mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
commit
6d4670f990
@ -1,18 +1,18 @@
|
||||
如何通过反向 SSH 隧道访问 NAT 后面的 Linux 服务器
|
||||
================================================================================
|
||||
你在家里运行着一台 Linux 服务器,访问它需要先经过 NAT 路由器或者限制性防火墙。现在你想不在家的时候用 SSH 登录到这台服务器。你如何才能做到呢?SSH 端口转发当然是一种选择。但是,如果你需要处理多个嵌套的 NAT 环境,端口转发可能会变得非常棘手。另外,在多种 ISP 特定条件下可能会受到干扰,例如阻塞转发端口的限制性 ISP 防火墙、或者在用户间共享 IPv4 地址的运营商级 NAT。
|
||||
你在家里运行着一台 Linux 服务器,它放在一个 NAT 路由器或者限制性防火墙后面。现在你想在外出时用 SSH 登录到这台服务器。你如何才能做到呢?SSH 端口转发当然是一种选择。但是,如果你需要处理多级嵌套的 NAT 环境,端口转发可能会变得非常棘手。另外,在多种 ISP 特定条件下可能会受到干扰,例如阻塞转发端口的限制性 ISP 防火墙、或者在用户间共享 IPv4 地址的运营商级 NAT。
|
||||
|
||||
### 什么是反向 SSH 隧道? ###
|
||||
|
||||
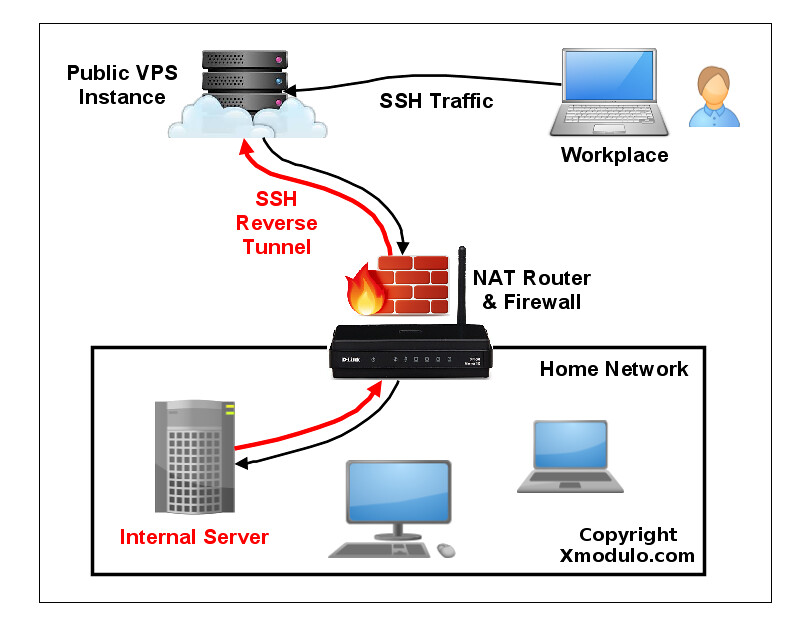
SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧道的概念非常简单。对于此,在限制性家庭网络之外你需要另一台主机(所谓的“中继主机”),你能从当前所在地通过 SSH 登录。你可以用有公共 IP 地址的 [VPS 实例][1] 配置一个中继主机。然后要做的就是从你家庭网络服务器中建立一个到公共中继主机的永久 SSH 隧道。有了这个隧道,你就可以从中继主机中连接“回”家庭服务器(这就是为什么称之为 “反向” 隧道)。不管你在哪里、你家庭网络中的 NAT 或 防火墙限制多么严重,只要你可以访问中继主机,你就可以连接到家庭服务器。
|
||||
SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧道的概念非常简单。使用这种方案,在你的受限的家庭网络之外你需要另一台主机(所谓的“中继主机”),你能从当前所在地通过 SSH 登录到它。你可以用有公网 IP 地址的 [VPS 实例][1] 配置一个中继主机。然后要做的就是从你的家庭网络服务器中建立一个到公网中继主机的永久 SSH 隧道。有了这个隧道,你就可以从中继主机中连接“回”家庭服务器(这就是为什么称之为 “反向” 隧道)。不管你在哪里、你的家庭网络中的 NAT 或 防火墙限制多么严格,只要你可以访问中继主机,你就可以连接到家庭服务器。
|
||||
|
||||
|
||||
|
||||
### 在 Linux 上设置反向 SSH 隧道 ###
|
||||
|
||||
让我们来看看怎样创建和使用反向 SSH 隧道。我们有如下假设。我们会设置一个从家庭服务器到中继服务器的反向 SSH 隧道,然后我们可以通过中继服务器从客户端计算机 SSH 登录到家庭服务器。**中继服务器** 的公共 IP 地址是 1.1.1.1。
|
||||
让我们来看看怎样创建和使用反向 SSH 隧道。我们做如下假设:我们会设置一个从家庭服务器(homeserver)到中继服务器(relayserver)的反向 SSH 隧道,然后我们可以通过中继服务器从客户端计算机(clientcomputer) SSH 登录到家庭服务器。本例中的**中继服务器** 的公网 IP 地址是 1.1.1.1。
|
||||
|
||||
在家庭主机上,按照以下方式打开一个到中继服务器的 SSH 连接。
|
||||
在家庭服务器上,按照以下方式打开一个到中继服务器的 SSH 连接。
|
||||
|
||||
homeserver~$ ssh -fN -R 10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
@ -20,11 +20,11 @@ SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧
|
||||
|
||||
“-R 10022:localhost:22” 选项定义了一个反向隧道。它转发中继服务器 10022 端口的流量到家庭服务器的 22 号端口。
|
||||
|
||||
用 “-fN” 选项,当你用一个 SSH 服务器成功通过验证时 SSH 会进入后台运行。当你不想在远程 SSH 服务器执行任何命令、就像我们的例子中只想转发端口的时候非常有用。
|
||||
用 “-fN” 选项,当你成功通过 SSH 服务器验证时 SSH 会进入后台运行。当你不想在远程 SSH 服务器执行任何命令,就像我们的例子中只想转发端口的时候非常有用。
|
||||
|
||||
运行上面的命令之后,你就会回到家庭主机的命令行提示框中。
|
||||
|
||||
登录到中继服务器,确认 127.0.0.1:10022 绑定到了 sshd。如果是的话就表示已经正确设置了反向隧道。
|
||||
登录到中继服务器,确认其 127.0.0.1:10022 绑定到了 sshd。如果是的话就表示已经正确设置了反向隧道。
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
@ -36,13 +36,13 @@ SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧
|
||||
|
||||
relayserver~$ ssh -p 10022 homeserver_user@localhost
|
||||
|
||||
需要注意的一点是你在本地输入的 SSH 登录/密码应该是家庭服务器的,而不是中继服务器的,因为你是通过隧道的本地端点登录到家庭服务器。因此不要输入中继服务器的登录/密码。成功登陆后,你就在家庭服务器上了。
|
||||
需要注意的一点是你在上面为localhost输入的 SSH 登录/密码应该是家庭服务器的,而不是中继服务器的,因为你是通过隧道的本地端点登录到家庭服务器,因此不要错误输入中继服务器的登录/密码。成功登录后,你就在家庭服务器上了。
|
||||
|
||||
### 通过反向 SSH 隧道直接连接到网络地址变换后的服务器 ###
|
||||
|
||||
上面的方法允许你访问 NAT 后面的 **家庭服务器**,但你需要登录两次:首先登录到 **中继服务器**,然后再登录到**家庭服务器**。这是因为中继服务器上 SSH 隧道的端点绑定到了回环地址(127.0.0.1)。
|
||||
|
||||
事实上,有一种方法可以只需要登录到中继服务器就能直接访问网络地址变换之后的家庭服务器。要做到这点,你需要让中继服务器上的 sshd 不仅转发回环地址上的端口,还要转发外部主机的端口。这通过指定中继服务器上运行的 sshd 的 **网关端口** 实现。
|
||||
事实上,有一种方法可以只需要登录到中继服务器就能直接访问NAT之后的家庭服务器。要做到这点,你需要让中继服务器上的 sshd 不仅转发回环地址上的端口,还要转发外部主机的端口。这通过指定中继服务器上运行的 sshd 的 **GatewayPorts** 实现。
|
||||
|
||||
打开**中继服务器**的 /etc/ssh/sshd_conf 并添加下面的行。
|
||||
|
||||
@ -74,23 +74,23 @@ SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧
|
||||
|
||||
tcp 0 0 1.1.1.1:10022 0.0.0.0:* LISTEN 1538/sshd: dev
|
||||
|
||||
不像之前的情况,现在隧道的端点是 1.1.1.1:10022(中继服务器的公共 IP 地址),而不是 127.0.0.1:10022。这就意味着从外部主机可以访问隧道的端点。
|
||||
不像之前的情况,现在隧道的端点是 1.1.1.1:10022(中继服务器的公网 IP 地址),而不是 127.0.0.1:10022。这就意味着从外部主机可以访问隧道的另一端。
|
||||
|
||||
现在在任何其它计算机(客户端计算机),输入以下命令访问网络地址变换之后的家庭服务器。
|
||||
|
||||
clientcomputer~$ ssh -p 10022 homeserver_user@1.1.1.1
|
||||
|
||||
在上面的命令中,1.1.1.1 是中继服务器的公共 IP 地址,家庭服务器用户必须是和家庭服务器相关联的用户账户。这是因为你真正登录到的主机是家庭服务器,而不是中继服务器。后者只是中继你的 SSH 流量到家庭服务器。
|
||||
在上面的命令中,1.1.1.1 是中继服务器的公共 IP 地址,homeserver_user必须是家庭服务器上的用户账户。这是因为你真正登录到的主机是家庭服务器,而不是中继服务器。后者只是中继你的 SSH 流量到家庭服务器。
|
||||
|
||||
### 在 Linux 上设置一个永久反向 SSH 隧道 ###
|
||||
|
||||
现在你已经明白了怎样创建一个反向 SSH 隧道,然后把隧道设置为 “永久”,这样隧道启动后就会一直运行(不管临时的网络拥塞、SSH 超时、中继主机重启,等等)。毕竟,如果隧道不是一直有效,你不可能可靠的登录到你的家庭服务器。
|
||||
现在你已经明白了怎样创建一个反向 SSH 隧道,然后把隧道设置为 “永久”,这样隧道启动后就会一直运行(不管临时的网络拥塞、SSH 超时、中继主机重启,等等)。毕竟,如果隧道不是一直有效,你就不能可靠的登录到你的家庭服务器。
|
||||
|
||||
对于永久隧道,我打算使用一个叫 autossh 的工具。正如名字暗示的,这个程序允许你不管任何理由自动重启 SSH 会话。因此对于保存一个反向 SSH 隧道有效非常有用。
|
||||
对于永久隧道,我打算使用一个叫 autossh 的工具。正如名字暗示的,这个程序可以让你的 SSH 会话无论因为什么原因中断都会自动重连。因此对于保持一个反向 SSH 隧道非常有用。
|
||||
|
||||
第一步,我们要设置从家庭服务器到中继服务器的[无密码 SSH 登录][2]。这样的话,autossh 可以不需要用户干预就能重启一个损坏的反向 SSH 隧道。
|
||||
|
||||
下一步,在初始化隧道的家庭服务器上[安装 autossh][3]。
|
||||
下一步,在建立隧道的家庭服务器上[安装 autossh][3]。
|
||||
|
||||
在家庭服务器上,用下面的参数运行 autossh 来创建一个连接到中继服务器的永久 SSH 隧道。
|
||||
|
||||
@ -113,7 +113,7 @@ SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇博文中,我介绍了你如何能从外部中通过反向 SSH 隧道访问限制性防火墙或 NAT 网关之后的 Linux 服务器。尽管我介绍了家庭网络中的一个使用事例,在企业网络中使用时你尤其要小心。这样的一个隧道可能被视为违反公司政策,因为它绕过了企业的防火墙并把企业网络暴露给外部攻击。这很可能被误用或者滥用。因此在使用之前一定要记住它的作用。
|
||||
在这篇博文中,我介绍了你如何能从外部通过反向 SSH 隧道访问限制性防火墙或 NAT 网关之后的 Linux 服务器。这里我介绍了家庭网络中的一个使用事例,但在企业网络中使用时你尤其要小心。这样的一个隧道可能被视为违反公司政策,因为它绕过了企业的防火墙并把企业网络暴露给外部攻击。这很可能被误用或者滥用。因此在使用之前一定要记住它的作用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -121,11 +121,11 @@ via: http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
[3]:http://ask.xmodulo.com/install-autossh-linux.html
|
||||
[2]:https://linux.cn/article-5444-1.html
|
||||
[3]:https://linux.cn/article-5459-1.html
|
||||
@ -1,53 +1,54 @@
|
||||
Autojump – 一个高级的‘cd’命令用以快速浏览 Linux 文件系统
|
||||
Autojump:一个可以在 Linux 文件系统快速导航的高级 cd 命令
|
||||
================================================================================
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行浏览有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行导航有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
现在,有一个用 Python 写的名为 `autojump` 的 Linux 命令行实用程序,它是 Linux ‘[cd][1]’命令的高级版本。
|
||||
|
||||

|
||||
|
||||
Autojump – 浏览 Linux 文件系统的最快方式
|
||||
*Autojump – Linux 文件系统导航的最快方式*
|
||||
|
||||
这个应用原本由 Joël Schaerer 编写,现在由 +William Ting 维护。
|
||||
|
||||
Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录浏览。与传统的 `cd` 命令相比,autojump 能够更加快速地浏览至目的目录。
|
||||
Autojump 应用可以从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录导航。与传统的 `cd` 命令相比,autojump 能够更加快速地导航至目的目录。
|
||||
|
||||
#### autojump 的特色 ####
|
||||
|
||||
- 免费且开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的浏览习惯中学习。
|
||||
- 更快速地浏览。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat and Fedora。
|
||||
- 自由开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的导航习惯中学习。
|
||||
- 更快速地导航。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat 和 Fedora。
|
||||
- 也能在其他平台中使用,例如 OS X(使用 Homebrew) 和 Windows (通过 Clink 来实现)
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以打开文件管理器来到达某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以用文件管理器打开某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
|
||||
#### 前提 ####
|
||||
|
||||
- 版本号不低于 2.6 的 Python
|
||||
|
||||
### 第 1 步: 做一次全局系统升级 ###
|
||||
### 第 1 步: 做一次完整的系统升级 ###
|
||||
|
||||
1. 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
1、 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [APT based systems]
|
||||
# yum update && yum upgrade [YUM based systems]
|
||||
# dnf update && dnf upgrade [DNF based systems]
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [基于 APT 的系统]
|
||||
# yum update && yum upgrade [基于 YUM 的系统]
|
||||
# dnf update && dnf upgrade [基于 DNF 的系统]
|
||||
|
||||
**注** : 这里特别提醒,在基于 YUM 或 DNF 的系统中,更新和升级执行相同的行动,大多数时间里它们是通用的,这点与基于 APT 的系统不同。
|
||||
|
||||
### 第 2 步: 下载和安装 Autojump ###
|
||||
|
||||
2. 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
2、 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
|
||||
#### 从源代码安装 ####
|
||||
|
||||
若没有安装 git,请安装它。我们需要使用它来克隆 git 仓库。
|
||||
|
||||
# apt-get install git [APT based systems]
|
||||
# yum install git [YUM based systems]
|
||||
# dnf install git [DNF based systems]
|
||||
# apt-get install git [基于 APT 的系统]
|
||||
# yum install git [基于 YUM 的系统]
|
||||
# dnf install git [基于 DNF 的系统]
|
||||
|
||||
一旦安装完 git,以常规用户身份登录,然后像下面那样来克隆 autojump:
|
||||
一旦安装完 git,以普通用户身份登录,然后像下面那样来克隆 autojump:
|
||||
|
||||
$ git clone git://github.com/joelthelion/autojump.git
|
||||
|
||||
@ -55,29 +56,29 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
$ cd autojump
|
||||
|
||||
下载,赋予脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
下载,赋予安装脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
|
||||
# chmod 755 install.py
|
||||
# ./install.py
|
||||
|
||||
#### 从软件仓库中安装 ####
|
||||
|
||||
3. 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
3、 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
|
||||
在 Debian, Ubuntu, Mint 及类似系统中安装 autojump :
|
||||
|
||||
# apt-get install autojump (注: 这里原文为 autojumo, 应该为 autojump)
|
||||
# apt-get install autojump
|
||||
|
||||
为了在 Fedora, CentOS, RedHat 及类似系统中安装 autojump, 你需要启用 [EPEL 软件仓库][2]。
|
||||
|
||||
# yum install epel-release
|
||||
# yum install autojump
|
||||
OR
|
||||
或
|
||||
# dnf install autojump
|
||||
|
||||
### 第 3 步: 安装后的配置 ###
|
||||
|
||||
4. 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
4、 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
|
||||
为了暂时激活 autojump 应用,即直到你关闭当前会话或打开一个新的会话之前让 autojump 均有效,你需要以常规用户身份运行下面的命令:
|
||||
|
||||
@ -89,7 +90,7 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
### 第 4 步: Autojump 的预测试和使用 ###
|
||||
|
||||
5. 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
5、 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
|
||||
$ cd
|
||||
$ cd
|
||||
@ -120,45 +121,45 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
现在,我们已经切换到过上面所列的目录,并为了测试创建了一些目录,一切准备就绪,让我们开始吧。
|
||||
|
||||
**需要记住的一点** : `j` 是 autojump 的一个包装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
**需要记住的一点** : `j` 是 autojump 的一个封装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
|
||||
6. 使用 -v 选项查看安装的 autojump 的版本。
|
||||
6、 使用 -v 选项查看安装的 autojump 的版本。
|
||||
|
||||
$ j -v
|
||||
or
|
||||
或
|
||||
$ autojump -v
|
||||
|
||||

|
||||
|
||||
查看 Autojump 的版本
|
||||
*查看 Autojump 的版本*
|
||||
|
||||
7. 跳到先前到过的目录 ‘/var/www‘。
|
||||
7、 跳到先前到过的目录 ‘/var/www‘。
|
||||
|
||||
$ j www
|
||||
|
||||
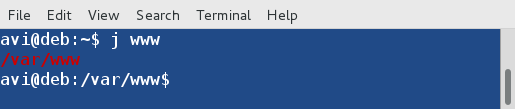
|
||||
|
||||
跳到目录
|
||||
*跳到目录*
|
||||
|
||||
8. 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
8、 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
|
||||
$ jc b
|
||||
|
||||

|
||||
|
||||
跳到子目录
|
||||
*跳到子目录*
|
||||
|
||||
9. 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
9、 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
|
||||
$ jo www
|
||||
|
||||
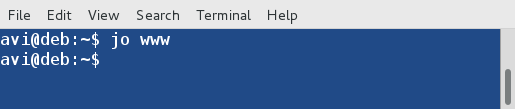
|
||||

|
||||
|
||||
跳到目录
|
||||
*打开目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开目录
|
||||
*在文件管理器中打开目录*
|
||||
|
||||
你也可以在一个文件管理器中打开一个子目录。
|
||||
|
||||
@ -166,19 +167,19 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||

|
||||
|
||||
打开子目录
|
||||
*打开子目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开子目录
|
||||
*在文件管理器中打开子目录*
|
||||
|
||||
10. 查看每个文件夹的关键权重和在所有目录权重中的总关键权重的相关统计数据。文件夹的关键权重代表在这个文件夹中所花的总时间。 目录权重是列表中目录的数目。(注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
10、 查看每个文件夹的权重和全部文件夹计算得出的总权重的统计数据。文件夹的权重代表在这个文件夹中所花的总时间。 文件夹权重是该列表中目录的数字。(LCTT 译注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
|
||||
$ j --stat
|
||||
|
||||

|
||||

|
||||
|
||||
查看目录统计数据
|
||||
*查看文件夹统计数据*
|
||||
|
||||
**提醒** : autojump 存储其运行日志和错误日志的地方是文件夹 `~/.local/share/autojump/`。千万不要重写这些文件,否则你将失去你所有的统计状态结果。
|
||||
|
||||
@ -186,15 +187,15 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
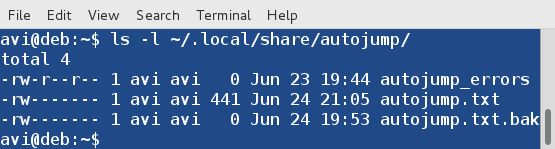
|
||||
|
||||
Autojump 的日志
|
||||
*Autojump 的日志*
|
||||
|
||||
11. 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
11、 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
|
||||
$ j --help
|
||||
|
||||

|
||||
|
||||
Autojump 的帮助和选项
|
||||
*Autojump 的帮助和选项*
|
||||
|
||||
### 功能需求和已知的冲突 ###
|
||||
|
||||
@ -204,18 +205,19 @@ Autojump 的帮助和选项
|
||||
|
||||
### 结论: ###
|
||||
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中浏览 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中导航 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
[3]:http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
@ -1,6 +1,6 @@
|
||||
如何在Ubuntu 14.04/15.04上配置Chef(服务端/客户端)
|
||||
如何在 Ubuntu 上安装配置管理系统 Chef (大厨)
|
||||
================================================================================
|
||||
Chef是对于信息技术专业人员的一款配置管理和自动化工具,它可以配置和管理你的设备无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,涉及到成百甚至上千的服务器和程序来支持大量的客户群。chef最有用的是让设备变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端设备或者终端用户。
|
||||
Chef是面对IT专业人员的一款配置管理和自动化工具,它可以配置和管理你的基础设施,无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,这涉及到可支持大量的客户群的成百上千的服务器和程序。chef最有用的是让基础设施变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端基础设施或者终端用户。
|
||||
|
||||
下面是我们将要在本篇中要设置和配置Chef的主要组件。
|
||||
|
||||
@ -10,34 +10,13 @@ Chef是对于信息技术专业人员的一款配置管理和自动化工具,
|
||||
|
||||
我们将在下面的基础环境下设置Chef配置管理系统。
|
||||
|
||||
注:表格
|
||||
<table width="701" style="height: 284px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="660" colspan="2"><strong>管理和配置工具:Chef</strong></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>基础操作系统</strong></td>
|
||||
<td width="492">Ubuntu 14.04.1 LTS (x86_64)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Server</strong></td>
|
||||
<td width="492">Version 12.1.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Manage</strong></td>
|
||||
<td width="492">Version 1.17.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Development Kit</strong></td>
|
||||
<td width="492">Version 0.6.2</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>内存和CPU</strong></td>
|
||||
<td width="492">4 GB , 2.0+2.0 GHZ</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|管理和配置工具:Chef||
|
||||
|-------------------------------|---|
|
||||
|基础操作系统|Ubuntu 14.04.1 LTS (x86_64)|
|
||||
|Chef Server|Version 12.1.0|
|
||||
|Chef Manage|Version 1.17.0|
|
||||
|Chef Development Kit|Version 0.6.2|
|
||||
|内存和CPU|4 GB , 2.0+2.0 GHz|
|
||||
|
||||
### Chef服务端的安装和配置 ###
|
||||
|
||||
@ -45,15 +24,15 @@ Chef服务端是核心组件,它存储配置以及其他和工作站交互的
|
||||
|
||||
我使用下面的命令来下载和安装它。
|
||||
|
||||
**1) 下载Chef服务端**
|
||||
####1) 下载Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**2) 安装Chef服务端**
|
||||
####2) 安装Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# dpkg -i chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**3) 重新配置Chef服务端**
|
||||
####3) 重新配置Chef服务端
|
||||
|
||||
现在运行下面的命令来启动所有的chef服务端服务,这步也许会花费一些时间,因为它有许多不同一起工作的服务组成来创建一个正常运作的系统。
|
||||
|
||||
@ -64,35 +43,35 @@ chef服务端启动命令'chef-server-ctl reconfigure'需要运行两次,这
|
||||
Chef Client finished, 342/350 resources updated in 113.71139964 seconds
|
||||
opscode Reconfigured!
|
||||
|
||||
**4) 重启系统 **
|
||||
####4) 重启系统
|
||||
|
||||
安装完成后重启系统使系统能最好的工作,不然我们或许会在创建用户的时候看到下面的SSL连接错误。
|
||||
|
||||
ERROR: Errno::ECONNRESET: Connection reset by peer - SSL_connect
|
||||
|
||||
**5) 创建心的管理员**
|
||||
####5) 创建新的管理员
|
||||
|
||||
运行下面的命令来创建一个新的用它自己的配置的管理员账户。创建过程中,用户的RSA私钥会自动生成并需要被保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
运行下面的命令来创建一个新的管理员账户及其配置。创建过程中,用户的RSA私钥会自动生成,它需要保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
|
||||
root@ubuntu-14-chef:/tmp# chef-server-ctl user-create kashi kashi kashi kashif.fareedi@gmail.com kashi123 --filename /root/kashi.pem
|
||||
|
||||
### Chef服务端的管理设置 ###
|
||||
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它启用了可视化的web用户界面并可以管理节点、数据包、规则、环境、配置和基于角色的访问控制(RBAC)
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它提供了可视化的web用户界面,可以管理节点、数据包、规则、环境、Cookbook 和基于角色的访问控制(RBAC)
|
||||
|
||||
**1) 下载Chef Manage**
|
||||
####1) 下载Chef Manage
|
||||
|
||||
从官网复制链接病下载chef manage的安装包。
|
||||
从官网复制链接并下载chef manage的安装包。
|
||||
|
||||
root@ubuntu-14-chef:~# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/opscode-manage_1.17.0-1_amd64.deb
|
||||
|
||||
**2) 安装Chef Manage**
|
||||
####2) 安装Chef Manage
|
||||
|
||||
使用下面的命令在root的家目录下安装它。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl install opscode-manage --path /root
|
||||
|
||||
**3) 重启Chef Manage和服务端**
|
||||
####3) 重启Chef Manage和服务端
|
||||
|
||||
安装完成后我们需要运行下面的命令来重启chef manage和服务端。
|
||||
|
||||
@ -101,28 +80,27 @@ Chef Manage是一个针对企业Chef用户的管理控制台,它启用了可
|
||||
|
||||
### Chef Manage网页控制台 ###
|
||||
|
||||
我们可以使用localhost访问网页控制台以及fqdn,并用已经创建的管理员登录
|
||||
我们可以使用localhost或它的全称域名来访问网页控制台,并用已经创建的管理员登录
|
||||
|
||||

|
||||
|
||||
**1) Chef Manage创建新的组织 **
|
||||
####1) Chef Manage创建新的组织
|
||||
|
||||
你或许被要求创建新的组织或者接受其他阻止的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
你或许被要求创建新的组织,或者也可以接受其他组织的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
|
||||

|
||||
|
||||
**2) 用命令行创建心的组织 **
|
||||
####2) 用命令行创建新的组织
|
||||
|
||||
We can also create new Organization from the command line by executing the following command.
|
||||
我们同样也可以运行下面的命令来创建新的组织。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create linux Linoxide Linux Org. --association_user kashi --filename linux.pem
|
||||
|
||||
### 设置工作站 ###
|
||||
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes、cookbooks、属性和其他任何的我们想要对Chef的修改。
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes([基础配置元素](https://docs.chef.io/recipes.html))、cookbooks([基础配置集](https://docs.chef.io/cookbooks.html))、attributes([节点属性](https://docs.chef.io/attributes.html))和其他任何的我们想要对Chef做的修改。
|
||||
|
||||
**1) 在Chef服务端上创建新的用户和组织 **
|
||||
####1) 在Chef服务端上创建新的用户和组织
|
||||
|
||||
为了设置工作站,我们用命令行创建一个新的用户和组织。
|
||||
|
||||
@ -130,25 +108,23 @@ We can also create new Organization from the command line by executing the follo
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create blogs Linoxide Blogs Inc. --association_user bloger --filename blogs.pem
|
||||
|
||||
**2) 下载工作站入门套件 **
|
||||
####2) 下载工作站入门套件
|
||||
|
||||
Now Download and Save starter-kit from the chef manage web console on a workstation and use it to work with Chef server.
|
||||
在工作站的网页控制台中下面并保存入门套件用于与服务端协同工作
|
||||
在工作站的网页控制台中下载保存入门套件,它用于与服务端协同工作
|
||||
|
||||

|
||||
|
||||
**3) 点击"Proceed"下载套件 **
|
||||
####3) 下载套件后,点击"Proceed"
|
||||
|
||||

|
||||
|
||||
### 对于工作站的Chef开发套件设置 ###
|
||||
### 用于工作站的Chef开发套件设置 ###
|
||||
|
||||
Chef开发套件是一款包含所有开发chef所需工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
Chef开发套件是一款包含开发chef所需的所有工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
|
||||
**1) 下载 Chef DK**
|
||||
####1) 下载 Chef DK
|
||||
|
||||
We can Download chef development kit from its official web link and choose the required operating system to get its chef development tool kit.
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来得到chef开发包。
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来下载chef开发包。
|
||||
|
||||

|
||||
|
||||
@ -156,13 +132,13 @@ We can Download chef development kit from its official web link and choose the r
|
||||
|
||||
root@ubuntu-15-WKS:~# wget https://opscode-omnibus-packages.s3.amazonaws.com/ubuntu/12.04/x86_64/chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**1) Chef开发套件安装**
|
||||
####2) Chef开发套件安装
|
||||
|
||||
使用dpkg命令安装开发套件
|
||||
|
||||
root@ubuntu-15-WKS:~# dpkg -i chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**3) Chef DK 验证**
|
||||
####3) Chef DK 验证
|
||||
|
||||
使用下面的命令验证客户端是否已经正确安装。
|
||||
|
||||
@ -195,7 +171,7 @@ We can Download chef development kit from its official web link and choose the r
|
||||
Verification of component 'chefspec' succeeded.
|
||||
Verification of component 'package installation' succeeded.
|
||||
|
||||
**连接Chef服务端**
|
||||
####4) 连接Chef服务端
|
||||
|
||||
我们将创建 ~/.chef并从chef服务端复制两个用户和组织的pem文件到chef的文件到这个目录下。
|
||||
|
||||
@ -209,7 +185,7 @@ We can Download chef development kit from its official web link and choose the r
|
||||
kashi.pem 100% 1678 1.6KB/s 00:00
|
||||
linux.pem 100% 1678 1.6KB/s 00:00
|
||||
|
||||
** 编辑配置来管理chef环境 **
|
||||
####5) 编辑配置来管理chef环境
|
||||
|
||||
现在使用下面的内容创建"~/.chef/knife.rb"。
|
||||
|
||||
@ -231,13 +207,13 @@ We can Download chef development kit from its official web link and choose the r
|
||||
|
||||
root@ubuntu-15-WKS:/# mkdir cookbooks
|
||||
|
||||
**测试Knife配置**
|
||||
####6) 测试Knife配置
|
||||
|
||||
运行“knife user list”和“knife client list”来验证knife是否在工作。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife user list
|
||||
|
||||
第一次运行的时候可能会得到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
第一次运行的时候可能会看到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
|
||||
ERROR: SSL Validation failure connecting to host: 172.25.10.173 - SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed
|
||||
ERROR: Could not establish a secure connection to the server.
|
||||
@ -245,24 +221,24 @@ We can Download chef development kit from its official web link and choose the r
|
||||
If your Chef Server uses a self-signed certificate, you can use
|
||||
`knife ssl fetch` to make knife trust the server's certificates.
|
||||
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl整数并重新运行knife user和client list,这时候应该就可以了。
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl证书,并重新运行knife user和client list,这时候应该就可以了。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife ssl fetch
|
||||
WARNING: Certificates from 172.25.10.173 will be fetched and placed in your trusted_cert
|
||||
directory (/.chef/trusted_certs).
|
||||
|
||||
knife没有办法验证这些是有效的证书。你应该在下载时候验证这些证书的真实性。
|
||||
knife没有办法验证这些是有效的证书。你应该在下载时候验证这些证书的真实性。
|
||||
|
||||
在/.chef/trusted_certs/ubuntu-14-chef_test_com.crt下面添加ubuntu-14-chef.test.com的证书。
|
||||
在/.chef/trusted_certs/ubuntu-14-chef_test_com.crt下面添加ubuntu-14-chef.test.com的证书。
|
||||
|
||||
在上面的命令取得ssl证书后,接着运行下面的命令。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef#knife client list
|
||||
kashi-linux
|
||||
|
||||
### 与chef服务端交互的新的节点 ###
|
||||
### 配置与chef服务端交互的新节点 ###
|
||||
|
||||
节点是执行所有设备自动化的chef客户端。因此是时侯添加新的服务端到我们的chef环境下,在配置完chef-server和knife工作站后配置新的节点与chef-server交互。
|
||||
节点是执行所有基础设施自动化的chef客户端。因此,在配置完chef-server和knife工作站后,通过配置新的与chef-server交互的节点,来添加新的服务端到我们的chef环境下。
|
||||
|
||||
我们使用下面的命令来添加新的节点与chef服务端工作。
|
||||
|
||||
@ -291,16 +267,16 @@ We can Download chef development kit from its official web link and choose the r
|
||||
172.25.10.170 to file /tmp/install.sh.26024/metadata.txt
|
||||
172.25.10.170 trying wget...
|
||||
|
||||
之后我们可以在knife节点列表下看到新创建的节点,也会新节点列表下创建新的客户端。
|
||||
之后我们可以在knife节点列表下看到新创建的节点,它也会在新节点创建新的客户端。
|
||||
|
||||
root@ubuntu-15-WKS:~# knife node list
|
||||
mydns
|
||||
|
||||
相似地我们只要提供ssh证书通过上面的knife命令来创建多个节点到chef设备上。
|
||||
相似地我们只要提供ssh证书通过上面的knife命令,就可以在chef设施上创建多个节点。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置浏览了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置基本了解了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -308,7 +284,7 @@ via: http://linoxide.com/ubuntu-how-to/install-configure-chef-ubuntu-14-04-15-04
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
178
published/20150717 How to collect NGINX metrics - Part 2.md
Normal file
178
published/20150717 How to collect NGINX metrics - Part 2.md
Normal file
@ -0,0 +1,178 @@
|
||||
|
||||
如何收集 NGINX 指标(第二篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### 如何获取你所需要的 NGINX 指标 ###
|
||||
|
||||
如何获取需要的指标取决于你正在使用的 NGINX 版本以及你希望看到哪些指标。(参见 [如何监控 NGINX(第一篇)][1] 来深入了解NGINX指标。)自由开源的 NGINX 和商业版的 NGINX Plus 都有可以报告指标度量的状态模块,NGINX 也可以在其日志中配置输出特定指标:
|
||||
|
||||
**指标可用性**
|
||||
|
||||
| 指标 | [NGINX (开源)](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source) | [NGINX Plus](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus) | [NGINX 日志](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#logs)|
|
||||
|-----|------|-------|-----|
|
||||
|accepts(接受) / accepted(已接受)|x|x| |
|
||||
|handled(已处理)|x|x| |
|
||||
|dropped(已丢弃)|x|x| |
|
||||
|active(活跃)|x|x| |
|
||||
|requests (请求数)/ total(全部请求数)|x|x| |
|
||||
|4xx 代码||x|x|
|
||||
|5xx 代码||x|x|
|
||||
|request time(请求处理时间)|||x|
|
||||
|
||||
#### 指标收集:NGINX(开源版) ####
|
||||
|
||||
开源版的 NGINX 会在一个简单的状态页面上显示几个与服务器状态有关的基本指标,它们由你启用的 HTTP [stub status module][2] 所提供。要检查该模块是否已启用,运行以下命令:
|
||||
|
||||
nginx -V 2>&1 | grep -o with-http_stub_status_module
|
||||
|
||||
如果你看到终端输出了 **http_stub_status_module**,说明该状态模块已启用。
|
||||
|
||||
如果该命令没有输出,你需要启用该状态模块。你可以在[从源代码构建 NGINX ][3]时使用 `--with-http_stub_status_module` 配置参数:
|
||||
|
||||
./configure \
|
||||
… \
|
||||
--with-http_stub_status_module
|
||||
make
|
||||
sudo make install
|
||||
|
||||
在验证该模块已经启用或你自己启用它后,你还需要修改 NGINX 配置文件,来给状态页面设置一个本地可访问的 URL(例如: /nginx_status):
|
||||
|
||||
server {
|
||||
location /nginx_status {
|
||||
stub_status on;
|
||||
|
||||
access_log off;
|
||||
allow 127.0.0.1;
|
||||
deny all;
|
||||
}
|
||||
}
|
||||
|
||||
注:nginx 配置中的 server 块通常并不放在主配置文件中(例如:/etc/nginx/nginx.conf),而是放在主配置会加载的辅助配置文件中。要找到主配置文件,首先运行以下命令:
|
||||
|
||||
nginx -t
|
||||
|
||||
打开列出的主配置文件,在以 http 块结尾的附近查找以 include 开头的行,如:
|
||||
|
||||
include /etc/nginx/conf.d/*.conf;
|
||||
|
||||
在其中一个包含的配置文件中,你应该会找到主 **server** 块,你可以如上所示配置 NGINX 的指标输出。更改任何配置后,通过执行以下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
现在,你可以浏览状态页看到你的指标:
|
||||
|
||||
Active connections: 24
|
||||
server accepts handled requests
|
||||
1156958 1156958 4491319
|
||||
Reading: 0 Writing: 18 Waiting : 6
|
||||
|
||||
请注意,如果你希望从远程计算机访问该状态页面,则需要将远程计算机的 IP 地址添加到你的状态配置文件的白名单中,在上面的配置文件中的白名单仅有 127.0.0.1。
|
||||
|
||||
NGINX 的状态页面是一种快速查看指标状况的简单方法,但当连续监测时,你需要按照标准间隔自动记录该数据。监控工具箱 [Nagios][4] 或者 [Datadog][5],以及收集统计信息的服务 [collectD][6] 已经可以解析 NGINX 的状态信息了。
|
||||
|
||||
#### 指标收集: NGINX Plus ####
|
||||
|
||||
商业版的 NGINX Plus 通过它的 ngx_http_status_module 提供了比开源版 NGINX [更多的指标][7]。NGINX Plus 以字节流的方式提供这些额外的指标,提供了关于上游系统和高速缓存的信息。NGINX Plus 也会报告所有的 HTTP 状态码类型(1XX,2XX,3XX,4XX,5XX)的计数。一个 NGINX Plus 状态报告例子[可在此查看][8]:
|
||||
|
||||

|
||||
|
||||
注:NGINX Plus 在状态仪表盘中的“Active”连接的定义和开源 NGINX 通过 stub_status_module 收集的“Active”连接指标略有不同。在 NGINX Plus 指标中,“Active”连接不包括Waiting状态的连接(即“Idle”连接)。
|
||||
|
||||
NGINX Plus 也可以输出 [JSON 格式的指标][9],可以用于集成到其他监控系统。在 NGINX Plus 中,你可以看到 [给定的上游服务器组][10]的指标和健康状况,或者简单地从上游服务器的[单个服务器][11]得到响应代码的计数:
|
||||
|
||||
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
|
||||
|
||||
要启动 NGINX Plus 指标仪表盘,你可以在 NGINX 配置文件的 http 块内添加状态 server 块。 (参见上一节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。)例如,要设置一个状态仪表盘 (http://your.ip.address:8080/status.html)和一个 JSON 接口(http://your.ip.address:8080/status),可以添加以下 server 块来设定:
|
||||
|
||||
server {
|
||||
listen 8080;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
location /status {
|
||||
status;
|
||||
}
|
||||
|
||||
location = /status.html {
|
||||
}
|
||||
}
|
||||
|
||||
当你重新加载 NGINX 配置后,状态页就可以用了:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
关于如何配置扩展状态模块,官方 NGINX Plus 文档有 [详细介绍][13] 。
|
||||
|
||||
#### 指标收集:NGINX 日志 ####
|
||||
|
||||
NGINX 的 [日志模块][14] 会把可自定义的访问日志写到你配置的指定位置。你可以通过[添加或移除变量][15]来自定义日志的格式和包含的数据。要存储详细的日志,最简单的方法是添加下面一行在你配置文件的 server 块中(参见上上节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。):
|
||||
|
||||
access_log logs/host.access.log combined;
|
||||
|
||||
更改 NGINX 配置文件后,执行如下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
默认包含的 “combined” 的日志格式,会包括[一系列关键的数据][17],如实际的 HTTP 请求和相应的响应代码。在下面的示例日志中,NGINX 记录了请求 /index.html 时的 200(成功)状态码和访问不存在的请求文件 /fail 的 404(未找到)错误。
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以通过在 NGINX 配置文件中的 http 块添加一个新的日志格式来记录请求处理时间:
|
||||
|
||||
log_format nginx '$remote_addr - $remote_user [$time_local] '
|
||||
'"$request" $status $body_bytes_sent $request_time '
|
||||
'"$http_referer" "$http_user_agent"';
|
||||
|
||||
并修改配置文件中 **server** 块的 access_log 行:
|
||||
|
||||
access_log logs/host.access.log nginx;
|
||||
|
||||
重新加载配置文件后(运行 `nginx -s reload`),你的访问日志将包括响应时间,如下所示。单位为秒,精度到毫秒。在这个例子中,服务器接收到一个对 /big.pdf 的请求时,发送 33973115 字节后返回 206(成功)状态码。处理请求用时 0.202 秒(202毫秒):
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以使用各种工具和服务来解析和分析 NGINX 日志。例如,[rsyslog][18] 可以监视你的日志,并将其传递给多个日志分析服务;你也可以使用自由开源工具,比如 [logstash][19] 来收集和分析日志;或者你可以使用一个统一日志记录层,如 [Fluentd][20] 来收集和解析你的 NGINX 日志。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
监视 NGINX 的哪一项指标将取决于你可用的工具,以及监控指标所提供的信息是否满足你们的需要。举例来说,错误率的收集是否足够重要到需要你们购买 NGINX Plus ,还是架设一个可以捕获和分析日志的系统就够了?
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。[在本文中][21]了解如何用 NGINX Datadog 来监控 ,并开始 [Datadog 的免费试用][22]吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
|
||||
[3]:http://wiki.nginx.org/InstallOptions
|
||||
[4]:https://exchange.nagios.org/directory/Plugins/Web-Servers/nginx
|
||||
[5]:http://docs.datadoghq.com/integrations/nginx/
|
||||
[6]:https://collectd.org/wiki/index.php/Plugin:nginx
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_status_module.html#data
|
||||
[8]:http://demo.nginx.com/status.html
|
||||
[9]:http://demo.nginx.com/status
|
||||
[10]:http://demo.nginx.com/status/upstreams/demoupstreams
|
||||
[11]:http://demo.nginx.com/status/upstreams/demoupstreams/0/responses
|
||||
[12]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[13]:http://nginx.org/en/docs/http/ngx_http_status_module.html#example
|
||||
[14]:http://nginx.org/en/docs/http/ngx_http_log_module.html
|
||||
[15]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[17]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[18]:http://www.rsyslog.com/
|
||||
[19]:https://www.elastic.co/products/logstash
|
||||
[20]:http://www.fluentd.org/
|
||||
[21]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[22]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#sign-up
|
||||
[23]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_collect_nginx_metrics.md
|
||||
[24]:https://github.com/DataDog/the-monitor/issues
|
||||
231
published/20150717 How to monitor NGINX- Part 1.md
Normal file
231
published/20150717 How to monitor NGINX- Part 1.md
Normal file
@ -0,0 +1,231 @@
|
||||
如何监控 NGINX(第一篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### NGINX 是什么? ###
|
||||
|
||||
[NGINX][1] (发音为 “engine X”) 是一种流行的 HTTP 和反向代理服务器。作为一个 HTTP 服务器,NGINX 可以使用较少的内存非常高效可靠地提供静态内容。作为[反向代理][2],它可以用作多个后端服务器或类似缓存和负载平衡这样的其它应用的单一访问控制点。NGINX 是一个自由开源的产品,并有一个具备更全的功能的叫做 NGINX Plus 的商业版。
|
||||
|
||||
NGINX 也可以用作邮件代理和通用的 TCP 代理,但本文并不直接讨论 NGINX 的那些用例的监控。
|
||||
|
||||
### NGINX 主要指标 ###
|
||||
|
||||
通过监控 NGINX 可以 捕获到两类问题:NGINX 本身的资源问题,和出现在你的基础网络设施的其它问题。大多数 NGINX 用户会用到以下指标的监控,包括**每秒请求数**,它提供了一个由所有最终用户活动组成的上层视图;**服务器错误率** ,这表明你的服务器已经多长没有处理看似有效的请求;还有**请求处理时间**,这说明你的服务器处理客户端请求的总共时长(并且可以看出性能降低或当前环境的其他问题)。
|
||||
|
||||
更一般地,至少有三个主要的指标类别来监视:
|
||||
|
||||
- 基本活动指标
|
||||
- 错误指标
|
||||
- 性能指标
|
||||
|
||||
下面我们将分析在每个类别中最重要的 NGINX 指标,以及用一个相当普遍但是值得特别提到的案例来说明:使用 NGINX Plus 作反向代理。我们还将介绍如何使用图形工具或可选择的监控工具来监控所有的指标。
|
||||
|
||||
本文引用指标术语[来自我们的“监控 101 系列”][3],,它提供了一个指标收集和警告框架。
|
||||
|
||||
#### 基本活跃指标 ####
|
||||
|
||||
无论你在怎样的情况下使用 NGINX,毫无疑问你要监视服务器接收多少客户端请求和如何处理这些请求。
|
||||
|
||||
NGINX Plus 上像开源 NGINX 一样可以报告基本活跃指标,但它也提供了略有不同的辅助模块。我们首先讨论开源的 NGINX,再来说明 NGINX Plus 提供的其他指标的功能。
|
||||
|
||||
**NGINX**
|
||||
|
||||
下图显示了一个客户端连接的过程,以及开源版本的 NGINX 如何在连接过程中收集指标。
|
||||
|
||||

|
||||
|
||||
Accepts(接受)、Handled(已处理)、Requests(请求)是一直在增加的计数器。Active(活跃)、Waiting(等待)、Reading(读)、Writing(写)随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepts | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Handled | 成功的客户端连接数 | 资源: 功能 |
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Dropped(已丢弃,计算得出)| 丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Requests | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
NGINX worker 进程接受 OS 的连接请求时 **Accepts** 计数器增加,而**Handled** 是当实际的请求得到连接时(通过建立一个新的连接或重新使用一个空闲的)。这两个计数器的值通常都是相同的,如果它们有差别则表明连接被**Dropped**,往往这是由于资源限制,比如已经达到 NGINX 的[worker_connections][4]的限制。
|
||||
|
||||
一旦 NGINX 成功处理一个连接时,连接会移动到**Active**状态,在这里对客户端请求进行处理:
|
||||
|
||||
Active状态
|
||||
|
||||
- **Waiting**: 活跃的连接也可以处于 Waiting 子状态,如果有在此刻没有活跃请求的话。新连接可以绕过这个状态并直接变为到 Reading 状态,最常见的是在使用“accept filter(接受过滤器)” 和 “deferred accept(延迟接受)”时,在这种情况下,NGINX 不会接收 worker 进程的通知,直到它具有足够的数据才开始响应。如果连接设置为 keep-alive ,那么它在发送响应后将处于等待状态。
|
||||
|
||||
- **Reading**: 当接收到请求时,连接离开 Waiting 状态,并且该请求本身使 Reading 状态计数增加。在这种状态下 NGINX 会读取客户端请求首部。请求首部是比较小的,因此这通常是一个快速的操作。
|
||||
|
||||
- **Writing**: 请求被读取之后,其使 Writing 状态计数增加,并保持在该状态,直到响应返回给客户端。这意味着,该请求在 Writing 状态时, 一方面 NGINX 等待来自上游系统的结果(系统放在 NGINX “后面”),另外一方面,NGINX 也在同时响应。请求往往会在 Writing 状态花费大量的时间。
|
||||
|
||||
通常,一个连接在同一时间只接受一个请求。在这种情况下,Active 连接的数目 == Waiting 的连接 + Reading 请求 + Writing 。然而,较新的 SPDY 和 HTTP/2 协议允许多个并发请求/响应复用一个连接,所以 Active 可小于 Waiting 的连接、 Reading 请求、Writing 请求的总和。 (在撰写本文时,NGINX 不支持 HTTP/2,但预计到2015年期间将会支持。)
|
||||
|
||||
**NGINX Plus**
|
||||
|
||||
正如上面提到的,所有开源 NGINX 的指标在 NGINX Plus 中是可用的,但另外也提供其他的指标。本节仅说明了 NGINX Plus 可用的指标。
|
||||
|
||||
|
||||

|
||||
|
||||
Accepted (已接受)、Dropped,总数是不断增加的计数器。Active、 Idle(空闲)和处于 Current(当前)处理阶段的各种状态下的连接或请求的当前数量随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepted | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Dropped |丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Idle | 没有当前请求的客户端连接| 资源: 功能 |
|
||||
| Total(全部) | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
当 NGINX Plus worker 进程接受 OS 的连接请求时 **Accepted** 计数器递增。如果 worker 进程为请求建立连接失败(通过建立一个新的连接或重新使用一个空闲),则该连接被丢弃, **Dropped** 计数增加。通常连接被丢弃是因为资源限制,如 NGINX Plus 的[worker_connections][4]的限制已经达到。
|
||||
|
||||
**Active** 和 **Idle** 和[如上所述][5]的开源 NGINX 的“active” 和 “waiting”状态是相同的,但是有一点关键的不同:在开源 NGINX 上,“waiting”状态包括在“active”中,而在 NGINX Plus 上“idle”的连接被排除在“active” 计数外。**Current** 和开源 NGINX 是一样的也是由“reading + writing” 状态组成。
|
||||
|
||||
**Total** 为客户端请求的累积计数。请注意,单个客户端连接可涉及多个请求,所以这个数字可能会比连接的累计次数明显大。事实上,(total / accepted)是每个连接的平均请求数量。
|
||||
|
||||
**开源 和 Plus 之间指标的不同**
|
||||
|
||||
|NGINX (开源) |NGINX Plus|
|
||||
|-----------------------|----------------|
|
||||
| accepts | accepted |
|
||||
| dropped 通过计算得来| dropped 直接得到 |
|
||||
| reading + writing| current|
|
||||
| waiting| idle|
|
||||
| active (包括 “waiting”状态) | active (排除 “idle” 状态)|
|
||||
| requests| total|
|
||||
|
||||
**提醒指标: 丢弃连接**
|
||||
|
||||
被丢弃的连接数目等于 Accepts 和 Handled 之差(NGINX 中),或是可直接得到标准指标(NGINX Plus 中)。在正常情况下,丢弃连接数应该是零。如果在每个单位时间内丢弃连接的速度开始上升,那么应该看看是否资源饱和了。
|
||||
|
||||

|
||||
|
||||
**提醒指标: 每秒请求数**
|
||||
|
||||
按固定时间间隔采样你的请求数据(开源 NGINX 的**requests**或者 NGINX Plus 中**total**) 会提供给你单位时间内(通常是分钟或秒)所接受的请求数量。监测这个指标可以查看进入的 Web 流量尖峰,无论是合法的还是恶意的,或者突然的下降,这通常都代表着出现了问题。每秒请求数若发生急剧变化可以提醒你的环境出现问题了,即使它不能告诉你确切问题的位置所在。请注意,所有的请求都同样计数,无论 URL 是什么。
|
||||
|
||||

|
||||
|
||||
**收集活跃指标**
|
||||
|
||||
开源的 NGINX 提供了一个简单状态页面来显示基本的服务器指标。该状态信息以标准格式显示,实际上任何图形或监控工具可以被配置去解析这些相关数据,以用于分析、可视化、或提醒。NGINX Plus 提供一个 JSON 接口来供给更多的数据。阅读相关文章“[NGINX 指标收集][6]”来启用指标收集的功能。
|
||||
|
||||
#### 错误指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 4xx 代码 | 客户端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
| 5xx 代码| 服务器端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
|
||||
NGINX 错误指标告诉你服务器是否经常返回错误而不是正常工作。客户端错误返回4XX状态码,服务器端错误返回5XX状态码。
|
||||
|
||||
**提醒指标: 服务器错误率**
|
||||
|
||||
服务器错误率等于在单位时间(通常为一到五分钟)内5xx错误状态代码的总数除以[状态码][7](1XX,2XX,3XX,4XX,5XX)的总数。如果你的错误率随着时间的推移开始攀升,调查可能的原因。如果突然增加,可能需要采取紧急行动,因为客户端可能收到错误信息。
|
||||
|
||||

|
||||
|
||||
关于客户端错误的注意事项:虽然监控4XX是很有用的,但从该指标中你仅可以捕捉有限的信息,因为它只是衡量客户的行为而不捕捉任何特殊的 URL。换句话说,4xx出现的变化可能是一个信号,例如网络扫描器正在寻找你的网站漏洞时。
|
||||
|
||||
**收集错误度量**
|
||||
|
||||
虽然开源 NGINX 不能马上得到用于监测的错误率,但至少有两种方法可以得到:
|
||||
|
||||
- 使用商业支持的 NGINX Plus 提供的扩展状态模块
|
||||
- 配置 NGINX 的日志模块将响应码写入访问日志
|
||||
|
||||
关于这两种方法,请阅读相关文章“[NGINX 指标收集][6]”。
|
||||
|
||||
#### 性能指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| request time (请求处理时间)| 处理每个请求的时间,单位为秒 | 工作:性能 | NGINX 日志|
|
||||
|
||||
**提醒指标: 请求处理时间**
|
||||
|
||||
请求处理时间指标记录了 NGINX 处理每个请求的时间,从读到客户端的第一个请求字节到完成请求。较长的响应时间说明问题在上游。
|
||||
|
||||
**收集处理时间指标**
|
||||
|
||||
NGINX 和 NGINX Plus 用户可以通过添加 $request_time 变量到访问日志格式中来捕捉处理时间数据。关于配置日志监控的更多细节在[NGINX指标收集][6]。
|
||||
|
||||
#### 反向代理指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 上游服务器的活跃链接 | 当前活跃的客户端连接 | 资源:功能 | NGINX Plus |
|
||||
| 上游服务器的 5xx 错误代码| 服务器错误 | 工作:错误 | NGINX Plus |
|
||||
| 每个上游组的可用服务器 | 服务器传递健康检查 | 资源:可用性| NGINX Plus
|
||||
|
||||
[反向代理][9]是 NGINX 最常见的使用方法之一。商业支持的 NGINX Plus 显示了大量有关后端(或“上游 upstream”)的服务器指标,这些与反向代理设置相关的。本节重点介绍了几个 NGINX Plus 用户可用的关键上游指标。
|
||||
|
||||
NGINX Plus 首先将它的上游指标按组分开,然后是针对单个服务器的。因此,例如,你的反向代理将请求分配到五个上游的 Web 服务器上,你可以一眼看出是否有单个服务器压力过大,也可以看出上游组中服务器的健康状况,以确保良好的响应时间。
|
||||
|
||||
**活跃指标**
|
||||
|
||||
**每上游服务器的活跃连接**的数量可以帮助你确认反向代理是否正确的分配工作到你的整个服务器组上。如果你正在使用 NGINX 作为负载均衡器,任何一台服务器处理的连接数的明显偏差都可能表明服务器正在努力消化请求,或者是你配置使用的负载均衡的方法(例如[round-robin 或 IP hashing][10])不是最适合你流量模式的。
|
||||
|
||||
**错误指标**
|
||||
|
||||
错误指标,上面所说的高于5XX(服务器错误)状态码,是监控指标中有价值的一个,尤其是响应码部分。 NGINX Plus 允许你轻松地提取**每个上游服务器的 5xx 错误代码**的数量,以及响应的总数量,以此来确定某个特定服务器的错误率。
|
||||
|
||||
**可用性指标**
|
||||
|
||||
对于 web 服务器的运行状况,还有另一种角度,NGINX 可以通过**每个组中当前可用服务器的总量**很方便监控你的上游组的健康。在一个大的反向代理上,你可能不会非常关心其中一个服务器的当前状态,就像你只要有可用的服务器组能够处理当前的负载就行了。但监视上游组内的所有工作的服务器总量可为判断 Web 服务器的健康状况提供一个更高层面的视角。
|
||||
|
||||
**收集上游指标**
|
||||
|
||||
NGINX Plus 上游指标显示在内部 NGINX Plus 的监控仪表盘上,并且也可通过一个JSON 接口来服务于各种外部监控平台。在我们的相关文章“[NGINX指标收集][6]”中有个例子。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经谈到了一些有用的指标,你可以使用表格来监控 NGINX 服务器。如果你是刚开始使用 NGINX,监控下面提供的大部分或全部指标,可以让你很好的了解你的网络基础设施的健康和活跃程度:
|
||||
|
||||
- [已丢弃的连接][12]
|
||||
- [每秒请求数][13]
|
||||
- [服务器错误率][14]
|
||||
- [请求处理数据][15]
|
||||
|
||||
最终,你会学到更多,更专业的衡量指标,尤其是关于你自己基础设施和使用情况的。当然,监控哪一项指标将取决于你可用的工具。参见相关的文章来[逐步指导你的指标收集][6],不管你使用 NGINX 还是 NGINX Plus。
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最少的设置来收集和监控所有 Web 服务器的指标。 [在本文中][17]了解如何用 NGINX Datadog来监控,并开始[免费试用 Datadog][18]吧。
|
||||
|
||||
### 诚谢 ###
|
||||
|
||||
在文章发表之前非常感谢 NGINX 团队审阅这篇,并提供重要的反馈和说明。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nginx.org/en/
|
||||
[2]:http://nginx.com/resources/glossary/reverse-proxy-server/
|
||||
[3]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
|
||||
[4]:http://nginx.org/en/docs/ngx_core_module.html#worker_connections
|
||||
[5]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#active-state
|
||||
[6]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[7]:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
[8]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[9]:https://en.wikipedia.org/wiki/Reverse_proxy
|
||||
[10]:http://nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[11]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[12]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#dropped-connections
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#requests-per-second
|
||||
[14]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#server-error-rate
|
||||
[15]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#request-processing-time
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[18]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#sign-up
|
||||
[19]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx.md
|
||||
[20]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -5,10 +5,12 @@
|
||||
我试着在Ubuntu中安装Emerald图标主题,而这个主题被打包成了.7z归档包。和以往一样,我试着通过在GUI中右击并选择“提取到这里”来将它解压缩。但是Ubuntu 15.04却并没有解压文件,取而代之的,却是丢给了我一个下面这样的错误信息:
|
||||
|
||||
> Could not open this file
|
||||
>
|
||||
> 无法打开该文件
|
||||
>
|
||||
> There is no command installed for 7-zip archive files. Do you want to search for a command to open this file?
|
||||
> 没有安装用于7-zip归档文件的命令。你是否想要搜索命令来打开该文件?
|
||||
>
|
||||
> 没有安装用于7-zip归档文件的命令。你是否想要搜索用于来打开该文件的命令?
|
||||
|
||||
错误信息看上去是这样的:
|
||||
|
||||
@ -42,7 +44,7 @@ via: http://itsfoss.com/fix-there-is-no-command-installed-for-7-zip-archive-file
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,16 @@
|
||||
在Linux中利用"Explain Shell"脚本更容易地理解Shell命令
|
||||
轻松使用“Explain Shell”脚本来理解 Shell 命令
|
||||
================================================================================
|
||||
在某些时刻, 当我们在Linux平台上工作时我们所有人都需要shell命令的帮助信息。 尽管内置的帮助像man pages、whatis命令是有帮助的, 但man pages的输出非常冗长, 除非是个有linux经验的人,不然从大量的man pages中获取帮助信息是非常困难的,而whatis命令的输出很少超过一行, 这对初学者来说是不够的。
|
||||
我们在Linux上工作时,每个人都会遇到需要查找shell命令的帮助信息的时候。 尽管内置的帮助像man pages、whatis命令有所助益, 但man pages的输出非常冗长, 除非是个有linux经验的人,不然从大量的man pages中获取帮助信息是非常困难的,而whatis命令的输出很少超过一行, 这对初学者来说是不够的。
|
||||
|
||||

|
||||
|
||||
在Linux Shell中解释Shell命令
|
||||
*在Linux Shell中解释Shell命令*
|
||||
|
||||
有一些第三方应用程序, 像我们在[Commandline Cheat Sheet for Linux Users][1]提及过的'cheat'命令。Cheat是个杰出的应用程序,即使计算机没有联网也能提供shell命令的帮助, 但是它仅限于预先定义好的命令。
|
||||
有一些第三方应用程序, 像我们在[Linux 用户的命令行速查表][1]提及过的'cheat'命令。cheat是个优秀的应用程序,即使计算机没有联网也能提供shell命令的帮助, 但是它仅限于预先定义好的命令。
|
||||
|
||||
Jackson写了一小段代码,它能非常有效地在bash shell里面解释shell命令,可能最美之处就是你不需要安装第三方包了。他把包含这段代码的的文件命名为”explain.sh“。
|
||||
Jackson写了一小段代码,它能非常有效地在bash shell里面解释shell命令,可能最美之处就是你不需要安装第三方包了。他把包含这段代码的的文件命名为“explain.sh”。
|
||||
|
||||
#### Explain工具的特性 ####
|
||||
#### explain.sh工具的特性 ####
|
||||
|
||||
- 易嵌入代码。
|
||||
- 不需要安装第三方工具。
|
||||
@ -18,22 +18,22 @@ Jackson写了一小段代码,它能非常有效地在bash shell里面解释she
|
||||
- 需要网络连接才能工作。
|
||||
- 纯命令行工具。
|
||||
- 可以解释bash shell里面的大部分shell命令。
|
||||
- 无需root账户参与。
|
||||
- 无需使用root账户。
|
||||
|
||||
**先决条件**
|
||||
|
||||
唯一的条件就是'curl'包了。 在如今大多数Linux发行版里面已经预安装了culr包, 如果没有你可以按照下面的命令来安装。
|
||||
唯一的条件就是'curl'包了。 在如今大多数Linux发行版里面已经预安装了curl包, 如果没有你可以按照下面的命令来安装。
|
||||
|
||||
# apt-get install curl [On Debian systems]
|
||||
# yum install curl [On CentOS systems]
|
||||
|
||||
### 在Linux上安装explain.sh工具 ###
|
||||
|
||||
我们要将下面这段代码插入'~/.bashrc'文件(LCTT注: 若没有该文件可以自己新建一个)中。我们必须为每个用户以及对应的'.bashrc'文件插入这段代码,笔者建议你不要加在root用户下。
|
||||
我们要将下面这段代码插入'~/.bashrc'文件(LCTT译注: 若没有该文件可以自己新建一个)中。我们要为每个用户以及对应的'.bashrc'文件插入这段代码,但是建议你不要加在root用户下。
|
||||
|
||||
我们注意到.bashrc文件的第一行代码以(#)开始, 这个是可选的并且只是为了区分余下的代码。
|
||||
|
||||
# explain.sh 标记代码的开始, 我们将代码插入.bashrc文件的底部。
|
||||
\# explain.sh 标记代码的开始, 我们将代码插入.bashrc文件的底部。
|
||||
|
||||
# explain.sh begins
|
||||
explain () {
|
||||
@ -53,7 +53,7 @@ Jackson写了一小段代码,它能非常有效地在bash shell里面解释she
|
||||
|
||||
### explain.sh工具的使用 ###
|
||||
|
||||
在插入代码并保存之后,你必须退出当前的会话然后重新登录来使改变生效(LCTT注:你也可以直接使用命令“source~/.bashrc”来让改变生效)。每件事情都是交由‘curl’命令处理, 它负责将需要解释的命令以及命令选项传送给mankier服务,然后将必要的信息打印到Linux命令行。不必说的就是使用这个工具你总是需要连接网络。
|
||||
在插入代码并保存之后,你必须退出当前的会话然后重新登录来使改变生效(LCTT译注:你也可以直接使用命令`source~/.bashrc` 来让改变生效)。每件事情都是交由‘curl’命令处理, 它负责将需要解释的命令以及命令选项传送给mankier服务,然后将必要的信息打印到Linux命令行。不必说的就是使用这个工具你总是需要连接网络。
|
||||
|
||||
让我们用explain.sh脚本测试几个笔者不懂的命令例子。
|
||||
|
||||
@ -63,7 +63,7 @@ Jackson写了一小段代码,它能非常有效地在bash shell里面解释she
|
||||
|
||||

|
||||
|
||||
获得du命令的帮助
|
||||
*获得du命令的帮助*
|
||||
|
||||
**2.如果你忘了'tar -zxvf'的作用,你可以简单地如此做:**
|
||||
|
||||
@ -71,7 +71,7 @@ Jackson写了一小段代码,它能非常有效地在bash shell里面解释she
|
||||
|
||||

|
||||
|
||||
Tar命令帮助
|
||||
*Tar命令帮助*
|
||||
|
||||
**3.我的一个朋友经常对'whatis'以及'whereis'命令的使用感到困惑,所以我建议他:**
|
||||
|
||||
@ -86,7 +86,7 @@ Tar命令帮助
|
||||
|
||||

|
||||
|
||||
Whatis/Whereis命令的帮助
|
||||
*Whatis/Whereis命令的帮助*
|
||||
|
||||
你只需要使用“Ctrl+c”就能退出交互模式。
|
||||
|
||||
@ -96,11 +96,11 @@ Whatis/Whereis命令的帮助
|
||||
|
||||

|
||||
|
||||
获取多条命令的帮助
|
||||
*获取多条命令的帮助*
|
||||
|
||||
同样地,你可以请求你的shell来解释任何shell命令。 前提是你需要一个可用的网络。输出的信息是基于解释的需要从服务器中生成的,因此输出的结果是不可定制的。
|
||||
同样地,你可以请求你的shell来解释任何shell命令。 前提是你需要一个可用的网络。输出的信息是基于需要解释的命令,从服务器中生成的,因此输出的结果是不可定制的。
|
||||
|
||||
对于我来说这个工具真的很有用并且它已经荣幸地添加在我的.bashrc文件中。你对这个项目有什么想法?它对你有用么?它的解释令你满意吗?请让我知道吧!
|
||||
对于我来说这个工具真的很有用,并且它已经荣幸地添加在我的.bashrc文件中。你对这个项目有什么想法?它对你有用么?它的解释令你满意吗?请让我知道吧!
|
||||
|
||||
请在下面评论为我们提供宝贵意见,喜欢并分享我们以及帮助我们得到传播。
|
||||
|
||||
@ -110,7 +110,7 @@ via: http://www.tecmint.com/explain-shell-commands-in-the-linux-shell/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,12 @@
|
||||
新手应知应会的Linux命令
|
||||
================================================================================
|
||||
|
||||
在Fedora上通过命令行使用dnf来管理系统更新
|
||||
|
||||
基于Linux的系统的优点之一,就是你可以通过终端中使用命令该ing来管理整个系统。使用命令行的优势在于,你可以使用相同的知识和技能来管理随便哪个Linux发行版。
|
||||
*在Fedora上通过命令行使用dnf来管理系统更新*
|
||||
|
||||
对于各个发行版以及桌面环境(DE)而言,要一致地使用图形化用户界面(GUI)却几乎是不可能的,因为它们都提供了各自的用户界面。要明确的是,有那么些情况,你需要在不同的发行版上使用不同的命令来部署某些特定的任务,但是,或多或少它们的概念和意图却仍然是一致的。
|
||||
基于Linux的系统最美妙的一点,就是你可以在终端中使用命令行来管理整个系统。使用命令行的优势在于,你可以使用相同的知识和技能来管理随便哪个Linux发行版。
|
||||
|
||||
对于各个发行版以及桌面环境(DE)而言,要一致地使用图形化用户界面(GUI)却几乎是不可能的,因为它们都提供了各自的用户界面。要明确的是,有些情况下在不同的发行版上需要使用不同的命令来执行某些特定的任务,但是,基本来说它们的思路和目的是一致的。
|
||||
|
||||
在本文中,我们打算讨论Linux用户应当掌握的一些基本命令。我将给大家演示怎样使用命令行来更新系统、管理软件、操作文件以及切换到root,这些操作将在三个主要发行版上进行:Ubuntu(也包括其定制版和衍生版,还有Debian),openSUSE,以及Fedora。
|
||||
|
||||
@ -15,7 +16,7 @@
|
||||
|
||||
Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会导致安全漏洞。所以,保持你的系统更新到最新是十分重要的。这么想吧:运行过时的操作系统,就像是你坐在全副武装的坦克里头,而门却没有锁。武器会保护你吗?任何人都可以进入开放的大门,对你造成伤害。同样,在你的系统中也有没有打补丁的漏洞,这些漏洞会危害到你的系统。开源社区,不像专利世界,在漏洞补丁方面反应是相当快的,所以,如果你保持系统最新,你也获得了安全保证。
|
||||
|
||||
留意新闻站点,了解安全漏洞。如果发现了一个漏洞,请阅读之,然后在补丁出来的第一时间更新。不管怎样,在生产机器上,你每星期必须至少运行一次更新命令。如果你运行这一台复杂的服务器,那么就要额外当心了。仔细阅读变更日志,以确保更新不会搞坏你的自定义服务。
|
||||
留意新闻站点,了解安全漏洞。如果发现了一个漏洞,了解它,然后在补丁出来的第一时间更新。不管怎样,在生产环境上,你每星期必须至少运行一次更新命令。如果你运行着一台复杂的服务器,那么就要额外当心了。仔细阅读变更日志,以确保更新不会搞坏你的自定义服务。
|
||||
|
||||
**Ubuntu**:牢记一点:你在升级系统或安装不管什么软件之前,都必须要刷新仓库(也就是repos)。在Ubuntu上,你可以使用下面的命令来更新系统,第一个命令用于刷新仓库:
|
||||
|
||||
@ -29,7 +30,7 @@ Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会
|
||||
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
**openSUSE**:如果你是在openSUSE上,你可以使用以下命令来更新系统(照例,第一个命令的意思是更新仓库)
|
||||
**openSUSE**:如果你是在openSUSE上,你可以使用以下命令来更新系统(照例,第一个命令的意思是更新仓库):
|
||||
|
||||
sudo zypper refresh
|
||||
sudo zypper up
|
||||
@ -42,7 +43,7 @@ Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会
|
||||
### 软件安装与移除 ###
|
||||
|
||||
你只可以安装那些你系统上启用的仓库中可用的包,各个发行版默认都附带有并启用了一些官方或者第三方仓库。
|
||||
**Ubuntu**: To install any package on Ubuntu, first update the repo and then use this syntax:
|
||||
|
||||
**Ubuntu**:要在Ubuntu上安装包,首先更新仓库,然后使用下面的语句:
|
||||
|
||||
sudo apt-get install [package_name]
|
||||
@ -75,9 +76,9 @@ Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会
|
||||
|
||||
### 如何管理第三方软件? ###
|
||||
|
||||
在一个庞大的开发者社区中,这些开发者们为用户提供了许多的软件。不同的发行版有不同的机制来使用这些第三方软件,将它们提供给用户。同时也取决于开发者怎样将这些软件提供给用户,有些开发者会提供二进制包,而另外一些开发者则将软件发布到仓库中。
|
||||
在一个庞大的开发者社区中,这些开发者们为用户提供了许多的软件。不同的发行版有不同的机制来将这些第三方软件提供给用户。当然,同时也取决于开发者怎样将这些软件提供给用户,有些开发者会提供二进制包,而另外一些开发者则将软件发布到仓库中。
|
||||
|
||||
Ubuntu严重依赖于PPA(个人包归档),但是,不幸的是,它却没有提供一个内建工具来帮助用于搜索这些PPA仓库。在安装软件前,你将需要通过Google搜索PPA,然后手工添加该仓库。下面就是添加PPA到系统的方法:
|
||||
Ubuntu很多地方都用到PPA(个人包归档),但是,不幸的是,它却没有提供一个内建工具来帮助用于搜索这些PPA仓库。在安装软件前,你将需要通过Google搜索PPA,然后手工添加该仓库。下面就是添加PPA到系统的方法:
|
||||
|
||||
sudo add-apt-repository ppa:<repository-name>
|
||||
|
||||
@ -85,7 +86,7 @@ Ubuntu严重依赖于PPA(个人包归档),但是,不幸的是,它却
|
||||
|
||||
sudo add-apt-repository ppa:libreoffice/ppa
|
||||
|
||||
它会要你按下回车键来导入秘钥。完成后,使用'update'命令来刷新仓库,然后安装该包。
|
||||
它会要你按下回车键来导入密钥。完成后,使用'update'命令来刷新仓库,然后安装该包。
|
||||
|
||||
openSUSE拥有一个针对第三方应用的优雅的解决方案。你可以访问software.opensuse.org,一键点击搜索并安装相应包,它会自动将对应的仓库添加到你的系统中。如果你想要手工添加仓库,可以使用该命令:
|
||||
|
||||
@ -97,13 +98,13 @@ openSUSE拥有一个针对第三方应用的优雅的解决方案。你可以访
|
||||
sudo zypper refresh
|
||||
sudo zypper install libreoffice
|
||||
|
||||
Fedora用户只需要添加RPMFusion(free和non-free仓库一起),该仓库包含了大量的应用。如果你需要添加仓库,命令如下:
|
||||
Fedora用户只需要添加RPMFusion(包括自由软件和非自由软件仓库),该仓库包含了大量的应用。如果你需要添加该仓库,命令如下:
|
||||
|
||||
dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
### 一些基本命令 ###
|
||||
|
||||
我已经写了一些关于使用CLI来管理你系统上的文件的[文章][1],下面介绍一些基本米ing令,这些命令在所有发行版上都经常会用到。
|
||||
我已经写了一些关于使用CLI来管理你系统上的文件的[文章][1],下面介绍一些基本命令,这些命令在所有发行版上都经常会用到。
|
||||
|
||||
拷贝文件或目录到一个新的位置:
|
||||
|
||||
@ -113,13 +114,13 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
cp path_of_files/* path_of_the_directory_where_you_want_to_copy/
|
||||
|
||||
将一个文件从某个位置移动到另一个位置(尾斜杠是说在该目录中):
|
||||
将一个文件从某个位置移动到另一个位置(尾斜杠是说放在该目录中):
|
||||
|
||||
mv path_of_file_1 path_of_the_directory_where_you_want_to_move/
|
||||
mv path_of_file_1 path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
将所有文件从一个位置移动到另一个位置:
|
||||
|
||||
mv path_of_directory_where_files_are/* path_of_the_directory_where_you_want_to_move/
|
||||
mv path_of_directory_where_files_are/* path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
删除一个文件:
|
||||
|
||||
@ -135,11 +136,11 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
### 创建新目录 ###
|
||||
|
||||
要创建一个新目录,首先输入你要创建的目录的位置。比如说,你想要在你的Documents目录中创建一个名为'foundation'的文件夹。让我们使用 cd (即change directory,改变目录)命令来改变目录:
|
||||
要创建一个新目录,首先进入到你要创建该目录的位置。比如说,你想要在你的Documents目录中创建一个名为'foundation'的文件夹。让我们使用 cd (即change directory,改变目录)命令来改变目录:
|
||||
|
||||
cd /home/swapnil/Documents
|
||||
|
||||
(替换'swapnil'为你系统中的用户)
|
||||
(替换'swapnil'为你系统中的用户名)
|
||||
|
||||
然后,使用 mkdir 命令来创建该目录:
|
||||
|
||||
@ -149,13 +150,13 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
mdkir /home/swapnil/Documents/foundation
|
||||
|
||||
如果你想要创建父-子目录,那是指目录中的目录,那么可以使用 -p 选项。它会在指定路径中创建所有目录:
|
||||
如果你想要连父目录一起创建,那么可以使用 -p 选项。它会在指定路径中创建所有目录:
|
||||
|
||||
mdkir -p /home/swapnil/Documents/linux/foundation
|
||||
|
||||
### 成为root ###
|
||||
|
||||
你或许需要成为root,或者具有sudo权力的用户,来实施一些管理任务,如管理软件包或者对根目录或其下的文件进行一些修改。其中一个例子就是编辑'fstab'文件,该文件记录了挂载的硬件驱动器。它在'etc'目录中,而该目录又在根目录中,你只能作为超级用户来修改该文件。在大多数的发行版中,你可以通过'切换用户'来成为root。比如说,在openSUSE上,我想要成为root,因为我要在根目录中工作,你可以使用下面的命令之一:
|
||||
你或许需要成为root,或者具有sudo权力的用户,来实施一些管理任务,如管理软件包或者对根目录或其下的文件进行一些修改。其中一个例子就是编辑'fstab'文件,该文件记录了挂载的硬盘驱动器。它在'etc'目录中,而该目录又在根目录中,你只能作为超级用户来修改该文件。在大多数的发行版中,你可以通过'su'来成为root。比如说,在openSUSE上,我想要成为root,因为我要在根目录中工作,你可以使用下面的命令之一:
|
||||
|
||||
sudo su -
|
||||
|
||||
@ -165,7 +166,7 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
该命令会要求输入密码,然后你就具有root特权了。记住一点:千万不要以root用户来运行系统,除非你知道你正在做什么。另外重要的一点需要注意的是,你以root什么对目录或文件进行修改后,会将它们的拥有关系从该用户或特定的服务改变为root。你必须恢复这些文件的拥有关系,否则该服务或用户就不能访问或写入到那些文件。要改变用户,命令如下:
|
||||
|
||||
sudo chown -R user:user /path_of_file_or_directory
|
||||
sudo chown -R 用户:组 文件或目录名
|
||||
|
||||
当你将其它发行版上的分区挂载到系统中时,你可能经常需要该操作。当你试着访问这些分区上的文件时,你可能会碰到权限拒绝错误,你只需要改变这些分区的拥有关系就可以访问它们了。需要额外当心的是,不要改变根目录的权限或者拥有关系。
|
||||
|
||||
@ -177,7 +178,7 @@ via: http://www.linux.com/learn/tutorials/842251-must-know-linux-commands-for-ne
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,65 @@
|
||||
使用 Find 命令来帮你找到那些需要清理的文件
|
||||
================================================================================
|
||||

|
||||
|
||||
*Credit: Sandra H-S*
|
||||
|
||||
有一个问题几乎困扰着所有的文件系统 -- 包括 Unix 和其他的 -- 那就是文件的不断积累。几乎没有人愿意花时间清理掉他们不再使用的文件和整理文件系统,结果,文件变得很混乱,很难找到有用的东西,要使它们运行良好、维护备份、易于管理,这将是一种持久的挑战。
|
||||
|
||||
我见过的一种解决问题的方法是建议使用者将所有的数据碎屑创建一个文件集合的总结报告或"概况",来报告诸如所有的文件数量;最老的,最新的,最大的文件;并统计谁拥有这些文件等数据。如果有人看到五年前的一个包含五十万个文件的文件夹,他们可能会去删除哪些文件 -- 或者,至少会归档和压缩。主要问题是太大的文件夹会使人担心误删一些重要的东西。如果有一个描述文件夹的方法能帮助显示文件的性质,那么你就可以去清理它了。
|
||||
|
||||
当我准备做 Unix 文件系统的总结报告时,几个有用的 Unix 命令能提供一些非常有用的统计信息。要计算目录中的文件数,你可以使用这样一个 find 命令。
|
||||
|
||||
$ find . -type f | wc -l
|
||||
187534
|
||||
|
||||
虽然查找最老的和最新的文件是比较复杂,但还是相当方便的。在下面的命令,我们使用 find 命令再次查找文件,以文件时间排序并按年-月-日的格式显示,在列表顶部的显然是最老的。
|
||||
|
||||
在第二个命令,我们做同样的,但打印的是最后一行,这是最新的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | sort | head -n 1
|
||||
2006-02-03+02:40:33 ./skel/.xemacs/init.el
|
||||
$ find -type f -printf '%T+ %p\n' | sort | tail -n 1
|
||||
2015-07-19+14:20:16 ./.bash_history
|
||||
|
||||
printf 命令输出 %T(文件日期和时间)和 %P(带路径的文件名)参数。
|
||||
|
||||
如果我们在查找家目录时,无疑会发现,history 文件(如 .bash_history)是最新的,这并没有什么用。你可以通过 "un-grepping" 来忽略这些文件,也可以忽略以.开头的文件,如下图所示的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | grep -v "\./\." | sort | tail -n 1
|
||||
2015-07-19+13:02:12 ./isPrime
|
||||
|
||||
寻找最大的文件使用 %s(大小)参数,包括文件名(%f),因为这就是我们想要在报告中显示的。
|
||||
|
||||
$ find -type f -printf '%s %f \n' | sort -n | uniq | tail -1
|
||||
20183040 project.org.tar
|
||||
|
||||
统计文件的所有者,使用%u(所有者)
|
||||
|
||||
$ find -type f -printf '%u \n' | grep -v "\./\." | sort | uniq -c
|
||||
180034 shs
|
||||
7500 jdoe
|
||||
|
||||
如果文件系统能记录上次的访问日期,也将是非常有用的,可以用来看该文件有没有被访问过,比方说,两年之内没访问过。这将使你能明确分辨这些文件的价值。这个最后访问(%a)参数这样使用:
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | head -n 1
|
||||
Fri Dec 15 03:00:30 2006+ ./statreport
|
||||
|
||||
当然,如果大多数最近访问的文件也是在很久之前的,这看起来你需要处理更多文件了。
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | tail -n 1
|
||||
Wed Nov 26 03:00:27 2007+ ./my-notes
|
||||
|
||||
要想层次分明,可以为一个文件系统或大目录创建一个总结报告,显示这些文件的日期范围、最大的文件、文件所有者们、最老的文件和最新访问时间,可以帮助文件拥有者判断当前有哪些文件夹是重要的哪些该清理了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2949898/linux/profiling-your-file-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -0,0 +1,75 @@
|
||||
选择成为软件开发工程师的5个原因
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
这个星期我将给本地一所高中做一次有关于程序猿是怎样工作的演讲。我是志愿(由 [Transfer][1] 组织的)来到这所学校谈论我的工作的。这个学校本周将有一个技术主题日,并且他们很想听听科技行业是怎样工作的。因为我是从事软件开发的,这也是我将和学生们讲的内容。演讲的其中一部分是我为什么觉得软件开发是一个很酷的职业。主要原因如下:
|
||||
|
||||
### 5个原因 ###
|
||||
|
||||
**1、创造性**
|
||||
|
||||
如果你问别人创造性的工作有哪些,别人通常会说像作家,音乐家或者画家那样的(工作)。但是极少有人知道软件开发也是一项非常具有创造性的工作。它是最符合创造性定义的了,因为你创造了一个以前没有的新功能。这种解决方案可以在整体和细节上以很多形式来展现。我们经常会遇到一些需要做权衡的场景(比如说运行速度与内存消耗的权衡)。当然前提是这种解决方案必须是正确的。这些所有的行为都是需要强大的创造性的。
|
||||
|
||||
**2、协作性**
|
||||
|
||||
另外一个表象是程序猿们独自坐在他们的电脑前,然后撸一天的代码。但是软件开发事实上通常总是一个团队努力的结果。你会经常和你的同事讨论编程问题以及解决方案,并且和产品经理、测试人员、客户讨论需求以及其他问题。
|
||||
经常有人说,结对编程(2个开发人员一起在一个电脑上编程)是一种流行的最佳实践。
|
||||
|
||||
**3、高需性**
|
||||
|
||||
世界上越来越多的人在用软件,正如 [Marc Andreessen](https://en.wikipedia.org/wiki/Marc_Andreessen) 所说 " [软件正在吞噬世界][2] "。虽然程序猿现在的数量非常巨大(在斯德哥尔摩,程序猿现在是 [最普遍的职业][3] ),但是,需求量一直处于供不应求的局面。据软件公司说,他们最大的挑战之一就是 [找到优秀的程序猿][4] 。我也经常接到那些想让我跳槽的招聘人员打来的电话。我知道至少除软件行业之外的其他行业的雇主不会那么拼(的去招聘)。
|
||||
|
||||
**4、高酬性**
|
||||
|
||||
软件开发可以带来不菲的收入。卖一份你已经开发好的软件的额外副本是没有 [边际成本][5] 的。这个事实与对程序猿的高需求意味着收入相当可观。当然还有许多更捞金的职业,但是相比一般人群,我认为软件开发者确实“日进斗金”(知足吧!骚年~~)。
|
||||
|
||||
**5、前瞻性**
|
||||
|
||||
有许多工作岗位消失,往往是由于它们可以被计算机和软件代替。但是所有这些新的程序依然需要开发和维护,因此,程序猿的前景还是相当好的。
|
||||
|
||||
### 但是...###
|
||||
|
||||
**外包又是怎么一回事呢?**
|
||||
|
||||
难道所有外包到其他国家的软件开发的薪水都很低吗?这是一个理想丰满,现实骨感的例子(有点像 [瀑布开发模型][6] )。软件开发基本上跟设计的工作一样,是一个探索发现的工作。它受益于强有力的合作。更进一步说,特别当你的主打产品是软件的时候,你所掌握的开发知识是绝对的优势。知识在整个公司中分享的越容易,那么公司的发展也将越来越好。
|
||||
|
||||
换一种方式去看待这个问题。软件外包已经存在了相当一段时间了。但是对本土程序猿的需求量依旧非常高。因为许多软件公司看到了雇佣本土程序猿的带来的收益要远远超过了相对较高的成本(其实还是赚了)。
|
||||
|
||||
### 如何成为人生大赢家 ###
|
||||
|
||||
虽然我有许多我认为软件开发是一件非常有趣的事情的理由 (详情见: [为什么我热爱编程][7] )。但是这些理由,并不适用于所有人。幸运的是,尝试编程是一件非常容易的事情。在互联网上有数不尽的学习编程的资源。例如,[Coursera][8] 和 [Udacity][9] 都拥有很好的入门课程。如果你从来没有撸过码,可以尝试其中一个免费的课程,找找感觉。
|
||||
|
||||
寻找一个既热爱又能谋生的事情至少有2个好处。首先,由于你天天去做,工作将比你简单的只为谋生要有趣的多。其次,如果你真的非常喜欢,你将更好的擅长它。我非常喜欢下面一副关于伟大工作组成的韦恩图(作者 [@eskimon)][10]) 。因为编码的薪水确实相当不错,我认为如果你真的喜欢它,你将有一个很好的机会,成为人生的大赢家!
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://henrikwarne.com/2014/12/08/5-reasons-why-software-developer-is-a-great-career-choice/
|
||||
|
||||
作者:[Henrik Warne][a]
|
||||
译者:[mousycoder](https://github.com/mousycoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:http://henrikwarne.com/
|
||||
[1]:http://www.transfer.nu/omoss/transferinenglish.jspx?pageId=23
|
||||
[2]:http://www.wsj.com/articles/SB10001424053111903480904576512250915629460
|
||||
[3]:http://www.di.se/artiklar/2014/6/12/jobbet-som-tar-over-landet/
|
||||
[4]:http://computersweden.idg.se/2.2683/1.600324/examinationstakten-racker-inte-for-branschens-behov
|
||||
[5]:https://en.wikipedia.org/wiki/Marginal_cost
|
||||
[6]:https://en.wikipedia.org/wiki/Waterfall_model
|
||||
[7]:http://henrikwarne.com/2012/06/02/why-i-love-coding/
|
||||
[8]:https://www.coursera.org/
|
||||
[9]:https://www.udacity.com/
|
||||
[10]:https://eskimon.wordpress.com/about/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
如何在 Linux 上运行命令前临时清空 Bash 环境变量
|
||||
================================================================================
|
||||
我是个 bash shell 用户。我想临时清空 bash shell 环境变量。但我不想删除或者 unset 一个输出的环境变量。我怎样才能在 bash 或 ksh shell 的临时环境中运行程序呢?
|
||||
|
||||
你可以在 Linux 或类 Unix 系统中使用 env 命令设置并打印环境。env 命令可以按命令行指定的变量来修改环境,之后再执行程序。
|
||||
|
||||
### 如何显示当前环境? ###
|
||||
|
||||
打开终端应用程序并输入下面的其中一个命令:
|
||||
|
||||
printenv
|
||||
|
||||
或
|
||||
|
||||
env
|
||||
|
||||
输出样例:
|
||||
|
||||
|
||||
|
||||
*Fig.01: Unix/Linux: 列出所有环境变量*
|
||||
|
||||
### 统计环境变量数目 ###
|
||||
|
||||
输入下面的命令:
|
||||
|
||||
env | wc -l
|
||||
printenv | wc -l # 或者
|
||||
|
||||
输出样例:
|
||||
|
||||
20
|
||||
|
||||
### 在干净的 bash/ksh/zsh 环境中运行程序 ###
|
||||
|
||||
语法如下所示:
|
||||
|
||||
env -i your-program-name-here arg1 arg2 ...
|
||||
|
||||
例如,要在不使用 http_proxy 和/或任何其它环境变量的情况下运行 wget 程序。临时清除所有 bash/ksh/zsh 环境变量并运行 wget 程序:
|
||||
|
||||
env -i /usr/local/bin/wget www.cyberciti.biz
|
||||
env -i wget www.cyberciti.biz # 或者
|
||||
|
||||
这当你想忽视任何已经设置的环境变量来运行命令时非常有用。我每天都会多次使用这个命令,以便忽视 http_proxy 和其它我设置的环境变量。
|
||||
|
||||
#### 例子:使用 http_proxy ####
|
||||
|
||||
$ wget www.cyberciti.biz
|
||||
--2015-08-03 23:20:23-- http://www.cyberciti.biz/
|
||||
Connecting to 10.12.249.194:3128... connected.
|
||||
Proxy request sent, awaiting response... 200 OK
|
||||
Length: unspecified [text/html]
|
||||
Saving to: 'index.html'
|
||||
index.html [ <=> ] 36.17K 87.0KB/s in 0.4s
|
||||
2015-08-03 23:20:24 (87.0 KB/s) - 'index.html' saved [37041]
|
||||
|
||||
#### 例子:忽视 http_proxy ####
|
||||
|
||||
$ env -i /usr/local/bin/wget www.cyberciti.biz
|
||||
--2015-08-03 23:25:17-- http://www.cyberciti.biz/
|
||||
Resolving www.cyberciti.biz... 74.86.144.194
|
||||
Connecting to www.cyberciti.biz|74.86.144.194|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: unspecified [text/html]
|
||||
Saving to: 'index.html.1'
|
||||
index.html.1 [ <=> ] 36.17K 115KB/s in 0.3s
|
||||
2015-08-03 23:25:18 (115 KB/s) - 'index.html.1' saved [37041]
|
||||
|
||||
-i 选项使 env 命令完全忽视它继承的环境。但是,它并不会阻止你的命令(例如 wget 或 curl)设置新的变量。同时,也要注意运行 bash/ksh shell 的副作用:
|
||||
|
||||
env -i env | wc -l ## 空的 ##
|
||||
# 现在运行 bash ##
|
||||
env -i bash
|
||||
## bash 设置了新的环境变量 ##
|
||||
env | wc -l
|
||||
|
||||
#### 例子:设置一个环境变量 ####
|
||||
|
||||
语法如下:
|
||||
|
||||
env var=value /path/to/command arg1 arg2 ...
|
||||
## 或 ##
|
||||
var=value /path/to/command arg1 arg2 ...
|
||||
|
||||
例如设置 http_proxy:
|
||||
|
||||
env http_proxy="http://USER:PASSWORD@server1.cyberciti.biz:3128/" /usr/local/bin/wget www.cyberciti.biz
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/linux-unix-temporarily-clearing-environment-variables-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,3 +1,5 @@
|
||||
martin
|
||||
|
||||
Interview: Larry Wall
|
||||
================================================================================
|
||||
> Perl 6 has been 15 years in the making, and is now due to be released at the end of this year. We speak to its creator to find out what’s going on.
|
||||
@ -122,4 +124,4 @@ via: http://www.linuxvoice.com/interview-larry-wall/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by ZTinoZ
|
||||
5 heroes of the Linux world
|
||||
================================================================================
|
||||
Who are these people, seen and unseen, whose work affects all of us every day?
|
||||
@ -96,4 +97,4 @@ via: http://www.itworld.com/article/2955001/linux/5-heros-of-the-linux-world.htm
|
||||
[7]:https://flic.kr/p/hBv8Pp
|
||||
[8]:https://en.wikipedia.org/wiki/Sysfs
|
||||
[9]:https://www.youtube.com/watch?v=CyHAeGBFS8k
|
||||
[10]:http://www.itworld.com/article/2873200/operating-systems/11-technologies-that-tick-off-linus-torvalds.html
|
||||
[10]:http://www.itworld.com/article/2873200/operating-systems/11-technologies-that-tick-off-linus-torvalds.html
|
||||
|
||||
60
sources/talk/20150810 For Linux, Supercomputers R Us.md
Normal file
60
sources/talk/20150810 For Linux, Supercomputers R Us.md
Normal file
@ -0,0 +1,60 @@
|
||||
Translating by xiaoyu33
|
||||
For Linux, Supercomputers R Us
|
||||
================================================================================
|
||||

|
||||
Credit: Michel Ngilen, CC BY 2.0, via Wikimedia Commons
|
||||
|
||||
> Almost all supercomputers run Linux, including the ones built from Raspberry Pi boards and PlayStation 3 game consoles
|
||||
|
||||
Supercomputers are serious things, called on to do serious computing. They tend to be engaged in serious pursuits like atomic bomb simulations, climate modeling and high-level physics. Naturally, they cost serious money. At the very top of the latest [Top500][1] supercomputer ranking is the Tianhe-2 supercomputer at China’s National University of Defense Technology. It cost about $390 million to build.
|
||||
|
||||
But then there’s the supercomputer that Joshua Kiepert, a doctoral student at Boise State’s Electrical and Computer Engineering department, [created with Raspberry Pi computers][2].It cost less than $2,000.
|
||||
|
||||
No, I’m not making that up. It’s an honest-to-goodness supercomputer made from overclocked 1-GHz [Model B Raspberry Pi][3] ARM11 processors with Videocore IV GPUs. Each one comes with 512MB of RAM, a pair of USB ports and a 10/100 BaseT Ethernet port.
|
||||
|
||||
And what do the Tianhe-2 and the Boise State supercomputer have in common? They both run Linux. As do [486 out of the world’s fastest 500 supercomputers][4]. It’s part of a domination of the category that began over 20 years ago. And now it’s trickling down to built-on-the-cheap supercomputers. Because Kiepert’s machine isn’t the only budget number cruncher out there.
|
||||
|
||||
Gaurav Khanna, an associate professor of physics at the University of Massachusetts Dartmouth, created a [supercomputer with something shy of 200 PlayStation 3 video game consoles][5].
|
||||
|
||||
The PlayStations are powered by a 3.2-GHz PowerPC-based Power Processing Element. Each comes with 512MB of RAM. You can still buy one, although Sony will be phasing them out by year’s end, for just over $200. Khanna started with only 16 PlayStation 3s for his first supercomputer, so you too could put a supercomputer on your credit card for less than four grand.
|
||||
|
||||
These machines may be built from toys, but they’re not playthings. Khanna has done serious astrophysics on his rig. A white-hat hacking group used a similar [PlayStation 3 supercomputer in 2008 to crack the SSL MD5 hashing algorithm][6] in 2008.
|
||||
|
||||
Two years later, the Air Force Research Laboratory [Condor Cluster was using 1,760 Sony PlayStation 3 processors][7] and 168 general-purpose graphical processing units. This bargain-basement supercomputer runs at about 500TFLOPs, or 500 trillion floating point operations per second.
|
||||
|
||||
Other cheap options for home supercomputers include specialist parallel-processing boards such as the [$99 credit-card-sized Parallella board][8], and high-end graphics boards such as [Nvidia’s Titan Z][9] and [AMD’s FirePro W9100][10]. Those high-end boards, coveted by gamers with visions of a dream machine or even a chance at winning the first-place prize of over $100,000 in the [Intel Extreme Masters World Championship League of][11] [Legends][12], cost considerably more, retailing for about $3,000. On the other hand, a single one can deliver over 2.5TFLOPS all by itself, and for scientists and researchers, they offer an affordable way to get a supercomputer they can call their own.
|
||||
|
||||
As for the Linux connection, that all started in 1994 at the Goddard Space Flight Center with the first [Beowulf supercomputer][13].
|
||||
|
||||
By our standards, there wasn’t much that was super about the first Beowulf. But in its day, the first homemade supercomputer, with its 16 Intel 486DX processors and 10Mbps Ethernet for the bus, was great. [Beowulf, designed by NASA contractors Don Becker and Thomas Sterling][14], was the first “maker” supercomputer. Its “compute components,” 486DX PCs, cost only a few thousand dollars. While its speed was only in single-digit gigaflops, [Beowulf][15] showed you could build supercomputers from commercial off-the-shelf (COTS) hardware and Linux.
|
||||
|
||||
I wish I’d had a part in its creation, but I’d already left Goddard by 1994 for a career as a full-time technology journalist. Darn it!
|
||||
|
||||
But even from this side of my reporter’s notebook, I can still appreciate how COTS and open-source software changed supercomputing forever. I hope you can too. Because, whether it’s a cluster of Raspberry Pis or a monster with over 3 million Intel Ivy Bridge and Xeon Phi chips, almost all of today’s supercomputers trace their ancestry to Beowulf.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.top500.org/
|
||||
[2]:http://www.zdnet.com/article/build-your-own-supercomputer-out-of-raspberry-pi-boards/
|
||||
[3]:https://www.raspberrypi.org/products/model-b/
|
||||
[4]:http://www.zdnet.com/article/linux-still-rules-supercomputing/
|
||||
[5]:http://www.nytimes.com/2014/12/23/science/an-economical-way-to-save-progress.html?smid=fb-nytimes&smtyp=cur&bicmp=AD&bicmlukp=WT.mc_id&bicmst=1409232722000&bicmet=1419773522000&_r=4
|
||||
[6]:http://www.computerworld.com/article/2529932/cybercrime-hacking/researchers-hack-verisign-s-ssl-scheme-for-securing-web-sites.html
|
||||
[7]:http://phys.org/news/2010-12-air-playstation-3s-supercomputer.html
|
||||
[8]:http://www.zdnet.com/article/parallella-the-99-linux-supercomputer/
|
||||
[9]:http://blogs.nvidia.com/blog/2014/03/25/titan-z/
|
||||
[10]:http://www.amd.com/en-us/press-releases/Pages/amd-flagship-professional-2014apr7.aspx
|
||||
[11]:http://en.intelextrememasters.com/news/check-out-the-intel-extreme-masters-katowice-prize-money-distribution/
|
||||
[12]:http://www.google.com/url?q=http%3A%2F%2Fen.intelextrememasters.com%2Fnews%2Fcheck-out-the-intel-extreme-masters-katowice-prize-money-distribution%2F&sa=D&sntz=1&usg=AFQjCNE6yoAGGz-Hpi2tPF4gdhuPBEckhQ
|
||||
[13]:http://www.beowulf.org/overview/history.html
|
||||
[14]:http://yclept.ucdavis.edu/Beowulf/aboutbeowulf.html
|
||||
[15]:http://www.beowulf.org/
|
||||
@ -1,149 +0,0 @@
|
||||
Install OpenQRM Cloud Computing Platform In Debian
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
**openQRM** is a web-based open source Cloud computing and datacenter management platform that integrates flexibly with existing components in enterprise data centers.
|
||||
|
||||
It supports the following virtualization technologies:
|
||||
|
||||
- KVM,
|
||||
- XEN,
|
||||
- Citrix XenServer,
|
||||
- VMWare ESX,
|
||||
- LXC,
|
||||
- OpenVZ.
|
||||
|
||||
The Hybrid Cloud Connector in openQRM supports a range of private or public cloud providers to extend your infrastructure on demand via **Amazon AWS**, **Eucalyptus** or **OpenStack**. It, also, automates provisioning, virtualization, storage and configuration management, and it takes care of high-availability. A self-service cloud portal with integrated billing system enables end-users to request new servers and application stacks on-demand.
|
||||
|
||||
openQRM is available in two different flavours such as:
|
||||
|
||||
- Enterprise Edition
|
||||
- Community Edition
|
||||
|
||||
You can view the difference between both editions [here][1].
|
||||
|
||||
### Features ###
|
||||
|
||||
- Private/Hybrid Cloud Computing Platform;
|
||||
- Manages physical and virtualized server systems;
|
||||
- Integrates with all major open and commercial storage technologies;
|
||||
- Cross-platform: Linux, Windows, OpenSolaris, and *BSD;
|
||||
- Supports KVM, XEN, Citrix XenServer, VMWare ESX(i), lxc, OpenVZ and VirtualBox;
|
||||
- Support for Hybrid Cloud setups using additional Amazon AWS, Eucalyptus, Ubuntu UEC cloud resources;
|
||||
- Supports P2V, P2P, V2P, V2V Migrations and High-Availability;
|
||||
- Integrates with the best Open Source management tools – like puppet, nagios/Icinga or collectd;
|
||||
- Over 50 plugins for extended features and integration with your infrastructure;
|
||||
- Self-Service Portal for end-users;
|
||||
- Integrated billing system.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Here, we will install openQRM in Ubuntu 14.04 LTS. Your server must atleast meet the following requirements.
|
||||
|
||||
- 1 GB RAM;
|
||||
- 100 GB Hdd;
|
||||
- Optional: Virtualization enabled (VT for Intel CPUs or AMD-V for AMD CPUs) in Bios.
|
||||
|
||||
First, install make package to compile openQRM source package.
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
sudo apt-get install make
|
||||
|
||||
Then, run the following commands one by one to install openQRM.
|
||||
|
||||
Download the latest available version [from here][2].
|
||||
|
||||
wget http://sourceforge.net/projects/openqrm/files/openQRM-Community-5.1/openqrm-community-5.1.tgz
|
||||
|
||||
tar -xvzf openqrm-community-5.1.tgz
|
||||
|
||||
cd openqrm-community-5.1/src/
|
||||
|
||||
sudo make
|
||||
|
||||
sudo make install
|
||||
|
||||
sudo make start
|
||||
|
||||
During installation, you’ll be asked to update the php.ini file.
|
||||
|
||||

|
||||
|
||||
Enter mysql root user password.
|
||||
|
||||

|
||||
|
||||
Re-enter password:
|
||||
|
||||

|
||||
|
||||
Select the mail server configuration type.
|
||||
|
||||

|
||||
|
||||
If you’re not sure, select Local only. In our case, I go with **Local only** option.
|
||||
|
||||

|
||||
|
||||
Enter your system mail name, and finally enter the Nagios administration password.
|
||||
|
||||

|
||||
|
||||
The above commands will take long time depending upon your Internet connection to download all packages required to run openQRM. Be patient.
|
||||
|
||||
Finally, you’ll get the openQRM configuration URL along with username and password.
|
||||
|
||||

|
||||
|
||||
### Configuration ###
|
||||
|
||||
After installing openQRM, open up your web browser and navigate to the URL: **http://ip-address/openqrm**.
|
||||
|
||||
For example, in my case http://192.168.1.100/openqrm.
|
||||
|
||||
The default username and password is: **openqrm/openqrm**.
|
||||
|
||||

|
||||
|
||||
Select a network card to use for the openQRM management network.
|
||||
|
||||

|
||||
|
||||
Select a database type. In our case, I selected mysql.
|
||||
|
||||

|
||||
|
||||
Now, configure the database connection and initialize openQRM. Here, I use **openQRM** as database name, and user as **root** and debian as password for the database. Be mindful that you should enter the mysql root user password that you have created while installing openQRM.
|
||||
|
||||

|
||||
|
||||
Congratulations!! openQRM has been installed and configured.
|
||||
|
||||

|
||||
|
||||
### Update openQRM ###
|
||||
|
||||
To update openQRM at any time run the following command:
|
||||
|
||||
cd openqrm/src/
|
||||
make update
|
||||
|
||||
What we have done so far is just installed and configured openQRM in our Ubuntu server. For creating, running Virtual Machines, managing Storage, integrating additional systems and running your own private Cloud, I suggest you to read the [openQRM Administrator Guide][3].
|
||||
|
||||
That’s all now. Cheers! Happy weekend!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-openqrm-cloud-computing-platform-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.openqrm-enterprise.com/products/edition-comparison.html
|
||||
[2]:http://sourceforge.net/projects/openqrm/files/?source=navbar
|
||||
[3]:http://www.openqrm-enterprise.com/fileadmin/Documents/Whitepaper/openQRM-Enterprise-Administrator-Guide-5.2.pdf
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by Ping
|
||||
How to set up a Replica Set on MongoDB
|
||||
================================================================================
|
||||
MongoDB has become the most famous NoSQL database on the market. MongoDB is document-oriented, and its scheme-free design makes it a really attractive solution for all kinds of web applications. One of the features that I like the most is Replica Set, where multiple copies of the same data set are maintained by a group of mongod nodes for redundancy and high availability.
|
||||
@ -179,4 +180,4 @@ via: http://xmodulo.com/setup-replica-set-mongodb.html
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
[1]:http://docs.mongodb.org/ecosystem/drivers/
|
||||
[1]:http://docs.mongodb.org/ecosystem/drivers/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating wi-cuckoo
|
||||
Shilpa Nair Shares Her Interview Experience on RedHat Linux Package Management
|
||||
================================================================================
|
||||
**Shilpa Nair has just graduated in the year 2015. She went to apply for Trainee position in a National News Television located in Noida, Delhi. When she was in the last year of graduation and searching for help on her assignments she came across Tecmint. Since then she has been visiting Tecmint regularly.**
|
||||
@ -345,4 +346,4 @@ via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Ezio
|
||||
|
||||
Process of the Linux kernel building
|
||||
================================================================================
|
||||
Introduction
|
||||
@ -671,4 +673,4 @@ via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,28 +1,28 @@
|
||||
How to Setup iTOP (IT Operational Portal) on CentOS 7
|
||||
如何在CentOS上安装iTOP(IT操作门户)
|
||||
================================================================================
|
||||
iTOP is a simple, Open source web based IT Service Management tool. It has all of ITIL functionality that includes with Service desk, Configuration Management, Incident Management, Problem Management, Change Management and Service Management. iTop relays on Apache/IIS, MySQL and PHP, so it can run on any operating system supporting these applications. Since iTop is a web based application you don’t need to deploy any client software on each user’s PC. A simple web browser is enough to perform day to day operations of an IT environment with iTOP.
|
||||
iTOP简单来说是一个简单的基于网络的开源IT服务管理工具。它有所有的ITIL功能包括服务台、配置管理、事件管理、问题管理、更改管理和服务管理。iTOP依赖于Apache/IIS、MySQL和PHP,因此它可以运行在任何支持这些软件的操作系统中。因为iTOP是一个网络程序,因此你不必在用户的PC端任何客户端程序。一个简单的浏览器就足够每天的IT环境操作了。
|
||||
|
||||
To install and configure iTOP we will be using CentOS 7 as base operating with basic LAMP Stack environment installed on it that will cover its almost all prerequisites.
|
||||
我们要在一台有满足基本需求的LAMP环境的CentOS 7上安装和配置iTOP。
|
||||
|
||||
### Downloading iTOP ###
|
||||
### 下载 iTOP ###
|
||||
|
||||
iTop download package is present on SourceForge, we can get its link from their official website [link][1].
|
||||
iTOP的下载包现在在SOurceForge上,我们可以从这获取它的官方[链接][1]。
|
||||
|
||||

|
||||
|
||||
We will the download link from here and get this zipped file on server with wget command as below.
|
||||
我们从这里的连接用wget命令获取压缩文件
|
||||
|
||||
[root@centos-007 ~]# wget http://downloads.sourceforge.net/project/itop/itop/2.1.0/iTop-2.1.0-2127.zip
|
||||
|
||||
### iTop Extensions and Web Setup ###
|
||||
### iTop扩展和网络安装 ###
|
||||
|
||||
By using unzip command we will extract the downloaded packages in the document root directory of our apache web server in a new directory with name itop.
|
||||
使用unzip命令解压到apache根目录下的itop文件夹下。
|
||||
|
||||
[root@centos-7 ~]# ls
|
||||
iTop-2.1.0-2127.zip
|
||||
[root@centos-7 ~]# unzip iTop-2.1.0-2127.zip -d /var/www/html/itop/
|
||||
|
||||
List the folder to view installation packages in it.
|
||||
列出安装包中的内容。
|
||||
|
||||
[root@centos-7 ~]# ls -lh /var/www/html/itop/
|
||||
total 68K
|
||||
@ -31,7 +31,7 @@ List the folder to view installation packages in it.
|
||||
-rw-r--r--. 1 root root 23K Dec 17 2014 README
|
||||
drwxr-xr-x. 19 root root 4.0K Jul 14 13:10 web
|
||||
|
||||
Here is all the extensions that we can install.
|
||||
这些是我们可以安装的扩展。
|
||||
|
||||
[root@centos-7 2.x]# ls
|
||||
authent-external itop-backup itop-config-mgmt itop-problem-mgmt itop-service-mgmt-provider itop-welcome-itil
|
||||
@ -40,135 +40,135 @@ Here is all the extensions that we can install.
|
||||
installation.xml itop-change-mgmt-itil itop-incident-mgmt-itil itop-request-mgmt-itil itop-tickets
|
||||
itop-attachments itop-config itop-knownerror-mgmt itop-service-mgmt itop-virtualization-mgmt
|
||||
|
||||
Now from the extracted web directory, moving through different data models we will migrate the required extensions from the datamodels into the web extensions directory of web document root directory with copy command.
|
||||
在解压的目录下,通过不同的数据模型用复制命令迁移需要的扩展从datamodels复制到web扩展目录下。
|
||||
|
||||
[root@centos-7 2.x]# pwd
|
||||
/var/www/html/itop/web/datamodels/2.x
|
||||
[root@centos-7 2.x]# cp -r itop-request-mgmt itop-service-mgmt itop-service-mgmt itop-config itop-change-mgmt /var/www/html/itop/web/extensions/
|
||||
|
||||
### Installing iTop Web Interface ###
|
||||
### 安装 iTop web界面 ###
|
||||
|
||||
Most of our server side settings and configurations are done.Finally we need to complete its web interface installation process to finalize the setup.
|
||||
大多数服务端设置和配置已经完成了。最后我们安装web界面来完成安装。
|
||||
|
||||
Open your favorite web browser and access the WordPress web directory in your web browser using your server IP or FQDN like.
|
||||
打开浏览器使用ip地址或者FQDN来访问WordPress web目录。
|
||||
|
||||
http://servers_ip_address/itop/web/
|
||||
|
||||
You will be redirected towards the web installation process for iTop. Let’s configure it as per your requirements like we did here in this tutorial.
|
||||
你会被重定向到iTOP的web安装页面。让我们按照要求配置,就像在这篇教程中做的那样。
|
||||
|
||||
#### Prerequisites Validation ####
|
||||
#### 先决要求验证 ####
|
||||
|
||||
At the stage you will be prompted for welcome screen with prerequisites validation ok. If you get some warning then you have to make resolve it by installing its prerequisites.
|
||||
这一步你就会看到验证完成的欢迎界面。如果你看到了一些警告信息,你需要先安装这些软件来解决这些问题。
|
||||
|
||||

|
||||
|
||||
At this stage one optional package named php mcrypt will be missing. Download the following rpm package then try to install php mcrypt package.
|
||||
这一步一个叫php mcrypt的可选包丢失了。下载下面的rpm包接着尝试安装php mcrypt包。
|
||||
|
||||
[root@centos-7 ~]#yum localinstall php-mcrypt-5.3.3-1.el6.x86_64.rpm libmcrypt-2.5.8-9.el6.x86_64.rpm.
|
||||
|
||||
After successful installation of php-mcrypt library we need to restart apache web service, then reload the web page and this time its prerequisites validation should be OK.
|
||||
成功安装完php-mcrypt后,我们需要重启apache服务,接着刷新页面,这时验证应该已经OK。
|
||||
|
||||
#### Install or Upgrade iTop ####
|
||||
#### 安装或者升级 iTop ####
|
||||
|
||||
Here we will choose the fresh installation as we have not installed iTop previously on our server.
|
||||
现在我们要在没有安装iTOP的服务器上选择全新安装。
|
||||
|
||||

|
||||
|
||||
#### iTop License Agreement ####
|
||||
#### iTop 许可协议 ####
|
||||
|
||||
Chose the option to accept the terms of the licenses of all the components of iTop and click "NEXT".
|
||||
勾选同意iTOP所有组件的许可协议并点击“NEXT”。
|
||||
|
||||

|
||||
|
||||
#### Database Configuration ####
|
||||
#### 数据库配置 ####
|
||||
|
||||
Here we the do Configuration of the database connection by giving our database servers credentials and then choose from the option to create new database as shown.
|
||||
现在我们输入数据库凭据来配置数据库连接,接着选择如下选择创建新数据库。
|
||||
|
||||

|
||||
|
||||
#### Administrator Account ####
|
||||
#### 管理员账户 ####
|
||||
|
||||
In this step we will configure an Admin account by filling out its login details as.
|
||||
这一步中我们会输入它的登录信息来配置管理员账户。
|
||||
|
||||

|
||||
|
||||
#### Miscellaneous Parameters ####
|
||||
#### 杂项参数 ####
|
||||
|
||||
Let's choose the additional parameters whether you want to install with demo contents or with fresh database and proceed forward.
|
||||
让我们选择额外的参数来选择你是否需要安装一个演示内容或者使用全新的数据库,接着下一步。
|
||||
|
||||

|
||||
|
||||
### iTop Configurations Management ###
|
||||
### iTop 配置管理 ###
|
||||
|
||||
The options below allow you to configure the type of elements that are to be managed inside iTop like all the base objects that are mandatory in the iTop CMDB, Manage Data Center devices, storage device and virtualization.
|
||||
下面的选项允许你配置在iTOP要管理的元素类型,像CMDB、数据中心设备、存储设备和虚拟化这些东西在iTOP中是必须的。
|
||||
|
||||

|
||||
|
||||
#### Service Management ####
|
||||
#### 服务管理 ####
|
||||
|
||||
Select from the choices that best describes the relationships between the services and the IT infrastructure in your IT environment. So we are choosing Service Management for Service Providers here.
|
||||
选择一个最能描述你的IT设备和环境之间的关系的选项。因此我们这里选择为服务提供商的服务管理。
|
||||
|
||||

|
||||
|
||||
#### iTop Tickets Management ####
|
||||
#### iTop Tickets 管理 ####
|
||||
|
||||
From the different available options we will Select the ITIL Compliant Tickets Management option to have different types of ticket for managing user requests and incidents.
|
||||
从不同的可用选项我们选择符合ITIL Tickets管理选项来管理不同类型的用户请求和事件。
|
||||
|
||||

|
||||
|
||||
#### Change Management Options ####
|
||||
#### 改变管理选项 ####
|
||||
|
||||
Select the type of tickets you want to use in order to manage changes to the IT infrastructure from the available options. We are going to choose ITIL change management option here.
|
||||
选择不同的ticket类型以便管理可用选项中的IT设备更改。我们选择ITTL更改管理选项。
|
||||
|
||||

|
||||
|
||||
#### iTop Extensions ####
|
||||
#### iTop 扩展 ####
|
||||
|
||||
In this section we can select the additional extensions to install or we can unchecked the ones that you want to skip.
|
||||
这一节我们选择额外的扩展来安装或者不选直接跳过。
|
||||
|
||||

|
||||
|
||||
### Ready to Start Web Installation ###
|
||||
### 准备开始web安装 ###
|
||||
|
||||
Now we are ready to start installing the components that we choose in previous steps. We can also drop down these installation parameters to view our configuration from the drop down.
|
||||
现在我们开始准备安装先前先前选择的组件。我们也可以下拉这些安装参数来浏览我们的配置。
|
||||
|
||||
Once you are confirmed with the installation parameters click on the install button.
|
||||
确认安装参数后点击安装按钮。
|
||||
|
||||

|
||||
|
||||
Let's wait for the progress bar to complete the installation process. It might takes few minutes to complete its installation process.
|
||||
让我们等待进度条来完成安装步骤。它也许会花费几分钟来完成安装步骤。
|
||||
|
||||

|
||||
|
||||
### iTop Installation Done ###
|
||||
### iTop安装完成 ###
|
||||
|
||||
Our iTop installation setup is complete, just need to do a simple manual operation as shown and then click to enter iTop.
|
||||
我们的iTOP安装已经完成了,只要如下一个简单的手动操作就可以进入到iTOP。
|
||||
|
||||

|
||||
|
||||
### Welcome to iTop (IT Operational Portal) ###
|
||||
### 欢迎来到iTop (IT操作门户) ###
|
||||
|
||||

|
||||
|
||||
### iTop Dashboard ###
|
||||
### iTop 面板 ###
|
||||
|
||||
You can manage configuration of everything from here Servers, computers, Contacts, Locations, Contracts, Network devices…. You can create your own. Just the fact, that the installed CMDB module is great which is an essential part of every bigger IT.
|
||||
你这里可以配置任何东西,服务、计算机、通讯录、位置、合同、网络设备等等。你可以创建你自己的。事实是刚安装的CMDB模块是每一个IT人员的必备模块。
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
### 总结 ###
|
||||
|
||||
ITOP is one of the best Open Source Service Desk solutions. We have successfully installed and configured it on our CentOS 7 cloud host. So, the most powerful aspect of iTop is the ease with which it can be customized via its “extensions”. Feel free to comment if you face any trouble during its setup.
|
||||
ITOP是一个最棒的开源桌面服务解决方案。我们已经在CentOS 7上成功地安装和配置了。因此,iTOP最强大的一方面是它可以很简单地通过扩展来自定义。如果你在安装中遇到任何问题欢迎评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/setup-itop-centos-7/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:http://www.combodo.com/spip.php?page=rubrique&id_rubrique=8
|
||||
[1]:http://www.combodo.com/spip.php?page=rubrique&id_rubrique=8
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
|
||||
Translating by dingdongnigetou
|
||||
|
||||
Howto Configure Nginx as Rreverse Proxy / Load Balancer with Weave and Docker
|
||||
================================================================================
|
||||
Hi everyone today we'll learnHowto configure Nginx as Rreverse Proxy / Load balancer with Weave and Docker Weave creates a virtual network that connects Docker containers with each other, deploys across multiple hosts and enables their automatic discovery. It allows us to focus on developing our application, rather than our infrastructure. It provides such an awesome environment that the applications uses the network as if its containers were all plugged into the same network without need to configure ports, mappings, link, etc. The services of the application containers on the network can be easily accessible to the external world with no matter where its running. Here, in this tutorial we'll be using weave to quickly and easily deploy nginx web server as a load balancer for a simple php application running in docker containers on multiple nodes in Amazon Web Services. Here, we will be introduced to WeaveDNS, which provides a simple way for containers to find each other using hostname with no changes in codes and tells other containers to connect to those names.
|
||||
@ -123,4 +126,4 @@ via: http://linoxide.com/linux-how-to/nginx-load-balancer-weave-docker/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
|
||||
@ -1,92 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
Linux Logging Basics
|
||||
================================================================================
|
||||
First we’ll describe the basics of what Linux logs are, where to find them, and how they get created. If you already know this stuff, feel free to skip to the next section.
|
||||
|
||||
### Linux System Logs ###
|
||||
|
||||
Many valuable log files are automatically created for you by Linux. You can find them in your /var/log directory. Here is what this directory looks like on a typical Ubuntu system:
|
||||
|
||||

|
||||
|
||||
Some of the most important Linux system logs include:
|
||||
|
||||
- /var/log/syslog or /var/log/messages stores all global system activity data, including startup messages. Debian-based systems like Ubuntu store this in /var/log/syslog. RedHat-based systems like RHEL or CentOS store this in /var/log/messages.
|
||||
- /var/log/auth.log or /var/log/secure stores logs from the Pluggable Authentication Module (pam) including successful logins, failed login attempts, and authentication methods. Ubuntu and Debian store authentication messages in /var/log/auth.log. RedHat and CentOS store this data in /var/log/secure.
|
||||
- /var/log/kern stores kernel error and warning data, which is particularly helpful for troubleshooting custom kernels.
|
||||
- /var/log/cron stores information about cron jobs. Use this data to verify that your cron jobs are running successfully.
|
||||
|
||||
Digital Ocean has a thorough [tutorial][1] on these files and how rsyslog creates them on common distributions like RedHat and CentOS.
|
||||
|
||||
Applications also write log files in this directory. For example, popular servers like Apache, Nginx, MySQL, and more can write log files here. Some of these log files are written by the application itself. Others are created through syslog (see below).
|
||||
|
||||
### What’s Syslog? ###
|
||||
|
||||
How do Linux system log files get created? The answer is through the syslog daemon, which listens for log messages on the syslog socket /dev/log and then writes them to the appropriate log file.
|
||||
|
||||
The word “syslog” is an overloaded term and is often used in short to refer to one of these:
|
||||
|
||||
1. **Syslog daemon** — a program to receive, process, and send syslog messages. It can [send syslog remotely][2] to a centralized server or write it to a local file. Common examples include rsyslogd and syslog-ng. In this usage, people will often say “sending to syslog.”
|
||||
1. **Syslog protocol** — a transport protocol specifying how logs can be sent over a network and a data format definition for syslog messages (below). It’s officially defined in [RFC-5424][3]. The standard ports are 514 for plaintext logs and 6514 for encrypted logs. In this usage, people will often say “sending over syslog.”
|
||||
1. **Syslog messages** — log messages or events in the syslog format, which includes a header with several standard fields. In this usage, people will often say “sending syslog.”
|
||||
|
||||
Syslog messages or events include a header with several standard fields, making analysis and routing easier. They include the timestamp, the name of the application, the classification or location in the system where the message originates, and the priority of the issue.
|
||||
|
||||
Here is an example log message with the syslog header included. It’s from the sshd daemon, which controls remote logins to the system. This message describes a failed login attempt:
|
||||
|
||||
<34>1 2003-10-11T22:14:15.003Z server1.com sshd - - pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
|
||||
|
||||
### Syslog Format and Fields ###
|
||||
|
||||
Each syslog message includes a header with fields. Fields are structured data that makes it easier to analyze and route the events. Here is the format we used to generate the above syslog example. You can match each value to a specific field name.
|
||||
|
||||
<%pri%>%protocol-version% %timestamp:::date-rfc3339% %HOSTNAME% %app-name% %procid% %msgid% %msg%n
|
||||
|
||||
Below, you’ll find descriptions of some of the most commonly used syslog fields when searching or troubleshooting issues.
|
||||
|
||||
#### Timestamp ####
|
||||
|
||||
The [timestamp][4] field (2003-10-11T22:14:15.003Z in the example) indicates the time and date that the message was generated on the system sending the message. That time can be different from when another system receives the message. The example timestamp breaks down like this:
|
||||
|
||||
- **2003-10-11** is the year, month, and day.
|
||||
- **T** is a required element of the TIMESTAMP field, separating the date and the time.
|
||||
- **22:14:15.003** is the 24-hour format of the time, including the number of milliseconds (**003**) into the next second.
|
||||
- **Z** is an optional element, indicating UTC time. Instead of Z, the example could have included an offset, such as -08:00, which indicates that the time is offset from UTC by 8 hours, PST.
|
||||
|
||||
#### Hostname ####
|
||||
|
||||
The [hostname][5] field (server1.com in the example above) indicates the name of the host or system that sent the message.
|
||||
|
||||
#### App-Name ####
|
||||
|
||||
The [app-name][6] field (sshd:auth in the example) indicates the name of the application that sent the message.
|
||||
|
||||
#### Priority ####
|
||||
|
||||
The priority field or [pri][7] for short (<34> in the example above) tells you how urgent or severe the event is. It’s a combination of two numerical fields: the facility and the severity. The severity ranges from the number 7 for debug events all the way to 0 which is an emergency. The facility describes which process created the event. It ranges from 0 for kernel messages to 23 for local application use.
|
||||
|
||||
Pri can be output in two ways. The first is as a single number prival which is calculated as the facility field value multiplied by 8, then the result is added to the severity field value: (facility)(8) + (severity). The second is pri-text which will output in the string format “facility.severity.” The latter format can often be easier to read and search but takes up more storage space.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/linux-logging-basics/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://www.digitalocean.com/community/tutorials/how-to-view-and-configure-linux-logs-on-ubuntu-and-centos
|
||||
[2]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.y2e9tdfk1cdb
|
||||
[3]:https://tools.ietf.org/html/rfc5424
|
||||
[4]:https://tools.ietf.org/html/rfc5424#section-6.2.3
|
||||
[5]:https://tools.ietf.org/html/rfc5424#section-6.2.4
|
||||
[6]:https://tools.ietf.org/html/rfc5424#section-6.2.5
|
||||
[7]:https://tools.ietf.org/html/rfc5424#section-6.2.1
|
||||
@ -1,69 +0,0 @@
|
||||
Linux FAQs with Answers--How to enable logging in Open vSwitch for debugging and troubleshooting
|
||||
================================================================================
|
||||
> **Question:** I am trying to troubleshoot my Open vSwitch deployment. For that I would like to inspect its debug messages generated by its built-in logging mechanism. How can I enable logging in Open vSwitch, and change its logging level (e.g., to INFO/DEBUG level) to check more detailed debug information?
|
||||
|
||||
Open vSwitch (OVS) is the most popular open-source implementation of virtual switch on the Linux platform. As the today's data centers increasingly rely on the software-defined network (SDN) architecture, OVS is fastly adopted as the de-facto standard network element in data center's SDN deployments.
|
||||
|
||||
Open vSwitch has a built-in logging mechanism called VLOG. The VLOG facility allows one to enable and customize logging within various components of the switch. The logging information generated by VLOG can be sent to a combination of console, syslog and a separate log file for inspection. You can configure OVS logging dynamically at run-time with a command-line tool called `ovs-appctl`.
|
||||
|
||||
|
||||
|
||||
Here is how to enable logging and customize logging levels in Open vSwitch with `ovs-appctl`.
|
||||
|
||||
The syntax of `ovs-appctl` to customize VLOG is as follows.
|
||||
|
||||
$ sudo ovs-appctl vlog/set module[:facility[:level]]
|
||||
|
||||
- **Module**: name of any valid component in OVS (e.g., netdev, ofproto, dpif, vswitchd, and many others)
|
||||
- **Facility**: destination of logging information (must be: console, syslog or file)
|
||||
- **Level**: verbosity of logging (must be: emer, err, warn, info, or dbg)
|
||||
|
||||
In OVS source code, module name is defined in each source file in the form of:
|
||||
|
||||
VLOG_DEFINE_THIS_MODULE(<module-name>);
|
||||
|
||||
For example, in lib/netdev.c, you will see:
|
||||
|
||||
VLOG_DEFINE_THIS_MODULE(netdev);
|
||||
|
||||
which indicates that lib/netdev.c is part of netdev module. Any logging messages generated in lib/netdev.c will belong to netdev module.
|
||||
|
||||
In OVS source code, there are multiple severity levels used to define several different kinds of logging messages: VLOG_INFO() for informational, VLOG_WARN() for warning, VLOG_ERR() for error, VLOG_DBG() for debugging, VLOG_EMERG for emergency. Logging level and facility determine which logging messages are sent where.
|
||||
|
||||
To see a full list of available modules, facilities, and their respective logging levels, run the following commands. This command must be invoked after you have started OVS.
|
||||
|
||||
$ sudo ovs-appctl vlog/list
|
||||
|
||||
|
||||
|
||||
The output shows the debug levels of each module for three different facilities (console, syslog, file). By default, all modules have their logging level set to INFO.
|
||||
|
||||
Given any one OVS module, you can selectively change the debug level of any particular facility. For example, if you want to see more detailed debug messages of dpif module at the console screen, run the following command.
|
||||
|
||||
$ sudo ovs-appctl vlog/set dpif:console:dbg
|
||||
|
||||
You will see that dpif module's console facility has changed its logging level to DBG. The logging level of two other facilities, syslog and file, remains unchanged.
|
||||
|
||||
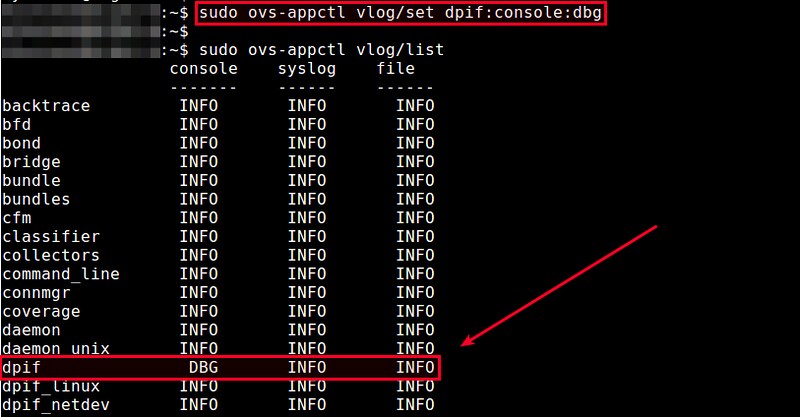
|
||||
|
||||
If you want to change the logging level for all modules, you can specify "ANY" as the module name. For example, the following command will change the console logging level of every module to DBG.
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:console:dbg
|
||||
|
||||
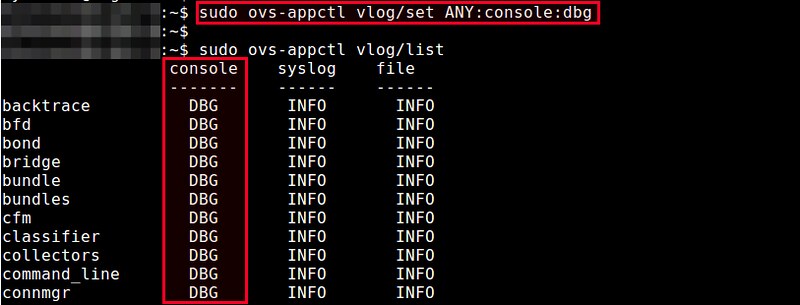
|
||||
|
||||
Also, if you want to change the logging level of all three facilities at once, you can specify "ANY" as the facility name. For example, the following command will change the logging level of all facilities for every module to DBG.
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:ANY:dbg
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/enable-logging-open-vswitch.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -1,49 +0,0 @@
|
||||
Linux FAQs with Answers--How to fix “ImportError: No module named wxversion” on Linux
|
||||
================================================================================
|
||||
> **Question:** I was trying to run a Python application on [insert your Linux distro], but I got an error "ImportError: No module named wxversion." How can I solve this error in the Python program?
|
||||
|
||||
Looking for python... 2.7.9 - Traceback (most recent call last):
|
||||
File "/home/dev/playonlinux/python/check_python.py", line 1, in
|
||||
import os, wxversion
|
||||
ImportError: No module named wxversion
|
||||
failed tests
|
||||
|
||||
This error indicates that your Python application is GUI-based, relying on a missing Python module called wxPython. [wxPython][1] is a Python extension module for the wxWidgets GUI library, popularly used by C++ programmers to design GUI applications. The wxPython extension allows Python developers to easily design and integrate GUI within any Python application.
|
||||
|
||||
To solve this import error, you need to install wxPython on your Linux, as described below.
|
||||
|
||||
### Install wxPython on Debian, Ubuntu or Linux Mint ###
|
||||
|
||||
$ sudo apt-get install python-wxgtk2.8
|
||||
|
||||
### Install wxPython on Fedora ###
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### Install wxPython on CentOS/RHEL ###
|
||||
|
||||
wxPython is available on the EPEL repository of CentOS/RHEL, not on base repositories. Thus, first [enable EPEL repository][2] on your system, and then use yum command.
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### Install wxPython on Arch Linux ###
|
||||
|
||||
$ sudo pacman -S wxpython
|
||||
|
||||
### Install wxPython on Gentoo ###
|
||||
|
||||
$ emerge wxPython
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/importerror-no-module-named-wxversion.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wxpython.org/
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -1,72 +0,0 @@
|
||||
Linux FAQs with Answers--How to install git on Linux
|
||||
================================================================================
|
||||
> **Question:** I am trying to clone a project from a public Git repository, but I am getting "git: command not found" error. How can I install git on [insert your Linux distro]?
|
||||
|
||||
Git is a popular open-source version control system (VCS) originally developed for Linux environment. Contrary to other VCS tools like CVS or SVN, Git's revision control is considered "distributed" in a sense that your local Git working directory can function as a fully-working repository with complete history and version-tracking capabilities. In this model, each collaborator commits to his or her local repository (as opposed to always committing to a central repository), and optionally push to a centralized repository if need be. This brings in scalability and redundancy to the revision control system, which is a must in any kind of large-scale collaboration.
|
||||
|
||||
|
||||
|
||||
### Install Git with a Package Manager ###
|
||||
|
||||
Git is shipped with all major Linux distributions. Thus the easiest way to install Git is by using your Linux distro's package manager.
|
||||
|
||||
**Debian, Ubuntu, or Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||
**Fedora, CentOS or RHEL**
|
||||
|
||||
$ sudo yum install git
|
||||
|
||||
**Arch Linux**
|
||||
|
||||
$ sudo pacman -S git
|
||||
|
||||
**OpenSUSE**
|
||||
|
||||
$ sudo zypper install git
|
||||
|
||||
**Gentoo**
|
||||
|
||||
$ emerge --ask --verbose dev-vcs/git
|
||||
|
||||
### Install Git from the Source ###
|
||||
|
||||
If for whatever reason you want to built Git from the source, you can follow the instructions below.
|
||||
|
||||
**Install Dependencies**
|
||||
|
||||
Before building Git, first install dependencies.
|
||||
|
||||
**Debian, Ubuntu or Linux**
|
||||
|
||||
$ sudo apt-get install libcurl4-gnutls-dev libexpat1-dev gettext libz-dev libssl-dev asciidoc xmlto docbook2x
|
||||
|
||||
**Fedora, CentOS or RHEL**
|
||||
|
||||
$ sudo yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel asciidoc xmlto docbook2x
|
||||
|
||||
#### Compile Git from the Source ####
|
||||
|
||||
Download the latest release of Git from [https://github.com/git/git/releases][1]. Then build and install Git under /usr as follows.
|
||||
|
||||
Note that if you want to install it under a different directory (e.g., /opt), replace "--prefix=/usr" in configure command with something else.
|
||||
|
||||
$ cd git-x.x.x
|
||||
$ make configure
|
||||
$ ./configure --prefix=/usr
|
||||
$ make all doc info
|
||||
$ sudo make install install-doc install-html install-info
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-git-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/git/git/releases
|
||||
@ -1,323 +0,0 @@
|
||||
[translating by xiqingongzi]
|
||||
RHCSA Series: How to Perform File and Directory Management – Part 2
|
||||
================================================================================
|
||||
In this article, RHCSA Part 2: File and directory management, we will review some essential skills that are required in the day-to-day tasks of a system administrator.
|
||||
|
||||

|
||||
|
||||
RHCSA: Perform File and Directory Management – Part 2
|
||||
|
||||
### Create, Delete, Copy, and Move Files and Directories ###
|
||||
|
||||
File and directory management is a critical competence that every system administrator should possess. This includes the ability to create / delete text files from scratch (the core of each program’s configuration) and directories (where you will organize files and other directories), and to find out the type of existing files.
|
||||
|
||||
The [touch command][1] can be used not only to create empty files, but also to update the access and modification times of existing files.
|
||||
|
||||

|
||||
|
||||
touch command example
|
||||
|
||||
You can use `file [filename]` to determine a file’s type (this will come in handy before launching your preferred text editor to edit it).
|
||||
|
||||
|
||||
|
||||
file command example
|
||||
|
||||
and `rm [filename]` to delete it.
|
||||
|
||||

|
||||
|
||||
rm command example
|
||||
|
||||
As for directories, you can create directories inside existing paths with `mkdir [directory]` or create a full path with `mkdir -p [/full/path/to/directory].`
|
||||
|
||||

|
||||
|
||||
mkdir command example
|
||||
|
||||
When it comes to removing directories, you need to make sure that they’re empty before issuing the `rmdir [directory]` command, or use the more powerful (handle with care!) `rm -rf [directory]`. This last option will force remove recursively the `[directory]` and all its contents – so use it at your own risk.
|
||||
|
||||
### Input and Output Redirection and Pipelining ###
|
||||
|
||||
The command line environment provides two very useful features that allows to redirect the input and output of commands from and to files, and to send the output of a command to another, called redirection and pipelining, respectively.
|
||||
|
||||
To understand those two important concepts, we must first understand the three most important types of I/O (Input and Output) streams (or sequences) of characters, which are in fact special files, in the *nix sense of the word.
|
||||
|
||||
- Standard input (aka stdin) is by default attached to the keyboard. In other words, the keyboard is the standard input device to enter commands to the command line.
|
||||
- Standard output (aka stdout) is by default attached to the screen, the device that “receives” the output of commands and display them on the screen.
|
||||
- Standard error (aka stderr), is where the status messages of a command is sent to by default, which is also the screen.
|
||||
|
||||
In the following example, the output of `ls /var` is sent to stdout (the screen), as well as the result of ls /tecmint. But in the latter case, it is stderr that is shown.
|
||||
|
||||

|
||||
|
||||
Input and Output Example
|
||||
|
||||
To more easily identify these special files, they are each assigned a file descriptor, an abstract representation that is used to access them. The essential thing to understand is that these files, just like others, can be redirected. What this means is that you can capture the output from a file or script and send it as input to another file, command, or script. This will allow you to store on disk, for example, the output of commands for later processing or analysis.
|
||||
|
||||
To redirect stdin (fd 0), stdout (fd 1), or stderr (fd 2), the following operators are available.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="226"></colgroup>
|
||||
<colgroup width="743"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Redirection Operator</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Effect</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Redirects standard output to a file containing standard output. If the destination file exists, it will be overwritten.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends standard output to a file.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Redirects standard error to a file containing standard output. If the destination file exists, it will be overwritten.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends standard error to the existing file.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">&></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Redirects both standard output and standard error to a file; if the specified file exists, it will be overwritten.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><</span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Uses the specified file as standard input.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">The specified file is used for both standard input and standard output.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
As opposed to redirection, pipelining is performed by adding a vertical bar `(|)` after a command and before another one.
|
||||
|
||||
Remember:
|
||||
|
||||
- Redirection is used to send the output of a command to a file, or to send a file as input to a command.
|
||||
- Pipelining is used to send the output of a command to another command as input.
|
||||
|
||||
#### Examples Of Redirection and Pipelining ####
|
||||
|
||||
**Example 1: Redirecting the output of a command to a file**
|
||||
|
||||
There will be times when you will need to iterate over a list of files. To do that, you can first save that list to a file and then read that file line by line. While it is true that you can iterate over the output of ls directly, this example serves to illustrate redirection.
|
||||
|
||||
# ls -1 /var/mail > mail.txt
|
||||
|
||||
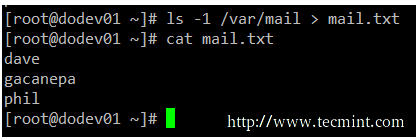
|
||||
|
||||
Redirect output of command tot a file
|
||||
|
||||
**Example 2: Redirecting both stdout and stderr to /dev/null**
|
||||
|
||||
In case we want to prevent both stdout and stderr to be displayed on the screen, we can redirect both file descriptors to `/dev/null`. Note how the output changes when the redirection is implemented for the same command.
|
||||
|
||||
# ls /var /tecmint
|
||||
# ls /var/ /tecmint &> /dev/null
|
||||
|
||||

|
||||
|
||||
Redirecting stdout and stderr ouput to /dev/null
|
||||
|
||||
#### Example 3: Using a file as input to a command ####
|
||||
|
||||
While the classic syntax of the [cat command][2] is as follows.
|
||||
|
||||
# cat [file(s)]
|
||||
|
||||
You can also send a file as input, using the correct redirection operator.
|
||||
|
||||
# cat < mail.txt
|
||||
|
||||
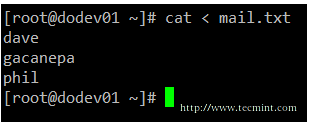
|
||||
|
||||
cat command example
|
||||
|
||||
#### Example 4: Sending the output of a command as input to another ####
|
||||
|
||||
If you have a large directory or process listing and want to be able to locate a certain file or process at a glance, you will want to pipeline the listing to grep.
|
||||
|
||||
Note that we use to pipelines in the following example. The first one looks for the required keyword, while the second one will eliminate the actual `grep command` from the results. This example lists all the processes associated with the apache user.
|
||||
|
||||
# ps -ef | grep apache | grep -v grep
|
||||
|
||||

|
||||
|
||||
Send output of command as input to another
|
||||
|
||||
### Archiving, Compressing, Unpacking, and Uncompressing Files ###
|
||||
|
||||
If you need to transport, backup, or send via email a group of files, you will use an archiving (or grouping) tool such as [tar][3], typically used with a compression utility like gzip, bzip2, or xz.
|
||||
|
||||
Your choice of a compression tool will be likely defined by the compression speed and rate of each one. Of these three compression tools, gzip is the oldest and provides the least compression, bzip2 provides improved compression, and xz is the newest and provides the best compression. Typically, files compressed with these utilities have .gz, .bz2, or .xz extensions, respectively.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="165"></colgroup>
|
||||
<colgroup width="137"></colgroup>
|
||||
<colgroup width="366"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Command</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Abbreviation</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –create</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">c</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Creates a tar archive</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –concatenate</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">A</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends tar files to an archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –append</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">r</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends non-tar files to an archive</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –update</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">u</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends files that are newer than those in an archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –diff or –compare</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">d</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Compares an archive to files on disk</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="20" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –list</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">t</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Lists the contents of a tarball</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –extract or –get</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">x</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Extracts files from an archive</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="258"></colgroup>
|
||||
<colgroup width="152"></colgroup>
|
||||
<colgroup width="803"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">Operation modifier</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">Abbreviation</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>directory dir</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> C</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Changes to directory dir before performing operations</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>same-permissions and <span style="font-family: Courier New;">—</span>same-owner</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> p</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Preserves permissions and ownership information, respectively.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –verbose</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> v</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Lists all files as they are read or extracted; if combined with –list, it also displays file sizes, ownership, and timestamps</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>exclude file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> —</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Excludes file from the archive. In this case, file can be an actual file or a pattern.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>gzip or <span style="font-family: Courier New;">—</span>gunzip</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> z</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Compresses an archive through gzip</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –bzip2</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> j</span></td>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;">Compresses an archive through bzip2</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –xz</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> J</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Compresses an archive through xz</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### Example 5: Creating a tarball and then compressing it using the three compression utilities ####
|
||||
|
||||
You may want to compare the effectiveness of each tool before deciding to use one or another. Note that while compressing small files, or a few files, the results may not show much differences, but may give you a glimpse of what they have to offer.
|
||||
|
||||
# tar cf ApacheLogs-$(date +%Y%m%d).tar /var/log/httpd/* # Create an ordinary tarball
|
||||
# tar czf ApacheLogs-$(date +%Y%m%d).tar.gz /var/log/httpd/* # Create a tarball and compress with gzip
|
||||
# tar cjf ApacheLogs-$(date +%Y%m%d).tar.bz2 /var/log/httpd/* # Create a tarball and compress with bzip2
|
||||
# tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* # Create a tarball and compress with xz
|
||||
|
||||

|
||||
|
||||
tar command examples
|
||||
|
||||
#### Example 6: Preserving original permissions and ownership while archiving and when ####
|
||||
|
||||
If you are creating backups from users’ home directories, you will want to store the individual files with the original permissions and ownership instead of changing them to that of the user account or daemon performing the backup. The following example preserves these attributes while taking the backup of the contents in the `/var/log/httpd` directory:
|
||||
|
||||
# tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* --same-permissions --same-owner
|
||||
|
||||
### Create Hard and Soft Links ###
|
||||
|
||||
In Linux, there are two types of links to files: hard links and soft (aka symbolic) links. Since a hard link represents another name for an existing file and is identified by the same inode, it then points to the actual data, as opposed to symbolic links, which point to filenames instead.
|
||||
|
||||
In addition, hard links do not occupy space on disk, while symbolic links do take a small amount of space to store the text of the link itself. The downside of hard links is that they can only be used to reference files within the filesystem where they are located because inodes are unique inside a filesystem. Symbolic links save the day, in that they point to another file or directory by name rather than by inode, and therefore can cross filesystem boundaries.
|
||||
|
||||
The basic syntax to create links is similar in both cases:
|
||||
|
||||
# ln TARGET LINK_NAME # Hard link named LINK_NAME to file named TARGET
|
||||
# ln -s TARGET LINK_NAME # Soft link named LINK_NAME to file named TARGET
|
||||
|
||||
#### Example 7: Creating hard and soft links ####
|
||||
|
||||
There is no better way to visualize the relation between a file and a hard or symbolic link that point to it, than to create those links. In the following screenshot you will see that the file and the hard link that points to it share the same inode and both are identified by the same disk usage of 466 bytes.
|
||||
|
||||
On the other hand, creating a hard link results in an extra disk usage of 5 bytes. Not that you’re going to run out of storage capacity, but this example is enough to illustrate the difference between a hard link and a soft link.
|
||||
|
||||

|
||||
|
||||
Difference between a hard link and a soft link
|
||||
|
||||
A typical usage of symbolic links is to reference a versioned file in a Linux system. Suppose there are several programs that need access to file fooX.Y, which is subject to frequent version updates (think of a library, for example). Instead of updating every single reference to fooX.Y every time there’s a version update, it is wiser, safer, and faster, to have programs look to a symbolic link named just foo, which in turn points to the actual fooX.Y.
|
||||
|
||||
Thus, when X and Y change, you only need to edit the symbolic link foo with a new destination name instead of tracking every usage of the destination file and updating it.
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have reviewed some essential file and directory management skills that must be a part of every system administrator’s tool-set. Make sure to review other parts of this series as well in order to integrate these topics with the content covered in this tutorial.
|
||||
|
||||
Feel free to let us know if you have any questions or comments. We are always more than glad to hear from our readers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[2]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
@ -1,3 +1,4 @@
|
||||
[translated by xiqingongzi]
|
||||
RHCSA Series: How to Manage Users and Groups in RHEL 7 – Part 3
|
||||
================================================================================
|
||||
Managing a RHEL 7 server, as it is the case with any other Linux server, will require that you know how to add, edit, suspend, or delete user accounts, and grant users the necessary permissions to files, directories, and other system resources to perform their assigned tasks.
|
||||
@ -245,4 +246,4 @@ via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://www.tecmint.com/ls-interview-questions/
|
||||
[4]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
|
||||
@ -1,91 +0,0 @@
|
||||
选择软件开发攻城师的5个原因
|
||||
================================================================================
|
||||
这个星期我将给本地一所高中做一次有关于程序猿是怎样工作的演讲,我是 [Transfer][1] 组织推荐来到这所学校,谈论我的工作。这个学校本周将有一个技术主题日,并且他们很想听听科技行业是怎样工作的。因为我是从事软件开发的,这也是我将和学生们讲的内容。我为什么觉得软件开发是一个很酷的职业将是演讲的其中一部分。主要原因如下:
|
||||
|
||||
### 5个原因 ###
|
||||
|
||||
**1 创造性**
|
||||
|
||||

|
||||
|
||||
如果你问别人创造性的工作有哪些,别人通常会说像作家,音乐家或者画家那样的(工作)。但是极少有人知道软件开发也是一项非常具有创造性的工作。因为你创造了一个以前没有的新功能,这样的功能基本上可以被定义为非常具有创造性。这种解决方案可以在整体和细节上以很多形式来展现。我们经常会遇到一些需要做权衡的场景(比如说运行速度与内存消耗的权衡)。当然前提是这种解决方案必须是正确的。其实这些所有的行为都是需要强大的创造性的。
|
||||
|
||||
**2 协作性**
|
||||
|
||||

|
||||
|
||||
另外一个表象是程序猿们独自坐在他们的电脑前,然后撸一天的代码。但是软件开发事实上通常总是一个团队努力的结果。你会经常和你的同事讨论编程问题以及解决方案,并且和产品经理,测试人员,客户讨论需求以及其他问题。
|
||||
经常有人说,结对编程(2个开发人员一起在一个电脑上编程)是一种流行的最佳实践。
|
||||
|
||||
|
||||
**3 高需性**
|
||||
|
||||

|
||||
|
||||
世界上越来越多的人在用软件,正如 [Marc Andreessen](https://en.wikipedia.org/wiki/Marc_Andreessen) 所说 " [软件正在吞噬世界][2] "。虽然程序猿现在的数量非常巨大(在斯德哥尔摩,程序猿现在是 [最普遍的职业][3] ),但是,需求量一直处于供不应求的局面。据软件公司报告,他们最大的挑战之一就是 [找到优秀的程序猿][4] 。我也经常接到那些想让我跳槽的招聘人员打来的电话。我知道至少除软件行业之外的其他行业的雇主不会那么拼(的去招聘)。
|
||||
|
||||
**4 高酬性**
|
||||
|
||||
|
||||

|
||||
|
||||
软件开发可以带来不菲的收入。卖一份你已经开发好的软件的额外副本是没有 [边际成本][5] 的。这个事实与对程序猿的高需求意味着收入相当可观。当然还有许多更捞金的职业,但是相比一般人群,我认为软件开发者确实“日进斗金”(知足吧!骚年~~)。
|
||||
|
||||
**5 前瞻性**
|
||||
|
||||

|
||||
|
||||
有许多工作岗位消失,往往是由于它们可以被计算机和软件代替。但是所有这些新的程序依然需要开发和维护,因此,程序猿的前景还是相当好的。
|
||||
|
||||
|
||||
### 但是...###
|
||||
|
||||
**外包又是怎么一回事呢?**
|
||||
|
||||

|
||||
|
||||
难道所有外包到其他地区的软件开发的薪水都很低吗?这是一个理想丰满,现实骨感的例子(有点像 [瀑布开发模型][6] )。软件开发基本上跟设计的工作一样,是一个探索发现的工作。它受益于强有力的合作。更进一步说,特别当你的主打产品是软件的时候,你所掌握的开发知识是绝对的优势。知识在整个公司中分享的越容易,那么公司的发展也将越来越好。
|
||||
|
||||
|
||||
换一种方式去看待这个问题。软件外包已经存在了相当一段时间了。但是对本土程序猿的需求量依旧非常高。因为许多软件公司看到了雇佣本土程序猿的带来的收益要远远超过了相对较高的成本(其实还是赚了)。
|
||||
|
||||
### 如何成为人生大赢家 ###
|
||||
|
||||
|
||||

|
||||
|
||||
虽然我有许多我认为软件开发是一件非常有趣的事情的理由 (详情见: [为什么我热爱编程][7] )。但是这些理由,并不适用于所有人。幸运的是,尝试编程是一件非常容易的事情。在互联网上有数不尽的学习编程的资源。例如,[Coursera][8] 和 [Udacity][9] 都拥有很好的入门课程。如果你从来没有撸过码,可以尝试其中一个免费的课程,找找感觉。
|
||||
|
||||
寻找一个既热爱又能谋生的事情至少有2个好处。首先,由于你天天去做,工作将比你简单的只为谋生要有趣的多。其次,如果你真的非常喜欢,你将更好的擅长它。我非常喜欢下面一副关于伟大工作组成的韦恩图(作者 [@eskimon)][10] 。因为编码的薪水确实相当不错,我认为如果你真的喜欢它,你将有一个很好的机会,成为人生的大赢家!
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://henrikwarne.com/2014/12/08/5-reasons-why-software-developer-is-a-great-career-choice/
|
||||
|
||||
作者:[Henrik Warne][a]
|
||||
译者:[mousycoder](https://github.com/mousycoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:http://henrikwarne.com/
|
||||
[1]:http://www.transfer.nu/omoss/transferinenglish.jspx?pageId=23
|
||||
[2]:http://www.wsj.com/articles/SB10001424053111903480904576512250915629460
|
||||
[3]:http://www.di.se/artiklar/2014/6/12/jobbet-som-tar-over-landet/
|
||||
[4]:http://computersweden.idg.se/2.2683/1.600324/examinationstakten-racker-inte-for-branschens-behov
|
||||
[5]:https://en.wikipedia.org/wiki/Marginal_cost
|
||||
[6]:https://en.wikipedia.org/wiki/Waterfall_model
|
||||
[7]:http://henrikwarne.com/2012/06/02/why-i-love-coding/
|
||||
[8]:https://www.coursera.org/
|
||||
[9]:https://www.udacity.com/
|
||||
[10]:https://eskimon.wordpress.com/about/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,148 @@
|
||||
在 Debian 中安装 OpenQRM 云计算平台
|
||||
================================================================================
|
||||
### 简介 ###
|
||||
|
||||
**openQRM**是一个基于 Web 的开源云计算和数据中心管理平台,可灵活地与企业数据中心的现存组件集成。
|
||||
|
||||
它支持下列虚拟技术:
|
||||
|
||||
- KVM,
|
||||
- XEN,
|
||||
- Citrix XenServer,
|
||||
- VMWare ESX,
|
||||
- LXC,
|
||||
- OpenVZ.
|
||||
|
||||
openQRM 中的杂交云连接器通过 **Amazon AWS**, **Eucalyptus** 或 **OpenStack** 来支持一系列的私有或公有云提供商,以此来按需扩展你的基础设施。它也自动地进行资源调配、 虚拟化、 存储和配置管理,且关注高可用性。集成计费系统的自助服务云门户可使终端用户按需请求新的服务器和应用堆栈。
|
||||
|
||||
openQRM 有两种不同风格的版本可获取:
|
||||
|
||||
- 企业版
|
||||
- 社区版
|
||||
|
||||
你可以在[这里][1] 查看这两个版本间的区别。
|
||||
|
||||
### 特点 ###
|
||||
|
||||
- 私有/杂交的云计算平台;
|
||||
- 可管理物理或虚拟的服务器系统;
|
||||
- 可与所有主流的开源或商业的存储技术集成;
|
||||
- 跨平台: Linux, Windows, OpenSolaris, and BSD;
|
||||
- 支持 KVM, XEN, Citrix XenServer, VMWare ESX(i), lxc, OpenVZ 和 VirtualBox;
|
||||
- 支持使用额外的 Amazon AWS, Eucalyptus, Ubuntu UEC 等云资源来进行杂交云设置;
|
||||
- 支持 P2V, P2P, V2P, V2V 迁移和高可用性;
|
||||
- 集成最好的开源管理工具 – 如 puppet, nagios/Icinga 或 collectd;
|
||||
- 有超过 50 个插件来支持扩展功能并与你的基础设施集成;
|
||||
- 针对终端用户的自助门户;
|
||||
- 集成计费系统.
|
||||
|
||||
### 安装 ###
|
||||
|
||||
在这里我们将在 in Debian 7.5 上安装 openQRM。你的服务器必须至少满足以下要求:
|
||||
|
||||
- 1 GB RAM;
|
||||
- 100 GB Hdd(硬盘驱动器);
|
||||
- 可选: Bios 支持虚拟化(Intel CPUs 的 VT 或 AMD CPUs AMD-V).
|
||||
|
||||
首先,安装 `make` 软件包来编译 openQRM 源码包:
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
sudo apt-get install make
|
||||
|
||||
然后,逐次运行下面的命令来安装 openQRM。
|
||||
|
||||
从[这里][2] 下载最新的可用版本:
|
||||
|
||||
wget http://sourceforge.net/projects/openqrm/files/openQRM-Community-5.1/openqrm-community-5.1.tgz
|
||||
|
||||
tar -xvzf openqrm-community-5.1.tgz
|
||||
|
||||
cd openqrm-community-5.1/src/
|
||||
|
||||
sudo make
|
||||
|
||||
sudo make install
|
||||
|
||||
sudo make start
|
||||
|
||||
安装期间,你将被询问去更新文件 `php.ini`
|
||||
|
||||

|
||||
|
||||
输入 mysql root 用户密码。
|
||||
|
||||

|
||||
|
||||
再次输入密码:
|
||||
|
||||

|
||||
|
||||
选择邮件服务器配置类型。
|
||||
|
||||

|
||||
|
||||
假如你不确定该如何选择,可选择 `Local only`。在我们的这个示例中,我选择了 **Local only** 选项。
|
||||
|
||||

|
||||
|
||||
输入你的系统邮件名称,并最后输入 Nagios 管理员密码。
|
||||
|
||||

|
||||
|
||||
根据你的网络连接状态,上面的命令可能将花费很长的时间来下载所有运行 openQRM 所需的软件包,请耐心等待。
|
||||
|
||||
最后你将得到 openQRM 配置 URL 地址以及相关的用户名和密码。
|
||||
|
||||

|
||||
|
||||
### 配置 ###
|
||||
|
||||
在安装完 openQRM 后,打开你的 Web 浏览器并转到 URL: **http://ip-address/openqrm**
|
||||
|
||||
例如,在我的示例中为 http://192.168.1.100/openqrm 。
|
||||
|
||||
默认的用户名和密码是: **openqrm/openqrm** 。
|
||||
|
||||

|
||||
|
||||
选择一个网卡来给 openQRM 管理网络使用。
|
||||
|
||||

|
||||
|
||||
选择一个数据库类型,在我们的示例中,我选择了 mysql。
|
||||
|
||||

|
||||
|
||||
现在,配置数据库连接并初始化 openQRM, 在这里,我使用 **openQRM** 作为数据库名称, **root** 作为用户的身份,并将 debian 作为数据库的密码。 请小心,你应该输入先前在安装 openQRM 时创建的 mysql root 用户密码。
|
||||
|
||||

|
||||
|
||||
祝贺你!! openQRM 已经安装并配置好了。
|
||||
|
||||

|
||||
|
||||
### 更新 openQRM ###
|
||||
|
||||
在任何时候可以使用下面的命令来更新 openQRM:
|
||||
|
||||
cd openqrm/src/
|
||||
make update
|
||||
|
||||
到现在为止,我们做的只是在我们的 Ubuntu 服务器中安装和配置 openQRM, 至于 创建、运行虚拟,管理存储,额外的系统集成和运行你自己的私有云等内容,我建议你阅读 [openQRM 管理员指南][3]。
|
||||
|
||||
就是这些了,欢呼吧!周末快乐!
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-openqrm-cloud-computing-platform-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.openqrm-enterprise.com/products/edition-comparison.html
|
||||
[2]:http://sourceforge.net/projects/openqrm/files/?source=navbar
|
||||
[3]:http://www.openqrm-enterprise.com/fileadmin/Documents/Whitepaper/openQRM-Enterprise-Administrator-Guide-5.2.pdf
|
||||
@ -1,237 +0,0 @@
|
||||
|
||||
如何收集NGINX指标 - 第2部分
|
||||
================================================================================
|
||||

|
||||
|
||||
### 如何获取你所需要的NGINX指标 ###
|
||||
|
||||
如何获取需要的指标取决于你正在使用的 NGINX 版本。(参见 [the companion article][1] 将深入探索NGINX指标。)免费,开源版的 NGINX 和商业版的 NGINX 都有指标度量的状态模块,NGINX 也可以在其日志中配置指标模块:
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: center;">
|
||||
<col style="text-align: center;">
|
||||
<col style="text-align: center;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th rowspan="2" style="text-align: left;">Metric</th>
|
||||
<th colspan="3" style="text-align: center;">Availability</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source">NGINX (open-source)</a></th>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus">NGINX Plus</a></th>
|
||||
<th style="text-align: center;"><a href="https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#logs">NGINX logs</a></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts / accepted</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">handled</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests / total</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;"></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">4xx codes</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">request time</td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;"></td>
|
||||
<td style="text-align: center;">x</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### 指标收集:NGINX(开源版) ####
|
||||
|
||||
开源版的 NGINX 会显示几个与服务器状态有关的指标在状态页面上,只要你启用了 HTTP [stub status module][2] 。要检查模块是否被加载,运行以下命令:
|
||||
|
||||
nginx -V 2>&1 | grep -o with-http_stub_status_module
|
||||
|
||||
如果你看到 http_stub_status_module 被输出在终端,说明状态模块已启用。
|
||||
|
||||
如果该命令没有输出,你需要启用状态模块。你可以使用 --with-http_stub_status_module 参数去配置 [building NGINX from source][3]:
|
||||
|
||||
./configure \
|
||||
… \
|
||||
--with-http_stub_status_module
|
||||
make
|
||||
sudo make install
|
||||
|
||||
验证模块已经启用或你自己启用它后,你还需要修改 NGINX 配置文件为状态页面设置本地访问的 URL(例如,/ nginx_status):
|
||||
|
||||
server {
|
||||
location /nginx_status {
|
||||
stub_status on;
|
||||
|
||||
access_log off;
|
||||
allow 127.0.0.1;
|
||||
deny all;
|
||||
}
|
||||
}
|
||||
|
||||
注:nginx 配置中的 server 块通常并不在主配置文件中(例如,/etc/nginx/nginx.conf),但主配置中会加载补充的配置文件。要找到主配置文件,首先运行以下命令:
|
||||
|
||||
nginx -t
|
||||
|
||||
打开主配置文件,在以 http 模块结尾的附近查找以 include 开头的行包,如:
|
||||
|
||||
include /etc/nginx/conf.d/*.conf;
|
||||
|
||||
在所包含的配置文件中,你应该会找到主服务器模块,你可以如上所示修改 NGINX 的指标报告。更改任何配置后,通过执行以下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
现在,你可以查看指标的状态页:
|
||||
|
||||
Active connections: 24
|
||||
server accepts handled requests
|
||||
1156958 1156958 4491319
|
||||
Reading: 0 Writing: 18 Waiting : 6
|
||||
|
||||
请注意,如果你正试图从远程计算机访问状态页面,则需要将远程计算机的 IP 地址添加到你的状态配置文件的白名单中,在上面的配置文件中 127.0.0.1 仅在白名单中。
|
||||
|
||||
nginx 的状态页面是一中查看指标快速又简单的方法,但当连续监测时,你需要每隔一段时间自动记录该数据。然后通过监控工具箱 [Nagios][4] 或者 [Datadog][5],以及收集统计信息的服务 [collectD][6] 来分析已保存的 NGINX 状态信息。
|
||||
|
||||
#### 指标收集: NGINX Plus ####
|
||||
|
||||
商业版的 NGINX Plus 通过 ngx_http_status_module 提供的可用指标比开源版 NGINX 更多 [many more metrics][7] 。NGINX Plus 附加了更多的字节流指标,以及负载均衡系统和高速缓存的信息。NGINX Plus 还报告所有的 HTTP 状态码类型(1XX,2XX,3XX,4XX,5XX)的计数。一个简单的 NGINX Plus 状态报告 [here][8]。
|
||||
|
||||

|
||||
|
||||
*注: NGINX Plus 在状态仪表盘"Active”连接定义的收集指标的状态模块和开源 NGINX 的略有不同。在 NGINX Plus 指标中,活动连接不包括等待状态(又叫空闲连接)连接。*
|
||||
|
||||
NGINX Plus 也集成了其他监控系统的报告 [JSON格式指标][9] 。用 NGINX Plus 时,你可以看到 [负载均衡服务器组的][10]指标和健康状况,或着再向下能取得的仅是响应代码计数[从单个服务器][11]在负载均衡服务器中:
|
||||
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
|
||||
|
||||
启动 NGINX Plus 指标仪表盘,你可以在 NGINX 配置文件的 http 块内添加状态 server 块。 ([参见上一页][12]查找相关的配置文件,收集开源 NGINX 版指标的说明。)例如,设立以下一个状态仪表盘在http://your.ip.address:8080/status.html 和一个 JSON 接口 http://your.ip.address:8080/status,可以添加以下 server block 来设定:
|
||||
|
||||
server {
|
||||
listen 8080;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
location /status {
|
||||
status;
|
||||
}
|
||||
|
||||
location = /status.html {
|
||||
}
|
||||
}
|
||||
|
||||
一旦你重新加载 NGINX 配置,状态页就会被加载:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
关于如何配置扩展状态模块,官方 NGINX Plus 文档有 [详细介绍][13] 。
|
||||
|
||||
#### 指标收集:NGINX日志 ####
|
||||
|
||||
NGINX 的 [日志模块][14] 写到配置可以自定义访问日志到指定文件。你可以自定义日志的格式和时间通过 [添加或移除变量][15]。捕获日志的详细信息,最简单的方法是添加下面一行在你配置文件的server 块中(参见[此节][16] 通过加载配置文件的信息来收集开源 NGINX 的指标):
|
||||
|
||||
access_log logs/host.access.log combined;
|
||||
|
||||
更改 NGINX 配置文件后,必须要重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
“combined” 的日志格式,只包含默认参数,包括[一些关键数据][17],如实际的 HTTP 请求和相应的响应代码。在下面的示例日志中,NGINX 记录了200(成功)状态码当请求 /index.html 时和404(未找到)错误不存在的请求文件 /fail。
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以记录请求处理的时间通过添加一个新的日志格式在 NGINX 配置文件中的 http 块:
|
||||
|
||||
log_format nginx '$remote_addr - $remote_user [$time_local] '
|
||||
'"$request" $status $body_bytes_sent $request_time '
|
||||
'"$http_referer" "$http_user_agent"';
|
||||
|
||||
通过修改配置文件中 server 块的 access_log 行:
|
||||
|
||||
access_log logs/host.access.log nginx;
|
||||
|
||||
重新加载配置文件(运行 nginx -s reload)后,你的访问日志将包括响应时间,如下图所示。单位为秒,毫秒。在这种情况下,服务器接收 /big.pdf 的请求时,发送33973115字节后返回206(成功)状态码。处理请求用时0.202秒(202毫秒):
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以使用各种工具和服务来收集和分析 NGINX 日志。例如,[rsyslog][18] 可以监视你的日志,并将其传递给多个日志分析服务;你也可以使用免费的开源工具,如[logstash][19]来收集和分析日志;或者你可以使用一个统一日志记录层,如[Fluentd][20]来收集和分析你的 NGINX 日志。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
监视 NGINX 的哪一项指标将取决于你提供的工具,以及是否由给定指标证明监控指标的开销。例如,通过收集和分析日志来定位问题是非常重要的在 NGINX Plus 或者 运行的系统中。
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。了解如何用 NGINX Datadog来监控 [在本文中][21],并开始使用 [免费的Datadog][22]。
|
||||
|
||||
----------
|
||||
|
||||
原文在这 [on GitHub][23]。问题,更正,补充等?请[让我们知道][24]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
|
||||
[3]:http://wiki.nginx.org/InstallOptions
|
||||
[4]:https://exchange.nagios.org/directory/Plugins/Web-Servers/nginx
|
||||
[5]:http://docs.datadoghq.com/integrations/nginx/
|
||||
[6]:https://collectd.org/wiki/index.php/Plugin:nginx
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_status_module.html#data
|
||||
[8]:http://demo.nginx.com/status.html
|
||||
[9]:http://demo.nginx.com/status
|
||||
[10]:http://demo.nginx.com/status/upstreams/demoupstreams
|
||||
[11]:http://demo.nginx.com/status/upstreams/demoupstreams/0/responses
|
||||
[12]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[13]:http://nginx.org/en/docs/http/ngx_http_status_module.html#example
|
||||
[14]:http://nginx.org/en/docs/http/ngx_http_log_module.html
|
||||
[15]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[17]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[18]:http://www.rsyslog.com/
|
||||
[19]:https://www.elastic.co/products/logstash
|
||||
[20]:http://www.fluentd.org/
|
||||
[21]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[22]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#sign-up
|
||||
[23]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_collect_nginx_metrics.md
|
||||
[24]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,416 +0,0 @@
|
||||
如何监控 NGINX - 第1部分
|
||||
================================================================================
|
||||

|
||||
|
||||
### NGINX 是什么? ###
|
||||
|
||||
[NGINX][1] (发音为 “engine X”) 是一种流行的 HTTP 和反向代理服务器。作为一个 HTTP 服务器,NGINX 提供静态内容非常高效可靠,使用较少的内存。作为[反向代理][2],它可以用作一个单一的控制器来为其他应用代理至后端的多个服务器上,如高速缓存和负载平衡。NGINX 是作为一个免费,开源的产品并有更全的功能,商业版的叫 NGINX Plus。
|
||||
|
||||
NGINX 也可以用作邮件代理和通用的 TCP 代理,但本文并不直接说明对 NGINX 的这些用例做监控。
|
||||
|
||||
### NGINX 主要指标 ###
|
||||
|
||||
通过监控 NGINX 可以捕捉两类问题:NGINX 本身的资源问题,也有很多问题会出现在你的基础网络设施处。大多数 NGINX 用户受益于以下指标的监控,包括**requests per second**,它提供了一个所有用户活动的高级视图;**server error rate** ,这表明你的服务器已经多长没有处理看似有效的请求;还有**request processing time**,这说明你的服务器处理客户端请求的总共时长(并且可以看出性能降低时或当前环境的其他问题)。
|
||||
|
||||
更一般地,至少有三个主要的指标类别来监视:
|
||||
|
||||
- 基本活动指标
|
||||
- 错误指标
|
||||
- 性能指标
|
||||
|
||||
下面我们将分析在每个类别中最重要的 NGINX 指标,以及用一个相当普遍的案例来说明,值得特别说明的是:使用 NGINX Plus 作反向代理。我们还将介绍如何使用图形工具或可选择的监控工具来监控所有的指标。
|
||||
|
||||
本文引用指标术语[介绍我们的监控在 101 系列][3],,它提供了指标收集和警告框架。
|
||||
|
||||
#### 基本活动指标 ####
|
||||
|
||||
无论你在怎样的情况下使用 NGINX,毫无疑问你要监视服务器接收多少客户端请求和如何处理这些请求。
|
||||
|
||||
NGINX Plus 上像开源 NGINX 一样可以报告基本活动指标,但它也提供了略有不同的辅助模块。我们首先讨论开源的 NGINX,再来说明 NGINX Plus 提供的其他指标的功能。
|
||||
|
||||
**NGINX**
|
||||
|
||||
下图显示了一个客户端连接,以及如何在连接过程中收集指标的活动周期在开源 NGINX 版本上。
|
||||
|
||||

|
||||
|
||||
接受,处理,增加请求的计数器。主动,等待,读,写增加和减少请求量。
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts</td>
|
||||
<td style="text-align: left;">Count of client connections attempted by NGINX</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">handled</td>
|
||||
<td style="text-align: left;">Count of successful client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped (calculated)</td>
|
||||
<td style="text-align: left;">Count of dropped connections (accepts – handled)</td>
|
||||
<td style="text-align: left;">Work: Errors*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests</td>
|
||||
<td style="text-align: left;">Count of client requests</td>
|
||||
<td style="text-align: left;">Work: Throughput</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan="3" style="text-align: left;">*<em>Strictly speaking, dropped connections is <a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics">a metric of resource saturation</a>, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as <a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics">a work metric</a>.</em></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
NGINX 进程接受 OS 的连接请求时**accepts** 计数器增加,而**handled** 是当实际的请求得到连接时(通过建立一个新的连接或重新使用一个空闲的)。这两个计数器的值通常都是相同的,表明连接正在被**dropped**,往往由于资源限制,如 NGINX 的[worker_connections][4]的限制已经达到。
|
||||
|
||||
一旦 NGINX 成功处理一个连接时,连接会移动到**active**状态,然后保持为客户端请求进行处理:
|
||||
|
||||
Active 状态
|
||||
|
||||
- **Waiting**: 活动的连接也可以是一个 Waiting 子状态,如果有在此刻没有活动请求。新连接绕过这个状态并直接移动到读,最常见的是使用“accept filter” 和 “deferred accept”,在这种情况下,NGINX 不会接收进程的通知,直到它具有足够的数据来开始响应工作。如果连接设置为 keep-alive ,连接在发送响应后将处于等待状态。
|
||||
|
||||
- **Reading**: 当接收到请求时,连接移出等待状态,并且该请求本身也被视为 Reading。在这种状态下NGINX 正在读取客户端请求首部。请求首部是比较少的,因此这通常是一个快速的操作。
|
||||
|
||||
- **Writing**: 请求被读取之后,将其计为 Writing,并保持在该状态,直到响应返回给客户端。这意味着,该请求在 Writing 时, NGINX 同时等待来自负载均衡服务器的结果(系统“背后”的 NGINX),NGINX 也同时响应。请求往往会花费大量的时间在 Writing 状态。
|
||||
|
||||
通常,一个连接在同一时间只接受一个请求。在这种情况下,Active 连接的数目 == Waiting 连接 + Reading 请求 + Writing 请求。然而,较新的 SPDY 和 HTTP/2 协议允许多个并发请求/响应对被复用的连接,所以 Active 可小于 Waiting,Reading,Writing 的总和。 (在撰写本文时,NGINX 不支持 HTTP/2,但预计到2015年期间将会支持。)
|
||||
|
||||
**NGINX Plus**
|
||||
|
||||
正如上面提到的,所有开源 NGINX 的指标在 NGINX Plus 中是可用的,但另外也提供其他的指标。本节仅说明了 NGINX Plus 可用的指标。
|
||||
|
||||
|
||||

|
||||
|
||||
接受,中断,总数是不断增加的。活动,空闲和已建立连接的,当前状态下每一个连接或请求的数量是随着请求量增加和收缩的。
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepted</td>
|
||||
<td style="text-align: left;">Count of client connections attempted by NGINX</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped</td>
|
||||
<td style="text-align: left;">Count of dropped connections</td>
|
||||
<td style="text-align: left;">Work: Errors*</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">idle</td>
|
||||
<td style="text-align: left;">Client connections with zero current requests</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">total</td>
|
||||
<td style="text-align: left;">Count of client requests</td>
|
||||
<td style="text-align: left;">Work: Throughput</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td colspan="3" style="text-align: left;">*<em>Strictly speaking, dropped connections is a metric of resource saturation, but since saturation causes NGINX to stop servicing some work (rather than queuing it up for later), “dropped” is best thought of as a work metric.</em></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
当 NGINX Plus 进程接受 OS 的连接请求时 **accepted** 计数器递增。如果进程请求连接失败(通过建立一个新的连接或重新使用一个空闲),则该连接断开 **dropped** 计数增加。通常连接被中断是因为资源限制,如 NGINX Plus 的[worker_connections][4]的限制已经达到。
|
||||
|
||||
**Active** 和 **idle** 和开源 NGINX 的“active” 和 “waiting”状态是相同的,[如上所述][5],有一个不同的地方:在开源 NGINX 上,“waiting”状态包括在“active”中,而在 NGINX Plus 上“idle”的连接被排除在“active” 计数外。**Current** 和开源 NGINX 是一样的也是由“reading + writing” 状态组成。
|
||||
|
||||
|
||||
**Total** 为客户端请求的累积计数。请注意,单个客户端连接可涉及多个请求,所以这个数字可能会比连接的累计次数明显大。事实上,(total / accepted)是每个连接请求的平均数量。
|
||||
|
||||
**开源 和 Plus 之间指标的不同**
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;">NGINX (open-source)</th>
|
||||
<th style="text-align: left;">NGINX Plus</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">accepts</td>
|
||||
<td style="text-align: left;">accepted</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">dropped must be calculated</td>
|
||||
<td style="text-align: left;">dropped is reported directly</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">reading + writing</td>
|
||||
<td style="text-align: left;">current</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">waiting</td>
|
||||
<td style="text-align: left;">idle</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">active (includes “waiting” states)</td>
|
||||
<td style="text-align: left;">active (excludes “idle” states)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">requests</td>
|
||||
<td style="text-align: left;">total</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
**提醒指标: 中断连接**
|
||||
|
||||
被中断的连接数目等于接受和处理之差(NGINX),或被公开直接作为指标的标准(NGINX加)。在正常情况下,中断连接数应该是零。如果每秒中中断连接的速度开始上升,寻找资源可能用尽的地方。
|
||||
|
||||

|
||||
|
||||
**提醒指标: 每秒请求数**
|
||||
|
||||
提供你(开源中的**requests**或者 Plus 中**total**)固定时间间隔每秒或每分钟请求的平均数据。监测这个指标可以查看 Web 的输入流量的最大值,无论是合法的还是恶意的,有可能会突然下降,通常可以看出问题。每秒的请求若发生急剧变化可以提醒你出问题了,即使它不能告诉你确切问题的位置所在。请注意,所有的请求都算作是相同的,无论哪个 URLs。
|
||||
|
||||

|
||||
|
||||
**收集活动指标**
|
||||
|
||||
开源的 NGINX 提供了一个简单状态页面来显示基本的服务器指标。该状态信息以标准格式被显示,实际上任何图形或监控工具可以被配置去解析相关的数据为分析,可视化,或提醒而用。NGINX Plus 提供一个 JSON 接口来显示更多的数据。阅读[NGINX 指标收集][6]后来启用指标收集的功能。
|
||||
|
||||
#### 错误指标 ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">4xx codes</td>
|
||||
<td style="text-align: left;">Count of client errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX logs, NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes</td>
|
||||
<td style="text-align: left;">Count of server errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX logs, NGINX Plus</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
NGINX 错误指标告诉你服务器经常返回哪些错误,这也是有用的。客户端错误返回4XX状态码,服务器端错误返回5XX状态码。
|
||||
|
||||
**提醒指标: 服务器错误率**
|
||||
|
||||
服务器错误率等于5xx错误状态代码的总数除以[状态码][7](1XX,2XX,3XX,4XX,5XX)的总数,每单位时间(通常为一到五分钟)的数目。如果你的错误率随着时间的推移开始攀升,调查可能的原因。如果突然增加,可能需要采取紧急行动,因为客户端可能收到错误信息。
|
||||
|
||||

|
||||
|
||||
客户端收到错误时的注意事项:虽然监控4XX是很有用的,但从该指标中你仅可以捕捉有限的信息,因为它只是衡量客户的行为而不捕捉任何特殊的 URLs。换句话说,在4xx出现时只是相当于一点噪音,例如寻找漏洞的网络扫描仪。
|
||||
|
||||
**收集错误度量**
|
||||
|
||||
虽然开源 NGINX 不会监测错误率,但至少有两种方法可以捕获其信息:
|
||||
|
||||
- 使用商业支持的 NGINX Plus 提供的可扩展状态模块
|
||||
- 配置 NGINX 的日志模块将响应码写入访问日志
|
||||
|
||||
阅读关于 NGINX 指标收集的后两个方法的详细说明。
|
||||
|
||||
#### 性能指标 ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">request time</td>
|
||||
<td style="text-align: left;">Time to process each request, in seconds</td>
|
||||
<td style="text-align: left;">Work: Performance</td>
|
||||
<td style="text-align: left;">NGINX logs</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
**提醒指标: 请求处理时间**
|
||||
|
||||
请求时间指标记录 NGINX 处理每个请求的时间,从第一个客户端的请求字节读出到完成请求。较长的响应时间可以将问题指向负载均衡服务器。
|
||||
|
||||
**收集处理时间指标**
|
||||
|
||||
NGINX 和 NGINX Plus 用户可以通过添加 $request_time 变量到访问日志格式中来捕捉处理时间数据。关于配置日志监控的更多细节在[NGINX指标收集][8]。
|
||||
|
||||
#### 反向代理指标 ####
|
||||
|
||||
注:表格
|
||||
<table>
|
||||
<colgroup>
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;">
|
||||
<col style="text-align: left;"> </colgroup>
|
||||
<thead>
|
||||
<tr>
|
||||
<th style="text-align: left;"><strong>Name</strong></th>
|
||||
<th style="text-align: left;"><strong>Description</strong></th>
|
||||
<th style="text-align: left;"><strong><a target="_blank" href="https://www.datadoghq.com/blog/monitoring-101-collecting-data/">Metric type</a></strong></th>
|
||||
<th style="text-align: left;"><strong>Availability</strong></th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td style="text-align: left;">Active connections by upstream server</td>
|
||||
<td style="text-align: left;">Currently active client connections</td>
|
||||
<td style="text-align: left;">Resource: Utilization</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">5xx codes by upstream server</td>
|
||||
<td style="text-align: left;">Server errors</td>
|
||||
<td style="text-align: left;">Work: Errors</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td style="text-align: left;">Available servers per upstream group</td>
|
||||
<td style="text-align: left;">Servers passing health checks</td>
|
||||
<td style="text-align: left;">Resource: Availability</td>
|
||||
<td style="text-align: left;">NGINX Plus</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
[反向代理][9]是 NGINX 最常见的使用方法之一。商业支持的 NGINX Plus 显示了大量有关后端(或“负载均衡”)的服务器指标,这是反向代理设置的。本节重点介绍了几个关键的负载均衡服务器的指标为 NGINX Plus 用户。
|
||||
|
||||
NGINX Plus 的负载均衡服务器指标首先是组的,然后是单个服务器的。因此,例如,你的反向代理将请求分配到五个 Web 负载均衡服务器上,你可以一眼看出是否有单个服务器压力过大,也可以看出负载均衡服务器组的健康状况,以确保良好的响应时间。
|
||||
|
||||
**活动指标**
|
||||
|
||||
**active connections per upstream server**的数量可以帮助你确认反向代理是否正确的分配工作到负载均衡服务器上。如果你正在使用 NGINX 作为负载均衡器,任何一台服务器处理的连接数有显著的偏差都可能表明服务器正在努力处理请求或你配置处理请求的负载均衡的方法(例如[round-robin or IP hashing][10])不是最适合你流量模式的。
|
||||
|
||||
**错误指标**
|
||||
|
||||
错误指标,上面所说的高于5XX(服务器错误)状态码,是监控指标中有价值的一个,尤其是响应码部分。 NGINX Plus 允许你轻松地提取每个负载均衡服务器 **5xx codes per upstream server**的数量,以及响应的总数量,以此来确定该特定服务器的错误率。
|
||||
|
||||
|
||||
**可用性指标**
|
||||
|
||||
对于 web 服务器的运行状况,另一种观点认为,NGINX 也可以很方便监控你的负载均衡服务器组的健康通过**servers currently available within each group**的总量。在一个大的反向代理上,你可能不会非常关心其中一个服务器的当前状态,就像你只要可用的服务器组能够处理当前的负载就行了。但监视负载均衡服务器组内的所有服务器可以提供一个高水平的图像来判断 Web 服务器的健康状况。
|
||||
|
||||
**收集负载均衡服务器的指标**
|
||||
|
||||
NGINX Plus 负载均衡服务器的指标显示在内部 NGINX Plus 的监控仪表盘上,并且也可通过一个JSON 接口来服务于所有外部的监控平台。在这儿看一个例子[收集 NGINX 指标][11]。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经谈到了一些有用的指标,你可以使用表格来监控 NGINX 服务器。如果你是刚开始使用 NGINX,下面提供了良好的网络基础设施的健康和活动的可视化工具来监控大部分或所有的指标:
|
||||
|
||||
- [Dropped connections][12]
|
||||
- [Requests per second][13]
|
||||
- [Server error rate][14]
|
||||
- [Request processing time][15]
|
||||
|
||||
最终,你会学到更多,更专业的衡量指标,尤其是关于你自己基础设施和使用情况的。当然,监控哪一项指标将取决于你可用的工具。参见[一步一步来说明指标收集][16],不管你使用 NGINX 还是 NGINX Plus。
|
||||
|
||||
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。了解如何用 NGINX Datadog来监控 [在本文中][17],并开始使用 [免费的 Datadog][18]。
|
||||
|
||||
### Acknowledgments ###
|
||||
|
||||
在文章发表之前非常感谢 NGINX 团队审阅这篇,并提供重要的反馈和说明。
|
||||
|
||||
----------
|
||||
|
||||
文章来源在这儿 [on GitHub][19]。问题,更正,补充等?请[告诉我们][20]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nginx.org/en/
|
||||
[2]:http://nginx.com/resources/glossary/reverse-proxy-server/
|
||||
[3]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
|
||||
[4]:http://nginx.org/en/docs/ngx_core_module.html#worker_connections
|
||||
[5]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#active-state
|
||||
[6]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[7]:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
[8]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[9]:https://en.wikipedia.org/wiki/Reverse_proxy
|
||||
[10]:http://nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[11]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[12]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#dropped-connections
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#requests-per-second
|
||||
[14]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#server-error-rate
|
||||
[15]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#request-processing-time
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[18]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#sign-up
|
||||
[19]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx.md
|
||||
[20]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,66 +0,0 @@
|
||||
|
||||
很实用的命令来分析你的 Unix 文件系统
|
||||
================================================================================
|
||||

|
||||
Credit: Sandra H-S
|
||||
|
||||
其中一个问题几乎困扰着所有的文件系统 -- 包括 Unix 和其他的 -- 那就是文件的不断积累。几乎没有人愿意花时间清理掉他们不再使用的文件和文件系统,结果,文件变得很混乱,很难找到有用的东西使它们运行良好,能够得到备份,并且易于管理,这将是一种持久的挑战。
|
||||
|
||||
我见过的一种解决问题的方法是鼓励使用者将所有的数据碎屑创建成一个总结报告或"profile"这样一个文件集合来报告所有的文件数量;最老的,最新的,最大的文件;并统计谁拥有这些文件。如果有人看到一个包含五十万个文件的文件夹并且时间不小于五年,他们可能会去删除哪些文件 -- 或者,至少归档和压缩。主要问题是太大的文件夹会使人产生压制性害怕误删一些重要的东西。有一个描述文件夹的方法能帮助显示文件的性质并期待你去清理它。
|
||||
|
||||
|
||||
当我准备做 Unix 文件系统的总结报告时,几个有用的 Unix 命令能提供一些非常有用的统计信息。要计算目录中的文件数,你可以使用这样一个 find 命令。
|
||||
|
||||
$ find . -type f | wc -l
|
||||
187534
|
||||
|
||||
查找最老的和最新的文件是比较复杂,但还是相当方便的。在下面的命令,我们使用 find 命令再次查找文件,以文件时间排序并按年-月-日的格式显示在顶部 -- 因此最老的 -- 的文件在列表中。
|
||||
|
||||
在第二个命令,我们做同样的,但打印的是最后一行 -- 这是最新的 -- 文件
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | sort | head -n 1
|
||||
2006-02-03+02:40:33 ./skel/.xemacs/init.el
|
||||
$ find -type f -printf '%T+ %p\n' | sort | tail -n 1
|
||||
2015-07-19+14:20:16 ./.bash_history
|
||||
|
||||
printf 命令输出 %T(文件日期和时间)和 %P(带路径的文件名)参数。
|
||||
|
||||
如果我们在查找家目录时,无疑会发现,history 文件是最新的,这不像是一个很有趣的信息。你可以通过 "un-grepping" 来忽略这些文件,也可以忽略以.开头的文件,如下图所示的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | grep -v "\./\." | sort | tail -n 1
|
||||
2015-07-19+13:02:12 ./isPrime
|
||||
|
||||
寻找最大的文件使用 %s(大小)参数,包括文件名(%f),因为这就是我们想要在报告中显示的。
|
||||
|
||||
$ find -type f -printf '%s %f \n' | sort -n | uniq | tail -1
|
||||
20183040 project.org.tar
|
||||
|
||||
打印文件的所有着者,使用%u(所有者)
|
||||
|
||||
$ find -type f -printf '%u \n' | grep -v "\./\." | sort | uniq -c
|
||||
180034 shs
|
||||
7500 jdoe
|
||||
|
||||
如果文件系统能记录上次的访问日期,也将是非常有用的来看该文件有没有被访问,比方说,两年之内。这将使你能明确分辨这些文件的价值。最后一个访问参数(%a)这样使用:
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | head -n 1
|
||||
Fri Dec 15 03:00:30 2006+ ./statreport
|
||||
|
||||
当然,如果最近访问的文件也是在很久之前的,这将使你有更多的处理时间。
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | tail -n 1
|
||||
Wed Nov 26 03:00:27 2007+ ./my-notes
|
||||
|
||||
一个文件系统要层次分明,为大目录创建一个总结报告,显示该文件的日期范围,最大的文件,文件所有者,最老的和访问时间都可以帮助文件拥有者判断当前有哪些文件夹是重要的哪些该清理了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2949898/linux/profiling-your-file-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Sandra-Henry_Stocker/
|
||||
90
translated/tech/20150803 Linux Logging Basics.md
Normal file
90
translated/tech/20150803 Linux Logging Basics.md
Normal file
@ -0,0 +1,90 @@
|
||||
Linux 日志基础
|
||||
================================================================================
|
||||
首先,我们将描述有关 Linux 日志是什么,到哪儿去找它们以及它们是如何创建的基础知识。如果你已经知道这些,请随意跳至下一节。
|
||||
|
||||
### Linux 系统日志 ###
|
||||
|
||||
许多有价值的日志文件都是由 Linux 自动地为你创建的。你可以在 `/var/log` 目录中找到它们。下面是在一个典型的 Ubuntu 系统中这个目录的样子:
|
||||
|
||||

|
||||
|
||||
一些最为重要的 Linux 系统日志包括:
|
||||
|
||||
- `/var/log/syslog` 或 `/var/log/messages` 存储所有的全局系统活动数据,包括开机信息。基于 Debian 的系统如 Ubuntu 在 `/var/log/syslog` 目录中存储它们,而基于 RedHat 的系统如 RHEL 或 CentOS 则在 `/var/log/messages` 中存储它们。
|
||||
- `/var/log/auth.log` 或 `/var/log/secure` 存储来自可插拔认证模块(PAM)的日志,包括成功的登录,失败的登录尝试和认证方式。Ubuntu 和 Debian 在 `/var/log/auth.log` 中存储认证信息,而 RedHat 和 CentOS 则在 `/var/log/secure` 中存储该信息。
|
||||
- `/var/log/kern` 存储内核错误和警告数据,这对于排除与自定义内核相关的故障尤为实用。
|
||||
- `/var/log/cron` 存储有关 cron 作业的信息。使用这个数据来确保你的 cron 作业正成功地运行着。
|
||||
|
||||
Digital Ocean 有一个完整的关于这些文件及 rsyslog 如何在常见的发行版本如 RedHat 和 CentOS 中创建它们的 [教程][1] 。
|
||||
|
||||
应用程序也会在这个目录中写入日志文件。例如像 Apache,Nginx,MySQL 等常见的服务器程序可以在这个目录中写入日志文件。其中一些日志文件由应用程序自己创建,其他的则通过 syslog (具体见下文)来创建。
|
||||
|
||||
### 什么是 Syslog? ###
|
||||
|
||||
Linux 系统日志文件是如何创建的呢?答案是通过 syslog 守护程序,它在 syslog
|
||||
套接字 `/dev/log` 上监听日志信息,然后将它们写入适当的日志文件中。
|
||||
|
||||
单词“syslog” 是一个重载的条目,并经常被用来简称如下的几个名称之一:
|
||||
|
||||
1. **Syslog 守护进程** — 一个用来接收,处理和发送 syslog 信息的程序。它可以[远程发送 syslog][2] 到一个集中式的服务器或写入一个本地文件。常见的例子包括 rsyslogd 和 syslog-ng。在这种使用方式中,人们常说 "发送到 syslog."
|
||||
1. **Syslog 协议** — 一个指定日志如何通过网络来传送的传输协议和一个针对 syslog 信息(具体见下文) 的数据格式的定义。它在 [RFC-5424][3] 中被正式定义。对于文本日志,标准的端口是 514,对于加密日志,端口是 6514。在这种使用方式中,人们常说"通过 syslog 传送."
|
||||
1. **Syslog 信息** — syslog 格式的日志信息或事件,它包括一个带有几个标准域的文件头。在这种使用方式中,人们常说"发送 syslog."
|
||||
|
||||
Syslog 信息或事件包括一个带有几个标准域的 header ,使得分析和路由更方便。它们包括时间戳,应用程序的名称,在系统中信息来源的分类或位置,以及事件的优先级。
|
||||
|
||||
下面展示的是一个包含 syslog header 的日志信息,它来自于 sshd 守护进程,它控制着到该系统的远程登录,这个信息描述的是一次失败的登录尝试:
|
||||
|
||||
<34>1 2003-10-11T22:14:15.003Z server1.com sshd - - pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
|
||||
|
||||
### Syslog 格式和域 ###
|
||||
|
||||
每条 syslog 信息包含一个带有域的 header,这些域是结构化的数据,使得分析和路由事件更加容易。下面是我们使用的用来产生上面的 syslog 例子的格式,你可以将每个值匹配到一个特定的域的名称上。
|
||||
|
||||
<%pri%>%protocol-version% %timestamp:::date-rfc3339% %HOSTNAME% %app-name% %procid% %msgid% %msg%n
|
||||
|
||||
下面,你将看到一些在查找或排错时最常使用的 syslog 域:
|
||||
|
||||
#### 时间戳 ####
|
||||
|
||||
[时间戳][4] (上面的例子为 2003-10-11T22:14:15.003Z) 暗示了在系统中发送该信息的时间和日期。这个时间在另一系统上接收该信息时可能会有所不同。上面例子中的时间戳可以分解为:
|
||||
|
||||
- **2003-10-11** 年,月,日.
|
||||
- **T** 为时间戳的必需元素,它将日期和时间分离开.
|
||||
- **22:14:15.003** 是 24 小时制的时间,包括进入下一秒的毫秒数(**003**).
|
||||
- **Z** 是一个可选元素,指的是 UTC 时间,除了 Z,这个例子还可以包括一个偏移量,例如 -08:00,这意味着时间从 UTC 偏移 8 小时,即 PST 时间.
|
||||
|
||||
#### 主机名 ####
|
||||
|
||||
[主机名][5] 域(在上面的例子中对应 server1.com) 指的是主机的名称或发送信息的系统.
|
||||
|
||||
#### 应用名 ####
|
||||
|
||||
[应用名][6] 域(在上面的例子中对应 sshd:auth) 指的是发送信息的程序的名称.
|
||||
|
||||
#### 优先级 ####
|
||||
|
||||
优先级域或缩写为 [pri][7] (在上面的例子中对应 <34>) 告诉我们这个事件有多紧急或多严峻。它由两个数字域组成:设备域和紧急性域。紧急性域从代表 debug 类事件的数字 7 一直到代表紧急事件的数字 0 。设备域描述了哪个进程创建了该事件。它从代表内核信息的数字 0 到代表本地应用使用的 23 。
|
||||
|
||||
Pri 有两种输出方式。第一种是以一个单独的数字表示,可以这样计算:先用设备域的值乘以 8,再加上紧急性域的值:(设备域)(8) + (紧急性域)。第二种是 pri 文本,将以“设备域.紧急性域” 的字符串格式输出。后一种格式更方便阅读和搜索,但占据更多的存储空间。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/linux-logging-basics/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://www.digitalocean.com/community/tutorials/how-to-view-and-configure-linux-logs-on-ubuntu-and-centos
|
||||
[2]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.y2e9tdfk1cdb
|
||||
[3]:https://tools.ietf.org/html/rfc5424
|
||||
[4]:https://tools.ietf.org/html/rfc5424#section-6.2.3
|
||||
[5]:https://tools.ietf.org/html/rfc5424#section-6.2.4
|
||||
[6]:https://tools.ietf.org/html/rfc5424#section-6.2.5
|
||||
[7]:https://tools.ietf.org/html/rfc5424#section-6.2.1
|
||||
@ -0,0 +1,69 @@
|
||||
Linux有问必答——如何启用Open vSwitch的日志功能以便调试和排障
|
||||
================================================================================
|
||||
> **问题** 我试着为我的Open vSwitch部署排障,鉴于此,我想要检查它的由内建日志机制生成的调试信息。我怎样才能启用Open vSwitch的日志功能,并且修改它的日志等级(如,修改成INFO/DEBUG级别)以便于检查更多详细的调试信息呢?
|
||||
|
||||
Open vSwitch(OVS)是Linux平台上用于虚拟切换的最流行的开源部署。由于当今的数据中心日益依赖于软件定义的网络(SDN)架构,OVS被作为数据中心的SDN部署中实际上的标准网络元素而快速采用。
|
||||
|
||||
Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允许你在各种切换组件中启用并自定义日志,由VLOG生成的日志信息可以被发送到一个控制台,syslog以及一个独立日志文件组合,以供检查。你可以通过一个名为`ovs-appctl`的命令行工具在运行时动态配置OVS日志。
|
||||
|
||||

|
||||
|
||||
这里为你演示如何使用`ovs-appctl`启用Open vSwitch中的日志功能,并进行自定义。
|
||||
|
||||
下面是`ovs-appctl`自定义VLOG的语法。
|
||||
|
||||
$ sudo ovs-appctl vlog/set module[:facility[:level]]
|
||||
|
||||
- **Module**:OVS中的任何合法组件的名称(如netdev,ofproto,dpif,vswitchd,以及其它大量组件)
|
||||
- **Facility**:日志信息的目的地(必须是:console,syslog,或者file)
|
||||
- **Level**:日志的详细程度(必须是:emer,err,warn,info,或者dbg)
|
||||
|
||||
在OVS源代码中,模块名称在源文件中是以以下格式定义的:
|
||||
|
||||
VLOG_DEFINE_THIS_MODULE(<module-name>);
|
||||
|
||||
例如,在lib/netdev.c中,你可以看到:
|
||||
|
||||
VLOG_DEFINE_THIS_MODULE(netdev);
|
||||
|
||||
这个表明,lib/netdev.c是netdev模块的一部分,任何在lib/netdev.c中生成的日志信息将属于netdev模块。
|
||||
|
||||
在OVS源代码中,有多个严重度等级用于定义几个不同类型的日志信息:VLOG_INFO()用于报告,VLOG_WARN()用于警告,VLOG_ERR()用于错误提示,VLOG_DBG()用于调试信息,VLOG_EMERG用于紧急情况。日志等级和工具确定哪个日志信息发送到哪里。
|
||||
|
||||
要查看可用模块、工具和各自日志级别的完整列表,请运行以下命令。该命令必须在你启动OVS后调用。
|
||||
|
||||
$ sudo ovs-appctl vlog/list
|
||||
|
||||

|
||||
|
||||
输出结果显示了用于三个工具(console,syslog,file)的各个模块的调试级别。默认情况下,所有模块的日志等级都被设置为INFO。
|
||||
|
||||
指定任何一个OVS模块,你可以选择性地修改任何特定工具的调试级别。例如,如果你想要在控制台屏幕中查看dpif更为详细的调试信息,可以运行以下命令。
|
||||
|
||||
$ sudo ovs-appctl vlog/set dpif:console:dbg
|
||||
|
||||
你将看到dpif模块的console工具已经将其日志等级修改为DBG,而其它两个工具syslog和file的日志级别仍然没有改变。
|
||||
|
||||

|
||||
|
||||
如果你想要修改所有模块的日志等级,你可以指定“ANY”作为模块名。例如,下面命令将修改每个模块的console的日志级别为DBG。
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:console:dbg
|
||||
|
||||

|
||||
|
||||
同时,如果你想要一次性修改所有三个工具的日志级别,你可以指定“ANY”作为工具名。例如,下面的命令将修改每个模块的所有工具的日志级别为DBG。
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:ANY:dbg
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/enable-logging-open-vswitch.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,49 @@
|
||||
Linux有问必答——如何修复Linux上的“ImportError: No module named wxversion”错误
|
||||
================================================================================
|
||||
|
||||
> **问题** 我试着在[你的Linux发行版]上运行一个Python应用,但是我得到了这个错误"ImportError: No module named wxversion."。我怎样才能解决Python程序中的这个错误呢?
|
||||
|
||||
Looking for python... 2.7.9 - Traceback (most recent call last):
|
||||
File "/home/dev/playonlinux/python/check_python.py", line 1, in
|
||||
import os, wxversion
|
||||
ImportError: No module named wxversion
|
||||
failed tests
|
||||
|
||||
该错误表明,你的Python应用是基于GUI的,依赖于一个名为wxPython的缺失模块。[wxPython][1]是一个用于wxWidgets GUI库的Python扩展模块,普遍被C++程序员用来设计GUI应用。该wxPython扩展允许Python开发者在任何Python应用中方便地设计和整合GUI。
|
||||
To solve this import error, you need to install wxPython on your Linux, as described below.
|
||||
|
||||
### 安装wxPython到Debian,Ubuntu或Linux Mint ###
|
||||
|
||||
$ sudo apt-get install python-wxgtk2.8
|
||||
|
||||
### 安装wxPython到Fedora ###
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### 安装wxPython到CentOS/RHEL ###
|
||||
|
||||
wxPython可以在CentOS/RHEL的EPEL仓库中获取到,而基本仓库中则没有。因此,首先要在你的系统中[启用EPEL仓库][2],然后使用yum命令来安装。
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### 安装wxPython到Arch Linux ###
|
||||
|
||||
$ sudo pacman -S wxpython
|
||||
|
||||
### 安装wxPython到Gentoo ###
|
||||
|
||||
$ emerge wxPython
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/importerror-no-module-named-wxversion.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wxpython.org/
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -0,0 +1,73 @@
|
||||
Linux问答 -- 如何在Linux上安装Git
|
||||
================================================================================
|
||||
|
||||
> **问题:** 我尝试从一个Git公共仓库克隆项目,但出现了这样的错误提示:“git: command not found”。 请问我该如何安装Git? [注明一下是哪个Linux发行版]?
|
||||
|
||||
Git是一个流行的并且开源的版本控制系统(VCS),最初是为Linux环境开发的。跟CVS或者SVN这些版本控制系统不同的是,Git的版本控制被认为是“分布式的”,某种意义上,git的本地工作目录可以作为一个功能完善的仓库来使用,它具备完整的历史记录和版本追踪能力。在这种工作模型之下,各个协作者将内容提交到他们的本地仓库中(与之相对的会直接提交到核心仓库),如果有必要,再有选择性地推送到核心仓库。这就为Git这个版本管理系统带来了大型协作系统所必须的可扩展能力和冗余能力。
|
||||
|
||||

|
||||
|
||||
### 使用包管理器安装Git ###
|
||||
|
||||
Git已经被所有的主力Linux发行版所支持。所以安装它最简单的方法就是使用各个Linux发行版的包管理器。
|
||||
|
||||
**Debian, Ubuntu, 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||
**Fedora, CentOS 或 RHEL**
|
||||
|
||||
$ sudo yum install git
|
||||
|
||||
**Arch Linux**
|
||||
|
||||
$ sudo pacman -S git
|
||||
|
||||
**OpenSUSE**
|
||||
|
||||
$ sudo zypper install git
|
||||
|
||||
**Gentoo**
|
||||
|
||||
$ emerge --ask --verbose dev-vcs/git
|
||||
|
||||
### 从源码安装Git ###
|
||||
|
||||
如果由于某些原因,你希望从源码安装Git,安装如下介绍操作。
|
||||
|
||||
**安装依赖包**
|
||||
|
||||
在构建Git之前,先安装它的依赖包。
|
||||
|
||||
**Debian, Ubuntu 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install libcurl4-gnutls-dev libexpat1-dev gettext libz-dev libssl-dev asciidoc xmlto docbook2x
|
||||
|
||||
**Fedora, CentOS 或 RHEL**
|
||||
|
||||
$ sudo yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel asciidoc xmlto docbook2x
|
||||
|
||||
#### 从源码编译Git ####
|
||||
|
||||
从 [https://github.com/git/git/releases][1] 下载最新版本的Git。然后在/usr下构建和安装。
|
||||
|
||||
注意,如果你打算安装到其他目录下(例如:/opt),那就把"--prefix=/usr"这个配置命令使用其他路径替换掉。
|
||||
|
||||
$ cd git-x.x.x
|
||||
$ make configure
|
||||
$ ./configure --prefix=/usr
|
||||
$ make all doc info
|
||||
$ sudo make install install-doc install-html install-info
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-git-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/git/git/releases
|
||||
@ -0,0 +1,325 @@
|
||||
RHCSA 系列: 如何执行文件并进行文件管理 – Part 2
|
||||
================================================================================
|
||||
|
||||
在本篇(RHCSA 第二篇:文件和目录管理)中,我们江回顾一些系统管理员日常任务需要的技能
|
||||
|
||||

|
||||
|
||||
|
||||
RHCSA : 运行文件以及进行文件夹管理 - 第二章
|
||||
### 创建,删除,复制和移动文件及目录 ###
|
||||
|
||||
文件和目录管理是每一个系统管理员都应该掌握的必要的技能.它包括了从头开始的创建、删除文本文件(每个程序的核心配置)以及目录(你用来组织文件和其他目录),以及识别存在的文件的类型
|
||||
|
||||
[touch 命令][1] 不仅仅能用来创建空文件,还能用来更新已存在的文件的权限和时间表
|
||||
|
||||

|
||||
|
||||
touch 命令示例
|
||||
|
||||
你可以使用 `file [filename]`来判断一个文件的类型 (在你用文本编辑器编辑之前,判断类型将会更方便编辑).
|
||||
|
||||

|
||||
|
||||
file 命令示例
|
||||
|
||||
使用`rm [filename]` 可以删除文件
|
||||
|
||||

|
||||
|
||||
rm 命令示例
|
||||
|
||||
对于目录,你可以使用`mkdir [directory]`在已经存在的路径中创建目录,或者使用 `mkdir -p [/full/path/to/directory].`带全路径创建文件夹
|
||||
|
||||
|
||||

|
||||
|
||||
mkdir 命令示例
|
||||
|
||||
当你想要去删除目录时,在你使用`rmdir [directory]` 前,你需要先确保目录是空的,或者使用更加强力的命令(小心使用它)`rm -rf [directory]`.后者会强制删除`[directory]`以及他的内容.所以使用这个命令存在一定的风险
|
||||
|
||||
### 输入输出重定向以及管道 ###
|
||||
|
||||
命令行环境提供了两个非常有用的功能:允许命令重定向的输入和输出到文件和发送到另一个文件,分别称为重定向和管道
|
||||
|
||||
To understand those two important concepts, we must first understand the three most important types of I/O (Input and Output) streams (or sequences) of characters, which are in fact special files, in the *nix sense of the word.
|
||||
为了理解这两个重要概念,我们首先需要理解通常情况下三个重要的输入输出流的形式
|
||||
|
||||
- 标准输入 (aka stdin) 是指默认使用键盘链接. 换句话说,键盘是输入命令到命令行的标准输入设备。
|
||||
- 标准输出 (aka stdout) 是指默认展示再屏幕上, 显示器接受输出命令,并且展示在屏幕上。
|
||||
- 标准错误 (aka stderr), 是指命令的状态默认输出, 同时也会展示在屏幕上
|
||||
|
||||
In the following example, the output of `ls /var` is sent to stdout (the screen), as well as the result of ls /tecmint. But in the latter case, it is stderr that is shown.
|
||||
在下面的例子中,`ls /var`的结果被发送到stdout(屏幕展示),就像ls /tecmint 的结果。但在后一种情况下,它是标准错误输出。
|
||||
|
||||

|
||||
输入和输出命令实例
|
||||
|
||||
为了更容易识别这些特殊文件,每个文件都被分配有一个文件描述符(用于控制他们的抽象标识)。主要要理解的是,这些文件就像其他人一样,可以被重定向。这就意味着你可以从一个文件或脚本中捕获输出,并将它传送到另一个文件、命令或脚本中。你就可以在在磁盘上存储命令的输出结果,用于稍后的分析
|
||||
|
||||
To redirect stdin (fd 0), stdout (fd 1), or stderr (fd 2), the following operators are available.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="226"></colgroup>
|
||||
<colgroup width="743"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">转向操作</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">效果</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">标准输出到一个文件。如果目标文件存在,内容就会被重写</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准输出到文件尾部</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">标准错误输出到一个文件。如果目标文件存在,内容就会被重写</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加标准错误输出到文件尾部.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">&></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">标准错误和标准输出都到一个文件。如果目标文件存在,内容就会被重写</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><</span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输出</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">使用特定的文件做标准输出和标准错误</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
相比与重定向,管道是通过在命令后添加一个竖杠`(|)`再添加另一个命令 .
|
||||
|
||||
记得:
|
||||
|
||||
- 重定向是用来定向命令的输出到一个文件,或定向一个文件作为输入到一个命令。
|
||||
- 管道是用来将命令的输出转发到另一个命令作为输入。
|
||||
|
||||
#### 重定向和管道的使用实例 ####
|
||||
|
||||
** 例1:将一个命令的输出到文件 **
|
||||
|
||||
有些时候,你需要遍历一个文件列表。要做到这样,你可以先将该列表保存到文件中,然后再按行读取该文件。虽然你可以遍历直接ls的输出,不过这个例子是用来说明重定向。
|
||||
|
||||
# ls -1 /var/mail > mail.txt
|
||||
|
||||

|
||||
|
||||
将一个命令的输出到文件
|
||||
|
||||
** 例2:重定向stdout和stderr到/dev/null **
|
||||
|
||||
如果不想让标准输出和标准错误展示在屏幕上,我们可以把文件描述符重定向到 `/dev/null` 请注意在执行这个命令时该如何更改输出
|
||||
|
||||
# ls /var /tecmint
|
||||
# ls /var/ /tecmint &> /dev/null
|
||||
|
||||

|
||||
|
||||
重定向stdout和stderr到/dev/null
|
||||
|
||||
#### 例3:使用一个文件作为命令的输入 ####
|
||||
|
||||
当官方的[cat 命令][2]的语法如下时
|
||||
|
||||
# cat [file(s)]
|
||||
|
||||
您还可以使用正确的重定向操作符传送一个文件作为输入。
|
||||
|
||||
# cat < mail.txt
|
||||
|
||||

|
||||
|
||||
cat 命令实例
|
||||
|
||||
#### 例4:发送一个命令的输出作为另一个命令的输入 ####
|
||||
|
||||
如果你有一个较大的目录或进程列表,并且想快速定位,你或许需要将列表通过管道传送给grep
|
||||
|
||||
接下来我们使用管道在下面的命令中,第一个是查找所需的关键词,第二个是除去产生的 `grep command`.这个例子列举了所有与apache用户有关的进程
|
||||
|
||||
# ps -ef | grep apache | grep -v grep
|
||||
|
||||

|
||||
|
||||
发送一个命令的输出作为另一个命令的输入
|
||||
|
||||
### 归档,压缩,解包,解压文件 ###
|
||||
|
||||
如果你需要传输,备份,或者通过邮件发送一组文件,你可以使用一个存档(或文件夹)如 [tar][3]工具,通常使用gzip,bzip2,或XZ压缩工具.
|
||||
|
||||
您选择的压缩工具每一个都有自己的定义的压缩速度和速率的。这三种压缩工具,gzip是最古老和提供最小压缩的工具,bzip2提供经过改进的压缩,以及XZ提供最信和最好的压缩。通常情况下,这些文件都是被压缩的如.gz .bz2或.xz
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="165"></colgroup>
|
||||
<colgroup width="137"></colgroup>
|
||||
<colgroup width="366"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">命令</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">缩写</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">描述</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –create</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">c</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">创建一个tar归档</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –concatenate</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">A</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">向归档中添加tar文件</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –append</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">r</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">向归档中添加非tar文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –update</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">u</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">添加比归档中的文件更新的文件</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –diff or –compare</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">d</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">将归档和硬盘的文件夹进行对比</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="20" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –list</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">t</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">列举一个tar的压缩包</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –extract or –get</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">x</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">从归档中解压文件</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="258"></colgroup>
|
||||
<colgroup width="152"></colgroup>
|
||||
<colgroup width="803"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">操作参数</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">缩写</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">描述</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>directory dir</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> C</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">在执行操作前更改目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>same-permissions and <span style="font-family: Courier New;">—</span>same-owner</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> p</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">分别保留权限和所有者信息</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –verbose</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> v</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">列举所有文件用于读取或提取,这里包含列表,并显示文件的大小、所有权和时间戳</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>exclude file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> —</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">排除存档文件。在这种情况下,文件可以是一个实际的文件或目录。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>gzip or <span style="font-family: Courier New;">—</span>gunzip</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> z</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用gzip压缩文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –bzip2</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> j</span></td>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;">使用bzip2压缩文件</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –xz</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> J</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">使用xz压缩文件</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### 例5:创建一个文件,然后使用三种压缩工具压缩####
|
||||
|
||||
在决定使用一个或另一个工具之前,您可能想比较每个工具的压缩效率。请注意压缩小文件或几个文件,结果可能不会有太大的差异,但可能会给你看出他们的差异
|
||||
|
||||
# tar cf ApacheLogs-$(date +%Y%m%d).tar /var/log/httpd/* # Create an ordinary tarball
|
||||
# tar czf ApacheLogs-$(date +%Y%m%d).tar.gz /var/log/httpd/* # Create a tarball and compress with gzip
|
||||
# tar cjf ApacheLogs-$(date +%Y%m%d).tar.bz2 /var/log/httpd/* # Create a tarball and compress with bzip2
|
||||
# tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* # Create a tarball and compress with xz
|
||||
|
||||

|
||||
|
||||
tar 命令实例
|
||||
|
||||
#### 例6:归档时同时保存原始权限和所有权 ####
|
||||
|
||||
如果你创建的是用户的主目录的备份,你需要要存储的个人文件与原始权限和所有权,而不是通过改变他们的用户帐户或守护进程来执行备份。下面的命令可以在归档时保留文件属性
|
||||
|
||||
# tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* --same-permissions --same-owner
|
||||
|
||||
### 创建软连接和硬链接 ###
|
||||
|
||||
在Linux中,有2种类型的链接文件:硬链接和软(也称为符号)链接。因为硬链接文件代表另一个名称是由同一点确定,然后链接到实际的数据;符号链接指向的文件名,而不是实际的数据
|
||||
|
||||
此外,硬链接不占用磁盘上的空间,而符号链接做占用少量的空间来存储的链接本身的文本。硬链接的缺点就是要求他们必须在同一个innode内。而符号链接没有这个限制,符号链接因为只保存了文件名和目录名,所以可以跨文件系统.
|
||||
|
||||
创建链接的基本语法看起来是相似的:
|
||||
|
||||
# ln TARGET LINK_NAME #从Link_NAME到Target的硬链接
|
||||
# ln -s TARGET LINK_NAME #从Link_NAME到Target的软链接
|
||||
|
||||
#### 例7:创建硬链接和软链接 ####
|
||||
|
||||
没有更好的方式来形象的说明一个文件和一个指向它的符号链接的关系,而不是创建这些链接。在下面的截图中你会看到文件的硬链接指向它共享相同的节点都是由466个字节的磁盘使用情况确定。
|
||||
|
||||
另一方面,在别的磁盘创建一个硬链接将占用5个字节,并不是说你将耗尽存储容量,而是这个例子足以说明一个硬链接和软链接之间的区别。
|
||||
|
||||

|
||||
|
||||
软连接和硬链接之间的不同
|
||||
|
||||
符号链接的典型用法是在Linux系统的版本文件参考。假设有需要一个访问文件foo X.Y 想图书馆一样经常被访问,你想更新一个就可以而不是更新所有的foo X.Y,这时使用软连接更为明智和安全。有文件被看成foo X.Y的链接符号,从而找到foo X.Y
|
||||
|
||||
这样的话,当你的X和Y发生变化后,你只需更新一个文件,而不是更新每个文件。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我们回顾了一些基本的文件和目录管理技能,这是每个系统管理员的工具集的一部分。请确保阅读了本系列的其他部分,以及复习并将这些主题与本教程所涵盖的内容相结合。
|
||||
|
||||
如果你有任何问题或意见,请随时告诉我们。我们总是很高兴从读者那获取反馈.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[2]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user