mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-07 22:11:09 +08:00
commit
68d823f3bc
@ -0,0 +1,300 @@
|
||||
用户指南:Linux 文件系统的链接
|
||||
============================================================
|
||||
|
||||
> 学习如何使用链接,通过从 Linux 文件系统多个位置来访问文件,可以让日常工作变得轻松。
|
||||
|
||||

|
||||
|
||||
Image by : [Paul Lewin][8]. Modified by Opensource.com. [CC BY-SA 2.0][9]
|
||||
|
||||
在我为 opensource.com 写过的关于 Linux 文件系统方方面面的文章中,包括 [Linux 的 EXT4 文件系统的历史、特性以及最佳实践][10]; [在 Linux 中管理设备][11];[Linux 文件系统概览][12] 和 [用户指南:逻辑卷管理][13],我曾简要的提到过 Linux 文件系统一个有趣的特性,它允许用户从多个位置来访问 Linux 文件目录树中的文件来简化一些任务。
|
||||
|
||||
Linux 文件系统中有两种<ruby>链接<rt>link</rt></ruby>:<ruby>硬链接<rt>hard link</rt></ruby>和<ruby>软链接<rt>soft link</rt></ruby>。虽然二者差别显著,但都用来解决相似的问题。它们都提供了对单个文件的多个目录项(引用)的访问,但实现却大为不同。链接的强大功能赋予了 Linux 文件系统灵活性,因为[一切皆是文件][14]。
|
||||
|
||||
举个例子,我曾发现一些程序要求特定的版本库方可运行。 当用升级后的库替代旧库后,程序会崩溃,提示旧版本库缺失。通常,库名的唯一变化就是版本号。出于直觉,我仅仅给程序添加了一个新的库链接,并以旧库名称命名。我试着再次启动程序,运行良好。程序就是一个游戏,人人都明白,每个玩家都会尽力使游戏进行下去。
|
||||
|
||||
事实上,几乎所有的应用程序链接库都使用通用的命名规则,链接名称中包含了主版本号,链接所指向的文件的文件名中同样包含了小版本号。再比如,程序的一些必需文件为了迎合 Linux 文件系统规范,从一个目录移动到另一个目录中,系统为了向后兼容那些不能获取这些文件新位置的程序在旧的目录中存放了这些文件的链接。如果你对 `/lib64` 目录做一个长清单列表,你会发现很多这样的例子。
|
||||
|
||||
```
|
||||
lrwxrwxrwx. 1 root root 36 Dec 8 2016 cracklib_dict.hwm -> ../../usr/share/cracklib/pw_dict.hwm
|
||||
lrwxrwxrwx. 1 root root 36 Dec 8 2016 cracklib_dict.pwd -> ../../usr/share/cracklib/pw_dict.pwd
|
||||
lrwxrwxrwx. 1 root root 36 Dec 8 2016 cracklib_dict.pwi -> ../../usr/share/cracklib/pw_dict.pwi
|
||||
lrwxrwxrwx. 1 root root 27 Jun 9 2016 libaccountsservice.so.0 -> libaccountsservice.so.0.0.0
|
||||
-rwxr-xr-x. 1 root root 288456 Jun 9 2016 libaccountsservice.so.0.0.0
|
||||
lrwxrwxrwx 1 root root 15 May 17 11:47 libacl.so.1 -> libacl.so.1.1.0
|
||||
-rwxr-xr-x 1 root root 36472 May 17 11:47 libacl.so.1.1.0
|
||||
lrwxrwxrwx. 1 root root 15 Feb 4 2016 libaio.so.1 -> libaio.so.1.0.1
|
||||
-rwxr-xr-x. 1 root root 6224 Feb 4 2016 libaio.so.1.0.0
|
||||
-rwxr-xr-x. 1 root root 6224 Feb 4 2016 libaio.so.1.0.1
|
||||
lrwxrwxrwx. 1 root root 30 Jan 16 16:39 libakonadi-calendar.so.4 -> libakonadi-calendar.so.4.14.26
|
||||
-rwxr-xr-x. 1 root root 816160 Jan 16 16:39 libakonadi-calendar.so.4.14.26
|
||||
lrwxrwxrwx. 1 root root 29 Jan 16 16:39 libakonadi-contact.so.4 -> libakonadi-contact.so.4.14.26
|
||||
```
|
||||
|
||||
`/lib64` 目录下的一些链接
|
||||
|
||||
在上面展示的 `/lib64` 目录清单列表中,文件模式第一个字母 `l` (小写字母 l)表示这是一个软链接(又称符号链接)。
|
||||
|
||||
### 硬链接
|
||||
|
||||
在 [Linux 的 EXT4 文件系统的历史、特性以及最佳实践][15]一文中,我曾探讨过这样一个事实,每个文件都有一个包含该文件信息的 inode,包含了该文件的位置信息。上述文章中的[图2][16]展示了一个指向 inode 的单一目录项。每个文件都至少有一个目录项指向描述该文件信息的 inode ,目录项是一个硬链接,因此每个文件至少都有一个硬链接。
|
||||
|
||||
如下图 1 所示,多个目录项指向了同一 inode 。这些目录项都是硬链接。我曾在三个目录项中使用波浪线 (`~`) 的缩写,这是用户目录的惯例表示,因此在该例中波浪线等同于 `/home/user` 。值得注意的是,第四个目录项是一个完全不同的目录,`/home/shared`,可能是该计算机上用户的共享文件目录。
|
||||
|
||||
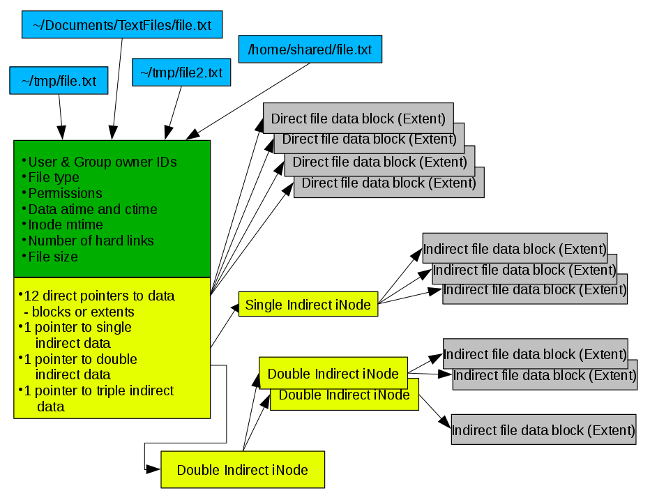
|
||||
|
||||
*图 1*
|
||||
|
||||
硬链接被限制在一个单一的文件系统中。此处的“文件系统” 是指挂载在特定挂载点上的分区或逻辑卷,此例中是 `/home`。这是因为在每个文件系统中的 inode 号都是唯一的。而在不同的文件系统中,如 `/var` 或 `/opt`,会有和 `/home` 中相同的 inode 号。
|
||||
|
||||
因为所有的硬链接都指向了包含文件元信息的单一 inode ,这些属性都是文件的一部分,像所属关系、权限、到该 inode 的硬链接数目,对每个硬链接来说这些特性没有什么不同的。这是一个文件所具有的一组属性。唯一能区分这些文件的是包含在 inode 信息中的文件名。链接到同一目录中的单一文件/ inode 的硬链接必须拥有不同的文件名,这是基于同一目录下不能存在重复的文件名的事实的。
|
||||
|
||||
文件的硬链接数目可通过 `ls -l` 来查看,如果你想查看实际节点号,可使用 `ls -li` 命令。
|
||||
|
||||
### 符号(软)链接
|
||||
|
||||
硬链接和软链接(也称为<ruby>符号链接<rt>symlink</rt></ruby>)的区别在于,硬链接直接指向属于该文件的 inode ,而软链接直接指向一个目录项,即指向一个硬链接。因为软链接指向的是一个文件的硬链接而非该文件的 inode ,所以它们并不依赖于 inode 号,这使得它们能跨越不同的文件系统、分区和逻辑卷起作用。
|
||||
|
||||
软链接的缺点是,一旦它所指向的硬链接被删除或重命名后,该软链接就失效了。软链接虽然还在,但所指向的硬链接已不存在。所幸的是,`ls` 命令能以红底白字的方式在其列表中高亮显示失效的软链接。
|
||||
|
||||
### 实验项目: 链接实验
|
||||
|
||||
我认为最容易理解链接用法及其差异的方法是动手搭建一个项目。这个项目应以非超级用户的身份在一个空目录下进行。我创建了 `~/temp` 目录做这个实验,你也可以这么做。这么做可为项目创建一个安全的环境且提供一个新的空目录让程序运作,如此以来这儿仅存放和程序有关的文件。
|
||||
|
||||
#### 初始工作
|
||||
|
||||
首先,在你要进行实验的目录下为该项目中的任务创建一个临时目录,确保当前工作目录(PWD)是你的主目录,然后键入下列命令。
|
||||
|
||||
```
|
||||
mkdir temp
|
||||
```
|
||||
|
||||
使用这个命令将当前工作目录切换到 `~/temp`。
|
||||
|
||||
```
|
||||
cd temp
|
||||
```
|
||||
|
||||
实验开始,我们需要创建一个能够链接到的文件,下列命令可完成该工作并向其填充内容。
|
||||
|
||||
```
|
||||
du -h > main.file.txt
|
||||
```
|
||||
|
||||
使用 `ls -l` 长列表命名确认文件正确地创建了。运行结果应类似于我的。注意文件大小只有 7 字节,但你的可能会有 1~2 字节的变动。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ls -l
|
||||
total 4
|
||||
-rw-rw-r-- 1 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
```
|
||||
|
||||
在列表中,文件模式串后的数字 `1` 代表存在于该文件上的硬链接数。现在应该是 1 ,因为我们还没有为这个测试文件建立任何硬链接。
|
||||
|
||||
#### 对硬链接进行实验
|
||||
|
||||
硬链接创建一个指向同一 inode 的新目录项,当为文件添加一个硬链接时,你会看到链接数目的增加。确保当前工作目录仍为 `~/temp`。创建一个指向 `main.file.txt` 的硬链接,然后查看该目录下文件列表。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln main.file.txt link1.file.txt
|
||||
[dboth@david temp]$ ls -l
|
||||
total 8
|
||||
-rw-rw-r-- 2 dboth dboth 7 Jun 13 07:34 link1.file.txt
|
||||
-rw-rw-r-- 2 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
```
|
||||
|
||||
目录中两个文件都有两个链接且大小相同,时间戳也一样。这就是有一个 inode 和两个硬链接(即该文件的目录项)的一个文件。再建立一个该文件的硬链接,并列出目录清单内容。你可以建立硬链接: `link1.file.txt` 或 `main.file.txt`。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln link1.file.txt link2.file.txt ; ls -l
|
||||
total 16
|
||||
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07:34 link1.file.txt
|
||||
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07:34 link2.file.txt
|
||||
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
```
|
||||
|
||||
注意,该目录下的每个硬链接必须使用不同的名称,因为同一目录下的两个文件不能拥有相同的文件名。试着创建一个和现存链接名称相同的硬链接。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln main.file.txt link2.file.txt
|
||||
ln: failed to create hard link 'link2.file.txt': File exists
|
||||
```
|
||||
|
||||
显然不行,因为 `link2.file.txt` 已经存在。目前为止我们只在同一目录下创建硬链接,接着在临时目录的父目录(你的主目录)中创建一个链接。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln main.file.txt ../main.file.txt ; ls -l ../main*
|
||||
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
```
|
||||
|
||||
上面的 `ls` 命令显示 `main.file.txt` 文件确实存在于主目录中,且与该文件在 `temp` 目录中的名称一致。当然它们不是不同的文件,它们是同一文件的两个链接,指向了同一文件的目录项。为了帮助说明下一点,在 `temp` 目录中添加一个非链接文件。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ touch unlinked.file ; ls -l
|
||||
total 12
|
||||
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 link1.file.txt
|
||||
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 link2.file.txt
|
||||
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
-rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
使用 `ls` 命令的 `i` 选项查看 inode 的硬链接号和新创建文件的硬链接号。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ls -li
|
||||
total 12
|
||||
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 link1.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 link2.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
注意上面文件模式左边的数字 `657024` ,这是三个硬链接文件所指的同一文件的 inode 号,你也可以使用 `i` 选项查看主目录中所创建的链接的节点号,和该值相同。而那个只有一个链接的 inode 号和其他的不同,在你的系统上看到的 inode 号或许不同于本文中的。
|
||||
|
||||
接着改变其中一个硬链接文件的大小。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ df -h > link2.file.txt ; ls -li
|
||||
total 12
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 link1.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 link2.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 main.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
现在所有的硬链接文件大小都比原来大了,因为多个目录项都链接着同一文件。
|
||||
|
||||
下个实验在我的电脑上会出现这样的结果,是因为我的 `/tmp` 目录在一个独立的逻辑卷上。如果你有单独的逻辑卷或文件系统在不同的分区上(如果未使用逻辑卷),确定你是否能访问那个分区或逻辑卷,如果不能,你可以在电脑上挂载一个 U 盘,如果上述方式适合你,你可以进行这个实验。
|
||||
|
||||
试着在 `/tmp` 目录中建立一个 `~/temp` 目录下文件的链接(或你的文件系统所在的位置)。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln link2.file.txt /tmp/link3.file.txt
|
||||
ln: failed to create hard link '/tmp/link3.file.txt' => 'link2.file.txt':
|
||||
Invalid cross-device link
|
||||
```
|
||||
|
||||
为什么会出现这个错误呢? 原因是每一个单独的可挂载文件系统都有一套自己的 inode 号。简单的通过 inode 号来跨越整个 Linux 文件系统结构引用一个文件会使系统困惑,因为相同的节点号会存在于每个已挂载的文件系统中。
|
||||
|
||||
有时你可能会想找到一个 inode 的所有硬链接。你可以使用 `ls -li` 命令。然后使用 `find` 命令找到所有硬链接的节点号。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ find . -inum 657024
|
||||
./main.file.txt
|
||||
./link1.file.txt
|
||||
./link2.file.txt
|
||||
```
|
||||
|
||||
注意 `find` 命令不能找到所属该节点的四个硬链接,因为我们在 `~/temp` 目录中查找。 `find` 命令仅在当前工作目录及其子目录中查找文件。要找到所有的硬链接,我们可以使用下列命令,指定你的主目录作为起始查找条件。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ find ~ -samefile main.file.txt
|
||||
/home/dboth/temp/main.file.txt
|
||||
/home/dboth/temp/link1.file.txt
|
||||
/home/dboth/temp/link2.file.txt
|
||||
/home/dboth/main.file.txt
|
||||
```
|
||||
|
||||
如果你是非超级用户,没有权限,可能会看到错误信息。这个命令也使用了 `-samefile` 选项而不是指定文件的节点号。这个效果和使用 inode 号一样且更容易,如果你知道其中一个硬链接名称的话。
|
||||
|
||||
#### 对软链接进行实验
|
||||
|
||||
如你刚才看到的,不能跨越文件系统边界创建硬链接,即在逻辑卷或文件系统中从一个文件系统到另一个文件系统。软链接给出了这个问题的解决方案。虽然它们可以达到相同的目的,但它们是非常不同的,知道这些差异是很重要的。
|
||||
|
||||
让我们在 `~/temp` 目录中创建一个符号链接来开始我们的探索。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln -s link2.file.txt link3.file.txt ; ls -li
|
||||
total 12
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 link1.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 link2.file.txt
|
||||
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15:21 link3.file.txt ->
|
||||
link2.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 main.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
拥有节点号 `657024` 的那些硬链接没有变化,且硬链接的数目也没有变化。新创建的符号链接有不同的 inode 号 `658270`。 名为 `link3.file.txt` 的软链接指向了 `link2.file.txt` 文件。使用 `cat` 命令查看 `link3.file.txt` 文件的内容。符号链接的 inode 信息以字母 `l` (小写字母 l)开头,意味着这个文件实际是个符号链接。
|
||||
|
||||
上例中软链接文件 `link3.file.txt` 的大小只有 14 字节。这是文本内容 `link3.file.txt` 的大小,即该目录项的实际内容。目录项 `link3.file.txt` 并不指向一个 inode ;它指向了另一个目录项,这在跨越文件系统建立链接时很有帮助。现在试着创建一个软链接,之前在 `/tmp` 目录中尝试过的。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln -s /home/dboth/temp/link2.file.txt
|
||||
/tmp/link3.file.txt ; ls -l /tmp/link*
|
||||
lrwxrwxrwx 1 dboth dboth 31 Jun 14 21:53 /tmp/link3.file.txt ->
|
||||
/home/dboth/temp/link2.file.txt
|
||||
```
|
||||
|
||||
#### 删除链接
|
||||
|
||||
当你删除硬链接或硬链接所指的文件时,需要考虑一些问题。
|
||||
|
||||
首先,让我们删除硬链接文件 `main.file.txt`。注意指向 inode 的每个目录项就是一个硬链接。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ rm main.file.txt ; ls -li
|
||||
total 8
|
||||
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14:14 link1.file.txt
|
||||
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14:14 link2.file.txt
|
||||
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15:21 link3.file.txt ->
|
||||
link2.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
`main.file.txt` 是该文件被创建时所创建的第一个硬链接。现在删除它,仍然保留着原始文件和硬盘上的数据以及所有剩余的硬链接。要删除原始文件,你必须删除它的所有硬链接。
|
||||
|
||||
现在删除 `link2.file.txt` 硬链接文件。
|
||||
|
||||
```
|
||||
[dboth@david temp]$ rm link2.file.txt ; ls -li
|
||||
total 8
|
||||
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14:14 link1.file.txt
|
||||
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15:21 link3.file.txt ->
|
||||
link2.file.txt
|
||||
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14:14 main.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
注意软链接的变化。删除软链接所指的硬链接会使该软链接失效。在我的系统中,断开的链接用颜色高亮显示,目标的硬链接会闪烁显示。如果需要修复这个损坏的软链接,你需要在同一目录下建立一个和旧链接相同名字的硬链接,只要不是所有硬链接都已删除就行。您还可以重新创建链接本身,链接保持相同的名称,但指向剩余的硬链接中的一个。当然如果软链接不再需要,可以使用 `rm` 命令删除它们。
|
||||
|
||||
`unlink` 命令在删除文件和链接时也有用。它非常简单且没有选项,就像 `rm` 命令一样。然而,它更准确地反映了删除的基本过程,因为它删除了目录项与被删除文件的链接。
|
||||
|
||||
### 写在最后
|
||||
|
||||
我用过这两种类型的链接很长一段时间后,我开始了解它们的能力和特质。我为我所教的 Linux 课程编写了一个实验室项目,以充分理解链接是如何工作的,并且我希望增进你的理解。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
戴维.布斯 - 戴维.布斯是 Linux 和开源倡导者,居住在北卡罗莱纳的罗列 。他在 IT 行业工作了四十年,为 IBM 工作了 20 多年的 OS/2。在 IBM 时,他在 1981 年编写了最初的 IBM PC 的第一个培训课程。他为 RedHat 教授过 RHCE 班,并曾在 MCI Worldcom、思科和北卡罗莱纳州工作。他已经用 Linux 和开源软件工作将近 20 年了。
|
||||
|
||||
---------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/6/linking-linux-filesystem
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[yongshouzhang](https://github.com/yongshouzhang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/article/17/6/linking-linux-filesystem?rate=YebHxA-zgNopDQKKOyX3_r25hGvnZms_33sYBUq-SMM
|
||||
[7]:https://opensource.com/user/14106/feed
|
||||
[8]:https://www.flickr.com/photos/digypho/7905320090
|
||||
[9]:https://creativecommons.org/licenses/by/2.0/
|
||||
[10]:https://linux.cn/article-8685-1.html
|
||||
[11]:https://linux.cn/article-8099-1.html
|
||||
[12]:https://linux.cn/article-8887-1.html
|
||||
[13]:https://opensource.com/business/16/9/linux-users-guide-lvm
|
||||
[14]:https://opensource.com/life/15/9/everything-is-a-file
|
||||
[15]:https://linux.cn/article-8685-1.html
|
||||
[16]:https://linux.cn/article-8685-1.html#3_19182
|
||||
[17]:https://opensource.com/users/dboth
|
||||
[18]:https://opensource.com/article/17/6/linking-linux-filesystem#comments
|
||||
@ -0,0 +1,80 @@
|
||||
面向初学者的 Linux 网络硬件:软件思维
|
||||
===========================================================
|
||||
|
||||

|
||||
|
||||
> 没有路由和桥接,我们将会成为孤独的小岛,你将会在这个网络教程中学到更多知识。
|
||||
|
||||
[Commons Zero][3]Pixabay
|
||||
|
||||
上周,我们学习了本地网络硬件知识,本周,我们将学习网络互联技术和在移动网络中的一些很酷的黑客技术。
|
||||
|
||||
### 路由器
|
||||
|
||||
网络路由器就是计算机网络中的一切,因为路由器连接着网络,没有路由器,我们就会成为孤岛。图一展示了一个简单的有线本地网络和一个无线接入点,所有设备都接入到互联网上,本地局域网的计算机连接到一个连接着防火墙或者路由器的以太网交换机上,防火墙或者路由器连接到网络服务供应商(ISP)提供的电缆箱、调制调节器、卫星上行系统……好像一切都在计算中,就像是一个带着不停闪烁的的小灯的盒子。当你的网络数据包离开你的局域网,进入广阔的互联网,它们穿过一个又一个路由器直到到达自己的目的地。
|
||||
|
||||

|
||||
|
||||
*图一:一个简单的有线局域网和一个无线接入点。*
|
||||
|
||||
路由器可以是各种样式:一个只专注于路由的小巧特殊的小盒子,一个将会提供路由、防火墙、域名服务,以及 VPN 网关功能的大点的盒子,一台重新设计的台式电脑或者笔记本,一个树莓派计算机或者一个 Arduino,体积臃肿矮小的像 PC Engines 这样的单板计算机,除了苛刻的用途以外,普通的商品硬件都能良好的工作运行。高端的路由器使用特殊设计的硬件每秒能够传输最大量的数据包。它们有多路数据总线,多个中央处理器和极快的存储。(可以通过了解 Juniper 和思科的路由器来感受一下高端路由器书什么样子的,而且能看看里面是什么样的构造。)
|
||||
|
||||
接入你的局域网的无线接入点要么作为一个以太网网桥,要么作为一个路由器。桥接器扩展了这个网络,所以在这个桥接器上的任意一端口上的主机都连接在同一个网络中。一台路由器连接的是两个不同的网络。
|
||||
|
||||
### 网络拓扑
|
||||
|
||||
有多种设置你的局域网的方式,你可以把所有主机接入到一个单独的<ruby>平面网络<rt>flat network</rt></ruby>,也可以把它们划分为不同的子网。如果你的交换机支持 VLAN 的话,你也可以把它们分配到不同的 VLAN 中。
|
||||
|
||||
平面网络是最简单的网络,只需把每一台设备接入到同一个交换机上即可,如果一台交换上的端口不够使用,你可以将更多的交换机连接在一起。有些交换机有特殊的上行端口,有些是没有这种特殊限制的上行端口,你可以连接其中的任意端口,你可能需要使用交叉类型的以太网线,所以你要查阅你的交换机的说明文档来设置。
|
||||
|
||||
平面网络是最容易管理的,你不需要路由器也不需要计算子网,但它也有一些缺点。它们的伸缩性不好,所以当网络规模变得越来越大的时候就会被广播网络所阻塞。将你的局域网进行分段将会提升安全保障, 把局域网分成可管理的不同网段将有助于管理更大的网络。图二展示了一个分成两个子网的局域网络:内部的有线和无线主机,和一个托管公开服务的主机。包含面向公共的服务器的子网称作非军事区域 DMZ,(你有没有注意到那些都是主要在电脑上打字的男人们的术语?)因为它被阻挡了所有的内部网络的访问。
|
||||
|
||||

|
||||
|
||||
*图二:一个分成两个子网的简单局域网。*
|
||||
|
||||
即使像图二那样的小型网络也可以有不同的配置方法。你可以将防火墙和路由器放置在一台单独的设备上。你可以为你的非军事区域设置一个专用的网络连接,把它完全从你的内部网络隔离,这将引导我们进入下一个主题:一切基于软件。
|
||||
|
||||
### 软件思维
|
||||
|
||||
你可能已经注意到在这个简短的系列中我们所讨论的硬件,只有网络接口、交换机,和线缆是特殊用途的硬件。
|
||||
其它的都是通用的商用硬件,而且都是软件来定义它的用途。Linux 是一个真实的网络操作系统,它支持大量的网络操作:网关、虚拟专用网关、以太网桥、网页、邮箱以及文件等等服务器、负载均衡、代理、服务质量、多种认证、中继、故障转移……你可以在运行着 Linux 系统的标准硬件上运行你的整个网络。你甚至可以使用 Linux 交换应用(LISA)和VDE2 协议来模拟以太网交换机。
|
||||
|
||||
有一些用于小型硬件的特殊发行版,如 DD-WRT、OpenWRT,以及树莓派发行版,也不要忘记 BSD 们和它们的特殊衍生用途如 pfSense 防火墙/路由器,和 FreeNAS 网络存储服务器。
|
||||
|
||||
你知道有些人坚持认为硬件防火墙和软件防火墙有区别?其实是没有区别的,就像说硬件计算机和软件计算机一样。
|
||||
|
||||
### 端口聚合和以太网绑定
|
||||
|
||||
聚合和绑定,也称链路聚合,是把两条以太网通道绑定在一起成为一条通道。一些交换机支持端口聚合,就是把两个交换机端口绑定在一起,成为一个是它们原来带宽之和的一条新的连接。对于一台承载很多业务的服务器来说这是一个增加通道带宽的有效的方式。
|
||||
|
||||
你也可以在以太网口进行同样的配置,而且绑定汇聚的驱动是内置在 Linux 内核中的,所以不需要任何其他的专门的硬件。
|
||||
|
||||
### 随心所欲选择你的移动宽带
|
||||
|
||||
我期望移动宽带能够迅速增长来替代 DSL 和有线网络。我居住在一个有 25 万人口的靠近一个城市的地方,但是在城市以外,要想接入互联网就要靠运气了,即使那里有很大的用户上网需求。我居住的小角落离城镇有 20 分钟的距离,但对于网络服务供应商来说他们几乎不会考虑到为这个地方提供网络。 我唯一的选择就是移动宽带;这里没有拨号网络、卫星网络(即使它很糟糕)或者是 DSL、电缆、光纤,但却没有阻止网络供应商把那些我在这个区域从没看到过的 Xfinity 和其它高速网络服务的传单塞进我的邮箱。
|
||||
|
||||
我试用了 AT&T、Version 和 T-Mobile。Version 的信号覆盖范围最广,但是 Version 和 AT&T 是最昂贵的。
|
||||
我居住的地方在 T-Mobile 信号覆盖的边缘,但迄今为止他们给了最大的优惠,为了能够能够有效的使用,我必须购买一个 WeBoost 信号放大器和一台中兴的移动热点设备。当然你也可以使用一部手机作为热点,但是专用的热点设备有着最强的信号。如果你正在考虑购买一台信号放大器,最好的选择就是 WeBoost,因为他们的服务支持最棒,而且他们会尽最大努力去帮助你。在一个小小的 APP [SignalCheck Pro][8] 的协助下设置将会精准的增强你的网络信号,他们有一个功能较少的免费的版本,但你将一点都不会后悔去花两美元使用专业版。
|
||||
|
||||
那个小巧的中兴热点设备能够支持 15 台主机,而且还有拥有基本的防火墙功能。 但你如果你使用像 Linksys WRT54GL这样的设备,可以使用 Tomato、OpenWRT,或者 DD-WRT 来替代普通的固件,这样你就能完全控制你的防护墙规则、路由配置,以及任何其它你想要设置的服务。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-think-software
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[4]:https://www.linux.com/files/images/fig-1png-7
|
||||
[5]:https://www.linux.com/files/images/fig-2png-4
|
||||
[6]:https://www.linux.com/files/images/soderskar-islandjpg
|
||||
[7]:https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-lan-hardware
|
||||
[8]:http://www.bluelinepc.com/signalcheck/
|
||||
81
published/20171120 Containers and Kubernetes Whats next.md
Normal file
81
published/20171120 Containers and Kubernetes Whats next.md
Normal file
@ -0,0 +1,81 @@
|
||||
容器技术和 K8S 的下一站
|
||||
============================================================
|
||||
> 想知道容器编排管理和 K8S 的最新展望么?来看看专家怎么说。
|
||||
|
||||

|
||||
|
||||
如果你想对容器在未来的发展方向有一个整体把握,那么你一定要跟着钱走,看看钱都投在了哪里。当然了,有很多很多的钱正在投入容器的进一步发展。相关研究预计 2020 年容器技术的投入将占有 [27 亿美元][4] 的市场份额。而在 2016 年,容器相关技术投入的总额为 7.62 亿美元,只有 2020 年投入预计的三分之一。巨额投入的背后是一些显而易见的基本因素,包括容器化的迅速增长以及并行化的大趋势。随着容器被大面积推广和使用,容器编排管理也会被理所当然的推广应用起来。
|
||||
|
||||
来自 [The new stack][5] 的调研数据表明,容器的推广使用是编排管理被推广的主要的催化剂。根据调研参与者的反馈数据,在已经将容器技术使用到生产环境中的使用者里,有六成使用者正在将 Kubernetes(K8S)编排管理广泛的应用在生产环境中,另外百分之十九的人员则表示他们已经处于部署 K8S 的初级阶段。在容器部署初期的使用者当中,虽然只有百分之五的人员表示已经在使用 K8S ,但是百分之五十八的人员表示他们正在计划和准备使用 K8S。总而言之,容器和 Kubernetes 的关系就好比是鸡和蛋一样,相辅相成紧密关联。众多专家一致认为编排管理工具对容器的[长周期管理][6] 以及其在市场中的发展有至关重要的作用。正如 [Cockroach 实验室][7] 的 Alex Robinson 所说,容器编排管理被更广泛的拓展和应用是一个总体的大趋势。毫无疑问,这是一个正在快速演变的领域,且未来潜力无穷。鉴于此,我们对 Robinson 和其他的一些容器的实际使用和推介者做了采访,来从他们作为容器技术的践行者的视角上展望一下容器编排以及 K8S 的下一步发展。
|
||||
|
||||
### 容器编排将被主流接受
|
||||
|
||||
像任何重要技术的转型一样,我们就像是处在一个高崖之上一般,在经过了初期步履蹒跚的跋涉之后将要来到一望无际的广袤平原。广大的新天地和平实真切的应用需求将会让这种新技术在主流应用中被迅速推广,尤其是在大企业环境中。正如 Alex Robinson 说的那样,容器技术的淘金阶段已经过去,早期的技术革新创新正在减速,随之而来的则是市场对容器技术的稳定性和可用性的强烈需求。这意味着未来我们将不会再见到大量的新的编排管理系统的涌现,而是会看到容器技术方面更多的安全解决方案,更丰富的管理工具,以及基于目前主流容器编排系统的更多的新特性。
|
||||
|
||||
### 更好的易用性
|
||||
|
||||
人们将在简化容器的部署方面下大功夫,因为容器部署的初期工作对很多公司和组织来说还是比较复杂的,尤其是容器的[长期管理维护][8]更是需要投入大量的精力。正如 [Codemill AB][9] 公司的 My Karlsson 所说,容器编排技术还是太复杂了,这导致很多使用者难以娴熟驾驭和充分利用容器编排的功能。很多容器技术的新用户都需要花费很多精力,走很多弯路,才能搭建小规模的或单个的以隔离方式运行的容器系统。这种现象在那些没有针对容器技术设计和优化的应用中更为明显。在简化容器编排管理方面有很多优化可以做,这些优化和改造将会使容器技术更加具有可用性。
|
||||
|
||||
### 在混合云以及多云技术方面会有更多侧重
|
||||
|
||||
随着容器和容器编排技术被越来越多的使用,更多的组织机构会选择扩展他们现有的容器技术的部署,从之前的把非重要系统部署在单一环境的使用情景逐渐过渡到更加[复杂的使用情景][10]。对很多公司来说,这意味着他们必须开始学会在 [混合云][11] 和 [多云][12] 的环境下,全局化的去管理那些容器化的应用和微服务。正如红帽 [Openshift 部门产品战略总监][14] [Brian Gracely][13] 所说,“容器和 K8S 技术的使用使得我们成功的实现了混合云以及应用的可移植性。结合 Open Service Broker API 的使用,越来越多的结合私有云和公有云资源的新应用将会涌现出来。”
|
||||
据 [CloudBees][15] 公司的高级工程师 Carlos Sanchez 分析,联合服务(Federation)将会得到极大推动,使一些诸如多地区部署和多云部署等的备受期待的新特性成为可能。
|
||||
|
||||
**[ 想知道 CIO 们对混合云和多云的战略构想么? 请参看我们的这条相关资源, [Hybrid Cloud: The IT leader's guide][16]。 ]**
|
||||
|
||||
### 平台和工具的持续整合及加强
|
||||
|
||||
对任何一种科技来说,持续的整合和加强从来都是大势所趋;容器编排管理技术在这方面也不例外。来自 [Sumo Logic][17] 的首席分析师 Ben Newton 表示,随着容器化渐成主流,软件工程师们正在很少数的一些技术上做持续整合加固的工作,来满足他们的一些微应用的需求。容器和 K8S 将会毫无疑问的成为容器编排管理方面的主流平台,并轻松碾压其它的一些小众平台方案。因为 K8S 提供了一个相当清晰的可以摆脱各种特有云生态的途径,K8S 将被大量公司使用,逐渐形成一个不依赖于某个特定云服务的<ruby>“中立云”<rt>cloud-neutral</rt></ruby>。
|
||||
|
||||
### K8S 的下一站
|
||||
|
||||
来自 [Alcide][18] 的 CTO 和联合创始人 Gadi Naor 表示,K8S 将会是一个有长期和远景发展的技术,虽然我们的社区正在大力推广和发展 K8S,K8S 仍有很长的路要走。
|
||||
|
||||
专家们对[日益流行的 K8S 平台][19]也作出了以下一些预测:
|
||||
|
||||
**_来自 Alcide 的 Gadi Naor 表示:_** “运营商会持续演进并趋于成熟,直到在 K8S 上运行的应用可以完全自治。利用 [OpenTracing][20] 和诸如 [istio][21] 技术的 service mesh 架构,在 K8S 上部署和监控微应用将会带来很多新的可能性。”
|
||||
|
||||
**_来自 Red Hat 的 Brian Gracely 表示:_** “K8S 所支持的应用的种类越来越多。今后在 K8S 上,你不仅可以运行传统的应用程序,还可以运行原生的云应用、大数据应用以及 HPC 或者基于 GPU 运算的应用程序,这将为灵活的架构设计带来无限可能。”
|
||||
|
||||
**_来自 Sumo Logic 的 Ben Newton 表示:_** “随着 K8S 成为一个具有统治地位的平台,我预计更多的操作机制将会被统一化,尤其是 K8S 将和第三方管理和监控平台融合起来。”
|
||||
|
||||
**_来自 CloudBees 的 Carlos Sanchez 表示:_** “在不久的将来我们就能看到不依赖于 Docker 而使用其它运行时环境的系统,这将会有助于消除任何可能的 lock-in 情景“ [编辑提示:[CRI-O][22] 就是一个可以借鉴的例子。]“而且我期待将来会出现更多的针对企业环境的存储服务新特性,包括数据快照以及在线的磁盘容量的扩展。”
|
||||
|
||||
**_来自 Cockroach Labs 的 Alex Robinson 表示:_** “ K8S 社区正在讨论的一个重大发展议题就是加强对[有状态程序][23]的管理。目前在 K8S 平台下,实现状态管理仍然非常困难,除非你所使用的云服务商可以提供远程固定磁盘。现阶段也有很多人在多方面试图改善这个状况,包括在 K8S 平台内部以及在外部服务商一端做出的一些改进。”
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/11/containers-and-kubernetes-whats-next
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[yunfengHe](https://github.com/yunfengHe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/11/kubernetes-numbers-10-compelling-stats
|
||||
[2]:https://enterprisersproject.com/article/2017/11/how-enterprise-it-uses-kubernetes-tame-container-complexity
|
||||
[3]:https://enterprisersproject.com/article/2017/11/5-kubernetes-success-tips-start-smart?sc_cid=70160000000h0aXAAQ
|
||||
[4]:https://451research.com/images/Marketing/press_releases/Application-container-market-will-reach-2-7bn-in-2020_final_graphic.pdf
|
||||
[5]:https://thenewstack.io/
|
||||
[6]:https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul
|
||||
[7]:https://www.cockroachlabs.com/
|
||||
[8]:https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul
|
||||
[9]:https://codemill.se/
|
||||
[10]:https://www.redhat.com/en/challenges/integration?intcmp=701f2000000tjyaAAA
|
||||
[11]:https://enterprisersproject.com/hybrid-cloud
|
||||
[12]:https://enterprisersproject.com/article/2017/7/multi-cloud-vs-hybrid-cloud-whats-difference
|
||||
[13]:https://enterprisersproject.com/user/brian-gracely
|
||||
[14]:https://www.redhat.com/en
|
||||
[15]:https://www.cloudbees.com/
|
||||
[16]:https://enterprisersproject.com/hybrid-cloud?sc_cid=70160000000h0aXAAQ
|
||||
[17]:https://www.sumologic.com/
|
||||
[18]:http://alcide.io/
|
||||
[19]:https://enterprisersproject.com/article/2017/10/how-explain-kubernetes-plain-english
|
||||
[20]:http://opentracing.io/
|
||||
[21]:https://istio.io/
|
||||
[22]:http://cri-o.io/
|
||||
[23]:https://opensource.com/article/17/2/stateful-applications
|
||||
[24]:https://enterprisersproject.com/article/2017/11/containers-and-kubernetes-whats-next?rate=PBQHhF4zPRHcq2KybE1bQgMkS2bzmNzcW2RXSVItmw8
|
||||
[25]:https://enterprisersproject.com/user/kevin-casey
|
||||
@ -0,0 +1,134 @@
|
||||
Photon 也许能成为你最喜爱的容器操作系统
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
>Phonton OS 专注于容器,是一个非常出色的平台。 —— Jack Wallen
|
||||
|
||||
容器在当下的火热,并不是没有原因的。正如[之前][13]讨论的,容器可以使您轻松快捷地将新的服务与应用部署到您的网络上,而且并不耗费太多的系统资源。比起专用硬件和虚拟机,容器都是更加划算的,除此之外,他们更容易更新与重用。
|
||||
|
||||
更重要的是,容器喜欢 Linux(反之亦然)。不需要太多时间和麻烦,你就可以启动一台 Linux 服务器,运行[Docker][14],然后部署容器。但是,哪种 Linux 发行版最适合部署容器呢?我们的选择很多。你可以使用标准的 Ubuntu 服务器平台(更容易安装 Docker 并部署容器)或者是更轻量级的发行版 —— 专门用于部署容器。
|
||||
|
||||
[Photon][15] 就是这样的一个发行版。这个特殊的版本是由 [VMware][16] 于 2005 年创建的,它包含了 Docker 的守护进程,并可与容器框架(如 Mesos 和 Kubernetes )一起使用。Photon 经过优化可与 [VMware vSphere][17] 协同工作,而且可用于裸机、[Microsoft Azure][18]、 [Google Compute Engine][19]、 [Amazon Elastic Compute Cloud][20] 或者 [VirtualBox][21] 等。
|
||||
|
||||
Photon 通过只安装 Docker 守护进程所必需的东西来保持它的轻量。而这样做的结果是,这个发行版的大小大约只有 300MB。但这足以让 Linux 的运行一切正常。除此之外,Photon 的主要特点还有:
|
||||
|
||||
* 内核为性能而调整。
|
||||
* 内核根据[内核自防护项目][6](KSPP)进行了加固。
|
||||
* 所有安装的软件包都根据加固的安全标识来构建。
|
||||
* 操作系统在信任验证后启动。
|
||||
* Photon 的管理进程可以管理防火墙、网络、软件包,和远程登录在 Photon 机器上的用户。
|
||||
* 支持持久卷。
|
||||
* [Project Lightwave][7] 整合。
|
||||
* 及时的安全补丁与更新。
|
||||
|
||||
Photon 可以通过 [ISO 镜像][22]、[OVA][23]、[Amazon Machine Image][24]、[Google Compute Engine 镜像][25] 和 [Azure VHD][26] 安装使用。现在我将向您展示如何使用 ISO 镜像在 VirtualBox 上安装 Photon。整个安装过程大概需要五分钟,在最后您将有一台随时可以部署容器的虚拟机。
|
||||
|
||||
### 创建虚拟机
|
||||
|
||||
在部署第一台容器之前,您必须先创建一台虚拟机并安装 Photon。为此,打开 VirtualBox 并点击“新建”按钮。跟着创建虚拟机向导进行配置(根据您的容器将需要的用途,为 Photon 提供必要的资源)。在创建好虚拟机后,您所需要做的第一件事就是更改配置。选择新建的虚拟机(在 VirtualBox 主窗口的左侧面板中),然后单击“设置”。在弹出的窗口中,点击“网络”(在左侧的导航中)。
|
||||
|
||||
在“网络”窗口(图1)中,你需要在“连接”的下拉窗口中选择桥接。这可以确保您的 Photon 服务与您的网络相连。完成更改后,单击确定。
|
||||
|
||||

|
||||
|
||||
*图 1: 更改 Photon 在 VirtualBox 中的网络设置。[经许可使用][1]*
|
||||
|
||||
从左侧的导航选择您的 Photon 虚拟机,点击启动。系统会提示您去加载 ISO 镜像。当您完成之后,Photon 安装程序将会启动并提示您按回车后开始安装。安装过程基于 ncurses(没有 GUI),但它非常简单。
|
||||
|
||||
接下来(图2),系统会询问您是要最小化安装,完整安装还是安装 OSTree 服务器。我选择了完整安装。选择您所需要的任意选项,然后按回车继续。
|
||||
|
||||

|
||||
|
||||
*图 2: 选择您的安装类型。[经许可使用][2]*
|
||||
|
||||
在下一个窗口,选择您要安装 Photon 的磁盘。由于我们将其安装在虚拟机,因此只有一块磁盘会被列出(图3)。选择“自动”按下回车。然后安装程序会让您输入(并验证)管理员密码。在这之后镜像开始安装在您的磁盘上并在不到 5 分钟的时间内结束。
|
||||
|
||||

|
||||
|
||||
*图 3: 选择安装 Photon 的硬盘。[经许可使用][3]*
|
||||
|
||||
安装完成后,重启虚拟机并使用安装时创建的用户 root 和它的密码登录。一切就绪,你准备好开始工作了。
|
||||
|
||||
在开始使用 Docker 之前,您需要更新一下 Photon。Photon 使用 `yum` 软件包管理器,因此在以 root 用户登录后输入命令 `yum update`。如果有任何可用更新,则会询问您是否确认(图4)。
|
||||
|
||||

|
||||
|
||||
*图 4: 更新 Photon。[经许可使用][4]*
|
||||
|
||||
### 用法
|
||||
|
||||
正如我所说的,Photon 提供了部署容器甚至创建 Kubernetes 集群所需要的所有包。但是,在使用之前还要做一些事情。首先要启动 Docker 守护进程。为此,执行以下命令:
|
||||
|
||||
```
|
||||
systemctl start docker
|
||||
systemctl enable docker
|
||||
```
|
||||
|
||||
现在我们需要创建一个标准用户,以便我们可以不用 root 去运行 `docker` 命令。为此,执行以下命令:
|
||||
|
||||
```
|
||||
useradd -m USERNAME
|
||||
passwd USERNAME
|
||||
```
|
||||
|
||||
其中 “USERNAME” 是我们新增的用户的名称。
|
||||
|
||||
接下来,我们需要将这个新用户添加到 “docker” 组,执行命令:
|
||||
|
||||
```
|
||||
usermod -a -G docker USERNAME
|
||||
```
|
||||
|
||||
其中 “USERNAME” 是刚刚创建的用户的名称。
|
||||
|
||||
注销 root 用户并切换为新增的用户。现在,您已经可以不必使用 `sudo` 命令或者切换到 root 用户来使用 `docker` 命令了。从 Docker Hub 中取出一个镜像开始部署容器吧。
|
||||
|
||||
### 一个优秀的容器平台
|
||||
|
||||
在专注于容器方面,Photon 毫无疑问是一个出色的平台。请注意,Photon 是一个开源项目,因此没有任何付费支持。如果您对 Photon 有任何的问题,请移步 Photon 项目的 GitHub 下的 [Issues][27],那里可以供您阅读相关问题,或者提交您的问题。如果您对 Photon 感兴趣,您也可以在该项目的官方 [GitHub][28]中找到源码。
|
||||
|
||||
尝试一下 Photon 吧,看看它是否能够使得 Docker 容器和 Kubernetes 集群的部署更加容易。
|
||||
|
||||
欲了解 Linux 的更多信息,可以通过学习 Linux 基金会和 edX 的免费课程,[“Linux 入门”][29]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/11/photon-could-be-your-new-favorite-container-os
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[KeyLD](https://github.com/KeyLd)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[6]:https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project
|
||||
[7]:http://vmware.github.io/lightwave/
|
||||
[8]:https://www.linux.com/files/images/photon0jpg
|
||||
[9]:https://www.linux.com/files/images/photon1jpg
|
||||
[10]:https://www.linux.com/files/images/photon2jpg
|
||||
[11]:https://www.linux.com/files/images/photon3jpg
|
||||
[12]:https://www.linux.com/files/images/photon-linuxjpg
|
||||
[13]:https://www.linux.com/learn/intro-to-linux/2017/11/how-install-and-use-docker-linux
|
||||
[14]:https://www.docker.com/
|
||||
[15]:https://vmware.github.io/photon/
|
||||
[16]:https://www.vmware.com/
|
||||
[17]:https://www.vmware.com/products/vsphere.html
|
||||
[18]:https://azure.microsoft.com/
|
||||
[19]:https://cloud.google.com/compute/
|
||||
[20]:https://aws.amazon.com/ec2/
|
||||
[21]:https://www.virtualbox.org/
|
||||
[22]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[23]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[24]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[25]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[26]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[27]:https://github.com/vmware/photon/issues
|
||||
[28]:https://github.com/vmware/photon
|
||||
[29]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,48 @@
|
||||
使用 DNSTrails 自动找出每个域名的拥有者
|
||||
============================================================
|
||||
|
||||
今天,我们很高兴地宣布我们最近几周做的新功能。它是 Whois 聚合工具,现在可以在 [DNSTrails][1] 上获得。
|
||||
|
||||
在过去,查找一个域名的所有者会花费很多时间,因为大部分时间你都需要把域名翻译为一个 IP 地址,以便找到同一个人拥有的其他域名。
|
||||
|
||||
使用老的方法,在得到你想要的域名列表之前,你在一个工具和另外一个工具的一日又一日的研究和交叉比较结果中经常会花费数个小时。
|
||||
|
||||
感谢这个新工具和我们的智能 [WHOIS 数据库][2],现在你可以搜索任何域名,并获得组织或个人注册的域名的完整列表,并在几秒钟内获得准确的结果。
|
||||
|
||||
### 我如何使用 Whois 聚合功能?
|
||||
|
||||
第一步:打开 [DNSTrails.com][3]
|
||||
|
||||
第二步:搜索任何域名,比如:godaddy.com
|
||||
|
||||
第三步:在得到域名的结果后,如下所见,定位下面的 Whois 信息:
|
||||
|
||||

|
||||
|
||||
第四步:你会看到那里有有关域名的电话和电子邮箱地址。
|
||||
|
||||
第五步:点击右边的链接,你会轻松地找到用相同电话和邮箱注册的域名。
|
||||
|
||||

|
||||
|
||||
如果你正在调查互联网上任何个人的域名所有权,这意味着即使域名甚至没有指向注册服务商的 IP,如果他们使用相同的电话和邮件地址,我们仍然可以发现其他域名。
|
||||
|
||||
想知道一个人拥有的其他域名么?亲自试试 [DNStrails][5] 的 [WHOIS 聚合功能][4]或者[使用我们的 API 访问][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://securitytrails.com/blog/find-every-domain-someone-owns
|
||||
|
||||
作者:[SECURITYTRAILS TEAM][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://securitytrails.com/blog/find-every-domain-someone-owns
|
||||
[1]:https://dnstrails.com/
|
||||
[2]:https://securitytrails.com/forensics
|
||||
[3]:https://dnstrails.com/
|
||||
[4]:http://dnstrails.com/#/domain/domain/ueland.com
|
||||
[5]:https://dnstrails.com/
|
||||
[6]:https://securitytrails.com/contact
|
||||
@ -1,68 +1,65 @@
|
||||
Translate Shell: 一款在 Linux 命令行中使用 Google Translate的工具
|
||||
Translate Shell :一款在 Linux 命令行中使用谷歌翻译的工具
|
||||
============================================================
|
||||
|
||||
我对 CLI 应用非常感兴趣,因此热衷于使用并分享 CLI 应用。 我之所以更喜欢 CLI 很大原因是因为我在大多数的时候都使用的是字符界面(black screen),已经习惯了使用 CLI 应用而不是 GUI 应用.
|
||||
我对 CLI 应用非常感兴趣,因此热衷于使用并分享 CLI 应用。 我之所以更喜欢 CLI 很大原因是因为我在大多数的时候都使用的是字符界面(black screen),已经习惯了使用 CLI 应用而不是 GUI 应用。
|
||||
|
||||
我写过很多关于 CLI 应用的文章。 最近我发现了一些 google 的 CLI 工具,像 “Google Translator”, “Google Calendar”, 和 “Google Contacts”。 这里,我想在给大家分享一下。
|
||||
我写过很多关于 CLI 应用的文章。 最近我发现了一些谷歌的 CLI 工具,像 “Google Translator”、“Google Calendar” 和 “Google Contacts”。 这里,我想在给大家分享一下。
|
||||
|
||||
今天我们要介绍的是 “Google Translator” 工具。 由于母语是泰米尔语,我在一天内用了很多次才理解了它的意义。
|
||||
今天我们要介绍的是 “Google Translator” 工具。 由于我的母语是泰米尔语,我在一天内用了很多次才理解了它的意义。
|
||||
|
||||
`Google translate` 为其他语系的人们所广泛使用。
|
||||
谷歌翻译为其它语系的人们所广泛使用。
|
||||
|
||||
### 什么是 Translate Shell
|
||||
|
||||
[Translate Shell][2] (之前叫做 Google Translate CLI) 是一款借助 `Google Translate`(默认), `Bing Translator`, `Yandex.Translate` 以及 `Apertium` 来翻译的命令行翻译器。
|
||||
它让你可以在终端访问这些翻译引擎. `Translate Shell` 在大多数Linux发行版中都能使用。
|
||||
[Translate Shell][2] (之前叫做 Google Translate CLI) 是一款借助谷歌翻译(默认)、必应翻译、Yandex.Translate 以及 Apertium 来翻译的命令行翻译器。它让你可以在终端访问这些翻译引擎。 Translate Shell 在大多数 Linux 发行版中都能使用。
|
||||
|
||||
### 如何安装 Translate Shell
|
||||
|
||||
有三种方法安装 `Translate Shell`。
|
||||
有三种方法安装 Translate Shell。
|
||||
|
||||
* 下载自包含的可执行文件
|
||||
|
||||
* 手工安装
|
||||
* 通过包管理器安装
|
||||
|
||||
* 通过包挂力气安装
|
||||
|
||||
#### 方法-1 : 下载自包含的可执行文件
|
||||
#### 方法 1 : 下载自包含的可执行文件
|
||||
|
||||
下载自包含的可执行文件放到 `/usr/bin` 目录中。
|
||||
|
||||
```shell
|
||||
```
|
||||
$ wget git.io/trans
|
||||
$ chmod +x ./trans
|
||||
$ sudo mv trans /usr/bin/
|
||||
```
|
||||
|
||||
#### 方法-2 : 手工安装
|
||||
#### 方法 2 : 手工安装
|
||||
|
||||
克隆 `Translate Shell` github 仓库然后手工编译。
|
||||
克隆 Translate Shell 的 GitHub 仓库然后手工编译。
|
||||
|
||||
```shell
|
||||
```
|
||||
$ git clone https://github.com/soimort/translate-shell && cd translate-shell
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
#### 方法-3 : Via Package Manager
|
||||
#### 方法 3 : 通过包管理器
|
||||
|
||||
有些发行版的官方仓库中包含了 `Translate Shell`,可以通过包管理器来安装。
|
||||
有些发行版的官方仓库中包含了 Translate Shell,可以通过包管理器来安装。
|
||||
|
||||
对于 Debian/Ubuntu, 使用 [APT-GET Command][3] 或者 [APT Command][4]来安装。
|
||||
对于 Debian/Ubuntu, 使用 [APT-GET 命令][3] 或者 [APT 命令][4]来安装。
|
||||
|
||||
```shell
|
||||
```
|
||||
$ sudo apt-get install translate-shell
|
||||
```
|
||||
|
||||
对于 Fedora, 使用 [DNF Command][5] 来安装。
|
||||
对于 Fedora, 使用 [DNF 命令][5] 来安装。
|
||||
|
||||
```shell
|
||||
```
|
||||
$ sudo dnf install translate-shell
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统, 使用 [Yaourt Command][6] 或 [Packer Command][7] 来从 AUR 仓库中安装。
|
||||
对于基于 Arch Linux 的系统, 使用 [Yaourt 命令][6] 或 [Packer 明快][7] 来从 AUR 仓库中安装。
|
||||
|
||||
```shell
|
||||
```
|
||||
$ yaourt -S translate-shell
|
||||
or
|
||||
$ packer -S translate-shell
|
||||
@ -70,7 +67,7 @@ $ packer -S translate-shell
|
||||
|
||||
### 如何使用 Translate Shell
|
||||
|
||||
安装好后,打开终端闭关输入下面命令。 `Google Translate` 会自动探测源文本是哪种语言,并且在默认情况下将之翻译成你的 `locale` 所对应的语言。
|
||||
安装好后,打开终端闭关输入下面命令。 谷歌翻译会自动探测源文本是哪种语言,并且在默认情况下将之翻译成你的 `locale` 所对应的语言。
|
||||
|
||||
```
|
||||
$ trans [Words]
|
||||
@ -119,7 +116,7 @@ thanks
|
||||
நன்றி
|
||||
```
|
||||
|
||||
要将一个单词翻译到多个语种可以使用下面命令(本例中, 我将单词翻译成泰米尔语以及印地语)。
|
||||
要将一个单词翻译到多个语种可以使用下面命令(本例中,我将单词翻译成泰米尔语以及印地语)。
|
||||
|
||||
```
|
||||
$ trans :ta+hi thanks
|
||||
@ -172,7 +169,7 @@ what is going on your life?
|
||||
உங்கள் வாழ்க்கையில் என்ன நடக்கிறது?
|
||||
```
|
||||
|
||||
下面命令独立地翻译各个单词。
|
||||
下面命令单独地翻译各个单词。
|
||||
|
||||
```
|
||||
$ trans :ta curios happy
|
||||
@ -208,14 +205,14 @@ happy
|
||||
சந்தோஷமாக, மகிழ்ச்சி, இனிய, சந்தோஷமா
|
||||
```
|
||||
|
||||
简洁模式: 默认情况下,`Translate Shell` 尽可能多的显示翻译信息. 如果你希望只显示简要信息,只需要加上`-b`选项。
|
||||
简洁模式:默认情况下,Translate Shell 尽可能多的显示翻译信息。如果你希望只显示简要信息,只需要加上 `-b`选项。
|
||||
|
||||
```
|
||||
$ trans -b :ta thanks
|
||||
நன்றி
|
||||
```
|
||||
|
||||
字典模式: 加上 `-d` 可以把 `Translate Shell` 当成字典来用.
|
||||
字典模式:加上 `-d` 可以把 Translate Shell 当成字典来用。
|
||||
|
||||
```
|
||||
$ trans -d :en thanks
|
||||
@ -294,14 +291,14 @@ See also
|
||||
Thanks!, thank, many thanks, thanks to, thanks to you, special thanks, give thanks, thousand thanks, Many thanks!, render thanks, heartfelt thanks, thanks to this
|
||||
```
|
||||
|
||||
使用下面格式可以使用 `Translate Shell` 来翻译文件。
|
||||
使用下面格式可以使用 Translate Shell 来翻译文件。
|
||||
|
||||
```shell
|
||||
```
|
||||
$ trans :ta file:///home/magi/gtrans.txt
|
||||
உங்கள் வாழ்க்கையில் என்ன நடக்கிறது?
|
||||
```
|
||||
|
||||
下面命令可以让 `Translate Shell` 进入交互模式. 在进入交互模式之前你需要明确指定源语言和目标语言。本例中,我将英文单词翻译成泰米尔语。
|
||||
下面命令可以让 Translate Shell 进入交互模式。 在进入交互模式之前你需要明确指定源语言和目标语言。本例中,我将英文单词翻译成泰米尔语。
|
||||
|
||||
```
|
||||
$ trans -shell en:ta thanks
|
||||
@ -324,13 +321,14 @@ thanks
|
||||
நன்றி
|
||||
```
|
||||
|
||||
想知道语言代码,可以执行下面语言。
|
||||
想知道语言代码,可以执行下面命令。
|
||||
|
||||
```shell
|
||||
```
|
||||
$ trans -R
|
||||
```
|
||||
或者
|
||||
```shell
|
||||
|
||||
```
|
||||
$ trans -T
|
||||
┌───────────────────────┬───────────────────────┬───────────────────────┐
|
||||
│ Afrikaans - af │ Hindi - hi │ Punjabi - pa │
|
||||
@ -375,9 +373,9 @@ $ trans -T
|
||||
└───────────────────────┴───────────────────────┴───────────────────────┘
|
||||
```
|
||||
|
||||
想了解更多选项的内容,可以查看 `man` 页.
|
||||
想了解更多选项的内容,可以查看其 man 手册。
|
||||
|
||||
```shell
|
||||
```
|
||||
$ man trans
|
||||
```
|
||||
|
||||
@ -386,8 +384,8 @@ $ man trans
|
||||
via: https://www.2daygeek.com/translate-shell-a-tool-to-use-google-translate-from-command-line-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[lujun9972](https://github.com/lujun9972 )
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
163
published/20171201 How to Manage Users with Groups in Linux.md
Normal file
163
published/20171201 How to Manage Users with Groups in Linux.md
Normal file
@ -0,0 +1,163 @@
|
||||
如何在 Linux 系统中通过用户组来管理用户
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 本教程可以了解如何通过用户组和访问控制表(ACL)来管理用户。
|
||||
|
||||
当你需要管理一台容纳多个用户的 Linux 机器时,比起一些基本的用户管理工具所提供的方法,有时候你需要对这些用户采取更多的用户权限管理方式。特别是当你要管理某些用户的权限时,这个想法尤为重要。比如说,你有一个目录,某个用户组中的用户可以通过读和写的权限访问这个目录,而其他用户组中的用户对这个目录只有读的权限。在 Linux 中,这是完全可以实现的。但前提是你必须先了解如何通过用户组和访问控制表(ACL)来管理用户。
|
||||
|
||||
我们将从简单的用户开始,逐渐深入到复杂的访问控制表(ACL)。你可以在你所选择的 Linux 发行版完成你所需要做的一切。本文的重点是用户组,所以不会涉及到关于用户的基础知识。
|
||||
|
||||
为了达到演示的目的,我将假设:
|
||||
|
||||
你需要用下面两个用户名新建两个用户:
|
||||
|
||||
* olivia
|
||||
* nathan
|
||||
|
||||
你需要新建以下两个用户组:
|
||||
|
||||
* readers
|
||||
* editors
|
||||
|
||||
olivia 属于 editors 用户组,而 nathan 属于 readers 用户组。reader 用户组对 `/DATA` 目录只有读的权限,而 editors 用户组则对 `/DATA` 目录同时有读和写的权限。当然,这是个非常小的任务,但它会给你基本的信息,你可以扩展这个任务以适应你其他更大的需求。
|
||||
|
||||
我将在 Ubuntu 16.04 Server 平台上进行演示。这些命令都是通用的,唯一不同的是,要是在你的发行版中不使用 `sudo` 命令,你必须切换到 root 用户来执行这些命令。
|
||||
|
||||
### 创建用户
|
||||
|
||||
我们需要做的第一件事是为我们的实验创建两个用户。可以用 `useradd` 命令来创建用户,我们不只是简单地创建一个用户,而需要同时创建用户和属于他们的家目录,然后给他们设置密码。
|
||||
|
||||
```
|
||||
sudo useradd -m olivia
|
||||
sudo useradd -m nathan
|
||||
```
|
||||
|
||||
我们现在创建了两个用户,如果你看看 `/home` 目录,你可以发现他们的家目录(因为我们用了 `-m` 选项,可以在创建用户的同时创建他们的家目录。
|
||||
|
||||
之后,我们可以用以下命令给他们设置密码:
|
||||
|
||||
```
|
||||
sudo passwd olivia
|
||||
sudo passwd nathan
|
||||
```
|
||||
|
||||
就这样,我们创建了两个用户。
|
||||
|
||||
### 创建用户组并添加用户
|
||||
|
||||
现在我们将创建 readers 和 editors 用户组,然后给它们添加用户。创建用户组的命令是:
|
||||
|
||||
```
|
||||
addgroup readers
|
||||
addgroup editors
|
||||
```
|
||||
|
||||
(LCTT 译注:当你使用 CentOS 等一些 Linux 发行版时,可能系统没有 `addgroup` 这个命令,推荐使用 `groupadd` 命令来替换 `addgroup` 命令以达到同样的效果)
|
||||
|
||||

|
||||
|
||||
*图一:我们可以使用刚创建的新用户组了。*
|
||||
|
||||
创建用户组后,我们需要添加我们的用户到这两个用户组。我们用以下命令来将 nathan 用户添加到 readers 用户组:
|
||||
|
||||
```
|
||||
sudo usermod -a -G readers nathan
|
||||
```
|
||||
|
||||
用以下命令将 olivia 添加到 editors 用户组:
|
||||
|
||||
```
|
||||
sudo usermod -a -G editors olivia
|
||||
```
|
||||
|
||||
现在我们可以通过用户组来管理用户了。
|
||||
|
||||
### 给用户组授予目录的权限
|
||||
|
||||
假设你有个目录 `/READERS` 且允许 readers 用户组的所有成员访问这个目录。首先,我们执行以下命令来更改目录所属用户组:
|
||||
|
||||
```
|
||||
sudo chown -R :readers /READERS
|
||||
```
|
||||
|
||||
接下来,执行以下命令收回目录所属用户组的写入权限:
|
||||
|
||||
```
|
||||
sudo chmod -R g-w /READERS
|
||||
```
|
||||
|
||||
然后我们执行下面的命令来收回其他用户对这个目录的访问权限(以防止任何不在 readers 组中的用户访问这个目录里的文件):
|
||||
|
||||
```
|
||||
sudo chmod -R o-x /READERS
|
||||
```
|
||||
|
||||
这时候,只有目录的所有者(root)和用户组 reader 中的用户可以访问 `/READES` 中的文件。
|
||||
|
||||
假设你有个目录 `/EDITORS` ,你需要给用户组 editors 里的成员这个目录的读和写的权限。为了达到这个目的,执行下面的这些命令是必要的:
|
||||
|
||||
```
|
||||
sudo chown -R :editors /EDITORS
|
||||
sudo chmod -R g+w /EDITORS
|
||||
sudo chmod -R o-x /EDITORS
|
||||
```
|
||||
|
||||
此时 editors 用户组的所有成员都可以访问和修改其中的文件。除此之外其他用户(除了 root 之外)无法访问 `/EDITORS` 中的任何文件。
|
||||
|
||||
使用这个方法的问题在于,你一次只能操作一个组和一个目录而已。这时候访问控制表(ACL)就可以派得上用场了。
|
||||
|
||||
### 使用访问控制表(ACL)
|
||||
|
||||
现在,让我们把这个问题变得棘手一点。假设你有一个目录 `/DATA` 并且你想给 readers 用户组的成员读取权限,并同时给 editors 用户组的成员读和写的权限。为此,你必须要用到 `setfacl` 命令。`setfacl` 命令可以为文件或文件夹设置一个访问控制表(ACL)。
|
||||
|
||||
这个命令的结构如下:
|
||||
|
||||
```
|
||||
setfacl OPTION X:NAME:Y /DIRECTORY
|
||||
```
|
||||
|
||||
其中 OPTION 是可选选项,X 可以是 `u`(用户)或者是 `g` (用户组),NAME 是用户或者用户组的名字,/DIRECTORY 是要用到的目录。我们将使用 `-m` 选项进行修改。因此,我们给 readers 用户组添加读取权限的命令是:
|
||||
|
||||
```
|
||||
sudo setfacl -m g:readers:rx -R /DATA
|
||||
```
|
||||
|
||||
现在 readers 用户组里面的每一个用户都可以读取 `/DATA` 目录里的文件了,但是他们不能修改里面的内容。
|
||||
|
||||
为了给 editors 用户组里面的用户读写权限,我们执行了以下命令:
|
||||
|
||||
```
|
||||
sudo setfacl -m g:editors:rwx -R /DATA
|
||||
```
|
||||
|
||||
上述命令将赋予 editors 用户组中的任何成员读取权限,同时保留 readers 用户组的只读权限。
|
||||
|
||||
### 更多的权限控制
|
||||
|
||||
使用访问控制表(ACL),你可以实现你所需的权限控制。你可以添加用户到用户组,并且灵活地控制这些用户组对每个目录的权限以达到你的需求。如果想了解上述工具的更多信息,可以执行下列的命令:
|
||||
|
||||
* `man usradd`
|
||||
* `man addgroup`
|
||||
* `man usermod`
|
||||
* `man sefacl`
|
||||
* `man chown`
|
||||
* `man chmod`
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/how-manage-users-groups-linux
|
||||
|
||||
作者:[Jack Wallen]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.linux.com/files/images/group-people-16453561920jpg
|
||||
[2]:https://www.linux.com/files/images/groups1jpg
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[4]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
34
published/20171201 Linux Journal Ceases Publication.md
Normal file
34
published/20171201 Linux Journal Ceases Publication.md
Normal file
@ -0,0 +1,34 @@
|
||||
Linux Journal 停止发行
|
||||
============================================================
|
||||
|
||||
EOF
|
||||
|
||||
伙计们,看起来我们要到终点了。如果按照计划而且没有什么其他的话,十一月份的 Linux Journal 将是我们的最后一期。
|
||||
|
||||
简单的事实是,我们已经用完了钱和期权。我们从来没有一个富有的母公司或者自己深厚的资金,从开始到结束,这使得我们变成一个反常的出版商。虽然我们在很长的一段时间内运营着,但当天平不可恢复地最终向相反方向倾斜时,我们在十一月份失去了最后一点支持。
|
||||
|
||||
虽然我们像看到出版业的过去那样看到出版业的未来 - 广告商赞助出版物的时代,因为他们重视品牌和读者 - 我们如今的广告宁愿追逐眼球,最好是在读者的浏览器中植入跟踪标记,并随时随地展示那些广告。但是,未来不是这样,过去的已经过去了。
|
||||
|
||||
我们猜想,有一个希望,那就是救世主可能会会来。但除了我们的品牌、我们的档案,我们的域名、我们的用户和读者之外,还必须是愿意承担我们一部分债务的人。如果你认识任何人能够提供认真的报价,请告诉我们。不然,请观看 LinuxJournal.com,并希望至少我们的遗留归档(可以追溯到 Linux Journal 诞生的 1994 年 4 月,当 Linux 命中 1.0 发布时)将不会消失。这里有很多很棒的东西,还有很多我们会痛恨世界失去的历史。
|
||||
|
||||
我们最大的遗憾是,我们甚至没有足够的钱回馈最看重我们的人:我们的用户。为此,我们不能更深刻或真诚地道歉。我们对订阅者而言有什么:
|
||||
|
||||
Linux Pro Magazine 为我们的用户提供了六本免费的杂志,我们在 Linux Journal 上一直赞叹这点。在我们需要的时候,他们是我们的第一批人,我们感谢他们的恩惠。我们今天刚刚完成了我们的 2017 年归档,其中包括我们曾经发表过的每一个问题,包括第一个和最后一个。通常我们以 25 美元的价格出售,但显然用户将免费获得。订阅者请注意有关两者的详细信息的电子邮件。
|
||||
|
||||
我们也希望在知道我们非常非常努力地让 Linux Journal 进行下去后能有一些安慰 ,而且我们已经用最精益、小的可能运营了很长一段时间。我们是一个大多数是自愿者的组织,有些员工已经几个月没有收到工资。我们还欠钱给自由职业者。这时一个限制发行商能够维持多长时间的限制,现在这个限制已经到头了。
|
||||
|
||||
伙计们,这是一个伟大的运营。乡亲。对每一个为我们的诞生、我们的成功和我们多年的坚持作出贡献的人致敬。我们列了一份名单,但是列表太长了,并且漏掉有价值的人的风险很高。你知道你是谁。我们再次感谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/linux-journal-ceases-publication
|
||||
|
||||
作者:[ Carlie Fairchild][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxjournal.com/users/carlie-fairchild
|
||||
[1]:https://www.linuxjournal.com/taxonomy/term/29
|
||||
[2]:https://www.linuxjournal.com/users/carlie-fairchild
|
||||
@ -1,86 +0,0 @@
|
||||
translating by hopefully2333
|
||||
|
||||
# [The One in Which I Call Out Hacker News][14]
|
||||
|
||||
|
||||
> “Implementing caching would take thirty hours. Do you have thirty extra hours? No, you don’t. I actually have no idea how long it would take. Maybe it would take five minutes. Do you have five minutes? No. Why? Because I’m lying. It would take much longer than five minutes. That’s the eternal optimism of programmers.”
|
||||
>
|
||||
> — Professor [Owen Astrachan][1] during 23 Feb 2004 lecture for [CPS 108][2]
|
||||
|
||||
[Accusing open-source software of being a royal pain to use][5] is not a new argument; it’s been said before, by those much more eloquent than I, and even by some who are highly sympathetic to the open-source movement. Why go over it again?
|
||||
|
||||
On Hacker News on Monday, I was amused to read some people saying that [writing StackOverflow was hilariously easy][6]—and proceeding to back up their claim by [promising to clone it over July 4th weekend][7]. Others chimed in, pointing to [existing][8] [clones][9] as a good starting point.
|
||||
|
||||
Let’s assume, for sake of argument, that you decide it’s okay to write your StackOverflow clone in ASP.NET MVC, and that I, after being hypnotized with a pocket watch and a small club to the head, have decided to hand you the StackOverflow source code, page by page, so you can retype it verbatim. We’ll also assume you type like me, at a cool 100 WPM ([a smidge over eight characters per second][10]), and unlike me, _you_ make zero mistakes. StackOverflow’s *.cs, *.sql, *.css, *.js, and *.aspx files come to 2.3 MB. So merely typing the source code back into the computer will take you about eighty hours if you make zero mistakes.
|
||||
|
||||
Except, of course, you’re not doing that; you’re going to implement StackOverflow from scratch. So even assuming that it took you a mere ten times longer to design, type out, and debug your own implementation than it would take you to copy the real one, that already has you coding for several weeks straight—and I don’t know about you, but I am okay admitting I write new code _considerably_ less than one tenth as fast as I copy existing code.
|
||||
|
||||
_Well, okay_ , I hear you relent. *So not the whole thing. But I can do **most** of it.*
|
||||
|
||||
Okay, so what’s “most”? There’s simply asking and responding to questions—that part’s easy. Well, except you have to implement voting questions and answers up and down, and the questioner should be able to accept a single answer for each question. And you can’t let people upvote or accept their own answers, so you need to block that. And you need to make sure that users don’t upvote or downvote another user too many times in a certain amount of time, to prevent spambots. Probably going to have to implement a spam filter, too, come to think of it, even in the basic design, and you also need to support user icons, and you’re going to have to find a sanitizing HTML library you really trust and that interfaces well with Markdown (provided you do want to reuse [that awesome editor][11] StackOverflow has, of course). You’ll also need to purchase, design, or find widgets for all the controls, plus you need at least a basic administration interface so that moderators can moderate, and you’ll need to implement that scaling karma thing so that you give users steadily increasing power to do things as they go.
|
||||
|
||||
But if you do _all that_ , you _will_ be done.
|
||||
|
||||
Except…except, of course, for the full-text search, especially its appearance in the search-as-you-ask feature, which is kind of indispensable. And user bios, and having comments on answers, and having a main page that shows you important questions but that bubbles down steadily à la reddit. Plus you’ll totally need to implement bounties, and support multiple OpenID logins per user, and send out email notifications for pertinent events, and add a tagging system, and allow administrators to configure badges by a nice GUI. And you’ll need to show users’ karma history, upvotes, and downvotes. And the whole thing has to scale really well, since it could be slashdotted/reddited/StackOverflown at any moment.
|
||||
|
||||
But _then_ ! **Then** you’re done!
|
||||
|
||||
…right after you implement upgrades, internationalization, karma caps, a CSS design that makes your site not look like ass, AJAX versions of most of the above, and G-d knows what else that’s lurking just beneath the surface that you currently take for granted, but that will come to bite you when you start to do a real clone.
|
||||
|
||||
Tell me: which of those features do you feel you can cut and still have a compelling offering? Which ones go under “most” of the site, and which can you punt?
|
||||
|
||||
Developers think cloning a site like StackOverflow is easy for the same reason that open-source software remains such a horrible pain in the ass to use. When you put a developer in front of StackOverflow, they don’t really _see_ StackOverflow. What they actually _see_ is this:
|
||||
|
||||
```
|
||||
create table QUESTION (ID identity primary key,
|
||||
TITLE varchar(255), --- why do I know you thought 255?
|
||||
BODY text,
|
||||
UPVOTES integer not null default 0,
|
||||
DOWNVOTES integer not null default 0,
|
||||
USER integer references USER(ID));
|
||||
create table RESPONSE (ID identity primary key,
|
||||
BODY text,
|
||||
UPVOTES integer not null default 0,
|
||||
DOWNVOTES integer not null default 0,
|
||||
QUESTION integer references QUESTION(ID))
|
||||
```
|
||||
|
||||
If you then tell a developer to replicate StackOverflow, what goes into his head are the above two SQL tables and enough HTML to display them without formatting, and that really _is_ completely doable in a weekend. The smarter ones will realize that they need to implement login and logout, and comments, and that the votes need to be tied to a user, but that’s still totally doable in a weekend; it’s just a couple more tables in a SQL back-end, and the HTML to show their contents. Use a framework like Django, and you even get basic users and comments for free.
|
||||
|
||||
But that’s _not_ what StackOverflow is about. Regardless of what your feelings may be on StackOverflow in general, most visitors seem to agree that the user experience is smooth, from start to finish. They feel that they’re interacting with a polished product. Even if I didn’t know better, I would guess that very little of what actually makes StackOverflow a continuing success has to do with the database schema—and having had a chance to read through StackOverflow’s source code, I know how little really does. There is a _tremendous_ amount of spit and polish that goes into making a major website highly usable. A developer, asked how hard something will be to clone, simply _does not think about the polish_ , because _the polish is incidental to the implementation._
|
||||
|
||||
That is why an open-source clone of StackOverflow will fail. Even if someone were to manage to implement most of StackOverflow “to spec,” there are some key areas that would trip them up. Badges, for example, if you’re targeting end-users, either need a GUI to configure rules, or smart developers to determine which badges are generic enough to go on all installs. What will actually happen is that the developers will bitch and moan about how you can’t implement a really comprehensive GUI for something like badges, and then bikeshed any proposals for standard badges so far into the ground that they’ll hit escape velocity coming out the other side. They’ll ultimately come up with the same solution that bug trackers like Roundup use for their workflow: the developers implement a generic mechanism by which anyone, truly anyone at all, who feels totally comfortable working with the system API in Python or PHP or whatever, can easily add their own customizations. And when PHP and Python are so easy to learn and so much more flexible than a GUI could ever be, why bother with anything else?
|
||||
|
||||
Likewise, the moderation and administration interfaces can be punted. If you’re an admin, you have access to the SQL server, so you can do anything really genuinely administrative-like that way. Moderators can get by with whatever django-admin and similar systems afford you, since, after all, few users are mods, and mods should understand how the sites _work_ , dammit. And, certainly, none of StackOverflow’s interface failings will be rectified. Even if StackOverflow’s stupid requirement that you have to have and know how to use an OpenID (its worst failing) eventually gets fixed, I’m sure any open-source clones will rabidly follow it—just as GNOME and KDE for years slavishly copied off Windows, instead of trying to fix its most obvious flaws.
|
||||
|
||||
Developers may not care about these parts of the application, but end-users do, and take it into consideration when trying to decide what application to use. Much as a good software company wants to minimize its support costs by ensuring that its products are top-notch before shipping, so, too, savvy consumers want to ensure products are good before they purchase them so that they won’t _have_ to call support. Open-source products fail hard here. Proprietary solutions, as a rule, do better.
|
||||
|
||||
That’s not to say that open-source doesn’t have its place. This blog runs on Apache, [Django][12], [PostgreSQL][13], and Linux. But let me tell you, configuring that stack is _not_ for the faint of heart. PostgreSQL needs vacuuming configured on older versions, and, as of recent versions of Ubuntu and FreeBSD, still requires the user set up the first database cluster. MS SQL requires neither of those things. Apache…dear heavens, don’t even get me _started_ on trying to explain to a novice user how to get virtual hosting, MovableType, a couple Django apps, and WordPress all running comfortably under a single install. Hell, just trying to explain the forking vs. threading variants of Apache to a technically astute non-developer can be a nightmare. IIS 7 and Apache with OS X Server’s very much closed-source GUI manager make setting up those same stacks vastly simpler. Django’s a great a product, but it’s nothing _but_ infrastructure—exactly the thing that I happen to think open-source _does_ do well, _precisely_ because of the motivations that drive developers to contribute.
|
||||
|
||||
The next time you see an application you like, think very long and hard about all the user-oriented details that went into making it a pleasure to use, before decrying how you could trivially reimplement the entire damn thing in a weekend. Nine times out of ten, when you think an application was ridiculously easy to implement, you’re completely missing the user side of the story.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bitquabit.com/post/one-which-i-call-out-hacker-news/
|
||||
|
||||
作者:[Benjamin Pollack][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bitquabit.com/meta/about/
|
||||
[1]:http://www.cs.duke.edu/~ola/
|
||||
[2]:http://www.cs.duke.edu/courses/cps108/spring04/
|
||||
[3]:https://bitquabit.com/categories/programming
|
||||
[4]:https://bitquabit.com/categories/technology
|
||||
[5]:http://blog.bitquabit.com/2009/06/30/one-which-i-say-open-source-software-sucks/
|
||||
[6]:http://news.ycombinator.com/item?id=678501
|
||||
[7]:http://news.ycombinator.com/item?id=678704
|
||||
[8]:http://code.google.com/p/cnprog/
|
||||
[9]:http://code.google.com/p/soclone/
|
||||
[10]:http://en.wikipedia.org/wiki/Words_per_minute
|
||||
[11]:http://github.com/derobins/wmd/tree/master
|
||||
[12]:http://www.djangoproject.com/
|
||||
[13]:http://www.postgresql.org/
|
||||
[14]:https://bitquabit.com/post/one-which-i-call-out-hacker-news/
|
||||
@ -0,0 +1,211 @@
|
||||
# Dynamic linker tricks: Using LD_PRELOAD to cheat, inject features and investigate programs
|
||||
|
||||
**This post assumes some basic C skills.**
|
||||
|
||||
Linux puts you in full control. This is not always seen from everyone’s perspective, but a power user loves to be in control. I’m going to show you a basic trick that lets you heavily influence the behavior of most applications, which is not only fun, but also, at times, useful.
|
||||
|
||||
#### A motivational example
|
||||
|
||||
Let us begin with a simple example. Fun first, science later.
|
||||
|
||||
|
||||
random_num.c:
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <time.h>
|
||||
|
||||
int main(){
|
||||
srand(time(NULL));
|
||||
int i = 10;
|
||||
while(i--) printf("%d\n",rand()%100);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Simple enough, I believe. I compiled it with no special flags, just
|
||||
|
||||
> ```
|
||||
> gcc random_num.c -o random_num
|
||||
> ```
|
||||
|
||||
I hope the resulting output is obvious – ten randomly selected numbers 0-99, hopefully different each time you run this program.
|
||||
|
||||
Now let’s pretend we don’t really have the source of this executable. Either delete the source file, or move it somewhere – we won’t need it. We will significantly modify this programs behavior, yet without touching it’s source code nor recompiling it.
|
||||
|
||||
For this, lets create another simple C file:
|
||||
|
||||
|
||||
unrandom.c:
|
||||
```
|
||||
int rand(){
|
||||
return 42; //the most random number in the universe
|
||||
}
|
||||
```
|
||||
|
||||
We’ll compile it into a shared library.
|
||||
|
||||
> ```
|
||||
> gcc -shared -fPIC unrandom.c -o unrandom.so
|
||||
> ```
|
||||
|
||||
So what we have now is an application that outputs some random data, and a custom library, which implements the rand() function as a constant value of 42\. Now… just run _random_num _ this way, and watch the result:
|
||||
|
||||
> ```
|
||||
> LD_PRELOAD=$PWD/unrandom.so ./random_nums
|
||||
> ```
|
||||
|
||||
If you are lazy and did not do it yourself (and somehow fail to guess what might have happened), I’ll let you know – the output consists of ten 42’s.
|
||||
|
||||
This may be even more impressive it you first:
|
||||
|
||||
> ```
|
||||
> export LD_PRELOAD=$PWD/unrandom.so
|
||||
> ```
|
||||
|
||||
and then run the program normally. An unchanged app run in an apparently usual manner seems to be affected by what we did in our tiny library…
|
||||
|
||||
###### **Wait, what? What did just happen?**
|
||||
|
||||
Yup, you are right, our program failed to generate random numbers, because it did not use the “real” rand(), but the one we provided – which returns 42 every time.
|
||||
|
||||
###### **But we *told* it to use the real one. We programmed it to use the real one. Besides, at the time we created that program, the fake rand() did not even exist!**
|
||||
|
||||
This is not entirely true. We did not choose which rand() we want our program to use. We told it just to use rand().
|
||||
|
||||
When our program is started, certain libraries (that provide functionality needed by the program) are loaded. We can learn which are these using _ldd_ :
|
||||
|
||||
> ```
|
||||
> $ ldd random_nums
|
||||
> linux-vdso.so.1 => (0x00007fff4bdfe000)
|
||||
> libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f48c03ec000)
|
||||
> /lib64/ld-linux-x86-64.so.2 (0x00007f48c07e3000)
|
||||
> ```
|
||||
|
||||
What you see as the output is the list of libs that are needed by _random_nums_ . This list is built into the executable, and is determined compile time. The exact output might slightly differ on your machine, but a **libc.so** must be there – this is the file which provides core C functionality. That includes the “real” rand().
|
||||
|
||||
We can have a peek at what functions does libc provide. I used the following to get a full list:
|
||||
|
||||
> ```
|
||||
> nm -D /lib/libc.so.6
|
||||
> ```
|
||||
|
||||
The _nm_ command lists symbols found in a binary file. The -D flag tells it to look for dynamic symbols, which makes sense, as libc.so.6 is a dynamic library. The output is very long, but it indeed lists rand() among many other standard functions.
|
||||
|
||||
Now what happens when we set up the environmental variable LD_PRELOAD? This variable **forces some libraries to be loaded for a program**. In our case, it loads _unrandom.so_ for _random_num_ , even though the program itself does not ask for it. The following command may be interesting:
|
||||
|
||||
> ```
|
||||
> $ LD_PRELOAD=$PWD/unrandom.so ldd random_nums
|
||||
> linux-vdso.so.1 => (0x00007fff369dc000)
|
||||
> /some/path/to/unrandom.so (0x00007f262b439000)
|
||||
> libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f262b044000)
|
||||
> /lib64/ld-linux-x86-64.so.2 (0x00007f262b63d000)
|
||||
> ```
|
||||
|
||||
Note that it lists our custom library. And indeed this is the reason why it’s code get’s executed: _random_num_ calls rand(), but if _unrandom.so_ is loaded it is our library that provides implementation for rand(). Neat, isn’t it?
|
||||
|
||||
#### Being transparent
|
||||
|
||||
This is not enough. I’d like to be able to inject some code into an application in a similar manner, but in such way that it will be able to function normally. It’s clear if we implemented open() with a simple “ _return 0;_ “, the application we would like to hack should malfunction. The point is to be **transparent**, and to actually call the original open:
|
||||
|
||||
inspect_open.c:
|
||||
```
|
||||
int open(const char *pathname, int flags){
|
||||
/* Some evil injected code goes here. */
|
||||
return open(pathname,flags); // Here we call the "real" open function, that is provided to us by libc.so
|
||||
}
|
||||
```
|
||||
|
||||
Hm. Not really. This won’t call the “original” open(…). Obviously, this is an endless recursive call.
|
||||
|
||||
How do we access the “real” open function? It is needed to use the programming interface to the dynamic linker. It’s simpler than it sounds. Have a look at this complete example, and then I’ll explain what happens there:
|
||||
|
||||
inspect_open.c:
|
||||
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <dlfcn.h>
|
||||
|
||||
typedef int (*orig_open_f_type)(const char *pathname, int flags);
|
||||
|
||||
int open(const char *pathname, int flags, ...)
|
||||
{
|
||||
/* Some evil injected code goes here. */
|
||||
|
||||
orig_open_f_type orig_open;
|
||||
orig_open = (orig_open_f_type)dlsym(RTLD_NEXT,"open");
|
||||
return orig_open(pathname,flags);
|
||||
}
|
||||
```
|
||||
|
||||
The _dlfcn.h_ is needed for _dlsym_ function we use later. That strange _#define_ directive instructs the compiler to enable some non-standard stuff, we need it to enable _RTLD_NEXT_ in _dlfcn.h_ . That typedef is just creating an alias to a complicated pointer-to-function type, with arguments just as the original open – the alias name is _orig_open_f_type_ , which we’ll use later.
|
||||
|
||||
The body of our custom open(…) consists of some custom code. The last part of it creates a new function pointer _orig_open_ which will point to the original open(…) function. In order to get the address of that function, we ask _dlsym_ to find for us the next “open” function on dynamic libraries stack. Finally, we call that function (passing the same arguments as were passed to our fake “open”), and return it’s return value as ours.
|
||||
|
||||
As the “evil injected code” I simply used:
|
||||
|
||||
inspect_open.c (fragment):
|
||||
|
||||
```
|
||||
printf("The victim used open(...) to access '%s'!!!\n",pathname); //remember to include stdio.h!
|
||||
```
|
||||
|
||||
To compile it, I needed to slightly adjust compiler flags:
|
||||
|
||||
> ```
|
||||
> gcc -shared -fPIC inspect_open.c -o inspect_open.so -ldl
|
||||
> ```
|
||||
|
||||
I had to append _-ldl_ , so that this shared library is linked to _libdl_ , which provides the _dlsym_ function. (Nah, I am not going to create a fake version of _dlsym_ , though this might be fun.)
|
||||
|
||||
So what do I have in result? A shared library, which implements the open(…) function so that it behaves **exactly** as the real open(…)… except it has a side effect of _printf_ ing the file path :-)
|
||||
|
||||
If you are not convinced this is a powerful trick, it’s the time you tried the following:
|
||||
|
||||
> ```
|
||||
> LD_PRELOAD=$PWD/inspect_open.so gnome-calculator
|
||||
> ```
|
||||
|
||||
I encourage you to see the result yourself, but basically it lists every file this application accesses. In real time.
|
||||
|
||||
I believe it’s not that hard to imagine why this might be useful for debugging or investigating unknown applications. Please note, however, that this particular trick is not quite complete, because _open()_ is not the only function that opens files… For example, there is also _open64()_ in the standard library, and for full investigation you would need to create a fake one too.
|
||||
|
||||
#### **Possible uses**
|
||||
|
||||
If you are still with me and enjoyed the above, let me suggest a bunch of ideas of what can be achieved using this trick. Keep in mind that you can do all the above without to source of the affected app!
|
||||
|
||||
1. ~~Gain root privileges.~~ Not really, don’t even bother, you won’t bypass any security this way. (A quick explanation for pros: no libraries will be preloaded this way if ruid != euid)
|
||||
|
||||
2. Cheat games: **Unrandomize.** This is what I did in the first example. For a fully working case you would need also to implement a custom _random()_ , _rand_r()_ _, random_r()_ . Also some apps may be reading from _/dev/urandom_ or so, you might redirect them to _/dev/null_ by running the original _open()_ with a modified file path. Furthermore, some apps may have their own random number generation algorithm, there is little you can do about that (unless: point 10 below). But this looks like an easy exercise for beginners.
|
||||
|
||||
3. Cheat games: **Bullet time. **Implement all standard time-related functions pretend the time flows two times slower. Or ten times slower. If you correctly calculate new values for time measurement, timed _sleep_ functions, and others, the affected application will believe the time runs slower (or faster, if you wish), and you can experience awesome bullet-time action.
|
||||
Or go **even one step further** and let your shared library also be a DBus client, so that you can communicate with it real time. Bind some shortcuts to custom commands, and with some additional calculations in your fake timing functions you will be able to enable&disable the slow-mo or fast-forward anytime you wish.
|
||||
|
||||
4. Investigate apps: **List accessed files.** That’s what my second example does, but this could be also pushed further, by recording and monitoring all app’s file I/O.
|
||||
|
||||
5. Investigate apps: **Monitor internet access.** You might do this with Wireshark or similar software, but with this trick you could actually gain control of what an app sends over the web, and not just look, but also affect the exchanged data. Lots of possibilities here, from detecting spyware, to cheating in multiplayer games, or analyzing & reverse-engineering protocols of closed-source applications.
|
||||
|
||||
6. Investigate apps: **Inspect GTK structures.** Why just limit ourselves to standard library? Let’s inject code in all GTK calls, so that we can learn what widgets does an app use, and how are they structured. This might be then rendered either to an image or even to a gtkbuilder file! Super useful if you want to learn how does some app manage its interface!
|
||||
|
||||
7. **Sandbox unsafe applications.** If you don’t trust some app and are afraid that it may wish to _ rm -rf / _ or do some other unwanted file activities, you might potentially redirect all it’s file IO to e.g. /tmp by appropriately modifying the arguments it passes to all file-related functions (not just _open_ , but also e.g. removing directories etc.). It’s more difficult trick that a chroot, but it gives you more control. It would be only as safe as complete your “wrapper” was, and unless you really know what you’re doing, don’t actually run any malicious software this way.
|
||||
|
||||
8. **Implement features.** [zlibc][1] is an actual library which is run this precise way; it uncompresses files on the go as they are accessed, so that any application can work on compressed data without even realizing it.
|
||||
|
||||
9. **Fix bugs. **Another real-life example: some time ago (I am not sure this is still the case) Skype – which is closed-source – had problems capturing video from some certain webcams. Because the source could not be modified as Skype is not free software, this was fixed by preloading a library that would correct these problems with video.
|
||||
|
||||
10. Manually **access application’s own memory**. Do note that you can access all app data this way. This may be not impressive if you are familiar with software like CheatEngine/scanmem/GameConqueror, but they all require root privileges to work. LD_PRELOAD does not. In fact, with a number of clever tricks your injected code might access all app memory, because, in fact, it gets executed by that application itself. You might modify everything this application can. You can probably imagine this allows a lot of low-level hacks… but I’ll post an article about it another time.
|
||||
|
||||
These are only the ideas I came up with. I bet you can find some too, if you do – share them by commenting!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://rafalcieslak.wordpress.com/2013/04/02/dynamic-linker-tricks-using-ld_preload-to-cheat-inject-features-and-investigate-programs/
|
||||
|
||||
作者:[Rafał Cieślak ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://rafalcieslak.wordpress.com/
|
||||
[1]:http://www.zlibc.linux.lu/index.html
|
||||
@ -0,0 +1,361 @@
|
||||
How to turn any syscall into an event: Introducing eBPF Kernel probes
|
||||
============================================================
|
||||
|
||||
|
||||
TL;DR: Using eBPF in recent (>=4.4) Linux kernel, you can turn any kernel function call into a user land event with arbitrary data. This is made easy by bcc. The probe is written in C while the data is handled by python.
|
||||
|
||||
If you are not familiar with eBPF or linux tracing, you really should read the full post. It tries to progressively go through the pitfalls I stumbled unpon while playing around with bcc / eBPF while saving you a lot of the time I spent searching and digging.
|
||||
|
||||
### A note on push vs pull in a Linux world
|
||||
|
||||
When I started to work on containers, I was wondering how we could update a load balancer configuration dynamically based on actual system state. A common strategy, which works, it to let the container orchestrator trigger a load balancer configuration update whenever it starts a container and then let the load balancer poll the container until some health check passes. It may be a simple “SYN” test.
|
||||
|
||||
While this configuration works, it has the downside of making your load balancer waiting for some system to be available while it should be… load balancing.
|
||||
|
||||
Can we do better?
|
||||
|
||||
When you want a program to react to some change in a system there are 2 possible strategies. The program may _poll_ the system to detect changes or, if the system supports it, the system may _push_ events and let the program react to them. Wether you want to use push or poll depends on the context. A good rule of the thumb is to use push events when the event rate is low with respect to the processing time and switch to polling when the events are coming fast or the system may become unusable. For example, typical network driver will wait for events from the network card while frameworks like dpdk will actively poll the card for events to achieve the highest throughput and lowest latency.
|
||||
|
||||
In an ideal world, we’d have some kernel interface telling us:
|
||||
|
||||
> * “Hey Mr. ContainerManager, I’ve just created a socket for the Nginx-ware of container _servestaticfiles_ , maybe you want to update your state?”
|
||||
>
|
||||
> * “Sure Mr. OS, Thanks for letting me know”
|
||||
|
||||
While Linux has a wide range of interfaces to deal with events, up to 3 for file events, there is no dedicated interface to get socket event notifications. You can get routing table events, neighbor table events, conntrack events, interface change events. Just, not socket events. Or maybe there is, deep hidden in a Netlink interface.
|
||||
|
||||
Ideally, we’d need a generic way to do it. How?
|
||||
|
||||
### Kernel tracing and eBPF, a bit of history
|
||||
|
||||
Until recently the only way was to patch the kernel or resort on SystemTap. [SytemTap][5] is a tracing Linux system. In a nutshell, it provides a DSL which is then compiled into a kernel module which is then live-loaded into the running kernel. Except that some production system disable dynamic module loading for security reasons. Including the one I was working on at that time. The other way would be to patch the kernel to trigger some events, probably based on netlink. This is not really convenient. Kernel hacking come with downsides including “interesting” new “features” and increased maintenance burden.
|
||||
|
||||
Hopefully, starting with Linux 3.15 the ground was laid to safely transform any traceable kernel function into userland events. “Safely” is common computer science expression referring to “some virtual machine”. This case is no exception. Linux has had one for years. Since Linux 2.1.75 released in 1997 actually. It’s called Berkeley Packet Filter of BPF for short. As its name suggests, it was originally developed for the BSD firewalls. It had only 2 registers and only allowed forward jumps meaning that you could not write loops with it (Well, you can, if you know the maximum iterations and you manually unroll them). The point was to guarantee the program would always terminate and hence never hang the system. Still not sure if it has any use while you have iptables? It serves as the [foundation of CloudFlare’s AntiDDos protection][6].
|
||||
|
||||
OK, so, with Linux the 3.15, [BPF was extended][7] turning it into eBPF. For “extended” BPF. It upgrades from 2 32 bits registers to 10 64 bits 64 registers and adds backward jumping among others. It has then been [further extended in Linux 3.18][8] moving it out of the networking subsystem, and adding tools like maps. To preserve the safety guarantees, it [introduces a checker][9] which validates all memory accesses and possible code path. If the checker can’t guarantee the code will terminate within fixed boundaries, it will deny the initial insertion of the program.
|
||||
|
||||
For more history, there is [an excellent Oracle presentation on eBPF][10].
|
||||
|
||||
Let’s get started.
|
||||
|
||||
### Hello from from `inet_listen`
|
||||
|
||||
As writing assembly is not the most convenient task, even for the best of us, we’ll use [bcc][11]. bcc is a collection of tools based on LLVM and Python abstracting the underlying machinery. Probes are written in C and the results can be exploited from python allowing to easily write non trivial applications.
|
||||
|
||||
Start by install bcc. For some of these examples, you may require a recent (read >= 4.4) version of the kernel. If you are willing to actually try these examples, I highly recommend that you setup a VM. _NOT_ a docker container. You can’t change the kernel in a container. As this is a young and dynamic projects, install instructions are highly platform/version dependant. You can find up to date instructions on [https://github.com/iovisor/bcc/blob/master/INSTALL.md][12]
|
||||
|
||||
So, we want to get an event whenever a program starts to listen on TCP socket. When calling the `listen()` syscall on a `AF_INET` + `SOCK_STREAM` socket, the underlying kernel function is [`inet_listen`][13]. We’ll start by hooking a “Hello World” `kprobe` on it’s entrypoint.
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
|
||||
# Hello BPF Program
|
||||
bpf_text = """
|
||||
#include <net/inet_sock.h>
|
||||
#include <bcc/proto.h>
|
||||
|
||||
// 1\. Attach kprobe to "inet_listen"
|
||||
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
|
||||
{
|
||||
bpf_trace_printk("Hello World!\\n");
|
||||
return 0;
|
||||
};
|
||||
"""
|
||||
|
||||
# 2\. Build and Inject program
|
||||
b = BPF(text=bpf_text)
|
||||
|
||||
# 3\. Print debug output
|
||||
while True:
|
||||
print b.trace_readline()
|
||||
|
||||
```
|
||||
|
||||
This program does 3 things: 1\. It attaches a kernel probe to “inet_listen” using a naming convention. If the function was called, say, “my_probe”, it could be explicitly attached with `b.attach_kprobe("inet_listen", "my_probe"`. 2\. It builds the program using LLVM new BPF backend, inject the resulting bytecode using the (new) `bpf()` syscall and automatically attaches the probes matching the naming convention. 3\. It reads the raw output from the kernel pipe.
|
||||
|
||||
Note: eBPF backend of LLVM is still young. If you think you’ve hit a bug, you may want to upgrade.
|
||||
|
||||
Noticed the `bpf_trace_printk` call? This is a stripped down version of the kernel’s `printk()`debug function. When used, it produces tracing informations to a special kernel pipe in `/sys/kernel/debug/tracing/trace_pipe`. As the name implies, this is a pipe. If multiple readers are consuming it, only 1 will get a given line. This makes it unsuitable for production.
|
||||
|
||||
Fortunately, Linux 3.19 introduced maps for message passing and Linux 4.4 brings arbitrary perf events support. I’ll demo the perf event based approach later in this post.
|
||||
|
||||
```
|
||||
# From a first console
|
||||
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
|
||||
nc-4940 [000] d... 22666.991714: : Hello World!
|
||||
|
||||
# From a second console
|
||||
ubuntu@bcc:~$ nc -l 0 4242
|
||||
^C
|
||||
|
||||
```
|
||||
|
||||
Yay!
|
||||
|
||||
### Grab the backlog
|
||||
|
||||
Now, let’s print some easily accessible data. Say the “backlog”. The backlog is the number of pending established TCP connections, pending to be `accept()`ed.
|
||||
|
||||
Just tweak a bit the `bpf_trace_printk`:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening with with up to %d pending connections!\\n", backlog);
|
||||
|
||||
```
|
||||
|
||||
If you re-run the example with this world-changing improvement, you should see something like:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
nc-5020 [000] d... 25497.154070: : Listening with with up to 1 pending connections!
|
||||
|
||||
```
|
||||
|
||||
`nc` is a single connection program, hence the backlog of 1\. Nginx or Redis would output 128 here. But that’s another story.
|
||||
|
||||
Easy hue? Now let’s get the port.
|
||||
|
||||
### Grab the port and IP
|
||||
|
||||
Studying `inet_listen` source from the kernel, we know that we need to get the `inet_sock` from the `socket` object. Just copy from the sources, and insert at the beginning of the tracer:
|
||||
|
||||
```
|
||||
// cast types. Intermediate cast not needed, kept for readability
|
||||
struct sock *sk = sock->sk;
|
||||
struct inet_sock *inet = inet_sk(sk);
|
||||
|
||||
```
|
||||
|
||||
The port can now be accessed from `inet->inet_sport` in network byte order (aka: Big Endian). Easy! So, we could just replace the `bpf_trace_printk` with:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening on port %d!\\n", inet->inet_sport);
|
||||
|
||||
```
|
||||
|
||||
Then run:
|
||||
|
||||
```
|
||||
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
|
||||
...
|
||||
R1 invalid mem access 'inv'
|
||||
...
|
||||
Exception: Failed to load BPF program kprobe__inet_listen
|
||||
|
||||
```
|
||||
|
||||
Except that it’s not (yet) so simple. Bcc is improving a _lot_ currently. While writing this post, a couple of pitfalls had already been addressed. But not yet all. This Error means the in-kernel checker could prove the memory accesses in program are correct. See the explicit cast. We need to help is a little by making the accesses more explicit. We’ll use `bpf_probe_read` trusted function to read an arbitrary memory location while guaranteeing all necessary checks are done with something like:
|
||||
|
||||
```
|
||||
// Explicit initialization. The "=0" part is needed to "give life" to the variable on the stack
|
||||
u16 lport = 0;
|
||||
|
||||
// Explicit arbitrary memory access. Read it:
|
||||
// Read into 'lport', 'sizeof(lport)' bytes from 'inet->inet_sport' memory location
|
||||
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
|
||||
|
||||
```
|
||||
|
||||
Reading the bound address for IPv4 is basically the same, using `inet->inet_rcv_saddr`. If we put is all together, we should get the backlog, the port and the bound IP:
|
||||
|
||||
```
|
||||
from bcc import BPF
|
||||
|
||||
# BPF Program
|
||||
bpf_text = """
|
||||
#include <net/sock.h>
|
||||
#include <net/inet_sock.h>
|
||||
#include <bcc/proto.h>
|
||||
|
||||
// Send an event for each IPv4 listen with PID, bound address and port
|
||||
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
|
||||
{
|
||||
// Cast types. Intermediate cast not needed, kept for readability
|
||||
struct sock *sk = sock->sk;
|
||||
struct inet_sock *inet = inet_sk(sk);
|
||||
|
||||
// Working values. You *need* to initialize them to give them "life" on the stack and use them afterward
|
||||
u32 laddr = 0;
|
||||
u16 lport = 0;
|
||||
|
||||
// Pull in details. As 'inet_sk' is internally a type cast, we need to use 'bpf_probe_read'
|
||||
// read: load into 'laddr' 'sizeof(laddr)' bytes from address 'inet->inet_rcv_saddr'
|
||||
bpf_probe_read(&laddr, sizeof(laddr), &(inet->inet_rcv_saddr));
|
||||
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
|
||||
|
||||
// Push event
|
||||
bpf_trace_printk("Listening on %x %d with %d pending connections\\n", ntohl(laddr), ntohs(lport), backlog);
|
||||
return 0;
|
||||
};
|
||||
"""
|
||||
|
||||
# Build and Inject BPF
|
||||
b = BPF(text=bpf_text)
|
||||
|
||||
# Print debug output
|
||||
while True:
|
||||
print b.trace_readline()
|
||||
|
||||
```
|
||||
|
||||
A test run should output something like:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
nc-5024 [000] d... 25821.166286: : Listening on 7f000001 4242 with 1 pending connections
|
||||
|
||||
```
|
||||
|
||||
Provided that you listen on localhost. The address is displayed as hex here to avoid dealing with the IP pretty printing but that’s all wired. And that’s cool.
|
||||
|
||||
Note: you may wonder why `ntohs` and `ntohl` can be called from BPF while they are not trusted. This is because they are macros and inline functions from “.h” files and a small bug was [fixed][14]while writing this post.
|
||||
|
||||
All done, one more piece: We want to get the related container. In the context of networking, that’s means we want the network namespace. The network namespace being the building block of containers allowing them to have isolated networks.
|
||||
|
||||
### Grab the network namespace: a forced introduction to perf events
|
||||
|
||||
On the userland, the network namespace can be determined by checking the target of `/proc/PID/ns/net`. It should look like `net:[4026531957]`. The number between brackets is the inode number of the network namespace. This said, we could grab it by scrapping ‘/proc’ but this is racy, we may be dealing with short-lived processes. And races are never good. We’ll grab the inode number directly from the kernel. Fortunately, that’s an easy one:
|
||||
|
||||
```
|
||||
// Create an populate the variable
|
||||
u32 netns = 0;
|
||||
|
||||
// Read the netns inode number, like /proc does
|
||||
netns = sk->__sk_common.skc_net.net->ns.inum;
|
||||
|
||||
```
|
||||
|
||||
Easy. And it works.
|
||||
|
||||
But if you’ve read so far, you may guess there is something wrong somewhere. And there is:
|
||||
|
||||
```
|
||||
bpf_trace_printk("Listening on %x %d with %d pending connections in container %d\\n", ntohl(laddr), ntohs(lport), backlog, netns);
|
||||
|
||||
```
|
||||
|
||||
If you try to run it, you’ll get some cryptic error message:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
error: in function kprobe__inet_listen i32 (%struct.pt_regs*, %struct.socket*, i32)
|
||||
too many args to 0x1ba9108: i64 = Constant<6>
|
||||
|
||||
```
|
||||
|
||||
What clang is trying to tell you is “Hey pal, `bpf_trace_printk` can only take 4 arguments, you’ve just used 5.“. I won’t dive into the details here, but that’s a BPF limitation. If you want to dig it, [here is a good starting point][15].
|
||||
|
||||
The only way to fix it is to… stop debugging and make it production ready. So let’s get started (and make sure run at least Linux 4.4). We’ll use perf events which supports passing arbitrary sized structures to userland. Additionally, only our reader will get it so that multiple unrelated eBPF programs can produce data concurrently without issues.
|
||||
|
||||
To use it, we need to:
|
||||
|
||||
1. define a structure
|
||||
|
||||
2. declare the event
|
||||
|
||||
3. push the event
|
||||
|
||||
4. re-declare the event on Python’s side (This step should go away in the future)
|
||||
|
||||
5. consume and format the event
|
||||
|
||||
This may seem like a lot, but it ain’t. See:
|
||||
|
||||
```
|
||||
// At the begining of the C program, declare our event
|
||||
struct listen_evt_t {
|
||||
u64 laddr;
|
||||
u64 lport;
|
||||
u64 netns;
|
||||
u64 backlog;
|
||||
};
|
||||
BPF_PERF_OUTPUT(listen_evt);
|
||||
|
||||
// In kprobe__inet_listen, replace the printk with
|
||||
struct listen_evt_t evt = {
|
||||
.laddr = ntohl(laddr),
|
||||
.lport = ntohs(lport),
|
||||
.netns = netns,
|
||||
.backlog = backlog,
|
||||
};
|
||||
listen_evt.perf_submit(ctx, &evt, sizeof(evt));
|
||||
|
||||
```
|
||||
|
||||
Python side will require a little more work, though:
|
||||
|
||||
```
|
||||
# We need ctypes to parse the event structure
|
||||
import ctypes
|
||||
|
||||
# Declare data format
|
||||
class ListenEvt(ctypes.Structure):
|
||||
_fields_ = [
|
||||
("laddr", ctypes.c_ulonglong),
|
||||
("lport", ctypes.c_ulonglong),
|
||||
("netns", ctypes.c_ulonglong),
|
||||
("backlog", ctypes.c_ulonglong),
|
||||
]
|
||||
|
||||
# Declare event printer
|
||||
def print_event(cpu, data, size):
|
||||
event = ctypes.cast(data, ctypes.POINTER(ListenEvt)).contents
|
||||
print("Listening on %x %d with %d pending connections in container %d" % (
|
||||
event.laddr,
|
||||
event.lport,
|
||||
event.backlog,
|
||||
event.netns,
|
||||
))
|
||||
|
||||
# Replace the event loop
|
||||
b["listen_evt"].open_perf_buffer(print_event)
|
||||
while True:
|
||||
b.kprobe_poll()
|
||||
|
||||
```
|
||||
|
||||
Give it a try. In this example, I have a redis running in a docker container and nc on the host:
|
||||
|
||||
```
|
||||
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
|
||||
Listening on 0 6379 with 128 pending connections in container 4026532165
|
||||
Listening on 0 6379 with 128 pending connections in container 4026532165
|
||||
Listening on 7f000001 6588 with 1 pending connections in container 4026531957
|
||||
|
||||
```
|
||||
|
||||
### Last word
|
||||
|
||||
Absolutely everything is now setup to use trigger events from arbitrary function calls in the kernel using eBPF, and you should have seen most of the common pitfalls I hit while learning eBPF. If you want to see the full version of this tool, along with some more tricks like IPv6 support, have a look at [https://github.com/iovisor/bcc/blob/master/tools/solisten.py][16]. It’s now an official tool, thanks to the support of the bcc team.
|
||||
|
||||
To go further, you may want to checkout Brendan Gregg’s blog, in particular [the post about eBPF maps and statistics][17]. He his one of the project’s main contributor.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/
|
||||
|
||||
作者:[Jean-Tiare Le Bigot ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.yadutaf.fr/about
|
||||
[1]:https://blog.yadutaf.fr/tags/linux
|
||||
[2]:https://blog.yadutaf.fr/tags/tracing
|
||||
[3]:https://blog.yadutaf.fr/tags/ebpf
|
||||
[4]:https://blog.yadutaf.fr/tags/bcc
|
||||
[5]:https://en.wikipedia.org/wiki/SystemTap
|
||||
[6]:https://blog.cloudflare.com/bpf-the-forgotten-bytecode/
|
||||
[7]:https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/TODO
|
||||
[8]:https://lwn.net/Articles/604043/
|
||||
[9]:http://lxr.free-electrons.com/source/kernel/bpf/verifier.c#L21
|
||||
[10]:http://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf
|
||||
[11]:https://github.com/iovisor/bcc
|
||||
[12]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[13]:http://lxr.free-electrons.com/source/net/ipv4/af_inet.c#L194
|
||||
[14]:https://github.com/iovisor/bcc/pull/453
|
||||
[15]:http://lxr.free-electrons.com/source/kernel/trace/bpf_trace.c#L86
|
||||
[16]:https://github.com/iovisor/bcc/blob/master/tools/solisten.py
|
||||
[17]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
110
sources/tech/20170209 INTRODUCING DOCKER SECRETS MANAGEMENT.md
Normal file
110
sources/tech/20170209 INTRODUCING DOCKER SECRETS MANAGEMENT.md
Normal file
@ -0,0 +1,110 @@
|
||||
INTRODUCING DOCKER SECRETS MANAGEMENT
|
||||
============================================================
|
||||
|
||||
Containers are changing how we view apps and infrastructure. Whether the code inside containers is big or small, container architecture introduces a change to how that code behaves with hardware – it fundamentally abstracts it from the infrastructure. Docker believes that there are three key components to container security and together they result in inherently safer apps.
|
||||
|
||||

|
||||
|
||||
A critical element of building safer apps is having a secure way of communicating with other apps and systems, something that often requires credentials, tokens, passwords and other types of confidential information—usually referred to as application secrets. We are excited to introduce Docker Secrets, a container native solution that strengthens the Trusted Delivery component of container security by integrating secret distribution directly into the container platform.
|
||||
|
||||
With containers, applications are now dynamic and portable across multiple environments. This made existing secrets distribution solutions inadequate because they were largely designed for static environments. Unfortunately, this led to an increase in mismanagement of application secrets, making it common to find insecure, home-grown solutions, such as embedding secrets into version control systems like GitHub, or other equally bad—bolted on point solutions as an afterthought.
|
||||
|
||||
### Introducing Docker Secrets Management
|
||||
|
||||
We fundamentally believe that apps are safer if there is a standardized interface for accessing secrets. Any good solution will also have to follow security best practices, such as encrypting secrets while in transit; encrypting secrets at rest; preventing secrets from unintentionally leaking when consumed by the final application; and strictly adhere to the principle of least-privilege, where an application only has access to the secrets that it needs—no more, no less.
|
||||
|
||||
By integrating secrets into Docker orchestration, we are able to deliver a solution for the secrets management problem that follows these exact principles.
|
||||
|
||||
The following diagram provides a high-level view of how the Docker swarm mode architecture is applied to securely deliver a new type of object to our containers: a secret object.
|
||||
|
||||

|
||||
|
||||
In Docker, a secret is any blob of data, such as a password, SSH private key, TLS Certificate, or any other piece of data that is sensitive in nature. When you add a secret to the swarm (by running `docker secret create`), Docker sends the secret over to the swarm manager over a mutually authenticated TLS connection, making use of the [built-in Certificate Authority][17] that gets automatically created when bootstrapping a new swarm.
|
||||
|
||||
```
|
||||
$ echo "This is a secret" | docker secret create my_secret_data -
|
||||
```
|
||||
|
||||
Once the secret reaches a manager node, it gets saved to the internal Raft store, which uses NACL’s Salsa20Poly1305 with a 256-bit key to ensure no data is ever written to disk unencrypted. Writing to the internal store gives secrets the same high availability guarantees that the the rest of the swarm management data gets.
|
||||
|
||||
When a swarm manager starts up, the encrypted Raft logs containing the secrets is decrypted using a data encryption key that is unique per-node. This key, and the node’s TLS credentials used to communicate with the rest of the cluster, can be encrypted with a cluster-wide key encryption key, called the unlock key, which is also propagated using Raft and will be required on manager start.
|
||||
|
||||
When you grant a newly-created or running service access to a secret, one of the manager nodes (only managers have access to all the stored secrets stored) will send it over the already established TLS connection exclusively to the nodes that will be running that specific service. This means that nodes cannot request the secrets themselves, and will only gain access to the secrets when provided to them by a manager – strictly for the services that require them.
|
||||
|
||||
```
|
||||
$ docker service create --name="redis" --secret="my_secret_data" redis:alpine
|
||||
```
|
||||
|
||||
The unencrypted secret is mounted into the container in an in-memory filesystem at /run/secrets/<secret_name>.
|
||||
|
||||
```
|
||||
$ docker exec $(docker ps --filter name=redis -q) ls -l /run/secrets
|
||||
total 4
|
||||
-r--r--r-- 1 root root 17 Dec 13 22:48 my_secret_data
|
||||
```
|
||||
|
||||
If a service gets deleted, or rescheduled somewhere else, the manager will immediately notify all the nodes that no longer require access to that secret to erase it from memory, and the node will no longer have any access to that application secret.
|
||||
|
||||
```
|
||||
$ docker service update --secret-rm="my_secret_data" redis
|
||||
|
||||
$ docker exec -it $(docker ps --filter name=redis -q) cat /run/secrets/my_secret_data
|
||||
|
||||
cat: can't open '/run/secrets/my_secret_data': No such file or directory
|
||||
```
|
||||
|
||||
Check out the [Docker secrets docs][18] for more information and examples on how to create and manage your secrets. And a special shout out to Laurens Van Houtven (https://www.lvh.io/[)][19] in collaboration with the Docker security and core engineering team to help make this feature a reality.
|
||||
|
||||
[Get safer apps for dev and ops w/ new #Docker secrets management][5]
|
||||
|
||||
[CLICK TO TWEET][6]
|
||||
|
||||
###
|
||||

|
||||
|
||||
### Safer Apps with Docker
|
||||
|
||||
Docker secrets is designed to be easily usable by developers and IT ops teams to build and run safer apps. Docker secrets is a container first architecture designed to keep secrets safe and used only when needed by the exact container that needs that secret to operate. From defining apps and secrets with Docker Compose through an IT admin deploying that Compose file directly in Docker Datacenter, the services, secrets, networks and volumes will travel securely, safely with the application.
|
||||
|
||||
Resources to learn more:
|
||||
|
||||
* [Docker Datacenter on 1.13 with Secrets, Security Scanning, Content Cache and More][7]
|
||||
|
||||
* [Download Docker][8] and get started today
|
||||
|
||||
* [Try secrets in Docker Datacenter][9]
|
||||
|
||||
* [Read the Documentation][10]
|
||||
|
||||
* Attend an [upcoming webinar][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/02/docker-secrets-management/
|
||||
|
||||
作者:[ Ying Li][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/yingli/
|
||||
[1]:http://www.linkedin.com/shareArticle?mini=true&url=http://dockr.ly/2k6gnOB&title=Introducing%20Docker%20Secrets%20Management&summary=Containers%20are%20changing%20how%20we%20view%20apps%20and%20infrastructure.%20Whether%20the%20code%20inside%20containers%20is%20big%20or%20small,%20container%20architecture%20introduces%20a%20change%20to%20how%20that%20code%20behaves%20with%20hardware%20-%20it%20fundamentally%20abstracts%20it%20from%20the%20infrastructure.%20Docker%20believes%20that%20there%20are%20three%20key%20components%20to%20container%20security%20and%20...
|
||||
[2]:http://www.reddit.com/submit?url=http://dockr.ly/2k6gnOB&title=Introducing%20Docker%20Secrets%20Management
|
||||
[3]:https://plus.google.com/share?url=http://dockr.ly/2k6gnOB
|
||||
[4]:http://news.ycombinator.com/submitlink?u=http://dockr.ly/2k6gnOB&t=Introducing%20Docker%20Secrets%20Management
|
||||
[5]:https://twitter.com/share?text=Get+safer+apps+for+dev+and+ops+w%2F+new+%23Docker+secrets+management+&via=docker&related=docker&url=http://dockr.ly/2k6gnOB
|
||||
[6]:https://twitter.com/share?text=Get+safer+apps+for+dev+and+ops+w%2F+new+%23Docker+secrets+management+&via=docker&related=docker&url=http://dockr.ly/2k6gnOB
|
||||
[7]:http://dockr.ly/AppSecurity
|
||||
[8]:https://www.docker.com/getdocker
|
||||
[9]:http://www.docker.com/trial
|
||||
[10]:https://docs.docker.com/engine/swarm/secrets/
|
||||
[11]:http://www.docker.com/webinars
|
||||
[12]:https://blog.docker.com/author/yingli/
|
||||
[13]:https://blog.docker.com/tag/container-security/
|
||||
[14]:https://blog.docker.com/tag/docker-security/
|
||||
[15]:https://blog.docker.com/tag/secrets-management/
|
||||
[16]:https://blog.docker.com/tag/security/
|
||||
[17]:https://docs.docker.com/engine/swarm/how-swarm-mode-works/pki/
|
||||
[18]:https://docs.docker.com/engine/swarm/secrets/
|
||||
[19]:https://lvh.io%29/
|
||||
@ -1,108 +0,0 @@
|
||||
Translating by aiwhj
|
||||
# How to Improve a Legacy Codebase
|
||||
|
||||
|
||||
It happens at least once in the lifetime of every programmer, project manager or teamleader. You get handed a steaming pile of manure, if you’re lucky only a few million lines worth, the original programmers have long ago left for sunnier places and the documentation - if there is any to begin with - is hopelessly out of sync with what is presently keeping the company afloat.
|
||||
|
||||
Your job: get us out of this mess.
|
||||
|
||||
After your first instinctive response (run for the hills) has passed you start on the project knowing full well that the eyes of the company senior leadership are on you. Failure is not an option. And yet, by the looks of what you’ve been given failure is very much in the cards. So what to do?
|
||||
|
||||
I’ve been (un)fortunate enough to be in this situation several times and me and a small band of friends have found that it is a lucrative business to be able to take these steaming piles of misery and to turn them into healthy maintainable projects. Here are some of the tricks that we employ:
|
||||
|
||||
### Backup
|
||||
|
||||
Before you start to do anything at all make a backup of _everything_ that might be relevant. This to make sure that no information is lost that might be of crucial importance somewhere down the line. All it takes is a silly question that you can’t answer to eat up a day or more once the change has been made. Especially configuration data is susceptible to this kind of problem, it is usually not versioned and you’re lucky if it is taken along in the periodic back-up scheme. So better safe than sorry, copy everything to a very safe place and never ever touch that unless it is in read-only mode.
|
||||
|
||||
### Important pre-requisite, make sure you have a build process and that it actually produces what runs in production
|
||||
|
||||
I totally missed this step on the assumption that it is obvious and likely already in place but many HN commenters pointed this out and they are absolutely right: step one is to make sure that you know what is running in production right now and that means that you need to be able to build a version of the software that is - if your platform works that way - byte-for-byte identical with the current production build. If you can’t find a way to achieve this then likely you will be in for some unpleasant surprises once you commit something to production. Make sure you test this to the best of your ability to make sure that you have all the pieces in place and then, after you’ve gained sufficient confidence that it will work move it to production. Be prepared to switch back immediately to whatever was running before and make sure that you log everything and anything that might come in handy during the - inevitable - post mortem.
|
||||
|
||||
### Freeze the DB
|
||||
|
||||
If at all possible freeze the database schema until you are done with the first level of improvements, by the time you have a solid understanding of the codebase and the legacy code has been fully left behind you are ready to modify the database schema. Change it any earlier than that and you may have a real problem on your hand, now you’ve lost the ability to run an old and a new codebase side-by-side with the database as the steady foundation to build on. Keeping the DB totally unchanged allows you to compare the effect your new business logic code has compared to the old business logic code, if it all works as advertised there should be no differences.
|
||||
|
||||
### Write your tests
|
||||
|
||||
Before you make any changes at all write as many end-to-end and integration tests as you can. Make sure these tests produce the right output and test any and all assumptions that you can come up with about how you _think_ the old stuff works (be prepared for surprises here). These tests will have two important functions: they will help to clear up any misconceptions at a very early stage and they will function as guardrails once you start writing new code to replace old code.
|
||||
|
||||
Automate all your testing, if you’re already experienced with CI then use it and make sure your tests run fast enough to run the full set of tests after every commit.
|
||||
|
||||
### Instrumentation and logging
|
||||
|
||||
If the old platform is still available for development add instrumentation. Do this in a completely new database table, add a simple counter for every event that you can think of and add a single function to increment these counters based on the name of the event. That way you can implement a time-stamped event log with a few extra lines of code and you’ll get a good idea of how many events of one kind lead to events of another kind. One example: User opens app, User closes app. If two events should result in some back-end calls those two counters should over the long term remain at a constant difference, the difference is the number of apps currently open. If you see many more app opens than app closes you know there has to be a way in which apps end (for instance a crash). For each and every event you’ll find there is some kind of relationship to other events, usually you will strive for constant relationships unless there is an obvious error somewhere in the system. You’ll aim to reduce those counters that indicate errors and you’ll aim to maximize counters further down in the chain to the level indicated by the counters at the beginning. (For instance: customers attempting to pay should result in an equal number of actual payments received).
|
||||
|
||||
This very simple trick turns every backend application into a bookkeeping system of sorts and just like with a real bookkeeping system the numbers have to match, as long as they don’t you have a problem somewhere.
|
||||
|
||||
This system will over time become invaluable in establishing the health of the system and will be a great companion next to the source code control system revision log where you can determine the point in time that a bug was introduced and what the effect was on the various counters.
|
||||
|
||||
I usually keep these counters at a 5 minute resolution (so 12 buckets for an hour), but if you have an application that generates fewer or more events then you might decide to change the interval at which new buckets are created. All counters share the same database table and so each counter is simply a column in that table.
|
||||
|
||||
### Change only one thing at the time
|
||||
|
||||
Do not fall into the trap of improving both the maintainability of the code or the platform it runs on at the same time as adding new features or fixing bugs. This will cause you huge headaches because you now have to ask yourself every step of the way what the desired outcome is of an action and will invalidate some of the tests you made earlier.
|
||||
|
||||
### Platform changes
|
||||
|
||||
If you’ve decided to migrate the application to another platform then do this first _but keep everything else exactly the same_ . If you want you can add more documentation or tests, but no more than that, all business logic and interdependencies should remain as before.
|
||||
|
||||
### Architecture changes
|
||||
|
||||
The next thing to tackle is to change the architecture of the application (if desired). At this point in time you are free to change the higher level structure of the code, usually by reducing the number of horizontal links between modules, and thus reducing the scope of the code active during any one interaction with the end-user. If the old code was monolithic in nature now would be a good time to make it more modular, break up large functions into smaller ones but leave names of variables and data-structures as they were.
|
||||
|
||||
HN user [mannykannot][1] points - rightfully - out that this is not always an option, if you’re particularly unlucky then you may have to dig in deep in order to be able to make any architecture changes. I agree with that and I should have included it here so hence this little update. What I would further like to add is if you do both do high level changes and low level changes at least try to limit them to one file or worst case one subsystem so that you limit the scope of your changes as much as possible. Otherwise you might have a very hard time debugging the change you just made.
|
||||
|
||||
### Low level refactoring
|
||||
|
||||
By now you should have a very good understanding of what each module does and you are ready for the real work: refactoring the code to improve maintainability and to make the code ready for new functionality. This will likely be the part of the project that consumes the most time, document as you go, do not make changes to a module until you have thoroughly documented it and feel you understand it. Feel free to rename variables and functions as well as datastructures to improve clarity and consistency, add tests (also unit tests, if the situation warrants them).
|
||||
|
||||
### Fix bugs
|
||||
|
||||
Now you’re ready to take on actual end-user visible changes, the first order of battle will be the long list of bugs that have accumulated over the years in the ticket queue. As usual, first confirm the problem still exists, write a test to that effect and then fix the bug, your CI and the end-to-end tests written should keep you safe from any mistakes you make due to a lack of understanding or some peripheral issue.
|
||||
|
||||
### Database Upgrade
|
||||
|
||||
If required after all this is done and you are on a solid and maintainable codebase again you have the option to change the database schema or to replace the database with a different make/model altogether if that is what you had planned to do. All the work you’ve done up to this point will help to assist you in making that change in a responsible manner without any surprises, you can completely test the new DB with the new code and all the tests in place to make sure your migration goes off without a hitch.
|
||||
|
||||
### Execute on the roadmap
|
||||
|
||||
Congratulations, you are out of the woods and are now ready to implement new functionality.
|
||||
|
||||
### Do not ever even attempt a big-bang rewrite
|
||||
|
||||
A big-bang rewrite is the kind of project that is pretty much guaranteed to fail. For one, you are in uncharted territory to begin with so how would you even know what to build, for another, you are pushing _all_ the problems to the very last day, the day just before you go ‘live’ with your new system. And that’s when you’ll fail, miserably. Business logic assumptions will turn out to be faulty, suddenly you’ll gain insight into why that old system did certain things the way it did and in general you’ll end up realizing that the guys that put the old system together weren’t maybe idiots after all. If you really do want to wreck the company (and your own reputation to boot) by all means, do a big-bang rewrite, but if you’re smart about it this is not even on the table as an option.
|
||||
|
||||
### So, the alternative, work incrementally
|
||||
|
||||
To untangle one of these hairballs the quickest path to safety is to take any element of the code that you do understand (it could be a peripheral bit, but it might also be some core module) and try to incrementally improve it still within the old context. If the old build tools are no longer available you will have to use some tricks (see below) but at least try to leave as much of what is known to work alive while you start with your changes. That way as the codebase improves so does your understanding of what it actually does. A typical commit should be at most a couple of lines.
|
||||
|
||||
### Release!
|
||||
|
||||
Every change along the way gets released into production, even if the changes are not end-user visible it is important to make the smallest possible steps because as long as you lack understanding of the system there is a fair chance that only the production environment will tell you there is a problem. If that problem arises right after you make a small change you will gain several advantages:
|
||||
|
||||
* it will probably be trivial to figure out what went wrong
|
||||
|
||||
* you will be in an excellent position to improve the process
|
||||
|
||||
* and you should immediately update the documentation to show the new insights gained
|
||||
|
||||
### Use proxies to your advantage
|
||||
|
||||
If you are doing web development praise the gods and insert a proxy between the end-users and the old system. Now you have per-url control over which requests go to the old system and which you will re-route to the new system allowing much easier and more granular control over what is run and who gets to see it. If your proxy is clever enough you could probably use it to send a percentage of the traffic to the new system for an individual URL until you are satisfied that things work the way they should. If your integration tests also connect to this interface it is even better.
|
||||
|
||||
### Yes, but all this will take too much time!
|
||||
|
||||
Well, that depends on how you look at it. It’s true there is a bit of re-work involved in following these steps. But it _does_ work, and any kind of optimization of this process makes the assumption that you know more about the system than you probably do. I’ve got a reputation to maintain and I _really_ do not like negative surprises during work like this. With some luck the company is already on the skids, or maybe there is a real danger of messing things up for the customers. In a situation like that I prefer total control and an iron clad process over saving a couple of days or weeks if that imperils a good outcome. If you’re more into cowboy stuff - and your bosses agree - then maybe it would be acceptable to take more risk, but most companies would rather take the slightly slower but much more sure road to victory.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jacquesmattheij.com/improving-a-legacy-codebase
|
||||
|
||||
作者:[Jacques Mattheij ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jacquesmattheij.com/
|
||||
[1]:https://news.ycombinator.com/item?id=14445661
|
||||
@ -0,0 +1,91 @@
|
||||
Why Car Companies Are Hiring Computer Security Experts
|
||||
============================================================
|
||||
|
||||
Photo
|
||||

|
||||
The cybersecurity experts Marc Rogers, left, of CloudFlare and Kevin Mahaffey of Lookout were able to control various Tesla functions from their physically connected laptop. They pose in CloudFlare’s lobby in front of Lava Lamps used to generate numbers for encryption.CreditChristie Hemm Klok for The New York Times
|
||||
|
||||
It started about seven years ago. Iran’s top nuclear scientists were being assassinated in a string of similar attacks: Assailants on motorcycles were pulling up to their moving cars, attaching magnetic bombs and detonating them after the motorcyclists had fled the scene.
|
||||
|
||||
In another seven years, security experts warn, assassins won’t need motorcycles or magnetic bombs. All they’ll need is a laptop and code to send driverless cars careering off a bridge, colliding with a driverless truck or coming to an unexpected stop in the middle of fast-moving traffic.
|
||||
|
||||
Automakers may call them self-driving cars. But hackers call them computers that travel over 100 miles an hour.
|
||||
|
||||
“These are no longer cars,” said Marc Rogers, the principal security researcher at the cybersecurity firm CloudFlare. “These are data centers on wheels. Any part of the car that talks to the outside world is a potential inroad for attackers.”
|
||||
|
||||
Those fears came into focus two years ago when two “white hat” hackers — researchers who look for computer vulnerabilities to spot problems and fix them, rather than to commit a crime or cause problems — successfully gained access to a Jeep Cherokee from their computer miles away. They rendered their crash-test dummy (in this case a nervous reporter) powerless over his vehicle and disabling his transmission in the middle of a highway.
|
||||
|
||||
The hackers, Chris Valasek and Charlie Miller (now security researchers respectively at Uber and Didi, an Uber competitor in China), discovered an [electronic route from the Jeep’s entertainment system to its dashboard][10]. From there, they had control of the vehicle’s steering, brakes and transmission — everything they needed to paralyze their crash test dummy in the middle of a highway.
|
||||
|
||||
“Car hacking makes great headlines, but remember: No one has ever had their car hacked by a bad guy,” Mr. Miller wrote on Twitter last Sunday. “It’s only ever been performed by researchers.”
|
||||
|
||||
Still, the research by Mr. Miller and Mr. Valasek came at a steep price for Jeep’s manufacturer, Fiat Chrysler, which was forced to recall 1.4 million of its vehicles as a result of the hacking experiment.
|
||||
|
||||
It is no wonder that Mary Barra, the chief executive of General Motors, called cybersecurity her company’s top priority last year. Now the skills of researchers and so-called white hat hackers are in high demand among automakers and tech companies pushing ahead with driverless car projects.
|
||||
|
||||
Uber, [Tesla][11], Apple and Didi in China have been actively recruiting white hat hackers like Mr. Miller and Mr. Valasek from one another as well as from traditional cybersecurity firms and academia.
|
||||
|
||||
Last year, Tesla poached Aaron Sigel, Apple’s manager of security for its iOS operating system. Uber poached Chris Gates, formerly a white hat hacker at Facebook. Didi poached Mr. Miller from Uber, where he had gone to work after the Jeep hack. And security firms have seen dozens of engineers leave their ranks for autonomous-car projects.
|
||||
|
||||
Mr. Miller said he left Uber for Didi, in part, because his new Chinese employer has given him more freedom to discuss his work.
|
||||
|
||||
“Carmakers seem to be taking the threat of cyberattack more seriously, but I’d still like to see more transparency from them,” Mr. Miller wrote on Twitter on Saturday.
|
||||
|
||||
Like a number of big tech companies, Tesla and Fiat Chrysler started paying out rewards to hackers who turn over flaws the hackers discover in their systems. GM has done something similar, though critics say GM’s program is limited when compared with the ones offered by tech companies, and so far no rewards have been paid out.
|
||||
|
||||
One year after the Jeep hack by Mr. Miller and Mr. Valasek, they demonstrated all the other ways they could mess with a Jeep driver, including hijacking the vehicle’s cruise control, swerving the steering wheel 180 degrees or slamming on the parking brake in high-speed traffic — all from a computer in the back of the car. (Those exploits ended with their test Jeep in a ditch and calls to a local tow company.)
|
||||
|
||||
Granted, they had to be in the Jeep to make all that happen. But it was evidence of what is possible.
|
||||
|
||||
The Jeep penetration was preceded by a [2011 hack by security researchers at the University of Washington][12] and the University of California, San Diego, who were the first to remotely hack a sedan and ultimately control its brakes via Bluetooth. The researchers warned car companies that the more connected cars become, the more likely they are to get hacked.
|
||||
|
||||
Security researchers have also had their way with Tesla’s software-heavy Model S car. In 2015, Mr. Rogers, together with Kevin Mahaffey, the chief technology officer of the cybersecurity company Lookout, found a way to control various Tesla functions from their physically connected laptop.
|
||||
|
||||
One year later, a team of Chinese researchers at Tencent took their research a step further, hacking a moving Tesla Model S and controlling its brakes from 12 miles away. Unlike Chrysler, Tesla was able to dispatch a remote patch to fix the security holes that made the hacks possible.
|
||||
|
||||
In all the cases, the car hacks were the work of well meaning, white hat security researchers. But the lesson for all automakers was clear.
|
||||
|
||||
The motivations to hack vehicles are limitless. When it learned of Mr. Rogers’s and Mr. Mahaffey’s investigation into Tesla’s Model S, a Chinese app-maker asked Mr. Rogers if he would be interested in sharing, or possibly selling, his discovery, he said. (The app maker was looking for a backdoor to secretly install its app on Tesla’s dashboard.)
|
||||
|
||||
Criminals have not yet shown they have found back doors into connected vehicles, though for years, they have been actively developing, trading and deploying tools that can intercept car key communications.
|
||||
|
||||
But as more driverless and semiautonomous cars hit the open roads, they will become a more worthy target. Security experts warn that driverless cars present a far more complex, intriguing and vulnerable “attack surface” for hackers. Each new “connected” car feature introduces greater complexity, and with complexity inevitably comes vulnerability.
|
||||
|
||||
Twenty years ago, cars had, on average, one million lines of code. The General Motors 2010 [Chevrolet Volt][13] had about 10 million lines of code — more than an [F-35 fighter jet][14].
|
||||
|
||||
Today, an average car has more than 100 million lines of code. Automakers predict it won’t be long before they have 200 million. When you stop to consider that, on average, there are 15 to 50 defects per 1,000 lines of software code, the potentially exploitable weaknesses add up quickly.
|
||||
|
||||
The only difference between computer code and driverless car code is that, “Unlike data center enterprise security — where the biggest threat is loss of data — in automotive security, it’s loss of life,” said David Barzilai, a co-founder of Karamba Security, an Israeli start-up that is working on addressing automotive security.
|
||||
|
||||
To truly secure autonomous vehicles, security experts say, automakers will have to address the inevitable vulnerabilities that pop up in new sensors and car computers, address inherent vulnerabilities in the base car itself and, perhaps most challenging of all, bridge the cultural divide between automakers and software companies.
|
||||
|
||||
“The genie is out of the bottle, and to solve this problem will require a major cultural shift,” said Mr. Mahaffey of the cybersecurity company Lookout. “And an automaker that truly values cybersecurity will treat security vulnerabilities the same they would an airbag recall. We have not seen that industrywide shift yet.”
|
||||
|
||||
There will be winners and losers, Mr. Mahaffey added: “Automakers that transform themselves into software companies will win. Others will get left behind.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html
|
||||
|
||||
作者:[NICOLE PERLROTH ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nytimes.com/by/nicole-perlroth
|
||||
[1]:https://www.nytimes.com/2016/06/09/technology/software-as-weaponry-in-a-computer-connected-world.html
|
||||
[2]:https://www.nytimes.com/2015/08/29/technology/uber-hires-two-engineers-who-showed-cars-could-be-hacked.html
|
||||
[3]:https://www.nytimes.com/2015/08/11/opinion/zeynep-tufekci-why-smart-objects-may-be-a-dumb-idea.html
|
||||
[4]:https://www.nytimes.com/by/nicole-perlroth
|
||||
[5]:https://www.nytimes.com/column/bits
|
||||
[6]:https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#story-continues-1
|
||||
[7]:http://www.nytimes.com/newsletters/sample/bits?pgtype=subscriptionspage&version=business&contentId=TU&eventName=sample&module=newsletter-sign-up
|
||||
[8]:https://www.nytimes.com/privacy
|
||||
[9]:https://www.nytimes.com/help/index.html
|
||||
[10]:https://bits.blogs.nytimes.com/2015/07/21/security-researchers-find-a-way-to-hack-cars/
|
||||
[11]:http://www.nytimes.com/topic/company/tesla-motors-inc?inline=nyt-org
|
||||
[12]:http://www.autosec.org/pubs/cars-usenixsec2011.pdf
|
||||
[13]:http://autos.nytimes.com/2011/Chevrolet/Volt/238/4117/329463/researchOverview.aspx?inline=nyt-classifier
|
||||
[14]:http://topics.nytimes.com/top/reference/timestopics/subjects/m/military_aircraft/f35_airplane/index.html?inline=nyt-classifier
|
||||
[15]:https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html?utm_source=wanqu.co&utm_campaign=Wanqu+Daily&utm_medium=website#story-continues-3
|
||||
@ -1,314 +0,0 @@
|
||||
Translating by yongshouzhang
|
||||
|
||||
|
||||
A user's guide to links in the Linux filesystem
|
||||
============================================================
|
||||
|
||||
### Learn how to use links, which make tasks easier by providing access to files from multiple locations in the Linux filesystem directory tree.
|
||||
|
||||
|
||||

|
||||
Image by : [Paul Lewin][8]. Modified by Opensource.com. [CC BY-SA 2.0][9]
|
||||
|
||||
In articles I have written about various aspects of Linux filesystems for Opensource.com, including [An introduction to Linux's EXT4 filesystem][10]; [Managing devices in Linux][11]; [An introduction to Linux filesystems][12]; and [A Linux user's guide to Logical Volume Management][13], I have briefly mentioned an interesting feature of Linux filesystems that can make some tasks easier by providing access to files from multiple locations in the filesystem directory tree.
|
||||
|
||||
There are two types of Linux filesystem links: hard and soft. The difference between the two types of links is significant, but both types are used to solve similar problems. They both provide multiple directory entries (or references) to a single file, but they do it quite differently. Links are powerful and add flexibility to Linux filesystems because [everything is a file][14].
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
I have found, for instance, that some programs required a particular version of a library. When a library upgrade replaced the old version, the program would crash with an error specifying the name of the old, now-missing library. Usually, the only change in the library name was the version number. Acting on a hunch, I simply added a link to the new library but named the link after the old library name. I tried the program again and it worked perfectly. And, okay, the program was a game, and everyone knows the lengths that gamers will go to in order to keep their games running.
|
||||
|
||||
In fact, almost all applications are linked to libraries using a generic name with only a major version number in the link name, while the link points to the actual library file that also has a minor version number. In other instances, required files have been moved from one directory to another to comply with the Linux file specification, and there are links in the old directories for backwards compatibility with those programs that have not yet caught up with the new locations. If you do a long listing of the **/lib64** directory, you can find many examples of both.
|
||||
|
||||
```
|
||||
lrwxrwxrwx. 1 root root 36 Dec 8 2016 cracklib_dict.hwm -> ../../usr/share/cracklib/pw_dict.hwm
|
||||
lrwxrwxrwx. 1 root root 36 Dec 8 2016 cracklib_dict.pwd -> ../../usr/share/cracklib/pw_dict.pwd
|
||||
lrwxrwxrwx. 1 root root 36 Dec 8 2016 cracklib_dict.pwi -> ../../usr/share/cracklib/pw_dict.pwi
|
||||
lrwxrwxrwx. 1 root root 27 Jun 9 2016 libaccountsservice.so.0 -> libaccountsservice.so.0.0.0
|
||||
-rwxr-xr-x. 1 root root 288456 Jun 9 2016 libaccountsservice.so.0.0.0
|
||||
lrwxrwxrwx 1 root root 15 May 17 11:47 libacl.so.1 -> libacl.so.1.1.0
|
||||
-rwxr-xr-x 1 root root 36472 May 17 11:47 libacl.so.1.1.0
|
||||
lrwxrwxrwx. 1 root root 15 Feb 4 2016 libaio.so.1 -> libaio.so.1.0.1
|
||||
-rwxr-xr-x. 1 root root 6224 Feb 4 2016 libaio.so.1.0.0
|
||||
-rwxr-xr-x. 1 root root 6224 Feb 4 2016 libaio.so.1.0.1
|
||||
lrwxrwxrwx. 1 root root 30 Jan 16 16:39 libakonadi-calendar.so.4 -> libakonadi-calendar.so.4.14.26
|
||||
-rwxr-xr-x. 1 root root 816160 Jan 16 16:39 libakonadi-calendar.so.4.14.26
|
||||
lrwxrwxrwx. 1 root root 29 Jan 16 16:39 libakonadi-contact.so.4 -> libakonadi-contact.so.4.14.26
|
||||
```
|
||||
|
||||
A few of the links in the **/lib64** directory
|
||||
|
||||
The long listing of the **/lib64** directory above shows that the first character in the filemode is the letter "l," which means that each is a soft or symbolic link.
|
||||
|
||||
### Hard links
|
||||
|
||||
In [An introduction to Linux's EXT4 filesystem][15], I discussed the fact that each file has one inode that contains information about that file, including the location of the data belonging to that file. [Figure 2][16] in that article shows a single directory entry that points to the inode. Every file must have at least one directory entry that points to the inode that describes the file. The directory entry is a hard link, thus every file has at least one hard link.
|
||||
|
||||
In Figure 1 below, multiple directory entries point to a single inode. These are all hard links. I have abbreviated the locations of three of the directory entries using the tilde (**~**) convention for the home directory, so that **~** is equivalent to **/home/user** in this example. Note that the fourth directory entry is in a completely different directory, **/home/shared**, which might be a location for sharing files between users of the computer.
|
||||
|
||||

|
||||
Figure 1
|
||||
|
||||
Hard links are limited to files contained within a single filesystem. "Filesystem" is used here in the sense of a partition or logical volume (LV) that is mounted on a specified mount point, in this case **/home**. This is because inode numbers are unique only within each filesystem, and a different filesystem, for example, **/var**or **/opt**, will have inodes with the same number as the inode for our file.
|
||||
|
||||
Because all the hard links point to the single inode that contains the metadata about the file, all of these attributes are part of the file, such as ownerships, permissions, and the total number of hard links to the inode, and cannot be different for each hard link. It is one file with one set of attributes. The only attribute that can be different is the file name, which is not contained in the inode. Hard links to a single **file/inode** located in the same directory must have different names, due to the fact that there can be no duplicate file names within a single directory.
|
||||
|
||||
The number of hard links for a file is displayed with the **ls -l** command. If you want to display the actual inode numbers, the command **ls -li** does that.
|
||||
|
||||
### Symbolic (soft) links
|
||||
|
||||
The difference between a hard link and a soft link, also known as a symbolic link (or symlink), is that, while hard links point directly to the inode belonging to the file, soft links point to a directory entry, i.e., one of the hard links. Because soft links point to a hard link for the file and not the inode, they are not dependent upon the inode number and can work across filesystems, spanning partitions and LVs.
|
||||
|
||||
The downside to this is: If the hard link to which the symlink points is deleted or renamed, the symlink is broken. The symlink is still there, but it points to a hard link that no longer exists. Fortunately, the **ls** command highlights broken links with flashing white text on a red background in a long listing.
|
||||
|
||||
### Lab project: experimenting with links
|
||||
|
||||
I think the easiest way to understand the use of and differences between hard and soft links is with a lab project that you can do. This project should be done in an empty directory as a _non-root user_ . I created the **~/temp** directory for this project, and you should, too. It creates a safe place to do the project and provides a new, empty directory to work in so that only files associated with this project will be located there.
|
||||
|
||||
### **Initial setup**
|
||||
|
||||
First, create the temporary directory in which you will perform the tasks needed for this project. Ensure that the present working directory (PWD) is your home directory, then enter the following command.
|
||||
|
||||
```
|
||||
mkdir temp
|
||||
```
|
||||
|
||||
Change into **~/temp** to make it the PWD with this command.
|
||||
|
||||
```
|
||||
cd temp
|
||||
```
|
||||
|
||||
To get started, we need to create a file we can link to. The following command does that and provides some content as well.
|
||||
|
||||
```
|
||||
du -h > main.file.txt
|
||||
```
|
||||
|
||||
Use the **ls -l** long list to verify that the file was created correctly. It should look similar to my results. Note that the file size is only 7 bytes, but yours may vary by a byte or two.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ls -l
|
||||
total 4
|
||||
-rw-rw-r-- 1 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
```
|
||||
|
||||
Notice the number "1" following the file mode in the listing. That number represents the number of hard links that exist for the file. For now, it should be 1 because we have not created any additional links to our test file.
|
||||
|
||||
### **Experimenting with hard links**
|
||||
|
||||
Hard links create a new directory entry pointing to the same inode, so when hard links are added to a file, you will see the number of links increase. Ensure that the PWD is still **~/temp**. Create a hard link to the file **main.file.txt**, then do another long list of the directory.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln main.file.txt link1.file.txt
|
||||
[dboth@david temp]$ ls -l
|
||||
total 8
|
||||
-rw-rw-r-- 2 dboth dboth 7 Jun 13 07:34 link1.file.txt
|
||||
-rw-rw-r-- 2 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
```
|
||||
|
||||
Notice that both files have two links and are exactly the same size. The date stamp is also the same. This is really one file with one inode and two links, i.e., directory entries to it. Create a second hard link to this file and list the directory contents. You can create the link to either of the existing ones: **link1.file.txt** or **main.file.txt**.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln link1.file.txt link2.file.txt ; ls -l
|
||||
total 16
|
||||
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07:34 link1.file.txt
|
||||
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07:34 link2.file.txt
|
||||
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
```
|
||||
|
||||
Notice that each new hard link in this directory must have a different name because two files—really directory entries—cannot have the same name within the same directory. Try to create another link with a target name the same as one of the existing ones.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln main.file.txt link2.file.txt
|
||||
ln: failed to create hard link 'link2.file.txt': File exists
|
||||
```
|
||||
|
||||
Clearly that does not work, because **link2.file.txt** already exists. So far, we have created only hard links in the same directory. So, create a link in your home directory, the parent of the temp directory in which we have been working so far.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln main.file.txt ../main.file.txt ; ls -l ../main*
|
||||
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
```
|
||||
|
||||
The **ls** command in the above listing shows that the **main.file.txt** file does exist in the home directory with the same name as the file in the temp directory. Of course, these are not different files; they are the same file with multiple links—directory entries—to the same inode. To help illustrate the next point, add a file that is not a link.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ touch unlinked.file ; ls -l
|
||||
total 12
|
||||
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 link1.file.txt
|
||||
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 link2.file.txt
|
||||
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
-rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
Look at the inode number of the hard links and that of the new file using the **-i**option to the **ls** command.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ls -li
|
||||
total 12
|
||||
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 link1.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 link2.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07:34 main.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
Notice the number **657024** to the left of the file mode in the example above. That is the inode number, and all three file links point to the same inode. You can use the **-i** option to view the inode number for the link we created in the home directory as well, and that will also show the same value. The inode number of the file that has only one link is different from the others. Note that the inode numbers will be different on your system.
|
||||
|
||||
Let's change the size of one of the hard-linked files.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ df -h > link2.file.txt ; ls -li
|
||||
total 12
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 link1.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 link2.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 main.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
The file size of all the hard-linked files is now larger than before. That is because there is really only one file that is linked to by multiple directory entries.
|
||||
|
||||
I know this next experiment will work on my computer because my **/tmp**directory is on a separate LV. If you have a separate LV or a filesystem on a different partition (if you're not using LVs), determine whether or not you have access to that LV or partition. If you don't, you can try to insert a USB memory stick and mount it. If one of those options works for you, you can do this experiment.
|
||||
|
||||
Try to create a link to one of the files in your **~/temp** directory in **/tmp** (or wherever your different filesystem directory is located).
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln link2.file.txt /tmp/link3.file.txt
|
||||
ln: failed to create hard link '/tmp/link3.file.txt' => 'link2.file.txt':
|
||||
Invalid cross-device link
|
||||
```
|
||||
|
||||
Why does this error occur? The reason is each separate mountable filesystem has its own set of inode numbers. Simply referring to a file by an inode number across the entire Linux directory structure can result in confusion because the same inode number can exist in each mounted filesystem.
|
||||
|
||||
There may be a time when you will want to locate all the hard links that belong to a single inode. You can find the inode number using the **ls -li** command. Then you can use the **find** command to locate all links with that inode number.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ find . -inum 657024
|
||||
./main.file.txt
|
||||
./link1.file.txt
|
||||
./link2.file.txt
|
||||
```
|
||||
|
||||
Note that the **find** command did not find all four of the hard links to this inode because we started at the current directory of **~/temp**. The **find** command only finds files in the PWD and its subdirectories. To find all the links, we can use the following command, which specifies your home directory as the starting place for the search.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ find ~ -samefile main.file.txt
|
||||
/home/dboth/temp/main.file.txt
|
||||
/home/dboth/temp/link1.file.txt
|
||||
/home/dboth/temp/link2.file.txt
|
||||
/home/dboth/main.file.txt
|
||||
```
|
||||
|
||||
You may see error messages if you do not have permissions as a non-root user. This command also uses the **-samefile** option instead of specifying the inode number. This works the same as using the inode number and can be easier if you know the name of one of the hard links.
|
||||
|
||||
### **Experimenting with soft links**
|
||||
|
||||
As you have just seen, creating hard links is not possible across filesystem boundaries; that is, from a filesystem on one LV or partition to a filesystem on another. Soft links are a means to answer that problem with hard links. Although they can accomplish the same end, they are very different, and knowing these differences is important.
|
||||
|
||||
Let's start by creating a symlink in our **~/temp** directory to start our exploration.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln -s link2.file.txt link3.file.txt ; ls -li
|
||||
total 12
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 link1.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 link2.file.txt
|
||||
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15:21 link3.file.txt ->
|
||||
link2.file.txt
|
||||
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14:14 main.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
The hard links, those that have the inode number **657024**, are unchanged, and the number of hard links shown for each has not changed. The newly created symlink has a different inode, number **658270**. The soft link named **link3.file.txt**points to **link2.file.txt**. Use the **cat** command to display the contents of **link3.file.txt**. The file mode information for the symlink starts with the letter "**l**" which indicates that this file is actually a symbolic link.
|
||||
|
||||
The size of the symlink **link3.file.txt** is only 14 bytes in the example above. That is the size of the text **link3.file.txt -> link2.file.txt**, which is the actual content of the directory entry. The directory entry **link3.file.txt** does not point to an inode; it points to another directory entry, which makes it useful for creating links that span file system boundaries. So, let's create that link we tried before from the **/tmp** directory.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ ln -s /home/dboth/temp/link2.file.txt
|
||||
/tmp/link3.file.txt ; ls -l /tmp/link*
|
||||
lrwxrwxrwx 1 dboth dboth 31 Jun 14 21:53 /tmp/link3.file.txt ->
|
||||
/home/dboth/temp/link2.file.txt
|
||||
```
|
||||
|
||||
### **Deleting links**
|
||||
|
||||
There are some other things that you should consider when you need to delete links or the files to which they point.
|
||||
|
||||
First, let's delete the link **main.file.txt**. Remember that every directory entry that points to an inode is simply a hard link.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ rm main.file.txt ; ls -li
|
||||
total 8
|
||||
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14:14 link1.file.txt
|
||||
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14:14 link2.file.txt
|
||||
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15:21 link3.file.txt ->
|
||||
link2.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
The link **main.file.txt** was the first link created when the file was created. Deleting it now still leaves the original file and its data on the hard drive along with all the remaining hard links. To delete the file and its data, you would have to delete all the remaining hard links.
|
||||
|
||||
Now delete the **link2.file.txt** hard link.
|
||||
|
||||
```
|
||||
[dboth@david temp]$ rm link2.file.txt ; ls -li
|
||||
total 8
|
||||
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14:14 link1.file.txt
|
||||
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15:21 link3.file.txt ->
|
||||
link2.file.txt
|
||||
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14:14 main.file.txt
|
||||
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08:18 unlinked.file
|
||||
```
|
||||
|
||||
Notice what happens to the soft link. Deleting the hard link to which the soft link points leaves a broken link. On my system, the broken link is highlighted in colors and the target hard link is flashing. If the broken link needs to be fixed, you can create another hard link in the same directory with the same name as the old one, so long as not all the hard links have been deleted. You could also recreate the link itself, with the link maintaining the same name but pointing to one of the remaining hard links. Of course, if the soft link is no longer needed, it can be deleted with the **rm** command.
|
||||
|
||||
The **unlink** command can also be used to delete files and links. It is very simple and has no options, as the **rm** command does. It does, however, more accurately reflect the underlying process of deletion, in that it removes the link—the directory entry—to the file being deleted.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
I worked with both types of links for a long time before I began to understand their capabilities and idiosyncrasies. It took writing a lab project for a Linux class I taught to fully appreciate how links work. This article is a simplification of what I taught in that class, and I hope it speeds your learning curve.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||
|
||||
---------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/6/linking-linux-filesystem
|
||||
|
||||
作者:[David Both ][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/article/17/6/linking-linux-filesystem?rate=YebHxA-zgNopDQKKOyX3_r25hGvnZms_33sYBUq-SMM
|
||||
[7]:https://opensource.com/user/14106/feed
|
||||
[8]:https://www.flickr.com/photos/digypho/7905320090
|
||||
[9]:https://creativecommons.org/licenses/by/2.0/
|
||||
[10]:https://opensource.com/article/17/5/introduction-ext4-filesystem
|
||||
[11]:https://opensource.com/article/16/11/managing-devices-linux
|
||||
[12]:https://opensource.com/life/16/10/introduction-linux-filesystems
|
||||
[13]:https://opensource.com/business/16/9/linux-users-guide-lvm
|
||||
[14]:https://opensource.com/life/15/9/everything-is-a-file
|
||||
[15]:https://opensource.com/article/17/5/introduction-ext4-filesystem
|
||||
[16]:https://opensource.com/article/17/5/introduction-ext4-filesystem#fig2
|
||||
[17]:https://opensource.com/users/dboth
|
||||
[18]:https://opensource.com/article/17/6/linking-linux-filesystem#comments
|
||||
@ -0,0 +1,172 @@
|
||||
How to answer questions in a helpful way
|
||||
============================================================
|
||||
|
||||
Your coworker asks you a slightly unclear question. How do you answer? I think asking questions is a skill (see [How to ask good questions][1]) and that answering questions in a helpful way is also a skill! Both of them are super useful.
|
||||
|
||||
To start out with – sometimes the people asking you questions don’t respect your time, and that sucks. I’m assuming here throughout that that’s not what happening – we’re going to assume that the person asking you questions is a reasonable person who is trying their best to figure something out and that you want to help them out. Everyone I work with is like that and so that’s the world I live in :)
|
||||
|
||||
Here are a few strategies for answering questions in a helpful way!
|
||||
|
||||
### If they’re not asking clearly, help them clarify
|
||||
|
||||
Often beginners don’t ask clear questions, or ask questions that don’t have the necessary information to answer the questions. Here are some strategies you can use to help them clarify.
|
||||
|
||||
* **Rephrase a more specific question** back at them (“Are you asking X?”)
|
||||
|
||||
* **Ask them for more specific information** they didn’t provide (“are you using IPv6?”)
|
||||
|
||||
* **Ask what prompted their question**. For example, sometimes people come into my team’s channel with questions about how our service discovery works. Usually this is because they’re trying to set up/reconfigure a service. In that case it’s helpful to ask “which service are you working with? Can I see the pull request you’re working on?”
|
||||
|
||||
A lot of these strategies come from the [how to ask good questions][2] post. (though I would never say to someone “oh you need to read this Document On How To Ask Good Questions before asking me a question”)
|
||||
|
||||
### Figure out what they know already
|
||||
|
||||
Before answering a question, it’s very useful to know what the person knows already!
|
||||
|
||||
Harold Treen gave me a great example of this:
|
||||
|
||||
> Someone asked me the other day to explain “Redux Sagas”. Rather than dive in and say “They are like worker threads that listen for actions and let you update the store!”
|
||||
> I started figuring out how much they knew about Redux, actions, the store and all these other fundamental concepts. From there it was easier to explain the concept that ties those other concepts together.
|
||||
|
||||
Figuring out what your question-asker knows already is important because they may be confused about fundamental concepts (“What’s Redux?”), or they may be an expert who’s getting at a subtle corner case. An answer building on concepts they don’t know is confusing, and an answer that recaps things they know is tedious.
|
||||
|
||||
One useful trick for asking what people know – instead of “Do you know X?”, maybe try “How familiar are you with X?”.
|
||||
|
||||
### Point them to the documentation
|
||||
|
||||
“RTFM” is the classic unhelpful answer to a question, but pointing someone to a specific piece of documentation can actually be really helpful! When I’m asking a question, I’d honestly rather be pointed to documentation that actually answers my question, because it’s likely to answer other questions I have too.
|
||||
|
||||
I think it’s important here to make sure you’re linking to documentation that actually answers the question, or at least check in afterwards to make sure it helped. Otherwise you can end up with this (pretty common) situation:
|
||||
|
||||
* Ali: How do I do X?
|
||||
|
||||
* Jada: <link to documentation>
|
||||
|
||||
* Ali: That doesn’t actually explain how to X, it only explains Y!
|
||||
|
||||
If the documentation I’m linking to is very long, I like to point out the specific part of the documentation I’m talking about. The [bash man page][3] is 44,000 words (really!), so just saying “it’s in the bash man page” is not that helpful :)
|
||||
|
||||
### Point them to a useful search
|
||||
|
||||
Often I find things at work by searching for some Specific Keyword that I know will find me the answer. That keyword might not be obvious to a beginner! So saying “this is the search I’d use to find the answer to that question” can be useful. Again, check in afterwards to make sure the search actually gets them the answer they need :)
|
||||
|
||||
### Write new documentation
|
||||
|
||||
People often come and ask my team the same questions over and over again. This is obviously not the fault of the people (how should _they_ know that 10 people have asked this already, or what the answer is?). So we’re trying to, instead of answering the questions directly,
|
||||
|
||||
1. Immediately write documentation
|
||||
|
||||
2. Point the person to the new documentation we just wrote
|
||||
|
||||
3. Celebrate!
|
||||
|
||||
Writing documentation sometimes takes more time than just answering the question, but it’s often worth it! Writing documentation is especially worth it if:
|
||||
|
||||
a. It’s a question which is being asked again and again b. The answer doesn’t change too much over time (if the answer changes every week or month, the documentation will just get out of date and be frustrating)
|
||||
|
||||
### Explain what you did
|
||||
|
||||
As a beginner to a subject, it’s really frustrating to have an exchange like this:
|
||||
|
||||
* New person: “hey how do you do X?”
|
||||
|
||||
* More Experienced Person: “I did it, it is done.”
|
||||
|
||||
* New person: ….. but what did you DO?!
|
||||
|
||||
If the person asking you is trying to learn how things work, it’s helpful to:
|
||||
|
||||
* Walk them through how to accomplish a task instead of doing it yourself
|
||||
|
||||
* Tell them the steps for how you got the answer you gave them!
|
||||
|
||||
This might take longer than doing it yourself, but it’s a learning opportunity for the person who asked, so that they’ll be better equipped to solve such problems in the future.
|
||||
|
||||
Then you can have WAY better exchanges, like this:
|
||||
|
||||
* New person: “I’m seeing errors on the site, what’s happening?”
|
||||
|
||||
* More Experienced Person: (2 minutes later) “oh that’s because there’s a database failover happening”
|
||||
|
||||
* New person: how did you know that??!?!?
|
||||
|
||||
* More Experienced Person: “Here’s what I did!”:
|
||||
1. Often these errors are due to Service Y being down. I looked at $PLACE and it said Service Y was up. So that wasn’t it.
|
||||
|
||||
2. Then I looked at dashboard X, and this part of that dashboard showed there was a database failover happening.
|
||||
|
||||
3. Then I looked in the logs for the service and it showed errors connecting to the database, here’s what those errors look like.
|
||||
|
||||
If you’re explaining how you debugged a problem, it’s useful both to explain how you found out what the problem was, and how you found out what the problem wasn’t. While it might feel good to look like you knew the answer right off the top of your head, it feels even better to help someone improve at learning and diagnosis, and understand the resources available.
|
||||
|
||||
### Solve the underlying problem
|
||||
|
||||
This one is a bit tricky. Sometimes people think they’ve got the right path to a solution, and they just need one more piece of information to implement that solution. But they might not be quite on the right path! For example:
|
||||
|
||||
* George: I’m doing X, and I got this error, how do I fix it
|
||||
|
||||
* Jasminda: Are you actually trying to do Y? If so, you shouldn’t do X, you should do Z instead
|
||||
|
||||
* George: Oh, you’re right!!! Thank you! I will do Z instead.
|
||||
|
||||
Jasminda didn’t answer George’s question at all! Instead she guessed that George didn’t actually want to be doing X, and she was right. That is helpful!
|
||||
|
||||
It’s possible to come off as condescending here though, like
|
||||
|
||||
* George: I’m doing X, and I got this error, how do I fix it?
|
||||
|
||||
* Jasminda: Don’t do that, you’re trying to do Y and you should do Z to accomplish that instead.
|
||||
|
||||
* George: Well, I am not trying to do Y, I actually want to do X because REASONS. How do I do X?
|
||||
|
||||
So don’t be condescending, and keep in mind that some questioners might be attached to the steps they’ve taken so far! It might be appropriate to answer both the question they asked and the one they should have asked: “Well, if you want to do X then you might try this, but if you’re trying to solve problem Y with that, you might have better luck doing this other thing, and here’s why that’ll work better”.
|
||||
|
||||
### Ask “Did that answer your question?”
|
||||
|
||||
I always like to check in after I _think_ I’ve answered the question and ask “did that answer your question? Do you have more questions?”.
|
||||
|
||||
It’s good to pause and wait after asking this because often people need a minute or two to know whether or not they’ve figured out the answer. I especially find this extra “did this answer your questions?” step helpful after writing documentation! Often when writing documentation about something I know well I’ll leave out something very important without realizing it.
|
||||
|
||||
### Offer to pair program/chat in real life
|
||||
|
||||
I work remote, so many of my conversations at work are text-based. I think of that as the default mode of communication.
|
||||
|
||||
Today, we live in a world of easy video conferencing & screensharing! At work I can at any time click a button and immediately be in a video call/screensharing session with someone. Some problems are easier to talk about using your voices!
|
||||
|
||||
For example, recently someone was asking about capacity planning/autoscaling for their service. I could tell there were a few things we needed to clear up but I wasn’t exactly sure what they were yet. We got on a quick video call and 5 minutes later we’d answered all their questions.
|
||||
|
||||
I think especially if someone is really stuck on how to get started on a task, pair programming for a few minutes can really help, and it can be a lot more efficient than email/instant messaging.
|
||||
|
||||
### Don’t act surprised
|
||||
|
||||
This one’s a rule from the Recurse Center: [no feigning surprise][4]. Here’s a relatively common scenario
|
||||
|
||||
* Human 1: “what’s the Linux kernel?”
|
||||
|
||||
* Human 2: “you don’t know what the LINUX KERNEL is?!!!!?!!!???”
|
||||
|
||||
Human 2’s reaction (regardless of whether they’re _actually_ surprised or not) is not very helpful. It mostly just serves to make Human 1 feel bad that they don’t know what the Linux kernel is.
|
||||
|
||||
I’ve worked on actually pretending not to be surprised even when I actually am a bit surprised the person doesn’t know the thing and it’s awesome.
|
||||
|
||||
### Answering questions well is awesome
|
||||
|
||||
Obviously not all these strategies are appropriate all the time, but hopefully you will find some of them helpful! I find taking the time to answer questions and teach people can be really rewarding.
|
||||
|
||||
Special thanks to Josh Triplett for suggesting this post and making many helpful additions, and to Harold Treen, Vaibhav Sagar, Peter Bhat Harkins, Wesley Aptekar-Cassels, and Paul Gowder for reading/commenting.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/answer-questions-well/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://jvns.ca/blog/good-questions/
|
||||
[2]:https://jvns.ca/blog/good-questions/
|
||||
[3]:https://linux.die.net/man/1/bash
|
||||
[4]:https://jvns.ca/blog/2017/04/27/no-feigning-surprise/
|
||||
@ -0,0 +1,114 @@
|
||||
Translating by qhwdw How to manage Linux containers with Ansible Container
|
||||
============================================================
|
||||
|
||||
### Ansible Container addresses Dockerfile shortcomings and offers complete management for containerized projects.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
I love containers and use the technology every day. Even so, containers aren't perfect. Over the past couple of months, however, a set of projects has emerged that addresses some of the problems I've experienced.
|
||||
|
||||
I started using containers with [Docker][11], since this project made the technology so popular. Aside from using the container engine, I learned how to use **[docker-compose][6]** and started managing my projects with it. My productivity skyrocketed! One command to run my project, no matter how complex it was. I was so happy.
|
||||
|
||||
After some time, I started noticing issues. The most apparent were related to the process of creating container images. The Docker tool uses a custom file format as a recipe to produce container images—Dockerfiles. This format is easy to learn, and after a short time you are ready to produce container images on your own. The problems arise once you want to master best practices or have complex scenarios in mind.
|
||||
|
||||
More on Ansible
|
||||
|
||||
* [How Ansible works][1]
|
||||
|
||||
* [Free Ansible eBooks][2]
|
||||
|
||||
* [Ansible quick start video][3]
|
||||
|
||||
* [Download and install Ansible][4]
|
||||
|
||||
Let's take a break and travel to a different land: the world of [Ansible][22]. You know it? It's awesome, right? You don't? Well, it's time to learn something new. Ansible is a project that allows you to manage your infrastructure by writing tasks and executing them inside environments of your choice. No need to install and set up any services; everything can easily run from your laptop. Many people already embrace Ansible.
|
||||
|
||||
Imagine this scenario: You invested in Ansible, you wrote plenty of Ansible roles and playbooks that you use to manage your infrastructure, and you are thinking about investing in containers. What should you do? Start writing container image definitions via shell scripts and Dockerfiles? That doesn't sound right.
|
||||
|
||||
Some people from the Ansible development team asked this question and realized that those same Ansible roles and playbooks that people wrote and use daily can also be used to produce container images. But not just that—they can be used to manage the complete lifecycle of containerized projects. From these ideas, the [Ansible Container][12] project was born. It utilizes existing Ansible roles that can be turned into container images and can even be used for the complete application lifecycle, from build to deploy in production.
|
||||
|
||||
Let's talk about the problems I mentioned regarding best practices in context of Dockerfiles. A word of warning: This is going to be very specific and technical. Here are the top three issues I have:
|
||||
|
||||
### 1\. Shell scripts embedded in Dockerfiles.
|
||||
|
||||
When writing Dockerfiles, you can specify a script that will be interpreted via **/bin/sh -c**. It can be something like:
|
||||
|
||||
```
|
||||
RUN dnf install -y nginx
|
||||
```
|
||||
|
||||
where RUN is a Dockerfile instruction and the rest are its arguments (which are passed to shell). But imagine a more complex scenario:
|
||||
|
||||
```
|
||||
RUN set -eux; \
|
||||
\
|
||||
# this "case" statement is generated via "update.sh"
|
||||
%%ARCH-CASE%%; \
|
||||
\
|
||||
url="https://golang.org/dl/go${GOLANG_VERSION}.${goRelArch}.tar.gz"; \
|
||||
wget -O go.tgz "$url"; \
|
||||
echo "${goRelSha256} *go.tgz" | sha256sum -c -; \
|
||||
```
|
||||
|
||||
This one is taken from [the official golang image][13]. It doesn't look pretty, right?
|
||||
|
||||
### 2\. You can't parse Dockerfiles easily.
|
||||
|
||||
Dockerfiles are a new format without a formal specification. This is tricky if you need to process Dockerfiles in your infrastructure (e.g., automate the build process a bit). The only specification is [the code][14] that is part of **dockerd**. The problem is that you can't use it as a library. The easiest solution is to write a parser on your own and hope for the best. Wouldn't it be better to use some well-known markup language, such as YAML or JSON?
|
||||
|
||||
### 3\. It's hard to control.
|
||||
|
||||
If you are familiar with the internals of container images, you may know that every image is composed of layers. Once the container is created, the layers are stacked onto each other (like pancakes) using union filesystem technology. The problem is, that you cannot explicitly control this layering—you can't say, "here starts a new layer." You are forced to change your Dockerfile in a way that may hurt readability. The bigger problem is that a set of best practices has to be followed to achieve optimal results—newcomers have a really hard time here.
|
||||
|
||||
### Comparing Ansible language and Dockerfiles
|
||||
|
||||
The biggest shortcoming of Dockerfiles in comparison to Ansible is that Ansible, as a language, is much more powerful. For example, Dockerfiles have no direct concept of variables, whereas Ansible has a complete templating system (variables are just one of its features). Ansible contains a large number of modules that can be easily utilized, such as [**wait_for**][15], which can be used for service readiness checks—e.g., wait until a service is ready before proceeding. With Dockerfiles, everything is a shell script. So if you need to figure out service readiness, it has to be done with shell (or installed separately). The other problem with shell scripts is that, with growing complexity, maintenance becomes a burden. Plenty of people have already figured this out and turned those shell scripts into Ansible.
|
||||
|
||||
If you are interested in this topic and would like to know more, please come to [Open Source Summit][16] in Prague to see [my presentation][17] on Monday, Oct. 23, at 4:20 p.m. in Palmovka room.
|
||||
|
||||
_Learn more in Tomas Tomecek's talk, [From Dockerfiles to Ansible Container][7], at [Open Source Summit EU][8], which will be held October 23-26 in Prague._
|
||||
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][18] Tomas Tomecek - Engineer. Hacker. Speaker. Tinker. Red Hatter. Likes containers, linux, open source, python 3, rust, zsh, tmux.[More about me][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/dockerfiles-ansible-container
|
||||
|
||||
作者:[Tomas Tomecek ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tomastomecek
|
||||
[1]:https://www.ansible.com/how-ansible-works?intcmp=701f2000000h4RcAAI
|
||||
[2]:https://www.ansible.com/ebooks?intcmp=701f2000000h4RcAAI
|
||||
[3]:https://www.ansible.com/quick-start-video?intcmp=701f2000000h4RcAAI
|
||||
[4]:https://docs.ansible.com/ansible/latest/intro_installation.html?intcmp=701f2000000h4RcAAI
|
||||
[5]:https://opensource.com/article/17/10/dockerfiles-ansible-container?imm_mid=0f9013&cmp=em-webops-na-na-newsltr_20171201&rate=Wiw_0D6PK_CAjqatYu_YQH0t1sNHEF6q09_9u3sYkCY
|
||||
[6]:https://github.com/docker/compose
|
||||
[7]:http://sched.co/BxIW
|
||||
[8]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[9]:https://opensource.com/users/tomastomecek
|
||||
[10]:https://opensource.com/user/175651/feed
|
||||
[11]:https://opensource.com/tags/docker
|
||||
[12]:https://www.ansible.com/ansible-container
|
||||
[13]:https://github.com/docker-library/golang/blob/master/Dockerfile-debian.template#L14
|
||||
[14]:https://github.com/moby/moby/tree/master/builder/dockerfile
|
||||
[15]:http://docs.ansible.com/wait_for_module.html
|
||||
[16]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
[17]:http://events.linuxfoundation.org/events/open-source-summit-europe/program/schedule
|
||||
[18]:https://opensource.com/users/tomastomecek
|
||||
[19]:https://opensource.com/users/tomastomecek
|
||||
[20]:https://opensource.com/users/tomastomecek
|
||||
[21]:https://opensource.com/article/17/10/dockerfiles-ansible-container?imm_mid=0f9013&cmp=em-webops-na-na-newsltr_20171201#comments
|
||||
[22]:https://opensource.com/tags/ansible
|
||||
[23]:https://opensource.com/tags/containers
|
||||
[24]:https://opensource.com/tags/ansible
|
||||
[25]:https://opensource.com/tags/docker
|
||||
[26]:https://opensource.com/tags/open-source-summit
|
||||
148
sources/tech/20171005 Reasons Kubernetes is cool.md
Normal file
148
sources/tech/20171005 Reasons Kubernetes is cool.md
Normal file
@ -0,0 +1,148 @@
|
||||
Reasons Kubernetes is cool
|
||||
============================================================
|
||||
|
||||
When I first learned about Kubernetes (a year and a half ago?) I really didn’t understand why I should care about it.
|
||||
|
||||
I’ve been working full time with Kubernetes for 3 months or so and now have some thoughts about why I think it’s useful. (I’m still very far from being a Kubernetes expert!) Hopefully this will help a little in your journey to understand what even is going on with Kubernetes!
|
||||
|
||||
I will try to explain some reason I think Kubenetes is interesting without using the words “cloud native”, “orchestration”, “container”, or any Kubernetes-specific terminology :). I’m going to explain this mostly from the perspective of a kubernetes operator / infrastructure engineer, since my job right now is to set up Kubernetes and make it work well.
|
||||
|
||||
I’m not going to try to address the question of “should you use kubernetes for your production systems?” at all, that is a very complicated question. (not least because “in production” has totally different requirements depending on what you’re doing)
|
||||
|
||||
### Kubernetes lets you run code in production without setting up new servers
|
||||
|
||||
The first pitch I got for Kubernetes was the following conversation with my partner Kamal:
|
||||
|
||||
Here’s an approximate transcript:
|
||||
|
||||
* Kamal: With Kubernetes you can set up a new service with a single command
|
||||
|
||||
* Julia: I don’t understand how that’s possible.
|
||||
|
||||
* Kamal: Like, you just write 1 configuration file, apply it, and then you have a HTTP service running in production
|
||||
|
||||
* Julia: But today I need to create new AWS instances, write a puppet manifest, set up service discovery, configure my load balancers, configure our deployment software, and make sure DNS is working, it takes at least 4 hours if nothing goes wrong.
|
||||
|
||||
* Kamal: Yeah. With Kubernetes you don’t have to do any of that, you can set up a new HTTP service in 5 minutes and it’ll just automatically run. As long as you have spare capacity in your cluster it just works!
|
||||
|
||||
* Julia: There must be a trap
|
||||
|
||||
There kind of is a trap, setting up a production Kubernetes cluster is (in my experience) is definitely not easy. (see [Kubernetes The Hard Way][3] for what’s involved to get started). But we’re not going to go into that right now!
|
||||
|
||||
So the first cool thing about Kubernetes is that it has the potential to make life way easier for developers who want to deploy new software into production. That’s cool, and it’s actually true, once you have a working Kubernetes cluster you really can set up a production HTTP service (“run 5 of this application, set up a load balancer, give it this DNS name, done”) with just one configuration file. It’s really fun to see.
|
||||
|
||||
### Kubernetes gives you easy visibility & control of what code you have running in production
|
||||
|
||||
IMO you can’t understand Kubernetes without understanding etcd. So let’s talk about etcd!
|
||||
|
||||
Imagine that I asked you today “hey, tell me every application you have running in production, what host it’s running on, whether it’s healthy or not, and whether or not it has a DNS name attached to it”. I don’t know about you but I would need to go look in a bunch of different places to answer this question and it would take me quite a while to figure out. I definitely can’t query just one API.
|
||||
|
||||
In Kubernetes, all the state in your cluster – applications running (“pods”), nodes, DNS names, cron jobs, and more – is stored in a single database (etcd). Every Kubernetes component is stateless, and basically works by
|
||||
|
||||
* Reading state from etcd (eg “the list of pods assigned to node 1”)
|
||||
|
||||
* Making changes (eg “actually start running pod A on node 1”)
|
||||
|
||||
* Updating the state in etcd (eg “set the state of pod A to ‘running’”)
|
||||
|
||||
This means that if you want to answer a question like “hey, how many nginx pods do I have running right now in that availabliity zone?” you can answer it by querying a single unified API (the Kubernetes API!). And you have exactly the same access to that API that every other Kubernetes component does.
|
||||
|
||||
This also means that you have easy control of everything running in Kubernetes. If you want to, say,
|
||||
|
||||
* Implement a complicated custom rollout strategy for deployments (deploy 1 thing, wait 2 minutes, deploy 5 more, wait 3.7 minutes, etc)
|
||||
|
||||
* Automatically [start a new webserver][1] every time a branch is pushed to github
|
||||
|
||||
* Monitor all your running applications to make sure all of them have a reasonable cgroups memory limit
|
||||
|
||||
all you need to do is to write a program that talks to the Kubernetes API. (a “controller”)
|
||||
|
||||
Another very exciting thing about the Kubernetes API is that you’re not limited to just functionality that Kubernetes provides! If you decide that you have your own opinions about how your software should be deployed / created / monitored, then you can write code that uses the Kubernetes API to do it! It lets you do everything you need.
|
||||
|
||||
### If every Kubernetes component dies, your code will still keep running
|
||||
|
||||
One thing I was originally promised (by various blog posts :)) about Kubernetes was “hey, if the Kubernetes apiserver and everything else dies, it’s ok, your code will just keep running”. I thought this sounded cool in theory but I wasn’t sure if it was actually true.
|
||||
|
||||
So far it seems to be actually true!
|
||||
|
||||
I’ve been through some etcd outages now, and what happens is
|
||||
|
||||
1. All the code that was running keeps running
|
||||
|
||||
2. Nothing _new_ happens (you can’t deploy new code or make changes, cron jobs will stop working)
|
||||
|
||||
3. When everything comes back, the cluster will catch up on whatever it missed
|
||||
|
||||
This does mean that if etcd goes down and one of your applications crashes or something, it can’t come back up until etcd returns.
|
||||
|
||||
### Kubernetes’ design is pretty resilient to bugs
|
||||
|
||||
Like any piece of software, Kubernetes has bugs. For example right now in our cluster the controller manager has a memory leak, and the scheduler crashes pretty regularly. Bugs obviously aren’t good but so far I’ve found that Kubernetes’ design helps mitigate a lot of the bugs in its core components really well.
|
||||
|
||||
If you restart any component, what happens is:
|
||||
|
||||
* It reads all its relevant state from etcd
|
||||
|
||||
* It starts doing the necessary things it’s supposed to be doing based on that state (scheduling pods, garbage collecting completed pods, scheduling cronjobs, deploying daemonsets, whatever)
|
||||
|
||||
Because all the components don’t keep any state in memory, you can just restart them at any time and that can help mitigate a variety of bugs.
|
||||
|
||||
For example! Let’s say you have a memory leak in your controller manager. Because the controller manager is stateless, you can just periodically restart it every hour or something and feel confident that you won’t cause any consistency issues. Or we ran into a bug in the scheduler where it would sometimes just forget about pods and never schedule them. You can sort of mitigate this just by restarting the scheduler every 10 minutes. (we didn’t do that, we fixed the bug instead, but you _could_ :) )
|
||||
|
||||
So I feel like I can trust Kubernetes’ design to help make sure the state in the cluster is consistent even when there are bugs in its core components. And in general I think the software is generally improving over time. The only stateful thing you have to operate is etcd
|
||||
|
||||
Not to harp on this “state” thing too much but – I think it’s cool that in Kubernetes the only thing you have to come up with backup/restore plans for is etcd (unless you use persistent volumes for your pods). I think it makes kubernetes operations a lot easier to think about.
|
||||
|
||||
### Implementing new distributed systems on top of Kubernetes is relatively easy
|
||||
|
||||
Suppose you want to implement a distributed cron job scheduling system! Doing that from scratch is a ton of work. But implementing a distributed cron job scheduling system inside Kubernetes is much easier! (still not trivial, it’s still a distributed system)
|
||||
|
||||
The first time I read the code for the Kubernetes cronjob controller I was really delighted by how simple it was. Here, go read it! The main logic is like 400 lines of Go. Go ahead, read it! => [cronjob_controller.go][4] <=
|
||||
|
||||
Basically what the cronjob controller does is:
|
||||
|
||||
* Every 10 seconds:
|
||||
* Lists all the cronjobs that exist
|
||||
|
||||
* Checks if any of them need to run right now
|
||||
|
||||
* If so, creates a new Job object to be scheduled & actually run by other Kubernetes controllers
|
||||
|
||||
* Clean up finished jobs
|
||||
|
||||
* Repeat
|
||||
|
||||
The Kubernetes model is pretty constrained (it has this pattern of resources are defined in etcd, controllers read those resources and update etcd), and I think having this relatively opinionated/constrained model makes it easier to develop your own distributed systems inside the Kubernetes framework.
|
||||
|
||||
Kamal introduced me to this idea of “Kubernetes is a good platform for writing your own distributed systems” instead of just “Kubernetes is a distributed system you can use” and I think it’s really interesting. He has a prototype of a [system to run an HTTP service for every branch you push to github][5]. It took him a weekend and is like 800 lines of Go, which I thought was impressive!
|
||||
|
||||
### Kubernetes lets you do some amazing things (but isn’t easy)
|
||||
|
||||
I started out by saying “kubernetes lets you do these magical things, you can just spin up so much infrastructure with a single configuration file, it’s amazing”. And that’s true!
|
||||
|
||||
What I mean by “Kubernetes isn’t easy” is that Kubernetes has a lot of moving parts learning how to successfully operate a highly available Kubernetes cluster is a lot of work. Like I find that with a lot of the abstractions it gives me, I need to understand what is underneath those abstractions in order to debug issues and configure things properly. I love learning new things so this doesn’t make me angry or anything, I just think it’s important to know :)
|
||||
|
||||
One specific example of “I can’t just rely on the abstractions” that I’ve struggled with is that I needed to learn a LOT [about how networking works on Linux][6] to feel confident with setting up Kubernetes networking, way more than I’d ever had to learn about networking before. This was very fun but pretty time consuming. I might write more about what is hard/interesting about setting up Kubernetes networking at some point.
|
||||
|
||||
Or I wrote a [2000 word blog post][7] about everything I had to learn about Kubernetes’ different options for certificate authorities to be able to set up my Kubernetes CAs successfully.
|
||||
|
||||
I think some of these managed Kubernetes systems like GKE (google’s kubernetes product) may be simpler since they make a lot of decisions for you but I haven’t tried any of them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/10/05/reasons-kubernetes-is-cool/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://github.com/kamalmarhubi/kubereview
|
||||
[2]:https://jvns.ca/categories/kubernetes
|
||||
[3]:https://github.com/kelseyhightower/kubernetes-the-hard-way
|
||||
[4]:https://github.com/kubernetes/kubernetes/blob/e4551d50e57c089aab6f67333412d3ca64bc09ae/pkg/controller/cronjob/cronjob_controller.go
|
||||
[5]:https://github.com/kamalmarhubi/kubereview
|
||||
[6]:https://jvns.ca/blog/2016/12/22/container-networking/
|
||||
[7]:https://jvns.ca/blog/2017/08/05/how-kubernetes-certificates-work/
|
||||
216
sources/tech/20171010 Operating a Kubernetes network.md
Normal file
216
sources/tech/20171010 Operating a Kubernetes network.md
Normal file
@ -0,0 +1,216 @@
|
||||
Operating a Kubernetes network
|
||||
============================================================
|
||||
|
||||
I’ve been working on Kubernetes networking a lot recently. One thing I’ve noticed is, while there’s a reasonable amount written about how to **set up** your Kubernetes network, I haven’t seen much about how to **operate** your network and be confident that it won’t create a lot of production incidents for you down the line.
|
||||
|
||||
In this post I’m going to try to convince you of three things: (all I think pretty reasonable :))
|
||||
|
||||
* Avoiding networking outages in production is important
|
||||
|
||||
* Operating networking software is hard
|
||||
|
||||
* It’s worth thinking critically about major changes to your networking infrastructure and the impact that will have on your reliability, even if very fancy Googlers say “this is what we do at Google”. (google engineers are doing great work on Kubernetes!! But I think it’s important to still look at the architecture and make sure it makes sense for your organization.)
|
||||
|
||||
I’m definitely not a Kubernetes networking expert by any means, but I have run into a few issues while setting things up and definitely know a LOT more about Kubernetes networking than I used to.
|
||||
|
||||
### Operating networking software is hard
|
||||
|
||||
Here I’m not talking about operating physical networks (I don’t know anything about that), but instead about keeping software like DNS servers & load balancers & proxies working correctly.
|
||||
|
||||
I have been working on a team that’s responsible for a lot of networking infrastructure for a year, and I have learned a few things about operating networking infrastructure! (though I still have a lot to learn obviously). 3 overall thoughts before we start:
|
||||
|
||||
* Networking software often relies very heavily on the Linux kernel. So in addition to configuring the software correctly you also need to make sure that a bunch of different sysctls are set correctly, and a misconfigured sysctl can easily be the difference between “everything is 100% fine” and “everything is on fire”.
|
||||
|
||||
* Networking requirements change over time (for example maybe you’re doing 5x more DNS lookups than you were last year! Maybe your DNS server suddenly started returning TCP DNS responses instead of UDP which is a totally different kernel workload!). This means software that was working fine before can suddenly start having issues.
|
||||
|
||||
* To fix a production networking issues you often need a lot of expertise. (for example see this [great post by Sophie Haskins on debugging a kube-dns issue][1]) I’m a lot better at debugging networking issues than I was, but that’s only after spending a huge amount of time investing in my knowledge of Linux networking.
|
||||
|
||||
I am still far from an expert at networking operations but I think it seems important to:
|
||||
|
||||
1. Very rarely make major changes to the production networking infrastructure (because it’s super disruptive)
|
||||
|
||||
2. When you _are_ making major changes, think really carefully about what the failure modes are for the new network architecture are
|
||||
|
||||
3. Have multiple people who are able to understand your networking setup
|
||||
|
||||
Switching to Kubernetes is obviously a pretty major networking change! So let’s talk about what some of the things that can go wrong are!
|
||||
|
||||
### Kubernetes networking components
|
||||
|
||||
The Kubernetes networking components we’re going to talk about in this post are:
|
||||
|
||||
* Your overlay network backend (like flannel/calico/weave net/romana)
|
||||
|
||||
* `kube-dns`
|
||||
|
||||
* `kube-proxy`
|
||||
|
||||
* Ingress controllers / load balancers
|
||||
|
||||
* The `kubelet`
|
||||
|
||||
If you’re going to set up HTTP services you probably need all of these. I’m not using most of these components yet but I’m trying to understand them, so that’s what this post is about.
|
||||
|
||||
### The simplest way: Use host networking for all your containers
|
||||
|
||||
Let’s start with the simplest possible thing you can do. This won’t let you run HTTP services in Kubernetes. I think it’s pretty safe because there are less moving parts.
|
||||
|
||||
If you use host networking for all your containers I think all you need to do is:
|
||||
|
||||
1. Configure the kubelet to configure DNS correctly inside your containers
|
||||
|
||||
2. That’s it
|
||||
|
||||
If you use host networking for literally every pod you don’t need kube-dns or kube-proxy. You don’t even need a working overlay network.
|
||||
|
||||
In this setup your pods can connect to the outside world (the same way any process on your hosts would talk to the outside world) but the outside world can’t connect to your pods.
|
||||
|
||||
This isn’t super important (I think most people want to run HTTP services inside Kubernetes and actually communicate with those services) but I do think it’s interesting to realize that at some level all of this networking complexity isn’t strictly required and sometimes you can get away without using it. Avoiding networking complexity seems like a good idea to me if you can.
|
||||
|
||||
### Operating an overlay network
|
||||
|
||||
The first networking component we’re going to talk about is your overlay network. Kubernetes assumes that every pod has an IP address and that you can communicate with services inside that pod by using that IP address. When I say “overlay network” this is what I mean (“the system that lets you refer to a pod by its IP address”).
|
||||
|
||||
All other Kubernetes networking stuff relies on the overlay networking working correctly. You can read more about the [kubernetes networking model here][10].
|
||||
|
||||
The way Kelsey Hightower describes in [kubernetes the hard way][11] seems pretty good but it’s not really viable on AWS for clusters more than 50 nodes or so, so I’m not going to talk about that.
|
||||
|
||||
There are a lot of overlay network backends (calico, flannel, weaveworks, romana) and the landscape is pretty confusing. But as far as I’m concerned an overlay network has 2 responsibilities:
|
||||
|
||||
1. Make sure your pods can send network requests outside your cluster
|
||||
|
||||
2. Keep a stable mapping of nodes to subnets and keep every node in your cluster updated with that mapping. Do the right thing when nodes are added & removed.
|
||||
|
||||
Okay! So! What can go wrong with your overlay network?
|
||||
|
||||
* The overlay network is responsible for setting up iptables rules (basically `iptables -A -t nat POSTROUTING -s $SUBNET -j MASQUERADE`) to ensure that containers can make network requests outside Kubernetes. If something goes wrong with this rule then your containers can’t connect to the external network. This isn’t that hard (it’s just a few iptables rules) but it is important. I made a [pull request][2] because I wanted to make sure this was resilient
|
||||
|
||||
* Something can go wrong with adding or deleting nodes. We’re using the flannel hostgw backend and at the time we started using it, node deletion [did not work][3].
|
||||
|
||||
* Your overlay network is probably dependent on a distributed database (etcd). If that database has an incident, this can cause issues. For example [https://github.com/coreos/flannel/issues/610][4] says that if you have data loss in your flannel etcd cluster it can result in containers losing network connectivity. (this has now been fixed)
|
||||
|
||||
* You upgrade Docker and everything breaks
|
||||
|
||||
* Probably more things!
|
||||
|
||||
I’m mostly talking about past issues in Flannel here but I promise I’m not picking on Flannel – I actually really **like** Flannel because I feel like it’s relatively simple (for instance the [vxlan backend part of it][12] is like 500 lines of code) and I feel like it’s possible for me to reason through any issues with it. And it’s obviously continuously improving. They’ve been great about reviewing pull requests.
|
||||
|
||||
My approach to operating an overlay network so far has been:
|
||||
|
||||
* Learn how it works in detail and how to debug it (for example the hostgw network backend for Flannel works by creating routes, so you mostly just need to do `sudo ip route list` to see whether it’s doing the correct thing)
|
||||
|
||||
* Maintain an internal build so it’s easy to patch it if needed
|
||||
|
||||
* When there are issues, contribute patches upstream
|
||||
|
||||
I think it’s actually really useful to go through the list of merged PRs and see bugs that have been fixed in the past – it’s a bit time consuming but is a great way to get a concrete list of kinds of issues other people have run into.
|
||||
|
||||
It’s possible that for other people their overlay networks just work but that hasn’t been my experience and I’ve heard other folks report similar issues. If you have an overlay network setup that is a) on AWS and b) works on a cluster more than 50-100 nodes where you feel more confident about operating it I would like to know.
|
||||
|
||||
### Operating kube-proxy and kube-dns?
|
||||
|
||||
Now that we have some thoughts about operating overlay networks, let’s talk about
|
||||
|
||||
There’s a question mark next to this one because I haven’t done this. Here I have more questions than answers.
|
||||
|
||||
Here’s how Kubernetes services work! A service is a collection of pods, which each have their own IP address (like 10.1.0.3, 10.2.3.5, 10.3.5.6)
|
||||
|
||||
1. Every Kubernetes service gets an IP address (like 10.23.1.2)
|
||||
|
||||
2. `kube-dns` resolves Kubernetes service DNS names to IP addresses (so my-svc.my-namespace.svc.cluster.local might map to 10.23.1.2)
|
||||
|
||||
3. `kube-proxy` sets up iptables rules in order to do random load balancing between them. Kube-proxy also has a userspace round-robin load balancer but my impression is that they don’t recommend using it.
|
||||
|
||||
So when you make a request to `my-svc.my-namespace.svc.cluster.local`, it resolves to 10.23.1.2, and then iptables rules on your local host (generated by kube-proxy) redirect it to one of 10.1.0.3 or 10.2.3.5 or 10.3.5.6 at random.
|
||||
|
||||
Some things that I can imagine going wrong with this:
|
||||
|
||||
* `kube-dns` is misconfigured
|
||||
|
||||
* `kube-proxy` dies and your iptables rules don’t get updated
|
||||
|
||||
* Some issue related to maintaining a large number of iptables rules
|
||||
|
||||
Let’s talk about the iptables rules a bit, since doing load balancing by creating a bajillion iptables rules is something I had never heard of before!
|
||||
|
||||
kube-proxy creates one iptables rule per target host like this: (these rules are from [this github issue][13])
|
||||
|
||||
```
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.20000000019 -j KUBE-SEP-E4QKA7SLJRFZZ2DD[b][c]
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.25000000000 -j KUBE-SEP-LZ7EGMG4DRXMY26H
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-RKIFTWKKG3OHTTMI
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-CGDKBCNM24SZWCMS
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -j KUBE-SEP-RI4SRNQQXWSTGE2Y
|
||||
|
||||
```
|
||||
|
||||
So kube-proxy creates a **lot** of iptables rules. What does that mean? What are the implications of that in for my network? There’s a great talk from Huawei called [Scale Kubernetes to Support 50,000 services][14] that says if you have 5,000 services in your kubernetes cluster, it takes **11 minutes** to add a new rule. If that happened to your real cluster I think it would be very bad.
|
||||
|
||||
I definitely don’t have 5,000 services in my cluster, but 5,000 isn’t SUCH a bit number. The proposal they give to solve this problem is to replace this iptables backend for kube-proxy with IPVS which is a load balancer that lives in the Linux kernel.
|
||||
|
||||
It seems like kube-proxy is going in the direction of various Linux kernel based load balancers. I think this is partly because they support UDP load balancing, and other load balancers (like HAProxy) don’t support UDP load balancing.
|
||||
|
||||
But I feel comfortable with HAProxy! Is it possible to replace kube-proxy with HAProxy! I googled this and I found this [thread on kubernetes-sig-network][15] saying:
|
||||
|
||||
> kube-proxy is so awesome, we have used in production for almost a year, it works well most of time, but as we have more and more services in our cluster, we found it was getting hard to debug and maintain. There is no iptables expert in our team, we do have HAProxy&LVS experts, as we have used these for several years, so we decided to replace this distributed proxy with a centralized HAProxy. I think this maybe useful for some other people who are considering using HAProxy with kubernetes, so we just update this project and make it open source: [https://github.com/AdoHe/kube2haproxy][5]. If you found it’s useful , please take a look and give a try.
|
||||
|
||||
So that’s an interesting option! I definitely don’t have answers here, but, some thoughts:
|
||||
|
||||
* Load balancers are complicated
|
||||
|
||||
* DNS is also complicated
|
||||
|
||||
* If you already have a lot of experience operating one kind of load balancer (like HAProxy), it might make sense to do some extra work to use that instead of starting to use an entirely new kind of load balancer (like kube-proxy)
|
||||
|
||||
* I’ve been thinking about where we want to be using kube-proxy or kube-dns at all – I think instead it might be better to just invest in Envoy and rely entirely on Envoy for all load balancing & service discovery. So then you just need to be good at operating Envoy.
|
||||
|
||||
As you can see my thoughts on how to operate your Kubernetes internal proxies are still pretty confused and I’m still not super experienced with them. It’s totally possible that kube-proxy and kube-dns are fine and that they will just work fine but I still find it helpful to think through what some of the implications of using them are (for example “you can’t have 5,000 Kubernetes services”).
|
||||
|
||||
### Ingress
|
||||
|
||||
If you’re running a Kubernetes cluster, it’s pretty likely that you actually need HTTP requests to get into your cluster so far. This blog post is already too long and I don’t know much about ingress yet so we’re not going to talk about that.
|
||||
|
||||
### Useful links
|
||||
|
||||
A couple of useful links, to summarize:
|
||||
|
||||
* [The Kubernetes networking model][6]
|
||||
|
||||
* How GKE networking works: [https://www.youtube.com/watch?v=y2bhV81MfKQ][7]
|
||||
|
||||
* The aforementioned talk on `kube-proxy` performance: [https://www.youtube.com/watch?v=4-pawkiazEg][8]
|
||||
|
||||
### I think networking operations is important
|
||||
|
||||
My sense of all this Kubernetes networking software is that it’s all still quite new and I’m not sure we (as a community) really know how to operate all of it well. This makes me worried as an operator because I really want my network to keep working! :) Also I feel like as an organization running your own Kubernetes cluster you need to make a pretty large investment into making sure you understand all the pieces so that you can fix things when they break. Which isn’t a bad thing, it’s just a thing.
|
||||
|
||||
My plan right now is just to keep learning about how things work and reduce the number of moving parts I need to worry about as much as possible.
|
||||
|
||||
As usual I hope this was helpful and I would very much like to know what I got wrong in this post!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/10/10/operating-a-kubernetes-network/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:http://blog.sophaskins.net/blog/misadventures-with-kube-dns/
|
||||
[2]:https://github.com/coreos/flannel/pull/808
|
||||
[3]:https://github.com/coreos/flannel/pull/803
|
||||
[4]:https://github.com/coreos/flannel/issues/610
|
||||
[5]:https://github.com/AdoHe/kube2haproxy
|
||||
[6]:https://kubernetes.io/docs/concepts/cluster-administration/networking/#kubernetes-model
|
||||
[7]:https://www.youtube.com/watch?v=y2bhV81MfKQ
|
||||
[8]:https://www.youtube.com/watch?v=4-pawkiazEg
|
||||
[9]:https://jvns.ca/categories/kubernetes
|
||||
[10]:https://kubernetes.io/docs/concepts/cluster-administration/networking/#kubernetes-model
|
||||
[11]:https://github.com/kelseyhightower/kubernetes-the-hard-way/blob/master/docs/11-pod-network-routes.md
|
||||
[12]:https://github.com/coreos/flannel/tree/master/backend/vxlan
|
||||
[13]:https://github.com/kubernetes/kubernetes/issues/37932
|
||||
[14]:https://www.youtube.com/watch?v=4-pawkiazEg
|
||||
[15]:https://groups.google.com/forum/#!topic/kubernetes-sig-network/3NlBVbTUUU0
|
||||
174
sources/tech/20171011 LEAST PRIVILEGE CONTAINER ORCHESTRATION.md
Normal file
174
sources/tech/20171011 LEAST PRIVILEGE CONTAINER ORCHESTRATION.md
Normal file
@ -0,0 +1,174 @@
|
||||
# LEAST PRIVILEGE CONTAINER ORCHESTRATION
|
||||
|
||||
|
||||
The Docker platform and the container has become the standard for packaging, deploying, and managing applications. In order to coordinate running containers across multiple nodes in a cluster, a key capability is required: a container orchestrator.
|
||||
|
||||

|
||||
|
||||
Orchestrators are responsible for critical clustering and scheduling tasks, such as:
|
||||
|
||||
* Managing container scheduling and resource allocation.
|
||||
|
||||
* Support service discovery and hitless application deploys.
|
||||
|
||||
* Distribute the necessary resources that applications need to run.
|
||||
|
||||
Unfortunately, the distributed nature of orchestrators and the ephemeral nature of resources in this environment makes securing orchestrators a challenging task. In this post, we will describe in detail the less-considered—yet vital—aspect of the security model of container orchestrators, and how Docker Enterprise Edition with its built-in orchestration capability, Swarm mode, overcomes these difficulties.
|
||||
|
||||
Motivation and threat model
|
||||
============================================================
|
||||
|
||||
One of the primary objectives of Docker EE with swarm mode is to provide an orchestrator with security built-in. To achieve this goal, we developed the first container orchestrator designed with the principle of least privilege in mind.
|
||||
|
||||
In computer science,the principle of least privilege in a distributed system requires that each participant of the system must only have access to the information and resources that are necessary for its legitimate purpose. No more, no less.
|
||||
|
||||
> #### ”A process must be able to access only the information and resources that are necessary for its legitimate purpose.”
|
||||
|
||||
#### Principle of Least Privilege
|
||||
|
||||
Each node in a Docker EE swarm is assigned role: either manager or worker. These roles define a coarsegrained level of privilege to the nodes: administration and task execution, respectively. However, regardless of its role, a node has access only to the information and resources it needs to perform the necessary tasks, with cryptographically enforced guarantees. As a result, it becomes easier to secure clusters against even the most sophisticated attacker models: attackers that control the underlying communication networks or even compromised cluster nodes.
|
||||
|
||||
# Secure-by-default core
|
||||
|
||||
There is an old security maxim that states: if it doesn’t come by default, no one will use it. Docker Swarm mode takes this notion to heart, and ships with secure-by-default mechanisms to solve three of the hardest and most important aspects of the orchestration lifecycle:
|
||||
|
||||
1. Trust bootstrap and node introduction.
|
||||
|
||||
2. Node identity issuance and management.
|
||||
|
||||
3. Authenticated, Authorized, Encrypted information storage and dissemination.
|
||||
|
||||
Let’s look at each of these aspects individually
|
||||
|
||||
### Trust Bootstrap and Node Introduction
|
||||
|
||||
The first step to a secure cluster is tight control over membership and identity. Without it, administrators cannot rely on the identities of their nodes and enforce strict workload separation between nodes. This means that unauthorized nodes can’t be allowed to join the cluster, and nodes that are already part of the cluster aren’t able to change identities, suddenly pretending to be another node.
|
||||
|
||||
To address this need, nodes managed by Docker EE’s Swarm mode maintain strong, immutable identities. The desired properties are cryptographically guaranteed by using two key building-blocks:
|
||||
|
||||
1. Secure join tokens for cluster membership.
|
||||
|
||||
2. Unique identities embedded in certificates issued from a central certificate authority.
|
||||
|
||||
### Joining the Swarm
|
||||
|
||||
To join the swarm, a node needs a copy of a secure join token. The token is unique to each operational role within the cluster—there are currently two types of nodes: workers and managers. Due to this separation, a node with a copy of a worker token will not be allowed to join the cluster as a manager. The only way to get this special token is for a cluster administrator to interactively request it from the cluster’s manager through the swarm administration API.
|
||||
|
||||
The token is securely and randomly generated, but it also has a special syntax that makes leaks of this token easier to detect: a special prefix that you can easily monitor for in your logs and repositories. Fortunately, even if a leak does occur, tokens are easy to rotate, and we recommend that you rotate them often—particularly in the case where your cluster will not be scaling up for a while.
|
||||
|
||||

|
||||
|
||||
### Bootstrapping trust
|
||||
|
||||
As part of establishing its identity, a new node will ask for a new identity to be issued by any of the network managers. However, under our threat model, all communications can be intercepted by a third-party. This begs the question: how does a node know that it is talking to a legitimate manager?
|
||||
|
||||

|
||||
|
||||
Fortunately, Docker has a built-in mechanism for preventing this from happening. The join token, which the host uses to join the swarm, includes a hash of the root CA’s certificate. The host can therefore use one-way TLS and use the hash to verify that it’s joining the right swarm: if the manager presents a certificate not signed by a CA that matches the hash, the node knows not to trust it.
|
||||
|
||||
### Node identity issuance and management
|
||||
|
||||
Identities in a swarm are embedded in x509 certificates held by each individual node. In a manifestation of the least privilege principle, the certificates’ private keys are restricted strictly to the hosts where they originate. In particular, managers do not have access to private keys of any certificate but their own.
|
||||
|
||||
### Identity Issuance
|
||||
|
||||
To receive their certificates without sharing their private keys, new hosts begin by issuing a certificate signing request (CSR), which the managers then convert into a certificate. This certificate now becomes the new host’s identity, making the node a full-fledged member of the swarm!
|
||||
|
||||
####
|
||||

|
||||
|
||||
When used alongside with the secure bootstrapping mechanism, this mechanism for issuing identities to joining nodes is secure by default: all communicating parties are authenticated, authorized and no sensitive information is ever exchanged in clear-text.
|
||||
|
||||
### Identity Renewal
|
||||
|
||||
However, securely joining nodes to a swarm is only part of the story. To minimize the impact of leaked or stolen certificates and to remove the complexity of managing CRL lists, Swarm mode uses short-lived certificates for the identities. These certificates have a default expiration of three months, but can be configured to expire every hour!
|
||||
|
||||

|
||||
|
||||
This short certificate expiration time means that certificate rotation can’t be a manual process, as it usually is for most PKI systems. With swarm, all certificates are rotated automatically and in a hitless fashion. The process is simple: using a mutually authenticated TLS connection to prove ownership over a particular identity, a Swarm node generates regularly a new public/private key pair and sends the corresponding CSR to be signed, creating a completely new certificate, but maintaining the same identity.
|
||||
|
||||
### Authenticated, Authorized, Encrypted information storage and dissemination.
|
||||
|
||||
During the normal operation of a swarm, information about the tasks has to be sent to the worker nodes for execution. This includes not only information on which containers are to be executed by a node;but also, it includes all the resources that are necessary for the successful execution of that container, including sensitive secrets such as private keys, passwords, and API tokens.
|
||||
|
||||
### Transport Security
|
||||
|
||||
The fact that every node participating in a swarm is in possession of a unique identity in the form of a X509 certificate, communicating securely between nodes is trivial: nodes can use their respective certificates to establish mutually authenticated connections between one another, inheriting the confidentiality, authenticity and integrity properties of TLS.
|
||||
|
||||

|
||||
|
||||
One interesting detail about Swarm mode is the fact that it uses a push model: only managers are allowed to send information to workers—significantly reducing the surface of attack manager nodes expose to the less privileged worker nodes.
|
||||
|
||||
### Strict Workload Separation Into Security Zones
|
||||
|
||||
One of the responsibilities of manager nodes is deciding which tasks to send to each of the workers. Managers make this determination using a variety of strategies; scheduling the workloads across the swarm depending on both the unique properties of each node and each workload.
|
||||
|
||||
In Docker EE with Swarm mode, administrators have the ability of influencing these scheduling decisions by using labels that are securely attached to the individual node identities. These labels allow administrators to group nodes together into different security zones limiting the exposure of particularly sensitive workloads and any secrets related to them.
|
||||
|
||||

|
||||
|
||||
### Secure Secret Distribution
|
||||
|
||||
In addition to facilitating the identity issuance process, manager nodes have the important task of storing and distributing any resources needed by a worker. Secrets are treated like any other type of resource, and are pushed down from the manager to the worker over the secure mTLS connection.
|
||||
|
||||

|
||||
|
||||
On the hosts, Docker EE ensures that secrets are provided only to the containers they are destined for. Other containers on the same host will not have access to them. Docker exposes secrets to a container as a temporary file system, ensuring that secrets are always stored in memory and never written to disk. This method is more secure than competing alternatives, such as [storing them in environment variables][12]. Once a task completes the secret is gone forever.
|
||||
|
||||
### Storing secrets
|
||||
|
||||
On manager hosts secrets are always encrypted at rest. By default, the key that encrypts these secrets (known as the Data Encryption Key, DEK) is also stored in plaintext on disk. This makes it easy for those with minimal security requirements to start using Docker Swarm mode.
|
||||
|
||||
However, once you are running a production cluster, we recommend you enable auto-lock mode. When auto-lock mode is enabled, a newly rotated DEK is encrypted with a separate Key Encryption Key (KEK). This key is never stored on the cluster; the administrator is responsible for storing it securely and providing it when the cluster starts up. This is known as unlocking the swarm.
|
||||
|
||||
Swarm mode supports multiple managers, relying on the Raft Consensus Algorithm for fault tolerance. Secure secret storage scales seamlessly in this scenario. Each manager host has a unique disk encryption key, in addition to the shared key. Furthermore, Raft logs are encrypted on disk and are similarly unavailable without the KEK when in autolock mode.
|
||||
|
||||
### What happens when a node is compromised?
|
||||
|
||||

|
||||
|
||||
In traditional orchestrators, recovering from a compromised host is a slow and complicated process. With Swarm mode, recovery is as easy as running the docker node rm command. This removes the affected node from the cluster, and Docker will take care of the rest, namely re-balancing services and making sure other hosts know not to talk to the affected node.
|
||||
|
||||
As we have seen, thanks to least privilege orchestration, even if the attacker were still active on the host, they would be cut off from the rest of the network. The host’s certificate — its identity — is blacklisted, so the managers will not accept it as valid.
|
||||
|
||||
# Conclusion
|
||||
|
||||
Docker EE with Swarm mode ensures security by default in all key areas of orchestration:
|
||||
|
||||
* Joining the cluster. Prevents malicious nodes from joining the cluster.
|
||||
|
||||
* Organizing hosts into security zones. Prevents lateral movement by attackers.
|
||||
|
||||
* Scheduling tasks. Tasks will be issued only to designated and allowed nodes.
|
||||
|
||||
* Allocating resources. A malicious node cannot “steal” another’s workload or resources.
|
||||
|
||||
* Storing secrets. Never stored in plaintext and never written to disk on worker nodes.
|
||||
|
||||
* Communicating with the workers. Encrypted using mutually authenticated TLS.
|
||||
|
||||
As Swarm mode continues to improve, the Docker team is working to take the principle of least privilege orchestration even further. The task we are tackling is: how can systems remain secure if a manager is compromised? The roadmap is in place, with some of the features already available such as the ability of whitelisting only specific Docker images, preventing managers from executing arbitrary workloads. This is achieved quite naturally using Docker Content Trust.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/10/least-privilege-container-orchestration/
|
||||
|
||||
作者:[Diogo Mónica ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/diogo/
|
||||
[1]:http://www.linkedin.com/shareArticle?mini=true&url=http://dockr.ly/2yZoNdy&title=Least%20Privilege%20Container%20Orchestration&summary=The%20Docker%20platform%20and%20the%20container%20has%20become%20the%20standard%20for%20packaging,%20deploying,%20and%20managing%20applications.%20In%20order%20to%20coordinate%20running%20containers%20across%20multiple%20nodes%20in%20a%20cluster,%20a%20key%20capability%20is%20required:%20a%20container%20orchestrator.Orchestrators%20are%20responsible%20for%20critical%20clustering%20and%20scheduling%20tasks,%20such%20as:%20%20%20%20Managing%20...
|
||||
[2]:http://www.reddit.com/submit?url=http://dockr.ly/2yZoNdy&title=Least%20Privilege%20Container%20Orchestration
|
||||
[3]:https://plus.google.com/share?url=http://dockr.ly/2yZoNdy
|
||||
[4]:http://news.ycombinator.com/submitlink?u=http://dockr.ly/2yZoNdy&t=Least%20Privilege%20Container%20Orchestration
|
||||
[5]:https://blog.docker.com/author/diogo/
|
||||
[6]:https://blog.docker.com/tag/docker-orchestration/
|
||||
[7]:https://blog.docker.com/tag/docker-secrets/
|
||||
[8]:https://blog.docker.com/tag/docker-security/
|
||||
[9]:https://blog.docker.com/tag/docker-swarm/
|
||||
[10]:https://blog.docker.com/tag/least-privilege-orchestrator/
|
||||
[11]:https://blog.docker.com/tag/tls/
|
||||
[12]:https://diogomonica.com/2017/03/27/why-you-shouldnt-use-env-variables-for-secret-data/
|
||||
@ -1,79 +0,0 @@
|
||||
Translating by FelixYFZ
|
||||
|
||||
Linux Networking Hardware for Beginners: Think Software
|
||||
============================================================
|
||||
|
||||

|
||||
Without routers and bridges, we would be lonely little islands; learn more in this networking tutorial.[Creative Commons Zero][3]Pixabay
|
||||
|
||||
Last week, we learned about [LAN (local area network) hardware][7]. This week, we'll learn about connecting networks to each other, and some cool hacks for mobile broadband.
|
||||
|
||||
### Routers
|
||||
|
||||
Network routers are everything in computer networking, because routers connect networks. Without routers we would be lonely little islands. Figure 1 shows a simple wired LAN (local area network) with a wireless access point, all connected to the Internet. Computers on the LAN connect to an Ethernet switch, which connects to a combination firewall/router, which connects to the big bad Internet through whatever interface your Internet service provider (ISP) provides, such as cable box, DSL modem, satellite uplink...like everything in computing, it's likely to be a box with blinky lights. When your packets leave your LAN and venture forth into the great wide Internet, they travel from router to router until they reach their destination.
|
||||
|
||||
### [fig-1.png][4]
|
||||
|
||||

|
||||
Figure 1: A simple wired LAN with a wireless access point.[Used with permission][1]
|
||||
|
||||
A router can look like pretty much anything: a nice little specialized box that does only routing and nothing else, a bigger box that provides routing, firewall, name services, and VPN gateway, a re-purposed PC or laptop, a Raspberry Pi or Arduino, stout little single-board computers like PC Engines...for all but the most demanding uses, ordinary commodity hardware works fine. The highest-end routers use specialized hardware that is designed to move the maximum number of packets per second. They have multiple fat data buses, multiple CPUs, and super-fast memory. (Look up Juniper and Cisco routers to see what high-end routers look like, and what's inside.)
|
||||
|
||||
A wireless access point connects to your LAN either as an Ethernet bridge or a router. A bridge extends the network, so hosts on both sides of the bridge are on the same network. A router connects two different networks.
|
||||
|
||||
### Network Topology
|
||||
|
||||
There are multitudes of ways to set up your LAN. You can put all hosts on a single flat network. You can divide it up into different subnets. You can divide it into virtual LANs, if your switch supports this.
|
||||
|
||||
A flat network is the simplest; just plug everyone into the same switch. If one switch isn't enough you can connect switches to each other. Some switches have special uplink ports, some don't care which ports you connect, and you may need to use a crossover Ethernet cable, so check your switch documentation.
|
||||
|
||||
Flat networks are the easiest to administer. You don't need routers and don't have to calculate subnets, but there are some downsides. They don't scale, so when they get too large they get bogged down by broadcast traffic. Segmenting your LAN provides a bit of security, and makes it easier to manage larger networks by dividing it into manageable chunks. Figure 2 shows a simplified LAN divided into two subnets: internal wired and wireless hosts, and one for servers that host public services. The subnet that contains the public-facing servers is called a DMZ, demilitarized zone (ever notice all the macho terminology for jobs that are mostly typing on a computer?) because it is blocked from all internal access.
|
||||
|
||||
### [fig-2.png][5]
|
||||
|
||||

|
||||
Figure 2: A simplified LAN divided into two subnets.[Used with permission][2]
|
||||
|
||||
Even in a network as small as Figure 2 there are several ways to set it up. You can put your firewall and router on a single device. You could have a dedicated Internet link for the DMZ, divorcing it completely from your internal network. Which brings us to our next topic: it's all software.
|
||||
|
||||
### Think Software
|
||||
|
||||
You may have noticed that of the hardware we have discussed in this little series, only network interfaces, switches, and cabling are special-purpose hardware. Everything else is general-purpose commodity hardware, and it's the software that defines its purpose. Linux is a true networking operating system, and it supports a multitude of network operations: VLANs, firewall, router, Internet gateway, VPN gateway, Ethernet bridge, Web/mail/file/etc. servers, load-balancer, proxy, quality of service, multiple authenticators, trunking, failover...you can run your entire network on commodity hardware with Linux. You can even use Linux to simulate an Ethernet switch with LISA (LInux Switching Appliance) and vde2.
|
||||
|
||||
There are specialized distributions for small hardware like DD-WRT, OpenWRT, and the Raspberry Pi distros, and don't forget the BSDs and their specialized offshoots like the pfSense firewall/router, and the FreeNAS network-attached storage server.
|
||||
|
||||
You know how some people insist there is a difference between a hardware firewall and a software firewall? There isn't. That's like saying there is a hardware computer and a software computer.
|
||||
|
||||
### Port Trunking and Ethernet Bonding
|
||||
|
||||
Trunking and bonding, also called link aggregation, is combining two Ethernet channels into one. Some Ethernet switches support port trunking, which is combining two switch ports to combine their bandwidth into a single link. This is a nice way to make a bigger pipe to a busy server.
|
||||
|
||||
You can do the same thing with Ethernet interfaces, and the bonding driver is built-in to the Linux kernel, so you don't need any special hardware.
|
||||
|
||||
### Bending Mobile Broadband to your Will
|
||||
|
||||
I expect that mobile broadband is going to grow in the place of DSL and cable Internet. I live near a city of 250,000 population, but outside the city limits good luck getting Internet, even though there is a large population to serve. My little corner of the world is 20 minutes from town, but it might as well be the moon as far as Internet service providers are concerned. My only option is mobile broadband; there is no dialup, satellite Internet is sold out (and it sucks), and haha lol DSL, cable, or fiber. That doesn't stop ISPs from stuffing my mailbox with flyers for Xfinity and other high-speed services my area will never see.
|
||||
|
||||
I tried AT&T, Verizon, and T-Mobile. Verizon has the strongest coverage, but Verizon and AT&T are expensive. I'm at the edge of T-Mobile coverage, but they give the best deal by far. To make it work, I had to buy a weBoost signal booster and ZTE mobile hotspot. Yes, you can use a smartphone as a hotspot, but the little dedicated hotspots have stronger radios. If you're thinking you might want a signal booster, I have nothing but praise for weBoost because their customer support is superb, and they will do their best to help you. Set it up with the help of a great little app that accurately measures signal strength, [SignalCheck Pro][8]. They have a free version with fewer features; spend the two bucks to get the pro version, you won't be sorry.
|
||||
|
||||
The little ZTE hotspots serve up to 15 hosts and have rudimentary firewalls. But we can do better: get something like the Linksys WRT54GL, replace the stock firmware with Tomato, OpenWRT, or DD-WRT, and then you have complete control of your firewall rules, routing, and any other services you want to set up.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-think-software
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[4]:https://www.linux.com/files/images/fig-1png-7
|
||||
[5]:https://www.linux.com/files/images/fig-2png-4
|
||||
[6]:https://www.linux.com/files/images/soderskar-islandjpg
|
||||
[7]:https://www.linux.com/learn/intro-to-linux/2017/10/linux-networking-hardware-beginners-lan-hardware
|
||||
[8]:http://www.bluelinepc.com/signalcheck/
|
||||
@ -1,83 +0,0 @@
|
||||
apply for translating
|
||||
|
||||
How Eclipse is advancing IoT development
|
||||
============================================================
|
||||
|
||||
### Open source organization's modular approach to development is a good match for the Internet of Things.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
[Eclipse][3] may not be the first open source organization that pops to mind when thinking about Internet of Things (IoT) projects. After all, the foundation has been around since 2001, long before IoT was a household word, supporting a community for commercially viable open source software development.
|
||||
|
||||
September's Eclipse IoT Day, held in conjunction with RedMonk's [ThingMonk 2017][4] event, emphasized the big role Eclipse is taking in [IoT development][5]. It currently hosts 28 projects that touch a wide range of IoT needs and projects. While at the conference, I talked with [Ian Skerritt][6], who heads marketing for Eclipse, about Eclipse's IoT projects and how Eclipse thinks about IoT more broadly.
|
||||
|
||||
### What's new about IoT?
|
||||
|
||||
I asked Ian how IoT is different from traditional industrial automation, given that sensors and tools have been connected in factories for the past several decades. Ian notes that many factories still are not connected.
|
||||
|
||||
Additionally, he says, "SCADA [supervisory control and data analysis] systems and even the factory floor technology are very proprietary, very siloed. It's hard to change it. It's hard to adapt to it… Right now, when you set up a manufacturing run, you need to manufacture hundreds of thousands of that piece, of that unit. What [manufacturers] want to do is to meet customer demand, to have manufacturing processes that are very flexible, that you can actually do a lot size of one." That's a big piece of what IoT is bringing to manufacturing.
|
||||
|
||||
### Eclipse's approach to IoT
|
||||
|
||||
He describes Eclipse's involvement in IoT by saying: "There's core fundamental technology that every IoT solution needs," and by using open source, "everyone can use it so they can get broader adoption." He says Eclipse see IoT as consisting of three connected software stacks. At a high level, these stacks mirror the (by now familiar) view that IoT can usually be described as spanning three layers. A given implementation may have even more layers, but they still generally map to the functions of this three-layer model:
|
||||
|
||||
* A stack of software for constrained devices (e.g., the device, endpoint, microcontroller unit (MCU), sensor hardware).
|
||||
|
||||
* Some type of gateway that aggregates information and data from the different sensors and sends it to the network. This layer also may take real-time actions based on what the sensors are observing.
|
||||
|
||||
* A software stack for the IoT platform on the backend. This backend cloud stores the data and can provide services based on collected data, such as analysis of historical trends and predictive analytics.
|
||||
|
||||
The three stacks are described in greater detail in Eclipse's whitepaper "[The Three Software Stacks Required for IoT Architectures][7]."
|
||||
|
||||
Ian says that, when developing a solution within those architectures, "there's very specific things that need to be built, but there's a lot of underlying technology that can be used, like messaging protocols, like gateway services. It needs to be a modular approach to scale up to the different use cases that are up there." This encapsulates Eclipse's activities around IoT: Developing modular open source components that can be used to build a range of business-specific services and solutions.
|
||||
|
||||
### Eclipse's IoT projects
|
||||
|
||||
Of Eclipse's many IoT projects currently in use, Ian says two of the most prominent relate to [MQTT][8], a machine-to-machine (M2M) messaging protocol for IoT. Ian describes it as "a publish‑subscribe messaging protocol that was designed specifically for oil and gas pipeline monitoring where power-management network latency is really important. MQTT has been a great success in terms of being a standard that's being widely adopted in IoT." [Eclipse Mosquitto][9] is MQTT's broker and [Eclipse Paho][10] its client.
|
||||
|
||||
[Eclipse Kura][11] is an IoT gateway that, in Ian's words, "provides northbound and southbound connectivity [for] a lot of different protocols" including Bluetooth, Modbus, controller-area network (CAN) bus, and OPC Unified Architecture, with more being added all the time. One benefit, he says, is "instead of you writing your own connectivity, Kura provides that and then connects you to the network via satellite, via Ethernet, or anything." In addition, it handles firewall configuration, network latency, and other functions. "If the network goes down, it will store messages until it comes back up," Ian says.
|
||||
|
||||
A newer project, [Eclipse Kapua][12], is taking a microservices approach to providing different services for an IoT cloud platform. For example, it handles aspects of connectivity, integration, management, storage, and analysis. Ian describes it as "up and coming. It's not being deployed yet, but Eurotech and Red Hat are very active in that."
|
||||
|
||||
Ian says [Eclipse hawkBit][13], which manages software updates, is one of the "most intriguing projects. From a security perspective, if you can't update your device, you've got a huge security hole." Most IoT security disasters are related to non-updated devices, he says. "HawkBit basically manages the backend of how you do scalable updates across your IoT system."
|
||||
|
||||
Indeed, the difficulty of updating software in IoT devices is regularly cited as one of its biggest security challenges. IoT devices aren't always connected and may be numerous, plus update processes for constrained devices can be hard to consistently get right. For this reason, projects relating to updating IoT software are likely to be important going forward.
|
||||
|
||||
### Why IoT is a good fit for Eclipse
|
||||
|
||||
One of the trends we've seen in IoT development has been around building blocks that are integrated and applied to solve particular business problems, rather than monolithic IoT platforms that apply across industries and companies. This is a good fit with Eclipse's approach to IoT, which focuses on a number of modular stacks; projects that provide specific and commonly needed functions; and brokers, gateways, and protocols that can tie together the components needed for a given implementation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gordon Haff - Gordon Haff is Red Hat’s cloud evangelist, is a frequent and highly acclaimed speaker at customer and industry events, and helps develop strategy across Red Hat’s full portfolio of cloud solutions. He is the author of Computing Next: How the Cloud Opens the Future in addition to numerous other publications. Prior to Red Hat, Gordon wrote hundreds of research notes, was frequently quoted in publications like The New York Times on a wide range of IT topics, and advised clients on product and...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/eclipse-and-iot
|
||||
|
||||
作者:[Gordon Haff ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://opensource.com/article/17/10/eclipse-and-iot?rate=u1Wr-MCMFCF4C45IMoSPUacCatoqzhdKz7NePxHOvwg
|
||||
[2]:https://opensource.com/user/21220/feed
|
||||
[3]:https://www.eclipse.org/home/
|
||||
[4]:http://thingmonk.com/
|
||||
[5]:https://iot.eclipse.org/
|
||||
[6]:https://twitter.com/ianskerrett
|
||||
[7]:https://iot.eclipse.org/resources/white-papers/Eclipse%20IoT%20White%20Paper%20-%20The%20Three%20Software%20Stacks%20Required%20for%20IoT%20Architectures.pdf
|
||||
[8]:http://mqtt.org/
|
||||
[9]:https://projects.eclipse.org/projects/technology.mosquitto
|
||||
[10]:https://projects.eclipse.org/projects/technology.paho
|
||||
[11]:https://www.eclipse.org/kura/
|
||||
[12]:https://www.eclipse.org/kapua/
|
||||
[13]:https://eclipse.org/hawkbit/
|
||||
[14]:https://opensource.com/users/ghaff
|
||||
[15]:https://opensource.com/users/ghaff
|
||||
[16]:https://opensource.com/article/17/10/eclipse-and-iot#comments
|
||||
@ -0,0 +1,711 @@
|
||||
Dive into BPF: a list of reading material
|
||||
============================================================
|
||||
|
||||
* [What is BPF?][143]
|
||||
|
||||
* [Dive into the bytecode][144]
|
||||
|
||||
* [Resources][145]
|
||||
* [Generic presentations][23]
|
||||
* [About BPF][1]
|
||||
|
||||
* [About XDP][2]
|
||||
|
||||
* [About other components related or based on eBPF][3]
|
||||
|
||||
* [Documentation][24]
|
||||
* [About BPF][4]
|
||||
|
||||
* [About tc][5]
|
||||
|
||||
* [About XDP][6]
|
||||
|
||||
* [About P4 and BPF][7]
|
||||
|
||||
* [Tutorials][25]
|
||||
|
||||
* [Examples][26]
|
||||
* [From the kernel][8]
|
||||
|
||||
* [From package iproute2][9]
|
||||
|
||||
* [From bcc set of tools][10]
|
||||
|
||||
* [Manual pages][11]
|
||||
|
||||
* [The code][27]
|
||||
* [BPF code in the kernel][12]
|
||||
|
||||
* [XDP hooks code][13]
|
||||
|
||||
* [BPF logic in bcc][14]
|
||||
|
||||
* [Code to manage BPF with tc][15]
|
||||
|
||||
* [BPF utilities][16]
|
||||
|
||||
* [Other interesting chunks][17]
|
||||
|
||||
* [LLVM backend][18]
|
||||
|
||||
* [Running in userspace][19]
|
||||
|
||||
* [Commit logs][20]
|
||||
|
||||
* [Troubleshooting][28]
|
||||
* [Errors at compilation time][21]
|
||||
|
||||
* [Errors at load and run time][22]
|
||||
|
||||
* [And still more!][29]
|
||||
|
||||
_~ [Updated][146] 2017-11-02 ~_
|
||||
|
||||
# What is BPF?
|
||||
|
||||
BPF, as in **B**erkeley **P**acket **F**ilter, was initially conceived in 1992 so as to provide a way to filter packets and to avoid useless packet copies from kernel to userspace. It initially consisted in a simple bytecode that is injected from userspace into the kernel, where it is checked by a verifier—to prevent kernel crashes or security issues—and attached to a socket, then run on each received packet. It was ported to Linux a couple of years later, and used for a small number of applications (tcpdump for example). The simplicity of the language as well as the existence of an in-kernel Just-In-Time (JIT) compiling machine for BPF were factors for the excellent performances of this tool.
|
||||
|
||||
Then in 2013, Alexei Starovoitov completely reshaped it, started to add new functionalities and to improve the performances of BPF. This new version is designated as eBPF (for “extended BPF”), while the former becomes cBPF (“classic” BPF). New features such as maps and tail calls appeared. The JIT machines were rewritten. The new language is even closer to native machine language than cBPF was. And also, new attach points in the kernel have been created.
|
||||
|
||||
Thanks to those new hooks, eBPF programs can be designed for a variety of use cases, that divide into two fields of applications. One of them is the domain of kernel tracing and event monitoring. BPF programs can be attached to kprobes and they compare with other tracing methods, with many advantages (and sometimes some drawbacks).
|
||||
|
||||
The other application domain remains network programming. In addition to socket filter, eBPF programs can be attached to tc (Linux traffic control tool) ingress or egress interfaces and perform a variety of packet processing tasks, in an efficient way. This opens new perspectives in the domain.
|
||||
|
||||
And eBPF performances are further leveraged through the technologies developed for the IO Visor project: new hooks have also been added for XDP (“eXpress Data Path”), a new fast path recently added to the kernel. XDP works in conjunction with the Linux stack, and relies on BPF to perform very fast packet processing.
|
||||
|
||||
Even some projects such as P4, Open vSwitch, [consider][155] or started to approach BPF. Some others, such as CETH, Cilium, are entirely based on it. BPF is buzzing, so we can expect a lot of tools and projects to orbit around it soon…
|
||||
|
||||
# Dive into the bytecode
|
||||
|
||||
As for me: some of my work (including for [BEBA][156]) is closely related to eBPF, and several future articles on this site will focus on this topic. Logically, I wanted to somehow introduce BPF on this blog before going down to the details—I mean, a real introduction, more developed on BPF functionalities that the brief abstract provided in first section: What are BPF maps? Tail calls? What do the internals look like? And so on. But there are a lot of presentations on this topic available on the web already, and I do not wish to create “yet another BPF introduction” that would come as a duplicate of existing documents.
|
||||
|
||||
So instead, here is what we will do. After all, I spent some time reading and learning about BPF, and while doing so, I gathered a fair amount of material about BPF: introductions, documentation, but also tutorials or examples. There is a lot to read, but in order to read it, one has to _find_ it first. Therefore, as an attempt to help people who wish to learn and use BPF, the present article introduces a list of resources. These are various kinds of readings, that hopefully will help you dive into the mechanics of this kernel bytecode.
|
||||
|
||||
# Resources
|
||||
|
||||

|
||||
|
||||
### Generic presentations
|
||||
|
||||
The documents linked below provide a generic overview of BPF, or of some closely related topics. If you are very new to BPF, you can try picking a couple of presentation among the first ones and reading the ones you like most. If you know eBPF already, you probably want to target specific topics instead, lower down in the list.
|
||||
|
||||
### About BPF
|
||||
|
||||
Generic presentations about eBPF:
|
||||
|
||||
* [_Making the Kernel’s Networking Data Path Programmable with BPF and XDP_][53] (Daniel Borkmann, OSSNA17, Los Angeles, September 2017):
|
||||
One of the best set of slides available to understand quickly all the basics about eBPF and XDP (mostly for network processing).
|
||||
|
||||
* [The BSD Packet Filter][54] (Suchakra Sharma, June 2017):
|
||||
A very nice introduction, mostly about the tracing aspects.
|
||||
|
||||
* [_BPF: tracing and more_][55] (Brendan Gregg, January 2017):
|
||||
Mostly about the tracing use cases.
|
||||
|
||||
* [_Linux BPF Superpowers_][56] (Brendan Gregg, March 2016):
|
||||
With a first part on the use of **flame graphs**.
|
||||
|
||||
* [_IO Visor_][57] (Brenden Blanco, SCaLE 14x, January 2016):
|
||||
Also introduces **IO Visor project**.
|
||||
|
||||
* [_eBPF on the Mainframe_][58] (Michael Holzheu, LinuxCon, Dubin, October 2015)
|
||||
|
||||
* [_New (and Exciting!) Developments in Linux Tracing_][59] (Elena Zannoni, LinuxCon, Japan, 2015)
|
||||
|
||||
* [_BPF — in-kernel virtual machine_][60] (Alexei Starovoitov, February 2015):
|
||||
Presentation by the author of eBPF.
|
||||
|
||||
* [_Extending extended BPF_][61] (Jonathan Corbet, July 2014)
|
||||
|
||||
**BPF internals**:
|
||||
|
||||
* Daniel Borkmann has been doing an amazing work to present **the internals** of eBPF, in particular about **its use with tc**, through several talks and papers.
|
||||
* [_Advanced programmability and recent updates with tc’s cls_bpf_][30] (netdev 1.2, Tokyo, October 2016):
|
||||
Daniel provides details on eBPF, its use for tunneling and encapsulation, direct packet access, and other features.
|
||||
|
||||
* [_cls_bpf/eBPF updates since netdev 1.1_][31] (netdev 1.2, Tokyo, October 2016, part of [this tc workshop][32])
|
||||
|
||||
* [_On getting tc classifier fully programmable with cls_bpf_][33] (netdev 1.1, Sevilla, February 2016):
|
||||
After introducing eBPF, this presentation provides insights on many internal BPF mechanisms (map management, tail calls, verifier). A must-read! For the most ambitious, [the full paper is available here][34].
|
||||
|
||||
* [_Linux tc and eBPF_][35] (fosdem16, Brussels, Belgium, January 2016)
|
||||
|
||||
* [_eBPF and XDP walkthrough and recent updates_][36] (fosdem17, Brussels, Belgium, February 2017)
|
||||
|
||||
These presentations are probably one of the best sources of documentation to understand the design and implementation of internal mechanisms of eBPF.
|
||||
|
||||
The [**IO Visor blog**][157] has some interesting technical articles about BPF. Some of them contain a bit of marketing talks.
|
||||
|
||||
**Kernel tracing**: summing up all existing methods, including BPF:
|
||||
|
||||
* [_Meet-cute between eBPF and Kerne Tracing_][62] (Viller Hsiao, July 2016):
|
||||
Kprobes, uprobes, ftrace
|
||||
|
||||
* [_Linux Kernel Tracing_][63] (Viller Hsiao, July 2016):
|
||||
Systemtap, Kernelshark, trace-cmd, LTTng, perf-tool, ftrace, hist-trigger, perf, function tracer, tracepoint, kprobe/uprobe…
|
||||
|
||||
Regarding **event tracing and monitoring**, Brendan Gregg uses eBPF a lot and does an excellent job at documenting some of his use cases. If you are in kernel tracing, you should see his blog articles related to eBPF or to flame graphs. Most of it are accessible [from this article][158] or by browsing his blog.
|
||||
|
||||
Introducing BPF, but also presenting **generic concepts of Linux networking**:
|
||||
|
||||
* [_Linux Networking Explained_][64] (Thomas Graf, LinuxCon, Toronto, August 2016)
|
||||
|
||||
* [_Kernel Networking Walkthrough_][65] (Thomas Graf, LinuxCon, Seattle, August 2015)
|
||||
|
||||
**Hardware offload**:
|
||||
|
||||
* eBPF with tc or XDP supports hardware offload, starting with Linux kernel version 4.9 and introduced by Netronome. Here is a presentation about this feature:
|
||||
[eBPF/XDP hardware offload to SmartNICs][147] (Jakub Kicinski and Nic Viljoen, netdev 1.2, Tokyo, October 2016)
|
||||
|
||||
About **cBPF**:
|
||||
|
||||
* [_The BSD Packet Filter: A New Architecture for User-level Packet Capture_][66] (Steven McCanne and Van Jacobson, 1992):
|
||||
The original paper about (classic) BPF.
|
||||
|
||||
* [The FreeBSD manual page about BPF][67] is a useful resource to understand cBPF programs.
|
||||
|
||||
* Daniel Borkmann realized at least two presentations on cBPF, [one in 2013 on mmap, BPF and Netsniff-NG][68], and [a very complete one in 2014 on tc and cls_bpf][69].
|
||||
|
||||
* On Cloudflare’s blog, Marek Majkowski presented his [use of BPF bytecode with the `xt_bpf`module for **iptables**][70]. It is worth mentioning that eBPF is also supported by this module, starting with Linux kernel 4.10 (I do not know of any talk or article about this, though).
|
||||
|
||||
* [Libpcap filters syntax][71]
|
||||
|
||||
### About XDP
|
||||
|
||||
* [XDP overview][72] on the IO Visor website.
|
||||
|
||||
* [_eXpress Data Path (XDP)_][73] (Tom Herbert, Alexei Starovoitov, March 2016):
|
||||
The first presentation about XDP.
|
||||
|
||||
* [_BoF - What Can BPF Do For You?_][74] (Brenden Blanco, LinuxCon, Toronto, August 2016).
|
||||
|
||||
* [_eXpress Data Path_][148] (Brenden Blanco, Linux Meetup at Santa Clara, July 2016):
|
||||
Contains some (somewhat marketing?) **benchmark results**! With a single core:
|
||||
* ip routing drop: ~3.6 million packets per second (Mpps)
|
||||
|
||||
* tc (with clsact qdisc) drop using BPF: ~4.2 Mpps
|
||||
|
||||
* XDP drop using BPF: 20 Mpps (<10 % CPU utilization)
|
||||
|
||||
* XDP forward (on port on which the packet was received) with rewrite: 10 Mpps
|
||||
|
||||
(Tests performed with the mlx4 driver).
|
||||
|
||||
* Jesper Dangaard Brouer has several excellent sets of slides, that are essential to fully understand the internals of XDP.
|
||||
* [_XDP − eXpress Data Path, Intro and future use-cases_][37] (September 2016):
|
||||
_“Linux Kernel’s fight against DPDK”_ . **Future plans** (as of this writing) for XDP and comparison with DPDK.
|
||||
|
||||
* [_Network Performance Workshop_][38] (netdev 1.2, Tokyo, October 2016):
|
||||
Additional hints about XDP internals and expected evolution.
|
||||
|
||||
* [_XDP – eXpress Data Path, Used for DDoS protection_][39] (OpenSourceDays, March 2017):
|
||||
Contains details and use cases about XDP, with **benchmark results**, and **code snippets** for **benchmarking** as well as for **basic DDoS protection** with eBPF/XDP (based on an IP blacklisting scheme).
|
||||
|
||||
* [_Memory vs. Networking, Provoking and fixing memory bottlenecks_][40] (LSF Memory Management Summit, March 2017):
|
||||
Provides a lot of details about current **memory issues** faced by XDP developers. Do not start with this one, but if you already know XDP and want to see how it really works on the page allocation side, this is a very helpful resource.
|
||||
|
||||
* [_XDP for the Rest of Us_][41] (netdev 2.1, Montreal, April 2017), with Andy Gospodarek:
|
||||
How to get started with eBPF and XDP for normal humans. This presentation was also summarized by Julia Evans on [her blog][42].
|
||||
|
||||
(Jesper also created and tries to extend some documentation about eBPF and XDP, see [related section][75].)
|
||||
|
||||
* [_XDP workshop — Introduction, experience, and future development_][76] (Tom Herbert, netdev 1.2, Tokyo, October 2016) — as of this writing, only the video is available, I don’t know if the slides will be added.
|
||||
|
||||
* [_High Speed Packet Filtering on Linux_][149] (Gilberto Bertin, DEF CON 25, Las Vegas, July 2017) — an excellent introduction to state-of-the-art packet filtering on Linux, oriented towards DDoS protection, talking about packet processing in the kernel, kernel bypass, XDP and eBPF.
|
||||
|
||||
### About other components related or based on eBPF
|
||||
|
||||
* [_P4 on the Edge_][77] (John Fastabend, May 2016):
|
||||
Presents the use of **P4**, a description language for packet processing, with BPF to create high-performance programmable switches.
|
||||
|
||||
* If you like audio presentations, there is an associated [OvS Orbit episode (#11), called _**P4** on the Edge_][78] , dating from August 2016\. OvS Orbit are interviews realized by Ben Pfaff, who is one of the core maintainers of Open vSwitch. In this case, John Fastabend is interviewed.
|
||||
|
||||
* [_P4, EBPF and Linux TC Offload_][79] (Dinan Gunawardena and Jakub Kicinski, August 2016):
|
||||
Another presentation on **P4**, with some elements related to eBPF hardware offload on Netronome’s **NFP** (Network Flow Processor) architecture.
|
||||
|
||||
* **Cilium** is a technology initiated by Cisco and relying on BPF and XDP to provide “fast in-kernel networking and security policy enforcement for containers based on eBPF programs generated on the fly”. [The code of this project][150] is available on GitHub. Thomas Graf has been performing a number of presentations of this topic:
|
||||
* [_Cilium: Networking & Security for Containers with BPF & XDP_][43] , also featuring a load balancer use case (Linux Plumbers conference, Santa Fe, November 2016)
|
||||
|
||||
* [_Cilium: Networking & Security for Containers with BPF & XDP_][44] (Docker Distributed Systems Summit, October 2016 — [video][45])
|
||||
|
||||
* [_Cilium: Fast IPv6 container Networking with BPF and XDP_][46] (LinuxCon, Toronto, August 2016)
|
||||
|
||||
* [_Cilium: BPF & XDP for containers_][47] (fosdem17, Brussels, Belgium, February 2017)
|
||||
|
||||
A good deal of contents is repeated between the different presentations; if in doubt, just pick the most recent one. Daniel Borkmann has also written [a generic introduction to Cilium][80] as a guest author on Google Open Source blog.
|
||||
|
||||
* There are also podcasts about **Cilium**: an [OvS Orbit episode (#4)][81], in which Ben Pfaff interviews Thomas Graf (May 2016), and [another podcast by Ivan Pepelnjak][82], still with Thomas Graf about eBPF, P4, XDP and Cilium (October 2016).
|
||||
|
||||
* **Open vSwitch** (OvS), and its related project **Open Virtual Network** (OVN, an open source network virtualization solution) are considering to use eBPF at various level, with several proof-of-concept prototypes already implemented:
|
||||
|
||||
* [Offloading OVS Flow Processing using eBPF][48] (William (Cheng-Chun) Tu, OvS conference, San Jose, November 2016)
|
||||
|
||||
* [Coupling the Flexibility of OVN with the Efficiency of IOVisor][49] (Fulvio Risso, Matteo Bertrone and Mauricio Vasquez Bernal, OvS conference, San Jose, November 2016)
|
||||
|
||||
These use cases for eBPF seem to be only at the stage of proposals (nothing merge to OvS main branch) as far as I know, but it will be very interesting to see what comes out of it.
|
||||
|
||||
* XDP is envisioned to be of great help for protection against Distributed Denial-of-Service (DDoS) attacks. More and more presentations focus on this. For example, the talks from people from Cloudflare ( [_XDP in practice: integrating XDP in our DDoS mitigation pipeline_][83] ) or from Facebook ( [_Droplet: DDoS countermeasures powered by BPF + XDP_][84] ) at the netdev 2.1 conference in Montreal, Canada, in April 2017, present such use cases.
|
||||
|
||||
* [_CETH for XDP_][85] (Yan Chan and Yunsong Lu, Linux Meetup, Santa Clara, July 2016):
|
||||
**CETH** stands for Common Ethernet Driver Framework for faster network I/O, a technology initiated by Mellanox.
|
||||
|
||||
* [**The VALE switch**][86], another virtual switch that can be used in conjunction with the netmap framework, has [a BPF extension module][87].
|
||||
|
||||
* **Suricata**, an open source intrusion detection system, [seems to rely on eBPF components][88] for its “capture bypass” features:
|
||||
[_The adventures of a Suricate in eBPF land_][89] (Éric Leblond, netdev 1.2, Tokyo, October 2016)
|
||||
[_eBPF and XDP seen from the eyes of a meerkat_][90] (Éric Leblond, Kernel Recipes, Paris, September 2017)
|
||||
|
||||
* [InKeV: In-Kernel Distributed Network Virtualization for DCN][91] (Z. Ahmed, M. H. Alizai and A. A. Syed, SIGCOMM, August 2016):
|
||||
**InKeV** is an eBPF-based datapath architecture for virtual networks, targeting data center networks. It was initiated by PLUMgrid, and claims to achieve better performances than OvS-based OpenStack solutions.
|
||||
|
||||
* [_**gobpf** - utilizing eBPF from Go_][92] (Michael Schubert, fosdem17, Brussels, Belgium, February 2017):
|
||||
A “library to create, load and use eBPF programs from Go”
|
||||
|
||||
* [**ply**][93] is a small but flexible open source dynamic **tracer** for Linux, with some features similar to the bcc tools, but with a simpler language inspired by awk and dtrace, written by Tobias Waldekranz.
|
||||
|
||||
* If you read my previous article, you might be interested in this talk I gave about [implementing the OpenState interface with eBPF][151], for stateful packet processing, at fosdem17.
|
||||
|
||||

|
||||
|
||||
### Documentation
|
||||
|
||||
Once you managed to get a broad idea of what BPF is, you can put aside generic presentations and start diving into the documentation. Below are the most complete documents about BPF specifications and functioning. Pick the one you need and read them carefully!
|
||||
|
||||
### About BPF
|
||||
|
||||
* The **specification of BPF** (both classic and extended versions) can be found within the documentation of the Linux kernel, and in particular in file[linux/Documentation/networking/filter.txt][94]. The use of BPF as well as its internals are documented there. Also, this is where you can find **information about errors thrown by the verifier** when loading BPF code fails. Can be helpful to troubleshoot obscure error messages.
|
||||
|
||||
* Also in the kernel tree, there is a document about **frequent Questions & Answers** on eBPF design in file [linux/Documentation/bpf/bpf_design_QA.txt][95].
|
||||
|
||||
* … But the kernel documentation is dense and not especially easy to read. If you look for a simple description of eBPF language, head for [its **summarized description**][96] on the IO Visor GitHub repository instead.
|
||||
|
||||
* By the way, the IO Visor project gathered a lot of **resources about BPF**. Mostly, it is split between[the documentation directory][97] of its bcc repository, and the whole content of [the bpf-docs repository][98], both on GitHub. Note the existence of this excellent [BPF **reference guide**][99] containing a detailed description of BPF C and bcc Python helpers.
|
||||
|
||||
* To hack with BPF, there are some essential **Linux manual pages**. The first one is [the `bpf(2)` man page][100] about the `bpf()` **system call**, which is used to manage BPF programs and maps from userspace. It also contains a description of BPF advanced features (program types, maps and so on). The second one is mostly addressed to people wanting to attach BPF programs to tc interface: it is [the `tc-bpf(8)` man page][101], which is a reference for **using BPF with tc**, and includes some example commands and samples of code.
|
||||
|
||||
* Jesper Dangaard Brouer initiated an attempt to **update eBPF Linux documentation**, including **the different kinds of maps**. [He has a draft][102] to which contributions are welcome. Once ready, this document should be merged into the man pages and into kernel documentation.
|
||||
|
||||
* The Cilium project also has an excellent [**BPF and XDP Reference Guide**][103], written by core eBPF developers, that should prove immensely useful to any eBPF developer.
|
||||
|
||||
* David Miller has sent several enlightening emails about eBPF/XDP internals on the [xdp-newbies][152]mailing list. I could not find a link that gathers them at a single place, so here is a list:
|
||||
* [bpf.h and you…][50]
|
||||
|
||||
* [Contextually speaking…][51]
|
||||
|
||||
* [BPF Verifier Overview][52]
|
||||
|
||||
The last one is possibly the best existing summary about the verifier at this date.
|
||||
|
||||
* Ferris Ellis started [a **blog post series about eBPF**][104]. As I write this paragraph, the first article is out, with some historical background and future expectations for eBPF. Next posts should be more technical, and look promising.
|
||||
|
||||
* [A **list of BPF features per kernel version**][153] is available in bcc repository. Useful is you want to know the minimal kernel version that is required to run a given feature. I contributed and added the links to the commits that introduced each feature, so you can also easily access the commit logs from there.
|
||||
|
||||
### About tc
|
||||
|
||||
When using BPF for networking purposes in conjunction with tc, the Linux tool for **t**raffic **c**ontrol, one may wish to gather information about tc’s generic functioning. Here are a couple of resources about it.
|
||||
|
||||
* It is difficult to find simple tutorials about **QoS on Linux**. The two links I have are long and quite dense, but if you can find the time to read it you will learn nearly everything there is to know about tc (nothing about BPF, though). There they are: [_Traffic Control HOWTO_ (Martin A. Brown, 2006)][105], and the [_Linux Advanced Routing & Traffic Control HOWTO_ (“LARTC”) (Bert Hubert & al., 2002)][106].
|
||||
|
||||
* **tc manual pages** may not be up-to-date on your system, since several of them have been added lately. If you cannot find the documentation for a particular queuing discipline (qdisc), class or filter, it may be worth checking the latest [manual pages for tc components][107].
|
||||
|
||||
* Some additional material can be found within the files of iproute2 package itself: the package contains [some documentation][108], including some files that helped me understand better [the functioning of **tc’s actions**][109].
|
||||
**Edit:** While still available from the Git history, these files have been deleted from iproute2 in October 2017.
|
||||
|
||||
* Not exactly documentation: there was [a workshop about several tc features][110] (including filtering, BPF, tc offload, …) organized by Jamal Hadi Salim during the netdev 1.2 conference (October 2016).
|
||||
|
||||
* Bonus information—If you use `tc` a lot, here are some good news: I [wrote a bash completion function][111] for this tool, and it should be shipped with package iproute2 coming with kernel version 4.6 and higher!
|
||||
|
||||
### About XDP
|
||||
|
||||
* Some [work-in-progress documentation (including specifications)][112] for XDP started by Jesper Dangaard Brouer, but meant to be a collaborative work. Under progress (September 2016): you should expect it to change, and maybe to be moved at some point (Jesper [called for contribution][113], if you feel like improving it).
|
||||
|
||||
* The [BPF and XDP Reference Guide][114] from Cilium project… Well, the name says it all.
|
||||
|
||||
### About P4 and BPF
|
||||
|
||||
[P4][159] is a language used to specify the behavior of a switch. It can be compiled for a number of hardware or software targets. As you may have guessed, one of these targets is BPF… The support is only partial: some P4 features cannot be translated towards BPF, and in a similar way there are things that BPF can do but that would not be possible to express with P4\. Anyway, the documentation related to **P4 use with BPF** [used to be hidden in bcc repository][160]. This changed with P4_16 version, the p4c reference compiler including [a backend for eBPF][161].
|
||||
|
||||

|
||||
|
||||
### Tutorials
|
||||
|
||||
Brendan Gregg has produced excellent **tutorials** intended for people who want to **use bcc tools** for tracing and monitoring events in the kernel. [The first tutorial about using bcc itself][162] comes with eleven steps (as of today) to understand how to use the existing tools, while [the one **intended for Python developers**][163] focuses on developing new tools, across seventeen “lessons”.
|
||||
|
||||
Sasha Goldshtein also has some [_**Linux Tracing Workshops Materials**_][164] involving the use of several BPF tools for tracing.
|
||||
|
||||
Another post by Jean-Tiare Le Bigot provides a detailed (and instructive!) example of [using perf and eBPF to setup a low-level tracer][165] for ping requests and replies
|
||||
|
||||
Few tutorials exist for network-related eBPF use cases. There are some interesting documents, including an _eBPF Offload Starting Guide_ , on the [Open NFP][166] platform operated by Netronome. Other than these, the talk from Jesper, [_XDP for the Rest of Us_][167] , is probably one of the best ways to get started with XDP.
|
||||
|
||||

|
||||
|
||||
### Examples
|
||||
|
||||
It is always nice to have examples. To see how things really work. But BPF program samples are scattered across several projects, so I listed all the ones I know of. The examples do not always use the same helpers (for instance, tc and bcc both have their own set of helpers to make it easier to write BPF programs in C language).
|
||||
|
||||
### From the kernel
|
||||
|
||||
The kernel contains examples for most types of program: filters to bind to sockets or to tc interfaces, event tracing/monitoring, and even XDP. You can find these examples under the [linux/samples/bpf/][168]directory.
|
||||
|
||||
Also do not forget to have a look to the logs related to the (git) commits that introduced a particular feature, they may contain some detailed example of the feature.
|
||||
|
||||
### From package iproute2
|
||||
|
||||
The iproute2 package provide several examples as well. They are obviously oriented towards network programming, since the programs are to be attached to tc ingress or egress interfaces. The examples dwell under the [iproute2/examples/bpf/][169] directory.
|
||||
|
||||
### From bcc set of tools
|
||||
|
||||
Many examples are [provided with bcc][170]:
|
||||
|
||||
* Some are networking example programs, under the associated directory. They include socket filters, tc filters, and a XDP program.
|
||||
|
||||
* The `tracing` directory include a lot of example **tracing programs**. The tutorials mentioned earlier are based on these. These programs cover a wide range of event monitoring functions, and some of them are production-oriented. Note that on certain Linux distributions (at least for Debian, Ubuntu, Fedora, Arch Linux), these programs have been [packaged][115] and can be “easily” installed by typing e.g. `# apt install bcc-tools`, but as of this writing (and except for Arch Linux), this first requires to set up IO Visor’s own package repository.
|
||||
|
||||
* There are also some examples **using Lua** as a different BPF back-end (that is, BPF programs are written with Lua instead of a subset of C, allowing to use the same language for front-end and back-end), in the third directory.
|
||||
|
||||
### Manual pages
|
||||
|
||||
While bcc is generally the easiest way to inject and run a BPF program in the kernel, attaching programs to tc interfaces can also be performed by the `tc` tool itself. So if you intend to **use BPF with tc**, you can find some example invocations in the [`tc-bpf(8)` manual page][171].
|
||||
|
||||

|
||||
|
||||
### The code
|
||||
|
||||
Sometimes, BPF documentation or examples are not enough, and you may have no other solution that to display the code in your favorite text editor (which should be Vim of course) and to read it. Or you may want to hack into the code so as to patch or add features to the machine. So here are a few pointers to the relevant files, finding the functions you want is up to you!
|
||||
|
||||
### BPF code in the kernel
|
||||
|
||||
* The file [linux/include/linux/bpf.h][116] and its counterpart [linux/include/uapi/bpf.h][117] contain **definitions** related to eBPF, to be used respectively in the kernel and to interface with userspace programs.
|
||||
|
||||
* On the same pattern, files [linux/include/linux/filter.h][118] and [linux/include/uapi/filter.h][119] contain information used to **run the BPF programs**.
|
||||
|
||||
* The **main pieces of code** related to BPF are under [linux/kernel/bpf/][120] directory. **The different operations permitted by the system call**, such as program loading or map management, are implemented in file `syscall.c`, while `core.c` contains the **interpreter**. The other files have self-explanatory names: `verifier.c` contains the **verifier** (no kidding), `arraymap.c` the code used to interact with **maps** of type array, and so on.
|
||||
|
||||
* The **helpers**, as well as several functions related to networking (with tc, XDP…) and available to the user, are implemented in [linux/net/core/filter.c][121]. It also contains the code to migrate cBPF bytecode to eBPF (since all cBPF programs are now translated to eBPF in the kernel before being run).
|
||||
|
||||
* The **JIT compilers** are under the directory of their respective architectures, such as file[linux/arch/x86/net/bpf_jit_comp.c][122] for x86.
|
||||
|
||||
* You will find the code related to **the BPF components of tc** in the [linux/net/sched/][123] directory, and in particular in files `act_bpf.c` (action) and `cls_bpf.c` (filter).
|
||||
|
||||
* I have not hacked with **event tracing** in BPF, so I do not really know about the hooks for such programs. There is some stuff in [linux/kernel/trace/bpf_trace.c][124]. If you are interested in this and want to know more, you may dig on the side of Brendan Gregg’s presentations or blog posts.
|
||||
|
||||
* Nor have I used **seccomp-BPF**. But the code is in [linux/kernel/seccomp.c][125], and some example use cases can be found in [linux/tools/testing/selftests/seccomp/seccomp_bpf.c][126].
|
||||
|
||||
### XDP hooks code
|
||||
|
||||
Once loaded into the in-kernel BPF virtual machine, **XDP** programs are hooked from userspace into the kernel network path thanks to a Netlink command. On reception, the function `dev_change_xdp_fd()` in file [linux/net/core/dev.c][172] is called and sets a XDP hook. Such hooks are located in the drivers of supported NICs. For example, the mlx4 driver used for some Mellanox hardware has hooks implemented in files under the [drivers/net/ethernet/mellanox/mlx4/][173] directory. File en_netdev.c receives Netlink commands and calls `mlx4_xdp_set()`, which in turns calls for instance `mlx4_en_process_rx_cq()` (for the RX side) implemented in file en_rx.c.
|
||||
|
||||
### BPF logic in bcc
|
||||
|
||||
One can find the code for the **bcc** set of tools [on the bcc GitHub repository][174]. The **Python code**, including the `BPF` class, is initiated in file [bcc/src/python/bcc/__init__.py][175]. But most of the interesting stuff—to my opinion—such as loading the BPF program into the kernel, happens [in the libbcc **C library**][176].
|
||||
|
||||
### Code to manage BPF with tc
|
||||
|
||||
The code related to BPF **in tc** comes with the iproute2 package, of course. Some of it is under the[iproute2/tc/][177] directory. The files f_bpf.c and m_bpf.c (and e_bpf.c) are used respectively to handle BPF filters and actions (and tc `exec` command, whatever this may be). File q_clsact.c defines the `clsact` qdisc especially created for BPF. But **most of the BPF userspace logic** is implemented in[iproute2/lib/bpf.c][178] library, so this is probably where you should head to if you want to mess up with BPF and tc (it was moved from file iproute2/tc/tc_bpf.c, where you may find the same code in older versions of the package).
|
||||
|
||||
### BPF utilities
|
||||
|
||||
The kernel also ships the sources of three tools (`bpf_asm.c`, `bpf_dbg.c`, `bpf_jit_disasm.c`) related to BPF, under the [linux/tools/net/][179] or [linux/tools/bpf/][180] directory depending on your version:
|
||||
|
||||
* `bpf_asm` is a minimal cBPF assembler.
|
||||
|
||||
* `bpf_dbg` is a small debugger for cBPF programs.
|
||||
|
||||
* `bpf_jit_disasm` is generic for both BPF flavors and could be highly useful for JIT debugging.
|
||||
|
||||
* `bpftool` is a generic utility written by Jakub Kicinski, and that can be used to interact with eBPF programs and maps from userspace, for example to show, dump, pin programs, or to show, create, pin, update, delete maps.
|
||||
|
||||
Read the comments at the top of the source files to get an overview of their usage.
|
||||
|
||||
### Other interesting chunks
|
||||
|
||||
If you are interested the use of less common languages with BPF, bcc contains [a **P4 compiler** for BPF targets][181] as well as [a **Lua front-end**][182] that can be used as alternatives to the C subset and (in the case of Lua) to the Python tools.
|
||||
|
||||
### LLVM backend
|
||||
|
||||
The BPF backend used by clang / LLVM for compiling C into eBPF was added to the LLVM sources in[this commit][183] (and can also be accessed on [the GitHub mirror][184]).
|
||||
|
||||
### Running in userspace
|
||||
|
||||
As far as I know there are at least two eBPF userspace implementations. The first one, [uBPF][185], is written in C. It contains an interpreter, a JIT compiler for x86_64 architecture, an assembler and a disassembler.
|
||||
|
||||
The code of uBPF seems to have been reused to produce a [generic implementation][186], that claims to support FreeBSD kernel, FreeBSD userspace, Linux kernel, Linux userspace and MacOSX userspace. It is used for the [BPF extension module for VALE switch][187].
|
||||
|
||||
The other userspace implementation is my own work: [rbpf][188], based on uBPF, but written in Rust. The interpreter and JIT-compiler work (both under Linux, only the interpreter for MacOSX and Windows), there may be more in the future.
|
||||
|
||||
### Commit logs
|
||||
|
||||
As stated earlier, do not hesitate to have a look at the commit log that introduced a particular BPF feature if you want to have more information about it. You can search the logs in many places, such as on [git.kernel.org][189], [on GitHub][190], or on your local repository if you have cloned it. If you are not familiar with git, try things like `git blame <file>` to see what commit introduced a particular line of code, then `git show <commit>` to have details (or search by keyword in `git log` results, but this may be tedious). See also [the list of eBPF features per kernel version][191] on bcc repository, that links to relevant commits.
|
||||
|
||||

|
||||
|
||||
### Troubleshooting
|
||||
|
||||
The enthusiasm about eBPF is quite recent, and so far I have not found a lot of resources intending to help with troubleshooting. So here are the few I have, augmented with my own recollection of pitfalls encountered while working with BPF.
|
||||
|
||||
### Errors at compilation time
|
||||
|
||||
* Make sure you have a recent enough version of the Linux kernel (see also [this document][127]).
|
||||
|
||||
* If you compiled the kernel yourself: make sure you installed correctly all components, including kernel image, headers and libc.
|
||||
|
||||
* When using the `bcc` shell function provided by `tc-bpf` man page (to compile C code into BPF): I once had to add includes to the header for the clang call:
|
||||
|
||||
```
|
||||
__bcc() {
|
||||
clang -O2 -I "/usr/src/linux-headers-$(uname -r)/include/" \
|
||||
-I "/usr/src/linux-headers-$(uname -r)/arch/x86/include/" \
|
||||
-emit-llvm -c $1 -o - | \
|
||||
llc -march=bpf -filetype=obj -o "`basename $1 .c`.o"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
(seems fixed as of today).
|
||||
|
||||
* For other problems with `bcc`, do not forget to have a look at [the FAQ][128] of the tool set.
|
||||
|
||||
* If you downloaded the examples from the iproute2 package in a version that does not exactly match your kernel, some errors can be triggered by the headers included in the files. The example snippets indeed assume that the same version of iproute2 package and kernel headers are installed on the system. If this is not the case, download the correct version of iproute2, or edit the path of included files in the examples to point to the headers included in iproute2 (some problems may or may not occur at runtime, depending on the features in use).
|
||||
|
||||
### Errors at load and run time
|
||||
|
||||
* To load a program with tc, make sure you use a tc binary coming from an iproute2 version equivalent to the kernel in use.
|
||||
|
||||
* To load a program with bcc, make sure you have bcc installed on the system (just downloading the sources to run the Python script is not enough).
|
||||
|
||||
* With tc, if the BPF program does not return the expected values, check that you called it in the correct fashion: filter, or action, or filter with “direct-action” mode.
|
||||
|
||||
* With tc still, note that actions cannot be attached directly to qdiscs or interfaces without the use of a filter.
|
||||
|
||||
* The errors thrown by the in-kernel verifier may be hard to interpret. [The kernel documentation][129]may help, so may [the reference guide][130] or, as a last resort, the source code (see above) (good luck!). For this kind of errors it is also important to keep in mind that the verifier _does not run_ the program. If you get an error about an invalid memory access or about uninitialized data, it does not mean that these problems actually occurred (or sometimes, that they can possibly occur at all). It means that your program is written in such a way that the verifier estimates that such errors could happen, and therefore it rejects the program.
|
||||
|
||||
* Note that `tc` tool has a verbose mode, and that it works well with BPF: try appending `verbose`at the end of your command line.
|
||||
|
||||
* bcc also has verbose options: the `BPF` class has a `debug` argument that can take any combination of the three flags `DEBUG_LLVM_IR`, `DEBUG_BPF` and `DEBUG_PREPROCESSOR` (see details in [the source file][131]). It even embeds [some facilities to print output messages][132] for debugging the code.
|
||||
|
||||
* LLVM v4.0+ [embeds a disassembler][133] for eBPF programs. So if you compile your program with clang, adding the `-g` flag for compiling enables you to later dump your program in the rather human-friendly format used by the kernel verifier. To proceed to the dump, use:
|
||||
|
||||
```
|
||||
$ llvm-objdump -S -no-show-raw-insn bpf_program.o
|
||||
|
||||
```
|
||||
|
||||
* Working with maps? You want to have a look at [bpf-map][134], a very userful tool in Go created for the Cilium project, that can be used to dump the contents of kernel eBPF maps. There also exists [a clone][135] in Rust.
|
||||
|
||||
* There is an old [`bpf` tag on **StackOverflow**][136], but as of this writing it has been hardly used—ever (and there is nearly nothing related to the new eBPF version). If you are a reader from the Future though, you may want to check whether there has been more activity on this side.
|
||||
|
||||

|
||||
|
||||
### And still more!
|
||||
|
||||
* In case you would like to easily **test XDP**, there is [a Vagrant setup][137] available. You can also **test bcc**[in a Docker container][138].
|
||||
|
||||
* Wondering where the **development and activities** around BPF occur? Well, the kernel patches always end up [on the netdev mailing list][139] (related to the Linux kernel networking stack development): search for “BPF” or “XDP” keywords. Since April 2017, there is also [a mailing list specially dedicated to XDP programming][140] (both for architecture or for asking for help). Many discussions and debates also occur [on the IO Visor mailing list][141], since BPF is at the heart of the project. If you only want to keep informed from time to time, there is also an [@IOVisor Twitter account][142].
|
||||
|
||||
And come back on this blog from time to time to see if they are new articles [about BPF][192]!
|
||||
|
||||
_Special thanks to Daniel Borkmann for the numerous [additional documents][154] he pointed to me so that I could complete this collection._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
|
||||
|
||||
作者:[Quentin Monnet ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://qmonnet.github.io/whirl-offload/about/
|
||||
[1]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-bpf
|
||||
[2]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp
|
||||
[3]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-other-components-related-or-based-on-ebpf
|
||||
[4]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-bpf-1
|
||||
[5]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-tc
|
||||
[6]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp-1
|
||||
[7]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-p4-and-bpf
|
||||
[8]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-the-kernel
|
||||
[9]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-package-iproute2
|
||||
[10]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#from-bcc-set-of-tools
|
||||
[11]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#manual-pages
|
||||
[12]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-code-in-the-kernel
|
||||
[13]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#xdp-hooks-code
|
||||
[14]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-logic-in-bcc
|
||||
[15]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#code-to-manage-bpf-with-tc
|
||||
[16]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#bpf-utilities
|
||||
[17]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#other-interesting-chunks
|
||||
[18]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#llvm-backend
|
||||
[19]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#running-in-userspace
|
||||
[20]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#commit-logs
|
||||
[21]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#errors-at-compilation-time
|
||||
[22]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#errors-at-load-and-run-time
|
||||
[23]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#generic-presentations
|
||||
[24]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#documentation
|
||||
[25]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#tutorials
|
||||
[26]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#examples
|
||||
[27]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#the-code
|
||||
[28]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#troubleshooting
|
||||
[29]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#and-still-more
|
||||
[30]:http://netdevconf.org/1.2/session.html?daniel-borkmann
|
||||
[31]:http://netdevconf.org/1.2/slides/oct5/07_tcws_daniel_borkmann_2016_tcws.pdf
|
||||
[32]:http://netdevconf.org/1.2/session.html?jamal-tc-workshop
|
||||
[33]:http://www.netdevconf.org/1.1/proceedings/slides/borkmann-tc-classifier-cls-bpf.pdf
|
||||
[34]:http://www.netdevconf.org/1.1/proceedings/papers/On-getting-tc-classifier-fully-programmable-with-cls-bpf.pdf
|
||||
[35]:https://archive.fosdem.org/2016/schedule/event/ebpf/attachments/slides/1159/export/events/attachments/ebpf/slides/1159/ebpf.pdf
|
||||
[36]:https://fosdem.org/2017/schedule/event/ebpf_xdp/
|
||||
[37]:http://people.netfilter.org/hawk/presentations/xdp2016/xdp_intro_and_use_cases_sep2016.pdf
|
||||
[38]:http://netdevconf.org/1.2/session.html?jesper-performance-workshop
|
||||
[39]:http://people.netfilter.org/hawk/presentations/OpenSourceDays2017/XDP_DDoS_protecting_osd2017.pdf
|
||||
[40]:http://people.netfilter.org/hawk/presentations/MM-summit2017/MM-summit2017-JesperBrouer.pdf
|
||||
[41]:http://netdevconf.org/2.1/session.html?gospodarek
|
||||
[42]:http://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
|
||||
[43]:http://www.slideshare.net/ThomasGraf5/clium-container-networking-with-bpf-xdp
|
||||
[44]:http://www.slideshare.net/Docker/cilium-bpf-xdp-for-containers-66969823
|
||||
[45]:https://www.youtube.com/watch?v=TnJF7ht3ZYc&list=PLkA60AVN3hh8oPas3cq2VA9xB7WazcIgs
|
||||
[46]:http://www.slideshare.net/ThomasGraf5/cilium-fast-ipv6-container-networking-with-bpf-and-xdp
|
||||
[47]:https://fosdem.org/2017/schedule/event/cilium/
|
||||
[48]:http://openvswitch.org/support/ovscon2016/7/1120-tu.pdf
|
||||
[49]:http://openvswitch.org/support/ovscon2016/7/1245-bertrone.pdf
|
||||
[50]:https://www.spinics.net/lists/xdp-newbies/msg00179.html
|
||||
[51]:https://www.spinics.net/lists/xdp-newbies/msg00181.html
|
||||
[52]:https://www.spinics.net/lists/xdp-newbies/msg00185.html
|
||||
[53]:http://schd.ws/hosted_files/ossna2017/da/BPFandXDP.pdf
|
||||
[54]:https://speakerdeck.com/tuxology/the-bsd-packet-filter
|
||||
[55]:http://www.slideshare.net/brendangregg/bpf-tracing-and-more
|
||||
[56]:http://fr.slideshare.net/brendangregg/linux-bpf-superpowers
|
||||
[57]:https://www.socallinuxexpo.org/sites/default/files/presentations/Room%20211%20-%20IOVisor%20-%20SCaLE%2014x.pdf
|
||||
[58]:https://events.linuxfoundation.org/sites/events/files/slides/ebpf_on_the_mainframe_lcon_2015.pdf
|
||||
[59]:https://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf
|
||||
[60]:https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[61]:https://lwn.net/Articles/603983/
|
||||
[62]:http://www.slideshare.net/vh21/meet-cutebetweenebpfandtracing
|
||||
[63]:http://www.slideshare.net/vh21/linux-kernel-tracing
|
||||
[64]:http://www.slideshare.net/ThomasGraf5/linux-networking-explained
|
||||
[65]:http://www.slideshare.net/ThomasGraf5/linuxcon-2015-linux-kernel-networking-walkthrough
|
||||
[66]:http://www.tcpdump.org/papers/bpf-usenix93.pdf
|
||||
[67]:http://www.gsp.com/cgi-bin/man.cgi?topic=bpf
|
||||
[68]:http://borkmann.ch/talks/2013_devconf.pdf
|
||||
[69]:http://borkmann.ch/talks/2014_devconf.pdf
|
||||
[70]:https://blog.cloudflare.com/introducing-the-bpf-tools/
|
||||
[71]:http://biot.com/capstats/bpf.html
|
||||
[72]:https://www.iovisor.org/technology/xdp
|
||||
[73]:https://github.com/iovisor/bpf-docs/raw/master/Express_Data_Path.pdf
|
||||
[74]:https://events.linuxfoundation.org/sites/events/files/slides/iovisor-lc-bof-2016.pdf
|
||||
[75]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#about-xdp-1
|
||||
[76]:http://netdevconf.org/1.2/session.html?herbert-xdp-workshop
|
||||
[77]:https://schd.ws/hosted_files/2016p4workshop/1d/Intel%20Fastabend-P4%20on%20the%20Edge.pdf
|
||||
[78]:https://ovsorbit.benpfaff.org/#e11
|
||||
[79]:http://open-nfp.org/media/pdfs/Open_NFP_P4_EBPF_Linux_TC_Offload_FINAL.pdf
|
||||
[80]:https://opensource.googleblog.com/2016/11/cilium-networking-and-security.html
|
||||
[81]:https://ovsorbit.benpfaff.org/
|
||||
[82]:http://blog.ipspace.net/2016/10/fast-linux-packet-forwarding-with.html
|
||||
[83]:http://netdevconf.org/2.1/session.html?bertin
|
||||
[84]:http://netdevconf.org/2.1/session.html?zhou
|
||||
[85]:http://www.slideshare.net/IOVisor/ceth-for-xdp-linux-meetup-santa-clara-july-2016
|
||||
[86]:http://info.iet.unipi.it/~luigi/vale/
|
||||
[87]:https://github.com/YutaroHayakawa/vale-bpf
|
||||
[88]:https://www.stamus-networks.com/2016/09/28/suricata-bypass-feature/
|
||||
[89]:http://netdevconf.org/1.2/slides/oct6/10_suricata_ebpf.pdf
|
||||
[90]:https://www.slideshare.net/ennael/kernel-recipes-2017-ebpf-and-xdp-eric-leblond
|
||||
[91]:https://github.com/iovisor/bpf-docs/blob/master/university/sigcomm-ccr-InKev-2016.pdf
|
||||
[92]:https://fosdem.org/2017/schedule/event/go_bpf/
|
||||
[93]:https://wkz.github.io/ply/
|
||||
[94]:https://www.kernel.org/doc/Documentation/networking/filter.txt
|
||||
[95]:https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/Documentation/bpf/bpf_design_QA.txt?id=2e39748a4231a893f057567e9b880ab34ea47aef
|
||||
[96]:https://github.com/iovisor/bpf-docs/blob/master/eBPF.md
|
||||
[97]:https://github.com/iovisor/bcc/tree/master/docs
|
||||
[98]:https://github.com/iovisor/bpf-docs/
|
||||
[99]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[100]:http://man7.org/linux/man-pages/man2/bpf.2.html
|
||||
[101]:http://man7.org/linux/man-pages/man8/tc-bpf.8.html
|
||||
[102]:https://prototype-kernel.readthedocs.io/en/latest/bpf/index.html
|
||||
[103]:http://docs.cilium.io/en/latest/bpf/
|
||||
[104]:https://ferrisellis.com/tags/ebpf/
|
||||
[105]:http://linux-ip.net/articles/Traffic-Control-HOWTO/
|
||||
[106]:http://lartc.org/lartc.html
|
||||
[107]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/man/man8
|
||||
[108]:https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc?h=v4.13.0
|
||||
[109]:https://git.kernel.org/pub/scm/linux/kernel/git/shemminger/iproute2.git/tree/doc/actions?h=v4.13.0
|
||||
[110]:http://netdevconf.org/1.2/session.html?jamal-tc-workshop
|
||||
[111]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/commit/bash-completion/tc?id=27d44f3a8a4708bcc99995a4d9b6fe6f81e3e15b
|
||||
[112]:https://prototype-kernel.readthedocs.io/en/latest/networking/XDP/index.html
|
||||
[113]:https://marc.info/?l=linux-netdev&m=147436253625672
|
||||
[114]:http://docs.cilium.io/en/latest/bpf/
|
||||
[115]:https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[116]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/bpf.h
|
||||
[117]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/bpf.h
|
||||
[118]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/filter.h
|
||||
[119]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/uapi/linux/filter.h
|
||||
[120]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/bpf
|
||||
[121]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/filter.c
|
||||
[122]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/arch/x86/net/bpf_jit_comp.c
|
||||
[123]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/sched
|
||||
[124]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/trace/bpf_trace.c
|
||||
[125]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/kernel/seccomp.c
|
||||
[126]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/testing/selftests/seccomp/seccomp_bpf.c
|
||||
[127]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[128]:https://github.com/iovisor/bcc/blob/master/FAQ.txt
|
||||
[129]:https://www.kernel.org/doc/Documentation/networking/filter.txt
|
||||
[130]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[131]:https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py
|
||||
[132]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#output
|
||||
[133]:https://www.spinics.net/lists/netdev/msg406926.html
|
||||
[134]:https://github.com/cilium/bpf-map
|
||||
[135]:https://github.com/badboy/bpf-map
|
||||
[136]:https://stackoverflow.com/questions/tagged/bpf
|
||||
[137]:https://github.com/iovisor/xdp-vagrant
|
||||
[138]:https://github.com/zlim/bcc-docker
|
||||
[139]:http://lists.openwall.net/netdev/
|
||||
[140]:http://vger.kernel.org/vger-lists.html#xdp-newbies
|
||||
[141]:http://lists.iovisor.org/pipermail/iovisor-dev/
|
||||
[142]:https://twitter.com/IOVisor
|
||||
[143]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#what-is-bpf
|
||||
[144]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#dive-into-the-bytecode
|
||||
[145]:https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/#resources
|
||||
[146]:https://github.com/qmonnet/whirl-offload/commits/gh-pages/_posts/2016-09-01-dive-into-bpf.md
|
||||
[147]:http://netdevconf.org/1.2/session.html?jakub-kicinski
|
||||
[148]:http://www.slideshare.net/IOVisor/express-data-path-linux-meetup-santa-clara-july-2016
|
||||
[149]:https://cdn.shopify.com/s/files/1/0177/9886/files/phv2017-gbertin.pdf
|
||||
[150]:https://github.com/cilium/cilium
|
||||
[151]:https://fosdem.org/2017/schedule/event/stateful_ebpf/
|
||||
[152]:http://vger.kernel.org/vger-lists.html#xdp-newbies
|
||||
[153]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[154]:https://github.com/qmonnet/whirl-offload/commit/d694f8081ba00e686e34f86d5ee76abeb4d0e429
|
||||
[155]:http://openvswitch.org/pipermail/dev/2014-October/047421.html
|
||||
[156]:https://qmonnet.github.io/whirl-offload/2016/07/15/beba-research-project/
|
||||
[157]:https://www.iovisor.org/resources/blog
|
||||
[158]:http://www.brendangregg.com/blog/2016-03-05/linux-bpf-superpowers.html
|
||||
[159]:http://p4.org/
|
||||
[160]:https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4
|
||||
[161]:https://github.com/p4lang/p4c/blob/master/backends/ebpf/README.md
|
||||
[162]:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md
|
||||
[163]:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
|
||||
[164]:https://github.com/goldshtn/linux-tracing-workshop
|
||||
[165]:https://blog.yadutaf.fr/2017/07/28/tracing-a-packet-journey-using-linux-tracepoints-perf-ebpf/
|
||||
[166]:https://open-nfp.org/dataplanes-ebpf/technical-papers/
|
||||
[167]:http://netdevconf.org/2.1/session.html?gospodarek
|
||||
[168]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/samples/bpf
|
||||
[169]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/examples/bpf
|
||||
[170]:https://github.com/iovisor/bcc/tree/master/examples
|
||||
[171]:http://man7.org/linux/man-pages/man8/tc-bpf.8.html
|
||||
[172]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/net/core/dev.c
|
||||
[173]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/drivers/net/ethernet/mellanox/mlx4/
|
||||
[174]:https://github.com/iovisor/bcc/
|
||||
[175]:https://github.com/iovisor/bcc/blob/master/src/python/bcc/__init__.py
|
||||
[176]:https://github.com/iovisor/bcc/blob/master/src/cc/libbpf.c
|
||||
[177]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/tc
|
||||
[178]:https://git.kernel.org/cgit/linux/kernel/git/shemminger/iproute2.git/tree/lib/bpf.c
|
||||
[179]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/tools/net
|
||||
[180]:https://git.kernel.org/pub/scm/linux/kernel/git/davem/net-next.git/tree/tools/bpf
|
||||
[181]:https://github.com/iovisor/bcc/tree/master/src/cc/frontends/p4/compiler
|
||||
[182]:https://github.com/iovisor/bcc/tree/master/src/lua
|
||||
[183]:https://reviews.llvm.org/D6494
|
||||
[184]:https://github.com/llvm-mirror/llvm/commit/4fe85c75482f9d11c5a1f92a1863ce30afad8d0d
|
||||
[185]:https://github.com/iovisor/ubpf/
|
||||
[186]:https://github.com/YutaroHayakawa/generic-ebpf
|
||||
[187]:https://github.com/YutaroHayakawa/vale-bpf
|
||||
[188]:https://github.com/qmonnet/rbpf
|
||||
[189]:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git
|
||||
[190]:https://github.com/torvalds/linux
|
||||
[191]:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
|
||||
[192]:https://qmonnet.github.io/whirl-offload/categories/#BPF
|
||||
95
sources/tech/20171107 GitHub welcomes all CI tools.md
Normal file
95
sources/tech/20171107 GitHub welcomes all CI tools.md
Normal file
@ -0,0 +1,95 @@
|
||||
translating---geekpi
|
||||
|
||||
GitHub welcomes all CI tools
|
||||
====================
|
||||
|
||||
|
||||
[][11]
|
||||
|
||||
Continuous Integration ([CI][12]) tools help you stick to your team's quality standards by running tests every time you push a new commit and [reporting the results][13] to a pull request. Combined with continuous delivery ([CD][14]) tools, you can also test your code on multiple configurations, run additional performance tests, and automate every step [until production][15].
|
||||
|
||||
There are several CI and CD tools that [integrate with GitHub][16], some of which you can install in a few clicks from [GitHub Marketplace][17]. With so many options, you can pick the best tool for the job—even if it's not the one that comes pre-integrated with your system.
|
||||
|
||||
The tools that will work best for you depends on many factors, including:
|
||||
|
||||
* Programming language and application architecture
|
||||
|
||||
* Operating system and browsers you plan to support
|
||||
|
||||
* Your team's experience and skills
|
||||
|
||||
* Scaling capabilities and plans for growth
|
||||
|
||||
* Geographic distribution of dependent systems and the people who use them
|
||||
|
||||
* Packaging and delivery goals
|
||||
|
||||
Of course, it isn't possible to optimize your CI tool for all of these scenarios. The people who build them have to choose which use cases to serve best—and when to prioritize complexity over simplicity. For example, if you like to test small applications written in a particular programming language for one platform, you won't need the complexity of a tool that tests embedded software controllers on dozens of platforms with a broad mix of programming languages and frameworks.
|
||||
|
||||
If you need a little inspiration for which CI tool might work best, take a look at [popular GitHub projects][18]. Many show the status of their integrated CI/CD tools as badges in their README.md. We've also analyzed the use of CI tools across more than 50 million repositories in the GitHub community, and found a lot of variety. The following diagram shows the relative percentage of the top 10 CI tools used with GitHub.com, based on the most used [commit status contexts][19] used within our pull requests.
|
||||
|
||||
_Our analysis also showed that many teams use more than one CI tool in their projects, allowing them to emphasize what each tool does best._
|
||||
|
||||
[][20]
|
||||
|
||||
If you'd like to check them out, here are the top 10 tools teams use:
|
||||
|
||||
* [Travis CI][1]
|
||||
|
||||
* [Circle CI][2]
|
||||
|
||||
* [Jenkins][3]
|
||||
|
||||
* [AppVeyor][4]
|
||||
|
||||
* [CodeShip][5]
|
||||
|
||||
* [Drone][6]
|
||||
|
||||
* [Semaphore CI][7]
|
||||
|
||||
* [Buildkite][8]
|
||||
|
||||
* [Wercker][9]
|
||||
|
||||
* [TeamCity][10]
|
||||
|
||||
It's tempting to just pick the default, pre-integrated tool without taking the time to research and choose the best one for the job, but there are plenty of [excellent choices][21] built for your specific use cases. And if you change your mind later, no problem. When you choose the best tool for a specific situation, you're guaranteeing tailored performance and the freedom of interchangability when it no longer fits.
|
||||
|
||||
Ready to see how CI tools can fit into your workflow?
|
||||
|
||||
[Browse GitHub Marketplace][22]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2463-github-welcomes-all-ci-tools
|
||||
|
||||
作者:[jonico ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/jonico
|
||||
[1]:https://travis-ci.org/
|
||||
[2]:https://circleci.com/
|
||||
[3]:https://jenkins.io/
|
||||
[4]:https://www.appveyor.com/
|
||||
[5]:https://codeship.com/
|
||||
[6]:http://try.drone.io/
|
||||
[7]:https://semaphoreci.com/
|
||||
[8]:https://buildkite.com/
|
||||
[9]:http://www.wercker.com/
|
||||
[10]:https://www.jetbrains.com/teamcity/
|
||||
[11]:https://user-images.githubusercontent.com/29592817/32509084-2d52c56c-c3a1-11e7-8c49-901f0f601faf.png
|
||||
[12]:https://en.wikipedia.org/wiki/Continuous_integration
|
||||
[13]:https://github.com/blog/2051-protected-branches-and-required-status-checks
|
||||
[14]:https://en.wikipedia.org/wiki/Continuous_delivery
|
||||
[15]:https://developer.github.com/changes/2014-01-09-preview-the-new-deployments-api/
|
||||
[16]:https://github.com/works-with/category/continuous-integration
|
||||
[17]:https://github.com/marketplace/category/continuous-integration
|
||||
[18]:https://github.com/explore?trending=repositories#trending
|
||||
[19]:https://developer.github.com/v3/repos/statuses/
|
||||
[20]:https://user-images.githubusercontent.com/7321362/32575895-ea563032-c49a-11e7-9581-e05ec882658b.png
|
||||
[21]:https://github.com/works-with/category/continuous-integration
|
||||
[22]:https://github.com/marketplace/category/continuous-integration
|
||||
@ -1,492 +0,0 @@
|
||||
Translating by qhwdw [Concurrent Servers: Part 4 - libuv][17]
|
||||
============================================================
|
||||
|
||||
This is part 4 of a series of posts on writing concurrent network servers. In this part we're going to use libuv to rewrite our server once again, and also talk about handling time-consuming tasks in callbacks using a thread pool. Finally, we're going to look under the hood of libuv for a bit to study how it wraps blocking file-system operations with an asynchronous API.
|
||||
|
||||
All posts in the series:
|
||||
|
||||
* [Part 1 - Introduction][7]
|
||||
|
||||
* [Part 2 - Threads][8]
|
||||
|
||||
* [Part 3 - Event-driven][9]
|
||||
|
||||
* [Part 4 - libuv][10]
|
||||
|
||||
### Abstracting away event-driven loops with libuv
|
||||
|
||||
In [part 3][11], we've seen how similar select-based and epoll-based servers are, and I mentioned it's very tempting to abstract away the minor differences between them. Numerous libraries are already doing this, however, so in this part I'm going to pick one and use it. The library I'm picking is [libuv][12], which was originally designed to serve as the underlying portable platform layer for Node.js, and has since found use in additional projects. libuv is written in C, which makes it highly portable and very suitable for tying into high-level languages like JavaScript and Python.
|
||||
|
||||
While libuv has grown to be a fairly large framework for abstracting low-level platform details, it remains centered on the concept of an _event loop_ . In our event-driven servers in part 3, the event loop was explicit in the main function; when using libuv, the loop is usually hidden inside the library itself, and user code just registers event handlers (as callback functions) and runs the loop. Furthermore, libuv will use the fastest event loop implementation for a given platform: for Linux this is epoll, etc.
|
||||
|
||||

|
||||
|
||||
libuv supports multiple event loops, and thus an event loop is a first class citizen within the library; it has a handle - uv_loop_t, and functions for creating/destroying/starting/stopping loops. That said, I will only use the "default" loop in this post, which libuv makes available via uv_default_loop(); multiple loops are mosly useful for multi-threaded event-driven servers, a more advanced topic I'll leave for future parts in the series.
|
||||
|
||||
### A concurrent server using libuv
|
||||
|
||||
To get a better feel for libuv, let's jump to our trusty protocol server that we've been vigorously reimplementing throughout the series. The structure of this server is going to be somewhat similar to the select and epoll-based servers of part 3, since it also relies on callbacks. The full [code sample is here][13]; we start with setting up the server socket bound to a local port:
|
||||
|
||||
```
|
||||
int portnum = 9090;
|
||||
if (argc >= 2) {
|
||||
portnum = atoi(argv[1]);
|
||||
}
|
||||
printf("Serving on port %d\n", portnum);
|
||||
|
||||
int rc;
|
||||
uv_tcp_t server_stream;
|
||||
if ((rc = uv_tcp_init(uv_default_loop(), &server_stream)) < 0) {
|
||||
die("uv_tcp_init failed: %s", uv_strerror(rc));
|
||||
}
|
||||
|
||||
struct sockaddr_in server_address;
|
||||
if ((rc = uv_ip4_addr("0.0.0.0", portnum, &server_address)) < 0) {
|
||||
die("uv_ip4_addr failed: %s", uv_strerror(rc));
|
||||
}
|
||||
|
||||
if ((rc = uv_tcp_bind(&server_stream, (const struct sockaddr*)&server_address, 0)) < 0) {
|
||||
die("uv_tcp_bind failed: %s", uv_strerror(rc));
|
||||
}
|
||||
```
|
||||
|
||||
Fairly standard socket fare here, except that it's all wrapped in libuv APIs. In return we get a portable interface that should work on any platform libuv supports.
|
||||
|
||||
This code also demonstrates conscientious error handling; most libuv functions return an integer status, with a negative number meaning an error. In our server we treat these errors as fatals, but one may imagine a more graceful recovery.
|
||||
|
||||
Now that the socket is bound, it's time to listen on it. Here we run into our first callback registration:
|
||||
|
||||
```
|
||||
// Listen on the socket for new peers to connect. When a new peer connects,
|
||||
// the on_peer_connected callback will be invoked.
|
||||
if ((rc = uv_listen((uv_stream_t*)&server_stream, N_BACKLOG, on_peer_connected)) < 0) {
|
||||
die("uv_listen failed: %s", uv_strerror(rc));
|
||||
}
|
||||
```
|
||||
|
||||
uv_listen registers a callback that the event loop will invoke when new peers connect to the socket. Our callback here is called on_peer_connected, and we'll examine it soon.
|
||||
|
||||
Finally, main runs the libuv loop until it's stopped (uv_run only returns when the loop has stopped or some error occurred).
|
||||
|
||||
```
|
||||
// Run the libuv event loop.
|
||||
uv_run(uv_default_loop(), UV_RUN_DEFAULT);
|
||||
|
||||
// If uv_run returned, close the default loop before exiting.
|
||||
return uv_loop_close(uv_default_loop());
|
||||
```
|
||||
|
||||
Note that only a single callback was registered by main prior to running the event loop; we'll soon see how additional callbacks are added. It's not a problem to add and remove callbacks throughout the runtime of the event loop - in fact, this is how most servers are expected to be written.
|
||||
|
||||
This is on_peer_connected, which handles new client connections to the server:
|
||||
|
||||
```
|
||||
void on_peer_connected(uv_stream_t* server_stream, int status) {
|
||||
if (status < 0) {
|
||||
fprintf(stderr, "Peer connection error: %s\n", uv_strerror(status));
|
||||
return;
|
||||
}
|
||||
|
||||
// client will represent this peer; it's allocated on the heap and only
|
||||
// released when the client disconnects. The client holds a pointer to
|
||||
// peer_state_t in its data field; this peer state tracks the protocol state
|
||||
// with this client throughout interaction.
|
||||
uv_tcp_t* client = (uv_tcp_t*)xmalloc(sizeof(*client));
|
||||
int rc;
|
||||
if ((rc = uv_tcp_init(uv_default_loop(), client)) < 0) {
|
||||
die("uv_tcp_init failed: %s", uv_strerror(rc));
|
||||
}
|
||||
client->data = NULL;
|
||||
|
||||
if (uv_accept(server_stream, (uv_stream_t*)client) == 0) {
|
||||
struct sockaddr_storage peername;
|
||||
int namelen = sizeof(peername);
|
||||
if ((rc = uv_tcp_getpeername(client, (struct sockaddr*)&peername,
|
||||
&namelen)) < 0) {
|
||||
die("uv_tcp_getpeername failed: %s", uv_strerror(rc));
|
||||
}
|
||||
report_peer_connected((const struct sockaddr_in*)&peername, namelen);
|
||||
|
||||
// Initialize the peer state for a new client: we start by sending the peer
|
||||
// the initial '*' ack.
|
||||
peer_state_t* peerstate = (peer_state_t*)xmalloc(sizeof(*peerstate));
|
||||
peerstate->state = INITIAL_ACK;
|
||||
peerstate->sendbuf[0] = '*';
|
||||
peerstate->sendbuf_end = 1;
|
||||
peerstate->client = client;
|
||||
client->data = peerstate;
|
||||
|
||||
// Enqueue the write request to send the ack; when it's done,
|
||||
// on_wrote_init_ack will be called. The peer state is passed to the write
|
||||
// request via the data pointer; the write request does not own this peer
|
||||
// state - it's owned by the client handle.
|
||||
uv_buf_t writebuf = uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
|
||||
uv_write_t* req = (uv_write_t*)xmalloc(sizeof(*req));
|
||||
req->data = peerstate;
|
||||
if ((rc = uv_write(req, (uv_stream_t*)client, &writebuf, 1,
|
||||
on_wrote_init_ack)) < 0) {
|
||||
die("uv_write failed: %s", uv_strerror(rc));
|
||||
}
|
||||
} else {
|
||||
uv_close((uv_handle_t*)client, on_client_closed);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This code is well commented, but there are a couple of important libuv idioms I'd like to highlight:
|
||||
|
||||
* Passing custom data into callbacks: since C has no closures, this can be challenging. libuv has a void* datafield in all its handle types; these fields can be used to pass user data. For example, note how client->data is made to point to a peer_state_t structure so that the callbacks registered by uv_write and uv_read_start can know which peer data they're dealing with.
|
||||
|
||||
* Memory management: event-driven programming is much easier in languages with garbage collection, because callbacks usually run in a completely different stack frame from where they were registered, making stack-based memory management difficult. It's almost always necessary to pass heap-allocated data to libuv callbacks (except in main, which remains alive on the stack when all callbacks run), and to avoid leaks much care is required about when these data are safe to free(). This is something that comes with a bit of practice [[1]][6].
|
||||
|
||||
The peer state for this server is:
|
||||
|
||||
```
|
||||
typedef struct {
|
||||
ProcessingState state;
|
||||
char sendbuf[SENDBUF_SIZE];
|
||||
int sendbuf_end;
|
||||
uv_tcp_t* client;
|
||||
} peer_state_t;
|
||||
```
|
||||
|
||||
It's fairly similar to the state in part 3; we no longer need sendptr, since uv_write will make sure to send the whole buffer it's given before invoking the "done writing" callback. We also keep a pointer to the client for other callbacks to use. Here's on_wrote_init_ack:
|
||||
|
||||
```
|
||||
void on_wrote_init_ack(uv_write_t* req, int status) {
|
||||
if (status) {
|
||||
die("Write error: %s\n", uv_strerror(status));
|
||||
}
|
||||
peer_state_t* peerstate = (peer_state_t*)req->data;
|
||||
// Flip the peer state to WAIT_FOR_MSG, and start listening for incoming data
|
||||
// from this peer.
|
||||
peerstate->state = WAIT_FOR_MSG;
|
||||
peerstate->sendbuf_end = 0;
|
||||
|
||||
int rc;
|
||||
if ((rc = uv_read_start((uv_stream_t*)peerstate->client, on_alloc_buffer,
|
||||
on_peer_read)) < 0) {
|
||||
die("uv_read_start failed: %s", uv_strerror(rc));
|
||||
}
|
||||
|
||||
// Note: the write request doesn't own the peer state, hence we only free the
|
||||
// request itself, not the state.
|
||||
free(req);
|
||||
}
|
||||
```
|
||||
|
||||
Then we know for sure that the initial '*' was sent to the peer, we start listening to incoming data from this peer by calling uv_read_start, which registers a callback (on_peer_read) that will be invoked by the event loop whenever new data is received on the socket from the client:
|
||||
|
||||
```
|
||||
void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
|
||||
if (nread < 0) {
|
||||
if (nread != uv_eof) {
|
||||
fprintf(stderr, "read error: %s\n", uv_strerror(nread));
|
||||
}
|
||||
uv_close((uv_handle_t*)client, on_client_closed);
|
||||
} else if (nread == 0) {
|
||||
// from the documentation of uv_read_cb: nread might be 0, which does not
|
||||
// indicate an error or eof. this is equivalent to eagain or ewouldblock
|
||||
// under read(2).
|
||||
} else {
|
||||
// nread > 0
|
||||
assert(buf->len >= nread);
|
||||
|
||||
peer_state_t* peerstate = (peer_state_t*)client->data;
|
||||
if (peerstate->state == initial_ack) {
|
||||
// if the initial ack hasn't been sent for some reason, ignore whatever
|
||||
// the client sends in.
|
||||
free(buf->base);
|
||||
return;
|
||||
}
|
||||
|
||||
// run the protocol state machine.
|
||||
for (int i = 0; i < nread; ++i) {
|
||||
switch (peerstate->state) {
|
||||
case initial_ack:
|
||||
assert(0 && "can't reach here");
|
||||
break;
|
||||
case wait_for_msg:
|
||||
if (buf->base[i] == '^') {
|
||||
peerstate->state = in_msg;
|
||||
}
|
||||
break;
|
||||
case in_msg:
|
||||
if (buf->base[i] == '$') {
|
||||
peerstate->state = wait_for_msg;
|
||||
} else {
|
||||
assert(peerstate->sendbuf_end < sendbuf_size);
|
||||
peerstate->sendbuf[peerstate->sendbuf_end++] = buf->base[i] + 1;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (peerstate->sendbuf_end > 0) {
|
||||
// we have data to send. the write buffer will point to the buffer stored
|
||||
// in the peer state for this client.
|
||||
uv_buf_t writebuf =
|
||||
uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
|
||||
uv_write_t* writereq = (uv_write_t*)xmalloc(sizeof(*writereq));
|
||||
writereq->data = peerstate;
|
||||
int rc;
|
||||
if ((rc = uv_write(writereq, (uv_stream_t*)client, &writebuf, 1,
|
||||
on_wrote_buf)) < 0) {
|
||||
die("uv_write failed: %s", uv_strerror(rc));
|
||||
}
|
||||
}
|
||||
}
|
||||
free(buf->base);
|
||||
}
|
||||
```
|
||||
|
||||
The runtime behavior of this server is very similar to the event-driven servers of part 3: all clients are handled concurrently in a single thread. Also similarly, a certain discipline has to be maintained in the server's code: the server's logic is implemented as an ensemble of callbacks, and long-running operations are a big no-no since they block the event loop. Let's explore this issue a bit further.
|
||||
|
||||
### Long-running operations in event-driven loops
|
||||
|
||||
The single-threaded nature of event-driven code makes it very susceptible to a common issue: long-running code blocks the entire loop. Consider this program:
|
||||
|
||||
```
|
||||
void on_timer(uv_timer_t* timer) {
|
||||
uint64_t timestamp = uv_hrtime();
|
||||
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
|
||||
|
||||
// "Work"
|
||||
if (random() % 5 == 0) {
|
||||
printf("Sleeping...\n");
|
||||
sleep(3);
|
||||
}
|
||||
}
|
||||
|
||||
int main(int argc, const char** argv) {
|
||||
uv_timer_t timer;
|
||||
uv_timer_init(uv_default_loop(), &timer);
|
||||
uv_timer_start(&timer, on_timer, 0, 1000);
|
||||
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
|
||||
}
|
||||
```
|
||||
|
||||
It runs a libuv event loop with a single registered callback: on_timer, which is invoked by the loop every second. The callback reports a timestamp, and once in a while simulates some long-running task by sleeping for 3 seconds. Here's a sample run:
|
||||
|
||||
```
|
||||
$ ./uv-timer-sleep-demo
|
||||
on_timer [4840 ms]
|
||||
on_timer [5842 ms]
|
||||
on_timer [6843 ms]
|
||||
on_timer [7844 ms]
|
||||
Sleeping...
|
||||
on_timer [11845 ms]
|
||||
on_timer [12846 ms]
|
||||
Sleeping...
|
||||
on_timer [16847 ms]
|
||||
on_timer [17849 ms]
|
||||
on_timer [18850 ms]
|
||||
...
|
||||
```
|
||||
|
||||
on_timer dutifully fires every second, until the random sleep hits in. At that point, on_timer is not invoked again until the sleep is over; in fact, _no other callbacks_ will be invoked in this time frame. The sleep call blocks the current thread, which is the only thread involved and is also the thread the event loop uses. When this thread is blocked, the event loop is blocked.
|
||||
|
||||
This example demonstrates why it's so important for callbacks to never block in event-driven calls, and applies equally to Node.js servers, client-side Javascript, most GUI programming frameworks, and many other asynchronous programming models.
|
||||
|
||||
But sometimes running time-consuming tasks is unavoidable. Not all tasks have asynchronous APIs; for example, we may be dealing with some library that only has a synchronous API, or just have to perform a potentially long computation. How can we combine such code with event-driven programming? Threads to the rescue!
|
||||
|
||||
### Threads for "converting" blocking calls into asynchronous calls
|
||||
|
||||
A thread pool can be used to turn blocking calls into asynchronous calls, by running alongside the event loop and posting events onto it when tasks are completed. Here's how it works, for a given blocking function do_work():
|
||||
|
||||
1. Instead of directly calling do_work() in a callback, we package it into a "task" and ask the thread pool to execute the task. We also register a callback for the loop to invoke when the task has finished; let's call iton_work_done().
|
||||
|
||||
2. At this point our callback can return and the event loop keeps spinning; at the same time, a thread in the pool is executing the task.
|
||||
|
||||
3. Once the task has finished executing, the main thread (the one running the event loop) is notified and on_work_done() is invoked by the event loop.
|
||||
|
||||
Let's see how this solves our previous timer/sleep example, using libuv's work scheduling API:
|
||||
|
||||
```
|
||||
void on_after_work(uv_work_t* req, int status) {
|
||||
free(req);
|
||||
}
|
||||
|
||||
void on_work(uv_work_t* req) {
|
||||
// "Work"
|
||||
if (random() % 5 == 0) {
|
||||
printf("Sleeping...\n");
|
||||
sleep(3);
|
||||
}
|
||||
}
|
||||
|
||||
void on_timer(uv_timer_t* timer) {
|
||||
uint64_t timestamp = uv_hrtime();
|
||||
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
|
||||
|
||||
uv_work_t* work_req = (uv_work_t*)malloc(sizeof(*work_req));
|
||||
uv_queue_work(uv_default_loop(), work_req, on_work, on_after_work);
|
||||
}
|
||||
|
||||
int main(int argc, const char** argv) {
|
||||
uv_timer_t timer;
|
||||
uv_timer_init(uv_default_loop(), &timer);
|
||||
uv_timer_start(&timer, on_timer, 0, 1000);
|
||||
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
|
||||
}
|
||||
```
|
||||
|
||||
Instead of calling sleep directly in on_timer, we enqueue a task, represented by a handle of type work_req [[2]][14], the function to run in the task (on_work) and the function to invoke once the task is completed (on_after_work). on_workis where the "work" (the blocking/time-consuming operation) happens. Note a crucial difference between the two callbacks passed into uv_queue_work: on_work runs in the thread pool, while on_after_work runs on the main thread which also runs the event loop - just like any other callback.
|
||||
|
||||
Let's see this version run:
|
||||
|
||||
```
|
||||
$ ./uv-timer-work-demo
|
||||
on_timer [89571 ms]
|
||||
on_timer [90572 ms]
|
||||
on_timer [91573 ms]
|
||||
on_timer [92575 ms]
|
||||
Sleeping...
|
||||
on_timer [93576 ms]
|
||||
on_timer [94577 ms]
|
||||
Sleeping...
|
||||
on_timer [95577 ms]
|
||||
on_timer [96578 ms]
|
||||
on_timer [97578 ms]
|
||||
...
|
||||
```
|
||||
|
||||
The timer ticks every second, even though the sleeping function is still invoked; sleeping is now done on a separate thread and doesn't block the event loop.
|
||||
|
||||
### A primality-testing server, with exercises
|
||||
|
||||
Since sleep isn't a very exciting way to simulate work, I've prepared a more comprehensive example - a server that accepts numbers from clients over a socket, checks whether these numbers are prime and sends back either "prime" or "composite". The full [code for this server is here][15] - I won't post it here since it's long, but will rather give readers the opportunity to explore it on their own with a couple of exercises.
|
||||
|
||||
The server deliberatly uses a naive primality test algorithm, so for large primes it can take quite a while to return an answer. On my machine it takes ~5 seconds to compute the answer for 2305843009213693951, but YMMV.
|
||||
|
||||
Exercise 1: the server has a setting (via an environment variable named MODE) to either run the primality test in the socket callback (meaning on the main thread) or in the libuv work queue. Play with this setting to observe the server's behavior when multiple clients are connecting simultaneously. In blocking mode, the server will not answer other clients while it's computing a big task; in non-blocking mode it will.
|
||||
|
||||
Exercise 2: libuv has a default thread-pool size, and it can be configured via an environment variable. Can you use multiple clients to discover experimentally what the default size is? Having found the default thread-pool size, play with different settings to see how it affects the server's responsiveness under heavy load.
|
||||
|
||||
### Non-blocking file-system operations using work queues
|
||||
|
||||
Delegating potentially-blocking operations to a thread pool isn't good for just silly demos and CPU-intensive computations; libuv itself makes heavy use of this capability in its file-system APIs. This way, libuv accomplishes the superpower of exposing the file-system with an asynchronous API, in a portable way.
|
||||
|
||||
Let's take uv_fs_read(), for example. This function reads from a file (represented by a uv_fs_t handle) into a buffer [[3]][16], and invokes a callback when the reading is completed. That is, uv_fs_read() always returns immediately, even if the file sits on an NFS-like system and it may take a while for the data to get to the buffer. In other words, this API is asynchronous in the way other libuv APIs are. How does this work?
|
||||
|
||||
At this point we're going to look under the hood of libuv; the internals are actually fairly straightforward, and it's a good exercise. Being a portable library, libuv has different implementations of many of its functions for Windows and Unix systems. We're going to be looking at src/unix/fs.c in the libuv source tree.
|
||||
|
||||
The code for uv_fs_read is:
|
||||
|
||||
```
|
||||
int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
|
||||
uv_file file,
|
||||
const uv_buf_t bufs[],
|
||||
unsigned int nbufs,
|
||||
int64_t off,
|
||||
uv_fs_cb cb) {
|
||||
if (bufs == NULL || nbufs == 0)
|
||||
return -EINVAL;
|
||||
|
||||
INIT(READ);
|
||||
req->file = file;
|
||||
|
||||
req->nbufs = nbufs;
|
||||
req->bufs = req->bufsml;
|
||||
if (nbufs > ARRAY_SIZE(req->bufsml))
|
||||
req->bufs = uv__malloc(nbufs * sizeof(*bufs));
|
||||
|
||||
if (req->bufs == NULL) {
|
||||
if (cb != NULL)
|
||||
uv__req_unregister(loop, req);
|
||||
return -ENOMEM;
|
||||
}
|
||||
|
||||
memcpy(req->bufs, bufs, nbufs * sizeof(*bufs));
|
||||
|
||||
req->off = off;
|
||||
POST;
|
||||
}
|
||||
```
|
||||
|
||||
It may seem puzzling at first, because it defers the real work to the INIT and POST macros, with some local variable setup for POST. This is done to avoid too much code duplication within the file.
|
||||
|
||||
The INIT macro is:
|
||||
|
||||
```
|
||||
#define INIT(subtype) \
|
||||
do { \
|
||||
req->type = UV_FS; \
|
||||
if (cb != NULL) \
|
||||
uv__req_init(loop, req, UV_FS); \
|
||||
req->fs_type = UV_FS_ ## subtype; \
|
||||
req->result = 0; \
|
||||
req->ptr = NULL; \
|
||||
req->loop = loop; \
|
||||
req->path = NULL; \
|
||||
req->new_path = NULL; \
|
||||
req->cb = cb; \
|
||||
} \
|
||||
while (0)
|
||||
```
|
||||
|
||||
It sets up the request, and most importantly sets the req->fs_type field to the actual FS request type. Since uv_fs_read invokes INIT(READ), it means req->fs_type gets assigned the constant UV_FS_READ.
|
||||
|
||||
The POST macro is:
|
||||
|
||||
```
|
||||
#define POST \
|
||||
do { \
|
||||
if (cb != NULL) { \
|
||||
uv__work_submit(loop, &req->work_req, uv__fs_work, uv__fs_done); \
|
||||
return 0; \
|
||||
} \
|
||||
else { \
|
||||
uv__fs_work(&req->work_req); \
|
||||
return req->result; \
|
||||
} \
|
||||
} \
|
||||
while (0)
|
||||
```
|
||||
|
||||
What it does depends on whether the callback is NULL. In libuv file-system APIs, a NULL callback means we actually want to perform the operation _synchronously_ . In this case POST invokes uv__fs_work directly (we'll get to what this function does in just a bit), whereas for a non-NULL callback, it submits uv__fs_work as a work item to the work queue (which is the thread pool), and registers uv__fs_done as the callback; that function does a bit of book-keeping and invokes the user-provided callback.
|
||||
|
||||
If we look at the code of uv__fs_work, we'll see it uses more macros to route work to the actual file-system call as needed. In our case, for UV_FS_READ the call will be made to uv__fs_read, which (at last!) does the reading using regular POSIX APIs. This function can be safely implemented in a _blocking_ manner, since it's placed on a thread-pool when called through the asynchronous API.
|
||||
|
||||
In Node.js, the fs.readFile function is mapped to uv_fs_read. Thus, reading files can be done in a non-blocking fashion even though the underlying file-system API is blocking.
|
||||
|
||||
* * *
|
||||
|
||||
|
||||
[[1]][1] To ensure that this server doesn't leak memory, I ran it under Valgrind with the leak checker enabled. Since servers are often designed to run forever, this was a bit challenging; to overcome this issue I've added a "kill switch" to the server - a special sequence received from a client makes it stop the event loop and exit. The code for this is in theon_wrote_buf handler.
|
||||
|
||||
|
||||
[[2]][2] Here we don't use work_req for much; the primality testing server discussed next will show how it's used to pass context information into the callback.
|
||||
|
||||
|
||||
[[3]][3] uv_fs_read() provides a generalized API similar to the preadv Linux system call: it takes multiple buffers which it fills in order, and supports an offset into the file. We can ignore these features for the sake of our discussion.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id2
|
||||
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id3
|
||||
[4]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[5]:https://eli.thegreenplace.net/tag/c-c
|
||||
[6]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id4
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[8]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[9]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[10]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
[11]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[12]:http://libuv.org/
|
||||
[13]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/uv-server.c
|
||||
[14]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id5
|
||||
[15]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/uv-isprime-server.c
|
||||
[16]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id6
|
||||
[17]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
311
sources/tech/20171112 Love Your Bugs.md
Normal file
311
sources/tech/20171112 Love Your Bugs.md
Normal file
@ -0,0 +1,311 @@
|
||||
Love Your Bugs
|
||||
============================================================
|
||||
|
||||
In early October I gave a keynote at [Python Brasil][1] in Belo Horizonte. Here is an aspirational and lightly edited transcript of the talk. There is also a video available [here][2].
|
||||
|
||||
### I love bugs
|
||||
|
||||
I’m currently a senior engineer at [Pilot.com][3], working on automating bookkeeping for startups. Before that, I worked for [Dropbox][4] on the desktop client team, and I’ll have a few stories about my work there. Earlier, I was a facilitator at the [Recurse Center][5], a writers retreat for programmers in NYC. I studied astrophysics in college and worked in finance for a few years before becoming an engineer.
|
||||
|
||||
But none of that is really important to remember – the only thing you need to know about me is that I love bugs. I love bugs because they’re entertaining. They’re dramatic. The investigation of a great bug can be full of twists and turns. A great bug is like a good joke or a riddle – you’re expecting one outcome, but the result veers off in another direction.
|
||||
|
||||
Over the course of this talk I’m going to tell you about some bugs that I have loved, explain why I love bugs so much, and then convince you that you should love bugs too.
|
||||
|
||||
### Bug #1
|
||||
|
||||
Ok, straight into bug #1\. This is a bug that I encountered while working at Dropbox. As you may know, Dropbox is a utility that syncs your files from one computer to the cloud and to your other computers.
|
||||
|
||||
|
||||
|
||||
```
|
||||
+--------------+ +---------------+
|
||||
| | | |
|
||||
| METASERVER | | BLOCKSERVER |
|
||||
| | | |
|
||||
+-+--+---------+ +---------+-----+
|
||||
^ | ^
|
||||
| | |
|
||||
| | +----------+ |
|
||||
| +---> | | |
|
||||
| | CLIENT +--------+
|
||||
+--------+ |
|
||||
+----------+
|
||||
```
|
||||
|
||||
|
||||
Here’s a vastly simplified diagram of Dropbox’s architecture. The desktop client runs on your local computer listening for changes in the file system. When it notices a changed file, it reads the file, then hashes the contents in 4MB blocks. These blocks are stored in the backend in a giant key-value store that we call blockserver. The key is the digest of the hashed contents, and the values are the contents themselves.
|
||||
|
||||
Of course, we want to avoid uploading the same block multiple times. You can imagine that if you’re writing a document, you’re probably mostly changing the end – we don’t want to upload the beginning over and over. So before uploading a block to the blockserver the client talks to a different server that’s responsible for managing metadata and permissions, among other things. The client asks metaserver whether it needs the block or has seen it before. The “metaserver” responds with whether or not each block needs to be uploaded.
|
||||
|
||||
So the request and response look roughly like this: The client says, “I have a changed file made up of blocks with hashes `'abcd,deef,efgh'`”. The server responds, “I have those first two, but upload the third.” Then the client sends the block up to the blockserver.
|
||||
|
||||
|
||||
```
|
||||
+--------------+ +---------------+
|
||||
| | | |
|
||||
| METASERVER | | BLOCKSERVER |
|
||||
| | | |
|
||||
+-+--+---------+ +---------+-----+
|
||||
^ | ^
|
||||
| | 'ok, ok, need' |
|
||||
'abcd,deef,efgh' | | +----------+ | efgh: [contents]
|
||||
| +---> | | |
|
||||
| | CLIENT +--------+
|
||||
+--------+ |
|
||||
+----------+
|
||||
```
|
||||
|
||||
|
||||
|
||||
That’s the setup. So here’s the bug.
|
||||
|
||||
|
||||
|
||||
```
|
||||
+--------------+
|
||||
| |
|
||||
| METASERVER |
|
||||
| |
|
||||
+-+--+---------+
|
||||
^ |
|
||||
| | '???'
|
||||
'abcdldeef,efgh' | | +----------+
|
||||
^ | +---> | |
|
||||
^ | | CLIENT +
|
||||
+--------+ |
|
||||
+----------+
|
||||
```
|
||||
|
||||
Sometimes the client would make a weird request: each hash value should have been sixteen characters long, but instead it was thirty-three characters long – twice as many plus one. The server wouldn’t know what to do with this and would throw an exception. We’d see this exception get reported, and we’d go look at the log files from the desktop client, and really weird stuff would be going on – the client’s local database had gotten corrupted, or python would be throwing MemoryErrors, and none of it would make sense.
|
||||
|
||||
If you’ve never seen this problem before, it’s totally mystifying. But once you’d seen it once, you can recognize it every time thereafter. Here’s a hint: the middle character of each 33-character string that we’d often see instead of a comma was `l`. These are the other characters we’d see in the middle position:
|
||||
|
||||
|
||||
```
|
||||
l \x0c < $ ( . -
|
||||
```
|
||||
|
||||
The ordinal value for an ascii comma – `,` – is 44\. The ordinal value for `l` is 108\. In binary, here’s how those two are represented:
|
||||
|
||||
```
|
||||
bin(ord(',')): 0101100
|
||||
bin(ord('l')): 1101100
|
||||
```
|
||||
|
||||
You’ll notice that an `l` is exactly one bit away from a comma. And herein lies your problem: a bitflip. One bit of memory that the desktop client is using has gotten corrupted, and now the desktop client is sending a request to the server that is garbage.
|
||||
|
||||
And here are the other characters we’d frequently see instead of the comma when a different bit had been flipped.
|
||||
|
||||
|
||||
|
||||
```
|
||||
, : 0101100
|
||||
l : 1101100
|
||||
\x0c : 0001100
|
||||
< : 0111100
|
||||
$ : 0100100
|
||||
( : 0101000
|
||||
. : 0101110
|
||||
- : 0101101
|
||||
```
|
||||
|
||||
|
||||
### Bitflips are real!
|
||||
|
||||
I love this bug because it shows that bitflips are a real thing that can happen, not just a theoretical concern. In fact, there are some domains where they’re more common than others. One such domain is if you’re getting requests from users with low-end or old hardware, which is true for a lot of laptops running Dropbox. Another domain with lots of bitflips is outer space – there’s no atmosphere in space to protect your memory from energetic particles and radiation, so bitflips are pretty common.
|
||||
|
||||
You probably really care about correctness in space – your code might be keeping astronauts alive on the ISS, for example, but even if it’s not mission-critical, it’s hard to do software updates to space. If you really need your application to defend against bitflips, there are a variety of hardware & software approaches you can take, and there’s a [very interesting talk][6] by Katie Betchold about this.
|
||||
|
||||
Dropbox in this context doesn’t really need to protect against bitflips. The machine that is corrupting memory is a user’s machine, so we can detect if the bitflip happens to fall in the comma – but if it’s in a different character we don’t necessarily know it, and if the bitflip is in the actual file data read off of disk, then we have no idea. There’s a pretty limited set of places where we could address this, and instead we decide to basically silence the exception and move on. Often this kind of bug resolves after the client restarts.
|
||||
|
||||
### Unlikely bugs aren’t impossible
|
||||
|
||||
This is one of my favorite bugs for a couple of reasons. The first is that it’s a reminder of the difference between unlikely and impossible. At sufficient scale, unlikely events start to happen at a noticable rate.
|
||||
|
||||
### Social bugs
|
||||
|
||||
My second favorite thing about this bug is that it’s a tremendously social one. This bug can crop up anywhere that the desktop client talks to the server, which is a lot of different endpoints and components in the system. This meant that a lot of different engineers at Dropbox would see versions of the bug. The first time you see it, you can _really_ scratch your head, but after that it’s easy to diagnose, and the investigation is really quick: you look at the middle character and see if it’s an `l`.
|
||||
|
||||
### Cultural differences
|
||||
|
||||
One interesting side-effect of this bug was that it exposed a cultural difference between the server and client teams. Occasionally this bug would be spotted by a member of the server team and investigated from there. If one of your _servers_ is flipping bits, that’s probably not random chance – it’s probably memory corruption, and you need to find the affected machine and get it out of the pool as fast as possible or you risk corrupting a lot of user data. That’s an incident, and you need to respond quickly. But if the user’s machine is corrupting data, there’s not a lot you can do.
|
||||
|
||||
### Share your bugs
|
||||
|
||||
So if you’re investigating a confusing bug, especially one in a big system, don’t forget to talk to people about it. Maybe your colleagues have seen a bug shaped like this one before. If they have, you might save a lot of time. And if they haven’t, don’t forget to tell people about the solution once you’ve figured it out – write it up or tell the story in your team meeting. Then the next time your teams hits something similar, you’ll all be more prepared.
|
||||
|
||||
### How bugs can help you learn
|
||||
|
||||
### Recurse Center
|
||||
|
||||
Before I joined Dropbox, I worked for the Recurse Center. The idea behind RC is that it’s a community of self-directed learners spending time together getting better as programmers. That is the full extent of the structure of RC: there’s no curriculum or assignments or deadlines. The only scoping is a shared goal of getting better as a programmer. We’d see people come to participate in the program who had gotten CS degrees but didn’t feel like they had a solid handle on practical programming, or people who had been writing Java for ten years and wanted to learn Clojure or Haskell, and many other profiles as well.
|
||||
|
||||
My job there was as a facilitator, helping people make the most of the lack of structure and providing guidance based on what we’d learned from earlier participants. So my colleagues and I were very interested in the best techniques for learning for self-motivated adults.
|
||||
|
||||
### Deliberate Practice
|
||||
|
||||
There’s a lot of different research in this space, and one of the ones I think is most interesting is the idea of deliberate practice. Deliberate practice is an attempt to explain the difference in performance between experts & amateurs. And the guiding principle here is that if you look just at innate characteristics – genetic or otherwise – they don’t go very far towards explaining the difference in performance. So the researchers, originally Ericsson, Krampe, and Tesch-Romer, set out to discover what did explain the difference. And what they settled on was time spent in deliberate practice.
|
||||
|
||||
Deliberate practice is pretty narrow in their definition: it’s not work for pay, and it’s not playing for fun. You have to be operating on the edge of your ability, doing a project appropriate for your skill level (not so easy that you don’t learn anything and not so hard that you don’t make any progress). You also have to get immediate feedback on whether or not you’ve done the thing correctly.
|
||||
|
||||
This is really exciting, because it’s a framework for how to build expertise. But the challenge is that as programmers this is really hard advice to apply. It’s hard to know whether you’re operating at the edge of your ability. Immediate corrective feedback is very rare – in some cases you’re lucky to get feedback ever, and in other cases maybe it takes months. You can get quick feedback on small things in the REPL and so on, but if you’re making a design decision or picking a technology, you’re not going to get feedback on those things for quite a long time.
|
||||
|
||||
But one category of programming where deliberate practice is a useful model is debugging. If you wrote code, then you had a mental model of how it worked when you wrote it. But your code has a bug, so your mental model isn’t quite right. By definition you’re on the boundary of your understanding – so, great! You’re about to learn something new. And if you can reproduce the bug, that’s a rare case where you can get immediate feedback on whether or not your fix is correct.
|
||||
|
||||
A bug like this might teach you something small about your program, or you might learn something larger about the system your code is running in. Now I’ve got a story for you about a bug like that.
|
||||
|
||||
### Bug #2
|
||||
|
||||
This bug also one that I encountered at Dropbox. At the time, I was investigating why some desktop client weren’t sending logs as consistently as we expected. I’d started digging into the client logging system and discovered a bunch of interesting bugs. I’ll tell you only the subset of those bugs that is relevant to this story.
|
||||
|
||||
Again here’s a very simplified architecture of the system.
|
||||
|
||||
|
||||
```
|
||||
+--------------+
|
||||
| |
|
||||
+---+ +----------> | LOG SERVER |
|
||||
|log| | | |
|
||||
+---+ | +------+-------+
|
||||
| |
|
||||
+-----+----+ | 200 ok
|
||||
| | |
|
||||
| CLIENT | <-----------+
|
||||
| |
|
||||
+-----+----+
|
||||
^
|
||||
+--------+--------+--------+
|
||||
| ^ ^ |
|
||||
+--+--+ +--+--+ +--+--+ +--+--+
|
||||
| log | | log | | log | | log |
|
||||
| | | | | | | |
|
||||
| | | | | | | |
|
||||
+-----+ +-----+ +-----+ +-----+
|
||||
```
|
||||
|
||||
The desktop client would generate logs. Those logs were compress, encrypted, and written to disk. Then every so often the client would send them up to the server. The client would read a log off of disk and send it to the log server. The server would decrypt it and store it, then respond with a 200.
|
||||
|
||||
If the client couldn’t reach the log server, it wouldn’t let the log directory grow unbounded. After a certain point it would start deleting logs to keep the directory under a maximum size.
|
||||
|
||||
The first two bugs were not a big deal on their own. The first one was that the desktop client sent logs up to the server starting with the oldest one instead of starting with the newest. This isn’t really what you want – for example, the server would tell the client to send logs if the client reported an exception, so probably you care about the logs that just happened and not the oldest logs that happen to be on disk.
|
||||
|
||||
The second bug was similar to the first: if the log directory hit its maximum size, the client would delete the logs starting with the newest instead of starting with the oldest. Again, you lose log files either way, but you probably care less about the older ones.
|
||||
|
||||
The third bug had to do with the encryption. Sometimes, the server would be unable to decrypt a log file. (We generally didn’t figure out why – maybe it was a bitflip.) We weren’t handling this error correctly on the backend, so the server would reply with a 500\. The client would behave reasonably in the face of a 500: it would assume that the server was down. So it would stop sending log files and not try to send up any of the others.
|
||||
|
||||
Returning a 500 on a corrupted log file is clearly not the right behavior. You could consider returning a 400, since it’s a problem with the client request. But the client also can’t fix the problem – if the log file can’t be decrypted now, we’ll never be able to decrypt it in the future. What you really want the client to do is just delete the log and move on. In fact, that’s the default behavior when the client gets a 200 back from the server for a log file that was successfully stored. So we said, ok – if the log file can’t be decrypted, just return a 200.
|
||||
|
||||
All of these bugs were straightforward to fix. The first two bugs were on the client, so we’d fixed them on the alpha build but they hadn’t gone out to the majority of clients. The third bug we fixed on the server and deployed.
|
||||
|
||||
### 📈
|
||||
|
||||
Suddenly traffic to the log cluster spikes. The serving team reaches out to us to ask if we know what’s going on. It takes me a minute to put all the pieces together.
|
||||
|
||||
Before these fixes, there were four things going on:
|
||||
|
||||
1. Log files were sent up starting with the oldest
|
||||
|
||||
2. Log files were deleted starting with the newest
|
||||
|
||||
3. If the server couldn’t decrypt a log file it would 500
|
||||
|
||||
4. If the client got a 500 it would stop sending logs
|
||||
|
||||
A client with a corrupted log file would try to send it, the server would 500, the client would give up sending logs. On its next run, it would try to send the same file again, fail again, and give up again. Eventually the log directory would get full, at which point the client would start deleting its newest files, leaving the corrupted one on disk.
|
||||
|
||||
The upshot of these three bugs: if a client ever had a corrupted log file, we would never see logs from that client again.
|
||||
|
||||
The problem is that there were a lot more clients in this state than we thought. Any client with a single corrupted file had been dammed up from sending logs to the server. Now that dam was cleared, and all of them were sending up the rest of the contents of their log directories.
|
||||
|
||||
### Our options
|
||||
|
||||
Ok, there’s a huge flood of traffic coming from machines around the world. What can we do? (This is a fun thing about working at a company with Dropbox’s scale, and particularly Dropbox’s scale of desktop clients: you can trigger a self-DDOS very easily.)
|
||||
|
||||
The first option when you do a deploy and things start going sideways is to rollback. Totally reasonable choice, but in this case, it wouldn’t have helped us. The state that we’d transformed wasn’t the state on the server but the state on the client – we’d deleted those files. Rolling back the server would prevent additional clients from entering this state but it wouldn’t solve the problem.
|
||||
|
||||
What about increasing the size of the logging cluster? We did that – and started getting even more requests, now that we’d increased our capacity. We increased it again, but you can’t do that forever. Why not? This cluster isn’t isolated. It’s making requests into another cluster, in this case to handle exceptions. If you have a DDOS pointed at one cluster, and you keep scaling that cluster, you’re going to knock over its depedencies too, and now you have two problems.
|
||||
|
||||
Another option we considered was shedding load – you don’t need every single log file, so can we just drop requests. One of the challenges here was that we didn’t have an easy way to tell good traffic from bad. We couldn’t quickly differentiate which log files were old and which were new.
|
||||
|
||||
The solution we hit on is one that’s been used at Dropbox on a number of different occassions: we have a custom header, `chillout`, which every client in the world respects. If the client gets a response with this header, then it doesn’t make any requests for the provided number of seconds. Someone very wise added this to the Dropbox client very early on, and it’s come in handy more than once over the years. The logging server didn’t have the ability to set that header, but that’s an easy problem to solve. So two of my colleagues, Isaac Goldberg and John Lai, implemented support for it. We set the logging cluster chillout to two minutes initially and then managed it down as the deluge subsided over the next couple of days.
|
||||
|
||||
### Know your system
|
||||
|
||||
The first lesson from this bug is to know your system. I had a good mental model of the interaction between the client and the server, but I wasn’t thinking about what would happen when the server was interacting with all the clients at once. There was a level of complexity that I hadn’t thought all the way through.
|
||||
|
||||
### Know your tools
|
||||
|
||||
The second lesson is to know your tools. If things go sideways, what options do you have? Can you reverse your migration? How will you know if things are going sideways and how can you discover more? All of those things are great to know before a crisis – but if you don’t, you’ll learn them during a crisis and then never forget.
|
||||
|
||||
### Feature flags & server-side gating
|
||||
|
||||
The third lesson is for you if you’re writing a mobile or a desktop application: _You need server-side feature gating and server-side flags._ When you discover a problem and you don’t have server-side controls, the resolution might take days or weeks as you push out a new release or submit a new version to the app store. That’s a bad situation to be in. The Dropbox desktop client isn’t going through an app store review process, but just pushing out a build to tens of millions of clients takes time. Compare that to hitting a problem in your feature and flipping a switch on the server: ten minutes later your problem is resolved.
|
||||
|
||||
This strategy is not without its costs. Having a bunch of feature flags in your code adds to the complexity dramatically. You get a combinatoric problem with your testing: what if feature A is enabled and feature B, or just one, or neither – multiplied across N features. It’s extremely difficult to get engineers to clean up their feature flags after the fact (and I was also guilty of this). Then for the desktop client there’s multiple versions in the wild at the same time, so it gets pretty hard to reason about.
|
||||
|
||||
But the benefit – man, when you need it, you really need it.
|
||||
|
||||
# How to love bugs
|
||||
|
||||
I’ve talked about some bugs that I love and I’ve talked about why to love bugs. Now I want to tell you how to love bugs. If you don’t love bugs yet, I know of exactly one way to learn, and that’s to have a growth mindset.
|
||||
|
||||
The sociologist Carol Dweck has done a ton of interesting research about how people think about intelligence. She’s found that there are two different frameworks for thinking about intelligence. The first, which she calls the fixed mindset, holds that intelligence is a fixed trait, and people can’t change how much of it they have. The other mindset is a growth mindset. Under a growth mindset, people believe that intelligence is malleable and can increase with effort.
|
||||
|
||||
Dweck found that a person’s theory of intelligence – whether they hold a fixed or growth mindset – can significantly influence the way they select tasks to work on, the way they respond to challenges, their cognitive performance, and even their honesty.
|
||||
|
||||
[I also talked about a growth mindset in my Kiwi PyCon keynote, so here are just a few excerpts. You can read the full transcript [here][7].]
|
||||
|
||||
Findings about honesty:
|
||||
|
||||
> After this, they had the students write letters to pen pals about the study, saying “We did this study at school, and here’s the score that I got.” They found that _almost half of the students praised for intelligence lied about their scores_ , and almost no one who was praised for working hard was dishonest.
|
||||
|
||||
On effort:
|
||||
|
||||
> Several studies found that people with a fixed mindset can be reluctant to really exert effort, because they believe it means they’re not good at the thing they’re working hard on. Dweck notes, “It would be hard to maintain confidence in your ability if every time a task requires effort, your intelligence is called into question.”
|
||||
|
||||
On responding to confusion:
|
||||
|
||||
> They found that students with a growth mindset mastered the material about 70% of the time, regardless of whether there was a confusing passage in it. Among students with a fixed mindset, if they read the booklet without the confusing passage, again about 70% of them mastered the material. But the fixed-mindset students who encountered the confusing passage saw their mastery drop to 30%. Students with a fixed mindset were pretty bad at recovering from being confused.
|
||||
|
||||
These findings show that a growth mindset is critical while debugging. We have to recover from confusion, be candid about the limitations of our understanding, and at times really struggle on the way to finding solutions – all of which is easier and less painful with a growth mindset.
|
||||
|
||||
### Love your bugs
|
||||
|
||||
I learned to love bugs by explicitly celebrating challenges while working at the Recurse Center. A participant would sit down next to me and say, “[sigh] I think I’ve got a weird Python bug,” and I’d say, “Awesome, I _love_ weird Python bugs!” First of all, this is definitely true, but more importantly, it emphasized to the participant that finding something where they struggled an accomplishment, and it was a good thing for them to have done that day.
|
||||
|
||||
As I mentioned, at the Recurse Center there are no deadlines and no assignments, so this attitude is pretty much free. I’d say, “You get to spend a day chasing down this weird bug in Flask, how exciting!” At Dropbox and later at Pilot, where we have a product to ship, deadlines, and users, I’m not always uniformly delighted about spending a day on a weird bug. So I’m sympathetic to the reality of the world where there are deadlines. However, if I have a bug to fix, I have to fix it, and being grumbly about the existence of the bug isn’t going to help me fix it faster. I think that even in a world where deadlines loom, you can still apply this attitude.
|
||||
|
||||
If you love your bugs, you can have more fun while you’re working on a tough problem. You can be less worried and more focused, and end up learning more from them. Finally, you can share a bug with your friends and colleagues, which helps you and your teammates.
|
||||
|
||||
### Obrigada!
|
||||
|
||||
My thanks to folks who gave me feedback on this talk and otherwise contributed to my being there:
|
||||
|
||||
* Sasha Laundy
|
||||
|
||||
* Amy Hanlon
|
||||
|
||||
* Julia Evans
|
||||
|
||||
* Julian Cooper
|
||||
|
||||
* Raphael Passini Diniz and the rest of the Python Brasil organizing team
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://akaptur.com/blog/2017/11/12/love-your-bugs/
|
||||
|
||||
作者:[Allison Kaptur ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://akaptur.com/about/
|
||||
[1]:http://2017.pythonbrasil.org.br/#
|
||||
[2]:http://www.youtube.com/watch?v=h4pZZOmv4Qs
|
||||
[3]:http://www.pilot.com/
|
||||
[4]:http://www.dropbox.com/
|
||||
[5]:http://www.recurse.com/
|
||||
[6]:http://www.youtube.com/watch?v=ETgNLF_XpEM
|
||||
[7]:http://akaptur.com/blog/2015/10/10/effective-learning-strategies-for-programmers/
|
||||
@ -0,0 +1,76 @@
|
||||
translating---geekpi
|
||||
|
||||
Glitch: write fun small web projects instantly
|
||||
============================================================
|
||||
|
||||
I just wrote about Jupyter Notebooks which are a fun interactive way to write Python code. That reminded me I learned about Glitch recently, which I also love!! I built a small app to [turn of twitter retweets][2] with it. So!
|
||||
|
||||
[Glitch][3] is an easy way to make Javascript webapps. (javascript backend, javascript frontend)
|
||||
|
||||
The fun thing about glitch is:
|
||||
|
||||
1. you start typing Javascript code into their web interface
|
||||
|
||||
2. as soon as you type something, it automagically reloads the backend of your website with the new code. You don’t even have to save!! It autosaves.
|
||||
|
||||
So it’s like Heroku, but even more magical!! Coding like this (you type, and the code runs on the public internet immediately) just feels really **fun** to me.
|
||||
|
||||
It’s kind of like sshing into a server and editing PHP/HTML code on your server and having it instantly available, which I kind of also loved. Now we have “better deployment practices” than “just edit the code and it is instantly on the internet” but we are not talking about Serious Development Practices, we are talking about writing tiny programs for fun.
|
||||
|
||||
### glitch has awesome example apps
|
||||
|
||||
Glitch seems like fun nice way to learn programming!
|
||||
|
||||
For example, there’s a space invaders game (code by [Mary Rose Cook][4]) at [https://space-invaders.glitch.me/][5]. The thing I love about this is that in just a few clicks I can
|
||||
|
||||
1. click “remix this”
|
||||
|
||||
2. start editing the code to make the boxes orange instead of black
|
||||
|
||||
3. have my own space invaders game!! Mine is at [http://julias-space-invaders.glitch.me/][1]. (i just made very tiny edits to make it orange, nothing fancy)
|
||||
|
||||
They have tons of example apps that you can start from – for instance [bots][6], [games][7], and more.
|
||||
|
||||
### awesome actually useful app: tweetstorms
|
||||
|
||||
The way I learned about Glitch was from this app which shows you tweetstorms from a given user: [https://tweetstorms.glitch.me/][8].
|
||||
|
||||
For example, you can see [@sarahmei][9]’s tweetstorms at [https://tweetstorms.glitch.me/sarahmei][10] (she tweets a lot of good tweetstorms!).
|
||||
|
||||
### my glitch app: turn off retweets
|
||||
|
||||
When I learned about Glitch I wanted to turn off retweets for everyone I follow on Twitter (I know you can do it in Tweetdeck!) and doing it manually was a pain – I had to do it one person at a time. So I wrote a tiny Glitch app to do it for me!
|
||||
|
||||
I liked that I didn’t have to set up a local development environment, I could just start typing and go!
|
||||
|
||||
Glitch only supports Javascript and I don’t really know Javascript that well (I think I’ve never written a Node program before), so the code isn’t awesome. But I had a really good time writing it – being able to type and just see my code running instantly was delightful. Here it is: [https://turn-off-retweets.glitch.me/][11].
|
||||
|
||||
### that’s all!
|
||||
|
||||
Using Glitch feels really fun and democratic. Usually if I want to fork someone’s web project and make changes I wouldn’t do it – I’d have to fork it, figure out hosting, set up a local dev environment or Heroku or whatever, install the dependencies, etc. I think tasks like installing node.js dependencies used to be interesting, like “cool i am learning something new” and now I just find them tedious.
|
||||
|
||||
So I love being able to just click “remix this!” and have my version on the internet instantly.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/13/glitch--write-small-web-projects-easily/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://julias-space-invaders.glitch.me/
|
||||
[2]:https://turn-off-retweets.glitch.me/
|
||||
[3]:https://glitch.com/
|
||||
[4]:https://maryrosecook.com/
|
||||
[5]:https://space-invaders.glitch.me/
|
||||
[6]:https://glitch.com/handy-bots
|
||||
[7]:https://glitch.com/games
|
||||
[8]:https://tweetstorms.glitch.me/
|
||||
[9]:https://twitter.com/sarahmei
|
||||
[10]:https://tweetstorms.glitch.me/sarahmei
|
||||
[11]:https://turn-off-retweets.glitch.me/
|
||||
61
sources/tech/20171114 Sysadmin 101 Patch Management.md
Normal file
61
sources/tech/20171114 Sysadmin 101 Patch Management.md
Normal file
@ -0,0 +1,61 @@
|
||||
【翻译中 @haoqixu】Sysadmin 101: Patch Management
|
||||
============================================================
|
||||
|
||||
* [HOW-TOs][1]
|
||||
|
||||
* [Servers][2]
|
||||
|
||||
* [SysAdmin][3]
|
||||
|
||||
|
||||
A few articles ago, I started a Sysadmin 101 series to pass down some fundamental knowledge about systems administration that the current generation of junior sysadmins, DevOps engineers or "full stack" developers might not learn otherwise. I had thought that I was done with the series, but then the WannaCry malware came out and exposed some of the poor patch management practices still in place in Windows networks. I imagine some readers that are still stuck in the Linux versus Windows wars of the 2000s might have even smiled with a sense of superiority when they heard about this outbreak.
|
||||
|
||||
The reason I decided to revive my Sysadmin 101 series so soon is I realized that most Linux system administrators are no different from Windows sysadmins when it comes to patch management. Honestly, in some areas (in particular, uptime pride), some Linux sysadmins are even worse than Windows sysadmins regarding patch management. So in this article, I cover some of the fundamentals of patch management under Linux, including what a good patch management system looks like, the tools you will want to put in place and how the overall patching process should work.
|
||||
|
||||
### What Is Patch Management?
|
||||
|
||||
When I say patch management, I'm referring to the systems you have in place to update software already on a server. I'm not just talking about keeping up with the latest-and-greatest bleeding-edge version of a piece of software. Even more conservative distributions like Debian that stick with a particular version of software for its "stable" release still release frequent updates that patch bugs or security holes.
|
||||
|
||||
Of course, if your organization decided to roll its own version of a particular piece of software, either because developers demanded the latest and greatest, you needed to fork the software to apply a custom change, or you just like giving yourself extra work, you now have a problem. Ideally you have put in a system that automatically packages up the custom version of the software for you in the same continuous integration system you use to build and package any other software, but many sysadmins still rely on the outdated method of packaging the software on their local machine based on (hopefully up to date) documentation on their wiki. In either case, you will need to confirm that your particular version has the security flaw, and if so, make sure that the new patch applies cleanly to your custom version.
|
||||
|
||||
### What Good Patch Management Looks Like
|
||||
|
||||
Patch management starts with knowing that there is a software update to begin with. First, for your core software, you should be subscribed to your Linux distribution's security mailing list, so you're notified immediately when there are security patches. If there you use any software that doesn't come from your distribution, you must find out how to be kept up to date on security patches for that software as well. When new security notifications come in, you should review the details so you understand how severe the security flaw is, whether you are affected and gauge a sense of how urgent the patch is.
|
||||
|
||||
Some organizations have a purely manual patch management system. With such a system, when a security patch comes along, the sysadmin figures out which servers are running the software, generally by relying on memory and by logging in to servers and checking. Then the sysadmin uses the server's built-in package management tool to update the software with the latest from the distribution. Then the sysadmin moves on to the next server, and the next, until all of the servers are patched.
|
||||
|
||||
There are many problems with manual patch management. First is the fact that it makes patching a laborious chore. The more work patching is, the more likely a sysadmin will put it off or skip doing it entirely. The second problem is that manual patch management relies too much on the sysadmin's ability to remember and recall all of the servers he or she is responsible for and keep track of which are patched and which aren't. This makes it easy for servers to be forgotten and sit unpatched.
|
||||
|
||||
The faster and easier patch management is, the more likely you are to do it. You should have a system in place that quickly can tell you which servers are running a particular piece of software at which version. Ideally, that system also can push out updates. Personally, I prefer orchestration tools like MCollective for this task, but Red Hat provides Satellite, and Canonical provides Landscape as central tools that let you view software versions across your fleet of servers and apply patches all from a central place.
|
||||
|
||||
Patching should be fault-tolerant as well. You should be able to patch a service and restart it without any overall down time. The same idea goes for kernel patches that require a reboot. My approach is to divide my servers into different high availability groups so that lb1, app1, rabbitmq1 and db1 would all be in one group, and lb2, app2, rabbitmq2 and db2 are in another. Then, I know I can patch one group at a time without it causing downtime anywhere else.
|
||||
|
||||
So, how fast is fast? Your system should be able to roll out a patch to a minor piece of software that doesn't have an accompanying service (such as bash in the case of the ShellShock vulnerability) within a few minutes to an hour at most. For something like OpenSSL that requires you to restart services, the careful process of patching and restarting services in a fault-tolerant way probably will take more time, but this is where orchestration tools come in handy. I gave examples of how to use MCollective to accomplish this in my recent MCollective articles (see the December 2016 and January 2017 issues), but ideally, you should put a system in place that makes it easy to patch and restart services in a fault-tolerant and automated way.
|
||||
|
||||
When patching requires a reboot, such as in the case of kernel patches, it might take a bit more time, but again, automation and orchestration tools can make this go much faster than you might imagine. I can patch and reboot the servers in an environment in a fault-tolerant way within an hour or two, and it would be much faster than that if I didn't need to wait for clusters to sync back up in between reboots.
|
||||
|
||||
Unfortunately, many sysadmins still hold on to the outdated notion that uptime is a badge of pride—given that serious kernel patches tend to come out at least once a year if not more often, to me, it's proof you don't take security seriously.
|
||||
|
||||
Many organizations also still have that single point of failure server that can never go down, and as a result, it never gets patched or rebooted. If you want to be secure, you need to remove these outdated liabilities and create systems that at least can be rebooted during a late-night maintenance window.
|
||||
|
||||
Ultimately, fast and easy patch management is a sign of a mature and professional sysadmin team. Updating software is something all sysadmins have to do as part of their jobs, and investing time into systems that make that process easy and fast pays dividends far beyond security. For one, it helps identify bad architecture decisions that cause single points of failure. For another, it helps identify stagnant, out-of-date legacy systems in an environment and provides you with an incentive to replace them. Finally, when patching is managed well, it frees up sysadmins' time and turns their attention to the things that truly require their expertise.
|
||||
|
||||
______________________
|
||||
|
||||
Kyle Rankin is senior security and infrastructure architect, the author of many books including Linux Hardening in Hostile Networks, DevOps Troubleshooting and The Official Ubuntu Server Book, and a columnist for Linux Journal. Follow him @kylerankin
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/sysadmin-101-patch-management
|
||||
|
||||
作者:[Kyle Rankin ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxjournal.com/users/kyle-rankin
|
||||
[1]:https://www.linuxjournal.com/tag/how-tos
|
||||
[2]:https://www.linuxjournal.com/tag/servers
|
||||
[3]:https://www.linuxjournal.com/tag/sysadmin
|
||||
[4]:https://www.linuxjournal.com/users/kyle-rankin
|
||||
68
sources/tech/20171114 Take Linux and Run With It.md
Normal file
68
sources/tech/20171114 Take Linux and Run With It.md
Normal file
@ -0,0 +1,68 @@
|
||||
Take Linux and Run With It
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
"How do you run an operating system?" may seem like a simple question, since most of us are accustomed to turning on our computers and seeing our system spin up. However, this common model is only one way of running an operating system. As one of Linux's greatest strengths is versatility, Linux offers the most methods and environments for running it.
|
||||
|
||||
To unleash the full power of Linux, and maybe even find a use for it you hadn't thought of, consider some less conventional ways of running it -- specifically, ones that don't even require installation on a computer's hard drive.
|
||||
|
||||
### We'll Do It Live!
|
||||
|
||||
Live-booting is a surprisingly useful and popular way to get the full Linux experience on the fly. While hard drives are where OSes reside most of the time, they actually can be installed to most major storage media, including CDs, DVDs and USB flash drives.
|
||||
|
||||
When an OS is installed to some device other than a computer's onboard hard drive and subsequently booted instead of that onboard drive, it's called "live-booting" or running a "live session."
|
||||
|
||||
At boot time, the user simply selects an external storage source for the hardware to look for boot information. If found, the computer follows the external device's boot instructions, essentially ignoring the onboard drive until the next time the user boots normally. Optical media are increasingly rare these days, so by far the most typical form that an external OS-carrying device takes is a USB stick.
|
||||
|
||||
Most mainstream Linux distributions offer a way to run a live session as a way of trying them out. The live session doesn't save any user activity, and the OS resets to the clean default state after every shutdown.
|
||||
|
||||
Live Linux sessions can be used for more than testing a distro, though. One application is for executing system repair for critically malfunctioning onboard (usually also Linux) systems. If an update or configuration made the onboard system unbootable, a full system backup is required, or the hard drive has sustained serious file corruption, the only recourse is to start up a live system and perform maintenance on the onboard drive.
|
||||
|
||||
In these and similar scenarios, the onboard drive cannot be manipulated or corrected while also keeping the system stored on it running, so a live system takes on those burdens instead, leaving all but the problematic files on the onboard drive at rest.
|
||||
|
||||
Live sessions also are perfectly suited for handling sensitive information. If you don't want a computer to retain any trace of the operations executed or information handled on it, especially if you are using hardware you can't vouch for -- like a public library or hotel business center computer -- a live session will provide you all the desktop computing functions to complete your task while retaining no trace of your session once you're finished. This is great for doing online banking or password input that you don't want a computer to remember.
|
||||
|
||||
### Linux Virtually Anywhere
|
||||
|
||||
Another approach for implementing Linux for more on-demand purposes is to run a virtual machine on another host OS. A virtual machine, or VM, is essentially a small computer running inside another computer and contained in a single large file.
|
||||
|
||||
To run a VM, users simply install a hypervisor program (a kind of launcher for the VM), select a downloaded Linux OS image file (usually ending with a ".iso" file extension), and walk through the setup process.
|
||||
|
||||
Most of the settings can be left at their defaults, but the key ones to configure are the amount of RAM and hard drive storage to lease to the VM. Fortunately, since Linux has a light footprint, you don't have to set these very high: 2 GB of RAM and 16 GB of storage should be plenty for the VM while still letting your host OS thrive.
|
||||
|
||||
So what does this offer that a live system doesn't? First, whereas live systems are ephemeral, VMs can retain the data stored on them. This is great if you want to set up your Linux VM for a special use case, like software development or even security.
|
||||
|
||||
When used for development, a Linux VM gives you the solid foundation of Linux's programming language suites and coding tools, and it lets you save your projects right in the VM to keep everything organized.
|
||||
|
||||
If security is your goal, Linux VMs allow you to impose an extra layer between a potential hazard and your system. If you do your browsing from the VM, a malicious program would have to compromise not only your virtual Linux system, but also the hypervisor -- and _then_ your host OS, a technical feat beyond all but the most skilled and determined adversaries.
|
||||
|
||||
Second, you can start up your VM on demand from your host system, without having to power it down and start it up again as you would have to with a live session. When you need it, you can quickly bring up the VM, and when you're finished, you just shut it down and go back to what you were doing before.
|
||||
|
||||
Your host system continues running normally while the VM is on, so you can attend to tasks simultaneously in each system.
|
||||
|
||||
### Look Ma, No Installation!
|
||||
|
||||
Just as there is no one form that Linux takes, there's also no one way to run it. Hopefully, this brief primer on the kinds of systems you can run has given you some ideas to expand your use models.
|
||||
|
||||
The best part is that if you're not sure how these can help, live booting and virtual machines don't hurt to try!
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html
|
||||
|
||||
作者:[ Jonathan Terrasi ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html#searchbyline
|
||||
[1]:https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html#
|
||||
[2]:https://www.linuxinsider.com/perl/mailit/?id=84951
|
||||
[3]:https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html
|
||||
[4]:https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html
|
||||
@ -0,0 +1,58 @@
|
||||
Security Jobs Are Hot: Get Trained and Get Noticed
|
||||
============================================================
|
||||
|
||||

|
||||
The Open Source Jobs Report, from Dice and The Linux Foundation, found that professionals with security experience are in high demand for the future.[Used with permission][1]
|
||||
|
||||
The demand for security professionals is real. On [Dice.com][4], 15 percent of the more than 75K jobs are security positions. “Every year in the U.S., 40,000 jobs for information security analysts go unfilled, and employers are struggling to fill 200,000 other cyber-security related roles, according to cyber security data tool [CyberSeek][5]” ([Forbes][6]). We know that there is a fast-increasing need for security specialists, but that the interest level is low.
|
||||
|
||||
### Security is the place to be
|
||||
|
||||
In my experience, few students coming out of college are interested in roles in security; so many people see security as niche. Entry-level tech pros are interested in business analyst or system analyst roles, because of a belief that if you want to learn and apply core IT concepts, you have to stick to analyst roles or those closer to product development. That’s simply not the case.
|
||||
|
||||
In fact, if you’re interested in getting in front of your business leaders, security is the place to be – as a security professional, you have to understand the business end-to-end; you have to look at the big picture to give your company the advantage.
|
||||
|
||||
### Be fearless
|
||||
|
||||
Analyst and security roles are not all that different. Companies continue to merge engineering and security roles out of necessity. Businesses are moving faster than ever with infrastructure and code being deployed through automation, which increases the importance of security being a part of all tech pros day to day lives. In our [Open Source Jobs Report with The Linux Foundation][7], 42 percent of hiring managers said professionals with security experience are in high demand for the future.
|
||||
|
||||
There has never been a more exciting time to be in security. If you stay up-to-date with tech news, you’ll see that a huge number of stories are related to security – data breaches, system failures and fraud. The security teams are working in ever-changing, fast-paced environments. A real challenge lies is in the proactive side of security, finding, and eliminating vulnerabilities while maintaining or even improving the end-user experience.
|
||||
|
||||
### Growth is imminent
|
||||
|
||||
Of any aspect of tech, security is the one that will continue to grow with the cloud. Businesses are moving more and more to the cloud and that’s exposing more security vulnerabilities than organizations are used to. As the cloud matures, security becomes increasingly important.
|
||||
|
||||
Regulations are also growing – Personally Identifiable Information (PII) is getting broader all the time. Many companies are finding that they must invest in security to stay in compliance and avoid being in the headlines. Companies are beginning to budget more and more for security tooling and staffing due to the risk of heavy fines, reputational damage, and, to be honest, executive job security.
|
||||
|
||||
### Training and support
|
||||
|
||||
Even if you don’t choose a security-specific role, you’re bound to find yourself needing to code securely, and if you don’t have the skills to do that, you’ll start fighting an uphill battle. There are certainly ways to learn on-the-job if your company offers that option, that’s encouraged but I recommend a combination of training, mentorship and constant practice. Without using your security skills, you’ll lose them fast with how quickly the complexity of malicious attacks evolve.
|
||||
|
||||
My recommendation for those seeking security roles is to find the people in your organization that are the strongest in engineering, development, or architecture areas – interface with them and other teams, do hands-on work, and be sure to keep the big-picture in mind. Be an asset to your organization that stands out – someone that can securely code and also consider strategy and overall infrastructure health.
|
||||
|
||||
### The end game
|
||||
|
||||
More and more companies are investing in security and trying to fill open roles in their tech teams. If you’re interested in management, security is the place to be. Executive leadership wants to know that their company is playing by the rules, that their data is secure, and that they’re safe from breaches and loss.
|
||||
|
||||
Security that is implemented wisely and with strategy in mind will get noticed. Security is paramount for executives and consumers alike – I’d encourage anyone interested in security to train up and contribute.
|
||||
|
||||
_[Download ][2]the full 2017 Open Source Jobs Report now._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/os-jobs-report/2017/11/security-jobs-are-hot-get-trained-and-get-noticed
|
||||
|
||||
作者:[ BEN COLLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bencollen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:http://bit.ly/2017OSSjobsreport
|
||||
[3]:https://www.linux.com/files/images/security-skillspng
|
||||
[4]:http://www.dice.com/
|
||||
[5]:http://cyberseek.org/index.html#about
|
||||
[6]:https://www.forbes.com/sites/jeffkauflin/2017/03/16/the-fast-growing-job-with-a-huge-skills-gap-cyber-security/#292f0a675163
|
||||
[7]:http://media.dice.com/report/the-2017-open-source-jobs-report-employers-prioritize-hiring-open-source-professionals-with-latest-skills/
|
||||
@ -0,0 +1,120 @@
|
||||
Why and How to Set an Open Source Strategy
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
This article explains how to walk through, measure, and define strategies collaboratively in an open source community.
|
||||
|
||||
_“If you don’t know where you are going, you’ll end up someplace else.” _ _—_ Yogi Berra
|
||||
|
||||
Open source projects are generally started as a way to scratch one’s itch — and frankly that’s one of its greatest attributes. Getting code down provides a tangible method to express an idea, showcase a need, and solve a problem. It avoids over thinking and getting a project stuck in analysis-paralysis, letting the project pragmatically solve the problem at hand.
|
||||
|
||||
Next, a project starts to scale up and gets many varied users and contributions, with plenty of opinions along the way. That leads to the next big challenge — how does a project start to build a strategic vision? In this article, I’ll describe how to walk through, measure, and define strategies collaboratively, in a community.
|
||||
|
||||
Strategy may seem like a buzzword of the corporate world rather something that an open source community would embrace, so I suggest stripping away the negative actions that are sometimes associated with this word (e.g., staff reductions, discontinuations, office closures). Strategy done right isn’t a tool to justify unfortunate actions but to help show focus and where each community member can contribute.
|
||||
|
||||
A good application of strategy achieves the following:
|
||||
|
||||
* Why the project exists?
|
||||
|
||||
* What the project looks to achieve?
|
||||
|
||||
* What is the ideal end state for a project is.
|
||||
|
||||
The key to success is answering these questions as simply as possible, with consensus from your community. Let’s look at some ways to do this.
|
||||
|
||||
### Setting a mission and vision
|
||||
|
||||
_“_ _Efforts and courage are not enough without purpose and direction.”_ — John F. Kennedy
|
||||
|
||||
All strategic planning starts off with setting a course for where the project wants to go. The two tools used here are _Mission_ and _Vision_ . They are complementary terms, describing both the reason a project exists (mission) and the ideal end state for a project (vision).
|
||||
|
||||
A great way to start this exercise with the intent of driving consensus is by asking each key community member the following questions:
|
||||
|
||||
* What drove you to join and/or contribute the project?
|
||||
|
||||
* How do you define success for your participation?
|
||||
|
||||
In a company, you’d ask your customers these questions usually. But in open source projects, the customers are the project participants — and their time investment is what makes the project a success.
|
||||
|
||||
Driving consensus means capturing the answers to these questions and looking for themes across them. At R Consortium, for example, I created a shared doc for the board to review each member’s answers to the above questions, and followed up with a meeting to review for specific themes that came from those insights.
|
||||
|
||||
Building a mission flows really well from this exercise. The key thing is to keep the wording of your mission short and concise. Open Mainframe Project has done this really well. Here’s their mission:
|
||||
|
||||
_Build community and adoption of Open Source on the mainframe by:_
|
||||
|
||||
* _Eliminating barriers to Open Source adoption on the mainframe_
|
||||
|
||||
* _Demonstrating value of the mainframe on technical and business levels_
|
||||
|
||||
* _Strengthening collaboration points and resources for the community to thrive_
|
||||
|
||||
At 40 words, it passes the key eye tests of a good mission statement; it’s clear, concise, and demonstrates the useful value the project aims for.
|
||||
|
||||
The next stage is to reflect on the mission statement and ask yourself this question: What is the ideal outcome if the project accomplishes its mission? That can be a tough one to tackle. Open Mainframe Project put together its vision really well:
|
||||
|
||||
_Linux on the Mainframe as the standard for enterprise class systems and applications._
|
||||
|
||||
You could read that as a [BHAG][1], but it’s really more of a vision, because it describes a future state that is what would be created by the mission being fully accomplished. It also hits the key pieces to an effective vision — it’s only 13 words, inspirational, clear, memorable, and concise.
|
||||
|
||||
Mission and vision add clarity on the who, what, why, and how for your project. But, how do you set a course for getting there?
|
||||
|
||||
### Goals, Objectives, Actions, and Results
|
||||
|
||||
_“I don’t focus on what I’m up against. I focus on my goals and I try to ignore the rest.”_ — Venus Williams
|
||||
|
||||
Looking at a mission and vision can get overwhelming, so breaking them down into smaller chunks can help the project determine how to get started. This also helps prioritize actions, either by importance or by opportunity. Most importantly, this step gives you guidance on what things to focus on for a period of time, and which to put off.
|
||||
|
||||
There are lots of methods of time bound planning, but the method I think works the best for projects is what I’ve dubbed the GOAR method. It’s an acronym that stands for:
|
||||
|
||||
* Goals define what the project is striving for and likely would align and support the mission. Examples might be “Grow a diverse contributor base” or “Become the leading project for X.” Goals are aspirational and set direction.
|
||||
|
||||
* Objectives show how you measure a goal’s completion, and should be clear and measurable. You might also have multiple objectives to measure the completion of a goal. For example, the goal “Grow a diverse contributor base” might have objectives such as “Have X total contributors monthly” and “Have contributors representing Y different organizations.”
|
||||
|
||||
* Actions are what the project plans to do to complete an objective. This is where you get tactical on exactly what needs done. For example, the objective “Have contributors representing Y different organizations” would like have actions of reaching out to interested organizations using the project, having existing contributors mentor new mentors, and providing incentives for first time contributors.
|
||||
|
||||
* Results come along the way, showing progress both positive and negative from the actions.
|
||||
|
||||
You can put these into a table like this:
|
||||
|
||||
| Goals | Objectives | Actions | Results |
|
||||
|:--|:--|:--|:--|
|
||||
| Grow a diverse contributor base | Have X total contributors monthly | Existing contributors mentor new mentors Providing incentives for first time contributors | |
|
||||
| | Have contributors representing Y different organizations | Reach out to interested organizations using the project | |
|
||||
|
||||
|
||||
In large organizations, monthly or quarterly goals and objectives often make sense; however, on open source projects, these time frames are unrealistic. Six- even 12-month tracking allows the project leadership to focus on driving efforts at a high level by nurturing the community along.
|
||||
|
||||
The end result is a rubric that provides clear vision on where the project is going. It also lets community members more easily find ways to contribute. For example, your project may include someone who knows a few organizations using the project — this person could help introduce those developers to the codebase and guide them through their first commit.
|
||||
|
||||
### What happens if the project doesn’t hit the goals?
|
||||
|
||||
_“I have not failed. I’ve just found 10,000 ways that won’t work.”_ — Thomas A. Edison
|
||||
|
||||
Figuring out what is within the capability of an organization — whether Fortune 500 or a small open source project — is hard. And, sometimes the expectations or market conditions change along the way. Does that make the strategy planning process a failure? Absolutely not!
|
||||
|
||||
Instead, you can use this experience as a way to better understand your project’s velocity, its impact, and its community, and perhaps as a way to prioritize what is important and what’s not.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/set-open-source-strategy/
|
||||
|
||||
作者:[ John Mertic][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/jmertic/
|
||||
[1]:https://en.wikipedia.org/wiki/Big_Hairy_Audacious_Goal
|
||||
[2]:https://www.linuxfoundation.org/author/jmertic/
|
||||
[3]:https://www.linuxfoundation.org/category/blog/
|
||||
[4]:https://www.linuxfoundation.org/category/audience/c-level/
|
||||
[5]:https://www.linuxfoundation.org/category/audience/developer-influencers/
|
||||
[6]:https://www.linuxfoundation.org/category/audience/entrepreneurs/
|
||||
[7]:https://www.linuxfoundation.org/category/campaigns/membership/how-to/
|
||||
[8]:https://www.linuxfoundation.org/category/campaigns/events-campaigns/linux-foundation/
|
||||
[9]:https://www.linuxfoundation.org/category/audience/open-source-developers/
|
||||
[10]:https://www.linuxfoundation.org/category/audience/open-source-professionals/
|
||||
[11]:https://www.linuxfoundation.org/category/audience/open-source-users/
|
||||
[12]:https://www.linuxfoundation.org/category/blog/thought-leadership/
|
||||
@ -1,59 +0,0 @@
|
||||
### System Logs: Understand Your Linux System
|
||||
|
||||

|
||||
By: [chabowski][1]
|
||||
|
||||
The following article is part of a series of articles that provide tips and tricks for Linux newbies – or Desktop users that are not yet experienced with regard to certain topics). This series intends to complement the special edition #30 “[Getting Started with Linux][2]” based on [openSUSE Leap][3], recently published by the [Linux Magazine,][4] with valuable additional information.
|
||||
|
||||
This article has been contributed by Romeo S. Romeo is a PDX-based enterprise Linux professional specializing in scalable solutions for innovative corporations looking to disrupt the marketplace.
|
||||
|
||||
System logs are incredibly important files in Linux. Special programs that run in the background (usually called daemons or servers) handle most of the tasks on your Linux system. Whenever these daemons do anything, they write the details of the task to a log file as a sort of “history” of what they’ve been up to. These daemons perform actions ranging from syncing your clock with an atomic clock to managing your network connection. All of this is written to log files so that if something goes wrong, you can look into the specific log file and see what happened.
|
||||
|
||||

|
||||
|
||||
Photo by Markus Spiske on Unsplash
|
||||
|
||||
There are many different logs on your Linux computer. Historically, they were mostly stored in the /var/log directory in a plain text format. Quite a few still are, and you can read them easily with the less pager. On your freshly installed openSUSE Leap 42.3 system, and on most modern systems, important logs are stored by the systemd init system. This is the system that handles starting up daemons and getting the computer ready for use on startup. The logs handled by systemd are stored in a binary format, which means that they take up less space and can more easily be viewed or exported in various formats, but the downside is that you need a special tool to view them. Luckily, this tool comes installed on your system: it’s called journalctl and by default, it records all of the logs from every daemon to one location.
|
||||
|
||||
To take a look at your systemd log, just run the journalctl command. This will open up the combined logs in the less pager. To get a better idea of what you’re looking at, see a single log entry from journalctl here:
|
||||
|
||||
```
|
||||
Jul 06 11:53:47 aaathats3as pulseaudio[2216]: [pulseaudio] alsa-util.c: Disabling timer-based scheduling because running inside a VM.
|
||||
```
|
||||
|
||||
This individual log entry contains (in order) the date and time of the entry, the hostname of the computer, the name of the process that logged the entry, the PID (process ID number) of the process that logged the entry, and then the log entry itself.
|
||||
|
||||
If a program running on your system is misbehaving, look at the log file and search (with the “/” key followed by the search term) for the name of the program. Chances are that if the program is reporting errors that are causing it to malfunction, then the errors will show up in the system log. Sometimes errors are verbose enough for you to be able to fix them yourself. Other times, you have to search for a solution on the Web. Google is usually the most convenient search engine to use for weird Linux problems
|
||||

|
||||
. However, be sure that you only enter the actual log entry, because the rest of the information at the beginning of the line (date, host name, PID) is unnecessary and could return false positives.
|
||||
|
||||
After you search for the problem, the first few results are usually pages containing various things that you can try for solutions. Of course, you shouldn’t just follow random instructions that you find on the Internet: always be sure to do additional research into what exactly you will be doing and what the effects of it are before following any instructions. With that being said, the results for a specific entry from the system’s log file are usually much more useful than results from searching more generic terms that describe the malfunctioning of the program directly. This is because many different things could cause a program to misbehave, and multiple problems could cause identical misbehaviors.
|
||||
|
||||
For example, a lack of audio on the system could be due to a massive amount of different reasons, ranging from speakers not being plugged in, to back end sound systems misbehaving, to a lack of the proper drivers. If you search for a general problem, you’re likely to see a lot of irrelevant solutions and you’ll end up wasting your time on a wild goose chase. With a specific search of an actual line from a log file, you can see other people who have had the same log entry. See Picture 1 and Picture 2 to compare and contrast between the two types of searching.
|
||||
|
||||

|
||||
|
||||
Picture 1 shows generic, unspecific Google results for a general misbehavior of the system. This type of searching generally doesn’t help much.
|
||||
|
||||

|
||||
|
||||
Picture 2 shows more specific, helpful Google results for a particular log file line. This type of searching is generally very helpful.
|
||||
|
||||
There are some systems that log their actions outside of journalctl. The most important ones that you may find yourself dealing with on a desktop system are /var/log/zypper.log for openSUSE’s package manager, /var/log/boot.log for those messages that scroll by too fast to be read when you turn your system on, and /var/log/ntp if your Network Time Protocol Daemon is having troubles syncing time. One more important place to look for errors if you’re having problems with specific hardware is the Kernel Ring Buffer, which you can read by typing the dmesg -H command (this opens in the less pager as well). The Kernel Ring Buffer is stored in RAM, so you lose it when you reboot your system, but it contains important messages from the Linux kernel about important events, such as hardware being added, modules being loaded, or strange network errors.
|
||||
|
||||
Hopefully you are prepared now to understand your Linux system better! Have a lot of fun!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.suse.com/communities/blog/system-logs-understand-linux-system/
|
||||
|
||||
作者:[chabowski]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.suse.com/communities/blog/author/chabowski/
|
||||
[2]:http://www.linux-magazine.com/Resources/Special-Editions/30-Getting-Started-with-Linux
|
||||
[3]:https://en.opensuse.org/Portal:42.3
|
||||
[4]:http://www.linux-magazine.com/
|
||||
@ -1,60 +0,0 @@
|
||||
Translating by ValoniaKim
|
||||
Language engineering for great justice
|
||||
============================================================
|
||||
|
||||
Whole-systems engineering, when you get good at it, goes beyond being entirely or even mostly about technical optimizations. Every artifact we make is situated in a context of human action that widens out to the economics of its use, the sociology of its users, and the entirety of what Austrian economists call “praxeology”, the science of purposeful human behavior in its widest scope.
|
||||
|
||||
This isn’t just abstract theory for me. When I wrote my papers on open-source development, they were exactly praxeology – they weren’t about any specific software technology or objective but about the context of human action within which technology is worked. An increase in praxeological understanding of technology can reframe it, leading to tremendous increases in human productivity and satisfaction, not so much because of changes in our tools but because of changes in the way we grasp them.
|
||||
|
||||
In this, the third of my unplanned series of posts about the twilight of C and the huge changes coming as we actually begin to see forward into a new era of systems programming, I’m going to try to cash that general insight out into some more specific and generative ideas about the design of computer languages, why they succeed, and why they fail.
|
||||
|
||||
In my last post I noted that every computer language is an embodiment of a relative-value claim, an assertion about the optimal tradeoff between spending machine resources and spending programmer time, all of this in a context where the cost of computing power steadily falls over time while programmer-time costs remain relatively stable or may even rise. I also highlighted the additional role of transition costs in pinning old tradeoff assertions into place. I described what language designers do as seeking a new optimum for present and near-future conditions.
|
||||
|
||||
Now I’m going to focus on that last concept. A language designer has lots of possible moves in language-design space from where the state of the art is now. What kind of type system? GC or manual allocation? What mix of imperative, functional, or OO approaches? But in praxeological terms his choice is, I think, usually much simpler: attack a near problem or a far problem?
|
||||
|
||||
“Near” and “far” are measured along the curves of falling hardware costs, rising software complexity, and increasing transition costs from existing languages. A near problem is one the designer can see right in front of him; a far problem is a set of conditions that can be seen coming but won’t necessarily arrive for some time. A near solution can be deployed immediately, to great practical effect, but may age badly as conditions change. A far solution is a bold bet that may smother under the weight of its own overhead before its future arrives, or never be adopted at all because moving to it is too expensive.
|
||||
|
||||
Back at the dawn of computing, FORTRAN was a near-problem design, LISP a far-problem one. Assemblers are near solutions. Illustrating that the categories apply to non-general-purpose languages, also roff markup. Later in the game, PHP and Javascript. Far solutions? Oberon. Ocaml. ML. XML-Docbook. Academic languages tend to be far because the incentive structure around them rewards originality and intellectual boldness (note that this is a praxeological cause, not a technical one!). The failure mode of academic languages is predictable; high inward transition costs, nobody goes there, failure to achieve community critical mass sufficient for mainstream adoption, isolation, and stagnation. (That’s a potted history of LISP in one sentence, and I say that as an old LISP-head with a deep love for the language…)
|
||||
|
||||
The failure modes of near designs are uglier. The best outcome to hope for is a graceful death and transition to a newer design. If they hang on (most likely to happen when transition costs out are high) features often get piled on them to keep them relevant, increasing complexity until they become teetering piles of cruft. Yes, C++, I’m looking at you. You too, Javascript. And (alas) Perl, though Larry Wall’s good taste mitigated the problem for many years – but that same good taste eventually moved him to blow up the whole thing for Perl 6.
|
||||
|
||||
This way of thinking about language design encourages reframing the designer’s task in terms of two objectives. (1) Picking a sweet spot on the near-far axis away from you into the projected future; and (2) Minimizing inward transition costs from one or more existing languages so you co-opt their userbases. And now let’s talk about about how C took over the world.
|
||||
|
||||
There is no more more breathtaking example than C than of nailing the near-far sweet spot in the entire history of computing. All I need to do to prove this is point at its extreme longevity as a practical, mainstream language that successfully saw off many competitors for its roles over much of its range. That timespan has now passed about 35 years (counting from when it swamped its early competitors) and is not yet with certainty ended.
|
||||
|
||||
OK, you can attribute some of C’s persistence to inertia if you want, but what are you really adding to the explanation if you use the word “inertia”? What it means is exactly that nobody made an offer that actually covered the transition costs out of the language!
|
||||
|
||||
Conversely, an underappreciated strength of the language was the low inward transition costs. C is an almost uniquely protean tool that, even at the beginning of its long reign, could readily accommodate programming habits acquired from languages as diverse as FORTRAN, Pascal, assemblers and LISP. I noticed back in the 1980s that I could often spot a new C programmer’s last language by his coding style, which was just the flip side of saying that C was damn good at gathering all those tribes unto itself.
|
||||
|
||||
C++ also benefited from having low transition costs in. Later, most new languages at least partly copied C syntax in order to minimize them.Notice what this does to the context of future language designs: it raises the value of being a C-like as possible in order to minimize inward transition costs from anywhere.
|
||||
|
||||
Another way to minimize inward transition costs is to simply be ridiculously easy to learn, even to people with no prior programming experience. This, however, is remarkably hard to pull off. I evaluate that only one language – Python – has made the major leagues by relying on this quality. I mention it only in passing because it’s not a strategy I expect to see a _systems_ language execute successfully, though I’d be delighted to be wrong about that.
|
||||
|
||||
So here we are in late 2017, and…the next part is going to sound to some easily-annoyed people like Go advocacy, but it isn’t. Go, itself, could turn out to fail in several easily imaginable ways. It’s troubling that the Go team is so impervious to some changes their user community is near-unanimously and rightly (I think) insisting it needs. Worst-case GC latency, or the throughput sacrifices made to lower it, could still turn out to drastically narrow the language’s application range.
|
||||
|
||||
That said, there is a grand strategy expressed in the Go design that I think is right. To understand it, we need to review what the near problem for a C replacement is. As I noted in the prequels, it is rising defect rates as systems projects scale up – and specifically memory-management bugs because that category so dominates crash bugs and security exploits.
|
||||
|
||||
We’ve now identified two really powerful imperatives for a C replacement: (1) solve the memory-management problem, and (2) minimize inward-transition costs from C. And the history – the praxeological context – of programming languages tells us that if a C successor candidate don’t address the transition-cost problem effectively enough, it almost doesn’t matter how good a job it does on anything else. Conversely, a C successor that _does_ address transition costs well buys itself a lot of slack for not being perfect in other ways.
|
||||
|
||||
This is what Go does. It’s not a theoretical jewel; it has annoying limitations; GC latency presently limits how far down the stack it can be pushed. But what it is doing is replicating the Unix/C infective strategy of being easy-entry and _good enough_ to propagate faster than alternatives that, if it didn’t exist, would look like better far bets.
|
||||
|
||||
Of course, the proboscid in the room when I say that is Rust. Which is, in fact, positioning itself as the better far bet. I’ve explained in previous installments why I don’t think it’s really ready to compete yet. The TIOBE and PYPL indices agree; it’s never made the TIOBE top 20 and on both indices does quite poorly against Go.
|
||||
|
||||
Where Rust will be in five years is a different question, of course. My advice to the Rust community, if they care, is to pay some serious attention to the transition-cost problem. My personal experience says the C to Rust energy barrier is _[nasty][2]_ . Code-lifting tools like Corrode won’t solve it if all they do is map C to unsafe Rust, and if there were an easy way to automate ownership/lifetime annotations they wouldn’t be needed at all – the compiler would just do that for you. I don’t know what a solution would look like, here, but I think they better find one.
|
||||
|
||||
I will finally note that Ken Thompson has a history of designs that look like minimal solutions to near problems but turn out to have an amazing quality of openness to the future, the capability to _be improved_ . Unix is like this, of course. It makes me very cautious about supposing that any of the obvious annoyances in Go that look like future-blockers to me (like, say, the lack of generics) actually are. Because for that to be true, I’d have to be smarter than Ken, which is not an easy thing to believe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7745
|
||||
|
||||
作者:[Eric Raymond ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7711&cpage=1#comment-1913931
|
||||
[3]:http://esr.ibiblio.org/?p=7745
|
||||
93
sources/tech/20171120 Adopting Kubernetes step by step.md
Normal file
93
sources/tech/20171120 Adopting Kubernetes step by step.md
Normal file
@ -0,0 +1,93 @@
|
||||
Adopting Kubernetes step by step
|
||||
============================================================
|
||||
|
||||
Why Docker and Kubernetes?
|
||||
|
||||
Containers allow us to build, ship and run distributed applications. They remove the machine constraints from applications and lets us create a complex application in a deterministic fashion.
|
||||
|
||||
Composing applications with containers allows us to make development, QA and production environments closer to each other (if you put the effort in to get there). By doing so, changes can be shipped faster and testing a full system can happen sooner.
|
||||
|
||||
[Docker][1] — the containerization platform — provides this, making software _independent_ of cloud providers.
|
||||
|
||||
However, even with containers the amount of work needed for shipping your application through any cloud provider (or in a private cloud) is significant. An application usually needs auto scaling groups, persistent remote discs, auto discovery, etc. But each cloud provider has different mechanisms for doing this. If you want to support these features, you very quickly become cloud provider dependent.
|
||||
|
||||
This is where [Kubernetes][2] comes in to play. It is an orchestration system for containers that allows you to manage, scale and deploy different pieces of your application — in a standardised way — with great tooling as part of it. It’s a portable abstraction that’s compatible with the main cloud providers (Google Cloud, Amazon Web Services and Microsoft Azure all have support for Kubernetes).
|
||||
|
||||
A way to visualise your application, containers and Kubernetes is to think about your application as a shark — stay with me — that exists in the ocean (in this example, the ocean is your machine). The ocean may have other precious things you don’t want your shark to interact with, like [clown fish][3]. So you move you shark (your application) into a sealed aquarium (Container). This is great but not very robust. Your aquarium can break or maybe you want to build a tunnel to another aquarium where other fish live. Or maybe you want many copies of that aquarium in case one needs cleaning or maintenance… this is where Kubernetes clusters come to play.
|
||||
|
||||
|
||||

|
||||
Evolution to Kubernetes
|
||||
|
||||
With Kubernetes being supported by the main cloud providers, it makes it easier for you and your team to have environments from _development _ to _production _ that are almost identical to each other. This is because Kubernetes has no reliance on proprietary software, services or infrastructure.
|
||||
|
||||
The fact that you can start your application in your machine with the same pieces as in production closes the gaps between a development and a production environment. This makes developers more aware of how an application is structured together even though they might only be responsible for one piece of it. It also makes it easier for your application to be fully tested earlier in the pipeline.
|
||||
|
||||
How do you work with Kubernetes?
|
||||
|
||||
With more people adopting Kubernetes new questions arise; how should I develop against a cluster based environment? Suppose you have 3 environments — development, QA and production — how do I fit Kubernetes in them? Differences across these environments will still exist, either in terms of development cycle (e.g. time spent to see my code changes in the application I’m running) or in terms of data (e.g. I probably shouldn’t test with production data in my QA environment as it has sensitive information).
|
||||
|
||||
So, should I always try to work inside a Kubernetes cluster, building images, recreating deployments and services while I code? Or maybe I should not try too hard to make my development environment be a Kubernetes cluster (or set of clusters) in development? Or maybe I should work in a hybrid way?
|
||||
|
||||
|
||||
|
||||
Development with a local cluster
|
||||
|
||||
If we carry on with our metaphor, the holes on the side represent a way to make changes to our app while keeping it in a development cluster. This is usually achieved via [volumes][4].
|
||||
|
||||
A Kubernetes series
|
||||
|
||||
The Kubernetes series repository is open source and available here:
|
||||
|
||||
### [https://github.com/red-gate/ks][5]
|
||||
|
||||
We’ve written this series as we experiment with different ways to build software. We’ve tried to constrain ourselves to use Kubernetes in all environments so that we can explore the impact these technologies will have on the development and management of data and the database.
|
||||
|
||||
The series starts with the basic creation of a React application hooked up to Kubernetes, and evolves to encompass more of our development requirements. By the end we’ll have covered all of our application development needs _and_ have understood how best to cater for the database lifecycle in this world of containers and clusters.
|
||||
|
||||
Here are the first 5 episodes of this series:
|
||||
|
||||
1. ks1: build a React app with Kubernetes
|
||||
|
||||
2. ks2: make minikube detect React code changes
|
||||
|
||||
3. ks3: add a python web server that hosts an API
|
||||
|
||||
4. ks4: make minikube detect Python code changes
|
||||
|
||||
5. ks5: create a test environment
|
||||
|
||||
The second part of the series will add a database and try to work out the best way to evolve our application alongside it.
|
||||
|
||||
By running Kubernetes in all environments, we’ve been forced to solve new problems as we try to keep the development cycle as fast as possible. The trade-off being that we are constantly exposed to Kubernetes and become more accustomed to it. By doing so, development teams become responsible for production environments, which is no longer difficult as all environments (development through production) are all managed in the same way.
|
||||
|
||||
What’s next?
|
||||
|
||||
We will continue this series by incorporating a database and experimenting to find the best way to have a seamless database lifecycle experience with Kubernetes.
|
||||
|
||||
_This Kubernetes series is brought to you by Foundry, Redgate’s R&D division. We’re working on making it easier to manage data alongside containerised environments, so if you’re working with data and containerised environments, we’d like to hear from you — reach out directly to the development team at _ [_foundry@red-gate.com_][6]
|
||||
|
||||
* * *
|
||||
|
||||
_We’re hiring_ _. Are you interested in uncovering product opportunities, building _ [_future technology_][7] _ and taking a startup-like approach (without the risk)? Take a look at our _ [_Software Engineer — Future Technologies_][8] _ role and read more about what it’s like to work at Redgate in _ [_Cambridge, UK_][9] _._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/ingeniouslysimple/adopting-kubernetes-step-by-step-f93093c13dfe
|
||||
|
||||
作者:[santiago arias][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@santiaago?source=post_header_lockup
|
||||
[1]:https://www.docker.com/what-docker
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.google.co.uk/search?biw=723&bih=753&tbm=isch&sa=1&ei=p-YCWpbtN8atkwWc8ZyQAQ&q=nemo+fish&oq=nemo+fish&gs_l=psy-ab.3..0i67k1l2j0l2j0i67k1j0l5.5128.9271.0.9566.9.9.0.0.0.0.81.532.9.9.0....0...1.1.64.psy-ab..0.9.526...0i7i30k1j0i7i10i30k1j0i13k1j0i10k1.0.FbAf9xXxTEM
|
||||
[4]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[5]:https://github.com/red-gate/ks
|
||||
[6]:mailto:foundry@red-gate.com
|
||||
[7]:https://www.red-gate.com/foundry/
|
||||
[8]:https://www.red-gate.com/our-company/careers/current-opportunities/software-engineer-future-technologies
|
||||
[9]:https://www.red-gate.com/our-company/careers/living-in-cambridge
|
||||
@ -1,73 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
|
||||
# LibreOffice Is Now Available on Flathub, the Flatpak App Store
|
||||
|
||||

|
||||
|
||||
LibreOffice is now available to install from [Flathub][3], the centralised Flatpak app store.
|
||||
|
||||
Its arrival allows anyone running a modern Linux distribution to install the latest stable release of LibreOffice in a click or two, without having to hunt down a PPA, tussle with tarballs or wait for a distro provider to package it up.
|
||||
|
||||
A [LibreOffice Flatpak][5] has been available for users to download and install since August of last year and the [LibreOffice 5.2][6] release.
|
||||
|
||||
What’s “new” here is the distribution method. Rather than release updates through their own dedicated server The Document Foundation has opted to use Flathub.
|
||||
|
||||
This is _great_ news for end users as it means there’s one less repo to worry about adding on a fresh install, but it’s also good news for Flatpak advocates too: LibreOffice is open-source software’s most popular productivity suite. Its support for both format and app store is sure to be warmly welcomed.
|
||||
|
||||
At the time of writing you can install LibreOffice 5.4.2 from Flathub. New stable releases will be added as and when they’re released.
|
||||
|
||||
### Enable Flathub on Ubuntu
|
||||
|
||||

|
||||
|
||||
Fedora, Arch, and Linux Mint 18.3 users have Flatpak installed, ready to go, out of the box. Mint even comes with the Flathub remote pre-enabled.
|
||||
|
||||
[Install LibreOffice from Flathub][7]
|
||||
|
||||
To get Flatpak up and running on Ubuntu you first have to install it:
|
||||
|
||||
```
|
||||
sudo apt install flatpak gnome-software-plugin-flatpak
|
||||
```
|
||||
|
||||
To be able to install apps from Flathub you need to add the Flathub remote server:
|
||||
|
||||
```
|
||||
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
```
|
||||
|
||||
That’s pretty much it. Just log out and back in (so that Ubuntu Software refreshes its cache) and you _should_ be able to find any Flatpak apps available on Flathub through the Ubuntu Software app.
|
||||
|
||||
In this instance, search for “LibreOffice” and locate the result that has a line of text underneath mentioning Flathub. (Do bear in mind that Ubuntu has tweaked the Software client to shows Snap app results above everything else, so you may need scroll down the list of results to see it).
|
||||
|
||||
There is a [bug with installing Flatpak apps][8] from a flatpakref file, so if the above method doesn’t work you can also install Flatpak apps form Flathub using the command line.
|
||||
|
||||
The Flathub website lists the command needed to install each app. Switch to the “Command Line” tab to see them.
|
||||
|
||||
#### More apps on Flathub
|
||||
|
||||
If you read this site regularly enough you’ll know that I _love_ Flathub. It’s home to some of my favourite apps (Corebird, Parlatype, GNOME MPV, Peek, Audacity, GIMP… etc). I get the latest, stable versions of these apps (plus any dependencies they need) without compromise.
|
||||
|
||||
And, as I tweeted a week or so back, most Flatpak apps now look great with GTK themes — no more [workarounds][9]required!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/11/libreoffice-now-available-flathub-flatpak-app-store
|
||||
|
||||
作者:[ JOEY SNEDDON ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[2]:http://www.omgubuntu.co.uk/category/news
|
||||
[3]:http://www.flathub.org/
|
||||
[4]:http://www.omgubuntu.co.uk/2017/11/libreoffice-now-available-flathub-flatpak-app-store
|
||||
[5]:http://www.omgubuntu.co.uk/2016/08/libreoffice-5-2-released-whats-new
|
||||
[6]:http://www.omgubuntu.co.uk/2016/08/libreoffice-5-2-released-whats-new
|
||||
[7]:https://flathub.org/repo/appstream/org.libreoffice.LibreOffice.flatpakref
|
||||
[8]:https://bugs.launchpad.net/ubuntu/+source/gnome-software/+bug/1716409
|
||||
[9]:http://www.omgubuntu.co.uk/2017/05/flatpak-theme-issue-fix
|
||||
116
sources/tech/20171123 Why microservices are a security issue.md
Normal file
116
sources/tech/20171123 Why microservices are a security issue.md
Normal file
@ -0,0 +1,116 @@
|
||||
Why microservices are a security issue
|
||||
============================================================
|
||||
|
||||
### Maybe you don't want to decompose all your legacy applications into microservices, but you might consider starting with your security functions.
|
||||
|
||||

|
||||
Image by : Opensource.com
|
||||
|
||||
I struggled with writing the title for this post, and I worry that it comes across as clickbait. If you've come to read this because it looked like clickbait, then sorry.[1][5]I hope you'll stay anyway: there are lots of fascinating[2][6] points and many[3][7]footnotes. What I _didn't_ mean to suggest is that microservices cause [security][15]problems—though like any component, of course, they can—but that microservices are appropriate objects of interest to those involved with security. I'd go further than that: I think they are an excellent architectural construct for those concerned with security.
|
||||
|
||||
And why is that? Well, for those of us with a [systems security][16] bent, the world is an interesting place at the moment. We're seeing a growth in distributed systems, as bandwidth is cheap and latency low. Add to this the ease of deploying to the cloud, and more architects are beginning to realise that they can break up applications, not just into multiple layers, but also into multiple components within the layer. Load balancers, of course, help with this when the various components in a layer are performing the same job, but the ability to expose different services as small components has led to a growth in the design, implementation, and deployment of _microservices_ .
|
||||
|
||||
More on Microservices
|
||||
|
||||
* [How to explain microservices to your CEO][1]
|
||||
|
||||
* [Free eBook: Microservices vs. service-oriented architecture][2]
|
||||
|
||||
* [Secured DevOps for microservices][3]
|
||||
|
||||
So, [what exactly is a microservice][23]? I quite like [Wikipedia's definition][24], though it's interesting that security isn't mentioned there.[4][17] One of the points that I like about microservices is that, when well-designed, they conform to the first two points of Peter H. Salus' description of the [Unix philosophy][25]:
|
||||
|
||||
1. Write programs that do one thing and do it well.
|
||||
|
||||
2. Write programs to work together.
|
||||
|
||||
3. Write programs to handle text streams, because that is a universal interface.
|
||||
|
||||
The last of the three is slightly less relevant, because the Unix philosophy is generally used to refer to standalone applications, which often have a command instantiation. It does, however, encapsulate one of the basic requirements of microservices: that they must have well-defined interfaces.
|
||||
|
||||
By "well-defined," I don't just mean a description of any externally accessible APIs' methods, but also of the normal operation of the microservice: inputs and outputs—and, if there are any, side-effects. As I described in a previous post, "[5 traits of good systems architecture][18]," data and entity descriptions are crucial if you're going to be able to design a system. Here, in our description of microservices, we get to see why these are so important, because, for me, the key defining feature of a microservices architecture is decomposability. And if you're going to decompose[5][8] your architecture, you need to be very, very clear which "bits" (components) are going to do what.
|
||||
|
||||
And here's where security starts to come in. A clear description of what a particular component should be doing allows you to:
|
||||
|
||||
* Check your design
|
||||
|
||||
* Ensure that your implementation meets the description
|
||||
|
||||
* Come up with reusable unit tests to check functionality
|
||||
|
||||
* Track mistakes in implementation and correct them
|
||||
|
||||
* Test for unexpected outcomes
|
||||
|
||||
* Monitor for misbehaviour
|
||||
|
||||
* Audit actual behaviour for future scrutiny
|
||||
|
||||
Now, are all these things possible in a larger architecture? Yes, they are. But they become increasingly difficult where entities are chained together or combined in more complex configurations. Ensuring _correct_ implementation and behaviour is much, much easier when you've got smaller pieces to work together. And deriving complex systems behaviours—and misbehaviours—is much more difficult if you can't be sure that the individual components are doing what they ought to be.
|
||||
|
||||
It doesn't stop here, however. As I've mentioned on many [previous occasions][19], writing good security code is difficult.[7][9] Proving that it does what it should do is even more difficult. There is every reason, therefore, to restrict code that has particular security requirements—password checking, encryption, cryptographic key management, authorisation, etc.—to small, well-defined blocks. You can then do all the things that I've mentioned above to try to make sure it's done correctly.
|
||||
|
||||
And yet there's more. We all know that not everybody is great at writing security-related code. By decomposing your architecture such that all security-sensitive code is restricted to well-defined components, you get the chance to put your best security people on that and restrict the danger that J. Random Coder[8][10] will put something in that bypasses or downgrades a key security control.
|
||||
|
||||
It can also act as an opportunity for learning: It's always good to be able to point to a design/implementation/test/monitoring tuple and say: "That's how it should be done. Hear, read, mark, learn, and inwardly digest.[9][11]"
|
||||
|
||||
Should you go about decomposing all of your legacy applications into microservices? Probably not. But given all the benefits you can accrue, you might consider starting with your security functions.
|
||||
|
||||
* * *
|
||||
|
||||
1Well, a little bit—it's always nice to have readers.
|
||||
|
||||
2I know they are: I wrote them.
|
||||
|
||||
3Probably less fascinating.
|
||||
|
||||
4At the time this article was written. It's entirely possible that I—or one of you—may edit the article to change that.
|
||||
|
||||
5This sounds like a gardening term, which is interesting. Not that I really like gardening, but still.[6][12]
|
||||
|
||||
6Amusingly, I first wrote, "…if you're going to decompose your architect…," which sounds like the strapline for an IT-themed murder film.
|
||||
|
||||
7Regular readers may remember a reference to the excellent film _The Thick of It_ .
|
||||
|
||||
8Other generic personae exist; please take your pick.
|
||||
|
||||
9Not a cryptographic digest: I don't think that's what the original writers had in mind.
|
||||
|
||||
_This article originally appeared on [Alice, Eve, and Bob—a security blog][13] and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/microservices-are-security-issue
|
||||
|
||||
作者:[Mike Bursell ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://blog.openshift.com/microservices-how-to-explain-them-to-your-ceo/?intcmp=7016000000127cYAAQ&src=microservices_resource_menu1
|
||||
[2]:https://www.openshift.com/promotions/microservices.html?intcmp=7016000000127cYAAQ&src=microservices_resource_menu2
|
||||
[3]:https://opensource.com/business/16/11/secured-devops-microservices?src=microservices_resource_menu3
|
||||
[4]:https://opensource.com/article/17/11/microservices-are-security-issue?rate=GDH4xOWsgYsVnWbjEIoAcT_92b8gum8XmgR6U0T04oM
|
||||
[5]:https://opensource.com/article/17/11/microservices-are-security-issue#1
|
||||
[6]:https://opensource.com/article/17/11/microservices-are-security-issue#2
|
||||
[7]:https://opensource.com/article/17/11/microservices-are-security-issue#3
|
||||
[8]:https://opensource.com/article/17/11/microservices-are-security-issue#5
|
||||
[9]:https://opensource.com/article/17/11/microservices-are-security-issue#7
|
||||
[10]:https://opensource.com/article/17/11/microservices-are-security-issue#8
|
||||
[11]:https://opensource.com/article/17/11/microservices-are-security-issue#9
|
||||
[12]:https://opensource.com/article/17/11/microservices-are-security-issue#6
|
||||
[13]:https://aliceevebob.com/2017/10/31/why-microservices-are-a-security-issue/
|
||||
[14]:https://opensource.com/user/105961/feed
|
||||
[15]:https://opensource.com/tags/security
|
||||
[16]:https://aliceevebob.com/2017/03/14/systems-security-why-it-matters/
|
||||
[17]:https://opensource.com/article/17/11/microservices-are-security-issue#4
|
||||
[18]:https://opensource.com/article/17/10/systems-architect
|
||||
[19]:https://opensource.com/users/mikecamel
|
||||
[20]:https://opensource.com/users/mikecamel
|
||||
[21]:https://opensource.com/users/mikecamel
|
||||
[22]:https://opensource.com/article/17/11/microservices-are-security-issue#comments
|
||||
[23]:https://opensource.com/resources/what-are-microservices
|
||||
[24]:https://en.wikipedia.org/wiki/Microservices
|
||||
[25]:https://en.wikipedia.org/wiki/Unix_philosophy
|
||||
@ -0,0 +1,78 @@
|
||||
translating---geekpi
|
||||
|
||||
AWS to Help Build ONNX Open Source AI Platform
|
||||
============================================================
|
||||

|
||||
|
||||
|
||||
Amazon Web Services has become the latest tech firm to join the deep learning community's collaboration on the Open Neural Network Exchange, recently launched to advance artificial intelligence in a frictionless and interoperable environment. Facebook and Microsoft led the effort.
|
||||
|
||||
As part of that collaboration, AWS made its open source Python package, ONNX-MxNet, available as a deep learning framework that offers application programming interfaces across multiple languages including Python, Scala and open source statistics software R.
|
||||
|
||||
The ONNX format will help developers build and train models for other frameworks, including PyTorch, Microsoft Cognitive Toolkit or Caffe2, AWS Deep Learning Engineering Manager Hagay Lupesko and Software Developer Roshani Nagmote wrote in an online post last week. It will let developers import those models into MXNet, and run them for inference.
|
||||
|
||||
### Help for Developers
|
||||
|
||||
Facebook and Microsoft this summer launched ONNX to support a shared model of interoperability for the advancement of AI. Microsoft committed its Cognitive Toolkit, Caffe2 and PyTorch to support ONNX.
|
||||
|
||||
Cognitive Toolkit and other frameworks make it easier for developers to construct and run computational graphs that represent neural networks, Microsoft said.
|
||||
|
||||
Initial versions of [ONNX code and documentation][4] were made available on Github.
|
||||
|
||||
AWS and Microsoft last month announced plans for Gluon, a new interface in Apache MXNet that allows developers to build and train deep learning models.
|
||||
|
||||
Gluon "is an extension of their partnership where they are trying to compete with Google's Tensorflow," observed Aditya Kaul, research director at [Tractica][5].
|
||||
|
||||
"Google's omission from this is quite telling but also speaks to their dominance in the market," he told LinuxInsider.
|
||||
|
||||
"Even Tensorflow is open source, and so open source is not the big catch here -- but the rest of the ecosystem teaming up to compete with Google is what this boils down to," Kaul said.
|
||||
|
||||
The Apache MXNet community earlier this month introduced version 0.12 of MXNet, which extends Gluon functionality to allow for new, cutting-edge research, according to AWS. Among its new features are variational dropout, which allows developers to apply the dropout technique for mitigating overfitting to recurrent neural networks.
|
||||
|
||||
Convolutional RNN, Long Short-Term Memory and gated recurrent unit cells allow datasets to be modeled using time-based sequence and spatial dimensions, AWS noted.
|
||||
|
||||
### Framework-Neutral Method
|
||||
|
||||
"This looks like a great way to deliver inference regardless of which framework generated a model," said Paul Teich, principal analyst at [Tirias Research][6].
|
||||
|
||||
"This is basically a framework-neutral way to deliver inference," he told LinuxInsider.
|
||||
|
||||
Cloud providers like AWS, Microsoft and others are under pressure from customers to be able to train on one network while delivering on another, in order to advance AI, Teich pointed out.
|
||||
|
||||
"I see this as kind of a baseline way for these vendors to check the interoperability box," he remarked.
|
||||
|
||||
"Framework interoperability is a good thing, and this will only help developers in making sure that models that they build on MXNet or Caffe or CNTK are interoperable," Tractica's Kaul pointed out.
|
||||
|
||||
As to how this interoperability might apply in the real world, Teich noted that technologies such as natural language translation or speech recognition would require that Alexa's voice recognition technology be packaged and delivered to another developer's embedded environment.
|
||||
|
||||
### Thanks, Open Source
|
||||
|
||||
"Despite their competitive differences, these companies all recognize they owe a significant amount of their success to the software development advancements generated by the open source movement," said Jeff Kaplan, managing director of [ThinkStrategies][7].
|
||||
|
||||
"The Open Neural Network Exchange is committed to producing similar benefits and innovations in AI," he told LinuxInsider.
|
||||
|
||||
A growing number of major technology companies have announced plans to use open source to speed the development of AI collaboration, in order to create more uniform platforms for development and research.
|
||||
|
||||
AT&T just a few weeks ago announced plans [to launch the Acumos Project][8] with TechMahindra and The Linux Foundation. The platform is designed to open up efforts for collaboration in telecommunications, media and technology.
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
|
||||
作者:[ David Jones ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html#searchbyline
|
||||
[1]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html#
|
||||
[2]:https://www.linuxinsider.com/perl/mailit/?id=84971
|
||||
[3]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
[4]:https://github.com/onnx/onnx
|
||||
[5]:https://www.tractica.com/
|
||||
[6]:http://www.tiriasresearch.com/
|
||||
[7]:http://www.thinkstrategies.com/
|
||||
[8]:https://www.linuxinsider.com/story/84926.html
|
||||
[9]:https://www.linuxinsider.com/story/AWS-to-Help-Build-ONNX-Open-Source-AI-Platform-84971.html
|
||||
110
sources/tech/20171128 The politics of the Linux desktop.md
Normal file
110
sources/tech/20171128 The politics of the Linux desktop.md
Normal file
@ -0,0 +1,110 @@
|
||||
The politics of the Linux desktop
|
||||
============================================================
|
||||
|
||||
### If you're working in open source, why would you use anything but Linux as your main desktop?
|
||||
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
At some point in 1997 or 1998—history does not record exactly when—I made the leap from Windows to the Linux desktop. I went through quite a few distributions, from Red Hat to SUSE to Slackware, then Debian, Debian Experimental, and (for a long time thereafter) Ubuntu. When I accepted a role at Red Hat, I moved to Fedora, and migrated both my kids (then 9 and 11) to Fedora as well.
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
For a few years, I kept Windows as a dual-boot option, and then realised that, if I was going to commit to Linux, then I ought to go for it properly. In losing Windows, I didn't miss much; there were a few games that I couldn't play, but it was around the time that the Civilization franchise was embracing Linux, so that kept me happy.
|
||||
|
||||
The move to Linux wasn't plain sailing, by any stretch of the imagination. If you wanted to use fairly new hardware in the early days, you had to first ensure that there were _any_ drivers for Linux, then learn how to compile and install them. If they were not quite my friends, **lsmod** and **modprobe** became at least close companions. I taught myself to compile a kernel and tweak the options to make use of (sometimes disastrous) new, "EXPERIMENTAL" features as they came out. Early on, I learned the lesson that you should always keep at least one kernel in your [LILO][12] list that you were _sure_ booted fully. I cursed NVidia and grew horrified by SCSI. I flirted with early journalling filesystem options and tried to work out whether the different preempt parameters made any noticeable difference to my user experience or not. I began to accept that printers would never print—and then they started to. I discovered that the Bluetooth stack suddenly started to connect to things.
|
||||
|
||||
Over the years, using Linux moved from being an uphill struggle to something that just worked. I moved my mother-in-law and then my father over to Linux so I could help administer their machines. And then I moved them off Linux so they could no longer ask me to help administer their machines.
|
||||
|
||||
Over the years, using Linux moved from being an uphill struggle to something that just worked.It wasn't just at home, either: I decided that I would use Linux as my desktop for work, as well. I even made it a condition of employment for at least one role. Linux desktop support in the workplace caused different sets of problems. The first was the "well, you're on your own: we're not going to support you" email from IT support. VPNs were touch and go, but in the end, usually go.
|
||||
|
||||
The biggest hurdle was Microsoft Office, until I discovered [CrossOver][13], which I bought with my own money, and which allowed me to run company-issued copies of Word, PowerPoint, and the rest on my Linux desktop. Fonts were sometimes a problem, and one company I worked for required Microsoft Lync. For this, and for a few other applications, I would sometimes have to run a Windows virtual machine (VM) on my Linux desktop. Was this a cop out? Well, a little bit: but I've always tried to restrict my usage of this approach to the bare minimum.
|
||||
|
||||
### But why?
|
||||
|
||||
"Why?" colleagues would ask. "Why do you bother? Why not just run Windows?"
|
||||
|
||||
"Because I enjoy pain," was usually my initial answer, and then the more honest, "because of the principle of the thing."
|
||||
|
||||
So this is it: I believe in open source. We have a number of very, very good desktop-compatible distributions these days, and most of the time they just work. If you use well-known or supported hardware, they're likely to "just work" pretty much as well as the two obvious alternatives, Windows or Mac. And they just work because many people have put much time into using them, testing them, and improving them. So it's not a case of why wouldn't I use Windows or Mac, but why would I ever consider _not_ using Linux? If, as I do, you believe in open source, and particularly if you work within the open source community or are employed by an open source organisation, I struggle to see why you would even consider not using Linux.
|
||||
|
||||
So it's not a case of why wouldn't I use Windows or Mac, but why would I ever consider not using Linux?I've spoken to people about this (of course I have), and here are the most common reasons—or excuses—I've heard.
|
||||
|
||||
1. I'm more productive on Windows/Mac.
|
||||
|
||||
2. I can't use app X on Linux, and I need it for my job.
|
||||
|
||||
3. I can't game on Linux.
|
||||
|
||||
4. It's what our customers use, so why we would alienate them?
|
||||
|
||||
5. "Open" means choice, and I prefer a proprietary desktop, so I use that.
|
||||
|
||||
Interestingly, I don't hear "Linux isn't good enough" much anymore, because it's manifestly untrue, and I can show that my own experience—and that of many colleagues—belies that.
|
||||
|
||||
### Rebuttals
|
||||
|
||||
If you believe in open source, then I contest that you should take the time to learn how to use a Linux desktop and the associated applications.Let's go through those answers and rebut them.
|
||||
|
||||
1. **I'm more productive on Windows/Mac.** I'm sure you are. Anyone is more productive when they're using a platform or a system they're used to. If you believe in open source, then I contest that you should take the time to learn how to use a Linux desktop and the associated applications. If you're working for an open source organisation, they'll probably help you along, and you're unlikely to find you're much less productive in the long term. And, you know what? If you are less productive in the long term, then get in touch with the maintainers of the apps that are causing you to be less productive and help improve them. You don't have to be a coder. You could submit bug reports, suggest improvements, write documentation, or just test the most recent versions of the software. And then you're helping yourself and the rest of the community. Welcome to open source.
|
||||
|
||||
1. **I can't use app X on Linux, and I need it for my job.** This may be true. But it's probably less true than you think. The people most often saying this with conviction are audio, video, or graphics experts. It was certainly the case for many years that Linux lagged behind in those areas, but have a look and see what the other options are. And try them, even if they're not perfect, and see how you can improve them. Alternatively, use a VM for that particular app.
|
||||
|
||||
1. **I can't game on Linux.** Well, you probably can, but not all the games that you enjoy. This, to be clear, shouldn't really be an excuse not to use Linux for most of what you do. It might be a reason to keep a dual-boot system or to do what I did (after much soul-searching) and buy a games console (because Elite Dangerous really _doesn't_ work on Linux, more's the pity). It should also be an excuse to lobby for your favourite games to be ported to Linux.
|
||||
|
||||
1. **It's what our customers use, so why would we alienate them?** I don't get this one. Does Microsoft ban visitors with Macs from their buildings? Does Apple ban Windows users? Does Google allow non-Android phones through their doors? You don't kowtow to the majority when you're the little guy or gal; if you're working in open source, surely you should be proud of that. You're not going to alienate your customer—you're really not.
|
||||
|
||||
1. **"Open" means choice, and I prefer a proprietary desktop, so I use that.**Being open certainly does mean you have a choice. You made that choice by working in open source. For many, including me, that's a moral and philosophical choice. Saying you embrace open source, but rejecting it in practice seems mealy mouthed, even insulting. Using openness to justify your choice is the wrong approach. Saying "I prefer a proprietary desktop, and company policy allows me to do so" is better. I don't agree with your decision, but at least you're not using the principle of openness to justify it.
|
||||
|
||||
Is using open source easy? Not always. But it's getting easier. I think that we should stand up for what we believe in, and if you're reading [Opensource.com][14], then you probably believe in open source. And that, I believe, means that you should run Linux as your main desktop.
|
||||
|
||||
_Note: I welcome comments, and would love to hear different points of view. I would ask that comments don't just list application X or application Y as not working on Linux. I concede that not all apps do. I'm more interested in justifications that I haven't covered above, or (perceived) flaws in my argument. Oh, and support for it, of course._
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][15]
|
||||
|
||||
Mike Bursell - I've been in and around Open Source since around 1997, and have been running (GNU) Linux as my main desktop at home and work since then: [not always easy][7]... I'm a security bod and architect, and am currently employed as Chief Security Architect for Red Hat. I have a blog - "[Alice, Eve & Bob][8]" - where I write (sometimes rather parenthetically) about security. I live in the UK and... [more about Mike Bursell][9][More about me][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/politics-linux-desktop
|
||||
|
||||
作者:[Mike Bursell ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/article/17/11/politics-linux-desktop?rate=do69ixoNzK0yg3jzFk0bc6ZOBsIUcqTYv6FwqaVvzUA
|
||||
[7]:https://opensource.com/article/17/11/politics-linux-desktop
|
||||
[8]:https://aliceevebob.com/
|
||||
[9]:https://opensource.com/users/mikecamel
|
||||
[10]:https://opensource.com/users/mikecamel
|
||||
[11]:https://opensource.com/user/105961/feed
|
||||
[12]:https://en.wikipedia.org/wiki/LILO_(boot_loader)
|
||||
[13]:https://en.wikipedia.org/wiki/CrossOver_(software)
|
||||
[14]:https://opensource.com/
|
||||
[15]:https://opensource.com/users/mikecamel
|
||||
[16]:https://opensource.com/users/mikecamel
|
||||
[17]:https://opensource.com/users/mikecamel
|
||||
[18]:https://opensource.com/article/17/11/politics-linux-desktop#comments
|
||||
[19]:https://opensource.com/tags/linux
|
||||
@ -0,0 +1,143 @@
|
||||
(translating by runningwater)
|
||||
Why Python and Pygame are a great pair for beginning programmers
|
||||
============================================================
|
||||
|
||||
### We look at three reasons Pygame is a good choice for learning to program.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
Last month, [Scott Nesbitt][10] wrote about [Mozilla awarding $500K to support open source projects][11]. Phaser, a HTML/JavaScript game platform, was [awarded $50,000][12]. I’ve been teaching Phaser to my pre-teen daughter for a year, and it's one of the best and easiest HTML game development platforms to learn. [Pygame][13], however, may be a better choice for beginners. Here's why.
|
||||
|
||||
### 1\. One long block of code
|
||||
|
||||
Pygame is based on Python, the [most popular language for introductory computer courses][14]. Python is great for writing out ideas in one long block of code. Kids start off with a single file and with a single block of code. Before they can get to functions or classes, they start with code that will soon resemble spaghetti. It’s like finger-painting, as they throw thoughts onto the page.
|
||||
|
||||
More Python Resources
|
||||
|
||||
* [What is Python?][1]
|
||||
|
||||
* [Top Python IDEs][2]
|
||||
|
||||
* [Top Python GUI frameworks][3]
|
||||
|
||||
* [Latest Python content][4]
|
||||
|
||||
* [More developer resources][5]
|
||||
|
||||
This approach to learning works. Kids will naturally start to break things into functions and classes as their code gets more difficult to manage. By learning the syntax of a language like Python prior to learning about functions, the student will gain basic programming knowledge before using global and local scope.
|
||||
|
||||
Most HTML games separate the structure, style, and programming logic into HTML, CSS, and JavaScript to some degree and require knowledge of CSS and HTML. While the separation is better in the long term, it can be a barrier for beginners. Once kids realize that they can quickly build web pages with HTML and CSS, they may get distracted by the visual excitement of colors, fonts, and graphics. Even those who stay focused on JavaScript coding will still need to learn the basic document structure that the JavaScript code sits in.
|
||||
|
||||
### 2\. Global variables are more obvious
|
||||
|
||||
Both Python and JavaScript use dynamically typed variables, meaning that a variable becomes a string, an integer, or float when it’s assigned; however, making mistakes is easier in JavaScript. Similar to typed variables, both JavaScript and Python have global and local variable scopes. In Python, global variables inside of a function are identified with the global keyword.
|
||||
|
||||
Let’s look at the basic [Making your first Phaser game tutorial][15], by Alvin Ourrad and Richard Davey, to understand the challenge of using Phaser to teach programming to beginners. In JavaScript, global variables—variables that can be accessed anywhere in the program—are difficult to keep track of and often are the source of bugs that are challenging to solve. Richard and Alvin are expert programmers and use global variables intentionally to keep things concise.
|
||||
|
||||
```
|
||||
var game = new Phaser.Game(800, 600, Phaser.AUTO, '', { preload: preload, create: create, update: update });
|
||||
|
||||
function preload() {
|
||||
|
||||
game.load.image('sky', 'assets/sky.png');
|
||||
|
||||
}
|
||||
|
||||
var player;
|
||||
var platforms;
|
||||
|
||||
function create() {
|
||||
game.physics.startSystem(Phaser.Physics.ARCADE);
|
||||
…
|
||||
```
|
||||
|
||||
In their Phaser programming book [_Interphase_ ,][16] Richard Davey and Ilija Melentijevic explain that global variables are commonly used in many Phaser projects because they make it easier to get things done quickly.
|
||||
|
||||
> “If you’ve ever worked on a game of any significant size then this approach is probably already making you cringe slightly... So why do we do it? The reason is simply because it’s the most concise and least complicated way to demonstrate what Phaser can do.”
|
||||
|
||||
Although structuring a Phaser application to use local variables and split things up nicely into separation of concerns is possible, that’s tough for kids to understand when they’re first learning to program.
|
||||
|
||||
If you’re set on teaching your kids to code with JavaScript, or if they already know how to code in another language like Python, a good Phaser course is [The Complete Mobile Game Development Course][17], by [Pablo Farias Navarro][18]. Although the title focuses on mobile games, the actual course focuses on JavaScript and Phaser. The JavaScript and Phaser apps are moved to a mobile phone with [PhoneGap][19].
|
||||
|
||||
### 3\. Pygame comes with less assembly required
|
||||
|
||||
Thanks to [Python Wheels][20], Pygame is now super [easy to install][21]. You can also install it on Fedora/Red Hat with the **yum** package manager:
|
||||
|
||||
```
|
||||
sudo yum install python3-pygame
|
||||
```
|
||||
|
||||
See the official [Pygame installation documentation][22] for more information.
|
||||
|
||||
Although Phaser itself is even easier to install, it does require more knowledge to use. As mentioned previously, the student will need to assemble their JavaScript code within an HTML document with some CSS. In addition to the three languages—HTML, CSS, and JavaScript—Phaser also requires the use of Firefox or Chrome development tools and an editor. The most common editors for JavaScript are Sublime, Atom, VS Code (probably in that order).
|
||||
|
||||
Phaser applications will not run if you open the HTML file in a browser directly, due to [same-origin policy][23]. You must run a web server and access the files by connecting to the web server. Fortunately, you don’t need to run Apache on your local computer; you can run something lightweight like [httpster][24] for most projects.
|
||||
|
||||
### Advantages of Phaser and JavaScript
|
||||
|
||||
With all the challenges of JavaScript and Phaser, why am I teaching them? Honestly, I held off for a long time. I worried about students learning variable hoisting and scope. I developed my own curriculum based on Pygame and Python, then I developed one based on Phaser. Eventually, I decided to use Pablo’s pre-made curriculum as a starting point.
|
||||
|
||||
There are really two reasons that I moved to JavaScript. First, JavaScript has emerged as a serious language used in serious applications. In addition to web applications, it’s used for mobile and server applications. JavaScript is everywhere, and it’s used widely in applications kids see every day. If their friends code in JavaScript, they'll likely want to as well. As I saw the momentum behind JavaScript, I looked into alternatives that could compile into JavaScript, primarily Dart and TypeScript. I didn’t mind the extra conversion step, but I still looked at JavaScript.
|
||||
|
||||
In the end, I chose to use Phaser and JavaScript because I realized that the problems could be solved with JavaScript and a bit of work. High-quality debugging tools and the work of some exceptionally smart people have made JavaScript a language that is both accessible and useful for teaching kids to code.
|
||||
|
||||
### Final word: Python vs. JavaScript
|
||||
|
||||
When people ask me what language to start their kids with, I immediately suggest Python and Pygame. There are tons of great curriculum options, many of which are free. I used ["Making Games with Python & Pygame"][25] by Al Sweigart with my son. I also used _[Think Python: How to Think Like a Computer Scientist][7]_ by Allen B. Downey. You can get Pygame on your Android phone with [RAPT Pygame][26] by [Tom Rothamel][27].
|
||||
|
||||
Despite my recommendation, I always suspect that kids soon move to JavaScript. And that’s okay—JavaScript is a mature language with great tools. They’ll have fun with JavaScript and learn a lot. But after years of helping my daughter’s older brother create cool games in Python, I’ll always have an emotional attachment to Python and Pygame.
|
||||
|
||||
### About the author
|
||||
|
||||
[][28]
|
||||
|
||||
Craig Oda - First elected president and co-founder of Tokyo Linux Users Group. Co-author of "Linux Japanese Environment" book published by O'Reilly Japan. Part of core team that established first ISP in Asia. Former VP of product management and product marketing for major Linux company. Partner at Oppkey, developer relations consulting firm in Silicon Valley.[More about me][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/pygame
|
||||
|
||||
作者:[Craig Oda ][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/codetricity
|
||||
[1]:https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[2]:https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[3]:https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[4]:https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[5]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[6]:https://opensource.com/article/17/11/pygame?rate=PV7Af00S0QwicZT2iv8xSjJrmJPdpfK1Kcm7LXxl_Xc
|
||||
[7]:http://greenteapress.com/thinkpython/html/index.html
|
||||
[8]:https://opensource.com/users/codetricity
|
||||
[9]:https://opensource.com/user/46031/feed
|
||||
[10]:https://opensource.com/users/scottnesbitt
|
||||
[11]:https://opensource.com/article/17/10/news-october-14
|
||||
[12]:https://www.patreon.com/photonstorm/posts
|
||||
[13]:https://www.pygame.org/news
|
||||
[14]:https://cacm.acm.org/blogs/blog-cacm/176450-python-is-now-the-most-popular-introductory-teaching-language-at-top-u-s-universities/fulltext
|
||||
[15]:http://phaser.io/tutorials/making-your-first-phaser-game
|
||||
[16]:https://phaser.io/interphase
|
||||
[17]:https://academy.zenva.com/product/the-complete-mobile-game-development-course-platinum-edition/
|
||||
[18]:https://gamedevacademy.org/author/fariazz/
|
||||
[19]:https://phonegap.com/
|
||||
[20]:https://pythonwheels.com/
|
||||
[21]:https://pypi.python.org/pypi/Pygame
|
||||
[22]:http://www.pygame.org/wiki/GettingStarted#Pygame%20Installation
|
||||
[23]:https://blog.chromium.org/2008/12/security-in-depth-local-web-pages.html
|
||||
[24]:https://simbco.github.io/httpster/
|
||||
[25]:https://inventwithpython.com/makinggames.pdf
|
||||
[26]:https://github.com/renpytom/rapt-pygame-example
|
||||
[27]:https://github.com/renpytom
|
||||
[28]:https://opensource.com/users/codetricity
|
||||
[29]:https://opensource.com/users/codetricity
|
||||
[30]:https://opensource.com/users/codetricity
|
||||
[31]:https://opensource.com/article/17/11/pygame#comments
|
||||
[32]:https://opensource.com/tags/python
|
||||
[33]:https://opensource.com/tags/programming
|
||||
@ -0,0 +1,143 @@
|
||||
translating by wangy325...
|
||||
|
||||
|
||||
10 open source technology trends for 2018
|
||||
============================================================
|
||||
|
||||
### What do you think will be the next open source tech trends? Here are 10 predictions.
|
||||
|
||||

|
||||
Image by : [Mitch Bennett][10]. Modified by Opensource.com. [CC BY-SA 4.0][11]
|
||||
|
||||
Technology is always evolving. New developments, such as OpenStack, Progressive Web Apps, Rust, R, the cognitive cloud, artificial intelligence (AI), the Internet of Things, and more are putting our usual paradigms on the back burner. Here is a rundown of the top open source trends expected to soar in popularity in 2018.
|
||||
|
||||
### 1\. OpenStack gains increasing acceptance
|
||||
|
||||
[OpenStack][12] is essentially a cloud operating system that offers admins the ability to provision and control huge compute, storage, and networking resources through an intuitive and user-friendly dashboard.
|
||||
|
||||
Many enterprises are using the OpenStack platform to build and manage cloud computing systems. Its popularity rests on its flexible ecosystem, transparency, and speed. It supports mission-critical applications with ease and lower costs compared to alternatives. But, OpenStack's complex structure and its dependency on virtualization, servers, and extensive networking resources has inhibited its adoption by a wider range of enterprises. Using OpenStack also requires a well-oiled machinery of skilled staff and resources.
|
||||
|
||||
The OpenStack Foundation is working overtime to fill the voids. Several innovations, either released or on the anvil, would resolve many of its underlying challenges. As complexities decrease, OpenStack will surge in acceptance. The fact that OpenStack is already backed by many big software development and hosting companies, in addition to thousands of individual members, makes it the future of cloud computing.
|
||||
|
||||
### 2\. Progressive Web Apps become popular
|
||||
|
||||
[Progressive Web Apps][13] (PWA), an aggregation of technologies, design concepts, and web APIs, offer an app-like experience in the mobile browser.
|
||||
|
||||
Traditional websites suffer from many inherent shortcomings. Apps, although offering a more personal and focused engagement than websites, place a huge demand on resources, including needing to be downloaded upfront. PWA delivers the best of both worlds. It delivers an app-like experience to users while being accessible on browsers, indexable on search engines, and responsive to fit any form factor. Like an app, a PWA updates itself to always display the latest real-time information, and, like a website, it is delivered in an ultra-safe HTTPS model. It runs in a standard container and is accessible to anyone who types in the URL, without having to install anything.
|
||||
|
||||
PWAs perfectly suit the needs of today's mobile users, who value convenience and personal engagement over everything else. That this technology is set to soar in popularity is a no-brainer.
|
||||
|
||||
### 3\. Rust to rule the roost
|
||||
|
||||
Most programming languages come with safety vs. control tradeoffs. [Rust][14] is an exception. The language co-opts extensive compile-time checking to offer 100% control without compromising safety. The last [Pwn2Own][15] competition threw up many serious vulnerabilities in Firefox on account of its underlying C++ language. If Firefox had been written in Rust, many of those errors would have manifested as compile-time bugs and resolved before the product rollout stage.
|
||||
|
||||
Rust's unique approach of built-in unit testing has led developers to consider it a viable first-choice open source language. It offers an effective alternative to languages such as C and Python to write secure code without sacrificing expressiveness. Rust has bright days ahead in 2018.
|
||||
|
||||
### 4\. R user community grows
|
||||
|
||||
The [R][16] programming language, a GNU project, is associated with statistical computing and graphics. It offers a wide array of statistical and graphical techniques and is extensible to boot. It starts where [S][17] ends. With the S language already the vehicle of choice for research in statistical methodology, R offers a viable open source route for data manipulation, calculation, and graphical display. An added benefit is R's attention to detail and care for the finer nuances.
|
||||
|
||||
Like Rust, R's fortunes are on the rise.
|
||||
|
||||
### 5\. XaaS expands in scope
|
||||
|
||||
XaaS, an acronym for "anything as a service," stands for the increasing number of services delivered over the internet, rather than on premises. Although software as a service (SaaS), infrastructure as a service (IaaS), and platform as a service (PaaS) are well-entrenched, new cloud-based models, such as network as a service (NaaS), storage as a service (SaaS or StaaS), monitoring as a service (MaaS), and communications as a service (CaaS), are soaring in popularity. A world where anything and everything is available "as a service" is not far away.
|
||||
|
||||
The scope of XaaS now extends to bricks-and-mortar businesses, as well. Good examples are companies such as Uber and Lyft leveraging digital technology to offer transportation as a service and Airbnb offering accommodations as a service.
|
||||
|
||||
High-speed networks and server virtualization that make powerful computing affordable have accelerated the popularity of XaaS, to the point that 2018 may become the "year of XaaS." The unmatched flexibility, agility, and scalability will propel the popularity of XaaS even further.
|
||||
|
||||
### 6\. Containers gain even more acceptance
|
||||
|
||||
Container technology is the approach of packaging pieces of code in a standardized way so they can be "plugged and run" quickly in any environment. Container technology allows enterprises to cut costs and implementation times. While the potential of containers to revolutionize IT infrastructure has been evident for a while, actual container use has remained complex.
|
||||
|
||||
Container technology is still evolving, and the complexities associated with the technology decrease with every advancement. The latest developments make containers quite intuitive and as easy as using a smartphone, not to mention tuned for today's needs, where speed and agility can make or break a business.
|
||||
|
||||
### 7\. Machine learning and artificial intelligence expand in scope
|
||||
|
||||
[Machine learning and AI][18] give machines the ability to learn and improve from experience without a programmer explicitly coding the instruction.
|
||||
|
||||
These technologies are already well entrenched, with several open source technologies leveraging them for cutting-edge services and applications.
|
||||
|
||||
[Gartner predicts][19] the scope of machine learning and artificial intelligence will expand in 2018\. Several greenfield areas, such as data preparation, integration, algorithm selection, training methodology selection, and model creation are all set for big-time enhancements through the infusion of machine learning.
|
||||
|
||||
New open source intelligent solutions are set to change the way people interact with systems and transform the very nature of work.
|
||||
|
||||
* Conversational platforms, such as chatbots, make the question-and-command experience, where a user asks a question and the platform responds, the default medium of interacting with machines.
|
||||
|
||||
* Autonomous vehicles and drones, fancy fads today, are expected to become commonplace by 2018.
|
||||
|
||||
* The scope of immersive experience will expand beyond video games and apply to real-life scenarios such as design, training, and visualization processes.
|
||||
|
||||
### 8\. Blockchain becomes mainstream
|
||||
|
||||
Blockchain has come a long way from Bitcoin. The technology is already in widespread use in finance, secure voting, authenticating academic credentials, and more. In the coming year, healthcare, manufacturing, supply chain logistics, and government services are among the sectors most likely to embrace blockchain technology.
|
||||
|
||||
Blockchain distributes digital information. The information resides on millions of nodes, in shared and reconciled databases. The fact that it's not controlled by any single authority and has no single point of failure makes it very robust, transparent, and incorruptible. It also solves the threat of a middleman manipulating the data. Such inherent strengths account for blockchain's soaring popularity and explain why it is likely to emerge as a mainstream technology in the immediate future.
|
||||
|
||||
### 9\. Cognitive cloud moves to center stage
|
||||
|
||||
Cognitive technologies, such as machine learning and artificial intelligence, are increasingly used to reduce complexity and personalize experiences across multiple sectors. One case in point is gamification apps in the financial sector, which offer investors critical investment insights and reduce the complexities of investment models. Digital trust platforms reduce the identity-verification process for financial institutions by about 80%, improving compliance and reducing chances of fraud.
|
||||
|
||||
Such cognitive cloud technologies are now moving to the cloud, making it even more potent and powerful. IBM Watson is the most well-known example of the cognitive cloud in action. IBM's UIMA architecture was made open source and is maintained by the Apache Foundation. DARPA's DeepDive project mirrors Watson's machine learning abilities to enhance decision-making capabilities over time by learning from human interactions. OpenCog, another open source platform, allows developers and data scientists to develop artificial intelligence apps and programs.
|
||||
|
||||
Considering the high stakes of delivering powerful and customized experiences, these cognitive cloud platforms are set to take center stage over the coming year.
|
||||
|
||||
### 10\. The Internet of Things connects more things
|
||||
|
||||
At its core, the Internet of Things (IoT) is the interconnection of devices through embedded sensors or other computing devices that enable the devices (the "things") to send and receive data. IoT is already predicted to be the next big major disruptor of the tech space, but IoT itself is in a continuous state of flux.
|
||||
|
||||
One innovation likely to gain widespread acceptance within the IoT space is Autonomous Decentralized Peer-to-Peer Telemetry ([ADEPT][20]), which is propelled by IBM and Samsung. It uses a blockchain-type technology to deliver a decentralized network of IoT devices. Freedom from a central control system facilitates autonomous communications between "things" in order to manage software updates, resolve bugs, manage energy, and more.
|
||||
|
||||
### Open source drives innovation
|
||||
|
||||
Digital disruption is the norm in today's tech-centric era. Within the technology space, open source is now pervasive, and in 2018, it will be the driving force behind most of the technology innovations.
|
||||
|
||||
Which open source trends and technologies would you add to this list? Let us know in the comments.
|
||||
|
||||
### Topics
|
||||
|
||||
[Business][25][Yearbook][26][2017 Open Source Yearbook][27]
|
||||
|
||||
### About the author
|
||||
|
||||
[][21] Sreejith - I have been programming since 2000, and professionally since 2007\. I currently lead the Open Source team at [Fingent][6] as we work on different technology stacks, ranging from the "boring"(read tried and trusted) to the bleeding edge. I like building, tinkering with and breaking things, not necessarily in that order. Hit me up at: [https://www.linkedin.com/in/futuregeek/][7][More about me][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/10-open-source-technology-trends-2018
|
||||
|
||||
作者:[Sreejith ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sreejith
|
||||
[1]:https://opensource.com/resources/what-is-openstack?intcmp=7016000000127cYAAQ
|
||||
[2]:https://opensource.com/resources/openstack/tutorials?intcmp=7016000000127cYAAQ
|
||||
[3]:https://opensource.com/tags/openstack?intcmp=7016000000127cYAAQ
|
||||
[4]:https://www.rdoproject.org/?intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/article/17/11/10-open-source-technology-trends-2018?rate=GJqOXhiWvZh0zZ6WVTUzJ2TDJBpVpFhngfuX9V-dz4I
|
||||
[6]:https://www.fingent.com/
|
||||
[7]:https://www.linkedin.com/in/futuregeek/
|
||||
[8]:https://opensource.com/users/sreejith
|
||||
[9]:https://opensource.com/user/185026/feed
|
||||
[10]:https://www.flickr.com/photos/mitchell3417/9206373620
|
||||
[11]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[12]:https://www.openstack.org/
|
||||
[13]:https://developers.google.com/web/progressive-web-apps/
|
||||
[14]:https://www.rust-lang.org/
|
||||
[15]:https://en.wikipedia.org/wiki/Pwn2Own
|
||||
[16]:https://en.wikipedia.org/wiki/R_(programming_language)
|
||||
[17]:https://en.wikipedia.org/wiki/S_(programming_language)
|
||||
[18]:https://opensource.com/tags/artificial-intelligence
|
||||
[19]:https://sdtimes.com/gartners-top-10-technology-trends-2018/
|
||||
[20]:https://insights.samsung.com/2016/03/17/block-chain-mobile-and-the-internet-of-things/
|
||||
[21]:https://opensource.com/users/sreejith
|
||||
[22]:https://opensource.com/users/sreejith
|
||||
[23]:https://opensource.com/users/sreejith
|
||||
[24]:https://opensource.com/article/17/11/10-open-source-technology-trends-2018#comments
|
||||
[25]:https://opensource.com/tags/business
|
||||
[26]:https://opensource.com/tags/yearbook
|
||||
[27]:https://opensource.com/yearbook/2017
|
||||
@ -0,0 +1,95 @@
|
||||
translating---aiwhj
|
||||
5 best practices for getting started with DevOps
|
||||
============================================================
|
||||
|
||||
### Are you ready to implement DevOps, but don't know where to begin? Try these five best practices.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Andrew Magill][8]. Modified by Opensource.com. [CC BY 4.0][9]
|
||||
|
||||
DevOps often stymies early adopters with its ambiguity, not to mention its depth and breadth. By the time someone buys into the idea of DevOps, their first questions usually are: "How do I get started?" and "How do I measure success?" These five best practices are a great road map to starting your DevOps journey.
|
||||
|
||||
### 1\. Measure all the things
|
||||
|
||||
You don't know for sure that your efforts are even making things better unless you can quantify the outcomes. Are my features getting out to customers more rapidly? Are fewer defects escaping to them? Are we responding to and recovering more quickly from failure?
|
||||
|
||||
Before you change anything, think about what kinds of outcomes you expect from your DevOps transformation. When you're further into your DevOps journey, you'll enjoy a rich array of near-real-time reports on everything about your service. But consider starting with these two metrics:
|
||||
|
||||
* **Time to market** measures the end-to-end, often customer-facing, business experience. It usually begins when a feature is formally conceived and ends when the customer can consume the feature in production. Time to market is not mainly an engineering team metric; more importantly it shows your business' complete end-to-end efficiency in bringing valuable new features to market and isolates opportunities for system-wide improvement.
|
||||
|
||||
* **Cycle time** measures the engineering team process. Once work on a new feature starts, when does it become available in production? This metric is very useful for understanding the efficiency of the engineering team and isolating opportunities for team-level improvement.
|
||||
|
||||
### 2\. Get your process off the ground
|
||||
|
||||
DevOps success requires an organization to put a regular (and hopefully effective) process in place and relentlessly improve upon it. It doesn't have to start out being effective, but it must be a regular process. Usually that it's some flavor of agile methodology like Scrum or Scrumban; sometimes it's a Lean derivative. Whichever way you go, pick a formal process, start using it, and get the basics right.
|
||||
|
||||
Regular inspect-and-adapt behaviors are key to your DevOps success. Make good use of opportunities like the stakeholder demo, team retrospectives, and daily standups to find opportunities to improve your process.
|
||||
|
||||
A lot of your DevOps success hinges on people working effectively together. People on a team need to work from a common process that they are empowered to improve upon. They also need regular opportunities to share what they are learning with other stakeholders, both upstream and downstream, in the process.
|
||||
|
||||
Good process discipline will help your organization consume the other benefits of DevOps at the great speed that comes as your success builds.
|
||||
|
||||
Although it's common for more development-oriented teams to successfully adopt processes like Scrum, operations-focused teams (or others that are more interrupt-driven) may opt for a process with a more near-term commitment horizon, such as Kanban.
|
||||
|
||||
### 3\. Visualize your end-to-end workflow
|
||||
|
||||
There is tremendous power in being able to see who's working on what part of your service at any given time. Visualizing your workflow will help people know what they need to work on next, how much work is in progress, and where the bottlenecks are in the process.
|
||||
|
||||
You can't effectively limit work in process until you can see it and quantify it. Likewise, you can't effectively eliminate bottlenecks until you can clearly see them.
|
||||
|
||||
Visualizing the entire workflow will help people in all parts of the organization understand how their work contributes to the success of the whole. It can catalyze relationship-building across organizational boundaries to help your teams collaborate more effectively towards a shared sense of success.
|
||||
|
||||
### 4\. Continuous all the things
|
||||
|
||||
DevOps promises a dizzying array of compelling automation. But Rome wasn't built in a day. One of the first areas you can focus your efforts on is [continuous integration][10] (CI). But don't stop there; you'll want to follow quickly with [continuous delivery][11] (CD) and eventually continuous deployment.
|
||||
|
||||
Your CD pipeline is your opportunity to inject all manner of automated quality testing into your process. The moment new code is committed, your CD pipeline should run a battery of tests against the code and the successfully built artifact. The artifact that comes out at the end of this gauntlet is what progresses along your process until eventually it's seen by customers in production.
|
||||
|
||||
Another "continuous" that doesn't get enough attention is continuous improvement. That's as simple as setting some time aside each day to ask your colleagues: "What small thing can we do today to get better at how we do our work?" These small, daily changes compound over time into more profound results. You'll be pleasantly surprised! But it also gets people thinking all the time about how to improve things.
|
||||
|
||||
### 5\. Gherkinize
|
||||
|
||||
Fostering more effective communication across your organization is crucial to fostering the sort of systems thinking prevalent in successful DevOps journeys. One way to help that along is to use a shared language between the business and the engineers to express the desired acceptance criteria for new features. A good product manager can learn [Gherkin][12] in a day and begin using it to express acceptance criteria in an unambiguous, structured form of plain English. Engineers can use this Gherkinized acceptance criteria to write acceptance tests against the criteria, and then develop their feature code until the tests pass. This is a simplification of [acceptance test-driven development][13](ATDD) that can also help kick start your DevOps culture and engineering practice.
|
||||
|
||||
### Start on your journey
|
||||
|
||||
Don't be discouraged by getting started with your DevOps practice. It's a journey. And hopefully these five ideas give you solid ways to get started.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][14]
|
||||
|
||||
Magnus Hedemark - Magnus has been in the IT industry for over 20 years, and a technology enthusiast for most of his life. He's presently Manager of DevOps Engineering at UnitedHealth Group. In his spare time, Magnus enjoys photography and paddling canoes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/5-keys-get-started-devops
|
||||
|
||||
作者:[Magnus Hedemark ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/magnus919
|
||||
[1]:https://opensource.com/tags/devops?src=devops_resource_menu1
|
||||
[2]:https://opensource.com/resources/devops?src=devops_resource_menu2
|
||||
[3]:https://www.openshift.com/promotions/devops-with-openshift.html?intcmp=7016000000127cYAAQ&src=devops_resource_menu3
|
||||
[4]:https://enterprisersproject.com/article/2017/5/9-key-phrases-devops?intcmp=7016000000127cYAAQ&src=devops_resource_menu4
|
||||
[5]:https://www.redhat.com/en/insights/devops?intcmp=7016000000127cYAAQ&src=devops_resource_menu5
|
||||
[6]:https://opensource.com/article/17/11/5-keys-get-started-devops?rate=oEOzMXx1ghbkfl2a5ae6AnvO88iZ3wzkk53K2CzbDWI
|
||||
[7]:https://opensource.com/user/25739/feed
|
||||
[8]:https://ccsearch.creativecommons.org/image/detail/7qRx_yrcN5isTMS0u9iKMA==
|
||||
[9]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[10]:https://martinfowler.com/articles/continuousIntegration.html
|
||||
[11]:https://martinfowler.com/bliki/ContinuousDelivery.html
|
||||
[12]:https://cucumber.io/docs/reference
|
||||
[13]:https://en.wikipedia.org/wiki/Acceptance_test%E2%80%93driven_development
|
||||
[14]:https://opensource.com/users/magnus919
|
||||
[15]:https://opensource.com/users/magnus919
|
||||
[16]:https://opensource.com/users/magnus919
|
||||
[17]:https://opensource.com/tags/devops
|
||||
@ -0,0 +1,70 @@
|
||||
Inside AGL: Familiar Open Source Components Ease Learning Curve
|
||||
============================================================
|
||||
|
||||

|
||||
Konsulko’s Matt Porter (pictured) and Scott Murray ran through the major components of the AGL’s Unified Code Base at Embedded Linux Conference Europe.[The Linux Foundation][1]
|
||||
|
||||
Among the sessions at the recent [Embedded Linux Conference Europe (ELCE)][5] — 57 of which are [available on YouTube][2] -- are several reports on the Linux Foundation’s [Automotive Grade Linux project][6]. These include [an overview from AGL Community Manager Walt Miner ][3]showing how AGL’s Unified Code Base (UCB) Linux distribution is expanding from in-vehicle infotainment (IVI) to ADAS. There was even a presentation on using AGL to build a remote-controlled robot (see links below).
|
||||
|
||||
Here we look at the “State of AGL: Plumbing and Services,” from Konsulko Group’s CTO Matt Porter and senior staff software engineer Scott Murray. Porter and Murray ran through the components of the current [UCB 4.0 “Daring Dab”][7] and detailed major upstream components and API bindings, many of which will be appear in the Electric Eel release due in Jan. 2018.
|
||||
|
||||
Despite the automotive focus of the AGL stack, most of the components are already familiar to Linux developers. “It looks a lot like a desktop distro,” Porter told the ELCE attendees in Prague. “All these familiar friends.”
|
||||
|
||||
Some of those friends include the underlying Yocto Project “Poky” with OpenEmbedded foundation, which is topped with layers like oe-core, meta-openembedded, and metanetworking. Other components are based on familiar open source software like systemd (application control), Wayland and Weston (graphics), BlueZ (Bluetooth), oFono (telephony), PulseAudio and ALSA (audio), gpsd (location), ConnMan (Internet), and wpa-supplicant (WiFi), among others.
|
||||
|
||||
UCB’s application framework is controlled through a WebSocket interface to the API bindings, thereby enabling apps to talk to each other. There’s also a new W3C widget for an alternative application packaging scheme, as well as support for SmartDeviceLink, a technology developed at Ford that automatically syncs up IVI systems with mobile phones.
|
||||
|
||||
AGL UCB’s Wayland/Weston graphics layer is augmented with an “IVI shell” that works with the layer manager. “One of the unique requirements of automotive is the ability to separate aspects of the application in the layers,” said Porter. “For example, in a navigation app, the graphics rendering for the map may be completely different than the engine used for the UI decorations. One engine layers to a surface in Wayland to expose the map while the decorations and controls are handled by another layer.”
|
||||
|
||||
For audio, ALSA and PulseAudio are joined by GENIVI AudioManager, which works together with PulseAudio. “We use AudioManager for policy driven audio routing,” explained Porter. “It allows you to write a very complex XML-based policy using a rules engine with audio routing.”
|
||||
|
||||
UCB leans primarily on the well-known [Smack Project][8] for security, and also incorporates Tizen’s [Cynara][9] safe policy-checker service. A Cynara-enabled D-Bus daemon is used to control Cynara security policies.
|
||||
|
||||
Porter and Murray went on to explain AGL’s API binding mechanism, which according to Murray “abstracts the UI from its back-end logic so you can replace it with your own custom UI.” You can re-use application logic with different UI implementations, such as moving from the default Qt to HTML5 or a native toolkit. Application binding requests and responses use JSON via HTTP or WebSocket. Binding calls can be made from applications or from other bindings, thereby enabling “stacking” of bindings.
|
||||
|
||||
Porter and Murray concluded with a detailed description of each binding. These include upstream bindings currently in various stages of development. The first is a Master binding that manages the application lifecycle, including tasks such as install, uninstall, start, and terminate. Other upstream bindings include the WiFi binding and the BlueZ-based Bluetooth binding, which in the future will be upgraded with Bluetooth [PBAP][10] (Phone Book Access Profile). PBAP can connect with contacts databases on your phone, and links to the Telephony binding to replicate caller ID.
|
||||
|
||||
The oFono-based Telephony binding also makes calls to the Bluetooth binding for Bluetooth Hands-Free-Profile (HFP) support. In the future, Telephony binding will add support for sent dial tones, call waiting, call forwarding, and voice modem support.
|
||||
|
||||
Support for AM/FM radio is not well developed in the Linux world, so for its Radio binding, AGL started by supporting [RTL-SDR][11] code for low-end radio dongles. Future plans call for supporting specific automotive tuner devices.
|
||||
|
||||
The MediaPlayer binding is in very early development, and is currently limited to GStreamer based audio playback and control. Future plans call for adding playlist controls, as well as one of the most actively sought features among manufacturers: video playback support.
|
||||
|
||||
Location bindings include the [gpsd][12] based GPS binding, as well as GeoClue and GeoFence. GeoClue, which is built around the [GeoClue][13] D-Bus geolocation service, “overlaps a little with GPS, which uses the same location data,” says Porter. GeoClue also gathers location data from WiFi AP databases, 3G/4G tower info, and the GeoIP database — sources that are useful “if you’re inside or don’t have a good fix,” he added.
|
||||
|
||||
GeoFence depends on the GPS binding, as well. It lets you establish a bounding box, and then track ingress and egress events. GeoFence also tracks “dwell” status, which is determined by arriving at home and staying for 10 minutes. “It then triggers some behavior based on a timeout,” said Porter. Future plans call for a customizable dwell transition time.
|
||||
|
||||
While most of these Upstream bindings are well established, there are also Work in Progress (WIP) bindings that are still in the early stages, including CAN, HomeScreen, and WindowManager bindings. Farther out, there are plans to add speech recognition and text-to-speech bindings, as well as a WWAN modem binding.
|
||||
|
||||
In conclusion, Porter noted: “Like any open source project, we desperately need more developers.” The Automotive Grade Linux project may seem peripheral to some developers, but it offers a nice mix of familiarity — grounded in many widely used open source projects -- along with the excitement of expanding into a new and potentially game changing computing form factor: your automobile. AGL has also demonstrated success — you can now [check out AGL in action in the 2018 Toyota Camry][14], followed in the coming month by most Toyota and Lexus vehicles sold in North America.
|
||||
|
||||
Watch the complete video below:
|
||||
|
||||
[视频][15]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/event/elce/2017/11/inside-agl-familiar-open-source-components-ease-learning-curve
|
||||
|
||||
作者:[ ERIC BROWN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/ericstephenbrown
|
||||
[1]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[2]:https://www.youtube.com/playlist?list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
|
||||
[3]:https://www.youtube.com/watch?v=kfwEmjSjAzM&index=14&list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
|
||||
[4]:https://www.linux.com/files/images/porter-elce-aglpng
|
||||
[5]:http://events.linuxfoundation.org/events/embedded-linux-conference-europe
|
||||
[6]:https://www.automotivelinux.org/
|
||||
[7]:https://www.linux.com/blog/2017/8/automotive-grade-linux-moves-ucb-40-launches-virtualization-workgroup
|
||||
[8]:http://schaufler-ca.com/
|
||||
[9]:https://wiki.tizen.org/Security:Cynara
|
||||
[10]:https://wiki.maemo.org/Bluetooth_PBAP
|
||||
[11]:https://www.rtl-sdr.com/about-rtl-sdr/
|
||||
[12]:http://www.catb.org/gpsd/
|
||||
[13]:https://www.freedesktop.org/wiki/Software/GeoClue/
|
||||
[14]:https://www.linux.com/blog/event/automotive-linux-summit/2017/6/linux-rolls-out-toyota-and-lexus-vehicles
|
||||
[15]:https://youtu.be/RgI-g5h1t8I
|
||||
@ -0,0 +1,301 @@
|
||||
Interactive Workflows for C++ with Jupyter
|
||||
============================================================
|
||||
|
||||
Scientists, educators and engineers not only use programming languages to build software systems, but also in interactive workflows, using the tools available to _explore _ a problem and _reason _ about it.
|
||||
|
||||
Running some code, looking at a visualization, loading data, and running more code. Quick iteration is especially important during the exploratory phase of a project.
|
||||
|
||||
For this kind of workflow, users of the C++ programming language currently have no choice but to use a heterogeneous set of tools that don’t play well with each other, making the whole process cumbersome, and difficult to reproduce.
|
||||
|
||||
_We currently lack a good story for interactive computing in C++_ .
|
||||
|
||||
In our opinion, this hurts the productivity of C++ developers:
|
||||
|
||||
* Most of the progress made in software projects comes from incrementalism. Obstacles to fast iteration hinder progress.
|
||||
|
||||
* This also makes C++ more difficult to teach. The first hours of a C++ class are rarely rewarding as the students must learn how to set up a small project before writing any code. And then, a lot more time is required before their work can result in any visual outcome.
|
||||
|
||||
### Project Jupyter and Interactive Computing
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
The goal of Project Jupyter is to provide a consistent set of tools for scientific computing and data science workflows, from the exploratory phase of the analysis to the presentation and the sharing of the results. The Jupyter stack was designed to be agnostic of the programming language, and also to allow alternative implementations of any component of the layered architecture (back-ends for programming languages, custom renderers for file types associated with Jupyter). The stack consists of
|
||||
|
||||
* a low-level specification for messaging protocols, standardized file formats,
|
||||
|
||||
* a reference implementation of these standards,
|
||||
|
||||
* applications built on the top of these libraries: the Notebook, JupyterLab, Binder, JupyterHub
|
||||
|
||||
* and visualization libraries integrated into the Notebook and JupyterLab.
|
||||
|
||||
Adoption of the Jupyter ecosystem has skyrocketed in the past years, with millions of users worldwide, over a million Jupyter notebooks shared on GitHub and large-scale deployments of Jupyter in universities, companies and high-performance computing centers.
|
||||
|
||||
### Jupyter and C++
|
||||
|
||||
One of the main extension points of the Jupyter stack is the _kernel_ , the part of the infrastructure responsible for executing the user’s code. Jupyter kernels exist for [numerous programming languages][14].
|
||||
|
||||
Most Jupyter kernels are implemented in the target programming language: the reference implementation [ipykernel][15] in Python, [IJulia][16] in Julia, leading to a duplication of effort for the implementation of the protocol. A common denominator to a lot of these interpreted languages is that the interpreter generally exposes a C API, allowing the embedding into a native application. In an effort to consolidate these commonalities and save work for future kernel builders, we developed _xeus_ .
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
[Xeus ][17]is a C++ implementation of the Jupyter kernel protocol. It is not a kernel itself but a library that facilitates the authoring of kernels, and other applications making use of the Jupyter kernel protocol.
|
||||
|
||||
A typical kernel implementation using xeus would in fact make use of the target interpreter _ as a library._
|
||||
|
||||
There are a number of benefits of using xeus over implementing your kernel in the target language:
|
||||
|
||||
* Xeus provides a complete implementation of the protocol, enabling a lot of features from the start for kernel authors, who only need to deal with the language bindings.
|
||||
|
||||
* Xeus-based kernels can very easily provide a back-end for Jupyter interactive widgets.
|
||||
|
||||
* Finally, xeus can be used to implement kernels for domain-specific languages such as SQL flavors. Existing approaches use a Python wrapper. With xeus, the resulting kernel won't require Python at run-time, leading to large performance benefits.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
Interpreted C++ is already a reality at CERN with the [Cling][18]C++ interpreter in the context of the [ROOT][19] data analysis environment.
|
||||
|
||||
As a first example for a kernel based on xeus, we have implemented [xeus-cling][20], a pure C++ kernel.
|
||||
|
||||
|
||||
|
||||
|
||||
Redirection of outputs to the Jupyter front-end, with different styling in the front-end.
|
||||
|
||||
Complex features of the C++ programming language such as, polymorphism, templates, lambdas, are supported by the cling interpreter, making the C++ Jupyter notebook a great prototyping and learning platform for the C++ users. See the image below for a demonstration:
|
||||
|
||||
|
||||
|
||||
|
||||
Features of the C++ programming language supported by the cling interpreter
|
||||
|
||||
Finally, xeus-cling supports live quick-help, fetching the content on [cppreference][21] in the case of the standard library.
|
||||
|
||||
|
||||
|
||||

|
||||
Live help for the C++standard library in the Jupyter notebook
|
||||
|
||||
> We realized that we started using the C++ kernel ourselves very early in the development of the project. For quick experimentation, or reproducing bugs. No need to set up a project with a cpp file and complicated project settings for finding the dependencies… Just write some code and hit Shift+Enter.
|
||||
|
||||
Visual output can also be displayed using the rich display mechanism of the Jupyter protocol.
|
||||
|
||||
|
||||
|
||||
|
||||
Using Jupyter's rich display mechanism to display an image inline in the notebook
|
||||
|
||||
|
||||

|
||||
|
||||
Another important feature of the Jupyter ecosystem are the [Jupyter Interactive Widgets][22]. They allow the user to build graphical interfaces and interactive data visualization inline in the Jupyter notebook. Moreover it is not just a collection of widgets, but a framework that can be built upon, to create arbitrary visual components. Popular interactive widget libraries include
|
||||
|
||||
* [bqplot][1] (2-D plotting with d3.js)
|
||||
|
||||
* [pythreejs][2] (3-D scene visualization with three.js)
|
||||
|
||||
* [ipyleaflet][3] (maps visualization with leaflet.js)
|
||||
|
||||
* [ipyvolume][4] (3-D plotting and volume rendering with three.js)
|
||||
|
||||
* [nglview][5] (molecular visualization)
|
||||
|
||||
Just like the rest of the Jupyter ecosystem, Jupyter interactive widgets were designed as a language-agnostic framework. Other language back-ends can be created reusing the front-end component, which can be installed separately.
|
||||
|
||||
[xwidgets][23], which is still at an early stage of development, is a native C++ implementation of the Jupyter widgets protocol. It already provides an implementation for most of the widget types available in the core Jupyter widgets package.
|
||||
|
||||
|
||||
|
||||
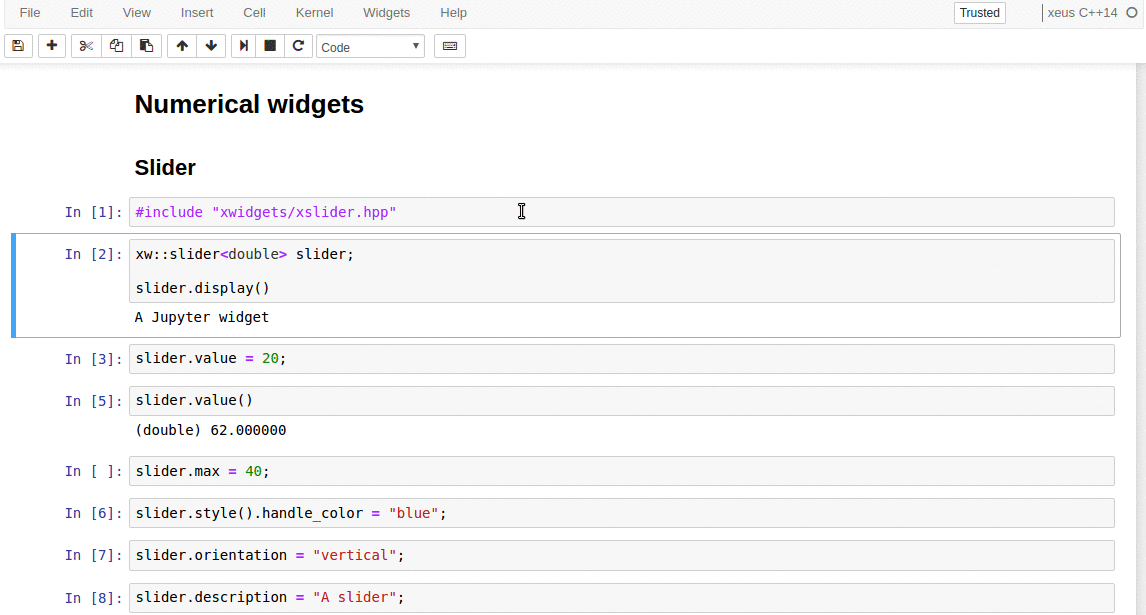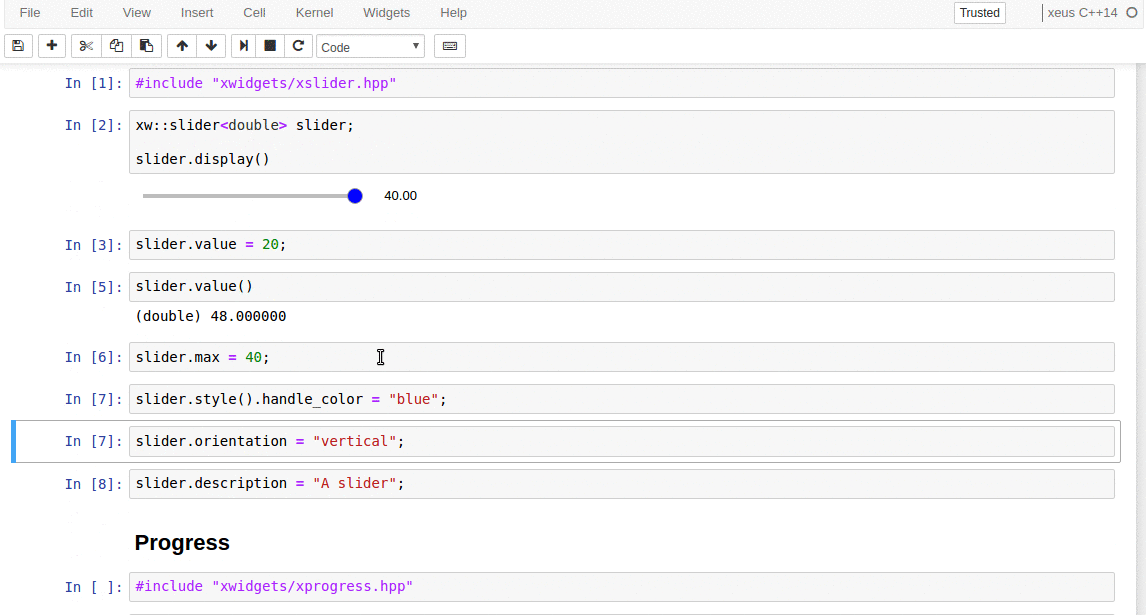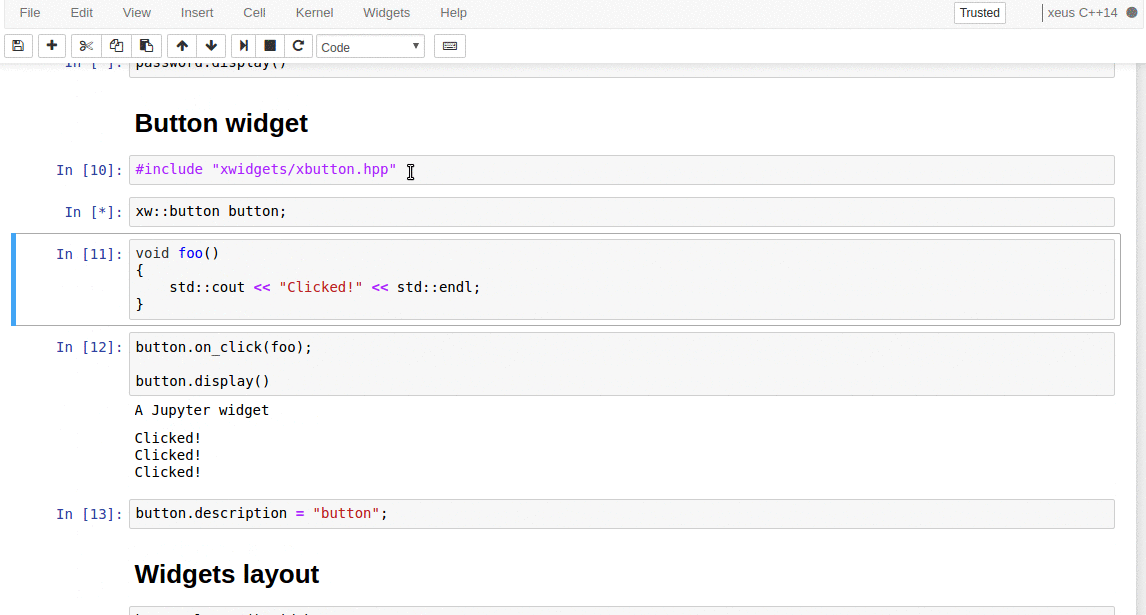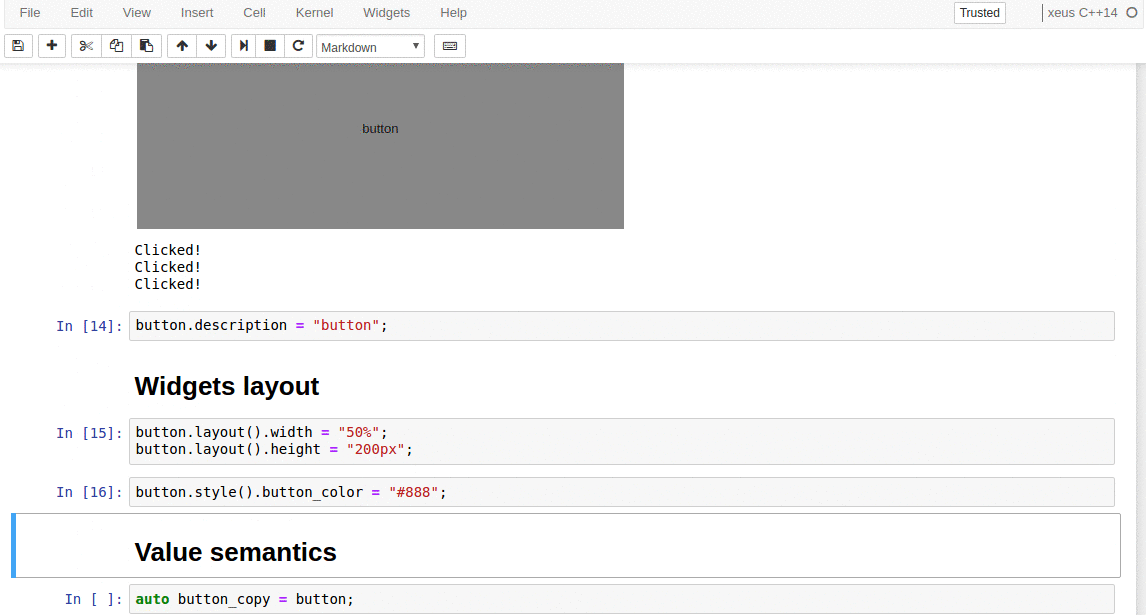
|
||||
C++ back-end to the Jupyter interactive widgets
|
||||
|
||||
Just like with ipywidgets, one can build upon xwidgets and implement C++ back-ends for the Jupyter widget libraries listed earlier, effectively enabling them for the C++ programming language and other xeus-based kernels: xplot, xvolume, xthreejs…
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
[xplot][24] is an experimental C++ back-end for the [bqplot][25] 2-D plotting library. It enables an API following the constructs of the [_Grammar of Graphics_][26] in C++.
|
||||
|
||||
In xplot, every item in a chart is a separate object that can be modified from the back-end, _dynamically_ .
|
||||
|
||||
Changing a property of a plot item, a scale, an axis or the figure canvas itself results in the communication of an update message to the front-end, which reflects the new state of the widget visually.
|
||||
|
||||
|
||||
|
||||

|
||||
Changing the data of a scatter plot dynamically to update the chart
|
||||
|
||||
> Warning: the xplot and xwidgets projects are still at an early stage of development and are changing drastically at each release.
|
||||
|
||||
Interactive computing environments like Jupyter are not the only missing tool in the C++ world. Two key ingredients to the success of Python as the _lingua franca_ of data science is the existence of libraries like [NumPy][27] and [Pandas][28] at the foundation of the ecosystem.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
[xtensor][29] is a C++ library meant for numerical analysis with multi-dimensional array expressions.
|
||||
|
||||
xtensor provides
|
||||
|
||||
* an extensible expression system enabling lazy NumPy-style broadcasting.
|
||||
|
||||
* an API following the _idioms_ of the C++ standard library.
|
||||
|
||||
* tools to manipulate array expressions and build upon xtensor.
|
||||
|
||||
xtensor exposes an API similar to that of NumPy covering a growing portion of the functionalities. A cheat sheet can be [found in the documentation][30]:
|
||||
|
||||
|
||||
|
||||

|
||||
Scrolling the NumPy to xtensor cheat sheet
|
||||
|
||||
However, xtensor internals are very different from NumPy. Using modern C++ techniques (template expressions, closure semantics) xtensor is a lazily evaluated library, avoiding the creation of temporary variables and unnecessary memory allocations, even in the case complex expressions involving broadcasting and language bindings.
|
||||
|
||||
Still, from a user perspective, the combination of xtensor with the C++ notebook provides an experience very similar to that of NumPy in a Python notebook.
|
||||
|
||||
|
||||
|
||||

|
||||
Using the xtensor array expression library in a C++ notebook
|
||||
|
||||
In addition to the core library, the xtensor ecosystem has a number of other components
|
||||
|
||||
* [xtensor-blas][6]: the counterpart to the numpy.linalg module.
|
||||
|
||||
* [xtensor-fftw][7]: bindings to the [fftw][8] library.
|
||||
|
||||
* [xtensor-io][9]: APIs to read and write various file formats (images, audio, NumPy's NPZ format).
|
||||
|
||||
* [xtensor-ros][10]: bindings for ROS, the robot operating system.
|
||||
|
||||
* [xtensor-python][11]: bindings for the Python programming language, allowing the use of NumPy arrays in-place, using the NumPy C API and the pybind11 library.
|
||||
|
||||
* [xtensor-julia][12]: bindings for the Julia programming language, allowing the use of Julia arrays in-place, using the C API of the Julia interpreter, and the CxxWrap library.
|
||||
|
||||
* [xtensor-r][13]: bindings for the R programming language, allowing the use of R arrays in-place.
|
||||
|
||||
Detailing further the features of the xtensor framework would be beyond the scope of this post.
|
||||
|
||||
If you are interested in trying the various notebooks presented in this post, there is no need to install anything. You can just use _binder_ :
|
||||
|
||||

|
||||
|
||||
[The Binder project][31], which is part of Project Jupyter, enables the deployment of containerized Jupyter notebooks, from a GitHub repository together with a manifest listing the dependencies (as conda packages).
|
||||
|
||||
All the notebooks in the screenshots above can be run online, by just clicking on one of the following links:
|
||||
|
||||
[xtensor][32]: the C++ N-D array expression library in a C++ notebook
|
||||
|
||||
[xwidgets][33]: the C++ back-end for Jupyter interactive widgets
|
||||
|
||||
[xplot][34]: the C++ back-end to the bqplot 2-D plotting library for Jupyter.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
[JupyterHub][35] is the multi-user infrastructure underlying open wide deployments of Jupyter like Binder but also smaller deployments for authenticated users.
|
||||
|
||||
The modular architecture of JupyterHub enables a great variety of scenarios on how users are authenticated, and what service is made available to them. JupyterHub deployment for several hundreds of users have been done in various universities and institutions, including the Paris-Sud University, where the C++ kernel was also installed for the students to use.
|
||||
|
||||
> In September 2017, the 350 first-year students at Paris-Sud University who took the “[Info 111: Introduction to Computer
|
||||
> Science][36]” class wrote their first lines of C++ in a Jupyter notebook.
|
||||
|
||||
The use of Jupyter notebooks in the context of teaching C++ proved especially useful for the first classes, where students can focus on the syntax of the language without distractions such as compiling and linking.
|
||||
|
||||
### Acknowledgements
|
||||
|
||||
The software presented in this post was built upon the work of a large number of people including the Jupyter team and the Cling developers.
|
||||
|
||||
We are especially grateful to [Patrick Bos ][37](who authored xtensor-fftw), Nicolas Thiéry, Min Ragan Kelley, Thomas Kluyver, Yuvi Panda, Kyle Cranmer, Axel Naumann and Vassil Vassilev.
|
||||
|
||||
We thank the [DIANA/HEP][38] organization for supporting travel to CERN and encouraging the collaboration between Project Jupyter and the ROOT team.
|
||||
|
||||
We are also grateful to the team at Paris-Sud University who worked on the JupyterHub deployment and the class materials, notably [Viviane Pons][39].
|
||||
|
||||
The development of xeus, xtensor, xwidgets and related packages at [QuantStack][40] is sponsored by [Bloomberg][41].
|
||||
|
||||
### About the authors (alphabetical order)
|
||||
|
||||
[_Sylvain Corlay_][42] _, _ Scientific Software Developer at [QuantStack][43]
|
||||
|
||||
[_Loic Gouarin_][44] _, _ Research Engineer at [Laboratoire de Mathématiques at Orsay][45]
|
||||
|
||||
[_Johan Mabille_][46] _, _ Scientific Software Developer at [QuantStack][47]
|
||||
|
||||
[_Wolf Vollprecht_][48] , Scientific Software Developer at [QuantStack][49]
|
||||
|
||||
Thanks to [Maarten Breddels][50], [Wolf Vollprecht][51], [Brian E. Granger][52], and [Patrick Bos][53].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.jupyter.org/interactive-workflows-for-c-with-jupyter-fe9b54227d92
|
||||
|
||||
作者:[QuantStack ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.jupyter.org/@QuantStack?source=post_header_lockup
|
||||
[1]:https://github.com/bloomberg/bqplot
|
||||
[2]:https://github.com/jovyan/pythreejs
|
||||
[3]:https://github.com/ellisonbg/ipyleaflet
|
||||
[4]:https://github.com/maartenbreddels/ipyvolume
|
||||
[5]:https://github.com/arose/nglview
|
||||
[6]:https://github.com/QuantStack/xtensor-blas
|
||||
[7]:https://github.com/egpbos/xtensor-fftw
|
||||
[8]:http://www.fftw.org/
|
||||
[9]:https://github.com/QuantStack/xtensor-io
|
||||
[10]:https://github.com/wolfv/xtensor_ros
|
||||
[11]:https://github.com/QuantStack/xtensor-python
|
||||
[12]:https://github.com/QuantStack/Xtensor.jl
|
||||
[13]:https://github.com/QuantStack/xtensor-r
|
||||
[14]:https://github.com/jupyter/jupyter/wiki/Jupyter-kernels
|
||||
[15]:https://github.com/ipython/ipykernel
|
||||
[16]:https://github.com/JuliaLang/IJulia.jl
|
||||
[17]:https://github.com/QuantStack/xeus
|
||||
[18]:https://root.cern.ch/cling
|
||||
[19]:https://root.cern.ch/
|
||||
[20]:https://github.com/QuantStack/xeus-cling
|
||||
[21]:http://en.cppreference.com/w/
|
||||
[22]:http://jupyter.org/widgets
|
||||
[23]:https://github.com/QUantStack/xwidgets
|
||||
[24]:https://github.com/QuantStack/xplot
|
||||
[25]:https://github.com/bloomberg/bqplot
|
||||
[26]:https://dl.acm.org/citation.cfm?id=1088896
|
||||
[27]:http://www.numpy.org/
|
||||
[28]:https://pandas.pydata.org/
|
||||
[29]:https://github.com/QuantStack/xtensor/
|
||||
[30]:http://xtensor.readthedocs.io/en/latest/numpy.html
|
||||
[31]:https://mybinder.org/
|
||||
[32]:https://beta.mybinder.org/v2/gh/QuantStack/xtensor/0.14.0-binder2?filepath=notebooks/xtensor.ipynb
|
||||
[33]:https://beta.mybinder.org/v2/gh/QuantStack/xwidgets/0.6.0-binder?filepath=notebooks/xwidgets.ipynb
|
||||
[34]:https://beta.mybinder.org/v2/gh/QuantStack/xplot/0.3.0-binder?filepath=notebooks
|
||||
[35]:https://github.com/jupyterhub/jupyterhub
|
||||
[36]:http://nicolas.thiery.name/Enseignement/Info111/
|
||||
[37]:https://twitter.com/egpbos
|
||||
[38]:http://diana-hep.org/
|
||||
[39]:https://twitter.com/pyviv
|
||||
[40]:https://twitter.com/QuantStack
|
||||
[41]:http://www.techatbloomberg.com/
|
||||
[42]:https://twitter.com/SylvainCorlay
|
||||
[43]:https://github.com/QuantStack/
|
||||
[44]:https://twitter.com/lgouarin
|
||||
[45]:https://www.math.u-psud.fr/
|
||||
[46]:https://twitter.com/johanmabille?lang=en
|
||||
[47]:https://github.com/QuantStack/
|
||||
[48]:https://twitter.com/wuoulf
|
||||
[49]:https://github.com/QuantStack/
|
||||
[50]:https://medium.com/@maartenbreddels?source=post_page
|
||||
[51]:https://medium.com/@wolfv?source=post_page
|
||||
[52]:https://medium.com/@ellisonbg?source=post_page
|
||||
[53]:https://medium.com/@egpbos?source=post_page
|
||||
@ -0,0 +1,41 @@
|
||||
Someone Tries to Bring Back Ubuntu's Unity from the Dead as an Official Spin
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
> The Ubuntu Unity remix would be supported for nine months
|
||||
|
||||
Canonical's sudden decision of killing its Unity user interface after seven years affected many Ubuntu users, and it looks like someone now tries to bring it back from the dead as an unofficial spin.
|
||||
|
||||
Long-time [Ubuntu][1] member Dale Beaudoin [ran a poll][2] last week on the official Ubuntu forums to take the pulse of the community and see if they are interested in an Ubuntu Unity Remix that would be released alongside Ubuntu 18.04 LTS (Bionic Beaver) next year and be supported for nine months or five years.
|
||||
|
||||
Thirty people voted in the poll, with 67 percent of them opting for an LTS (Long Term Support) release of the so-called Ubuntu Unity Remix, while 33 percent voted for the 9-month supported release. It also looks like this upcoming Ubuntu Unity Spin [looks to become an official flavor][3], yet this means commitment from those developing it.
|
||||
|
||||
"A recent poll voted 2/3rds in favor of Ubuntu Unity to become an LTS distribution. We should try to work this cycle assuming that it will be LTS and an official flavor," said Dale Beaudoin. "We will try and release an updated ISO once every week or 10 days using the current 18.04 daily builds of default Ubuntu Bionic Beaver as a platform."
|
||||
|
||||
### Is Ubuntu Unity making a comeback?
|
||||
|
||||
The last Ubuntu version to ship with Unity by default was Ubuntu 17.04 (Zesty Zapus), which will reach end of life on January 2018\. Ubuntu 17.10 (Artful Artful), the current stable release of the popular operating system, is the first to use the GNOME desktop environment by default for the main Desktop edition as Canonical CEO [announced][4] earlier this year that Unity would no longer be developed.
|
||||
|
||||
However, Canonical is still offering the Unity desktop environment from the official software repositories, so if someone wants to install it, it's one click away. But the bad news is that they'll be supported up until the release of Ubuntu 18.04 LTS (Bionic Beaver) in April 2018, so the developers of the Ubuntu Unity Remix would have to continue to keep in on life support on their a separate repository.
|
||||
|
||||
On the other hand, we don't believe Canonical will change their mind and accept this Ubuntu Unity Spin to become an official flavor, which would mean they failed to continue development of Unity, and now a handful of people can do it. Most probably, if interest in this Ubuntu Unity Remix won't fade away soon, it will be an unofficial spin supported by the nostalgic community.
|
||||
|
||||
Question is, would you be interested in an Ubuntu Unity spin, official or not?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/someone-tries-to-bring-back-ubuntu-s-unity-from-the-dead-as-an-unofficial-spin-518778.shtml
|
||||
|
||||
作者:[Marius Nestor ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://linux.softpedia.com/downloadTag/Ubuntu
|
||||
[2]:https://community.ubuntu.com/t/poll-unity-7-distro-9-month-spin-or-lts-for-18-04/2066
|
||||
[3]:https://community.ubuntu.com/t/unity-maintenance-roadmap/2223
|
||||
[4]:http://news.softpedia.com/news/canonical-to-stop-developing-unity-8-ubuntu-18-04-lts-ships-with-gnome-desktop-514604.shtml
|
||||
[5]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
@ -1,3 +1,4 @@
|
||||
Yoliver istranslating.
|
||||
Excellent Business Software Alternatives For Linux
|
||||
-------
|
||||
|
||||
|
||||
@ -0,0 +1,294 @@
|
||||
translating by lujun9972
|
||||
How to find all files with a specific text using Linux shell
|
||||
------
|
||||
### Objective
|
||||
|
||||
The following article provides some useful tips on how to find all files within any specific directory or entire file-system containing any specific word or string.
|
||||
|
||||
### Difficulty
|
||||
|
||||
EASY
|
||||
|
||||
### Conventions
|
||||
|
||||
* # - requires given command to be executed with root privileges either directly as a root user or by use of sudo command
|
||||
|
||||
* $ - given command to be executed as a regular non-privileged user
|
||||
|
||||
### Examples
|
||||
|
||||
### Find all files with a specific string non-recursively
|
||||
|
||||
The first command example will search for a string
|
||||
|
||||
`stretch`
|
||||
|
||||
in all files within
|
||||
|
||||
`/etc/`
|
||||
|
||||
directory while excluding any sub-directories:
|
||||
|
||||
```
|
||||
# grep -s stretch /etc/*
|
||||
/etc/os-release:PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
|
||||
/etc/os-release:VERSION="9 (stretch)"
|
||||
```
|
||||
`-s`
|
||||
|
||||
grep option will suppress error messages about nonexistent or unreadable files. The output shows filenames as well as prints the actual line containing requested string.
|
||||
|
||||
### Find all files with a specific string recursively
|
||||
|
||||
The above command omitted all sub-directories. To search recursively means to also traverse all sub-directories. The following command will search for a string
|
||||
|
||||
`stretch`
|
||||
|
||||
in all files within
|
||||
|
||||
`/etc/`
|
||||
|
||||
directory including all sub-directories:
|
||||
|
||||
```
|
||||
# grep -R stretch /etc/*
|
||||
/etc/apt/sources.list:# deb cdrom:[Debian GNU/Linux testing _Stretch_ - Official Snapshot amd64 NETINST Binary-1 20170109-05:56]/ stretch main
|
||||
/etc/apt/sources.list:#deb cdrom:[Debian GNU/Linux testing _Stretch_ - Official Snapshot amd64 NETINST Binary-1 20170109-05:56]/ stretch main
|
||||
/etc/apt/sources.list:deb http://ftp.au.debian.org/debian/ stretch main
|
||||
/etc/apt/sources.list:deb-src http://ftp.au.debian.org/debian/ stretch main
|
||||
/etc/apt/sources.list:deb http://security.debian.org/debian-security stretch/updates main
|
||||
/etc/apt/sources.list:deb-src http://security.debian.org/debian-security stretch/updates main
|
||||
/etc/dictionaries-common/words:backstretch
|
||||
/etc/dictionaries-common/words:backstretch's
|
||||
/etc/dictionaries-common/words:backstretches
|
||||
/etc/dictionaries-common/words:homestretch
|
||||
/etc/dictionaries-common/words:homestretch's
|
||||
/etc/dictionaries-common/words:homestretches
|
||||
/etc/dictionaries-common/words:outstretch
|
||||
/etc/dictionaries-common/words:outstretched
|
||||
/etc/dictionaries-common/words:outstretches
|
||||
/etc/dictionaries-common/words:outstretching
|
||||
/etc/dictionaries-common/words:stretch
|
||||
/etc/dictionaries-common/words:stretch's
|
||||
/etc/dictionaries-common/words:stretched
|
||||
/etc/dictionaries-common/words:stretcher
|
||||
/etc/dictionaries-common/words:stretcher's
|
||||
/etc/dictionaries-common/words:stretchers
|
||||
/etc/dictionaries-common/words:stretches
|
||||
/etc/dictionaries-common/words:stretchier
|
||||
/etc/dictionaries-common/words:stretchiest
|
||||
/etc/dictionaries-common/words:stretching
|
||||
/etc/dictionaries-common/words:stretchy
|
||||
/etc/grub.d/00_header:background_image -m stretch `make_system_path_relative_to_its_root "$GRUB_BACKGROUND"`
|
||||
/etc/os-release:PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
|
||||
/etc/os-release:VERSION="9 (stretch)"
|
||||
```
|
||||
|
||||
The above
|
||||
|
||||
`grep`
|
||||
|
||||
command example lists all files containing string
|
||||
|
||||
`stretch`
|
||||
|
||||
. Meaning the lines with
|
||||
|
||||
`stretches`
|
||||
|
||||
,
|
||||
|
||||
`stretched`
|
||||
|
||||
etc. are also shown. Use grep's
|
||||
|
||||
`-w`
|
||||
|
||||
option to show only a specific word:
|
||||
|
||||
```
|
||||
# grep -Rw stretch /etc/*
|
||||
/etc/apt/sources.list:# deb cdrom:[Debian GNU/Linux testing _Stretch_ - Official Snapshot amd64 NETINST Binary-1 20170109-05:56]/ stretch main
|
||||
/etc/apt/sources.list:#deb cdrom:[Debian GNU/Linux testing _Stretch_ - Official Snapshot amd64 NETINST Binary-1 20170109-05:56]/ stretch main
|
||||
/etc/apt/sources.list:deb http://ftp.au.debian.org/debian/ stretch main
|
||||
/etc/apt/sources.list:deb-src http://ftp.au.debian.org/debian/ stretch main
|
||||
/etc/apt/sources.list:deb http://security.debian.org/debian-security stretch/updates main
|
||||
/etc/apt/sources.list:deb-src http://security.debian.org/debian-security stretch/updates main
|
||||
/etc/dictionaries-common/words:stretch
|
||||
/etc/dictionaries-common/words:stretch's
|
||||
/etc/grub.d/00_header:background_image -m stretch `make_system_path_relative_to_its_root "$GRUB_BACKGROUND"`
|
||||
/etc/os-release:PRETTY_NAME="Debian GNU/Linux 9 (stretch)"
|
||||
/etc/os-release:VERSION="9 (stretch)"
|
||||
```
|
||||
|
||||
The above commands may produce an unnecessary output. The next example will only show all file names containing string
|
||||
|
||||
`stretch`
|
||||
|
||||
within
|
||||
|
||||
`/etc/`
|
||||
|
||||
directory recursively:
|
||||
|
||||
```
|
||||
# grep -Rl stretch /etc/*
|
||||
/etc/apt/sources.list
|
||||
/etc/dictionaries-common/words
|
||||
/etc/grub.d/00_header
|
||||
/etc/os-release
|
||||
```
|
||||
|
||||
All searches are by default case sensitive which means that any search for a string
|
||||
|
||||
`stretch`
|
||||
|
||||
will only show files containing the exact uppercase and lowercase match. By using grep's
|
||||
|
||||
`-i`
|
||||
|
||||
option the command will also list any lines containing
|
||||
|
||||
`Stretch`
|
||||
|
||||
,
|
||||
|
||||
`STRETCH`
|
||||
|
||||
,
|
||||
|
||||
`StReTcH`
|
||||
|
||||
etc., hence, to perform case-insensitive search.
|
||||
|
||||
```
|
||||
# grep -Ril stretch /etc/*
|
||||
/etc/apt/sources.list
|
||||
/etc/dictionaries-common/default.hash
|
||||
/etc/dictionaries-common/words
|
||||
/etc/grub.d/00_header
|
||||
/etc/os-release
|
||||
```
|
||||
|
||||
Using
|
||||
|
||||
`grep`
|
||||
|
||||
command it is also possible to include only specific files as part of the search. For example we only would like to search for a specific text/string within configuration files with extension
|
||||
|
||||
`.conf`
|
||||
|
||||
. The next example will find all files with extension
|
||||
|
||||
`.conf`
|
||||
|
||||
within
|
||||
|
||||
`/etc`
|
||||
|
||||
directory containing string
|
||||
|
||||
`bash`
|
||||
|
||||
:
|
||||
|
||||
```
|
||||
# grep -Ril bash /etc/*.conf
|
||||
OR
|
||||
# grep -Ril --include=\*.conf bash /etc/*
|
||||
/etc/adduser.conf
|
||||
```
|
||||
`--exclude`
|
||||
|
||||
option we can exclude any specific filenames:
|
||||
|
||||
```
|
||||
# grep -Ril --exclude=\*.conf bash /etc/*
|
||||
/etc/alternatives/view
|
||||
/etc/alternatives/vim
|
||||
/etc/alternatives/vi
|
||||
/etc/alternatives/vimdiff
|
||||
/etc/alternatives/rvim
|
||||
/etc/alternatives/ex
|
||||
/etc/alternatives/rview
|
||||
/etc/bash.bashrc
|
||||
/etc/bash_completion.d/grub
|
||||
/etc/cron.daily/apt-compat
|
||||
/etc/cron.daily/exim4-base
|
||||
/etc/dictionaries-common/default.hash
|
||||
/etc/dictionaries-common/words
|
||||
/etc/inputrc
|
||||
/etc/passwd
|
||||
/etc/passwd-
|
||||
/etc/profile
|
||||
/etc/shells
|
||||
/etc/skel/.profile
|
||||
/etc/skel/.bashrc
|
||||
/etc/skel/.bash_logout
|
||||
```
|
||||
|
||||
Same as with files grep can also exclude specific directories from the search. Use
|
||||
|
||||
`--exclude-dir`
|
||||
|
||||
option to exclude directory from search. The following search example will find all files containing string
|
||||
|
||||
`stretch`
|
||||
|
||||
within
|
||||
|
||||
`/etc`
|
||||
|
||||
directory and exclude
|
||||
|
||||
`/etc/grub.d`
|
||||
|
||||
from search:
|
||||
|
||||
```
|
||||
# grep --exclude-dir=/etc/grub.d -Rwl stretch /etc/*
|
||||
/etc/apt/sources.list
|
||||
/etc/dictionaries-common/words
|
||||
/etc/os-release
|
||||
```
|
||||
|
||||
By using
|
||||
|
||||
`-n`
|
||||
|
||||
option grep will also provide an information regarding a line number where the specific string was found:
|
||||
|
||||
```
|
||||
# grep -Rni bash /etc/*.conf
|
||||
/etc/adduser.conf:6:DSHELL=/bin/bash
|
||||
```
|
||||
|
||||
The last example will use
|
||||
|
||||
`-v`
|
||||
|
||||
option to list all files NOT containing a specific keyword. For example the following search will list all files within
|
||||
|
||||
`/etc/`
|
||||
|
||||
directory which do not contain string
|
||||
|
||||
`stretch`
|
||||
|
||||
:
|
||||
|
||||
```
|
||||
# grep -Rlv stretch /etc/*
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-find-all-files-with-a-specific-text-using-linux-shell
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -1,168 +0,0 @@
|
||||
translating---imquanquan
|
||||
|
||||
How to Manage Users with Groups in Linux
|
||||
============================================================
|
||||
|
||||
### [group-of-people-1645356_1920.jpg][1]
|
||||
|
||||

|
||||
|
||||
Learn how to work with users, via groups and access control lists in this tutorial.
|
||||
|
||||
[Creative Commons Zero][4]
|
||||
|
||||
Pixabay
|
||||
|
||||
When you administer a Linux machine that houses multiple users, there might be times when you need to take more control over those users than the basic user tools offer. This idea comes to the fore especially when you need to manage permissions for certain users. Say, for example, you have a directory that needs to be accessed with read/write permissions by one group of users and only read permissions for another group. With Linux, this is entirely possible. To make this happen, however, you must first understand how to work with users, via groups and access control lists (ACLs).
|
||||
|
||||
We’ll start from the beginning with users and work our way to the more complex ACLs. Everything you need to make this happen will be included in your Linux distribution of choice. We won’t touch on the basics of users, as the focus on this article is about groups.
|
||||
|
||||
For the purpose of this piece, I’m going to assume the following:
|
||||
|
||||
You need to create two users with usernames:
|
||||
|
||||
* olivia
|
||||
|
||||
* nathan
|
||||
|
||||
You need to create two groups:
|
||||
|
||||
* readers
|
||||
|
||||
* editors
|
||||
|
||||
Olivia needs to be a member of the group editors, while nathan needs to be a member of the group readers. The group readers needs to only have read permission to the directory /DATA, whereas the group editors needs to have both read and write permission to the /DATA directory. This, of course, is very minimal, but it will give you the basic information you need to expand the tasks to fit your much larger needs.
|
||||
|
||||
I’ll be demonstrating on the Ubuntu 16.04 Server platform. The commands will be universal—the only difference would be if your distribution of choice doesn’t make use of sudo. If this is the case, you’ll have to first su to the root user to issue the commands that require sudo in the demonstrations.
|
||||
|
||||
### Creating the users
|
||||
|
||||
The first thing we need to do is create the two users for our experiment. User creation is handled with the useradd command. Instead of just simply creating the users we need to create them both with their own home directories and then give them passwords.
|
||||
|
||||
The first thing we do is create the users. To do this, issue the commands:
|
||||
|
||||
```
|
||||
sudo useradd -m olivia
|
||||
|
||||
sudo useradd -m nathan
|
||||
```
|
||||
|
||||
Next each user must have a password. To add passwords into the mix, you’d issue the following commands:
|
||||
|
||||
```
|
||||
sudo passwd olivia
|
||||
|
||||
sudo passwd nathan
|
||||
```
|
||||
|
||||
That’s it, your users are created.
|
||||
|
||||
### Creating groups and adding users
|
||||
|
||||
Now we’re going to create the groups readers and editors and then add users to them. The commands to create our groups are:
|
||||
|
||||
```
|
||||
addgroup readers
|
||||
|
||||
addgroup editors
|
||||
```
|
||||
|
||||
### [groups_1.jpg][2]
|
||||
|
||||

|
||||
|
||||
Figure 1: Our new groups ready to be used.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
With our groups created, we need to add our users. We’ll add user nathan to group readers with the command:
|
||||
|
||||
```
|
||||
sudo usermod -a -G readers nathan
|
||||
```
|
||||
|
||||
```
|
||||
sudo usermod -a -G editors olivia
|
||||
```
|
||||
|
||||
### Giving groups permissions to directories
|
||||
|
||||
Let’s say you have the directory /READERS and you need to allow all members of the readers group access to that directory. First, change the group of the folder with the command:
|
||||
|
||||
```
|
||||
sudo chown -R :readers /READERS
|
||||
```
|
||||
|
||||
```
|
||||
sudo chmod -R g-w /READERS
|
||||
```
|
||||
|
||||
```
|
||||
sudo chmod -R o-x /READERS
|
||||
```
|
||||
|
||||
Let’s say you have the directory /EDITORS and you need to give members of the editors group read and write permission to its contents. To do that, the following command would be necessary:
|
||||
|
||||
```
|
||||
sudo chown -R :editors /EDITORS
|
||||
|
||||
sudo chmod -R g+w /EDITORS
|
||||
|
||||
sudo chmod -R o-x /EDITORS
|
||||
```
|
||||
|
||||
The problem with using this method is you can only add one group to a directory at a time. This is where access control lists come in handy.
|
||||
|
||||
### Using access control lists
|
||||
|
||||
Now, let’s get tricky. Say you have a single folder—/DATA—and you want to give members of the readers group read permission and members of the group editors read/write permissions. To do that, you must take advantage of the setfacl command. The setfacl command sets file access control lists for files and folders.
|
||||
|
||||
The structure of this command looks like this:
|
||||
|
||||
```
|
||||
setfacl OPTION X:NAME:Y /DIRECTORY
|
||||
```
|
||||
|
||||
```
|
||||
sudo setfacl -m g:readers:rx -R /DATA
|
||||
```
|
||||
|
||||
To give members of the editors group read/write permissions (while retaining read permissions for the readers group), we’d issue the command;
|
||||
|
||||
```
|
||||
sudo setfacl -m g:editors:rwx -R /DATA
|
||||
```
|
||||
|
||||
### All the control you need
|
||||
|
||||
And there you have it. You can now add members to groups and control those groups’ access to various directories with all the power and flexibility you need. To read more about the above tools, issue the commands:
|
||||
|
||||
* man usradd
|
||||
|
||||
* man addgroup
|
||||
|
||||
* man usermod
|
||||
|
||||
* man sefacl
|
||||
|
||||
* man chown
|
||||
|
||||
* man chmod
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/how-manage-users-groups-linux
|
||||
|
||||
作者:[Jack Wallen ]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.linux.com/files/images/group-people-16453561920jpg
|
||||
[2]:https://www.linux.com/files/images/groups1jpg
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[4]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
@ -0,0 +1,78 @@
|
||||
|
||||
Translating by FelixYFZ
|
||||
How to find a publisher for your tech book
|
||||
============================================================
|
||||
|
||||
### Writing a technical book takes more than a good idea. You need to know a bit about how the publishing industry works.
|
||||
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
You've got an idea for a technical book—congratulations! Like a hiking the Appalachian trail, or learning to cook a soufflé, writing a book is one of those things that people talk about, but never take beyond the idea stage. That makes sense, because the failure rate is pretty high. Making it real involves putting your idea in front of a publisher, and finding out whether it's good enough to become a book. That step is scary enough, but the lack of information about how to do it complicates matters.
|
||||
|
||||
If you want to work with a traditional publisher, you'll need to get your book in front of them and hopefully start on the path to publication. I'm the Managing Editor at the [Pragmatic Bookshelf][4], so I see proposals all the time, as well as helping authors to craft good ones. Some are good, others are bad, but I often see proposals that just aren't right for Pragmatic. I'll help you with the process of finding the right publisher, and how to get your idea noticed.
|
||||
|
||||
### Identify your target
|
||||
|
||||
Your first step is to figure out which publisher is the a good fit for your idea. To start, think about the publishers that you buy books from, and that you enjoy. The odds are pretty good that your book will appeal to people like you, so starting with your favorites makes for a pretty good short list. If you don't have much of a book collection, you can visit a bookstore, or take a look on Amazon. Make a list of a handful of publishers that you personally like to start with.
|
||||
|
||||
Next, winnow your prospects. Although most technical publishers look alike from a distance, they often have distinctive audiences. Some publishers go for broadly popular topics, such as C++ or Java. Your book on Elixir may not be a good fit for that publisher. If your prospective book is about teaching programming to kids, you probably don't want to go with the traditional academic publisher.
|
||||
|
||||
Once you've identified a few targets, do some more research into the publishers' catalogs, either on their own site, or on Amazon. See what books they have that are similar to your idea. If they have a book that's identical, or nearly so, you'll have a tough time convincing them to sign yours. That doesn't necessarily mean you should drop that publisher from your list. You can make some changes to your proposal to differentiate it from the existing book: target a different audience, or a different skill level. Maybe the existing book is outdated, and you could focus on new approaches to the technology. Make your proposal into a book that complements the existing one, rather than competes.
|
||||
|
||||
If your target publisher has no books that are similar, that can be a good sign, or a very bad one. Sometimes publishers choose not to publish on specific technologies, either because they don't believe their audience is interested, or they've had trouble with that technology in the past. New languages and libraries pop up all the time, and publishers have to make informed guesses about which will appeal to their readers. Their assessment may not be the same as yours. Their decision might be final, or they might be waiting for the right proposal. The only way to know is to propose and find out.
|
||||
|
||||
### Work your network
|
||||
|
||||
Identifying a publisher is the first step; now you need to make contact. Unfortunately, publishing is still about _who_ you know, more than _what_ you know. The person you want to know is an _acquisitions editor,_ the editor whose job is to find new markets, authors, and proposals. If you know someone who has connections with a publisher, ask for an introduction to an acquisitions editor. These editors often specialize in particular subject areas, particularly at larger publishers, but you don't need to find the right one yourself. They're usually happy to connect you with the correct person.
|
||||
|
||||
Sometimes you can find an acquisitions editor at a technical conference, especially one where the publisher is a sponsor, and has a booth. Even if there's not an acquisitions editor on site at the time, the staff at the booth can put you in touch with one. If conferences aren't your thing, you'll need to work your network to get an introduction. Use LinkedIn, or your informal contacts, to get in touch with an editor.
|
||||
|
||||
For smaller publishers, you may find acquisitions editors listed on the company website, with contact information if you're lucky. If not, search for the publisher's name on Twitter, and see if you can turn up their editors. You might be nervous about trying to reach out to a stranger over social media to show them your book, but don't worry about it. Making contact is what acquisitions editors do. The worst-case result is they ignore you.
|
||||
|
||||
Once you've made contact, the acquisitions editor will assist you with the next steps. They may have some feedback on your proposal right away, or they may want you to flesh it out according to their guidelines before they'll consider it. After you've put in the effort to find an acquisitions editor, listen to their advice. They know their system better than you do.
|
||||
|
||||
### If all else fails
|
||||
|
||||
If you can't find an acquisitions editor to contact, the publisher almost certainly has a blind proposal alias, usually of the form `proposals@[publisher].com`. Check the web site for instructions on what to send to a proposal alias; some publishers have specific requirements. Follow these instructions. If you don't, you have a good chance of your proposal getting thrown out before anybody looks at it. If you have questions, or aren't sure what the publisher wants, you'll need to try again to find an editor to talk to, because the proposal alias is not the place to get questions answered. Put together what they've asked for (which is a topic for a separate article), send it in, and hope for the best.
|
||||
|
||||
### And ... wait
|
||||
|
||||
No matter how you've gotten in touch with a publisher, you'll probably have to wait. If you submitted to the proposals alias, it's going to take a while before somebody does anything with that proposal, especially at a larger company. Even if you've found an acquisitions editor to work with, you're probably one of many prospects she's working with simultaneously, so you might not get rapid responses. Almost all publishers have a committee that decides on which proposals to accept, so even if your proposal is awesome and ready to go, you'll still need to wait for the committee to meet and discuss it. You might be waiting several weeks, or even a month before you hear anything.
|
||||
|
||||
After a couple of weeks, it's fine to check back in with the editor to see if they need any more information. You want to be polite in this e-mail; if they haven't answered because they're swamped with proposals, being pushy isn't going to get you to the front of the line. It's possible that some publishers will never respond at all instead of sending a rejection notice, but that's uncommon. There's not a lot to do at this point other than be patient. Of course, if it's been months and nobody's returning your e-mails, you're free to approach a different publisher or consider self-publishing.
|
||||
|
||||
### Good luck
|
||||
|
||||
If this process seems somewhat scattered and unscientific, you're right; it is. Getting published depends on being in the right place, at the right time, talking to the right person, and hoping they're in the right mood. You can't control all of those variables, but having a better knowledge of how the industry works, and what publishers are looking for, can help you optimize the ones you can control.
|
||||
|
||||
Finding a publisher is one step in a lengthy process. You need to refine your idea and create the proposal, as well as other considerations. At SeaGL this year [I presented][5] an introduction to the entire process. Check out [the video][6] for more detailed information.
|
||||
|
||||
### About the author
|
||||
|
||||
[][7]
|
||||
|
||||
Brian MacDonald - Brian MacDonald is Managing Editor at the Pragmatic Bookshelf. Over the last 20 years in tech publishing, he's been an editor, author, and occasional speaker and trainer. He currently spends a lot of his time talking to new authors about how they can best present their ideas. You can follow him on Twitter at @bmac_editor.[More about me][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/how-find-publisher-your-book
|
||||
|
||||
作者:[Brian MacDonald ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bmacdonald
|
||||
[1]:https://opensource.com/article/17/12/how-find-publisher-your-book?rate=o42yhdS44MUaykAIRLB3O24FvfWxAxBKa5WAWSnSY0s
|
||||
[2]:https://opensource.com/users/bmacdonald
|
||||
[3]:https://opensource.com/user/190176/feed
|
||||
[4]:https://pragprog.com/
|
||||
[5]:https://archive.org/details/SeaGL2017WritingTheNextGreatTechBook
|
||||
[6]:https://archive.org/details/SeaGL2017WritingTheNextGreatTechBook
|
||||
[7]:https://opensource.com/users/bmacdonald
|
||||
[8]:https://opensource.com/users/bmacdonald
|
||||
[9]:https://opensource.com/users/bmacdonald
|
||||
[10]:https://opensource.com/article/17/12/how-find-publisher-your-book#comments
|
||||
@ -0,0 +1,161 @@
|
||||
translating by wenwensnow
|
||||
Randomize your WiFi MAC address on Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
_Your device’s MAC address can be used to track you across the WiFi networks you connect to. That data can be shared and sold, and often identifies you as an individual. It’s possible to limit this tracking by using pseudo-random MAC addresses._
|
||||
|
||||

|
||||
|
||||
_Image courtesy of [Cloudessa][4]_
|
||||
|
||||
Every network device like a WiFi or Ethernet card has a unique identifier called a MAC address, for example `b4:b6:76:31:8c:ff`. It’s how networking works: any time you connect to a WiFi network, the router uses that address to send and receive packets to your machine and distinguish it from other devices in the area.
|
||||
|
||||
The snag with this design is that your unique, unchanging MAC address is just perfect for tracking you. Logged into Starbucks WiFi? Noted. London Underground? Logged.
|
||||
|
||||
If you’ve ever put your real name into one of those Craptive Portals on a WiFi network you’ve now tied your identity to that MAC address. Didn’t read the terms and conditions? You might assume that free airport WiFi is subsidised by flogging ‘customer analytics’ (your personal information) to hotels, restaurant chains and whomever else wants to know about you.
|
||||
|
||||
I don’t subscribe to being tracked and sold by mega-corps, so I spent a few hours hacking a solution.
|
||||
|
||||
### MAC addresses don’t need to stay the same
|
||||
|
||||
Fortunately, it’s possible to spoof your MAC address to a random one without fundamentally breaking networking.
|
||||
|
||||
I wanted to randomize my MAC address, but with three particular caveats:
|
||||
|
||||
1. The MAC should be different across different networks. This means Starbucks WiFi sees a different MAC from London Underground, preventing linking my identity across different providers.
|
||||
|
||||
2. The MAC should change regularly to prevent a network knowing that I’m the same person who walked past 75 times over the last year.
|
||||
|
||||
3. The MAC stays the same throughout each working day. When the MAC address changes, most networks will kick you off, and those with Craptive Portals will usually make you sign in again - annoying.
|
||||
|
||||
### Manipulating NetworkManager
|
||||
|
||||
My first attempt of using the `macchanger` tool was unsuccessful as NetworkManager would override the MAC address according to its own configuration.
|
||||
|
||||
I learned that NetworkManager 1.4.1+ can do MAC address randomization right out the box. If you’re using Ubuntu 17.04 upwards, you can get most of the way with [this config file][7]. You can’t quite achieve all three of my requirements (you must choose _random_ or _stable_ but it seems you can’t do _stable-for-one-day_ ).
|
||||
|
||||
Since I’m sticking with Ubuntu 16.04 which ships with NetworkManager 1.2, I couldn’t make use of the new functionality. Supposedly there is some randomization support but I failed to actually make it work, so I scripted up a solution instead.
|
||||
|
||||
Fortunately NetworkManager 1.2 does allow for spoofing your MAC address. You can see this in the ‘Edit connections’ dialog for a given network:
|
||||
|
||||
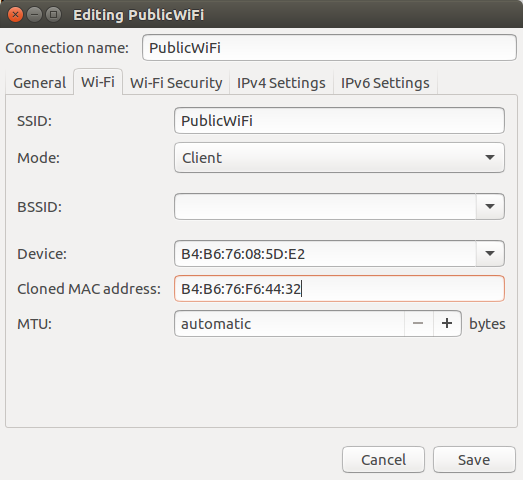
|
||||
|
||||
NetworkManager also supports hooks - any script placed in `/etc/NetworkManager/dispatcher.d/pre-up.d/` is run before a connection is brought up.
|
||||
|
||||
### Assigning pseudo-random MAC addresses
|
||||
|
||||
To recap, I wanted to generate random MAC addresses based on the _network_ and the _date_ . We can use the NetworkManager command line, nmcli, to show a full list of networks:
|
||||
|
||||
```
|
||||
> nmcli connection
|
||||
NAME UUID TYPE DEVICE
|
||||
Gladstone Guest 618545ca-d81a-11e7-a2a4-271245e11a45 802-11-wireless wlp1s0
|
||||
DoESDinky 6e47c080-d81a-11e7-9921-87bc56777256 802-11-wireless --
|
||||
PublicWiFi 79282c10-d81a-11e7-87cb-6341829c2a54 802-11-wireless --
|
||||
virgintrainswifi 7d0c57de-d81a-11e7-9bae-5be89b161d22 802-11-wireless --
|
||||
|
||||
```
|
||||
|
||||
Since each network has a unique identifier, to achieve my scheme I just concatenated the UUID with today’s date and hashed the result:
|
||||
|
||||
```
|
||||
|
||||
# eg 618545ca-d81a-11e7-a2a4-271245e11a45-2017-12-03
|
||||
|
||||
> echo -n "${UUID}-$(date +%F)" | md5sum
|
||||
|
||||
53594de990e92f9b914a723208f22b3f -
|
||||
|
||||
```
|
||||
|
||||
That produced bytes which can be substituted in for the last octets of the MAC address.
|
||||
|
||||
Note that the first byte `02` signifies the address is [locally administered][8]. Real, burned-in MAC addresses start with 3 bytes designing their manufacturer, for example `b4:b6:76` for Intel.
|
||||
|
||||
It’s possible that some routers may reject locally administered MACs but I haven’t encountered that yet.
|
||||
|
||||
On every connection up, the script calls `nmcli` to set the spoofed MAC address for every connection:
|
||||
|
||||
|
||||
|
||||
As a final check, if I look at `ifconfig` I can see that the `HWaddr` is the spoofed one, not my real MAC address:
|
||||
|
||||
```
|
||||
> ifconfig
|
||||
wlp1s0 Link encap:Ethernet HWaddr b4:b6:76:45:64:4d
|
||||
inet addr:192.168.0.86 Bcast:192.168.0.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::648c:aff2:9a9d:764/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:12107812 errors:0 dropped:2 overruns:0 frame:0
|
||||
TX packets:18332141 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:11627977017 (11.6 GB) TX bytes:20700627733 (20.7 GB)
|
||||
|
||||
```
|
||||
|
||||
The full script is [available on Github][9].
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
# /etc/NetworkManager/dispatcher.d/pre-up.d/randomize-mac-addresses
|
||||
|
||||
# Configure every saved WiFi connection in NetworkManager with a spoofed MAC
|
||||
# address, seeded from the UUID of the connection and the date eg:
|
||||
# 'c31bbcc4-d6ad-11e7-9a5a-e7e1491a7e20-2017-11-20'
|
||||
|
||||
# This makes your MAC impossible(?) to track across WiFi providers, and
|
||||
# for one provider to track across days.
|
||||
|
||||
# For craptive portals that authenticate based on MAC, you might want to
|
||||
# automate logging in :)
|
||||
|
||||
# Note that NetworkManager >= 1.4.1 (Ubuntu 17.04+) can do something similar
|
||||
# automatically.
|
||||
|
||||
export PATH=$PATH:/usr/bin:/bin
|
||||
|
||||
LOG_FILE=/var/log/randomize-mac-addresses
|
||||
|
||||
echo "$(date): $*" > ${LOG_FILE}
|
||||
|
||||
WIFI_UUIDS=$(nmcli --fields type,uuid connection show |grep 802-11-wireless |cut '-d ' -f3)
|
||||
|
||||
for UUID in ${WIFI_UUIDS}
|
||||
do
|
||||
UUID_DAILY_HASH=$(echo "${UUID}-$(date +F)" | md5sum)
|
||||
|
||||
RANDOM_MAC="02:$(echo -n ${UUID_DAILY_HASH} | sed 's/^\(..\)\(..\)\(..\)\(..\)\(..\).*$/\1:\2:\3:\4:\5/')"
|
||||
|
||||
CMD="nmcli connection modify ${UUID} wifi.cloned-mac-address ${RANDOM_MAC}"
|
||||
|
||||
echo "$CMD" >> ${LOG_FILE}
|
||||
$CMD &
|
||||
done
|
||||
|
||||
wait
|
||||
```
|
||||
Enjoy!
|
||||
|
||||
_Update: [Use locally administered MAC addresses][5] to avoid clashing with real Intel ones. Thanks [@_fink][6]_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.paulfurley.com/randomize-your-wifi-mac-address-on-ubuntu-1604-xenial/
|
||||
|
||||
作者:[Paul M Furley ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.paulfurley.com/
|
||||
[1]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f/raw/5f02fc8f6ff7fca5bca6ee4913c63bf6de15abca/randomize-mac-addresses
|
||||
[2]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f#file-randomize-mac-addresses
|
||||
[3]:https://github.com/
|
||||
[4]:http://cloudessa.com/products/cloudessa-aaa-and-captive-portal-cloud-service/
|
||||
[5]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f/revisions#diff-824d510864d58c07df01102a8f53faef
|
||||
[6]:https://twitter.com/fink_/status/937305600005943296
|
||||
[7]:https://gist.github.com/paulfurley/978d4e2e0cceb41d67d017a668106c53/
|
||||
[8]:https://en.wikipedia.org/wiki/MAC_address#Universal_vs._local
|
||||
[9]:https://gist.github.com/paulfurley/46e0547ce5c5ea7eabeaef50dbacef3f
|
||||
@ -0,0 +1,321 @@
|
||||
Python
|
||||
============================================================
|
||||
|
||||
Python has rich tools for packaging, distributing and sandboxing applications. Snapcraft builds on top of these familiar tools such as `pip`, `setup.py` and `requirements.txt` to create snaps for people to install on Linux.
|
||||
|
||||
### What problems do snaps solve for Python applications?
|
||||
|
||||
Linux install instructions for Python applications often get complicated. System dependencies, which differ from distribution to distribution, must be separately installed. To prevent modules from different Python applications clashing with each other, developer tools like `virtualenv` or `venv` must be used. With snapcraft it’s one command to produce a bundle that works anywhere.
|
||||
|
||||
Here are some snap advantages that will benefit many Python projects:
|
||||
|
||||
* Bundle all the runtime requirements, including the exact versions of system libraries and the Python interpreter.
|
||||
|
||||
* Simplify installation instructions, regardless of distribution, to `snap install mypythonapp`.
|
||||
|
||||
* Directly control the delivery of automatic application updates.
|
||||
|
||||
* Extremely simple creation of daemons.
|
||||
|
||||
### Getting started
|
||||
|
||||
Let’s take a look at offlineimap and youtube-dl by way of examples. Both are command line applications. offlineimap uses Python 2 and only has Python module requirements. youtube-dl uses Python 3 and has system package requirements, in this case `ffmpeg`.
|
||||
|
||||
### offlineimap
|
||||
|
||||
Snaps are defined in a single yaml file placed in the root of your project. The offlineimap example shows the entire `snapcraft.yaml` for an existing project. We’ll break this down.
|
||||
|
||||
```
|
||||
name: offlineimap
|
||||
version: git
|
||||
summary: OfflineIMAP
|
||||
description: |
|
||||
OfflineIMAP is software that downloads your email mailbox(es) as local
|
||||
Maildirs. OfflineIMAP will synchronize both sides via IMAP.
|
||||
|
||||
grade: devel
|
||||
confinement: devmode
|
||||
|
||||
apps:
|
||||
offlineimap:
|
||||
command: bin/offlineimap
|
||||
|
||||
parts:
|
||||
offlineimap:
|
||||
plugin: python
|
||||
python-version: python2
|
||||
source: .
|
||||
|
||||
```
|
||||
|
||||
#### Metadata
|
||||
|
||||
The `snapcraft.yaml` starts with a small amount of human-readable metadata, which usually can be lifted from the GitHub description or project README.md. This data is used in the presentation of your app in the Snap Store. The `summary:` can not exceed 79 characters. You can use a pipe with the `description:` to declare a multi-line description.
|
||||
|
||||
```
|
||||
name: offlineimap
|
||||
version: git
|
||||
summary: OfflineIMAP
|
||||
description: |
|
||||
OfflineIMAP is software that downloads your email mailbox(es) as local
|
||||
Maildirs. OfflineIMAP will synchronize both sides via IMAP.
|
||||
|
||||
```
|
||||
|
||||
#### Confinement
|
||||
|
||||
To get started we won’t confine this application. Unconfined applications, specified with `devmode`, can only be released to the hidden “edge” channel where you and other developers can install them.
|
||||
|
||||
```
|
||||
confinement: devmode
|
||||
|
||||
```
|
||||
|
||||
#### Parts
|
||||
|
||||
Parts define how to build your app. Parts can be anything: programs, libraries, or other assets needed to create and run your application. In this case we have one: the offlineimap source code. In other cases these can point to local directories, remote git repositories, or tarballs.
|
||||
|
||||
The Python plugin will also bundle Python in the snap, so you can be sure that the version of Python you test against is included with your app. Dependencies from `install_requires` in your `setup.py` will also be bundled. Dependencies from a `requirements.txt` file can also be bundled using the `requirements:` option.
|
||||
|
||||
```
|
||||
parts:
|
||||
offlineimap:
|
||||
plugin: python
|
||||
python-version: python2
|
||||
source: .
|
||||
|
||||
```
|
||||
|
||||
#### Apps
|
||||
|
||||
Apps are the commands and services exposed to end users. If your command name matches the snap `name`, users will be able run the command directly. If the names differ, then apps are prefixed with the snap `name`(`offlineimap.command-name`, for example). This is to avoid conflicting with apps defined by other installed snaps.
|
||||
|
||||
If you don’t want your command prefixed you can request an alias for it on the [Snapcraft forum][1]. These command aliases are set up automatically when your snap is installed from the Snap Store.
|
||||
|
||||
```
|
||||
apps:
|
||||
offlineimap:
|
||||
command: bin/offlineimap
|
||||
|
||||
```
|
||||
|
||||
If your application is intended to run as a service, add the line `daemon: simple` after the command keyword. This will automatically keep the service running on install, update and reboot.
|
||||
|
||||
### Building the snap
|
||||
|
||||
You’ll first need to [install snap support][2], and then install the snapcraft tool:
|
||||
|
||||
```
|
||||
sudo snap install --beta --classic snapcraft
|
||||
|
||||
```
|
||||
|
||||
If you have just installed snap support, start a new shell so your `PATH` is updated to include `/snap/bin`. You can then build this example yourself:
|
||||
|
||||
```
|
||||
git clone https://github.com/snapcraft-docs/offlineimap
|
||||
cd offlineimap
|
||||
snapcraft
|
||||
|
||||
```
|
||||
|
||||
The resulting snap can be installed locally. This requires the `--dangerous` flag because the snap is not signed by the Snap Store. The `--devmode` flag acknowledges that you are installing an unconfined application:
|
||||
|
||||
```
|
||||
sudo snap install offlineimap_*.snap --devmode --dangerous
|
||||
|
||||
```
|
||||
|
||||
You can then try it out:
|
||||
|
||||
```
|
||||
offlineimap
|
||||
|
||||
```
|
||||
|
||||
Removing the snap is simple too:
|
||||
|
||||
```
|
||||
sudo snap remove offlineimap
|
||||
|
||||
```
|
||||
|
||||
Jump ahead to [Share with your friends][3] or continue to read another example.
|
||||
|
||||
### youtube-dl
|
||||
|
||||
The youtube-dl example shows a `snapcraft.yaml` using a tarball of a Python application and `ffmpeg` bundled in the snap to satisfy the runtime requirements. Here is the entire `snapcraft.yaml` for youtube-dl. We’ll break this down.
|
||||
|
||||
```
|
||||
name: youtube-dl
|
||||
version: 2017.06.18
|
||||
summary: YouTube Downloader.
|
||||
description: |
|
||||
youtube-dl is a small command-line program to download videos from
|
||||
YouTube.com and a few more sites.
|
||||
|
||||
grade: devel
|
||||
confinement: devmode
|
||||
|
||||
parts:
|
||||
youtube-dl:
|
||||
source: https://github.com/rg3/youtube-dl/archive/$SNAPCRAFT_PROJECT_VERSION.tar.gz
|
||||
plugin: python
|
||||
python-version: python3
|
||||
after: [ffmpeg]
|
||||
|
||||
apps:
|
||||
youtube-dl:
|
||||
command: bin/youtube-dl
|
||||
|
||||
```
|
||||
|
||||
#### Parts
|
||||
|
||||
The `$SNAPCRAFT_PROJECT_VERSION` variable is derived from the `version:` stanza and used here to reference the matching release tarball. Because the `python` plugin is used, snapcraft will bundle a copy of Python in the snap using the version specified in the `python-version:` stanza, in this case Python 3.
|
||||
|
||||
youtube-dl makes use of `ffmpeg` to transcode or otherwise convert the audio and video file it downloads. In this example, youtube-dl is told to build after the `ffmpeg` part. Because the `ffmpeg` part specifies no plugin, it will be fetched from the parts repository. This is a collection of community-contributed definitions which can be used by anyone when building a snap, saving you from needing to specify the source and build rules for each system dependency. You can use `snapcraft search` to find more parts to use and `snapcraft define <part-name>` to verify how the part is defined.
|
||||
|
||||
```
|
||||
parts:
|
||||
youtube-dl:
|
||||
source: https://github.com/rg3/youtube-dl/archive/$SNAPCRAFT_PROJECT_VERSION.tar.gz
|
||||
plugin: python
|
||||
python-version: python3
|
||||
after: [ffmpeg]
|
||||
|
||||
```
|
||||
|
||||
### Building the snap
|
||||
|
||||
You can build this example yourself by running the following:
|
||||
|
||||
```
|
||||
git clone https://github.com/snapcraft-docs/youtube-dl
|
||||
cd youtube-dl
|
||||
snapcraft
|
||||
|
||||
```
|
||||
|
||||
The resulting snap can be installed locally. This requires the `--dangerous` flag because the snap is not signed by the Snap Store. The `--devmode` flag acknowledges that you are installing an unconfined application:
|
||||
|
||||
```
|
||||
sudo snap install youtube-dl_*.snap --devmode --dangerous
|
||||
|
||||
```
|
||||
|
||||
Run the command:
|
||||
|
||||
```
|
||||
youtube-dl “https://www.youtube.com/watch?v=k-laAxucmEQ”
|
||||
|
||||
```
|
||||
|
||||
Removing the snap is simple too:
|
||||
|
||||
```
|
||||
sudo snap remove youtube-dl
|
||||
|
||||
```
|
||||
|
||||
### Share with your friends
|
||||
|
||||
To share your snaps you need to publish them in the Snap Store. First, create an account on [the dashboard][4]. Here you can customize how your snaps are presented, review your uploads and control publishing.
|
||||
|
||||
You’ll need to choose a unique “developer namespace” as part of the account creation process. This name will be visible by users and associated with your published snaps.
|
||||
|
||||
Make sure the `snapcraft` command is authenticated using the email address attached to your Snap Store account:
|
||||
|
||||
```
|
||||
snapcraft login
|
||||
|
||||
```
|
||||
|
||||
### Reserve a name for your snap
|
||||
|
||||
You can publish your own version of a snap, provided you do so under a name you have rights to.
|
||||
|
||||
```
|
||||
snapcraft register mypythonsnap
|
||||
|
||||
```
|
||||
|
||||
Be sure to update the `name:` in your `snapcraft.yaml` to match this registered name, then run `snapcraft` again.
|
||||
|
||||
### Upload your snap
|
||||
|
||||
Use snapcraft to push the snap to the Snap Store.
|
||||
|
||||
```
|
||||
snapcraft push --release=edge mypthonsnap_*.snap
|
||||
|
||||
```
|
||||
|
||||
If you’re happy with the result, you can commit the snapcraft.yaml to your GitHub repo and [turn on automatic builds][5] so any further commits automatically get released to edge, without requiring you to manually build locally.
|
||||
|
||||
### Further customisations
|
||||
|
||||
Here are all the Python plugin-specific keywords:
|
||||
|
||||
```
|
||||
- requirements:
|
||||
(string)
|
||||
Path to a requirements.txt file
|
||||
- constraints:
|
||||
(string)
|
||||
Path to a constraints file
|
||||
- process-dependency-links:
|
||||
(bool; default: false)
|
||||
Enable the processing of dependency links in pip, which allow one project
|
||||
to provide places to look for another project
|
||||
- python-packages:
|
||||
(list)
|
||||
A list of dependencies to get from PyPI
|
||||
- python-version:
|
||||
(string; default: python3)
|
||||
The python version to use. Valid options are: python2 and python3
|
||||
|
||||
```
|
||||
|
||||
You can view them locally by running:
|
||||
|
||||
```
|
||||
snapcraft help python
|
||||
|
||||
```
|
||||
|
||||
### Extending and overriding behaviour
|
||||
|
||||
You can [extend the behaviour][6] of any part in your `snapcraft.yaml` with shell commands. These can be run after pulling the source code but before building by using the `prepare` keyword. The build process can be overridden entirely using the `build` keyword and shell commands. The `install` keyword is used to run shell commands after building your code, useful for making post build modifications such as relocating build assets.
|
||||
|
||||
Using the youtube-dl example above, we can run the test suite at the end of the build. If this fails, the snap creation will be terminated:
|
||||
|
||||
```
|
||||
parts:
|
||||
youtube-dl:
|
||||
source: https://github.com/rg3/youtube-dl/archive/$SNAPCRAFT_PROJECT_VERSION.tar.gz
|
||||
plugin: python
|
||||
python-version: python3
|
||||
stage-packages: [ffmpeg, python-nose]
|
||||
install: |
|
||||
nosetests
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://docs.snapcraft.io/build-snaps/python
|
||||
|
||||
作者:[Snapcraft.io ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:Snapcraft.io
|
||||
|
||||
[1]:https://forum.snapcraft.io/t/process-for-reviewing-aliases-auto-connections-and-track-requests/455
|
||||
[2]:https://docs.snapcraft.io/core/install
|
||||
[3]:https://docs.snapcraft.io/build-snaps/python#share-with-your-friends
|
||||
[4]:https://dashboard.snapcraft.io/openid/login/?next=/dev/snaps/
|
||||
[5]:https://build.snapcraft.io/
|
||||
[6]:https://docs.snapcraft.io/build-snaps/scriptlets
|
||||
129
sources/tech/20171202 docker - Use multi-stage builds.md
Normal file
129
sources/tech/20171202 docker - Use multi-stage builds.md
Normal file
@ -0,0 +1,129 @@
|
||||
【iron0x翻译中】
|
||||
|
||||
Use multi-stage builds
|
||||
============================================================
|
||||
|
||||
Multi-stage builds are a new feature requiring Docker 17.05 or higher on the daemon and client. Multistage builds are useful to anyone who has struggled to optimize Dockerfiles while keeping them easy to read and maintain.
|
||||
|
||||
> Acknowledgment: Special thanks to [Alex Ellis][1] for granting permission to use his blog post [Builder pattern vs. Multi-stage builds in Docker][2] as the basis of the examples below.
|
||||
|
||||
### Before multi-stage builds
|
||||
|
||||
One of the most challenging things about building images is keeping the image size down. Each instruction in the Dockerfile adds a layer to the image, and you need to remember to clean up any artifacts you don’t need before moving on to the next layer. To write a really efficient Dockerfile, you have traditionally needed to employ shell tricks and other logic to keep the layers as small as possible and to ensure that each layer has the artifacts it needs from the previous layer and nothing else.
|
||||
|
||||
It was actually very common to have one Dockerfile to use for development (which contained everything needed to build your application), and a slimmed-down one to use for production, which only contained your application and exactly what was needed to run it. This has been referred to as the “builder pattern”. Maintaining two Dockerfiles is not ideal.
|
||||
|
||||
Here’s an example of a `Dockerfile.build` and `Dockerfile` which adhere to the builder pattern above:
|
||||
|
||||
`Dockerfile.build`:
|
||||
|
||||
```
|
||||
FROM golang:1.7.3
|
||||
WORKDIR /go/src/github.com/alexellis/href-counter/
|
||||
RUN go get -d -v golang.org/x/net/html
|
||||
COPY app.go .
|
||||
RUN go get -d -v golang.org/x/net/html \
|
||||
&& CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
|
||||
|
||||
```
|
||||
|
||||
Notice that this example also artificially compresses two `RUN` commands together using the Bash `&&` operator, to avoid creating an additional layer in the image. This is failure-prone and hard to maintain. It’s easy to insert another command and forget to continue the line using the `\` character, for example.
|
||||
|
||||
`Dockerfile`:
|
||||
|
||||
```
|
||||
FROM alpine:latest
|
||||
RUN apk --no-cache add ca-certificates
|
||||
WORKDIR /root/
|
||||
COPY app .
|
||||
CMD ["./app"]
|
||||
|
||||
```
|
||||
|
||||
`build.sh`:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
echo Building alexellis2/href-counter:build
|
||||
|
||||
docker build --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy \
|
||||
-t alexellis2/href-counter:build . -f Dockerfile.build
|
||||
|
||||
docker create --name extract alexellis2/href-counter:build
|
||||
docker cp extract:/go/src/github.com/alexellis/href-counter/app ./app
|
||||
docker rm -f extract
|
||||
|
||||
echo Building alexellis2/href-counter:latest
|
||||
|
||||
docker build --no-cache -t alexellis2/href-counter:latest .
|
||||
rm ./app
|
||||
|
||||
```
|
||||
|
||||
When you run the `build.sh` script, it needs to build the first image, create a container from it in order to copy the artifact out, then build the second image. Both images take up room on your system and you still have the `app` artifact on your local disk as well.
|
||||
|
||||
Multi-stage builds vastly simplify this situation!
|
||||
|
||||
### Use multi-stage builds
|
||||
|
||||
With multi-stage builds, you use multiple `FROM` statements in your Dockerfile. Each `FROM` instruction can use a different base, and each of them begins a new stage of the build. You can selectively copy artifacts from one stage to another, leaving behind everything you don’t want in the final image. To show how this works, Let’s adapt the Dockerfile from the previous section to use multi-stage builds.
|
||||
|
||||
`Dockerfile`:
|
||||
|
||||
```
|
||||
FROM golang:1.7.3
|
||||
WORKDIR /go/src/github.com/alexellis/href-counter/
|
||||
RUN go get -d -v golang.org/x/net/html
|
||||
COPY app.go .
|
||||
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
|
||||
|
||||
FROM alpine:latest
|
||||
RUN apk --no-cache add ca-certificates
|
||||
WORKDIR /root/
|
||||
COPY --from=0 /go/src/github.com/alexellis/href-counter/app .
|
||||
CMD ["./app"]
|
||||
|
||||
```
|
||||
|
||||
You only need the single Dockerfile. You don’t need a separate build script, either. Just run `docker build`.
|
||||
|
||||
```
|
||||
$ docker build -t alexellis2/href-counter:latest .
|
||||
|
||||
```
|
||||
|
||||
The end result is the same tiny production image as before, with a significant reduction in complexity. You don’t need to create any intermediate images and you don’t need to extract any artifacts to your local system at all.
|
||||
|
||||
How does it work? The second `FROM` instruction starts a new build stage with the `alpine:latest` image as its base. The `COPY --from=0` line copies just the built artifact from the previous stage into this new stage. The Go SDK and any intermediate artifacts are left behind, and not saved in the final image.
|
||||
|
||||
### Name your build stages
|
||||
|
||||
By default, the stages are not named, and you refer to them by their integer number, starting with 0 for the first `FROM` instruction. However, you can name your stages, by adding an `as <NAME>` to the `FROM` instruction. This example improves the previous one by naming the stages and using the name in the `COPY` instruction. This means that even if the instructions in your Dockerfile are re-ordered later, the `COPY` won’t break.
|
||||
|
||||
```
|
||||
FROM golang:1.7.3 as builder
|
||||
WORKDIR /go/src/github.com/alexellis/href-counter/
|
||||
RUN go get -d -v golang.org/x/net/html
|
||||
COPY app.go .
|
||||
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
|
||||
|
||||
FROM alpine:latest
|
||||
RUN apk --no-cache add ca-certificates
|
||||
WORKDIR /root/
|
||||
COPY --from=builder /go/src/github.com/alexellis/href-counter/app .
|
||||
CMD ["./app"]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://docs.docker.com/engine/userguide/eng-image/multistage-build/#name-your-build-stages
|
||||
|
||||
作者:[docker docs ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://docs.docker.com/engine/userguide/eng-image/multistage-build/
|
||||
[1]:https://twitter.com/alexellisuk
|
||||
[2]:http://blog.alexellis.io/mutli-stage-docker-builds/
|
||||
188
sources/tech/20171203 Best Network Monitoring Tools For Linux.md
Normal file
188
sources/tech/20171203 Best Network Monitoring Tools For Linux.md
Normal file
@ -0,0 +1,188 @@
|
||||
Best Network Monitoring Tools For Linux
|
||||
===============================
|
||||
|
||||
|
||||
Keeping control of our network is vital to prevent any program from overusing it and slows down the overall system operation. There are several
|
||||
|
||||
**network monitoring tools**
|
||||
|
||||
for different operating systems today. In this article, we will talk about
|
||||
|
||||
**10 network monitoring tools for Linux**
|
||||
|
||||
that will run from a terminal, ideal for users who do not use GUI or for those who want to keep a control of the network use of a server through from ssh.
|
||||
|
||||
### Iftop
|
||||
|
||||
[][2]
|
||||
|
||||
Linux users are generally familiar with Top. This tool is a system monitor that allows us to know in real time all the processes that are running in our system and can manage them easily. Iftop is an application similar to Top but specialized in the monitoring of the network, being able to know a multitude of details regarding the network and all the processes that are making use of it.
|
||||
|
||||
We can obtain more information about this tool and download the necessary packages from the
|
||||
|
||||
[following link][3]
|
||||
|
||||
.
|
||||
|
||||
### Vnstat
|
||||
|
||||
[][4] **Vnstat**
|
||||
|
||||
is a network monitor that is included, by default, in most Linux distributions. It allows us to obtain a real-time control of the traffic sent and received in a period of time, chosen by the user.
|
||||
|
||||
|
||||
|
||||
We can obtain more information about this tool and download the necessary packages from the
|
||||
|
||||
[following link.][5]
|
||||
|
||||
### Iptraf
|
||||
|
||||
[][6] **IPTraf**
|
||||
|
||||
is a console-based, real-time network monitoring utility for Linux. (IP LAN) - Collects a wide variety of information as an IP traffic monitor that passes through the network, including TCP flags information, ICMP details, TCP / UDP traffic faults, TCP connection packet and Byne account. It also collects statistics information from the general and detailed interface of TCP, UDP,,, checksum errors IP not IP ICMP IP, interface activity, etc.
|
||||
|
||||
|
||||
|
||||
We can obtain more information about this tool and download the necessary packages from the
|
||||
|
||||
[following link.][7]
|
||||
|
||||
### Monitorix - System and Monitoring Network
|
||||
|
||||
[][8]
|
||||
|
||||
Monitorix is a lightweight free utility that is designed to run and monitor system and network resources with as many Linux / Unix servers as possible. An HTTP web server has been added that regularly collects system and network information and displays them in the graphs. It will track the average system load and its usage, memory allocation, disk health, system services, network ports, mail statistics (Sendmail, Postfix, Dovecot, etc.), MySQL statistics and many more. It is designed to control the overall performance of the system and helps in detecting faults, bottlenecks, abnormal activities, etc.
|
||||
|
||||
|
||||
|
||||
Download and more
|
||||
|
||||
[information here][9]
|
||||
|
||||
.
|
||||
|
||||
### Dstat
|
||||
|
||||
[][10]
|
||||
|
||||
A monitor is somewhat less known than the previous ones but also usually comes by default in many distributions.
|
||||
|
||||
|
||||
|
||||
We can obtain more information about this tool and download the necessary packages from the
|
||||
|
||||
[following link][11]
|
||||
|
||||
.
|
||||
|
||||
### Bwm-ng
|
||||
|
||||
[][12]
|
||||
|
||||
One of the simplest tools. It allows you to get data from the connection interactively and, at the same time, export them to a certain format for easier reference on another device.
|
||||
|
||||
|
||||
|
||||
We can obtain more information about this tool and download the necessary packages from the
|
||||
|
||||
[following link][13]
|
||||
|
||||
.
|
||||
|
||||
### Ibmonitor
|
||||
|
||||
[][14]
|
||||
|
||||
Similar to the above, it shows network traffic filtered by connection interface and clearly separates the traffic sent from the received traffic.
|
||||
|
||||
|
||||
|
||||
We can obtain more information about this tool and download the necessary packages from the
|
||||
|
||||
[following link][15]
|
||||
|
||||
.
|
||||
|
||||
### Htop - Linux Process Tracking
|
||||
|
||||
[][16]
|
||||
|
||||
Htop is a much more advanced, interactive and real-time Linux tool for tracking processes. It is similar to the top Linux command but has some advanced features such as an easy-to-use interface for process management, shortcut keys, vertical and horizontal view of processes and much more. Htop is a third-party tool and is not included on Linux systems, you must install it using
|
||||
|
||||
**YUM**
|
||||
|
||||
(or
|
||||
|
||||
**APT-GET)**
|
||||
|
||||
or whatever your package management tool. For more information on installation, read
|
||||
|
||||
[this article][17]
|
||||
|
||||
.
|
||||
|
||||
We can obtain more information about this tool and download the necessary packages from the
|
||||
|
||||
[following link.][18]
|
||||
|
||||
### Arpwatch - Ethernet Activity Monitor
|
||||
|
||||
[][19]
|
||||
|
||||
Arpwatch is a program that is designed to control the resolution of addresses (MAC and changes in the IP address) of Ethernet network traffic in a Linux network. It is continuously monitoring the Ethernet traffic and records the changes in the IP addresses and MAC addresses, the changes of pairs along with the timestamps in a network. It also has a function to send an e-mail notifying the administrator, when a couple is added or changes. It is very useful in detecting ARP impersonation in a network.
|
||||
|
||||
We can obtain more information about this tool and download the necessary packages from the
|
||||
|
||||
[following link.][20]
|
||||
|
||||
### Wireshark - Network Monitoring tool
|
||||
|
||||
[][21] **[Wireshark][1]**
|
||||
|
||||
is a free application that enables you to catch and view the information going forward and backward on your system, giving the capacity to bore down and read the substance of every parcel – separated to meet your particular needs. It is generally used to investigate arrange issues and additionally to create and test programming. This open-source convention analyzer is generally acknowledged as the business standard, prevailing upon what's coming to it's of honors the years.
|
||||
|
||||
Initially known as Ethereal, Wireshark highlights an easy to understand interface that can show information from many diverse conventions on all real system sorts.
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this article, we have taken a gander at a few open source network monitoring tools. Because we concentrated on these instruments as the "best" does not really mean they are the best for your need. For instance, there are numerous other open source monitoring apparatuses that exist, for example, OpenNMS, Cacti, and Zennos and you need to consider the advantages of everyone from the point of view of your prerequisite.
|
||||
|
||||
Additionally, there are different apparatuses that might be more good for your need that is not open source.
|
||||
|
||||
|
||||
|
||||
What more network monitors do you use or know to use in Linux in terminal format?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-network-monitoring-tools-for-linux
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:https://www.wireshark.org/
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/iftop_orig.png
|
||||
[3]:http://www.ex-parrot.com/pdw/iftop/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/vnstat.png
|
||||
[5]:http://humdi.net/vnstat/
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/iptraf_orig.gif
|
||||
[7]:http://iptraf.seul.org/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/monitorix_orig.png
|
||||
[9]:http://www.monitorix.org
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/dstat_orig.png
|
||||
[11]:http://dag.wiee.rs/home-made/dstat/
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/bwm-ng_orig.png
|
||||
[13]:http://sourceforge.net/projects/bwmng/
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ibmonitor_orig.jpg
|
||||
[15]:http://ibmonitor.sourceforge.net/
|
||||
[16]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/htop_orig.png
|
||||
[17]:http://wesharethis.com/knowledgebase/htop-and-atop/
|
||||
[18]:http://hisham.hm/htop/
|
||||
[19]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/arpwatch_orig.png
|
||||
[20]:http://linux.softpedia.com/get/System/Monitoring/arpwatch-NG-7612.shtml
|
||||
[21]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/how-to-use-wireshark_1_orig.jpg
|
||||
@ -0,0 +1,308 @@
|
||||
yixunx translating
|
||||
|
||||
30 Best Linux Games On Steam You Should Play in 2017
|
||||
============================================================
|
||||
|
||||
When it comes to Gaming, a system running on Windows platform is what anyone would recommend. It still is a superior choice for gamers with better graphics driver support and perfect hardware compatibility. But, what about the thought of [gaming on a Linux system][9]? Well, yes, of course – it is possible – maybe you thought of it at some point in time but the collection of Linux games on [Steam for Linux][10] platform wasn’t appealing at all few years back.
|
||||
|
||||
However, that’s not true at all for the current scene. The Steam store now has a lot of great games listed for Linux platform (including a lot of major titles). So, in this article, we’ll be taking a look at the best Linux games on Steam.
|
||||
|
||||
But before we do that, let me tell you a money saving trick. If you are an avid gamer who spends plenty of time and money on gaming, you should subscribe to Humble Monthly. This monthly subscription program from [Humble Bundle][11] gives you $100 in games for just $12 each month.
|
||||
|
||||
Not all games might be available on Linux though but it is still a good deal because you get additional 10% discount on any games or books you buy from [Humble Bundle website][12].
|
||||
|
||||
The best thing here is that every purchase you make supports a charity organization. So, you are not just gaming, you are also making a difference to the world.
|
||||
|
||||
### Best Linux games on Steam
|
||||
|
||||
The list of best Linux games on steam is in no particular ranking order.
|
||||
|
||||
Additional Note: While there’s a lot of games available on Steam for Linux, there are still a lot of problems you would face as a Linux gamer. You can refer to one of our articles to know about the [annoying experiences every Linux gamer encounters][14].
|
||||
|
||||
Jump Directly to your preferred genre of Games:
|
||||
|
||||
* [Action Games][3]
|
||||
|
||||
* [RPG Games][4]
|
||||
|
||||
* [Racing/Sports/Simulation Games][5]
|
||||
|
||||
* [Adventure Games][6]
|
||||
|
||||
* [Indie Games][7]
|
||||
|
||||
* [Strategy Games][8]
|
||||
|
||||
### Best Action Games for Linux On Steam
|
||||
|
||||
### 1\. Counter-Strike: Global Offensive (Multiplayer)
|
||||
|
||||
CS GO is definitely one of the best FPS games for Linux on Steam. I don’t think this game needs an introduction but in case you are unaware of it – I must mention that it is one of the most enjoyable FPS multiplayer game you would ever play. You’ll observe CS GO is one of the games contributing a major part to the e-sports scene. To up your rank – you need to play competitive matches. In either case, you can continue playing casual matches.
|
||||
|
||||
I could have listed Rainbow Six siege instead of Counter-Strike, but we still don’t have it for Linux/Steam OS.
|
||||
|
||||
[CS: GO (Purchase)][15]
|
||||
|
||||
### 2\. Left 4 Dead 2 (Multiplayer/Singleplayer)
|
||||
|
||||
One of the most loved first-person zombie shooter multiplayer game. You may get it for as low as 1.3 USD on a Steam sale. It is an interesting game which gives you the chills and thrills you’d expect from a zombie game. The game features swamps, cities, cemetries, and a lot more environments to keep things interesting and horrific. The guns aren’t super techy but definitely provides a realistic experience considering it’s an old game.
|
||||
|
||||
[Left 4 Dead 2 (Purchase)][16]
|
||||
|
||||
### 3\. Borderlands 2 (Singleplayer/Co-op)
|
||||
|
||||
Borderlands 2 is an interesting take on FPS games for PC. It isn’t anything like you experienced before. The graphics look sketchy and cartoony but that does not let you miss the real action you always look for in a first-person shooter game. You can trust me on that!
|
||||
|
||||
If you are looking for one of the best Linux games with tons of DLC – Borderlands 2 will definitely suffice.
|
||||
|
||||
[Borderlands 2 (Purchase)][17]
|
||||
|
||||
### 4\. Insurgency (Multiplayer)
|
||||
|
||||
Insurgency is yet another impressive FPS game available on Steam for Linux machines. It takes a different approach by eliminating the HUD or the ammo counter. As most of the reviewers mentioned – pure shooting game focusing on the weapon and the tactics of your team. It may not be the best FPS game – but it surely is one of them if you like – Delta Force kinda shooters along with your squad.
|
||||
|
||||
[Insurgency (Purchase)][18]
|
||||
|
||||
### 5\. Bioshock: Infinite (Singleplayer)
|
||||
|
||||
Bioshock Infinite would definitely remain as one of the best singleplayer FPS games ever developed for PC. You get unrealistic powers to kill your enemies. And, so do your enemies have a lot of tricks up in the sleeves. It is a story-rich FPS game which you should not miss playing on your Linux system!
|
||||
|
||||
[BioShock: Infinite (Purchase)][19]
|
||||
|
||||
### 6\. HITMAN – Game of the Year Edition (Singleplayer)
|
||||
|
||||
The Hitman series is obviously one of the most loved game series for a PC gamer. The recent iteration of HITMAN series saw an episodic release which wasn’t appreciated much but now with Square Enix gone, the GOTY edition announced with a few more additions is back to the spotlight. Make sure to get creative with your assassinations in the game Agent 47!
|
||||
|
||||
[HITMAN (GOTY)][20]
|
||||
|
||||
### 7\. Portal 2
|
||||
|
||||
Portal 2 is the perfect blend of action and adventure. It is a puzzle game which lets you join co-op sessions and create interesting puzzles. The co-op mode features a completely different campaign when compared to the single player mode.
|
||||
|
||||
[Portal 2 (Purchase)][21]
|
||||
|
||||
### 8\. Deux Ex: Mankind Divided
|
||||
|
||||
If you are on the lookout for a shooter game focused on stealth skills – Deux Ex would be the perfect addition to your Steam library. It is indeed a very beautiful game with some state-of-the-art weapons and crazy fighting mechanics.
|
||||
|
||||
[Deus Ex: Mankind Divided (Purchase)][22]
|
||||
|
||||
### 9\. Metro 2033 Redux / Metro Last Light Redux
|
||||
|
||||
Both Metro 2033 Redux and the Last Light are the definitive editions of the classic hit Metro 2033 and Last Light. The game has a post-apocalyptic setting. You need to eliminate all the mutants in order to ensure the survival of mankind. You should explore the rest when you get to play it!
|
||||
|
||||
[Metro 2033 Redux (Purchase)][23]
|
||||
|
||||
[Metro Last Light Redux (Purchase)][24]
|
||||
|
||||
### 10\. Tannenberg (Multiplayer)
|
||||
|
||||
Tannenberg is a brand new game – announced a month before this article was published. The game is based on the Eastern Front (1914-1918) as a part of World War I. It is a multiplayer-only game. So, if you want to experience WWI gameplay experience, look no further!
|
||||
|
||||
[Tannenberg (Purchase)][25]
|
||||
|
||||
### Best RPG Games for Linux on Steam
|
||||
|
||||
### 11\. Shadow of Mordor
|
||||
|
||||
Shadow of Mordor is one of the most exciting open world RPG game you will find listed on Steam for Linux systems. You have to fight as a ranger (Talion) with the bright master (Celebrimbor) to defeat Sauron’s army (and then approach killing him). The fighting mechanics are very impressive. It is a must try game!
|
||||
|
||||
[SOM (Purchase)][26]
|
||||
|
||||
### 12\. Divinity: Original Sin – Enhanced Edition
|
||||
|
||||
Divinity: Original is a kick-ass Indie-RPG game that’s unique in itself and very much enjoyable. It is probably one of the highest rated RPG games with a mixture of Adventure & Strategy. The enhanced edition includes new game modes and a complete revamp of voice-overs, controller support, co-op sessions, and so much more.
|
||||
|
||||
[Divinity: Original Sin (Purchase)][27]
|
||||
|
||||
### 13\. Wasteland 2: Director’s Cut
|
||||
|
||||
Wasteland 2 is an amazing CRPG game. If Fallout 4 was to be ported down as a CRPG as well – this is what we would have expected it to be. The director’s cut edition includes a complete visual overhaul with hundred new characters.
|
||||
|
||||
[Wasteland 2 (Purchase)][28]
|
||||
|
||||
### 14\. Darkwood
|
||||
|
||||
A horror-filled top-down view RPG game. You get to explore the world, scavenging materials, and craft weapons to survive.
|
||||
|
||||
[Darkwood (Purchase)][29]
|
||||
|
||||
### Best Racing/Sports/Simulation Games
|
||||
|
||||
### 15\. Rocket League
|
||||
|
||||
Rocket League is an action-packed soccer game conceptualized by rocket-powered battle cars. Not just driving the car and heading to the goal – you can even make your opponents go – kaboom!
|
||||
|
||||
A fantastic sports-action game every gamer must have installed!
|
||||
|
||||
[Rocket League (Purchase)][30]
|
||||
|
||||
### 16\. Road Redemption
|
||||
|
||||
Missing Road Rash? Well, Road Redemption will quench your thirst as a spiritual successor to Road Rash. Ofcourse, it is not officially “Road Rash II” – but it is equally enjoyable. If you loved Road Rash, you’ll like it too.
|
||||
|
||||
[Road Redemption (Purchase)][31]
|
||||
|
||||
### 17\. Dirt Rally
|
||||
|
||||
Dirt Rally is for the gamers who want to experience off-road and on-road racing game. The visuals are breathtaking and the game is enjoyable with near to perfect driving mechanics.
|
||||
|
||||
[Dirt Rally (Purchase)][32]
|
||||
|
||||
### 18\. F1 2017
|
||||
|
||||
F1 2017 is yet another impressive car racing game from the developers of Dirt Rally (Codemasters & Feral Interactive). It features all of the iconic F1 racing cars that you need to experience.
|
||||
|
||||
[F1 2017 (Purchase)][33]
|
||||
|
||||
### 19. GRID Autosport
|
||||
|
||||
GRID is one of the most underrated car racing games available out there. GRID Autosport is the sequel to GRID 2\. The gameplay seems stunning to me. With even better cars than GRID 2, the GRID Autosport is a recommended racing game for every PC gamer out there. The game also supports a multiplayer mode where you can play with your friends – representing as a team.
|
||||
|
||||
[GRID Autosport (Purchase)][34]
|
||||
|
||||
### Best Adventure Games
|
||||
|
||||
### 20\. ARK: Survival Evolved
|
||||
|
||||
ARK Survival Evolved is a quite decent survival game with exciting adventures following in the due course. You find yourself in the middle of nowhere (ARK Island) and have got no choice except training the dinosaurs, teaming up with other players, hunt someone to get the required resources, and craft items to maximize your chances to survive and escape the Island.
|
||||
|
||||
[ARK: Survival Evolved (Purchase)][35]
|
||||
|
||||
### 21\. This War of Mine
|
||||
|
||||
A unique game where you aren’t a soldier but a civilian facing the hardships of wartime. You’ve to make your way through highly-skilled enemies and help out other survivors as well.
|
||||
|
||||
[This War of Mine (Purchase)][36]
|
||||
|
||||
### 22\. Mad Max
|
||||
|
||||
Mad Max is all about survival and brutality. It includes powerful cars, an open-world setting, weapons, and hand-to-hand combat. You need to keep exploring the place and also focus on upgrading your vehicle to prepare for the worst. You need to think carefully and have a strategy before you make a decision.
|
||||
|
||||
[Mad Max (Purchase)][37]
|
||||
|
||||
### Best Indie Games
|
||||
|
||||
### 23\. Terraria
|
||||
|
||||
It is a 2D game which has received overwhelmingly positive reviews on Steam. Dig, fight, explore, and build to keep your journey going. The environments are automatically generated. So, it isn’t anything static. You might encounter something first and your friend might encounter the same after a while. You’ll also get to experience creative 2D action-packed sequences.
|
||||
|
||||
[Terraria (Purchase)][38]
|
||||
|
||||
### 24\. Kingdoms and Castles
|
||||
|
||||
With Kingdoms and Castles, you get to build your own kingdom. You have to manage your kingdom by collecting tax (as funds necessary) from the people, take care of the forests, handle the city
|
||||
|
||||
design, and also make sure no one raids your kingdom by implementing proper defences.
|
||||
|
||||
It is a fairly new game but quite trending among the Indie genre of games.
|
||||
|
||||
[Kingdoms and Castles][39]
|
||||
|
||||
### Best Strategy Games on Steam For Linux Machines
|
||||
|
||||
### 25\. Sid Meier’s Civilization V
|
||||
|
||||
Sid Meier’s Civilization V is one of the best-rated strategy game available for PC. You could opt for Civilization VI – if you want. But, the gamers still root for Sid Meier’s Civilization V because of its originality and creative implementation.
|
||||
|
||||
[Civilization V (Purchase)][40]
|
||||
|
||||
### 26\. Total War: Warhammer
|
||||
|
||||
Total War: Warhammer is an incredible turn-based strategy game available for PC. Sadly, the Warhammer II isn’t available for Linux as of yet. But 2016’s Warhammer is still a great choice if you like real-time battles that involve building/destroying empires with flying creatures and magical powers.
|
||||
|
||||
[Warhammer I (Purchase)][41]
|
||||
|
||||
### 27\. Bomber Crew
|
||||
|
||||
Wanted a strategy simulation game that’s equally fun to play? Bomber Crew is the answer to it. You need to choose the right crew and maintain it in order to win it all.
|
||||
|
||||
[Bomber Crew (Purchase)][42]
|
||||
|
||||
### 28\. Age of Wonders III
|
||||
|
||||
A very popular strategy title with a mixture of empire building, role playing, and warfare. A polished turn-based strategy game you must try!
|
||||
|
||||
[Age of Wonders III (Purchase)][43]
|
||||
|
||||
### 29\. Cities: Skylines
|
||||
|
||||
A pretty straightforward strategy game to build a city from scratch and manage everything in it. You’ll experience the thrills and hardships of building and maintaining a city. I wouldn’t expect every gamer to like this game – it has a very specific userbase.
|
||||
|
||||
[Cities: Skylines (Purchase)][44]
|
||||
|
||||
### 30\. XCOM 2
|
||||
|
||||
XCOM 2 is one of the best turn-based strategy game available for PC. I wonder how crazy it could have been to have XCOM 2 as a first person shooter game. However, it’s still a masterpiece with an overwhelming response from almost everyone who bought the game. If you have the budget to spend more on this game, do get the – “War of the Chosen” – DLC.
|
||||
|
||||
[XCOM 2 (Purchase)][45]
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Among all the games available for Linux, we did include most of the major titles and some the latest games with an overwhelming response from the gamers.
|
||||
|
||||
Do you think we missed any of your favorite Linux game available on Steam? Also, what are the games that you would like to see on Steam for Linux platform?
|
||||
|
||||
Let us know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-linux-games-steam/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://itsfoss.com/author/ankush/
|
||||
[2]:https://itsfoss.com/best-linux-games-steam/#comments
|
||||
[3]:https://itsfoss.com/best-linux-games-steam/#action
|
||||
[4]:https://itsfoss.com/best-linux-games-steam/#rpg
|
||||
[5]:https://itsfoss.com/best-linux-games-steam/#racing
|
||||
[6]:https://itsfoss.com/best-linux-games-steam/#adv
|
||||
[7]:https://itsfoss.com/best-linux-games-steam/#indie
|
||||
[8]:https://itsfoss.com/best-linux-games-steam/#strategy
|
||||
[9]:https://itsfoss.com/linux-gaming-guide/
|
||||
[10]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[11]:https://www.humblebundle.com/?partner=itsfoss
|
||||
[12]:https://www.humblebundle.com/store?partner=itsfoss
|
||||
[13]:https://www.humblebundle.com/monthly?partner=itsfoss
|
||||
[14]:https://itsfoss.com/linux-gaming-problems/
|
||||
[15]:http://store.steampowered.com/app/730/CounterStrike_Global_Offensive/
|
||||
[16]:http://store.steampowered.com/app/550/Left_4_Dead_2/
|
||||
[17]:http://store.steampowered.com/app/49520/?snr=1_5_9__205
|
||||
[18]:http://store.steampowered.com/app/222880/?snr=1_5_9__205
|
||||
[19]:http://store.steampowered.com/agecheck/app/8870/
|
||||
[20]:http://store.steampowered.com/app/236870/?snr=1_5_9__205
|
||||
[21]:http://store.steampowered.com/app/620/?snr=1_5_9__205
|
||||
[22]:http://store.steampowered.com/app/337000/?snr=1_5_9__205
|
||||
[23]:http://store.steampowered.com/app/286690/?snr=1_5_9__205
|
||||
[24]:http://store.steampowered.com/app/287390/?snr=1_5_9__205
|
||||
[25]:http://store.steampowered.com/app/633460/?snr=1_5_9__205
|
||||
[26]:http://store.steampowered.com/app/241930/?snr=1_5_9__205
|
||||
[27]:http://store.steampowered.com/app/373420/?snr=1_5_9__205
|
||||
[28]:http://store.steampowered.com/app/240760/?snr=1_5_9__205
|
||||
[29]:http://store.steampowered.com/app/274520/?snr=1_5_9__205
|
||||
[30]:http://store.steampowered.com/app/252950/?snr=1_5_9__205
|
||||
[31]:http://store.steampowered.com/app/300380/?snr=1_5_9__205
|
||||
[32]:http://store.steampowered.com/app/310560/?snr=1_5_9__205
|
||||
[33]:http://store.steampowered.com/app/515220/?snr=1_5_9__205
|
||||
[34]:http://store.steampowered.com/app/255220/?snr=1_5_9__205
|
||||
[35]:http://store.steampowered.com/app/346110/?snr=1_5_9__205
|
||||
[36]:http://store.steampowered.com/app/282070/?snr=1_5_9__205
|
||||
[37]:http://store.steampowered.com/app/234140/?snr=1_5_9__205
|
||||
[38]:http://store.steampowered.com/app/105600/?snr=1_5_9__205
|
||||
[39]:http://store.steampowered.com/app/569480/?snr=1_5_9__205
|
||||
[40]:http://store.steampowered.com/app/8930/?snr=1_5_9__205
|
||||
[41]:http://store.steampowered.com/app/364360/?snr=1_5_9__205
|
||||
[42]:http://store.steampowered.com/app/537800/?snr=1_5_9__205
|
||||
[43]:http://store.steampowered.com/app/226840/?snr=1_5_9__205
|
||||
[44]:http://store.steampowered.com/app/255710/?snr=1_5_9__205
|
||||
[45]:http://store.steampowered.com/app/268500/?snr=1_5_9__205
|
||||
[46]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fbest-linux-games-steam%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[47]:https://twitter.com/share?original_referer=/&text=30+Best+Linux+Games+On+Steam+You+Should+Play+in+2017&url=https://itsfoss.com/best-linux-games-steam/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=ankushdas9
|
||||
[48]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fbest-linux-games-steam%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[49]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fbest-linux-games-steam%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[50]:https://www.reddit.com/submit?url=https://itsfoss.com/best-linux-games-steam/&title=30+Best+Linux+Games+On+Steam+You+Should+Play+in+2017
|
||||
@ -0,0 +1,99 @@
|
||||
我号召黑客新闻的理由之一
|
||||
实现高速缓存会花费 30 个小时,你有额外的 30 个小时吗?
|
||||
不,你没有。
|
||||
我实际上并不知道它会花多少时间,可能它会花五分钟,你有五分钟吗?不,你还是没有。为什么?因为我在撒谎。它会消耗远超五分钟的时间,这是程序员永远的
|
||||
乐观主义。
|
||||
- Owen Astrachan 教授于 2004 年 2 月 23 日在 CPS 108 上的讲座
|
||||
|
||||
指责开源软件的使用存在着高昂的代价已经不是一个新论点了,它之前就被提过,而且说的比我更有信服力,即使一些人已经在高度赞扬开源软件的运作。
|
||||
这种事为什么会重复发生?
|
||||
|
||||
在周一的黑客新闻上,我愉悦地看着某些人一边说写 Stack Overflow 简单的简直搞笑,一边通过允许七月第四个周末之后的克隆来开始备份他们的提问。
|
||||
其他的声明中也指出现存的克隆是一个好的出发点。
|
||||
|
||||
让我们假设,为了争辩,你觉得将自己的 Stack Overflow 通过 ASP.NET 和 MVC 克隆是正确的,然后被一块廉价的手表和一个小型俱乐部头领忽悠之后,
|
||||
决定去手动拷贝你 Stack Overflow 的源代码,一页又一页,所以你可以逐字逐句地重新输入,我们同样会假定你像我一样打字,很酷的有 100 WPM
|
||||
(差不多每秒8个字符),不和我一样的话,你不会犯错。
|
||||
|
||||
Stack Overflow 的 *.cs、*.sql、*.css、*.js 和 *.aspx 文件大约 2.3 MB,因此如果你想将这些源代码输进电脑里去的话,即使你不犯错也需要大约 80 个小时。
|
||||
|
||||
除非......当然,你是不会那样做的:你打算从头开始实现 Stack Overflow 。所以即使我们假设,你花了十倍的时间去设计、输出,然后调试你自己的实现而不是去拷
|
||||
贝已有的那份,那已经让你已经编译了好几个星期。我不知道你,但是我可以承认我写的新代码大大小于我复制的现有代码的十分之一。
|
||||
|
||||
好,ok,我听见你松了口气。所以不是全部。但是我可以做大部分。
|
||||
|
||||
行,所以什么是大部分?这只是询问和回答问题,这个部分很简单。那么,除了你必须实现对问题和答案投票、赞同还是反对,而且提问者应该能够去接收每一个问题的
|
||||
单一答案。你不能让人们赞同或者反对他们自己的回答。所以你需要去阻止。你需要去确保用户在一定的时间内不会赞同或反对其他用户太多次。以预防垃圾邮件,
|
||||
你可能也需要去实现一个垃圾邮件过滤器,即使在一个基本的设计里,也要考虑到这一点。而且还需要去支持用户图标。并且你将不得不寻找一个自己真正信任的并且
|
||||
与 markdown 接合很好的 HTML 库(当然,你确实希望重新使用那个令人敬畏的编辑器 Stack Overflow ),你还需要为所有控件购买,设计或查找小部件,此外
|
||||
你至少需要一个基本的管理界面,以便用户可以调节,并且你需要实现可扩展的业务量,以便能稳定地给用户越来越多的功能去实现他们想做的。
|
||||
|
||||
如果你这样做了,你可以完成它。
|
||||
|
||||
除了...除了全文检索外,特别是它在“寻找问题”功能中的表现,这是必不可少的。然后用户的基本信息,和回答的意见,然后有一个主要展示你的重要问题,
|
||||
但是它会稳定的冒泡式下降。另外你需要去实现奖励,并支持每个用户的多个 OpenID 登录,然后为相关的事件发送邮件通知,并添加一个标签系统,
|
||||
接着允许管理员通过一个不错的图形界面配置徽章。你需要去显示用户的 karma 历史,点赞和差评。整个事情的规模都非常好,因为它随时都可以被
|
||||
slashdotted、reddited 或是 Stack Overflow 。
|
||||
|
||||
在这之后!你就已经完成了!
|
||||
|
||||
...在正确地实现升级、国际化、业绩上限和一个 css 设计之后,使你的站点看起来不像是一个屁股,上面的大部分 AJAX 版本和 G-d 知道什么会同样潜伏
|
||||
在你所信任的界面下,但是当你开始做一个真正的克隆的时候,就会遇到它。
|
||||
|
||||
告诉我:这些功能中哪个是你感觉可以削减而让它仍然是一个引人注目的产品,哪些是大部分网站之下的呢?哪个你可以剔除呢?
|
||||
|
||||
开发者因为开源软件的使用是一个可怕的痛苦这样一个相同的理由认为克隆一个像 Stack Overflow 的站点很简单。当你把一个开发者放在 Stack Overflow 前面,
|
||||
他们并不真的看到 Stack Overflow,他们实际上看的是这些:
|
||||
|
||||
create table QUESTION (ID identity primary key,
|
||||
TITLE varchar(255), --- 为什么我知道你认为是 255
|
||||
BODY text,
|
||||
UPVOTES integer not null default 0,
|
||||
DOWNVOTES integer not null default 0,
|
||||
USER integer references USER(ID));
|
||||
create table RESPONSE (ID identity primary key,
|
||||
BODY text,
|
||||
UPVOTES integer not null default 0,
|
||||
DOWNVOTES integer not null default 0,
|
||||
QUESTION integer references QUESTION(ID))
|
||||
|
||||
如果你告诉一个开发者去复制 Stack Overflow ,进入他脑海中的就是上面的两个 SQL 表和足够的 HTML 文件来显示它们,而不用格式化,这在一个周末里是完全
|
||||
可以实现的,聪明的人会意识到他们需要实现登陆、注销和评论,点赞需要绑定到用户。但是这在一个周末内仍然是完全可行的。这仅仅是在 SQL 后端里加上两张
|
||||
左右的表,而 HTML 则用来展示内容,使用像 Django 这样的框架,你甚至可以免费获得基本的用户和评论。
|
||||
|
||||
但是那不是和 Stack Overflow 相关的,无论你对 Stack Overflow 的感受如何,大多数访问者似乎都认为用户体验从头到尾都很流畅,他们感觉他们和一个
|
||||
好产品相互影响。即使我没有更好的了解,我也会猜测 Stack Overflow 在数据库模式方面取得了持续的成功-并且有机会去阅读 Stack Overflow 的源代码,
|
||||
我知道它实际上有多么的小,这些是一个极大的 spit 和 Polish 的集合,成为了一个具有高可用性的主要网站,一个开发者,问一个东西被克隆有多难,
|
||||
仅仅不认为和 Polish 相关,因为 Polish 是实现结果附带的。
|
||||
|
||||
这就是为什么 Stack Overflow 的开放源代码克隆会失败,即使一些人在设法实现大部分 Stack Overflow 的“规范”,也会有一些关键区域会将他们绊倒,
|
||||
举个例子,如果你把目标市场定在了终端用户上,你要么需要一个图形界面去配置规则,要么聪明的开发者会决定哪些徽章具有足够的通用性,去继续所有的
|
||||
安装,实际情况是,开发者发牢骚和抱怨你不能实现一个真实的综合性的像 badges 的图形用户界面,然后 bikeshed 任何的建议,为因为标准的 badges
|
||||
在范围内太远,他们会迅速避开选择其他方向,他们最后会带着相同的有 bug 追踪器的解决方案赶上,就像他们工作流程的概要使用一样:
|
||||
开发者通过任意一种方式实现一个通用的机制,任何一个人完全都能轻松地使用 Python、PHP 或任意一门语言中的系统 API 来工作,能简单为他们自己增加
|
||||
自定义设置,PHP 和 Python 是学起来很简单的,并且比起曾经的图形界面更加的灵活,为什么还要操心其他事呢?
|
||||
|
||||
同样的,节制和管理界面可以被削减。如果你是一个管理员,你可以进入 SQL 服务器,所以你可以做任何真正的管理-就像这样,管理员可以通过任何的 Django
|
||||
管理和类似的系统给你提供支持,因为,毕竟只有少数用户是 mods,mods 应该理解网站是怎么运作、停止的。当然,没有 Stack Overflow 的接口失败会被纠正
|
||||
,即使 Stack Overflow 的愚蠢的要求,你必须知道如何去使用 openID (它是最糟糕的缺点)最后得到修复。我确信任何的开源的克隆都会狂热地跟随它-
|
||||
即使 GNOME 和 KDE 多年来亦步亦趋地复制 windows ,而不是尝试去修复它自己最明显的缺陷。
|
||||
|
||||
开发者可能不会关心应用的这些部分,但是最终用户会,当他们尝试去决定使用哪个应用时会去考虑这些。就好像一家好的软件公司希望通过确保其产品在出货之前
|
||||
是一流的来降低其支持成本一样,所以,同样的,懂行的消费者想在他们购买这些产品之前确保产品好用,以便他们不需要去寻求帮助,开源产品就失败在这种地方
|
||||
,一般来说,专有解决方案会做得更好。
|
||||
|
||||
这不是说开源软件没有他们自己的立足之地,这个博客运行在 Apache,Django,PostgreSQL 和 Linux 上。但是让我告诉你,配置这些堆栈不是为了让人心灰意懒
|
||||
,PostgreSQL 需要在老版本上移除设置。然后,在 Ubuntu 和 FreeBSD 最新的版本上,仍然要求用户搭建第一个数据库集群,MS SQL不需要这些东西,Apache...
|
||||
天啊,甚至没有让我开始尝试去向一个初学者用户解释如何去得到虚拟机,MovableType,一对 Django 应用程序,而且所有的 WordPress 都可以在一个单一的安装下
|
||||
顺利运行,像在地狱一样,只是试图解释 Apache 的分叉线程变换给技术上精明的非开发人员就是一个噩梦,IIS 7 和操作系统的 Apache 服务器是非常闭源的,
|
||||
图形界面管理程序配置这些这些相同的堆栈非常的简单,Django 是一个伟大的产品,但是它只是基础架构而已,我认为开源软件做的很好,恰恰是因为推动开发者去
|
||||
贡献的动机
|
||||
|
||||
下次你看见一个你喜欢的应用,认为所有面向用户的细节非常长和辛苦,就会去让它用起来更令人开心,在谴责你如何能普通的实现整个的可恶的事在一个周末,
|
||||
十分之九之后,当你认为一个应用的实现简单地简直可笑,你就完全的错失了故事另一边的用户
|
||||
|
||||
via: https://bitquabit.com/post/one-which-i-call-out-hacker-news/
|
||||
|
||||
作者:Benjamin Pollack 译者:hopefully2333 校对:校对者ID
|
||||
|
||||
本文由 LCTT 原创编译,Linux中国 荣誉推出
|
||||
@ -0,0 +1,167 @@
|
||||
Linux 用户的逻辑卷管理指南
|
||||
============================================================
|
||||
|
||||
")
|
||||
Image by : opensource.com
|
||||
|
||||
管理磁盘空间对系统管理员来说是一件重要的日常工作。因为磁盘空间耗尽而去启动一系列的耗时而又复杂的任务,来提升磁盘分区中可用的磁盘空间。它会要求系统离线。通常会涉及到安装一个新的硬盘、引导至恢复模式或者单用户模式、在新硬盘上创建一个分区和一个文件系统、挂载到临时挂载点去从一个太小的文件系统中移动数据到较大的新位置、修改 /etc/fstab 文件内容去反映出新分区的正确设备名、以及重新引导去重新挂载新的文件系统到正确的挂载点。
|
||||
|
||||
我想告诉你的是,当 LVM (逻辑卷管理)首次出现在 Fedora Linux 中时,我是非常抗拒它的。我最初的反应是,我并不需要在我和我的设备之间有这种额外的抽象层。结果是我错了,逻辑卷管理是非常有用的。
|
||||
|
||||
LVM 让磁盘空间管理非常灵活。它提供的功能诸如在文件系统已挂载和活动时,很可靠地增加磁盘空间到一个逻辑卷和它的文件系统中,并且,它允许你将多个物理磁盘和分区融合进一个可以分割成逻辑卷的单个卷组中。
|
||||
|
||||
卷管理也允许你去减少分配给一个逻辑卷的磁盘空间数量,但是,这里有两个要求,第一,卷必须是未挂载的。第二,在卷空间调整之前,文件系统本身的空间大小必须被减少。
|
||||
|
||||
有一个重要的提示是,文件系统本身必须允许重新调整大小的操作。当重新提升文件系统大小的时候,EXT2、3、和 4 文件系统都允许离线(未挂载状态)或者在线(挂载状态)重新调整大小。你应该去认真了解你打算去调整的文件系统的详细情况,去验证它们是否可以完全调整大小,尤其是否可以在线调整大小。
|
||||
|
||||
### 在使用中扩展一个文件系统
|
||||
|
||||
在我安装一个新的发行版到我的生产用机器中之前,我总是喜欢在一个 VirtualBox 虚拟机中运行这个新的发行版一段时间,以确保它没有任何的致命的问题存在。在几年前的一个早晨,我在我的主要使用的工作站上的虚拟机中安装一个新发行的 Fedora 版本。我认为我有足够的磁盘空间分配给安装虚拟机的主文件系统。但是,我错了,大约在第三个安装时,我耗尽了我的文件系统的空间。幸运的是,VirtualBox 检测到了磁盘空间不足的状态,并且暂停了虚拟机,然后显示了一个明确指出问题所在的错误信息。
|
||||
|
||||
请注意,这个问题并不是虚拟机磁盘太小造成的,而是由于宿主机上空间不足,导致虚拟机上的虚拟磁盘在宿主机上的逻辑卷中没有足够的空间去扩展。
|
||||
|
||||
因为许多现在的发行版都缺省使用了逻辑卷管理,并且在我的卷组中有一些可用的空余空间,我可以分配额外的磁盘空间到适当的逻辑卷,然后在使用中扩展宿主机的文件系统。这意味着我不需要去重新格式化整个硬盘,以及重新安装操作系统或者甚至是重启机器。我不过是分配了一些可用空间到适当的逻辑卷中,并且重新调整了文件系统的大小 — 所有的这些操作都在文件系统在线并且运行着程序的状态下进行的,虚拟机也一直使用着宿主机文件系统。在调整完逻辑卷和文件系统的大小之后,我恢复了虚拟机的运行,并且继续进行安装过程,就像什么问题都没有发生过一样。
|
||||
|
||||
虽然这种问题你可能从来也没有遇到过,但是,许多人都遇到过重要程序在运行过程中发生磁盘空间不足的问题。而且,虽然许多程序,尤其是 Windows 程序,并不像 VirtualBox 一样写的很好,且富有弹性,Linux 逻辑卷管理可以使它在不丢失数据的情况下去恢复,也不需要去进行耗时的安装过程。
|
||||
|
||||
### LVM 结构
|
||||
|
||||
逻辑卷管理的磁盘环境结构如下面的图 1 所示。逻辑卷管理允许多个单独的硬盘和/或磁盘分区组合成一个单个的卷组(VG)。卷组然后可以再划分为逻辑卷(LV)或者被用于分配成一个大的单一的卷。普通的文件系统,如EXT3 或者 EXT4,可以创建在一个逻辑卷上。
|
||||
|
||||
在图 1 中,两个完整的物理硬盘和一个第三块硬盘的一个分区组合成一个单个的卷组。在这个卷组中创建了两个逻辑卷,和一个文件系统,比如,可以在每个逻辑卷上创建一个 EXT3 或者 EXT4 的文件系统。
|
||||
|
||||

|
||||
|
||||
_图 1: LVM 允许组合分区和整个硬盘到卷组中_
|
||||
|
||||
在一个主机上增加磁盘空间是非常简单的,在我的经历中,这种事情是很少的。下面列出了基本的步骤。你也可以创建一个完整的新卷组或者增加新的空间到一个已存在的逻辑卷中,或者创建一个新的逻辑卷。
|
||||
|
||||
### 增加一个新的逻辑卷
|
||||
|
||||
有时候需要在主机上增加一个新的逻辑卷。例如,在被提示包含我的 VirtualBox 虚拟机的虚拟磁盘的 /home 文件系统被填满时,我决定去创建一个新的逻辑卷,用于去存储虚拟机数据,包含虚拟磁盘。这将在我的 /home 文件系统中释放大量的空间,并且也允许我去独立地管理虚拟机的磁盘空间。
|
||||
|
||||
增加一个新的逻辑卷的基本步骤如下:
|
||||
|
||||
1. 如有需要,安装一个新硬盘。
|
||||
|
||||
2. 可选 1: 在硬盘上创建一个分区
|
||||
|
||||
3. 在硬盘上创建一个完整的物理卷(PV)或者一个分区。
|
||||
|
||||
4. 分配新的物理卷到一个已存在的卷组(VG)中,或者创建一个新的卷组。
|
||||
|
||||
5. 从卷空间中创建一个新的逻辑卷(LV)。
|
||||
|
||||
6. 在新的逻辑卷中创建一个文件系统。
|
||||
|
||||
7. 在 /etc/fstab 中增加适当的条目以挂载文件系统。
|
||||
|
||||
8. 挂载文件系统。
|
||||
|
||||
为了更详细的介绍,接下来将使用一个示例作为一个实验去教授关于 Linux 文件系统的知识。
|
||||
|
||||
### 示例
|
||||
|
||||
这个示例展示了怎么用命令行去扩展一个已存在的卷组,并给它增加更多的空间,在那个空间上创建一个新的逻辑卷,然后在逻辑卷上创建一个文件系统。这个过程一直在运行和挂载的文件系统上执行。
|
||||
|
||||
警告:仅 EXT3 和 EXT4 文件系统可以在运行和挂载状态下调整大小。许多其它的文件系统,包括 BTRFS 和 ZFS 是不能这样做的。
|
||||
|
||||
### 安装硬盘
|
||||
|
||||
如果在系统中现有硬盘上的卷组中没有足够的空间去增加,那么可能需要去增加一块新的硬盘,然后去创建空间增加到逻辑卷中。首先,安装物理硬盘,然后,接着执行后面的步骤。
|
||||
|
||||
### 从硬盘上创建物理卷
|
||||
|
||||
首先需要去创建一个新的物理卷(PV)。使用下面的命令,它假设新硬盘已经分配为 /dev/hdd。
|
||||
|
||||
```
|
||||
pvcreate /dev/hdd
|
||||
```
|
||||
|
||||
在新硬盘上创建一个任意分区并不是必需的。创建的物理卷将被逻辑卷管理器识别为一个新安装的未处理的磁盘或者一个类型为 83 的Linux 分区。如果你想去使用整个硬盘,创建一个分区并没有什么特别的好处,以及另外的物理卷部分的元数据所使用的磁盘空间。
|
||||
|
||||
### 扩展已存在的卷组
|
||||
|
||||
在这个示例中,我将扩展一个已存在的卷组,而不是创建一个新的;你可以选择其它的方式。在物理磁盘已经创建之后,扩展已存在的卷组(VG)去包含新 PV 的空间。在这个示例中,已存在的卷组命名为:MyVG01。
|
||||
|
||||
```
|
||||
vgextend /dev/MyVG01 /dev/hdd
|
||||
```
|
||||
|
||||
### 创建一个逻辑卷
|
||||
|
||||
首先,在卷组中从已存在的空余空间中创建逻辑卷。下面的命令创建了一个 50 GB 大小的 LV。这个卷组的名字为 MyVG01,然后,逻辑卷的名字为 Stuff。
|
||||
|
||||
```
|
||||
lvcreate -L +50G --name Stuff MyVG01
|
||||
```
|
||||
|
||||
### 创建文件系统
|
||||
|
||||
创建逻辑卷并不会创建文件系统。这个任务必须被单独执行。下面的命令在新创建的逻辑卷中创建了一个 EXT4 文件系统。
|
||||
|
||||
```
|
||||
mkfs -t ext4 /dev/MyVG01/Stuff
|
||||
```
|
||||
|
||||
### 增加一个文件系统卷标
|
||||
|
||||
增加一个文件系统卷标,更易于在文件系统以后出现问题时识别它。
|
||||
|
||||
```
|
||||
e2label /dev/MyVG01/Stuff Stuff
|
||||
```
|
||||
|
||||
### 挂载文件系统
|
||||
|
||||
在这个时候,你可以创建一个挂载点,并在 /etc/fstab 文件系统中添加合适的条目,以挂载文件系统。
|
||||
|
||||
你也可以去检查并校验创建的卷是否正确。你可以使用 **df**、**lvs**、和 **vgs** 命令去做这些工作。
|
||||
|
||||
### 提示
|
||||
|
||||
过去几年来,我学习了怎么去做让逻辑卷管理更加容易的一些知识,希望这些提示对你有价值。
|
||||
|
||||
* 除非你有一个明确的原因去使用其它的文件系统外,推荐使用可扩展的文件系统。除了 EXT2、3、和 4 外,并不是所有的文件系统都支持调整大小。EXT 文件系统不但速度快,而且它很高效。在任何情况下,如果默认的参数不能满足你的需要,它们(指的是文件系统参数)可以通过一位知识丰富的系统管理员来调优它。
|
||||
|
||||
* 使用有意义的卷和卷组名字。
|
||||
|
||||
* 使用 EXT 文件系统标签
|
||||
|
||||
我知道,像我一样,大多数的系统管理员都抗拒逻辑卷管理。我希望这篇文章能够鼓励你至少去尝试一个 LVM。如果你能那样做,我很高兴;因为,自从我使用它之后,我的硬盘管理任务变得如此的简单。
|
||||
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][10]
|
||||
|
||||
David Both - 是一位 Linux 和开源软件的倡导者,住在 Raleigh, North Carolina。他在 IT 行业工作了 40 多年,在 IBM 工作了 20 多年。在 IBM 期间,他在 1981 年为最初的 IBM PC 编写了第一个培训课程。他曾教授红帽的 RHCE 课程,并在 MCI Worldcom、Cisco和 North Carolina 工作。他已经使用 Linux 和开源软件工作了将近 20 年。... [more about David Both][7][More about me][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/9/linux-users-guide-lvm
|
||||
|
||||
作者:[David Both](a)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/business/16/9/linux-users-guide-lvm?rate=79vf1js7A7rlp-I96YFneopUQqsa2SuB-g-og7eiF1U
|
||||
[7]:https://opensource.com/users/dboth
|
||||
[8]:https://opensource.com/users/dboth
|
||||
[9]:https://opensource.com/user/14106/feed
|
||||
[10]:https://opensource.com/users/dboth
|
||||
[11]:https://opensource.com/users/dboth
|
||||
[12]:https://opensource.com/users/dboth
|
||||
[13]:https://opensource.com/business/16/9/linux-users-guide-lvm#comments
|
||||
[14]:https://opensource.com/tags/business
|
||||
[15]:https://opensource.com/tags/linux
|
||||
[16]:https://opensource.com/tags/how-tos-and-tutorials
|
||||
[17]:https://opensource.com/tags/sysadmin
|
||||
@ -1,41 +1,27 @@
|
||||
如何在 Linux 系统里用 Scrot 截屏
|
||||
============================================================
|
||||
|
||||
### 文章主要内容
|
||||
|
||||
1. [关于 Scrot][12]
|
||||
2. [安装 Scrot][13]
|
||||
3. [Scrot 的使用和特点][14]
|
||||
1. [获取程序版本][1]
|
||||
2. [抓取当前窗口][2]
|
||||
3. [抓取选定窗口][3]
|
||||
4. [在截屏时包含窗口边框][4]
|
||||
5. [延时截屏][5]
|
||||
6. [截屏前倒数][6]
|
||||
7. [图片质量][7]
|
||||
8. [生成缩略图][8]
|
||||
9. [拼接多显示器截屏][9]
|
||||
10. [在保存截图后执行操作][10]
|
||||
11. [特殊字符串][11]
|
||||
4. [结论][15]
|
||||
|
||||
最近,我们介绍过 [gnome-screenshot][17] 工具,这是一个很优秀的屏幕抓取工具。但如果你想找一个在命令行运行的更好用的截屏工具,你一定要试试 Scrot。这个工具有一些 gnome-screenshot 没有的独特功能。在这片文章里,我们会通过简单易懂的例子来详细介绍 Scrot。
|
||||
最近,我们介绍过 [gnome-screenshot][17] 工具,这是一个很优秀的屏幕抓取工具。但如果你想找一个在命令行运行的更好用的截屏工具,你一定要试试 Scrot。这个工具有一些 gnome-screenshot 没有的独特功能。在这篇文章里,我们会通过简单易懂的例子来详细介绍 Scrot。
|
||||
|
||||
请注意一下,这篇文章里的所有例子都在 Ubuntu 16.04 LTS 上测试过,我们用的 scrot 版本是 0.8。
|
||||
|
||||
### 关于 Scrot
|
||||
|
||||
[Scrot][18] (**SCR**eensh**OT**) 是一个屏幕抓取工具,使用 imlib2 库来获取和保存图片。由 Tom Gilbert 用 C 语言开发完成,通过 BSD 协议授权。
|
||||
[Scrot][18] (**SCR**eensh**OT**) 是一个屏幕抓取工具,使用 imlib2 库来获取和保存图片。由 Tom Gilbert 用 C 语言开发完成,通过 BSD 协议授权。
|
||||
|
||||
### 安装 Scrot
|
||||
|
||||
scort 工具可能在你的 Ubuntu 系统里预装了,不过如果没有的话,你可以用下面的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-get install scrot
|
||||
```
|
||||
|
||||
安装完成后,你可以通过下面的命令来使用:
|
||||
|
||||
```
|
||||
scrot [options] [filename]
|
||||
```
|
||||
|
||||
**注意**:方括号里的参数是可选的。
|
||||
|
||||
@ -51,13 +37,17 @@ scrot [options] [filename]
|
||||
|
||||
默认情况下,抓取的截图会用带时间戳的文件名保存到当前目录下,不过你也可以在运行命令时指定截图文件名。比如:
|
||||
|
||||
```
|
||||
scrot [image-name].png
|
||||
```
|
||||
|
||||
### 获取程序版本
|
||||
|
||||
你想的话,可以用 -v 选项来查看 scrot 的版本。
|
||||
你想的话,可以用 `-v` 选项来查看 scrot 的版本。
|
||||
|
||||
```
|
||||
scrot -v
|
||||
```
|
||||
|
||||
这是例子:
|
||||
|
||||
@ -67,10 +57,11 @@ scrot -v
|
||||
|
||||
### 抓取当前窗口
|
||||
|
||||
这个工具可以限制抓取当前的焦点窗口。这个功能可以通过 -u 选项打开。
|
||||
这个工具可以限制抓取当前的焦点窗口。这个功能可以通过 `-u` 选项打开。
|
||||
|
||||
```
|
||||
scrot -u
|
||||
|
||||
```
|
||||
例如,这是我在命令行执行上边命令时的桌面:
|
||||
|
||||
[
|
||||
@ -85,9 +76,11 @@ scrot -u
|
||||
|
||||
### 抓取选定窗口
|
||||
|
||||
这个工具还可以让你抓取任意用鼠标点击的窗口。这个功能可以用 -s 选项打开。
|
||||
这个工具还可以让你抓取任意用鼠标点击的窗口。这个功能可以用 `-s` 选项打开。
|
||||
|
||||
```
|
||||
scrot -s
|
||||
```
|
||||
|
||||
例如,在下面的截图里你可以看到,我有两个互相重叠的终端窗口。我在上层的窗口里执行上面的命令。
|
||||
|
||||
@ -95,7 +88,7 @@ scrot -s
|
||||
|
||||
][23]
|
||||
|
||||
现在假如我想抓取下层的终端窗口。这样我只要在执行命令后点击窗口就可以了 - 在你用鼠标点击之前,命令的执行不会结束。
|
||||
现在假如我想抓取下层的终端窗口。这样我只要在执行命令后点击窗口就可以了 —— 在你用鼠标点击之前,命令的执行不会结束。
|
||||
|
||||
这是我点击了下层终端窗口后的截图:
|
||||
|
||||
@ -107,9 +100,11 @@ scrot -s
|
||||
|
||||
### 在截屏时包含窗口边框
|
||||
|
||||
我们之前介绍的 -u 选项在截屏时不会包含窗口边框。不过,需要的话你也可以在截屏时包含窗口边框。这个功能可以通过 -b 选项打开(当然要和 -u 选项一起)。
|
||||
我们之前介绍的 `-u` 选项在截屏时不会包含窗口边框。不过,需要的话你也可以在截屏时包含窗口边框。这个功能可以通过 `-b` 选项打开(当然要和 `-u` 选项一起)。
|
||||
|
||||
```
|
||||
scrot -ub
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -121,11 +116,13 @@ scrot -ub
|
||||
|
||||
### 延时截屏
|
||||
|
||||
你可以在开始截屏时增加一点延时。需要在 --delay 或 -d 选项后设定一个时间值参数。
|
||||
你可以在开始截屏时增加一点延时。需要在 `--delay` 或 `-d` 选项后设定一个时间值参数。
|
||||
|
||||
```
|
||||
scrot --delay [NUM]
|
||||
|
||||
scrot --delay 5
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
@ -137,11 +134,13 @@ scrot --delay 5
|
||||
|
||||
### 截屏前倒数
|
||||
|
||||
这个工具也可以在你使用延时功能后显示一个倒计时。这个功能可以通过 -c 选项打开。
|
||||
这个工具也可以在你使用延时功能后显示一个倒计时。这个功能可以通过 `-c` 选项打开。
|
||||
|
||||
```
|
||||
scrot –delay [NUM] -c
|
||||
|
||||
scrot -d 5 -c
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -153,11 +152,13 @@ scrot -d 5 -c
|
||||
|
||||
你可以使用这个工具来调整截图的图片质量,范围是 1-100 之间。较大的值意味着更大的文件大小以及更低的压缩率。默认值是 75,不过最终效果根据选择的文件类型也会有一些差异。
|
||||
|
||||
这个功能可以通过 --quality 或 -q 选项打开,但是你必须提供一个 1-100 之间的数值作为参数。
|
||||
这个功能可以通过 `--quality` 或 `-q` 选项打开,但是你必须提供一个 1 - 100 之间的数值作为参数。
|
||||
|
||||
```
|
||||
scrot –quality [NUM]
|
||||
|
||||
scrot –quality 10
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -165,17 +166,19 @@ scrot –quality 10
|
||||
|
||||
][28]
|
||||
|
||||
你可以看到,-q 选项的参数更靠近 1 让图片质量下降了很多。
|
||||
你可以看到,`-q` 选项的参数更靠近 1 让图片质量下降了很多。
|
||||
|
||||
### 生成缩略图
|
||||
|
||||
scort 工具还可以生成截屏的缩略图。这个功能可以通过 --thumb 选项打开。这个选项也需要一个 NUM 数值作为参数,基本上是指定原图大小的百分比。
|
||||
scort 工具还可以生成截屏的缩略图。这个功能可以通过 `--thumb` 选项打开。这个选项也需要一个 NUM 数值作为参数,基本上是指定原图大小的百分比。
|
||||
|
||||
```
|
||||
scrot --thumb NUM
|
||||
|
||||
scrot --thumb 50
|
||||
```
|
||||
|
||||
**注意**:加上 --thumb 选项也会同时保存原始截图文件。
|
||||
**注意**:加上 `--thumb` 选项也会同时保存原始截图文件。
|
||||
|
||||
例如,下面是我测试的原始截图:
|
||||
|
||||
@ -191,9 +194,11 @@ scrot --thumb 50
|
||||
|
||||
### 拼接多显示器截屏
|
||||
|
||||
如果你的电脑接了多个显示设备,你可以用 scort 抓取并拼接这些显示设备的截图。这个功能可以通过 -m 选项打开。
|
||||
如果你的电脑接了多个显示设备,你可以用 scort 抓取并拼接这些显示设备的截图。这个功能可以通过 `-m` 选项打开。
|
||||
|
||||
```
|
||||
scrot -m
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -203,9 +208,11 @@ scrot -m
|
||||
|
||||
### 在保存截图后执行操作
|
||||
|
||||
使用这个工具,你可以在保存截图后执行各种操作 - 例如,用像 gThumb 这样的图片编辑器打开截图。这个功能可以通过 -e 选项打开。下面是例子:
|
||||
使用这个工具,你可以在保存截图后执行各种操作 —— 例如,用像 gThumb 这样的图片编辑器打开截图。这个功能可以通过 `-e` 选项打开。下面是例子:
|
||||
|
||||
scrot abc.png -e ‘gthumb abc.png’
|
||||
```
|
||||
scrot abc.png -e 'gthumb abc.png'
|
||||
```
|
||||
|
||||
这个命令里的 gthumb 是一个图片编辑器,上面的命令在执行后会自动打开。
|
||||
|
||||
@ -223,29 +230,33 @@ scrot abc.png -e ‘gthumb abc.png’
|
||||
|
||||
你可以看到 scrot 抓取了屏幕截图,然后再启动了 gThumb 图片编辑器打开刚才保存的截图图片。
|
||||
|
||||
如果你截图时没有指定文件名,截图将会用带有时间戳的文件名保存到当前目录 - 这是 scrot 的默认设定,我们前面已经说过。
|
||||
如果你截图时没有指定文件名,截图将会用带有时间戳的文件名保存到当前目录 —— 这是 scrot 的默认设定,我们前面已经说过。
|
||||
|
||||
下面是一个使用默认名字并且加上 -e 选项来截图的例子:
|
||||
下面是一个使用默认名字并且加上 `-e` 选项来截图的例子:
|
||||
|
||||
scrot -e ‘gthumb $n’
|
||||
```
|
||||
scrot -e 'gthumb $n'
|
||||
```
|
||||
|
||||
[
|
||||
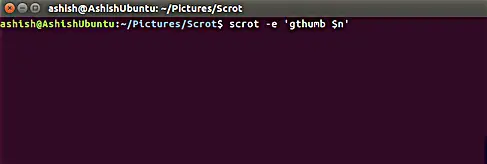
|
||||
][34]
|
||||
|
||||
有个地方要注意的是 $n 是一个特殊字符串,用来获取当前截图的文件名。关于特殊字符串的更多细节,请继续看下个小节。
|
||||
有个地方要注意的是 `$n` 是一个特殊字符串,用来获取当前截图的文件名。关于特殊字符串的更多细节,请继续看下个小节。
|
||||
|
||||
### 特殊字符串
|
||||
|
||||
scrot 的 -e(或 --exec)选项和文件名参数可以使用格式说明符。有两种类型格式。第一种是以 '%' 加字母组成,用来表示日期和时间,第二种以 '$' 开头,scrot 内部使用。
|
||||
scrot 的 `-e`(或 `--exec`)选项和文件名参数可以使用格式说明符。有两种类型格式。第一种是以 `%` 加字母组成,用来表示日期和时间,第二种以 `$` 开头,scrot 内部使用。
|
||||
|
||||
下面介绍几个 --exec 和文件名参数接受的说明符。
|
||||
下面介绍几个 `--exec` 和文件名参数接受的说明符。
|
||||
|
||||
**$f** – 让你可以使用截图的全路径(包括文件名)。
|
||||
`$f` – 让你可以使用截图的全路径(包括文件名)。
|
||||
|
||||
例如
|
||||
例如:
|
||||
|
||||
```
|
||||
scrot ashu.jpg -e ‘mv $f ~/Pictures/Scrot/ashish/’
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -253,17 +264,19 @@ scrot ashu.jpg -e ‘mv $f ~/Pictures/Scrot/ashish/’
|
||||
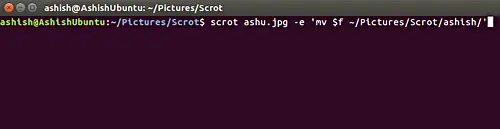
|
||||
][35]
|
||||
|
||||
如果你没有指定文件名,scrot 默认会用日期格式的文件名保存截图。这个是 scrot 的默认文件名格式:%yy-%mm-%dd-%hhmmss_$wx$h_scrot.png。
|
||||
如果你没有指定文件名,scrot 默认会用日期格式的文件名保存截图。这个是 scrot 的默认文件名格式:`%yy-%mm-%dd-%hhmmss_$wx$h_scrot.png`。
|
||||
|
||||
**$n** – 提供截图文件名。下面是示例截图:
|
||||
`$n` – 提供截图文件名。下面是示例截图:
|
||||
|
||||
[
|
||||
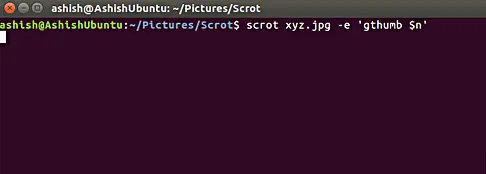
|
||||
][36]
|
||||
|
||||
**$s** – 获取截图的文件大小。这个功能可以像下面这样使用。
|
||||
`$s` – 获取截图的文件大小。这个功能可以像下面这样使用。
|
||||
|
||||
```
|
||||
scrot abc.jpg -e ‘echo $s’
|
||||
```
|
||||
|
||||
下面是示例截图:
|
||||
|
||||
@ -271,22 +284,19 @@ scrot abc.jpg -e ‘echo $s’
|
||||
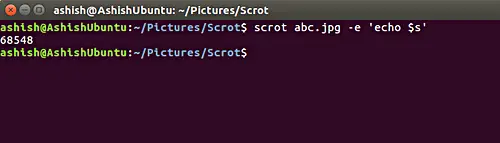
|
||||
][37]
|
||||
|
||||
类似的,你也可以使用其他格式字符串 **$p**, **$w**, **$h**, **$t**, **$$** 以及 **\n** 来分别获取图片像素大小,图像宽度,图像高度,图像格式,输入 $ 字符,以及换行。你可以像上面介绍的 **$s** 格式那样使用这些字符串。
|
||||
类似的,你也可以使用其他格式字符串 `$p`、`$w`、 `$h`、`$t`、`$$` 以及 `\n` 来分别获取图片像素大小、图像宽度、图像高度、图像格式、输入 `$` 字符、以及换行。你可以像上面介绍的 `$s` 格式那样使用这些字符串。
|
||||
|
||||
### 结论
|
||||
|
||||
这个应用能轻松地安装在 Ubuntu 系统上,对初学者比较友好。scrot 也提供了一些高级功能,比如支持格式化字符串,方便专业用户用脚本处理。当然,如果你想用起来的话有一点轻微的学习曲线。
|
||||
|
||||

|
||||
[vie][16]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-take-screenshots-in-linux-with-scrot/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
104
translated/tech/20170530 How to Improve a Legacy Codebase.md
Normal file
104
translated/tech/20170530 How to Improve a Legacy Codebase.md
Normal file
@ -0,0 +1,104 @@
|
||||
# 如何改善遗留的代码库
|
||||
|
||||
这在每一个程序员,项目管理员,团队领导的一生中都会至少发生一次。原来的程序员早已离职去度假了,留下了一坨几百万行屎一样的代码和文档(如果有的话),一旦接手这些代码,想要跟上公司的进度简直让人绝望。
|
||||
|
||||
你的工作是带领团队摆脱这个混乱的局面
|
||||
|
||||
当你的第一反应过去之后,你开始去熟悉这个项目,公司的管理层都在关注着你,所以项目只能成功,然而,看了一遍代码之后却发现很大的可能会失败。那么该怎么办呢?
|
||||
|
||||
幸运(不幸)的是我已经遇到好几次这种情况了,我和我的小伙伴发现将这坨热气腾腾的屎变成一个健康可维护的项目是非常值得一试的。下面这些是我们的一些经验:
|
||||
|
||||
### 备份
|
||||
|
||||
在开始做任何事情之前备份与之可能相关的所有文件。这样可以确保不会丢失任何可能会在另外一些地方很重要的信息。一旦修改其中一些文件,你可能花费一天或者更多天都解决不了这个愚蠢的问题,配置数据通常不受版本控制,所以特别容易受到这方面影响,如果定期备份数据时连带着它一起备份了,还是比较幸运的。所以谨慎总比后悔好,复制所有东西到一个绝对安全的地方吧,除非这些文件是只读模式否则不要轻易碰它。
|
||||
|
||||
### 必须确保代码能够在生产环境下构建运行并产出,这是重要的先决条件。
|
||||
|
||||
之前我假设环境已经存在,所以完全丢了这一步,Hacker News 的众多网友指出了这一点并且证明他们是对的:第一步是确认你知道在生产环境下运行着什么东西,也意味着你需要在你的设备上构建一个跟生产环境上运行的版本每一个字节都一模一样的版本。如果你找不到实现它的办法,一旦你将它投入生产环境,你很可能会遭遇一些很糟糕的事情。确保每一部分都尽力测试,之后在你足够信任它能够很好的运行的时候将它部署生产环境下。无论它运行的怎么样都要做好能够马上切换回旧版本的准备,确保日志记录下了所有情况,以便于接下来不可避免的 “验尸” 。
|
||||
|
||||
### 冻结数据库
|
||||
|
||||
直到你修改代码之前尽可能冻结你的数据库,在你特别熟悉代码库和遗留代码之后再去修改数据库。在这之前过早的修改数据库的话,你可能会碰到大问题,你会失去让新旧代码和数据库一起构建稳固的基础的能力。保持数据库完全不变,就能比较新的逻辑代码和旧的逻辑代码运行的结果,比较的结果应该跟预期的没有差别。
|
||||
|
||||
### 写测试
|
||||
|
||||
在你做任何改变之前,尽可能多的写下端到端测试和集成测试。在你能够清晰的知道旧的是如何工作的情况下确保这些测试能够正确的输出(准备好应对一些突发状况)。这些测试有两个重要的作用,其一,他们能够在早期帮助你抛弃一些错误观念,其二,在你写新代码替换旧代码的时候也有一定防护作用。
|
||||
|
||||
自动化测试,如果你也有 CI 的使用经验请使用它,并且确保在你提交代码之后能够快速的完成所有测试。
|
||||
|
||||
### 日志监控
|
||||
|
||||
如果旧设备依然可用,那么添加上监控功能。使用一个全新的数据库,为每一个你能想到的事件都添加一个简单的计数器,并且根据这些事件的名字添加一个函数增加这些计数器。用一些额外的代码实现一个带有时间戳的事件日志,这是一个好办法知道有多少事件导致了另外一些种类的事件。例如:用户打开 APP ,用户关闭 APP 。如果这两个事件导致后端调用的数量维持长时间的不同,这个数量差就是当前打开的 APP 的数量。如果你发现打开 APP 比关闭 APP 多的时候,你就必须要知道是什么原因导致 APP 关闭了(例如崩溃)。你会发现每一个事件都跟其他的一些事件有许多不同种类的联系,通常情况下你应该尽量维持这些固定的联系,除非在系统上有一个明显的错误。你的目标是减少那些错误的事件,尽可能多的在开始的时候通过使用计数器在调用链中降低到指定的级别。(例如:用户支付应该得到相同数量的支付回调)。
|
||||
|
||||
这是简单的技巧去将每一个后端应用变成一个就像真实的簿记系统一样,所有数字必须匹配,只要他们在某个地方都不会有什么问题。
|
||||
|
||||
随着时间的推移,这个系统在监控健康方面变得非常宝贵,而且它也是使用源码控制修改系统日志的一个好伙伴,你可以使用它确认 BUG 出现的位置,以及对多种计数器造成的影响。
|
||||
|
||||
我通常保持 5 分钟(一小时 12 次)记录一次计数器,如果你的应用生成了更多或者更少的事件,你应该修改这个时间间隔。所有的计数器公用一个数据表,每一个记录都只是简单的一行。
|
||||
|
||||
### 一次只修改一处
|
||||
|
||||
不要完全陷入在提高代码或者平台可用性的同时添加新特性或者是修复 BUG 的陷阱。这会让你头大而且将会使你之前建立的测试失效,现在必须问问你自己,每一步的操作想要什么样的结果。
|
||||
|
||||
### 修改平台
|
||||
|
||||
如果你决定转移你的应用到另外一个平台,最主要的是跟之前保持一样。如果你觉得你会添加更多的文档和测试,但是不要忘记这一点,所有的业务逻辑和相互依赖跟从前一样保持不变。
|
||||
|
||||
### 修改架构
|
||||
|
||||
接下来处理的是改变应用的结构(如果需要)。这一点上,你可以自由的修改高层的代码,通常是降低模块间的横向联系,这样可以降低代码活动期间对终端用户造成的影响范围。如果老代码是庞大的,那么现在正是让他模块化的时候,将大段代码分解成众多小的,不过不要把变量的名字和他的数据结构分开。
|
||||
|
||||
Hacker News [mannykannot][1] 网友指出,修改架构并不总是可行,如果你特别不幸的话,你可能为了改变一些架构必须付出沉重的代价。我也赞同这一点,我应该加上这一点,因此这里有一些补充。我非常想补充的是如果你修改高级代码的时候修改了一点点底层代码,那么试着限制只修改一个文件或者最坏的情况是只修改一个子系统,所以尽可能限制修改的范围。否则你可能很难调试刚才所做的更改。
|
||||
|
||||
### 底层代码的重构
|
||||
|
||||
现在,你应该非常理解每一个模块的作用了,准备做一些真正的工作吧:重构代码以提高其可维护性并且使代码做好添加新功能的准备。这很可能是项目中最消耗时间的部分,记录你所做的任何操作,在你彻底的记录模块并且理解之前不要对它做任何修改。之后你可以自由的修改变量名、函数名以及数据结构以提高代码的清晰度和统一性,然后请做测试(情况允许的话,包括单元测试)。
|
||||
|
||||
### 修复 bugs
|
||||
|
||||
现在准备做一些用户可见的修改,战斗的第一步是修复很多积累了一整年的bugs,像往常一样,首先证实 bug 仍然存在,然后编写测试并修复这个 bug,你的 CI 和端对端测试应该能避免一些由于不太熟悉或者一些额外的事情而犯的错误。
|
||||
|
||||
### 升级数据库
|
||||
|
||||
|
||||
如果在一个坚实且可维护的代码库上完成所有工作,如果你有更改数据库模式的计划,可以使用不同的完全替换数据库。
|
||||
把所有的这些都做完将能够帮助你更可靠的修改而不会碰到问题,你会完全的测试新数据库和新代码,所有测试可以确保你顺利的迁移。
|
||||
|
||||
### 按着路线图执行
|
||||
|
||||
祝贺你脱离的困境并且可以准备添加新功能了。
|
||||
|
||||
### 任何时候都不要尝试彻底重写
|
||||
|
||||
彻底重写是那种注定会失败的项目,一方面,你在一个未知的领域开始,所以你甚至不知道构建什么,另一方面,你会把所以的问题都推到新系统马上就要上线的前一天,非常不幸的是,这也是你失败的时候,假设业务逻辑存在问题,你会得到异样的眼光,那时您会突然明白为什么旧系统会用某种奇怪的方式来工作,最终也会意识到能将旧系统放在一起工作的人也不都是白痴。在那之后。如果你真的想破坏公司(和你自己的声誉),那就重写吧,但如果你足够聪明,彻底重写系统通常不会成为一个摆到桌上讨论的选项。
|
||||
|
||||
### 所以,替代方法是增量迭代工作
|
||||
|
||||
要解开这些线团最快方法是,使用你熟悉的代码中任何的元素(它可能是外部的,他可以是内核模块),试着使用旧的上下文去增量提升,如果旧的构建工具已经不能用了,你将必须使用一些技巧(看下面)至少当你开始做修改的时候,试着尽力保留已知的工作。那样随着代码库的提升你也对代码的作用更加理解。一个典型的代码提交应该最多两行。
|
||||
|
||||
### 发布!
|
||||
|
||||
每一次的修改都发布到生产环境,即使一些修改不是用户可见的。使用最少的步骤也是很重要的,因为当你缺乏对系统的了解时,只有生产环境能够告诉你问题在哪里,如果你只做了一个很小的修改之后出了问题,会有一些好处:
|
||||
|
||||
* 很容易弄清楚出了什么问题
|
||||
* 这是一个改进流程的好位置
|
||||
* 你应该马上更新文档展示你的新见解
|
||||
|
||||
### 使用代理的好处
|
||||
如果你做 web 开发时在旧系统和用户之间加了代理。你能很容易的控制每一个网址哪些请求旧系统,哪些重定向到新系统,从而更轻松更精确的控制运行的内容以及谁能够看到。如果你的代理足够的聪明,你可以使用它发送一定比例的流量到个人的 URL,直到你满意为止,如果你的集成测试也连接到这个接口那就更好了。
|
||||
|
||||
### 是的,这会花费很多时间
|
||||
这取决于你怎样看待它的,这是事实会有一些重复的工作涉及到这些步骤中。但是它确实有效,对于进程的任何一个优化都将使你对这样系统更加熟悉。我会保持声誉,并且我真的不喜欢在工作期间有负面的意外。如果运气好的话,公司系统已经出现问题,而且可能会影响客户。在这样的情况下,如果你更多地是牛仔的做事方式,并且你的老板同意可以接受冒更大的风险,我比较喜欢完全控制整个流程得到好的结果而不是节省两天或者一星期,但是大多数公司宁愿采取稍微慢一点但更确定的胜利之路。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jacquesmattheij.com/improving-a-legacy-codebase
|
||||
|
||||
作者:[Jacques Mattheij][a]
|
||||
译者:[aiwhj](https://github.com/aiwhj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jacquesmattheij.com/
|
||||
[1]:https://news.ycombinator.com/item?id=14445661
|
||||
42
translated/tech/20170910 Cool vim feature sessions.md
Normal file
42
translated/tech/20170910 Cool vim feature sessions.md
Normal file
@ -0,0 +1,42 @@
|
||||
vim 的酷功能:会话!
|
||||
============================================================
|
||||
|
||||
昨天我在编写我的[vimrc][5]的时候了解到一个很酷的 vim 功能!(主要为了添加 fzf 和 ripgrep 插件)。这是一个内置功能,不需要特别的插件。
|
||||
|
||||
所以我画了一个漫画。
|
||||
|
||||
基本上你可以用下面的命令保存所有你打开的文件和当前的状态
|
||||
|
||||
```
|
||||
:mksession ~/.vim/sessions/foo.vim
|
||||
|
||||
```
|
||||
|
||||
接着用 `:source ~/.vim/sessions/foo.vim` 或者 `vim -S ~/.vim/sessions/foo.vim` 还原会话。非常酷!
|
||||
|
||||
一些 vim 插件给 vim 会话添加了额外的功能:
|
||||
|
||||
* [https://github.com/tpope/vim-obsession][1]
|
||||
* [https://github.com/mhinz/vim-startify][2]
|
||||
* [https://github.com/xolox/vim-session][3]
|
||||
|
||||
这是漫画:
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/09/10/vim-sessions/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://github.com/tpope/vim-obsession
|
||||
[2]:https://github.com/mhinz/vim-startify
|
||||
[3]:https://github.com/xolox/vim-session
|
||||
[4]:https://jvns.ca/categories/vim
|
||||
[5]:https://github.com/jvns/vimconfig/blob/master/vimrc
|
||||
@ -0,0 +1,77 @@
|
||||
translated by smartgrids
|
||||
Eclipse 如何助力 IoT 发展
|
||||
============================================================
|
||||
|
||||
### 开源组织的模块发开发方式非常适合物联网。
|
||||
|
||||

|
||||
图片来源: opensource.com
|
||||
|
||||
[Eclipse][3] 可能不是第一个去研究物联网的开源组织。但是,远在 IoT 家喻户晓之前,该基金会在 2001 年左右就开始支持开源软件发展商业化。九月 Eclipse 物联网日和 RedMonk 的 [ThingMonk 2017][4] 一块举行,着重强调了 Eclipse 在 [物联网发展][5] 中的重要作用。它现在已经包含了 28 个项目,覆盖了大部分物联网项目需求。会议过程中,我和负责 Eclipse 市场化运作的 [Ian Skerritt][6] 讨论了 Eclipse 的物联网项目以及如何拓展它。
|
||||
|
||||
###物联网的最新进展?
|
||||
我问 Ian 物联网同传统工业自动化,也就是前几十年通过传感器和相应工具来实现工厂互联的方式有什么不同。 Ian 指出很多工厂是还没有互联的。
|
||||
另外,他说“ SCADA[监控和数据分析] 系统以及工厂底层技术都是私有、独立性的。我们很难去改变它,也很难去适配它们…… 现在,如果你想运行一套生产系统,你需要设计成百上千的单元。生产线想要的是满足用户需求,使制造过程更灵活,从而可以不断产出。” 这也就是物联网会带给制造业的一个很大的帮助。
|
||||
|
||||
|
||||
###Eclipse 物联网方面的研究
|
||||
Ian 对于 Eclipse 在物联网的研究是这样描述的:“满足任何物联网解决方案的核心基础技术” ,通过使用开源技术,“每个人都可以使用从而可以获得更好的适配性。” 他说,Eclipse 将物联网视为包括三层互联的软件栈。从更高的层面上看,这些软件栈(按照大家常见的说法)将物联网描述为跨越三个层面的网络。特定的观念可能认为含有更多的层面,但是他们一直符合这个三层模型的功能的:
|
||||
|
||||
* 一种可以装载设备(例如设备、终端、微控制器、传感器)用软件的堆栈。
|
||||
* 将不同的传感器采集到的数据信息聚合起来并传输到网上的一类网关。这一层也可能会针对传感器数据检测做出实时反映。
|
||||
* 物联网平台后端的一个软件栈。这个后端云存储数据并能根据采集的数据比如历史趋势、预测分析提供服务。
|
||||
|
||||
这三个软件栈在 Eclipse 的白皮书 “ [The Three Software Stacks Required for IoT Architectures][7] ”中有更详细的描述。
|
||||
|
||||
Ian 说在这些架构中开发一种解决方案时,“需要开发一些特殊的东西,但是很多底层的技术是可以借用的,像通信协议、网关服务。需要一种模块化的方式来满足不用的需求场合。” Eclipse 关于物联网方面的研究可以概括为:开发模块化开源组件从而可以被用于开发大量的特定性商业服务和解决方案。
|
||||
|
||||
###Eclipse 的物联网项目
|
||||
|
||||
在众多一杯应用的 Eclipse 物联网应用中, Ian 举了两个和 [MQTT][8] 有关联的突出应用,一个设备与设备互联(M2M)的物联网协议。 Ian 把它描述成“一个专为重视电源管理工作的油气传输线监控系统的信息发布/订阅协议。MQTT 已经是众多物联网广泛应用标准中很成功的一个。” [Eclipse Mosquitto][9] 是 MQTT 的代理,[Eclipse Paho][10] 是他的客户端。
|
||||
[Eclipse Kura][11] 是一个物联网网关,引用 Ian 的话,“它连接了很多不同的协议间的联系”包括蓝牙、Modbus、CANbus 和 OPC 统一架构协议,以及一直在不断添加的协议。一个优势就是,他说,取代了你自己写你自己的协议, Kura 提供了这个功能并将你通过卫星、网络或其他设备连接到网络。”另外它也提供了防火墙配置、网络延时以及其它功能。Ian 也指出“如果网络不通时,它会存储信息直到网络恢复。”
|
||||
|
||||
最新的一个项目中,[Eclipse Kapua][12] 正尝试通过微服务来为物联网云平台提供不同的服务。比如,它集成了通信、汇聚、管理、存储和分析功能。Ian 说“它正在不断前进,虽然还没被完全开发出来,但是 Eurotech 和 RedHat 在这个项目上非常积极。”
|
||||
Ian 说 [Eclipse hawkBit][13] ,软件更新管理的软件,是一项“非常有趣的项目。从安全的角度说,如果你不能更新你的设备,你将会面临巨大的安全漏洞。”很多物联网安全事故都和无法更新的设备有关,他说,“ HawkBit 可以基本负责通过物联网系统来完成扩展性更新的后端管理。”
|
||||
|
||||
物联网设备软件升级的难度一直被看作是难度最高的安全挑战之一。物联网设备不是一直连接的,而且数目众多,再加上首先设备的更新程序很难完全正常。正因为这个原因,关于无赖女王软件升级的项目一直是被当作重要内容往前推进。
|
||||
|
||||
###为什么物联网这么适合 Eclipse
|
||||
|
||||
在物联网发展趋势中的一个方面就是关于构建模块来解决商业问题,而不是宽约工业和公司的大物联网平台。 Eclipse 关于物联网的研究放在一系列模块栈、提供特定和大众化需求功能的项目,还有就是指定目标所需的可捆绑式中间件、网关和协议组件上。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Gordon Haff - Gordon Haff 是红帽公司的云营销员,经常在消费者和工业会议上讲话,并且帮助发展红帽全办公云解决方案。他是 计算机前言:云如何如何打开众多出版社未来之门 的作者。在红帽之前, Gordon 写了成百上千的研究报告,经常被引用到公众刊物上,像纽约时报关于 IT 的议题和产品建议等……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
转自: https://opensource.com/article/17/10/eclipse-and-iot
|
||||
|
||||
作者:[Gordon Haff ][a]
|
||||
译者:[smartgrids](https://github.com/smartgrids)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://opensource.com/article/17/10/eclipse-and-iot?rate=u1Wr-MCMFCF4C45IMoSPUacCatoqzhdKz7NePxHOvwg
|
||||
[2]:https://opensource.com/user/21220/feed
|
||||
[3]:https://www.eclipse.org/home/
|
||||
[4]:http://thingmonk.com/
|
||||
[5]:https://iot.eclipse.org/
|
||||
[6]:https://twitter.com/ianskerrett
|
||||
[7]:https://iot.eclipse.org/resources/white-papers/Eclipse%20IoT%20White%20Paper%20-%20The%20Three%20Software%20Stacks%20Required%20for%20IoT%20Architectures.pdf
|
||||
[8]:http://mqtt.org/
|
||||
[9]:https://projects.eclipse.org/projects/technology.mosquitto
|
||||
[10]:https://projects.eclipse.org/projects/technology.paho
|
||||
[11]:https://www.eclipse.org/kura/
|
||||
[12]:https://www.eclipse.org/kapua/
|
||||
[13]:https://eclipse.org/hawkbit/
|
||||
[14]:https://opensource.com/users/ghaff
|
||||
[15]:https://opensource.com/users/ghaff
|
||||
[16]:https://opensource.com/article/17/10/eclipse-and-iot#comments
|
||||
@ -0,0 +1,137 @@
|
||||
如何使用 GPG 加解密文件
|
||||
------
|
||||
### 目标
|
||||
|
||||
使用 GPG 加密文件
|
||||
|
||||
### 发行版
|
||||
|
||||
适用于任何发行版
|
||||
|
||||
### 要求
|
||||
|
||||
安装了 GPG 的 Linux 或者拥有 root 权限来安装它。
|
||||
|
||||
### 难度
|
||||
|
||||
简单
|
||||
|
||||
### 约定
|
||||
|
||||
* # - 需要使用 root 权限来执行指定命令,可以直接使用 root 用户来执行也可以使用 sudo 命令
|
||||
|
||||
* $ - 可以使用普通用户来执行指定命令
|
||||
|
||||
### 介绍
|
||||
|
||||
加密非常重要。它对于保护敏感信息来说是必不可少的。
|
||||
你的私人文件应该要被加密,而 GPG 提供了很好的解决方案。
|
||||
|
||||
### 安装 GPG
|
||||
|
||||
GPG 的使用非常广泛。你在几乎每个发行版的仓库中都能找到它。
|
||||
如果你还没有安装它,那现在就来安装一下吧。
|
||||
|
||||
#### Debian/Ubuntu
|
||||
|
||||
```shell
|
||||
$ sudo apt install gnupg
|
||||
```
|
||||
#### Fedora
|
||||
```shell
|
||||
# dnf install gnupg2
|
||||
```
|
||||
#### Arch
|
||||
```shell
|
||||
# pacman -S gnupg
|
||||
```
|
||||
#### Gentoo
|
||||
```shell
|
||||
# emerge --ask app-crypt/gnupg
|
||||
```
|
||||
### Create a Key
|
||||
你需要一个密钥对来加解密文件。如果你为 SSH 已经生成过了密钥对,那么你可以直接使用它。
|
||||
如果没有,GPG 包含工具来生成密钥对。
|
||||
|
||||
```shell
|
||||
$ gpg --full-generate-key
|
||||
```
|
||||
GPG 有一个命令行程序帮你一步一步的生成密钥。它还有一个简单得多的工具,但是这个工具不能让你设置密钥类型,密钥的长度以及过期时间,因此不推荐使用这个工具。
|
||||
|
||||
GPG 首先会询问你密钥的类型。没什么特别的话选择默认值就好。
|
||||
|
||||
下一步需要设置密钥长度。`4096` 是一个不错的选择。
|
||||
|
||||
之后,可以设置过期的日期。 如果希望密钥永不过期则设置为 `0`
|
||||
|
||||
然后,输入你的名称。
|
||||
|
||||
最后,输入电子邮件地址。
|
||||
|
||||
如果你需要的话,还能添加一个注释。
|
||||
|
||||
所有这些都完成后,GPG 会让你校验一下这些信息。
|
||||
|
||||
GPG 还会问你是否需要为密钥设置密码。这一步是可选的, 但是会增加保护的程度。
|
||||
若需要设置密码,则 GPG 会收集你的操作信息来增加密钥的健壮性。 所有这些都完成后, GPG 会显示密钥相关的信息。
|
||||
|
||||
### 加密的基本方法
|
||||
|
||||
现在你拥有了自己的密钥,加密文件非常简单。 使用虾米那命令在 `/tmp` 目录中创建一个空白文本文件。
|
||||
|
||||
```shell
|
||||
$ touch /tmp/test.txt
|
||||
```
|
||||
|
||||
然后用 GPG 来加密它。这里 `-e` 标志告诉 GPG 你想要加密文件, `-r` 标志指定接收者。
|
||||
|
||||
```shell
|
||||
$ gpg -e -r "Your Name" /tmp/test.txt
|
||||
```
|
||||
|
||||
GPG 需要知道这个文件的接收者和发送者。由于这个文件给是你的,因此无需指定发送者,而接收者就是你自己。
|
||||
|
||||
### 解密的基本方法
|
||||
|
||||
你收到加密文件后,就需要对它进行解密。 你无需指定解密用的密钥。 这个信息被编码在文件中。 GPG 会尝试用其中的密钥进行解密。
|
||||
|
||||
```shel
|
||||
$ gpg -d /tmp/test.txt.gpg
|
||||
```
|
||||
|
||||
### 发送文件
|
||||
假设你需要发送文件给别人。你需要有接收者的公钥。 具体怎么获得密钥由你自己决定。 你可以让他们直接把公钥发送给你, 也可以通过密钥服务器来获取。
|
||||
|
||||
收到对方公钥后,导入公钥到 GPG 中。
|
||||
|
||||
```shell
|
||||
$ gpg --import yourfriends.key
|
||||
```
|
||||
|
||||
这些公钥与你自己创建的密钥一样,自带了名称和电子邮件地址的信息。
|
||||
记住,为了让别人能解密你的文件,别人也需要你的公钥。 因此导出公钥并将之发送出去。
|
||||
|
||||
```shell
|
||||
gpg --export -a "Your Name" > your.key
|
||||
```
|
||||
|
||||
现在可以开始加密要发送的文件了。它跟之前的步骤差不多, 只是需要指定你自己为发送人。
|
||||
```
|
||||
$ gpg -e -u "Your Name" -r "Their Name" /tmp/test.txt
|
||||
```
|
||||
|
||||
### 结语
|
||||
就这样了。GPG 还有一些高级选项, 不过你在 99% 的时间内都不会用到这些高级选项。 GPG 就是这么易于使用。
|
||||
你也可以使用创建的密钥对来发送和接受加密邮件,其步骤跟上面演示的差不多, 不过大多数的电子邮件客户端在拥有密钥的情况下会自动帮你做这个动作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-encrypt-and-decrypt-individual-files-with-gpg
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者 ID](https://github.com/校对者 ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
37
translated/tech/20171108 Archiving repositories.md
Normal file
37
translated/tech/20171108 Archiving repositories.md
Normal file
@ -0,0 +1,37 @@
|
||||
归档仓库
|
||||
====================
|
||||
|
||||
|
||||
因为仓库不再活跃开发或者你不想接受额外的贡献并不意味着你想要删除它。现在在 Github 上归档仓库让它变成只读。
|
||||
|
||||
[][1]
|
||||
|
||||
归档一个仓库让它对所有人只读(包括仓库拥有者)。这包括编辑仓库、问题、合并请求、标记、里程碑、维基、发布、提交、标签、分支、反馈和评论。没有人可以在一个归档的仓库上创建新的问题、合并请求或者评论,但是你仍可以 fork 仓库-允许归档的仓库在其他地方继续开发。
|
||||
|
||||
要归档一个仓库,进入仓库设置页面并点在这个仓库上点击归档。
|
||||
|
||||
[][2]
|
||||
|
||||
在归档你的仓库前,确保你已经更改了它的设置并考虑关闭所有的开放问题和合并请求。你还应该更新你的 README 和描述来让它让访问者了解他不再能够贡献。
|
||||
|
||||
如果你改变了主意想要解除归档你的仓库,在相同的地方点击解除归档。请注意大多数归档仓库的设置是隐藏的,并且你需要解除归档来改变它们。
|
||||
|
||||
[][3]
|
||||
|
||||
要了解更多,请查看[这份文档][4]中的归档仓库部分。归档快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2460-archiving-repositories
|
||||
|
||||
作者:[MikeMcQuaid ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/MikeMcQuaid
|
||||
[1]:https://user-images.githubusercontent.com/7321362/32558403-450458dc-c46a-11e7-96f9-af31d2206acb.png
|
||||
[2]:https://user-images.githubusercontent.com/125011/32273119-0fc5571e-bef9-11e7-9909-d137268a1d6d.png
|
||||
[3]:https://user-images.githubusercontent.com/125011/32541128-9d67a064-c466-11e7-857e-3834054ba3c9.png
|
||||
[4]:https://help.github.com/articles/about-archiving-repositories/
|
||||
493
translated/tech/20171109 Concurrent Servers- Part 4 - libuv.md
Normal file
493
translated/tech/20171109 Concurrent Servers- Part 4 - libuv.md
Normal file
@ -0,0 +1,493 @@
|
||||
[并发服务器:第四部分 - libuv][17]
|
||||
============================================================
|
||||
|
||||
这是写并发网络服务器系列文章的第四部分。在这一部分中,我们将使用 libuv 去再次重写我们的服务器,并且也讨论关于使用一个线程池在回调中去处理耗时任务。最终,我们去看一下底层的 libuv,花一点时间去学习如何用异步 API 对文件系统阻塞操作进行封装。
|
||||
|
||||
这一系列的所有文章包括:
|
||||
|
||||
* [第一部分 - 简介][7]
|
||||
|
||||
* [第二部分 - 线程][8]
|
||||
|
||||
* [第三部分 - 事件驱动][9]
|
||||
|
||||
* [第四部分 - libuv][10]
|
||||
|
||||
### 使用 Linux 抽象出事件驱动循环
|
||||
|
||||
在 [第三部分][11] 中,我们看到了基于 `select` 和 `epoll` 的相似之处,并且,我说过,在它们之间抽象出细微的差别是件很有魅力的事。Numerous 库已经做到了这些,但是,因为在这一部分中,我将去选一个并使用它。我选的这个库是 [libuv][12],它最初设计用于 Node.js 底层的轻便的平台层,并且,后来发现在其它的项目中已有使用。libuv 是用 C 写的,因此,它具有很高的可移植性,非常适用嵌入到像 JavaScript 和 Python 这样的高级语言中。
|
||||
|
||||
虽然 libuv 为抽象出底层平台细节已经有了一个非常大的框架,但它仍然是一个以 _事件循环_ 思想为中心的。在我们第三部分的事件驱动服务器中,事件循环在 main 函数中是很明确的;当使用 libuv 时,循环通常隐藏在库自身中,而用户代码仅需要注册事件句柄(作为一个回调函数)和运行这个循环。此外,libuv 将为给定的平台实现更快的事件循环实现。对于 Linux 它是 epoll,等等。
|
||||
|
||||

|
||||
|
||||
libuv 支持多路事件循环,并且,因此一个事件循环在库中是非常重要的;它有一个句柄 - `uv_loop_t`,和创建/杀死/启动/停止循环的函数。也就是说,在这篇文章中,我将仅需要使用 “默认的” 循环,libuv 可通过 `uv_default_loop()` 提供它;多路循环大多用于多线程事件驱动的服务器,这是一个更高级别的话题,我将留在这一系列文章的以后部分。
|
||||
|
||||
### 使用 libuv 的并发服务器
|
||||
|
||||
为了对 libuv 有一个更深的印象,让我们跳转到我们的可靠的协议服务器,它通过我们的这个系列已经有了一个强大的重新实现。这个服务器的结构与第三部分中的基于 select 和 epoll 的服务器有一些相似之处。因为,它也依赖回调。完整的 [示例代码在这里][13];我们开始设置这个服务器的套接字绑定到一个本地端口:
|
||||
|
||||
```
|
||||
int portnum = 9090;
|
||||
if (argc >= 2) {
|
||||
portnum = atoi(argv[1]);
|
||||
}
|
||||
printf("Serving on port %d\n", portnum);
|
||||
|
||||
int rc;
|
||||
uv_tcp_t server_stream;
|
||||
if ((rc = uv_tcp_init(uv_default_loop(), &server_stream)) < 0) {
|
||||
die("uv_tcp_init failed: %s", uv_strerror(rc));
|
||||
}
|
||||
|
||||
struct sockaddr_in server_address;
|
||||
if ((rc = uv_ip4_addr("0.0.0.0", portnum, &server_address)) < 0) {
|
||||
die("uv_ip4_addr failed: %s", uv_strerror(rc));
|
||||
}
|
||||
|
||||
if ((rc = uv_tcp_bind(&server_stream, (const struct sockaddr*)&server_address, 0)) < 0) {
|
||||
die("uv_tcp_bind failed: %s", uv_strerror(rc));
|
||||
}
|
||||
```
|
||||
|
||||
除了它被封装进 libuv APIs 中之外,你看到的是一个相当标准的套接字。在它的返回中,我们取得一个可工作于任何 libuv 支持的平台上的轻便的接口。
|
||||
|
||||
这些代码也很认真负责地演示了错误处理;多数的 libuv 函数返回一个整数状态,返回一个负数意味着出现了一个错误。在我们的服务器中,我们把这些错误按致命的问题处理,但也可以设想为一个更优雅的恢复。
|
||||
|
||||
现在,那个套接字已经绑定,是时候去监听它了。这里我们运行一个回调注册:
|
||||
|
||||
```
|
||||
// Listen on the socket for new peers to connect. When a new peer connects,
|
||||
// the on_peer_connected callback will be invoked.
|
||||
if ((rc = uv_listen((uv_stream_t*)&server_stream, N_BACKLOG, on_peer_connected)) < 0) {
|
||||
die("uv_listen failed: %s", uv_strerror(rc));
|
||||
}
|
||||
```
|
||||
|
||||
当新的对端连接到这个套接字,`uv_listen` 将被调用去注册一个事件循环回调。我们的回调在这里被称为 `on_peer_connected`,并且我们一会儿将去检测它。
|
||||
|
||||
最终,main 运行这个 libuv 循环,直到它被停止(`uv_run` 仅在循环被停止或者发生错误时返回)
|
||||
|
||||
```
|
||||
// Run the libuv event loop.
|
||||
uv_run(uv_default_loop(), UV_RUN_DEFAULT);
|
||||
|
||||
// If uv_run returned, close the default loop before exiting.
|
||||
return uv_loop_close(uv_default_loop());
|
||||
```
|
||||
|
||||
注意,那个仅是一个单一的通过 main 优先去运行的事件循环回调;我们不久将看到怎么去添加更多的另外的回调。在事件循环的整个运行时中,添加和删除回调并不是一个问题 - 事实上,大多数服务器就是这么写的。
|
||||
|
||||
这是一个 `on_peer_connected`,它处理到服务器的新的客户端连接:
|
||||
|
||||
```
|
||||
void on_peer_connected(uv_stream_t* server_stream, int status) {
|
||||
if (status < 0) {
|
||||
fprintf(stderr, "Peer connection error: %s\n", uv_strerror(status));
|
||||
return;
|
||||
}
|
||||
|
||||
// client will represent this peer; it's allocated on the heap and only
|
||||
// released when the client disconnects. The client holds a pointer to
|
||||
// peer_state_t in its data field; this peer state tracks the protocol state
|
||||
// with this client throughout interaction.
|
||||
uv_tcp_t* client = (uv_tcp_t*)xmalloc(sizeof(*client));
|
||||
int rc;
|
||||
if ((rc = uv_tcp_init(uv_default_loop(), client)) < 0) {
|
||||
die("uv_tcp_init failed: %s", uv_strerror(rc));
|
||||
}
|
||||
client->data = NULL;
|
||||
|
||||
if (uv_accept(server_stream, (uv_stream_t*)client) == 0) {
|
||||
struct sockaddr_storage peername;
|
||||
int namelen = sizeof(peername);
|
||||
if ((rc = uv_tcp_getpeername(client, (struct sockaddr*)&peername,
|
||||
&namelen)) < 0) {
|
||||
die("uv_tcp_getpeername failed: %s", uv_strerror(rc));
|
||||
}
|
||||
report_peer_connected((const struct sockaddr_in*)&peername, namelen);
|
||||
|
||||
// Initialize the peer state for a new client: we start by sending the peer
|
||||
// the initial '*' ack.
|
||||
peer_state_t* peerstate = (peer_state_t*)xmalloc(sizeof(*peerstate));
|
||||
peerstate->state = INITIAL_ACK;
|
||||
peerstate->sendbuf[0] = '*';
|
||||
peerstate->sendbuf_end = 1;
|
||||
peerstate->client = client;
|
||||
client->data = peerstate;
|
||||
|
||||
// Enqueue the write request to send the ack; when it's done,
|
||||
// on_wrote_init_ack will be called. The peer state is passed to the write
|
||||
// request via the data pointer; the write request does not own this peer
|
||||
// state - it's owned by the client handle.
|
||||
uv_buf_t writebuf = uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
|
||||
uv_write_t* req = (uv_write_t*)xmalloc(sizeof(*req));
|
||||
req->data = peerstate;
|
||||
if ((rc = uv_write(req, (uv_stream_t*)client, &writebuf, 1,
|
||||
on_wrote_init_ack)) < 0) {
|
||||
die("uv_write failed: %s", uv_strerror(rc));
|
||||
}
|
||||
} else {
|
||||
uv_close((uv_handle_t*)client, on_client_closed);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这些代码都有很好的注释,但是,这里有一些重要的 libuv 语法我想去强调一下:
|
||||
|
||||
* 进入回调中的自定义数据:因为 C 还没有停用,这可能是个挑战,libuv 在它的处理类型中有一个 `void*` 数据域;这些域可以被用于进入到用户数据。例如,注意 `client->data` 是如何指向到一个 `peer_state_t` 结构上,以便于通过 `uv_write` 和 `uv_read_start` 注册的回调可以知道它们正在处理的是哪个客户端的数据。
|
||||
|
||||
* 内存管理:事件驱动编程在语言中使用垃圾回收是非常容易的,因为,回调通常运行在一个它们注册的完全不同的栈框架中,使得基于栈的内存管理很困难。它总是需要传递堆分配的数据到 libuv 回调中(当所有回调运行时,除了 main,其它的都运行在栈上),并且,为了避免泄漏,许多情况下都要求这些数据去安全释放。这些都是些需要实践的内容 [[1]][6]。
|
||||
|
||||
这个服务器上对端的状态如下:
|
||||
|
||||
```
|
||||
typedef struct {
|
||||
ProcessingState state;
|
||||
char sendbuf[SENDBUF_SIZE];
|
||||
int sendbuf_end;
|
||||
uv_tcp_t* client;
|
||||
} peer_state_t;
|
||||
```
|
||||
|
||||
它与第三部分中的状态非常类似;我们不再需要 sendptr,因为,在调用 "done writing" 回调之前,`uv_write` 将确保去发送它提供的整个缓冲。我们也为其它的回调使用保持了一个到客户端的指针。这里是 `on_wrote_init_ack`:
|
||||
|
||||
```
|
||||
void on_wrote_init_ack(uv_write_t* req, int status) {
|
||||
if (status) {
|
||||
die("Write error: %s\n", uv_strerror(status));
|
||||
}
|
||||
peer_state_t* peerstate = (peer_state_t*)req->data;
|
||||
// Flip the peer state to WAIT_FOR_MSG, and start listening for incoming data
|
||||
// from this peer.
|
||||
peerstate->state = WAIT_FOR_MSG;
|
||||
peerstate->sendbuf_end = 0;
|
||||
|
||||
int rc;
|
||||
if ((rc = uv_read_start((uv_stream_t*)peerstate->client, on_alloc_buffer,
|
||||
on_peer_read)) < 0) {
|
||||
die("uv_read_start failed: %s", uv_strerror(rc));
|
||||
}
|
||||
|
||||
// Note: the write request doesn't own the peer state, hence we only free the
|
||||
// request itself, not the state.
|
||||
free(req);
|
||||
}
|
||||
```
|
||||
|
||||
然后,我们确信知道了这个初始的 '*' 已经被发送到对端,我们通过调用 `uv_read_start` 去监听从这个对端来的入站数据,它注册一个回调(`on_peer_read`)去被调用,不论什么时候,事件循环都在套接字上接收来自客户端的调用:
|
||||
|
||||
```
|
||||
void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
|
||||
if (nread < 0) {
|
||||
if (nread != uv_eof) {
|
||||
fprintf(stderr, "read error: %s\n", uv_strerror(nread));
|
||||
}
|
||||
uv_close((uv_handle_t*)client, on_client_closed);
|
||||
} else if (nread == 0) {
|
||||
// from the documentation of uv_read_cb: nread might be 0, which does not
|
||||
// indicate an error or eof. this is equivalent to eagain or ewouldblock
|
||||
// under read(2).
|
||||
} else {
|
||||
// nread > 0
|
||||
assert(buf->len >= nread);
|
||||
|
||||
peer_state_t* peerstate = (peer_state_t*)client->data;
|
||||
if (peerstate->state == initial_ack) {
|
||||
// if the initial ack hasn't been sent for some reason, ignore whatever
|
||||
// the client sends in.
|
||||
free(buf->base);
|
||||
return;
|
||||
}
|
||||
|
||||
// run the protocol state machine.
|
||||
for (int i = 0; i < nread; ++i) {
|
||||
switch (peerstate->state) {
|
||||
case initial_ack:
|
||||
assert(0 && "can't reach here");
|
||||
break;
|
||||
case wait_for_msg:
|
||||
if (buf->base[i] == '^') {
|
||||
peerstate->state = in_msg;
|
||||
}
|
||||
break;
|
||||
case in_msg:
|
||||
if (buf->base[i] == '$') {
|
||||
peerstate->state = wait_for_msg;
|
||||
} else {
|
||||
assert(peerstate->sendbuf_end < sendbuf_size);
|
||||
peerstate->sendbuf[peerstate->sendbuf_end++] = buf->base[i] + 1;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (peerstate->sendbuf_end > 0) {
|
||||
// we have data to send. the write buffer will point to the buffer stored
|
||||
// in the peer state for this client.
|
||||
uv_buf_t writebuf =
|
||||
uv_buf_init(peerstate->sendbuf, peerstate->sendbuf_end);
|
||||
uv_write_t* writereq = (uv_write_t*)xmalloc(sizeof(*writereq));
|
||||
writereq->data = peerstate;
|
||||
int rc;
|
||||
if ((rc = uv_write(writereq, (uv_stream_t*)client, &writebuf, 1,
|
||||
on_wrote_buf)) < 0) {
|
||||
die("uv_write failed: %s", uv_strerror(rc));
|
||||
}
|
||||
}
|
||||
}
|
||||
free(buf->base);
|
||||
}
|
||||
```
|
||||
|
||||
这个服务器的运行时行为非常类似于第三部分的事件驱动服务器:所有的客户端都在一个单个的线程中并发处理。并且一些行为被维护在服务器代码中:服务器的逻辑实现为一个集成的回调,并且长周期运行是禁止的,因为它会阻塞事件循环。这一点也很类似。让我们进一步探索这个问题。
|
||||
|
||||
### 在事件驱动循环中的长周期运行的操作
|
||||
|
||||
单线程的事件驱动代码使它先天地对一些常见问题非常敏感:整个循环中的长周期运行的代码块。参见如下的程序:
|
||||
|
||||
```
|
||||
void on_timer(uv_timer_t* timer) {
|
||||
uint64_t timestamp = uv_hrtime();
|
||||
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
|
||||
|
||||
// "Work"
|
||||
if (random() % 5 == 0) {
|
||||
printf("Sleeping...\n");
|
||||
sleep(3);
|
||||
}
|
||||
}
|
||||
|
||||
int main(int argc, const char** argv) {
|
||||
uv_timer_t timer;
|
||||
uv_timer_init(uv_default_loop(), &timer);
|
||||
uv_timer_start(&timer, on_timer, 0, 1000);
|
||||
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
|
||||
}
|
||||
```
|
||||
|
||||
它用一个单个注册的回调运行一个 libuv 事件循环:`on_timer`,它被每秒钟循环调用一次。回调报告一个时间戳,并且,偶尔通过睡眠 3 秒去模拟一个长周期运行。这是运行示例:
|
||||
|
||||
```
|
||||
$ ./uv-timer-sleep-demo
|
||||
on_timer [4840 ms]
|
||||
on_timer [5842 ms]
|
||||
on_timer [6843 ms]
|
||||
on_timer [7844 ms]
|
||||
Sleeping...
|
||||
on_timer [11845 ms]
|
||||
on_timer [12846 ms]
|
||||
Sleeping...
|
||||
on_timer [16847 ms]
|
||||
on_timer [17849 ms]
|
||||
on_timer [18850 ms]
|
||||
...
|
||||
```
|
||||
|
||||
`on_timer` 忠实地每秒执行一次,直到随机出现的睡眠为止。在那个时间点,`on_timer` 不再被调用,直到睡眠时间结束;事实上,_没有其它的回调_ 在这个时间帧中被调用。这个睡眠调用阻塞当前线程,它正是被调用的线程,并且也是事件循环使用的线程。当这个线程被阻塞后,事件循环也被阻塞。
|
||||
|
||||
这个示例演示了在事件驱动的调用中为什么回调不能被阻塞是多少的重要。并且,同样适用于 Node.js 服务器、客户端侧的 Javascript、大多数的 GUI 编程框架、以及许多其它的异步编程模型。
|
||||
|
||||
但是,有时候运行耗时的任务是不可避免的。并不是所有任务都有一个异步 APIs;例如,我们可能使用一些仅有同步 API 的库去处理,或者,正在执行一个可能的长周期计算。我们如何用事件驱动编程去结合这些代码?线程可以帮到你!
|
||||
|
||||
### “转换” 阻塞调用到异步调用的线程
|
||||
|
||||
一个线程池可以被用于去转换阻塞调用到异步调用,通过与事件循环并行运行,并且当任务完成时去由它去公布事件。一个给定的阻塞函数 `do_work()`,这里介绍了它是怎么运行的:
|
||||
|
||||
1. 在一个回调中,用 `do_work()` 代表直接调用,我们将它打包进一个 “任务”,并且请求线程池去运行这个任务。当任务完成时,我们也为循环去调用它注册一个回调;我们称它为 `on_work_done()`。
|
||||
|
||||
2. 在这个时间点,我们的回调可以返回并且事件循环保持运行;在同一时间点,线程池中的一个线程运行这个任务。
|
||||
|
||||
3. 一旦任务运行完成,通知主线程(指正在运行事件循环的线程),并且,通过事件循环调用 `on_work_done()`。
|
||||
|
||||
让我们看一下,使用 libuv 的工作调度 API,是怎么去解决我们前面的 timer/sleep 示例中展示的问题的:
|
||||
|
||||
```
|
||||
void on_after_work(uv_work_t* req, int status) {
|
||||
free(req);
|
||||
}
|
||||
|
||||
void on_work(uv_work_t* req) {
|
||||
// "Work"
|
||||
if (random() % 5 == 0) {
|
||||
printf("Sleeping...\n");
|
||||
sleep(3);
|
||||
}
|
||||
}
|
||||
|
||||
void on_timer(uv_timer_t* timer) {
|
||||
uint64_t timestamp = uv_hrtime();
|
||||
printf("on_timer [%" PRIu64 " ms]\n", (timestamp / 1000000) % 100000);
|
||||
|
||||
uv_work_t* work_req = (uv_work_t*)malloc(sizeof(*work_req));
|
||||
uv_queue_work(uv_default_loop(), work_req, on_work, on_after_work);
|
||||
}
|
||||
|
||||
int main(int argc, const char** argv) {
|
||||
uv_timer_t timer;
|
||||
uv_timer_init(uv_default_loop(), &timer);
|
||||
uv_timer_start(&timer, on_timer, 0, 1000);
|
||||
return uv_run(uv_default_loop(), UV_RUN_DEFAULT);
|
||||
}
|
||||
```
|
||||
|
||||
通过一个 work_req [[2]][14] 类型的句柄,我们进入一个任务队列,代替在 `on_timer` 上直接调用 sleep,这个函数在任务中(`on_work`)运行,并且,一旦任务完成(`on_after_work`),这个函数被调用一次。`on_work` 在这里是指发生的 “work”(阻塞中的/耗时的操作)。在这两个回调传递到 `uv_queue_work` 时,注意一个关键的区别:`on_work` 运行在线程池中,而 `on_after_work` 运行在事件循环中的主线程上 - 就好像是其它的回调一样。
|
||||
|
||||
让我们看一下这种方式的运行:
|
||||
|
||||
```
|
||||
$ ./uv-timer-work-demo
|
||||
on_timer [89571 ms]
|
||||
on_timer [90572 ms]
|
||||
on_timer [91573 ms]
|
||||
on_timer [92575 ms]
|
||||
Sleeping...
|
||||
on_timer [93576 ms]
|
||||
on_timer [94577 ms]
|
||||
Sleeping...
|
||||
on_timer [95577 ms]
|
||||
on_timer [96578 ms]
|
||||
on_timer [97578 ms]
|
||||
...
|
||||
```
|
||||
|
||||
即便在 sleep 函数被调用时,定时器也每秒钟滴答一下,睡眠(sleeping)现在运行在一个单独的线程中,并且不会阻塞事件循环。
|
||||
|
||||
### 一个用于练习的素数测试服务器
|
||||
|
||||
因为通过睡眼去模拟工作并不是件让人兴奋的事,我有一个事先准备好的更综合的一个示例 - 一个基于套接字接受来自客户端的数字的服务器,检查这个数字是否是素数,然后去返回一个 “prime" 或者 “composite”。完整的 [服务器代码在这里][15] - 我不在这里粘贴了,因为它太长了,更希望读者在一些自己的练习中去体会它。
|
||||
|
||||
这个服务器使用了一个原生的素数测试算法,因此,对于大的素数可能花很长时间才返回一个回答。在我的机器中,对于 2305843009213693951,它花了 ~5 秒钟去计算,但是,你的方法可能不同。
|
||||
|
||||
练习 1:服务器有一个设置(通过一个名为 MODE 的环境变量)要么去在套接字回调(意味着在主线程上)中运行素数测试,要么在 libuv 工作队列中。当多个客户端同时连接时,使用这个设置来观察服务器的行为。当它计算一个大的任务时,在阻塞模式中,服务器将不回复其它客户端,而在非阻塞模式中,它会回复。
|
||||
|
||||
练习 2;libuv 有一个缺省大小的线程池,并且线程池的大小可以通过环境变量配置。你可以通过使用多个客户端去实验找出它的缺省值是多少?找到线程池缺省值后,使用不同的设置去看一下,在重负载下怎么去影响服务器的响应能力。
|
||||
|
||||
### 在非阻塞文件系统中使用工作队列
|
||||
|
||||
对于仅傻傻的演示和 CPU 密集型的计算来说,将可能的阻塞操作委托给一个线程池并不是明智的;libuv 在它的文件系统 APIs 中本身就大量使用了这种性能。通过这种方式,libuv 使用一个异步 API,在一个轻便的方式中,显示出它强大的文件系统的处理能力。
|
||||
|
||||
让我们使用 `uv_fs_read()`,例如,这个函数从一个文件中(以一个 `uv_fs_t` 句柄为代表)读取一个文件到一个缓冲中 [[3]][16],并且当读取完成后调用一个回调。换句话说,`uv_fs_read()` 总是立即返回,甚至如果文件在一个类似 NFS 的系统上,并且,数据到达缓冲区可能需要一些时间。换句话说,这个 API 与这种方式中其它的 libuv APIs 是异步的。这是怎么工作的呢?
|
||||
|
||||
在这一点上,我们看一下 libuv 的底层;内部实际上非常简单,并且它是一个很好的练习。作为一个便携的库,libuv 对于 Windows 和 Unix 系统在它的许多函数上有不同的实现。我们去看一下在 libuv 源树中的 src/unix/fs.c。
|
||||
|
||||
这是 `uv_fs_read` 的代码:
|
||||
|
||||
```
|
||||
int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
|
||||
uv_file file,
|
||||
const uv_buf_t bufs[],
|
||||
unsigned int nbufs,
|
||||
int64_t off,
|
||||
uv_fs_cb cb) {
|
||||
if (bufs == NULL || nbufs == 0)
|
||||
return -EINVAL;
|
||||
|
||||
INIT(READ);
|
||||
req->file = file;
|
||||
|
||||
req->nbufs = nbufs;
|
||||
req->bufs = req->bufsml;
|
||||
if (nbufs > ARRAY_SIZE(req->bufsml))
|
||||
req->bufs = uv__malloc(nbufs * sizeof(*bufs));
|
||||
|
||||
if (req->bufs == NULL) {
|
||||
if (cb != NULL)
|
||||
uv__req_unregister(loop, req);
|
||||
return -ENOMEM;
|
||||
}
|
||||
|
||||
memcpy(req->bufs, bufs, nbufs * sizeof(*bufs));
|
||||
|
||||
req->off = off;
|
||||
POST;
|
||||
}
|
||||
```
|
||||
|
||||
第一次看可能觉得很困难,因为它延缓真实的工作到 INIT 和 POST 宏中,在 POST 中与一些本地变量一起设置。这样做可以避免了文件中的许多重复代码。
|
||||
|
||||
这是 INIT 宏:
|
||||
|
||||
```
|
||||
#define INIT(subtype) \
|
||||
do { \
|
||||
req->type = UV_FS; \
|
||||
if (cb != NULL) \
|
||||
uv__req_init(loop, req, UV_FS); \
|
||||
req->fs_type = UV_FS_ ## subtype; \
|
||||
req->result = 0; \
|
||||
req->ptr = NULL; \
|
||||
req->loop = loop; \
|
||||
req->path = NULL; \
|
||||
req->new_path = NULL; \
|
||||
req->cb = cb; \
|
||||
} \
|
||||
while (0)
|
||||
```
|
||||
|
||||
它设置了请求,并且更重要的是,设置 `req->fs_type` 域为真实的 FS 请求类型。因为 `uv_fs_read` 调用 invokes INIT(READ),它意味着 `req->fs_type` 被分配一个常数 `UV_FS_READ`。
|
||||
|
||||
这是 POST 宏:
|
||||
|
||||
```
|
||||
#define POST \
|
||||
do { \
|
||||
if (cb != NULL) { \
|
||||
uv__work_submit(loop, &req->work_req, uv__fs_work, uv__fs_done); \
|
||||
return 0; \
|
||||
} \
|
||||
else { \
|
||||
uv__fs_work(&req->work_req); \
|
||||
return req->result; \
|
||||
} \
|
||||
} \
|
||||
while (0)
|
||||
```
|
||||
|
||||
它做什么取决于回调是否为 NULL。在 libuv 文件系统 APIs 中,一个 NULL 回调意味着我们真实地希望去执行一个 _同步_ 操作。在这种情况下,POST 直接调用 `uv__fs_work`(我们需要了解一下这个函数的功能),而对于一个 non-NULL 回调,它提交 `uv__fs_work` 作为一个工作事项到工作队列(指的是线程池),然后,注册 `uv__fs_done` 作为回调;该函数执行一些登记并调用用户提供的回调。
|
||||
|
||||
如果我们去看 `uv__fs_work` 的代码,我们将看到它使用很多宏去按需路由工作到真实的文件系统调用。在我们的案例中,对于 `UV_FS_READ` 这个调用将被 `uv__fs_read` 生成,它(最终)使用普通的 POSIX APIs 去读取。这个函数可以在一个 _阻塞_ 方式中很安全地实现。因为,它通过异步 API 调用时被置于一个线程池中。
|
||||
|
||||
在 Node.js 中,fs.readFile 函数是映射到 `uv_fs_read` 上。因此,可以在一个非阻塞模式中读取文件,甚至是当底层文件系统 API 是阻塞方式时。
|
||||
|
||||
* * *
|
||||
|
||||
|
||||
[[1]][1] 为确保服务器不泄露内存,我在一个启用泄露检查的 Valgrind 中运行它。因为服务器经常是被设计为永久运行,这是一个挑战;为克服这个问题,我在服务器上添加了一个 “kill 开关” - 一个从客户端接收的特定序列,以使它可以停止事件循环并退出。这个代码在 `theon_wrote_buf` 句柄中。
|
||||
|
||||
|
||||
[[2]][2] 在这里我们不过多地使用 `work_req`;讨论的素数测试服务器接下来将展示怎么被用于去传递上下文信息到回调中。
|
||||
|
||||
|
||||
[[3]][3] `uv_fs_read()` 提供了一个类似于 preadv Linux 系统调用的通用 API:它使用多缓冲区用于排序,并且支持一个到文件中的偏移。基于我们讨论的目的可以忽略这些特性。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id2
|
||||
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id3
|
||||
[4]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[5]:https://eli.thegreenplace.net/tag/c-c
|
||||
[6]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id4
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[8]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[9]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[10]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
[11]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[12]:http://libuv.org/
|
||||
[13]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/uv-server.c
|
||||
[14]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id5
|
||||
[15]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/uv-isprime-server.c
|
||||
[16]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/#id6
|
||||
[17]:https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
|
||||
@ -0,0 +1,48 @@
|
||||
介绍 GitHub 上的安全警报
|
||||
====================================
|
||||
|
||||
|
||||
上个月,我们用依赖关系图让你更容易跟踪你代码依赖的的项目,目前支持 Javascript 和 Ruby。如今,超过 75% 的 GitHub 项目有依赖,我们正在帮助你做更多的事情,而不只是关注那些重要的项目。在启用依赖关系图后,当我们检测到你的依赖中有漏洞或者来自 Github 社区中建议的已知修复时通知你。
|
||||
|
||||
[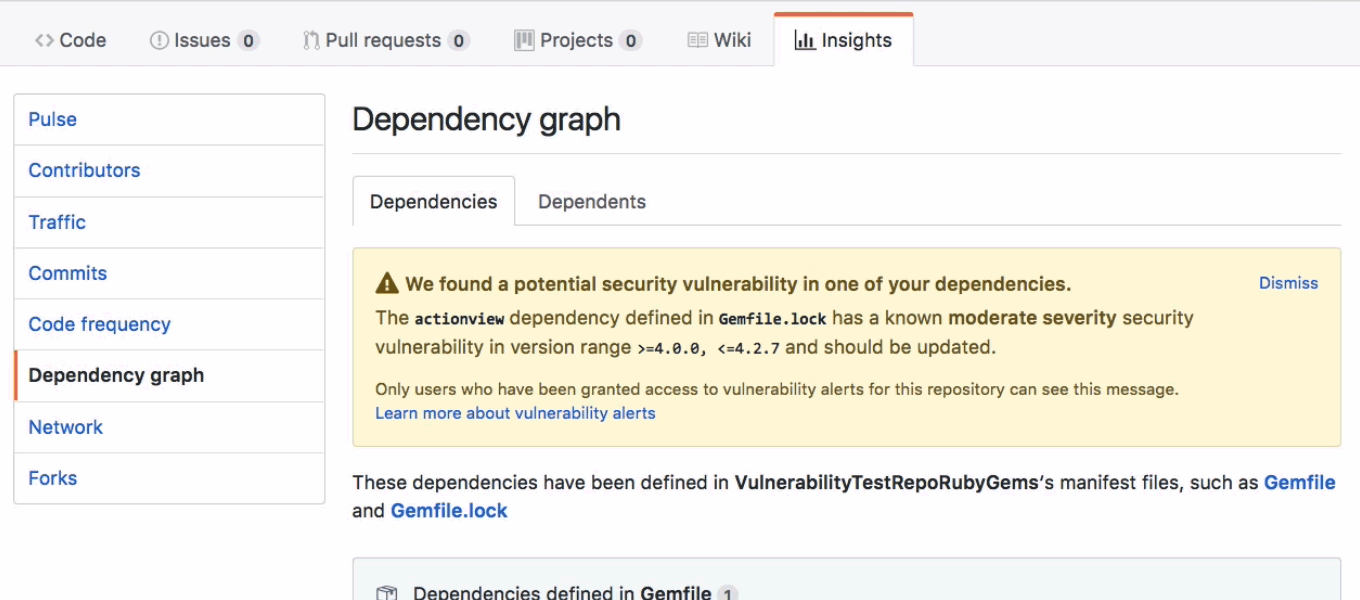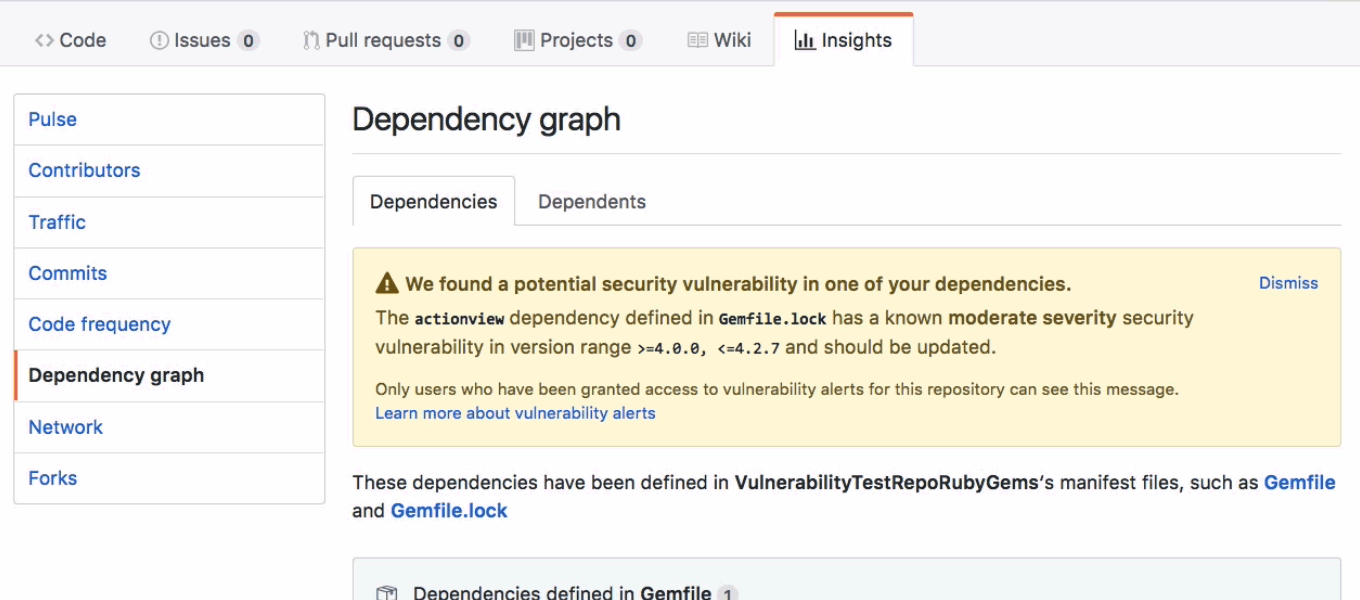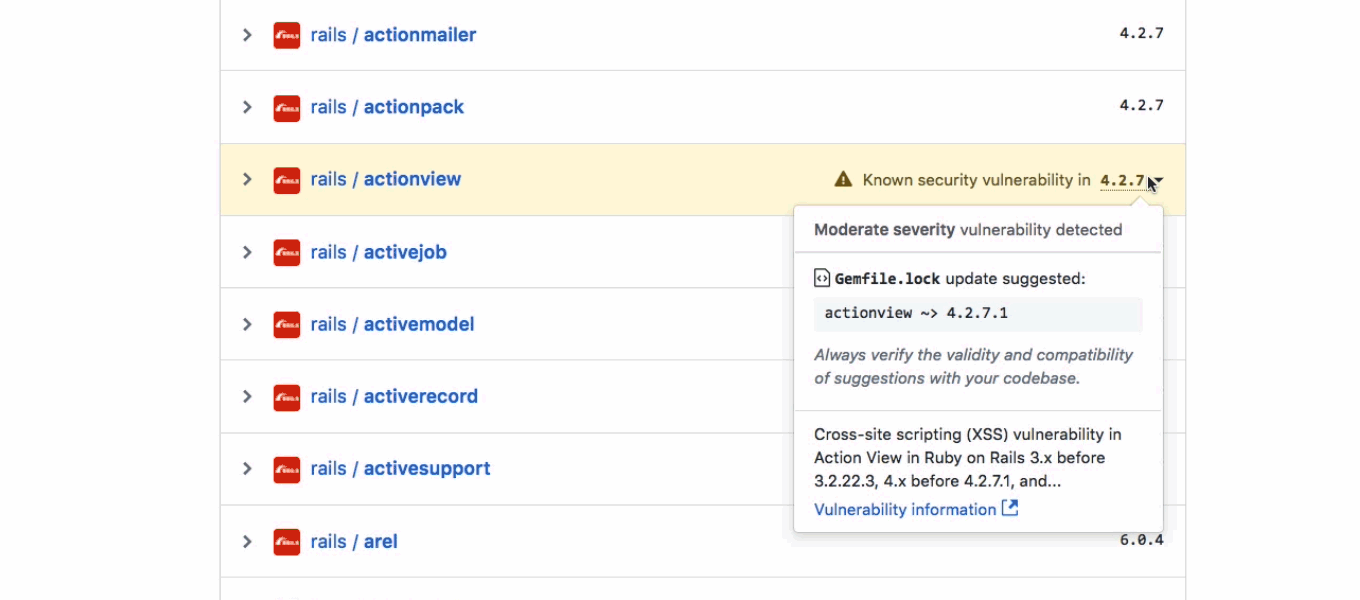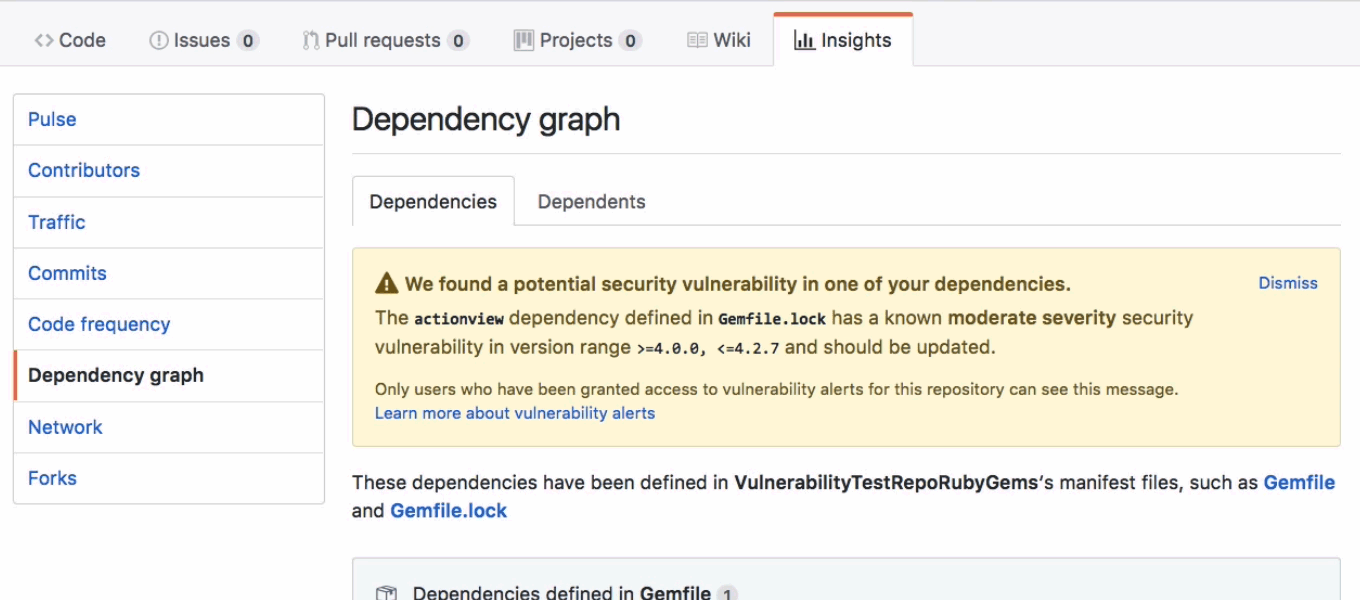][1]
|
||||
|
||||
### 如何开始使用安全警报
|
||||
|
||||
无论你的项目时私有还是公有的,安全警报都会为团队中的正确人员提供重要的漏洞信息。
|
||||
|
||||
启用你的依赖图
|
||||
|
||||
公开仓库将自动启用依赖关系图和安全警报。对于私人仓库,你需要在仓库设置中添加安全警报,或者在 “Insights” 选项卡中允许访问仓库的 “依赖关系图” 部分。
|
||||
|
||||
设置通知选项
|
||||
|
||||
启用依赖关系图后,管理员将默认收到安全警报。管理员还可以在依赖关系图设置中将团队或个人添加为安全警报的收件人。
|
||||
|
||||
警报响应
|
||||
|
||||
当我们通知你潜在的漏洞时,我们将突出显示我们建议更新的任何依赖关系。如果存在已知的安全版本,我们将使用机器学习和公开数据中选择一个,并将其包含在我们的建议中。
|
||||
|
||||
### 漏洞覆盖率
|
||||
|
||||
有 [CVE ID][2](公开披露的[国家漏洞数据库][3]中的漏洞)的漏洞将包含在安全警报中。但是,并非所有漏洞都有 CVE ID,甚至许多公开披露的漏洞也没有。随着安全数据的增长,我们将继续更好地识别漏洞。如需更多帮助来管理安全问题,请查看我们的[ GitHub Marketplace 中的安全合作伙伴][4]。
|
||||
|
||||
这是使用世界上最大的开源数据集的下一步,可以帮助你保持代码安全并做到最好。依赖关系图和安全警报目前支持 JavaScript 和 Ruby,并将在 2018 年提供 Python 支持。
|
||||
|
||||
[了解更多关于安全警报][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/blog/2470-introducing-security-alerts-on-github
|
||||
|
||||
作者:[mijuhan ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/mijuhan
|
||||
[1]:https://user-images.githubusercontent.com/594029/32851987-76c36e4a-c9eb-11e7-98fc-feb39fddaadb.gif
|
||||
[2]:https://cve.mitre.org/
|
||||
[3]:https://nvd.nist.gov/
|
||||
[4]:https://github.com/marketplace/category/security
|
||||
[5]:https://help.github.com/articles/about-security-alerts-for-vulnerable-dependencies/
|
||||
@ -0,0 +1,68 @@
|
||||
### 系统日志: 了解你的Linux系统
|
||||
|
||||

|
||||
By: [chabowski][1]
|
||||
|
||||
本文摘自教授Linux小白(或者非资深桌面用户)技巧的系列文章. 该系列文章旨在为由LinuxMagazine基于 [openSUSE Leap][3] 发布的第30期特别版 “[Getting Started with Linux][2]” 提供补充说明.
|
||||
|
||||
本文作者是 Romeo S. Romeo, 他是一名 PDX-based enterprise Linux 专家,转为创新企业提供富有伸缩性的解决方案.
|
||||
|
||||
Linux系统日志非常重要. 后台运行的程序(通常被称为守护进程或者服务进程)处理了你Linux系统中的大部分任务. 当这些守护进程工作时,它们将任务的详细信息记录进日志文件中,作为他们做过什么的历史信息. 这些守护进程的工作内容涵盖从使用原子钟同步时钟到管理网络连接. 所有这些都被记录进日志文件,这样当有错误发生时,你可以通过查阅特定的日志文件来看出发生了什么.
|
||||
|
||||

|
||||
|
||||
Photo by Markus Spiske on Unsplash
|
||||
|
||||
有很多不同的日志. 历史上, 他们一般以纯文本的格式存储到 `/var/log` 目录中. 现在依然有很多日志这样做, 你可以很方便的使用 `less` 来查看它们.
|
||||
在新装的 `openSUSE Leap 42.3` 以及大多数现代操作系统上,重要的日志由 `systemd` 初始化系统存储. `systemd`这套系统负责启动守护进程并在系统启动时让计算机做好被使用的准备。
|
||||
由 `systemd` 记录的日志以二进制格式存储, 这使地它们消耗的空间更小,更容易被浏览,也更容易被导出成其他各种格式,不过坏处就是你必须使用特定的工具才能查看.
|
||||
好在, 这个工具已经预安装在你的系统上了: 它的名字叫 `journalctl`,而且默认情况下, 它会将每个守护进程的所有日志都记录到一个地方.
|
||||
|
||||
只需要运行 `journalctl` 命令就能查看你的 `systemd` 日志了. 它会用 `less` 分页器显示各种日志. 为了让你有个直观的感受, 下面是`journalctl` 中摘录的一条日志记录:
|
||||
|
||||
```
|
||||
Jul 06 11:53:47 aaathats3as pulseaudio[2216]: [pulseaudio] alsa-util.c: Disabling timer-based scheduling because running inside a VM.
|
||||
```
|
||||
|
||||
这条独立的日志记录以此包含了记录的日期和时间, 计算机名, 记录日志的进程名, 记录日志的进程PID, 以及日志内容本身.
|
||||
|
||||
若系统中某个程序运行出问题了, 则可以查看日志文件并搜索(使用 “/” 加上要搜索的关键字)程序名称. 有可能导致该程序出问题的错误会记录到系统日志中.
|
||||
有时,错误信息会足够详细让你能够修复该问题. 其他时候, 你需要在Web上搜索解决方案. Google就很适合来搜索奇怪的Linux问题.
|
||||

|
||||
不过搜索时请注意你只输入了日志的内容, 行首的那些信息(日期, 主机名, 进程ID) 是无意义的,会干扰搜索结果.
|
||||
|
||||
解决方法一般在搜索结果的前几个连接中就会有了. 当然,你不能只是无脑得运行从互联网上找到的那些命令: 请一定先搞清楚你要做的事情是什么,它的效果会是什么.
|
||||
据说, 从系统日志中查询日志要比直接搜索描述故障的关键字要有用的多. 因为程序出错有很多原因, 而且同样的故障表现也可能由多种问题引发的.
|
||||
|
||||
比如, 系统无法发声的原因有很多, 可能是播放器没有插好, 也可能是声音系统出故障了, 还可能是缺少合适的驱动程序.
|
||||
如果你只是泛泛的描述故障表现, 你会找到很多无关的解决方法,而你也会浪费大量的时间. 而指定搜索日志文件中的内容, 你只会查询出他人也有相同日志内容的结果.
|
||||
你可以对比一下图1和图2.
|
||||
|
||||

|
||||
|
||||
图 1 搜索系统的故障表现只会显示泛泛的,不精确的结果. 这种搜索通常没什么用.
|
||||
|
||||

|
||||
|
||||
图 2 搜索特定的日志行会显示出精确的,有用的结果. 这种搜索通常很有用.
|
||||
|
||||
也有一些系统不用 `journalctl` 来记录日志. 在桌面系统中最常见的这类日志包括用于 `/var/log/zypper.log` 记录openSUSE包管理器的行为; `/var/log/boot.log` 记录系统启动时的消息,这类消息往往滚动的特别块,根本看不过来; `/var/log/ntp` 用来记录 Network Time Protocol 守护进程同步时间时发生的错误.
|
||||
另一个存放硬件故障信息的地方是 `Kernel Ring Buffer`(内核环状缓冲区), 你可以输入 `demesg -H` 命令来查看(这条命令也会调用 `less` 分页器来查看).
|
||||
`Kernel Ring Buffer` 存储在内存中, 因此会在重启电脑后丢失. 不过它包含了Linux内核中的重要事件, 比如新增了硬件, 加载了模块, 以及奇怪的网络错误.
|
||||
|
||||
希望你已经准备好深入了解你的Linux系统了! 祝你玩的开心!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.suse.com/communities/blog/system-logs-understand-linux-system/
|
||||
|
||||
作者:[chabowski]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.suse.com/communities/blog/author/chabowski/
|
||||
[2]:http://www.linux-magazine.com/Resources/Special-Editions/30-Getting-Started-with-Linux
|
||||
[3]:https://en.opensuse.org/Portal:42.3
|
||||
[4]:http://www.linux-magazine.com/
|
||||
@ -0,0 +1,59 @@
|
||||
-最合理的语言工程模式
|
||||
-============================================================
|
||||
-
|
||||
-当你熟练掌握一体化工程技术时,你就会发现它逐渐超过了技术优化的层面。我们制作的每件手工艺品都在一个大环境背景下,在这个环境中,人类的行为逐渐突破了经济意义,社会学意义,达到了奥地利经济学家所称的“人类行为学”,这是目的明确的人类行为所能达到的最大范围。
|
||||
-
|
||||
-对我来说这并不只是抽象理论。当我在开源发展项目中编写时,我的行为就十分符合人类行为学的理论,这行为不是针对任何特定的软件技术或某个客观事物,它指的是在开发科技的过程中人类行为的背景环境。从人类行为学角度对科技进行的解读不断增加,大量的这种解读可以重塑科技框架,带来人类生产力和满足感的极大幅度增长,而这并不是由于我们换了工具,而是在于我们改变了掌握它们的方式。
|
||||
-
|
||||
-在这个背景下,我在第三篇额外的文章中谈到了 C 语言的衰退和正在到来的巨大改变,而我们也确实能够感受到系统编程的新时代的到来,在这个时刻,我决定把我之前有的大体的预感具象化为更加具体的,更实用的点子,它们主要是关于计算机语言设计的分析,例如为什么他们会成功,或为什么他们会失败。
|
||||
-
|
||||
-在我最近的一篇文章中,我写道:所有计算机语言都是对机器资源的成本和程序员工作成本的相对权衡的结果,和对其相对价值的体现。这些都是在一个计算能力成本不断下降但程序员工作成本不减反增的背景下产生的。我还强调了转化成本在使原有交易主张适用于当下环境中的新增角色。在文中我将编程人员描述为一个寻找今后最适方案的探索者。
|
||||
-
|
||||
-现在我要讲一讲最后一点。以现有水平为起点,一个语言工程师有极大可能通过多种方式推动语言设计的发展。通过什么系统呢? GC 还是人工分配?使用何种配置,命令式语言,函数程式语言或是面向对象语言?但是从人类行为学的角度来说,我认为它的形式会更简洁,也许只是选择解决长期问题还是短期问题?
|
||||
-
|
||||
-所谓的“远”“近”之分,是指硬件成本的逐渐降低,软件复杂程度的上升和由现有语言向其他语言转化的成本的增加,根据它们的变化曲线所做出的判断。短期问题指编程人员眼下发现的问题,长期问题指可预见的一系列情况,但它们一段时间内不会到来。针对近期问题所做出的部署需要非常及时且有效,但随着情况的变化,短期解决方案有可能很快就不适用了。而长期的解决方案可能因其过于超前而夭折,或因其代价过高无法被接受。
|
||||
-
|
||||
-在计算机刚刚面世的时候, FORTRAN 是近期亟待解决的问题, LISP 是远期问题。汇编语言是短期解决方案,图解说明非通用语言的分类应用,还有关门电阻不断上涨的成本。随着计算机技术的发展,PHP 和 Javascript逐渐应用于游戏中。至于长期的解决方案? Oberon , Ocaml , ML , XML-Docbook 都可以。 他们形成的激励机制带来了大量具有突破性和原创性的想法,事态蓬勃但未形成体系,那个时候距离专业语言的面世还很远,(值得注意的是这些想法的出现都是人类行为学中的因果,并非由于某种技术)。专业语言会失败,这是显而易见的,它的转入成本高昂,让大部分人望而却步,因此不能没能达到能够让主流群体接受的水平,被孤立,被搁置。这也是 LISP 不为人知的的过去,作为前 LISP 管理层人员,出于对它深深的爱,我为你们讲述了这段历史。
|
||||
-
|
||||
-如果短期解决方案出现故障,它的后果更加惨不忍睹,最好的结果是期待一个相对体面的失败,好转换到另一个设计方案。(通常在转化成本较高时)如果他们执意继续,通常造成众多方案相互之间藕断丝连,形成一个不断扩张的复合体,一直维持到不能运转下去,变成一堆摇摇欲坠的杂物。是的,我说的就是 C++ 语言,还有 Java 描述语言,(唉)还有 Perl,虽然 Larry Wall 的好品味成功地让他维持了很多年,问题一直没有爆发,但在 Perl 6 发行时,他的好品味最终引爆了整个问题。
|
||||
-
|
||||
-这种思考角度激励了编程人员向着两个不同的目的重新塑造语言设计: ①以远近为轴,在自身和预计的未来之间选取一个最适点,然后 ②降低由一种或多种语言转化为自身语言的转入成本,这样你就可以吸纳他们的用户群。接下来我会讲讲 C 语言是怎样占领全世界的。
|
||||
-
|
||||
-在整个计算机发展史中,没有谁能比 C 语言完美地把握最适点的选取了,我要做的只是证明这一点,作为一种实用的主流语言, C 语言有着更长的寿命,它目睹了无数个竞争者的兴衰,但它的地位仍旧不可取代。从淘汰它的第一个竞争者到现在已经过了 35 年,但看起来C语言的终结仍旧不会到来。
|
||||
-
|
||||
-当然,如果你愿意的话,可以把 C 语言的持久存在归功于人类的文化惰性,但那是对“文化惰性”这个词的曲解, C 语言一直得以延续的真正原因是没有人提供足够的转化费用!
|
||||
-
|
||||
-相反的, C 语言低廉的内部转化费用未得到应有的重视,C 语言是如此的千变万化,从它漫长统治时期的初期开始,它就可以适用于多种语言如 FORTRAN , Pascal , 汇编语言和 LISP 的编程习惯。在二十世纪八十年代我就注意到,我可以根据编程人员的编码风格判断出他的母语是什么,这也从另一方面证明了C 语言的魅力能够吸引全世界的人使用它。
|
||||
-
|
||||
-C++ 语言同样胜在它低廉的转化费用。很快,大部分新兴的语言为了降低自身转化费用,纷纷参考 C 语言语法。请注意这给未来的语言设计环境带来了什么影响:它尽可能地提高了 C-like 语言的价值,以此来降低其他语言转化为 C 语言的转化成本。
|
||||
-
|
||||
-另一种降低转入成本的方法十分简单,即使没接触过编程的人都能学会,但这种方法很难完成。我认为唯一使用了这种方法的 Python就是靠这种方法进入了职业比赛。对这个方法我一带而过,是因为它并不是我希望看到的,顺利执行的系统语言战略,虽然我很希望它不是那样的。
|
||||
-
|
||||
-今天我们在2017年年底聚集在这里,下一项我们应该为某些暴躁的团体发声,如 Go 团队,但事实并非如此。 Go 这个项目漏洞百出,我甚至可以想象出它失败的各种可能,Go 团队太过固执独断,即使几乎整个用户群体都认为 Go 需要做出改变了,Go 团队也无动于衷,这是个大问题。 一旦发生故障, GC 发生延迟或者用牺牲生产量来弥补延迟,但无论如何,它都会严重影响到这种语言的应用,大幅缩小这种语言的适用范围。
|
||||
-
|
||||
-即便如此,在 Go 的设计中,还是有一个我颇为认同的远大战略目标,想要理解这个目标,我们需要回想一下如果想要取代 C 语言,要面临的短期问题是什么。同我之前提到的,随着项目计划的不断扩张,故障率也在持续上升,这其中内存管理方面的故障尤其多,而内存管理一直是崩溃漏洞和安全漏洞的高发领域。
|
||||
-
|
||||
-我们现在已经知道了两件十分中重要的紧急任务,要想取代 C 语言,首先要先做到这两点:(1)解决内存管理问题;(2)降低由 C 语言向本语言转化时所需的转入成本。纵观编程语言的历史——从人类行为学的角度来看,作为 C 语言的准替代者,如果不能有效解决转入成本过高这个问题,那他们所做的其他部分做得再好都不算数。相反的,如果他们把转入成本过高这个问题解决地很好,即使他们其他部分做的不是最好的,人们也不会对他们吹毛求疵。
|
||||
-
|
||||
-这正是 Go 的做法,但这个理论并不是完美无瑕的,它也有局限性。目前 GC 延迟限制了它的发展,但 Go 现在选择照搬 Unix 下 C 语言的传染战略,让自身语言变成易于转入,便于传播的语言,其繁殖速度甚至快于替代品。但从长远角度看,这并不是个好办法。
|
||||
-
|
||||
-当然, Rust 语言的不足是个十分明显的问题,我们不应当回避它。而它,正将自己定位为适用于长远计划的选择。在之前的部分中我已经谈到了为什么我觉得它还不完美,Rust 语言在 TIBOE 和PYPL 指数上的成就也证明了我的说法,在 TIBOE 上 Rust 从来没有进过前20名,在 PYPL 指数上它的成就也比 Go 差很多。
|
||||
-
|
||||
-五年后 Rust 能发展的怎样还是个问题,如果他们愿意改变,我建议他们重视转入成本问题。以我个人经历来说,由 C 语言转入 Rust 语言的能量壁垒使人望而却步。如果编码提升工具比如 Corrode 只能把 C 语言映射为不稳定的 Rust 语言,但不能解决能量壁垒的问题;或者如果有更简单的方法能够自动注释所有权或试用期,人们也不再需要它们了——这些问题编译器就能够解决。目前我不知道怎样解决这个问题,但我觉得他们最好找出解决方案。
|
||||
-
|
||||
-在最后我想强调一下,虽然在 Ken Thompson 的设计经历中,他看起来很少解决短期问题,但他对未来有着极大的包容性,并且这种包容性还在不断提升。当然 Unix 也是这样的, 它让我不禁暗自揣测,让我认为 Go 语言中令人不快的地方都其实是他们未来事业的基石(例如缺乏泛型)。如果要确认这件事是真假,我需要比 Ken 还要聪明,但这并不是一件容易让人相信的事情。
|
||||
-
|
||||
---------------------------------------------------------------------------------
|
||||
-
|
||||
-via: http://esr.ibiblio.org/?p=7745
|
||||
-
|
||||
-作者:[Eric Raymond ][a]
|
||||
-译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
-校对:[校对者ID](https://github.com/校对者ID)
|
||||
-
|
||||
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
-
|
||||
-[a]:http://esr.ibiblio.org/?author=2
|
||||
-[1]:http://esr.ibiblio.org/?author=2
|
||||
-[2]:http://esr.ibiblio.org/?p=7711&cpage=1#comment-1913931
|
||||
-[3]:http://esr.ibiblio.org/?p=7745
|
||||
@ -1,80 +0,0 @@
|
||||
容器技术和 k8s 的下一站:
|
||||
============================================================
|
||||
### 想知道容器编排管理和 K8s 的最新展望么?来看看专家怎么说。
|
||||
|
||||

|
||||
|
||||
如果你想对容器在未来的发展方向有一个整体把握,那么你一定要跟着钱走,看看钱都投在了哪里。当然了,有很多很多的钱正在投入容器的进一步发展。相关研究预计 2020 年容器技术的投入将占有 [27 亿美元][4] 的市场份额 。而在 2016 年,容器相关技术投入的总额为 7.62 亿美元,只有 2020 年投入预计的三分之一。巨额投入的背后是一些显而易见的基本因素,包括容器化的迅速增长以及并行化的大趋势。随着容器被大面积推广和使用,容器编排管理也会被理所当然的推广应用起来。
|
||||
|
||||
来自 [_The new stack_][5] 的调研数据表明,容器的推广使用是编排管理被推广的主要的催化剂。根据调研参与者的反馈数据,在已经将容器技术使用到生产环境中的使用者里,有六成正在将 kubernetes(k8s)编排管理广泛的应用在生产环境中,另外百分之十九的人员则表示他们已经处于部署 k8s 的初级阶段。在容器部署初期的使用者当中,虽然只有百分之五的人员表示已经在使用 K8s ,但是百分之五十八的人员表示他们正在计划和准备使用 K8s。总而言之,容器和 Kuebernetes 的关系就好比是鸡和蛋一样,相辅相成紧密关联。众多专家一致认为编排管理工具对容器的[长周期管理][6] 以及其在市场中的发展有至关重要的作用。正如 [Cockroach 实验室][7] 的 Alex Robinson 所说,容器编排管理被更广泛的拓展和应用是一个总体的大趋势。毫无疑问,这是一个正在快速演变的领域,且未来潜力无穷。鉴于此,我们对罗宾逊和其他的一些容器的实际使用和推介者做了采访,来从他们作为容器技术的践行者的视角上展望一下容器编排以及 k8s 的下一步发展。
|
||||
|
||||
### **容器编排将被主流接受**
|
||||
|
||||
像任何重要技术的转型一样,我们就像是处在一个高崖之上一般,在经过了初期步履蹒跚的跋涉之后将要来到一望无际的广袤平原。广大的新天地和平实真切的应用需求将会让这种新技术在主流应用中被迅速推广,尤其是在大企业环境中。正如 Alex Robinson 说的那样,容器技术的淘金阶段已经过去,早期的技术革新创新正在减速,随之而来的则是市场对容器技术的稳定性和可用性的强烈需求。这意味着未来我们将不会再见到大量的新的编排管理系统的涌现,而是会看到容器技术方面更多的安全解决方案,更丰富的管理工具,以及基于目前主流容器编排系统的更多的新特性。
|
||||
|
||||
### **更好的易用性**
|
||||
|
||||
人们将在简化容器的部署方面下大功夫,因为容器部署的初期工作对很多公司和组织来说还是比较复杂的,尤其是容器的[长期管理维护][8]更是需要投入大量的精力。正如 [Codemill AB][9] 公司的 My Karlsson 所说,容器编排技术还是太复杂了,这导致很多使用者难以娴熟驾驭和充分利用容器编排的功能。很多容器技术的新用户都需要花费很多精力,走很多弯路,才能搭建小规模的,单个的,被隔离的容器系统。这种现象在那些没有针对容器技术设计和优化的应用中更为明显。在简化容器编排管理方面有很多优化可以做,这些优化和改造将会使容器技术更加具有可用性。
|
||||
|
||||
### **在 hybrid cloud 以及 multi-cloud 技术方面会有更多侧重**
|
||||
|
||||
随着容器和容器编排技术被越来越多的使用,更多的组织机构会选择扩展他们现有的容器技术的部署,从之前的把非重要系统部署在单一环境的使用情景逐渐过渡到更加[复杂的使用情景][10]。对很多公司来说,这意味着他们必须开始学会在 [hybrid cloud][11] 和 [muilti-cloud][12] 的环境下,全局化的去管理那些容器化的应用和微服务。正如红帽 [Openshift 部门产品战略总监][14] [Brian Gracely][13] 所说,容器和 k8s 技术的使用使得我们成功的实现了混合云以及应用的可移植性。结合 Open Service Broker API 的使用,越来越多的结合私有云和公有云资源的新应用将会涌现出来。
|
||||
据 [CloudBees][15] 公司的高级工程师 Carlos Sanchez 分析,联合服务(Federation)将会得到极大推动,使一些诸如多地区部署和多云部署等的备受期待的新特性成为可能。
|
||||
|
||||
**[ 想知道 CIO 们对 hybrid cloud 和 multi cloud 的战略构想么? 请参看我们的这条相关资源, **[**Hybrid Cloud: The IT leader's guide**][16]**. ]**
|
||||
|
||||
### **平台和工具的持续整合及加强**
|
||||
|
||||
对任何一种科技来说,持续的整合和加强从来都是大势所趋; 容器编排管理技术在这方面也不例外。来自 [Sumo Logic][17] 的首席分析师 Ben Newton 表示,随着容器化渐成主流,软件工程师们正在很少数的一些技术上做持续整合加固的工作,来满足他们的一些微应用的需求。容器和 K8s 将会毫无疑问的成为容器编排管理方面的主流平台,并轻松碾压其他的一些小众平台方案。因为 K8s 提供了一个相当清晰的可以摆脱各种特有云生态的途径,K8s 将被大量公司使用,逐渐形成一个不依赖于某个特定云服务的“中立云”(cloud-neutral)。
|
||||
|
||||
### **K8s 的下一站**
|
||||
|
||||
来自 [Alcide][18] 的 CTO 和联合创始人 Gadi Naor 表示,k8s 将会是一个有长期和远景发展的技术,虽然我们的社区正在大力推广和发展 k8s,k8s 仍有很长的路要走。
|
||||
专家们对[日益流行的 k8s 平台][19]也作出了以下一些预测:
|
||||
|
||||
**_来自 Alcide 的 Gadi Naor 表示:_** “运营商会持续演进并趋于成熟,直到在 k8s 上运行的应用可以完全自治。利用 [OpenTracing][20] 和诸如 [istio][21] 技术的 service mesh 架构,在 k8s 上部署和监控微应用将会带来很多新的可能性。”
|
||||
|
||||
**_来自 Red Hat 的 Brian Gracely 表示:_** “k8s 所支持的应用的种类越来越多。今后在 k8s 上,你不仅可以运行传统的应用程序,还可以运行原生的云应用,大数据应用以及 HPC 或者基于 GPU 运算的应用程序,这将为灵活的架构设计带来无限可能。”
|
||||
|
||||
**_来自 Sumo Logic 的 Ben Newton 表示:_** “随着 k8s 成为一个具有统治地位的平台,我预计更多的操作机制将会被统一化,尤其是 k8s 将和第三方管理和监控平台融合起来。”
|
||||
|
||||
**_来自 CloudBees 的 Carlos Sanchez 表示:_** “在不久的将来我们就能看到不依赖于 Docker 而使用其他运行时环境的系统,这将会有助于消除任何可能的 lock-in 情景“ [小编提示:[CRI-O][22] 就是一个可以借鉴的例子。]“而且我期待将来会出现更多的针对企业环境的存储服务新特性,包括数据快照以及在线的磁盘容量的扩展。”
|
||||
|
||||
**_来自 Cockroach Labs 的 Alex Robinson 表示:_** “ k8s 社区正在讨论的一个重大发展议题就是加强对[有状态程序][23]的管理。目前在 k8s 平台下,实现状态管理仍然非常困难,除非你所使用的云服务商可以提供远程固定磁盘。现阶段也有很多人在多方面试图改善这个状况,包括在 k8s 平台内部以及在外部服务商一端做出的一些改进。”
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/11/containers-and-kubernetes-whats-next
|
||||
|
||||
作者:[Kevin Casey ][a]
|
||||
译者:[yunfengHe](https://github.com/yunfengHe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/11/kubernetes-numbers-10-compelling-stats
|
||||
[2]:https://enterprisersproject.com/article/2017/11/how-enterprise-it-uses-kubernetes-tame-container-complexity
|
||||
[3]:https://enterprisersproject.com/article/2017/11/5-kubernetes-success-tips-start-smart?sc_cid=70160000000h0aXAAQ
|
||||
[4]:https://451research.com/images/Marketing/press_releases/Application-container-market-will-reach-2-7bn-in-2020_final_graphic.pdf
|
||||
[5]:https://thenewstack.io/
|
||||
[6]:https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul
|
||||
[7]:https://www.cockroachlabs.com/
|
||||
[8]:https://enterprisersproject.com/article/2017/10/microservices-and-containers-6-management-tips-long-haul
|
||||
[9]:https://codemill.se/
|
||||
[10]:https://www.redhat.com/en/challenges/integration?intcmp=701f2000000tjyaAAA
|
||||
[11]:https://enterprisersproject.com/hybrid-cloud
|
||||
[12]:https://enterprisersproject.com/article/2017/7/multi-cloud-vs-hybrid-cloud-whats-difference
|
||||
[13]:https://enterprisersproject.com/user/brian-gracely
|
||||
[14]:https://www.redhat.com/en
|
||||
[15]:https://www.cloudbees.com/
|
||||
[16]:https://enterprisersproject.com/hybrid-cloud?sc_cid=70160000000h0aXAAQ
|
||||
[17]:https://www.sumologic.com/
|
||||
[18]:http://alcide.io/
|
||||
[19]:https://enterprisersproject.com/article/2017/10/how-explain-kubernetes-plain-english
|
||||
[20]:http://opentracing.io/
|
||||
[21]:https://istio.io/
|
||||
[22]:http://cri-o.io/
|
||||
[23]:https://opensource.com/article/17/2/stateful-applications
|
||||
[24]:https://enterprisersproject.com/article/2017/11/containers-and-kubernetes-whats-next?rate=PBQHhF4zPRHcq2KybE1bQgMkS2bzmNzcW2RXSVItmw8
|
||||
[25]:https://enterprisersproject.com/user/kevin-casey
|
||||
@ -0,0 +1,70 @@
|
||||
# LibreOffice 现在在 Flatpak 的 Flathub 应用商店提供
|
||||
|
||||

|
||||
|
||||
LibreOffice 现在可以从集中化的 Flatpak 应用商店 [Flathub][3] 进行安装。
|
||||
|
||||
它的到来使任何运行现代 Linux 发行版的人都能只点击一两次安装 LibreOffice 的最新稳定版本,而无需搜索 PPA,纠缠 tar 包或等待发行商将其打包。
|
||||
|
||||
自去年 8 月份以来,[LibreOffice Flatpak][5] 已经可供用户下载和安装 [LibreOffice 5.2][6]。
|
||||
|
||||
这里“新”的是发行方法。文档基金会选择使用 Flathub 而不是专门的服务器来发布更新。
|
||||
|
||||
这对于终端用户来说是一个_很好_的消息,因为这意味着不需要在新安装时担心仓库,但对于 Flatpak 的倡议者来说也是一个好消息:LibreOffice 是开源软件最流行的生产力套件。它对格式和应用商店的支持肯定会受到热烈的欢迎。
|
||||
|
||||
在撰写本文时,你可以从 Flathub 安装 LibreOffice 5.4.2。新的稳定版本将在发布时添加。
|
||||
|
||||
### 在 Ubuntu 上启用 Flathub
|
||||
|
||||

|
||||
|
||||
Fedora、Arch 和 Linux Mint 18.3 用户已经安装了 Flatpak,随时可以开箱即用。Mint 甚至预启用了 Flathub remote。
|
||||
|
||||
[从 Flathub 安装 LibreOffice][7]
|
||||
|
||||
要在 Ubuntu 上启动并运行 Flatpak,首先必须安装它:
|
||||
|
||||
```
|
||||
sudo apt install flatpak gnome-software-plugin-flatpak
|
||||
```
|
||||
|
||||
为了能够从 Flathub 安装应用程序,你需要添加 Flathub 远程服务器:
|
||||
|
||||
```
|
||||
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
```
|
||||
|
||||
这就行了。只需注销并返回(以便 Ubuntu Software 刷新其缓存),之后你应该能够通过 Ubuntu Software 看到 Flathub 上的任何 Flatpak 程序了。
|
||||
|
||||
在本例中,搜索 “LibreOffice” 并在结果中找到下面有 Flathub 提示的结果。(请记住,Ubuntu 已经调整了客户端,来将 Snap 程序显示在最上面,所以你可能需要向下滚动列表来查看它)。
|
||||
|
||||
从 flatpakref 中[安装 Flatpak 程序有一个 bug][8],所以如果上面的方法不起作用,你也可以使用命令行从 Flathub 中安装 Flathub 程序。
|
||||
|
||||
Flathub 网站列出了安装每个程序所需的命令。切换到“命令行”选项卡来查看它们。
|
||||
|
||||
#### Flathub 上更多的应用
|
||||
|
||||
如果你经常看这个网站,你就会知道我喜欢 Flathub。这是我最喜欢的一些应用(Corebird、Parlatype、GNOME MPV、Peek、Audacity、GIMP 等)的家园。我无需折衷就能获得这些应用程序的最新,稳定版本(加上它们需要的所有依赖)。
|
||||
|
||||
而且,在我 twiiter 上发布一周左右后,大多数 Flatpak 应用现在看起来有很棒 GTK 主题 - 不再需要[临时方案][9]了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/11/libreoffice-now-available-flathub-flatpak-app-store
|
||||
|
||||
作者:[ JOEY SNEDDON ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[2]:http://www.omgubuntu.co.uk/category/news
|
||||
[3]:http://www.flathub.org/
|
||||
[4]:http://www.omgubuntu.co.uk/2017/11/libreoffice-now-available-flathub-flatpak-app-store
|
||||
[5]:http://www.omgubuntu.co.uk/2016/08/libreoffice-5-2-released-whats-new
|
||||
[6]:http://www.omgubuntu.co.uk/2016/08/libreoffice-5-2-released-whats-new
|
||||
[7]:https://flathub.org/repo/appstream/org.libreoffice.LibreOffice.flatpakref
|
||||
[8]:https://bugs.launchpad.net/ubuntu/+source/gnome-software/+bug/1716409
|
||||
[9]:http://www.omgubuntu.co.uk/2017/05/flatpak-theme-issue-fix
|
||||
@ -1,147 +0,0 @@
|
||||
Photon也许能成为你最喜爱的容器操作系统
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Phonton OS专注于容器,是一个非常出色的平台。 —— Jack Wallen
|
||||
|
||||
容器在当下的火热,并不是没有原因的。正如[之前][13]讨论的,容器可以使您轻松快捷地将新的服务与应用部署到您的网络上,而且并不耗费太多的系统资源。比起专用硬件和虚拟机,容器都是更加划算的,除此之外,他们更容易更新与重用。
|
||||
|
||||
更重要的是,容器喜欢Linux(反之亦然)。不需要太多时间和麻烦,你就可以启动一台Linux服务器,运行[Docker][14],再是部署容器。但是,哪种Linux发行版最适合部署容器呢?我们的选择很多。你可以使用标准的Ubuntu服务器平台(更容易安装Docker并部署容器)或者是更轻量级的发行版 —— 专门用于部署容器。
|
||||
|
||||
[Photon][15]就是这样的一个发行版。这个特殊的版本是由[VMware][16]于2005年创建的,它包含了Docker的守护进程,并与容器框架(如Mesos和Kubernetes)一起使用。Photon经过优化可与[VMware vSphere][17]协同工作,而且可用于裸机,[Microsoft Azure][18], [Google Compute Engine][19], [Amazon Elastic Compute Cloud][20], 或者 [VirtualBox][21]等。
|
||||
|
||||
Photon通过只安装Docker守护进程所必需的东西来保持它的轻量。而这样做的结果是,这个发行版的大小大约只有300MB。但这足以让Linux的运行一切正常。除此之外,Photon的主要特点还有:
|
||||
|
||||
* 内核调整为性能模式。
|
||||
|
||||
* 内核根据[内核自防护项目][6](KSPP)进行了加固。
|
||||
|
||||
* 所有安装的软件包都根据加固的安全标识来构建。
|
||||
|
||||
* 操作系统在信任验证后启动。
|
||||
|
||||
* Photon管理进程管理防火墙,网络,软件包,和远程登录在Photon机子上的用户。
|
||||
|
||||
* 支持持久卷。
|
||||
|
||||
* [Project Lightwave][7] 整合。
|
||||
|
||||
* 及时的安全补丁与更新。
|
||||
|
||||
Photon可以通过[ISO][22],[OVA][23],[Amazon Machine Image][24],[Google Compute Engine image][25]和[Azure VHD][26]安装使用。现在我将向您展示如何使用ISO镜像在VirtualBox上安装Photon。整个安装过程大概需要五分钟,在最后您将有一台随时可以部署容器的虚拟机。
|
||||
|
||||
### 创建虚拟机
|
||||
|
||||
在部署第一台容器之前,您必须先创建一台虚拟机并安装Photon。为此,打开VirtualBox并点击“新建”按钮。跟着创建虚拟机向导进行配置(根据您的容器将需要的用途,为Photon提供必要的资源)。在创建好虚拟机后,您所需要做的第一件事就是更改配置。选择新建的虚拟机(在VirtualBox主窗口的左侧面板中),然后单击“设置”。在弹出的窗口中,点击“网络”(在左侧的导航中)。
|
||||
|
||||
在“网络”窗口(图1)中,你需要在“连接”的下拉窗口中选择桥接。这可以确保您的Photon服务与您的网络相连。完成更改后,单击确定。
|
||||
|
||||
### [photon_0.jpg][8]
|
||||
|
||||

|
||||
图 1: 更改Photon在VirtualBox中的网络设置。[经许可使用][1]
|
||||
|
||||
从左侧的导航选择您的Photon虚拟机,点击启动。系统会提示您去加载IOS镜像。当您完成之后,Photon安装程序将会启动并提示您按回车后开始安装。安装过程基于ncurses(没有GUI),但它非常简单。
|
||||
|
||||
接下来(图2),系统会询问您是要最小化安装,完整安装还是安装OSTree服务器。我选择了完整安装。选择您所需要的任意选项,然后按回车继续。
|
||||
|
||||
### [photon_1.jpg][9]
|
||||
|
||||

|
||||
图 2: 选择您的安装类型.[经许可使用][2]
|
||||
|
||||
在下一个窗口,选择您要安装Photon的磁盘。由于我们将其安装在虚拟机,因此只有一块磁盘会被列出(图3)。选择“自动”按下回车。然后安装程序会让您输入(并验证)管理员密码。在这之后镜像开始安装在您的磁盘上并在不到5分钟的时间内结束。
|
||||
|
||||
### [photon_2.jpg][]
|
||||
|
||||

|
||||
图 3: 选择安装Photon的硬盘.[经许可使用][3]
|
||||
|
||||
安装完成后,重启虚拟机并使用安装时创建的用户root和它的密码登录。一切就绪,你准备好开始工作了。
|
||||
|
||||
在开始使用Docker之前,您需要更新一下Photon。Photon使用 _yum_ 软件包管理器,因此在以root用户登录后输入命令 _yum update_。如果有任何可用更新,则会询问您是否确认(图4)。
|
||||
|
||||
### [photon_3.jpg][11]
|
||||
|
||||

|
||||
图 4: 更新 Photon.[经许可使用][4]
|
||||
|
||||
用法
|
||||
|
||||
正如我所说的,Photon提供了部署容器甚至创建Kubernetes集群所需要的所有包。但是,在使用之前还要做一些事情。首先要启动Docker守护进程。为此,执行以下命令:
|
||||
|
||||
```
|
||||
systemctl start docker
|
||||
|
||||
systemctl enable docker
|
||||
```
|
||||
|
||||
现在我们需要创建一个标准用户,因此我们没有以root去运行docker命令。为此,执行以下命令:
|
||||
|
||||
```
|
||||
useradd -m USERNAME
|
||||
|
||||
passwd USERNAME
|
||||
```
|
||||
|
||||
其中USERNAME是我们新增的用户的名称。
|
||||
|
||||
接下来,我们需要将这个新用户添加到 _docker_ 组,执行命令:
|
||||
|
||||
```
|
||||
usermod -a -G docker USERNAME
|
||||
```
|
||||
|
||||
其中USERNAME是刚刚创建的用户的名称。
|
||||
|
||||
注销root用户并切换为新增的用户。现在,您已经可以不必使用 _sudo_ 命令或者是切换到root用户来使用 _docker_命令了。从Docker Hub中取出一个镜像开始部署容器吧。
|
||||
|
||||
### 一个优秀的容器平台
|
||||
|
||||
在专注于容器方面,Photon毫无疑问是一个出色的平台。请注意,Photon是一个开源项目,因此没有任何付费支持。如果您对Photon有任何的问题,请移步Photon项目的Github下的[Issues][27],那里可以供您阅读相关问题,或者提交您的问题。如果您对Photon感兴趣,您也可以在项目的官方[Github][28]中找到源码。
|
||||
|
||||
尝试一下Photon吧,看看它是否能够使得Docker容器和Kubernetes集群的部署更加容易。
|
||||
|
||||
欲了解Linux的更多信息,可以通过学习Linux基金会和edX的免费课程,[“Linux 入门”][29]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/11/photon-could-be-your-new-favorite-container-os
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[KeyLD](https://github.com/KeyLd)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[6]:https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project
|
||||
[7]:http://vmware.github.io/lightwave/
|
||||
[8]:https://www.linux.com/files/images/photon0jpg
|
||||
[9]:https://www.linux.com/files/images/photon1jpg
|
||||
[10]:https://www.linux.com/files/images/photon2jpg
|
||||
[11]:https://www.linux.com/files/images/photon3jpg
|
||||
[12]:https://www.linux.com/files/images/photon-linuxjpg
|
||||
[13]:https://www.linux.com/learn/intro-to-linux/2017/11/how-install-and-use-docker-linux
|
||||
[14]:https://www.docker.com/
|
||||
[15]:https://vmware.github.io/photon/
|
||||
[16]:https://www.vmware.com/
|
||||
[17]:https://www.vmware.com/products/vsphere.html
|
||||
[18]:https://azure.microsoft.com/
|
||||
[19]:https://cloud.google.com/compute/
|
||||
[20]:https://aws.amazon.com/ec2/
|
||||
[21]:https://www.virtualbox.org/
|
||||
[22]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[23]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[24]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[25]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[26]:https://github.com/vmware/photon/wiki/Downloading-Photon-OS
|
||||
[27]:https://github.com/vmware/photon/issues
|
||||
[28]:https://github.com/vmware/photon
|
||||
[29]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,163 @@
|
||||
如何判断Linux服务器是否被入侵
|
||||
--------------
|
||||
|
||||
本指南中所谓的服务器被入侵或者说被黑了的意思是指未经认证的人或程序为了自己的目的登录到服务器上去并使用其计算资源, 通常会产生不好的影响。
|
||||
|
||||
免责声明: 若你的服务器被类似NSA这样的国家机关或者某个犯罪集团如请,那么你并不会发现有任何问题,这些技术也无法发觉他们的存在。
|
||||
|
||||
然而, 大多数被攻破的服务器都是被类似自动攻击程序这样的程序或者类似“脚本小子”这样的廉价攻击者,以及蠢蛋犯罪所入侵的。
|
||||
|
||||
这类攻击者会在访问服务器的同时滥用服务器资源,并且不怎么会采取措施来隐藏他们正在做的事情。
|
||||
|
||||
### 入侵服务器的症状
|
||||
|
||||
当服务器被没有经验攻击者或者自动攻击程序入侵了的话,他们往往会消耗100%的资源. 他们可能消耗CPU资源来进行数字货币的采矿或者发送垃圾邮件,也可能消耗带宽来发动 `DoS` 攻击。
|
||||
|
||||
因此出现问题的第一个表现就是服务器 “变慢了”. 这可能表现在网站的页面打开的很慢, 或者电子邮件要花很长时间才能发送出去。
|
||||
|
||||
那么你应该查看那些东西呢?
|
||||
|
||||
#### 检查 1 - 当前都有谁在登录?
|
||||
|
||||
你首先要查看当前都有谁登录在服务器上. 发现攻击者登录到服务器上进行操作并不罕见。
|
||||
|
||||
其对应的命令是 `w`. 运行 `w` 会输出如下结果:
|
||||
|
||||
```
|
||||
08:32:55 up 98 days, 5:43, 2 users, load average: 0.05, 0.03, 0.00
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
root pts/0 113.174.161.1 08:26 0.00s 0.03s 0.02s ssh root@coopeaa12
|
||||
root pts/1 78.31.109.1 08:26 0.00s 0.01s 0.00s w
|
||||
|
||||
```
|
||||
|
||||
第一个IP是英国IP,而第二个IP是越南IP. 这个不是个好兆头。
|
||||
|
||||
停下来做个深呼吸, 不要紧,只需要杀掉他们的SSH连接就好了. Unless you can stop then re-entering the server they will do so quickly and quite likely kick you off and stop you getting back in。
|
||||
|
||||
请参阅本文最后的 `入侵之后怎么办` 这一章节来看发现被入侵的证据后应该怎么办。
|
||||
|
||||
`whois` 命令可以接一个IP地址然后告诉你IP注册的组织的所有信息, 当然就包括所在国家的信息。
|
||||
|
||||
#### 检查 2 - 谁曾经登录过?
|
||||
|
||||
Linux 服务器会记录下哪些用户,从哪个IP,在什么时候登录的以及登陆了多长时间这些信息. 使用 `last` 命令可以查看这些信息。
|
||||
|
||||
输出类似这样:
|
||||
|
||||
```
|
||||
root pts/1 78.31.109.1 Thu Nov 30 08:26 still logged in
|
||||
root pts/0 113.174.161.1 Thu Nov 30 08:26 still logged in
|
||||
root pts/1 78.31.109.1 Thu Nov 30 08:24 - 08:26 (00:01)
|
||||
root pts/0 113.174.161.1 Wed Nov 29 12:34 - 12:52 (00:18)
|
||||
root pts/0 14.176.196.1 Mon Nov 27 13:32 - 13:53 (00:21)
|
||||
|
||||
```
|
||||
|
||||
这里可以看到英国IP和越南IP交替出现, 而且最上面两个IP现在还处于登录状态. 如果你看到任何未经授权的IP,那么请参阅最后章节。
|
||||
|
||||
登录历史记录会以文本格式记录到 `~/.bash_history`(注:这里作者应该写错了)中,因此很容易被删除。
|
||||
通常攻击者会直接把这个文件删掉,以掩盖他们的攻击行为. 因此, 若你运行了 `last` 命令却只看得见你的当前登录,那么这就是个不妙的信号。
|
||||
|
||||
如果没有登录历史的话,请一定小心,继续留意入侵的其他线索。
|
||||
|
||||
#### 检查 3 - 回顾命令历史
|
||||
|
||||
这个层次的攻击者通常不会注意掩盖命令的历史记录,因此运行 `history` 命令会显示出他们曾经做过的所有事情。
|
||||
一定留意有没有用 `wget` 或 `curl` 命令来下载类似垃圾邮件机器人或者挖矿程序之类的软件。
|
||||
|
||||
命令历史存储在 `~/.bash_history` 文件中,因此有些攻击者会删除该文件以掩盖他们的所作所为。
|
||||
跟登录历史一样, 若你运行 `history` 命令却没有输出任何东西那就表示历史文件被删掉了. 这也是个不妙的信号,你需要很小心地检查一下服务器了。
|
||||
|
||||
#### 检查 4 - 哪些进程在消耗CPU?
|
||||
|
||||
你常遇到的这类攻击者通常不怎么会去掩盖他们做的事情. 他们会运行一些特别消耗CPU的进程. 这就很容易发着这些进程了. 只需要运行 `top` 然后看最前的那几个进程就行了。
|
||||
|
||||
这也能显示出那些未登录的攻击者来. 比如,可能有人在用未受保护的邮件脚本来发送垃圾邮件。
|
||||
|
||||
如果你最上面的进程对不了解,那么你可以google一下进程名称,或者通过 `losf` 和 `strace` 来看看它做的事情是什么。
|
||||
|
||||
使用这些工具,第一步从 `top` 中拷贝出进程的 PID,然后运行:
|
||||
|
||||
```shell
|
||||
strace -p PID
|
||||
|
||||
```
|
||||
|
||||
这会显示出进程调用的所有系统调用. 它产生的内容会很多,但这些信息能告诉你这个进程在做什么。
|
||||
|
||||
```
|
||||
lsof -p PID
|
||||
|
||||
```
|
||||
|
||||
这个程序会列出进程打开的文件. 通过查看它访问的文件可以很好的理解它在做的事情。
|
||||
|
||||
#### 检查 5 - 检查所有的系统进程
|
||||
|
||||
消耗CPU不严重的未认证进程可能不会在 `top` 中显露出来,不过它依然可以通过 `ps` 列出来. 命令 `ps auxf` 就能显示足够清晰的信息了。
|
||||
|
||||
你需要检查一下每个不认识的进程. 经常运行 `ps` (这是个好习惯) 能帮助你发现奇怪的进程。
|
||||
|
||||
#### 检查 6 - 检查进程的网络使用情况
|
||||
|
||||
`iftop` 的功能类似 `top`,他会显示一系列收发网络数据的进程以及他们的源地址和目的地址。
|
||||
类似 `DoS` 攻击或垃圾制造器这样的进程很容易显示在列表的最顶端。
|
||||
|
||||
#### 检查 7 - 哪些进程在监听网络连接?
|
||||
|
||||
通常攻击者会安装一个后门程序专门监听网络端口接受指令. 该进程等待期间是不会消耗CPU和带宽的,因此也就不容易通过 `top` 之类的命令发现。
|
||||
|
||||
`lsof` 和 `netstat` 命令都会列出所有的联网进程. 我通常会让他们带上下面这些参数:
|
||||
|
||||
```
|
||||
lsof -i
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
netstat -plunt
|
||||
|
||||
```
|
||||
|
||||
你需要留意那些处于 `LISTEN` 和 `ESTABLISHED` 状态的进程,这些进程要么正在等待连接(LISTEN),要么已经连接(ESTABLISHED)。
|
||||
如果遇到不认识的进程,使用 `strace` 和 `lsof` 来看看它们在做什么东西。
|
||||
|
||||
### 被入侵之后该怎么办呢?
|
||||
|
||||
首先,不要紧张, 尤其当攻击者正处于登陆状态时更不能紧张. 你需要在攻击者警觉到你已经发现他之前夺回机器的控制权。
|
||||
如果他发现你已经发觉到他了,那么他可能会锁死你不让你登陆服务器,然后开始毁尸灭迹。
|
||||
|
||||
如果你技术不太好那么就直接关机吧. 你可以在服务器上运行 `shutdown -h now` 或者 `systemctl poweroff` 这两条命令. 也可以登陆主机提供商的控制面板中关闭服务器。
|
||||
关机后,你就可以开始配置防火墙或者咨询一下供应商的意见。
|
||||
|
||||
如果你对自己颇有自信,而你的主机提供商也有提供上游防火墙,那么你只需要以此创建并启用下面两条规则就行了:
|
||||
|
||||
1. 只允许从你的IP地址登陆SSH
|
||||
|
||||
2. 封禁除此之外的任何东西,不仅仅是SSH,还包括任何端口上的任何协议。
|
||||
|
||||
这样会立即关闭攻击者的SSH会话,而只留下你访问服务器。
|
||||
|
||||
如果你无法访问上游防火墙,那么你就需要在服务器本身创建并启用这些防火墙策略,然后在防火墙规则起效后使用 `kill` 命令关闭攻击者的ssh会话。
|
||||
|
||||
最后还有一种方法, 就是通过诸如串行控制台之类的带外连接登陆服务器,然后通过 `systemctl stop network.service` 停止网络功能。
|
||||
这会关闭所有服务器上的网络连接,这样你就可以慢慢的配置那些防火墙规则了。
|
||||
|
||||
重夺服务器的控制权后,也不要以为就万事大吉了。
|
||||
|
||||
不要试着修复这台服务器,让后接着用. 你永远不知道攻击者做过什么因此你也永远无法保证这台服务器还是安全的。
|
||||
|
||||
最好的方法就是拷贝出所有的资料,然后重装系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/server-hacked/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
Loading…
Reference in New Issue
Block a user