mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
20150410-1 选题
This commit is contained in:
parent
c738eb59ba
commit
6cbaa482e4
@ -0,0 +1,89 @@
|
||||
How to run Ubuntu Snappy Core on Raspberry Pi 2
|
||||
================================================================================
|
||||
The Internet of Things (IoT) is upon us. In a couple of years some of us might ask ourselves how we ever survived without it, just like we question our past without cellphones today. Canonical is a contender in this fast growing, but still wide open market. The company wants to claim their stakes in IoT just as they already did for the cloud. At the end of January, the company launched a small operating system that goes by the name of [Ubuntu Snappy Core][1] which is based on Ubuntu Core.
|
||||
|
||||
Snappy, the new component in the mix, represents a package format that is derived from DEB, is a frontend to update the system that lends its idea from atomic upgrades used in CoreOS, Red Hat's Atomic and elsewhere. As soon as the Raspberry Pi 2 was marketed, Canonical released Snappy Core for that plattform. The first edition of the Raspberry Pi was not able to run Ubuntu because Ubuntu's ARM images use the ARMv7 architecture, while the first Raspberry Pis were based on ARMv6. That has changed now, and Canonical, by releasing a RPI2-Image of Snappy Core, took the opportunity to make clear that Snappy was meant for the cloud and especially for IoT.
|
||||
|
||||
Snappy also runs on other platforms like Amazon EC2, Microsofts Azure, and Google's Compute Engine, and can also be virtualized with KVM, Virtualbox, or Vagrant. Canonical has embraced big players like Microsoft, Google, Docker or OpenStack and, at the same time, also included small projects from the maker scene as partners. Besides startups like Ninja Sphere and Erle Robotics, there are board manufacturers like Odroid, Banana Pro, Udoo, PCDuino and Parallella as well as Allwinner. Snappy Core will also run in routers soon to help with the poor upgrade policy that vendors perform.
|
||||
|
||||
In this post, let's see how we can test Ubuntu Snappy Core on Raspberry Pi 2.
|
||||
|
||||
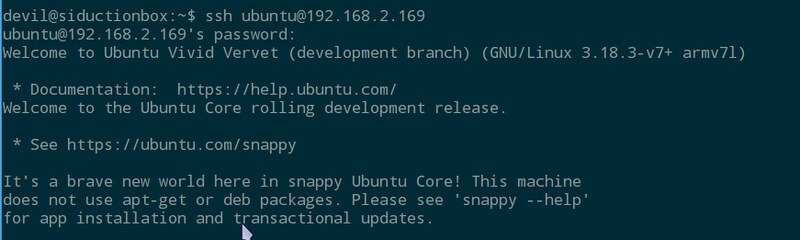
The image for Snappy Core for the RPI2 can be downloaded from the [Raspberry Pi website][2]. Unpacked from the archive, the resulting image should be [written to an SD card][3] of at least 8 GB. Even though the OS is small, atomic upgrades and the rollback function eat up quite a bit of space. After booting up your Raspberry Pi 2 with Snappy Core, you can log into the system with the default username and password being 'ubuntu'.
|
||||
|
||||
|
||||
|
||||
sudo is already configured and ready for use. For security reasons you should change the username with:
|
||||
|
||||
$ sudo usermod -l <new name> <old name>
|
||||
|
||||
Alternatively, you can add a new user with the command `adduser`.
|
||||
|
||||
Due to the lack of a hardware clock on the RPI, that the Snappy Core image does not take account of, the image has a small bug that will throw a lot of errors when processing commands. It is easy to fix.
|
||||
|
||||
To find out if the bug affects you, use the command:
|
||||
|
||||
$ date
|
||||
|
||||
If the output is "Thu Jan 1 01:56:44 UTC 1970", you can fix it with:
|
||||
|
||||
$ sudo date --set="Sun Apr 04 17:43:26 UTC 2015"
|
||||
|
||||
adapted to your actual time.
|
||||
|
||||

|
||||
|
||||
Now you might want to check if there are any updates available. Note that the usual commands:
|
||||
|
||||
$ sudo apt-get update && sudo apt-get distupgrade
|
||||
|
||||
will not get you very far though, as Snappy uses its own simplified package management system which is based on dpkg. This makes sense, as Snappy will run on a lot of embedded appliances, and you want things to be as simple as possible.
|
||||
|
||||
Let's dive into the engine room for a minute to understand how things work with Snappy. The SD card you run Snappy on has three partitions besides the boot partition. Two of those house a duplicated file system. Both of those parallel file systems are permanently mounted as "read only", and only one is active at any given time. The third partition holds a partial writable file system and the users persistent data. With a fresh system, the partition labeled 'system-a' holds one complete file system, called a core, leaving the parallel partition still empty.
|
||||
|
||||

|
||||
|
||||
If we run the following command now:
|
||||
|
||||
$ sudo snappy update
|
||||
|
||||
the system will install the update as a complete core, similar to an image, on 'system-b'. You will be asked to reboot your device afterwards to activate the new core.
|
||||
|
||||
After the reboot, run the following command to check if your system is up to date and which core is active.
|
||||
|
||||
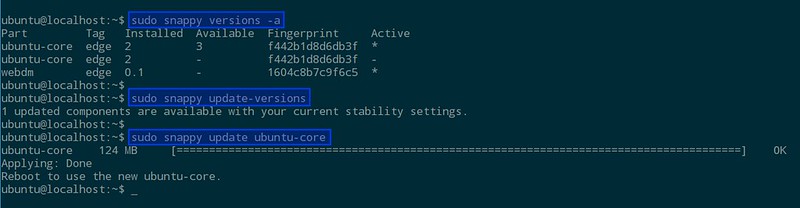
$ sudo snappy versions -a
|
||||
|
||||
After rolling out the update and rebooting, you should see that the core that is now active has changed.
|
||||
|
||||
As we have not installed any apps yet, the following command:
|
||||
|
||||
$ sudo snappy update ubuntu-core
|
||||
|
||||
would have been sufficient, and is the way if you want to upgrade just the underlying OS. Should something go wrong, you can rollback by:
|
||||
|
||||
$ sudo snappy rollback ubuntu-core
|
||||
|
||||
which will take you back to the system's state before the update.
|
||||
|
||||
|
||||
|
||||
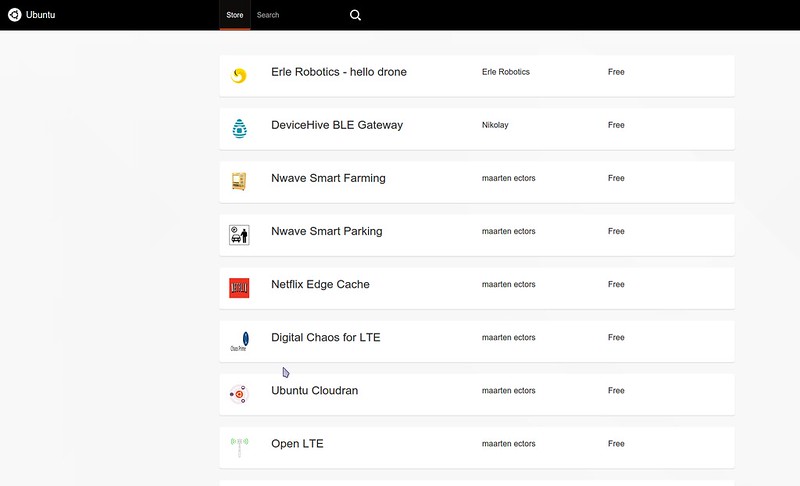
Speaking of apps, they are what makes Snappy useful. There are not that many at this point, but the IRC channel #snappy on Freenode is humming along nicely and with a lot of people involved, the Snappy App Store gets new apps added on a regular basis. You can visit the shop by pointing your browser to http://<ip-address>:4200, and you can install apps right from the shop and then launch them with http://webdm.local in your browser. Building apps yourself for Snappy is not all that hard, and [well documented][4]. You can also port DEB packages into the snappy format quite easily.
|
||||
|
||||
|
||||
|
||||
Ubuntu Snappy Core, due to the limited number of available apps, is not overly useful in a productive way at this point in time, although it invites us to dive into the new Snappy package format and play with atomic upgrades the Canonical way. Since it is easy to set up, this seems like a good opportunity to learn something new.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/ubuntu-snappy-core-raspberry-pi-2.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/ferdinand
|
||||
[1]:http://www.ubuntu.com/things
|
||||
[2]:http://www.raspberrypi.org/downloads/
|
||||
[3]:http://xmodulo.com/write-raspberry-pi-image-sd-card.html
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
@ -0,0 +1,144 @@
|
||||
What is a good alternative to wget or curl on Linux
|
||||
================================================================================
|
||||
If you often need to access a web server non-interactively in a terminal environment (e.g., download a file from the web, or test REST-ful web service APIs), chances are that wget or curl is your go-to tool. With extensive command-line options, both of these tools can handle a variety of non-interactive web access use cases (examples [here][1], [here][2] and [here][3]). However, even powerful tools like these are only as good as your knowledge of how to use them. Unless you are well versed in the nitty and gritty details of their syntax, these tools are nothing more than simple web downloaders for you.
|
||||
|
||||
Billed as a "curl-like tool for humans," [HTTPie][4] is designed to improve on wget and curl in terms of usability. Its main goal is to make command-line interaction of a web server as human-friendly as possible. For that, HTTPie comes with expressive, yet very simple and intuitive syntax. It also displays responses in colorized formats for readability, and offers nice goodies like excellent JSON support and persistent sessions to streamline your workflows.
|
||||
|
||||
I know some of you will be skeptical about replacing a ubiquitously available, perfectly good tool such as wget or curl with totally unheard of software. This view has merit especially if you are a system admin who works with many different hardware boxes. For developers or end-users, however, I would say it's all about productivity. If I've found a user-friendly alternative of a tool, I don't see any problem adopting the easy to use version in my work environment to save my precious time. No need to be loyal and religious about what's being replaced. After all, choice is the best thing about Linux.
|
||||
|
||||
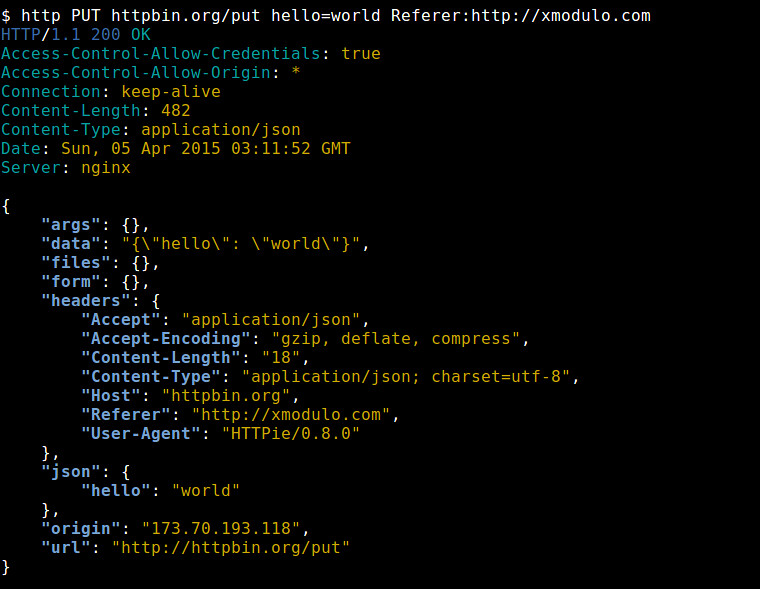
In this post, let me review HTTPie, and show you what I mean by HTTPie being a user-friendly alternative of wget and curl.
|
||||
|
||||
|
||||
|
||||
### Install HTTPie on Linux ###
|
||||
|
||||
HTTPie is written in Python, so you can install it pretty much everywhere (Linux, MacOSX, Windows). Even better, it comes as a prebuilt package on most Linux distributions.
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint: ####
|
||||
|
||||
$ sudo apt-get install httpie
|
||||
|
||||
#### Fedora: ####
|
||||
|
||||
$ sudo yum install httpie
|
||||
|
||||
#### CentOS/RHEL: ####
|
||||
|
||||
First, enable [EPEL repository][5] and then run:
|
||||
|
||||
$ sudo yum install httpie
|
||||
|
||||
For any Linux distribution, an alternative installation method is to use [pip][6].
|
||||
|
||||
$ sudo pip install --upgrade httpie
|
||||
|
||||
### HTTPie Examples ###
|
||||
|
||||
Once you install HTTPie, you can invoke it by typing http command. In the rest of this article, let me show several useful examples of http command.
|
||||
|
||||
#### Example 1: Custom Headers ####
|
||||
|
||||
You can set custom headers in the format of <header:value>. For example, let's send an HTTP GET request to www.test.com, with custom user-agent and referer, as well as a custom header (e.g., MyParam).
|
||||
|
||||
$ http www.test.com User-Agent:Xmodulo/1.0 Referer:http://xmodulo.com MyParam:Foo
|
||||
|
||||
Note that when HTTP GET method is used, you don't need to specify any HTTP method.
|
||||
|
||||
The HTTP request will look like:
|
||||
|
||||
GET / HTTP/1.1
|
||||
Host: www.test.com
|
||||
Accept: */*
|
||||
Referer: http://xmodulo.com
|
||||
Accept-Encoding: gzip, deflate, compress
|
||||
MyParam: Foo
|
||||
User-Agent: Xmodulo/1.0
|
||||
|
||||
#### Example 2: Download a File ####
|
||||
|
||||
You can use http as a file downloader tool. You will need to redirect output to a file as follows.
|
||||
|
||||
$ http www.test.com/my_file.zip > my_file.zip
|
||||
|
||||
Alternatively:
|
||||
|
||||
$ http --download www.test.com/my_file.zip
|
||||
|
||||
#### Example 3: Custom HTTP Method ####
|
||||
|
||||
Besides the default GET method, you can use other methods (e.g., PUT, POST, HEAD). For example, to sent an HTTP PUT request:
|
||||
|
||||
$ http PUT www.test.com name='Dan Nanni' email=dan@email.com
|
||||
|
||||
#### Example 4: Submit a Form ####
|
||||
|
||||
Submitting a form with http command is as easy as:
|
||||
|
||||
$ http -f POST www.test.com name='Dan Nanni' comment='Hi there'
|
||||
|
||||
The '-f' option lets http command serialize data fields, and set 'Content-Type' to "application/x-www-form-urlencoded; charset=utf-8".
|
||||
|
||||
The HTTP POST request will look like:
|
||||
|
||||
POST / HTTP/1.1
|
||||
Host: www.test.com
|
||||
Content-Length: 31
|
||||
Content-Type: application/x-www-form-urlencoded; charset=utf-8
|
||||
Accept-Encoding: gzip, deflate, compress
|
||||
Accept: */*
|
||||
User-Agent: HTTPie/0.8.0
|
||||
|
||||
name=Dan+Nanni&comment=Hi+there
|
||||
|
||||
#### Example 5: JSON Support ####
|
||||
|
||||
HTTPie comes with built-in JSON support, which is nice considering its growing popularity as a data exchange format. In fact, the default content-type used by HTTPie is JSON. So if you send data fields without specifying any content-type, they will automatically be serialized as a JSON object.
|
||||
|
||||
$ http POST www.test.com name='Dan Nanni' comment='Hi there'
|
||||
|
||||
The HTTP POST request will look like:
|
||||
|
||||
POST / HTTP/1.1
|
||||
Host: www.test.com
|
||||
Content-Length: 44
|
||||
Content-Type: application/json; charset=utf-8
|
||||
Accept-Encoding: gzip, deflate, compress
|
||||
Accept: application/json
|
||||
User-Agent: HTTPie/0.8.0
|
||||
|
||||
{"name": "Dan Nanni", "comment": "Hi there"}
|
||||
|
||||
#### Example 6: Input Redirect ####
|
||||
|
||||
Another nice user-friendly feature of HTTPie is input redirection, where you can feed an HTTP request body with buffered data. For example, you can do things like:
|
||||
|
||||
$ http POST api.test.com/db/lookup < my_info.json
|
||||
|
||||
or:
|
||||
|
||||
$ echo '{"name": "Dan Nanni"}' | http POST api.test.com/db/lookup
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, I introduce to you HTTPie, a possible alternative to wget or curl. Besides these simple examples presented here, you can find a lot of interesting use cases of HTTPie at the [official site][7]. Again, a powerful tool is only as good as your knowledge about the tool. Personally I am sold on HTTPie, as I was looking for a way to test complicated web APIs more easily.
|
||||
|
||||
What's your thought?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/wget-curl-alternative-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-download-multiple-files-with-wget.html
|
||||
[2]:http://xmodulo.com/how-to-use-custom-http-headers-with-wget.html
|
||||
[3]:http://ask.xmodulo.com/custom-http-header-curl.html
|
||||
[4]:https://github.com/jakubroztocil/httpie
|
||||
[5]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[6]:http://ask.xmodulo.com/install-pip-linux.html
|
||||
[7]:https://github.com/jakubroztocil/httpie
|
||||
Loading…
Reference in New Issue
Block a user