mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
6d3879ded7
@ -1,83 +0,0 @@
|
||||
MarineFish translating
|
||||
|
||||
A 3-step process for making more transparent decisions
|
||||
======
|
||||

|
||||
|
||||
One of the most powerful ways to make your work as a leader more transparent is to take an existing process, open it up for feedback from your team, and then change the process to account for this feedback. The following exercise makes transparency more tangible, and it helps develop the "muscle memory" needed for continually evaluating and adjusting your work with transparency in mind.
|
||||
|
||||
I would argue that you can undertake this activity this with any process--even processes that might seem "off limits," like the promotion or salary adjustment processes. But if that's too big for a first bite, then you might consider beginning with a less sensitive process, such as the travel approval process or your system for searching for candidates to fill open positions on your team. (I've done this with our hiring process and promotion processes, for example.)
|
||||
|
||||
Opening up processes and making them more transparent builds your credibility and enhances trust with team members. It forces you to "walk the transparency walk" in ways that might challenge your assumptions or comfort level. Working this way does create additional work, particularly at the beginning of the process--but, ultimately, this works well for holding managers (like me) accountable to team members, and it creates more consistency.
|
||||
|
||||
### Phase 1: Pick a process
|
||||
|
||||
**Step 1.** Think of a common or routine process your team uses, but one that is not generally open for scrutiny. Some examples might include:
|
||||
|
||||
* Hiring: How are job descriptions created, interview teams selected, candidates screened and final hiring decisions made?
|
||||
* Planning: How are your team or organizational goals determined for the year or quarter?
|
||||
* Promotions: How do you select candidates for promotion, consider them, and decide who gets promoted?
|
||||
* Manager performance appraisals: Who receives the opportunity to provide feedback on manager performance, and how are they able to do it?
|
||||
* Travel: How is the travel budget apportioned, and how do you make decisions about whether to approval travel (or whether to nominate someone for travel)?
|
||||
|
||||
|
||||
|
||||
One of the above examples may resonate with you, or you may identify something else that you feel is more appropriate. Perhaps you've received questions about a particular process, or you find yourself explaining the rationale for a particular kind of decision frequently. Choose something that you are able to control or influence--and something you believe your constituents care about.
|
||||
|
||||
**Step 2.** Now answer the following questions about the process:
|
||||
|
||||
* Is the process currently documented in a place that all constituents know about and can access? If not, go ahead and create that documentation now (it doesn't have to be too detailed; just explain the different steps of the process and how it works). You may find that the process isn't clear or consistent enough to document. In that case, document it the way you think it should work in the ideal case.
|
||||
* Does the completed process documentation explain how decisions are made at various points? For example, in a travel approval process, does it explain how a decision to approve or deny a request is made?
|
||||
* What are the inputs of the process? For example, when determining departmental goals for the year, what data is used for key performance indicators? Whose feedback is sought and incorporated? Who has the opportunity to review or "sign off"?
|
||||
* What assumptions does this process make? For example, in promotion decisions, do you assume that all candidates for promotion will be put forward by their managers at the appropriate time?
|
||||
* What are the outputs of the process? For example, in assessing the performance of the managers, is the result shared with the manager being evaluated? Are any aspects of the review shared more broadly with the manager's direct reports (areas for improvement, for example)?
|
||||
|
||||
|
||||
|
||||
Avoid making judgements when answering the above questions. If the process doesn't clearly explain how a decision is made, that might be fine. The questions are simply an opportunity to assess the current state.
|
||||
|
||||
Next, revise the documentation of the process until you are satisfied that it adequately explains the process and anticipates the potential questions.
|
||||
|
||||
### Phase 2: Gather feedback
|
||||
|
||||
The next phase involves sharing the process with your constituents and asking for feedback. Sharing is easier said than done.
|
||||
|
||||
**Step 1.** Encourage people to provide feedback. Consider a variety of mechanisms for doing this:
|
||||
|
||||
* Post the process somewhere people can find it internally and note where they can make comments or provide feedback. A Google document works great with the ability to comment on specific text or suggest changes directly in the text.
|
||||
* Share the process document via email, inviting feedback
|
||||
* Mention the process document and ask for feedback during team meetings or one-on-one conversations
|
||||
* Give people a time window within which to provide feedback, and send periodic reminders during that window.
|
||||
|
||||
|
||||
|
||||
If you don't get much feedback, don't assume that silence is equal to endorsement. Try asking people directly if they have any idea why feedback is not coming in. Are people too busy? Is the process not as important to people as you thought? Have you effectively articulated what you're asking for?
|
||||
|
||||
**Step 2.** Iterate. As you get feedback about the process, engage the team in revising and iterating on the process. Incorporate ideas and suggestions for improvement, and ask for confirmation that the intended feedback has been applied. If you don't agree with a suggestion, be open to the discussion and ask yourself why you don't agree and what the merits are of one method versus another.
|
||||
|
||||
Setting a timebox for collecting feedback and iterating is helpful to move things forward. Once feedback has been collected and reviewed, discussed and applied, post the final process for the team to review.
|
||||
|
||||
### Phase 3: Implement
|
||||
|
||||
Implementing a process is often the hardest phase of the initiative. But if you've taken account of feedback when revising your process, people should already been anticipating it and will likely be more supportive. The documentation you have from the iterative process above is a great tool to keep you accountable on the implementation.
|
||||
|
||||
**Step 1.** Review requirements for implementation. Many processes that can benefit from increased transparency simply require doing things a little differently, but you do want to review whether you need any other support (tooling, for example).
|
||||
|
||||
**Step 2.** Set a timeline for implementation. Review the timeline with constituents so they know what to expect. If the new process requires a process change for others, be sure to provide enough time for people to adapt to the new behavior, and provide communication and reminders.
|
||||
|
||||
**Step 3.** Follow up. After using the process for 3-6 months, check in with your constituents to see how it's going. Is the new process more transparent? More effective? More predictable? Do you have any lessons learned that could be used to improve the process further?
|
||||
|
||||
### About The Author
|
||||
Sam Knuth;I Have The Privilege To Lead The Customer Content Services Team At Red Hat;Which Produces All Of The Documentation We Provide For Our Customers. Our Goal Is To Provide Customers With The Insights They Need To Be Successful With Open Source Technology In The Enterprise. Connect With Me On Twitter
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/9/exercise-in-transparent-decisions
|
||||
|
||||
作者:[a][Sam Knuth]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/samfw
|
||||
@ -1,260 +0,0 @@
|
||||
Translating by cielllll
|
||||
|
||||
Three Alternatives for Enabling Two Factor Authentication For SSH On Ubuntu 16.04 And Debian Jessie
|
||||
======
|
||||
Security is now more important than ever and securing your SSH server is one of the most important things that you can do as a systems administrator. Traditionally this has meant disabling password authentication and instead using SSH keys. Whilst this is absolutely the first thing you should do that doesn't mean that SSH can't be made even more secure.
|
||||
|
||||
Two-factor authentication simply means that two means of identification are required to log in. These could be a password and an SSH key, or a key and a 3rd party service like Google. It means that the compromise of a single authentication method does not compromise the server.
|
||||
|
||||
The following guides are three ways to enable two-factor authentication for SSH.
|
||||
|
||||
Whenever you are modifying the configuration of SSH always ensure that you have a second terminal open to the server. The second terminal means that you will be able to fix any mistakes you make with the SSH configuration. Open terminals will stay open even through SSH restarts.
|
||||
|
||||
### SSH Key and Password
|
||||
|
||||
SSH supports the ability to require more than a single authentication method for logins.
|
||||
|
||||
The authentication methods are set with the `AuthenticationMethods` option in the SSH server's configuration file at `/etc/ssh/sshd_config`.
|
||||
|
||||
When the following line is added into `/etc/ssh/sshd_config` SSH requires an SSH key to be submitted and then a password is prompted for:
|
||||
```
|
||||
AuthenticationMethods "publickey,password"
|
||||
|
||||
```
|
||||
|
||||
If you want to set these methods on a per use basis then use the following additional configuration:
|
||||
```
|
||||
Match User jsmith
|
||||
AuthenticationMethods "publickey,password"
|
||||
|
||||
```
|
||||
|
||||
When you have edited and saved the new `sshd_config` file you should check that you did not make any errors by running this command:
|
||||
```
|
||||
sshd -t
|
||||
|
||||
```
|
||||
|
||||
Any syntax or other errors that would stop SSH from starting will be flagged here. When `ssh -t` runs without error use `systemctl` to restart SSH"
|
||||
```
|
||||
systemctl restart sshd
|
||||
|
||||
```
|
||||
|
||||
Now you can log in with a new terminal to check that you are prompted for a password and your SSH key is required. If you use `ssh -v` e.g.:
|
||||
```
|
||||
ssh -v jsmith@example.com
|
||||
|
||||
```
|
||||
|
||||
you will be able to see every step of the login.
|
||||
|
||||
Note, if you do set `password` as a required authentication method then you will need to ensure that `PasswordAuthentication` option is set to `yes`.
|
||||
|
||||
### SSH With Google Authenticator
|
||||
|
||||
Google's two-factor authentication system that is used on Google's own products can be integrated into your SSH server. This makes this method very convenient if you already have use the Google Authenticator app.
|
||||
|
||||
Although the `libpam-google-authenticator` is written by Google it is [open source][1]. Also, the Google Authenticator app is written by Google but does not require a Google account to work. Thanks to [Sitaram Chamarty][2] for the heads up on that.
|
||||
|
||||
If you don't already have the Google Authenticator app installed and configured on your phone please see the instructions [here][3].
|
||||
|
||||
First, we need to install the Google Authenticator package on the server. The following commands will update your system and install the needed packages:
|
||||
```
|
||||
apt-get update
|
||||
apt-get upgrade
|
||||
apt-get install libpam-google-authenticator
|
||||
|
||||
```
|
||||
|
||||
Now, we need to register the server with the Google Authenticator app on your phone. This is done by first running the program we just installed:
|
||||
```
|
||||
google-authenticator
|
||||
|
||||
```
|
||||
|
||||
You will be asked a few questions when you run this. You should answer in the way that suits your setup, however, the most secure options are to answer `y` to every question. If you need to change these later you can simply re-run `google-authenticator` and select different options.
|
||||
|
||||
When you run `google-authenticator` a QR code will be printed to the terminal and some codes that look like:
|
||||
```
|
||||
Your new secret key is: VMFY27TYDFRDNKFY
|
||||
Your verification code is 259652
|
||||
Your emergency scratch codes are:
|
||||
96915246
|
||||
70222983
|
||||
31822707
|
||||
25181286
|
||||
28919992
|
||||
|
||||
```
|
||||
|
||||
You should record all of these codes to a secure location like a password manager. The scratch codes are single use codes that will always allow you access even if your phone is unavailable.
|
||||
|
||||
All you need to do to register your server with the Authenticator app is to open the app and hit the red plus symbol on the bottom right. Then select the **Scan a barcode** option and scan the QR code that was printed to the terminal. Your server and the app are now linked.
|
||||
|
||||
Back on the server, we now need to edit the PAM (Pluggable Authentication Module) for SSH so that it uses the authenticator package we just installed. PAM is the standalone system that takes care of most authentication on a Linux server.
|
||||
|
||||
The PAM file for SSH that needs modifying is located at `/etc/pam.d/sshd` and edited with the following command:
|
||||
```
|
||||
nano /etc/pam.d/sshd
|
||||
|
||||
```
|
||||
|
||||
Add the following line to the top of the file:
|
||||
```
|
||||
auth required pam_google_authenticator.so
|
||||
|
||||
```
|
||||
|
||||
In addition, we also need to comment out a line so that PAM will not prompt for a password. Change this line:
|
||||
```
|
||||
# Standard Un*x authentication.
|
||||
@include common-auth
|
||||
|
||||
```
|
||||
|
||||
To this:
|
||||
```
|
||||
# Standard Un*x authentication.
|
||||
# @include common-auth
|
||||
|
||||
```
|
||||
|
||||
Next, we need to edit the SSH server configuration file:
|
||||
```
|
||||
nano /etc/ssh/sshd_config
|
||||
|
||||
```
|
||||
|
||||
And change this line:
|
||||
```
|
||||
ChallengeResponseAuthentication no
|
||||
|
||||
```
|
||||
|
||||
To:
|
||||
```
|
||||
ChallengeResponseAuthentication yes
|
||||
|
||||
```
|
||||
|
||||
Next, add the following line to enable two authentication schemes; SSH keys and Google Authenticator (keyboard-interactive):
|
||||
```
|
||||
AuthenticationMethods "publickey,keyboard-interactive"
|
||||
|
||||
```
|
||||
|
||||
Before we reload the SSH server it is a good idea to check that we did not make any errors in the configuration. This is done with the following command:
|
||||
```
|
||||
sshd -t
|
||||
|
||||
```
|
||||
|
||||
If this does not flag any errors, reload SSH with the new configuration:
|
||||
```
|
||||
systemctl reload sshd.service
|
||||
|
||||
```
|
||||
|
||||
Everything should now be working. Now, when you log into to your server you will need to use your SSH keys and when you are prompted for the:
|
||||
```
|
||||
Verification code:
|
||||
|
||||
```
|
||||
|
||||
open the Authenticator app and enter the 6 digit code that is displaying for your server.
|
||||
|
||||
### Authy
|
||||
|
||||
[Authy][4] is a two-factor authentication service that, like Google, offers time-based codes. However, Authy does not require a phone as they provide desktop and tables clients. They also enable offline authentication and do not require a Google account.
|
||||
|
||||
You will need to install the Authy app from your app store, or the desktop client all of which are linked to from the Authy [download page][5].
|
||||
|
||||
After you have installed the app you will need an API key that will be used on the server. This process requires a few steps:
|
||||
|
||||
1. Sign up for an account [here][6].
|
||||
2. Scroll down to the **Authy** section.
|
||||
3. Enable 2FA on the account.
|
||||
4. Return to the **Authy** section.
|
||||
5. Create a new Application for your server.
|
||||
6. Obtain the API key from the top of the `General Settings` page for the new Application. You need to click the eye symbol next to the `PRODUCTION API KEY` line to reveal the key. Shown here:
|
||||
|
||||
|
||||
|
||||
![][7]
|
||||
|
||||
Take a note of the API key somewhere secure.
|
||||
|
||||
Now, go back to your server and run the following commands as root:
|
||||
```
|
||||
curl -O 'https://raw.githubusercontent.com/authy/authy-ssh/master/authy-ssh'
|
||||
bash authy-ssh install /usr/local/bin
|
||||
|
||||
```
|
||||
|
||||
Enter the API key when prompted. If you input it incorrectly you can always edit `/usr/local/bin/authy-ssh.conf` and add it again.
|
||||
|
||||
Authy is now installed. However, it will not start working until it is enabled for a user. The command to enable Authy has the form:
|
||||
```
|
||||
/usr/local/bin/authy-ssh enable <system-user> <your-email> <your-phone-country-code> <your-phone-number>
|
||||
|
||||
```
|
||||
|
||||
With some example details for **root** logins:
|
||||
```
|
||||
/usr/local/bin/authy-ssh enable root john@example.com 44 20822536476
|
||||
|
||||
```
|
||||
|
||||
If everything was successful you will see:
|
||||
```
|
||||
User was registered
|
||||
|
||||
```
|
||||
|
||||
You can test Authy now by running the command:
|
||||
```
|
||||
authy-ssh test
|
||||
|
||||
```
|
||||
|
||||
Finally, reload SSH to implement the new configuration:
|
||||
```
|
||||
systemctl reload sshd.service
|
||||
|
||||
```
|
||||
|
||||
Authy is now working and will be required for SSH logins.
|
||||
|
||||
Now, when you log in you will see the following prompt:
|
||||
```
|
||||
Authy Token (type 'sms' to request a SMS token):
|
||||
|
||||
```
|
||||
|
||||
You can either enter the code from the Authy app on your phone or desktop client. Or you can type `sms` and Authy will send you an SMS message with a login code.
|
||||
|
||||
Authy is uninstalled by running the following:
|
||||
```
|
||||
/usr/local/bin/authy-ssh uninstall
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/ssh-2fa/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
[1]:https://github.com/google/google-authenticator-libpam
|
||||
[2]:https://plus.google.com/115609618223925128756
|
||||
[3]:https://support.google.com/accounts/answer/1066447?hl=en
|
||||
[4]:https://authy.com/
|
||||
[5]:https://authy.com/download/
|
||||
[6]:https://www.authy.com/signup
|
||||
[7]:/images/guides/2FA/twilio-authy-api.png
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
17 Ways To Check Size Of Physical Memory (RAM) In Linux
|
||||
======
|
||||
Most of the system administrators checks CPU & Memory utilization when they were facing some performance issue.
|
||||
|
||||
@ -1,165 +0,0 @@
|
||||
HackChow translating
|
||||
|
||||
5 alerting and visualization tools for sysadmins
|
||||
======
|
||||
These open source tools help users understand system behavior and output, and provide alerts for potential problems.
|
||||
|
||||

|
||||
|
||||
You probably know (or can guess) what alerting and visualization tools are used for. Why would we discuss them as observability tools, especially since some systems include visualization as a feature?
|
||||
|
||||
Observability comes from control theory and describes our ability to understand a system based on its inputs and outputs. This article focuses on the output component of observability.
|
||||
|
||||
Alerting and visualization tools analyze the outputs of other systems and provide structured representations of these outputs. Alerts are basically a synthesized understanding of negative system outputs, and visualizations are disambiguated structured representations that facilitate user comprehension.
|
||||
|
||||
### Common types of alerts and visualizations
|
||||
|
||||
#### Alerts
|
||||
|
||||
Let’s first cover what alerts are _not_. Alerts should not be sent if the human responder can’t do anything about the problem. This includes alerts that are sent to multiple individuals with only a few who can respond, or situations where every anomaly in the system triggers an alert. This leads to alert fatigue and receivers ignoring all alerts within a specific medium until the system escalates to a medium that isn’t already saturated.
|
||||
|
||||
For example, if an operator receives hundreds of emails a day from the alerting system, that operator will soon ignore all emails from the alerting system. The operator will respond to a real incident only when he or she is experiencing the problem, emailed by a customer, or called by the boss. In this case, alerts have lost their meaning and usefulness.
|
||||
|
||||
Alerts are not a constant stream of information or a status update. They are meant to convey a problem from which the system can’t automatically recover, and they are sent only to the individual most likely to be able to recover the system. Everything that falls outside this definition isn’t an alert and will only damage your employees and company culture.
|
||||
|
||||
Everyone has a different set of alert types, so I won't discuss things like priority levels (P1-P5) or models that use words like "Informational," "Warning," and "Critical." Instead, I’ll describe the generic categories emergent in complex systems’ incident response.
|
||||
|
||||
You might have noticed I mentioned an “Informational” alert type right after I wrote that alerts shouldn’t be informational. Well, not everyone agrees, but I don’t consider something an alert if it isn’t sent to anyone. It is a data point that many systems refer to as an alert. It represents some event that should be known but not responded to. It is generally part of the visualization system of the alerting tool and not an event that triggers actual notifications. Mike Julian covers this and other aspects of alerting in his book [Practical Monitoring][1]. It's a must read for work in this area.
|
||||
|
||||
Non-informational alerts consist of types that can be responded to or require action. I group these into two categories: internal outage and external outage. (Most companies have more than two levels for prioritizing their response efforts.) Degraded system performance is considered an outage in this model, as the impact to each user is usually unknown.
|
||||
|
||||
Internal outages are a lower priority than external outages, but they still need to be responded to quickly. They often include internal systems that company employees use or components of applications that are visible only to company employees.
|
||||
|
||||
External outages consist of any system outage that would immediately impact a customer. These don’t include a system outage that prevents releasing updates to the system. They do include customer-facing application failures, database outages, and networking partitions that hurt availability or consistency if either can impact a user. They also include outages of tools that may not have a direct impact on users, as the application continues to run but this transparent dependency impacts performance. This is common when the system uses some external service or data source that isn’t necessary for full functionality but may cause delays as the application performs retries or handles errors from this external dependency.
|
||||
|
||||
### Visualizations
|
||||
|
||||
There are many visualization types, and I won’t cover them all here. It’s a fascinating area of research. On the data analytics side of my career, learning and applying that knowledge is a constant challenge. We need to provide simple representations of complex system outputs for the widest dissemination of information. [Google Charts][2] and [Tableau][3] have a wide selection of visualization types. We’ll cover the most common visualizations and some innovative solutions for quickly understanding systems.
|
||||
|
||||
#### Line chart
|
||||
|
||||
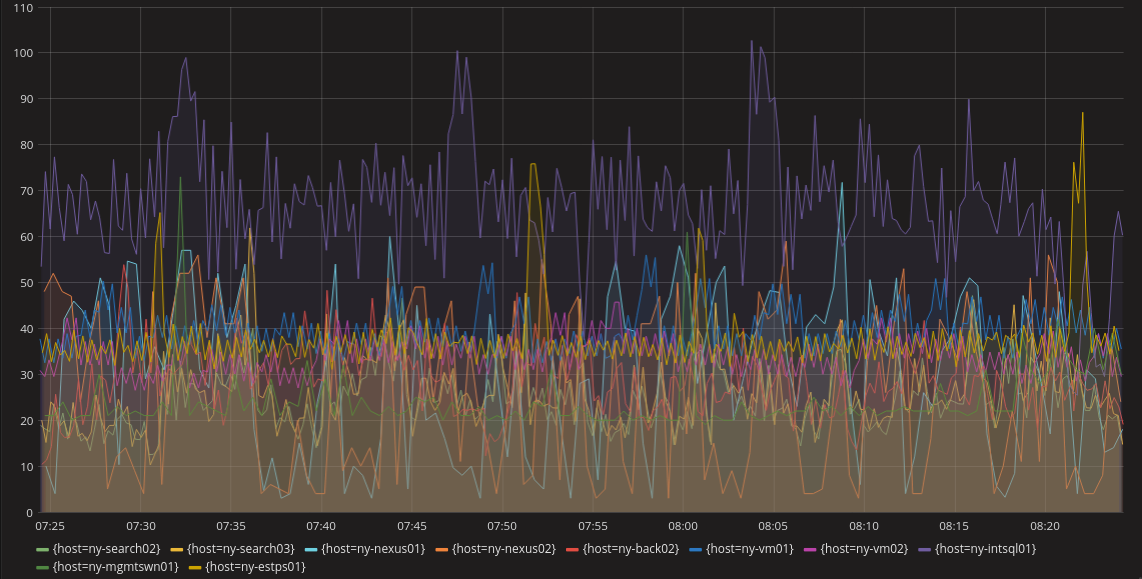
The line chart is probably the most common visualization. It does a pretty good job of producing an understanding of a system over time. A line chart in a metrics system would have a line for each unique metric or some aggregation of metrics. This can get confusing when there are a lot of metrics in the same dashboard (as shown below), but most systems can select specific metrics to view rather than having all of them visible. Also, anomalous behavior is easy to spot if it’s significant enough to escape the noise of normal operations. Below we can see purple, yellow, and light blue lines that might indicate anomalous behavior.
|
||||
|
||||
|
||||
|
||||
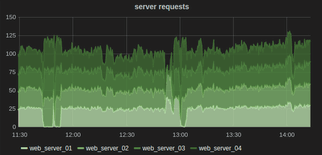
Another feature of a line chart is that you can often stack them to show relationships. For example, you might want to look at requests on each server individually, but also in aggregate. This allows you to understand the overall system as well as each instance in the same graph.
|
||||
|
||||
|
||||
|
||||
#### Heatmaps
|
||||
|
||||
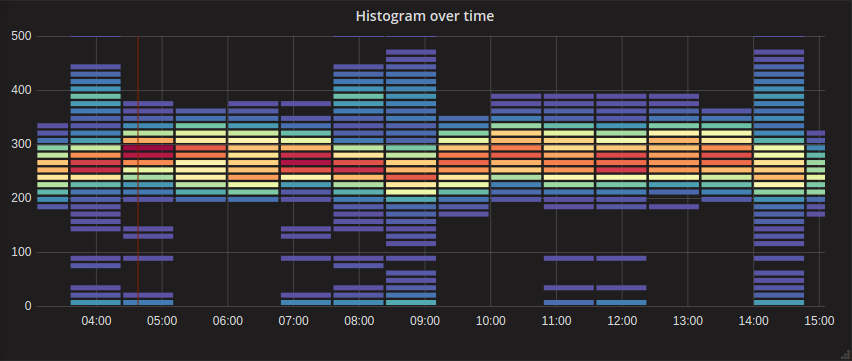
Another common visualization is the heatmap. It is useful when looking at histograms. This type of visualization is similar to a bar chart but can show gradients within the bars representing the different percentiles of the overall metric. For example, suppose you’re looking at request latencies and you want to quickly understand the overall trend as well as the distribution of all requests. A heatmap is great for this, and it can use color to disambiguate the quantity of each section with a quick glance.
|
||||
|
||||
The heatmap below shows the higher concentration around the centerline of the graph with an easy-to-understand visualization of the distribution vertically for each time bucket. We might want to review a couple of points in time where the distribution gets wide while the others are fairly tight like at 14:00. This distribution might be a negative performance indicator.
|
||||
|
||||
|
||||
|
||||
#### Gauges
|
||||
|
||||
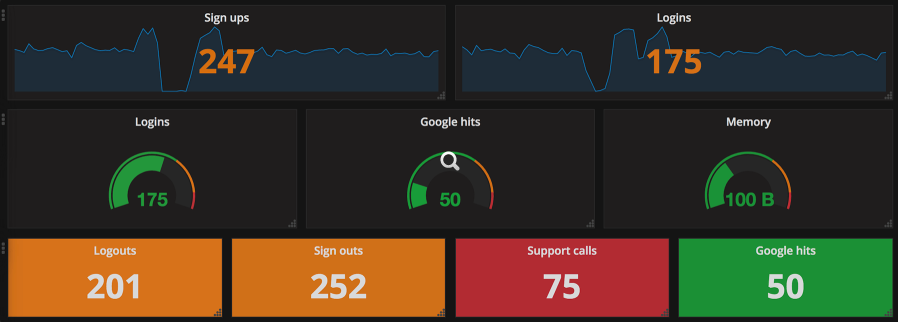
The last common visualization I’ll cover here is the gauge, which helps users understand a single metric quickly. Gauges can represent a single metric, like your speedometer represents your driving speed or your gas gauge represents the amount of gas in your car. Similar to the gas gauge, most monitoring gauges clearly indicate what is good and what isn’t. Often (as is shown below), good is represented by green, getting worse by orange, and “everything is breaking” by red. The middle row below shows traditional gauges.
|
||||
|
||||
|
||||
|
||||
This image shows more than just traditional gauges. The other gauges are single stat representations that are similar to the function of the classic gauge. They all use the same color scheme to quickly indicate system health with just a glance. Arguably, the bottom row is probably the best example of a gauge that allows you to glance at a dashboard and know that everything is healthy (or not). This type of visualization is usually what I put on a top-level dashboard. It offers a full, high-level understanding of system health in seconds.
|
||||
|
||||
#### Flame graphs
|
||||
|
||||
A less common visualization is the flame graph, introduced by [Netflix’s Brendan Gregg][4] in 2011. It’s not ideal for dashboarding or quickly observing high-level system concerns; it’s normally seen when trying to understand a specific application problem. This visualization focuses on CPU and memory and the associated frames. The X-axis lists the frames alphabetically, and the Y-axis shows stack depth. Each rectangle is a stack frame and includes the function being called. The wider the rectangle, the more it appears in the stack. This method is invaluable when trying to diagnose system performance at the application level and I urge everyone to give it a try.
|
||||
|
||||
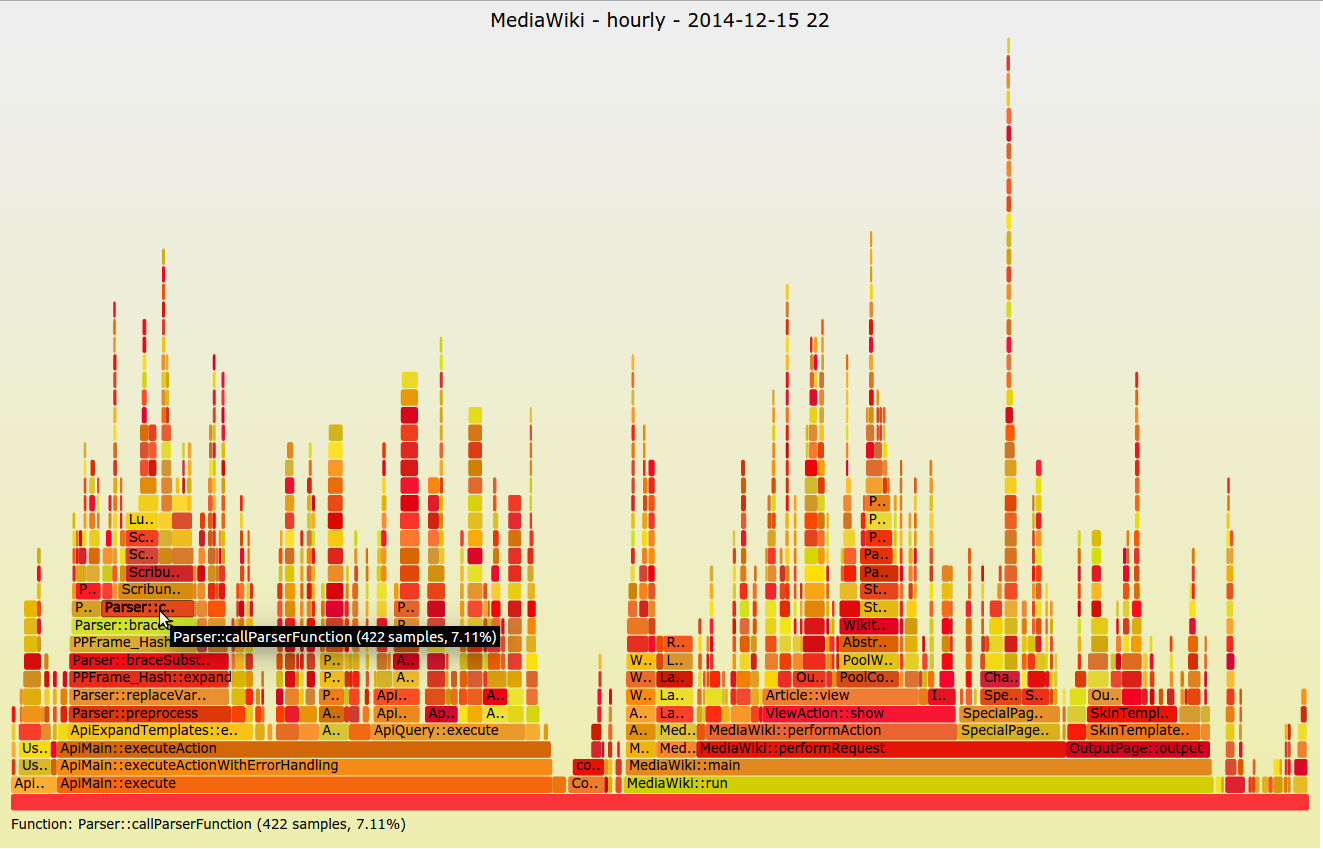
|
||||
|
||||
### Tool options
|
||||
|
||||
There are several commercial options for alerting, but since this is Opensource.com, I’ll cover only systems that are being used at scale by real companies that you can use at no cost. Hopefully, you’ll be able to contribute new and innovative features to make these systems even better.
|
||||
|
||||
### Alerting tools
|
||||
|
||||
#### Bosun
|
||||
|
||||
If you’ve ever done anything with computers and gotten stuck, the help you received was probably thanks to a Stack Exchange system. Stack Exchange runs many different websites around a crowdsourced question-and-answer model. [Stack Overflow][5] is very popular with developers, and [Super User][6] is popular with operations. However, there are now hundreds of sites ranging from parenting to sci-fi and philosophy to bicycles.
|
||||
|
||||
Stack Exchange open-sourced its alert management system, [Bosun][7], around the same time Prometheus and its [AlertManager][8] system were released. There were many similarities in the two systems, and that’s a really good thing. Like Prometheus, Bosun is written in Golang. Bosun’s scope is more extensive than Prometheus’ as it can interact with systems beyond metrics aggregation. It can also ingest data from log and event aggregation systems. It supports Graphite, InfluxDB, OpenTSDB, and Elasticsearch.
|
||||
|
||||
Bosun’s architecture consists of a single server binary, a backend like OpenTSDB, Redis, and [scollector agents][9]. The scollector agents automatically detect services on a host and report metrics for those processes and other system resources. This data is sent to a metrics backend. The Bosun server binary then queries the backends to determine if any alerts need to be fired. Bosun can also be used by tools like [Grafana][10] to query the underlying backends through one common interface. Redis is used to store state and metadata for Bosun.
|
||||
|
||||
A really neat feature of Bosun is that it lets you test your alerts against historical data. This was something I missed in Prometheus several years ago, when I had data for an issue I wanted alerts on but no easy way to test it. To make sure my alerts were working, I had to create and insert dummy data. This system alleviates that very time-consuming process.
|
||||
|
||||
Bosun also has the usual features like showing simple graphs and creating alerts. It has a powerful expression language for writing alerting rules. However, it only has email and HTTP notification configurations, which means connecting to Slack and other tools requires a bit more customization ([which its documentation covers][11]). Similar to Prometheus, Bosun can use templates for these notifications, which means they can look as awesome as you want them to. You can use all your HTML and CSS skills to create the baddest email alert anyone has ever seen.
|
||||
|
||||
#### Cabot
|
||||
|
||||
[Cabot][12] was created by a company called [Arachnys][13]. You may not know who Arachnys is or what it does, but you have probably felt its impact: It built the leading cloud-based solution for fighting financial crimes. That sounds pretty cool, right? At a previous company, I was involved in similar functions around [“know your customer"][14] laws. Most companies would consider it a very bad thing to be linked to a terrorist group, for example, funneling money through their systems. These solutions also help defend against less-atrocious offenders like fraudsters who could also pose a risk to the institution.
|
||||
|
||||
So why did Arachnys create Cabot? Well, it is kind of a Christmas present to everyone, as it was a Christmas project built because its developers couldn’t wrap their heads around [Nagios][15]. And really, who can blame them? Cabot was written with Django and Bootstrap, so it should be easy for most to contribute to the project. (Another interesting factoid: The name comes from the creator’s dog.)
|
||||
|
||||
The Cabot architecture is similar to Bosun in that it doesn’t collect any data. Instead, it accesses data through the APIs of the tools it is alerting for. Therefore, Cabot uses a pull (rather than a push) model for alerting. It reaches out into each system’s API and retrieves the information it needs to make a decision based on a specific check. Cabot stores the alerting data in a Postgres database and also has a cache using Redis.
|
||||
|
||||
Cabot natively supports [Graphite][16], but it also supports [Jenkins][17], which is rare in this area. [Arachnys][13] uses Jenkins like a centralized cron, but I like this idea of treating build failures like outages. Obviously, a build failure isn’t as critical as a production outage, but it could still alert the team and escalate if the failure isn’t resolved. Who actually checks Jenkins every time an email comes in about a build failure? Yeah, me too!
|
||||
|
||||
Another interesting feature is that Cabot can integrate with Google Calendar for on-call rotations. Cabot calls this feature Rota, which is a British term for a roster or rotation. This makes a lot of sense, and I wish other systems would take this idea further. Cabot doesn’t support anything more complex than primary and backup personnel, but there is certainly room for additional features. The docs say if you want something more advanced, you should look at a commercial option.
|
||||
|
||||
#### StatsAgg
|
||||
|
||||
[StatsAgg][18]? How did that make the list? Well, it’s not every day you come across a publishing company that has created an alerting platform. I think that deserves recognition. Of course, [Pearson][19] isn’t just a publishing company anymore; it has several web presences and a joint venture with [O’Reilly Media][20]. However, I still think of it as the company that published my schoolbooks and tests.
|
||||
|
||||
StatsAgg isn’t just an alerting platform; it’s also a metrics aggregation platform. And it’s kind of like a proxy for other systems. It supports Graphite, StatsD, InfluxDB, and OpenTSDB as inputs, but it can also forward those metrics to their respective platforms. This is an interesting concept, but potentially risky as loads increase on a central service. However, if the StatsAgg infrastructure is robust enough, it can still produce alerts even when a backend storage platform has an outage.
|
||||
|
||||
StatsAgg is written in Java and consists only of the main server and UI, which keeps complexity to a minimum. It can send alerts based on regular expression matching and is focused on alerting by service rather than host or instance. Its goal is to fill a void in the open source observability stack, and I think it does that quite well.
|
||||
|
||||
### Visualization tools
|
||||
|
||||
#### Grafana
|
||||
|
||||
Almost everyone knows about [Grafana][10], and many have used it. I have used it for years whenever I need a simple dashboard. The tool I used before was deprecated, and I was fairly distraught about that until Grafana made it okay. Grafana was gifted to us by Torkel Ödegaard. Like Cabot, Grafana was also created around Christmastime, and released in January 2014. It has come a long way in just a few years. It started life as a Kibana dashboarding system, and Torkel forked it into what became Grafana.
|
||||
|
||||
Grafana’s sole focus is presenting monitoring data in a more usable and pleasing way. It can natively gather data from Graphite, Elasticsearch, OpenTSDB, Prometheus, and InfluxDB. There’s an Enterprise version that uses plugins for more data sources, but there’s no reason those other data source plugins couldn’t be created as open source, as the Grafana plugin ecosystem already offers many other data sources.
|
||||
|
||||
What does Grafana do for me? It provides a central location for understanding my system. It is web-based, so anyone can access the information, although it can be restricted using different authentication methods. Grafana can provide knowledge at a glance using many different types of visualizations. However, it has started integrating alerting and other features that aren’t traditionally combined with visualizations.
|
||||
|
||||
Now you can set alerts visually. That means you can look at a graph, maybe even one showing where an alert should have triggered due to some degradation of the system, click on the graph where you want the alert to trigger, and then tell Grafana where to send the alert. That’s a pretty powerful addition that won’t necessarily replace an alerting platform, but it can certainly help augment it by providing a different perspective on alerting criteria.
|
||||
|
||||
Grafana has also introduced more collaboration features. Users have been able to share dashboards for a long time, meaning you don’t have to create your own dashboard for your [Kubernetes][21] cluster because there are several already available—with some maintained by Kubernetes developers and others by Grafana developers.
|
||||
|
||||
The most significant addition around collaboration is annotations. Annotations allow a user to add context to part of a graph. Other users can then use this context to understand the system better. This is an invaluable tool when a team is in the middle of an incident and communication and common understanding are critical. Having all the information right where you’re already looking makes it much more likely that knowledge will be shared across the team quickly. It’s also a nice feature to use during blameless postmortems when the team is trying to understand how the failure occurred and learn more about their system.
|
||||
|
||||
#### Vizceral
|
||||
|
||||
Netflix created [Vizceral][22] to understand its traffic patterns better when performing a traffic failover. Unlike Grafana, which is a more general tool, Vizceral serves a very specific use case. Netflix no longer uses this tool internally and says it is no longer actively maintained, but it still updates the tool periodically. I highlight it here primarily to point out an interesting visualization mechanism and how it can help solve a problem. It’s worth running it in a demo environment just to better grasp the concepts and witness what’s possible with these systems.
|
||||
|
||||
### What to read next
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/alerting-and-visualization-tools-sysadmins
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.practicalmonitoring.com/
|
||||
[2]: https://developers.google.com/chart/interactive/docs/gallery
|
||||
[3]: https://libguides.libraries.claremont.edu/c.php?g=474417&p=3286401
|
||||
[4]: http://www.brendangregg.com/flamegraphs.html
|
||||
[5]: https://stackoverflow.com/
|
||||
[6]: https://superuser.com/
|
||||
[7]: http://bosun.org/
|
||||
[8]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[9]: https://bosun.org/scollector/
|
||||
[10]: https://grafana.com/
|
||||
[11]: https://bosun.org/notifications
|
||||
[12]: https://cabotapp.com/
|
||||
[13]: https://www.arachnys.com/
|
||||
[14]: https://en.wikipedia.org/wiki/Know_your_customer
|
||||
[15]: https://www.nagios.org/
|
||||
[16]: https://graphiteapp.org/
|
||||
[17]: https://jenkins.io/
|
||||
[18]: https://github.com/PearsonEducation/StatsAgg
|
||||
[19]: https://www.pearson.com/us/
|
||||
[20]: https://www.oreilly.com/
|
||||
[21]: https://opensource.com/resources/what-is-kubernetes
|
||||
[22]: https://github.com/Netflix/vizceral
|
||||
@ -1,3 +1,5 @@
|
||||
HankChow translating
|
||||
|
||||
Machine learning with Python: Essential hacks and tricks
|
||||
======
|
||||
Master machine learning, AI, and deep learning with Python.
|
||||
|
||||
@ -0,0 +1,80 @@
|
||||
A 3-step process for making more transparent decisions
|
||||
======
|
||||

|
||||
|
||||
要让你的领导工作更加透明,其中一个最有效的方法就是将一个现有的程序开放给你的团队进行反馈,然后根据反馈去改变程序。下面这些练习能让透明度更佳切实,并且它有助于开发“肌肉记忆”,此二者可以持续评估且调整你的工作。
|
||||
|
||||
我想说,你可以通过任何程序来完成这项工作—即使是那些“范围外的”的程序,像是晋升或者自行调整程序。但是如果第一次它对于机内测试设备来说太大了,那么你可能需要从一个不那么程序的方法开始,比如旅行批准程序或者你的寻找团队空缺候选人的系统。(举个例子,我使用了在我们的招聘和晋升程序)
|
||||
|
||||
开放程序并使其更佳透明可以建立你的信誉并增强团队成员对你的信任。它会迫使你以一种可能超乎你设想和舒适程度的方式 “走透明的路”。以这种方式工作确实会产生额外的工作,尤其是在过程的开始阶段——但是,最终这种方法对于让管理者(比如我)对团队成员很有效的负责,而且它会更加相容。
|
||||
|
||||
### 阶段一:选择一个程序
|
||||
|
||||
**第一步.** 想想你的团队使用的一个普通的或常规的程序,但是这个程序通常不需要仔细检查。下面有一些例子:
|
||||
|
||||
* 招聘:如何创建职位描述、如何挑选面试团队、如何筛选候选人以及如何做出最终的招聘决定。
|
||||
* 规划:你的团队或组织如何确定目标年度或季度。
|
||||
* 升职:你如何选择并考虑升职候选人,并决定谁升职。
|
||||
* 经理绩效评估:谁有机会就经理绩效提供反馈,以及他们是如何反馈。
|
||||
* 旅游:旅游预算如何分配,以及你如何决定是否批准旅行(或提名某人是否旅行)。
|
||||
|
||||
|
||||
|
||||
上面的某个例子可能会引起你的共鸣,或者你可能会发现一些你觉得更合适的东西。也许你已经收到了关于某个特定程序的问题,又或者你发现自己屡次解释某个特定决策的基本原理。选择一些你能够控制或影响的东西——一些你相信你的成员关心的东西。
|
||||
|
||||
**第二步.** 现在回答以下关于这个程序的问题:
|
||||
|
||||
* 该程序目前是否记录在一个所有成员都知道并可以访问的地方?如果没有,现在就开始创建文档(不必太详细;只需要解释这个程序的不同步骤以及它是如何工作的)。你可能会发现这个过程不够清晰或一致,无法进行文档记录。在这种情况下,用你认为理想情况下应该使用的方式去记录它。
|
||||
* 完成程序的文档是否说明了在不同的点上是如何做出决定?例如,在旅行批准程序中,它是否解释了如何批准或拒绝请求。
|
||||
* 程序的输入是什么?例如,在确定部门年度目标时,哪些数据用于关键绩效指标,查找或者采纳谁的反馈,谁有机会回顾或“停止活动”。
|
||||
* 这个过程会做出什么假设?例如,在升职决策中,你是否认为所有的晋升候选人都会在适当的时间被他们的经理提出。
|
||||
* 程序的输出是什么?例如,在评估经理的绩效时,评估的结果是否会与经理共享,任何审查的方面是否会与经理的直接报告(例如,改进的领域)更广泛地共享?
|
||||
|
||||
|
||||
|
||||
回答上述问题时,避免作出判断。如果这个程序不能清楚地解释一个决定是如何做出的,那也可以接受。这些问题只是评估现状的一个机会。
|
||||
|
||||
接下来,修改程序的文档,直到你对它充分说明了程序并预测潜在的问题感到满意。
|
||||
|
||||
### 阶段二:收集反馈
|
||||
|
||||
下一个阶段牵涉与你的成员分享这个程序并要求反馈。分享说起来容易做起来难。
|
||||
|
||||
**第一步.** 鼓励人们提供反馈。考虑一下实现此目的的各种机制:
|
||||
|
||||
* 把这个程序公布在人们可以在内部找到的地方,并注意他们可以在哪里发表评论或提供反馈。谷歌文档可以很好地评论特定的文本或直接建议文本中的更改。
|
||||
* 通过电子邮件分享过程文档,邀请反馈。
|
||||
* 提及程序文档,在团队会议或一对一的谈话时要求反馈。
|
||||
* 给人们一个他们可以提供反馈的时间窗口,并在此窗口定期发送提醒。
|
||||
|
||||
|
||||
|
||||
如果你得不到太多的反馈,不要认为沉默就等于认可。你可以试着直接询问人们,他们为什么没有反馈。是因为他们太忙了吗?这个过程对他们来说不像你想的那么重要吗?你清楚地表达了你的要求吗?
|
||||
|
||||
**第二步.** 迭代。当你获得关于程序的反馈时,请让团队对流程进行修改和迭代。加入改进的想法和建议,并要求确认预期的反馈已经被应用。如果你不同意某个建议,那就接受讨论,问问自己为什么不同意,以及一种方法和另一种方法的优点是什么。
|
||||
设置一个收集反馈和迭代的时间盒有助于向前推进。一旦反馈被收集和审查,你应当讨论和应用它,并且发布最终的程序供团队审查。
|
||||
|
||||
### 阶段三:实现
|
||||
|
||||
实现程序通常是计划中最困难的阶段。但如果你在修改过程中考虑了反馈意见,人们应该已经预料到了,并且可能会更支持你。从上面迭代过程中获得的文档是一个很好的工具,可以让你对实现负责。
|
||||
|
||||
**第一步.** 审查实施需求。许多可以从提高透明度中获益的程序只需要做一点不同的事情,但是你确实需要检查你是否需要其他支持(例如工具)。
|
||||
|
||||
**第二步.** 设置实现的时间表。与成员一起回顾时间表,这样他们就知道会发生什么。如果新程序需要对其他程序进行更改,请确保为人们提供足够的时间去适应新性能,并提供沟通和提醒。
|
||||
|
||||
**第三步.** 跟进。在使用程序3-6个月后,与你的成员联系,看看进展如何。新流程是否更加透明,更有效,更可预测?你有什么经验教训可以用来进一步改进这个程序吗?
|
||||
|
||||
### 关于作者
|
||||
Sam Knuth;我有幸在 Red Hat 领导客户内容服务团队;我们提供给我们的客户所有产生的文档。我们的目标是为客户提供他们在企业中使用开源技术取得成功所需要的洞察力。在Twitter上与我联系
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/9/exercise-in-transparent-decisions
|
||||
|
||||
作者:[a][Sam Knuth]
|
||||
译者:[MarineFish](https://github.com/MarineFish)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/samfw<!doctype html>
|
||||
@ -0,0 +1,237 @@
|
||||
在 Ubuntu16.04 和 Debian Jessie 上启用双因素身份验证的三种备选方案
|
||||
=====
|
||||
|
||||
如今,安全比以往更加重要,保护 SSH 服务器是作为系统管理员可以做的最为重要的事情之一。传统地,这意味着禁用密码身份验证而改用 SSH 密钥。无疑这是你首先应该做的,但这并不意味着 SSH 无法变得更加安全。
|
||||
|
||||
双因素身份验证就是指需要两种身份验证才能登录。可以是密码和 SSH 密钥,也可以是密钥和第三方服务,比如 Google。这意味着单个验证方法的泄露不会危及服务器。
|
||||
|
||||
以下指南是为 SSH 启用双因素验证的三种方式。
|
||||
|
||||
当你修改 SSH 配置时,总是要确保有一个对服务器开放的第二终端。第二终端意味着你可以修复你在 SSH 配置中犯的任何错误。开放终端将保持开放,即便 SSH 重启。
|
||||
|
||||
### SSH 密钥和密码
|
||||
|
||||
SSH 支持对登录要求不止一个身份验证方法。
|
||||
|
||||
在 `/etc/sh/sshd_config` 中的 SSH 服务器配置文件中的 `AuthenticationMethods` 选项中设置了身份验证方法。
|
||||
|
||||
当在 `/etc/ssh/sshd_config` 中添加下一行时,SSH需要提交一个 SSH 密钥,然后提示输入密码:
|
||||
|
||||
`AuthenticationMethods“publickey,password”`
|
||||
|
||||
|
||||
如果你想要根据使用情况设置这些方法,那么请使用以下附加配置:
|
||||
|
||||
```
|
||||
Match User jsmith
|
||||
AuthenticationMethods“publickey,password”
|
||||
```
|
||||
|
||||
当你已经编辑或保存了新的 `sshd_config` 文件,你应该通过运行以下程序来确保你没有犯任何错误:
|
||||
|
||||
`sshd -t`
|
||||
|
||||
任何阻止 SSH 启动的语法或其他错误都将在这里标记。当 `ssh-t` 运行时没有错误,使用 `systemctl` 重新启动 SSH
|
||||
|
||||
`systemctl restart sshd`
|
||||
|
||||
现在,你可以使用新终端登录,以核实你会被提示输入密码并需要 SSH 密钥。如果你用 `ssh-v` 例如:
|
||||
|
||||
`ssh -v jsmith@example.com`
|
||||
|
||||
你将可以看到登录的每一步。
|
||||
|
||||
注意,如果你确实将密码设置成必需的身份验证方法,你要确保将 ` PasswordAuthentication` 选项设置成 `yes`。
|
||||
|
||||
### 使用 Google Authenticator 的 SSH
|
||||
|
||||
Google 在 Google 自己的产品上使用的双因素身份验证系统可以集成到你的 SSH 服务器中。如果你已经使用了Google Authenticator,那么此方法将非常方便。
|
||||
|
||||
虽然 libpam-google-authenticator 是由 Google 编写的,但它是[开源][1]的。此外,Google Authenticator 是由Google 编写的,但不需要 Google 帐户才能工作。多亏了 [Sitaram Chamarty][2] 的贡献。
|
||||
|
||||
如果你还没有在手机上安装和配置 Google Authenticator,请参阅 [这里][3]的说明。
|
||||
|
||||
首先,我们需要在服务器上安装 Google Authenticatior 安装包。以下命令将更新你的系统并安装所需的软件包:
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get upgrade
|
||||
|
||||
apt-get install libpam-google-authenticator
|
||||
|
||||
|
||||
|
||||
现在,我们需要在你的手机上使用 Google Authenticatior APP 注册服务器。这是通过首先运行我们刚刚安装的程序完成的:
|
||||
|
||||
`google-authenticator`
|
||||
|
||||
运行这个程序时,有几个问题会被问到。你应该以适合你的设置的方式回答,然而,最安全的选项是对每个问题回答`y`。如果以后需要更改这些选项,您可以简单地重新运行 `google-authenticator` 并选择不同的选项。
|
||||
|
||||
当你运行 `google-authenticator` 时,一个二维码会被打印到终端上,有些代码看起来像这样:
|
||||
|
||||
Your new secret key is:VMFY27TYDFRDNKFY
|
||||
|
||||
Your verification code is:259652
|
||||
|
||||
Your emergency scratch codes are:
|
||||
|
||||
96915246
|
||||
|
||||
70222983
|
||||
|
||||
31822707
|
||||
|
||||
25181286
|
||||
|
||||
28919992
|
||||
|
||||
|
||||
你应该将所有这些代码记录到一个像密码管理器一样安全的位置。scratch codes 是单一的使用代码,即使你的手机不可用,它总是允许你访问。
|
||||
|
||||
要将服务器注册到 Authenticator APP 中,只需打开应用程序并点击右下角的红色加号即可。然后选择扫描条码选项,扫描打印到终端的二维码。你的服务器和应用程序现在连接。
|
||||
|
||||
回到服务器上,我们现在需要编辑用于 SSH 的 PAM (可插入身份验证模块),以便它使用我们刚刚安装的身份验证器安装包。PAM 是独立系统,负责 Linux 服务器上的大多数身份验证。
|
||||
|
||||
需要修改的 SSH PAM 文件位于 ` /etc/ pamc。d/sshd` ,用以下命令编辑:
|
||||
|
||||
`nano/etc/pam.d/sshd`
|
||||
|
||||
|
||||
在文件顶部添加以下行:
|
||||
|
||||
`auth required pam_google_authenticator.so`
|
||||
|
||||
|
||||
此外,我们还需要注释掉一行,这样 PAM 就不会提示输入密码。改变这行:
|
||||
|
||||
|
||||
#Standard Un*x authentication.
|
||||
@include common-auth
|
||||
|
||||
|
||||
|
||||
为如下:
|
||||
|
||||
|
||||
#Standard Un*x authentication.
|
||||
# @include common-auth
|
||||
|
||||
|
||||
接下来,我们需要编辑 SSH 服务器配置文件:
|
||||
|
||||
`nano/etc/ssh/sshd_config`
|
||||
|
||||
|
||||
改变这一行:
|
||||
|
||||
`ChallengeResponseAuthentication no`
|
||||
|
||||
|
||||
为:
|
||||
|
||||
`ChallengeResponseAuthentication yes`
|
||||
|
||||
|
||||
接下来,添加以下代码行来启用两个身份验证方案; SSH 密钥和谷歌认证器(键盘交互):
|
||||
|
||||
`AuthenticationMethods“publickey keyboard-interactive”`
|
||||
|
||||
|
||||
在重新加载 SSH 服务器之前,最好检查一下在配置中没有出现任何错误。执行以下命令:
|
||||
|
||||
`sshd - t`
|
||||
|
||||
|
||||
如果这没有标记任何错误,用新的配置重载 SSH:
|
||||
|
||||
`systemctl reload sshd.service`
|
||||
|
||||
|
||||
现在一切都应该开始工作了。现在,当你登录到你的服务器时,你将需要使用 SSH 密钥,并且当你被提示输入:
|
||||
|
||||
`Verification code:`
|
||||
|
||||
|
||||
打开 Authenticator APP 并输入为您的服务器显示的6位代码。
|
||||
|
||||
### Authy
|
||||
|
||||
[Authy][4] 是一个双重身份验证服务,与 Google 一样,它提供基于时间的代码。然而,Authy 不需要手机,因为它提供桌面和表客户端。它们还支持离线身份验证,不需要 Google 帐户。
|
||||
|
||||
你需要从应用程序商店安装 Authy 应用程序,或从 Authy [下载页面][5]链接到的桌面客户端。
|
||||
|
||||
安装完应用程序后,需要在服务器上使用 API 密钥。这个过程需要几个步骤:
|
||||
|
||||
1.在[这里][6]注册一个账户。
|
||||
|
||||
2.向下滚动到 **Authy** 部分。
|
||||
|
||||
3.在帐户上启用 2FA。
|
||||
|
||||
4.回 **Authy** 部分。
|
||||
|
||||
5.为你的服务器创建一个新的应用程序。
|
||||
|
||||
6.从新应用程序的 `General Settings`页面顶部获取 API 密钥。你需要`PRODUCTION API KEY`旁边的眼睛符号来显示密钥。所示:
|
||||
|
||||
在某个安全的地方记下API密钥。
|
||||
|
||||
现在,回到服务器,以root身份运行以下命令:
|
||||
|
||||
curl - o ' https://raw.githubusercontent.com/authy/authy-ssh/master/authy-ssh '
|
||||
bash authy-ssh install/usr/local/bin
|
||||
|
||||
当提示时输入API键。如果输入错误,你始终可以编辑`/usr/local/bin/authy-ssh`。再添加一次。
|
||||
|
||||
Authy 现已安装。但是,在为用户启用它之前,它不会开始工作。启用 Authy 的命令有以下形式:
|
||||
|
||||
/usr/local/bin/authy-ssh<system-user> <your-email> <your-phone-country-code> <your-phone-number>
|
||||
|
||||
root登录的一些示例细节:
|
||||
|
||||
/usr/local/bin/authy-ssh enable root john@example.com 44 20822536476
|
||||
|
||||
如果一切顺利,你会看到:
|
||||
|
||||
User was registered
|
||||
|
||||
现在可以通过运行以下命令来测试 Authy:
|
||||
|
||||
authy-ssh test
|
||||
|
||||
最后,重载 SSH 实现新的配置:
|
||||
|
||||
Systemctl reload sshd.service
|
||||
|
||||
Authy 现在正在工作,需要 SSH 登录。
|
||||
|
||||
现在,当你登录时,你将看到以下提示:
|
||||
|
||||
`Authy Token(type'sms'to request a SMS token):`
|
||||
|
||||
|
||||
你可以从手机或桌面客户端上的 Authy APP 输入代码。或者你可以输入 sms, Authy 会给你发送一条带有登录码的 sms 消息。
|
||||
|
||||
通过运行以下命令卸载 Authy:
|
||||
|
||||
/usr/local/bin/authy-ssh uninstall
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/ssh-2fa/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[cielllll](https://github.com/cielllll)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
[1]:https://github.com/google/google-authenticator-libpam
|
||||
[2]:https://plus.google.com/115609618223925128756
|
||||
[3]:https://support.google.com/accounts/answer/1066447?hl=en
|
||||
[4]:https://authy.com/
|
||||
[5]:https://authy.com/download/
|
||||
[6]:https://www.authy.com/signup
|
||||
[7]:/images/guides/2FA/twilio-authy-api.png
|
||||
|
||||
@ -1,34 +1,29 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
How To Add, Enable And Disable A Repository In Linux
|
||||
如何在 Linux 中添加,启用和禁用一个仓库
|
||||
======
|
||||
Many of us using yum package manager to manage package installation, remove, update, search, etc, on RPM based system such as RHEL, CentOS, etc,.
|
||||
|
||||
Linux distributions gets most of its software from distribution official repositories. The official distribution repositories contain good amount of free and open source apps/software’s. It’s readily available to install and use.
|
||||
在基于 RPM 的系统上,例如 RHEL, CentOS 等,我们中的许多人使用 yum 包管理器来管理软件的安装,删除,更新,搜索等。
|
||||
|
||||
RPM based distribution doesn’t offer some of the packages in their official distribution repository due to some limitation and proprietary issue. Also it won’t offer latest version of core packages due to stability.
|
||||
Linux 发行版的大部分软件都来自发行版官方仓库。官方仓库包含大量免费和开源的应用和软件。它很容易安装和使用。
|
||||
|
||||
To overcome this situation/issue, we need to install/enable the requires third party repository. There are many third party repositories are available for RPM based systems but only few of the repositories are advised to use because they didn’t replace large amount of base packages.
|
||||
由于一些限制和专有问题,基于 RPM 的发行版在其官方仓库中没有提供某些包。另外,出于稳定性考虑,它不会提供最新版本的核心包。
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [YUM Command To Manage Packages on RHEL/CentOS Systems][1]
|
||||
**(#)** [DNF (Fork of YUM) Command To Manage Packages on Fedora System][2]
|
||||
**(#)** [List of Command line Package Manager & Usage][3]
|
||||
**(#)** [A Graphical front-end tool for Linux Package Manager][4]
|
||||
为了克服这种情况,我们需要安装或启用需要的第三方仓库。对于基于 RPM 的系统,有许多第三方仓库可用,但建议使用的仓库很少,因为它们不会替换大量的基础包。
|
||||
|
||||
This can be done on RPM based system such as RHEL, CentOS, OEL, Fedora, etc,.
|
||||
**建议阅读:**
|
||||
**(#)** [在 RHEL/CentOS 系统中使用 YUM 命令管理包][1]
|
||||
**(#)** [在 Fedora 系统中使用 DNF (YUM 的分支) 命令来管理包][2]
|
||||
**(#)** [命令行包管理器和用法列表][3]
|
||||
**(#)** [Linux 包管理器的图形化工具][4]
|
||||
|
||||
* Fedora system uses “dnf config-manager [options] [section …]”
|
||||
* Other RPM based system uses “yum-config-manager [options] [section …]”
|
||||
这可以在基于 RPM 的系统上完成,比如 RHEL, CentOS, OEL, Fedora 等。
|
||||
* Fedora 系统使用 “dnf config-manager [options] [section …]”
|
||||
* 其它基于 RPM 的系统使用 “yum-config-manager [options] [section …]”
|
||||
|
||||
### 如何列出启用的仓库
|
||||
|
||||
只需运行以下命令即可检查系统上启用的仓库列表。
|
||||
|
||||
### How To List Enabled Repositories
|
||||
|
||||
Just run the below command to check list of enabled repositories on your system.
|
||||
|
||||
For CentOS/RHEL/OLE systems
|
||||
对于 CentOS/RHEL/OLE 系统:
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, security
|
||||
@ -41,33 +36,32 @@ repolist: 8,014
|
||||
|
||||
```
|
||||
|
||||
For Fedora system
|
||||
对于 Fedora 系统:
|
||||
```
|
||||
# dnf repolist
|
||||
|
||||
```
|
||||
|
||||
### How To Add A New Repository In System
|
||||
### 如何在系统中添加一个新仓库
|
||||
|
||||
Every repositories commonly provide their own `.repo` file. To add such a repository to your system, run the
|
||||
following command as root user. In our case, we are going to add `EPEL Repository` and `IUS Community Repo`, see below.
|
||||
每个仓库通常都提供自己的 `.repo` 文件。要将此类仓库添加到系统中,使用 root 用户运行以下命令。在我们的例子中将添加 `EPEL Repository` 和 `IUS Community Repo`,见下文。
|
||||
|
||||
There is no `.repo` files are available for these repositories. Hence, we are installing by using below methods.
|
||||
但是没有 `.repo` 文件可用于这些仓库。因此,我们使用以下方法进行安装。
|
||||
|
||||
For **EPEL Repository** , since it’s available from CentOS extra repository so, run the below command to install it.
|
||||
对于 **EPEL Repository**,因为它可以从 CentOS 额外仓库获得(to 校正:额外仓库什么意思?),所以运行以下命令来安装它。
|
||||
```
|
||||
# yum install epel-release -y
|
||||
|
||||
```
|
||||
|
||||
For **IUS Community Repo** , run the below bash script to install it.
|
||||
对于 **IUS Community Repo**,运行以下 bash 脚本来安装。
|
||||
```
|
||||
# curl 'https://setup.ius.io/' -o setup-ius.sh
|
||||
# sh setup-ius.sh
|
||||
|
||||
```
|
||||
|
||||
If you have `.repo` file, simple run the following command to add a repository on RHEL/CentOS/OEL.
|
||||
如果你有 `.repo` 文件,在 RHEL/CentOS/OEL 中,只需运行以下命令来添加一个仓库。
|
||||
```
|
||||
# yum-config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
@ -79,7 +73,7 @@ repo saved to /etc/yum.repos.d/example.repo
|
||||
|
||||
```
|
||||
|
||||
For Fedora system, run the below command to add a repository.
|
||||
对于 Fedora 系统,运行以下命令来添加一个仓库。
|
||||
```
|
||||
# dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
@ -87,9 +81,9 @@ adding repo from: http://www.example.com/example.repo
|
||||
|
||||
```
|
||||
|
||||
If you run `yum repolist` command after adding these repositories, you can able to see newly added repositories. Yes, i saw that.
|
||||
如果在添加这些仓库之后运行 `yum repolist` 命令,你就可以看到新添加的仓库了。Yes,我看到了。
|
||||
|
||||
Make a note: whenever you run “yum repolist” command, that automatically fetch updates from corresponding repository and save the caches in local system.
|
||||
注意:每当运行 “yum repolist” 命令时,该命令会自动从相应的仓库获取更新,并将缓存保存在本地系统中。
|
||||
```
|
||||
# yum repolist
|
||||
|
||||
@ -109,7 +103,7 @@ repolist: 20,909
|
||||
|
||||
```
|
||||
|
||||
Each repository has multiple channels such as Testing, Dev, Archive. You can understand this better by navigating to repository files location.
|
||||
每个仓库都有多个渠道,比如测试,开发和存档(Testing, Dev, Archive)。通过导航到仓库文件位置,你可以更好地理解这一点。
|
||||
```
|
||||
# ls -lh /etc/yum.repos.d
|
||||
total 64K
|
||||
@ -130,11 +124,11 @@ total 64K
|
||||
|
||||
```
|
||||
|
||||
### How To Enable A Repository In System
|
||||
### 如何在系统中启用一个仓库
|
||||
|
||||
When you add a new repository by default it’s enable the their stable repository that’s why we are getting the repository information when we ran “yum repolist” command. In some cases if you want to enable their Testing or Dev or Archive repo, use the following command. Also, we can enable any disabled repo using this command.
|
||||
当你在默认情况下添加一个新仓库时,它将启用它们的稳定仓库,这就是为什么我们在运行 “yum repolist” 命令时要获取仓库信息。在某些情况下,如果你希望启用它们的测试,开发或存档仓库,使用以下命令。另外,我们还可以使用此命令启用任何禁用的仓库。
|
||||
|
||||
To validate this, we are going to enable `epel-testing.repo` by running the below command.
|
||||
为了验证这一点,我们将启用 `epel-testing.repo`,运行下面的命令:
|
||||
```
|
||||
# yum-config-manager --enable epel-testing
|
||||
|
||||
@ -190,7 +184,7 @@ username =
|
||||
|
||||
```
|
||||
|
||||
Run the “yum repolist” command to check whether “epel-testing” is enabled or not. It’s enabled, i could able to see the repo.
|
||||
运行 “yum repolist” 命令来检查是否启用了 “epel-testing”。它被启用了,我可以从列表中看到它。
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, security
|
||||
@ -223,23 +217,23 @@ repolist: 22,250
|
||||
|
||||
```
|
||||
|
||||
If you want to enable multiple repositories at once, use the below format. This command will enable epel, epel-testing, and ius repositories.
|
||||
如果你想同时启用多个仓库,使用以下格式。这个命令将启用 epel, epel-testing 和 ius 仓库。
|
||||
```
|
||||
# yum-config-manager --enable epel epel-testing ius
|
||||
|
||||
```
|
||||
|
||||
For Fedora system, run the below command to enable a repository.
|
||||
对于 Fedora 系统,运行下面的命令来启用仓库。
|
||||
```
|
||||
# dnf config-manager --set-enabled epel-testing
|
||||
|
||||
```
|
||||
|
||||
### How To Disable A Repository In System
|
||||
### 如何在系统中禁用一个仓库
|
||||
|
||||
Whenever you add a new repository by default it enables their stable repository that’s why we are getting the repository information when we ran “yum repolist” command. If you dont want to use the repository then disable that by running below command.
|
||||
无论何时你在默认情况下添加一个新的仓库,它都会启用它们的稳定仓库,这就是为什么我们在运行 “yum repolist” 命令时要获取仓库信息。如果你不想使用仓库,那么可以通过下面的命令来禁用它。
|
||||
|
||||
To validate this, we are going to disable `epel-testing.repo` & `ius.repo` by running below command.
|
||||
为了验证这点,我们将要禁用 `epel-testing.repo` 和 `ius.repo`,运行以下命令:
|
||||
```
|
||||
# yum-config-manager --disable epel-testing ius
|
||||
|
||||
@ -344,7 +338,7 @@ username =
|
||||
|
||||
```
|
||||
|
||||
Run the “yum repolist” command to check whether “epel-testing” & “ius” repositories are disabled or not. It’s disabled, i could not able to see those repo in the below list except “epel”.
|
||||
运行 “yum repolist” 命令检查 “epel-testing” 和 “ius” 仓库是否被禁用。它被禁用了,我不能看到那些仓库,除了 “epel”。
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, security
|
||||
@ -360,7 +354,7 @@ repolist: 21,051
|
||||
|
||||
```
|
||||
|
||||
Alternatively, we can run the following command to see the details.
|
||||
或者,我们可以运行以下命令查看详细信息。
|
||||
```
|
||||
# yum repolist all | grep "epel*\|ius*"
|
||||
* epel: mirror.steadfast.net
|
||||
@ -385,16 +379,15 @@ ius-testing-source IUS Community Packages for Enterprise disabled
|
||||
|
||||
```
|
||||
|
||||
For Fedora system, run the below command to enable a repository.
|
||||
对于 Fedora 系统,运行以下命令来启用一个仓库。
|
||||
```
|
||||
# dnf config-manager --set-disabled epel-testing
|
||||
|
||||
```
|
||||
|
||||
Alternatively this can be done by editing the appropriate repo file manually. To do, open the corresponding repo file and change the value from `enabled=0`
|
||||
to `enabled=1` (To enable the repo) or from `enabled=1` to `enabled=0` (To disable the repo).
|
||||
或者,可以通过手动编辑适当的 repo 文件来完成。为此,打开相应的 repo 文件并将值从 `enabled=0` 改为 `enabled=1`(启用仓库)或从 `enabled=1` 变为 `enabled=0`(禁用仓库)。
|
||||
|
||||
From:
|
||||
即从:
|
||||
```
|
||||
[epel]
|
||||
name=Extra Packages for Enterprise Linux 6 - $basearch
|
||||
@ -406,8 +399,7 @@ gpgcheck=1
|
||||
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||
|
||||
```
|
||||
|
||||
To:
|
||||
改为
|
||||
```
|
||||
[epel]
|
||||
name=Extra Packages for Enterprise Linux 6 - $basearch
|
||||
@ -426,7 +418,7 @@ via: https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-con
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,39 +1,40 @@
|
||||
SDKMAN – A CLI Tool To Easily Manage Multiple Software Development Kits
|
||||
SDKMAN – 轻松管理多个软件开发套件 (SDK) 的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
Are you a developer who often install and test applications on different SDKs? I’ve got a good news for you! Say hello to **SDKMAN** , a CLI tool that helps you to easily manage multiple software development kits. It provides a convenient way to install, switch, list and remove candidates. Using SDKMAN, you can now manage parallel versions of multiple SDKs easily on any Unix-like operating system. It allows the developers to install Software Development Kits for the JVM such as Java, Groovy, Scala, Kotlin and Ceylon. Ant, Gradle, Grails, Maven, SBT, Spark, Spring Boot, Vert.x and many others are also supported. SDKMAN is free, light weight, open source and written in **Bash**.
|
||||
你是否是一个经常在不同的 SDK 下安装和测试应用的开发者?我有一个好消息要告诉你!**SDKMAN**,一个可以帮你轻松管理多个 SDK 的命令行工具。它为安装、切换、列出和移除 SDK 提供了一个简便的方式。有了 SDKMAN,你可以在任何类 Unix 的操作系统上轻松地并行管理多个 SDK 的多个版本。它允许开发者为 JVM 安装不同的 SDK,例如 Java、Groovy、Scala、Kotlin 和 Ceylon、Ant、Gradle、Grails、Maven、SBT、Spark、Spring Boot、Vert.x,以及许多其他支持的 SDK。SDKMAN 是免费、轻量、开源、使用 **Bash** 编写的程序。
|
||||
|
||||
### Installing SDKMAN
|
||||
### 安装 SDKMAN
|
||||
|
||||
Installing SDKMAN is trivial. First, make sure you have installed **zip** and **unzip** applications. It is available in the default repositories of most Linux distributions. For instance, to install unzip on Debian-based systems, simply run:
|
||||
安装 SDKMAN 很简单。首先,确保你已经安装了 **zip** 和 **unzip** 这两个应用。它们在大多数的 Linux 发行版的默认仓库中。
|
||||
例如,在基于 Debian 的系统上安装 unzip,只需要运行:
|
||||
```
|
||||
$ sudo apt-get install zip unzip
|
||||
|
||||
```
|
||||
|
||||
Then, install SDKMAN using command:
|
||||
然后使用下面的命令安装 SDKMAN:
|
||||
```
|
||||
$ curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
It’s that simple. Once the installation is completed, run the following command:
|
||||
在安装完成之后,运行以下命令:
|
||||
```
|
||||
$ source "$HOME/.sdkman/bin/sdkman-init.sh"
|
||||
|
||||
```
|
||||
|
||||
If you want to install it in a custom location of your choice other than **$HOME/.sdkman** , for example **/usr/local/** , do:
|
||||
如果你希望自定义安装到其他位置,例如 **/usr/local/**,你可以这样做:
|
||||
```
|
||||
$ export SDKMAN_DIR="/usr/local/sdkman" && curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
Make sure your user has full access rights to this folder.
|
||||
确保你的用户有足够的权限访问这个目录。
|
||||
|
||||
Finally, check if the installation is succeeded using command:
|
||||
最后,在安装完成后使用下面的命令检查一下:
|
||||
```
|
||||
$ sdk version
|
||||
==== BROADCAST =================================================================
|
||||
@ -46,17 +47,17 @@ SDKMAN 5.7.2+323
|
||||
|
||||
```
|
||||
|
||||
Congratulations! SDKMAN has been installed. Let us go ahead and see how to install and manage SDKs.
|
||||
恭喜你!SDKMAN 已经安装完成了。让我们接下来看如何安装和管理 SDKs 吧。
|
||||
|
||||
### Manage Multiple Software Development Kits
|
||||
### 管理多个 SDK
|
||||
|
||||
To view the list of available candidates(SDKs), run:
|
||||
查看可用的 SDK 清单,运行:
|
||||
```
|
||||
$ sdk list
|
||||
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
将会输出:
|
||||
```
|
||||
================================================================================
|
||||
Available Candidates
|
||||
@ -81,15 +82,15 @@ tasks.
|
||||
|
||||
```
|
||||
|
||||
As you can see, SDKMAN list one candidate at a time along with the description of the candidate and it’s official website and the installation command. Press ENTER key to list the next candidates.
|
||||
就像你看到的,SDK 每次列出众多 SDK 中的一个,以及该 SDK 的描述信息、官方网址和安装命令。按回车键继续下一个。
|
||||
|
||||
To install a SDK, for example Java JDK, run:
|
||||
安装一个新的 SDK,例如 Java JDK,运行:
|
||||
```
|
||||
$ sdk install java
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
将会输出:
|
||||
```
|
||||
Downloading: java 8.0.172-zulu
|
||||
|
||||
@ -108,27 +109,27 @@ Setting java 8.0.172-zulu as default.
|
||||
|
||||
```
|
||||
|
||||
If you have multiple SDKs, it will prompt if you want the currently installed version to be set as **default**. Answering **Yes** will set the currently installed version as default.
|
||||
如果你安装了多个 SDK,它将会提示你是否想要将当前安装的版本设置为 **默认版本**。回答 **Yes** 将会把当前版本设置为默认版本。
|
||||
|
||||
To install particular version of a SDK, do:
|
||||
使用以下命令安装一个 SDK 的其他版本:
|
||||
```
|
||||
$ sdk install ant 1.10.1
|
||||
|
||||
```
|
||||
|
||||
If you already have local installation of a specific candidate, you can set it as local version like below.
|
||||
如果你之前已经在本地安装了一个 SDK,你可以像下面这样设置它为本地版本。
|
||||
```
|
||||
$ sdk install groovy 3.0.0-SNAPSHOT /path/to/groovy-3.0.0-SNAPSHOT
|
||||
|
||||
```
|
||||
|
||||
To list a particular candidates versions:
|
||||
列出一个 SDK 的多个版本:
|
||||
```
|
||||
$ sdk list ant
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
将会输出
|
||||
```
|
||||
================================================================================
|
||||
Available Ant Versions
|
||||
@ -147,21 +148,21 @@ Available Ant Versions
|
||||
|
||||
```
|
||||
|
||||
Like I already said, If you have installed multiple versions, SDKMAN will prompt you if you want the currently installed version to be set as **default**. You can answer Yes to set it as default. Also, you can do that later by using the following command:
|
||||
像我之前说的,如果你安装了多个版本,SDKMAN 会提示你是否想要设置当前安装的版本为 **默认版本**。你可以回答 Yes 设置它为默认版本。当然,你也可以在稍后使用下面的命令设置:
|
||||
```
|
||||
$ sdk default ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
The above command will set Apache Ant version 1.9.9 as default.
|
||||
上面的命令将会设置 Apache Ant 1.9.9 为默认版本。
|
||||
|
||||
You can choose which version of an installed candidate to use by using the following command:
|
||||
你可以根据自己的需要选择使用任何已安装的 SDK 版本,仅需运行以下命令:
|
||||
```
|
||||
$ sdk use ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
To check what is currently in use for a Candidate, for example Java, run:
|
||||
检查某个具体 SDK 当前的版本号,例如 Java,运行:
|
||||
```
|
||||
$ sdk current java
|
||||
|
||||
@ -169,7 +170,7 @@ Using java version 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
To check what is currently in use for all Candidates, for example Java, run:
|
||||
检查所有当下在使用的 SDK 版本号,运行:
|
||||
```
|
||||
$ sdk current
|
||||
|
||||
@ -180,19 +181,19 @@ java: 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
To upgrade an outdated candidate, do:
|
||||
升级过时的 SDK,运行:
|
||||
```
|
||||
$ sdk upgrade scala
|
||||
|
||||
```
|
||||
|
||||
You can also check what is outdated for all Candidates as well.
|
||||
你也可以检查所有的 SDKs 中还有哪些是过时的。
|
||||
```
|
||||
$ sdk upgrade
|
||||
|
||||
```
|
||||
|
||||
SDKMAN has offline mode feature that allows the SDKMAN to function when working offline. You can enable or disable the offline mode at any time by using the following commands:
|
||||
SDKMAN 有离线模式,可以让 SDKMAN 在离线时也正常运作。你可以使用下面的命令在任何时间开启或者关闭离线模式:
|
||||
```
|
||||
$ sdk offline enable
|
||||
|
||||
@ -200,13 +201,13 @@ $ sdk offline disable
|
||||
|
||||
```
|
||||
|
||||
To remove an installed SDK, run:
|
||||
要移除已安装的 SDK,运行:
|
||||
```
|
||||
$ sdk uninstall ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
For more details, check the help section.
|
||||
要了解更多的细节,参阅帮助章节。
|
||||
```
|
||||
$ sdk help
|
||||
|
||||
@ -238,15 +239,15 @@ version : where optional, defaults to latest stable if not provided
|
||||
|
||||
```
|
||||
|
||||
### Update SDKMAN
|
||||
### 更新 SDKMAN
|
||||
|
||||
The following command installs a new version of SDKMAN if it is available.
|
||||
如果有可用的新版本,可以使用下面的命令安装:
|
||||
```
|
||||
$ sdk selfupdate
|
||||
|
||||
```
|
||||
|
||||
SDKMAN will also periodically check for any updates and let you know with instruction on how to update.
|
||||
SDKMAN 会定期检查更新,以及让你了解如何更新的指令。
|
||||
```
|
||||
WARNING: SDKMAN is out-of-date and requires an update.
|
||||
|
||||
@ -255,30 +256,29 @@ Adding new candidates(s): scala
|
||||
|
||||
```
|
||||
|
||||
### Remove cache
|
||||
### 清除缓存
|
||||
|
||||
It is recommended to clean the cache that contains the downloaded SDK binaries for time to time. To do so, simply run:
|
||||
建议时不时的清理缓存(包括那些下载的 SDK 的二进制文件)。仅需运行下面的命令就可以了:
|
||||
```
|
||||
$ sdk flush archives
|
||||
|
||||
```
|
||||
|
||||
It is also good to clean temporary folder to save up some space:
|
||||
它也可以用于清理空的文件夹,节省一点空间:
|
||||
```
|
||||
$ sdk flush temp
|
||||
|
||||
```
|
||||
|
||||
### Uninstall SDKMAN
|
||||
### 卸载 SDKMAN
|
||||
|
||||
If you don’t need SDKMAN or don’t like it, remove as shown below.
|
||||
如果你觉得不需要或者不喜欢 SDKMAN,可以使用下面的命令删除。
|
||||
```
|
||||
$ tar zcvf ~/sdkman-backup_$(date +%F-%kh%M).tar.gz -C ~/ .sdkman
|
||||
$ rm -rf ~/.sdkman
|
||||
|
||||
```
|
||||
|
||||
Finally, open your **.bashrc** , **.bash_profile** and/or **.profile** files and find and remove the following lines.
|
||||
最后打开你的 **.bashrc**,**.bash_profile** 和/或者 **.profile**,找到并删除下面这几行。
|
||||
```
|
||||
#THIS MUST BE AT THE END OF THE FILE FOR SDKMAN TO WORK!!!
|
||||
export SDKMAN_DIR="/home/sk/.sdkman"
|
||||
@ -286,11 +286,14 @@ export SDKMAN_DIR="/home/sk/.sdkman"
|
||||
|
||||
```
|
||||
|
||||
If you use ZSH, remove the above line from the **.zshrc** file.
|
||||
如果你使用的是 ZSH,就从 **.zshrc** 中删除上面这一行。
|
||||
|
||||
And, that’s all for today. I hope you find SDKMAN useful. More good stuffs to come. Stay tuned!
|
||||
这就是所有的内容了。我希望 SDKMAN 可以帮到你。还有更多的干货即将到来。敬请期待!
|
||||
|
||||
Cheers!
|
||||
祝近祺!
|
||||
|
||||
|
||||
:)
|
||||
|
||||
|
||||
|
||||
@ -300,7 +303,7 @@ via: https://www.ostechnix.com/sdkman-a-cli-tool-to-easily-manage-multiple-softw
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,162 @@
|
||||
5 个适合系统管理员使用的告警可视化工具
|
||||
======
|
||||
这些开源的工具能够通过输出帮助用户了解系统的运行状况,并对可能发生的潜在问题作出告警。
|
||||
|
||||

|
||||
|
||||
你大概已经已经知道告警可视化工具是用来做什么的了。下面我们就要来说一下,为什么要讨论这样的工具,甚至某些系统专门将可视化作为特有的功能。
|
||||
|
||||
可观察性的概念来自控制理论,这个概念描述了我们通过对系统的输入和系统的输出来了解系统的能力。本文将重点介绍具有可观察性的输出组件。
|
||||
|
||||
告警可视化工具可以对系统的输出进行分析,进而对输出的信息结构化。告警实际上是对系统异常状态的描述,而可视化则是让用户能够直观理解的结构化表示。
|
||||
|
||||
### 常见的可视化告警
|
||||
|
||||
#### 告警
|
||||
|
||||
首先要明确一下告警的含义。在人员无法响应告警内容情况下,不应该发送告警。包括那些发给多个人,但只有其中少数人可以响应的告警,以及系统中的每个异常都触发的告警。因为这样会产生告警疲劳,告警接收者也往往会对这些过多的告警采取忽视的态度。
|
||||
|
||||
例如,如果管理员每天都会收到告警系统发来的数百封告警邮件,他就很容易会忽略告警系统的所有邮件。除非问题真正发生,并且受到了客户或上级的询问时,管理员才会重新重视告警信息。在这种情况下,告警已经失去了原有的意义和用途。
|
||||
|
||||
告警不是一个持续的信息流或者状态更新。告警的目的在于暴露系统无法自动恢复的问题,而且告警应该只发送给最有可能解决问题的人员。超出这个定义的内容都不应该作为告警,否则将会对实际工作造成不良的影响。
|
||||
|
||||
不同的告警体系都会有各自的告警类型,因此不能用优先级(P1-P5)或者诸如“信息”、“警告”、“严重”之类的字眼来一概而论,而应该使用一些通用的分类方式来对复杂系统事件进行描述。
|
||||
|
||||
刚才我提到了一个“信息”这个告警类型,但实际上告警不应该是一个信息,尽管有些人可能会不这样认为。但我觉得如果一个告警没有发送给任何一个人,它就不应该是警报,而只是一些在系统中被视为警报的数据点,代表了一些应该知晓但不需要响应的事件。它更应该作为告警可视化工具的一部分,而不是会导致触发告警的事件。《[实用监控][1]》是这个领域的必读书籍,其作者 Mike Julian 在书中就介绍了他自己关于告警的看法。
|
||||
|
||||
而非信息警报则代表告警需要被响应以及需要相关的操作。我将这些告警大致分为内部故障和外部故障两种类型,而对于大多数公司来说,通常会有两个以上的级别来确定响应告警的优先级。系统性能下降就是一种故障,因为这种现象对用户的影响通常都是未知的。
|
||||
|
||||
内部故障比外部故障的优先级低,但也需要快速响应。内部故障通常包括公司员工使用的内部系统或仅对公司员工可见的应用故障。
|
||||
|
||||
外部则包括任何会产生业务影响的系统故障,但不包括影响系统更新的故障。外部故障一般包括客户端应用故障、数据库故障和导致系统可用性或一致性失效的网络故障,这些都会影响用户的正常使用。对于不直接影响用户的依赖组件故障也属于外部故障,随着应用程序的不断运行,一旦依赖组件发生故障,系统的性能也会受到波及。这种情况对于使用某些外部服务或数据源的系统来说很常见,尽管这些外部服务或数据源对于可能不涉及到系统的主要功能,但是当系统在处理相关依赖组件的错误时可能会出现较明显的延迟。
|
||||
|
||||
### 可视化
|
||||
|
||||
可视化的种类有很多,我就不一一赘述了。这是一个有趣的研究领域,在我这些年的数据分析经历当中,学习和应用可视化方面的知识可以说是相当有挑战性。我们需要将复杂的系统输出通过直观的方式来向他人展示,才能有效地把信息传播出去。[Google Charts][2] 和 [Tableau][3] 都提供了很多可视化方面的工具。下面将会介绍一些最常见的可视化创新解决方案。
|
||||
|
||||
#### 折线图
|
||||
|
||||
折线图可能是最常见的可视化方式了,它可以让用户很直观地按照时间维度了解系统的情况。系统中每个不同的指标都会以一条独立的折线在图表中体现。但当同一个图表中同时存在多条折线时,就可能会对阅读有所影响(如下图所示),所以大多数情况下都可以选择仅查看其中的少数几条折线,而不是让所有折线同时显示。如果某个指标的数值产生了大于正常范围的波动,就会很容易发现。例如下图中异常的紫线、黄线、浅蓝线。
|
||||
|
||||

|
||||
|
||||
折线图的另一个用法是可以将多条折线堆积起来以显示它们之间的关系。例如对于通过折线图反映服务器的请求数量,可以单独显示每台服务器上的请求,也可以把多台服务器的数据合在一起显示。这就可以在同一个图表中灵活查看整个系统中每个实例的情况了。
|
||||
|
||||

|
||||
|
||||
#### 热力图
|
||||
|
||||
另一种常见的可视化方式是热力图。热力图与条形图比较类似,还可以在条形图的基础上显示某部分在整体中占比的变化情况。例如在查看网络请求延时的时候,就可以使用热力图快速查看到所有网络请求的总体趋势和分布情况,另外,它可以使用不同颜色来表示不同部分的数值。
|
||||
|
||||
在以下这个热力图中,通过竖直方向上每个时间段的色块数量分布,可以清楚地看到大部分数据集中在整个范围的中心位置。我们还可以发现,大多数时间段的色块分布都是比较宽松的,而 14:00 到 15:00 这一段则分布得很密集,这样的分布有可能意味着一种不健康的状态。
|
||||
|
||||

|
||||
|
||||
#### 仪表图
|
||||
|
||||
还有一种常见的可视化方式是仪表图,用户可以通过仪表图快速了解单个指标。仪表一般用于单个指标的显示,例如车速表代表汽车的行驶速度、油量表代表油箱中的汽油量等等。大多数的仪表图都有一个共通点,就是会划分出所示指标的对应状态。如下图所示,绿色表示正常的状态,橙色表示不良的状态,而红色则表示极差的状态。中间一行则模拟了真实仪表的显示情况。
|
||||
|
||||

|
||||
|
||||
上面图表中,除了常规仪表样式的显示方式之外,还有较为直接的数据显示方式,配合相同的配色方案,一眼就可以看出各个指标所处的状态,这一点与和仪表的特点类似。所以,最下面一行可能是仪表图的最佳显示方式,用户不需要仔细阅读,就可以大致了解各个指标的不同状态。这种类型的可视化是我最常用的类型,在数秒钟之间,我就可以全面地总览系统各方面地运行情况。
|
||||
|
||||
#### 火焰图
|
||||
|
||||
由 [Netflix 的 Brendan Gregg][4] 在 2011 年开始使用的火焰图是一种较为少见地可视化方式。它不像仪表图那样可以从图表中快速得到关键信息,通常只会在需要解决某个应用的问题的时候才会用到这种图表。火焰图主要用于 CPU、内存和相关帧方面的表示,X 轴按字母顺序将帧一一列出,而 Y 轴则表示堆栈的深度。图中每个矩形都是一个标明了调用的函数的堆栈帧。矩形越宽,就表示它在堆栈中出现越频繁。在分析系统性能问题的时候,火焰图能够起到很大的作用,大家不妨尝试一下。
|
||||
|
||||

|
||||
|
||||
### 工具的选择
|
||||
|
||||
在告警工具方面,有几个商用的工具相当不错。但由于这是一篇介绍开源技术的文章,我只会介绍那些已经被广泛使用的免费工具。希望你也能够为这些工具贡献你自己的代码,让它们更加完善。
|
||||
|
||||
### 告警工具
|
||||
|
||||
#### Bosun
|
||||
|
||||
如果你的电脑出现问题,得多亏 Stack Exchange 你才能在网上查到解决办法。Stack Exchange 以众包问答的模式运营着很多不同类型的网站。其中就有广受开发者欢迎的 [Stack Overflow][5],以及运维方面有名的 [Super User][6]。除此以外,从育儿经验到科幻小说、从哲学讨论到单车论坛,Stack Exchange 都有涉猎。
|
||||
|
||||
Stack Exchange 开源了它的开源告警管理系统 [Bosun][7],同时也发布了使用 [AlertManager][8] 的 Prometheus 系统。这两个系统有共通点。Bosun 和 Prometheus 一样使用 Golang 开发,但 Bosun 比 Prometheus 更为强大,因为它可以使用<ruby>权值聚合<rt>metrics aggregation</rt></ruby>以外的方式与系统交互。Bosun 还可以从日志收集系统中提取数据,并且支持 Graphite、InfluxDB、OpenTSDB 和 Elasticsearch。
|
||||
|
||||
Bosun 的架构包括一个二进制服务文件,以及一个诸如 OpenTSDB 的后端、Redis 以及 [scollector agents][9]。 scollector agents 会自动检测主机上正在运行的服务,并反馈这些进程和其它的系统资源情况。这些数据将发送到后端。随后 Bosun 二进制服务文件会向后端发起查询,确定是否需要触发告警。也可以通过 [Grafana][10] 这些工具通过一个通用接口查询 Bosun 的底层后端。而 Redis 则用于存储 Bosun 的状态信息和元数据。
|
||||
|
||||
Bosun 有一个非常巧妙的功能,就是可以根据历史数据来测试告警。这是我几年前在使用 Prometheus 的时候就非常需要的功能,当时我有一个异常的数据需要产生告警,但没有一个可以用于测试的简便方法。为了确保告警能够正常触发,我不得不造出对应的数据来进行测试。而 Bosun 让这个步骤的耗时大大缩短。
|
||||
|
||||
Bosun 更是涵盖了所有常用过的功能,包括简单的图形化表示和告警的创建。它还带有强大的用于编写告警规则的表达式语言。但 Bosun 默认只带有电子邮件通知配置和 HTTP 通知配置,因此如果需要连接到 Slack 或其它工具,就需要对配置作出更大程度的定制化。类似于 Prometheus,Bosun 还可以使用模板通知,你可以使用 HTML 和 CSS 来创建你所需要的电子邮件通知。
|
||||
|
||||
#### Cabot
|
||||
|
||||
[Cabot][12] 由 [Arachnys][13] 公司开发。你或许对 Arachnys 公司并不了解,但它很有影响力:Arachnys 公司构建了一个基于云的先进解决方案,用于防范金融犯罪。在以前的公司,我也曾经参与过类似“[了解你的客户][14]”的工作。但大多数公司都认为与恐怖组织产生联系会造成相当不好的影响,因为恐怖组织可能会利用自己的系统来筹集资金。而这些解决方案将有助于防范欺诈类犯罪,尽管这类犯罪情节相对较轻,但仍然也会对机构产生风险。
|
||||
|
||||
Arachnys 公司为什么要开发 Cabot 呢?其实只是因为 Arachnys 的开发人员对 [Nagios][15] 不太熟悉。Cabot 的出现对很多人来说都是一个好消息,它基于 Django 和 Bootstrap 开发,因此如果相对这个项目做出自己的贡献,门槛并不高。另外值得一提的是,Cabot 这个名字来源于开发者的狗。
|
||||
|
||||
与 Bosun 类似,Cabot 也不对数据进行收集,而是使用监控对象的 API 提供的数据。因此,Cabot 告警的模式是 pull 而不是 push。它通过访问每个监控对象的 API,根据特定的指标检索所需的数据,然后将告警数据使用 Redis 缓存,进而持久化存储到 Postgres 数据库。
|
||||
|
||||
Cabot 的一个较为少见的特点是,它原生支持 [Graphite][16],同时也支持 [Jenkins][17]。Jenkins 在这里被视为一个集中式的 cron,它会以对待故障的方式去对待构建失败的状况。构建失败当然没有系统故障那么紧急,但一旦出现构建失败,还是需要团队采取措施去处理,毕竟并不是每个人在收到构建失败的电子邮件时都会亲自去检查 Jenkins。
|
||||
|
||||
Cabot 另一个有趣的功能是它可以接入 Google 日历安排值班人员,这个称为 Rota 的功能用处很大,希望其它告警系统也能加入类似的功能。Cabot 目前仅支持安排主备联系人,但还有继续改进的空间。它自己的文档也提到,如果需要全面的功能,更应该考虑付费的解决方案。
|
||||
|
||||
#### StatsAgg
|
||||
|
||||
[Pearson][19] 作为一家开发了 [StatsAgg][18] 告警平台的出版公司,这是极为罕见的,当然也很值得敬佩。除此以外,Pearson 还运营着另外几个网站,以及和 [O'Reilly Media][20] 合资的企业。但我仍然会将它视为出版教学书籍的公司。
|
||||
|
||||
StatsAgg 除了是一个告警平台,还是一个指标聚合平台,甚至也有点类似其它系统的代理。StatsAgg 支持通过 Graphite、StatsD、InfluxDB 和 OpenTSDB 输入数据,也支持将其转发到各种平台。但随着中心服务的负载不断增加,风险也不断增大。尽管如此,如果 StatsAgg 的基础架构足够强壮,即使后端存储平台出现故障,也不会对它产生告警的过程造成影响。
|
||||
|
||||
StatsAgg 是用 Java 开发的,为了尽可能降低复杂性,它仅包括主服务和一个 UI。StatsAgg 支持基于正则表达式匹配来发送告警,而且它更注重于服务方面的告警,而不是服务器基础告警。我认为它填补了开源监控工具方面的空白,而这正式它自己的目标。
|
||||
|
||||
### 可视化工具
|
||||
|
||||
#### Grafana
|
||||
|
||||
[Grafana][10] 的知名度很高,它也被广泛采用。每当我需要用到数据面板的时候,我总是会想到它,因为它比我使用过的任何一款类似的产品都要好。Grafana 由 Torkel Ödegaard 在圣诞节期间开发,并在 2014 年 1 月发布。在短短几年之间,它已经有了长足的发展。Grafana 基于 Kibana 开发,Torkel 开启了新的分支并将其命名为 Grafana。
|
||||
|
||||
Grafana 着重体现了实用性已经数据呈现的美观性。它可以原生地从 Graphite、Elasticsearch、OpenTSDB、Prometheus 和 InfluxDB 收集数据。此外有一个 Grafana 商用版插件可以从更多数据源获取数据,尽管这个插件没有开源,但 Grafana 的生态系统提供的各种数据源已经足够了。
|
||||
|
||||
Grafana 提供了一个集系统各种数据于一身的平台。它通过 web 来展示数据,任何人都有机会访问到相关信息,因此需要使用身份验证来对访问进行限制。Grafana 还支持不同类型的可视化方式,包括集成告警可视化的功能。
|
||||
|
||||
现在你可以更直观地设置告警了。通过Grafana,可以查看图表,还可以设置系统性能下降触发告警的阈值,并告诉 Grafana 应该如何发送告警。这是一个对告警体系非常强大的补充。告警平台不一定会因此而被取代,但告警系统一定会由此得到更多启发和发展。
|
||||
|
||||
Grafana 还引入了很多团队协作的功能。不同用户之间能够共享数据面板,你不再需要为 [Kubernetes][21] 集群创建独立的数据面板,因为由 Kubernetes 开发者和 Grafana 开发者共同维护的一些数据面板已经可以即插即用。
|
||||
|
||||
团队协作过程中一个重要的功能是注释。注释功能允许用户将上下文添加到图表当中,其他用户就可以通过上下文更直观地理解图表。当团队成员在处理某个事件,并且需要沟通和理解时,这个功能就十分重要了。将所有相关信息都放在需要的位置,可以让整个团队中快速达成共识。在团队需要调查故障原因和定位事件责任时,这个功能就可以发挥作用了。
|
||||
|
||||
#### Vizceral
|
||||
|
||||
[Vizceral][22] 由 Netflix 开发,用于在故障发生时更有效地了解流量的情况。Grafana 是一种通用性更强的工具,而 Vizceral 则专用于某些领域。 尽管 Netflix 表示已经不再在内部使用 Vizceral,也不再主动对其展开维护,但 Vizceral 仍然会定期更新。我在这里介绍这个工具,主要是为了介绍它的的可视化机制,以及如何利用它来协助解决问题。你可以在样例环境中用它来更好地掌握这一类系统的特性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/alerting-and-visualization-tools-sysadmins
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.practicalmonitoring.com/
|
||||
[2]: https://developers.google.com/chart/interactive/docs/gallery
|
||||
[3]: https://libguides.libraries.claremont.edu/c.php?g=474417&p=3286401
|
||||
[4]: http://www.brendangregg.com/flamegraphs.html
|
||||
[5]: https://stackoverflow.com/
|
||||
[6]: https://superuser.com/
|
||||
[7]: http://bosun.org/
|
||||
[8]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[9]: https://bosun.org/scollector/
|
||||
[10]: https://grafana.com/
|
||||
[11]: https://bosun.org/notifications
|
||||
[12]: https://cabotapp.com/
|
||||
[13]: https://www.arachnys.com/
|
||||
[14]: https://en.wikipedia.org/wiki/Know_your_customer
|
||||
[15]: https://www.nagios.org/
|
||||
[16]: https://graphiteapp.org/
|
||||
[17]: https://jenkins.io/
|
||||
[18]: https://github.com/PearsonEducation/StatsAgg
|
||||
[19]: https://www.pearson.com/us/
|
||||
[20]: https://www.oreilly.com/
|
||||
[21]: https://opensource.com/resources/what-is-kubernetes
|
||||
[22]: https://github.com/Netflix/vizceral
|
||||
|
||||
Loading…
Reference in New Issue
Block a user