mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge pull request #11210 from lujun9972/add-MjAxODExMTQgTWVldCBUaURCLSBBbiBvcGVuIHNvdXJjZSBOZXdTUUwgZGF0YWJhc2UubWQK
选题: Meet TiDB: An open source NewSQL database
This commit is contained in:
commit
6fd0679239
@ -0,0 +1,101 @@
|
||||
Meet TiDB: An open source NewSQL database
|
||||
======
|
||||
5 key differences between MySQL and TiDB for scaling in the cloud
|
||||
|
||||

|
||||
|
||||
As businesses adopt cloud-native architectures, conversations will naturally lead to what we can do to make the database horizontally scalable. The answer will likely be to take a closer look at [TiDB][1].
|
||||
|
||||
TiDB is an open source [NewSQL][2] database released under the Apache 2.0 License. Because it speaks the [MySQL][3] protocol, your existing applications will be able to connect to it using any MySQL connector, and [most SQL functionality][4] remains identical (joins, subqueries, transactions, etc.).
|
||||
|
||||
Step under the covers, however, and there are differences. If your architecture is based on MySQL with Read Replicas, you'll see things work a little bit differently with TiDB. In this post, I'll go through the top five key differences I've found between TiDB and MySQL.
|
||||
|
||||
### 1. TiDB natively distributes query execution and storage
|
||||
|
||||
With MySQL, it is common to scale-out via replication. Typically you will have one MySQL master with many slaves, each with a complete copy of the data. Using either application logic or technology like [ProxySQL][5], queries are routed to the appropriate server (offloading queries from the master to slaves whenever it is safe to do so).
|
||||
|
||||
Scale-out replication works very well for read-heavy workloads, as the query execution can be divided between replication slaves. However, it becomes a bottleneck for write-heavy workloads, since each replica must have a full copy of the data. Another way to look at this is that MySQL Replication scales out SQL processing, but it does not scale out the storage. (By the way, this is true for traditional replication as well as newer solutions such as Galera Cluster and Group Replication.)
|
||||
|
||||
TiDB works a little bit differently:
|
||||
|
||||
* Query execution is handled via a layer of TiDB servers. Scaling out SQL processing is possible by adding new TiDB servers, which is very easy to do using Kubernetes [ReplicaSets][6]. This is because TiDB servers are [stateless][7]; its [TiKV][8] storage layer is responsible for all of the data persistence.
|
||||
|
||||
* The data for tables is automatically sharded into small chunks and distributed among TiKV servers. Three copies of each data region (the TiKV name for a shard) are kept in the TiKV cluster, but no TiKV server requires a full copy of the data. To use MySQL terminology: Each TiKV server is both a master and a slave at the same time, since for some data regions it will contain the primary copy, and for others, it will be secondary.
|
||||
|
||||
* TiDB supports queries across data regions or, in MySQL terminology, cross-shard queries. The metadata about where the different regions are located is maintained by the Placement Driver, the management server component of any TiDB Cluster. All operations are fully [ACID][9] compliant, and an operation that modifies data across two regions uses a [two-phase commit][10].
|
||||
|
||||
|
||||
|
||||
|
||||
For MySQL users learning TiDB, a simpler explanation is the TiDB servers are like an intelligent proxy that translates SQL into batched key-value requests to be sent to TiKV. TiKV servers store your tables with range-based partitioning. The ranges automatically balance to keep each partition at 96MB (by default, but configurable), and each range can be stored on a different TiKV server. The Placement Driver server keeps track of which ranges are located where and automatically rebalances a range if it becomes too large or too hot.
|
||||
|
||||
This design has several advantages of scale-out replication:
|
||||
|
||||
* It independently scales the SQL Processing and Data Storage tiers. For many workloads, you will hit one bottleneck before the other.
|
||||
|
||||
* It incrementally scales by adding nodes (for both SQL and Data Storage).
|
||||
|
||||
* It utilizes hardware better. To scale out MySQL to one master and four replicas, you would have five copies of the data. TiDB would use only three replicas, with hotspots automatically rebalanced via the Placement Driver.
|
||||
|
||||
|
||||
|
||||
|
||||
### 2. TiDB's storage engine is RocksDB
|
||||
|
||||
MySQL's default storage engine has been InnoDB since 2010. Internally, InnoDB uses a [B+tree][11] data structure, which is similar to what traditional commercial databases use.
|
||||
|
||||
By contrast, TiDB uses RocksDB as the storage engine with TiKV. RocksDB has advantages for large datasets because it can compress data more effectively and insert performance does not degrade when indexes can no longer fit in memory.
|
||||
|
||||
Note that both MySQL and TiDB support an API that allows new storage engines to be made available. For example, Percona Server and MariaDB both support RocksDB as an option.
|
||||
|
||||
### 3. TiDB gathers metrics in Prometheus/Grafana
|
||||
|
||||
Tracking key metrics is an important part of maintaining database health. MySQL centralizes these fast-changing metrics in Performance Schema. Performance Schema is a set of in-memory tables that can be queried via regular SQL queries.
|
||||
|
||||
With TiDB, rather than retaining the metrics inside the server, a strategic choice was made to ship the information to a best-of-breed service. Prometheus+Grafana is a common technology stack among operations teams today, and the included graphs make it easy to create your own or configure thresholds for alarms.
|
||||
|
||||
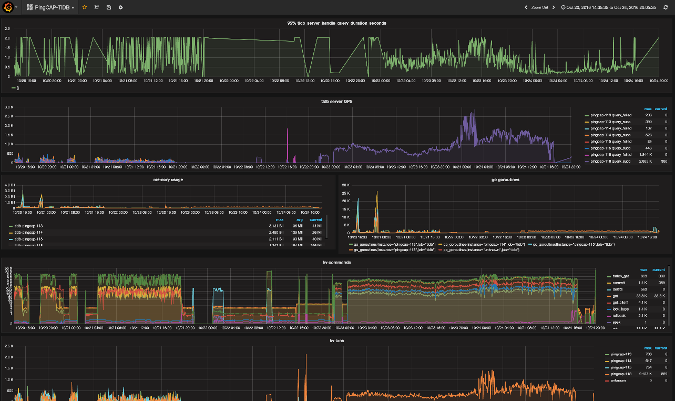
|
||||
|
||||
### 4. TiDB handles DDL significantly better
|
||||
|
||||
If we ignore for a second that not all data definition language (DDL) changes in MySQL are online, a larger challenge when running a distributed MySQL system is externalizing schema changes on all nodes at the same time. Think about a scenario where you have 10 shards and add a column, but each shard takes a different length of time to complete the modification. This challenge still exists without sharding, since replicas will process DDL after a master.
|
||||
|
||||
TiDB implements online DDL using the [protocol introduced by the Google F1 paper][12]. In short, DDL changes are broken up into smaller transition stages so they can prevent data corruption scenarios, and the system tolerates an individual node being behind up to one DDL version at a time.
|
||||
|
||||
### 5. TiDB is designed for HTAP workloads
|
||||
|
||||
The MySQL team has traditionally focused its attention on optimizing performance for online transaction processing ([OLTP][13]) queries. That is, the MySQL team spends more time making simpler queries perform better instead of making all or complex queries perform better. There is nothing wrong with this approach since many applications only use simple queries.
|
||||
|
||||
TiDB is designed to perform well across hybrid transaction/analytical processing ([HTAP][14]) queries. This is a major selling point for those who want real-time analytics on their data because it eliminates the need for batch loads between their MySQL database and an analytics database.
|
||||
|
||||
### Conclusion
|
||||
|
||||
These are my top five observations based on 15 years in the MySQL world and coming to TiDB. While many of them refer to internal differences, I recommend checking out the TiDB documentation on [MySQL Compatibility][4]. It describes some of the finer points about any differences that may affect your applications.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/key-differences-between-mysql-and-tidb
|
||||
|
||||
作者:[Morgan Tocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/morgo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pingcap.com/docs/
|
||||
[2]: https://en.wikipedia.org/wiki/NewSQL
|
||||
[3]: https://en.wikipedia.org/wiki/MySQL
|
||||
[4]: https://www.pingcap.com/docs/sql/mysql-compatibility/
|
||||
[5]: https://proxysql.com/
|
||||
[6]: https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
|
||||
[7]: https://en.wikipedia.org/wiki/State_(computer_science)
|
||||
[8]: https://github.com/tikv/tikv/wiki
|
||||
[9]: https://en.wikipedia.org/wiki/ACID_(computer_science)
|
||||
[10]: https://en.wikipedia.org/wiki/Two-phase_commit_protocol
|
||||
[11]: https://en.wikipedia.org/wiki/B%2B_tree
|
||||
[12]: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/41344.pdf
|
||||
[13]: https://en.wikipedia.org/wiki/Online_transaction_processing
|
||||
[14]: https://en.wikipedia.org/wiki/Hybrid_transactional/analytical_processing_(HTAP)
|
||||
Loading…
Reference in New Issue
Block a user