mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
meger from LCTT
This commit is contained in:
commit
6fa7c779fb
2
.travis.yml
Normal file
2
.travis.yml
Normal file
@ -0,0 +1,2 @@
|
||||
language: c
|
||||
script: make -s check
|
||||
45
Makefile
Normal file
45
Makefile
Normal file
@ -0,0 +1,45 @@
|
||||
RULES := rule-source-added \
|
||||
rule-translation-requested \
|
||||
rule-translation-completed \
|
||||
rule-translation-revised \
|
||||
rule-translation-published
|
||||
.PHONY: check match $(RULES)
|
||||
|
||||
CHANGE_FILE := /tmp/changes
|
||||
|
||||
check: $(CHANGE_FILE)
|
||||
echo 'PR #$(TRAVIS_PULL_REQUEST) Changes:'
|
||||
cat $(CHANGE_FILE)
|
||||
echo
|
||||
echo 'Check for rules...'
|
||||
make -k $(RULES) 2>/dev/null | grep '^Rule Matched: '
|
||||
|
||||
$(CHANGE_FILE):
|
||||
git --no-pager diff $(TRAVIS_BRANCH) FETCH_HEAD --no-renames --name-status > $@
|
||||
|
||||
rule-source-added:
|
||||
[ $(shell grep '^A\s\+sources/[a-zA-Z0-9_-/ ]*\.md' $(CHANGE_FILE) | wc -l) -ge 1 ]
|
||||
[ $(shell grep -v '^A\s\+sources/[a-zA-Z0-9_-/ ]*\.md' $(CHANGE_FILE) | wc -l) = 0 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-requested:
|
||||
[ $(shell grep '^M\s\+sources/[a-zA-Z0-9_-/ ]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-completed:
|
||||
[ $(shell grep '^D\s\+sources/[a-zA-Z0-9_-/ ]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell grep '^A\s\+translated/[a-zA-Z0-9_-/ ]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 2 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-revised:
|
||||
[ $(shell grep '^M\s\+translated/[a-zA-Z0-9_-/ ]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-published:
|
||||
[ $(shell grep '^D\s\+translated/[a-zA-Z0-9_-/ ]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell grep '^A\s\+published/[a-zA-Z0-9_-/ ]*\.md' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 2 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
@ -0,0 +1,87 @@
|
||||
# [因为这个我要点名批评 Hacker News ][14]
|
||||
|
||||
|
||||
> “实现高速缓存会花费 30 个小时,你有额外的 30 个小时吗?
|
||||
不,你没有。我实际上并不知道它会花多少时间,可能它会花五分钟,你有五分钟吗?不,你还是没有。为什么?因为我在撒谎。它会消耗远超五分钟的时间。这一切把问题简单化的假设都只不过是程序员单方面的乐观主义。”
|
||||
>
|
||||
> — 出自 [Owen Astrachan][1] 教授于 2004 年 2 月 23 日在 [CPS 108][2] 上的讲座
|
||||
|
||||
[指责开源软件总是离奇难用已经不是一个新论点了][5];这样的论点之前就被很多比我更为雄辩的人提及过,甚至是出自一些人非常推崇开源软件的人士口中。那么为什么我要在这里老调重弹呢?
|
||||
|
||||
在周一的 Hacker News 期刊上,一段文章把我逗乐了。文章谈到,一些人认为 [编写代码实现和一个跟 StackOverflow 一样的系统可以简单到爆][6],并自信的 [声称他们可以在 7 月 4 号的周末就写出一版和 StackOverflow 原版一模一样的程序][7],以此来证明这一切是多么容易。另一些人则插话说,[现有的][8][那些仿制产品][9] 就已经是一个很好的例证了。
|
||||
|
||||
秉承着自由讨论的精神,我们来假设一个场景。你在思考了一阵之后认为你可以用 ASP.NET MVC 来编写一套你自己的 StackOverflow 。我呢,在被一块儿摇晃着的怀表催眠之后,脑袋又挨了别人一顿棒槌,然后像个二哈一样一页一页的把 StackOverflow 的源码递给你,让你照原样重新拿键盘逐字逐句的在你的环境下把那些代码再敲一遍,做成你的 StackOverflow。假设你可以像我一样打字飞快,一分钟能敲 100 个词 ([也就是大约每秒敲八个字母][10]),但是却可以牛叉到我无法企及的打字零错误率。从 StackOverflow 的大小共计 2.3MB 的源码来估计(包括 .CS、 .SQL、 .CSS、 .JS 和 .aspx 文件),就单单是照着源代码这么飞速敲一遍而且一气呵成中间一个字母都不错,你也要差不多用掉至少 80 个小时的时间。
|
||||
|
||||
或者你打算从零开始编码实现你自己的 StackOverflow,虽然我知道你肯定是不会那样做的。我们假设你从设计程序,到敲代码,再到最终完成调试只需要区区十倍于抄袭 StackOverflow 源代码的时间。即使在这样的假设条件下,你也要耗费几周的时间昼夜不停得狂写代码。不知道你是否愿意,但是至少我可以欣然承认,如果只给我照抄 StackOverflow 源代码用时的十倍时间来让我自己写 StackOverflow,我可是打死也做不到。
|
||||
|
||||
_好的_,我知道你在听到这些假设的时候已经开始觉得泄气了。*你在想,如果不是全部实现,而只是实现 StackOverflow __大部分__ 的功能呢?这总归会容易很多了吧。*
|
||||
|
||||
好的,问题是什么是 “大部分” 功能?如果只去实现提问和回答问题的功能?这个部分应该很简单吧。其实不然,因为实现问和答的功能还要求你必须做出一个对问题及其答案的投票系统,来显示大家对某个答案是赞同还是反对。因为只有这样你才能保证提问者可以得到这个问题的唯一的可信答案。当然,你还不能让人们赞同或者反对他们自己给出的答案,所以你还要去实现这种禁止自投自票的机制。除此之外,你需要去确保用户在一定的时间内不能赞同或反对其他用户太多次,以此来防止有人用机器人程序作弊乱投票。你很可能还需要去实现一个垃圾评论过滤器,即使这个过滤器很基础很简陋,你也要考虑如何去设计它。而且你恐怕还需要去支持用户图标(头像)的功能。并且你将不得不寻找一个自己真正信任的并且与 Markdown 结合很好的干净的 HTML 库(当然,假设你确实想要复用 StackOverflow 的 [那个超棒的编辑器][11] )。你还需要为所有控件购买或者设计一些小图标、小部件,此外你至少需要实现一个基本的管理界面,以便那些喜欢捣鼓的用户可以调整和改动他们的个性化设置。并且你需要实现类似于 Karma 的声望累积系统,以便用户可以随着不断地使用来稳步提升他们的话语权和解锁更多的功能以及可操作性。
|
||||
|
||||
但是如果你实现了以上_所有_功能,可以说你_就已经_把要做的都做完了。
|
||||
|
||||
除非……除非你还要做全文检索功能。尤其是在“边问边搜”(动态检索)的特性中,支持全文检索是必不可少的。此外,录入和显示用户的基本信息,实现对问题答案的评论功能,以及实现一个显示热点提问的页面,以及热点问题和帖子随着时间推移沉下去的这些功能,都将是不可或缺的。另外你肯定还需要去实现回答奖励系统,并支持每个用户用多个不同的 OpenID 账户去登录,然后将这些相关的登录事件通过邮件发送出去来通知用户,并添加一个标签或徽章系统,接着允许管理员通过一个不错的图形界面来配置这些标签和<ruby>徽章<rt>Badge</rt></ruby>。你需要去显示用户的 Karma 历史,以及他们的历史点赞和差评。而且整个页面还需要很流畅的展开和拉伸,因为这个系统的页面随时都可能被 Slashdot、Reddit 或是 StackOverflow 这些动作影响到。
|
||||
|
||||
在这之后!你会以为你基本已经大功告成了!
|
||||
|
||||
……为了产品的完整性,在上面所述的工作都完成之后,你又奋不顾身的去实现了升级功能,界面语言的国际化,Karma 值上限,以及让网站更专业的 CSS 设计、AJAX,还有那些看起来理所当然做起来却让人吐血的功能和特性。如果你不是真的动手来尝试做一个和 StackOverflow 一模一样的系统,你肯定不会意识到在整个程序设计实施的过程中,你会踩到无数的鬼才会知道的大坑。
|
||||
|
||||
那么请你告诉我:如果你要做一个让人满意的类似产品出来,上述的哪一个功能是你可以省略掉的呢?哪些是“大部分”网站都具备的功能,哪些又不是呢?
|
||||
|
||||
正因为这些很容易被忽视的问题,开发者才会以为做一个 StackOverflow 的仿制版产品会很简单。也同样是因为这些被忽视了的因素,开源软件才一直让人用起来很痛苦。很多软件开发人员在看到 StackOverflow 的时候,他们并不能察觉到 StackOverflow 产品的全貌。他们会简单的把 Stackoverflow 的实现抽象成下面一段逻辑和代码:
|
||||
|
||||
```
|
||||
create table QUESTION (ID identity primary key,
|
||||
TITLE varchar(255), --- 为什么我知道你认为是 255
|
||||
BODY text,
|
||||
UPVOTES integer not null default 0,
|
||||
DOWNVOTES integer not null default 0,
|
||||
USER integer references USER(ID));
|
||||
create table RESPONSE (ID identity primary key,
|
||||
BODY text,
|
||||
UPVOTES integer not null default 0,
|
||||
DOWNVOTES integer not null default 0,
|
||||
QUESTION integer references QUESTION(ID))
|
||||
```
|
||||
|
||||
如果你让这些开发者去实现 StackOverflow,进入他脑海中的就是上面的两个 SQL 表和一个用以呈现表格数据的 HTML 文件。他们甚至会忽略数据的格式问题,进而单纯的以为他们可以在一个周末的时间里就把 StackOverflow 做出来。一些稍微老练的开发者可能会意识到他们还要去实现登录和注销功能、评论功能、投票系统,但是仍然会自信的认为这不过也就是利用一个周末就能完成了;因为这些功能也不过意味着在后端多了几张 SQL 表和 HTML 文件。如果借助于 Django 之类的构架和工具,他们甚至可以直接拿来主义地不花一分钱就实现用户登录和评论的功能。
|
||||
|
||||
但这种简单的实现却_远远不能_体现出 StackOverflow 的精髓。无论你对 StackOverflow 的感觉如何,大多数使用者似乎都同意 StackOverflow 的用户体验从头到尾都很流畅。使用 StackOverflow 的过程就是在跟一个精心打磨过的产品在愉快地交互。即使我没有深入了解过 StackOverflow ,我也能猜测出这个产品的成功和它的数据库的 Schema 没有多大关系 —— 实际上在有幸研读过 StackOverflow 的源码之后,我得以印证了自己的想法,StackOverflow 的成功确实和它的数据库设计关系甚小。真正让它成为一个极其易用的网站的原因,是它背后_大量的_精雕细琢的设计和实施。多数的开发人员在谈及仿制和克隆一款产品的难度时,真的_很少会去考虑到产品背后的打磨和雕琢工作_,因为他们认为_这些打磨和雕琢都是偶然的,甚至是无足轻重的。_
|
||||
|
||||
这就是为什么用开源工具去克隆和山寨 StackOverflow 其实是很容易失败的。即使这些开源开发者只是想去实现 StackOverflow 的主要的“规范和标准特性”,而非全面的高级特性,他们也会在实现的过程中遭遇种种关键和核心的问题,让他们阴沟翻船,半途而废。拿徽章功能来说,如果你要针对普通终端用户来设计徽章, 则要么需要实现一个用户可用来个性化设置徽章的 GUI,要么则取巧的设计出一个比较通用的徽章,供所有的安装版本来使用。而开源设计的实际情况是,开发者会有很多的抱怨和牢骚,认为给徽章这种东西设计一个功能全面的 GUI 是根本不可能的。而且他们会固执地把任何标准徽章的提案踢回去,踢出第一宇宙速度,击穿地壳甩到地球的另一端。最终这些开发者还是会搞出一个类似于 Roundup 的 bug tracker 程序都在使用的流程和方案:即实现一个通用的机制,提供以 Python 或 PHP 为基础的一些系统 API, 以便那些可以自如使用 Python 或 PHP 的人可以轻松的通过这些编程接口来定制化他们自己的徽章。而且老实说,PHP 和 Python 可是比任何可能的 GUI 接口都要好用和强大得多,为什么还要考虑 GUI 的方案呢?(出自开源开发者的想法)
|
||||
|
||||
同样的,开源开发者会认为那些系统设置和管理员界面也一样可以省略掉。在他们看来,假如你是一个管理员,有 SQL 服务器的权限,那么你就理所当然的具备那些系统管理员该有的知识和技能。那么你其实可以使用 Djang-admin 或者任何类似的工具来轻松的对 StackOverflow 做很多设置和改造工作。毕竟如果你是一个 mods (懂如何 mod 的人)那么你肯定知道网站是怎么工作的,懂得如何利用专业工具去设置和改造一个网站。对啊!这不就得了! 毋庸置疑,在开源开发者重做他们自己的 StackOverflow 的时候,他们也不会把任何 StackOverflow 在接口上面的失败设计纠正过来。即使是原版 StackOverflow 里面最愚蠢最失败的那个设计(即要求用户必须拥有一个 OpenID 并知道如何使用它)在某个将来最终被 StackOverflow 删除和修正掉了, 我相信正在复制 StackOverflow 模式的那些开源克隆产品也还是会不假思索的把这个 OpenID 的功能仿制出来。这就好比是 GNOME 和 KDE 多年以来一直在做的事情,他们并没有把精力放在如何在设计之初就避免 Windows 的那些显而易见的毛病和问题,相反的却是在亦步亦趋的重复着 Windows 的设计,想办法用开源的方式做出一个比拟 Windows 功能的系统。
|
||||
|
||||
开发者可能不会关心一个应用的上述设计细节,但是终端用户一定会。尤其是当他们在尝试去选择要使用哪个应用的时候,这些终端用户更会重视这些接口设计是否易用。就好像一家好的软件公司希望通过确保其产品在出货之前就有一流的质量,以降低售后维护支持的成本一样,懂行的消费者也会在他们购买这些产品之前就确保产品好用,以防在使用的时候不知所措,然后无奈的打电话给售后来解决问题。开源产品就失败在这里,而且相当之失败。一般来讲,付费软件则在这方面做得好很多。
|
||||
|
||||
这不是说开源软件没有自己的立足之地,这个博客就运行在 Apache、[Django][12]、[PostgreSQL][13] 和 Linux 搭建的开源系统之上。但是让我来告诉你吧,配置这些堆栈可不是谁都可以做的。老版本的 PostgreSQL 需要手工配置 Vacuuming 来确保数据库的自动清理,而即使是最新版本的 Ubuntu 和 FreeBSD 也仍然要求用户去手工配置他们的第一个数据库集群。
|
||||
|
||||
相比之下,MS SQL (微软的 SQL 数据库) 则不需要你手工配置以上的任何一样东西。至于 Apache …… 我的天,Apache 简直复杂到让我根本来不及去尝试给一个新用户讲解我们如何可以通过一个一次性的安装过程就能把虚拟机、MovableType,几个 Diango apps 和 WordPress 配置在一起并流畅地使用。单单是给那些技术背景还不错但并非软件开发者的用户解释清楚 Apache 的那些针对多进程和多线程的设置参数就已经够我喝一壶的了。相比之下,微软的 IIS 7 或者是使用了 OS X 服务器的那个几乎闭源的 GUI 管理器的 Apache ,在配置的时候就要简单上不止一个数量级了。Django 确实是一个好的开源产品,但它也 _只是_ 一个基础构架,而并非是一个可以直接面向终端普通用户的商业产品。而开源真正的强项就 _恰恰在_ 这种基础构架的开发和创新上,这也正是驱使开发者为开源做贡献的最本真的动力。
|
||||
|
||||
所以我的结论是,如果下次你再看到一个你喜欢的应用程序,请好好细心地揣摩一下这款产品,揣摩一下所有的那些针对用户的体贴入微的设计细节。而不是武断的认为你可以轻轻松松的在一周之内就用开源工具做一个和这个应用一摸一样的产品出来。那些认为制作和实现一个应用程序如此简单的人,十之八九都是因为忽略了软件开发的最终产品是要交给用户去用的。
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
via: https://bitquabit.com/post/one-which-i-call-out-hacker-news/
|
||||
|
||||
作者:[Benjamin Pollack][a]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333),[yunfengHe](https://github.com/yunfengHe)
|
||||
校对:[yunfengHe](https://github.com/yunfengHe),[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bitquabit.com/meta/about/
|
||||
[1]:http://www.cs.duke.edu/~ola/
|
||||
[2]:http://www.cs.duke.edu/courses/cps108/spring04/
|
||||
[3]:https://bitquabit.com/categories/programming
|
||||
[4]:https://bitquabit.com/categories/technology
|
||||
[5]:http://blog.bitquabit.com/2009/06/30/one-which-i-say-open-source-software-sucks/
|
||||
[6]:http://news.ycombinator.com/item?id=678501
|
||||
[7]:http://news.ycombinator.com/item?id=678704
|
||||
[8]:http://code.google.com/p/cnprog/
|
||||
[9]:http://code.google.com/p/soclone/
|
||||
[10]:http://en.wikipedia.org/wiki/Words_per_minute
|
||||
[11]:http://github.com/derobins/wmd/tree/master
|
||||
[12]:http://www.djangoproject.com/
|
||||
[13]:http://www.postgresql.org/
|
||||
[14]:https://bitquabit.com/post/one-which-i-call-out-hacker-news/
|
||||
130
published/20170413 More Unknown Linux Commands.md
Normal file
130
published/20170413 More Unknown Linux Commands.md
Normal file
@ -0,0 +1,130 @@
|
||||
更多你所不知道的 Linux 命令
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 在这篇文章中和 Carla Schroder 一起探索 Linux 中的一些鲜为人知的强大工具。
|
||||
|
||||
本文是一篇关于一些有趣但鲜为人知的工具 `termsaver`、`pv` 和 `calendar` 的文章。`termsaver` 是一个终端 ASCII 屏保,`pv` 能够测量数据吞吐量并模拟输入。Debian 的 `calendar` 拥有许多不同的日历,并且你还可以制定你自己的日历。
|
||||
|
||||
### 终端屏保
|
||||
|
||||
难道只有图形桌面能够拥有有趣的屏保吗?现在,你可以通过安装 `termsaver` 来享受 ASCII 屏保,比如 matrix(LCTT 译注:电影《黑客帝国》中出现的黑客屏保)、时钟、星球大战以及两个<ruby>不太安全<rt>not-safe-for-work</rt></ruby>(NSFW)的屏保。 NSFW 屏保还有很多。
|
||||
|
||||
`termsaver` 可以从 Debian/Ubuntu 的包管理器中直接下载安装,如果你使用别的不包含该软件包的发行版比如 CentOS,那么你可以从 [termsaver.brunobraga.net][7] 下载,然后按照安装指导进行安装。
|
||||
|
||||
运行 `termsaver -h` 来查看一系列屏保:
|
||||
|
||||
```
|
||||
randtxt displays word in random places on screen
|
||||
starwars runs the asciimation Star Wars movie
|
||||
urlfetcher displays url contents with typing animation
|
||||
quotes4all displays recent quotes from quotes4all.net
|
||||
rssfeed displays rss feed information
|
||||
matrix displays a matrix movie alike screensaver
|
||||
clock displays a digital clock on screen
|
||||
rfc randomly displays RFC contents
|
||||
jokes4all displays recent jokes from jokes4all.net (NSFW)
|
||||
asciiartfarts displays ascii images from asciiartfarts.com (NSFW)
|
||||
programmer displays source code in typing animation
|
||||
sysmon displays a graphical system monitor
|
||||
```
|
||||
|
||||

|
||||
|
||||
*图片 1: 星球大战屏保。*
|
||||
|
||||
你可以通过运行命令 `termsaver [屏保名]` 来使用屏保,比如 `termsaver matrix` ,然后按 `Ctrl+c` 停止。你也可以通过运行 `termsaver [屏保名] -h` 命令来获取关于某一个特定屏保的信息。图片 1 来自 `startwars` 屏保,它运行的是古老但受人喜爱的 [Asciimation Wars][8] 。
|
||||
|
||||
那些不太安全(NSFW)的屏保通过在线获取资源的方式运行,我并不喜欢它们,但好消息是,由于 `termsaver` 是一些 Python 脚本文件,因此,你可以很容易的利用它们连接到任何你想要的 RSS 资源。
|
||||
|
||||
### pv
|
||||
|
||||
`pv` 命令是一个非常有趣的小工具但却很实用。它的用途是监测数据复制的过程,比如,当你运行 `rsync` 命令或创建一个 `tar` 归档的时候。当你不带任何选项运行 `pv` 命令时,默认参数为:
|
||||
|
||||
* -p :进程
|
||||
* -t :时间,到当前总运行时间
|
||||
* -e :预计完成时间,这往往是不准确的,因为 `pv` 通常不知道需要移动的数据的大小
|
||||
* -r :速率计数器,或吞吐量
|
||||
* -b :字节计数器
|
||||
|
||||
一次 `rsync` 传输看起来像这样:
|
||||
|
||||
```
|
||||
$ rsync -av /home/carla/ /media/carla/backup/ | pv
|
||||
sending incremental file list
|
||||
[...]
|
||||
103GiB 0:02:48 [ 615MiB/s] [ <=>
|
||||
```
|
||||
|
||||
创建一个 tar 归档,就像下面这个例子:
|
||||
|
||||
```
|
||||
$ tar -czf - /file/path| (pv > backup.tgz)
|
||||
885MiB 0:00:30 [28.6MiB/s] [ <=>
|
||||
```
|
||||
|
||||
`pv` 能够监测进程,因此也可以监测 Web 浏览器的最大活动,令人惊讶的是,它产生了如此多的活动:
|
||||
|
||||
```
|
||||
$ pv -d 3095
|
||||
58:/home/carla/.pki/nssdb/key4.db: 0 B 0:00:33
|
||||
[ 0 B/s] [<=> ]
|
||||
78:/home/carla/.config/chromium/Default/Visited Links:
|
||||
256KiB 0:00:33 [ 0 B/s] [<=> ]
|
||||
]
|
||||
85:/home/carla/.con...romium/Default/data_reduction_proxy_leveldb/LOG:
|
||||
298 B 0:00:33 [ 0 B/s] [<=> ]
|
||||
```
|
||||
|
||||
在网上,我偶然发现一个使用 `pv` 最有趣的方式:使用 `pv` 来回显输入的内容:
|
||||
|
||||
```
|
||||
$ echo "typing random stuff to pipe through pv" | pv -qL 8
|
||||
typing random stuff to pipe through pv
|
||||
```
|
||||
|
||||
普通的 `echo` 命令会瞬间打印一整行内容。通过管道传给 `pv` 之后能够让内容像是重新输入一样的显示出来。我不知道这是否有实际的价值,但是我非常喜欢它。`-L` 选项控制回显的速度,即多少字节每秒。
|
||||
|
||||
`pv` 是一个非常古老且非常有趣的命令,这么多年以来,它拥有了许多的选项,包括有趣的格式化选项,多种输出选项,以及传输速度修改器。你可以通过 `man pv` 来查看所有的选项。
|
||||
|
||||
### /usr/bin/calendar
|
||||
|
||||
通过浏览 `/usr/bin` 目录以及其他命令目录和阅读 man 手册,你能够学到很多东西。在 Debian/Ubuntu 上的 `/usr/bin/calendar` 是 BSD 日历的一个变种,但它漏掉了月亮历和太阳历。它保留了多个日历包括 `calendar.computer, calendar.discordian, calendar.music` 以及 `calendar.lotr`。在我的系统上,man 手册列出了 `/usr/bin/calendar` 里存在的不同日历。下面这个例子展示了指环王日历接下来的 60 天:
|
||||
|
||||
```
|
||||
$ calendar -f /usr/share/calendar/calendar.lotr -A 60
|
||||
Apr 17 An unexpected party
|
||||
Apr 23 Crowning of King Ellesar
|
||||
May 19 Arwen leaves Lorian to wed King Ellesar
|
||||
Jun 11 Sauron attacks Osgilliath
|
||||
```
|
||||
|
||||
这些日历是纯文本文件,因此,你可以轻松的创建你自己的日历。最简单的方式就是复制已经存在的日历文件的格式。你可以通过 `man calendar` 命令来查看创建个人日历文件的更详细的指导。
|
||||
|
||||
又一次很快走到了尽头。你可以花费一些时间来浏览你的文件系统,挖掘更多有趣的命令。
|
||||
|
||||
_你可以通过来自 Linux 基金会和 edx 的免费课程 ["Introduction to Linux"][5] 来学习更过关于 Linux 的知识_。
|
||||
|
||||
(题图:[CC Zero][2] Pixabay)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/4/more-unknown-linux-commands
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/linux-commands-fig-1png
|
||||
|
||||
[4]:https://www.linux.com/files/images/outer-limits-linuxjpg
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[6]:https://www.addtoany.com/share#url=https%3A%2F%2Fwww.linux.com%2Flearn%2Fintro-to-linux%2F2017%2F4%2Fmore-unknown-linux-commands&amp;amp;title=More%20Unknown%20Linux%20Commands
|
||||
[7]:http://termsaver.brunobraga.net/
|
||||
[8]:http://www.asciimation.co.nz/
|
||||
@ -0,0 +1,219 @@
|
||||
在红帽企业版 Linux 中将系统服务容器化(一)
|
||||
====================
|
||||
|
||||
在 2017 年红帽峰会上,有几个人问我“我们通常用完整的虚拟机来隔离如 DNS 和 DHCP 等网络服务,那我们可以用容器来取而代之吗?”答案是可以的,下面是在当前红帽企业版 Linux 7 系统上创建一个系统容器的例子。
|
||||
|
||||
### 我们的目的
|
||||
|
||||
**创建一个可以独立于任何其它系统服务而更新的网络服务,并且可以从主机端容易地管理和更新。**
|
||||
|
||||
让我们来探究一下在容器中建立一个运行在 systemd 之下的 BIND 服务器。在这一部分,我们将了解到如何建立自己的容器以及管理 BIND 配置和数据文件。
|
||||
|
||||
在本系列的第二部分,我们将看到如何整合主机中的 systemd 和容器中的 systemd。我们将探究如何管理容器中的服务,并且使它作为一种主机中的服务。
|
||||
|
||||
### 创建 BIND 容器
|
||||
|
||||
为了使 systemd 在一个容器中轻松运行,我们首先需要在主机中增加两个包:`oci-register-machine` 和 `oci-systemd-hook`。`oci-systemd-hook` 这个钩子允许我们在一个容器中运行 systemd,而不需要使用特权容器或者手工配置 tmpfs 和 cgroups。`oci-register-machine` 这个钩子允许我们使用 systemd 工具如 `systemctl` 和 `machinectl` 来跟踪容器。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# yum install oci-register-machine oci-systemd-hook
|
||||
```
|
||||
|
||||
回到创建我们的 BIND 容器上。[红帽企业版 Linux 7 基础镜像][6]包含了 systemd 作为其初始化系统。我们可以如我们在典型的系统中做的那样安装并激活 BIND。你可以从 [git 仓库中下载这份 Dockerfile][8]。
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# vi Dockerfile
|
||||
|
||||
# Dockerfile for BIND
|
||||
FROM registry.access.redhat.com/rhel7/rhel
|
||||
ENV container docker
|
||||
RUN yum -y install bind && \
|
||||
yum clean all && \
|
||||
systemctl enable named
|
||||
STOPSIGNAL SIGRTMIN+3
|
||||
EXPOSE 53
|
||||
EXPOSE 53/udp
|
||||
CMD [ "/sbin/init" ]
|
||||
```
|
||||
|
||||
因为我们以 PID 1 来启动一个初始化系统,当我们告诉容器停止时,需要改变 docker CLI 发送的信号。从 `kill` 系统调用手册中 (`man 2 kill`):
|
||||
|
||||
> 唯一可以发送给 PID 1 进程(即 init 进程)的信号,是那些初始化系统明确安装了<ruby>信号处理器<rt>signal handler</rt></ruby>的信号。这是为了避免系统被意外破坏。
|
||||
|
||||
对于 systemd 信号处理器,`SIGRTMIN+3` 是对应于 `systemd start halt.target` 的信号。我们也需要为 BIND 暴露 TCP 和 UDP 端口号,因为这两种协议可能都要使用。
|
||||
|
||||
### 管理数据
|
||||
|
||||
有了一个可以工作的 BIND 服务,我们还需要一种管理配置文件和区域文件的方法。目前这些都放在容器里面,所以我们任何时候都可以进入容器去更新配置或者改变一个区域文件。从管理的角度来说,这并不是很理想。当要更新 BIND 时,我们将需要重建这个容器,所以镜像中的改变将会丢失。任何时候我们需要更新一个文件或者重启服务时,都需要进入这个容器,而这增加了步骤和时间。
|
||||
|
||||
相反的,我们将从这个容器中提取出配置文件和数据文件,把它们拷贝到主机上,然后在运行的时候挂载它们。用这种方式我们可以很容易地重启或者重建容器,而不会丢失所做出的更改。我们也可以使用容器外的编辑器来更改配置和区域文件。因为这个容器的数据看起来像“该系统所提供服务的特定站点数据”,让我们遵循 Linux <ruby>文件系统层次标准<rt>File System Hierarchy</rt></ruby>,并在当前主机上创建 `/srv/named` 目录来保持管理权分离。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# mkdir -p /srv/named/etc
|
||||
|
||||
[root@rhel7-host ~]# mkdir -p /srv/named/var/named
|
||||
```
|
||||
|
||||
*提示:如果你正在迁移一个已有的配置文件,你可以跳过下面的步骤并且将它直接拷贝到 `/srv/named` 目录下。你也许仍然要用一个临时容器来检查一下分配给这个容器的 GID。*
|
||||
|
||||
让我们建立并运行一个临时容器来检查 BIND。在将 init 进程以 PID 1 运行时,我们不能交互地运行这个容器来获取一个 shell。我们会在容器启动后执行 shell,并且使用 `rpm` 命令来检查重要文件。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker build -t named .
|
||||
|
||||
[root@rhel7-host ~]# docker exec -it $( docker run -d named ) /bin/bash
|
||||
|
||||
[root@0e77ce00405e /]# rpm -ql bind
|
||||
```
|
||||
|
||||
对于这个例子来说,我们将需要 `/etc/named.conf` 和 `/var/named/` 目录下的任何文件。我们可以使用 `machinectl` 命令来提取它们。如果注册了一个以上的容器,我们可以在任一机器上使用 `machinectl status` 命令来查看运行的是什么。一旦有了这些配置,我们就可以终止这个临时容器了。
|
||||
|
||||
*如果你喜欢,资源库中也有一个[样例 `named.conf` 和针对 `example.com` 的区域文件][8]。*
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# machinectl list
|
||||
|
||||
MACHINE CLASS SERVICE
|
||||
8824c90294d5a36d396c8ab35167937f container docker
|
||||
|
||||
[root@rhel7-host ~]# machinectl copy-from 8824c90294d5a36d396c8ab35167937f /etc/named.conf /srv/named/etc/named.conf
|
||||
|
||||
[root@rhel7-host ~]# machinectl copy-from 8824c90294d5a36d396c8ab35167937f /var/named /srv/named/var/named
|
||||
|
||||
[root@rhel7-host ~]# docker stop infallible_wescoff
|
||||
```
|
||||
|
||||
### 最终的创建
|
||||
|
||||
为了创建和运行最终的容器,添加卷选项以挂载:
|
||||
|
||||
- 将文件 `/srv/named/etc/named.conf` 映射为 `/etc/named.conf`
|
||||
- 将目录 `/srv/named/var/named` 映射为 `/var/named`
|
||||
|
||||
因为这是我们最终的容器,我们将提供一个有意义的名字,以供我们以后引用。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker run -d -p 53:53 -p 53:53/udp -v /srv/named/etc/named.conf:/etc/named.conf:Z -v /srv/named/var/named:/var/named:Z --name named-container named
|
||||
```
|
||||
|
||||
在最终容器运行时,我们可以更改本机配置来改变这个容器中 BIND 的行为。这个 BIND 服务器将需要在这个容器分配的任何 IP 上监听。请确保任何新文件的 GID 与来自这个容器中的其余的 BIND 文件相匹配。
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# cp named.conf /srv/named/etc/named.conf
|
||||
|
||||
[root@rhel7-host ~]# cp example.com.zone /srv/named/var/named/example.com.zone
|
||||
|
||||
[root@rhel7-host ~]# cp example.com.rr.zone /srv/named/var/named/example.com.rr.zone
|
||||
```
|
||||
|
||||
> 很好奇为什么我不需要在主机目录中改变 SELinux 上下文?^注1
|
||||
|
||||
我们将运行这个容器提供的 `rndc` 二进制文件重新加载配置。我们可以使用 `journald` 以同样的方式检查 BIND 日志。如果运行出现错误,你可以在主机中编辑该文件,并且重新加载配置。在主机中使用 `host` 或 `dig`,我们可以检查来自该容器化服务的 example.com 的响应。
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker exec -it named-container rndc reload
|
||||
server reload successful
|
||||
|
||||
[root@rhel7-host ~]# docker exec -it named-container journalctl -u named -n
|
||||
-- Logs begin at Fri 2017-05-12 19:15:18 UTC, end at Fri 2017-05-12 19:29:17 UTC. --
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: 9.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: A.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: B.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: 8.B.D.0.1.0.0.2.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: reloading configuration succeeded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: reloading zones succeeded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: zone 1.0.10.in-addr.arpa/IN: loaded serial 2001062601
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: zone 1.0.10.in-addr.arpa/IN: sending notifies (serial 2001062601)
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: all zones loaded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: running
|
||||
|
||||
[root@rhel7-host bind]# host www.example.com localhost
|
||||
Using domain server:
|
||||
Name: localhost
|
||||
Address: ::1#53
|
||||
Aliases:
|
||||
www.example.com is an alias for server1.example.com.
|
||||
server1.example.com is an alias for mail
|
||||
```
|
||||
|
||||
> 你的区域文件没有更新吗?可能是因为你的编辑器,而不是序列号。^注2
|
||||
|
||||
### 终点线
|
||||
|
||||
我们已经达成了我们打算完成的目标,从容器中为 DNS 请求和区域文件提供服务。我们已经得到一个持久化的位置来管理更新和配置,并且更新后该配置不变。
|
||||
|
||||
在这个系列的第二部分,我们将看到怎样将一个容器看作为主机中的一个普通服务来运行。
|
||||
|
||||
---
|
||||
|
||||
[关注 RHEL 博客](http://redhatstackblog.wordpress.com/feed/),通过电子邮件来获得本系列第二部分和其它新文章的更新。
|
||||
|
||||
---
|
||||
|
||||
### 附加资源
|
||||
|
||||
- **所附带文件的 Github 仓库:** [https://github.com/nzwulfin/named-container](https://github.com/nzwulfin/named-container)
|
||||
- **注1:** **通过容器访问本地文件的 SELinux 上下文**
|
||||
|
||||
你可能已经注意到当我从容器向本地主机拷贝文件时,我没有运行 `chcon` 将主机中的文件类型改变为 `svirt_sandbox_file_t`。为什么它没有出错?将一个文件拷贝到 `/srv` 会将这个文件标记为类型 `var_t`。我 `setenforce 0` (关闭 SELinux)了吗?
|
||||
|
||||
当然没有,这将让 [Dan Walsh 大哭](https://stopdisablingselinux.com/)(LCTT 译注:RedHat 的 SELinux 团队负责人,倡议不要禁用 SELinux)。是的,`machinectl` 确实将文件标记类型设置为期望的那样,可以看一下:
|
||||
|
||||
启动一个容器之前:
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# ls -Z /srv/named/etc/named.conf
|
||||
-rw-r-----. unconfined_u:object_r:var_t:s0 /srv/named/etc/named.conf
|
||||
```
|
||||
|
||||
不过,运行中我使用了一个卷选项可以使 Dan Walsh 先生高兴起来,`:Z`。`-v /srv/named/etc/named.conf:/etc/named.conf:Z` 命令的这部分做了两件事情:首先它表示这需要使用一个私有卷的 SELiunx 标记来重新标记;其次它表明以读写挂载。
|
||||
|
||||
启动容器之后:
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# ls -Z /srv/named/etc/named.conf
|
||||
-rw-r-----. root 25 system_u:object_r:svirt_sandbox_file_t:s0:c821,c956 /srv/named/etc/named.conf
|
||||
```
|
||||
|
||||
- **注2:** **VIM 备份行为能改变 inode**
|
||||
|
||||
如果你在本地主机中使用 `vim` 来编辑配置文件,而你没有看到容器中的改变,你可能不经意的创建了容器感知不到的新文件。在编辑时,有三种 `vim` 设定影响备份副本:`backup`、`writebackup` 和 `backupcopy`。
|
||||
|
||||
我摘录了 RHEL 7 中的来自官方 VIM [backup_table][9] 中的默认配置。
|
||||
|
||||
```
|
||||
backup writebackup
|
||||
off on backup current file, deleted afterwards (default)
|
||||
```
|
||||
所以我们不创建残留下的 `~` 副本,而是创建备份。另外的设定是 `backupcopy`,`auto` 是默认的设置:
|
||||
|
||||
```
|
||||
"yes" make a copy of the file and overwrite the original one
|
||||
"no" rename the file and write a new one
|
||||
"auto" one of the previous, what works best
|
||||
```
|
||||
|
||||
这种组合设定意味着当你编辑一个文件时,除非 `vim` 有理由(请查看文档了解其逻辑),你将会得到一个包含你编辑内容的新文件,当你保存时它会重命名为原先的文件。这意味着这个文件获得了新的 inode。对于大多数情况,这不是问题,但是这里容器的<ruby>绑定挂载<rt>bind mount</rt></ruby>对 inode 的改变很敏感。为了解决这个问题,你需要改变 `backupcopy` 的行为。
|
||||
|
||||
不管是在 `vim` 会话中还是在你的 `.vimrc`中,请添加 `set backupcopy=yes`。这将确保原先的文件被清空并覆写,维持了 inode 不变并且将该改变传递到了容器中。
|
||||
|
||||
------------
|
||||
|
||||
via: http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/
|
||||
|
||||
作者:[Matt Micene][a]
|
||||
译者:[liuxinyu123](https://github.com/liuxinyu123)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/
|
||||
[1]:http://rhelblog.redhat.com/author/mmicenerht/
|
||||
[2]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#repo
|
||||
[3]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#sidebar_1
|
||||
[4]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#sidebar_2
|
||||
[5]:http://redhatstackblog.wordpress.com/feed/
|
||||
[6]:https://access.redhat.com/containers
|
||||
[7]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#repo
|
||||
[8]:https://github.com/nzwulfin/named-container
|
||||
[9]:http://vimdoc.sourceforge.net/htmldoc/editing.html#backup-table
|
||||
@ -0,0 +1,75 @@
|
||||
在 Linux 启动或重启时执行命令与脚本
|
||||
======
|
||||
|
||||
有时可能会需要在重启时或者每次系统启动时运行某些命令或者脚本。我们要怎样做呢?本文中我们就对此进行讨论。 我们会用两种方法来描述如何在 CentOS/RHEL 以及 Ubuntu 系统上做到重启或者系统启动时执行命令和脚本。 两种方法都通过了测试。
|
||||
|
||||
### 方法 1 – 使用 rc.local
|
||||
|
||||
这种方法会利用 `/etc/` 中的 `rc.local` 文件来在启动时执行脚本与命令。我们在文件中加上一行来执行脚本,这样每次启动系统时,都会执行该脚本。
|
||||
|
||||
不过我们首先需要为 `/etc/rc.local` 添加执行权限,
|
||||
|
||||
```
|
||||
$ sudo chmod +x /etc/rc.local
|
||||
```
|
||||
|
||||
然后将要执行的脚本加入其中:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/rc.local
|
||||
```
|
||||
|
||||
在文件最后加上:
|
||||
|
||||
```
|
||||
sh /root/script.sh &
|
||||
```
|
||||
|
||||
然后保存文件并退出。使用 `rc.local` 文件来执行命令也是一样的,但是一定要记得填写命令的完整路径。 想知道命令的完整路径可以运行:
|
||||
|
||||
```
|
||||
$ which command
|
||||
```
|
||||
|
||||
比如:
|
||||
|
||||
```
|
||||
$ which shutter
|
||||
/usr/bin/shutter
|
||||
```
|
||||
|
||||
如果是 CentOS,我们修改的是文件 `/etc/rc.d/rc.local` 而不是 `/etc/rc.local`。 不过我们也需要先为该文件添加可执行权限。
|
||||
|
||||
注意:- 启动时执行的脚本,请一定保证是以 `exit 0` 结尾的。
|
||||
|
||||
### 方法 2 – 使用 Crontab
|
||||
|
||||
该方法最简单了。我们创建一个 cron 任务,这个任务在系统启动后等待 90 秒,然后执行命令和脚本。
|
||||
|
||||
要创建 cron 任务,打开终端并执行
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
```
|
||||
|
||||
然后输入下行内容,
|
||||
|
||||
```
|
||||
@reboot ( sleep 90 ; sh \location\script.sh )
|
||||
```
|
||||
|
||||
这里 `\location\script.sh` 就是待执行脚本的地址。
|
||||
|
||||
我们的文章至此就完了。如有疑问,欢迎留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/executing-commands-scripts-at-reboot/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
72
published/20170922 How to disable USB storage on Linux.md
Normal file
72
published/20170922 How to disable USB storage on Linux.md
Normal file
@ -0,0 +1,72 @@
|
||||
Linux 上如何禁用 USB 存储
|
||||
======
|
||||
|
||||
为了保护数据不被泄漏,我们使用软件和硬件防火墙来限制外部未经授权的访问,但是数据泄露也可能发生在内部。 为了消除这种可能性,机构会限制和监测访问互联网,同时禁用 USB 存储设备。
|
||||
|
||||
在本教程中,我们将讨论三种不同的方法来禁用 Linux 机器上的 USB 存储设备。所有这三种方法都在 CentOS 6&7 机器上通过测试。那么让我们一一讨论这三种方法,
|
||||
|
||||
(另请阅读: [Ultimate guide to securing SSH sessions][1])
|
||||
|
||||
### 方法 1 – 伪安装
|
||||
|
||||
在本方法中,我们往配置文件中添加一行 `install usb-storage /bin/true`, 这会让安装 usb-storage 模块的操作实际上变成运行 `/bin/true`, 这也是为什么这种方法叫做`伪安装`的原因。 具体来说就是,在文件夹 `/etc/modprobe.d` 中创建并打开一个名为 `block_usb.conf` (也可能叫其他名字) ,
|
||||
|
||||
```
|
||||
$ sudo vim /etc/modprobe.d/block_usb.conf
|
||||
```
|
||||
|
||||
然后将下行内容添加进去:
|
||||
|
||||
```
|
||||
install usb-storage /bin/true
|
||||
```
|
||||
|
||||
最后保存文件并退出。
|
||||
|
||||
### 方法 2 – 删除 USB 驱动
|
||||
|
||||
这种方法要求我们将 USB 存储的驱动程序(`usb_storage.ko`)删掉或者移走,从而达到无法再访问 USB 存储设备的目的。 执行下面命令可以将驱动从它默认的位置移走:
|
||||
|
||||
```
|
||||
$ sudo mv /lib/modules/$(uname -r)/kernel/drivers/usb/storage/usb-storage.ko /home/user1
|
||||
```
|
||||
|
||||
现在在默认的位置上无法再找到驱动程序了,因此当 USB 存储器连接到系统上时也就无法加载到驱动程序了,从而导致磁盘不可用。 但是这个方法有一个小问题,那就是当系统内核更新的时候,`usb-storage` 模块会再次出现在它的默认位置。
|
||||
|
||||
### 方法 3 - 将 USB 存储器纳入黑名单
|
||||
|
||||
我们也可以通过 `/etc/modprobe.d/blacklist.conf` 文件将 usb-storage 纳入黑名单。这个文件在 RHEL/CentOS 6 是现成就有的,但在 7 上可能需要自己创建。 要将 USB 存储列入黑名单,请使用 vim 打开/创建上述文件:
|
||||
|
||||
```
|
||||
$ sudo vim /etc/modprobe.d/blacklist.conf
|
||||
```
|
||||
|
||||
并输入以下行将 USB 纳入黑名单:
|
||||
|
||||
```
|
||||
blacklist usb-storage
|
||||
```
|
||||
|
||||
保存文件并退出。`usb-storage` 就在就会被系统阻止加载,但这种方法有一个很大的缺点,即任何特权用户都可以通过执行以下命令来加载 `usb-storage` 模块,
|
||||
|
||||
```
|
||||
$ sudo modprobe usb-storage
|
||||
```
|
||||
|
||||
这个问题使得这个方法不是那么理想,但是对于非特权用户来说,这个方法效果很好。
|
||||
|
||||
在更改完成后重新启动系统,以使更改生效。请尝试用这些方法来禁用 USB 存储,如果您遇到任何问题或有什么疑问,请告知我们。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/disable-usb-storage-linux/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject)原创编译,[Linux 中国](https://linux.cn/)荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/ultimate-guide-to-securing-ssh-sessions/
|
||||
@ -0,0 +1,102 @@
|
||||
如何使用 Wine 在 Linux 下玩魔兽世界
|
||||
======
|
||||
|
||||
**目标:**在 Linux 中运行魔兽世界
|
||||
|
||||
**发行版:**适用于几乎所有的 Linux 发行版。
|
||||
|
||||
**要求:**具有 root 权限的 Linux 系统,搭配上比较现代化的显卡并安装了最新的图形驱动程序。
|
||||
|
||||
**难度:**简单
|
||||
|
||||
**约定:**
|
||||
|
||||
* `#` - 要求以 root 权限执行命令,可以直接用 root 用户来执行也可以使用 `sudo` 命令
|
||||
* `$` - 使用普通非特权用户执行
|
||||
|
||||
### 简介
|
||||
|
||||
魔兽世界已经出现差不多有 13 年了,但它依然是最流行的 MMORPG。 不幸的是, 一直以来暴雪从未发布过官方的 Linux 客户端。 不过还好,我们有 Wine。
|
||||
|
||||
### 安装 Wine
|
||||
|
||||
你可以试着用一下普通的 Wine,但它在游戏性能方面改进不大。 Wine Staging 以及带 Gallium Nine 补丁的 Wine 几乎在各方面都要更好一点。 如果你使用了闭源的驱动程序, 那么 Wine Staging 是最好的选择。 若使用了 Mesa 驱动程序, 则还需要打上 Gallium Nine 补丁。
|
||||
|
||||
根据你使用的发行版,参考 [Wine 安装指南][6] 来安装。
|
||||
|
||||
### Winecfg
|
||||
|
||||
打开 `winecfg`。确保第一个标签页中的 Windows 版本已经设置成了 `Windows 7`。 暴雪不再对之前的版本提供支持。 然后进入 “Staging” 标签页。 这里根据你用的是 staging 版本的 Wine 还是打了 Gallium 补丁的 Wine 来进行选择。
|
||||
|
||||
![Winecfg Staging Settings][1]
|
||||
|
||||
不管是哪个版本的 Wine,都需要启用 VAAPI 以及 EAX。 至于是否隐藏 Wine 的版本则由你自己决定。
|
||||
|
||||
如果你用的是 Staging 补丁,则启用 CSMT。 如果你用的是 Gallium Nine,则启用 Gallium Nine。 但是你不能两个同时启用。
|
||||
|
||||
### Winetricks
|
||||
|
||||
下一步轮到 Winetricks 了。如果你对它不了解,那我告诉你, Winetricks 一个用来为 Wine 安装各种 Windows 库以及组件以便程序正常运行的脚本。 更多信息可以阅读我们的这篇文章 [Winetricks 指南][7]:
|
||||
|
||||
![Winetricks Corefonts Installed][2]
|
||||
|
||||
要让 WoW 以及<ruby>战网启动程序<rt>Battle.net launcher</rt></ruby>工作需要安装一些东西。首先,在 “Fonts” 部分中安装 `corefonts`。 然后下面这一步是可选的, 如果你希望来自互联网上的所有数据都显示在战网启动程序中的话,就还需要安装 DLL 部分中的 ie8。
|
||||
|
||||
### Battle.net
|
||||
|
||||
现在你配置好了 Wine 了,可以安装 Battle.net 应用了。 Battle.net 应用用来安装和升级 WoW 以及其他暴雪游戏。 它经常在升级后会出现问题。 因此若它突然出现问题,请查看 [WineHQ 页面][8]。
|
||||
|
||||
毫无疑问,你可以从 [Blizzard 的官网上][9] 下载 Battle.net 应用。
|
||||
|
||||
下载完毕后,使用 Wine 打开 `.exe` 文件, 然后按照安装指引一步步走下去,就跟在 Windows 上一样。
|
||||
|
||||
![Battle.net Launcher With WoW Installed][3]
|
||||
|
||||
应用安装完成后,登录/新建帐号就会进入启动器界面。 你在那可以安装和管理游戏。 然后开始安装 WoW。 这可得好一会儿。
|
||||
|
||||
### 运行游戏
|
||||
|
||||
![WoW Advanced Settings][4]
|
||||
|
||||
在 Battle.net 应用中点击 “Play” 按钮就能启动 WoW 了。你需要等一会儿才能出现登录界面, 这个性能简直堪称垃圾。 之所以这么慢是因为 WoW 默认使用 DX11 来加速。 进入设置窗口中的 “Advanced” 标签页, 设置图像 API 为 DX9。 保存然后退出游戏。 退出成功后再重新打开游戏。
|
||||
|
||||
现在游戏应该可以玩了。请注意,游戏的性能严重依赖于你的硬件水平。 WoW 是一个很消耗 CPU 的游戏, 而 Wine 更加加剧了 CPU 的负担。 如果你的 CPU 不够强劲, 你的体验会很差。 不过 WoW 支持低特效,因此你可以调低画质让游戏更流畅。
|
||||
|
||||
#### 性能调优
|
||||
|
||||
![WoW Graphics Settings][5]
|
||||
|
||||
很难说什么样的设置最适合你。WoW 在基本设置中有一个很简单的滑动比例条。 它的配置应该要比在 Windows 上低几个等级,毕竟这里的性能不像 Windows 上那么好。
|
||||
|
||||
先调低最可能的罪魁祸首。像<ruby>抗锯齿<rt>anti-aliasing</rt></ruby>和<ruby>粒子<rt>particles</rt></ruby>就常常会导致低性能。 另外,试试对比一下窗口模式和全屏模式。 有时候这两者之间的差距还是蛮大的。
|
||||
|
||||
WoW 对 “Raid and Battleground” 有专门的配置项。这可以在 “Raid and Battleground” 实例中的内容创建更精细的画面。 有时间 WoW 在开放地图中表现不错, 但当很多玩家出现在屏幕中时就变得很垃圾了。
|
||||
|
||||
实验然后看看哪些配置最适合你的系统。这完全取决于你的硬件和你的系统配置。
|
||||
|
||||
### 最后结语
|
||||
|
||||
虽然从未发布过 Linux 版的魔兽世界,但它在 Wine 上已经运行很多年了。 事实上, 它几乎一直都工作的很好。 甚至有传言说暴雪的开发人员会在 Wine 上测试以保证它是有效的。
|
||||
|
||||
虽然有这个说法,但后续的更新和补丁还是会影响到这个古老的游戏, 所以请随时做好出问题的准备。 不管怎样, 就算出问题了,也总是早已有了解决方案, 你只需要找到它而已。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-play-world-of-warcraft-on-linux-with-wine
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
[1]:https://linuxconfig.org/images/wow-wine-staging.jpg
|
||||
[2]:https://linuxconfig.org/images/wow-wine-corefonts.jpg
|
||||
[3]:https://linuxconfig.org/images/wow-bnet.jpg
|
||||
[4]:https://linuxconfig.org/images/wow-api.jpg
|
||||
[5]:https://linuxconfig.org/images/wow-settings.jpg
|
||||
[6]:https://linuxconfig.org/installing-wine
|
||||
[7]:https://linuxconfig.org/configuring-wine-with-winetricks
|
||||
[8]:https://appdb.winehq.org/objectManager.php?sClass=version&iId=28855&iTestingId=98594
|
||||
[9]:http://us.battle.net/en/app/
|
||||
@ -0,0 +1,140 @@
|
||||
使用 VirtualBox 创建 Vagrant Boxes 的完全指南
|
||||
======
|
||||
|
||||
Vagrant 是一个用来创建和管理虚拟机环境的工具,常用于建设开发环境。 它在 Docker、VirtualBox、Hyper-V、Vmware、AWS 等技术的基础上构建了一个易于使用且易于复制、重建的环境。
|
||||
|
||||
Vagrant Boxes 简化了软件配置部分的工作,并且完全解决了软件开发项目中经常遇到的“它能在我机器上工作”的问题,从而提高开发效率。
|
||||
|
||||
在本文中,我们会在 Linux 机器上学习使用 VirtualBox 来配置 Vagrant Boxes。
|
||||
|
||||
### 前置条件
|
||||
|
||||
Vagrant 是基于虚拟化环境运行的,这里我们使用 VirtualBox 来提供虚拟化环境。 关于如何安装 VirutalBox 我们在“[在 Linux 上安装 VirtualBox][1]” 中有详细描述,请阅读该文并安装 VirtualBox。
|
||||
|
||||
安装好 VirtualBox 后,下一步就是配置 Vagrant 了。
|
||||
|
||||
- 推荐阅读:[创建你的 Docker 容器][2]
|
||||
|
||||
### 安装
|
||||
|
||||
VirtualBox 准备好后,我们来安装最新的 vagrant 包。 在写本文的时刻, Vagrant 的最新版本为 2.0.0。 使用下面命令下载最新的 rpm 文件:
|
||||
|
||||
```
|
||||
$ wget https://releases.hashicorp.com/vagrant/2.0.0/vagrant_2.0.0_x86_64.rpm
|
||||
```
|
||||
|
||||
然后安装这个包:
|
||||
|
||||
```
|
||||
$ sudo yum install vagrant_2.0.0_x86_64.rpm
|
||||
```
|
||||
|
||||
如果是 Ubuntu,用下面这个命令来下载最新的 vagrant 包:
|
||||
|
||||
```
|
||||
$ wget https://releases.hashicorp.com/vagrant/2.0.0/vagrant_2.0.0_x86_64.deb
|
||||
```
|
||||
|
||||
然后安装它,
|
||||
|
||||
```
|
||||
$ sudo dpkg -i vagrant_2.0.0_x86_64.deb
|
||||
```
|
||||
|
||||
安装结束后,就该进入配置环节了。
|
||||
|
||||
### 配置
|
||||
|
||||
首先,我们需要创建一个目录给 vagrant 来安装我们需要的操作系统,
|
||||
|
||||
```
|
||||
$ mkdir /home/dan
|
||||
$ cd /home/dan/vagrant
|
||||
```
|
||||
|
||||
**注意:** 推荐在你的用户主目录下创建 vagrant,否则你可能会遇到本地用户相关的权限问题。
|
||||
|
||||
现在执行下面命令来安装操作系统,比如 CentOS:
|
||||
|
||||
```
|
||||
$ sudo vagrant init centos/7
|
||||
```
|
||||
|
||||
如果要安装 Ubuntu 则运行:
|
||||
|
||||
```
|
||||
$ sudo vagrant init ubuntu/trusty64
|
||||
```
|
||||
|
||||
![vagrant boxes][4]
|
||||
|
||||
这还会在存放 vagrant OS 的目录中创建一个叫做 `Vagrantfile` 的配置文件。它包含了一些关于操作系统、私有 IP 网络、转发端口、主机名等信息。 若我们需要创建一个新的操作系统, 也可以编辑这个问题。
|
||||
|
||||
一旦我们用 vagrant 创建/修改了操作系统,我们可以用下面命令启动它:
|
||||
|
||||
```
|
||||
$ sudo vagrant up
|
||||
```
|
||||
|
||||
这可能要花一些时间,因为这条命令要构建操作系统,它需要从网络上下载所需的文件。 因此根据互联网的速度, 这个过程可能会比较耗时。
|
||||
|
||||
![vagrant boxes][6]
|
||||
|
||||
这个过程完成后,你就可以使用下面这些命令来管理 vagrant 实例了。
|
||||
|
||||
启动 vagrant 服务器:
|
||||
|
||||
```
|
||||
$ sudo vagrant up
|
||||
```
|
||||
|
||||
关闭服务器:
|
||||
|
||||
```
|
||||
$ sudo vagrant halt
|
||||
```
|
||||
|
||||
完全删除服务器:
|
||||
|
||||
```
|
||||
$ sudo vagrant destroy
|
||||
```
|
||||
|
||||
使用 ssh 访问服务器:
|
||||
|
||||
```
|
||||
$ sudo vagrant ssh
|
||||
```
|
||||
|
||||
我们可以从 Vagrant Box 的启动过程中得到 ssh 的详细信息(参见上面的截屏)。
|
||||
|
||||
如果想看创建的 vagrant OS,可以打开 VirtualBox,然后你就能在 VirtualBox 创建的虚拟机中找到它了。 如果在 VirtualBox 中没有找到, 使用 `sudo` 权限打开 virtualbox, 然后应该就能看到了。
|
||||
|
||||
![vagrant boxes][8]
|
||||
|
||||
**注意:** 在 [Vagrant 官方网站](https://app.vagrantup.com/boxes/search)上可以下载预先配置好的 Vagrant OS。
|
||||
|
||||
这就是本文的内容了。如有疑问请在下方留言,我们会尽快回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/creating-vagrant-virtual-boxes-virtualbox/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/installing-virtualbox-on-linux-centos-ubuntu/
|
||||
[2]:http://linuxtechlab.com/create-first-docker-container-beginners-guide/
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=721%2C87
|
||||
[4]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/vagrant-1.png?resize=721%2C87
|
||||
[5]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=980%2C414
|
||||
[6]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/vagrant-2-e1510557565780.png?resize=980%2C414
|
||||
[7]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=769%2C582
|
||||
[8]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/vagrant-3.png?resize=769%2C582
|
||||
[9]:https://www.facebook.com/linuxtechlab/
|
||||
[10]:https://twitter.com/LinuxTechLab
|
||||
[11]:https://plus.google.com/+linuxtechlab
|
||||
@ -1,43 +1,50 @@
|
||||
translated by smartgrids
|
||||
Eclipse 如何助力 IoT 发展
|
||||
============================================================
|
||||
|
||||
### 开源组织的模块发开发方式非常适合物联网。
|
||||
|
||||
> 开源组织的模块化开发方式非常适合物联网。
|
||||
|
||||

|
||||
|
||||
图片来源: opensource.com
|
||||
|
||||
[Eclipse][3] 可能不是第一个去研究物联网的开源组织。但是,远在 IoT 家喻户晓之前,该基金会在 2001 年左右就开始支持开源软件发展商业化。九月 Eclipse 物联网日和 RedMonk 的 [ThingMonk 2017][4] 一块举行,着重强调了 Eclipse 在 [物联网发展][5] 中的重要作用。它现在已经包含了 28 个项目,覆盖了大部分物联网项目需求。会议过程中,我和负责 Eclipse 市场化运作的 [Ian Skerritt][6] 讨论了 Eclipse 的物联网项目以及如何拓展它。
|
||||
[Eclipse][3] 可能不是第一个去研究物联网的开源组织。但是,远在 IoT 家喻户晓之前,该基金会在 2001 年左右就开始支持开源软件发展商业化。
|
||||
|
||||
九月份的 Eclipse 物联网日和 RedMonk 的 [ThingMonk 2017][4] 一块举行,着重强调了 Eclipse 在 [物联网发展][5] 中的重要作用。它现在已经包含了 28 个项目,覆盖了大部分物联网项目需求。会议过程中,我和负责 Eclipse 市场化运作的 [Ian Skerritt][6] 讨论了 Eclipse 的物联网项目以及如何拓展它。
|
||||
|
||||
### 物联网的最新进展?
|
||||
|
||||
###物联网的最新进展?
|
||||
我问 Ian 物联网同传统工业自动化,也就是前几十年通过传感器和相应工具来实现工厂互联的方式有什么不同。 Ian 指出很多工厂是还没有互联的。
|
||||
另外,他说“ SCADA[监控和数据分析] 系统以及工厂底层技术都是私有、独立性的。我们很难去改变它,也很难去适配它们…… 现在,如果你想运行一套生产系统,你需要设计成百上千的单元。生产线想要的是满足用户需求,使制造过程更灵活,从而可以不断产出。” 这也就是物联网会带给制造业的一个很大的帮助。
|
||||
|
||||
另外,他说 “SCADA [<ruby>监控和数据分析<rt>supervisory control and data analysis</rt></ruby>] 系统以及工厂底层技术都是非常私有的、独立性的。我们很难去改变它,也很难去适配它们 …… 现在,如果你想运行一套生产系统,你需要设计成百上千的单元。生产线想要的是满足用户需求,使制造过程更灵活,从而可以不断产出。” 这也就是物联网会带给制造业的一个很大的帮助。
|
||||
|
||||
###Eclipse 物联网方面的研究
|
||||
Ian 对于 Eclipse 在物联网的研究是这样描述的:“满足任何物联网解决方案的核心基础技术” ,通过使用开源技术,“每个人都可以使用从而可以获得更好的适配性。” 他说,Eclipse 将物联网视为包括三层互联的软件栈。从更高的层面上看,这些软件栈(按照大家常见的说法)将物联网描述为跨越三个层面的网络。特定的观念可能认为含有更多的层面,但是他们一直符合这个三层模型的功能的:
|
||||
### Eclipse 物联网方面的研究
|
||||
|
||||
Ian 对于 Eclipse 在物联网的研究是这样描述的:“满足任何物联网解决方案的核心基础技术” ,通过使用开源技术,“每个人都可以使用,从而可以获得更好的适配性。” 他说,Eclipse 将物联网视为包括三层互联的软件栈。从更高的层面上看,这些软件栈(按照大家常见的说法)将物联网描述为跨越三个层面的网络。特定的实现方式可能含有更多的层,但是它们一般都可以映射到这个三层模型的功能上:
|
||||
|
||||
* 一种可以装载设备(例如设备、终端、微控制器、传感器)用软件的堆栈。
|
||||
* 将不同的传感器采集到的数据信息聚合起来并传输到网上的一类网关。这一层也可能会针对传感器数据检测做出实时反映。
|
||||
* 将不同的传感器采集到的数据信息聚合起来并传输到网上的一类网关。这一层也可能会针对传感器数据检测做出实时反应。
|
||||
* 物联网平台后端的一个软件栈。这个后端云存储数据并能根据采集的数据比如历史趋势、预测分析提供服务。
|
||||
|
||||
这三个软件栈在 Eclipse 的白皮书 “ [The Three Software Stacks Required for IoT Architectures][7] ”中有更详细的描述。
|
||||
这三个软件栈在 Eclipse 的白皮书 “[The Three Software Stacks Required for IoT Architectures][7] ”中有更详细的描述。
|
||||
|
||||
Ian 说在这些架构中开发一种解决方案时,“需要开发一些特殊的东西,但是很多底层的技术是可以借用的,像通信协议、网关服务。需要一种模块化的方式来满足不用的需求场合。” Eclipse 关于物联网方面的研究可以概括为:开发模块化开源组件从而可以被用于开发大量的特定性商业服务和解决方案。
|
||||
Ian 说在这些架构中开发一种解决方案时,“需要开发一些特殊的东西,但是很多底层的技术是可以借用的,像通信协议、网关服务。需要一种模块化的方式来满足不同的需求场合。” Eclipse 关于物联网方面的研究可以概括为:开发模块化开源组件,从而可以被用于开发大量的特定性商业服务和解决方案。
|
||||
|
||||
###Eclipse 的物联网项目
|
||||
### Eclipse 的物联网项目
|
||||
|
||||
在众多一杯应用的 Eclipse 物联网应用中, Ian 举了两个和 [MQTT][8] 有关联的突出应用,一个设备与设备互联(M2M)的物联网协议。 Ian 把它描述成“一个专为重视电源管理工作的油气传输线监控系统的信息发布/订阅协议。MQTT 已经是众多物联网广泛应用标准中很成功的一个。” [Eclipse Mosquitto][9] 是 MQTT 的代理,[Eclipse Paho][10] 是他的客户端。
|
||||
[Eclipse Kura][11] 是一个物联网网关,引用 Ian 的话,“它连接了很多不同的协议间的联系”包括蓝牙、Modbus、CANbus 和 OPC 统一架构协议,以及一直在不断添加的协议。一个优势就是,他说,取代了你自己写你自己的协议, Kura 提供了这个功能并将你通过卫星、网络或其他设备连接到网络。”另外它也提供了防火墙配置、网络延时以及其它功能。Ian 也指出“如果网络不通时,它会存储信息直到网络恢复。”
|
||||
在众多已被应用的 Eclipse 物联网应用中, Ian 举了两个和 [MQTT][8] 有关联的突出应用,一个设备与设备互联(M2M)的物联网协议。 Ian 把它描述成“一个专为重视电源管理工作的油气传输线监控系统的信息发布/订阅协议。MQTT 已经是众多物联网广泛应用标准中很成功的一个。” [Eclipse Mosquitto][9] 是 MQTT 的代理,[Eclipse Paho][10] 是他的客户端。
|
||||
|
||||
[Eclipse Kura][11] 是一个物联网网关,引用 Ian 的话,“它连接了很多不同的协议间的联系”,包括蓝牙、Modbus、CANbus 和 OPC 统一架构协议,以及一直在不断添加的各种协议。他说,一个优势就是,取代了你自己写你自己的协议, Kura 提供了这个功能并将你通过卫星、网络或其他设备连接到网络。”另外它也提供了防火墙配置、网络延时以及其它功能。Ian 也指出“如果网络不通时,它会存储信息直到网络恢复。”
|
||||
|
||||
最新的一个项目中,[Eclipse Kapua][12] 正尝试通过微服务来为物联网云平台提供不同的服务。比如,它集成了通信、汇聚、管理、存储和分析功能。Ian 说“它正在不断前进,虽然还没被完全开发出来,但是 Eurotech 和 RedHat 在这个项目上非常积极。”
|
||||
Ian 说 [Eclipse hawkBit][13] ,软件更新管理的软件,是一项“非常有趣的项目。从安全的角度说,如果你不能更新你的设备,你将会面临巨大的安全漏洞。”很多物联网安全事故都和无法更新的设备有关,他说,“ HawkBit 可以基本负责通过物联网系统来完成扩展性更新的后端管理。”
|
||||
|
||||
物联网设备软件升级的难度一直被看作是难度最高的安全挑战之一。物联网设备不是一直连接的,而且数目众多,再加上首先设备的更新程序很难完全正常。正因为这个原因,关于无赖女王软件升级的项目一直是被当作重要内容往前推进。
|
||||
Ian 说 [Eclipse hawkBit][13] ,一个软件更新管理的软件,是一项“非常有趣的项目。从安全的角度说,如果你不能更新你的设备,你将会面临巨大的安全漏洞。”很多物联网安全事故都和无法更新的设备有关,他说,“HawkBit 可以基本负责通过物联网系统来完成扩展性更新的后端管理。”
|
||||
|
||||
###为什么物联网这么适合 Eclipse
|
||||
物联网设备软件升级的难度一直被看作是难度最高的安全挑战之一。物联网设备不是一直连接的,而且数目众多,再加上首先设备的更新程序很难完全正常。正因为这个原因,关于 IoT 软件升级的项目一直是被当作重要内容往前推进。
|
||||
|
||||
在物联网发展趋势中的一个方面就是关于构建模块来解决商业问题,而不是宽约工业和公司的大物联网平台。 Eclipse 关于物联网的研究放在一系列模块栈、提供特定和大众化需求功能的项目,还有就是指定目标所需的可捆绑式中间件、网关和协议组件上。
|
||||
### 为什么物联网这么适合 Eclipse
|
||||
|
||||
在物联网发展趋势中的一个方面就是关于构建模块来解决商业问题,而不是跨越行业和公司的大物联网平台。 Eclipse 关于物联网的研究放在一系列模块栈、提供特定和大众化需求功能的项目上,还有就是指定目标所需的可捆绑式中间件、网关和协议组件上。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -46,15 +53,15 @@ Ian 说 [Eclipse hawkBit][13] ,软件更新管理的软件,是一项“非
|
||||
|
||||
作者简介:
|
||||
|
||||
Gordon Haff - Gordon Haff 是红帽公司的云营销员,经常在消费者和工业会议上讲话,并且帮助发展红帽全办公云解决方案。他是 计算机前言:云如何如何打开众多出版社未来之门 的作者。在红帽之前, Gordon 写了成百上千的研究报告,经常被引用到公众刊物上,像纽约时报关于 IT 的议题和产品建议等……
|
||||
Gordon Haff - Gordon Haff 是红帽公司的云专家,经常在消费者和行业会议上讲话,并且帮助发展红帽全面云化解决方案。他是《计算机前沿:云如何如何打开众多出版社未来之门》的作者。在红帽之前, Gordon 写了成百上千的研究报告,经常被引用到公众刊物上,像纽约时报关于 IT 的议题和产品建议等……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
转自: https://opensource.com/article/17/10/eclipse-and-iot
|
||||
via: https://opensource.com/article/17/10/eclipse-and-iot
|
||||
|
||||
作者:[Gordon Haff ][a]
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[smartgrids](https://github.com/smartgrids)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,217 @@
|
||||
怎么使用 SVG 作为一个图像占位符
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
*从图像中生成的 SVG 可以用作占位符。请继续阅读!*
|
||||
|
||||
我对怎么去让 web 性能更优化和图像加载的更快充满了热情。在这些感兴趣的领域中的其中一项研究就是占位符:当图像还没有被加载的时候应该去展示些什么?
|
||||
|
||||
在前些天,我偶然发现了使用 SVG 的一些加载技术,我将在这篇文章中谈论它。
|
||||
|
||||
在这篇文章中我们将涉及如下的主题:
|
||||
|
||||
* 不同的占位符类型的概述
|
||||
* 基于 SVG 的占位符(边缘、形状和轮廓)
|
||||
* 自动化处理
|
||||
|
||||
### 不同的占位符类型的概述
|
||||
|
||||
之前 [我写过一篇关于图像占位符和<ruby>延迟加载<rt>lazy-loading</rt></ruby>][28] 的文章以及 [关于它的讨论][29]。当进行一个图像的延迟加载时,一个很好的办法是提供一个东西作为占位符,因为它可能会很大程度上影响用户的感知体验。之前我提供了几个选择:
|
||||
|
||||

|
||||
|
||||
在图像被加载之前,有几种办法去填充图像区域:
|
||||
|
||||
* 在图像区域保持空白:在一个响应式设计的环境中,这种方式防止了内容的跳跃。从用户体验的角度来看,那些布局的改变是非常差的作法。但是,它是为了性能的考虑,否则,每次为了获取图像尺寸,浏览器就要被迫进行布局重新计算,以便为它留下空间。
|
||||
* 占位符:在图像那里显示一个用户配置的图像。我们可以在背景上显示一个轮廓。它一直显示直到实际的图像被加载完成,它也被用于当请求失败或者当用户根本没有设置头像图像的情况下。这些图像一般都是矢量图,并且由于尺寸非常小,可以作为内联图片。
|
||||
* 单一颜色:从图像中获取颜色,并将其作为占位符的背景颜色。这可能是图像的主要颜色、最具活力的颜色 … 这个想法是基于你正在加载的图像,并且它将有助于在没有图像和图像加载完成之间进行平滑过渡。
|
||||
* 模糊的图像:也被称为模糊技术。你提供一个极小版本的图像,然后再去过渡到完整的图像。最初显示的图像的像素和尺寸是极小的。为去除<ruby>细节<rt>artifacts</rt></ruby>,该图像会被放大并模糊化。我在前面写的 [Medium 是怎么做的渐进加载图像][1]、[使用 WebP 去创建极小的预览图像][2]、和[渐进加载图像的更多示例][3] 中讨论过这方面的内容。
|
||||
|
||||
此外还有其它的更多的变种,许多聪明的人也开发了其它的创建占位符的技术。
|
||||
|
||||
其中一个就是用梯度图代替单一的颜色。梯度图可以创建一个更精确的最终图像的预览,它整体上非常小(提升了有效载荷)。
|
||||
|
||||

|
||||
|
||||
*使用梯度图作为背景。这是来自 Gradify 的截屏,它现在已经不在线了,代码 [在 GitHub][4]。*
|
||||
|
||||
另外一种技术是使用基于 SVG 的技术,它在最近的实验和研究中取得到了一些进展。
|
||||
|
||||
### 基于 SVG 的占位符
|
||||
|
||||
我们知道 SVG 是完美的矢量图像。而在大多数情况下我们是希望加载一个位图,所以,问题是怎么去矢量化一个图像。其中一些方法是使用边缘、形状和轮廓。
|
||||
|
||||
#### 边缘
|
||||
|
||||
在 [前面的文章中][30],我解释了怎么去找出一个图像的边缘并创建一个动画。我最初的目标是去尝试绘制区域,矢量化该图像,但是我并不知道该怎么去做到。我意识到使用边缘也可能是一种创新,我决定去让它们动起来,创建一个 “绘制” 的效果。
|
||||
|
||||
- [范例](https://codepen.io/jmperez/embed/oogqdp?default-tabs=html%2Cresult&embed-version=2&height=600&host=https%3A%2F%2Fcodepen.io&referrer=https%3A%2F%2Fmedium.freecodecamp.org%2Fmedia%2F8c5c44a4adf82b09692a34eb4daa3e2e%3FpostId%3Dbed1b810ab2c&slug-hash=oogqdp#result-box)
|
||||
|
||||
> [使用边缘检测绘制图像和 SVG 动画][31]
|
||||
|
||||
> 在以前,很少使用和支持 SVG。一段时间以后,我们开始用它去作为一个某些图标的传统位图的替代品……
|
||||
|
||||
#### 形状
|
||||
|
||||
SVG 也可以用于根据图像绘制区域而不是边缘/边界。用这种方法,我们可以矢量化一个位图来创建一个占位符。
|
||||
|
||||
在以前,我尝试去用三角形做类似的事情。你可以在 [CSSConf][33] 和 [Render Conf][34] 上我的演讲中看到它。
|
||||
|
||||
- [范例](https://codepen.io/jmperez/embed/BmaWmQ?default-tabs=html%2Cresult&embed-version=2&height=600&host=https%3A%2F%2Fcodepen.io&referrer=https%3A%2F%2Fmedium.freecodecamp.org%2Fmedia%2F05d1ee44f0537f8257258124d7b94613%3FpostId%3Dbed1b810ab2c&slug-hash=BmaWmQ#result-box)
|
||||
|
||||
上面的 codepen 是一个由 245 个三角形组成的基于 SVG 占位符的概念验证。生成的三角形是基于 [Delaunay triangulation][35] 的,使用了 [Possan’s polyserver][36]。正如预期的那样,使用更多的三角形,文件尺寸就更大。
|
||||
|
||||
#### Primitive 和 SQIP,一个基于 SVG 的 LQIP 技术
|
||||
|
||||
Tobias Baldauf 正在致力于另一个使用 SVG 的低质量图像占位符技术,它被称为 [SQIP][37]。在深入研究 SQIP 之前,我先简单介绍一下 [Primitive][38],它是基于 SQIP 的一个库。
|
||||
|
||||
Primitive 是非常吸引人的,我强烈建议你去了解一下。它讲解了一个位图怎么变成由重叠形状组成的 SVG。它尺寸比较小,适合于直接内联放置到页面中。当步骤较少时,在初始的 HTML 载荷中作为占位符是非常有意义的。
|
||||
|
||||
Primitive 基于三角形、长方形、和圆形等形状生成一个图像。在每一步中它增加一个新形状。很多步之后,图像的结果看起来非常接近原始图像。如果你输出的是 SVG,它意味着输出代码的尺寸将很大。
|
||||
|
||||
为了理解 Primitive 是怎么工作的,我通过几个图像来跑一下它。我用 10 个形状和 100 个形状来为这个插画生成 SVG:
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
使用 Primitive 处理 ,使用 [10 个形状][6] 、 [100 形状][7]、 [原图][5]。
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
使用 Primitive 处理,使用 [10 形状][9] 、 [100 形状][10]、 [原图][8] 。
|
||||
|
||||
当在图像中使用 10 个形状时,我们基本构画出了原始图像。在图像占位符这种使用场景里,我们可以使用这种 SVG 作为潜在的占位符。实际上,使用 10 个形状的 SVG 代码已经很小了,大约是 1030 字节,当通过 SVGO 传输时,它将下降到约 640 字节。
|
||||
|
||||
```
|
||||
<svg xmlns=”http://www.w3.org/2000/svg" width=”1024" height=”1024"><path fill=”#817c70" d=”M0 0h1024v1024H0z”/><g fill-opacity=”.502"><path fill=”#03020f” d=”M178 994l580 92L402–62"/><path fill=”#f2e2ba” d=”M638 894L614 6l472 440"/><path fill=”#fff8be” d=”M-62 854h300L138–62"/><path fill=”#76c2d9" d=”M410–62L154 530–62 38"/><path fill=”#62b4cf” d=”M1086–2L498–30l484 508"/><path fill=”#010412" d=”M430–2l196 52–76 356"/><path fill=”#eb7d3f” d=”M598 594l488–32–308 520"/><path fill=”#080a18" d=”M198 418l32 304 116–448"/><path fill=”#3f201d” d=”M1086 1062l-344–52 248–148"/><path fill=”#ebd29f” d=”M630 658l-60–372 516 320"/></g></svg>
|
||||
```
|
||||
|
||||
正如我们预计的那样,使用 100 个形状生成的图像更大,在 SVGO(之前是 8kB)之后,大小约为 5kB。它们在细节上已经很好了,但是仍然是个很小的载荷。使用多少三角形主要取决于图像类型和细腻程度(如,对比度、颜色数量、复杂度)。
|
||||
|
||||
还可以创建一个类似于 [cpeg-dssim][39] 的脚本,去调整所使用的形状的数量,以满足 [结构相似][40] 的阈值(或者最差情况中的最大数量)。
|
||||
|
||||
这些生成的 SVG 也可以用作背景图像。因为尺寸约束和矢量化,它们在展示<ruby>超大题图<rt>hero image</rt></ruby>和大型背景图像时是很好的选择。
|
||||
|
||||
#### SQIP
|
||||
|
||||
用 [Tobias 自己的话说][41]:
|
||||
|
||||
> SQIP 尝试在这两个极端之间找到一种平衡:它使用 [Primitive][42] 去生成一个 SVG,由几种简单的形状构成,近似于图像中可见的主要特征,使用 [SVGO][43] 优化 SVG,并且为它增加高斯模糊滤镜。产生的最终的 SVG 占位符后大小仅为约 800~1000 字节,在屏幕上看起来更为平滑,并提供一个图像内容的视觉提示。
|
||||
|
||||
这个结果和使用一个用了模糊技术的极小占位符图像类似。(看看 [Medium][44] 和 [其它站点][45] 是怎么做的)。区别在于它们使用了一个位图图像,如 JPG 或者 WebP,而这里是使用的占位符是 SVG。
|
||||
|
||||
如果我们使用 SQIP 而不是原始图像,我们将得到这样的效果:
|
||||
|
||||

|
||||

|
||||
|
||||
*[第一张图像][11] 和 [第二张图像][12] 使用了 SQIP 后的输出图像。*
|
||||
|
||||
输出的 SVG 约 900 字节,并且通过检查代码,我们可以发现 `feGaussianBlur` 过滤被应用到该组形状上:
|
||||
|
||||
```
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 2000 2000"><filter id="b"><feGaussianBlur stdDeviation="12" /></filter><path fill="#817c70" d="M0 0h2000v2000H0z"/><g filter="url(#b)" transform="translate(4 4) scale(7.8125)" fill-opacity=".5"><ellipse fill="#000210" rx="1" ry="1" transform="matrix(50.41098 -3.7951 11.14787 148.07886 107 194.6)"/><ellipse fill="#eee3bb" rx="1" ry="1" transform="matrix(-56.38179 17.684 -24.48514 -78.06584 205 110.1)"/><ellipse fill="#fff4bd" rx="1" ry="1" transform="matrix(35.40604 -5.49219 14.85017 95.73337 16.4 123.6)"/><ellipse fill="#79c7db" cx="21" cy="39" rx="65" ry="65"/><ellipse fill="#0c1320" cx="117" cy="38" rx="34" ry="47"/><ellipse fill="#5cb0cd" rx="1" ry="1" transform="matrix(-39.46201 77.24476 -54.56092 -27.87353 219.2 7.9)"/><path fill="#e57339" d="M271 159l-123–16 43 128z"/><ellipse fill="#47332f" cx="214" cy="237" rx="242" ry="19"/></g></svg>
|
||||
```
|
||||
|
||||
SQIP 也可以输出一个带有 Base64 编码的 SVG 内容的图像标签:
|
||||
|
||||
```
|
||||
<img width="640" height="640" src="example.jpg” alt="Add descriptive alt text" style="background-size: cover; background-image: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAw…<stripped base 64>…PjwvZz48L3N2Zz4=);">
|
||||
```
|
||||
|
||||
#### 轮廓
|
||||
|
||||
我们刚才看了使用了边缘和原始形状的 SVG。另外一种矢量化图像的方式是 “描绘” 它们。在几天前 [Mikael Ainalem][47] 分享了一个 [codepen][48] 代码,展示了怎么去使用两色轮廓作为一个占位符。结果非常漂亮:
|
||||
|
||||

|
||||
|
||||
SVG 在这种情况下是手工绘制的,但是,这种技术可以用工具快速生成并自动化处理。
|
||||
|
||||
* [Gatsby][13],一个用 React 支持的描绘 SVG 的静态网站生成器。它使用 [一个 potrace 算法的 JS 移植][14] 去矢量化图像。
|
||||
* [Craft 3 CMS][15],它也增加了对轮廓的支持。它使用了 [一个 potrace 算法的 PHP 移植][16]。
|
||||
* [image-trace-loader][17],一个使用了 potrace 算法去处理图像的 Webpack 加载器。
|
||||
|
||||
如果感兴趣,可以去看一下 Emil 的 webpack 加载器 (基于 potrace) 和 Mikael 的手工绘制 SVG 之间的比较。
|
||||
|
||||
这里我假设该输出是使用默认选项的 potrace 生成的。但是可以对它们进行优化。查看 [图像描绘加载器的选项][49],[传递给 potrace 的选项][50]非常丰富。
|
||||
|
||||
### 总结
|
||||
|
||||
我们看到了从图像中生成 SVG 并使用它们作为占位符的各种不同的工具和技术。与 [WebP 是一个用于缩略图的奇妙格式][51] 一样,SVG 也是一个用于占位符的有趣格式。我们可以控制细节的级别(和它们的大小),它是高可压缩的,并且很容易用 CSS 和 JS 进行处理。
|
||||
|
||||
#### 额外的资源
|
||||
|
||||
这篇文章上到了 [Hacker News 热文][52]。对此以及在该页面的评论中分享的其它资源的链接,我表示非常感谢。下面是其中一部分。
|
||||
|
||||
* [Geometrize][18] 是用 Haxe 写的 Primitive 的一个移植。也有[一个 JS 实现][19],你可以直接 [在你的浏览器上][20]尝试它。
|
||||
* [Primitive.js][21],它也是 Primitive 在 JS 中的一个移植,[primitive.nextgen][22],它是使用 Primitive.js 和 Electron 的 Primitive 的桌面版应用的一个移植。
|
||||
* 这里有两个 Twitter 帐户,里面你可以看到一些用 Primitive 和 Geometrize 生成的图像示例。访问 [@PrimitivePic][23] 和 [@Geometrizer][24]。
|
||||
* [imagetracerjs][25],它是在 JavaScript 中的光栅图像描绘器和矢量化程序。这里也有为 [Java][26] 和 [Android][27] 提供的移植。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/using-svg-as-placeholders-more-image-loading-techniques-bed1b810ab2c
|
||||
|
||||
作者:[José M. Pérez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@jmperezperez?source=post_header_lockup
|
||||
[1]:https://medium.com/@jmperezperez/how-medium-does-progressive-image-loading-fd1e4dc1ee3d
|
||||
[2]:https://medium.com/@jmperezperez/using-webp-to-create-tiny-preview-images-3e9b924f28d6
|
||||
[3]:https://medium.com/@jmperezperez/more-examples-of-progressive-image-loading-f258be9f440b
|
||||
[4]:https://github.com/fraser-hemp/gradify
|
||||
[5]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square.jpg
|
||||
[6]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square-10.svg
|
||||
[7]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square-100.svg
|
||||
[8]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-618463-square.jpg
|
||||
[9]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-618463-square-10.svg
|
||||
[10]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-618463-square-100.svg
|
||||
[11]:https://jmperezperez.com/assets/images/posts/svg-placeholders/pexels-photo-281184-square-sqip.svg
|
||||
[12]:https://jmperezperez.com/svg-placeholders/%28/assets/images/posts/svg-placeholders/pexels-photo-618463-square-sqip.svg
|
||||
[13]:https://www.gatsbyjs.org/
|
||||
[14]:https://www.npmjs.com/package/potrace
|
||||
[15]:https://craftcms.com/
|
||||
[16]:https://github.com/nystudio107/craft3-imageoptimize/blob/master/src/lib/Potracio.php
|
||||
[17]:https://github.com/EmilTholin/image-trace-loader
|
||||
[18]:https://github.com/Tw1ddle/geometrize-haxe
|
||||
[19]:https://github.com/Tw1ddle/geometrize-haxe-web
|
||||
[20]:http://www.samcodes.co.uk/project/geometrize-haxe-web/
|
||||
[21]:https://github.com/ondras/primitive.js
|
||||
[22]:https://github.com/cielito-lindo-productions/primitive.nextgen
|
||||
[23]:https://twitter.com/PrimitivePic
|
||||
[24]:https://twitter.com/Geometrizer
|
||||
[25]:https://github.com/jankovicsandras/imagetracerjs
|
||||
[26]:https://github.com/jankovicsandras/imagetracerjava
|
||||
[27]:https://github.com/jankovicsandras/imagetracerandroid
|
||||
[28]:https://medium.com/@jmperezperez/lazy-loading-images-on-the-web-to-improve-loading-time-and-saving-bandwidth-ec988b710290
|
||||
[29]:https://www.youtube.com/watch?v=szmVNOnkwoU
|
||||
[30]:https://medium.com/@jmperezperez/drawing-images-using-edge-detection-and-svg-animation-16a1a3676d3
|
||||
[31]:https://medium.com/@jmperezperez/drawing-images-using-edge-detection-and-svg-animation-16a1a3676d3
|
||||
[32]:https://medium.com/@jmperezperez/drawing-images-using-edge-detection-and-svg-animation-16a1a3676d3
|
||||
[33]:https://jmperezperez.com/cssconfau16/#/45
|
||||
[34]:https://jmperezperez.com/renderconf17/#/46
|
||||
[35]:https://en.wikipedia.org/wiki/Delaunay_triangulation
|
||||
[36]:https://github.com/possan/polyserver
|
||||
[37]:https://github.com/technopagan/sqip
|
||||
[38]:https://github.com/fogleman/primitive
|
||||
[39]:https://github.com/technopagan/cjpeg-dssim
|
||||
[40]:https://en.wikipedia.org/wiki/Structural_similarity
|
||||
[41]:https://github.com/technopagan/sqip
|
||||
[42]:https://github.com/fogleman/primitive
|
||||
[43]:https://github.com/svg/svgo
|
||||
[44]:https://medium.com/@jmperezperez/how-medium-does-progressive-image-loading-fd1e4dc1ee3d
|
||||
[45]:https://medium.com/@jmperezperez/more-examples-of-progressive-image-loading-f258be9f440b
|
||||
[46]:http://www.w3.org/2000/svg
|
||||
[47]:https://twitter.com/mikaelainalem
|
||||
[48]:https://codepen.io/ainalem/full/aLKxjm/
|
||||
[49]:https://github.com/EmilTholin/image-trace-loader#options
|
||||
[50]:https://www.npmjs.com/package/potrace#parameters
|
||||
[51]:https://medium.com/@jmperezperez/using-webp-to-create-tiny-preview-images-3e9b924f28d6
|
||||
[52]:https://news.ycombinator.com/item?id=15696596
|
||||
@ -1,20 +1,19 @@
|
||||
归档仓库
|
||||
如何归档 GitHub 仓库
|
||||
====================
|
||||
|
||||
|
||||
因为仓库不再活跃开发或者你不想接受额外的贡献并不意味着你想要删除它。现在在 Github 上归档仓库让它变成只读。
|
||||
如果仓库不再活跃开发或者你不想接受额外的贡献,但这并不意味着你想要删除它。现在可以在 Github 上归档仓库让它变成只读。
|
||||
|
||||
[][1]
|
||||
|
||||
归档一个仓库让它对所有人只读(包括仓库拥有者)。这包括编辑仓库、问题、合并请求、标记、里程碑、维基、发布、提交、标签、分支、反馈和评论。没有人可以在一个归档的仓库上创建新的问题、合并请求或者评论,但是你仍可以 fork 仓库-允许归档的仓库在其他地方继续开发。
|
||||
归档一个仓库会让它对所有人只读(包括仓库拥有者)。这包括对仓库的编辑、<ruby>问题<rt>issue</rt></ruby>、<ruby>合并请求<rt>pull request</rt></ruby>(PR)、标记、里程碑、项目、维基、发布、提交、标签、分支、反馈和评论。谁都不可以在一个归档的仓库上创建新的问题、合并请求或者评论,但是你仍可以 fork 仓库——以允许归档的仓库在其它地方继续开发。
|
||||
|
||||
要归档一个仓库,进入仓库设置页面并点在这个仓库上点击归档。
|
||||
要归档一个仓库,进入仓库设置页面并点在这个仓库上点击“<ruby>归档该仓库<rt>Archive this repository</rt></ruby>”。
|
||||
|
||||
[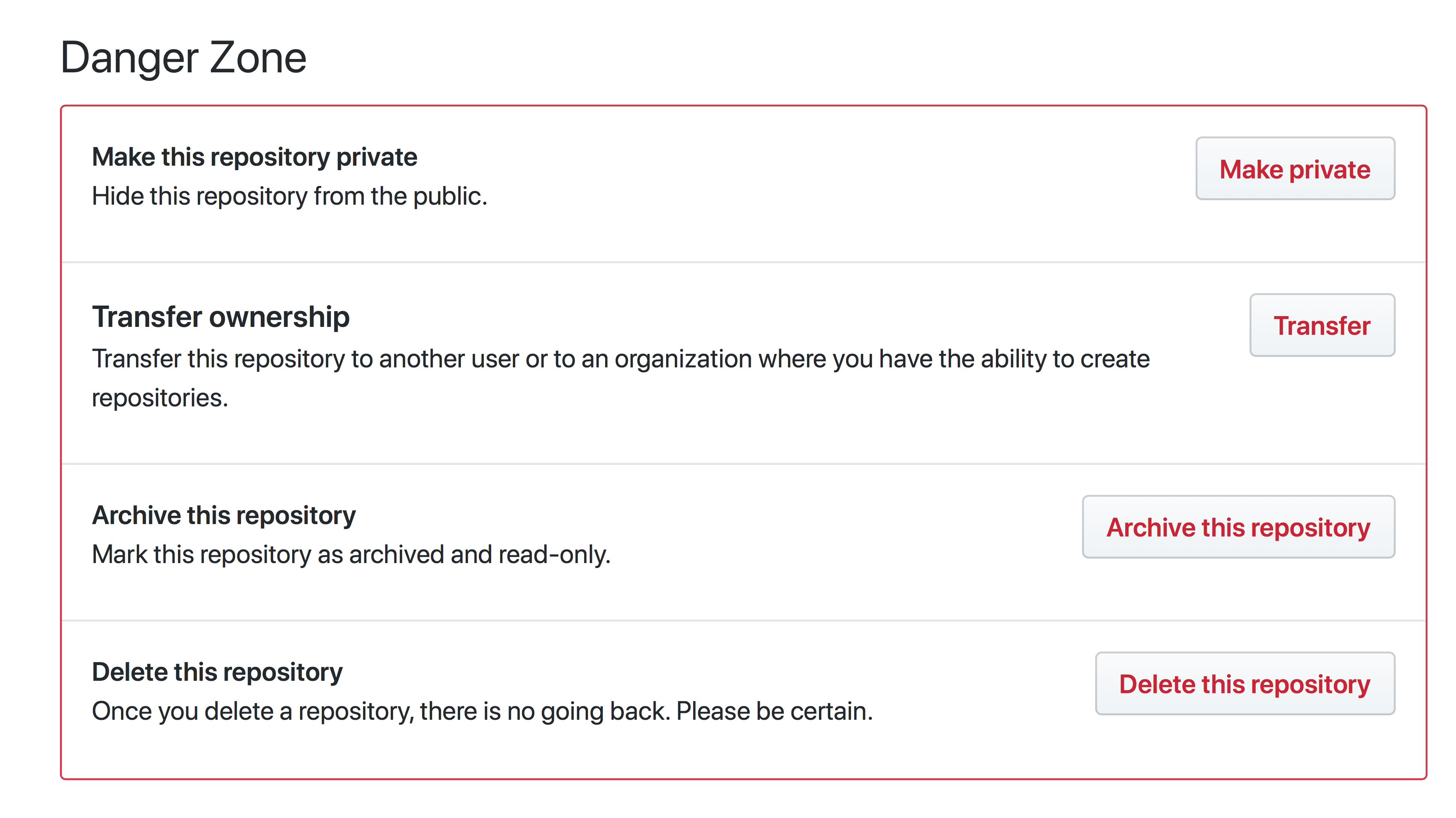][2]
|
||||
|
||||
在归档你的仓库前,确保你已经更改了它的设置并考虑关闭所有的开放问题和合并请求。你还应该更新你的 README 和描述来让它让访问者了解他不再能够贡献。
|
||||
在归档你的仓库前,确保你已经更改了它的设置并考虑关闭所有的开放问题和合并请求。你还应该更新你的 README 和描述来让它让访问者了解他不再能够对之贡献。
|
||||
|
||||
如果你改变了主意想要解除归档你的仓库,在相同的地方点击解除归档。请注意大多数归档仓库的设置是隐藏的,并且你需要解除归档来改变它们。
|
||||
如果你改变了主意想要解除归档你的仓库,在相同的地方点击“<ruby>解除归档该仓库<rt>Unarchive this repository</rt></ruby>”。请注意归档仓库的大多数设置是隐藏的,你需要解除归档才能改变它们。
|
||||
|
||||
[][3]
|
||||
|
||||
@ -24,9 +23,9 @@
|
||||
|
||||
via: https://github.com/blog/2460-archiving-repositories
|
||||
|
||||
作者:[MikeMcQuaid ][a]
|
||||
作者:[MikeMcQuaid][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,18 @@
|
||||
Glitch:立即写出有趣的小型网站项目
|
||||
Glitch:可以让你立即写出有趣的小型网站
|
||||
============================================================
|
||||
|
||||
我刚写了一篇关于 Jupyter Notebooks 是一个有趣的交互式写 Python 代码的方式。这让我想起我最近学习了 Glitch,这个我同样喜爱!我构建了一个小的程序来用于[关闭转发 twitter][2]。因此有了这篇文章!
|
||||
我刚写了一篇关于 Jupyter Notebooks 的文章,它是一个有趣的交互式写 Python 代码的方式。这让我想起我最近学习了 Glitch,这个我同样喜爱!我构建了一个小的程序来用于[关闭转发 twitter][2]。因此有了这篇文章!
|
||||
|
||||
[Glitch][3] 是一个简单的构建 Javascript web 程序的方式(javascript 后端、javascript 前端)
|
||||
[Glitch][3] 是一个简单的构建 Javascript web 程序的方式(javascript 后端、javascript 前端)。
|
||||
|
||||
关于 glitch 有趣的事有:
|
||||
关于 glitch 有趣的地方有:
|
||||
|
||||
1. 你在他们的网站输入 Javascript 代码
|
||||
|
||||
2. 只要输入了任何代码,它会自动用你的新代码重载你的网站。你甚至不必保存!它会自动保存。
|
||||
|
||||
所以这就像 Heroku,但更神奇!像这样的编码(你输入代码,代码立即在公共网络上运行)对我而言感觉很**有趣**。
|
||||
|
||||
这有点像 ssh 登录服务器,编辑服务器上的 PHP/HTML 代码,并让它立即可用,这也是我所喜爱的。现在我们有了“更好的部署实践”,而不是“编辑代码,它立即出现在互联网上”,但我们并不是在谈论严肃的开发实践,而是在讨论编写微型程序的乐趣。
|
||||
这有点像用 ssh 登录服务器,编辑服务器上的 PHP/HTML 代码,它立即就可用了,而这也是我所喜爱的方式。虽然现在我们有了“更好的部署实践”,而不是“编辑代码,让它立即出现在互联网上”,但我们并不是在谈论严肃的开发实践,而是在讨论编写微型程序的乐趣。
|
||||
|
||||
### Glitch 有很棒的示例应用程序
|
||||
|
||||
@ -22,18 +21,16 @@ Glitch 似乎是学习编程的好方式!
|
||||
比如,这有一个太空侵略者游戏(由 [Mary Rose Cook][4] 编写):[https://space-invaders.glitch.me/][5]。我喜欢的是我只需要点击几下。
|
||||
|
||||
1. 点击 “remix this”
|
||||
|
||||
2. 开始编辑代码使箱子变成橘色而不是黑色
|
||||
|
||||
3. 制作我自己太空侵略者游戏!我的在这:[http://julias-space-invaders.glitch.me/][1]。(我只做了很小的更改使其变成橘色,没什么神奇的)
|
||||
|
||||
他们有大量的示例程序,你可以从中启动 - 例如[机器人][6]、[游戏][7]等等。
|
||||
|
||||
### 实际有用的非常好的程序:tweetstorms
|
||||
|
||||
我学习 Glitch 的方式是从这个程序:[https://tweetstorms.glitch.me/][8],它会向你展示给定用户的 tweetstorm。
|
||||
我学习 Glitch 的方式是从这个程序开始的:[https://tweetstorms.glitch.me/][8],它会向你展示给定用户的推特云。
|
||||
|
||||
比如,你可以在 [https://tweetstorms.glitch.me/sarahmei][10] 看到 [@sarahmei][9] 的 tweetstorm(她发布了很多好的 tweetstorm!)。
|
||||
比如,你可以在 [https://tweetstorms.glitch.me/sarahmei][10] 看到 [@sarahmei][9] 的推特云(她发布了很多好的 tweetstorm!)。
|
||||
|
||||
### 我的 Glitch 程序: 关闭转推
|
||||
|
||||
@ -41,11 +38,11 @@ Glitch 似乎是学习编程的好方式!
|
||||
|
||||
我喜欢我不必设置一个本地开发环境,我可以直接开始输入然后开始!
|
||||
|
||||
Glitch 只支持 Javascript,我不非常了解 Javascript(我之前从没写过一个 Node 程序),所以代码不是很好。但是编写它很愉快 - 能够输入并立即看到我的代码运行是令人愉快的。这是我的项目:[https://turn-off-retweets.glitch.me/][11]。
|
||||
Glitch 只支持 Javascript,我不是非常了解 Javascript(我之前从没写过一个 Node 程序),所以代码不是很好。但是编写它很愉快 - 能够输入并立即看到我的代码运行是令人愉快的。这是我的项目:[https://turn-off-retweets.glitch.me/][11]。
|
||||
|
||||
### 就是这些!
|
||||
|
||||
使用 Glitch 感觉真的很有趣和民主。通常情况下,如果我想 fork 某人的 Web 项目,并做出更改,我不会这样做 - 我必须 fork,找一个托管,设置本地开发环境或者 Heroku 或其他,安装依赖项等。我认为像安装 node.js 依赖关系这样的任务过去很有趣,就像“我正在学习新东西很酷”,现在我觉得它们很乏味。
|
||||
使用 Glitch 感觉真的很有趣和民主。通常情况下,如果我想 fork 某人的 Web 项目,并做出更改,我不会这样做 - 我必须 fork,找一个托管,设置本地开发环境或者 Heroku 或其他,安装依赖项等。我认为像安装 node.js 依赖关系这样的任务在过去很有趣,就像“我正在学习新东西很酷”,但现在我觉得它们很乏味。
|
||||
|
||||
所以我喜欢只需点击 “remix this!” 并立即在互联网上能有我的版本。
|
||||
|
||||
@ -53,9 +50,9 @@ Glitch 只支持 Javascript,我不非常了解 Javascript(我之前从没写
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/13/glitch--write-small-web-projects-easily/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
作者:[Julia Evans][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,7 @@
|
||||
介绍 GitHub 上的安全警报
|
||||
====================================
|
||||
|
||||
|
||||
上个月,我们用依赖关系图让你更容易跟踪你代码依赖的的项目,目前支持 Javascript 和 Ruby。如今,超过 75% 的 GitHub 项目有依赖,我们正在帮助你做更多的事情,而不只是关注那些重要的项目。在启用依赖关系图后,当我们检测到你的依赖中有漏洞或者来自 Github 社区中建议的已知修复时通知你。
|
||||
上个月,我们用依赖关系图让你更容易跟踪你代码依赖的的项目,它目前支持 Javascript 和 Ruby。如今,超过 75% 的 GitHub 项目有依赖,我们正在帮助你做更多的事情,而不只是关注那些重要的项目。在启用依赖关系图后,当我们检测到你的依赖中有漏洞时会通知你,并给出来自 Github 社区中的已知修复。
|
||||
|
||||
[][1]
|
||||
|
||||
@ -10,33 +9,33 @@
|
||||
|
||||
无论你的项目时私有还是公有的,安全警报都会为团队中的正确人员提供重要的漏洞信息。
|
||||
|
||||
启用你的依赖图
|
||||
**启用你的依赖图:**
|
||||
|
||||
公开仓库将自动启用依赖关系图和安全警报。对于私人仓库,你需要在仓库设置中添加安全警报,或者在 “Insights” 选项卡中允许访问仓库的 “依赖关系图” 部分。
|
||||
|
||||
设置通知选项
|
||||
**设置通知选项:**
|
||||
|
||||
启用依赖关系图后,管理员将默认收到安全警报。管理员还可以在依赖关系图设置中将团队或个人添加为安全警报的收件人。
|
||||
|
||||
警报响应
|
||||
**警报响应:**
|
||||
|
||||
当我们通知你潜在的漏洞时,我们将突出显示我们建议更新的任何依赖关系。如果存在已知的安全版本,我们将使用机器学习和公开数据中选择一个,并将其包含在我们的建议中。
|
||||
当我们通知你潜在的漏洞时,我们将突出显示我们建议更新的任何依赖关系。如果存在已知的安全版本,我们将通过机器学习和公开数据选择一个,并将其包含在我们的建议中。
|
||||
|
||||
### 漏洞覆盖率
|
||||
|
||||
有 [CVE ID][2](公开披露的[国家漏洞数据库][3]中的漏洞)的漏洞将包含在安全警报中。但是,并非所有漏洞都有 CVE ID,甚至许多公开披露的漏洞也没有。随着安全数据的增长,我们将继续更好地识别漏洞。如需更多帮助来管理安全问题,请查看我们的[ GitHub Marketplace 中的安全合作伙伴][4]。
|
||||
有 [CVE ID][2]([国家漏洞数据库][3]公开披露的漏洞)的漏洞将包含在安全警报中。但是,并非所有漏洞都有 CVE ID,甚至许多公开披露的漏洞也没有。随着安全数据的增长,我们将继续更好地识别漏洞。如需更多帮助来管理安全问题,请查看我们的 [GitHub Marketplace 中的安全合作伙伴][4]。
|
||||
|
||||
这是使用世界上最大的开源数据集的下一步,可以帮助你保持代码安全并做到最好。依赖关系图和安全警报目前支持 JavaScript 和 Ruby,并将在 2018 年提供 Python 支持。
|
||||
|
||||
[了解更多关于安全警报][5]
|
||||
- [了解更多关于安全警报][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2470-introducing-security-alerts-on-github
|
||||
|
||||
作者:[mijuhan ][a]
|
||||
作者:[mijuhan][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,59 @@
|
||||
用系统日志了解你的 Linux 系统
|
||||
============
|
||||
|
||||
本文摘自为 Linux 小白(或者非资深桌面用户)传授技巧的系列文章。该系列文章旨在为 LinuxMagazine 发布的第 30 期特别版 “[Linux 入门][2]” (基于 [openSUSE Leap][3] )提供补充说明。
|
||||
|
||||
本文作者是 Romeo S.,她是一名基于 PDX 的企业 Linux 专家,专注于为创新企业提供富有伸缩性的解决方案。
|
||||
|
||||
Linux 系统日志非常重要。后台运行的程序(通常被称为守护进程或者服务进程)处理了你 Linux 系统中的大部分任务。当这些守护进程工作时,它们将任务的详细信息记录进日志文件中,作为它们做过什么的“历史”信息。这些守护进程的工作内容涵盖从使用原子钟同步时钟到管理网络连接。所有这些都被记录进日志文件,这样当有错误发生时,你可以通过查阅特定的日志文件来看出发生了什么。
|
||||
|
||||

|
||||
|
||||
*Photo by Markus Spiske on Unsplash*
|
||||
|
||||
在你的 Linux 计算机上有很多不同的日志。历史上,它们一般以纯文本的格式存储到 `/var/log` 目录中。现在依然有很多日志这样做,你可以很方便的使用 `less` 来查看它们。
|
||||
|
||||
在新装的 openSUSE Leap 42.3 以及大多数现代操作系统上,重要的日志由 `systemd` 初始化系统存储。 `systemd`这套系统负责启动守护进程,并在系统启动时让计算机做好被使用的准备。由 `systemd` 记录的日志以二进制格式存储,这使得它们消耗的空间更小,更容易被浏览,也更容易被导出成其他各种格式,不过坏处就是你必须使用特定的工具才能查看。好在这个工具已经预安装在你的系统上了:它的名字叫 `journalctl`,而且默认情况下,它会将每个守护进程的所有日志都记录到一个地方。
|
||||
|
||||
只需要运行 `journalctl` 命令就能查看你的 `systemd` 日志了。它会用 `less` 分页器显示各种日志。为了让你有个直观的感受, 下面是 `journalctl` 中摘录的一条日志记录:
|
||||
|
||||
```
|
||||
Jul 06 11:53:47 aaathats3as pulseaudio[2216]: [pulseaudio] alsa-util.c: Disabling timer-based scheduling because running inside a VM.
|
||||
```
|
||||
|
||||
这条独立的日志记录以此包含了记录的日期和时间、计算机名、记录日志的进程名、记录日志的进程 PID,以及日志内容本身。
|
||||
|
||||
若系统中某个程序运行出问题了,则可以查看日志文件并搜索(使用 `/` 加上要搜索的关键字)程序名称。有可能导致该程序出问题的错误会记录到系统日志中。 有时,错误信息会足够详细到让你能够修复该问题。其他时候,你需要在 Web 上搜索解决方案。 Google 就很适合来搜索奇怪的 Linux 问题。不过搜索时请注意你只输入了日志的实际内容,行首的那些信息(日期、主机名、进程 ID) 对搜索来说是无意义的,会干扰搜索结果。
|
||||
|
||||
解决方法一般在搜索结果的前几个连接中就会有了。当然,你不能只是无脑得运行从互联网上找到的那些命令:请一定先搞清楚你要做的事情是什么,它的效果会是什么。据说,搜索系统日志中的特定条目要比直接描述该故障通用关键字要有用的多。因为程序出错有很多原因,而且同样的故障表现也可能由多种问题引发的。
|
||||
|
||||
比如,系统无法发声的原因有很多,可能是播放器没有插好,也可能是声音系统出故障了,还可能是缺少合适的驱动程序。如果你只是泛泛的描述故障表现,你会找到很多无关的解决方法,而你也会浪费大量的时间。而专门搜索日志文件中的实际内容,你也许会查询出其它人也有相同日志内容的结果。
|
||||
|
||||
你可以对比一下图 1 和图 2。
|
||||
|
||||

|
||||
|
||||
图 1 搜索系统的故障表现只会显示泛泛的,不精确的结果。这种搜索通常没什么用。
|
||||
|
||||

|
||||
|
||||
图 2 搜索特定的日志行会显示出精确的,有用的结果。这种搜索通常很有用。
|
||||
|
||||
也有一些系统不用 `journalctl` 来记录日志。在桌面系统中最常见的这类日志包括用于记录 openSUSE 包管理器的行为的 `/var/log/zypper.log`; 记录系统启动时消息的 `/var/log/boot.log` ,开机时这类消息往往滚动的特别快,根本看不过来;`/var/log/ntp` 用来记录 Network Time Protocol (NTP)守护进程同步时间时发生的错误。 另一个存放硬件故障信息的地方是 “Kernel Ring Buffer”(内核环状缓冲区),你可以输入 `demesg -H` 命令来查看(这条命令也会调用 `less` 分页器来查看)。“Kernel Ring Buffer” 存储在内存中,因此会在重启电脑后丢失。不过它包含了 Linux 内核中的重要事件,比如新增了硬件、加载了模块,以及奇怪的网络错误.
|
||||
|
||||
希望你已经准备好深入了解你的 Linux 系统了! 祝你玩的开心!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.suse.com/communities/blog/system-logs-understand-linux-system/
|
||||
|
||||
作者:[chabowski]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.suse.com/communities/blog/author/chabowski/
|
||||
[2]:http://www.linux-magazine.com/Resources/Special-Editions/30-Getting-Started-with-Linux
|
||||
[3]:https://en.opensuse.org/Portal:42.3
|
||||
[4]:http://www.linux-magazine.com/
|
||||
@ -1,27 +1,22 @@
|
||||
# LibreOffice 现在在 Flatpak 的 Flathub 应用商店提供
|
||||
LibreOffice 上架 Flathub 应用商店
|
||||
===============
|
||||
|
||||

|
||||
|
||||
LibreOffice 现在可以从集中化的 Flatpak 应用商店 [Flathub][3] 进行安装。
|
||||
> LibreOffice 现在可以从集中化的 Flatpak 应用商店 [Flathub][3] 进行安装。
|
||||
|
||||
它的到来使任何运行现代 Linux 发行版的人都能只点击一两次安装 LibreOffice 的最新稳定版本,而无需搜索 PPA,纠缠 tar 包或等待发行商将其打包。
|
||||
它的到来使任何运行现代 Linux 发行版的人都能只点击一两次即可安装 LibreOffice 的最新稳定版本,而无需搜索 PPA,纠缠于 tar 包或等待发行版将其打包。
|
||||
|
||||
自去年 8 月份以来,[LibreOffice Flatpak][5] 已经可供用户下载和安装 [LibreOffice 5.2][6]。
|
||||
自去年 8 月份 [LibreOffice 5.2][6] 发布以来,[LibreOffice Flatpak][5] 已经可供用户下载和安装。
|
||||
|
||||
这里“新”的是发行方法。文档基金会选择使用 Flathub 而不是专门的服务器来发布更新。
|
||||
这里“新”的是指发行方法。<ruby>文档基金会<rt>Document Foundation</rt></ruby>选择使用 Flathub 而不是专门的服务器来发布更新。
|
||||
|
||||
这对于终端用户来说是一个_很好_的消息,因为这意味着不需要在新安装时担心仓库,但对于 Flatpak 的倡议者来说也是一个好消息:LibreOffice 是开源软件最流行的生产力套件。它对格式和应用商店的支持肯定会受到热烈的欢迎。
|
||||
这对于终端用户来说是一个_很好_的消息,因为这意味着不需要在新安装时担心仓库,但对于 Flatpak 的倡议者来说也是一个好消息:LibreOffice 是开源软件里最流行的生产力套件。它对该格式和应用商店的支持肯定会受到热烈的欢迎。
|
||||
|
||||
在撰写本文时,你可以从 Flathub 安装 LibreOffice 5.4.2。新的稳定版本将在发布时添加。
|
||||
|
||||
### 在 Ubuntu 上启用 Flathub
|
||||
|
||||

|
||||
|
||||
Fedora、Arch 和 Linux Mint 18.3 用户已经安装了 Flatpak,随时可以开箱即用。Mint 甚至预启用了 Flathub remote。
|
||||
|
||||
[从 Flathub 安装 LibreOffice][7]
|
||||
|
||||
要在 Ubuntu 上启动并运行 Flatpak,首先必须安装它:
|
||||
|
||||
```
|
||||
@ -34,17 +29,25 @@ sudo apt install flatpak gnome-software-plugin-flatpak
|
||||
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
```
|
||||
|
||||
这就行了。只需注销并返回(以便 Ubuntu Software 刷新其缓存),之后你应该能够通过 Ubuntu Software 看到 Flathub 上的任何 Flatpak 程序了。
|
||||
这就行了。只需注销并重新登录(以便 Ubuntu Software 刷新其缓存),之后你应该能够通过 Ubuntu Software 看到 Flathub 上的任何 Flatpak 程序了。
|
||||
|
||||

|
||||
|
||||
*Fedora、Arch 和 Linux Mint 18.3 用户已经安装了 Flatpak,随时可以开箱即用。Mint 甚至预启用了 Flathub remote。*
|
||||
|
||||
在本例中,搜索 “LibreOffice” 并在结果中找到下面有 Flathub 提示的结果。(请记住,Ubuntu 已经调整了客户端,来将 Snap 程序显示在最上面,所以你可能需要向下滚动列表来查看它)。
|
||||
|
||||
### 从 Flathub 安装 LibreOffice
|
||||
|
||||
- [从 Flathub 安装 LibreOffice][7]
|
||||
|
||||
从 flatpakref 中[安装 Flatpak 程序有一个 bug][8],所以如果上面的方法不起作用,你也可以使用命令行从 Flathub 中安装 Flathub 程序。
|
||||
|
||||
Flathub 网站列出了安装每个程序所需的命令。切换到“命令行”选项卡来查看它们。
|
||||
|
||||
#### Flathub 上更多的应用
|
||||
### Flathub 上更多的应用
|
||||
|
||||
如果你经常看这个网站,你就会知道我喜欢 Flathub。这是我最喜欢的一些应用(Corebird、Parlatype、GNOME MPV、Peek、Audacity、GIMP 等)的家园。我无需折衷就能获得这些应用程序的最新,稳定版本(加上它们需要的所有依赖)。
|
||||
如果你经常看这个网站,你就会知道我喜欢 Flathub。这是我最喜欢的一些应用(Corebird、Parlatype、GNOME MPV、Peek、Audacity、GIMP 等)的家园。我无需等待就能获得这些应用程序的最新、稳定版本(加上它们需要的所有依赖)。
|
||||
|
||||
而且,在我 twiiter 上发布一周左右后,大多数 Flatpak 应用现在看起来有很棒 GTK 主题 - 不再需要[临时方案][9]了!
|
||||
|
||||
@ -52,9 +55,9 @@ Flathub 网站列出了安装每个程序所需的命令。切换到“命令行
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/11/libreoffice-now-available-flathub-flatpak-app-store
|
||||
|
||||
作者:[ JOEY SNEDDON ][a]
|
||||
作者:[JOEY SNEDDON][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
Django ORM 简介
|
||||
============================================================
|
||||
|
||||
### 学习怎么去使用 Python 的 web 框架中的对象关系映射与你的数据库交互,就像你使用 SQL 一样。
|
||||
> 学习怎么去使用 Python 的 web 框架中的对象关系映射与你的数据库交互,就像你使用 SQL 一样。
|
||||
|
||||
|
||||

|
||||
Image by : [Christian Holmér][10]. Modified by Opensource.com. [CC BY-SA 4.0][11]
|
||||
|
||||
|
||||
你可能听说过 [Django][12],它是一个被称为“完美主义者的最后期限” 的 Python web 框架。它是一匹 [可爱的小矮马][13]。
|
||||
|
||||
Django 的其中一个强大的功能是它的对象关系映射(ORM),它允许你去和你的数据库交互,就像你使用 SQL 一样。事实上,Django 的 ORM 就是创建 SQL 去查询和维护数据库的一个 Python 的方法,并且在一个 Python 方法中获取结果。 我说 _就是_ 一种方法,但实际上,它是一项非常聪明的工程,它利用了 Python 中比较复杂的部分,使得开发过程更容易。
|
||||
Django 的一个强大的功能是它的<ruby>对象关系映射<rt>Object-Relational Mapper</rt></ruby>(ORM),它允许你就像使用 SQL 一样去和你的数据库交互。事实上,Django 的 ORM 就是创建 SQL 去查询和操作数据库的一个 Python 式方式,并且获得 Python 风格的结果。 我说的_是_一种方式,但实际上,它是一种非常聪明的工程方法,它利用了 Python 中一些很复杂的部分,而使得开发者更加轻松。
|
||||
|
||||
在我们开始去了解 ORM 是怎么工作的之前,我们需要一个去操作的数据库。和任何一个关系型数据库一样,我们需要去定义一堆表和它们的关系(即,它们相互之间联系起来的方式)。让我们使用我们熟悉的东西。比如说,我们需要去建立一个有博客文章和作者的博客。每个作者有一个名字。一位作者可以有很多的博客文章。一篇博客文章可以有很多的作者、标题、内容和发布日期。
|
||||
在我们开始去了解 ORM 是怎么工作之前,我们需要一个可以操作的数据库。和任何一个关系型数据库一样,我们需要去定义一堆表和它们的关系(即,它们相互之间联系起来的方式)。让我们使用我们熟悉的东西。比如说,我们需要去建模一个有博客文章和作者的博客。每个作者有一个名字。一位作者可以有很多的博客文章。一篇博客文章可以有很多的作者、标题、内容和发布日期。
|
||||
|
||||
在 Django-ville 中,这个文章和作者的概念可以被称为博客应用。在这个语境中,一个应用是一个自包含一系列描述我们的博客行为和功能的模型和视图。用正确的方式打包,以便于其它的 Django 项目可以使用我们的博客应用。在我们的项目中,博客正是其中的一个应用。比如,我们也可以有一个论坛应用。但是,我们仍然坚持我们的博客应用的原有范围。
|
||||
在 Django 村里,这个文章和作者的概念可以被称为博客应用。在这个语境中,一个应用是一个自包含一系列描述我们的博客行为和功能的模型和视图的集合。用正确的方式打包,以便于其它的 Django 项目可以使用我们的博客应用。在我们的项目中,博客正是其中的一个应用。比如,我们也可以有一个论坛应用。但是,我们仍然坚持我们的博客应用的原有范围。
|
||||
|
||||
这是为这个教程事先准备的 `models.py`:
|
||||
|
||||
@ -36,23 +36,11 @@ class Post(models.Model):
|
||||
return self.title
|
||||
```
|
||||
|
||||
更多的 Python 资源
|
||||
现在,看上去似乎有点令人恐惧,因此,我们把它分解来看。我们有两个模型:作者(`Author`)和文章(`Post`)。它们都有名字(`name`)或者标题(`title`)。文章有个放内容的大的文本字段,以及用于发布时间和日期的 `DateTimeField`。文章也有一个 `ManyToManyField`,它同时链接到文章和作者。
|
||||
|
||||
* [Python 是什么?][1]
|
||||
大多数的教程都是从头开始的,但是,在实践中并不会发生这种情况。实际上,你会得到一堆已存在的代码,就像上面的 `model.py` 一样,而你必须去搞清楚它们是做什么的。
|
||||
|
||||
* [最好的 Python IDEs][2]
|
||||
|
||||
* [最好的 Python GUI 框架][3]
|
||||
|
||||
* [最新的 Python 内容][4]
|
||||
|
||||
* [更多的开发者资源][5]
|
||||
|
||||
现在,看上去似乎有点令人恐惧,因此,我们把它分解来看。我们有两个模型:作者和文章。它们都有名字或者标题。文章为内容设置一个大文本框,以及为发布的时间和日期设置一个 `DateTimeField`。文章也有一个 `ManyToManyField`,它同时链接到文章和作者。
|
||||
|
||||
大多数的教程都是从 scratch—but 开始的,但是,在实践中并不会发生这种情况。实际上,它会提供给你一堆已存在的代码,就像上面的 `model.py` 一样,而你必须去搞清楚它们是做什么的。
|
||||
|
||||
因此,现在你的任务是去进入到应用程序中去了解它。做到这一点有几种方法,你可以登入到 [Django admin][14],一个 Web 后端,它有全部列出的应用和操作它们的方法。我们先退出它,现在我们感兴趣的东西是 ORM。
|
||||
因此,现在你的任务是去进入到应用程序中去了解它。做到这一点有几种方法,你可以登入到 [Django admin][14],这是一个 Web 后端,它会列出全部的应用和操作它们的方法。我们先退出它,现在我们感兴趣的东西是 ORM。
|
||||
|
||||
我们可以在 Django 项目的主目录中运行 `python manage.py shell` 去访问 ORM。
|
||||
|
||||
@ -74,13 +62,13 @@ Type "help", "copyright", "credits" or "license" for more information.
|
||||
|
||||
它导入了全部的博客模型,因此,我们可以玩我们的博客了。
|
||||
|
||||
首先,我们列出所有的作者。
|
||||
首先,我们列出所有的作者:
|
||||
|
||||
```
|
||||
>>> Author.objects.all()
|
||||
```
|
||||
|
||||
我们将从这个命令取得结果,它是一个 `QuerySet`,它列出了所有我们的作者对象。它不会充满我们的整个控制台,因为,如果有很多查询结果,Django 将自动截断输出结果。
|
||||
我们将从这个命令取得结果,它是一个 `QuerySet`,它列出了我们所有的作者对象。它不会充满我们的整个控制台,因为,如果有很多查询结果,Django 将自动截断输出结果。
|
||||
|
||||
```
|
||||
>>> Author.objects.all()
|
||||
@ -88,7 +76,7 @@ Type "help", "copyright", "credits" or "license" for more information.
|
||||
<Author: Jen Wike Huger>, '...(remaining elements truncated)...']
|
||||
```
|
||||
|
||||
我们可以使用 `get` 代替 `all` 去检索单个作者。但是,我们需要一些更多的信息去 `get` 一个单个记录。在关系型数据库中,表有一个主键,它唯一标识了表中的每个记录,但是,作者名并不唯一。许多人都 [重名][16],因此,它不是唯一约束的一个好的选择。解决这个问题的一个方法是使用一个序列(1、2、3...)或者一个通用唯一标识符(UUID)作为主键。但是,因为它对人类并不可用,我们可以通过使用 `name` 来操作我们的作者对象。
|
||||
我们可以使用 `get` 代替 `all` 去检索单个作者。但是,我们需要一些更多的信息才能 `get` 一个单个记录。在关系型数据库中,表有一个主键,它唯一标识了表中的每个记录,但是,作者名并不唯一。许多人都 [重名][16],因此,它不是唯一约束的好选择。解决这个问题的一个方法是使用一个序列(1、2、3 ……)或者一个通用唯一标识符(UUID)作为主键。但是,因为它对人类并不好用,我们可以通过使用 `name` 来操作我们的作者对象。
|
||||
|
||||
```
|
||||
>>> Author.objects.get(name="VM (Vicky) Brasseur")
|
||||
@ -105,7 +93,7 @@ u'VM (Vicky) Brasseur'
|
||||
|
||||
然后,很酷的事件发生了。通常在关系型数据库中,如果我们希望去展示其它表的信息,我们需要去写一个 `LEFT JOIN`,或者其它的表耦合函数,并确保它们之间有匹配的外键。而 Django 可以为我们做到这些。
|
||||
|
||||
在我们的模型中,由于作者写了很多的文章,因此,我们的作者对象可以检查它自己的文章。
|
||||
在我们的模型中,由于作者写了很多的文章,因此,我们的作者对象可以检索他自己的文章。
|
||||
|
||||
```
|
||||
>>> vmb.posts.all()
|
||||
@ -114,8 +102,8 @@ QuerySet[<Post: "7 tips for nailing your job interview">,
|
||||
<Post: "Quit making these 10 common resume mistakes">,
|
||||
'...(remaining elements truncated)...']
|
||||
```
|
||||
|
||||
We can manipulate `QuerySets` using normal pythonic list manipulations.
|
||||
|
||||
我们可以使用正常的 Python 式的列表操作方式来操作 `QuerySets`。
|
||||
|
||||
```
|
||||
>>> for post in vmb.posts.all():
|
||||
@ -126,20 +114,18 @@ We can manipulate `QuerySets` using normal pythonic list manipulations.
|
||||
Quit making these 10 common resume mistakes
|
||||
```
|
||||
|
||||
去实现更复杂的查询,我们可以使用过滤得到我们想要的内容。这是非常微妙的。在 SQL 中,你可以有一些选项,比如,`like`、`contains`、和其它的过滤对象。在 ORM 中这些事情也可以做到。但是,是通过 _特别的_ 方式实现的:是通过使用一个隐式(而不是显式)定义的函数实现的。
|
||||
要实现更复杂的查询,我们可以使用过滤得到我们想要的内容。这有点复杂。在 SQL 中,你可以有一些选项,比如,`like`、`contains` 和其它的过滤对象。在 ORM 中这些事情也可以做到。但是,是通过 _特别的_ 方式实现的:是通过使用一个隐式(而不是显式)定义的函数实现的。
|
||||
|
||||
如果在我的 Python 脚本中调用了一个函数 `do_thing()`,我期望在某个地方有一个匹配 `def do_thing`。这是一个显式的函数定义。然而,在 ORM 中,你可以调用一个 _不显式定义的_ 函数。之前,我们使用 `name` 去匹配一个名字。但是,如果我们想做一个子串搜索,我们可以使用 `name__contains`。
|
||||
如果在我的 Python 脚本中调用了一个函数 `do_thing()`,我会期望在某个地方有一个匹配的 `def do_thing`。这是一个显式的函数定义。然而,在 ORM 中,你可以调用一个 _不显式定义的_ 函数。之前,我们使用 `name` 去匹配一个名字。但是,如果我们想做一个子串搜索,我们可以使用 `name__contains`。
|
||||
|
||||
```
|
||||
>>> Author.objects.filter(name__contains="Vic")
|
||||
QuerySet[<Author: VM (Vicky) Brasseur>, <Author: Victor Hugo">]
|
||||
```
|
||||
|
||||
现在,关于双下划线(`__`)我有一个小小的提示。这些是 Python _特有的_。在 Python 的世界里,你可以看到如 `__main__` 或者 `__repr__`。这些有时被称为 `dunder methods`,是 “双下划线” 的缩写。这里仅有几个非字母数字字符可以被用于 Python 中的对象名字;下划线是其中的一个。这些在 ORM 中被用于不同的过滤关键字的显式分隔。在底层,字符串被这些下划线分割。并且这个标记是分开处理的。`name__contains` 被替换成 `attribute: name, filter: contains`。在其它编程语言中,你可以使用箭头代替,比如,在 PHP 中是 `name->contains`。不要被双下划线吓着你,正好相反,它们是 Python 的好帮手(并且如果你斜着看,你就会发现它看起来像一条小蛇,想去帮你写代码的小蟒蛇)。
|
||||
现在,关于双下划线(`__`)我有一个小小的提示。这些是 Python _特有的_。在 Python 的世界里,你可以看到如 `__main__` 或者 `__repr__`。这些有时被称为 `dunder methods`,是 “<ruby>双下划线<rt>double underscore</rt></ruby>” 的缩写。仅有几个非字母数字的字符可以被用于 Python 中的对象名字;下划线是其中的一个。这些在 ORM 中被用于显式分隔<ruby>过滤关键字<rt>filter key name</rt></ruby>的各个部分。在底层,字符串用这些下划线分割开,然后这些标记分开处理。`name__contains` 被替换成 `attribute: name, filter: contains`。在其它编程语言中,你可以使用箭头代替,比如,在 PHP 中是 `name->contains`。不要被双下划线吓着你,正好相反,它们是 Python 的好帮手(并且如果你斜着看,你就会发现它看起来像一条小蛇,想去帮你写代码的小蟒蛇)。
|
||||
|
||||
ORM 是非常强大并且是 Python 特有的。不过,在 Django 的管理网站上我提到过上面的内容。
|
||||
|
||||
### [django-admin.png][6]
|
||||
ORM 是非常强大并且是 Python 特有的。不过,还记得我在上面提到过的 Django 的管理网站吗?
|
||||
|
||||

|
||||
|
||||
@ -147,13 +133,13 @@ Django 的其中一个非常精彩的用户可访问特性是它的管理界面
|
||||
|
||||
ORM,有多强大?
|
||||
|
||||
### [django-admin-author.png][7]
|
||||
|
||||

|
||||
|
||||
好吧!给你一些代码去创建最初的模型,Django 转到基于 web 的门户,它是非常强大的,它可以使用我们前面用过的同样的原生函数。默认情况下,这个管理门户只有基本的东西,但这只是在你的模型中添加一些定义去改变外观的问题。例如,在早期的这些 `__str__` 方法中,我们使用这些去定义作者对象应该有什么?(在这种情况中,比如,作者的名字),做了一些工作后,你可以创建一个界面,让它看起来像一个内容管理系统,以允许你的用户去编辑他们的内容。(例如,为一个标记为 “已发布” 的文章,增加一些输入框和过滤)。
|
||||
好吧!给你一些代码去创建最初的模型,Django 就变成了一个基于 web 的门户,它是非常强大的,它可以使用我们前面用过的同样的原生函数。默认情况下,这个管理门户只有基本的东西,但这只是在你的模型中添加一些定义去改变外观的问题。例如,在早期的这些 `__str__` 方法中,我们使用这些去定义作者对象应该有什么?(在这种情况中,比如,作者的名字),做了一些工作后,你可以创建一个界面,让它看起来像一个内容管理系统,以允许你的用户去编辑他们的内容。(例如,为一个标记为 “已发布” 的文章,增加一些输入框和过滤)。
|
||||
|
||||
如果你想去了解更多内容,[Django 美女的教程][17] 中关于 [the ORM][18] 的节有详细的介绍。在 [Django project website][19] 上也有丰富的文档。
|
||||
如果你想去了解更多内容,[Django 美女的教程][17] 中关于 [the ORM][18] 的节有详细的介绍。在 [Django project website][19] 上也有丰富的文档。
|
||||
|
||||
(题图 [Christian Holmér][10],Opensource.com 修改. [CC BY-SA 4.0][11])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -165,9 +151,9 @@ Katie McLaughlin - Katie 在过去的这几年有许多不同的头衔,她以
|
||||
|
||||
via: https://opensource.com/article/17/11/django-orm
|
||||
|
||||
作者:[Katie McLaughlin Feed ][a]
|
||||
作者:[Katie McLaughlin][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,27 +3,27 @@ AWS 帮助构建 ONNX 开源 AI 平台
|
||||

|
||||
|
||||
|
||||
AWS 已经成为最近加入深度学习社区的开放神经网络交换(ONNX)协作的最新技术公司,最近在无摩擦和可互操作的环境中推出了高级人工智能。由 Facebook 和微软领头。
|
||||
AWS 最近成为了加入深度学习社区的<ruby>开放神经网络交换<rt>Open Neural Network Exchange</rt></ruby>(ONNX)协作的技术公司,最近在<ruby>无障碍和可互操作<rt>frictionless and interoperable</rt></ruby>的环境中推出了高级人工智能。由 Facebook 和微软领头了该协作。
|
||||
|
||||
作为该合作的一部分,AWS 将其开源 Python 软件包 ONNX-MxNet 作为一个深度学习框架提供,该框架提供跨多种语言的编程接口,包括 Python、Scala 和开源统计软件 R。
|
||||
作为该合作的一部分,AWS 开源其深度学习框架 Python 软件包 ONNX-MXNet,该框架提供了跨多种语言的编程接口(API),包括 Python、Scala 和开源统计软件 R。
|
||||
|
||||
AWS 深度学习工程经理 Hagay Lupesko 和软件开发人员 Roshani Nagmote 上周在一篇帖子中写道:ONNX 格式将帮助开发人员构建和训练其他框架的模型,包括 PyTorch、Microsoft Cognitive Toolkit 或 Caffe2。它可以让开发人员将这些模型导入 MXNet,并运行它们进行推理。
|
||||
AWS 深度学习工程经理 Hagay Lupesko 和软件开发人员 Roshani Nagmote 上周在一篇帖子中写道,ONNX 格式将帮助开发人员构建和训练其它框架的模型,包括 PyTorch、Microsoft Cognitive Toolkit 或 Caffe2。它可以让开发人员将这些模型导入 MXNet,并运行它们进行推理。
|
||||
|
||||
### 对开发者的帮助
|
||||
|
||||
今年夏天,Facebook 和微软推出了 ONNX,以支持共享模式的互操作性,来促进 AI 的发展。微软提交了其 Cognitive Toolkit、Caffe2 和 PyTorch 来支持 ONNX。
|
||||
|
||||
微软表示:Cognitive Toolkit 和其他框架使开发人员更容易构建和运行代表神经网络的计算图。
|
||||
微软表示:Cognitive Toolkit 和其他框架使开发人员更容易构建和运行计算图以表达神经网络。
|
||||
|
||||
Github 上提供了[ ONNX 代码和文档][4]的初始版本。
|
||||
[ONNX 代码和文档][4]的初始版本已经放到了 Github。
|
||||
|
||||
AWS 和微软上个月宣布了在 Apache MXNet 上的一个新 Gluon 接口计划,该计划允许开发人员构建和训练深度学习模型。
|
||||
|
||||
[Tractica][5] 的研究总监 Aditya Kaul 观察到:“Gluon 是他们与 Google 的 Tensorflow 竞争的合作伙伴关系的延伸”。
|
||||
[Tractica][5] 的研究总监 Aditya Kaul 观察到:“Gluon 是他们试图与 Google 的 Tensorflow 竞争的合作伙伴关系的延伸”。
|
||||
|
||||
他告诉 LinuxInsider,“谷歌在这点上的疏忽是非常明显的,但也说明了他们在市场上的主导地位。
|
||||
他告诉 LinuxInsider,“谷歌在这点上的疏忽是非常明显的,但也说明了他们在市场上的主导地位。”
|
||||
|
||||
Kaul 说:“甚至 Tensorflow 是开源的,所以开源在这里并不是什么大事,但这归结到底是其他生态系统联手与谷歌竞争。”
|
||||
Kaul 说:“甚至 Tensorflow 也是开源的,所以开源在这里并不是什么大事,但这归结到底是其他生态系统联手与谷歌竞争。”
|
||||
|
||||
根据 AWS 的说法,本月早些时候,Apache MXNet 社区推出了 MXNet 的 0.12 版本,它扩展了 Gluon 的功能,以便进行新的尖端研究。它的新功能之一是变分 dropout,它允许开发人员使用 dropout 技术来缓解递归神经网络中的过拟合。
|
||||
|
||||
@ -52,15 +52,15 @@ Tractica 的 Kaul 指出:“框架互操作性是一件好事,这会帮助
|
||||
越来越多的大型科技公司已经宣布使用开源技术来加快 AI 协作开发的计划,以便创建更加统一的开发和研究平台。
|
||||
|
||||
AT&T 几周前宣布了与 TechMahindra 和 Linux 基金会合作[推出 Acumos 项目][8]的计划。该平台旨在开拓电信、媒体和技术方面的合作。
|
||||

|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
|
||||
作者:[ David Jones ][a]
|
||||
作者:[David Jones][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,41 @@
|
||||
有人试图挽救 Ubuntu Unity ,将其做为官方分支
|
||||
============================================================
|
||||
|
||||
> Ubuntu Unity Remix 将支持九个月。
|
||||
|
||||

|
||||
|
||||
Canonical 在七年之后突然决定抛弃它的 Unity 用户界面影响了许多 Ubuntu 用户,现在看起来有人试图把它从死亡中带回来,成为官方<ruby>分支<rt>spin</rt></ruby>。
|
||||
|
||||
长期 [Ubuntu][1] 成员 Dale Beaudoin 上周在官方的 Ubuntu 论坛上[进行了一项调查][2]来了解社区意向,看看他们是否对随同明年的 Ubuntu 18.04 LTS(Bionic Beaver)一起发布的 Ubuntu Unity Remix 感兴趣,它将支持 9 个月或 5 年。
|
||||
|
||||
有 30 人进行了投票,其中 67% 的人选择了所谓的 Ubuntu Unity Remix 的 LTS(长期支持)版本,33% 的人投票支持 9 个月的支持版本。看起来这个即将到来的 Ubuntu Unity Spin [看起来会成为官方特色版本][3],而这意味着开发它的承诺。
|
||||
|
||||
Dale Beaudoin 表示:“最近的一项民意调查显示,2/3 的人支持 Ubuntu Unity 成为 LTS 发行版,我们应该按照它成为 LTS 和官方特色版的更新周期去努力。我们将尝试使用当前默认的 Ubuntu Bionic Beaver 18.04 的每日构建版本作为平台,每周或每 10 天发布一次更新的 ISO。”
|
||||
|
||||
### Ubuntu Unity 是否会卷土重来?
|
||||
|
||||
正常情况下,最后一个带有 Unity 的 Ubuntu 版本应该是 Ubuntu 17.04(Zesty Zapus),它将在 2018 年 1 月终止支持。当前流行操作系统的稳定版本 Ubuntu 17.10(Artful Artful),是今年早些时候 Canonical CEO [宣布][4]之后第一个默认使用 GNOME 桌面环境的版本,Unity 将不再开发。
|
||||
|
||||
然而,Canonical 仍然在官方软件仓库提供 Unity 桌面环境,所以如果有人想要安装它,只需点击一下即可。但坏消息是,它们支持到 2018 年 4 月发布 Ubuntu 18.04 LTS(Bionic Beaver)之前,所以 Ubuntu Unity Remix 的开发者们将不得不在独立的仓库中继续支持。
|
||||
|
||||
另一方面,我们不相信 Canonical 会改变主意,接受这个 Ubuntu Unity Spin 成为官方的特色版,这意味着他们不会继续开发 Unity,现在只有一小部分人可以做这个开发。最有可能的是,如果对 Ubuntu Unity Remix 的兴趣没有很快消失,那么,这可能会是一个由怀旧社区支持的非官方版本。
|
||||
|
||||
问题是,你会对 Ubuntu Unity Spin 感兴趣么,官方或者非官方?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/someone-tries-to-bring-back-ubuntu-s-unity-from-the-dead-as-an-unofficial-spin-518778.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://linux.softpedia.com/downloadTag/Ubuntu
|
||||
[2]:https://community.ubuntu.com/t/poll-unity-7-distro-9-month-spin-or-lts-for-18-04/2066
|
||||
[3]:https://community.ubuntu.com/t/unity-maintenance-roadmap/2223
|
||||
[4]:http://news.softpedia.com/news/canonical-to-stop-developing-unity-8-ubuntu-18-04-lts-ships-with-gnome-desktop-514604.shtml
|
||||
[5]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
@ -0,0 +1,127 @@
|
||||
Suplemon:带有多光标支持的现代 CLI 文本编辑器
|
||||
======
|
||||
|
||||
Suplemon 是一个 CLI 中的现代文本编辑器,它模拟 [Sublime Text][1] 的多光标行为和其它特性。它是轻量级的,非常易于使用,就像 Nano 一样。
|
||||
|
||||
使用 CLI 编辑器的好处之一是,无论你使用的 Linux 发行版是否有 GUI,你都可以使用它。这种文本编辑器也很简单、快速和强大。
|
||||
|
||||
你可以在其[官方仓库][2]中找到有用的信息和源代码。
|
||||
|
||||
### 功能
|
||||
|
||||
这些是一些它有趣的功能:
|
||||
|
||||
* 多光标支持
|
||||
* 撤销/重做
|
||||
* 复制和粘贴,带有多行支持
|
||||
* 鼠标支持
|
||||
* 扩展
|
||||
* 查找、查找所有、查找下一个
|
||||
* 语法高亮
|
||||
* 自动完成
|
||||
* 自定义键盘快捷键
|
||||
|
||||
### 安装
|
||||
|
||||
首先,确保安装了最新版本的 python3 和 pip3。
|
||||
|
||||
然后在终端输入:
|
||||
|
||||
```
|
||||
$ sudo pip3 install suplemon
|
||||
```
|
||||
|
||||
### 使用
|
||||
|
||||
#### 在当前目录中创建一个新文件
|
||||
|
||||
打开一个终端并输入:
|
||||
|
||||
```
|
||||
$ suplemon
|
||||
```
|
||||
|
||||
你将看到如下:
|
||||
|
||||

|
||||
|
||||
#### 打开一个或多个文件
|
||||
|
||||
打开一个终端并输入:
|
||||
|
||||
```
|
||||
$ suplemon <filename1> <filename2> ... <filenameN>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
$ suplemon example1.c example2.c
|
||||
```
|
||||
|
||||
### 主要配置
|
||||
|
||||
你可以在 `~/.config/suplemon/suplemon-config.json` 找到配置文件。
|
||||
|
||||
编辑这个文件很简单,你只需要进入命令模式(进入 suplemon 后)并运行 `config` 命令。你可以通过运行 `config defaults` 来查看默认配置。
|
||||
|
||||
#### 键盘映射配置
|
||||
|
||||
我会展示 suplemon 的默认键映射。如果你想编辑它们,只需运行 `keymap` 命令。运行 `keymap default` 来查看默认的键盘映射文件。
|
||||
|
||||
| 操作 | 快捷键 |
|
||||
| ---- | ---- |
|
||||
| 退出| `Ctrl + Q`|
|
||||
| 复制行到缓冲区|`Ctrl + C`|
|
||||
| 剪切行缓冲区| `Ctrl + X`|
|
||||
| 插入缓冲区| `Ctrl + V`|
|
||||
| 复制行| `Ctrl + K`|
|
||||
| 跳转| `Ctrl + G`。 你可以跳转到一行或一个文件(只需键入一个文件名的开头)。另外,可以输入类似于 `exam:50` 跳转到 `example.c` 第 `50` 行。|
|
||||
| 用字符串或正则表达式搜索| `Ctrl + F`|
|
||||
| 搜索下一个| `Ctrl + D`|
|
||||
| 去除空格| `Ctrl + T`|
|
||||
| 在箭头方向添加新的光标| `Alt + 方向键`|
|
||||
| 跳转到上一个或下一个单词或行| `Ctrl + 左/右`|
|
||||
| 恢复到单光标/取消输入提示| `Esc`|
|
||||
| 向上/向下移动行| `Page Up` / `Page Down`|
|
||||
| 保存文件|`Ctrl + S`|
|
||||
| 用新名称保存文件|`F1`|
|
||||
| 重新载入当前文件|`F2`|
|
||||
| 打开文件|`Ctrl + O`|
|
||||
| 关闭文件|`Ctrl + W`|
|
||||
| 切换到下一个/上一个文件|`Ctrl + Page Up` / `Ctrl + Page Down`|
|
||||
| 运行一个命令|`Ctrl + E`|
|
||||
| 撤消|`Ctrl + Z`|
|
||||
| 重做|`Ctrl + Y`|
|
||||
| 触发可见的空格|`F7`|
|
||||
| 切换鼠标模式|`F8`|
|
||||
| 显示行号|`F9`|
|
||||
| 显示全屏|`F11`|
|
||||
|
||||
|
||||
|
||||
#### 鼠标快捷键
|
||||
|
||||
* 将光标置于指针位置:左键单击
|
||||
* 在指针位置添加一个光标:右键单击
|
||||
* 垂直滚动:向上/向下滚动滚轮
|
||||
|
||||
### 总结
|
||||
|
||||
在尝试 Suplemon 一段时间后,我改变了对 CLI 文本编辑器的看法。我以前曾经尝试过 Nano,是的,我喜欢它的简单性,但是它的现代特征的缺乏使它在日常使用中变得不实用。
|
||||
|
||||
这个工具有 CLI 和 GUI 世界最好的东西……简单性和功能丰富!所以我建议你试试看,并在评论中写下你的想法 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/tools/suplemon-cli-text-editor-multi-cursor/
|
||||
|
||||
作者:[Ivo Ursino][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/ursinov/
|
||||
[1]:https://linoxide.com/tools/install-sublime-text-editor-linux/
|
||||
[2]:https://github.com/richrd/suplemon/
|
||||
@ -1,18 +1,14 @@
|
||||
如何在 Linux shell 中找出所有包含指定文本的文件
|
||||
------
|
||||
### 目标
|
||||
===========
|
||||
|
||||
本文提供一些关于如何搜索出指定目录或整个文件系统中那些包含指定单词或字符串的文件。
|
||||
**目标:**本文提供一些关于如何搜索出指定目录或整个文件系统中那些包含指定单词或字符串的文件。
|
||||
|
||||
### 难度
|
||||
**难度:**容易
|
||||
|
||||
容易
|
||||
**约定:**
|
||||
|
||||
### 约定
|
||||
|
||||
* \# - 需要使用 root 权限来执行指定命令,可以直接使用 root 用户来执行也可以使用 sudo 命令
|
||||
|
||||
* \$ - 可以使用普通用户来执行指定命令
|
||||
* `#` - 需要使用 root 权限来执行指定命令,可以直接使用 root 用户来执行也可以使用 `sudo` 命令
|
||||
* `$` - 可以使用普通用户来执行指定命令
|
||||
|
||||
### 案例
|
||||
|
||||
@ -25,12 +21,14 @@
|
||||
/etc/os-release:PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
|
||||
/etc/os-release:VERSION="9 (stretch)"
|
||||
```
|
||||
grep 的 `-s` 选项会在发现不能存在或者不能读取的文件时抑制报错信息。结果现实除了文件名外还有包含请求字符串的行也被一起输出了。
|
||||
|
||||
`grep` 的 `-s` 选项会在发现不存在或者不能读取的文件时隐藏报错信息。结果显示除了文件名之外,还有包含请求字符串的行也被一起输出了。
|
||||
|
||||
#### 递归地搜索包含指定字符串的文件
|
||||
|
||||
上面案例中忽略了所有的子目录。所谓递归搜索就是指同时搜索所有的子目录。
|
||||
下面的命令会在 `/etc/` 及其子目录中搜索包含 `stretch` 字符串的文件:
|
||||
|
||||
下面的命令会在 `/etc/` 及其子目录中搜索包含 `stretch` 字符串的文件:
|
||||
|
||||
```shell
|
||||
# grep -R stretch /etc/*
|
||||
@ -67,7 +65,8 @@ grep 的 `-s` 选项会在发现不能存在或者不能读取的文件时抑制
|
||||
```
|
||||
|
||||
#### 搜索所有包含特定单词的文件
|
||||
上面 `grep` 命令的案例中列出的是所有包含字符串 `stretch` 的文件。也就是说包含 `stretches` , `stretched` 等内容的行也会被显示。 使用 grep 的 `-w` 选项会只显示包含特定单词的行:
|
||||
|
||||
上面 `grep` 命令的案例中列出的是所有包含字符串 `stretch` 的文件。也就是说包含 `stretches` , `stretched` 等内容的行也会被显示。 使用 `grep` 的 `-w` 选项会只显示包含特定单词的行:
|
||||
|
||||
```shell
|
||||
# grep -Rw stretch /etc/*
|
||||
@ -84,8 +83,9 @@ grep 的 `-s` 选项会在发现不能存在或者不能读取的文件时抑制
|
||||
/etc/os-release:VERSION="9 (stretch)"
|
||||
```
|
||||
|
||||
#### 显示包含特定文本文件的文件名
|
||||
上面的命令都会产生多余的输出。下一个案例则会递归地搜索 `etc` 目录中包含 `stretch` 的文件并只输出文件名:
|
||||
#### 显示包含特定文本的文件名
|
||||
|
||||
上面的命令都会产生多余的输出。下一个案例则会递归地搜索 `etc` 目录中包含 `stretch` 的文件并只输出文件名:
|
||||
|
||||
```shell
|
||||
# grep -Rl stretch /etc/*
|
||||
@ -96,8 +96,10 @@ grep 的 `-s` 选项会在发现不能存在或者不能读取的文件时抑制
|
||||
```
|
||||
|
||||
#### 大小写不敏感的搜索
|
||||
默认情况下搜索 hi 大小写敏感的,也就是说当搜索字符串 `stretch` 时只会包含大小写一致内容的文件。
|
||||
通过使用 grep 的 `-i` 选项,grep 命令还会列出所有包含 `Stretch` , `STRETCH` , `StReTcH` 等内容的文件,也就是说进行的是大小写不敏感的搜索。
|
||||
|
||||
默认情况下搜索是大小写敏感的,也就是说当搜索字符串 `stretch` 时只会包含大小写一致内容的文件。
|
||||
|
||||
通过使用 `grep` 的 `-i` 选项,`grep` 命令还会列出所有包含 `Stretch` , `STRETCH` , `StReTcH` 等内容的文件,也就是说进行的是大小写不敏感的搜索。
|
||||
|
||||
```shell
|
||||
# grep -Ril stretch /etc/*
|
||||
@ -108,8 +110,9 @@ grep 的 `-s` 选项会在发现不能存在或者不能读取的文件时抑制
|
||||
/etc/os-release
|
||||
```
|
||||
|
||||
#### 搜索是包含/排除指定文件
|
||||
`grep` 命令也可以只在指定文件中进行搜索。比如,我们可以只在配置文件(扩展名为`.conf`)中搜索指定的文本/字符串。 下面这个例子就会在 `/etc` 目录中搜索带字符串 `bash` 且所有扩展名为 `.conf` 的文件:
|
||||
#### 搜索时包含/排除指定文件
|
||||
|
||||
`grep` 命令也可以只在指定文件中进行搜索。比如,我们可以只在配置文件(扩展名为`.conf`)中搜索指定的文本/字符串。 下面这个例子就会在 `/etc` 目录中搜索带字符串 `bash` 且所有扩展名为 `.conf` 的文件:
|
||||
|
||||
```shell
|
||||
# grep -Ril bash /etc/*.conf
|
||||
@ -118,7 +121,7 @@ OR
|
||||
/etc/adduser.conf
|
||||
```
|
||||
|
||||
类似的,也可以使用 `--exclude` 来排除特定的文件:
|
||||
类似的,也可以使用 `--exclude` 来排除特定的文件:
|
||||
|
||||
```shell
|
||||
# grep -Ril --exclude=\*.conf bash /etc/*
|
||||
@ -146,8 +149,10 @@ OR
|
||||
```
|
||||
|
||||
#### 搜索时排除指定目录
|
||||
跟文件一样,grep 也能在搜索时排除指定目录。 使用 `--exclude-dir` 选项就行。
|
||||
下面这个例子会搜索 `/etc` 目录中搜有包含字符串 `stretch` 的文件,但不包括 `/etc/grub.d` 目录下的文件:
|
||||
|
||||
跟文件一样,`grep` 也能在搜索时排除指定目录。 使用 `--exclude-dir` 选项就行。
|
||||
|
||||
下面这个例子会搜索 `/etc` 目录中搜有包含字符串 `stretch` 的文件,但不包括 `/etc/grub.d` 目录下的文件:
|
||||
|
||||
```shell
|
||||
# grep --exclude-dir=/etc/grub.d -Rwl stretch /etc/*
|
||||
@ -157,6 +162,7 @@ OR
|
||||
```
|
||||
|
||||
#### 显示包含搜索字符串的行号
|
||||
|
||||
`-n` 选项还会显示指定字符串所在行的行号:
|
||||
|
||||
```shell
|
||||
@ -165,8 +171,10 @@ OR
|
||||
```
|
||||
|
||||
#### 寻找不包含指定字符串的文件
|
||||
最后这个例子使用 `-v` 来列出所有 *不* 包含指定字符串的文件。
|
||||
例如下面命令会搜索 `/etc` 目录中不包含 `stretch` 的所有文件:
|
||||
|
||||
最后这个例子使用 `-v` 来列出所有**不**包含指定字符串的文件。
|
||||
|
||||
例如下面命令会搜索 `/etc` 目录中不包含 `stretch` 的所有文件:
|
||||
|
||||
```shell
|
||||
# grep -Rlv stretch /etc/*
|
||||
@ -178,7 +186,7 @@ via: https://linuxconfig.org/how-to-find-all-files-with-a-specific-text-using-li
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者 ID](https://github.com/校对者 ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
### [Fedora 课堂会议: Ansible 101][2]
|
||||
|
||||
### By Sachin S Kamath
|
||||
Fedora 课堂会议:Ansible 101
|
||||
==========
|
||||
|
||||

|
||||
|
||||
@ -13,19 +12,12 @@ Fedora 课堂会议本周继续进行,本周的主题是 Ansible。 会议的
|
||||
本课堂课程涵盖以下主题:
|
||||
|
||||
1. SSH 简介
|
||||
|
||||
2. 了解不同的术语
|
||||
|
||||
3. Ansible 简介
|
||||
|
||||
4. Ansible 安装和设置
|
||||
|
||||
5. 建立无密码连接
|
||||
|
||||
6. Ad-hoc 命令
|
||||
|
||||
7. 管理 inventory
|
||||
|
||||
8. Playbooks 示例
|
||||
|
||||
之后还将有 Ansible 102 的后续会议。该会议将涵盖复杂的 playbooks,playbooks 角色(roles),动态 inventory 文件,流程控制和 Ansible Galaxy 命令行工具.
|
||||
@ -43,7 +35,6 @@ Fedora 课堂会议本周继续进行,本周的主题是 Ansible。 会议的
|
||||
本次会议将在 [BlueJeans][10] 上进行。下面的信息可以帮你加入到会议:
|
||||
|
||||
* 网址: [https://bluejeans.com/3466040121][1]
|
||||
|
||||
* 会议 ID (桌面版): 3466040121
|
||||
|
||||
我们希望您可以参加,学习,并享受这个会议!如果您对会议有任何反馈意见,有什么新的想法或者想要主持一个会议, 可以随时在这篇文章发表评论或者查看[课堂 wiki 页面][11].
|
||||
@ -54,7 +45,7 @@ via: https://fedoramagazine.org/fedora-classroom-session-ansible-101/
|
||||
|
||||
作者:[Sachin S Kamath]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,161 @@
|
||||
在 Ubuntu 16.04 下随机化你的 WiFi MAC 地址
|
||||
============================================================
|
||||
|
||||
> 你的设备的 MAC 地址可以在不同的 WiFi 网络中记录你的活动。这些信息能被共享后出售,用于识别特定的个体。但可以用随机生成的伪 MAC 地址来阻止这一行为。
|
||||
|
||||
|
||||

|
||||
|
||||
_Image courtesy of [Cloudessa][4]_
|
||||
|
||||
每一个诸如 WiFi 或者以太网卡这样的网络设备,都有一个叫做 MAC 地址的唯一标识符,如:`b4:b6:76:31:8c:ff`。这就是你能上网的原因:每当你连上 WiFi,路由器就会用这一地址来向你接受和发送数据,并且用它来区别你和这一网络的其它设备。
|
||||
|
||||
这一设计的缺陷在于唯一性,不变的 MAC 地址正好可以用来追踪你。连上了星巴克的 WiFi? 好,注意到了。在伦敦的地铁上? 也记录下来。
|
||||
|
||||
如果你曾经在某一个 WiFi 验证页面上输入过你的真实姓名,你就已经把自己和这一 MAC 地址建立了联系。没有仔细阅读许可服务条款、你可以认为,机场的免费 WiFi 正通过出售所谓的 ‘顾客分析数据’(你的个人信息)获利。出售的对象包括酒店,餐饮业,和任何想要了解你的人。
|
||||
|
||||
我不想信息被记录,再出售给多家公司,所以我花了几个小时想出了一个解决方案。
|
||||
|
||||
### MAC 地址不一定总是不变的
|
||||
|
||||
幸运的是,在不断开网络的情况下,是可以随机生成一个伪 MAC 地址的。
|
||||
|
||||
我想随机生成我的 MAC 地址,但是有三个要求:
|
||||
|
||||
1. MAC 地址在不同网络中是不相同的。这意味着,我在星巴克和在伦敦地铁网络中的 MAC 地址是不相同的,这样在不同的服务提供商中就无法将我的活动系起来。
|
||||
2. MAC 地址需要经常更换,这样在网络上就没人知道我就是去年在这儿经过了 75 次的那个人。
|
||||
3. MAC 地址一天之内应该保持不变。当 MAC 地址更改时,大多数网络都会与你断开连接,然后必须得进入验证页面再次登陆 - 这很烦人。
|
||||
|
||||
### 操作<ruby>网络管理器<rt>NetworkManager</rt></ruby>
|
||||
|
||||
我第一次尝试用一个叫做 `macchanger` 的工具,但是失败了。因为<ruby>网络管理器<rt>NetworkManager</rt></ruby>会根据它自己的设置恢复默认的 MAC 地址。
|
||||
|
||||
我了解到,网络管理器 1.4.1 以上版本可以自动生成随机的 MAC 地址。如果你在使用 Ubuntu 17.04 版本,你可以根据[这一配置文件][7]实现这一目的。但这并不能完全符合我的三个要求(你必须在<ruby>随机<rt>random</rt></ruby>和<ruby>稳定<rt>stable</rt></ruby>这两个选项之中选择一个,但没有一天之内保持不变这一选项)
|
||||
|
||||
因为我使用的是 Ubuntu 16.04,网络管理器版本为 1.2,不能直接使用高版本这一新功能。可能网络管理器有一些随机化方法支持,但我没能成功。所以我编了一个脚本来实现这一目标。
|
||||
|
||||
幸运的是,网络管理器 1.2 允许模拟 MAC 地址。你在已连接的网络中可以看见 ‘编辑连接’ 这一选项:
|
||||
|
||||

|
||||
|
||||
网络管理器也支持钩子处理 —— 任何位于 `/etc/NetworkManager/dispatcher.d/pre-up.d/` 的脚本在建立网络连接之前都会被执行。
|
||||
|
||||
|
||||
### 分配随机生成的伪 MAC 地址
|
||||
|
||||
我想根据网络 ID 和日期来生成新的随机 MAC 地址。 我们可以使用网络管理器的命令行工具 nmcli 来显示所有可用网络:
|
||||
|
||||
|
||||
```
|
||||
> nmcli connection
|
||||
NAME UUID TYPE DEVICE
|
||||
Gladstone Guest 618545ca-d81a-11e7-a2a4-271245e11a45 802-11-wireless wlp1s0
|
||||
DoESDinky 6e47c080-d81a-11e7-9921-87bc56777256 802-11-wireless --
|
||||
PublicWiFi 79282c10-d81a-11e7-87cb-6341829c2a54 802-11-wireless --
|
||||
virgintrainswifi 7d0c57de-d81a-11e7-9bae-5be89b161d22 802-11-wireless --
|
||||
```
|
||||
|
||||
因为每个网络都有一个唯一标识符(UUID),为了实现我的计划,我将 UUID 和日期拼接在一起,然后使用 MD5 生成 hash 值:
|
||||
|
||||
```
|
||||
# eg 618545ca-d81a-11e7-a2a4-271245e11a45-2017-12-03
|
||||
|
||||
> echo -n "${UUID}-$(date +%F)" | md5sum
|
||||
|
||||
53594de990e92f9b914a723208f22b3f -
|
||||
```
|
||||
|
||||
生成的结果可以代替 MAC 地址的最后八个字节。
|
||||
|
||||
|
||||
值得注意的是,最开始的字节 `02` 代表这个地址是[自行指定][8]的。实际上,真实 MAC 地址的前三个字节是由制造商决定的,例如 `b4:b6:76` 就代表 Intel。
|
||||
|
||||
有可能某些路由器会拒绝自己指定的 MAC 地址,但是我还没有遇到过这种情况。
|
||||
|
||||
每次连接到一个网络,这一脚本都会用 `nmcli` 来指定一个随机生成的伪 MAC 地址:
|
||||
|
||||

|
||||
|
||||
最后,我查看了 `ifconfig` 的输出结果,我发现 MAC 地址 `HWaddr` 已经变成了随机生成的地址(模拟 Intel 的),而不是我真实的 MAC 地址。
|
||||
|
||||
|
||||
```
|
||||
> ifconfig
|
||||
wlp1s0 Link encap:Ethernet HWaddr b4:b6:76:45:64:4d
|
||||
inet addr:192.168.0.86 Bcast:192.168.0.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::648c:aff2:9a9d:764/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:12107812 errors:0 dropped:2 overruns:0 frame:0
|
||||
TX packets:18332141 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:11627977017 (11.6 GB) TX bytes:20700627733 (20.7 GB)
|
||||
|
||||
```
|
||||
|
||||
### 脚本
|
||||
|
||||
完整的脚本也可以[在 Github 上查看][9]。
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
# /etc/NetworkManager/dispatcher.d/pre-up.d/randomize-mac-addresses
|
||||
|
||||
# Configure every saved WiFi connection in NetworkManager with a spoofed MAC
|
||||
# address, seeded from the UUID of the connection and the date eg:
|
||||
# 'c31bbcc4-d6ad-11e7-9a5a-e7e1491a7e20-2017-11-20'
|
||||
|
||||
# This makes your MAC impossible(?) to track across WiFi providers, and
|
||||
# for one provider to track across days.
|
||||
|
||||
# For craptive portals that authenticate based on MAC, you might want to
|
||||
# automate logging in :)
|
||||
|
||||
# Note that NetworkManager >= 1.4.1 (Ubuntu 17.04+) can do something similar
|
||||
# automatically.
|
||||
|
||||
export PATH=$PATH:/usr/bin:/bin
|
||||
|
||||
LOG_FILE=/var/log/randomize-mac-addresses
|
||||
|
||||
echo "$(date): $*" > ${LOG_FILE}
|
||||
|
||||
WIFI_UUIDS=$(nmcli --fields type,uuid connection show |grep 802-11-wireless |cut '-d ' -f3)
|
||||
|
||||
for UUID in ${WIFI_UUIDS}
|
||||
do
|
||||
UUID_DAILY_HASH=$(echo "${UUID}-$(date +F)" | md5sum)
|
||||
|
||||
RANDOM_MAC="02:$(echo -n ${UUID_DAILY_HASH} | sed 's/^\(..\)\(..\)\(..\)\(..\)\(..\).*$/\1:\2:\3:\4:\5/')"
|
||||
|
||||
CMD="nmcli connection modify ${UUID} wifi.cloned-mac-address ${RANDOM_MAC}"
|
||||
|
||||
echo "$CMD" >> ${LOG_FILE}
|
||||
$CMD &
|
||||
done
|
||||
|
||||
wait
|
||||
```
|
||||
|
||||
_更新:[使用自己指定的 MAC 地址][5]可以避免和真正的 intel 地址冲突。感谢 [@_fink][6]_
|
||||
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.paulfurley.com/randomize-your-wifi-mac-address-on-ubuntu-1604-xenial/
|
||||
|
||||
作者:[Paul M Furley][a]
|
||||
译者:[wenwensnow](https://github.com/wenwensnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.paulfurley.com/
|
||||
[1]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f/raw/5f02fc8f6ff7fca5bca6ee4913c63bf6de15abcarandomize-mac-addresses
|
||||
[2]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f#file-randomize-mac-addresses
|
||||
[3]:https://github.com/
|
||||
[4]:http://cloudessa.com/products/cloudessa-aaa-and-captive-portal-cloud-service/
|
||||
[5]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f/revisions#diff-824d510864d58c07df01102a8f53faef
|
||||
[6]:https://twitter.com/fink_/status/937305600005943296
|
||||
[7]:https://gist.github.com/paulfurley/978d4e2e0cceb41d67d017a668106c53/
|
||||
[8]:https://en.wikipedia.org/wiki/MAC_address#Universal_vs._local
|
||||
[9]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f
|
||||
122
published/20171202 docker - Use multi-stage builds.md
Normal file
122
published/20171202 docker - Use multi-stage builds.md
Normal file
@ -0,0 +1,122 @@
|
||||
Docker:使用多阶段构建镜像
|
||||
============================================================
|
||||
|
||||
多阶段构建是 Docker 17.05 及更高版本提供的新功能。这对致力于优化 Dockerfile 的人来说,使得 Dockerfile 易于阅读和维护。
|
||||
|
||||
> 致谢: 特别感谢 [Alex Ellis][1] 授权使用他的关于 Docker 多阶段构建的博客文章 [Builder pattern vs. Multi-stage builds in Docker][2] 作为以下示例的基础。
|
||||
|
||||
### 在多阶段构建之前
|
||||
|
||||
关于构建镜像最具挑战性的事情之一是保持镜像体积小巧。 Dockerfile 中的每条指令都会在镜像中增加一层,并且在移动到下一层之前,需要记住清除不需要的构件。要编写一个非常高效的 Dockerfile,你通常需要使用 shell 技巧和其它方式来尽可能地减少层数,并确保每一层都具有上一层所需的构件,而其它任何东西都不需要。
|
||||
|
||||
实际上最常见的是,有一个 Dockerfile 用于开发(其中包含构建应用程序所需的所有内容),而另一个裁剪过的用于生产环境,它只包含您的应用程序以及运行它所需的内容。这被称为“构建器模式”。但是维护两个 Dockerfile 并不理想。
|
||||
|
||||
下面分别是一个 `Dockerfile.build` 和遵循上面的构建器模式的 `Dockerfile` 的例子:
|
||||
|
||||
`Dockerfile.build`:
|
||||
|
||||
```
|
||||
FROM golang:1.7.3
|
||||
WORKDIR /go/src/github.com/alexellis/href-counter/
|
||||
RUN go get -d -v golang.org/x/net/html
|
||||
COPY app.go .
|
||||
RUN go get -d -v golang.org/x/net/html \
|
||||
&& CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
|
||||
```
|
||||
|
||||
注意这个例子还使用 Bash 的 `&&` 运算符人为地将两个 `RUN` 命令压缩在一起,以避免在镜像中创建额外的层。这很容易失败,难以维护。例如,插入另一个命令时,很容易忘记继续使用 `\` 字符。
|
||||
|
||||
`Dockerfile`:
|
||||
|
||||
```
|
||||
FROM alpine:latest
|
||||
RUN apk --no-cache add ca-certificates
|
||||
WORKDIR /root/
|
||||
COPY app .
|
||||
CMD ["./app"]
|
||||
```
|
||||
|
||||
`build.sh`:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
echo Building alexellis2/href-counter:build
|
||||
|
||||
docker build --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy \
|
||||
-t alexellis2/href-counter:build . -f Dockerfile.build
|
||||
|
||||
docker create --name extract alexellis2/href-counter:build
|
||||
docker cp extract:/go/src/github.com/alexellis/href-counter/app ./app
|
||||
docker rm -f extract
|
||||
|
||||
echo Building alexellis2/href-counter:latest
|
||||
|
||||
docker build --no-cache -t alexellis2/href-counter:latest .
|
||||
rm ./app
|
||||
```
|
||||
|
||||
当您运行 `build.sh` 脚本时,它会构建第一个镜像,从中创建一个容器,以便将该构件复制出来,然后构建第二个镜像。 这两个镜像会占用您的系统的空间,而你仍然会一个 `app` 构件存放在你的本地磁盘上。
|
||||
|
||||
多阶段构建大大简化了这种情况!
|
||||
|
||||
### 使用多阶段构建
|
||||
|
||||
在多阶段构建中,您需要在 Dockerfile 中多次使用 `FROM` 声明。每次 `FROM` 指令可以使用不同的基础镜像,并且每次 `FROM` 指令都会开始新阶段的构建。您可以选择将构件从一个阶段复制到另一个阶段,在最终镜像中,不会留下您不需要的所有内容。为了演示这是如何工作的,让我们调整前一节中的 Dockerfile 以使用多阶段构建。
|
||||
|
||||
`Dockerfile`:
|
||||
|
||||
```
|
||||
FROM golang:1.7.3
|
||||
WORKDIR /go/src/github.com/alexellis/href-counter/
|
||||
RUN go get -d -v golang.org/x/net/html
|
||||
COPY app.go .
|
||||
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
|
||||
|
||||
FROM alpine:latest
|
||||
RUN apk --no-cache add ca-certificates
|
||||
WORKDIR /root/
|
||||
COPY --from=0 /go/src/github.com/alexellis/href-counter/app .
|
||||
CMD ["./app"]
|
||||
```
|
||||
|
||||
您只需要单一个 Dockerfile。 不需要另外的构建脚本。只需运行 `docker build` 即可。
|
||||
|
||||
```
|
||||
$ docker build -t alexellis2/href-counter:latest .
|
||||
```
|
||||
|
||||
最终的结果是和以前体积一样小的生产镜像,复杂性显著降低。您不需要创建任何中间镜像,也不需要将任何构件提取到本地系统。
|
||||
|
||||
它是如何工作的呢?第二条 `FROM` 指令以 `alpine:latest` 镜像作为基础开始新的建造阶段。`COPY --from=0` 这一行将刚才前一个阶段产生的构件复制到这个新阶段。Go SDK 和任何中间构件都被留在那里,而不会保存到最终的镜像中。
|
||||
|
||||
### 命名您的构建阶段
|
||||
|
||||
默认情况下,这些阶段没有命名,您可以通过它们的整数来引用它们,从第一个 `FROM` 指令的 0 开始。但是,你可以通过在 `FROM` 指令中使用 `as <NAME>` 来为阶段命名。以下示例通过命名阶段并在 `COPY` 指令中使用名称来改进前一个示例。这意味着,即使您的 `Dockerfile` 中的指令稍后重新排序,`COPY` 也不会出问题。
|
||||
|
||||
```
|
||||
FROM golang:1.7.3 as builder
|
||||
WORKDIR /go/src/github.com/alexellis/href-counter/
|
||||
RUN go get -d -v golang.org/x/net/html
|
||||
COPY app.go .
|
||||
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
|
||||
|
||||
FROM alpine:latest
|
||||
RUN apk --no-cache add ca-certificates
|
||||
WORKDIR /root/
|
||||
COPY --from=builder /go/src/github.com/alexellis/href-counter/app .
|
||||
CMD ["./app"]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://docs.docker.com/engine/userguide/eng-image/multistage-build/
|
||||
|
||||
作者:[docker][a]
|
||||
译者:[iron0x](https://github.com/iron0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://docs.docker.com/engine/userguide/eng-image/multistage-build/
|
||||
[1]:https://twitter.com/alexellisuk
|
||||
[2]:http://blog.alexellis.io/mutli-stage-docker-builds/
|
||||
129
published/20171203 Best Network Monitoring Tools For Linux.md
Normal file
129
published/20171203 Best Network Monitoring Tools For Linux.md
Normal file
@ -0,0 +1,129 @@
|
||||
十个不错的 Linux 网络监视工具
|
||||
===============================
|
||||
|
||||

|
||||
|
||||
保持对我们的网络的管理,防止任何程序过度使用网络、导致整个系统操作变慢,对管理员来说是至关重要的。有几个网络监视工具可以用于不同的操作系统。在这篇文章中,我们将讨论从 Linux 终端中运行的 10 个网络监视工具。它对不使用 GUI 而希望通过 SSH 来保持对网络管理的用户来说是非常理想的。
|
||||
|
||||
### iftop
|
||||
|
||||
[][2]
|
||||
|
||||
Linux 用户通常都熟悉 `top` —— 这是一个系统监视工具,它允许我们知道在我们的系统中实时运行的进程,并可以很容易地管理它们。`iftop` 与 `top` 应用程序类似,但它是专门监视网络的,通过它可以知道更多的关于网络的详细情况和使用网络的所有进程。
|
||||
|
||||
我们可以从 [这个链接][3] 获取关于这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### vnstat
|
||||
|
||||
[][4]
|
||||
|
||||
`vnstat` 是一个缺省包含在大多数 Linux 发行版中的网络监视工具。它允许我们对一个用户选择的时间周期内发送和接收的流量进行实时控制。
|
||||
|
||||
我们可以从 [这个链接][5] 获取关于这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### iptraf
|
||||
|
||||
[][6]
|
||||
|
||||
IPTraf 是一个基于控制台的 Linux 实时网络监视程序。它会收集经过这个网络的各种各样的信息作为一个 IP 流量监视器,包括 TCP 标志信息、ICMP 详细情况、TCP / UDP 流量故障、TCP 连接包和字节计数。它也收集接口上全部的 TCP、UDP、…… IP 协议和非 IP 协议 ICMP 的校验和错误、接口活动等等的详细情况。(LCTT 译注:此处原文有误,径改之)
|
||||
|
||||
我们可以从 [这个链接][7] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Monitorix - 系统和网络监视
|
||||
|
||||
[][8]
|
||||
|
||||
Monitorix 是一个轻量级的免费应用程序,它设计用于去监视尽可能多的 Linux / Unix 服务器的系统和网络资源。它里面添加了一个 HTTP web 服务器,可以定期去收集系统和网络信息,并且在一个图表中显示它们。它跟踪平均系统负载、内存分配、磁盘健康状态、系统服务、网络端口、邮件统计信息(Sendmail、Postfix、Dovecot 等等)、MySQL 统计信息以及其它的更多内容。它设计用于去管理系统的整体性能,以及帮助检测故障、瓶颈、异常活动等等。
|
||||
|
||||
下载及更多 [信息在这里][9]。
|
||||
|
||||
### dstat
|
||||
|
||||
[][10]
|
||||
|
||||
这个监视器相比前面的几个知名度低一些,但是,在一些发行版中已经缺省包含了。
|
||||
|
||||
我们可以从 [这个链接][11] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### bwm-ng
|
||||
|
||||
[][12]
|
||||
|
||||
这是最简化的工具之一。它允许你去从连接中交互式取得数据,并且,为了便于其它设备使用,在取得数据的同时,能以某些格式导出它们。
|
||||
|
||||
我们可以从 [这个链接][13] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### ibmonitor
|
||||
|
||||
[][14]
|
||||
|
||||
与上面的类似,它显示连接接口上过滤后的网络流量,并且,明确地将接收流量和发送流量区分开。
|
||||
|
||||
我们可以从 [这个链接][15] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Htop - Linux 进程跟踪
|
||||
|
||||
[][16]
|
||||
|
||||
Htop 是一个更先进的、交互式的、实时的 Linux 进程跟踪工具。它类似于 Linux 的 top 命令,但是有一些更高级的特性,比如,一个更易于使用的进程管理界面、快捷键、水平和垂直的进程视图等更多特性。Htop 是一个第三方工具,它不包含在 Linux 系统中,你必须使用 **YUM** 或者 **APT-GET** 或者其它的包管理工具去安装它。关于安装它的更多信息,读[这篇文章][17]。
|
||||
|
||||
我们可以从 [这个链接][18] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### arpwatch - 以太网活动监视器
|
||||
|
||||
[][19]
|
||||
|
||||
arpwatch 是一个设计用于在 Linux 网络中去管理以太网通讯的地址解析程序。它持续监视以太网通讯并记录一个网络中的 IP 地址和 MAC 地址的变化,该变化同时也会记录一个时间戳。它也有一个功能是当一对 IP 和 MAC 地址被添加或者发生变化时,发送一封邮件给系统管理员。在一个网络中发生 ARP 攻击时,这个功能非常有用。
|
||||
|
||||
我们可以从 [这个链接][20] 获取这个工具的更多信息以及下载必要的包。
|
||||
|
||||
### Wireshark - 网络监视工具
|
||||
|
||||
[][21]
|
||||
|
||||
[Wireshark][1] 是一个自由的应用程序,它允许你去捕获和查看前往你的系统和从你的系统中返回的信息,它可以去深入到数据包中并查看每个包的内容 —— 以分别满足你的不同需求。它一般用于去研究协议问题和去创建和测试程序的特别情况。这个开源分析器是一个被公认的分析器商业标准,它的流行要归功于其久负盛名。
|
||||
|
||||
最初它被叫做 Ethereal,Wireshark 有轻量化的、易于理解的界面,它能分类显示来自不同的真实系统上的协议信息。
|
||||
|
||||
### 结论
|
||||
|
||||
在这篇文章中,我们看了几个开源的网络监视工具。虽然我们从这些工具中挑选出来的认为是“最佳的”,并不意味着它们都是最适合你的需要的。例如,现在有很多的开源监视工具,比如,OpenNMS、Cacti、和 Zennos,并且,你需要去从你的个体情况考虑它们的每个工具的优势。
|
||||
|
||||
另外,还有不同的、更适合你的需要的不开源的工具。
|
||||
|
||||
你知道的或者使用的在 Linux 终端中的更多网络监视工具还有哪些?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-network-monitoring-tools-for-linux
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:https://www.wireshark.org/
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/iftop_orig.png
|
||||
[3]:http://www.ex-parrot.com/pdw/iftop/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/vnstat.png
|
||||
[5]:http://humdi.net/vnstat/
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/iptraf_orig.gif
|
||||
[7]:http://iptraf.seul.org/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/monitorix_orig.png
|
||||
[9]:http://www.monitorix.org
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/dstat_orig.png
|
||||
[11]:http://dag.wiee.rs/home-made/dstat/
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/bwm-ng_orig.png
|
||||
[13]:http://sourceforge.net/projects/bwmng/
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ibmonitor_orig.jpg
|
||||
[15]:http://ibmonitor.sourceforge.net/
|
||||
[16]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/htop_orig.png
|
||||
[17]:http://wesharethis.com/knowledgebase/htop-and-atop/
|
||||
[18]:http://hisham.hm/htop/
|
||||
[19]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/arpwatch_orig.png
|
||||
[20]:http://linux.softpedia.com/get/System/Monitoring/arpwatch-NG-7612.shtml
|
||||
[21]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/how-to-use-wireshark_1_orig.jpg
|
||||
|
||||
|
||||
@ -0,0 +1,140 @@
|
||||
如何在执行一个命令或程序之前就了解它会做什么
|
||||
======
|
||||
|
||||
有没有想过在执行一个 Unix 命令前就知道它干些什么呢?并不是每个人都会知道一个特定的命令或者程序将会做什么。当然,你可以用 [Explainshell][2] 来查看它。你可以在 Explainshell 网站中粘贴你的命令,然后它可以让你了解命令的每个部分做了什么。但是,这是没有必要的。现在,我们从终端就可以轻易地在执行一个命令或者程序前就知道它会做什么。 `maybe` ,一个简单的工具,它允许你运行一条命令并可以查看此命令对你的文件做了什么,而实际上这条命令却并未执行!在查看 `maybe` 的输出列表后,你可以决定是否真的想要运行这条命令。
|
||||
|
||||

|
||||
|
||||
### `maybe` 是如何工作的
|
||||
|
||||
根据开发者的介绍:
|
||||
|
||||
> `maybe` 利用 `python-ptrace` 库在 `ptrace` 控制下运行了一个进程。当它截取到一个即将更改文件系统的系统调用时,它会记录该调用,然后修改 CPU 寄存器,将这个调用重定向到一个无效的系统调用 ID(效果上将其变成一个无效操作(no-op)),并将这个无效操作(no-op)的返回值设置为有效操作的返回值。结果,这个进程认为,它所做的一切都发生了,实际上什么都没有改变。
|
||||
|
||||
警告:在生产环境或者任何你所关心的系统里面使用这个工具时都应该小心。它仍然可能造成严重的损失,因为它只能阻止少数系统调用。
|
||||
|
||||
#### 安装 `maybe`
|
||||
|
||||
确保你已经在你的 Linux 系统中已经安装了 `pip` 。如果没有,可以根据您使用的发行版,按照如下指示进行安装。
|
||||
|
||||
在 Arch Linux 及其衍生产品(如 Antergos、Manjaro Linux)上,使用以下命令安装 `pip` :
|
||||
|
||||
```
|
||||
sudo pacman -S python-pip
|
||||
```
|
||||
|
||||
在 RHEL,CentOS 上:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
sudo yum install python-pip
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
sudo dnf install epel-release
|
||||
sudo dnf install python-pip
|
||||
```
|
||||
|
||||
在 Debian,Ubuntu,Linux Mint 上:
|
||||
|
||||
```
|
||||
sudo apt-get install python-pip
|
||||
```
|
||||
|
||||
在 SUSE、 openSUSE 上:
|
||||
|
||||
```
|
||||
sudo zypper install python-pip
|
||||
```
|
||||
|
||||
安装 `pip` 后,运行以下命令安装 `maybe` :
|
||||
|
||||
```
|
||||
sudo pip install maybe
|
||||
```
|
||||
|
||||
### 了解一个命令或程序在执行前会做什么
|
||||
|
||||
用法是非常简单的!只要在要执行的命令前加上 `maybe` 即可。
|
||||
|
||||
让我给你看一个例子:
|
||||
|
||||
```
|
||||
$ maybe rm -r ostechnix/
|
||||
```
|
||||
|
||||
如你所看到的,我从我的系统中删除一个名为 `ostechnix` 的文件夹。下面是示例输出:
|
||||
|
||||
```
|
||||
maybe has prevented rm -r ostechnix/ from performing 5 file system operations:
|
||||
|
||||
delete /home/sk/inboxer-0.4.0-x86_64.AppImage
|
||||
delete /home/sk/Docker.pdf
|
||||
delete /home/sk/Idhayathai Oru Nodi.mp3
|
||||
delete /home/sk/dThmLbB334_1398236878432.jpg
|
||||
delete /home/sk/ostechnix
|
||||
|
||||
Do you want to rerun rm -r ostechnix/ and permit these operations? [y/N] y
|
||||
```
|
||||
|
||||
[][3]
|
||||
|
||||
`maybe` 执行了 5 个文件系统操作,并向我显示该命令(`rm -r ostechnix/`)究竟会做什么。现在我可以决定是否应该执行这个操作。是不是很酷呢?确实很酷!
|
||||
|
||||
这是另一个例子。我要为 Gmail 安装 Inboxer 桌面客户端。这是我得到的输出:
|
||||
|
||||
```
|
||||
$ maybe ./inboxer-0.4.0-x86_64.AppImage
|
||||
fuse: bad mount point `/tmp/.mount_inboxemDzuGV': No such file or directory
|
||||
squashfuse 0.1.100 (c) 2012 Dave Vasilevsky
|
||||
|
||||
Usage: /home/sk/Downloads/inboxer-0.4.0-x86_64.AppImage [options] ARCHIVE MOUNTPOINT
|
||||
|
||||
FUSE options:
|
||||
-d -o debug enable debug output (implies -f)
|
||||
-f foreground operation
|
||||
-s disable multi-threaded operation
|
||||
|
||||
open dir error: No such file or directory
|
||||
maybe has prevented ./inboxer-0.4.0-x86_64.AppImage from performing 1 file system operations:
|
||||
|
||||
create directory /tmp/.mount_inboxemDzuGV
|
||||
|
||||
Do you want to rerun ./inboxer-0.4.0-x86_64.AppImage and permit these operations? [y/N]
|
||||
```
|
||||
|
||||
如果它没有检测到任何文件系统操作,那么它会只显示如下所示的结果。
|
||||
|
||||
例如,我运行下面这条命令来更新我的 Arch Linux。
|
||||
|
||||
```
|
||||
$ maybe sudo pacman -Syu
|
||||
sudo: effective uid is not 0, is /usr/bin/sudo on a file system with the 'nosuid' option set or an NFS file system without root privileges?
|
||||
maybe has not detected any file system operations from sudo pacman -Syu.
|
||||
```
|
||||
|
||||
看到没?它没有检测到任何文件系统操作,所以没有任何警告。这非常棒,而且正是我所预料到的结果。从现在开始,我甚至可以在执行之前知道一个命令或一个程序将执行什么操作。我希望这对你也会有帮助。
|
||||
|
||||
Cheers!
|
||||
|
||||
资源:
|
||||
|
||||
* [`maybe` GitHub 主页][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/know-command-program-will-exactly-executing/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/p-e-w/maybe
|
||||
[2]:https://www.ostechnix.com/explainshell-find-part-linux-command/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/12/maybe-1.png
|
||||
[4]:https://www.ostechnix.com/inboxer-unofficial-google-inbox-desktop-client/
|
||||
@ -1,26 +1,25 @@
|
||||
NETSTAT 命令: 通过案例学习使用 netstate
|
||||
通过示例学习使用 netstat
|
||||
======
|
||||
Netstat 是一个告诉我们系统中所有 tcp/udp/unix socket 连接状态的命令行工具。它会列出所有已经连接或者等待连接状态的连接。 该工具在识别某个应用监听哪个端口时特别有用,我们也能用它来判断某个应用是否正常的在监听某个端口。
|
||||
|
||||
Netstat 命令还能显示其他各种各样的网络相关信息,例如路由表, 网卡统计信息, 虚假连接以及多播成员等。
|
||||
netstat 是一个告诉我们系统中所有 tcp/udp/unix socket 连接状态的命令行工具。它会列出所有已经连接或者等待连接状态的连接。 该工具在识别某个应用监听哪个端口时特别有用,我们也能用它来判断某个应用是否正常的在监听某个端口。
|
||||
|
||||
本文中,我们会通过几个例子来学习 Netstat。
|
||||
netstat 命令还能显示其它各种各样的网络相关信息,例如路由表, 网卡统计信息, 虚假连接以及多播成员等。
|
||||
|
||||
(推荐阅读: [Learn to use CURL command with examples][1] )
|
||||
本文中,我们会通过几个例子来学习 netstat。
|
||||
|
||||
Netstat with examples
|
||||
============================================================
|
||||
(推荐阅读: [通过示例学习使用 CURL 命令][1] )
|
||||
|
||||
### 1- 检查所有的连接
|
||||
### 1 - 检查所有的连接
|
||||
|
||||
使用 `a` 选项可以列出系统中的所有连接,
|
||||
|
||||
```shell
|
||||
$ netstat -a
|
||||
```
|
||||
|
||||
这会显示系统所有的 tcp,udp 以及 unix 连接。
|
||||
这会显示系统所有的 tcp、udp 以及 unix 连接。
|
||||
|
||||
### 2- 检查所有的 tcp/udp/unix socket 连接
|
||||
### 2 - 检查所有的 tcp/udp/unix socket 连接
|
||||
|
||||
使用 `t` 选项只列出 tcp 连接,
|
||||
|
||||
@ -28,19 +27,19 @@ $ netstat -a
|
||||
$ netstat -at
|
||||
```
|
||||
|
||||
类似的,使用 `u` 选项只列出 udp 连接 to list out only the udp connections on our system, we can use ‘u’ option with netstat,
|
||||
类似的,使用 `u` 选项只列出 udp 连接,
|
||||
|
||||
```shell
|
||||
$ netstat -au
|
||||
```
|
||||
|
||||
使用 `x` 选项只列出 Unix socket 连接,we can use ‘x’ options,
|
||||
使用 `x` 选项只列出 Unix socket 连接,
|
||||
|
||||
```shell
|
||||
$ netstat -ax
|
||||
```
|
||||
|
||||
### 3- 同时列出进程 ID/进程名称
|
||||
### 3 - 同时列出进程 ID/进程名称
|
||||
|
||||
使用 `p` 选项可以在列出连接的同时也显示 PID 或者进程名称,而且它还能与其他选项连用,
|
||||
|
||||
@ -48,15 +47,15 @@ $ netstat -ax
|
||||
$ netstat -ap
|
||||
```
|
||||
|
||||
### 4- 列出端口号而不是服务名
|
||||
### 4 - 列出端口号而不是服务名
|
||||
|
||||
使用 `n` 选项可以加快输出,它不会执行任何反向查询(译者注:这里原文说的是 "it will perform any reverse lookup",应该是写错了),而是直接输出数字。 由于无需查询,因此结果输出会快很多。
|
||||
使用 `n` 选项可以加快输出,它不会执行任何反向查询(LCTT 译注:这里原文有误),而是直接输出数字。 由于无需查询,因此结果输出会快很多。
|
||||
|
||||
```shell
|
||||
$ netstat -an
|
||||
```
|
||||
|
||||
### 5- 只输出监听端口
|
||||
### 5 - 只输出监听端口
|
||||
|
||||
使用 `l` 选项只输出监听端口。它不能与 `a` 选项连用,因为 `a` 会输出所有端口,
|
||||
|
||||
@ -64,15 +63,15 @@ $ netstat -an
|
||||
$ netstat -l
|
||||
```
|
||||
|
||||
### 6- 输出网络状态
|
||||
### 6 - 输出网络状态
|
||||
|
||||
使用 `s` 选项输出每个协议的统计信息,包括接收/发送的包数量
|
||||
使用 `s` 选项输出每个协议的统计信息,包括接收/发送的包数量,
|
||||
|
||||
```shell
|
||||
$ netstat -s
|
||||
```
|
||||
|
||||
### 7- 输出网卡状态
|
||||
### 7 - 输出网卡状态
|
||||
|
||||
使用 `I` 选项只显示网卡的统计信息,
|
||||
|
||||
@ -80,7 +79,7 @@ $ netstat -s
|
||||
$ netstat -i
|
||||
```
|
||||
|
||||
### 8- 显示多播组(multicast group)信息
|
||||
### 8 - 显示<ruby>多播组<rt>multicast group</rt></ruby>信息
|
||||
|
||||
使用 `g` 选项输出 IPV4 以及 IPV6 的多播组信息,
|
||||
|
||||
@ -88,7 +87,7 @@ $ netstat -i
|
||||
$ netstat -g
|
||||
```
|
||||
|
||||
### 9- 显示网络路由信息
|
||||
### 9 - 显示网络路由信息
|
||||
|
||||
使用 `r` 输出网络路由信息,
|
||||
|
||||
@ -96,7 +95,7 @@ $ netstat -g
|
||||
$ netstat -r
|
||||
```
|
||||
|
||||
### 10- 持续输出
|
||||
### 10 - 持续输出
|
||||
|
||||
使用 `c` 选项持续输出结果
|
||||
|
||||
@ -104,7 +103,7 @@ $ netstat -r
|
||||
$ netstat -c
|
||||
```
|
||||
|
||||
### 11- 过滤出某个端口
|
||||
### 11 - 过滤出某个端口
|
||||
|
||||
与 `grep` 连用来过滤出某个端口的连接,
|
||||
|
||||
@ -112,17 +111,17 @@ $ netstat -c
|
||||
$ netstat -anp | grep 3306
|
||||
```
|
||||
|
||||
### 12- 统计连接个数
|
||||
### 12 - 统计连接个数
|
||||
|
||||
通过与 wc 和 grep 命令连用,可以统计指定端口的连接数量
|
||||
通过与 `wc` 和 `grep` 命令连用,可以统计指定端口的连接数量
|
||||
|
||||
```shell
|
||||
$ netstat -anp | grep 3306 | wc -l
|
||||
```
|
||||
|
||||
这回输出 mysql 服务端口(即 3306)的连接数。
|
||||
这会输出 mysql 服务端口(即 3306)的连接数。
|
||||
|
||||
这就是我们间断的案例指南了,希望它带给你的信息量足够。 有任何疑问欢迎提出。
|
||||
这就是我们简短的案例指南了,希望它带给你的信息量足够。 有任何疑问欢迎提出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -130,7 +129,7 @@ via: http://linuxtechlab.com/learn-use-netstat-with-examples/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
如何在 Linux 上安装友好的交互式 shell,Fish
|
||||
如何在 Linux 上安装友好的交互式 shell:Fish
|
||||
======
|
||||
Fish,友好的交互式 shell 的缩写,它是一个适用于类 Unix 系统的装备良好,智能而且用户友好的 shell。Fish 有着很多重要的功能,比如自动建议,语法高亮,可搜索的历史记录(像在 bash 中 CTRL+r),智能搜索功能,极好的 VGA 颜色支持,基本的 web 设置,完善的手册页和许多开箱即用的功能。尽管安装并立即使用它吧。无需更多其他配置,你也不需要安装任何额外的附加组件/插件!
|
||||
|
||||
在这篇教程中,我们讨论如何在 linux 中安装和使用 fish shell。
|
||||
Fish,<ruby>友好的交互式 shell<rt>Friendly Interactive SHell</rt></ruby> 的缩写,它是一个适于装备于类 Unix 系统的智能而用户友好的 shell。Fish 有着很多重要的功能,比如自动建议、语法高亮、可搜索的历史记录(像在 bash 中 `CTRL+r`)、智能搜索功能、极好的 VGA 颜色支持、基于 web 的设置方式、完善的手册页和许多开箱即用的功能。尽管安装并立即使用它吧。无需更多其他配置,你也不需要安装任何额外的附加组件/插件!
|
||||
|
||||
在这篇教程中,我们讨论如何在 Linux 中安装和使用 fish shell。
|
||||
|
||||
#### 安装 Fish
|
||||
|
||||
尽管 fish 是一个非常用户友好的并且功能丰富的 shell,但在大多数 Linux 发行版的默认仓库中它并没有被包括。它只能在少数 Linux 发行版中的官方仓库中找到,如 Arch Linux,Gentoo,NixOS,和 Ubuntu 等。然而,安装 fish 并不难。
|
||||
尽管 fish 是一个非常用户友好的并且功能丰富的 shell,但并没有包括在大多数 Linux 发行版的默认仓库中。它只能在少数 Linux 发行版中的官方仓库中找到,如 Arch Linux,Gentoo,NixOS,和 Ubuntu 等。然而,安装 fish 并不难。
|
||||
|
||||
在 Arch Linux 和它的衍生版上,运行以下命令来安装它。
|
||||
|
||||
@ -18,13 +19,7 @@ sudo pacman -S fish
|
||||
|
||||
```
|
||||
cd /etc/yum.repos.d/
|
||||
```
|
||||
|
||||
```
|
||||
wget https://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
@ -32,13 +27,7 @@ yum install fish
|
||||
|
||||
```
|
||||
cd /etc/yum.repos.d/
|
||||
```
|
||||
|
||||
```
|
||||
wget https://download.opensuse.org/repositories/shells:fish:release:2/CentOS_6/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
@ -46,21 +35,9 @@ yum install fish
|
||||
|
||||
```
|
||||
wget -nv https://download.opensuse.org/repositories/shells:fish:release:2/Debian_9.0/Release.key -O Release.key
|
||||
```
|
||||
|
||||
```
|
||||
apt-key add - < Release.key
|
||||
```
|
||||
|
||||
```
|
||||
echo 'deb http://download.opensuse.org/repositories/shells:/fish:/release:/2/Debian_9.0/ /' > /etc/apt/sources.list.d/fish.list
|
||||
```
|
||||
|
||||
```
|
||||
apt-get update
|
||||
```
|
||||
|
||||
```
|
||||
apt-get install fish
|
||||
```
|
||||
|
||||
@ -68,21 +45,9 @@ apt-get install fish
|
||||
|
||||
```
|
||||
wget -nv https://download.opensuse.org/repositories/shells:fish:release:2/Debian_8.0/Release.key -O Release.key
|
||||
```
|
||||
|
||||
```
|
||||
apt-key add - < Release.key
|
||||
```
|
||||
|
||||
```
|
||||
echo 'deb http://download.opensuse.org/repositories/shells:/fish:/release:/2/Debian_8.0/ /' > /etc/apt/sources.list.d/fish.list
|
||||
```
|
||||
|
||||
```
|
||||
apt-get update
|
||||
```
|
||||
|
||||
```
|
||||
apt-get install fish
|
||||
```
|
||||
|
||||
@ -90,9 +55,6 @@ apt-get install fish
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/Fedora_26/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
dnf install fish
|
||||
```
|
||||
|
||||
@ -100,9 +62,6 @@ dnf install fish
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/Fedora_25/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
dnf install fish
|
||||
```
|
||||
|
||||
@ -110,9 +69,6 @@ dnf install fish
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/Fedora_24/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
dnf install fish
|
||||
```
|
||||
|
||||
@ -120,9 +76,6 @@ dnf install fish
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/shells:fish:release:2/Fedora_23/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
dnf install fish
|
||||
```
|
||||
|
||||
@ -136,13 +89,7 @@ zypper install fish
|
||||
|
||||
```
|
||||
cd /etc/yum.repos.d/
|
||||
```
|
||||
|
||||
```
|
||||
wget https://download.opensuse.org/repositories/shells:fish:release:2/RHEL_7/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
@ -150,13 +97,7 @@ yum install fish
|
||||
|
||||
```
|
||||
cd /etc/yum.repos.d/
|
||||
```
|
||||
|
||||
```
|
||||
wget https://download.opensuse.org/repositories/shells:fish:release:2/RedHat_RHEL-6/shells:fish:release:2.repo
|
||||
```
|
||||
|
||||
```
|
||||
yum install fish
|
||||
```
|
||||
|
||||
@ -164,9 +105,6 @@ yum install fish
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
```
|
||||
sudo apt-get install fish
|
||||
```
|
||||
|
||||
@ -181,44 +119,43 @@ $ fish
|
||||
Welcome to fish, the friendly interactive shell
|
||||
```
|
||||
|
||||
你可以在 ~/.config/fish/config.fish 上找到默认的 fish 配置(类似于 .bashrc)。如果它不存在,就创建它吧。
|
||||
你可以在 `~/.config/fish/config.fish` 上找到默认的 fish 配置(类似于 `.bashrc`)。如果它不存在,就创建它吧。
|
||||
|
||||
#### 自动建议
|
||||
|
||||
当我输入一个命令,它自动建议一个浅灰色的命令。所以,我需要输入一个 Linux 命令的前几个字母,然后按下 tab 键来完成这个命令。
|
||||
当我输入一个命令,它以浅灰色自动建议一个命令。所以,我需要输入一个 Linux 命令的前几个字母,然后按下 `tab` 键来完成这个命令。
|
||||
|
||||
[][2]
|
||||
|
||||
如果有更多的可能性,它将会列出它们。你可以使用上/下箭头键从列表中选择列出的命令。在选择你想运行的命令后,只需按下右箭头键,然后按下 ENTER 运行它。
|
||||
如果有更多的可能性,它将会列出它们。你可以使用上/下箭头键从列表中选择列出的命令。在选择你想运行的命令后,只需按下右箭头键,然后按下 `ENTER` 运行它。
|
||||
|
||||
[][3]
|
||||
|
||||
无需 CTRL+r 了!正如你已知道的,我们通过按 ctrl+r 来反向搜索 Bash shell 中的历史命令。但在 fish shell 中是没有必要的。由于它有自动建议功能,只需输入命令的前几个字母,然后从历史记录中选择已经执行的命令。Cool,是吗?
|
||||
无需 `CTRL+r` 了!正如你已知道的,我们通过按 `CTRL+r` 来反向搜索 Bash shell 中的历史命令。但在 fish shell 中是没有必要的。由于它有自动建议功能,只需输入命令的前几个字母,然后从历史记录中选择已经执行的命令。很酷,是吧。
|
||||
|
||||
#### 智能搜索
|
||||
|
||||
我们也可以使用智能搜索来查找一个特定的命令,文件或者目录。例如,我输入一个命令的子串,然后按向下箭头键进行智能搜索,再次输入一个字母来从列表中选择所需的命令。
|
||||
我们也可以使用智能搜索来查找一个特定的命令、文件或者目录。例如,我输入一个命令的一部分,然后按向下箭头键进行智能搜索,再次输入一个字母来从列表中选择所需的命令。
|
||||
|
||||
[][4]
|
||||
|
||||
#### 语法高亮
|
||||
|
||||
|
||||
当你输入一个命令时,你将注意到语法高亮。请看下面当我在 Bash shell 和 fish shell 中输入相同的命令时截图的区别。
|
||||
|
||||
Bash:
|
||||
Bash:
|
||||
|
||||
[][5]
|
||||
|
||||
Fish:
|
||||
Fish:
|
||||
|
||||
[][6]
|
||||
|
||||
正如你所看到的,“sudo” 在 fish shell 中已经被高亮显示。此外,默认情况下它将以红色显示无效命令。
|
||||
正如你所看到的,`sudo` 在 fish shell 中已经被高亮显示。此外,默认情况下它将以红色显示无效命令。
|
||||
|
||||
#### 基于 web 的配置
|
||||
#### 基于 web 的配置方式
|
||||
|
||||
这是 fish shell 另一个很酷的功能。我们可以设置我们的颜色,更改 fish 提示,并从网页上查看所有功能,变量,历史记录,键绑定。
|
||||
这是 fish shell 另一个很酷的功能。我们可以设置我们的颜色、更改 fish 提示符,并从网页上查看所有功能、变量、历史记录、键绑定。
|
||||
|
||||
启动 web 配置接口,只需输入:
|
||||
|
||||
@ -228,9 +165,9 @@ fish_config
|
||||
|
||||
[][7]
|
||||
|
||||
#### 手册页完成
|
||||
#### 手册页补完
|
||||
|
||||
Bash 和 其它 shells 支持可编程完成,但只有 fish 会通过解析已安装的手册自动生成他们。
|
||||
Bash 和 其它 shells 支持可编程的补完,但只有 fish 可以通过解析已安装的手册来自动生成它们。
|
||||
|
||||
为此,请运行:
|
||||
|
||||
@ -245,9 +182,9 @@ Parsing man pages and writing completions to /home/sk/.local/share/fish/generate
|
||||
3435 / 3435 : zramctl.8.gz
|
||||
```
|
||||
|
||||
#### 禁用问候
|
||||
#### 禁用问候语
|
||||
|
||||
默认情况下,fish 在启动时问候你(Welcome to fish, the friendly interactive shell)。如果你不想要这个问候消息,可以禁用它。为此,编辑 fish 配置文件:
|
||||
默认情况下,fish 在启动时问候你(“Welcome to fish, the friendly interactive shell”)。如果你不想要这个问候消息,可以禁用它。为此,编辑 fish 配置文件:
|
||||
|
||||
```
|
||||
vi ~/.config/fish/config.fish
|
||||
@ -260,7 +197,6 @@ set -g -x fish_greeting ''
|
||||
```
|
||||
|
||||
你也可以设置任意自定义的问候语,而不是禁用 fish 问候。
|
||||
Instead of disabling fish greeting, you can also set any custom greeting message.
|
||||
|
||||
```
|
||||
set -g -x fish_greeting 'Welcome to OSTechNix'
|
||||
@ -268,7 +204,7 @@ set -g -x fish_greeting 'Welcome to OSTechNix'
|
||||
|
||||
#### 获得帮助
|
||||
|
||||
这是另一个引人注目的令人印象深刻的功能。要在终端的默认 web 浏览器中打开 fish 文档页面,只需输入:
|
||||
这是另一个吸引我的令人印象深刻的功能。要在终端的默认 web 浏览器中打开 fish 文档页面,只需输入:
|
||||
|
||||
```
|
||||
help
|
||||
@ -282,13 +218,13 @@ man fish
|
||||
|
||||
#### 设置 fish 为默认 shell
|
||||
|
||||
非常喜欢它?太好了!设置它作为默认 shell 吧。为此,请使用命令 chsh:
|
||||
非常喜欢它?太好了!设置它作为默认 shell 吧。为此,请使用命令 `chsh`:
|
||||
|
||||
```
|
||||
chsh -s /usr/bin/fish
|
||||
```
|
||||
|
||||
在这里,/usr/bin/fish 是 fish shell 的路径。如果你不知道正确的路径,以下命令将会帮助你:
|
||||
在这里,`/usr/bin/fish` 是 fish shell 的路径。如果你不知道正确的路径,以下命令将会帮助你:
|
||||
|
||||
```
|
||||
which fish
|
||||
@ -298,7 +234,7 @@ which fish
|
||||
|
||||
请记住,为 Bash 编写的许多 shell 脚本可能不完全兼容 fish。
|
||||
|
||||
要切换会 Bash,只需运行:
|
||||
要切换回 Bash,只需运行:
|
||||
|
||||
```
|
||||
bash
|
||||
@ -310,13 +246,13 @@ bash
|
||||
chsh -s /bin/bash
|
||||
```
|
||||
|
||||
对目前的各位,这就是全部了。在这个阶段,你可能会得到一个有关 fish shell 使用的基本概念。 如果你正在寻找一个Bash的替代品,fish 可能是一个不错的选择。
|
||||
各位,这就是全部了。在这个阶段,你可能会得到一个有关 fish shell 使用的基本概念。 如果你正在寻找一个Bash的替代品,fish 可能是一个不错的选择。
|
||||
|
||||
Cheers!
|
||||
|
||||
资源:
|
||||
|
||||
* [fish shell website][1]
|
||||
* [fish shell 官网][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -324,7 +260,7 @@ via: https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[kimii](https://github.com/kimii)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
165
published/20171206 How to extract substring in Bash.md
Normal file
165
published/20171206 How to extract substring in Bash.md
Normal file
@ -0,0 +1,165 @@
|
||||
如何在 Bash 中抽取子字符串
|
||||
======
|
||||
|
||||
所谓“子字符串”就是出现在其它字符串内的字符串。 比如 “3382” 就是 “this is a 3382 test” 的子字符串。 我们有多种方法可以从中把数字或指定部分字符串抽取出来。
|
||||
|
||||
[][2]
|
||||
|
||||
本文会向你展示在 bash shell 中如何获取或者说查找出子字符串。
|
||||
|
||||
### 在 Bash 中抽取子字符串
|
||||
|
||||
其语法为:
|
||||
|
||||
```shell
|
||||
## 格式 ##
|
||||
${parameter:offset:length}
|
||||
```
|
||||
|
||||
子字符串扩展是 bash 的一项功能。它会扩展成 `parameter` 值中以 `offset` 为开始,长为 `length` 个字符的字符串。 假设, `$u` 定义如下:
|
||||
|
||||
```shell
|
||||
## 定义变量 u ##
|
||||
u="this is a test"
|
||||
```
|
||||
|
||||
那么下面参数的子字符串扩展会抽取出子字符串:
|
||||
|
||||
```shell
|
||||
var="${u:10:4}"
|
||||
echo "${var}"
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
```
|
||||
test
|
||||
```
|
||||
|
||||
其中这些参数分别表示:
|
||||
|
||||
+ 10 : 偏移位置
|
||||
+ 4 : 长度
|
||||
|
||||
### 使用 IFS
|
||||
|
||||
根据 bash 的 man 页说明:
|
||||
|
||||
> [IFS (内部字段分隔符)][3]用于在扩展后进行单词分割,并用内建的 read 命令将行分割为词。默认值是<space><tab><newline>。
|
||||
|
||||
另一种 <ruby>POSIX 就绪<rt>POSIX ready</rt></ruby>的方案如下:
|
||||
|
||||
```shell
|
||||
u="this is a test"
|
||||
set -- $u
|
||||
echo "$1"
|
||||
echo "$2"
|
||||
echo "$3"
|
||||
echo "$4"
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
```shell
|
||||
this
|
||||
is
|
||||
a
|
||||
test
|
||||
```
|
||||
|
||||
下面是一段 bash 代码,用来从 Cloudflare cache 中去除带主页的 url。
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
####################################################
|
||||
## Author - Vivek Gite {https://www.cyberciti.biz/}
|
||||
## Purpose - Purge CF cache
|
||||
## License - Under GPL ver 3.x+
|
||||
####################################################
|
||||
## set me first ##
|
||||
zone_id="YOUR_ZONE_ID_HERE"
|
||||
api_key="YOUR_API_KEY_HERE"
|
||||
email_id="YOUR_EMAIL_ID_HERE"
|
||||
|
||||
## hold data ##
|
||||
home_url=""
|
||||
amp_url=""
|
||||
urls="$@"
|
||||
|
||||
## Show usage
|
||||
[ "$urls" == "" ] && { echo "Usage: $0 url1 url2 url3"; exit 1; }
|
||||
|
||||
## Get home page url as we have various sub dirs on domain
|
||||
## /tips/
|
||||
## /faq/
|
||||
|
||||
get_home_url(){
|
||||
local u="$1"
|
||||
IFS='/'
|
||||
set -- $u
|
||||
echo "${1}${IFS}${IFS}${3}${IFS}${4}${IFS}"
|
||||
}
|
||||
|
||||
echo
|
||||
echo "Purging cache from Cloudflare。.。"
|
||||
echo
|
||||
for u in $urls
|
||||
do
|
||||
home_url="$(get_home_url $u)"
|
||||
amp_url="${u}amp/"
|
||||
curl -X DELETE "https://api.cloudflare.com/client/v4/zones/${zone_id}/purge_cache" \
|
||||
-H "X-Auth-Email: ${email_id}" \
|
||||
-H "X-Auth-Key: ${api_key}" \
|
||||
-H "Content-Type: application/json" \
|
||||
--data "{\"files\":[\"${u}\",\"${amp_url}\",\"${home_url}\"]}"
|
||||
echo
|
||||
done
|
||||
echo
|
||||
```
|
||||
|
||||
它的使用方法为:
|
||||
|
||||
```shell
|
||||
~/bin/cf.clear.cache https://www.cyberciti.biz/faq/bash-for-loop/ https://www.cyberciti.biz/tips/linux-security.html
|
||||
```
|
||||
|
||||
### 借助 cut 命令
|
||||
|
||||
可以使用 `cut` 命令来将文件中每一行或者变量中的一部分删掉。它的语法为:
|
||||
|
||||
```shell
|
||||
u="this is a test"
|
||||
echo "$u" | cut -d' ' -f 4
|
||||
echo "$u" | cut --delimiter=' ' --fields=4
|
||||
##########################################
|
||||
## WHERE
|
||||
## -d' ' : Use a whitespace as delimiter
|
||||
## -f 4 : Select only 4th field
|
||||
##########################################
|
||||
var="$(cut -d' ' -f 4 <<< $u)"
|
||||
echo "${var}"
|
||||
```
|
||||
|
||||
想了解更多请阅读 bash 的 man 页:
|
||||
|
||||
```shell
|
||||
man bash
|
||||
man cut
|
||||
```
|
||||
|
||||
另请参见: [Bash String Comparison: Find Out IF a Variable Contains a Substring][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-extract-substring-in-bash/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/bash-find-out-if-variable-contains-substring/
|
||||
[2]:https://www.cyberciti.biz/media/new/faq/2017/12/How-to-Extract-substring-in-Bash-Shell-on-Linux-or-Unix.jpg
|
||||
[3]:https://bash.cyberciti.biz/guide/$IFS
|
||||
@ -0,0 +1,401 @@
|
||||
7 个使用 bcc/BPF 的性能分析神器
|
||||
============================================================
|
||||
|
||||
> 使用<ruby>伯克利包过滤器<rt>Berkeley Packet Filter</rt></ruby>(BPF)<ruby>编译器集合<rt>Compiler Collection</rt></ruby>(BCC)工具深度探查你的 linux 代码。
|
||||
|
||||

|
||||
|
||||
在 Linux 中出现的一种新技术能够为系统管理员和开发者提供大量用于性能分析和故障排除的新工具和仪表盘。它被称为<ruby>增强的伯克利数据包过滤器<rt>enhanced Berkeley Packet Filter</rt></ruby>(eBPF,或 BPF),虽然这些改进并不是由伯克利开发的,而且它们不仅仅是处理数据包,更多的是过滤。我将讨论在 Fedora 和 Red Hat Linux 发行版中使用 BPF 的一种方法,并在 Fedora 26 上演示。
|
||||
|
||||
BPF 可以在内核中运行由用户定义的沙盒程序,可以立即添加新的自定义功能。这就像按需给 Linux 系统添加超能力一般。 你可以使用它的例子包括如下:
|
||||
|
||||
* **高级性能跟踪工具**:对文件系统操作、TCP 事件、用户级事件等的可编程的低开销检测。
|
||||
* **网络性能**: 尽早丢弃数据包以提高对 DDoS 的恢复能力,或者在内核中重定向数据包以提高性能。
|
||||
* **安全监控**: 7x24 小时的自定义检测和记录内核空间与用户空间内的可疑事件。
|
||||
|
||||
在可能的情况下,BPF 程序必须通过一个内核验证机制来保证它们的安全运行,这比写自定义的内核模块更安全。我在此假设大多数人并不编写自己的 BPF 程序,而是使用别人写好的。在 GitHub 上的 [BPF Compiler Collection (bcc)][12] 项目中,我已发布许多开源代码。bcc 为 BPF 开发提供了不同的前端支持,包括 Python 和 Lua,并且是目前最活跃的 BPF 工具项目。
|
||||
|
||||
### 7 个有用的 bcc/BPF 新工具
|
||||
|
||||
为了了解 bcc/BPF 工具和它们的检测内容,我创建了下面的图表并添加到 bcc 项目中。
|
||||
|
||||
|
||||
|
||||
这些是命令行界面工具,你可以通过 SSH 使用它们。目前大多数分析,包括我的老板,都是用 GUI 和仪表盘进行的。SSH 是最后的手段。但这些命令行工具仍然是预览 BPF 能力的好方法,即使你最终打算通过一个可用的 GUI 使用它。我已着手向一个开源 GUI 添加 BPF 功能,但那是另一篇文章的主题。现在我想向你分享今天就可以使用的 CLI 工具。
|
||||
|
||||
#### 1、 execsnoop
|
||||
|
||||
从哪儿开始呢?如何查看新的进程。那些会消耗系统资源,但很短暂的进程,它们甚至不会出现在 `top(1)` 命令或其它工具中的显示之中。这些新进程可以使用 [execsnoop][15] 进行检测(或使用行业术语说,可以<ruby>被追踪<rt>traced</rt></ruby>)。 在追踪时,我将在另一个窗口中通过 SSH 登录:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/execsnoop
|
||||
PCOMM PID PPID RET ARGS
|
||||
sshd 12234 727 0 /usr/sbin/sshd -D -R
|
||||
unix_chkpwd 12236 12234 0 /usr/sbin/unix_chkpwd root nonull
|
||||
unix_chkpwd 12237 12234 0 /usr/sbin/unix_chkpwd root chkexpiry
|
||||
bash 12239 12238 0 /bin/bash
|
||||
id 12241 12240 0 /usr/bin/id -un
|
||||
hostname 12243 12242 0 /usr/bin/hostname
|
||||
pkg-config 12245 12244 0 /usr/bin/pkg-config --variable=completionsdir bash-completion
|
||||
grepconf.sh 12246 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12247 12246 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
tty 12249 12248 0 /usr/bin/tty -s
|
||||
tput 12250 12248 0 /usr/bin/tput colors
|
||||
dircolors 12252 12251 0 /usr/bin/dircolors --sh /etc/DIR_COLORS
|
||||
grep 12253 12239 0 /usr/bin/grep -qi ^COLOR.*none /etc/DIR_COLORS
|
||||
grepconf.sh 12254 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12255 12254 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
grepconf.sh 12256 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12257 12256 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
```
|
||||
|
||||
哇哦。 那是什么? 什么是 `grepconf.sh`? 什么是 `/etc/GREP_COLORS`? 是 `grep` 在读取它自己的配置文件……由 `grep` 运行的? 这究竟是怎么工作的?
|
||||
|
||||
欢迎来到有趣的系统追踪世界。 你可以学到很多关于系统是如何工作的(或者根本不工作,在有些情况下),并且发现一些简单的优化方法。 `execsnoop` 通过跟踪 `exec()` 系统调用来工作,`exec()` 通常用于在新进程中加载不同的程序代码。
|
||||
|
||||
#### 2、 opensnoop
|
||||
|
||||
接着上面继续,所以,`grepconf.sh` 可能是一个 shell 脚本,对吧? 我将运行 `file(1)` 来检查它,并使用[opensnoop][16] bcc 工具来查看打开的文件:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
PID COMM FD ERR PATH
|
||||
12420 file 3 0 /etc/ld.so.cache
|
||||
12420 file 3 0 /lib64/libmagic.so.1
|
||||
12420 file 3 0 /lib64/libz.so.1
|
||||
12420 file 3 0 /lib64/libc.so.6
|
||||
12420 file 3 0 /usr/lib/locale/locale-archive
|
||||
12420 file -1 2 /etc/magic.mgc
|
||||
12420 file 3 0 /etc/magic
|
||||
12420 file 3 0 /usr/share/misc/magic.mgc
|
||||
12420 file 3 0 /usr/lib64/gconv/gconv-modules.cache
|
||||
12420 file 3 0 /usr/libexec/grepconf.sh
|
||||
1 systemd 16 0 /proc/565/cgroup
|
||||
1 systemd 16 0 /proc/536/cgroup
|
||||
```
|
||||
|
||||
像 `execsnoop` 和 `opensnoop` 这样的工具会将每个事件打印一行。上图显示 `file(1)` 命令当前打开(或尝试打开)的文件:返回的文件描述符(“FD” 列)对于 `/etc/magic.mgc` 是 -1,而 “ERR” 列指示它是“文件未找到”。我不知道该文件,也不知道 `file(1)` 正在读取的 `/usr/share/misc/magic.mgc` 文件是什么。我不应该感到惊讶,但是 `file(1)` 在识别文件类型时没有问题:
|
||||
|
||||
```
|
||||
# file /usr/share/misc/magic.mgc /etc/magic
|
||||
/usr/share/misc/magic.mgc: magic binary file for file(1) cmd (version 14) (little endian)
|
||||
/etc/magic: magic text file for file(1) cmd, ASCII text
|
||||
```
|
||||
|
||||
`opensnoop` 通过跟踪 `open()` 系统调用来工作。为什么不使用 `strace -feopen file` 命令呢? 在这种情况下是可以的。然而,`opensnoop` 的一些优点在于它能在系统范围内工作,并且跟踪所有进程的 `open()` 系统调用。注意上例的输出中包括了从 systemd 打开的文件。`opensnoop` 应该系统开销更低:BPF 跟踪已经被优化过,而当前版本的 `strace(1)` 仍然使用较老和较慢的 `ptrace(2)` 接口。
|
||||
|
||||
#### 3、 xfsslower
|
||||
|
||||
bcc/BPF 不仅仅可以分析系统调用。[xfsslower][17] 工具可以跟踪大于 1 毫秒(参数)延迟的常见 XFS 文件系统操作。
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/xfsslower 1
|
||||
Tracing XFS operations slower than 1 ms
|
||||
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
14:17:34 systemd-journa 530 S 0 0 1.69 system.journal
|
||||
14:17:35 auditd 651 S 0 0 2.43 audit.log
|
||||
14:17:42 cksum 4167 R 52976 0 1.04 at
|
||||
14:17:45 cksum 4168 R 53264 0 1.62 [
|
||||
14:17:45 cksum 4168 R 65536 0 1.01 certutil
|
||||
14:17:45 cksum 4168 R 65536 0 1.01 dir
|
||||
14:17:45 cksum 4168 R 65536 0 1.17 dirmngr-client
|
||||
14:17:46 cksum 4168 R 65536 0 1.06 grub2-file
|
||||
14:17:46 cksum 4168 R 65536 128 1.01 grub2-fstest
|
||||
[...]
|
||||
```
|
||||
|
||||
在上图输出中,我捕获到了多个延迟超过 1 毫秒 的 `cksum(1)` 读取操作(字段 “T” 等于 “R”)。这是在 `xfsslower` 工具运行的时候,通过在 XFS 中动态地检测内核函数实现的,并当它结束的时候解除该检测。这个 bcc 工具也有其它文件系统的版本:`ext4slower`、`btrfsslower`、`zfsslower` 和 `nfsslower`。
|
||||
|
||||
这是个有用的工具,也是 BPF 追踪的重要例子。对文件系统性能的传统分析主要集中在块 I/O 统计信息 —— 通常你看到的是由 `iostat(1)` 工具输出,并由许多性能监视 GUI 绘制的图表。这些统计数据显示的是磁盘如何执行,而不是真正的文件系统如何执行。通常比起磁盘来说,你更关心的是文件系统的性能,因为应用程序是在文件系统中发起请求和等待。并且,文件系统的性能可能与磁盘的性能大为不同!文件系统可以完全从内存缓存中读取数据,也可以通过预读算法和回写缓存来填充缓存。`xfsslower` 显示了文件系统的性能 —— 这是应用程序直接体验到的性能。通常这对于排除整个存储子系统的问题是有用的;如果确实没有文件系统延迟,那么性能问题很可能是在别处。
|
||||
|
||||
#### 4、 biolatency
|
||||
|
||||
虽然文件系统性能对于理解应用程序性能非常重要,但研究磁盘性能也是有好处的。当各种缓存技巧都无法挽救其延迟时,磁盘的低性能终会影响应用程序。 磁盘性能也是容量规划研究的目标。
|
||||
|
||||
`iostat(1)` 工具显示了平均磁盘 I/O 延迟,但平均值可能会引起误解。 以直方图的形式研究 I/O 延迟的分布是有用的,这可以通过使用 [biolatency] 来实现[18]:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency
|
||||
Tracing block device I/O... Hit Ctrl-C to end.
|
||||
^C
|
||||
usecs : count distribution
|
||||
0 -> 1 : 0 | |
|
||||
2 -> 3 : 0 | |
|
||||
4 -> 7 : 0 | |
|
||||
8 -> 15 : 0 | |
|
||||
16 -> 31 : 0 | |
|
||||
32 -> 63 : 1 | |
|
||||
64 -> 127 : 63 |**** |
|
||||
128 -> 255 : 121 |********* |
|
||||
256 -> 511 : 483 |************************************ |
|
||||
512 -> 1023 : 532 |****************************************|
|
||||
1024 -> 2047 : 117 |******** |
|
||||
2048 -> 4095 : 8 | |
|
||||
```
|
||||
|
||||
这是另一个有用的工具和例子;它使用一个名为 maps 的 BPF 特性,它可以用来实现高效的内核摘要统计。从内核层到用户层的数据传输仅仅是“计数”列。 用户级程序生成其余的。
|
||||
|
||||
值得注意的是,这种工具大多支持 CLI 选项和参数,如其使用信息所示:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency -h
|
||||
usage: biolatency [-h] [-T] [-Q] [-m] [-D] [interval] [count]
|
||||
|
||||
Summarize block device I/O latency as a histogram
|
||||
|
||||
positional arguments:
|
||||
interval output interval, in seconds
|
||||
count number of outputs
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-T, --timestamp include timestamp on output
|
||||
-Q, --queued include OS queued time in I/O time
|
||||
-m, --milliseconds millisecond histogram
|
||||
-D, --disks print a histogram per disk device
|
||||
|
||||
examples:
|
||||
./biolatency # summarize block I/O latency as a histogram
|
||||
./biolatency 1 10 # print 1 second summaries, 10 times
|
||||
./biolatency -mT 1 # 1s summaries, milliseconds, and timestamps
|
||||
./biolatency -Q # include OS queued time in I/O time
|
||||
./biolatency -D # show each disk device separately
|
||||
```
|
||||
|
||||
它们的行为就像其它 Unix 工具一样,以利于采用而设计。
|
||||
|
||||
#### 5、 tcplife
|
||||
|
||||
另一个有用的工具是 [tcplife][19] ,该例显示 TCP 会话的生命周期和吞吐量统计。
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/tcplife
|
||||
PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS
|
||||
12759 sshd 192.168.56.101 22 192.168.56.1 60639 2 3 1863.82
|
||||
12783 sshd 192.168.56.101 22 192.168.56.1 60640 3 3 9174.53
|
||||
12844 wget 10.0.2.15 34250 54.204.39.132 443 11 1870 5712.26
|
||||
12851 curl 10.0.2.15 34252 54.204.39.132 443 0 74 505.90
|
||||
```
|
||||
|
||||
在你说 “我不是可以只通过 `tcpdump(8)` 就能输出这个?” 之前请注意,运行 `tcpdump(8)` 或任何数据包嗅探器,在高数据包速率的系统上的开销会很大,即使 `tcpdump(8)` 的用户层和内核层机制已经过多年优化(要不可能更差)。`tcplife` 不会测试每个数据包;它只会有效地监视 TCP 会话状态的变化,并由此得到该会话的持续时间。它还使用已经跟踪了吞吐量的内核计数器,以及进程和命令信息(“PID” 和 “COMM” 列),这些对于 `tcpdump(8)` 等线上嗅探工具是做不到的。
|
||||
|
||||
#### 6、 gethostlatency
|
||||
|
||||
之前的每个例子都涉及到内核跟踪,所以我至少需要一个用户级跟踪的例子。 这就是 [gethostlatency][20],它检测用于名称解析的 `gethostbyname(3)` 和相关的库调用:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/gethostlatency
|
||||
TIME PID COMM LATms HOST
|
||||
06:43:33 12903 curl 188.98 opensource.com
|
||||
06:43:36 12905 curl 8.45 opensource.com
|
||||
06:43:40 12907 curl 6.55 opensource.com
|
||||
06:43:44 12911 curl 9.67 opensource.com
|
||||
06:45:02 12948 curl 19.66 opensource.cats
|
||||
06:45:06 12950 curl 18.37 opensource.cats
|
||||
06:45:07 12952 curl 13.64 opensource.cats
|
||||
06:45:19 13139 curl 13.10 opensource.cats
|
||||
```
|
||||
|
||||
是的,总是有 DNS 请求,所以有一个工具来监视系统范围内的 DNS 请求会很方便(这只有在应用程序使用标准系统库时才有效)。看看我如何跟踪多个对 “opensource.com” 的查找? 第一个是 188.98 毫秒,然后更快,不到 10 毫秒,毫无疑问,这是缓存的作用。它还追踪多个对 “opensource.cats” 的查找,一个不存在的可怜主机名,但我们仍然可以检查第一个和后续查找的延迟。(第二次查找后是否有一些否定缓存的影响?)
|
||||
|
||||
#### 7、 trace
|
||||
|
||||
好的,再举一个例子。 [trace][21] 工具由 Sasha Goldshtein 提供,并提供了一些基本的 `printf(1)` 功能和自定义探针。 例如:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/trace 'pam:pam_start "%s: %s", arg1, arg2'
|
||||
PID TID COMM FUNC -
|
||||
13266 13266 sshd pam_start sshd: root
|
||||
```
|
||||
|
||||
在这里,我正在跟踪 `libpam` 及其 `pam_start(3)` 函数,并将其两个参数都打印为字符串。 `libpam` 用于插入式身份验证模块系统,该输出显示 sshd 为 “root” 用户调用了 `pam_start()`(我登录了)。 其使用信息中有更多的例子(`trace -h`),而且所有这些工具在 bcc 版本库中都有手册页和示例文件。 例如 `trace_example.txt` 和 `trace.8`。
|
||||
|
||||
### 通过包安装 bcc
|
||||
|
||||
安装 bcc 最佳的方法是从 iovisor 仓储库中安装,按照 bcc 的 [INSTALL.md][22] 进行即可。[IO Visor][23] 是包括了 bcc 的 Linux 基金会项目。4.x 系列 Linux 内核中增加了这些工具所使用的 BPF 增强功能,直到 4.9 添加了全部支持。这意味着拥有 4.8 内核的 Fedora 25 可以运行这些工具中的大部分。 使用 4.11 内核的 Fedora 26 可以全部运行它们(至少在目前是这样)。
|
||||
|
||||
如果你使用的是 Fedora 25(或者 Fedora 26,而且这个帖子已经在很多个月前发布了 —— 你好,来自遥远的过去!),那么这个通过包安装的方式是可以工作的。 如果您使用的是 Fedora 26,那么请跳至“通过源代码安装”部分,它避免了一个[已修复的][26]的[已知][25]错误。 这个错误修复目前还没有进入 Fedora 26 软件包的依赖关系。 我使用的系统是:
|
||||
|
||||
```
|
||||
# uname -a
|
||||
Linux localhost.localdomain 4.11.8-300.fc26.x86_64 #1 SMP Thu Jun 29 20:09:48 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
|
||||
# cat /etc/fedora-release
|
||||
Fedora release 26 (Twenty Six)
|
||||
```
|
||||
|
||||
以下是我所遵循的安装步骤,但请参阅 INSTALL.md 获取更新的版本:
|
||||
|
||||
```
|
||||
# echo -e '[iovisor]\nbaseurl=https://repo.iovisor.org/yum/nightly/f25/$basearch\nenabled=1\ngpgcheck=0' | sudo tee /etc/yum.repos.d/iovisor.repo
|
||||
# dnf install bcc-tools
|
||||
[...]
|
||||
Total download size: 37 M
|
||||
Installed size: 143 M
|
||||
Is this ok [y/N]: y
|
||||
```
|
||||
|
||||
安装完成后,您可以在 `/usr/share` 中看到新的工具:
|
||||
|
||||
```
|
||||
# ls /usr/share/bcc/tools/
|
||||
argdist dcsnoop killsnoop softirqs trace
|
||||
bashreadline dcstat llcstat solisten ttysnoop
|
||||
[...]
|
||||
```
|
||||
|
||||
试着运行其中一个:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
chdir(/lib/modules/4.11.8-300.fc26.x86_64/build): No such file or directory
|
||||
Traceback (most recent call last):
|
||||
File "/usr/share/bcc/tools/opensnoop", line 126, in
|
||||
b = BPF(text=bpf_text)
|
||||
File "/usr/lib/python3.6/site-packages/bcc/__init__.py", line 284, in __init__
|
||||
raise Exception("Failed to compile BPF module %s" % src_file)
|
||||
Exception: Failed to compile BPF module
|
||||
```
|
||||
|
||||
运行失败,提示 `/lib/modules/4.11.8-300.fc26.x86_64/build` 丢失。 如果你也遇到这个问题,那只是因为系统缺少内核头文件。 如果你看看这个文件指向什么(这是一个符号链接),然后使用 `dnf whatprovides` 来搜索它,它会告诉你接下来需要安装的包。 对于这个系统,它是:
|
||||
|
||||
```
|
||||
# dnf install kernel-devel-4.11.8-300.fc26.x86_64
|
||||
[...]
|
||||
Total download size: 20 M
|
||||
Installed size: 63 M
|
||||
Is this ok [y/N]: y
|
||||
[...]
|
||||
```
|
||||
|
||||
现在:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
PID COMM FD ERR PATH
|
||||
11792 ls 3 0 /etc/ld.so.cache
|
||||
11792 ls 3 0 /lib64/libselinux.so.1
|
||||
11792 ls 3 0 /lib64/libcap.so.2
|
||||
11792 ls 3 0 /lib64/libc.so.6
|
||||
[...]
|
||||
```
|
||||
|
||||
运行起来了。 这是捕获自另一个窗口中的 ls 命令活动。 请参阅前面的部分以使用其它有用的命令。
|
||||
|
||||
### 通过源码安装
|
||||
|
||||
如果您需要从源代码安装,您还可以在 [INSTALL.md][27] 中找到文档和更新说明。 我在 Fedora 26 上做了如下的事情:
|
||||
|
||||
```
|
||||
sudo dnf install -y bison cmake ethtool flex git iperf libstdc++-static \
|
||||
python-netaddr python-pip gcc gcc-c++ make zlib-devel \
|
||||
elfutils-libelf-devel
|
||||
sudo dnf install -y luajit luajit-devel # for Lua support
|
||||
sudo dnf install -y \
|
||||
http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm
|
||||
sudo pip install pyroute2
|
||||
sudo dnf install -y clang clang-devel llvm llvm-devel llvm-static ncurses-devel
|
||||
```
|
||||
|
||||
除 `netperf` 外一切妥当,其中有以下错误:
|
||||
|
||||
```
|
||||
Curl error (28): Timeout was reached for http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm [Connection timed out after 120002 milliseconds]
|
||||
```
|
||||
|
||||
不必理会,`netperf` 是可选的,它只是用于测试,而 bcc 没有它也会编译成功。
|
||||
|
||||
以下是余下的 bcc 编译和安装步骤:
|
||||
|
||||
```
|
||||
git clone https://github.com/iovisor/bcc.git
|
||||
mkdir bcc/build; cd bcc/build
|
||||
cmake .. -DCMAKE_INSTALL_PREFIX=/usr
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
|
||||
现在,命令应该可以工作了:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
PID COMM FD ERR PATH
|
||||
4131 date 3 0 /etc/ld.so.cache
|
||||
4131 date 3 0 /lib64/libc.so.6
|
||||
4131 date 3 0 /usr/lib/locale/locale-archive
|
||||
4131 date 3 0 /etc/localtime
|
||||
[...]
|
||||
```
|
||||
|
||||
### 写在最后和其他的前端
|
||||
|
||||
这是一个可以在 Fedora 和 Red Hat 系列操作系统上使用的新 BPF 性能分析强大功能的快速浏览。我演示了 BPF 的流行前端 [bcc][28] ,并包括了其在 Fedora 上的安装说明。bcc 附带了 60 多个用于性能分析的新工具,这将帮助您充分利用 Linux 系统。也许你会直接通过 SSH 使用这些工具,或者一旦 GUI 监控程序支持 BPF 的话,你也可以通过它们来使用相同的功能。
|
||||
|
||||
此外,bcc 并不是正在开发的唯一前端。[ply][29] 和 [bpftrace][30],旨在为快速编写自定义工具提供更高级的语言支持。此外,[SystemTap][31] 刚刚发布[版本3.2][32],包括一个早期的实验性 eBPF 后端。 如果这个继续开发,它将为运行多年来开发的许多 SystemTap 脚本和 tapset(库)提供一个安全和高效的生产级引擎。(随同 eBPF 使用 SystemTap 将是另一篇文章的主题。)
|
||||
|
||||
如果您需要开发自定义工具,那么也可以使用 bcc 来实现,尽管语言比 SystemTap、ply 或 bpftrace 要冗长得多。我的 bcc 工具可以作为代码示例,另外我还贡献了用 Python 开发 bcc 工具的[教程][33]。 我建议先学习 bcc 的 multi-tools,因为在需要编写新工具之前,你可能会从里面获得很多经验。 您可以从它们的 bcc 存储库[funccount] [34],[funclatency] [35],[funcslower] [36],[stackcount] [37],[trace] [38] ,[argdist] [39] 的示例文件中研究 bcc。
|
||||
|
||||
感谢[Opensource.com] [40]进行编辑。
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][43]
|
||||
|
||||
Brendan Gregg 是 Netflix 的一名高级性能架构师,在那里他进行大规模的计算机性能设计、分析和调优。
|
||||
|
||||
(题图:opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://opensource.com/article/17/11/bccbpf-performance
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[yongshouzhang](https://github.com/yongshouzhang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/brendang
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/participate
|
||||
[7]:https://opensource.com/users/brendang
|
||||
[8]:https://opensource.com/users/brendang
|
||||
[9]:https://opensource.com/user/77626/feed
|
||||
[10]:https://opensource.com/article/17/11/bccbpf-performance?rate=r9hnbg3mvjFUC9FiBk9eL_ZLkioSC21SvICoaoJjaSM
|
||||
[11]:https://opensource.com/article/17/11/bccbpf-performance#comments
|
||||
[12]:https://github.com/iovisor/bcc
|
||||
[13]:https://opensource.com/file/376856
|
||||
[14]:https://opensource.com/usr/share/bcc/tools/trace
|
||||
[15]:https://github.com/brendangregg/perf-tools/blob/master/execsnoop
|
||||
[16]:https://github.com/brendangregg/perf-tools/blob/master/opensnoop
|
||||
[17]:https://github.com/iovisor/bcc/blob/master/tools/xfsslower.py
|
||||
[18]:https://github.com/iovisor/bcc/blob/master/tools/biolatency.py
|
||||
[19]:https://github.com/iovisor/bcc/blob/master/tools/tcplife.py
|
||||
[20]:https://github.com/iovisor/bcc/blob/master/tools/gethostlatency.py
|
||||
[21]:https://github.com/iovisor/bcc/blob/master/tools/trace.py
|
||||
[22]:https://github.com/iovisor/bcc/blob/master/INSTALL.md#fedora---binary
|
||||
[23]:https://www.iovisor.org/
|
||||
[24]:https://opensource.com/article/17/11/bccbpf-performance#InstallViaSource
|
||||
[25]:https://github.com/iovisor/bcc/issues/1221
|
||||
[26]:https://reviews.llvm.org/rL302055
|
||||
[27]:https://github.com/iovisor/bcc/blob/master/INSTALL.md#fedora---source
|
||||
[28]:https://github.com/iovisor/bcc
|
||||
[29]:https://github.com/iovisor/ply
|
||||
[30]:https://github.com/ajor/bpftrace
|
||||
[31]:https://sourceware.org/systemtap/
|
||||
[32]:https://sourceware.org/ml/systemtap/2017-q4/msg00096.html
|
||||
[33]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[34]:https://github.com/iovisor/bcc/blob/master/tools/funccount_example.txt
|
||||
[35]:https://github.com/iovisor/bcc/blob/master/tools/funclatency_example.txt
|
||||
[36]:https://github.com/iovisor/bcc/blob/master/tools/funcslower_example.txt
|
||||
[37]:https://github.com/iovisor/bcc/blob/master/tools/stackcount_example.txt
|
||||
[38]:https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt
|
||||
[39]:https://github.com/iovisor/bcc/blob/master/tools/argdist_example.txt
|
||||
[40]:http://opensource.com/
|
||||
[41]:https://opensource.com/tags/linux
|
||||
[42]:https://opensource.com/tags/sysadmin
|
||||
[43]:https://opensource.com/users/brendang
|
||||
[44]:https://opensource.com/users/brendang
|
||||
@ -0,0 +1,78 @@
|
||||
什么是僵尸进程,如何找到并杀掉僵尸进程?
|
||||
======
|
||||
|
||||
[][1]
|
||||
|
||||
如果你经常使用 Linux,你应该遇到这个术语“<ruby>僵尸进程<rt>Zombie Processes</rt></ruby>”。 那么什么是僵尸进程? 它们是怎么产生的? 它们是否对系统有害? 我要怎样杀掉这些进程? 下面将会回答这些问题。
|
||||
|
||||
### 什么是僵尸进程?
|
||||
|
||||
我们都知道进程的工作原理。我们启动一个程序,开始我们的任务,然后等任务结束了,我们就停止这个进程。 进程停止后, 该进程就会从进程表中移除。
|
||||
|
||||
你可以通过 `System-Monitor` 查看当前进程。
|
||||
|
||||
[][2]
|
||||
|
||||
但是,有时候有些程序即使执行完了也依然留在进程表中。
|
||||
|
||||
那么,这些完成了生命周期但却依然留在进程表中的进程,我们称之为 “僵尸进程”。
|
||||
|
||||
### 它们是如何产生的?
|
||||
|
||||
当你运行一个程序时,它会产生一个父进程以及很多子进程。 所有这些子进程都会消耗内核分配给它们的内存和 CPU 资源。
|
||||
|
||||
这些子进程完成执行后会发送一个 Exit 信号然后死掉。这个 Exit 信号需要被父进程所读取。父进程需要随后调用 `wait` 命令来读取子进程的退出状态,并将子进程从进程表中移除。
|
||||
|
||||
若父进程正确第读取了子进程的 Exit 信号,则子进程会从进程表中删掉。
|
||||
|
||||
但若父进程未能读取到子进程的 Exit 信号,则这个子进程虽然完成执行处于死亡的状态,但也不会从进程表中删掉。
|
||||
|
||||
### 僵尸进程对系统有害吗?
|
||||
|
||||
**不会**。由于僵尸进程并不做任何事情, 不会使用任何资源也不会影响其它进程, 因此存在僵尸进程也没什么坏处。 不过由于进程表中的退出状态以及其它一些进程信息也是存储在内存中的,因此存在太多僵尸进程有时也会是一些问题。
|
||||
|
||||
**你可以想象成这样:**
|
||||
|
||||
“你是一家建筑公司的老板。你每天根据工人们的工作量来支付工资。 有一个工人每天来到施工现场,就坐在那里, 你不用付钱, 他也不做任何工作。 他只是每天都来然后呆坐在那,仅此而已!”
|
||||
|
||||
这个工人就是僵尸进程的一个活生生的例子。**但是**, 如果你有很多僵尸工人, 你的建设工地就会很拥堵从而让那些正常的工人难以工作。
|
||||
|
||||
### 那么如何找出僵尸进程呢?
|
||||
|
||||
打开终端并输入下面命令:
|
||||
|
||||
```
|
||||
ps aux | grep Z
|
||||
```
|
||||
|
||||
会列出进程表中所有僵尸进程的详细内容。
|
||||
|
||||
### 如何杀掉僵尸进程?
|
||||
|
||||
正常情况下我们可以用 `SIGKILL` 信号来杀死进程,但是僵尸进程已经死了, 你不能杀死已经死掉的东西。 因此你需要输入的命令应该是
|
||||
|
||||
```
|
||||
kill -s SIGCHLD pid
|
||||
```
|
||||
|
||||
将这里的 pid 替换成父进程的进程 id,这样父进程就会删除所有以及完成并死掉的子进程了。
|
||||
|
||||
**你可以把它想象成:**
|
||||
|
||||
"你在道路中间发现一具尸体,于是你联系了死者的家属,随后他们就会将尸体带离道路了。"
|
||||
|
||||
不过许多程序写的不是那么好,无法删掉这些子僵尸(否则你一开始也见不到这些僵尸了)。 因此确保删除子僵尸的唯一方法就是杀掉它们的父进程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/what-are-zombie-processes-and-how-to-find-kill-zombie-processes
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/what-are-zombie-processes-and-how-to-find-kill-zombie-processes
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux-check-zombie-processes_orig.jpg
|
||||
@ -0,0 +1,149 @@
|
||||
如何为 Linux 无线网卡配置无线唤醒功能
|
||||
======
|
||||
|
||||
我有一台用于备份我的所有设备的网络存储(NAS)服务器。然而当我备份我的 Linux 笔记本时遇到了困难。当它休眠或挂起时我不能备份它。当我使用基于 Intel 的无线网卡时,我可以配置笔记本上的 WiFi 接受无线唤醒吗?
|
||||
|
||||
<ruby>[网络唤醒][2]<rt>Wake-on-LAN</rt></ruby>(WOL)是一个以太网标准,它允许服务器通过一个网络消息而被打开。你需要发送一个“魔法数据包”到支持网络唤醒的以太网卡和主板,以便打开被唤醒的系统。
|
||||
|
||||
[![linux-configire-wake-on-wireless-lan-wowlan][1]][1]
|
||||
|
||||
<ruby>无线唤醒<rt>wireless wake-on-lan</rt></ruby>(WoWLAN 或 WoW)允许 Linux 系统进入低耗电模式的情况下保持无线网卡处于激活状态,依然与热点连接。这篇教程演示了如何在一台安装无线网卡的 Linux 笔记本或桌面电脑上启用 WoWLAN / WoW 模式。
|
||||
|
||||
> 请注意,不是所有的无线网卡和 Linux 驱动程序都支持 WoWLAN。
|
||||
|
||||
### 语法
|
||||
|
||||
在 Linux 系统上,你需要使用 `iw` 命令来查看和操作无线设备及其配置。 其格式为:
|
||||
|
||||
```
|
||||
iw command
|
||||
iw [options] command
|
||||
```
|
||||
|
||||
### 列出所有的无线设备及其功能
|
||||
|
||||
输入下面命令:
|
||||
|
||||
```
|
||||
$ iw list
|
||||
$ iw list | more
|
||||
$ iw dev
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
```
|
||||
phy#0
|
||||
Interface wlp3s0
|
||||
ifindex 3
|
||||
wdev 0x1
|
||||
addr 6c:88:14:ff:36:d0
|
||||
type managed
|
||||
channel 149 (5745 MHz),width: 40 MHz, center1: 5755 MHz
|
||||
txpower 15.00 dBm
|
||||
```
|
||||
|
||||
请记下这个 `phy0`。
|
||||
|
||||
### 查看无线唤醒的当前状态
|
||||
|
||||
打开终端并输入下面命令来查看无线网络的状态:
|
||||
|
||||
```
|
||||
$ iw phy0 wowlan show
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
```
|
||||
WoWLAN is disabled
|
||||
```
|
||||
|
||||
### 如何启用无线唤醒
|
||||
|
||||
启用的语法为:
|
||||
|
||||
`sudo iw phy {phyname} wowlan enable {option}`
|
||||
|
||||
其中,
|
||||
|
||||
1. `{phyname}` - 使用 `iw dev` 来获取其物理名。
|
||||
2. `{option}` - 可以是 `any`、`disconnect`、`magic-packet` 等。
|
||||
|
||||
比如,我想为 `phy0` 开启无线唤醒:
|
||||
|
||||
```
|
||||
$ sudo iw phy0 wowlan enable any
|
||||
```
|
||||
或者:
|
||||
|
||||
```
|
||||
$ sudo iw phy0 wowlan enable magic-packet disconnect
|
||||
```
|
||||
|
||||
检查一下:
|
||||
|
||||
```
|
||||
$ iw phy0 wowlan show
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
```
|
||||
WoWLAN is enabled:
|
||||
* wake up on disconnect
|
||||
* wake up on magic packet
|
||||
```
|
||||
|
||||
### 测试一下
|
||||
|
||||
将你的笔记本挂起或者进入休眠模式:
|
||||
|
||||
```
|
||||
$ sudo sh -c 'echo mem > /sys/power/state'
|
||||
```
|
||||
|
||||
从 NAS 服务器上使用 [ping 命令][3] 发送 ping 请求
|
||||
|
||||
```
|
||||
$ ping your-laptop-ip
|
||||
```
|
||||
|
||||
也可以 [使用 `wakeonlan` 命令发送魔法数据包][4]:
|
||||
|
||||
```
|
||||
$ wakeonlan laptop-mac-address-here
|
||||
$ etherwake MAC-Address-Here
|
||||
```
|
||||
|
||||
### 如何禁用无线唤醒?
|
||||
|
||||
语法为:
|
||||
|
||||
```
|
||||
$ sudo phy {phyname} wowlan disable
|
||||
$ sudo phy0 wowlan disable
|
||||
```
|
||||
|
||||
更多信息请阅读 `iw` 命令的 man 页:
|
||||
|
||||
```
|
||||
$ man iw
|
||||
$ iw --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/configure-wireless-wake-on-lan-for-linux-wifi-wowlan-card/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/nixcraft
|
||||
[1]: https://www.cyberciti.biz/media/new/faq/2017/12/linux-configire-wake-on-wireless-lan-wowlan.jpg
|
||||
[2]: https://www.cyberciti.biz/tips/linux-send-wake-on-lan-wol-magic-packets.html
|
||||
[3]: https://www.cyberciti.biz/faq/unix-ping-command-examples/ (See Linux/Unix ping command examples for more info)
|
||||
[4]: https://www.cyberciti.biz/faq/apple-os-x-wake-on-lancommand-line-utility/
|
||||
@ -1,63 +0,0 @@
|
||||
Book review: Ours to Hack and to Own
|
||||
============================================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
It seems like the age of ownership is over, and I'm not just talking about the devices and software that many of us bring into our homes and our lives. I'm also talking about the platforms and services on which those devices and apps rely.
|
||||
|
||||
While many of the services that we use are free, we don't have any control over them. The firms that do, in essence, control what we see, what we hear, and what we read. Not only that, but many of them are also changing the nature of work. They're using closed platforms to power a shift away from full-time work to the [gig economy][2], one that offers little in the way of security or certainty.
|
||||
|
||||
This move has wide-ranging implications for the Internet and for everyone who uses and relies on it. The vision of the open Internet from just 20-odd-years ago is fading and is rapidly being replaced by an impenetrable curtain.
|
||||
|
||||
One remedy that's becoming popular is building [platform cooperatives][3], which are digital platforms that their users own. The idea behind platform cooperatives has many of the same roots as open source, as the book "[Ours to Hack and to Own][4]" explains.
|
||||
|
||||
Scholar Trebor Scholz and writer Nathan Schneider have collected 40 essays discussing the rise of, and the need for, platform cooperatives as tools ordinary people can use to promote openness, and to counter the opaqueness and the restrictions of closed systems.
|
||||
|
||||
### Where open source fits in
|
||||
|
||||
At or near the core of any platform cooperative lies open source; not necessarily open source technologies, but the principles and the ethos that underlie open source—openness, transparency, cooperation, collaboration, and sharing.
|
||||
|
||||
In his introduction to the book, Trebor Scholz points out that:
|
||||
|
||||
> In opposition to the black-box systems of the Snowden-era Internet, these platforms need to distinguish themselves by making their data flows transparent. They need to show where the data about customers and workers are stored, to whom they are sold, and for what purpose.
|
||||
|
||||
It's that transparency, so essential to open source, which helps make platform cooperatives so appealing and a refreshing change from much of what exists now.
|
||||
|
||||
Open source software can definitely play a part in the vision of platform cooperatives that "Ours to Hack and to Own" shares. Open source software can provide a fast, inexpensive way for groups to build the technical infrastructure that can power their cooperatives.
|
||||
|
||||
Mickey Metts illustrates this in the essay, "Meet Your Friendly Neighborhood Tech Co-Op." Metts works for a firm called Agaric, which uses Drupal to build for groups and small business what they otherwise couldn't do for themselves. On top of that, Metts encourages anyone wanting to build and run their own business or co-op to embrace free and open source software. Why? It's high quality, it's inexpensive, you can customize it, and you can connect with large communities of helpful, passionate people.
|
||||
|
||||
### Not always about open source, but open source is always there
|
||||
|
||||
Not all of the essays in this book focus or touch on open source; however, the key elements of the open source way—cooperation, community, open governance, and digital freedom—are always on or just below the surface.
|
||||
|
||||
In fact, as many of the essays in "Ours to Hack and to Own" argue, platform cooperatives can be important building blocks of a more open, commons-based economy and society. That can be, in Douglas Rushkoff's words, organizations like Creative Commons compensating "for the privatization of shared intellectual resources." It can also be what Francesca Bria, Barcelona's CTO, describes as cities running their own "distributed common data infrastructures with systems that ensure the security and privacy and sovereignty of citizens' data."
|
||||
|
||||
### Final thought
|
||||
|
||||
If you're looking for a blueprint for changing the Internet and the way we work, "Ours to Hack and to Own" isn't it. The book is more a manifesto than user guide. Having said that, "Ours to Hack and to Own" offers a glimpse at what we can do if we apply the principles of the open source way to society and to the wider world.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Scott Nesbitt - Writer. Editor. Soldier of fortune. Ocelot wrangler. Husband and father. Blogger. Collector of pottery. Scott is a few of these things. He's also a long-time user of free/open source software who extensively writes and blogs about it. You can find Scott on Twitter, GitHub
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/review-book-ours-to-hack-and-own
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/1/review-book-ours-to-hack-and-own?rate=dgkFEuCLLeutLMH2N_4TmUupAJDjgNvFpqWqYCbQb-8
|
||||
[2]:https://en.wikipedia.org/wiki/Access_economy
|
||||
[3]:https://en.wikipedia.org/wiki/Platform_cooperative
|
||||
[4]:http://www.orbooks.com/catalog/ours-to-hack-and-to-own/
|
||||
[5]:https://opensource.com/user/14925/feed
|
||||
[6]:https://opensource.com/users/scottnesbitt
|
||||
@ -1,211 +0,0 @@
|
||||
# Dynamic linker tricks: Using LD_PRELOAD to cheat, inject features and investigate programs
|
||||
|
||||
**This post assumes some basic C skills.**
|
||||
|
||||
Linux puts you in full control. This is not always seen from everyone’s perspective, but a power user loves to be in control. I’m going to show you a basic trick that lets you heavily influence the behavior of most applications, which is not only fun, but also, at times, useful.
|
||||
|
||||
#### A motivational example
|
||||
|
||||
Let us begin with a simple example. Fun first, science later.
|
||||
|
||||
|
||||
random_num.c:
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <time.h>
|
||||
|
||||
int main(){
|
||||
srand(time(NULL));
|
||||
int i = 10;
|
||||
while(i--) printf("%d\n",rand()%100);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Simple enough, I believe. I compiled it with no special flags, just
|
||||
|
||||
> ```
|
||||
> gcc random_num.c -o random_num
|
||||
> ```
|
||||
|
||||
I hope the resulting output is obvious – ten randomly selected numbers 0-99, hopefully different each time you run this program.
|
||||
|
||||
Now let’s pretend we don’t really have the source of this executable. Either delete the source file, or move it somewhere – we won’t need it. We will significantly modify this programs behavior, yet without touching it’s source code nor recompiling it.
|
||||
|
||||
For this, lets create another simple C file:
|
||||
|
||||
|
||||
unrandom.c:
|
||||
```
|
||||
int rand(){
|
||||
return 42; //the most random number in the universe
|
||||
}
|
||||
```
|
||||
|
||||
We’ll compile it into a shared library.
|
||||
|
||||
> ```
|
||||
> gcc -shared -fPIC unrandom.c -o unrandom.so
|
||||
> ```
|
||||
|
||||
So what we have now is an application that outputs some random data, and a custom library, which implements the rand() function as a constant value of 42\. Now… just run _random_num _ this way, and watch the result:
|
||||
|
||||
> ```
|
||||
> LD_PRELOAD=$PWD/unrandom.so ./random_nums
|
||||
> ```
|
||||
|
||||
If you are lazy and did not do it yourself (and somehow fail to guess what might have happened), I’ll let you know – the output consists of ten 42’s.
|
||||
|
||||
This may be even more impressive it you first:
|
||||
|
||||
> ```
|
||||
> export LD_PRELOAD=$PWD/unrandom.so
|
||||
> ```
|
||||
|
||||
and then run the program normally. An unchanged app run in an apparently usual manner seems to be affected by what we did in our tiny library…
|
||||
|
||||
###### **Wait, what? What did just happen?**
|
||||
|
||||
Yup, you are right, our program failed to generate random numbers, because it did not use the “real” rand(), but the one we provided – which returns 42 every time.
|
||||
|
||||
###### **But we *told* it to use the real one. We programmed it to use the real one. Besides, at the time we created that program, the fake rand() did not even exist!**
|
||||
|
||||
This is not entirely true. We did not choose which rand() we want our program to use. We told it just to use rand().
|
||||
|
||||
When our program is started, certain libraries (that provide functionality needed by the program) are loaded. We can learn which are these using _ldd_ :
|
||||
|
||||
> ```
|
||||
> $ ldd random_nums
|
||||
> linux-vdso.so.1 => (0x00007fff4bdfe000)
|
||||
> libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f48c03ec000)
|
||||
> /lib64/ld-linux-x86-64.so.2 (0x00007f48c07e3000)
|
||||
> ```
|
||||
|
||||
What you see as the output is the list of libs that are needed by _random_nums_ . This list is built into the executable, and is determined compile time. The exact output might slightly differ on your machine, but a **libc.so** must be there – this is the file which provides core C functionality. That includes the “real” rand().
|
||||
|
||||
We can have a peek at what functions does libc provide. I used the following to get a full list:
|
||||
|
||||
> ```
|
||||
> nm -D /lib/libc.so.6
|
||||
> ```
|
||||
|
||||
The _nm_ command lists symbols found in a binary file. The -D flag tells it to look for dynamic symbols, which makes sense, as libc.so.6 is a dynamic library. The output is very long, but it indeed lists rand() among many other standard functions.
|
||||
|
||||
Now what happens when we set up the environmental variable LD_PRELOAD? This variable **forces some libraries to be loaded for a program**. In our case, it loads _unrandom.so_ for _random_num_ , even though the program itself does not ask for it. The following command may be interesting:
|
||||
|
||||
> ```
|
||||
> $ LD_PRELOAD=$PWD/unrandom.so ldd random_nums
|
||||
> linux-vdso.so.1 => (0x00007fff369dc000)
|
||||
> /some/path/to/unrandom.so (0x00007f262b439000)
|
||||
> libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f262b044000)
|
||||
> /lib64/ld-linux-x86-64.so.2 (0x00007f262b63d000)
|
||||
> ```
|
||||
|
||||
Note that it lists our custom library. And indeed this is the reason why it’s code get’s executed: _random_num_ calls rand(), but if _unrandom.so_ is loaded it is our library that provides implementation for rand(). Neat, isn’t it?
|
||||
|
||||
#### Being transparent
|
||||
|
||||
This is not enough. I’d like to be able to inject some code into an application in a similar manner, but in such way that it will be able to function normally. It’s clear if we implemented open() with a simple “ _return 0;_ “, the application we would like to hack should malfunction. The point is to be **transparent**, and to actually call the original open:
|
||||
|
||||
inspect_open.c:
|
||||
```
|
||||
int open(const char *pathname, int flags){
|
||||
/* Some evil injected code goes here. */
|
||||
return open(pathname,flags); // Here we call the "real" open function, that is provided to us by libc.so
|
||||
}
|
||||
```
|
||||
|
||||
Hm. Not really. This won’t call the “original” open(…). Obviously, this is an endless recursive call.
|
||||
|
||||
How do we access the “real” open function? It is needed to use the programming interface to the dynamic linker. It’s simpler than it sounds. Have a look at this complete example, and then I’ll explain what happens there:
|
||||
|
||||
inspect_open.c:
|
||||
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <dlfcn.h>
|
||||
|
||||
typedef int (*orig_open_f_type)(const char *pathname, int flags);
|
||||
|
||||
int open(const char *pathname, int flags, ...)
|
||||
{
|
||||
/* Some evil injected code goes here. */
|
||||
|
||||
orig_open_f_type orig_open;
|
||||
orig_open = (orig_open_f_type)dlsym(RTLD_NEXT,"open");
|
||||
return orig_open(pathname,flags);
|
||||
}
|
||||
```
|
||||
|
||||
The _dlfcn.h_ is needed for _dlsym_ function we use later. That strange _#define_ directive instructs the compiler to enable some non-standard stuff, we need it to enable _RTLD_NEXT_ in _dlfcn.h_ . That typedef is just creating an alias to a complicated pointer-to-function type, with arguments just as the original open – the alias name is _orig_open_f_type_ , which we’ll use later.
|
||||
|
||||
The body of our custom open(…) consists of some custom code. The last part of it creates a new function pointer _orig_open_ which will point to the original open(…) function. In order to get the address of that function, we ask _dlsym_ to find for us the next “open” function on dynamic libraries stack. Finally, we call that function (passing the same arguments as were passed to our fake “open”), and return it’s return value as ours.
|
||||
|
||||
As the “evil injected code” I simply used:
|
||||
|
||||
inspect_open.c (fragment):
|
||||
|
||||
```
|
||||
printf("The victim used open(...) to access '%s'!!!\n",pathname); //remember to include stdio.h!
|
||||
```
|
||||
|
||||
To compile it, I needed to slightly adjust compiler flags:
|
||||
|
||||
> ```
|
||||
> gcc -shared -fPIC inspect_open.c -o inspect_open.so -ldl
|
||||
> ```
|
||||
|
||||
I had to append _-ldl_ , so that this shared library is linked to _libdl_ , which provides the _dlsym_ function. (Nah, I am not going to create a fake version of _dlsym_ , though this might be fun.)
|
||||
|
||||
So what do I have in result? A shared library, which implements the open(…) function so that it behaves **exactly** as the real open(…)… except it has a side effect of _printf_ ing the file path :-)
|
||||
|
||||
If you are not convinced this is a powerful trick, it’s the time you tried the following:
|
||||
|
||||
> ```
|
||||
> LD_PRELOAD=$PWD/inspect_open.so gnome-calculator
|
||||
> ```
|
||||
|
||||
I encourage you to see the result yourself, but basically it lists every file this application accesses. In real time.
|
||||
|
||||
I believe it’s not that hard to imagine why this might be useful for debugging or investigating unknown applications. Please note, however, that this particular trick is not quite complete, because _open()_ is not the only function that opens files… For example, there is also _open64()_ in the standard library, and for full investigation you would need to create a fake one too.
|
||||
|
||||
#### **Possible uses**
|
||||
|
||||
If you are still with me and enjoyed the above, let me suggest a bunch of ideas of what can be achieved using this trick. Keep in mind that you can do all the above without to source of the affected app!
|
||||
|
||||
1. ~~Gain root privileges.~~ Not really, don’t even bother, you won’t bypass any security this way. (A quick explanation for pros: no libraries will be preloaded this way if ruid != euid)
|
||||
|
||||
2. Cheat games: **Unrandomize.** This is what I did in the first example. For a fully working case you would need also to implement a custom _random()_ , _rand_r()_ _, random_r()_ . Also some apps may be reading from _/dev/urandom_ or so, you might redirect them to _/dev/null_ by running the original _open()_ with a modified file path. Furthermore, some apps may have their own random number generation algorithm, there is little you can do about that (unless: point 10 below). But this looks like an easy exercise for beginners.
|
||||
|
||||
3. Cheat games: **Bullet time. **Implement all standard time-related functions pretend the time flows two times slower. Or ten times slower. If you correctly calculate new values for time measurement, timed _sleep_ functions, and others, the affected application will believe the time runs slower (or faster, if you wish), and you can experience awesome bullet-time action.
|
||||
Or go **even one step further** and let your shared library also be a DBus client, so that you can communicate with it real time. Bind some shortcuts to custom commands, and with some additional calculations in your fake timing functions you will be able to enable&disable the slow-mo or fast-forward anytime you wish.
|
||||
|
||||
4. Investigate apps: **List accessed files.** That’s what my second example does, but this could be also pushed further, by recording and monitoring all app’s file I/O.
|
||||
|
||||
5. Investigate apps: **Monitor internet access.** You might do this with Wireshark or similar software, but with this trick you could actually gain control of what an app sends over the web, and not just look, but also affect the exchanged data. Lots of possibilities here, from detecting spyware, to cheating in multiplayer games, or analyzing & reverse-engineering protocols of closed-source applications.
|
||||
|
||||
6. Investigate apps: **Inspect GTK structures.** Why just limit ourselves to standard library? Let’s inject code in all GTK calls, so that we can learn what widgets does an app use, and how are they structured. This might be then rendered either to an image or even to a gtkbuilder file! Super useful if you want to learn how does some app manage its interface!
|
||||
|
||||
7. **Sandbox unsafe applications.** If you don’t trust some app and are afraid that it may wish to _ rm -rf / _ or do some other unwanted file activities, you might potentially redirect all it’s file IO to e.g. /tmp by appropriately modifying the arguments it passes to all file-related functions (not just _open_ , but also e.g. removing directories etc.). It’s more difficult trick that a chroot, but it gives you more control. It would be only as safe as complete your “wrapper” was, and unless you really know what you’re doing, don’t actually run any malicious software this way.
|
||||
|
||||
8. **Implement features.** [zlibc][1] is an actual library which is run this precise way; it uncompresses files on the go as they are accessed, so that any application can work on compressed data without even realizing it.
|
||||
|
||||
9. **Fix bugs. **Another real-life example: some time ago (I am not sure this is still the case) Skype – which is closed-source – had problems capturing video from some certain webcams. Because the source could not be modified as Skype is not free software, this was fixed by preloading a library that would correct these problems with video.
|
||||
|
||||
10. Manually **access application’s own memory**. Do note that you can access all app data this way. This may be not impressive if you are familiar with software like CheatEngine/scanmem/GameConqueror, but they all require root privileges to work. LD_PRELOAD does not. In fact, with a number of clever tricks your injected code might access all app memory, because, in fact, it gets executed by that application itself. You might modify everything this application can. You can probably imagine this allows a lot of low-level hacks… but I’ll post an article about it another time.
|
||||
|
||||
These are only the ideas I came up with. I bet you can find some too, if you do – share them by commenting!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://rafalcieslak.wordpress.com/2013/04/02/dynamic-linker-tricks-using-ld_preload-to-cheat-inject-features-and-investigate-programs/
|
||||
|
||||
作者:[Rafał Cieślak ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://rafalcieslak.wordpress.com/
|
||||
[1]:http://www.zlibc.linux.lu/index.html
|
||||
@ -1,361 +0,0 @@
|
||||
How to turn any syscall into an event: Introducing eBPF Kernel probes
|
||||
============================================================
|
||||
|
||||
|
||||
TL;DR: Using eBPF in recent (>=4.4) Linux kernel, you can turn any kernel function call into a user land event with arbitrary data. This is made easy by bcc. The probe is written in C while the data is handled by python.
|
||||
|
||||
If you are not familiar with eBPF or linux tracing, you really should read the full post. It tries to progressively go through the pitfalls I stumbled unpon while playing around with bcc / eBPF while saving you a lot of the time I spent searching and digging.
|
||||
|
||||
### A note on push vs pull in a Linux world
|
||||
|
||||
When I started to work on containers, I was wondering how we could update a load balancer configuration dynamically based on actual system state. A common strategy, which works, it to let the container orchestrator trigger a load balancer configuration update whenever it starts a container and then let the load balancer poll the container until some health check passes. It may be a simple “SYN” test.
|
||||
|
||||
While this configuration works, it has the downside of making your load balancer waiting for some system to be available while it should be… load balancing.
|
||||
|
||||
Can we do better?
|
||||
|
||||
When you want a program to react to some change in a system there are 2 possible strategies. The program may _poll_ the system to detect changes or, if the system supports it, the system may _push_ events and let the program react to them. Wether you want to use push or poll depends on the context. A good rule of the thumb is to use push events when the event rate is low with respect to the processing time and switch to polling when the events are coming fast or the system may become unusable. For example, typical network driver will wait for events from the network card while frameworks like dpdk will actively poll the card for events to achieve the highest throughput and lowest latency.
|
||||
|
||||
In an ideal world, we’d have some kernel interface telling us:
|
||||
|
||||
> * “Hey Mr. ContainerManager, I’ve just created a socket for the Nginx-ware of container _servestaticfiles_ , maybe you want to update your state?”
|
||||
>
|
||||
> * “Sure Mr. OS, Thanks for letting me know”
|
||||
|
||||
While Linux has a wide range of interfaces to deal with events, up to 3 for file events, there is no dedicated interface to get socket event notifications. You can get routing table events, neighbor table events, conntrack events, interface change events. Just, not socket events. Or maybe there is, deep hidden in a Netlink interface.
|
||||
|
||||
Ideally, we’d need a generic way to do it. How?
|
||||
|
||||
### Kernel tracing and eBPF, a bit of history
|
||||
|
||||
Until recently the only way was to patch the kernel or resort on SystemTap. [SytemTap][5] is a tracing Linux system. In a nutshell, it provides a DSL which is then compiled into a kernel module which is then live-loaded into the running kernel. Except that some production system disable dynamic module loading for security reasons. Including the one I was working on at that time. The other way would be to patch the kernel to trigger some events, probably based on netlink. This is not really convenient. Kernel hacking come with downsides including “interesting” new “features” and increased maintenance burden.
|
||||
|
||||
Hopefully, starting with Linux 3.15 the ground was laid to safely transform any traceable kernel function into userland events. “Safely” is common computer science expression referring to “some virtual machine”. This case is no exception. Linux has had one for years. Since Linux 2.1.75 released in 1997 actually. It’s called Berkeley Packet Filter of BPF for short. As its name suggests, it was originally developed for the BSD firewalls. It had only 2 registers and only allowed forward jumps meaning that you could not write loops with it (Well, you can, if you know the maximum iterations and you manually unroll them). The point was to guarantee the program would always terminate and hence never hang the system. Still not sure if it has any use while you have iptables? It serves as the [foundation of CloudFlare’s AntiDDos protection][6].
|
||||
|
||||
OK, so, with Linux the 3.15, [BPF was extended][7] turning it into eBPF. For “extended” BPF. It upgrades from 2 32 bits registers to 10 64 bits 64 registers and adds backward jumping among others. It has then been [further extended in Linux 3.18][8] moving it out of the networking subsystem, and adding tools like maps. To preserve the safety guarantees, it [introduces a checker][9] which validates all memory accesses and possible code path. If the checker can’t guarantee the code will terminate within fixed boundaries, it will deny the initial insertion of the program.
|
||||
|
||||
For more history, there is [an excellent Oracle presentation on eBPF][10].
|
||||
|
||||
Let’s get started.
|
||||
|
||||
### Hello from from `inet_listen`
|
||||
|
||||
As writing assembly is not the most convenient task, even for the best of us, we’ll use [bcc][11]. bcc is a collection of tools based on LLVM and Python abstracting the underlying machinery. Probes are written in C and the results can be exploited from python allowing to easily write non trivial applications.
|
||||
|
||||
Start by install bcc. For some of these examples, you may require a recent (read >= 4.4) version of the kernel. If you are willing to actually try these examples, I highly recommend that you setup a VM. _NOT_ a docker container. You can’t change the kernel in a container. As this is a young and dynamic projects, install instructions are highly platform/version dependant. You can find up to date instructions on [https://github.com/iovisor/bcc/blob/master/INSTALL.md][12]
|
||||
|
||||
So, we want to get an event whenever a program starts to listen on TCP socket. When calling the `listen()` syscall on a `AF_INET` + `SOCK_STREAM` socket, the underlying kernel function is [`inet_listen`][13]. We’ll start by hooking a “Hello World” `kprobe` on it’s entrypoint.
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
|
||||
# Hello BPF Program
|
||||
bpf_text = """
|
||||
#include <net/inet_sock.h>
|
||||
#include <bcc/proto.h>
|
||||
|
||||
// 1\. Attach kprobe to "inet_listen"
|
||||
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
|
||||
{
|
||||
bpf_trace_printk("Hello World!\\n");
|
||||
return 0;
|
||||
};
|
||||
"""
|
||||
|
||||
# 2\. Build and Inject program
|
||||
b = BPF(text=bpf_text)
|
||||
|
||||
# 3\. Print debug output
|
||||
while True:
|
||||
print b.trace_readline()
|
||||
|
||||
```
|
||||
|
||||
This program does 3 things: 1\. It attaches a kernel probe to “inet_listen” using a naming convention. If the function was called, say, “my_probe”, it could be explicitly attached with `b.attach_kprobe("inet_listen", "my_probe"`. 2\. It builds the program using LLVM new BPF backend, inject the resulting bytecode using the (new) `bpf()` syscall and automatically attaches the probes matching the naming convention. 3\. It reads the raw output from the kernel pipe.
|
||||
|
||||
Note: eBPF backend of LLVM is still young. If you think you’ve hit a bug, you may want to upgrade.
|
||||
|
||||
Noticed the `bpf_trace_printk` call? This is a stripped down version of the kernel’s `printk()`debug function. When used, it produces tracing informations to a special kernel pipe in `/sys/kernel/debug/tracing/trace_pipe`. As the name implies, this is a pipe. If multiple readers are consuming it, only 1 will get a given line. This makes it unsuitable for production.
|
||||
|
||||
Fortunately, Linux 3.19 introduced maps for message passing and Linux 4.4 brings arbitrary perf events support. I’ll demo the perf event based approach later in this post.
|
||||
|
||||
```
|
||||
# From a first console
|
||||
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
|
||||
nc-4940 [000] d... 22666.991714: : Hello World!
|
||||
|
||||
# From a second console
|
||||
ubuntu@bcc:~$ nc -l 0 4242
|
||||
^C
|
||||
|
||||
```
|
||||
|
||||
Yay!
|
||||
|
||||
### Grab the backlog
|
||||
|
||||
Now, let’s print some easily accessible data. Say the “backlog”. The backlog is the number of pending established TCP connections, pending to be `accept()`ed.
|
||||
|
||||
Just tweak a bit the `bpf_trace_printk`:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening with with up to %d pending connections!\\n", backlog);
|
||||
|
||||
```
|
||||
|
||||
If you re-run the example with this world-changing improvement, you should see something like:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
nc-5020 [000] d... 25497.154070: : Listening with with up to 1 pending connections!
|
||||
|
||||
```
|
||||
|
||||
`nc` is a single connection program, hence the backlog of 1\. Nginx or Redis would output 128 here. But that’s another story.
|
||||
|
||||
Easy hue? Now let’s get the port.
|
||||
|
||||
### Grab the port and IP
|
||||
|
||||
Studying `inet_listen` source from the kernel, we know that we need to get the `inet_sock` from the `socket` object. Just copy from the sources, and insert at the beginning of the tracer:
|
||||
|
||||
```
|
||||
// cast types. Intermediate cast not needed, kept for readability
|
||||
struct sock *sk = sock->sk;
|
||||
struct inet_sock *inet = inet_sk(sk);
|
||||
|
||||
```
|
||||
|
||||
The port can now be accessed from `inet->inet_sport` in network byte order (aka: Big Endian). Easy! So, we could just replace the `bpf_trace_printk` with:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening on port %d!\\n", inet->inet_sport);
|
||||
|
||||
```
|
||||
|
||||
Then run:
|
||||
|
||||
```
|
||||
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
|
||||
...
|
||||
R1 invalid mem access 'inv'
|
||||
...
|
||||
Exception: Failed to load BPF program kprobe__inet_listen
|
||||
|
||||
```
|
||||
|
||||
Except that it’s not (yet) so simple. Bcc is improving a _lot_ currently. While writing this post, a couple of pitfalls had already been addressed. But not yet all. This Error means the in-kernel checker could prove the memory accesses in program are correct. See the explicit cast. We need to help is a little by making the accesses more explicit. We’ll use `bpf_probe_read` trusted function to read an arbitrary memory location while guaranteeing all necessary checks are done with something like:
|
||||
|
||||
```
|
||||
// Explicit initialization. The "=0" part is needed to "give life" to the variable on the stack
|
||||
u16 lport = 0;
|
||||
|
||||
// Explicit arbitrary memory access. Read it:
|
||||
// Read into 'lport', 'sizeof(lport)' bytes from 'inet->inet_sport' memory location
|
||||
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
|
||||
|
||||
```
|
||||
|
||||
Reading the bound address for IPv4 is basically the same, using `inet->inet_rcv_saddr`. If we put is all together, we should get the backlog, the port and the bound IP:
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
|
||||
# BPF Program
|
||||
bpf_text = """
|
||||
#include <net/sock.h>
|
||||
#include <net/inet_sock.h>
|
||||
#include <bcc/proto.h>
|
||||
|
||||
// Send an event for each IPv4 listen with PID, bound address and port
|
||||
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
|
||||
{
|
||||
// Cast types. Intermediate cast not needed, kept for readability
|
||||
struct sock *sk = sock->sk;
|
||||
struct inet_sock *inet = inet_sk(sk);
|
||||
|
||||
// Working values. You *need* to initialize them to give them "life" on the stack and use them afterward
|
||||
u32 laddr = 0;
|
||||
u16 lport = 0;
|
||||
|
||||
// Pull in details. As 'inet_sk' is internally a type cast, we need to use 'bpf_probe_read'
|
||||
// read: load into 'laddr' 'sizeof(laddr)' bytes from address 'inet->inet_rcv_saddr'
|
||||
bpf_probe_read(&laddr, sizeof(laddr), &(inet->inet_rcv_saddr));
|
||||
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
|
||||
|
||||
// Push event
|
||||
bpf_trace_printk("Listening on %x %d with %d pending connections\\n", ntohl(laddr), ntohs(lport), backlog);
|
||||
return 0;
|
||||
};
|
||||
"""
|
||||
|
||||
# Build and Inject BPF
|
||||
b = BPF(text=bpf_text)
|
||||
|
||||
# Print debug output
|
||||
while True:
|
||||
print b.trace_readline()
|
||||
|
||||
```
|
||||
|
||||
A test run should output something like:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
nc-5024 [000] d... 25821.166286: : Listening on 7f000001 4242 with 1 pending connections
|
||||
|
||||
```
|
||||
|
||||
Provided that you listen on localhost. The address is displayed as hex here to avoid dealing with the IP pretty printing but that’s all wired. And that’s cool.
|
||||
|
||||
Note: you may wonder why `ntohs` and `ntohl` can be called from BPF while they are not trusted. This is because they are macros and inline functions from “.h” files and a small bug was [fixed][14]while writing this post.
|
||||
|
||||
All done, one more piece: We want to get the related container. In the context of networking, that’s means we want the network namespace. The network namespace being the building block of containers allowing them to have isolated networks.
|
||||
|
||||
### Grab the network namespace: a forced introduction to perf events
|
||||
|
||||
On the userland, the network namespace can be determined by checking the target of `/proc/PID/ns/net`. It should look like `net:[4026531957]`. The number between brackets is the inode number of the network namespace. This said, we could grab it by scrapping ‘/proc’ but this is racy, we may be dealing with short-lived processes. And races are never good. We’ll grab the inode number directly from the kernel. Fortunately, that’s an easy one:
|
||||
|
||||
```
|
||||
// Create an populate the variable
|
||||
u32 netns = 0;
|
||||
|
||||
// Read the netns inode number, like /proc does
|
||||
netns = sk->__sk_common.skc_net.net->ns.inum;
|
||||
|
||||
```
|
||||
|
||||
Easy. And it works.
|
||||
|
||||
But if you’ve read so far, you may guess there is something wrong somewhere. And there is:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening on %x %d with %d pending connections in container %d\\n", ntohl(laddr), ntohs(lport), backlog, netns);
|
||||
|
||||
```
|
||||
|
||||
If you try to run it, you’ll get some cryptic error message:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
error: in function kprobe__inet_listen i32 (%struct.pt_regs*, %struct.socket*, i32)
|
||||
too many args to 0x1ba9108: i64 = Constant<6>
|
||||
|
||||
```
|
||||
|
||||
What clang is trying to tell you is “Hey pal, `bpf_trace_printk` can only take 4 arguments, you’ve just used 5.“. I won’t dive into the details here, but that’s a BPF limitation. If you want to dig it, [here is a good starting point][15].
|
||||
|
||||
The only way to fix it is to… stop debugging and make it production ready. So let’s get started (and make sure run at least Linux 4.4). We’ll use perf events which supports passing arbitrary sized structures to userland. Additionally, only our reader will get it so that multiple unrelated eBPF programs can produce data concurrently without issues.
|
||||
|
||||
To use it, we need to:
|
||||
|
||||
1. define a structure
|
||||
|
||||
2. declare the event
|
||||
|
||||
3. push the event
|
||||
|
||||
4. re-declare the event on Python’s side (This step should go away in the future)
|
||||
|
||||
5. consume and format the event
|
||||
|
||||
This may seem like a lot, but it ain’t. See:
|
||||
|
||||
```
|
||||
// At the begining of the C program, declare our event
|
||||
struct listen_evt_t {
|
||||
u64 laddr;
|
||||
u64 lport;
|
||||
u64 netns;
|
||||
u64 backlog;
|
||||
};
|
||||
BPF_PERF_OUTPUT(listen_evt);
|
||||
|
||||
// In kprobe__inet_listen, replace the printk with
|
||||
struct listen_evt_t evt = {
|
||||
.laddr = ntohl(laddr),
|
||||
.lport = ntohs(lport),
|
||||
.netns = netns,
|
||||
.backlog = backlog,
|
||||
};
|
||||
listen_evt.perf_submit(ctx, &evt, sizeof(evt));
|
||||
|
||||
```
|
||||
|
||||
Python side will require a little more work, though:
|
||||
|
||||
```
|
||||
# We need ctypes to parse the event structure
|
||||
import ctypes
|
||||
|
||||
# Declare data format
|
||||
class ListenEvt(ctypes.Structure):
|
||||
_fields_ = [
|
||||
("laddr", ctypes.c_ulonglong),
|
||||
("lport", ctypes.c_ulonglong),
|
||||
("netns", ctypes.c_ulonglong),
|
||||
("backlog", ctypes.c_ulonglong),
|
||||
]
|
||||
|
||||
# Declare event printer
|
||||
def print_event(cpu, data, size):
|
||||
event = ctypes.cast(data, ctypes.POINTER(ListenEvt)).contents
|
||||
print("Listening on %x %d with %d pending connections in container %d" % (
|
||||
event.laddr,
|
||||
event.lport,
|
||||
event.backlog,
|
||||
event.netns,
|
||||
))
|
||||
|
||||
# Replace the event loop
|
||||
b["listen_evt"].open_perf_buffer(print_event)
|
||||
while True:
|
||||
b.kprobe_poll()
|
||||
|
||||
```
|
||||
|
||||
Give it a try. In this example, I have a redis running in a docker container and nc on the host:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
Listening on 0 6379 with 128 pending connections in container 4026532165
|
||||
Listening on 0 6379 with 128 pending connections in container 4026532165
|
||||
Listening on 7f000001 6588 with 1 pending connections in container 4026531957
|
||||
|
||||
```
|
||||
|
||||
### Last word
|
||||
|
||||
Absolutely everything is now setup to use trigger events from arbitrary function calls in the kernel using eBPF, and you should have seen most of the common pitfalls I hit while learning eBPF. If you want to see the full version of this tool, along with some more tricks like IPv6 support, have a look at [https://github.com/iovisor/bcc/blob/master/tools/solisten.py][16]. It’s now an official tool, thanks to the support of the bcc team.
|
||||
|
||||
To go further, you may want to checkout Brendan Gregg’s blog, in particular [the post about eBPF maps and statistics][17]. He his one of the project’s main contributor.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/
|
||||
|
||||
作者:[Jean-Tiare Le Bigot ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.yadutaf.fr/about
|
||||
[1]:https://blog.yadutaf.fr/tags/linux
|
||||
[2]:https://blog.yadutaf.fr/tags/tracing
|
||||
[3]:https://blog.yadutaf.fr/tags/ebpf
|
||||
[4]:https://blog.yadutaf.fr/tags/bcc
|
||||
[5]:https://en.wikipedia.org/wiki/SystemTap
|
||||
[6]:https://blog.cloudflare.com/bpf-the-forgotten-bytecode/
|
||||
[7]:https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/TODO
|
||||
[8]:https://lwn.net/Articles/604043/
|
||||
[9]:http://lxr.free-electrons.com/source/kernel/bpf/verifier.c#L21
|
||||
[10]:http://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf
|
||||
[11]:https://github.com/iovisor/bcc
|
||||
[12]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[13]:http://lxr.free-electrons.com/source/net/ipv4/af_inet.c#L194
|
||||
[14]:https://github.com/iovisor/bcc/pull/453
|
||||
[15]:http://lxr.free-electrons.com/source/kernel/trace/bpf_trace.c#L86
|
||||
[16]:https://github.com/iovisor/bcc/blob/master/tools/solisten.py
|
||||
[17]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
@ -0,0 +1,159 @@
|
||||
Annoying Experiences Every Linux Gamer Never Wanted!
|
||||
============================================================
|
||||
|
||||
|
||||
[][10]
|
||||
|
||||
[Gaming on Linux][12] has come a long way. There are dedicated [Linux gaming distributions][13] now. But this doesn’t mean that gaming experience on Linux is as smooth as on Windows.
|
||||
|
||||
What are the obstacles that should be thought about to ensure that we enjoy games as much as Windows users do?
|
||||
|
||||
[Wine][14], [PlayOnLinux][15] and other similar tools are not always able to play every popular Windows game. In this article, I would like to discuss various factors that must be dealt with in order to have the best possible Linux gaming experience.
|
||||
|
||||
### #1 SteamOS is Open Source, Steam for Linux is NOT
|
||||
|
||||
As stated on the [SteamOS page][16], even though SteamOS is open source, Steam for Linux continues to be proprietary. Had it also been open source, the amount of support from the open source community would have been tremendous! Since it is not, [the birth of Project Ascension was inevitable][17]:
|
||||
|
||||
[video](https://youtu.be/07UiS5iAknA)
|
||||
|
||||
Project Ascension is an open source game launcher designed to launch games that have been bought and downloaded from anywhere – they can be Steam games, [Origin games][18], Uplay games, games downloaded directly from game developer websites or from DVD/CD-ROMs.
|
||||
|
||||
Here is how it all began: [Sharing The Idea][19] resulted in a very interesting discussion with readers all over from the gaming community pitching in their own opinions and suggestions.
|
||||
|
||||
### #2 Performance compared to Windows
|
||||
|
||||
Getting Windows games to run on Linux is not always an easy task. But thanks to a feature called [CSMT][20] (command stream multi-threading), PlayOnLinux is now better equipped to deal with these performance issues, though it’s still a long way to achieve Windows level outcomes.
|
||||
|
||||
Native Linux support for games has not been so good for past releases.
|
||||
|
||||
Last year, it was reported that SteamOS performed [significantly worse][21] than Windows. Tomb Raider was released on SteamOS/Steam for Linux last year. However, benchmark results were [not at par][22] with performance on Windows.
|
||||
|
||||
[video](https://youtu.be/nkWUBRacBNE)
|
||||
|
||||
This was much obviously due to the fact that the game had been developed with [DirectX][23] in mind and not [OpenGL][24].
|
||||
|
||||
Tomb Raider is the [first Linux game that uses TressFX][25]. This video includes TressFX comparisons:
|
||||
|
||||
[video](https://youtu.be/-IeY5ZS-LlA)
|
||||
|
||||
Here is another interesting comparison which shows Wine+CSMT performing much better than the native Linux version itself on Steam! This is the power of Open Source!
|
||||
|
||||
[Suggested readA New Linux OS "OSu" Vying To Be Ubuntu Of Arch Linux World][26]
|
||||
|
||||
[video](https://youtu.be/sCJkC6oJ08A)
|
||||
|
||||
TressFX has been turned off in this case to avoid FPS loss.
|
||||
|
||||
Here is another Linux vs Windows comparison for the recently released “[Life is Strange][27]” on Linux:
|
||||
|
||||
[video](https://youtu.be/Vlflu-pIgIY)
|
||||
|
||||
It’s good to know that [_Steam for Linux_][28] has begun to show better improvements in performance for this new Linux game.
|
||||
|
||||
Before launching any game for Linux, developers should consider optimizing them especially if it’s a DirectX game and requires OpenGL translation. We really do hope that [Deus Ex: Mankind Divided on Linux][29] gets benchmarked well, upon release. As its a DirectX game, we hope it’s being ported well for Linux. Here’s [what the Executive Game Director had to say][30].
|
||||
|
||||
### #3 Proprietary NVIDIA Drivers
|
||||
|
||||
[AMD’s support for Open Source][31] is definitely commendable when compared to [NVIDIA][32]. Though [AMD][33] driver support is [pretty good on Linux][34] now due to its better open source driver, NVIDIA graphic card owners will still have to use the proprietary NVIDIA drivers because of the limited capabilities of the open-source version of NVIDIA’s graphics driver called Nouveau.
|
||||
|
||||
In the past, legendary Linus Torvalds has also shared his thoughts about Linux support from NVIDIA to be totally unacceptable:
|
||||
|
||||
[video](https://youtu.be/O0r6Pr_mdio)
|
||||
|
||||
You can watch the complete talk [here][35]. Although NVIDIA responded with [a commitment for better linux support][36], the open source graphics driver still continues to be weak as before.
|
||||
|
||||
### #4 Need for Uplay and Origin DRM support on Linux
|
||||
|
||||
[video](https://youtu.be/rc96NFwyxWU)
|
||||
|
||||
The above video describes how to install the [Uplay][37] DRM on Linux. The uploader also suggests that the use of wine as the main tool of games and applications is not recommended on Linux. Rather, preference to native applications should be encouraged instead.
|
||||
|
||||
The following video is a guide about installing the [Origin][38] DRM on Linux:
|
||||
|
||||
[video](https://youtu.be/ga2lNM72-Kw)
|
||||
|
||||
Digital Rights Management Software adds another layer for game execution and hence it adds up to the already challenging task to make a Windows game run well on Linux. So in addition to making the game execute, W.I.N.E has to take care of running the DRM software such as Uplay or Origin as well. It would have been great if, like Steam, Linux could have got its own native versions of Uplay and Origin.
|
||||
|
||||
[Suggested readLinux Foundation Head Calls 2017 'Year of the Linux Desktop'... While Running Apple's macOS Himself][39]
|
||||
|
||||
### #5 DirectX 11 support for Linux
|
||||
|
||||
Even though we have tools on Linux to run Windows applications, every game comes with its own set of tweak requirements for it to be playable on Linux. Though there was an announcement about [DirectX 11 support for Linux][40] last year via Code Weavers, it’s still a long way to go to make playing newly launched titles on Linux a possibility. Currently, you can
|
||||
|
||||
Currently, you can [buy Crossover from Codeweavers][41] to get the best DirectX 11 support available. This [thread][42] on the Arch Linux forums clearly shows how much more effort is required to make this dream a possibility. Here is an interesting [find][43] from a [Reddit thread][44], which mentions Wine getting [DirectX 11 patches from Codeweavers][45]. Now that’s definitely some good news.
|
||||
|
||||
### #6 100% of Steam games are not available for Linux
|
||||
|
||||
This is an important point to ponder as Linux gamers continue to miss out on every major game release since most of them land up on Windows. Here is a guide to [install Steam for Windows on Linux][46].
|
||||
|
||||
### #7 Better Support from video game publishers for OpenGL
|
||||
|
||||
Currently, developers and publishers focus primarily on DirectX for video game development rather than OpenGL. Now as Steam is officially here for Linux, developers should start considering development in OpenGL as well.
|
||||
|
||||
[Direct3D][47] is made solely for the Windows platform. The OpenGL API is an open standard, and implementations exist for not only Windows but a wide variety of other platforms.
|
||||
|
||||
Though quite an old article, [this valuable resource][48] shares a lot of thoughtful information on the realities of OpenGL and DirectX. The points made are truly very sensible and enlightens the reader about the facts based on actual chronological events.
|
||||
|
||||
Publishers who are launching their titles on Linux should definitely not leave out the fact that developing the game on OpenGL would be a much better deal than translating it from DirectX to OpenGL. If conversion has to be done, the translations must be well optimized and carefully looked into. There might be a delay in releasing the games but still it would definitely be worth the wait.
|
||||
|
||||
Have more annoyances to share? Do let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-gaming-problems/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/avimanyu/
|
||||
[1]:https://itsfoss.com/author/avimanyu/
|
||||
[2]:https://itsfoss.com/linux-gaming-problems/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21&url=https://itsfoss.com/linux-gaming-problems/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=itsfoss2
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/linux-gaming-problems/&title=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21
|
||||
[8]:https://www.reddit.com/submit?url=https://itsfoss.com/linux-gaming-problems/&title=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg
|
||||
[10]:https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg
|
||||
[11]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg&url=https://itsfoss.com/linux-gaming-problems/&is_video=false&description=Linux%20gamer%27s%20problem
|
||||
[12]:https://itsfoss.com/linux-gaming-guide/
|
||||
[13]:https://itsfoss.com/linux-gaming-distributions/
|
||||
[14]:https://itsfoss.com/use-windows-applications-linux/
|
||||
[15]:https://www.playonlinux.com/en/
|
||||
[16]:http://store.steampowered.com/steamos/
|
||||
[17]:http://www.ibtimes.co.uk/reddit-users-want-replace-steam-open-source-game-launcher-project-ascension-1498999
|
||||
[18]:https://www.origin.com/
|
||||
[19]:https://www.reddit.com/r/pcmasterrace/comments/33xcvm/we_hate_valves_monopoly_over_pc_gaming_why/
|
||||
[20]:https://github.com/wine-compholio/wine-staging/wiki/CSMT
|
||||
[21]:http://arstechnica.com/gaming/2015/11/ars-benchmarks-show-significant-performance-hit-for-steamos-gaming/
|
||||
[22]:https://www.gamingonlinux.com/articles/tomb-raider-benchmark-video-comparison-linux-vs-windows-10.7138
|
||||
[23]:https://en.wikipedia.org/wiki/DirectX
|
||||
[24]:https://en.wikipedia.org/wiki/OpenGL
|
||||
[25]:https://www.gamingonlinux.com/articles/tomb-raider-released-for-linux-video-thoughts-port-report-included-the-first-linux-game-to-use-tresfx.7124
|
||||
[26]:https://itsfoss.com/osu-new-linux/
|
||||
[27]:http://lifeisstrange.com/
|
||||
[28]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[29]:https://itsfoss.com/deus-ex-mankind-divided-linux/
|
||||
[30]:http://wccftech.com/deus-ex-mankind-divided-director-console-ports-on-pc-is-disrespectful/
|
||||
[31]:http://developer.amd.com/tools-and-sdks/open-source/
|
||||
[32]:http://nvidia.com/
|
||||
[33]:http://amd.com/
|
||||
[34]:http://www.makeuseof.com/tag/open-source-amd-graphics-now-awesome-heres-get/
|
||||
[35]:https://youtu.be/MShbP3OpASA
|
||||
[36]:https://itsfoss.com/nvidia-optimus-support-linux/
|
||||
[37]:http://uplay.com/
|
||||
[38]:http://origin.com/
|
||||
[39]:https://itsfoss.com/linux-foundation-head-uses-macos/
|
||||
[40]:http://www.pcworld.com/article/2940470/hey-gamers-directx-11-is-coming-to-linux-thanks-to-codeweavers-and-wine.html
|
||||
[41]:https://itsfoss.com/deal-run-windows-software-and-games-on-linux-with-crossover-15-66-off/
|
||||
[42]:https://bbs.archlinux.org/viewtopic.php?id=214771
|
||||
[43]:https://ghostbin.com/paste/sy3e2
|
||||
[44]:https://www.reddit.com/r/linux_gaming/comments/3ap3uu/directx_11_support_coming_to_codeweavers/
|
||||
[45]:https://www.codeweavers.com/about/blogs/caron/2015/12/10/directx-11-really-james-didnt-lie
|
||||
[46]:https://itsfoss.com/linux-gaming-guide/
|
||||
[47]:https://en.wikipedia.org/wiki/Direct3D
|
||||
[48]:http://blog.wolfire.com/2010/01/Why-you-should-use-OpenGL-and-not-DirectX
|
||||
68
sources/tech/20161216 GitHub Is Building a Coder Paradise.md
Normal file
68
sources/tech/20161216 GitHub Is Building a Coder Paradise.md
Normal file
@ -0,0 +1,68 @@
|
||||
translating by zrszrszrs
|
||||
GitHub Is Building a Coder’s Paradise. It’s Not Coming Cheap
|
||||
============================================================
|
||||
|
||||
The VC-backed unicorn startup lost $66 million in nine months of 2016, financial documents show.
|
||||
|
||||
|
||||
Though the name GitHub is practically unknown outside technology circles, coders around the world have embraced the software. The startup operates a sort of Google Docs for programmers, giving them a place to store, share and collaborate on their work. But GitHub Inc. is losing money through profligate spending and has stood by as new entrants emerged in a software category it essentially gave birth to, according to people familiar with the business and financial paperwork reviewed by Bloomberg.
|
||||
|
||||
The rise of GitHub has captivated venture capitalists. Sequoia Capital led a $250 million investment in mid-2015\. But GitHub management may have been a little too eager to spend the new money. The company paid to send employees jetting across the globe to Amsterdam, London, New York and elsewhere. More costly, it doubled headcount to 600 over the course of about 18 months.
|
||||
|
||||
GitHub lost $27 million in the fiscal year that ended in January 2016, according to an income statement seen by Bloomberg. It generated $95 million in revenue during that period, the internal financial document says.
|
||||
|
||||

|
||||
GitHub CEO Chris Wanstrath.Photographer: David Paul Morris/Bloomberg
|
||||
|
||||
Sitting in a conference room featuring an abstract art piece on the wall and a Mad Men-style rollaway bar cart in the corner, GitHub’s Chris Wanstrath says the business is running more smoothly now and growing. “What happened to 2015?” says the 31-year-old co-founder and chief executive officer. “Nothing was getting done, maybe? I shouldn’t say that. Strike that.”
|
||||
|
||||
GitHub recently hired Mike Taylor, the former treasurer and vice president of finance at Tesla Motors Inc., to manage spending as chief financial officer. It also hopes to add a seasoned chief operating officer. GitHub has already surpassed last year’s revenue in nine months this year, with $98 million, the financial document shows. “The whole product road map, we have all of our shit together in a way that we’ve never had together. I’m pretty elated right now with the way things are going,” says Wanstrath. “We’ve had a lot of ups and downs, and right now we’re definitely in an up.”
|
||||
|
||||
Also up: expenses. The income statement shows a loss of $66 million in the first three quarters of this year. That’s more than twice as much lost in any nine-month time frame by Twilio Inc., another maker of software tools founded the same year as GitHub. At least a dozen members of GitHub’s leadership team have left since last year, several of whom expressed unhappiness with Wanstrath’s management style. GitHub says the company has flourished under his direction but declined to comment on finances. Wanstrath says: “We raised $250 million last year, and we’re putting it to use. We’re not expecting to be profitable right now.”
|
||||
|
||||
Wanstrath started GitHub with three friends during the recession of 2008 and bootstrapped the business for four years. They encouraged employees to [work remotely][1], which forced the team to adopt GitHub’s tools for their own projects and had the added benefit of saving money on office space. GitHub quickly became essential to the code-writing process at technology companies of all sizes and gave birth to a new generation of programmers by hosting their open-source code for free.
|
||||
|
||||
Peter Levine, a partner at Andreessen Horowitz, courted the founders and eventually convinced them to take their first round of VC money in 2012\. The firm led a $100 million cash infusion, and Levine joined the board. The next year, GitHub signed a seven-year lease worth about $35 million for a headquarters in San Francisco, says a person familiar with the project.
|
||||
|
||||
The new digs gave employees a reason to come into the office. Visitors would enter a lobby modeled after the White House’s Oval Office before making their way to a replica of the Situation Room. The company also erected a statue of its mascot, a cartoon octopus-cat creature known as the Octocat. The 55,000-square-foot space is filled with wooden tables and modern art.
|
||||
|
||||
In GitHub’s cultural hierarchy, the coder is at the top. The company has strived to create the best product possible for software developers and watch them to flock to it. In addition to offering its base service for free, GitHub sells more advanced programming tools to companies big and small. But it found that some chief information officers want a human touch and began to consider building out a sales team.
|
||||
|
||||
The issue took on a new sense of urgency in 2014 with the formation of a rival startup with a similar name. GitLab Inc. went after large businesses from the start, offering them a cheaper alternative to GitHub. “The big differentiator for GitLab is that it was designed for the enterprise, and GitHub was not,” says GitLab CEO Sid Sijbrandij. “One of the values is frugality, and this is something very close to our heart. We want to treat our team members really well, but we don’t want to waste any money where it’s not needed. So we don’t have a big fancy office because we can be effective without it.”
|
||||
|
||||
Y Combinator, a Silicon Valley business incubator, welcomed GitLab into the fold last year. GitLab says more than 110,000 organizations, including IBM and Macy’s Inc., use its software. (IBM also uses GitHub.) Atlassian Corp. has taken a similar top-down approach with its own code repository Bitbucket.
|
||||
|
||||
Wanstrath says the competition has helped validate GitHub’s business. “When we started, people made fun of us and said there is no money in developer tools,” he says. “I’ve kind of been waiting for this for a long time—to be proven right, that this is a real market.”
|
||||
|
||||

|
||||
Source: GitHub
|
||||
|
||||
It also spurred GitHub into action. With fresh capital last year valuing the company at $2 billion, it went on a hiring spree. It spent $71 million on salaries and benefits last fiscal year, according to the financial document seen by Bloomberg. This year, those costs rose to $108 million from February to October, with three months still to go in the fiscal year, the document shows. This was the startup’s biggest expense by far.
|
||||
|
||||
The emphasis on sales seemed to be making an impact, but the team missed some of its targets, says a person familiar with the matter. In September 2014, subscription revenue on an annualized basis was about $25 million each from enterprise sales and organizations signing up through the site, according to another financial document. After GitHub staffed up, annual recurring revenue from large clients increased this year to $70 million while the self-service business saw healthy, if less dramatic, growth to $52 million.
|
||||
|
||||
But the uptick in revenue wasn’t keeping pace with the aggressive hiring. GitHub cut about 20 employees in recent weeks. “The unicorn trap is that you’ve sold equity against a plan that you often can’t hit; then what do you do?” says Nick Sturiale, a VC at Ignition Partners.
|
||||
|
||||
Such business shifts are risky, and stumbles aren’t uncommon, says Jason Lemkin, a corporate software VC who’s not an investor in GitHub. “That transition from a self-service product in its early days to being enterprise always has bumps,” he says. GitHub says it has 18 million users, and its Enterprise service is used by half of the world’s 10 highest-grossing companies, including Wal-Mart Stores Inc. and Ford Motor Co.
|
||||
|
||||
Some longtime GitHub fans weren’t happy with the new direction, though. More than 1,800 developers signed an online petition, saying: “Those of us who run some of the most popular projects on GitHub feel completely ignored by you.”
|
||||
|
||||
The backlash was a wake-up call, Wanstrath says. GitHub is now more focused on its original mission of catering to coders, he says. “I want us to be judged on, ‘Are we making developers more productive?’” he says. At GitHub’s developer conference in September, Wanstrath introduced several new features, including an updated process for reviewing code. He says 2016 was a “marquee year.”
|
||||
|
||||
|
||||
At least five senior staffers left in 2015, and turnover among leadership continued this year. Among them was co-founder and CIO Scott Chacon, who says he left to start a new venture. “GitHub was always very good to me, from the first day I started when it was just the four of us,” Chacon says. “They allowed me to travel the world representing them; they supported my teaching and evangelizing Git and remote work culture for a long time.”
|
||||
|
||||
The travel excursions are expected to continue at GitHub, and there’s little evidence it can rein in spending any time soon. The company says about half its staff is remote and that the trips bring together GitHub’s distributed workforce and encourage collaboration. Last week, at least 20 employees on GitHub’s human-resources team convened in Rancho Mirage, California, for a retreat at the Ritz Carlton.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.bloomberg.com/news/articles/2016-12-15/github-is-building-a-coder-s-paradise-it-s-not-coming-cheap
|
||||
|
||||
作者:[Eric Newcomer ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.bloomberg.com/authors/ASFMS16EsvU/eric-newcomer
|
||||
[1]:https://www.bloomberg.com/news/articles/2016-09-06/why-github-finally-abandoned-its-bossless-workplace
|
||||
@ -0,0 +1,104 @@
|
||||
New Year’s resolution: Donate to 1 free software project every month
|
||||
============================================================
|
||||
|
||||
### Donating just a little bit helps ensure the open source software I use remains alive
|
||||
|
||||
Free and open source software is an absolutely critical part of our world—and the future of technology and computing. One problem that consistently plagues many free software projects, though, is the challenge of funding ongoing development (and support and documentation).
|
||||
|
||||
With that in mind, I have finally settled on a New Year’s resolution for 2017: to donate to one free software project (or group) every month—or the whole year. After all, these projects are saving me a boatload of money because I don’t need to buy expensive, proprietary packages to accomplish the same things.
|
||||
|
||||
#### + Also on Network World: [Free Software Foundation shakes up its list of priority projects][19] +
|
||||
|
||||
I’m not setting some crazy goal here—not requiring that I donate beyond my means. Heck, some months I may be able to donate only a few bucks. But every little bit helps, right?
|
||||
|
||||
To help me accomplish that goal, below is a list of free software projects with links to where I can donate to them. Organized by categories, just because. I’m scheduling a monthly calendar item to remind me to bring up this page and donate to one of these projects.
|
||||
|
||||
This isn’t a complete list—not by any measure—but it’s a good starting point. Apologies to the (many) great projects out there that I missed.
|
||||
|
||||
#### Linux distributions
|
||||
|
||||
[elementary OS][20] — In addition to the distribution itself (which is based, in part, on Ubuntu), this team also develops the Pantheon desktop environment.
|
||||
|
||||
[Solus][21] — This is a “from scratch” distro using their own custom-developed desktop environment, “Budgie.”
|
||||
|
||||
[Ubuntu MATE][22] — It’s Ubuntu—with Unity ripped off and replaced with MATE. I like to think of this as “What Ubuntu was like back when I still used Ubuntu.”
|
||||
|
||||
[Debian][23] — If you use Ubuntu or elementary or Mint, you are using a system based on Debian. Personally, I use Debian on my [PocketCHIP][24].
|
||||
|
||||
#### Linux components
|
||||
|
||||
[PulseAudio][25] — PulsAudio is all over the place now. If it stopped being supported and maintained, that would be… highly inconvenient.
|
||||
|
||||
#### Productivity/Creation
|
||||
|
||||
[Gimp][26] — The GNU Image Manipulation Program is one of the most famous free software projects—and the standard for cross-platform raster design tools.
|
||||
|
||||
[FreeCAD][27] — When people talk about difficulty in moving from Windows to Linux, the lack of CAD software often crops up. Supporting projects such as FreeCAD helps to remove that barrier.
|
||||
|
||||
[OpenShot][28] — Video editing on Linux (and other free software desktops) has improved tremendously over the past few years. But there is still work to be done.
|
||||
|
||||
[Blender][29] — What is Blender? A 3D modelling suite? A video editor? A game creation system? All three (and more)? Whatever you use Blender for, it’s amazing.
|
||||
|
||||
[Inkscape][30] — This is the most fantastic vector graphics editing suite on the planet (in my oh-so-humble opinion).
|
||||
|
||||
[LibreOffice / The Document Foundation][31] — I am writing this very document in LibreOffice. Donating to their foundation to help further development seems to be in my best interests.
|
||||
|
||||
#### Software development
|
||||
|
||||
[Python Software Foundation][32] — Python is a great language and is used all over the place.
|
||||
|
||||
#### Free and open source foundations
|
||||
|
||||
[Free Software Foundation][33] — “The Free Software Foundation (FSF) is a nonprofit with a worldwide mission to promote computer user freedom. We defend the rights of all software users.”
|
||||
|
||||
[Software Freedom Conservancy][34] — “Software Freedom Conservancy helps promote, improve, develop and defend Free, Libre and Open Source Software (FLOSS) projects.”
|
||||
|
||||
Again—this is, by no means, a complete list. Not even close. Luckily many projects provide easy donation mechanisms on their websites.
|
||||
|
||||
Join the Network World communities on [Facebook][17] and [LinkedIn][18] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3160174/linux/new-years-resolution-donate-to-1-free-software-project-every-month.html
|
||||
|
||||
作者:[ Bryan Lunduke][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Bryan-Lunduke/
|
||||
[1]:https://www.networkworld.com/article/3143583/linux/linux-y-things-i-am-thankful-for.html
|
||||
[2]:https://www.networkworld.com/article/3152745/linux/5-rock-solid-linux-distros-for-developers.html
|
||||
[3]:https://www.networkworld.com/article/3130760/open-source-tools/elementary-os-04-review-and-interview-with-the-founder.html
|
||||
[4]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[5]:https://twitter.com/intent/tweet?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3160174%2Flinux%2Fnew-years-resolution-donate-to-1-free-software-project-every-month.html&via=networkworld&text=New+Year%E2%80%99s+resolution%3A+Donate+to+1+free+software+project+every+month
|
||||
[6]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3160174%2Flinux%2Fnew-years-resolution-donate-to-1-free-software-project-every-month.html
|
||||
[7]:http://www.linkedin.com/shareArticle?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3160174%2Flinux%2Fnew-years-resolution-donate-to-1-free-software-project-every-month.html&title=New+Year%E2%80%99s+resolution%3A+Donate+to+1+free+software+project+every+month
|
||||
[8]:https://plus.google.com/share?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3160174%2Flinux%2Fnew-years-resolution-donate-to-1-free-software-project-every-month.html
|
||||
[9]:http://reddit.com/submit?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3160174%2Flinux%2Fnew-years-resolution-donate-to-1-free-software-project-every-month.html&title=New+Year%E2%80%99s+resolution%3A+Donate+to+1+free+software+project+every+month
|
||||
[10]:http://www.stumbleupon.com/submit?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3160174%2Flinux%2Fnew-years-resolution-donate-to-1-free-software-project-every-month.html
|
||||
[11]:https://www.networkworld.com/article/3160174/linux/new-years-resolution-donate-to-1-free-software-project-every-month.html#email
|
||||
[12]:https://www.networkworld.com/article/3143583/linux/linux-y-things-i-am-thankful-for.html
|
||||
[13]:https://www.networkworld.com/article/3152745/linux/5-rock-solid-linux-distros-for-developers.html
|
||||
[14]:https://www.networkworld.com/article/3130760/open-source-tools/elementary-os-04-review-and-interview-with-the-founder.html
|
||||
[15]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[16]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[17]:https://www.facebook.com/NetworkWorld/
|
||||
[18]:https://www.linkedin.com/company/network-world
|
||||
[19]:http://www.networkworld.com/article/3158685/open-source-tools/free-software-foundation-shakes-up-its-list-of-priority-projects.html
|
||||
[20]:https://www.patreon.com/elementary
|
||||
[21]:https://www.patreon.com/solus
|
||||
[22]:https://www.patreon.com/ubuntu_mate
|
||||
[23]:https://www.debian.org/donations
|
||||
[24]:http://www.networkworld.com/article/3157210/linux/review-pocketchipsuper-cheap-linux-terminal-that-fits-in-your-pocket.html
|
||||
[25]:https://www.patreon.com/tanuk
|
||||
[26]:https://www.gimp.org/donating/
|
||||
[27]:https://www.patreon.com/yorikvanhavre
|
||||
[28]:https://www.patreon.com/openshot
|
||||
[29]:https://www.blender.org/foundation/donation-payment/
|
||||
[30]:https://inkscape.org/en/support-us/donate/
|
||||
[31]:https://www.libreoffice.org/donate/
|
||||
[32]:https://www.python.org/psf/donations/
|
||||
[33]:http://www.fsf.org/associate/
|
||||
[34]:https://sfconservancy.org/supporter/
|
||||
@ -1,3 +1,6 @@
|
||||
|
||||
translating by HardworkFish
|
||||
|
||||
INTRODUCING DOCKER SECRETS MANAGEMENT
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,72 @@
|
||||
How to auto start LXD containers at boot time in Linux
|
||||
======
|
||||
I am using LXD ("Linux container") based VM. How do I set an LXD container to start on boot in Linux operating system?
|
||||
|
||||
You can always start the container when LXD starts on boot. You need to set boot.autostart to true. You can define the order to start the containers in (starting with highest first) using boot.autostart.priority (default value is 0) option. You can also define the number of seconds to wait after the container started before starting the next one using boot.autostart.delay (default value 0) option.
|
||||
|
||||
### Syntax
|
||||
|
||||
Above discussed keys can be set using the lxc tool with the following syntax:
|
||||
```
|
||||
$ lxc config set {vm-name} {key} {value}
|
||||
$ lxc config set {vm-name} boot.autostart {true|false}
|
||||
$ lxc config set {vm-name} boot.autostart.priority integer
|
||||
$ lxc config set {vm-name} boot.autostart.delay integer
|
||||
```
|
||||
|
||||
### How do I set an LXD container to start on boot in Ubuntu Linux 16.10?
|
||||
|
||||
Type the following command:
|
||||
`$ lxc config set {vm-name} boot.autostart true`
|
||||
Set an LXD container name 'nginx-vm' to start on boot
|
||||
`$ lxc config set nginx-vm boot.autostart true`
|
||||
You can verify setting using the following syntax:
|
||||
```
|
||||
$ lxc config get {vm-name} boot.autostart
|
||||
$ lxc config get nginx-vm boot.autostart
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
true
|
||||
```
|
||||
|
||||
You can the 10 seconds to wait after the container started before starting the next one using the following syntax:
|
||||
`$ lxc config set nginx-vm boot.autostart.delay 10`
|
||||
Finally, define the order to start the containers in by setting with highest value. Make sure db_vm container start first and next start nginx_vm
|
||||
```
|
||||
$ lxc config set db_vm boot.autostart.priority 100
|
||||
$ lxc config set nginx_vm boot.autostart.priority 99
|
||||
```
|
||||
Use [the following bash for loop on Linux to view all][1] values:
|
||||
```
|
||||
#!/bin/bash
|
||||
echo 'The current values of each vm boot parameters:'
|
||||
for c in db_vm nginx_vm memcache_vm
|
||||
do
|
||||
echo "*** VM: $c ***"
|
||||
for v in boot.autostart boot.autostart.priority boot.autostart.delay
|
||||
do
|
||||
echo "Key: $v => $(lxc config get $c $v) "
|
||||
done
|
||||
echo ""
|
||||
done
|
||||
```
|
||||
|
||||
|
||||
Sample outputs:
|
||||
![Fig.01: Get autostarting LXD containers values using a bash shell script][2]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-auto-start-lxd-containers-at-boot-time-in-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[2]:https://www.cyberciti.biz/media/new/faq/2017/02/Autostarting-LXD-containers-values.jpg
|
||||
@ -0,0 +1,168 @@
|
||||
Which Official Ubuntu Flavor Is Best for You?
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Ubuntu Budgie is just one of the few officially recognized flavors of Ubuntu. Jack Wallen takes a look at some important differences between them.[Used with permission][7]
|
||||
|
||||
Ubuntu Linux comes in a few officially recognized flavors, as well as several derivative distributions. The recognized flavors are:
|
||||
|
||||
* [Kubuntu][9] - Ubuntu with the KDE desktop
|
||||
|
||||
* [Lubuntu][10] - Ubuntu with the LXDE desktop
|
||||
|
||||
* [Mythbuntu][11] - Ubuntu MythTV
|
||||
|
||||
* [Ubuntu Budgie][12] - Ubuntu with the Budgie desktop
|
||||
|
||||
* [Xubuntu][8] - Ubuntu with Xfce
|
||||
|
||||
Up until recently, the official Ubuntu Linux included the in-house Unity desktop and a sixth recognized flavor existed: Ubuntu GNOME -- Ubuntu with the GNOME desktop environment.
|
||||
|
||||
When Mark Shuttleworth decided to nix Unity, the choice was obvious to Canonical—make GNOME the official desktop of Ubuntu Linux. This begins with Ubuntu 18.04 (so April, 2018) and we’ll be down to the official distribution and four recognized flavors.
|
||||
|
||||
For those already enmeshed in the Linux community, that’s some seriously simple math to do—you know which Linux desktop you like, so making the choice between Ubuntu, Kubuntu, Lubuntu, Mythbuntu, Ubuntu Budgie, and Xubuntu couldn’t be easier. Those that haven’t already been indoctrinated into the way of Linux won’t see that as such a cut-and-dried decision.
|
||||
|
||||
To that end, I thought it might be a good idea to help newer users decide which flavor is best for them. After all, choosing the wrong distribution out of the starting gate can make for a less-than-ideal experience.
|
||||
|
||||
And so, if you’re considering a flavor of Ubuntu, and you want your experience to be as painless as possible, read on.
|
||||
|
||||
### Ubuntu
|
||||
|
||||
I’ll begin with the official flavor of Ubuntu. I am also going to warp time a bit and skip Unity, to launch right into the upcoming GNOME-based distribution. Beyond GNOME being an incredibly stable and easy to use desktop environment, there is one very good reason to select the official flavor—support. The official flavor of Ubuntu is commercially supported by Canonical. For $150.00 per year, you can purchase [official support][20] for the Ubuntu desktop. There is, of course, a 50-desktop minimum for this level of support. For individuals, the best bet for support would be the [Ubuntu Forums][21], the [Ubuntu documentation][22], or the [Community help wiki][23].
|
||||
|
||||
Beyond the commercial support, the reason to choose the official Ubuntu flavor would be if you’re looking for a modern, full-featured desktop that is incredibly reliable and easy to use. GNOME has been designed to serve as a platform perfectly suited for both desktops and laptops (Figure 1). Unlike its predecessor, Unity, GNOME can be far more easily customized to suit your needs—to a point. If you’re not one to tinker with the desktop, fear not, GNOME just works. In fact, the out of the box experience with GNOME might well be one of the finest on the market—even rivaling (or besting) Mac OS X. If tinkering and tweaking is of primary interest, you will find GNOME somewhat limiting. The [GNOME Tweak Tool][24] and [GNOME Shell Extensions ][25]will only take you so far, before you find yourself wanting more.
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 1: The GNOME desktop with a Unity-like flavor might be what we see with Ubuntu 18.04.[Used with permission][1]
|
||||
|
||||
### Kubuntu
|
||||
|
||||
The [K Desktop Environment][26] (otherwise known as KDE) has been around as long as GNOME and has, at times, been maligned as a lesser desktop. With the release of KDE Plasma 5, that changed. KDE has become an incredibly powerful, efficient, and stable desktop that can stand toe to toe with the best of them. But why would you select Kubuntu over the official Ubuntu? The answer to that question is quite simple—you’re used to the Windows XP/7 desktop metaphor. Start menu, taskbar, system tray, etc., KDE has those and more, all fashioned in such a way that will make you feel like you’re using the best of the past and current technologies. In fact, if you’re looking for one of the most Windows 7-like official Ubuntu flavors, you won’t find one that better fits the bill.
|
||||
|
||||
One of the nice things about Kubuntu, is that you’ll find it a bit more flexible than any Windows iteration you’ve ever used—and equally reliable/user-friendly. And don’t think, because KDE opts to offer a desktop somewhat similar to Windows 7, that it doesn’t have a modern flavor. In fact, Kubuntu takes what worked well with the Windows 7 interface and updates it to meet a more modern aesthetic (Figure 2).
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 2: Kubuntu offers a modern take on an old UX.[Used with permission][2]
|
||||
|
||||
The official Ubuntu is not the only flavor to offer desktop support. Kubuntu users also can pay for [commercial support][27]. Be warned, it’s not cheap. One hour of support time will cost you $103.88 cents.
|
||||
|
||||
### Lubuntu
|
||||
|
||||
If you’re looking for an easy-to-use desktop that is very fast (so that older hardware will feel like new) and far more flexible than just about any desktop you’ve ever used, Lubuntu is what you want. The only caveat to Lubuntu is that you’re looking at a bit more bare bones on the desktop then you may be accustomed to. Lubuntu makes use of the [LXDE desktop][28] and includes a list of applications that continues the lightweight theme. So if you’re looking for blazing fast speeds on the desktop, Lubuntu might be a good choice.
|
||||
However, there is a caveat with Lubuntu and, for some users, this might be a deal breaker. Along with the small footprint of Lubuntu come pre-installed applications that might not stand up to task. For example, instead of the full-blown office suite, you’ll find the [AibWord word processor][29] and the [Gnumeric spreadsheet][30] tool. Don’t get me wrong; both of these are fine tools. However, if you’re looking for software that’s business-ready, you will find them lacking. On the other hand, if you want to install more work-centric tools (e.g., LibreOffice), Lubuntu includes the Synaptic Package Manager to make installation of third-party software simple.
|
||||
|
||||
Even with the limited default software, Lubuntu offers a clean and easy to use desktop (Figure 3), that anyone could start using with little to no learning curve.
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 3: What Lubuntu lacks in software, it makes up for in speed and simplicity.[Used with permission][3]
|
||||
|
||||
### Mythbuntu
|
||||
|
||||
Mythbuntu is a sort of odd bird here, because it isn’t really a desktop variant. Instead, Mythbuntu is a special flavor of Ubuntu designed to be a multimedia powerhouse. Using Mythbuntu requires TV Tuners and TV Out cards. And, during the installation, there are a number of additional steps that must be taken (choosing how to set up the frontend/backend as well as setting up your IR remotes).
|
||||
|
||||
If you do happen to have the hardware (and the desire to create your own Ubuntu-powered entertainment system), Mythbuntu is the distribution you want. Once you’ve installed Mythbuntu, you will then be prompted to walk through the setup of your Capture cards, recording profiles, video sources, and Input connections (Figure 4).
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 4: Getting ready to set up Mythbuntu.[Used with permission][4]
|
||||
|
||||
### Ubuntu Budgie
|
||||
|
||||
Ubuntu Budgie is the new kid on the block to the official flavor list. Sporting the Budgie Desktop, this is a beautiful and modern take on Linux that will please just about any type of user. The goal of Ubuntu Budgie was to create an elegant and simple desktop interface. Mission accomplished. If you’re looking for a beautiful desktop to work on top of the remarkably stable Ubuntu Linux platform, look no further than Ubuntu Budgie.
|
||||
|
||||
Adding this particular spin on Ubuntu to the list of official variants was a smart move on the part of Canonical. With Unity going away, they needed a desktop that would offer the elegance found in Unity. Customization of Budgie is very easy, and the list of included software will get you working and browsing immediately.
|
||||
|
||||
And, unlike the learning curve many users encountered with Unity, the developers/designers of Ubuntu Budgie have done a remarkable job of keeping this take on Ubuntu familiar. Click on the “start” button to reveal a fairly standard menu of applications. Budgie also includes an easy to use Dock (Figure 5) that holds applications launchers for quick access.
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 5: This is one beautiful desktop.[Used with permission][5]
|
||||
|
||||
Another really nice feature found in Ubuntu Budgie is a sidebar that can be quickly revealed and hidden. This sidebar holds applets and notifications. With this in play, your desktop can be both incredibly useful, while remaining clutter free.
|
||||
|
||||
In the end, if you’re looking for something a bit different, that happens to also be a very modern take on the desktop—with features and functions not found on other distributions—Ubuntu Budgie is what you’re looking for.
|
||||
|
||||
### Xubuntu
|
||||
|
||||
Another official flavor of Ubuntu that does a nice job of providing a small footprint version of Linux is [Xubuntu][32]. The difference between Xubuntu and Lubuntu is that, where Lubuntu uses the LXDE desktop, Xubuntu makes use of [Xfce][33]. What you get with that difference is a lightweight desktop that is far more configurable (than Lubuntu) as well as one that includes the more business-ready LibreOffice office suite.
|
||||
|
||||
Xubuntu is an out of the box experience that anyone, regardless of experience, can use. But don't think that immediate familiarity means this flavor of Ubuntu is locked out of making it your own. If you're looking for a take on Ubuntu that's somewhat old-school out of the box, but can be heavily tweaked to better resemble a more modern desktop, Xubuntu is what you want.
|
||||
|
||||
One really handy addition to Xubuntu that I've always enjoyed (one that harks back to Enlightenment) is the ability to bring up the "start" menu by right-clicking anywhere on the desktop (Figure 6). This can make for very efficient usage.
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 6: Xubuntu lets you bring up the "start" menu by right-clicking anywhere on the desktop.[Used with permission][6]
|
||||
|
||||
### The choice is yours
|
||||
|
||||
There is a flavor of Ubuntu to meet nearly any need—which one you choose is up to you. As yourself questions such as:
|
||||
|
||||
* What are your needs?
|
||||
|
||||
* What type of desktop do you prefer to interact with?
|
||||
|
||||
* Is your hardware aging?
|
||||
|
||||
* Do you prefer a Windows XP/7 feel?
|
||||
|
||||
* Are you wanting a multimedia system?
|
||||
|
||||
Your answers to the above questions will go a long way to determining which flavor of Ubuntu is right for you. The good news is that you can’t really go wrong with any of the available options.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][31]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/5/which-official-ubuntu-flavor-best-you
|
||||
|
||||
作者:[ JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/used-permission
|
||||
[7]:https://www.linux.com/licenses/category/used-permission
|
||||
[8]:http://xubuntu.org/
|
||||
[9]:http://www.kubuntu.org/
|
||||
[10]:http://lubuntu.net/
|
||||
[11]:http://www.mythbuntu.org/
|
||||
[12]:https://ubuntubudgie.org/
|
||||
[13]:https://www.linux.com/files/images/ubuntuflavorajpg
|
||||
[14]:https://www.linux.com/files/images/ubuntuflavorbjpg
|
||||
[15]:https://www.linux.com/files/images/ubuntuflavorcjpg
|
||||
[16]:https://www.linux.com/files/images/ubuntuflavordjpg
|
||||
[17]:https://www.linux.com/files/images/ubuntuflavorejpg
|
||||
[18]:https://www.linux.com/files/images/xubuntujpg
|
||||
[19]:https://www.linux.com/files/images/ubuntubudgiejpg
|
||||
[20]:https://buy.ubuntu.com/collections/ubuntu-advantage-for-desktop
|
||||
[21]:https://ubuntuforums.org/
|
||||
[22]:https://help.ubuntu.com/?_ga=2.155705979.1922322560.1494162076-828730842.1481046109
|
||||
[23]:https://help.ubuntu.com/community/CommunityHelpWiki?_ga=2.155705979.1922322560.1494162076-828730842.1481046109
|
||||
[24]:https://apps.ubuntu.com/cat/applications/gnome-tweak-tool/
|
||||
[25]:https://extensions.gnome.org/
|
||||
[26]:https://www.kde.org/
|
||||
[27]:https://kubuntu.emerge-open.com/buy
|
||||
[28]:http://lxde.org/
|
||||
[29]:https://www.abisource.com/
|
||||
[30]:http://www.gnumeric.org/
|
||||
[31]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[32]:https://xubuntu.org/
|
||||
[33]:https://www.xfce.org/
|
||||
@ -1,93 +0,0 @@
|
||||
Translating by XiatianSummer
|
||||
|
||||
Why Car Companies Are Hiring Computer Security Experts
|
||||
============================================================
|
||||
|
||||
Photo
|
||||

|
||||
The cybersecurity experts Marc Rogers, left, of CloudFlare and Kevin Mahaffey of Lookout were able to control various Tesla functions from their physically connected laptop. They pose in CloudFlare’s lobby in front of Lava Lamps used to generate numbers for encryption.CreditChristie Hemm Klok for The New York Times
|
||||
|
||||
It started about seven years ago. Iran’s top nuclear scientists were being assassinated in a string of similar attacks: Assailants on motorcycles were pulling up to their moving cars, attaching magnetic bombs and detonating them after the motorcyclists had fled the scene.
|
||||
|
||||
In another seven years, security experts warn, assassins won’t need motorcycles or magnetic bombs. All they’ll need is a laptop and code to send driverless cars careering off a bridge, colliding with a driverless truck or coming to an unexpected stop in the middle of fast-moving traffic.
|
||||
|
||||
Automakers may call them self-driving cars. But hackers call them computers that travel over 100 miles an hour.
|
||||
|
||||
“These are no longer cars,” said Marc Rogers, the principal security researcher at the cybersecurity firm CloudFlare. “These are data centers on wheels. Any part of the car that talks to the outside world is a potential inroad for attackers.”
|
||||
|
||||
Those fears came into focus two years ago when two “white hat” hackers — researchers who look for computer vulnerabilities to spot problems and fix them, rather than to commit a crime or cause problems — successfully gained access to a Jeep Cherokee from their computer miles away. They rendered their crash-test dummy (in this case a nervous reporter) powerless over his vehicle and disabling his transmission in the middle of a highway.
|
||||
|
||||
The hackers, Chris Valasek and Charlie Miller (now security researchers respectively at Uber and Didi, an Uber competitor in China), discovered an [electronic route from the Jeep’s entertainment system to its dashboard][10]. From there, they had control of the vehicle’s steering, brakes and transmission — everything they needed to paralyze their crash test dummy in the middle of a highway.
|
||||
|
||||
“Car hacking makes great headlines, but remember: No one has ever had their car hacked by a bad guy,” Mr. Miller wrote on Twitter last Sunday. “It’s only ever been performed by researchers.”
|
||||
|
||||
Still, the research by Mr. Miller and Mr. Valasek came at a steep price for Jeep’s manufacturer, Fiat Chrysler, which was forced to recall 1.4 million of its vehicles as a result of the hacking experiment.
|
||||
|
||||
It is no wonder that Mary Barra, the chief executive of General Motors, called cybersecurity her company’s top priority last year. Now the skills of researchers and so-called white hat hackers are in high demand among automakers and tech companies pushing ahead with driverless car projects.
|
||||
|
||||
Uber, [Tesla][11], Apple and Didi in China have been actively recruiting white hat hackers like Mr. Miller and Mr. Valasek from one another as well as from traditional cybersecurity firms and academia.
|
||||
|
||||
Last year, Tesla poached Aaron Sigel, Apple’s manager of security for its iOS operating system. Uber poached Chris Gates, formerly a white hat hacker at Facebook. Didi poached Mr. Miller from Uber, where he had gone to work after the Jeep hack. And security firms have seen dozens of engineers leave their ranks for autonomous-car projects.
|
||||
|
||||
Mr. Miller said he left Uber for Didi, in part, because his new Chinese employer has given him more freedom to discuss his work.
|
||||
|
||||
“Carmakers seem to be taking the threat of cyberattack more seriously, but I’d still like to see more transparency from them,” Mr. Miller wrote on Twitter on Saturday.
|
||||
|
||||
Like a number of big tech companies, Tesla and Fiat Chrysler started paying out rewards to hackers who turn over flaws the hackers discover in their systems. GM has done something similar, though critics say GM’s program is limited when compared with the ones offered by tech companies, and so far no rewards have been paid out.
|
||||
|
||||
One year after the Jeep hack by Mr. Miller and Mr. Valasek, they demonstrated all the other ways they could mess with a Jeep driver, including hijacking the vehicle’s cruise control, swerving the steering wheel 180 degrees or slamming on the parking brake in high-speed traffic — all from a computer in the back of the car. (Those exploits ended with their test Jeep in a ditch and calls to a local tow company.)
|
||||
|
||||
Granted, they had to be in the Jeep to make all that happen. But it was evidence of what is possible.
|
||||
|
||||
The Jeep penetration was preceded by a [2011 hack by security researchers at the University of Washington][12] and the University of California, San Diego, who were the first to remotely hack a sedan and ultimately control its brakes via Bluetooth. The researchers warned car companies that the more connected cars become, the more likely they are to get hacked.
|
||||
|
||||
Security researchers have also had their way with Tesla’s software-heavy Model S car. In 2015, Mr. Rogers, together with Kevin Mahaffey, the chief technology officer of the cybersecurity company Lookout, found a way to control various Tesla functions from their physically connected laptop.
|
||||
|
||||
One year later, a team of Chinese researchers at Tencent took their research a step further, hacking a moving Tesla Model S and controlling its brakes from 12 miles away. Unlike Chrysler, Tesla was able to dispatch a remote patch to fix the security holes that made the hacks possible.
|
||||
|
||||
In all the cases, the car hacks were the work of well meaning, white hat security researchers. But the lesson for all automakers was clear.
|
||||
|
||||
The motivations to hack vehicles are limitless. When it learned of Mr. Rogers’s and Mr. Mahaffey’s investigation into Tesla’s Model S, a Chinese app-maker asked Mr. Rogers if he would be interested in sharing, or possibly selling, his discovery, he said. (The app maker was looking for a backdoor to secretly install its app on Tesla’s dashboard.)
|
||||
|
||||
Criminals have not yet shown they have found back doors into connected vehicles, though for years, they have been actively developing, trading and deploying tools that can intercept car key communications.
|
||||
|
||||
But as more driverless and semiautonomous cars hit the open roads, they will become a more worthy target. Security experts warn that driverless cars present a far more complex, intriguing and vulnerable “attack surface” for hackers. Each new “connected” car feature introduces greater complexity, and with complexity inevitably comes vulnerability.
|
||||
|
||||
Twenty years ago, cars had, on average, one million lines of code. The General Motors 2010 [Chevrolet Volt][13] had about 10 million lines of code — more than an [F-35 fighter jet][14].
|
||||
|
||||
Today, an average car has more than 100 million lines of code. Automakers predict it won’t be long before they have 200 million. When you stop to consider that, on average, there are 15 to 50 defects per 1,000 lines of software code, the potentially exploitable weaknesses add up quickly.
|
||||
|
||||
The only difference between computer code and driverless car code is that, “Unlike data center enterprise security — where the biggest threat is loss of data — in automotive security, it’s loss of life,” said David Barzilai, a co-founder of Karamba Security, an Israeli start-up that is working on addressing automotive security.
|
||||
|
||||
To truly secure autonomous vehicles, security experts say, automakers will have to address the inevitable vulnerabilities that pop up in new sensors and car computers, address inherent vulnerabilities in the base car itself and, perhaps most challenging of all, bridge the cultural divide between automakers and software companies.
|
||||
|
||||
“The genie is out of the bottle, and to solve this problem will require a major cultural shift,” said Mr. Mahaffey of the cybersecurity company Lookout. “And an automaker that truly values cybersecurity will treat security vulnerabilities the same they would an airbag recall. We have not seen that industrywide shift yet.”
|
||||
|
||||
There will be winners and losers, Mr. Mahaffey added: “Automakers that transform themselves into software companies will win. Others will get left behind.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html
|
||||
|
||||
作者:[NICOLE PERLROTH ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nytimes.com/by/nicole-perlroth
|
||||
[1]:https://www.nytimes.com/2016/06/09/technology/software-as-weaponry-in-a-computer-connected-world.html
|
||||
[2]:https://www.nytimes.com/2015/08/29/technology/uber-hires-two-engineers-who-showed-cars-could-be-hacked.html
|
||||
[3]:https://www.nytimes.com/2015/08/11/opinion/zeynep-tufekci-why-smart-objects-may-be-a-dumb-idea.html
|
||||
[4]:https://www.nytimes.com/by/nicole-perlroth
|
||||
[5]:https://www.nytimes.com/column/bits
|
||||
[6]:https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#story-continues-1
|
||||
[7]:http://www.nytimes.com/newsletters/sample/bits?pgtype=subscriptionspage&version=business&contentId=TU&eventName=sample&module=newsletter-sign-up
|
||||
[8]:https://www.nytimes.com/privacy
|
||||
[9]:https://www.nytimes.com/help/index.html
|
||||
[10]:https://bits.blogs.nytimes.com/2015/07/21/security-researchers-find-a-way-to-hack-cars/
|
||||
[11]:http://www.nytimes.com/topic/company/tesla-motors-inc?inline=nyt-org
|
||||
[12]:http://www.autosec.org/pubs/cars-usenixsec2011.pdf
|
||||
[13]:http://autos.nytimes.com/2011/Chevrolet/Volt/238/4117/329463/researchOverview.aspx?inline=nyt-classifier
|
||||
[14]:http://topics.nytimes.com/top/reference/timestopics/subjects/m/military_aircraft/f35_airplane/index.html?inline=nyt-classifier
|
||||
[15]:https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#story-continues-3
|
||||
@ -1,232 +0,0 @@
|
||||
translating by liuxinyu123
|
||||
|
||||
Containing System Services in Red Hat Enterprise Linux – Part 1
|
||||
============================================================
|
||||
|
||||
|
||||
At the 2017 Red Hat Summit, several people asked me “We normally use full VMs to separate network services like DNS and DHCP, can we use containers instead?”. The answer is yes, and here’s an example of how to create a system container in Red Hat Enterprise Linux 7 today.
|
||||
|
||||
### **THE GOAL**
|
||||
|
||||
#### _Create a network service that can be updated independently of any other services of the system, yet easily managed and updated from the host._
|
||||
|
||||
Let’s explore setting up a BIND server running under systemd in a container. In this part, we’ll look at building our container, as well as managing the BIND configuration and data files.
|
||||
|
||||
In Part Two, we’ll look at how systemd on the host integrates with systemd in the container. We’ll explore managing the service in the container, and enabling it as a service on the host.
|
||||
|
||||
### **CREATING THE BIND CONTAINER**
|
||||
|
||||
To get systemd working inside a container easily, we first need to add two packages on the host: `oci-register-machine` and `oci-systemd-hook`. The `oci-systemd-hook` hook allows us to run systemd in a container without needing to use a privileged container or manually configuring tmpfs and cgroups. The `oci-register-machine` hook allows us to keep track of the container with the systemd tools like `systemctl` and `machinectl`.
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# yum install oci-register-machine oci-systemd-hook
|
||||
```
|
||||
|
||||
On to creating our BIND container. The [Red Hat Enterprise Linux 7 base image][6] includes systemd as an init system. We can install and enable BIND the same way we would on a typical system. You can [download this Dockerfile from the git repository][7] in the Resources.
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# vi Dockerfile
|
||||
|
||||
# Dockerfile for BIND
|
||||
FROM registry.access.redhat.com/rhel7/rhel
|
||||
ENV container docker
|
||||
RUN yum -y install bind && \
|
||||
yum clean all && \
|
||||
systemctl enable named
|
||||
STOPSIGNAL SIGRTMIN+3
|
||||
EXPOSE 53
|
||||
EXPOSE 53/udp
|
||||
CMD [ "/sbin/init" ]
|
||||
```
|
||||
|
||||
Since we’re starting with an init system as PID 1, we need to change the signal sent by the docker CLI when we tell the container to stop. From the `kill` system call man pages (`man 2 kill`):
|
||||
|
||||
```
|
||||
The only signals that can be sent to process ID 1, the init
|
||||
process, are those for which init has explicitly installed
|
||||
signal handlers. This is done to assure the system is not
|
||||
brought down accidentally.
|
||||
```
|
||||
|
||||
For the systemd signal handlers, `SIGRTMIN+3` is the signal that corresponds to `systemd start halt.target`. We also expose both TCP and UDP ports for BIND, since both protocols could be in use.
|
||||
|
||||
### **MANAGING DATA**
|
||||
|
||||
With a functional BIND service, we need a way to manage the configuration and zone files. Currently those are inside the container, so we _could_ enter the container any time we wanted to update the configs or make a zone file change. This isn’t ideal from a management perspective. We’ll need to rebuild the container when we need to update BIND, so changes in the images would be lost. Having to enter the container any time we need to update a file or restart the service adds steps and time.
|
||||
|
||||
Instead, we’ll extract the configuration and data files from the container and copy them to the host, then mount them at run time. This way we can easily restart or rebuild the container without losing changes. We can also modify configs and zones by using an editor outside of the container. Since this container data looks like “ _site-specific data served by this system_ ”, let’s follow the File System Hierarchy and create `/srv/named` on the local host to maintain administrative separation.
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# mkdir -p /srv/named/etc
|
||||
|
||||
[root@rhel7-host ~]# mkdir -p /srv/named/var/named
|
||||
```
|
||||
|
||||
##### _NOTE: If you are migrating an existing configuration, you can skip the following step and copy it directly to the`/srv/named` directories. You may still want to check the container assigned GID with a temporary container._
|
||||
|
||||
Let’s build and run an temporary container to examine BIND. With a init process as PID 1, we can’t run the container interactively to get a shell. We’ll exec into it after it launches, and check for important files with `rpm`.
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker build -t named .
|
||||
|
||||
[root@rhel7-host ~]# docker exec -it $( docker run -d named ) /bin/bash
|
||||
|
||||
[root@0e77ce00405e /]# rpm -ql bind
|
||||
```
|
||||
|
||||
For this example, we’ll need `/etc/named.conf` and everything under `/var/named/`. We can extract these with `machinectl`. If there’s more than one container registered, we can see what’s running in any machine with `machinectl status`. Once we have the configs we can stop the temporary container.
|
||||
|
||||
_There’s also a[ sample `named.conf` and zone files for `example.com` in the Resources][2] if you prefer._
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# machinectl list
|
||||
|
||||
MACHINE CLASS SERVICE
|
||||
8824c90294d5a36d396c8ab35167937f container docker
|
||||
|
||||
[root@rhel7-host ~]# machinectl copy-from 8824c90294d5a36d396c8ab35167937f /etc/named.conf /srv/named/etc/named.conf
|
||||
|
||||
[root@rhel7-host ~]# machinectl copy-from 8824c90294d5a36d396c8ab35167937f /var/named /srv/named/var/named
|
||||
|
||||
[root@rhel7-host ~]# docker stop infallible_wescoff
|
||||
```
|
||||
|
||||
### **FINAL CREATION**
|
||||
|
||||
To create and run the final container, add the volume options to mount:
|
||||
|
||||
* file `/srv/named/etc/named.conf` as `/etc/named.conf`
|
||||
|
||||
* directory `/srv/named/var/named` as `/var/named`
|
||||
|
||||
Since this is our final container, we’ll also provide a meaningful name that we can refer to later.
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker run -d -p 53:53 -p 53:53/udp -v /srv/named/etc/named.conf:/etc/named.conf:Z -v /srv/named/var/named:/var/named:Z --name named-container named
|
||||
```
|
||||
|
||||
With the final container running, we can modify the local configs to change the behavior of BIND in the container. The BIND server will need to listen on any IP that the container might be assigned. Be sure the GID of any new file matches the rest of the BIND files from the container.
|
||||
|
||||
```
|
||||
[root@rhel7-host bind]# cp named.conf /srv/named/etc/named.conf
|
||||
|
||||
[root@rhel7-host ~]# cp example.com.zone /srv/named/var/named/example.com.zone
|
||||
|
||||
[root@rhel7-host ~]# cp example.com.rr.zone /srv/named/var/named/example.com.rr.zone
|
||||
```
|
||||
|
||||
> [Curious why I didn’t need to change SELinux context on the host directories?][3]
|
||||
|
||||
We’ll reload the config by exec’ing the `rndc` binary provided by the container. We can use `journald` in the same fashion to check the BIND logs. If you run into errors, you can edit the file on the host, and reload the config. Using `host` or `dig` on the host, we can check the responses from the contained service for example.com.
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# docker exec -it named-container rndc reload
|
||||
server reload successful
|
||||
|
||||
[root@rhel7-host ~]# docker exec -it named-container journalctl -u named -n
|
||||
-- Logs begin at Fri 2017-05-12 19:15:18 UTC, end at Fri 2017-05-12 19:29:17 UTC. --
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: 9.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: A.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: B.E.F.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: automatic empty zone: 8.B.D.0.1.0.0.2.IP6.ARPA
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: reloading configuration succeeded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: reloading zones succeeded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: zone 1.0.10.in-addr.arpa/IN: loaded serial 2001062601
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: zone 1.0.10.in-addr.arpa/IN: sending notifies (serial 2001062601)
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: all zones loaded
|
||||
May 12 19:29:17 ac1752c314a7 named[27]: running
|
||||
|
||||
[root@rhel7-host bind]# host www.example.com localhost
|
||||
Using domain server:
|
||||
Name: localhost
|
||||
Address: ::1#53
|
||||
Aliases:
|
||||
www.example.com is an alias for server1.example.com.
|
||||
server1.example.com is an alias for mail
|
||||
```
|
||||
|
||||
> [Did your zone file not update? It might be your editor not the serial number.][4]
|
||||
|
||||
### THE FINISH LINE (?)
|
||||
|
||||
We’ve got what we set out to accomplish. DNS requests and zones are being served from a container. We’ve got a persistent location to manage data and configurations across updates.
|
||||
|
||||
In Part 2 of this series, we’ll see how to treat the container as a normal service on the host.
|
||||
|
||||
* * *
|
||||
|
||||
_[Follow the RHEL Blog][5] to receive updates on Part 2 of this series and other new posts via email._
|
||||
|
||||
* * *
|
||||
|
||||
### _**Additional Resources:**_
|
||||
|
||||
#### GitHub repository for accompanying files: [https://github.com/nzwulfin/named-container][8]
|
||||
|
||||
#### **SIDEBAR 1: ** _SELinux context on local files accessed by a container_
|
||||
|
||||
You may have noticed that when I copied the files from the container to the local host, I didn’t run a `chcon` to change the files on the host to type `svirt_sandbox_file_t`. Why didn’t it break? Copying a file into `/srv` should have made that file label type `var_t`. Did I `setenforce 0`?
|
||||
|
||||
Of course not, that would make Dan Walsh cry. And yes, `machinectl` did indeed set the label type as expected, take a look:
|
||||
|
||||
Before starting the container:
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# ls -Z /srv/named/etc/named.conf
|
||||
|
||||
-rw-r-----. unconfined_u:object_r:var_t:s0 /srv/named/etc/named.conf
|
||||
```
|
||||
|
||||
No, I used a volume option in run that makes Dan Walsh happy, `:Z`. This part of the command `-v /srv/named/etc/named.conf:/etc/named.conf:Z` does two things: first it says this needs to be relabeled with a private volume SELinux label, and second it says to mount it read / write.
|
||||
|
||||
After starting the container:
|
||||
|
||||
```
|
||||
[root@rhel7-host ~]# ls -Z /srv/named/etc/named.conf
|
||||
|
||||
-rw-r-----. root 25 system_u:object_r:svirt_sandbox_file_t:s0:c821,c956 /srv/named/etc/named.conf
|
||||
```
|
||||
|
||||
#### **SIDEBAR 2: ** _VIM backup behavior can change inodes_
|
||||
|
||||
If you made the edits to the config file with `vim` on the local host and you aren’t seeing the changes in the container, you may have inadvertently created a new file that the container isn’t aware of. There are three `vim` settings that affect backup copies during editing: backup, writebackup, and backupcopy.
|
||||
|
||||
I’ve snipped out the defaults that apply for RHEL 7 from the official VIM backup_table [http://vimdoc.sourceforge.net/htmldoc/editing.html#backup-table]
|
||||
|
||||
```
|
||||
backup writebackup
|
||||
|
||||
off on backup current file, deleted afterwards (default)
|
||||
```
|
||||
|
||||
So we don’t create tilde copies that stick around, but we are creating backups. The other setting is backupcopy, where `auto` is the shipped default:
|
||||
|
||||
```
|
||||
"yes" make a copy of the file and overwrite the original one
|
||||
"no" rename the file and write a new one
|
||||
"auto" one of the previous, what works best
|
||||
```
|
||||
|
||||
This combo means that when you edit a file, unless `vim` sees a reason not to (check the docs for the logic) you will end up with a new file that contains your edits, which will be renamed to the original filename when you save. This means the file gets a new inode. For most situations this isn’t a problem, but here the bind mount into the container *is* senstive to inode changes. To solve this, you need to change the backupcopy behavior.
|
||||
|
||||
Either in the `vim` session or in your `.vimrc`, add `set backupcopy=yes`. This will make sure the original file gets truncated and overwritten, preserving the inode and propagating the changes into the container.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/
|
||||
|
||||
作者:[Matt Micene ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/
|
||||
[1]:http://rhelblog.redhat.com/author/mmicenerht/
|
||||
[2]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#repo
|
||||
[3]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#sidebar_1
|
||||
[4]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#sidebar_2
|
||||
[5]:http://redhatstackblog.wordpress.com/feed/
|
||||
[6]:https://access.redhat.com/containers
|
||||
[7]:http://rhelblog.redhat.com/2017/07/19/containing-system-services-in-red-hat-enterprise-linux-part-1/#repo
|
||||
[8]:https://github.com/nzwulfin/named-container
|
||||
@ -0,0 +1,217 @@
|
||||
translating by liuxinyu123
|
||||
|
||||
Complete “Beginners to PRO” guide for GIT commands
|
||||
======
|
||||
In our [**earlier tutorial,**][1] we have learned to install git on our machines. In this tutorial, we will discuss how we can use git i.e. various commands that are used with git. So let's start,In our earlier tutorial, we have learned to install git on our machines. In this tutorial, we will discuss how we can use git i.e. various commands that are used with git. So let's start,
|
||||
|
||||
( **Recommended Read** : [**How to install GIT on Linux (Ubuntu & CentOS)**][1] )
|
||||
|
||||
### Setting user information
|
||||
|
||||
This should the first step after installing git. We will add user information (user name & email), so that the when we commit the code, commit messages will be generated with the user information which makes it easier to keep track of the commit progress. To add user information about user, command is 'git config'
|
||||
|
||||
**$ git config - - global user.name "Daniel"**
|
||||
|
||||
**$ git config - - global user.email "dan.mike@xyz.com"**
|
||||
|
||||
After adding the information, we will now check if the information has been updated successfully by running,
|
||||
|
||||
**$ git config - - list**
|
||||
|
||||
& we should see our user information as the output.
|
||||
|
||||
( **Also Read** : [**Scheduling important jobs with CRONTAB**][3] )
|
||||
|
||||
### GIT Commands
|
||||
|
||||
#### Create a new repository
|
||||
|
||||
To create a new repository, run
|
||||
|
||||
**$ git init**
|
||||
|
||||
|
||||
#### Search a repository
|
||||
|
||||
To search a repository, command is
|
||||
|
||||
**$ git grep "repository"**
|
||||
|
||||
|
||||
#### Connect to a remote repository
|
||||
|
||||
To connect to a remote repository, run
|
||||
|
||||
**$ git remote add origin remote_server**
|
||||
|
||||
Then to check all the configured remote server,
|
||||
|
||||
**$ git remote -v**
|
||||
|
||||
|
||||
#### Clone a repository
|
||||
|
||||
To clone a repository from a local server, run the following commands
|
||||
|
||||
**$ git clone repository_path**
|
||||
|
||||
If we want to clone a repository locate at remote server, then the command to clone the repository is,
|
||||
|
||||
**$ git clone[[email protected]][2] :/repository_path**
|
||||
|
||||
|
||||
#### List Branches in repository
|
||||
|
||||
To check list all the available & the current working branch, execute
|
||||
|
||||
**$ git branch**
|
||||
|
||||
|
||||
#### Create new branch
|
||||
|
||||
To create & use a new branch, command is
|
||||
|
||||
**$ git checkout -b 'branchname'**
|
||||
|
||||
|
||||
#### Deleting a branch
|
||||
|
||||
To delete a branch, execute
|
||||
|
||||
**$ git branch -d 'branchname'**
|
||||
|
||||
To delete a branch on remote repository, execute
|
||||
|
||||
**$ git push origin : 'branchname'**
|
||||
|
||||
|
||||
#### Switch to another branch
|
||||
|
||||
To switch to another branch from current branch, use
|
||||
|
||||
**$ git checkout 'branchname'**
|
||||
|
||||
|
||||
#### Adding files
|
||||
|
||||
To add a file to the repo, run
|
||||
|
||||
**$ git add filename**
|
||||
|
||||
|
||||
#### Status of files
|
||||
|
||||
To check status of files (files that are to be commited or are to added), run
|
||||
|
||||
**$ git status**
|
||||
|
||||
|
||||
#### Commit the changes
|
||||
|
||||
After we have added a file or made changes to one, we will commit the code by running,
|
||||
|
||||
**$ git commit -a**
|
||||
|
||||
To commit changes to head and not to remote repository, command is
|
||||
|
||||
**$ git commit -m "message"**
|
||||
|
||||
|
||||
#### Push changes
|
||||
|
||||
To push changes made to the master branch of the repository, run
|
||||
|
||||
**$ git push origin master**
|
||||
|
||||
|
||||
#### Push branch to repository
|
||||
|
||||
To push the changes made on a single branch to remote repository, run
|
||||
|
||||
**$ git push origin 'branchname'**
|
||||
|
||||
To push all branches to remote repository, run
|
||||
|
||||
**$ git push -all origin**
|
||||
|
||||
|
||||
#### Merge two branches
|
||||
|
||||
To merge another branch into the current active branch, use
|
||||
|
||||
**$ git merge 'branchname'**
|
||||
|
||||
|
||||
#### Merge from remote to local server
|
||||
|
||||
To download/pull changes to working directory on local server from remote server, run
|
||||
|
||||
**$ git pull**
|
||||
|
||||
|
||||
#### Checking merge conflicts
|
||||
|
||||
To view merge conflicts against base file, run
|
||||
|
||||
**$ git diff -base 'filename'**
|
||||
|
||||
To see all the conflicts, run
|
||||
|
||||
**$ git diff**
|
||||
|
||||
If we want to preview all the changes before merging, execute
|
||||
|
||||
**$ git diff 'source-branch' 'target-branch'**
|
||||
|
||||
|
||||
#### Creating tags
|
||||
|
||||
To create tags to mark any significant changes, run
|
||||
|
||||
**$ git tag 'tag number' 'commit id'**
|
||||
|
||||
We can find commit id by running,
|
||||
|
||||
**$ git log**
|
||||
|
||||
|
||||
#### Push tags
|
||||
|
||||
To push all the created tags to remote server, run
|
||||
|
||||
**$ git push -tags origin**
|
||||
|
||||
|
||||
#### Revert changes made
|
||||
|
||||
If we want to replace changes made on current working tree with the last changes in head, run
|
||||
|
||||
**$ git checkout -'filename'**
|
||||
|
||||
We can also fetch the latest history from remote server & point it local repository's master branch, rather than dropping all local changes made. To do this, run
|
||||
|
||||
**$ git fetch origin**
|
||||
|
||||
**$ git reset -hard master**
|
||||
|
||||
That's it guys, these are the commands that we can use with git server. We will be back soon with more interesting tutorials. If you wish that we write a tutorial on a specific topic, please let us know via comment box below. As usual, your comments & suggestions are always welcome.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/beginners-to-pro-guide-for-git-commands/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1] http://linuxtechlab.com/install-git-linux-ubuntu-centos/
|
||||
[2] /cdn-cgi/l/email-protection
|
||||
[3] http://linuxtechlab.com/scheduling-important-jobs-crontab/
|
||||
[4] https://www.facebook.com/linuxtechlab/
|
||||
[5] https://twitter.com/LinuxTechLab
|
||||
[6] https://plus.google.com/+linuxtechlab
|
||||
[7] http://linuxtechlab.com/contact-us-2/
|
||||
@ -0,0 +1,265 @@
|
||||
translating by liuxinyu123
|
||||
|
||||
Useful Linux Commands that you should know
|
||||
======
|
||||
If you are Linux system administrator or just a Linux enthusiast/lover, than
|
||||
you love & use command line aks CLI. Until some years ago majority of Linux
|
||||
work was accomplished using CLI only & even there are some limitations to GUI
|
||||
. Though there are plenty of Linux distributions that can complete tasks with
|
||||
GUI but still learning CLI is major part of mastering Linux.
|
||||
|
||||
To this effect, we present you list of useful Linux commands that you should
|
||||
know.
|
||||
|
||||
**Note:-** There is no definite order to all these commands & all of these
|
||||
commands are equally important to learn & master in order to excel in Linux
|
||||
administration. One more thing, we have only used some of the options for each
|
||||
command for an example, you can refer to 'man pages' for complete list of
|
||||
options for each command.
|
||||
|
||||
### 1- top command
|
||||
|
||||
'top' command displays the real time summary/information of our system. It
|
||||
also displays the processes and all the threads that are running & are being
|
||||
managed by the system kernel.
|
||||
|
||||
Information provided by top command includes uptime, number of users, Load
|
||||
average, running/sleeping/zombie processes, CPU usage in percentage based on
|
||||
users/system etc, system memory free & used, swap memory etc.
|
||||
|
||||
To use top command, open terminal & execute the comamnd,
|
||||
|
||||
**$ top**
|
||||
|
||||
To exit out the command, either press 'q' or 'ctrl+c'.
|
||||
|
||||
### 2- free command
|
||||
|
||||
'free' command is used to specifically used to get the information about
|
||||
system memory or RAM. With this command we can get information regarding
|
||||
physical memory, swap memory as well as system buffers. It provided amount of
|
||||
total, free & used memory available on the system.
|
||||
|
||||
To use this utility, execute following command in terminal
|
||||
|
||||
**$ free**
|
||||
|
||||
It will present all the data in kb or kilobytes, for megabytes use options
|
||||
'-m' & '-g ' for gb.
|
||||
|
||||
#### 3- cp command
|
||||
|
||||
'cp' or copy command is used to copy files among the folders. Syntax for using
|
||||
'cp' command is,
|
||||
|
||||
**$ cp source destination**
|
||||
|
||||
### 4- cd command
|
||||
|
||||
'cd' command is used for changing directory . We can switch among directories
|
||||
using cd command.
|
||||
|
||||
To use it, execute
|
||||
|
||||
**$ cd directory_location**
|
||||
|
||||
### 5- ifconfig
|
||||
|
||||
'Ifconfig' is very important utility for viewing & configuring network
|
||||
information on Linux machine.
|
||||
|
||||
To use it, execute
|
||||
|
||||
**$ ifconfig**
|
||||
|
||||
This will present the network information of all the networking devices on the
|
||||
system. There are number of options that can be used with 'ifconfig' for
|
||||
configuration, in fact they are some many options that we have created a
|
||||
separate article for it ( **Read it here ||[IFCONFIG command : Learn with some
|
||||
examples][1]** ).
|
||||
|
||||
### 6- crontab command
|
||||
|
||||
'Crontab' is another important utility that is used schedule a job on Linux
|
||||
system. With crontab, we can make sure that a command or a script is executed
|
||||
at the pre-defined time. To create a cron job, run
|
||||
|
||||
**$ crontab -e**
|
||||
|
||||
To display all the created jobs, run
|
||||
|
||||
**$ crontab -l**
|
||||
|
||||
You can read our detailed article regarding crontab ( **Read it here ||[
|
||||
Scheduling Important Jobs with Crontab][2]** )
|
||||
|
||||
### 7- cat command
|
||||
|
||||
'cat' command has many uses, most common use is that it's used to display
|
||||
content of a file,
|
||||
|
||||
**$ cat file.txt**
|
||||
|
||||
But it can also be used to merge two or more file using the syntax below,
|
||||
|
||||
**$ cat file1 file2 file3 file4 > file_new**
|
||||
|
||||
We can also use 'cat' command to clone a whole disk ( **Read it here ||
|
||||
[Cloning Disks using dd & cat commands for Linux systems][3]** )
|
||||
|
||||
### 8- df command
|
||||
|
||||
'df' command is used to show the disk utilization of our whole Linux file
|
||||
system. Simply run.
|
||||
|
||||
**$ df**
|
||||
|
||||
& we will be presented with disk complete utilization of all the partitions on
|
||||
our Linux machine.
|
||||
|
||||
### 9- du command
|
||||
|
||||
'du' command shows the amount of disk that is being utilized by the files &
|
||||
directories on our Linux machine. To run it, type
|
||||
|
||||
**$ du /directory**
|
||||
|
||||
( **Recommended Read :[Use of du & df commands with examples][4]** )
|
||||
|
||||
### 10- mv command
|
||||
|
||||
'mv' command is used to move the files or folders from one location to
|
||||
another. Command syntax for moving the files/folders is,
|
||||
|
||||
**$ mv /source/filename /destination**
|
||||
|
||||
We can also use 'mv' command to rename a file/folder. Syntax for changing name
|
||||
is,
|
||||
|
||||
**$ mv file_oldname file_newname**
|
||||
|
||||
### 11- rm command
|
||||
|
||||
'rm' command is used to remove files\folders from Linux system. To use it, run
|
||||
|
||||
**$ rm filename**
|
||||
|
||||
We can also use '-rf' option with 'rm' command to completely remove a
|
||||
file\folder from the system but we must use this with caution.
|
||||
|
||||
### 12- vi/vim command
|
||||
|
||||
VI or VIM is very famous & one of the widely used CLI-based text editor for
|
||||
Linux. It takes some time to master it but it has a great number of utilities,
|
||||
which makes it a favorite for Linux users.
|
||||
|
||||
For detailed knowledge of VIM, kindly refer to the articles [**Beginner 's
|
||||
Guide to LVM (Logical Volume Management)** & **Working with Vi/Vim Editor :
|
||||
Advanced concepts.**][5]
|
||||
|
||||
### 13- ssh command
|
||||
|
||||
SSH utility is to remotely access another machine from the current Linux
|
||||
machine. To access a machine, execute
|
||||
|
||||
**$ ssh[[email protected]][6] OR machine_name**
|
||||
|
||||
Once we have remote access to machine, we can work on CLI of that machine as
|
||||
if we are working on local machine.
|
||||
|
||||
### 14- tar command
|
||||
|
||||
'tar' command is used to compress & extract the files\folders. To compress the
|
||||
files\folders using tar, execute
|
||||
|
||||
**$ tar -cvf file.tar file_name**
|
||||
|
||||
where file.tar will be the name of compressed folder & 'file_name' is the name
|
||||
of source file or folders. To extract a compressed folder,
|
||||
|
||||
**$ tar -xvf file.tar**
|
||||
|
||||
For more details on 'tar' command, read [**Tar command : Compress & Decompress
|
||||
the files\directories**][7]
|
||||
|
||||
### 15- locate command
|
||||
|
||||
'locate' command is used to locate files & folders on your Linux machines. To
|
||||
use it, run
|
||||
|
||||
**$ locate file_name**
|
||||
|
||||
### 16- grep command
|
||||
|
||||
'grep' command another very important command that a Linux administrator
|
||||
should know. It comes especially handy when we want to grab a keyword or
|
||||
multiple keywords from a file. Syntax for using it is,
|
||||
|
||||
**$ grep 'pattern' file.txt**
|
||||
|
||||
It will search for 'pattern' in the file 'file.txt' and produce the output on
|
||||
the screen. We can also redirect the output to another file,
|
||||
|
||||
**$ grep 'pattern' file.txt > newfile.txt**
|
||||
|
||||
### 17- ps command
|
||||
|
||||
'ps' command is especially used to get the process id of a running process. To
|
||||
get information of all the processes, run
|
||||
|
||||
**$ ps -ef**
|
||||
|
||||
To get information regarding a single process, executed
|
||||
|
||||
**$ ps -ef | grep java**
|
||||
|
||||
### 18- kill command
|
||||
|
||||
'kill' command is used to kill a running process. To kill a process we will
|
||||
need its process id, which we can get using above 'ps' command. To kill a
|
||||
process, run
|
||||
|
||||
**$ kill -9 process_id**
|
||||
|
||||
### 19- ls command
|
||||
|
||||
'ls' command is used list all the files in a directory. To use it, execute
|
||||
|
||||
**$ ls**
|
||||
|
||||
### 20- mkdir command
|
||||
|
||||
To create a directory in Linux machine, we use command 'mkdir'. Syntax for
|
||||
using 'mkdir' is
|
||||
|
||||
**$ mkdir new_dir**
|
||||
|
||||
These were some of the useful linux commands that every System Admin should
|
||||
know, we will soon be sharing another list of some more important commands
|
||||
that you should know being a Linux lover. You can also leave your suggestions
|
||||
and queries in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/useful-linux-commands-you-should-know/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com
|
||||
[1]:http://linuxtechlab.com/ifconfig-command-learn-examples/
|
||||
[2]:http://linuxtechlab.com/scheduling-important-jobs-crontab/
|
||||
[3]:http://linuxtechlab.com/linux-disk-cloning-using-dd-cat-commands/
|
||||
[4]:http://linuxtechlab.com/du-df-commands-examples/
|
||||
[5]:http://linuxtechlab.com/working-vivim-editor-advanced-concepts/
|
||||
[6]:/cdn-cgi/l/email-protection#bbcec8dec9d5dad6defbf2ebdadfdfc9dec8c8
|
||||
[7]:http://linuxtechlab.com/tar-command-compress-decompress-files
|
||||
[8]:https://www.facebook.com/linuxtechlab/
|
||||
[9]:https://twitter.com/LinuxTechLab
|
||||
[10]:https://plus.google.com/+linuxtechlab
|
||||
[11]:http://linuxtechlab.com/contact-us-2/
|
||||
|
||||
@ -1,59 +0,0 @@
|
||||
translating by lujun9972
|
||||
How to disable USB storage on Linux
|
||||
======
|
||||
To secure our infrastructure of data breaches, we use software & hardware firewalls to restrict unauthorized access from outside but data breaches can occur from inside as well. To remove such a possibility, organizations limit & monitor the access to internet & also disable usb storage devices.
|
||||
|
||||
In this tutorial, we are going to discuss three different ways to disable USB storage devices on Linux machines. All the three methods have been tested on CentOS 6 & 7 machine & are working as they are supposed to . So let’s discuss all the three methods one by one,
|
||||
|
||||
( Also Read : [Ultimate guide to securing SSH sessions][1] )
|
||||
|
||||
### Method 1 – Fake install
|
||||
|
||||
In this method, we add a line ‘install usb-storage /bin/true’ which causes the ‘/bin/true’ to run instead of installing usb-storage module & that’s why it’s also called ‘Fake Install’ . To do this, create and open a file named ‘block_usb.conf’ (it can be something as well) in the folder ‘/etc/modprobe.d’,
|
||||
|
||||
$ sudo vim /etc/modprobe.d/block_usb.conf
|
||||
|
||||
& add the below mentioned line,
|
||||
|
||||
install usb-storage /bin/true
|
||||
|
||||
Now save the file and exit.
|
||||
|
||||
### Method 2 – Removing the USB driver
|
||||
|
||||
Using this method, we can remove/move the drive for usb-storage (usb_storage.ko) from our machines, thus making it impossible to access a usb-storage device from the mahcine. To move the driver from it’s default location, execute the following command,
|
||||
|
||||
$ sudo mv /lib/modules/$(uname -r)/kernel/drivers/usb/storage/usb-storage.ko /home/user1
|
||||
|
||||
Now the driver is not available on its default location & thus would not be loaded when a usb-storage device is attached to the system & device would not be able to work. But this method has one little issue, that is when the kernel of the system is updated the usb-storage module would again show up in it’s default location.
|
||||
|
||||
### Method 3- Blacklisting USB-storage
|
||||
|
||||
We can also blacklist usb-storage using the file ‘/etc/modprobe.d/blacklist.conf’. This file is available on RHEL/CentOS 6 but might need to be created on 7\. To blacklist usb-storage, open/create the above mentioned file using vim,
|
||||
|
||||
$ sudo vim /etc/modprobe.d/blacklist.conf
|
||||
|
||||
& enter the following line to blacklist the usb,
|
||||
|
||||
blacklist usb-storage
|
||||
|
||||
Save file & exit. USB-storage will now be blocked on the system but this method has one major downside i.e. any privileged user can load the usb-storage module by executing the following command,
|
||||
|
||||
$ sudo modprobe usb-storage
|
||||
|
||||
This issue makes this method somewhat not desirable but it works well for non-privileged users.
|
||||
|
||||
Reboot your system after the changes have been made to implement the changes made for all the above mentioned methods. Do check these methods to disable usb storage & let us know if you face any issue or have a query using the comment box below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/disable-usb-storage-linux/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/ultimate-guide-to-securing-ssh-sessions/
|
||||
@ -1,4 +1,4 @@
|
||||
fuzheng1998 translating
|
||||
|
||||
A Large-Scale Study of Programming Languages and Code Quality in GitHub
|
||||
============================================================
|
||||
|
||||
@ -36,7 +36,7 @@ Our language and project data was extracted from the _GitHub Archive_ , a data
|
||||
|
||||
**Identifying top languages.** We aggregate projects based on their primary language. Then we select the languages with the most projects for further analysis, as shown in [Table 1][48]. A given project can use many languages; assigning a single language to it is difficult. Github Archive stores information gathered from GitHub Linguist which measures the language distribution of a project repository using the source file extensions. The language with the maximum number of source files is assigned as the _primary language_ of the project.
|
||||
|
||||
[][49]
|
||||
[][49]
|
||||
**Table 1\. Top 3 projects in each language.**
|
||||
|
||||
**Retrieving popular projects.** For each selected language, we filter the project repositories written primarily in that language by its popularity based on the associated number of _stars._ This number indicates how many people have actively expressed interest in the project, and is a reasonable proxy for its popularity. Thus, the top 3 projects in C are _linux, git_ , and _php-src_ ; and for C++ they are _node-webkit, phantomjs_ , and _mongo_ ; and for `Java` they are _storm, elasticsearch_ , and _ActionBarSherlock._ In total, we select the top 50 projects in each language.
|
||||
@ -47,7 +47,7 @@ To ensure that these projects have a sufficient development history, we drop the
|
||||
|
||||
[Table 2][51] summarizes our data set. Since a project may use multiple languages, the second column of the table shows the total number of projects that use a certain language at some capacity. We further exclude some languages from a project that have fewer than 20 commits in that language, where 20 is the first quartile value of the total number of commits per project per language. For example, we find 220 projects that use more than 20 commits in C. This ensures sufficient activity for each language–project pair.
|
||||
|
||||
[][52]
|
||||
[][52]
|
||||
**Table 2\. Study subjects.**
|
||||
|
||||
In summary, we study 728 projects developed in 17 languages with 18 years of history. This includes 29,000 different developers, 1.57 million commits, and 564,625 bug fix commits.
|
||||
@ -57,14 +57,14 @@ In summary, we study 728 projects developed in 17 languages with 18 years of his
|
||||
|
||||
We define language classes based on several properties of the language thought to influence language quality,[7][9], [8][10], [12][11] as shown in [Table 3][53]. The _Programming Paradigm_ indicates whether the project is written in an imperative procedural, imperative scripting, or functional language. In the rest of the paper, we use the terms procedural and scripting to indicate imperative procedural and imperative scripting respectively.
|
||||
|
||||
[][54]
|
||||
[][54]
|
||||
**Table 3\. Different types of language classes.**
|
||||
|
||||
_Type Checking_ indicates static or dynamic typing. In statically typed languages, type checking occurs at compile time, and variable names are bound to a value and to a type. In addition, expressions (including variables) are classified by types that correspond to the values they might take on at run-time. In dynamically typed languages, type checking occurs at run-time. Hence, in the latter, it is possible to bind a variable name to objects of different types in the same program.
|
||||
|
||||
_Implicit Type Conversion_ allows access of an operand of type T1 as a different type T2, without an explicit conversion. Such implicit conversion may introduce type-confusion in some cases, especially when it presents an operand of specific type T1, as an instance of a different type T2\. Since not all implicit type conversions are immediately a problem, we operationalize our definition by showing examples of the implicit type confusion that can happen in all the languages we identified as allowing it. For example, in languages like `Perl, JavaScript`, and `CoffeeScript` adding a string to a number is permissible (e.g., "5" + 2 yields "52"). The same operation yields 7 in `Php`. Such an operation is not permitted in languages such as `Java` and `Python` as they do not allow implicit conversion. In C and C++ coercion of data types can result in unintended results, for example, `int x; float y; y=3.5; x=y`; is legal C code, and results in different values for x and y, which, depending on intent, may be a problem downstream.[a][12] In `Objective-C` the data type _id_ is a generic object pointer, which can be used with an object of any data type, regardless of the class.[b][13] The flexibility that such a generic data type provides can lead to implicit type conversion and also have unintended consequences.[c][14]Hence, we classify a language based on whether its compiler _allows_ or _disallows_ the implicit type conversion as above; the latter explicitly detects type confusion and reports it.
|
||||
|
||||
Disallowing implicit type conversion could result from static type inference within a compiler (e.g., with `Java`), using a type-inference algorithm such as Hindley[10][15] and Milner,[17][16] or at run-time using a dynamic type checker. In contrast, a type-confusion can occur silently because it is either undetected or is unreported. Either way, implicitly allowing type conversion provides flexibility but may eventually cause errors that are difficult to localize. To abbreviate, we refer to languages allowing implicit type conversion as _implicit_ and those that disallow it as _explicit._
|
||||
Disallowing implicit type conversion could result from static type inference within a compiler (e.g., with `Java`), using a type-inference algorithm such as Hindley[10][15] and Milner,[17][16] or at run-time using a dynamic type checker. In contrast, a type-confusion can occur silently because it is either undetected or is unreported. Either way, implicitly allowing type conversion provides flexibility but may eventually cause errors that are difficult to localize. To abbreviate, we refer to languages allowing implicit type conversion as _implicit_ and those that disallow it as _explicit._
|
||||
|
||||
_Memory Class_ indicates whether the language requires developers to manage memory. We treat `Objective-C` as unmanaged, in spite of it following a hybrid model, because we observe many memory errors in its codebase, as discussed in RQ4 in Section 3.
|
||||
|
||||
@ -77,7 +77,7 @@ We classify the studied projects into different domains based on their features
|
||||
|
||||
We detect 30 distinct domains, that is, topics, and estimate the probability that each project belonging to each domain. Since these auto-detected domains include several project-specific keywords, for example, facebook, it is difficult to identify the underlying common functions. In order to assign a meaningful name to each domain, we manually inspect each of the 30 domains to identify projectname-independent, domain-identifying keywords. We manually rename all of the 30 auto-detected domains and find that the majority of the projects fall under six domains: Application, Database, CodeAnalyzer, Middleware, Library, and Framework. We also find that some projects do not fall under any of the above domains and so we assign them to a catchall domain labeled as _Other_ . This classification of projects into domains was subsequently checked and confirmed by another member of our research group. [Table 4][57] summarizes the identified domains resulting from this process.
|
||||
|
||||
[][58]
|
||||
[][58]
|
||||
**Table 4\. Characteristics of domains.**
|
||||
|
||||

|
||||
@ -87,7 +87,7 @@ While fixing software bugs, developers often leave important information in the
|
||||
|
||||
First, we categorize the bugs based on their _Cause_ and _Impact. Causes_ are further classified into disjoint subcategories of errors: Algorithmic, Concurrency, Memory, generic Programming, and Unknown. The bug _Impact_ is also classified into four disjoint subcategories: Security, Performance, Failure, and Other unknown categories. Thus, each bug-fix commit also has an induced Cause and an Impact type. [Table 5][59] shows the description of each bug category. This classification is performed in two phases:
|
||||
|
||||
[][60]
|
||||
[][60]
|
||||
**Table 5\. Categories of bugs and their distribution in the whole dataset.**
|
||||
|
||||
**(1) Keyword search.** We randomly choose 10% of the bug-fix messages and use a keyword based search technique to automatically categorize them as potential bug types. We use this annotation, separately, for both Cause and Impact types. We chose a restrictive set of keywords and phrases, as shown in [Table 5][61]. Such a restrictive set of keywords and phrases helps reduce false positives.
|
||||
@ -119,7 +119,7 @@ We begin with a straightforward question that directly addresses the core of wha
|
||||
|
||||
We use a regression model to compare the impact of each language on the number of defects with the average impact of all languages, against defect fixing commits (see [Table 6][64]).
|
||||
|
||||
[][65]
|
||||
[][65]
|
||||
**Table 6\. Some languages induce fewer defects than other languages.**
|
||||
|
||||
We include some variables as controls for factors that will clearly influence the response. Project age is included as older projects will generally have a greater number of defect fixes. Trivially, the number of commits to a project will also impact the response. Additionally, the number of developers who touch a project and the raw size of the project are both expected to grow with project activity.
|
||||
@ -128,11 +128,11 @@ The sign and magnitude of the estimated coefficients in the above model relates
|
||||
|
||||
One should take care not to overestimate the impact of language on defects. While the observed relationships are statistically significant, the effects are quite small. Analysis of deviance reveals that language accounts for less than 1% of the total explained deviance.
|
||||
|
||||
[][66]
|
||||
[][66]
|
||||
|
||||
We can read the model coefficients as the expected change in the log of the response for a one unit change in the predictor with all other predictors held constant; that is, for a coefficient _β<sub style="border: 0px; outline: 0px; font-size: smaller; vertical-align: sub; background: transparent;">i</sub>_ , a one unit change in _β<sub style="border: 0px; outline: 0px; font-size: smaller; vertical-align: sub; background: transparent;">i</sub>_ yields an expected change in the response of e _βi_ . For the factor variables, this expected change is compared to the average across all languages. Thus, if, for some number of commits, a particular project developed in an _average_ language had four defective commits, then the choice to use C++ would mean that we should expect one additional defective commit since e0.18 × 4 = 4.79\. For the same project, choosing `Haskell` would mean that we should expect about one fewer defective commit as _e_ −0.26 × 4 = 3.08\. The accuracy of this prediction depends on all other factors remaining the same, a challenging proposition for all but the most trivial of projects. All observational studies face similar limitations; we address this concern in more detail in Section 5.
|
||||
|
||||
**Result 1:** _Some languages have a greater association with defects than other languages, although the effect is small._
|
||||
**Result 1:** _Some languages have a greater association with defects than other languages, although the effect is small._
|
||||
|
||||
In the remainder of this paper we expand on this basic result by considering how different categories of application, defect, and language, lead to further insight into the relationship between languages and defect proneness.
|
||||
|
||||
@ -150,26 +150,26 @@ Rather than considering languages individually, we aggregate them by language cl
|
||||
|
||||
As with language (earlier in [Table 6][67]), we are comparing language _classes_ with the average behavior across all language classes. The model is presented in [Table 7][68]. It is clear that `Script-Dynamic-Explicit-Managed` class has the smallest magnitude coefficient. The coefficient is insignificant, that is, the z-test for the coefficient cannot distinguish the coefficient from zero. Given the magnitude of the standard error, however, we can assume that the behavior of languages in this class is very close to the average across all languages. We confirm this by recoding the coefficient using `Proc-Static-Implicit-Unmanaged` as the base level and employing treatment, or dummy coding that compares each language class with the base level. In this case, `Script-Dynamic-Explicit-Managed` is significantly different with _p_ = 0.00044\. We note here that while choosing different coding methods affects the coefficients and z-scores, the models are identical in all other respects. When we change the coding we are rescaling the coefficients to reflect the comparison that we wish to make.[4][28] Comparing the other language classes to the grand mean, `Proc-Static-Implicit-Unmanaged` languages are more likely to induce defects. This implies that either implicit type conversion or memory management issues contribute to greater defect proneness as compared with other procedural languages.
|
||||
|
||||
[][69]
|
||||
[][69]
|
||||
**Table 7\. Functional languages have a smaller relationship to defects than other language classes whereas procedural languages are greater than or similar to the average.**
|
||||
|
||||
Among scripting languages we observe a similar relationship between languages that allow versus those that do not allow implicit type conversion, providing some evidence that implicit type conversion (vs. explicit) is responsible for this difference as opposed to memory management. We cannot state this conclusively given the correlation between factors. However when compared to the average, as a group, languages that do not allow implicit type conversion are less error-prone while those that do are more error-prone. The contrast between static and dynamic typing is also visible in functional languages.
|
||||
|
||||
The functional languages as a group show a strong difference from the average. Statically typed languages have a substantially smaller coefficient yet both functional language classes have the same standard error. This is strong evidence that functional static languages are less error-prone than functional dynamic languages, however, the z-tests only test whether the coefficients are different from zero. In order to strengthen this assertion, we recode the model as above using treatment coding and observe that the `Functional-Static-Explicit-Managed` language class is significantly less defect-prone than the `Functional-Dynamic-Explicit-Managed`language class with _p_ = 0.034.
|
||||
|
||||
[][70]
|
||||
[][70]
|
||||
|
||||
As with language and defects, the relationship between language class and defects is based on a small effect. The deviance explained is similar, albeit smaller, with language class explaining much less than 1% of the deviance.
|
||||
|
||||
We now revisit the question of application domain. Does domain have an interaction with language class? Does the choice of, for example, a functional language, have an advantage for a particular domain? As above, a Chi-square test for the relationship between these factors and the project domain yields a value of 99.05 and _df_ = 30 with _p_ = 2.622e–09 allowing us to reject the null hypothesis that the factors are independent. Cramer's-V yields a value of 0.133, a weak level of association. Consequently, although there is some relation between domain and language, there is only a weak relationship between domain and language class.
|
||||
|
||||
**Result 2:** _There is a small but significant relationship between language class and defects. Functional languages are associated with fewer defects than either procedural or scripting languages._
|
||||
**Result 2:** _There is a small but significant relationship between language class and defects. Functional languages are associated with fewer defects than either procedural or scripting languages._
|
||||
|
||||
It is somewhat unsatisfying that we do not observe a strong association between language, or language class, and domain within a project. An alternative way to view this same data is to disregard projects and aggregate defects over all languages and domains. Since this does not yield independent samples, we do not attempt to analyze it statistically, rather we take a descriptive, visualization-based approach.
|
||||
|
||||
We define _Defect Proneness_ as the ratio of bug fix commits over total commits per language per domain. [Figure 1][71] illustrates the interaction between domain and language using a heat map, where the defect proneness increases from lighter to darker zone. We investigate which language factors influence defect fixing commits across a collection of projects written across a variety of languages. This leads to the following research question:
|
||||
|
||||
[][72]
|
||||
[][72]
|
||||
**Figure 1\. Interaction of language's defect proneness with domain. Each cell in the heat map represents defect proneness of a language (row header) for a given domain (column header). The "Overall" column represents defect proneness of a language over all the domains. The cells with white cross mark indicate null value, that is, no commits were made corresponding to that cell.**
|
||||
|
||||
**RQ3\. Does language defect proneness depend on domain?**
|
||||
@ -178,9 +178,9 @@ In order to answer this question we first filtered out projects that would have
|
||||
|
||||
We see only a subdued variation in this heat map which is a result of the inherent defect proneness of the languages as seen in RQ1\. To validate this, we measure the pairwise rank correlation between the language defect proneness for each domain with the overall. For all of the domains except Database, the correlation is positive, and p-values are significant (<0.01). Thus, w.r.t. defect proneness, the language ordering in each domain is strongly correlated with the overall language ordering.
|
||||
|
||||
[][74]
|
||||
[][74]
|
||||
|
||||
**Result 3:** _There is no general relationship between application domain and language defect proneness._
|
||||
**Result 3:** _There is no general relationship between application domain and language defect proneness._
|
||||
|
||||
We have shown that different languages induce a larger number of defects and that this relationship is not only related to particular languages but holds for general classes of languages; however, we find that the type of project does not mediate this relationship to a large degree. We now turn our attention to categorization of the response. We want to understand how language relates to specific kinds of defects and how this relationship compares to the more general relationship that we observe. We divide the defects into categories as described in [Table 5][75] and ask the following question:
|
||||
|
||||
@ -188,12 +188,12 @@ We have shown that different languages induce a larger number of defects and tha
|
||||
|
||||
We use an approach similar to RQ3 to understand the relation between languages and bug categories. First, we study the relation between bug categories and language class. A heat map ([Figure 2][76]) shows aggregated defects over language classes and bug types. To understand the interaction between bug categories and languages, we use an NBR regression model for each category. For each model we use the same control factors as RQ1 as well as languages encoded with weighted effects to predict defect fixing commits.
|
||||
|
||||
[][77]
|
||||
[][77]
|
||||
**Figure 2\. Relation between bug categories and language class. Each cell represents percentage of bug fix commit out of all bug fix commits per language class (row header) per bug category (column header). The values are normalized column wise.**
|
||||
|
||||
The results along with the anova value for language are shown in [Table 8][78]. The overall deviance for each model is substantially smaller and the proportion explained by language for a specific defect type is similar in magnitude for most of the categories. We interpret this relationship to mean that language has a greater impact on specific categories of bugs, than it does on bugs overall. In the next section we expand on these results for the bug categories with significant bug counts as reported in [Table 5][79]. However, our conclusion generalizes for all categories.
|
||||
|
||||
[][80]
|
||||
[][80]
|
||||
**Table 8\. While the impact of language on defects varies across defect category, language has a greater impact on specific categories than it does on defects in general.**
|
||||
|
||||
**Programming errors.** Generic programming errors account for around 88.53% of all bug fix commits and occur in all the language classes. Consequently, the regression analysis draws a similar conclusion as of RQ1 (see [Table 6][81]). All languages incur programming errors such as faulty error-handling, faulty definitions, typos, etc.
|
||||
@ -202,7 +202,7 @@ The results along with the anova value for language are shown in [Table 8][78].
|
||||
|
||||
**Concurrency errors.** 1.99% of the total bug fix commits are related to concurrency errors. The heat map shows that `Proc-Static-Implicit-Unmanaged` dominates this error type. C and C++ introduce 19.15% and 7.89% of the errors, and they are distributed across the projects.
|
||||
|
||||
[][84]
|
||||
[][84]
|
||||
|
||||
Both of the `Static-Strong-Managed` language classes are in the darker zone in the heat map confirming, in general static languages produce more concurrency errors than others. Among the dynamic languages, only `Erlang` is more prone to concurrency errors, perhaps relating to the greater use of this language for concurrent applications. Likewise, the negative coefficients in [Table 8][85] shows that projects written in dynamic languages like `Ruby` and `Php` have fewer concurrency errors. Note that, certain languages like `JavaScript, CoffeeScript`, and `TypeScript` do not support concurrency, in its traditional form, while `Php` has a limited support depending on its implementations. These languages introduce artificial zeros in the data, and thus the concurrency model coefficients in [Table 8][86] for those languages cannot be interpreted like the other coefficients. Due to these artificial zeros, the average over all languages in this model is smaller, which may affect the sizes of the coefficients, since they are given w.r.t. the average, but it will not affect their relative relationships, which is what we are after.
|
||||
|
||||
@ -210,7 +210,7 @@ A textual analysis based on word-frequency of the bug fix messages suggests that
|
||||
|
||||
**Security and other impact errors.** Around 7.33% of all the bug fix commits are related to Impact errors. Among them `Erlang, C++`, and `Python` associate with more security errors than average ([Table 8][87]). `Clojure` projects associate with fewer security errors ([Figure 2][88]). From the heat map we also see that `Static` languages are in general more prone to failure and performance errors, these are followed by `Functional-Dynamic-Explicit-Managed` languages such as `Erlang`. The analysis of deviance results confirm that language is strongly associated with failure impacts. While security errors are the weakest among the categories, the deviance explained by language is still quite strong when compared with the residual deviance.
|
||||
|
||||
**Result 4:** _Defect types are strongly associated with languages; some defect type like memory errors and concurrency errors also depend on language primitives. Language matters more for specific categories than it does for defects overall._
|
||||
**Result 4:** _Defect types are strongly associated with languages; some defect type like memory errors and concurrency errors also depend on language primitives. Language matters more for specific categories than it does for defects overall._
|
||||
|
||||
[Back to Top][89]
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
# LEAST PRIVILEGE CONTAINER ORCHESTRATION
|
||||
|
||||
|
||||
@ -172,3 +173,5 @@ via: https://blog.docker.com/2017/10/least-privilege-container-orchestration/
|
||||
[10]:https://blog.docker.com/tag/least-privilege-orchestrator/
|
||||
[11]:https://blog.docker.com/tag/tls/
|
||||
[12]:https://diogomonica.com/2017/03/27/why-you-shouldnt-use-env-variables-for-secret-data/
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,190 @@
|
||||
3 Simple, Excellent Linux Network Monitors
|
||||
============================================================
|
||||
KeyLD translating
|
||||
|
||||

|
||||
Learn more about your network connections with the iftop, Nethogs, and vnstat tools.[Used with permission][3]
|
||||
|
||||
You can learn an amazing amount of information about your network connections with these three glorious Linux networking commands. iftop tracks network connections by process number, Nethogs quickly reveals what is hogging your bandwidth, and vnstat runs as a nice lightweight daemon to record your usage over time.
|
||||
|
||||
### iftop
|
||||
|
||||
The excellent [iftop][8] listens to the network interface that you specify, and displays connections in a top-style interface.
|
||||
|
||||
This is a great little tool for quickly identifying hogs, measuring speed, and also to maintain a running total of your network traffic. It is rather surprising to see how much bandwidth we use, especially for us old people who remember the days of telephone land lines, modems, screaming kilobits of speed, and real live bauds. We abandoned bauds a long time ago in favor of bit rates. Baud measures signal changes, which sometimes were the same as bit rates, but mostly not.
|
||||
|
||||
If you have just one network interface, run iftop with no options. iftop requires root permissions:
|
||||
|
||||
```
|
||||
$ sudo iftop
|
||||
```
|
||||
|
||||
When you have more than one, specify the interface you want to monitor:
|
||||
|
||||
```
|
||||
$ sudo iftop -i wlan0
|
||||
```
|
||||
|
||||
Just like top, you can change the display options while it is running.
|
||||
|
||||
* **h** toggles the help screen.
|
||||
|
||||
* **n** toggles name resolution.
|
||||
|
||||
* **s** toggles source host display, and **d** toggles the destination hosts.
|
||||
|
||||
* **s** toggles port numbers.
|
||||
|
||||
* **N** toggles port resolution; to see all port numbers toggle resolution off.
|
||||
|
||||
* **t** toggles the text interface. The default display requires ncurses. I think the text display is more readable and better-organized (Figure 1).
|
||||
|
||||
* **p** pauses the display.
|
||||
|
||||
* **q** quits the program.
|
||||
|
||||
|
||||

|
||||
Figure 1: The text display is readable and organized.[Used with permission][1]
|
||||
|
||||
When you toggle the display options, iftop continues to measure all traffic. You can also select a single host to monitor. You need the host's IP address and netmask. I was curious how much of a load Pandora put on my sad little meager bandwidth cap, so first I used dig to find their IP address:
|
||||
|
||||
```
|
||||
$ dig A pandora.com
|
||||
[...]
|
||||
;; ANSWER SECTION:
|
||||
pandora.com. 267 IN A 208.85.40.20
|
||||
pandora.com. 267 IN A 208.85.40.50
|
||||
```
|
||||
|
||||
What's the netmask? [ipcalc][9] tells us:
|
||||
|
||||
```
|
||||
$ ipcalc -b 208.85.40.20
|
||||
Address: 208.85.40.20
|
||||
Netmask: 255.255.255.0 = 24
|
||||
Wildcard: 0.0.0.255
|
||||
=>
|
||||
Network: 208.85.40.0/24
|
||||
```
|
||||
|
||||
Now feed the address and netmask to iftop:
|
||||
|
||||
```
|
||||
$ sudo iftop -F 208.85.40.20/24 -i wlan0
|
||||
```
|
||||
|
||||
Is that not seriously groovy? I was surprised to learn that Pandora is easy on my precious bits, using around 500Kb per hour. And, like most streaming services, Pandora's traffic comes in spurts and relies on caching to smooth out the lumps and bumps.
|
||||
|
||||
You can do the same with IPv6 addresses, using the **-G** option. Consult the fine man page to learn the rest of iftop's features, including customizing your default options with a personal configuration file, and applying custom filters (see [PCAP-FILTER][10] for a filter reference).
|
||||
|
||||
### Nethogs
|
||||
|
||||
When you want to quickly learn who is sucking up your bandwidth, Nethogs is fast and easy. Run it as root and specify the interface to listen on. It displays the hoggy application and the process number, so that you may kill it if you so desire:
|
||||
|
||||
```
|
||||
$ sudo nethogs wlan0
|
||||
|
||||
NetHogs version 0.8.1
|
||||
|
||||
PID USER PROGRAM DEV SENT RECEIVED
|
||||
7690 carla /usr/lib/firefox wlan0 12.494 556.580 KB/sec
|
||||
5648 carla .../chromium-browser wlan0 0.052 0.038 KB/sec
|
||||
TOTAL 12.546 556.618 KB/sec
|
||||
```
|
||||
|
||||
Nethogs has few options: cycling between kb/s, kb, b, and mb, sorting by received or sent packets, and adjusting the delay between refreshes. See `man nethogs`, or run `nethogs -h`.
|
||||
|
||||
### vnstat
|
||||
|
||||
[vnstat][11] is the easiest network data collector to use. It is lightweight and does not need root permissions. It runs as a daemon and records your network statistics over time. The `vnstat`command displays the accumulated data:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0
|
||||
Database updated: Tue Oct 17 08:36:38 2017
|
||||
|
||||
wlan0 since 10/17/2017
|
||||
|
||||
rx: 45.27 MiB tx: 3.77 MiB total: 49.04 MiB
|
||||
|
||||
monthly
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
Oct '17 45.27 MiB | 3.77 MiB | 49.04 MiB | 0.28 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 85 MiB | 5 MiB | 90 MiB |
|
||||
|
||||
daily
|
||||
rx | tx | total | avg. rate
|
||||
------------------------+-------------+-------------+---------------
|
||||
today 45.27 MiB | 3.77 MiB | 49.04 MiB | 12.96 kbit/s
|
||||
------------------------+-------------+-------------+---------------
|
||||
estimated 125 MiB | 8 MiB | 133 MiB |
|
||||
```
|
||||
|
||||
By default it displays all network interfaces. Use the `-i` option to select a single interface. Merge the data of multiple interfaces this way:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan0+eth0+eth1
|
||||
```
|
||||
|
||||
You can filter the display in several ways:
|
||||
|
||||
* **-h** displays statistics by hours.
|
||||
|
||||
* **-d** displays statistics by days.
|
||||
|
||||
* **-w** and **-m** displays statistics by weeks and months.
|
||||
|
||||
* Watch live updates with the **-l** option.
|
||||
|
||||
This command deletes the database for wlan1 and stops watching it:
|
||||
|
||||
```
|
||||
$ vnstat -i wlan1 --delete
|
||||
```
|
||||
|
||||
This command creates an alias for a network interface. This example uses one of the weird interface names from Ubuntu 16.04:
|
||||
|
||||
```
|
||||
$ vnstat -u -i enp0s25 --nick eth0
|
||||
```
|
||||
|
||||
By default vnstat monitors eth0\. You can change this in `/etc/vnstat.conf`, or create your own personal configuration file in your home directory. See `man vnstat` for a complete reference.
|
||||
|
||||
You can also install vnstati to create simple, colored graphs (Figure 2):
|
||||
|
||||
```
|
||||
$ vnstati -s -i wlx7cdd90a0a1c2 -o vnstat.png
|
||||
```
|
||||
|
||||
|
||||

|
||||
Figure 2: You can create simple colored graphs with vnstati.[Used with permission][2]
|
||||
|
||||
See `man vnstati` for complete options.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][7]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/3-simple-excellent-linux-network-monitors
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/files/images/fig-1png-8
|
||||
[5]:https://www.linux.com/files/images/fig-2png-5
|
||||
[6]:https://www.linux.com/files/images/bannerpng-3
|
||||
[7]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[8]:http://www.ex-parrot.com/pdw/iftop/
|
||||
[9]:https://www.linux.com/learn/intro-to-linux/2017/8/how-calculate-network-addresses-ipcalc
|
||||
[10]:http://www.tcpdump.org/manpages/pcap-filter.7.html
|
||||
[11]:http://humdi.net/vnstat/
|
||||
@ -1,713 +0,0 @@
|
||||
Translating by qhwdw Dive into BPF: a list of reading material
|
||||
============================================================
|
||||
|
||||
* [What is BPF?][143]
|
||||
|
||||
* [Dive into the bytecode][144]
|
||||
|
||||
* [Resources][145]
|
||||
* [Generic presentations][23]
|
||||
* [About BPF][1]
|
||||
|
||||
* [About XDP][2]
|
||||
|
||||
* [About other components related or based on eBPF][3]
|
||||
|
||||
* [Documentation][24]
|
||||
* [About BPF][4]
|
||||
|
||||
* [About tc][5]
|
||||
|
||||
* [About XDP][6]
|
||||
|
||||
* [About P4 and BPF][7]
|
||||
|
||||
* [Tutorials][25]
|
||||
|
||||
* [Examples][26]
|
||||
* [From the kernel][8]
|
||||
|
||||
* [From package iproute2][9]
|
||||
|
||||
* [From bcc set of tools][10]
|
||||
|
||||
* [Manual pages][11]
|
||||
|
||||
* [The code][27]
|
||||
* [BPF code in the kernel][12]
|
||||
|
||||
* [XDP hooks code][13]
|
||||
|
||||
* [BPF logic in bcc][14]
|
||||
|
||||
* [Code to manage BPF with tc][15]
|
||||
|
||||
* [BPF utilities][16]
|
||||
|
||||
* [Other interesting chunks][17]
|
||||
|
||||
* [LLVM backend][18]
|
||||
|
||||
* [Running in userspace][19]
|
||||
|
||||
* [Commit logs][20]
|
||||
|
||||
* [Troubleshooting][28]
|
||||
* [Errors at compilation time][21]
|
||||
|
||||
* [Errors at load and run time][22]
|
||||
|
||||
* [And still more!][29]
|
||||
|
||||
_~ [Updated][146] 2017-11-02 ~_
|
||||
|
||||
# What is BPF?
|
||||
|
||||
BPF, as in **B**erkeley **P**acket **F**ilter, was initially conceived in 1992 so as to provide a way to filter packets and to avoid useless packet copies from kernel to userspace. It initially consisted in a simple bytecode that is injected from userspace into the kernel, where it is checked by a verifier—to prevent kernel crashes or security issues—and attached to a socket, then run on each received packet. It was ported to Linux a couple of years later, and used for a small number of applications (tcpdump for example). The simplicity of the language as well as the existence of an in-kernel Just-In-Time (JIT) compiling machine for BPF were factors for the excellent performances of this tool.
|
||||
|
||||
Then in 2013, Alexei Starovoitov completely reshaped it, started to add new functionalities and to improve the performances of BPF. This new version is designated as eBPF (for “extended BPF”), while the former becomes cBPF (“classic” BPF). New features such as maps and tail calls appeared. The JIT machines were rewritten. The new language is even closer to native machine language than cBPF was. And also, new attach points in the kernel have been created.
|
||||
|
||||
Thanks to those new hooks, eBPF programs can be designed for a variety of use cases, that divide into two fields of applications. One of them is the domain of kernel tracing and event monitoring. BPF programs can be attached to kprobes and they compare with other tracing methods, with many advantages (and sometimes some drawbacks).
|
||||
|
||||
The other application domain remains network programming. In addition to socket filter, eBPF programs can be attached to tc (Linux traffic control tool) ingress or egress interfaces and perform a variety of packet processing tasks, in an efficient way. This opens new perspectives in the domain.
|
||||
|
||||
And eBPF performances are further leveraged through the technologies developed for the IO Visor project: new hooks have also been added for XDP (“eXpress Data Path”), a new fast path recently added to the kernel. XDP works in conjunction with the Linux stack, and relies on BPF to perform very fast packet processing.
|
||||
|
||||
Even some projects such as P4, Open vSwitch, [consider][155] or started to approach BPF. Some others, such as CETH, Cilium, are entirely based on it. BPF is buzzing, so we can expect a lot of tools and projects to orbit around it soon…
|
||||
|
||||
# Dive into the bytecode
|
||||
|
||||
As for me: some of my work (including for [BEBA][156]) is closely related to eBPF, and several future articles on this site will focus on this topic. Logically, I wanted to somehow introduce BPF on this blog before going down to the details—I mean, a real introduction, more developed on BPF functionalities that the brief abstract provided in first section: What are BPF maps? Tail calls? What do the internals look like? And so on. But there are a lot of presentations on this topic available on the web already, and I do not wish to create “yet another BPF introduction” that would come as a duplicate of existing documents.
|
||||
|
||||
So instead, here is what we will do. After all, I spent some time reading and learning about BPF, and while doing so, I gathered a fair amount of material about BPF: introductions, documentation, but also tutorials or examples. There is a lot to read, but in order to read it, one has to _find_ it first. Therefore, as an attempt to help people who wish to learn and use BPF, the present article introduces a list of resources. These are various kinds of readings, that hopefully will help you dive into the mechanics of this kernel bytecode.
|
||||
|
||||
# Resources
|
||||
|
||||

|
||||
|
||||
### Generic presentations
|
||||
|
||||
The documents linked below provide a generic overview of BPF, or of some closely related topics. If you are very new to BPF, you can try picking a couple of presentation among the first ones and reading the ones you like most. If you know eBPF already, you probably want to target specific topics instead, lower down in the list.
|
||||
|
||||
### About BPF
|
||||
|
||||
Generic presentations about eBPF:
|
||||
|
||||
* [_Making the Kernel’s Networking Data Path Programmable with BPF and XDP_][53] (Daniel Borkmann, OSSNA17, Los Angeles, September 2017):
|
||||
One of the best set of slides available to understand quickly all the basics about eBPF and XDP (mostly for network processing).
|
||||
|
||||
* [The BSD Packet Filter][54] (Suchakra Sharma, June 2017):
|
||||
A very nice introduction, mostly about the tracing aspects.
|
||||
|
||||
* [_BPF: tracing and more_][55] (Brendan Gregg, January 2017):
|
||||
Mostly about the tracing use cases.
|
||||
|
||||
* [_Linux BPF Superpowers_][56] (Brendan Gregg, March 2016):
|
||||
With a first part on the use of **flame graphs**.
|
||||
|
||||
* [_IO Visor_][57] (Brenden Blanco, SCaLE 14x, January 2016):
|
||||
Also introduces **IO Visor project**.
|
||||
|
||||
* [_eBPF on the Mainframe_][58] (Michael Holzheu, LinuxCon, Dubin, October 2015)
|
||||
|
||||
* [_New (and Exciting!) Developments in Linux Tracing_][59] (Elena Zannoni, LinuxCon, Japan, 2015)
|
||||
|
||||
* [_BPF — in-kernel virtual machine_][60] (Alexei Starovoitov, February 2015):
|
||||
Presentation by the author of eBPF.
|
||||
|
||||
* [_Extending extended BPF_][61] (Jonathan Corbet, July 2014)
|
||||
|
||||
**BPF internals**:
|
||||
|
||||
* Daniel Borkmann has been doing an amazing work to present **the internals** of eBPF, in particular about **its use with tc**, through several talks and papers.
|
||||
* [_Advanced programmability and recent updates with tc’s cls_bpf_][30] (netdev 1.2, Tokyo, October 2016):
|
||||
Daniel provides details on eBPF, its use for tunneling and encapsulation, direct packet access, and other features.
|
||||
|
||||
* [_cls_bpf/eBPF updates since netdev 1.1_][31] (netdev 1.2, Tokyo, October 2016, part of [this tc workshop][32])
|
||||
|
||||
* [_On getting tc classifier fully programmable with cls_bpf_][33] (netdev 1.1, Sevilla, February 2016):
|
||||
After introducing eBPF, this presentation provides insights on many internal BPF mechanisms (map management, tail calls, verifier). A must-read! For the most ambitious, [the full paper is available here][34].
|
||||
|
||||
* [_Linux tc and eBPF_][35] (fosdem16, Brussels, Belgium, January 2016)
|
||||
|
||||
* [_eBPF and XDP walkthrough and recent updates_][36] (fosdem17, Brussels, Belgium, February 2017)
|
||||
|
||||
These presentations are probably one of the best sources of documentation to understand the design and implementation of internal mechanisms of eBPF.
|
||||
|
||||
The [**IO Visor blog**][157] has some interesting technical articles about BPF. Some of them contain a bit of marketing talks.
|
||||
|
||||
**Kernel tracing**: summing up all existing methods, including BPF:
|
||||
|
||||
* [_Meet-cute between eBPF and Kerne Tracing_][62] (Viller Hsiao, July 2016):
|
||||
Kprobes, uprobes, ftrace
|
||||
|
||||
* [_Linux Kernel Tracing_][63] (Viller Hsiao, July 2016):
|
||||
Systemtap, Kernelshark, trace-cmd, LTTng, perf-tool, ftrace, hist-trigger, perf, function tracer, tracepoint, kprobe/uprobe…
|
||||
|
||||
Regarding **event tracing and monitoring**, Brendan Gregg uses eBPF a lot and does an excellent job at documenting some of his use cases. If you are in kernel tracing, you should see his blog articles related to eBPF or to flame graphs. Most of it are accessible [from this article][158] or by browsing his blog.
|
||||
|
||||
Introducing BPF, but also presenting **generic concepts of Linux networking**:
|
||||
|
||||
* [_Linux Networking Explained_][64] (Thomas Graf, LinuxCon, Toronto, August 2016)
|
||||
|
||||
* [_Kernel Networking Walkthrough_][65] (Thomas Graf, LinuxCon, Seattle, August 2015)
|
||||
|
||||
**Hardware offload**:
|
||||
|
||||
* eBPF with tc or XDP supports hardware offload, starting with Linux kernel version 4.9 and introduced by Netronome. Here is a presentation about this feature:
|
||||
[eBPF/XDP hardware offload to SmartNICs][147] (Jakub Kicinski and Nic Viljoen, netdev 1.2, Tokyo, October 2016)
|
||||
|
||||
About **cBPF**:
|
||||
|
||||
* [_The BSD Packet Filter: A New Architecture for User-level Packet Capture_][66] (Steven McCanne and Van Jacobson, 1992):
|
||||
The original paper about (classic) BPF.
|
||||
|
||||
* [The FreeBSD manual page about BPF][67] is a useful resource to understand cBPF programs.
|
||||
|
||||
* Daniel Borkmann realized at least two presentations on cBPF, [one in 2013 on mmap, BPF and Netsniff-NG][68], and [a very complete one in 2014 on tc and cls_bpf][69].
|
||||
|
||||
* On Cloudflare’s blog, Marek Majkowski presented his [use of BPF bytecode with the `xt_bpf`module for **iptables**][70]. It is worth mentioning that eBPF is also supported by this module, starting with Linux kernel 4.10 (I do not know of any talk or article about this, though).
|
||||
|
||||
* [Libpcap filters syntax][71]
|
||||
|
||||
### About XDP
|
||||
|
||||
* [XDP overview][72] on the IO Visor website.
|
||||
|
||||
* [_eXpress Data Path (XDP)_][73] (Tom Herbert, Alexei Starovoitov, March 2016):
|
||||
The first presentation about XDP.
|
||||
|
||||
* [_BoF - What Can BPF Do For You?_][74] (Brenden Blanco, LinuxCon, Toronto, August 2016).
|
||||
|
||||
* [_eXpress Data Path_][148] (Brenden Blanco, Linux Meetup at Santa Clara, July 2016):
|
||||
Contains some (somewhat marketing?) **benchmark results**! With a single core:
|
||||
* ip routing drop: ~3.6 million packets per second (Mpps)
|
||||
|
||||
* tc (with clsact qdisc) drop using BPF: ~4.2 Mpps
|
||||
|
||||
* XDP drop using BPF: 20 Mpps (<10 % CPU utilization)
|
||||
|
||||
* XDP forward (on port on which the packet was received) with rewrite: 10 Mpps
|
||||
|
||||
(Tests performed with the mlx4 driver).
|
||||
|
||||
* Jesper Dangaard Brouer has several excellent sets of slides, that are essential to fully understand the internals of XDP.
|
||||
* [_XDP − eXpress Data Path, Intro and future use-cases_][37] (September 2016):
|
||||
_“Linux Kernel’s fight against DPDK”_ . **Future plans** (as of this writing) for XDP and comparison with DPDK.
|
||||
|
||||
* [_Network Performance Workshop_][38] (netdev 1.2, Tokyo, October 2016):
|
||||
Additional hints about XDP internals and expected evolution.
|
||||
|
||||
* [_XDP – eXpress Data Path, Used for DDoS protection_][39] (OpenSourceDays, March 2017):
|
||||
Contains details and use cases about XDP, with **benchmark results**, and **code snippets** for **benchmarking** as well as for **basic DDoS protection** with eBPF/XDP (based on an IP blacklisting scheme).
|
||||
|
||||
* [_Memory vs. Networking, Provoking and fixing memory bottlenecks_][40] (LSF Memory Management Summit, March 2017):
|
||||
Provides a lot of details about current **memory issues** faced by XDP developers. Do not start with this one, but if you already know XDP and want to see how it really works on the page allocation side, this is a very helpful resource.
|
||||
|
||||
* [_XDP for the Rest of Us_][41] (netdev 2.1, Montreal, April 2017), with Andy Gospodarek:
|
||||
How to get started with eBPF and XDP for normal humans. This presentation was also summarized by Julia Evans on [her blog][42].
|
||||
|
||||
(Jesper also created and tries to extend some documentation about eBPF and XDP, see [related section][75].)
|
||||
|
||||
* [_XDP workshop — Introduction, experience, and future development_][76] (Tom Herbert, netdev 1.2, Tokyo, October 2016) — as of this writing, only the video is available, I don’t know if the slides will be added.
|
||||
|
||||
* [_High Speed Packet Filtering on Linux_][149] (Gilberto Bertin, DEF CON 25, Las Vegas, July 2017) — an excellent introduction to state-of-the-art packet filtering on Linux, oriented towards DDoS protection, talking about packet processing in the kernel, kernel bypass, XDP and eBPF.
|
||||
|
||||
### About other components related or based on eBPF
|
||||
|
||||
* [_P4 on the Edge_][77] (John Fastabend, May 2016):
|
||||
Presents the use of **P4**, a description language for packet processing, with BPF to create high-performance programmable switches.
|
||||
|
||||
* If you like audio presentations, there is an associated [OvS Orbit episode (#11), called _**P4** on the Edge_][78] , dating from August 2016\. OvS Orbit are interviews realized by Ben Pfaff, who is one of the core maintainers of Open vSwitch. In this case, John Fastabend is interviewed.
|
||||
|
||||
* [_P4, EBPF and Linux TC Offload_][79] (Dinan Gunawardena and Jakub Kicinski, August 2016):
|
||||
Another presentation on **P4**, with some elements related to eBPF hardware offload on Netronome’s **NFP** (Network Flow Processor) architecture.
|
||||
|
||||
* **Cilium** is a technology initiated by Cisco and relying on BPF and XDP to provide “fast in-kernel networking and security policy enforcement for containers based on eBPF programs generated on the fly”. [The code of this project][150] is available on GitHub. Thomas Graf has been performing a number of presentations of this topic:
|
||||
* [_Cilium: Networking & Security for Containers with BPF & XDP_][43] , also featuring a load balancer use case (Linux Plumbers conference, Santa Fe, November 2016)
|
||||
|
||||
* [_Cilium: Networking & Security for Containers with BPF & XDP_][44] (Docker Distributed Systems Summit, October 2016 — [video][45])
|
||||
|
||||
* [_Cilium: Fast IPv6 container Networking with BPF and XDP_][46] (LinuxCon, Toronto, August 2016)
|
||||
|
||||
* [_Cilium: BPF & XDP for containers_][47] (fosdem17, Brussels, Belgium, February 2017)
|
||||
|
||||
A good deal of contents is repeated between the different presentations; if in doubt, just pick the most recent one. Daniel Borkmann has also written [a generic introduction to Cilium][80] as a guest author on Google Open Source blog.
|
||||
|
||||
* There are also podcasts about **Cilium**: an [OvS Orbit episode (#4)][81], in which Ben Pfaff interviews Thomas Graf (May 2016), and [another podcast by Ivan Pepelnjak][82], still with Thomas Graf about eBPF, P4, XDP and Cilium (October 2016).
|
||||
|
||||
* **Open vSwitch** (OvS), and its related project **Open Virtual Network** (OVN, an open source network virtualization solution) are considering to use eBPF at various level, with several proof-of-concept prototypes already implemented:
|
||||
|
||||
* [Offloading OVS Flow Processing using eBPF][48] (William (Cheng-Chun) Tu, OvS conference, San Jose, November 2016)
|
||||
|
||||
* [Coupling the Flexibility of OVN with the Efficiency of IOVisor][49] (Fulvio Risso, Matteo Bertrone and Mauricio Vasquez Bernal, OvS conference, San Jose, November 2016)
|
||||
|
||||
These use cases for eBPF seem to be only at the stage of proposals (nothing merge to OvS main branch) as far as I know, but it will be very interesting to see what comes out of it.
|
||||
|
||||
* XDP is envisioned to be of great help for protection against Distributed Denial-of-Service (DDoS) attacks. More and more presentations focus on this. For example, the talks from people from Cloudflare ( [_XDP in practice: integrating XDP in our DDoS mitigation pipeline_][83] ) or from Facebook ( [_Droplet: DDoS countermeasures powered by BPF + XDP_][84] ) at the netdev 2.1 conference in Montreal, Canada, in April 2017, present such use cases.
|
||||
|
||||
* [_CETH for XDP_][85] (Yan Chan and Yunsong Lu, Linux Meetup, Santa Clara, July 2016):
|
||||
**CETH** stands for Common Ethernet Driver Framework for faster network I/O, a technology initiated by Mellanox.
|
||||
|
||||
* [**The VALE switch**][86], another virtual switch that can be used in conjunction with the netmap framework, has [a BPF extension module][87].
|
||||
|
||||
* **Suricata**, an open source intrusion detection system, [seems to rely on eBPF components][88] for its “capture bypass” features:
|
||||
[_The adventures of a Suricate in eBPF land_][89] (Éric Leblond, netdev 1.2, Tokyo, October 2016)
|
||||
[_eBPF and XDP seen from the eyes of a meerkat_][90] (Éric Leblond, Kernel Recipes, Paris, September 2017)
|
||||
|
||||
* [InKeV: In-Kernel Distributed Network Virtualization for DCN][91] (Z. Ahmed, M. H. Alizai and A. A. Syed, SIGCOMM, August 2016):
|
||||
**InKeV** is an eBPF-based datapath architecture for virtual networks, targeting data center networks. It was initiated by PLUMgrid, and claims to achieve better performances than OvS-based OpenStack solutions.
|
||||
|
||||
* [_**gobpf** - utilizing eBPF from Go_][92] (Michael Schubert, fosdem17, Brussels, Belgium, February 2017):
|
||||
A “library to create, load and use eBPF programs from Go”
|
||||
|
||||
* [**ply**][93] is a small but flexible open source dynamic **tracer** for Linux, with some features similar to the bcc tools, but with a simpler language inspired by awk and dtrace, written by Tobias Waldekranz.
|
||||
|
||||
* If you read my previous article, you might be interested in this talk I gave about [implementing the OpenState interface with eBPF][151], for stateful packet processing, at fosdem17.
|
||||
|
||||

|
||||
|
||||
### Documentation
|
||||
|
||||
Once you managed to get a broad idea of what BPF is, you can put aside generic presentations and start diving into the documentation. Below are the most complete documents about BPF specifications and functioning. Pick the one you need and read them carefully!
|
||||
|
||||
### About BPF
|
||||
|
||||
* The **specification of BPF** (both classic and extended versions) can be found within the documentation of the Linux kernel, and in particular in file[linux/Documentation/networking/filter.txt][94]. The use of BPF as well as its internals are documented there. Also, this is where you can find **information about errors thrown by the verifier** when loading BPF code fails. Can be helpful to troubleshoot obscure error messages.
|
||||
|
||||
* Also in the kernel tree, there is a document about **frequent Questions & Answers** on eBPF design in file [linux/Documentation/bpf/bpf_design_QA.txt][95].
|
||||
|
||||
* … But the kernel documentation is dense and not especially easy to read. If you look for a simple description of eBPF language, head for [its **summarized description**][96] on the IO Visor GitHub repository instead.
|
||||
|
||||
* By the way, the IO Visor project gathered a lot of **resources about BPF**. Mostly, it is split between[the documentation directory][97] of its bcc repository, and the whole content of [the bpf-docs repository][98], both on GitHub. Note the existence of this excellent [BPF **reference guide**][99] containing a detailed description of BPF C and bcc Python helpers.
|
||||
|
||||
* To hack with BPF, there are some essential **Linux manual pages**. The first one is [the `bpf(2)` man page][100] about the `bpf()` **system call**, which is used to manage BPF programs and maps from userspace. It also contains a description of BPF advanced features (program types, maps and so on). The second one is mostly addressed to people wanting to attach BPF programs to tc interface: it is [the `tc-bpf(8)` man page][101], which is a reference for **using BPF with tc**, and includes some example commands and samples of code.
|
||||
|
||||
* Jesper Dangaard Brouer initiated an attempt to **update eBPF Linux documentation**, including **the different kinds of maps**. [He has a draft][102] to which contributions are welcome. Once ready, this document should be merged into the man pages and into kernel documentation.
|
||||
|
||||
* The Cilium project also has an excellent [**BPF and XDP Reference Guide**][103], written by core eBPF developers, that should prove immensely useful to any eBPF developer.
|
||||
|
||||
* David Miller has sent several enlightening emails about eBPF/XDP internals on the [xdp-newbies][152]mailing list. I could not find a link that gathers them at a single place, so here is a list:
|
||||
* [bpf.h and you…][50]
|
||||
|
||||
* [Contextually speaking…][51]
|
||||
|
||||
* [BPF Verifier Overview][52]
|
||||
|
||||
The last one is possibly the best existing summary about the verifier at this date.
|
||||
|
||||
* Ferris Ellis started [a **blog post series about eBPF**][104]. As I write this paragraph, the first article is out, with some historical background and future expectations for eBPF. Next posts should be more technical, and look promising.
|
||||
|
||||
* [A **list of BPF features per kernel version**][153] is available in bcc repository. Useful is you want to know the minimal kernel version that is required to run a given feature. I contributed and added the links to the commits that introduced each feature, so you can also easily access the commit logs from there.
|
||||
|
||||
### About tc
|
||||
|
||||
When using BPF for networking purposes in conjunction with tc, the Linux tool for **t**raffic **c**ontrol, one may wish to gather information about tc’s generic functioning. Here are a couple of resources about it.
|
||||
|
||||
* It is difficult to find simple tutorials about **QoS on Linux**. The two links I have are long and quite dense, but if you can find the time to read it you will learn nearly everything there is to know about tc (nothing about BPF, though). There they are: [_Traffic Control HOWTO_ (Martin A. Brown, 2006)][105], and the [_Linux Advanced Routing & Traffic Control HOWTO_ (“LARTC”) (Bert Hubert & al., 2002)][106].
|
||||
|
||||
* **tc manual pages** may not be up-to-date on your system, since several of them have been added lately. If you cannot find the documentation for a particular queuing discipline (qdisc), class or filter, it may be worth checking the latest [manual pages for tc components][107].
|
||||
|
||||
* Some additional material can be found within the files of iproute2 package itself: the package contains [some documentation][108], including some files that helped me understand better [the functioning of **tc’s actions**][109].
|
||||
**Edit:** While still available from the Git history, these files have been deleted from iproute2 in October 2017.
|
||||
|
||||
* Not exactly documentation: there was [a workshop about several tc features][110] (including filtering, BPF, tc offload, …) organized by Jamal Hadi Salim during the netdev 1.2 conference (October 2016).
|
||||
|
||||
* Bonus information—If you use `tc` a lot, here are some good news: I [wrote a bash completion function][111] for this tool, and it should be shipped with package iproute2 coming with kernel version 4.6 and higher!
|
||||
|
||||
### About XDP
|
||||
|
||||
* Some [work-in-progress documentation (including specifications)][112] for XDP started by Jesper Dangaard Brouer, but meant to be a collaborative work. Under progress (September 2016): you should expect it to change, and maybe to be moved at some point (Jesper [called for contribution][113], if you feel like improving it).
|
||||
|
||||
* The [BPF and XDP Reference Guide][114] from Cilium project… Well, the name says it all.
|
||||
|
||||
### About P4 and BPF
|
||||
|
||||
[P4][159] is a language used to specify the behavior of a switch. It can be compiled for a number of hardware or software targets. As you may have guessed, one of these targets is BPF… The support is only partial: some P4 features cannot be translated towards BPF, and in a similar way there are things that BPF can do but that would not be possible to express with P4\. Anyway, the documentation related to **P4 use with BPF** [used to be hidden in bcc repository][160]. This changed with P4_16 version, the p4c reference compiler including [a backend for eBPF][161].
|
||||
|
||||

|
||||
|
||||
### Tutorials
|
||||
|
||||
Brendan Gregg has produced excellent **tutorials** intended for people who want to **use bcc tools** for tracing and monitoring events in the kernel. [The first tutorial about using bcc itself][162] comes with eleven steps (as of today) to understand how to use the existing tools, while [the one **intended for Python developers**][163] focuses on developing new tools, across seventeen “lessons”.
|
||||
|
||||
Sasha Goldshtein also has some [_**Linux Tracing Workshops Materials**_][164] involving the use of several BPF tools for tracing.
|
||||
|
||||
Another post by Jean-Tiare Le Bigot provides a detailed (and instructive!) example of [using perf and eBPF to setup a low-level tracer][165] for ping requests and replies
|
||||
|
||||
Few tutorials exist for network-related eBPF use cases. There are some interesting documents, including an _eBPF Offload Starting Guide_ , on the [Open NFP][166] platform operated by Netronome. Other than these, the talk from Jesper, [_XDP for the Rest of Us_][167] , is probably one of the best ways to get started with XDP.
|
||||
|
||||

|
||||
|
||||
### Examples
|
||||
|
||||
It is always nice to have examples. To see how things really work. But BPF program samples are scattered across several projects, so I listed all the ones I know of. The examples do not always use the same helpers (for instance, tc and bcc both have their own set of helpers to make it easier to write BPF programs in C language).
|
||||
|
||||
### From the kernel
|
||||
|
||||
The kernel contains examples for most types of program: filters to bind to sockets or to tc interfaces, event tracing/monitoring, and even XDP. You can find these examples under the [linux/samples/bpf/][168]directory.
|
||||
|
||||
Also do not forget to have a look to the logs related to the (git) commits that introduced a particular feature, they may contain some detailed example of the feature.
|
||||
|
||||
### From package iproute2
|
||||
|
||||
The iproute2 package provide several examples as well. They are obviously oriented towards network programming, since the programs are to be attached to tc ingress or egress interfaces. The examples dwell under the [iproute2/examples/bpf/][169] directory.
|
||||
|
||||
### From bcc set of tools
|
||||
|
||||
Many examples are [provided with bcc][170]:
|
||||
|
||||
* Some are networking example programs, under the associated directory. They include socket filters, tc filters, and a XDP program.
|
||||
|
||||
* The `tracing` directory include a lot of example **tracing programs**. The tutorials mentioned earlier are based on these. These programs cover a wide range of event monitoring functions, and some of them are production-oriented. Note that on certain Linux distributions (at least for Debian, Ubuntu, Fedora, Arch Linux), these programs have been [packaged][115] and can be “easily” installed by typing e.g. `# apt install bcc-tools`, but as of this writing (and except for Arch Linux), this first requires to set up IO Visor’s own package repository.
|
||||
|
||||
* There are also some examples **using Lua** as a different BPF back-end (that is, BPF programs are written with Lua instead of a subset of C, allowing to use the same language for front-end and back-end), in the third directory.
|
||||
|
||||
### Manual pages
|
||||
|
||||
While bcc is generally the easiest way to inject and run a BPF program in the kernel, attaching programs to tc interfaces can also be performed by the `tc` tool itself. So if you intend to **use BPF with tc**, you can find some example invocations in the [`tc-bpf(8)` manual page][171].
|
||||
|
||||

|
||||
|
||||
### The code
|
||||
|
||||
Sometimes, BPF documentation or examples are not enough, and you may have no other solution that to display the code in your favorite text editor (which should be Vim of course) and to read it. Or you may want to hack into the code so as to patch or add features to the machine. So here are a few pointers to the relevant files, finding the functions you want is up to you!
|
||||
|
||||
### BPF code in the kernel
|
||||
|
||||
* The file [linux/include/linux/bpf.h][116] and its counterpart [linux/include/uapi/bpf.h][117] contain **definitions** related to eBPF, to be used respectively in the kernel and to interface with userspace programs.
|
||||
|
||||
* On the same pattern, files [linux/include/linux/filter.h][118] and [linux/include/uapi/filter.h][119] contain information used to **run the BPF programs**.
|
||||
|
||||
* The **main pieces of code** related to BPF are under [linux/kernel/bpf/][120] directory. **The different operations permitted by the system call**, such as program loading or map management, are implemented in file `syscall.c`, while `core.c` contains the **interpreter**. The other files have self-explanatory names: `verifier.c` contains the **verifier** (no kidding), `arraymap.c` the code used to interact with **maps** of type array, and so on.
|
||||
|
||||
* The **helpers**, as well as several functions related to networking (with tc, XDP…) and available to the user, are implemented in [linux/net/core/filter.c][121]. It also contains the code to migrate cBPF bytecode to eBPF (since all cBPF programs are now translated to eBPF in the kernel before being run).
|
||||
|
||||
* The **JIT compilers** are under the directory of their respective architectures, such as file[linux/arch/x86/net/bpf_jit_comp.c][122] for x86.
|
||||
|
||||
* You will find the code related to **the BPF components of tc** in the [linux/net/sched/][123] directory, and in particular in files `act_bpf.c` (action) and `cls_bpf.c` (filter).
|
||||
|
||||
* I have not hacked with **event tracing** in BPF, so I do not really know about the hooks for such programs. There is some stuff in [linux/kernel/trace/bpf_trace.c][124]. If you are interested in this and want to know more, you may dig on the side of Brendan Gregg’s presentations or blog posts.
|
||||
|
||||
* Nor have I used **seccomp-BPF**. But the code is in [linux/kernel/seccomp.c][125], and some example use cases can be found in [linux/tools/testing/selftests/seccomp/seccomp_bpf.c][126].
|
||||
|
||||
### XDP hooks code
|
||||
|
||||
Once loaded into the in-kernel BPF virtual machine, **XDP** programs are hooked from userspace into the kernel network path thanks to a Netlink command. On reception, the function `dev_change_xdp_fd()` in file [linux/net/core/dev.c][172] is called and sets a XDP hook. Such hooks are located in the drivers of supported NICs. For example, the mlx4 driver used for some Mellanox hardware has hooks implemented in files under the [drivers/net/ethernet/mellanox/mlx4/][173] directory. File en_netdev.c receives Netlink commands and calls `mlx4_xdp_set()`, which in turns calls for instance `mlx4_en_process_rx_cq()` (for the RX side) implemented in file en_rx.c.
|
||||
|
||||
### BPF logic in bcc
|
||||
|
||||
One can find the code for the **bcc** set of tools [on the bcc GitHub repository][174]. The **Python code**, including the `BPF` class, is initiated in file [bcc/src/python/bcc/__init__.py][175]. But most of the interesting stuff—to my opinion—such as loading the BPF program into the kernel, happens [in the libbcc **C library**][176].
|
||||
|
||||
### Code to manage BPF with tc
|
||||
|
||||
The code related to BPF **in tc** comes with the iproute2 package, of course. Some of it is under the[iproute2/tc/][177] directory. The files f_bpf.c and m_bpf.c (and e_bpf.c) are used respectively to handle BPF filters and actions (and tc `exec` command, whatever this may be). File q_clsact.c defines the `clsact` qdisc especially created for BPF. But **most of the BPF userspace logic** is implemented in[iproute2/lib/bpf.c][178] library, so this is probably where you should head to if you want to mess up with BPF and tc (it was moved from file iproute2/tc/tc_bpf.c, where you may find the same code in older versions of the package).
|
||||
|
||||
### BPF utilities
|
||||
|
||||
The kernel also ships the sources of three tools (`bpf_asm.c`, `bpf_dbg.c`, `bpf_jit_disasm.c`) related to BPF, under the [linux/tools/net/][179] or [linux/tools/bpf/][180] directory depending on your version:
|
||||
|
||||
* `bpf_asm` is a minimal cBPF assembler.
|
||||
|
||||
* `bpf_dbg` is a small debugger for cBPF programs.
|
||||
|
||||
* `bpf_jit_disasm` is generic for both BPF flavors and could be highly useful for JIT debugging.
|
||||
|
||||
* `bpftool` is a generic utility written by Jakub Kicinski, and that can be used to interact with eBPF programs and maps from userspace, for example to show, dump, pin programs, or to show, create, pin, update, delete maps.
|
||||
|
||||
Read the comments at the top of the source files to get an overview of their usage.
|
||||
|
||||
### Other interesting chunks
|
||||
|
||||
If you are interested the use of less common languages with BPF, bcc contains [a **P4 compiler** for BPF targets][181] as well as [a **Lua front-end**][182] that can be used as alternatives to the C subset and (in the case of Lua) to the Python tools.
|
||||
|
||||
### LLVM backend
|
||||
|
||||
The BPF backend used by clang / LLVM for compiling C into eBPF was added to the LLVM sources in[this commit][183] (and can also be accessed on [the GitHub mirror][184]).
|
||||
|
||||
### Running in userspace
|
||||
|
||||
As far as I know there are at least two eBPF userspace implementations. The first one, [uBPF][185], is written in C. It contains an interpreter, a JIT compiler for x86_64 architecture, an assembler and a disassembler.
|
||||
|
||||
The code of uBPF seems to have been reused to produce a [generic implementation][186], that claims to support FreeBSD kernel, FreeBSD userspace, Linux kernel, Linux userspace and MacOSX userspace. It is used for the [BPF extension module for VALE switch][187].
|
||||
|
||||
The other userspace implementation is my own work: [rbpf][188], based on uBPF, but written in Rust. The interpreter and JIT-compiler work (both under Linux, only the interpreter for MacOSX and Windows), there may be more in the future.
|
||||
|
||||
### Commit logs
|
||||
|
||||
As stated earlier, do not hesitate to have a look at the commit log that introduced a particular BPF feature if you want to have more information about it. You can search the logs in many places, such as on [git.kernel.org][189], [on GitHub][190], or on your local repository if you have cloned it. If you are not familiar with git, try things like `git blame <file>` to see what commit introduced a particular line of code, then `git show <commit>` to have details (or search by keyword in `git log` results, but this may be tedious). See also [the list of eBPF features per kernel version][191] on bcc repository, that links to relevant commits.
|
||||
|
||||

|
||||
|
||||
### Troubleshooting
|
||||
|
||||
The enthusiasm about eBPF is quite recent, and so far I have not found a lot of resources intending to help with troubleshooting. So here are the few I have, augmented with my own recollection of pitfalls encountered while working with BPF.
|
||||
|
||||
### Errors at compilation time
|
||||
|
||||
* Make sure you have a recent enough version of the Linux kernel (see also [this document][127]).
|
||||
|
||||
* If you compiled the kernel yourself: make sure you installed correctly all components, including kernel image, headers and libc.
|
||||
|
||||
* When using the `bcc` shell function provided by `tc-bpf` man page (to compile C code into BPF): I once had to add includes to the header for the clang call:
|
||||
|
||||
```
|
||||
__bcc() {
|
||||
clang -O2 -I "/usr/src/linux-headers-$(uname -r)/include/" \
|
||||
-I "/usr/src/linux-headers-$(uname -r)/arch/x86/include/" \
|
||||
-emit-llvm -c $1 -o - | \
|
||||
llc -march=bpf -filetype=obj -o "`basename $1 .c`.o"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
(seems fixed as of today).
|
||||
|
||||
* For other problems with `bcc`, do not forget to have a look at [the FAQ][128] of the tool set.
|
||||
|
||||
* If you downloaded the examples from the iproute2 package in a version that does not exactly match your kernel, some errors can be triggered by the headers included in the files. The example snippets indeed assume that the same version of iproute2 package and kernel headers are installed on the system. If this is not the case, download the correct version of iproute2, or edit the path of included files in the examples to point to the headers included in iproute2 (some problems may or may not occur at runtime, depending on the features in use).
|
||||
|
||||
### Errors at load and run time
|
||||
|
||||
* To load a program with tc, make sure you use a tc binary coming from an iproute2 version equivalent to the kernel in use.
|
||||
|
||||
* To load a program with bcc, make sure you have bcc installed on the system (just downloading the sources to run the Python script is not enough).
|
||||
|
||||
* With tc, if the BPF program does not return the expected values, check that you called it in the correct fashion: filter, or action, or filter with “direct-action” mode.
|
||||
|
||||
* With tc still, note that actions cannot be attached directly to qdiscs or interfaces without the use of a filter.
|
||||
|
||||
* The errors thrown by the in-kernel verifier may be hard to interpret. [The kernel documentation][129]may help, so may [the reference guide][130] or, as a last resort, the source code (see above) (good luck!). For this kind of errors it is also important to keep in mind that the verifier _does not run_ the program. If you get an error about an invalid memory access or about uninitialized data, it does not mean that these problems actually occurred (or sometimes, that they can possibly occur at all). It means that your program is written in such a way that the verifier estimates that such errors could happen, and therefore it rejects the program.
|
||||
|
||||
* Note that `tc` tool has a verbose mode, and that it works well with BPF: try appending `verbose`at the end of your command line.
|
||||
|
||||
* bcc also has verbose options: the `BPF` class has a `debug` argument that can take any combination of the three flags `DEBUG_LLVM_IR`, `DEBUG_BPF` and `DEBUG_PREPROCESSOR` (see details in [the source file][131]). It even embeds [some facilities to print output messages][132] for debugging the code.
|
||||
|
||||
* LLVM v4.0+ [embeds a disassembler][133] for eBPF programs. So if you compile your program with clang, adding the `-g` flag for compiling enables you to later dump your program in the rather human-friendly format used by the kernel verifier. To proceed to the dump, use:
|
||||
|
||||
```
|
||||
$ llvm-objdump -S -no-show-raw-insn bpf_program.o
|
||||
|
||||
```
|
||||
|
||||
* Working with maps? You want to have a look at [bpf-map][134], a very userful tool in Go created for the Cilium project, that can be used to dump the contents of kernel eBPF maps. There also exists [a clone][135] in Rust.
|
||||
|
||||
* There is an old [`bpf` tag on **StackOverflow**][136], but as of this writing it has been hardly used—ever (and there is nearly nothing related to the new eBPF version). If you are a reader from the Future though, you may want to check whether there has been more activity on this side.
|
||||
|
||||

|
||||
|
||||
### And still more!
|
||||
|
||||
* In case you would like to easily **test XDP**, there is [a Vagrant setup][137] available. You can also **test bcc**[in a Docker container][138].
|
||||
|
||||
* Wondering where the **development and activities** around BPF occur? Well, the kernel patches always end up [on the netdev mailing list][139] (related to the Linux kernel networking stack development): search for “BPF” or “XDP” keywords. Since April 2017, there is also [a mailing list specially dedicated to XDP programming][140] (both for architecture or for asking for help). Many discussions and debates also occur [on the IO Visor mailing list][141], since BPF is at the heart of the project. If you only want to keep informed from time to time, there is also an [@IOVisor Twitter account][142].
|
||||
|
||||
And come back on this blog from time to time to see if they are new articles [about BPF][192]!
|
||||
|
||||
_Special thanks to Daniel Borkmann for the numerous [additional documents][154] he pointed to me so that I could complete this collection._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
|
||||
|
||||
作者:[Quentin Monnet ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://qmonnet.github.io/whirl-offload/about/
|
||||
[1]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-bpf
|
||||
[2]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp
|
||||
[3]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-other-components-related-or-based-on-ebpf
|
||||
[4]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-bpf-1
|
||||
[5]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-tc
|
||||
[6]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp-1
|
||||
[7]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-p4-and-bpf
|
||||
[8]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-the-kernel
|
||||
[9]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-package-iproute2
|
||||
[10]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-bcc-set-of-tools
|
||||
[11]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#manual-pages
|
||||
[12]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-code-in-the-kernel
|
||||
[13]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#xdp-hooks-code
|
||||
[14]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-logic-in-bcc
|
||||
[15]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#code-to-manage-bpf-with-tc
|
||||
[16]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-utilities
|
||||
[17]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#other-interesting-chunks
|
||||
[18]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#llvm-backend
|
||||
[19]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#running-in-userspace
|
||||
[20]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#commit-logs
|
||||
[21]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#errors-at-compilation-time
|
||||
[22]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#errors-at-load-and-run-time
|
||||
[23]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#generic-presentations
|
||||
[24]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#documentation
|
||||
[25]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#tutorials
|
||||
[26]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#examples
|
||||
[27]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#the-code
|
||||
[28]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#troubleshooting
|
||||
[29]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#and-still-more
|
||||
[30]:http://netdevconf.org/1.2/session.html?daniel-borkmann
|
||||
[31]:http://netdevconf.org/1.2/slides/oct5/07_tcws_daniel_borkmann_2016_tcws.pdf
|
||||
[32]:http://netdevconf.org/1.2/session.html?jamal-tc-workshop
|
||||
[33]:http://www.netdevconf.org/1.1/proceedings/slides/borkmann-tc-classifier-cls-bpf.pdf
|
||||
[34]:http://www.netdevconf.org/1.1/proceedings/papers/On-getting-tc-classifier-fully-programmable-with-cls-bpf.pdf
|
||||
[35]:https://archive.fosdem.org/2016/schedule/event/ebpf/attachments/slides/1159/export/events/attachments/ebpf/slides/1159/ebpf.pdf
|
||||
[36]:https://fosdem.org/2017/schedule/event/ebpf_xdp/
|
||||
[37]:http://people.netfilter.org/hawk/presentations/xdp2016/xdp_intro_and_use_cases_sep2016.pdf
|
||||
[38]:http://netdevconf.org/1.2/session.html?jesper-performance-workshop
|
||||
[39]:http://people.netfilter.org/hawk/presentations/OpenSourceDays2017/XDP_DDoS_protecting_osd2017.pdf
|
||||
[40]:http://people.netfilter.org/hawk/presentations/MM-summit2017/MM-summit2017-JesperBrouer.pdf
|
||||
[41]:http://netdevconf.org/2.1/session.html?gospodarek
|
||||
[42]:http://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
|
||||
[43]:http://www.slideshare.net/ThomasGraf5/clium-container-networking-with-bpf-xdp
|
||||
[44]:http://www.slideshare.net/Docker/cilium-bpf-xdp-for-containers-66969823
|
||||
[45]:https://www.youtube.com/watch?v=TnJF7ht3ZYc&list=PLkA60AVN3hh8oPas3cq2VA9xB7WazcIgs
|
||||
[46]:http://www.slideshare.net/ThomasGraf5/cilium-fast-ipv6-container-networking-with-bpf-and-xdp
|
||||
[47]:https://fosdem.org/2017/schedule/event/cilium/
|
||||
[48]:http://openvswitch.org/support/ovscon2016/7/1120-tu.pdf
|
||||
[49]:http://openvswitch.org/support/ovscon2016/7/1245-bertrone.pdf
|
||||
[50]:https://www.spinics.net/lists/xdp-newbies/msg00179.html
|
||||
[51]:https://www.spinics.net/lists/xdp-newbies/msg00181.html
|
||||
[52]:https://www.spinics.net/lists/xdp-newbies/msg00185.html
|
||||
[53]:http://schd.ws/hosted_files/ossna2017/da/BPFandXDP.pdf
|
||||
[54]:https://speakerdeck.com/tuxology/the-bsd-packet-filter
|
||||
[55]:http://www.slideshare.net/brendangregg/bpf-tracing-and-more
|
||||
[56]:http://fr.slideshare.net/brendangregg/linux-bpf-superpowers
|
||||
[57]:https://www.socallinuxexpo.org/sites/default/files/presentations/Room%20211%20-%20IOVisor%20-%20SCaLE%2014x.pdf
|
||||
[58]:https://events.linuxfoundation.org/sites/events/files/slides/ebpf_on_the_mainframe_lcon_2015.pdf
|
||||
[59]:https://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf
|
||||
[60]:https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[61]:https://lwn.net/Articles/603983/
|
||||
[62]:http://www.slideshare.net/vh21/meet-cutebetweenebpfandtracing
|
||||
[63]:http://www.slideshare.net/vh21/linux-kernel-tracing
|
||||
[64]:http://www.slideshare.net/ThomasGraf5/linux-networking-explained
|
||||
[65]:http://www.slideshare.net/ThomasGraf5/linuxcon-2015-linux-kernel-networking-walkthrough
|
||||
[66]:http://www.tcpdump.org/papers/bpf-usenix93.pdf
|
||||
[67]:http://www.gsp.com/cgi-bin/man.cgi?topic=bpf
|
||||
[68]:http://borkmann.ch/talks/2013_devconf.pdf
|
||||
[69]:http://borkmann.ch/talks/2014_devconf.pdf
|
||||
[70]:https://blog.cloudflare.com/introducing-the-bpf-tools/
|
||||
[71]:http://biot.com/capstats/bpf.html
|
||||
[72]:https://www.iovisor.org/technology/xdp
|
||||
[73]:https://github.com/iovisor/bpf-docs/raw/master/Express_Data_Path.pdf
|
||||
[74]:https://events.linuxfoundation.org/sites/events/files/slides/iovisor-lc-bof-2016.pdf
|
||||
[75]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp-1
|
||||
[76]:http://netdevconf.org/1.2/session.html?herbert-xdp-workshop
|
||||
[77]:https://schd.ws/hosted_files/2016p4workshop/1d/Intel%20Fastabend-P4%20on%20the%20Edge.pdf
|
||||
[78]:https://ovsorbit.benpfaff.org/#e11
|
||||
[79]:http://open-nfp.org/media/pdfs/Open_NFP_P4_EBPF_Linux_TC_Offload_FINAL.pdf
|
||||
[80]:https://opensource.googleblog.com/2016/11/cilium-networking-and-security.html
|
||||
[81]:https://ovsorbit.benpfaff.org/
|
||||
[82]:http://blog.ipspace.net/2016/10/fast-linux-packet-forwarding-with.html
|
||||
[83]:http://netdevconf.org/2.1/session.html?bertin
|
||||
[84]:http://netdevconf.org/2.1/session.html?zhou
|
||||
[85]:http://www.slideshare.net/IOVisor/ceth-for-xdp-linux-meetup-santa-clara-july-2016
|
||||
[86]:http://info.iet.unipi.it/~luigi/vale/
|
||||
[87]:https://github.com/YutaroHayakawa/vale-bpf
|
||||
[88]:https://www.stamus-networks.com/2016/09/28/suricata-bypass-feature/
|
||||
[89]:http://netdevconf.org/1.2/slides/oct6/10_suricata_ebpf.pdf
|
||||
[90]:https://www.slideshare.net/ennael/kernel-recipes-2017-ebpf-and-xdp-eric-leblond
|
||||
[91]:https://github.com/iovisor/bpf-docs/blob/master/university/sigcomm-ccr-InKev-2016.pdf
|
||||
[92]:https://fosdem.org/2017/schedule/event/go_bpf/
|
||||
[93]:https://wkz.github.io/ply/
|
||||
[94]:https://www.kernel.org/doc/Documentation/networking/filter.txt
|
||||
[95]:https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/Documentation/bpf/bpf_design_QA.txt?id=2e39748a4231a893f057567e9b880ab34ea47aef
|
||||
[96]:https://github.com/iovisor/bpf-docs/blob/master/eBPF.md
|
||||
[97]:https://github.com/iovisor/bcc/tree/master/docs
|
||||
[98]:https://github.com/iovisor/bpf-docs/
|
||||
[99]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[100]:http://man7.org/linux/man-pages/man2/bpf.2.html
|
||||
[101]:http://man7.org/linux/man-pages/man8/tc-bpf.8.html
|
||||
[102]:https://prototype-kernel.readthedocs.io/en/latest/bpf/index.html
|
||||
[103]:http://docs.cilium.io/en/latest/bpf/
|
||||
[104]:https://ferrisellis.com/tags/ebpf/
|
||||
[105]:http://linux-ip.net/articles/Traffic-Control-HOWTO/
|
||||
[106]:http://lartc.org/lartc.html
|
||||
[107]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/man/man8
|
||||
[108]:https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc?h=v4.13.0
|
||||
[109]:https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc/actions?h=v4.13.0
|
||||
[110]:http://netdevconf.org/1.2/session.html?jamal-tc-workshop
|
||||
[111]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/commit/bash-completion/tc?id=27d44f3a8a4708bcc99995a4d9b6fe6f81e3e15b
|
||||
[112]:https://prototype-kernel.readthedocs.io/en/latest/networking/XDP/index.html
|
||||
[113]:https://marc.info/?l=linux-netdev&m=147436253625672
|
||||
[114]:http://docs.cilium.io/en/latest/bpf/
|
||||
[115]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[116]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/bpf.h
|
||||
[117]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/bpf.h
|
||||
[118]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/filter.h
|
||||
[119]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/filter.h
|
||||
[120]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/bpf
|
||||
[121]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/filter.c
|
||||
[122]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/arch/x86/net/bpf_jit_comp.c
|
||||
[123]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/sched
|
||||
[124]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/trace/bpf_trace.c
|
||||
[125]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/seccomp.c
|
||||
[126]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/testing/selftests/seccomp/seccomp_bpf.c
|
||||
[127]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[128]:https://github.com/iovisor/bcc/blob/master/FAQ.txt
|
||||
[129]:https://www.kernel.org/doc/Documentation/networking/filter.txt
|
||||
[130]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[131]:https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py
|
||||
[132]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#output
|
||||
[133]:https://www.spinics.net/lists/netdev/msg406926.html
|
||||
[134]:https://github.com/cilium/bpf-map
|
||||
[135]:https://github.com/badboy/bpf-map
|
||||
[136]:https://stackoverflow.com/questions/tagged/bpf
|
||||
[137]:https://github.com/iovisor/xdp-vagrant
|
||||
[138]:https://github.com/zlim/bcc-docker
|
||||
[139]:http://lists.openwall.net/netdev/
|
||||
[140]:http://vger.kernel.org/vger-lists.html#xdp-newbies
|
||||
[141]:http://lists.iovisor.org/pipermail/iovisor-dev/
|
||||
[142]:https://twitter.com/IOVisor
|
||||
[143]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#what-is-bpf
|
||||
[144]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#dive-into-the-bytecode
|
||||
[145]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#resources
|
||||
[146]:https://github.com/qmonnet/whirl-offload/commits/gh-pages/_posts/2016-09-01-dive-into-bpf.md
|
||||
[147]:http://netdevconf.org/1.2/session.html?jakub-kicinski
|
||||
[148]:http://www.slideshare.net/IOVisor/express-data-path-linux-meetup-santa-clara-july-2016
|
||||
[149]:https://cdn.shopify.com/s/files/1/0177/9886/files/phv2017-gbertin.pdf
|
||||
[150]:https://github.com/cilium/cilium
|
||||
[151]:https://fosdem.org/2017/schedule/event/stateful_ebpf/
|
||||
[152]:http://vger.kernel.org/vger-lists.html#xdp-newbies
|
||||
[153]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[154]:https://github.com/qmonnet/whirl-offload/commit/d694f8081ba00e686e34f86d5ee76abeb4d0e429
|
||||
[155]:http://openvswitch.org/pipermail/dev/2014-October/047421.html
|
||||
[156]:https://qmonnet.github.io/whirl-offload/2016/07/15/beba-research-project/
|
||||
[157]:https://www.iovisor.org/resources/blog
|
||||
[158]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[159]:http://p4.org/
|
||||
[160]:https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4
|
||||
[161]:https://github.com/p4lang/p4c/blob/master/backends/ebpf/README.md
|
||||
[162]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[163]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[164]:https://github.com/goldshtn/linux-tracing-workshop
|
||||
[165]:https://blog.yadutaf.fr/2017/07/28/tracing-a-packet-journey-using-linux-tracepoints-perf-ebpf/
|
||||
[166]:https://open-nfp.org/dataplanes-ebpf/technical-papers/
|
||||
[167]:http://netdevconf.org/2.1/session.html?gospodarek
|
||||
[168]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/samples/bpf
|
||||
[169]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/examples/bpf
|
||||
[170]:https://github.com/iovisor/bcc/tree/master/examples
|
||||
[171]:http://man7.org/linux/man-pages/man8/tc-bpf.8.html
|
||||
[172]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/dev.c
|
||||
[173]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/drivers/net/ethernet/mellanox/mlx4/
|
||||
[174]:https://github.com/iovisor/bcc/
|
||||
[175]:https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py
|
||||
[176]:https://github.com/iovisor/bcc/blob/master/src/cc/libbpf.c
|
||||
[177]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/tc
|
||||
[178]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/lib/bpf.c
|
||||
[179]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/net
|
||||
[180]:https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/bpf
|
||||
[181]:https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4/compiler
|
||||
[182]:https://github.com/iovisor/bcc/tree/master/src/lua
|
||||
[183]:https://reviews.llvm.org/D6494
|
||||
[184]:https://github.com/llvm-mirror/llvm/commit/4fe85c75482f9d11c5a1f92a1863ce30afad8d0d
|
||||
[185]:https://github.com/iovisor/ubpf/
|
||||
[186]:https://github.com/YutaroHayakawa/generic-ebpf
|
||||
[187]:https://github.com/YutaroHayakawa/vale-bpf
|
||||
[188]:https://github.com/qmonnet/rbpf
|
||||
[189]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git
|
||||
[190]:https://github.com/torvalds/linux
|
||||
[191]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[192]:https://qmonnet.github.io/whirl-offload/categories/#BPF
|
||||
|
||||
|
||||
@ -1,95 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
GitHub welcomes all CI tools
|
||||
====================
|
||||
|
||||
|
||||
[][11]
|
||||
|
||||
Continuous Integration ([CI][12]) tools help you stick to your team's quality standards by running tests every time you push a new commit and [reporting the results][13] to a pull request. Combined with continuous delivery ([CD][14]) tools, you can also test your code on multiple configurations, run additional performance tests, and automate every step [until production][15].
|
||||
|
||||
There are several CI and CD tools that [integrate with GitHub][16], some of which you can install in a few clicks from [GitHub Marketplace][17]. With so many options, you can pick the best tool for the job—even if it's not the one that comes pre-integrated with your system.
|
||||
|
||||
The tools that will work best for you depends on many factors, including:
|
||||
|
||||
* Programming language and application architecture
|
||||
|
||||
* Operating system and browsers you plan to support
|
||||
|
||||
* Your team's experience and skills
|
||||
|
||||
* Scaling capabilities and plans for growth
|
||||
|
||||
* Geographic distribution of dependent systems and the people who use them
|
||||
|
||||
* Packaging and delivery goals
|
||||
|
||||
Of course, it isn't possible to optimize your CI tool for all of these scenarios. The people who build them have to choose which use cases to serve best—and when to prioritize complexity over simplicity. For example, if you like to test small applications written in a particular programming language for one platform, you won't need the complexity of a tool that tests embedded software controllers on dozens of platforms with a broad mix of programming languages and frameworks.
|
||||
|
||||
If you need a little inspiration for which CI tool might work best, take a look at [popular GitHub projects][18]. Many show the status of their integrated CI/CD tools as badges in their README.md. We've also analyzed the use of CI tools across more than 50 million repositories in the GitHub community, and found a lot of variety. The following diagram shows the relative percentage of the top 10 CI tools used with GitHub.com, based on the most used [commit status contexts][19] used within our pull requests.
|
||||
|
||||
_Our analysis also showed that many teams use more than one CI tool in their projects, allowing them to emphasize what each tool does best._
|
||||
|
||||
[][20]
|
||||
|
||||
If you'd like to check them out, here are the top 10 tools teams use:
|
||||
|
||||
* [Travis CI][1]
|
||||
|
||||
* [Circle CI][2]
|
||||
|
||||
* [Jenkins][3]
|
||||
|
||||
* [AppVeyor][4]
|
||||
|
||||
* [CodeShip][5]
|
||||
|
||||
* [Drone][6]
|
||||
|
||||
* [Semaphore CI][7]
|
||||
|
||||
* [Buildkite][8]
|
||||
|
||||
* [Wercker][9]
|
||||
|
||||
* [TeamCity][10]
|
||||
|
||||
It's tempting to just pick the default, pre-integrated tool without taking the time to research and choose the best one for the job, but there are plenty of [excellent choices][21] built for your specific use cases. And if you change your mind later, no problem. When you choose the best tool for a specific situation, you're guaranteeing tailored performance and the freedom of interchangability when it no longer fits.
|
||||
|
||||
Ready to see how CI tools can fit into your workflow?
|
||||
|
||||
[Browse GitHub Marketplace][22]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2463-github-welcomes-all-ci-tools
|
||||
|
||||
作者:[jonico ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/jonico
|
||||
[1]:https://travis-ci.org/
|
||||
[2]:https://circleci.com/
|
||||
[3]:https://jenkins.io/
|
||||
[4]:https://www.appveyor.com/
|
||||
[5]:https://codeship.com/
|
||||
[6]:http://try.drone.io/
|
||||
[7]:https://semaphoreci.com/
|
||||
[8]:https://buildkite.com/
|
||||
[9]:http://www.wercker.com/
|
||||
[10]:https://www.jetbrains.com/teamcity/
|
||||
[11]:https://user-images.githubusercontent.com/29592817/32509084-2d52c56c-c3a1-11e7-8c49-901f0f601faf.png
|
||||
[12]:https://en.wikipedia.org/wiki/Continuous_integration
|
||||
[13]:https://github.com/blog/2051-protected-branches-and-required-status-checks
|
||||
[14]:https://en.wikipedia.org/wiki/Continuous_delivery
|
||||
[15]:https://developer.github.com/changes/2014-01-09-preview-the-new-deployments-api/
|
||||
[16]:https://github.com/works-with/category/continuous-integration
|
||||
[17]:https://github.com/marketplace/category/continuous-integration
|
||||
[18]:https://github.com/explore?trending=repositories#trending
|
||||
[19]:https://developer.github.com/v3/repos/statuses/
|
||||
[20]:https://user-images.githubusercontent.com/7321362/32575895-ea563032-c49a-11e7-9581-e05ec882658b.png
|
||||
[21]:https://github.com/works-with/category/continuous-integration
|
||||
[22]:https://github.com/marketplace/category/continuous-integration
|
||||
@ -1,313 +0,0 @@
|
||||
yixunx translating
|
||||
|
||||
Love Your Bugs
|
||||
============================================================
|
||||
|
||||
In early October I gave a keynote at [Python Brasil][1] in Belo Horizonte. Here is an aspirational and lightly edited transcript of the talk. There is also a video available [here][2].
|
||||
|
||||
### I love bugs
|
||||
|
||||
I’m currently a senior engineer at [Pilot.com][3], working on automating bookkeeping for startups. Before that, I worked for [Dropbox][4] on the desktop client team, and I’ll have a few stories about my work there. Earlier, I was a facilitator at the [Recurse Center][5], a writers retreat for programmers in NYC. I studied astrophysics in college and worked in finance for a few years before becoming an engineer.
|
||||
|
||||
But none of that is really important to remember – the only thing you need to know about me is that I love bugs. I love bugs because they’re entertaining. They’re dramatic. The investigation of a great bug can be full of twists and turns. A great bug is like a good joke or a riddle – you’re expecting one outcome, but the result veers off in another direction.
|
||||
|
||||
Over the course of this talk I’m going to tell you about some bugs that I have loved, explain why I love bugs so much, and then convince you that you should love bugs too.
|
||||
|
||||
### Bug #1
|
||||
|
||||
Ok, straight into bug #1\. This is a bug that I encountered while working at Dropbox. As you may know, Dropbox is a utility that syncs your files from one computer to the cloud and to your other computers.
|
||||
|
||||
|
||||
|
||||
```
|
||||
+--------------+ +---------------+
|
||||
| | | |
|
||||
| METASERVER | | BLOCKSERVER |
|
||||
| | | |
|
||||
+-+--+---------+ +---------+-----+
|
||||
^ | ^
|
||||
| | |
|
||||
| | +----------+ |
|
||||
| +---> | | |
|
||||
| | CLIENT +--------+
|
||||
+--------+ |
|
||||
+----------+
|
||||
```
|
||||
|
||||
|
||||
Here’s a vastly simplified diagram of Dropbox’s architecture. The desktop client runs on your local computer listening for changes in the file system. When it notices a changed file, it reads the file, then hashes the contents in 4MB blocks. These blocks are stored in the backend in a giant key-value store that we call blockserver. The key is the digest of the hashed contents, and the values are the contents themselves.
|
||||
|
||||
Of course, we want to avoid uploading the same block multiple times. You can imagine that if you’re writing a document, you’re probably mostly changing the end – we don’t want to upload the beginning over and over. So before uploading a block to the blockserver the client talks to a different server that’s responsible for managing metadata and permissions, among other things. The client asks metaserver whether it needs the block or has seen it before. The “metaserver” responds with whether or not each block needs to be uploaded.
|
||||
|
||||
So the request and response look roughly like this: The client says, “I have a changed file made up of blocks with hashes `'abcd,deef,efgh'`”. The server responds, “I have those first two, but upload the third.” Then the client sends the block up to the blockserver.
|
||||
|
||||
|
||||
```
|
||||
+--------------+ +---------------+
|
||||
| | | |
|
||||
| METASERVER | | BLOCKSERVER |
|
||||
| | | |
|
||||
+-+--+---------+ +---------+-----+
|
||||
^ | ^
|
||||
| | 'ok, ok, need' |
|
||||
'abcd,deef,efgh' | | +----------+ | efgh: [contents]
|
||||
| +---> | | |
|
||||
| | CLIENT +--------+
|
||||
+--------+ |
|
||||
+----------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
That’s the setup. So here’s the bug.
|
||||
|
||||
|
||||
|
||||
```
|
||||
+--------------+
|
||||
| |
|
||||
| METASERVER |
|
||||
| |
|
||||
+-+--+---------+
|
||||
^ |
|
||||
| | '???'
|
||||
'abcdldeef,efgh' | | +----------+
|
||||
^ | +---> | |
|
||||
^ | | CLIENT +
|
||||
+--------+ |
|
||||
+----------+
|
||||
```
|
||||
|
||||
Sometimes the client would make a weird request: each hash value should have been sixteen characters long, but instead it was thirty-three characters long – twice as many plus one. The server wouldn’t know what to do with this and would throw an exception. We’d see this exception get reported, and we’d go look at the log files from the desktop client, and really weird stuff would be going on – the client’s local database had gotten corrupted, or python would be throwing MemoryErrors, and none of it would make sense.
|
||||
|
||||
If you’ve never seen this problem before, it’s totally mystifying. But once you’d seen it once, you can recognize it every time thereafter. Here’s a hint: the middle character of each 33-character string that we’d often see instead of a comma was `l`. These are the other characters we’d see in the middle position:
|
||||
|
||||
|
||||
```
|
||||
l \x0c < $ ( . -
|
||||
```
|
||||
|
||||
The ordinal value for an ascii comma – `,` – is 44\. The ordinal value for `l` is 108\. In binary, here’s how those two are represented:
|
||||
|
||||
```
|
||||
bin(ord(',')): 0101100
|
||||
bin(ord('l')): 1101100
|
||||
```
|
||||
|
||||
You’ll notice that an `l` is exactly one bit away from a comma. And herein lies your problem: a bitflip. One bit of memory that the desktop client is using has gotten corrupted, and now the desktop client is sending a request to the server that is garbage.
|
||||
|
||||
And here are the other characters we’d frequently see instead of the comma when a different bit had been flipped.
|
||||
|
||||
|
||||
|
||||
```
|
||||
, : 0101100
|
||||
l : 1101100
|
||||
\x0c : 0001100
|
||||
< : 0111100
|
||||
$ : 0100100
|
||||
( : 0101000
|
||||
. : 0101110
|
||||
- : 0101101
|
||||
```
|
||||
|
||||
|
||||
### Bitflips are real!
|
||||
|
||||
I love this bug because it shows that bitflips are a real thing that can happen, not just a theoretical concern. In fact, there are some domains where they’re more common than others. One such domain is if you’re getting requests from users with low-end or old hardware, which is true for a lot of laptops running Dropbox. Another domain with lots of bitflips is outer space – there’s no atmosphere in space to protect your memory from energetic particles and radiation, so bitflips are pretty common.
|
||||
|
||||
You probably really care about correctness in space – your code might be keeping astronauts alive on the ISS, for example, but even if it’s not mission-critical, it’s hard to do software updates to space. If you really need your application to defend against bitflips, there are a variety of hardware & software approaches you can take, and there’s a [very interesting talk][6] by Katie Betchold about this.
|
||||
|
||||
Dropbox in this context doesn’t really need to protect against bitflips. The machine that is corrupting memory is a user’s machine, so we can detect if the bitflip happens to fall in the comma – but if it’s in a different character we don’t necessarily know it, and if the bitflip is in the actual file data read off of disk, then we have no idea. There’s a pretty limited set of places where we could address this, and instead we decide to basically silence the exception and move on. Often this kind of bug resolves after the client restarts.
|
||||
|
||||
### Unlikely bugs aren’t impossible
|
||||
|
||||
This is one of my favorite bugs for a couple of reasons. The first is that it’s a reminder of the difference between unlikely and impossible. At sufficient scale, unlikely events start to happen at a noticable rate.
|
||||
|
||||
### Social bugs
|
||||
|
||||
My second favorite thing about this bug is that it’s a tremendously social one. This bug can crop up anywhere that the desktop client talks to the server, which is a lot of different endpoints and components in the system. This meant that a lot of different engineers at Dropbox would see versions of the bug. The first time you see it, you can _really_ scratch your head, but after that it’s easy to diagnose, and the investigation is really quick: you look at the middle character and see if it’s an `l`.
|
||||
|
||||
### Cultural differences
|
||||
|
||||
One interesting side-effect of this bug was that it exposed a cultural difference between the server and client teams. Occasionally this bug would be spotted by a member of the server team and investigated from there. If one of your _servers_ is flipping bits, that’s probably not random chance – it’s probably memory corruption, and you need to find the affected machine and get it out of the pool as fast as possible or you risk corrupting a lot of user data. That’s an incident, and you need to respond quickly. But if the user’s machine is corrupting data, there’s not a lot you can do.
|
||||
|
||||
### Share your bugs
|
||||
|
||||
So if you’re investigating a confusing bug, especially one in a big system, don’t forget to talk to people about it. Maybe your colleagues have seen a bug shaped like this one before. If they have, you might save a lot of time. And if they haven’t, don’t forget to tell people about the solution once you’ve figured it out – write it up or tell the story in your team meeting. Then the next time your teams hits something similar, you’ll all be more prepared.
|
||||
|
||||
### How bugs can help you learn
|
||||
|
||||
### Recurse Center
|
||||
|
||||
Before I joined Dropbox, I worked for the Recurse Center. The idea behind RC is that it’s a community of self-directed learners spending time together getting better as programmers. That is the full extent of the structure of RC: there’s no curriculum or assignments or deadlines. The only scoping is a shared goal of getting better as a programmer. We’d see people come to participate in the program who had gotten CS degrees but didn’t feel like they had a solid handle on practical programming, or people who had been writing Java for ten years and wanted to learn Clojure or Haskell, and many other profiles as well.
|
||||
|
||||
My job there was as a facilitator, helping people make the most of the lack of structure and providing guidance based on what we’d learned from earlier participants. So my colleagues and I were very interested in the best techniques for learning for self-motivated adults.
|
||||
|
||||
### Deliberate Practice
|
||||
|
||||
There’s a lot of different research in this space, and one of the ones I think is most interesting is the idea of deliberate practice. Deliberate practice is an attempt to explain the difference in performance between experts & amateurs. And the guiding principle here is that if you look just at innate characteristics – genetic or otherwise – they don’t go very far towards explaining the difference in performance. So the researchers, originally Ericsson, Krampe, and Tesch-Romer, set out to discover what did explain the difference. And what they settled on was time spent in deliberate practice.
|
||||
|
||||
Deliberate practice is pretty narrow in their definition: it’s not work for pay, and it’s not playing for fun. You have to be operating on the edge of your ability, doing a project appropriate for your skill level (not so easy that you don’t learn anything and not so hard that you don’t make any progress). You also have to get immediate feedback on whether or not you’ve done the thing correctly.
|
||||
|
||||
This is really exciting, because it’s a framework for how to build expertise. But the challenge is that as programmers this is really hard advice to apply. It’s hard to know whether you’re operating at the edge of your ability. Immediate corrective feedback is very rare – in some cases you’re lucky to get feedback ever, and in other cases maybe it takes months. You can get quick feedback on small things in the REPL and so on, but if you’re making a design decision or picking a technology, you’re not going to get feedback on those things for quite a long time.
|
||||
|
||||
But one category of programming where deliberate practice is a useful model is debugging. If you wrote code, then you had a mental model of how it worked when you wrote it. But your code has a bug, so your mental model isn’t quite right. By definition you’re on the boundary of your understanding – so, great! You’re about to learn something new. And if you can reproduce the bug, that’s a rare case where you can get immediate feedback on whether or not your fix is correct.
|
||||
|
||||
A bug like this might teach you something small about your program, or you might learn something larger about the system your code is running in. Now I’ve got a story for you about a bug like that.
|
||||
|
||||
### Bug #2
|
||||
|
||||
This bug also one that I encountered at Dropbox. At the time, I was investigating why some desktop client weren’t sending logs as consistently as we expected. I’d started digging into the client logging system and discovered a bunch of interesting bugs. I’ll tell you only the subset of those bugs that is relevant to this story.
|
||||
|
||||
Again here’s a very simplified architecture of the system.
|
||||
|
||||
|
||||
```
|
||||
+--------------+
|
||||
| |
|
||||
+---+ +----------> | LOG SERVER |
|
||||
|log| | | |
|
||||
+---+ | +------+-------+
|
||||
| |
|
||||
+-----+----+ | 200 ok
|
||||
| | |
|
||||
| CLIENT | <-----------+
|
||||
| |
|
||||
+-----+----+
|
||||
^
|
||||
+--------+--------+--------+
|
||||
| ^ ^ |
|
||||
+--+--+ +--+--+ +--+--+ +--+--+
|
||||
| log | | log | | log | | log |
|
||||
| | | | | | | |
|
||||
| | | | | | | |
|
||||
+-----+ +-----+ +-----+ +-----+
|
||||
```
|
||||
|
||||
The desktop client would generate logs. Those logs were compress, encrypted, and written to disk. Then every so often the client would send them up to the server. The client would read a log off of disk and send it to the log server. The server would decrypt it and store it, then respond with a 200.
|
||||
|
||||
If the client couldn’t reach the log server, it wouldn’t let the log directory grow unbounded. After a certain point it would start deleting logs to keep the directory under a maximum size.
|
||||
|
||||
The first two bugs were not a big deal on their own. The first one was that the desktop client sent logs up to the server starting with the oldest one instead of starting with the newest. This isn’t really what you want – for example, the server would tell the client to send logs if the client reported an exception, so probably you care about the logs that just happened and not the oldest logs that happen to be on disk.
|
||||
|
||||
The second bug was similar to the first: if the log directory hit its maximum size, the client would delete the logs starting with the newest instead of starting with the oldest. Again, you lose log files either way, but you probably care less about the older ones.
|
||||
|
||||
The third bug had to do with the encryption. Sometimes, the server would be unable to decrypt a log file. (We generally didn’t figure out why – maybe it was a bitflip.) We weren’t handling this error correctly on the backend, so the server would reply with a 500\. The client would behave reasonably in the face of a 500: it would assume that the server was down. So it would stop sending log files and not try to send up any of the others.
|
||||
|
||||
Returning a 500 on a corrupted log file is clearly not the right behavior. You could consider returning a 400, since it’s a problem with the client request. But the client also can’t fix the problem – if the log file can’t be decrypted now, we’ll never be able to decrypt it in the future. What you really want the client to do is just delete the log and move on. In fact, that’s the default behavior when the client gets a 200 back from the server for a log file that was successfully stored. So we said, ok – if the log file can’t be decrypted, just return a 200.
|
||||
|
||||
All of these bugs were straightforward to fix. The first two bugs were on the client, so we’d fixed them on the alpha build but they hadn’t gone out to the majority of clients. The third bug we fixed on the server and deployed.
|
||||
|
||||
### 📈
|
||||
|
||||
Suddenly traffic to the log cluster spikes. The serving team reaches out to us to ask if we know what’s going on. It takes me a minute to put all the pieces together.
|
||||
|
||||
Before these fixes, there were four things going on:
|
||||
|
||||
1. Log files were sent up starting with the oldest
|
||||
|
||||
2. Log files were deleted starting with the newest
|
||||
|
||||
3. If the server couldn’t decrypt a log file it would 500
|
||||
|
||||
4. If the client got a 500 it would stop sending logs
|
||||
|
||||
A client with a corrupted log file would try to send it, the server would 500, the client would give up sending logs. On its next run, it would try to send the same file again, fail again, and give up again. Eventually the log directory would get full, at which point the client would start deleting its newest files, leaving the corrupted one on disk.
|
||||
|
||||
The upshot of these three bugs: if a client ever had a corrupted log file, we would never see logs from that client again.
|
||||
|
||||
The problem is that there were a lot more clients in this state than we thought. Any client with a single corrupted file had been dammed up from sending logs to the server. Now that dam was cleared, and all of them were sending up the rest of the contents of their log directories.
|
||||
|
||||
### Our options
|
||||
|
||||
Ok, there’s a huge flood of traffic coming from machines around the world. What can we do? (This is a fun thing about working at a company with Dropbox’s scale, and particularly Dropbox’s scale of desktop clients: you can trigger a self-DDOS very easily.)
|
||||
|
||||
The first option when you do a deploy and things start going sideways is to rollback. Totally reasonable choice, but in this case, it wouldn’t have helped us. The state that we’d transformed wasn’t the state on the server but the state on the client – we’d deleted those files. Rolling back the server would prevent additional clients from entering this state but it wouldn’t solve the problem.
|
||||
|
||||
What about increasing the size of the logging cluster? We did that – and started getting even more requests, now that we’d increased our capacity. We increased it again, but you can’t do that forever. Why not? This cluster isn’t isolated. It’s making requests into another cluster, in this case to handle exceptions. If you have a DDOS pointed at one cluster, and you keep scaling that cluster, you’re going to knock over its depedencies too, and now you have two problems.
|
||||
|
||||
Another option we considered was shedding load – you don’t need every single log file, so can we just drop requests. One of the challenges here was that we didn’t have an easy way to tell good traffic from bad. We couldn’t quickly differentiate which log files were old and which were new.
|
||||
|
||||
The solution we hit on is one that’s been used at Dropbox on a number of different occassions: we have a custom header, `chillout`, which every client in the world respects. If the client gets a response with this header, then it doesn’t make any requests for the provided number of seconds. Someone very wise added this to the Dropbox client very early on, and it’s come in handy more than once over the years. The logging server didn’t have the ability to set that header, but that’s an easy problem to solve. So two of my colleagues, Isaac Goldberg and John Lai, implemented support for it. We set the logging cluster chillout to two minutes initially and then managed it down as the deluge subsided over the next couple of days.
|
||||
|
||||
### Know your system
|
||||
|
||||
The first lesson from this bug is to know your system. I had a good mental model of the interaction between the client and the server, but I wasn’t thinking about what would happen when the server was interacting with all the clients at once. There was a level of complexity that I hadn’t thought all the way through.
|
||||
|
||||
### Know your tools
|
||||
|
||||
The second lesson is to know your tools. If things go sideways, what options do you have? Can you reverse your migration? How will you know if things are going sideways and how can you discover more? All of those things are great to know before a crisis – but if you don’t, you’ll learn them during a crisis and then never forget.
|
||||
|
||||
### Feature flags & server-side gating
|
||||
|
||||
The third lesson is for you if you’re writing a mobile or a desktop application: _You need server-side feature gating and server-side flags._ When you discover a problem and you don’t have server-side controls, the resolution might take days or weeks as you push out a new release or submit a new version to the app store. That’s a bad situation to be in. The Dropbox desktop client isn’t going through an app store review process, but just pushing out a build to tens of millions of clients takes time. Compare that to hitting a problem in your feature and flipping a switch on the server: ten minutes later your problem is resolved.
|
||||
|
||||
This strategy is not without its costs. Having a bunch of feature flags in your code adds to the complexity dramatically. You get a combinatoric problem with your testing: what if feature A is enabled and feature B, or just one, or neither – multiplied across N features. It’s extremely difficult to get engineers to clean up their feature flags after the fact (and I was also guilty of this). Then for the desktop client there’s multiple versions in the wild at the same time, so it gets pretty hard to reason about.
|
||||
|
||||
But the benefit – man, when you need it, you really need it.
|
||||
|
||||
# How to love bugs
|
||||
|
||||
I’ve talked about some bugs that I love and I’ve talked about why to love bugs. Now I want to tell you how to love bugs. If you don’t love bugs yet, I know of exactly one way to learn, and that’s to have a growth mindset.
|
||||
|
||||
The sociologist Carol Dweck has done a ton of interesting research about how people think about intelligence. She’s found that there are two different frameworks for thinking about intelligence. The first, which she calls the fixed mindset, holds that intelligence is a fixed trait, and people can’t change how much of it they have. The other mindset is a growth mindset. Under a growth mindset, people believe that intelligence is malleable and can increase with effort.
|
||||
|
||||
Dweck found that a person’s theory of intelligence – whether they hold a fixed or growth mindset – can significantly influence the way they select tasks to work on, the way they respond to challenges, their cognitive performance, and even their honesty.
|
||||
|
||||
[I also talked about a growth mindset in my Kiwi PyCon keynote, so here are just a few excerpts. You can read the full transcript [here][7].]
|
||||
|
||||
Findings about honesty:
|
||||
|
||||
> After this, they had the students write letters to pen pals about the study, saying “We did this study at school, and here’s the score that I got.” They found that _almost half of the students praised for intelligence lied about their scores_ , and almost no one who was praised for working hard was dishonest.
|
||||
|
||||
On effort:
|
||||
|
||||
> Several studies found that people with a fixed mindset can be reluctant to really exert effort, because they believe it means they’re not good at the thing they’re working hard on. Dweck notes, “It would be hard to maintain confidence in your ability if every time a task requires effort, your intelligence is called into question.”
|
||||
|
||||
On responding to confusion:
|
||||
|
||||
> They found that students with a growth mindset mastered the material about 70% of the time, regardless of whether there was a confusing passage in it. Among students with a fixed mindset, if they read the booklet without the confusing passage, again about 70% of them mastered the material. But the fixed-mindset students who encountered the confusing passage saw their mastery drop to 30%. Students with a fixed mindset were pretty bad at recovering from being confused.
|
||||
|
||||
These findings show that a growth mindset is critical while debugging. We have to recover from confusion, be candid about the limitations of our understanding, and at times really struggle on the way to finding solutions – all of which is easier and less painful with a growth mindset.
|
||||
|
||||
### Love your bugs
|
||||
|
||||
I learned to love bugs by explicitly celebrating challenges while working at the Recurse Center. A participant would sit down next to me and say, “[sigh] I think I’ve got a weird Python bug,” and I’d say, “Awesome, I _love_ weird Python bugs!” First of all, this is definitely true, but more importantly, it emphasized to the participant that finding something where they struggled an accomplishment, and it was a good thing for them to have done that day.
|
||||
|
||||
As I mentioned, at the Recurse Center there are no deadlines and no assignments, so this attitude is pretty much free. I’d say, “You get to spend a day chasing down this weird bug in Flask, how exciting!” At Dropbox and later at Pilot, where we have a product to ship, deadlines, and users, I’m not always uniformly delighted about spending a day on a weird bug. So I’m sympathetic to the reality of the world where there are deadlines. However, if I have a bug to fix, I have to fix it, and being grumbly about the existence of the bug isn’t going to help me fix it faster. I think that even in a world where deadlines loom, you can still apply this attitude.
|
||||
|
||||
If you love your bugs, you can have more fun while you’re working on a tough problem. You can be less worried and more focused, and end up learning more from them. Finally, you can share a bug with your friends and colleagues, which helps you and your teammates.
|
||||
|
||||
### Obrigada!
|
||||
|
||||
My thanks to folks who gave me feedback on this talk and otherwise contributed to my being there:
|
||||
|
||||
* Sasha Laundy
|
||||
|
||||
* Amy Hanlon
|
||||
|
||||
* Julia Evans
|
||||
|
||||
* Julian Cooper
|
||||
|
||||
* Raphael Passini Diniz and the rest of the Python Brasil organizing team
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://akaptur.com/blog/2017/11/12/love-your-bugs/
|
||||
|
||||
作者:[Allison Kaptur ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://akaptur.com/about/
|
||||
[1]:http://2017.pythonbrasil.org.br/#
|
||||
[2]:http://www.youtube.com/watch?v=h4pZZOmv4Qs
|
||||
[3]:http://www.pilot.com/
|
||||
[4]:http://www.dropbox.com/
|
||||
[5]:http://www.recurse.com/
|
||||
[6]:http://www.youtube.com/watch?v=ETgNLF_XpEM
|
||||
[7]:http://akaptur.com/blog/2015/10/10/effective-learning-strategies-for-programmers/
|
||||
@ -1,61 +0,0 @@
|
||||
【翻译中 @haoqixu】Sysadmin 101: Patch Management
|
||||
============================================================
|
||||
|
||||
* [HOW-TOs][1]
|
||||
|
||||
* [Servers][2]
|
||||
|
||||
* [SysAdmin][3]
|
||||
|
||||
|
||||
A few articles ago, I started a Sysadmin 101 series to pass down some fundamental knowledge about systems administration that the current generation of junior sysadmins, DevOps engineers or "full stack" developers might not learn otherwise. I had thought that I was done with the series, but then the WannaCry malware came out and exposed some of the poor patch management practices still in place in Windows networks. I imagine some readers that are still stuck in the Linux versus Windows wars of the 2000s might have even smiled with a sense of superiority when they heard about this outbreak.
|
||||
|
||||
The reason I decided to revive my Sysadmin 101 series so soon is I realized that most Linux system administrators are no different from Windows sysadmins when it comes to patch management. Honestly, in some areas (in particular, uptime pride), some Linux sysadmins are even worse than Windows sysadmins regarding patch management. So in this article, I cover some of the fundamentals of patch management under Linux, including what a good patch management system looks like, the tools you will want to put in place and how the overall patching process should work.
|
||||
|
||||
### What Is Patch Management?
|
||||
|
||||
When I say patch management, I'm referring to the systems you have in place to update software already on a server. I'm not just talking about keeping up with the latest-and-greatest bleeding-edge version of a piece of software. Even more conservative distributions like Debian that stick with a particular version of software for its "stable" release still release frequent updates that patch bugs or security holes.
|
||||
|
||||
Of course, if your organization decided to roll its own version of a particular piece of software, either because developers demanded the latest and greatest, you needed to fork the software to apply a custom change, or you just like giving yourself extra work, you now have a problem. Ideally you have put in a system that automatically packages up the custom version of the software for you in the same continuous integration system you use to build and package any other software, but many sysadmins still rely on the outdated method of packaging the software on their local machine based on (hopefully up to date) documentation on their wiki. In either case, you will need to confirm that your particular version has the security flaw, and if so, make sure that the new patch applies cleanly to your custom version.
|
||||
|
||||
### What Good Patch Management Looks Like
|
||||
|
||||
Patch management starts with knowing that there is a software update to begin with. First, for your core software, you should be subscribed to your Linux distribution's security mailing list, so you're notified immediately when there are security patches. If there you use any software that doesn't come from your distribution, you must find out how to be kept up to date on security patches for that software as well. When new security notifications come in, you should review the details so you understand how severe the security flaw is, whether you are affected and gauge a sense of how urgent the patch is.
|
||||
|
||||
Some organizations have a purely manual patch management system. With such a system, when a security patch comes along, the sysadmin figures out which servers are running the software, generally by relying on memory and by logging in to servers and checking. Then the sysadmin uses the server's built-in package management tool to update the software with the latest from the distribution. Then the sysadmin moves on to the next server, and the next, until all of the servers are patched.
|
||||
|
||||
There are many problems with manual patch management. First is the fact that it makes patching a laborious chore. The more work patching is, the more likely a sysadmin will put it off or skip doing it entirely. The second problem is that manual patch management relies too much on the sysadmin's ability to remember and recall all of the servers he or she is responsible for and keep track of which are patched and which aren't. This makes it easy for servers to be forgotten and sit unpatched.
|
||||
|
||||
The faster and easier patch management is, the more likely you are to do it. You should have a system in place that quickly can tell you which servers are running a particular piece of software at which version. Ideally, that system also can push out updates. Personally, I prefer orchestration tools like MCollective for this task, but Red Hat provides Satellite, and Canonical provides Landscape as central tools that let you view software versions across your fleet of servers and apply patches all from a central place.
|
||||
|
||||
Patching should be fault-tolerant as well. You should be able to patch a service and restart it without any overall down time. The same idea goes for kernel patches that require a reboot. My approach is to divide my servers into different high availability groups so that lb1, app1, rabbitmq1 and db1 would all be in one group, and lb2, app2, rabbitmq2 and db2 are in another. Then, I know I can patch one group at a time without it causing downtime anywhere else.
|
||||
|
||||
So, how fast is fast? Your system should be able to roll out a patch to a minor piece of software that doesn't have an accompanying service (such as bash in the case of the ShellShock vulnerability) within a few minutes to an hour at most. For something like OpenSSL that requires you to restart services, the careful process of patching and restarting services in a fault-tolerant way probably will take more time, but this is where orchestration tools come in handy. I gave examples of how to use MCollective to accomplish this in my recent MCollective articles (see the December 2016 and January 2017 issues), but ideally, you should put a system in place that makes it easy to patch and restart services in a fault-tolerant and automated way.
|
||||
|
||||
When patching requires a reboot, such as in the case of kernel patches, it might take a bit more time, but again, automation and orchestration tools can make this go much faster than you might imagine. I can patch and reboot the servers in an environment in a fault-tolerant way within an hour or two, and it would be much faster than that if I didn't need to wait for clusters to sync back up in between reboots.
|
||||
|
||||
Unfortunately, many sysadmins still hold on to the outdated notion that uptime is a badge of pride—given that serious kernel patches tend to come out at least once a year if not more often, to me, it's proof you don't take security seriously.
|
||||
|
||||
Many organizations also still have that single point of failure server that can never go down, and as a result, it never gets patched or rebooted. If you want to be secure, you need to remove these outdated liabilities and create systems that at least can be rebooted during a late-night maintenance window.
|
||||
|
||||
Ultimately, fast and easy patch management is a sign of a mature and professional sysadmin team. Updating software is something all sysadmins have to do as part of their jobs, and investing time into systems that make that process easy and fast pays dividends far beyond security. For one, it helps identify bad architecture decisions that cause single points of failure. For another, it helps identify stagnant, out-of-date legacy systems in an environment and provides you with an incentive to replace them. Finally, when patching is managed well, it frees up sysadmins' time and turns their attention to the things that truly require their expertise.
|
||||
|
||||
______________________
|
||||
|
||||
Kyle Rankin is senior security and infrastructure architect, the author of many books including Linux Hardening in Hostile Networks, DevOps Troubleshooting and The Official Ubuntu Server Book, and a columnist for Linux Journal. Follow him @kylerankin
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/sysadmin-101-patch-management
|
||||
|
||||
作者:[Kyle Rankin ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxjournal.com/users/kyle-rankin
|
||||
[1]:https://www.linuxjournal.com/tag/how-tos
|
||||
[2]:https://www.linuxjournal.com/tag/servers
|
||||
[3]:https://www.linuxjournal.com/tag/sysadmin
|
||||
[4]:https://www.linuxjournal.com/users/kyle-rankin
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Security Jobs Are Hot: Get Trained and Get Noticed
|
||||
============================================================
|
||||
|
||||
|
||||
266
sources/tech/20171119 10 Best LaTeX Editors For Linux.md
Normal file
266
sources/tech/20171119 10 Best LaTeX Editors For Linux.md
Normal file
@ -0,0 +1,266 @@
|
||||
FSSlc Translating
|
||||
|
||||
10 Best LaTeX Editors For Linux
|
||||
======
|
||||
**Brief: Once you get over the learning curve, there is nothing like LaTex.
|
||||
Here are the best LaTex editors for Linux and other systems.**
|
||||
|
||||
## What is LaTeX?
|
||||
|
||||
[LaTeX][1] is a document preparation system. Unlike plain text editor, you
|
||||
can't just write a plain text using LaTeX editors. Here, you will have to
|
||||
utilize LaTeX commands in order to manage the content of the document.
|
||||
|
||||
![LaTex Sample][2]![LaTex Sample][3]
|
||||
|
||||
LaTex Editors are generally used to publish scientific research documents or
|
||||
books for academic purposes. Most importantly, LaText editors come handy while
|
||||
dealing with a document containing complex Mathematical notations. Surely,
|
||||
LaTeX editors are fun to use. But, not that useful unless you have specific
|
||||
needs for a document.
|
||||
|
||||
## Why should you use LaTex?
|
||||
|
||||
Well, just like I previously mentioned, LaTeX editors are meant for specific
|
||||
purposes. You do not need to be a geek head in order to figure out the way to
|
||||
use LaTeX editors but it is not a productive solution for users who deal with
|
||||
basic text editors.
|
||||
|
||||
If you are looking to craft a document but you are not interested in spending
|
||||
time formatting the text, then LaTeX editors should be the one you should go
|
||||
for. With LaTeX editors, you just have to specify the type of document, and
|
||||
the text font and sizes will be taken care of accordingly. No wonder it is
|
||||
considered one of the [best open source tools for writers][4].
|
||||
|
||||
Do note that it isn't something automated, you will have to first learn LaTeX
|
||||
commands to let the editor handle the text formatting with precision.
|
||||
|
||||
## 10 Of The Best LaTeX Editors For Linux
|
||||
|
||||
Just for information, the list is not in any specific order. Editor at number
|
||||
three is not better than the editor at number seven.
|
||||
|
||||
### 1\. Lyx
|
||||
|
||||
![][2]
|
||||
|
||||
![][5]
|
||||
|
||||
Lyx is an open source LaTeX Editor. In other words, it is one of the best
|
||||
document processors available on the web.LyX helps you focus on the structure
|
||||
of the write-up, just as every LaTeX editor should and lets you forget about
|
||||
the word formatting. LyX would manage whatsoever depending on the type of
|
||||
document specified. You get to control a lot of stuff while you have it
|
||||
installed. The margins, headers/footers, spacing/indents, tables, and so on.
|
||||
|
||||
If you are into crafting scientific documents, research thesis, or similar,
|
||||
you will be delighted to experience Lyx's formula editor which should be a
|
||||
charm to use. LyX also includes a set of tutorials to get started without much
|
||||
of a hassle.
|
||||
|
||||
[Lyx][6]
|
||||
|
||||
### 2\. Texmaker
|
||||
|
||||
![][2]
|
||||
|
||||
![][7]
|
||||
|
||||
Texmaker is considered to be one of the best LaTeX editors for GNOME desktop
|
||||
environment. It presents a great user interface which results in a good user
|
||||
experience. It is also crowned to be one among the most useful LaTeX editor
|
||||
there is.If you perform PDF conversions often, you will find TeXmaker to be
|
||||
relatively faster than other LaTeX editors. You can take a look at a preview
|
||||
of what the final document would look like while you write. Also, one could
|
||||
observe the symbols being easy to reach when needed.
|
||||
|
||||
Texmaker also offers an extensive support for hotkeys configuration. Why not
|
||||
give it a try?
|
||||
|
||||
[Texmaker][8]
|
||||
|
||||
### 3\. TeXstudio
|
||||
|
||||
![][2]
|
||||
|
||||
![][9]
|
||||
|
||||
If you want a LaTeX editor which offers you a decent level of customizability
|
||||
along with an easy-to-use interface, then TeXstudio would be the perfect one
|
||||
to have installed. The UI is surely very simple but not clumsy. TeXstudio lets
|
||||
you highlight syntax, comes with an integrated viewer, lets you check the
|
||||
references and also bundles some other assistant tools.
|
||||
|
||||
It also supports some cool features like auto-completion, link overlay,
|
||||
bookmarks, multi-cursors, and so on - which makes writing a LaTeX document
|
||||
easier than ever before.
|
||||
|
||||
TeXstudio is actively maintained, which makes it a compelling choice for both
|
||||
novice users and advanced writers.
|
||||
|
||||
[TeXstudio][10]
|
||||
|
||||
### 4\. Gummi
|
||||
|
||||
![][2]
|
||||
|
||||
![][11]
|
||||
|
||||
Gummi is a very simple LaTeX editor based on the GTK+ toolkit. Well, you may
|
||||
not find a lot of fancy options here but if you are just starting out - Gummi
|
||||
will be our recommendation.It supports exporting the documents to PDF format,
|
||||
lets you highlight syntax, and helps you with some basic error checking
|
||||
functionalities. Though Gummi isn't actively maintained via GitHub it works
|
||||
just fine.
|
||||
|
||||
[Gummi][12]
|
||||
|
||||
### 5\. TeXpen
|
||||
|
||||
![][2]
|
||||
|
||||
![][13]
|
||||
|
||||
TeXpen is yet another simplified tool to go with. You get the auto-completion
|
||||
functionality with this LaTeX editor. However, you may not find the user
|
||||
interface impressive. If you do not mind the UI, but want a super easy LaTeX
|
||||
editor, TeXpen could fulfill that wish for you.Also, TeXpen lets you
|
||||
correct/improve the English grammar and expressions used in the document.
|
||||
|
||||
[TeXpen][14]
|
||||
|
||||
### 6\. ShareLaTeX
|
||||
|
||||
![][2]
|
||||
|
||||
![][15]
|
||||
|
||||
ShareLaTeX is an online LaTeX editor. If you want someone (or a group of
|
||||
people) to collaborate on documents you are working on, this is what you need.
|
||||
|
||||
It offers a free plan along with several paid packages. Even the students of
|
||||
Harvard University & Oxford University utilize this for their projects. With
|
||||
the free plan, you get the ability to add one collaborator.
|
||||
|
||||
The paid packages let you sync the documents on GitHub and Dropbox along with
|
||||
the ability to record the full document history. You can choose to have
|
||||
multiple collaborators as per your plan. For students, there's a separate
|
||||
pricing plan available.
|
||||
|
||||
[ShareLaTeX][16]
|
||||
|
||||
### 7\. Overleaf
|
||||
|
||||
![][2]
|
||||
|
||||
![][17]
|
||||
|
||||
Overleaf is yet another online LaTeX editor. Similar to ShareLaTeX, it offers
|
||||
separate pricing plans for professionals and students. It also includes a free
|
||||
plan where you can sync with GitHub, check your revision history, and add
|
||||
multiple collaborators.
|
||||
|
||||
There's a limit on the number of files you can create per project - so it
|
||||
could bother if you are a professional working with LaTeX documents most of
|
||||
the time.
|
||||
|
||||
[Overleaf][18]
|
||||
|
||||
### 8\. Authorea
|
||||
|
||||
![][2]
|
||||
|
||||
![][19]
|
||||
|
||||
Authorea is a wonderful online LaTeX editor. However, it is not the best out
|
||||
there - when considering the pricing plans. For free, it offers just 100 MB of
|
||||
data upload limit and 1 private document at a time. The paid plans offer you
|
||||
more perks but it may not be the cheapest from the lot.The only reason you
|
||||
should choose Authorea is the user interface. If you love to work with a tool
|
||||
offering an impressive user interface, there's no looking back.
|
||||
|
||||
[Authorea][20]
|
||||
|
||||
### 9\. Papeeria
|
||||
|
||||
![][2]
|
||||
|
||||
![][21]
|
||||
|
||||
Papeeria is the cheapest LaTeX editor you can find on the Internet -
|
||||
considering it is as reliable as the others. You do not get private projects
|
||||
if you want to utilize it for free. But, if you prefer public projects it lets
|
||||
you work on an unlimited number of projects with numerous collaborators. It
|
||||
features a pretty simple plot builder and includes Git sync for no additional
|
||||
cost.If you opt for the paid plan, it will empower you with the ability to
|
||||
work on 10 private projects.
|
||||
|
||||
[Papeeria][22]
|
||||
|
||||
### 10\. Kile
|
||||
|
||||
![Kile LaTeX editor][2]
|
||||
|
||||
![Kile LaTeX editor][23]
|
||||
|
||||
Last entry in our list of best LaTeX editor is Kile. Some people swear by
|
||||
Kile. Primarily because of the features it provides.
|
||||
|
||||
Kile is more than just an editor. It is an IDE tool like Eclipse that provides
|
||||
a complete environment to work on documents and projects. Apart from quick
|
||||
compilation and preview, you get features like auto-completion of commands,
|
||||
insert citations, organize document in chapters etc. You really have to use
|
||||
Kile to realize its true potential.
|
||||
|
||||
Kile is available for Linux and Windows.
|
||||
|
||||
[Kile][24]
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
So, there go our recommendations for the LaTeX editors you should utilize on
|
||||
Ubuntu/Linux.
|
||||
|
||||
There are chances that we might have missed some interesting LaTeX editors
|
||||
available for Linux. If you happen to know about any, let us know down in the
|
||||
comments below.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/latex-editors-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
译者:[翻译者ID](https://github.com/翻译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://www.latex-project.org/
|
||||
[2]:data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||
[3]:https://itsfoss.com/wp-content/uploads/2017/11/latex-sample-example.jpeg
|
||||
[4]:https://itsfoss.com/open-source-tools-writers/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2017/10/lyx_latex_editor.jpg
|
||||
[6]:https://www.lyx.org/
|
||||
[7]:https://itsfoss.com/wp-content/uploads/2017/10/texmaker_latex_editor.jpg
|
||||
[8]:http://www.xm1math.net/texmaker/
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2017/10/tex_studio_latex_editor.jpg
|
||||
[10]:https://www.texstudio.org/
|
||||
[11]:https://itsfoss.com/wp-content/uploads/2017/10/gummi_latex_editor.jpg
|
||||
[12]:https://github.com/alexandervdm/gummi
|
||||
[13]:https://itsfoss.com/wp-content/uploads/2017/10/texpen_latex_editor.jpg
|
||||
[14]:https://sourceforge.net/projects/texpen/
|
||||
[15]:https://itsfoss.com/wp-content/uploads/2017/10/sharelatex.jpg
|
||||
[16]:https://www.sharelatex.com/
|
||||
[17]:https://itsfoss.com/wp-content/uploads/2017/10/overleaf.jpg
|
||||
[18]:https://www.overleaf.com/
|
||||
[19]:https://itsfoss.com/wp-content/uploads/2017/10/authorea.jpg
|
||||
[20]:https://www.authorea.com/
|
||||
[21]:https://itsfoss.com/wp-content/uploads/2017/10/papeeria_latex_editor.jpg
|
||||
[22]:https://www.papeeria.com/
|
||||
[23]:https://itsfoss.com/wp-content/uploads/2017/11/kile-latex-800x621.png
|
||||
[24]:https://kile.sourceforge.io/
|
||||
@ -0,0 +1,78 @@
|
||||
translating by imquanquan
|
||||
Useful GNOME Shell Keyboard Shortcuts You Might Not Know About
|
||||
======
|
||||
As Ubuntu has moved to Gnome Shell in its 17.10 release, many users may be interested to discover some of the most useful shortcuts in Gnome as well as how to create your own shortcuts. This article will explain both.
|
||||
|
||||
If you expect GNOME to ship with hundreds or thousands of shell shortcuts, you will be disappointed to learn this isn't the case. The list of shortcuts isn't miles long, and not all of them will be useful to you, but there are still many keyboard shortcuts you can take advantage of.
|
||||
|
||||
![gnome-shortcuts-01-settings][1]
|
||||
|
||||
![gnome-shortcuts-01-settings][1]
|
||||
|
||||
To access the list of shortcuts, go to "Settings -> Devices -> Keyboard." Here are some less popular, yet useful shortcuts.
|
||||
|
||||
* Ctrl + Alt + T - this combination launches the terminal; you can use this from anywhere within GNOME
|
||||
|
||||
|
||||
|
||||
Two shortcuts I personally use quite frequently are:
|
||||
|
||||
* Alt + F4 - close the window on focus
|
||||
* Alt + F8 - resize the window
|
||||
|
||||
|
||||
Most of you know how to switch between open applications (Alt + Tab), but you may not know you can use Alt + Shift + Tab to cycle through applications in reverse direction.
|
||||
|
||||
Another useful combination for switching within the windows of an application is Alt + (key above Tab) (example: Alt + ` on a US keyboard).
|
||||
|
||||
If you want to show the Activities overview, use Alt + F1.
|
||||
|
||||
There are quite a lot of shortcuts related to workspaces. If you are like me and don't use multiple workspaces frequently, these shortcuts are useless to you. Still, some of the ones worth noting are the following:
|
||||
|
||||
* Super + PageUp (or PageDown) moves to the workspace above or below
|
||||
* Ctrl + Alt + Left (or Right) moves to the workspace on the left/right
|
||||
|
||||
If you add Shift to these commands, e.g. Shift + Ctrl + Alt + Left, you move the window one worskpace above, below, to the left, or to the right.
|
||||
|
||||
Another favorite keyboard shortcut of mine is in the Accessibility section - Increase/Decrease Text Size. You can use Ctrl + + (and Ctrl + -) to zoom text size quickly. In some cases, this may be disabled by default, so do check it out before you try it.
|
||||
|
||||
The above-mentioned shortcuts are lesser known, yet useful keyboard shortcuts. If you are curious to see what else is available, you can check [the official GNOME shell cheat sheet][2].
|
||||
|
||||
If the default shortcuts are not to your liking, you can change them or create new ones. You do this from the same "Settings -> Devices -> Keyboard" dialog. Just select the entry you want to change, and the following dialog will popup.
|
||||
|
||||
![gnome-shortcuts-02-change-shortcut][3]
|
||||
|
||||
![gnome-shortcuts-02-change-shortcut][3]
|
||||
|
||||
Enter the keyboard combination you want.
|
||||
|
||||
![gnome-shortcuts-03-set-shortcut][4]
|
||||
|
||||
![gnome-shortcuts-03-set-shortcut][4]
|
||||
|
||||
If it is already in use you will get a message. If not, just click Set, and you are done.
|
||||
|
||||
If you want to add new shortcuts rather than change existing ones, scroll down until you see the "Plus" sign, click it, and in the dialog that appears, enter the name and keys of your new keyboard shortcut.
|
||||
|
||||
![gnome-shortcuts-04-add-custom-shortcut][5]
|
||||
|
||||
![gnome-shortcuts-04-add-custom-shortcut][5]
|
||||
|
||||
GNOME doesn't come with tons of shell shortcuts by default, and the above listed ones are some of the more useful ones. If these shortcuts are not enough for you, you can always create your own. Let us know if this is helpful to you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/gnome-shell-keyboard-shortcuts/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[1]https://www.maketecheasier.com/assets/uploads/2017/10/gnome-shortcuts-01-settings.jpg (gnome-shortcuts-01-settings)
|
||||
[2]https://wiki.gnome.org/Projects/GnomeShell/CheatSheet
|
||||
[3]https://www.maketecheasier.com/assets/uploads/2017/10/gnome-shortcuts-02-change-shortcut.png (gnome-shortcuts-02-change-shortcut)
|
||||
[4]https://www.maketecheasier.com/assets/uploads/2017/10/gnome-shortcuts-03-set-shortcut.png (gnome-shortcuts-03-set-shortcut)
|
||||
[5]https://www.maketecheasier.com/assets/uploads/2017/10/gnome-shortcuts-04-add-custom-shortcut.png (gnome-shortcuts-04-add-custom-shortcut)
|
||||
@ -1,118 +0,0 @@
|
||||
**translating by [erlinux](https://github.com/erlinux)**
|
||||
|
||||
Why microservices are a security issue
|
||||
============================================================
|
||||
|
||||
### Maybe you don't want to decompose all your legacy applications into microservices, but you might consider starting with your security functions.
|
||||
|
||||

|
||||
Image by : Opensource.com
|
||||
|
||||
I struggled with writing the title for this post, and I worry that it comes across as clickbait. If you've come to read this because it looked like clickbait, then sorry.[1][5]I hope you'll stay anyway: there are lots of fascinating[2][6] points and many[3][7]footnotes. What I _didn't_ mean to suggest is that microservices cause [security][15]problems—though like any component, of course, they can—but that microservices are appropriate objects of interest to those involved with security. I'd go further than that: I think they are an excellent architectural construct for those concerned with security.
|
||||
|
||||
And why is that? Well, for those of us with a [systems security][16] bent, the world is an interesting place at the moment. We're seeing a growth in distributed systems, as bandwidth is cheap and latency low. Add to this the ease of deploying to the cloud, and more architects are beginning to realise that they can break up applications, not just into multiple layers, but also into multiple components within the layer. Load balancers, of course, help with this when the various components in a layer are performing the same job, but the ability to expose different services as small components has led to a growth in the design, implementation, and deployment of _microservices_ .
|
||||
|
||||
More on Microservices
|
||||
|
||||
* [How to explain microservices to your CEO][1]
|
||||
|
||||
* [Free eBook: Microservices vs. service-oriented architecture][2]
|
||||
|
||||
* [Secured DevOps for microservices][3]
|
||||
|
||||
So, [what exactly is a microservice][23]? I quite like [Wikipedia's definition][24], though it's interesting that security isn't mentioned there.[4][17] One of the points that I like about microservices is that, when well-designed, they conform to the first two points of Peter H. Salus' description of the [Unix philosophy][25]:
|
||||
|
||||
1. Write programs that do one thing and do it well.
|
||||
|
||||
2. Write programs to work together.
|
||||
|
||||
3. Write programs to handle text streams, because that is a universal interface.
|
||||
|
||||
The last of the three is slightly less relevant, because the Unix philosophy is generally used to refer to standalone applications, which often have a command instantiation. It does, however, encapsulate one of the basic requirements of microservices: that they must have well-defined interfaces.
|
||||
|
||||
By "well-defined," I don't just mean a description of any externally accessible APIs' methods, but also of the normal operation of the microservice: inputs and outputs—and, if there are any, side-effects. As I described in a previous post, "[5 traits of good systems architecture][18]," data and entity descriptions are crucial if you're going to be able to design a system. Here, in our description of microservices, we get to see why these are so important, because, for me, the key defining feature of a microservices architecture is decomposability. And if you're going to decompose[5][8] your architecture, you need to be very, very clear which "bits" (components) are going to do what.
|
||||
|
||||
And here's where security starts to come in. A clear description of what a particular component should be doing allows you to:
|
||||
|
||||
* Check your design
|
||||
|
||||
* Ensure that your implementation meets the description
|
||||
|
||||
* Come up with reusable unit tests to check functionality
|
||||
|
||||
* Track mistakes in implementation and correct them
|
||||
|
||||
* Test for unexpected outcomes
|
||||
|
||||
* Monitor for misbehaviour
|
||||
|
||||
* Audit actual behaviour for future scrutiny
|
||||
|
||||
Now, are all these things possible in a larger architecture? Yes, they are. But they become increasingly difficult where entities are chained together or combined in more complex configurations. Ensuring _correct_ implementation and behaviour is much, much easier when you've got smaller pieces to work together. And deriving complex systems behaviours—and misbehaviours—is much more difficult if you can't be sure that the individual components are doing what they ought to be.
|
||||
|
||||
It doesn't stop here, however. As I've mentioned on many [previous occasions][19], writing good security code is difficult.[7][9] Proving that it does what it should do is even more difficult. There is every reason, therefore, to restrict code that has particular security requirements—password checking, encryption, cryptographic key management, authorisation, etc.—to small, well-defined blocks. You can then do all the things that I've mentioned above to try to make sure it's done correctly.
|
||||
|
||||
And yet there's more. We all know that not everybody is great at writing security-related code. By decomposing your architecture such that all security-sensitive code is restricted to well-defined components, you get the chance to put your best security people on that and restrict the danger that J. Random Coder[8][10] will put something in that bypasses or downgrades a key security control.
|
||||
|
||||
It can also act as an opportunity for learning: It's always good to be able to point to a design/implementation/test/monitoring tuple and say: "That's how it should be done. Hear, read, mark, learn, and inwardly digest.[9][11]"
|
||||
|
||||
Should you go about decomposing all of your legacy applications into microservices? Probably not. But given all the benefits you can accrue, you might consider starting with your security functions.
|
||||
|
||||
* * *
|
||||
|
||||
1Well, a little bit—it's always nice to have readers.
|
||||
|
||||
2I know they are: I wrote them.
|
||||
|
||||
3Probably less fascinating.
|
||||
|
||||
4At the time this article was written. It's entirely possible that I—or one of you—may edit the article to change that.
|
||||
|
||||
5This sounds like a gardening term, which is interesting. Not that I really like gardening, but still.[6][12]
|
||||
|
||||
6Amusingly, I first wrote, "…if you're going to decompose your architect…," which sounds like the strapline for an IT-themed murder film.
|
||||
|
||||
7Regular readers may remember a reference to the excellent film _The Thick of It_ .
|
||||
|
||||
8Other generic personae exist; please take your pick.
|
||||
|
||||
9Not a cryptographic digest: I don't think that's what the original writers had in mind.
|
||||
|
||||
_This article originally appeared on [Alice, Eve, and Bob—a security blog][13] and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/microservices-are-security-issue
|
||||
|
||||
作者:[Mike Bursell ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://blog.openshift.com/microservices-how-to-explain-them-to-your-ceo/?intcmp=7016000000127cYAAQ&src=microservices_resource_menu1
|
||||
[2]:https://www.openshift.com/promotions/microservices.html?intcmp=7016000000127cYAAQ&src=microservices_resource_menu2
|
||||
[3]:https://opensource.com/business/16/11/secured-devops-microservices?src=microservices_resource_menu3
|
||||
[4]:https://opensource.com/article/17/11/microservices-are-security-issue?rate=GDH4xOWsgYsVnWbjEIoAcT_92b8gum8XmgR6U0T04oM
|
||||
[5]:https://opensource.com/article/17/11/microservices-are-security-issue#1
|
||||
[6]:https://opensource.com/article/17/11/microservices-are-security-issue#2
|
||||
[7]:https://opensource.com/article/17/11/microservices-are-security-issue#3
|
||||
[8]:https://opensource.com/article/17/11/microservices-are-security-issue#5
|
||||
[9]:https://opensource.com/article/17/11/microservices-are-security-issue#7
|
||||
[10]:https://opensource.com/article/17/11/microservices-are-security-issue#8
|
||||
[11]:https://opensource.com/article/17/11/microservices-are-security-issue#9
|
||||
[12]:https://opensource.com/article/17/11/microservices-are-security-issue#6
|
||||
[13]:https://aliceevebob.com/2017/10/31/why-microservices-are-a-security-issue/
|
||||
[14]:https://opensource.com/user/105961/feed
|
||||
[15]:https://opensource.com/tags/security
|
||||
[16]:https://aliceevebob.com/2017/03/14/systems-security-why-it-matters/
|
||||
[17]:https://opensource.com/article/17/11/microservices-are-security-issue#4
|
||||
[18]:https://opensource.com/article/17/10/systems-architect
|
||||
[19]:https://opensource.com/users/mikecamel
|
||||
[20]:https://opensource.com/users/mikecamel
|
||||
[21]:https://opensource.com/users/mikecamel
|
||||
[22]:https://opensource.com/article/17/11/microservices-are-security-issue#comments
|
||||
[23]:https://opensource.com/resources/what-are-microservices
|
||||
[24]:https://en.wikipedia.org/wiki/Microservices
|
||||
[25]:https://en.wikipedia.org/wiki/Unix_philosophy
|
||||
@ -0,0 +1,221 @@
|
||||
Protecting Your Website From Application Layer DOS Attacks With mod
|
||||
======
|
||||
There exist many ways of maliciously taking a website offline. The more complicated methods involve technical knowledge of databases and programming. A far simpler method is known as a "Denial Of Service", or "DOS" attack. This attack derives its name from its goal which is to deny your regular clients or site visitors normal website service.
|
||||
|
||||
There are, generally speaking, two forms of DOS attack;
|
||||
|
||||
1. Layer 3,4 or Network-Layer attacks.
|
||||
2. Layer 7 or Application-Layer attacks.
|
||||
|
||||
|
||||
|
||||
The first type of DOS attack, network-layer, is when a huge quantity of junk traffic is directed at the web server. When the quantity of junk traffic exceeds the capacity of the network infrastructure the website is taken offline.
|
||||
|
||||
The second type of DOS attack, application-layer, is where instead of junk traffic legitimate looking page requests are made. When the number of page requests exceeds the capacity of the web server to serve pages legitimate visitors will not be able to use the site.
|
||||
|
||||
This guide will look at mitigating application-layer attacks. This is because mitigating networking-layer attacks requires huge quantities of available bandwidth and the co-operation of upstream providers. This is usually not something that can be protected against through configuration of the web server.
|
||||
|
||||
An application-layer attack, at least a modest one, can be protected against through the configuration of a normal web server. Protecting against this form of attack is important because [Cloudflare][1] have [recently reported][2] that the number of network-layer attacks is diminishing while the number of application-layer attacks is increasing.
|
||||
|
||||
This guide will explain using the Apache2 module [mod_evasive][3] by [zdziarski][4].
|
||||
|
||||
In addition, mod_evasive will stop an attacker trying to guess a username/password combination by attempting hundreds of combinations i.e. a brute force attack.
|
||||
|
||||
Mod_evasive works by keeping a record of the number of requests arriving from each IP address. When this number exceeds one of the several thresholds that IP is served an error page. Error pages require far fewer resources than a site page keeping the site online for legitimate visitors.
|
||||
|
||||
### Installing mod_evasive on Ubuntu 16.04
|
||||
|
||||
Mod_evasive is contained in the default Ubuntu 16.04 repositories with the package name "libapache2-mod-evasive". A simple `apt-get` will get it installed:
|
||||
```
|
||||
apt-get update
|
||||
apt-get upgrade
|
||||
apt-get install libapache2-mod-evasive
|
||||
|
||||
```
|
||||
|
||||
We now need to configure mod_evasive.
|
||||
|
||||
It's configuration file is located at `/etc/apache2/mods-available/evasive.conf`. By default, all the modules settings are commented after installation. Therefore, the module won't interfere with site traffic until the configuration file has been edited.
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
#DOSHashTableSize 3097
|
||||
#DOSPageCount 2
|
||||
#DOSSiteCount 50
|
||||
#DOSPageInterval 1
|
||||
#DOSSiteInterval 1
|
||||
#DOSBlockingPeriod 10
|
||||
|
||||
#DOSEmailNotify you@yourdomain.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
#DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
The first block of directives mean as follows:
|
||||
|
||||
* **DOSHashTableSize** - The current list of accessing IP's and their request count.
|
||||
* **DOSPageCount** - The threshold number of page requests per DOSPageInterval.
|
||||
* **DOSPageInterval** - The amount of time in which mod_evasive counts up the page requests.
|
||||
* **DOSSiteCount** - The same as the DOSPageCount but counts requests from the same IP for any page on the site.
|
||||
* **DOSSiteInterval** - The amount of time that mod_evasive counts up the site requests.
|
||||
* **DOSBlockingPeriod** - The amount of time in seconds that an IP is blocked for.
|
||||
|
||||
|
||||
|
||||
If the default configuration shown above is used then an IP will be blocked if it:
|
||||
|
||||
* Requests a single page more than twice a second.
|
||||
* Requests more than 50 pages different pages per second.
|
||||
|
||||
|
||||
|
||||
If an IP exceeds these thresholds it is blocked for 10 seconds.
|
||||
|
||||
This may not seem like a lot, however, mod_evasive will continue monitoring the page requests even for blocked IP's and reset their block period. As long as an IP is attempting to DOS the site it will remain blocked.
|
||||
|
||||
The remaining directives are:
|
||||
|
||||
* **DOSEmailNotify** - An email address to receive notification of DOS attacks and IP's being blocked.
|
||||
* **DOSSystemCommand** - A command to run in the event of a DOS.
|
||||
* **DOSLogDir** - The directory where mod_evasive keeps some temporary files.
|
||||
|
||||
|
||||
|
||||
### Configuring mod_evasive
|
||||
|
||||
The default configuration is a good place to start as it should not block any legitimate users. The configuration file with all directives (apart from DOSSystemCommand) uncommented looks like the following:
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
DOSHashTableSize 3097
|
||||
DOSPageCount 2
|
||||
DOSSiteCount 50
|
||||
DOSPageInterval 1
|
||||
DOSSiteInterval 1
|
||||
DOSBlockingPeriod 10
|
||||
|
||||
DOSEmailNotify JohnW@example.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
The log directory must be created and given the same owner as the apache process. Here it is created at `/var/log/mod_evasive` and given the owner and group of the Apache web server on Ubuntu `www-data`:
|
||||
```
|
||||
mkdir /var/log/mod_evasive
|
||||
chown www-data:www-data /var/log/mod_evasive
|
||||
|
||||
```
|
||||
|
||||
After editing Apache's configuration, especially on a live website, it is always a good idea to check the syntax of the edits before restarting or reloading. This is because a syntax error will stop Apache from re-starting and taking your site offline.
|
||||
|
||||
Apache comes packaged with a helper command that has a configuration syntax checker. Simply run the following command to check your edits:
|
||||
```
|
||||
apachectl configtest
|
||||
|
||||
```
|
||||
|
||||
If your configuration is correct you will get the response:
|
||||
```
|
||||
Syntax OK
|
||||
|
||||
```
|
||||
|
||||
However, if there is a problem you will be told where it occurred and what it was, e.g.:
|
||||
```
|
||||
AH00526: Syntax error on line 6 of /etc/apache2/mods-enabled/evasive.conf:
|
||||
DOSSiteInterval takes one argument, Set site interval
|
||||
Action 'configtest' failed.
|
||||
The Apache error log may have more information.
|
||||
|
||||
```
|
||||
|
||||
If your configuration passes the configtest then the module can be safely enabled and Apache reloaded:
|
||||
```
|
||||
a2enmod evasive
|
||||
systemctl reload apache2.service
|
||||
|
||||
```
|
||||
|
||||
Mod_evasive is now configured and running.
|
||||
|
||||
### Testing
|
||||
|
||||
In order to test mod_evasive, we simply need to make enough web requests to the server that we exceed the threshold and record the response codes from Apache.
|
||||
|
||||
A normal, successful page request will receive the response:
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
```
|
||||
|
||||
However, one that has been denied by mod_evasive will return the following:
|
||||
```
|
||||
HTTP/1.1 403 Forbidden
|
||||
|
||||
```
|
||||
|
||||
The following script will make HTTP requests to `127.0.0.1:80`, that is localhost on port 80, as rapidly as possible and print out the response code of every request.
|
||||
|
||||
All you need to do is to copy the following bash script into a file e.g. `mod_evasive_test.sh`:
|
||||
```
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
for i in {1..50}; do
|
||||
curl -s -I 127.0.0.1 | head -n 1
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
The parts of this script mean as follows:
|
||||
|
||||
* curl - This is a command to make web requests.
|
||||
* -s - Hide the progress meter.
|
||||
* -I - Only display the response header information.
|
||||
* head - Print the first part of a file.
|
||||
* -n 1 - Only display the first line.
|
||||
|
||||
|
||||
|
||||
Then make it executable:
|
||||
```
|
||||
chmod 755 mod_evasive_test.sh
|
||||
|
||||
```
|
||||
|
||||
When the script is run **before** mod_evasive is enabled you will see 50 lines of `HTTP/1.1 200 OK` returned.
|
||||
|
||||
However, after mod_evasive is enabled you will see the following:
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
HTTP/1.1 200 OK
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
The first two requests were allowed, but then once a third in the same second was made mod_evasive denied any further requests. You will also receive an email letting you know that a DOS attempt was detected to the address you set with the `DOSEmailNotify` option.
|
||||
|
||||
Mod_evasive is now protecting your site!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/mod_proxy/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net/about/
|
||||
[1]:https://www.cloudflare.com
|
||||
[2]:https://blog.cloudflare.com/the-new-ddos-landscape/
|
||||
[3]:https://github.com/jzdziarski/mod_evasive
|
||||
[4]:https://www.zdziarski.com/blog/
|
||||
@ -0,0 +1,109 @@
|
||||
Easily Upgrade Ubuntu to a Newer Version with This Single Command
|
||||
======
|
||||
[zzupdate][1] is an open source command line utility that makes the task of upgrading Ubuntu Desktop and Server to newer versions a tad bit easier by combining several update commands into one single command.
|
||||
|
||||
Upgrading an Ubuntu system to a newer release is not a herculean task. Either with the GUI or with a couple of commands, you can easily upgrade your system to the latest release.
|
||||
|
||||
On the other hand, zzupdate written by Gianluigi 'Zane' Zanettini handles clean, update, autoremove, version upgrade and composer self-update for your Ubuntu system with just a single command.
|
||||
|
||||
It cleans up the local cache, updates available package information, and then perform a distribution upgrade. In the next step, it updates the Composer and removes the unused packages.
|
||||
|
||||
The script must run as root user.
|
||||
|
||||
### Installing zzupdate to upgrade Ubuntu to a newer version
|
||||
|
||||
![Upgrade Ubuntu to a newer version with a single command][2]
|
||||
|
||||
![Upgrade Ubuntu to a newer version with a single command][3]
|
||||
|
||||
To install zzupdate, execute the below command in a Terminal.
|
||||
```
|
||||
curl -s https://raw.githubusercontent.com/TurboLabIt/zzupdate/master/setup.sh | sudo sh
|
||||
```
|
||||
|
||||
And then copy the provided sample configuration file to zzupdate.conf and set your preferences.
|
||||
```
|
||||
sudo cp /usr/local/turbolab.it/zzupdate/zzupdate.default.conf /etc/turbolab.it/zzupdate.conf
|
||||
```
|
||||
|
||||
Once you have everything, just use the following command and it will start upgrading your Ubuntu system to a newer version (if there is any).
|
||||
|
||||
`sudo zzupdate`
|
||||
|
||||
Note that zzupdate upgrades the system to the next available version in case of a normal release. However, when you are running Ubuntu 16.04 LTS, it tries to search for the next long-term support version only and not the latest version available.
|
||||
|
||||
If you want to move out of the LTS release and upgrade to the latest release, you will have change some options.
|
||||
|
||||
For Ubuntu desktop, open **Software & Updates** and under **Updates** tab and change Notify me of a new Ubuntu version to " **For any new version** ".
|
||||
|
||||
![Software Updater in Ubuntu][2]
|
||||
|
||||
![Software Updater in Ubuntu][4]
|
||||
|
||||
For Ubuntu server, edit the release-upgrades file.
|
||||
```
|
||||
vi /etc/update-manager/release-upgrades
|
||||
|
||||
Prompt=normal
|
||||
```
|
||||
|
||||
### Configuring zzupdate [optional]
|
||||
|
||||
zzupdate options to configure
|
||||
```
|
||||
REBOOT=1
|
||||
```
|
||||
|
||||
If this value is 1, a system restart is performed after an upgrade.
|
||||
```
|
||||
REBOOT_TIMEOUT=15
|
||||
```
|
||||
|
||||
This sets up the reboot timeout to 900 seconds as some hardware takes much longer to reboot than others.
|
||||
```
|
||||
VERSION_UPGRADE=1
|
||||
```
|
||||
|
||||
Executes version progression if an upgrade is available.
|
||||
```
|
||||
VERSION_UPGRADE_SILENT=0
|
||||
```
|
||||
|
||||
Version progression occurs automatically.
|
||||
```
|
||||
COMPOSER_UPGRADE=1
|
||||
```
|
||||
|
||||
Value '1' will automatically upgrade the composer.
|
||||
```
|
||||
SWITCH_PROMPT_TO_NORMAL=0
|
||||
```
|
||||
|
||||
This features switches the Ubuntu Version updated to normal i.e. if you have an LTS release running, zzupdate won't upgrade it to Ubuntu 17.10 if its set to 0. It will search for an LTS version only. In contrast, value 1 searches for the latest release whether you are running an LTS or a normal release.
|
||||
|
||||
Once done, all you have to do is run in console to run a complete update of your Ubuntu system
|
||||
```
|
||||
sudo zzupdate
|
||||
```
|
||||
|
||||
### Final Words
|
||||
|
||||
Though the upgrade process for Ubuntu is in itself an easy one, zzupdate reduces it to mere one command. No coding knowledge is necessary and the process is complete config file driven. I personally found itself a good tool to update several Ubuntu systems without the need of taking care of different things separately.
|
||||
|
||||
Are you willing to give it a try?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/zzupdate-upgrade-ubuntu/
|
||||
|
||||
作者:[Ambarish Kumar;Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com
|
||||
[1]:https://github.com/TurboLabIt/zzupdate
|
||||
[2]:data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||
[3]:https://itsfoss.com/wp-content/uploads/2017/11/upgrade-ubuntu-single-command-featured-800x450.jpg
|
||||
[4]:https://itsfoss.com/wp-content/uploads/2017/11/software-update-any-new-version-800x378.jpeg
|
||||
@ -1,43 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Someone Tries to Bring Back Ubuntu's Unity from the Dead as an Official Spin
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
> The Ubuntu Unity remix would be supported for nine months
|
||||
|
||||
Canonical's sudden decision of killing its Unity user interface after seven years affected many Ubuntu users, and it looks like someone now tries to bring it back from the dead as an unofficial spin.
|
||||
|
||||
Long-time [Ubuntu][1] member Dale Beaudoin [ran a poll][2] last week on the official Ubuntu forums to take the pulse of the community and see if they are interested in an Ubuntu Unity Remix that would be released alongside Ubuntu 18.04 LTS (Bionic Beaver) next year and be supported for nine months or five years.
|
||||
|
||||
Thirty people voted in the poll, with 67 percent of them opting for an LTS (Long Term Support) release of the so-called Ubuntu Unity Remix, while 33 percent voted for the 9-month supported release. It also looks like this upcoming Ubuntu Unity Spin [looks to become an official flavor][3], yet this means commitment from those developing it.
|
||||
|
||||
"A recent poll voted 2/3rds in favor of Ubuntu Unity to become an LTS distribution. We should try to work this cycle assuming that it will be LTS and an official flavor," said Dale Beaudoin. "We will try and release an updated ISO once every week or 10 days using the current 18.04 daily builds of default Ubuntu Bionic Beaver as a platform."
|
||||
|
||||
### Is Ubuntu Unity making a comeback?
|
||||
|
||||
The last Ubuntu version to ship with Unity by default was Ubuntu 17.04 (Zesty Zapus), which will reach end of life on January 2018\. Ubuntu 17.10 (Artful Artful), the current stable release of the popular operating system, is the first to use the GNOME desktop environment by default for the main Desktop edition as Canonical CEO [announced][4] earlier this year that Unity would no longer be developed.
|
||||
|
||||
However, Canonical is still offering the Unity desktop environment from the official software repositories, so if someone wants to install it, it's one click away. But the bad news is that they'll be supported up until the release of Ubuntu 18.04 LTS (Bionic Beaver) in April 2018, so the developers of the Ubuntu Unity Remix would have to continue to keep in on life support on their a separate repository.
|
||||
|
||||
On the other hand, we don't believe Canonical will change their mind and accept this Ubuntu Unity Spin to become an official flavor, which would mean they failed to continue development of Unity, and now a handful of people can do it. Most probably, if interest in this Ubuntu Unity Remix won't fade away soon, it will be an unofficial spin supported by the nostalgic community.
|
||||
|
||||
Question is, would you be interested in an Ubuntu Unity spin, official or not?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/someone-tries-to-bring-back-ubuntu-s-unity-from-the-dead-as-an-unofficial-spin-518778.shtml
|
||||
|
||||
作者:[Marius Nestor ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://linux.softpedia.com/downloadTag/Ubuntu
|
||||
[2]:https://community.ubuntu.com/t/poll-unity-7-distro-9-month-spin-or-lts-for-18-04/2066
|
||||
[3]:https://community.ubuntu.com/t/unity-maintenance-roadmap/2223
|
||||
[4]:http://news.softpedia.com/news/canonical-to-stop-developing-unity-8-ubuntu-18-04-lts-ships-with-gnome-desktop-514604.shtml
|
||||
[5]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
@ -1,153 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Suplemon - Modern CLI Text Editor with Multi Cursor Support
|
||||
======
|
||||
Suplemon is a modern text editor for CLI that emulates the multi cursor behavior and other features of [Sublime Text][1]. It's lightweight and really easy to use, just as Nano is.
|
||||
|
||||
One of the benefits of using a CLI editor is that you can use it whether the Linux distribution that you're using has a GUI or not. This type of text editors also stands out as being simple, fast and powerful.
|
||||
|
||||
You can find useful information and the source code in the [official repository][2].
|
||||
|
||||
### Features
|
||||
|
||||
These are some of its interesting features:
|
||||
|
||||
* Multi cursor support
|
||||
|
||||
* Undo / Redo
|
||||
|
||||
* Copy and Paste, with multi line support
|
||||
|
||||
* Mouse support
|
||||
|
||||
* Extensions
|
||||
|
||||
* Find, find all, find next
|
||||
|
||||
* Syntax highlighting
|
||||
|
||||
* Autocomplete
|
||||
|
||||
* Custom keyboard shortcuts
|
||||
|
||||
### Installation
|
||||
|
||||
First, make sure you have the latest version of python3 and pip3 installed.
|
||||
|
||||
Then type in a terminal:
|
||||
|
||||
```
|
||||
$ sudo pip3 install suplemon
|
||||
```
|
||||
|
||||
Create a new file in the current directory
|
||||
|
||||
Open a terminal and type:
|
||||
|
||||
```
|
||||
$ suplemon
|
||||
```
|
||||
|
||||

|
||||
|
||||
Open one or multiple files
|
||||
|
||||
Open a terminal and type:
|
||||
|
||||
```
|
||||
$ suplemon ...
|
||||
```
|
||||
|
||||
```
|
||||
$ suplemon example1.c example2.c
|
||||
```
|
||||
|
||||
Main configuration
|
||||
|
||||
You can find the configuration file at ~/.config/suplemon/suplemon-config.json.
|
||||
|
||||
Editing this file is easy, you just have to enter command mode (once you are inside suplemon) and run the config command. You can view the default configuration by running config defaults.
|
||||
|
||||
Keymap configuration
|
||||
|
||||
I'll show you the default key mappings for suplemon. If you want to edit them, just run keymap command. Run keymap default to view the default keymap file.
|
||||
|
||||
* Exit: Ctrl + Q
|
||||
|
||||
* Copy line(s) to buffer: Ctrl + C
|
||||
|
||||
* Cut line(s) to buffer: Ctrl + X
|
||||
|
||||
* Insert buffer: Ctrl + V
|
||||
|
||||
* Duplicate line: Ctrl + K
|
||||
|
||||
* Goto: Ctrl + G. You can go to a line or to a file (just type the beginning of a file name). Also, it is possible to type something like 'exam:50' to go to the line 50 of the file example.c at line 50.
|
||||
|
||||
* Search for string or regular expression: Ctrl + F
|
||||
|
||||
* Search next: Ctrl + D
|
||||
|
||||
* Trim whitespace: Ctrl + T
|
||||
|
||||
* Add new cursor in arrow direction: Alt + Arrow key
|
||||
|
||||
* Jump to previous or next word or line: Ctrl + Left / Right
|
||||
|
||||
* Revert to single cursor / Cancel input prompt: Esc
|
||||
|
||||
* Move line(s) up / down: Page Up / Page Down
|
||||
|
||||
* Save file: Ctrl + S
|
||||
|
||||
* Save file with new name: F1
|
||||
|
||||
* Reload current file: F2
|
||||
|
||||
* Open file: Ctrl + O
|
||||
|
||||
* Close file: Ctrl + W
|
||||
|
||||
* Switch to next/previous file: Ctrl + Page Up / Ctrl + Page Down
|
||||
|
||||
* Run a command: Ctrl + E
|
||||
|
||||
* Undo: Ctrl + Z
|
||||
|
||||
* Redo: Ctrl + Y
|
||||
|
||||
* Toggle visible whitespace: F7
|
||||
|
||||
* Toggle mouse mode: F8
|
||||
|
||||
* Toggle line numbers: F9
|
||||
|
||||
* Toggle Full screen: F11
|
||||
|
||||
Mouse shortcuts
|
||||
|
||||
* Set cursor at pointer position: Left Click
|
||||
|
||||
* Add a cursor at pointer position: Right Click
|
||||
|
||||
* Scroll vertically: Scroll Wheel Up / Down
|
||||
|
||||
### Wrapping up
|
||||
|
||||
After trying Suplemon for some time, I have changed my opinion about CLI text editors. I had tried Nano before, and yes, I liked its simplicity, but its modern-feature lack made it non-practical for my everyday use.
|
||||
|
||||
This tool has the best of both CLI and GUI worlds... Simplicity and feature-richness! So I suggest you give it a try, and write your thoughts in the comments :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/tools/suplemon-cli-text-editor-multi-cursor/
|
||||
|
||||
作者:[Ivo Ursino][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/ursinov/
|
||||
[1]:https://linoxide.com/tools/install-sublime-text-editor-linux/
|
||||
[2]:https://github.com/richrd/suplemon/
|
||||
@ -0,0 +1,117 @@
|
||||
TLDR pages: Simplified Alternative To Linux Man Pages
|
||||
============================================================
|
||||
|
||||
[][22]
|
||||
|
||||
Working on the terminal and using various commands to carry out important tasks is an indispensable part of a Linux desktop experience. This open-source operating system possesses an [abundance of commands][23] that **makes** it impossible for any user to remember all of them. To make things more complex, each command has its own set of options to bring a wider set of functionality.
|
||||
|
||||
To solve this problem, [Man Pages][12], short for manual pages, were created. First written in English, it contains tons of in-depth information about different commands. Sometimes, when you’re looking for just basic information on a command, it can also become overwhelming. To solve this issue,[ TLDR pages][13] was created.
|
||||
|
||||
_Before going ahead and knowing more about it, don’t forget to check a few more terminal tricks:_
|
||||
|
||||
* _**[Watch Star Wars in terminal ][1]**_
|
||||
|
||||
* _**[Use StackOverflow in terminal][2]**_
|
||||
|
||||
* _**[Get Weather report in terminal][3]**_
|
||||
|
||||
* _**[Access Google through terminal][4]**_
|
||||
|
||||
* [**_Use Wikipedia from command line_**][7]
|
||||
|
||||
* _**[Check Cryptocurrency Prices From Terminal][5]**_
|
||||
|
||||
* _**[Search and download torrent in terminal][6]**_
|
||||
|
||||
### What are TLDR pages?
|
||||
|
||||
The GitHub page of TLDR pages for Linux/Unix describes it as a collection of simplified and community-driven man pages. It’s an effort to make the experience of using man pages simpler with the help of practical examples. For those who don’t know, TLDR is taken from common internet slang _ Too Long Didn’t Read_ .
|
||||
|
||||
In case you wish to compare, let’s take the example of tar command. The usual man page extends over 1,000 lines. It’s an archiving utility that’s often combined with a compression method like bzip or gzip. Take a look at its man page:
|
||||
|
||||
[][14] On the other hand, TLDR pages lets you simply take a glance at the command and see how it works. Tar’s TLDR page simply looks like this and comes with some handy examples of the most common tasks you can complete with this utility:
|
||||
|
||||
[][15] Let’s take another example and show you what TLDR pages has to offer when it comes to apt:
|
||||
|
||||
[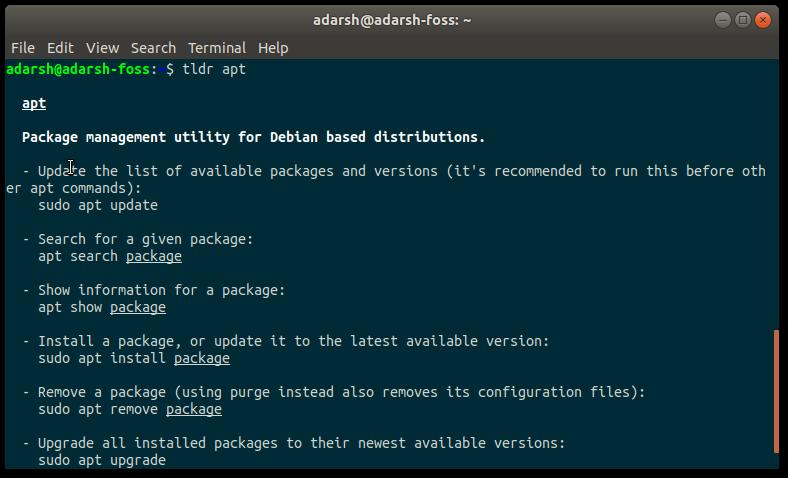][16] Having shown you how TLDR works and makes your life easier, let’s tell you how to install it on your Linux-based operating system.
|
||||
|
||||
### How to install and use TLDR pages on Linux?
|
||||
|
||||
The most mature TLDR client is based on Node.js and you can install it easily using NPM package manager. In case Node and NPM are not available on your system, run the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install nodejs
|
||||
|
||||
sudo apt-get install npm
|
||||
```
|
||||
|
||||
In case you’re using an OS other than Debian, Ubuntu, or Ubuntu’s derivatives, you can use yum, dnf, or pacman package manager as per your convenience.
|
||||
|
||||
Now, by running the following command in terminal, install TLDR client on your Linux machine:
|
||||
|
||||
```
|
||||
sudo npm install -g tldr
|
||||
```
|
||||
|
||||
Once you’ve installed this terminal utility, it would be a good idea to update its cache before trying it out. To do so, run the following command:
|
||||
|
||||
```
|
||||
tldr --update
|
||||
```
|
||||
|
||||
After doing this, feel free to read the TLDR page of any Linux command. To do so, simply type:
|
||||
|
||||
```
|
||||
tldr <commandname>
|
||||
```
|
||||
|
||||
[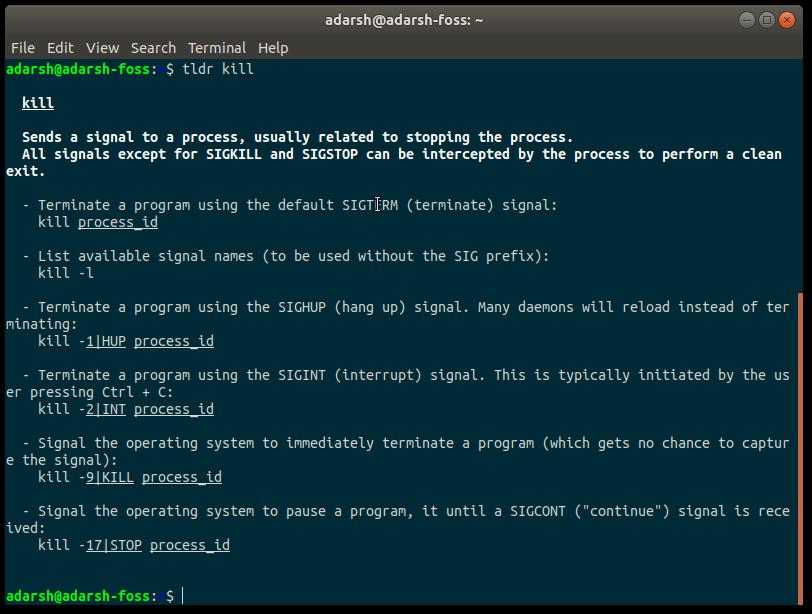][17]
|
||||
|
||||
You can also run the following help command to see all different parameters that can be used with TLDR to get the desired output. As usual, this help page is also accompanied with examples.
|
||||
|
||||
### TLDR web, Android, and iOS versions
|
||||
|
||||
You would be pleasantly surprised to know that TLDR pages isn’t limited to your Linux desktop. Instead, it can also be used in your web browser, which can be accessed from any machine.
|
||||
|
||||
To use TLDR web version, visit [tldr.ostera.io][18] and perform the required search operation.
|
||||
|
||||
Alternatively, you can also download the [iOS][19] and [Android][20] apps and keep learning new commands on the go.
|
||||
|
||||
[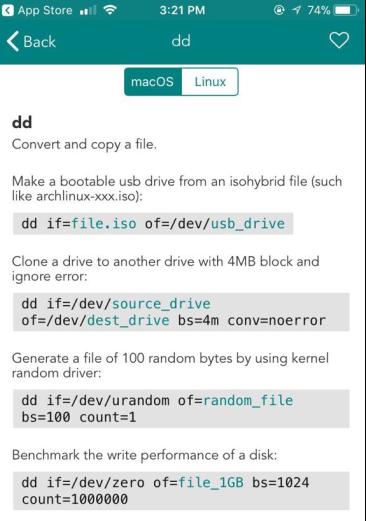][21]
|
||||
|
||||
Did you find this cool Linux terminal trick interesting? Do give it a try and let us know your feedback.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fossbytes.com/tldr-pages-linux-man-pages-alternative/
|
||||
|
||||
作者:[Adarsh Verma ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fossbytes.com/author/adarsh/
|
||||
[1]:https://fossbytes.com/watch-star-wars-command-prompt-via-telnet/
|
||||
[2]:https://fossbytes.com/use-stackoverflow-linux-terminal-mac/
|
||||
[3]:https://fossbytes.com/single-command-curl-wttr-terminal-weather-report/
|
||||
[4]:https://fossbytes.com/how-to-google-search-in-command-line-using-googler/
|
||||
[5]:https://fossbytes.com/check-bitcoin-cryptocurrency-prices-command-line-coinmon/
|
||||
[6]:https://fossbytes.com/review-torrench-download-torrents-using-terminal-linux/
|
||||
[7]:https://fossbytes.com/use-wikipedia-termnianl-wikit/
|
||||
[8]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Ffossbytes.com%2Ftldr-pages-linux-man-pages-alternative%2F
|
||||
[9]:https://twitter.com/intent/tweet?text=TLDR+pages%3A+Simplified+Alternative+To+Linux+Man+Pages&url=https%3A%2F%2Ffossbytes.com%2Ftldr-pages-linux-man-pages-alternative%2F&via=%40fossbytes14
|
||||
[10]:http://plus.google.com/share?url=https://fossbytes.com/tldr-pages-linux-man-pages-alternative/
|
||||
[11]:http://pinterest.com/pin/create/button/?url=https://fossbytes.com/tldr-pages-linux-man-pages-alternative/&media=https://fossbytes.com/wp-content/uploads/2017/11/tldr-page-ubuntu.jpg
|
||||
[12]:https://fossbytes.com/linux-lexicon-man-pages-navigation/
|
||||
[13]:https://github.com/tldr-pages/tldr
|
||||
[14]:https://fossbytes.com/wp-content/uploads/2017/11/tar-man-page.jpg
|
||||
[15]:https://fossbytes.com/wp-content/uploads/2017/11/tar-tldr-page.jpg
|
||||
[16]:https://fossbytes.com/wp-content/uploads/2017/11/tldr-page-of-apt.jpg
|
||||
[17]:https://fossbytes.com/wp-content/uploads/2017/11/tldr-kill-command.jpg
|
||||
[18]:https://tldr.ostera.io/
|
||||
[19]:https://itunes.apple.com/us/app/tldt-pages/id1071725095?ls=1&mt=8
|
||||
[20]:https://play.google.com/store/apps/details?id=io.github.hidroh.tldroid
|
||||
[21]:https://fossbytes.com/wp-content/uploads/2017/11/tldr-app-ios.jpg
|
||||
[22]:https://fossbytes.com/wp-content/uploads/2017/11/tldr-page-ubuntu.jpg
|
||||
[23]:https://fossbytes.com/a-z-list-linux-command-line-reference/
|
||||
@ -0,0 +1,85 @@
|
||||
# [Google launches TensorFlow-based vision recognition kit for RPi Zero W][26]
|
||||
|
||||
|
||||

|
||||
Google’s $45 “AIY Vision Kit” for the Raspberry Pi Zero W performs TensorFlow-based vision recognition using a “VisionBonnet” board with a Movidius chip.
|
||||
|
||||
Google’s AIY Vision Kit for on-device neural network acceleration follows an earlier [AIY Projects][7] voice/AI kit for the Raspberry Pi that shipped to MagPi subscribers back in May. Like the voice kit and the older Google Cardboard VR viewer, the new AIY Vision Kit has a cardboard enclosure. The kit differs from the [Cloud Vision API][8], which was demo’d in 2015 with a Raspberry Pi based GoPiGo robot, in that it runs entirely on local processing power rather than requiring a cloud connection. The AIY Vision Kit is available now for pre-order at $45, with shipments due in early December.
|
||||
|
||||
|
||||
[][9] [][10]
|
||||
**AIY Vision Kit, fully assembled (left) and Raspberry Pi Zero W**
|
||||
(click images to enlarge)
|
||||
|
||||
|
||||
The kit’s key processing element, aside from the 1GHz ARM11-based Broadcom BCM2836 SoC found on the required [Raspberry Pi Zero W][21] SBC, is Google’s new VisionBonnet RPi accessory board. The VisionBonnet pHAT board uses a Movidius MA2450, a version of the [Movidius Myriad 2 VPU][22] processor. On the VisionBonnet, the processor runs Google’s open source [TensorFlow][23]machine intelligence library for neural networking. The chip enables visual perception processing at up to 30 frames per second.
|
||||
|
||||
The AIY Vision Kit requires a user-supplied RPi Zero W, a [Raspberry Pi Camera v2][11], and a 16GB micro SD card for downloading the Linux-based image. The kit includes the VisionBonnet, an RGB arcade-style button, a piezo speaker, a macro/wide lens kit, and the cardboard enclosure. You also get flex cables, standoffs, a tripod mounting nut, and connecting components.
|
||||
|
||||
|
||||
[][12] [][13]
|
||||
**AIY Vision Kit kit components (left) and VisonBonnet accessory board**
|
||||
(click images to enlarge)
|
||||
|
||||
|
||||
Three neural network models are available. There’s a general-purpose model that can recognize 1,000 common objects, a facial detection model that can also score facial expression on a “joy scale” that ranges from “sad” to “laughing,” and a model that can identify whether the image contains a dog, cat, or human. The 1,000-image model derives from Google’s open source [MobileNets][24], a family of TensorFlow based computer vision models designed for the restricted resources of a mobile or embedded device.
|
||||
|
||||
MobileNet models offer low latency and low power consumption, and are parameterized to meet the resource constraints of different use cases. The models can be built for classification, detection, embeddings, and segmentation, says Google. Earlier this month, Google released a developer preview of a mobile-friendly [TensorFlow Lite][14] library for Android and iOS that is compatible with MobileNets and the Android Neural Networks API.
|
||||
|
||||
|
||||
[][15]
|
||||
**AIY Vision Kit assembly views**
|
||||
(click image to enlarge)
|
||||
|
||||
|
||||
In addition to providing the three models, the AIY Vision Kit provides basic TensorFlow code and a compiler, so users can develop their own models. In addition, Python developers can write new software to customize RGB button colors, piezo element sounds, and 4x GPIO pins on the VisionBonnet that can add additional lights, buttons, or servos. Potential models include recognizing food items, opening a dog door based on visual input, sending a text when your car leaves the driveway, or playing particular music based on facial recognition of a person entering the camera’s viewpoint.
|
||||
|
||||
|
||||
[][16] [][17]
|
||||
**Myriad 2 VPU block diagram (left) and reference board**
|
||||
(click image to enlarge)
|
||||
|
||||
|
||||
The Movidius Myriad 2 processor provides TeraFLOPS of performance within a nominal 1 Watt power envelope. The chip appeared on early Project Tango reference platforms, and is built into the Ubuntu-driven [Fathom][25] neural processing USB stick that Movidius debuted in May 2016, prior to being acquired by Intel. According to Movidius, the Myriad 2 is available “in millions of devices on the market today.”
|
||||
|
||||
**Further information**
|
||||
|
||||
The AIY Vision Kit is available for pre-order from Micro Center at $44.99, with shipments due in early December. More information may be found in the AIY Vision Kit [announcement][18], [Google Blog notice][19], and [Micro Center shopping page][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
|
||||
作者:[ Eric Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[1]:http://twitter.com/share?url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/&text=Google%20launches%20TensorFlow-based%20vision%20recognition%20kit%20for%20RPi%20Zero%20W%20
|
||||
[2]:https://plus.google.com/share?url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[3]:http://www.facebook.com/sharer.php?u=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[4]:http://www.linkedin.com/shareArticle?mini=true&url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[5]:http://reddit.com/submit?url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/&title=Google%20launches%20TensorFlow-based%20vision%20recognition%20kit%20for%20RPi%20Zero%20W
|
||||
[6]:mailto:?subject=Google%20launches%20TensorFlow-based%20vision%20recognition%20kit%20for%20RPi%20Zero%20W&body=%20http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[7]:http://linuxgizmos.com/free-raspberry-pi-voice-kit-taps-google-assistant-sdk/
|
||||
[8]:http://linuxgizmos.com/google-releases-cloud-vision-api-with-demo-for-pi-based-robot/
|
||||
[9]:http://linuxgizmos.com/files/google_aiyvisionkit.jpg
|
||||
[10]:http://linuxgizmos.com/files/rpi_zerow.jpg
|
||||
[11]:http://linuxgizmos.com/raspberry-pi-cameras-jump-to-8mp-keep-25-dollar-price/
|
||||
[12]:http://linuxgizmos.com/files/google_aiyvisionkit_pieces.jpg
|
||||
[13]:http://linuxgizmos.com/files/google_visionbonnet.jpg
|
||||
[14]:https://developers.googleblog.com/2017/11/announcing-tensorflow-lite.html
|
||||
[15]:http://linuxgizmos.com/files/google_aiyvisionkit_assembly.jpg
|
||||
[16]:http://linuxgizmos.com/files/movidius_myriad2vpu_block.jpg
|
||||
[17]:http://linuxgizmos.com/files/movidius_myriad2_reference_board.jpg
|
||||
[18]:https://blog.google/topics/machine-learning/introducing-aiy-vision-kit-make-devices-see/
|
||||
[19]:https://developers.googleblog.com/2017/11/introducing-aiy-vision-kit-add-computer.html
|
||||
[20]:http://www.microcenter.com/site/content/Google_AIY.aspx?ekw=aiy&rd=1
|
||||
[21]:http://linuxgizmos.com/raspberry-pi-zero-w-adds-wifi-and-bluetooth-for-only-5-more/
|
||||
[22]:https://www.movidius.com/solutions/vision-processing-unit
|
||||
[23]:https://www.tensorflow.org/
|
||||
[24]:https://research.googleblog.com/2017/06/mobilenets-open-source-models-for.html
|
||||
[25]:http://linuxgizmos.com/usb-stick-brings-neural-computing-functions-to-devices/
|
||||
[26]:http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
@ -0,0 +1,187 @@
|
||||
translating by zrszrszr
|
||||
12 MySQL/MariaDB Security Best Practices for Linux
|
||||
============================================================
|
||||
|
||||
MySQL is the world’s most popular open source database system and MariaDB (a fork of MySQL) is the world’s fastest growing open source database system. After installing MySQL server, it is insecure in it’s default configuration, and securing it is one of the essential tasks in general database management.
|
||||
|
||||
This will contribute to hardening and boosting of overall Linux server security, as attackers always scan vulnerabilities in any part of a system, and databases have in the past been key target areas. A common example is the brute-forcing of the root password for the MySQL database.
|
||||
|
||||
In this guide, we will explain useful MySQL/MariaDB security best practice for Linux.
|
||||
|
||||
### 1\. Secure MySQL Installation
|
||||
|
||||
This is the first recommended step after installing MySQL server, towards securing the database server. This script facilitates in improving the security of your MySQL server by asking you to:
|
||||
|
||||
* set a password for the root account, if you didn’t set it during installation.
|
||||
|
||||
* disable remote root user login by removing root accounts that are accessible from outside the local host.
|
||||
|
||||
* remove anonymous-user accounts and test database which by default can be accessed by all users, even anonymous users.
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
```
|
||||
|
||||
After running it, set the root password and answer the series of questions by entering [Yes/Y] and press [Enter].
|
||||
|
||||
[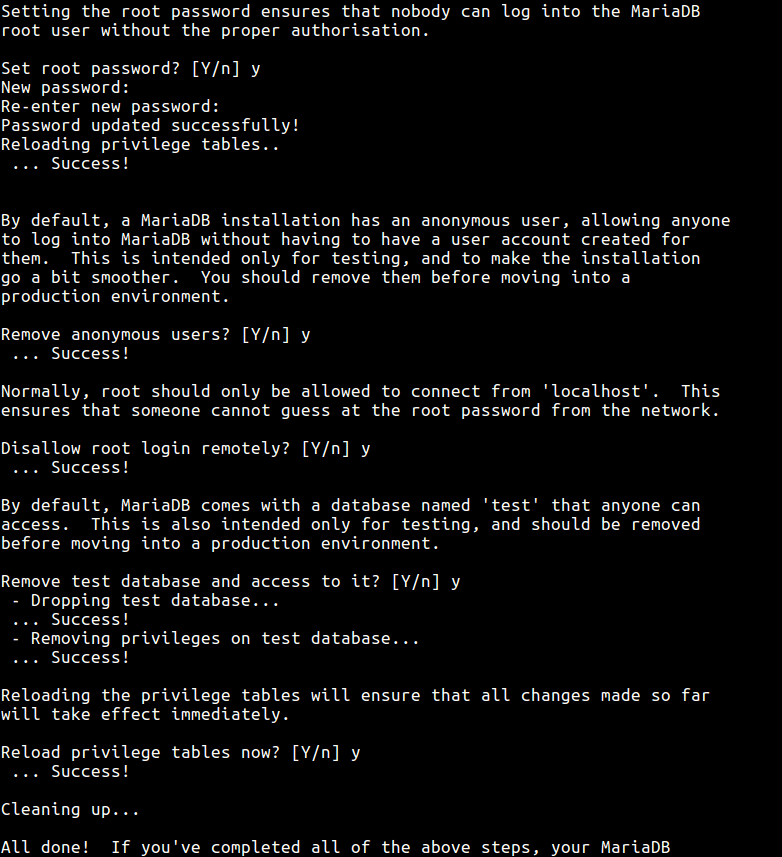][2]
|
||||
|
||||
Secure MySQL Installation
|
||||
|
||||
### 2\. Bind Database Server To Loopback Address
|
||||
|
||||
This configuration will restrict access from remote machines, it tells the MySQL server to only accept connections from within the localhost. You can set it in main configuration file.
|
||||
|
||||
```
|
||||
# vi /etc/my.cnf [RHEL/CentOS]
|
||||
# vi /etc/mysql/my.conf [Debian/Ubuntu]
|
||||
OR
|
||||
# vi /etc/mysql/mysql.conf.d/mysqld.cnf [Debian/Ubuntu]
|
||||
```
|
||||
|
||||
Add the following line below under `[mysqld]` section.
|
||||
|
||||
```
|
||||
bind-address = 127.0.0.1
|
||||
```
|
||||
|
||||
### 3\. Disable LOCAL INFILE in MySQL
|
||||
|
||||
As part of security hardening, you need to disable local_infile to prevent access to the underlying filesystem from within MySQL using the following directive under `[mysqld]` section.
|
||||
|
||||
```
|
||||
local-infile=0
|
||||
```
|
||||
|
||||
### 4\. Change MYSQL Default Port
|
||||
|
||||
The Port variable sets the MySQL port number that will be used to listen on TCP/ IP connections. The default port number is 3306 but you can change it under the [mysqld] section as shown.
|
||||
|
||||
```
|
||||
Port=5000
|
||||
```
|
||||
|
||||
### 5\. Enable MySQL Logging
|
||||
|
||||
Logs are one of the best ways to understand what happens on a server, in case of any attacks, you can easily see any intrusion-related activities from log files. You can enable MySQL logging by adding the following variable under the `[mysqld]` section.
|
||||
|
||||
```
|
||||
log=/var/log/mysql.log
|
||||
```
|
||||
|
||||
### 6\. Set Appropriate Permission on MySQL Files
|
||||
|
||||
Ensure that you have appropriate permissions set for all mysql server files and data directories. The /etc/my.conf file should only be writeable to root. This blocks other users from changing database server configurations.
|
||||
|
||||
```
|
||||
# chmod 644 /etc/my.cnf
|
||||
```
|
||||
|
||||
### 7\. Delete MySQL Shell History
|
||||
|
||||
All commands you execute on MySQL shell are stored by the mysql client in a history file: ~/.mysql_history. This can be dangerous, because for any user accounts that you will create, all usernames and passwords typed on the shell will recorded in the history file.
|
||||
|
||||
```
|
||||
# cat /dev/null > ~/.mysql_history
|
||||
```
|
||||
|
||||
### 8\. Don’t Run MySQL Commands from Commandline
|
||||
|
||||
As you already know, all commands you type on the terminal are stored in a history file, depending on the shell you are using (for example ~/.bash_history for bash). An attacker who manages to gain access to this history file can easily see any passwords recorded there.
|
||||
|
||||
It is strongly not recommended to type passwords on the command line, something like this:
|
||||
|
||||
```
|
||||
# mysql -u root -ppassword_
|
||||
```
|
||||
[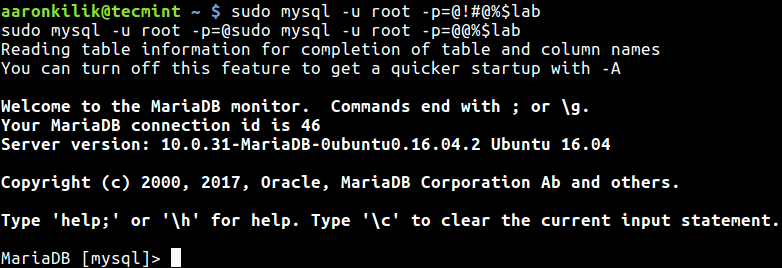][3]
|
||||
|
||||
Connect MySQL with Password
|
||||
|
||||
When you check the last section of the command history file, you will see the password typed above.
|
||||
|
||||
```
|
||||
# history
|
||||
```
|
||||
[][4]
|
||||
|
||||
Check Command History
|
||||
|
||||
The appropriate way to connect MySQL is.
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
Enter password:
|
||||
```
|
||||
|
||||
### 9\. Define Application-Specific Database Users
|
||||
|
||||
For each application running on the server, only give access to a user who is in charge of a database for a given application. For example, if you have a wordpress site, create a specific user for the wordpress site database as follows.
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
MariaDB [(none)]> CREATE DATABASE osclass_db;
|
||||
MariaDB [(none)]> CREATE USER 'osclassdmin'@'localhost' IDENTIFIED BY 'osclass@dmin%!2';
|
||||
MariaDB [(none)]> GRANT ALL PRIVILEGES ON osclass_db.* TO 'osclassdmin'@'localhost';
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
MariaDB [(none)]> exit
|
||||
```
|
||||
|
||||
and remember to always remove user accounts that are no longer managing any application database on the server.
|
||||
|
||||
### 10\. Use Additional Security Plugins and Libraries
|
||||
|
||||
MySQL includes a number of security plugins for: authenticating attempts by clients to connect to mysql server, password-validation and securing storage for sensitive information, which are all available in the free version.
|
||||
|
||||
You can find more here: [https://dev.mysql.com/doc/refman/5.7/en/security-plugins.html][5]
|
||||
|
||||
### 11\. Change MySQL Passwords Regularly
|
||||
|
||||
This is a common piece of information/application/system security advice. How often you do this will entirely depend on your internal security policy. However, it can prevent “snoopers” who might have been tracking your activity over an long period of time, from gaining access to your mysql server.
|
||||
|
||||
```
|
||||
MariaDB [(none)]> USE mysql;
|
||||
MariaDB [(none)]> UPDATE user SET password=PASSWORD('YourPasswordHere') WHERE User='root' AND Host = 'localhost';
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
### 12\. Update MySQL Server Package Regularly
|
||||
|
||||
It is highly recommended to upgrade mysql/mariadb packages regularly to keep up with security updates and bug fixes, from the vendor’s repository. Normally packages in default operating system repositories are outdated.
|
||||
|
||||
```
|
||||
# yum update
|
||||
# apt update
|
||||
```
|
||||
|
||||
After making any changes to the mysql/mariadb server, always restart the service.
|
||||
|
||||
```
|
||||
# systemctl restart mariadb #RHEL/CentOS
|
||||
# systemctl restart mysql #Debian/Ubuntu
|
||||
```
|
||||
|
||||
Read Also: [15 Useful MySQL/MariaDB Performance Tuning and Optimization Tips][6]
|
||||
|
||||
That’s all! We love to hear from you via the comment form below. Do share with us any MySQL/MariaDB security tips missing in the above list.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.tecmint.com/mysql-mariadb-security-best-practices-for-linux/
|
||||
|
||||
作者:[ Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/learn-mysql-mariadb-for-beginners/
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2017/12/Secure-MySQL-Installation.png
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2017/12/Connect-MySQL-with-Password.png
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/12/Check-Command-History.png
|
||||
[5]:https://dev.mysql.com/doc/refman/5.7/en/security-plugins.html
|
||||
[6]:https://www.tecmint.com/mysql-mariadb-performance-tuning-and-optimization/
|
||||
[7]:https://www.tecmint.com/author/aaronkili/
|
||||
[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,78 +0,0 @@
|
||||
|
||||
Translating by FelixYFZ
|
||||
How to find a publisher for your tech book
|
||||
============================================================
|
||||
|
||||
### Writing a technical book takes more than a good idea. You need to know a bit about how the publishing industry works.
|
||||
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
You've got an idea for a technical book—congratulations! Like a hiking the Appalachian trail, or learning to cook a soufflé, writing a book is one of those things that people talk about, but never take beyond the idea stage. That makes sense, because the failure rate is pretty high. Making it real involves putting your idea in front of a publisher, and finding out whether it's good enough to become a book. That step is scary enough, but the lack of information about how to do it complicates matters.
|
||||
|
||||
If you want to work with a traditional publisher, you'll need to get your book in front of them and hopefully start on the path to publication. I'm the Managing Editor at the [Pragmatic Bookshelf][4], so I see proposals all the time, as well as helping authors to craft good ones. Some are good, others are bad, but I often see proposals that just aren't right for Pragmatic. I'll help you with the process of finding the right publisher, and how to get your idea noticed.
|
||||
|
||||
### Identify your target
|
||||
|
||||
Your first step is to figure out which publisher is the a good fit for your idea. To start, think about the publishers that you buy books from, and that you enjoy. The odds are pretty good that your book will appeal to people like you, so starting with your favorites makes for a pretty good short list. If you don't have much of a book collection, you can visit a bookstore, or take a look on Amazon. Make a list of a handful of publishers that you personally like to start with.
|
||||
|
||||
Next, winnow your prospects. Although most technical publishers look alike from a distance, they often have distinctive audiences. Some publishers go for broadly popular topics, such as C++ or Java. Your book on Elixir may not be a good fit for that publisher. If your prospective book is about teaching programming to kids, you probably don't want to go with the traditional academic publisher.
|
||||
|
||||
Once you've identified a few targets, do some more research into the publishers' catalogs, either on their own site, or on Amazon. See what books they have that are similar to your idea. If they have a book that's identical, or nearly so, you'll have a tough time convincing them to sign yours. That doesn't necessarily mean you should drop that publisher from your list. You can make some changes to your proposal to differentiate it from the existing book: target a different audience, or a different skill level. Maybe the existing book is outdated, and you could focus on new approaches to the technology. Make your proposal into a book that complements the existing one, rather than competes.
|
||||
|
||||
If your target publisher has no books that are similar, that can be a good sign, or a very bad one. Sometimes publishers choose not to publish on specific technologies, either because they don't believe their audience is interested, or they've had trouble with that technology in the past. New languages and libraries pop up all the time, and publishers have to make informed guesses about which will appeal to their readers. Their assessment may not be the same as yours. Their decision might be final, or they might be waiting for the right proposal. The only way to know is to propose and find out.
|
||||
|
||||
### Work your network
|
||||
|
||||
Identifying a publisher is the first step; now you need to make contact. Unfortunately, publishing is still about _who_ you know, more than _what_ you know. The person you want to know is an _acquisitions editor,_ the editor whose job is to find new markets, authors, and proposals. If you know someone who has connections with a publisher, ask for an introduction to an acquisitions editor. These editors often specialize in particular subject areas, particularly at larger publishers, but you don't need to find the right one yourself. They're usually happy to connect you with the correct person.
|
||||
|
||||
Sometimes you can find an acquisitions editor at a technical conference, especially one where the publisher is a sponsor, and has a booth. Even if there's not an acquisitions editor on site at the time, the staff at the booth can put you in touch with one. If conferences aren't your thing, you'll need to work your network to get an introduction. Use LinkedIn, or your informal contacts, to get in touch with an editor.
|
||||
|
||||
For smaller publishers, you may find acquisitions editors listed on the company website, with contact information if you're lucky. If not, search for the publisher's name on Twitter, and see if you can turn up their editors. You might be nervous about trying to reach out to a stranger over social media to show them your book, but don't worry about it. Making contact is what acquisitions editors do. The worst-case result is they ignore you.
|
||||
|
||||
Once you've made contact, the acquisitions editor will assist you with the next steps. They may have some feedback on your proposal right away, or they may want you to flesh it out according to their guidelines before they'll consider it. After you've put in the effort to find an acquisitions editor, listen to their advice. They know their system better than you do.
|
||||
|
||||
### If all else fails
|
||||
|
||||
If you can't find an acquisitions editor to contact, the publisher almost certainly has a blind proposal alias, usually of the form `proposals@[publisher].com`. Check the web site for instructions on what to send to a proposal alias; some publishers have specific requirements. Follow these instructions. If you don't, you have a good chance of your proposal getting thrown out before anybody looks at it. If you have questions, or aren't sure what the publisher wants, you'll need to try again to find an editor to talk to, because the proposal alias is not the place to get questions answered. Put together what they've asked for (which is a topic for a separate article), send it in, and hope for the best.
|
||||
|
||||
### And ... wait
|
||||
|
||||
No matter how you've gotten in touch with a publisher, you'll probably have to wait. If you submitted to the proposals alias, it's going to take a while before somebody does anything with that proposal, especially at a larger company. Even if you've found an acquisitions editor to work with, you're probably one of many prospects she's working with simultaneously, so you might not get rapid responses. Almost all publishers have a committee that decides on which proposals to accept, so even if your proposal is awesome and ready to go, you'll still need to wait for the committee to meet and discuss it. You might be waiting several weeks, or even a month before you hear anything.
|
||||
|
||||
After a couple of weeks, it's fine to check back in with the editor to see if they need any more information. You want to be polite in this e-mail; if they haven't answered because they're swamped with proposals, being pushy isn't going to get you to the front of the line. It's possible that some publishers will never respond at all instead of sending a rejection notice, but that's uncommon. There's not a lot to do at this point other than be patient. Of course, if it's been months and nobody's returning your e-mails, you're free to approach a different publisher or consider self-publishing.
|
||||
|
||||
### Good luck
|
||||
|
||||
If this process seems somewhat scattered and unscientific, you're right; it is. Getting published depends on being in the right place, at the right time, talking to the right person, and hoping they're in the right mood. You can't control all of those variables, but having a better knowledge of how the industry works, and what publishers are looking for, can help you optimize the ones you can control.
|
||||
|
||||
Finding a publisher is one step in a lengthy process. You need to refine your idea and create the proposal, as well as other considerations. At SeaGL this year [I presented][5] an introduction to the entire process. Check out [the video][6] for more detailed information.
|
||||
|
||||
### About the author
|
||||
|
||||
[][7]
|
||||
|
||||
Brian MacDonald - Brian MacDonald is Managing Editor at the Pragmatic Bookshelf. Over the last 20 years in tech publishing, he's been an editor, author, and occasional speaker and trainer. He currently spends a lot of his time talking to new authors about how they can best present their ideas. You can follow him on Twitter at @bmac_editor.[More about me][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/how-find-publisher-your-book
|
||||
|
||||
作者:[Brian MacDonald ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bmacdonald
|
||||
[1]:https://opensource.com/article/17/12/how-find-publisher-your-book?rate=o42yhdS44MUaykAIRLB3O24FvfWxAxBKa5WAWSnSY0s
|
||||
[2]:https://opensource.com/users/bmacdonald
|
||||
[3]:https://opensource.com/user/190176/feed
|
||||
[4]:https://pragprog.com/
|
||||
[5]:https://archive.org/details/SeaGL2017WritingTheNextGreatTechBook
|
||||
[6]:https://archive.org/details/SeaGL2017WritingTheNextGreatTechBook
|
||||
[7]:https://opensource.com/users/bmacdonald
|
||||
[8]:https://opensource.com/users/bmacdonald
|
||||
[9]:https://opensource.com/users/bmacdonald
|
||||
[10]:https://opensource.com/article/17/12/how-find-publisher-your-book#comments
|
||||
@ -0,0 +1,85 @@
|
||||
Launching an Open Source Project: A Free Guide
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Launching a project and then rallying community support can be complicated, but the new guide to Starting an Open Source Project can help.
|
||||
|
||||
Increasingly, as open source programs become more pervasive at organizations of all sizes, tech and DevOps workers are choosing to or being asked to launch their own open source projects. From Google to Netflix to Facebook, companies are also releasing their open source creations to the community. It’s become common for open source projects to start from scratch internally, after which they benefit from collaboration involving external developers.
|
||||
|
||||
Launching a project and then rallying community support can be more complicated than you think, however. A little up-front work can help things go smoothly, and that’s exactly where the new guide to[ Starting an Open Source Project][1] comes in.
|
||||
|
||||
This free guide was created to help organizations already versed in open source learn how to start their own open source projects. It starts at the beginning of the process, including deciding what to open source, and moves on to budget and legal considerations, and more. The road to creating an open source project may be foreign, but major companies, from Google to Facebook, have opened up resources and provided guidance. In fact, Google has[ an extensive online destination][2] dedicated to open source best practices and how to open source projects.
|
||||
|
||||
“No matter how many smart people we hire inside the company, there’s always smarter people on the outside,” notes Jared Smith, Open Source Community Manager at Capital One. “We find it is worth it to us to open source and share our code with the outside world in exchange for getting some great advice from people on the outside who have expertise and are willing to share back with us.”
|
||||
|
||||
In the new guide, noted open source expert Ibrahim Haddad provides five reasons why an organization might open source a new project:
|
||||
|
||||
1. Accelerate an open solution; provide a reference implementation to a standard; share development costs for strategic functions
|
||||
|
||||
2. Commoditize a market; reduce prices of non-strategic software components.
|
||||
|
||||
3. Drive demand by building an ecosystem for your products.
|
||||
|
||||
4. Partner with others; engage customers; strengthen relationships with common goals.
|
||||
|
||||
5. Offer your customers the ability to self-support: the ability to adapt your code without waiting for you.
|
||||
|
||||
The guide notes: “The decision to release or create a new open source project depends on your circumstances. Your company should first achieve a certain level of open source mastery by using open source software and contributing to existing projects. This is because consuming can teach you how to leverage external projects and developers to build your products. And participation can bring more fluency in the conventions and culture of open source communities. (See our guides on [Using Open Source Code][3] and [Participating in Open Source Communities][4]) But once you have achieved open source fluency, the best time to start launching your own open source projects is simply ‘early’ and ‘often.’”
|
||||
|
||||
The guide also notes that planning can keep you and your organization out of legal trouble. Issues pertaining to licensing, distribution, support options, and even branding require thinking ahead if you want your project to flourish.
|
||||
|
||||
“I think it is a crucial thing for a company to be thinking about what they’re hoping to achieve with a new open source project,” said John Mertic, Director of Program Management at The Linux Foundation. “They must think about the value of it to the community and developers out there and what outcomes they’re hoping to get out of it. And then they must understand all the pieces they must have in place to do this the right way, including legal, governance, infrastructure and a starting community. Those are the things I always stress the most when you’re putting an open source project out there.”
|
||||
|
||||
The[ Starting an Open Source Project][5] guide can help you with everything from licensing issues to best development practices, and it explores how to seamlessly and safely weave existing open components into your open source projects. It is one of a new collection of free guides from The Linux Foundation and The TODO Group that are all extremely valuable for any organization running an open source program.[ The guides are available][6]now to help you run an open source program office where open source is supported, shared, and leveraged. With such an office, organizations can establish and execute on their open source strategies efficiently, with clear terms.
|
||||
|
||||
These free resources were produced based on expertise from open source leaders.[ Check out all the guides here][7] and stay tuned for our continuing coverage.
|
||||
|
||||
Also, don’t miss the previous articles in the series:
|
||||
|
||||
[How to Create an Open Source Program][8]
|
||||
|
||||
[Tools for Managing Open Source Programs][9]
|
||||
|
||||
[Measuring Your Open Source Program’s Success][10]
|
||||
|
||||
[Effective Strategies for Recruiting Open Source Developers][11]
|
||||
|
||||
[Participating in Open Source Communities][12]
|
||||
|
||||
[Using Open Source Code][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/launching-open-source-project-free-guide/
|
||||
|
||||
作者:[Sam Dean ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/sdean/
|
||||
[1]:https://www.linuxfoundation.org/resources/open-source-guides/starting-open-source-project/
|
||||
[2]:https://www.linux.com/blog/learn/chapter/open-source-management/2017/5/googles-new-home-all-things-open-source-runs-deep
|
||||
[3]:https://www.linuxfoundation.org/using-open-source-code/
|
||||
[4]:https://www.linuxfoundation.org/participating-open-source-communities/
|
||||
[5]:https://www.linuxfoundation.org/resources/open-source-guides/starting-open-source-project/
|
||||
[6]:https://github.com/todogroup/guides
|
||||
[7]:https://github.com/todogroup/guides
|
||||
[8]:https://github.com/todogroup/guides/blob/master/creating-an-open-source-program.md
|
||||
[9]:https://www.linuxfoundation.org/blog/managing-open-source-programs-free-guide/
|
||||
[10]:https://www.linuxfoundation.org/measuring-your-open-source-program-success/
|
||||
[11]:https://www.linuxfoundation.org/blog/effective-strategies-recruiting-open-source-developers/
|
||||
[12]:https://www.linuxfoundation.org/participating-open-source-communities/
|
||||
[13]:https://www.linuxfoundation.org/using-open-source-code/
|
||||
[14]:https://www.linuxfoundation.org/author/sdean/
|
||||
[15]:https://www.linuxfoundation.org/category/audience/attorneys/
|
||||
[16]:https://www.linuxfoundation.org/category/blog/
|
||||
[17]:https://www.linuxfoundation.org/category/audience/c-level/
|
||||
[18]:https://www.linuxfoundation.org/category/audience/developer-influencers/
|
||||
[19]:https://www.linuxfoundation.org/category/audience/entrepreneurs/
|
||||
[20]:https://www.linuxfoundation.org/category/content-placement/lf-brand/
|
||||
[21]:https://www.linuxfoundation.org/category/audience/open-source-developers/
|
||||
[22]:https://www.linuxfoundation.org/category/audience/open-source-professionals/
|
||||
[23]:https://www.linuxfoundation.org/category/audience/open-source-users/
|
||||
@ -1,161 +0,0 @@
|
||||
translating by wenwensnow
|
||||
Randomize your WiFi MAC address on Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
_Your device’s MAC address can be used to track you across the WiFi networks you connect to. That data can be shared and sold, and often identifies you as an individual. It’s possible to limit this tracking by using pseudo-random MAC addresses._
|
||||
|
||||

|
||||
|
||||
_Image courtesy of [Cloudessa][4]_
|
||||
|
||||
Every network device like a WiFi or Ethernet card has a unique identifier called a MAC address, for example `b4:b6:76:31:8c:ff`. It’s how networking works: any time you connect to a WiFi network, the router uses that address to send and receive packets to your machine and distinguish it from other devices in the area.
|
||||
|
||||
The snag with this design is that your unique, unchanging MAC address is just perfect for tracking you. Logged into Starbucks WiFi? Noted. London Underground? Logged.
|
||||
|
||||
If you’ve ever put your real name into one of those Craptive Portals on a WiFi network you’ve now tied your identity to that MAC address. Didn’t read the terms and conditions? You might assume that free airport WiFi is subsidised by flogging ‘customer analytics’ (your personal information) to hotels, restaurant chains and whomever else wants to know about you.
|
||||
|
||||
I don’t subscribe to being tracked and sold by mega-corps, so I spent a few hours hacking a solution.
|
||||
|
||||
### MAC addresses don’t need to stay the same
|
||||
|
||||
Fortunately, it’s possible to spoof your MAC address to a random one without fundamentally breaking networking.
|
||||
|
||||
I wanted to randomize my MAC address, but with three particular caveats:
|
||||
|
||||
1. The MAC should be different across different networks. This means Starbucks WiFi sees a different MAC from London Underground, preventing linking my identity across different providers.
|
||||
|
||||
2. The MAC should change regularly to prevent a network knowing that I’m the same person who walked past 75 times over the last year.
|
||||
|
||||
3. The MAC stays the same throughout each working day. When the MAC address changes, most networks will kick you off, and those with Craptive Portals will usually make you sign in again - annoying.
|
||||
|
||||
### Manipulating NetworkManager
|
||||
|
||||
My first attempt of using the `macchanger` tool was unsuccessful as NetworkManager would override the MAC address according to its own configuration.
|
||||
|
||||
I learned that NetworkManager 1.4.1+ can do MAC address randomization right out the box. If you’re using Ubuntu 17.04 upwards, you can get most of the way with [this config file][7]. You can’t quite achieve all three of my requirements (you must choose _random_ or _stable_ but it seems you can’t do _stable-for-one-day_ ).
|
||||
|
||||
Since I’m sticking with Ubuntu 16.04 which ships with NetworkManager 1.2, I couldn’t make use of the new functionality. Supposedly there is some randomization support but I failed to actually make it work, so I scripted up a solution instead.
|
||||
|
||||
Fortunately NetworkManager 1.2 does allow for spoofing your MAC address. You can see this in the ‘Edit connections’ dialog for a given network:
|
||||
|
||||
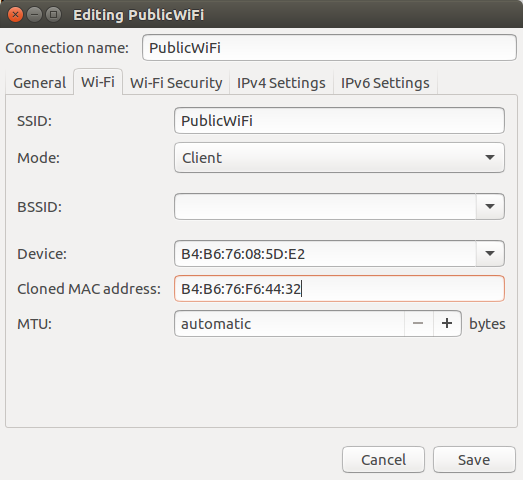
|
||||
|
||||
NetworkManager also supports hooks - any script placed in `/etc/NetworkManager/dispatcher.d/pre-up.d/` is run before a connection is brought up.
|
||||
|
||||
### Assigning pseudo-random MAC addresses
|
||||
|
||||
To recap, I wanted to generate random MAC addresses based on the _network_ and the _date_ . We can use the NetworkManager command line, nmcli, to show a full list of networks:
|
||||
|
||||
```
|
||||
> nmcli connection
|
||||
NAME UUID TYPE DEVICE
|
||||
Gladstone Guest 618545ca-d81a-11e7-a2a4-271245e11a45 802-11-wireless wlp1s0
|
||||
DoESDinky 6e47c080-d81a-11e7-9921-87bc56777256 802-11-wireless --
|
||||
PublicWiFi 79282c10-d81a-11e7-87cb-6341829c2a54 802-11-wireless --
|
||||
virgintrainswifi 7d0c57de-d81a-11e7-9bae-5be89b161d22 802-11-wireless --
|
||||
|
||||
```
|
||||
|
||||
Since each network has a unique identifier, to achieve my scheme I just concatenated the UUID with today’s date and hashed the result:
|
||||
|
||||
```
|
||||
|
||||
# eg 618545ca-d81a-11e7-a2a4-271245e11a45-2017-12-03
|
||||
|
||||
> echo -n "${UUID}-$(date +%F)" | md5sum
|
||||
|
||||
53594de990e92f9b914a723208f22b3f -
|
||||
|
||||
```
|
||||
|
||||
That produced bytes which can be substituted in for the last octets of the MAC address.
|
||||
|
||||
Note that the first byte `02` signifies the address is [locally administered][8]. Real, burned-in MAC addresses start with 3 bytes designing their manufacturer, for example `b4:b6:76` for Intel.
|
||||
|
||||
It’s possible that some routers may reject locally administered MACs but I haven’t encountered that yet.
|
||||
|
||||
On every connection up, the script calls `nmcli` to set the spoofed MAC address for every connection:
|
||||
|
||||
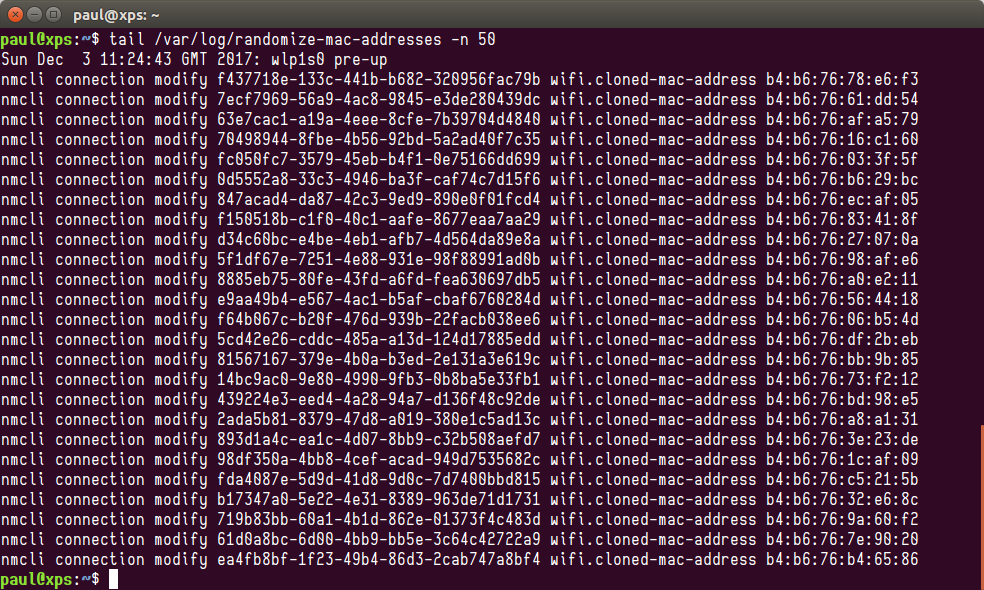
|
||||
|
||||
As a final check, if I look at `ifconfig` I can see that the `HWaddr` is the spoofed one, not my real MAC address:
|
||||
|
||||
```
|
||||
> ifconfig
|
||||
wlp1s0 Link encap:Ethernet HWaddr b4:b6:76:45:64:4d
|
||||
inet addr:192.168.0.86 Bcast:192.168.0.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::648c:aff2:9a9d:764/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:12107812 errors:0 dropped:2 overruns:0 frame:0
|
||||
TX packets:18332141 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:11627977017 (11.6 GB) TX bytes:20700627733 (20.7 GB)
|
||||
|
||||
```
|
||||
|
||||
The full script is [available on Github][9].
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
# /etc/NetworkManager/dispatcher.d/pre-up.d/randomize-mac-addresses
|
||||
|
||||
# Configure every saved WiFi connection in NetworkManager with a spoofed MAC
|
||||
# address, seeded from the UUID of the connection and the date eg:
|
||||
# 'c31bbcc4-d6ad-11e7-9a5a-e7e1491a7e20-2017-11-20'
|
||||
|
||||
# This makes your MAC impossible(?) to track across WiFi providers, and
|
||||
# for one provider to track across days.
|
||||
|
||||
# For craptive portals that authenticate based on MAC, you might want to
|
||||
# automate logging in :)
|
||||
|
||||
# Note that NetworkManager >= 1.4.1 (Ubuntu 17.04+) can do something similar
|
||||
# automatically.
|
||||
|
||||
export PATH=$PATH:/usr/bin:/bin
|
||||
|
||||
LOG_FILE=/var/log/randomize-mac-addresses
|
||||
|
||||
echo "$(date): $*" > ${LOG_FILE}
|
||||
|
||||
WIFI_UUIDS=$(nmcli --fields type,uuid connection show |grep 802-11-wireless |cut '-d ' -f3)
|
||||
|
||||
for UUID in ${WIFI_UUIDS}
|
||||
do
|
||||
UUID_DAILY_HASH=$(echo "${UUID}-$(date +F)" | md5sum)
|
||||
|
||||
RANDOM_MAC="02:$(echo -n ${UUID_DAILY_HASH} | sed 's/^\(..\)\(..\)\(..\)\(..\)\(..\).*$/\1:\2:\3:\4:\5/')"
|
||||
|
||||
CMD="nmcli connection modify ${UUID} wifi.cloned-mac-address ${RANDOM_MAC}"
|
||||
|
||||
echo "$CMD" >> ${LOG_FILE}
|
||||
$CMD &
|
||||
done
|
||||
|
||||
wait
|
||||
```
|
||||
Enjoy!
|
||||
|
||||
_Update: [Use locally administered MAC addresses][5] to avoid clashing with real Intel ones. Thanks [@_fink][6]_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.paulfurley.com/randomize-your-wifi-mac-address-on-ubuntu-1604-xenial/
|
||||
|
||||
作者:[Paul M Furley ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.paulfurley.com/
|
||||
[1]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f/raw/5f02fc8f6ff7fca5bca6ee4913c63bf6de15abca/randomize-mac-addresses
|
||||
[2]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f#file-randomize-mac-addresses
|
||||
[3]:https://github.com/
|
||||
[4]:http://cloudessa.com/products/cloudessa-aaa-and-captive-portal-cloud-service/
|
||||
[5]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f/revisions#diff-824d510864d58c07df01102a8f53faef
|
||||
[6]:https://twitter.com/fink_/status/937305600005943296
|
||||
[7]:https://gist.github.com/paulfurley/978d4e2e0cceb41d67d017a668106c53/
|
||||
[8]:https://en.wikipedia.org/wiki/MAC_address#Universal_vs._local
|
||||
[9]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f
|
||||
@ -1,129 +0,0 @@
|
||||
【iron0x翻译中】
|
||||
|
||||
Use multi-stage builds
|
||||
============================================================
|
||||
|
||||
Multi-stage builds are a new feature requiring Docker 17.05 or higher on the daemon and client. Multistage builds are useful to anyone who has struggled to optimize Dockerfiles while keeping them easy to read and maintain.
|
||||
|
||||
> Acknowledgment: Special thanks to [Alex Ellis][1] for granting permission to use his blog post [Builder pattern vs. Multi-stage builds in Docker][2] as the basis of the examples below.
|
||||
|
||||
### Before multi-stage builds
|
||||
|
||||
One of the most challenging things about building images is keeping the image size down. Each instruction in the Dockerfile adds a layer to the image, and you need to remember to clean up any artifacts you don’t need before moving on to the next layer. To write a really efficient Dockerfile, you have traditionally needed to employ shell tricks and other logic to keep the layers as small as possible and to ensure that each layer has the artifacts it needs from the previous layer and nothing else.
|
||||
|
||||
It was actually very common to have one Dockerfile to use for development (which contained everything needed to build your application), and a slimmed-down one to use for production, which only contained your application and exactly what was needed to run it. This has been referred to as the “builder pattern”. Maintaining two Dockerfiles is not ideal.
|
||||
|
||||
Here’s an example of a `Dockerfile.build` and `Dockerfile` which adhere to the builder pattern above:
|
||||
|
||||
`Dockerfile.build`:
|
||||
|
||||
```
|
||||
FROM golang:1.7.3
|
||||
WORKDIR /go/src/github.com/alexellis/href-counter/
|
||||
RUN go get -d -v golang.org/x/net/html
|
||||
COPY app.go .
|
||||
RUN go get -d -v golang.org/x/net/html \
|
||||
&& CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
|
||||
|
||||
```
|
||||
|
||||
Notice that this example also artificially compresses two `RUN` commands together using the Bash `&&` operator, to avoid creating an additional layer in the image. This is failure-prone and hard to maintain. It’s easy to insert another command and forget to continue the line using the `\` character, for example.
|
||||
|
||||
`Dockerfile`:
|
||||
|
||||
```
|
||||
FROM alpine:latest
|
||||
RUN apk --no-cache add ca-certificates
|
||||
WORKDIR /root/
|
||||
COPY app .
|
||||
CMD ["./app"]
|
||||
|
||||
```
|
||||
|
||||
`build.sh`:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
echo Building alexellis2/href-counter:build
|
||||
|
||||
docker build --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy \
|
||||
-t alexellis2/href-counter:build . -f Dockerfile.build
|
||||
|
||||
docker create --name extract alexellis2/href-counter:build
|
||||
docker cp extract:/go/src/github.com/alexellis/href-counter/app ./app
|
||||
docker rm -f extract
|
||||
|
||||
echo Building alexellis2/href-counter:latest
|
||||
|
||||
docker build --no-cache -t alexellis2/href-counter:latest .
|
||||
rm ./app
|
||||
|
||||
```
|
||||
|
||||
When you run the `build.sh` script, it needs to build the first image, create a container from it in order to copy the artifact out, then build the second image. Both images take up room on your system and you still have the `app` artifact on your local disk as well.
|
||||
|
||||
Multi-stage builds vastly simplify this situation!
|
||||
|
||||
### Use multi-stage builds
|
||||
|
||||
With multi-stage builds, you use multiple `FROM` statements in your Dockerfile. Each `FROM` instruction can use a different base, and each of them begins a new stage of the build. You can selectively copy artifacts from one stage to another, leaving behind everything you don’t want in the final image. To show how this works, Let’s adapt the Dockerfile from the previous section to use multi-stage builds.
|
||||
|
||||
`Dockerfile`:
|
||||
|
||||
```
|
||||
FROM golang:1.7.3
|
||||
WORKDIR /go/src/github.com/alexellis/href-counter/
|
||||
RUN go get -d -v golang.org/x/net/html
|
||||
COPY app.go .
|
||||
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
|
||||
|
||||
FROM alpine:latest
|
||||
RUN apk --no-cache add ca-certificates
|
||||
WORKDIR /root/
|
||||
COPY --from=0 /go/src/github.com/alexellis/href-counter/app .
|
||||
CMD ["./app"]
|
||||
|
||||
```
|
||||
|
||||
You only need the single Dockerfile. You don’t need a separate build script, either. Just run `docker build`.
|
||||
|
||||
```
|
||||
$ docker build -t alexellis2/href-counter:latest .
|
||||
|
||||
```
|
||||
|
||||
The end result is the same tiny production image as before, with a significant reduction in complexity. You don’t need to create any intermediate images and you don’t need to extract any artifacts to your local system at all.
|
||||
|
||||
How does it work? The second `FROM` instruction starts a new build stage with the `alpine:latest` image as its base. The `COPY --from=0` line copies just the built artifact from the previous stage into this new stage. The Go SDK and any intermediate artifacts are left behind, and not saved in the final image.
|
||||
|
||||
### Name your build stages
|
||||
|
||||
By default, the stages are not named, and you refer to them by their integer number, starting with 0 for the first `FROM` instruction. However, you can name your stages, by adding an `as <NAME>` to the `FROM` instruction. This example improves the previous one by naming the stages and using the name in the `COPY` instruction. This means that even if the instructions in your Dockerfile are re-ordered later, the `COPY` won’t break.
|
||||
|
||||
```
|
||||
FROM golang:1.7.3 as builder
|
||||
WORKDIR /go/src/github.com/alexellis/href-counter/
|
||||
RUN go get -d -v golang.org/x/net/html
|
||||
COPY app.go .
|
||||
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
|
||||
|
||||
FROM alpine:latest
|
||||
RUN apk --no-cache add ca-certificates
|
||||
WORKDIR /root/
|
||||
COPY --from=builder /go/src/github.com/alexellis/href-counter/app .
|
||||
CMD ["./app"]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://docs.docker.com/engine/userguide/eng-image/multistage-build/#name-your-build-stages
|
||||
|
||||
作者:[docker docs ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://docs.docker.com/engine/userguide/eng-image/multistage-build/
|
||||
[1]:https://twitter.com/alexellisuk
|
||||
[2]:http://blog.alexellis.io/mutli-stage-docker-builds/
|
||||
@ -0,0 +1,307 @@
|
||||
Top 20 GNOME Extensions You Should Be Using Right Now
|
||||
============================================================
|
||||
|
||||
_Brief: You can enhance the capacity of your GNOME desktop with extensions. Here, we list the best GNOME extensions to save you the trouble of finding them on your own._
|
||||
|
||||
[GNOME extensions][9] are a major part of the [GNOME][10] experience. These extensions add a lot of value to the ecosystem whether it is to mold the Gnome Desktop Environment (DE) to your workflow, to add more functionality than there is by default, or just simply to freshen up the experience.
|
||||
|
||||
With default [Ubuntu 17.10][11] switching from [Unity to Gnome][12], now is the time to familiarize yourself with the various extensions that the GNOME community has to offer. We already showed you[ how to enable and manage GNOME extensions][13]. But finding good extensions could be a daunting task. That’s why I created this list of best GNOME extensions to save you some trouble.
|
||||
|
||||
### Best GNOME Extensions
|
||||
|
||||

|
||||
|
||||
The list is in alphabetical order but there is no ranking involved here. Extension at number 1 position is not better than the rest of the extensions.
|
||||
|
||||
### 1\. Appfolders Management extensions
|
||||
|
||||
One of the major features that I think GNOME is missing is the ability to organize the default application grid. This is something included by default in [KDE][14]‘s Application Dashboard, in [Elementary OS][15]‘s Slingshot Launcher, and even in macOS, yet as of [GNOME 3.26][16] it isn’t something that comes baked in. Appfolders Management extension changes that.
|
||||
|
||||
This extension gives the user an easy way to organize their applications into various folders with a simple right click > add to folder. Creating folders and adding applications to them is not only simple through this extension, but it feels so natively implemented that you will wonder why this isn’t built into the default GNOME experience.
|
||||
|
||||

|
||||
|
||||
[Appfolders Management extension][17]
|
||||
|
||||
### 2\. Apt Update Indicator
|
||||
|
||||
For distributions that utilize [Apt as their package manager][18], such as Ubuntu or Debian, the Apt Update Indicator extension allows for a more streamlined update experience in GNOME.
|
||||
|
||||
The extension settles into your top bar and notifies the user of updates waiting on their system. It also displays recently added repos, residual config files, files that are auto removable, and allows the user to manually check for updates all in one basic drop-down menu.
|
||||
|
||||
It is a simple extension that adds an immense amount of functionality to any system.
|
||||
|
||||

|
||||
|
||||
[Apt Update Indicator][19]
|
||||
|
||||
### 3\. Auto Move Windows
|
||||
|
||||
If, like me, you utilize multiple virtual desktops than this extension will make your workflow much easier. Auto Move Windows allows you to set your applications to automatically open on a virtual desktop of your choosing. It is as simple as adding an application to the list and selecting the desktop you would like that application to open on.
|
||||
|
||||
From then on every time you open that application it will open on that desktop. This makes all the difference when as soon as you login to your computer all you have to do is open the application and it immediately opens to where you want it to go without manually having to move it around every time before you can get to work.
|
||||
|
||||

|
||||
|
||||
[Auto Move Windows][20]
|
||||
|
||||
### 4\. Caffeine
|
||||
|
||||
Caffeine allows the user to keep their computer screen from auto-suspending at the flip of a switch. The coffee mug shaped extension icon embeds itself into the right side of your top bar and with a click shows that your computer is “caffeinated” with a subtle addition of steam to the mug and a notification.
|
||||
|
||||
The same is true to turn off Caffeine, enabling auto suspend and/or screensave again. It’s incredibly simple to use and works just as you would expect.
|
||||
|
||||
Caffeine Disabled:
|
||||

|
||||
|
||||
Caffeine Enabled:
|
||||

|
||||
|
||||
[Caffeine][21]
|
||||
|
||||
### 5\. CPU Power Management [Only for Intel CPUs]
|
||||
|
||||
This is an extension that, at first, I didn’t think would be very useful, but after some time using it I have found that functionality like this should be backed into all computers by default. At least all laptops. CPU Power Management allows you to chose how much of your computer’s resources are being used at any given time.
|
||||
|
||||
Its simple drop-down menu allows the user to change between various preset or user made profiles that control at what frequency your CPU is to run. For example, you can set your CPU to the “Quiet” present which tells your computer to only us a maximum of 30% of its resources in this case.
|
||||
|
||||
On the other hand, you can set it to the “High Performance” preset to allow your computer to run at full potential. This comes in handy if you have loud fans and want to minimize the amount of noise they make or if you just need to save some battery life.
|
||||
|
||||
One thing to note is that _this only works on computers with an Intel CPU_ , so keep that in mind.
|
||||
|
||||

|
||||
|
||||
[CPU Power Management][22]
|
||||
|
||||
### 6\. Clipboard Indicator
|
||||
|
||||
Clipboard Indicator is a clean and simple clipboard management tool. The extension sits in the top bar and caches your recent clipboard history (things you copy and paste). It will continue to save this information until the user clears the extension’s history.
|
||||
|
||||
If you know that you are about to work with documentation that you don’t want to be saved in this way, like Credit Card numbers or any of your personal information, Clipboard Indicator offers a private mode that the user can toggle on and off for such cases.
|
||||
|
||||

|
||||
|
||||
[Clipboard Indicator][23]
|
||||
|
||||
### 7\. Extensions
|
||||
|
||||
The Extensions extension allows the user to enable/disable other extensions and to access their settings in one singular extension. Extensions either sit next to your other icons and extensions in the panel or in the user drop-down menu.
|
||||
|
||||
Redundancies aside, Extensions is a great way to gain easy access to all your extensions without the need to open up the GNOME Tweak Tool to do so.
|
||||
|
||||

|
||||
|
||||
[Extensions][24]
|
||||
|
||||
### 8\. Frippery Move Clock
|
||||
|
||||
For those of us who are used to having the clock to the right of the Panel in Unity, this extension does the trick. Frippery Move Clock moves the clock from the middle of the top panel to the right side. It takes the calendar and notification window with it but does not migrate the notifications themselves. We have another application later in this list, Panel OSD, that can add bring your notifications over to the right as well.
|
||||
|
||||
Before Frippery:
|
||||

|
||||
|
||||
After Frippery:
|
||||

|
||||
|
||||
[Frippery Move Clock][25]
|
||||
|
||||
### 9\. Gno-Menu
|
||||
|
||||
Gno-Menu brings a more traditional menu to the GNOME DE. Not only does it add an applications menu to the top panel but it also brings a ton of functionality and customization with it. If you are used to using the Applications Menu extension traditionally found in GNOME but don’t want the bugs and issues that Ubuntu 17.10 brought to is, Gno-Meny is an awesome alternative.
|
||||
|
||||

|
||||
|
||||
[Gno-Menu][26]
|
||||
|
||||
### 10\. User Themes
|
||||
|
||||
User Themes is a must for anyone looking to customize their GNOME desktop. By default, GNOME Tweaks lets its users change the theme of the applications themselves, icons, and cursors but not the theme of the shell. User Themes fixes that by enabling us to change the theme of GNOME Shell, allowing us to get the most out of our customization experience. Check out our [video][27] or read our article to know how to [install new themes][28].
|
||||
|
||||
User Themes Off:
|
||||

|
||||
User Themes On:
|
||||

|
||||
|
||||
[User Themes][29]
|
||||
|
||||
### 11\. Hide Activities Button
|
||||
|
||||
Hide Activities Button does exactly what you would expect. It hides the activities button found a the leftmost corner of the top panel. This button traditionally actives the activities overview in GNOME, but plenty of people use the Super Key on the keyboard to do this same function.
|
||||
|
||||
Though this disables the button itself, it does not disable the hot corner. Since Ubuntu 17.10 offers the ability to shut off the hot corner int he native settings application this not a huge deal for Ubuntu users. For other distributions, there are a plethora of other ways to disable the hot corner if you so desire, which we will not cover in this particular article.
|
||||
|
||||
Before:  After:
|
||||

|
||||
|
||||
#### [Hide Activities Button][30]
|
||||
|
||||
### 12\. MConnect
|
||||
|
||||
MConnect offers a way to seamlessly integrate the [KDE Connect][31] application within the GNOME desktop. Though KDE Connect offers a way for users to connect their Android handsets with virtually any Linux DE its indicator lacks a good way to integrate more seamlessly into any other DE than [Plasma][32].
|
||||
|
||||
MConnect fixes that, giving the user a straightforward drop-down menu that allows them to send SMS messages, locate their phones, browse their phone’s file system, and to send files to their phone from the desktop. Though I had to do some tweaking to get MConnect to work just as I would expect it to, I couldn’t be any happier with the extension.
|
||||
|
||||
Do remember that you will need KDE Connect installed alongside MConnect in order to get it to work.
|
||||
|
||||

|
||||
|
||||
[MConnect][33]
|
||||
|
||||
### 13\. OpenWeather
|
||||
|
||||
OpenWeather adds an extension to the panel that gives the user weather information at a glance. It is customizable, it lets the user view weather information for whatever location they want to, and it doesn’t rely on the computers location services. OpenWeather gives the user the choice between [OpenWeatherMap][34] and [Dark Sky][35] to provide the weather information that is to be displayed.
|
||||
|
||||

|
||||
|
||||
[OpenWeather][36]
|
||||
|
||||
### 14\. Panel OSD
|
||||
|
||||
This is the extension I mentioned earlier which allows the user to customize the location in which their desktop notifications appear on the screen. Not only does this allow the user to move their notifications over to the right, but Panel OSD gives the user the option to put their notifications literally anywhere they want on the screen. But for us migrating from Unity to GNOME, switching the notifications from the top middle to the top right may make us feel more at home.
|
||||
|
||||
Before:
|
||||

|
||||
|
||||
After:
|
||||

|
||||
|
||||
#### [Panel OSD][37]
|
||||
|
||||
### 15\. Places Status Indicator
|
||||
|
||||
Places Status Indicator has been a recommended extension for as long as people have started recommending extensions. Places adds a drop-down menu to the panel that gives the user quick access to various areas of the file system, from the home directory to serves your computer has access to and anywhere in between.
|
||||
|
||||
The convenience and usefulness of this extension become more apparent as you use it, becoming a fundamental way you navigate your system. I couldn’t recommend it more highly enough.
|
||||
|
||||

|
||||
|
||||
[Places Status Indicator][38]
|
||||
|
||||
### 16\. Refresh Wifi Connections
|
||||
|
||||
One minor annoyance in GNOME is that the Wi-Fi Networks dialog box does not have a refresh button on it when you are trying to connect to a new Wi-Fi network. Instead, it makes the user wait while the system automatically refreshes the list. Refresh Wifi Connections fixes this. It simply adds that desired refresh button to the dialog box, adding functionality that really should be included out of the box.
|
||||
|
||||
Before:
|
||||

|
||||
|
||||
After:
|
||||

|
||||
|
||||
#### [Refresh Wifi Connections][39]
|
||||
|
||||
### 17\. Remove Dropdown Arrows
|
||||
|
||||
The Remove Dropdown Arrows extension removes the arrows on the panel that signify when an icon has a drop-down menu that you can interact with. This is purely an aesthetic tweak and isn’t always necessary as some themes remove these arrows by default. But themes such as [Numix][40], which happens to be my personal favorite, don’t remove them.
|
||||
|
||||
Remove Dropdown Arrows brings that clean look to the GNOME Shell that removes some unneeded clutter. The only bug I have encountered is that the CPU Management extension I mentioned earlier will randomly “respawn” the drop-down arrow. To turn it back off I have to disable Remove Dropdown Arrows and then enable it again until once more it randomly reappears out of nowhere.
|
||||
|
||||
Before:
|
||||

|
||||
|
||||
After:
|
||||

|
||||
|
||||
[Remove Dropdown Arrows][41]
|
||||
|
||||
### 18\. Status Area Horizontal Spacing
|
||||
|
||||
This is another extension that is purely aesthetic and is only “necessary” in certain themes. Status Area Horizontal Spacing allows the user to control the amount of space between the icons in the status bar. If you think your status icons are too close or too spaced out, then this extension has you covered. Just select the padding you would like and you’re set.
|
||||
|
||||
Maximum Spacing:
|
||||

|
||||
|
||||
Minimum Spacing:
|
||||

|
||||
|
||||
#### [Status Area Horizontal Spacing][42]
|
||||
|
||||
### 19\. Steal My Focus
|
||||
|
||||
By default, when you open an application in GNOME is will sometimes stay behind what you have open if a different application has focus. GNOME then notifies you that the application you selected has opened and it is up to you to switch over to it. But, in my experience, this isn’t always consistent. There are certain applications that seem to jump to the front when opened while the rest rely on you to see the notifications to know they opened.
|
||||
|
||||
Steal My Focus changes that by removing the notification and immediately giving the user focus of the application they just opened. Because of this inconsistency, it was difficult for me to get a screenshot so you just have to trust me on this one. ;)
|
||||
|
||||
#### [Steal My Focus][43]
|
||||
|
||||
### 20\. Workspaces to Dock
|
||||
|
||||
This extension changed the way I use GNOME. Period. It allows me to be more productive and aware of my virtual desktop, making for a much better user experience. Workspaces to Dock allows the user to customize their overview workspaces by turning into an interactive dock.
|
||||
|
||||
You can customize its look, size, functionality, and even position. It can be used purely for aesthetics, but I think the real gold is using it to make the workspaces more fluid, functional, and consistent with the rest of the UI.
|
||||
|
||||

|
||||
|
||||
[Workspaces to Dock][44]
|
||||
|
||||
### Honorable Mentions: Dash to Dock and Dash to Panel
|
||||
|
||||
Dash to Dock and Dash to Panel are not included in the official 20 extensions of this article for one main reason: Ubuntu Dock. Both extensions allow the user to make the GNOME Dash either a dock or a panel respectively and add more customization than comes by default.
|
||||
|
||||
The problem is that to get the full functionality of these two extensions you will need to jump through some hoops to disable Ubuntu Dock, which I won’t outline in this article. We acknowledge that not everyone will be using Ubuntu 17.10, so for those of you that aren’t this may not apply to you. That being said, bot of these extensions are great and are included among some of the most popular GNOME extensions you will find.
|
||||
|
||||
Currently, there is a “bug” in Dash to Dock whereby changing its setting, even with the extension disabled, the changes apply to the Ubuntu Dock as well. I say “bug” because I actually use this myself to customize Ubuntu Dock without the need for the extensions to be activated. This may get patched in the future, but until then consider that a free tip.
|
||||
|
||||
### [Dash to Dock][45] [Dash to Panel][46]
|
||||
|
||||
So there you have it, our top 20 GNOME Extensions you should try right now. Which of these extensions do you particularly like? Which do you dislike? Let us know in the comments below and don’t be afraid to say something if there is anything you think we missed.
|
||||
|
||||
### About Phillip Prado
|
||||
|
||||
Phillip Prado is an avid follower of all things tech, culture, and art. Not only is he an all-around geek, he has a BA in cultural communications and considers himself a serial hobbyist. He loves hiking, cycling, poetry, video games, and movies. But no matter what his passions are there is only one thing he loves more than Linux and FOSS: coffee. You can find him (nearly) everywhere on the web as @phillipprado.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-gnome-extensions/
|
||||
|
||||
作者:[ Phillip Prado][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://itsfoss.com/author/phillip/
|
||||
[2]:https://itsfoss.com/best-gnome-extensions/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fbest-gnome-extensions%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=Top+20+GNOME+Extensions+You+Should+Be+Using+Right+Now&url=https://itsfoss.com/best-gnome-extensions/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=phillipprado
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fbest-gnome-extensions%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fbest-gnome-extensions%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/best-gnome-extensions/&title=Top+20+GNOME+Extensions+You+Should+Be+Using+Right+Now
|
||||
[8]:https://www.reddit.com/submit?url=https://itsfoss.com/best-gnome-extensions/&title=Top+20+GNOME+Extensions+You+Should+Be+Using+Right+Now
|
||||
[9]:https://extensions.gnome.org/
|
||||
[10]:https://www.gnome.org/
|
||||
[11]:https://itsfoss.com/ubuntu-17-10-release-features/
|
||||
[12]:https://itsfoss.com/ubuntu-unity-shutdown/
|
||||
[13]:https://itsfoss.com/gnome-shell-extensions/
|
||||
[14]:https://www.kde.org/
|
||||
[15]:https://elementary.io/
|
||||
[16]:https://itsfoss.com/gnome-3-26-released/
|
||||
[17]:https://extensions.gnome.org/extension/1217/appfolders-manager/
|
||||
[18]:https://en.wikipedia.org/wiki/APT_(Debian)
|
||||
[19]:https://extensions.gnome.org/extension/1139/apt-update-indicator/
|
||||
[20]:https://extensions.gnome.org/extension/16/auto-move-windows/
|
||||
[21]:https://extensions.gnome.org/extension/517/caffeine/
|
||||
[22]:https://extensions.gnome.org/extension/945/cpu-power-manager/
|
||||
[23]:https://extensions.gnome.org/extension/779/clipboard-indicator/
|
||||
[24]:https://extensions.gnome.org/extension/1036/extensions/
|
||||
[25]:https://extensions.gnome.org/extension/2/move-clock/
|
||||
[26]:https://extensions.gnome.org/extension/608/gnomenu/
|
||||
[27]:https://youtu.be/9TNvaqtVKLk
|
||||
[28]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[29]:https://extensions.gnome.org/extension/19/user-themes/
|
||||
[30]:https://extensions.gnome.org/extension/744/hide-activities-button/
|
||||
[31]:https://community.kde.org/KDEConnect
|
||||
[32]:https://www.kde.org/plasma-desktop
|
||||
[33]:https://extensions.gnome.org/extension/1272/mconnect/
|
||||
[34]:http://openweathermap.org/
|
||||
[35]:https://darksky.net/forecast/40.7127,-74.0059/us12/en
|
||||
[36]:https://extensions.gnome.org/extension/750/openweather/
|
||||
[37]:https://extensions.gnome.org/extension/708/panel-osd/
|
||||
[38]:https://extensions.gnome.org/extension/8/places-status-indicator/
|
||||
[39]:https://extensions.gnome.org/extension/905/refresh-wifi-connections/
|
||||
[40]:https://numixproject.github.io/
|
||||
[41]:https://extensions.gnome.org/extension/800/remove-dropdown-arrows/
|
||||
[42]:https://extensions.gnome.org/extension/355/status-area-horizontal-spacing/
|
||||
[43]:https://extensions.gnome.org/extension/234/steal-my-focus/
|
||||
[44]:https://extensions.gnome.org/extension/427/workspaces-to-dock/
|
||||
[45]:https://extensions.gnome.org/extension/307/dash-to-dock/
|
||||
[46]:https://extensions.gnome.org/extension/1160/dash-to-panel/
|
||||
@ -0,0 +1,81 @@
|
||||
5 Tips to Improve Technical Writing for an International Audience
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Writing in English for an international audience takes work; here are some handy tips to remember.[Creative Commons Zero][2]
|
||||
|
||||
Writing in English for an international audience does not necessarily put native English speakers in a better position. On the contrary, they tend to forget that the document's language might not be the first language of the audience. Let's have a look at the following simple sentence as an example: “Encrypt the password using the 'foo bar' command.”
|
||||
|
||||
Grammatically, the sentence is correct. Given that "-ing" forms (gerunds) are frequently used in the English language, most native speakers would probably not hesitate to phrase a sentence like this. However, on closer inspection, the sentence is ambiguous: The word “using” may refer either to the object (“the password”) or to the verb (“encrypt”). Thus, the sentence can be interpreted in two different ways:
|
||||
|
||||
* Encrypt the password that uses the 'foo bar' command.
|
||||
|
||||
* Encrypt the password by using the 'foo bar' command.
|
||||
|
||||
As long as you have previous knowledge about the topic (password encryption or the 'foo bar' command), you can resolve this ambiguity and correctly decide that the second reading is the intended meaning of this sentence. But what if you lack in-depth knowledge of the topic? What if you are not an expert but a translator with only general knowledge of the subject? Or, what if you are a non-native speaker of English who is unfamiliar with advanced grammatical forms?
|
||||
|
||||
### Know Your Audience
|
||||
|
||||
Even native English speakers may need some training to write clear and straightforward technical documentation. Raising awareness of usability and potential problems is the first step. This article, based on my talk at[ Open Source Summit EU][5], offers several useful techniques. Most of them are useful not only for technical documentation but also for everyday written communication, such as writing email or reports.
|
||||
|
||||
**1. Change perspective. **Step into your audience's shoes. Step one is to know your intended audience. If you are a developer writing for end users, view the product from their perspective. The [persona technique][6] can help to focus on the target audience and to provide the right level of detail for your readers.
|
||||
|
||||
**2\. Follow the KISS principle. **Keep it short and simple. The principle can be applied to several levels, like grammar, sentences, or words. Here are some examples:
|
||||
|
||||
_Words: _ Uncommon and long words slow down reading and might be obstacles for non-native speakers. Use simpler alternatives:
|
||||
|
||||
“utilize” → “use”
|
||||
|
||||
“indicate” → “show”, “tell”, “say”
|
||||
|
||||
“prerequisite” → “requirement”
|
||||
|
||||
_Grammar: _ Use the simplest tense that is appropriate. For example, use present tense when mentioning the result of an action: "Click _OK_ . The _Printer Options_ dialog appears.”
|
||||
|
||||
_Sentences: _ As a rule of thumb, present one idea in one sentence. However, restricting sentence length to a certain amount of words is not useful in my opinion. Short sentences are not automatically easy to understand (especially if they are a cluster of nouns). Sometimes, trimming down sentences to a certain word count can introduce ambiquities, which can, in turn, make sentences even more difficult to understand.
|
||||
|
||||
**3\. Beware of ambiguities. **As authors, we often do not notice ambiguity in a sentence. Having your texts reviewed by others can help identify such problems. If that's not an option, try to look at each sentence from different perspectives: Does the sentence also work for readers without in-depth knowledge of the topic? Does it work for readers with limited language skills? Is the grammatical relationship between all sentence parts clear? If the sentence does not meet these requirements, rephrase it to resolve the ambiguity.
|
||||
|
||||
**4\. Be consistent. **This applies to choice of words, spelling, and punctuation as well as phrases and structure. For lists, use parallel grammatical construction. For example:
|
||||
|
||||
Why white space is important:
|
||||
|
||||
* It focuses attention.
|
||||
|
||||
* It visually separates sections.
|
||||
|
||||
* It splits content into chunks.
|
||||
|
||||
**5\. Remove redundant content.** Keep only information that is relevant for your target audience. On a sentence level, avoid fillers (basically, easily) and unnecessary modifications:
|
||||
|
||||
"already existing" → "existing"
|
||||
|
||||
"completely new" → "new"
|
||||
|
||||
As you might have guessed by now, writing is rewriting. Good writing requires effort and practice. But even if you write only occasionally, you can significantly improve your texts by focusing on the target audience and by using basic writing techniques. The better the readability of a text, the easier it is to process, even for an audience with varying language skills. When it comes to localization especially, good quality of the source text is important: Garbage in, garbage out. If the original text has deficiencies, it will take longer to translate the text, resulting in higher costs. In the worst case, the flaws will be multiplied during translation and need to be corrected in various languages.
|
||||
|
||||
|
||||

|
||||
|
||||
Tanja Roth, Technical Documentation Specialist at SUSE Linux GmbH[Used with permission][1]
|
||||
|
||||
_Driven by an interest in both language and technology, Tanja has been working as a technical writer in mechanical engineering, medical technology, and IT for many years. She joined SUSE in 2005 and contributes to a wide range of product and project documentation, including High Availability and Cloud topics._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/event/open-source-summit-eu/2017/12/technical-writing-international-audience?sf175396579=1
|
||||
|
||||
作者:[TANJA ROTH ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/tanja-roth
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/tanja-rothjpg
|
||||
[4]:https://www.linux.com/files/images/typewriter-8019211920jpg
|
||||
[5]:https://osseu17.sched.com/event/ByIW
|
||||
[6]:https://en.wikipedia.org/wiki/Persona_(user_experience)
|
||||
@ -1,145 +0,0 @@
|
||||
translating by imquanquan
|
||||
|
||||
How To Know What A Command Or Program Will Exactly Do Before Executing It
|
||||
======
|
||||
Ever wondered what a Unix command will do before executing it? Not everyone knows what a particular command or program will do. Of course, you can check it with [Explainshell][2]. You need to copy/paste the command in Explainshell website and it let you know what each part of a Linux command does. However, it is not necessary. Now, we can easily know what a command or program will exactly do before executing it, right from the Terminal. Say hello to “maybe”, a simple tool that allows you to run a command and see what it does to your files without actually doing it! After reviewing the output listed, you can then decide whether you really want to run it or not.
|
||||
|
||||
#### How “maybe” works?
|
||||
|
||||
According to the developer,
|
||||
|
||||
> “maybe” runs processes under the control of ptrace with the help of python-ptrace library. When it intercepts a system call that is about to make changes to the file system, it logs that call, and then modifies CPU registers to both redirect the call to an invalid syscall ID (effectively turning it into a no-op) and set the return value of that no-op call to one indicating success of the original call. As a result, the process believes that everything it is trying to do is actually happening, when in reality nothing is.
|
||||
|
||||
Warning: You should be very very careful when using this utility in a production system or in any systems you care about. It can still do serious damages, because it will block only a handful of syscalls.
|
||||
|
||||
#### Installing “maybe”
|
||||
|
||||
Make sure you have installed pip in your Linux system. If not, install it as shown below depending upon the distribution you use.
|
||||
|
||||
On Arch Linux and its derivatives like Antergos, Manjaro Linux, install pip using the following command:
|
||||
|
||||
```
|
||||
sudo pacman -S python-pip
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
|
||||
```
|
||||
sudo yum install python-pip
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
sudo dnf install epel-release
|
||||
```
|
||||
|
||||
```
|
||||
sudo dnf install python-pip
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
sudo apt-get install python-pip
|
||||
```
|
||||
|
||||
On SUSE, openSUSE:
|
||||
|
||||
```
|
||||
sudo zypper install python-pip
|
||||
```
|
||||
|
||||
Once pip installed, run the following command to install “maybe”.
|
||||
|
||||
```
|
||||
sudo pip install maybe
|
||||
```
|
||||
|
||||
#### Know What A Command Or Program Will Exactly Do Before Executing It
|
||||
|
||||
Usage is absolutely easy! Just add “maybe” in front of a command that you want to execute.
|
||||
|
||||
Allow me to show you an example.
|
||||
|
||||
```
|
||||
$ maybe rm -r ostechnix/
|
||||
```
|
||||
|
||||
As you can see, I am going to delete a folder called “ostechnix” from my system. Here is the sample output.
|
||||
|
||||
```
|
||||
maybe has prevented rm -r ostechnix/ from performing 5 file system operations:
|
||||
|
||||
delete /home/sk/inboxer-0.4.0-x86_64.AppImage
|
||||
delete /home/sk/Docker.pdf
|
||||
delete /home/sk/Idhayathai Oru Nodi.mp3
|
||||
delete /home/sk/dThmLbB334_1398236878432.jpg
|
||||
delete /home/sk/ostechnix
|
||||
|
||||
Do you want to rerun rm -r ostechnix/ and permit these operations? [y/N] y
|
||||
```
|
||||
|
||||
[][3]
|
||||
|
||||
The “maybe” tool performs 5 file system operations and shows me what this command (rm -r ostechnix/) will exactly do. Now I can decide whether I should perform this operation or not. Cool, yeah? Indeed!
|
||||
|
||||
Here is another example. I am going to install [Inboxer][4] desktop client for Gmail. This is what I got.
|
||||
|
||||
```
|
||||
$ maybe ./inboxer-0.4.0-x86_64.AppImage
|
||||
fuse: bad mount point `/tmp/.mount_inboxemDzuGV': No such file or directory
|
||||
squashfuse 0.1.100 (c) 2012 Dave Vasilevsky
|
||||
|
||||
Usage: /home/sk/Downloads/inboxer-0.4.0-x86_64.AppImage [options] ARCHIVE MOUNTPOINT
|
||||
|
||||
FUSE options:
|
||||
-d -o debug enable debug output (implies -f)
|
||||
-f foreground operation
|
||||
-s disable multi-threaded operation
|
||||
|
||||
open dir error: No such file or directory
|
||||
maybe has prevented ./inboxer-0.4.0-x86_64.AppImage from performing 1 file system operations:
|
||||
|
||||
create directory /tmp/.mount_inboxemDzuGV
|
||||
|
||||
Do you want to rerun ./inboxer-0.4.0-x86_64.AppImage and permit these operations? [y/N]
|
||||
```
|
||||
|
||||
If it not detects any file system operations, then it will simply display a result something like below.
|
||||
|
||||
For instance, I run this command to update my Arch Linux.
|
||||
|
||||
```
|
||||
$ maybe sudo pacman -Syu
|
||||
sudo: effective uid is not 0, is /usr/bin/sudo on a file system with the 'nosuid' option set or an NFS file system without root privileges?
|
||||
maybe has not detected any file system operations from sudo pacman -Syu.
|
||||
```
|
||||
|
||||
See? It didn’t detect any file system operations, so there were no warnings. This is absolutely brilliant and exactly what I was looking for. From now on, I can easily know what a command or a program will do even before executing it. I hope this will be useful to you too. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
Resource:
|
||||
|
||||
* [“maybe” GitHub page][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/know-command-program-will-exactly-executing/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/p-e-w/maybe
|
||||
[2]:https://www.ostechnix.com/explainshell-find-part-linux-command/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/12/maybe-1.png
|
||||
[4]:https://www.ostechnix.com/inboxer-unofficial-google-inbox-desktop-client/
|
||||
113
sources/tech/20171204 Improve your Bash scripts with Argbash.md
Normal file
113
sources/tech/20171204 Improve your Bash scripts with Argbash.md
Normal file
@ -0,0 +1,113 @@
|
||||
# [Improve your Bash scripts with Argbash][1]
|
||||
|
||||
|
||||
|
||||
Do you write or maintain non-trivial bash scripts? If so, you probably want them to accept command-line arguments in a standard and robust way. Fedora recently got [a nice addition][2] which can help you produce better scripts. And don’t worry, it won’t cost you much of your time or energy.
|
||||
|
||||
### Why Argbash?
|
||||
|
||||
Bash is an interpreted command-line language with no standard library. Therefore, if you write bash scripts and want command-line interfaces that conform to [POSIX][3] and [GNU CLI][4] standards, you’re used to only two options:
|
||||
|
||||
1. Write the argument-parsing functionality tailored to your script yourself (possibly using the `getopts` builtin).
|
||||
|
||||
2. Use an external bash module.
|
||||
|
||||
The first option looks incredibly silly as implementing the interface properly is not trivial. However, it is suggested as the best choice on various sites ranging from [Stack Overflow][5] to the [Bash Hackers][6] wiki.
|
||||
|
||||
The second option looks smarter, but using a module has its issues. The biggest is you have to bundle its code with your script. This may mean either:
|
||||
|
||||
* You distribute the library as a separate file, or
|
||||
|
||||
* You include the library code at the beginning of your script.
|
||||
|
||||
Having two files instead of one is awkward. So is polluting your bash scripts with a chunk of complex code over thousand lines long.
|
||||
|
||||
This was the main reason why the Argbash [project came to life][7]. Argbash is a code generator, so it generates a tailor-made parsing library for your script. Unlike the generic code of other bash modules, it produces minimal code your script needs. Moreover, you can request even simpler code if you don’t need 100% conformance to these CLI standards.
|
||||
|
||||
### Example
|
||||
|
||||
### Analysis
|
||||
|
||||
Let’s say you want to implement a script that [draws a bar][8] across the terminal window. You do that by repeating a single character of your choice multiple times. This means you need to get the following information from the command-line:
|
||||
|
||||
* _The character which is the element of the line. If not specified, use a dash._ On the command-line, this would be a single-valued positional argument _character_ with a default value of -.
|
||||
|
||||
* _Length of the line. If not specified, go for 80._ This is a single-valued optional argument _–length_ with a default of 80.
|
||||
|
||||
* _Verbose mode (for debugging)._ This is a boolean argument _verbose_ , off by default.
|
||||
|
||||
As the body of the script is really simple, this article focuses on getting the input of the user from the command-line to appropriate script variables. Argbash generates code that saves parsing results to shell variables __arg_character_ , __arg_length_ and __arg_verbose_ .
|
||||
|
||||
### Execution
|
||||
|
||||
In order to proceed, you need the _argbash-init_ and _argbash_ bash scripts that are parts of the _argbash_ package. Therefore, run this command:
|
||||
|
||||
```
|
||||
sudo dnf install argbash
|
||||
```
|
||||
|
||||
Then, use _argbash-init_ to generate a template for _argbash_ , which generates the executable script. You want three arguments: a positional one called _character_ , an optional _length_ and an optional boolean _verbose_ . Tell this to _argbash-init_ , and then pass the output to _argbash_ :
|
||||
|
||||
```
|
||||
argbash-init --pos character --opt length --opt-bool verbose script-template.sh
|
||||
argbash script-template.sh -o script
|
||||
./script
|
||||
```
|
||||
|
||||
See the help message? Looks like the script doesn’t know about the default option for the character argument. So take a look at the [Argbash API][9], and then fix the issue by editing the template section of the script:
|
||||
|
||||
```
|
||||
# ...
|
||||
# ARG_OPTIONAL_SINGLE([length],[l],[Length of the line],[80])
|
||||
# ARG_OPTIONAL_BOOLEAN([verbose],[V],[Debug mode])
|
||||
# ARG_POSITIONAL_SINGLE([character],[The element of the line],[-])
|
||||
# ARG_HELP([The line drawer])
|
||||
# ...
|
||||
```
|
||||
|
||||
Argbash is so smart that it tries to make every generated script a template of itself. This means you don’t have to worry about storing source templates for further use. You just shouldn’t lose your generated bash scripts. Now, try to regenerate the future line drawer to work as expected:
|
||||
|
||||
```
|
||||
argbash script -o script
|
||||
./script
|
||||
```
|
||||
|
||||
As you can see, everything is working all right. The only thing left to do is fill in the line drawing functionality itself.
|
||||
|
||||
### Conclusion
|
||||
|
||||
You might find the section containing parsing code quite long, but consider that it allows you to call _./script.sh x -Vl50_ and it will be understood the same way as _./script -V -l 50 x. I_ t does require some code to get this right.
|
||||
|
||||
However, you can shift the balance between generated code complexity and parsing abilities towards more simple code by calling _argbash-init_ with argument _–mode_ set to _minimal_ . This option reduces the size of the script by about 20 lines, which corresponds to a roughly 25% decrease of the generated parsing code size. On the other hand, the _full_ mode makes the script even smarter.
|
||||
|
||||
If you want to examine the generated code, give _argbash_ the argument _–commented_ , which puts comments into the parsing code that reveal the intent behind various sections. Compare that to other argument parsing libraries such as [shflags][10], [argsparse][11] or [bash-modules/arguments][12], and you’ll see the powerful simplicity of Argbash. If something goes horribly wrong and you need to fix a glitch in the parsing functionality quickly, Argbash allows you to do that as well.
|
||||
|
||||
As you’re most likely a Fedora user, you can enjoy the luxury of having command-line Argbash installed from the official repositories. However, there is also an [online parsing code generator][13] at your service. Furthermore, if you’re working on a server with Docker, you can appreciate the [Argbash Docker image][14].
|
||||
|
||||
So enjoy and make sure that your scripts have a command-line interface that pleases your users. Argbash is here to help, with minimal effort required from your side.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/improve-bash-scripts-argbash/
|
||||
|
||||
作者:[Matěj Týč ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/bubla/
|
||||
[1]:https://fedoramagazine.org/improve-bash-scripts-argbash/
|
||||
[2]:https://argbash.readthedocs.io/
|
||||
[3]:http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap12.html
|
||||
[4]:https://www.gnu.org/prep/standards/html_node/Command_002dLine-Interfaces.html
|
||||
[5]:https://stackoverflow.com/questions/192249/how-do-i-parse-command-line-arguments-in-bash
|
||||
[6]:http://wiki.bash-hackers.org/howto/getopts_tutorial
|
||||
[7]:https://argbash.readthedocs.io/
|
||||
[8]:http://wiki.bash-hackers.org/snipplets/print_horizontal_line
|
||||
[9]:http://argbash.readthedocs.io/en/stable/guide.html#argbash-api
|
||||
[10]:https://raw.githubusercontent.com/Anvil/bash-argsparse/master/argsparse.sh
|
||||
[11]:https://raw.githubusercontent.com/Anvil/bash-argsparse/master/argsparse.sh
|
||||
[12]:https://raw.githubusercontent.com/vlisivka/bash-modules/master/main/bash-modules/src/bash-modules/arguments.sh
|
||||
[13]:https://argbash.io/generate
|
||||
[14]:https://hub.docker.com/r/matejak/argbash/
|
||||
@ -0,0 +1,210 @@
|
||||
# Tutorial on how to write basic udev rules in Linux
|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Objective][4]
|
||||
|
||||
* [2. Requirements][5]
|
||||
|
||||
* [3. Difficulty][6]
|
||||
|
||||
* [4. Conventions][7]
|
||||
|
||||
* [5. Introduction][8]
|
||||
|
||||
* [6. How rules are organized][9]
|
||||
|
||||
* [7. The rules syntax][10]
|
||||
|
||||
* [8. A test case][11]
|
||||
|
||||
* [9. Operators][12]
|
||||
* * [9.1.1. == and != operators][1]
|
||||
|
||||
* [9.1.2. The assignment operators: = and :=][2]
|
||||
|
||||
* [9.1.3. The += and -= operators][3]
|
||||
|
||||
* [10. The keys we used][13]
|
||||
|
||||
### Objective
|
||||
|
||||
Understanding the base concepts behind udev, and learn how to write simple rules
|
||||
|
||||
### Requirements
|
||||
|
||||
* Root permissions
|
||||
|
||||
### Difficulty
|
||||
|
||||
MEDIUM
|
||||
|
||||
### Conventions
|
||||
|
||||
* **#** - requires given command to be executed with root privileges either directly as a root user or by use of `sudo` command
|
||||
|
||||
* **$** - given command to be executed as a regular non-privileged user
|
||||
|
||||
### Introduction
|
||||
|
||||
In a GNU/Linux system, while devices low level support is handled at the kernel level, the management of events related to them is managed in userspace by `udev`, and more precisely by the `udevd` daemon. Learning how to write rules to be applied on the occurring of those events can be really useful to modify the behavior of the system and adapt it to our needs.
|
||||
|
||||
### How rules are organized
|
||||
|
||||
Udev rules are defined into files with the `.rules` extension. There are two main locations in which those files can be placed: `/usr/lib/udev/rules.d` it's the directory used for system-installed rules, `/etc/udev/rules.d/`is reserved for custom made rules.
|
||||
|
||||
The files in which the rules are defined are conventionally named with a number as prefix (e.g `50-udev-default.rules`) and are processed in lexical order independently of the directory they are in. Files installed in `/etc/udev/rules.d`, however, override those with the same name installed in the system default path.
|
||||
|
||||
### The rules syntax
|
||||
|
||||
The syntax of udev rules is not very complicated once you understand the logic behind it. A rule is composed by two main sections: the "match" part, in which we define the conditions for the rule to be applied, using a series of keys separated by a comma, and the "action" part, in which we perform some kind of action, when the conditions are met.
|
||||
|
||||
### A test case
|
||||
|
||||
What a better way to explain possible options than to configure an actual rule? As an example, we are going to define a rule to disable the touchpad when a mouse is connected. Obviously the attributes provided in the rule definition, will reflect my hardware.
|
||||
|
||||
We will write our rule in the `/etc/udev/rules.d/99-togglemouse.rules` file with the help of our favorite text editor. A rule definition can span over multiple lines, but if that's the case, a backslash must be used before the newline character, as a line continuation, just as in shell scripts. Here is our rule:
|
||||
```
|
||||
ACTION=="add" \
|
||||
, ATTRS{idProduct}=="c52f" \
|
||||
, ATTRS{idVendor}=="046d" \
|
||||
, ENV{DISPLAY}=":0" \
|
||||
, ENV{XAUTHORITY}="/run/user/1000/gdm/Xauthority" \
|
||||
, RUN+="/usr/bin/xinput --disable 16"
|
||||
```
|
||||
Let's analyze it.
|
||||
|
||||
### Operators
|
||||
|
||||
First of all, an explanation of the used and possible operators:
|
||||
|
||||
#### == and != operators
|
||||
|
||||
The `==` is the equality operator and the `!=` is the inequality operator. By using them we establish that for the rule to be applied the defined keys must match, or not match the defined value respectively.
|
||||
|
||||
#### The assignment operators: = and :=
|
||||
|
||||
The `=` assignment operator, is used to assign a value to the keys that accepts one. We use the `:=` operator, instead, when we want to assign a value and we want to make sure that it is not overridden by other rules: the values assigned with this operator, in facts, cannot be altered.
|
||||
|
||||
#### The += and -= operators
|
||||
|
||||
The `+=` and `-=` operators are used respectively to add or to remove a value from the list of values defined for a specific key.
|
||||
|
||||
### The keys we used
|
||||
|
||||
Let's now analyze the keys we used in the rule. First of all we have the `ACTION` key: by using it, we specified that our rule is to be applied when a specific event happens for the device. Valid values are `add`, `remove` and `change`
|
||||
|
||||
We then used the `ATTRS` keyword to specify an attribute to be matched. We can list a device attributes by using the `udevadm info` command, providing its name or `sysfs` path:
|
||||
```
|
||||
udevadm info -ap /devices/pci0000:00/0000:00:1d.0/usb2/2-1/2-1.2/2-1.2:1.1/0003:046D:C52F.0010/input/input39
|
||||
|
||||
Udevadm info starts with the device specified by the devpath and then
|
||||
walks up the chain of parent devices. It prints for every device
|
||||
found, all possible attributes in the udev rules key format.
|
||||
A rule to match, can be composed by the attributes of the device
|
||||
and the attributes from one single parent device.
|
||||
|
||||
looking at device '/devices/pci0000:00/0000:00:1d.0/usb2/2-1/2-1.2/2-1.2:1.1/0003:046D:C52F.0010/input/input39':
|
||||
KERNEL=="input39"
|
||||
SUBSYSTEM=="input"
|
||||
DRIVER==""
|
||||
ATTR{name}=="Logitech USB Receiver"
|
||||
ATTR{phys}=="usb-0000:00:1d.0-1.2/input1"
|
||||
ATTR{properties}=="0"
|
||||
ATTR{uniq}==""
|
||||
|
||||
looking at parent device '/devices/pci0000:00/0000:00:1d.0/usb2/2-1/2-1.2/2-1.2:1.1/0003:046D:C52F.0010':
|
||||
KERNELS=="0003:046D:C52F.0010"
|
||||
SUBSYSTEMS=="hid"
|
||||
DRIVERS=="hid-generic"
|
||||
ATTRS{country}=="00"
|
||||
|
||||
looking at parent device '/devices/pci0000:00/0000:00:1d.0/usb2/2-1/2-1.2/2-1.2:1.1':
|
||||
KERNELS=="2-1.2:1.1"
|
||||
SUBSYSTEMS=="usb"
|
||||
DRIVERS=="usbhid"
|
||||
ATTRS{authorized}=="1"
|
||||
ATTRS{bAlternateSetting}==" 0"
|
||||
ATTRS{bInterfaceClass}=="03"
|
||||
ATTRS{bInterfaceNumber}=="01"
|
||||
ATTRS{bInterfaceProtocol}=="00"
|
||||
ATTRS{bInterfaceSubClass}=="00"
|
||||
ATTRS{bNumEndpoints}=="01"
|
||||
ATTRS{supports_autosuspend}=="1"
|
||||
|
||||
looking at parent device '/devices/pci0000:00/0000:00:1d.0/usb2/2-1/2-1.2':
|
||||
KERNELS=="2-1.2"
|
||||
SUBSYSTEMS=="usb"
|
||||
DRIVERS=="usb"
|
||||
ATTRS{authorized}=="1"
|
||||
ATTRS{avoid_reset_quirk}=="0"
|
||||
ATTRS{bConfigurationValue}=="1"
|
||||
ATTRS{bDeviceClass}=="00"
|
||||
ATTRS{bDeviceProtocol}=="00"
|
||||
ATTRS{bDeviceSubClass}=="00"
|
||||
ATTRS{bMaxPacketSize0}=="8"
|
||||
ATTRS{bMaxPower}=="98mA"
|
||||
ATTRS{bNumConfigurations}=="1"
|
||||
ATTRS{bNumInterfaces}==" 2"
|
||||
ATTRS{bcdDevice}=="3000"
|
||||
ATTRS{bmAttributes}=="a0"
|
||||
ATTRS{busnum}=="2"
|
||||
ATTRS{configuration}=="RQR30.00_B0009"
|
||||
ATTRS{devnum}=="12"
|
||||
ATTRS{devpath}=="1.2"
|
||||
ATTRS{idProduct}=="c52f"
|
||||
ATTRS{idVendor}=="046d"
|
||||
ATTRS{ltm_capable}=="no"
|
||||
ATTRS{manufacturer}=="Logitech"
|
||||
ATTRS{maxchild}=="0"
|
||||
ATTRS{product}=="USB Receiver"
|
||||
ATTRS{quirks}=="0x0"
|
||||
ATTRS{removable}=="removable"
|
||||
ATTRS{speed}=="12"
|
||||
ATTRS{urbnum}=="1401"
|
||||
ATTRS{version}==" 2.00"
|
||||
|
||||
[...]
|
||||
```
|
||||
Above is the truncated output received after running the command. As you can read it from the output itself, `udevadm` starts with the specified path that we provided, and gives us information about all the parent devices. Notice that attributes of the device are reported in singular form (e.g `KERNEL`), while the parent ones in plural form (e.g `KERNELS`). The parent information can be part of a rule but only one of the parents can be referenced at a time: mixing attributes of different parent devices will not work. In the rule we defined above, we used the attributes of one parent device: `idProduct` and `idVendor`.
|
||||
|
||||
The next thing we have done in our rule, is to use the `ENV` keyword: it can be used to both set or try to match environment variables. We assigned a value to the `DISPLAY` and `XAUTHORITY` ones. Those variables are essential when interacting with the X server programmatically, to setup some needed information: with the `DISPLAY` variable, we specify on what machine the server is running, what display and what screen we are referencing, and with `XAUTHORITY` we provide the path to the file which contains Xorg authentication and authorization information. This file is usually located in the users "home" directory.
|
||||
|
||||
Finally we used the `RUN` keyword: this is used to run external programs. Very important: this is not executed immediately, but the various actions are executed once all the rules have been parsed. In this case we used the `xinput` utility to change the status of the touchpad. I will not explain the syntax of xinput here, it would be out of context, just notice that `16` is the id of the touchpad.
|
||||
|
||||
Once our rule is set, we can debug it by using the `udevadm test` command. This is useful for debugging but it doesn't really run commands specified using the `RUN` key:
|
||||
```
|
||||
$ udevadm test --action="add" /devices/pci0000:00/0000:00:1d.0/usb2/2-1/2-1.2/2-1.2:1.1/0003:046D:C52F.0010/input/input39
|
||||
```
|
||||
What we provided to the command is the action to simulate, using the `--action` option, and the sysfs path of the device. If no errors are reported, our rule should be good to go. To run it in the real world, we must reload the rules:
|
||||
```
|
||||
# udevadm control --reload
|
||||
```
|
||||
This command will reload the rules files, however, will have effect only on new generated events.
|
||||
|
||||
We have seen the basic concepts and logic used to create an udev rule, however we only scratched the surface of the many options and possible settings. The udev manpage provides an exhaustive list: please refer to it for a more in-depth knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux
|
||||
|
||||
作者:[Egidio Docile ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://disqus.com/by/egidiodocile/
|
||||
[1]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h9-1-1-and-operators
|
||||
[2]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h9-1-2-the-assignment-operators-and
|
||||
[3]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h9-1-3-the-and-operators
|
||||
[4]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h1-objective
|
||||
[5]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h2-requirements
|
||||
[6]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h3-difficulty
|
||||
[7]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h4-conventions
|
||||
[8]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h5-introduction
|
||||
[9]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h6-how-rules-are-organized
|
||||
[10]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h7-the-rules-syntax
|
||||
[11]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h8-a-test-case
|
||||
[12]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h9-operators
|
||||
[13]:https://linuxconfig.org/tutorial-on-how-to-write-basic-udev-rules-in-linux#h10-the-keys-we-used
|
||||
@ -0,0 +1,102 @@
|
||||
ANNOUNCING THE GENERAL AVAILABILITY OF CONTAINERD 1.0, THE INDUSTRY-STANDARD RUNTIME USED BY MILLIONS OF USERS
|
||||
============================================================
|
||||
|
||||
Today, we’re pleased to announce that containerd (pronounced Con-Tay-Ner-D), an industry-standard runtime for building container solutions, has reached its 1.0 milestone. containerd has already been deployed in millions of systems in production today, making it the most widely adopted runtime and an essential upstream component of the Docker platform.
|
||||
|
||||
Built to address the needs of modern container platforms like Docker and orchestration systems like Kubernetes, containerd ensures users have a consistent dev to ops experience. From [Docker’s initial announcement][22] last year that it was spinning out its core runtime to [its donation to the CNCF][23] in March 2017, the containerd project has experienced significant growth and progress over the past 12 months. .
|
||||
|
||||
Within both the Docker and Kubernetes communities, there has been a significant uptick in contributions from independents and CNCF member companies alike including Docker, Google, NTT, IBM, Microsoft, AWS, ZTE, Huawei and ZJU. Similarly, the maintainers have been working to add key functionality to containerd.The initial containerd donation provided everything users need to ensure a seamless container experience including methods for:
|
||||
|
||||
* transferring container images,
|
||||
|
||||
* container execution and supervision,
|
||||
|
||||
* low-level local storage and network interfaces and
|
||||
|
||||
* the ability to work on both Linux, Windows and other platforms.
|
||||
|
||||
Additional work has been done to add even more powerful capabilities to containerd including a:
|
||||
|
||||
* Complete storage and distribution system that supports both OCI and Docker image formats and
|
||||
|
||||
* Robust events system
|
||||
|
||||
* More sophisticated snapshot model to manage container filesystems
|
||||
|
||||
These changes helped the team build out a smaller interface for the snapshotters, while still fulfilling the requirements needed from things like a builder. It also reduces the amount of code needed, making it much easier to maintain in the long run.
|
||||
|
||||
The containerd 1.0 milestone comes after several months testing both the alpha and version versions, which enabled the team to implement many performance improvements. Some of these,improvements include the creation of a stress testing system, improvements in garbage collection and shim memory usage.
|
||||
|
||||
“In 2017 key functionality has been added containerd to address the needs of modern container platforms like Docker and orchestration systems like Kubernetes,” said Michael Crosby, Maintainer for containerd and engineer at Docker. “Since our announcement in December, we have been progressing the design of the project with the goal of making it easily embeddable in higher level systems to provide core container capabilities. We will continue to work with the community to create a runtime that’s lightweight yet powerful, balancing new functionality with the desire for code that is easy to support and maintain.”
|
||||
|
||||
containerd is already being used by Kubernetes for its[ cri-containerd project][24], which enables users to run Kubernetes clusters using containerd as the underlying runtime. containerd is also an essential upstream component of the Docker platform and is currently used by millions of end users. There is also strong alignment with other CNCF projects: containerd exposes an API using [gRPC][25] and exposes metrics in the [Prometheus][26] format. containerd also fully leverages the Open Container Initiative (OCI) runtime, image format specifications and OCI reference implementation ([runC][27]), and will pursue OCI certification when it is available.
|
||||
|
||||
Key Milestones in the progress to 1.0 include:
|
||||
|
||||

|
||||
|
||||
Notable containerd facts and figures:
|
||||
|
||||
* 1994 GitHub stars, 401 forks
|
||||
|
||||
* 108 contributors
|
||||
|
||||
* 8 maintainers from independents and and member companies alike including Docker, Google, IBM, ZTE and ZJU .
|
||||
|
||||
* 3030+ commits, 26 releases
|
||||
|
||||
Availability and Resources
|
||||
|
||||
To participate in containerd: [github.com/containerd/containerd][28]
|
||||
|
||||
* Getting Started with containerd: [http://mobyproject.org/blog/2017/08/15/containerd-getting-started/][8]
|
||||
|
||||
* Roadmap: [https://github.com/containerd/containerd/blob/master/ROADMAP.md][1]
|
||||
|
||||
* Scope table: [https://github.com/containerd/containerd#scope][2]
|
||||
|
||||
* Architecture document: [https://github.com/containerd/containerd/blob/master/design/architecture.md][3]
|
||||
|
||||
* APIs: [https://github.com/containerd/containerd/tree/master/api/][9].
|
||||
|
||||
* Learn more about containerd at KubeCon by attending Justin Cormack’s [LinuxKit & Kubernetes talk at Austin Docker Meetup][10], Patrick Chanezon’s [Moby session][11] [Phil Estes’ session][12] or the [containerd salon][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/12/cncf-containerd-1-0-ga-announcement/
|
||||
|
||||
作者:[Patrick Chanezon ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/chanezon/
|
||||
[1]:https://github.com/docker/containerd/blob/master/ROADMAP.md
|
||||
[2]:https://github.com/docker/containerd#scope
|
||||
[3]:https://github.com/docker/containerd/blob/master/design/architecture.md
|
||||
[4]:http://www.linkedin.com/shareArticle?mini=true&url=http://dockr.ly/2ArQe3G&title=Announcing%20the%20General%20Availability%20of%20containerd%201.0%2C%20the%20industry-standard%20runtime%20used%20by%20millions%20of%20users&summary=Today,%20we%E2%80%99re%20pleased%20to%20announce%20that%20containerd%20(pronounced%20Con-Tay-Ner-D),%20an%20industry-standard%20runtime%20for%20building%20container%20solutions,%20has%20reached%20its%201.0%20milestone.%20containerd%20has%20already%20been%20deployed%20in%20millions%20of%20systems%20in%20production%20today,%20making%20it%20the%20most%20widely%20adopted%20runtime%20and%20an%20essential%20upstream%20component%20of%20the%20Docker%20platform.%20Built%20...
|
||||
[5]:http://www.reddit.com/submit?url=http://dockr.ly/2ArQe3G&title=Announcing%20the%20General%20Availability%20of%20containerd%201.0%2C%20the%20industry-standard%20runtime%20used%20by%20millions%20of%20users
|
||||
[6]:https://plus.google.com/share?url=http://dockr.ly/2ArQe3G
|
||||
[7]:http://news.ycombinator.com/submitlink?u=http://dockr.ly/2ArQe3G&t=Announcing%20the%20General%20Availability%20of%20containerd%201.0%2C%20the%20industry-standard%20runtime%20used%20by%20millions%20of%20users
|
||||
[8]:http://mobyproject.org/blog/2017/08/15/containerd-getting-started/
|
||||
[9]:https://github.com/docker/containerd/tree/master/api/
|
||||
[10]:https://www.meetup.com/Docker-Austin/events/245536895/
|
||||
[11]:http://sched.co/CU6G
|
||||
[12]:https://kccncna17.sched.com/event/CU6g/embedding-the-containerd-runtime-for-fun-and-profit-i-phil-estes-ibm
|
||||
[13]:https://kccncna17.sched.com/event/Cx9k/containerd-salon-hosted-by-derek-mcgowan-docker-lantao-liu-google
|
||||
[14]:https://blog.docker.com/author/chanezon/
|
||||
[15]:https://blog.docker.com/tag/cloud-native-computing-foundation/
|
||||
[16]:https://blog.docker.com/tag/cncf/
|
||||
[17]:https://blog.docker.com/tag/container-runtime/
|
||||
[18]:https://blog.docker.com/tag/containerd/
|
||||
[19]:https://blog.docker.com/tag/cri-containerd/
|
||||
[20]:https://blog.docker.com/tag/grpc/
|
||||
[21]:https://blog.docker.com/tag/kubernetes/
|
||||
[22]:https://blog.docker.com/2016/12/introducing-containerd/
|
||||
[23]:https://blog.docker.com/2017/03/docker-donates-containerd-to-cncf/
|
||||
[24]:http://blog.kubernetes.io/2017/11/containerd-container-runtime-options-kubernetes.html
|
||||
[25]:http://www.grpc.io/
|
||||
[26]:https://prometheus.io/
|
||||
[27]:https://github.com/opencontainers/runc
|
||||
[28]:http://github.com/containerd/containerd
|
||||
154
sources/tech/20171205 Ubuntu 18.04 – New Features.md
Normal file
154
sources/tech/20171205 Ubuntu 18.04 – New Features.md
Normal file
@ -0,0 +1,154 @@
|
||||
Ubuntu 18.04 – New Features, Release Date & More
|
||||
============================================================
|
||||
|
||||
|
||||
We’ve all been waiting for it – the new LTS release of Ubuntu – 18.04\. Learn more about new features, the release dates, and more.
|
||||
|
||||
> Note: we’ll frequently update this article with new information, so bookmark this page and check back soon.
|
||||
|
||||
### Basic information about Ubuntu 18.04
|
||||
|
||||
Let’s start with some basic information.
|
||||
|
||||
* It’s a new LTS (Long Term Support) release. So you get 5 years of support for both the desktop and server version.
|
||||
|
||||
* Named “Bionic Beaver”. The founder of Canonical, Mark Shuttleworth, explained the meaning behind the name. The mascot is a Beaver because it’s energetic, industrious, and an awesome engineer – which perfectly describes a typical Ubuntu user, and the new Ubuntu release itself. The “Bionic” adjective is due to the increased number of robots that run on the Ubuntu Core.
|
||||
|
||||
### Ubuntu 18.04 Release Dates & Schedule
|
||||
|
||||
If you’re new to Ubuntu, you may not be familiar the actual version numbers mean. It’s the year and month of the official release. So Ubuntu’s 18.04 official release will be in the 4th month of the year 2018. Ubuntu 17.10 was released in 2017, in the 10th month of the year.
|
||||
|
||||
To go into further details, here are the important dates and need to know about Ubuntu 18.04 LTS:
|
||||
|
||||
* November 30th, 2017 – Feature Definition Freeze.
|
||||
|
||||
* January 4th, 2018 – First Alpha release. So if you opted-in to receive new Alpha releases, you’ll get the Alpha 1 update on this date.
|
||||
|
||||
* February 1st, 2018 – Second Alpha release.
|
||||
|
||||
* March 1st, 2018 – Feature Freeze. No new features will be introduced or released. So the development team will only work on improving existing features and fixing bugs. With exceptions, of course. If you’re not a developer or an experienced user, but would still like to try the new Ubuntu ASAP, then I’d personally recommend starting with this release.
|
||||
|
||||
* March 8th, 2018 – First Beta release. If you opted-in for receiving Beta updates, you’ll get your update on this day.
|
||||
|
||||
* March 22nd, 2018 – User Interface Freeze. It means that no further changes or updates will be done to the actual user interface, so if you write documentation, [tutorials][1], and use screenshots, it’s safe to start then.
|
||||
|
||||
* March 29th, 2018 – Documentation String Freeze. There won’t be any edits or new stuff (strings) added to the documentation, so translators can start translating the documentation.
|
||||
|
||||
* April 5th, 2018 – Final Beta release. This is also a good day to start using the new release.
|
||||
|
||||
* April 19th, 2018 – Final Freeze. Everything’s pretty much done now. Images for the release are created and distributed, and will likely not have any changes.
|
||||
|
||||
* April 26th, 2018 – Official, Final release of Ubuntu 18.04\. Everyone should start using it starting this day, even on production servers. We recommend getting an Ubuntu 18.04 server from [Vultr][2] and testing out the new features. Servers at [Vultr][3] start at $2.5 per month.
|
||||
|
||||
### What’s New in Ubuntu 18.04
|
||||
|
||||
All the new features in Ubuntu 18.04 LTS:
|
||||
|
||||
### Color emojis are now supported
|
||||
|
||||
With previous versions, Ubuntu only supported monochrome (black and white) emojis, which quite frankly, didn’t look so good. Ubuntu 18.04 will support colored emojis by using the [Noto Color Emoji font][7]. With 18.04, you can view and add color emojis with ease everywhere. They are supported natively – so you can use them without using 3-rd party apps or installing/configuring anything extra. You can always disable the color emojis by removing the font.
|
||||
|
||||
### GNOME desktop environment
|
||||
|
||||
[][8]
|
||||
|
||||
Ubuntu started using the GNOME desktop environment with Ubuntu 17.10 instead of the default Unity environment. Ubuntu 18.04 will continue using GNOME. This is a major change to Ubuntu.
|
||||
|
||||
### Ubuntu 18.04 Desktop will have a new default theme
|
||||
|
||||
Ubuntu 18.04 is saying Goodbye to the old ‘Ambience’ default theme with a new GTK theme. If you want to help with the new theme, check out some screenshots and more, go [here][9].
|
||||
|
||||
As of now, there is speculation that Suru will be the [new default icon theme][10] for Ubuntu 18.04\. Here’s a screenshot:
|
||||
|
||||
[][11]
|
||||
|
||||
> Worth noting: all new features in Ubuntu 16.10, 17.04, and 17.10 will roll through to Ubuntu 18.04\. So updates like Window buttons to the right, a better login screen, imrpoved Bluetooth support etc. will roll out to Ubuntu 18.04\. We won’t include a special section since it’s not really new to Ubuntu 18.04 itself. If you want to learn more about all the changes from 16.04 to 18.04, google it for each version in between.
|
||||
|
||||
### Download Ubuntu 18.04
|
||||
|
||||
First off, if you’re already using Ubuntu, you can just upgrade to Ubuntu 18.04.
|
||||
|
||||
If you need to download Ubuntu 18.04:
|
||||
|
||||
Go to the [official Ubuntu download page][12] after the final release.
|
||||
|
||||
For the daily builds (alpha, beta, and non-final releases), go [here][13].
|
||||
|
||||
### FAQs
|
||||
|
||||
Now for some of the frequently asked questions (with answers) that should give you more information about all of this.
|
||||
|
||||
### When is it safe to switch to Ubuntu 18.04?
|
||||
|
||||
On the official final release date, of course. But if you can’t wait, start using the desktop version on March 1st, 2018, and start testing out the server version on April 5th, 2018\. But for you to truly be “safe”, you’ll need to wait for the final release, maybe even more so the 3-rd party services and apps you are using are tested and working well on the new release.
|
||||
|
||||
### How do I upgrade my server to Ubuntu 18.04?
|
||||
|
||||
It’s a fairly simple process but has huge potential risks. We may publish a tutorial sometime in the near future, but you’ll basically need to use ‘do-release-upgrade’. Again, upgrading your server has potential risks, and if you’re on a production server, I’d think twice before upgrading. Especially if you’re on 16.04 which has a few years of support left.
|
||||
|
||||
### How can I help with Ubuntu 18.04?
|
||||
|
||||
Even if you’re not an experienced developer and Ubuntu user, you can still help by:
|
||||
|
||||
* Spreading the word. Let people know about Ubuntu 18.04\. A simple share on social media helps a bit too.
|
||||
|
||||
* Using and testing the release. Start using the release and test it. Again, you don’t have to be a developer. You can still find and report bugs, or send feedback.
|
||||
|
||||
* Translating. Join the translating teams and start translating documentation and/or applications.
|
||||
|
||||
* Helping other people. Join some online Ubuntu communities and help others with issues they’re having with Ubuntu 18.04\. Sometimes people need help with simple stuff like “where can I download Ubuntu?”
|
||||
|
||||
### What does Ubuntu 18.04 mean for other distros like Lubuntu?
|
||||
|
||||
All distros that are based on Ubuntu will have similar new features and a similar release schedule. You’ll need to check your distro’s official website for more information.
|
||||
|
||||
### Is Ubuntu 18.04 an LTS release?
|
||||
|
||||
Yes, Ubuntu 18.04 is an LTS (Long Term Support) release, so you’ll get support for 5 years.
|
||||
|
||||
### Can I switch from Windows/OS X to Ubuntu 18.04?
|
||||
|
||||
Of course! You’ll most likely experience a performance boost too. Switching from a different OS to Ubuntu is fairly easy, there are quite a lot of tutorials for doing that. You can even set up a dual-boot where you’ll be using multiple OSes, so you can use both Windows and Ubuntu 18.04.
|
||||
|
||||
### Can I try Ubuntu 18.04 without installing it?
|
||||
|
||||
Sure. You can use something like [VirtualBox][14] to create a “virtual desktop” – you can install it on your local machine and use Ubuntu 18.04 without actually installing Ubuntu.
|
||||
|
||||
Or you can try an Ubuntu 18.04 server at [Vultr][15] for $2.5 per month. It’s essentially free if you use some [free credits][16].
|
||||
|
||||
### Why can’t I find a 32-bit version of Ubuntu 18.04?
|
||||
|
||||
Because there is no 32bit version. Ubuntu dropped 32bit versions with its 17.10 release. If you’re using old hardware, you’re better off using a different [lightweight Linux distro][17] instead of Ubuntu 18.04 anyway.
|
||||
|
||||
### Any other question?
|
||||
|
||||
Leave a comment below! Share your thoughts, we’re super excited and we’re gonna update this article as soon as new information comes in. Stay tuned and be patient!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://thishosting.rocks/ubuntu-18-04-new-features-release-date/
|
||||
|
||||
作者:[ thishosting.rocks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:thishosting.rocks
|
||||
[1]:https://thishosting.rocks/category/knowledgebase/
|
||||
[2]:https://thishosting.rocks/go/vultr/
|
||||
[3]:https://thishosting.rocks/go/vultr/
|
||||
[4]:https://thishosting.rocks/category/knowledgebase/
|
||||
[5]:https://thishosting.rocks/tag/ubuntu/
|
||||
[6]:https://thishosting.rocks/2017/12/05/
|
||||
[7]:https://www.google.com/get/noto/help/emoji/
|
||||
[8]:https://thishosting.rocks/wp-content/uploads/2017/12/ubuntu-17-10-gnome.jpg
|
||||
[9]:https://community.ubuntu.com/t/call-for-participation-an-ubuntu-default-theme-lead-by-the-community/1545
|
||||
[10]:http://www.omgubuntu.co.uk/2017/11/suru-default-icon-theme-ubuntu-18-04-lts
|
||||
[11]:https://thishosting.rocks/wp-content/uploads/2017/12/suru-icon-theme-ubuntu-18-04.jpg
|
||||
[12]:https://www.ubuntu.com/download
|
||||
[13]:http://cdimage.ubuntu.com/daily-live/current/
|
||||
[14]:https://www.virtualbox.org/
|
||||
[15]:https://thishosting.rocks/go/vultr/
|
||||
[16]:https://thishosting.rocks/vultr-coupons-for-2017-free-credits-and-more/
|
||||
[17]:https://thishosting.rocks/best-lightweight-linux-distros/
|
||||
@ -1,402 +0,0 @@
|
||||
translating by yongshouzhang
|
||||
|
||||
7 tools for analyzing performance in Linux with bcc/BPF
|
||||
============================================================
|
||||
|
||||
### Look deeply into your Linux code with these Berkeley Packet Filter (BPF) Compiler Collection (bcc) tools.
|
||||
|
||||
[][7] 21 Nov 2017 [Brendan Gregg][8] [Feed][9]
|
||||
|
||||
43[up][10]
|
||||
|
||||
[4 comments][11]
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
A new technology has arrived in Linux that can provide sysadmins and developers with a large number of new tools and dashboards for performance analysis and troubleshooting. It's called the enhanced Berkeley Packet Filter (eBPF, or just BPF), although these enhancements weren't developed in Berkeley, they operate on much more than just packets, and they do much more than just filtering. I'll discuss one way to use BPF on the Fedora and Red Hat family of Linux distributions, demonstrating on Fedora 26.
|
||||
|
||||
BPF can run user-defined sandboxed programs in the kernel to add new custom capabilities instantly. It's like adding superpowers to Linux, on demand. Examples of what you can use it for include:
|
||||
|
||||
* Advanced performance tracing tools: programmatic low-overhead instrumentation of filesystem operations, TCP events, user-level events, etc.
|
||||
|
||||
* Network performance: dropping packets early on to improve DDOS resilience, or redirecting packets in-kernel to improve performance
|
||||
|
||||
* Security monitoring: 24x7 custom monitoring and logging of suspicious kernel and userspace events
|
||||
|
||||
BPF programs must pass an in-kernel verifier to ensure they are safe to run, making it a safer option, where possible, than writing custom kernel modules. I suspect most people won't write BPF programs themselves, but will use other people's. I've published many on GitHub as open source in the [BPF Compiler Collection (bcc)][12] project. bcc provides different frontends for BPF development, including Python and Lua, and is currently the most active project for BPF tooling.
|
||||
|
||||
### 7 useful new bcc/BPF tools
|
||||
|
||||
To understand the bcc/BPF tools and what they instrument, I created the following diagram and added it to the bcc project:
|
||||
|
||||
### [bcc_tracing_tools.png][13]
|
||||
|
||||

|
||||
|
||||
Brendan Gregg, [CC BY-SA 4.0][14]
|
||||
|
||||
These are command-line interface (CLI) tools you can use over SSH (secure shell). Much analysis nowadays, including at my employer, is conducted using GUIs and dashboards. SSH is a last resort. But these CLI tools are still a good way to preview BPF capabilities, even if you ultimately intend to use them only through a GUI when available. I've began adding BPF capabilities to an open source GUI, but that's a topic for another article. Right now I'd like to share the CLI tools, which you can use today.
|
||||
|
||||
### 1\. execsnoop
|
||||
|
||||
Where to start? How about watching new processes. These can consume system resources, but be so short-lived they don't show up in top(1) or other tools. They can be instrumented (or, using the industry jargon for this, they can be traced) using [execsnoop][15]. While tracing, I'll log in over SSH in another window:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/execsnoop
|
||||
PCOMM PID PPID RET ARGS
|
||||
sshd 12234 727 0 /usr/sbin/sshd -D -R
|
||||
unix_chkpwd 12236 12234 0 /usr/sbin/unix_chkpwd root nonull
|
||||
unix_chkpwd 12237 12234 0 /usr/sbin/unix_chkpwd root chkexpiry
|
||||
bash 12239 12238 0 /bin/bash
|
||||
id 12241 12240 0 /usr/bin/id -un
|
||||
hostname 12243 12242 0 /usr/bin/hostname
|
||||
pkg-config 12245 12244 0 /usr/bin/pkg-config --variable=completionsdir bash-completion
|
||||
grepconf.sh 12246 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12247 12246 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
tty 12249 12248 0 /usr/bin/tty -s
|
||||
tput 12250 12248 0 /usr/bin/tput colors
|
||||
dircolors 12252 12251 0 /usr/bin/dircolors --sh /etc/DIR_COLORS
|
||||
grep 12253 12239 0 /usr/bin/grep -qi ^COLOR.*none /etc/DIR_COLORS
|
||||
grepconf.sh 12254 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12255 12254 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
grepconf.sh 12256 12239 0 /usr/libexec/grepconf.sh -c
|
||||
grep 12257 12256 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
|
||||
```
|
||||
|
||||
Welcome to the fun of system tracing. You can learn a lot about how the system is really working (or not working, as the case may be) and discover some easy optimizations along the way. execsnoop works by tracing the exec() system call, which is usually used to load different program code in new processes.
|
||||
|
||||
### 2\. opensnoop
|
||||
|
||||
Continuing from above, so, grepconf.sh is likely a shell script, right? I'll run file(1) to check, and also use the [opensnoop][16] bcc tool to see what file is opening:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
PID COMM FD ERR PATH
|
||||
12420 file 3 0 /etc/ld.so.cache
|
||||
12420 file 3 0 /lib64/libmagic.so.1
|
||||
12420 file 3 0 /lib64/libz.so.1
|
||||
12420 file 3 0 /lib64/libc.so.6
|
||||
12420 file 3 0 /usr/lib/locale/locale-archive
|
||||
12420 file -1 2 /etc/magic.mgc
|
||||
12420 file 3 0 /etc/magic
|
||||
12420 file 3 0 /usr/share/misc/magic.mgc
|
||||
12420 file 3 0 /usr/lib64/gconv/gconv-modules.cache
|
||||
12420 file 3 0 /usr/libexec/grepconf.sh
|
||||
1 systemd 16 0 /proc/565/cgroup
|
||||
1 systemd 16 0 /proc/536/cgroup
|
||||
```
|
||||
|
||||
```
|
||||
# file /usr/share/misc/magic.mgc /etc/magic
|
||||
/usr/share/misc/magic.mgc: magic binary file for file(1) cmd (version 14) (little endian)
|
||||
/etc/magic: magic text file for file(1) cmd, ASCII text
|
||||
```
|
||||
|
||||
### 3\. xfsslower
|
||||
|
||||
bcc/BPF can analyze much more than just syscalls. The [xfsslower][17] tool traces common XFS filesystem operations that have a latency of greater than 1 millisecond (the argument):
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/xfsslower 1
|
||||
Tracing XFS operations slower than 1 ms
|
||||
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
|
||||
14:17:34 systemd-journa 530 S 0 0 1.69 system.journal
|
||||
14:17:35 auditd 651 S 0 0 2.43 audit.log
|
||||
14:17:42 cksum 4167 R 52976 0 1.04 at
|
||||
14:17:45 cksum 4168 R 53264 0 1.62 [
|
||||
14:17:45 cksum 4168 R 65536 0 1.01 certutil
|
||||
14:17:45 cksum 4168 R 65536 0 1.01 dir
|
||||
14:17:45 cksum 4168 R 65536 0 1.17 dirmngr-client
|
||||
14:17:46 cksum 4168 R 65536 0 1.06 grub2-file
|
||||
14:17:46 cksum 4168 R 65536 128 1.01 grub2-fstest
|
||||
[...]
|
||||
```
|
||||
|
||||
This is a useful tool and an important example of BPF tracing. Traditional analysis of filesystem performance focuses on block I/O statistics—what you commonly see printed by the iostat(1) tool and plotted by many performance-monitoring GUIs. Those statistics show how the disks are performing, but not really the filesystem. Often you care more about the filesystem's performance than the disks, since it's the filesystem that applications make requests to and wait for. And the performance of filesystems can be quite different from that of disks! Filesystems may serve reads entirely from memory cache and also populate that cache via a read-ahead algorithm and for write-back caching. xfsslower shows filesystem performance—what the applications directly experience. This is often useful for exonerating the entire storage subsystem; if there is really no filesystem latency, then performance issues are likely to be elsewhere.
|
||||
|
||||
### 4\. biolatency
|
||||
|
||||
Although filesystem performance is important to study for understanding application performance, studying disk performance has merit as well. Poor disk performance will affect the application eventually, when various caching tricks can no longer hide its latency. Disk performance is also a target of study for capacity planning.
|
||||
|
||||
The iostat(1) tool shows the average disk I/O latency, but averages can be misleading. It can be useful to study the distribution of I/O latency as a histogram, which can be done using [biolatency][18]:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency
|
||||
Tracing block device I/O... Hit Ctrl-C to end.
|
||||
^C
|
||||
usecs : count distribution
|
||||
0 -> 1 : 0 | |
|
||||
2 -> 3 : 0 | |
|
||||
4 -> 7 : 0 | |
|
||||
8 -> 15 : 0 | |
|
||||
16 -> 31 : 0 | |
|
||||
32 -> 63 : 1 | |
|
||||
64 -> 127 : 63 |**** |
|
||||
128 -> 255 : 121 |********* |
|
||||
256 -> 511 : 483 |************************************ |
|
||||
512 -> 1023 : 532 |****************************************|
|
||||
1024 -> 2047 : 117 |******** |
|
||||
2048 -> 4095 : 8 | |
|
||||
```
|
||||
|
||||
It's worth noting that many of these tools support CLI options and arguments as shown by their USAGE message:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/biolatency -h
|
||||
usage: biolatency [-h] [-T] [-Q] [-m] [-D] [interval] [count]
|
||||
|
||||
Summarize block device I/O latency as a histogram
|
||||
|
||||
positional arguments:
|
||||
interval output interval, in seconds
|
||||
count number of outputs
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-T, --timestamp include timestamp on output
|
||||
-Q, --queued include OS queued time in I/O time
|
||||
-m, --milliseconds millisecond histogram
|
||||
-D, --disks print a histogram per disk device
|
||||
|
||||
examples:
|
||||
./biolatency # summarize block I/O latency as a histogram
|
||||
./biolatency 1 10 # print 1 second summaries, 10 times
|
||||
./biolatency -mT 1 # 1s summaries, milliseconds, and timestamps
|
||||
./biolatency -Q # include OS queued time in I/O time
|
||||
./biolatency -D # show each disk device separately
|
||||
```
|
||||
|
||||
### 5\. tcplife
|
||||
|
||||
Another useful tool and example, this time showing lifespan and throughput statistics of TCP sessions, is [tcplife][19]:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/tcplife
|
||||
PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS
|
||||
12759 sshd 192.168.56.101 22 192.168.56.1 60639 2 3 1863.82
|
||||
12783 sshd 192.168.56.101 22 192.168.56.1 60640 3 3 9174.53
|
||||
12844 wget 10.0.2.15 34250 54.204.39.132 443 11 1870 5712.26
|
||||
12851 curl 10.0.2.15 34252 54.204.39.132 443 0 74 505.90
|
||||
```
|
||||
|
||||
### 6\. gethostlatency
|
||||
|
||||
Every previous example involves kernel tracing, so I need at least one user-level tracing example. Here is [gethostlatency][20], which instruments gethostbyname(3) and related library calls for name resolution:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/gethostlatency
|
||||
TIME PID COMM LATms HOST
|
||||
06:43:33 12903 curl 188.98 opensource.com
|
||||
06:43:36 12905 curl 8.45 opensource.com
|
||||
06:43:40 12907 curl 6.55 opensource.com
|
||||
06:43:44 12911 curl 9.67 opensource.com
|
||||
06:45:02 12948 curl 19.66 opensource.cats
|
||||
06:45:06 12950 curl 18.37 opensource.cats
|
||||
06:45:07 12952 curl 13.64 opensource.cats
|
||||
06:45:19 13139 curl 13.10 opensource.cats
|
||||
```
|
||||
|
||||
### 7\. trace
|
||||
|
||||
Okay, one more example. The [trace][21] tool was contributed by Sasha Goldshtein and provides some basic printf(1) functionality with custom probes. For example:
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/trace 'pam:pam_start "%s: %s", arg1, arg2'
|
||||
PID TID COMM FUNC -
|
||||
13266 13266 sshd pam_start sshd: root
|
||||
```
|
||||
|
||||
### Install bcc via packages
|
||||
|
||||
The best way to install bcc is from an iovisor repository, following the instructions from the bcc [INSTALL.md][22]. [IO Visor][23] is the Linux Foundation project that includes bcc. The BPF enhancements these tools use were added in the 4.x series Linux kernels, up to 4.9\. This means that Fedora 25, with its 4.8 kernel, can run most of these tools; and Fedora 26, with its 4.11 kernel, can run them all (at least currently).
|
||||
|
||||
If you are on Fedora 25 (or Fedora 26, and this post was published many months ago—hello from the distant past!), then this package approach should just work. If you are on Fedora 26, then skip to the [Install via Source][24] section, which avoids a [known][25] and [fixed][26] bug. That bug fix hasn't made its way into the Fedora 26 package dependencies at the moment. The system I'm using is:
|
||||
|
||||
```
|
||||
# uname -a
|
||||
Linux localhost.localdomain 4.11.8-300.fc26.x86_64 #1 SMP Thu Jun 29 20:09:48 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
|
||||
# cat /etc/fedora-release
|
||||
Fedora release 26 (Twenty Six)
|
||||
```
|
||||
|
||||
```
|
||||
# echo -e '[iovisor]\nbaseurl=https://repo.iovisor.org/yum/nightly/f25/$basearch\nenabled=1\ngpgcheck=0' | sudo tee /etc/yum.repos.d/iovisor.repo
|
||||
# dnf install bcc-tools
|
||||
[...]
|
||||
Total download size: 37 M
|
||||
Installed size: 143 M
|
||||
Is this ok [y/N]: y
|
||||
```
|
||||
|
||||
```
|
||||
# ls /usr/share/bcc/tools/
|
||||
argdist dcsnoop killsnoop softirqs trace
|
||||
bashreadline dcstat llcstat solisten ttysnoop
|
||||
[...]
|
||||
```
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
chdir(/lib/modules/4.11.8-300.fc26.x86_64/build): No such file or directory
|
||||
Traceback (most recent call last):
|
||||
File "/usr/share/bcc/tools/opensnoop", line 126, in
|
||||
b = BPF(text=bpf_text)
|
||||
File "/usr/lib/python3.6/site-packages/bcc/__init__.py", line 284, in __init__
|
||||
raise Exception("Failed to compile BPF module %s" % src_file)
|
||||
Exception: Failed to compile BPF module
|
||||
```
|
||||
|
||||
```
|
||||
# dnf install kernel-devel-4.11.8-300.fc26.x86_64
|
||||
[...]
|
||||
Total download size: 20 M
|
||||
Installed size: 63 M
|
||||
Is this ok [y/N]: y
|
||||
[...]
|
||||
```
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
PID COMM FD ERR PATH
|
||||
11792 ls 3 0 /etc/ld.so.cache
|
||||
11792 ls 3 0 /lib64/libselinux.so.1
|
||||
11792 ls 3 0 /lib64/libcap.so.2
|
||||
11792 ls 3 0 /lib64/libc.so.6
|
||||
[...]
|
||||
```
|
||||
|
||||
### Install via source
|
||||
|
||||
If you need to install from source, you can also find documentation and updated instructions in [INSTALL.md][27]. I did the following on Fedora 26:
|
||||
|
||||
```
|
||||
sudo dnf install -y bison cmake ethtool flex git iperf libstdc++-static \
|
||||
python-netaddr python-pip gcc gcc-c++ make zlib-devel \
|
||||
elfutils-libelf-devel
|
||||
sudo dnf install -y luajit luajit-devel # for Lua support
|
||||
sudo dnf install -y \
|
||||
http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm
|
||||
sudo pip install pyroute2
|
||||
sudo dnf install -y clang clang-devel llvm llvm-devel llvm-static ncurses-devel
|
||||
```
|
||||
|
||||
```
|
||||
Curl error (28): Timeout was reached for http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm [Connection timed out after 120002 milliseconds]
|
||||
```
|
||||
|
||||
Here are the remaining bcc compilation and install steps:
|
||||
|
||||
```
|
||||
git clone https://github.com/iovisor/bcc.git
|
||||
mkdir bcc/build; cd bcc/build
|
||||
cmake .. -DCMAKE_INSTALL_PREFIX=/usr
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
|
||||
```
|
||||
# /usr/share/bcc/tools/opensnoop
|
||||
PID COMM FD ERR PATH
|
||||
4131 date 3 0 /etc/ld.so.cache
|
||||
4131 date 3 0 /lib64/libc.so.6
|
||||
4131 date 3 0 /usr/lib/locale/locale-archive
|
||||
4131 date 3 0 /etc/localtime
|
||||
[...]
|
||||
```
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
This was a quick tour of the new BPF performance analysis superpowers that you can use on the Fedora and Red Hat family of operating systems. I demonstrated the popular
|
||||
|
||||
[bcc][28]
|
||||
|
||||
frontend to BPF and included install instructions for Fedora. bcc comes with more than 60 new tools for performance analysis, which will help you get the most out of your Linux systems. Perhaps you will use these tools directly over SSH, or perhaps you will use the same functionality via monitoring GUIs once they support BPF.
|
||||
|
||||
Also, bcc is not the only frontend in development. There are [ply][29] and [bpftrace][30], which aim to provide higher-level language for quickly writing custom tools. In addition, [SystemTap][31] just released [version 3.2][32], including an early, experimental eBPF backend. Should this continue to be developed, it will provide a production-safe and efficient engine for running the many SystemTap scripts and tapsets (libraries) that have been developed over the years. (Using SystemTap with eBPF would be good topic for another post.)
|
||||
|
||||
If you need to develop custom tools, you can do that with bcc as well, although the language is currently much more verbose than SystemTap, ply, or bpftrace. My bcc tools can serve as code examples, plus I contributed a [tutorial][33] for developing bcc tools in Python. I'd recommend learning the bcc multi-tools first, as you may get a lot of mileage from them before needing to write new tools. You can study the multi-tools from their example files in the bcc repository: [funccount][34], [funclatency][35], [funcslower][36], [stackcount][37], [trace][38], and [argdist][39].
|
||||
|
||||
Thanks to [Opensource.com][40] for edits.
|
||||
|
||||
### Topics
|
||||
|
||||
[Linux][41][SysAdmin][42]
|
||||
|
||||
### About the author
|
||||
|
||||
[][43] Brendan Gregg
|
||||
|
||||
-
|
||||
|
||||
Brendan Gregg is a senior performance architect at Netflix, where he does large scale computer performance design, analysis, and tuning.[More about me][44]
|
||||
|
||||
* [Learn how you can contribute][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://opensource.com/article/17/11/bccbpf-performance
|
||||
|
||||
作者:[Brendan Gregg ][a]
|
||||
译者:[yongshouzhang](https://github.com/yongshouzhang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/participate
|
||||
[7]:https://opensource.com/users/brendang
|
||||
[8]:https://opensource.com/users/brendang
|
||||
[9]:https://opensource.com/user/77626/feed
|
||||
[10]:https://opensource.com/article/17/11/bccbpf-performance?rate=r9hnbg3mvjFUC9FiBk9eL_ZLkioSC21SvICoaoJjaSM
|
||||
[11]:https://opensource.com/article/17/11/bccbpf-performance#comments
|
||||
[12]:https://github.com/iovisor/bcc
|
||||
[13]:https://opensource.com/file/376856
|
||||
[14]:https://opensource.com/usr/share/bcc/tools/trace
|
||||
[15]:https://github.com/brendangregg/perf-tools/blob/master/execsnoop
|
||||
[16]:https://github.com/brendangregg/perf-tools/blob/master/opensnoop
|
||||
[17]:https://github.com/iovisor/bcc/blob/master/tools/xfsslower.py
|
||||
[18]:https://github.com/iovisor/bcc/blob/master/tools/biolatency.py
|
||||
[19]:https://github.com/iovisor/bcc/blob/master/tools/tcplife.py
|
||||
[20]:https://github.com/iovisor/bcc/blob/master/tools/gethostlatency.py
|
||||
[21]:https://github.com/iovisor/bcc/blob/master/tools/trace.py
|
||||
[22]:https://github.com/iovisor/bcc/blob/master/INSTALL.md#fedora---binary
|
||||
[23]:https://www.iovisor.org/
|
||||
[24]:https://opensource.com/article/17/11/bccbpf-performance#InstallViaSource
|
||||
[25]:https://github.com/iovisor/bcc/issues/1221
|
||||
[26]:https://reviews.llvm.org/rL302055
|
||||
[27]:https://github.com/iovisor/bcc/blob/master/INSTALL.md#fedora---source
|
||||
[28]:https://github.com/iovisor/bcc
|
||||
[29]:https://github.com/iovisor/ply
|
||||
[30]:https://github.com/ajor/bpftrace
|
||||
[31]:https://sourceware.org/systemtap/
|
||||
[32]:https://sourceware.org/ml/systemtap/2017-q4/msg00096.html
|
||||
[33]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[34]:https://github.com/iovisor/bcc/blob/master/tools/funccount_example.txt
|
||||
[35]:https://github.com/iovisor/bcc/blob/master/tools/funclatency_example.txt
|
||||
[36]:https://github.com/iovisor/bcc/blob/master/tools/funcslower_example.txt
|
||||
[37]:https://github.com/iovisor/bcc/blob/master/tools/stackcount_example.txt
|
||||
[38]:https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt
|
||||
[39]:https://github.com/iovisor/bcc/blob/master/tools/argdist_example.txt
|
||||
[40]:http://opensource.com/
|
||||
[41]:https://opensource.com/tags/linux
|
||||
[42]:https://opensource.com/tags/sysadmin
|
||||
[43]:https://opensource.com/users/brendang
|
||||
[44]:https://opensource.com/users/brendang
|
||||
@ -0,0 +1,197 @@
|
||||
translating---geekpi
|
||||
|
||||
Cheat – A Collection Of Practical Linux Command Examples
|
||||
======
|
||||
Many of us very often checks **[Man Pages][1]** to know about command switches
|
||||
(options), it shows you the details about command syntax, description,
|
||||
details, and available switches but it doesn 't has any practical examples.
|
||||
Hence, we are face some trouble to form a exact command format which we need.
|
||||
|
||||
Are you really facing the trouble on this and want a better solution? i would
|
||||
advise you to check about cheat utility.
|
||||
|
||||
#### What Is Cheat
|
||||
|
||||
[Cheat][2] allows you to create and view interactive cheatsheets on the
|
||||
command-line. It was designed to help remind *nix system administrators of
|
||||
options for commands that they use frequently, but not frequently enough to
|
||||
remember.
|
||||
|
||||
#### How to Install Cheat
|
||||
|
||||
Cheat package was developed using python, so install pip package to install
|
||||
cheat on your system.
|
||||
|
||||
For **`Debian/Ubuntu`** , use [apt-get command][3] or [apt command][4] to
|
||||
install pip.
|
||||
|
||||
```
|
||||
|
||||
[For Python2]
|
||||
|
||||
|
||||
$ sudo apt install python-pip python-setuptools
|
||||
|
||||
|
||||
|
||||
[For Python3]
|
||||
|
||||
|
||||
$ sudo apt install python3-pip
|
||||
|
||||
```
|
||||
|
||||
pip doesn't shipped with **`RHEL/CentOS`** system official repository so,
|
||||
enable [EPEL Repository][5] and use [YUM command][6] to install pip.
|
||||
|
||||
```
|
||||
|
||||
$ sudo yum install python-pip python-devel python-setuptools
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** system, use [dnf Command][7] to install pip.
|
||||
|
||||
```
|
||||
|
||||
[For Python2]
|
||||
|
||||
|
||||
$ sudo dnf install python-pip
|
||||
|
||||
|
||||
|
||||
[For Python3]
|
||||
|
||||
|
||||
$ sudo dnf install python3
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use [Pacman Command][8] to install pip.
|
||||
|
||||
```
|
||||
|
||||
[For Python2]
|
||||
|
||||
|
||||
$ sudo pacman -S python2-pip python-setuptools
|
||||
|
||||
|
||||
|
||||
[For Python3]
|
||||
|
||||
|
||||
$ sudo pacman -S python-pip python3-setuptools
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** system, use [Zypper Command][9] to install pip.
|
||||
|
||||
```
|
||||
|
||||
[For Python2]
|
||||
|
||||
|
||||
$ sudo pacman -S python-pip
|
||||
|
||||
|
||||
|
||||
[For Python3]
|
||||
|
||||
|
||||
$ sudo pacman -S python3-pip
|
||||
|
||||
```
|
||||
|
||||
pip is a python module bundled with setuptools, it's one of the recommended
|
||||
tool for installing Python packages in Linux.
|
||||
|
||||
```
|
||||
|
||||
$ sudo pip install cheat
|
||||
|
||||
```
|
||||
|
||||
#### How to Use Cheat
|
||||
|
||||
Run `cheat` followed by corresponding `command` to view the cheatsheet, For
|
||||
demonstration purpose, we are going to check about `tar` command examples.
|
||||
|
||||
```
|
||||
|
||||
$ cheat tar
|
||||
# To extract an uncompressed archive:
|
||||
tar -xvf /path/to/foo.tar
|
||||
|
||||
# To create an uncompressed archive:
|
||||
tar -cvf /path/to/foo.tar /path/to/foo/
|
||||
|
||||
# To extract a .gz archive:
|
||||
tar -xzvf /path/to/foo.tgz
|
||||
|
||||
# To create a .gz archive:
|
||||
tar -czvf /path/to/foo.tgz /path/to/foo/
|
||||
|
||||
# To list the content of an .gz archive:
|
||||
tar -ztvf /path/to/foo.tgz
|
||||
|
||||
# To extract a .bz2 archive:
|
||||
tar -xjvf /path/to/foo.tgz
|
||||
|
||||
# To create a .bz2 archive:
|
||||
tar -cjvf /path/to/foo.tgz /path/to/foo/
|
||||
|
||||
# To extract a .tar in specified Directory:
|
||||
tar -xvf /path/to/foo.tar -C /path/to/destination/
|
||||
|
||||
# To list the content of an .bz2 archive:
|
||||
tar -jtvf /path/to/foo.tgz
|
||||
|
||||
# To create a .gz archive and exclude all jpg,gif,... from the tgz
|
||||
tar czvf /path/to/foo.tgz --exclude=\*.{jpg,gif,png,wmv,flv,tar.gz,zip} /path/to/foo/
|
||||
|
||||
# To use parallel (multi-threaded) implementation of compression algorithms:
|
||||
tar -z ... -> tar -Ipigz ...
|
||||
tar -j ... -> tar -Ipbzip2 ...
|
||||
tar -J ... -> tar -Ipixz ...
|
||||
|
||||
```
|
||||
|
||||
Run the following command to see what cheatsheets are available.
|
||||
|
||||
```
|
||||
|
||||
$ cheat -l
|
||||
|
||||
```
|
||||
|
||||
Navigate to help page for more details.
|
||||
|
||||
```
|
||||
|
||||
$ cheat -h
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/cheat-a-collection-of-practical-linux-command-examples/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com
|
||||
[1]:https://www.2daygeek.com/linux-color-man-pages-configuration-less-most-command/
|
||||
[2]:https://github.com/chrisallenlane/cheat
|
||||
[3]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]:https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||
[6]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[7]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[8]:https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[9]:https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,171 @@
|
||||
How To Find Files Based On their Permissions
|
||||
======
|
||||
Finding files in Linux is not a big deal. There are plenty of free and open source graphical utilities available on the market. In my opinion, finding files from command line is much easier and faster. We already knew how to [**find and sort files based on access and modification date and time**][1]. Today, we will see how to find files based on their permissions in Unix-like operating systems.
|
||||
|
||||
For the purpose of this guide, I am going to create three files namely **file1** , **file2** and **file3** with permissions **777** , **766** , **655** respectively in a folder named **ostechnix**.
|
||||
```
|
||||
mkdir ostechnix && cd ostechnix/
|
||||
```
|
||||
```
|
||||
install -b -m 777 /dev/null file1
|
||||
```
|
||||
```
|
||||
install -b -m 766 /dev/null file2
|
||||
```
|
||||
```
|
||||
install -b -m 655 /dev/null file3
|
||||
```
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
Now let us find the files based on their permissions.
|
||||
|
||||
### Find files Based On their Permissions
|
||||
|
||||
The typical syntax to find files based on their permissions is:
|
||||
```
|
||||
find -perm mode
|
||||
```
|
||||
|
||||
The MODE can be either with numeric or octal permission (like 777, 666.. etc) or symbolic permission (like u=x, a=r+x).
|
||||
|
||||
Before going further, we can specify the MODE in three different ways.
|
||||
|
||||
1. If we specify the mode without any prefixes, it will find files of **exact** permissions.
|
||||
2. If we use **" -"** prefix with mode, at least the files should have the given permission, not the exact permission.
|
||||
3. If we use **" /"** prefix, either the owner, the group, or other should have permission to the file.
|
||||
|
||||
|
||||
|
||||
Allow me to explain with some examples, so you can understand better.
|
||||
|
||||
First, we will see finding files based on numeric permissions.
|
||||
|
||||
### Find Files Based On their Numeric (octal) Permissions
|
||||
|
||||
Now let me run the following command:
|
||||
```
|
||||
find -perm 777
|
||||
```
|
||||
|
||||
This command will find the files with permission of **exactly 777** in the current directory.
|
||||
|
||||
[![][2]][4]
|
||||
|
||||
As you see in the above output, file1 is the only one that has **exact 777 permission**.
|
||||
|
||||
Now, let us use "-" prefix and see what happens.
|
||||
```
|
||||
find -perm -766
|
||||
```
|
||||
|
||||
[![][2]][5]
|
||||
|
||||
As you see, the above command displays two files. We have set 766 permission to file2, but this command displays two files, why? Because, here we have used "-" prefix". It means that this command will find all files where the file owner has read/write/execute permissions, file group members have read/write permissions and everything else has also read/write permission. In our case, file1 and file2 have met this criteria. In other words, the files need not to have exact 766 permission. It will display any files that falls under this 766 permission.
|
||||
|
||||
Next, we will use "/" prefix and see what happens.
|
||||
```
|
||||
find -perm /222
|
||||
```
|
||||
|
||||
[![][2]][6]
|
||||
|
||||
The above command will find files which are writable by somebody (either their owner, or their group, or anybody else). Here is another example.
|
||||
```
|
||||
find -perm /220
|
||||
```
|
||||
|
||||
This command will find files which are writable by either their owner or their group. That means the files **don 't have to be writable** by **both the owner and group** to be matched; **either** will do.
|
||||
|
||||
But if you run the same command with "-" prefix, you will only see the files only which are writable by both owner and group.
|
||||
```
|
||||
find -perm -220
|
||||
```
|
||||
|
||||
The following screenshot will show you the difference between these two prefixes.
|
||||
|
||||
[![][2]][7]
|
||||
|
||||
Like I already said, we can also use symbolic notation to represent the file permissions.
|
||||
|
||||
Also read:
|
||||
|
||||
### Find Files Based On their Permissions using symbolic notation
|
||||
|
||||
In the following examples, we use symbolic notations such as **u** ( for user), **g** (group), **o** (others). We can also use the letter **a** to represent all three of these categories. The permissions can be specified using letters **r** (read), **w** (write), **x** (executable).
|
||||
|
||||
For instance, to find any file with group **write** permission, run:
|
||||
```
|
||||
find -perm -g=w
|
||||
```
|
||||
|
||||
[![][2]][8]
|
||||
|
||||
As you see in the above example, file1 and file2 have group **write** permission. Please note that you can use either "=" or "+" for symbolic notation. It doesn't matter. For example, the following two commands do the same thing.
|
||||
```
|
||||
find -perm -g=w
|
||||
find -perm -g+w
|
||||
```
|
||||
|
||||
To find any file which are writable by the file owner, run:
|
||||
```
|
||||
find -perm -u=w
|
||||
```
|
||||
|
||||
To find any file which are writable by all (the file owner, group and everyone else), run:
|
||||
```
|
||||
find -perm -a=w
|
||||
```
|
||||
|
||||
To find files which are writable by **both** their **owner** and their **group** , use this command:
|
||||
```
|
||||
find -perm -g+w,u+w
|
||||
```
|
||||
|
||||
The above command is equivalent of "find -perm -220" command.
|
||||
|
||||
To find files which are writable by **either** their **owner** or their **group** , run:
|
||||
```
|
||||
find -perm /u+w,g+w
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
find -perm /u=w,g=w
|
||||
```
|
||||
|
||||
These two commands does the same job as "find -perm /220" command.
|
||||
|
||||
For more details, refer the man pages.
|
||||
```
|
||||
man find
|
||||
```
|
||||
|
||||
Also, check the [**man pages alternatives**][9] to learn more simplified examples of any Linux command.
|
||||
|
||||
And, that's all for now folks. I hope this guide was useful. More good stuffs to come. Stay tuned.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-files-based-permissions/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1] https://www.ostechnix.com/find-sort-files-based-access-modification-date-time-linux/
|
||||
[2] data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-1-1.png ()
|
||||
[4] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-2.png ()
|
||||
[5] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-3.png ()
|
||||
[6] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-6.png ()
|
||||
[7] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-7.png ()
|
||||
[8] http://www.ostechnix.com/wp-content/uploads/2017/12/find-files-8.png ()
|
||||
[9] https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
@ -0,0 +1,233 @@
|
||||
How to use KVM cloud images on Ubuntu Linux
|
||||
======
|
||||
|
||||
Kernel-based Virtual Machine (KVM) is a virtualization module for the Linux kernel that turns it into a hypervisor. You can create an Ubuntu cloud image with KVM from the command line using Ubuntu virtualisation front-end for libvirt and KVM.
|
||||
|
||||
How do I download and use a cloud image with kvm running on an Ubuntu Linux server? How do I create create a virtual machine without the need of a complete installation on an Ubuntu Linux 16.04 LTS server?Kernel-based Virtual Machine (KVM) is a virtualization module for the Linux kernel that turns it into a hypervisor. You can create an Ubuntu cloud image with KVM from the command line using Ubuntu virtualisation front-end for libvirt and KVM.
|
||||
|
||||
This quick tutorial shows to install and use uvtool that provides a unified and integrated VM front-end to Ubuntu cloud image downloads, libvirt, and cloud-init.
|
||||
|
||||
### Step 1 - Install KVM
|
||||
|
||||
You must have kvm installed and configured. Use the [apt command][1]/[apt-get command][2] as follows:
|
||||
```
|
||||
$ sudo apt install qemu-kvm libvirt-bin virtinst bridge-utils cpu-checker
|
||||
$ kvm-ok
|
||||
## [configure bridged networking as described here][3]
|
||||
$ sudo vi /etc/network/interfaces
|
||||
$ sudo systemctl restart networking
|
||||
$ sudo brctl show
|
||||
```
|
||||
See "[How to install KVM on Ubuntu 16.04 LTS Headless Server][4]" for more info.
|
||||
|
||||
### Step 2 - Install uvtool
|
||||
|
||||
Type the following [apt command][1]/[apt-get command][2]:
|
||||
```
|
||||
$ sudo apt install uvtool
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
[sudo] password for vivek:
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following packages were automatically installed and are no longer required:
|
||||
gksu libgksu2-0 libqt5designer5 libqt5help5 libqt5printsupport5 libqt5sql5 libqt5sql5-sqlite libqt5xml5 python3-dbus.mainloop.pyqt5 python3-notify2 python3-pyqt5 python3-sip
|
||||
Use 'sudo apt autoremove' to remove them.
|
||||
The following additional packages will be installed:
|
||||
cloud-image-utils distro-info python-boto python-pyinotify python-simplestreams socat ubuntu-cloudimage-keyring uvtool-libvirt
|
||||
Suggested packages:
|
||||
cloud-utils-euca shunit2 python-pyinotify-doc
|
||||
The following NEW packages will be installed:
|
||||
cloud-image-utils distro-info python-boto python-pyinotify python-simplestreams socat ubuntu-cloudimage-keyring uvtool uvtool-libvirt
|
||||
0 upgraded, 9 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 1,211 kB of archives.
|
||||
After this operation, 6,876 kB of additional disk space will be used.
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu artful/main amd64 distro-info amd64 0.17 [20.3 kB]
|
||||
Get:2 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 python-boto all 2.44.0-1ubuntu2 [740 kB]
|
||||
Get:3 http://in.archive.ubuntu.com/ubuntu artful/main amd64 python-pyinotify all 0.9.6-1 [24.6 kB]
|
||||
Get:4 http://in.archive.ubuntu.com/ubuntu artful/main amd64 ubuntu-cloudimage-keyring all 2013.11.11 [4,504 B]
|
||||
Get:5 http://in.archive.ubuntu.com/ubuntu artful/main amd64 cloud-image-utils all 0.30-0ubuntu2 [17.2 kB]
|
||||
Get:6 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 python-simplestreams all 0.1.0~bzr450-0ubuntu1 [29.7 kB]
|
||||
Get:7 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 socat amd64 1.7.3.2-1 [342 kB]
|
||||
Get:8 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 uvtool all 0~git122-0ubuntu1 [6,498 B]
|
||||
Get:9 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 uvtool-libvirt all 0~git122-0ubuntu1 [26.9 kB]
|
||||
Fetched 1,211 kB in 3s (393 kB/s)
|
||||
Selecting previously unselected package distro-info.
|
||||
(Reading database ... 199933 files and directories currently installed.)
|
||||
Preparing to unpack .../0-distro-info_0.17_amd64.deb ...
|
||||
Unpacking distro-info (0.17) ...
|
||||
Selecting previously unselected package python-boto.
|
||||
Preparing to unpack .../1-python-boto_2.44.0-1ubuntu2_all.deb ...
|
||||
Unpacking python-boto (2.44.0-1ubuntu2) ...
|
||||
Selecting previously unselected package python-pyinotify.
|
||||
Preparing to unpack .../2-python-pyinotify_0.9.6-1_all.deb ...
|
||||
Unpacking python-pyinotify (0.9.6-1) ...
|
||||
Selecting previously unselected package ubuntu-cloudimage-keyring.
|
||||
Preparing to unpack .../3-ubuntu-cloudimage-keyring_2013.11.11_all.deb ...
|
||||
Unpacking ubuntu-cloudimage-keyring (2013.11.11) ...
|
||||
Selecting previously unselected package cloud-image-utils.
|
||||
Preparing to unpack .../4-cloud-image-utils_0.30-0ubuntu2_all.deb ...
|
||||
Unpacking cloud-image-utils (0.30-0ubuntu2) ...
|
||||
Selecting previously unselected package python-simplestreams.
|
||||
Preparing to unpack .../5-python-simplestreams_0.1.0~bzr450-0ubuntu1_all.deb ...
|
||||
Unpacking python-simplestreams (0.1.0~bzr450-0ubuntu1) ...
|
||||
Selecting previously unselected package socat.
|
||||
Preparing to unpack .../6-socat_1.7.3.2-1_amd64.deb ...
|
||||
Unpacking socat (1.7.3.2-1) ...
|
||||
Selecting previously unselected package uvtool.
|
||||
Preparing to unpack .../7-uvtool_0~git122-0ubuntu1_all.deb ...
|
||||
Unpacking uvtool (0~git122-0ubuntu1) ...
|
||||
Selecting previously unselected package uvtool-libvirt.
|
||||
Preparing to unpack .../8-uvtool-libvirt_0~git122-0ubuntu1_all.deb ...
|
||||
Unpacking uvtool-libvirt (0~git122-0ubuntu1) ...
|
||||
Setting up distro-info (0.17) ...
|
||||
Setting up ubuntu-cloudimage-keyring (2013.11.11) ...
|
||||
Setting up cloud-image-utils (0.30-0ubuntu2) ...
|
||||
Setting up socat (1.7.3.2-1) ...
|
||||
Setting up python-pyinotify (0.9.6-1) ...
|
||||
Setting up python-boto (2.44.0-1ubuntu2) ...
|
||||
Setting up python-simplestreams (0.1.0~bzr450-0ubuntu1) ...
|
||||
Processing triggers for doc-base (0.10.7) ...
|
||||
Processing 1 added doc-base file...
|
||||
Setting up uvtool (0~git122-0ubuntu1) ...
|
||||
Processing triggers for man-db (2.7.6.1-2) ...
|
||||
Setting up uvtool-libvirt (0~git122-0ubuntu1) ...
|
||||
```
|
||||
|
||||
|
||||
### Step 3 - Download the Ubuntu Cloud image
|
||||
|
||||
You need to use the uvt-simplestreams-libvirt command. It maintains a libvirt volume storage pool as a local mirror of a subset of images available from a simplestreams source, such as Ubuntu cloud images. To update uvtool's libvirt volume storage pool with all current amd64 images, run:
|
||||
`$ uvt-simplestreams-libvirt sync arch=amd64`
|
||||
To just update/grab Ubuntu 16.04 LTS (xenial/amd64) image run:
|
||||
`$ uvt-simplestreams-libvirt --verbose sync release=xenial arch=amd64`
|
||||
Sample outputs:
|
||||
```
|
||||
Adding: com.ubuntu.cloud:server:16.04:amd64 20171121.1
|
||||
```
|
||||
|
||||
Pass the query option to queries the local mirror:
|
||||
`$ uvt-simplestreams-libvirt query`
|
||||
Sample outputs:
|
||||
```
|
||||
release=xenial arch=amd64 label=release (20171121.1)
|
||||
```
|
||||
|
||||
Now, I have an image for Ubuntu xenial and I create the VM.
|
||||
|
||||
### Step 4 - Create the SSH keys
|
||||
|
||||
You need ssh keys for login into KVM VMs. Use the ssh-keygen command to create a new one if you do not have any keys at all.
|
||||
`$ ssh-keygen`
|
||||
See "[How To Setup SSH Keys on a Linux / Unix System][5]" and "[Linux / UNIX: Generate SSH Keys][6]" for more info.
|
||||
|
||||
### Step 5 - Create the VM
|
||||
|
||||
It is time to create the VM named vm1 i.e. create an Ubuntu Linux 16.04 LTS VM:
|
||||
`$ uvt-kvm create vm1`
|
||||
By default vm1 created using the following characteristics:
|
||||
|
||||
1. RAM/memory : 512M
|
||||
2. Disk size: 8GiB
|
||||
3. CPU: 1 vCPU core
|
||||
|
||||
|
||||
|
||||
To control ram, disk, cpu, and other characteristics use the following syntax:
|
||||
`$ uvt-kvm create vm1 \
|
||||
--memory MEMORY \
|
||||
--cpu CPU \
|
||||
--disk DISK \
|
||||
--bridge BRIDGE \
|
||||
--ssh-public-key-file /path/to/your/SSH_PUBLIC_KEY_FILE \
|
||||
--packages PACKAGES1, PACKAGES2, .. \
|
||||
--run-script-once RUN_SCRIPT_ONCE \
|
||||
--password PASSWORD
|
||||
`
|
||||
Where,
|
||||
|
||||
1. **\--password PASSWORD** : Set the password for the ubuntu user and allow login using the ubuntu user (not recommended use ssh keys).
|
||||
2. **\--run-script-once RUN_SCRIPT_ONCE** : Run RUN_SCRIPT_ONCE script as root on the VM the first time it is booted, but never again. Give full path here. This is useful to run custom task on VM such as setting up security or other stuff.
|
||||
3. **\--packages PACKAGES1, PACKAGES2, ..** : Install the comma-separated packages on first boot.
|
||||
|
||||
|
||||
|
||||
To get help, run:
|
||||
```
|
||||
$ uvt-kvm -h
|
||||
$ uvt-kvm create -h
|
||||
```
|
||||
|
||||
#### How do I delete my VM?
|
||||
|
||||
To destroy/delete your VM named vm1, run (please use the following command with care as there would be no confirmation box):
|
||||
`$ uvt-kvm destroy vm1`
|
||||
|
||||
#### To find out the IP address of the vm1, run:
|
||||
|
||||
`$ uvt-kvm ip vm1`
|
||||
192.168.122.52
|
||||
|
||||
#### To list all VMs run
|
||||
|
||||
`$ uvt-kvm list`
|
||||
Sample outputs:
|
||||
```
|
||||
vm1
|
||||
freebsd11.1
|
||||
|
||||
```
|
||||
|
||||
### Step 6 - How to login to the vm named vm1
|
||||
|
||||
The syntax is:
|
||||
`$ uvt-kvm ssh vm1`
|
||||
Sample outputs:
|
||||
```
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-101-generic x86_64)
|
||||
|
||||
comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md Documentation: https://help.ubuntu.com
|
||||
comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md Management: https://landscape.canonical.com
|
||||
comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md Support: https://ubuntu.com/advantage
|
||||
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
|
||||
0 packages can be updated.
|
||||
0 updates are security updates.
|
||||
|
||||
|
||||
Last login: Thu Dec 7 09:55:06 2017 from 192.168.122.1
|
||||
|
||||
```
|
||||
|
||||
Another option is to use the regular ssh command from macOS/Linux/Unix/Windows client:
|
||||
`$ ssh [[email protected]][7]
|
||||
$ ssh -i ~/.ssh/id_rsa [[email protected]][7]`
|
||||
Sample outputs:
|
||||
[![Connect to the running VM using ssh][8]][8]
|
||||
Once vim created you can use the virsh command as usual:
|
||||
`$ virsh list`
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-use-kvm-cloud-images-on-ubuntu-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/faq/how-to-create-bridge-interface-ubuntu-linux/
|
||||
[4]:https://www.cyberciti.biz/faq/installing-kvm-on-ubuntu-16-04-lts-server/
|
||||
[5]:https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-generating-ssh-keys/
|
||||
[7]:https://www.cyberciti.biz/cdn-cgi/l/email-protection
|
||||
[8]:https://www.cyberciti.biz/media/new/faq/2017/12/connect-to-the-running-VM-using-ssh.jpg
|
||||
@ -0,0 +1,251 @@
|
||||
24 Must Have Essential Linux Applications In 2017
|
||||
======
|
||||
Brief: What are the must have applications for Linux? The answer is subjective and it depends on for what purpose do you use your desktop Linux. But there are still some essentials Linux apps that are more likely to be used by most Linux user. We have listed such best Linux applications that you should have installed in every Linux distribution you use.
|
||||
|
||||
The world of Linux, everything is full of alternatives. You have to choose a distro? You have got several dozens of them. Are you trying to find a decent music player? Alternatives are there too.
|
||||
|
||||
But not all of them are built with the same thing in mind – some of them might target minimalism while others might offer tons of features. Finding the right application for your needs can be quite confusing and a tiresome task. Let’s make that a bit easier.
|
||||
|
||||
### Best free applications for Linux users
|
||||
|
||||
I’m putting together a list of essential free Linux applications I prefer to use in different categories. I’m not saying that they are the best, but I have tried lots of applications in each category and finally liked the listed ones better. So, you are more than welcome to mention your favorite applications in the comment section.
|
||||
|
||||
We have also compiled a nice video of this list. Do subscribe to our YouTube channel for more such educational Linux videos:
|
||||
|
||||
### Web Browser
|
||||
|
||||

|
||||
[Save][1]Web Browsers
|
||||
|
||||
#### [Google Chrome][12]
|
||||
|
||||
Google Chrome is a powerful and complete solution for a web browser. It comes with excellent syncing capabilities and offers a vast collection of extensions. If you are accustomed to Google eco-system Google Chrome is for you without any doubt. If you prefer a more open source solution, you may want to try out [Chromium][13], which is the project Google Chrome is based on.
|
||||
|
||||
#### [Firefox][14]
|
||||
|
||||
If you are not a fan of Google Chrome, you can try out Firefox. It’s been around for a long time and is a very stable and robust web browser.
|
||||
|
||||
#### [Vivaldi][15]
|
||||
|
||||
However, if you want something new and different, you can check out Vivaldi. Vivaldi takes a completely fresh approach towards web browser. It’s from former team members of Opera and built on top of the Chromium project. It’s lightweight and customizable. Though it is still quite new and still missing out some features, it feels amazingly refreshing and does a really decent job.
|
||||
|
||||
[Suggested read[Review] Otter Browser Brings Hope To Opera Lovers][40]
|
||||
|
||||
### Download Manager
|
||||
|
||||

|
||||
[Save][2]Download Managers
|
||||
|
||||
#### [uGet][16]
|
||||
|
||||
uGet is the best download manager I have come across. It is open source and offers everything you can expect from a download manager. uGet offers advanced settings for managing downloads. It can queue and resume downloads, use multiple connections for downloading large files, download files to different directories according to categories and so on.
|
||||
|
||||
#### [XDM][17]
|
||||
|
||||
Xtreme Download Manager (XDM) is a powerful and open source tool developed with Java. It has all the basic features of a download manager, including – video grabber, smart scheduler and browser integration.
|
||||
|
||||
[Suggested read4 Best Download Managers For Linux][41]
|
||||
|
||||
### BitTorrent Client
|
||||
|
||||

|
||||
[Save][3]BitTorrent Clients
|
||||
|
||||
#### [Deluge][18]
|
||||
|
||||
Deluge is a open source BitTorrent client. It has a beautiful user interface. If you are used to using uTorrent for Windows, Deluge interface will feel familiar. It has various configuration options as well as plugins support for various tasks.
|
||||
|
||||
#### [Transmission][19]
|
||||
|
||||
Transmission takes the minimal approach. It is an open source BitTorrent client with a minimal user interface. Transmission comes pre-installed with many Linux distributions.
|
||||
|
||||
[Suggested readTop 5 Torrent Clients For Ubuntu Linux][42]
|
||||
|
||||
### Cloud Storage
|
||||
|
||||

|
||||
[Save][4]Cloud Storages
|
||||
|
||||
#### [Dropbox][20]
|
||||
|
||||
Dropbox is one of the most popular cloud storage service available out there. It gives you 2GB free storage to start with. Dropbox has a robust and straight-forward Linux client.
|
||||
|
||||
#### [MEGA][21]
|
||||
|
||||
MEGA offers 50GB of free storage. But that is not the best thing about it. The best thing about MEGA is that it has end-to-end encryption support for your files. MEGA has a solid Linux client named MEGAsync.
|
||||
|
||||
[Suggested readBest Free Cloud Services For Linux in 2017][43]
|
||||
|
||||
### Communication
|
||||
|
||||

|
||||
[Save][5]Communication Apps
|
||||
|
||||
#### [Pidgin][22]
|
||||
|
||||
Pidgin is an open source instant messenger client. It supports many chatting platforms including – Google Talk, Yahoo and even IRC. Pidgin is extensible through third-party plugins, that can provide a lot of additional functionalities to Pidgin.
|
||||
|
||||
You can also use [Franz][23] or [Rambox][24] to use several messaging services in one application.
|
||||
|
||||
#### [Skype][25]
|
||||
|
||||
We all know Skype, it is one of the most popular video chatting platforms. Recently it has [released a brand new desktop client][26] for Linux.
|
||||
|
||||
[Suggested read6 Best Messaging Apps Available For Linux In 2017][44]
|
||||
|
||||
### Office Suite
|
||||
|
||||

|
||||
[Save][6]Office Suites
|
||||
|
||||
#### [LibreOffice][27]
|
||||
|
||||
LibreOffice is the most actively developed open source office suite for Linux. It has mainly six modules – Writer, Calc, Impress, Draw, Math and Base. And every one of them supports a wide range of file formats. LibreOffice also supports third-party extensions. It is the default office suite for many of the Linux distributions.
|
||||
|
||||
#### [WPS Office][28]
|
||||
|
||||
If you want to try out something other than LibreOffice, WPS Office might be your go-to. WPS Office suite includes writer, presentation and spreadsheets support.
|
||||
|
||||
[Suggested read6 Best Open Source Alternatives to Microsoft Office for Linux][45]
|
||||
|
||||
### Music Player
|
||||
|
||||

|
||||
[Save][7]Music Players
|
||||
|
||||
#### [Lollypop][29]
|
||||
|
||||
This is a relatively new music player. Lollypop is open source and has a beautiful yet simple user interface. It offers a nice music organizer, scrobbling support, online radio and a party mode. Though it is a simple music player without so many advanced features, it is worth giving it a try.
|
||||
|
||||
#### [Rhythmbox][30]
|
||||
|
||||
Rhythmbox is the music player mainly developed for GNOME desktop environment but it works on other desktop environments as well. It does all the basic tasks of a music player, including – CD Ripping & Burning, scribbling etc. It also has support for iPod.
|
||||
|
||||
#### [cmus][31]
|
||||
|
||||
If you want minimalism and love your terminal window, cmus is for you. Personally, I’m a fan and user of this one. cmus is a small, fast and powerful console music player for Unix-like operating systems. It has all the basic music player features. And you can also extend its functionalities with additional extensions and scripts.
|
||||
|
||||
[Suggested readHow To Install Tomahawk Player In Ubuntu 14.04 And Linux Mint 17][46]
|
||||
|
||||
### Video Player
|
||||
|
||||

|
||||
[Save][8]Video Players
|
||||
|
||||
#### [VLC][32]
|
||||
|
||||
VLC is an open source media player. It is simple, fast, lightweight and really powerful. VLC can play almost any media formats you can throw at it out-of-the-box. It can also stream online medias. It also have some nifty extensions for various tasks like downloading subtitles right from the player.
|
||||
|
||||
#### [Kodi][33]
|
||||
|
||||
Kodi is a full-fledged media center. Kodi is open source and very popular among its user base. It can handle videos, music, pictures, podcasts and even games, from both local and network media storage. You can even record TV with it. The behavior of Kodi can be customized via add-ons and skins.
|
||||
|
||||
[Suggested read4 Format Factory Alternative In Linux][47]
|
||||
|
||||
### Photo Editor
|
||||
|
||||

|
||||
[Save][9]Photo Editors
|
||||
|
||||
#### [GIMP][34]
|
||||
|
||||
GIMP is the Photoshop alternative for Linux. It is open source, full-featured and professional photo editing software. It is packed with a wide range of tools for manipulating images. And on top of that, there is various customization options and third-party plugins for enhancing the experience.
|
||||
|
||||
#### [Krita][35]
|
||||
|
||||
Krita is mainly a painting tool but serves as a photo editing application as well. It is open source and packed with lots of sophisticated and advanced tools.
|
||||
|
||||
[Suggested readBest Photo Applications For Linux][48]
|
||||
|
||||
### Text Editor
|
||||
|
||||
Every Linux distribution comes with their own solution for text editors. Generally, they are quite simple and without much functionality. But here are some text editors with enhanced capabilities.
|
||||
|
||||

|
||||
[Save][10]Text Editors
|
||||
|
||||
#### [Atom][36]
|
||||
|
||||
Atom is the modern and hackable text editor maintained by GitHub. It is completely open-source and offers everything you can think of to get out of a text editor. You can use it right out-of-the-box or you can customize and tune it just the way you want. And it has a ton of extensions and themes from the community up for grab.
|
||||
|
||||
#### [Sublime Text][37]
|
||||
|
||||
Sublime Text is one of the most popular text editors. Though it is not free, it allows you to use the software for evaluation without any time limit. Sublime Text is a feature-rich and sophisticated piece of software. And of course, it has plugins and themes support.
|
||||
|
||||
[Suggested read4 Best Modern Open Source Code Editors For Linux][49]
|
||||
|
||||
### Launcher
|
||||
|
||||

|
||||
[Save][11]Launchers
|
||||
|
||||
#### [Albert][38]
|
||||
|
||||
Albert is inspired by Alfred (a productivity application for Mac, which is totally kickass by-the-way) and still in the development phase. Albert is fast, extensible and customizable. The goal is to “Access everything with virtually zero effort”. It integrates with your Linux distribution nicely and helps you to boost your productivity.
|
||||
|
||||
#### [Synapse][39]
|
||||
|
||||
Synapse has been around for years. It’s a simple launcher that can search and run applications. It can also speed up various workflows like – controlling music, searching files, directories, bookmarks etc., running commands and such.
|
||||
|
||||
As Abhishek advised, we will keep this list of best Linux software updated with our readers’ (i.e. yours) feedback. So, what are your favorite must have Linux applications? Share with us and do suggest more categories of software to add to this list.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/essential-linux-applications/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Web-Browser-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Web%20Browsers
|
||||
[2]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Download-Manager-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Download%20Managers
|
||||
[3]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-BitTorrent-Client-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=BitTorrent%20Clients
|
||||
[4]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Cloud-Storage-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Cloud%20Storages
|
||||
[5]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Communication-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Communication%20Apps
|
||||
[6]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Office-Suite-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Office%20Suites
|
||||
[7]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Music-Player-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Music%20Players
|
||||
[8]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Video-Player-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Video%20Player
|
||||
[9]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Photo-Editor-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Photo%20Editors
|
||||
[10]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Text-Editor-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Text%20Editors
|
||||
[11]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/10/Essential-Linux-Apps-Launcher-1024x512.jpg&url=https://itsfoss.com/essential-linux-applications/&is_video=false&description=Launchers
|
||||
[12]:https://www.google.com/chrome/browser
|
||||
[13]:https://www.chromium.org/Home
|
||||
[14]:https://www.mozilla.org/en-US/firefox
|
||||
[15]:https://vivaldi.com
|
||||
[16]:http://ugetdm.com/
|
||||
[17]:http://xdman.sourceforge.net/
|
||||
[18]:http://deluge-torrent.org/
|
||||
[19]:https://transmissionbt.com/
|
||||
[20]:https://www.dropbox.com
|
||||
[21]:https://mega.nz/
|
||||
[22]:https://www.pidgin.im/
|
||||
[23]:https://itsfoss.com/franz-messaging-app/
|
||||
[24]:http://rambox.pro/
|
||||
[25]:https://www.skype.com
|
||||
[26]:https://itsfoss.com/skpe-alpha-linux/
|
||||
[27]:https://www.libreoffice.org
|
||||
[28]:https://www.wps.com
|
||||
[29]:http://gnumdk.github.io/lollypop-web/
|
||||
[30]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[31]:https://cmus.github.io/
|
||||
[32]:http://www.videolan.org
|
||||
[33]:https://kodi.tv
|
||||
[34]:https://www.gimp.org/
|
||||
[35]:https://krita.org/en/
|
||||
[36]:https://atom.io/
|
||||
[37]:http://www.sublimetext.com/
|
||||
[38]:https://github.com/ManuelSchneid3r/albert
|
||||
[39]:https://launchpad.net/synapse-project
|
||||
[40]:https://itsfoss.com/otter-browser-review/
|
||||
[41]:https://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[42]:https://itsfoss.com/best-torrent-ubuntu/
|
||||
[43]:https://itsfoss.com/cloud-services-linux/
|
||||
[44]:https://itsfoss.com/best-messaging-apps-linux/
|
||||
[45]:https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[46]:https://itsfoss.com/install-tomahawk-ubuntu-1404-linux-mint-17/
|
||||
[47]:https://itsfoss.com/format-factory-alternative-linux/
|
||||
[48]:https://itsfoss.com/image-applications-ubuntu-linux/
|
||||
[49]:https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
@ -0,0 +1,79 @@
|
||||
translating---geekpi
|
||||
|
||||
OnionShare - Share Files Anonymously
|
||||
======
|
||||
In this Digital World, we share our media, documents, important files via the Internet using different cloud storage like Dropbox, Mega, Google Drive and many more. But every cloud storage comes with two major problems, one is the Size and the other Security. After getting used to Bit Torrent the size is not a matter anymore, but the security is.
|
||||
|
||||
Even though you send your files through the secure cloud services they will be noted by the company, if the files are confidential, even the government can have them. So to overcome these problems we use OnionShare, as per the name it uses the Onion internet i.e Tor to share files Anonymously to anyone.
|
||||
|
||||
### How to Use **OnionShare**?
|
||||
|
||||
* First Download the [OnionShare][1] and [Tor Browser][2]. After downloading install both of them.
|
||||
|
||||
|
||||
|
||||
[![install onionshare and tor browser][3]][3]
|
||||
|
||||
* Now open OnionShare from the start menu
|
||||
|
||||
|
||||
|
||||
[![onionshare share files anonymously][4]][4]
|
||||
|
||||
* Click on Add and add a File/Folder to share.
|
||||
* Click start sharing. It produces a .onion URL, you could share the URL with your recipient.
|
||||
|
||||
|
||||
|
||||
[![share file with onionshare anonymously][5]][5]
|
||||
|
||||
* To Download file from the URL, copy the URL and open Tor Browser and paste it. Open the URL and download the Files/Folder.
|
||||
|
||||
|
||||
|
||||
[![receive file with onionshare anonymously][6]][6]
|
||||
|
||||
### Start of **OnionShare**
|
||||
|
||||
A few years back when Glenn Greenwald found that some of the NSA documents which he received from Edward Snowden had been corrupted. But he needed the documents and decided to get the files by using a USB. It was not successful.
|
||||
|
||||
After reading the book written by Greenwald, Micah Lee crypto expert at The Intercept, released the OnionShare - simple, free software to share files anonymously and securely. He created the program to share big data dumps via a direct channel encrypted and protected by the anonymity software Tor, making it hard to get the files for the eavesdroppers.
|
||||
|
||||
### How Does **OnionShare** Work?
|
||||
|
||||
OnionShare starts a web server at 127.0.0.1 for sharing the file on a random port. It chooses any of two words from the wordlist of 6800-wordlist called slug. It makes the server available as Tor onion service to send the file. The final URL looks like:
|
||||
|
||||
`http://qx2d7lctsnqwfdxh.onion/subside-durable`
|
||||
|
||||
The OnionShare shuts down after downloading. There is an option to allow the files to be downloaded multiple times. This makes the file not available on the internet anymore.
|
||||
|
||||
### Advantages of using **OnionShare**
|
||||
|
||||
Other Websites or Applications have access to your files: The file the sender shares using OnionShare is not stored on any server. It is directly hosted on the sender's system.
|
||||
|
||||
No one can spy on the shared files: As the connection between the users is encrypted by the Onion service and Tor Browser. This makes the connection secure and hard to eavesdroppers to get the files.
|
||||
|
||||
Both users are Anonymous: OnionShare and Tor Browser make both sender and recipient anonymous.
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this article, I have explained how to **share your documents, files anonymously**. I also explained how it works. Hope you have understood how OnionShare works, and if you still have a doubt regarding anything, just drop in a comment.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theitstuff.com/onionshare-share-files-anonymously-2
|
||||
|
||||
作者:[Anirudh Rayapeddi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.theitstuff.com
|
||||
[1]https://onionshare.org/
|
||||
[2]https://www.torproject.org/projects/torbrowser.html.en
|
||||
[3]http://www.theitstuff.com/wp-content/uploads/2017/12/Icons.png
|
||||
[4]http://www.theitstuff.com/wp-content/uploads/2017/12/Onion-Share.png
|
||||
[5]http://www.theitstuff.com/wp-content/uploads/2017/12/With-Link.png
|
||||
[6]http://www.theitstuff.com/wp-content/uploads/2017/12/Tor.png
|
||||
@ -0,0 +1,95 @@
|
||||
translating---geekpi
|
||||
|
||||
The Biggest Problems With UC Browser
|
||||
======
|
||||
Before we even begin talking about the cons, I want to establish the fact that
|
||||
I have been a devoted UC Browser user for the past 3 years. I really love the
|
||||
download speeds I get, the ultra-sleek user interface and eye-catching icons
|
||||
used for tools. I was a Chrome for Android user in the beginning but I
|
||||
migrated to UC on a friend's recommendation. But in the past 1 year or so, I
|
||||
have seen some changes that have made me rethink about my choice and now I
|
||||
feel like migrating back to chrome again.
|
||||
|
||||
### The Unwanted **Notifications**
|
||||
|
||||
I am sure I am not the only one who gets these unwanted notifications every
|
||||
few hours. These clickbait articles are a real pain and the worst part is that
|
||||
you get them every few hours.
|
||||
|
||||
[![uc browser's annoying ads notifications][1]][1]
|
||||
|
||||
I tried closing them down from the notification settings but they still kept
|
||||
appearing with a less frequency.
|
||||
|
||||
### The **News Homepage**
|
||||
|
||||
Another unwanted section that is completely useless. We completely understand
|
||||
that UC browser is free to download and it may require funding but this is not
|
||||
the way to do it. The homepage features news articles that are extremely
|
||||
distracting and unwanted. Sometimes when you are in a professional or family
|
||||
environment some of these click baits might even cause awkwardness.
|
||||
|
||||
[![uc browser's embarrassing news homepage][2]][2]
|
||||
|
||||
And they even have a setting for that. To Turn the **UC** **News Display ON /
|
||||
OFF.** And guess what, I tried that too **.** In the image below, You can see
|
||||
my efforts on the left-hand side and the output on the right-hand side.[![uc
|
||||
browser homepage settings][3]][3]
|
||||
|
||||
And click bait news isn't enough, they have started adding some unnecessary
|
||||
features. So let's include them as well.
|
||||
|
||||
### UC **Music**
|
||||
|
||||
UC browser integrated a **music player** in their browser to play music. It 's
|
||||
just something that works, nothing too fancy. So why even have it? What's the
|
||||
point? Who needs a music player in their browsers?
|
||||
|
||||
[![uc browser adds uc music player][4]][4]
|
||||
|
||||
It's not even like it will play audio from the web directly via that player in
|
||||
the background. Instead, it is a music player that plays offline music. So why
|
||||
have it? I mean it is not even good enough to be used as a primary music
|
||||
player. Even if it was, it doesn't run independently of UC Browser. So why
|
||||
would someone have his/her browser running just to use your Music Player?
|
||||
|
||||
### The **Quick** Access Bar
|
||||
|
||||
I have seen 9 out of 10 average users have this bar hanging around in their
|
||||
notification area because it comes default with the installation and they
|
||||
don't know how to get rid of it. The settings on the right get the job done.
|
||||
|
||||
[![uc browser annoying quick access bar][5]][5]
|
||||
|
||||
But I still wanna ask, "Why does it come by default ?". It's a headache for
|
||||
most users. If we want it we will enable it. Why forcing the users though.
|
||||
|
||||
### Conclusion
|
||||
|
||||
UC browser is still one of the top players in the game. It provides one of the
|
||||
best experiences, however, I am not sure what UC is trying to prove by packing
|
||||
more and more unwanted features in their browser and forcing the user to use
|
||||
them.
|
||||
|
||||
I have loved UC for its speed and design. But recent experiences have led to
|
||||
me having a second thought about my primary browser.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theitstuff.com/biggest-problems-uc-browser
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.theitstuff.com/author/reevkandari
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-6.png
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-1-1.png
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/12/uceffort.png
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-3-1.png
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-4-1.png
|
||||
|
||||
@ -0,0 +1,224 @@
|
||||
The Best Linux Laptop (2017-2018): A Buyer’s Guide with Picks from an RHCE
|
||||
======
|
||||
![][1]
|
||||
|
||||
If you don't posses the right knowledge & the experience, then finding the best Linux laptop can be a daunting task. And thus you can easily end-up with something that looks great, features great performance, but struggles to cope with 'Linux', shame! So, as a **RedHat Certified Engineer** , the author & the webmaster of this blog, and as a **' Linux' user with 14+ years of experience**, I used all my knowledge to recommend to you a couple of laptops that I personally guarantee will let you run 'Linux' with ease. After 20+ hours of research (carefully looking through the hardware details & reading user feedback) I chose [Dell XP S9360-3591-SLV][2], at the top of the line. If you want a laptop that's equipped with modern features & excellent performance **that 'just works' with Linux**, then this is your best pick.
|
||||
|
||||
It's well built (aluminium chassis), lightweight (2.7 lb), features powerful hardware, long battery life, includes an excellent 13.3 inch Gorilla Glass touchscreen with 3200×1800 QHD resolution which should give you excellently sharp images without making anything too small & difficult to read, a good & roomy track-pad (earlier versions had a few issues with it, but now they seem to be gone) with rubber-like palm rest area and a good keyboard (the key travel is not deep, but it's a very think laptop so…) with Backlit, two USB 3.0 ports. Most importantly, two of the most common elements of a laptop that can give 'Linux' user a headache, the wireless adapter & the GPU (yes the Intel HD Graphics 620 **can play 4K videos at 60fps** ), they are both **super compatible with 'Linux'** on this Dell.
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
One drawback is that it doesn't have an HDMI port. In its place, Dell has added a Thunderbolt 3 port. So your only option is to use a Thunderbolt to HDMI converter (they're pretty cheap). Secondly, you can't upgrade the 8GB of RAM after purchasing (you can change the hardware configuration -- CPU, RAM & SSD, before purchasing), but in my opinion, 8GB is more than enough to run any 'Linux' distribution for doing everyday tasks with ease. I for one have an Asus laptop (received it as a gift) with a 5th generation of Core i7, 4GB of RAM, I use it as my main computer. With Chrome having opened 15-20 tabs, VLC running in the background, file manager & a code editor opened, it handles it with ease. If I cut back some of the browser tabs (say reduce them to to 4-5), then with the rest of the apps opened, I can even work with a virtual machine on Virtualbox. That's with having 4GB of RAM, so with 8GB of RAM and other more powerful hardware, you should be absolutely fine.
|
||||
|
||||
> **Note:** I 've chosen a solid set of [hardware for you][2], but if you want, you can further customize it. However, don't choose the '8GB RAM/128GB SSD' option. Because that version gives you the 1920×1080 FHD screen, and that resolution on a 13.3″ screen can make things like menus to appear a bit smaller, slightly difficult to read.
|
||||
|
||||
### **Best Cheap Linux Laptop**
|
||||
|
||||
![][5]
|
||||
|
||||
If the Dell is a bit pricey and you want something that is affordable, but still gives you surprisingly similar performance & really good compatibility on 'Linux, then your 2nd best option is to go for the [Acer Aspire E 15 E5-575G-57D4][6]. Its 15.6″ display is certainly not as good as the one Dell gives you, but the 1920×1080 Full HD resolution should still fits nicely with the 15.6″ screen making things sharp & clear. The rest of the hardware is actually very similar to the ones the more pricier Dell gives you, but **at 5.2 lb it 's a little heavy.**
|
||||
|
||||
You can actually customize it a lot. The basic setup includes a 7th generation Core i5 CPU, 15.6 inch FullHD (1920 x 1080) screen, 8GB of DDR4 RAM, 256GB SSD drive, Intel HD Graphics 620 GPU and also a separate (discreet) Nvidia 940 MX GPU, for ports: HDMI 2 USB 3.0, 1 x USB 2.0 & 1 USB 3.1. For $549, it also **includes a DVD burner** … [**it 's a bargain**][6].
|
||||
|
||||
As far as the 'Linux' compatibility goes, it's really good. It may not be top notched as the Dell XPS, yet, as far as I can see, if there is one thing that can give you troubles it's that Nvidia GPU. Except for one user, all the others who have given feedback on its 'Linux' compatibility say it runs very smoothly. Only one user has complained that he came up with a minor issue after installing the proprietary Nvidia driver in Linux Mint, but he says it's certainly not a deal breaker. This feedback is also in accordance with my experience with a mobile Nvidia GPU as well.
|
||||
|
||||
For instance, nowadays I use an Asus laptop and apart from the integrated Intel GPU, it also comes with a discreet Nvidia 920M GPU. I've been using it for about an year and a half. [I've run couple of 'Linux' distributions on it][7], and the only major issue I've had so far was that after installing the proprietary driver [on Ubuntu 17.10][8] and activating Nvidia as the default GPU the auto-user-login function stopped working. And every time I had to enter my login details at the login screen for entering into the desktop. It's nowhere near being a major issue, and I'm sure it could've been fixed by editing some configuration settings of the login-manager, but I didn't even care because I rarely use the Nvidia GPU. Therefore, I simply changed the GPU back to Intel and all was back to normal. Also, a while ago I [enabled 'Motion Interpolation' on the same Nvidia GPU][9] on [Ubuntu 16.04 LTS][10] and everything worked like a charm!
|
||||
|
||||
What I'm trying to say is that GPU drivers such as those from Nvidia & AMD/ATI used give users a real hard time in the past in 'Linux', but nowadays things have progressed a lot, or so it seems. Unless you have at your disposal a very recently released high-end GPU, chances are 'Linux' is going to work without lots of major issues.
|
||||
|
||||
### **Linux Gaming Laptop**
|
||||
|
||||
![][11]
|
||||
|
||||
Most of the time, with gaming laptops, you'll have to manually tweak things a bit. And those 'things' are mostly associated with the GPU. It can be as simple as installing the proprietary driver, to dealing with a system that refuses even to boot into the live CD/USB. But with enough patience, most of the time, they can be fixed. If your gaming laptop comes with a very recently released Nvidia/AMD GPU and if the issue is related to the driver, then fixing it simply means waiting for an updated driver. Sometimes that can take time. But if you buy a laptop with a GPU that's released a couple of months ago, then that alone should increase your chances of fixing any existing issues to a great degree.
|
||||
|
||||
So with that in mind, I've chosen the [Dell Inspiron i5577-7342BLK-PUS][12] as the gaming laptop choice. It's a powerful gaming laptop that has a power tag below 1000 bucks. The reason being is the 15.6″ FullHD (1920 x 1080) display mostly. Because when you look at the rest of the configuration (yes you can further customize it), it includes a 7th generation Core i7 CPU (quad-core), 16GB DDR4 RAM (up to 32GB), 512GB SSD drive and an Nvidia GTX 1050 GPU which has received lots of positive reviews. You won't be able to play high-end games in QHD or 4K resolutions with it say on an external display, but it can handle lots of games in FullHD resolution on its 15.6″ display nonetheless.
|
||||
|
||||
And the other reason I've chosen a Dell over the other is, for some reason, most Dell laptops (or computers in general) are quite compatible with 'Linux'. It's pretty much the same with this one as well. I've manually checked the hardware details on Dell, while I cannot vouch for any issues you might come up with that Nvidia GPU, the rest of the hardware should work very well on major 'Linux' distributions (such as with Ubuntu for instance).
|
||||
|
||||
### **Is that it?**
|
||||
|
||||
Actually yes, because I believe less is better.
|
||||
|
||||
Look, I could've added bunch of laptops here and thrust them at you by 'recommending' them. But I take very seriously what I do on this blog. So I can't just 'recommend' 10-12 laptops unless I'm confident that they're suited to run 'Linux' as smoothly as possible. While the list is at the moment, confined to 3 laptops, I've made sure that they will run 'Linux' comfortably (again, even with the gaming laptop, apart from the Nvidia GPU, the rest of the hardware SHOULD work), plus, the three models should cover requirements of a large audience in my opinion. That said, as time goes on, if I find laptops from other manufactures I can predict with confidence that will run 'Linux' quite well, then I'll add them. But for now, these are my recommendations. However, if you're not happy with these recommendations, then below are couple of simple things to look for. Once you get the basic idea, you can pretty easily predict with good accuracy whether a laptop is going to give you a difficult time running 'Linux' or not. I've already mentioned most of them above, but here they are anyway.
|
||||
|
||||
* **Find more information about the hardware:**
|
||||
|
||||
|
||||
|
||||
When you come up with a laptop take a note of its model. Now, on most websites, details such as the manufacturer of the Wireless adapter or the audio chip etc aren't given. But on most occasions such information can be easily extracted using a simple trick. And this is what I usually do.
|
||||
|
||||
If you know the model number and the manufacturer of the laptop, just search for its drivers in Google. Let's take the Dell gaming laptop I just mentioned as an example. If you take its name and search for its drivers in Google ('`Dell Inspiron i5577-7342BLK-PUS drivers`'), Google doesn't display an official Dell drivers page. This is not surprising because Dell (and other manufactures) sell laptops under the same generic model name with few (2 or three) hardware variations. So, to further narrow things down, starting from the left side, let's use the first three fields of the name and search for its drivers in Google ('`Dell Inspiron i5577 drivers`'), then as shown below, Google lists us, among other websites, an official Dell's drivers page for the Inspiron 5577 (without the 'i').
|
||||
|
||||
![][13]
|
||||
|
||||
If you enter into this page and look around the various drivers & hardware listed there and compare them with the model we're interested in, then you'll see that the hardware listed in the '`Dell Inspiron i5577-7342BLK-PUS`' are also listed there. I'm usually more keen to look for what's listed under 'audio' & 'network', because the exact model names of these chips are the most difficult to obtain from a buyer's website and others such as the GPU, CPU etc are listed. So if you look what's displayed under 'network' then you'll see that Dell gives us couple of drivers. One is for Realtek Ethernet adapter (Ethernet adapter are usually well supported in 'Linux'), Qualcomm QCA61x4A-QCA9377 Wireless adapter (if you further research the 'QCA61x4A' & 'QCA9377' separately, because they're separated by '-', then you'll find that these are actually two different yet very similar Wireless chips from Qualcomm. In other words, Dell has included two drivers in a single package), and couple of Intel wireless adapters (Intel hardware too is well supported in 'Linux').
|
||||
|
||||
But Qualcomm devices can sometimes give issues. I've come up with one or two, but none of it were ever major ones. That said, when in doubt, it's always best to seek. So take that 'Qualcomm QCA61x4A-QCA9377' (it doesn't really matter if you use one adapter or use the two names combined) and add to it a keyword like 'linux' or 'ubuntu' and Google it. If I search for something like 'Qualcomm QCA61x4A-QCA9377 ubuntu' then Google lists few results. The first one I get is from [AskUbuntu][14] (a community driven website dedicated to answer end-user's Q & A, excellent resource for fixing issues related to Ubuntu).
|
||||
|
||||
![][15]
|
||||
|
||||
If you go over to that page then you can see that the user complains that Qualcomm QCA9377 wireless adapter is giving him hard time on Ubuntu 15.10. Fortunately, that question has been answered. Plus, this seems to be an issue with Ubuntu 15.10 which was released back in October 2015, so this is two years ago. So there is a high probability that this particular issue is already fixed in the latter Ubuntu releases. Also remember that, this issue seem to related to the Qualcomm QCA9377 wireless chip not the QCA61x4A. So if our 'Linux' gaming Dell laptop has the latter chip, then most probably you wouldn't come up with this at all.
|
||||
|
||||
I hope I didn't over complicate things. I just wanted to give you a pointer on how to find subtle details about the hardware of the laptop that you're hoping to run 'Linux', so that you can better evaluate the situation. Use this technique with some common sense, and with experience, you'll become very efficient at it.
|
||||
|
||||
* **Don 't stop at the GPU & the Network Adapter:**
|
||||
|
||||
|
||||
|
||||
![][16]
|
||||
|
||||
While its true that the GPU and the Network adapter are among the two most common hardware devices that give you big issues in 'Linux' since you're buying a laptop, it's always good practice to research the compatibility of the audio, the touch-pad and the keyboard & its associated features (for instance, my old Dell's Backlit keyboard had a minor issue under 'Linux'. Backlit keyboards can give minor issues in 'Linux', again, it's from experience) as well.
|
||||
|
||||
* **If it 's too 'hot', wait 2-3 months:**
|
||||
|
||||
|
||||
|
||||
As far as the computer end-users are concerned, the market share of 'Linux' is quite small. Therefore, hardware manufacturers don't take 'Linux' seriously, yet. Thus, it take them a bit longer to fix any existing major issues with the drivers of their recently released hardware devices. This is even true to open-source drivers also, but they tend to come up with 'fixes' fast compared to proprietary ones in my experience. So, if you're buying a laptop that features hardware devices (mainly CPU & the GPU) that have been very recently released, then it's better to wait 2 or 3 months before buying the laptop to see if there are any major issues in 'Linux'. And hopefully by that time, you'll be able to find a fix or at least to predict when the fix is mostly likely to arrive.
|
||||
|
||||
* **What about the Screen & HiDPI support in 'Linux'?**
|
||||
|
||||
|
||||
|
||||
![][17]
|
||||
|
||||
'Pixel density' or 'High Pixel Density' displays are quite popular terms these days. And most people assume that having lots of pixels means better quality. While that maybe true with the common intuition, technically speaking, it's not accurate. This subject can be bit too complicated to understand, so I'll just go ever the basics so that you'll know enough to avoid unnecessary confusion.
|
||||
|
||||
Things that are displayed on your screen such as texts and icons are designed with certain fixed sizes. And these sizes are defined by what is called 'Dots per inch' or 'DPI' for short. This basically defines how many dots (pixels) there should be per inch for these items to appear correctly. And 72 dots per inch is the standard set by Apple and that's what matters. I'm sure you've heard that Windows use a different standard, 96 dots per inch, but that is not entirely correct. I'm not going to go into the details, but if you want to know more, [read Wikipedia][18]. In any case, all that you want to know to make sure that the display screen of your 'Linux' laptop is going to look sharp and readable simultaneously, is to do the following. First take a note of its size (13.3″, 15.6″, 17″…) and the resolution. Then go to [PXCALC.com][19] website which gives you a nice dots per inch calculator. Then enter the values in the correct fields. Once done, take a note of the DPI value the calculator gives you (it's on the top right corner, as shown below). Then take that value and simply divide it by 72, and here's the crucial part.
|
||||
|
||||
![][20]
|
||||
|
||||
If the answer you get resembles an integer increase such as 2, 3, 4 (+0.2 -- 0.2 variation is fine. The best ones may give you +0.1 -- 0.1 variation only. The finest will give you near 0.0 ones, such as the iMac 27 5K) then you have nothing to worry about. The higher the integer increase is (provided that the variation stays within the margins), the more sharper the screen is going to be. To give you a better idea, let's take an example.
|
||||
|
||||
Take the first laptop I gave you (Dell XPS 13.3″ with the QHD resolution) as an example. Once you're done with the calculation it'll give you answer '3.83' which roughly equals to '3.8' which is not an integer but as pointed out, it's safely within the margin (-0.2 to be precise). If you do the same calculation with the Acer laptop I recommend to you as the best cheapest option, then it'll give you a value of '1.95' which is roughly '2.0'. So other features (brightness, viewing angle etc) aside, the display on Dell is almost twice as sharp compared to Acer (trust me, this display still looks great and sharp. It'll look far better compared to a resolution of 1366 x 768 on either a 13.3″ or a 15.6″ screen).
|
||||
|
||||
* **RAM Size?**
|
||||
|
||||
|
||||
|
||||
![][21]
|
||||
|
||||
KDE and GNOME are the two most popular desktop environments in 'Linux'. While there are many others, I advice you to stick with one of them. These days my preference lies with KDE. KDE plasma is actually more lightweight & efficient compared to GNOME, as far as I can tell. If you want some numbers, then in [my Ubuntu 16.10 flavors review][22] (which is about an year old now), KDE plasma consumed about 369 MiB while GNOME edition of Ubuntu consumed 781 MiB! That's **112% increase!**
|
||||
|
||||
These days I use Kubuntu 17.10, although I haven't reviewed it, but I can tell that its memory consumption too is somewhere around 380-400 MiB. Coming back to the point, I would like to advice you **not to go below 8GB** when it comes to choosing RAM size for your 'Linux' laptop. That way, I can guarantee with great probability that you'll be able to use it for at least 4 years into the future without having to worry about laptop becoming slow and not being able to cope with the requirements set by distribution vendors and by most end-users.
|
||||
|
||||
If you're looking for **a laptop for gaming in 'Linux'**, then of course you should **go 12GB or more**. Other than that, 8GB is more than enough for most end-user needs.
|
||||
|
||||
* **What about an SSD?**
|
||||
|
||||
|
||||
|
||||
![][23]
|
||||
|
||||
Despite what operating system you use, adding an SSD will improve the overall performance & responsiveness of your laptop immediately because they are much faster than the rotational disks, as simple as that. That being said, in my experience, even though efficient and lightweight, KDE distributions take more time to boot compared to GNOME counterparts. Some 'Linux' distributions such as Ubuntu and Kubuntu come with a especially designed utility called 'ureadahead' that improves boot-up times (sometimes by **30%** or even more), unfortunately not all distributions come with such tools. And on such occasions, **KDE can take 50 seconds+ to boot on a 5400 rpm SATA drive**. [Manjaro 17.0.2 KDE][24] is one such example (shown in the graph above).
|
||||
|
||||
Thus, by simply making sure to buy a laptop that features an SSD can immensely help you out. **My Kubuntu 17.10 is on a smaller SSD drive (20GB) and it boots within 13-15 seconds**.
|
||||
|
||||
* **The GPU?**
|
||||
|
||||
|
||||
|
||||
As mentioned many time, if possible, always go with an Intel GPU. Just like Dell who's known to produce 'Linux friendly' hardware, Intel has also thoroughly invested in open-source projects, and some of its hardware too is such like. You won't regret it.
|
||||
|
||||
* **What about automatic GPU switching (e.g: Nvidia Optimus), will it work?**
|
||||
|
||||
|
||||
|
||||
If you're bought a laptop with a discreet graphics card, then in Windows, Nvidia has a feature called 'Optimus' which automatically switch between the integrated (weak) GPU and the discreet (more capable) GPU. ATI also has this capability. There is no official support of such features in 'Linux', but there are experimental work such as the [Bumblebee project][25]. But it does not always work as expected. I simply prefer to have installed the proprietary GPU driver and switch between each whenever I want, manually. To their credit, Fedora team has also been working on a solution of their own, I don't honestly know how far they've gone. Better [ask Christian][26] I guess.
|
||||
|
||||
* **Can 'Linux' give you good battery life?**
|
||||
|
||||
|
||||
|
||||
Of course it can! Once your hardware devices are properly configured, I recommend that you install a power usage optimizer. There are a few applications, but I recommend '[TLP][27]'. It's easy to install, cuts down the power usage impressively in my experience, and usually it requires no manual tweaks to work.
|
||||
|
||||
Below are two screenshots from my latest Ubuntu 17.10 review. First screenshot shows the power usage before installing 'tlp' and the second one shows the readings after installing it (the pictures say it all):
|
||||
|
||||
![][28]
|
||||
|
||||
![][29]
|
||||
|
||||
'tlp' should be available in major 'Linux' distributions. On Ubuntu based ones, you should be able to install it by issuing the following commands:
|
||||
|
||||
`sudo apt update`
|
||||
|
||||
`sudo apt install tlp`
|
||||
|
||||
Now reboot the computer, and you're done!
|
||||
|
||||
* **How did you measure the power usage in 'Linux'?**
|
||||
|
||||
|
||||
|
||||
Glad you asked! It's called '[powerstat][30]'. It's this amazing little utility (designed by Colin King, an Ubuntu developer) that gathers useful data that's related to power consumption (and debugging) and puts them all into a single screen. On Ubuntu based systems, enter the below commands to install it:
|
||||
|
||||
`sudo apt update`
|
||||
|
||||
`sudo apt install powerstat`
|
||||
|
||||
Most major 'Linux' distributions make it available through their software repositories these days.
|
||||
|
||||
* **Are there any 'Linux' operating systems you recommend?**
|
||||
|
||||
|
||||
|
||||
Well, my main operating system these days is Kubuntu 17.10. Now I have not reviewed it, but to make a long story short, I love it! It's very easy to install, beginner friendly, stable, beautiful, power efficient and easy to use. These days I literally laugh at GNOME! So if you're new to 'Linux', then I advice you to [try Kubuntu ][31] or [Linux Mint][32], first ('Mint' gives you couple of desktop choices. Go with either the KDE version or with 'Cinnamon').
|
||||
|
||||
Then once you get the hang of things, then you can move on to others, that's the best approach for a beginner.
|
||||
|
||||
### **Final Words**
|
||||
|
||||
Recall what I said at the beginning. If you're looking for a laptop that runs 'Linux' almost effortlessly, then by all means go with the [Dell XP S9360-3591-SLV][2]. It's a well build, powerful, very popular, ultra-portable laptop that not only can let you run 'Linux' easily, but also feature a great display screen that has been praised by many reviewers. If however, you want something cheap, then go with the [Acer Aspire E 15 E5-575G-57D4][6]. As far as 'Linux' compatibility goes, it's almost as good as the Dell, plus it's a great value for the money.
|
||||
|
||||
Thirdly, if you're looking for a laptop to do some gaming on 'Linux', then [Dell Inspiron i5577-7342BLK-PUS][12] looks pretty solid to me. Again, there are many other gaming laptops out there, true, but I specifically chose this one because, it features hardware that are already compatible with 'Linux', although I cannot vouch for the Nvidia GTX 1050 with the same confidence. That said, you shouldn't buy a 'Linux' gaming laptop without wanting to get your hands dirty a bit. In that case, if you're not happy with its hardware capabilities (it's quite capable) and would like to do the research and choose a different one, then by all means do so.
|
||||
|
||||
I wish you good luck with your purchase and thank you for reading!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.hecticgeek.com/2017/12/best-linux-laptop/
|
||||
|
||||
作者:[Gayan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.hecticgeek.com/author/gayan/
|
||||
[1]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Dell-XPS-9360-Linux.png
|
||||
[2]:https://www.amazon.com/gp/product/B01LQTXED8?ie=UTF8&tag=flooclea01-20&camp=1789&linkCode=xm2&creativeASIN=B01LQTXED8
|
||||
[3]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Dell-XPS-9360-keyboard-the-track-pad.png
|
||||
[4]:https://www.hecticgeek.com/wp-content/uploads/2017/12/XPS-13.3-ports.png
|
||||
[5]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Acer-Aspire-E-15-E5-575G-57D4-affordable-linux-laptop.png
|
||||
[6]:https://www.amazon.com/gp/product/B01LD4MGY4?ie=UTF8&tag=flooclea01-20&camp=1789&linkCode=xm2&creativeASIN=B01LD4MGY4
|
||||
[7]:https://www.hecticgeek.com/gnu-linux/
|
||||
[8]:https://www.hecticgeek.com/2017/11/ubuntu-17-10-review/
|
||||
[9]:https://www.hecticgeek.com/2016/06/motion-interpolation-linux-svp/
|
||||
[10]:https://www.hecticgeek.com/2016/04/ubuntu-16-04-lts-review/
|
||||
[11]:https://www.hecticgeek.com/wp-content/uploads/2017/12/DELL-Inspiron-15-i5577-5328BLK-linux-gaming-laptop.png
|
||||
[12]:https://www.amazon.com/gp/product/B06XFC44CL?ie=UTF8&tag=flooclea01-20&camp=1789&linkCode=xm2&creativeASIN=B06XFC44CL
|
||||
[13]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Trying-to-gather-more-data-about-the-hardware-of-a-Dell-laptop-for-linux.png
|
||||
[14]:https://askubuntu.com/
|
||||
[15]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Trying-to-find-if-the-network-adapter-from-Qualcomm-is-compatible-with-Linux.png
|
||||
[16]:https://www.hecticgeek.com/wp-content/uploads/2017/12/computer-hardware-illustration.jpg
|
||||
[17]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Display-Scalling-Settings-on-KDE-Plasma-5.10.5.png
|
||||
[18]:https://en.wikipedia.org/wiki/Dots_per_inch#Computer_monitor_DPI_standards
|
||||
[19]:http://pxcalc.com/
|
||||
[20]:https://www.hecticgeek.com/wp-content/uploads/2017/12/Using-PXCALC-dpi-calculator.png
|
||||
[21]:https://www.hecticgeek.com/wp-content/uploads/2016/11/Ubuntu-16.10-vs-Ubuntu-GNOME-16.10-vs-Kubuntu-16.10-vs-Xubuntu-16.10-Memory-Usage-Graph.png
|
||||
[22]:https://www.hecticgeek.com/2016/11/ubuntu-16-10-flavors-comparison/
|
||||
[23]:https://www.hecticgeek.com/wp-content/uploads/2017/07/Kubuntu-16.10-vs-Ubuntu-17.04-vs-Manjaro-17.0.2-KDE-Boot_up-Times-Graph.png
|
||||
[24]:https://www.hecticgeek.com/2017/07/manjaro-17-0-2-kde-review/
|
||||
[25]:https://bumblebee-project.org/
|
||||
[26]:https://blogs.gnome.org/uraeus/2016/11/01/discrete-graphics-and-fedora-workstation-25/
|
||||
[27]:http://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html
|
||||
[28]:https://www.hecticgeek.com/wp-content/uploads/2017/11/Ubuntu-17.10-Power-Usage-idle.png
|
||||
[29]:https://www.hecticgeek.com/wp-content/uploads/2017/11/Ubuntu-17.10-Power-Usage-idle-after-installing-TLP.png
|
||||
[30]:https://www.hecticgeek.com/2012/02/powerstat-power-calculator-ubuntu-linux/
|
||||
[31]:https://kubuntu.org/
|
||||
[32]:https://linuxmint.com/
|
||||
[33]:https://twitter.com/share
|
||||
[34]:https://www.hecticgeek.com/2017/12/best-linux-laptop/?share=email (Click to email this to a friend)
|
||||
49
sources/tech/20171211 A tour of containerd 1.0.md
Normal file
49
sources/tech/20171211 A tour of containerd 1.0.md
Normal file
@ -0,0 +1,49 @@
|
||||
A tour of containerd 1.0
|
||||
======
|
||||
|
||||
![containerd][1]
|
||||
|
||||
We have done a few talks in the past on different features of containerd, how it was designed, and some of the problems that we have fixed along the way. Containerd is used by Docker, Kubernetes CRI, and a few other projects but this is a post for people who may not know what containerd actually does within these platforms. I would like to do more posts on the feature set and design of containerd in the future but for now, we will start with the basics.
|
||||
|
||||
I think the container ecosystem can be confusing at times. Especially with the terminology that we use. Whats this? A runtime. And this? A runtime… containerd (pronounced " _container-dee "_) as the name implies, not contain nerd as some would like to troll me with, is a container daemon. It was originally built as an integration point for OCI runtimes like runc but over the past six months it has added a lot of functionality to bring it up to par with the needs of modern container platforms like Docker and orchestration systems like Kubernetes.
|
||||
|
||||
So what do you actually get using containerd? You get push and pull functionality as well as image management. You get container lifecycle APIs to create, execute, and manage containers and their tasks. An entire API dedicated to snapshot management and an openly governed project to depend on. Basically everything that you need to build a container platform without having to deal with the underlying OS details. I think the most important part of containerd is having a versioned and stable API that will have bug fixes and security patches backported.
|
||||
|
||||
![containerd][2]
|
||||
|
||||
Since there is no such thing as Linux containers in the kernel, containers are various kernel features tied together, when you are building a large platform or distributed system you want an abstraction layer between your management code and the syscalls and duct tape of features to run a container. That is where containerd lives. It provides a client a layer of stable types that platforms can build on top of without ever having to drop down to the kernel level. It's so much nicer to work with Container, Task, and Snapshot types than it is to manage calls to clone() or mount(). Balanced with the flexibility to directly interact with the runtime or host-machine, these objects avoid the sacrifice of capabilities that typically come with higher-level abstractions. The result is that easy tasks are simple to complete and hard tasks are possible.
|
||||
|
||||
![containerd][3]Containerd was designed to be used by Docker and Kubernetes as well as any other container system that wants to abstract away syscalls or OS specific functionality to run containers on Linux, Windows, Solaris, or other Operating Systems. With these users in mind, we wanted to make sure that containerd has only what they need and nothing that they don't. Realistically this is impossible but at least that is what we try for. While networking is out of scope for containerd, what it doesn't do lets higher level systems have full control. The reason for this is, when you are building a distributed system, networking is a very central aspect. With SDN and service discovery today, networking is way more platform specific than abstracting away netlink calls on linux. Most of the new overlay networks are route based and require routing tables to be updated each time a new container is created or deleted. Service discovery, DNS, etc all have to be notified of these changes as well. It would be a large chunk of code to be able to support all the different network interfaces, hooks, and integration points to support this if we added networking to containerd. What we did instead is opted for a robust events system inside containerd so that multiple consumers can subscribe to the events that they care about. We also expose a [Task API ][4]that lets users create a running task, have the ability to add interfaces to the network namespace of the container, and then start the container's process without the need for complex hooks in various points of a container's lifecycle.
|
||||
|
||||
Another area that has been added to containerd over the past few months is a complete storage and distribution system that supports both OCI and Docker image formats. You have a complete content addressed storage system across the containerd API that works not only for images but also metadata, checkpoints, and arbitrary data attached to containers.
|
||||
|
||||
We also took the time to [rethink how "graphdrivers" work][5]. These are the overlay or block level filesystems that allow images to have layers and you to perform efficient builds. Graphdrivers were initially written by Solomon and I when we added support for devicemapper. Docker only supported AUFS at the time so we modeled the graphdrivers after the overlay filesystem. However, making a block level filesystem such as devicemapper/lvm act like an overlay filesystem proved to be much harder to do in the long run. The interfaces had to expand over time to support different features than what we originally thought would be needed. With containerd, we took a different approach, make overlay filesystems act like a snapshotter instead of vice versa. This was much easier to do as overlay filesystems provide much more flexibility than snapshotting filesystems like BTRFS, ZFS, and devicemapper as they don't have a strict parent/child relationship. This helped us build out [a smaller interface for the snapshotters][6] while still fulfilling the requirements needed from things [like a builder][7] as well as reduce the amount of code needed, making it much easier to maintain in the long run.
|
||||
|
||||
![][8]
|
||||
|
||||
You can find more details about the architecture of containerd in [Stephen Day's Dec 7th 2017 KubeCon SIG Node presentation][9].
|
||||
|
||||
In addition to the technical and design changes in the 1.0 codebase, we also switched the containerd [governance model from the long standing BDFL to a Technical Steering Committee][10] giving the community an independent third party resource to rely on.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/12/containerd-ga-features-2/
|
||||
|
||||
作者:[Michael Crosby][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/michael/
|
||||
[1]:https://i0.wp.com/blog.docker.com/wp-content/uploads/950cf948-7c08-4df6-afd9-cc9bc417cabe-6.jpg?resize=400%2C120&ssl=1
|
||||
[2]:https://i1.wp.com/blog.docker.com/wp-content/uploads/4a7666e4-ebdb-4a40-b61a-26ac7c3f663e-4.jpg?resize=906%2C470&ssl=1 (containerd)
|
||||
[3]:https://i1.wp.com/blog.docker.com/wp-content/uploads/2a73a4d8-cd40-4187-851f-6104ae3c12ba-1.jpg?resize=1140%2C680&ssl=1
|
||||
[4]:https://github.com/containerd/containerd/blob/master/api/services/tasks/v1/tasks.proto
|
||||
[5]:https://blog.mobyproject.org/where-are-containerds-graph-drivers-145fc9b7255
|
||||
[6]:https://github.com/containerd/containerd/blob/master/api/services/snapshots/v1/snapshots.proto
|
||||
[7]:https://blog.mobyproject.org/introducing-buildkit-17e056cc5317
|
||||
[8]:https://i1.wp.com/blog.docker.com/wp-content/uploads/d0fb5eb9-c561-415d-8d57-e74442a879a2-1.jpg?resize=1140%2C556&ssl=1
|
||||
[9]:https://speakerdeck.com/stevvooe/whats-happening-with-containerd-and-the-cri
|
||||
[10]:https://github.com/containerd/containerd/pull/1748
|
||||
@ -0,0 +1,284 @@
|
||||
translating by wenwensnow
|
||||
How to Install Arch Linux [Step by Step Guide]
|
||||
======
|
||||
**Brief: This tutorial shows you how to install Arch Linux in easy to follow steps.**
|
||||
|
||||
[Arch Linux][1] is a x86-64 general-purpose Linux distribution which has been popular among the [DIY][2] enthusiasts and hardcore Linux users. The default installation covers only a minimal base system and expects the end user to configure and use it. Based on the KISS - Keep It Simple, Stupid! principle, Arch Linux focus on elegance, code correctness, minimalist system and simplicity.
|
||||
|
||||
Arch Linux supports the Rolling release model and has its own package manager - [pacman][3]. With the aim to provide a cutting-edge operating system, Arch never misses out to have an up-to-date repository. The fact that it provides a minimal base system gives you a choice to install it even on low-end hardware and then install only the required packages over it.
|
||||
|
||||
Also, its one of the most popular OS for learning Linux from scratch. If you like to experiment with a DIY attitude, you should give Arch Linux a try. It's what many Linux users consider a core Linux experience.
|
||||
|
||||
In this article, we will see how to install and set up Arch Linux and then a desktop environment over it.
|
||||
|
||||
## How to install Arch Linux
|
||||
|
||||
![How to install Arch Linux][4]
|
||||
|
||||
![How to install Arch Linux][5]
|
||||
|
||||
The method we are going to discuss here **wipes out existing operating system** (s) from your computer and install Arch Linux on it. So if you are going to follow this tutorial, make sure that you have backed up your files or else you'll lose all of it. You have been warned.
|
||||
|
||||
But before we see how to install Arch Linux from a USB, please make sure that you have the following requirements:
|
||||
|
||||
### Requirements for installing Arch Linux:
|
||||
|
||||
* A x86_64 (i.e. 64 bit) compatible machine
|
||||
* Minimum 512 MB of RAM (recommended 2 GB)
|
||||
* At least 1 GB of free disk space (recommended 20 GB for basic usage)
|
||||
* An active internet connection
|
||||
* A USB drive with minimum 2 GB of storage capacity
|
||||
* Familiarity with Linux command line
|
||||
|
||||
|
||||
|
||||
Once you have made sure that you have all the requirements, let's proceed to install Arch Linux.
|
||||
|
||||
### Step 1: Download the ISO
|
||||
|
||||
You can download the ISO from the [official website][6]. Arch Linux requires a x86_64 (i.e. 64 bit) compatible machine with a minimum of 512 MB RAM and 800 MB disk space for a minimal installation. However, it is recommended to have 2 GB of RAM and at least 20 GB of storage for a GUI to work without hassle.
|
||||
|
||||
### Step 2: Create a live USB of Arch Linux
|
||||
|
||||
We will have to create a live USB of Arch Linux from the ISO you just downloaded.
|
||||
|
||||
If you are on Linux, you can use **dd command** to create a live USB. Replace /path/to/archlinux.iso with the path where you have downloaded ISO file, and /dev/sdx with your drive in the example below. You can get your drive information using [lsblk][7] command.
|
||||
```
|
||||
dd bs=4M if=/path/to/archlinux.iso of=/dev/sdx status=progress && sync
|
||||
```
|
||||
|
||||
On Windows, there are several tools to create a live USB. The recommended tool is Rufus. We have already covered a tutorial on [how to create a live USB of Antergos Linux using Rufus][8] in the past. Since Antergos is based on Arch, you can follow the same tutorial.
|
||||
|
||||
### Step 3: Boot from the live USB
|
||||
|
||||
Once you have created a live USB for Arch Linux, shut down your PC. Plugin your USB and boot your system. While booting keep pressing F2, F10 or F1dependinging upon your system) to go into boot settings. In here, select to boot from USB or removable disk.
|
||||
|
||||
Once you select that, you should see an option like this:
|
||||
|
||||
![Arch Linux][4]
|
||||
|
||||
![Arch Linux][9]
|
||||
Select Boot Arch Linux (x86_64). After various checks, Arch Linux will boot to login prompt with root user.
|
||||
|
||||
Select Boot Arch Linux (x86_64). After various checks, Arch Linux will boot to login prompt with root user.
|
||||
|
||||
Next steps include partitioning disk, creating the filesystem and mounting it.
|
||||
|
||||
### Step 4: Partitioning the disks
|
||||
|
||||
The first step includes partitioning your hard disk. A single root partition is the simplest one where we will create a root partition (/), a swapfile and home partition.
|
||||
|
||||
I have a 19 GB disk where I want to install Arch Linux. To create a disk, type
|
||||
```
|
||||
fdisk /dev/sda
|
||||
```
|
||||
|
||||
Type "n" for a new partition. Type in "p" for a primary partition and select the partition number.
|
||||
|
||||
The First sector is automatically selected and you just need to press Enter. For Last sector, type the size you want to allocate for this partition.
|
||||
|
||||
Create two more partitions similarly for home and swap, and press 'w' to save the changes and exit.
|
||||
|
||||
![root partition][4]
|
||||
|
||||
![root partition][10]
|
||||
|
||||
### Step 4: Creating filesystem
|
||||
|
||||
Since we have created 3 different partitions, the next step is to format the partition and create a filesystem.
|
||||
|
||||
We will use mkfs for root and home partition and mkswap for creating swap space. We are formatting our disk with ext4 filesystem.
|
||||
```
|
||||
mkfs.ext4 /dev/sda1
|
||||
mkfs.ext4 /dev/sda3
|
||||
|
||||
mkswap /dev/sda2
|
||||
swapon /dev/sda2
|
||||
```
|
||||
|
||||
Lets mount these filesystems to root and home
|
||||
```
|
||||
mount /dev/sda1 /mnt
|
||||
mkdir /mnt/home
|
||||
mount /dev/sda3 /mnt/home
|
||||
```
|
||||
|
||||
### Step 5: Installation
|
||||
|
||||
Since we have created partitioning and mounted it, let's install the base package. A base package contains all the necessary package to run a system, some of which are the GNU BASH shell, data compression tool, file system utilities, C library, compression tools, Linux kernels and modules, library packages, system utilities, USB devices utilities, vi text editor etc.
|
||||
```
|
||||
pacstrap /mnt base base-devel
|
||||
```
|
||||
|
||||
### **Step 6: Configuring the system**
|
||||
|
||||
Generate a fstab file to define how disk partitions, block devices or remote file systems are mounted into the filesystem.
|
||||
```
|
||||
genfstab -U /mnt >> /mnt/etc/fstab
|
||||
```
|
||||
|
||||
Change root into the new system, this allows changing the root directory for the current running process and the child process.
|
||||
```
|
||||
arch-chroot /mnt
|
||||
```
|
||||
|
||||
Some systemd tools which require an active dbus connection can not be used inside a chroot, hence it would be better if we exit from it. To exit chroot, simpy use the below command:
|
||||
```
|
||||
exit
|
||||
```
|
||||
|
||||
### Step 7. Setting Timezone
|
||||
|
||||
Use below command to set the time zone.
|
||||
```
|
||||
ln -sf /usr/share/<zoneinfo>/<Region>/<City> /etc/localtime
|
||||
```
|
||||
|
||||
To get a list of zone, type
|
||||
```
|
||||
ls /usr/share/zoneinfo
|
||||
```
|
||||
|
||||
Run hwclock to set the hardware clock.
|
||||
```
|
||||
hwclock --systohc --utc
|
||||
```
|
||||
|
||||
### Step 8. Setting up Locale.
|
||||
|
||||
File /etc/locale.gen contains all the local settings and system language in a commented format. Open the file using vi editor and un-comment the language you prefer. I had done it for **en_GB.UTF-8**.
|
||||
|
||||
Now generate the locale config in /etc directory file using the commands below:
|
||||
```
|
||||
locale-gen
|
||||
echo LANG=en_GB.UTF-8 > /etc/locale.conf
|
||||
export LANG=en_GB.UTF-8
|
||||
```
|
||||
|
||||
### Step 9. Installing bootloader, setting up hostname and root password
|
||||
|
||||
Create a /etc/hostname file and add a matching entry to host.
|
||||
|
||||
127.0.1.1 myhostname.localdomain myhostname
|
||||
|
||||
I am adding ItsFossArch as a hostname:
|
||||
```
|
||||
echo ItsFossArch > /etc/hostname
|
||||
```
|
||||
|
||||
and then to the /etc/hosts file.
|
||||
|
||||
To install a bootloader use below commands :
|
||||
```
|
||||
pacman -S grub
|
||||
grub-install /dev/sda
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
To create root password, type
|
||||
```
|
||||
passwd
|
||||
```
|
||||
|
||||
and enter your desired password.
|
||||
|
||||
Once done, update your system. Chances are that you already have an updated system since you have downloaded the latest ISO file.
|
||||
```
|
||||
pacman -Syu
|
||||
```
|
||||
|
||||
Congratulations! You have successfully installed a minimal command line Arch Linux.
|
||||
|
||||
In the next step, we will see how to set up a desktop environment or Graphical User Interface for the Arch Linux. I am a big fan of GNOME desktop environment, and we will be working on installing the same.
|
||||
|
||||
### Step 10: Install a desktop environment (GNOME in this case)
|
||||
|
||||
Before you can install a desktop environment, you will need to configure the network first.
|
||||
|
||||
You can see the interface name with below command:
|
||||
```
|
||||
ip link
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
![][11]
|
||||
|
||||
For me, it's **enp0s3.**
|
||||
|
||||
Add the following entries in the file
|
||||
```
|
||||
vi /etc/systemd/network/enp0s3.network
|
||||
|
||||
[Match]
|
||||
name=en*
|
||||
[Network]
|
||||
DHCP=yes
|
||||
```
|
||||
|
||||
Save and exit. Restart your systemd network for the changes to reflect.
|
||||
```
|
||||
systemctl restart systemd-networkd
|
||||
systemctl enable systemd-networkd
|
||||
```
|
||||
|
||||
And then add the below two entries in /etc/resolv.conf file.
|
||||
```
|
||||
nameserver 8.8.8.8
|
||||
nameserver 8.8.4.4
|
||||
```
|
||||
|
||||
Next step is to install X environment.
|
||||
|
||||
Type the below command to install the Xorg as display server.
|
||||
```
|
||||
pacman -S xorg xorg-server
|
||||
```
|
||||
|
||||
gnome contains the base GNOME desktop. gnome-extra contains GNOME applications, archive manager, disk manager, text editors and more.
|
||||
```
|
||||
pacman -S gnome gnome-extra
|
||||
```
|
||||
|
||||
The last step includes enabling the display manager GDM for Arch.
|
||||
```
|
||||
systemctl start gdm.service
|
||||
systemctl enable gdm.service
|
||||
```
|
||||
|
||||
Restart your system and you can see the GNOME login screen.
|
||||
|
||||
## Final Words on Arch Linux installation
|
||||
|
||||
A similar approach has been demonstrated in this video (watch in full screen to see the commands) by It's FOSS reader Gonzalo Tormo:
|
||||
|
||||
You might have realized by now that installing Arch Linux is not as easy as [installing Ubuntu][12]. However, with a little patience, you can surely accomplish it and then tell the world that you use Arch Linux.
|
||||
|
||||
Arch Linux installation itself provides a great deal of learning. And once you have installed it, I recommend referring to its comprehensive [wiki][13] where you can find steps to install various other desktop environments and learn more about the OS. You can keep playing with it and see how powerful Arch is.
|
||||
|
||||
Let us know in the comments if you face any difficulty while installing Arch Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-arch-linux/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1] https://www.archlinux.org/
|
||||
[2] https://en.wikipedia.org/wiki/Do_it_yourself
|
||||
[3] https://wiki.archlinux.org/index.php/pacman
|
||||
[4] data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||
[5] https://itsfoss.com/wp-content/uploads/2017/12/install-arch-linux-featured-800x450.png
|
||||
[6] https://www.archlinux.org/download/
|
||||
[7] https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/deployment_guide/s1-sysinfo-filesystems
|
||||
[8] https://itsfoss.com/live-usb-antergos/
|
||||
[9] https://itsfoss.com/wp-content/uploads/2017/11/1-2.jpg
|
||||
[10] https://itsfoss.com/wp-content/uploads/2017/11/4-root-partition.png
|
||||
[11] https://itsfoss.com/wp-content/uploads/2017/12/11.png
|
||||
[12] https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[13] https://wiki.archlinux.org/
|
||||
@ -0,0 +1,65 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Search PDF Files from the Terminal with pdfgrep
|
||||
======
|
||||
Command line utilities such as [grep][1] and [ack-grep][2] are great for searching plain-text files for patterns matching a specified [regular expression][3]. But have you ever tried using these utilities to search for patterns in a PDF file? Well, don't! You will not get any result as these tools cannot read PDF files; they only read plain-text files.
|
||||
|
||||
[pdfgrep][4], as the name suggests, is a small command line utility that makes it possible to search for text in a PDF file without opening the file. It is insanely fast - faster than the search provided by virtually all PDF document viewers. A great distinction between grep and pdfgrep is that pdfgrep operates on pages, whereas grep operates on lines. It also prints a single line multiple times if more than one match is found on that line. Let's look at how exactly to use the tool.
|
||||
|
||||
For Ubuntu and other Linux distros based on Ubuntu, it is pretty simple:
|
||||
```
|
||||
sudo apt install pdfgrep
|
||||
```
|
||||
|
||||
For other distros, just provide `pdfgrep` as input for the [package manager][5], and that should get it installed. You can also check out the project's [GitLab page][6], in case you want to play around with the code.
|
||||
|
||||
Now that you have the tool installed, let's go for a test run. pdfgrep command takes this format:
|
||||
```
|
||||
pdfgrep [OPTION...] PATTERN [FILE...]
|
||||
```
|
||||
|
||||
**OPTION** is a list of extra attributes to give the command such as `-i` or `--ignore-case`, which both ignore the case distinction between the regular pattern specified and the once matching it from the file.
|
||||
|
||||
**PATTERN** is just an extended regular expression.
|
||||
|
||||
**FILE** is just the name of the file, if it is in the same working directory, or the path to the file.
|
||||
|
||||
I ran the command on Python 3.6 official documentation. The following image is the result.
|
||||
|
||||
![pdfgrep search][7]
|
||||
|
||||
![pdfgrep search][7]
|
||||
|
||||
The red highlights indicate all the places the word "queue" was encountered. Passing `-i` as option to the command included matches of the word "Queue." Remember, the case does not matter when `-i` is passed as an option.
|
||||
|
||||
pdfgrep has quite a number of interesting options to use. However, I'll cover only a few here.
|
||||
|
||||
* `-c` or `--count`: this suppresses the normal output of matches. Instead of displaying the long output of the matches, it only displays a value representing the number of times the word was encountered in the file
|
||||
* `-p` or `--page-count`: this option prints out the page numbers of matches and the number of occurrences of the pattern on the page
|
||||
* `-m` or `--max-count` [number]: specifies the maximum number of matches. That means when the number of matches is reached, the command stops reading the file.
|
||||
|
||||
|
||||
|
||||
The full list of supported options can be found in the man pages or in the pdfgrep online [documenation][8]. Don't forget pdfgrep can search multiple files at the same time, in case you're working with some bulk files. The default match highlight color can be changed by altering the GREP_COLORS environment variable.
|
||||
|
||||
The next time you think of opening up a PDF file to search for anything. think of using pdfgrep. The tool comes in handy and will save you time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/search-pdf-files-pdfgrep/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1] https://www.maketecheasier.com/what-is-grep-and-uses/
|
||||
[2] https://www.maketecheasier.com/ack-a-better-grep/
|
||||
[3] https://www.maketecheasier.com/the-beginner-guide-to-regular-expressions/
|
||||
[4] https://pdfgrep.org/
|
||||
[5] https://www.maketecheasier.com/install-software-in-various-linux-distros/
|
||||
[6] https://gitlab.com/pdfgrep/pdfgrep
|
||||
[7] https://www.maketecheasier.com/assets/uploads/2017/11/pdfgrep-screenshot.png (pdfgrep search)
|
||||
[8] https://pdfgrep.org/doc.html
|
||||
@ -0,0 +1,116 @@
|
||||
How to enable Nested Virtualization in KVM on CentOS 7 / RHEL 7
|
||||
======
|
||||
**Nested virtualization** means to configure virtualization environment inside a virtual machine. In other words we can say nested virtualization is a feature in the hypervisor which allows us to install & run a virtual machine inside a virtual server via hardware acceleration from the **hypervisor** (host).
|
||||
|
||||
In this article, we will discuss how to enable nested virtualization in KVM on CentOS 7 / RHEL 7. I am assuming you have already configured KVM hypervisor. In case you have not familiar on how to install and configure **KVM hypervisor** , then refer the following article
|
||||
|
||||
Let's jump into the hypervisor and verify whether nested virtualization is enabled or not on your KVM host
|
||||
|
||||
For Intel based Processors run the command,
|
||||
```
|
||||
[root@kvm-hypervisor ~]# cat /sys/module/kvm_intel/parameters/nested
|
||||
N
|
||||
[root@kvm-hypervisor ~]#
|
||||
```
|
||||
|
||||
For AMD based Processors run the command,
|
||||
```
|
||||
[root@kvm-hypervisor ~]# cat /sys/module/kvm_amd/parameters/nested
|
||||
N
|
||||
[root@kvm-hypervisor ~]#
|
||||
```
|
||||
|
||||
In the above command output 'N' indicates that Nested virtualization is disabled. If we get the output as 'Y' then it indicates that nested virtualization is enabled on your host.
|
||||
|
||||
Now to enable nested virtualization, create a file with the name " **/etc/modprobe.d/kvm-nested.conf** " with the following content.
|
||||
```
|
||||
[root@kvm-hypervisor ~]# vi /etc/modprobe.d/kvm-nested.conf
|
||||
options kvm-intel nested=1
|
||||
options kvm-intel enable_shadow_vmcs=1
|
||||
options kvm-intel enable_apicv=1
|
||||
options kvm-intel ept=1
|
||||
```
|
||||
|
||||
Save & exit the file
|
||||
|
||||
Now remove ' **kvm_intel** ' module and then add the same module with modprobe command. Before removing the module, make sure VMs are shutdown otherwise we will get error message like " **modprobe: FATAL: Module kvm_intel is in use** "
|
||||
```
|
||||
[root@kvm-hypervisor ~]# modprobe -r kvm_intel
|
||||
[root@kvm-hypervisor ~]# modprobe -a kvm_intel
|
||||
[root@kvm-hypervisor ~]#
|
||||
```
|
||||
|
||||
Now verify whether nested virtualization feature enabled or not.
|
||||
```
|
||||
[root@kvm-hypervisor ~]# cat /sys/module/kvm_intel/parameters/nested
|
||||
Y
|
||||
[root@kvm-hypervisor ~]#
|
||||
```
|
||||
|
||||
####
|
||||
|
||||
Test Nested Virtualization
|
||||
|
||||
Let's suppose we have a VM with name "director" on KVM hypervisor on which I have enabled nested virtualization. Before testing, make sure CPU mode for the VM is either as " **host-model** " or " **host-passthrough** " , to check cpu mode of a virtual machine use either Virt-Manager GUI or virsh edit command
|
||||
|
||||
![cpu_mode_vm_kvm][1]
|
||||
|
||||
![cpu_mode_vm_kvm][2]
|
||||
|
||||
Now login to the director VM and run lscpu and lsmod command
|
||||
```
|
||||
[root@kvm-hypervisor ~]# ssh 192.168.126.1 -l root
|
||||
root@192.168.126.1's password:
|
||||
Last login: Sun Dec 10 07:05:59 2017 from 192.168.126.254
|
||||
[root@director ~]# lsmod | grep kvm
|
||||
kvm_intel 170200 0
|
||||
kvm 566604 1 kvm_intel
|
||||
irqbypass 13503 1 kvm
|
||||
[root@director ~]#
|
||||
[root@director ~]# lscpu
|
||||
```
|
||||
|
||||
![lscpu_command_rhel7_centos7][1]
|
||||
|
||||
![lscpu_command_rhel7_centos7][3]
|
||||
|
||||
Let's try creating a virtual machine either from virtual manager GUI or virt-install inside the director vm, in my case i am using virt-install command
|
||||
```
|
||||
[root@director ~]# virt-install -n Nested-VM --description "Test Nested VM" --os-type=Linux --os-variant=rhel7 --ram=2048 --vcpus=2 --disk path=/var/lib/libvirt/images/nestedvm.img,bus=virtio,size=10 --graphics none --location /var/lib/libvirt/images/CentOS-7-x86_64-DVD-1511.iso --extra-args console=ttyS0
|
||||
Starting install...
|
||||
Retrieving file .treeinfo... | 1.1 kB 00:00:00
|
||||
Retrieving file vmlinuz... | 4.9 MB 00:00:00
|
||||
Retrieving file initrd.img... | 37 MB 00:00:00
|
||||
Allocating 'nestedvm.img' | 10 GB 00:00:00
|
||||
Connected to domain Nested-VM
|
||||
Escape character is ^]
|
||||
[ 0.000000] Initializing cgroup subsys cpuset
|
||||
[ 0.000000] Initializing cgroup subsys cpu
|
||||
[ 0.000000] Initializing cgroup subsys cpuacct
|
||||
[ 0.000000] Linux version 3.10.0-327.el7.x86_64 (builder@kbuilder.dev.centos.org) (gcc version 4.8.3 20140911 (Red Hat 4.8.3-9) (GCC) ) #1 SMP Thu Nov 19 22:10:57 UTC 2015
|
||||
………………………………………………
|
||||
```
|
||||
|
||||
![cli-installer-virt-install-command-kvm][1]
|
||||
|
||||
![cli-installer-virt-install-command-kvm][4]
|
||||
|
||||
This confirms that nested virtualization has been enabled successfully as we are able to create virtual machine inside a virtual machine.
|
||||
|
||||
This Concludes the article, please do share your feedback and comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/enable-nested-virtualization-kvm-centos-7-rhel-7/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com
|
||||
[1]:https://www.linuxtechi.com/wp-content/plugins/lazy-load/images/1x1.trans.gif
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2017/12/cpu_mode_vm_kvm.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2017/12/lscpu_command_rhel7_centos7-1024x408.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2017/12/cli-installer-virt-install-command-kvm.jpg
|
||||
@ -0,0 +1,314 @@
|
||||
Personal Backups with Duplicati on Linux
|
||||
======
|
||||
|
||||
This tutorial is for performing personal backups to local USB hard drives, having encryption, deduplication and compression.
|
||||
|
||||
The procedure was tested using [Duplicati 2.0.2.1][1] on [Debian 9.2][2]
|
||||
|
||||
### Duplicati Installation
|
||||
|
||||
Download the latest version from <https://www.duplicati.com/download>
|
||||
|
||||
The software requires several libraries to work, mostly mono libraries. The easiest way to install the software is to let it fail the installation through dpkg and then install the missing packages with apt-get:
|
||||
|
||||
sudo dpkg -i duplicati_2.0.2.1-1_all.deb
|
||||
sudo apt-get --fix-broken install
|
||||
|
||||
Note that the installation of the package fails on the first instance, then we use apt to install the dependencies.
|
||||
|
||||
Start the daemon:
|
||||
|
||||
sudo systemctl start duplicati.service
|
||||
|
||||
And if you wish for it to start automatically with the OS use:
|
||||
|
||||
sudo systemctl enable duplicati.service
|
||||
|
||||
To check that the service is running:
|
||||
|
||||
netstat -ltn | grep 8200
|
||||
|
||||
And you should receive a response like this one:
|
||||
|
||||
[![][3]][4]
|
||||
|
||||
After these steps you should be able to run the browser and access the local web service at http://localhost:8200
|
||||
|
||||
[![][5]][6]
|
||||
|
||||
### Create a Backup Job
|
||||
|
||||
Go to "Add backup" to configure a new backup job:
|
||||
|
||||
[![][7]][8]
|
||||
|
||||
Set a name for the job and a passphrase for encryption. You will need the passphrase to restore files, so pick a strong password and make sure you don't forget it:
|
||||
|
||||
[![][9]][10]
|
||||
|
||||
Set the destination: the directory where you are going to store the backup files:
|
||||
|
||||
[![][11]][12]
|
||||
|
||||
Select the source files to backup. I will pick just the Desktop folder for this example:
|
||||
|
||||
[![][13]][14]
|
||||
|
||||
Specify filters and exclusions if necessary:
|
||||
|
||||
[![][15]][16]
|
||||
|
||||
Configure a schedule, or disable automatic backups if you prefer to run them manually:
|
||||
|
||||
[![][17]][18]
|
||||
|
||||
I like to use manual backups when using USB drive destinations, and scheduled if I have a server to send backups through SSH or a Cloud based destination.
|
||||
|
||||
Specify the versions to keep, and the Upload volume size (size of each partial file):
|
||||
|
||||
[![][19]][20]
|
||||
|
||||
Finally you should see the job created in a summary like this:
|
||||
|
||||
[![][21]][22]
|
||||
|
||||
### Run the Backup
|
||||
|
||||
In the last seen summary, under Home, click "run now" to start the backup job. A progress bar will be seen by the top of the screen.
|
||||
|
||||
After finishing the backup, you can see in the destination folder, a set of files called something like:
|
||||
```
|
||||
duplicati-20171206T143926Z.dlist.zip.aes
|
||||
duplicati-bdfad38a0b1f34b5db56c1de166260cd8.dblock.zip.aes
|
||||
duplicati-i00d8dff418a749aa9d67d0c54b0e4149.dindex.zip.aes
|
||||
```
|
||||
|
||||
The size of the blocks will be the one specified in the Upload volume size option. The files are compressed, and encrypted using the previously set passphrase.
|
||||
|
||||
Once finished, you will see in the summary the last backup taken and the size:
|
||||
|
||||
[![][23]][24]
|
||||
|
||||
In this case it is only 1MB because I took a test folder.
|
||||
|
||||
### Restore Files
|
||||
|
||||
To restore files, simply access the web administration in http://localhost:8200, go to the "Restore" menu and select the backup job name. Then select the files to restore and click "continue":
|
||||
|
||||
[![][25]][26]
|
||||
|
||||
Select the restore files or folders and the restoration options:
|
||||
|
||||
[![][27]][28]
|
||||
|
||||
The restoration will start running, showing a progress bar on the top of the user interface.
|
||||
|
||||
### Fixate the backup destination
|
||||
|
||||
If you use a USB drive to perform the backups, it is a good idea to specify in the /etc/fstab the UUID of the drive, so that it always mount automatically in the /mnt/backup directory (or the directory of your choosing).
|
||||
|
||||
To do so, connect your drive and check for the UUID:
|
||||
|
||||
sudo blkid
|
||||
```
|
||||
...
|
||||
/dev/sdb1: UUID="4d608d85-e138-4546-9f22-4d78bef0b6a7" TYPE="ext4" PARTUUID="983a72cb-01"
|
||||
...
|
||||
```
|
||||
|
||||
And copy the UUID to include an entry in the /etc/fstab file:
|
||||
```
|
||||
...
|
||||
UUID=4d608d85-e138-4546-9f22-4d78bef0b6a7 /mnt/backup ext4 defaults 0 0
|
||||
...
|
||||
```
|
||||
|
||||
### Remote Access to the GUI
|
||||
|
||||
By default, Duplicati listens on localhost only, and it's meant to be that way. However it includes the possibility to add a password and to be accessible from the network:
|
||||
|
||||
[![][29]][30]
|
||||
|
||||
This setting is not recommended, as Duplicati has no SSL capabilities yet. What I would recommend if you need to use the backup GUI remotely, is using an SSH tunnel.
|
||||
|
||||
To accomplish this, first enable SSH server in case you don't have it yet, the easiest way is running:
|
||||
|
||||
sudo tasksel
|
||||
|
||||
[![][31]][32]
|
||||
|
||||
Once you have the SSH server running on the Duplicati host. Go to the computer from where you want to connect to the GUI and set the tunnel
|
||||
|
||||
Let's consider that:
|
||||
|
||||
* Duplicati backups and its GUI are running in the remote host 192.168.0.150 (that we call the server).
|
||||
* The GUI on the server is listening on port 8200.
|
||||
* jorge is a valid user name in the server.
|
||||
* I will access the GUI from a host on the local port 12345.
|
||||
|
||||
|
||||
|
||||
Then to open an SSH tunnel I run on the client:
|
||||
|
||||
ssh -f jorge@192.168.0.150 -L 12345:localhost:8200 -N
|
||||
|
||||
With netstat it can be checked that the port is open for localhost:
|
||||
|
||||
netstat -ltn | grep :12345
|
||||
```
|
||||
tcp 0 0 127.0.0.1:12345 0.0.0.0:* LISTEN
|
||||
tcp6 0 0 ::1:12345 :::* LISTEN
|
||||
```
|
||||
|
||||
And now I can access the remote GUI by accessing http://127.0.0.1:12345 from the client browser
|
||||
|
||||
[![][34]][35]
|
||||
|
||||
Finally if you want to close the connection to the SSH tunnel you may kill the ssh process. First identify the PID:
|
||||
|
||||
ps x | grep "[s]sh -f"
|
||||
```
|
||||
26348 ? Ss 0:00 ssh -f [[email protected]][33] -L 12345:localhost:8200 -N
|
||||
```
|
||||
|
||||
And kill it:
|
||||
|
||||
kill -9 26348
|
||||
|
||||
Or you can do it all in one:
|
||||
|
||||
kill -9 $(ps x | grep "[s]sh -f" | cut -d" " -f1)
|
||||
|
||||
### Other Backup Repository Options
|
||||
|
||||
If you prefer to store your backups on a remote server rather than on a local hard drive, Duplicati has several options. Standard protocols such as:
|
||||
|
||||
* FTP
|
||||
* OpenStack Object Storage / Swift
|
||||
* SFTP (SSH)
|
||||
* WebDAV
|
||||
|
||||
|
||||
|
||||
And a wider list of proprietary protocols, such as:
|
||||
|
||||
* Amazon Cloud Drive
|
||||
* Amazon S3
|
||||
* Azure
|
||||
* B2 Cloud Storage
|
||||
* Box.com
|
||||
* Dropbox
|
||||
* Google Cloud Storage
|
||||
* Google Drive
|
||||
* HubiC
|
||||
* Jottacloud
|
||||
* mega.nz
|
||||
* Microsoft One Drive
|
||||
* Microsoft One Drive for Business
|
||||
* Microsoft Sharepoint
|
||||
* OpenStack Simple Storage
|
||||
* Rackspace CloudFiles
|
||||
|
||||
|
||||
|
||||
For FTP, SFTP, WebDAV is as simple as setting the server hostname or IP address, adding credentials and then using the whole previous process. As a result, I don't believe it is of any value describing them.
|
||||
|
||||
However, as I find it useful for personal matters having a cloud based backup, I will describe the configuration for Dropbox, which uses the same procedure as for Google Drive and Microsoft OneDrive.
|
||||
|
||||
#### Dropbox
|
||||
|
||||
Let's create a new backup job and set the destination to Dropbox. All the configurations are exactly the same except for the destination that should be set like this:
|
||||
|
||||
[![][36]][37]
|
||||
|
||||
Once you set up "Dropbox" from the drop-down menu, and configured the destination folder, click on the OAuth link to set the authentication.
|
||||
|
||||
A pop-up will emerge for you to login to Dropbox (or Google Drive or OneDrive depending on your choosing):
|
||||
|
||||
[![][38]][39]
|
||||
|
||||
After logging in you will be prompted to allow Duplicati app to your cloud storage:
|
||||
|
||||
[![][40]][41]
|
||||
|
||||
After finishing the last process, the AuthID field will be automatically filled in:
|
||||
|
||||
[![][42]][43]
|
||||
|
||||
Click on "Test Connection". When testing the connection you will be asked to create the folder in the case it does not exist:
|
||||
|
||||
[![][44]][45]
|
||||
|
||||
And finally it will give you a notification that the connection is successful:
|
||||
|
||||
[![][46]][47]
|
||||
|
||||
If you access your Dropbox account you will see the files, in the same format that we have seen before, under the defined folder:
|
||||
|
||||
[![][48]][49]
|
||||
|
||||
### Conclusions
|
||||
|
||||
Duplicati is a multi-platform, feature-rich, easy to use backup solution for personal computers. It supports a wide variety of backup repositories what makes it a very versatile tool that can adapt to most personal needs.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/personal-backups-with-duplicati-on-linux/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://updates.duplicati.com/beta/duplicati_2.0.2.1-1_all.deb
|
||||
[2]:https://www.debian.org/releases/stable/
|
||||
[3]:https://www.howtoforge.com/images/personal_backups_with_duplicati/installation-netstat.png
|
||||
[4]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/installation-netstat.png
|
||||
[5]:https://www.howtoforge.com/images/personal_backups_with_duplicati/installation-web.png
|
||||
[6]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/installation-web.png
|
||||
[7]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-1.png
|
||||
[8]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-1.png
|
||||
[9]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-2.png
|
||||
[10]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-2.png
|
||||
[11]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-3.png
|
||||
[12]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-3.png
|
||||
[13]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-4.png
|
||||
[14]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-4.png
|
||||
[15]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-5.png
|
||||
[16]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-5.png
|
||||
[17]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-6.png
|
||||
[18]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-6.png
|
||||
[19]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-7.png
|
||||
[20]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-7.png
|
||||
[21]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-8.png
|
||||
[22]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-8.png
|
||||
[23]:https://www.howtoforge.com/images/personal_backups_with_duplicati/run-1.png
|
||||
[24]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/run-1.png
|
||||
[25]:https://www.howtoforge.com/images/personal_backups_with_duplicati/restore-1.png
|
||||
[26]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/restore-1.png
|
||||
[27]:https://www.howtoforge.com/images/personal_backups_with_duplicati/restore-2.png
|
||||
[28]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/restore-2.png
|
||||
[29]:https://www.howtoforge.com/images/personal_backups_with_duplicati/remote-1.png
|
||||
[30]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/remote-1.png
|
||||
[31]:https://www.howtoforge.com/images/personal_backups_with_duplicati/remote-sshd.png
|
||||
[32]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/remote-sshd.png
|
||||
[33]:https://www.howtoforge.com/cdn-cgi/l/email-protection
|
||||
[34]:https://www.howtoforge.com/images/personal_backups_with_duplicati/remote-sshtun.png
|
||||
[35]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/remote-sshtun.png
|
||||
[36]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-1.png
|
||||
[37]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-1.png
|
||||
[38]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-2.png
|
||||
[39]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-2.png
|
||||
[40]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-4.png
|
||||
[41]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-4.png
|
||||
[42]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-5.png
|
||||
[43]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-5.png
|
||||
[44]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-6.png
|
||||
[45]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-6.png
|
||||
[46]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-7.png
|
||||
[47]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-7.png
|
||||
[48]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-8.png
|
||||
[49]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-8.png
|
||||
@ -0,0 +1,282 @@
|
||||
Toplip – A Very Strong File Encryption And Decryption CLI Utility
|
||||
======
|
||||
There are numerous file encryption tools available on the market to protect
|
||||
your files. We have already reviewed some encryption tools such as
|
||||
[**Cryptomater**][1], [**Cryptkeeper**][2], [**CryptGo**][3], [**Cryptr**][4],
|
||||
[**Tomb**][5], and [**GnuPG**][6] etc. Today, we will be discussing yet
|
||||
another file encryption and decryption command line utility named **"
|
||||
Toplip"**. It is a free and open source encryption utility that uses a very
|
||||
strong encryption method called **[AES256][7]** , along with an **XTS-AES**
|
||||
design to safeguard your confidential data. Also, it uses [**Scrypt**][8], a
|
||||
password-based key derivation function, to protect your passphrases against
|
||||
brute-force attacks.
|
||||
|
||||
### Prominent features
|
||||
|
||||
Compared to other file encryption tools, toplip ships with the following
|
||||
unique and prominent features.
|
||||
|
||||
* Very strong XTS-AES256 based encryption method.
|
||||
* Plausible deniability.
|
||||
* Encrypt files inside images (PNG/JPG).
|
||||
* Multiple passphrase protection.
|
||||
* Simplified brute force recovery protection.
|
||||
* No identifiable output markers.
|
||||
* Open source/GPLv3.
|
||||
|
||||
### Installing Toplip
|
||||
|
||||
There is no installation required. Toplip is a standalone executable binary
|
||||
file. All you have to do is download the latest toplip from the [**official
|
||||
products page**][9] and make it as executable. To do so, just run:
|
||||
|
||||
```
|
||||
chmod +x toplip
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
If you run toplip without any arguments, you will see the help section.
|
||||
|
||||
```
|
||||
./toplip
|
||||
```
|
||||
|
||||
[![][10]][11]
|
||||
|
||||
Allow me to show you some examples.
|
||||
|
||||
For the purpose of this guide, I have created two files namely **file1** and
|
||||
**file2**. Also, I have an image file which we need it to hide the files
|
||||
inside it. And finally, I have **toplip** executable binary file. I have kept
|
||||
them all in a directory called **test**.
|
||||
|
||||
[![][12]][13]
|
||||
|
||||
**Encrypt/decrypt a single file**
|
||||
|
||||
Now, let us encrypt **file1**. To do so, run:
|
||||
|
||||
```
|
||||
./toplip file1 > file1.encrypted
|
||||
```
|
||||
|
||||
This command will prompt you to enter a passphrase. Once you have given the
|
||||
passphrase, it will encrypt the contents of **file1** and save them in a file
|
||||
called **file1.encrypted** in your current working directory.
|
||||
|
||||
Sample output of the above command would be:
|
||||
|
||||
```
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip file1 Passphrase #1: generating keys...Done
|
||||
Encrypting...Done
|
||||
```
|
||||
|
||||
To verify if the file is really encrypted., try to open it and you will see
|
||||
some random characters.
|
||||
|
||||
To decrypt the encrypted file, use **-d** flag like below:
|
||||
|
||||
```
|
||||
./toplip -d file1.encrypted
|
||||
```
|
||||
|
||||
This command will decrypt the given file and display the contents in the
|
||||
Terminal window.
|
||||
|
||||
To restore the file instead of writing to stdout, do:
|
||||
|
||||
```
|
||||
./toplip -d file1.encrypted > file1.decrypted
|
||||
```
|
||||
|
||||
Enter the correct passphrase to decrypt the file. All contents of **file1.encrypted** will be restored in a file called **file1.decrypted**.
|
||||
|
||||
Please don't follow this naming method. I used it for the sake of easy understanding. Use any other name(s) which is very hard to predict.
|
||||
|
||||
**Encrypt/decrypt multiple files
|
||||
**
|
||||
|
||||
Now we will encrypt two files with two separate passphrases for each one.
|
||||
|
||||
```
|
||||
./toplip -alt file1 file2 > file3.encrypted
|
||||
```
|
||||
|
||||
You will be asked to enter passphrase for each file. Use different
|
||||
passphrases.
|
||||
|
||||
Sample output of the above command will be:
|
||||
|
||||
```
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
**file2 Passphrase #1** : generating keys...Done
|
||||
**file1 Passphrase #1** : generating keys...Done
|
||||
Encrypting...Done
|
||||
```
|
||||
|
||||
What the above command will do is encrypt the contents of two files and save
|
||||
them in a single file called **file3.encrypted**. While restoring, just give
|
||||
the respective password. For example, if you give the passphrase of the file1,
|
||||
toplip will restore file1. If you enter the passphrase of file2, toplip will
|
||||
restore file2.
|
||||
|
||||
Each **toplip** encrypted output may contain up to four wholly independent
|
||||
files, and each created with their own separate and unique passphrase. Due to
|
||||
the way the encrypted output is put together, there is no way to easily
|
||||
determine whether or not multiple files actually exist in the first place. By
|
||||
default, even if only one file is encrypted using toplip, random data is added
|
||||
automatically. If more than one file is specified, each with their own
|
||||
passphrase, then you can selectively extract each file independently and thus
|
||||
deny the existence of the other files altogether. This effectively allows a
|
||||
user to open an encrypted bundle with controlled exposure risk, and no
|
||||
computationally inexpensive way for an adversary to conclusively identify that
|
||||
additional confidential data exists. This is called **Plausible deniability**
|
||||
, one of the notable feature of toplip.
|
||||
|
||||
To decrypt **file1** from **file3.encrypted** , just enter:
|
||||
|
||||
```
|
||||
./toplip -d file3.encrypted > file1.encrypted
|
||||
```
|
||||
|
||||
You will be prompted to enter the correct passphrase of file1.
|
||||
|
||||
To decrypt **file2** from **file3.encrypted** , enter:
|
||||
|
||||
```
|
||||
./toplip -d file3.encrypted > file2.encrypted
|
||||
```
|
||||
|
||||
Do not forget to enter the correct passphrase of file2.
|
||||
|
||||
**Use multiple passphrase protection**
|
||||
|
||||
This is another cool feature that I admire. We can provide multiple
|
||||
passphrases for a single file when encrypting it. It will protect the
|
||||
passphrases against brute force attempts.
|
||||
|
||||
```
|
||||
./toplip -c 2 file1 > file1.encrypted
|
||||
```
|
||||
|
||||
Here, **-c 2** represents two different passphrases. Sample output of above
|
||||
command would be:
|
||||
|
||||
```
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
**file1 Passphrase #1:** generating keys...Done
|
||||
**file1 Passphrase #2:** generating keys...Done
|
||||
Encrypting...Done
|
||||
```
|
||||
|
||||
As you see in the above example, toplip prompted me to enter two passphrases.
|
||||
Please note that you must **provide two different passphrases** , not a single
|
||||
passphrase twice.
|
||||
|
||||
To decrypt this file, do:
|
||||
|
||||
```
|
||||
$ ./toplip -c 2 -d file1.encrypted > file1.decrypted
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
**file1.encrypted Passphrase #1:** generating keys...Done
|
||||
**file1.encrypted Passphrase #2:** generating keys...Done
|
||||
Decrypting...Done
|
||||
```
|
||||
|
||||
**Hide files inside image**
|
||||
|
||||
The practice of concealing a file, message, image, or video within another
|
||||
file is called **steganography**. Fortunately, this feature exists in toplip
|
||||
by default.
|
||||
|
||||
To hide a file(s) inside images, use **-m** flag as shown below.
|
||||
|
||||
```
|
||||
$ ./toplip -m image.png file1 > image1.png
|
||||
This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
file1 Passphrase #1: generating keys...Done
|
||||
Encrypting...Done
|
||||
```
|
||||
|
||||
This command conceals the contents of file1 inside an image named image1.png.
|
||||
To decrypt it, run:
|
||||
|
||||
```
|
||||
$ ./toplip -d image1.png > file1.decrypted This is toplip v1.20 (C) 2015, 2016 2 Ton Digital. Author: Jeff Marrison A showcase piece for the HeavyThing library. Commercial support available Proudly made in Cooroy, Australia. More info: https://2ton.com.au/toplip
|
||||
image1.png Passphrase #1: generating keys...Done
|
||||
Decrypting...Done
|
||||
```
|
||||
|
||||
**Increase password complexity**
|
||||
|
||||
To make things even harder to break, we can increase the password complexity
|
||||
like below.
|
||||
|
||||
```
|
||||
./toplip -c 5 -i 0x8000 -alt file1 -c 10 -i 10 file2 > file3.encrypted
|
||||
```
|
||||
|
||||
The above command will prompt to you enter 10 passphrases for the file1, 5
|
||||
passphrases for the file2 and encrypt both of them in a single file called
|
||||
"file3.encrypted". As you may noticed, we have used one more additional flag
|
||||
**-i** in this example. This is used to specify key derivation iterations.
|
||||
This option overrides the default iteration count of 1 for scrypt's initial
|
||||
and final PBKDF2 stages. Hexadecimal or decimal values permitted, e.g.
|
||||
**0x8000** , **10** , etc. Please note that this can dramatically increase the
|
||||
calculation times.
|
||||
|
||||
To decrypt file1, use:
|
||||
|
||||
```
|
||||
./toplip -c 5 -i 0x8000 -d file3.encrypted > file1.decrypted
|
||||
```
|
||||
|
||||
To decrypt file2, use:
|
||||
|
||||
```
|
||||
./toplip -c 10 -i 10 -d file3.encrypted > file2.decrypted
|
||||
```
|
||||
|
||||
To know more about the underlying technical information and crypto methods
|
||||
used in toplip, refer its official website given at the end.
|
||||
|
||||
My personal recommendation to all those who wants to protect their data. Don't
|
||||
rely on single method. Always use more than one tools/methods to encrypt
|
||||
files. Do not write passphrases/passwords in a paper and/or do not save them
|
||||
in your local or cloud storage. Just memorize them and destroy the notes. If
|
||||
you're poor at remembering passwords, consider to use any trustworthy password
|
||||
managers.
|
||||
|
||||
And, that's all. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/toplip-strong-file-encryption-decryption-cli-utility/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/cryptomator-open-source-client-side-encryption-tool-cloud/
|
||||
[2]:https://www.ostechnix.com/how-to-encrypt-your-personal-foldersdirectories-in-linux-mint-ubuntu-distros/
|
||||
[3]:https://www.ostechnix.com/cryptogo-easy-way-encrypt-password-protect-files/
|
||||
[4]:https://www.ostechnix.com/cryptr-simple-cli-utility-encrypt-decrypt-files/
|
||||
[5]:https://www.ostechnix.com/tomb-file-encryption-tool-protect-secret-files-linux/
|
||||
[6]:https://www.ostechnix.com/an-easy-way-to-encrypt-and-decrypt-files-from-commandline-in-linux/
|
||||
[7]:http://en.wikipedia.org/wiki/Advanced_Encryption_Standard
|
||||
[8]:http://en.wikipedia.org/wiki/Scrypt
|
||||
[9]:https://2ton.com.au/Products/
|
||||
[10]:https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2.png%201366w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2-300x157.png%20300w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2-768x403.png%20768w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2-1024x537.png%201024w
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/12/toplip-2.png
|
||||
[12]:https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-1.png%20779w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-1-300x101.png%20300w,%20https://www.ostechnix.com/wp-content/uploads/2017/12/toplip-1-768x257.png%20768w
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2017/12/toplip-1.png
|
||||
|
||||
58
sources/tech/20171213 Will DevOps steal my job-.md
Normal file
58
sources/tech/20171213 Will DevOps steal my job-.md
Normal file
@ -0,0 +1,58 @@
|
||||
Will DevOps steal my job?
|
||||
======
|
||||
|
||||
>Are you worried automation will replace people in the workplace? You may be right, but here's why that's not a bad thing.
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
It's a common fear: Will DevOps be the end of my job? After all, DevOps means developers doing operations, right? DevOps is automation. What if I automate myself out of a job? Do continuous delivery and containers mean operations staff are obsolete? DevOps is all about coding: infrastructure-as-code and testing-as-code and this-or-that-as-code. What if I don't have the skill set to be a part of this?
|
||||
|
||||
[DevOps][1] is a looming change, disruptive in the field, with seemingly fanatical followers talking about changing the world with the [Three Ways][2]--the three underpinnings of DevOps--and the tearing down of walls. It can all be overwhelming. So what's it going to be--is DevOps going to steal my job?
|
||||
|
||||
### The first fear: I'm not needed
|
||||
|
||||
As developers managing the entire lifecycle of an application, it's all too easy to get caught up in the idea of DevOps. Containers are probably a big contributing factor to this line of thought. When containers exploded onto the scene, they were touted as a way for developers to build, test, and deploy their code all-in-one. What role does DevOps leave for the operations team, or testing, or QA?
|
||||
|
||||
This stems from a misunderstanding of the principles of DevOps. The first principle of DevOps, or the First Way, is _Systems Thinking_ , or placing emphasis on a holistic approach to managing and understanding the whole lifecycle of an application or service. This does not mean that the developers of the application learn and manage the whole process. Rather, it is the collaboration of talented and skilled individuals to ensure success as a whole. To make developers solely responsible for the process is practically the extreme opposite of this tenant--essentially the enshrining of a single silo with the importance of the entire lifecycle.
|
||||
|
||||
There is a place for specialization in DevOps. Just as the classically educated software engineer with knowledge of linear regression and binary search is wasted writing Ansible playbooks and Docker files, the highly skilled sysadmin with the knowledge of how to secure a system and optimize database performance is wasted writing CSS and designing user flows. The most effective group to write, test, and maintain an application is a cross-discipline, functional team of people with diverse skill sets and backgrounds.
|
||||
|
||||
### The second fear: My job will be automated
|
||||
|
||||
Accurate or not, DevOps can sometimes be seen as a synonym for automation. What work is left for operations staff and testing teams when automated builds, testing, deployment, monitoring, and notifications are a huge part of the application lifecycle? This focus on automation can be partially related to the Second Way: _Amplify Feedback Loops_. This second tenant of DevOps deals with prioritizing quick feedback between teams in the opposite direction an application takes to deployment --from monitoring and maintaining to deployment, testing, development, etc., and the emphasis to make the feedback important and actionable. While the Second Way is not specifically related to automation, many of the automation tools teams use within their deployment pipelines facilitate quick notification and quick action, or course-correction based on feedback in support of this tenant. Traditionally done by humans, it is easy to understand why a focus on automation might lead to anxiety about the future of one's job.
|
||||
|
||||
Automation is just a tool, not a replacement for people. Smart people trapped doing the same things over and over, pushing the big red George Jetson button are a wasted, untapped wealth of intelligence and creativity. Automation of the drudgery of daily work means more time to spend solving real problems and coming up with creative solutions. Humans are needed to figure out the "how and why;" computers can handle the "copy and paste."
|
||||
|
||||
There will be no end of repetitive, predictable things to automate, and automation frees teams to focus on higher-order tasks in their field. Monitoring teams, no longer spending all their time configuring alerts or managing trending configuration, can start to focus on predicting alarms, correlating statistics, and creating proactive solutions. Systems administrators, freed of scheduled patching or server configuration, can spend time focusing on fleet management, performance, and scaling. Unlike the striking images of factory floors and assembly lines totally devoid of humans, automated tasks in the DevOps world mean humans can focus on creative, rewarding tasks instead of mind-numbing drudgery.
|
||||
|
||||
### The third fear: I do not have the skillset for this
|
||||
|
||||
"How am I going to keep up with this? I don't know how to automate. Everything is code now--do I have to be a developer and write code for a living to work in DevOps?" The third fear is ultimately a fear of self-confidence. As the culture changes, yes, teams will be asked to change along with it, and some may fear they lack the skills to perform what their jobs will become.
|
||||
|
||||
Most folks, however, are probably already closer than they think. What is the Dockerfile, or configuration management like Puppet or Ansible, but environment as code? System administrators already write shell scripts and Python programs to handle repetitive tasks for them. It's hardly a stretch to learn a little more and begin using some of the tools already at their disposal to solve more problems--orchestration, deployment, maintenance-as-code--especially when freed from the drudgery of manual tasks to focus on growth.
|
||||
|
||||
The answer to this fear lies in the third tenant of DevOps, the Third Way: _A Culture of Continual Experimentation and Learning_. The ability to try and fail and learn from mistakes without blame is a major factor in creating ever-more creative solutions. The Third Way is empowered by the first two ways --allowing for for quick detection of and repair of problems, and just as the developer is free to try and learn, other teams are as well. Operations teams that have never used configuration management or written programs to automate infrastructure provisioning are free to try and learn. Testing and QA teams are free to implement new testing pipelines and automate approval and release processes. In a culture that embraces learning and growing, everyone has the freedom to acquire the skills they need to succeed at and enjoy their job.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Any disruptive practice or change in an industry can create fear or uncertainty, and DevOps is no exception. A concern for one's job is a reasonable response to the hundreds of articles and presentations enumerating the countless practices and technologies seemingly dedicated to empowering developers to take responsibility for every aspect of the industry.
|
||||
|
||||
In truth, however, DevOps is "[a cross-disciplinary community of practice dedicated to the study of building, evolving, and operating rapidly changing resilient systems at scale][3]." DevOps means the end of silos, but not specialization. It is the delegation of drudgery to automated systems, freeing you to do what people do best: think and imagine. And if you're motivated to learn and grow, there will be no end of opportunities to solve new and challenging problems.
|
||||
|
||||
Will DevOps take away your job? Yes, but it will give you a better one.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/will-devops-steal-my-job
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clcollins
|
||||
[1]:https://opensource.com/resources/devops
|
||||
[2]:http://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[3]:https://theagileadmin.com/what-is-devops/
|
||||
118
sources/tech/20171214 6 open source home automation tools.md
Normal file
118
sources/tech/20171214 6 open source home automation tools.md
Normal file
@ -0,0 +1,118 @@
|
||||
6 open source home automation tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
The [Internet of Things][13] isn't just a buzzword, it's a reality that's expanded rapidly since we last published a review article on home automation tools in 2016\. In 2017, [26.5% of U.S. households][14] already had some type of smart home technology in use; within five years that percentage is expected to double.
|
||||
|
||||
With an ever-expanding number of devices available to help you automate, protect, and monitor your home, it has never been easier nor more tempting to try your hand at home automation. Whether you're looking to control your HVAC system remotely, integrate a home theater, protect your home from theft, fire, or other threats, reduce your energy usage, or just control a few lights, there are countless devices available at your disposal.
|
||||
|
||||
But at the same time, many users worry about the security and privacy implications of bringing new devices into their homes—a very real and [serious consideration][15]. They want to control who has access to the vital systems that control their appliances and record every moment of their everyday lives. And understandably so: In an era when even your refrigerator may now be a smart device, don't you want to know if your fridge is phoning home? Wouldn't you want some basic assurance that, even if you give a device permission to communicate externally, it is only accessible to those who are explicitly authorized?
|
||||
|
||||
[Security concerns][16] are among the many reasons why open source will be critical to our future with connected devices. Being able to fully understand the programs that control your home means you can view, and if necessary modify, the source code running on the devices themselves.
|
||||
|
||||
While connected devices often contain proprietary components, a good first step in bringing open source into your home automation system is to ensure that the device that ties your devices together—and presents you with an interface to them (the "hub")—is open source. Fortunately, there are many choices out there, with options to run on everything from your always-on personal computer to a Raspberry Pi.
|
||||
|
||||
Here are just a few of our favorites.
|
||||
|
||||
### Calaos
|
||||
|
||||
[Calaos][17] is designed as a full-stack home automation platform, including a server application, touchscreen interface, web application, native mobile applications for iOS and Android, and a preconfigured Linux operating system to run underneath. The Calaos project emerged from a French company, so its support forums are primarily in French, although most of the instructional material and documentation have been translated into English.
|
||||
|
||||
Calaos is licensed under version 3 of the [GPL][18] and you can view its source on [GitHub][19].
|
||||
|
||||
### Domoticz
|
||||
|
||||
[Domoticz][20] is a home automation system with a pretty wide library of supported devices, ranging from weather stations to smoke detectors to remote controls, and a large number of additional third-party [integrations][21] are documented on the project's website. It is designed with an HTML5 frontend, making it accessible from desktop browsers and most modern smartphones, and is lightweight, running on many low-power devices like the Raspberry Pi.
|
||||
|
||||
Domoticz is written primarily in C/C++ under the [GPLv3][22], and its [source code][23] can be browsed on GitHub.
|
||||
|
||||
### Home Assistant
|
||||
|
||||
[Home Assistant][24] is an open source home automation platform designed to be easily deployed on almost any machine that can run Python 3, from a Raspberry Pi to a network-attached storage (NAS) device, and it even ships with a Docker container to make deploying on other systems a breeze. It integrates with a large number of open source as well as commercial offerings, allowing you to link, for example, IFTTT, weather information, or your Amazon Echo device, to control hardware from locks to lights.
|
||||
|
||||
Home Assistant is released under an [MIT license][25], and its source can be downloaded from [GitHub][26].
|
||||
|
||||
### MisterHouse
|
||||
|
||||
[MisterHouse][27] has gained a lot of ground since 2016, when we mentioned it as "another option to consider" on this list. It uses Perl scripts to monitor anything that can be queried by a computer or control anything capable of being remote controlled. It responds to voice commands, time of day, weather, location, and other events to turn on the lights, wake you up, record your favorite TV show, announce phone callers, warn that your front door is open, report how long your son has been online, tell you if your daughter's car is speeding, and much more. It runs on Linux, macOS, and Windows computers and can read/write from a wide variety of devices including security systems, weather stations, caller ID, routers, vehicle location systems, and more
|
||||
|
||||
MisterHouse is licensed under the [GPLv2][28] and you can view its source code on [GitHub][29].
|
||||
|
||||
### OpenHAB
|
||||
|
||||
[OpenHAB][30] (short for Open Home Automation Bus) is one of the best-known home automation tools among open source enthusiasts, with a large user community and quite a number of supported devices and integrations. Written in Java, openHAB is portable across most major operating systems and even runs nicely on the Raspberry Pi. Supporting hundreds of devices, openHAB is designed to be device-agnostic while making it easier for developers to add their own devices or plugins to the system. OpenHAB also ships iOS and Android apps for device control, as well as design tools so you can create your own UI for your home system.
|
||||
|
||||
You can find openHAB's [source code][31] on GitHub licensed under the [Eclipse Public License][32].
|
||||
|
||||
### OpenMotics
|
||||
|
||||
[OpenMotics][33] is a home automation system with both hardware and software under open source licenses. It's designed to provide a comprehensive system for controlling devices, rather than stitching together many devices from different providers. Unlike many of the other systems designed primarily for easy retrofitting, OpenMotics focuses on a hardwired solution. For more, see our [full article][34] from OpenMotics backend developer Frederick Ryckbosch.
|
||||
|
||||
The source code for OpenMotics is licensed under the [GPLv2][35] and is available for download on [GitHub][36].
|
||||
|
||||
These aren't the only options available, of course. Many home automation enthusiasts go with a different solution, or even decide to roll their own. Other users choose to use individual smart home devices without integrating them into a single comprehensive system.
|
||||
|
||||
If the solutions above don't meet your needs, here are some potential alternatives to consider:
|
||||
|
||||
* [EventGhost][1] is an open source ([GPL v2][2]) home theater automation tool that operates only on Microsoft Windows PCs. It allows users to control media PCs and attached hardware by using plugins that trigger macros or by writing custom Python scripts.
|
||||
|
||||
* [ioBroker][3] is a JavaScript-based IoT platform that can control lights, locks, thermostats, media, webcams, and more. It will run on any hardware that runs Node.js, including Windows, Linux, and macOS, and is open sourced under the [MIT license][4].
|
||||
|
||||
* [Jeedom][5] is a home automation platform comprised of open source software ([GPL v2][6]) to control lights, locks, media, and more. It includes a mobile app (Android and iOS) and operates on Linux PCs; the company also sells hubs that it says provide a ready-to-use solution for setting up home automation.
|
||||
|
||||
* [LinuxMCE][7] bills itself as the "'digital glue' between your media and all of your electrical appliances." It runs on Linux (including Raspberry Pi), is released under the Pluto open source [license][8], and can be used for home security, telecom (VoIP and voice mail), A/V equipment, home automation, and—uniquely—to play video games.
|
||||
|
||||
* [OpenNetHome][9], like the other solutions in this category, is open source software for controlling lights, alarms, appliances, etc. It's based on Java and Apache Maven, operates on Windows, macOS, and Linux—including Raspberry Pi, and is released under [GPLv3][10].
|
||||
|
||||
* [Smarthomatic][11] is an open source home automation framework that concentrates on hardware devices and software, rather than user interfaces. Licensed under [GPLv3][12], it's used for things such as controlling lights, appliances, and air humidity, measuring ambient temperature, and remembering to water your plants.
|
||||
|
||||
Now it's your turn: Do you already have an open source home automation system in place? Or perhaps you're researching the options to create one. What advice would you have to a newcomer to home automation, and what system or systems would you recommend?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/17/12/home-automation-tools
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://www.eventghost.net/
|
||||
[2]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[3]:http://iobroker.net/
|
||||
[4]:https://github.com/ioBroker/ioBroker#license
|
||||
[5]:https://www.jeedom.com/site/en/index.html
|
||||
[6]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
|
||||
[7]:http://www.linuxmce.com/
|
||||
[8]:http://wiki.linuxmce.org/index.php/License
|
||||
[9]:http://opennethome.org/
|
||||
[10]:https://github.com/NetHome/NetHomeServer/blob/master/LICENSE
|
||||
[11]:https://www.smarthomatic.org/
|
||||
[12]:https://github.com/breaker27/smarthomatic/blob/develop/GPL3.txt
|
||||
[13]:https://opensource.com/resources/internet-of-things
|
||||
[14]:https://www.statista.com/outlook/279/109/smart-home/united-states
|
||||
[15]:http://www.crn.com/slide-shows/internet-of-things/300089496/black-hat-2017-9-iot-security-threats-to-watch.htm
|
||||
[16]:https://opensource.com/business/15/5/why-open-source-means-stronger-security
|
||||
[17]:https://calaos.fr/en/
|
||||
[18]:https://github.com/calaos/calaos-os/blob/master/LICENSE
|
||||
[19]:https://github.com/calaos
|
||||
[20]:https://domoticz.com/
|
||||
[21]:https://www.domoticz.com/wiki/Integrations_and_Protocols
|
||||
[22]:https://github.com/domoticz/domoticz/blob/master/License.txt
|
||||
[23]:https://github.com/domoticz/domoticz
|
||||
[24]:https://home-assistant.io/
|
||||
[25]:https://github.com/home-assistant/home-assistant/blob/dev/LICENSE.md
|
||||
[26]:https://github.com/balloob/home-assistant
|
||||
[27]:http://misterhouse.sourceforge.net/
|
||||
[28]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[29]:https://github.com/hollie/misterhouse
|
||||
[30]:http://www.openhab.org/
|
||||
[31]:https://github.com/openhab/openhab
|
||||
[32]:https://github.com/openhab/openhab/blob/master/LICENSE.TXT
|
||||
[33]:https://www.openmotics.com/
|
||||
[34]:https://opensource.com/life/14/12/open-source-home-automation-system-opemmotics
|
||||
[35]:http://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[36]:https://github.com/openmotics
|
||||
@ -0,0 +1,121 @@
|
||||
How to Install and Use Encryptpad on Ubuntu 16.04
|
||||
======
|
||||
|
||||
EncryptPad is a free and open source software application that can be used for viewing and editing encrypted text using a simple and convenient graphical and command line interface. It uses OpenPGP RFC 4880 file format. You can easily encrypt and decrypt file using EncryptPad. Using EncryptPad, you can save your private information like, password, credit card information and access the file using a password or key files.
|
||||
|
||||
#### Features
|
||||
|
||||
* Supports Windows, Linux and Mac OS
|
||||
* Customisable passphrase generator helps create strong random passphrases.
|
||||
* Random key file and password generator.
|
||||
* Supports GPG and EPD file formats.
|
||||
* You can download key automatically from remote storage using CURL.
|
||||
* Path to a key file can be stored in an encrypted file. If enabled, you do not need to specify the key file every time you open files.
|
||||
* Provide read only mode to prevent file modification.
|
||||
* Encrypt binary files such as, images, videos, archives.
|
||||
|
||||
|
||||
|
||||
In this tutorial, we will learn how to install and use the software EncryptPad on Ubuntu 16.04.
|
||||
|
||||
### Requirements
|
||||
|
||||
* Ubuntu 16.04 desktop version installed on your system.
|
||||
* A normal user with sudo privileges setup on your system.
|
||||
|
||||
|
||||
|
||||
### Install EncryptPad
|
||||
|
||||
By default, EncryptPad is not available in Ubuntu 16.04 default repository. So you will need to install an additional repository for EncryptPad first. You can add it with the following command:
|
||||
|
||||
sudo apt-add-repository ppa:nilarimogard/webupd8
|
||||
|
||||
Next, update the repository using the following command:
|
||||
|
||||
sudo apt-get update -y
|
||||
|
||||
Finally, install EncryptPad by running the following command:
|
||||
|
||||
sudo apt-get install encryptpad encryptcli -y
|
||||
|
||||
Once the installation is completed, you should locate it under Ubuntu dashboard.
|
||||
|
||||
### Access EncryptPad and Generate Key and Passphrase
|
||||
|
||||
Now, go to the **Ubuntu Dash** and type **encryptpad** , you should see the following screen:
|
||||
|
||||
[![Ubuntu Desktop][1]][2]
|
||||
|
||||
Next, click on the **EncryptPad** icon, you should see the first screen of the EncryptPad in following screen. It is a simple text editor and has a menu bar on the top.
|
||||
|
||||
[![EncryptPad][3]][4]
|
||||
|
||||
First, you will need to generate a key and passphrase for future encryption/decryption tasks. To do so, click on **Encryption > Generate Key** option from the top menu, you should see the following screen:
|
||||
|
||||
[![Generate Key][5]][6]
|
||||
|
||||
Here, select the path where you want to save the file and click on the **Ok** button, you should see the following screen:
|
||||
|
||||
[![Passphrase for key file][7]][8]
|
||||
|
||||
Now, enter passphrase for the key file and click on the **Ok** button, you should see the following screen:
|
||||
|
||||
[![Use generated key for this file][9]][10]
|
||||
|
||||
Now, click on the yes button to finish the process.
|
||||
|
||||
### Encrypt and Decrypt File
|
||||
|
||||
Now, the key file and passphrase are generated, it's time to perform encryption and decryption operation. To do so, open any text file in this editor and click on the **encryption** icon, you should see the following screen:
|
||||
|
||||
[![Encrypt or Decrypt file][11]][12]
|
||||
|
||||
Here, provide input file which you want to encrypt and specify the output file, provide passphrase and the path of the key file which we have generated earlier, then click on the Start button to start the process. Once the file has been encrypted successfully, you should see the following screen:
|
||||
|
||||
[![File encrypted successfully][13]][14]
|
||||
|
||||
Your file is now encrypted with key and passphrase.
|
||||
|
||||
If you want to decrypt this file, open **EncryptPad** , click on **File Encryption** , choose **Decryptio** option, provide the path of your encrypted file and path of the output file where you want to save the decrypted file, then provide path of the key file and click on the Start button, it will ask you for passphrase, enter your passphrase and click on Ok button to start the Decryption process. Once the process is completed successfully, you should see the "File has been decrypted successfully message".
|
||||
|
||||
[![File encryption settings][15]][16]
|
||||
|
||||
[![Passphrase][17]][18]
|
||||
|
||||
[![File has been encrypted][19]][20]
|
||||
|
||||
**Note:** If you forgot your passphrase or lost a key file, there is no way that can be done to open your encrypted information. There are no backdoors in the formats that EncryptPad supports.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-use-encryptpad-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dash.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dash.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dashboard.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-key.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-key.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-use-key-file.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-use-key-file.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-start-encryption.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-start-encryption.png
|
||||
[13]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-page.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-page.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
@ -0,0 +1,144 @@
|
||||
How to squeeze the most out of Linux file compression
|
||||
======
|
||||
If you have any doubt about the many commands and options available on Linux systems for file compression, you might want to take a look at the output of the **apropos compress** command. Chances are you'll be surprised by the many commands that you can use for compressing and decompressing files, as well as for comparing compressed files, examining and searching through the content of compressed files, and even changing a compressed file from one format to another (i.e., .z format to .gz format).
|
||||
|
||||
You're likely to see all of these entries just for the suite of bzip2 compression commands. Add in zip, gzip, and xz, and you've got a lot of interesting options.
|
||||
```
|
||||
$ apropos compress | grep ^bz
|
||||
bzcat (1) - decompresses files to stdout
|
||||
bzcmp (1) - compare bzip2 compressed files
|
||||
bzdiff (1) - compare bzip2 compressed files
|
||||
bzegrep (1) - search possibly bzip2 compressed
|
||||
files for a regular expression
|
||||
bzexe (1) - compress executable files in place
|
||||
bzfgrep (1) - search possibly bzip2 compressed
|
||||
files for a regular expression
|
||||
bzgrep (1) - search possibly bzip2 compressed
|
||||
files for a regular expression
|
||||
bzip2 (1) - a block-sorting file compressor,
|
||||
v1.0.6
|
||||
bzless (1) - file perusal filter for crt viewing
|
||||
of bzip2 compressed text
|
||||
bzmore (1) - file perusal filter for crt viewing
|
||||
of bzip2 compressed text
|
||||
|
||||
```
|
||||
|
||||
On my Ubuntu system, over 60 commands were listed in response to the apropos compress command.
|
||||
|
||||
### Compression algorithms
|
||||
|
||||
Compression is not a one-size-fits-all issue. Some compression tools are "lossy," such as those used to reduce the size of mp3 files while allowing listeners to have what is nearly the same musical experience as listening to the originals. But algorithms used on the Linux command line to compress or archive user files have to be able to reproduce the original content exactly. In other words, they have to be lossless.
|
||||
|
||||
How is that done? It's easy to imagine how 300 of the same character in a row could be compressed to something like "300X," but this type of algorithm wouldn't be of much benefit for most files because they wouldn't contain long sequences of the same character any more than they would completely random data. Compression algorithms are far more complex and have only been getting more so since compression was first introduced in the toddler years of Unix.
|
||||
|
||||
### Compression commands on Linux systems
|
||||
|
||||
The commands most commonly used for file compression on Linux systems include zip, gzip, bzip2 and xz. All of those commands work in similar ways, but there are some tradeoffs in terms of how much the file content is squeezed (how much space you save), how long the compression takes, and how compatible the compressed files are with other systems you might need to use them on.
|
||||
|
||||
Sometimes the time and effort of compressing a file doesn't pay off very well. In the example below, the "compressed" file is actually larger than the original. While this isn't generally the case, it can happen -- especially when the file content approaches some degree of randomness.
|
||||
```
|
||||
$ time zip bigfile.zip bigfile
|
||||
adding: bigfile (deflated 0%)
|
||||
|
||||
real 1m6.310s
|
||||
user 0m52.424s
|
||||
sys 0m2.288s
|
||||
$
|
||||
$ ls -l bigfile*
|
||||
-rw-rw-r-- 1 shs shs 1073741824 Dec 8 10:06 bigfile
|
||||
-rw-rw-r-- 1 shs shs 1073916184 Dec 8 11:39 bigfile.zip
|
||||
|
||||
```
|
||||
|
||||
Note that the compressed version of the file (bigfile.zip) is actually a little larger than the original file. If compression increases the size of a file or reduces its size by some very small percentage, the only benefit may be that you may have a convenient online backup. If you see a message like this after compressing a file, you're not gaining much.
|
||||
```
|
||||
(deflated 1%)
|
||||
|
||||
```
|
||||
|
||||
The content of a file plays a large role in how well it will compress. The file that grew in size in the example above was fairly random. Compress a file containing only zeroes, and you'll see an amazing compression ratio. In this admittedly extremely unlikely scenario, all three of the commonly used compression tools do an excellent job.
|
||||
```
|
||||
-rw-rw-r-- 1 shs shs 10485760 Dec 8 12:31 zeroes.txt
|
||||
-rw-rw-r-- 1 shs shs 49 Dec 8 17:28 zeroes.txt.bz2
|
||||
-rw-rw-r-- 1 shs shs 10219 Dec 8 17:28 zeroes.txt.gz
|
||||
-rw-rw-r-- 1 shs shs 1660 Dec 8 12:31 zeroes.txt.xz
|
||||
-rw-rw-r-- 1 shs shs 10360 Dec 8 12:24 zeroes.zip
|
||||
|
||||
```
|
||||
|
||||
While impressive, you're not likely to see files with over 10 million bytes compressing down to fewer than 50, since files like these are extremely unlikely.
|
||||
|
||||
In this more realistic example, the size differences are altogether different -- and not very significant -- for a fairly small jpg file.
|
||||
```
|
||||
-rw-r--r-- 1 shs shs 13522 Dec 11 18:58 image.jpg
|
||||
-rw-r--r-- 1 shs shs 13875 Dec 11 18:58 image.jpg.bz2
|
||||
-rw-r--r-- 1 shs shs 13441 Dec 11 18:58 image.jpg.gz
|
||||
-rw-r--r-- 1 shs shs 13508 Dec 11 18:58 image.jpg.xz
|
||||
-rw-r--r-- 1 shs shs 13581 Dec 11 18:58 image.jpg.zip
|
||||
|
||||
```
|
||||
|
||||
Do the same thing with a large text file, and you're likely to see some significant differences.
|
||||
```
|
||||
$ ls -l textfile*
|
||||
-rw-rw-r-- 1 shs shs 8740836 Dec 11 18:41 textfile
|
||||
-rw-rw-r-- 1 shs shs 1519807 Dec 11 18:41 textfile.bz2
|
||||
-rw-rw-r-- 1 shs shs 1977669 Dec 11 18:41 textfile.gz
|
||||
-rw-rw-r-- 1 shs shs 1024700 Dec 11 18:41 textfile.xz
|
||||
-rw-rw-r-- 1 shs shs 1977808 Dec 11 18:41 textfile.zip
|
||||
|
||||
```
|
||||
|
||||
In this case, xz reduced the size considerably more than the other commands with bzip2 coming in second.
|
||||
|
||||
### Looking at compressed files
|
||||
|
||||
The *more commands (bzmore and others) allow you to view the contents of compressed files without having to uncompress them first.
|
||||
```
|
||||
bzmore (1) - file perusal filter for crt viewing of bzip2 compressed text
|
||||
lzmore (1) - view xz or lzma compressed (text) files
|
||||
xzmore (1) - view xz or lzma compressed (text) files
|
||||
zmore (1) - file perusal filter for crt viewing of compressed text
|
||||
|
||||
```
|
||||
|
||||
These commands are all doing a good amount of work, since they have to decompress a file's content just to display it to you. They do not, on the other hand, leave uncompressed file content on the system. They simply decompress on the fly.
|
||||
```
|
||||
$ xzmore textfile.xz | head -1
|
||||
Here is the agenda for tomorrow's staff meeting:
|
||||
|
||||
```
|
||||
|
||||
### Comparing compressed files
|
||||
|
||||
While several of the compression toolsets include a diff command (e.g., xzdiff), these tools pass the work off to cmp and diff and are not doing any algorithm-specific comparisons. For example, the xzdiff command will compare bz2 files as easily as it will compare xz files.
|
||||
|
||||
### How to choose the best Linux compression tool
|
||||
|
||||
The best tool for the job depends on the job. In some cases, the choice may depend on the content of the data being compressed, but it's more likely that your organization's conventions are just as important unless you're in a real pinch for disk space. The best general suggestions seem to be these:
|
||||
|
||||
**zip** is best when files need to be shared with or used on Windows systems.
|
||||
|
||||
**gzip** may be best when you want the files to be usable on any Unix/Linux system. Though bzip2 is becoming nearly as ubiquitous, it is likely to take longer to run.
|
||||
|
||||
**bzip2** uses a different algorithm than gzip and is likely to yield a smaller file, but they take a little longer to get the job done.
|
||||
|
||||
**xz** generally offers the best compression rates, but also takes considerably longer to run. It's also newer than the other tools and may not yet exist on all the systems you need to work with.
|
||||
|
||||
### Wrap-up
|
||||
|
||||
There are a number of choices when it comes to how to compress files and only a few situations in which they don't yield valuable disk space savings.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3240938/linux/how-to-squeeze-the-most-out-of-linux-file-compression.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com
|
||||
125
sources/tech/20171214 Peeking into your Linux packages.md
Normal file
125
sources/tech/20171214 Peeking into your Linux packages.md
Normal file
@ -0,0 +1,125 @@
|
||||
Peeking into your Linux packages
|
||||
======
|
||||
Do you ever wonder how many _thousands_ of packages are installed on your Linux system? And, yes, I said "thousands." Even a fairly modest Linux system is likely to have well over a thousand packages installed. And there are many ways to get details on what they are.
|
||||
|
||||
First, to get a quick count of your installed packages on a Debian-based distribution such as Ubuntu, use the command **apt list --installed** like this:
|
||||
```
|
||||
$ apt list --installed | wc -l
|
||||
2067
|
||||
|
||||
```
|
||||
|
||||
This number is actually one too high because the output contains "Listing..." as its first line. This command would be more accurate:
|
||||
```
|
||||
$ apt list --installed | grep -v "^Listing" | wc -l
|
||||
2066
|
||||
|
||||
```
|
||||
|
||||
To get some details on what all these packages are, browse the list like this:
|
||||
```
|
||||
$ apt list --installed | more
|
||||
Listing...
|
||||
a11y-profile-manager-indicator/xenial,now 0.1.10-0ubuntu3 amd64 [installed]
|
||||
account-plugin-aim/xenial,now 3.12.11-0ubuntu3 amd64 [installed]
|
||||
account-plugin-facebook/xenial,xenial,now 0.12+16.04.20160126-0ubuntu1 all [installed]
|
||||
account-plugin-flickr/xenial,xenial,now 0.12+16.04.20160126-0ubuntu1 all [installed]
|
||||
account-plugin-google/xenial,xenial,now 0.12+16.04.20160126-0ubuntu1 all [installed]
|
||||
account-plugin-jabber/xenial,now 3.12.11-0ubuntu3 amd64 [installed]
|
||||
account-plugin-salut/xenial,now 3.12.11-0ubuntu3 amd64 [installed]
|
||||
|
||||
```
|
||||
|
||||
That's a lot of detail to absorb -- especially if you let your eyes wander through all 2,000+ files rolling by. It contains the package names, versions, and more but isn't the easiest information display for us humans to parse. The dpkg-query makes the descriptions quite a bit easier to understand, but they will wrap around your command window unless it's _very_ wide. So, the data display below has been split into the left and right hand sides to make this post easier to read.
|
||||
|
||||
Left side:
|
||||
```
|
||||
$ dpkg-query -l | more
|
||||
Desired=Unknown/Install/Remove/Purge/Hold
|
||||
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|
||||
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
|
||||
||/ Name Version
|
||||
+++-==============================================-=================================-
|
||||
ii a11y-profile-manager-indicator 0.1.10-0ubuntu3
|
||||
ii account-plugin-aim 3.12.11-0ubuntu3
|
||||
ii account-plugin-facebook 0.12+16.04.20160126-0ubuntu1
|
||||
ii account-plugin-flickr 0.12+16.04.20160126-0ubuntu1
|
||||
ii account-plugin-google 0.12+16.04.20160126-0ubuntu1
|
||||
ii account-plugin-jabber 3.12.11-0ubuntu3
|
||||
ii account-plugin-salut 3.12.11-0ubuntu3
|
||||
ii account-plugin-twitter 0.12+16.04.20160126-0ubuntu1
|
||||
rc account-plugin-windows-live 0.11+14.04.20140409.1-0ubuntu2
|
||||
|
||||
```
|
||||
|
||||
Right side:
|
||||
```
|
||||
Architecture Description
|
||||
============-=====================================================================
|
||||
amd64 Accessibility Profile Manager - Unity desktop indicator
|
||||
amd64 Messaging account plugin for AIM
|
||||
all GNOME Control Center account plugin for single signon - facebook
|
||||
all GNOME Control Center account plugin for single signon - flickr
|
||||
all GNOME Control Center account plugin for single signon
|
||||
amd64 Messaging account plugin for Jabber/XMPP
|
||||
amd64 Messaging account plugin for Local XMPP (Salut)
|
||||
all GNOME Control Center account plugin for single signon - twitter
|
||||
all GNOME Control Center account plugin for single signon - windows live
|
||||
|
||||
```
|
||||
|
||||
The "ii" and "rc" designations at the beginning of each line (see "Left side" above) are package state indicators. The first letter represents the desirable package state:
|
||||
```
|
||||
u -- unknown
|
||||
i -- install
|
||||
r -- remove/deinstall
|
||||
p -- purge (remove including config files)
|
||||
h -- hold
|
||||
|
||||
```
|
||||
|
||||
The second represents the current package state:
|
||||
```
|
||||
n -- not-installed
|
||||
i -- installed
|
||||
c -- config-files (only the config files are installed)
|
||||
U -- unpacked
|
||||
F -- half-configured (the configuration failed for some reason)
|
||||
h -- half-installed (installation failed for some reason)
|
||||
W -- triggers-awaited (the package is waiting for a trigger from another package)
|
||||
t -- triggers-pending (the package has been triggered)
|
||||
|
||||
```
|
||||
|
||||
An added "R" at the end of the normally two-character field would indicate that reinstallation is required. You may never run into these.
|
||||
|
||||
One easy way to take a quick look at your overall package status is to count how many packages are in which of the different states:
|
||||
```
|
||||
$ dpkg-query -l | tail -n +6 | awk '{print $1}' | sort | uniq -c
|
||||
2066 ii
|
||||
134 rc
|
||||
|
||||
```
|
||||
|
||||
I excluded the top five lines from the dpkg-query output above because these are the header lines that would have confused the output.
|
||||
|
||||
The two lines basically tell us that on this system, 2,066 packages should be and are installed, while 134 other packages have been removed but have left configuration files behind. You can always remove a package's remaining configuration files with a command like this:
|
||||
```
|
||||
$ sudo dpkg --purge xfont-mathml
|
||||
|
||||
```
|
||||
|
||||
Note that the command above would have removed the package binaries along with the configuration files if both were still installed.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3242808/linux/peeking-into-your-linux-packages.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -0,0 +1,116 @@
|
||||
yixunx translating
|
||||
The Most Famous Classic Text-based Adventure Game
|
||||
======
|
||||
**Colossal Cave Adventure** , also known as **ADVENT** , **Colossal Cave** , or **Adventure** , is a most popular text-based adventure game in the period of early 80s and late 90s. This game is also known to be historic first "interactive fiction" game. In 1976, a Programmer named **Will Crowther** wrote the early version of this game, and later a fellow programmer **Don Woods** improved the game with many features by adding scoring system, more fantasy characters and locations. This game is originally developed for **PDP-10** , a good-old giant Mainframe computer. Later, it was ported to normal home desktop computers like IBM PC and Commodore 64. The original game was written using Fortran, and later it was introduced in MS-DOS 1.0 in the early 1980s by Microsoft.
|
||||
|
||||

|
||||
|
||||
The **Adventure 2.5** final version released in 1995 has never been packaged for modern operating systems. It went nearly extinct. Thankfully, after several years the open source advocate **Eric Steven Raymond** has ported this classic game to modern operating systems with the permission from original authors. He open sourced this classic game and hosted the source code in GitLab with a new name **" open-adventure"**.
|
||||
|
||||
The main objective of this game is to find a cave rumored to be filled with a lot of treasure and gold and get out of it alive. The player earns points as he moves around the imaginary cave. The total number of points is 430. This game is mainly inspired by the extensive knowledge of cave exploration of the original author **Will Crowther**. He had been actively exploring in caves, particularly Mammoth Cave in Kentucky. Since the game 's cave structured loosely around the Mammoth Cave, you may notice many similarities between the locations in the game and those in Mammoth Cave.
|
||||
|
||||
### Installing Colossal Cave Adventure game
|
||||
|
||||
Open-Adventure has been packaged for Arch based systems and is available in [**AUR**][1]. So, we can install it using any AUR helpers in Arch Linux and its variants such as Antergos, and Manjaro Linux.
|
||||
|
||||
Using [**Pacaur**][2]:
|
||||
```
|
||||
pacaur -S open-adventure
|
||||
```
|
||||
|
||||
Using [**Packer**][3]:
|
||||
```
|
||||
packer -S open-adventure
|
||||
```
|
||||
|
||||
Using [**Yaourt**][4]:
|
||||
```
|
||||
yaourt -S open-adventure
|
||||
```
|
||||
|
||||
On other Linux distros, you might need to compile and install it from the source as described below.
|
||||
|
||||
Install the perquisites first:
|
||||
|
||||
On Debian and Ubuntu:
|
||||
```
|
||||
sudo apt-get install python3-yaml libedit-dev
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
```
|
||||
sudo dnf install python3-PyYAML libedit-devel
|
||||
```
|
||||
|
||||
You can also use pip to install PyYAML:
|
||||
```
|
||||
sudo pip3 install PyYAML
|
||||
```
|
||||
|
||||
After installing the prerequisites, compile and install open-adventure from source as shown below:
|
||||
```
|
||||
git clone https://gitlab.com/esr/open-adventure.git
|
||||
```
|
||||
```
|
||||
make
|
||||
```
|
||||
```
|
||||
make check
|
||||
```
|
||||
|
||||
Finally, run 'advent' binary to play:
|
||||
```
|
||||
advent
|
||||
```
|
||||
|
||||
There is also an Android version of this game available in [**Google Play store**][5].
|
||||
|
||||
### How to play?
|
||||
|
||||
To start the game, just type the following from Terminal:
|
||||
```
|
||||
advent
|
||||
```
|
||||
|
||||
You will see a welcome screen. Type "y" if you want instructions or type "n" to get into the adventurous trip.
|
||||
|
||||
![][6]
|
||||
|
||||
The game begins in-front of a small brick building. The player needs to direct the character with simple one or two word commands in simple English. To move your character, just type commands like **in** , **out** , **enter** , **exit** , **building** , **forest** , **east** , **west** , **north** , **south** , **up** , or **down**. You can also use one-word letters to specify the direction. Here are some one letters to direct the character to move: **N** , **S** , **E** , **W** , **NW** , **SE** , etc.
|
||||
|
||||
For example, if you type **" south"** or simply **" s"** the character will go south side of the present location. Please note that the character will understand only the first five characters. So when you have to type some long words, such as **northeast** , just use NE (small or caps). To specify southeast use SE. To pick up an item, type **pick**. To exit from a place, type **exit**. To go inside the building or any place, type **in**. To exit from any place, type **exit** and so on. It also warns you if there are any danger along the way. Also you can interact with two-word commands like **" eat food"**, **" drink water"**, **" get lamp"**, **" light lamp"**, **" kill snake"** etc. You can display the help section at any time by simply typing "help".
|
||||
|
||||
![][8]
|
||||
|
||||
I spent my entire afternoon to see what is in this game. Oh dear, it was super fun, exciting, thrill and adventurous experience!
|
||||
|
||||
![][9]
|
||||
|
||||
I went into many levels and explored many locations along the way. I even got gold and was attacked by a snake and a dwarf once. I must admit that this game is really addictive and best time killer.
|
||||
|
||||
If you left the cave safely with treasure, you win and you will get full credit to the treasure. You will also get partial credit just for locating the treasure. To end your adventure early, type **" quit"**. To suspend your adventure, type **" suspend"** (or "pause" or "save"). You can resume the adventure later. To see how well you're doing, type **" score"**. Please remember that you will lose points for getting killed, or for quitting.
|
||||
|
||||
Have fun! Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/colossal-cave-adventure-famous-classic-text-based-adventure-game/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://aur.archlinux.org/packages/open-adventure/
|
||||
[2]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[3]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[4]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[5]:https://play.google.com/store/apps/details?id=com.ecsoftwareconsulting.adventure430
|
||||
[6]:https://www.ostechnix.com/wp-content/uploads/2017/12/Colossal-Cave-Adventure-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/12/Colossal-Cave-Adventure-2.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/12/Colossal-Cave-Adventure-3.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/12/Colossal-Cave-Adventure-1.png
|
||||
@ -0,0 +1,87 @@
|
||||
5 of the Best Bitcoin Clients for Linux
|
||||
======
|
||||
By now you have probably heard of [Bitcoin][1] or the [Blockchain][2]. The price of Bitcoin has skyrocketed several times in the past months, and the trend continues almost daily. The demand for Bitcoin seems to grow astronomically by the minute.
|
||||
|
||||
Accompanying the demand for the digital currency is the demand for software to manage the currency: Bitcoin clients. A quick search of "Bitcoin client" on Google Play or the App Store will yield quite a number of results. There are many Bitcoin clients that support Linux, but only 5 interesting ones are mentioned here, in no particular order.
|
||||
|
||||
### Why Use a Client?
|
||||
A client makes it easy to manage your Bitcoin or Bitcoins. Many provide different levels of security to make sure you don't lose your precious digital currency. In short, you'll find it helpful, trust me.
|
||||
|
||||
#### 1. Bitcoin Core
|
||||
|
||||
![Bitcoin Core][3]
|
||||
|
||||
This is the core Bitcoin client, as the name suggests. It is has a very simple interface. It is secure and provides the best privacy compared to other popular clients. On the down side, it has to download all Bitcoin transaction history, which is over a 150 GB of data. Hence, it uses more resources than many other clients.
|
||||
|
||||
To get the Bitcoin Core client, visit the download [page][4]. Ubuntu users can install it via PPA:
|
||||
```
|
||||
sudo add-apt-repository ppa:bitcoin / bitcoin
|
||||
sudo apt update
|
||||
sudo apt install bitcoin*
|
||||
```
|
||||
|
||||
#### 2. Electrum
|
||||
![Electrum][5]
|
||||
|
||||
Electrum is another interesting Bitcoin client. It is more forgiving than most clients as funds can be recovered from a secret passphrase - no need to ever worry about forgetting keys. It provides several other features that make it convenient to manage Bitcoins such as multisig and cold storage. A plus for Electrum is the ability to see the fiat currency equivalent of your Bitcoins. Unlike Bitcoin Core, it does not require a full copy of your Bitcoin transaction history.
|
||||
|
||||
The following is how to get Electrum:
|
||||
```
|
||||
sudo apt-get install python3-setuptools python3-pyqt5 python3-pip
|
||||
sudo pip3 install https://download.electrum.org/3.0.3/Electrum-3.0.3.tar.gz
|
||||
```
|
||||
|
||||
Make sure to check out the appropriate version you want to install on the [website][6].
|
||||
|
||||
#### 3. Bitcoin Knots
|
||||
|
||||
![Bitcoin Knots][13]
|
||||
|
||||
Bitcoin Knots is only different from Bitcoin Core in that it provides more advanced features than Bitcoin Core. In fact, it is derived from Bitcoin Core. It is important to know some of these features are not well-tested.
|
||||
|
||||
As with Bitcoin Core, Bitcoin Knots also uses a huge amount of space, as a copy of the full Bitcoin transaction is downloaded.
|
||||
|
||||
The PPA and tar files can be found [here][7].
|
||||
|
||||
#### 4. Bither
|
||||
|
||||
![Bither][8]
|
||||
|
||||
Bither has a really simple user interface and is very simple to use. It allows password access and has an exchange rate viewer and cold/hot modes. The client is simple, and it works!
|
||||
|
||||
Download Bither [here][9].
|
||||
|
||||
#### 5. Armory
|
||||
|
||||
![Armory][10]
|
||||
|
||||
Armory is another common Bitcoin client. It includes numerous features such as cold storage. This enables you to manage your Bitcoins without connecting to the Internet. Moreover, there are additional security measures to ensure private keys are fully secured from attacks.
|
||||
|
||||
You can get the deb file from this download [site][11]. Open the deb file and install on Ubuntu or Debian. You can also get the project on [GitHub][12].
|
||||
|
||||
Now that you know a Bitcoin client to manage your digital currency, sit back, relax, and watch your Bitcoin value grow.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/bitcoin-clients-for-linux/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1]:https://www.maketecheasier.com/what-is-bitcoin-and-how-you-can-utilize-it-online/
|
||||
[2]:https://www.maketecheasier.com/bitcoin-blockchain-bundle-deals/
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/12/bitcoin-core-interface.png (Bitcoin Core)
|
||||
[4]:https://bitcoin.org/en/download
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/12/electrum-interface.png (Electrum)
|
||||
[6]:https://electrum.org/
|
||||
[7]:https://bitcoinknots.org/
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2017/12/bitter-interface.png (Bither)
|
||||
[9]:https://bither.net/
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/12/armory-logo2.png (Armory)
|
||||
[11]:https://www.bitcoinarmory.com/download/
|
||||
[12]:https://github.com/goatpig/BitcoinArmory
|
||||
[13]:https://www.maketecheasier.com/assets/uploads/2017/12/bitcoin-core-interface.png
|
||||
@ -0,0 +1,120 @@
|
||||
How to find and tar files into a tar ball
|
||||
======
|
||||
|
||||
I would like to find all documents file *.doc and create a tarball of those files and store in /nfs/backups/docs/file.tar. Is it possible to find and tar files on a Linux or Unix-like system?
|
||||
|
||||
The find command used to search for files in a directory hierarchy as per given criteria. The tar command is an archiving utility for Linux and Unix-like system to create tarballs.
|
||||
|
||||
[![How to find and tar files on linux unix][1]][1]
|
||||
|
||||
Let us see how to combine tar command with find command to create a tarball in a single command line option.
|
||||
|
||||
## Find command
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
find /path/to/search -name "file-to-search" -options
|
||||
## find all Perl (*.pl) files ##
|
||||
find $HOME -name "*.pl" -print
|
||||
## find all *.doc files ##
|
||||
find $HOME -name "*.doc" -print
|
||||
## find all *.sh (shell scripts) and run ls -l command on it ##
|
||||
find . -iname "*.sh" -exec ls -l {} +
|
||||
```
|
||||
Sample outputs from the last command:
|
||||
```
|
||||
-rw-r--r-- 1 vivek vivek 1169 Apr 4 2017 ./backups/ansible/cluster/nginx.build.sh
|
||||
-rwxr-xr-x 1 vivek vivek 1500 Dec 6 14:36 ./bin/cloudflare.pure.url.sh
|
||||
lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/cmspostupload.sh -> postupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/cmspreupload.sh -> preupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/cmssuploadimage.sh -> uploadimage.sh
|
||||
lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/faqpostupload.sh -> postupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/faqpreupload.sh -> preupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/faquploadimage.sh -> uploadimage.sh
|
||||
-rw-r--r-- 1 vivek vivek 778 Nov 6 14:44 ./bin/mirror.sh
|
||||
-rwxr-xr-x 1 vivek vivek 136 Apr 25 2015 ./bin/nixcraft.com.301.sh
|
||||
-rwxr-xr-x 1 vivek vivek 547 Jan 30 2017 ./bin/paypal.sh
|
||||
-rwxr-xr-x 1 vivek vivek 531 Dec 31 2013 ./bin/postupload.sh
|
||||
-rwxr-xr-x 1 vivek vivek 437 Dec 31 2013 ./bin/preupload.sh
|
||||
-rwxr-xr-x 1 vivek vivek 1046 May 18 2017 ./bin/purge.all.cloudflare.domain.sh
|
||||
lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/tipspostupload.sh -> postupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/tipspreupload.sh -> preupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/tipsuploadimage.sh -> uploadimage.sh
|
||||
-rwxr-xr-x 1 vivek vivek 1193 Oct 18 2013 ./bin/uploadimage.sh
|
||||
-rwxr-xr-x 1 vivek vivek 29 Nov 6 14:33 ./.vim/plugged/neomake/tests/fixtures/errors.sh
|
||||
-rwxr-xr-x 1 vivek vivek 215 Nov 6 14:33 ./.vim/plugged/neomake/tests/helpers/trap.sh
|
||||
```
|
||||
|
||||
## Tar command
|
||||
|
||||
To [create a tar ball of /home/vivek/projects directory][2], run:
|
||||
```
|
||||
$ tar -cvf /home/vivek/projects.tar /home/vivek/projects
|
||||
```
|
||||
|
||||
## Combining find and tar commands
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
find /dir/to/search/ -name "*.doc" -exec tar -rvf out.tar {} \;
|
||||
```
|
||||
OR
|
||||
```
|
||||
find /dir/to/search/ -name "*.doc" -exec tar -rvf out.tar {} +
|
||||
```
|
||||
For example:
|
||||
```
|
||||
find $HOME -name "*.doc" -exec tar -rvf /tmp/all-doc-files.tar "{}" \;
|
||||
```
|
||||
OR
|
||||
```
|
||||
find $HOME -name "*.doc" -exec tar -rvf /tmp/all-doc-files.tar "{}" +
|
||||
```
|
||||
Where, find command options:
|
||||
|
||||
* **-name "*.doc"** : Find file as per given pattern/criteria. In this case find all *.doc files in $HOME.
|
||||
* **-exec tar ...** : Execute tar command on all files found by the find command.
|
||||
|
||||
Where, tar command options:
|
||||
|
||||
* **-r** : Append files to the end of an archive. Arguments have the same meaning as for -c option.
|
||||
* **-v** : Verbose output.
|
||||
* **-f** : out.tar : Append all files to out.tar file.
|
||||
|
||||
|
||||
|
||||
It is also possible to pipe output of the find command to the tar command as follows:
|
||||
```
|
||||
find $HOME -name "*.doc" -print0 | tar -cvf /tmp/file.tar --null -T -
|
||||
```
|
||||
The -print0 option passed to the find command deals with special file names. The -null and -T - option tells the tar command to read its input from stdin/pipe. It is also possible to use the xargs command:
|
||||
```
|
||||
find $HOME -type f -name "*.sh" | xargs tar cfvz /nfs/x230/my-shell-scripts.tgz
|
||||
```
|
||||
See the following man pages for more info:
|
||||
```
|
||||
$ man tar
|
||||
$ man find
|
||||
$ man xargs
|
||||
$ man bash
|
||||
```
|
||||
|
||||
------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on Twitter, Facebook, Google+.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/linux-unix-find-tar-files-into-tarball-command/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2017/12/How-to-find-and-tar-files-on-linux-unix.jpg
|
||||
[2]:https://www.cyberciti.biz/faq/creating-a-tar-file-linux-command-line/
|
||||
141
sources/tech/20171215 Linux Vs Unix.md
Normal file
141
sources/tech/20171215 Linux Vs Unix.md
Normal file
@ -0,0 +1,141 @@
|
||||
|
||||
[][1]
|
||||
|
||||
In computer time, a substantial part of the population has a misconception that the **Unix** and **Linux** operating systems are one and the same. However, the opposite is true. Let's look at it from a closer look.
|
||||
|
||||
### What is Unix?
|
||||
|
||||
[][2]
|
||||
|
||||
In IT, we come across
|
||||
|
||||
[Unix][3]
|
||||
|
||||
as an operating system (under the trademark), which was created by AT & T in 1969 in New Jersey, USA. Most operating systems are inspired by Unix, but Unix has also been inspired by the Multics system, which has not been completed. Another version of Unix was Plan 9 from Bell Labs.
|
||||
|
||||
### Where is Unix used?
|
||||
|
||||
As an operating system, Unix is used in particular for servers, workstations, and nowadays also for personal computers. It played a very important role in the creation of the Internet, the creation of computer networks or also the client-server model.
|
||||
|
||||
#### Characteristics of the Unix system:
|
||||
|
||||
* supports multitasking (multitasking)
|
||||
|
||||
* Simplicity of control compared to Multics
|
||||
|
||||
* all data is stored as plain text
|
||||
|
||||
* tree saving of a single-root file
|
||||
|
||||
* access to multiple user accounts
|
||||
|
||||
#### Unix Operating System Composition:
|
||||
|
||||
|
||||
|
||||
**a)**
|
||||
|
||||
a monolithic operating system kernel that takes care of low-level and user-initiated operations, the total communication takes place via a system call.
|
||||
|
||||
**b)**
|
||||
|
||||
system utilities (or so-called utilities)
|
||||
|
||||
**c)**
|
||||
|
||||
many other applications
|
||||
|
||||
### What is Linux?
|
||||
|
||||
[][4]
|
||||
|
||||
This is an open source operating system built on the principle of a Unix system. As the name of the open-source description suggests, it is a freely-downloadable system that can be downloaded externally, but it is also possible to interfere with the system's editing, adding, and then extending the source code. It's one of the biggest benefits, unlike today's operating systems that are paid (Windows, Mac OS X, ...). Not only was Unix a model for creating a new operating system, another important factor was the MINIX system. Unlike
|
||||
|
||||
**Linus**
|
||||
|
||||
, this version was used by its creator (
|
||||
|
||||
**Andrew Tanenbaum**
|
||||
|
||||
) as a commercial system.
|
||||
|
||||
|
||||
|
||||
[Linux][5]
|
||||
|
||||
began to be developed by
|
||||
|
||||
**Linus Torvalds**
|
||||
|
||||
in 1991, which was a system that dealt with as a hobby. One of the main reasons why Linux started to deal with Unix was the simplicity of the system. The first official release of the provisory version of Linux (0.01) occurred on September 17, 1991\. Even though the system was completely imperfect and complete, it was of great interest to him, and within a few days, Linus started to write emails with other ideas about expansion or source codes.
|
||||
|
||||
### Characteristics of Linux
|
||||
|
||||
The cornerstone of Linux is the Unix kernel, which is based on the basic characteristics of Unix and the standards that are
|
||||
|
||||
**POSIX**
|
||||
|
||||
and Single
|
||||
|
||||
**UNIX Specification**
|
||||
|
||||
. As it may seem, the official name of the operating system is taken from the creator of
|
||||
|
||||
**Linus**
|
||||
|
||||
, where the end of the operating system name "x" is just a link to the
|
||||
|
||||
**Unix system**
|
||||
|
||||
.
|
||||
|
||||
#### Main features:
|
||||
|
||||
* run multiple tasks at once (multitasking)
|
||||
|
||||
* programs may consist of one or more processes (multipurpose system), and each process may have one or more threads
|
||||
|
||||
* multiuser, so it can run multiple user programs
|
||||
|
||||
* individual accounts are protected by appropriate authorization
|
||||
|
||||
* so the accounts have precisely defined system control rights
|
||||
|
||||
The author of
|
||||
|
||||
**Tuxe Penguin's**
|
||||
|
||||
logo is Larry Ewing of 1996, who accepted him as a mascot for his open-source
|
||||
|
||||
**Linux operating system**
|
||||
|
||||
.
|
||||
|
||||
**Linux Torvalds**
|
||||
|
||||
proposed the initial name of the new operating system as "Freax" as free + freak + x (
|
||||
|
||||
**Unix system**
|
||||
|
||||
), but it did not like the
|
||||
|
||||
**FTP server**
|
||||
|
||||
where the provisory version of Linux was running.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/linux-vs-unix
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/linux-vs-unix
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/unix_orig.png
|
||||
[3]:http://www.unix.org/what_is_unix.html
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux_orig.png
|
||||
[5]:https://www.linux.com
|
||||
144
sources/tech/20171215 Top 5 Linux Music Players.md
Normal file
144
sources/tech/20171215 Top 5 Linux Music Players.md
Normal file
@ -0,0 +1,144 @@
|
||||
Top 5 Linux Music Players
|
||||
======
|
||||
|
||||
 and your platform is Linux, you're going to want a good GUI player to enjoy that music.
|
||||
|
||||
Fortunately, Linux has no lack of digital music players. In fact, there are quite a few, most of which are open source and available for free. Let's take a look at a few such players, to see which one might suit your needs.
|
||||
|
||||
### Clementine
|
||||
|
||||
I wanted to start out with the player that has served as my default for years. [Clementine][1] offers probably the single best ratio of ease-of-use to flexibility you'll find in any player. Clementine is a fork of the new defunct [Amarok][2] music player, but isn't limited to Linux-only; Clementine is also available for Mac OS and Windows platforms. The feature set is seriously impressive and includes the likes of:
|
||||
|
||||
* Built-in equalizer
|
||||
|
||||
* Customizable interface (display current album cover as background -- Figure 1)
|
||||
|
||||
* Play local music or from Spotify, Last.fm, and more
|
||||
|
||||
* Sidebar for easy library navigation
|
||||
|
||||
* Built-in audio transcoding (into MP3, OGG, Flac, and more)
|
||||
|
||||
* Remote control using [Android app][3]
|
||||
|
||||
* Handy search function
|
||||
|
||||
* Tabbed playlists
|
||||
|
||||
* Easy creation of regular and smart playlists
|
||||
|
||||
* CUE sheet support
|
||||
|
||||
* Tag support
|
||||
|
||||
|
||||
|
||||
|
||||
![Clementine][5]
|
||||
|
||||
|
||||
Figure 1: The Clementine interface might be a bit old-school, but it's incredibly user-friendly and flexible.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
Of all the music players I have used, Clementine is by far the most feature-rich and easy to use. It also includes one of the finest equalizers you'll find on a Linux music player (with 10 bands to adjust). Although it may not enjoy a very modern interface, it is absolutely unmatched for its ability to create and manipulate playlists. If your music collection is large, and you want total control over it, this is the player you want.
|
||||
|
||||
Clementine can be found in the standard repositories and installed from either your distribution's software center or the command line.
|
||||
|
||||
### Rhythmbox
|
||||
|
||||
[Rhythmbox][7] is the default player for the GNOME desktop, but it does function well on other desktops. The Rhythmbox interface is slightly more modern than Clementine and takes a minimal approach to design. That doesn't mean the app is bereft of features. Quite the opposite. Rhythmbox offers gapless playback, Soundcloud support, album cover display, audio scrobbling from Last.fm and Libre.fm, Jamendo support, podcast subscription (from [Apple iTunes][8]), web remote control, and more.
|
||||
|
||||
One very nice feature found in Rhythmbox is plugin support, which allows you to enable features like DAAP Music Sharing, FM Radio, Cover art search, notifications, ReplayGain, Song Lyrics, and more.
|
||||
|
||||
The Rhythmbox playlist feature isn't quite as powerful as that found in Clementine, but it still makes it fairly easy to organize your music into quick playlists for any mood. Although Rhythmbox does offer a slightly more modern interface than Clementine (Figure 2), it's not quite as flexible.
|
||||
|
||||
![Rhythmbox][10]
|
||||
|
||||
|
||||
Figure 2: The Rhythmbox interface is simple and straightforward.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
### VLC Media Player
|
||||
|
||||
For some, [VLC][11] cannot be beat for playing videos. However, VLC isn't limited to the playback of video. In fact, VLC does a great job of playing audio files. For [KDE Neon][12] users, VLC serves as your default for both music and video playback. Although VLC is one of the finest video players on the Linux market (it's my default), it does suffer from some minor limitations with audio--namely the lack of playlists and the inability to connect to remote directories on your network. But if you're looking for an incredibly simple and reliable means to play local files or network mms/rtsp streams VLC is a quality tool.
|
||||
|
||||
VLC does include an equalizer (Figure 3), a compressor, and a spatializer as well as the ability to record from a capture device.
|
||||
|
||||
![VLC][14]
|
||||
|
||||
|
||||
Figure 3: The VLC equalizer in action.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
### Audacious
|
||||
|
||||
If you're looking for a lightweight music player, Audacious perfectly fits that bill. This particular music player is fairly single minded, but it does include an equalizer and a small selection of effects that will please many an audiophile (e.g., Echo, Silence removal, Speed and Pitch, Voice Removal, and more--Figure 4).
|
||||
|
||||
![Audacious ][16]
|
||||
|
||||
|
||||
Figure 4: The Audacious EQ and plugins.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
Audacious also includes a really handy alarm feature, that allows you to set an alarm that will start playing your currently selected track at a user-specified time and duration.
|
||||
|
||||
### Spotify
|
||||
|
||||
I must confess, I use spotify daily. I'm a subscriber and use it to find new music to purchase--which means I am constantly searching and discovering. Fortunately, there is a desktop client for Spotify (Figure 5) that can be easily installed using the [official Spotify Linux installation instructions][17]. Outside of listening to vinyl, I probably make use of Spotify more than any other music player. It also helps that I can seamlessly jump between the desktop client and the [Android app][18], so I never miss out on the music I enjoy.
|
||||
|
||||
![Spotify][20]
|
||||
|
||||
|
||||
Figure 5: The official Spotify client on Linux.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
The Spotify interface is very easy to use and, in fact, it beats the web player by leaps and bounds. Do not settle for the [Spotify Web Player][21] on Linux, as the desktop client makes it much easier to create and manage your playlists. If you're a Spotify power user, don't even bother with the built-in support for the streaming client in the other desktop apps--once you've used the Spotify Desktop Client, the other apps pale in comparison.
|
||||
|
||||
### The choice is yours
|
||||
|
||||
Other options are available (check your desktop software center), but these five clients (in my opinion) are the best of the best. For me, the one-two punch of Clementine and Spotify gives me the best of all possible worlds. Try them out and see which one best meets your needs.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][22]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/top-5-linux-music-players
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com
|
||||
[1]:https://www.clementine-player.org/
|
||||
[2]:https://en.wikipedia.org/wiki/Amarok_(software)
|
||||
[3]:https://play.google.com/store/apps/details?id=de.qspool.clementineremote
|
||||
[4]:https://www.linux.com/files/images/clementinejpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/clementine.jpg?itok=_k13MtM3 (Clementine)
|
||||
[6]:https://www.linux.com/licenses/category/used-permission
|
||||
[7]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[8]:https://www.apple.com/itunes/
|
||||
[9]:https://www.linux.com/files/images/rhythmboxjpg
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/rhythmbox.jpg?itok=GOjs9vTv (Rhythmbox)
|
||||
[11]:https://www.videolan.org/vlc/index.html
|
||||
[12]:https://neon.kde.org/
|
||||
[13]:https://www.linux.com/files/images/vlcjpg
|
||||
[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/vlc.jpg?itok=hn7iKkmK (VLC)
|
||||
[15]:https://www.linux.com/files/images/audaciousjpg
|
||||
[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/audacious.jpg?itok=9YALPzOx (Audacious )
|
||||
[17]:https://www.spotify.com/us/download/linux/
|
||||
[18]:https://play.google.com/store/apps/details?id=com.spotify.music
|
||||
[19]:https://www.linux.com/files/images/spotifyjpg
|
||||
[20]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/spotify.jpg?itok=P3FLfcYt (Spotify)
|
||||
[21]:https://open.spotify.com/browse/featured
|
||||
[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,73 @@
|
||||
translating by lujun9972
|
||||
Saving window position in Xfce session
|
||||
======
|
||||
|
||||
TLDR: If you're having problems saving window position in your Xfce session, enable save on logout and then log out and back in. This will probably fix the problem (permanently, if you like keeping the same session and turn saving back off again). See below for the details.
|
||||
|
||||
I've been using Xfce for my desktop for some years now, and have had a recurring problem with saved sessions after a reboot. After logging in, all the applications from my saved session would be started, but all the workspace and window positioning data would be lost, so they'd just pile onto the default workspace like a train wreck.
|
||||
|
||||
Various other people on-line have reported this over the years (there are open bugs in Ubuntu, Xfce, and Red Hat bug trackers), and there was apparently a related bug fixed in Xfce 4.10, but I'm using 4.12. I would have given up (and have several times in the past), except that on one of my systems this works correctly. All the windows go back to their proper positions.
|
||||
|
||||
Today, I dug into the difference and finally solved it. Here it is, in case someone else stumbles across it.
|
||||
|
||||
Some up-front caveats that are or may be related:
|
||||
|
||||
1. I rarely log out of my Xfce session, since this is a single-user laptop. I hibernate and keep restoring until I decide to do a reboot for kernel patches, or (and this is somewhat more likely) some change to the system invalidates the hibernate image and the system hangs on restore from hibernate and I force-reboot it. I also only sometimes use the Xfce toolbar to do a reboot; often, I just run `reboot`.
|
||||
|
||||
2. I use xterm and Emacs, which are not horribly sophisticated X applications and which don't remember their own window positioning.
|
||||
|
||||
|
||||
|
||||
|
||||
Xfce stores sessions in `.cache/sessions` in your home directory. The key discovery on close inspection is that there were two types of files in that directory on the working system, and only one on the non-working system.
|
||||
|
||||
The typical file will have a name like `xfce4-session-hostname:0` and contains things like:
|
||||
```
|
||||
Client9_ClientId=2a654109b-e4d0-40e4-a910-e58717faa80b
|
||||
Client9_Hostname=local/hostname
|
||||
Client9_CloneCommand=xterm
|
||||
Client9_RestartCommand=xterm,-xtsessionID,2a654109b-e4d0-40e4-a910-e58717faa80b
|
||||
Client9_Program=xterm
|
||||
Client9_UserId=user
|
||||
|
||||
```
|
||||
|
||||
This is the file that remembers all of the running applications. If you go into Settings -> Session and Startup and clear the session cache, files like this will be deleted. If you save your current session, a file like this will be created. This is how Xfce knows to start all of the same applications. But notice that nothing in the above preserves the positioning of the window. (I went down a rabbit hole thinking the session ID was somehow linking to that information elsewhere, but it's not.)
|
||||
|
||||
The working system had a second type of file in that directory named `xfwm4-2d4c9d4cb-5f6b-41b4-b9d7-5cf7ac3d7e49.state`. Looking in that file reveals entries like:
|
||||
```
|
||||
[CLIENT] 0x200000f
|
||||
[CLIENT_ID] 2a9e5b8ed-1851-4c11-82cf-e51710dcf733
|
||||
[CLIENT_LEADER] 0x200000f
|
||||
[RES_NAME] xterm
|
||||
[RES_CLASS] XTerm
|
||||
[WM_NAME] xterm
|
||||
[WM_COMMAND] (1) "xterm"
|
||||
[GEOMETRY] (860,35,817,1042)
|
||||
[GEOMETRY-MAXIMIZED] (860,35,817,1042)
|
||||
[SCREEN] 0
|
||||
[DESK] 2
|
||||
[FLAGS] 0x0
|
||||
|
||||
```
|
||||
|
||||
Notice the geometry and desk, which are exactly what we're looking for: the window location and the workspace it should be on. So the problem with window position not being saved was the absence of this file.
|
||||
|
||||
After some more digging, I discovered that while the first file is saved when you explicitly save your session, the second is not. However, it is saved on logout. So, I went to Settings -> Session and Startup and enabled automatically save session on logout in the General tab, logged out and back in again, and tada, the second file appeared. I then turned saving off again (since I set up my screens and then save them and don't want any subsequent changes saved unless I do so explicitly), and now my window position is reliably restored.
|
||||
|
||||
This also explains why some people see this and others don't: some people probably regularly use the Log Out button, and others ignore it and manually reboot (or just have their system crash).
|
||||
|
||||
Incidentally, this sort of problem, and the amount of digging that I had to do to solve it, is the reason why I'm in favor of writing man pages or some other documentation for every state file your software stores. Not only does it help people digging into weird problems, it helps you as the software author notice surprising oddities, like splitting session state across two separate state files, when you go to document them for the user.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.eyrie.org/~eagle/journal/2017-12/001.html
|
||||
|
||||
作者:[J. R. R. Tolkien][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.eyrie.org
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user