mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
6df3d1d209
225
published/20161201 How to Configure a Firewall with UFW.md
Normal file
225
published/20161201 How to Configure a Firewall with UFW.md
Normal file
@ -0,0 +1,225 @@
|
||||
在 Ubuntu 中用 UFW 配置防火墙
|
||||
============================================================
|
||||
|
||||
UFW,即简单防火墙(uncomplicated firewall),是一个 Arch Linux、Debian 或 Ubuntu 中管理防火墙规则的前端。 UFW 通过命令行使用(尽管它有可用的 GUI),它的目的是使防火墙配置简单(即不复杂(uncomplicated))。
|
||||
|
||||

|
||||
|
||||
### 开始之前
|
||||
|
||||
1、 熟悉我们的[入门][1]指南,并完成设置服务器主机名和时区的步骤。
|
||||
|
||||
2、 本指南将尽可能使用 `sudo`。 在完成[保护你的服务器][2]指南的章节,创建一个标准用户帐户,强化 SSH 访问和移除不必要的网络服务。 **但不要**跟着创建防火墙部分 - 本指南是介绍使用 UFW 的,它对于 iptables 而言是另外一种控制防火墙的方法。
|
||||
|
||||
3、 更新系统
|
||||
|
||||
**Arch Linux**
|
||||
```
|
||||
sudo pacman -Syu
|
||||
```
|
||||
**Debian / Ubuntu**
|
||||
```
|
||||
sudo apt-get update && sudo apt-get upgrade
|
||||
```
|
||||
### 安装 UFW
|
||||
|
||||
UFW 默认包含在 Ubuntu 中,但在 Arch 和 Debian 中需要安装。 Debian 将自动启用 UFW 的 systemd 单元,并使其在重新启动时启动,但 Arch 不会。 这与告诉 UFW 启用防火墙规则不同,因为使用 systemd 或者 upstart 启用 UFW 仅仅是告知 init 系统打开 UFW 守护程序。
|
||||
|
||||
默认情况下,UFW 的规则集为空,因此即使守护程序正在运行,也不会强制执行任何防火墙规则。 强制执行防火墙规则集的部分[在下面][3]。
|
||||
|
||||
#### Arch Linux
|
||||
|
||||
1、 安装 UFW:
|
||||
|
||||
```
|
||||
sudo pacman -S ufw
|
||||
```
|
||||
|
||||
2、 启动并启用 UFW 的 systemd 单元:
|
||||
|
||||
```
|
||||
sudo systemctl start ufw
|
||||
sudo systemctl enable ufw
|
||||
```
|
||||
|
||||
#### Debian / Ubuntu
|
||||
|
||||
1、 安装 UFW
|
||||
|
||||
```
|
||||
sudo apt-get install ufw
|
||||
```
|
||||
|
||||
### 使用 UFW 管理防火墙规则
|
||||
|
||||
#### 设置默认规则
|
||||
|
||||
大多数系统只需要打开少量的端口接受传入连接,并且关闭所有剩余的端口。 从一个简单的规则基础开始,`ufw default`命令可以用于设置对传入和传出连接的默认响应动作。 要拒绝所有传入并允许所有传出连接,那么运行:
|
||||
|
||||
```
|
||||
sudo ufw default allow outgoing
|
||||
sudo ufw default deny incoming
|
||||
```
|
||||
|
||||
`ufw default` 也允许使用 `reject` 参数。
|
||||
|
||||
> 警告:
|
||||
|
||||
> 除非明确设置允许规则,否则配置默认 `deny` 或 `reject` 规则会锁定你的服务器。确保在应用默认 `deny` 或 `reject` 规则之前,已按照下面的部分配置了 SSH 和其他关键服务的允许规则。
|
||||
|
||||
#### 添加规则
|
||||
|
||||
可以有两种方式添加规则:用**端口号**或者**服务名**表示。
|
||||
|
||||
要允许 SSH 的 22 端口的传入和传出连接,你可以运行:
|
||||
|
||||
```
|
||||
sudo ufw allow ssh
|
||||
```
|
||||
|
||||
你也可以运行:
|
||||
|
||||
```
|
||||
sudo ufw allow 22
|
||||
```
|
||||
|
||||
相似的,要在特定端口(比如 111)上 `deny` 流量,你需要运行:
|
||||
|
||||
```
|
||||
sudo ufw deny 111
|
||||
```
|
||||
|
||||
为了更好地调整你的规则,你也可以允许基于 TCP 或者 UDP 的包。下面例子会允许 80 端口的 TCP 包:
|
||||
|
||||
```
|
||||
sudo ufw allow 80/tcp
|
||||
sudo ufw allow http/tcp
|
||||
```
|
||||
|
||||
这个会允许 1725 端口上的 UDP 包:
|
||||
|
||||
```
|
||||
sudo ufw allow 1725/udp
|
||||
```
|
||||
|
||||
#### 高级规则
|
||||
|
||||
除了基于端口的允许或阻止,UFW 还允许您按照 IP 地址、子网和 IP 地址/子网/端口的组合来允许/阻止。
|
||||
|
||||
允许从一个 IP 地址连接:
|
||||
|
||||
```
|
||||
sudo ufw allow from 123.45.67.89
|
||||
```
|
||||
|
||||
允许特定子网的连接:
|
||||
|
||||
```
|
||||
sudo ufw allow from 123.45.67.89/24
|
||||
```
|
||||
|
||||
允许特定 IP/ 端口的组合:
|
||||
|
||||
```
|
||||
sudo ufw allow from 123.45.67.89 to any port 22 proto tcp
|
||||
```
|
||||
|
||||
`proto tcp` 可以删除或者根据你的需求改成 `proto udp`,所有例子的 `allow` 都可以根据需要变成 `deny`。
|
||||
|
||||
#### 删除规则
|
||||
|
||||
要删除一条规则,在规则的前面加上 `delete`。如果你希望不再允许 HTTP 流量,你可以运行:
|
||||
|
||||
```
|
||||
sudo ufw delete allow 80
|
||||
```
|
||||
|
||||
删除规则同样可以使用服务名。
|
||||
|
||||
### 编辑 UFW 的配置文件
|
||||
|
||||
虽然可以通过命令行添加简单的规则,但仍有可能需要添加或删除更高级或特定的规则。 在运行通过终端输入的规则之前,UFW 将运行一个文件 `before.rules`,它允许回环接口、ping 和 DHCP 等服务。要添加或改变这些规则,编辑 `/etc/ufw/before.rules` 这个文件。 同一目录中的 `before6.rules` 文件用于 IPv6 。
|
||||
|
||||
还存在一个 `after.rule` 和 `after6.rule` 文件,用于添加在 UFW 运行你通过命令行输入的规则之后需要添加的任何规则。
|
||||
|
||||
还有一个配置文件位于 `/etc/default/ufw`。 从此处可以禁用或启用 IPv6,可以设置默认规则,并可以设置 UFW 以管理内置防火墙链。
|
||||
|
||||
### UFW 状态
|
||||
|
||||
你可以在任何时候使用命令:`sudo ufw status` 查看 UFW 的状态。这会显示所有规则列表,以及 UFW 是否处于激活状态:
|
||||
|
||||
```
|
||||
Status: active
|
||||
|
||||
To Action From
|
||||
-- ------ ----
|
||||
22 ALLOW Anywhere
|
||||
80/tcp ALLOW Anywhere
|
||||
443 ALLOW Anywhere
|
||||
22 (v6) ALLOW Anywhere (v6)
|
||||
80/tcp (v6) ALLOW Anywhere (v6)
|
||||
443 (v6) ALLOW Anywhere (v6)
|
||||
```
|
||||
|
||||
### 启用防火墙
|
||||
|
||||
随着你选择规则完成,你初始运行 `ufw status` 可能会输出 `Status: inactive`。 启用 UFW 并强制执行防火墙规则:
|
||||
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
相似地,禁用 UFW 规则:
|
||||
|
||||
```
|
||||
sudo ufw disable
|
||||
```
|
||||
|
||||
> UFW 会继续运行,并且在下次启动时会再次启动。
|
||||
|
||||
### 日志记录
|
||||
|
||||
你可以用下面的命令启动日志记录:
|
||||
|
||||
```
|
||||
sudo ufw logging on
|
||||
```
|
||||
|
||||
可以通过运行 `sudo ufw logging low|medium|high` 设计日志级别,可以选择 `low`、 `medium` 或者 `high`。默认级别是 `low`。
|
||||
|
||||
常规日志类似于下面这样,位于 `/var/logs/ufw`:
|
||||
|
||||
```
|
||||
Sep 16 15:08:14 <hostname> kernel: [UFW BLOCK] IN=eth0 OUT= MAC=00:00:00:00:00:00:00:00:00:00:00:00:00:00 SRC=123.45.67.89 DST=987.65.43.21 LEN=40 TOS=0x00 PREC=0x00 TTL=249 ID=8475 PROTO=TCP SPT=48247 DPT=22 WINDOW=1024 RES=0x00 SYN URGP=0
|
||||
```
|
||||
|
||||
前面的值列出了你的服务器的日期、时间、主机名。剩下的重要信息包括:
|
||||
|
||||
* **[UFW BLOCK]**:这是记录事件的描述开始的位置。在此例中,它表示阻止了连接。
|
||||
* **IN**:如果它包含一个值,那么代表该事件是传入事件
|
||||
* **OUT**:如果它包含一个值,那么代表事件是传出事件
|
||||
* **MAC**:目的地和源 MAC 地址的组合
|
||||
* **SRC**:包源的 IP
|
||||
* **DST**:包目的地的 IP
|
||||
* **LEN**:数据包长度
|
||||
* **TTL**:数据包 TTL,或称为 time to live。 在找到目的地之前,它将在路由器之间跳跃,直到它过期。
|
||||
* **PROTO**:数据包的协议
|
||||
* **SPT**:包的源端口
|
||||
* **DPT**:包的目标端口
|
||||
* **WINDOW**:发送方可以接收的数据包的大小
|
||||
* **SYN URGP**:指示是否需要三次握手。 `0` 表示不需要。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linode.com/docs/security/firewalls/configure-firewall-with-ufw
|
||||
|
||||
作者:[Linode][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linode.com/docs/security/firewalls/configure-firewall-with-ufw
|
||||
[1]:https://www.linode.com/docs/getting-started
|
||||
[2]:https://www.linode.com/docs/security/securing-your-server
|
||||
[3]:http://localhost:4567/docs/security/firewalls/configure-firewall-with-ufw#enable-the-firewall
|
||||
@ -0,0 +1,161 @@
|
||||
sshpass:一个很棒的免交互 SSH 登录工具,但不要用在生产服务器上
|
||||
============================================================
|
||||
|
||||
在大多数情况下,Linux 系统管理员使用 SSH 登录到程 Linux 服务器时,要么是通过密码,要么是[无密码 SSH 登录][1]或基于密钥的 SSH 身份验证。
|
||||
|
||||
如果你想自动在 SSH 登录提示符中提供**密码**和**用户名**怎么办?这时 **sshpass** 就可以帮到你了。
|
||||
|
||||
sshpass 是一个简单、轻量级的命令行工具,通过它我们能够向命令提示符本身提供密码(非交互式密码验证),这样就可以通过 [cron 调度器][2]执行自动化的 shell 脚本进行备份。
|
||||
|
||||
ssh 直接使用 TTY 访问,以确保密码是用户键盘输入的。 sshpass 在专门的 tty 中运行 ssh,以误导 ssh 相信它是从用户接收到的密码。
|
||||
|
||||
重要:使用 **sshpass** 是最不安全的,因为所有系统上的用户在命令行中通过简单的 “**ps**” 命令就可看到密码。因此,如果必要,比如说在生产环境,我强烈建议使用 [SSH 无密码身份验证][3]。
|
||||
|
||||
### 在 Linux 中安装 sshpass
|
||||
|
||||
在基于 **RedHat/CentOS** 的系统中,首先需要[启用 Epel 仓库][4]并使用 [yum 命令][5]安装它。
|
||||
|
||||
```
|
||||
# yum install sshpass
|
||||
# dnf install sshpass [Fedora 22 及以上版本]
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu 和它的衍生版中,你可以使用 [apt-get 命令][6]来安装。
|
||||
|
||||
```
|
||||
$ sudo apt-get install sshpass
|
||||
```
|
||||
|
||||
另外,你也可以从最新的源码安装 `sshpass`,首先下载源码并从 tar 文件中解压出内容:
|
||||
|
||||
```
|
||||
$ wget http://sourceforge.net/projects/sshpass/files/latest/download -O sshpass.tar.gz
|
||||
$ tar -xvf sshpass.tar.gz
|
||||
$ cd sshpass-1.06
|
||||
$ ./configure
|
||||
# sudo make install
|
||||
```
|
||||
|
||||
### 如何在 Linux 中使用 sshpass
|
||||
|
||||
**sshpass** 与 **ssh** 一起使用,使用下面的命令可以查看 `sshpass` 的使用选项的完整描述:
|
||||
|
||||
```
|
||||
$ sshpass -h
|
||||
```
|
||||
|
||||
下面为显示的 sshpass 帮助内容:
|
||||
|
||||
```
|
||||
Usage: sshpass [-f|-d|-p|-e] [-hV] command parameters
|
||||
-f filename Take password to use from file
|
||||
-d number Use number as file descriptor for getting password
|
||||
-p password Provide password as argument (security unwise)
|
||||
-e Password is passed as env-var "SSHPASS"
|
||||
With no parameters - password will be taken from stdin
|
||||
-h Show help (this screen)
|
||||
-V Print version information
|
||||
At most one of -f, -d, -p or -e should be used
|
||||
```
|
||||
|
||||
正如我之前提到的,**sshpass** 在用于脚本时才更可靠及更有用,请看下面的示例命令。
|
||||
|
||||
使用用户名和密码登录到远程 Linux ssh 服务器(10.42.0.1),并[检查文件系统磁盘使用情况][7],如图所示。
|
||||
|
||||
```
|
||||
$ sshpass -p 'my_pass_here' ssh aaronkilik@10.42.0.1 'df -h'
|
||||
```
|
||||
|
||||
**重要提示**:此处,在命令行中提供了密码,这是不安全的,不建议使用此选项。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
*sshpass – 使用 SSH 远程登录 Linux*
|
||||
|
||||
但是,为了防止在屏幕上显示密码,可以使用 `-e` 标志,并将密码作为 SSHPASS 环境变量的值输入,如下所示:
|
||||
|
||||
```
|
||||
$ export SSHPASS='my_pass_here'
|
||||
$ echo $SSHPASS
|
||||
$ sshpass -e ssh aaronkilik@10.42.0.1 'df -h'
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*sshpass – 在终端中隐藏密码*
|
||||
|
||||
**注意:**在上面的示例中,`SSHPASS` 环境变量仅用于临时目的,并将在重新启动后删除。
|
||||
|
||||
要永久设置 `SSHPASS` 环境变量,打开 `/etc/profile` 文件,并在文件开头输入 `export` 语句:
|
||||
|
||||
```
|
||||
export SSHPASS='my_pass_here'
|
||||
```
|
||||
|
||||
保存文件并退出,接着运行下面的命令使更改生效:
|
||||
|
||||
```
|
||||
$ source /etc/profile
|
||||
```
|
||||
|
||||
另外,也可以使用 `-f` 标志,并把密码放在一个文件中。 这样,您可以从文件中读取密码,如下所示:
|
||||
|
||||
```
|
||||
$ sshpass -f password_filename ssh aaronkilik@10.42.0.1 'df -h'
|
||||
```
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
*sshpass – 在登录时提供密码文件*
|
||||
|
||||
你也可以使用 `sshpass` [通过 scp 传输文件][11]或者 [rsync 备份/同步文件][12],如下所示:
|
||||
|
||||
```
|
||||
------- Transfer Files Using SCP -------
|
||||
$ scp -r /var/www/html/example.com --rsh="sshpass -p 'my_pass_here' ssh -l aaronkilik" 10.42.0.1:/var/www/html
|
||||
------- Backup or Sync Files Using Rsync -------
|
||||
$ rsync --rsh="sshpass -p 'my_pass_here' ssh -l aaronkilik" 10.42.0.1:/data/backup/ /backup/
|
||||
```
|
||||
|
||||
更多的用法,建议阅读 `sshpass` 的 man 页面,输入:
|
||||
|
||||
```
|
||||
$ man sshpass
|
||||
```
|
||||
|
||||
在本文中,我们解释了 `sshpass` 是一个非交互式密码验证的简单工具。 虽然这个工具可能是有帮助的,但还是强烈建议使用更安全的 ssh 公钥认证机制。
|
||||
|
||||
请在下面的评论栏写下任何问题或评论,以便可以进一步讨论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:Aaron Kili 是一位 Linux 和 F.O.S.S 爱好者,未来的 Linux 系统管理员,web 开发人员, 还是 TecMint 原创作者,热爱电脑工作,并乐于分享知识。
|
||||
|
||||
-----------
|
||||
|
||||
via: http://www.tecmint.com/sshpass-non-interactive-ssh-login-shell-script-ssh-password/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[4]:https://linux.cn/article-2324-1.html
|
||||
[5]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[6]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[7]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/sshpass-Linux-Remote-Login.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/12/sshpass-Hide-Password-in-Prompt.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/12/sshpass-Provide-Password-File.png
|
||||
[11]:http://www.tecmint.com/scp-commands-examples/
|
||||
[12]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
@ -1,83 +0,0 @@
|
||||
What is SRE (Site Reliability Engineering)?
|
||||
============================================================
|
||||
|
||||
Site Reliability Engineer is a job title we are starting to see more and more these days. What does it mean? Where does it come from? Learn from Google's SRE team.
|
||||
|
||||

|
||||
|
||||
This is an excerpt from [Site Reliability Engineering][9], edited by Niall Richard Murphy, Jennifer Petoff, Chris Jones, Betsy Beyer.
|
||||
|
||||
Site Reliability Engineering will also be covered at the [O'Reilly Velocity Conference, Nov. 7-10 in Amsterdam][10].
|
||||
|
||||
### Introduction
|
||||
|
||||
> Hope is not a strategy.
|
||||
>
|
||||
> Traditional SRE saying
|
||||
|
||||
It is a truth universally acknowledged that systems do not run themselves. How, then, _should_ a system—particularly a complex computing system that operates at a large scale—be run?
|
||||
|
||||
|
||||
### The Sysadmin Approach to Service Management
|
||||
|
||||
The sysadmin model of service management has several advantages. For companies deciding how to run and staff a service, this approach is relatively easy to implement: as a familiar industry paradigm, there are many examples from which to learn and emulate. A relevant talent pool is already widely available. An array of existing tools, software components (off the shelf or otherwise), and integration companies are available to help run those assembled systems, so a novice sysadmin team doesn’t have to reinvent the wheel and design a system from scratch.
|
||||
|
||||
Traditional operations teams and their counterparts in product development thus often end up in conflict, most visibly over how quickly software can be released to production. At their core, the development teams want to launch new features and see them adopted by users. At _their_ core, the ops teams want to make sure the service doesn’t break while they are holding the pager. Because most outages are caused by some kind of change—a new configuration, a new feature launch, or a new type of user traffic—the two teams’ goals are fundamentally in tension.
|
||||
|
||||
Both groups understand that it is unacceptable to state their interests in the baldest possible terms ("We want to launch anything, any time, without hindrance" versus "We won’t want to ever change anything in the system once it works"). And because their vocabulary and risk assumptions differ, both groups often resort to a familiar form of trench warfare to advance their interests. The ops team attempts to safeguard the running system against the risk of change by introducing launch and change gates. For example, launch reviews may contain an explicit check for _every_ problem that has _ever_ caused an outage in the past—that could be an arbitrarily long list, with not all elements providing equal value. The dev team quickly learns how to respond. They have fewer "launches" and more "flag flips," "incremental updates," or "cherrypicks." They adopt tactics such as sharding the product so that fewer features are subject to the launch review.
|
||||
|
||||
|
||||
### Google’s Approach to Service Management: Site Reliability Engineering
|
||||
|
||||
Conflict isn’t an inevitable part of offering a software service. Google has chosen to run our systems with a different approach: our Site Reliability Engineering teams focus on hiring software engineers to run our products and to create systems to accomplish the work that would otherwise be performed, often manually, by sysadmins.
|
||||
|
||||
What exactly is Site Reliability Engineering, as it has come to be defined at Google? My explanation is simple: SRE is what happens when you ask a software engineer to design an operations team. When I joined Google in 2003 and was tasked with running a "Production Team" of seven engineers, my entire life up to that point had been software engineering. So I designed and managed the group the way _I_ would want it to work if I worked as an SRE myself. That group has since matured to become Google’s present-day SRE team, which remains true to its origins as envisioned by a lifelong software engineer.
|
||||
|
||||
A primary building block of Google’s approach to service management is the composition of each SRE team. As a whole, SRE can be broken down two main categories.
|
||||
|
||||
50–60% are Google Software Engineers, or more precisely, people who have been hired via the standard procedure for Google Software Engineers. The other 40–50% are candidates who were very close to the Google Software Engineering qualifications (i.e., 85–99% of the skill set required), and who _in addition_ had a set of technical skills that is useful to SRE but is rare for most software engineers. By far, UNIX system internals and networking (Layer 1 to Layer 3) expertise are the two most common types of alternate technical skills we seek.
|
||||
|
||||
Common to all SREs is the belief in and aptitude for developing software systems to solve complex problems. Within SRE, we track the career progress of both groups closely, and have to date found no practical difference in performance between engineers from the two tracks. In fact, the somewhat diverse background of the SRE team frequently results in clever, high-quality systems that are clearly the product of the synthesis of several skill sets.
|
||||
|
||||
The result of our approach to hiring for SRE is that we end up with a team of people who (a) will quickly become bored by performing tasks by hand, and (b) have the skill set necessary to write software to replace their previously manual work, even when the solution is complicated. SREs also end up sharing academic and intellectual background with the rest of the development organization. Therefore, SRE is fundamentally doing work that has historically been done by an operations team, but using engineers with software expertise, and banking on the fact that these engineers are inherently both predisposed to, and have the ability to, design and implement automation with software to replace human labor.
|
||||
|
||||
By design, it is crucial that SRE teams are focused on engineering. Without constant engineering, operations load increases and teams will need more people just to keep pace with the workload. Eventually, a traditional ops-focused group scales linearly with service size: if the products supported by the service succeed, the operational load will grow with traffic. That means hiring more people to do the same tasks over and over again.
|
||||
|
||||
To avoid this fate, the team tasked with managing a service needs to code or it will drown. Therefore, Google places _a 50% cap on the aggregate "ops" work for all SREs_—tickets, on-call, manual tasks, etc. This cap ensures that the SRE team has enough time in their schedule to make the service stable and operable. This cap is an upper bound; over time, left to their own devices, the SRE team should end up with very little operational load and almost entirely engage in development tasks, because the service basically runs and repairs itself: we want systems that are _automatic_, not just _automated_. In practice, scale and new features keep SREs on their toes.
|
||||
|
||||
Google’s rule of thumb is that an SRE team must spend the remaining 50% of its time actually doing development. So how do we enforce that threshold? In the first place, we have to measure how SRE time is spent. With that measurement in hand, we ensure that the teams consistently spending less than 50% of their time on development work change their practices. Often this means shifting some of the operations burden back to the development team, or adding staff to the team without assigning that team additional operational responsibilities. Consciously maintaining this balance between ops and development work allows us to ensure that SREs have the bandwidth to engage in creative, autonomous engineering, while still retaining the wisdom gleaned from the operations side of running a service.
|
||||
|
||||
We’ve found that Google SRE’s approach to running large-scale systems has many advantages. Because SREs are directly modifying code in their pursuit of making Google’s systems run themselves, SRE teams are characterized by both rapid innovation and a large acceptance of change. Such teams are relatively inexpensive—supporting the same service with an ops-oriented team would require a significantly larger number of people. Instead, the number of SREs needed to run, maintain, and improve a system scales sublinearly with the size of the system. Finally, not only does SRE circumvent the dysfunctionality of the dev/ops split, but this structure also improves our product development teams: easy transfers between product development and SRE teams cross-train the entire group, and improve skills of developers who otherwise may have difficulty learning how to build a million-core distributed system.
|
||||
|
||||
Despite these net gains, the SRE model is characterized by its own distinct set of challenges. One continual challenge Google faces is hiring SREs: not only does SRE compete for the same candidates as the product development hiring pipeline, but the fact that we set the hiring bar so high in terms of both coding and system engineering skills means that our hiring pool is necessarily small. As our discipline is relatively new and unique, not much industry information exists on how to build and manage an SRE team (although hopefully this book will make strides in that direction!). And once an SRE team is in place, their potentially unorthodox approaches to service management require strong management support. For example, the decision to stop releases for the remainder of the quarter once an error budget is depleted might not be embraced by a product development team unless mandated by their management.
|
||||
|
||||
###### DevOps or SRE?
|
||||
|
||||
The term “DevOps” emerged in industry in late 2008 and as of this writing (early 2016) is still in a state of flux. Its core principles—involvement of the IT function in each phase of a system’s design and development, heavy reliance on automation versus human effort, the application of engineering practices and tools to operations tasks—are consistent with many of SRE’s principles and practices. One could view DevOps as a generalization of several core SRE principles to a wider range of organizations, management structures, and personnel. One could equivalently view SRE as a specific implementation of DevOps with some idiosyncratic extensions.
|
||||
|
||||
------------------------
|
||||
|
||||
作者简介:Benjamin Treynor Sloss coined the term "Site Reliability Engineering" and has been responsible for global operations, networking, and production engineering at Google since 2003\. As of 2016, he manages a team of approximately 4,000 software, hardware, and network engineers across the globe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/what-is-sre-site-reliability-engineering
|
||||
|
||||
作者:[Benjamin Treynor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/benjamin-treynor-sloss
|
||||
[1]:https://shop.oreilly.com/product/0636920053385.do
|
||||
[2]:https://shop.oreilly.com/product/0636920053385.do
|
||||
[3]:https://www.oreilly.com/ideas/what-is-sre-site-reliability-engineering
|
||||
[4]:https://shop.oreilly.com/product/0636920053385.do
|
||||
[5]:https://shop.oreilly.com/product/0636920053385.do
|
||||
[6]:https://www.oreilly.com/people/benjamin-treynor-sloss
|
||||
[7]:https://pixabay.com/
|
||||
[8]:https://www.oreilly.com/people/benjamin-treynor-sloss
|
||||
[9]:http://shop.oreilly.com/product/0636920041528.do?intcmp=il-webops-books-videos-update-na_new_site_site_reliability_engineering_text_cta
|
||||
[10]:http://conferences.oreilly.com/velocity/devops-web-performance-eu?intcmp=il-webops-confreg-update-vleu16_new_site_what_is_sre_text_cta
|
||||
[11]:https://pixabay.com/
|
||||
@ -1,184 +0,0 @@
|
||||
It's translated by GitFuture now.
|
||||
|
||||
Getting Started with HTTP/2: Part 2
|
||||
============================================================
|
||||

|
||||
|
||||
Firmly planting a flag in the sand for HTTP/2 best practices for front end development.
|
||||
|
||||
|
||||
If you have been keeping up with the talk of HTTP/2, you have probably attempted it or at least thought of how incorporate it into your projects. While there are a lot of hypotheses on how to its features can change your workflow and improve speed and efficiency on the web, best practices still haven't quite been pinned down yet. What I want to cover in this post are some HTTP/2 best practices I have discovered on a recent project.
|
||||
|
||||
If you aren't quite sure what HTTP/2 is or why it offers to improve your work, [check out my first post for a bit of background][4].
|
||||
|
||||
One note though: before we can get going, I need to mention that while your browser probably supports HTTP/2, your server probably doesn't. Check in with your hosting service to see if they offer HTTP/2 compatibility. Otherwise, you may be able to spin up your own server. This post does not cover how to do that unfortunately, but you can always check out the [http2 github][5] for some tools to get going in that direction.
|
||||
|
||||
### 🙏 [Rubs Hands Together]
|
||||
|
||||
A good way to start is to first organize your files. Take a look at the file tree below for a starting point to organize your stylesheets:
|
||||
|
||||
```
|
||||
`/styles
|
||||
|── /setup
|
||||
| /* variables, mixins and functions */
|
||||
|── /global
|
||||
| /* reusable components that could be within any component or section */
|
||||
|── /components
|
||||
| /* specific components and sections */
|
||||
|── setup.scss // index for setup styles
|
||||
|── global.scss // index for global styles`
|
||||
```
|
||||
|
||||
This breaks out your styles into three main categories: Setup, Global and Components. I will get into what each of these directories offer to your project next.
|
||||
|
||||
### Setting Up
|
||||
|
||||
The Setup level directory will hold all of your variables, functions, mixins and any other definition that another file will need to compile properly. To make this directory fully reusable, it's a good idea to import the contents of this directory into `setup.scss` so that it looks something like this:
|
||||
|
||||
```
|
||||
`/* setup.scss */
|
||||
|
||||
/* variables */
|
||||
@import "setup/variables/colors";
|
||||
|
||||
/* mixins */
|
||||
@import "setup/mixins/color";
|
||||
|
||||
/* functions */
|
||||
@import "setup/functions/color";
|
||||
|
||||
... etc`
|
||||
```
|
||||
|
||||
Now that we have a quick reference to any definition on the site, we should be sure to include it at the top of any style file we create from here on out.
|
||||
|
||||
### Going Global
|
||||
|
||||
Your next directory, Global, should contain components that can be reused across the site within multiple sections, or on every single page. Things like buttons, text and heading styles as well as your browser resets should go here. I do not recommend putting your header or footer styles in here because on some projects, the header is absent or different on certain pages. Furthermore, the footer is always the last element on the page, so it should not be a huge priority to load the styles for it before the user has loaded anything else on the site.
|
||||
|
||||
Keeping in mind that your Global styles probably won't work without the things we defined in the Setup directory, your Global file should look something like this:
|
||||
|
||||
```
|
||||
`/* global.scss */
|
||||
|
||||
/* application definitions */
|
||||
@import "setup";
|
||||
|
||||
/* global styles */
|
||||
@import "global/reset";
|
||||
@import "global/buttons";
|
||||
@import "global/typography";
|
||||
@import "global/grid";
|
||||
|
||||
... etc`
|
||||
```
|
||||
|
||||
Note that the first thing to import is the Setup styles. This way, any following file that uses something defined in that will have a reference to pull from.
|
||||
|
||||
Since the Global styles will be needed on every page of the site, we can load them in the typical way, using a `<link>` in the `<head>`. What you will have will be a very light CSS file, or theoretically light, depending on how much global style you need.
|
||||
|
||||
### Finally, Your Components
|
||||
|
||||
Notice that I did not include an index file for the Components directory in the file tree above. This is really where HTTP/2 comes into play. Up until now, we have been following standard practices for typical site build out, maintaining a fairly lean infrastructure and opting to globalize only the most necessary styles. Components act as their own index files.
|
||||
|
||||
Most developers have their own way of organizing their components, so I am not going to bother going into strategies here. However, all of your components should look something like this:
|
||||
|
||||
```
|
||||
`/* header.scss */
|
||||
|
||||
/* application definitions */
|
||||
@import "../setup";
|
||||
|
||||
header {
|
||||
// styles
|
||||
}
|
||||
|
||||
... etc`
|
||||
```
|
||||
|
||||
This way, again, you have those Setup styles there to make sure that everything is defined during compilation. You don't have to concatenate, minify or really do anything to these files other than compile them, and probably place them in an /assets directory, easy to find for your templates.
|
||||
|
||||
Now that our stylesheets are ready to go, building out the site should be simple.
|
||||
|
||||
### Building Out the Components
|
||||
|
||||
You probably have your own templating language of choice depending on the projects you are on, be it Twig, Rails, Jade or Handlebars. I think the best way to think about your components is that if it has its own template file, it should have a corresponding style with the same name. This way your project has a nice 1:1 ratio across your templates and styles and you know where which file everything is in because they are named accordingly.
|
||||
|
||||
Now that that is out of the way, taking advantage of HTTP/2's multiplexing is really simple, so let's build a template:
|
||||
|
||||
```
|
||||
`{# header.html #}
|
||||
|
||||
{# compiled header styles #}
|
||||
<link href="assets/components/header.css" rel="stylesheet" media="all">
|
||||
|
||||
<header>
|
||||
<h1>This Awesome HTTP/2 Site</h1>
|
||||
... etc`
|
||||
```
|
||||
|
||||
And that is pretty much it! You probably have a less heavy-handed way of linking to assets within your templates, but this shows you that all you need to do is link to that one small header style in the template file before you start your markup. This allows your site to only load the specific assets to the components on any given page, and furthermore, prioritizing the components from the top of your page to the bottom.
|
||||
|
||||
### Mixing It All Together
|
||||
|
||||
Now that all the components have a structure, the browser will render them something like this:
|
||||
|
||||
```
|
||||
`<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<link rel="stylesheet" media="all" href="/assets/global.css">
|
||||
</head>
|
||||
<body>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/header.css">
|
||||
<header>
|
||||
... etc
|
||||
</header>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/title.css">
|
||||
<section class="title">
|
||||
... etc
|
||||
</section>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/image-component.css">
|
||||
<section class="image-component">
|
||||
... etc
|
||||
</section>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/text-component.css">
|
||||
<section class="text-component">
|
||||
... etc
|
||||
</section>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/footer.css">
|
||||
<footer>
|
||||
... etc
|
||||
</footer>
|
||||
|
||||
</body>
|
||||
</html>`
|
||||
```
|
||||
|
||||
This is an upper level approach, but you will probably have finer-tuned components on your project. For example, you may have a `<nav>` component within the header that has its own stylesheet to load. Feel free to go as deep as you want with your components in a way that makes sense - HTTP/2 will not penalize you with those extra requests!
|
||||
|
||||
### Conclusion
|
||||
|
||||
This is just a basic look at how to build a project with HTTP/2 in mind on the front end, but this only scratches the surface. Perhaps you noticed a method I used that can be improved upon. Please bring it up in the comments! As stated in my first post, HTTP/2 is probably going to undo some of the standards we have held since HTTP/1, so it will take some serious thinking and experimenting to move into a fully efficient world of HTTP/2 development.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.viget.com/articles/getting-started-with-http-2-part-2
|
||||
|
||||
作者:[Ben][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.viget.com/about/team/btinsley
|
||||
[1]:https://twitter.com/home?status=Firmly%20planting%20a%20flag%20in%20the%20sand%20for%20HTTP%2F2%20best%20practices%20for%20front%20end%20development.%20https%3A%2F%2Fwww.viget.com%2Farticles%2Fgetting-started-with-http-2-part-2
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fwww.viget.com%2Farticles%2Fgetting-started-with-http-2-part-2
|
||||
[3]:http://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Fwww.viget.com%2Farticles%2Fgetting-started-with-http-2-part-2
|
||||
[4]:https://www.viget.com/articles/getting-started-with-http-2-part-1
|
||||
[5]:https://github.com/http2/http2-spec/wiki/Tools
|
||||
@ -1,3 +1,5 @@
|
||||
translating by ypingcn.
|
||||
|
||||
CLOUD FOCUSED LINUX DISTROS FOR PEOPLE WHO BREATHE ONLINE
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,177 +0,0 @@
|
||||
Vic020
|
||||
|
||||
Build, Deploy and Manage Custom Apps with IBM Bluemix
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
_IBM’s Bluemix affords developers an opportunity to build, deploy and manage custom apps. Bluemix is built on Cloud Foundry. It supports a number of programming languages as well as OpenWhisk, which allows developers to call any function without the need for resource management._
|
||||
|
||||
Bluemix is an open standards, cloud-based platform implemented by IBM. It has an open architecture which enables organisations to create, develop and manage their applications on the cloud. It is based on Cloud Foundry and hence can be considered as a Platform as a Service (PaaS). With Bluemix, developers need not worry about cloud configurations, but can concentrate on their applications. Cloud configurations will be done automatically by Bluemix.
|
||||
|
||||
Bluemix also provides a dashboard, with which developers can create, manage and view services and applications, while monitoring resource usage also.
|
||||
It supports the following programming languages:
|
||||
|
||||
* Java
|
||||
* Python
|
||||
* Ruby on Rails
|
||||
* PHP
|
||||
* Node.js
|
||||
|
||||
It also supports OpenWhisk (Function as a Service), which is also an IBM product that allows developers to call any function without requiring any resource management.
|
||||
|
||||

|
||||
|
||||
Figure 1: An Overview of IBM Bluemix
|
||||
|
||||

|
||||
|
||||
Figure 2: The IBM Bluemix architecture
|
||||
|
||||

|
||||
|
||||
Figure 3: Creating an organisation in IBM Bluemix
|
||||
|
||||
**How IBM Bluemix works**
|
||||
Bluemix is built on top of IBM’s SoftLayer IaaS (Infrastructure as a Service). It uses Cloud Foundry as an open source PaaS. It starts by pushing code through Cloud Foundry, which plays the role of combining the code and suitable runtime environment based on the programming language in which the application is written. IBM services, third party services or community built services can be used for different functionalities. Secure connectors can be used to connect to on-premise systems and the cloud.
|
||||
|
||||
|
||||
|
||||
Figure 4: Setting up Space in IBM Bluemix
|
||||
|
||||

|
||||
|
||||
Figure 5: The app template
|
||||
|
||||
|
||||
|
||||
Figure 6: IBM Bluemix supported programming languages
|
||||
|
||||
**Creating an app in Bluemix**
|
||||
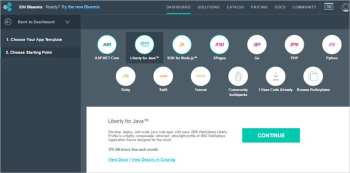
In this article, we will create a sample ‘Hello World’ application in IBM Bluemix by using the Liberty for Java starter pack, in just a few simple steps.
|
||||
|
||||
1\. Go to [_https://console.ng.bluemix.net/registration/_][2].
|
||||
|
||||
2\. Confirm the Bluemix account.
|
||||
|
||||
3\. Click on the confirmation link in the mail to complete the sign up process.
|
||||
|
||||
4\. Give your email ID and click on _Continue_ to log in.
|
||||
|
||||
5\. Enter the password and click on _Log in._
|
||||
|
||||
6. _Set up_ and _Environment_ share resources in specific regions.
|
||||
|
||||
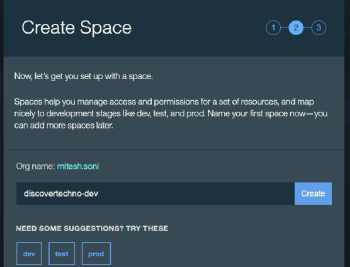
7\. Create Space to manage access and roll-back in Bluemix. We can map Spaces to development stages such as dev, test, uat, pre-prod and prod.
|
||||
|
||||

|
||||
|
||||
Figure 7: Naming the app
|
||||
|
||||

|
||||
|
||||
Figure 8: Knowing when the app is ready
|
||||
|
||||
|
||||
|
||||
Figure 9: The IBM Bluemix Java App
|
||||
|
||||
8\. Once this initial configuration is completed, click on_ I’m ready_. _Good to Go_!
|
||||
|
||||
9\. Verify the IBM Bluemix dashboard after successfully logging in, specifically sections such as Cloud Foundry Apps where 2GB is available and Virtual Server where 0 instances are available, as of now.
|
||||
|
||||
10\. Click on _Create app_. Choose the template for app creation. In our case, we will go for a Web app.
|
||||
|
||||
11\. How do you get started? Click on Liberty for Java, and then verify the description.
|
||||
|
||||
12\. Click on _Continue_.
|
||||
|
||||
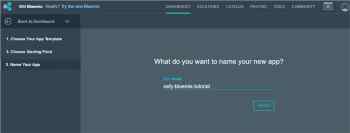
13\. What do you want to name your new app? For this article, let’s use osfy-bluemix-tutorial and click on _Finish_.
|
||||
|
||||
14\. It will take some time to create resources and to host an application on Bluemix.
|
||||
|
||||
15\. In a few minutes, your app will be up and running. Note the URL of the application.
|
||||
|
||||
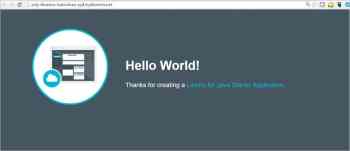
16\. Visit the application’s URL _http://osfy-bluemix-tutorial.au-syd.mybluemix.net/_. Bingo, our first Java application is up and running on IBM Bluemix.
|
||||
|
||||
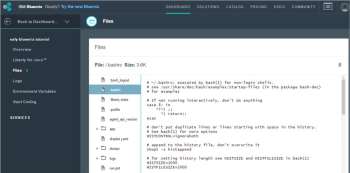
17\. To verify the source code, click on _Files_ and navigate to different files and folders in the portal.
|
||||
|
||||
18\. The _Logs_ section provides all the activity logs, starting from the application’s creation.
|
||||
|
||||
19\. The _Environment Variables_ section provides details on all the environment variables of VCAP_Services as well as those that are user defined.
|
||||
|
||||
20\. To verify the application’s consumption of resources, go to the Liberty for Java section.
|
||||
|
||||
21\. The _Overview_ section of each application contains details regarding resources, the application’s health, and activity logs, by default.
|
||||
|
||||
22\. Open Eclipse, go to the Help menu and click on _Eclipse Marketplace_.
|
||||
|
||||
23\. Find _IBM Eclipse tools_ for _Bluemix_ and click on _Install_.
|
||||
|
||||
24\. Confirm the selected features and install them in Eclipse.
|
||||
|
||||
25\. Download the application starter code. Import it into Eclipse by clicking on _File Menu_, select _Import Existing Projects_ into _Workspace_ and start modifying the existing code.
|
||||
|
||||
|
||||
|
||||
Figure 10: The Java app source files
|
||||
|
||||
|
||||
|
||||
Figure 11: The Java app logs
|
||||
|
||||

|
||||
|
||||
Figure 12: Java app — Liberty for Java
|
||||
|
||||
**[
|
||||
][1]Why IBM Bluemix?**
|
||||
Here are some compelling reasons to use IBM Bluemix:
|
||||
|
||||
* Supports multiple languages and platforms
|
||||
* Free trial
|
||||
|
||||
1\. Minimal registration process
|
||||
|
||||
2\. No credit card required
|
||||
|
||||
3\. 30-days trial period – with quotas of 2GB of runtime, 20 services, 500 routes
|
||||
|
||||
4\. Unlimited access to standard support
|
||||
|
||||
5\. No production use limitations
|
||||
|
||||
* Pay only for the use of each runtime and service
|
||||
* Quick set-up – hence faster time to market
|
||||
* Continuous delivery of new features
|
||||
* Secure integration with on-premise resources
|
||||
* Use cases
|
||||
|
||||
1\. Web applications and mobile back-ends
|
||||
|
||||
2\. APIs and on-premise integration
|
||||
|
||||
* DevOps services are available as SaaS on the cloud and support continuous delivery of:
|
||||
|
||||
1\. Web IDE
|
||||
|
||||
2\. SCM
|
||||
|
||||
3\. Agile planning
|
||||
|
||||
4\. Delivery pipeline service
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensourceforu.com/2016/11/build-deploy-manage-custom-apps-ibm-bluemix/
|
||||
|
||||
作者:[MITESH_SONI][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensourceforu.com/author/mitesh_soni/
|
||||
[1]:http://opensourceforu.com/wp-content/uploads/2016/10/Figure-7-Naming-the-app.jpg
|
||||
[2]:https://console.ng.bluemix.net/registration/
|
||||
@ -1,142 +0,0 @@
|
||||
翻译中-byzky001
|
||||
Compiling Vim from source is actually not that difficult.
|
||||
Here's what you should do:
|
||||
|
||||
1. First, install all the prerequisite libraries, including Git.
|
||||
For a Debian-like Linux distribution like Ubuntu,
|
||||
that would be the following:
|
||||
|
||||
```sh
|
||||
sudo apt-get install libncurses5-dev libgnome2-dev libgnomeui-dev \
|
||||
libgtk2.0-dev libatk1.0-dev libbonoboui2-dev \
|
||||
libcairo2-dev libx11-dev libxpm-dev libxt-dev python-dev \
|
||||
python3-dev ruby-dev lua5.1 lua5.1-dev libperl-dev git
|
||||
```
|
||||
|
||||
On Ubuntu 16.04, `liblua5.1-dev` is the lua dev package name not `lua5.1-dev`.
|
||||
|
||||
(If you know what languages you'll be using, feel free to leave out
|
||||
packages you won't need, e.g. Python2 `python-dev` or Ruby `ruby-dev`.
|
||||
This principle heavily applies to the whole page.)
|
||||
|
||||
For Fedora 20, that would be the following:
|
||||
|
||||
```sh
|
||||
sudo yum install -y ruby ruby-devel lua lua-devel luajit \
|
||||
luajit-devel ctags git python python-devel \
|
||||
python3 python3-devel tcl-devel \
|
||||
perl perl-devel perl-ExtUtils-ParseXS \
|
||||
perl-ExtUtils-XSpp perl-ExtUtils-CBuilder \
|
||||
perl-ExtUtils-Embed
|
||||
```
|
||||
|
||||
This step is needed to rectify an issue with how Fedora 20 installs XSubPP:
|
||||
|
||||
```sh
|
||||
# symlink xsubpp (perl) from /usr/bin to the perl dir
|
||||
sudo ln -s /usr/bin/xsubpp /usr/share/perl5/ExtUtils/xsubpp
|
||||
```
|
||||
|
||||
2. Remove vim if you have it already.
|
||||
|
||||
```sh
|
||||
sudo apt-get remove vim vim-runtime gvim
|
||||
```
|
||||
|
||||
On Ubuntu 12.04.2 you probably have to remove these packages as well:
|
||||
|
||||
```sh
|
||||
sudo apt-get remove vim-tiny vim-common vim-gui-common vim-nox
|
||||
```
|
||||
|
||||
3. Once everything is installed, getting the source is easy.
|
||||
|
||||
Note: If you are using Python, your config directory might have
|
||||
a machine-specific name (e.g. `config-3.5m-x86_64-linux-gnu`).
|
||||
Check in /usr/lib/python[2/3/3.5] to find yours, and change
|
||||
the `python-config-dir` and/or `python3-config-dir` arguments accordingly.
|
||||
|
||||
Add/remove the flags below to fit your setup. For example, you can leave out
|
||||
`enable-luainterp` if you don't plan on writing any Lua.
|
||||
|
||||
Also, if you're not using vim 8.0,
|
||||
make sure to set the VIMRUNTIMEDIR variable correctly below
|
||||
(for instance, with vim 8.0a, use /usr/share/vim/vim80a).
|
||||
Keep in mind that some vim installations are located directly
|
||||
inside /usr/share/vim; adjust to fit your system:
|
||||
|
||||
```sh
|
||||
cd ~
|
||||
git clone https://github.com/vim/vim.git
|
||||
cd vim
|
||||
./configure --with-features=huge \
|
||||
--enable-multibyte \
|
||||
--enable-rubyinterp=yes \
|
||||
--enable-pythoninterp=yes \
|
||||
--with-python-config-dir=/usr/lib/python2.7/config \
|
||||
--enable-python3interp=yes \
|
||||
--with-python3-config-dir=/usr/lib/python3.5/config \
|
||||
--enable-perlinterp=yes \
|
||||
--enable-luainterp=yes \
|
||||
--enable-gui=gtk2 --enable-cscope --prefix=/usr
|
||||
make VIMRUNTIMEDIR=/usr/share/vim/vim80
|
||||
```
|
||||
On Ubuntu 16.04, Python support was not working due to enabling both Python2 and Python3. Read [answer by chirinosky](http://stackoverflow.com/questions/23023783/vim-compiled-with-python-support-but-cant-see-sys-version) for workaround.
|
||||
|
||||
If you want to be able to easily uninstall vim use `checkinstall`.
|
||||
|
||||
```sh
|
||||
sudo apt-get install checkinstall
|
||||
cd ~/vim
|
||||
sudo checkinstall
|
||||
```
|
||||
|
||||
Otherwise, you can use `make` to install.
|
||||
|
||||
```sh
|
||||
cd ~/vim
|
||||
sudo make install
|
||||
```
|
||||
|
||||
Set vim as your default editor with `update-alternatives`.
|
||||
|
||||
```sh
|
||||
sudo update-alternatives --install /usr/bin/editor editor /usr/bin/vim 1
|
||||
sudo update-alternatives --set editor /usr/bin/vim
|
||||
sudo update-alternatives --install /usr/bin/vi vi /usr/bin/vim 1
|
||||
sudo update-alternatives --set vi /usr/bin/vim
|
||||
```
|
||||
|
||||
4. Double check that you are in fact running the new Vim binary by looking at
|
||||
the output of `vim --version`.
|
||||
|
||||
**If you don't get gvim working (on ubuntu 12.04.1 LTS), try changing
|
||||
`--enable-gui=gtk2` to `--enable-gui=gnome2`**
|
||||
|
||||
If you have problems, double check that you `configure`d using the correct Python config
|
||||
directory, as noted at the beginning of Step 3.
|
||||
|
||||
These `configure` and `make` calls assume a Debian-like distro where Vim's
|
||||
runtime files directory is placed in `/usr/share/vim/vim80/`,
|
||||
which is not Vim's default. Same thing goes for `--prefix=/usr` in the
|
||||
`configure` call. Those values may need to be different with a Linux
|
||||
distro that is not based on Debian. In such a case, try to remove the
|
||||
`--prefix` variable in the `configure` call and the `VIMRUNTIMEDIR` in the
|
||||
`make` call (in other words, go with the defaults).
|
||||
|
||||
If you get stuck, here's some [other useful information on building Vim]
|
||||
(http://vim.wikia.com/wiki/Building_Vim).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
|
||||
作者:[Val Markovic][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/Valloric
|
||||
@ -1,144 +0,0 @@
|
||||
GHLandy Translating
|
||||
|
||||
使用 NTP 进行时间同步
|
||||
============================================================
|
||||
|
||||
NTP 是通过网络来同步时间的一种 TCP/IP 协议。通常客户端向服务器请求当前的时间,并根据结果来设置其时钟。
|
||||
|
||||
Behind this simple description, there is a lot of complexity - there are tiers of NTP servers, with the tier one NTP servers connected to atomic clocks, and tier two and three servers spreading the load of actually handling requests across the Internet. Also the client software is a lot more complex than you might think - it has to factor out communication delays, and adjust the time in a way that does not upset all the other processes that run on the server. But luckily all that complexity is hidden from you!
|
||||
|
||||
Ubuntu uses ntpdate and ntpd.
|
||||
|
||||
* [timedatectl][4]
|
||||
* [timesyncd][5]
|
||||
* [ntpdate][6]
|
||||
* [timeservers][7]
|
||||
* [ntpd][8]
|
||||
* [安装][9]
|
||||
* [配置][10]
|
||||
* [View status][11]
|
||||
* [PPS Support][12]
|
||||
* [参考资料][13]
|
||||
|
||||
### timedatectl
|
||||
|
||||
In recent Ubuntu releases timedatectl replaces ntpdate. By default timedatectl syncs the time once on boot and later on uses socket activation to recheck once network connections become active.
|
||||
|
||||
If ntpdate / ntp is installed timedatectl steps back to let you keep your old setup. That shall ensure that no two time syncing services are fighting and also to retain any kind of old behaviour/config that you had through an upgrade. But it also implies that on an upgrade from a former release ntp/ntpdate might still be installed and therefore renders the new systemd based services disabled.
|
||||
|
||||
### timesyncd
|
||||
|
||||
In recent Ubuntu releases timesyncd replaces the client portion of ntpd. By default timesyncd regularly checks and keeps the time in sync. It also stores time updates locally, so that after reboots monotonically advances if applicable.
|
||||
|
||||
The current status of time and time configuration via timedatectl and timesyncd can be checked with timedatectl status.
|
||||
|
||||
```
|
||||
timedatectl status
|
||||
Local time: Fri 2016-04-29 06:32:57 UTC
|
||||
Universal time: Fri 2016-04-29 06:32:57 UTC
|
||||
RTC time: Fri 2016-04-29 07:44:02
|
||||
Time zone: Etc/UTC (UTC, +0000)
|
||||
Network time on: yes
|
||||
NTP synchronized: no
|
||||
RTC in local TZ: no
|
||||
```
|
||||
|
||||
If NTP is installed and replaces the activity of timedatectl the line "NTP synchronized" is set to yes.
|
||||
|
||||
The nameserver to fetch time for timedatectl and timesyncd from can be specified in /etc/systemd/timesyncd.conf and with flexible additional config files in /etc/systemd/timesyncd.conf.d/.
|
||||
|
||||
### ntpdate
|
||||
|
||||
ntpdate is considered deprecated in favour of timedatectl and thereby no more installed by default. If installed it will run once at boot time to set up your time according to Ubuntu's NTP server. Later on anytime a new interface comes up it retries to update the time - while doing so it will try to slowly drift time as long as the delta it has to cover isn't too big. That behaviour can be controlled with the -B/-b switches.
|
||||
|
||||
```
|
||||
ntpdate ntp.ubuntu.com
|
||||
```
|
||||
|
||||
### timeservers
|
||||
|
||||
By default the systemd based tools request time information at ntp.ubuntu.com. In classic ntpd based service uses the pool of [0-3].ubuntu.pool.ntp.org Of the pool number 2.ubuntu.pool.ntp.org as well as ntp.ubuntu.com also support ipv6 if needed. If one needs to force ipv6 there also is ipv6.ntp.ubuntu.com which is not configured by default.
|
||||
|
||||
### ntpd
|
||||
|
||||
The ntp daemon ntpd calculates the drift of your system clock and continuously adjusts it, so there are no large corrections that could lead to inconsistent logs for instance. The cost is a little processing power and memory, but for a modern server this is negligible.
|
||||
|
||||
### 安装
|
||||
|
||||
To install ntpd, from a terminal prompt enter:
|
||||
|
||||
```
|
||||
sudo apt install ntp
|
||||
```
|
||||
|
||||
### 配置
|
||||
|
||||
Edit /etc/ntp.conf to add/remove server lines. By default these servers are configured:
|
||||
|
||||
```
|
||||
# Use servers from the NTP Pool Project. Approved by Ubuntu Technical Board
|
||||
# on 2011-02-08 (LP: #104525). See http://www.pool.ntp.org/join.html for
|
||||
# more information.
|
||||
server 0.ubuntu.pool.ntp.org
|
||||
server 1.ubuntu.pool.ntp.org
|
||||
server 2.ubuntu.pool.ntp.org
|
||||
server 3.ubuntu.pool.ntp.org
|
||||
```
|
||||
|
||||
After changing the config file you have to reload the ntpd:
|
||||
|
||||
```
|
||||
sudo systemctl reload ntp.service
|
||||
```
|
||||
|
||||
### View status
|
||||
|
||||
Use ntpq to see more info:
|
||||
|
||||
```
|
||||
# sudo ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================================
|
||||
+stratum2-2.NTP. 129.70.130.70 2 u 5 64 377 68.461 -44.274 110.334
|
||||
+ntp2.m-online.n 212.18.1.106 2 u 5 64 377 54.629 -27.318 78.882
|
||||
*145.253.66.170 .DCFa. 1 u 10 64 377 83.607 -30.159 68.343
|
||||
+stratum2-3.NTP. 129.70.130.70 2 u 5 64 357 68.795 -68.168 104.612
|
||||
+europium.canoni 193.79.237.14 2 u 63 64 337 81.534 -67.968 92.792
|
||||
```
|
||||
|
||||
### PPS Support
|
||||
|
||||
Since 16.04 ntp supports PPS discipline which can be used to augment ntp with local timesources for better accuracy. For more details on configuration see the external pps ressource listed below.
|
||||
|
||||
### 参考资料
|
||||
|
||||
* See the [Ubuntu Time][1] wiki page for more information.
|
||||
|
||||
* [ntp.org, home of the Network Time Protocol project][2]
|
||||
|
||||
* [ntp.org faq on configuring PPS][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://help.ubuntu.com/lts/serverguide/NTP.html
|
||||
|
||||
作者:[Ubuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://help.ubuntu.com/lts/serverguide/NTP.html
|
||||
[1]:https://help.ubuntu.com/community/UbuntuTime
|
||||
[2]:http://www.ntp.org/
|
||||
[3]:http://www.ntp.org/ntpfaq/NTP-s-config-adv.htm#S-CONFIG-ADV-PPS
|
||||
[4]:https://help.ubuntu.com/lts/serverguide/NTP.html#timedatectl
|
||||
[5]:https://help.ubuntu.com/lts/serverguide/NTP.html#timesyncd
|
||||
[6]:https://help.ubuntu.com/lts/serverguide/NTP.html#ntpdate
|
||||
[7]:https://help.ubuntu.com/lts/serverguide/NTP.html#timeservers
|
||||
[8]:https://help.ubuntu.com/lts/serverguide/NTP.html#ntpd
|
||||
[9]:https://help.ubuntu.com/lts/serverguide/NTP.html#ntp-installation
|
||||
[10]:https://help.ubuntu.com/lts/serverguide/NTP.html#timeservers-conf
|
||||
[11]:https://help.ubuntu.com/lts/serverguide/NTP.html#ntp-status
|
||||
[12]:https://help.ubuntu.com/lts/serverguide/NTP.html#ntp-pps
|
||||
[13]:https://help.ubuntu.com/lts/serverguide/NTP.html#ntp-references
|
||||
@ -1,222 +0,0 @@
|
||||
Rusking translating
|
||||
|
||||
Manage Samba4 AD Domain Controller DNS and Group Policy from Windows – Part 4
|
||||
============================================================
|
||||
|
||||
Continuing the previous tutorial on [how to administer Samba4 from Windows 10 via RSAT][4], in this part we’ll see how to remotely manage our Samba AD Domain controller DNS server from Microsoft DNS Manager, how to create DNS records, how to create a Reverse Lookup Zone and how to create a domain policy via Group Policy Management tool.
|
||||
|
||||
#### Requirements
|
||||
|
||||
1. [Create an AD Infrastructure with Samba4 on Ubuntu 16.04 – Part 1][1]
|
||||
2. [Manage Samba4 AD Infrastructure from Linux Command Line – Part 2][2]
|
||||
3. [Manage Samba4 Active Directory Infrastructure from Windows10 via RSAT – Part 3][3]
|
||||
|
||||
### Step 1: Manage Samba DNS Server
|
||||
|
||||
Samba4 AD DC uses an internal DNS resolver module which is created during the initial domain provision (if BIND9 DLZ module is not specifically used).
|
||||
|
||||
Samba4 internal DNS module supports the basic features needed for an AD Domain Controller. The domain DNS server can be managed in two ways, directly from command line through samba-tool interface or remotely from a Microsoft workstation which is part of the domain via RSAT DNS Manager.
|
||||
|
||||
Here, we’ll cover the second method because it’s more intuitive and not so prone to errors.
|
||||
|
||||
1. To administer the DNS service for your domain controller via RSAT, go to your Windows machine, open Control Panel -> System and Security -> Administrative Tools and run DNS Manager utility.
|
||||
|
||||
Once the tool opens, it will ask you on what DNS running server you want to connect. Choose The following computer, type your domain name in the field (or IP Address or FQDN can be used as well), check the box that says ‘Connect to the specified computer now’ and hit OK to open your Samba DNSservice.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Connect Samba4 DNS on Windows
|
||||
|
||||
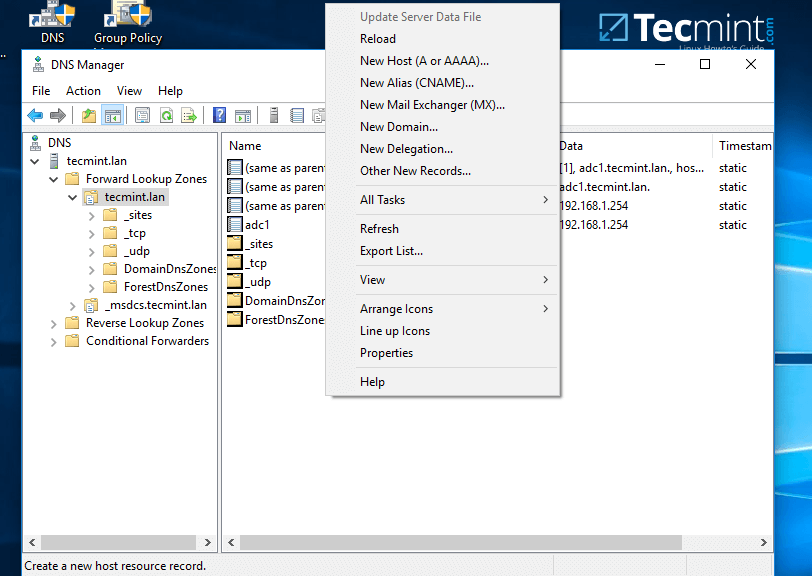
2. In order to add a DNS record (as an example we will add an `A` record that will point to our LAN gateway), navigate to domain Forward Lookup Zone, right click on the right plane and choose New Host(`A` or `AAA`).
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
Add DNS A Record on Windows
|
||||
|
||||
3. On the New host opened window, type the name and the IP Address of your DNS resource. The FQDNwill be automatically written for you by DNS utility. When finished, hit the Add Host button and a pop-up window will inform you that your DNS A record has been successfully created.
|
||||
|
||||
Make sure you add DNS A records only for those resources in your network [configured with static IP Addresses][7]. Don’t add DNS A records for hosts which are configured to acquire network configurations from a DHCP server or their IP Addresses change often.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Configure Samba Host on Windows
|
||||
|
||||
To update a DNS record just double click on it and write your modifications. To delete the record right click on the record and choose delete from the menu.
|
||||
|
||||
In the same way you can add other types of DNS records for your domain, such as CNAME (also known as DNS alias record) MX records (very useful for mail servers) or other type of records (SPF, TXT, SRVetc).
|
||||
|
||||
### Step 2: Create a Reverse Lookup Zone
|
||||
|
||||
By default, Samba4 Ad DC doesn’t automatically add a reverse lookup zone and PTR records for your domain because these types of records are not crucial for a domain controller to function correctly.
|
||||
|
||||
Instead, a DNS reverse zone and its PTR records are crucial for the functionality of some important network services, such as an e-mail service because these type of records can be used to verify the identity of clients requesting a service.
|
||||
|
||||
Practically, PTR records are just the opposite of standard DNS records. The clients know the IP address of a resource and queries the DNS server to find out their registered DNS name.
|
||||
|
||||
4. In order to a create a reverse lookup zone for Samba AD DC, open DNS Manager, right click on Reverse Lookup Zone from the left plane and choose New Zone from the menu.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Create Reverse Lookup DNS Zone
|
||||
|
||||
5. Next, hit Next button and choose Primary zone from Zone Type Wizard.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Select DNS Zone Type
|
||||
|
||||
6. Next, choose To all DNS servers running on domain controllers in this domain from the AD Zone Replication Scope, chose IPv4 Reverse Lookup Zone and hit Next to continue.
|
||||
|
||||
[
|
||||
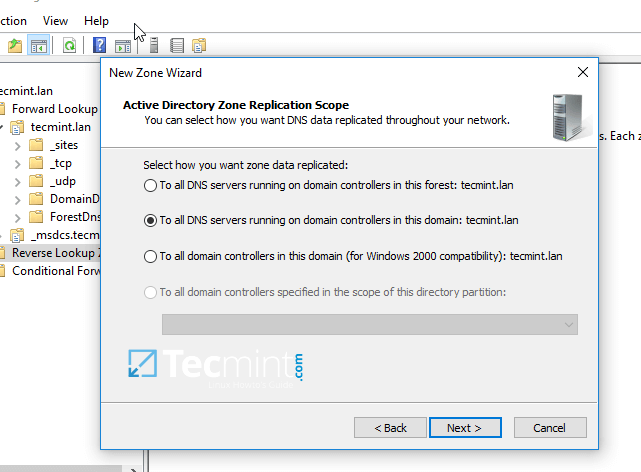
|
||||
][11]
|
||||
|
||||
Select DNS for Samba Domain Controller
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Add Reverse Lookup Zone Name
|
||||
|
||||
7. Next, type the IP network address for your LAN in Network ID filed and hit Next to continue.
|
||||
|
||||
All PTR records added in this zone for your resources will point back only to 192.168.1.0/24 network portion. If you want to create a PTR record for a server that does not reside in this network segment (for example mail server which is located in 10.0.0.0/24 network), then you’ll need to create a new reverse lookup zone for that network segment as well.
|
||||
|
||||
[
|
||||
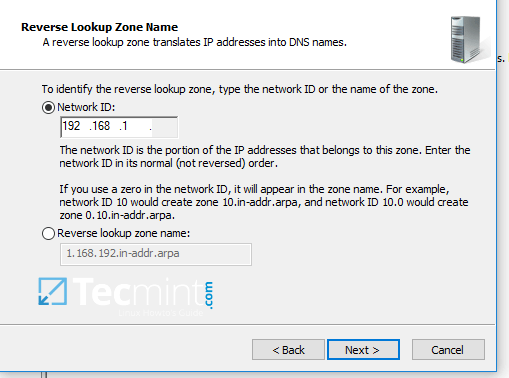
|
||||
][13]
|
||||
|
||||
Add IP Address of Reverse Lookup DNS Zone
|
||||
|
||||
8. On the next screen choose to Allow only secure dynamic updates, hit next to continue and, finally hit on finish to complete zone creation.
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Enable Secure Dynamic Updates
|
||||
|
||||
[
|
||||
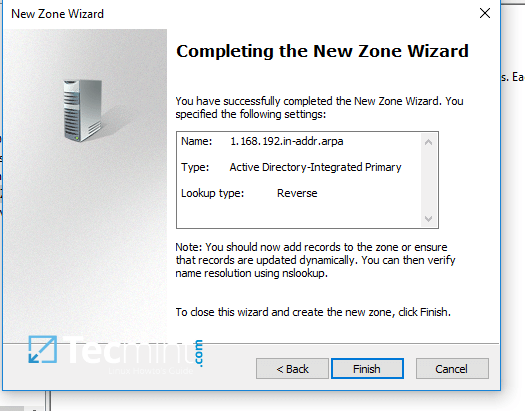
|
||||
][15]
|
||||
|
||||
New DNS Zone Summary
|
||||
|
||||
9. At this point you have a valid DNS reverse lookup zone configured for your domain. In order to add a PTR record in this zone, right click on the right plane and choose to create a PTR record for a network resource.
|
||||
|
||||
In this case we’ve created a pointer for our gateway. In order to test if the record was properly added and works as expected from client’s point of view, open a Command Prompt and issue a nslookup query against the name of the resource and another query for its IP Address.
|
||||
|
||||
Both queries should return the correct answer for your DNS resource.
|
||||
|
||||
```
|
||||
nslookup gate.tecmint.lan
|
||||
nslookup 192.168.1.1
|
||||
ping gate
|
||||
```
|
||||
[
|
||||
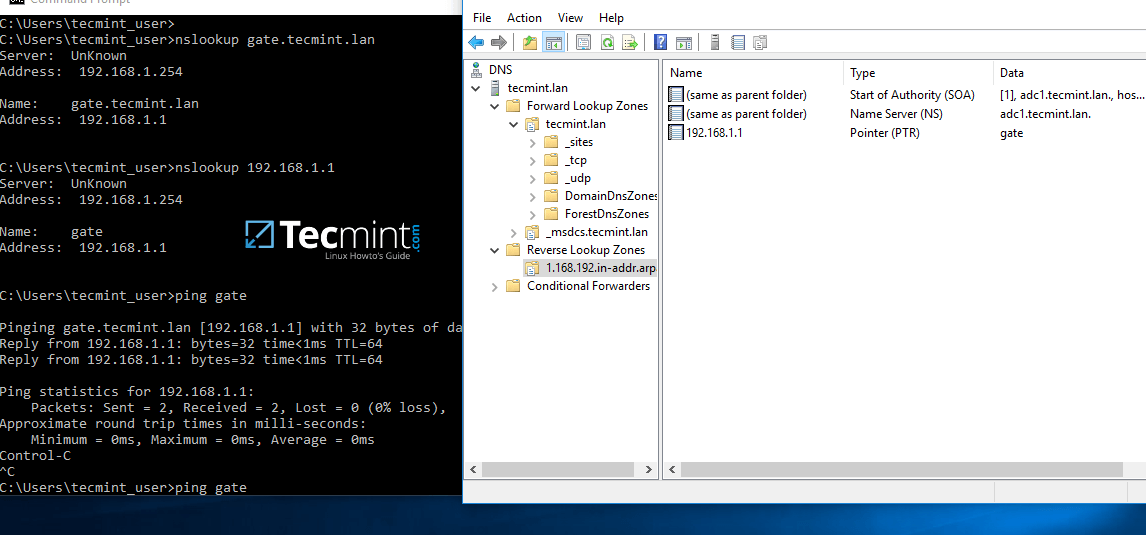
|
||||
][16]
|
||||
|
||||
Add DNS PTR Record and Query PTR
|
||||
|
||||
### Step 3: Domain Group Policy Management
|
||||
|
||||
10. An important aspect of a domain controller is its ability to control system resources and security from a single central point. This type of task can be easily achieved in a domain controller with the help of Domain Group Policy.
|
||||
|
||||
Unfortunately, the only way to edit or manage group policy in a samba domain controller is through RSAT GPM console provided by Microsoft.
|
||||
|
||||
In the below example we’ll see how simple can be to manipulate group policy for our samba domain in order to create an interactive logon banner for our domain users.
|
||||
|
||||
In order to access group policy console, go to Control Panel -> System and Security -> Administrative Tools and open Group Policy Management console.
|
||||
|
||||
Expand the fields for your domain and right click on Default Domain Policy. Choose Edit from the menu and a new windows should appear.
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
Manage Samba Domain Group Policy
|
||||
|
||||
11. On Group Policy Management Editor window go to Computer Configuration -> Policies -> Windows Settings -> Security settings -> Local Policies -> Security Options and a new options list should appear in the right plane.
|
||||
|
||||
In the right plane search and edit with your custom settings following two entries presented on the below screenshot.
|
||||
|
||||
[
|
||||
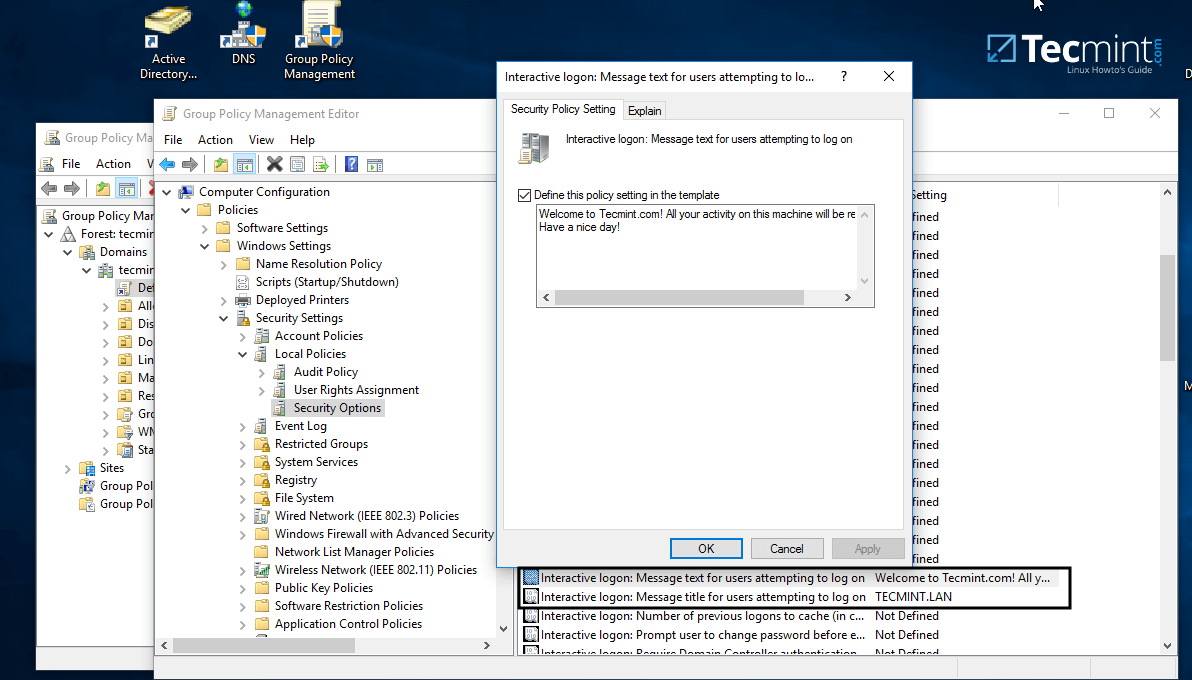
|
||||
][18]
|
||||
|
||||
Configure Samba Domain Group Policy
|
||||
|
||||
12. After finishing editing the two entries, close all windows, open an elevated Command prompt and force group policy to apply on your machine by issuing the below command:
|
||||
|
||||
```
|
||||
gpupdate /force
|
||||
```
|
||||
[
|
||||
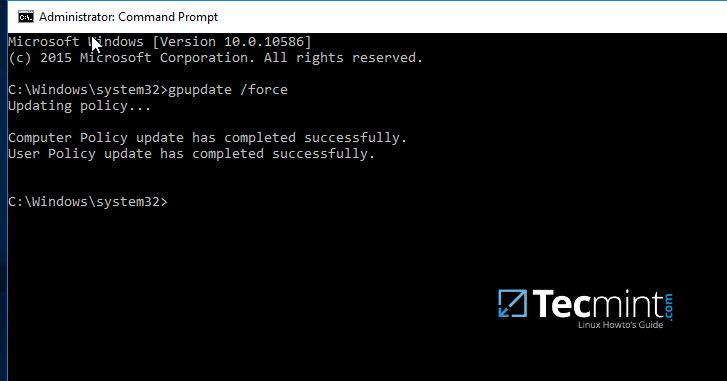
|
||||
][19]
|
||||
|
||||
Update Samba Domain Group Policy
|
||||
|
||||
13. Finally, reboot your computer and you’ll see the logon banner in action when you’ll try to perform logon.
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
Samba4 AD Domain Controller Logon Banner
|
||||
|
||||
That’s all! Group Policy is a very complex and sensitive subject and should be treated with maximum care by system admins. Also, be aware that group policy settings won’t apply in any way to Linux systems integrated into the realm.
|
||||
|
||||
------
|
||||
|
||||
作者简介:I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/
|
||||
|
||||
作者:[Matei Cezar ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
[1]:http://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:http://www.tecmint.com/manage-samba4-active-directory-linux-command-line/
|
||||
[3]:http://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[4]:http://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/Connect-Samba4-DNS-on-Windows.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/12/Add-DNS-A-Record.png
|
||||
[7]:http://www.tecmint.com/set-add-static-ip-address-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Samba-Host-on-Windows.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/12/Create-Reverse-Lookup-DNS-Zone.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-DNS-Zone-Type.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-DNS-for-Samba-Domain-Controller.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/12/Add-Reverse-Lookup-Zone-Name.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2016/12/Add-IP-Address-of-Reverse-DNS-Zone.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/12/Enable-Secure-Dynamic-Updates.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2016/12/New-DNS-Zone-Summary.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Add-DNS-PTR-Record-and-Query.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2016/12/Manage-Samba-Domain-Group-Policy.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Samba-Domain-Group-Policy.png
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2016/12/Update-Samba-Domain-Group-Policy.png
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2016/12/Samba4-Domain-Controller-User-Login.png
|
||||
[21]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#
|
||||
[22]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#
|
||||
[23]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#
|
||||
[24]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#
|
||||
[25]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#comments
|
||||
@ -1,192 +0,0 @@
|
||||
translating by beyondworld
|
||||
|
||||
9 Open Source/Commercial Software for Data Center Infrastructure Management
|
||||
============================================================
|
||||
|
||||
When a company grows its demand in computing resources grows as well. It works as for regular companies as for providers, including those renting out dedicated servers. When the total number of racks exceed 10 you’ll start facing issues.
|
||||
|
||||
How to inventory servers and spares? How to maintain a data center in a good health, locating and fixing potential threats on time. How to find the rack with broken equipment? How to prepare physical machines to work? Carrying out these tasks manually will take too much time otherwise will require having a huge team of administrators in your IT-department.
|
||||
|
||||
|
||||
However there is a better solution – using a special software that automates Data Center management. Let’s have a review of the tools for running a DC that we have on a market today.
|
||||
|
||||
### 1\. Opendcim
|
||||
|
||||
Currently it’s the one and the only free software in its class. It has an open source-code and designed to be an alternative to commercial DCIM solutions. Allows to keep inventory, draw a DC map and monitor temperature and power consumption.
|
||||
|
||||
On the other hand, it doesn’t support remote power-off, server rebooting, and OS installation functionality. Nevertheless, it is widely used in non-commercial organizations all around the globe.
|
||||
|
||||
Thanks to its open source code, [Opendcims][2] should work fine for the companies having their own developers.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
openDCIM
|
||||
|
||||
### 2\. NOC-PS
|
||||
|
||||
A commercial system, designed for provisioning physical and virtual machines. Has a wide functionality for advance preparation of equipment: OS and other software installation and setting up network configurations, there is WHMCS and Blesta integrations. However, it won’t be your best choice if you need to have a DC map at hand and see the racks location.
|
||||
|
||||
[NOC-PS][4] will cost you a 100€ per year for every 100 dedicated servers bundle. Suits for small-to-middle scale companies.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
NOC-PS
|
||||
|
||||
### 3\. DCImanager
|
||||
|
||||
[DCImanager][6] is a proprietary class solution developed, as announced, considering the needs of DC engineers and hosting providers. Has an integration with popular billing software like WHMCS, Hostbill, BILLmanager.
|
||||
|
||||
Main features are: server provisioning, OS installation from templates, sensors monitoring, traffic and power consumption reports, VLAN management. In addition to said above, Enterprise edition allows you to build a DC map and keep servers and spares inventorying.
|
||||
|
||||
|
||||
You can try a free license for up to 5 physical servers while a yearly license costs 120€ for 100 dedicated machines.
|
||||
|
||||
Depending on edition, can be a good fit for both SMBs and large-scale enterprises.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
DCImanager
|
||||
|
||||
### 4\. EasyDCIM
|
||||
|
||||
[EasyDCIM][9] is a paid software mainly oriented on server provisioning. Brings OS and other software installation features and facilitates DC navigation allowing to draw a scheme of racks.
|
||||
|
||||
Meanwhile the product itself doesn’t include IPs and DNS management, control over the switches. These and other features become available after additional modules installation, both free and paid (including WHMCS integration).
|
||||
|
||||
100 server license starts from $999 per year. Due to the pricing EasyDCIM may be a bit expensive for small companies, while middle and large companies can give it a try.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
EasyDCIM
|
||||
|
||||
### 5\. Ansible Tower
|
||||
|
||||
[Ansible Tower][11] is a Enterprise level computing infrastructure management tool from RedHat. The main idea of this solution was the possibility of a centralized deployment as for servers as for the different user devices.
|
||||
|
||||
Thanks to that Ansible Tower can perform almost any possible program operation with integrated software and has an amazing statistics collecting module. On the dark side we have the lack of integration with popular billing systems and pricing.
|
||||
|
||||
$5000 per year for 100 devices. Will work for large and gigantic companies..
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Ansible Tower
|
||||
|
||||
### 6\. Puppet Enterprise
|
||||
|
||||
Developed on a commercial basis and considered as an accessorial software for IT-departments. Designed for OS and other software installation on servers and user devices both at the initial deployment and a further exploitation stages.
|
||||
|
||||
Unfortunately, inventorying and the more advanced interaction schemes between devices (cable connection, protocols and other) is still under development.
|
||||
|
||||
[Puppet Enterprise][13] has a free and fully-functional version for 10 computers. A yearly license cost is $120 per device.
|
||||
|
||||
Can work for big corporations.
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Puppet Enterprise
|
||||
|
||||
### 7\. Device 42
|
||||
|
||||
Mostly designed for a Data Center monitoring. Has a great tools for inventorying, builds hardware/software dependence map automatically. DC map drawn by [Device 42][15] reflects temperature, spare space and other parameters of a rack as in graphics as marking the racks with specific colour. However software installation and billing integration aren’t supported.
|
||||
|
||||
100 servers license will cost $1499 per year. Probably can be a good shot for middle-to-large companies.
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
Device42
|
||||
|
||||
### 8\. CenterOS
|
||||
|
||||
It’s an operating system for a Data Center management with a main focus on equipment inventorying. Besides creating a DC map, schemes of racks and connections a well-thought integrated system of server statuses facilitates managing the internal technical works.
|
||||
|
||||
Another great feature allows to find and reach out to a right person related with a certain piece of equipment within a few clicks (it may be an owner, technician, or manufacturer), what can be truly handful in case of any emergencies.
|
||||
|
||||
**Suggested Read:** [8 Open Source/Commercial Billing Platforms for Hosting Providers][17]
|
||||
|
||||
The source code for [Centeros][18] is closed and pricing is available only upon request.
|
||||
|
||||
A mystery about the pricing complicates determining a target audience of the product, however it’s possible to make an assumption that Centeros is designed mostly for larger companies.
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
CenterOS
|
||||
|
||||
### 9\. LinMin
|
||||
|
||||
It’s an instrument for preparing a physical equipment for a further usager. Uses PXE install the chosen OS and deploys the requested set of additional software afterwards.
|
||||
|
||||
Unlike most of its analogs, [LinMin][20] has a well-developed backup system for hard drives, that speeds up an after-crush recovery and facilitates the mass deployments of the servers with a same configuration.
|
||||
|
||||
Price starts from $1999/year for 100 servers. Middle-to-large companies can keep LinMin in mind.
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
LinMin
|
||||
|
||||
Now let’s summarize everything. I would say that most of the products for automating operations with a high volume of infrastructure, that we have on a market today, can be divided in two categories.
|
||||
|
||||
The first is mainly designed for preparing an equipment for a further exploitation while the second manages inventorying. It’s not so easy to find a universal solution that will contain all the necessary features so you can give up on the many tools with a narrow functionality provided by an equipment manufacturer.
|
||||
|
||||
However now you have a list of such solutions and you are welcome to check it yourself. It’s worth to notice that an open source products is on the list as well, so if you have a good developer, it’s possible to customize it for your specific needs.
|
||||
|
||||
I hope that my review will help you to find a right software for your case and make your life easier. Long life to your servers!
|
||||
|
||||
|
||||
-----------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I'm a technical evangelist at hosting software developing company from Siberia, Russia. I'm curious and like to expand my knowledge whether from new Linux software tools or to Hosting Industry trends, possibilities, journey and opportunities.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/data-center-server-management-tools/
|
||||
|
||||
作者:[ Nikita Nesmiyanov][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/nesmiyanov/
|
||||
[1]:http://www.tecmint.com/web-control-panels-to-manage-linux-servers/
|
||||
[2]:http://opendcim.org/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/12/openDCIM.png
|
||||
[4]:http://noc-ps.com/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/NOC-PS.png
|
||||
[6]:https://www.ispsystem.com/software/dcimanager
|
||||
[7]:http://www.tecmint.com/opensource-commercial-control-panels-manage-virtual-machines/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/DCImanager.png
|
||||
[9]:https://www.easydcim.com/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/12/EasyDCIM.png
|
||||
[11]:https://www.ansible.com/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/12/Ansible_Tower.png
|
||||
[13]:https://puppet.com/
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/12/Puppet-Enterprise.png
|
||||
[15]:http://www.device42.com/
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Device42.png
|
||||
[17]:http://www.tecmint.com/open-source-commercial-billing-software-system-web-hosting/
|
||||
[18]:http://www.centeros.com/
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2016/12/CenterOS.png
|
||||
[20]:http://www.linmin.com/
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2016/12/LinMin.jpg
|
||||
@ -1,171 +1,169 @@
|
||||
alim0x translating
|
||||
|
||||
The (updated) history of Android
|
||||
安卓编年史
|
||||
============================================================
|
||||
|
||||
> Follow the endless iterations from Android 0.5 to Android 7 and beyond.
|
||||
> 让我们跟着安卓从 0.5 版本到 7 的无尽迭代来看看它的发展历史。
|
||||
|
||||
### Android TV
|
||||
|
||||
|
||||
* [
|
||||

|
||||

|
||||
][2]
|
||||
* [
|
||||
|
||||

|
||||
][3]
|
||||
* [
|
||||

|
||||

|
||||
][4]
|
||||
* [
|
||||
|
||||

|
||||
][5]
|
||||
* [
|
||||
|
||||

|
||||
][6]
|
||||
* [
|
||||
|
||||

|
||||
][7]
|
||||
* [
|
||||
|
||||

|
||||
][8]
|
||||
* [
|
||||
|
||||

|
||||
][9]
|
||||
* [
|
||||
|
||||

|
||||
][10]
|
||||
|
||||
November 2014 saw Android continue its march to take over everything with a screen as Google unveiled Android TV. A division inside the company had previously tried to take over the living room with Google TV during the Honeycomb era, but this was a total reboot of the idea directly from the Android team. Android TV took Android 5.0 Lollipop and gave it a Material Design interface purpose-built for the biggest screen in the house. For launch hardware, Google tapped Asus to build the "Nexus Player," an underpowered-but-versatile set top box.
|
||||
2014 年 11 月谷歌公布了安卓 TV,安卓继续进行它带着一块屏幕征服一切的征程。这家公司里的一个部门之前在蜂巢时代尝试过用谷歌 TV 掌控客厅,但这次完全是来自安卓团队的新点子。安卓 TV 使用安卓 5.0 棒棒糖,并给了它一个为室内最大屏幕设计的 Material Design 界面。首发硬件谷歌选择了华硕来代工“Nexus Player”,这是一个配置不足但够用的机顶盒。
|
||||
|
||||
Android TV was really about three things: video, music, and games. You controlled the TV with a tiny remote consisting only of a D-Pad with 4 buttons: Back, Home, Microphone, and Play/Pause. For games, Asus simply cloned the Xbox 360 controller, giving players a million buttons and a pair of analog sticks.
|
||||
安卓 TV 专注于三样东西:视频,音乐,以及游戏。你可以用一个小遥控器控制电视,它只有四向方向键以及四个按钮,后退、主页、麦克风以及播放/暂停。至于游戏,华硕克隆了一个 Xbox 360 手柄,给了玩家一堆按键和一对摇杆。
|
||||
|
||||
The interface was pretty simple. Large horizontally-scrolling media thumbnails occupied the screen, filling the TV with content from YouTube, Google Play, Netflix, Hulu, and other sources. Instead of soiling everything in an app, the thumbnails were actually "recommended" items from many different content sources. Below that you could directly access the apps and settings.
|
||||
安卓 TV 的界面很简单。大幅的媒体略缩图占据了屏幕,可以横向滚动,这些媒体中有 Youtube、Google Play、Netflix、Hulu 以及其它来源。这些略缩图实际上是来自不同媒体源的“推荐”项目,它不是简单地将一个应用的内容填满屏幕。在那下面你可以直接访问应用和设置。
|
||||
|
||||
The voice interface was great. You could ask Android TV to play whatever you wanted, instead of hunting it down through the GUI. You could also run clever search results on content, like "show me movies with Harrison Ford." And instead of app silos, every app could provide content to the indexing service. All these apps were housed in a TV-version of the Play Store. Developers specifically supporting Android TV devices also supported the Google cast protocol, allowing users to beam videos and music from their phones and tablets to the TV.
|
||||
语音界面很赞。你可以告诉安卓 TV 播放任意你想要的内容,而不用通过图形界面去寻找。你还能在内容里获得更聪明的搜索结果,比如“显示和 Harrison Ford 有关的电影”。每个应用都可以给索引服务提供内容,而不是简单的应用集合。所有的这些应用都在 Play 商店有一个 TV 版本。开发者对安卓 TV 的特别支持还包括谷歌 cast 协议,允许用户从他们的手机和平板向电视投射视频和音乐。
|
||||
|
||||
### Android 5.1 Lollipop
|
||||
|
||||
* [
|
||||
|
||||

|
||||
][11]
|
||||
* [
|
||||
|
||||

|
||||
][12]
|
||||
* [
|
||||
|
||||

|
||||
][13]
|
||||
* [
|
||||

|
||||

|
||||
][14]
|
||||
* [
|
||||
|
||||

|
||||
][15]
|
||||
* [
|
||||

|
||||

|
||||
][16]
|
||||
* [
|
||||

|
||||

|
||||
][17]
|
||||
* [
|
||||
|
||||

|
||||
][18]
|
||||
* [
|
||||

|
||||

|
||||
][19]
|
||||
* [
|
||||

|
||||

|
||||
][20]
|
||||
* [
|
||||
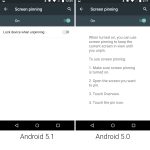
|
||||

|
||||
][21]
|
||||
* [
|
||||
|
||||

|
||||
][22]
|
||||
* [
|
||||
|
||||

|
||||
][23]
|
||||
* [
|
||||
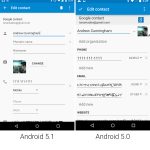
|
||||

|
||||
][24]
|
||||
* [
|
||||
|
||||

|
||||
][25]
|
||||
* [
|
||||

|
||||

|
||||
][26]
|
||||
* [
|
||||
|
||||

|
||||
][27]
|
||||
* [
|
||||

|
||||

|
||||
][28]
|
||||
* [
|
||||
|
||||

|
||||
][29]
|
||||
* [
|
||||

|
||||

|
||||
][30]
|
||||
* [
|
||||
|
||||

|
||||
][31]
|
||||
|
||||
Android 5.1 came out in March 2015 and was the tiniest of updates. The goal here was mainly to [fix encryption performance][43] on the Nexus 6, along with adding device protection and a few interface tweaks.
|
||||
安卓 5.1 在 2015 年 3 月发布,这是安卓最小的更新。它的目的主要是[修复 Nexus 6 上的加密性能问题][43],还添加了设备保护和一些小的界面调整。
|
||||
|
||||
Device protection's only UI addition took the form of a new warning during setup. The feature offered to "Protect your device from reuse" if it was stolen. Once a lock screen was set, device protection would kick in, and could be triggered during a device wipe. If you wiped the phone the way an owner normally would—by unlocking the phone and picking "reset" from the settings—nothing would happen. If you wipe the phone through developer tools though, the device would demand that you "verify a previously-synced Google Account" during the next setup.
|
||||
设备保护是唯一的新增界面,采用的是在开机设置显示新警告的形式。这个特性在设备被偷了之后“保护你的设备不被再次利用”。一旦设置了锁屏,设备保护就开始介入,并且会在擦除设备的时候被触发。如果你以机主正常的方式擦除设备——解锁手机并从设置选择“重置”——什么都不会发生。但如果你通过开发者工具擦除,设备会在下次开机设置的时候要求你“验证之前同步的谷歌账户”。
|
||||
|
||||
The idea was that a developer would know the pervious Google credentials on the device, but a thief would not so they'd be stuck at setup. In practice this triggered [a cat and mouse game][44] of people finding exploits that get around device protection, and Google getting word of the bug and patching it. Software features added by OEM skins also introduced fun new bugs to get around device protection.
|
||||
这个想法是基于开发者是会知道之前登录的谷歌帐号凭证的,但小偷就不知道了,他们会卡在设置这一步。在现实中这引发了[一个猫鼠游戏][44],人们寻找漏洞来绕过设备保护,而谷歌知道了这个 bug 并修补它。OEM 定制也引入了一些有趣的 bug 来绕过设备保护。
|
||||
|
||||
There was also a whole host of extremely minor UI changes that we have dutifully cataloged in the gallery, above. There's not much to say about them beyond the captions.
|
||||
还有很多特别微小的界面改动,我们没法一一列在上面的图中。除了上面的图片描述之外没什么可说的了。
|
||||
|
||||
### Android Auto
|
||||
|
||||
* [
|
||||

|
||||

|
||||
][32]
|
||||
* [
|
||||

|
||||

|
||||
][33]
|
||||
* [
|
||||
|
||||

|
||||
][34]
|
||||
* [
|
||||
|
||||

|
||||
][35]
|
||||
* [
|
||||
|
||||

|
||||
][36]
|
||||
* [
|
||||
|
||||

|
||||
][37]
|
||||
* [
|
||||
|
||||

|
||||
][38]
|
||||
* [
|
||||
|
||||

|
||||
][39]
|
||||
* [
|
||||
|
||||

|
||||
][40]
|
||||
* [
|
||||
|
||||

|
||||
][41]
|
||||
|
||||
Also in March 2015, Google launched "Android Auto," a new Android-inspired interface for car infotainment systems. Android Auto was Google's answer to Apple's CarPlay and worked much the same way. It wasn't a full operating system—it's a "casted" interface that runs on your phone and uses the car's built-in screen as an external monitor. Running Android Auto means having a compatible car, installing the Android Auto app on your phone (Android 5.0 and above), and hooking the phone up to the car with a USB cable.
|
||||
同样是在 2015 年 3 月,谷歌发布了“安卓 Auto”,一个基于安卓界面的全新车载娱乐信息系统。安卓 Auto 是谷歌面对苹果的 CarPlay 交出的答卷,它们很多地方都很相似。安卓 Auto 不完全是个操作系统——它是一个运行在你手机上的“投射”界面,使用车载显示屏作为一块外置显示器。运行安卓 Auto 意味着拥有一款兼容的汽车,在手机上(安卓 5.0 及以上版本)安装了安卓 Auto 应用,并用 USB 线将手机连接到汽车。
|
||||
|
||||
Android Auto brought Google's Material Design interface to your existing infotainment system, bringing top-tier software design to a platform that [typically struggles][45] with designing good software. Android Auto was a ground up redesign of the Android interface made specifically to comply with the myriad of infotainment regulations around the world. There was no tradition "home screen" full of app icons, instead Android's navigation bar was changed into an always-on app launcher (almost like a tabbed interface).
|
||||
安卓 Auto 给你已有的车载系统带来了谷歌的 Material Design 界面,给这个[通常挣扎于]设计好软件的平台带来了顶级的软件设计。安卓 Auto 是个对安卓界面的完全重新设计,以遵循世界各地对车载系统无数的规定。它没有通常充满应用图标的“主屏”,安卓的导航栏也变为了一个常驻的应用启动器(几乎像是个标签页式的界面)。
|
||||
|
||||
The paired down feature set only really had four sections, from left to right on the navigation bar: Google Maps, a dialer/contacts screen, the "home" section that was a hybrid of Google Now and a notification panel, and a music page. The last button was an "OEM" page that let you exit Android Auto and return to the stock infotainment system (it was also meant to eventually house custom car manufacturer features). There was Google's voice command system, which took the form of a microphone button on the top right of the screen.
|
||||
算下来特性实际上只有四部分,导航栏从左到右是:谷歌地图,一个拨号/联系人界面,“主屏”部分混合了 Google Now 和一个通知面板,还有一个音乐页面。最后一个按钮是一个“OEM”页面,让你可以退出安卓 Auto,返回到自带的车载系统(这也是为了放置汽车制造商的定制特性)。安卓 Auto 还带有谷歌的语音命令系统,以一个麦克风按钮的形式显示在屏幕右上角。
|
||||
|
||||
There wasn't much in the way of apps for Android Auto. Only two categories were allowed: music and messaging apps. Infotainment regulations meant customizing the UI wasn't really an option. Messaging apps had no interface and could just plug into the voice system, and music apps couldn't change the interface much, only tweaking the colors and iconography of Google's default "music app" template. What really mattered was delivering the music and messages though, and apps could do that.
|
||||
安卓 Auto 的应用没有多少。它只允许两个类别的应用:音乐和信息应用。车载信息娱乐系统的规定意味着自定义界面不是个好选择。信息应用没有界面,并且可以接入语音系统,音乐应用也不会太多地改变界面,仅仅只是调整一下谷歌默认的“音乐应用”模板的颜色和图标。但实际上重要的是音乐和消息的送达,在不让驾驶员太多分心的情况下,一般的应用就没法使用了。
|
||||
|
||||
Android Auto hasn't seen much in the way of updates after its initial launch, but it has seen a ton of car manufacturer support. In 2017, there will be [over 100][46] compatible vehicle models.
|
||||
安卓 Auto 在它的最初发布之后就没看到多少更新了,但已经逐渐有很多汽车制造商支持了。到了 2017 年,将会有[超过 100][46] 款支持的汽车型号。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
Ron 是 Ars Technica 的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -173,7 +171,7 @@ Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS an
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/30/
|
||||
|
||||
作者:[RON AMADEO][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
84
translated/tech/20160425 What is SRE.md
Normal file
84
translated/tech/20160425 What is SRE.md
Normal file
@ -0,0 +1,84 @@
|
||||
什么是SRE(网站可靠性工程)?
|
||||
============================================================
|
||||
|
||||
网站可靠性工程师是近来越来越多看到的一个职位。它是什么意思?它来自哪里?让我们从 Google SRE 团队来学习。
|
||||
|
||||

|
||||
|
||||
这里有一篇由 Niall Richard Murphy、Jennifer Petoff、Chris Jones、Betsy Beyer 编辑一篇来自[网站可靠性工程][9]的摘录。
|
||||
|
||||
网站可靠性工程也在[11月7-10日在阿姆斯特丹举办的 O'Reilly Velocity 会议][10]上有提到。
|
||||
|
||||
### 介绍
|
||||
|
||||
> 希望不是一种策略。
|
||||
>
|
||||
> 传统的 SRE 说
|
||||
|
||||
一个公认的事实是系统不会自己。 那么,一个特定系统的复杂大规模系统_应该_怎么运行呢?
|
||||
|
||||
|
||||
### sysadmin 服务管理方法
|
||||
|
||||
sysadmin服务管理模型有几个优点。对于决定该如何运行和服务的公司而言,这种方法相对容易实现:它作为一个熟悉的行业范例,有很多例子可以从中学习和效仿。相关人才库已经广泛普及。有一系列现有的工具,软件组件(现成的或其他)和集成公司可用于帮助运行这些组装的系统,所以新手sysadmin团队不必重新发明轮子以及从头设计系统。
|
||||
|
||||
因此,传统运营团队及其在产品开发中的同行往往会发生冲突,最突出的是如何将软件发布到生产环境。在他们核心中,开发团队希望推出新功能,并看到它们被用户采纳。在_他们_的核心上,ops 团队希望确保服务在运行中不会中断。因为大多数中断是由某种变化引起的 - 新的配置、新的功能发布或者新的用户流量类型 - 这两个团队的目标基本上处于紧张状态。
|
||||
|
||||
两个团队都明白,以最可能的条款(“我们可以没有阻碍地在任何时间发布任何东西”以及“我们不想在系统工作后改变任何东西”)来表达他们的利益是不可接受的。因为他们的词汇和风险假设都不同,两个团体经常采用熟悉斗争形式来提高他们的利益。 ops 团队试图通过发布介绍和提高门槛来保护运行中的系统免受更改的风险。例如,发布审查可能包含对_每个_问题的显式审查,这些问题过去都_曾经_引起过服务中断 - 它可能是一个任意长度的列表,并且不是所有元素都提供相等的值。开发团队很快学会了如何回应。他们有较少的“发布”和更多的“标志翻转”、“增量更新”或“cherrypicks”。他们采取诸如分割产品功能的策略,以便更少的功能受到发布审查。
|
||||
|
||||
|
||||
### Google 服务管理的方法:网站可靠性工程
|
||||
|
||||
冲突不是提供软件服务的必然部分。Google 选择以不同的方式运行我们的系统:我们的网站可靠性工程团队专注于雇佣软件工程师来运行我们的产品,并创建系统来完成那些本来由sysadmins手动完成的工作。
|
||||
|
||||
什么是网站可靠性工程,是如它在谷歌定义的那样么?我的解释很简单:SRE 是当你要求一位软件工程师设计一个运维团队时会发生的那样。当我在2003年加入 Google 并负责运行一个由 7 名工程师组成的“生产团队”时,那时我工作的全部都是软件工程。所以我设计和管理了一个假如我是一名 SRE ,_我_想要的团队的样子。这个团队已经成为了 Google 的目前的 SRE 团队,它仍然是一名终生软件工程师所想象的那个样子。
|
||||
|
||||
Google 服务管理方法的主要构成部分是由每个 SRE 团队的组成。作为一个整体,SRE可以分为两大类。
|
||||
|
||||
50-60% 的人是 Google 软件工程师,或者更确切地说,是通过 Google 软件工程师的标准程序招聘的人。其他 40-50% 的候选人非常接近 Google 软件工程师资格(即所需技能集的 85-99%),以及一些具有大多数软件工程师没有的一些 SRE 技术技能的人。到目前为止,UNIX 系统内部和网络(第1层到第3层)的专业知识是我们寻求的两种最常见的替代技术技能。
|
||||
|
||||
所有 SRE 的共同点是对开发软件系统以解决复杂问题的信念和能力。在 SRE 中,我们密切跟踪两个团队的职业发展,并且迄今为止发现在两种工程师之间的表现没有实际差异。事实上,SRE 团队的多样背景经常产生聪明、高质量的系统,这显然是几个技能集合成的产物。
|
||||
|
||||
我们这样招聘 SRE 的结果是,我们有了这样一个团队:(a)手动执行任务很快会变得无聊。(b)他们有必要的技能集来写出软件以取代以前的手动操作,即使解决方案很复杂。SRE 还会与其他开发部门分享学术以及知识背景。因此,SRE 从根本上做了一个运维团队历来做的工作,但它使用具有软件专业知识的工程师,并期望这些内在倾向于用软件,并且有能力用软件的人用软件设计并实现自动化来代替人力劳动。
|
||||
|
||||
按照设计,至关重要的是 SRE 团队专注于工程。没有恒定的工程,运维工作增加,团队将需要更多的人来上工作量。最终,传统的以 ops 为中心的团队与服务规模呈线性关系:如果服务支持的产品成功,运维工作将随着流量而增长。这意味着雇用更多的人一遍又一遍地完成相同的任务。
|
||||
|
||||
为了避免这种命运,负责管理服务的团队需要写代码否则就会被工作淹没。因此,Google _设置了一个 “ops” 工作如 ticket、紧急呼叫、手动任务最多只占 50% SRE 工作的上限_。此上限确保SRE团队在其计划中有足够的时间使服务稳定及可操作。50% 是上限;随着时间的推移,除了自己的设备,SRE 团队应该只有很少的运维工作,他们几乎可以完全从事开发任务,因为服务基本上可以运行和维修自己:我们想要的系统是_自动的_,而不只是_自动化_。在实践中,规模和新功能始终 SRE 要考虑的
|
||||
|
||||
Google的经验法则是,SRE团队必须花费剩余的 50% 的时间来进行实际开发。那么我们该如何执行这个阈值呢?首先,我们必须测量 SRE 如何花费时间。通过测量,我们确保团队不断花费不到 50% 的时间用于开发改变他们实践的工作上。通常这意味着会将一些运维负担转移回开发团队,或者给团队添加新的员工,而不指派该团队额外的运维责任。意识到在运维和开发工作之间保持这种平衡使我们能保证 SRE 具有参与创造性的自主工程的空间,同时仍然保留从运维那学来的智慧。
|
||||
|
||||
我们发现Google SRE 的运行大规模系统的方法有很多优点。由于 SRE 是直接修改代码以使Google的系统运行自己,SRE团队的特点是快速创新以及大量接受变革。这样的团队能相对价廉地支持相同的服务,面向运维的团队需要大量的人。相反,运行、维护和改进系统所需的 SRE 的数量随系统的大小而线性地缩放。最后,SRE 不仅规避了开发/运维分裂的障碍,而且这种结构也改善了我们的产品开发团队:产品开发和 SRE 团队之间的轻松转移交叉培训整个团队,并且提高了那些在学习构建百万级别分布式系统上有困难的开发人员的技能。
|
||||
|
||||
尽管有这些好处,SRE 模型的特点是其自身独特的挑战。 Google 面临的一个持续挑战是招聘 SRE:SRE 不仅与产品开发招聘流程竞争相同的候选人,而且我们将招聘人员的编码和系统工程技能都设置得如此之高,这意味着我们的招聘池必然很小。由于我们的学科相对新颖独特,在如何建立和管理 SRE 团队方面没有太多的行业信息(尽管希望这本书能朝着这个方向迈进!)。一旦 SRE 团队到位,他们潜在的非正统的服务管理方法需要强有力的管理支持。例如,一旦错误预估耗尽,除非是管理层的强制要求, 否则在季度剩余的时间里决定停止发布可能不会被产品开发团队所接受。
|
||||
|
||||
###### DevOps 或者 SRE?
|
||||
|
||||
“DevOps” 这个术语在 2008 年末出现,并在写这篇文章时(2016 年早期)仍在发生变动。 其核心原则:IT部门在系统设计和开发的每个阶段的参与、对自动化与人力投入的严重依赖、工程实践和工具在操作任务中的应用,与许多 SRE 的原则和实践一致。 人们可以将 DevOps 视为向更广泛的组织,管理结构和人员的几种核心SRE原则。 可以等价地将 SRE 视为具有某些特殊扩展的 DevOps 的特定实现。
|
||||
|
||||
|
||||
------------------------
|
||||
|
||||
作者简介:Benjamin Treynor Sloss 创造了“网站可靠性工程”一词,他自2003年以来一直负责 Google 的全球运营、网络和生产工程。截至2016年,他管理着全球范围内一个大约4000名软硬件和网络工程师团队。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/what-is-sre-site-reliability-engineering
|
||||
|
||||
作者:[Benjamin Treynor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/benjamin-treynor-sloss
|
||||
[1]:https://shop.oreilly.com/product/0636920053385.do
|
||||
[2]:https://shop.oreilly.com/product/0636920053385.do
|
||||
[3]:https://www.oreilly.com/ideas/what-is-sre-site-reliability-engineering
|
||||
[4]:https://shop.oreilly.com/product/0636920053385.do
|
||||
[5]:https://shop.oreilly.com/product/0636920053385.do
|
||||
[6]:https://www.oreilly.com/people/benjamin-treynor-sloss
|
||||
[7]:https://pixabay.com/
|
||||
[8]:https://www.oreilly.com/people/benjamin-treynor-sloss
|
||||
[9]:http://shop.oreilly.com/product/0636920041528.do?intcmp=il-webops-books-videos-update-na_new_site_site_reliability_engineering_text_cta
|
||||
[10]:http://conferences.oreilly.com/velocity/devops-web-performance-eu?intcmp=il-webops-confreg-update-vleu16_new_site_what_is_sre_text_cta
|
||||
[11]:https://pixabay.com/
|
||||
181
translated/tech/20160929 Getting Started with HTTP2 - Part 2.md
Normal file
181
translated/tech/20160929 Getting Started with HTTP2 - Part 2.md
Normal file
@ -0,0 +1,181 @@
|
||||
初识 HTTP/2(第二部分)
|
||||
============================================================
|
||||

|
||||
|
||||
首先制定一个坚定的 HTTP/2 前端开发目标。
|
||||
|
||||
如果你对 HTTP/2 有所了解,那你可能用过它,或者至少想过怎样能把它融入你的项目中。尽管有很多关于它如何改变你的工作流程,提高网络的速度和效率等方面的猜想,但最好的使用方式还没有定下来。这里我想讲的就是我在之前的项目中所发现的 HTTP /2 的优点。
|
||||
|
||||
如果你还不确定什么是 HTTP/2,或者为什么它能帮助你工作,[看看我介绍背景方面的第一篇文章][4]。
|
||||
|
||||
记住:开始之前,我要告诉你,尽管你的浏览器可能支持 HTTP/2,但你的服务器可能不支持。检查你的主机服务,看看他们是否提供 HTTP/2 的支持。否则你可能玩坏你的服务器。这篇文章并不会讲怎么做,但你可以查看 [http2 github][5] 页面,找一找这方面的工具。
|
||||
|
||||
### 🙏 [Rubs Hands Together]
|
||||
|
||||
首先组织好你的文件。看一看下面的文件树结构作为组织样式表的起点:
|
||||
|
||||
```
|
||||
`/styles
|
||||
|── /setup
|
||||
| /* variables, mixins and functions */
|
||||
|── /global
|
||||
| /* reusable components that could be within any component or section */
|
||||
|── /components
|
||||
| /* specific components and sections */
|
||||
|── setup.scss // index for setup styles
|
||||
|── global.scss // index for global styles`
|
||||
```
|
||||
|
||||
这会把你的样式分到三个目录下面:Setup,Global 和 Componenets。接下来我会说明这些目录对你的项目有什么用。
|
||||
|
||||
### Setting Up 目录
|
||||
|
||||
Setup 目录保存所有的变量,函数,混合<!-- mixins -->以及其它文件需要编译的任意定义。要想让这个它物尽其用,把这个目录下所有内容导入到 `setup.scss`文件中是个很不错的主意,这样这个文件就会像下面所展示的一样:
|
||||
|
||||
```
|
||||
`/* setup.scss */
|
||||
|
||||
/* variables */
|
||||
@import "setup/variables/colors";
|
||||
|
||||
/* mixins */
|
||||
@import "setup/mixins/color";
|
||||
|
||||
/* functions */
|
||||
@import "setup/functions/color";
|
||||
|
||||
... etc`
|
||||
```
|
||||
|
||||
现在我们能快速引用这个站点中的所有定义,应该确保在所有的样式文件顶部包含我们这里创建的这个文件。
|
||||
|
||||
### Global 目录
|
||||
|
||||
接下来的目录,Global,应该包含可在当前站点的多个部分或者每一个页面中重复使用的容器。像按钮、文本、主要样式以及你的浏览器默认设置应该放在这里。我不建议把顶部或底部样式放在这儿,因为某些项目中没有顶部或者不同页面顶部不同。而且,底部永远是页面的最后一个元素,所以在用户加载完当前站点的其它东西前,不必过分优先考虑加载底部样式。
|
||||
|
||||
记住,如果没有那些定义在 Setup 目录下的东西,你的全局样式就可能没有作用,你的全局文件看起来应该像这样:
|
||||
|
||||
```
|
||||
`/* global.scss */
|
||||
|
||||
/* application definitions */
|
||||
@import "setup";
|
||||
|
||||
/* global styles */
|
||||
@import "global/reset";
|
||||
@import "global/buttons";
|
||||
@import "global/typography";
|
||||
@import "global/grid";
|
||||
|
||||
... etc`
|
||||
```
|
||||
|
||||
注意,首先要做的就是导入 Setup 样式。这样的话,这个样式里定义的所有文件都能够获得引用。
|
||||
|
||||
由于全局样式需要存在于每个页面中,我们可以用默认的方法加载它们,在 `<head>` 标签内用一个 `<link>` 标签。你所看到的将是一个十分小巧的 css 文件,或者说理论上小巧的,这取决于你需要多少全局样式。
|
||||
|
||||
### 最后,你的容器
|
||||
|
||||
注意我没有在上述文件树中的容器目录里包含索引文件。这是 HTTP/2 所带来的效用。直到现在,我们已经按照标准步骤构建了一个典型的站点,包含相当高效的结构<!-- fairly lean infrastructure -->,选择仅仅全局化那些最重要的样式。容器表现的就像他们有单独的索引文件。
|
||||
|
||||
大多数开发者有独特的组织容器的方式,因此我并不想影响你的策略。但是,你所有的容器看起来应该像这样:
|
||||
|
||||
```
|
||||
`/* header.scss */
|
||||
|
||||
/* application definitions */
|
||||
@import "../setup";
|
||||
|
||||
header {
|
||||
// styles
|
||||
}
|
||||
|
||||
... etc`
|
||||
```
|
||||
|
||||
同样的,你要把 Setup 样式包含进来,确保所有东西在编译时都有定义。你不必链接、压缩<!-- concatenate minify --> 或者改变什么文件,除了编译他们和可能要把他们放到 /assets 目录,很容易就找出个模版。
|
||||
|
||||
现在样式表已经差不多了,构建页面应该很简单。
|
||||
|
||||
### 构建容器
|
||||
|
||||
或许对于标准语言你有自己的选择,这取决于你的项目,有可能是 Twig, Rails, Jade 或者 Handlebars。我认为考虑容器最好的方式是它是否有自己的模版文件,它该有个与名字相应的样式。这样你的项目中,模版和样式的比例就会是个不错的 1:1 的比例,而且你知道哪个文件有哪些东西,哪里有哪个文件,因为它们的命名是有规律的。
|
||||
|
||||
现在它正步入正轨,用好 HTTP/2 的多种功能十分简单,让我们做一个模版:
|
||||
|
||||
```
|
||||
`{# header.html #}
|
||||
|
||||
{# compiled header styles #}
|
||||
<link href="assets/components/header.css" rel="stylesheet" media="all">
|
||||
|
||||
<header>
|
||||
<h1>This Awesome HTTP/2 Site</h1>
|
||||
... etc`
|
||||
```
|
||||
|
||||
非常好!你就能在模版里用更简单的方式链接资源,但这也显示出你所要做的仅是在开始构建时,在模版文件中链接一个小小的头部样式。这将允许你的站点仅仅加载特定资源到任意给定页面的容器中,而且,能够设定页面从头到脚的优先级。
|
||||
|
||||
### 结合在一起
|
||||
|
||||
现在所有的容器都有结构,浏览器将会渲染类似以下的内容:
|
||||
|
||||
```
|
||||
`<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<link rel="stylesheet" media="all" href="/assets/global.css">
|
||||
</head>
|
||||
<body>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/header.css">
|
||||
<header>
|
||||
... etc
|
||||
</header>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/title.css">
|
||||
<section class="title">
|
||||
... etc
|
||||
</section>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/image-component.css">
|
||||
<section class="image-component">
|
||||
... etc
|
||||
</section>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/text-component.css">
|
||||
<section class="text-component">
|
||||
... etc
|
||||
</section>
|
||||
|
||||
<link rel="stylesheet" media="all" href="/assets/components/footer.css">
|
||||
<footer>
|
||||
... etc
|
||||
</footer>
|
||||
|
||||
</body>
|
||||
</html>`
|
||||
```
|
||||
|
||||
这是一个高级方法,但你的项目中可能有调整的更好<!-- finer-tuned -->的容器,你可以用 `<nav>` 容器包含顶部,它会加载自己的样式表。尽你所能地自由发挥,让容器更有作用 - HTTP/2 不会因这些需求而阻碍<!-- penalize -->你。
|
||||
|
||||
### 结论
|
||||
|
||||
这只是一个简单的方法,如何用前端思想和 HTTP/2 构建项目,但这仅是皮毛而已。你可能注意到我上面的所用的方法还有改进的空间。请不吝赐教!正如我在第一篇文章中所说的,HTTP/2 可能颠覆自 HTTP/1 以来我们所熟知的某些标准,所以要慎重思考和实践,以便高效使用 HTTP/2 的开发环境。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.viget.com/articles/getting-started-with-http-2-part-2
|
||||
|
||||
作者:[Ben][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.viget.com/about/team/btinsley
|
||||
[1]:https://twitter.com/home?status=Firmly%20planting%20a%20flag%20in%20the%20sand%20for%20HTTP%2F2%20best%20practices%20for%20front%20end%20development.%20https%3A%2F%2Fwww.viget.com%2Farticles%2Fgetting-started-with-http-2-part-2
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fwww.viget.com%2Farticles%2Fgetting-started-with-http-2-part-2
|
||||
[3]:http://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Fwww.viget.com%2Farticles%2Fgetting-started-with-http-2-part-2
|
||||
[4]:https://www.viget.com/articles/getting-started-with-http-2-part-1
|
||||
[5]:https://github.com/http2/http2-spec/wiki/Tools
|
||||
@ -0,0 +1,175 @@
|
||||
使用IBM Bluemix构建,部署和管理自定义应用程序
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
IBM Bluemix为开发人员提供了构建,部署和管理自定义应用程序的机会。Bluemix建立在Cloud Foundry上。它支持多种编程语言包括IBM的OpenWhisk,它允许开发人员调用任何函数但不需要资源管理。
|
||||
|
||||
Bluemix是由IBM实现的开放标准的基于云的平台。它具有开放的架构,其允许组织能够在云上创建,开发和管理其应用程序。它基于Cloud Foundry,因此可以被视为平台即服务(PaaS)。使用Bluemix,开发人员不必关心云配置,可以专注于他们的应用程序。 云配置将由Bluemix自动完成。
|
||||
|
||||
Bluemix还提供了一个仪表板,通过它,开发人员可以创建,管理和查看服务和应用程序,同时还可以监控资源使用情况。
|
||||
它支持以下编程语言:
|
||||
|
||||
* Java
|
||||
* Python
|
||||
* Ruby on Rails
|
||||
* PHP
|
||||
* Node.js
|
||||
|
||||
它还支持OpenWhisk(FaaS),这也是一个IBM的产品,其允许开发人员调用任一功能而不需要任何资源管理。
|
||||
|
||||

|
||||
|
||||
图1 IBM Bluemix概述
|
||||
|
||||

|
||||
|
||||
图2 IBM Bluemix体系结构
|
||||
|
||||

|
||||
|
||||
图3 在IBM Bluemix中创建组织
|
||||
|
||||
**IBM Bluemix如何工作**
|
||||
|
||||
Bluemix构建在IBM的SoftLayer IaaS(基础架构即服务)之上。它使用Cloud Foundry作为开源PaaS平台。它通过将代码推送到Cloud Foundry开始,Cloud Foundry通过使用其编写应用程序的编程语言,扮演了组合代码和适当的运行时环境的角色。IBM服务,第三方服务或社区构建的服务可用于不同的功能。安全连接器可用于连接本地系统到云。
|
||||
|
||||

|
||||
|
||||
图4 在IBM Bluemix中设置空间
|
||||
|
||||

|
||||
|
||||
图5 应用程序模板
|
||||
|
||||

|
||||
|
||||
图6 IBM Bluemix支持的编程语言
|
||||
|
||||
**在Bluemix中创建应用程序**
|
||||
在本文中,我们将使用Liberty for Java的入门包在IBM Bluemix中创建一个示例“Hello World”应用程序,只需几个简单的步骤。
|
||||
|
||||
1. 打开[_https://console.ng.bluemix.net/registration/_] [2]
|
||||
|
||||
2. 注册Bluemix帐户
|
||||
|
||||
3. 点击邮件中的确认链接完成注册过程
|
||||
|
||||
4. 输入您的电子邮件ID,然后点击_Continue_进行登录
|
||||
|
||||
5. 输入密码并点击_Log in_
|
||||
|
||||
6. 进入_Set up_->_Environment_设置特定区域中的资源共享
|
||||
|
||||
7. 创建空间方便管理访问控制和在Bluemix中回滚操作。 我们可以将空间映射到多个开发阶段,如dev,test,uat,pre-prod和prod
|
||||
|
||||

|
||||
|
||||
图7 命名应用程序
|
||||
|
||||

|
||||
|
||||
图8 了解应用程序何时准备就绪
|
||||
|
||||

|
||||
|
||||
图9 IBM Bluemix Java应用程序
|
||||
|
||||
8. 完成初始配置后,单击_ I'm ready_ -> _Good to Go_!
|
||||
|
||||
9. 成功登录后,此时检查IBM Bluemix仪表板,特别是Cloud Foundry Apps(其中2GB可用)和Virtual Server(其中0个实例可用)的部分
|
||||
|
||||
10. 点击_Create app_,选择应用创建模板。在我们的例子中,我们将使用一个Web应用程序
|
||||
|
||||
11. 如何开始?单击Liberty for Java,然后检查其描述
|
||||
|
||||
12. 单击_Continue_
|
||||
|
||||
13. 为新应用命名。对于本文,让我们使用osfy-bluemix-tutorial命名然后单击_Finish_
|
||||
|
||||
14. 在Bluemix上创建资源和托管应用程序需要等待一些时间。
|
||||
|
||||
15. 几分钟后,应用程式就会开始运作。注意应用程序的URL。
|
||||
|
||||
16. 访问应用程序的URL _http://osfy-bluemix-tutorial.au-syd.mybluemix.net/_, Bingo,我们的第一个在IBM Bluemix上的Java应用程序成功运行。
|
||||
|
||||
17. 为了检查源代码,请单击_Files_并在门户中导航到不同文件和文件夹
|
||||
|
||||
18. _Logs_部分提供所有活动日志,包括从应用程序的创建时起
|
||||
|
||||
19. _Environment Variables_部分提供关于VCAP_Services的所有环境变量以及用户定义的环境变量的详细信息
|
||||
|
||||
20. 要检查应用程序的资源消耗,需要到Liberty for Java部分。
|
||||
|
||||
21. 默认情况下,每个应用程序的_Overview_部分包含资源,应用程序的运行状况和活动日志的详细信息
|
||||
|
||||
22. 打开Eclipse,转到帮助菜单,然后单击_Eclipse Marketplace_
|
||||
|
||||
23. 查找_IBM Eclipse tools for Bluemix_并单击_Install_
|
||||
|
||||
24. 确认所选的功能并将其安装在Eclipse中
|
||||
|
||||
25. 下载应用程序启动器代码。点击_File Menu_,将它导入到Eclipse中,选择_Import Existing Projects_ -> _Workspace_, 然后开始修改代码
|
||||
|
||||

|
||||
|
||||
图10 Java应用程序源文件
|
||||
|
||||

|
||||
|
||||
图11 Java应用程序日志
|
||||
|
||||

|
||||
|
||||
图12 Java应用程序 - Liberty for Java
|
||||
|
||||
**为什么选择IBM Bluemix?**
|
||||
以下是使用IBM Bluemix的一些令人信服的理由:
|
||||
|
||||
* 支持多种语言和平台
|
||||
* 免费试用
|
||||
|
||||
1. 简化的注册过程
|
||||
|
||||
2. 不需要信用卡
|
||||
|
||||
3. 30天试用期 - 配额2GB的运行时,支持20个服务,500个route
|
||||
|
||||
4. 无限制地访问标准支持
|
||||
|
||||
5. 没有生产使用限制
|
||||
|
||||
* 仅为每个使用的运行时和服务付费
|
||||
* 快速设置 - 从而加快上市时间
|
||||
* 持续交付新功能
|
||||
* 与本地资源的安全集成
|
||||
* 用例
|
||||
|
||||
1. Web应用程序和移动后端
|
||||
|
||||
2. API和内部集成
|
||||
|
||||
* DevOps服务可部署在云上的SaaS,并支持持续交付:
|
||||
|
||||
1. Web IDE
|
||||
|
||||
2. SCM
|
||||
|
||||
3. 敏捷规划
|
||||
|
||||
4. 交货管道服务
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensourceforu.com/2016/11/build-deploy-manage-custom-apps-ibm-bluemix/
|
||||
|
||||
作者:[MITESH_SONI][a]
|
||||
译者:[Vic020](http//www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensourceforu.com/author/mitesh_soni/
|
||||
[1]:http://opensourceforu.com/wp-content/uploads/2016/10/Figure-7-Naming-the-app.jpg
|
||||
[2]:https://console.ng.bluemix.net/registration/
|
||||
127
translated/tech/20161126 Building Vim from source.md
Normal file
127
translated/tech/20161126 Building Vim from source.md
Normal file
@ -0,0 +1,127 @@
|
||||
从源代码编译Vim实际上并不困难。
|
||||
这里是你所想要做的内容:
|
||||
|
||||
1.首先,安装包括Git在内的所有提前需要的库。
|
||||
对于一个Debian Linux发行像Ubuntu,
|
||||
这将是以下命令:
|
||||
|
||||
```sh
|
||||
sudo apt-get install libncurses5-dev libgnome2-dev libgnomeui-dev \
|
||||
libgtk2.0-dev libatk1.0-dev libbonoboui2-dev \
|
||||
libcairo2-dev libx11-dev libxpm-dev libxt-dev python-dev \
|
||||
python3-dev ruby-dev lua5.1 lua5.1-dev libperl-dev git
|
||||
```
|
||||
|
||||
在Ubuntu 16.04, `liblua5.1-dev` 作为lua开发包的名称而非`lua5.1-dev`.
|
||||
|
||||
(如果你知道你将使用哪种语言,随意删去你不需要的包。例如:Python2 `python-dev` 或者是 Ruby `ruby-dev`。这一原则适用于整个页面的大部分内容。)
|
||||
|
||||
对于Fedora 20, 将是以下命令:
|
||||
|
||||
```sh
|
||||
sudo yum install -y ruby ruby-devel lua lua-devel luajit \
|
||||
luajit-devel ctags git python python-devel \
|
||||
python3 python3-devel tcl-devel \
|
||||
perl perl-devel perl-ExtUtils-ParseXS \
|
||||
perl-ExtUtils-XSpp perl-ExtUtils-CBuilder \
|
||||
perl-ExtUtils-Embed
|
||||
```
|
||||
|
||||
这一步需要纠正的问题是如何安装Fedora 20的XSubPP:
|
||||
|
||||
```sh
|
||||
# symlink xsubpp (perl) from /usr/bin to the perl dir
|
||||
sudo ln -s /usr/bin/xsubpp /usr/share/perl5/ExtUtils/xsubpp
|
||||
```
|
||||
|
||||
2. 如果你已经装上vim,删掉它。
|
||||
|
||||
```sh
|
||||
sudo apt-get remove vim vim-runtime gvim
|
||||
```
|
||||
|
||||
在Ubuntu 12.04.2你或许也需要同时删除下面这些软件包:
|
||||
|
||||
```sh
|
||||
sudo apt-get remove vim-tiny vim-common vim-gui-common vim-nox
|
||||
```
|
||||
|
||||
3. 一旦上述内容被安装好之后,获取vim源代码很容易。
|
||||
注意:如果你使用python,你的配置路径或许有一个特定的机器的名字 (例如`config-3.5m-x86_64-linux-gnu`)。
|
||||
检查/usr/lib/python[2/3/3.5]路径来找到你的python配置路径, 据此更改`python-config-dir`和/或`python3-config-dir`的参数。
|
||||
|
||||
添加/删除下面的的标记符以适合您的设置。例如,如果您不打算写任何Lua,您可以删去`enable-luainterp`。
|
||||
|
||||
同时,如果你不使用vim8.0,确认下面VIMRUNTIMEDIR参数设置正确
|
||||
(例如,使用vim 8.0a, 就用/usr/share/vim/vim80a).
|
||||
记住一些vim安装是直接安装在/usr/share/vim;调整好以适应你的系统:
|
||||
|
||||
```sh
|
||||
cd ~
|
||||
git clone https://github.com/vim/vim.git
|
||||
cd vim
|
||||
./configure --with-features=huge \
|
||||
--enable-multibyte \
|
||||
--enable-rubyinterp=yes \
|
||||
--enable-pythoninterp=yes \
|
||||
--with-python-config-dir=/usr/lib/python2.7/config \
|
||||
--enable-python3interp=yes \
|
||||
--with-python3-config-dir=/usr/lib/python3.5/config \
|
||||
--enable-perlinterp=yes \
|
||||
--enable-luainterp=yes \
|
||||
--enable-gui=gtk2 --enable-cscope --prefix=/usr
|
||||
make VIMRUNTIMEDIR=/usr/share/vim/vim80
|
||||
```
|
||||
在Ubuntu 16.04,由于同时开启了Python2和Python3,Python支持将不工作。 阅读 [answer by chirinosky](http://stackoverflow.com/questions/23023783/vim-compiled-with-python-support-but-cant-see-sys-version) 以获取变通的处理方法。
|
||||
|
||||
如果你想要可以轻松卸载vim请使用`checkinstall`.
|
||||
|
||||
```sh
|
||||
sudo apt-get install checkinstall
|
||||
cd ~/vim
|
||||
sudo checkinstall
|
||||
```
|
||||
|
||||
否则, 你可以使用`make`来安装.
|
||||
|
||||
```sh
|
||||
cd ~/vim
|
||||
sudo make install
|
||||
```
|
||||
|
||||
让vim成为你默认的编辑器请使用`update-alternatives`.
|
||||
|
||||
```sh
|
||||
sudo update-alternatives --install /usr/bin/editor editor /usr/bin/vim 1
|
||||
sudo update-alternatives --set editor /usr/bin/vim
|
||||
sudo update-alternatives --install /usr/bin/vi vi /usr/bin/vim 1
|
||||
sudo update-alternatives --set vi /usr/bin/vim
|
||||
```
|
||||
|
||||
4. 仔细检查,你查看输出`vim --version`来获取实际上在运行新的Vim应用程序版本.
|
||||
|
||||
**如果你的gvim不工作 (在 ubuntu 12.04.1 LTS),试着把
|
||||
`--enable-gui=gtk2`参数变为`--enable-gui=gnome2`**
|
||||
|
||||
如果你遇到问题,仔细检查在步骤3开始提到的你`configure`配置使用的是正确的Python的config目录。
|
||||
|
||||
这些`configure`和`make`命令假设你是一个Debian发行版,Vim的运行库文件目录放在
|
||||
`/usr/share/vim/vim80/`,这不是vim的默认。 在`configure`命令中的`--prefix=/usr`也是如此。这些参数或许对一个不是基于Debian的Linux发行版来说是有所不同的,在类似的场景中, 试着移除 `configure`命令中的
|
||||
`--prefix`变量和`make`命令中的`VIMRUNTIMEDIR`(换句话说,使用默认的)。
|
||||
|
||||
如果你遇到麻烦, 这里是一些 [其它编译Vim的有用的信息]
|
||||
(http://vim.wikia.com/wiki/Building_Vim).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.dataquest.io/blog/data-science-portfolio-project/
|
||||
|
||||
作者:[Val Markovic][a]
|
||||
|
||||
译者:[译者ID](https://github.com/zky001)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/Valloric
|
||||
@ -1,251 +0,0 @@
|
||||
如何用UFW配置防火墙
|
||||
============================================================
|
||||
|
||||
UFW或者称之为_uncomplicated firewall_,是一个Arch Linux、Debian或Ubuntu中管理防火墙规则的前端。 UFW通过命令行使用(尽管它有可用的GUI),它的目的是使防火墙配置简单(或不复杂)。
|
||||
|
||||

|
||||
|
||||
### 开始之前
|
||||
|
||||
1. 熟悉我们的[入门][1]指南,并完成设置Linode主机名和时区的步骤。
|
||||
|
||||
2. 本指南将尽可能使用`sudo`。 完成[保护你的服务器][2]指南的部分创建一个标准用户帐户,加强SSH访问和删除不必要的网络服务。 **不要**遵循创建防火墙部分 - 本指南是介绍使用UFW的,它对于iptables而言是一个单独的控制防火墙的方法。
|
||||
|
||||
3. 升级系统
|
||||
|
||||
**Arch Linux**
|
||||
|
||||
```
|
||||
sudo pacman -Syu
|
||||
```
|
||||
|
||||
|
||||
**Debian / Ubuntu**
|
||||
|
||||
```
|
||||
sudo apt-get update && sudo apt-get upgrade
|
||||
```
|
||||
|
||||
|
||||
### 安装 UFW
|
||||
|
||||
UFW默认包含在Ubuntu中,但必须安装在Arch和Debian中。 Debian将自动启用UFW的systemd单元,并使其在重新启动时启动,但Arch不会。 _这与告诉UFW启用防火墙规则不同_,因为使用systemd或者upstart启用UFW仅告知init系统打开UFW守护程序。
|
||||
|
||||
默认情况下,UFW的规则集为空,因此即使守护程序正在运行,也不会强制执行任何防火墙规则。 强制执行防火墙规则集的部分[在下面][3]。
|
||||
|
||||
### Arch Linux
|
||||
|
||||
1. 安装 UFW:
|
||||
|
||||
```
|
||||
sudo pacman -S ufw
|
||||
```
|
||||
|
||||
|
||||
2. 启动并启用UFW的systemd单元:
|
||||
|
||||
```
|
||||
sudo systemctl start ufw
|
||||
sudo systemctl enable ufw
|
||||
```
|
||||
|
||||
### Debian / Ubuntu
|
||||
|
||||
1. 安装 UFW
|
||||
|
||||
```
|
||||
sudo apt-get install ufw
|
||||
```
|
||||
|
||||
|
||||
### 使用UFW管理防火墙规则
|
||||
|
||||
### 设置默认规则
|
||||
|
||||
大多数系统只需要少量的端口打开传入连接,并且所有剩余的端口都关闭。 要一个简单的规则基础开始,`ufw default`命令可以用于设置对传入和传出连接的默认响应。 要拒绝所有传入并允许所有传出连接,那么运行:
|
||||
|
||||
```
|
||||
sudo ufw default allow outgoing
|
||||
sudo ufw default deny incoming
|
||||
```
|
||||
|
||||
|
||||
`ufw default`也允许使用`reject`参数。
|
||||
|
||||
> 除非明确允许规则,否则配置默认deny或reject规则会锁定你的Linode。确保在应用默认deny或reject规则之前,已按照下面的部分配置了SSH和其他关键服务的允许规则。
|
||||
|
||||
### 添加规则
|
||||
|
||||
可以有两种方式添加规则:用**端口号**或者**服务名**表示。
|
||||
|
||||
要允许SSH的22端口的传入和传出连接,你可以运行:
|
||||
|
||||
```
|
||||
sudo ufw allow ssh
|
||||
```
|
||||
|
||||
你也可以运行:
|
||||
|
||||
```
|
||||
sudo ufw allow 22
|
||||
```
|
||||
|
||||
相似的,要在特定端口(比如111)上**deny**流量,你需要运行:
|
||||
|
||||
```
|
||||
sudo ufw deny 111
|
||||
```
|
||||
|
||||
为了更好地调整你的规则,你也可以允许基于TCP或者UDP的包。下面例子会允许80端口的TCP包:
|
||||
|
||||
|
||||
```
|
||||
sudo ufw allow 80/tcp
|
||||
sudo ufw allow http/tcp
|
||||
```
|
||||
|
||||
这个会允许1725端口上的UDP包:
|
||||
|
||||
|
||||
```
|
||||
sudo ufw allow 1725/udp
|
||||
```
|
||||
|
||||
|
||||
### 高级规则
|
||||
|
||||
除了基于端口的允许或阻止,UFW还允许您通过IP地址、子网和IP地址/子网/端口组合来允许/阻止。
|
||||
|
||||
允许从IP地址连接:
|
||||
|
||||
```
|
||||
sudo ufw allow from 123.45.67.89
|
||||
```
|
||||
|
||||
|
||||
允许特定子网的连接:
|
||||
|
||||
```
|
||||
sudo ufw allow from 123.45.67.89/24
|
||||
```
|
||||
|
||||
允许特定IP/端口组合:
|
||||
|
||||
```
|
||||
sudo ufw allow from 123.45.67.89 to any port 22 proto tcp
|
||||
```
|
||||
|
||||
|
||||
`proto tcp`可以删除或者根据你的需求变成`proto udp`,所有例子的`allow`都可以根据需要变成`deny`。
|
||||
|
||||
### 删除规则
|
||||
|
||||
要删除一条规则,在规则的前面加上`delete`。如果你希望不在允许HTTP流量,你可以运行:
|
||||
|
||||
|
||||
```
|
||||
sudo ufw delete allow 80
|
||||
```
|
||||
|
||||
删除规则同样允许基于服务名。
|
||||
|
||||
### 编辑UFW的配置文件
|
||||
|
||||
虽然可以通过命令行添加简单的规则,但仍有可能需要添加或删除更高级或特定的规则。 在通过终端运行规则输入之前,UFW将运行一个文件`before.rules`,它允许回环、ping和DHCP。要添加或改变这些规则,编辑`/etc/ufw/before.rules`这个文件。 `before6.rules`文件也位于IPv6的同一目录中。
|
||||
|
||||
还存在一个`after.rule`和`after6.rule`文件,用于添加在UFW运行添加命令行规则后需要添加的任何规则。
|
||||
|
||||
额外的配置文件位于`/etc/default/ufw`。 从此处可以禁用或启用IPv6,可以设置默认规则,并可以设置UFW以管理内置防火墙链。
|
||||
|
||||
### UFW状态
|
||||
|
||||
你可以在任何时候使用命令:`sudo ufw status`查看UFW的状态。这会显示所有规则列表,以及UFW是否是激活状态:
|
||||
|
||||
```
|
||||
Status: active
|
||||
|
||||
To Action From
|
||||
-- ------ ----
|
||||
22 ALLOW Anywhere
|
||||
80/tcp ALLOW Anywhere
|
||||
443 ALLOW Anywhere
|
||||
22 (v6) ALLOW Anywhere (v6)
|
||||
80/tcp (v6) ALLOW Anywhere (v6)
|
||||
443 (v6) ALLOW Anywhere (v6)
|
||||
```
|
||||
|
||||
### 启用防火墙
|
||||
|
||||
随着你选择规则完成,你初始运行`ufw status`可能会输出`Status: inactive`。 启用UFW并强制执行防火墙规则:
|
||||
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
相似地,禁用UFW规则:
|
||||
|
||||
```
|
||||
sudo ufw disable
|
||||
```
|
||||
|
||||
> 这让UFW继续运行并且在下次启动时再次启动。
|
||||
|
||||
### 日志记录
|
||||
|
||||
你可以用下面的命令启动日志记录:
|
||||
|
||||
```
|
||||
sudo ufw logging on
|
||||
```
|
||||
|
||||
可以通过运行`sudo ufw logging low|medium|high`设计日志级别,可以选择`low`、 `medium` 或者 `high`。默认级别是`low`。
|
||||
|
||||
常规日志类似于下面这样,位于`/var/logs/ufw`:
|
||||
|
||||
```
|
||||
Sep 16 15:08:14 <hostname> kernel: [UFW BLOCK] IN=eth0 OUT= MAC=00:00:00:00:00:00:00:00:00:00:00:00:00:00 SRC=123.45.67.89 DST=987.65.43.21 LEN=40 TOS=0x00 PREC=0x00 TTL=249 ID=8475 PROTO=TCP SPT=48247 DPT=22 WINDOW=1024 RES=0x00 SYN URGP=0
|
||||
```
|
||||
|
||||
|
||||
初始的值有你的Linode的日期、时间、主机名。额外的信息包括:
|
||||
|
||||
* ** [UFW BLOCK]:**此位置是记录事件的描述所在的位置。在这种例子中,它阻止了连接。
|
||||
|
||||
* ** IN:**如果这包含一个值,那么事件传入的
|
||||
|
||||
* ** OUT:**如果这包含一个值,那么事件是传出的
|
||||
|
||||
* ** MAC:**目的地和源MAC地址的组合
|
||||
|
||||
* ** SRC:**包源的IP
|
||||
|
||||
* ** DST:**包目的地的IP
|
||||
|
||||
* ** LEN:**数据包长度
|
||||
|
||||
* ** TTL:**数据包TTL,或称为_time to live_。 如果没有找到目的地,它将在路由器之间跳跃,直到它过期。
|
||||
|
||||
* ** PROTO:**数据包的协议
|
||||
|
||||
* ** SPT:**包的源端口
|
||||
|
||||
* ** DPT:**包的目标端口
|
||||
|
||||
* ** WINDOW:**发送方可以接收的数据包的大小
|
||||
|
||||
* ** SYN URGP:**指示是否需要三次握手。 `0`表示不是。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linode.com/docs/security/firewalls/configure-firewall-with-ufw
|
||||
|
||||
作者:[Linode ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linode.com/docs/security/firewalls/configure-firewall-with-ufw
|
||||
[1]:https://www.linode.com/docs/getting-started
|
||||
[2]:https://www.linode.com/docs/security/securing-your-server
|
||||
[3]:http://localhost:4567/docs/security/firewalls/configure-firewall-with-ufw#enable-the-firewall
|
||||
132
translated/tech/20161201 Using the NTP time synchronization.md
Normal file
132
translated/tech/20161201 Using the NTP time synchronization.md
Normal file
@ -0,0 +1,132 @@
|
||||
使用 NTP 进行时间同步
|
||||
==========
|
||||
|
||||
NTP 是通过网络来同步时间的一种 TCP/IP 协议。通常客户端向服务器请求当前的时间,并根据结果来设置其时钟。
|
||||
|
||||
这个描述是挺简单的,实现这一功能是极为复杂的——首先要有多层 NTP 服务器,其中的第一次链接着原子时钟,第二层、第三层则担起负载均衡的责任,以处理因特网传来的所有请求。并且,客户端可能也超乎你想象的复杂——时间同步存在着通讯延迟,使用一种方法来调整时间并不能使用所有运行在服务器中进程的到同步设置。幸运的是,所有的这些复杂性都进行了封装,你是不可见也不需要见到的。
|
||||
|
||||
在 Ubuntu 中,是使用 ntpdate 和 ntpd 来同步时间的。
|
||||
|
||||
* [timedatectl](#timedatectl)
|
||||
* [timesyncd](#timesyncd)
|
||||
* [ntpdate](#ntpdate)
|
||||
* [timeservers](#timeservers)
|
||||
* [ntpd](#ntpd)
|
||||
* [安装](#installation)
|
||||
* [配置](#configuration)
|
||||
* [View status](#status)
|
||||
* [PPS Support](#Support)
|
||||
* [参考资料](#reference)
|
||||
|
||||
### <sapan id="timedatectl">timedatectl</sapan>
|
||||
|
||||
在最新的 Ubuntu 版本中,timedatectl 替代了老旧的 ntpdate。默认情况下,timedatectl 在系统启动的时候会立刻同步时间,同时还开启 socket 以便恢复网络之后进行同步。
|
||||
|
||||
如果已安装 ntpdate / ntp,timedatectl 会让你使用之前的设置。这样确保了在有两个时间同步服务的时候不会相互冲突,同时在你进行的时候还保留原本的配置。但这也意味着升级时旧版本的 ntp / ntpdate 仍会安装,迁移到新的 systemd 服务是默认禁用的。
|
||||
|
||||
### <sapan id="timesyncd">timesyncd</sapan>
|
||||
|
||||
在最新的 Ubuntu 版本中,timesyncd 替代了 ntpd 的客户端的部分,它默认情况下会定期检测并同步时间。它还会在本地存储时间更新计划,以便在系统重启时做时间单步递增调整。
|
||||
|
||||
通过 timedatectl 和 timesyncd 设置的当前的时间状态和时间配置,现在可以使用 timedatectl status 命令来进行确认。
|
||||
|
||||
```
|
||||
timedatectl status
|
||||
Local time: Fri 2016-04-29 06:32:57 UTC
|
||||
Universal time: Fri 2016-04-29 06:32:57 UTC
|
||||
RTC time: Fri 2016-04-29 07:44:02
|
||||
Time zone: Etc/UTC (UTC, +0000)
|
||||
Network time on: yes
|
||||
NTP synchronized: no
|
||||
RTC in local TZ: no
|
||||
```
|
||||
|
||||
如果安装了 NTP,并用它替代 timedatectl 来同步时间,则 "NTP synchronized" 是 "yes"。
|
||||
|
||||
timedatectl 和 timesyncd 用以同步时间的 nameserver 可以通过 /etc/systemd/timesyncd.conf 来指定,另外还有一个非常灵活的配置目录 /etc/systemd/timesyncd.conf.d/。
|
||||
|
||||
### <sapan id="ntpdate">ntpdate</sapan>
|
||||
|
||||
由于 timedatectl 的存在,各发行版已经弃用了 ntpdate,所有默认不在进行安装。如果你安装了,它会在系统启动的时候根据 Ubuntu 的 NTP 服务器来设置你电脑的时间。之后的任意时刻中,它会有一个接口用来重新尝试同步时间——在这期间只要其涵盖的时间增量不是太大,它就会慢慢偏移时间。该行为可以通过 -B/-b 开关来进行控制。
|
||||
|
||||
```
|
||||
ntpdate ntp.ubuntu.com
|
||||
```
|
||||
|
||||
### <sapan id="timeservers">timeservers</sapan>
|
||||
|
||||
默认情况下,基于 systemd 的工具都是从 ntp.ubuntu.com 请求时间同步的。经典的 ntpd 服务基本上都是使用的 [0-3].ubuntu.pool.ntp.org 池,这等同于 ntp.ubuntu.com,并且需要的话还支持 IPv6。如果说你想强制使用 IPv6,可以使用 ipv6.ntp.ubuntu.com,当然这并非默认配置。
|
||||
|
||||
### <sapan id="ntpd">ntpd</sapan>
|
||||
|
||||
ntp 的守护进程 ntpd 会计算你的系统时钟的时间偏移量并且持续的进行调整,所以不会出现时间差距较大的更正,以保证不会导致不连续的日志。该进程只花费少量的进程资源和内存,但对于现代的服务器来说实在是微不足道的了。
|
||||
|
||||
### <sapan id="installation">安装</sapan>
|
||||
|
||||
打开终端命令行来安装 ntpd:
|
||||
|
||||
```
|
||||
sudo apt install ntp
|
||||
```
|
||||
|
||||
### <sapan id="configuration">配置</sapan>
|
||||
|
||||
编辑 /etc/ntp.conf ——增加/移除 server 行。默认配置有一下服务器:
|
||||
|
||||
```
|
||||
# Use servers from the NTP Pool Project. Approved by Ubuntu Technical Board
|
||||
# on 2011-02-08 (LP: #104525). See http://www.pool.ntp.org/join.html for
|
||||
# more information.
|
||||
server 0.ubuntu.pool.ntp.org
|
||||
server 1.ubuntu.pool.ntp.org
|
||||
server 2.ubuntu.pool.ntp.org
|
||||
server 3.ubuntu.pool.ntp.org
|
||||
```
|
||||
|
||||
修改配置文件之后,你需要重新加载 ntpd:
|
||||
|
||||
```
|
||||
sudo systemctl reload ntp.service
|
||||
```
|
||||
|
||||
### <sapan id="status">查看状态</sapan>
|
||||
|
||||
使用 ntpq 来查看更多信息:
|
||||
|
||||
```
|
||||
# sudo ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================================
|
||||
+stratum2-2.NTP. 129.70.130.70 2 u 5 64 377 68.461 -44.274 110.334
|
||||
+ntp2.m-online.n 212.18.1.106 2 u 5 64 377 54.629 -27.318 78.882
|
||||
*145.253.66.170 .DCFa. 1 u 10 64 377 83.607 -30.159 68.343
|
||||
+stratum2-3.NTP. 129.70.130.70 2 u 5 64 357 68.795 -68.168 104.612
|
||||
+europium.canoni 193.79.237.14 2 u 63 64 337 81.534 -67.968 92.792
|
||||
```
|
||||
|
||||
### <sapan id="Support">PPS Support</sapan>
|
||||
|
||||
从 Ubuntu 16.04 开始,ntp 支持 PPS 规范,增强了本地时间资源已提供更高的精度。查看下边列出的链接来获取更多信息。
|
||||
|
||||
### <sapan id="reference">参考资料</sapan>
|
||||
|
||||
* 参考 [Ubuntu Time][1] wiki 页来获取更多信息
|
||||
|
||||
* [ntp.org,网络时间协议项目主页][2]
|
||||
|
||||
* [ntp.org,关于配置 PPS 的 FAQ][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://help.ubuntu.com/lts/serverguide/NTP.html
|
||||
|
||||
作者:[Ubuntu][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://help.ubuntu.com/lts/serverguide/NTP.html
|
||||
[1]:https://help.ubuntu.com/community/UbuntuTime
|
||||
[2]:http://www.ntp.org/
|
||||
[3]:http://www.ntp.org/ntpfaq/NTP-s-config-adv.htm#S-CONFIG-ADV-PPS
|
||||
@ -0,0 +1,218 @@
|
||||
Manage Samba4 AD Domain Controller DNS and Group Policy from Windows – Part 4
|
||||
============================================================
|
||||
在 Windows 系统下管理 Samba4 AD 域管制器 DNS 和组策略(四)
|
||||
|
||||
接着前一篇教程写的关于[使用 Windows 10 系统的 RSAT 工具来管理 Samba4 活动目录架构][4],在这篇文章中我们将学习如何使用微软 DNS 管理器远程管理我们的 Samba AD 域控制器的 DNS 服务器,如何创建 DNS 记录,如何创建反向查找区域以及如何通过组策略管理工具来创建域策略。
|
||||
|
||||
#### 需求
|
||||
|
||||
1、 [在 Ubuntu16.04 系统上使用 Samba4 软件来创建活动目录架构(一)][1]
|
||||
2、 [在 Linux 命令行下管理 Samba4 AD 架构(二)][2]
|
||||
3、 [使用 Windows 10 系统的 RSAT 工具来管理 Samba4 活动目录架构 (三)][3]
|
||||
|
||||
### 第 1 步:管理 Samba DNS 服务器
|
||||
|
||||
Samba4 AD DC 使用内部的 DNS 解析模块,该模块在初始化域提供的过程中被创建完成(如果 BIND9 DLZ 模块未特定使用的情况下)。
|
||||
|
||||
Samba4 内部的 DNS 域模块支持 AD 域控制器所必须的基本功能。有两种方式来管理域 DNS 服务器,直接在命令行下通过 samba-tool 接口来管理,或者使用已加入域的微软工作站中的 RSAT DNS 管理器远程进行管理。
|
||||
|
||||
在这篇文章中,我们使用第二种方式来进行管理,因为这种方式很直观,也不容易出错。
|
||||
|
||||
1、要使用 RSAT 工具来管理域控制器上的 DNS 服务器,在 Windows 机器上,打开控制面板 -> 系统和安全 -> 管理工具,然后运行 DNS 管理器工具。
|
||||
|
||||
当打开这个工具时,它会询问你将要连接到哪台正在运行的 DNS 服务器。选择使用下面的计算机,输入域名(IP 地址或 FQDN 地址都可以使用),勾选‘现在连接到指定计算机’,然后单击 OK 按钮以开启 Samba DNS 服务。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
在 Windows 系统上连接 Samba4 DNS 服务器
|
||||
|
||||
2、为了添加一条 DNS 记录(比如我们添加一条指向 LAN 网关的记录 ‘A'),打开 DNS 管理器,找到域正向查找区,在右侧单击右键选择新的主机(’A‘ 或 ’AAA‘)。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
在 Windows 下添加一条 DNS 记录
|
||||
|
||||
3、在打开的新主机窗口界面,输入 DNS 服务器的主机名和 IP 地址。 DNS 管理器工具会自动填写完成 FQDN 地址。填写完成后,点击添加主机按钮,之后会弹出一个新的窗口提示你 DNS A 记录已经创建完成。
|
||||
|
||||
确保你添加的 DNS A 记录是你们网络中的资源[已配置静态 IP][7]。不要为那些从 DHCP 服务器自动获取 IP 地址或者经常变换 IP 地址的主机添加 DNS A 记录。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
在 Windows 系统下配置 Samba 主机
|
||||
|
||||
要更新一条 DNS 记录只需要双击那条记录,然后输入更改原因即可。要删除一条记录时,只需要在这条记录上单击右键,选择从菜单删除即可。
|
||||
|
||||
同样的方式,你也可以为你的域添加其它类型的 DNS 记录,比如说 CNAME 记录(也称为 DNS 别名记录),MX 记录(在邮件服务器上非常有用)或者其它类型的记录(SPE、TXT、SRVetc类型)。
|
||||
|
||||
### 第 2 步:创建反向查找区域
|
||||
|
||||
默认情况下, Samba4 AD DC 不会自动为你的域添加一个反向查找区域和 PTR 记录,因为这些类型的记录对于域控制器的正常工作来说是无关紧要的。
|
||||
|
||||
相反,DNS 反向区和 PTR 记录在一些重要的网络服务中显得非常有用,比如邮件服务,因为这些类型的记录可以用于验证客户端请求服务的身份。
|
||||
|
||||
实际上, PTR 记录的功能与标准的 DNS 记录功能相反。客户端知道资源的 IP 地址,然后去查询 DNS 服务器来识别出已注册的 DNS 名字。
|
||||
|
||||
4、要创建 Samba AD DC 的反向查找区域,打开 DNS 管理器,在左侧反向查找区域目录上单击右键,然后选择菜单中的新区域。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
创建 DNS 反向查找区域
|
||||
|
||||
5、下一步,单击下一步按钮,然后从区域类型向导中选择主区域。
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
选择 DNS 区域类型
|
||||
|
||||
6、下一步,在 AD 区域复制范围中选择复制到该域里运行在域控制器上的所有的 DNS 服务器,选择 IPv4 反向查找区域然后单击下一步继续。
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
为 Samba 域控制器选择 DNS 服务器
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
添加反向查找区域名
|
||||
|
||||
7、下一步,在网络ID 框中输入你的 LAN IP 地址,然后单击下一步继续。
|
||||
|
||||
资源在这个区域内添加的所有 PTR 记录仅指向 192.168.1.0/24 网络段。如果你想要为一个不在该网段中的服务器创建一个 PTR 记录(比如邮件服务器位于 10.0.0.0/24 这个网段的时候),那么你还得为那个网段创建一个新的反向查找区域。
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
添加 DNS 反向查找区域的 IP 地址
|
||||
|
||||
8、在下一个截图中选择仅允许安全的动态更新,单击下一步继续,最后单击完成按钮以完成反向查找区域的创建。
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
启用安全动态更新
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
新 DNS 区域概述
|
||||
|
||||
9、此时,你已经为你的域环境创建完成了一个有效的 DNS 反向查找区域。为了在这个区域中添加一个 PTR 记录,在右侧右键单击,选择为网络资源创建一个 PTR 记录。
|
||||
|
||||
这个时候,我们已经为网关创建了一个指向。为了测试这条记录对于客户端是否添加正确和工作正常,打开命令行提示符执行 nslookup 查询资源名,再执行另外一条命令查询 IP 地址。
|
||||
|
||||
两个查询都应该为你的 DNS 资源返回正确的结果。
|
||||
|
||||
```
|
||||
nslookup gate.tecmint.lan
|
||||
nslookup 192.168.1.1
|
||||
ping gate
|
||||
```
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
添加及查询 PTR 记录
|
||||
### 第 3 步:管理域控制策略
|
||||
|
||||
10、域控制器最重要的作用就是集中控制系统资源及安全。使用域控制器的域组策略功能很容易实现这些类型的任务。
|
||||
|
||||
遗憾的是,在 Samba 域控制器上唯一用来编辑或管理组策略的方法是通过微软的 RSAT GPM 工具。
|
||||
|
||||
在下面的实例中,我们将看到通过组策略来实现在 Samba 域环境中为域用户创建一种交互式的登录方式是多么的简单。
|
||||
|
||||
要访问组策略控制台,打开控制面板 -> 系统和安全 -> 管理工具,然后打开组策略管理控制台。
|
||||
|
||||
展开你的域下面的目录,在默认组策略上右键,选择菜单中的编辑,将出现一个新的窗口。
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
管理 Samba 域组策略
|
||||
|
||||
11、在组策略管理编辑器窗口中,进入到电脑配置 -> 组策略 -> Windows 设置 -> 安全设置 -> 本地策略 -> 安全选项,你将在右侧看到一个新的选项列表。
|
||||
|
||||
在右侧查询并编辑你的定制化设置,参考下图中的两条设置内容。
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
配置 Samba 域组策略
|
||||
|
||||
12、这两个条目编辑完成后,关闭所有窗口,打开 CMD 窗口,执行以下命令来强制应用组策略。
|
||||
|
||||
```
|
||||
gpupdate /force
|
||||
```
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
更新 Samba 域组策略
|
||||
|
||||
13、最后,重启你的电脑,当你准备登录进入系统的时候,你就会看到登录提示生效了。
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
Samba4 AD 域控制器登录提示
|
||||
|
||||
就写到这里吧!组策略是一个操作起来很繁琐和很谨慎的主题,在管理系统的过程中你得非常的小心。还有,注意你设置的组策略不会以任何方式应用到已加入域的 Linux 系统中。
|
||||
|
||||
------
|
||||
|
||||
作者简介:我是一个电脑迷,开源软件及 Linux 系统爱好者,有近4年的 Linux 桌面和服务器系统及 bash 编程经验。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/
|
||||
|
||||
作者:[Matei Cezar ][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
[1]:http://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:http://www.tecmint.com/manage-samba4-active-directory-linux-command-line/
|
||||
[3]:http://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[4]:http://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/Connect-Samba4-DNS-on-Windows.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2016/12/Add-DNS-A-Record.png
|
||||
[7]:http://www.tecmint.com/set-add-static-ip-address-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Samba-Host-on-Windows.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/12/Create-Reverse-Lookup-DNS-Zone.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-DNS-Zone-Type.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-DNS-for-Samba-Domain-Controller.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/12/Add-Reverse-Lookup-Zone-Name.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2016/12/Add-IP-Address-of-Reverse-DNS-Zone.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/12/Enable-Secure-Dynamic-Updates.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2016/12/New-DNS-Zone-Summary.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Add-DNS-PTR-Record-and-Query.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2016/12/Manage-Samba-Domain-Group-Policy.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Samba-Domain-Group-Policy.png
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2016/12/Update-Samba-Domain-Group-Policy.png
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2016/12/Samba4-Domain-Controller-User-Login.png
|
||||
[21]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#
|
||||
[22]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#
|
||||
[23]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#
|
||||
[24]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#
|
||||
[25]:http://www.tecmint.com/manage-samba4-dns-group-policy-from-windows/#comments
|
||||
@ -0,0 +1,200 @@
|
||||
|
||||
九款开源或商业的数据中心基础设施管理软件
|
||||
============================================================
|
||||
|
||||
|
||||
当一个公司发展壮大时,相应地对计算资源的需求也会与日俱增。无论是普通公司还是服务提供商,包括那些出租服务器的公司,当服务器数量过多时都不得不面对很多问题。
|
||||
|
||||
如何盘存服务器和备件?如何维护使数据中心保持健康运作,及时定位和修复潜在的威胁?如何快速找到宕机设备的机架位置?如何准备物理机上线工作?做完这些事情需要花费大量的时间,或者需要 IT 部门有一大帮管理员支持才能办到。
|
||||
|
||||
现在有一个更好的方案解决这些问题,使用特定软件来实现数据中心管理自动化,下文将介绍当前市场上已有的一些数据中心管理工具。
|
||||
|
||||
### 1\. Opendcim
|
||||
|
||||
这是该类目前唯一的免费软件,该软件开源并且按照商业化<ruby>数据中心基础设施管理<rt>Data Center Infrastructure Management</rt></ruby>(DCIM)解决方案的替代方案来设计。该软件可以管理库存、生成数据中心的地图和监控机房温度与电力消耗。
|
||||
|
||||
不过,它不支持远程关机,服务器重启,操作系统安装等功能。尽管如此,它仍然被全球很多非商业机构使用。
|
||||
|
||||
多亏了该软件开源,有研发能力的公司可以修改它,使 [Opendcims][2] 更适合自己的公司。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
*openDCIM*
|
||||
|
||||
### 2\. NOC-PS
|
||||
|
||||
这是一款可以管理物理和虚拟设备的商业软件。有很多可以用于初始化设备的工具,比如:操作系统和其他软件安装、网络配置,并且集成了 WHMCS 和 Blesta。美中不足的是,如果你希望能够看到数据中心设备地图或者机架位置,那该软件就不是你的最佳选择了。
|
||||
|
||||
[NOC-PS][4] 每 100 台服务器每年管理费需要 100€,比较适合中小企业使用。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
*NOC-PS*
|
||||
|
||||
### 3\. DCImanager
|
||||
|
||||
[DCImanager][6] 是一个专用的解决方案,正如宣传所说的,考虑了 DC 工程师和托管服务提供商的需求。该软件集成了很多有名的计费软件,比如 WHMCS、Hostbill、BILLmanager 等。
|
||||
|
||||
该软件的主要功能有:服务器配置、模板化安装操作系统、传感器监控、流量和电力消耗报告、VLAN管理。除此之外,企业版还可以生成数据中心服务器地图、以及对服务器和备件进行盘点管理。
|
||||
|
||||
你可以试用免费版,但是免费版最多支持 5 台物理服务器管理,而收费版每 100 台服务器每年的授权使用费是 120€。
|
||||
|
||||
根据版本不同,收费版可适用中小企业或者大企业。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
*DCImanager*
|
||||
|
||||
### 4\. EasyDCIM
|
||||
|
||||
[EasyDCIM][9] 是一款主要面向服务提供商的收费软件。拥有可以安装操作或其他软件的特点,并且能方便地生成机房目录及机架分布图。
|
||||
|
||||
该软件本身并不支持通过开关对 IP 和 DNS 进行管理。不过可以通过安装模块的方式获得这些功能,这些模块可能付费或者免费(包括 WHMCS 集成模块)。
|
||||
|
||||
该软件每 100 台服务器每年的服务费起步价 $999。对于小公司来说这个价格有点贵,不过中型或者大型企业可以尝试使用。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
*EasyDCIM*
|
||||
|
||||
### 5\. Ansible Tower
|
||||
|
||||
[Ansible Tower][11] 是红帽出品的企业级计算中心管理软件。该解决方案的核心思想是实现对服务器和不同用户设备的集中式部署。
|
||||
|
||||
|
||||
感谢 **Ansible Tower** 能够通过集成软件的方式使用几乎所有的工具程序,并且该软件的数据统计收集模块特别好用。不好的一面则是缺乏和当前比较流行的计费软件的集成,而且价格也不便宜。
|
||||
|
||||
每 100 台设备每年的服务器费是 $5000,这个价格估计只有大公司才能接受。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
*Ansible Tower*
|
||||
|
||||
### 6\. Puppet Enterprise
|
||||
|
||||
在商业基础上发展而来并作为 IT 部门的辅助软件。该软件用于在服务器或者用户设备上安装操作系统及其他软件,无论是初步部署或者进一步开发都适用。
|
||||
|
||||
不幸的是,盘存和其他更好的交互方案(电缆连接、协议等)仍然处于开发中。
|
||||
|
||||
[Puppet Enterprise][13]对于小于 10 台服务器的管理免费并且开放全部功能。而收费版则是每台服务器每年 $120。
|
||||
|
||||
这个价格适合大公司使用.
|
||||
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
*Puppet Enterprise*
|
||||
|
||||
### 7\. Device 42
|
||||
|
||||
该软件主要用于数据中心监控。有一个很棒的盘存工具,自动创建软硬件依赖关系图。通过 [Device 42][15] 生成数据中心地图,给不同机架标特定颜色,并可以通过图表方式反映温度、空闲空间情况和机架的其他指标。但是不支持软件安装和计费软件的集成。
|
||||
|
||||
每 100 台服务器每年的收费是 $1499,这个价位比较适合大中型企业。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
*Device42*
|
||||
|
||||
### 8\. CenterOS
|
||||
|
||||
这是一款适合数据中心管理的操作系统,主要功能是设备盘点。除此之外可以生成数据中心地图及机架方案,并连接了一个评价不错的服务器状态监控系统,方便内部技术管理工作。
|
||||
|
||||
|
||||
该软件还有一个特性就是能够通过简单的几次点击就可以找到某个设备对应的人(可能是设备所有人、技术管理员或者该设备的制造商),当出现紧急问题时这个就特别有用了。
|
||||
|
||||
**建议阅读:** [8 Open Source/Commercial Billing Platforms for Hosting Providers][17]
|
||||
|
||||
该软件不是开源的,并且价格也只能在咨询后才能知道。
|
||||
|
||||
该软件价格的神秘性也决定了软件的目标客户,极有可能这个软件是给大公司用的。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
*CenterOS*
|
||||
|
||||
### 9\. LinMin
|
||||
|
||||
这个一款用于初始化物理设备以便后期使用的软件。使用 PXE 安装选定的操作系统,并可随后部署一系列必要的软件安装。
|
||||
|
||||
与同类软件不同的是,[LinMin][20] 有一个开发完善的硬盘备份系统,可以迅速在系统崩溃后恢复以及大规模部署相同配置的服务器。
|
||||
|
||||
该软件每 100 台服务器一年的收费是 $1999,这价格也只有大中型企业能用了。
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
*LinMin*
|
||||
|
||||
现在来总结下,当前市场上大部分能够自动化管理大量的基础设施的软件,可以分为两类。
|
||||
|
||||
第一类,主要用于完成设备的准备工作,以便能够进一步管理。另一类就是设备的盘点管理。找到一个通用的包含所有功能的软件并不容易,你在选择的时候可以放弃一些设备提供商提供的那些功能比较有限的工具。
|
||||
|
||||
现在你知道了这些解决方案,那么你可以逐个尝试下。值得注意的是这里列出的开源产品,如果你有好的开发人员,那么可以尝试定制软件来满足你需求。
|
||||
|
||||
希望通过这篇回顾能够帮你找到适合的软件让你的工作更轻松。另,祝您的服务器永不出错。
|
||||
|
||||
|
||||
|
||||
-----------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
我是一名俄罗斯西伯利亚托管软件开发公司的技术专家。我希望能够在新的 Linux 软件工具和托管行业的发展趋势、可能性、发展历史和发展机遇等方面拓展我的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/data-center-server-management-tools/
|
||||
|
||||
作者:[ Nikita Nesmiyanov][a]
|
||||
译者:[beyondworld](https://github.com/beyondworld)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/nesmiyanov/
|
||||
[1]:http://www.tecmint.com/web-control-panels-to-manage-linux-servers/
|
||||
[2]:http://opendcim.org/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/12/openDCIM.png
|
||||
[4]:http://noc-ps.com/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2016/12/NOC-PS.png
|
||||
[6]:https://www.ispsystem.com/software/dcimanager
|
||||
[7]:http://www.tecmint.com/opensource-commercial-control-panels-manage-virtual-machines/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/DCImanager.png
|
||||
[9]:https://www.easydcim.com/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/12/EasyDCIM.png
|
||||
[11]:https://www.ansible.com/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2016/12/Ansible_Tower.png
|
||||
[13]:https://puppet.com/
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2016/12/Puppet-Enterprise.png
|
||||
[15]:http://www.device42.com/
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Device42.png
|
||||
[17]:http://www.tecmint.com/open-source-commercial-billing-software-system-web-hosting/
|
||||
[18]:http://www.centeros.com/
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2016/12/CenterOS.png
|
||||
[20]:http://www.linmin.com/
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2016/12/LinMin.jpg
|
||||
@ -1,23 +1,22 @@
|
||||
在Ubuntu上搭建一台Email服务器(四)
|
||||
在 Ubuntu 上搭建一台 Email 服务器(三)
|
||||
============================================================
|
||||
|
||||
### [mail-server.jpg][2]
|
||||
|
||||

|
||||
本系列的第四部分我们将详细介绍在Dovecot和Postfix中设置虚拟用户。以[Creative Commons Zero][2]Pixabay方式授权发布
|
||||
在本系列的最后,我们将详细介绍如何在 Dovecot 和 Postfix 中设置虚拟用户和邮箱。
|
||||
|
||||
欢迎回来,我热心的Linux系统管理员们! 在本系列的[第一部分][3]和[第二部分][4]中,我们学习了如何将Postfix和Dovecot组合在一起,搭建一个不错的IMAP和POP3邮件服务器。 现在我们将学习设置虚拟用户,以便我们可以管理所有在Dovecot中的用户。
|
||||
欢迎回来,热心的 Linux 系统管理员们! 在本系列的[第一部分][3]和[第二部分][4]中,我们学习了如何将 Postfix 和 Dovecot 组合在一起,搭建一个不错的 IMAP 和 POP3 邮件服务器。 现在我们将学习设置虚拟用户,以便我们可以管理所有 Dovecot 中的用户。
|
||||
|
||||
### 抱歉还不能配置SSL
|
||||
### 抱歉,还不能配置SSL
|
||||
|
||||
我知道我答应教你们如何设置一个正确的受SSL保护的服务器。 不幸的是,我低估了这个话题的范围。 所以,我会下个月再写一个全面的教程。
|
||||
我知道我答应过教你们如何设置一个受 SSL 保护的服务器。 不幸的是,我低估了这个话题的范围。 所以,我会下个月再写一个全面的教程。
|
||||
|
||||
对于今天,在本系列的最后一部分中,我们将详细介绍如何在Dovecot和Postfix中设置虚拟用户和邮箱。 在你看来这是有点奇怪,所以我尽量让下面的例子是简单点。我们将使用纯文件和纯文本来进行身份验证。 你也可以选择使用数据库后端和很好的加密认证形式,具体请参阅文末链接了解有关这些的更多信息。
|
||||
今天,在本系列的最后一部分中,我们将详细介绍如何在 Dovecot 和 Postfix 中设置虚拟用户和邮箱。 在你看来这是有点奇怪,所以我尽量让下面的例子简单点。我们将使用纯文本文件和纯文本来进行身份验证。 你也可以选择使用数据库后端和较强的加密认证形式,具体请参阅文末链接了解有关这些的更多信息。
|
||||
|
||||
### 虚拟用户
|
||||
|
||||
You want virtual users on your email server and not Linux system users. Using Linux system users does not scale, and it exposes their logins, and your Linux server, to unnecessary risk. Setting up virtual users requires editing configuration files in both Postfix and Dovecot. We'll start with Postfix. First, we'll start with a clean, simplified `/etc/postfix/main.cf`. Move your original `main.cf` out of the way and create a new clean one with these contents:
|
||||
你希望电子邮件服务器上的是虚拟用户而不是Linux系统用户。使用Linux系统用户不能扩展,并且它们会暴露登录账号以及会给你的服务器带来不必要的风险。 设置虚拟用户需要在Postfix和Dovecot中编辑配置文件。我们将从Postfix开始。首先,我们将从一个干净、简单的`/etc /postfix/main.cf`开始。移动你原始的`main.cf`到别处,创建一个新的干净的文件:
|
||||
你希望邮件服务器上的是虚拟用户而不是 Linux 系统用户。使用 Linux 系统用户不能扩展,并且它们会暴露登录账号,给你的服务器带来不必要的风险。 设置虚拟用户需要在 Postfix 和 Dovecot 中编辑配置文件。我们将从 Postfix 开始。首先,我们将从一个干净、简化的 `/etc /postfix/main.cf` 开始。移动你原始的`main.cf` 到别处,创建一个新的干净的文件,内容如下:
|
||||
|
||||
```
|
||||
|
||||
@ -44,9 +43,9 @@ virtual_gid_maps = static:5000
|
||||
virtual_transport = lmtp:unix:private/dovecot-lmtp0
|
||||
```
|
||||
|
||||
你或许可以直接拷贝这份文件除了`mynetworks`的参数`192.168.0.0/24`,它反映了你的本地子网掩码。
|
||||
你可以直接拷贝这份文件,除了 `mynetworks` 参数的设置 `192.168.0.0/24`,它应为你的本地子网掩码。
|
||||
|
||||
接下来,创建用户和组`vmail`,它会拥有你的虚拟邮箱。虚拟邮箱存在 `vmail`的家目录下。
|
||||
接下来,创建用户和组 `vmail` 来拥有你的虚拟邮箱。虚拟邮箱保存在 `vmail` 的家目录下。
|
||||
|
||||
```
|
||||
|
||||
@ -54,7 +53,7 @@ $ sudo groupadd -g 5000 vmail
|
||||
$ sudo useradd -m -u 5000 -g 5000 -s /bin/bash vmail
|
||||
```
|
||||
|
||||
接下来重新加载Postfix配置:
|
||||
接下来重新加载 Postfix 配置:
|
||||
|
||||
```
|
||||
|
||||
@ -63,16 +62,16 @@ $ sudo postfix reload
|
||||
postfix/postfix-script: refreshing the Postfix mail system
|
||||
```
|
||||
|
||||
### Dovecot虚拟用户
|
||||
### Dovecot 虚拟用户
|
||||
|
||||
我们会使用Dovecot的`lmtp`协议来连接到Postfix。你可以这样安装:
|
||||
我们会使用 Dovecot 的 `lmtp` 协议来连接到 Postfix。你可以这样安装:
|
||||
|
||||
```
|
||||
|
||||
$ sudo apt-get install dovecot-lmtpd
|
||||
```
|
||||
|
||||
`main.cf`的最后一行参考`lmtp`。复制这个例子`/etc/dovecot/dovecot.conf`来替换已存在的文件。再说一次,我们只使用这个文件,而不是`/etc/dovecot/conf.d`内的所有文件。
|
||||
`main.cf` 的最后一行涉及到 `lmtp`。复制这个 `/etc/dovecot/dovecot.conf` 示例文件来替换已存在的文件。再说一次,我们只使用这个文件,而不是 `/etc/dovecot/conf.d` 内的所有文件。
|
||||
|
||||
```
|
||||
|
||||
@ -112,7 +111,7 @@ service lmtp {
|
||||
}
|
||||
```
|
||||
|
||||
最后,你快可以创建一个含有用户和密码的文件 `/etc/dovecot/passwd`。对于纯文本验证,我们只需要用户的完整邮箱地址和密码:
|
||||
最后,你可以创建一个含有用户和密码的文件 `/etc/dovecot/passwd`。对于纯文本验证,我们只需要用户的完整邮箱地址和密码:
|
||||
|
||||
```
|
||||
|
||||
@ -123,7 +122,7 @@ molly@studio:{PLAIN}password
|
||||
benny@studio:{PLAIN}password
|
||||
```
|
||||
|
||||
Dovecot虚拟用户独立于Postfix虚拟用户,因此你需要管理Dovecot中的用户。保存所有的设置并重启Postfix和Dovecot:
|
||||
Dovecot 虚拟用户独立于 Postfix 虚拟用户,因此你需要管理 Dovecot 中的用户。保存所有的设置并重启 Postfix 和 Dovecot:
|
||||
|
||||
```
|
||||
|
||||
@ -131,7 +130,7 @@ $ sudo service postfix restart
|
||||
$ sudo service dovecot restart
|
||||
```
|
||||
|
||||
现在让我们使用较旧的telnet来看下Dovecot是否设置正确了。
|
||||
现在让我们使用老朋友 telnet 来看下 Dovecot 是否设置正确。
|
||||
|
||||
```
|
||||
|
||||
@ -149,7 +148,7 @@ quit
|
||||
Connection closed by foreign host.
|
||||
```
|
||||
|
||||
现在一切都好!让我们用`mail`测试发送消息给我们的用户。确保使用用户的电子邮箱地址而不只是用户名。
|
||||
现在一切都好!让我们用 `mail` 命令,发送测试消息给我们的用户。确保使用用户的完整电子邮箱地址而不只是用户名。
|
||||
|
||||
```
|
||||
|
||||
@ -159,7 +158,7 @@ Please enjoy your new mail account!
|
||||
.
|
||||
```
|
||||
|
||||
最后一行的点是发送消息。让我们看下它是否到达了正确的邮箱。
|
||||
最后一行的句点表示发送消息。让我们看下它是否到达了正确的邮箱。
|
||||
|
||||
```
|
||||
|
||||
@ -191,15 +190,19 @@ From: carla@localhost (carla)
|
||||
Please enjoy your new mail account!
|
||||
```
|
||||
|
||||
你还可以使用telnet进行测试,如本系列前面部分所述,并在你最喜欢的邮件客户端中设置帐户,如Thunderbird,Claws-Mail或KMail。
|
||||
你还可以使用 telnet 进行测试,如本系列前面部分所述,并在你最喜欢的邮件客户端中设置帐户,如 Thunderbird,Claws-Mail 或 KMail。
|
||||
|
||||
### 故障排查
|
||||
|
||||
当它不工作时,请检查日志文件(请参阅配置示例),然后运行`journalctl -xe`。 这时应该就会给你提供输入错误、已卸载的包和可以谷歌的字词了。
|
||||
当邮件工作不正常时,请检查日志文件(请参阅配置示例),然后运行 `journalctl -xe`。 这时会提供定位输入错误、未安装包和可以 Google 的短语等所有需要的信息。
|
||||
|
||||
### 接下来?
|
||||
|
||||
假设你的LAN名称服务配置正确,你现在有一台很好用的LAN邮件服务器。 显然以纯文本发送消息不是最佳的,并且对于Internet邮件也是绝对否定的。 请参阅[Dovecot SSL配置][5]和[Postfix TLS支持][6]。 [VirtualUserFlatFilesPostfix][7]涵盖TLS和数据库后端。并记得看即将到来的SSL指南。这次我说的是真的。
|
||||
假设你的 LAN 名称服务配置正确,你现在有一台很好用的 LAN 邮件服务器。 显然,以纯文本发送消息不是最佳的,对于 Internet 邮件也是绝对不可以的。 请参阅[ Dovecot SSL 配置][5]和[ Postfix TLS 支持][6],涵盖了 TLS 和数据库后端。并请期待我之后的 SSL 指南。这次我说的是真的。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -207,7 +210,7 @@ via: https://www.linux.com/learn/sysadmin/building-email-server-ubuntu-linux-par
|
||||
|
||||
作者:[ CARLA SCHRODER][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,158 +0,0 @@
|
||||
sshpass:一个很棒的无交互SSH登录工具 - 不要在生产服务器上使用
|
||||
============================================================
|
||||
|
||||
在大多数情况下,Linux系统管理员使用SSH通过密码或[无密码SSH登录][1]或基于密钥的SSH身份验证登录到远程Linux服务器。
|
||||
|
||||
如果你想自动在SSH中提供密码和用户名怎么办?这是可以用sshpass了。
|
||||
|
||||
sshpass是一个简单、轻量级的命令行工具,使我们能够向命令提示符本身提供密码(非交互式密码验证),以便可以通过[cron调度器][2]执行自动化的shell脚本进行备份。
|
||||
|
||||
ssh直接使用TTY访问,以确保密码是用户键盘输入的。 sshpass在专门的tty中运行ssh,以误导它相信它是从用户接收到的密码。
|
||||
|
||||
重要:使用sshpass被认为是最不安全的,因为它通过简单的“ps”命令就可在命令行上显示所有系统用户的密码。我强烈建议使用[SSH无密码身份验证][3]。
|
||||
|
||||
### 在Linux中安装sshpass
|
||||
|
||||
在基于RedHat/CentOS的系统中,首先需要[启用Epel仓库][4]并使用[yum命令安装][5]它。
|
||||
|
||||
```
|
||||
# yum install sshpass
|
||||
# dnf install sshpass [On Fedora 22+ versions]
|
||||
```
|
||||
|
||||
在Debian/Ubuntu和它的衍生版中,你可以使用[apt-get命令][6]来安装。
|
||||
|
||||
```
|
||||
$ sudo apt-get install sshpass
|
||||
```
|
||||
|
||||
另外你也可以从最新的源码安装sshpass,首先下载源码并从tar文件中解压出内容:
|
||||
|
||||
```
|
||||
$ wget http://sourceforge.net/projects/sshpass/files/latest/download -O sshpass.tar.gz
|
||||
$ tar -xvf sshpass.tar.gz
|
||||
$ cd sshpass-1.06
|
||||
$ ./configure
|
||||
# sudo make install
|
||||
```
|
||||
|
||||
### 如何在Linux中使用sshpass
|
||||
|
||||
sshpass与ssh一起使用,可以使用下面的命令查看sshpass的使用使用选项的完整描述:
|
||||
|
||||
```
|
||||
$ sshpass -h
|
||||
```
|
||||
sshpass Help
|
||||
```
|
||||
Usage: sshpass [-f|-d|-p|-e] [-hV] command parameters
|
||||
-f filename Take password to use from file
|
||||
-d number Use number as file descriptor for getting password
|
||||
-p password Provide password as argument (security unwise)
|
||||
-e Password is passed as env-var "SSHPASS"
|
||||
With no parameters - password will be taken from stdin
|
||||
-h Show help (this screen)
|
||||
-V Print version information
|
||||
At most one of -f, -d, -p or -e should be used
|
||||
```
|
||||
|
||||
正如我之前提到的,sshpass在用于脚本时才更可靠及更有用,考虑下面的示例命令。
|
||||
|
||||
使用用户名和密码登录到远程Linux ssh服务器(10.42.0.1),并如图所示[检查文件系统磁盘使用情况] [7]。
|
||||
|
||||
```
|
||||
$ sshpass -p 'my_pass_here' ssh aaronkilik@10.42.0.1 'df -h'
|
||||
```
|
||||
|
||||
重要提示:此处,密码在命令行中提供,实际上不安全,不建议使用此选项。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
sshpass – 使用SSH远程登录Linux
|
||||
|
||||
但是,为了防止在屏幕上显示密码,可以使用`-e`标志,并输入密码作为SSHPASS环境变量的值,如下所示:
|
||||
|
||||
```
|
||||
$ export SSHPASS='my_pass_here'
|
||||
$ echo $SSHPASS
|
||||
$ sshpass -e ssh aaronkilik@10.42.0.1 'df -h'
|
||||
```
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
sshpass – 在终端中隐藏密码
|
||||
|
||||
注意:在上面的示例中,SSHPASS环境变量仅用于临时目的,并将在重新启动后删除。
|
||||
|
||||
要永久设置SSHPASS环境变量,打开/etc/profile文件,并在文件开头输入export语句:
|
||||
|
||||
```
|
||||
export SSHPASS='my_pass_here'
|
||||
```
|
||||
|
||||
保存文件并退出,接着运行下面的命令使更改生效:
|
||||
|
||||
```
|
||||
$ source /etc/profile
|
||||
```
|
||||
|
||||
另一方面,你也可以使用`-f'标志,并把密码放在一个文件中。 这样,您可以从文件中读取密码,如下所示:
|
||||
|
||||
```
|
||||
$ sshpass -f password_filename ssh aaronkilik@10.42.0.1 'df -h'
|
||||
```
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
sshpass – 在登录时提供密码文件
|
||||
|
||||
你也可以使用sshpass[使用scp传输文件][11]或者[使用rsync备份/同步文件][12],如下所示:
|
||||
|
||||
```
|
||||
------- Transfer Files Using SCP -------
|
||||
$ scp -r /var/www/html/example.com --rsh="sshpass -p 'my_pass_here' ssh -l aaronkilik" 10.42.0.1:/var/www/html
|
||||
------- Backup or Sync Files Using Rsync -------
|
||||
$ rsync --rsh="sshpass -p 'my_pass_here' ssh -l aaronkilik" 10.42.0.1:/data/backup/ /backup/
|
||||
```
|
||||
|
||||
更多的用法,我建议你阅读一下sshpass的man页面,输入:
|
||||
|
||||
```
|
||||
$ man sshpass
|
||||
```
|
||||
|
||||
在本文中,我们解释了sshpass是一个启用非交互式密码验证的简单工具。 虽然这个工具可能是有帮助的,但是强烈建议使用更安全的ssh公钥认证机制。
|
||||
|
||||
请在下面的评论栏写下任何问题或评论,以便可以进一步讨论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
-----------
|
||||
|
||||
via: http://www.tecmint.com/sshpass-non-interactive-ssh-login-shell-script-ssh-password/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[4]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[5]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[6]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[7]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2016/12/sshpass-Linux-Remote-Login.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2016/12/sshpass-Hide-Password-in-Prompt.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2016/12/sshpass-Provide-Password-File.png
|
||||
[11]:http://www.tecmint.com/scp-commands-examples/
|
||||
[12]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
Loading…
Reference in New Issue
Block a user