mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
694ea80870
@ -1,57 +1,58 @@
|
||||
iWant – 一个分散的点对点共享文件的命令行应用程序
|
||||
iWant:一个去中心化的点对点共享文件的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
不久之前,我们编写了一个指南,内容是一个文件共享实用程序,名为 [**transfer.sh**][1],它是一个免费的 Web 服务,允许你在 Internet 上轻松快速地共享文件,还有 [**PSiTransfer**][2],一个简单的开源自托管文件共享解决方案。今天,我们将看到另一个名为 **"iWant"** 的文件共享实用程序。它是一个免费的,基于 CLI 的开源分散式点对点文件共享应用程序。
|
||||
不久之前,我们编写了一个指南,内容是一个文件共享实用程序,名为 [transfer.sh][1],它是一个免费的 Web 服务,允许你在 Internet 上轻松快速地共享文件,还有 [PSiTransfer][2],一个简单的开源自托管文件共享解决方案。今天,我们将看到另一个名为 “iWant” 的文件共享实用程序。它是一个基于命令行的自由开源的去中心化点对点文件共享应用程序。
|
||||
|
||||
你可能想知道,它与其它文件共享应用程序有什么不同?以下是 iWant 的一些突出特点。
|
||||
|
||||
* 它是一个命令行应用程序。这意味着你不需要消耗内存来加载 GUI 实用程序。你只需要一个终端。
|
||||
* 它是分散的。这意味着你的数据不会在任何中心位置存储。因此,不会因为中心失败而失败。
|
||||
* 它是去中心化的。这意味着你的数据不会在任何中心位置存储。因此,不会因为中心点失败而失败。
|
||||
* iWant 允许中断下载,你可以在以后随时恢复。你不需要从头开始下载,它会从你停止的位置恢复下载。
|
||||
* 共享目录中文件所作的任何更改(如删除、添加、修改)都会立即反映在网络中。
|
||||
* 就像种子一样,iWant 从多个节点下载文件。如果任何节点离开群组或未能响应,它将继续从另一个节点下载。
|
||||
* 它是跨平台的,因此你可以在 GNU/Linux, MS Windows 或者 Mac OS X 中使用它。
|
||||
* 它是跨平台的,因此你可以在 GNU/Linux、MS Windows 或者 Mac OS X 中使用它。
|
||||
|
||||
### iWant – 一个基于 CLI 的分散点对点文件共享解决方案
|
||||
|
||||
#### 安装 iWant
|
||||
### 安装 iWant
|
||||
|
||||
iWant 可以使用 PIP 包管理器轻松安装。确保你在 Linux 发行版中安装了 pip。如果尚未安装,参考以下指南。
|
||||
|
||||
[如何使用 Pip 管理 Python 包](https://www.ostechnix.com/manage-python-packages-using-pip/)
|
||||
|
||||
安装 PIP 后,确保你有以下依赖项:
|
||||
安装 pip 后,确保你有以下依赖项:
|
||||
|
||||
* libffi-dev
|
||||
* libssl-dev
|
||||
|
||||
比如说,在 Ubuntu 上,你可以使用以下命令安装这些依赖项:
|
||||
|
||||
```
|
||||
$ sudo apt-get install libffi-dev libssl-dev
|
||||
|
||||
```
|
||||
|
||||
安装完所有依赖项后,使用以下命令安装 iWant:
|
||||
|
||||
```
|
||||
$ sudo pip install iwant
|
||||
|
||||
```
|
||||
|
||||
现在我们的系统中已经有了 iWant,让我们来看看如何使用它来通过网络传输文件。
|
||||
|
||||
#### 用法
|
||||
### 用法
|
||||
|
||||
首先,使用以下命令启动 iWant 服务器:
|
||||
|
||||
(LCTT 译注:虽然这个软件是叫 iWant,但是其命令名为 `iwanto`,另外这个软件至少一年没有更新了。)
|
||||
|
||||
```
|
||||
$ iwanto start
|
||||
|
||||
```
|
||||
|
||||
第一次启动时,iWant 会询问想要分享和下载文件夹的位置,所以需要输入两个文件夹的位置。然后,选择要使用的网卡。
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Shared/Download folder details looks empty..
|
||||
Note: Shared and Download folder cannot be the same
|
||||
@ -66,31 +67,31 @@ now scanning /home/sk/myshare
|
||||
Updating Leader 56f6d5e8-654e-11e7-93c8-08002712f8c1
|
||||
[Adding] /home/sk/myshare 0.0
|
||||
connecting to 192.168.43.2:1235 for hashdump
|
||||
|
||||
```
|
||||
|
||||
如果你看到类似上面的输出,你可以立即开始使用 iWant。
|
||||
如果你看到类似上面的输出,你可以立即开始使用 iWant 了。
|
||||
|
||||
同样,在网络种的所有系统上启动 iWant 服务,指定有效的分享和下载文件夹的位置,并选择合适的网卡。
|
||||
同样,在网络中的所有系统上启动 iWant 服务,指定有效的分享和下载文件夹的位置,并选择合适的网卡。
|
||||
|
||||
iWant 服务将继续在当前终端窗口中运行,直到你按下 **CTRL+C** 退出为止。你需要打开一个新选项卡或新的终端窗口来使用 iWant。
|
||||
iWant 服务将继续在当前终端窗口中运行,直到你按下 `CTRL+C` 退出为止。你需要打开一个新选项卡或新的终端窗口来使用 iWant。
|
||||
|
||||
iWant 的用法非常简单,它的命令很少,如下所示。
|
||||
|
||||
* **iwanto start** – 启动 iWant 服务。
|
||||
* **iwanto search <name>** – 查找文件。
|
||||
* **iwanto download <hash>** – 下载一个文件。
|
||||
* **iwanto share <path>** – 更改共享文件夹的位置。
|
||||
* **iwanto download to <destination>** – 更改下载文件夹位置。
|
||||
* **iwanto view config** – 查看共享和下载文件夹。
|
||||
* **iwanto –version** – 显示 iWant 版本。
|
||||
* **iwanto -h** – 显示帮助信息。
|
||||
* `iwanto start` – 启动 iWant 服务。
|
||||
* `iwanto search <name>` – 查找文件。
|
||||
* `iwanto download <hash>` – 下载一个文件。
|
||||
* `iwanto share <path>` – 更改共享文件夹的位置。
|
||||
* `iwanto download to <destination>` – 更改下载文件夹位置。
|
||||
* `iwanto view config` – 查看共享和下载文件夹。
|
||||
* `iwanto –version` – 显示 iWant 版本。
|
||||
* `iwanto -h` – 显示帮助信息。
|
||||
|
||||
让我向你展示一些例子。
|
||||
|
||||
**查找文件**
|
||||
#### 查找文件
|
||||
|
||||
要查找一个文件,运行:
|
||||
|
||||
```
|
||||
$ iwanto search <filename>
|
||||
|
||||
@ -99,84 +100,86 @@ $ iwanto search <filename>
|
||||
请注意,你无需指定确切的名称。
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ iwanto search command
|
||||
|
||||
```
|
||||
|
||||
上面的命令将搜索包含 "command" 字符串的所有文件。
|
||||
上面的命令将搜索包含 “command” 字符串的所有文件。
|
||||
|
||||
我的 Ubuntu 系统会输出:
|
||||
|
||||
```
|
||||
Filename Size Checksum
|
||||
------------------------------------------- ------- --------------------------------
|
||||
/home/sk/myshare/THE LINUX COMMAND LINE.pdf 3.85757 efded6cc6f34a3d107c67c2300459911
|
||||
|
||||
```
|
||||
|
||||
**下载文件**
|
||||
#### 下载文件
|
||||
|
||||
你可以在你的网络上的任何系统下载文件。要下载文件,只需提供文件的哈希(校验和),如下所示。你可以使用 `iwanto search` 命令获取共享的哈希值。
|
||||
|
||||
你可以在你的网络上的任何系统下载文件。要下载文件,只需提供文件的哈希(校验和),如下所示。你可以使用 "iwanto search" 命令获取共享的哈希值。
|
||||
```
|
||||
$ iwanto download efded6cc6f34a3d107c67c2300459911
|
||||
|
||||
```
|
||||
|
||||
文件将保存在你的下载位置,在本文中是 `/home/sk/mydownloads/` 位置。
|
||||
|
||||
```
|
||||
Filename: /home/sk/mydownloads/THE LINUX COMMAND LINE.pdf
|
||||
Size: 3.857569 MB
|
||||
|
||||
```
|
||||
|
||||
**查看配置**
|
||||
#### 查看配置
|
||||
|
||||
要查看配置,例如共享和下载文件夹的位置,运行:
|
||||
|
||||
```
|
||||
$ iwanto view config
|
||||
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Shared folder:/home/sk/myshare
|
||||
Download folder:/home/sk/mydownloads
|
||||
|
||||
```
|
||||
|
||||
**更改共享和下载文件夹的位置**
|
||||
#### 更改共享和下载文件夹的位置
|
||||
|
||||
你可以更改共享文件夹和下载文件夹。
|
||||
|
||||
```
|
||||
$ iwanto share /home/sk/ostechnix
|
||||
|
||||
```
|
||||
|
||||
现在,共享位置已更改为 `/home/sk/ostechnix`。
|
||||
|
||||
同样,你可以使用以下命令更改下载位置:
|
||||
|
||||
```
|
||||
$ iwanto download to /home/sk/Downloads
|
||||
|
||||
```
|
||||
|
||||
要查看所做的更改,运行 `config` 命令:
|
||||
要查看所做的更改,运行命令:
|
||||
|
||||
```
|
||||
$ iwanto view config
|
||||
|
||||
```
|
||||
|
||||
**停止 iWant**
|
||||
#### 停止 iWant
|
||||
|
||||
一旦你不想用 iWant 了,可以按下 **CTRL+C** 退出。
|
||||
一旦你不想用 iWant 了,可以按下 `CTRL+C` 退出。
|
||||
|
||||
如果它不起作用,那可能是由于防火墙或你的路由器不支持多播。你可以在 ** ~/.iwant/.iwant.log** 文件中查看所有日志。有关更多详细信息,参阅最后提供的项目的 GitHub 页面。
|
||||
如果它不起作用,那可能是由于防火墙或你的路由器不支持多播。你可以在 `~/.iwant/.iwant.log` 文件中查看所有日志。有关更多详细信息,参阅最后提供的项目的 GitHub 页面。
|
||||
|
||||
差不多就是全部了。希望这个工具有所帮助。下次我会带着另一个有趣的指南再次来到这里。在那之前,请继续关注 OSTechNix!
|
||||
差不多就是全部了。希望这个工具有所帮助。下次我会带着另一个有趣的指南再次来到这里。
|
||||
|
||||
干杯!
|
||||
|
||||
### 资源
|
||||
|
||||
-[iWant GitHub](https://github.com/nirvik/iWant)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -185,7 +188,7 @@ via: https://www.ostechnix.com/iwant-decentralized-peer-peer-file-sharing-comman
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why DevOps is the most important tech strategy today)
|
||||
[#]: via: (https://opensource.com/article/19/3/devops-most-important-tech-strategy)
|
||||
[#]: author: (Kelly AlbrechtWilly-Peter Schaub https://opensource.com/users/ksalbrecht/users/brentaaronreed/users/wpschaub/users/wpschaub/users/ksalbrecht)
|
||||
|
||||
Why DevOps is the most important tech strategy today
|
||||
======
|
||||
Clearing up some of the confusion about DevOps.
|
||||
![CICD with gears][1]
|
||||
|
||||
Many people first learn about [DevOps][2] when they see one of its outcomes and ask how it happened. It's not necessary to understand why something is part of DevOps to implement it, but knowing that—and why a DevOps strategy is important—can mean the difference between being a leader or a follower in an industry.
|
||||
|
||||
Maybe you've heard some the incredible outcomes attributed to DevOps, such as production environments that are so resilient they can handle thousands of releases per day while a "[Chaos Monkey][3]" is running around randomly unplugging things. This is impressive, but on its own, it's a weak business case, essentially burdened with [proving a negative][4]: The DevOps environment is resilient because a serious failure hasn't been observed… yet.
|
||||
|
||||
There is a lot of confusion about DevOps and many people are still trying to make sense of it. Here's an example from someone in my LinkedIn feed:
|
||||
|
||||
> Recently attended few #DevOps sessions where some speakers seemed to suggest #Agile is a subset of DevOps. Somehow, my understanding was just the opposite.
|
||||
>
|
||||
> Would like to hear your thoughts. What do you think is the relationship between Agile and DevOps?
|
||||
>
|
||||
> 1. DevOps is a subset of Agile
|
||||
> 2. Agile is a subset of DevOps
|
||||
> 3. DevOps is an extension of Agile, starts where Agile ends
|
||||
> 4. DevOps is the new version of Agile
|
||||
>
|
||||
|
||||
|
||||
Tech industry professionals have been weighing in on the LinkedIn post with a wide range of answers. How would you respond?
|
||||
|
||||
### DevOps' roots in lean and agile
|
||||
|
||||
DevOps makes a lot more sense if we start with the strategies of Henry Ford and the Toyota Production System's refinements of Ford's model. Within this history is the birthplace of lean manufacturing, which has been well studied. In [_Lean Thinking_][5], James P. Womack and Daniel T. Jones distill it into five principles:
|
||||
|
||||
1. Specify the value desired by the customer
|
||||
2. Identify the value stream for each product providing that value and challenge all of the wasted steps currently necessary to provide it
|
||||
3. Make the product flow continuously through the remaining value-added steps
|
||||
4. Introduce pull between all steps where continuous flow is possible
|
||||
5. Manage toward perfection so that the number of steps and the amount of time and information needed to serve the customer continually falls
|
||||
|
||||
|
||||
|
||||
Lean seeks to continuously remove waste and increase the flow of value to the customer. This is easily recognizable and understood through a core tenet of lean: single piece flow. We can do a number of activities to learn why moving single pieces at a time is magnitudes faster than batches of many pieces; the [Penny Game][6] and the [Airplane Game][7] are two of them. In the Penny Game, if a batch of 20 pennies takes two minutes to get to the customer, they get the whole batch after waiting two minutes. If you move one penny at a time, the customer gets the first penny in about five seconds and continues getting pennies until the 20th penny arrives approximately 25 seconds later.
|
||||
|
||||
This is a huge difference, but not everything in life is as simple and predictable as the penny in the Penny Game. This is where agile comes in. We certainly see lean principles on high-performing agile teams, but these teams need more than lean to do what they do.
|
||||
|
||||
To be able to handle the unpredictability and variance of typical software development tasks, agile methodology focuses on awareness, deliberation, decision, and action to adjust course in the face of a constantly changing reality. For example, agile frameworks (like scrum) increase awareness with ceremonies like the daily standup and the sprint review. If the scrum team becomes aware of a new reality, the framework allows and encourages them to adjust course if necessary.
|
||||
|
||||
For teams to make these types of decisions, they need to be self-organizing in a high-trust environment. High-performing agile teams working this way achieve a fast flow of value while continuously adjusting course, removing the waste of going in the wrong direction.
|
||||
|
||||
### Optimal batch size
|
||||
|
||||
To understand the power of DevOps in software development, it helps to understand the economics of batch size. Consider the following U-curve optimization illustration from Donald Reinertsen's _[Principles of Product Development Flow][8]:_
|
||||
|
||||
![U-curve optimization illustration of optimal batch size][9]
|
||||
|
||||
This can be explained with an analogy about grocery shopping. Suppose you need to buy some eggs and you live 30 minutes from the store. Buying one egg (far left on the illustration) at a time would mean a 30-minute trip each time. This is your _transaction cost_. The _holding cost_ might represent the eggs spoiling and taking up space in your refrigerator over time. The _total cost_ is the _transaction cost_ plus your _holding cost_. This U-curve explains why, for most people, buying a dozen eggs at a time is their _optimal batch size_. If you lived next door to the store, it'd cost you next to nothing to walk there, and you'd probably buy a smaller carton each time to save room in your refrigerator and enjoy fresher eggs.
|
||||
|
||||
This U-curve optimization illustration can shed some light on why productivity increases significantly in successful agile transformations. Consider the effect of agile transformation on decision making in an organization. In traditional hierarchical organizations, decision-making authority is centralized. This leads to larger decisions made less frequently by fewer people. An agile methodology will effectively reduce an organization's transaction cost for making decisions by decentralizing the decisions to where the awareness and information is the best known: across the high-trust, self-organizing agile teams.
|
||||
|
||||
The following animation shows how reducing transaction cost shifts the optimal batch size to the left. You can't understate the value to an organization in making faster decisions more frequently.
|
||||
|
||||
![U-curve optimization illustration][10]
|
||||
|
||||
### Where does DevOps fit in?
|
||||
|
||||
Automation is one of the things DevOps is most known for. The previous illustration shows the value of automation in great detail. Through automation, we reduce our transaction costs to nearly zero, essentially getting our testing and deployments for free. This lets us take advantage of smaller and smaller batch sizes of work. Smaller batches of work are easier to understand, commit to, test, review, and know when they are done. These smaller batch sizes also contain less variance and risk, making them easier to deploy and, if something goes wrong, to troubleshoot and recover from. With automation combined with a solid agile practice, we can get our feature development very close to single piece flow, providing value to customers quickly and continuously.
|
||||
|
||||
More traditionally, DevOps is understood as a way to knock down the walls of confusion between the dev and ops teams. In this model, development teams develop new features, while operations teams keep the system stable and running smoothly. Friction occurs because new features from development introduce change into the system, increasing the risk of an outage, which the operations team doesn't feel responsible for—but has to deal with anyway. DevOps is not just trying to get people working together, it's more about trying to make more frequent changes safely in a complex environment.
|
||||
|
||||
We can look to [Ron Westrum][11] for research about achieving safety in complex organizations. In researching why some organizations are safer than others, he found that an organization's culture is predictive of its safety. He identified three types of culture: Pathological, Bureaucratic, and Generative. He found that the Pathological culture was predictive of less safety and the Generative culture was predictive of more safety (e.g., far fewer plane crashes or accidental hospital deaths in his main areas of research).
|
||||
|
||||
![Three types of culture identified by Ron Westrum][12]
|
||||
|
||||
Effective DevOps teams achieve a Generative culture with lean and agile practices, showing that speed and safety are complementary, or two sides of the same coin. By reducing the optimal batch sizes of decisions and features to become very small, DevOps achieves a faster flow of information and value while removing waste and reducing risk.
|
||||
|
||||
In line with Westrum's research, change can happen easily with safety and reliability improving at the same time. When an agile DevOps team is trusted to make its own decisions, we get the tools and techniques DevOps is most known for today: automation and continuous delivery. Through this automation, transaction costs are reduced further than ever, and a near single piece lean flow is achieved, creating the potential for thousands of decisions and releases per day, as we've seen happen in high-performing DevOps organizations.
|
||||
|
||||
### Flow, feedback, learning
|
||||
|
||||
DevOps doesn't stop there. We've mainly been talking about DevOps achieving a revolutionary flow, but lean and agile practices are further amplified through similar efforts that achieve faster feedback loops and faster learning. In the [_DevOps Handbook_][13], the authors explain in detail how, beyond its fast flow, DevOps achieves telemetry across its entire value stream for fast and continuous feedback. Further, leveraging the [kaizen][14] bursts of lean and the [retrospectives][15] of scrum, high-performing DevOps teams will continuously drive learning and continuous improvement deep into the foundations of their organizations, achieving a lean manufacturing revolution in the software product development industry.
|
||||
|
||||
### Start with a DevOps assessment
|
||||
|
||||
The first step in leveraging DevOps is, either after much study or with the help of a DevOps consultant and coach, to conduct an assessment across a suite of dimensions consistently found in high-performing DevOps teams. The assessment should identify weak or non-existent team norms that need improvement. Evaluate the assessment's results to find quick wins—focus areas with high chances for success that will produce high-impact improvement. Quick wins are important for gaining the momentum needed to tackle more challenging areas. The teams should generate ideas that can be tried quickly and start to move the needle on the DevOps transformation.
|
||||
|
||||
After some time, the team should reassess on the same dimensions to measure improvements and identify new high-impact focus areas, again with fresh ideas from the team. A good coach will consult, train, mentor, and support as needed until the team owns its own continuous improvement and achieves near consistency on all dimensions by continually reassessing, experimenting, and learning.
|
||||
|
||||
In the [second part][16] of this article, we'll look at results from a DevOps survey in the Drupal community and see where the quick wins are most likely to be found.
|
||||
|
||||
* * *
|
||||
|
||||
_Rob_ _Bayliss and Kelly Albrecht will present[DevOps: Why, How, and What][17] and host a follow-up [Birds of a][18]_ [_Feather_][18] _[discussion][18] at [DrupalCon 2019][19] in Seattle, April 8-12._
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/devops-most-important-tech-strategy
|
||||
|
||||
作者:[Kelly AlbrechtWilly-Peter Schaub][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksalbrecht/users/brentaaronreed/users/wpschaub/users/wpschaub/users/ksalbrecht
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://opensource.com/resources/devops
|
||||
[3]: https://github.com/Netflix/chaosmonkey
|
||||
[4]: https://en.wikipedia.org/wiki/Burden_of_proof_(philosophy)#Proving_a_negative
|
||||
[5]: https://www.amazon.com/dp/B0048WQDIO/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
|
||||
[6]: https://youtu.be/5t6GhcvKB8o?t=54
|
||||
[7]: https://www.shmula.com/paper-airplane-game-pull-systems-push-systems/8280/
|
||||
[8]: https://www.amazon.com/dp/B00K7OWG7O/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
|
||||
[9]: https://opensource.com/sites/default/files/uploads/batch_size_optimal_650.gif (U-curve optimization illustration of optimal batch size)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/batch_size_650.gif (U-curve optimization illustration)
|
||||
[11]: https://en.wikipedia.org/wiki/Ron_Westrum
|
||||
[12]: https://opensource.com/sites/default/files/uploads/information_flow.png (Three types of culture identified by Ron Westrum)
|
||||
[13]: https://www.amazon.com/DevOps-Handbook-World-Class-Reliability-Organizations/dp/1942788002/ref=sr_1_3?keywords=DevOps+handbook&qid=1553197361&s=books&sr=1-3
|
||||
[14]: https://en.wikipedia.org/wiki/Kaizen
|
||||
[15]: https://www.scrum.org/resources/what-is-a-sprint-retrospective
|
||||
[16]: https://opensource.com/article/19/3/where-drupal-community-stands-devops-adoption
|
||||
[17]: https://events.drupal.org/seattle2019/sessions/devops-why-how-and-what
|
||||
[18]: https://events.drupal.org/seattle2019/bofs/devops-getting-started
|
||||
[19]: https://events.drupal.org/seattle2019
|
||||
@ -0,0 +1,115 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Continuous response: The essential process we're ignoring in DevOps)
|
||||
[#]: via: (https://opensource.com/article/19/3/continuous-response-devops)
|
||||
[#]: author: (Randy Bias https://opensource.com/users/randybias)
|
||||
|
||||
Continuous response: The essential process we're ignoring in DevOps
|
||||
======
|
||||
You probably practice CI and CD, but if you aren't thinking about
|
||||
continuous response, you aren't really doing DevOps.
|
||||
![CICD with gears][1]
|
||||
|
||||
Continuous response (CR) is an overlooked link in the DevOps process chain. The two other major links—[continuous integration (CI) and continuous delivery (CD)][2]—are well understood, but CR is not. Yet, CR is the essential element of follow-through required to make customers happy and fulfill the promise of greater speed and agility. At the heart of the DevOps movement is the need for greater velocity and agility to bring businesses into our new digital age. CR plays a pivotal role in enabling this.
|
||||
|
||||
### Defining CR
|
||||
|
||||
We need a crisp definition of CR to move forward with breaking it down. To put it into context, let's revisit the definitions of continuous integration (CI) and continuous delivery (CD). Here are Gartner's definitions when I wrote this them down in 2017:
|
||||
|
||||
> [Continuous integration][3] is the practice of integrating, building, testing, and delivering functional software on a scheduled, repeatable, and automated basis.
|
||||
>
|
||||
> Continuous delivery is a software engineering approach where teams keep producing valuable software in short cycles while ensuring that the software can be reliably released at any time.
|
||||
|
||||
I propose the following definition for CR:
|
||||
|
||||
> Continuous response is a practice where developers and operators instrument, measure, observe, and manage their deployed software looking for changes in performance, resiliency, end-user behavior, and security posture and take corrective actions as necessary.
|
||||
|
||||
We can argue about whether these definitions are 100% correct. They are good enough for our purposes, which is framing the definition of CR in rough context so we can understand it is really just the last link in the chain of a holistic cycle.
|
||||
|
||||
![The holistic DevOps cycle][4]
|
||||
|
||||
What is this multi-colored ring, you ask? It's the famous [OODA Loop][5]. Before continuing, let's touch on what the OODA Loop is and why it's relevant to DevOps. We'll keep it brief though, as there is already a long history between the OODA Loop and DevOps.
|
||||
|
||||
#### A brief aside: The OODA Loop
|
||||
|
||||
At the heart of core DevOps thinking is using the OODA Loop to create a proactive process for evolving and responding to changing environments. A quick [web search][6] makes it easy to learn the long history between the OODA Loop and DevOps, but if you want the deep dive, I highly recommend [The Tao of Boyd: How to Master the OODA Loop][7].
|
||||
|
||||
Here is the "evolved OODA Loop" presented by John Boyd:
|
||||
|
||||
![OODA Loop][8]
|
||||
|
||||
The most important thing to understand about the OODA Loop is that it's a cognitive process for adapting to and handling changing circumstances.
|
||||
|
||||
The second most important thing to understand about the OODA Loop is, since it is a thought process that is meant to evolve, it depends on driving feedback back into the earlier parts of the cycle as you iterate.
|
||||
|
||||
As you can see in the diagram above, CI, CD, and CR are all their own isolated OODA Loops within the overall DevOps OODA Loop. The key here is that each OODA Loop is an evolving thought process for how test, release, and success are measured. Simply put, those who can execute on the OODA Loop fastest will win.
|
||||
|
||||
Put differently, DevOps wants to drive speed (executing the OODA Loop faster) combined with agility (taking feedback and using it to constantly adjust the OODA Loop). This is why CR is a vital piece of the DevOps process. We must drive production feedback into the DevOps maturation process. The DevOps notion of Culture, Automation, Measurement, and Sharing ([CAMS][9]) partially but inadequately captures this, whereas CR provides a much cleaner continuation of CI/CD in my mind.
|
||||
|
||||
### Breaking CR down
|
||||
|
||||
CR has more depth and breadth than CI or CD. This is natural, given that what we're categorizing is the post-deployment process by which our software is taking a variety of actions from autonomic responses to analytics of customer experience. I think, when it's broken down, there are three key buckets that CR components fall into. Each of these three areas forms a complete OODA Loop; however, the level of automation throughout the OODA Loop varies significantly.
|
||||
|
||||
The following table will help clarify the three areas of CR:
|
||||
|
||||
CR Type | Purpose | Examples
|
||||
---|---|---
|
||||
Real-time | Autonomics for availability and resiliency | Auto-scaling, auto-healing, developer-in-the-loop automated responses to real-time failures, automated root-cause analysis
|
||||
Analytic | Feature/fix pipeline | A/B testing, service response times, customer interaction models
|
||||
Predictive | History-based planning | Capacity planning, hardware failure prediction models, cost-basis analysis
|
||||
|
||||
_Real-time CR_ is probably the best understood of the three. This kind of CR is where our software has been instrumented for known issues and can take an immediate, automated response (autonomics). Examples of known issues include responding to high or low demand (e.g., elastic auto-scaling), responding to expected infrastructure resource failures (e.g., auto-healing), and responding to expected distributed application failures (e.g., circuit breaker pattern). In the future, we will see machine learning (ML) and similar technologies applied to automated root-cause analysis and event correlation, which will then provide a path towards "no ops" or "zero ops" operational models.
|
||||
|
||||
_Analytic CR_ is still the most manual of the CR processes. This kind of CR is focused primarily on observing end-user experience and providing feedback to the product development cycle to add features or fix existing functionality. Examples of this include traditional A/B website testing, measuring page-load times or service-response times, post-mortems of service failures, and so on.
|
||||
|
||||
_Predictive CR_ , due to the resurgence of AI and ML, is one of the innovation areas in CR. It uses historical data to predict future needs. ML techniques are allowing this area to become more fully automated. Examples include automated and predictive capacity planning (primarily for the infrastructure layer), automated cost-basis analysis of service delivery, and real-time reallocation of infrastructure resources to resolve capacity and hardware failure issues before they impact the end-user experience.
|
||||
|
||||
### Diving deeper on CR
|
||||
|
||||
CR, like CI or CD, is a DevOps process supported by a set of underlying tools. CI and CD are not Jenkins, unit tests, or automated deployments alone. They are a process flow. Similarly, CR is a process flow that begins with the delivery of new code via CD, which open source tools like [Spinnaker][10] give us. CR is not monitoring, machine learning, or auto-scaling, but a diverse set of processes that occur after code deployment, supported by a variety of tools. CR is also different in two specific ways.
|
||||
|
||||
First, it is different because, by its nature, it is broader. The general software development lifecycle (SDLC) process means that most [CI/CD processes][11] are similar. However, code running in production differs from app to app or service to service. This means that CR differs as well.
|
||||
|
||||
Second, CR is different because it is nascent. Like CI and CD before it, the process and tools existed before they had a name. Over time, CI/CD became more normalized and easier to scope. CR is new, hence there is lots of room to discuss what's in or out. I welcome your comments in this regard and hope you will run with these ideas.
|
||||
|
||||
### CR: Closing the loop on DevOps
|
||||
|
||||
DevOps arose because of the need for greater service delivery velocity and agility. Essentially, DevOps is an extension of agile software development practices to an operational mindset. It's a direct response to the flexibility and automation possibilities that cloud computing affords. However, much of the thinking on DevOps to date has focused on deploying the code to production and ends there. But our jobs don't end there. As professionals, we must also make certain our code is behaving as expected, we are learning as it runs in production, and we are taking that learning back into the product development process.
|
||||
|
||||
This is where CR lives and breathes. DevOps without CR is the same as saying there is no OODA Loop around the DevOps process itself. It's like saying that operators' and developers' jobs end with the code being deployed. We all know this isn't true. Customer experience is the ultimate measurement of our success. Can people use the software or service without hiccups or undue friction? If not, we need to fix it. CR is the final link in the DevOps chain that enables delivering the truest customer experience.
|
||||
|
||||
If you aren't thinking about continuous response, you aren't doing DevOps. Share your thoughts on CR, and tell me what you think about the concept and the definition.
|
||||
|
||||
* * *
|
||||
|
||||
_This article is based on[The Essential DevOps Process We're Ignoring: Continuous Response][12], which originally appeared on the Cloudscaling blog under a [CC BY 4.0][13] license and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/continuous-response-devops
|
||||
|
||||
作者:[Randy Bias][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/randybias
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
|
||||
[2]: https://opensource.com/article/18/8/what-cicd
|
||||
[3]: https://www.gartner.com/doc/3187420/guidance-framework-continuous-integration-continuous
|
||||
[4]: https://opensource.com/sites/default/files/uploads/holistic-devops-cycle-smaller.jpeg (The holistic DevOps cycle)
|
||||
[5]: https://en.wikipedia.org/wiki/OODA_loop
|
||||
[6]: https://www.google.com/search?q=site%3Ablog.b3k.us+ooda+loop&rlz=1C5CHFA_enUS730US730&oq=site%3Ablog.b3k.us+ooda+loop&aqs=chrome..69i57j69i58.8660j0j4&sourceid=chrome&ie=UTF-8#q=devops+ooda+loop&*
|
||||
[7]: http://www.artofmanliness.com/2014/09/15/ooda-loop/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/ooda-loop-2-1.jpg (OODA Loop)
|
||||
[9]: https://itrevolution.com/devops-culture-part-1/
|
||||
[10]: https://www.spinnaker.io
|
||||
[11]: https://opensource.com/article/18/12/cicd-tools-sysadmins
|
||||
[12]: http://cloudscaling.com/blog/devops/the-essential-devops-process-were-ignoring-continuous-response/
|
||||
[13]: https://creativecommons.org/licenses/by/4.0/
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why do organizations have open secrets?)
|
||||
[#]: via: (https://opensource.com/open-organization/19/3/open-secrets-bystander-effect)
|
||||
[#]: author: (Laura Hilliger https://opensource.com/users/laurahilliger/users/maryjo)
|
||||
|
||||
Why do organizations have open secrets?
|
||||
======
|
||||
Everyone sees something, but no one says anything—that's the bystander
|
||||
effect. And it's damaging your organizational culture.
|
||||
![][1]
|
||||
|
||||
[The five characteristics of an open organization][2] must work together to ensure healthy and happy communities inside our organizations. Even the most transparent teams, departments, and organizations require equal doses of additional open principles—like inclusivity and collaboration—to avoid dysfunction.
|
||||
|
||||
The "open secrets" phenomenon illustrates the limitations of transparency when unaccompanied by additional open values. [A recent article in Harvard Business Review][3] explored the way certain organizational issues—widely apparent but seemingly impossible to solve—lead to discomfort in the workforce. Authors Insiya Hussain and Subra Tangirala performed a number of studies, and found that the more people in an organization who knew about a particular "secret," be it a software bug or a personnel issue, the less likely any one person would be to report the issue or otherwise _do_ something about it.
|
||||
|
||||
Hussain and Tangirala explain that so-called "open secrets" are the result of a [bystander effect][4], which comes into play when people think, "Well, if _everyone_ knows, surely _I_ don't need to be the one to point it out." The authors mention several causes of this behavior, but let's take a closer look at why open secrets might be circulating in your organization—with an eye on what an open leader might do to [create a safe space for whistleblowing][5].
|
||||
|
||||
### 1\. Fear
|
||||
|
||||
People don't want to complain about a known problem only to have their complaint be the one that initiates the quality assurance, integrity, or redress process. What if new information emerges that makes their report irrelevant? What if they are simply _wrong_?
|
||||
|
||||
At the root of all bystander behavior is fear—fear of repercussions, fear of losing reputation or face, or fear that the very thing you've stood up against turns out to be a non-issue for everyone else. Going on record as "the one who reported" carries with it a reputational risk that is very intimidating.
|
||||
|
||||
The first step to ensuring that your colleagues report malicious behavior, code, or _whatever_ needs reporting is to create a fear-free workplace. We're inundated with the idea that making a mistake is bad or wrong. We're taught that we have to "protect" our reputations. However, the qualities of a good and moral character are _always_ subjective.
|
||||
|
||||
_Tip for leaders_ : Reward courage and strength every time you see it, regardless of whether you deem it "necessary." For example, if in a meeting where everyone except one person agrees on something, spend time on that person's concerns. Be patient and kind in helping that person change their mind, and be open minded about that person being able to change yours. Brains work in different ways; never forget that one person might have a perspective that changes the lay of the land.
|
||||
|
||||
### 2\. Policies
|
||||
|
||||
Usually, complaint procedures and policies are designed to ensure fairness towards all parties involved in the complaint. Discouraging false reporting and ensuring such fairness in situations like these is certainly a good idea. But policies might actually deter people from standing up—because a victim might be discouraged from reporting an experience if the formal policy for reporting doesn't make them feel protected. Standing up to someone in a position of power and saying "Your behavior is horrid, and I'm not going to take it" isn't easy for anyone, but it's particularly difficult for marginalized groups.
|
||||
|
||||
The "open secrets" phenomenon illustrates the limitations of transparency when unaccompanied by additional open values.
|
||||
|
||||
To ensure fairness to all parties, we need to adjust for victims. As part of making the decision to file a report, a victim will be dealing with a variety of internal fears. They'll wonder what might happen to their self-worth if they're put in a situation where they have to talk to someone about their experience. They'll wonder if they'll be treated differently if they're the one who stands up, and how that will affect their future working environments and relationships. Especially in a situation involving an open secret, asking a victim to be strong is asking them to have to trust that numerous other people will back them up. This fear shouldn't be part of their workplace experience; it's just not fair.
|
||||
|
||||
Remember that if one feels responsible for a problem (e.g., "Crap, that's _my code_ that's bringing down the whole server!"), then that person might feel fear at pointing out the mistake. _The important thing is dealing with the situation, not finding someone to blame._ Policies that make people feel personally protected—no matter what the situation—are absolutely integral to ensuring the organization deals with open secrets.
|
||||
|
||||
_Tip for leaders_ : Make sure your team's or organization's policy regarding complaints makes anonymous reporting possible. Asking a victim to "go on record" puts them in the position of having to defend their perspective. If they feel they're the victim of harassment, they're feeling as if they are harassed _and_ being asked to defend their experience. This means they're doing double the work of the perpetrator, who only has to defend themselves.
|
||||
|
||||
### 3\. Marginalization
|
||||
|
||||
Women, LGBTQ people, racial minorities, people with physical disabilities, people who are neuro-atypical, and other marginalized groups often find themselves in positions that them feel routinely dismissed, disempowered, disrespected—and generally dissed. These feelings are valid (and shouldn't be too surprising to anyone who has spent some time looking at issues of diversity and inclusion). Our emotional safety matters, and we tend to be quite protective of it—even if it means letting open secrets go unaddressed.
|
||||
|
||||
Marginalized groups have enough worries weighing on them, even when they're _not_ running the risk of damaging their relationships with others at work. Being seen and respected in both an organization and society more broadly is difficult enough _without_ drawing potentially negative attention.
|
||||
|
||||
Policies that make people feel personally protected—no matter what the situation—are absolutely integral to ensuring the organization deals with open secrets.
|
||||
|
||||
Luckily, in recent years attitudes towards marginalized groups have become visible, and we as a society have begun to talk about our experiences as "outliers." We've also come to realize that marginalized groups aren't actually "outliers" at all; we can thank the colorful, beautiful internet for that.
|
||||
|
||||
_Tip for leaders_ : Diversity and inclusion plays a role in dispelling open secrets. Make sure your diversity and inclusion practices and policies truly encourage a diverse workplace.
|
||||
|
||||
### Model the behavior
|
||||
|
||||
The best way to create a safe workplace and give people the ability to call attention to pervasive problems found within it is to _model the behaviors that you want other people to display_. Dysfunction occurs in cultures that don't pay attention to and value the principles upon which they are built. In order to discourage bystander behavior, transparent, inclusive, adaptable and collaborative communities must create policies that support calling attention to open secrets and then empathetically dealing with whatever the issue may be.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/3/open-secrets-bystander-effect
|
||||
|
||||
作者:[Laura Hilliger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/laurahilliger/users/maryjo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_secret_ingredient_520x292.png?itok=QbKzJq-N
|
||||
[2]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
[3]: https://hbr.org/2019/01/why-open-secrets-exist-in-organizations
|
||||
[4]: https://www.psychologytoday.com/us/basics/bystander-effect
|
||||
[5]: https://opensource.com/open-organization/19/2/open-leaders-whistleblowers
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How Kubeflow is evolving without ksonnet)
|
||||
[#]: via: (https://opensource.com/article/19/4/kubeflow-evolution)
|
||||
[#]: author: (Jonathan Gershater (Red Hat) https://opensource.com/users/jgershat/users/jgershat)
|
||||
|
||||
How Kubeflow is evolving without ksonnet
|
||||
======
|
||||
There are big differences in how open source communities handle change compared to closed source vendors.
|
||||
![Chat bubbles][1]
|
||||
|
||||
Many software projects depend on modules that are run as separate open source projects. When one of those modules loses support (as is inevitable), the community around the main project must determine how to proceed.
|
||||
|
||||
This situation is happening right now in the [Kubeflow][2] community. Kubeflow is an evolving open source platform for developing, orchestrating, deploying, and running scalable and portable machine learning workloads on [Kubernetes][3]. Recently, the primary supporter of the Kubeflow component [ksonnet][4] announced that it would [no longer support][5] the software.
|
||||
|
||||
When a piece of software loses support, the decision-making process (and the outcome) differs greatly depending on whether the software is open source or closed source.
|
||||
|
||||
### A cellphone analogy
|
||||
|
||||
To illustrate the differences in how an open source community and a closed source/single software vendor proceed when a component loses support, let's use an example from hardware design.
|
||||
|
||||
Suppose you buy cellphone Model A and it stops working. When you try to get it repaired, you discover the manufacturer is out of business and no longer offering support. Since the cellphone's design is proprietary and closed, no other manufacturers can support it.
|
||||
|
||||
Now, suppose you buy cellphone Model B, it stops working, and its manufacturer is also out of business and no longer offering support. However, Model B's design is open, and another company is in business manufacturing, repairing and upgrading Model B cellphones.
|
||||
|
||||
This illustrates one difference between software written using closed and open source principles. If the vendor of a closed source software solution goes out of business, support disappears with the vendor, unless the vendor sells the software's design and intellectual property. But, if the vendor of an open source solution goes out of business, there is no intellectual property to sell. By the principles of open source, the source code is available for anyone to use and modify, under license, so another vendor can continue to maintain the software.
|
||||
|
||||
### How Kubeflow is evolving without ksonnet
|
||||
|
||||
The ramification of ksonnet's backers' decision to cease development illustrates Kubeflow's open and collaborative design process. Kubeflow's designers have several options, such as replacing ksonnet, adopting and developing ksonnet, etc. Because Kubeflow is an open source project, all options are discussed in the open on the Kubeflow mailing list. Some of the community's suggestions include:
|
||||
|
||||
> * Should we look at projects that are CNCF/Apache projects e.g. [helm][6]
|
||||
> * I would opt for back to the basics. KISS. How about plain old jsonnet + kubectl + makefile/scripts ? Thats how e.g. the coreos [prometheus operator][7] does it. It would also lower the entry barrier (no new tooling) and let vendors of k8s (gke, openshift, etc) easily build on top of that.
|
||||
> * I vote for using a simple, _programmatic_ context, be it manual jsonnet + kubectl, or simple Python scripts + Python K8s client, or any tool be can build on top of these.
|
||||
>
|
||||
|
||||
|
||||
The members of the mailing list are discussing and debating alternatives to ksonnet and will arrive at a decision to continue development. What I love about the open source way of adapting is that it's done communally. Unlike closed source software, which is often designed by one vendor, the organizations that are members of an open source project can collaboratively steer the project in the direction they best see fit. As Kubeflow evolves, it will benefit from an open, collaborative decision-making framework.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/kubeflow-evolution
|
||||
|
||||
作者:[Jonathan Gershater (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jgershat/users/jgershat
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_communication_team.png?itok=CYfZ_gE7 (Chat bubbles)
|
||||
[2]: https://www.kubeflow.org/
|
||||
[3]: https://github.com/kubernetes
|
||||
[4]: https://ksonnet.io/
|
||||
[5]: https://blogs.vmware.com/cloudnative/2019/02/05/welcoming-heptio-open-source-projects-to-vmware/
|
||||
[6]: https://landscape.cncf.io
|
||||
[7]: https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Making computer science curricula as adaptable as our code)
|
||||
[#]: via: (https://opensource.com/open-organization/19/4/adaptable-curricula-computer-science)
|
||||
[#]: author: (Amarachi Achonu https://opensource.com/users/amarach1/users/johnsontanner3)
|
||||
|
||||
Making computer science curricula as adaptable as our code
|
||||
======
|
||||
No two computer science students are alike—so teachers need curricula
|
||||
that are open and adaptable.
|
||||
![][1]
|
||||
|
||||
Educators in elementary computer science face a lack of adaptable curricula. Calls for more modifiable, non-rigid curricula are therefore enticing—assuming that such curricula could benefit teachers by increasing their ability to mold resources for individual classrooms and, ultimately, produce better teaching experiences and learning outcomes.
|
||||
|
||||
Our team at [CSbyUs][2] noticed this scarcity, and we've created an open source web platform to facilitate more flexible, adaptable, and tested curricula for computer science educators. The mission of the CSbyUs team has always been utilizing open source technology to improve pedagogy in computer science, which includes increasing support for teachers. Therefore, this project primarily seeks to use open source principles—and the benefits inherent in them—to expand the possibilities of modern curriculum-making and support teachers by increasing access to more adaptable curricula.
|
||||
|
||||
### Rigid, monotonous, mundane
|
||||
|
||||
Why is the lack of adaptable curricula a problem for computer science education? Rigid curricula dominates most classrooms today, primarily through monotonous and routinely distributed lesson plans. Many of these plans are developed without the capacity for dynamic use and application to different classroom atmospheres. In contrast, an _adaptable_ curriculum is one that would _account_ for dynamic and changing classroom environments.
|
||||
|
||||
An adaptable curriculum means freedom and more options for educators. This is especially important in elementary-level classrooms, where instructors are introducing students to computer science for the first time, and in classrooms with higher populations of groups typically underrepresented in the field of computer science. Here especially, it's advantageous for instructors to have access to curricula that explicitly consider diverse classroom landscapes and grants the freedom necessary to adapt to specific student populations.
|
||||
|
||||
### Making it adaptable
|
||||
|
||||
This kind of adaptability is certainly at work at CSbyUs. Hayley Barton—a member of both the organization's curriculum-making team and its teaching team, and a senior at Duke University majoring in Economics and minoring in Computer Science and Spanish—recently demonstrated the benefits of adaptable curricula during an engagement in the field. Reflecting on her teaching experiences, Barton describes a major reason why curriculum adaptation is necessary in computer science classrooms. "We are seeing the range of students that we work with," she says, "and trying to make the curriculum something that can be tailored to different students."
|
||||
|
||||
An adaptable curriculum means freedom and more options for educators.
|
||||
|
||||
A more adaptable curriculum is necessary for truly challenging students, Barton continues.
|
||||
|
||||
The need for change became most evident to Barton when working students to make their own preliminary apps. Barton collaborated with students who appeared to be at different levels of focus and attention. On the one hand, a group of more advanced students took well to the style of a demonstrative curriculum and remained attentive and engaged to the task. On the other hand, another group of students seemed to have more trouble focusing in the classroom or even being motivated to engage with topics of computer science skills. Witnessing this difference among students, it became important that curriculum would need to be adaptable in multiple ways to be able to engage more students at their level.
|
||||
|
||||
"We want to challenge every student without making it too challenging for any individual student," Barton says. "Thinking about those things definitely feeds into how I'm thinking about the curriculum in terms of making it accessible for all the students."
|
||||
|
||||
As a curriculum-maker, she subsequently uses experiences like this to make changes to the original curriculum.
|
||||
|
||||
"If those other students have one-on-one time themselves, they could be doing even more amazing things with their apps," says Barton.
|
||||
|
||||
Taking this advice, Barton would potentially incorporate into the curriculum more emphasis on cultivating students' sense of ownership in computer science, since this is important to their focus and productivity. For this, students may be afforded that sense of one-on-one time. The result will affect the next round of teachers who use the curriculum.
|
||||
|
||||
For these changes to be effective, the onus is on teachers to notice the dynamics of the classroom. In the future, curriculum adaptation may depend on paying particular attention to and identifying these subtle differences of style of curriculum. Identifying and commenting about these subtleties allows the possibility of applying a different strategy, and these are the changes that are applied to the curriculum.
|
||||
|
||||
Curriculum adaptation should be iterative, as it involves learning from experience, returning to the drawing board, making changes, and finally, utilizing the curriculum again.
|
||||
|
||||
"We've gone through a lot of stages of development," Barton says. "The goal is to have this kind of back and forth, where the curriculum is something that's been tested, where we've used our feedback, and also used other research that we've done, to make it something that's actually impactful."
|
||||
|
||||
Hayley's "back and forth" process is an iterative process of curriculum-making. Between utilizing curricula and modifying curricula, instructors like Hayley can take a once-rigid curriculum and mold it to any degree that the user sees fit—again and again. This iterative process depends on tests performed first in the classroom, and it depends on the teacher's rationale and reflection on how curricula uniquely pans out for them.
|
||||
|
||||
Adaptability of curriculum is the most important principle on which the CSbyUs platform is built. Much like Hayley's process of curriculum-making, curriculum adaptation should be _iterative_ , as it involves learning from experience, returning to the drawing board, making changes, and finally, utilizing the curriculum again. Once launched, the CSbyUS website will document this iterative process.
|
||||
|
||||
The open-focused pedagogy behind the CSByUs platform, then, brings to life the flexibility inherent in the process of curriculum adaptation. First, it invites and collects the valuable first-hand perspectives of real educators working with real curricula to produce real learning. Next, it capitalizes on an iterative processes of development—one familiar to open source programmers—to enable modifications to curriculum (and the documentation of those modifications). Finally, it transforms the way teachers encounter curricula by helping them make selections from different versions of both modified curriculum and "the original." Our platform's open source strategy is crucial to cultivating a hub of flexible curricula for educators.
|
||||
|
||||
Open source practices can be a key difference in making rigid curricula more moldable for educators. Furthermore, since this approach effectively melds open source technologies with open-focused pedagogy, open pedagogy can potentially provide flexibility for educators teaching various curriculum across disciplines.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/4/adaptable-curricula-computer-science
|
||||
|
||||
作者:[Amarachi Achonu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/amarach1/users/johnsontanner3
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003588_01_rd3os.combacktoschoolserieshe_rh_051x_0.png?itok=gIzbmxuI
|
||||
[2]: https://csbyus.herokuapp.com/
|
||||
@ -1,3 +1,4 @@
|
||||
Moelf translating
|
||||
Myths about /dev/urandom
|
||||
======
|
||||
|
||||
|
||||
@ -1,101 +0,0 @@
|
||||
tomjlw is translating
|
||||
Rediscovering make: the power behind rules
|
||||
======
|
||||
|
||||

|
||||
|
||||
I used to think makefiles were just a convenient way to list groups of shell commands; over time I've learned how powerful, flexible, and full-featured they are. This post brings to light over some of those features related to rules.
|
||||
|
||||
### Rules
|
||||
|
||||
Rules are instructions that indicate `make` how and when a file called the target should be built. The target can depend on other files called prerequisites.
|
||||
|
||||
You instruct `make` how to build the target in the recipe, which is no more than a set of shell commands to be executed, one at a time, in the order they appear. The syntax looks like this:
|
||||
```
|
||||
target_name : prerequisites
|
||||
recipe
|
||||
```
|
||||
|
||||
Once you have defined a rule, you can build the target from the command line by executing:
|
||||
```
|
||||
$ make target_name
|
||||
```
|
||||
|
||||
Once the target is built, `make` is smart enough to not run the recipe ever again unless at least one of the prerequisites has changed.
|
||||
|
||||
### More on prerequisites
|
||||
|
||||
Prerequisites indicate two things:
|
||||
|
||||
* When the target should be built: if a prerequisite is newer than the target, `make` assumes that the target should be built.
|
||||
* An order of execution: since prerequisites can, in turn, be built by another rule on the makefile, they also implicitly set an order on which rules are executed.
|
||||
|
||||
|
||||
|
||||
If you want to define an order, but you don't want to rebuild the target if the prerequisite changes, you can use a special kind of prerequisite called order only, which can be placed after the normal prerequisites, separated by a pipe (`|`)
|
||||
|
||||
### Patterns
|
||||
|
||||
For convenience, `make` accepts patterns for targets and prerequisites. A pattern is defined by including the `%` character, a wildcard that matches any number of literal characters or an empty string. Here are some examples:
|
||||
|
||||
* `%`: match any file
|
||||
* `%.md`: match all files with the `.md` extension
|
||||
* `prefix%.go`: match all files that start with `prefix` that have the `.go` extension
|
||||
|
||||
|
||||
|
||||
### Special targets
|
||||
|
||||
There's a set of target names that have special meaning for `make` called special targets.
|
||||
|
||||
You can find the full list of special targets in the [documentation][1]. As a rule of thumb, special targets start with a dot followed by uppercase letters.
|
||||
|
||||
Here are a few useful ones:
|
||||
|
||||
**.PHONY** : Indicates `make` that the prerequisites of this target are considered to be phony targets, which means that `make` will always run it's recipe regardless of whether a file with that name exists or what its last-modification time is.
|
||||
|
||||
**.DEFAULT** : Used for any target for which no rules are found.
|
||||
|
||||
**.IGNORE** : If you specify prerequisites for `.IGNORE`, `make` will ignore errors in execution of their recipes.
|
||||
|
||||
### Substitutions
|
||||
|
||||
Substitutions are useful when you need to modify the value of a variable with alterations that you specify.
|
||||
|
||||
A substitution has the form `$(var:a=b)` and its meaning is to take the value of the variable `var`, replace every `a` at the end of a word with `b` in that value, and substitute the resulting string. For example:
|
||||
```
|
||||
foo := a.o
|
||||
bar : = $(foo:.o=.c) # sets bar to a.c
|
||||
```
|
||||
|
||||
note: special thanks to [Luis Lavena][2] for letting me know about the existence of substitutions.
|
||||
|
||||
### Archive Files
|
||||
|
||||
Archive files are used to collect multiple data files together into a single file (same concept as a zip file), they are built with the `ar` Unix utility. `ar` can be used to create archives for any purpose, but has been largely replaced by `tar` for any other purposes than [static libraries][3].
|
||||
|
||||
In `make`, you can use an individual member of an archive file as a target or prerequisite as follows:
|
||||
```
|
||||
archive(member) : prerequisite
|
||||
recipe
|
||||
```
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
There's a lot more to discover about make, but at least this counts as a start, I strongly encourage you to check the [documentation][4], create a dumb makefile, and just play with it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://monades.roperzh.com/rediscovering-make-power-behind-rules/
|
||||
|
||||
作者:[Roberto Dip][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://monades.roperzh.com
|
||||
[1]:https://www.gnu.org/software/make/manual/make.html#Special-Targets
|
||||
[2]:https://twitter.com/luislavena/
|
||||
[3]:http://tldp.org/HOWTO/Program-Library-HOWTO/static-libraries.html
|
||||
[4]:https://www.gnu.org/software/make/manual/make.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating by robsean
|
||||
|
||||
12 Best GTK Themes for Ubuntu and other Linux Distributions
|
||||
======
|
||||
**Brief: Let’s have a look at some of the beautiful GTK themes that you can use not only in Ubuntu but other Linux distributions that use GNOME.**
|
||||
|
||||
@ -1,137 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Oomox – Customize And Create Your Own GTK2, GTK3 Themes)
|
||||
[#]: via: (https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/)
|
||||
[#]: author: (EDITOR https://www.ostechnix.com/author/editor/)
|
||||
|
||||
Oomox – Customize And Create Your Own GTK2, GTK3 Themes
|
||||
======
|
||||
|
||||

|
||||
|
||||
Theming and Visual customization is one of the main advantages of Linux. Since all the code is open, you can change how your Linux system looks and behaves to a greater degree than you ever could with Windows/Mac OS. GTK theming is perhaps the most popular way in which people customize their Linux desktops. The GTK toolkit is used by a wide variety of desktop environments like Gnome, Cinnamon, Unity, XFCE, and budgie. This means that a single theme made for GTK can be applied to any of these Desktop Environments with little changes.
|
||||
|
||||
There are a lot of very high quality popular GTK themes out there, such as **Arc** , **Numix** , and **Adapta**. But if you want to customize these themes and create your own visual design, you can use **Oomox**.
|
||||
|
||||
The Oomox is a graphical app for customizing and creating your own GTK theme complete with your own color, icon and terminal style. It comes with several presets, which you can apply on a Numix, Arc, or Materia style theme to create your own GTK theme.
|
||||
|
||||
### Installing Oomox
|
||||
|
||||
On Arch Linux and its variants:
|
||||
|
||||
Oomox is available on [**AUR**][1], so you can install it using any AUR helper programs like [**Yay**][2].
|
||||
|
||||
```
|
||||
$ yay -S oomox
|
||||
|
||||
```
|
||||
|
||||
On Debian/Ubuntu/Linux Mint, download `oomox.deb`package from [**here**][3] and install it as shown below. As of writing this guide, the latest version was **oomox_1.7.0.5.deb**.
|
||||
|
||||
```
|
||||
$ sudo dpkg -i oomox_1.7.0.5.deb
|
||||
$ sudo apt install -f
|
||||
|
||||
```
|
||||
|
||||
On Fedora, Oomox is available in third-party **COPR** repository.
|
||||
|
||||
```
|
||||
$ sudo dnf copr enable tcg/themes
|
||||
$ sudo dnf install oomox
|
||||
|
||||
```
|
||||
|
||||
Oomox is also available as a [**Flatpak app**][4]. Make sure you have installed Flatpak as described in [**this guide**][5]. And then, install and run Oomox using the following commands:
|
||||
|
||||
```
|
||||
$ flatpak install flathub com.github.themix_project.Oomox
|
||||
|
||||
$ flatpak run com.github.themix_project.Oomox
|
||||
|
||||
```
|
||||
|
||||
For other Linux distributions, go to the Oomox project page (Link is given at the end of this guide) on Github and compile and install it manually from source.
|
||||
|
||||
### Customize And Create Your Own GTK2, GTK3 Themes
|
||||
|
||||
**Theme Customization**
|
||||
|
||||
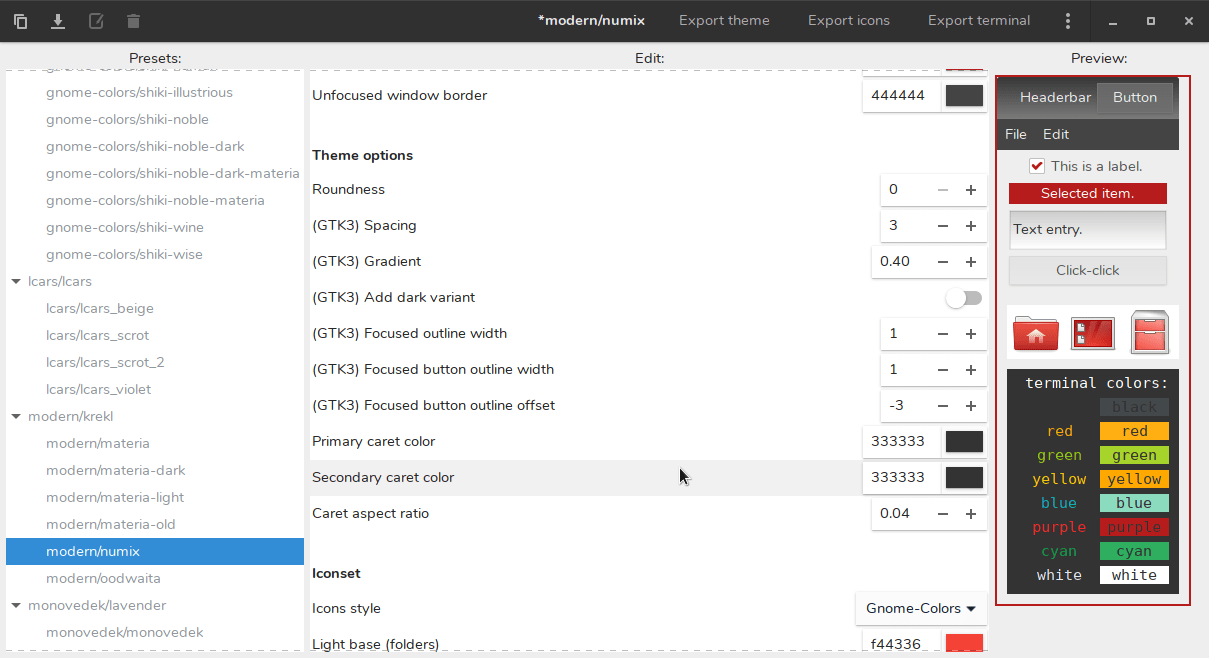
|
||||
|
||||
You can change the colour of practically every UI element, like:
|
||||
|
||||
1. Headers
|
||||
2. Buttons
|
||||
3. Buttons inside Headers
|
||||
4. Menus
|
||||
5. Selected Text
|
||||
|
||||
|
||||
|
||||
To the left, there are a number of presets, like the Cars theme, modern themes like Materia, and Numix, and retro themes. Then, at the top of the main window, there’s an option called **Theme Style** , that lets you set the overall visual style of the theme. You can choose from between Numix, Arc, and Materia.
|
||||
|
||||
With certain styles like Numix, you can even change things like the Header Gradient, Outline Width and Panel Opacity. You can also add a Dark Mode for your theme that will be automatically created from the default theme.
|
||||
|
||||
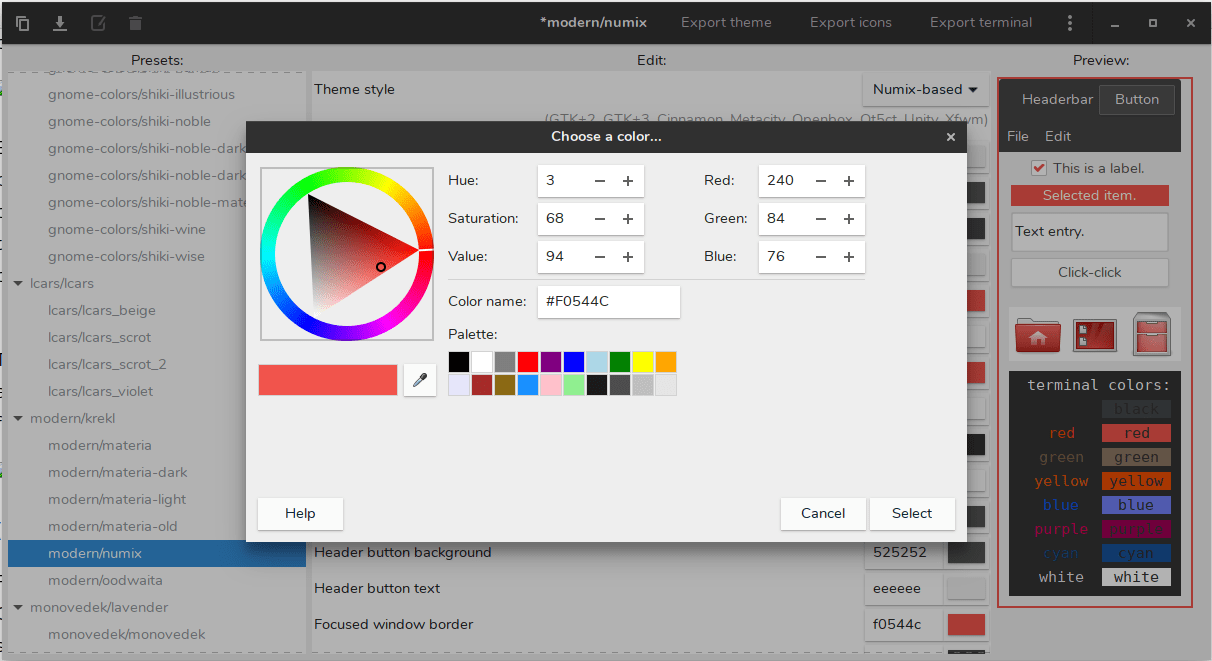
|
||||
|
||||
**Iconset Customization**
|
||||
|
||||
You can customize the iconset that will be used for the theme icons. There are 2 options – Gnome Colors and Archdroid. You an change the base, and stroke colours of the iconset.
|
||||
|
||||
**Terminal Customization**
|
||||
|
||||
You can also customize the terminal colours. The app has several presets for this, but you can customize the exact colour code for each colour value like red, green,black, and so on. You can also auto swap the foreground and background colours.
|
||||
|
||||
**Spotify Theme**
|
||||
|
||||
A unique feature this app has is that you can theme the spotify app to your liking. You can change the foreground, background, and accent color of the spotify app to match the overall GTK theme.
|
||||
|
||||
Then, just press the **Apply Spotify Theme** button, and you’ll get this window:
|
||||
|
||||
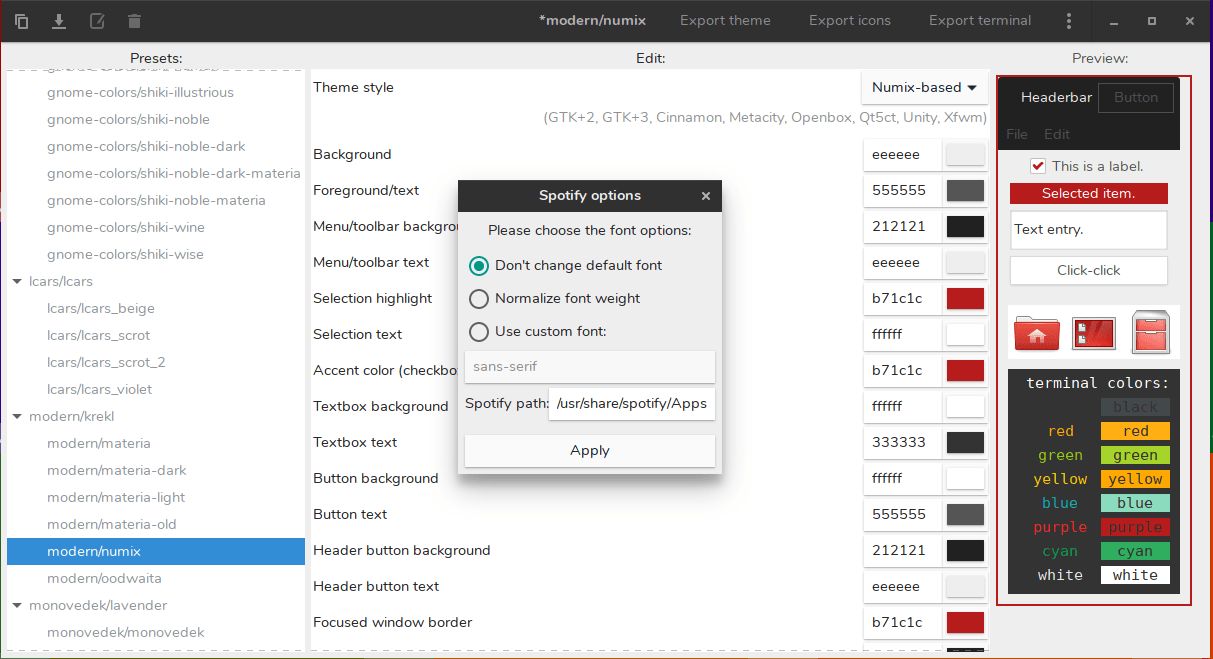
|
||||
|
||||
Just hit apply, and you’re done.
|
||||
|
||||
**Exporting your Theme**
|
||||
|
||||
Once you’re done customizing the theme to your liking, you can rename it by clicking the rename button at the top left:
|
||||
|
||||

|
||||
|
||||
And then, just hit **Export Theme** to export the theme to your system.
|
||||
|
||||
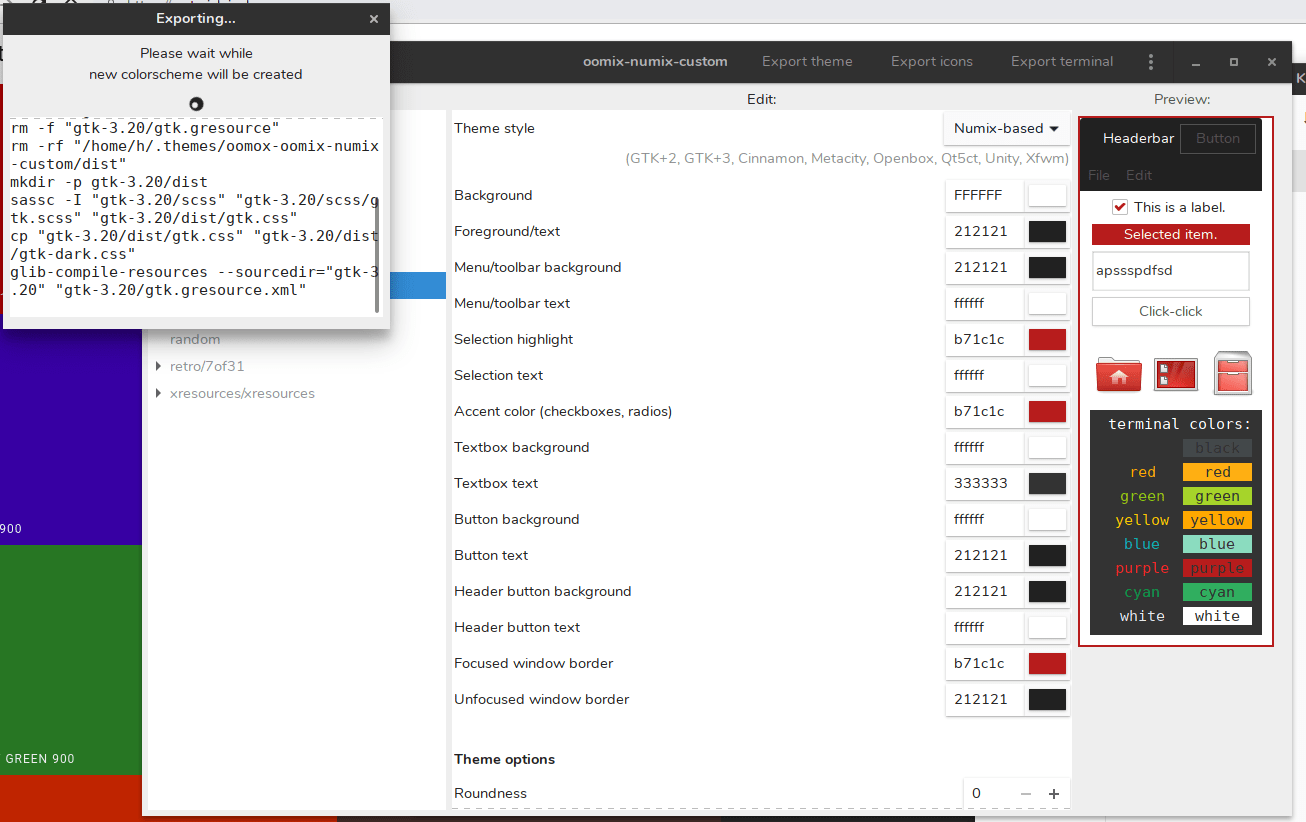
|
||||
|
||||
You can also just export just the Iconset or the terminal theme.
|
||||
|
||||
After this, you can open any Visual Customization app for your Desktop Environment, like Tweaks for Gnome based DEs, or the **XFCE Appearance Settings** , and select your exported GTK and Shell theme.
|
||||
|
||||
### Verdict
|
||||
|
||||
If you are a Linux theme junkie, and you know exactly how each button, how each header in your system should look like, Oomox is worth a look. For extreme customizers, it lets you change virtually everything about how your system looks. For people who just want to tweak an existing theme a little bit, it has many, many presets so you can get what you want without a lot of effort.
|
||||
|
||||
Have you tried it? What are your thoughts on Oomox? Put them in the comments below!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://aur.archlinux.org/packages/oomox/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[3]: https://github.com/themix-project/oomox/releases
|
||||
[4]: https://flathub.org/apps/details/com.github.themix_project.Oomox
|
||||
[5]: https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
@ -1,77 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 Best VPN Services For 2019)
|
||||
[#]: via: (https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/)
|
||||
[#]: author: (Editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
7 Best VPN Services For 2019
|
||||
======
|
||||
|
||||
At least 67 percent of global businesses in the past three years have faced data breaching. The breaching has been reported to expose hundreds of millions of customers. Studies show that an estimated 93 percent of these breaches would have been avoided had data security fundamentals been considered beforehand.
|
||||
|
||||
Understand that poor data security can be extremely costly, especially to a business and could quickly lead to widespread disruption and possible harm to your brand reputation. Although some businesses can pick up the pieces the hard way, there are still those that fail to recover. Today however, you are fortunate to have access to data and network security software.
|
||||
|
||||

|
||||
|
||||
As you start 2019, keep off cyber-attacks by investing in a **V** irtual **P** rivate **N** etwork commonly known as **VPN**. When it comes to online privacy and security, there are many uncertainties. There are hundreds of different VPN providers, and picking the right one means striking just the right balance between pricing, services, and ease of use.
|
||||
|
||||
If you are looking for a solid 100 percent tested and secure VPN, you might want to do your due diligence and identify the best match. Here are the top 7 Best tried and tested VPN services For 2019.
|
||||
|
||||
### 1. Vpnunlimitedapp
|
||||
|
||||
With VPN Unlimited, you have total security. This VPN allows you to use any WIFI without worrying that your personal data can be leaked. With AES-256, your data is encrypted and protected against prying third-parties and hackers. This VPN ensures you stay anonymous and untracked on all websites no matter the location. It offers a 7-day trial and a variety of protocol options: OpenVPN, IKEv2, and KeepSolid Wise. Demanding users are entitled to special extras such as a personal server, lifetime VPN subscription, and personal IP options.
|
||||
|
||||
### 2. VPN Lite
|
||||
|
||||
VPN Lite is an easy-to-use and **free VPN service** that allows you to browse the internet at no charges. You remain anonymous and your privacy is protected. It obscures your IP and encrypts your data meaning third parties are not able to track your activities on all online platforms. You also get to access all online content. With VPN Lite, you get to access blocked sites in your state. You can also gain access to public WIFI without the worry of having sensitive information tracked and hacked by spyware and hackers.
|
||||
|
||||
### 3. HotSpot Shield
|
||||
|
||||
Launched in 2005, this is a popular VPN embraced by the majority of users. The VPN protocol here is integrated by at least 70 percent of the largest security companies globally. It is also known to have thousands of servers across the globe. It comes with two free options. One is completely free but supported by online advertisements, and the second one is a 7-day trial which is the flagship product. It contains military grade data encryption and protects against malware. HotSpot Shield guaranteed secure browsing and offers lightning-fast speeds.
|
||||
|
||||
### 4. TunnelBear
|
||||
|
||||
This is the best way to start if you are new to VPNs. It comes to you with a user-friendly interface complete with animated bears. With the help of TunnelBear, users are able to connect to servers in at least 22 countries at great speeds. It uses **AES 256-bit encryption** guaranteeing no data logging meaning your data stays protected. You also get unlimited data for up to five devices.
|
||||
|
||||
### 5. ProtonVPN
|
||||
|
||||
This VPN offers you a strong premium service. You may suffer from reduced connection speeds, but you also get to enjoy its unlimited data. It features an intuitive interface easy to use, and comes with a multi-platform compatibility. Proton’s servers are said to be specifically optimized for torrenting and thus cannot give access to Netflix. You get strong security features such as protocols and encryptions meaning your browsing activities remain secure.
|
||||
|
||||
### 6. ExpressVPN
|
||||
|
||||
This is known as the best offshore VPN for unblocking and privacy. It has gained recognition for being the top VPN service globally resulting from solid customer support and fast speeds. It offers routers that come with browser extensions and custom firmware. ExpressVPN also has an admirable scope of quality apps, plenty of servers, and can only support up to three devices.
|
||||
|
||||
It’s not entirely free, and happens to be one of the most expensive VPNs on the market today because it is fully packed with the most advanced features. With it comes a 30-day money-back guarantee, meaning you can freely test this VPN for a month. Good thing is; it is completely risk-free. If you need a VPN for a short duration to bypass online censorship for instance, this could, be your go-to solution. You don’t want to give trials to a spammy, slow, free program.
|
||||
|
||||
It is also one of the best ways to enjoy online streaming as well as outdoor security. Should you need to continue using it, you only have to renew or cancel your free trial if need be. Express VPN has over 2000 servers across 90 countries, unblocks Netflix, gives lightning fast connections, and gives users total privacy.
|
||||
|
||||
### 7. PureVPN
|
||||
|
||||
While this VPN may not be completely free, it falls under the most budget-friendly services on this list. Users can sign up for a free seven days trial and later choose one of its paid plans. With this VPN, you get to access 750-plus servers in at least 140 countries. There is also access to easy installation on almost all devices. All its paid features can still be accessed within the free trial window. That includes unlimited data transfers, IP leakage protection, and ISP invisibility. The supproted operating systems are iOS, Android, Windows, Linux, and macOS.
|
||||
|
||||
### Summary
|
||||
|
||||
With the large variety of available freemium VPN services today, why not take that opportunity to protect yourself and your customers? Understand that there are some great VPN services. Even the most secure free service however, cannot be touted as risk free. You might want to upgrade to a premium one for increased protection. Premium VPN allows you to test freely offering risk-free money-back guarantee. Whether you plan to sign up for a paid VPN or commit to a free one, it is highly advisable to have a VPN.
|
||||
|
||||
**About the author:**
|
||||
|
||||
**Renetta K. Molina** is a tech enthusiast and fitness enthusiast. She writes about technology, apps, WordPress and a variety of other topics. In her free time, she likes to play golf and read books. She loves to learn and try new things.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/
|
||||
|
||||
作者:[Editor][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,188 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Check If A Port Is Open On Multiple Remote Linux System Using Shell Script With nc Command?)
|
||||
[#]: via: (https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Check If A Port Is Open On Multiple Remote Linux System Using Shell Script With nc Command?
|
||||
======
|
||||
|
||||
We had recently written an article to check if a port is open on the remote Linux server. It will help you to check for single server.
|
||||
|
||||
If you want to check for five servers then no issues, you can use any of the one following command such as nc (netcat), nmap and telnet.
|
||||
|
||||
If you would like to check for 50+ servers then what will be the solution?
|
||||
|
||||
It’s not easy to check all servers, if you do the same then there is no point and you will be wasting a lots of time unnecessarily.
|
||||
|
||||
To overcome this situation, i had coded a small shell script using nc command that will allow us to scan any number of servers with given port.
|
||||
|
||||
If you are looking for a single server scan then you have multiple options, to know more about it. Simply navigate to the following URL to **[Check Whether A Port Is Open On The Remote Linux System?][1]**
|
||||
|
||||
There are two scripts available in this tutorial and both the scripts are useful.
|
||||
|
||||
Both scripts are used for different purpose, which you can easily understand by reading a head line.
|
||||
|
||||
I will ask you few questions before you are reading this article, just answer yourself if you know or you can get it by reading this article.
|
||||
|
||||
How to check, if a port is open on the remote Linux server?
|
||||
|
||||
How to check, if a port is open on the multiple remote Linux server?
|
||||
|
||||
How to check, if multiple ports are open on the multiple remote Linux server?
|
||||
|
||||
### What Is nc (netcat) Command?
|
||||
|
||||
nc stands for netcat. Netcat is a simple Unix utility which reads and writes data across network connections, using TCP or UDP protocol.
|
||||
|
||||
It is designed to be a reliable “back-end” tool that can be used directly or easily driven by other programs and scripts.
|
||||
|
||||
At the same time, it is a feature-rich network debugging and exploration tool, since it can create almost any kind of connection you would need and has several interesting built-in capabilities.
|
||||
|
||||
Netcat has three main modes of functionality. These are the connect mode, the listen mode, and the tunnel mode.
|
||||
|
||||
**Common Syntax for nc (netcat):**
|
||||
|
||||
```
|
||||
$ nc [-options] [HostName or IP] [PortNumber]
|
||||
```
|
||||
|
||||
### How To Check If A Port Is Open On Multiple Remote Linux Server?
|
||||
|
||||
Use the following shell script if you would like to check the given port is open on multiple remote Linux servers or not.
|
||||
|
||||
In my case, we are going to check whether the port 22 is open in the following remote servers or not? Make sure you have to update your servers list in the file instead of us.
|
||||
|
||||
Make sure you have to update the servers list into `server-list.txt file`. Each server should be in separate line.
|
||||
|
||||
```
|
||||
# cat server-list.txt
|
||||
192.168.1.2
|
||||
192.168.1.3
|
||||
192.168.1.4
|
||||
192.168.1.5
|
||||
192.168.1.6
|
||||
192.168.1.7
|
||||
```
|
||||
|
||||
Use the following script to achieve this.
|
||||
|
||||
```
|
||||
# vi port_scan.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
#echo $i
|
||||
nc -zvw3 $server 22
|
||||
done
|
||||
```
|
||||
|
||||
Set an executable permission to `port_scan.sh` file.
|
||||
|
||||
```
|
||||
$ chmod +x port_scan.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# sh port_scan.sh
|
||||
|
||||
Connection to 192.168.1.2 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.3 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.4 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.5 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.6 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
|
||||
```
|
||||
|
||||
### How To Check If Multiple Ports Are Open On Multiple Remote Linux Server?
|
||||
|
||||
Use the following script if you want to check the multiple ports in multiple servers.
|
||||
|
||||
In my case, we are going to check whether the port 22 and 80 is open or not in the given servers. Make sure you have to replace your required ports and servers name instead of us.
|
||||
|
||||
Make sure you have to update the port lists into `port-list.txt` file. Each port should be in a separate line.
|
||||
|
||||
```
|
||||
# cat port-list.txt
|
||||
22
|
||||
80
|
||||
```
|
||||
|
||||
Make sure you have to update the servers list into `server-list.txt` file. Each server should be in separate line.
|
||||
|
||||
```
|
||||
# cat server-list.txt
|
||||
192.168.1.2
|
||||
192.168.1.3
|
||||
192.168.1.4
|
||||
192.168.1.5
|
||||
192.168.1.6
|
||||
192.168.1.7
|
||||
```
|
||||
|
||||
Use the following script to achieve this.
|
||||
|
||||
```
|
||||
# vi multiple_port_scan.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
for port in `more port-list.txt`
|
||||
do
|
||||
#echo $server
|
||||
nc -zvw3 $server $port
|
||||
echo ""
|
||||
done
|
||||
done
|
||||
```
|
||||
|
||||
Set an executable permission to `multiple_port_scan.sh` file.
|
||||
|
||||
```
|
||||
$ chmod +x multiple_port_scan.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# sh multiple_port_scan.sh
|
||||
Connection to 192.168.1.2 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.2 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.3 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.3 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.4 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.4 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.5 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.5 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.6 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.6 80 port [tcp/http] succeeded!
|
||||
|
||||
Connection to 192.168.1.7 22 port [tcp/ssh] succeeded!
|
||||
Connection to 192.168.1.7 80 port [tcp/http] succeeded!
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-a-open-port-on-multiple-remote-linux-server-using-nc-command/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bringing Kubernetes to the bare-metal edge)
|
||||
[#]: via: (https://opensource.com/article/19/3/bringing-kubernetes-bare-metal-edge)
|
||||
[#]: author: (John Studarus https://opensource.com/users/studarus)
|
||||
|
||||
Bringing Kubernetes to the bare-metal edge
|
||||
======
|
||||
New Kubespray features enable Kubernetes clusters to be deployed across
|
||||
next-generation edge locations.
|
||||
![cubes coming together to create a larger cube][1]
|
||||
|
||||
[Kubespray][2], a community project that provides Ansible playbooks for the deployment and management of Kubernetes clusters, recently added support for the bare-metal cloud [Packet][3]. This allows Kubernetes clusters to be deployed across next-generation edge locations, including [cell-tower based micro datacenters][4].
|
||||
|
||||
Packet, which is unique in its bare-metal focus, expands Kubespray's support beyond the usual clouds—Amazon Web Services, Google Compute Engine, Azure, OpenStack, vSphere, and Oracle Cloud Infrastructure. Kubespray removes the complexities of standing up a Kubernetes cluster through automation using Terraform and Ansible. Terraform provisions the infrastructure and installs the prerequisites for the Ansible installation. Terraform provider plugins enable support for a variety of different cloud providers. The Ansible playbook then deploys and configures Kubernetes.
|
||||
|
||||
Since there are already [detailed instructions online][5] for deploying with Kubespray on Packet, I'll focus on why bare-metal support is important for Kubernetes and what's required to make it happen.
|
||||
|
||||
### Why bare metal?
|
||||
|
||||
Historically, Kubernetes deployments relied upon the "creature comforts" of a public cloud or a fully managed private cloud to provide virtual machines and networking infrastructure for running Kubernetes. This adds a layer of abstraction (e.g., a hypervisor with virtual machines) that Kubernetes doesn't necessarily need. In fact, Kubernetes began its life on bare metal as Google's Borg.
|
||||
|
||||
As we move workloads closer to the end user (in the form of edge computing) and deploy to more diverse environments (including hybrid and on-premises infrastructure of different architectures and sizes), relying on a homogenous public cloud substrate isn't always possible or ideal. For instance, with edge locations being resource constrained, it is more efficient and practical to run Kubernetes directly on bare metal.
|
||||
|
||||
### Mind the gaps
|
||||
|
||||
Without a full-featured public cloud underneath a bare-metal cluster, some traditional capabilities, such as load balancing and storage orchestration, will need to be managed directly within the Kubernetes cluster. Luckily there are projects, such as [MetalLB][6] and [Rook][7], that provide this support for Kubernetes.
|
||||
|
||||
MetalLB, a Layer 2 and Layer 3 load balancer, is integrated into Kubespray, and it's easy to install support for Rook, which orchestrates Ceph to provide distributed and replicated storage for a Kubernetes cluster, on a bare-metal cluster. In addition to enabling full functionality, this "bring your own" approach to storage and load balancing removes reliance upon specific cloud services, helping you avoid lock-in with an approach that can be installed anywhere.
|
||||
|
||||
Kubespray has support for ARM64 processors. The ARM architecture (which is starting to show up regularly in datacenter-grade hardware, SmartNICs, and other custom accelerators) has a long history in mobile and embedded devices, making it well-suited for edge deployments.
|
||||
|
||||
Going forward, I hope to see deeper integration with MetalLB and Rook as well as bare-metal continuous integration (CI) of daily builds atop a number of different hardware configurations. Access to automated bare metal at Packet enables testing and maintaining support across various processor types, storage options, and networking setups. This will help ensure that Kubespray-powered Kubernetes can be deployed and managed confidently across public clouds, bare metal, and edge environments.
|
||||
|
||||
### It takes a village
|
||||
|
||||
Kubespray is an open source project driven by the community, indebted to its core developers and contributors as well as the folks that assisted with the Packet integration. Contributors include [Maxime Guyot][8] and [Aivars Sterns][9] for the initial commits and code reviews, [Rong Zhang][10] and [Ed Vielmetti][11] for document reviews, as well as [Tomáš Karásek][12] (who maintains the Packet Go library and Terraform provider).
|
||||
|
||||
* * *
|
||||
|
||||
_John Studarus will present[The Open Micro Edge Data Center][13] at the [Open Infrastructure Summit][14], April 29-May 1 in Denver._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/bringing-kubernetes-bare-metal-edge
|
||||
|
||||
作者:[John Studarus][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/studarus
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ (cubes coming together to create a larger cube)
|
||||
[2]: https://kubespray.io/
|
||||
[3]: https://www.packet.com/
|
||||
[4]: https://twitter.com/packethost/status/1062147355108085760
|
||||
[5]: https://github.com/kubernetes-sigs/kubespray/blob/master/docs/packet.md
|
||||
[6]: https://metallb.universe.tf/
|
||||
[7]: https://rook.io/
|
||||
[8]: https://twitter.com/Miouge
|
||||
[9]: https://github.com/Atoms
|
||||
[10]: https://github.com/riverzhang
|
||||
[11]: https://twitter.com/vielmetti
|
||||
[12]: https://t0mk.github.io/
|
||||
[13]: https://www.openstack.org/summit/denver-2019/summit-schedule/events/23153/the-open-micro-edge-data-center
|
||||
[14]: https://openstack.org/summit
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
108
sources/tech/20190328 How to run PostgreSQL on Kubernetes.md
Normal file
108
sources/tech/20190328 How to run PostgreSQL on Kubernetes.md
Normal file
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to run PostgreSQL on Kubernetes)
|
||||
[#]: via: (https://opensource.com/article/19/3/how-run-postgresql-kubernetes)
|
||||
[#]: author: (Jonathan S. Katz https://opensource.com/users/jkatz05)
|
||||
|
||||
How to run PostgreSQL on Kubernetes
|
||||
======
|
||||
Create uniformly managed, cloud-native production deployments with the
|
||||
flexibility to deploy a personalized database-as-a-service.
|
||||
![cubes coming together to create a larger cube][1]
|
||||
|
||||
By running a [PostgreSQL][2] database on [Kubernetes][3], you can create uniformly managed, cloud-native production deployments with the flexibility to deploy a personalized database-as-a-service tailored to your specific needs.
|
||||
|
||||
Using an Operator allows you to provide additional context to Kubernetes to [manage a stateful application][4]. An Operator is also helpful when using an open source database like PostgreSQL to help with actions including provisioning, scaling, high availability, and user management.
|
||||
|
||||
Let's explore how to get PostgreSQL up and running on Kubernetes.
|
||||
|
||||
### Set up the PostgreSQL operator
|
||||
|
||||
The first step to using PostgreSQL with Kubernetes is installing an Operator. You can get up and running with the open source [Crunchy PostgreSQL Operator][5] on any Kubernetes-based environment with the help of Crunchy's [quickstart script][6] for Linux.
|
||||
|
||||
The quickstart script has a few prerequisites:
|
||||
|
||||
* The [Wget][7] utility installed
|
||||
* [kubectl][8] installed
|
||||
* A [StorageClass][9] defined on your Kubernetes cluster
|
||||
* Access to a Kubernetes user account with cluster-admin privileges. This is required to install the Operator [RBAC][10] rules
|
||||
* A [namespace][11] to hold the PostgreSQL Operator
|
||||
|
||||
|
||||
|
||||
Executing the script will give you a default PostgreSQL Operator deployment that assumes [dynamic storage][12] and a StorageClass named **standard**. User-provided values are allowed by the script to override these defaults.
|
||||
|
||||
You can download the quickstart script and set it to be executable with the following commands:
|
||||
|
||||
```
|
||||
wget <https://raw.githubusercontent.com/CrunchyData/postgres-operator/master/examples/quickstart.sh>
|
||||
chmod +x ./quickstart.sh
|
||||
```
|
||||
|
||||
Then you can execute the quickstart script:
|
||||
|
||||
```
|
||||
./examples/quickstart.sh
|
||||
```
|
||||
|
||||
After the script prompts you for some basic information about your Kubernetes cluster, it performs the following operations:
|
||||
|
||||
* Downloads the Operator configuration files
|
||||
* Sets the **$HOME/.pgouser** file to default settings
|
||||
* Deploys the Operator as a Kubernetes [Deployment][13]
|
||||
* Sets your **.bashrc** to include the Operator environmental variables
|
||||
* Sets your **$HOME/.bash_completion** file to be the **pgo bash_completion** file
|
||||
|
||||
|
||||
|
||||
During the quickstart's execution, you'll be prompted to set up the RBAC rules for your Kubernetes cluster. In a separate terminal, execute the command the quickstart command tells you to use.
|
||||
|
||||
Once the script completes, you'll get information on setting up a port forward to the PostgreSQL Operator pod. In a separate terminal, execute the port forward; this will allow you to begin executing commands to the PostgreSQL Operator! Try creating a cluster by entering:
|
||||
|
||||
```
|
||||
pgo create cluster mynewcluster
|
||||
```
|
||||
|
||||
You can test that your cluster is up and running with by entering:
|
||||
|
||||
```
|
||||
pgo test mynewcluster
|
||||
```
|
||||
|
||||
You can now manage your PostgreSQL databases in your Kubernetes environment! You can find a full reference to commands, including those for scaling, high availability, backups, and more, in the [documentation][14].
|
||||
|
||||
* * *
|
||||
|
||||
_Parts of this article are based on[Get Started Running PostgreSQL on Kubernetes][15] that the author wrote for the Crunchy blog._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/how-run-postgresql-kubernetes
|
||||
|
||||
作者:[Jonathan S. Katz][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jkatz05
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ (cubes coming together to create a larger cube)
|
||||
[2]: https://www.postgresql.org/
|
||||
[3]: https://kubernetes.io/
|
||||
[4]: https://opensource.com/article/19/2/scaling-postgresql-kubernetes-operators
|
||||
[5]: https://github.com/CrunchyData/postgres-operator
|
||||
[6]: https://crunchydata.github.io/postgres-operator/stable/installation/#quickstart-script
|
||||
[7]: https://www.gnu.org/software/wget/
|
||||
[8]: https://kubernetes.io/docs/tasks/tools/install-kubectl/
|
||||
[9]: https://kubernetes.io/docs/concepts/storage/storage-classes/
|
||||
[10]: https://kubernetes.io/docs/reference/access-authn-authz/rbac/
|
||||
[11]: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||
[12]: https://kubernetes.io/docs/concepts/storage/dynamic-provisioning/
|
||||
[13]: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
|
||||
[14]: https://crunchydata.github.io/postgres-operator/stable/#documentation
|
||||
[15]: https://info.crunchydata.com/blog/get-started-runnning-postgresql-on-kubernetes
|
||||
@ -0,0 +1,176 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (ShadowReader: Serverless load tests for replaying production traffic)
|
||||
[#]: via: (https://opensource.com/article/19/3/shadowreader-serverless)
|
||||
[#]: author: (Yuki Sawa https://opensource.com/users/yukisawa1/users/yongsanchez)
|
||||
|
||||
ShadowReader: Serverless load tests for replaying production traffic
|
||||
======
|
||||
This open source tool recreates serverless production conditions to
|
||||
pinpoint causes of memory leaks and other errors that aren't visible in
|
||||
the QA environment.
|
||||
![Traffic lights at night][1]
|
||||
|
||||
While load testing has become more accessible, configuring load tests that faithfully re-create production conditions can be difficult. A good load test must use a set of URLs that are representative of production traffic and achieve request rates that mimic real users. Even performing distributed load tests requires the upkeep of a fleet of servers.
|
||||
|
||||
[ShadowReader][2] aims to solve these problems. It gathers URLs and request rates straight from production logs and replays them using AWS Lambda. Being serverless, it is more cost-efficient and performant than traditional distributed load tests; in practice, it has scaled beyond 50,000 requests per minute.
|
||||
|
||||
At Edmunds, we have been able to utilize these capabilities to solve problems, such as Node.js memory leaks that were happening only in production, by recreating the same conditions in our QA environment. We're also using it daily to generate load for pre-production canary deployments.
|
||||
|
||||
The memory leak problem we faced in our Node.js application confounded our engineering team; as it was only occurring in our production environment; we could not reproduce it in QA until we introduced ShadowReader to replay production traffic into QA.
|
||||
|
||||
### The incident
|
||||
|
||||
On Christmas Eve 2017, we suffered an incident where there was a jump in response time across the board with error rates tripling and impacting many users of our website.
|
||||
|
||||
![Christmas Eve 2017 incident][3]
|
||||
|
||||
![Christmas Eve 2017 incident][4]
|
||||
|
||||
Monitoring during the incident helped identify and resolve the issue quickly, but we still needed to understand the root cause.
|
||||
|
||||
At Edmunds, we leverage a robust continuous delivery (CD) pipeline that releases new updates to production multiple times a day. We also dynamically scale up our applications to accommodate peak traffic and scale down to save costs. Unfortunately, this had the side effect of masking a memory leak.
|
||||
|
||||
In our investigation, we saw that the memory leak had existed for weeks, since early December. Memory usage would climb to 60%, along with a slow increase in 99th percentile response time.
|
||||
|
||||
Between our CD pipeline and autoscaling events, long-running containers were frequently being shut down and replaced by newer ones. This inadvertently masked the memory leak until December, when we decided to stop releasing software to ensure stability during the holidays.
|
||||
|
||||
![Slow increase in 99th percentile response time][5]
|
||||
|
||||
### Our CD pipeline
|
||||
|
||||
At a glance, Edmunds' CD pipeline looks like this:
|
||||
|
||||
1. Unit test
|
||||
2. Build a Docker image for the application
|
||||
3. Integration test
|
||||
4. Load test/performance test
|
||||
5. Canary release
|
||||
|
||||
|
||||
|
||||
The solution is fully automated and requires no manual cutover. The final step is a canary deployment directly into the live website, allowing us to release multiple times a day.
|
||||
|
||||
For our load testing, we leveraged custom tooling built on top of JMeter. It takes random samples of production URLs and can simulate various percentages of traffic. Unfortunately, however, our load tests were not able to reproduce the memory leak in any of our pre-production environments.
|
||||
|
||||
### Solving the memory leak
|
||||
|
||||
When looking at the memory patterns in QA, we noticed there was a very healthy pattern. Our initial hypothesis was that our JMeter load testing in QA was unable to simulate production traffic in a way that allows us to predict how our applications will perform.
|
||||
|
||||
While the load test takes samples from production URLs, it can't precisely simulate the URLs customers use and the exact frequency of calls (i.e., the burst rate).
|
||||
|
||||
Our first step was to re-create the problem in QA. We used a new tool called ShadowReader, a project that evolved out of our hackathons. While many projects we considered were product-focused, this was the only operations-centric one. It is a load-testing tool that runs on AWS Lambda and can replay production traffic and usage patterns against our QA environment.
|
||||
|
||||
The results it returned were immediate:
|
||||
|
||||
![QA results in ShadowReader][6]
|
||||
|
||||
Knowing that we could re-create the problem in QA, we took the additional step to point ShadowReader to our local environment, as this allowed us to trigger Node.js heap dumps. After analyzing the contents of the dumps, it was obvious the memory leak was coming from two excessively large objects containing only strings. At the time the snapshot dumped, these objects contained 373MB and 63MB of strings!
|
||||
|
||||
![Heap dumps show source of memory leak][7]
|
||||
|
||||
We found that both objects were temporary lookup caches containing metadata to be used on the client side. Neither of these caches was ever intended to be persisted on the server side. The user's browser cached only its own metadata, but on the server side, it cached the metadata for all users. This is why we were unable to reproduce the leak with synthetic testing. Synthetic tests always resulted in the same fixed set of metadata in the server-side caches. The leak surfaced only when we had a sufficient amount of unique metadata being generated from a variety of users.
|
||||
|
||||
Once we identified the problem, we were able to remove the large caches that we observed in the heap dumps. We've since instrumented the application to start collecting metrics that can help detect issues like this faster.
|
||||
|
||||
![Collecting metrics][8]
|
||||
|
||||
After making the fix in QA, we saw that the memory usage was constant and the leak was plugged.
|
||||
|
||||
![Graph showing memory leak fixed][9]
|
||||
|
||||
### What is ShadowReader?
|
||||
|
||||
ShadowReader is a serverless load-testing framework powered by AWS Lambda and S3 to replay production traffic. It mimics real user traffic by replaying URLs from production at the same rate as the live website. We are happy to announce that after months of internal usage, we have released it as open source!
|
||||
|
||||
#### Features
|
||||
|
||||
* ShadowReader mimics real user traffic by replaying user requests (URLs). It can also replay certain headers, such as True-Client-IP and User-Agent, along with the URL.
|
||||
|
||||
|
||||
* It is more efficient cost- and performance-wise than traditional distributed load tests that run on a fleet of servers. Managing a fleet of servers for distributed load testing can cost $1,000 or more per month; with a serverless stack, it can be reduced to $100 per month by provisioning compute resources on demand.
|
||||
|
||||
|
||||
* We've scaled it up to 50,000 requests per minute, but it should be able to handle more than 100,000 reqs/min.
|
||||
|
||||
|
||||
* New load tests can be spun up and stopped instantly, unlike traditional load-testing tools, which can take many minutes to generate the test plan and distribute the test data to the load-testing servers.
|
||||
|
||||
|
||||
* It can ramp traffic up or down by a percentage value to function as a more traditional load test.
|
||||
|
||||
|
||||
* Its plugin system enables you to switch out plugins to change its behavior. For instance, you can switch from past replay (i.e., replays past requests) to live replay (i.e., replays requests as they come in).
|
||||
|
||||
|
||||
* Currently, it can replay logs from the [Application Load Balancer][10] and [Classic Load Balancer][11] Elastic Load Balancers (ELBs), and support for other load balancers is coming soon.
|
||||
|
||||
|
||||
|
||||
### How it works
|
||||
|
||||
ShadowReader is composed of four different Lambdas: a Parser, an Orchestrator, a Master, and a Worker.
|
||||
|
||||
![ShadowReader architecture][12]
|
||||
|
||||
When a user visits a website, a load balancer (in this case, an ELB) typically routes the request. As the ELB routes the request, it will log the event and ship it to S3.
|
||||
|
||||
Next, ShadowReader triggers a Parser Lambda every minute via a CloudWatch event, which parses the latest access (ELB) logs on S3 for that minute, then ships the parsed URLs into another S3 bucket.
|
||||
|
||||
On the other side of the system, ShadowReader also triggers an Orchestrator lambda every minute. This Lambda holds the configurations and state of the system.
|
||||
|
||||
The Orchestrator then invokes a Master Lambda function. From the Orchestrator, the Master receives information on which time slice to replay and downloads the respective data from the S3 bucket of parsed URLs (deposited there by the Parser).
|
||||
|
||||
The Master Lambda divides the load-test URLs into smaller batches, then invokes and passes each batch into a Worker Lambda. If 800 requests must be sent out, then eight Worker Lambdas will be invoked, each one handling 100 URLs.
|
||||
|
||||
Finally, the Worker receives the URLs passed from the Master and starts load-testing the chosen test environment.
|
||||
|
||||
### The bigger picture
|
||||
|
||||
The challenge of reproducibility in load testing serverless infrastructure becomes increasingly important as we move from steady-state application sizing to on-demand models. While ShadowReader is designed and used with Edmunds' infrastructure in mind, any application leveraging ELBs can take full advantage of it. Soon, it will have support to replay the traffic of any service that generates traffic logs.
|
||||
|
||||
As the project moves forward, we would love to see it evolve to be compatible with next-generation serverless runtimes such as Knative. We also hope to see other open source communities build similar toolchains for their infrastructure as serverless becomes more prevalent.
|
||||
|
||||
### Getting started
|
||||
|
||||
If you would like to test drive ShadowReader, check out the [GitHub repo][2]. The README contains how-to guides and a batteries-included [demo][13] that will deploy all the necessary resources to try out live replay in your AWS account.
|
||||
|
||||
We would love to hear what you think and welcome contributions. See the [contributing guide][14] to get started!
|
||||
|
||||
* * *
|
||||
|
||||
_This article is based on "[How we fixed a Node.js memory leak by using ShadowReader to replay production traffic into QA][15]," published on the_ _Edmunds Tech Blog_ _with the help of Carlos Macasaet, Sharath Gowda, and Joey Davis._ _Yuki_ _Sawa_ _also presented this_ as* [ShadowReader—Serverless load tests for replaying production traffic][16] at ([SCaLE 17x][17]) March 7-10 in Pasadena, Calif.*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/shadowreader-serverless
|
||||
|
||||
作者:[Yuki Sawa][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/yukisawa1/users/yongsanchez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/traffic-light-go.png?itok=nC_851ys (Traffic lights at night)
|
||||
[2]: https://github.com/edmunds/shadowreader
|
||||
[3]: https://opensource.com/sites/default/files/uploads/shadowreader_incident1_0.png (Christmas Eve 2017 incident)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/shadowreader_incident2.png (Christmas Eve 2017 incident)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/shadowreader_99thpercentile.png (Slow increase in 99th percentile response time)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/shadowreader_qa.png (QA results in ShadowReader)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/shadowreader_heapdumps.png (Heap dumps show source of memory leak)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/shadowreader_code.png (Collecting metrics)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/shadowreader_leakplugged.png (Graph showing memory leak fixed)
|
||||
[10]: https://docs.aws.amazon.com/elasticloadbalancing/latest/application/introduction.html
|
||||
[11]: https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/introduction.html
|
||||
[12]: https://opensource.com/sites/default/files/uploads/shadowreader_architecture.png (ShadowReader architecture)
|
||||
[13]: https://github.com/edmunds/shadowreader#live-replay
|
||||
[14]: https://github.com/edmunds/shadowreader/blob/master/CONTRIBUTING.md
|
||||
[15]: https://technology.edmunds.com/2018/08/25/Investigating-a-Memory-Leak-and-Introducing-ShadowReader/
|
||||
[16]: https://www.socallinuxexpo.org/scale/17x/speakers/yuki-sawa
|
||||
[17]: https://www.socallinuxexpo.org/
|
||||
226
sources/tech/20190401 Build and host a website with Git.md
Normal file
226
sources/tech/20190401 Build and host a website with Git.md
Normal file
@ -0,0 +1,226 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Build and host a website with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/building-hosting-website-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
Build and host a website with Git
|
||||
======
|
||||
Publishing your own website is easy if you let Git help you out. Learn
|
||||
how in the first article in our series about little-known Git uses.
|
||||
![web development and design, desktop and browser][1]
|
||||
|
||||
[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git.
|
||||
|
||||
Creating a website used to be both sublimely simple and a form of black magic all at once. Back in the old days of Web 1.0 (that's not what anyone actually called it), you could just open up any website, view its source code, and reverse engineer the HTML—with all its inline styling and table-based layout—and you felt like a programmer after an afternoon or two. But there was still the matter of getting the page you created on the internet, which meant dealing with servers and FTP and webroot directories and file permissions. While the modern web has become far more complex since then, self-publication can be just as easy (or easier!) if you let Git help you out.
|
||||
|
||||
### Create a website with Hugo
|
||||
|
||||
[Hugo][3] is an open source static site generator. Static sites are what the web used to be built on (if you go back far enough, it was _all_ the web was). There are several advantages to static sites: they're relatively easy to write because you don't have to code them, they're relatively secure because there's no code executed on the pages, and they can be quite fast because there's no processing aside from transferring whatever you have on the page.
|
||||
|
||||
Hugo isn't the only static site generator out there. [Grav][4], [Pico][5], [Jekyll][6], [Podwrite][7], and many others provide an easy way to create a full-featured website with minimal maintenance. Hugo happens to be one with GitLab integration built in, which means you can generate and host your website with a free GitLab account.
|
||||
|
||||
Hugo has some pretty big fans, too. For instance, if you've ever gone to the Let's Encrypt website, then you've used a site built with Hugo.
|
||||
|
||||
![Let's Encrypt website][8]
|
||||
|
||||
#### Install Hugo
|
||||
|
||||
Hugo is cross-platform, and you can find installation instructions for MacOS, Windows, Linux, OpenBSD, and FreeBSD in [Hugo's getting started resources][9].
|
||||
|
||||
If you're on Linux or BSD, it's easiest to install Hugo from a software repository or ports tree. The exact command varies depending on what your distribution provides, but on Fedora you would enter:
|
||||
|
||||
```
|
||||
$ sudo dnf install hugo
|
||||
```
|
||||
|
||||
Confirm you have installed it correctly by opening a terminal and typing:
|
||||
|
||||
```
|
||||
$ hugo help
|
||||
```
|
||||
|
||||
This prints all the options available for the **hugo** command. If you don't see that, you may have installed Hugo incorrectly or need to [add the command to your path][10].
|
||||
|
||||
#### Create your site
|
||||
|
||||
To build a Hugo site, you must have a specific directory structure, which Hugo will generate for you by entering:
|
||||
|
||||
```
|
||||
$ hugo new site mysite
|
||||
```
|
||||
|
||||
You now have a directory called **mysite** , and it contains the default directories you need to build a Hugo website.
|
||||
|
||||
Git is your interface to get your site on the internet, so change directory to your new **mysite** folder and initialize it as a Git repository:
|
||||
|
||||
```
|
||||
$ cd mysite
|
||||
$ git init .
|
||||
```
|
||||
|
||||
Hugo is pretty Git-friendly, so you can even use Git to install a theme for your site. Unless you plan on developing the theme you're installing, you can use the **\--depth** option to clone the latest state of the theme's source:
|
||||
|
||||
```
|
||||
$ git clone --depth 1 \
|
||||
<https://github.com/darshanbaral/mero.git\\>
|
||||
themes/mero
|
||||
```
|
||||
|
||||
|
||||
Now create some content for your site:
|
||||
|
||||
```
|
||||
$ hugo new posts/hello.md
|
||||
```
|
||||
|
||||
Use your favorite text editor to edit the **hello.md** file in the **content/posts** directory. Hugo accepts Markdown files and converts them to themed HTML files at publication, so your content must be in [Markdown format][11].
|
||||
|
||||
If you want to include images in your post, create a folder called **images** in the **static** directory. Place your images into this folder and reference them in your markup using the absolute path starting with **/images**. For example:
|
||||
|
||||
```
|
||||

|
||||
```
|
||||
|
||||
#### Choose a theme
|
||||
|
||||
You can find more themes at [themes.gohugo.io][12], but it's best to stay with a basic theme while testing. The canonical Hugo test theme is [Ananke][13]. Some themes have complex dependencies, and others don't render pages the way you might expect without complex configuration. The Mero theme used in this example comes bundled with a detailed **config.toml** configuration file, but (for the sake of simplicity) I'll provide just the basics here. Open the file called **config.toml** in a text editor and add three configuration parameters:
|
||||
|
||||
```
|
||||
|
||||
languageCode = "en-us"
|
||||
title = "My website on the web"
|
||||
theme = "mero"
|
||||
|
||||
[params]
|
||||
author = "Seth Kenlon"
|
||||
description = "My hugo demo"
|
||||
```
|
||||
|
||||
#### Preview your site
|
||||
|
||||
You don't have to put anything on the internet until you're ready to publish it. While you work, you can preview your site by launching the local-only web server that ships with Hugo.
|
||||
|
||||
```
|
||||
$ hugo server --buildDrafts --disableFastRender
|
||||
```
|
||||
|
||||
Open a web browser and navigate to **<http://localhost:1313>** to see your work in progress.
|
||||
|
||||
### Publish with Git to GitLab
|
||||
|
||||
To publish and host your site on GitLab, create a repository for the contents of your site.
|
||||
|
||||
To create a repository in GitLab, click on the **New Project** button in your GitLab Projects page. Create an empty repository called **yourGitLabUsername.gitlab.io** , replacing **yourGitLabUsername** with your GitLab user name or group name. You must use this scheme as the name of your project. If you want to add a custom domain later, you can.
|
||||
|
||||
Do not include a license or a README file (because you've started a project locally, adding these now would make pushing your data to GitLab more complex, and you can always add them later).
|
||||
|
||||
Once you've created the empty repository on GitLab, add it as the remote location for the local copy of your Hugo site, which is already a Git repository:
|
||||
|
||||
```
|
||||
$ git remote add origin git@gitlab.com:skenlon/mysite.git
|
||||
```
|
||||
|
||||
Create a GitLab site configuration file called **.gitlab-ci.yml** and enter these options:
|
||||
|
||||
```
|
||||
image: monachus/hugo
|
||||
|
||||
variables:
|
||||
GIT_SUBMODULE_STRATEGY: recursive
|
||||
|
||||
pages:
|
||||
script:
|
||||
- hugo
|
||||
artifacts:
|
||||
paths:
|
||||
- public
|
||||
only:
|
||||
- master
|
||||
```
|
||||
|
||||
The **image** parameter defines a containerized image that will serve your site. The other parameters are instructions telling GitLab's servers what actions to execute when you push new code to your remote repository. For more information on GitLab's CI/CD (Continuous Integration and Delivery) options, see the [CI/CD section of GitLab's docs][14].
|
||||
|
||||
#### Set the excludes
|
||||
|
||||
Your Git repository is configured, the commands to build your site on GitLab's servers are set, and your site ready to publish. For your first Git commit, you must take a few extra precautions so you're not version-controlling files you don't intend to version-control.
|
||||
|
||||
First, add the **/public** directory that Hugo creates when building your site to your **.gitignore** file. You don't need to manage the finished site in Git; all you need to track are your source Hugo files.
|
||||
|
||||
```
|
||||
$ echo "/public" >> .gitignore
|
||||
```
|
||||
|
||||
You can't maintain a Git repository within a Git repository without creating a Git submodule. For the sake of keeping this simple, move the embedded **.git** directory so that the theme is just a theme.
|
||||
|
||||
Note that you _must_ add your theme files to your Git repository so GitLab will have access to the theme. Without committing your theme files, your site cannot successfully build.
|
||||
|
||||
```
|
||||
$ mv themes/mero/.git ~/.local/share/Trash/files/
|
||||
```
|
||||
|
||||
Alternately, use a **trash** command such as [Trashy][15]:
|
||||
|
||||
```
|
||||
$ trash themes/mero/.git
|
||||
```
|
||||
|
||||
Now you can add all the contents of your local project directory to Git and push it to GitLab:
|
||||
|
||||
```
|
||||
$ git add .
|
||||
$ git commit -m 'hugo init'
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
### Go live with GitLab
|
||||
|
||||
Once your code has been pushed to GitLab, take a look at your project page. An icon indicates GitLab is processing your build. It might take several minutes the first time you push your code, so be patient. However, don't be _too_ patient, because the icon doesn't always update reliably.
|
||||
|
||||
![GitLab processing your build][16]
|
||||
|
||||
While you're waiting for GitLab to assemble your site, go to your project settings and find the **Pages** panel. Once your site is ready, its URL will be provided for you. The URL is **yourGitLabUsername.gitlab.io/yourProjectName**. Navigate to that address to view the fruits of your labor.
|
||||
|
||||
![Previewing Hugo site][17]
|
||||
|
||||
If your site fails to assemble correctly, GitLab provides insight into the CI/CD pipeline logs. Review the error message for an indication of what went wrong.
|
||||
|
||||
### Git and the web
|
||||
|
||||
Hugo (or Jekyll or similar tools) is just one way to leverage Git as your web publishing tool. With server-side Git hooks, you can design your own Git-to-web pipeline with minimal scripting. With the community edition of GitLab, you can self-host your own GitLab instance or you can use an alternative like [Gitolite][18] or [Gitea][19] and use this article as inspiration for a custom solution. Have fun!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/building-hosting-website-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web_browser_desktop_devlopment_design_system_computer.jpg?itok=pfqRrJgh (web development and design, desktop and browser)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://gohugo.io
|
||||
[4]: http://getgrav.org
|
||||
[5]: http://picocms.org/
|
||||
[6]: https://jekyllrb.com
|
||||
[7]: http://slackermedia.info/podwrite/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/letsencrypt-site.jpg (Let's Encrypt website)
|
||||
[9]: https://gohugo.io/getting-started/installing
|
||||
[10]: https://opensource.com/article/17/6/set-path-linux
|
||||
[11]: https://commonmark.org/help/
|
||||
[12]: https://themes.gohugo.io/
|
||||
[13]: https://themes.gohugo.io/gohugo-theme-ananke/
|
||||
[14]: https://docs.gitlab.com/ee/ci/#overview
|
||||
[15]: http://slackermedia.info/trashy
|
||||
[16]: https://opensource.com/sites/default/files/uploads/hugo-gitlab-cicd.jpg (GitLab processing your build)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/hugo-demo-site.jpg (Previewing Hugo site)
|
||||
[18]: http://gitolite.com
|
||||
[19]: http://gitea.io
|
||||
@ -0,0 +1,168 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to create a filesystem on a Linux partition or logical volume)
|
||||
[#]: via: (https://opensource.com/article/19/4/create-filesystem-linux-partition)
|
||||
[#]: author: (Kedar Vijay Kulkarni (Red Hat) https://opensource.com/users/kkulkarn)
|
||||
|
||||
How to create a filesystem on a Linux partition or logical volume
|
||||
======
|
||||
Learn to create a filesystem and mount it persistently or
|
||||
non-persistently in your system.
|
||||
![Filing papers and documents][1]
|
||||
|
||||
In computing, a filesystem controls how data is stored and retrieved and helps organize the files on the storage media. Without a filesystem, information in storage would be one large block of data, and you couldn't tell where one piece of information stopped and the next began. A filesystem helps manage all of this by providing names to files that store data and maintaining a table of files and directories—along with their start/end location, total size, etc.—on disks within the filesystem.
|
||||
|
||||
In Linux, when you create a hard disk partition or a logical volume, the next step is usually to create a filesystem by formatting the partition or logical volume. This how-to assumes you know how to create a partition or a logical volume, and you just want to format it to contain a filesystem and mount it.
|
||||
|
||||
### Create a filesystem
|
||||
|
||||
Imagine you just added a new disk to your system and created a partition named **/dev/sda1** on it.
|
||||
|
||||
1. To verify that the Linux kernel can see the partition, you can **cat** out **/proc/partitions** like this:
|
||||
|
||||
```
|
||||
[root@localhost ~]# cat /proc/partitions
|
||||
major minor #blocks name
|
||||
|
||||
253 0 10485760 vda
|
||||
253 1 8192000 vda1
|
||||
11 0 1048575 sr0
|
||||
11 1 374 sr1
|
||||
8 0 10485760 sda
|
||||
8 1 10484736 sda1
|
||||
252 0 3145728 dm-0
|
||||
252 1 2097152 dm-1
|
||||
252 2 1048576 dm-2
|
||||
8 16 1048576 sdb
|
||||
```
|
||||
|
||||
|
||||
2. Decide what kind of filesystem you want to create, such as ext4, XFS, or anything else. Here are a few options:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkfs.<tab><tab>
|
||||
mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.minix mkfs.xfs
|
||||
```
|
||||
|
||||
|
||||
3. For the purposes of this exercise, choose ext4. (I like ext4 because it allows you to shrink the filesystem if you need to, a thing that isn't as straightforward with XFS.) Here's how it can be done (the output may differ based on device name/sizes):
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkfs.ext4 /dev/sda1
|
||||
mke2fs 1.42.9 (28-Dec-2013)
|
||||
Filesystem label=
|
||||
OS type: Linux
|
||||
Block size=4096 (log=2)
|
||||
Fragment size=4096 (log=2)
|
||||
Stride=0 blocks, Stripe width=8191 blocks
|
||||
194688 inodes, 778241 blocks
|
||||
38912 blocks (5.00%) reserved for the super user
|
||||
First data block=0
|
||||
Maximum filesystem blocks=799014912
|
||||
24 block groups
|
||||
32768 blocks per group, 32768 fragments per group
|
||||
8112 inodes per group
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376, 294912
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (16384 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
```
|
||||
|
||||
4. In the previous step, if you want to create a different kind of filesystem, use a different **mkfs** command variation.
|
||||
|
||||
|
||||
|
||||
### Mount a filesystem
|
||||
|
||||
After you create your filesystem, you can mount it in your operating system.
|
||||
|
||||
1. First, identify the UUID of your new filesystem. Issue the **blkid** command to list all known block storage devices and look for **sda1** in the output:
|
||||
|
||||
```
|
||||
[root@localhost ~]# blkid
|
||||
/dev/vda1: UUID="716e713d-4e91-4186-81fd-c6cfa1b0974d" TYPE="xfs"
|
||||
/dev/sr1: UUID="2019-03-08-16-17-02-00" LABEL="config-2" TYPE="iso9660"
|
||||
/dev/sda1: UUID="wow9N8-dX2d-ETN4-zK09-Gr1k-qCVF-eCerbF" TYPE="LVM2_member"
|
||||
/dev/mapper/test-test1: PTTYPE="dos"
|
||||
/dev/sda1: UUID="ac96b366-0cdd-4e4c-9493-bb93531be644" TYPE="ext4"
|
||||
[root@localhost ~]#
|
||||
```
|
||||
|
||||
|
||||
2. Run the following command to mount the **/dev/sd1** device :
|
||||
|
||||
```
|
||||
[root@localhost ~]# mkdir /mnt/mount_point_for_dev_sda1
|
||||
[root@localhost ~]# ls /mnt/
|
||||
mount_point_for_dev_sda1
|
||||
[root@localhost ~]# mount -t ext4 /dev/sda1 /mnt/mount_point_for_dev_sda1/
|
||||
[root@localhost ~]# df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/vda1 7.9G 920M 7.0G 12% /
|
||||
devtmpfs 443M 0 443M 0% /dev
|
||||
tmpfs 463M 0 463M 0% /dev/shm
|
||||
tmpfs 463M 30M 434M 7% /run
|
||||
tmpfs 463M 0 463M 0% /sys/fs/cgroup
|
||||
tmpfs 93M 0 93M 0% /run/user/0
|
||||
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
|
||||
[root@localhost ~]#
|
||||
```
|
||||
The **df -h** command shows which filesystem is mounted on which mount point. Look for **/dev/sd1**. The mount command above used the device name **/dev/sda1**. Substitute it with the UUID identified in the **blkid** command. Also, note that a new directory was created to mount **/dev/sda1** under **/mnt**.
|
||||
|
||||
|
||||
|
||||
3. A problem with using the mount command directly on the command line (as in the previous step) is that the mount won't persist across reboots. To mount the filesystem persistently, edit the **/etc/fstab** file to include your mount information:
|
||||
|
||||
```
|
||||
UUID=ac96b366-0cdd-4e4c-9493-bb93531be644 /mnt/mount_point_for_dev_sda1/ ext4 defaults 0 0
|
||||
```
|
||||
|
||||
|
||||
|
||||
4. After you edit **/etc/fstab** , you can **umount /mnt/mount_point_for_dev_sda1** and run the command **mount -a** to mount everything listed in **/etc/fstab**. If everything went right, you can still list **df -h** and see your filesystem mounted:
|
||||
|
||||
```
|
||||
root@localhost ~]# umount /mnt/mount_point_for_dev_sda1/
|
||||
[root@localhost ~]# mount -a
|
||||
[root@localhost ~]# df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/vda1 7.9G 920M 7.0G 12% /
|
||||
devtmpfs 443M 0 443M 0% /dev
|
||||
tmpfs 463M 0 463M 0% /dev/shm
|
||||
tmpfs 463M 30M 434M 7% /run
|
||||
tmpfs 463M 0 463M 0% /sys/fs/cgroup
|
||||
tmpfs 93M 0 93M 0% /run/user/0
|
||||
/dev/sda1 2.9G 9.0M 2.7G 1% /mnt/mount_point_for_dev_sda1
|
||||
```
|
||||
|
||||
5. You can also check whether the filesystem was mounted:
|
||||
|
||||
```
|
||||
[root@localhost ~]# mount | grep ^/dev/sd
|
||||
/dev/sda1 on /mnt/mount_point_for_dev_sda1 type ext4 (rw,relatime,seclabel,stripe=8191,data=ordered)
|
||||
```
|
||||
|
||||
|
||||
|
||||
Now you know how to create a filesystem and mount it persistently or non-persistently within your system.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/create-filesystem-linux-partition
|
||||
|
||||
作者:[Kedar Vijay Kulkarni (Red Hat)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kkulkarn
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/documents_papers_file_storage_work.png?itok=YlXpAqAJ (Filing papers and documents)
|
||||
94
sources/tech/20190402 Automate password resets with PWM.md
Normal file
94
sources/tech/20190402 Automate password resets with PWM.md
Normal file
@ -0,0 +1,94 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Automate password resets with PWM)
|
||||
[#]: via: (https://opensource.com/article/19/4/automate-password-resets-pwm)
|
||||
[#]: author: (James Mawson https://opensource.com/users/dxmjames)
|
||||
|
||||
Automate password resets with PWM
|
||||
======
|
||||
PWM puts responsibility for password resets in users' hands, freeing IT
|
||||
for more pressing tasks.
|
||||
![Password][1]
|
||||
|
||||
One of the things that can be "death by a thousand cuts" for any IT team's sanity and patience is constantly being asked to reset passwords.
|
||||
|
||||
The best way we've found to handle this is to ditch your hashing algorithms and store your passwords in plaintext so that your users can retrieve them at any time.
|
||||
|
||||
Ha! I am, of course, kidding. That's a terrible idea.
|
||||
|
||||
When your users forget their passwords, you'll still need to reset them. But is there a way to break free from the monotonous, repetitive task of doing it manually?
|
||||
|
||||
### PWM puts password resets in users' hands
|
||||
|
||||
[PWM][2] is an open source ([GPLv2][3]) [JavaServer Pages][4] application that provides a webpage where users can submit their own password resets. If certain conditions are met—which you can configure—PWM will send a password reset instruction to whichever directory service you've connected it to.
|
||||
|
||||
![PWM password reset screen][5]
|
||||
|
||||
One thing that's great about PWM is it's very easy to add it to an existing network. If you're largely happy with what you've already built—just sick of processing password requests manually—you can just throw PWM into the mix.
|
||||
|
||||
PWM works with any implementation of [LDAP][6] and written to run on [Apache Tomcat][7]. Once you get it up and running, you can administer it through a browser-based dashboard.
|
||||
|
||||
### Why PWM is better than Microsoft SSPR
|
||||
|
||||
As much as our team prefers open source, we still have to deal with Windows networks. Of course, Microsoft has its own password-reset tool, called Self Service Password Reset (SSPR). But I prefer PWM, and not just because of a general preference for open source. I believe PWM is better for my use case for the following reasons:
|
||||
|
||||
* **SSPR has a very complex licensing system**. You need different products depending on what servers you're running and whose metal they're running on. This is a constraint on your flexibility and a whole extra pain in the neck when it's time to move to new architecture. For [the busy admin who wants to go home on time][8], it's extra bureaucracy to get the purchase approved. PWM just works on what it's configured to work on at no cost.
|
||||
|
||||
* **PWM is not just for Windows**. It works with any kind of LDAP server. So, it's one less part you need to worry about if you ever stop using Windows for a certain role. It also means that, once you've gotten the hang of it, you have something in your bag of tricks that you can use in many different environments.
|
||||
|
||||
* **PWM is easy to install**. If you know how to install Linux as a virtual machine—and, let's face it, if you're running a network, you probably do—then you're already most of the way there.
|
||||
|
||||
|
||||
|
||||
|
||||
PWM can run on Windows, but we prefer to include it in a Windows network by running it on a Linux virtual machine, [for example, Ubuntu Server 16.04][9].
|
||||
|
||||
### Risks and rewards of automation
|
||||
|
||||
Password resets are an attack vector, so be thoughtful about where and how you use PWM. Automating your password resets can mean an attacker is potentially just one unencrypted email connection away from resetting a password.
|
||||
|
||||
To some extent, automating your password resets trades a bit of security for some convenience. So maybe this isn't the right way to handle C-suite user accounts that approve large payments.
|
||||
|
||||
On the other hand, manual resets are not 100% secure either—they can be gamed with targeted attacks like spear phishing and social engineering. It's much easier to fall for these scams if your team gets frequent reset requests and is sick of dealing with them. You may benefit from automating the bulk of lower-risk requests so you can focus on protecting the higher-risk accounts manually; this is possible given the time you can save using PWM.
|
||||
|
||||
Some of the risks associated with shifting resets to users can be mitigated with PWM's built-in features, such as insisting users verify their password reset request by email or SMS. You can also make PWM accessible only on the intranet.
|
||||
|
||||
![PWM configuration options][10]
|
||||
|
||||
PWM doesn't store any passwords, so that's one less headache. It does, however, store answers to users' secret questions in a MySQL database that can be configured to be stored locally or on a separate server, depending on your preference.
|
||||
|
||||
There are a ton of ways to make PWM look and feel like a polished part of your team's infrastructure. With a little bit of CSS know-how, you can customize the user interface for your business' branding. There are also more options for implementation than you can shake a stick at.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
PWM is a great open source project, it's actively developed, and it has a helpful online community. It's a great alternative to Microsoft's Azure SSPR solution for small to midsized businesses that have to keep a tight grip on the purse strings, and it slots in neatly to any existing Active Directory infrastructure. It also saves IT's time by outsourcing this mundane task to users.
|
||||
|
||||
I advise every network admin to dive in and have a look at the cool stuff PWM offers. Check out the [getting started resources][11] and reach out to the community if you have any questions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/automate-password-resets-pwm
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dxmjames
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/password.jpg?itok=ec6z6YgZ (Password)
|
||||
[2]: https://github.com/pwm-project/pwm
|
||||
[3]: https://github.com/pwm-project/pwm/blob/master/LICENSE
|
||||
[4]: https://www.oracle.com/technetwork/java/index-jsp-138231.html
|
||||
[5]: https://opensource.com/sites/default/files/uploads/pwm_password-reset.png (PWM password reset screen)
|
||||
[6]: https://opensource.com/business/14/5/top-4-open-source-ldap-implementations
|
||||
[7]: http://tomcat.apache.org/
|
||||
[8]: https://opensource.com/article/18/7/tools-admin
|
||||
[9]: https://blog.dxmtechsupport.com.au/adding-pwm-password-reset-tool-to-windows-network/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/pwm-configuration.png (PWM configuration options)
|
||||
[11]: https://github.com/pwm-project/pwm#links
|
||||
240
sources/tech/20190402 Manage your daily schedule with Git.md
Normal file
240
sources/tech/20190402 Manage your daily schedule with Git.md
Normal file
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Manage your daily schedule with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/calendar-git)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
Manage your daily schedule with Git
|
||||
======
|
||||
Treat time like source code and maintain your calendar with the help of
|
||||
Git.
|
||||
![website design image][1]
|
||||
|
||||
[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git. Today, we'll look at using Git to keep track of your calendar.
|
||||
|
||||
### Keep track of your schedule with Git
|
||||
|
||||
What if time itself was but source code that could be managed and version controlled? While proving or disproving such a theory is probably beyond the scope of this article, it happens that you can treat time like source code and manage your daily schedule with the help of Git.
|
||||
|
||||
The reigning champion for calendaring is the [CalDAV][3] protocol, which drives popular open source calendaring applications like [NextCloud][4] as well as popular closed source ones. There's nothing wrong with CalDAV (commenters, take heed). But it's not for everyone, and besides there's nothing less inspiring than a mono-culture.
|
||||
|
||||
Because I have no interest in becoming invested in largely GUI-dependent CalDAV clients (although if you're looking for a good terminal CalDAV viewer, see [khal][5]), I started investigating text-based alternatives. Text-based calendaring has all the usual benefits of working in [plaintext][6]. It's lightweight, it's highly portable, and as long as it's structured, it's easy to parse and beautify (whatever _beauty_ means to you).
|
||||
|
||||
And best of all, it's exactly what Git was designed to manage.
|
||||
|
||||
### Org mode not in a scary way
|
||||
|
||||
If you don't impose structure on your plaintext, it quickly falls into a pandemonium of off-the-cuff thoughts and devil-may-care notation. Luckily, a markup syntax exists for calendaring, and it's contained in the venerable productivity Emacs mode, [Org mode][7] (which, admit it, you've been meaning to start using anyway).
|
||||
|
||||
The amazing thing about Org mode that many people don't realize is [you don't need to know or even use Emacs][8] to take advantage of conventions established by Org mode. You get a lot of great features if you _do_ use Emacs, but if Emacs intimidates you, then you can implement a Git-based Org-mode calendaring system without so much as installing Emacs.
|
||||
|
||||
The only part of Org mode that you need to know is its syntax. Org-mode syntax is low-maintenance and fairly intuitive. The biggest difference in calendaring with Org mode instead of a GUI calendaring app is the workflow: instead of going to a calendar and finding the day you want to schedule a task, you create a list of tasks and then assign each one a day and time.
|
||||
|
||||
Lists in Org mode use asterisks (*) as bullets. Here's my gaming task list: ****
|
||||
|
||||
```
|
||||
* Gaming
|
||||
** Build Stardrifter character
|
||||
** Read Stardrifter rules
|
||||
** Stardrifter playtest
|
||||
|
||||
** Blue Planet @ Mike's
|
||||
|
||||
** Run Rappan Athuk
|
||||
*** Purchase hard copy
|
||||
*** Skim Rappan Athuk
|
||||
*** Build Rappan Athuk maps in maptool
|
||||
*** Sort Rappan Athuk tokens
|
||||
```
|
||||
|
||||
If you're familiar with [CommonMark][9] or Markdown, you'll notice that instead of using whitespace to create a subtask, Org mode favors the more explicit use of additional bullets. Whatever your background with lists, this is an intuitive and easy way to build a list, and it obviously is not inherently tied to Emacs (although using Emacs provides you with shortcuts so you can rearrange your list quickly).
|
||||
|
||||
To turn your list into scheduled tasks or events in a calendar, go back through and add the keywords **SCHEDULED** and, optionally, **:CATEGORY:**.
|
||||
|
||||
```
|
||||
* Gaming
|
||||
:CATEGORY: Game
|
||||
** Build Stardrifter character
|
||||
SCHEDULED: <2019-03-22 18:00-19:00>
|
||||
** Read Stardrifter rules
|
||||
SCHEDULED: <2019-03-22 19:00-21:00>
|
||||
** Stardrifter playtest
|
||||
SCHEDULED: <2019-03-25 0900-1300>
|
||||
** Blue Planet @ Mike's
|
||||
SCHEDULED: <2019-03-18 18:00-23:00 +1w>
|
||||
|
||||
and so on...
|
||||
```
|
||||
|
||||
The **SCHEDULED** keyword marks the entry as an event that you expect to be notified about and the optional **:CATEGORY:** keyword is an arbitrary tagging system for your own use (and in Emacs, you can color-code entries according to category).
|
||||
|
||||
For a repeating event, you can use notation such as **+1w** to create a weekly event or **+2w** for a fortnightly event, and so on.
|
||||
|
||||
All the fancy markup available for Org mode is [documented][10], so don't hesitate to find more tricks to help it fit your needs.
|
||||
|
||||
### Put it into Git
|
||||
|
||||
Without Git, your Org-mode appointments are just a file on your local machine. It's the 21st century, though, so you at least need your calendar on your mobile phone, if not on all of your personal computers. You can use Git to publish your calendar for yourself and others.
|
||||
|
||||
First, create a directory for your **.org** files. I store mine in **~/cal**.
|
||||
|
||||
```
|
||||
$ mkdir ~/cal
|
||||
```
|
||||
|
||||
Change into your directory and make it a Git repository:
|
||||
|
||||
```
|
||||
$ cd cal
|
||||
$ git init
|
||||
```
|
||||
|
||||
Move your **.org** file to your local Git repo. In practice, I maintain one **.org** file per category.
|
||||
|
||||
```
|
||||
$ mv ~/*.org ~/cal
|
||||
$ ls
|
||||
Game.org Meal.org Seth.org Work.org
|
||||
```
|
||||
|
||||
Stage and commit your files:
|
||||
|
||||
```
|
||||
$ git add *.org
|
||||
$ git commit -m 'cal init'
|
||||
```
|
||||
|
||||
### Create a Git remote
|
||||
|
||||
To make your calendar available from anywhere, you must have a Git repository on the internet. Your calendar is plaintext, so any Git repository will do. You can put your calendar on [GitLab][11] or any other public Git hosting service (even proprietary ones), and as long as your host allows it, you can even mark the repository as private. If you don't want to post your calendar to a server you don't control, it's easy to host a Git repository yourself, either using a bare repository for a single user or using a frontend service like [Gitolite][12] or [Gitea][13].
|
||||
|
||||
In the interest of simplicity, I'll assume a self-hosted bare Git repository. You can create a bare remote repository on any server you have SSH access to with one Git command:
|
||||
```
|
||||
$ ssh -p 22122 [seth@example.com][14]
|
||||
[remote]$ mkdir cal.git
|
||||
[remote]$ cd cal.git
|
||||
[remote]$ git init --bare
|
||||
[remote]$ exit
|
||||
```
|
||||
|
||||
This bare repository can serve as your calendar's home on the internet.
|
||||
|
||||
Set it as the remote source for your local (on your computer, not your server) Git repository:
|
||||
|
||||
```
|
||||
$ git remote add origin seth@example.com:/home/seth/cal.git
|
||||
```
|
||||
|
||||
And then push your calendar data to the server:
|
||||
|
||||
```
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
With your calendar in a Git repository, it's available to you on any device running Git. That means you can make updates and changes to your schedule and push your changes upstream so it updates everywhere.
|
||||
|
||||
I use this method to keep my calendar in sync between my work laptop and my home workstation. Since I use Emacs every day for most of the day, being able to view and edit my calendar in Emacs is a major convenience. The same is true for most people with a mobile device, so the next step is to set up an Org-mode calendaring system on a mobile.
|
||||
|
||||
### Mobile Git
|
||||
|
||||
Since your calendar data is in plaintext, strictly speaking, you can "use" it on any device that can read a text file. That's part of the beauty of this system; you're never without, at the very least, your raw data. But to integrate your calendar on a mobile device the way you'd expect a modern calendar to work, you need two components: a mobile Git client and a mobile Org-mode viewer.
|
||||
|
||||
#### Git client for mobile
|
||||
|
||||
[MGit][15] is a good Git client for Android. There are Git clients for iOS, as well.
|
||||
|
||||
Once you've installed MGit (or a similar Git client), you must clone your calendar repository so your phone has a copy. To access your server from your mobile device, you must set up an SSH key for authentication. MGit can generate and store a key for you, which you must add to your server's **~/.ssh/authorized_keys** file or to your SSH keys in the settings of your hosted Git account.
|
||||
|
||||
You must do this manually. MGit does not have an interface to log into your server or hosted Git account. If you do not do this, your mobile device cannot access your server to access your calendar data.
|
||||
|
||||
I did it by copying the key file I generated in MGit to my laptop over [KDE Connect][16] (but you can do the same over Bluetooth, or with an SD card reader, or a USB cable, depending on your preferred method of accessing data on your phone). I copied the key (a file called **calkey** to my server with this command:
|
||||
|
||||
```
|
||||
$ cat calkey | ssh seth@example.com "cat >> /home/seth/.ssh/authorized_keys"
|
||||
```
|
||||
|
||||
You may have a different way of doing it, but if you ever set your server up for passwordless login, this is exactly the same process. If you're using a hosted Git service like GitLab, you must copy and paste the contents of your key file into your user account's SSH Key panel.
|
||||
|
||||
![Adding key file data to GitLab][17]
|
||||
|
||||
Once that's done, your mobile device can authorize to your server, but it still needs to know where to go to find your calendar data. Different apps may use different notation, but MGit uses plain old Git-over-SSH. That means if you're using a non-standard SSH port, you must specify the SSH port to use:
|
||||
|
||||
```
|
||||
$ git clone ssh://seth@example.com:22122//home/seth/git/cal.git
|
||||
```
|
||||
|
||||
![Specifying SSH port in MGit][18]
|
||||
|
||||
If you use a different app, it may use a different syntax that allows you to provide a port in a special field or drop the **ssh://** prefix. Refer to the app documentation if you experience issues.
|
||||
|
||||
Clone the repository to your phone.
|
||||
|
||||
![Cloned repositories][19]
|
||||
|
||||
Few Git apps are set to automatically update the repository. There are a few apps you can use to automate pulls, or you can set up Git hooks to push updates from your server—but I won't get into that here. For now, after you make an update to your calendar, be sure to pull new changes manually in MGit (or if you change events on your phone, push the changes to your server).
|
||||
|
||||
![MGit push/pull settings][20]
|
||||
|
||||
#### Mobile calendar
|
||||
|
||||
There are a few different apps that provide frontends for Org mode on a mobile device. [Orgzly][21] is a great open source Android app that provides an interface for Org mode's greatest features, from the Agenda mode to the TODO lists. Install and launch it.
|
||||
|
||||
From the Main menu, choose Setting Sync Repositories and select the directory containing your calendar files (i.e., the Git repository you cloned from your server).
|
||||
|
||||
Give Orgzly a moment to import the data, then use Orgzly's [hamburger][22] menu to select the Agenda view.
|
||||
|
||||
![Orgzly's agenda view][23]
|
||||
|
||||
In Orgzly's Settings Reminders menu, you can choose which event types trigger a notification on your phone. You can get notifications for **SCHEDULED** tasks, **DEADLINE** tasks, or anything with an event time assigned to it. If you use your phone as your taskmaster, you'll never miss an event with Org mode and Orgzly.
|
||||
|
||||
![Orgzly notification][24]
|
||||
|
||||
Orgzly isn't just a parser. You can edit and update events, and even mark events **DONE**.
|
||||
|
||||
![Orgzly to-do list][25]
|
||||
|
||||
### Designed for and by you
|
||||
|
||||
The important thing to understand about using Org mode and Git is that both applications are highly flexible, and it's expected that you'll customize how and what they do so they will adapt to your needs. If something in this article is an affront to how you organize your life or manage your weekly schedule, but you like other parts of what this proposal offers, then throw out the part you don't like. You can use Org mode in Emacs if you want, or you can just use it as calendar markup. You can set your phone to pull Git data right off your computer at the end of the day instead of a server on the internet, or you can configure your computer to sync calendars whenever your phone is plugged in, or you can manage it daily as you load up your phone with all the stuff you need for the workday. It's up to you, and that's the most significant thing about Git, about Org mode, and about open source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/calendar-git
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web-design-monitor-website.png?itok=yUK7_qR0 (website design image)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://tools.ietf.org/html/rfc4791
|
||||
[4]: http://nextcloud.com
|
||||
[5]: https://github.com/pimutils/khal
|
||||
[6]: https://plaintextproject.online/
|
||||
[7]: https://orgmode.org
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
[9]: https://commonmark.org/
|
||||
[10]: https://orgmode.org/manual/
|
||||
[11]: http://gitlab.com
|
||||
[12]: http://gitolite.com/gitolite/index.html
|
||||
[13]: https://gitea.io/en-us/
|
||||
[14]: mailto:seth@example.com
|
||||
[15]: https://f-droid.org/en/packages/com.manichord.mgit
|
||||
[16]: https://community.kde.org/KDEConnect
|
||||
[17]: https://opensource.com/sites/default/files/uploads/gitlab-add-key.jpg (Adding key file data to GitLab)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/mgit-0.jpg (Specifying SSH port in MGit)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/mgit-1.jpg (Cloned repositories)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/mgit-2.jpg (MGit push/pull settings)
|
||||
[21]: https://f-droid.org/en/packages/com.orgzly/
|
||||
[22]: https://en.wikipedia.org/wiki/Hamburger_button
|
||||
[23]: https://opensource.com/sites/default/files/uploads/orgzly-agenda.jpg (Orgzly's agenda view)
|
||||
[24]: https://opensource.com/sites/default/files/uploads/orgzly-cal-notify.jpg (Orgzly notification)
|
||||
[25]: https://opensource.com/sites/default/files/uploads/orgzly-cal-todo.jpg (Orgzly to-do list)
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Parallel computation in Python with Dask)
|
||||
[#]: via: (https://opensource.com/article/19/4/parallel-computation-python-dask)
|
||||
[#]: author: (Moshe Zadka (Community Moderator) https://opensource.com/users/moshez)
|
||||
|
||||
Parallel computation in Python with Dask
|
||||
======
|
||||
The Dask library scales Python computation to multiple cores or even to
|
||||
multiple machines.
|
||||
![Pair programming][1]
|
||||
|
||||
One frequent complaint about Python performance is the [global interpreter lock][2] (GIL). Because of GIL, only one thread can execute Python byte code at a time. As a consequence, using threads does not speed up computation—even on modern, multi-core machines.
|
||||
|
||||
But when you need to parallelize to many cores, you don't need to stop using Python: the **[Dask][3]** library will scale computation to multiple cores or even to multiple machines. Some setups configure Dask on thousands of machines, each with multiple cores; while there are scaling limits, they are not easy to hit.
|
||||
|
||||
While Dask has many built-in array operations, as an example of something not built-in, we can calculate the [skewness][4]:
|
||||
```
|
||||
import numpy
|
||||
import dask
|
||||
from dask import array as darray
|
||||
|
||||
arr = dask.from_array(numpy.array(my_data), chunks=(1000,))
|
||||
mean = darray.mean()
|
||||
stddev = darray.std(arr)
|
||||
unnormalized_moment = darry.mean(arr * arr * arr)
|
||||
## See formula in wikipedia:
|
||||
skewness = ((unnormalized_moment - (3 * mean * stddev ** 2) - mean ** 3) /
|
||||
stddev ** 3)
|
||||
```
|
||||
|
||||
Notice that each operation will use as many cores as needed. This will parallelize across all cores, even when calculating across billions of elements.
|
||||
|
||||
Of course, it is not always the case that our operations can be parallelized by the library; sometimes we need to implement parallelism on our own.
|
||||
|
||||
For that, Dask has a "delayed" functionality:
|
||||
```
|
||||
import dask
|
||||
|
||||
def is_palindrome(s):
|
||||
return s == s[::-1]
|
||||
|
||||
palindromes = [dask.delayed(is_palindrome)(s) for s in string_list]
|
||||
total = dask.delayed(sum)(palindromes)
|
||||
result = total.compute()
|
||||
```
|
||||
|
||||
This will calculate whether strings are palindromes in parallel and will return a count of the palindromic ones.
|
||||
|
||||
While Dask was created for data scientists, it is by no means limited to data science. Whenever we need to parallelize tasks in Python, we can turn to Dask—GIL or no GIL.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/parallel-computation-python-dask
|
||||
|
||||
作者:[Moshe Zadka (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/collab-team-pair-programming-code-keyboard.png?itok=kBeRTFL1 (Pair programming)
|
||||
[2]: https://wiki.python.org/moin/GlobalInterpreterLock
|
||||
[3]: https://github.com/dask/dask
|
||||
[4]: https://en.wikipedia.org/wiki/Skewness#Definition
|
||||
124
sources/tech/20190403 5 useful open source log analysis tools.md
Normal file
124
sources/tech/20190403 5 useful open source log analysis tools.md
Normal file
@ -0,0 +1,124 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 useful open source log analysis tools)
|
||||
[#]: via: (https://opensource.com/article/19/4/log-analysis-tools)
|
||||
[#]: author: (Sam Bocetta https://opensource.com/users/sambocetta)
|
||||
|
||||
5 useful open source log analysis tools
|
||||
======
|
||||
Monitoring network activity is as important as it is tedious. These
|
||||
tools can make it easier.
|
||||
![People work on a computer server][1]
|
||||
|
||||
Monitoring network activity can be a tedious job, but there are good reasons to do it. For one, it allows you to find and investigate suspicious logins on workstations, devices connected to networks, and servers while identifying sources of administrator abuse. You can also trace software installations and data transfers to identify potential issues in real time rather than after the damage is done.
|
||||
|
||||
Those logs also go a long way towards keeping your company in compliance with the [General Data Protection Regulation][2] (GDPR) that applies to any entity operating within the European Union. If you have a website that is viewable in the EU, you qualify.
|
||||
|
||||
Logging—both tracking and analysis—should be a fundamental process in any monitoring infrastructure. A transaction log file is necessary to recover a SQL server database from disaster. Further, by tracking log files, DevOps teams and database administrators (DBAs) can maintain optimum database performance or find evidence of unauthorized activity in the case of a cyber attack. For this reason, it's important to regularly monitor and analyze system logs. It's a reliable way to re-create the chain of events that led up to whatever problem has arisen.
|
||||
|
||||
There are quite a few open source log trackers and analysis tools available today, making choosing the right resources for activity logs easier than you think. The free and open source software community offers log designs that work with all sorts of sites and just about any operating system. Here are five of the best I've used, in no particular order.
|
||||
|
||||
### Graylog
|
||||
|
||||
[Graylog][3] started in Germany in 2011 and is now offered as either an open source tool or a commercial solution. It is designed to be a centralized log management system that receives data streams from various servers or endpoints and allows you to browse or analyze that information quickly.
|
||||
|
||||
![Graylog screenshot][4]
|
||||
|
||||
Graylog has built a positive reputation among system administrators because of its ease in scalability. Most web projects start small but can grow exponentially. Graylog can balance loads across a network of backend servers and handle several terabytes of log data each day.
|
||||
|
||||
IT administrators will find Graylog's frontend interface to be easy to use and robust in its functionality. Graylog is built around the concept of dashboards, which allows you to choose which metrics or data sources you find most valuable and quickly see trends over time.
|
||||
|
||||
When a security or performance incident occurs, IT administrators want to be able to trace the symptoms to a root cause as fast as possible. Search functionality in Graylog makes this easy. It has built-in fault tolerance that can run multi-threaded searches so you can analyze several potential threats together.
|
||||
|
||||
### Nagios
|
||||
|
||||
[Nagios][5] started with a single developer back in 1999 and has since evolved into one of the most reliable open source tools for managing log data. The current version of Nagios can integrate with servers running Microsoft Windows, Linux, or Unix.
|
||||
|
||||
![Nagios Core][6]
|
||||
|
||||
Its primary product is a log server, which aims to simplify data collection and make information more accessible to system administrators. The Nagios log server engine will capture data in real-time and feed it into a powerful search tool. Integrating with a new endpoint or application is easy thanks to the built-in setup wizard.
|
||||
|
||||
Nagios is most often used in organizations that need to monitor the security of their local network. It can audit a range of network-related events and help automate the distribution of alerts. Nagios can even be configured to run predefined scripts if a certain condition is met, allowing you to resolve issues before a human has to get involved.
|
||||
|
||||
As part of network auditing, Nagios will filter log data based on the geographic location where it originates. That means you can build comprehensive dashboards with mapping technology to understand how your web traffic is flowing.
|
||||
|
||||
### Elastic Stack (the "ELK Stack")
|
||||
|
||||
[Elastic Stack][7], often called the ELK Stack, is one of the most popular open source tools among organizations that need to sift through large sets of data and make sense of their system logs (and it's a personal favorite, too).
|
||||
|
||||
![ELK Stack][8]
|
||||
|
||||
Its primary offering is made up of three separate products: Elasticsearch, Kibana, and Logstash:
|
||||
|
||||
* As its name suggests, _**Elasticsearch**_ is designed to help users find matches within datasets using a wide range of query languages and types. Speed is this tool's number one advantage. It can be expanded into clusters of hundreds of server nodes to handle petabytes of data with ease.
|
||||
|
||||
* _**Kibana**_ is a visualization tool that runs alongside Elasticsearch to allow users to analyze their data and build powerful reports. When you first install the Kibana engine on your server cluster, you will gain access to an interface that shows statistics, graphs, and even animations of your data.
|
||||
|
||||
* The final piece of ELK Stack is _**Logstash**_ , which acts as a purely server-side pipeline into the Elasticsearch database. You can integrate Logstash with a variety of coding languages and APIs so that information from your websites and mobile applications will be fed directly into your powerful Elastic Stalk search engine.
|
||||
|
||||
|
||||
|
||||
|
||||
A unique feature of ELK Stack is that it allows you to monitor applications built on open source installations of WordPress. In contrast to most out-of-the-box security audit log tools that [track admin and PHP logs][9] but little else, ELK Stack can sift through web server and database logs.
|
||||
|
||||
Poor log tracking and database management are one of the [most common causes of poor website performance][10]. Failure to regularly check, optimize, and empty database logs can not only slow down a site but could lead to a complete crash as well. Thus, the ELK Stack is an excellent tool for every WordPress developer's toolkit.
|
||||
|
||||
### LOGalyze
|
||||
|
||||
[LOGalyze][11] is an organization based in Hungary that builds open source tools for system administrators and security experts to help them manage server logs and turn them into useful data points. Its primary product is available as a free download for either personal or commercial use.
|
||||
|
||||
![LOGalyze][12]
|
||||
|
||||
LOGalyze is designed to work as a massive pipeline in which multiple servers, applications, and network devices can feed information using the Simple Object Access Protocol (SOAP) method. It provides a frontend interface where administrators can log in to monitor the collection of data and start analyzing it.
|
||||
|
||||
From within the LOGalyze web interface, you can run dynamic reports and export them into Excel files, PDFs, or other formats. These reports can be based on multi-dimensional statistics managed by the LOGalyze backend. It can even combine data fields across servers or applications to help you spot trends in performance.
|
||||
|
||||
LOGalyze is designed to be installed and configured in less than an hour. It has prebuilt functionality that allows it to gather audit data in formats required by regulatory acts. For example, LOGalyze can easily run different HIPAA reports to ensure your organization is adhering to health regulations and remaining compliant.
|
||||
|
||||
### Fluentd
|
||||
|
||||
If your organization has data sources living in many different locations and environments, your goal should be to centralize them as much as possible. Otherwise, you will struggle to monitor performance and protect against security threats.
|
||||
|
||||
[Fluentd][13] is a robust solution for data collection and is entirely open source. It does not offer a full frontend interface but instead acts as a collection layer to help organize different pipelines. Fluentd is used by some of the largest companies worldwide but can be implemented in smaller organizations as well.
|
||||
|
||||
![Fluentd architecture][14]
|
||||
|
||||
The biggest benefit of Fluentd is its compatibility with the most common technology tools available today. For example, you can use Fluentd to gather data from web servers like Apache, sensors from smart devices, and dynamic records from MongoDB. What you do with that data is entirely up to you.
|
||||
|
||||
Fluentd is based around the JSON data format and can be used in conjunction with [more than 500 plugins][15] created by reputable developers. This allows you to extend your logging data into other applications and drive better analysis from it with minimal manual effort.
|
||||
|
||||
### The bottom line
|
||||
|
||||
If you aren't already using activity logs for security reasons, governmental compliance, and measuring productivity, commit to changing that. There are plenty of plugins on the market that are designed to work with multiple environments and platforms, even on your internal network. Don't wait for a serious incident to justify taking a proactive approach to logs maintenance and oversight.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/log-analysis-tools
|
||||
|
||||
作者:[Sam Bocetta][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sambocetta
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux11x_cc.png?itok=XMDOouJR (People work on a computer server)
|
||||
[2]: https://opensource.com/article/18/4/gdpr-impact
|
||||
[3]: https://www.graylog.org/products/open-source
|
||||
[4]: https://opensource.com/sites/default/files/uploads/graylog-data.png (Graylog screenshot)
|
||||
[5]: https://www.nagios.org/downloads/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/nagios_core_4.0.8.png (Nagios Core)
|
||||
[7]: https://www.elastic.co/products
|
||||
[8]: https://opensource.com/sites/default/files/uploads/elk-stack.png (ELK Stack)
|
||||
[9]: https://www.wpsecurityauditlog.com/benefits-wordpress-activity-log/
|
||||
[10]: https://websitesetup.org/how-to-speed-up-wordpress/
|
||||
[11]: http://www.logalyze.com/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/logalyze.jpg (LOGalyze)
|
||||
[13]: https://www.fluentd.org/
|
||||
[14]: https://opensource.com/sites/default/files/uploads/fluentd-architecture.png (Fluentd architecture)
|
||||
[15]: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
141
sources/tech/20190403 Use Git as the backend for chat.md
Normal file
141
sources/tech/20190403 Use Git as the backend for chat.md
Normal file
@ -0,0 +1,141 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use Git as the backend for chat)
|
||||
[#]: via: (https://opensource.com/article/19/4/git-based-chat)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
Use Git as the backend for chat
|
||||
======
|
||||
GIC is a prototype chat application that showcases a novel way to use Git.
|
||||
![Team communication, chat][1]
|
||||
|
||||
[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git. Today, we'll look at GIC, a Git-based chat application
|
||||
|
||||
### Meet GIC
|
||||
|
||||
While the authors of Git probably expected frontends to be created for Git, they undoubtedly never expected Git would become the backend for, say, a chat client. Yet, that's exactly what developer Ephi Gabay did with his experimental proof-of-concept [GIC][3]: a chat client written in [Node.js][4] using Git as its backend database.
|
||||
|
||||
GIC is by no means intended for production use. It's purely a programming exercise, but it's one that demonstrates the flexibility of open source technology. What's astonishing is that the client consists of just 300 lines of code, excluding the Node libraries and Git itself. And that's one of the best things about the chat client and about open source; the ability to build upon existing work. Seeing is believing, so you should give GIC a look for yourself.
|
||||
|
||||
### Get set up
|
||||
|
||||
GIC uses Git as its engine, so you need an empty Git repository to serve as its chatroom and logger. The repository can be hosted anywhere, as long as you and anyone who needs access to the chat service has access to it. For instance, you can set up a Git repository on a free Git hosting service like GitLab and grant chat users contributor access to the Git repository. (They must be able to make commits to the repository, because each chat message is a literal commit.)
|
||||
|
||||
If you're hosting it yourself, create a centrally located bare repository. Each user in the chat must have an account on the server where the bare repository is located. You can create accounts specific to Git with Git hosting software like [Gitolite][5] or [Gitea][6], or you can give them individual user accounts on your server, possibly using **git-shell** to restrict their access to Git.
|
||||
|
||||
Performance is best on a self-hosted instance. Whether you host your own or you use a hosting service, the Git repository you create must have an active branch, or GIC won't be able to make commits as users chat because there is no Git HEAD. The easiest way to ensure that a branch is initialized and active is to commit a README or license file upon creation. If you don't do that, you can create and commit one after the fact:
|
||||
|
||||
```
|
||||
$ echo "chat logs" > README
|
||||
$ git add README
|
||||
$ git commit -m 'just creating a HEAD ref'
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
### Install GIC
|
||||
|
||||
Since GIC is based on Git and written in Node.js, you must first install Git, Node.js, and the Node package manager, npm (which should be bundled with Node). The command to install these differs depending on your Linux or BSD distribution, but here's an example command on Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install git nodejs
|
||||
```
|
||||
|
||||
If you're not running Linux or BSD, follow the installation instructions on [git-scm.com][7] and [nodejs.org][8].
|
||||
|
||||
There's no install process, as such, for GIC. Each user (Alice and Bob, in this example) must clone the repository to their hard drive:
|
||||
|
||||
```
|
||||
$ git cone https://github.com/ephigabay/GIC GIC
|
||||
```
|
||||
|
||||
Change directory into the GIC directory and install the Node.js dependencies with **npm** :
|
||||
|
||||
```
|
||||
$ cd GIC
|
||||
$ npm install
|
||||
```
|
||||
|
||||
Wait for the Node modules to download and install.
|
||||
|
||||
### Configure GIC
|
||||
|
||||
The only configuration GIC requires is the location of your Git chat repository. Edit the **config.js** file:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
gitRepo: '[seth@example.com][9]:/home/gitchat/chatdemo.git',
|
||||
messageCheckInterval: 500,
|
||||
branchesCheckInterval: 5000
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
Test your connection to the Git repository before trying GIC, just to make sure your configuration is sane:
|
||||
|
||||
```
|
||||
$ git clone --quiet seth@example.com:/home/gitchat/chatdemo.git > /dev/null
|
||||
```
|
||||
|
||||
Assuming you receive no errors, you're ready to start chatting.
|
||||
|
||||
### Chat with Git
|
||||
|
||||
From within the GIC directory, start the chat client:
|
||||
|
||||
```
|
||||
$ npm start
|
||||
```
|
||||
|
||||
When the client first launches, it must clone the chat repository. Since it's nearly an empty repository, it won't take long. Type your message and press Enter to send a message.
|
||||
|
||||
![GIC][10]
|
||||
|
||||
A Git-based chat client. What will they think of next?
|
||||
|
||||
As the greeting message says, a branch in Git serves as a chatroom or channel in GIC. There's no way to create a new branch from within the GIC UI, but if you create one in another terminal session or in a web UI, it shows up immediately in GIC. It wouldn't take much to patch some IRC-style commands into GIC.
|
||||
|
||||
After chatting for a while, take a look at your Git repository. Since the chat happens in Git, the repository itself is also a chat log:
|
||||
|
||||
```
|
||||
$ git log --pretty=format:"%p %cn %s"
|
||||
4387984 Seth Kenlon Hey Chani, did you submit a talk for All Things Open this year?
|
||||
36369bb Chani No I didn't get a chance. Did you?
|
||||
[...]
|
||||
```
|
||||
|
||||
### Exit GIC
|
||||
|
||||
Not since Vim has there been an application as difficult to stop as GIC. You see, there is no way to stop GIC. It will continue to run until it is killed. When you're ready to stop GIC, open another terminal tab or window and issue this command:
|
||||
|
||||
```
|
||||
$ kill `pgrep npm`
|
||||
```
|
||||
|
||||
GIC is a novelty. It's a great example of how an open source ecosystem encourages and enables creativity and exploration and challenges us to look at applications from different angles. Try GIC out. Maybe it will give you ideas. At the very least, it's a great excuse to spend an afternoon with Git.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/git-based-chat
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://github.com/ephigabay/GIC
|
||||
[4]: https://nodejs.org/en/
|
||||
[5]: http://gitolite.com
|
||||
[6]: http://gitea.io
|
||||
[7]: http://git-scm.com
|
||||
[8]: http://nodejs.org
|
||||
[9]: mailto:seth@example.com
|
||||
[10]: https://opensource.com/sites/default/files/uploads/gic.jpg (GIC)
|
||||
@ -0,0 +1,101 @@
|
||||
重新发现 make: 规则背后的力量
|
||||
======
|
||||
|
||||

|
||||
|
||||
我过去认为 makefiles 只是一种将一组组的 shell 命令列出来的简便方法;过了一段时间我了解到它们是有多么的强大、灵活以及功能齐全。这篇文章带你领略其中一些有关规则的特性。
|
||||
|
||||
### 规则
|
||||
|
||||
规则是表明 `make` 如何并且何时搭建一个被称作为目标(target)的文件的指令。目标文件可以依赖于其它被称作为前提(prerequisite)的文件。
|
||||
|
||||
你指明 `make` 如何在配方(recipe)中搭建目标,这个过程不过是一套按照出现顺序一次执行一个的 shell 命令。像这样的句法:
|
||||
```
|
||||
target_name : prerequisites
|
||||
recipe
|
||||
```
|
||||
|
||||
一但你定义好了规则,你就可以通过从命令行执行以下命令搭建目标:
|
||||
```
|
||||
$ make target_name
|
||||
```
|
||||
|
||||
目标一经搭建,除非前提改变,否则 `make` 会足够聪明地不再去运行配方。
|
||||
|
||||
### 关于前提的更多信息
|
||||
|
||||
前提表明了两件事情:
|
||||
|
||||
* 当目标应当被搭建时:如果其中一个前提比目标更新,`make` 假定目的应当被搭建。
|
||||
* 执行的顺序:鉴于前提可以反过来在 makefile 中被另一套规则所搭建,它们同样暗中定下了一个执行规则的顺序。
|
||||
|
||||
|
||||
|
||||
如果你想要定义一个顺序但是你不想在前提改变的时候重新搭建目标,你可以使用一种特别的叫做“唯顺序”的前提。这种前提可以被放在普通的前提之后,用管道符(`|`)进行分隔。
|
||||
|
||||
### 样式
|
||||
|
||||
为了便利,`make` 接受目标和前提的样式。通过包含 `%` 符号可以定义一种式样。这个符号是一个可以匹配任何长度的文字符号或者空隔的通配符。以下有一些示例:
|
||||
|
||||
* `%`:匹配任何文件
|
||||
* `%.md`:匹配所有 `.md` 结尾的文件
|
||||
* `prefix%.go`:匹配所有以 `prefix` 开头以 `go` 结尾的文件
|
||||
|
||||
|
||||
|
||||
### 特殊目标
|
||||
|
||||
有一系列目标名字,它们对于 `make` 来说有特殊的意义,被称作特殊目标。
|
||||
|
||||
你可以在这个[文档][1]发现全套特殊目标。作为一种经验法则,特殊目标以点开始后面跟着大写字母。
|
||||
|
||||
以下是几个有用的特殊目标:
|
||||
|
||||
**.PHONY**:向 `make` 表明此目标的前提被当成伪目标。这意味着 `make` 将总是运行无论有那个名字的文件是否存在或者上次被修改的时间是什么。
|
||||
|
||||
**.DEFAULT**:被用于任何没有规则的目标。
|
||||
|
||||
**.IGNORE**:如果你指定 **.IGNORE** 为前提,`make` 将忽略执行配方过程中的错误。
|
||||
|
||||
### 替代(substitution)
|
||||
|
||||
当你需要以你指定的改动方式改变一个变量的值,替代就十分有用了。
|
||||
|
||||
一个替代有着 `$(var:a=b)` 的形式,它的意思是获取变量 `var` 的值,用值里面的 `b` 替代词末尾的每个 `a` 以代替最终的字符串。例如:
|
||||
```
|
||||
foo := a.o
|
||||
bar : = $(foo:.o=.c) # sets bar to a.c
|
||||
```
|
||||
|
||||
|
||||
注意:特别感谢 [Luis Lavena][2] 让我们知道替代的存在。
|
||||
|
||||
### 档案文件
|
||||
|
||||
档案文件是用来一起将多个数据文档(和压缩文件同样的概念)收集成一个文件。它们由 `ar` Unix 设施搭建。`ar` 可以被用来为任何目的创建档案,但除了在[静态库][3]方面已经被 `tar` 大量替代。
|
||||
|
||||
在 `make` 中,你可以使用一个档案文件中的单独一个成员作为目标或者前提,就像这样:
|
||||
```
|
||||
archive(member) : prerequisite
|
||||
recipe
|
||||
```
|
||||
|
||||
### 最后的想法
|
||||
|
||||
关于 make 还有更多可探索的,但是至少这是一个起点,我强烈鼓励你去查看[文档][4],创建一个笨拙的 makefile 然后就可以探索它了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://monades.roperzh.com/rediscovering-make-power-behind-rules/
|
||||
|
||||
作者:[Roberto Dip][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://monades.roperzh.com
|
||||
[1]:https://www.gnu.org/software/make/manual/make.html#Special-Targets
|
||||
[2]:https://twitter.com/luislavena/
|
||||
[3]:http://tldp.org/HOWTO/Program-Library-HOWTO/static-libraries.html
|
||||
[4]:https://www.gnu.org/software/make/manual/make.html
|
||||
@ -0,0 +1,136 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Oomox – Customize And Create Your Own GTK2, GTK3 Themes)
|
||||
[#]: via: (https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/)
|
||||
[#]: author: (EDITOR https://www.ostechnix.com/author/editor/)
|
||||
|
||||
Oomox - 定制并创建你自己的 GTK2、GTK3 主题
|
||||
======
|
||||
|
||||

|
||||
|
||||
主题和可视化定制是 Linux 的主要优势之一。由于所有代码都是开放的,因此你可以比 Windows/Mac OS 更大程度上地改变 Linux 系统的外观和行为方式。GTK 主题可能是人们定制 Linux 桌面的最流行方式。GTK 工具包被各种桌面环境使用,如 Gnome、Cinnamon、Unity、XFC E和 budgie。这意味着为 GTK 制作的单个主题只需很少的修改就能应用于任何这些桌面环境。
|
||||
|
||||
有很多非常高品质的流行 GTK 主题,例如 **Arc**、**Numix** 和 **Adapta**。但是如果你想自定义这些主题并创建自己的视觉设计,你可以使用 **Oomox**。
|
||||
|
||||
Oomox 是一个图形应用,可以完全使用自己的颜色,图标和终端风格自定义和创建自己的 GTK 主题。它自带几个预设,你可以在 Numix、Arc 或 Materia 主题样式上创建自己的 GTK 主题。
|
||||
|
||||
### 安装 Oomox
|
||||
|
||||
在 Arch Linux 及其衍生版中:
|
||||
|
||||
Oomox 可以在 [**AUR**][1] 中找到,所以你可以使用任何 AUR 助手程序安装它,如 [**Yay**][2]。
|
||||
|
||||
```
|
||||
$ yay -S oomox
|
||||
|
||||
```
|
||||
|
||||
在 Debian/Ubuntu/Linux Mint 中,在[**这里**][3]下载 `oomox.deb` 包并按如下所示进行安装。在写本指南时,最新版本为 **oomox_1.7.0.5.deb**。
|
||||
|
||||
```
|
||||
$ sudo dpkg -i oomox_1.7.0.5.deb
|
||||
$ sudo apt install -f
|
||||
|
||||
```
|
||||
|
||||
在 Fedora 上,Oomox 可以在第三方 **COPR** 仓库中找到。
|
||||
|
||||
```
|
||||
$ sudo dnf copr enable tcg/themes
|
||||
$ sudo dnf install oomox
|
||||
|
||||
```
|
||||
|
||||
Oomox 也有 [**Flatpak 应用**][4]。确保已按照[**本指南**][5]中的说明安装了 Flatpak。然后,使用以下命令安装并运行 Oomox:
|
||||
|
||||
```
|
||||
$ flatpak install flathub com.github.themix_project.Oomox
|
||||
|
||||
$ flatpak run com.github.themix_project.Oomox
|
||||
|
||||
```
|
||||
|
||||
对于其他 Linux 发行版,请进入 Github 上的 Oomox 项目页面(本指南末尾给出链接),并从源代码手动编译和安装。
|
||||
|
||||
### 自定义并创建自己的 GTK2、GTK3 主题
|
||||
|
||||
**主题定制**
|
||||
|
||||

|
||||
|
||||
你可以更改几乎每个 UI 元素的颜色,例如:
|
||||
|
||||
1. 标题
|
||||
2. 按钮
|
||||
3. 标题内的按钮
|
||||
4. 菜单
|
||||
5. 选定的文字
|
||||
|
||||
|
||||
|
||||
在左边,有许多预设,如汽车主题、现代主题,如 Materia、和 Numix,以及复古主题。在窗口的顶部,有一个名为**主题样式**的选项,可让你设置主题的整体视觉样式。你可以在 Numix、Arc 和 Materia 之间进行选择。
|
||||
|
||||
使用某些像 Numix 这样的样式,你甚至可以更改标题渐变,边框宽度和面板透明度等内容。你还可以为主题添加黑暗模式,该模式将从默认主题自动创建。
|
||||
|
||||

|
||||
|
||||
**图标集定制**
|
||||
|
||||
你可以自定义用于主题图标的图标集。有两个选项 - Gnome Colors 和 Archdroid。你可以更改图标集的基础和笔触颜色。
|
||||
|
||||
**终端定制**
|
||||
|
||||
你还可以自定义终端颜色。该应用有几个预设,但你可以为每个颜色,如红色,绿色,黑色等自定义确切的颜色代码。你还可以自动交换前景色和背景色。
|
||||
|
||||
**Spotify 主题**
|
||||
|
||||
这个应用的一个独特功能是你可以根据喜好定义 spotify 主题。你可以更改 spotify 的前景色、背景色和强调色来匹配整体的 GTK 主题。
|
||||
|
||||
然后,只需按下**应用 Spotify 主题**按钮,你就会看到这个窗口:
|
||||
|
||||

|
||||
|
||||
点击应用即可
|
||||
|
||||
**导出主题**
|
||||
|
||||
根据自己的喜好自定义主题后,可以通过单击左上角的重命名按钮重命名主题:
|
||||
|
||||

|
||||
|
||||
然后,只需点击**导出主题**将主题导出到你的系统。
|
||||
|
||||

|
||||
|
||||
你也可以只导出图标集或终端主题。
|
||||
|
||||
之后你可以打开桌面环境中的任何可视化自定义应用,例如基于 Gnome 桌面的 Tweaks,或者 **XFCE Appearance Settings**。选择你导出的 GTK 或者 shell 主题。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你是一个 Linux 主题迷,并且你确切知道系统中的每个按钮、每个标题应该怎样,Oomox 值得一试。 对于极致的定制者,它可以让你几乎更改系统外观的所有内容。 对于那些只想稍微调整现有主题的人来说,它有很多很多预设,所以你可以毫不费力地得到你想要的东西。
|
||||
|
||||
你试过吗? 你对 Oomox 有什么看法? 请在下面留言!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://aur.archlinux.org/packages/oomox/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[3]: https://github.com/themix-project/oomox/releases
|
||||
[4]: https://flathub.org/apps/details/com.github.themix_project.Oomox
|
||||
[5]: https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
77
translated/tech/20190204 7 Best VPN Services For 2019.md
Normal file
77
translated/tech/20190204 7 Best VPN Services For 2019.md
Normal file
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 Best VPN Services For 2019)
|
||||
[#]: via: (https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/)
|
||||
[#]: author: (Editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
2019 年最好的 7 款 VPN 服务
|
||||
======
|
||||
|
||||
在过去三年中,全球至少有 67% 的企业面临着数据泄露,亿万用户受到影响。研究表明,如果事先对数据安全采取最基本的保护措施,那么预计有 93% 的漏洞是可以避免的。
|
||||
|
||||
糟糕的数据安全会带来极大的代价,特别是对企业而言。它会迅速造成破坏并损坏您的品牌声誉。尽管有些企业可以艰难地收拾残局,但仍有一些企业无法从事故中完全恢复。不过现在,您很幸运地可以得到数据及网络安全软件。
|
||||
|
||||

|
||||
|
||||
到了 2019 年,您可以通过**虚拟私人网络**,也就是我们熟知的 **VPN** 来保护您免受网络攻击。当涉及到在线隐私和安全时,常常存在许多不确定因素。有数百个不同的 VPN 提供商,选择合适的供应商也同时意味着在定价、服务和易用性之间谋取恰当的平衡。
|
||||
|
||||
如果您正在寻找一个可靠的 100% 经过测试和安全的 VPN,您可能需要进行详尽的调查并作出最佳选择。这里为您提供在 2019 年 7 款最好用并经过测试的 VPN 服务。
|
||||
|
||||
### 1. Vpnunlimitedapp
|
||||
|
||||
通过这款不限流量的 VPN ,您的数据安全将得到全面的保障。此 VPN 允许您连接任何 WiFi ,而无需担心您的个人数据可能被泄露。您的数据通过 AES-256 算法加密,保护您不受第三方和黑客的窥探。无论您身处何处,这款 VPN 都可确保您在所有网站上保持匿名且不受跟踪。它提供 7 天的免费试用和多种协议选项:openvpn、IKEv2 和 KeepSolidWise。有特殊需求的用户会获得特殊的额外服务,如个人服务器、终身 VPN 订阅和个人 IP 选项。
|
||||
|
||||
### 2. VPN Lite
|
||||
|
||||
VPN Lite 是一款易于使用而且**免费**的用于上网的 VPN 服务。您可以通过它在网络上保持匿名并保护您的个人隐私。它会模糊您的 IP 并加密您的数据,这意味着第三方无法跟踪您的所有线上活动。您还可以访问网络上的全部内容。使用 VPN Lite,您可以访问在您所在国家被拦截的网站。您还放心地可以访问公共 WiFi 而不必担心敏感信息被间谍软件窃取和来自黑客的跟踪和攻击。
|
||||
|
||||
### 3. HotSpot Shield
|
||||
|
||||
这是一款在 2005 年推出的大受欢迎的 VPN。这套 VPN 协议整合了至少全球 70% 的数据安全公司,并在全球有数千台服务器。它提供两种免费模式:一种为完全免费,但会有线上广告;另一种则为七天试用。它提供军事级的数据加密和恶意软件防护。HotSpot Shield 保证网络安全并保证高速网络。
|
||||
|
||||
### 4. TunnelBear
|
||||
|
||||
如果您是一名 VPN 新手,那么 TunnelBear 将是您的最佳选择。它带有一个用户友好的界面,并配有动画熊引导。您可以在 TunnelBear 的帮助下以极快的速度连接至少 22 个国家的服务器。它使用 **AES 256-bit** 加密算法,保证无登陆记录并保护数据。您还可以在最多五台设备上获得无限流量。
|
||||
|
||||
### 5. ProtonVPN
|
||||
|
||||
这款 VPN 为您提供强大的优质服务。您的连接速度可能会受到影响,但您也可以享受到无限流量。它具有易于使用的用户界面,提供多平台兼容。 ProtonVPN 的服务据说是因为为种子下载提供了优化因而无法访问 Netflix。您可以获得如协议和加密等安全功能来保证您的网络安全。
|
||||
|
||||
### 6. ExpressVPN
|
||||
|
||||
ExpressVPN 被认为是最好的用于接触封锁和保护隐私的离岸 VPN。凭借强大的客户支持和快速的速度,它已成为全球顶尖的 VPN 服务。它提供带有浏览器扩展和自定义固件的路由。 ExpressVPN 拥有一系列令人赞叹高质量应用程序,配有大量的服务器,并且最多只能支持三台设备。
|
||||
|
||||
ExpressVPN 并不是完全免费的,恰恰相反,正是由于它所提供的高质量服务而使之成为了市场上最贵的 VPN 之一。ExpressVPN 有 30 天内退款保证,因此您可以免费试用一个月。好消息是,这是完全没有风险的。例如,如果您在短时间内需要 VPN 来绕过在线审查,这可能是您的首选解决方案。您当然不会随意想给一个会发送垃圾邮件、缓慢的免费的程序进行试验。
|
||||
|
||||
ExpressVPN 也是享受在线流媒体和户外安全的最佳方式之一。如果您需要继续使用它,您只需要续订或取消您的免费试用。ExpressVPN 在 90 多个国家架设有 2000 多台服务器,可以解锁 Netflix,提供快速连接,并为用户提供完全隐私。
|
||||
|
||||
### 7. PureVPN
|
||||
|
||||
虽然 PureVPN 可能不是完全免费的,但它却是此列表中最实惠的一个。用户可以注册获得 7 天的免费试用,并在之后选择任一付费计划。通过这款 VPN,您可以访问到至少 140 个国家中的 750 余台服务器。它还可以在几乎所有设备上轻松安装。它的所有付费特性仍然可以在免费试用期间使用。包括无限数据流量、IP泄漏保护和ISP不可见性。它支持的系统有 iOS、Android、Windows、Linux和 macOS。
|
||||
|
||||
### 总结
|
||||
|
||||
如今,可用的免费 VPN 服务越来越多,为什么不抓住这个机会来保护您自己和您的客户呢?在了解到有那么多优秀的 VPN 服务后,我们知道即使是最安全的免费服务也不一定就完全没有风险。您可能需要付费升级到高级版以增强保护。Premium VPN 为您提供了免费试用,提供无风险退款保证。无论您打算花钱购买 VPN 还是准备使用免费 VPN,我们都强烈建议您使用它。
|
||||
|
||||
**关于作者:**
|
||||
|
||||
**Renetta K. Molina** 是一个技术爱好者和健身爱好者。她撰写有关技术、应用程序、 WordPress 和其他任何领域的文章。她喜欢在空余时间打高尔夫球和读书。她喜欢学习和尝试新事物。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/
|
||||
|
||||
作者:[Editor][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Modrisco](https://github.com/Modrisco)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -7,87 +7,85 @@
|
||||
[#]: via: (https://www.2daygeek.com/bd-quickly-go-back-to-a-specific-parent-directory-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Quickly Go Back To A Specific Parent Directory Using bd Command In Linux
|
||||
在 Linux 中使用 bd 命令快速返回到特定的父目录
|
||||
======
|
||||
|
||||
Two days back we had written an article about autocd. It’s a builtin shell variable that helps us to **[navigate to inside a directory without cd command][1]**.
|
||||
<to 校正:我在 ubuntu 上似乎没有按照这个教程成功使用 bd 命令,难道我的姿势不对?>
|
||||
|
||||
If you want to come back to previous directory then you have to type `cd ..`.
|
||||
两天前我们写了一篇关于 `autocd` 的文章,它是一个内置的 `shell` 变量,可以帮助我们在**[没有 `cd` 命令的情况下导航到目录中][1]**.
|
||||
|
||||
If you want to go back to two directories then you have to type `cd ../..`.
|
||||
如果你想回到上一级目录,那么你需要输入 `cd ..`。
|
||||
|
||||
It’s normal in Linux but if you want to come back from 9th directory to 3rd directory, then it’s horrible to use cd command.
|
||||
如果你想回到上两级目录,那么你需要输入 `cd ../..`。
|
||||
|
||||
What will be the solution for this.
|
||||
这在 Linux 中是正常的,但如果你想从第九个目录回到第三个目录,那么使用 cd 命令是很糟糕的。
|
||||
|
||||
Yes, we have a solution in Linux for everything. We can go with bd command, to make easy this kind of situation.
|
||||
有什么解决方案呢?
|
||||
|
||||
### What Is bd Command?
|
||||
是的,在 Linux 中有一个解决方案。我们可以使用 bd 命令来轻松应对这种情况。
|
||||
|
||||
bd command allow users to quickly go back to a parent directory in Linux instead of typing `cd ../../..` repeatedly.
|
||||
### 什么是 bd 命令?
|
||||
|
||||
You can list the contents of a given directory without mentioning the full path `ls `bd Directory_Name``. It supports following other commands such as ls, ln, echo, zip, tar etc..
|
||||
bd 命令允许用户快速返回 Linux 中的父目录,而不是反复输入 `cd ../../..`。
|
||||
|
||||
Also, it allow us to execute a shell file without mentioning the full path `bd p`/shell_file.sh`.
|
||||
你可以列出给定目录的内容,而不用提供完整路径 `ls `bd Directory_Name``。它支持以下其它命令,如 ls、ln、echo、zip、tar 等。
|
||||
|
||||
### How To Install bd Command in Linux?
|
||||
另外,它还允许我们执行 shell 文件而不用提供完整路径 `bd p`/shell_file.sh``。
|
||||
|
||||
There is no official distribution package for bd except Debian/Ubuntu. Hence, we need to perform manual method.
|
||||
### 如何在 Linux 中安装 bd 命令?
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][2]** or **[APT Command][3]** to install bd.
|
||||
除了 Debian/Ubuntu 之外,bd 没有官方发行包。因此,我们需要手动执行方法。
|
||||
|
||||
对于 **`Debian/Ubuntu`** 系统,使用 **[APT-GET 命令][2]**或**[APT 命令][3]**来安装 bd。
|
||||
|
||||
```
|
||||
$ sudo apt install bd
|
||||
```
|
||||
|
||||
For other Linux distributions.
|
||||
|
||||
Download the bd executable binary file using **[wget command][4]**.
|
||||
对于其它 Linux 发行版,使用 **[wget 命令][4]**下载 bd 可执行二进制文件。
|
||||
|
||||
```
|
||||
$ sudo wget --no-check-certificate -O /usr/local/bin/bd https://raw.github.com/vigneshwaranr/bd/master/bd
|
||||
```
|
||||
|
||||
Set executable permission to the bd binary file.
|
||||
设置 bd 二进制文件的可执行权限。
|
||||
|
||||
```
|
||||
$ sudo chmod +rx /usr/local/bin/bd
|
||||
```
|
||||
|
||||
Append the below values in the `.bashrc` file.
|
||||
在 `.bashrc` 文件中添加以下值。
|
||||
|
||||
```
|
||||
$ echo 'alias bd=". bd -si"' >> ~/.bashrc
|
||||
```
|
||||
|
||||
Run the following command to make the changes to take effect.
|
||||
|
||||
运行以下命令以使更改生效。
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
To enable auto completion, perform the following two steps.
|
||||
|
||||
要启用自动完成,执行以下两个步骤。
|
||||
```
|
||||
$ sudo wget -O /etc/bash_completion.d/bd https://raw.github.com/vigneshwaranr/bd/master/bash_completion.d/bd
|
||||
$ sudo source /etc/bash_completion.d/bd
|
||||
```
|
||||
|
||||
We have successfully installed and configured the bd utility on the system. It’s time to test it.
|
||||
我们已经在系统上成功安装并配置了 bd 实用程序,现在是时候测试一下了。
|
||||
|
||||
I’m going to take the below directory path for this testing.
|
||||
我将使用下面的目录路径进行测试。
|
||||
|
||||
Run the `pwd` command or `dirs` command or `tree` command to know your current location.
|
||||
运行 `pwd` 命令或 `dirs` 命令,亦或是 `tree` 命令来了解你当前的路径。
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ pwd
|
||||
or
|
||||
或者
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ dirs
|
||||
|
||||
/usr/share/icons/Adwaita/256x256/apps
|
||||
```
|
||||
|
||||
I’m currently in `/usr/share/icons/Adwaita/256x256/apps` and if i want to go to `icons` directory quickly then simple type the following command.
|
||||
我现在在 `/usr/share/icons/Adwaita/256x256/apps` 目录,如果我想快速跳转到 `icons` 目录,那么只需输入以下命令即可。
|
||||
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ bd icons
|
||||
@ -95,17 +93,16 @@ daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ bd icons
|
||||
daygeek@Ubuntu18:/usr/share/icons$
|
||||
```
|
||||
|
||||
Even, you no need to type full directory name instead you can type few letters.
|
||||
|
||||
甚至,你不需要输入完整的目录名称,也可以输入几个字母。
|
||||
```
|
||||
daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ bd i
|
||||
/usr/share/icons/
|
||||
daygeek@Ubuntu18:/usr/share/icons$
|
||||
```
|
||||
|
||||
`Note:` If there are more than one directories with same name up in the hierarchy, bd will take you to the closest. (Not considering the immediate parent.)
|
||||
`注意:` 如果层次结构中有多个同名的目录,bd 会将你带到最近的目录。(不考虑直接的父目录)
|
||||
|
||||
If you would like to list a given directory contents then the following format. It prints the contents of `/usr/share/icons/`.
|
||||
如果要列出给定的目录内容,使用以下格式。它会打印出 `/usr/share/icons/` 的内容。
|
||||
|
||||
```
|
||||
$ ls -lh `bd icons`
|
||||
@ -131,7 +128,7 @@ drwxr-xr-x 10 root root 4.0K Feb 25 15:46 ubuntu-mono-light
|
||||
drwxr-xr-x 3 root root 4.0K Jul 25 2018 whiteglass
|
||||
```
|
||||
|
||||
If you want to execute a file somewhere in a parent directory then use the following format. It will run the following shell file `/usr/share/icons/users-list.sh`.
|
||||
如果要在父目录中的某个位置执行文件,使用以下格式。它将运行 shell 文件 `/usr/share/icons/users-list.sh`。
|
||||
|
||||
```
|
||||
$ `bd i`/users-list.sh
|
||||
@ -150,7 +147,7 @@ user2
|
||||
user3
|
||||
```
|
||||
|
||||
If you reside in `/usr/share/icons/Adwaita/256x256/apps` and would you like to navigate to different parent directory then use the following format. The below command will navigate to `/usr/share/icons/gnome` directory.
|
||||
如果你位于 `/usr/share/icons/Adwaita/256x256/apps` 中,想要导航到不同的父目录,使用以下格式。以下命令将导航到 `/usr/share/icons/gnome` 目录。
|
||||
|
||||
```
|
||||
$ cd `bd i`/gnome
|
||||
@ -159,7 +156,7 @@ daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ cd `bd icon`/gnome
|
||||
daygeek@Ubuntu18:/usr/share/icons/gnome$
|
||||
```
|
||||
|
||||
If you reside in `/usr/share/icons/Adwaita/256x256/apps` and would you like to create a new directory under `/usr/share/icons/` then use the following format.
|
||||
如果你位于 `/usr/share/icons/Adwaita/256x256/apps` ,你想在 `/usr/share/icons/` 下创建一个新目录,使用以下格式。
|
||||
|
||||
```
|
||||
$ daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ sudo mkdir `bd icons`/2g
|
||||
@ -168,9 +165,9 @@ daygeek@Ubuntu18:/usr/share/icons/Adwaita/256x256/apps$ ls -ld `bd icon`/2g
|
||||
drwxr-xr-x 2 root root 4096 Mar 16 05:44 /usr/share/icons//2g
|
||||
```
|
||||
|
||||
This tutorial allows you to quickly go back to a specific parent directory but there is no option to move forward quickly.
|
||||
本教程允许你快速返回到特定的父目录,但没有快速前进的选项。
|
||||
|
||||
We have another solution for this, will come up with new solution shortly. Please stay tune with us.
|
||||
我们有另一个解决方案,很快就会提出新的解决方案,请跟我们保持联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -178,7 +175,7 @@ via: https://www.2daygeek.com/bd-quickly-go-back-to-a-specific-parent-directory-
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user