mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
68af30be4e
102
published/20090203 How the Kernel Manages Your Memory.md
Normal file
102
published/20090203 How the Kernel Manages Your Memory.md
Normal file
@ -0,0 +1,102 @@
|
||||
内核如何管理内存
|
||||
============================================================
|
||||
|
||||
在学习了进程的 [虚拟地址布局][1] 之后,让我们回到内核,来学习它管理用户内存的机制。这里再次使用 Gonzo:
|
||||
|
||||
|
||||
|
||||
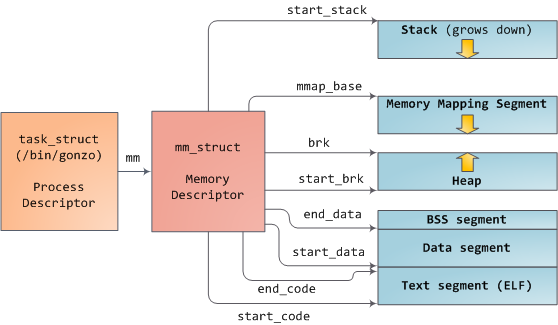
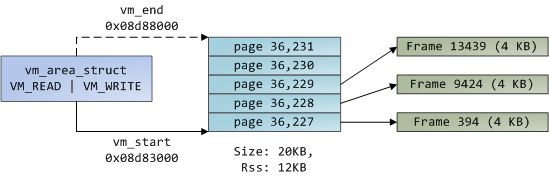
Linux 进程在内核中是作为进程描述符 [task_struct][2] (LCTT 译注:它是在 Linux 中描述进程完整信息的一种数据结构)的实例来实现的。在 task_struct 中的 [mm][3] 域指向到**内存描述符**,[mm_struct][4] 是一个程序在内存中的执行摘要。如上图所示,它保存了起始和结束内存段,进程使用的物理内存页面的 [数量][5](RSS <ruby>常驻内存大小<rt>Resident Set Size</rt></ruby> )、虚拟地址空间使用的 [总数量][6]、以及其它片断。 在内存描述符中,我们可以获悉它有两种管理内存的方式:**虚拟内存区域**集和**页面表**。Gonzo 的内存区域如下所示:
|
||||
|
||||
|
||||
|
||||
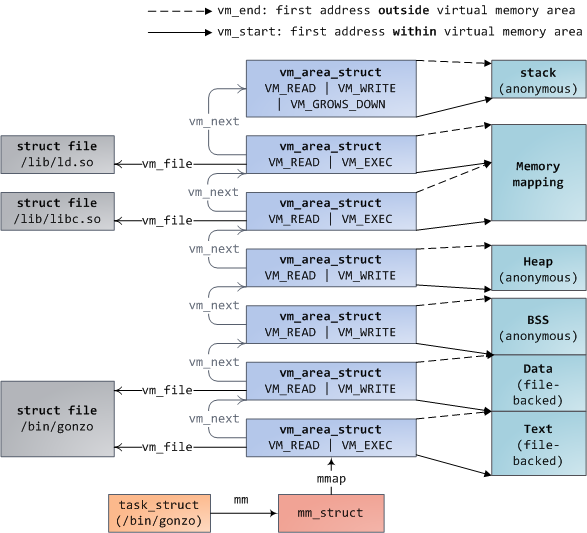
每个虚拟内存区域(VMA)是一个连续的虚拟地址范围;这些区域绝对不会重叠。一个 [vm_area_struct][7] 的实例完整地描述了一个内存区域,包括它的起始和结束地址,[flags][8] 决定了访问权限和行为,并且 [vm_file][9] 域指定了映射到这个区域的文件(如果有的话)。(除了内存映射段的例外情况之外,)一个 VMA 是不能**匿名**映射文件的。上面的每个内存段(比如,堆、栈)都对应一个单个的 VMA。虽然它通常都使用在 x86 的机器上,但它并不是必需的。VMA 也不关心它们在哪个段中。
|
||||
|
||||
一个程序的 VMA 在内存描述符中是作为 [mmap][10] 域的一个链接列表保存的,以起始虚拟地址为序进行排列,并且在 [mm_rb][12] 域中作为一个 [红黑树][11] 的根。红黑树允许内核通过给定的虚拟地址去快速搜索内存区域。在你读取文件 `/proc/pid_of_process/maps` 时,内核只是简单地读取每个进程的 VMA 的链接列表并[显示它们][13]。
|
||||
|
||||
在 Windows 中,[EPROCESS][14] 块大致类似于一个 task_struct 和 mm_struct 的结合。在 Windows 中模拟一个 VMA 的是虚拟地址描述符,或称为 [VAD][15];它保存在一个 [AVL 树][16] 中。你知道关于 Windows 和 Linux 之间最有趣的事情是什么吗?其实它们只有一点小差别。
|
||||
|
||||
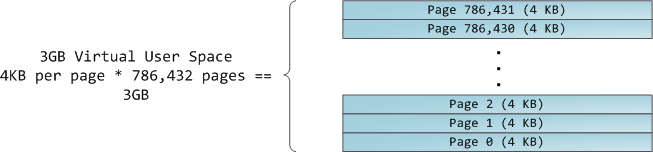
4GB 虚拟地址空间被分配到**页面**中。在 32 位模式中的 x86 处理器中支持 4KB、2MB、以及 4MB 大小的页面。Linux 和 Windows 都使用大小为 4KB 的页面去映射用户的一部分虚拟地址空间。字节 0-4095 在页面 0 中,字节 4096-8191 在页面 1 中,依次类推。VMA 的大小 _必须是页面大小的倍数_ 。下图是使用 4KB 大小页面的总数量为 3GB 的用户空间:
|
||||
|
||||
|
||||
|
||||
处理器通过查看**页面表**去转换一个虚拟内存地址到一个真实的物理内存地址。每个进程都有它自己的一组页面表;每当发生进程切换时,用户空间的页面表也同时切换。Linux 在内存描述符的 [pgd][17] 域中保存了一个指向进程的页面表的指针。对于每个虚拟页面,页面表中都有一个相应的**页面表条目**(PTE),在常规的 x86 页面表中,它是一个简单的如下所示的大小为 4 字节的记录:
|
||||
|
||||

|
||||
|
||||
Linux 通过函数去 [读取][18] 和 [设置][19] PTE 条目中的每个标志位。标志位 P 告诉处理器这个虚拟页面是否**在**物理内存中。如果该位被清除(设置为 0),访问这个页面将触发一个页面故障。请记住,当这个标志位为 0 时,内核可以在剩余的域上**做任何想做的事**。R/W 标志位是读/写标志;如果被清除,这个页面将变成只读的。U/S 标志位表示用户/超级用户;如果被清除,这个页面将仅被内核访问。这些标志都是用于实现我们在前面看到的只读内存和内核空间保护。
|
||||
|
||||
标志位 D 和 A 用于标识页面是否是“**脏的**”或者是已**被访问过**。一个脏页面表示已经被写入,而一个被访问过的页面则表示有一个写入或者读取发生过。这两个标志位都是粘滞位:处理器只能设置它们,而清除则是由内核来完成的。最终,PTE 保存了这个页面相应的起始物理地址,它们按 4KB 进行整齐排列。这个看起来不起眼的域是一些痛苦的根源,因为它限制了物理内存最大为 [4 GB][20]。其它的 PTE 域留到下次再讲,因为它是涉及了物理地址扩展的知识。
|
||||
|
||||
由于在一个虚拟页面上的所有字节都共享一个 U/S 和 R/W 标志位,所以内存保护的最小单元是一个虚拟页面。但是,同一个物理内存可能被映射到不同的虚拟页面,这样就有可能会出现相同的物理内存出现不同的保护标志位的情况。请注意,在 PTE 中是看不到运行权限的。这就是为什么经典的 x86 页面上允许代码在栈上被执行的原因,这样会很容易导致挖掘出栈缓冲溢出漏洞(可能会通过使用 [return-to-libc][21] 和其它技术来找出非可执行栈)。由于 PTE 缺少禁止运行标志位说明了一个更广泛的事实:在 VMA 中的权限标志位有可能或可能不完全转换为硬件保护。内核只能做它能做到的,但是,最终的架构限制了它能做的事情。
|
||||
|
||||
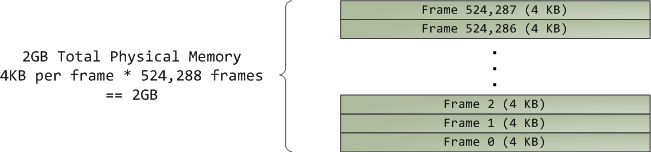
虚拟内存不保存任何东西,它只是简单地 _映射_ 一个程序的地址空间到底层的物理内存上。物理内存被当作一个称之为**物理地址空间**的巨大块而由处理器访问。虽然内存的操作[涉及到某些][22]总线,我们在这里先忽略它,并假设物理地址范围从 0 到可用的最大值按字节递增。物理地址空间被内核进一步分解为**页面帧**。处理器并不会关心帧的具体情况,这一点对内核也是至关重要的,因为,**页面帧是物理内存管理的最小单元**。Linux 和 Windows 在 32 位模式下都使用 4KB 大小的页面帧;下图是一个有 2 GB 内存的机器的例子:
|
||||
|
||||
|
||||
|
||||
在 Linux 上每个页面帧是被一个 [描述符][23] 和 [几个标志][24] 来跟踪的。通过这些描述符和标志,实现了对机器上整个物理内存的跟踪;每个页面帧的具体状态是公开的。物理内存是通过使用 [Buddy 内存分配][25] (LCTT 译注:一种内存分配算法)技术来管理的,因此,如果一个页面帧可以通过 Buddy 系统分配,那么它是**未分配的**(free)。一个被分配的页面帧可以是**匿名的**、持有程序数据的、或者它可能处于页面缓存中、持有数据保存在一个文件或者块设备中。还有其它的异形页面帧,但是这些异形页面帧现在已经不怎么使用了。Windows 有一个类似的页面帧号(Page Frame Number (PFN))数据库去跟踪物理内存。
|
||||
|
||||
我们把虚拟内存区域(VMA)、页面表条目(PTE),以及页面帧放在一起来理解它们是如何工作的。下面是一个用户堆的示例:
|
||||
|
||||
|
||||
|
||||
蓝色的矩形框表示在 VMA 范围内的页面,而箭头表示页面表条目映射页面到页面帧。一些缺少箭头的虚拟页面,表示它们对应的 PTE 的当前标志位被清除(置为 0)。这可能是因为这个页面从来没有被使用过,或者是它的内容已经被交换出去了。在这两种情况下,即便这些页面在 VMA 中,访问它们也将导致产生一个页面故障。对于这种 VMA 和页面表的不一致的情况,看上去似乎很奇怪,但是这种情况却经常发生。
|
||||
|
||||
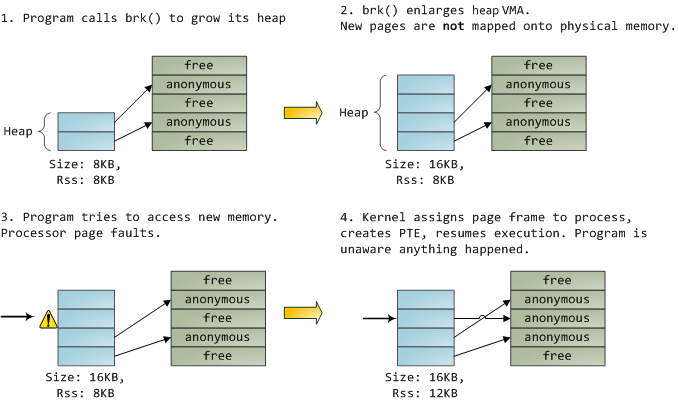
一个 VMA 像一个在你的程序和内核之间的合约。你请求它做一些事情(分配内存、文件映射、等等),内核会回应“收到”,然后去创建或者更新相应的 VMA。 但是,它 _并不立刻_ 去“兑现”对你的承诺,而是它会等待到发生一个页面故障时才去 _真正_ 做这个工作。内核是个“懒惰的家伙”、“不诚实的人渣”;这就是虚拟内存的基本原理。它适用于大多数的情况,有一些类似情况和有一些意外的情况,但是,它是规则是,VMA 记录 _约定的_ 内容,而 PTE 才反映这个“懒惰的内核” _真正做了什么_。通过这两种数据结构共同来管理程序的内存;它们共同来完成解决页面故障、释放内存、从内存中交换出数据、等等。下图是内存分配的一个简单案例:
|
||||
|
||||
|
||||
|
||||
当程序通过 [brk()][26] 系统调用来请求一些内存时,内核只是简单地 [更新][27] 堆的 VMA 并给程序回复“已搞定”。而在这个时候并没有真正地分配页面帧,并且新的页面也没有映射到物理内存上。一旦程序尝试去访问这个页面时,处理器将发生页面故障,然后调用 [do_page_fault()][28]。这个函数将使用 [find_vma()][30] 去 [搜索][29] 发生页面故障的 VMA。如果找到了,然后在 VMA 上进行权限检查以防范恶意访问(读取或者写入)。如果没有合适的 VMA,也没有所尝试访问的内存的“合约”,将会给进程返回段故障。
|
||||
|
||||
当[找到][31]了一个合适的 VMA,内核必须通过查找 PTE 的内容和 VMA 的类型去[处理][32]故障。在我们的案例中,PTE 显示这个页面是 [不存在的][33]。事实上,我们的 PTE 是全部空白的(全部都是 0),在 Linux 中这表示虚拟内存还没有被映射。由于这是匿名 VMA,我们有一个完全的 RAM 事务,它必须被 [do_anonymous_page()][34] 来处理,它分配页面帧,并且用一个 PTE 去映射故障虚拟页面到一个新分配的帧。
|
||||
|
||||
有时候,事情可能会有所不同。例如,对于被交换出内存的页面的 PTE,在当前(Present)标志位上是 0,但它并不是空白的。而是在交换位置仍有页面内容,它必须从磁盘上读取并且通过 [do_swap_page()][35] 来加载到一个被称为 [major fault][36] 的页面帧上。
|
||||
|
||||
这是我们通过探查内核的用户内存管理得出的前半部分的结论。在下一篇文章中,我们通过将文件加载到内存中,来构建一个完整的内存框架图,以及对性能的影响。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://linux.cn/article-9255-1.html
|
||||
[2]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1075
|
||||
[3]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1129
|
||||
[4]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L173
|
||||
[5]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L197
|
||||
[6]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L206
|
||||
[7]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L99
|
||||
[8]:http://lxr.linux.no/linux+v2.6.28/include/linux/mm.h#L76
|
||||
[9]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L150
|
||||
[10]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L174
|
||||
[11]:http://en.wikipedia.org/wiki/Red_black_tree
|
||||
[12]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L175
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28.1/fs/proc/task_mmu.c#L201
|
||||
[14]:http://www.nirsoft.net/kernel_struct/vista/EPROCESS.html
|
||||
[15]:http://www.nirsoft.net/kernel_struct/vista/MMVAD.html
|
||||
[16]:http://en.wikipedia.org/wiki/AVL_tree
|
||||
[17]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L185
|
||||
[18]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L173
|
||||
[19]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L230
|
||||
[20]:http://www.google.com/search?hl=en&amp;amp;amp;amp;q=2^20+*+2^12+bytes+in+GB
|
||||
[21]:http://en.wikipedia.org/wiki/Return-to-libc_attack
|
||||
[22]:http://duartes.org/gustavo/blog/post/getting-physical-with-memory
|
||||
[23]:http://lxr.linux.no/linux+v2.6.28/include/linux/mm_types.h#L32
|
||||
[24]:http://lxr.linux.no/linux+v2.6.28/include/linux/page-flags.h#L14
|
||||
[25]:http://en.wikipedia.org/wiki/Buddy_memory_allocation
|
||||
[26]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||||
[27]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L2050
|
||||
[28]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L583
|
||||
[29]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L692
|
||||
[30]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1466
|
||||
[31]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L711
|
||||
[32]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2653
|
||||
[33]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2674
|
||||
[34]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2681
|
||||
[35]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2280
|
||||
[36]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2316
|
||||
@ -1,15 +1,15 @@
|
||||
学习你的工具:驾驭你的 Git 历史
|
||||
学习用工具来驾驭 Git 历史
|
||||
============================================================
|
||||
|
||||
在你的日常工作中,不可能每天都从头开始去开发一个新的应用程序。而真实的情况是,在日常工作中,我们大多数时候所面对的都是遗留下来的一个代码库,我们能够去修改一些特性的内容或者现存的一些代码行,是我们在日常工作中很重要的一部分。而这也就是分布式版本控制系统 `git` 的价值所在。现在,我们来深入了解怎么去使用 `git` 的历史以及如何很轻松地去浏览它的历史。
|
||||
在你的日常工作中,不可能每天都从头开始去开发一个新的应用程序。而真实的情况是,在日常工作中,我们大多数时候所面对的都是遗留下来的一个代码库,去修改一些特性的内容或者现存的一些代码行,这是我们在日常工作中很重要的一部分。而这也就是分布式版本控制系统 `git` 的价值所在。现在,我们来深入了解怎么去使用 `git` 的历史以及如何很轻松地去浏览它的历史。
|
||||
|
||||
### Git 历史
|
||||
|
||||
首先和最重要的事是,什么是 `git` 历史?正如其名字一样,它是一个 `git` 仓库的提交历史。它包含一堆提交信息,其中有它们的作者的名字、提交的哈希值以及提交日期。查看一个 `git` 仓库历史的方法很简单,就是一个 `git log` 命令。
|
||||
首先和最重要的事是,什么是 `git` 历史?正如其名字一样,它是一个 `git` 仓库的提交历史。它包含一堆提交信息,其中有它们的作者的名字、该提交的哈希值以及提交日期。查看一个 `git` 仓库历史的方法很简单,就是一个 `git log` 命令。
|
||||
|
||||
> _*旁注:**为便于本文的演示,我们使用 Ruby 在 Rails 仓库的 `master` 分支。之所以选择它的理由是因为,Rails 有很好的 `git` 历史,有很好的提交信息、引用以及每个变更的解释。如果考虑到代码库的大小、维护者的年龄和数据,Rails 肯定是我见过的最好的仓库。当然了,我并不是说其它 `git` 仓库做的不好,它只是我见过的比较好的一个仓库。_
|
||||
> _旁注:为便于本文的演示,我们使用 Ruby on Rails 的仓库的 `master` 分支。之所以选择它的理由是因为,Rails 有良好的 `git` 历史,漂亮的提交信息、引用以及对每个变更的解释。如果考虑到代码库的大小、维护者的年龄和数量,Rails 肯定是我见过的最好的仓库。当然了,我并不是说其它的 `git` 仓库做的不好,它只是我见过的比较好的一个仓库。_
|
||||
|
||||
因此,回到 Rails 仓库。如果你在 Ralis 仓库上运行 `git log`。你将看到如下所示的输出:
|
||||
那么,回到 Rails 仓库。如果你在 Ralis 仓库上运行 `git log`。你将看到如下所示的输出:
|
||||
|
||||
```
|
||||
commit 66ebbc4952f6cfb37d719f63036441ef98149418
|
||||
@ -72,7 +72,7 @@ Date: Thu Jun 2 21:26:53 2016 -0500
|
||||
[skip ci] Make header bullets consistent in engines.md
|
||||
```
|
||||
|
||||
正如你所见,`git log` 展示了提交哈希、作者和他的 email 以及提交日期。当然,`git` 输出的可定制性很强大,它允许你去定制 `git log` 命令的输出格式。比如说,我们希望看到提交的信息显示在一行上,我们可以运行 `git log --oneline`,它将输出一个更紧凑的日志:
|
||||
正如你所见,`git log` 展示了提交的哈希、作者及其 email 以及该提交创建的日期。当然,`git` 输出的可定制性很强大,它允许你去定制 `git log` 命令的输出格式。比如说,我们只想看提交信息的第一行,我们可以运行 `git log --oneline`,它将输出一个更紧凑的日志:
|
||||
|
||||
```
|
||||
66ebbc4 Dont re-define class SQLite3Adapter on test
|
||||
@ -89,15 +89,15 @@ e98caf8 [skip ci] Make header bullets consistent in engines.md
|
||||
|
||||
如果你想看 `git log` 的全部选项,我建议你去查阅 `git log` 的 man 页面,你可以在一个终端中输入 `man git-log` 或者 `git help log` 来获得。
|
||||
|
||||
> _**小提示:**如果你觉得 `git log` 看起来太恐怖或者过于复杂,或者你觉得看它太无聊了,我建议你去寻找一些 `git` GUI 命令行工具。在以前的文章中,我使用过 [GitX][1] ,我觉得它很不错,但是,由于我看命令行更“亲切”一些,在我尝试了 [tig][2] 之后,就再也没有去用过它。_
|
||||
> _小提示:如果你觉得 `git log` 看起来太恐怖或者过于复杂,或者你觉得看它太无聊了,我建议你去寻找一些 `git` 的 GUI 或命令行工具。在之前,我使用过 [GitX][1] ,我觉得它很不错,但是,由于我看命令行更“亲切”一些,在我尝试了 [tig][2] 之后,就再也没有去用过它。_
|
||||
|
||||
### 查找尼莫
|
||||
### 寻找尼莫
|
||||
|
||||
现在,我们已经知道了关于 `git log` 命令一些很基础的知识之后,我们来看一下,在我们的日常工作中如何使用它更加高效地浏览历史。
|
||||
现在,我们已经知道了关于 `git log` 命令的一些很基础的知识之后,我们来看一下,在我们的日常工作中如何使用它更加高效地浏览历史。
|
||||
|
||||
假如,我们怀疑在 `String#classify` 方法中有一个预期之外的行为,我们希望能够找出原因,并且定位出实现它的代码行。
|
||||
|
||||
为达到上述目的,你可以使用的第一个命令是 `git grep`,通过它可以找到这个方法定义在什么地方。简单来说,这个命令输出了给定的某些“样品”的匹配行。现在,我们来找出定义它的方法,它非常简单 —— 我们对 `def classify` 运行 grep,然后看到的输出如下:
|
||||
为达到上述目的,你可以使用的第一个命令是 `git grep`,通过它可以找到这个方法定义在什么地方。简单来说,这个命令输出了匹配特定模式的那些行。现在,我们来找出定义它的方法,它非常简单 —— 我们对 `def classify` 运行 grep,然后看到的输出如下:
|
||||
|
||||
```
|
||||
➜ git grep 'def classify'
|
||||
@ -113,7 +113,7 @@ activesupport/lib/active_support/core_ext/string/inflections.rb: def classifyact
|
||||
activesupport/lib/active_support/core_ext/string/inflections.rb:205: def classifyactivesupport/lib/active_support/inflector/methods.rb:186: def classify(table_name)tools/profile:112: def classify
|
||||
```
|
||||
|
||||
更好看了,是吧?考虑到上下文,我们可以很轻松地找到,这个方法在`activesupport/lib/active_support/core_ext/string/inflections.rb` 的第 205 行的 `classify` 方法,它看起来像这样,是不是很容易?
|
||||
更好看了,是吧?考虑到上下文,我们可以很轻松地找到,这个方法在 `activesupport/lib/active_support/core_ext/string/inflections.rb` 的第 205 行的 `classify` 方法,它看起来像这样,是不是很容易?
|
||||
|
||||
```
|
||||
# Creates a class name from a plural table name like Rails does for table names to models.
|
||||
@ -127,7 +127,7 @@ activesupport/lib/active_support/core_ext/string/inflections.rb:205: def classi
|
||||
end
|
||||
```
|
||||
|
||||
尽管这个方法我们找到的是在 `String` 上的一个常见的调用,它涉及到`ActiveSupport::Inflector` 上的另一个方法,使用了相同的名字。获得了 `git grep` 的结果,我们可以很轻松地导航到这里,因此,我们看到了结果的第二行, `activesupport/lib/active_support/inflector/methods.rb` 在 186 行上。我们正在寻找的方法是:
|
||||
尽管我们找到的这个方法是在 `String` 上的一个常见的调用,它调用了 `ActiveSupport::Inflector` 上的另一个同名的方法。根据之前的 `git grep` 的结果,我们可以很轻松地发现结果的第二行, `activesupport/lib/active_support/inflector/methods.rb` 在 186 行上。我们正在寻找的方法是这样的:
|
||||
|
||||
```
|
||||
# Creates a class name from a plural table name like Rails does for table
|
||||
@ -146,17 +146,17 @@ def classify(table_name)
|
||||
end
|
||||
```
|
||||
|
||||
酷!考虑到 Rails 仓库的大小,我们借助 `git grep` 找到它,用时没有超越 30 秒。
|
||||
酷!考虑到 Rails 仓库的大小,我们借助 `git grep` 找到它,用时都没有超越 30 秒。
|
||||
|
||||
### 那么,最后的变更是什么?
|
||||
|
||||
我们已经掌握了有用的方法,现在,我们需要搞清楚这个文件所经历的变更。由于我们已经知道了正确的文件名和行数,我们可以使用 `git blame`。这个命令展示了一个文件中每一行的最后修订者和修订的内容。我们来看一下这个文件最后的修订都做了什么:
|
||||
现在,我们已经找到了所要找的方法,现在,我们需要搞清楚这个文件所经历的变更。由于我们已经知道了正确的文件名和行数,我们可以使用 `git blame`。这个命令展示了一个文件中每一行的最后修订者和修订的内容。我们来看一下这个文件最后的修订都做了什么:
|
||||
|
||||
```
|
||||
git blame activesupport/lib/active_support/inflector/methods.rb
|
||||
```
|
||||
|
||||
虽然我们得到了这个文件每一行的最后的变更,但是,我们更感兴趣的是对指定的方法(176 到 189 行)的最后变更。让我们在 `git blame` 命令上增加一个选项,它将只显示那些行。此外,我们将在命令上增加一个 `-s` (阻止) 选项,去跳过那一行变更时的作者名字和修订(提交)的时间戳:
|
||||
虽然我们得到了这个文件每一行的最后的变更,但是,我们更感兴趣的是对特定方法(176 到 189 行)的最后变更。让我们在 `git blame` 命令上增加一个选项,让它只显示那些行的变化。此外,我们将在命令上增加一个 `-s` (忽略)选项,去跳过那一行变更时的作者名字和修订(提交)的时间戳:
|
||||
|
||||
```
|
||||
git blame -L 176,189 -s activesupport/lib/active_support/inflector/methods.rb
|
||||
@ -183,13 +183,13 @@ git blame -L 176,189 -s activesupport/lib/active_support/inflector/methods.rb
|
||||
git show 5bb1d4d2
|
||||
```
|
||||
|
||||
你亲自做实验了吗?如果没有做,我直接告诉你结果,这个令人惊叹的 [提交][3] 是由 [Schneems][4] 做的,他通过使用 frozen 字符串做了一个非常有趣的性能优化,这在我们当前的上下文中是非常有意义的。但是,由于我们在这个假设的调试会话中,这样做并不能告诉我们当前问题所在。因此,我们怎么样才能够通过研究来发现,我们选定的方法经过了哪些变更?
|
||||
你亲自做实验了吗?如果没有做,我直接告诉你结果,这个令人惊叹的 [提交][3] 是由 [Schneems][4] 完成的,他通过使用 frozen 字符串做了一个非常有趣的性能优化,这在我们当前的场景中是非常有意义的。但是,由于我们在这个假设的调试会话中,这样做并不能告诉我们当前问题所在。因此,我们怎么样才能够通过研究来发现,我们选定的方法经过了哪些变更?
|
||||
|
||||
### 搜索日志
|
||||
|
||||
现在,我们回到 `git` 日志,现在的问题是,怎么能够看到 `classify` 方法经历了哪些修订?
|
||||
|
||||
`git log` 命令非常强大,因此它提供了非常多的列表选项。我们尝试去看一下保存了这个文件的 `git` 日志内容。使用 `-p` 选项,它的意思是在 `git` 日志中显示这个文件的完整补丁:
|
||||
`git log` 命令非常强大,因此它提供了非常多的列表选项。我们尝试使用 `-p` 选项去看一下保存了这个文件的 `git` 日志内容,这个选项的意思是在 `git` 日志中显示这个文件的完整补丁:
|
||||
|
||||
```
|
||||
git log -p activesupport/lib/active_support/inflector/methods.rb
|
||||
@ -201,13 +201,13 @@ git log -p activesupport/lib/active_support/inflector/methods.rb
|
||||
git log -L 176,189:activesupport/lib/active_support/inflector/methods.rb
|
||||
```
|
||||
|
||||
`git log` 命令接受了 `-L` 选项,它有一个行的范围和文件名做为参数。它的格式可能有点奇怪,格式解释如下:
|
||||
`git log` 命令接受 `-L` 选项,它用一个行的范围和文件名做为参数。它的格式可能有点奇怪,格式解释如下:
|
||||
|
||||
```
|
||||
git log -L <start-line>,<end-line>:<path-to-file>
|
||||
```
|
||||
|
||||
当我们去运行这个命令之后,我们可以看到对这些行的一个修订列表,它将带我们找到创建这个方法的第一个修订:
|
||||
当我们运行这个命令之后,我们可以看到对这些行的一个修订列表,它将带我们找到创建这个方法的第一个修订:
|
||||
|
||||
```
|
||||
commit 51xd6bb829c418c5fbf75de1dfbb177233b1b154
|
||||
@ -238,11 +238,11 @@ diff--git a/activesupport/lib/active_support/inflector/methods.rb b/activesuppor
|
||||
|
||||
现在,我们再来看一下 —— 它是在 2011 年提交的。`git` 可以让我们重回到这个时间。这是一个很好的例子,它充分说明了足够的提交信息对于重新了解当时的上下文环境是多么的重要,因为从这个提交信息中,我们并不能获得足够的信息来重新理解当时的创建这个方法的上下文环境,但是,话说回来,你**不应该**对此感到恼怒,因为,你看到的这些项目,它们的作者都是无偿提供他们的工作时间和精力来做开源工作的。(向开源项目贡献者致敬!)
|
||||
|
||||
回到我们的正题,我们并不能确认 `classify` 方法最初实现是怎么回事,考虑到这个第一次的提交只是一个重构。现在,如果你认为,“或许、有可能、这个方法不在 176 行到 189 行的范围之内,那么就你应该在这个文件中扩大搜索范围”,这样想是对的。我们看到在它的修订提交的信息中提到了“重构”这个词,它意味着这个方法可能在那个文件中是真实存在的,只是在重构之后它才存在于那个行的范围内。
|
||||
回到我们的正题,我们并不能确认 `classify` 方法最初实现是怎么回事,考虑到这个第一次的提交只是一个重构。现在,如果你认为,“或许、有可能、这个方法不在 176 行到 189 行的范围之内,那么就你应该在这个文件中扩大搜索范围”,这样想是对的。我们看到在它的修订提交的信息中提到了“重构”这个词,它意味着这个方法可能在那个文件中是真实存在的,而且是在重构之后它才存在于那个行的范围内。
|
||||
|
||||
但是,我们如何去确认这一点呢?不管你信不信,`git` 可以再次帮助你。`git log` 命令有一个 `-S` 选项,它可以传递一个特定的字符串作为参数,然后去查找代码变更(添加或者删除)。也就是说,如果我们执行 `git log -S classify` 这样的命令,我们可以看到所有包含 `classify` 字符串的变更行的提交。
|
||||
|
||||
如果你在 Ralis 仓库上运行上述命令,首先你会发现这个命令运行有点慢。但是,你应该会发现 `git` 真的解析了在那个仓库中的所有修订来匹配这个字符串,因为仓库非常大,实际上它的运行速度是非常快的。在你的指尖下 `git` 再次展示了它的强大之处。因此,如果去找关于 `classify` 方法的第一个修订,我们可以运行如下的命令:
|
||||
如果你在 Ralis 仓库上运行上述命令,首先你会发现这个命令运行有点慢。但是,你应该会发现 `git` 实际上解析了在那个仓库中的所有修订来匹配这个字符串,其实它的运行速度是非常快的。在你的指尖下 `git` 再次展示了它的强大之处。因此,如果去找关于 `classify` 方法的第一个修订,我们可以运行如下的命令:
|
||||
|
||||
```
|
||||
git log -S 'def classify'
|
||||
@ -258,7 +258,7 @@ Date: Wed Nov 24 01:04:44 2004 +0000
|
||||
git-svn-id: http://svn-commit.rubyonrails.org/rails/trunk@4 5ecf4fe2-1ee6-0310-87b1-e25e094e27de
|
||||
```
|
||||
|
||||
很酷!是吧?它初次被提交到 Rails,是由 DHHD 在一个 `svn` 仓库上做的!这意味着 `classify` 提交到 Rails 仓库的大概时间。现在,我们去看一下这个提交的所有变更信息,我们运行如下的命令:
|
||||
很酷!是吧?它初次被提交到 Rails,是由 DHH 在一个 `svn` 仓库上做的!这意味着 `classify` 大概在一开始就被提交到了 Rails 仓库。现在,我们去看一下这个提交的所有变更信息,我们运行如下的命令:
|
||||
|
||||
```
|
||||
git show db045dbbf60b53dbe013ef25554fd013baf88134
|
||||
@ -268,7 +268,7 @@ git show db045dbbf60b53dbe013ef25554fd013baf88134
|
||||
|
||||
### 下次见
|
||||
|
||||
当然,我们并不会真的去修改任何 bug,因为我们只是去尝试使用一些 `git` 命令,来演示如何查看 `classify` 方法的演变历史。但是不管怎样,`git` 是一个非常强大的工具,我们必须学好它、用好它。我希望这篇文章可以帮助你掌握更多的关于如何使用 `git` 的知识。
|
||||
当然,我们并没有真的去修改任何 bug,因为我们只是去尝试使用一些 `git` 命令,来演示如何查看 `classify` 方法的演变历史。但是不管怎样,`git` 是一个非常强大的工具,我们必须学好它、用好它。我希望这篇文章可以帮助你掌握更多的关于如何使用 `git` 的知识。
|
||||
|
||||
你喜欢这些内容吗?
|
||||
|
||||
@ -284,9 +284,9 @@ git show db045dbbf60b53dbe013ef25554fd013baf88134
|
||||
|
||||
via: https://ieftimov.com/learn-your-tools-navigating-git-history
|
||||
|
||||
作者:[Ilija Eftimov ][a]
|
||||
作者:[Ilija Eftimov][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
如何在 Linux/Unix 中不重启 Vim 而重新加载 .vimrc 文件
|
||||
======
|
||||
|
||||
我是一位新的 Vim 编辑器用户。我通常使用 `:vs ~/.vimrc` 来加载 `~/.vimrc` 配置。而当我编辑 `.vimrc` 时,我需要不重启 Vim 会话而重新加载它。在 Linux 或者类 Unix 系统中,如何在编辑 `.vimrc` 后,重新加载它而不用重启 Vim 呢?
|
||||
|
||||
Vim 是自由开源并且向上兼容 Vi 的编辑器。它可以用来编辑各种文本。它在编辑用 C/Perl/Python 编写的程序时特别有用。可以用它来编辑 Linux/Unix 配置文件。`~/.vimrc` 是你个人的 Vim 初始化和自定义文件。
|
||||
|
||||
### 如何在不重启 Vim 会话的情况下重新加载 .vimrc
|
||||
|
||||
在 Vim 中重新加载 `.vimrc` 而不重新启动的流程:
|
||||
|
||||
1. 输入 `vim filename` 启动 vim
|
||||
2. 按下 `Esc` 接着输入 `:vs ~/.vimrc` 来加载 vim 配置
|
||||
3. 像这样添加自定义配置:
|
||||
|
||||
```
|
||||
filetype indent plugin on
|
||||
set number
|
||||
syntax on
|
||||
```
|
||||
4. 使用 `:wq` 保存文件,并从 `~/.vimrc` 窗口退出
|
||||
5. 输入下面任一命令重载 `~/.vimrc`:`:so $MYVIMRC` 或者 `:source ~/.vimrc`。
|
||||
|
||||
[![How to reload .vimrc file without restarting vim][1]][1]
|
||||
|
||||
*图1:编辑 ~/.vimrc 并在需要时重载它而不用退出 vim,这样你就可以继续编辑程序了*
|
||||
|
||||
`:so[urce]! {file}` 这个 vim 命令会从给定的文件比如 `~/.vimrc` 读取配置。就像你输入的一样,这些命令是在普通模式下执行的。当你在 `:global`、:`argdo`、 `:windo`、`:bufdo` 之后、循环中或者跟着另一个命令时,显示不会再在执行命令时更新。
|
||||
|
||||
### 如何设置按键来编辑并重载 ~/.vimrc
|
||||
|
||||
在你的 `~/.vimrc` 后面跟上这些:
|
||||
|
||||
```
|
||||
" Edit vimr configuration file
|
||||
nnoremap confe :e $MYVIMRC<CR>
|
||||
" Reload vims configuration file
|
||||
nnoremap confr :source $MYVIMRC<CR>
|
||||
```
|
||||
|
||||
现在只要按下 `Esc` 接着输入 `confe` 就可以编辑 `~/.vimrc`。按下 `Esc` ,接着输入 `confr` 以重新加载。一些人喜欢在 `.vimrc` 中使用 `<Leader>` 键。因此上面的映射变成:
|
||||
|
||||
```
|
||||
" Edit vimr configuration file
|
||||
nnoremap <Leader>ve :e $MYVIMRC<CR>
|
||||
" Reload vimr configuration file
|
||||
nnoremap <Leader>vr :source $MYVIMRC<CR>
|
||||
```
|
||||
|
||||
`<Leader>` 键默认映射成 `\` 键。因此只要输入 `\` 接着 `ve` 就能编辑文件。按下 `\` 接着 `vr` 就能重载 `~/vimrc`。
|
||||
|
||||
这就完成了,你可以不用再重启 Vim 就能重新加载 `.vimrc` 了。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,经验丰富的系统管理员,也是 Linux / Unix shell 脚本的培训师。他曾与全球客户以及IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter][9]、[Facebook][10]、[Google +][11] 上关注他。通过[RSS/XML 订阅][5]获取最新的系统管理、Linux/Unix 以及开源主题教程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-reload-vimrc-file-without-restarting-vim-on-linux-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/02/How-to-reload-.vimrc-file-without-restarting-vim.jpg
|
||||
[2]:https://twitter.com/nixcraft
|
||||
[3]:https://facebook.com/nixcraft
|
||||
[4]:https://plus.google.com/+CybercitiBiz
|
||||
[5]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -1,9 +1,9 @@
|
||||
如何在 Ubuntu 16.04 上使用 Gogs 安装 Go 语言编写的 Git 服务器
|
||||
如何在 Ubuntu 安装 Go 语言编写的 Git 服务器 Gogs
|
||||
======
|
||||
|
||||
Gogs 是由 Go 语言编写,提供开源且免费的 Git 服务。Gogs 是一款无痛式自托管的 Git 服务器,能在尽可能小的硬件资源开销上搭建并运行您的私有 Git 服务器。Gogs 的网页界面和 GitHub 十分相近,且提供 MySQL、PostgreSQL 和 SQLite 数据库支持。
|
||||
Gogs 是由 Go 语言编写的,自由开源的 Git 服务。Gogs 是一款无痛式自托管的 Git 服务器,能在尽可能小的硬件资源开销上搭建并运行您的私有 Git 服务器。Gogs 的网页界面和 GitHub 十分相近,且提供 MySQL、PostgreSQL 和 SQLite 数据库支持。
|
||||
|
||||
在本教程中,我们将使用 Gogs 在 Ununtu 16.04 上按步骤,指导您安装和配置您的私有 Git 服务器。这篇教程中涵盖了如何在 Ubuntu 上安装 Go 语言、PostgreSQL 和安装并且配置 Nginx 网页服务器作为 Go 应用的反向代理的细节内容。
|
||||
在本教程中,我们将使用 Gogs 在 Ununtu 16.04 上按步骤指导您安装和配置您的私有 Git 服务器。这篇教程中涵盖了如何在 Ubuntu 上安装 Go 语言、PostgreSQL 和安装并且配置 Nginx 网页服务器作为 Go 应用的反向代理的细节内容。
|
||||
|
||||
### 搭建环境
|
||||
|
||||
@ -22,9 +22,11 @@ Gogs 是由 Go 语言编写,提供开源且免费的 Git 服务。Gogs 是一
|
||||
8. 测试
|
||||
|
||||
### 步骤 1 - 更新和升级系统
|
||||
|
||||
继续之前,更新 Ubuntu 所有的库,升级所有包。
|
||||
|
||||
运行下面的 apt 命令
|
||||
运行下面的 `apt` 命令:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt upgrade
|
||||
@ -36,12 +38,14 @@ Gogs 提供 MySQL、PostgreSQL、SQLite 和 TiDB 数据库系统支持。
|
||||
|
||||
此步骤中,我们将使用 PostgreSQL 作为 Gogs 程序的数据库。
|
||||
|
||||
使用下面的 apt 命令安装 PostgreSQL。
|
||||
使用下面的 `apt` 命令安装 PostgreSQL。
|
||||
|
||||
```
|
||||
sudo apt install -y postgresql postgresql-client libpq-dev
|
||||
```
|
||||
|
||||
安装完成之后,启动 PostgreSQL 服务并设置为开机启动。
|
||||
|
||||
```
|
||||
systemctl start postgresql
|
||||
systemctl enable postgresql
|
||||
@ -51,62 +55,71 @@ systemctl enable postgresql
|
||||
|
||||
之后,我们需要为 Gogs 创建数据库和用户。
|
||||
|
||||
使用 'postgres' 用户登陆并运行 ‘psql’ 命令获取 PostgreSQL 操作界面.
|
||||
使用 `postgres` 用户登录并运行 `psql` 命令以访问 PostgreSQL 操作界面。
|
||||
|
||||
```
|
||||
su - postgres
|
||||
psql
|
||||
```
|
||||
|
||||
创建一个名为 ‘git’ 的新用户,给予此用户 ‘CREATEDB’ 权限。
|
||||
创建一个名为 `git` 的新用户,给予此用户 `CREATEDB` 权限。
|
||||
|
||||
```
|
||||
CREATE USER git CREATEDB;
|
||||
\password git
|
||||
```
|
||||
|
||||
创建名为 ‘gogs_production’ 的数据库,设置 ‘git’ 用户作为其所有者。
|
||||
创建名为 `gogs_production` 的数据库,设置 `git` 用户作为其所有者。
|
||||
|
||||
```
|
||||
CREATE DATABASE gogs_production OWNER git;
|
||||
```
|
||||
|
||||
[![创建 Gogs 数据库][1]][2]
|
||||
|
||||
作为 Gogs 安装时的 ‘gogs_production’ PostgreSQL 数据库和 ‘git’ 用户已经创建完毕。
|
||||
用于 Gogs 的 `gogs_production` PostgreSQL 数据库和 `git` 用户已经创建完毕。
|
||||
|
||||
### 步骤 3 - 安装 Go 和 Git
|
||||
|
||||
使用下面的 apt 命令从库中安装 Git。
|
||||
使用下面的 `apt` 命令从库中安装 Git。
|
||||
|
||||
```
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
此时,为系统创建名为 ‘git’ 的新用户。
|
||||
此时,为系统创建名为 `git` 的新用户。
|
||||
|
||||
```
|
||||
sudo adduser --disabled-login --gecos 'Gogs' git
|
||||
```
|
||||
|
||||
登陆 ‘git’ 账户并且创建名为 ‘local’ 的目录。
|
||||
登录 `git` 账户并且创建名为 `local` 的目录。
|
||||
|
||||
```
|
||||
su - git
|
||||
mkdir -p /home/git/local
|
||||
```
|
||||
|
||||
切换到 ‘local’ 目录,依照下方所展示的内容,使用 wget 命令下载 ‘Go’(最新版)。
|
||||
切换到 `local` 目录,依照下方所展示的内容,使用 `wget` 命令下载 Go(最新版)。
|
||||
|
||||
```
|
||||
cd ~/local
|
||||
wget <https://dl.google.com/go/go1.9.2.linux-amd64.tar.gz>
|
||||
wget https://dl.google.com/go/go1.9.2.linux-amd64.tar.gz
|
||||
```
|
||||
|
||||
[![安装 Go 和 Git][3]][4]
|
||||
|
||||
解压并且删除 go 的压缩文件。
|
||||
|
||||
```
|
||||
tar -xf go1.9.2.linux-amd64.tar.gz
|
||||
rm -f go1.9.2.linux-amd64.tar.gz
|
||||
```
|
||||
|
||||
‘Go’ 二进制文件已经被下载到 ‘~/local/go’ 目录。此时我们需要设置环境变量 - 设置 ‘GOROOT’ 和 ‘GOPATH’ 目录到系统环境,这样,我们就可以在 ‘git’ 用户下执行 ‘go’ 命令。
|
||||
Go 二进制文件已经被下载到 `~/local/go` 目录。此时我们需要设置环境变量 - 设置 `GOROOT` 和 `GOPATH` 目录到系统环境,这样,我们就可以在 `git` 用户下执行 `go` 命令。
|
||||
|
||||
执行下方的命令。
|
||||
|
||||
```
|
||||
cd ~/
|
||||
echo 'export GOROOT=$HOME/local/go' >> $HOME/.bashrc
|
||||
@ -114,7 +127,8 @@ echo 'export GOPATH=$HOME/go' >> $HOME/.bashrc
|
||||
echo 'export PATH=$PATH:$GOROOT/bin:$GOPATH/bin' >> $HOME/.bashrc
|
||||
```
|
||||
|
||||
之后通过运行 'source ~/.bashrc' 重载 Bash,如下:
|
||||
之后通过运行 `source ~/.bashrc` 重载 Bash,如下:
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
@ -123,7 +137,8 @@ source ~/.bashrc
|
||||
|
||||
[![安装 Go 编程语言][5]][6]
|
||||
|
||||
现在运行 'go' 的版本查看命令。
|
||||
现在运行 `go` 的版本查看命令。
|
||||
|
||||
```
|
||||
go version
|
||||
```
|
||||
@ -132,27 +147,30 @@ go version
|
||||
|
||||
[![检查 go 版本][7]][8]
|
||||
|
||||
现在,Go 已经安装在系统的 ‘git’ 用户下了。
|
||||
现在,Go 已经安装在系统的 `git` 用户下了。
|
||||
|
||||
### 步骤 4 - 使用 Gogs 安装 Git 服务
|
||||
|
||||
使用 ‘git’ 用户登陆并且使用 ‘go’ 命令从 GitHub 下载 ‘Gogs’。
|
||||
使用 `git` 用户登录并且使用 `go` 命令从 GitHub 下载 Gogs。
|
||||
|
||||
```
|
||||
su - git
|
||||
go get -u github.com/gogits/gogs
|
||||
```
|
||||
|
||||
此命令将在 ‘GOPATH/src’ 目录下载 Gogs 的所有源代码。
|
||||
此命令将在 `GOPATH/src` 目录下载 Gogs 的所有源代码。
|
||||
|
||||
切换至 `$GOPATH/src/github.com/gogits/gogs` 目录,并且使用下列命令搭建 Gogs。
|
||||
|
||||
切换至 '$GOPATH/src/github.com/gogits/gogs' 目录,并且使用下列命令搭建 gogs。
|
||||
```
|
||||
cd $GOPATH/src/github.com/gogits/gogs
|
||||
go build
|
||||
```
|
||||
|
||||
确保您没有捕获到错误。
|
||||
确保您没有遇到错误。
|
||||
|
||||
现在使用下面的命令运行 Gogs Go Git 服务器。
|
||||
|
||||
```
|
||||
./gogs web
|
||||
```
|
||||
@ -161,31 +179,34 @@ go build
|
||||
|
||||
[![安装 Gogs Go Git 服务][9]][10]
|
||||
|
||||
打开网页浏览器,键入您的 IP 地址和端口号,我的是<http://192.168.33.10:3000/>
|
||||
打开网页浏览器,键入您的 IP 地址和端口号,我的是 http://192.168.33.10:3000/ 。
|
||||
|
||||
您应该会得到于下方一致的反馈。
|
||||
您应该会得到与下方一致的反馈。
|
||||
|
||||
[![Gogs 网页服务器][11]][12]
|
||||
|
||||
Gogs 已经在您的 Ubuntu 系统上安装完毕。现在返回到您的终端,并且键入 'Ctrl + c' 中止服务。
|
||||
Gogs 已经在您的 Ubuntu 系统上安装完毕。现在返回到您的终端,并且键入 `Ctrl + C` 中止服务。
|
||||
|
||||
### 步骤 5 - 配置 Gogs Go Git 服务器
|
||||
|
||||
本步骤中,我们将为 Gogs 创建惯例配置。
|
||||
|
||||
进入 Gogs 安装目录并新建 ‘custom/conf’ 目录。
|
||||
进入 Gogs 安装目录并新建 `custom/conf` 目录。
|
||||
|
||||
```
|
||||
cd $GOPATH/src/github.com/gogits/gogs
|
||||
mkdir -p custom/conf/
|
||||
```
|
||||
|
||||
复制默认的配置文件到 custom 目录,并使用 [vim][13] 修改。
|
||||
复制默认的配置文件到 `custom` 目录,并使用 [vim][13] 修改。
|
||||
|
||||
```
|
||||
cp conf/app.ini custom/conf/app.ini
|
||||
vim custom/conf/app.ini
|
||||
```
|
||||
|
||||
在 ‘ **[server]** ’ 选项中,修改 ‘HOST_ADDR’ 为 ‘127.0.0.1’.
|
||||
在 `[server]` 小节中,修改 `HOST_ADDR` 为 `127.0.0.1`。
|
||||
|
||||
```
|
||||
[server]
|
||||
PROTOCOL = http
|
||||
@ -193,23 +214,23 @@ vim custom/conf/app.ini
|
||||
ROOT_URL = %(PROTOCOL)s://%(DOMAIN)s:%(HTTP_PORT)s/
|
||||
HTTP_ADDR = 127.0.0.1
|
||||
HTTP_PORT = 3000
|
||||
|
||||
```
|
||||
|
||||
在 ‘ **[database]** ’ 选项中,按照您的数据库信息修改。
|
||||
在 `[database]` 选项中,按照您的数据库信息修改。
|
||||
|
||||
```
|
||||
[database]
|
||||
DB_TYPE = postgres
|
||||
HOST = 127.0.0.1:5432
|
||||
NAME = gogs_production
|
||||
USER = git
|
||||
PASSWD = [email protected]#
|
||||
|
||||
PASSWD = aqwe123@#
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
运行下面的命令验证配置项。
|
||||
|
||||
```
|
||||
./gogs web
|
||||
```
|
||||
@ -218,54 +239,57 @@ vim custom/conf/app.ini
|
||||
|
||||
[![配置服务器][14]][15]
|
||||
|
||||
Gogs 现在已经按照自定义配置下运行在 ‘localhost’ 的 3000 端口上了。
|
||||
Gogs 现在已经按照自定义配置下运行在 `localhost` 的 3000 端口上了。
|
||||
|
||||
### 步骤 6 - 运行 Gogs 服务器
|
||||
|
||||
这一步,我们将在 Ubuntu 系统上配置 Gogs 服务器。我们会在 ‘/etc/systemd/system’ 目录下创建一个新的服务器配置文件 ‘gogs.service’。
|
||||
这一步,我们将在 Ubuntu 系统上配置 Gogs 服务器。我们会在 `/etc/systemd/system` 目录下创建一个新的服务器配置文件 `gogs.service`。
|
||||
|
||||
切换到 `/etc/systemd/system` 目录,使用 [vim][13] 创建服务器配置文件 `gogs.service`。
|
||||
|
||||
切换到 ‘/etc/systemd/system’ 目录,使用 [vim][13] 创建服务器配置文件 ‘gogs.service’。
|
||||
```
|
||||
cd /etc/systemd/system
|
||||
vim gogs.service
|
||||
```
|
||||
|
||||
粘贴下面的代码到 gogs 服务器配置文件中。
|
||||
粘贴下面的代码到 Gogs 服务器配置文件中。
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Gogs
|
||||
After=syslog.target
|
||||
After=network.target
|
||||
After=mariadb.service mysqld.service postgresql.service memcached.service redis.service
|
||||
Description=Gogs
|
||||
After=syslog.target
|
||||
After=network.target
|
||||
After=mariadb.service mysqld.service postgresql.service memcached.service redis.service
|
||||
|
||||
[Service]
|
||||
# Modify these two values and uncomment them if you have
|
||||
# repos with lots of files and get an HTTP error 500 because
|
||||
# of that
|
||||
###
|
||||
#LimitMEMLOCK=infinity
|
||||
#LimitNOFILE=65535
|
||||
Type=simple
|
||||
User=git
|
||||
Group=git
|
||||
WorkingDirectory=/home/git/go/src/github.com/gogits/gogs
|
||||
ExecStart=/home/git/go/src/github.com/gogits/gogs/gogs web
|
||||
Restart=always
|
||||
Environment=USER=git HOME=/home/git
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
[Service]
|
||||
# Modify these two values and uncomment them if you have
|
||||
# repos with lots of files and get an HTTP error 500 because
|
||||
# of that
|
||||
###
|
||||
#LimitMEMLOCK=infinity
|
||||
#LimitNOFILE=65535
|
||||
Type=simple
|
||||
User=git
|
||||
Group=git
|
||||
WorkingDirectory=/home/git/go/src/github.com/gogits/gogs
|
||||
ExecStart=/home/git/go/src/github.com/gogits/gogs/gogs web
|
||||
Restart=always
|
||||
Environment=USER=git HOME=/home/git
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
之后保存并且退出。
|
||||
|
||||
现在可以重载系统服务器。
|
||||
|
||||
```
|
||||
systemctl daemon-reload
|
||||
```
|
||||
|
||||
使用下面的命令开启 gogs 服务器并设置为开机启动。
|
||||
使用下面的命令开启 Gogs 服务器并设置为开机启动。
|
||||
|
||||
```
|
||||
systemctl start gogs
|
||||
systemctl enable gogs
|
||||
@ -276,6 +300,7 @@ systemctl enable gogs
|
||||
Gogs 服务器现在已经运行在 Ubuntu 系统上了。
|
||||
|
||||
使用下面的命令检测:
|
||||
|
||||
```
|
||||
netstat -plntu
|
||||
systemctl status gogs
|
||||
@ -290,23 +315,27 @@ systemctl status gogs
|
||||
在本步中,我们将为 Gogs 安装和配置 Nginx 反向代理。我们会在自己的库中调用 Nginx 包。
|
||||
|
||||
使用下面的命令添加 Nginx 库。
|
||||
|
||||
```
|
||||
sudo add-apt-repository -y ppa:nginx/stable
|
||||
```
|
||||
|
||||
此时更新所有的库并且使用下面的命令安装 Nginx。
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install nginx -y
|
||||
```
|
||||
|
||||
之后,进入 ‘/etc/nginx/sites-available’ 目录并且创建虚拟主机文件 ‘gogs’。
|
||||
之后,进入 `/etc/nginx/sites-available` 目录并且创建虚拟主机文件 `gogs`。
|
||||
|
||||
```
|
||||
cd /etc/nginx/sites-available
|
||||
vim gogs
|
||||
```
|
||||
|
||||
粘贴下面的代码到配置项。
|
||||
粘贴下面的代码到配置文件。
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
@ -316,21 +345,21 @@ server {
|
||||
proxy_pass http://localhost:3000;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
保存退出。
|
||||
|
||||
**注意:**
|
||||
使用您的域名修改 ‘server_name’ 项。
|
||||
**注意:** 请使用您的域名修改 `server_name` 项。
|
||||
|
||||
现在激活虚拟主机并且测试 nginx 配置。
|
||||
|
||||
```
|
||||
ln -s /etc/nginx/sites-available/gogs /etc/nginx/sites-enabled/
|
||||
nginx -t
|
||||
```
|
||||
|
||||
确保没有抛错,重启 Nginx 服务器。
|
||||
确保没有遇到错误,重启 Nginx 服务器。
|
||||
|
||||
```
|
||||
systemctl restart nginx
|
||||
```
|
||||
@ -339,25 +368,25 @@ systemctl restart nginx
|
||||
|
||||
### 步骤 8 - 测试
|
||||
|
||||
打开您的网页浏览器并且输入您的 gogs URL,我的是 <http://git.hakase-labs.co>
|
||||
打开您的网页浏览器并且输入您的 Gogs URL,我的是 http://git.hakase-labs.co
|
||||
|
||||
现在您将进入安装界面。在页面的顶部,输入您所有的 PostgreSQL 数据库信息。
|
||||
|
||||
[![Gogs 安装][22]][23]
|
||||
|
||||
之后,滚动到底部,点击 ‘Admin account settings’ 下拉选项。
|
||||
之后,滚动到底部,点击 “Admin account settings” 下拉选项。
|
||||
|
||||
输入您的管理者用户名和邮箱。
|
||||
|
||||
[![键入 gogs 安装设置][24]][25]
|
||||
|
||||
之后点击 ‘Install Gogs’ 按钮。
|
||||
之后点击 “Install Gogs” 按钮。
|
||||
|
||||
然后您将会被重定向到下图显示的 Gogs 用户面板。
|
||||
|
||||
[![Gogs 面板][26]][27]
|
||||
|
||||
下面是 Gogs ‘Admin Dashboard(管理员面板)’。
|
||||
下面是 Gogs 的 “Admin Dashboard(管理员面板)”。
|
||||
|
||||
[![浏览 Gogs 面板][28]][29]
|
||||
|
||||
@ -369,7 +398,7 @@ via: https://www.howtoforge.com/tutorial/how-to-install-gogs-go-git-service-on-u
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Record and Share Terminal Session with Showterm
|
||||
======
|
||||
|
||||
|
||||
@ -1,99 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Partclone – A Versatile Free Software for Partition Imaging and Cloning
|
||||
======
|
||||
|
||||
|
||||
|
||||
**[Partclone][1]** is a free and open-source tool for creating and cloning partition images brought to you by the developers of **Clonezilla**. In fact, **Partclone** is one of the tools that **Clonezilla** is based on.
|
||||
|
||||
It provides users with the tools required to backup and restores used partition blocks along with high compatibility with several file systems thanks to its ability to use existing libraries like **e2fslibs** to read and write partitions e.g. **ext2**.
|
||||
|
||||
Its best stronghold is the variety of formats it supports including ext2, ext3, ext4, hfs+, reiserfs, reiser4, btrfs, vmfs3, vmfs5, xfs, jfs, ufs, ntfs, fat(12/16/32), exfat, f2fs, and nilfs.
|
||||
|
||||
It also has a plethora of available programs including **partclone.ext2** (ext3 & ext4), partclone.ntfs, partclone.exfat, partclone.hfsp, and partclone.vmfs (v3 and v5), among others.
|
||||
|
||||
### Features in Partclone
|
||||
|
||||
* **Freeware:** **Partclone** is free for everyone to download and use.
|
||||
* **Open Source:** **Partclone** is released under the GNU GPL license and is open to contribution on [GitHub][2].
|
||||
* **Cross-Platform** : Available on Linux, Windows, MAC, ESX file system backup/restore, and FreeBSD.
|
||||
* An online [Documentation page][3] from where you can view help docs and track its GitHub issues.
|
||||
* An online [user manual][4] for beginners and pros alike.
|
||||
* Rescue support.
|
||||
* Clone partitions to image files.
|
||||
* Restore image files to partitions.
|
||||
* Duplicate partitions quickly.
|
||||
* Support for raw clone.
|
||||
* Displays transfer rate and elapsed time.
|
||||
* Supports piping.
|
||||
* Support for crc32.
|
||||
* Supports vmfs for ESX vmware server and ufs for FreeBSD file system.
|
||||
|
||||
|
||||
|
||||
There are a lot more features bundled in **Partclone** and you can see the rest of them [here][5].
|
||||
|
||||
[__Download Partclone for Linux][6]
|
||||
|
||||
### How to Install and Use Partclone
|
||||
|
||||
To install Partclone on Linux.
|
||||
```
|
||||
$ sudo apt install partclone [On Debian/Ubuntu]
|
||||
$ sudo yum install partclone [On CentOS/RHEL/Fedora]
|
||||
|
||||
```
|
||||
|
||||
Clone partition to image.
|
||||
```
|
||||
# partclone.ext4 -d -c -s /dev/sda1 -o sda1.img
|
||||
|
||||
```
|
||||
|
||||
Restore image to partition.
|
||||
```
|
||||
# partclone.ext4 -d -r -s sda1.img -o /dev/sda1
|
||||
|
||||
```
|
||||
|
||||
Partition to partition clone.
|
||||
```
|
||||
# partclone.ext4 -d -b -s /dev/sda1 -o /dev/sdb1
|
||||
|
||||
```
|
||||
|
||||
Display image information.
|
||||
```
|
||||
# partclone.info -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
Check image.
|
||||
```
|
||||
# partclone.chkimg -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
Are you a **Partclone** user? I wrote on [**Deepin Clone**][7] just recently and apparently, there are certain tasks Partclone is better at handling. What has been your experience with other backup and restore utility tools?
|
||||
|
||||
Do share your thoughts and suggestions with us in the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/partclone-linux-backup-clone-tool/
|
||||
|
||||
作者:[Martins D. Okoi;View All Posts;Peter Beck;Martins Divine Okoi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://partclone.org/
|
||||
[2]:https://github.com/Thomas-Tsai/partclone
|
||||
[3]:https://partclone.org/help/
|
||||
[4]:https://partclone.org/usage/
|
||||
[5]:https://partclone.org/features/
|
||||
[6]:https://partclone.org/download/
|
||||
[7]:https://www.fossmint.com/deepin-clone-system-backup-restore-for-deepin-users/
|
||||
@ -1,265 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Monitor your Kubernetes Cluster
|
||||
======
|
||||
This article originally appeared on [Kevin Monroe's blog][1]
|
||||
|
||||
Keeping an eye on logs and metrics is a necessary evil for cluster admins. The benefits are clear: metrics help you set reasonable performance goals, while log analysis can uncover issues that impact your workloads. The hard part, however, is getting a slew of applications to work together in a useful monitoring solution.
|
||||
|
||||
In this post, I'll cover monitoring a Kubernetes cluster with [Graylog][2] (for logging) and [Prometheus][3] (for metrics). Of course that's not just wiring 3 things together. In fact, it'll end up looking like this:
|
||||
|
||||
![][4]
|
||||
|
||||
As you know, Kubernetes isn't just one thing -- it's a system of masters, workers, networking bits, etc(d). Similarly, Graylog comes with a supporting cast (apache2, mongodb, etc), as does Prometheus (telegraf, grafana, etc). Connecting the dots in a deployment like this may seem daunting, but the right tools can make all the difference.
|
||||
|
||||
I'll walk through this using [conjure-up][5] and the [Canonical Distribution of Kubernetes][6] (CDK). I find the conjure-up interface really helpful for deploying big software, but I know some of you hate GUIs and TUIs and probably other UIs too. For those folks, I'll do the same deployment again from the command line.
|
||||
|
||||
Before we jump in, note that Graylog and Prometheus will be deployed alongside Kubernetes and not in the cluster itself. Things like the Kubernetes Dashboard and Heapster are excellent sources of information from within a running cluster, but my objective is to provide a mechanism for log/metric analysis whether the cluster is running or not.
|
||||
|
||||
### The Walk Through
|
||||
|
||||
First things first, install conjure-up if you don't already have it. On Linux, that's simply:
|
||||
```
|
||||
sudo snap install conjure-up --classic
|
||||
```
|
||||
|
||||
There's also a brew package for macOS users:
|
||||
```
|
||||
brew install conjure-up
|
||||
```
|
||||
|
||||
You'll need at least version 2.5.2 to take advantage of the recent CDK spell additions, so be sure to `sudo snap refresh conjure-up` or `brew update && brew upgrade conjure-up` if you have an older version installed.
|
||||
|
||||
Once installed, run it:
|
||||
```
|
||||
conjure-up
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
You'll be presented with a list of various spells. Select CDK and press `Enter`.
|
||||
|
||||
![][8]
|
||||
|
||||
At this point, you'll see additional components that are available for the CDK spell. We're interested in Graylog and Prometheus, so check both of those and hit `Continue`.
|
||||
|
||||
You'll be guided through various cloud choices to determine where you want your cluster to live. After that, you'll see options for post-deployment steps, followed by a review screen that lets you see what is about to be deployed:
|
||||
|
||||
![][9]
|
||||
|
||||
In addition to the typical K8s-related applications (etcd, flannel, load-balancer, master, and workers), you'll see additional applications related to our logging and metric selections.
|
||||
|
||||
The Graylog stack includes the following:
|
||||
|
||||
* apache2: reverse proxy for the graylog web interface
|
||||
* elasticsearch: document database for the logs
|
||||
* filebeat: forwards logs from K8s master/workers to graylog
|
||||
* graylog: provides an api for log collection and an interface for analysis
|
||||
* mongodb: database for graylog metadata
|
||||
|
||||
|
||||
|
||||
The Prometheus stack includes the following:
|
||||
|
||||
* grafana: web interface for metric-related dashboards
|
||||
* prometheus: metric collector and time series database
|
||||
* telegraf: sends host metrics to prometheus
|
||||
|
||||
|
||||
|
||||
You can fine tune the deployment from this review screen, but the defaults will suite our needs. Click `Deploy all Remaining Applications` to get things going.
|
||||
|
||||
The deployment will take a few minutes to settle as machines are brought online and applications are configured in your cloud. Once complete, conjure-up will show a summary screen that includes links to various interesting endpoints for you to browse:
|
||||
|
||||
![][10]
|
||||
|
||||
#### Exploring Logs
|
||||
|
||||
Now that Graylog has been deployed and configured, let's take a look at some of the data we're gathering. By default, the filebeat application will send both syslog and container log events to graylog (that's `/var/log/*.log` and `/var/log/containers/*.log` from the kubernetes master and workers).
|
||||
|
||||
Grab the apache2 address and graylog admin password as follows:
|
||||
```
|
||||
juju status --format yaml apache2/0 | grep public-address
|
||||
public-address: <your-apache2-ip>
|
||||
juju run-action --wait graylog/0 show-admin-password
|
||||
admin-password: <your-graylog-password>
|
||||
```
|
||||
|
||||
Browse to `http://<your-apache2-ip>` and login with admin as the username and <your-graylog-password> as the password. **Note:** if the interface is not immediately available, please wait as the reverse proxy configuration may take up to 5 minutes to complete.
|
||||
|
||||
Once logged in, head to the `Sources` tab to get an overview of the logs collected from our K8s master and workers:
|
||||
|
||||
![][11]
|
||||
|
||||
Drill into those logs by clicking the `System / Inputs` tab and selecting `Show received messages` for the filebeat input:
|
||||
|
||||
![][12]
|
||||
|
||||
From here, you may want to play around with various filters or setup Graylog dashboards to help identify the events that are most important to you. Check out the [Graylog Dashboard][13] docs for details on customizing your view.
|
||||
|
||||
#### Exploring Metrics
|
||||
|
||||
Our deployment exposes two types of metrics through our grafana dashboards: system metrics include things like cpu/memory/disk utilization for the K8s master and worker machines, and cluster metrics include container-level data scraped from the K8s cAdvisor endpoints.
|
||||
|
||||
Grab the grafana address and admin password as follows:
|
||||
```
|
||||
juju status --format yaml grafana/0 | grep public-address
|
||||
public-address: <your-grafana-ip>
|
||||
juju run-action --wait grafana/0 get-admin-password
|
||||
password: <your-grafana-password>
|
||||
```
|
||||
|
||||
Browse to `http://<your-grafana-ip>:3000` and login with admin as the username and <your-grafana-password> as the password. Once logged in, check out the cluster metric dashboard by clicking the `Home` drop-down box and selecting `Kubernetes Metrics (via Prometheus)`:
|
||||
|
||||
![][14]
|
||||
|
||||
We can also check out the system metrics of our K8s host machines by switching the drop-down box to `Node Metrics (via Telegraf) `
|
||||
|
||||
![][15]
|
||||
|
||||
|
||||
### The Other Way
|
||||
|
||||
As alluded to in the intro, I prefer the wizard-y feel of conjure-up to guide me through complex software deployments like Kubernetes. Now that we've seen the conjure-up way, some of you may want to see a command line approach to achieve the same results. Still others may have deployed CDK previously and want to extend it with the Graylog/Prometheus components described above. Regardless of why you've read this far, I've got you covered.
|
||||
|
||||
The tool that underpins conjure-up is [Juju][16]. Everything that the CDK spell did behind the scenes can be done on the command line with Juju. Let's step through how that works.
|
||||
|
||||
**Starting From Scratch**
|
||||
|
||||
If you're on Linux, install Juju like this:
|
||||
```
|
||||
sudo snap install juju --classic
|
||||
```
|
||||
|
||||
For macOS, Juju is available from brew:
|
||||
```
|
||||
brew install juju
|
||||
```
|
||||
|
||||
Now setup a controller for your preferred cloud. You may be prompted for any required cloud credentials:
|
||||
```
|
||||
juju bootstrap
|
||||
```
|
||||
|
||||
We then need to deploy the base CDK bundle:
|
||||
```
|
||||
juju deploy canonical-kubernetes
|
||||
```
|
||||
|
||||
**Starting From CDK**
|
||||
|
||||
With our Kubernetes cluster deployed, we need to add all the applications required for Graylog and Prometheus:
|
||||
```
|
||||
## deploy graylog-related applications
|
||||
juju deploy xenial/apache2
|
||||
juju deploy xenial/elasticsearch
|
||||
juju deploy xenial/filebeat
|
||||
juju deploy xenial/graylog
|
||||
juju deploy xenial/mongodb
|
||||
```
|
||||
```
|
||||
## deploy prometheus-related applications
|
||||
juju deploy xenial/grafana
|
||||
juju deploy xenial/prometheus
|
||||
juju deploy xenial/telegraf
|
||||
```
|
||||
|
||||
Now that the software is deployed, connect them together so they can communicate:
|
||||
```
|
||||
## relate graylog applications
|
||||
juju relate apache2:reverseproxy graylog:website
|
||||
juju relate graylog:elasticsearch elasticsearch:client
|
||||
juju relate graylog:mongodb mongodb:database
|
||||
juju relate filebeat:beats-host kubernetes-master:juju-info
|
||||
juju relate filebeat:beats-host kubernetes-worker:jujuu-info
|
||||
```
|
||||
```
|
||||
## relate prometheus applications
|
||||
juju relate prometheus:grafana-source grafana:grafana-source
|
||||
juju relate telegraf:prometheus-client prometheus:target
|
||||
juju relate kubernetes-master:juju-info telegraf:juju-info
|
||||
juju relate kubernetes-worker:juju-info telegraf:juju-info
|
||||
```
|
||||
|
||||
At this point, all the applications can communicate with each other, but we have a bit more configuration to do (e.g., setting up the apache2 reverse proxy, telling prometheus how to scrape k8s, importing our grafana dashboards, etc):
|
||||
```
|
||||
## configure graylog applications
|
||||
juju config apache2 enable_modules="headers proxy_html proxy_http"
|
||||
juju config apache2 vhost_http_template="$(base64 <vhost-tmpl>)"
|
||||
juju config elasticsearch firewall_enabled="false"
|
||||
juju config filebeat \
|
||||
logpath="/var/log/*.log /var/log/containers/*.log"
|
||||
juju config filebeat logstash_hosts="<graylog-ip>:5044"
|
||||
juju config graylog elasticsearch_cluster_name="<es-cluster>"
|
||||
```
|
||||
```
|
||||
## configure prometheus applications
|
||||
juju config prometheus scrape-jobs="<scraper-yaml>"
|
||||
juju run-action --wait grafana/0 import-dashboard \
|
||||
dashboard="$(base64 <dashboard-json>)"
|
||||
```
|
||||
|
||||
Some of the above steps need values specific to your deployment. You can get these in the same way that conjure-up does:
|
||||
|
||||
* <vhost-tmpl>: fetch our sample [template][17] from github
|
||||
* <graylog-ip>: `juju run --unit graylog/0 'unit-get private-address'`
|
||||
* <es-cluster>: `juju config elasticsearch cluster-name`
|
||||
* <scraper-yaml>: fetch our sample [scraper][18] from github; [substitute][19]appropriate values for `[K8S_PASSWORD][20]` and `[K8S_API_ENDPOINT][21]`
|
||||
* <dashboard-json>: fetch our [host][22] and [k8s][23] dashboards from github
|
||||
|
||||
|
||||
|
||||
Finally, you'll want to expose the apache2 and grafana applications to make their web interfaces accessible:
|
||||
```
|
||||
## expose relevant endpoints
|
||||
juju expose apache2
|
||||
juju expose grafana
|
||||
```
|
||||
|
||||
Now that we have everything deployed, related, configured, and exposed, you can login and poke around using the same steps from the **Exploring Logs** and **Exploring Metrics** sections above.
|
||||
|
||||
### The Wrap Up
|
||||
|
||||
My goal here was to show you how to deploy a Kubernetes cluster with rich monitoring capabilities for logs and metrics. Whether you prefer a guided approach or command line steps, I hope it's clear that monitoring complex deployments doesn't have to be a pipe dream. The trick is to figure out how all the moving parts work, make them work together repeatably, and then break/fix/repeat for a while until everyone can use it.
|
||||
|
||||
This is where tools like conjure-up and Juju really shine. Leveraging the expertise of contributors to this ecosystem makes it easy to manage big software. Start with a solid set of apps, customize as needed, and get back to work!
|
||||
|
||||
Give these bits a try and let me know how it goes. You can find enthusiasts like me on Freenode IRC in **#conjure-up** and **#juju**. Thanks for reading!
|
||||
|
||||
### About the author
|
||||
|
||||
Kevin joined Canonical in 2014 with his focus set on modeling complex software. He found his niche on the Juju Big Software team where his mission is to capture operational knowledge of Big Data and Machine Learning applications into repeatable (and reliable!) solutions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2018/01/16/monitor-your-kubernetes-cluster/
|
||||
|
||||
作者:[Kevin Monroe][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/kwmonroe/
|
||||
[1]:https://medium.com/@kwmonroe/monitor-your-kubernetes-cluster-a856d2603ec3
|
||||
[2]:https://www.graylog.org/
|
||||
[3]:https://prometheus.io/
|
||||
[4]:https://insights.ubuntu.com/wp-content/uploads/706b/1_TAA57DGVDpe9KHIzOirrBA.png
|
||||
[5]:https://conjure-up.io/
|
||||
[6]:https://jujucharms.com/canonical-kubernetes
|
||||
[7]:https://insights.ubuntu.com/wp-content/uploads/98fd/1_o0UmYzYkFiHIs2sBgj7G9A.png
|
||||
[8]:https://insights.ubuntu.com/wp-content/uploads/0351/1_pgVaO_ZlalrjvYd5pOMJMA.png
|
||||
[9]:https://insights.ubuntu.com/wp-content/uploads/9977/1_WXKxMlml2DWA5Kj6wW9oXQ.png
|
||||
[10]:https://insights.ubuntu.com/wp-content/uploads/8588/1_NWq7u6g6UAzyFxtbM-ipqg.png
|
||||
[11]:https://insights.ubuntu.com/wp-content/uploads/a1c3/1_hHK5mSrRJQi6A6u0yPSGOA.png
|
||||
[12]:https://insights.ubuntu.com/wp-content/uploads/937f/1_cP36lpmSwlsPXJyDUpFluQ.png
|
||||
[13]:http://docs.graylog.org/en/2.3/pages/dashboards.html
|
||||
[14]:https://insights.ubuntu.com/wp-content/uploads/9256/1_kskust3AOImIh18QxQPgRw.png
|
||||
[15]:https://insights.ubuntu.com/wp-content/uploads/2037/1_qJpjPOTGMQbjFY5-cZsYrQ.png
|
||||
[16]:https://jujucharms.com/
|
||||
[17]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/graylog/steps/01_install-graylog/graylog-vhost.tmpl
|
||||
[18]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/prometheus-scrape-k8s.yaml
|
||||
[19]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L25
|
||||
[20]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L10
|
||||
[21]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L11
|
||||
[22]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-telegraf.json
|
||||
[23]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-k8s.json
|
||||
@ -1,171 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Never miss a Magazine's article, build your own RSS notification system
|
||||
======
|
||||
|
||||

|
||||
|
||||
Python is a great programming language to quickly build applications that make our life easier. In this article we will learn how to use Python to build a RSS notification system, the goal being to have fun learning Python using Fedora. If you are looking for a complete RSS notifier application, there are a few already packaged in Fedora.
|
||||
|
||||
### Fedora and Python - getting started
|
||||
|
||||
Python 3.6 is available by default in Fedora, that includes Python's extensive standard library. The standard library provides a collection of modules which make some tasks simpler for us. For example, in our case we will use the [**sqlite3**][1] module to create, add and read data from a database. In the case where a particular problem we are trying to solve is not covered by the standard library, the chance is that someone has already developed a module for everyone to use. The best place to search for such modules is the Python Package Index known as [PyPI][2]. In our example we are going to use the [**feedparser**][3] to parse an RSS feed.
|
||||
|
||||
Since **feedparser** is not in the standard library, we have to install it in our system. Luckily for us there is an rpm package in Fedora, so the installation of **feedparser** is as simple as:
|
||||
```
|
||||
$ sudo dnf install python3-feedparser
|
||||
```
|
||||
|
||||
We now have everything we need to start coding our application.
|
||||
|
||||
### Storing the feed data
|
||||
|
||||
We need to store data from the articles that have already been published so that we send a notification only for new articles. The data we want to store will give us a unique way to identify an article. Therefore we will store the **title** and the **publication date** of the article.
|
||||
|
||||
So let's create our database using python **sqlite3** module and a simple SQL query. We are also adding the modules we are going to use later ( **feedparser** , **smtplib** and **email** ).
|
||||
|
||||
#### Creating the Database
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
import sqlite3
|
||||
import smtplib
|
||||
from email.mime.text import MIMEText
|
||||
|
||||
import feedparser
|
||||
|
||||
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
|
||||
db = db_connection.cursor()
|
||||
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
|
||||
|
||||
```
|
||||
|
||||
These few lines of code create a new sqlite database stored in a file called 'magazine_rss.sqlite', and then create a new table within the database called 'magazine'. This table has two columns - 'title' and 'date' - that can store data of the type TEXT, which means that the value of each column will be a text string.
|
||||
|
||||
#### Checking the Database for old articles
|
||||
|
||||
Since we only want to add new articles to our database we need a function that will check if the article we get from the RSS feed is already in our database or not. We will use it to decide if we should send an email notification (new article) or not (old article). Ok let's code this function.
|
||||
```
|
||||
def article_is_not_db(article_title, article_date):
|
||||
""" Check if a given pair of article title and date
|
||||
is in the database.
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_date (str): The publication date of an article
|
||||
Return:
|
||||
True if the article is not in the database
|
||||
False if the article is already present in the database
|
||||
"""
|
||||
db.execute("SELECT * from magazine WHERE title=? AND date=?", (article_title, article_date))
|
||||
if not db.fetchall():
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
```
|
||||
|
||||
The main part of this function is the SQL query we execute to search through the database. We are using a SELECT instruction to define which column of our magazine table we will run the query on. We are using the 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh symbol to select all columns ( title and date). Then we ask to select only the rows of the table WHERE the article_title and article_date string are equal to the value of the title and date column.
|
||||
|
||||
To finish, we have a simple logic that will return True if the query did not return any results and False if the query found an article in database matching our title, date pair.
|
||||
|
||||
#### Adding a new article to the Database
|
||||
|
||||
Now we can code the function to add a new article to the database.
|
||||
```
|
||||
def add_article_to_db(article_title, article_date):
|
||||
""" Add a new article title and date to the database
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_date (str): The publication date of an article
|
||||
"""
|
||||
db.execute("INSERT INTO magazine VALUES (?,?)", (article_title, article_date))
|
||||
db_connection.commit()
|
||||
```
|
||||
|
||||
This function is straight forward, we are using a SQL query to INSERT a new row INTO the magazine table with the VALUES of the article_title and article_date. Then we commit the change to make it persistent.
|
||||
|
||||
That's all we need from the database's point of view, let's look at the notification system and how we can use python to send emails.
|
||||
|
||||
### Sending an email notification
|
||||
|
||||
Let's create a function to send an email using the python standard library module **smtplib.** We are also using the **email** module from the standard library to format our email message.
|
||||
```
|
||||
def send_notification(article_title, article_url):
|
||||
""" Add a new article title and date to the database
|
||||
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_url (str): The url to access the article
|
||||
"""
|
||||
|
||||
smtp_server = smtplib.SMTP('smtp.gmail.com', 587)
|
||||
smtp_server.ehlo()
|
||||
smtp_server.starttls()
|
||||
smtp_server.login('your_email@gmail.com', '123your_password')
|
||||
msg = MIMEText(f'\nHi there is a new Fedora Magazine article : {article_title}. \nYou can read it here {article_url}')
|
||||
msg['Subject'] = 'New Fedora Magazine Article Available'
|
||||
msg['From'] = 'your_email@gmail.com'
|
||||
msg['To'] = 'destination_email@gmail.com'
|
||||
smtp_server.send_message(msg)
|
||||
smtp_server.quit()
|
||||
```
|
||||
|
||||
In this example I am using the Google mail smtp server to send an email, but this will work with any email services that provides you with a SMTP server. Most of this function is boilerplate needed to configure the access to the smtp server. You will need to update the code with your email address and credentials.
|
||||
|
||||
If you are using 2 Factor Authentication with your gmail account you can setup a password app that will give you a unique password to use for this application. Check out this help [page][4].
|
||||
|
||||
### Reading Fedora Magazine RSS feed
|
||||
|
||||
We now have functions to store an article in the database and send an email notification, let's create a function that parses the Fedora Magazine RSS feed and extract the articles' data.
|
||||
```
|
||||
def read_article_feed():
|
||||
""" Get articles from RSS feed """
|
||||
feed = feedparser.parse('https://fedoramagazine.org/feed/')
|
||||
for article in feed['entries']:
|
||||
if article_is_not_db(article['title'], article['published']):
|
||||
send_notification(article['title'], article['link'])
|
||||
add_article_to_db(article['title'], article['published'])
|
||||
|
||||
if __name__ == '__main__':
|
||||
read_article_feed()
|
||||
db_connection.close()
|
||||
```
|
||||
|
||||
Here we are making use of the **feedparser.parse** function. The function returns a dictionary representation of the RSS feed, for the full reference of the representation you can consult **feedparser** 's [documentation][5].
|
||||
|
||||
The RSS feed parser will return the last 10 articles as entries and then we extract the following information: the title, the link and the date the article was published. As a result, we can now use the functions we have previously defined to check if the article is not in the database, then send a notification email and finally, add the article to our database.
|
||||
|
||||
The last if statement is used to execute our read_article_feed function and then close the database connection when we execute our script.
|
||||
|
||||
### Running our script
|
||||
|
||||
Finally, to run our script we need to give the correct permission to the file. Next, we make use of the **cron** utility to automatically execute our script every hour (1 minute past the hour). **cron** is a job scheduler that we can use to run a task at a fixed time.
|
||||
```
|
||||
$ chmod a+x my_rss_notifier.py
|
||||
$ sudo cp my_rss_notifier.py /etc/cron.hourly
|
||||
```
|
||||
|
||||
To keep this tutorial simple, we are using the cron.hourly directory to execute the script every hours, I you wish to learn more about **cron** and how to configure the **crontab,** please read **cron 's** wikipedia [page][6].
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this tutorial we have learned how to use Python to create a simple sqlite database, parse an RSS feed and send emails. I hope that this showed you how you can easily build your own application using Python and Fedora.
|
||||
|
||||
The script is available on github [here][7].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notification-system/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://docs.python.org/3/library/sqlite3.html
|
||||
[2]:https://pypi.python.org/pypi
|
||||
[3]:https://pypi.python.org/pypi/feedparser/5.2.1
|
||||
[4]:https://support.google.com/accounts/answer/185833?hl=en
|
||||
[5]:https://pythonhosted.org/feedparser/reference.html
|
||||
[6]:https://en.wikipedia.org/wiki/Cron
|
||||
[7]:https://github.com/cverna/rss_feed_notifier
|
||||
@ -0,0 +1,268 @@
|
||||
Protecting Code Integrity with PGP — Part 1: Basic Concepts and Tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this article series, we take an in-depth look at using PGP to ensure the integrity of software. These articles will provide practical guidelines aimed at developers working on free software projects and will cover the following topics:
|
||||
|
||||
1. PGP basics and best practices
|
||||
|
||||
2. How to use PGP with Git
|
||||
|
||||
3. How to protect your developer accounts
|
||||
|
||||
|
||||
|
||||
|
||||
We use the term "Free" as in "Freedom," but the guidelines set out in this series can also be used for any other kind of software that relies on contributions from a distributed team of developers. If you write code that goes into public source repositories, you can benefit from getting acquainted with and following this guide.
|
||||
|
||||
### Structure
|
||||
|
||||
Each section is split into two areas:
|
||||
|
||||
* The checklist that can be adapted to your project's needs
|
||||
|
||||
* Free-form list of considerations that explain what dictated these decisions, together with configuration instructions
|
||||
|
||||
|
||||
|
||||
|
||||
#### Checklist priority levels
|
||||
|
||||
The items in each checklist include the priority level, which we hope will help guide your decision:
|
||||
|
||||
* (ESSENTIAL) items should definitely be high on the consideration list. If not implemented, they will introduce high risks to the code that gets committed to the open-source project.
|
||||
|
||||
* (NICE) to have items will improve the overall security, but will affect how you interact with your work environment, and probably require learning new habits or unlearning old ones.
|
||||
|
||||
|
||||
|
||||
|
||||
Remember, these are only guidelines. If you feel these priority levels do not reflect your project's commitment to security, you should adjust them as you see fit.
|
||||
|
||||
## Basic PGP concepts and tools
|
||||
|
||||
### Checklist
|
||||
|
||||
1. Understand the role of PGP in Free Software Development (ESSENTIAL)
|
||||
|
||||
2. Understand the basics of Public Key Cryptography (ESSENTIAL)
|
||||
|
||||
3. Understand PGP Encryption vs. Signatures (ESSENTIAL)
|
||||
|
||||
4. Understand PGP key identities (ESSENTIAL)
|
||||
|
||||
5. Understand PGP key validity (ESSENTIAL)
|
||||
|
||||
6. Install GnuPG utilities (version 2.x) (ESSENTIAL)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
The Free Software community has long relied on PGP for assuring the authenticity and integrity of software products it produced. You may not be aware of it, but whether you are a Linux, Mac or Windows user, you have previously relied on PGP to ensure the integrity of your computing environment:
|
||||
|
||||
* Linux distributions rely on PGP to ensure that binary or source packages have not been altered between when they have been produced and when they are installed by the end-user.
|
||||
|
||||
* Free Software projects usually provide detached PGP signatures to accompany released software archives, so that downstream projects can verify the integrity of downloaded releases before integrating them into their own distributed downloads.
|
||||
|
||||
* Free Software projects routinely rely on PGP signatures within the code itself in order to track provenance and verify integrity of code committed by project developers.
|
||||
|
||||
|
||||
|
||||
|
||||
This is very similar to developer certificates/code signing mechanisms used by programmers working on proprietary platforms. In fact, the core concepts behind these two technologies are very much the same -- they differ mostly in the technical aspects of the implementation and the way they delegate trust. PGP does not rely on centralized Certification Authorities, but instead lets each user assign their own trust to each certificate.
|
||||
|
||||
Our goal is to get your project on board using PGP for code provenance and integrity tracking, following best practices and observing basic security precautions.
|
||||
|
||||
### Extremely Basic Overview of PGP operations
|
||||
|
||||
You do not need to know the exact details of how PGP works -- understanding the core concepts is enough to be able to use it successfully for our purposes. PGP relies on Public Key Cryptography to convert plain text into encrypted text. This process requires two distinct keys:
|
||||
|
||||
* A public key that is known to everyone
|
||||
|
||||
* A private key that is only known to the owner
|
||||
|
||||
|
||||
|
||||
|
||||
#### Encryption
|
||||
|
||||
For encryption, PGP uses the public key of the owner to create a message that is only decryptable using the owner's private key:
|
||||
|
||||
1. The sender generates a random encryption key ("session key")
|
||||
|
||||
2. The sender encrypts the contents using that session key (using a symmetric cipher)
|
||||
|
||||
3. The sender encrypts the session key using the recipient's public PGP key
|
||||
|
||||
4. The sender sends both the encrypted contents and the encrypted session key to the recipient
|
||||
|
||||
|
||||
|
||||
|
||||
To decrypt:
|
||||
|
||||
1. The recipient decrypts the session key using their private PGP key
|
||||
|
||||
2. The recipient uses the session key to decrypt the contents of the message
|
||||
|
||||
|
||||
|
||||
|
||||
#### Signatures
|
||||
|
||||
For creating signatures, the private/public PGP keys are used the opposite way:
|
||||
|
||||
1. The signer generates the checksum hash of the contents
|
||||
|
||||
2. The signer uses their own private PGP key to encrypt that checksum
|
||||
|
||||
3. The signer provides the encrypted checksum alongside the contents
|
||||
|
||||
|
||||
|
||||
|
||||
To verify the signature:
|
||||
|
||||
1. The verifier generates their own checksum hash of the contents
|
||||
|
||||
2. The verifier uses the signer's public PGP key to decrypt the provided checksum
|
||||
|
||||
3. If the checksums match, the integrity of the contents is verified
|
||||
|
||||
|
||||
|
||||
|
||||
#### Combined usage
|
||||
|
||||
Frequently, encrypted messages are also signed with the sender's own PGP key. This should be the default whenever using encrypted messaging, as encryption without authentication is not very meaningful (unless you are a whistleblower or a secret agent and need plausible deniability).
|
||||
|
||||
### Understanding Key Identities
|
||||
|
||||
Each PGP key must have one or multiple Identities associated with it. Usually, an "Identity" is the person's full name and email address in the following format:
|
||||
```
|
||||
Alice Engineer <alice.engineer@example.com>
|
||||
|
||||
```
|
||||
|
||||
Sometimes it will also contain a comment in brackets, to tell the end-user more about that particular key:
|
||||
```
|
||||
Bob Designer (obsolete 1024-bit key) <bob.designer@example.com>
|
||||
|
||||
```
|
||||
|
||||
Since people can be associated with multiple professional and personal entities, they can have multiple identities on the same key:
|
||||
```
|
||||
Alice Engineer <alice.engineer@example.com>
|
||||
Alice Engineer <aengineer@personalmail.example.org>
|
||||
Alice Engineer <webmaster@girlswhocode.example.net>
|
||||
|
||||
```
|
||||
|
||||
When multiple identities are used, one of them would be marked as the "primary identity" to make searching easier.
|
||||
|
||||
### Understanding Key Validity
|
||||
|
||||
To be able to use someone else's public key for encryption or verification, you need to be sure that it actually belongs to the right person (Alice) and not to an impostor (Eve). In PGP, this certainty is called "key validity:"
|
||||
|
||||
* Validity: full -- means we are pretty sure this key belongs to Alice
|
||||
|
||||
* Validity: marginal -- means we are somewhat sure this key belongs to Alice
|
||||
|
||||
* Validity: unknown -- means there is no assurance at all that this key belongs to Alice
|
||||
|
||||
|
||||
|
||||
|
||||
#### Web of Trust (WOT) vs. Trust on First Use (TOFU)
|
||||
|
||||
PGP incorporates a trust delegation mechanism known as the "Web of Trust." At its core, this is an attempt to replace the need for centralized Certification Authorities of the HTTPS/TLS world. Instead of various software makers dictating who should be your trusted certifying entity, PGP leaves this responsibility to each user.
|
||||
|
||||
Unfortunately, very few people understand how the Web of Trust works, and even fewer bother to keep it going. It remains an important aspect of the OpenPGP specification, but recent versions of GnuPG (2.2 and above) have implemented an alternative mechanism called "Trust on First Use" (TOFU).
|
||||
|
||||
You can think of TOFU as "the SSH-like approach to trust." With SSH, the first time you connect to a remote system, its key fingerprint is recorded and remembered. If the key changes in the future, the SSH client will alert you and refuse to connect, forcing you to make a decision on whether you choose to trust the changed key or not.
|
||||
|
||||
Similarly, the first time you import someone's PGP key, it is assumed to be trusted. If at any point in the future GnuPG comes across another key with the same identity, both the previously imported key and the new key will be marked as invalid and you will need to manually figure out which one to keep.
|
||||
|
||||
In this guide, we will be using the TOFU trust model.
|
||||
|
||||
### Installing OpenPGP software
|
||||
|
||||
First, it is important to understand the distinction between PGP, OpenPGP, GnuPG and gpg:
|
||||
|
||||
* PGP ("Pretty Good Privacy") is the name of the original commercial software
|
||||
|
||||
* OpenPGP is the IETF standard compatible with the original PGP tool
|
||||
|
||||
* GnuPG ("Gnu Privacy Guard") is free software that implements the OpenPGP standard
|
||||
|
||||
* The command-line tool for GnuPG is called "gpg"
|
||||
|
||||
|
||||
|
||||
|
||||
Today, the term "PGP" is almost universally used to mean "the OpenPGP standard," not the original commercial software, and therefore "PGP" and "OpenPGP" are interchangeable. The terms "GnuPG" and "gpg" should only be used when referring to the tools, not to the output they produce or OpenPGP features they implement. For example:
|
||||
|
||||
* PGP (not GnuPG or GPG) key
|
||||
|
||||
* PGP (not GnuPG or GPG) signature
|
||||
|
||||
* PGP (not GnuPG or GPG) keyserver
|
||||
|
||||
|
||||
|
||||
|
||||
Understanding this should protect you from an inevitable pedantic "actually" from other PGP users you come across.
|
||||
|
||||
#### Installing GnuPG
|
||||
|
||||
If you are using Linux, you should already have GnuPG installed. On a Mac, you should install [GPG-Suite][1] or you can use brew install gnupg2. On a Windows PC, you should install [GPG4Win][2], and you will probably need to adjust some of the commands in the guide to work for you, unless you have a unix-like environment set up. For all other platforms, you'll need to do your own research to find the correct places to download and install GnuPG.
|
||||
|
||||
#### GnuPG 1 vs. 2
|
||||
|
||||
Both GnuPG v.1 and GnuPG v.2 implement the same standard, but they provide incompatible libraries and command-line tools, so many distributions ship both the legacy version 1 and the latest version 2. You need to make sure you are always using GnuPG v.2.
|
||||
|
||||
First, run:
|
||||
```
|
||||
$ gpg --version | head -n1
|
||||
|
||||
```
|
||||
|
||||
If you see gpg (GnuPG) 1.4.x, then you are using GnuPG v.1. Try the gpg2 command:
|
||||
```
|
||||
$ gpg2 --version | head -n1
|
||||
|
||||
```
|
||||
|
||||
If you see gpg (GnuPG) 2.x.x, then you are good to go. This guide will assume you have the version 2.2 of GnuPG (or later). If you are using version 2.0 of GnuPG, some of the commands in this guide will not work, and you should consider installing the latest 2.2 version of GnuPG.
|
||||
|
||||
#### Making sure you always use GnuPG v.2
|
||||
|
||||
If you have both gpg and gpg2 commands, you should make sure you are always using GnuPG v2, not the legacy version. You can make sure of this by setting the alias:
|
||||
```
|
||||
$ alias gpg=gpg2
|
||||
|
||||
```
|
||||
|
||||
You can put that in your .bashrc to make sure it's always loaded whenever you use the gpg commands.
|
||||
|
||||
In part 2 of this series, we will explain the basic steps for generating and protecting your master PGP key.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://gpgtools.org/
|
||||
[2]:https://www.gpg4win.org/
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,5 +1,7 @@
|
||||
The List Of Useful Bash Keyboard Shortcuts
|
||||
======
|
||||
translating by heart4lor
|
||||
|
||||

|
||||
|
||||
Nowadays, I spend more time in Terminal, trying to accomplish more in CLI than GUI. I learned many BASH tricks over time. And, here is the list of useful of BASH shortcuts that every Linux users should know to get things done faster in their BASH shell. I won’t claim that this list is a complete list of BASH shortcuts, but just enough to move around your BASH shell faster than before. Learning how to navigate faster in BASH Shell not only saves some time, but also makes you proud of yourself for learning something worth. Well, let’s get started.
|
||||
|
||||
@ -1,250 +0,0 @@
|
||||
Getting started with SQL
|
||||
======
|
||||
|
||||

|
||||
|
||||
Building a database using SQL is simpler than most people think. In fact, you don't even need to be an experienced programmer to use SQL to create a database. In this article, I'll explain how to create a simple relational database management system (RDMS) using MySQL 5.6. Before I get started, I want to quickly thank [SQL Fiddle][1], which I used to run my script. It provides a useful sandbox for testing simple scripts.
|
||||
|
||||
|
||||
In this tutorial, I'll build a database that uses the simple schema shown in the entity relationship diagram (ERD) below. The database lists students and the course each is studying. I used two entities (i.e., tables) to keep things simple, with only a single relationship and dependency. The entities are called `dbo_students` and `dbo_courses`.
|
||||
|
||||
|
||||
|
||||
The multiplicity of the database is 1-to-many, as each course can contain many students, but each student can study only one course.
|
||||
|
||||
A quick note on terminology:
|
||||
|
||||
1. A table is called an entity.
|
||||
2. A field is called an attribute.
|
||||
3. A record is called a tuple.
|
||||
4. The script used to construct the database is called a schema.
|
||||
|
||||
|
||||
|
||||
### Constructing the schema
|
||||
|
||||
To construct the database, use the `CREATE TABLE <table name>` command, then define each field name and data type. This database uses `VARCHAR(n)` (string) and `INT(n)` (integer), where n refers to the number of values that can be stored. For example `INT(2)` could be 01.
|
||||
|
||||
This is the code used to create the two tables:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
|
||||
```
|
||||
|
||||
`NOT NULL` means that the field cannot be empty, and `AUTO_INCREMENT` means that when a new tuple is added, the ID number will be auto-generated with 1 added to the previously stored ID number in order to enforce referential integrity across entities. `PRIMARY KEY` is the unique identifier attribute for each table. This means each tuple has its own distinct identity.
|
||||
|
||||
### Relationships as a constraint
|
||||
|
||||
As it stands, the two tables exist on their own with no connections or relationships. To connect them, a foreign key must be identified. In `dbo_students`, the foreign key is `course_studied`, the source of which is within `dbo_courses`, meaning that the field is referenced. The specific command within SQL is called a `CONSTRAINT`, and this relationship will be added using another command called `ALTER TABLE`, which allows tables to be edited even after the schema has been constructed.
|
||||
|
||||
The following code adds the relationship to the database construction script:
|
||||
```
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
```
|
||||
|
||||
Using the `CONSTRAINT` command is not actually necessary, but it's good practice because it means the constraint can be named and it makes maintenance easier. Now that the database is complete, it's time to add some data.
|
||||
|
||||
### Adding data to the database
|
||||
|
||||
`INSERT INTO <table name>` is the command used to directly choose which attributes (i.e., fields) data is added to. The entity name is defined first, then the attributes. Underneath this command is the data that will be added to that entity, creating a tuple. If `NOT NULL` has been specified, it means that the attribute cannot be left blank. The following code shows how to add records to the table:
|
||||
```
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
```
|
||||
|
||||
Now that the database schema is complete and data is added, it's time to run queries on the database.
|
||||
|
||||
### Queries
|
||||
|
||||
Queries follow a set structure using these commands:
|
||||
```
|
||||
SELECT <attributes>
|
||||
|
||||
FROM <entity>
|
||||
|
||||
WHERE <condition>
|
||||
|
||||
```
|
||||
|
||||
To display all records within the `dbo_courses` entity and display the course code and course name, use an asterisk. This is a wildcard that eliminates the need to type all attribute names. (Its use is not recommended in production databases.) The code for this query is:
|
||||
```
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
|
||||
```
|
||||
|
||||
The output of this query shows all tuples in the table, so all available courses can be displayed:
|
||||
```
|
||||
| course_id | course_name |
|
||||
|
||||
|-----------|----------------------|
|
||||
|
||||
| 1 | Software Engineering |
|
||||
|
||||
| 2 | Computer Science |
|
||||
|
||||
| 3 | Computing |
|
||||
|
||||
```
|
||||
|
||||
In a future article, I'll explain more complicated queries using one of the three types of joins: Inner, Outer, or Cross.
|
||||
|
||||
Here is the completed script:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
|
||||
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
|
||||
```
|
||||
|
||||
### Learning more
|
||||
|
||||
SQL isn't difficult; I think it is simpler than programming, and the language is universal to different database systems. Note that `dbo.<entity>` is not a required entity-naming convention; I used it simply because it is the standard in Microsoft SQL Server.
|
||||
|
||||
If you'd like to learn more, the best guide this side of the internet is [W3Schools.com][2]'s comprehensive guide to SQL for all database platforms.
|
||||
|
||||
Please feel free to play around with my database. Also, if you have suggestions or questions, please respond in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/getting-started-sql
|
||||
|
||||
作者:[Aaron Cocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaroncocker
|
||||
[1]:http://sqlfiddle.com
|
||||
[2]:https://www.w3schools.com/sql/default.asp
|
||||
@ -0,0 +1,176 @@
|
||||
Protecting Code Integrity with PGP — Part 2: Generating Your Master Key
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this article series, we're taking an in-depth look at using PGP and provide practical guidelines for developers working on free software projects. In the previous article, we provided an introduction to [basic tools and concepts][1]. In this installment, we show how to generate and protect your master PGP key.
|
||||
|
||||
### Checklist
|
||||
|
||||
1. Generate a 4096-bit RSA master key (ESSENTIAL)
|
||||
|
||||
2. Back up the master key using paperkey (ESSENTIAL)
|
||||
|
||||
3. Add all relevant identities (ESSENTIAL)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Understanding the "Master" (Certify) key
|
||||
|
||||
In this and next section we'll talk about the "master key" and "subkeys." It is important to understand the following:
|
||||
|
||||
1. There are no technical differences between the "master key" and "subkeys."
|
||||
|
||||
2. At creation time, we assign functional limitations to each key by giving it specific capabilities.
|
||||
|
||||
3. A PGP key can have four capabilities.
|
||||
|
||||
* [S] key can be used for signing
|
||||
|
||||
* [E] key can be used for encryption
|
||||
|
||||
* [A] key can be used for authentication
|
||||
|
||||
* [C] key can be used for certifying other keys
|
||||
|
||||
4. A single key may have multiple capabilities.
|
||||
|
||||
|
||||
|
||||
|
||||
The key carrying the [C] (certify) capability is considered the "master" key because it is the only key that can be used to indicate relationship with other keys. Only the [C] key can be used to:
|
||||
|
||||
* Add or revoke other keys (subkeys) with S/E/A capabilities
|
||||
|
||||
* Add, change or revoke identities (uids) associated with the key
|
||||
|
||||
* Add or change the expiration date on itself or any subkey
|
||||
|
||||
* Sign other people's keys for the web of trust purposes
|
||||
|
||||
|
||||
|
||||
|
||||
In the Free Software world, the [C] key is your digital identity. Once you create that key, you should take extra care to protect it and prevent it from falling into malicious hands.
|
||||
|
||||
#### Before you create the master key
|
||||
|
||||
Before you create your master key you need to pick your primary identity and your master passphrase.
|
||||
|
||||
##### Primary identity
|
||||
|
||||
Identities are strings using the same format as the "From" field in emails:
|
||||
```
|
||||
Alice Engineer <alice.engineer@example.org>
|
||||
|
||||
```
|
||||
|
||||
You can create new identities, revoke old ones, and change which identity is your "primary" one at any time. Since the primary identity is shown in all GnuPG operations, you should pick a name and address that are both professional and the most likely ones to be used for PGP-protected communication, such as your work address or the address you use for signing off on project commits.
|
||||
|
||||
##### Passphrase
|
||||
|
||||
The passphrase is used exclusively for encrypting the private key with a symmetric algorithm while it is stored on disk. If the contents of your .gnupg directory ever get leaked, a good passphrase is the last line of defense between the thief and them being able to impersonate you online, which is why it is important to set up a good passphrase.
|
||||
|
||||
A good guideline for a strong passphrase is 3-4 words from a rich or mixed dictionary that are not quotes from popular sources (songs, books, slogans). You'll be using this passphrase fairly frequently, so it should be both easy to type and easy to remember.
|
||||
|
||||
##### Algorithm and key strength
|
||||
|
||||
Even though GnuPG has had support for Elliptic Curve crypto for a while now, we'll be sticking to RSA keys, at least for a little while longer. While it is possible to start using ED25519 keys right now, it is likely that you will come across tools and hardware devices that will not be able to handle them correctly.
|
||||
|
||||
You may also wonder why the master key is 4096-bit, if later in the guide we state that 2048-bit keys should be good enough for the lifetime of RSA public key cryptography. The reasons are mostly social and not technical: master keys happen to be the most visible ones on the keychain, and some of the developers you interact with will inevitably judge you negatively if your master key has fewer bits than theirs.
|
||||
|
||||
#### Generate the master key
|
||||
|
||||
To generate your new master key, issue the following command, putting in the right values instead of "Alice Engineer:"
|
||||
```
|
||||
$ gpg --quick-generate-key 'Alice Engineer <alice@example.org>' rsa4096 cert
|
||||
|
||||
```
|
||||
|
||||
A dialog will pop up asking to enter the passphrase. Then, you may need to move your mouse around or type on some keys to generate enough entropy until the command completes.
|
||||
|
||||
Review the output of the command, it will be something like this:
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid Alice Engineer <alice@example.org>
|
||||
|
||||
```
|
||||
|
||||
Note the long string on the second line -- that is the full fingerprint of your newly generated key. Key IDs can be represented in three different forms:
|
||||
|
||||
* Fingerprint, a full 40-character key identifier
|
||||
|
||||
* Long, last 16-characters of the fingerprint (AAAABBBBCCCCDDDD)
|
||||
|
||||
* Short, last 8 characters of the fingerprint (CCCCDDDD)
|
||||
|
||||
|
||||
|
||||
|
||||
You should avoid using 8-character "short key IDs" as they are not sufficiently unique.
|
||||
|
||||
At this point, I suggest you open a text editor, copy the fingerprint of your new key and paste it there. You'll need to use it for the next few steps, so having it close by will be handy.
|
||||
|
||||
#### Back up your master key
|
||||
|
||||
For disaster recovery purposes -- and especially if you intend to use the Web of Trust and collect key signatures from other project developers -- you should create a hardcopy backup of your private key. This is supposed to be the "last resort" measure in case all other backup mechanisms have failed.
|
||||
|
||||
The best way to create a printable hardcopy of your private key is using the paperkey software written for this very purpose. Paperkey is available on all Linux distros, as well as installable via brew install paperkey on Macs.
|
||||
|
||||
Run the following command, replacing [fpr] with the full fingerprint of your key:
|
||||
```
|
||||
$ gpg --export-secret-key [fpr] | paperkey -o /tmp/key-backup.txt
|
||||
|
||||
```
|
||||
|
||||
The output will be in a format that is easy to OCR or input by hand, should you ever need to recover it. Print out that file, then take a pen and write the key passphrase on the margin of the paper. This is a required step because the key printout is still encrypted with the passphrase, and if you ever change the passphrase on your key, you will not remember what it used to be when you had first created it -- guaranteed.
|
||||
|
||||
Put the resulting printout and the hand-written passphrase into an envelope and store in a secure and well-protected place, preferably away from your home, such as your bank vault.
|
||||
|
||||
**Note on printers:** Long gone are days when printers were dumb devices connected to your computer's parallel port. These days they have full operating systems, hard drives, and cloud integration. Since the key content we send to the printer will be encrypted with the passphrase, this is a fairly safe operation, but use your best paranoid judgement.
|
||||
|
||||
#### Add relevant identities
|
||||
|
||||
If you have multiple relevant email addresses (personal, work, open-source project, etc), you should add them to your master key. You don't need to do this for any addresses that you don't expect to use with PGP (e.g., probably not your school alumni address).
|
||||
|
||||
The command is (put the full key fingerprint instead of [fpr]):
|
||||
```
|
||||
$ gpg --quick-add-uid [fpr] 'Alice Engineer <allie@example.net>'
|
||||
|
||||
```
|
||||
|
||||
You can review the UIDs you've already added using:
|
||||
```
|
||||
$ gpg --list-key [fpr] | grep ^uid
|
||||
|
||||
```
|
||||
|
||||
##### Pick the primary UID
|
||||
|
||||
GnuPG will make the latest UID you add as your primary UID, so if that is different from what you want, you should fix it back:
|
||||
```
|
||||
$ gpg --quick-set-primary-uid [fpr] 'Alice Engineer <alice@example.org>'
|
||||
|
||||
```
|
||||
|
||||
Next time, we'll look at generating PGP subkeys, which are the keys you'll actually be using for day-to-day work.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][2]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/PGP/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,103 +0,0 @@
|
||||
内核如何管理内存
|
||||
============================================================
|
||||
|
||||
|
||||
在学习了进程的 [虚拟地址布局][1] 之后,我们回到内核,来学习它管理用户内存的机制。这里再次使用 Gonzo:
|
||||
|
||||

|
||||
|
||||
Linux 进程在内核中是作为进程描述符 [task_struct][2] (译者注:它是在 Linux 中描述进程完整信息的一种数据结构)的实例来实现的。在 task_struct 中的 [mm][3] 域指向到内存描述符,[mm_struct][4] 是一个程序在内存中的执行摘要。它保存了起始和结束内存段,如下图所示,进程使用的物理内存页面的 [数量][5](RSS 译者注:(Resident Set Size)常驻内存大小 )、虚拟地址空间使用的 [总数量][6]、以及其它片断。 在内存描述中,我们可以获悉它有两种管理内存的方式:虚拟内存区域集和页面表。Gonzo 的内存区域如下所示:
|
||||
|
||||

|
||||
|
||||
每个虚拟内存区域(VMA)是一个连续的虚拟地址范围;这些区域绝对不会重叠。一个 [vm_area_struct][7] 的实例完整描述了一个内存区域,包括它的起始和结束地址,[flags][8] 决定了访问权限和行为,并且 [vm_file][9] 域指定了映射到这个区域的文件(如果有的话)。除了内存映射段的例外情况之外,一个 VMA 是不能匿名映射文件的,上面的每个内存段(比如,堆、栈)都对应一个单个的 VMA。虽然它通常都使用在 x86 的机器上,但它并不是必需的。VMAs 也不关心它们在哪个段中。
|
||||
|
||||
一个程序的 VMAs 在内存描述符中作为 [mmap][10] 域的一个链接列表保存的,以起始虚拟地址为序进行排列,并且在 [mm_rb][12] 域中作为一个 [红黑树][11] 的根。红黑树允许内核通过给定的虚拟地址去快速搜索内存区域。在你读取文件 `/proc/pid_of_process/maps`时,内核只是简单地读取每个进程的 VMAs 的链接列表并显示它们。
|
||||
|
||||
在 Windows 中,[EPROCESS][14] 块大致类似于一个 task_struct 和 mm_struct 的结合。在 Windows 中模拟一个 VMA 的是虚拟地址描述符,或称为 [VAD][15];它保存在一个 [AVL 树][16] 中。你知道关于 Windows 和 Linux 之间最有趣的事情是什么吗?其实它们只有一点小差别。
|
||||
|
||||
4GB 虚拟地址空间被分为两个页面。在 32 位模式中的 x86 处理器中支持 4KB、2MB、以及 4MB 大小的页面。Linux 和 Windows 都使用大小为 4KB 的页面去映射用户的一部分虚拟地址空间。字节 0-4095 在 page 0 中,字节 4096-8191 在 page 1 中,依次类推。VMA 的大小 _必须是页面大小的倍数_ 。下图是使用 4KB 大小页面的总数量为 3GB 的用户空间:
|
||||
|
||||

|
||||
|
||||
处理器通过查看页面表去转换一个虚拟内存地址到一个真实的物理内存地址。每个进程都有它自己的一组页面表;每当发生进程切换时,用户空间的页面表也同时切换。Linux 在内存描述符的 [pgd][17] 域中保存了一个指向处理器页面表的指针。对于每个虚拟页面,页面表中都有一个相应的页面表条目(PTE),在常规的 x86 页面表中,它是一个简单的如下所示的大小为 4 字节的一条记录:
|
||||
|
||||

|
||||
|
||||
Linux 通过函数去 [读取][18] 和 [设置][19] PTE 条目中的每个标志位。标志位 P 告诉处理器这个虚拟页面是否在物理内存中。如果被清除(设置为 0),访问这个页面将触发一个页面故障。请记住,当这个标志位为 0 时,内核可以在剩余的域上做任何想做的事。R/W 标志位是读/写标志;如果被清除,这个页面将变成只读的。U/S 标志位表示用户/超级用户;如果被清除,这个页面将仅被内核访问。这些标志都是用于实现我们在前面看到的只读内存和内核空间保护。
|
||||
|
||||
标志位 D 和 A 用于标识页面是否是“脏的”或者是已被访问过。一个脏页面表示已经被写入,而一个被访问过的页面则表示有一个写入或者读取发生过。这两个标志位都是粘滞位:处理器只能设置它们,而清除则是由内核来完成的。最终,PTE 保存了这个页面相应的起始物理地址,它们按 4KB 进行整齐排列。这个看起来有点小的域是一些痛苦的根源,因为它限制了物理内存最大为 [4 GB][20]。其它的 PTE 域留到下次再讲,因为它是涉及了物理地址扩展的知识。
|
||||
|
||||
由于在一个虚拟页面上的所有字节都共享一个 U/S 和 R/W 标志位,所以内存保护的最小单元是一个虚拟页面。但是,同一个物理内存可能被映射到不同的虚拟页面,这样就有可能会出现相同的物理内存出现不同的保护标志位的情况。请注意,在 PTE 中是看不到运行权限的。这就是为什么经典的 x86 页面上允许代码在栈上被执行的原因,这样会很容易导致挖掘栈缓冲溢出的漏洞(可能会通过使用 [return-to-libc][21] 和其它技术来开发非可执行栈)。由于 PTE 缺少禁止运行标志位说明了一个更广泛的事实:在 VMA 中的权限标志位有可能或者不可能完全转换为硬件保护。内核只能做它能做到的,但是,最终的架构限制了它能做的事情。
|
||||
|
||||
虚拟内存不能保存任何东西,它只是简单地 _映射_ 一个程序的地址空间到底层的物理内存上。物理内存被当作一个被称为物理地址空间的巨大块来被处理器访问。虽然内存的操作[涉及到某些][22] 总线,我们在这里先忽略它,并假设物理地址范围从 0 到可用的最大值按字节递增。物理地址空间被内核进一步分解为页面帧。处理器并不会关心帧的具体情况,这一点对内核也是至关重要的,因为,页面帧是物理内存管理的最小单元。Linux 和 Windows 在 32 位模式下都使用 4KB 大小的页面帧;下图是一个有 2 GB 内存的机器的例子:
|
||||
|
||||

|
||||
|
||||
在 Linux 上每个页面帧是被一个 [描述符][23] 和 [几个标志][24] 来跟踪的。通过这些描述符和标志,实现了对机器上整个物理内存的跟踪;每个页面帧的具体状态是公开的。物理内存是通过使用 [Buddy 内存分配][25] (译者注:一种内存分配算法)技术来管理的,因此,如果可以通过 Buddy 系统分配内存,那么一个页面帧是未分配的(free)。一个被分配的页面帧可以是匿名的、持有程序数据的、或者它可能处于页面缓存中、持有数据保存在一个文件或者块设备中。还有其它的异形页面帧,但是这些异形页面帧现在已经不怎么使用了。Windows 有一个类似的页面帧号(Page Frame Number (PFN))数据库去跟踪物理内存。
|
||||
|
||||
我们把虚拟内存区域(VMA)、页面表条目(PTE)、以及页面帧放在一起来理解它们是如何工作的。下面是一个用户堆的示例:
|
||||
|
||||

|
||||
|
||||
蓝色的矩形框表示在 VMA 范围内的页面,而箭头表示页面表条目映射页面到页面帧。一些缺少箭头的虚拟页面,表示它们对应的 PTEs 的当前标志位被清除(置为 0)。这可能是因为这个页面从来没有被使用过,或者是它的内容已经被交换出去了(swapped out)。在这两种情况下,即便这些页面在 VMA 中,访问它们也将导致产生一个页面故障。对于这种 VMA 和页面表的不一致的情况,看上去似乎很奇怪,但是这种情况却经常发生。
|
||||
|
||||
一个 VMA 像一个在你的程序和内核之间的合约。你请求它做一些事情(分配内存、文件映射、等等),内核会回应“收到”,然后去创建或者更新相应的 VMA。 但是,它 _并不立刻_ 去“兑现”对你的承诺,而是它会等待到发生一个页面故障时才去 _真正_ 做这个工作。内核是个“懒惰的家伙”、“不诚实的人渣”;这就是虚拟内存的基本原理。它适用于大多数的、一些类似的和意外的情况,但是,它是规则是,VMAs 记录 _约定的_ 内容,而 PTEs 才反映这个“懒惰的内核” _真正做了什么_。通过这两种数据结构共同来管理程序的内存;它们共同来完成解决页面故障、释放内存、从内存中交换出数据、等等。下图是内存分配的一个简单案例:
|
||||
|
||||

|
||||
|
||||
当程序通过 [brk()][26] 系统调用来请求一些内存时,内核只是简单地 [更新][27] 堆的 VMA 并给程序回复“已搞定”。而在这个时候并没有真正地分配页面帧并且新的页面也没有映射到物理内存上。一旦程序尝试去访问这个页面时,将发生页面故障,然后处理器调用 [do_page_fault()][28]。这个函数将使用 [find_vma()][30] 去 [搜索][29] 发生页面故障的 VMA。如果找到了,然后在 VMA 上进行权限检查以防范恶意访问(读取或者写入)。如果没有合适的 VMA,也没有尝试访问的内存的“合约”,将会给进程返回段故障。
|
||||
|
||||
当找到了一个合适的 VMA,内核必须通过查找 PTE 的内容和 VMA 的类型去处理故障。在我们的案例中,PTE 显示这个页面是 [不存在的][33]。事实上,我们的 PTE 是全部空白的(全部都是 0),在 Linux 中这表示虚拟内存还没有被映射。由于这是匿名 VMA,我们有一个完全的 RAM 事务,它必须被 [do_anonymous_page()][34] 来处理,它分配页面帧,并且用一个 PTE 去映射故障虚拟页面到一个新分配的帧。
|
||||
|
||||
有时候,事情可能会有所不同。例如,对于被交换出内存的页面的 PTE,在当前(Present)标志位上是 0,但它并不是空白的。而是在交换位置仍有页面内容,它必须从磁盘上读取并且通过 [do_swap_page()][35] 来加载到一个被称为 [major fault][36] 的页面帧上。
|
||||
|
||||
这是我们通过探查内核的用户内存管理得出的前半部分的结论。在下一篇文章中,我们通过将文件加载到内存中,来构建一个完整的内存框架图,以及对性能的影响。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory
|
||||
[2]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1075
|
||||
[3]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1129
|
||||
[4]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L173
|
||||
[5]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L197
|
||||
[6]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L206
|
||||
[7]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L99
|
||||
[8]:http://lxr.linux.no/linux+v2.6.28/include/linux/mm.h#L76
|
||||
[9]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L150
|
||||
[10]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L174
|
||||
[11]:http://en.wikipedia.org/wiki/Red_black_tree
|
||||
[12]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L175
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28.1/fs/proc/task_mmu.c#L201
|
||||
[14]:http://www.nirsoft.net/kernel_struct/vista/EPROCESS.html
|
||||
[15]:http://www.nirsoft.net/kernel_struct/vista/MMVAD.html
|
||||
[16]:http://en.wikipedia.org/wiki/AVL_tree
|
||||
[17]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L185
|
||||
[18]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L173
|
||||
[19]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L230
|
||||
[20]:http://www.google.com/search?hl=en&amp;amp;amp;amp;q=2^20+*+2^12+bytes+in+GB
|
||||
[21]:http://en.wikipedia.org/wiki/Return-to-libc_attack
|
||||
[22]:http://duartes.org/gustavo/blog/post/getting-physical-with-memory
|
||||
[23]:http://lxr.linux.no/linux+v2.6.28/include/linux/mm_types.h#L32
|
||||
[24]:http://lxr.linux.no/linux+v2.6.28/include/linux/page-flags.h#L14
|
||||
[25]:http://en.wikipedia.org/wiki/Buddy_memory_allocation
|
||||
[26]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||||
[27]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L2050
|
||||
[28]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L583
|
||||
[29]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L692
|
||||
[30]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1466
|
||||
[31]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L711
|
||||
[32]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2653
|
||||
[33]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2674
|
||||
[34]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2681
|
||||
[35]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2280
|
||||
[36]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2316
|
||||
@ -0,0 +1,97 @@
|
||||
Partclone - 多功能的分区和克隆免费软件
|
||||
======
|
||||
|
||||

|
||||
|
||||
**[Partclone][1]** 是由 **Clonezilla** 开发者开发的免费开源的用于创建和克隆分区镜像的软件。实际上,**Partclone** 是基于 **Clonezilla** 的工具之一。
|
||||
|
||||
它为用户提供了备份与恢复占用的分区块工具,并与多个文件系统的高度兼容,这要归功于它能够使用像 **e2fslibs** 这样的现有库来读取和写入分区,例如 **ext2**。
|
||||
|
||||
它最大的优点是支持各种格式,包括 ext2、ext3、ext4、hfs +、reiserfs、reiser4、btrfs、vmfs3、vmfs5、xfs、jfs、ufs、ntfs、fat(12/16/32)、exfat、f2fs 和 nilfs。
|
||||
|
||||
它还有许多的程序,包括 **partclone.ext2**ext3&ext4)、partclone.ntfs、partclone.exfat、partclone.hfsp 和 partclone.vmfs(v3和v5) 等等。
|
||||
|
||||
### Partclone中的功能
|
||||
|
||||
* **免费软件:** **Partclone**免费供所有人下载和使用。
|
||||
* **开源:** **Partclone**是在 GNU GPL 许可下发布的,并在 [GitHub][2] 上公开。
|
||||
* **跨平台**:适用于 Linux、Windows、MAC、ESX 文件系统备份/恢复和 FreeBSD。
|
||||
* 一个在线的[文档页面][3],你可以从中查看帮助文档并跟踪其 GitHub 问题。
|
||||
* 为初学者和专业人士提供的在线[用户手册][4]。
|
||||
* 支持救援。
|
||||
* 克隆分区成镜像文件。
|
||||
* 将镜像文件恢复到分区。
|
||||
* 快速复制分区。
|
||||
* 支持 raw 克隆。
|
||||
* 显示传输速率和持续时间。
|
||||
* 支持管道。
|
||||
* 支持 crc32。
|
||||
* 支持 ESX vmware server 的 vmfs 和 FreeBSD 的文件系统 ufs。
|
||||
|
||||
|
||||
|
||||
**Partclone** 中还捆绑了更多功能,你可以在[这里][5]查看其余的功能。
|
||||
|
||||
[下载 Linux 中的 Partclone][6]
|
||||
|
||||
### 如何安装和使用 Partclone
|
||||
|
||||
在 Linux 上安装 Partclone。
|
||||
```
|
||||
$ sudo apt install partclone [On Debian/Ubuntu]
|
||||
$ sudo yum install partclone [On CentOS/RHEL/Fedora]
|
||||
|
||||
```
|
||||
|
||||
克隆分区为镜像。
|
||||
```
|
||||
# partclone.ext4 -d -c -s /dev/sda1 -o sda1.img
|
||||
|
||||
```
|
||||
|
||||
将镜像恢复到分区。
|
||||
```
|
||||
# partclone.ext4 -d -r -s sda1.img -o /dev/sda1
|
||||
|
||||
```
|
||||
|
||||
分区到分区克隆。
|
||||
```
|
||||
# partclone.ext4 -d -b -s /dev/sda1 -o /dev/sdb1
|
||||
|
||||
```
|
||||
|
||||
显示镜像信息。
|
||||
```
|
||||
# partclone.info -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
检查镜像。
|
||||
```
|
||||
# partclone.chkimg -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
你是 **Partclone** 的用户吗?我最近在 [**Deepin Clone**][7] 上写了一篇文章,显然,Partclone 有擅长处理的任务。你使用其他备份和恢复工具的经验是什么?
|
||||
|
||||
请在下面的评论区与我们分享你的想法和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/partclone-linux-backup-clone-tool/
|
||||
|
||||
作者:[Martins D. Okoi;View All Posts;Peter Beck;Martins Divine Okoi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://partclone.org/
|
||||
[2]:https://github.com/Thomas-Tsai/partclone
|
||||
[3]:https://partclone.org/help/
|
||||
[4]:https://partclone.org/usage/
|
||||
[5]:https://partclone.org/features/
|
||||
[6]:https://partclone.org/download/
|
||||
[7]:https://www.fossmint.com/deepin-clone-system-backup-restore-for-deepin-users/
|
||||
266
translated/tech/20180116 Monitor your Kubernetes Cluster.md
Normal file
266
translated/tech/20180116 Monitor your Kubernetes Cluster.md
Normal file
@ -0,0 +1,266 @@
|
||||
监视 Kubernetes 集群
|
||||
======
|
||||
这篇文章最初发表在 [Kevin Monroe 的博客][1] 上
|
||||
|
||||
监视日志和指标状态是集群管理员的重点工作。它的好处很明显:指标能帮你设置一个合理的性能目标,而日志分析可以发现影响你工作负载的问题。然而,困难的是如何找到一个与大量运行的应用程序一起工作的监视解决方案。
|
||||
|
||||
在本文中,我将使用 [Graylog][2] (用于日志)和 [Prometheus][3] (用于指标)去打造一个Kubernetes 集群的监视解决方案。当然了,这不仅是将三个东西连接起来那么简单,实现上,最终结果看起来应该如下图所示:
|
||||
|
||||
![][4]
|
||||
|
||||
正如你所了解的,Kubernetes 不仅做一件事情 —— 它是 master、workers、networking bit 等等。同样,Graylog 是一个配角(apache2、mongodb、等等),Prometheus 也一样(telegraf、grafana 等等)。在部署中连接这些点看起来似乎有些让人恐惧,但是使用合适的工具将不会那么困难。
|
||||
|
||||
我将使用 [conjure-up][5] 和 [Canonical Distribution of Kubernetes][6] (CDK) 去探索 Kubernetes。我发现 conjure-up 接口对部署大型软件很有帮助,但是我知道一些人可能不喜欢 GUIs、TUIs 以及其它 UIs。对于这些人,我将用命令行再去部署一遍。
|
||||
|
||||
在开始之前需要注意的一点是,Graylog 和 Prometheus 是部署在 Kubernetes 侧而不是集群上。像 Kubernetes 仪表盘和 Heapster 是运行的集群中非常好的信息来源,但是我的目标是为日志/指标提供一个分析机制,而不管集群运行与否。
|
||||
|
||||
### 开始探索
|
||||
|
||||
如果你的系统上没有 conjure-up,首先要做的第一件事情是,请先安装它,在 Linux 上,这很简单:
|
||||
```
|
||||
sudo snap install conjure-up --classic
|
||||
```
|
||||
|
||||
对于 macOS 用户也提供了 brew 包:
|
||||
```
|
||||
brew install conjure-up
|
||||
```
|
||||
|
||||
你需要最新的 2.5.2 版,它的好处是添加了 CDK spell,因此,如果你的系统上已经安装了旧的版本,请使用 `sudo snap refresh conjure-up` 或者 `brew update && brew upgrade conjure-up` 去更新它。
|
||||
|
||||
安装完成后,运行它:
|
||||
```
|
||||
conjure-up
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
你将发现有一个 spell 列表。选择 CDK 然后按下 `Enter`。
|
||||
|
||||
![][8]
|
||||
|
||||
这个时候,你将看到 CDK spell 可用的附加组件。我们感兴趣的是 Graylog 和 Prometheus,因此选择这两个,然后点击 `Continue`。
|
||||
|
||||
它将引导你选择各种云,以决定你的集群部署的地方。之后,你将看到一些部署的后续步骤,接下来是回顾屏幕,让你再次确认部署内容:
|
||||
|
||||
![][9]
|
||||
|
||||
除了典型的 K8s 相关的应用程序(etcd、flannel、load-balancer、master、以及 workers)之外,你将看到我们选择的日志和指标相关的额外应用程序。
|
||||
|
||||
Graylog 栈包含如下:
|
||||
|
||||
* apache2:graylog web 接口的反向代理
|
||||
* elasticsearch:日志使用的文档数据库
|
||||
* filebeat:从 K8s master/workers 转发日志到 graylog
|
||||
* graylog:为日志收集器提供一个 api,以及提供一个日志分析界面
|
||||
* mongodb:保存 graylog 元数据的数据库
|
||||
|
||||
|
||||
|
||||
Prometheus 栈包含如下:
|
||||
|
||||
* grafana:指标相关的仪表板的 web 界面
|
||||
* prometheus:指标收集器以及时序数据库
|
||||
* telegraf:发送主机的指标到 prometheus 中
|
||||
|
||||
|
||||
|
||||
你可以在回顾屏幕上微调部署,但是默认组件是必选 的。点击 `Deploy all Remaining Applications` 继续。
|
||||
|
||||
部署工作将花费一些时间,它将部署你的机器和配置你的云。完成后,conjure-up 将展示一个摘要屏幕,它包含一些链连,你可以用你的终端去浏览各种感兴趣的内容:
|
||||
|
||||
![][10]
|
||||
|
||||
#### 浏览日志
|
||||
|
||||
现在,Graylog 已经部署和配置完成,我们可以看一下采集到的一些数据。默认情况下,filebeat 应用程序将从 Kubernetes 的 master 和 workers 中转发系统日志( `/var/log/*.log` )和容器日志(`/var/log/containers/*.log`)到 graylog 中。
|
||||
|
||||
记住如下的 apache2 的地址和 graylog 的 admin 密码:
|
||||
```
|
||||
juju status --format yaml apache2/0 | grep public-address
|
||||
public-address: <your-apache2-ip>
|
||||
juju run-action --wait graylog/0 show-admin-password
|
||||
admin-password: <your-graylog-password>
|
||||
```
|
||||
|
||||
在浏览器中输入 `http://<your-apache2-ip>` ,然后以管理员用户名(admin)和密码(<your-graylog-password>)登入。
|
||||
|
||||
**注意:** 如果这个界面不可用,请等待大约 5 分钟时间,以便于配置的反向代理生效。
|
||||
|
||||
登入后,顶部的 `Sources` 选项卡可以看到从 K8s 的 master 和 workers 中收集日志的概述:
|
||||
|
||||
![][11]
|
||||
|
||||
通过点击 `System / Inputs` 选项卡深入这些日志,选择 `Show received messages` 查看 filebeat 的输入:
|
||||
|
||||
![][12]
|
||||
|
||||
在这里,你可以应用各种过滤或者设置 Graylog 仪表板去帮助识别大多数比较重要的事件。查看 [Graylog Dashboard][13] 文档,可以了解如何定制你的视图的详细资料。
|
||||
|
||||
#### 浏览指标
|
||||
|
||||
我们的部署通过 grafana 仪表板提供了两种类型的指标:系统指标,包括像 K8s master 和 workers 的 cpu/内存/磁盘使用情况,以及集群指标,包括像从 K8s cAdvisor 端点上收集的容器级指标。
|
||||
|
||||
记住如下的 grafana 的地址和 admin 密码:
|
||||
```
|
||||
juju status --format yaml grafana/0 | grep public-address
|
||||
public-address: <your-grafana-ip>
|
||||
juju run-action --wait grafana/0 get-admin-password
|
||||
password: <your-grafana-password>
|
||||
```
|
||||
|
||||
在浏览器中输入 `http://<your-grafana-ip>:3000`,输入管理员用户(admin)和密码(<your-grafana-password>)登入。成功登入后,点击 `Home` 下拉框,选取 `Kubernetes Metrics (via Prometheus)` 去查看集群指标仪表板:
|
||||
|
||||
![][14]
|
||||
|
||||
我们也可以通过下拉框切换到 `Node Metrics (via Telegraf) ` 去查看 K8s 主机的系统指标。
|
||||
|
||||
![][15]
|
||||
|
||||
|
||||
### 另一种方法
|
||||
|
||||
正如在文章开始的介绍中提到的,我喜欢 conjure-up 的 “魔法之杖” 去指导我完成像 Kubernetes 这种复杂软件的部署。现在,我们来看一下 conjure-up 的另一种方法,你可能希望去看到实现相同结果的一些命令行的方法。还有其它的可能已经部署了前面的 CDK,想去扩展使用上述的 Graylog/Prometheus 组件。不管什么原因你既然看到这了,既来之则安之,继续向下看吧。
|
||||
|
||||
支持 conjure-up 的工具是 [Juju][16]。CDK spell 所做的一切,都可以使用 juju 命令行来完成。我们来看一下,如何一步步完成这些工作。
|
||||
|
||||
**从 Scratch 中启动**
|
||||
|
||||
如果你使用的是 Linux,安装 Juju 很简单,命令如下:
|
||||
```
|
||||
sudo snap install juju --classic
|
||||
```
|
||||
|
||||
对于 macOS,Juju 也可以从 brew 中安装:
|
||||
```
|
||||
brew install juju
|
||||
```
|
||||
|
||||
现在为你选择的云配置一个控制器。你或许会被提示请求一个凭据(用户名密码):
|
||||
```
|
||||
juju bootstrap
|
||||
```
|
||||
|
||||
我们接下来需要基于 CDK 捆绑部署:
|
||||
```
|
||||
juju deploy canonical-kubernetes
|
||||
```
|
||||
|
||||
**从 CDK 开始**
|
||||
|
||||
使用我们部署的 Kubernetes 集群,我们需要去添加 Graylog 和 Prometheus 所需要的全部应用程序:
|
||||
```
|
||||
## deploy graylog-related applications
|
||||
juju deploy xenial/apache2
|
||||
juju deploy xenial/elasticsearch
|
||||
juju deploy xenial/filebeat
|
||||
juju deploy xenial/graylog
|
||||
juju deploy xenial/mongodb
|
||||
```
|
||||
```
|
||||
## deploy prometheus-related applications
|
||||
juju deploy xenial/grafana
|
||||
juju deploy xenial/prometheus
|
||||
juju deploy xenial/telegraf
|
||||
```
|
||||
|
||||
现在软件已经部署完毕,将它们连接到一起,以便于它们之间可以相互通讯:
|
||||
```
|
||||
## relate graylog applications
|
||||
juju relate apache2:reverseproxy graylog:website
|
||||
juju relate graylog:elasticsearch elasticsearch:client
|
||||
juju relate graylog:mongodb mongodb:database
|
||||
juju relate filebeat:beats-host kubernetes-master:juju-info
|
||||
juju relate filebeat:beats-host kubernetes-worker:jujuu-info
|
||||
```
|
||||
```
|
||||
## relate prometheus applications
|
||||
juju relate prometheus:grafana-source grafana:grafana-source
|
||||
juju relate telegraf:prometheus-client prometheus:target
|
||||
juju relate kubernetes-master:juju-info telegraf:juju-info
|
||||
juju relate kubernetes-worker:juju-info telegraf:juju-info
|
||||
```
|
||||
|
||||
这个时候,所有的应用程序已经可以相互之间进行通讯了,但是我们还需要多做一点配置(比如,配置 apache2 反向代理、告诉 prometheus 如何从 K8s 中取数、导入到 grafana 仪表板等等):
|
||||
```
|
||||
## configure graylog applications
|
||||
juju config apache2 enable_modules="headers proxy_html proxy_http"
|
||||
juju config apache2 vhost_http_template="$(base64 <vhost-tmpl>)"
|
||||
juju config elasticsearch firewall_enabled="false"
|
||||
juju config filebeat \
|
||||
logpath="/var/log/*.log /var/log/containers/*.log"
|
||||
juju config filebeat logstash_hosts="<graylog-ip>:5044"
|
||||
juju config graylog elasticsearch_cluster_name="<es-cluster>"
|
||||
```
|
||||
```
|
||||
## configure prometheus applications
|
||||
juju config prometheus scrape-jobs="<scraper-yaml>"
|
||||
juju run-action --wait grafana/0 import-dashboard \
|
||||
dashboard="$(base64 <dashboard-json>)"
|
||||
```
|
||||
|
||||
以上的步骤需要根据你的部署来指定一些值。你可以用与 conjure-up 相同的方法得到这些:
|
||||
|
||||
* <vhost-tmpl>: 从 github 获取我们的示例 [模板][17]
|
||||
* <graylog-ip>: `juju run --unit graylog/0 'unit-get private-address'`
|
||||
* <es-cluster>: `juju config elasticsearch cluster-name`
|
||||
* <scraper-yaml>: 从 github 获取我们的示例 [scraper][18] ;`[K8S_PASSWORD][20]` 和 `[K8S_API_ENDPOINT][21]` [substitute][19] 的正确值
|
||||
* <dashboard-json>: 从 github 获取我们的 [主机][22] 和 [k8s][23] 仪表板
|
||||
|
||||
|
||||
|
||||
最后,发布 apache2 和 grafana 应用程序,以便于可以通过它们的 web 界面访问:
|
||||
```
|
||||
## expose relevant endpoints
|
||||
juju expose apache2
|
||||
juju expose grafana
|
||||
```
|
||||
|
||||
现在我们已经完成了所有的部署、配置、和发布工作,你可以使用与上面的**浏览日志**和**浏览指标**部分相同的方法去查看它们。
|
||||
|
||||
### 总结
|
||||
|
||||
我的目标是向你展示如何去部署一个 Kubernetes 集群,很方便地去监视它的日志和指标。无论你是喜欢向导的方式还是命令行的方式,我希望你清楚地看到部署一个监视系统并不复杂。关键是要搞清楚所有部分是如何工作的,并将它们连接到一起工作,通过断开/修复/重复的方式,直到它们每一个都能正常工作。
|
||||
|
||||
这里有一些非常好的工具像 conjure-up 和 Juju。充分发挥这个生态系统贡献者的专长让管理大型软件变得更容易。从一套可靠的应用程序开始,按需定制,然后投入到工作中!
|
||||
|
||||
大胆去尝试吧,然后告诉我你用的如何。你可以在 Freenode IRC 的 **#conjure-up** 和 **#juju** 中找到像我这样的爱好者。感谢阅读!
|
||||
|
||||
### 关于作者
|
||||
|
||||
Kevin 在 2014 年加入 Canonical 公司,他专注于复杂软件建模。他在 Juju 大型软件团队中找到了自己的位置,他的任务是将大数据和机器学习应用程序转化成可重复的(可靠的)解决方案。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2018/01/16/monitor-your-kubernetes-cluster/
|
||||
|
||||
作者:[Kevin Monroe][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/kwmonroe/
|
||||
[1]:https://medium.com/@kwmonroe/monitor-your-kubernetes-cluster-a856d2603ec3
|
||||
[2]:https://www.graylog.org/
|
||||
[3]:https://prometheus.io/
|
||||
[4]:https://insights.ubuntu.com/wp-content/uploads/706b/1_TAA57DGVDpe9KHIzOirrBA.png
|
||||
[5]:https://conjure-up.io/
|
||||
[6]:https://jujucharms.com/canonical-kubernetes
|
||||
[7]:https://insights.ubuntu.com/wp-content/uploads/98fd/1_o0UmYzYkFiHIs2sBgj7G9A.png
|
||||
[8]:https://insights.ubuntu.com/wp-content/uploads/0351/1_pgVaO_ZlalrjvYd5pOMJMA.png
|
||||
[9]:https://insights.ubuntu.com/wp-content/uploads/9977/1_WXKxMlml2DWA5Kj6wW9oXQ.png
|
||||
[10]:https://insights.ubuntu.com/wp-content/uploads/8588/1_NWq7u6g6UAzyFxtbM-ipqg.png
|
||||
[11]:https://insights.ubuntu.com/wp-content/uploads/a1c3/1_hHK5mSrRJQi6A6u0yPSGOA.png
|
||||
[12]:https://insights.ubuntu.com/wp-content/uploads/937f/1_cP36lpmSwlsPXJyDUpFluQ.png
|
||||
[13]:http://docs.graylog.org/en/2.3/pages/dashboards.html
|
||||
[14]:https://insights.ubuntu.com/wp-content/uploads/9256/1_kskust3AOImIh18QxQPgRw.png
|
||||
[15]:https://insights.ubuntu.com/wp-content/uploads/2037/1_qJpjPOTGMQbjFY5-cZsYrQ.png
|
||||
[16]:https://jujucharms.com/
|
||||
[17]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/graylog/steps/01_install-graylog/graylog-vhost.tmpl
|
||||
[18]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/prometheus-scrape-k8s.yaml
|
||||
[19]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L25
|
||||
[20]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L10
|
||||
[21]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L11
|
||||
[22]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-telegraf.json
|
||||
[23]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-k8s.json
|
||||
@ -0,0 +1,169 @@
|
||||
构建你自己的 RSS 提示系统——让杂志文章一篇也不会错过
|
||||
======
|
||||
|
||||

|
||||
|
||||
人生苦短,我用 Python,Python 是非常棒的快速构建应用程序的编程语言。在这篇文章中我们将学习如何使用 Python 去构建一个 RSS 提示系统,目标是使用 Fedora 快乐地学习 Python。如果你正在寻找一个完整的 RSS 提示应用程序,在 Fedora 中已经准备好了几个包。
|
||||
|
||||
### Fedora 和 Python —— 入门知识
|
||||
|
||||
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [**sqlite3**][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是在标准库中没有的特定的问题,也有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [**feedparser**][3] 去解析 RSS 源。
|
||||
|
||||
因为 **feedparser** 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 **feedparser**:
|
||||
```
|
||||
$ sudo dnf install python3-feedparser
|
||||
```
|
||||
|
||||
我们现在已经拥有了编写我们的应用程序所需的东西了。
|
||||
|
||||
### 存储源数据
|
||||
|
||||
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的**标题**和**发布日期**。
|
||||
|
||||
因此,我们来使用 Python **sqlite3** 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(**feedparse**,**smtplib**,和 **email**)。
|
||||
|
||||
#### 创建数据库
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
import sqlite3
|
||||
import smtplib
|
||||
from email.mime.text import MIMEText
|
||||
|
||||
import feedparser
|
||||
|
||||
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
|
||||
db = db_connection.cursor()
|
||||
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
|
||||
|
||||
```
|
||||
|
||||
这几行代码创建一个新的保存在一个名为 'magazine_rss.sqlite' 文件中的 sqlite 数据库,然后在数据库创建一个名为 'magazine' 的新表。这个表有两个列 —— 'title' 和 'date' —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
|
||||
|
||||
#### 检查数据库中的旧文章
|
||||
|
||||
由于我们仅希望增加新的文章到我们的数据库中,因此我们需要一个功能去检查 RSS 源中的文章在数据库中是否存在。我们将根据它来判断是否发送(有新文章的)邮件提示。Ok,现在我们来写这个功能的代码。
|
||||
```
|
||||
def article_is_not_db(article_title, article_date):
|
||||
""" Check if a given pair of article title and date
|
||||
is in the database.
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_date (str): The publication date of an article
|
||||
Return:
|
||||
True if the article is not in the database
|
||||
False if the article is already present in the database
|
||||
"""
|
||||
db.execute("SELECT * from magazine WHERE title=? AND date=?", (article_title, article_date))
|
||||
if not db.fetchall():
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
```
|
||||
|
||||
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 SELECT 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(title 和 date)。然后,我们使用查询的 WHERE 条件 `article_title` and `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
|
||||
|
||||
最后,我们使用一个简单的返回 `True` 或者 `False` 的逻辑来表示是否在数据库中找到匹配的文章。
|
||||
|
||||
#### 在数据库中添加新文章
|
||||
|
||||
现在我们可以写一些代码去添加新文章到数据库中。
|
||||
```
|
||||
def add_article_to_db(article_title, article_date):
|
||||
""" Add a new article title and date to the database
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_date (str): The publication date of an article
|
||||
"""
|
||||
db.execute("INSERT INTO magazine VALUES (?,?)", (article_title, article_date))
|
||||
db_connection.commit()
|
||||
```
|
||||
|
||||
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 'magazine' 表的 article_title 和 article_date 列中。然后提交它到数据库中永久保存。
|
||||
|
||||
这些就是在数据库中所需要的东西,接下来我们看一下,如何使用 Python 实现提示系统和发送电子邮件。
|
||||
|
||||
### 发送电子邮件提示
|
||||
|
||||
我们来使用 Python 标准库模块 **smtplib** 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 **email** 模块去格式化我们的电子邮件信息。
|
||||
```
|
||||
def send_notification(article_title, article_url):
|
||||
""" Add a new article title and date to the database
|
||||
|
||||
Args:
|
||||
article_title (str): The title of an article
|
||||
article_url (str): The url to access the article
|
||||
"""
|
||||
|
||||
smtp_server = smtplib.SMTP('smtp.gmail.com', 587)
|
||||
smtp_server.ehlo()
|
||||
smtp_server.starttls()
|
||||
smtp_server.login('your_email@gmail.com', '123your_password')
|
||||
msg = MIMEText(f'\nHi there is a new Fedora Magazine article : {article_title}. \nYou can read it here {article_url}')
|
||||
msg['Subject'] = 'New Fedora Magazine Article Available'
|
||||
msg['From'] = 'your_email@gmail.com'
|
||||
msg['To'] = 'destination_email@gmail.com'
|
||||
smtp_server.send_message(msg)
|
||||
smtp_server.quit()
|
||||
```
|
||||
|
||||
在这个示例中,我使用了谷歌邮件系统的 smtp 服务器去发送电子邮件,在你自己的代码中你需要将它更改为你自己的电子邮件服务提供者的 SMTP 服务器。这个功能是个样板,大多数的内容要根据你的 smtp 服务器的参数来配置。代码中的电子邮件地址和凭证也要更改为你自己的。
|
||||
|
||||
如果在你的 Gmail 帐户中使用了双因子认证,那么你需要配置一个密码应用程序为你的这个应用程序提供一个唯一密码。可以看这个 [帮助页面][4]。
|
||||
|
||||
### 读取 Fedora Magazine 的 RSS 源
|
||||
|
||||
我们已经有了在数据库中存储文章和发送提示电子邮件的功能,现在来创建一个解析 Fedora Magazine RSS 源并提取文章数据的功能。
|
||||
```
|
||||
def read_article_feed():
|
||||
""" Get articles from RSS feed """
|
||||
feed = feedparser.parse('https://fedoramagazine.org/feed/')
|
||||
for article in feed['entries']:
|
||||
if article_is_not_db(article['title'], article['published']):
|
||||
send_notification(article['title'], article['link'])
|
||||
add_article_to_db(article['title'], article['published'])
|
||||
|
||||
if __name__ == '__main__':
|
||||
read_article_feed()
|
||||
db_connection.close()
|
||||
```
|
||||
|
||||
在这里我们将使用 **feedparser.parse** 功能。这个功能返回一个用字典表示的 RSS 源,对于 **feedparser** 的完整描述可以参考它的 [文档][5]。
|
||||
|
||||
RSS 源解析将返回最后的 10 篇文章作为 `entries`,然后我们提取以下信息:标题、链接、文章发布日期。因此,我们现在可以使用前面定义的检查文章是否在数据库中存在的功能,然后,发送提示电子邮件并将这个文章添加到数据库中。
|
||||
|
||||
当运行我们的脚本时,最后的 if 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
|
||||
|
||||
### 运行我们的脚本
|
||||
|
||||
给脚本文件赋于正确运行权限。接下来,我们使用 **cron** 实用程序去每小时自动运行一次我们的脚本。**cron** 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
|
||||
```
|
||||
$ chmod a+x my_rss_notifier.py
|
||||
$ sudo cp my_rss_notifier.py /etc/cron.hourly
|
||||
```
|
||||
|
||||
**为了使该教程保持简单**,我们使用了 cron.hourly 目录每小时运行一次我们的脚本,如果你想学习关于 **cron** 的更多知识以及如何配置 **crontab**,请阅读 **cron** 的 wikipedia [页面][6]。
|
||||
|
||||
### 总结
|
||||
|
||||
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,**使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事**。
|
||||
|
||||
这个脚本在 [GitHub][7] 上可以找到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notification-system/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://docs.python.org/3/library/sqlite3.html
|
||||
[2]:https://pypi.python.org/pypi
|
||||
[3]:https://pypi.python.org/pypi/feedparser/5.2.1
|
||||
[4]:https://support.google.com/accounts/answer/185833?hl=en
|
||||
[5]:https://pythonhosted.org/feedparser/reference.html
|
||||
[6]:https://en.wikipedia.org/wiki/Cron
|
||||
[7]:https://github.com/cverna/rss_feed_notifier
|
||||
@ -1,83 +0,0 @@
|
||||
如何在 Linux/Unix 中不重启 vim 而重新加载 .vimrc 文件
|
||||
======
|
||||
|
||||
我是一位新的 vim 编辑器用户。我通常加载 ~/.vimrc 用于配置。在编辑 .vimrc 时,我需要不重启 vim 会话而重新加载它。在 Linux 或者类 Unix 系统中,如何在编辑 .vimrc 后,重新加载它而不用重启 vim?
|
||||
|
||||
vim 是免费开源并且向上兼容 vi 的编辑器。它可以用来编辑各种文本。它在编辑用 C/Perl/Python 编写的程序时特别有用。可以用它来编辑 Linux/Unix 配置文件。~/.vimrc 是你个人的 vim 初始化和自定义文件。
|
||||
|
||||
### 如何在不重启 vim 会话的情况下重新加载 .vimrc
|
||||
|
||||
在 vim 中重新加载 .vimrc 而不重新启动的流程:
|
||||
|
||||
1. 输入 `vim filename` 启动 vim
|
||||
2. 按下 `Esc` 接着输入 `:vs ~/.vimrc` 来加载 vim 配置
|
||||
3. 像这样添加自定义:
|
||||
|
||||
```
|
||||
filetype indent plugin on
|
||||
set number
|
||||
syntax on
|
||||
```
|
||||
|
||||
4. 使用 `:wq` 保存文件,并从 ~/.vimrc 窗口退出
|
||||
5. 输入下面任一命令重载 ~/.vimrc:
|
||||
|
||||
```
|
||||
:so $MYVIMRC
|
||||
```
|
||||
或者
|
||||
```
|
||||
:source ~/.vimrc
|
||||
```
|
||||
|
||||
[![How to reload .vimrc file without restarting vim][1]][1]
|
||||
图1:编辑 ~/.vimrc 并在需要的时候重载而不用退出 vim,这样你就可以继续编辑程序了
|
||||
|
||||
`:so[urce]! {file}` 这个 vim 命令会从给定的文件比如 ~/.vimrc 读取配置。这些命令是在正常模式下执行,就像你输入它们一样。当你在 :global、:argdo、 :windo、:bufdo 之后、循环中或者跟着另一个命令时,显示不会再在执行命令时更新。
|
||||
|
||||
### 如何编辑按键来编辑并重载 ~/.vimrc
|
||||
|
||||
在你的 ~/.vimrc 后面跟上这些
|
||||
|
||||
```
|
||||
" Edit vimr configuration file
|
||||
nnoremap confe :e $MYVIMRC<CR>
|
||||
"
|
||||
|
||||
Reload vims configuration file
|
||||
nnoremap confr :source $MYVIMRC<CR>
|
||||
```
|
||||
|
||||
现在只要按下 `Esc` 接着输入 `confe` 开编辑 ~/.vimrc。按下 `Esc` ,接着输入 `confr` 来重新加载。一些喜欢在 .vimrc 中使用 <Leader>。因此上面的映射变成:
|
||||
|
||||
```
|
||||
" Edit vimr configuration file
|
||||
nnoremap <Leader>ve :e $MYVIMRC<CR>
|
||||
"
|
||||
" Reload vimr configuration file
|
||||
nnoremap <Leader>vr :source $MYVIMRC<CR>
|
||||
```
|
||||
|
||||
<Leader> 键默认映射成 \\ 键。因此只要输入 \\ 接着 ve 就能编辑文件。按下 \\ 接着 vr 就能重载 ~/vimrc。
|
||||
这就完成了,你可以不用再重启 vim 就能重新加载 .vimrc 了。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,经验丰富的系统管理员,也是 Linux 操作系统/Unix shell 脚本的培训师。他曾与全球客户以及IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter][9]、[Facebook][10]、[Google +][11] 上关注他。通过[我的 RSS/XML 订阅][5]获取**最新的系统管理、Linux/Unix 以及开源主题教程**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-reload-vimrc-file-without-restarting-vim-on-linux-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/02/How-to-reload-.vimrc-file-without-restarting-vim.jpg
|
||||
[2]:https://twitter.com/nixcraft
|
||||
[3]:https://facebook.com/nixcraft
|
||||
[4]:https://plus.google.com/+CybercitiBiz
|
||||
[5]:https://www.cyberciti.biz/atom/atom.xml
|
||||
239
translated/tech/20180221 Getting started with SQL.md
Normal file
239
translated/tech/20180221 Getting started with SQL.md
Normal file
@ -0,0 +1,239 @@
|
||||
开始使用 SQL
|
||||
======
|
||||
|
||||

|
||||
|
||||
使用 SQL 构建数据库比大多数人想象得要简单。实际上,你甚至不需要成为一个有经验的程序员来使用 SQL 创建数据库。在本文中,我将解释如何使用 MySQL 5.6 来创建简单的关系型数据库管理系统(RDMS)。在开始之前,我想快速地感谢 [SQL Fiddle][1],这是我用来运行脚本的工具。它提供了一个用于测试简单脚本的有用的沙箱。
|
||||
|
||||
在本教程中,我将构建一个使用下面实体关系图(ERD)中显示的简单架构的数据库。数据库列出了学生和正在学习的课程。为了保持简单,我使用了两个实体(即表),只有一种关系和依赖关系。这两个实体称为 `dbo_students` 和 `dbo_courses`。
|
||||
|
||||

|
||||
|
||||
数据库的多样性是一对多的,因为每门课程可以包含很多学生,但每个学生只能学习一门课程。
|
||||
|
||||
关于术语的快速说明:
|
||||
|
||||
1. 一张表称为一个实体。
|
||||
2. 一个字段称为一个属性。
|
||||
3. 一条记录称为一个元组。
|
||||
4. 用于构建数据库的脚本称为架构。
|
||||
|
||||
### 构建架构
|
||||
|
||||
要构建数据库,使用 `CREATE TABLE <表名>` 命令,然后定义每个字段的名称和数据类型。数据库使用 `VARCHAR(n)` (字符串)和 `INT(n)` (整数),其中 n 表示可以存储的值的长度。例如 `INT(2)` 可能是 01。
|
||||
|
||||
这是用于创建两个表的代码:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
```
|
||||
|
||||
`NOT NULL` 意味着字段不能为空,`AUTO_INCREMENT` 意味着当一个新的元组被添加时,ID 号将自动生成,并将 1 添加到先前存储的 ID 号,来强化各实体之间的完整参照性。 `PRIMARY KEY` 是每个表的惟一标识符属性。这意味着每个元组都有自己的不同的标识。
|
||||
|
||||
### 关系作为一种约束
|
||||
|
||||
就目前来看,这两张表格是独立存在的,没有任何联系或关系。要连接它们,必须标识一个外键。在 `dbo_students` 中,外键是 `course_studied`,其来源在 `dbo_courses` 中,意味着该字段被引用。SQL 中的特定命令为 `CONSTRAINT`,并且将使用另一个名为 `ALTER TABLE` 的命令添加这种关系,这样即使在架构构建完毕后,也可以编辑表。
|
||||
|
||||
以下代码将关系添加到数据库构造脚本中:
|
||||
```
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
```
|
||||
使用 `CONSTRAINT` 命令实际上并不是必要的,但这是一个好习惯,因为它意味着约束可以被命名并且使维护更容易。现在数据库已经完成了,是时候添加一些数据了。
|
||||
|
||||
### 将数据添加到数据库
|
||||
|
||||
`INSERT INTO <表名>`是用于直接选择将数据添加到哪些属性(即字段)的命令。首先声明实体名称,然后声明属性。命令下边是添加到实体的数据,从而创建一个元组。如果指定了 `NOT NULL`,这表示该属性不能留空。以下代码将展示如何向表中添加记录:
|
||||
```
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
```
|
||||
|
||||
现在数据库架构已经完成并添加了数据,现在是时候在数据库上运行查询了。
|
||||
|
||||
### 查询
|
||||
|
||||
查询遵循使用以下命令的集合结构:
|
||||
```
|
||||
SELECT <attributes>
|
||||
|
||||
FROM <entity>
|
||||
|
||||
WHERE <condition>
|
||||
```
|
||||
|
||||
要显示 `dbo_courses` 实体内的所有记录并显示课程代码和课程名称,请使用 * 。 这是一个通配符,它消除了键入所有属性名称的需要。(在生产数据库中不建议使用它。)此处查询的代码是:
|
||||
```
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
```
|
||||
|
||||
此处查询的输出显示表中的所有元组,因此可显示所有可用课程:
|
||||
```
|
||||
| course_id | course_name |
|
||||
|
||||
|-----------|----------------------|
|
||||
|
||||
| 1 | Software Engineering |
|
||||
|
||||
| 2 | Computer Science |
|
||||
|
||||
| 3 | Computing |
|
||||
```
|
||||
|
||||
在以后的文章中,我将使用三种类型的连接之一来解释更复杂的查询:Inner,Outer 或 Cross。
|
||||
|
||||
这是完整的脚本:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
|
||||
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
```
|
||||
|
||||
### 学习更多
|
||||
|
||||
SQL 并不困难;我认为它比编程简单,并且该语言对于不同的数据库系统是通用的。 请注意,`dbo.<实体>` (译者注:文章中使用的是 `dbo_<实体>`) 不是必需的实体命名约定;我之所以使用,仅仅是因为它是 Microsoft SQL Server 中的标准。
|
||||
|
||||
如果你想了解更多,在网络上这方面的最佳指南是 [W3Schools.com][2] 中对所有数据库平台的 SQL 综合指南。
|
||||
|
||||
请随意使用我的数据库。另外,如果你有任何建议或疑问,请在评论中回复。(译注:请点击原文地址进行评论回应)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: [https://opensource.com/article/18/2/getting-started-sql](https://opensource.com/article/18/2/getting-started-sql)
|
||||
|
||||
作者:[Aaron Cocker][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaroncocker
|
||||
[1]:http://sqlfiddle.com
|
||||
[2]:https://www.w3schools.com/sql/default.asp
|
||||
Loading…
Reference in New Issue
Block a user