mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
6c94783e29
@ -1,67 +1,66 @@
|
||||
实验 6:网络驱动程序
|
||||
Caffeinated 6.828:实验 6:网络驱动程序
|
||||
======
|
||||
### 实验 6:网络驱动程序(缺省的最终设计)
|
||||
|
||||
### 简介
|
||||
|
||||
这个实验是缺省的最终项目中你自己能够做的最后的实验。
|
||||
这个实验是默认你能够自己完成的最终项目。
|
||||
|
||||
现在你有了一个文件系统,一个典型的操作系统都应该有一个网络栈。在本实验中,你将继续为一个网卡去写一个驱动程序。这个网卡基于 Intel 82540EM 芯片,也就是众所周知的 E1000 芯片。
|
||||
现在你已经有了一个文件系统,一个典型的操作系统都应该有一个网络栈。在本实验中,你将继续为一个网卡去写一个驱动程序。这个网卡基于 Intel 82540EM 芯片,也就是众所周知的 E1000 芯片。
|
||||
|
||||
##### 预备知识
|
||||
#### 预备知识
|
||||
|
||||
使用 Git 去提交你的实验 5 的源代码(如果还没有提交的话),获取课程仓库的最新版本,然后创建一个名为 `lab6` 的本地分支,它跟踪我们的远程分支 `origin/lab6`:
|
||||
|
||||
```c
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'my solution to lab5'
|
||||
nothing to commit (working directory clean)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab6 origin/lab6
|
||||
Branch lab6 set up to track remote branch refs/remotes/origin/lab6.
|
||||
Switched to a new branch "lab6"
|
||||
athena% git merge lab5
|
||||
Merge made by recursive.
|
||||
fs/fs.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'my solution to lab5'
|
||||
nothing to commit (working directory clean)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab6 origin/lab6
|
||||
Branch lab6 set up to track remote branch refs/remotes/origin/lab6.
|
||||
Switched to a new branch "lab6"
|
||||
athena% git merge lab5
|
||||
Merge made by recursive.
|
||||
fs/fs.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
然后,仅有网卡驱动程序并不能够让你的操作系统接入因特网。在新的实验 6 的代码中,我们为你提供了网络栈和一个网络服务器。与以前的实验一样,使用 git 去拉取这个实验的代码,合并到你自己的代码中,并去浏览新的 `net/` 目录中的内容,以及在 `kern/` 中的新文件。
|
||||
然后,仅有网卡驱动程序并不能够让你的操作系统接入互联网。在新的实验 6 的代码中,我们为你提供了网络栈和一个网络服务器。与以前的实验一样,使用 git 去拉取这个实验的代码,合并到你自己的代码中,并去浏览新的 `net/` 目录中的内容,以及在 `kern/` 中的新文件。
|
||||
|
||||
除了写这个驱动程序以外,你还需要去创建一个访问你的驱动程序的系统调用。你将要去实现那些在网络服务器中缺失的代码,以便于在网络栈和你的驱动程序之间传输包。你还需要通过完成一个 web 服务器来将所有的东西连接到一起。你的新 web 服务器还需要你的文件系统来提供所需要的文件。
|
||||
|
||||
大部分的内核设备驱动程序代码都需要你自己去从头开始编写。本实验提供的指导比起前面的实验要少一些:没有框架文件、没有现成的系统调用接口、并且很多设计都由你自己决定。因此,我们建议你在开始任何单独练习之前,阅读全部的编写任务。许多学生都反应这个实验比前面的实验都难,因此请根据你的实际情况计划你的时间。
|
||||
|
||||
##### 实验要求
|
||||
#### 实验要求
|
||||
|
||||
与以前一样,你需要做实验中全部的常规练习和至少一个挑战问题。在实验中写出你的详细答案,并将挑战问题的方案描述写入到 `answers-lab6.txt` 文件中。
|
||||
|
||||
#### QEMU 的虚拟网络
|
||||
### QEMU 的虚拟网络
|
||||
|
||||
我们将使用 QEMU 的用户模式网络栈,因为它不需要以管理员权限运行。QEMU 的文档的[这里][1]有更多关于用户网络的内容。我们更新后的 makefile 启用了 QEMU 的用户模式网络栈和虚拟的 E1000 网卡。
|
||||
|
||||
缺省情况下,QEMU 提供一个运行在 IP 地址 10.2.2.2 上的虚拟路由器,它给 JOS 分配的 IP 地址是 10.0.2.15。为了简单起见,我们在 `net/ns.h` 中将这些缺省值硬编码到网络服务器上。
|
||||
|
||||
虽然 QEMU 的虚拟网络允许 JOS 随意连接因特网,但 JOS 的 10.0.2.15 的地址并不能在 QEMU 中的虚拟网络之外使用(也就是说,QEMU 还得做一个 NAT),因此我们并不能直接连接到 JOS 上运行的服务器,即便是从运行 QEMU 的主机上连接也不行。为解决这个问题,我们配置 QEMU 在主机的某些端口上运行一个服务器,这个服务器简单地连接到 JOS 中的一些端口上,并在你的真实主机和虚拟网络之间传递数据。
|
||||
虽然 QEMU 的虚拟网络允许 JOS 随意连接互联网,但 JOS 的 10.0.2.15 的地址并不能在 QEMU 中的虚拟网络之外使用(也就是说,QEMU 还得做一个 NAT),因此我们并不能直接连接到 JOS 上运行的服务器,即便是从运行 QEMU 的主机上连接也不行。为解决这个问题,我们配置 QEMU 在主机的某些端口上运行一个服务器,这个服务器简单地连接到 JOS 中的一些端口上,并在你的真实主机和虚拟网络之间传递数据。
|
||||
|
||||
你将在端口 7(echo)和端口 80(http)上运行 JOS,为避免在共享的 Athena 机器上发生冲突,makefile 将为这些端口基于你的用户 ID 来生成转发端口。你可以运行 `make which-ports` 去找出是哪个 QEMU 端口转发到你的开发主机上。为方便起见,makefile 也提供 `make nc-7` 和 `make nc-80`,它允许你在终端上直接与运行这些端口的服务器去交互。(这些目标仅能连接到一个运行中的 QEMU 实例上;你必须分别去启动它自己的 QEMU)
|
||||
|
||||
##### 包检查
|
||||
#### 包检查
|
||||
|
||||
makefile 也可以配置 QEMU 的网络栈去记录所有的入站和出站数据包,并将它保存到你的实验目录中的 `qemu.pcap` 文件中。
|
||||
|
||||
使用 `tcpdump` 命令去获取一个捕获的 hex/ASCII 包转储:
|
||||
|
||||
```
|
||||
tcpdump -XXnr qemu.pcap
|
||||
tcpdump -XXnr qemu.pcap
|
||||
```
|
||||
|
||||
或者,你可以使用 [Wireshark][2] 以图形化界面去检查 pcap 文件。Wireshark 也知道如何去解码和检查成百上千的网络协议。如果你在 Athena 上,你可以使用 Wireshark 的前辈:ethereal,它运行在加锁的保密互联网协议网络中。
|
||||
|
||||
##### 调试 E1000
|
||||
#### 调试 E1000
|
||||
|
||||
我们非常幸运能够去使用仿真硬件。由于 E1000 是在软件中运行的,仿真的 E1000 能够给我们提供一个人类可读格式的报告、它的内部状态以及它遇到的任何问题。通常情况下,对祼机上做驱动程序开发的人来说,这是非常难能可贵的。
|
||||
|
||||
@ -78,15 +77,15 @@ E1000 能够产生一些调试输出,因此你可以去打开一个专门的
|
||||
| eeprom | 读取 EEPROM 的日志 |
|
||||
| interrupt | 中断和中断寄存器变更日志 |
|
||||
|
||||
例如,你可以使用 `make E1000_DEBUG=tx,txerr` 去打开 "tx" 和 "txerr" 日志功能。
|
||||
例如,你可以使用 `make E1000_DEBUG=tx,txerr` 去打开 “tx” 和 “txerr” 日志功能。
|
||||
|
||||
注意:`E1000_DEBUG` 标志仅能在打了 6.828 补丁的 QEMU 版本上工作。
|
||||
|
||||
你可以使用软件去仿真硬件,来做进一步的调试工作。如果你使用它时卡壳了,不明白为什么 E1000 没有如你预期那样响应你,你可以查看在 `hw/e1000.c` 中的 QEMU 的 E1000 实现。
|
||||
|
||||
#### 网络服务器
|
||||
### 网络服务器
|
||||
|
||||
从头开始写一个网络栈是很困难的。因此我们将使用 lwIP,它是一个开源的、轻量级 TCP/IP 协议套件,它能做包括一个网络栈在内的很多事情。你能在 [这里][3] 找到很多关于 IwIP 的信息。在这个任务中,对我们而言,lwIP 就是一个实现了一个 BSD 套接字接口和拥有一个包输入端口和包输出端口的黑盒子。
|
||||
从头开始写一个网络栈是很困难的。因此我们将使用 lwIP,它是一个开源的、轻量级 TCP/IP 协议套件,它能做包括一个网络栈在内的很多事情。你能在 [这里][3] 找到很多关于 lwIP 的信息。在这个任务中,对我们而言,lwIP 就是一个实现了一个 BSD 套接字接口和拥有一个包输入端口和包输出端口的黑盒子。
|
||||
|
||||
一个网络服务器其实就是一个有以下四个环境的混合体:
|
||||
|
||||
@ -95,59 +94,53 @@ E1000 能够产生一些调试输出,因此你可以去打开一个专门的
|
||||
* 输出环境
|
||||
* 定时器环境
|
||||
|
||||
|
||||
|
||||
下图展示了各个环境和它们之间的关系。下图展示了包括设备驱动的整个系统,我们将在后面详细讲到它。在本实验中,你将去实现图中绿色高亮的部分。
|
||||
|
||||
![Network server architecture][4]
|
||||
|
||||
##### 核心网络服务器环境
|
||||
#### 核心网络服务器环境
|
||||
|
||||
核心网络服务器环境由套接字调用派发器和 IwIP 自身组成的。套接字调用派发器就像一个文件服务器一样。用户环境使用 stubs(可以在 `lib/nsipc.c` 中找到它)去发送 IPC 消息到核心网络服务器环境。如果你看了 `lib/nsipc.c`,你就会发现核心网络服务器与我们创建的文件服务器 `i386_init` 的工作方式是一样的,`i386_init` 是使用 NS_TYPE_NS 创建的 NS 环境,因此我们检查 `envs`,去查找这个特殊的环境类型。对于每个用户环境的 IPC,网络服务器中的派发器将调用相应的、由 IwIP 提供的、代表用户的 BSD 套接字接口函数。
|
||||
核心网络服务器环境由套接字调用派发器和 lwIP 自身组成的。套接字调用派发器就像一个文件服务器一样。用户环境使用 stubs(可以在 `lib/nsipc.c` 中找到它)去发送 IPC 消息到核心网络服务器环境。如果你看了 `lib/nsipc.c`,你就会发现核心网络服务器与我们创建的文件服务器 `i386_init` 的工作方式是一样的,`i386_init` 是使用 NS_TYPE_NS 创建的 NS 环境,因此我们检查 `envs`,去查找这个特殊的环境类型。对于每个用户环境的 IPC,网络服务器中的派发器将调用相应的、由 lwIP 提供的、代表用户的 BSD 套接字接口函数。
|
||||
|
||||
普通用户环境不能直接使用 `nsipc_*` 调用。而是通过在 `lib/sockets.c` 中的函数来使用它们,这些函数提供了基于文件描述符的套接字 API。以这种方式,用户环境通过文件描述符来引用套接字,就像它们引用磁盘上的文件一样。一些操作(`connect`、`accept`、等等)是特定于套接字的,但 `read`、`write`、和 `close` 是通过 `lib/fd.c` 中一般的文件描述符设备派发代码的。就像文件服务器对所有的打开的文件维护唯一的内部 ID 一样,lwIP 也为所有的打开的套接字生成唯一的 ID。不论是文件服务器还是网络服务器,我们都使用存储在 `struct Fd` 中的信息去映射每个环境的文件描述符到这些唯一的 ID 空间上。
|
||||
普通用户环境不能直接使用 `nsipc_*` 调用。而是通过在 `lib/sockets.c` 中的函数来使用它们,这些函数提供了基于文件描述符的套接字 API。以这种方式,用户环境通过文件描述符来引用套接字,就像它们引用磁盘上的文件一样。一些操作(`connect`、`accept` 等等)是特定于套接字的,但 `read`、`write` 和 `close` 是通过 `lib/fd.c` 中一般的文件描述符设备派发代码的。就像文件服务器对所有的打开的文件维护唯一的内部 ID 一样,lwIP 也为所有的打开的套接字生成唯一的 ID。不论是文件服务器还是网络服务器,我们都使用存储在 `struct Fd` 中的信息去映射每个环境的文件描述符到这些唯一的 ID 空间上。
|
||||
|
||||
尽管看起来文件服务器的网络服务器的 IPC 派发器行为是一样的,但它们之间还有很重要的差别。BSD 套接字调用(像 `accept` 和 `recv`)能够无限期阻塞。如果派发器让 lwIP 去执行其中一个调用阻塞,派发器也将被阻塞,并且在整个系统中,同一时间只能有一个未完成的网络调用。由于这种情况是无法接受的,所以网络服务器使用用户级线程以避免阻塞整个服务器环境。对于每个入站 IPC 消息,派发器将创建一个线程,然后在新创建的线程上来处理请求。如果线程被阻塞,那么只有那个线程被置入休眠状态,而其它线程仍然处于运行中。
|
||||
|
||||
除了核心网络环境外,还有三个辅助环境。核心网络服务器环境除了接收来自用户应用程序的消息之外,它的派发器也接收来自输入环境和定时器环境的消息。
|
||||
|
||||
##### 输出环境
|
||||
#### 输出环境
|
||||
|
||||
在为用户环境套接字调用提供服务时,lwIP 将为网卡生成用于发送的包。IwIP 将使用 `NSREQ_OUTPUT` 去发送在 IPC 消息页参数中附加了包的 IPC 消息。输出环境负责接收这些消息,并通过你稍后创建的系统调用接口来转发这些包到设备驱动程序上。
|
||||
在为用户环境套接字调用提供服务时,lwIP 将为网卡生成用于发送的包。lwIP 将使用 `NSREQ_OUTPUT` 去发送在 IPC 消息页参数中附加了包的 IPC 消息。输出环境负责接收这些消息,并通过你稍后创建的系统调用接口来转发这些包到设备驱动程序上。
|
||||
|
||||
##### 输入环境
|
||||
#### 输入环境
|
||||
|
||||
网卡接收到的包需要传递到 lwIP 中。输入环境将每个由设备驱动程序接收到的包拉进内核空间(使用你将要实现的内核系统调用),并使用 `NSREQ_INPUT` IPC 消息将这些包发送到核心网络服务器环境。
|
||||
网卡接收到的包需要传递到 lwIP 中。输入环境将每个由设备驱动程序接收到的包拉进内核空间(使用你将要实现的内核系统调用),并使用 `NSREQ_INPUT` IPC 消息将这些包发送到核心网络服务器环境。
|
||||
|
||||
包输入功能是独立于核心网络环境的,因为在 JOS 上同时实现接收 IPC 消息并从设备驱动程序中查询或等待包有点困难。我们在 JOS 中没有实现 `select` 系统调用,这是一个允许环境去监视多个输入源以识别准备处理哪个输入的系统调用。
|
||||
|
||||
如果你查看了 `net/input.c` 和 `net/output.c`,你将会看到在它们中都需要去实现那个系统调用。这主要是因为实现它要依赖你的系统调用接口。在你实现了驱动程序和系统调用接口之后,你将要为这两个辅助环境写这个代码。
|
||||
|
||||
##### 定时器环境
|
||||
#### 定时器环境
|
||||
|
||||
定时器环境周期性发送 `NSREQ_TIMER` 类型的消息到核心服务器,以提醒它那个定时器已过期。IwIP 使用来自线程的定时器消息来实现各种网络超时。
|
||||
定时器环境周期性发送 `NSREQ_TIMER` 类型的消息到核心服务器,以提醒它那个定时器已过期。lwIP 使用来自线程的定时器消息来实现各种网络超时。
|
||||
|
||||
### Part A:初始化和发送包
|
||||
|
||||
你的内核还没有一个时间概念,因此我们需要去添加它。这里有一个由硬件产生的每 10 ms 一次的时钟中断。每收到一个时钟中断,我们将增加一个变量值,以表示时间已过去 10 ms。它在 `kern/time.c` 中已实现,但还没有完全集成到你的内核中。
|
||||
|
||||
```markdown
|
||||
练习 1、为 `kern/trap.c` 中的每个时钟中断增加一个到 `time_tick` 的调用。实现 `sys_time_msec` 并增加到 `kern/syscall.c` 中的 `syscall`,以便于用户空间能够访问时间。
|
||||
```
|
||||
> **练习 1**、为 `kern/trap.c` 中的每个时钟中断增加一个到 `time_tick` 的调用。实现 `sys_time_msec` 并增加到 `kern/syscall.c` 中的 `syscall`,以便于用户空间能够访问时间。
|
||||
|
||||
使用 `make INIT_CFLAGS=-DTEST_NO_NS run-testtime` 去测试你的代码。你应该会看到环境计数从 5 开始以 1 秒为间隔减少。"-DTEST_NO_NS” 参数禁止在网络服务器环境上启动,因为在当前它将导致 JOS 崩溃。
|
||||
使用 `make INIT_CFLAGS=-DTEST_NO_NS run-testtime` 去测试你的代码。你应该会看到环境计数从 5 开始以 1 秒为间隔减少。`-DTEST_NO_NS` 参数禁止在网络服务器环境上启动,因为在当前它将导致 JOS 崩溃。
|
||||
|
||||
#### 网卡
|
||||
|
||||
写驱动程序要求你必须深入了解硬件和软件中的接口。本实验将给你提供一个如何使用 E1000 接口的高度概括的文档,但是你在写驱动程序时还需要大量去查询 Intel 的手册。
|
||||
|
||||
```markdown
|
||||
练习 2、为开发 E1000 驱动,去浏览 Intel 的 [软件开发者手册][5]。这个手册涵盖了几个与以太网控制器紧密相关的东西。QEMU 仿真了 82540EM。
|
||||
> **练习 2**、为开发 E1000 驱动,去浏览 Intel 的 [软件开发者手册][5]。这个手册涵盖了几个与以太网控制器紧密相关的东西。QEMU 仿真了 82540EM。
|
||||
|
||||
现在,你应该去浏览第 2 章,以对设备获得一个整体概念。写驱动程序时,你需要熟悉第 3 到 14 章,以及 4.1(不包括 4.1 的子节)。你也应该去参考第 13 章。其它章涵盖了 E1000 的组件,你的驱动程序并不与这些组件去交互。现在你不用担心过多细节的东西;只需要了解文档的整体结构,以便于你后面需要时容易查找。
|
||||
> 现在,你应该去浏览第 2 章,以对设备获得一个整体概念。写驱动程序时,你需要熟悉第 3 到 14 章,以及 4.1(不包括 4.1 的子节)。你也应该去参考第 13 章。其它章涵盖了 E1000 的组件,你的驱动程序并不与这些组件去交互。现在你不用担心过多细节的东西;只需要了解文档的整体结构,以便于你后面需要时容易查找。
|
||||
|
||||
在阅读手册时,记住,E1000 是一个拥有很多高级特性的很复杂的设备,一个能让 E1000 工作的驱动程序仅需要它一小部分的特性和 NIC 提供的接口即可。仔细考虑一下,如何使用最简单的方式去使用网卡的接口。我们强烈推荐你在使用高级特性之前,只去写一个基本的、能够让网卡工作的驱动程序即可。
|
||||
```
|
||||
> 在阅读手册时,记住,E1000 是一个拥有很多高级特性的很复杂的设备,一个能让 E1000 工作的驱动程序仅需要它一小部分的特性和 NIC 提供的接口即可。仔细考虑一下,如何使用最简单的方式去使用网卡的接口。我们强烈推荐你在使用高级特性之前,只去写一个基本的、能够让网卡工作的驱动程序即可。
|
||||
|
||||
##### PCI 接口
|
||||
|
||||
@ -156,10 +149,10 @@ E1000 是一个 PCI 设备,也就是说它是插到主板的 PCI 总线插槽
|
||||
我们在 `kern/pci.c` 中已经为你提供了使用 PCI 的代码。PCI 初始化是在引导期间执行的,PCI 代码遍历PCI 总线来查找设备。当它找到一个设备时,它读取它的供应商 ID 和设备 ID,然后使用这两个值作为关键字去搜索 `pci_attach_vendor` 数组。这个数组是由像下面这样的 `struct pci_driver` 条目组成:
|
||||
|
||||
```c
|
||||
struct pci_driver {
|
||||
uint32_t key1, key2;
|
||||
int (*attachfn) (struct pci_func *pcif);
|
||||
};
|
||||
struct pci_driver {
|
||||
uint32_t key1, key2;
|
||||
int (*attachfn) (struct pci_func *pcif);
|
||||
};
|
||||
```
|
||||
|
||||
如果发现的设备的供应商 ID 和设备 ID 与数组中条目匹配,那么 PCI 代码将调用那个条目的 `attachfn` 去执行设备初始化。(设备也可以按类别识别,那是通过 `kern/pci.c` 中其它的驱动程序表来实现的。)
|
||||
@ -167,50 +160,46 @@ E1000 是一个 PCI 设备,也就是说它是插到主板的 PCI 总线插槽
|
||||
绑定函数是传递一个 _PCI 函数_ 去初始化。一个 PCI 卡能够发布多个函数,虽然这个 E1000 仅发布了一个。下面是在 JOS 中如何去表示一个 PCI 函数:
|
||||
|
||||
```c
|
||||
struct pci_func {
|
||||
struct pci_bus *bus;
|
||||
struct pci_func {
|
||||
struct pci_bus *bus;
|
||||
|
||||
uint32_t dev;
|
||||
uint32_t func;
|
||||
uint32_t dev;
|
||||
uint32_t func;
|
||||
|
||||
uint32_t dev_id;
|
||||
uint32_t dev_class;
|
||||
uint32_t dev_id;
|
||||
uint32_t dev_class;
|
||||
|
||||
uint32_t reg_base[6];
|
||||
uint32_t reg_size[6];
|
||||
uint8_t irq_line;
|
||||
};
|
||||
uint32_t reg_base[6];
|
||||
uint32_t reg_size[6];
|
||||
uint8_t irq_line;
|
||||
};
|
||||
```
|
||||
|
||||
上面的结构反映了在 Intel 开发者手册里第 4.1 节的表 4-1 中找到的一些条目。`struct pci_func` 的最后三个条目我们特别感兴趣的,因为它们将记录这个设备协商的内存、I/O、以及中断资源。`reg_base` 和 `reg_size` 数组包含最多六个基址寄存器或 BAR。`reg_base` 为映射到内存中的 I/O 区域(对于 I/O 端口而言是基 I/O 端口)保存了内存的基地址,`reg_size` 包含了以字节表示的大小或来自 `reg_base` 的相关基值的 I/O 端口号,而 `irq_line` 包含了为中断分配给设备的 IRQ 线。在表 4-2 的后半部分给出了 E1000 BAR 的具体涵义。
|
||||
|
||||
当设备调用了绑定函数后,设备已经被发现,但没有被启用。这意味着 PCI 代码还没有确定分配给设备的资源,比如地址空间和 IRQ 线,也就是说,`struct pci_func` 结构的最后三个元素还没有被填入。绑定函数将调用 `pci_func_enable`,它将去启用设备、协商这些资源、并在结构 `struct pci_func` 中填入它。
|
||||
|
||||
```markdown
|
||||
练习 3、实现一个绑定函数去初始化 E1000。添加一个条目到 `kern/pci.c` 中的数组 `pci_attach_vendor` 上,如果找到一个匹配的 PCI 设备就去触发你的函数(确保一定要把它放在表末尾的 `{0, 0, 0}` 条目之前)。你在 5.2 节中能找到 QEMU 仿真的 82540EM 的供应商 ID 和设备 ID。在引导期间,当 JOS 扫描 PCI 总线时,你也可以看到列出来的这些信息。
|
||||
> **练习 3**、实现一个绑定函数去初始化 E1000。添加一个条目到 `kern/pci.c` 中的数组 `pci_attach_vendor` 上,如果找到一个匹配的 PCI 设备就去触发你的函数(确保一定要把它放在表末尾的 `{0, 0, 0}` 条目之前)。你在 5.2 节中能找到 QEMU 仿真的 82540EM 的供应商 ID 和设备 ID。在引导期间,当 JOS 扫描 PCI 总线时,你也可以看到列出来的这些信息。
|
||||
|
||||
到目前为止,我们通过 `pci_func_enable` 启用了 E1000 设备。通过本实验我们将添加更多的初始化。
|
||||
> 到目前为止,我们通过 `pci_func_enable` 启用了 E1000 设备。通过本实验我们将添加更多的初始化。
|
||||
|
||||
我们已经为你提供了 `kern/e1000.c` 和 `kern/e1000.h` 文件,这样你就不会把构建系统搞糊涂了。不过它们现在都是空的;你需要在本练习中去填充它们。你还可能在内核的其它地方包含这个 `e1000.h` 文件。
|
||||
> 我们已经为你提供了 `kern/e1000.c` 和 `kern/e1000.h` 文件,这样你就不会把构建系统搞糊涂了。不过它们现在都是空的;你需要在本练习中去填充它们。你还可能在内核的其它地方包含这个 `e1000.h` 文件。
|
||||
|
||||
当你引导你的内核时,你应该会看到它输出的信息显示 E1000 的 PCI 函数已经启用。这时你的代码已经能够通过 `make grade` 的 `pci attach` 测试了。
|
||||
```
|
||||
> 当你引导你的内核时,你应该会看到它输出的信息显示 E1000 的 PCI 函数已经启用。这时你的代码已经能够通过 `make grade` 的 `pci attach` 测试了。
|
||||
|
||||
##### 内存映射的 I/O
|
||||
|
||||
软件与 E1000 通过内存映射的 I/O(MMIO) 来沟通。你在 JOS 的前面部分可能看到过 MMIO 两次:CGA 控制台和 LAPIC 都是通过写入和读取“内存”来控制和查询设备的。但这些读取和写入不是去往内存芯片的,而是直接到这些设备的。
|
||||
软件与 E1000 通过内存映射的 I/O(MMIO)来沟通。你在 JOS 的前面部分可能看到过 MMIO 两次:CGA 控制台和 LAPIC 都是通过写入和读取“内存”来控制和查询设备的。但这些读取和写入不是去往内存芯片的,而是直接到这些设备的。
|
||||
|
||||
`pci_func_enable` 为 E1000 协调一个 MMIO 区域,来存储它在 BAR 0 的基址和大小(也就是 `reg_base[0]` 和 `reg_size[0]`),这是一个分配给设备的一段物理内存地址,也就是说你可以通过虚拟地址访问它来做一些事情。由于 MMIO 区域一般分配高位物理地址(一般是 3GB 以上的位置),因此你不能使用 `KADDR` 去访问它们,因为 JOS 被限制为最大使用 256MB。因此,你可以去创建一个新的内存映射。我们将使用 `MMIOBASE`(从实验 4 开始,你的 `mmio_map_region` 区域应该确保不能被 LAPIC 使用的映射所覆盖)以上的部分。由于在 JOS 创建用户环境之前,PCI 设备就已经初始化了,因此你可以在 `kern_pgdir` 处创建映射,并且让它始终可用。
|
||||
|
||||
```markdown
|
||||
练习 4、在你的绑定函数中,通过调用 `mmio_map_region`(它就是你在实验 4 中写的,是为了支持 LAPIC 内存映射)为 E1000 的 BAR 0 创建一个虚拟地址映射。
|
||||
> **练习 4**、在你的绑定函数中,通过调用 `mmio_map_region`(它就是你在实验 4 中写的,是为了支持 LAPIC 内存映射)为 E1000 的 BAR 0 创建一个虚拟地址映射。
|
||||
|
||||
你将希望在一个变量中记录这个映射的位置,以便于后面访问你映射的寄存器。去看一下 `kern/lapic.c` 中的 `lapic` 变量,它就是一个这样的例子。如果你使用一个指针指向设备寄存器映射,一定要声明它为 `volatile`;否则,编译器将允许缓存它的值,并可以在内存中再次访问它。
|
||||
> 你将希望在一个变量中记录这个映射的位置,以便于后面访问你映射的寄存器。去看一下 `kern/lapic.c` 中的 `lapic` 变量,它就是一个这样的例子。如果你使用一个指针指向设备寄存器映射,一定要声明它为 `volatile`;否则,编译器将允许缓存它的值,并可以在内存中再次访问它。
|
||||
|
||||
为测试你的映射,尝试去输出设备状态寄存器(第 12.4.2 节)。这是一个在寄存器空间中以字节 8 开头的 4 字节寄存器。你应该会得到 `0x80080783`,它表示以 1000 MB/s 的速度启用一个全双工的链路,以及其它信息。
|
||||
```
|
||||
> 为测试你的映射,尝试去输出设备状态寄存器(第 12.4.2 节)。这是一个在寄存器空间中以字节 8 开头的 4 字节寄存器。你应该会得到 `0x80080783`,它表示以 1000 MB/s 的速度启用一个全双工的链路,以及其它信息。
|
||||
|
||||
提示:你将需要一些常数,像寄存器位置和掩码位数。如果从开发者手册中复制这些东西很容易出错,并且导致调试过程很痛苦。我们建议你使用 QEMU 的 [`e1000_hw.h`][6] 头文件做为基准。我们不建议完全照抄它,因为它定义的值远超过你所需要,并且定义的东西也不见得就是你所需要的,但它仍是一个很好的参考。
|
||||
提示:你将需要一些常数,像寄存器位置和掩码位数。如果从开发者手册中复制这些东西很容易出错,并且导致调试过程很痛苦。我们建议你使用 QEMU 的 [e1000_hw.h][6] 头文件做为基准。我们不建议完全照抄它,因为它定义的值远超过你所需要,并且定义的东西也不见得就是你所需要的,但它仍是一个很好的参考。
|
||||
|
||||
##### DMA
|
||||
|
||||
@ -224,13 +213,13 @@ E1000 是一个 PCI 设备,也就是说它是插到主板的 PCI 总线插槽
|
||||
|
||||
#### 发送包
|
||||
|
||||
E1000 中的发送和接收功能本质上是独立的,因此我们可以同时进行发送接收。我们首先去攻克简单的数据包发送,因为我们在没有先去发送一个 “I'm here!" 包之前是无法测试接收包功能的。
|
||||
E1000 中的发送和接收功能本质上是独立的,因此我们可以同时进行发送接收。我们首先去攻克简单的数据包发送,因为我们在没有先去发送一个 “I'm here!” 包之前是无法测试接收包功能的。
|
||||
|
||||
首先,你需要初始化网卡以准备发送,详细步骤查看 14.5 节(不必着急看子节)。发送初始化的第一步是设置发送队列。队列的详细结构在 3.4 节中,描述符的结构在 3.3.3 节中。我们先不要使用 E1000 的 TCP offload 特性,因此你只需专注于 “传统的发送描述符格式” 即可。你应该现在就去阅读这些章节,并要熟悉这些结构。
|
||||
|
||||
##### C 结构
|
||||
|
||||
你可以用 C `struct` 很方便地描述 E1000 的结构。正如你在 `struct Trapframe` 中所看到的结构那样,C `struct` 可以让你很方便地在内存中描述准确的数据布局。C 可以在字段中插入数据,但是 E1000 的结构就是这样布局的,这样就不会是个问题。如果你遇到字段对齐问题,进入 GCC 查看它的 "packed” 属性。
|
||||
你可以用 C `struct` 很方便地描述 E1000 的结构。正如你在 `struct Trapframe` 中所看到的结构那样,C `struct` 可以让你很方便地在内存中描述准确的数据布局。C 可以在字段中插入数据,但是 E1000 的结构就是这样布局的,这样就不会是个问题。如果你遇到字段对齐问题,进入 GCC 查看它的 "packed” 属性。
|
||||
|
||||
查看手册中表 3-8 所给出的一个传统的发送描述符,将它复制到这里作为一个示例:
|
||||
|
||||
@ -246,31 +235,29 @@ E1000 中的发送和接收功能本质上是独立的,因此我们可以同
|
||||
从结构右上角第一个字节开始,我们将它转变成一个 C 结构,从上到下,从右到左读取。如果你从右往左看,你将看到所有的字段,都非常适合一个标准大小的类型:
|
||||
|
||||
```c
|
||||
struct tx_desc
|
||||
{
|
||||
uint64_t addr;
|
||||
uint16_t length;
|
||||
uint8_t cso;
|
||||
uint8_t cmd;
|
||||
uint8_t status;
|
||||
uint8_t css;
|
||||
uint16_t special;
|
||||
};
|
||||
struct tx_desc
|
||||
{
|
||||
uint64_t addr;
|
||||
uint16_t length;
|
||||
uint8_t cso;
|
||||
uint8_t cmd;
|
||||
uint8_t status;
|
||||
uint8_t css;
|
||||
uint16_t special;
|
||||
};
|
||||
```
|
||||
|
||||
你的驱动程序将为发送描述符数组去保留内存,并由发送描述符指向到包缓冲区。有几种方式可以做到,从动态分配页到在全局变量中简单地声明它们。无论你如何选择,记住,E1000 是直接访问物理内存的,意味着它能访问的任何缓存区在物理内存中必须是连续的。
|
||||
|
||||
处理包缓存也有几种方式。我们推荐从最简单的开始,那就是在驱动程序初始化期间,为每个描述符保留包缓存空间,并简单地将包数据复制进预留的缓冲区中或从其中复制出来。一个以太网包最大的尺寸是 1518 字节,这就限制了这些缓存区的大小。主流的成熟驱动程序都能够动态分配包缓存区(即:当网络使用率很低时,减少内存使用量),或甚至跳过缓存区,直接由用户空间提供(就是“零复制”技术),但我们还是从简单开始为好。
|
||||
|
||||
```markdown
|
||||
练习 5、执行一个 14.5 节中的初始化步骤(它的子节除外)。对于寄存器的初始化过程使用 13 节作为参考,对发送描述符和发送描述符数组参考 3.3.3 节和 3.4 节。
|
||||
> **练习 5**、执行一个 14.5 节中的初始化步骤(它的子节除外)。对于寄存器的初始化过程使用 13 节作为参考,对发送描述符和发送描述符数组参考 3.3.3 节和 3.4 节。
|
||||
|
||||
要记住,在发送描述符数组中要求对齐,并且数组长度上有限制。因为 TDLEN 必须是 128 字节对齐的,而每个发送描述符是 16 字节,你的发送描述符数组必须是 8 个发送描述符的倍数。并且不能使用超过 64 个描述符,以及不能在我们的发送环形缓存测试中溢出。
|
||||
> 要记住,在发送描述符数组中要求对齐,并且数组长度上有限制。因为 TDLEN 必须是 128 字节对齐的,而每个发送描述符是 16 字节,你的发送描述符数组必须是 8 个发送描述符的倍数。并且不能使用超过 64 个描述符,以及不能在我们的发送环形缓存测试中溢出。
|
||||
|
||||
对于 TCTL.COLD,你可以假设为全双工操作。对于 TIPG、IEEE 802.3 标准的 IPG(不要使用 14.5 节中表上的值),参考在 13.4.34 节中表 13-77 中描述的缺省值。
|
||||
```
|
||||
> 对于 TCTL.COLD,你可以假设为全双工操作。对于 TIPG、IEEE 802.3 标准的 IPG(不要使用 14.5 节中表上的值),参考在 13.4.34 节中表 13-77 中描述的缺省值。
|
||||
|
||||
尝试运行 `make E1000_DEBUG=TXERR,TX qemu`。如果你使用的是打了 6.828 补丁的 QEMU,当你设置 TDT(发送描述符尾部)寄存器时你应该会看到一个 “e1000: tx disabled" 的信息,并且不会有更多 "e1000” 信息了。
|
||||
尝试运行 `make E1000_DEBUG=TXERR,TX qemu`。如果你使用的是打了 6.828 补丁的 QEMU,当你设置 TDT(发送描述符尾部)寄存器时你应该会看到一个 “e1000: tx disabled” 的信息,并且不会有更多 “e1000” 信息了。
|
||||
|
||||
现在,发送初始化已经完成,你可以写一些代码去发送一个数据包,并且通过一个系统调用使它可以访问用户空间。你可以将要发送的数据包添加到发送队列的尾部,也就是说复制数据包到下一个包缓冲区中,然后更新 TDT 寄存器去通知网卡在发送队列中有另外的数据包。(注意,TDT 是一个进入发送描述符数组的索引,不是一个字节偏移量;关于这一点文档中说明的不是很清楚。)
|
||||
|
||||
@ -278,76 +265,64 @@ E1000 中的发送和接收功能本质上是独立的,因此我们可以同
|
||||
|
||||
如果用户调用你的发送系统调用,但是下一个描述符的 DD 位没有设置,表示那个发送队列已满,该怎么办?在这种情况下,你该去决定怎么办了。你可以简单地丢弃数据包。网络协议对这种情况的处理很灵活,但如果你丢弃大量的突发数据包,协议可能不会去重新获得它们。可能需要你替代网络协议告诉用户环境让它重传,就像你在 `sys_ipc_try_send` 中做的那样。在环境上回推产生的数据是有好处的。
|
||||
|
||||
```
|
||||
练习 6、写一个函数去发送一个数据包,它需要检查下一个描述符是否空闲、复制包数据到下一个描述符并更新 TDT。确保你处理的发送队列是满的。
|
||||
```
|
||||
> **练习 6**、写一个函数去发送一个数据包,它需要检查下一个描述符是否空闲、复制包数据到下一个描述符并更新 TDT。确保你处理的发送队列是满的。
|
||||
|
||||
现在,应该去测试你的包发送代码了。通过从内核中直接调用你的发送函数来尝试发送几个包。在测试时,你不需要去创建符合任何特定网络协议的数据包。运行 `make E1000_DEBUG=TXERR,TX qemu` 去测试你的代码。你应该看到类似下面的信息:
|
||||
|
||||
```c
|
||||
e1000: index 0: 0x271f00 : 9000002a 0
|
||||
...
|
||||
e1000: index 0: 0x271f00 : 9000002a 0
|
||||
...
|
||||
```
|
||||
|
||||
在你发送包时,每行都给出了在发送数组中的序号、那个发送的描述符的缓存地址、`cmd/CSO/length` 字段、以及 `special/CSS/status` 字段。如果 QEMU 没有从你的发送描述符中输出你预期的值,检查你的描述符中是否有合适的值和你配置的正确的 TDBAL 和 TDBAH。如果你收到的是 "e1000: TDH wraparound @0, TDT x, TDLEN y" 的信息,意味着 E1000 的发送队列持续不断地运行(如果 QEMU 不去检查它,它将是一个无限循环),这意味着你没有正确地维护 TDT。如果你收到了许多 "e1000: tx disabled" 的信息,那么意味着你没有正确设置发送控制寄存器。
|
||||
在你发送包时,每行都给出了在发送数组中的序号、那个发送的描述符的缓存地址、`cmd/CSO/length` 字段、以及 `special/CSS/status` 字段。如果 QEMU 没有从你的发送描述符中输出你预期的值,检查你的描述符中是否有合适的值和你配置的正确的 TDBAL 和 TDBAH。如果你收到的是 “e1000: TDH wraparound @0, TDT x, TDLEN y” 的信息,意味着 E1000 的发送队列持续不断地运行(如果 QEMU 不去检查它,它将是一个无限循环),这意味着你没有正确地维护 TDT。如果你收到了许多 “e1000: tx disabled” 的信息,那么意味着你没有正确设置发送控制寄存器。
|
||||
|
||||
一旦 QEMU 运行,你就可以运行 `tcpdump -XXnr qemu.pcap` 去查看你发送的包数据。如果从 QEMU 中看到预期的 "e1000: index” 信息,但你捕获的包是空的,再次检查你发送的描述符,是否填充了每个必需的字段和位。(E1000 或许已经遍历了你的发送描述符,但它认为不需要去发送)
|
||||
一旦 QEMU 运行,你就可以运行 `tcpdump -XXnr qemu.pcap` 去查看你发送的包数据。如果从 QEMU 中看到预期的 “e1000: index” 信息,但你捕获的包是空的,再次检查你发送的描述符,是否填充了每个必需的字段和位。(E1000 或许已经遍历了你的发送描述符,但它认为不需要去发送)
|
||||
|
||||
```
|
||||
练习 7、添加一个系统调用,让你从用户空间中发送数据包。详细的接口由你来决定。但是不要忘了检查从用户空间传递给内核的所有指针。
|
||||
```
|
||||
> **练习 7**、添加一个系统调用,让你从用户空间中发送数据包。详细的接口由你来决定。但是不要忘了检查从用户空间传递给内核的所有指针。
|
||||
|
||||
#### 发送包:网络服务器
|
||||
|
||||
现在,你已经有一个系统调用接口可以发送包到你的设备驱动程序端了。输出辅助环境的目标是在一个循环中做下面的事情:从核心网络服务器中接收 `NSREQ_OUTPUT` IPC 消息,并使用你在上面增加的系统调用去发送伴随这些 IPC 消息的数据包。这个 `NSREQ_OUTPUT` IPC 是通过 `net/lwip/jos/jif/jif.c` 中的 `low_level_output` 函数来发送的。它集成 lwIP 栈到 JOS 的网络系统。每个 IPC 将包含一个页,这个页由一个 `union Nsipc` 和在 `struct jif_pkt pkt` 字段中的一个包组成(查看 `inc/ns.h`)。`struct jif_pkt` 看起来像下面这样:
|
||||
|
||||
```c
|
||||
struct jif_pkt {
|
||||
int jp_len;
|
||||
char jp_data[0];
|
||||
};
|
||||
struct jif_pkt {
|
||||
int jp_len;
|
||||
char jp_data[0];
|
||||
};
|
||||
```
|
||||
|
||||
`jp_len` 表示包的长度。在 IPC 页上的所有后续字节都是为了包内容。在结构的结尾处使用一个长度为 0 的数组来表示缓存没有一个预先确定的长度(像 `jp_data` 一样),这是一个常见的 C 技巧(也有人说这是一个令人讨厌的做法)。因为 C 并不做数组边界的检查,只要你确保结构后面有足够的未使用内存即可,你可以把 `jp_data` 作为一个任意大小的数组来使用。
|
||||
|
||||
当设备驱动程序的发送队列中没有足够的空间时,一定要注意在设备驱动程序、输出环境和核心网络服务器之间的交互。核心网络服务器使用 IPC 发送包到输出环境。如果输出环境在由于一个发送包的系统调用而挂起,导致驱动程序没有足够的缓存去容纳新数据包,这时核心网络服务器将阻塞以等待输出服务器去接收 IPC 调用。
|
||||
|
||||
```markdown
|
||||
练习 8、实现 `net/output.c`。
|
||||
```
|
||||
> **练习 8**、实现 `net/output.c`。
|
||||
|
||||
你可以使用 `net/testoutput.c` 去测试你的输出代码而无需整个网络服务器参与。尝试运行 `make E1000_DEBUG=TXERR,TX run-net_testoutput`。你将看到如下的输出:
|
||||
|
||||
```c
|
||||
Transmitting packet 0
|
||||
e1000: index 0: 0x271f00 : 9000009 0
|
||||
Transmitting packet 1
|
||||
e1000: index 1: 0x2724ee : 9000009 0
|
||||
...
|
||||
Transmitting packet 0
|
||||
e1000: index 0: 0x271f00 : 9000009 0
|
||||
Transmitting packet 1
|
||||
e1000: index 1: 0x2724ee : 9000009 0
|
||||
...
|
||||
```
|
||||
|
||||
运行 `tcpdump -XXnr qemu.pcap` 将输出:
|
||||
|
||||
|
||||
```c
|
||||
reading from file qemu.pcap, link-type EN10MB (Ethernet)
|
||||
-5:00:00.600186 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 30 Packet.00
|
||||
-5:00:00.610080 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 31 Packet.01
|
||||
...
|
||||
reading from file qemu.pcap, link-type EN10MB (Ethernet)
|
||||
-5:00:00.600186 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 30 Packet.00
|
||||
-5:00:00.610080 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 31 Packet.01
|
||||
...
|
||||
```
|
||||
|
||||
使用更多的数据包去测试,可以运行 `make E1000_DEBUG=TXERR,TX NET_CFLAGS=-DTESTOUTPUT_COUNT=100 run-net_testoutput`。如果它导致你的发送队列溢出,再次检查你的 DD 状态位是否正确,以及是否告诉硬件去设置 DD 状态位(使用 RS 命令位)。
|
||||
|
||||
你的代码应该会通过 `make grade` 的 `testoutput` 测试。
|
||||
|
||||
```
|
||||
问题
|
||||
|
||||
1、你是如何构造你的发送实现的?在实践中,如果发送缓存区满了,你该如何处理?
|
||||
```
|
||||
|
||||
> **问题 1**、你是如何构造你的发送实现的?在实践中,如果发送缓存区满了,你该如何处理?
|
||||
|
||||
### Part B:接收包和 web 服务器
|
||||
|
||||
@ -355,9 +330,7 @@ E1000 中的发送和接收功能本质上是独立的,因此我们可以同
|
||||
|
||||
就像你在发送包中做的那样,你将去配置 E1000 去接收数据包,并提供一个接收描述符队列和接收描述符。在 3.2 节中描述了接收包的操作,包括接收队列结构和接收描述符、以及在 14.4 节中描述的详细的初始化过程。
|
||||
|
||||
```
|
||||
练习 9、阅读 3.2 节。你可以忽略关于中断和 offload 校验和方面的内容(如果在后面你想去使用这些特性,可以再返回去阅读),你现在不需要去考虑阈值的细节和网卡内部缓存是如何工作的。
|
||||
```
|
||||
> **练习 9**、阅读 3.2 节。你可以忽略关于中断和 offload 校验和方面的内容(如果在后面你想去使用这些特性,可以再返回去阅读),你现在不需要去考虑阈值的细节和网卡内部缓存是如何工作的。
|
||||
|
||||
除了接收队列是由一系列的等待入站数据包去填充的空缓存包以外,接收队列的其它部分与发送队列非常相似。所以,当网络空闲时,发送队列是空的(因为所有的包已经被发送出去了),而接收队列是满的(全部都是空缓存包)。
|
||||
|
||||
@ -365,123 +338,108 @@ E1000 中的发送和接收功能本质上是独立的,因此我们可以同
|
||||
|
||||
如果 E1000 在一个接收描述符中接收到了一个比包缓存还要大的数据包,它将按需从接收队列中检索尽可能多的描述符以保存数据包的全部内容。为表示发生了这种情况,它将在所有的这些描述符上设置 DD 状态位,但仅在这些描述符的最后一个上设置 EOP 状态位。在你的驱动程序上,你可以去处理这种情况,也可以简单地配置网卡拒绝接收这种”长包“(这种包也被称为”巨帧“),你要确保接收缓存有足够的空间尽可能地去存储最大的标准以太网数据包(1518 字节)。
|
||||
|
||||
```markdown
|
||||
练习 10、设置接收队列并按 14.4 节中的流程去配置 E1000。你可以不用支持 ”长包“ 或多播。到目前为止,我们不用去配置网卡使用中断;如果你在后面决定去使用接收中断时可以再去改。另外,配置 E1000 去除以太网的 CRC 校验,因为我们的评级脚本要求必须去掉校验。
|
||||
> **练习 10**、设置接收队列并按 14.4 节中的流程去配置 E1000。你可以不用支持 ”长包“ 或多播。到目前为止,我们不用去配置网卡使用中断;如果你在后面决定去使用接收中断时可以再去改。另外,配置 E1000 去除以太网的 CRC 校验,因为我们的评级脚本要求必须去掉校验。
|
||||
|
||||
默认情况下,网卡将过滤掉所有的数据包。你必须使用网卡的 MAC 地址去配置接收地址寄存器(RAL 和 RAH)以接收发送到这个网卡的数据包。你可以简单地硬编码 QEMU 的默认 MAC 地址 52:54:00:12:34:56(我们已经在 lwIP 中硬编码了这个地址,因此这样做不会有问题)。使用字节顺序时要注意;MAC 地址是从低位字节到高位字节的方式来写的,因此 52:54:00:12 是 MAC 地址的低 32 位,而 34:56 是它的高 16 位。
|
||||
> 默认情况下,网卡将过滤掉所有的数据包。你必须使用网卡的 MAC 地址去配置接收地址寄存器(RAL 和 RAH)以接收发送到这个网卡的数据包。你可以简单地硬编码 QEMU 的默认 MAC 地址 52:54:00:12:34:56(我们已经在 lwIP 中硬编码了这个地址,因此这样做不会有问题)。使用字节顺序时要注意;MAC 地址是从低位字节到高位字节的方式来写的,因此 52:54:00:12 是 MAC 地址的低 32 位,而 34:56 是它的高 16 位。
|
||||
|
||||
E1000 的接收缓存区大小仅支持几个指定的设置值(在 13.4.22 节中描述的 RCTL.BSIZE 值)。如果你的接收包缓存够大,并且拒绝长包,那你就不用担心跨越多个缓存区的包。另外,要记住的是,和发送一样,接收队列和包缓存必须是连接的物理内存。
|
||||
> E1000 的接收缓存区大小仅支持几个指定的设置值(在 13.4.22 节中描述的 RCTL.BSIZE 值)。如果你的接收包缓存够大,并且拒绝长包,那你就不用担心跨越多个缓存区的包。另外,要记住的是,和发送一样,接收队列和包缓存必须是连接的物理内存。
|
||||
|
||||
你应该使用至少 128 个接收描述符。
|
||||
```
|
||||
> 你应该使用至少 128 个接收描述符。
|
||||
|
||||
现在,你可以做接收功能的基本测试了,甚至都无需写代码去接收包了。运行 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput`。`testinput` 将发送一个 ARP(地址解析协议)通告包(使用你的包发送的系统调用),而 QEMU 将自动回复它,即便是你的驱动尚不能接收这个回复,你也应该会看到一个 "e1000: unicast match[0]: 52:54:00:12:34:56" 的消息,表示 E1000 接收到一个包,并且匹配了配置的接收过滤器。如果你看到的是一个 "e1000: unicast mismatch: 52:54:00:12:34:56” 消息,表示 E1000 过滤掉了这个包,意味着你的 RAL 和 RAH 的配置不正确。确保你按正确的顺序收到了字节,并不要忘记设置 RAH 中的 "Address Valid” 位。如果你没有收到任何 "e1000” 消息,或许是你没有正确地启用接收功能。
|
||||
现在,你可以做接收功能的基本测试了,甚至都无需写代码去接收包了。运行 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput`。`testinput` 将发送一个 ARP(地址解析协议)通告包(使用你的包发送的系统调用),而 QEMU 将自动回复它,即便是你的驱动尚不能接收这个回复,你也应该会看到一个 “e1000: unicast match[0]: 52:54:00:12:34:56” 的消息,表示 E1000 接收到一个包,并且匹配了配置的接收过滤器。如果你看到的是一个 “e1000: unicast mismatch: 52:54:00:12:34:56” 消息,表示 E1000 过滤掉了这个包,意味着你的 RAL 和 RAH 的配置不正确。确保你按正确的顺序收到了字节,并不要忘记设置 RAH 中的 “Address Valid” 位。如果你没有收到任何 “e1000” 消息,或许是你没有正确地启用接收功能。
|
||||
|
||||
现在,你准备去实现接收数据包。为了接收数据包,你的驱动程序必须持续跟踪希望去保存下一下接收到的包的描述符(提示:按你的设计,这个功能或许已经在 E1000 中的一个寄存器来实现了)。与发送类似,官方文档上表示,RDH 寄存器状态并不能从软件中可靠地读取,因为确定一个包是否被发送到描述符的包缓存中,你需要去读取描述符中的 DD 状态位。如果 DD 位被设置,你就可以从那个描述符的缓存中复制出这个数据包,然后通过更新队列的尾索引 RDT 来告诉网卡那个描述符是空闲的。
|
||||
|
||||
如果 DD 位没有被设置,表明没有接收到包。这就与发送队列满的情况一样,这时你可以有几种做法。你可以简单地返回一个 ”重传“ 错误来要求对端重发一次。对于满的发送队列,由于那是个临时状况,这种做法还是很好的,但对于空的接收队列来说就不太合理了,因为接收队列可能会保持好长一段时间的空的状态。第二个方法是挂起调用环境,直到在接收队列中处理了这个包为止。这个策略非常类似于 `sys_ipc_recv`。就像在 IPC 的案例中,因为我们每个 CPU 仅有一个内核栈,一旦我们离开内核,栈上的状态就会被丢弃。我们需要设置一个标志去表示那个环境由于接收队列下溢被挂起并记录系统调用参数。这种方法的缺点是过于复杂:E1000 必须被指示去产生接收中断,并且驱动程序为了恢复被阻塞等待一个包的环境,必须处理这个中断。
|
||||
|
||||
```
|
||||
练习 11、写一个函数从 E1000 中接收一个包,然后通过一个系统调用将它发布到用户空间。确保你将接收队列处理成空的。
|
||||
```
|
||||
> **练习 11**、写一个函数从 E1000 中接收一个包,然后通过一个系统调用将它发布到用户空间。确保你将接收队列处理成空的。
|
||||
|
||||
```markdown
|
||||
小挑战!如果发送队列是满的或接收队列是空的,环境和你的驱动程序可能会花费大量的 CPU 周期是轮询、等待一个描述符。一旦完成发送或接收描述符,E1000 能够产生一个中断,以避免轮询。修改你的驱动程序,处理发送和接收队列是以中断而不是轮询的方式进行。
|
||||
.
|
||||
|
||||
注意,一旦确定为中断,它将一直处于中断状态,直到你的驱动程序明确处理完中断为止。在你的中断服务程序中,一旦处理完成要确保清除掉中断状态。如果你不那样做,从你的中断服务程序中返回后,CPU 将再次跳转到你的中断服务程序中。除了在 E1000 网卡上清除中断外,也需要使用 `lapic_eoi` 在 LAPIC 上清除中断。
|
||||
```
|
||||
> 小挑战!如果发送队列是满的或接收队列是空的,环境和你的驱动程序可能会花费大量的 CPU 周期是轮询、等待一个描述符。一旦完成发送或接收描述符,E1000 能够产生一个中断,以避免轮询。修改你的驱动程序,处理发送和接收队列是以中断而不是轮询的方式进行。
|
||||
|
||||
> 注意,一旦确定为中断,它将一直处于中断状态,直到你的驱动程序明确处理完中断为止。在你的中断服务程序中,一旦处理完成要确保清除掉中断状态。如果你不那样做,从你的中断服务程序中返回后,CPU 将再次跳转到你的中断服务程序中。除了在 E1000 网卡上清除中断外,也需要使用 `lapic_eoi` 在 LAPIC 上清除中断。
|
||||
|
||||
#### 接收包:网络服务器
|
||||
|
||||
在网络服务器输入环境中,你需要去使用你的新的接收系统调用以接收数据包,并使用 `NSREQ_INPUT` IPC 消息将它传递到核心网络服务器环境。这些 IPC 输入消息应该会有一个页,这个页上绑定了一个 `union Nsipc`,它的 `struct jif_pkt pkt` 字段中有从网络上接收到的包。
|
||||
|
||||
```markdown
|
||||
练习 12、实现 `net/input.c`。
|
||||
```
|
||||
> **练习 12**、实现 `net/input.c`。
|
||||
|
||||
使用 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput` 再次运行 `testinput`,你应该会看到:
|
||||
|
||||
```c
|
||||
Sending ARP announcement...
|
||||
Waiting for packets...
|
||||
e1000: index 0: 0x26dea0 : 900002a 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
input: 0000 5254 0012 3456 5255 0a00 0202 0806 0001
|
||||
input: 0010 0800 0604 0002 5255 0a00 0202 0a00 0202
|
||||
input: 0020 5254 0012 3456 0a00 020f 0000 0000 0000
|
||||
input: 0030 0000 0000 0000 0000 0000 0000 0000 0000
|
||||
Sending ARP announcement...
|
||||
Waiting for packets...
|
||||
e1000: index 0: 0x26dea0 : 900002a 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
input: 0000 5254 0012 3456 5255 0a00 0202 0806 0001
|
||||
input: 0010 0800 0604 0002 5255 0a00 0202 0a00 0202
|
||||
input: 0020 5254 0012 3456 0a00 020f 0000 0000 0000
|
||||
input: 0030 0000 0000 0000 0000 0000 0000 0000 0000
|
||||
```
|
||||
|
||||
"input:” 打头的行是一个 QEMU 的 ARP 回复的十六进制转储。
|
||||
“input:” 打头的行是一个 QEMU 的 ARP 回复的十六进制转储。
|
||||
|
||||
你的代码应该会通过 `make grade` 的 `testinput` 测试。注意,在没有发送至少一个包去通知 QEMU 中的 JOS 的 IP 地址上时,是没法去测试包接收的,因此在你的发送代码中的 bug 可能会导致测试失败。
|
||||
|
||||
为彻底地测试你的网络代码,我们提供了一个称为 `echosrv` 的守护程序,它在端口 7 上设置运行 `echo` 的服务器,它将回显通过 TCP 连接发送给它的任何内容。使用 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-echosrv` 在一个终端中启动 `echo` 服务器,然后在另一个终端中通过 `make nc-7` 去连接它。你输入的每一行都被这个服务器回显出来。每次在仿真的 E1000 上接收到一个包,QEMU 将在控制台上输出像下面这样的内容:
|
||||
|
||||
```c
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
e1000: index 2: 0x26ea7c : 9000036 0
|
||||
e1000: index 3: 0x26f06a : 9000039 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
e1000: index 2: 0x26ea7c : 9000036 0
|
||||
e1000: index 3: 0x26f06a : 9000039 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
```
|
||||
|
||||
做到这一点后,你应该也就能通过 `echosrv` 的测试了。
|
||||
|
||||
```
|
||||
问题
|
||||
> **问题 2**、你如何构造你的接收实现?在实践中,如果接收队列是空的并且一个用户环境要求下一个入站包,你怎么办?
|
||||
|
||||
2、你如何构造你的接收实现?在实践中,如果接收队列是空的并且一个用户环境要求下一个入站包,你怎么办?
|
||||
```
|
||||
.
|
||||
|
||||
> 小挑战!在开发者手册中阅读关于 EEPROM 的内容,并写出从 EEPROM 中加载 E1000 的 MAC 地址的代码。目前,QEMU 的默认 MAC 地址是硬编码到你的接收初始化代码和 lwIP 中的。修复你的初始化代码,让它能够从 EEPROM 中读取 MAC 地址,和增加一个系统调用去传递 MAC 地址到 lwIP 中,并修改 lwIP 去从网卡上读取 MAC 地址。通过配置 QEMU 使用一个不同的 MAC 地址去测试你的变更。
|
||||
|
||||
```
|
||||
小挑战!在开发者手册中阅读关于 EEPROM 的内容,并写出从 EEPROM 中加载 E1000 的 MAC 地址的代码。目前,QEMU 的默认 MAC 地址是硬编码到你的接收初始化代码和 lwIP 中的。修复你的初始化代码,让它能够从 EEPROM 中读取 MAC 地址,和增加一个系统调用去传递 MAC 地址到 lwIP 中,并修改 lwIP 去从网卡上读取 MAC 地址。通过配置 QEMU 使用一个不同的 MAC 地址去测试你的变更。
|
||||
```
|
||||
.
|
||||
|
||||
```
|
||||
小挑战!修改你的 E1000 驱动程序去使用 "零复制" 技术。目前,数据包是从用户空间缓存中复制到发送包缓存中,和从接收包缓存中复制回到用户空间缓存中。一个使用 ”零复制“ 技术的驱动程序可以通过直接让用户空间和 E1000 共享包缓存内存来实现。还有许多不同的方法去实现 ”零复制“,包括映射内容分配的结构到用户空间或直接传递用户提供的缓存到 E1000。不论你选择哪种方法,都要注意你如何利用缓存的问题,因为你不能在用户空间代码和 E1000 之间产生争用。
|
||||
```
|
||||
> 小挑战!修改你的 E1000 驱动程序去使用 "零复制" 技术。目前,数据包是从用户空间缓存中复制到发送包缓存中,和从接收包缓存中复制回到用户空间缓存中。一个使用 ”零复制“ 技术的驱动程序可以通过直接让用户空间和 E1000 共享包缓存内存来实现。还有许多不同的方法去实现 ”零复制“,包括映射内容分配的结构到用户空间或直接传递用户提供的缓存到 E1000。不论你选择哪种方法,都要注意你如何利用缓存的问题,因为你不能在用户空间代码和 E1000 之间产生争用。
|
||||
|
||||
```
|
||||
小挑战!把 ”零复制“ 的概念用到 lwIP 中。
|
||||
.
|
||||
|
||||
一个典型的包是由许多头构成的。用户发送的数据被发送到 lwIP 中的一个缓存中。TCP 层要添加一个 TCP 包头,IP 层要添加一个 IP 包头,而 MAC 层有一个以太网头。甚至还有更多的部分增加到包上,这些部分要正确地连接到一起,以便于设备驱动程序能够发送最终的包。
|
||||
> 小挑战!把 “零复制” 的概念用到 lwIP 中。
|
||||
|
||||
E1000 的发送描述符设计是非常适合收集分散在内存中的包片段的,像在 IwIP 中创建的包的帧。如果你排队多个发送描述符,但仅设置最后一个描述符的 EOP 命令位,那么 E1000 将在内部把这些描述符串成包缓存,并在它们标记完 EOP 后仅发送串起来的缓存。因此,独立的包片段不需要在内存中把它们连接到一起。
|
||||
> 一个典型的包是由许多头构成的。用户发送的数据被发送到 lwIP 中的一个缓存中。TCP 层要添加一个 TCP 包头,IP 层要添加一个 IP 包头,而 MAC 层有一个以太网头。甚至还有更多的部分增加到包上,这些部分要正确地连接到一起,以便于设备驱动程序能够发送最终的包。
|
||||
|
||||
修改你的驱动程序,以使它能够发送由多个缓存且无需复制的片段组成的包,并且修改 lwIP 去避免它合并包片段,因为它现在能够正确处理了。
|
||||
```
|
||||
> E1000 的发送描述符设计是非常适合收集分散在内存中的包片段的,像在 lwIP 中创建的包的帧。如果你排队多个发送描述符,但仅设置最后一个描述符的 EOP 命令位,那么 E1000 将在内部把这些描述符串成包缓存,并在它们标记完 EOP 后仅发送串起来的缓存。因此,独立的包片段不需要在内存中把它们连接到一起。
|
||||
|
||||
```markdown
|
||||
小挑战!增加你的系统调用接口,以便于它能够为多于一个的用户环境提供服务。如果有多个网络栈(和多个网络服务器)并且它们各自都有自己的 IP 地址运行在用户模式中,这将是非常有用的。接收系统调用将决定它需要哪个环境来转发每个入站的包。
|
||||
> 修改你的驱动程序,以使它能够发送由多个缓存且无需复制的片段组成的包,并且修改 lwIP 去避免它合并包片段,因为它现在能够正确处理了。
|
||||
|
||||
注意,当前的接口并不知道两个包之间有何不同,并且如果多个环境去调用包接收的系统调用,各个环境将得到一个入站包的子集,而那个子集可能并不包含调用环境指定的那个包。
|
||||
.
|
||||
|
||||
在 [这篇][7] 外内核论文的 2.2 节和 3 节中对这个问题做了深度解释,并解释了在内核中(如 JOS)处理它的一个方法。用这个论文中的方法去解决这个问题,你不需要一个像论文中那么复杂的方案。
|
||||
```
|
||||
> 小挑战!增加你的系统调用接口,以便于它能够为多于一个的用户环境提供服务。如果有多个网络栈(和多个网络服务器)并且它们各自都有自己的 IP 地址运行在用户模式中,这将是非常有用的。接收系统调用将决定它需要哪个环境来转发每个入站的包。
|
||||
|
||||
> 注意,当前的接口并不知道两个包之间有何不同,并且如果多个环境去调用包接收的系统调用,各个环境将得到一个入站包的子集,而那个子集可能并不包含调用环境指定的那个包。
|
||||
|
||||
> 在 [这篇][7] 外内核论文的 2.2 节和 3 节中对这个问题做了深度解释,并解释了在内核中(如 JOS)处理它的一个方法。用这个论文中的方法去解决这个问题,你不需要一个像论文中那么复杂的方案。
|
||||
|
||||
#### Web 服务器
|
||||
|
||||
一个最简单的 web 服务器类型是发送一个文件的内容到请求的客户端。我们在 `user/httpd.c` 中提供了一个非常简单的 web 服务器的框架代码。这个框架内码处理入站连接并解析请求头。
|
||||
|
||||
```markdown
|
||||
练习 13、这个 web 服务器中缺失了发送一个文件的内容到客户端的处理代码。通过实现 `send_file` 和 `send_data` 完成这个 web 服务器。
|
||||
```
|
||||
> **练习 13**、这个 web 服务器中缺失了发送一个文件的内容到客户端的处理代码。通过实现 `send_file` 和 `send_data` 完成这个 web 服务器。
|
||||
|
||||
在你完成了这个 web 服务器后,启动这个 web 服务器(`make run-httpd-nox`),使用你喜欢的浏览器去浏览 http:// _host_ : _port_ /index.html 地址。其中 _host_ 是运行 QEMU 的计算机的名字(如果你在 athena 上运行 QEMU,使用 `hostname.mit.edu`(其中 hostname 是在 athena 上运行 `hostname` 命令的输出,或者如果你在运行 QEMU 的机器上运行 web 浏览器的话,直接使用 `localhost`),而 _port_ 是 web 服务器运行 `make which-ports` 命令报告的端口号。你应该会看到一个由运行在 JOS 中的 HTTP 服务器提供的一个 web 页面。
|
||||
在你完成了这个 web 服务器后,启动这个 web 服务器(`make run-httpd-nox`),使用你喜欢的浏览器去浏览 `http://host:port/index.html` 地址。其中 _host_ 是运行 QEMU 的计算机的名字(如果你在 athena 上运行 QEMU,使用 `hostname.mit.edu`(其中 hostname 是在 athena 上运行 `hostname` 命令的输出,或者如果你在运行 QEMU 的机器上运行 web 浏览器的话,直接使用 `localhost`),而 _port_ 是 web 服务器运行 `make which-ports` 命令报告的端口号。你应该会看到一个由运行在 JOS 中的 HTTP 服务器提供的一个 web 页面。
|
||||
|
||||
到目前为止,你的评级测试得分应该是 105 分(满分为105)。
|
||||
到目前为止,你的评级测试得分应该是 105 分(满分为 105)。
|
||||
|
||||
```markdown
|
||||
小挑战!在 JOS 中添加一个简单的聊天服务器,多个人可以连接到这个服务器上,并且任何用户输入的内容都被发送到其它用户。为实现它,你需要找到一个一次与多个套接字通讯的方法,并且在同一时间能够在同一个套接字上同时实现发送和接收。有多个方法可以达到这个目的。lwIP 为 `recv`(查看 `net/lwip/api/sockets.c` 中的 `lwip_recvfrom`)提供了一个 MSG_DONTWAIT 标志,以便于你不断地轮询所有打开的套接字。注意,虽然网络服务器的 IPC 支持 `recv` 标志,但是通过普通的 `read` 函数并不能访问它们,因此你需要一个方法来传递这个标志。一个更高效的方法是为每个连接去启动一个或多个环境,并且使用 IPC 去协调它们。而且碰巧的是,对于一个套接字,在结构 Fd 中找到的 lwIP 套接字 ID 是全局的(不是每个环境私有的),因此,比如一个 `fork` 的子环境继承了它的父环境的套接字。或者,一个环境通过构建一个包含了正确套接字 ID 的 Fd 就能够发送到另一个环境的套接字上。
|
||||
```
|
||||
> 小挑战!在 JOS 中添加一个简单的聊天服务器,多个人可以连接到这个服务器上,并且任何用户输入的内容都被发送到其它用户。为实现它,你需要找到一个一次与多个套接字通讯的方法,并且在同一时间能够在同一个套接字上同时实现发送和接收。有多个方法可以达到这个目的。lwIP 为 `recv`(查看 `net/lwip/api/sockets.c` 中的 `lwip_recvfrom`)提供了一个 MSG_DONTWAIT 标志,以便于你不断地轮询所有打开的套接字。注意,虽然网络服务器的 IPC 支持 `recv` 标志,但是通过普通的 `read` 函数并不能访问它们,因此你需要一个方法来传递这个标志。一个更高效的方法是为每个连接去启动一个或多个环境,并且使用 IPC 去协调它们。而且碰巧的是,对于一个套接字,在结构 Fd 中找到的 lwIP 套接字 ID 是全局的(不是每个环境私有的),因此,比如一个 `fork` 的子环境继承了它的父环境的套接字。或者,一个环境通过构建一个包含了正确套接字 ID 的 Fd 就能够发送到另一个环境的套接字上。
|
||||
|
||||
```
|
||||
问题
|
||||
> **问题 3**、由 JOS 的 web 服务器提供的 web 页面显示了什么?
|
||||
|
||||
.
|
||||
|
||||
> **问题 4**、你做这个实验大约花了多长的时间?
|
||||
|
||||
3、由 JOS 的 web 服务器提供的 web 页面显示了什么?
|
||||
4. 你做这个实验大约花了多长的时间?
|
||||
```
|
||||
|
||||
**本实验到此结束了。**一如既往,不要忘了运行 `make grade` 并去写下你的答案和挑战问题的解决方案的描述。在你动手之前,使用 `git status` 和 `git diff` 去检查你的变更,并不要忘了去 `git add answers-lab6.txt`。当你完成之后,使用 `git commit -am 'my solutions to lab 6’` 去提交你的变更,然后 `make handin` 并关注它的动向。
|
||||
|
||||
@ -492,7 +450,7 @@ via: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10450-1.html)
|
||||
[#]: subject: (Winterize your Bash prompt in Linux)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-bash-prompt)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
在 Linux 中冬季化你的 Bash 提示符
|
||||
在 Linux 中打扮你的冬季 Bash 提示符
|
||||
======
|
||||
你的 Linux 终端可能支持 Unicode,那么为何不利用它在提示符中添加季节性的图标呢?
|
||||
|
||||
> 你的 Linux 终端可能支持 Unicode,那么为何不利用它在提示符中添加季节性的图标呢?
|
||||
|
||||
|
||||
|
||||
欢迎再次来到 Linux 命令行玩具日历的另一篇。如果这是你第一次访问该系列,你甚至可能会问自己什么是命令行玩具?我们对此非常开放:它会是终端上有任何有趣的消遣,对于任何节日主题相关的还有额外的加分。
|
||||
欢迎再次来到 Linux 命令行玩具日历的另一篇。如果这是你第一次访问该系列,你甚至可能会问自己什么是命令行玩具?我们对此比较随意:它会是终端上有任何有趣的消遣,对于任何节日主题相关的还有额外的加分。
|
||||
|
||||
也许你以前见过其中的一些,也许你没有。不管怎样,我们希望你玩得开心。
|
||||
|
||||
今天的玩具非常简单:它是你的 Bash 提示符。你的 Bash 提示符?是的!我们还有几个星期的假期可以盯着它看,在北半球冬天还会再多几周,所以为什么不玩玩它。
|
||||
|
||||
目前你的 Bash 提示符号可能是一个简单的美元符号( **$**),或者更有可能是一个更长的东西。如果你不确定你的 Bash 提示符是什么,你可以在环境变量 $PS1 中找到它。要查看它,请输入:
|
||||
目前你的 Bash 提示符号可能是一个简单的美元符号( `$`),或者更有可能是一个更长的东西。如果你不确定你的 Bash 提示符是什么,你可以在环境变量 `$PS1` 中找到它。要查看它,请输入:
|
||||
|
||||
```
|
||||
echo $PS1
|
||||
@ -30,9 +32,9 @@ echo $PS1
|
||||
[\u@\h \W]\$
|
||||
```
|
||||
|
||||
**\u**、 **\h** 和 **\W** 分别是用户名、主机名和工作目录的特殊字符。你还可以使用其他一些符号。为了帮助构建你的 Bash 提示符,你可以使用 [EzPrompt][1],这是一个 PS1 配置的在线生成器,它包含了许多选项,包括日期和时间、Git 状态等。
|
||||
`\u`、`\h` 和 `\W` 分别是用户名、主机名和工作目录的特殊字符。你还可以使用其他一些符号。为了帮助构建你的 Bash 提示符,你可以使用 [EzPrompt][1],这是一个 `PS1` 配置的在线生成器,它包含了许多选项,包括日期和时间、Git 状态等。
|
||||
|
||||
你可能还有其他变量来组成 Bash 提示符。对我来说,**$PS2** 包含了我命令提示符的结束括号。有关详细信息,请参阅[这篇文章][2]。
|
||||
你可能还有其他变量来组成 Bash 提示符。对我来说,`$PS2` 包含了我命令提示符的结束括号。有关详细信息,请参阅 [这篇文章][2]。
|
||||
|
||||
要更改提示符,只需在终端中设置环境变量,如下所示:
|
||||
|
||||
@ -41,9 +43,9 @@ $ PS1='\u is cold: '
|
||||
jehb is cold:
|
||||
```
|
||||
|
||||
要永久设置它,请使用你喜欢的文本编辑器将相同的代码添加到 **/etc/bashrc** 中。
|
||||
要永久设置它,请使用你喜欢的文本编辑器将相同的代码添加到 `/etc/bashrc` 中。
|
||||
|
||||
那么这些与冬季化有什么关系呢?好吧,你很有可能有现代机器,你的终端支持 Unicode,所以你不仅限于标准的 ASCII 字符集。你可以使用任何符合 Unicode 规范的 emoji,包括雪花 ❄、雪人 ☃ 或一对滑雪者 🎿。你有很多冬季 emoji 可供选择。
|
||||
那么这些与冬季化有什么关系呢?好吧,你很有可能有现代一下的机器,你的终端支持 Unicode,所以你不仅限于标准的 ASCII 字符集。你可以使用任何符合 Unicode 规范的 emoji,包括雪花 ❄、雪人 ☃ 或一对滑雪板 🎿。你有很多冬季 emoji 可供选择。
|
||||
|
||||
```
|
||||
🎄 圣诞树
|
||||
@ -60,7 +62,8 @@ jehb is cold:
|
||||
⛄ 没有雪的雪人
|
||||
🎁 包装好的礼物
|
||||
```
|
||||
选择你最喜欢的,享受冬天的欢乐。有趣的事实:现代文件系统也支持文件名中的 Unicode 字符,这意味着技术上你可以将你下个程序命名为 **“❄❄❄❄❄.py”**。只是说说,不要这么做。
|
||||
|
||||
选择你最喜欢的,享受冬天的欢乐。有趣的事实:现代文件系统也支持文件名中的 Unicode 字符,这意味着技术上你可以将你下个程序命名为 `❄❄❄❄❄.py`。只是说说,不要这么做。
|
||||
|
||||
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
|
||||
|
||||
@ -68,11 +71,14 @@ jehb is cold:
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://opensource.com/article/18/12/linux-toy-bash-prompt
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://ezprompt.net/
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (runningwater)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10453-1.html)
|
||||
[#]: subject: (How To Install Microsoft .NET Core SDK On Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-install-microsoft-net-core-sdk-on-linux/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
@ -38,7 +38,7 @@ $ sudo apt-get update
|
||||
$ sudo apt-get install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**Debian 8 系统上安装:**
|
||||
**Debian 8 系统上安装:**
|
||||
|
||||
增加微软密钥,添加 .NET 仓库源:
|
||||
|
||||
@ -51,14 +51,14 @@ $ sudo chown root:root /etc/apt/trusted.gpg.d/microsoft.asc.gpg
|
||||
$ sudo chown root:root /etc/apt/sources.list.d/microsoft-prod.list
|
||||
```
|
||||
|
||||
安装 .NET SDK:
|
||||
安装 .NET SDK:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**Fedora 28 系统上安装:**
|
||||
**Fedora 28 系统上安装:**
|
||||
|
||||
增加微软密钥,添加 .NET 仓库源:
|
||||
|
||||
@ -69,7 +69,7 @@ $ sudo mv prod.repo /etc/yum.repos.d/microsoft-prod.repo
|
||||
$ sudo chown root:root /etc/yum.repos.d/microsoft-prod.repo
|
||||
```
|
||||
|
||||
现在, 可以安装 .NET SDK 了:
|
||||
现在, 可以安装 .NET SDK 了:
|
||||
|
||||
```
|
||||
$ sudo dnf update
|
||||
@ -87,29 +87,29 @@ $ sudo mv prod.repo /etc/yum.repos.d/microsoft-prod.repo
|
||||
$ sudo chown root:root /etc/yum.repos.d/microsoft-prod.repo
|
||||
```
|
||||
|
||||
接着安装 .NET SDK ,命令如下:
|
||||
接着安装 .NET SDK ,命令如下:
|
||||
|
||||
```
|
||||
$ sudo dnf update
|
||||
$ sudo dnf install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**CentOS/Oracle 版本的 Linux 系统上:**
|
||||
**CentOS/Oracle 版本的 Linux 系统上:**
|
||||
|
||||
增加微软密钥,添加 .NET 仓库源,使其可用
|
||||
增加微软密钥,添加 .NET 仓库源,使其可用:
|
||||
|
||||
```
|
||||
$ sudo rpm -Uvh https://packages.microsoft.com/config/rhel/7/packages-microsoft-prod.rpm
|
||||
```
|
||||
|
||||
更新源仓库,安装 .NET SDK:
|
||||
更新源仓库,安装 .NET SDK:
|
||||
|
||||
```
|
||||
$ sudo yum update
|
||||
$ sudo yum install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**openSUSE Leap 版本的系统上:**
|
||||
**openSUSE Leap 版本的系统上:**
|
||||
|
||||
添加密钥,使仓库源可用,安装必需的依赖包,其命令如下:
|
||||
|
||||
@ -128,7 +128,7 @@ $ sudo zypper update
|
||||
$ sudo zypper install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**Ubuntu 18.04 LTS 版本的系统上:**
|
||||
**Ubuntu 18.04 LTS 版本的系统上:**
|
||||
|
||||
注册微软的密钥和 .NET Core 仓库源,命令如下:
|
||||
|
||||
@ -137,13 +137,13 @@ $ wget -q https://packages.microsoft.com/config/ubuntu/18.04/packages-microsoft-
|
||||
$ sudo dpkg -i packages-microsoft-prod.deb
|
||||
```
|
||||
|
||||
使 ‘Universe’ 仓库可用:
|
||||
使 Universe 仓库可用:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository universe
|
||||
```
|
||||
|
||||
然后,安装 .NET Core SDK ,命令如下:
|
||||
然后,安装 .NET Core SDK ,命令如下:
|
||||
|
||||
```
|
||||
$ sudo apt-get install apt-transport-https
|
||||
@ -151,7 +151,7 @@ $sudo apt-get update
|
||||
$ sudo apt-get install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**Ubuntu 16.04 LTS 版本的系统上:**
|
||||
**Ubuntu 16.04 LTS 版本的系统上:**
|
||||
|
||||
注册微软的密钥和 .NET Core 仓库源,命令如下:
|
||||
|
||||
@ -160,7 +160,7 @@ $ wget -q https://packages.microsoft.com/config/ubuntu/16.04/packages-microsoft-
|
||||
$ sudo dpkg -i packages-microsoft-prod.deb
|
||||
```
|
||||
|
||||
然后安装 .NET core SDK:
|
||||
然后安装 .NET core SDK:
|
||||
|
||||
```
|
||||
$ sudo apt-get install apt-transport-https
|
||||
@ -172,13 +172,13 @@ $ sudo apt-get install dotnet-sdk-2.2
|
||||
|
||||
我们已经成功的在 Linux 机器中安装了 .NET Core SDK。是时候使用 dotnet 创建第一个应用程序了。
|
||||
|
||||
接下来的目的,我们会创建一个名为 **“ostechnixApp”** 的应用程序。为此,可以简单的运行如下命令:
|
||||
接下来的目的,我们会创建一个名为 ostechnixApp 的应用程序。为此,可以简单的运行如下命令:
|
||||
|
||||
```
|
||||
$ dotnet new console -o ostechnixApp
|
||||
```
|
||||
|
||||
**简单的输出:**
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
Welcome to .NET Core!
|
||||
@ -220,21 +220,21 @@ $ ls
|
||||
obj ostechnixApp.csproj Program.cs
|
||||
```
|
||||
|
||||
可以看到有两个名为 **ostechnixApp.csproj** 和 **Program.cs** 的文件,以及一个名为 **ojb** 的目录。默认情况下, `Program.cs` 文件包含有可以在控制台中运行的 'Hello World' 程序代码。可以看看此代码:
|
||||
可以看到有两个名为 `ostechnixApp.csproj` 和 `Program.cs` 的文件,以及一个名为 `ojb` 的目录。默认情况下, `Program.cs` 文件包含有可以在控制台中运行的 “Hello World” 程序代码。可以看看此代码:
|
||||
|
||||
```
|
||||
$ cat Program.cs
|
||||
$ cat Program.cs
|
||||
using System;
|
||||
|
||||
namespace ostechnixApp
|
||||
{
|
||||
class Program
|
||||
{
|
||||
static void Main(string[] args)
|
||||
{
|
||||
Console.WriteLine("Hello World!");
|
||||
}
|
||||
}
|
||||
class Program
|
||||
{
|
||||
static void Main(string[] args)
|
||||
{
|
||||
Console.WriteLine("Hello World!");
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@ -247,13 +247,12 @@ Hello World!
|
||||
|
||||

|
||||
|
||||
很简单,对吧?是的,就是如此简单。现在你可以在 **Program.cs** 这文件中写上自己的代码,然后像上面所示的执行。
|
||||
很简单,对吧?是的,就是如此简单。现在你可以在 `Program.cs` 这文件中写上自己的代码,然后像上面所示的执行。
|
||||
|
||||
或者,你可以创建一个新的目录,如例子所示的 `mycode` 目录,命令如下:
|
||||
|
||||
```
|
||||
$ mkdir ~/.mycode
|
||||
|
||||
$ cd mycode/
|
||||
```
|
||||
|
||||
@ -263,7 +262,7 @@ $ cd mycode/
|
||||
$ dotnet new console
|
||||
```
|
||||
|
||||
简单的输出:
|
||||
示例输出:
|
||||
|
||||
```
|
||||
The template "Console Application" was created successfully.
|
||||
@ -278,9 +277,9 @@ Restore completed in 331.87 ms for /home/sk/mycode/mycode.csproj.
|
||||
Restore succeeded.
|
||||
```
|
||||
|
||||
上的命令会创建两个名叫 **mycode.csproj** 和 **Program.cs** 的文件及一个名为 **obj** 的目录。用你喜欢的编辑器打开 `Program.cs` 文件, 删除或修改原来的 'hello world' 代码段,然后编写自己的代码。
|
||||
上的命令会创建两个名叫 `mycode.csproj` 和 `Program.cs` 的文件及一个名为 `obj` 的目录。用你喜欢的编辑器打开 `Program.cs` 文件, 删除或修改原来的 “hello world” 代码段,然后编写自己的代码。
|
||||
|
||||
写完代码,保存,关闭 Program.cs 文件,然后运行此应用程序,命令如下:
|
||||
写完代码,保存,关闭 `Program.cs` 文件,然后运行此应用程序,命令如下:
|
||||
|
||||
```
|
||||
$ dotnet run
|
||||
@ -301,17 +300,17 @@ $ dotnet --help
|
||||
|
||||
### 使用微软的 Visual Studio Code 编辑器
|
||||
|
||||
要编写代码,你可以任选自己喜欢的编辑器。同时微软自己也有一款支持 .NET 的编辑器,其名为 “ **Microsoft Visual Studio Code** ”。它是一款开源、轻量级、功能强大的源代码编辑器。其内置了对 JavaScript、TypeScript 和 Node.js 的支持,并为其它语言(如 C++、C#、Python、PHP、Go)和运行时态(如 .NET 和 Unity)提供了丰富的扩展,已经形成一个完整的生态系统。它是一款跨平台的代码编辑器,所以在微软的 Windows 系统、GNU/Linux 系统和 Mac OS X 系统都可以使用。如果对其感兴趣,就可以使用。
|
||||
要编写代码,你可以任选自己喜欢的编辑器。同时微软自己也有一款支持 .NET 的编辑器,其名为 “Microsoft Visual Studio Code”。它是一款开源、轻量级、功能强大的源代码编辑器。其内置了对 JavaScript、TypeScript 和 Node.js 的支持,并为其它语言(如 C++、C#、Python、PHP、Go)和运行时态(如 .NET 和 Unity)提供了丰富的扩展,已经形成一个完整的生态系统。它是一款跨平台的代码编辑器,所以在微软的 Windows 系统、GNU/Linux 系统和 Mac OS X 系统都可以使用。如果对其感兴趣,就可以使用。
|
||||
|
||||
To know how to install and use it on Linux, please refer the following guide.想了解如何在 Linux 上安装和使用,请参阅以下指南。
|
||||
想了解如何在 Linux 上安装和使用,请参阅以下指南。
|
||||
|
||||
[Linux 中安装 Microsoft Visual Studio Code][3]
|
||||
|
||||
关于 Visual Studio Code editor 中 .NET Core 和 .NET Core SDK 工具的使用,[**此网页**][1]有一些基础的教程。想了解更多就去看看吧。
|
||||
关于 Visual Studio Code editor 中 .NET Core 和 .NET Core SDK 工具的使用,[此网页][1]有一些基础的教程。想了解更多就去看看吧。
|
||||
|
||||
### Telemetry
|
||||
|
||||
默认情况下,.NET core SDK 会采集用户使用情况数据,此功能被称为 **‘Telemetry’**。采集数据是匿名的,并根据[知识共享署名许可][2]分享给其开发团队和社区。因此 .NET 团队会知道这些工具的使用状况,然后根据统计做出决策,改进产品。如果你不想分享自己的使用信息的话,可以使用顺手的 shell 工具把名为 **DOTNET_CLI_TELEMETRY_OPTOUT** 的环境变量参数设置为 **‘1’** 或 **‘true’**,这样就简单的关闭此功能了。
|
||||
默认情况下,.NET core SDK 会采集用户使用情况数据,此功能被称为 Telemetry。采集数据是匿名的,并根据[知识共享署名许可][2]分享给其开发团队和社区。因此 .NET 团队会知道这些工具的使用状况,然后根据统计做出决策,改进产品。如果你不想分享自己的使用信息的话,可以使用顺手的 shell 工具把名为 `DOTNET_CLI_TELEMETRY_OPTOUT` 的环境变量参数设置为 `1` 或 `true`,这样就简单的关闭此功能了。
|
||||
|
||||
就这样。你已经知道如何在各 Linux 平台上安装 .NET Core SDK 以及知道如何创建基本的应用程序了。想了解更多 .NET 使用知识的话,请参阅此文章末尾给出的链接。
|
||||
|
||||
@ -319,6 +318,9 @@ To know how to install and use it on Linux, please refer the following guide.想
|
||||
|
||||
祝贺下!
|
||||
|
||||
### 资源
|
||||
|
||||
- [.NET Core](https://dotnet.microsoft.com/)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -328,7 +330,7 @@ via: https://www.ostechnix.com/how-to-install-microsoft-net-core-sdk-on-linux/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,17 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wwhio)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10454-1.html)
|
||||
[#]: subject: (Get started with Wekan, an open source kanban board)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-wekan)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 Wekan 吧,一款开源看板软件
|
||||
======
|
||||
这是开源工具类软件推荐的第二期,本文将让你在 2019 年更具生产力。来,让我们一起看看 Wekan 吧。
|
||||
|
||||
> 这是开源工具类软件推荐的第二期,本文将让你在 2019 年更具生产力。来,让我们一起看看 Wekan 吧。
|
||||
|
||||

|
||||
|
||||
每年年初,人们似乎都在想方设法地让自己更具生产力。对新年目标、期待,当然还有“新年新气象”这样的口号等等都促人上进。可大部分生产力软件的推荐都严重偏向闭源的专有软件,但事实上并不用这样。
|
||||
@ -22,7 +24,7 @@
|
||||
|
||||
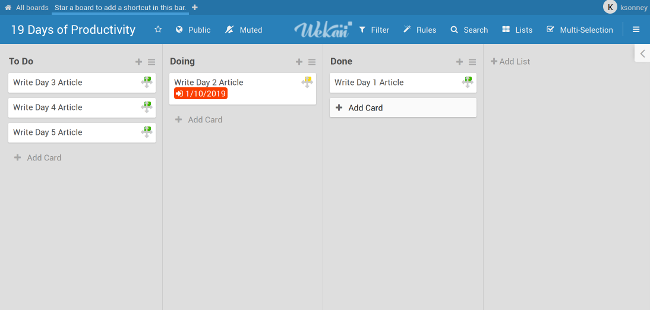
|
||||
|
||||
但这些 APP 通常需要连接到一个工作账户或者商业服务中。而 [Wekan][3] 作为一款开源看板工具,你可以让他完全在本地运行,或者使用你自己选择的服务运行它。其他的看板 APP 提供的功能在 Wekan 里几乎都有,例如创建看板、列表、泳道、卡片,在列表间拖放,给指定的用户安排任务,给卡片添加标签等等,基本上你对一款现代看板软件的功能需求它都能提供。
|
||||
但这些 APP 通常需要连接到一个工作账户或者商业服务中。而 [Wekan][3] 作为一款开源看板工具,你可以让它完全在本地运行,或者使用你自己选择的服务运行它。其他的看板 APP 提供的功能在 Wekan 里几乎都有,例如创建看板、列表、泳道、卡片,在列表间拖放,给指定的用户安排任务,给卡片添加标签等等,基本上你对一款现代看板软件的功能需求它都能提供。
|
||||
|
||||
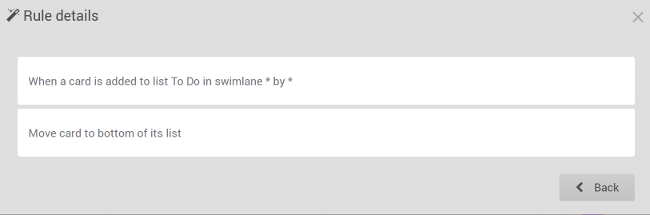
|
||||
|
||||
@ -52,7 +54,7 @@ via: https://opensource.com/article/19/1/productivity-tool-wekan
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wwhio](https://github.com/wwhio)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,97 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Getting started with Turtl, an open source alternative to Evernote
|
||||
======
|
||||

|
||||
|
||||
Just about everyone I know takes notes, and many people use an online note-taking application like Evernote, Simplenote, or Google Keep. Those are all good tools, but you have to wonder about the security and privacy of your information—especially in light of [Evernote's privacy flip-flop of 2016][1]. If you want more control over your notes and your data, you really need to turn to an open source tool.
|
||||
|
||||
Whatever your reasons for moving away from Evernote, there are open source alternatives out there. Let's look at one of those alternatives: Turtl.
|
||||
|
||||
### Getting started
|
||||
|
||||
The developers behind [Turtl][2] want you to think of it as "Evernote with ultimate privacy." To be honest, I can't vouch for the level of privacy that Turtl offers, but it is a quite a good note-taking tool.
|
||||
|
||||
To get started with Turtl, [download][3] a desktop client for Linux, Mac OS, or Windows, or grab the [Android app][4]. Install it, then fire up the client or app. You'll be asked for a username and passphrase. Turtl uses the passphrase to generate a cryptographic key that, according to the developers, encrypts your notes before storing them anywhere on your device or on their servers.
|
||||
|
||||
### Using Turtl
|
||||
|
||||
You can create the following types of notes with Turtl:
|
||||
|
||||
* Password
|
||||
|
||||
* File
|
||||
|
||||
* Image
|
||||
|
||||
* Bookmark
|
||||
|
||||
* Text note
|
||||
|
||||
No matter what type of note you choose, you create it in a window that's similar for all types of notes:
|
||||
|
||||
### [turtl-new-note-520.png][5]
|
||||
|
||||
|
||||
|
||||
Creating a new text note in Turtl
|
||||
|
||||
Add information like the title of the note, some text, and (if you're creating a File or Image note) attach a file or an image. Then click Save.
|
||||
|
||||
You can add formatting to your notes via [Markdown][6]. You need to add the formatting by hand—there are no toolbar shortcuts.
|
||||
|
||||
If you need to organize your notes, you can add them to Boards. Boards are just like notebooks in Evernote. To create a new board, click on the Boards tab, then click the Create a board button. Type a title for the board, then click Create.
|
||||
|
||||
### [turtl-boards-520.png][7]
|
||||
|
||||
|
||||
|
||||
Creating a new board in Turtl
|
||||
|
||||
To add a note to a board, create or edit the note, then click the This note is not in any boards link at the bottom of the note. Select one or more boards, then click Done.
|
||||
|
||||
To add tags to a note, click the Tags icon at the bottom of a note, enter one or more keywords separated by commas, and click Done.
|
||||
|
||||
### Syncing your notes across your devices
|
||||
|
||||
If you use Turtl across several computers and an Android device, for example, Turtl will sync your notes whenever you're online. However, I've encountered a small problem with syncing: Every so often, a note I've created on my phone doesn't sync to my laptop. I tried to sync manually by clicking the icon in the top left of the window and then clicking Sync Now, but that doesn't always work. I found that I occasionally need to click that icon, click Your settings, and then click Clear local data. I then need to log back into Turtl, but all the data syncs properly.
|
||||
|
||||
### A question, and a couple of problems
|
||||
|
||||
When I started using Turtl, I was dogged by one question: Where are my notes kept online? It turns out that the developers behind Turtl are based in the U.S., and that's also where their servers are. Although the encryption that Turtl uses is [quite strong][8] and your notes are encrypted on the server, the paranoid part of me says that you shouldn't save anything sensitive in Turtl (or any online note-taking tool, for that matter).
|
||||
|
||||
Turtl displays notes in a tiled view, reminiscent of Google Keep:
|
||||
|
||||
### [turtl-notes-520.png][9]
|
||||
|
||||
|
||||
|
||||
A collection of notes in Turtl
|
||||
|
||||
There's no way to change that to a list view, either on the desktop or on the Android app. This isn't a problem for me, but I've heard some people pan Turtl because it lacks a list view.
|
||||
|
||||
Speaking of the Android app, it's not bad; however, it doesn't integrate with the Android Share menu. If you want to add a note to Turtl based on something you've seen or read in another app, you need to copy and paste it manually.
|
||||
|
||||
I've been using a Turtl for several months on a Linux-powered laptop, my [Chromebook running GalliumOS][10], and an Android-powered phone. It's been a pretty seamless experience across all those devices. Although it's not my favorite open source note-taking tool, Turtl does a pretty good job. Give it a try; it might be the simple note-taking tool you're looking for.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/using-turtl-open-source-alternative-evernote
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://blog.evernote.com/blog/2016/12/15/evernote-revisits-privacy-policy/
|
||||
[2]:https://turtlapp.com/
|
||||
[3]:https://turtlapp.com/download/
|
||||
[4]:https://turtlapp.com/download/
|
||||
[5]:https://opensource.com/file/378346
|
||||
[6]:https://en.wikipedia.org/wiki/Markdown
|
||||
[7]:https://opensource.com/file/378351
|
||||
[8]:https://turtlapp.com/docs/security/encryption-specifics/
|
||||
[9]:https://opensource.com/file/378356
|
||||
[10]:https://opensource.com/article/17/4/linux-chromebook-gallium-os
|
||||
@ -1,141 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
Working with modules in Fedora 28
|
||||
======
|
||||

|
||||
The recent Fedora Magazine article entitled [Modularity in Fedora 28 Server Edition][1] did a great job of explaining Modularity in Fedora 28. It also pointed out a few example modules and explained the problems they solve. This article puts one of those modules to practical use, covering installation and setup of Review Board 3.0 using modules.
|
||||
|
||||
### Getting started
|
||||
|
||||
To follow along with this article and use modules, you need a system running [Fedora 28 Server Edition][2] along with [sudo administrative privileges][3]. Also, run this command to make sure all the packages on the system are current:
|
||||
```
|
||||
sudo dnf -y update
|
||||
|
||||
```
|
||||
|
||||
While you can use modules on Fedora 28 non-server editions, be aware of the [caveats described in the comments of the previous article][4].
|
||||
|
||||
### Examining modules
|
||||
|
||||
First, take a look at what modules are available for Fedora 28. Run the following command:
|
||||
```
|
||||
dnf module list
|
||||
|
||||
```
|
||||
|
||||
The output lists a collection of modules that shows the associated stream, version, and available installation profiles for each. A [d] next to a particular module stream indicates the default stream used if the named module is installed.
|
||||
|
||||
The output also shows most modules have a profile named default. That’s not a coincidence, since default is the name used for the default profile.
|
||||
|
||||
To see where all those modules are coming from, run:
|
||||
```
|
||||
dnf repolist
|
||||
|
||||
```
|
||||
|
||||
Along with the usual [fedora and updates package repositories][5], the output shows the fedora-modular and updates-modular repositories.
|
||||
|
||||
The introduction stated you’d be setting up Review Board 3.0. Perhaps a module named reviewboard caught your attention in the earlier output. Next, to get some details about that module, run this command:
|
||||
```
|
||||
dnf module info reviewboard
|
||||
|
||||
```
|
||||
|
||||
The description confirms it is the Review Board module, but also says it’s the 2.5 stream. However, you want 3.0. Look at the available reviewboard modules:
|
||||
```
|
||||
dnf module list reviewboard
|
||||
|
||||
```
|
||||
|
||||
The [d] next to the 2.5 stream means it is configured as the default stream for reviewboard. Therefore, be explicit about the stream you want:
|
||||
```
|
||||
dnf module info reviewboard:3.0
|
||||
|
||||
```
|
||||
|
||||
Now for even more details about the reviewboard:3.0 module, add the verbose option:
|
||||
```
|
||||
dnf module info reviewboard:3.0 -v
|
||||
|
||||
```
|
||||
|
||||
### Installing the Review Board 3.0 module
|
||||
|
||||
Now that you’ve tracked down the module you want, install it with this command:
|
||||
```
|
||||
sudo dnf -y module install reviewboard:3.0
|
||||
|
||||
```
|
||||
|
||||
The output shows the ReviewBoard package was installed, along with several other dependent packages, including several from the django:1.6 module. The installation also enabled the reviewboard:3.0 module and the dependent django:1.6 module.
|
||||
|
||||
Next, to see enabled modules, use this command:
|
||||
```
|
||||
dnf module list --enabled
|
||||
|
||||
```
|
||||
|
||||
The output shows [e] for enabled streams, and [i] for installed profiles. In the case of the reviewboard:3.0 module, the default profile was installed. You could have specified a different profile when installing the module. In fact, you still can — and this time you don’t need to specify the 3.0 stream since it was already enabled:
|
||||
```
|
||||
sudo dnf -y module install reviewboard/server
|
||||
|
||||
```
|
||||
|
||||
However, installation of the reviewboard:3.0/server profile is rather uneventful. The reviewboard:3.0 module’s server profile is the same as the default profile — so there’s nothing more to install.
|
||||
|
||||
### Spin up a Review Board site
|
||||
|
||||
Now that the Review Board 3.0 module and its dependent packages are installed, [create a Review Board site][6] running on the local system. Without further ado or explanation, copy and paste the following commands to do that:
|
||||
```
|
||||
sudo rb-site install --noinput \
|
||||
--domain-name=localhost --db-type=sqlite3 \
|
||||
--db-name=/var/www/rev.local/data/reviewboard.db \
|
||||
--admin-user=rbadmin --admin-password=secret \
|
||||
/var/www/rev.local
|
||||
sudo chown -R apache /var/www/rev.local/htdocs/media/uploaded \
|
||||
/var/www/rev.local/data
|
||||
sudo ln -s /var/www/rev.local/conf/apache-wsgi.conf \
|
||||
/etc/httpd/conf.d/reviewboard-localhost.conf
|
||||
sudo setsebool -P httpd_can_sendmail=1 httpd_can_network_connect=1 \
|
||||
httpd_can_network_memcache=1 httpd_unified=1
|
||||
sudo systemctl enable --now httpd
|
||||
|
||||
```
|
||||
|
||||
Now fire up a web browser on the system, point it at <http://localhost>, and enjoy the shiny new Review Board site! To login as the Review Board admin, use the userid and password seen in the rb-site command above.
|
||||
|
||||
### Module cleanup
|
||||
|
||||
It’s good practice to clean up after yourself. To do that, remove the Review Board module and the site directory:
|
||||
```
|
||||
sudo dnf -y module remove reviewboard:3.0
|
||||
sudo rm -rf /var/www/rev.local
|
||||
|
||||
```
|
||||
|
||||
### Closing remarks
|
||||
|
||||
Now that you’ve explored how to examine and administer the Review Board module, go experiment with the other modules available in Fedora 28.
|
||||
|
||||
Learn more about using modules in Fedora 28 on the [Fedora Modularity][7] web site. The dnf manual page’s Module Command section also contains useful information.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/working-modules-fedora-28/
|
||||
|
||||
作者:[Merlin Mathesius][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/merlinm/
|
||||
[1]:https://fedoramagazine.org/modularity-fedora-28-server-edition/
|
||||
[2]:https://getfedora.org/server/
|
||||
[3]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]:https://fedoramagazine.org/modularity-fedora-28-server-edition/#comment-476696
|
||||
[5]:https://fedoraproject.org/wiki/Repositories
|
||||
[6]:https://www.reviewboard.org/docs/manual/dev/admin/installation/creating-sites/
|
||||
[7]:https://docs.pagure.org/modularity/
|
||||
@ -1,3 +1,4 @@
|
||||
Scoutydren is translating.
|
||||
5 open source strategy and simulation games for Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
translating by cycoe
|
||||
cycoe 翻译中
|
||||
9 flowchart and diagramming tools for Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,88 @@
|
||||
开始使用 Turtl 这个 Evernote 的开源替代品
|
||||
======
|
||||

|
||||
|
||||
我认识的每个人都会记笔记,许多人使用在线笔记应用,如 Evernote、Simplenote 或 Google Keep。这些都是很好的工具,但你不得不担忧信息的安全性和隐私性 - 特别是考虑到 [Evernote 2016 年的隐私策略变更][1]。如果你想要更好地控制笔记和数据,你需要转向开源工具。
|
||||
|
||||
无论你离开 Evernote 的原因是什么,都有开源替代品。让我们来看看其中一个选择:Turtl。
|
||||
|
||||
### 入门
|
||||
|
||||
[Turtl][2] 背后的开发人员希望你将其视为“具有绝对隐私的 Evernote”。说实话,我不能保证 Turtl 提供的隐私级别,但它是一个非常好的笔记工具。
|
||||
|
||||
要开始使用 Turtl,[下载][3]适用于 Linux、Mac OS 或 Windows 的桌面客户端,或者获取 [Android 应用][4]。安装它,然后启动客户端或应用。系统会要求你输入用户名和密码。Turtl 使用密码来生成加密密钥,根据开发人员的说法,加密密钥会在将笔记存储在设备或服务器上之前对其进行加密。
|
||||
|
||||
### 使用 Turtl
|
||||
|
||||
你可以使用 Turtl 创建以下类型的笔记:
|
||||
|
||||
* 密码
|
||||
|
||||
* 档案
|
||||
|
||||
* 图片
|
||||
|
||||
* 书签
|
||||
|
||||
* 文字笔记
|
||||
|
||||
无论你选择何种类型的笔记,你都可以在类似的窗口中创建:
|
||||
|
||||
|
||||

|
||||
|
||||
在 Turtl 中创建新笔记
|
||||
|
||||
添加笔记标题,文字并(如果你正在创建文件或图像笔记)附加文件或图像等信息。然后单击“保存”。
|
||||
|
||||
你可以通过 [Markdown][6] 为你的笔记添加格式。因为没有工具栏快捷方式,所以你需要手动添加格式。
|
||||
|
||||
如果你需要整理笔记,可以将它们添加到“白板”中。白板就像 Evernote 中的笔记本。要创建新的白板,请单击 “Board” 选项卡,然后单击“创建”按钮。输入白板的标题,然后单击“创建”。
|
||||
|
||||

|
||||
|
||||
在 Turtl 中创建新的白板
|
||||
|
||||
要向白板添加笔记,请创建或编辑笔记,然后单击笔记底部的“此笔记不在任何白板”的链接。选择一个或多个白板,然后单击“完成”。
|
||||
|
||||
要为笔记添加标记,请单击记事本底部的“标记”图标,输入一个或多个以逗号分隔的关键字,然后单击“完成”。
|
||||
|
||||
### 跨设备同步你的笔记
|
||||
|
||||
例如,如果你在多台计算机和 Android 设备上使用 Turtl,Turtl 会在你上线时同步你的笔记。但是,我在同步时遇到了一个小问题:我手机上创建的笔记经常不会同步到我的笔记本电脑上。我尝试通过单击窗口左上角的图标手动同步,然后单击立即同步,但这并不总是有效。我发现偶尔需要单击“设置”图标,然后单击“清除本地数据”。然后我需要重新登录 Turtl,但所有数据都能正确同步了。
|
||||
|
||||
### 一个疑问和一些问题
|
||||
|
||||
当我开始使用 Turtl 时,我被一个疑问所困扰:我的笔记保存在哪里?事实证明,Turtl 背后的开发人员位于美国,这也是他们服务器的所在地。虽然 Turtl 使用的加密[非常强大][8]并且你的笔记在服务器上加密,但我偏执地认为你不应该在 Turtl 中保存任何敏感内容(或在任何类似的在线笔记中)。
|
||||
|
||||
Turtl 以平铺视图显示笔记,让人想起 Google Keep:
|
||||
|
||||
|
||||

|
||||
|
||||
Turtl 中的一系列笔记
|
||||
|
||||
无法在桌面或 Android 应用上将其更改为列表视图。这对我来说不是问题,但我听说有些人因为它没有列表视图而不喜欢 Turtl。
|
||||
|
||||
说到 Android 应用,它并不坏。但是,它没有与 Android 共享菜单集成。如果你想把在其他应用中看到或阅读的内容添加到 Turtl 笔记中,则需要手动复制并粘贴。
|
||||
|
||||
我已经在我的 Linux 笔记本,[运行 GalliumOS 的 Chromebook][10],还有一台 Android 手机上使用 Turtl 几个月了。对所有这些设备来说这都是一种非常无缝的体验。虽然它不是我最喜欢的开源笔记工具,但 Turtl 做得非常好。试试看它,它可能是你正在寻找的简单的笔记工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/using-turtl-open-source-alternative-evernote
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://blog.evernote.com/blog/2016/12/15/evernote-revisits-privacy-policy/
|
||||
[2]:https://turtlapp.com/
|
||||
[3]:https://turtlapp.com/download/
|
||||
[4]:https://turtlapp.com/download/
|
||||
[6]:https://en.wikipedia.org/wiki/Markdown
|
||||
[8]:https://turtlapp.com/docs/security/encryption-specifics/
|
||||
[10]:https://opensource.com/article/17/4/linux-chromebook-gallium-os
|
||||
134
translated/tech/20180606 Working with modules in Fedora 28.md
Normal file
134
translated/tech/20180606 Working with modules in Fedora 28.md
Normal file
@ -0,0 +1,134 @@
|
||||
使用 Fedora 28 中的模块
|
||||
======
|
||||

|
||||
最近 Fedora Magazine 中题为 [Fedora 28 服务器版的模块化][1]在解释 Fedora 28 中的模块化方面做得很好。它还给出了一些示例模块并解释了它们解决的问题。本文将其中一个模块用于实际应用,包括使用模块安装设置 Review Board 3.0。
|
||||
|
||||
### 入门
|
||||
|
||||
想要继续并使用模块,你需要一个 [Fedora 28 服务器版][2]并拥有 [sudo 管理权限][3]。另外,运行此命令以确保系统上的所有软件包都是最新的:
|
||||
|
||||
```
|
||||
sudo dnf -y update
|
||||
```
|
||||
|
||||
虽然你可以在 Fedora 28 非服务器版本上使用模块,但请注意[上一篇文章评论中提到的警告][4]。
|
||||
|
||||
### 检查模块
|
||||
|
||||
首先,看看 Fedora 28 可用的模块。运行以下命令:
|
||||
|
||||
```
|
||||
dnf module list
|
||||
```
|
||||
|
||||
输出列出了一组模块,这些模块显示了每个模块的关联流,版本和可用安装配置文件。模块流旁边的 [d] 表示安装命名模块时使用的默认流。
|
||||
|
||||
输出还显示大多数模块都有名为 default 的配置文件。这不是巧合,因为 default 是默认配置文件使用的名称。
|
||||
|
||||
要查看所有这些模块的来源,请运行:
|
||||
|
||||
```
|
||||
dnf repolist
|
||||
```
|
||||
|
||||
与通常的 [fedora 和更新包仓库][5]一起,输出还显示了fedora-modular 和 updates-modular 仓库。
|
||||
|
||||
介绍声明你将设置 Review Board 3.0。也许名为 reviewboard 的模块在之前的输出中引起了你的注意。接下来,要获取有关该模块的一些详细信息,请运行以下命令:
|
||||
|
||||
```
|
||||
dnf module info reviewboard
|
||||
```
|
||||
|
||||
根据描述确认它是 Review Board 模块,但也说明是 2.5 的流。然而你想要 3.0 的。查看可用的 reviewboard 模块:
|
||||
|
||||
```
|
||||
dnf module list reviewboard
|
||||
```
|
||||
|
||||
2.5 旁边的 [d] 表示它被配置为 reviewboard 的默认流。因此,请明确你想要的流:
|
||||
|
||||
```
|
||||
dnf module info reviewboard:3.0
|
||||
```
|
||||
|
||||
有关 reviewboard:3.0 模块的更多详细信息,请添加详细选项:
|
||||
|
||||
```
|
||||
dnf module info reviewboard:3.0 -v
|
||||
```
|
||||
|
||||
### 安装 Review Board 3.0 模块
|
||||
|
||||
现在你已经跟踪了所需的模块,请使用以下命令安装它:
|
||||
|
||||
```
|
||||
sudo dnf -y module install reviewboard:3.0
|
||||
```
|
||||
|
||||
输出显示已安装 ReviewBoard 以及其他几个依赖软件包,其中包括 django:1.6 模块中的几个软件包。安装还启用了reviewboard:3.0 模块和相关的 django:1.6 模块。
|
||||
|
||||
接下来,要查看已启用的模块,请使用以下命令:
|
||||
|
||||
```
|
||||
dnf module list --enabled
|
||||
```
|
||||
|
||||
输出中,[e] 表示已启用的流,[i] 表示已安装的配置。对于 reviewboard:3.0 模块,已安装默认配置。你可以在安装模块时指定其他配置。实际上,你仍然可以安装它,而且这次你不需要指定 3.0,因为它已经启用:
|
||||
|
||||
```
|
||||
sudo dnf -y module install reviewboard/server
|
||||
```
|
||||
|
||||
但是,安装 reviewboard:3.0/服务配置非常平常。reviewboard:3.0 模块的服务器配置与默认配置文件相同 - 因此无需安装。
|
||||
|
||||
### 启动 Review Board 网站
|
||||
|
||||
现在已经安装了 Review Board 3.0 模块及其相关软件包,[创建一个本地运行的 Review Board 网站][6]。无需解释,请复制并粘贴以下命令:
|
||||
|
||||
```
|
||||
sudo rb-site install --noinput \
|
||||
--domain-name=localhost --db-type=sqlite3 \
|
||||
--db-name=/var/www/rev.local/data/reviewboard.db \
|
||||
--admin-user=rbadmin --admin-password=secret \
|
||||
/var/www/rev.local
|
||||
sudo chown -R apache /var/www/rev.local/htdocs/media/uploaded \
|
||||
/var/www/rev.local/data
|
||||
sudo ln -s /var/www/rev.local/conf/apache-wsgi.conf \
|
||||
/etc/httpd/conf.d/reviewboard-localhost.conf
|
||||
sudo setsebool -P httpd_can_sendmail=1 httpd_can_network_connect=1 \
|
||||
httpd_can_network_memcache=1 httpd_unified=1
|
||||
sudo systemctl enable --now httpd
|
||||
```
|
||||
|
||||
现在启动系统中的 Web 浏览器,打开 <http://localhost>,然后享受全新的 Review Board 网站!要以 Review Board 管理员身份登录,请使用上面 rb-site 命令中的用户 ID 和密码。
|
||||
|
||||
### 模块清理
|
||||
|
||||
完成后清理是个好习惯。为此,删除 Review Board 模块和站点目录:
|
||||
|
||||
```
|
||||
sudo dnf -y module remove reviewboard:3.0
|
||||
sudo rm -rf /var/www/rev.local
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
现在你已经探索了如何检测和管理 Review Board 模块,那么去体验 Fedora 28 中提供的其他模块吧。
|
||||
|
||||
在 [Fedora 模块化][7]网站上了解有关在 Fedora 28 中使用模块的更多信息。dnf 手册页中的 module 命令部分也包含了有用的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://fedoramagazine.org/working-modules-fedora-28/
|
||||
作者:[Merlin Mathesius][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
[a]:https://fedoramagazine.org/author/merlinm/
|
||||
[1]:https://fedoramagazine.org/modularity-fedora-28-server-edition/
|
||||
[2]:https://getfedora.org/server/
|
||||
[3]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]:https://fedoramagazine.org/modularity-fedora-28-server-edition/#comment-476696
|
||||
[5]:https://fedoraproject.org/wiki/Repositories
|
||||
[6]:https://www.reviewboard.org/docs/manual/dev/admin/installation/creating-sites/
|
||||
[7]:https://docs.pagure.org/modularity/
|
||||
Loading…
Reference in New Issue
Block a user