mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
704ae05096
@ -1,16 +1,18 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Create/Configure LVM (Logical Volume Management) in Linux)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12670-1.html)
|
||||
[#]: subject: (How to Create/Configure LVM in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Linux 中创建/配置 LVM(逻辑卷管理)?
|
||||
如何在 Linux 中创建/配置 LVM(逻辑卷管理)
|
||||
======
|
||||
|
||||
逻辑卷管理器 (LVM) 在 Linux 系统中扮演着重要的角色,它可以提高磁盘管理的可用性、磁盘 I/O、性能和能力。
|
||||

|
||||
|
||||
<ruby>逻辑卷管理<rt>Logical Volume Management</rt></ruby>(LVM)在 Linux 系统中扮演着重要的角色,它可以提高可用性、磁盘 I/O、性能和磁盘管理的能力。
|
||||
|
||||
LVM 是一种被广泛使用的技术,对于磁盘管理来说,它是非常灵活的。
|
||||
|
||||
@ -18,15 +20,15 @@ LVM 是一种被广泛使用的技术,对于磁盘管理来说,它是非常
|
||||
|
||||
LVM 允许你在需要的时候轻松地调整、扩展和减少逻辑卷的大小。
|
||||
|
||||
![][1]
|
||||
|
||||
|
||||
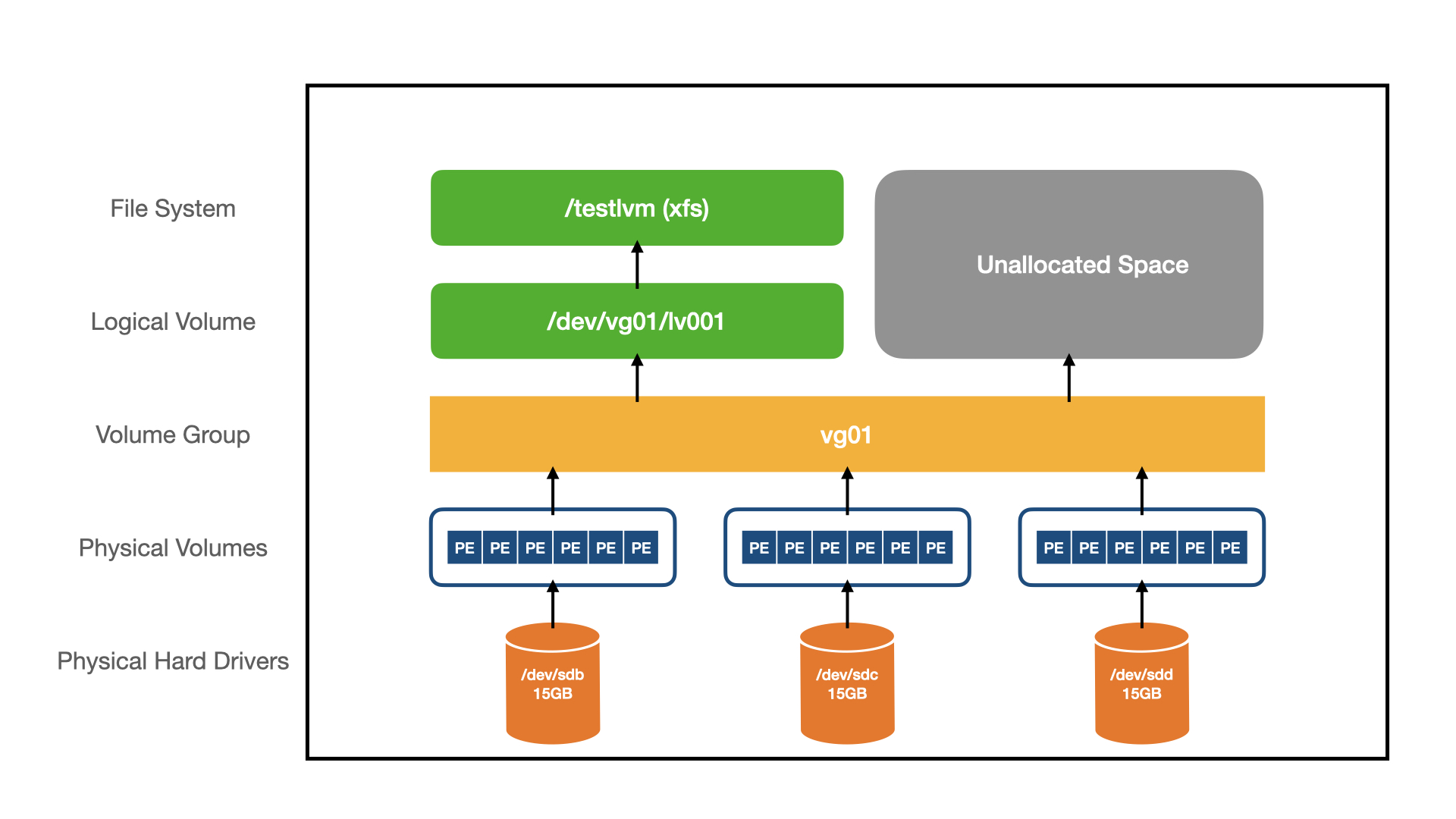
### 如何创建 LVM 物理卷?
|
||||
|
||||
你可以使用任何磁盘、RAID 阵列、SAN 磁盘或分区作为 LVM 物理卷。
|
||||
你可以使用任何磁盘、RAID 阵列、SAN 磁盘或分区作为 LVM <ruby>物理卷<rt>Physical Volume</rt></ruby>(PV)。
|
||||
|
||||
让我们想象一下,你已经添加了三个磁盘,它们是 /dev/sdb、/dev/sdc 和 /dev/sdd。
|
||||
让我们想象一下,你已经添加了三个磁盘,它们是 `/dev/sdb`、`/dev/sdc` 和 `/dev/sdd`。
|
||||
|
||||
运行以下命令来**[发现 Linux 中新添加的 LUN 或磁盘][2]**:
|
||||
运行以下命令来[发现 Linux 中新添加的 LUN 或磁盘][2]:
|
||||
|
||||
```
|
||||
# ls /sys/class/scsi_host
|
||||
@ -41,13 +43,13 @@ host0
|
||||
# fdisk -l
|
||||
```
|
||||
|
||||
**创建物理卷 (pvcreate) 的一般语法:**
|
||||
**创建物理卷 (`pvcreate`) 的一般语法:**
|
||||
|
||||
```
|
||||
pvcreate [物理卷名]
|
||||
```
|
||||
|
||||
当在系统中检测到磁盘,使用 pvcreate 命令初始化 LVM PV(物理卷):
|
||||
当在系统中检测到磁盘,使用 `pvcreate` 命令初始化 LVM PV:
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdb /dev/sdc /dev/sdd
|
||||
@ -58,12 +60,10 @@ Physical volume "/dev/sdd" successfully created
|
||||
|
||||
**请注意:**
|
||||
|
||||
* 上面的命令将删除给定磁盘 /dev/sdb、/dev/sdc 和 /dev/sdd 上的所有数据。
|
||||
* 物理磁盘可以直接添加到 LVM PV 中,而不是磁盘分区。
|
||||
* 上面的命令将删除给定磁盘 `/dev/sdb`、`/dev/sdc` 和 `/dev/sdd` 上的所有数据。
|
||||
* 物理磁盘可以直接添加到 LVM PV 中,而不必是磁盘分区。
|
||||
|
||||
|
||||
|
||||
使用 pvdisplay 和 pvs 命令来显示你创建的 PV。pvs 命令显示的是摘要输出,pvdisplay 显示的是 PV 的详细输出:
|
||||
使用 `pvdisplay` 和 `pvs` 命令来显示你创建的 PV。`pvs` 命令显示的是摘要输出,`pvdisplay` 显示的是 PV 的详细输出:
|
||||
|
||||
```
|
||||
# pvs
|
||||
@ -115,9 +115,9 @@ PV UUID d92fa769-e00f-4fd7-b6ed-ecf7224af7faS
|
||||
|
||||
### 如何创建一个卷组
|
||||
|
||||
卷组是 LVM 结构中的另一层。基本上,卷组由你创建的 LVM 物理卷组成,你可以将物理卷添加到现有的卷组中,或者根据需要为物理卷创建新的卷组。
|
||||
<ruby>卷组<rt>Volume Group</rt></ruby>(VG)是 LVM 结构中的另一层。基本上,卷组由你创建的 LVM 物理卷组成,你可以将物理卷添加到现有的卷组中,或者根据需要为物理卷创建新的卷组。
|
||||
|
||||
**创建卷组 (vgcreate) 的一般语法:**
|
||||
**创建卷组 (`vgcreate`) 的一般语法:**
|
||||
|
||||
```
|
||||
vgcreate [卷组名] [物理卷名]
|
||||
@ -130,9 +130,9 @@ vgcreate [卷组名] [物理卷名]
|
||||
Volume group "vg01" successfully created
|
||||
```
|
||||
|
||||
**请注意:**默认情况下,它使用 4MB 的物理范围,但你可以根据你的需要改变它。
|
||||
**请注意:**默认情况下,它使用 4MB 的<ruby>物理范围<rt>Physical Extent</rt></ruby>(PE),但你可以根据你的需要改变它。
|
||||
|
||||
使用 vgs 和 vgdisplay 命令来显示你创建的 VG 的信息:
|
||||
使用 `vgs` 和 `vgdisplay` 命令来显示你创建的 VG 的信息:
|
||||
|
||||
```
|
||||
# vgs vg01
|
||||
@ -168,7 +168,7 @@ VG UUID d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
|
||||
如果 VG 没有空间,请使用以下命令将新的物理卷添加到现有卷组中。
|
||||
|
||||
**卷组扩展 (vgextend) 的一般语法:**
|
||||
**卷组扩展 (`vgextend`)的一般语法:**
|
||||
|
||||
```
|
||||
vgextend [已有卷组名] [物理卷名]
|
||||
@ -181,24 +181,24 @@ vgextend [已有卷组名] [物理卷名]
|
||||
|
||||
### 如何以 GB 为单位创建逻辑卷?
|
||||
|
||||
逻辑卷是 LVM 结构中的顶层。逻辑卷是由卷组创建的块设备。它作为一个虚拟磁盘分区,可以使用 LVM 命令轻松管理。
|
||||
<ruby>逻辑卷<rt>Logical Volume</rt></ruby>(LV)是 LVM 结构中的顶层。逻辑卷是由卷组创建的块设备。它作为一个虚拟磁盘分区,可以使用 LVM 命令轻松管理。
|
||||
|
||||
你可以使用 lvcreate 命令创建一个新的逻辑卷。
|
||||
你可以使用 `lvcreate` 命令创建一个新的逻辑卷。
|
||||
|
||||
**创建逻辑卷 (lvcreate) 的一般语法:**
|
||||
**创建逻辑卷(`lvcreate`) 的一般语法:**
|
||||
|
||||
```
|
||||
lvcreate –n [逻辑卷名] –L [逻辑卷大小] [要创建的 LV 所在的卷组名称]
|
||||
```
|
||||
|
||||
运行下面的命令,创建一个大小为 10GB 的逻辑卷 lv001:
|
||||
运行下面的命令,创建一个大小为 10GB 的逻辑卷 `lv001`:
|
||||
|
||||
```
|
||||
# lvcreate -n lv001 -L 10G vg01
|
||||
Logical volume "lv001" created
|
||||
```
|
||||
|
||||
使用 lvs 和 lvdisplay 命令来显示你所创建的 LV 的信息:
|
||||
使用 `lvs` 和 `lvdisplay` 命令来显示你所创建的 LV 的信息:
|
||||
|
||||
```
|
||||
# lvs /dev/vg01/lvol01
|
||||
@ -228,19 +228,19 @@ Block device 253:4
|
||||
|
||||
### 如何以 PE 大小创建逻辑卷?
|
||||
|
||||
或者,你可以使用物理扩展 (PE) 大小创建逻辑卷。
|
||||
或者,你可以使用物理范围(PE)大小创建逻辑卷。
|
||||
|
||||
### 如何计算 PE 值?
|
||||
|
||||
很简单,例如,如果你有一个 10GB 的卷组,那么 PE 大小是多少?
|
||||
|
||||
默认情况下,它使用 4MB 的物理扩展,但通过运行 vgdisplay 命令来检查正确的 PE 大小,因为这可以根据需求进行更改。
|
||||
默认情况下,它使用 4MB 的物理范围,但可以通过运行 `vgdisplay` 命令来检查正确的 PE 大小,因为这可以根据需求进行更改。
|
||||
|
||||
```
|
||||
10GB = 10240MB / 4MB (PE 大小) = 2560 PEs
|
||||
10GB = 10240MB / 4MB (PE 大小) = 2560 PE
|
||||
```
|
||||
|
||||
**用 PE 大小创建逻辑卷 (lvcreate) 的一般语法:**
|
||||
**用 PE 大小创建逻辑卷 (`lvcreate`) 的一般语法:**
|
||||
|
||||
```
|
||||
lvcreate –n [逻辑卷名] –l [物理扩展 (PE) 大小] [要创建的 LV 所在的卷组名称]
|
||||
@ -262,7 +262,7 @@ lvcreate –n [逻辑卷名] –l [物理扩展 (PE) 大小] [要创建的 L
|
||||
mkfs –t [文件系统类型] /dev/[LV 所在的卷组名称]/[LV 名称]
|
||||
```
|
||||
|
||||
使用以下命令将逻辑卷 lv001 格式化为 ext4 文件系统:
|
||||
使用以下命令将逻辑卷 `lv001` 格式化为 ext4 文件系统:
|
||||
|
||||
```
|
||||
# mkfs -t ext4 /dev/vg01/lv001
|
||||
@ -276,7 +276,7 @@ mkfs –t [文件系统类型] /dev/[LV 所在的卷组名称]/[LV 名称]
|
||||
|
||||
### 挂载逻辑卷
|
||||
|
||||
最后,你需要挂载逻辑卷来使用它。确保在 **/etc/fstab** 中添加一个条目,以便系统启动时自动加载。
|
||||
最后,你需要挂载逻辑卷来使用它。确保在 `/etc/fstab` 中添加一个条目,以便系统启动时自动加载。
|
||||
|
||||
创建一个目录来挂载逻辑卷:
|
||||
|
||||
@ -284,20 +284,20 @@ mkfs –t [文件系统类型] /dev/[LV 所在的卷组名称]/[LV 名称]
|
||||
# mkdir /lvmtest
|
||||
```
|
||||
|
||||
使用挂载命令 **[挂载逻辑卷][3]**:
|
||||
使用挂载命令[挂载逻辑卷][3]:
|
||||
|
||||
```
|
||||
# mount /dev/vg01/lv001 /lvmtest
|
||||
```
|
||||
|
||||
在 **[/etc/fstab 文件][4]**中添加新的逻辑卷详细信息,以便系统启动时自动挂载:
|
||||
在 [/etc/fstab 文件][4]中添加新的逻辑卷详细信息,以便系统启动时自动挂载:
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
/dev/vg01/lv001 /lvmtest xfs defaults 0 0
|
||||
```
|
||||
|
||||
使用 **[df 命令][5]**检查新挂载的卷:
|
||||
使用 [df 命令][5]检查新挂载的卷:
|
||||
|
||||
```
|
||||
# df -h /lvmtest
|
||||
@ -312,13 +312,13 @@ via: https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[1]: https://www.2daygeek.com/wp-content/uploads/2020/09/create-lvm-storage-logical-volume-manager-in-linux-2.png
|
||||
[2]: https://www.2daygeek.com/scan-detect-luns-scsi-disks-on-redhat-centos-oracle-linux/
|
||||
[3]: https://www.2daygeek.com/mount-unmount-file-system-partition-in-linux/
|
||||
[4]: https://www.2daygeek.com/understanding-linux-etc-fstab-file/
|
||||
@ -1,24 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Extend/Increase LVM’s (Logical Volume Resize) in Linux)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12673-1.html)
|
||||
[#]: subject: (How to Extend/Increase LVM’s in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/extend-increase-resize-lvm-logical-volume-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Linux 中扩展/增加 LVM 大小(逻辑卷调整)
|
||||
======
|
||||
|
||||

|
||||
|
||||
扩展逻辑卷非常简单,只需要很少的步骤,而且不需要卸载某个逻辑卷就可以在线完成。
|
||||
|
||||
LVM 的主要目的是灵活的磁盘管理,当你需要的时候,可以很方便地调整、扩展和缩小逻辑卷的大小。
|
||||
|
||||
如果你是逻辑卷管理(LVM) 新手,我建议你从我们之前的文章开始学习。
|
||||
|
||||
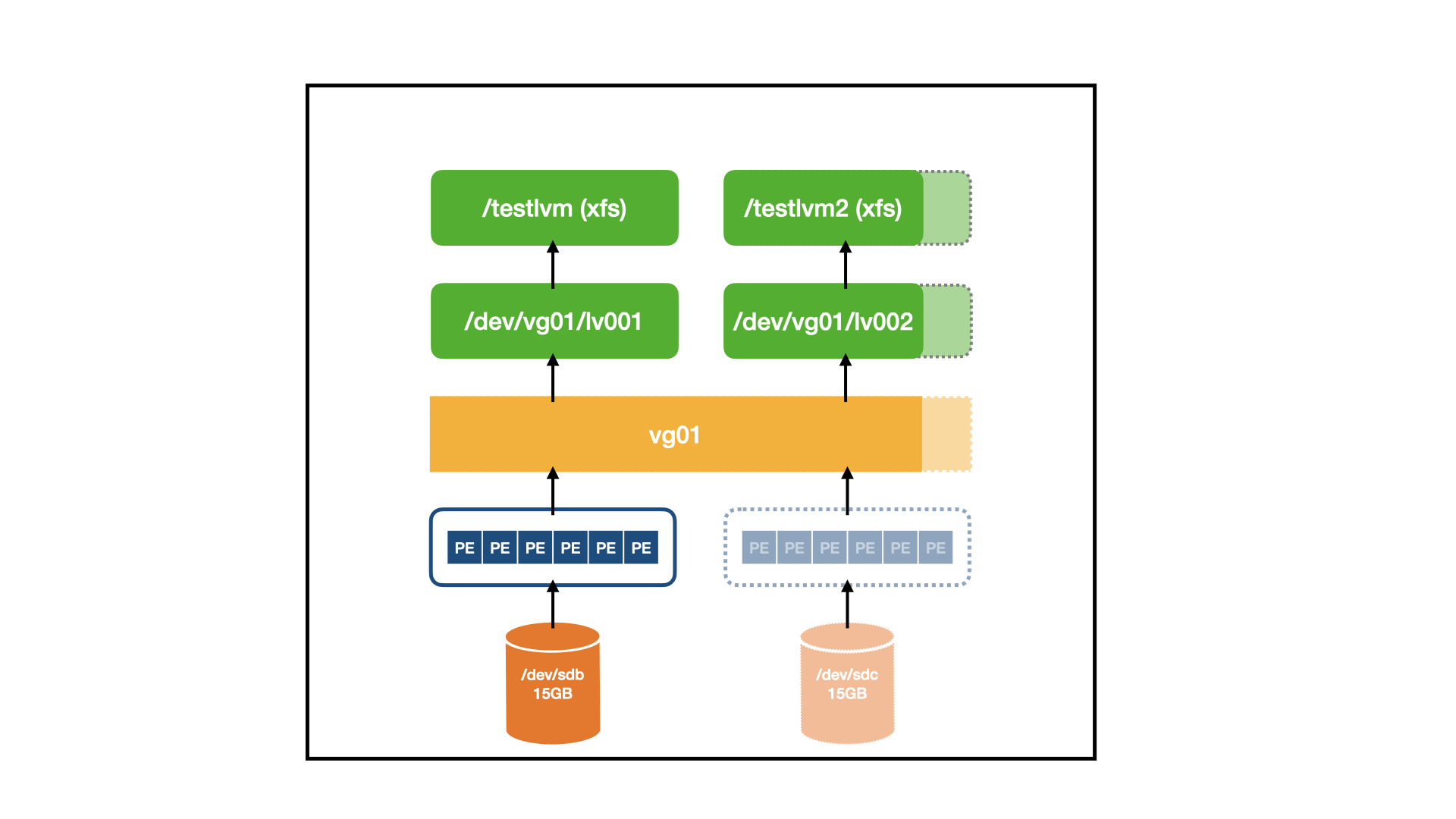
* **第一部分:[如何在 Linux 中创建/配 置LVM(逻辑卷管理)][1]**
|
||||
* **第一部分:[如何在 Linux 中创建/配置 LVM(逻辑卷管理)][1]**
|
||||
|
||||
![][2]
|
||||
|
||||
|
||||
扩展逻辑卷涉及到以下步骤:
|
||||
|
||||
@ -67,7 +69,7 @@ PV UUID 69d9dd18-36be-4631-9ebb-78f05fe3217f
|
||||
|
||||
### 如何扩展卷组
|
||||
|
||||
使用以下命令在现有的卷组中添加一个新的物理卷:
|
||||
使用以下命令在现有的卷组(VG)中添加一个新的物理卷:
|
||||
|
||||
```
|
||||
# vgextend vg01 /dev/sdc
|
||||
@ -104,7 +106,7 @@ VG UUID d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
|
||||
使用以下命令增加现有逻辑卷大小。
|
||||
|
||||
逻辑卷扩展(`lvextend`)的常用语法:
|
||||
**逻辑卷扩展(`lvextend`)的常用语法:**
|
||||
|
||||
```
|
||||
lvextend [要增加的额外空间] [现有逻辑卷名称]
|
||||
@ -166,6 +168,6 @@ via: https://www.2daygeek.com/extend-increase-resize-lvm-logical-volume-in-linux
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux/
|
||||
[1]: https://linux.cn/article-12670-1.html
|
||||
[2]: https://www.2daygeek.com/wp-content/uploads/2020/09/extend-increase-resize-lvm-logical-volume-in-linux-3.png
|
||||
[3]: https://www.2daygeek.com/linux-check-disk-space-usage-df-command/
|
||||
@ -1,154 +1,158 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "lxbwolf"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-12671-1.html"
|
||||
[#]: subject: "10 Open Source Static Site Generators to Create Fast and Resource-Friendly Websites"
|
||||
[#]: via: "https://itsfoss.com/open-source-static-site-generators/"
|
||||
[#]: author: "Ankush Das https://itsfoss.com/author/ankush/"
|
||||
|
||||
10 个用来创建快速和资源友好网站的静态网站生成工具
|
||||
10 大静态网站生成工具
|
||||
======
|
||||
|
||||
_**摘要:在寻找部署静态网页的方法吗?这几个开源的静态网站生成工具可以帮你迅速部署界面优美、功能强大的静态网站,无需掌握复杂的 HTML 和 CSS 技能。**_
|
||||

|
||||
|
||||
> 在寻找部署静态网页的方法吗?这几个开源的静态网站生成工具可以帮你迅速部署界面优美、功能强大的静态网站,无需掌握复杂的 HTML 和 CSS 技能。
|
||||
|
||||
### 静态网站是什么?
|
||||
|
||||
技术上来讲,一个静态网站的网页不是由服务器动态生成的。HTML、CSS 和 JavaScript 文件就静静地躺在服务器的某个路径下,它们的内容与终端用户接收到时看到的是一样的。源码文件已经提前编译好了,源码在每次请求后都不会变化。
|
||||
技术上来讲,静态网站是指网页不是由服务器动态生成的。HTML、CSS 和 JavaScript 文件就静静地躺在服务器的某个路径下,它们的内容与终端用户接收到的版本是一样的。原始的源码文件已经提前编译好了,源码在每次请求后都不会变化。
|
||||
|
||||
It’s FOSS 是一个依赖多个数据库的动态网站,网页是在你的浏览器发出请求时即时生成和服务的。大部分网站是动态的,你与这些网站互动时,会有大量的内容在变化。
|
||||
Linux.CN 是一个依赖多个数据库的动态网站,当有浏览器的请求时,网页就会生成并提供服务。大部分网站是动态的,你与这些网站互动时,大量的内容会经常改变。
|
||||
|
||||
静态网站有一些好处,比如加载时间更短,请求的服务器资源更少,更安全(有争议?)。
|
||||
静态网站有一些好处,比如加载时间更短,请求的服务器资源更少、更安全(值得商榷)。
|
||||
|
||||
传统意义上,静态网站更适合于创建只有少量网页、内容变化不频繁的小网站。
|
||||
传统上,静态网站更适合于创建只有少量网页、内容变化不频繁的小网站。
|
||||
|
||||
然而,当静态网站生成工具出现后,静态网站的适用范围越来越大。你还可以使用这些工具搭建博客网站。
|
||||
然而,随着静态网站生成工具出现后,静态网站的适用范围越来越大。你还可以使用这些工具搭建博客网站。
|
||||
|
||||
我列出了几个开源的静态网站生成工具,这些工具可以帮你搭建界面优美的网站。
|
||||
我整理了几个开源的静态网站生成工具,这些工具可以帮你搭建界面优美的网站。
|
||||
|
||||
### 最好的开源静态网站生成工具
|
||||
|
||||
请注意,静态网站不会提供很复杂的功能。如果你需要复杂的功能,那么你可以参考适用于动态网站的[最好的开源 CMS][1]列表
|
||||
请注意,静态网站不会提供很复杂的功能。如果你需要复杂的功能,那么你可以参考适用于动态网站的[最佳开源 CMS][1]列表。
|
||||
|
||||
#### 1\. Jekyll
|
||||
#### 1、Jekyll
|
||||
|
||||
![][2]
|
||||
|
||||
Jekyll 是用 [Ruby][3] 写的最受欢迎的开源静态生成工具之一。实际上,Jekyll 是 [GitHub 页面][4] 的引擎,它可以让你免费用 GitHub 维护自己的网站。
|
||||
Jekyll 是用 [Ruby][3] 写的最受欢迎的开源静态生成工具之一。实际上,Jekyll 是 [GitHub 页面][4] 的引擎,它可以让你免费用 GitHub 托管网站。
|
||||
|
||||
你可以很轻松地跨平台配置 Jekyll,包括 Ubuntu。它利用 [Markdown][5]、[Liquid][5](模板语言)、HTML 和 CSS 来生成静态的网页文件。如果你要搭建一个没有广告或推广自己工具或服务的产品页的博客网站,它是个不错的选择。
|
||||
|
||||
它还支持从常见的 CMS(<ruby>内容管理系统<rt>Content management system</rt></ruby>)如 Ghost、WordPress、Drupal 7 迁移你的博客。你可以管理永久链接、类别、页面、文章,还可以自定义布局,这些功能都很强大。因此,即使你已经有了一个网站,如果你想转成静态网站,Jekyll 会是一个完美的解决方案。你可以参考[官方文档][6]或 [GitHub 页面][7]了解更多内容。
|
||||
|
||||
[Jekyll][8]
|
||||
- [Jekyll][8]
|
||||
|
||||
#### 2\. Hugo
|
||||
#### 2、Hugo
|
||||
|
||||
![][9]
|
||||
|
||||
Hugo 是另一个很受欢迎的用于搭建静态网站的开源框架。它是用 [Go 语言][10]写的。
|
||||
|
||||
它运行速度快,使用简单,可靠性高。如果你需要,它也可以提供更高级的主题。它还提供了能提高你效率的实用快捷键。无论是组合展示网站还是博客网站,Hogo 都有能力管理大量的内容类型。
|
||||
它运行速度快、使用简单、可靠性高。如果你需要,它也可以提供更高级的主题。它还提供了一些有用的快捷方式来帮助你轻松完成任务。无论是组合展示网站还是博客网站,Hogo 都有能力管理大量的内容类型。
|
||||
|
||||
如果你想使用 Hugo,你可以参照它的[官方文档][11]或它的 [GitHub 页面][12]来安装以及了解更多相关的使用方法。你还可以用 Hugo 在 GitHub 页面或 CDN(如果有需要)部署网站。
|
||||
如果你想使用 Hugo,你可以参照它的[官方文档][11]或它的 [GitHub 页面][12]来安装以及了解更多相关的使用方法。如果需要的话,你还可以将 Hugo 部署在 GitHub 页面或任何 CDN 上。
|
||||
|
||||
[Hugo][13]
|
||||
- [Hugo][13]
|
||||
|
||||
#### 3\. Hexo
|
||||
#### 3、Hexo
|
||||
|
||||
![][14]
|
||||
|
||||
Hexo 基于 [Node.js][15] 的一个有趣的开源框架。像其他的工具一样,你可以用它搭建相当快速的网站,不仅如此,它还提供了丰富的主题和插件。
|
||||
Hexo 是一个有趣的开源框架,基于 [Node.js][15]。像其他的工具一样,你可以用它搭建相当快速的网站,不仅如此,它还提供了丰富的主题和插件。
|
||||
|
||||
它还根据用户的每个需求提供了强大的 API 来扩展功能。如果你已经有一个网站,你可以用它的[迁移][16]扩展轻松完成迁移工作。
|
||||
|
||||
你可以参照[官方文档][17]或 [GitHub 页面][18] 来使用 Hexo。
|
||||
|
||||
[Hexo][19]
|
||||
- [Hexo][19]
|
||||
|
||||
#### 4\. Gatsby
|
||||
#### 4、Gatsby
|
||||
|
||||
![][20]
|
||||
|
||||
Gatsby 是一个不断发展的流行开源网站生成框架。它使用 [React.js][21] 来生成快速、界面优美的网站。
|
||||
Gatsby 是一个越来越流行的开源网站生成框架。它使用 [React.js][21] 来生成快速、界面优美的网站。
|
||||
|
||||
几年前在一个实验性的项目中,我曾经非常想尝试一下这个工具,它提供的成千上万的新插件和主题的能力让我印象深刻。与其他静态网站生成工具不同的是,你可以用 Gatsby 在不损失任何功能的前提下来生成静态网站。
|
||||
几年前在一个实验性的项目中,我曾经非常想尝试一下这个工具,它提供的成千上万的新插件和主题的能力让我印象深刻。与其他静态网站生成工具不同的是,你可以使用 Gatsby 生成一个网站,并在不损失任何功能的情况下获得静态网站的好处。
|
||||
|
||||
它提供了与很多流行的服务的整合功能。当然,你可以不使用它的复杂的功能,或选择一个流行的 CMS 与它配合使用,这也会很有趣。你可以查看他们的[官方文档][22]或它的 [GitHub 页面][23]了解更多内容。
|
||||
它提供了与很多流行的服务的整合功能。当然,你可以不使用它的复杂的功能,或将其与你选择的流行 CMS 配合使用,这也会很有趣。你可以查看他们的[官方文档][22]或它的 [GitHub 页面][23]了解更多内容。
|
||||
|
||||
[Gatsby][24]
|
||||
- [Gatsby][24]
|
||||
|
||||
#### 5\. VuePress
|
||||
#### 5、VuePress
|
||||
|
||||
![][25]
|
||||
|
||||
VuePress 是基于 [Vue.js][26] 的静态网站生成工具,同时也是开源的渐进式 JavaScript 框架。
|
||||
VuePress 是由 [Vue.js][26] 支持的静态网站生成工具,而 Vue.js 是一个开源的渐进式 JavaScript 框架。
|
||||
|
||||
如果你了解 HTML、CSS 和 JavaScript,那么你可以无压力地使用 VuePress。如果你想在搭建网站时抢先别人一步,那么你应该找几个有用的插件和主题。此外,看起来 Vue.js 更新地一直很活跃,很多开发者都在关注 Vue.js,这是一件好事。
|
||||
如果你了解 HTML、CSS 和 JavaScript,那么你可以无压力地使用 VuePress。你应该可以找到几个有用的插件和主题来为你的网站建设开个头。此外,看起来 Vue.js 的更新一直很活跃,很多开发者都在关注 Vue.js,这是一件好事。
|
||||
|
||||
你可以参照他们的[官方文档][27]和 [GitHub 页面][28]了解更多。
|
||||
|
||||
[VuePress][29]
|
||||
- [VuePress][29]
|
||||
|
||||
#### 6\. Nuxt.js
|
||||
#### 6、Nuxt.js
|
||||
|
||||
![][30]
|
||||
|
||||
Nuxt.js 使用 Vue.js 和 Node.js,但它致力于模块化,并且有能力依赖服务端而非客户端。不仅如此,它还志在通过描述详尽的错误和其他方面更详细的文档来为开发者提供直观的体验。
|
||||
Nuxt.js 使用了 Vue.js 和 Node.js,但它致力于模块化,并且有能力依赖服务端而非客户端。不仅如此,它的目标是为开发者提供直观的体验,并提供描述性错误,以及详细的文档等。
|
||||
|
||||
正如它声称的那样,在你用来搭建静态网站的所有工具中,Nuxt.js 在功能和灵活性两个方面都是佼佼者。他们还提供了一个 [Nuxt 线上沙盒][31]让你直接测试。
|
||||
正如它声称的那样,在你用来搭建静态网站的所有工具中,Nuxt.js 可以做到功能和灵活性两全其美。他们还提供了一个 [Nuxt 线上沙盒][31],让你不费吹灰之力就能直接测试它。
|
||||
|
||||
你可以查看它的 [GitHub 页面][32]和[官方网站][33]了解更多。
|
||||
|
||||
#### 7\. Docusaurus
|
||||
- [Nuxt.js][33]
|
||||
|
||||
#### 7、Docusaurus
|
||||
|
||||
![][34]
|
||||
|
||||
Docusaurus 是一个为搭建文档类网站量身定制的有趣的开源静态网站生成工具。它还是 [Facebook 开源计划][35]的一个项目。
|
||||
Docusaurus 是一个有趣的开源静态网站生成工具,为搭建文档类网站量身定制。它还是 [Facebook 开源计划][35]的一个项目。
|
||||
|
||||
Docusaurus 是用 React 构建的。你可以使用所有必要的功能,像文档版本管理、文档搜索,还有大部分已经预先配置好的翻译。如果你想为你的产品或服务搭建一个文档网站,那么可以试试 Docusaurus。
|
||||
Docusaurus 是用 React 构建的。你可以使用所有的基本功能,像文档版本管理、文档搜索和翻译大多是预先配置的。如果你想为你的产品或服务搭建一个文档网站,那么可以试试 Docusaurus。
|
||||
|
||||
你可以从它的 [GitHub 页面][36]和它的[官网][37]获取更多信息。
|
||||
|
||||
[Docusaurus][37]
|
||||
- [Docusaurus][37]
|
||||
|
||||
#### 8\. Eleventy
|
||||
#### 8、Eleventy
|
||||
|
||||
![][38]
|
||||
|
||||
Eleventy 自称是 Jekyll 的替代品,志在为创建更快的静态网站提供更简单的方式。
|
||||
Eleventy 自称是 Jekyll 的替代品,旨在以更简单的方法来制作更快的静态网站。
|
||||
|
||||
使用 Eleventy 看起来很简单,它也提供了能解决你的问题的文档。如果你想找一个简单的静态网站生成工具,Eleventy 似乎会是一个有趣的选择。
|
||||
它似乎很容易上手,而且它还提供了适当的文档来帮助你。如果你想找一个简单的静态网站生成工具,Eleventy 似乎会是一个有趣的选择。
|
||||
|
||||
你可以参照它的 [GitHub 页面][39]和[官网][40]来了解更多的细节。
|
||||
|
||||
[Eleventy][40]
|
||||
- [Eleventy][40]
|
||||
|
||||
#### 9\. Publii
|
||||
#### 9、Publii
|
||||
|
||||
![][41]
|
||||
|
||||
Publii 是一个令人印象深刻的开源 CMS,它能使生成一个静态网站变得很容易。它是用 [Electron][42] 和 Vue.js 构建的。如果有需要,你也可以把你的文章从 WorkPress 网站迁移过来。此外,它还提供了与 GitHub 页面、Netlify 及其它类似服务的一键同步功能。
|
||||
|
||||
利用 Publii 生成的静态网站,自带所见即所得编辑器。你可以从[官网][43]下载它,或者从它的 [GitHub 页面][44]了解更多信息。
|
||||
如果你利用 Publii 生成一个静态网站,你还可以得到一个所见即所得的编辑器。你可以从[官网][43]下载它,或者从它的 [GitHub 页面][44]了解更多信息。
|
||||
|
||||
[Publii][43]
|
||||
- [Publii][43]
|
||||
|
||||
#### 10\. Primo
|
||||
#### 10、Primo
|
||||
|
||||
![][45]
|
||||
|
||||
一个有趣的开源静态网站生成工具,目前开发工作仍很活跃。虽然与其他的静态生成工具相比,它还不是一个成熟的解决方案,有些功能还不完善,但它是一个独一无二的项目。
|
||||
一个有趣的开源静态网站生成工具,目前开发工作仍很活跃。虽然与其他的静态生成工具相比,它还不是一个成熟的解决方案,有些功能还不完善,但它是一个独特的项目。
|
||||
|
||||
Primo 志在使用可视化的构建器帮你构建和搭建网站,这样你就可以轻松编辑和部署到任意主机上。
|
||||
Primo 旨在使用可视化的构建器帮你构建和搭建网站,这样你就可以轻松编辑和部署到任意主机上。
|
||||
|
||||
你可以参照[官网][46]或查看它的 [GitHub 页面][47]了解更多信息。
|
||||
|
||||
[Primo][46]
|
||||
- [Primo][46]
|
||||
|
||||
### 结语
|
||||
|
||||
还有很多文章中没有列出的网站生成工具。然而,我已经尽力写出了能提供最快的加载速度、最好的安全性和令人印象最深刻的灵活性的最好的静态生成工具了。
|
||||
还有很多文章中没有列出的网站生成工具。然而,我试图提到最好的静态生成器,为您提供最快的加载时间,最好的安全性和令人印象深刻的灵活性。
|
||||
|
||||
列表中没有你最喜欢的工具?在下面的评论中告诉我。
|
||||
|
||||
@ -159,7 +163,7 @@ via: https://itsfoss.com/open-source-static-site-generators/
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,337 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (TCP window scaling, timestamps and SACK)
|
||||
[#]: via: (https://fedoramagazine.org/tcp-window-scaling-timestamps-and-sack/)
|
||||
[#]: author: (Florian Westphal https://fedoramagazine.org/author/strlen/)
|
||||
|
||||
TCP window scaling, timestamps and SACK
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
The Linux TCP stack has a myriad of _sysctl_ knobs that allow to change its behavior. This includes the amount of memory that can be used for receive or transmit operations, the maximum number of sockets and optional features and protocol extensions.
|
||||
|
||||
There are multiple articles that recommend to disable TCP extensions, such as timestamps or selective acknowledgments (SACK) for various “performance tuning” or “security” reasons.
|
||||
|
||||
This article provides background on what these extensions do, why they
|
||||
are enabled by default, how they relate to one another and why it is normally a bad idea to turn them off.
|
||||
|
||||
### TCP Window scaling
|
||||
|
||||
The data transmission rate that TCP can sustain is limited by several factors. Some of these are:
|
||||
|
||||
* Round trip time (RTT). This is the time it takes for a packet to get to the destination and a reply to come back. Lower is better.
|
||||
* lowest link speed of the network paths involved
|
||||
* frequency of packet loss
|
||||
* the speed at which new data can be made available for transmission
|
||||
For example, the CPU needs to be able to pass data to the network adapter fast enough. If the CPU needs to encrypt the data first, the adapter might have to wait for new data. In similar fashion disk storage can be a bottleneck if it can’t read the data fast enough.
|
||||
* The maximum possible size of the TCP receive window. The receive window determines how much data (in bytes) TCP can transmit before it has to wait for the receiver to report reception of that data. This is announced by the receiver. The receiver will constantly update this value as it reads and acknowledges reception of the incoming data. The receive windows current value is contained in the [TCP header][2] that is part of every segment sent by TCP. The sender is thus aware of the current receive window whenever it receives an acknowledgment from the peer. This means that the higher the round-trip time, the longer it takes for sender to get receive window updates.
|
||||
|
||||
|
||||
|
||||
TCP is limited to at most 64 kilobytes of unacknowledged (in-flight) data. This is not even close to what is needed to sustain a decent data rate in most networking scenarios. Let us look at some examples.
|
||||
|
||||
##### Theoretical data rate
|
||||
|
||||
With a round-trip-time of 100 milliseconds, TCP can transfer at most 640 kilobytes per second. With a 1 second delay, the maximum theoretical data rate drops down to only 64 kilobytes per second.
|
||||
|
||||
This is because of the receive window. Once 64kbyte of data have been sent the receive window is already full. The sender must wait until the peer informs it that at least some of the data has been read by the application.
|
||||
|
||||
The first segment sent reduces the TCP window by the size of that segment. It takes one round-trip before an update of the receive window value will become available. When updates arrive with a 1 second delay, this results in a 64 kilobyte limit even if the link has plenty of bandwidth available.
|
||||
|
||||
In order to fully utilize a fast network with several milliseconds of delay, a window size larger than what classic TCP supports is a must. The ’64 kilobyte limit’ is an artifact of the protocols specification: The TCP header reserves only 16bits for the receive window size. This allows receive windows of up to 64KByte. When the TCP protocol was originally designed, this size was not seen as a limit.
|
||||
|
||||
Unfortunately, its not possible to just change the TCP header to support a larger maximum window value. Doing so would mean all implementations of TCP would have to be updated simultaneously or they wouldn’t understand one another anymore. To solve this, the interpretation of the receive window value is changed instead.
|
||||
|
||||
The ‘window scaling option’ allows to do this while keeping compatibility to existing implementations.
|
||||
|
||||
#### TCP Options: Backwards-compatible protocol extensions
|
||||
|
||||
TCP supports optional extensions. This allows to enhance the protocol with new features without the need to update all implementations at once. When a TCP initiator connects to the peer, it also send a list of supported extensions. All extensions follow the same format: an unique option number followed by the length of the option and the option data itself.
|
||||
|
||||
The TCP responder checks all the option numbers contained in the connection request. If it does not understand an option number it skips
|
||||
‘length’ bytes of data and checks the next option number. The responder omits those it did not understand from the reply. This allows both the sender and receiver to learn the common set of supported options.
|
||||
|
||||
With window scaling, the option data always consist of a single number.
|
||||
|
||||
### The window scaling option
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
Window Scale option (WSopt): Kind: 3, Length: 3
|
||||
+---------+---------+---------+
|
||||
| Kind=3 |Length=3 |shift.cnt|
|
||||
+---------+---------+---------+
|
||||
1 1 1
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
The [window scaling][3] option tells the peer that the receive window value found in the TCP header should be scaled by the given number to get the real size.
|
||||
|
||||
For example, a TCP initiator that announces a window scaling factor of 7 tries to instruct the responder that any future packets that carry a receive window value of 512 really announce a window of 65536 byte. This is an increase by a factor of 128. This would allow a maximum TCP Window of 8 Megabytes.
|
||||
|
||||
A TCP responder that does not understand this option ignores it. The TCP packet sent in reply to the connection request (the syn-ack) then does not contain the window scale option. In this case both sides can only use a 64k window size. Fortunately, almost every TCP stack supports and enables this option by default, including Linux.
|
||||
|
||||
The responder includes its own desired scaling factor. Both peers can use a different number. Its also legitimate to announce a scaling factor of 0. This means the peer should treat the receive window value it receives verbatim, but it allows scaled values in the reply direction — the recipient can then use a larger receive window.
|
||||
|
||||
Unlike SACK or TCP timestamps, the window scaling option only appears in the first two packets of a TCP connection, it cannot be changed afterwards. It is also not possible to determine the scaling factor by looking at a packet capture of a connection that does not contain the initial connection three-way handshake.
|
||||
|
||||
The largest supported scaling factor is 14. This allows TCP window sizes
|
||||
of up to one Gigabyte.
|
||||
|
||||
##### Window scaling downsides
|
||||
|
||||
It can cause data corruption in very special cases. Before you disable the option – it is impossible under normal circumstances. There is also a solution in place that prevents this. Unfortunately, some people disable this solution without realizing the relationship with window scaling. First, let’s have a look at the actual problem that needs to be addressed. Imagine the following sequence of events:
|
||||
|
||||
1. The sender transmits segments: s_1, s_2, s_3, … s_n
|
||||
2. The receiver sees: s_1, s_3, .. s_n and sends an acknowledgment for s_1.
|
||||
3. The sender considers s_2 lost and sends it a second time. It also sends new data contained in segment s_n+1.
|
||||
4. The receiver then sees: s_2, s_n+1, s_2: the packet s_2 is received twice.
|
||||
|
||||
|
||||
|
||||
This can happen for example when a sender triggers re-transmission too early. Such erroneous re-transmits are never a problem in normal cases, even with window scaling. The receiver will just discard the duplicate.
|
||||
|
||||
#### Old data to new data
|
||||
|
||||
The TCP sequence number can be at most 4 Gigabyte. If it becomes larger than this, the sequence wraps back to 0 and then increases again. This is not a problem in itself, but if this occur fast enough then the above scenario can create an ambiguity.
|
||||
|
||||
If a wrap-around occurs at the right moment, the sequence number s_2 (the re-transmitted packet) can already be larger than s_n+1. Thus, in the last step (4), the receiver may interpret this as: s_2, s_n+1, s_n+m, i.e. it could view the ‘old’ packet s_2 as containing new data.
|
||||
|
||||
Normally, this won’t happen because a ‘wrap around’ occurs only every couple of seconds or minutes even on high bandwidth links. The interval between the original and a unneeded re-transmit will be a lot smaller.
|
||||
|
||||
For example,with a transmit speed of 50 Megabytes per second, a
|
||||
duplicate needs to arrive more than one minute late for this to become a problem. The sequence numbers do not wrap fast enough for small delays to induce this problem.
|
||||
|
||||
Once TCP approaches ‘Gigabyte per second’ throughput rates, the sequence numbers can wrap so fast that even a delay by only a few milliseconds can create duplicates that TCP cannot detect anymore. By solving the problem of the too small receive window, TCP can now be used for network speeds that were impossible before – and that creates a new, albeit rare problem. To safely use Gigabytes/s speed in environments with very low RTT receivers must be able to detect such old duplicates without relying on the sequence number alone.
|
||||
|
||||
### TCP time stamps
|
||||
|
||||
#### A best-before date
|
||||
|
||||
In the most simple terms, [TCP timestamps][3] just add a time stamp to the packets to resolve the ambiguity caused by very fast sequence number wrap around. If a segment appears to contain new data, but its timestamp is older than the last in-window packet, then the sequence number has wrapped and the ”new” packet is actually an older duplicate. This resolves the ambiguity of re-transmits even for extreme corner cases.
|
||||
|
||||
But this extension allows for more than just detection of old packets. The other major feature made possible by TCP timestamps are more precise round-trip time measurements (RTTm).
|
||||
|
||||
#### A need for precise round-trip-time estimation
|
||||
|
||||
When both peers support timestamps, every TCP segment carries two additional numbers: a timestamp value and a timestamp echo.
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
TCP Timestamp option (TSopt): Kind: 8, Length: 10
|
||||
+-------+----+----------------+-----------------+
|
||||
|Kind=8 | 10 |TS Value (TSval)|EchoReply (TSecr)|
|
||||
+-------+----+----------------+-----------------+
|
||||
1 1 4 4
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
An accurate RTT estimate is crucial for TCP performance. TCP automatically re-sends data that was not acknowledged. Re-transmission is triggered by a timer: If it expires, TCP considers one or more packets that it has not yet received an acknowledgment for to be lost. They are then sent again.
|
||||
|
||||
But “has not been acknowledged” does not mean the segment was lost. It is also possible that the receiver did not send an acknowledgment so far or that the acknowledgment is still in flight. This creates a dilemma: TCP must wait long enough for such slight delays to not matter, but it can’t wait for too long either.
|
||||
|
||||
##### Low versus high network delay
|
||||
|
||||
In networks with a high delay, if the timer fires too fast, TCP frequently wastes time and bandwidth with unneeded re-sends.
|
||||
|
||||
In networks with a low delay however, waiting for too long causes reduced throughput when a real packet loss occurs. Therefore, the timer should expire sooner in low-delay networks than in those with a high delay. The tcp retransmit timeout therefore cannot use a fixed constant value as a timeout. It needs to adapt the value based on the delay that it experiences in the network.
|
||||
|
||||
##### Round-trip time measurement
|
||||
|
||||
TCP picks a retransmit timeout that is based on the expected round-trip time (RTT). The RTT is not known in advance. RTT is estimated by measuring the delta between the time a segment is sent and the time TCP receives an acknowledgment for the data carried by that segment.
|
||||
|
||||
This is complicated by several factors.
|
||||
|
||||
* For performance reasons, TCP does not generate a new acknowledgment for every packet it receives. It waits for a very small amount of time: If more segments arrive, their reception can be acknowledged with a single ACK packet. This is called “cumulative ACK”.
|
||||
* The round-trip-time is not constant. This is because of a myriad of factors. For example, a client might be a mobile phone switching to different base stations as its moved around. Its also possible that packet switching takes longer when link or CPU utilization increases.
|
||||
* a packet that had to be re-sent must be ignored during computation. This is because the sender cannot tell if the ACK for the re-transmitted segment is acknowledging the original transmission (that arrived after all) or the re-transmission.
|
||||
|
||||
|
||||
|
||||
This last point is significant: When TCP is busy recovering from a loss, it may only receives ACKs for re-transmitted segments. It then can’t measure (update) the RTT during this recovery phase. As a consequence it can’t adjust the re-transmission timeout, which then keeps growing exponentially. That’s a pretty specific case (it assumes that other mechanisms such as fast retransmit or SACK did not help). Nevertheless, with TCP timestamps, RTT evaluation is done even in this case.
|
||||
|
||||
If the extension is used, the peer reads the timestamp value from the TCP segments extension space and stores it locally. It then places this value in all the segments it sends back as the “timestamp echo”.
|
||||
|
||||
Therefore the option carries two timestamps: Its senders own timestamp and the most recent timestamp it received from the peer. The “echo timestamp” is used by the original sender to compute the RTT. Its the delta between its current timestamp clock and what was reflected in the “timestamp echo”.
|
||||
|
||||
##### Other timestamp uses
|
||||
|
||||
TCP timestamps even have other uses beyond PAWS and RTT measurements. For example it becomes possible to detect if a retransmission was unnecessary. If the acknowledgment carries an older timestamp echo, the acknowledgment was for the initial packet, not the re-transmitted one.
|
||||
|
||||
Another, more obscure use case for TCP timestamps is related to the TCP [syn cookie][4] feature.
|
||||
|
||||
##### TCP connection establishment on server side
|
||||
|
||||
When connection requests arrive faster than a server application can accept the new incoming connection, the connection backlog will eventually reach its limit. This can occur because of a mis-configuration of the system or a bug in the application. It also happens when one or more clients send connection requests without reacting to the ‘syn ack’ response. This fills the connection queue with incomplete connections. It takes several seconds for these entries to time out. This is called a “syn flood attack”.
|
||||
|
||||
##### TCP timestamps and TCP syn cookies
|
||||
|
||||
Some TCP stacks allow to accept new connections even if the queue is full. When this happens, the Linux kernel will print a prominent message to the system log:
|
||||
|
||||
> Possible SYN flooding on port P. Sending Cookies. Check SNMP counters.
|
||||
|
||||
This mechanism bypasses the connection queue entirely. The information that is normally stored in the connection queue is encoded into the SYN/ACK responses TCP sequence number. When the ACK comes back, the queue entry can be rebuilt from the sequence number.
|
||||
|
||||
The sequence number only has limited space to store information. Connections established using the ‘TCP syn cookie’ mechanism can not support TCP options for this reason.
|
||||
|
||||
The TCP options that are common to both peers can be stored in the timestamp, however. The ACK packet reflects the value back in the timestamp echo field which allows to recover the agreed-upon TCP options as well. Else, cookie-connections are restricted by the standard 64 kbyte receive window.
|
||||
|
||||
##### Common myths – timestamps are bad for performance
|
||||
|
||||
Unfortunately some guides recommend disabling TCP timestamps to reduce the number of times the kernel needs to access the timestamp clock to get the current time. This is not correct. As explained before, RTT estimation is a necessary part of TCP. For this reason, the kernel always takes a microsecond-resolution time stamp when a packet is received/sent.
|
||||
|
||||
Linux re-uses the clock timestamp taken for the RTT estimation for the remainder of the packet processing step. This also avoids the extra clock access to add a timestamp to an outgoing TCP packet.
|
||||
|
||||
The entire timestamp option only requires 10 bytes of TCP option space in each packet, this is not a significant decrease in space available for packet payload.
|
||||
|
||||
##### common myths – timestamps are a security problem
|
||||
|
||||
Some security audit tools and (older) blog posts recommend to disable TCP
|
||||
timestamps because they allegedly leak system uptime: This would then allow to estimate the patch level of the system/kernel. This was true in the past: The timestamp clock is based on a constantly increasing value that starts at a fixed value on each system boot. A timestamp value would give a estimate as to how long the machine has been running (uptime).
|
||||
|
||||
As of Linux 4.12 TCP timestamps do not reveal the uptime anymore. All timestamp values sent use a peer-specific offset. Timestamp values also wrap every 49 days.
|
||||
|
||||
In other words, connections from or to address “A” see a different timestamp than connections to the remote address “B”.
|
||||
|
||||
Run _sysctl net.ipv4.tcp_timestamps=2_ to disable the randomization offset. This makes analyzing packet traces recorded by tools like _wireshark_ or _tcpdump_ easier – packets sent from the host then all have the same clock base in their TCP option timestamp. For normal operation the default setting should be left as-is.
|
||||
|
||||
### Selective Acknowledgments
|
||||
|
||||
TCP has problems if several packets in the same window of data are lost. This is because TCP Acknowledgments are cumulative, but only for packets
|
||||
that arrived in-sequence. Example:
|
||||
|
||||
* Sender transmits segments s_1, s_2, s_3, … s_n
|
||||
* Sender receives ACK for s_2
|
||||
* This means that both s_1 and s_2 were received and the
|
||||
sender no longer needs to keep these segments around.
|
||||
* Should s_3 be re-transmitted? What about s_4? s_n?
|
||||
|
||||
|
||||
|
||||
The sender waits for a “retransmission timeout” or ‘duplicate ACKs’ for s_2 to arrive. If a retransmit timeout occurs or several duplicate ACKs for s_2 arrive, the sender transmits s_3 again.
|
||||
|
||||
If the sender receives an acknowledgment for s_n, s_3 was the only missing packet. This is the ideal case. Only the single lost packet was re-sent.
|
||||
|
||||
If the sender receives an acknowledged segment that is smaller than s_n, for example s_4, that means that more than one packet was lost. The
|
||||
sender needs to re-transmit the next segment as well.
|
||||
|
||||
##### Re-transmit strategies
|
||||
|
||||
Its possible to just repeat the same sequence: re-send the next packet until the receiver indicates it has processed all packet up to s_n. The problem with this approach is that it requires one RTT until the sender knows which packet it has to re-send next. While such strategy avoids unnecessary re-transmissions, it can take several seconds and more until TCP has re-sent the entire window of data.
|
||||
|
||||
The alternative is to re-send several packets at once. This approach allows TCP to recover more quickly when several packets have been lost. In the above example TCP re-send s_3, s_4, s_5, .. while it can only be sure that s_3 has been lost.
|
||||
|
||||
From a latency point of view, neither strategy is optimal. The first strategy is fast if only a single packet has to be re-sent, but takes too long when multiple packets were lost.
|
||||
|
||||
The second one is fast even if multiple packet have to be re-sent, but at the cost of wasting bandwidth. In addition, such a TCP sender could have transmitted new data already while it was doing the unneeded re-transmissions.
|
||||
|
||||
With the available information TCP cannot know which packets were lost. This is where TCP [Selective Acknowledgments][5] (SACK) come in. Just like window scaling and timestamps, it is another optional, yet very useful TCP feature.
|
||||
|
||||
##### The SACK option
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
TCP Sack-Permitted Option: Kind: 4, Length 2
|
||||
+---------+---------+
|
||||
| Kind=4 | Length=2|
|
||||
+---------+---------+
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
A sender that supports this extension includes the “Sack Permitted” option in the connection request. If both endpoints support the extension, then a peer that detects a packet is missing in the data stream can inform the sender about this.
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
TCP SACK Option: Kind: 5, Length: Variable
|
||||
+--------+--------+
|
||||
| Kind=5 | Length |
|
||||
+--------+--------+--------+--------+
|
||||
| Left Edge of 1st Block |
|
||||
+--------+--------+--------+--------+
|
||||
| Right Edge of 1st Block |
|
||||
+--------+--------+--------+--------+
|
||||
| |
|
||||
/ . . . /
|
||||
| |
|
||||
+--------+--------+--------+--------+
|
||||
| Left Edge of nth Block |
|
||||
+--------+--------+--------+--------+
|
||||
| Right Edge of nth Block |
|
||||
+--------+--------+--------+--------+
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
A receiver that encounters segment_s2 followed by s_5…s_n, it will include a SACK block when it sends the acknowledgment for s_2:
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
+--------+-------+
|
||||
| Kind=5 | 10 |
|
||||
+--------+------+--------+-------+
|
||||
| Left edge: s_5 |
|
||||
+--------+--------+-------+------+
|
||||
| Right edge: s_n |
|
||||
+--------+-------+-------+-------+
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
This tells the sender that segments up to s_2 arrived in-sequence, but it also lets the sender know that the segments s_5 to s_n were also received. The sender can then re-transmit these two packets and proceed to send new data.
|
||||
|
||||
##### The mythical lossless network
|
||||
|
||||
In theory SACK provides no advantage if the connection cannot experience packet loss. Or the connection has such a low latency that even waiting one full RTT does not matter.
|
||||
|
||||
In practice lossless behavior is virtually impossible to ensure.
|
||||
Even if the network and all its switches and routers have ample bandwidth and buffer space packets can still be lost:
|
||||
|
||||
* The host operating system might be under memory pressure and drop
|
||||
packets. Remember that a host might be handling tens of thousands of packet streams simultaneously.
|
||||
* The CPU might not be able to drain incoming packets from the network interface fast enough. This causes packet drops in the network adapter itself.
|
||||
* If TCP timestamps are not available even a connection with a very small RTT can stall momentarily during loss recovery.
|
||||
|
||||
|
||||
|
||||
Use of SACK does not increase the size of TCP packets unless a connection experiences packet loss. Because of this, there is hardly a reason to disable this feature. Almost all TCP stacks support SACK – it is typically only absent on low-power IOT-alike devices that are not doing TCP bulk data transfers.
|
||||
|
||||
When a Linux system accepts a connection from such a device, TCP automatically disables SACK for the affected connection.
|
||||
|
||||
### Summary
|
||||
|
||||
The three TCP extensions examined in this post are all related to TCP performance and should best be left to the default setting: enabled.
|
||||
|
||||
The TCP handshake ensures that only extensions that are understood by both parties are used, so there is never a need to disable an extension globally just because a peer might not support it.
|
||||
|
||||
Turning these extensions off results in severe performance penalties, especially in case of TCP Window Scaling and SACK. TCP timestamps can be disabled without an immediate disadvantage, however there is no compelling reason to do so anymore. Keeping them enabled also makes it possible to support TCP options even when SYN cookies come into effect.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/tcp-window-scaling-timestamps-and-sack/
|
||||
|
||||
作者:[Florian Westphal][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/strlen/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/08/tcp-window-scaling-816x346.png
|
||||
[2]: https://en.wikipedia.org/wiki/Transmission_Control_Protocol#TCP_segment_structure
|
||||
[3]: https://www.rfc-editor.org/info/rfc7323
|
||||
[4]: https://en.wikipedia.org/wiki/SYN_cookies
|
||||
[5]: https://www.rfc-editor.org/info/rfc2018
|
||||
@ -1,149 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A practical guide to learning awk)
|
||||
[#]: via: (https://opensource.com/article/20/9/awk-ebook)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
A practical guide to learning awk
|
||||
======
|
||||
Get a better handle on the awk command by downloading our free eBook.
|
||||
![Person programming on a laptop on a building][1]
|
||||
|
||||
Of all the [Linux][2] commands out there (and there are many), the three most quintessential seem to be `sed`, `awk`, and `grep`. Maybe it's the arcane sound of their names, or the breadth of their potential use, or just their age, but when someone's giving an example of a "Linuxy" command, it's usually one of those three. And while `sed` and `grep` have several simple one-line standards, the less prestigious `awk` remains persistently prominent for being particularly puzzling.
|
||||
|
||||
You're likely to use `sed` for a quick string replacement or `grep` to filter for a pattern on a daily basis. You're far less likely to compose an `awk` command. I often wonder why this is, and I attribute it to a few things. First of all, many of us barely use `sed` and `grep` for anything but some variation upon these two commands:
|
||||
|
||||
|
||||
```
|
||||
$ sed -e 's/foo/bar/g' file.txt
|
||||
$ grep foo file.txt
|
||||
```
|
||||
|
||||
So, even though you might feel more comfortable with `sed` and `grep`, you may not use their full potential. Of course, there's no obligation to learn more about `sed` or `grep`, but I sometimes wonder about the way I "learn" commands. Instead of learning _how_ a command works, I often learn a specific incantation that includes a command. As a result, I often feel a false familiarity with the command. I think I know a command because I can name three or four options off the top of my head, even though I don't know what the options do and can't quite put my finger on the syntax.
|
||||
|
||||
And that's the problem, I believe, that many people face when confronted with the power and flexibility of `awk`.
|
||||
|
||||
### Learning awk to use awk
|
||||
|
||||
The basics of `awk` are surprisingly simple. It's often noted that `awk` is a programming language, and although it's a relatively basic one, it's true. This means you can learn `awk` the same way you learn a new coding language: learn its syntax using some basic commands, learn its vocabulary so you can build up to complex actions, and then practice, practice, practice.
|
||||
|
||||
### How awk parses input
|
||||
|
||||
`Awk` sees input, essentially, as an array. When `awk` scans over a text file, it treats each line, individually and in succession, as a _record_. Each record is broken into _fields_. Of course, `awk` must keep track of this information, and you can see that data using the `NR` (number of records) and `NF` (number of fields) built-in variables. For example, this gives you the line count of a file:
|
||||
|
||||
|
||||
```
|
||||
$ awk 'END { print NR;}' example.txt
|
||||
36
|
||||
```
|
||||
|
||||
This also reveals something about `awk` syntax. Whether you're writing `awk` as a one-liner or as a self-contained script, the structure of an `awk` instruction is:
|
||||
|
||||
|
||||
```
|
||||
`pattern or keyword { actions }`
|
||||
```
|
||||
|
||||
In this example, the word `END` is a special, reserved keyword rather than a pattern. A similar keyword is `BEGIN`. With both of these keywords, `awk` just executes the action in braces at the start or end of parsing data.
|
||||
|
||||
You can use a _pattern_ as a filter or qualifier so that `awk` only executes a given action when it is able to match your pattern to the current record. For instance, suppose you want to use `awk`, much as you would `grep`, to find the word _Linux_ in a file of text:
|
||||
|
||||
|
||||
```
|
||||
$ awk '/Linux/ { print $0; }' os.txt
|
||||
OS: CentOS Linux (10.1.1.8)
|
||||
OS: CentOS Linux (10.1.1.9)
|
||||
OS: Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
OS: Elementary Linux (10.1.2.4)
|
||||
OS: Elementary Linux (10.1.2.5)
|
||||
OS: Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
For `awk`, each line in the file is a record, and each word in a record is a field. By default, fields are separated by a space. You can change that with the `--field-separator` option, which sets the `FS` (field separator) variable to whatever you want it to be:
|
||||
|
||||
|
||||
```
|
||||
$ awk --field-separator ':' '/Linux/ { print $2; }' os.txt
|
||||
CentOS Linux (10.1.1.8)
|
||||
CentOS Linux (10.1.1.9)
|
||||
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
Elementary Linux (10.1.2.4)
|
||||
Elementary Linux (10.1.2.5)
|
||||
Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
In this sample, there's an empty space before each listing because there's a blank space after each colon (`:`) in the source text. This isn't `cut`, though, so the field separator needn't be limited to one character:
|
||||
|
||||
|
||||
```
|
||||
$ awk --field-separator ': ' '/Linux/ { print $2; }' os.txt
|
||||
CentOS Linux (10.1.1.8)
|
||||
CentOS Linux (10.1.1.9)
|
||||
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
Elementary Linux (10.1.2.4)
|
||||
Elementary Linux (10.1.2.5)
|
||||
Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
### Functions in awk
|
||||
|
||||
You can build your own functions in `awk` using this syntax:
|
||||
|
||||
|
||||
```
|
||||
`name(parameters) { actions }`
|
||||
```
|
||||
|
||||
Functions are important because they allow you to write code once and reuse it throughout your work. When constructing one-liners, custom functions are a little less useful than they are in scripts, but `awk` defines many functions for you already. They work basically the same as any function in any other language or spreadsheet: You learn the order that the function needs information from you, and you can feed it whatever you want to get the results.
|
||||
|
||||
There are functions to perform mathematical operations and string processing. The math ones are often fairly straightforward. You provide a number, and it crunches it:
|
||||
|
||||
|
||||
```
|
||||
$ awk 'BEGIN { print sqrt(1764); }'
|
||||
42
|
||||
```
|
||||
|
||||
String functions can be more complex but are well documented in the [GNU awk manual][3]. For example, the `split` function takes an entity that `awk` views as a single field and splits it into different parts. It requires a field, a variable to use as an array containing each part of the split, and the character you want to use as the delimiter.
|
||||
|
||||
Using the output of the previous examples, I know that there's an IP address at the very end of each record. In this case, I can send just the last field of a record to the `split` function by referencing the variable `NF` because it contains the number of fields (and the final field must be the highest number):
|
||||
|
||||
|
||||
```
|
||||
$ awk --field-separator ': ' '/Linux/ { split($NF, IP, "."); print "subnet: " IP[3]; }' os.txt
|
||||
subnet: 1
|
||||
subnet: 1
|
||||
subnet: 1
|
||||
subnet: 2
|
||||
subnet: 2
|
||||
subnet: 2
|
||||
```
|
||||
|
||||
There are many more functions, and there's no reason to limit yourself to one per block of `awk` code. You can construct complex pipelines with `awk` in your terminal, or you can write `awk` scripts to define and utilize your own functions.
|
||||
|
||||
### Download the eBook
|
||||
|
||||
Learning `awk` is mostly a matter of using `awk`. Use it even if it means duplicating functionality you already have with `sed` or `grep` or `cut` or `tr` or any other perfectly valid commands. Once you get comfortable with it, you can write Bash functions that invoke your custom `awk` commands for easier use. And eventually, you'll be able to write scripts to parse complex datasets.
|
||||
|
||||
**[Download our][4]** **[eBook][4] **to learn everything you need to know about `awk`, and start using it today.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/9/awk-ebook
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV (Person programming on a laptop on a building)
|
||||
[2]: https://opensource.com/resources/linux
|
||||
[3]: https://www.gnu.org/software/gawk/manual/gawk.html
|
||||
[4]: https://opensource.com/downloads/awk-ebook
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (rakino)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,303 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (TCP window scaling, timestamps and SACK)
|
||||
[#]: via: (https://fedoramagazine.org/tcp-window-scaling-timestamps-and-sack/)
|
||||
[#]: author: (Florian Westphal https://fedoramagazine.org/author/strlen/)
|
||||
|
||||
TCP 窗口缩放,时间戳和 SACK
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Linux TCP 协议栈具有无数个 _sysctl_ 旋钮,允许更改其行为。 这包括可用于接收或发送操作的内存量,套接字的最大数量、可选特性和协议扩展。
|
||||
|
||||
有很多文章出于各种“性能调优”或“安全性”原因,建议禁用 TCP 扩展,比如时间戳或<ruby>选择性确认<rt>selective acknowledgments</rt></ruby> (SACK)。
|
||||
|
||||
本文提供了这些扩展的功能背景,默认情况下处于启用状态的原因,它们之间是如何关联的,以及为什么通常情况下将它们关闭是个坏主意。
|
||||
|
||||
### TCP 窗口缩放
|
||||
|
||||
TCP 可以维持的数据传输速率受到几个因素的限制。其中包括:
|
||||
|
||||
* 往返时间(RTT)。这是数据包到达目的地并返回回复所花费的时间。越低越好。
|
||||
* 所涉及的网络路径的最低链路速度
|
||||
* 丢包频率
|
||||
* 新数据可用于传输的速度。 例如,CPU 需要能够以足够快的速度将数据传递到网络适配器。如果 CPU 需要首先加密数据,则适配器可能必须等待新数据。同样地,如果磁盘存储不能足够快地读取数据,则磁盘存储可能会成为瓶颈。
|
||||
* TCP 接收窗口的最大可能大小。接收窗口决定 TCP 在必须等待接收方报告接收到该数据之前可以传输多少数据 (以字节为单位)。这是由接收方宣布的。接收方将在读取并确认接收到传入数据时不断更新此值。接收窗口当前值包含在 [TCP 报头][2] 中,它是 TCP 发送的每个数据段的一部分。因此,只要发送方接收到来自对等方的确认,它就知道当前的接收窗口。这意味着往返时间(RTT)越长,发送方获得接收窗口更新所需的时间就越长。
|
||||
|
||||
|
||||
TCP 被限制为最多 64KB 的未确认(正在传输)数据。在大多数网络场景中,这甚至还不足以维持一个像样的数据速率。让我们看看一些例子。
|
||||
|
||||
##### 理论数据速率
|
||||
|
||||
由于往返时间 (RTT) 为 100 毫秒,TCP 每秒最多可以传输 640KB。在延迟 1 秒的情况下,最大理论数据速率降至 64KB/s。
|
||||
|
||||
这是因为接收窗口的原因。一旦发送了 64KB 的数据,接收窗口就已经满了。发送方必须等待,直到对等方通知它应用程序已经读取了至少一部分数据。
|
||||
|
||||
发送的第一个段会把 TCP 窗口缩减一个自身的大小。在接收窗口值的更新可用之前,需要往返一次。当更新以 1 秒的延迟到达时,即使链路有足够的可用带宽,也会导致 64KB 的限制。
|
||||
|
||||
为了充分利用一个具有几毫秒延迟的快速网络,必须有一个比传统 TCP 支持的窗口大的窗口。“64KB 限制”是协议规范的产物:TCP 头只为接收窗口大小保留 16 位。这允许接收窗口高达 64KB。在 TCP 协议最初设计时,这个大小并没有被视为一个限制。
|
||||
|
||||
不幸的是,想通过仅仅更改 TCP 头来支持更大的最大窗口值是不可能的。如果这样做就意味着 TCP 的所有实现都必须同时更新,否则它们将无法相互理解。为了解决这个问题,需要改变接收窗口值的解释。
|
||||
|
||||
“窗口缩放选项”允许这样做,同时保持与现有实现的兼容性。
|
||||
|
||||
#### TCP 选项:向后兼容的协议扩展
|
||||
|
||||
TCP 支持可选扩展。 这允许使用新特性增强协议,而无需立即更新所有实现。 当 TCP 启动器连接到对等方时,它还会发送一个支持的扩展列表。 所有扩展名都遵循相同的格式:一个唯一的选项号,后跟选项的长度以及选项数据本身。
|
||||
|
||||
TCP 响应程序检查连接请求中包含的所有选项号。 如果它遇到一个不能理解的选项号,则会跳过
|
||||
该选项号附带的“长度”字节的数据,并检查下一个选项号。 响应者忽略了从答复中无法理解的内容。 这使发送方和接收方都够了解所支持的通用选项集。
|
||||
|
||||
使用窗口缩放时,选项数据总是由单个数字组成。
|
||||
|
||||
### 窗口缩放选项
|
||||
|
||||
```
|
||||
窗口缩放选项 (WSopt): Kind: 3, Length: 3
|
||||
+---------+---------+---------+
|
||||
| Kind=3 |Length=3 |shift.cnt|
|
||||
+---------+---------+---------+
|
||||
1 1 1
|
||||
```
|
||||
|
||||
[窗口缩放][3] 选项告诉对等点,应该使用给定的数字缩放 TCP 标头中的接收窗口值,以获取实际大小。
|
||||
|
||||
例如,一个宣告窗口缩放比例因子为 7 的 TCP 启动器试图指示响应程序,任何将来携带接收窗口值为 512 的数据包实际上都会宣告 65536 字节的窗口。 增加了 128 倍。这将允许最大为 8MB 的 TCP 窗口。
|
||||
|
||||
不能理解此选项的 TCP 响应程序将会忽略它。 为响应连接请求而发送的 TCP 数据包(SYN-ACK)不包含窗口缩放选项。在这种情况下,双方只能使用 64k 的窗口大小。幸运的是,默认情况下,几乎每个 TCP 堆栈都支持并启用此选项,包括 Linux。
|
||||
|
||||
响应程序包括它自己所需的比例因子。两个对等点可以使用不同的号码。宣布比例因子为 0 也是合法的。这意味着对等点应该逐字处理它接收到的接收窗口值,但它允许应答方向上的缩放值,然后接收方可以使用更大的接收窗口。
|
||||
|
||||
与 SACK 或 TCP 时间戳不同,窗口缩放选项仅出现在 TCP 连接的前两个数据包中,之后无法更改。也不可能通过查看不包含初始连接三次握手的连接的数据包捕获来确定比例因子。
|
||||
|
||||
支持的最大比例因子为 14。这将允许 TCP 窗口的大小高达 1GB。
|
||||
|
||||
##### 窗口缩放的缺点
|
||||
|
||||
在非常特殊的情况下,它可能导致数据损坏。 在禁用该选项之前——通常情况下是不可能的。 还有一种解决方案可以防止这种情况。不幸的是,有些人在没有意识到与窗口缩放的关系的情况下禁用了该解决方案。 首先,让我们看一下需要解决的实际问题。 想象以下事件序列:
|
||||
|
||||
1. 发送方发送段:s_1,s_2,s_3,... s_n
|
||||
2. 接收方看到:s_1,s_3,.. s_n,并发送对 s_1 的确认。
|
||||
3. 发送方认为 s_2 丢失,然后再次发送。 它还发送段 s_n+1 中包含的新数据。
|
||||
4. 接收方然后看到:s_2,s_n+1,s_2:数据包 s_2 被接收两次。
|
||||
|
||||
例如,当发送方过早触发重新传输时,可能会发生这种情况。 在正常情况下,即使使用窗口缩放,这种错误的重传也绝不会成为问题。 接收方将只丢弃重复项。
|
||||
|
||||
#### 从旧数据到新数据
|
||||
|
||||
TCP 序列号最多可以为 4GB。如果它变得大于此值,则序列会回绕到 0,然后再次增加。这本身不是问题,但是如果这种问题发生得足够快,则上述情况可能会造成歧义。
|
||||
|
||||
如果在正确的时刻发生回绕,则序列号 s_2(重新发送的数据包)可能已经大于 s_n+1。 因此,在最后的步骤(4)中,接收器可以将其解释为:s_2,s_n+1,s_n+m,即它可以将 **“旧”** 数据包 s_2 视为包含新数据。
|
||||
|
||||
通常,这不会发生,因为即使在高带宽链接上,“回绕”也只会每隔几秒钟或几分钟发生一次。原始和不需要的重传之间的间隔将小得多。
|
||||
|
||||
例如,对于 50MB/s 的传输速度,副本要延迟到一分钟以上才会成为问题。序列号的包装速度不够快,小的延迟才会导致这个问题。
|
||||
|
||||
一旦 TCP 达到 “GB/s” 的吞吐率,序列号的包装速度就会非常快,以至于即使只有几毫秒的延迟也可能会造成 TCP 无法再检测到的重复项。通过解决接收窗口太小的问题,TCP 现在可以用于以前无法实现的网络速度,这会产生一个新的,尽管很少见的问题。为了在 RTT 非常低的环境中安全使用 GB/s 的速度,接收方必须能够检测到这些旧副本,而不必仅依赖序列号。
|
||||
|
||||
### TCP 时间戳
|
||||
|
||||
#### 最佳使用日期。
|
||||
|
||||
用最简单的术语来说,[TCP 时间戳][3]只是在数据包上添加时间戳,以解决由非常快速的序列号回绕引起的歧义。 如果一个段看起来包含新数据,但其时间戳早于最后一个在窗口内的数据包,则该序列号已被重新包装,而“新”数据包实际上是一个较旧的副本。 这解决了即使在极端情况下重传的歧义。
|
||||
|
||||
但是,该扩展不仅仅是检测旧数据包。 TCP 时间戳的另一个主要功能是更精确的往返时间测量(RTTm)。
|
||||
|
||||
#### 需要准确的 RTT 估算
|
||||
|
||||
当两个对等方都支持时间戳时,每个 TCP 段都携带两个附加数字:时间戳值和时间戳回显。
|
||||
|
||||
```
|
||||
TCP 时间戳选项 (TSopt): Kind: 8, Length: 10
|
||||
+-------+----+----------------+-----------------+
|
||||
|Kind=8 | 10 |TS Value (TSval)|EchoReply (TSecr)|
|
||||
+-------+----+----------------+-----------------+
|
||||
1 1 4 4
|
||||
```
|
||||
|
||||
准确的 RTT 估算对于 TCP 性能至关重要。 TCP 自动重新发送未确认的数据。 重传由计时器触发:如果超时,则 TCP 会将尚未收到确认的一个或多个数据包视为丢失。 然后再发送一次。
|
||||
|
||||
但是,“尚未得到确认” 并不意味着该段已丢失。 也有可能是接收方到目前为止没有发送确认,或者确认仍在传输中。 这就造成了一个两难的困境:TCP 必须等待足够长的时间,才能让这种轻微的延迟变得无关紧要,但它也不能等待太久。
|
||||
|
||||
##### 低网络延迟 VS 高网络延迟
|
||||
|
||||
在延迟较高的网络中,如果计时器触发过快,TCP 经常会将时间和带宽浪费在不必要的重发上。
|
||||
|
||||
然而,在延迟较低的网络中,等待太长时间会导致真正发生数据包丢失时吞吐量降低。因此,在低延迟网络中,计时器应该比高延迟网络中更早到期。 所以,TCP 重传超时不能使用固定常量值作为超时。它需要根据其在网络中所经历的延迟来调整该值。
|
||||
|
||||
##### RTT(往返时间)的测量
|
||||
|
||||
TCP 选择基于预期往返时间(RTT)的重传超时。 RTT 事先是未知的。它是通过测量发送段与 TCP 接收到该段所承载数据的确认之间的增量来估算的。
|
||||
|
||||
由于多种因素使其而变得复杂。
|
||||
|
||||
* 出于性能原因,TCP 不会为收到的每个数据包生成新的确认。它等待的时间非常短:如果有更多的数据段到达,则可以通过单个 ACK 数据包确认其接收。这称为<ruby>“累积确认”<rt>cumulative ACK</rt></ruby>。
|
||||
* 往返时间并不恒定。 这是有多种因素造成的。例如,客户端可能是一部移动电话,随其移动而切换到不同的基站。也可能是当链路或 CPU 利用率提高时,数据包交换花费了更长的时间。
|
||||
* 必须重新发送的数据包在计算过程中必须被忽略。
|
||||
这是因为发送方无法判断重传数据段的 ACK 是在确认原始传输 (毕竟已到达) 还是在确认重传。
|
||||
|
||||
最后一点很重要:当 TCP 忙于从丢失中恢复时,它可能仅接收到重传段的 ACK。这样,它就无法在此恢复阶段测量(更新)RTT。所以,它无法调整重传超时,然后超时将以指数级增长。那是一种非常具体的情况(它假设其他机制,如快速重传或 SACK 不起作用)。但是,使用 TCP 时间戳,即使在这种情况下也会进行 RTT 评估。
|
||||
|
||||
如果使用了扩展,则对等方将从 TCP 段扩展空间中读取时间戳值并将其存储在本地。然后,它将该值放入作为 “时间戳回显” 发回的所有数据段中。
|
||||
|
||||
因此,该选项带有两个时间戳:它的发送方自己的时间戳和它从对等方收到的最新时间戳。原始发送方使用“回显时间戳”来计算 RTT。它是当前时间戳时钟与“时间戳回显”中所反映的值之间的增量。
|
||||
|
||||
##### 时间戳的其他用用途
|
||||
|
||||
TCP 时间戳甚至还有除 PAWS 和 RTT 测量以外的其他用途。例如,可以检测是否不需要重发。如果该确认携带较旧的时间戳回显,则该确认针对的是初始数据包,而不是重新发送的数据包。
|
||||
|
||||
TCP 时间戳的另一个更晦涩的用例与 TCP [syn cookie][4] 功能有关。
|
||||
|
||||
##### 在服务器端建立 TCP 连接
|
||||
|
||||
当连接请求到达的速度快于服务器应用程序可以接受新的传入连接的速度时,连接积压最终将达到其极限。这可能是由于系统配置错误或应用程序中的错误引起的。当一个或多个客户端发送连接请求而不对 “SYN ACK” 响应做出反应时,也会发生这种情况。这将用不完整的连接填充连接队列。这些条目需要几秒钟才会超时。这被称为<ruby>“同步洪水攻击”<rt>syn flood attack</rt></ruby>。
|
||||
|
||||
##### TCP 时间戳和 TCP Syn Cookie
|
||||
|
||||
即使队列已满,某些 TCP 协议栈也允许继续接受新连接。发生这种情况时,Linux 内核将在系统日志中打印一条突出的消息:
|
||||
|
||||
> P 端口上可能发生 SYN 泛洪。正在发送 Cookie。检查 SNMP 计数器。
|
||||
|
||||
此机制将完全绕过连接队列。通常存储在连接队列中的信息被编码到 SYN/ACK 响应 TCP 序列号中。当 ACK 返回时,可以根据序列号重建队列条目。
|
||||
|
||||
序列号只有有限的空间来存储信息。 因此,使用 “TCP Syn Cookie” 机制建立的连接不能支持 TCP 选项。
|
||||
|
||||
但是,对两个对等点都通用的 TCP 选项可以存储在时间戳中。 ACK 数据包在时间戳回显字段中反映了该值,这也允许恢复已达成共识的 TCP 选项。否则,cookie 连接受标准的 64KB 接收窗口限制。
|
||||
|
||||
##### 常见误区 —— 时间戳不利于性能
|
||||
|
||||
不幸的是,一些指南建议禁用 TCP 时间戳,以减少内核访问时间戳时钟来获取当前时间所需的次数。这是不正确的。如前所述,RTT 估算是 TCP 的必要部分。因此,内核在接收/发送数据包时总是采用微秒级的时间戳。
|
||||
|
||||
在包处理步骤的其余部分中,Linux 会重用 RTT 估算所需的时钟时间戳。这还避免了将时间戳添加到传出 TCP 数据包的额外时钟访问。
|
||||
|
||||
整个时间戳选项在每个数据包中仅需要 10 个字节的 TCP 选项空间,这并没有显著减少可用于数据包有效负载的空间。
|
||||
|
||||
##### 常见误区 —— 时间戳是个安全问题
|
||||
|
||||
一些安全审计工具和 (较旧的) 博客文章建议禁用 TCP 时间戳,因为据称它们泄露了系统正常运行时间:这样一来,便可以估算系统/内核的补丁级别。这在过去是正确的:时间戳时钟基于不断增加的值,该值在每次系统引导时都以固定值开始。时间戳值可以估计机器已经运行了多长时间 (正常运行时间)。
|
||||
|
||||
从 Linux 4.12 开始,TCP 时间戳不再显示正常运行时间。发送的所有时间戳值都使用对等设备特定的偏移量。时间戳值也每 49 天换行一次。
|
||||
|
||||
换句话说,从地址 “A” 出发,或者终到地址 “A” 的连接看到的时间戳与到远程地址 “B” 的连接看到的时间戳不同。
|
||||
|
||||
运行 _sysctl net.ipv4.tcp_timeamp=2_ 以禁用随机化偏移。这使得分析由诸如 _Wireshark_ 或 _tcpdump_ 之类的工具记录的数据包跟踪变得更容易 —— 从主机发送的数据包在其 TCP 选项时间戳中都具有相同的时钟基准。因此,对于正常操作,默认设置应保持不变。
|
||||
|
||||
### 选择性确认
|
||||
|
||||
如果丢失同一数据窗口中的多个数据包,TCP 将会出现问题。 这是因为 TCP 确认是累积的,但仅适用于按顺序到达的数据包。例如:
|
||||
|
||||
* 发送方发送段 s_1,s_2,s_3,... s_n
|
||||
* 发送方收到 s_2 的 ACK
|
||||
* 这意味着 s_1 和 s_2 都已收到,并且发送方不再需要保留这些段。
|
||||
* s_3 是否应该重新发送? s_4呢? s_n?
|
||||
|
||||
发送方等待 “重传超时” 或 “重复 ACK” 以使 s_2 到达。如果发生重传超时或到达 s_2 的多个重复 ACK,则发送方再次发送 s_3。
|
||||
|
||||
如果发送方收到对 s_n 的确认,则 s_3 是唯一丢失的数据包。这是理想的情况。仅发送单个丢失的数据包。
|
||||
|
||||
如果发送方收到的确认段小于 s_n,例如 s_4,则意味着丢失了多个数据包。
|
||||
发送方也需要重传下一个数据段。
|
||||
|
||||
##### 重传策略
|
||||
|
||||
可能只是重复相同的序列:重新发送下一个数据包,直到接收方指示它已处理了直至 s_n 的所有数据包为止。这种方法的问题在于,它需要一个 RTT,直到发送方知道接下来必须重新发送的数据包为止。尽管这种策略可以避免不必要的重传,但要等到 TCP 重新发送整个数据窗口后,它可能要花几秒钟甚至更长的时间。
|
||||
|
||||
另一种方法是一次重新发送几个数据包。当丢失了几个数据包时,此方法可使 TCP 恢复更快。在上面的示例中,TCP 重新发送了 s_3,s_4,s_5,...,但是只能确保已丢失 s_3。
|
||||
|
||||
从延迟的角度来看,这两种策略都不是最佳的。如果只有一个数据包需要重新发送,第一种策略是快速的,但是当多个数据包丢失时,它花费的时间太长。
|
||||
|
||||
即使必须重新发送多个数据包,第二个也是快速的,但是以浪费带宽为代价。此外,这样的 TCP 发送方在进行不必要的重传时可能已经发送了新数据。
|
||||
|
||||
通过可用信息,TCP 无法知道丢失了哪些数据包。这就是 TCP [选择性确认][5](SACK)的用武之地了。就像窗口缩放和时间戳一样,它是另一个可选的但非常有用的 TCP 特性。
|
||||
|
||||
##### SACK 选项
|
||||
|
||||
```
|
||||
TCP Sack-Permitted Option: Kind: 4, Length 2
|
||||
+---------+---------+
|
||||
| Kind=4 | Length=2|
|
||||
+---------+---------+
|
||||
```
|
||||
|
||||
支持此扩展的发送方在连接请求中包括 “允许 SACK” 选项。如果两个端点都支持扩展,则检测到数据流中丢失数据包的对等点可以将此信息通知发送方。
|
||||
|
||||
```
|
||||
TCP SACK Option: Kind: 5, Length: Variable
|
||||
+--------+--------+
|
||||
| Kind=5 | Length |
|
||||
+--------+--------+--------+--------+
|
||||
| Left Edge of 1st Block |
|
||||
+--------+--------+--------+--------+
|
||||
| Right Edge of 1st Block |
|
||||
+--------+--------+--------+--------+
|
||||
| |
|
||||
/ . . . /
|
||||
| |
|
||||
+--------+--------+--------+--------+
|
||||
| Left Edge of nth Block |
|
||||
+--------+--------+--------+--------+
|
||||
| Right Edge of nth Block |
|
||||
+--------+--------+--------+--------+
|
||||
```
|
||||
|
||||
接收方遇到 segment_s2 后跟 s_5 ... s_n,则在发送对 s_2 的确认时将包括一个 SACK 块:
|
||||
|
||||
```
|
||||
|
||||
+--------+-------+
|
||||
| Kind=5 | 10 |
|
||||
+--------+------+--------+-------+
|
||||
| Left edge: s_5 |
|
||||
+--------+--------+-------+------+
|
||||
| Right edge: s_n |
|
||||
+--------+-------+-------+-------+
|
||||
```
|
||||
|
||||
这告诉发送方到 s_2 的段都是按顺序到达的,但也让发送方知道段 s_5 至 s_n 也已收到。 然后,发送方可以重新发送这两个数据包,并继续发送新数据。
|
||||
|
||||
##### 神话般的无损网络
|
||||
|
||||
从理论上讲,如果连接不会丢包,那么 SACK 就没有任何优势。或者连接具有如此低的延迟,甚至等待一个完整的 RTT 都无关紧要。
|
||||
|
||||
在实践中,无损行为几乎是不可能保证的。
|
||||
即使网络及其所有交换机和路由器具有足够的带宽和缓冲区空间,数据包仍然可能丢失:
|
||||
|
||||
* 主机操作系统可能面临内存压力并丢弃数据包。请记住,一台主机可能同时处理数万个数据包流。
|
||||
* CPU 可能无法足够快地消耗掉来自网络接口的传入数据包。这会导致网络适配器本身中的数据包丢失。
|
||||
* 如果 TCP 时间戳不可用,即使一个非常小的 RTT 的连接也可能在丢失恢复期间暂时停止。
|
||||
|
||||
使用 SACK 不会增加 TCP 数据包的大小,除非连接遇到数据包丢失。因此,几乎没有理由禁用此功能。几乎所有的 TCP 协议栈都支持 SACK —— 它通常只在不进行 TCP 批量数据传输的低功耗 IOT 类似设备上才不存在。
|
||||
|
||||
当 Linux 系统接受来自此类设备的连接时,TCP 会自动为受影响的连接禁用 SACK。
|
||||
|
||||
### 总结
|
||||
|
||||
本文中研究的三个 TCP 扩展都与 TCP 性能有关,最好都保留其默认设置:enabled。
|
||||
|
||||
TCP 握手可确保仅使用双方都可以理解的扩展,因此,永远不需因为对等方可能不支持而全局禁用扩展。
|
||||
|
||||
关闭这些扩展会导致严重的性能损失,尤其是在 TCP 窗口缩放和 SACK 的情况下。 可以禁用 TCP 时间戳而不会立即造成不利影响,但是现在没有令人信服的理由这样做了。
|
||||
启用它们还可以支持 TCP 选项,即使在 SYN cookie 生效时也是如此。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/tcp-window-scaling-timestamps-and-sack/
|
||||
|
||||
作者:[Florian Westphal][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/gxlct008)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/strlen/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/08/tcp-window-scaling-816x346.png
|
||||
[2]: https://en.wikipedia.org/wiki/Transmission_Control_Protocol#TCP_segment_structure
|
||||
[3]: https://www.rfc-editor.org/info/rfc7323
|
||||
[4]: https://en.wikipedia.org/wiki/SYN_cookies
|
||||
[5]: https://www.rfc-editor.org/info/rfc2018
|
||||
149
translated/tech/20200903 A practical guide to learning awk.md
Normal file
149
translated/tech/20200903 A practical guide to learning awk.md
Normal file
@ -0,0 +1,149 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A practical guide to learning awk)
|
||||
[#]: via: (https://opensource.com/article/20/9/awk-ebook)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
awk 实用学习指南
|
||||
======
|
||||
下载我们的电子书,学习如何更好地使用 `awk`。
|
||||
![Person programming on a laptop on a building][1]
|
||||
|
||||
在众多 [Linux][2] 命令中,`sed`、`awk` 和 `grep` 恐怕是其中最经典的三个命令了。它们引人注目或许是由于名字发音与众不同,也可能是它们无处不在,甚至是因为它们存在已久,但无论如何,如果要问哪些命令很有 Linux 风格,这三个命令是当之无愧的。其中 `sed` 和 `grep` 已经有很多简洁的标准用法了,但 `awk` 的使用难度却相对突出。
|
||||
|
||||
在日常使用中,通过 `sed` 实现字符串替换、通过 `grep` 实现过滤,这些都是司空见惯的操作了,但 `awk` 命令相对来说是用得比较少的。在我看来,可能的原因是大多数人都只使用 `sed` 或者 `grep` 的一些变体实现某些功能,例如:
|
||||
|
||||
|
||||
```
|
||||
$ sed -e 's/foo/bar/g' file.txt
|
||||
$ grep foo file.txt
|
||||
```
|
||||
|
||||
因此,尽管你可能会觉得 `sed` 和 `grep` 使用起来更加顺手,但实际上它们还有更多更强大的作用没有发挥出来。当然,我们没有必要在这两个命令上钻研得很深入,但我还是想理解自己是如何学习一个命令的。很多时候我会把一整串命令记住,但不会去了解其中的运行过程,这就让我产生了一种很熟悉命令的错觉,我可以随口说出某个命令的好几个选项参数,但这些参数具体有什么作用,以及它们的相关语法,我都并不明确。
|
||||
|
||||
这大概就是很多人对 `awk` 缺乏了解的原因了。
|
||||
|
||||
### 为使用而学习 awk
|
||||
|
||||
`awk` 并不深奥。它是一种相对基础的编程语言,因此你可以把它当成一门新的编程语言来学习:使用一些基本命令来熟悉语法、了解语言中的关键字并实现更复杂的功能,然后再多加练习就可以了。
|
||||
|
||||
### awk 是如何解析输入内容的
|
||||
|
||||
`awk` 的本质是将输入的内容看作是一个数组。当 `awk` 扫描一个文本文件时,会把每一行作为一条<ruby>记录<rt>record</rt></ruby>,每一条记录中又分割为多个<ruby>字段<rt>field</rt></ruby>。`awk` 记录了各条记录各个字段的信息,并通过内置变量 `NR`(记录数) 和 `NF`(字段数) 来调用相关信息。例如一下这个命令可以查看文件的行数:
|
||||
|
||||
|
||||
```
|
||||
$ awk 'END { print NR;}' example.txt
|
||||
36
|
||||
```
|
||||
|
||||
从上面的命令可以看出 `awk` 的基本语法,无论是一个单行命令还是一整个脚本,语法都是这样的:
|
||||
|
||||
|
||||
```
|
||||
`样式或关键字 { 操作 }`
|
||||
```
|
||||
|
||||
在上面的例子中,`END` 是一个关键字而不是样式,与此类似的另一个关键字是 `BEGIN`。使用 `BEGIN` 或 `END` 可以让 `awk` 在解析内容前或解析内容后执行大括号中指定的操作。
|
||||
|
||||
你可以使用<ruby>样式<rt>pattern</rt></ruby>作为过滤器或限定符,这样 `awk` 只会对匹配样式的对应记录执行指定的操作。以下这个例子就是使用 `awk` 实现 `grep` 命令在文件中查找“Linux”字符串的功能:
|
||||
|
||||
|
||||
```
|
||||
$ awk '/Linux/ { print $0; }' os.txt
|
||||
OS: CentOS Linux (10.1.1.8)
|
||||
OS: CentOS Linux (10.1.1.9)
|
||||
OS: Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
OS: Elementary Linux (10.1.2.4)
|
||||
OS: Elementary Linux (10.1.2.5)
|
||||
OS: Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
`awk` 会将文件中的每一行作为一条记录,将一条记录中的每个单词作为一个字段,默认情况下会按照空格作为<ruby>分隔符<rt>field separator</rt></ruby>(`FS`)切割出记录中的字段。如果想要使用其它内容作为分隔符,可以使用 `--field-separator` 选项指定分隔符:
|
||||
|
||||
|
||||
```
|
||||
$ awk --field-separator ':' '/Linux/ { print $2; }' os.txt
|
||||
CentOS Linux (10.1.1.8)
|
||||
CentOS Linux (10.1.1.9)
|
||||
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
Elementary Linux (10.1.2.4)
|
||||
Elementary Linux (10.1.2.5)
|
||||
Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
在上面的例子中,可以看到在 `awk` 处理后每一行的行首都有一个空格,那是因为在源文件中每个冒号(`:`)后面都带有一个空格。和 `cut` 有所不同的是,`awk` 可以指定一个字符串作为分隔符,就像这样:
|
||||
|
||||
|
||||
```
|
||||
$ awk --field-separator ': ' '/Linux/ { print $2; }' os.txt
|
||||
CentOS Linux (10.1.1.8)
|
||||
CentOS Linux (10.1.1.9)
|
||||
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
Elementary Linux (10.1.2.4)
|
||||
Elementary Linux (10.1.2.5)
|
||||
Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
### awk 中的函数
|
||||
|
||||
可以通过这样的语法在 `awk` 中自定义函数:
|
||||
|
||||
|
||||
```
|
||||
`函数名称(参数) { 操作 }`
|
||||
```
|
||||
|
||||
函数的好处在于只需要编写一次就可以多次复用,因此函数在脚本中起到的作用会比在构造单行命令时大。同时 `awk` 自身也带有很多预定义的函数,并且工作原理和其它编程语言或电子表格保持一致。你只需要了解函数需要接受什么参数,就可以放心使用了。
|
||||
|
||||
`awk` 中提供了数学运算和字符串处理的相关函数。数学运算函数通常比较简单,传入一个数字,它就会传出一个结果:
|
||||
|
||||
|
||||
```
|
||||
$ awk 'BEGIN { print sqrt(1764); }'
|
||||
42
|
||||
```
|
||||
|
||||
而字符串处理函数则稍微复杂一点,但 [GNU awk 手册][3]中也有充足的文档。例如 `split()` 函数需要传入一个待分割的单一字段、一个数组用于存放分割结果,以及用于分割的<ruby>定界符<rt>delimiter</rt></ruby>。
|
||||
|
||||
例如前面示例中的输出内容,每条记录的末尾都包含了一个 IP 地址。由于变量 `NF` 代表的是每条记录的字段数量,刚好对应的是每条记录中最后一个字段的序号,因此可以通过引用 `NF` 将每条记录的最后一个字段传入 `split()` 函数:
|
||||
|
||||
|
||||
```
|
||||
$ awk --field-separator ': ' '/Linux/ { split($NF, IP, "."); print "subnet: " IP[3]; }' os.txt
|
||||
subnet: 1
|
||||
subnet: 1
|
||||
subnet: 1
|
||||
subnet: 2
|
||||
subnet: 2
|
||||
subnet: 2
|
||||
```
|
||||
|
||||
实际上 `awk` 的功能还远远不止于此,你还可以跳出 `awk` 本身,通过命令管道和脚本来自定义更多功能。
|
||||
|
||||
### 下载电子书
|
||||
|
||||
使用 `awk` 本身就是一个学习 `awk` 的过程,即使某些操作使用 `sed`、`grep`、`cut`、`tr` 命令已经完全足够了,也可以尝试使用 `awk` 来实现。只要熟悉了 `awk`,就可以在 Bash 中自定义一些 `awk` 函数,进而解析复杂的数据。
|
||||
|
||||
[下载我们的电子书][4]学习并开始使用 `awk` 吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/9/awk-ebook
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/hankchow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV (Person programming on a laptop on a building)
|
||||
[2]: https://opensource.com/resources/linux
|
||||
[3]: https://www.gnu.org/software/gawk/manual/gawk.html
|
||||
[4]: https://opensource.com/downloads/awk-ebook
|
||||
Loading…
Reference in New Issue
Block a user