
|
||||
Clone the Repository and add a README.md file.
|
||||
|
||||
```
|
||||
git clone https://hakase@gitlab.irsyadf.me/hakase/howtoforge.git
|
||||
cd howtoforge/
|
||||
vim README.md
|
||||
```
|
||||
|
||||
You will be asked for the 'hakase' user password. Please type the same password that you used when we accessed GitLab the first time.
|
||||
|
||||
Commit a new file to the howtoforge repository.
|
||||
|
||||
```
|
||||
git add .
|
||||
git commit -m 'Add README.md file by hakase-labs'
|
||||
```
|
||||
|
||||
Next, push the change to the repository on the GitLab server.
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
Type in your password and press Enter to continue. You will see the result as below.
|
||||
|
||||
[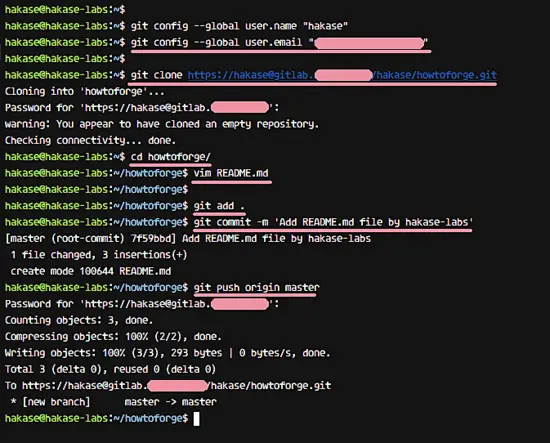][36]
|
||||
|
||||
Now open the howtoforge project from your web browser, and you will see that the new README.md file has been added to the repository.
|
||||
|
||||
[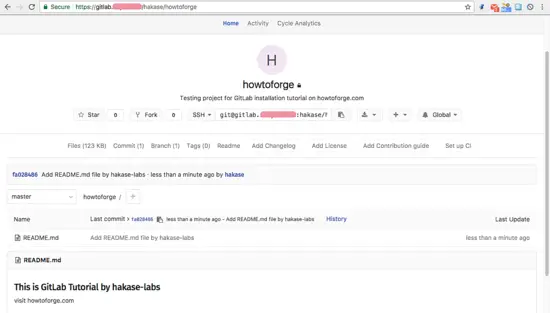][37]
|
||||
|
||||
Gitlab has been installed on a Ubuntu 16.04 Xenial Xerus server.
|
||||
|
||||
### Preferences
|
||||
|
||||
* [https://about.gitlab.com/downloads/#ubuntu1604][10][][11]
|
||||
|
||||
* [https://docs.gitlab.com/ce/][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/#step-install-required-ubuntu-packages
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/#step-install-gitlab
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/#step-configure-gitlab-main-url
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/#step-generate-ssl-lets-encrypt-and-dhparam-certificate
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/#step-enable-nginx-https-for-gitlab
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/#step-configure-ufw-firewall
|
||||
[7]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/#step-gitlab-postinstallation
|
||||
[8]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/#step-testing
|
||||
[9]:https://www.howtoforge.com/tutorial/how-to-install-and-configure-gitlab-on-ubuntu-16-04/#preferences
|
||||
[10]:https://about.gitlab.com/downloads/#ubuntu1604
|
||||
[11]:https://about.gitlab.com/downloads/#ubuntu1604
|
||||
[12]:https://docs.gitlab.com/ce/
|
||||
[13]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/1.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/2.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/3.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/Nano.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/41.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/5.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/6.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/7.png
|
||||
[21]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/8.png
|
||||
[22]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/9.png
|
||||
[23]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/10.png
|
||||
[24]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/11.png
|
||||
[25]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/12.png
|
||||
[26]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/13.png
|
||||
[27]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/14.png
|
||||
[28]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/15.png
|
||||
[29]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/16.png
|
||||
[30]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/17.png
|
||||
[31]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/18.png
|
||||
[32]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/19.png
|
||||
[33]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/20.png
|
||||
[34]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/21.png
|
||||
[35]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/22.png
|
||||
[36]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/23.png
|
||||
[37]:https://www.howtoforge.com/images/how_to_install_and_configure_gitlab_on_ubuntu_1604/big/24.png
|
||||
@ -0,0 +1,121 @@
|
||||
你为什么使用 Linux 和开源软件?
|
||||
============================================================
|
||||
|
||||
>LinuxQuestions.org 的用户分享了他们使用 Linux 和开源技术的原因。Opensource.com 的用户如何回答这个问题?
|
||||
|
||||

|
||||
>图片来源:opensource.com
|
||||
|
||||
当我在网站问答区提到这个问题时,尽管我有时候只是回答一些来自用户具有代表性的问题但偶尔我也会反过来问读者一些问题。我并没有在问答区第一列问这个问题,因为回答时间已经过期了。我最近在 LinuxQuestions.org 上提问了两个相关的问题收到了很多回复。让我们看看 Opensource.com 的用户对同样的问题和 LinuxQuestions.org 的回答的对比。
|
||||
|
||||
### 你为什么使用 Linux?
|
||||
|
||||
我向 LinuxQuestions.org 社区提问的第一个问题是:**[你们使用 Linux 的原因是什么?][1]**
|
||||
|
||||
### 回答集锦
|
||||
|
||||
_oldwierdal_:我用 Linux 是因为它运行效率快,安全,可靠。在全世界的贡献者的参与下,Linux 或许已经成为当前我们能用到的最先进和最创新的软件。Linux 的用户体验就像红丝绒蛋糕上的糖衣一样令人回味无穷;此外,Linux是免费的。
|
||||
|
||||
|
||||
_Timothy Miller_:我最开始使用 Linux 是因为它免费而且那时候我的经济条件无法承受购买新的 Windows 系统正版授权的费用。
|
||||
|
||||
_ondoho_ :因为它是一个拥有全球性社区为之努力,独立的草根操作系统。因为它在各方面都是自由的。因为它有足够多的理由让我们信任它。
|
||||
|
||||
|
||||
_joham34_:稳定,免费,安全,能够运行在低配置的电脑上,不错的提供技术支持的社区,感染病毒的几率更小。
|
||||
|
||||
|
||||
_Ook_:我用 Linux 是因为它仅仅做你要求的工作,对我来说 Windows 系统在某些事上从来都不能做好。我不得不浪费时间和金钱让 Windows 继续流畅正常运行并维持下去。
|
||||
|
||||
|
||||
_rhamel_:我非常担心个人隐私泄露在网上。我意识到我不得不在隐私和便利之间做出妥协。我可能是在骗自己但我确实认为 Linux 至少在某种程度上给了我一定的隐私权。
|
||||
|
||||
|
||||
_educateme_:我使用 Linux 因为它的开放,好学,热情乐于助人的社区。而且,它是免费的。
|
||||
|
||||
|
||||
_colinetsegers_:我为什么用 Linux?原因不止一个。简单的说有以下几点:
|
||||
|
||||
1. 自由分享知识的哲学。
|
||||
2. 浏览网页的时候有安全感。
|
||||
3. 大量免费、有用的软件。
|
||||
|
||||
|
||||
_bamunds_:因为我热爱自由。
|
||||
|
||||
|
||||
_cecilskinner1989_:我用 Linux 的两个原因:稳定性和隐秘性。
|
||||
|
||||
|
||||
### 你为什么使用开源软件?
|
||||
|
||||
|
||||
|
||||
第二个问题相对更加宽泛:**[你为什么使用开源软件?][2]**你会注意到尽管有些回复是有重复的部分,但用户的回答大体上的语气是不同的,有些用户的回答得到很多人的赞同和支持,也有不少用户的回答不怎么被其他人认同。
|
||||
|
||||
### 回答集锦
|
||||
|
||||
_robert leleu_:温馨、合作的氛围是我沉溺于开源的主要原因。
|
||||
|
||||
|
||||
_cjturner_:作为应用到应用程序的产品,开源差不多算是帕累托法则的反例,用软件的人也能够改写软件;OOTB(开箱即用),一个软件包可能你最终只使用了它的 80% 来满足自己的需求,但是你不得不保留剩下 20% 你用不到的部分。开源给了你一个途径、社区来避免这种不必要的负担,你可以自己努力实现(如果你有相关的技能)或者花钱有偿请人实现你的需求。
|
||||
|
||||
|
||||
_Timothy Miller_:我喜欢这种体验,我能够自己检查源代码来确定我所选择的软件是安全的。
|
||||
|
||||
|
||||
_teckk_:没有繁琐的许可要求或者数字版权管理而且每个人都可以获得它。
|
||||
|
||||
|
||||
_rokytnji_ :像零花钱,摩托车部件,孙辈的生日礼物那样令人愉悦。
|
||||
|
||||
|
||||
_timl_:没有自由软件避免隐私的泄露是不可能。
|
||||
|
||||
|
||||
_hazel_:我喜欢自由软件的哲学,但如果 Linux 是一个糟糕的操作系统我也会理性的不去使用它。我使用 Linux 是因为我热爱 Linux,而且你也能免费获得它就像免费的啤酒一样。事实上它就像在言论自由的环境下对话一样自由不受拘束,因为使用开源软件让我感觉很舒服。但是如果我发现我的机器有一个部件需要专有软件的配合才能发挥功能,我也会使用专有软件。
|
||||
|
||||
|
||||
_lm8_:我使用开源软件是因为我不必担心由于开发公司的破产或者决定停止维护它导致它可能会变得过时或者被废弃。我能够自己来完成后续的更新、维护。如果我想让软件能够做我想的任何事情,我也可以进一步定制它,但是如果有更多的特性,那就更好了。我也喜欢开源,因为开源我才能够和朋友、同事们分享我喜欢的程序。
|
||||
|
||||
|
||||
_donguitar_:因为它能够让我学到很多也让我让别人学到了很多。
|
||||
|
||||
|
||||
### 该你回答了
|
||||
|
||||
所以,_**你**_ 使用 Linux 的原因是什么? _**你**_ 使用开源软件的原因是什么?请在评论区告诉我们。
|
||||
|
||||
|
||||
### 最后的补充
|
||||
|
||||
|
||||
最后,在以后的文章里你想看到什么问题的回答?是社区的建立和维护的相关问题,还是你想知道如何对一个开源项目作出贡献,还是更有技术性的问题 — [向我们提交你对 Linux 和 开源的问题][5]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
Jeremy Garcia - Jeremy Garcia 是 LinuxQuestions.org 的创立者同时也是一位热情中不乏现实主义的开源倡导者。你可以在 Twitter 上关注 Jeremy:@linuxquestions
|
||||
|
||||
------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software
|
||||
|
||||
作者:[Jeremy Garcia ][a]
|
||||
译者:[WangYueScream](https://github.com/WangYueScream)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jeremy-garcia
|
||||
[1]:http://www.linuxquestions.org/questions/linux-general-1/what-are-the-reasons-you-use-linux-4175600842/
|
||||
[2]:http://www.linuxquestions.org/questions/linux-general-1/what-are-the-reasons-you-use-open-source-software-4175600843/
|
||||
[3]:https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software?rate=lVazcbF6Oern5CpV86PgNrRNZltZ8aJZwrUp7SrZIAw
|
||||
[4]:https://opensource.com/tags/queue-column
|
||||
[5]:https://opensource.com/thequeue-submit-question
|
||||
[6]:https://opensource.com/user/86816/feed
|
||||
[7]:https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software#comments
|
||||
[8]:https://opensource.com/users/jeremy-garcia
|
||||
@ -1,83 +0,0 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||

|
||||
安卓市场的新设计试水“卡片式”界面,这将成为谷歌的主要风格。
|
||||
Ron Amadeo 供图
|
||||
|
||||
安卓推向市场已经有两年半时间了,安卓市场放出了它的第四版设计。这个新设计十分重要,因为它已经很接近谷歌的“卡片式”界面了。通过在小方块中显示应用或其他内容,谷歌可以使其设计在不同尺寸屏幕下无缝过渡而不受影响。内容可以像一个相册应用里的照片一样显示——给布局渲染填充一个内容块列表,加上屏幕包装,就完成了。更大的屏幕一次可以看到更多的内容块,小点的屏幕一次看到的内容就少。内容用了不一样的方式显示,谷歌还在右边新增了一个“分类”板块,顶部还有个巨大的热门应用滚动显示。
|
||||
|
||||
虽然设计上为更容易配置界面准备好准备好了,但功能上还没有。最初发布的市场版本锁定为横屏模式,而且还是蜂巢独占的。
|
||||
|
||||

|
||||
应用详情页和“我的应用”界面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
新的市场不仅出售应用,还加入了书籍和电影租借。谷歌从2010年开始出售图书;之前只通过网站出售。新的市场将谷歌所有的内容销售聚合到了一处,进一步向苹果 iTunes 的主宰展开较量。虽然在“安卓市场”出售这些东西有点品牌混乱,因为大部分内容都不依赖于安卓才能使用。
|
||||
|
||||

|
||||
浏览器看起来非常像 Chrome,联系人使用了双面板界面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
新浏览器界面顶部添加了标签页栏。尽管这个浏览器并不是 Chrome ,它模仿了许多 Chrome 的设计和特性。除了这个探索性的顶部标签页界面,浏览器还加入了隐身标签,在浏览网页时不保存历史记录和自动补全记录。它还有个选项可以让你拥有一个 Chrome 风格的新标签页,页面上包含你最经常访问的网页略缩图。
|
||||
|
||||
新浏览器甚至还能和 Chrome 同步。在浏览器登录后,它会下载你的 Chrome 书签并且自动登录你的谷歌账户。收藏一个页面只需点击地址栏的星形标志即可,和谷歌地图一样,浏览器抛弃了缩放按钮,完全改用手势控制。
|
||||
|
||||
联系人应用最终从电话应用中移除,并且独立为一个应用。之前的联系人/拨号混合式设计相对于人们使用现代智能手机的方式来说,过于以电话为中心了。联系人中存有电子邮件,IM,短信,地址,生日,以及社交网络等信息,所以将它们捆绑在电话应用里的意义和将它们放进谷歌地图里差不多。抛开了电话通讯功能,联系人能够简化成没有标签页的联系人列表。蜂巢采用了双面板视图,在左侧显示完整的联系人列表,右侧是联系人详情。应用利用了 Fragments API,通过它应用可以在同一屏显示多个面板界面。
|
||||
|
||||
蜂巢版本的联系人应用是第一个拥有快速滚动功能的版本。当按住左侧滚动条的时候,你可以快速上下拖动,应用会显示列表当前位置的首字母预览。
|
||||
|
||||

|
||||
新 Youtube 应用看起来像是来自黑客帝国。
|
||||
Ron Amadeo 供图
|
||||
|
||||
谢天谢地 Youtube 终于抛弃了自安卓 2.3 以来的谷歌给予这个视频服务的“独特”设计,新界面设计与系统更加一体化。主界面是一个水平滚动的曲面墙,上面显示着最热门或者(登录之后)个人关注的视频。虽然谷歌从来没有将这个设计带到手机上,但它可以被认为是一个易于重新配置的卡片界面。操作栏在这里是个可配置的工具栏。没有登录时,操作栏由一个搜索栏填满。当你登录后,搜索缩小为一个按钮,“首页”,“浏览”和“你的频道”标签将会显示出来。
|
||||
|
||||

|
||||
蜂巢用一个蓝色框架的电脑界面来驱动主屏。电影工作室完全采用橙色电子风格主题。
|
||||
Ron Amadeo 供图
|
||||
|
||||
蜂巢新增的应用“电影工作室”,这不是一个不言自明的应用,而且没有任何的解释或说明。就我们所知,你可以导入视频,剪切它们,添加文本和场景过渡。编辑视频——电脑上你可以做的最耗时,困难,以及处理器密集型任务之一——在平板上完成感觉有点野心过大了,谷歌在之后的版本里将其完全移除了。电影工作室里我们最喜欢的部分是它完全的电子风格主题。虽然系统的其它部分使用蓝色高亮,在这里是橙色的。(电影工作室是个邪恶的程序!)
|
||||
|
||||

|
||||
小部件!
|
||||
Ron Amadeo 供图
|
||||
|
||||
蜂巢带来了新的部件框架,允许部件滚动,Gmail,Email 以及日历部件都升级了以支持改功能。Youtube 和书籍使用了新的部件,内容卡片可以自动滚动切换。在小部件上轻轻向上或向下滑动可以切换卡片。我们不确定你的书籍中哪些书会被显示出来,但如果你想要的话它就在那儿。尽管所有的这些小部件在10英寸屏幕上运行良好,谷歌从未将它们重新设计给手机,这让它们在安卓最流行的规格上几乎毫无用处。所有的小部件有个大块的标识标题栏,而且通常占据大半屏幕只显示很少的内容。
|
||||
|
||||

|
||||
安卓3.1中可滚动的最近应用以及可自定义大小的小部件。
|
||||
Ron Amadeo 供图
|
||||
|
||||
蜂巢后续的版本修复了3.0早期的一些问题。安卓3.1在蜂巢的第一个版本之后三个月放出,并带来了一些改进。小部件自定义大小是添加的最大特性之一。长按小部件之后,一个带有拖拽按钮的蓝色外框会显示出来,拖动按钮可以改变小部件尺寸。最近应用界面现在可以垂直滚动并且承载更多应用。这个版本唯一缺失的功能是滑动关闭应用。
|
||||
|
||||
在今天,一个0.1版本的升级是个主要更新,但是在蜂巢,那只是个小更新。除了一些界面调整,3.1添加了对游戏手柄,键盘,鼠标以及其它USB和蓝牙输入设备的支持。它还提供了更多的开发者API。
|
||||
|
||||

|
||||
安卓3.2的兼容性缩放和一个安卓平板上典型的展开视图应用。
|
||||
Ron Amadeo 供图
|
||||
|
||||
安卓3.2在3.1发布后两个月放出,添加了七到八英寸的小尺寸平板支持。3.2终于启用了SD卡支持,Xoom 在生命最初的五个月像是抱着个不完整的肢体一样。
|
||||
|
||||
蜂巢匆匆问世是为了成为一个生态系统建设者。如果应用没有平板版本,没人会想要一个安卓平板的,所以谷歌知道需要尽快将东西送到开发者手中。在这个安卓平板生态的早期阶段,应用还没有到齐。这是拥有 Xoom 的人们所面临的最大的问题。
|
||||
|
||||
3.2添加了“兼容缩放”,给了用户一个新选项,可以将应用拉伸适应屏幕(如右侧图片显示的那样)或缩放成正常的应用布局来适应屏幕。这些选项都不是很理想,没有应用生态来支持平板,蜂巢设备销售状况惨淡。但谷歌的平板决策最终还是会得到回报。今天,安卓平板已经[取代 iOS 占据了最大的市场份额][1]。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/18/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://techcrunch.com/2014/03/03/gartner-195m-tablets-sold-in-2013-android-grabs-top-spot-from-ipad-with-62-share/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,71 +0,0 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||

|
||||
姜饼上的 Google Music Beta。
|
||||
Ron Amadeo 供图
|
||||
|
||||
### Google Music Beta —— 取代内容商店的云存储 ###
|
||||
|
||||
尽管蜂巢改进了 Google Music 的界面,但是音乐应用的设计并没有从蜂巢直接进化到冰淇淋三明治。2011年5月,谷歌发布了“[Google Music Beta][1]”,和新的 Google Music 应用一同到来的在线音乐存储。
|
||||
|
||||
新 Google Music 为安卓2.2及以上版本设计,借鉴了 Cooliris 相册的设计语言,但也有改变之处,背景使用了模糊处理的图片。几乎所有东西都是透明的:弹出菜单,顶部标签页,还有底部的正在播放栏。可以下载单独的歌曲或整个播放列表到设备上离线播放,这让 Google Music 成为一个让音乐同步到你所有设备的好途径。除了移动应用外,Google Music 还有一个 Web 应用,让它可以在任何一台桌面电脑上使用。
|
||||
|
||||
谷歌和唱片公司关于内容的合约还没有谈妥,音乐商店还没准备好,所以它的权宜之计是允许用户存储音乐到线上并下载到设备上。如今谷歌除了音乐存储服务外,还有单曲购买和订阅模式。
|
||||
|
||||
### Android 4.0, 冰淇淋三明治 —— 摩登时代 ###
|
||||
|
||||

|
||||
三星 Galaxy Nexus,安卓4.0的首发设备。
|
||||
|
||||
安卓4.0,冰淇淋三明治,在2011年10月发布,系统发布回到正轨,带来定期发布的手机和平板,并且安卓再次开源。这是自姜饼以来手机设备的第一个更新,意味着最主要的安卓用户群体近乎一年没有见到更新了。4.0随处可见缩小版的蜂巢设计,还将虚拟按键,操作栏(Action Bar),全新的设计语言带到了手机上。
|
||||
|
||||
冰淇淋三明治在三星 Galaxy Nexus 上首次亮相,也是最早带有720p显示屏的安卓手机之一。随着分辨率的提高,Galaxy Nexus 使用了更大的4.65英寸显示屏——几乎比最初的 Nexus One 大了一整英寸。这被许多批评者认为“太大了”,但如今的安卓设备甚至更大。(5英寸现在是“正常”的。)冰淇淋三明治比姜饼的性能要求更高,Galaxy Nexus 配备了一颗双核,1.2Ghz 德州仪器 OMAP 处理器和1GB的内存。
|
||||
|
||||
在美国,Galaxy Nexus 在 Verizon 首发并且支持 LTE。不像之前的 Nexus 设备,最流行的型号——Verizon版——是在运营商的控制之下,谷歌的软件和更新在手机得到更新之前要经过 Verizon 的核准。这导致了更新的延迟以及 Verizon 不喜欢的应用被移除,即便是 Google Wallet 也不例外。
|
||||
|
||||
多亏了冰淇淋三明治的软件改进,谷歌终于达成了移除手机上按钮的目标。有了虚拟导航键,实体电容按钮就可以移除了,最终 Galaxy Nexus 仅有电源和音量是实体按键。
|
||||
|
||||

|
||||
安卓4.0将很多蜂巢的设计缩小了。
|
||||
Ron Amadeo 供图
|
||||
|
||||
电子质感的审美在蜂巢中显得有点多。于是在冰淇淋三明治中,谷歌开始减少科幻风的设计。科幻风的时钟字体从半透明折叠风格转变成纤细,优雅,看起来更加正常的字体。解锁环的水面波纹效果被去除了,蜂巢中的外星风格时钟小部件也被极简设计所取代。系统按钮也经过了重新设计,原先的蓝色轮廓,偶尔的厚边框变成了细的,设置带有白色轮廓。默认壁纸从蜂巢的蓝色太空船内部变成条纹状,破碎的彩虹,给默认布局增添了不少迟来的色彩。
|
||||
|
||||
蜂巢的系统栏在手机上一分为二。在顶上是传统的状态栏,底部是新的系统栏,放着三个系统按钮:后退,主屏幕,最近应用。一个固定的搜索栏放置在了主屏幕顶部。该栏以和底栏一样的方式固定在屏幕上,所以在五个主屏上,它总共占据了20个图标大小的位置。在蜂巢的锁屏上,内部的小圆圈可以向大圆圈外的任意位置滑动来解锁设备。在冰淇淋三明治,你得把小圆圈移动到解锁图标上。这个新准确度要求允许谷歌向锁屏添加新的选项:一个相机快捷方式。将小圆圈拖向相机图标会直接启动相机,跳过了主屏幕。
|
||||
|
||||

|
||||
一个手机系统意味着更多的应用,通知面板重新回到了全屏界面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
应用抽屉还是标签页式的,但是蜂巢中的“我的应用”标签被“部件”标签页替代,这是个简单的2×3部件略缩图视图。像蜂巢里的那样,这个应用抽屉是分页的,需要水平滑动换页。(如今安卓仍在使用这个应用抽屉设计。)应用抽屉里新增的是 Google+ 应用,后来独立存在。还有一个“Messenger”快捷方式,是 Google+ 的私密信息服务。(不要混淆 “Messenger” 和已有的 “Messaging” 短信应用。)
|
||||
|
||||
因为我们现在回到了手机上,所以短信,新闻和天气,电话,以及语音拨号都回来了,以及Cordy,一个平板的游戏,被移除了。尽管不是 Nexus 设备,我们的截图还是来自 Verizon 版的设备,可以从图上看到有像 “My Verizon Mobile” 和 “VZ Backup Assistant” 这样没用的应用。为了和冰淇淋三明治的去电子风格主题一致,日历和相机图标现在看起来更像是来自地球的东西而不是来自外星球。时钟,下载,电话,以及安卓市场同样得到了新图标,联系人“Contacts”获得了新图标,还有新名字“People”。
|
||||
|
||||
通知面板进行了大改造,特别是和[之前姜饼中的设计][2]相比而言。面板头部有个日期,一个设置的快捷方式,以及“清除所有”按钮。虽然蜂巢的第一个版本就允许用户通过通知右边的“X”消除单个通知,但是冰淇淋三明治的实现更加优雅:只要从左向右滑动通知即可。蜂巢有着蓝色高亮,但是蓝色色调到处都是。冰淇淋三明治几乎把所有地方的蓝色统一成一个(如果你想知道确定的值,hex码是#33B5E5)。通知面板的背景是透明的,底部的“把手”变为一个简单的小蓝圈,带着不透明的黑色背景。
|
||||
|
||||

|
||||
安卓市场的主页背景变成了黑色。
|
||||
Ron Amadeo 供图
|
||||
|
||||
市场获得了又一个新设计。它终于再次支持纵向模式,并且添加了音乐到商店中,你可以从中购买音乐。新的市场拓展了从蜂巢中引入的卡片概念,它还是第一个同时使用在手机和平板上的版本。主页上的卡片通常不是链接到应用的,而是指向特别的促销页面,像是“编辑精选”或季度促销。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/19/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2011/05/hands-on-grooving-on-the-go-with-impressive-google-music-beta/
|
||||
[2]:http://cdn.arstechnica.net/wp-content/uploads/2014/02/32.png
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -3,22 +3,6 @@
|
||||

|
||||
Ron Amadeo 供图
|
||||
|
||||
### Google Play 和直接面向消费者出售设备的回归 ###
|
||||
|
||||
2012年3月6日,谷歌将旗下提供的所有内容统一到 “Google Play”。安卓市场变为了 Google Play 商店,Google Books 变为 Google Play Books,Google Music 变为 Google Play Music,还有 Android Market Movies 变为 Google Play Movies & TV。尽管应用界面的变化不是很大,这四个内容应用都获得了新的名称和图标。在 Play 商店购买的内容会下载到对应的应用中,Play 商店和 Play 内容应用一道给用户提供了易管理的内容体验。
|
||||
|
||||
Google Play 更新是谷歌第一个大的更新周期外更新。四个自带应用都没有通过系统更新获得升级,它们都是直接通过安卓市场/ Play商店更新的。对单独的应用启用周期外更新是谷歌的重大关注点之一,而能够实现这样的更新,是自姜饼时代开始的工程努力的顶峰。谷歌一直致力于对应用从系统“解耦”,从而让它们能够通过安卓市场/ Play 商店进行分发。
|
||||
|
||||
尽管一两个应用(主要是地图和 Gmail)之前就在安卓市场上,从这里开始你会看到许多更重大的更新,而其和系统发布无关。系统更新需要 OEM 厂商和运营商的合作,所以很难保证推送到每个用户手上。而 Play 商店更新则完全掌握在谷歌手上,给了谷歌一条直接到达用户设备的途径。因为 Google Play 的发布,安卓市场对自身升级到了 Google Play Store,在那之后,图书,音乐以及电影应用都下发了 Google Play 式的更新。
|
||||
|
||||
Google Play 系列应用的设计仍然不尽相同。每个应用的外观和功能各有差异,但暂且来说,一个统一的品牌标识是个好的开始。从品牌标识中去除“安卓”字样是很有必要的,因为很多服务是在浏览器中提供的,不需要安卓设备也能使用。
|
||||
|
||||
2012年4月,谷歌[再次开始通过 Play 商店销售设备][1],恢复在 Nexus One 发布时尝试的直接面向消费者销售的方式。尽管距 Nexus One 销售结束仅有两年,但往上购物现在更加寻常,在接触到物品之前就购买它并不像在2010年时听起来那么疯狂。
|
||||
|
||||
谷歌也看到了价格敏感的用户在面对 Nexus One 530美元的价格时的反应。第一部销售的设备是无锁的,GSM 版本的 Galaxy Nexus,价格399美元。在那之后,价格变得更低。350美元成为了最近两台 Nexus 设备的入门价,7英寸 Nexus 平板的价格更是只有200美元到220美元。
|
||||
|
||||
今天,Play 商店销售八款不同的安卓设备,四款 Chromebook,一款自动调温器,以及许多配件,设备商店已经是谷歌新产品发布的实际地点了。新产品发布总是如此受欢迎,站点往往无法承载如此大的流量,新 Nexus 手机也在几小时内售空。
|
||||
|
||||
### 安卓 4.1,果冻豆——Google Now指明未来
|
||||
|
||||

|
||||
|
||||
@ -1,23 +1,21 @@
|
||||
GitFuture is translating!
|
||||
|
||||
OpenGL & Go Tutorial Part 3: Implementing the Game
|
||||
OpenGL 与 Go 教程第三节:实现游戏
|
||||
============================================================
|
||||
|
||||
[Part 1: Hello, OpenGL][8] | [Part 2: Drawing the Game Board][9] | [Part 3: Implementing the Game][10]
|
||||
[第一节: Hello, OpenGL][8] | [第二节: 绘制游戏面板][9] | [第三节:实现游戏功能][10]
|
||||
|
||||
The full source code of the tutorial is available on [GitHub][11].
|
||||
该教程的完整源代码可以从 [GitHub][11] 上获得。
|
||||
|
||||
Welcome back to the OpenGL & Go Tutorial! If you haven’t gone through [Part 1][12] and [Part 2][13] you’ll definitely want to take a step back and check them out.
|
||||
欢迎回到《OpenGL 与 Go 教程》!如果你还没有看过 [第一节][12] 和 [第二节][13],那就要回过头去看一看。
|
||||
|
||||
At this point you should have a grid system created and a matrix of cells to represent each unit of the grid. Now it’s time to implement Conway’s Game of Life using the grid as the game board.
|
||||
到目前为止,你应该懂得如何创建网格系统以及创建代表方格中每一个单元的格子阵列。现在可以开始把网格当作游戏面板实现《Conway's Game of Life》。
|
||||
|
||||
Let’s get started!
|
||||
开始吧!
|
||||
|
||||
### Implement Conway’s Game
|
||||
### 实现 《Conway’s Game》
|
||||
|
||||
One of the keys to Conway’s game is that each cell must determine its next state based on the current state of the board, at the same time. This means that if Cell (X=3, Y=4) changes state during its calculation, its neighbor at (X=4, Y=4) must determine its own state based on what (X=3, Y=4) was, not what is has become. Basically, this means we must loop through the cells and determine their next state without modifying their current state before we draw, and then on the next loop of the game we apply the new state and repeat.
|
||||
《Conway's Game》的其中一个要点是所有 cell 必须同时基于当前 cell 在面板中的状态确定下一个 cell 的状态。也就是说如果 Cell (X=3,Y=4)在计算过程中状态发生了改变,那么邻近的 cell (X=4,Y=4)必须基于(X=3,T=4)的状态决定自己的状态变化,而不是基于自己现在的状态。简单的讲,这意味着我们必须遍历 cell ,确定下一个 cell 的状态,在绘制之前,不改变他们的当前状态,然后在下一次循环中我们将新状态应用到游戏里,依此循环往复。
|
||||
|
||||
In order to accomplish this, we’ll add two booleans to the cell struct:
|
||||
为了完成这个功能,我们需要在 cell 结构体中添加两个布尔型变量:
|
||||
|
||||
```
|
||||
type cell struct {
|
||||
@ -31,39 +29,39 @@ type cell struct {
|
||||
}
|
||||
```
|
||||
|
||||
Now let’s add two functions that we’ll use to determine the cell’s state:
|
||||
现在添加两个函数,我们会用它们来确定 cell 的状态:
|
||||
|
||||
```
|
||||
// checkState determines the state of the cell for the next tick of the game.
|
||||
// checkState 函数决定下一次游戏循环时的 cell 状态
|
||||
func (c *cell) checkState(cells [][]*cell) {
|
||||
c.alive = c.aliveNext
|
||||
c.aliveNext = c.alive
|
||||
|
||||
liveCount := c.liveNeighbors(cells)
|
||||
if c.alive {
|
||||
// 1\. Any live cell with fewer than two live neighbours dies, as if caused by underpopulation.
|
||||
// 1\. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
||||
if liveCount < 2 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
|
||||
// 2\. Any live cell with two or three live neighbours lives on to the next generation.
|
||||
// 2\. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
||||
if liveCount == 2 || liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
|
||||
// 3\. Any live cell with more than three live neighbours dies, as if by overpopulation.
|
||||
// 3\. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
||||
if liveCount > 3 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
} else {
|
||||
// 4\. Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.
|
||||
// 4\. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
||||
if liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// liveNeighbors returns the number of live neighbors for a cell.
|
||||
// liveNeighbors 函数返回当前 cell 附近存活的 cell 数
|
||||
func (c *cell) liveNeighbors(cells [][]*cell) int {
|
||||
var liveCount int
|
||||
add := func(x, y int) {
|
||||
@ -97,9 +95,9 @@ func (c *cell) liveNeighbors(cells [][]*cell) int {
|
||||
}
|
||||
```
|
||||
|
||||
What’s more interesting is the liveNeighbors function where we return the number of neighbors to the current cell that are in an alivestate. We define an inner function called add that will do some repetitive validation on X and Y coordinates. What it does is check if we’ve passed a number that exceeds the bounds of the board - for example, if cell (X=0, Y=5) wants to check on its neighbor to the left, it has to wrap around to the other side of the board to cell (X=9, Y=5), and likewise for the Y-axis.
|
||||
更加值得注意的是 liveNeighbors 函数里在返回地方,我们返回的是当前处于存活状态的 cell 的邻居个数。我们定义了一个叫做 add 的内嵌函数,它会对 X 和 Y 坐标做一些重复性的验证。它所做的事情是检查我们传递的数字是否超出了范围——比如说,如果 cell(X=0,Y=5)想要验证它左边的 cell,它就得验证面板另一边的 cell(X=9,Y=5),Y 轴与之类似。
|
||||
|
||||
Below the inner add function we call add with each of the cell’s eight neighbors, depicted below:
|
||||
在 add 内嵌函数后面,我们给当前 cell 附近的八个 cell 分别调用 add 函数,示意如下:
|
||||
|
||||
```
|
||||
[
|
||||
@ -111,9 +109,9 @@ Below the inner add function we call add with each of the cell’s eight nei
|
||||
]
|
||||
```
|
||||
|
||||
In this depiction, each cell labeled N is a neighbor to C.
|
||||
在该示意中,每一个叫做 N 的 cell 是与 C 相邻的 cell。
|
||||
|
||||
Now in our main function, where we have our core game loop, let’s call checkState on each cell prior to drawing:
|
||||
现在是我们的主函数,在我们执行循环核心游戏的地方,调用每个 cell 的 checkState 函数进行绘制:
|
||||
|
||||
```
|
||||
func main() {
|
||||
@ -142,7 +140,7 @@ func (c *cell) draw() {
|
||||
}
|
||||
```
|
||||
|
||||
Let’s fix that. Back in makeCells we’ll use a random number between 0.0 and 1.0 to set the initial state of the game. We’ll define a constant threshold of 0.15 meaning that each cell has a 15% chance of starting in an alive state:
|
||||
现在完善这个函数。回到 makeCells 函数,我们用 0.0 到 1.0 之间的一个随机数来设置游戏的初始状态。我们会定义一个大小为 0.15 的常量阈值,也就是说每个 cell 都有 15% 的几率处于存活状态。
|
||||
|
||||
```
|
||||
import (
|
||||
@ -176,11 +174,11 @@ func makeCells() [][]*cell {
|
||||
}
|
||||
```
|
||||
|
||||
Next in the loop, after creating a cell with the newCell function we set its alive state equal to the result of a random float, between 0.0and 1.0, being less than threshold (0.15). Again, this means each cell has a 15% chance of starting out alive. You can play with this number to increase or decrease the number of living cells at the outset of the game. We also set aliveNext equal to alive, otherwise we’ll get a massive die-off on the first iteration because aliveNext will always be false!
|
||||
接下来在循环中,在用 newCell 函数创造一个新的 cell 时,我们根据随机数的大小设置它的存活状态,随机数在 0.0 到 1.0 之间,如果比阈值(0.15)小,就是存活状态。再次强调,这意味着每个 cell 在开始时都有 15% 的几率是存活的。你可以修改数值大小,增加或者减少当前游戏中存活的 cell。我们还把 aliveNext 设成 alive 状态,否则在第一次迭代之后我们会发现一大片 cell 消亡了,这是因为 aliveNext 将永远是 false。
|
||||
|
||||
Now go ahead and give it a run, and you’ll likely see a quick flash of cells that you can’t make heads or tails of. The reason is that your computer is probably way too fast and is running through (or even finishing) the simulation before you have a chance to really see it.
|
||||
现在接着往下看,运行它,你很有可能看到 cell 们一闪而过,但你却无法理解这是为什么。原因可能在于你的电脑太快了,在你能够看清楚之前就运行了(甚至完成了)模拟过程。
|
||||
|
||||
Let’s reduce the game speed by introducing a frames-per-second limitation in the main loop:
|
||||
降低游戏速度,在主循环中引入一个 frames-per-second 限制:
|
||||
|
||||
```
|
||||
const (
|
||||
@ -210,7 +208,7 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
Now you should be able to see some patterns, albeit very slowly. Increase the FPS to 10 and the size of the grid to 100x100 and you should see some really cool simulations:
|
||||
现在你能给看出一些图案了,尽管它变换的很慢。把 FPS 加到 10,把方格的尺寸加到 100x100,你就能看到更真实的模拟:
|
||||
|
||||
```
|
||||
const (
|
||||
@ -225,34 +223,34 @@ const (
|
||||
)
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
Try playing with the constants to see how they impact the simulation - cool right? Your very first OpenGL application with Go!
|
||||
试着修改常量,看看它们是怎么影响模拟过程的 —— 这是你用 Go 语言写的第一个 OpenGL 程序,很酷吧?
|
||||
|
||||
### What’s Next?
|
||||
### 进阶内容?
|
||||
|
||||
This concludes the OpenGL with Go Tutorial, but that doesn’t mean you should stop now. Here’s a few challenges to further improve your OpenGL (and Go) knowledge:
|
||||
这是《OpenGL 与 Go 教程》的最后一节,但是这不意味着到此而止。这里有些新的挑战,能够增进你对 OpenGL (以及 Go)的理解。
|
||||
|
||||
1. Give each cell a unique color.
|
||||
2. Allow the user to specify, via command-line arguments, the grid size, frame rate, seed and threshold. You can see this one implemented on GitHub at [github.com/KyleBanks/conways-gol][4].
|
||||
3. Change the shape of the cells into something more interesting, like a hexagon.
|
||||
4. Use color to indicate the cell’s state - for example, make cells green on the first frame that they’re alive, and make them yellow if they’ve been alive more than three frames.
|
||||
5. Automatically close the window if the simulation completes, meaning all cells are dead or no cells have changed state in the last two frames.
|
||||
6. Move the shader source code out into their own files, rather than having them as string constants in the Go source code.
|
||||
1. 给每个 cell 一种不同的颜色。
|
||||
2. 让用户能够通过命令行参数指定格子尺寸,帧率,种子和阈值。在 GitHub 上的 [github.com/KyleBanks/conways-gol][4] 里你可以看到一个已经实现的程序。
|
||||
3. 把格子的形状变成其它更有意思的,比如六边形。
|
||||
4. 用颜色表示 cell 的状态 —— 比如,在第一帧把存活状态的格子设成绿色,如果它们存活了超过三帧的时间,就变成黄色。
|
||||
5. 如果模拟过程结束了,就自动关闭窗口,也就是说所有 cell 都消亡了,或者是最后两帧里没有格子的状态有改变。
|
||||
6. 将着色器源代码放到单独的文件中,而不是把它们用字符串的形式放在 Go 的源代码中。
|
||||
|
||||
### Summary
|
||||
### 总结
|
||||
|
||||
Hopefully this tutorial has been helpful in gaining a foundation on OpenGL (and maybe even Go)! It was a lot of fun to make so I can only hope it was fun to go through and learn.
|
||||
希望这篇教程对想要入门 OpenGL (或者是 Go)的人有所帮助!这很有趣,因此我也希望理解学习它也很有趣。
|
||||
|
||||
As I’ve mentioned, OpenGL can be very intimidating, but it’s really not so bad once you get started. You just want to break down your goals into small, achievable steps, and enjoy each victory because while OpenGL isn’t always as tough as it looks, it can certainly be very unforgiving. One thing that I have found helpful when stuck on OpenGL issues was to understand that the way go-gl is generated means you can always use C code as a reference, which is much more popular in tutorials around the internet. The only difference usually between the C and Go code is that functions in Go are prefixed with gl. instead of gl, and constants are prefixed with gl instead of GL_. This vastly increases the pool of knowledge you have to draw from!
|
||||
正如我所说的,OpenGL 可能是非常恐怖的,但只要你开始着手了就不会太差。你只用制定一个个可达成的小目标,然后享受每一次成功,因为尽管 OpenGL 不会总像它看上去的那么难,但也肯定有些难懂的东西。我发现,当遇到一个难于用 go-gl 方式理解的 OpenGL 问题时,你总是可以参考一下在网上更流行的当作教程的 C 语言代码,这很有用。通常 C 语言和 Go 语言的唯一区别是在 Go 中,gl 的前缀是 gl. 而不是 GL_。这极大地增加了你的绘制知识!
|
||||
|
||||
[Part 1: Hello, OpenGL][14] | [Part 2: Drawing the Game Board][15] | [Part 3: Implementing the Game][16]
|
||||
[第一节: Hello, OpenGL][14] | [第二节: 绘制游戏面板][15] | [第三节:实现游戏功能][16]
|
||||
|
||||
The full source code of the tutorial is available on [GitHub][17].
|
||||
该教程的完整源代码可从 [GitHub][17] 上获得。
|
||||
|
||||
### Checkpoint
|
||||
### 回顾
|
||||
|
||||
Here’s the final contents of main.go:
|
||||
这是 main.go 文件最终的内容:
|
||||
|
||||
```
|
||||
package main
|
||||
@ -414,36 +412,36 @@ func (c *cell) draw() {
|
||||
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3))
|
||||
}
|
||||
|
||||
// checkState determines the state of the cell for the next tick of the game.
|
||||
// checkState 函数决定下一次游戏循环时的 cell 状态
|
||||
func (c *cell) checkState(cells [][]*cell) {
|
||||
c.alive = c.aliveNext
|
||||
c.aliveNext = c.alive
|
||||
c.alive = c.aliveNext
|
||||
c.aliveNext = c.alive
|
||||
|
||||
liveCount := c.liveNeighbors(cells)
|
||||
if c.alive {
|
||||
// 1\. Any live cell with fewer than two live neighbours dies, as if caused by underpopulation.
|
||||
if liveCount < 2 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
liveCount := c.liveNeighbors(cells)
|
||||
if c.alive {
|
||||
// 1\. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
||||
if liveCount < 2 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
|
||||
// 2\. Any live cell with two or three live neighbours lives on to the next generation.
|
||||
if liveCount == 2 || liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
// 2\. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
||||
if liveCount == 2 || liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
|
||||
// 3\. Any live cell with more than three live neighbours dies, as if by overpopulation.
|
||||
if liveCount > 3 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
} else {
|
||||
// 4\. Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.
|
||||
if liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
}
|
||||
// 3\. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
||||
if liveCount > 3 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
} else {
|
||||
// 4\. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
||||
if liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// liveNeighbors returns the number of live neighbors for a cell.
|
||||
// liveNeighbors 函数返回当前 cell 附近存活的 cell 数
|
||||
func (c *cell) liveNeighbors(cells [][]*cell) int {
|
||||
var liveCount int
|
||||
add := func(x, y int) {
|
||||
@ -476,7 +474,7 @@ func (c *cell) liveNeighbors(cells [][]*cell) int {
|
||||
return liveCount
|
||||
}
|
||||
|
||||
// initGlfw initializes glfw and returns a Window to use.
|
||||
// initGlfw 初始化 glfw,返回一个可用的 Window
|
||||
func initGlfw() *glfw.Window {
|
||||
if err := glfw.Init(); err != nil {
|
||||
panic(err)
|
||||
@ -496,7 +494,7 @@ func initGlfw() *glfw.Window {
|
||||
return window
|
||||
}
|
||||
|
||||
// initOpenGL initializes OpenGL and returns an intiialized program.
|
||||
// initOpenGL 初始化 OpenGL 并返回一个已经编译好的着色器程序
|
||||
func initOpenGL() uint32 {
|
||||
if err := gl.Init(); err != nil {
|
||||
panic(err)
|
||||
@ -521,7 +519,7 @@ func initOpenGL() uint32 {
|
||||
return prog
|
||||
}
|
||||
|
||||
// makeVao initializes and returns a vertex array from the points provided.
|
||||
// makeVao 初始化并从提供的点里面返回一个顶点数组
|
||||
func makeVao(points []float32) uint32 {
|
||||
var vbo uint32
|
||||
gl.GenBuffers(1, &vbo)
|
||||
@ -562,18 +560,18 @@ func compileShader(source string, shaderType uint32) (uint32, error) {
|
||||
}
|
||||
```
|
||||
|
||||
Let me know if this post was helpful on Twitter
|
||||
请在 Twitter 上告诉我这篇文章对你是否有帮助。
|
||||
|
||||
[@kylewbanks][18]
|
||||
|
||||
or down below, and follow me to keep up with future posts!
|
||||
或者在 Twitter 下方关注我以便及时获取最新文章!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
|
||||
作者:[kylewbanks ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,212 @@
|
||||
FreeFileSync - 在 Ubuntu 中对比及同步文件
|
||||
============================================================
|
||||
|
||||
|
||||
FreeFileSync 是一个免费、开源以及跨平台的文件夹对比及同步软件,它可以帮助你[同步 Linux、Windows 和 Mac OS 中的文件和文件夹][2]。
|
||||
|
||||
它是可移植的并可以被本地安装在系统中,它的功能丰富,旨在节省设置和执行备份操作的时间,同时具有有吸引力的图形界面。
|
||||
|
||||
#### FreeFileSync 功能
|
||||
|
||||
下面是它的主要功能:
|
||||
|
||||
1. 它可以同步网络共享和本地磁盘。
|
||||
2. 它可以同步 MTP 设备(Android、iPhone、平板电脑、数码相机)。
|
||||
3. 它也可以通过 [SFTP(SSH 文件传输协议)][1]进行同步。
|
||||
4. 它可以识别被移动和被重命名的文件和文件夹。
|
||||
5. 使用目录树显示磁盘空间使用情况。
|
||||
6. 支持复制锁定文件(卷影复制服务)。
|
||||
7. 确定冲突并同步删除(propagate deletions)。
|
||||
8. 支持按内容比较文件。
|
||||
9. 它可以配置为处理符号链接。
|
||||
10. 支持批量自动同步。
|
||||
11. 支持多个文件夹比较。
|
||||
12. 支持深入详细的错误报告。
|
||||
13. 支持复制 NTFS 扩展属性,如(压缩、加密、稀疏)。
|
||||
14. 还支持复制 NTFS 安全权限和 NTFS 备用数据流。
|
||||
15. 支持超过 260 个字符的长文件路径。
|
||||
16. 支持故障安全的文件复制防止数据损坏。
|
||||
17. 允许扩展环境变量,例如 %UserProfile%。
|
||||
18. 支持通过卷名访问可变驱动器盘符(U盘)。
|
||||
19. 支持管理已删除/更新文件的版本。
|
||||
20. 通过最佳同步序列防止光盘空间问题。
|
||||
21. 支持完整的 Unicode。
|
||||
22. 提供高度优化的运行时性能。
|
||||
23. 支持过滤器包含和排除文件等。
|
||||
|
||||
### 如何在 Ubuntu 中安装 FreeFileSync
|
||||
|
||||
我们会添加官方的 FreeFileSync PPA,这只在 Ubuntu 14.04 和 Ubuntu 15.10 上有,那么像这样更新系统仓库列表并安装它:
|
||||
|
||||
```
|
||||
-------------- 在 Ubuntu 14.04 和 15.10 上 --------------
|
||||
$ sudo apt-add-repository ppa:freefilesync/ffs
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install freefilesync
|
||||
```
|
||||
|
||||
对于 Ubuntu 16.04 或者更新的版本,进入[ FreeFileSync 的下载页][3]为你的 Ubuntu 和 Debian 获取合适的包。
|
||||
|
||||
接下来,进入下载文件夹,如下解压 FreeFileSync_*.tar.gz 到 /opt 目录中:
|
||||
|
||||
```
|
||||
$ cd Downloads/
|
||||
$ sudo tar xvf FreeFileSync_*.tar.gz -C /opt/
|
||||
$ cd /opt/
|
||||
$ ls
|
||||
$ sudo unzip FreeFileSync/Resources.zip -d /opt/FreeFileSync/Resources/
|
||||
```
|
||||
|
||||
下载我们会使用 Gnome Panel创建一个程序启动器(.desktop 文件)。要浏览系统中 `.desktop` 文件的例子,列出 /usr/share/applications 目录的内容:
|
||||
|
||||
```
|
||||
$ ls /usr/share/applications
|
||||
```
|
||||
|
||||
为防你没有安装 Gnome Panel,输入下面的命令来安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install --no-install-recommends gnome-panel
|
||||
```
|
||||
|
||||
接下来,运行下面的命令来创建程序启动器:
|
||||
|
||||
```
|
||||
$ sudo gnome-desktop-item-edit /usr/share/applications/ --create-new
|
||||
```
|
||||
|
||||
并定义下面的值:
|
||||
|
||||
```
|
||||
Type: Application
|
||||
Name: FreeFileSync
|
||||
Command: /opt/FreeFileSync/FreeFileSync
|
||||
Comment: Folder Comparison and Synchronization
|
||||
```
|
||||
|
||||
要为启动器添加一个图标,只需要点击图标选择:/opt/FreeFileSync/Resources/FreeFileSync.png。
|
||||
|
||||
当你设置完成之后,点击 OK 创建。
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
创建桌面启动器
|
||||
|
||||
如果你不想要创建桌面启动器,你可以从目录中启动 FreeFileSync。
|
||||
|
||||
```
|
||||
$ ./FreeFileSync
|
||||
```
|
||||
|
||||
### 如何在 Ubuntu 中使用 FreeFileSync
|
||||
|
||||
在 Ubuntu 中,在 Unity Dash 中搜索 FreeFileSync,然而在 Linux Mint 中,在 System Menu 中搜索,并点击 FreeFileSync 图标打开。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
FreeFileSync
|
||||
|
||||
#### 使用 FreeFileSync 比较两个文件夹
|
||||
|
||||
在下面的例子中,我们使用:
|
||||
|
||||
```
|
||||
Source Folder: /home/aaronkilik/bin
|
||||
Destination Folder: /media/aaronkilik/J_CPRA_X86F/scripts
|
||||
```
|
||||
|
||||
要比较文件时间以及两个文件夹的大小(默认设置),只要点击比较按钮。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
在 Linux 中比较两个文件夹
|
||||
|
||||
通过下面的界面,可以在两个文件夹中按 `F6` 来更改要比较的内容:文件时间和大小、内容或文件大小。请注意,你选择的每个选项的含义也包括在内。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
文件比较设置
|
||||
|
||||
#### 使用 FreeFileSync 同步两个文件夹
|
||||
|
||||
你可以开始比较两个文件夹,接着点击 Synchronize 按钮启动同步进程。在之后出现的对话框中点击 Start:
|
||||
|
||||
```
|
||||
Source Folder: /home/aaronkilik/Desktop/tecmint-files
|
||||
Destination Folder: /media/aaronkilik/Data/Tecmint
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
比较以及同步两个文件夹
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
开始文件同步
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
文件同步完成
|
||||
|
||||
在下面的界面中按下 `F8` 设置默认同步选项:two way、mirror、update 或 custom。每个选项的意义都包含在内。
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
文件同步设置
|
||||
|
||||
要了解更多信息,访问 FreeFileSync 主页:[http://www.freefilesync.org/][12]
|
||||
|
||||
就是这样了!在本篇中,我们向你展示了如何在 Ubuntu 以及它的衍生版 Linux Mint、Kubuntu 等等中安装 FreeFileSync。在下面的评论栏中分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ravi Saive,TecMint 的原创作者。一个喜爱在互联网上分享技巧和提示的计算机 geek 和 Linux 老手。我的大多数服务运行在 Linux 开源平台上。请在 Twitter、Facebook、Google+ 上关注我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/freefilesync-compare-synchronize-files-in-ubuntu/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[00]:https://twitter.com/ravisaive
|
||||
[01]:https://www.facebook.com/ravi.saive
|
||||
[02]:https://plus.google.com/u/0/+RaviSaive
|
||||
|
||||
[1]:http://www.tecmint.com/sftp-command-examples/
|
||||
[2]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[3]:http://www.freefilesync.org/download.php
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Create-Desktop-Launcher.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/FreeFileSync-launched.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/compare-two-folders.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/comparison-settings.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/compare-and-sychronize-two-folders.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/start-sychronization.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/synchronization-complete.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/synchronization-setttings.png
|
||||
[12]:http://www.freefilesync.org/
|
||||
[13]:http://www.tecmint.com/author/admin/
|
||||
[14]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[15]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -75,7 +75,7 @@ via: https://opensource.com/article/17/5/much-ado-about-communication
|
||||
|
||||
作者:[ Jono Bacon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user