mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
691710663c
@ -0,0 +1,67 @@
|
||||
在Ubuntu 14.10上安装基于Web的监控工具:Linux-Dash
|
||||
================================================================================
|
||||
|
||||
Linux-Dash是一个用于GNU/Linux机器的,低开销的监控仪表盘。您可以安装试试!Linux Dash的界面提供了您的服务器的所有关键信息的详细视图,可监测的信息包括RAM、磁盘使用率、网络、安装的软件、用户、运行的进程等。所有的信息都被分成几类,您可以通过主页工具栏中的按钮跳到任何一类中。Linux Dash并不是最先进的监测工具,但它十分适合寻找灵活、轻量级、容易部署的应用的用户。
|
||||
|
||||
### Linux-Dash的功能 ###
|
||||
|
||||
- 使用一个基于Web的漂亮的仪表盘界面来监控服务器信息
|
||||
- 实时的按照你的要求监控RAM、负载、运行时间、磁盘配置、用户和许多其他系统状态
|
||||
- 支持基于Apache2/niginx + PHP的服务器
|
||||
- 通过点击和拖动来重排列控件
|
||||
- 支持多种类型的linux服务器
|
||||
|
||||
### 当前控件列表 ###
|
||||
|
||||
- 通用信息
|
||||
- 平均负载
|
||||
- RAM
|
||||
- 磁盘使用量
|
||||
- 用户
|
||||
- 软件
|
||||
- IP
|
||||
- 网络速率
|
||||
- 在线状态
|
||||
- 处理器
|
||||
- 日志
|
||||
|
||||
### 在Ubuntu server 14.10上安装Linux-Dash ###
|
||||
|
||||
首先您需要确认您安装了[Ubuntu LAMP server 14.10][1],接下来您需要安装下面的包:
|
||||
|
||||
sudo apt-get install php5-json unzip
|
||||
|
||||
安装这个模块后,需要在apache2中启用该模块,所以您需要使用下面的命令重启apache2服务器:
|
||||
|
||||
sudo service apache2 restart
|
||||
|
||||
现在您需要下载linux-dash的安装包并安装它:
|
||||
|
||||
wget https://github.com/afaqurk/linux-dash/archive/master.zip
|
||||
|
||||
unzip master.zip
|
||||
|
||||
sudo mv linux-dash-master/ /var/www/html/linux-dash-master/
|
||||
|
||||
接下来您需要使用下面的命令来改变权限:
|
||||
|
||||
sudo chmod 755 /var/www/html/linux-dash-master/
|
||||
|
||||
现在您便可以访问http://serverip/linux-dash-master/了。您应该会看到类似下面的输出:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-linux-dash-web-based-monitoring-tool-on-ubntu-14-10.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.ubuntugeek.com/step-by-step-ubuntu-14-10-utopic-unicorn-lamp-server-setup.html
|
||||
@ -1,12 +1,13 @@
|
||||
走进Linux之systemd启动过程
|
||||
================================================================================
|
||||
Linux系统的启动方式有点复杂,而且总是有需要优化的地方。传统的Linux系统启动过程主要由著名的init进程(也被称为SysV init启动系统)处理,而基于init的启动系统也被确认会有效率不足的问题,systemd是Linux系统机器的另一种启动方式,宣称弥补了以[传统Linux SysV init][2]为基础的系统的缺点。在这里我们将着重讨论systemd的特性和争议,但是为了更好地理解它,也会看一下通过传统的以SysV init为基础的系统的Linux启动过程是什么样的。友情提醒一下systemd仍然处在测试阶段,而未来发布的Linux操作系统也正准备用systemd启动管理程序替代当前的启动过程。
|
||||
|
||||
Linux系统的启动方式有点复杂,而且总是有需要优化的地方。传统的Linux系统启动过程主要由著名的init进程(也被称为SysV init启动系统)处理,而基于init的启动系统被认为有效率不足的问题,systemd是Linux系统机器的另一种启动方式,宣称弥补了以[传统Linux SysV init][2]为基础的系统的缺点。在这里我们将着重讨论systemd的特性和争议,但是为了更好地理解它,也会看一下通过传统的以SysV init为基础的系统的Linux启动过程是什么样的。友情提醒一下,systemd仍然处在测试阶段,而未来发布的Linux操作系统也正准备用systemd启动管理程序替代当前的启动过程(LCTT 译注:截止到本文发表,主流的Linux发行版已经有很多采用了 systemd)。
|
||||
|
||||
### 理解Linux启动过程 ###
|
||||
|
||||
在我们打开Linux电脑的电源后第一个启动的进程就是init。分配给init进程的PID是1。它是系统其他所有进程的父进程。当一台Linux电脑启动后,处理器会先在系统存储中查找BIOS,之后BIOS会测试系统资源然后找到第一个引导设备,通常设置为硬盘,然后会查找硬盘的主引导记录(MBR),然后加载到内存中并把控制权交给它,以后的启动过程就由MBR控制。
|
||||
在我们打开Linux电脑的电源后第一个启动的进程就是init。分配给init进程的PID是1。它是系统其他所有进程的父进程。当一台Linux电脑启动后,处理器会先在系统存储中查找BIOS,之后BIOS会检测系统资源然后找到第一个引导设备,通常为硬盘,然后会查找硬盘的主引导记录(MBR),然后加载到内存中并把控制权交给它,以后的启动过程就由MBR控制。
|
||||
|
||||
主引导记录会初始化引导程序(Linux上有两个著名的引导程序,GRUB和LILO,80%的Linux系统在用GRUB引导程序),这个时候GRUB或LILO会加载内核模块。内核会马上查找/sbin下的init进程并执行它。从这里开始init成为了Linux系统的父进程。init读取的第一个文件是/etc/inittab,通过它init会确定我们Linux操作系统的运行级别。它会从文件/etc/fstab里查找分区表信息然后做相应的挂载。然后init会启动/etc/init.d里指定的默认启动级别的所有服务/脚本。所有服务在这里通过init一个一个被初始化。在这个过程里,init每次只启动一个服务,所有服务/守护进程都在后台执行并由init来管理。
|
||||
主引导记录会初始化引导程序(Linux上有两个著名的引导程序,GRUB和LILO,80%的Linux系统在用GRUB引导程序),这个时候GRUB或LILO会加载内核模块。内核会马上查找/sbin下的“init”程序并执行它。从这里开始init成为了Linux系统的父进程。init读取的第一个文件是/etc/inittab,通过它init会确定我们Linux操作系统的运行级别。它会从文件/etc/fstab里查找分区表信息然后做相应的挂载。然后init会启动/etc/init.d里指定的默认启动级别的所有服务/脚本。所有服务在这里通过init一个一个被初始化。在这个过程里,init每次只启动一个服务,所有服务/守护进程都在后台执行并由init来管理。
|
||||
|
||||
关机过程差不多是相反的过程,首先init停止所有服务,最后阶段会卸载文件系统。
|
||||
|
||||
@ -14,9 +15,9 @@ Linux系统的启动方式有点复杂,而且总是有需要优化的地方。
|
||||
|
||||
### 理解Systemd ###
|
||||
|
||||
开发Systemd的主要目的就是减少系统引导时间和计算开销。Systemd(系统管理守护进程),最开始以GNU GPL协议授权开发,现在已转为使用GNU LGPL协议,它是如今讨论最热烈的引导和服务管理程序。如果你的Linux系统配置为使用Systemd引导程序,那么代替传统的SysV init,启动过程将交给systemd处理。Systemd的一个核心功能是它同时支持SysV init的后开机启动脚本。
|
||||
开发Systemd的主要目的就是减少系统引导时间和计算开销。Systemd(系统管理守护进程),最开始以GNU GPL协议授权开发,现在已转为使用GNU LGPL协议,它是如今讨论最热烈的引导和服务管理程序。如果你的Linux系统配置为使用Systemd引导程序,它取替传统的SysV init,启动过程将交给systemd处理。Systemd的一个核心功能是它同时支持SysV init的后开机启动脚本。
|
||||
|
||||
Systemd引入了并行启动的概念,它会为每个需要启动的守护进程建立一个管道套接字,这些套接字对于使用它们的进程来说是抽象的,这样它们可以允许不同守护进程之间进行交互。Systemd会创建新进程并为每个进程分配一个控制组。处于不同控制组的进程之间可以通过内核来互相通信。[systemd处理开机启动进程][2]的方式非常漂亮,和传统基于init的系统比起来优化了太多。让我们看下Systemd的一些核心功能。
|
||||
Systemd引入了并行启动的概念,它会为每个需要启动的守护进程建立一个套接字,这些套接字对于使用它们的进程来说是抽象的,这样它们可以允许不同守护进程之间进行交互。Systemd会创建新进程并为每个进程分配一个控制组(cgroup)。处于不同控制组的进程之间可以通过内核来互相通信。[systemd处理开机启动进程][2]的方式非常漂亮,和传统基于init的系统比起来优化了太多。让我们看下Systemd的一些核心功能。
|
||||
|
||||
- 和init比起来引导过程简化了很多
|
||||
- Systemd支持并发引导过程从而可以更快启动
|
||||
@ -81,7 +82,9 @@ Systemd提供了工具用于识别和定位引导相关的问题或性能影响
|
||||
234ms httpd.service
|
||||
191ms vmms.service
|
||||
|
||||
**systemd-analyze verify** 显示在所有系统单元中是否有语法错误。**systemd-analyze plot** 可以用来把整个引导过程写入一个SVG格式文件里。整个引导过程非常长不方便阅读,所以通过这个命令我们可以把输出写入一个文件,之后再查看和分析。下面这个命令就是做这个。
|
||||
**systemd-analyze verify** 显示在所有系统单元中是否有语法错误。
|
||||
|
||||
**systemd-analyze plot** 可以用来把整个引导过程写入一个SVG格式文件里。整个引导过程非常长不方便阅读,所以通过这个命令我们可以把输出写入一个文件,之后再查看和分析。下面这个命令就是做这个。
|
||||
|
||||
systemd-analyze plot > boot.svg
|
||||
|
||||
@ -89,9 +92,9 @@ Systemd提供了工具用于识别和定位引导相关的问题或性能影响
|
||||
|
||||
Systemd并没有幸运地获得所有人的青睐,一些专家和管理员对于它的工作方式和开发有不同意见。根据对于Systemd的批评,它不是“类Unix”方式因为它试着替换一些系统服务。一些专家也不喜欢使用二进制配置文件的想法。据说编辑systemd配置非常困难而且没有一个可用的图形工具。
|
||||
|
||||
### 在Ubuntu 14.04和12.04上测试Systemd ###
|
||||
### 如何在Ubuntu 14.04和12.04上测试Systemd ###
|
||||
|
||||
本来,Ubuntu决定从Ubuntu 16.04 LTS开始使用Systemd来替换当前的引导过程。Ubuntu 16.04预计在2016年4月发布,但是考虑到Systemd的流行和需求,即将发布的**Ubuntu 15.04**将采用它作为默认引导程序。好消息是Ubuntu 14.04 Trusty Tahr和Ubuntu 12.04 Precise Pangolin的用户可以在他们的机器上测试Systemd。测试过程并不复杂,你所要做的只是把相关的PPA包含到系统中,更新仓库并升级系统。
|
||||
本来,Ubuntu决定从Ubuntu 16.04 LTS开始使用Systemd来替换当前的引导过程。Ubuntu 16.04预计在2016年4月发布,但是考虑到Systemd的流行和需求,刚刚发布的**Ubuntu 15.04**采用它作为默认引导程序。另外,Ubuntu 14.04 Trusty Tahr和Ubuntu 12.04 Precise Pangolin的用户可以在他们的机器上测试Systemd。测试过程并不复杂,你所要做的只是把相关的PPA包含到系统中,更新仓库并升级系统。
|
||||
|
||||
**声明**:请注意它仍然处于Ubuntu的测试和开发阶段。升级测试包可能会带来一些未知错误,最坏的情况下有可能损坏你的系统配置。请确保在尝试升级前已经备份好重要数据。
|
||||
|
||||
@ -127,7 +130,7 @@ Systemd并没有幸运地获得所有人的青睐,一些专家和管理员对
|
||||
|
||||

|
||||
|
||||
就这样,你的Ubuntu系统已经不在使用传统的引导程序了,改为使用Systemd管理器。重启你的机器然后查看systemd引导过程吧。
|
||||
就这样,你的Ubuntu系统已经不再使用传统的引导程序了,改为使用Systemd管理器。重启你的机器然后查看systemd引导过程吧。
|
||||
|
||||

|
||||
|
||||
@ -141,7 +144,7 @@ via: http://linoxide.com/linux-how-to/systemd-boot-process/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
Linux有问必答-- 如何在VPS上安装和访问CentOS远程桌面
|
||||
Linux有问必答:如何在VPS上安装和访问CentOS 7远程桌面
|
||||
================================================================================
|
||||
> **提问**: 我想在VPS中安装CentOS桌面,并可以直接从我家远程访问GUI桌面。有什么建议可以在VPS上设置和访问CentOS远程桌面?
|
||||
> **提问**: 我想在VPS中安装CentOS桌面,并可以直接从我家远程访问GUI桌面。在VPS上设置和访问CentOS远程桌面有什么建议吗?
|
||||
|
||||
如何远程办公或者远程弹性化工作制在技术领域正变得越来越流行。这个趋势背后的一个技术就是远程桌面。你的桌面环境在云中,你可以在任何你去的地方,或者在家或者工作场所访问你的远程桌面。
|
||||
|
||||
@ -10,7 +10,7 @@ Linux有问必答-- 如何在VPS上安装和访问CentOS远程桌面
|
||||
|
||||
### 第一步: 安装CentOS桌面 ###
|
||||
|
||||
如果现在的CentOS版本是没有桌面的最小版本,你需要先在VPS上安装桌面(比如GNOME)。比如,DigitalOcean的镜像就是最小版本,它需要如下安装[桌面GUI][2]
|
||||
如果你现在安装的CentOS版本是没有桌面的最小版本,你需要先在VPS上安装桌面(比如GNOME)。比如,DigitalOcean的镜像就是最小版本,它需要如下安装[桌面GUI][2]
|
||||
|
||||
# yum groupinstall "GNOME Desktop"
|
||||
|
||||
@ -36,15 +36,15 @@ CentOS依靠systemd来管理和配置系统服务。所以我们将使用systemd
|
||||
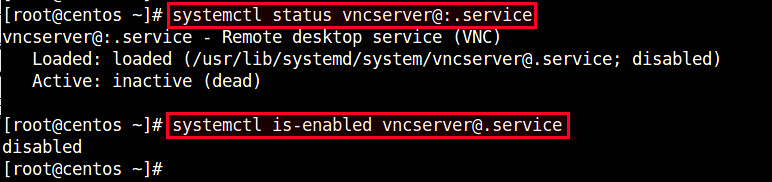
# systemctl status vncserver@:.service
|
||||
# systemctl is-enabled vncserver@.service
|
||||
|
||||
默认上,刚安装的VNC服务并没有激活(禁用)。
|
||||
默认的,刚安装的VNC服务并没有激活(禁用)。
|
||||
|
||||
|
||||
|
||||
现在服务一份通用的VNC服务文件来位用户xmodulo创建一个VNC服务配置。
|
||||
现在复制一份通用的VNC服务文件来为用户xmodulo创建一个VNC服务配置。
|
||||
|
||||
# cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
|
||||
|
||||
用本文编辑器来打开配置文件,用实际的用户名(比如:xmodulo)来替换[Service]下面的<USER>。同样。在ExecStart后面追加 "-geometry <resolution>" 参数。最后,要修改下面两行加粗字体的两行。
|
||||
用本文编辑器来打开配置文件,用实际的用户名(比如:xmodulo)来替换[Service]下面的<USER>。同样。在ExecStart后面追加 "-geometry <resolution>" 参数。最后,要修改下面“ExecStart”和“PIDFile”两行。
|
||||
|
||||
# vi /etc/systemd/system/vncserver@:1.service
|
||||
|
||||
@ -85,7 +85,7 @@ CentOS依靠systemd来管理和配置系统服务。所以我们将使用systemd
|
||||
|
||||
### 第三步:通过SSH连接到远程桌面 ###
|
||||
|
||||
设计上,VNC使用的远程帧缓存(RFB)并不是一种安全的协议。那么在VNC客户端上直接连接到VNC服务器上并不是一个好主意。任何敏感信息比如密码都可以在VNC流量中被轻易地泄露。因此,我强烈建议使用SSH隧道来[加密你的VNC流量][3]。
|
||||
从设计上说,VNC使用的远程帧缓存(RFB)并不是一种安全的协议,那么在VNC客户端上直接连接到VNC服务器上并不是一个好主意。任何敏感信息比如密码都可以在VNC流量中被轻易地泄露。因此,我强烈建议使用SSH隧道来[加密你的VNC流量][3]。
|
||||
|
||||
在你要运行VNC客户端的本机上,使用下面的命令来创建一个连接到远程VPS的SSH通道。当被要输入SSH密码时,输入用户的密码。
|
||||
|
||||
@ -99,7 +99,7 @@ CentOS依靠systemd来管理和配置系统服务。所以我们将使用systemd
|
||||
|
||||
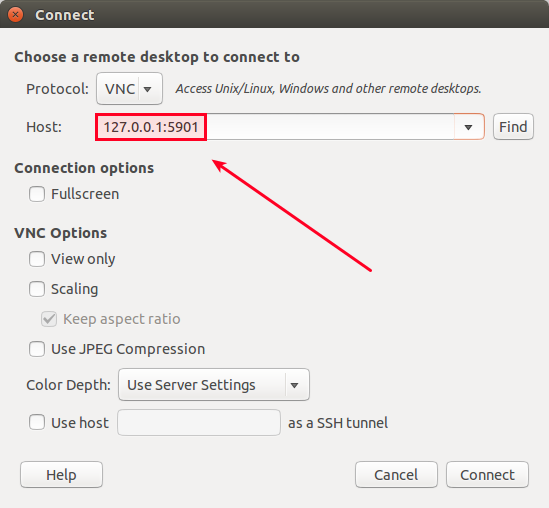
|
||||
|
||||
你将被要求输入VNC密码。当你输入VNC密码时,你就可以安全地连接到CentOS的远程桌面了.
|
||||
你将被要求输入VNC密码。当你输入VNC密码时,你就可以安全地连接到CentOS的远程桌面了。
|
||||
|
||||
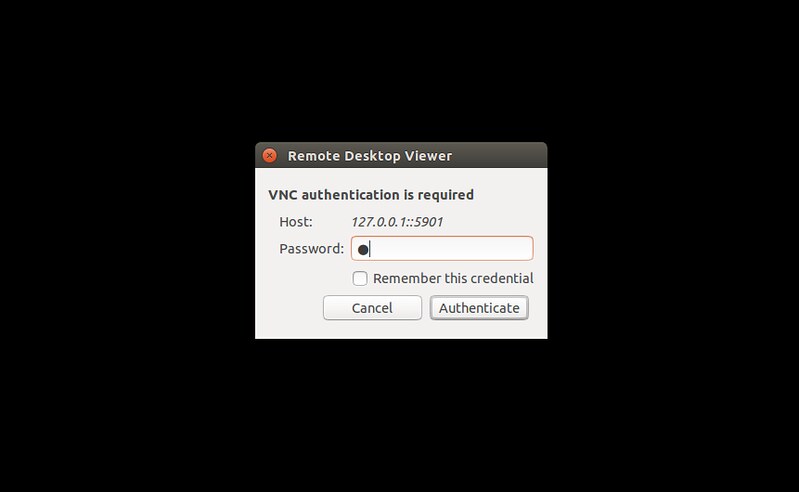
|
||||
|
||||
@ -111,7 +111,7 @@ via: http://ask.xmodulo.com/centos-remote-desktop-vps.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
怎样在Github上做开源代码库的主人
|
||||
怎样在Github上托管开源代码库
|
||||
================================================================================
|
||||
大家好,今天我们要学习一下怎样管理github.com库中的开源软件源代码。GitHub是一个基于web的Git库托管服务,提供分布式修改控制和Git的源代码管理(SCM)功能并加入了自身的特点。它给开源和私有项目提供了一个互相协作的工作区、代码预览和代码管理功能。不像Git,一个完完全全的命令行工具,GitHub提供了一个基于web的图形化界面和桌面,也整合了手机。GitHub同时提供了私有库付费计划和免费账号,都是用来管理开源软件项目的。
|
||||
|
||||
大家好,今天我们要学习一下怎样在github.com提供的仓库中托管开源软件源代码。GitHub是一个基于web的Git仓库托管服务,提供基于 git 的分布式版本控制和源代码管理(SCM)功能,并加入了自身的特点。它给开源项目和私有项目提供了一个互相协作的工作区、代码预览和代码管理功能。不像Git是一个完完全全的命令行工具,GitHub提供了一个基于web的图形化界面和桌面,也整合了手机操作。GitHub同时提供了私有库付费计划和通常用来管理开源软件项目的免费账号。
|
||||
|
||||

|
||||
|
||||
这是一种快速灵活,基于web的托管服务,它使用方便,管理分布式修改控制系统也是相当容易,任何人都能为了将它们使用、贡献、共享、问题跟踪和更多的全球各地数以百万计的人在github的库里管理他们的软件源代码。这里有一些简单快速地管理软件源代码的方法。
|
||||
这是一种快速灵活,基于web的托管服务,它使用方便,管理分布式版本控制系统也是相当容易,任何人都能将他们的软件源代码托管到 github,让全球各地数以百万计的人可以使用它、参与贡献、共享它、进行问题跟踪以及更多的用途。这里有一些简单快速地托管软件源代码的方法。
|
||||
|
||||
### 1. 创建一个新的Github账号 ###
|
||||
|
||||
@ -20,7 +21,7 @@
|
||||
|
||||
### 2. 创建一个新的库 ###
|
||||
|
||||
成功注册新账号或登录上Github之后,我们需要创建一个新的库来开始我们的正题。
|
||||
成功注册新账号或登录上Github之后,我们需要创建一个新的库来开始我们的征程。
|
||||
|
||||
点击位于顶部靠右账号id旁边的**(+)**按钮,然后点击“New Repository”。
|
||||
|
||||
@ -46,13 +47,13 @@
|
||||
|
||||
现在git已经准备就绪,我们要上传代码了。
|
||||
|
||||
**注意**:为了避免错误,不要用**README**文件、许可证或gitignore文件来初始化新库,你可以在项目推送到Github上之后再添加它们。
|
||||
**注意**:为了避免错误,不要在初始化的新库中包含**README**、license或gitignore等文件,你可以在项目推送到Github上之后再添加它们。
|
||||
|
||||
在终端上,我们需要把当前工作目录更改为你的本地项目,然后将本地目录初始化为Git库。
|
||||
在终端上,我们需要切换当前工作目录为你的本地项目的目录,然后将其初始化为Git库。
|
||||
|
||||
$ git init
|
||||
|
||||
接着我们在我们的新的本地库里添加的文件来作为我们的首次提交内容。
|
||||
接着我们添加新的本地库里中的文件,作为我们的首次提交内容。
|
||||
|
||||
$ git add .
|
||||
|
||||
@ -62,16 +63,16 @@
|
||||
|
||||

|
||||
|
||||
在终端上,我们要给远程库添加URL地址,用于以后我们能提交我们本地的库。
|
||||
在终端上,添加远程库的URL地址,以便我们的本地库推送到远程。
|
||||
|
||||
$ git remote add origin remote Repository url
|
||||
$ git remote add origin 远程库的URL
|
||||
$ git remote -v
|
||||
|
||||

|
||||
|
||||
注意:请确保将远程库的URL替换成了自己的远程库的URL。
|
||||
注意:请确保将上述“远程库的URL”替换成了你自己的远程库的URL。
|
||||
|
||||
现在,要将我们的本地库提交至GitHub版本库中,我们需要运行一下命令并且输入所需的用户名和密码。
|
||||
现在,要将我们的本地库的改变推送至GitHub的版本库中,我们需要运行以下命令,并且输入所需的用户名和密码。
|
||||
|
||||
$ git push origin master
|
||||
|
||||
@ -87,9 +88,9 @@
|
||||
|
||||
请把以上这条URL地址更改成你想要克隆的地址。
|
||||
|
||||
### 更新改动 ###
|
||||
### 推送改动 ###
|
||||
|
||||
如果我们对我们的代码做了更改并想把它们提交至我们的远程库中,我们应该在该目录下运行以下命令。
|
||||
如果我们对我们的代码做了更改并想把它们推送至我们的远程库中,我们应该在该目录下运行以下命令。
|
||||
|
||||
$ git add .
|
||||
$ git commit -m "Updating"
|
||||
@ -97,7 +98,7 @@
|
||||
|
||||
### 结论 ###
|
||||
|
||||
啊哈!我们已经成功地管理我们在Github库中的项目源代码了。快速灵活的Github基于web的托管服务,分布式修改控制系统使用起来方便容易。数百万个非常棒的开源项目驻扎在github上。所以,如果你有任何问题、建议或反馈,请在评论中告诉我们。谢谢大家!好好享受吧 :-)
|
||||
啊哈!我们已经成功地将我们的项目源代码托管到Github的库中了。Github是快速灵活的基于web的托管服务,分布式版本控制系统使用起来方便容易。数百万个非常棒的开源项目驻扎在github上。所以,如果你有任何问题、建议或反馈,请在评论中告诉我们。谢谢大家!好好享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -105,7 +106,7 @@ via: http://linoxide.com/usr-mgmt/host-open-source-code-repository-github/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
一些重要Docker命令的简单介绍
|
||||
一些重要 Docker 命令的简单介绍
|
||||
================================================================================
|
||||
大家好,今天我们来学习一些在你使用Docker之前需要了解的重要的 Docker 命令。Docker 是一个提供开发平台去打包,装载和运行任何应用的轻量级容器开源项目。它没有语言支持,框架和打包系统的限制,能从一个小的家庭电脑到高端服务器,在任何地方任何时间运行。这使得它们成为不依赖于一个特定的栈或供应商,部署和扩展web应用,数据库和后端服务很好的构建块。
|
||||
大家好,今天我们来学习一些在你使用 Docker 之前需要了解的重要的 Docker 命令。[Docker][1] 是一个开源项目,提供了一个可以打包、装载和运行任何应用的轻量级容器的开放平台。它没有语言支持、框架和打包系统的限制,从小型的家用电脑到高端服务器,在何时何地都可以运行。这使它们可以不依赖于特定软件栈和供应商,像一块块积木一样部署和扩展网络应用、数据库和后端服务。
|
||||
|
||||
Docker 命令简单易学,也很容易实现或实践。这是一些你运行 Docker 并充分利用它需要知道的简单 Docker 命令。
|
||||
|
||||
### 1. 拉取一个 Docker 镜像 ###
|
||||
### 1. 拉取 Docker 镜像 ###
|
||||
|
||||
由于容器是由 Docker 镜像构建的,首先我们需要拉取一个 docker 镜像来开始。我们可以从 Docker 注册 Hub 获取需要的 docker 镜像。在我们使用 pull 命令拉取任何镜像之前,由于pull命令被标识为恶意命令,我们需要保护我们的系统。为了保护我们的系统不受这个问题影响,我们需要添加 **127.0.0.1 index.docker.io** 到 /etc/hosts 条目。我们可以通过使用喜欢的文本编辑器完成。
|
||||
由于容器是由 Docker 镜像构建的,首先我们需要拉取一个 docker 镜像来开始。我们可以从 Docker Registry Hub 获取所需的 docker 镜像。在我们使用 pull 命令拉取任何镜像之前,为了避免 pull 命令的一些恶意风险,我们需要保护我们的系统。为了保护我们的系统不受这个风险影响,我们需要添加 **127.0.0.1 index.docker.io** 到 /etc/hosts 条目。我们可以通过使用喜欢的文本编辑器完成。
|
||||
|
||||
# nano /etc/hosts
|
||||
|
||||
@ -16,7 +16,7 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||

|
||||
|
||||
要拉取一个 docker 进行,我们需要运行下面的命令。
|
||||
要拉取一个 docker 镜像,我们需要运行下面的命令。
|
||||
|
||||
# docker pull registry.hub.docker.com/busybox
|
||||
|
||||
@ -28,9 +28,9 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||

|
||||
|
||||
### 2. 运行一个 Docker 容器 ###
|
||||
### 2. 运行 Docker 容器 ###
|
||||
|
||||
现在,成功地拉取要求或需要的 Docker 镜像之后,我们当然想运行这个 Docker 镜像。我们可以用 docker run 命令在镜像上运行一个 docker 容器。在 Docker 镜像之上运行一个 docker 容易时我们有很多选项和标记。我们使用 -t 和 -i 标记运行一个 docker 镜像并进入容器,如下面所示。
|
||||
现在,成功地拉取要求的或所需的 Docker 镜像之后,我们当然想运行这个 Docker 镜像。我们可以用 docker run 命令在镜像上运行一个 docker 容器。在 Docker 镜像上运行一个 docker 容器时我们有很多选项和标记。我们使用 -t 和 -i 选项来运行一个 docker 镜像并进入容器,如下面所示。
|
||||
|
||||
# docker run -it busybox
|
||||
|
||||
@ -50,7 +50,7 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||

|
||||
|
||||
### 3. 查看容器 ###
|
||||
### 3. 检查容器运行 ###
|
||||
|
||||
不论容器是否运行,查看日志文件都很简单。我们可以使用下面的命令去检查是否有 docker 容器在实时运行。
|
||||
|
||||
@ -62,17 +62,17 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||

|
||||
|
||||
### 4. 检查 Docker 容器 ###
|
||||
### 4. 查看容器信息 ###
|
||||
|
||||
我们可以使用 inspect 命令检查一个 Docker 容器的每条信息。
|
||||
我们可以使用 inspect 命令查看一个 Docker 容器的各种信息。
|
||||
|
||||
# docker inspect <container id>
|
||||
|
||||

|
||||
|
||||
### 5. 杀死或删除命令 ###
|
||||
### 5. 杀死或删除 ###
|
||||
|
||||
我们可以使用 docker id 杀死或者停止进程或 docker 容器,如下所示。
|
||||
我们可以使用容器 id 杀死或者停止 docker 容器(进程),如下所示。
|
||||
|
||||
# docker stop <container id>
|
||||
|
||||
@ -90,7 +90,7 @@ Docker 命令简单易学,也很容易实现或实践。这是一些你运行
|
||||
|
||||
### 结论 ###
|
||||
|
||||
这些都是学习充分实现和利用 Docker 很基本的 docker 命令。有了这些命令,Docker 变得很简单,提供给端用户一个简单的计算平台。根据上面的教程,任何人学习 Docker 命令都非常简单。如果你有任何问题,建议,反馈,请写到下面的评论框中以便我们改进和更新内容。多谢!享受吧 :-)
|
||||
这些都是充分学习和使用 Docker 很基本的 docker 命令。有了这些命令,Docker 变得很简单,可以提供给最终用户一个易用的计算平台。根据上面的教程,任何人学习 Docker 命令都非常简单。如果你有任何问题,建议,反馈,请写到下面的评论框中以便我们改进和更新内容。多谢! 希望你喜欢 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -98,8 +98,9 @@ via: http://linoxide.com/linux-how-to/important-docker-commands/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://www.docker.com/
|
||||
@ -0,0 +1,181 @@
|
||||
Web缓存基础:术语、HTTP报头和缓存策略
|
||||
=====================================================================
|
||||
|
||||
### 简介
|
||||
|
||||
对于您的站点的访问者来说,智能化的内容缓存是提高用户体验最有效的方式之一。缓存,或者对之前的请求的临时存储,是HTTP协议实现中最核心的内容分发策略之一。分发路径中的组件均可以缓存内容来加速后续的请求,这受控于对该内容所声明的缓存策略。
|
||||
|
||||
在这份指南中,我们将讨论一些Web内容缓存的基本概念。这主要包括如何选择缓存策略以保证互联网范围内的缓存能够正确的处理您的内容。我们将谈一谈缓存带来的好处、副作用以及不同的策略能带来的性能和灵活性的最大结合。
|
||||
|
||||
###什么是缓存(caching)?
|
||||
|
||||
缓存(caching)是一个描述存储可重用资源以便加快后续请求的行为的术语。有许多不同类型的缓存,每种都有其自身的特点,应用程序缓存和内存缓存由于其对特定回复的加速,都很常用。
|
||||
|
||||
这份指南的主要讲述的Web缓存是一种不同类型的缓存。Web缓存是HTTP协议的一个核心特性,它能最小化网络流量,并且提升用户所感知的整个系统响应速度。内容从服务器到浏览器的传输过程中,每个层面都可以找到缓存的身影。
|
||||
|
||||
Web缓存根据特定的规则缓存相应HTTP请求的响应。对于缓存内容的后续请求便可以直接由缓存满足而不是重新发送请求到Web服务器。
|
||||
|
||||
###好处
|
||||
|
||||
有效的缓存技术不仅可以帮助用户,还可以帮助内容的提供者。缓存对内容分发带来的好处有:
|
||||
|
||||
- **减少网络开销**:内容可以在从内容提供者到内容消费者网络路径之间的许多不同的地方被缓存。当内容在距离内容消费者更近的地方被缓存时,由于缓存的存在,请求将不会消耗额外的网络资源。
|
||||
- **加快响应速度**:由于并不是必须通过整个网络往返,缓存可以使内容的获得变得更快。缓存放在距用户更近的地方,例如浏览器缓存,使得内容的获取几乎是瞬时的。
|
||||
- **在同样的硬件上提高速度**:对于保存原始内容的服务器来说,更多的性能可以通过允许激进的缓存策略从硬件上压榨出来。内容拥有者们可以利用分发路径上某个强大的服务器来应对特定内容负载的冲击。
|
||||
- **网络中断时内容依旧可用**:使用某种策略,缓存可以保证在原始服务器变得不可用时,相应的内容对用户依旧可用。
|
||||
|
||||
###术语
|
||||
|
||||
在面对缓存时,您可能对一些经常遇到的术语可能不太熟悉。一些常见的术语如下:
|
||||
|
||||
- **原始服务器**:原始服务器是内容的原始存放地点。如果您是Web服务器管理员,它就是您所管理的机器。它负责为任何不能从缓存中得到的内容进行回复,并且负责设置所有内容的缓存策略。
|
||||
- **缓存命中率**:一个缓存的有效性依照缓存的命中率进行度量。它是可以从缓存中得到数据的请求数与所有请求数的比率。缓存命中率高意味着有很高比例的数据可以从缓存中获得。这通常是大多数管理员想要的结果。
|
||||
- **新鲜度**:新鲜度用来描述一个缓存中的项目是否依旧适合返回给客户端。缓存中的内容只有在由缓存策略指定的新鲜期内才会被返回。
|
||||
- **过期内容**:缓存中根据缓存策略的新鲜期设置已过期的内容。过期的内容被标记为“陈旧”。通常,过期内容不能用于回复客户端的请求。必须重新从原始服务器请求新的内容或者至少验证缓存的内容是否仍然准确。
|
||||
- **校验**:缓存中的过期内容可以验证是否有效以便刷新过期时间。验证过程包括联系原始服务器以检查缓存的数据是否依旧代表了最近的版本。
|
||||
- **失效**:失效是依据过期日期从缓存中移除内容的过程。当内容在原始服务器上已被改变时就必须这样做,缓存中过期的内容会导致客户端发生问题。
|
||||
|
||||
还有许多其他的缓存术语,不过上面的这些应该能帮助您开始。
|
||||
|
||||
###什么能被缓存?
|
||||
|
||||
某些特定的内容比其他内容更容易被缓存。对大多数站点来说,一些适合缓存的内容如下:
|
||||
|
||||
- Logo和商标图像
|
||||
- 普通的不变化的图像(例如,导航图标)
|
||||
- CSS样式表
|
||||
- 普通的Javascript文件
|
||||
- 可下载的内容
|
||||
- 媒体文件
|
||||
|
||||
这些文件更倾向于不经常改变,所以长时间的对它们进行缓存能获得好处。
|
||||
|
||||
一些项目在缓存中必须加以注意:
|
||||
|
||||
- HTML页面
|
||||
- 会替换改变的图像
|
||||
- 经常修改的Javascript和CSS文件
|
||||
- 需要有认证后的cookies才能访问的内容
|
||||
|
||||
一些内容从来不应该被缓存:
|
||||
|
||||
- 与敏感信息相关的资源(银行数据,等)
|
||||
- 用户相关且经常更改的数据
|
||||
|
||||
除上面的通用规则外,通常您需要指定一些规则以便于更好地缓存不同种类的内容。例如,如果登录的用户都看到的是同样的网站视图,就应该在任何地方缓存这个页面。如果登录的用户会在一段时间内看到站点中用户特定的视图,您应该让用户的浏览器缓存该数据而不应让任何中介节点缓存该视图。
|
||||
|
||||
###Web内容缓存的位置
|
||||
|
||||
Web内容会在整个分发路径中的许多不同的位置被缓存:
|
||||
|
||||
- **浏览器缓存**:Web浏览器自身会维护一个小型缓存。典型地,浏览器使用一种策略指示缓存最重要的内容。这可能是用户相关的内容或可能会再次请求且下载代价较高。
|
||||
- **中间缓存代理**:任何在客户端和您的基础架构之间的服务器都可以按期望缓存一些内容。这些缓存可能由ISP(网络服务提供者)或者其他独立组织提供。
|
||||
- **反向缓存**:您的服务器基础架构可以为后端的服务实现自己的缓存。如果实现了缓存,那么便可以在处理请求的位置返回相应的内容而不用每次请求都使用后端服务。
|
||||
|
||||
上面的这些位置通常都可以根据它们自身的缓存策略和内容源的缓存策略缓存一些相应的内容。
|
||||
|
||||
###缓存头部
|
||||
|
||||
缓存策略依赖于两个不同的因素。所缓存的实体本身需要决定是否应该缓存可接受的内容。它可以只缓存部分可以缓存的内容,但不能缓存超过限制的内容。
|
||||
|
||||
缓存行为主要由缓存策略决定,而缓存策略由内容拥有者设置。这些策略主要通过特定的HTTP头部来清晰地表达。
|
||||
|
||||
经过几个不同HTTP协议的变化,出现了一些不同的针对缓存方面的头部,它们的复杂度各不相同。下面列出了那些你也许应该注意的:
|
||||
|
||||
- **`Expires`**:尽管使用范围相当有限,但`Expires`头部是非常简洁明了的。通常它设置一个未来的时间,内容会在此时间过期。这时,任何对同样内容的请求都应该回到原始服务器处。这个头部或许仅仅最适合回退模式(fall back)。
|
||||
- **`Cache-Control`**:这是`Expires`的一个更加现代化的替换物。它已被很好的支持,且拥有更加灵活的实现。在大多数案例中,它比`Expires`更好,但同时设置两者的值也无妨。稍后我们将讨论您可以设置的`Cache-Control`的详细选项。
|
||||
- **`ETag`**:`ETag`用于缓存验证。源服务器可以在首次服务一个内容时为该内容提供一个独特的`ETag`。当一个缓存需要验证这个内容是否即将过期,他会将相应的`ETag`发送回服务器。源服务器或者告诉缓存内容是一致的,或者发送更新后的内容(带着新的`ETag`)。
|
||||
- **`Last-Modified`**:这个头部指明了相应的内容最后一次被修改的时间。它可能会作为保证内容新鲜度的验证策略的一部分被使用。
|
||||
- **`Content-Length`**:尽管并没有在缓存中明确涉及,`Content-Length`头部在设置缓存策略时很重要。某些软件如果不提前获知内容的大小以留出足够空间,则会拒绝缓存该内容。
|
||||
- **`Vary`**:缓存系统通常使用请求的主机和路径作为存储该资源的键。当判断一个请求是否是请求同样内容时,`Vary`头部可以被用来提醒缓存系统需要注意另一个附加头部。它通常被用来告诉缓存系统同样注意`Accept-Encoding`头部,以便缓存系统能够区分压缩和未压缩的内容。
|
||||
|
||||
### Vary头部的隐语
|
||||
|
||||
`Vary`头部提供给您存储同一个内容的不同版本的能力,代价是降低了缓存的容量。
|
||||
|
||||
在使用`Accept-Encoding`时,设置`Vary`头部允许明确区分压缩和未压缩的内容。这在服务某些不能处理压缩数据的浏览器时很重要,它可以保证基本的可用性。`Vary`的一个典型的值是`Accept-Encoding`,它只有两到三个可选的值。
|
||||
|
||||
一开始看上去`User-Agent`这样的头部可以用于区分移动浏览器和桌面浏览器,以便您的站点提供差异化的服务。但`User-Agent`字符串是非标准的,结果将会造成在中间缓存中保存同一内容的许多不同版本的缓存,这会导致缓存命中率的降低。`Vary`头部应该谨慎使用,尤其是您不具备在您控制的中间缓存中使请求标准化的能力(也许可以,比如您可以控制CDN的话)。
|
||||
|
||||
###缓存控制标志怎样影响缓存
|
||||
|
||||
上面我们提到了`Cache-Control`头部如何被用与现代缓存策略标准。能够通过这个头部设定许多不同的缓存指令,多个不同的指令通过逗号分隔。
|
||||
|
||||
一些您可以使用的指示内容缓存策略的`Cache-Control`的选项如下:
|
||||
|
||||
- **`no-cache`**:这个指令指示所有缓存的内容在新的请求到达时必须先重新验证,再发送给客户端。这条指令实际将内容立刻标记为过期的,但允许通过验证手段重新验证以避免重新下载整个内容。
|
||||
- **`no-store`**:这条指令指示缓存的内容不能以任何方式被缓存。它适合在回复敏感信息时设置。
|
||||
- **`public`**:它将内容标记为公有的,这意味着它能被浏览器和其他任何中间节点缓存。通常,对于使用了HTTP验证的请求,其回复被默认标记为`private`。`public`标记将会覆盖这个设置。
|
||||
- **`private`**:它将内容标记为私有的。私有数据可以被用户的浏览器缓存,但*不能*被任何中间节点缓存。它通常用于用户相关的数据。
|
||||
- **`max-age`**:这个设置指示了缓存内容的最大生存期,它在最大生存期后必须在源服务器处被验证或被重新下载。在现代浏览器中这个选项大体上取代了`Expires`头部,浏览器也将其作为决定内容的新鲜度的基础。这个选项的值以秒为单位表示,最大可以表示一年的新鲜期(31536000秒)。
|
||||
- **`s-maxage`**:这个选项非常类似于`max-age`,它指明了内容能够被缓存的时间。区别是这个选项只在中间节点的缓存中有效。结合这两个选项可以构建更加灵活的缓存策略。
|
||||
- **`must-revalidate`**:它指明了由`max-age`、`s-maxage`或`Expires`头部指明的新鲜度信息必须被严格的遵守。它避免了缓存的数据在网络中断等类似的场景中被使用。
|
||||
- **`proxy-revalidate`**:它和上面的选项有着一样的作用,但只应用于中间的代理节点。在这种情况下,用户的浏览器可以在网络中断时使用过期内容,但中间缓存内容不能用于此目的。
|
||||
- **`no-transform`**:这个选项告诉缓存在任何情况下都不能因为性能的原因修改接收到的内容。这意味着,缓存不允许压缩接收到的内容(没有从原始服务器处接收过压缩版本的该内容)并发送。
|
||||
|
||||
这些选项能够以不同的方式结合以获得不同的缓存行为。一些互斥的值如下:
|
||||
|
||||
- `no-cache`,`no-store`以及由其他前面未提到的选项指明的常用的缓存行为
|
||||
- `public`和`private`
|
||||
|
||||
如果`no-store`和`no-cache`都被设置,那么`no-store`会取代`no-cache`。对于非授权的请求的回复,`public`是隐含的设置。对于授权的请求的回复,`private`选项是隐含的。他们可以通过在`Cache-Control`头部中指明相应的相反的选项以覆盖。
|
||||
|
||||
###开发一种缓存策略
|
||||
|
||||
在理想情况下,任何内容都可以被尽可能缓存,而您的服务器只需要偶尔的提供一些验证内容即可。但这在现实中很少发生,因此您应该尝试设置一些明智的缓存策略,以在长期缓存和站点改变的需求间达到平衡。
|
||||
|
||||
### 常见问题
|
||||
|
||||
在许多情况中,由于内容被产生的方式(如根据每个用户动态的产生)或者内容的特性(例如银行的敏感数据),这些内容不应该被缓存。另一些许多管理员在设置缓存时可能面对的问题是外部缓存的数据未过期,但新版本的数据已经产生。
|
||||
|
||||
这些都是经常遇到的问题,它们会影响缓存的性能和您提供的数据的准确性。然而,我们可以通过开发提前预见这些问题的缓存策略来缓解这些问题。
|
||||
|
||||
### 一般性建议
|
||||
|
||||
尽管您的实际情况会指导您选择的缓存策略,但是下面的建议能帮助您获得一些合理的决定。
|
||||
|
||||
在您担心使用哪一个特定的头部之前,有一些特定的步骤可以帮助您提高您的缓存命中率。一些建议如下:
|
||||
|
||||
- **为图像、CSS和共享的内容建立特定的文件夹**:将内容放到特定的文件夹内使得您可以方便的从您的站点中的任何页面引用这些内容。
|
||||
- **使用同样的URL来表示同样的内容**:由于缓存使用内容请求中的主机名和路径作为键,因此应保证您的所有页面中的该内容的引用方式相同,前一个建议能让这点更加容易做到。
|
||||
- **尽可能使用CSS图像拼接**:对于像图标和导航等内容,使用CSS图像拼接能够减少渲染您页面所需要的请求往返,并且允许对拼接缓存很长一段时间。
|
||||
- **尽可能将主机脚本和外部资源本地化**:如果您使用Javascript脚本和其他外部资源,如果上游没有提供合适的缓存头部,那么您应考虑将这些内容放在您自己的服务器上。您应该注意上游的任何更新,以便更新本地的拷贝。
|
||||
- **对缓存内容收集文件摘要**:静态的内容比如CSS和Javascript文件等通常比较适合收集文件摘要。这意味着为文件名增加一个独特的标志符(通常是这个文件的哈希值)可以在文件修改后绕开缓存保证新的内容被重新获取。有很多工具可以帮助您创建文件摘要并且修改HTML文档中的引用。
|
||||
|
||||
对于不同的文件正确地选择不同的头部这件事,下面的内容可以作为一般性的参考:
|
||||
|
||||
- **允许所有的缓存存储一般内容**:静态内容以及非用户相关的内容应该在分发链的所有节点被缓存。这使得中间节点可以将该内容回复给多个用户。
|
||||
- **允许浏览器缓存用户相关的内容**:对于每个用户的数据,通常在用户自己的浏览器中缓存是可以被接受且有益的。缓存在用户自身的浏览器能够使得用户在接下来的浏览中能够瞬时读取,但这些内容不适合在任何中间代理节点缓存。
|
||||
- **将时间敏感的内容作为特例**:如果您的数据是时间敏感的,那么相对上面两条参考,应该将这些数据作为特例,以保证过期的数据不会在关键的情况下被使用。例如,您的站点有一个购物车,它应该立刻反应购物车里面的物品。依据内容的特点,可以在`Cache-Control`头部中使用`no-cache`或`no-store`选项。
|
||||
- **总是提供验证器**:验证器使得过期的内容可以无需重新下载而得到刷新。设置`ETag`和`Last-Modified`头部将允许缓存向原始服务器验证内容,并在内容未修改时刷新该内容新鲜度以减少负载。
|
||||
- **对于支持的内容设置长的新鲜期**:为了更加有效的利用缓存,一些作为支持性的内容应该被设置较长的新鲜期。这通常比较适合图像和CSS等由用户请求用来渲染HTML页面的内容。和文件摘要一起,设置延长的新鲜期将允许缓存长时间的存储这些资源。如果资源发生改变,修改的文件摘要将会使缓存的数据无效并触发对新的内容的下载。那时,新的支持的内容会继续被缓存。
|
||||
- **对父内容设置短的新鲜期**:为了使得前面的模式正常工作,容器类的内容应该相应的设置短的新鲜期,或者设置不全部缓存。这通常是在其他协助内容中使用的HTML页面。这个HTML页面将会被频繁的下载,使得它能快速的响应改变。支持性的内容因此可以被尽量缓存。
|
||||
|
||||
关键之处便在于达到平衡,一方面可以尽量的进行缓存,另一方面为未来保留当改变发生时从而改变整个内容的机会。您的站点应该同时具有:
|
||||
|
||||
- 尽量缓存的内容
|
||||
- 拥有短的新鲜期的缓存内容,可以被重新验证
|
||||
- 完全不被缓存的内容
|
||||
|
||||
这样做的目的便是将内容尽可能的移动到第一个分类(尽量缓存)中的同时,维持可以接受的缓存命中率。
|
||||
|
||||
结论
|
||||
----
|
||||
|
||||
花时间确保您的站点使用了合适的缓存策略将对您的站点产生重要的影响。缓存使得您可以在保证服务同样内容的同时减少带宽的使用。您的服务器因此可以靠同样的硬件处理更多的流量。或许更重要的是,客户们能在您的网站中获得更快的体验,这会使得他们更愿意频繁的访问您的站点。尽管有效的Web缓存并不是银弹,但设置合适的缓存策略会使您以最小的代价获得可观的收获。
|
||||
|
||||
---
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/web-caching-basics-terminology-http-headers-and-caching-strategies
|
||||
|
||||
作者: [Justin Ellingwood](https://www.digitalocean.com/community/users/jellingwood)
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
推荐:[royaso](https://github.com/royaso)
|
||||
|
||||
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
@ -1,12 +1,11 @@
|
||||
Linux有问必答--如何安装autossh
|
||||
Linux有问必答:如何安装autossh
|
||||
================================================================================
|
||||
> **提问**: 我打算在linux上安装autossh,我应该怎么做呢?
|
||||
|
||||
[autossh][1] 是一款开源工具,可以帮助管理SSH会话,自动重连和停止转发流量。autossh会假定目标主机已经设定[无密码SSH登陆][2],以便autossh可以重连断开的SSH会话而不用用户操作。
|
||||
[autossh][1] 是一款开源工具,可以帮助管理SSH会话、自动重连和停止转发流量。autossh会假定目标主机已经设定[无密码SSH登陆][2],以便autossh可以重连断开的SSH会话而不用用户操作。
|
||||
|
||||
只要你建立[反向SSH隧道][3]或者[挂载基于SSH的远程文件夹][4],autossh迟早会派上用场。基本上只要需要维持SSH会话,autossh肯定是有用的。
|
||||
|
||||
|
||||
|
||||
|
||||
下面有许多linux发行版autossh的安装方法。
|
||||
@ -29,8 +28,7 @@ CentOS/RHEL 6 或早期版本, 需要开启第三库[Repoforge库][5], 然后才
|
||||
|
||||
$ sudo yum install autossh
|
||||
|
||||
CentOS/RHEL 7以后,autossh 已经不在Repoforge库中. 你需要从源码编译安装(例子在下面).
|
||||
|
||||
CentOS/RHEL 7以后,autossh 已经不在Repoforge库中. 你需要从源码编译安装(例子在下面)。
|
||||
|
||||
### Arch Linux 系统 ###
|
||||
|
||||
@ -66,13 +64,13 @@ via: http://ask.xmodulo.com/install-autossh-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://www.harding.motd.ca/autossh/
|
||||
[2]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
[2]:https://linux.cn/article-5444-1.html
|
||||
[3]:http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
[4]:http://xmodulo.com/how-to-mount-remote-directory-over-ssh-on-linux.html
|
||||
[5]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
@ -1,12 +1,15 @@
|
||||
14 个 grep 命令的例子
|
||||
===========
|
||||
|
||||
###概述:###
|
||||
|
||||
所有类linux系统都会提供一个名为**grep(global regular expression print)**的搜索工具。grep命令在基于模式对一个或多个文件内容进行搜索的情况下是非常有用的。一个模式可以是单个字符、多个字符、单个单词、或者是一个句子。
|
||||
所有的类linux系统都会提供一个名为**grep(global regular expression print,全局正则表达式输出)**的搜索工具。grep命令在对一个或多个文件的内容进行基于模式的搜索的情况下是非常有用的。模式可以是单个字符、多个字符、单个单词、或者是一个句子。
|
||||
|
||||
当命令匹配到执行命令时指定的模式时,grep会将包含模式的一行输出,但是并不对原文件内容进行修改。
|
||||
|
||||
在本文中,我们将会讨论到14个grep命令的例子。
|
||||
|
||||
###1 在文件中查找模式(单词)###
|
||||
###例1 在文件中查找模式(单词)###
|
||||
|
||||
在/etc/passwd文件中查找单词“linuxtechi”
|
||||
|
||||
@ -14,7 +17,7 @@
|
||||
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
###2 在多个文件中查找模式。###
|
||||
###例2 在多个文件中查找模式。###
|
||||
|
||||
root@Linux-world:~# grep linuxtechi /etc/passwd /etc/shadow /etc/gshadow
|
||||
/etc/passwd:linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
@ -28,14 +31,14 @@
|
||||
/etc/gshadow:sambashare:!::linuxtechi
|
||||
root@Linux-world:~#
|
||||
|
||||
###3 使用-l参数列出包含指定模式的文件的文件名。###
|
||||
###例3 使用-l参数列出包含指定模式的文件的文件名。###
|
||||
|
||||
root@Linux-world:~# grep -l linuxtechi /etc/passwd /etc/shadow /etc/fstab /etc/mtab
|
||||
/etc/passwd
|
||||
/etc/shadow
|
||||
root@Linux-world:~#
|
||||
|
||||
###4 使用-n参数,在文件中查找指定模式及其相关的行号###
|
||||
###例4 使用-n参数,在文件中查找指定模式并显示匹配行的行号###
|
||||
|
||||
root@Linux-world:~# grep -n linuxtechi /etc/passwd
|
||||
39:linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
@ -45,7 +48,7 @@ root@Linux-world:~# grep -n root /etc/passwd /etc/shadow
|
||||
|
||||

|
||||
|
||||
###5 使用-v参数输出不包含指定模式的行###
|
||||
###例5 使用-v参数输出不包含指定模式的行###
|
||||
|
||||
输出/etc/passwd文件中所有不含单词“linuxtechi”的行
|
||||
|
||||
@ -53,15 +56,15 @@ root@Linux-world:~# grep -n root /etc/passwd /etc/shadow
|
||||
|
||||
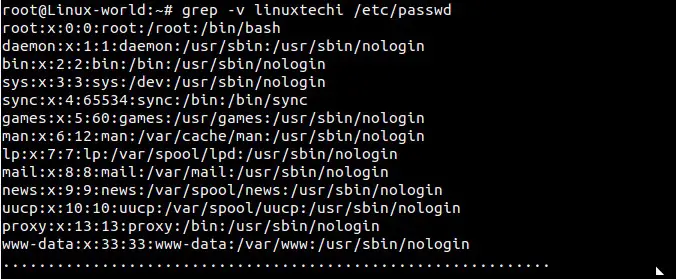
|
||||
|
||||
###6 使用^符号输出所有以某指定模式开头的行###
|
||||
###例6 使用 ^ 符号输出所有以某指定模式开头的行###
|
||||
|
||||
Bash脚本将^符号当作特殊字符处理,用于指定一行或者一个单词的开始。例如输出/etc/passes文件中所有以“root”开头的行
|
||||
Bash脚本将 ^ 符号视作特殊字符,用于指定一行或者一个单词的开始。例如输出/etc/passes文件中所有以“root”开头的行
|
||||
|
||||
root@Linux-world:~# grep ^root /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
###7 使用 $ 符号输出所有以指定模式结尾的行。###
|
||||
###例7 使用 $ 符号输出所有以指定模式结尾的行。###
|
||||
|
||||
输出/etc/passwd文件中所有以“bash”结尾的行。
|
||||
|
||||
@ -70,10 +73,9 @@ Bash脚本将^符号当作特殊字符处理,用于指定一行或者一个单
|
||||
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
Bash脚本将美元($)符号当作特殊字符,用于指定一行或者一个单词的结尾。
|
||||
|
||||
###8 使用 -r 参数递归的查找特定模式###
|
||||
Bash脚本将美元($)符号视作特殊字符,用于指定一行或者一个单词的结尾。
|
||||
|
||||
###例8 使用 -r 参数递归地查找特定模式###
|
||||
|
||||
root@Linux-world:~# grep -r linuxtechi /etc/
|
||||
/etc/subuid:linuxtechi:100000:65536
|
||||
@ -91,14 +93,14 @@ Bash脚本将美元($)符号当作特殊字符,用于指定一行或者一个
|
||||
|
||||
上面的命令将会递归的在/etc目录中查找“linuxtechi”单词
|
||||
|
||||
###9 使用grep查找文件中所有的空行
|
||||
###例9 使用 grep 查找文件中所有的空行
|
||||
|
||||
root@Linux-world:~# grep ^$ /etc/shadow
|
||||
root@Linux-world:~#
|
||||
|
||||
由于/etc/shadow文件中没有空行,所以没有任何输出
|
||||
|
||||
###10 使用“grep -i”参数查找模式###
|
||||
###例10 使用 -i 参数查找模式###
|
||||
|
||||
grep命令的-i参数在查找时忽略字符的大小写。
|
||||
|
||||
@ -108,7 +110,7 @@ grep命令的-i参数在查找时忽略字符的大小写。
|
||||
linuxtechi:x:1001:1001::/home/linuxtechi:/bin/bash
|
||||
nextstep4it@localhost:~$
|
||||
|
||||
###11 使用-e参数查找多个模式###
|
||||
###例11 使用 -e 参数查找多个模式###
|
||||
|
||||
例如,我想在一条grep命令中查找‘linuxtechi’和‘root’单词,使用-e参数,我们可以查找多个模式。
|
||||
|
||||
@ -117,7 +119,7 @@ grep命令的-i参数在查找时忽略字符的大小写。
|
||||
linuxtechi:x:1000:1000:linuxtechi,,,:/home/linuxtechi:/bin/bash
|
||||
root@Linux-world:~#
|
||||
|
||||
###12 使用“grep -f”从一个文件中获取待查找的模式###
|
||||
###例12 使用 -f 用文件指定待查找的模式###
|
||||
|
||||
首先,在当前目录中创建一个搜索模式文件“grep_pattern”,我想文件中输入的如下内容。
|
||||
|
||||
@ -133,7 +135,7 @@ grep命令的-i参数在查找时忽略字符的大小写。
|
||||
|
||||
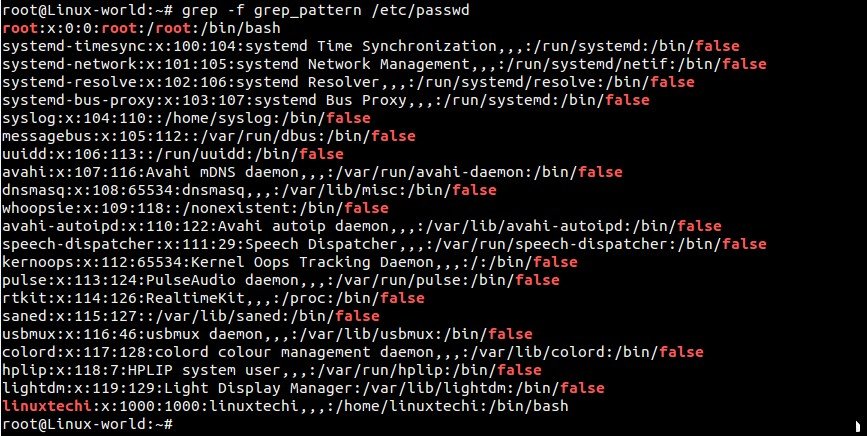
|
||||
|
||||
###13 使用-c参数计算模式匹配的数量###
|
||||
###例13 使用 -c 参数计算模式匹配到的数量###
|
||||
|
||||
继续上面例子,我们在grep命令中使用-c命令计算匹配指定模式的数量
|
||||
|
||||
@ -141,7 +143,7 @@ grep命令的-i参数在查找时忽略字符的大小写。
|
||||
22
|
||||
root@Linux-world:~#
|
||||
|
||||
###14 输出匹配指定模式行的前或者后面N行###
|
||||
###例14 输出匹配指定模式行的前或者后面N行###
|
||||
|
||||
a)使用-B参数输出匹配行的前4行
|
||||
|
||||
@ -167,7 +169,7 @@ via: http://www.linuxtechi.com/linux-grep-command-with-14-different-examples/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
Square 2.0 Icon Pack Is Twice More Beautiful
|
||||
================================================================================
|
||||

|
||||
|
||||
Elegant, modern looking [Square icon theme][1] has recently been upgraded to version 2.0, which makes it more beautiful than ever. Square icon packs are compatible with all major desktop environments such as **Unity, GNOME, KDE, MATE** etc. Which means that you can use them for all popular Linux distributions such as Ubuntu, Fedora, Linux Mint, elementary OS etc. The vastness of this icon pack can be estimated from the fact it contains over 15,000 icons.
|
||||
|
||||
### Install and use Square icon pack 2.0 in Linux ###
|
||||
|
||||
There are two variants of Square icons, dark and light. Based on your preference, you can choose either of the two. For experimentation sake, I would advise you to download both variants of the icon theme.
|
||||
|
||||
You can download the icon pack from the link below. The files are stored in Google Drive, so don’t be suspicious if you don’t see a standard website like [SourceForge][2].
|
||||
|
||||
- [Square Dark Icons][3]
|
||||
- [Square Light Icons][4]
|
||||
|
||||
To use the icon theme, extract the downloaded files in ~/.icons directory. If this doesn’t exist, create it. Once you have the files in the right place, based on your desktop environment, use a tool to change the icon theme. I have written some small tutorials in the past on this topic. Feel free to refer to them if you need further help:
|
||||
|
||||
- [How to change themes in Ubuntu Unity][5]
|
||||
- [How to change themes in GNOME Shell][6]
|
||||
- [How to change themes in Linux Mint][7]
|
||||
- [How to change theme in Elementary OS Freya][8]
|
||||
|
||||
### Give it a try ###
|
||||
|
||||
Here is what my Ubuntu 14.04 looks like with Square icons. I am using [Ubuntu 15.04 default wallpaper][9] in the background.
|
||||
|
||||

|
||||
|
||||
A quick look at several icons in the Square theme:
|
||||
|
||||

|
||||
|
||||
How do you find it? Do you think it can be considered as one of the [best icon themes for Ubuntu 14.04][10]? Do share your thoughts and stay tuned for more articles on customizing your Linux desktop.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/square-2-0-icon-pack-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://gnome-look.org/content/show.php/Square?content=163513
|
||||
[2]:http://sourceforge.net/
|
||||
[3]:http://gnome-look.org/content/download.php?content=163513&id=1&tan=62806435
|
||||
[4]:http://gnome-look.org/content/download.php?content=163513&id=2&tan=19789941
|
||||
[5]:http://itsfoss.com/how-to-install-themes-in-ubuntu-13-10/
|
||||
[6]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[7]:http://itsfoss.com/install-icon-linux-mint/
|
||||
[8]:http://itsfoss.com/install-themes-icons-elementary-os-freya/
|
||||
[9]:http://itsfoss.com/default-wallpapers-ubuntu-1504/
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -1,42 +0,0 @@
|
||||
Translating by H-mudcup
|
||||
Synfig Studio 1.0 — Open Source Animation Gets Serious
|
||||
================================================================================
|
||||

|
||||
|
||||
**A brand new version of the free, open-source 2D animation software Synfig Studio is now available to download. **
|
||||
|
||||
The first release of the cross-platform software in well over a year, Synfig Studio 1.0 builds on its claim of offering “industrial-strength solution for creating film-quality animation” with a suite of new and improved features.
|
||||
|
||||
Among them is an improved user interface that the project developers say is ‘easier’ and ‘more intuitive’ to use. The client adds a new **single-window mode** for tidy working and has been **reworked to use the latest GTK3 libraries**.
|
||||
|
||||
On the features front there are several notable changes, including the addition of a fully-featured bone system.
|
||||
|
||||
This **joint-and-pivot ‘skeleton’ framework** is well suited to 2D cut-out animation and should prove super efficient when coupled with the complex deformations new to this release, or used with Synfig’s popular ‘automatic interpolated keyframes’ (read: frame-to-frame morphing).
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/M8zW1qCq8ng?feature=oembed"></iframe>
|
||||
|
||||
New non-destructive cutout tools, friction effects and initial support for full frame-by-frame bitmap animation, may help unlock the creativity of open-source animators, as might the addition of a sound layer for syncing the animation timeline with a soundtrack!
|
||||
|
||||
### Download Synfig Studio 1.0 ###
|
||||
|
||||
Synfig Studio is not a tool suited for everyone, though the latest batch of improvements in this latest release should help persuade some animators to give the free animation software a try.
|
||||
|
||||
If you want to find out what open-source animation software is like for yourself, you can grab an installer for Ubuntu for the latest release direct from the project’s Sourceforge page using the links below.
|
||||
|
||||
- [Download Synfig 1.0 (64bit) .deb Installer][1]
|
||||
- [Download Synfig 1.0 (32bit) .deb Installer][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/04/synfig-studio-new-release-features
|
||||
|
||||
作者:[oey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_amd64.deb/download
|
||||
[2]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_x86.deb/download
|
||||
@ -1,3 +1,5 @@
|
||||
translating by wwy-hust
|
||||
|
||||
Guake 0.7.0 Released – A Drop-Down Terminal for Gnome Desktops
|
||||
================================================================================
|
||||
Linux commandline is the best and most powerful thing that fascinates a new user and provides extreme power to experienced users and geeks. For those who work on Server and Production, they are already aware of this fact. It would be interesting to know that Linux console was one of those first features of the kernel that was written by Linus Torvalds way back in the year 1991.
|
||||
@ -112,4 +114,4 @@ via: http://www.tecmint.com/install-guake-terminal-ubuntu-mint-fedora/
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/linux-terminal-emulators/
|
||||
[2]:https://github.com/Guake/guake/releases/tag/0.7.0
|
||||
[2]:https://github.com/Guake/guake/releases/tag/0.7.0
|
||||
|
||||
@ -0,0 +1,103 @@
|
||||
New to Linux? 5 Apps You Didn’t Know You Were Missing
|
||||
================================================================================
|
||||

|
||||
|
||||
When you moved to Linux, you went straight for the obvious browsers, cloud clients, music players, email clients, and perhaps image editors, right? As a result, you’ve missed several vital, productive tools. Here’s a roundup of five umissable Linux apps that you really need to install.
|
||||
|
||||
### [Synergy][1] ###
|
||||
|
||||
Synergy is a godsend if you use multiple desktops. It’s an open-source app that allows you to use a single mouse and keyboard across multiple computers, displays, and operating systems. Switching the mouse and keyboard functionality between the desktops is easy. Just move the mouse out the edge of one screen and into another.
|
||||
|
||||

|
||||
|
||||
When you open Synergy for the first time, it will run you through the setup wizard. The primary desktop is the one whose input devices you’ll be sharing with the other desktops. Configure that as the server. Add the remaining computers as clients.
|
||||
|
||||

|
||||
|
||||
Synergy maintains a common clipboard across all connected desktops. It also merges the lock screen setup, i.e. you need to bypass the lock screen just once to log in to all the computers together. Under **Edit > Settings**, you can make a few more tweaks such as adding a password and setting Synergy to launch on startup.
|
||||
|
||||
### [BasKet Note Pads][2] ###
|
||||
|
||||
Using BasKet Note Pads is somewhat like mapping your brain onto a computer. It helps make sense of all the ideas floating around in your head by allowing you to organize them in digestible chunks. You can use BasKet Note Pads for various tasks such as taking notes, creating idea maps and to-do lists, saving links, managing research, and keeping track of project data.
|
||||
|
||||
Each main idea or project goes into a section called a basket. To split ideas further, you can have one or more sub-baskets or sibling baskets. The baskets are further broken down into notes, which hold all the bits and pieces of a project. You can group them, tag them, and filter them.
|
||||
|
||||
The left pane in the application’s two-pane structure displays a tree-like view of all the baskets you have created.
|
||||
|
||||

|
||||
|
||||
BasKet Note Pads might seem a little complex on day one, but you’ll get the hang of it soon. When you’re not using it, the app sits in the system tray, ready for quick access.
|
||||
|
||||
Want a [simpler note-taking alternative][3] on Linux? Try [Springseed][4].
|
||||
|
||||
### [Caffeine][5]###
|
||||
|
||||
How do you ensure that your computer doesn’t go to sleep right in the middle of an [interesting movie][6]? Caffeine is the answer. No, you don’t need to brew a cup of coffee for your computer. You just need to install a lightweight indicator applet called Caffeine. It prevents the screen-saver, lock screen, or the Sleep mode from being activated when the computer is idle, only if the current window is in full-screen mode.
|
||||
|
||||
To install the applet, [download its latest version][7]. If you want to go [the ppa way][8], here’s how you can:
|
||||
|
||||
$ sudo add-apt-repository ppa:caffeine-developers/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install caffeine
|
||||
|
||||
On Ubuntu versions 14.10 and 15.04 (and their derivatives), you’ll also need to install certain dependency packages:
|
||||
|
||||
$ sudo apt-get install libappindicator3-1 gir1.2-appindicator3-0.1
|
||||
|
||||
After finishing the installation, add **caffeine-indicator** to your list of startup applications to make the indicator appear in the system tray. You can turn Caffeine’s functionality on and off via the app’s context menu, which pops up when you right-click on the tray icon.
|
||||
|
||||

|
||||
|
||||
### Easystroke ###
|
||||
|
||||
Easystroke makes an excellent [Linux mouse hack][9]. Use it to set up a series of customized mouse/touchpad/pen gestures to simulate common actions such as keystrokes, commands, and scrolls. Setting up Easystroke gestures is straightforward enough, thanks to the clear instructions that appear at all the right moments when you’re navigating the UI.
|
||||
|
||||

|
||||
|
||||
Begin by choosing the mouse button you’d like to use for performing gestures. Throw in a modifier if you like. You’ll find this setting under **Preferences > Behavior > Gesture Button**. Now head to the **Actions** tab and record strokes for your most commonly used actions.
|
||||
|
||||

|
||||
|
||||
Using the **Preferences** and **Advanced** tabs, you can make other tweaks like setting Easystroke to autostart, adding a system tray icon, and changing scroll speed.
|
||||
|
||||
### Guake ###
|
||||
|
||||
I saved my favorite Linux find for last. Guake is a dropdown command line modeled after the one in the first-person shooter video game [Quake][10]. Whether you’re [learning about terminal commands][11] or executing them on a regular basis, Guake is a great way to keep the terminal handy. You can bring it up or hide it in a single keystroke.
|
||||
|
||||
As you can see in the image below, when in action, Guake appears as an overlay on the current window. Right-click within the terminal to access the **Preferences** section, from where you can change Guake’s appearance, its scroll action, keyboard shortcuts, and more.
|
||||
|
||||

|
||||
|
||||
If KDE is your [Linux desktop of choice][12], do check out [Yakuake][13], which provides a similar functionality.
|
||||
|
||||
### Name Your Favorite Linux Discovery! ###
|
||||
|
||||
There are many more [super useful Linux apps][14] waiting to be discovered. Rest assured that we’ll keep introducing you to them.
|
||||
|
||||
Which Linux app were you happiest to learn about? Which one do you consider a must-have? Tell us in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/new-linux-5-apps-didnt-know-missing/
|
||||
|
||||
作者:[Akshata][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.makeuseof.com/tag/author/akshata/
|
||||
[1]:http://synergy-project.org/
|
||||
[2]:http://basket.kde.org/
|
||||
[3]:http://www.makeuseof.com/tag/try-these-3-beautiful-note-taking-apps-that-work-offline/
|
||||
[4]:http://getspringseed.com/
|
||||
[5]:https://launchpad.net/caffeine
|
||||
[6]:http://www.makeuseof.com/tag/popular-apps-movies-according-google/
|
||||
[7]:http://ppa.launchpad.net/caffeine-developers/ppa/ubuntu/pool/main/c/caffeine/
|
||||
[8]:http://www.makeuseof.com/tag/ubuntu-ppa-technology-explained/
|
||||
[9]:http://www.makeuseof.com/tag/4-astounding-linux-mouse-hacks/
|
||||
[10]:http://en.wikipedia.org/wiki/Quake_%28video_game%29
|
||||
[11]:http://www.makeuseof.com/tag/4-ways-teach-terminal-commands-linux-si/
|
||||
[12]:http://www.makeuseof.com/tag/10-top-linux-desktop-environments-available/
|
||||
[13]:https://yakuake.kde.org/
|
||||
[14]:http://www.makeuseof.com/tag/linux-treasures-x-sublime-native-linux-apps-will-make-want-switch/
|
||||
@ -0,0 +1,71 @@
|
||||
This Ubuntu App Applies Instagram Style Filters to Your Photos
|
||||
================================================================================
|
||||
**Looking for an Ubuntu app to apply Instagram style filters to your photos in Ubuntu?**
|
||||
|
||||
Grab your selfie stick and step this way…
|
||||
|
||||

|
||||
XnRetro is a photo editing app
|
||||
|
||||
### XnRetro Photo Editor ###
|
||||
|
||||
**XnRetro** is a simple image editing application that lets you quickly add “Instagram like” effects to your photos.
|
||||
|
||||
You know the sort of effects I’m talking about: scratches, noises, and frames, over processing, vintage washes and nostalgic tints (because in this age of digital transience we must know that endless selfies and sandwich snaps are unlikely to ever become nostalgic of themselves).
|
||||
|
||||
Whether you consider such effects to be of asinine artistic value or shortcut to being creative, these kinds of filters are popular and can help add a splash of personality to an otherwise so-so photo.
|
||||
|
||||
#### XnRetro Features ####
|
||||
|
||||
**XnRetro features the following:**
|
||||
|
||||
- 20 color filters
|
||||
- 15 light effects (bokeh, leaks, etc)
|
||||
- 28 frames and borders
|
||||
- 5 Vignettes (with strength control)
|
||||
- Image adjustments for contrast, gamma, saturation, etc
|
||||
- Square crop option
|
||||
|
||||

|
||||
Small tweak to make light effects work
|
||||
|
||||
You can save edited images (in theory) as .jpg or .png files and share them straight to social media from within the app.
|
||||
|
||||
I say “in theory” because .jpg saving doesn’t actually work in the Linux version of the app (you can save edited images as .png files though). Similarly, most of the built-in social networking links are borked or just flat out fail on export.
|
||||
|
||||
To get the **15 light leaks** to work you will need to re-save each .jpg image in XnRetro ‘light’ folder as a .png file. Edit the ‘light.xml’ to match the new file names, hit save and the light effects will load up in XnRetro without issue.
|
||||
|
||||
> ‘For user-friendly image editing XnRetro is hard to beat — once you make it work.’
|
||||
|
||||
**Is XnRetro Worth Installing?**
|
||||
|
||||
XnRetro is not perfect. It’s is pretty old-looking, difficult to properly install and has not been updated for several years.
|
||||
|
||||
It does still work, barring .jpg saving, and is a nimble alternative to an advanced app like The Gimp or Shotwell’s set of ‘serious’ image adjustment tools.
|
||||
|
||||
While web apps and Chrome Apps¹ like [Pixlr Touch Up][1] and [Polarr][2] offer similar features you may be looking for a truly native solution.
|
||||
|
||||
And for that, for user-friendly image editing based around easy-to-apply filters, XnRetro is hard to beat.
|
||||
|
||||
### Download XnRetro for Ubuntu ###
|
||||
|
||||
XnRetro is not available as an installable .deb package. It is distributed as a binary file, meaning you need to double-click on the program file run it each and every time. It’s also 32-bit only.
|
||||
|
||||
You can download XnRetro using the link below. Once completed you need to extract the archive and enter the folder it creates. Double-click on the ‘xnretro’ program binary inside.
|
||||
|
||||
- [Download XnRetro for Linux (32bit, tar.gz)][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/05/instagram-photo-filters-ubuntu-desktop-app
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgchrome.com/?s=pixlr
|
||||
[2]:http://www.omgchrome.com/the-best-chrome-apps-of-2014/
|
||||
[3]:http://www.xnview.com/en/xnretro/#downloads
|
||||
@ -1,446 +0,0 @@
|
||||
translating by wwy-hust
|
||||
|
||||
Web Caching Basics: Terminology, HTTP Headers, and Caching Strategies
|
||||
=====================================================================
|
||||
|
||||
### Introduction
|
||||
|
||||
Intelligent content caching is one of the most effective ways to improve
|
||||
the experience for your site's visitors. Caching, or temporarily storing
|
||||
content from previous requests, is part of the core content delivery
|
||||
strategy implemented within the HTTP protocol. Components throughout the
|
||||
delivery path can all cache items to speed up subsequent requests,
|
||||
subject to the caching policies declared for the content.
|
||||
|
||||
In this guide, we will discuss some of the basic concepts of web content
|
||||
caching. This will mainly cover how to select caching policies to ensure
|
||||
that caches throughout the internet can correctly process your content.
|
||||
We will talk about the benefits that caching affords, the side effects
|
||||
to be aware of, and the different strategies to employ to provide the
|
||||
best mixture of performance and flexibility.
|
||||
|
||||
What Is Caching?
|
||||
----------------
|
||||
|
||||
Caching is the term for storing reusable responses in order to make
|
||||
subsequent requests faster. There are many different types of caching
|
||||
available, each of which has its own characteristics. Application caches
|
||||
and memory caches are both popular for their ability to speed up certain
|
||||
responses.
|
||||
|
||||
Web caching, the focus of this guide, is a different type of cache. Web
|
||||
caching is a core design feature of the HTTP protocol meant to minimize
|
||||
network traffic while improving the perceived responsiveness of the
|
||||
system as a whole. Caches are found at every level of a content's
|
||||
journey from the original server to the browser.
|
||||
|
||||
Web caching works by caching the HTTP responses for requests according
|
||||
to certain rules. Subsequent requests for cached content can then be
|
||||
fulfilled from a cache closer to the user instead of sending the request
|
||||
all the way back to the web server.
|
||||
|
||||
Benefits
|
||||
--------
|
||||
|
||||
Effective caching aids both content consumers and content providers.
|
||||
Some of the benefits that caching brings to content delivery are:
|
||||
|
||||
- **Decreased network costs**: Content can be cached at various points
|
||||
in the network path between the content consumer and content origin.
|
||||
When the content is cached closer to the consumer, requests will not
|
||||
cause much additional network activity beyond the cache.
|
||||
- **Improved responsiveness**: Caching enables content to be retrieved
|
||||
faster because an entire network round trip is not necessary. Caches
|
||||
maintained close to the user, like the browser cache, can make this
|
||||
retrieval nearly instantaneous.
|
||||
- **Increased performance on the same hardware**: For the server where
|
||||
the content originated, more performance can be squeezed from the
|
||||
same hardware by allowing aggressive caching. The content owner can
|
||||
leverage the powerful servers along the delivery path to take the
|
||||
brunt of certain content loads.
|
||||
- **Availability of content during network interruptions**: With
|
||||
certain policies, caching can be used to serve content to end users
|
||||
even when it may be unavailable for short periods of time from the
|
||||
origin servers.
|
||||
|
||||
Terminology
|
||||
-----------
|
||||
|
||||
When dealing with caching, there are a few terms that you are likely to
|
||||
come across that might be unfamiliar. Some of the more common ones are
|
||||
below:
|
||||
|
||||
- **Origin server**: The origin server is the original location of the
|
||||
content. If you are acting as the web server administrator, this is
|
||||
the machine that you control. It is responsible for serving any
|
||||
content that could not be retrieved from a cache along the request
|
||||
route and for setting the caching policy for all content.
|
||||
- **Cache hit ratio**: A cache's effectiveness is measured in terms of
|
||||
its cache hit ratio or hit rate. This is a ratio of the requests
|
||||
able to be retrieved from a cache to the total requests made. A high
|
||||
cache hit ratio means that a high percentage of the content was able
|
||||
to be retrieved from the cache. This is usually the desired outcome
|
||||
for most administrators.
|
||||
- **Freshness**: Freshness is a term used to describe whether an item
|
||||
within a cache is still considered a candidate to serve to a client.
|
||||
Content in a cache will only be used to respond if it is within the
|
||||
freshness time frame specified by the caching policy.
|
||||
- **Stale content**: Items in the cache expire according to the cache
|
||||
freshness settings in the caching policy. Expired content is
|
||||
"stale". In general, expired content cannot be used to respond to
|
||||
client requests. The origin server must be re-contacted to retrieve
|
||||
the new content or at least verify that the cached content is still
|
||||
accurate.
|
||||
- **Validation**: Stale items in the cache can be validated in order
|
||||
to refresh their expiration time. Validation involves checking in
|
||||
with the origin server to see if the cached content still represents
|
||||
the most recent version of item.
|
||||
- **Invalidation**: Invalidation is the process of removing content
|
||||
from the cache before its specified expiration date. This is
|
||||
necessary if the item has been changed on the origin server and
|
||||
having an outdated item in cache would cause significant issues for
|
||||
the client.
|
||||
|
||||
There are plenty of other caching terms, but the ones above should help
|
||||
you get started.
|
||||
|
||||
What Can be Cached?
|
||||
-------------------
|
||||
|
||||
Certain content lends itself more readily to caching than others. Some
|
||||
very cache-friendly content for most sites are:
|
||||
|
||||
- Logos and brand images
|
||||
- Non-rotating images in general (navigation icons, for example)
|
||||
- Style sheets
|
||||
- General Javascript files
|
||||
- Downloadable Content
|
||||
- Media Files
|
||||
|
||||
These tend to change infrequently, so they can benefit from being cached
|
||||
for longer periods of time.
|
||||
|
||||
Some items that you have to be careful in caching are:
|
||||
|
||||
- HTML pages
|
||||
- Rotating images
|
||||
- Frequently modified Javascript and CSS
|
||||
- Content requested with authentication cookies
|
||||
|
||||
Some items that should almost never be cached are:
|
||||
|
||||
- Assets related to sensitive data (banking info, etc.)
|
||||
- Content that is user-specific and frequently changed
|
||||
|
||||
In addition to the above general rules, it's possible to specify
|
||||
policies that allow you to cache different types of content
|
||||
appropriately. For instance, if authenticated users all see the same
|
||||
view of your site, it may be possible to cache that view anywhere. If
|
||||
authenticated users see a user-sensitive view of the site that will be
|
||||
valid for some time, you may tell the user's browser to cache, but tell
|
||||
any intermediary caches not to store the view.
|
||||
|
||||
Locations Where Web Content Is Cached
|
||||
-------------------------------------
|
||||
|
||||
Content can be cached at many different points throughout the delivery
|
||||
chain:
|
||||
|
||||
- **Browser cache**: Web browsers themselves maintain a small cache.
|
||||
Typically, the browser sets a policy that dictates the most
|
||||
important items to cache. This may be user-specific content or
|
||||
content deemed expensive to download and likely to be requested
|
||||
again.
|
||||
- **Intermediary caching proxies**: Any server in between the client
|
||||
and your infrastructure can cache certain content as desired. These
|
||||
caches may be maintained by ISPs or other independent parties.
|
||||
- **Reverse Cache**: Your server infrastructure can implement its own
|
||||
cache for backend services. This way, content can be served from the
|
||||
point-of-contact instead of hitting backend servers on each request.
|
||||
|
||||
Each of these locations can and often do cache items according to their
|
||||
own caching policies and the policies set at the content origin.
|
||||
|
||||
Caching Headers
|
||||
---------------
|
||||
|
||||
Caching policy is dependent upon two different factors. The caching
|
||||
entity itself gets to decide whether or not to cache acceptable content.
|
||||
It can decide to cache less than it is allowed to cache, but never more.
|
||||
|
||||
The majority of caching behavior is determined by the caching policy,
|
||||
which is set by the content owner. These policies are mainly articulated
|
||||
through the use of specific HTTP headers.
|
||||
|
||||
Through various iterations of the HTTP protocol, a few different
|
||||
cache-focused headers have arisen with varying levels of sophistication.
|
||||
The ones you probably still need to pay attention to are below:
|
||||
|
||||
- **`Expires`**: The `Expires` header is very straight-forward,
|
||||
although fairly limited in scope. Basically, it sets a time in the
|
||||
future when the content will expire. At this point, any requests for
|
||||
the same content will have to go back to the origin server. This
|
||||
header is probably best used only as a fall back.
|
||||
- **`Cache-Control`**: This is the more modern replacement for the
|
||||
`Expires` header. It is well supported and implements a much more
|
||||
flexible design. In almost all cases, this is preferable to
|
||||
`Expires`, but it may not hurt to set both values. We will discuss
|
||||
the specifics of the options you can set with `Cache-Control` a bit
|
||||
later.
|
||||
- **`Etag`**: The `Etag` header is used with cache validation. The
|
||||
origin can provide a unique `Etag` for an item when it initially
|
||||
serves the content. When a cache needs to validate the content it
|
||||
has on-hand upon expiration, it can send back the `Etag` it has for
|
||||
the content. The origin will either tell the cache that the content
|
||||
is the same, or send the updated content (with the new `Etag`).
|
||||
- **`Last-Modified`**: This header specifies the last time that the
|
||||
item was modified. This may be used as part of the validation
|
||||
strategy to ensure fresh content.
|
||||
- **`Content-Length`**: While not specifically involved in caching,
|
||||
the `Content-Length` header is important to set when defining
|
||||
caching policies. Certain software will refuse to cache content if
|
||||
it does not know in advanced the size of the content it will need to
|
||||
reserve space for.
|
||||
- **`Vary`**: A cache typically uses the requested host and the path
|
||||
to the resource as the key with which to store the cache item. The
|
||||
`Vary` header can be used to tell caches to pay attention to an
|
||||
additional header when deciding whether a request is for the same
|
||||
item. This is most commonly used to tell caches to key by the
|
||||
`Accept-Encoding` header as well, so that the cache will know to
|
||||
differentiate between compressed and uncompressed content.
|
||||
|
||||
### An Aside about the Vary Header
|
||||
|
||||
The `Vary` header provides you with the ability to store different
|
||||
versions of the same content at the expense of diluting the entries in
|
||||
the cache.
|
||||
|
||||
In the case of `Accept-Encoding`, setting the `Vary` header allows for a
|
||||
critical distinction to take place between compressed and uncompressed
|
||||
content. This is needed to correctly serve these items to browsers that
|
||||
cannot handle compressed content and is necessary in order to provide
|
||||
basic usability. One characteristic that tells you that
|
||||
`Accept-Encoding` may be a good candidate for `Vary` is that it only has
|
||||
two or three possible values.
|
||||
|
||||
Items like `User-Agent` might at first glance seem to be a good way to
|
||||
differentiate between mobile and desktop browsers to serve different
|
||||
versions of your site. However, since `User-Agent` strings are
|
||||
non-standard, the result will likely be many versions of the same
|
||||
content on intermediary caches, with a very low cache hit ratio. The
|
||||
`Vary` header should be used sparingly, especially if you do not have
|
||||
the ability to normalize the requests in intermediate caches that you
|
||||
control (which may be possible, for instance, if you leverage a content
|
||||
delivery network).
|
||||
|
||||
How Cache-Control Flags Impact Caching
|
||||
--------------------------------------
|
||||
|
||||
Above, we mentioned how the `Cache-Control` header is used for modern
|
||||
cache policy specification. A number of different policy instructions
|
||||
can be set using this header, with multiple instructions being separated
|
||||
by commas.
|
||||
|
||||
Some of the `Cache-Control` options you can use to dictate your
|
||||
content's caching policy are:
|
||||
|
||||
- **`no-cache`**: This instruction specifies that any cached content
|
||||
must be re-validated on each request before being served to a
|
||||
client. This, in effect, marks the content as stale immediately, but
|
||||
allows it to use revalidation techniques to avoid re-downloading the
|
||||
entire item again.
|
||||
- **`no-store`**: This instruction indicates that the content cannot
|
||||
be cached in any way. This is appropriate to set if the response
|
||||
represents sensitive data.
|
||||
- **`public`**: This marks the content as public, which means that it
|
||||
can be cached by the browser and any intermediate caches. For
|
||||
requests that utilized HTTP authentication, responses are marked
|
||||
`private` by default. This header overrides that setting.
|
||||
- **`private`**: This marks the content as `private`. Private content
|
||||
may be stored by the user's browser, but must *not* be cached by any
|
||||
intermediate parties. This is often used for user-specific data.
|
||||
- **`max-age`**: This setting configures the maximum age that the
|
||||
content may be cached before it must revalidate or re-download the
|
||||
content from the origin server. In essence, this replaces the
|
||||
`Expires` header for modern browsing and is the basis for
|
||||
determining a piece of content's freshness. This option takes its
|
||||
value in seconds with a maximum valid freshness time of one year
|
||||
(31536000 seconds).
|
||||
- **`s-maxage`**: This is very similar to the `max-age` setting, in
|
||||
that it indicates the amount of time that the content can be cached.
|
||||
The difference is that this option is applied only to intermediary
|
||||
caches. Combining this with the above allows for more flexible
|
||||
policy construction.
|
||||
- **`must-revalidate`**: This indicates that the freshness information
|
||||
indicated by `max-age`, `s-maxage` or the `Expires` header must be
|
||||
obeyed strictly. Stale content cannot be served under any
|
||||
circumstance. This prevents cached content from being used in case
|
||||
of network interruptions and similar scenarios.
|
||||
- **`proxy-revalidate`**: This operates the same as the above setting,
|
||||
but only applies to intermediary proxies. In this case, the user's
|
||||
browser can potentially be used to serve stale content in the event
|
||||
of a network interruption, but intermediate caches cannot be used
|
||||
for this purpose.
|
||||
- **`no-transform`**: This option tells caches that they are not
|
||||
allowed to modify the received content for performance reasons under
|
||||
any circumstances. This means, for instance, that the cache is not
|
||||
able to send compressed versions of content it did not receive from
|
||||
the origin server compressed and is not allowed.
|
||||
|
||||
These can be combined in different ways to achieve various caching
|
||||
behavior. Some mutually exclusive values are:
|
||||
|
||||
- `no-cache`, `no-store`, and the regular caching behavior indicated
|
||||
by absence of either
|
||||
- `public` and `private`
|
||||
|
||||
The `no-store` option supersedes the `no-cache` if both are present. For
|
||||
responses to unauthenticated requests, `public` is implied. For
|
||||
responses to authenticated requests, `private` is implied. These can be
|
||||
overridden by including the opposite option in the `Cache-Control`
|
||||
header.
|
||||
|
||||
Developing a Caching Strategy
|
||||
-----------------------------
|
||||
|
||||
In a perfect world, everything could be cached aggressively and your
|
||||
servers would only be contacted to validate content occasionally. This
|
||||
doesn't often happen in practice though, so you should try to set some
|
||||
sane caching policies that aim to balance between implementing long-term
|
||||
caching and responding to the demands of a changing site.
|
||||
|
||||
### Common Issues
|
||||
|
||||
There are many situations where caching cannot or should not be
|
||||
implemented due to how the content is produced (dynamically generated
|
||||
per user) or the nature of the content (sensitive banking information,
|
||||
for example). Another problem that many administrators face when setting
|
||||
up caching is the situation where older versions of your content are out
|
||||
in the wild, not yet stale, even though new versions have been
|
||||
published.
|
||||
|
||||
These are both frequently encountered issues that can have serious
|
||||
impacts on cache performance and the accuracy of content you are
|
||||
serving. However, we can mitigate these issues by developing caching
|
||||
policies that anticipate these problems.
|
||||
|
||||
### General Recommendations
|
||||
|
||||
While your situation will dictate the caching strategy you use, the
|
||||
following recommendations can help guide you towards some reasonable
|
||||
decisions.
|
||||
|
||||
There are certain steps that you can take to increase your cache hit
|
||||
ratio before worrying about the specific headers you use. Some ideas
|
||||
are:
|
||||
|
||||
- **Establish specific directories for images, css, and shared
|
||||
content**: Placing content into dedicated directories will allow you
|
||||
to easily refer to them from any page on your site.
|
||||
- **Use the same URL to refer to the same items**: Since caches key
|
||||
off of both the host and the path to the content requested, ensure
|
||||
that you refer to your content in the same way on all of your pages.
|
||||
The previous recommendation makes this significantly easier.
|
||||
- **Use CSS image sprites where possible**: CSS image sprites for
|
||||
items like icons and navigation decrease the number of round trips
|
||||
needed to render your site and allow your site to cache that single
|
||||
sprite for a long time.
|
||||
- **Host scripts and external resources locally where possible**: If
|
||||
you utilize javascript scripts and other external resources,
|
||||
consider hosting those resources on your own servers if the correct
|
||||
headers are not being provided upstream. Note that you will have to
|
||||
be aware of any updates made to the resource upstream so that you
|
||||
can update your local copy.
|
||||
- **Fingerprint cache items**: For static content like CSS and
|
||||
Javascript files, it may be appropriate to fingerprint each item.
|
||||
This means adding a unique identifier to the filename (often a hash
|
||||
of the file) so that if the resource is modified, the new resource
|
||||
name can be requested, causing the requests to correctly bypass the
|
||||
cache. There are a variety of tools that can assist in creating
|
||||
fingerprints and modifying the references to them within HTML
|
||||
documents.
|
||||
|
||||
In terms of selecting the correct headers for different items, the
|
||||
following can serve as a general reference:
|
||||
|
||||
- **Allow all caches to store generic assets**: Static content and
|
||||
content that is not user-specific can and should be cached at all
|
||||
points in the delivery chain. This will allow intermediary caches to
|
||||
respond with the content for multiple users.
|
||||
- **Allow browsers to cache user-specific assets**: For per-user
|
||||
content, it is often acceptable and useful to allow caching within
|
||||
the user's browser. While this content would not be appropriate to
|
||||
cache on any intermediary caching proxies, caching in the browser
|
||||
will allow for instant retrieval for users during subsequent visits.
|
||||
- **Make exceptions for essential time-sensitive content**: If you
|
||||
have content that is time-sensitive, make an exception to the above
|
||||
rules so that the out-dated content is not served in critical
|
||||
situations. For instance, if your site has a shopping cart, it
|
||||
should reflect the items in the cart immediately. Depending on the
|
||||
nature of the content, the `no-cache` or `no-store` options can be
|
||||
set in the `Cache-Control` header to achieve this.
|
||||
- **Always provide validators**: Validators allow stale content to be
|
||||
refreshed without having to download the entire resource again.
|
||||
Setting the `Etag` and the `Last-Modified` headers allow caches to
|
||||
validate their content and re-serve it if it has not been modified
|
||||
at the origin, further reducing load.
|
||||
- **Set long freshness times for supporting content**: In order to
|
||||
leverage caching effectively, elements that are requested as
|
||||
supporting content to fulfill a request should often have a long
|
||||
freshness setting. This is generally appropriate for items like
|
||||
images and CSS that are pulled in to render the HTML page requested
|
||||
by the user. Setting extended freshness times, combined with
|
||||
fingerprinting, allows caches to store these resources for long
|
||||
periods of time. If the assets change, the modified fingerprint will
|
||||
invalidate the cached item and will trigger a download of the new
|
||||
content. Until then, the supporting items can be cached far into the
|
||||
future.
|
||||
- **Set short freshness times for parent content**: In order to make
|
||||
the above scheme work, the containing item must have relatively
|
||||
short freshness times or may not be cached at all. This is typically
|
||||
the HTML page that calls in the other assisting content. The HTML
|
||||
itself will be downloaded frequently, allowing it to respond to
|
||||
changes rapidly. The supporting content can then be cached
|
||||
aggressively.
|
||||
|
||||
The key is to strike a balance that favors aggressive caching where
|
||||
possible while leaving opportunities to invalidate entries in the future
|
||||
when changes are made. Your site will likely have a combination of:
|
||||
|
||||
- Aggressively cached items
|
||||
- Cached items with a short freshness time and the ability to
|
||||
re-validate
|
||||
- Items that should not be cached at all
|
||||
|
||||
The goal is to move content into the first categories when possible
|
||||
while maintaining an acceptable level of accuracy.
|
||||
|
||||
Conclusion
|
||||
----------
|
||||
|
||||
Taking the time to ensure that your site has proper caching policies in
|
||||
place can have a significant impact on your site. Caching allows you to
|
||||
cut down on the bandwidth costs associated with serving the same content
|
||||
repeatedly. Your server will also be able to handle a greater amount of
|
||||
traffic with the same hardware. Perhaps most importantly, clients will
|
||||
have a faster experience on your site, which may lead them to return
|
||||
more frequently. While effective web caching is not a silver bullet,
|
||||
setting up appropriate caching policies can give you measurable gains
|
||||
with minimal work.
|
||||
|
||||
|
||||
---
|
||||
|
||||
作者: [Justin Ellingwood](https://www.digitalocean.com/community/users/jellingwood)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
推荐:[royaso](https://github.com/royaso)
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/web-caching-basics-terminology-http-headers-and-caching-strategies
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,71 +0,0 @@
|
||||
Install Linux-Dash (Web Based Monitoring tool) on Ubntu 14.10
|
||||
================================================================================
|
||||
|
||||
A low-overhead monitoring web dashboard for a GNU/Linux machine. Simply drop-in the app and go!.Linux Dash's interface provides a detailed overview of all vital aspects of your server, including RAM and disk usage, network, installed software, users, and running processes. All information is organized into sections, and you can jump to a specific section using the buttons in the main toolbar. Linux Dash is not the most advanced monitoring tool out there, but it might be a good fit for users looking for a slick, lightweight, and easy to deploy application.
|
||||
|
||||
### Linux-Dash Features ###
|
||||
|
||||
A beautiful web-based dashboard for monitoring server info
|
||||
|
||||
Live, on-demand monitoring of RAM, Load, Uptime, Disk Allocation, Users and many more system stats
|
||||
|
||||
Drop-in install for servers with Apache2/nginx + PHP
|
||||
|
||||
Click and drag to re-arrange widgets
|
||||
|
||||
Support for wide range of linux server flavors
|
||||
|
||||
### List of Current Widgets ###
|
||||
|
||||
- General info
|
||||
- Load Average
|
||||
- RAM
|
||||
- Disk Usage
|
||||
- Users
|
||||
- Software
|
||||
- IP
|
||||
- Internet Speed
|
||||
- Online
|
||||
- Processes
|
||||
- Logs
|
||||
|
||||
### Install Linux-dash on ubuntu server 14.10 ###
|
||||
|
||||
First you need to make sure you have [Ubuntu LAMP server 14.10][1] installed and Now you have to install the following package
|
||||
|
||||
sudo apt-get install php5-json unzip
|
||||
|
||||
After the installation this module will enable for apache2 so you need to restart the apache2 server using the following command
|
||||
|
||||
sudo service apache2 restart
|
||||
|
||||
Now you need to download the linux-dash package and install
|
||||
|
||||
wget https://github.com/afaqurk/linux-dash/archive/master.zip
|
||||
|
||||
unzip master.zip
|
||||
|
||||
sudo mv linux-dash-master/ /var/www/html/linux-dash-master/
|
||||
|
||||
Now you need to change the permissions using the following command
|
||||
|
||||
sudo chmod 755 /var/www/html/linux-dash-master/
|
||||
|
||||
Now you need to go to http://serverip/linux-dash-master/ you should see similar to the following output
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-linux-dash-web-based-monitoring-tool-on-ubntu-14-10.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.ubuntugeek.com/step-by-step-ubuntu-14-10-utopic-unicorn-lamp-server-setup.html
|
||||
@ -1,184 +0,0 @@
|
||||
translating wi-cuckoo
|
||||
Useful Commands to Create Commandline Chat Server and Remove Unwanted Packages in Linux
|
||||
================================================================================
|
||||
Here we are with the next part of Linux Command Line Tips and Tricks. If you missed our previous post on Linux Tricks you may find it here.
|
||||
|
||||
- [5 Linux Command Line Tricks][1]
|
||||
|
||||
In this post we will be introducing 6 command Line tips namely create Linux Command line chat using Netcat command, perform addition of a column on the fly from the output of a command, remove orphan packages from Debian and CentOS, get local and remote IP from command Line, get colored output in terminal and decode various color code and last but not the least hash tags implementation in Linux command Line. Lets check them one by one.
|
||||
|
||||

|
||||
6 Useful Commandline Tricks and Tips
|
||||
|
||||
### 1. Create Linux Commandline Chat Server ###
|
||||
|
||||
We all have been using chat service since a long time. We are familiar with Google chat, Hangout, Facebook chat, Whatsapp, Hike and several other application and integrated chat services. Do you know Linux nc command can make your Linux box a chat server with just one line of command.
|
||||
What is nc command in Linux and what it does?
|
||||
|
||||
nc is the depreciation of Linux netcat command. The nc utility is often referred as Swiss army knife based upon the number of its built-in capabilities. It is used as debugging tool, investigation tool, reading and writing to network connection using TCP/UDP, DNS forward/reverse checking.
|
||||
|
||||
It is prominently used for port scanning, file transferring, backdoor and port listening. nc has the ability to use any local unused port and any local network source address.
|
||||
|
||||
Use nc command (On Server with IP address: 192.168.0.7) to create a command line messaging server instantly.
|
||||
|
||||
$ nc -l -vv -p 11119
|
||||
|
||||
Explanation of the above command switches.
|
||||
|
||||
- -v : means Verbose
|
||||
- -vv : more verbose
|
||||
- -p : The local port Number
|
||||
|
||||
You may replace 11119 with any other local port number.
|
||||
|
||||
Next on the client machine (IP address: 192.168.0.15) run the following command to initialize chat session to machine (where messaging server is running).
|
||||
|
||||
$ nc 192.168.0.7 11119
|
||||
|
||||

|
||||
|
||||
**Note**: You can terminate chat session by hitting ctrl+c key and also nc chat is one-to-one service.
|
||||
|
||||
### 2. How to Sum Values in a Column in Linux ###
|
||||
|
||||
How to sum the numerical values of a column, generated as an output of a command, on the fly in the terminal.
|
||||
|
||||
The output of the ‘ls -l‘ command.
|
||||
|
||||
$ ls -l
|
||||
|
||||

|
||||
|
||||
Notice that the second column is numerical which represents number of symbolic links and the 5th column is numerical which represents the size of he file. Say we need to sum the values of fifth column on the fly.
|
||||
|
||||
List the content of 5th column without printing anything else. We will be using ‘awk‘ command to do this. ‘$5‘ represents 5th column.
|
||||
|
||||
$ ls -l | awk '{print $5}'
|
||||
|
||||

|
||||
|
||||
Now use awk to print the sum of the output of 5th column by pipelining it.
|
||||
|
||||
$ ls -l | awk '{print $5}' | awk '{total = total + $1}END{print total}'
|
||||
|
||||

|
||||
|
||||
### How to Remove Orphan Packages in Linux? ###
|
||||
|
||||
Orphan packages are those packages that are installed as a dependency of another package and no longer required when the original package is removed.
|
||||
|
||||
Say we installed a package gtprogram which was dependent of gtdependency. We can’t install gtprogram unless gtdependency is installed.
|
||||
|
||||
When we remove gtprogram it won’t remove gtdependency by default. And if we don’t remove gtdependency, it will remain as Orpahn Package with no connection to any other package.
|
||||
|
||||
# yum autoremove [On RedHat Systems]
|
||||
|
||||

|
||||
|
||||
# apt-get autoremove [On Debian Systems]
|
||||
|
||||

|
||||
|
||||
You should always remove Orphan Packages to keep the Linux box loaded with just necessary stuff and nothing else.
|
||||
|
||||
### 4. How to Get Local and Public IP Address of Linux Server ###
|
||||
|
||||
To get you local IP address run the below one liner script.
|
||||
|
||||
$ ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
|
||||
|
||||
You must have installed ifconfig, if not, apt or yum the required packages. Here we will be pipelining the output of ifconfig with grep command to find the string “intel addr:”.
|
||||
|
||||
We know ifconfig command is sufficient to output local IP Address. But ifconfig generate lots of other outputs and our concern here is to generate only local IP address and nothing else.
|
||||
|
||||
# ifconfig | grep "inet addr:"
|
||||
|
||||

|
||||
|
||||
Although the output is more custom now, but we need to filter our local IP address only and nothing else. For this we will use awk to print the second column only by pipelining it with the above script.
|
||||
|
||||
# ifconfig | grep “inet addr:” | awk '{print $2}'
|
||||
|
||||

|
||||
|
||||
Clear from the above image that we have customised the output very much but still not what we want. The loopback address 127.0.0.1 is still there in the result.
|
||||
|
||||
We use use -v flag with grep that will print only those lines that don’t match the one provided in argument. Every machine have the same loopback address 127.0.0.1, so use grep -v to print those lines that don’t have this string, by pipelining it with above output.
|
||||
|
||||
# ifconfig | grep "inet addr" | awk '{print $2}' | grep -v '127.0.0.1'
|
||||
|
||||

|
||||
|
||||
We have almost generated desired output, just replace the string `(addr:)` from the beginning. We will use cut command to print only column two. The column 1 and column 2 are not separated by tab but by `(:)`, so we need to use delimiter `(-d)` by pipelining the above output.
|
||||
|
||||
# ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
|
||||
|
||||

|
||||
|
||||
Finally! The desired result has been generated.
|
||||
|
||||
### 5. How to Color Linux Terminal ###
|
||||
|
||||
You might have seen colored output in terminal. Also you would be knowing to enable/disable colored output in terminal. If not you may follow the below steps.
|
||||
|
||||
In Linux every user has `'.bashrc'` file, this file is used to handle your terminal output. Open and edit this file with your choice of editor. Note that, this file is hidden (dot beginning of file means hidden).
|
||||
|
||||
$ vi /home/$USER/.bashrc
|
||||
|
||||
Make sure that the following lines below are uncommented. ie., it don’t start with a #.
|
||||
|
||||
if [ -x /usr/bin/dircolors ]; then
|
||||
test -r ~/.dircolors && eval "$(dircolors -b ~/.dircolors)" || eval "$(dirc$
|
||||
alias ls='ls --color=auto'
|
||||
#alias dir='dir --color=auto'
|
||||
#alias vdir='vdir --color=auto'
|
||||
|
||||
alias grep='grep --color=auto'
|
||||
alias fgrep='fgrep --color=auto'
|
||||
alias egrep='egrep --color=auto'
|
||||
fi
|
||||
|
||||

|
||||
|
||||
Once done! Save and exit. To make the changes taken into effect logout and again login.
|
||||
|
||||
Now you will see files and folders are listed in various colors based upon type of file. To decode the color code run the below command.
|
||||
|
||||
$ dircolors -p
|
||||
|
||||
Since the output is too long, lets pipeline the output with less command so that we get output one screen at a time.
|
||||
|
||||
$ dircolors -p | less
|
||||
|
||||

|
||||
|
||||
### 6. How to Hash Tag Linux Commands and Scripts ###
|
||||
|
||||
We are using hash tags on Twitter, Facebook and Google Plus (may be some other places, I have not noticed). These hash tags make it easier for others to search for a hash tag. Very few know that we can use hash tag in Linux command Line.
|
||||
|
||||
We already know that `#` in configuration files and most of the programming languages is treated as comment line and is excluded from execution.
|
||||
|
||||
Run a command and then create a hash tag of the command so that we can find it later. Say we have a long script that was executed in point 4 above. Now create a hash tag for this. We know ifconfig can be run by sudo or root user hence acting as root.
|
||||
|
||||
# ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d: #myip
|
||||
|
||||
The script above has been hash tagged with ‘myip‘. Now search for the hash tag in reverse-i-serach (press ctrl+r), in the terminal and type ‘myip‘. You may execute it from there, as well.
|
||||
|
||||

|
||||
|
||||
You may create as many hash tags for every command and find it later using reverse-i-search.
|
||||
|
||||
That’s all for now. We have been working hard to produce interesting and knowledgeable contents for you. What do you think how we are doing? Any suggestion is welcome. You may comment in the box below. Keep connected! Kudos.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-commandline-chat-server-and-remove-unwanted-packages/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/5-linux-command-line-tricks/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
Install uGet Download Manager 2.0 in Debian, Ubuntu, Linux Mint and Fedora
|
||||
================================================================================
|
||||
After a long development period, which includes more than 11 developement releases, finally uGet project team pleased to announce the immediate availability of the latest stable version of uGet 2.0. The latest version includes numerous attractive features, such as a new setting dialog, improved BitTorrent and Metalink support added in the aria2 plugin, as well as better support for uGet RSS messages in the banner, other features include:
|
||||
@ -131,4 +133,4 @@ via: http://www.tecmint.com/install-uget-download-manager-in-linux/
|
||||
[2]:http://ugetdm.com/downloads
|
||||
[3]:http://www.tecmint.com/install-aria2-a-multi-protocol-command-line-download-manager-in-rhel-centos-fedora/
|
||||
[4]:http://ugetdm.com/downloads-aria2
|
||||
[5]:http://ugetdm.com/downloads
|
||||
[5]:http://ugetdm.com/downloads
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
zhangboyue 翻译中
|
||||
45 Zypper Commands to Manage ‘Suse’ Linux Package Management
|
||||
================================================================================
|
||||
SUSE (Software and System Entwicklung (Germany) meaning Software and System Development, in English) Linux lies on top of Linux Kernel brought by Novell. SUSE comes in two pack. One of them is called OpenSUSE, which is freely available (free as in speech as well as free as in wine). It is a community driven project packed with latest application support, the latest stable release of OpenSUSE Linux is 13.2.
|
||||
@ -823,4 +824,4 @@ via: http://www.tecmint.com/zypper-commands-to-manage-suse-linux-package-managem
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/installation-of-suse-linux-enterprise-server-12/
|
||||
[1]:http://www.tecmint.com/installation-of-suse-linux-enterprise-server-12/
|
||||
|
||||
@ -1,96 +0,0 @@
|
||||
A Shell Script to Monitor Network, Disk Usage, Uptime, Load Average and RAM Usage in Linux
|
||||
================================================================================
|
||||
The duty of System Administrator is really tough as he/she has to monitor the servers, users, logs, create backup and blah blah blah. For the most repetitive task most of the administrator write a script to automate their day-to-day repetitive task. Here we have written a shell Script that do not aims to automate the task of a typical system admin, but it may be helpful at places and specially for those newbies who can get most of the information they require about their System, Network, Users, Load, Ram, host, Internal IP, External IP, Uptime, etc.
|
||||
|
||||
We have taken care of formatting the output (to certain extent). The Script don’t contains any Malicious contents and it can be run using Normal user Account. In-fact it is recommended to run this script as user and not as root.
|
||||
|
||||
|
||||
Shell Script to Monitor Linux System Health
|
||||
|
||||
You are free to use/modify/redistribute the below piece of code by giving proper credit to Tecmint and Author. We have tried to customize the output to the extent that nothing other than the required output is generated. We have tried to use those variables which are generally not used by Linux System and are probably free.
|
||||
|
||||
#### Minimum System Requirement ####
|
||||
|
||||
All you need to have is a working Linux box.
|
||||
|
||||
#### Dependency ####
|
||||
|
||||
There is no dependency required to use this package for a standard Linux Distribution. Moreover the script don’t requires root permission for execution purpose. However if you want to Install it, you need to enter root password once.
|
||||
|
||||
#### Security ####
|
||||
|
||||
We have taken care to ensure security of the system. Nothing additional package is required/installed. No root access required to run. Moreover code has been released under Apache 2.0 License, that means you are free to edit, modify and re-distribute by keeping Tecmint copyright.
|
||||
|
||||
### How Do I Install and Run Script? ###
|
||||
|
||||
First, use following [wget command][1] to download the monitor script `"tecmint_monitor.sh"` and make it executable by setting appropriate permissions.
|
||||
|
||||
# wget http://tecmint.com/wp-content/scripts/tecmint_monitor.sh
|
||||
# chmod 755 tecmint_monitor.sh
|
||||
|
||||
It is strongly advised to install the script as user and not as root. It will ask for root password and will install the necessary components at required places.
|
||||
|
||||
To install `"tecmint_monitor.sh"` script, simple use -i (install) option as shown below.
|
||||
|
||||
/tecmint_monitor.sh -i
|
||||
|
||||
Enter root password when prompted. If everything goes well you will get a success message like shown below.
|
||||
|
||||
Password:
|
||||
Congratulations! Script Installed, now run monitor Command
|
||||
|
||||
After installation, you can run the script by calling command `'monitor'` from any location or user. If you don’t like to install it, you need to include the location every-time you want to run it.
|
||||
|
||||
# ./Path/to/script/tecmint_monitor.sh
|
||||
|
||||
Now run monitor command from anywhere using any user account simply as:
|
||||
|
||||
$ monitor
|
||||
|
||||
|
||||
|
||||
As soon as you run the command you get various System related information which are:
|
||||
|
||||
- Internet Connectivity
|
||||
- OS Type
|
||||
- OS Name
|
||||
- OS Version
|
||||
- Architecture
|
||||
- Kernel Release
|
||||
- Hostname
|
||||
- Internal IP
|
||||
- External IP
|
||||
- Name Servers
|
||||
- Logged In users
|
||||
- Ram Usages
|
||||
- Swap Usages
|
||||
- Disk Usages
|
||||
- Load Average
|
||||
- System Uptime
|
||||
|
||||
Check the installed version of script using -v (version) switch.
|
||||
|
||||
$ monitor -v
|
||||
|
||||
tecmint_monitor version 0.1
|
||||
Designed by Tecmint.com
|
||||
Released Under Apache 2.0 License
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
This script is working out of the box on a few machines I have checked. It should work the same for you as well. If you find any bug let us know in the comments. This is not the end. This is the beginning. You can take it to any level from here. If you feel like editing the script and carry it further you are free to do so giving us proper credit and also share the updated script with us so that we can update this article by giving you proper credit.
|
||||
|
||||
Don’t forget to share your thoughts or your script with us. We will be here to help you. Thank you for all the love you have given us. Keep Connected! Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-server-health-monitoring-script/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
@ -1,107 +0,0 @@
|
||||
How To Run Docker Client Inside Windows OS
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn about Docker in Windows Operating System and about the installation of Docker Windows Client in it. Docker Engine uses Linux Specific Kernel features so it cannot use Windows Kernel to run so, the Docker Engine creates a small Virtual Machine running Linux and utilizes its resources and Kernel. The Windows Docker Client uses the virtualized Docker Engine to build, run and manage Docker Containers out of the box. There is an application developed by the Boot2Docker Team called Boot2Docker which creates the virtual machine running a small Linux based on [Tiny Core Linux][1] made specifically to run [Docker][2] containers on Windows. It runs completely from RAM, weighs ~27MB and boots in ~5s (YMMV). So, until the Docker Engine for Windows is developed, we can only run Linux containers in our Windows Machine.
|
||||
|
||||
Here is some easy and simple steps which will allow us to install the Docker Client and run containers on top of it.
|
||||
|
||||
### 1. Downloading Boot2Docker ###
|
||||
|
||||
Now, before we start the installation, we'll need the executable file for Boot2Docker. The latest version of Boot2Docker can be downloaded from [its Github][3]. Here, in this tutorial, we'll download version v1.6.1 from the site. Here, we'll download the file named [docker-install.exe][4] from that page using our favorite Web Browser or Download Manager.
|
||||
|
||||

|
||||
|
||||
### 2. Installing Boot2Docker ###
|
||||
|
||||
Now, we'll simply run the installer which will install Windows Docker Client, Git for Windows (MSYS-git), VirtualBox, The Boot2Docker Linux ISO, and the Boot2Docker management tool which are essential for the total functioning of Docker Engine out of the box.
|
||||
|
||||

|
||||
|
||||
### 3. Running Boot2Docker ###
|
||||
|
||||

|
||||
|
||||
After installing the necessary stuffs, we'll run Boot2Docker by simply running the Boot2Docker Start shortcut from the Desktop. This will ask you to enter an SSH key paraphrase that we'll require in future for authentication. It will start a unix shell already configured to manage Docker running inside the virtual machine.
|
||||
|
||||

|
||||
|
||||
Now to check whether it is correctly configured or not, simply run docker version as shown below.
|
||||
|
||||
docker version
|
||||
|
||||

|
||||
|
||||
### 4. Running Docker ###
|
||||
|
||||
As **Boot2Docker Start** automatically starts a shell with environment variables correctly set so we can simply start using Docker right away. **Please note that, if we are Boot2Docker as remote Docker Daemon , then do not type the sudo before the docker commands.**
|
||||
|
||||
Now, Let's try the **hello-world** example image which will download the hello-world image, executes it and gives an output "Hello from Docker" message.
|
||||
|
||||
$ docker run hello-world
|
||||
|
||||

|
||||
|
||||
### 5. Running Docker using Command Prompt (CMD) ###
|
||||
|
||||
Now, if you are wanting to get started with Docker using Command Prompt, you can simply launch the command prompt (CMD.exe). As Boot2Docker requires ssh.exe to be in the PATH, therefore we need to include bin folder of the Git installation to the %PATH% environment variable by running the following command in the command prompt.
|
||||
|
||||
set PATH=%PATH%;"c:\Program Files (x86)\Git\bin"
|
||||
|
||||

|
||||
|
||||
After running the above command, we can run the **boot2docker start** command in the command prompt to start the Boot2Docker VM.
|
||||
|
||||
boot2docker start
|
||||
|
||||

|
||||
|
||||
**Note**: If you get an error saying machine does not exist then run **boot2docker init** command in it.
|
||||
|
||||
Then copy the instructions for cmd.exe shown in the console to set the environment variables to the console window and we are ready to run docker containers as usual.
|
||||
|
||||
### 6. Running Docker using PowerShell ###
|
||||
|
||||
In order to run Docker on PowerShell, we simply need to launch a PowerShell window then add ssh.exe to our PATH variable.
|
||||
|
||||
$Env:Path = "${Env:Path};c:\Program Files (x86)\Git\bin"
|
||||
|
||||
After running the above command, we'll need to run
|
||||
|
||||
boot2docker start
|
||||
|
||||

|
||||
|
||||
This will print PowerShell commands to set the environment variables to connect Docker running inside VM. We'll simply run those commands in the PowerShell and we are ready to run docker containers as usual.
|
||||
|
||||
### 7. Logging with PUTTY ###
|
||||
|
||||
Boot2Docker generates and uses the public or private key pair inside %USERPROFILE%\.ssh directory so to login, we'll need use the private key from this same directory. That private key needs to be converted into the PuTTY 's format. We can use puttygen.exe to do that.
|
||||
|
||||
We need to open puttygen.exe and load ("File"->"Load" menu) the private key from %USERPROFILE%\.ssh\id_boot2docker then click on "Save Private Key". Then use the saved file to login with PuTTY using docker@127.0.0.1:2022 .
|
||||
|
||||
### 8. Boot2Docker Options ###
|
||||
|
||||
The Boot2Docker management tool provides several commands as shown below.
|
||||
|
||||
$ boot2docker
|
||||
|
||||
Usage: boot2docker.exe [<options>] {help|init|up|ssh|save|down|poweroff|reset|restart|config|status|info|ip|shellinit|delete|download|upgrade|version} [<args>]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Using Docker with Docker Windows Client is fun. The Boot2Docker management tool is an awesome application developed which enables every Docker containers to run smoothly as running in Linux host. If you are more curious, the username for the boot2docker default user is docker and the password is tcuser. The latest version of boot2docker sets up a host only network adapter which provides access to the container's ports. Typically, it is 192.168.59.103, but it could get changed by Virtualbox's DHCP implementation. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/run-docker-client-inside-windows-os/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://tinycorelinux.net/
|
||||
[2]:https://www.docker.io/
|
||||
[3]:https://github.com/boot2docker/windows-installer/releases/latest
|
||||
[4]:https://github.com/boot2docker/windows-installer/releases/download/v1.6.1/docker-install.exe
|
||||
@ -0,0 +1,188 @@
|
||||
How to Install Percona Server on CentOS 7
|
||||
================================================================================
|
||||
In this article we are going to learn about percona server, an opensource drop-in replacement for MySQL and also for MariaDB. The InnoDB database engine make it very attractive and a good alternative if you need performance, reliability and a cost efficient solution
|
||||
|
||||
In the following sections I am going to cover the installation of the percona server on the CentOS 7, I will also cover the steps needed to make backup of your current data, configuration and how to restore your backup.
|
||||
|
||||
### Table of contents ###
|
||||
|
||||
1. What is and why use percona
|
||||
1. Backup your databases
|
||||
1. Remove previous SQL server
|
||||
1. Installing Percona binaries
|
||||
1. Configuring Percona
|
||||
1. Securing your environment
|
||||
1. Restore your backup
|
||||
|
||||
### 1. What is and why use Percona ###
|
||||
|
||||
Percona is an opensource alternative to the MySQL and MariaDB databases, it's a fork of the MySQL with many improvements and unique features that makes it more reliable, powerful and faster than MySQL, and yet is fully compatible with it, you can even use replication between Oracle's MySQL and Percona.
|
||||
|
||||
#### Features exclusive to Percona ####
|
||||
|
||||
- Partitioned Adaptive Hash Search
|
||||
- Fast Checksum Algorithm
|
||||
- Buffer Pool Pre-Load
|
||||
- Support for FlashCache
|
||||
|
||||
#### MySQL Enterprise and Percona specific features ####
|
||||
|
||||
- Import Tables From Different Servers
|
||||
- PAM authentication
|
||||
- Audit Log
|
||||
- Threadpool
|
||||
|
||||
Now that you are pretty excited to see all these good things together, we are going show you how to install and do basic configuration of Percona Server.
|
||||
|
||||
### 2. Backup your databases ###
|
||||
|
||||
The following, command creates a mydatabases.sql file with the SQL commands to recreate/restore salesdb and employeedb databases, replace the databases names to reflect your setup, skip if this is a brand new setup
|
||||
|
||||
mysqldump -u root -p --databases employeedb salesdb > mydatabases.sql
|
||||
|
||||
Copy the current configuration file, you can also skip this in fresh setups
|
||||
|
||||
cp my.cnf my.cnf.bkp
|
||||
|
||||
### 3. Remove your previous SQL Server ###
|
||||
|
||||
Stop the MySQL/MariaDB if it's running.
|
||||
|
||||
systemctl stop mysql.service
|
||||
|
||||
Uninstall MariaDB and MySQL
|
||||
|
||||
yum remove MariaDB-server MariaDB-client MariaDB-shared mysql mysql-server
|
||||
|
||||
Move / Rename the MariaDB files in **/var/lib/mysql**, it's a safer and faster than just removing, it's like a 2nd level instant backup. :)
|
||||
|
||||
mv /var/lib/mysql /var/lib/mysql_mariadb
|
||||
|
||||
### 4. Installing Percona binaries ###
|
||||
|
||||
You can choose from a number of options on how to install Percona, in a CentOS system it's generally a better idea to use yum or RPM, so these are the way that are covered by this article, compiling and install from sources are not covered by this article.
|
||||
|
||||
Installing from Yum repository:
|
||||
|
||||
First you need to set the Percona's Yum repository with this:
|
||||
|
||||
yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm
|
||||
|
||||
And then install Percona with:
|
||||
|
||||
yum install Percona-Server-client-56 Percona-Server-server-56
|
||||
|
||||
The above command installs Percona server and clients, shared libraries, possibly Perl and perl modules such as DBI::MySQL, if that are not already installed, and also other dependencies as needed.
|
||||
|
||||
Installing from RPM package:
|
||||
|
||||
We can download all rpm packages with the help of wget:
|
||||
|
||||
wget -r -l 1 -nd -A rpm -R "*devel*,*debuginfo*" \ http://www.percona.com/downloads/Percona-Server-5.5/Percona-Server-5.5.42-37.1/binary/redhat/7/x86_64/
|
||||
|
||||
And with rpm utility, you install all the packages once:
|
||||
|
||||
rpm -ivh Percona-Server-server-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-client-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-shared-55-5.5.42-rel37.1.el7.x86_64.rpm
|
||||
|
||||
Note the backslash '\' on the end of the sentences on the above commands, if you install individual packages, remember that to met dependencies, the shared package must be installed before client and client before server.
|
||||
|
||||
### 5. Configuring Percona Server ###
|
||||
|
||||
#### Restoring previous configuration ####
|
||||
|
||||
As we are moving from MariaDB, you can just restore the backup of my.cnf file that you made in earlier steps.
|
||||
|
||||
cp /etc/my.cnf.bkp /etc/my.cnf
|
||||
|
||||
#### Creating a new my.cnf ####
|
||||
|
||||
If you need a new configuration file that fit your needs or if you don't have made a copy of my.cnf, you can use this wizard, it will generate for you, through simple steps.
|
||||
|
||||
Here is a sample my.cnf file that comes with Percona-Server package
|
||||
|
||||
# Percona Server template configuration
|
||||
|
||||
[mysqld]
|
||||
#
|
||||
# Remove leading # and set to the amount of RAM for the most important data
|
||||
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
|
||||
# innodb_buffer_pool_size = 128M
|
||||
#
|
||||
# Remove leading # to turn on a very important data integrity option: logging
|
||||
# changes to the binary log between backups.
|
||||
# log_bin
|
||||
#
|
||||
# Remove leading # to set options mainly useful for reporting servers.
|
||||
# The server defaults are faster for transactions and fast SELECTs.
|
||||
# Adjust sizes as needed, experiment to find the optimal values.
|
||||
# join_buffer_size = 128M
|
||||
# sort_buffer_size = 2M
|
||||
# read_rnd_buffer_size = 2M
|
||||
datadir=/var/lib/mysql
|
||||
socket=/var/lib/mysql/mysql.sock
|
||||
|
||||
# Disabling symbolic-links is recommended to prevent assorted security risks
|
||||
symbolic-links=0
|
||||
|
||||
[mysqld_safe]
|
||||
log-error=/var/log/mysqld.log
|
||||
pid-file=/var/run/mysqld/mysqld.pid
|
||||
|
||||
After making your my.cnf file fit your needs, it's time to start the service:
|
||||
|
||||
systemctl restart mysql.service
|
||||
|
||||
If everything goes fine, your server is now up and ready to ready to receive SQL commands, you can try the following command to check:
|
||||
|
||||
mysql -u root -p -e 'SHOW VARIABLES LIKE "version_comment"'
|
||||
|
||||
If you can't start the service, you can look for a reason in **/var/log/mysql/mysqld.log** this file is set by the **log-error** option in my.cnf's **[mysqld_safe]** session.
|
||||
|
||||
tail /var/log/mysql/mysqld.log
|
||||
|
||||
You can also take a look in a file inside **/var/lib/mysql/** with name in the form of **[hostname].err** as the following example:
|
||||
|
||||
tail /var/lib/mysql/centos7.err
|
||||
|
||||
If this also fail in show what is wrong, you can also try strace:
|
||||
|
||||
yum install strace && systemctl stop mysql.service && strace -f -f mysqld_safe
|
||||
|
||||
The above command is extremely verbous and it's output is quite low level but can show you the reason you can't start service in most times.
|
||||
|
||||
### 6. Securing your environment ###
|
||||
|
||||
Ok, you now have your RDBMS ready to receive SQL queries, but it's not a good idea to put your precious data on a server without minimum security, it's better to make it safer with mysql_secure_instalation, this utility helps in removing unused default features, also set the root main password and make access restrictions for using this user.
|
||||
Just invoke it by the shell and follow instructions on the screen.
|
||||
|
||||
mysql_secure_install
|
||||
|
||||
### 7. Restore your backup ###
|
||||
|
||||
If you are coming from a previous setup, now you can restore your databases, just use mysqldump once again.
|
||||
|
||||
mysqldump -u root -p < mydatabases.sql
|
||||
|
||||
Congratulations, you just installed Percona on your CentOS Linux, your server is now fully ready for use; You can now use your service as it was MySQL, and your services are fully compatible with it.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
There is a lot of things to configure in order to achieve better performance, but here is some straightforward options to improve your setup. When using innodb engine it's also a good idea to set the **innodb_file_per_table** option **on**, it gonna distribute table indexes in a file per table basis, it means that each table have it's own index file, it makes the overall system, more robust and easier to repair.
|
||||
|
||||
Other option to have in mind is the **innodb_buffer_pool_size** option, InnoDB should have large enough to your datasets, and some value **between 70% and 80%** of the total available memory should be reasonable.
|
||||
|
||||
By setting the **innodb-flush-method** to **O_DIRECT** you disable write cache, if you have **RAID**, this should be set to improved performance as this cache is already done in a lower level.
|
||||
|
||||
If your data is not that critical and you don't need fully **ACID** compliant transactions, you can adjust to 2 the option **innodb_flush_log_at_trx_commit**, this will also lead to improved performance.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/percona-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
@ -0,0 +1,179 @@
|
||||
Install ‘Tails 1.4′ Linux Operating System to Preserve Privacy and Anonymity
|
||||
================================================================================
|
||||
In this Internet world and the world of Internet we perform most of our task online be it Ticket booking, Money transfer, Studies, Business, Entertainment, Social Networking and what not. We spend a major part of our time online daily. It has been getting hard to remain anonymous with each passing day specially when backdoors are being planted by organizations like NSA (National Security Agency) who are putting their nose in between every thing that we come across online. We have least or no privacy online. All the searches are logged upon the basis of user Internet surfing activity and machine activity.
|
||||
|
||||
A wonderful browser from Tor project is used by millions which help us surfing the web anonymously however it is not difficult to trace your browsing habits and hence tor alone is not the guarantee of your safety online. You may like to check Tor features and installation instructions here:
|
||||
|
||||
- [Anonymous Web Browsing using Tor][1]
|
||||
|
||||
There is a operating system named Tails by Tor Projects. Tails (The Amnesic Incognito Live System) is a live operating system, based on Debian Linux distribution, which mainly focused on preserving privacy and anonymity on the web while browsing internet, means all it’s outgoing connection are forced to pass through the Tor and direct (non-anonymous) requests are blocked. The system is designed to run from any boot-able media be it USB stick or DVD.
|
||||
|
||||
The latest stable release of Tails OS is 1.4 which was released on May 12, 2015. Powered by open source Monolithic Linux Kernel and built on top of Debian GNU/Linux Tails aims at Personal Computer Market and includes GNOME 3 as default user Interface.
|
||||
|
||||
#### Features of Tails OS 1.4 ####
|
||||
|
||||
- Tails is a free operating system, free as in beer and free as in speech.
|
||||
- Built on top of Debian/GNU Linux. The most widely used OS that is Universal.
|
||||
- Security Focused Distribution.
|
||||
- Windows 8 camouflage.
|
||||
- Need not to be installed and browse Internet anonymously using Live Tails CD/DVD.
|
||||
- Leave no trace on the computer, while tails is running.
|
||||
- Advanced cryptographic tools used to encrypt everything that concerns viz., files, emails, etc.
|
||||
- Sends and Receive traffic through tor network.
|
||||
- In true sense it provides privacy for anyone, anywhere.
|
||||
- Comes with several applications ready to be used from Live Environment.
|
||||
- All the softwares comes per-configured to connect to INTERNET only through Tor network.
|
||||
- Any application that tries to connect to Internet without Tor Network is blocked, automatically.
|
||||
- Restricts someone who is watching what sites you visit and restricts sites to learn your geographical location.
|
||||
- Connect to websites that are blocked and/or censored.
|
||||
- Designed specially not to use space used by parent OS even when there is free swap space.
|
||||
- The whole OS loads on RAM and is flushed when we reboot/shutdown. Hence no trace of running.
|
||||
- Advanced security implementation by encrypting USB disk, HTTPS ans Encrypt and sign emails and documents.
|
||||
|
||||
#### What can you expect in Tails 1.4 ####
|
||||
|
||||
- Tor Browser 4.5 with a security Slider.
|
||||
- Tor Upgraded to version 0.2.6.7.
|
||||
- Several Security holes fixed.
|
||||
- Many of the bug fixed and patches applied to Applications like curl, OpenJDK 7, tor Network, openldap, etc.
|
||||
|
||||
To get a complete list of change logs you may visit [HERE][2]
|
||||
|
||||
**Note**: It is strongly recommended to upgrade to Tails 1.4, if you’re using any older version of Tails.
|
||||
|
||||
#### Why should I use Tails Operating System ####
|
||||
|
||||
You need Tails because you need:
|
||||
|
||||
- Freedom from network surveillance
|
||||
- Defend freedom, privacy and confidentiality
|
||||
- Security aka traffic analysis
|
||||
|
||||
This tutorial will walk through the installation of Tails 1.4 OS with a short review.
|
||||
|
||||
### Tails 1.4 Installation Guide ###
|
||||
|
||||
1. To download the latest Tails OS 1.4, you may use wget command to download directly.
|
||||
|
||||
$ wget http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
|
||||
|
||||
Alternatively you may download Tails 1.4 Direct ISO image or use a Torrent Client to pull the iso image file for you. Here is the link to both downloads:
|
||||
|
||||
- [tails-i386-1.4.iso][3]
|
||||
- [tails-i386-1.4.torrent][4]
|
||||
|
||||
2. After downloading, verify ISO Integrity by matching SHA256 checksum with the SHA256SUM provided on the official website..
|
||||
|
||||
$ sha256sum tails-i386-1.4.iso
|
||||
|
||||
339c8712768c831e59c4b1523002b83ccb98a4fe62f6a221fee3a15e779ca65d
|
||||
|
||||
If you are interested in knowing OpenPGP, checking Tails signing key against Debian keyring and anything related to Tails cryptographic signature, you may like to point your browser [HERE][5].
|
||||
|
||||
3. Next you need to write the image to USB stick or DVD ROM. You may like to check the article, [How to Create Live Bootable USB][6] for details on how to make a flash drive bootable and write ISO to it.
|
||||
|
||||
4. Insert the Tails OS Bootable flash drive or DVD ROM in the disk and boot from it (select from BIOS to boot). The first screen – two options to select from ‘Live‘ and ‘Live (failsafe)‘. Select ‘Live‘ and press Enter.
|
||||
|
||||

|
||||
Tails Boot Menu
|
||||
|
||||
5. Just before login. You have two options. Click ‘More Options‘ if you want to configure and set advanced options else click ‘No‘.
|
||||
|
||||

|
||||
Tails Welcome Screen
|
||||
|
||||
6. After clicking Advanced option, you need to setup root password. This is important if you want to upgrade it. This root password is valid till you shutdown/reboot the machine.
|
||||
|
||||
Also you may enable Windows Camouflage, if you want to run this OS on a public place, so that it seems as you are running Windows 8 operating system. Good option indeed! Is not it? Also you have a option to configure Network and Mac Address. Click ‘Login‘ when done!.
|
||||
|
||||

|
||||
Tails OS Configuration
|
||||
|
||||
7. This is Tails GNU/Linux OS camouflaged by Windows Skin.
|
||||
|
||||

|
||||
Tails Windows Look
|
||||
|
||||
8. It will start Tor Network in the background. Check the Notification on the top-right corner of the screen – Tor is Ready / You are now connected to the Internet.
|
||||
|
||||
Also check what it contains under Internet Menu. Notice – It has Tor Browser (safe) and Unsafe Web Browser (Where incoming and outgoing data don’t pass through TOR Network) along with other applications.
|
||||
|
||||
|
||||
Tails Menu and Tools
|
||||
|
||||
9. Click Tor and check your IP Address. It confirms my physical location is not shared and my privacy is intact.
|
||||
|
||||

|
||||
Check Privacy on Tails
|
||||
|
||||
10. You may Invoke Tails Installer to clone & Install, Clone & Upgrade and Upgrade from ISO.
|
||||
|
||||

|
||||
Tails Installer Options
|
||||
|
||||
11. The other option was to select Tor without any advanced option, just before login (Check step #5 above).
|
||||
|
||||

|
||||
Tails Without Advance Option
|
||||
|
||||
12. You will get log-in to Gnome3 Desktop Environment.
|
||||
|
||||

|
||||
Tails Gnome Desktop
|
||||
|
||||
13. If you click to Launch Unsafe browser in Camouflage or without Camouflage, you will be notified.
|
||||
|
||||

|
||||
Tails Browsing Notification
|
||||
|
||||
If you do, this is what you get in a Browser.
|
||||
|
||||

|
||||
Tails Browsing Alert
|
||||
|
||||
#### Is Tails for me? ####
|
||||
|
||||
To get the above question answered, first answer a few question.
|
||||
|
||||
- Do you need your privacy to be intact while you are online?
|
||||
- Do you want to remain hidden from Identity thieves?
|
||||
- Do you want somebody to put your nose in between your private chat online?
|
||||
- Do you really want to show your geographical location to anybody there?
|
||||
- Do you carry out banking transactions online?
|
||||
- Are you happy with the censorship by government and ISP?
|
||||
|
||||
If the answer to any of the above question is ‘YES‘ you preferably need Tails. If answer to all the above question is ‘NO‘ you perhaps don’t need it.
|
||||
|
||||
To know more about Tails? Point your browser to user Documentation : [https://tails.boum.org/doc/index.en.html][7]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Tails is an OS which is must for those who work in an unsafe environment. An OS focused on security yet contains bundles of Application – Gnome Desktop, Tor, Firefox (Iceweasel), Network Manager, Pidgin, Claws mail, Liferea feed addregator, Gobby, Aircrack-ng, I2P.
|
||||
|
||||
It also contain several tools for Encryption and Privacy Under the Hood, viz., LUKS, GNUPG, PWGen, Shamir’s Secret Sharing, Virtual Keyboard (against Hardware Keylogging), MAT, KeePassX Password Manager, etc.
|
||||
|
||||
That’s all for now. Keep Connected to Tecmint. Share your thoughts on Tails GNU/Linux Operating System. What do you think about the future of the Project? Also test it Locally and let us know your experience.
|
||||
|
||||
You may run it in [Virtualbox][8] as well. Remember Tails loads the whole OS in RAM hence give enough RAM to run Tails in VM.
|
||||
|
||||
I tested in 1GB Environment and it worked without lagging. Thanks to all our readers for their Support. In making Tecmint a one place for all Linux related stuffs your co-operation is needed. Kudos!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-tails-1-4-linux-operating-system-to-preserve-privacy-and-anonymity/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
[2]:https://tails.boum.org/news/version_1.4/index.en.html
|
||||
[3]:http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
|
||||
[4]:https://tails.boum.org/torrents/files/tails-i386-1.4.torrent
|
||||
[5]:https://tails.boum.org/download/index.en.html#verify
|
||||
[6]:http://www.tecmint.com/install-linux-from-usb-device/
|
||||
[7]:https://tails.boum.org/doc/index.en.html
|
||||
[8]:http://www.tecmint.com/install-virtualbox-on-redhat-centos-fedora/
|
||||
@ -0,0 +1,56 @@
|
||||
Square 2.0图标包更漂亮了
|
||||
================================================================================
|
||||

|
||||
|
||||
优雅、现代的[Square图标主题][1]最近更新到了2.0版,这让它比以前更漂亮了。Square图标包与其他主要的桌面环境如**Unity、 GNOME、KDE、 MATE等等**兼容。这意味着你可以在所有的流行Linux发行版如Ubuntu、Fedora、Linux Mint、elementary OS等等中使用它。 这个图标包估计包含超过了15000个图标。
|
||||
|
||||
### 在Linux中安装Square 2.0图标包 ###
|
||||
|
||||
有两种不同的Square图标,暗色和亮色。基于你的洗好,你可以选择二者之一。出于实验,我建议你两个主题包都下载。
|
||||
|
||||
你可以用下面的链接下载图标包。文件存储在Google Drive,因此如果你没有看见像[SourceForge][2]这样标准的下载网站时怀疑。
|
||||
|
||||
- [Square Dark Icons][3]
|
||||
- [Square Light Icons][4]
|
||||
|
||||
要使用图标主题,解压下载的文件到~/.icons文件夹下。如果它不存在,就创建它。当你在正确的地方有这些文件后,基于你的桌面环境,使用一个工具来改变图标主题。我以前写了一些关于这个主题的教程。如果你需要额外的帮助,那么欢迎指出来:
|
||||
|
||||
- [如何在Ubuntu Unity中改变主题][5]
|
||||
- [如何在GNOME Shell中改变主题][6]
|
||||
- [如何在Linux Mint中改变主题][7]
|
||||
- [如何在Elementary OS Freya中改变主题][8]
|
||||
|
||||
### 试一下 ###
|
||||
|
||||
这是我用Square图标在Ubuntu 14.04中的效果。我背景使用的是[Ubuntu 15.04 默认壁纸][9]。
|
||||
|
||||

|
||||
|
||||
Square主题中几个图标的样子:
|
||||
|
||||

|
||||
|
||||
你怎么找到它的?你认为它是[Ubuntu 14.04中最佳的图标主题][10]之一么?你会分享它病期待更多关于自定义Linux桌面的文章么?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/square-2-0-icon-pack-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://gnome-look.org/content/show.php/Square?content=163513
|
||||
[2]:http://sourceforge.net/
|
||||
[3]:http://gnome-look.org/content/download.php?content=163513&id=1&tan=62806435
|
||||
[4]:http://gnome-look.org/content/download.php?content=163513&id=2&tan=19789941
|
||||
[5]:http://itsfoss.com/how-to-install-themes-in-ubuntu-13-10/
|
||||
[6]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[7]:http://itsfoss.com/install-icon-linux-mint/
|
||||
[8]:http://itsfoss.com/install-themes-icons-elementary-os-freya/
|
||||
[9]:http://itsfoss.com/default-wallpapers-ubuntu-1504/
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -0,0 +1,43 @@
|
||||
Translating by H-mudcup
|
||||
|
||||
Synfig Studio 1.0 —— 开源动画动真格的了
|
||||
================================================================================
|
||||

|
||||
|
||||
**现在可以下载 Synfig Studio 这个自由、开源的2D动画软件的全新版本了。 **
|
||||
|
||||
在第一次发行这个跨平台的软件一年以后,Synfig Studio 1.0 带着一套全新改和改进过的功能,实现它所承诺的“创造电影级别的动画的产业级解决方案”。
|
||||
|
||||
在众多功能之上的是一个改进过的用户界面,据工程开发者说那是个用起来‘更简单’、‘更直观’的界面。客户端添加了新的**单窗口模式**,让界面更整洁,而且**为了使用最新的 GTK3 库而被重新制作**。
|
||||
|
||||
在功能方面有几个值得注意的变化,包括新加的全功能骨骼系统。
|
||||
|
||||
这套**关节和转轴的‘骨骼’构架**非常适合2D剪纸动画,再配上这个版本新加的复杂的变形控制系统或是 Synfig 受欢迎的‘关键帧自动插入’(阅读:画面与画面间的变形)应该会变得非常有效率的。
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/M8zW1qCq8ng?feature=oembed"></iframe>
|
||||
|
||||
新的无损剪切工具,摩擦力效果和对逐帧位图动画的支持,可能会有助于释放开源动画师们的创造力,更别说新加的用于同步动画的时间线和声音的声效层!
|
||||
|
||||
### 下载 Synfig Studio 1.0 ###
|
||||
|
||||
Synfig Studio 并不是任何人都能用的工具套件,这最新发行版的最新一批改进应该能吸引一些动画制作者试一试这个软件。
|
||||
|
||||
If you want to find out what open-source animation software is like for yourself, you can grab an installer for Ubuntu for the latest release direct from the project’s page using the links below. 如果你想看看开源动画制作软件是什么样的,你可以通过下面的链接直接从工程的 Sourceforge 页下载一个适用于 Ubuntu 的最新版本的安装器。
|
||||
|
||||
- [Download Synfig 1.0 (64bit) .deb Installer][1]
|
||||
- [Download Synfig 1.0 (32bit) .deb Installer][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/04/synfig-studio-new-release-features
|
||||
|
||||
作者:[oey-Elijah Sneddon][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_amd64.deb/download
|
||||
[2]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_x86.deb/download
|
||||
@ -0,0 +1,177 @@
|
||||
Linux中,创建聊天服务器、移除冗余软件包的实用命令
|
||||
=============================================================================
|
||||
这里,我们来看Linux命令行实用技巧的下一个部分。如果你错过了Linux Tracks之前的文章,可以从这里找到。
|
||||
|
||||
- [5 Linux Command Line Tracks][1]
|
||||
|
||||
本篇中,我们将会介绍6个命令行小技巧,包括使用Netcat命令创建Linux命令行聊天,从某个命令的输出中对某一列做加法,移除Debian和CentOS上多余的包,从命令行中获取本地与远程的IP地址,在终端获得彩色的输出与解码各样的颜色,最后是Linux命令行里井号标签的使用。让我们来一个一个地看一下。
|
||||
|
||||

|
||||
6个实用的命令行技巧
|
||||
|
||||
### 1. 创建Linux命令行聊天服务 ###
|
||||
我们大家使用聊天服务都有很长一段时间了。对于Google Chat,Hangout,Facebook Chat,Whatsapp,Hike和其他一些应用与集成的聊天服务,我们都很熟悉了。那你知道Linux的nc命令可以使你的Linux盒子变成一个聊天服务器,而仅仅只需要一行命令吗。什么是nc命令,它又是怎么工作的呢?
|
||||
|
||||
nc是Linux netcat命令的旧版。nc就像瑞士军刀一样,内建呢大量的功能。nc可用做调式工具,调查工具,使用TCP/UDP读写网络连接,DNS正向/反向检查。
|
||||
|
||||
nc主要用在端口扫描,文件传输,后台和端口监听。nc可以使用任何闲置的端口和任何本地网络源地址。
|
||||
|
||||
使用nc命令(在192.168.0.7的服务器上)创建一个命令行即时信息传输服务器。
|
||||
|
||||
$ nc -l -vv 11119
|
||||
|
||||
对上述命令的解释。
|
||||
|
||||
- -v : 表示 Verbose
|
||||
- -vv : 更多的 Verbose
|
||||
- -p : 本地端口号
|
||||
|
||||
你可以用任何其他的本地端口号替换11119。
|
||||
|
||||
接下来在客户端机器(IP地址:192.168.0.15),运行下面的命令初始化聊天会话(信息传输服务正在运行)。
|
||||
|
||||
$ nc 192.168.0.7:11119
|
||||
|
||||

|
||||
|
||||
**注意**:你可以按下ctrl+c终止会话,同时nc聊天是一个一对一的服务。
|
||||
|
||||
### 2. Linux中如何统计某一列的总值 ###
|
||||
|
||||
如何统计在终端里,某个命令的输出中,其中一列的数值总和,
|
||||
|
||||
‘ls -l’命令的输出。
|
||||
|
||||
$ ls -l
|
||||
|
||||

|
||||
|
||||
注意到第二列代表软连接的数量,第五列则是文件的大小。假设我们需要汇总第五列的数值。
|
||||
|
||||
仅仅列出第五列的内容。我们会使用‘awk’命令做到这点。‘$5’即代表第五列。
|
||||
|
||||
$ ls -l | awk '{print $5}'
|
||||
|
||||

|
||||
|
||||
现在,通过管道连接,使用awk打印出第五列数值的总和。
|
||||
|
||||
$ ls -l | awk '{print $5}' | awk '{total = total + $1}END{print total}'
|
||||
|
||||

|
||||
|
||||
### 在Linux里如何移除废弃包 ###
|
||||
|
||||
废弃包是指那些作为其他包的依赖而被安装,但是当源包被移除之后就不再需要的包。
|
||||
|
||||
假设我们安装了gtprogram,依赖是gtdependency。除非我们安装了gtdependency,否则安装不了gtprogram。
|
||||
|
||||
当我们移除gtprogram的时候,默认并不会移除gtdependency。并且如果我们不移除gtdependency的话,它就会遗留下来成为废弃包,与其他任何包再无联系。
|
||||
|
||||
# yum autoremove [On RedHat Systems]
|
||||
|
||||

|
||||
|
||||
# apt-get autoremove [On Debian Systems]
|
||||
|
||||

|
||||
|
||||
你应该经常移除废弃包,保持Linux机器仅仅加载一些需要的东西。
|
||||
|
||||
### 4. 如何获得Linux服务器本地的与公网的IP地址 ###
|
||||
|
||||
为了获得本地IP地址,运行下面的一行脚本。
|
||||
|
||||
$ ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
|
||||
|
||||
你必须安装了ifconfig,如果没有,使用apt或者yum工具安装需要的包。这里我们将会管道连接ifconfig的输出,并且结合grep命令找到包含“intel addr:”的字符串。
|
||||
|
||||
我们知道对于输出本地IP地址,ifconfig命令足够用了。但是ifconfig生成了许多的输出,而我们关注的地方仅仅是本地IP地址,不是其他的。
|
||||
|
||||
# ifconfig | grep "inet addr:"
|
||||
|
||||

|
||||
|
||||
尽管目前的输出好多了,但是我们需要过滤出本地的IP地址,不含其他东西。针对这个,我们将会使用awk打印出第二列输出,通过管道连接上述的脚本。
|
||||
|
||||
# ifconfig | grep “inet addr:” | awk '{print $2}'
|
||||
|
||||

|
||||
|
||||
上面图片清楚的表示,我们已经很大程度上自定义了输出,当仍然不是我们想要的。本地环路地址 127.0.0.1 仍然在结果中。
|
||||
|
||||
我们可以使用grep的-v选项,这样会打印出不匹配给定参数的其他行。每个机器都有同样的环路地址 127.0.0.1,所以使用grep -v打印出不包含127.0.0.1的行,通过管道连接前面的脚本。
|
||||
|
||||
# ifconfig | grep "inet addr" | awk '{print $2}' | grep -v '127.0.0.1'
|
||||
|
||||

|
||||
|
||||
我们差不多得到想要的输出了,仅仅需要从开头替换掉字符串`(addr:)`。我们将会使用cut命令单独打印出第二列。一二列之间并不是用tab分割,而是`(:)`,所以我们需要使用到域分割符选项`(-d)`,通过管道连接上面的输出。
|
||||
|
||||
# ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
|
||||
|
||||

|
||||
|
||||
最后!期望的结果出来了。
|
||||
|
||||
### 5.如何在Linux终端彩色输出 ###
|
||||
|
||||
你可能在终端看见过彩色的输出。同时你也可能知道在终端里允许/禁用彩色输出。如果都不知道的话,里可以参考下面的步骤。
|
||||
|
||||
在Linux中,每个用户都有`'.bashrc'`文件,被用来管理你的终端输出。打开并且编辑该文件,用你喜欢的编辑器。注意一下,这个文件是隐藏的(文件开头为点的代表隐藏文件)。
|
||||
|
||||
$ vi /home/$USER/.bashrc
|
||||
|
||||
确保以下的行没有被注释掉。ie.,行开头没有#。
|
||||
|
||||
if [ -x /usr/bin/dircolors ]; then
|
||||
test -r ~/.dircolors && eval "$(dircolors -b ~/.dircolors)" || eval "$(dirc$
|
||||
alias ls='ls --color=auto'
|
||||
#alias dir='dir --color=auto'
|
||||
#alias vdir='vdir --color=auto'
|
||||
|
||||
alias grep='grep --color=auto'
|
||||
alias fgrep='fgrep --color=auto'
|
||||
alias egrep='egrep --color=auto'
|
||||
fi
|
||||
|
||||

|
||||
|
||||
完成后!保存并退出。为了让改动生效,需要注销账户后再次登录。
|
||||
|
||||
现在,你会看见列出的文件和文件夹名字有着不同的颜色,根据文件类型来决定。为了解码颜色,可以运行下面的命令。
|
||||
|
||||
$ dircolors -p | less
|
||||
|
||||

|
||||
|
||||
### 6.如何用井号标记和Linux命令和脚本 ###
|
||||
|
||||
我们一直在Twitter,Facebook和Google Plus(可能是其他我们没有提到的地方)上使用井号标签。那些井号标签使得其他人搜索一个标签更加容易。可是很少人知道,我们可以在Linux命令行使用井号标签。
|
||||
|
||||
我们已经知道配置文件里的`#`,在大多数的编程语言中,这个符号被用作注释行,即不被执行。
|
||||
|
||||
运行一个命令,然后为这个命令创建一个井号标签,这样之后我们就可以找到它。假设我们有一个很长的脚本,就上面第四点被执行的命令。现在为它创建一个井号标签。我们知道ifconfig可以被sudo或者root执行,因此用root来执行。
|
||||
|
||||
# ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d: #myip
|
||||
|
||||
上述脚本被’mytag‘给标记了。现在在reverse-i-search(按下ctrl+r)搜索一下这个标签,在终端里,并输入’mytag‘。你可以从这里开始执行。
|
||||
|
||||

|
||||
|
||||
你可以创建很多的井号标签,为每个命令,之后使用reverse-i-search找到它。
|
||||
|
||||
目前就这么多了。我们一直在辛苦的工作,创造有趣的,有知识性的内容给你。你觉得我们是如何工作的呢?欢迎咨询任何问题。你可以在下面评论。保持联络!Kudox。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-commandline-chat-server-and-remove-unwanted-packages/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/5-linux-command-line-tricks/
|
||||
@ -0,0 +1,96 @@
|
||||
Linux中用于监控网络、磁盘使用、开机时间、平均负载和内存使用率的shell脚本
|
||||
================================================================================
|
||||
系统管理员的任务真的很艰难,因为他/她必须监控服务器、用户、日志,还得创建备份,等等等等。对于大多数重复性的任务,大多数管理员都会写一个自动化脚本来日复一日重复这些任务。这里,我们已经写了一个shell脚本给大家,用来自动化完成系统管理员所要完成的常规任务,这可能在多数情况下,尤其是对于新手而言十分有用,他们能通过该脚本获取到大多数的他们想要的信息,包括系统、网络、用户、负载、内存、主机、内部IP、外部IP、开机时间等。
|
||||
|
||||
我们已经注意并进行了格式化输出(在一定程度上哦)。此脚本不包含任何恶意内容,并且它能以普通用户帐号运行。事实上,我们也推荐你以普通用户运行该脚本,而不是root。
|
||||
|
||||

|
||||
监控Linux系统健康的Shell脚本
|
||||
|
||||
你可以通过给Tecmint和脚本作者合适的积分,获得自由使用/修改/再分发下面代码的权利。我们已经试着在一定程度上自定义了输出结果,除了要求的输出内容外,其它内容都不会生成。我们也已经试着使用了那些Linux系统中通常不使用的变量,这些变量可能也是自由代码。
|
||||
|
||||
#### 最小系统要求 ####
|
||||
|
||||
你所需要的一切,就是一台正常运转的Linux盒子。
|
||||
|
||||
#### 依赖性 ####
|
||||
|
||||
对于一个标准的Linux发行版,使用此包时没有任何依赖。此外,该脚本不需要root权限来执行。但是,如果你想要安装,则必须输入一次root密码。
|
||||
|
||||
#### 安全性 ####
|
||||
|
||||
我们也关注到了系统安全问题,所以在安装此包时,不需要安装任何额外包,也不需要root访问权限来运行。此外,源代码是采用Apache 2.0许可证发布的,这意味着只要你保留Tecmint的版权,你可以自由地编辑、修改并再分发该代码。
|
||||
|
||||
### 如何安装和运行脚本? ###
|
||||
|
||||
首先,使用[wget命令][1]下载监控脚本`“tecmint_monitor.sh”`,给它赋予合适的执行权限。
|
||||
|
||||
# wget http://tecmint.com/wp-content/scripts/tecmint_monitor.sh
|
||||
# chmod 755 tecmint_monitor.sh
|
||||
|
||||
强烈建议你以普通用户身份安装该脚本,而不是root。安装过程中会询问root密码,并且在需要的时候安装必要的组件。
|
||||
|
||||
要安装`“tecmint_monitor.sh”`脚本,只需像下面这样使用-i(安装)选项就可以了。
|
||||
|
||||
/tecmint_monitor.sh -i
|
||||
|
||||
在提示你输入root密码时输入该密码。如果一切顺利,你会看到像下面这样的安装成功信息。
|
||||
|
||||
Password:
|
||||
Congratulations! Script Installed, now run monitor Command
|
||||
|
||||
安装完毕后,你可以通过在任何位置,以任何用户调用命令`‘monitor’`来运行该脚本。如果你不喜欢安装,你需要在每次运行时输入路径。
|
||||
|
||||
# ./Path/to/script/tecmint_monitor.sh
|
||||
|
||||
现在,以任何用户从任何地方运行monitor命令,就是这么简单:
|
||||
|
||||
$ monitor
|
||||
|
||||

|
||||
|
||||
你一运行命令,就会获得下面这些各种各样和系统相关的信息:
|
||||
|
||||
- 互联网连通性
|
||||
- 操作系统类型
|
||||
- 操作系统名称
|
||||
- 操作系统版本
|
||||
- 架构
|
||||
- 内核版本
|
||||
- 主机名
|
||||
- 内部IP
|
||||
- 外部IP
|
||||
- 域名服务器
|
||||
- 已登录用户
|
||||
- 内存使用率
|
||||
- 交换分区使用率
|
||||
- 磁盘使用率
|
||||
- 平均负载
|
||||
- 系统开机时间
|
||||
|
||||
使用-v(版本)开关来检查安装的脚本的版本。
|
||||
|
||||
$ monitor -v
|
||||
|
||||
tecmint_monitor version 0.1
|
||||
Designed by Tecmint.com
|
||||
Released Under Apache 2.0 License
|
||||
|
||||
### 小结 ###
|
||||
|
||||
该脚本在一些机器上可以开机即用,这一点我已经检查过。相信对于你而言,它也会正常工作。如果你们发现了什么毛病,可以在评论中告诉我。这个脚本还不是结束,这仅仅是个开始。从这里开始,你可以将它提升到任何等级。如果你想要编辑脚本,将它带入一个更深的层次,尽管随意去做吧,别忘了给我们合适的积分,也别忘了把你更新后的脚本拿出来和我们分享哦,这样,我们也能通过给你合适的积分来更新此文。
|
||||
|
||||
别忘了和我们分享你的想法或者脚本,我们会在这儿帮助你。谢谢你们给予的所有挚爱。保持连线,不要走开哦。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-server-health-monitoring-script/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
@ -0,0 +1,107 @@
|
||||
如何在 Windows 操作系统中运行 Docker 客户端
|
||||
================================================================================
|
||||
大家好,今天我们来了解一下 Windows 操作系统中的 Docker 以及在其中安装 Docker Windows 客户端的知识。Docker 引擎使用 Linux 特定内核特性,因此不能通过 Windows 内核运行,Docker 引擎创建一个小的虚拟系统运行 Linux 并利用它的资源和内核。Windows Docker 客户端用虚拟化 Docker 引擎构建,运行以及管理 盒子以外的 Docker 容器。这里有个由 Boot2Docker 团队开发的名为 Boot2Docker 的应用程序,它创建运行在基于[Linux 微内核][1]的小型 Linux 系统上的虚拟机,是特意为在 Windows 上运行 [Docker][2] 容器开发的。它完全运行在 RAM 中,需要大约 27M 内存并能在 5s(YMMV,译者注:your mileage may vary,因人而异) 内启动。因此,在用于 Windows 的 Docker 引擎被开发出来之前,我们在 Windows 机器里只能运行 Linux 容器。
|
||||
|
||||
下面是安装 Docker 客户端并在上面运行容器的简单步骤。
|
||||
|
||||
### 1. 下载 Boot2Docker ###
|
||||
|
||||
在我们开始安装之前,我们需要 Boot2Docker 的可执行文件。可以从 [它的 Github][3] 下载最新版本的 Boot2Docker。在这篇指南中,我们从网站中下载版本 v1.6.1。我们从那网页中用我们喜欢的浏览器或者下载管理器下载了名为 [docker-install.exe][4] 的文件。
|
||||
|
||||

|
||||
|
||||
### 2. 安装 Boot2Docker ###
|
||||
|
||||
现在我们运行安装文件,它会安装 Window Docker 客户端、用于 Windows 的 Git(MSYS-git)、VirtualBox、Boot2Docker Linux ISO 以及 Boot2Docker 管理工具,这些对于在盒子之外运行 Docker 引擎都至关重要。
|
||||
|
||||

|
||||
|
||||
### 3. 运行 Boot2Docker ###
|
||||
|
||||

|
||||
|
||||
安装完成必要的组件之后,我们从桌面 Boot2Docker 快捷方式启动 Boot2Docker。它会要求你输入以后用于验证的 SSH 密钥。然后会启动一个配置好的用于管理在虚拟机中运行的 Docker 的 unix shell。
|
||||
|
||||

|
||||
|
||||
为了检查是否正确配置,运行下面的 docker version 命令。
|
||||
|
||||
docker version
|
||||
|
||||

|
||||
|
||||
### 4. 运行 Docker ###
|
||||
|
||||
由于 **Boot2Docker Start** 自动启动了一个已经正确设置好环境变量的 shell,我们可以马上开始使用 Docker。**请注意,如果我们将 Boot2Docker 作为一个远程 Docker 守护进程,那么不要在 docker 命令之前加 sudo。**
|
||||
|
||||
现在,让我们来试试 **hello-world** 例子镜像,它会下载 hello-world 镜像,运行并输出 "Hello from Docker" 信息。
|
||||
|
||||
$ docker run hello-world
|
||||
|
||||

|
||||
|
||||
### 5. 使用命令提示符(CMD) 运行 Docker###
|
||||
|
||||
现在,如果你想开始用命令提示符使用 Docker,你可以打开命令提示符(CMD.exe)。由于 Boot2Docker 要求 ssh.exe 在 PATH 中,我们需要在命令提示符中输入以下命令使得 %PATH% 环境变量中包括 Git 安装目录下的 bin 文件夹。
|
||||
|
||||
set PATH=%PATH%;"c:\Program Files (x86)\Git\bin"
|
||||
|
||||

|
||||
|
||||
运行上面的命令之后,我们可以在命令提示符中运行 **boot2docker start** 启动 Boot2Docker 虚拟机。
|
||||
|
||||
boot2docker start
|
||||
|
||||

|
||||
|
||||
**注意**: 如果你看到 machine does no exist 的错误信息,就运行 **boot2docker init** 命令。
|
||||
|
||||
然后复制控制台中的命令到 cmd.exe 中为控制台窗口设置环境变量,然后我们就可以像平常一样运行 docker 容器了。
|
||||
|
||||
### 6. 使用 PowerShell 运行 Docker ###
|
||||
|
||||
为了能在 PowerShell 中运行 Docker,我们需要启动一个 PowerShell 窗口并添加 ssh.exe 到 PATH 变量。
|
||||
|
||||
$Env:Path = "${Env:Path};c:\Program Files (x86)\Git\bin"
|
||||
|
||||
运行完上面的命令,我们还需要运行
|
||||
|
||||
boot2docker start
|
||||
|
||||

|
||||
|
||||
这会打印用于设置环境变量连接到虚拟机内部运行的 Docker 的 PowerShell 命令。我们只需要在 PowerShell 中运行这些命令就可以和平常一样运行 docker 容器。
|
||||
|
||||
### 7. 用 PUTTY 登录 ###
|
||||
|
||||
Boot2Docker 在%USERPROFILE%\.ssh 目录生成和使用用于登录的公共和私有密钥,我们也需要使用这个文件夹中的私有密钥。私有密钥需要转换为 PuTTY 的格式。我们可以通过 puttygen.exe 实现。
|
||||
|
||||
我们需要打开 puttygen.exe 并从 %USERPROFILE%\.ssh\id_boot2docker 中导入("File"->"Load" 菜单)私钥,然后点击 "Save Private Key"。然后用保存的文件通过 PuTTY 用 docker@127.0.0.1:2022 登录。
|
||||
|
||||
### 8. Boot2Docker 选项 ###
|
||||
|
||||
Boot2Docker 管理工具提供了一些命令,如下所示。
|
||||
|
||||
$ boot2docker
|
||||
|
||||
Usage: boot2docker.exe [<options>] {help|init|up|ssh|save|down|poweroff|reset|restart|config|status|info|ip|shellinit|delete|download|upgrade|version} [<args>]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
通过 Docker Windows 客户端使用 Docker 很有趣。Boot2Docker 管理工具是一个能使任何 Docker 容器能像在 Linux 主机上平稳运行的很棒的应用程序。如果你更仔细的话,你会发现 boot2docker 默认用户的用户名是 docker,密码是 tcuser。最新版本的 boot2docker 设置了一个 host-only 的网络适配器提供访问容器的端口。一般来说是 192.168.59.103,但可以通过 VirtualBox 的 DHCP 实现改变。如果你有任何问题、建议、反馈,请在下面的评论框中写下来然后我们可以改进或者更新我们的内容。非常感谢!Enjoy:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/run-docker-client-inside-windows-os/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://tinycorelinux.net/
|
||||
[2]:https://www.docker.io/
|
||||
[3]:https://github.com/boot2docker/windows-installer/releases/latest
|
||||
[4]:https://github.com/boot2docker/windows-installer/releases/download/v1.6.1/docker-install.exe
|
||||
@ -0,0 +1,106 @@
|
||||
关于Docker容器的基础网络命令
|
||||
================================================================================
|
||||
各位好,今天我们将学习一些Docker容器的基础命令。Docker是一个提供了开放平台来打包、发布并以一个轻量级容器运行任意程序的开放平台。它没有语言支持、框架或者打包系统的限制,可在任何时间、任何地方在小到家用电脑大到高端服务器上运行。这使得在部署和扩展网络应用、数据库和终端服务时不依赖于特定的栈或者提供商。Docker注定是用于网络的如它正应用于数据中心、ISP和越来越多的网络服务。
|
||||
|
||||
因此,这里有一些你在管理Docker容器的时候会用到的一些命令。
|
||||
|
||||
### 1. 找到Docker接口 ###
|
||||
|
||||
Docker默认会创建一个名为docker0的网桥接口来连接外部的世界。docker容器运行时直接连接到网桥接口docker0。默认上,docker会分配172.17.42.1/16给docker0,它是所有运行容器ip地址的子网。得到Docker接口的ip地址非常简单。要找出docker0网桥接口和连接到网桥上的docker容器,我们可以在终端或者安装了docker的shell中运行ip命令。
|
||||
|
||||
# ip a
|
||||
|
||||

|
||||
|
||||
### 2. 得到Docker容器的ip地址 ###
|
||||
|
||||
如我们上面读到的,docker在主机中创建了一个叫docker0的网桥接口。如我们创建一个心的docker容器一样,它自动被默认分配了一个在子网范围内的ip地址。因此,要检测运行中的Docker容器的ip地址,我们需要进入一个正在运行的容器并用下面的命令检查ip地址。首先,我们运行一个新的容器并进入。如果你已经有一个正在运行的容器,你可以跳过这个步骤。
|
||||
|
||||
# docker run -it ubuntu
|
||||
|
||||
现在,我们可以运行ip a来得到容器的ip地址了。
|
||||
|
||||
# ip a
|
||||
|
||||

|
||||
|
||||
### 3. 映射暴露的端口 ###
|
||||
|
||||
要映射配置在Dockerfile的暴露端口,我们只需用下面带上-P标志的命令。这会打开docker容器的随机端口并映射到Dockerfile中定义的端口。下面是使用-P来打开/映射定义的端口的例子。
|
||||
|
||||
# docker run -itd -P httpd
|
||||
|
||||

|
||||
|
||||
上面的命令会映射Dockerfile中定义的httpd 80端口到容器的端口上。我们用下面的命令来查看正在运行的容器暴露的端口。
|
||||
|
||||
# docker ps
|
||||
|
||||
并且可以用下面的curl命令来检查。
|
||||
|
||||
# curl http://localhost:49153
|
||||
|
||||

|
||||
|
||||
### 4. 映射到特定的端口上 ###
|
||||
|
||||
我们也可以映射暴露端口或者docker容器端口到我们指定的端口上。要实现这个,我们用-p标志来定义我们的需要。这里是我们的一个例子。
|
||||
|
||||
# docker run -itd -p 8080:80 httpd
|
||||
|
||||
上面的命令会映射8080端口到80上。我们可以运行curl来检查这点。
|
||||
|
||||
# curl http://localhost:8080
|
||||
|
||||

|
||||
|
||||
### 5. 创建自己的网桥 ###
|
||||
|
||||
要给容器创建一个自定义的IP地址,在本篇中我们会创建一个名为bro的新网桥。要分配需要的ip地址,我们需要在运行docker的主机中运行下面的命令。
|
||||
|
||||
# stop docker.io
|
||||
# ip link add br0 type bridge
|
||||
# ip addr add 172.30.1.1/20 dev br0
|
||||
# ip link set br0 up
|
||||
# docker -d -b br0
|
||||
|
||||

|
||||
|
||||
创建完docker网桥之后,我们要让docker的守护进程知道它。
|
||||
|
||||
# echo 'DOCKER_OPTS="-b=br0"' >> /etc/default/docker
|
||||
# service docker.io start
|
||||
|
||||

|
||||
|
||||
到这里,桥接后的接口将会分配给容器新的在桥接子网内的ip地址。
|
||||
|
||||
### 6. 链接到另外一个容器上 ###
|
||||
|
||||
我们可以用Dokcer连接一个容器到另外一个上。我们可以在不容的容器上运行不同的程序,并且相互连接或链接。链接允许容器间相互连接并安全地从一个容器上传输信息给另一个容器。要做到这个,我们可以使用--link标志。首先,我们使用--name标志来表示training/postgres镜像。
|
||||
|
||||
# docker run -d --name db training/postgres
|
||||
|
||||

|
||||
|
||||
完成之后,我们将容器db与training/webapp链接来形成新的叫web的容器。
|
||||
|
||||
# docker run -d -P --name web --link db:db training/webapp python app.py
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
Docker网络很神奇也好玩,因为有我们可以对docker容器做很多事情。这里有些简单和基础的我们可以把玩docker网络命令。docker的网络是非常高级的。我们可以用它做很多事情。如果你有任何的问题、建议、反馈请在下面的评论栏写下来以便于我们我们可以提升或者更新文章的内容。谢谢! 玩得开心!:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/networking-commands-docker-containers/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
Loading…
Reference in New Issue
Block a user