mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
OneNewLife translated
This commit is contained in:
parent
785ffe63df
commit
6884428057
@ -1,61 +1,43 @@
|
||||
OneNewLife translating
|
||||
|
||||
The truth about traditional JavaScript benchmarks
|
||||
探索传统 JavaScript 基准测试
|
||||
============================================================
|
||||
|
||||
可以很公平地说,[JavaScript][22] 是当下软件工程最为重要的技术。由于在语言设计者看来,JavaScript 不是十分优雅;在编译器工程师看来,它的性能没有多卓越;并且它还没有一个足够庞大的标准库,所以对于深入接触过编程语言、编译器和虚拟机的人来说,这依然是一个惊喜。取决于你和谁吐槽,JavaScript 的缺点花上数周都列举不完,不过你总会找到一些你从所未知的神奇的东西。尽管这看起来明显困难重重,不过 JavaScript 今天还是成为了 web 的核心,并且还成为服务器/云端的主要技术(通过 [Node.js][23]),甚至还开辟了进入物联网领域的道路。
|
||||
|
||||
It is probably fair to say that [JavaScript][22] is _the most important technology_ these days when it comes to software engineering. To many of us who have been into programming languages, compilers and virtual machines for some time, this still comes a bit as a surprise, as JavaScript is neither very elegant from the language designers point of view, nor very optimizable from the compiler engineers point of view, nor does it have a great standard library. Depending on who you talk to, you can enumerate shortcomings of JavaScript for weeks and still find another odd thing you didn’t know about. Despite what seem to be obvious obstacles, JavaScript is at the core of not only the web today, but it’s also becoming the dominant technology on the server-/cloud-side (via [Node.js][23]), and even finding its way into the IoT space.
|
||||
问题来了,为什么 JavaScript 如此受欢迎/成功?我从未得到一个很好的答案。如今我们有很多理由使用 JavaScript,或许最重要的是围绕其构建的庞大的生态系统以及今天大量可用的资源。但所有这一切实际上是发展到一定程度的结果。为什么 JavaScript 变得流行起来了?嗯,你或许会说,这是 web 多年来的通用语了。但是在很长一段时间里,人们极其讨厌 JavaScript。回顾过去,似乎第一次 JavaScript 浪潮爆发在上个年代的后半段。不出所料,那个时候 JavaScript 引擎在不同的负载下实现了巨大的加速,这可能刷新了很多人对 JavaScript 的看法。
|
||||
|
||||
That raises the question, why is JavaScript so popular/successful? There is no one great answer to this I’d be aware of. There are many good reasons to use JavaScript today, probably most importantly the great ecosystem that was built around it, and the huge amount of resources available today. But all of this is actually a consequence to some extent. Why did JavaScript became popular in the first place? Well, it was the lingua franca of the web for ages, you might say. But that was the case for a long time, and people hated JavaScript with passion. Looking back in time, it seems the first JavaScript popularity boosts happened in the second half of the last decade. Unsurprisingly this was the time when JavaScript engines accomplished huge speed-ups on various different workloads, which probably changed the way that many people looked at JavaScript.
|
||||
回到过去那些日子,这些加速测试使用了今天所谓的传统 JavaScript 基准,从苹果的 [SunSpider 基准][24](所有 JavaScript 微基准之母)到 Mozilla 的 [Kraken 基准][25] 和谷歌的 V8 基准。后来,V8 基准被 [Octane 基准][26] 取代,而苹果发布了自家新的 [JetStream 基准][27]。这些传统的 JavaScript 基准测试驱动了令人惊叹的努力,使 JavaScript 的性能达到一个在本世纪初没人能预料到的水平。据报道加速达到了 1000 倍,一夜之间在网站使用 `<script>` 标签不再是魔鬼的舞蹈,做客户端不仅仅是可能的,甚至是被鼓励的。
|
||||
|
||||
Back in the days, these speed-ups were measured with what is now called _traditional JavaScript benchmarks_, starting with Apple’s [SunSpider benchmark][24], the mother of all JavaScript micro-benchmarks, followed by Mozilla’s [Kraken benchmark][25] and Google’s V8 benchmark. Later the V8 benchmark was superseded by the[Octane benchmark][26] and Apple released its new [JetStream benchmark][27]. These traditional JavaScript benchmarks drove amazing efforts to bring a level of performance to JavaScript that noone would have expected at the beginning of the century. Speed-ups up to a factor of 1000 were reported, and all of a sudden using `<script>` within a website was no longer a dance with the devil, and doing work client-side was not only possible, but even encouraged.
|
||||
[][28]
|
||||
|
||||
[
|
||||

|
||||
][28]
|
||||
在 2016 年,所有(相关的)JavaScript 引擎达到了一个令人难以置信的水平,web 应用可以像端应用一样快。引擎配有复杂的优化编译器,通过根据收集的关于类型/形状的反馈来推测某些操作(即属性访问、二进制操作、比较、调用等),生成高度优化的机器代码的短序列。大多数这些优化是由 SunSpider 或 Kraken 等微基准以及 Octane 和 JetStream 等静态测试套件驱动的。由于有基于像 [asm.js][29] 和 [Emscripten][30] 这样的 JavaScript 技术,我们甚至可以将大型 C++ 应用编译成 JavaScript,并在你的浏览器上运行,而无需下载或安装任何东西。例如,现在你可以在 web 上玩 [AngryBots][31],无需沙盒,而过去的 web 游戏需要安装一堆诸如 Adobe Flash 或 Chrome PNaCl 的插件。
|
||||
|
||||
这些成就绝大多数都要归功于这些微基准和静态性能测试套件,以及这些传统 JavaScript 基准间至关重要的竞争。你可以说你可以用 SunSpider 来干什么,但很显然,没有 SunSpider,JavaScript 的性能可能达不到今天的高度。好的,赞美到此为止。现在看看另一面,所有的静态性能测试——无论是微基准还是大型应用的宏基准,都注定要随着时间的推移变得不相关!为什么?因为在开始游戏前,基准只能教你这么多。一旦达到某个阔值以上(或以下),那么有益于特定基准的优化的一般实用性将呈指数下降。例如,我们将 Octane 作为现实世界中 web 应用性能的代理,并且在相当长一段时间里,它可能做得相当不错,但是现在,Octane 与现实世界中的时间分布是截然不同的,因此当前优化 Octane 以超越自身可能在现实中得不到任何显著的改进(无论是通用 web 还是 Node.js 的工作负载)。
|
||||
|
||||
Now in 2016, all (relevant) JavaScript engines reached a level of performance that is incredible and web apps are as snappy as native apps (or can be as snappy as native apps). The engines ship with sophisticated optimizing compilers, that generate short sequences of highly optimized machine code by speculating on the type/shape that hit certain operations (i.e. property access, binary operations, comparisons, calls, etc.) based on feedback collected about types/shapes seen in the past. Most of these optimizations were driven by micro-benchmarks like SunSpider or Kraken, and static test suites like Octane and JetStream. Thanks to JavaScript-based technologies like [asm.js][29] and [Emscripten][30] it is even possible to compile large C++ applications to JavaScript and run them in your web browser, without having to download or install anything, for example you can play [AngryBots][31] on the web out-of-the-box, whereas in the past gaming on the web required special plugins like Adobe Flash or Chrome’s PNaCl.
|
||||
[][32]
|
||||
|
||||
The vast majority of these accomplishments were due to the presence of these micro-benchmarks and static performance test suites, and the vital competition that resulted from having these traditional JavaScript benchmarks. You can say what you want about SunSpider, but it’s clear that without SunSpider, JavaScript performance would likely not be where it is today. Okay, so much for the praise… now on to the flip side of the coin: Any kind of static performance test - be it a micro-benchmark or a large application macro-benchmark - is doomed to become irrelevant over time! Why? Because the benchmark can only teach you so much before you start gaming it. Once you get above (or below) a certain threshold, the general applicability of optimizations that benefit a particular benchmark will decrease exponentially. For example we built Octane as a proxy for performance of real world web applications, and it probably did a fairly good job at that for quite some time, but nowadays the distribution of time in Octane vs. real world is quite different, so optimizing for Octane beyond where it is currently, is likely not going to yield any significant improvements in the real world (neither general web nor Node.js workloads).
|
||||
由于传统 JavaScript 基准(包括最新版的 JetStream 和 Octane)可能已经超越其有用性变得越来越明显,我们开始调查新的方法来测量年初(2016 年)真实世界的性能,为 V8 和 Chrome 添加了大量新的性能追踪钩子。我们特意添加了一些机制来查看我们在浏览 web 时花费的时间,即是否是脚本执行、垃圾回收、编译等,并且这些调查的结果非常有趣和令人惊讶。从上面的幻灯片可以看出,运行 Octane 花费超过 70% 的时间执行 JavaScript 和回收垃圾,而浏览 web 的时候,通常执行 JavaScript 花费的时间不到 30%,垃圾回收占用的时间永远不会超过 5%。而花费大量时间来解析和编译,这不像 Octane 的作风。因此,将更多的时间用在优化 JavaScript 执行上将提高你的 Octane 跑分,但不会对加载 [youtube.com][33] 有任何积极的影响。事实上,花费更多的时间来优化 JavaScript 执行甚至可能会损伤你的真实性能,因为编译器需要更多的时间,或者你需要跟踪额外的反馈,从而最终为编译、IC 和运行时桶开销更多的时间。
|
||||
|
||||
[
|
||||

|
||||
][32]
|
||||
[][34]
|
||||
|
||||
还有另外一组基准测试用于测试浏览器整体性能(包括 JavaScript 和 DOM 性能),最新推出的是 [Speedometer 基准][35]。基准试图通过运行一个用不同的主流 web 框架实现的简单的 [TodoMVC][36] 应用(现在看来有点过时了,不过新版本正在研发中)以捕获真实性能。各种在 Octane 下的测试(angular、ember、react、vanilla、flight 和 bbackbone)都囊括在幻灯片中,你可以看到这些测试似乎更好地代表了现在的性能指标。但是请注意,这些数据收集与本文撰写将近 6 个月以前,而且我们优化了更多的现实世界模式(例如我们正在重构 IC 系统以显著地减小开销,并且 [解析器也正在重新设计][37])。还要注意的是,虽然这看起来像是只和浏览器相关,但我们有非常强有力的证据表明传统的峰值性能基准也不是现实世界 Node.js 应用性能的一个好代表。
|
||||
|
||||
Since it became more and more obvious that all the traditional benchmarks for measuring JavaScript performance, including the most recent versions of JetStream and Octane, might have outlived their usefulness, we started investigating new ways to measure real-world performance beginning of the year, and added a lot of new profiling and tracing hooks to V8 and Chrome. We especially added mechanisms to see where exactly we spend time when browsing the web, i.e. whether it’s script execution, garbage collection, compilation, etc., and the results of these investigations were highly interesting and surprising. As you can see from the slide above, running Octane spends more than 70% of the time executing JavaScript and collecting garbage, while browsing the web you always spend less than 30% of the time actually executing JavaScript, and never more than 5% collecting garbage. Instead a significant amount of time goes to parsing and compiling, which is not reflected in Octane. So spending a lot of time to optimize JavaScript execution will boost your score on Octane, but won’t have any positive impact on loading [youtube.com][33]. In fact, spending more time on optimizing JavaScript execution might even hurt your real-world performance since the compiler takes more time, or you need to track additional feedback, thus eventually adding more time to the Compile, IC and Runtime buckets.
|
||||
[][38]
|
||||
|
||||
[
|
||||

|
||||
][34]
|
||||
这些可能已经为大多数人所知了,因此我将用本文剩下的部分强调一些关于我为什么认为这不仅有用,而且对于 JavaScript 社区停止关注某一阔值的静态峰值性能基准测试的健康很关键的具体案例。让我通过一些例子说明 JavaScript 引擎如何做游戏基准。
|
||||
|
||||
There’s another set of benchmarks, which try to measure overall browser performance, including JavaScript **and** DOM performance, with the most recent addition being the [Speedometer benchmark][35]. The benchmark tries to capture real world performance more realistically by running a simple [TodoMVC][36] application implemented with different popular web frameworks (it’s a bit outdated now, but a new version is in the makings). The various tests are included in the slide above next to octane (angular, ember, react, vanilla, flight and backbone), and as you can see these seem to be a better proxy for real world performance at this point in time. Note however that this data is already six months old at the time of this writing and things might have changed as we optimized more real world patterns (for example we are refactoring the IC system to reduce overhead significantly, and the [parser is being redesigned][37]). Also note that while this looks like it’s only relevant in the browser space, we have very strong evidence that traditional peak performance benchmarks are also not a good proxy for real world Node.js application performance.
|
||||
### 臭名昭著的 SunSpider 案例
|
||||
|
||||
[
|
||||

|
||||
][38]
|
||||
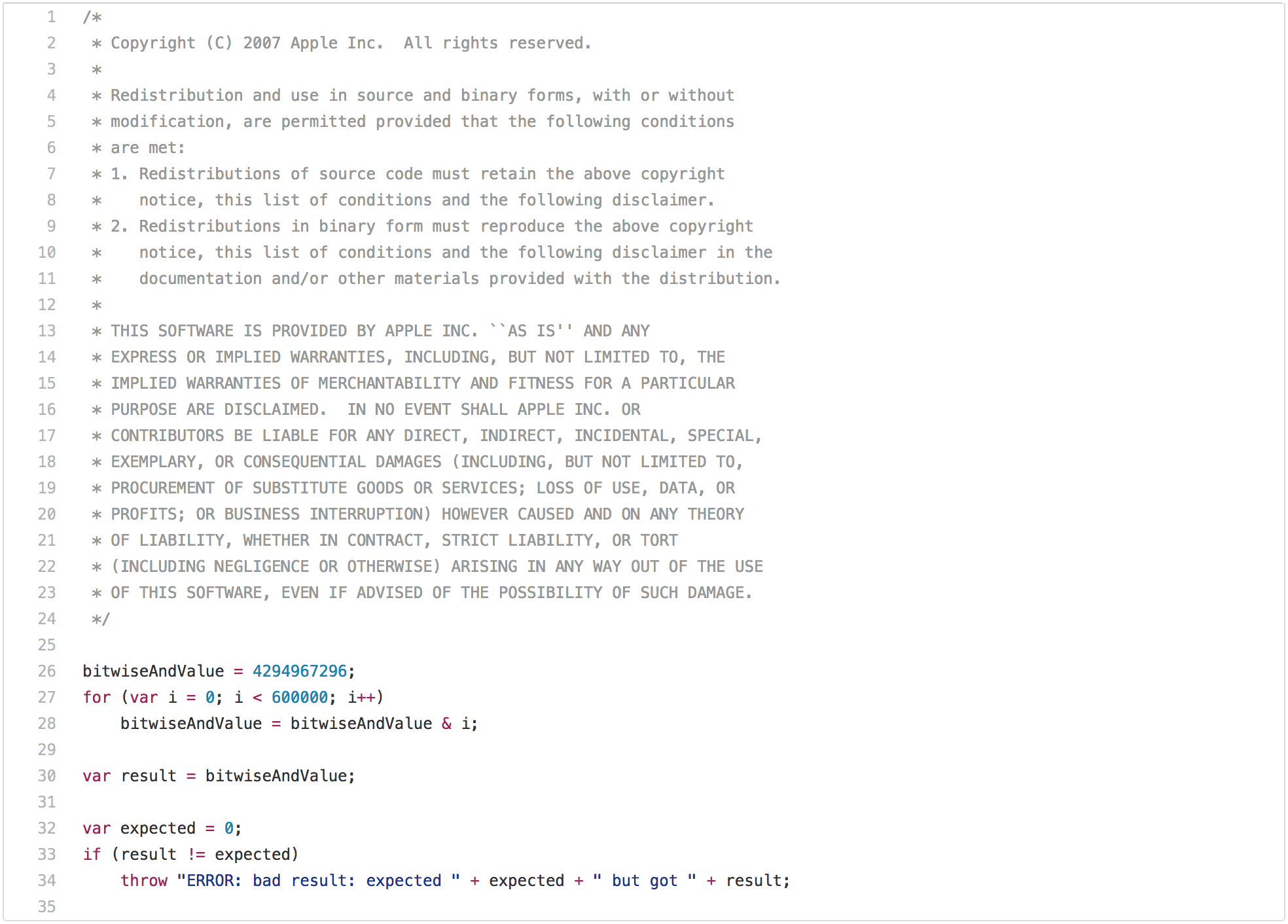
一篇关于传统 JavaScript 基准测试的博客文章如果没有指出 SunSpider 的问题是不完整的。让我们从性能测试的最佳例子开始,它在现实世界中不是很使用:[`bitops-bitwise-and.js` 性能测试][39]
|
||||
|
||||
[][40]
|
||||
|
||||
All of this is probably already known to a wider audience, so I’ll use the rest of this post to highlight a few concrete examples, why I think it’s not only useful, but crucial for the health of the JavaScript community to stop paying attention to static peak performance benchmarks above a certain threshold. So let me run you through a couple of example how JavaScript engines can and do game benchmarks.
|
||||
有一些算法需要快速的位运算,特别是从 C/C++ 转译成 JavaScript 的地方,所以它确实有一些意义,能够快速执行此操作.然而,现实世界的网页可能不关心引擎是否可以执行位运算,并且在循环中比另一个引擎快两倍.但是再盯着这段代码几秒钟,你可能会注意到在第一次循环迭代之后 `bitwiseAndValue` 将变成 `0`,并且在接下来的 599999 次迭代中将保持为 `0`。所以一旦你在此获得好的性能,即在体面的硬件上所有测试均低于 5ms,在经过尝试认识到只有循环的第一次是必要的,而剩余的迭代只是在浪费时间(例如 [loop peeling][41] 后面的死代码),你就可以用这个基准来测试游戏了。这需要 JavaScript 中的一些机制来执行这种转换,即你需要检查 `bitwiseAndValue` 是全局对象的常规属性还是在执行脚本之前不存在,全局对象必须没有拦截器,或者它的原型等等,但如果你真的想要赢得这个基准,并且你愿意全身心投入,那么你可以在不到 1ms 的时间内执行这个测试。然而,这种优化将局限于这种特殊情况,并且测试的轻微修改可能不再触发它。
|
||||
|
||||
### The notorious SunSpider examples
|
||||
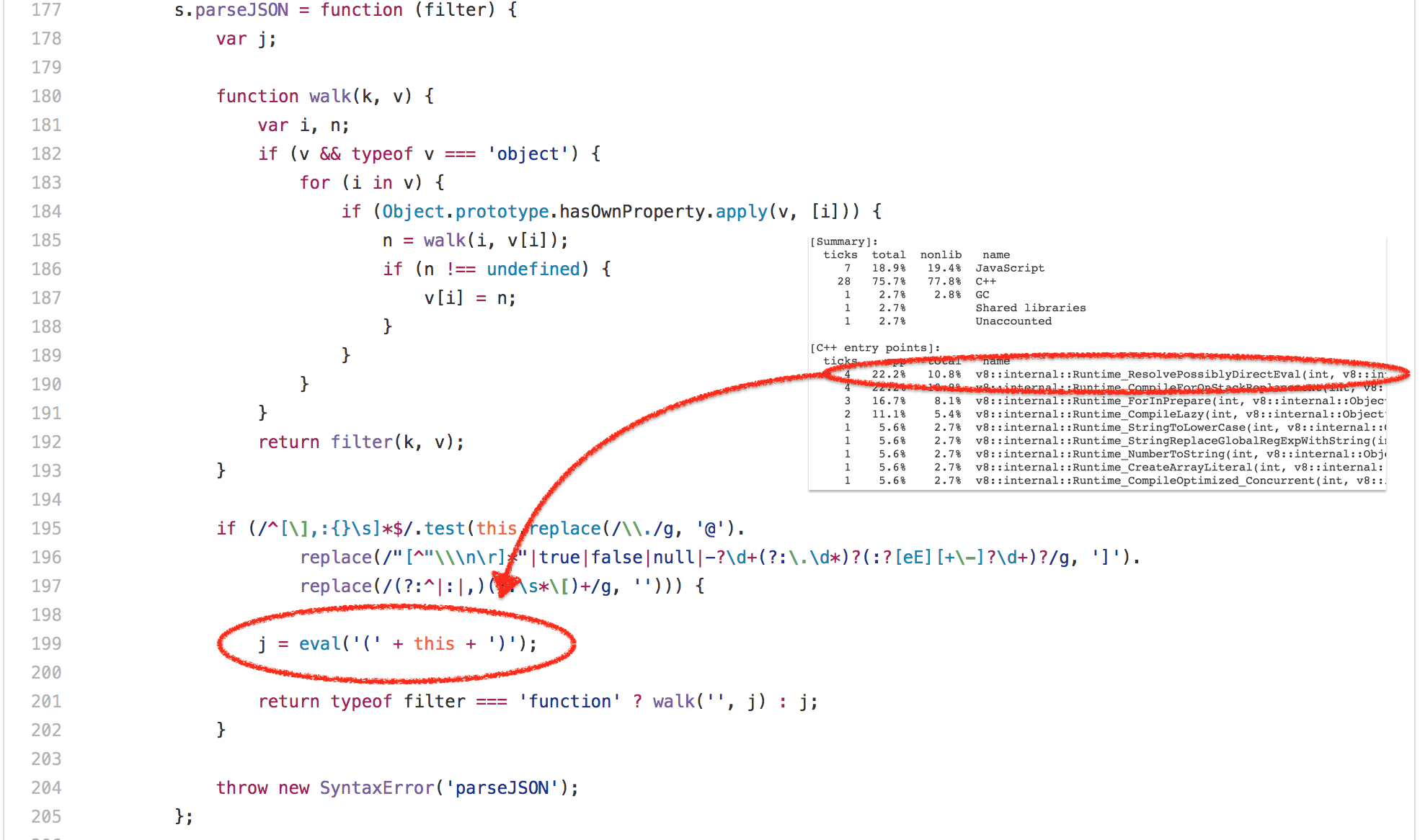
好的,那么 [`bitops-bitwise-and.js`][42] 测试彻底肯定是微基准最失败的案例。让我们继续转移到 SunSpider 中更真实的世界——[`string-tagcloud.js`][43] 测试,它基本上运行着一个较早版本的 `json.js` polyfill。该测试可以说看起来更合理,但是查看基准的配置之后立刻显示:大量的时间浪费在一条 `eval` 表达式(高达 20% 的总执行时间被用于解析和编译,再加上实际执行编译后代码的 10% 的时间)。
|
||||
|
||||
A blog post on traditional JavaScript benchmarks wouldn’t be complete without pointing out the obvious SunSpider problems. So let’s start with the prime example of performance test that has limited applicability in real world: The [`bitops-bitwise-and.js`][39] performance test.
|
||||
[][44]
|
||||
|
||||
[
|
||||

|
||||
][40]
|
||||
|
||||
There are a couple of algorithms that need fast bitwise and, especially in the area of code transpiled from C/C++ to JavaScript, so it does indeed make some sense to be able to perform this operation quickly. However real world web pages will probably not care whether an engine can execute bitwise and in a loop 2x faster than another engine. But staring at this code for another couple of seconds, you’ll probably notice that `bitwiseAndValue` will be `0` after the first loop iteration and will remain `0` for the next 599999 iterations. So once you get this to good performance, i.e. anything below 5ms on decent hardware, you can start gaming this benchmark by trying to recognize that only the first iteration of the loop is necessary, while the remaining iterations are a waste of time (i.e. dead code after [loop peeling][41]). This needs some machinery in JavaScript to perform this transformation, i.e. you need to check that `bitwiseAndValue` is either a regular property of the global object or not present before you execute the script, there must be no interceptor on the global object or it’s prototypes, etc., but if you really want to win this benchmark, and you are willing to go all in, then you can execute this test in less than 1ms. However this optimization would be limited to this special case, and slight modifications of the test would probably no longer trigger it.
|
||||
|
||||
Ok, so that [`bitops-bitwise-and.js`][42] test was definitely the worst example of a micro-benchmark. Let’s move on to something more real worldish in SunSpider, the [`string-tagcloud.js`][43] test, which essentially runs a very early version of the `json.js` polyfill. The test arguably looks a lot more reasonable that the bitwise and test, but looking at the profile of the benchmark for some time immediately reveals that a lot of time is spent on a single `eval` expression (up to 20% of the overall execution time for parsing and compiling plus up to 10% for actually executing the compiled code):
|
||||
|
||||
[
|
||||

|
||||
][44]
|
||||
|
||||
Looking closer reveals that this `eval` is executed exactly once, and is passed a JSONish string, that contains an array of 2501 objects with `tag` and `popularity` fields:
|
||||
仔细看看,这个 `eval` 只执行了一次,并传递一个 JSON 格式的字符串,它包含一个由 2501 个含有 `tag` 和 `popularity` 字段的对象组成的数组:
|
||||
|
||||
```
|
||||
([
|
||||
@ -95,7 +77,7 @@ Looking closer reveals that this `eval` is executed exactly once, and is passe
|
||||
])
|
||||
```
|
||||
|
||||
Obviously parsing these object literals, generating native code for it and then executing that code, comes at a high cost. It would be a lot cheaper to just parse the input string as JSON and generate an appropriate object graph. So one trick to speed up this benchmark is to mock with `eval` and try to always interpret the data as JSON first and only fallback to real parse, compile, execute if the attempt to read JSON failed (some additional magic is required to skip the parenthesis, though). Back in 2007, this wouldn’t even be a bad hack, since there was no [`JSON.parse`][45], but in 2017 this is just technical debt in the JavaScript engine and potentially slows down legit uses of `eval`. In fact updating the benchmark to modern JavaScript
|
||||
显然,解析这些对象字面量,为其生成本地代码,然后执行该代码的成本很高。将输入的字符串解析为 JSON 并生成适当的对象图的开销将更加低。所以,加快这个基准的一个窍门是模拟 `eval`,并尝试总是将数据首先作为 JSON 解析,然后再回溯到真实的解析、编译、执行,直到尝试读取 JSON 失败(尽管需要一些额外的魔法来跳过括号)。回到 2007 年,这甚至不算是一个坏的手段,因为没有 [`JSON.parse`][45],不过在 2017 年这只是 JavaScript 引擎的技术债,可能会放慢 `eval` 的合法使用。
|
||||
|
||||
```
|
||||
--- string-tagcloud.js.ORIG 2016-12-14 09:00:52.869887104 +0100
|
||||
@ -111,7 +93,7 @@ Obviously parsing these object literals, generating native code for it and then
|
||||
}
|
||||
```
|
||||
|
||||
yields an immediate performance boost, dropping runtime from 36ms to 26ms for V8 LKGR as of today, a 30% improvement!
|
||||
事实上,将基准测试更新到现代 JavaScript 会立刻提升性能,正如今天的 V8 LKGR 从 36ms 降到了 26ms,性能足足提升了 30%!
|
||||
|
||||
```
|
||||
$ node string-tagcloud.js.ORIG
|
||||
@ -123,85 +105,65 @@ v8.0.0-pre
|
||||
$
|
||||
```
|
||||
|
||||
This is a common problem with static benchmarks and performance test suites. Today noone would seriously use `eval` to parse JSON data (also for obvious security reaons, not only for the performance issues), but rather stick to [`JSON.parse`][46] for all code written in the last five years. In fact using `eval` to parse JSON would probably be considered a bug in production code today! So the engine writers effort of focusing on performance of newly written code is not reflected in this ancient benchmark, instead it would be beneficial to make `eval`unnecessarily ~~smart~~complex to win on `string-tagcloud.js`.
|
||||
这是静态基准测试和性能测试套件常见的一个问题。今天,没人会认真地使用 `eval` 来解析 JSON 数据(不仅是因为性能问题,还出于显著的安全性考虑),而是坚持为过去五年写的所有代码使用 [`JSON.parse`][46]。事实上,使用 `eval` 来解析 JSON 可能会被视作生产代码中的一个漏洞!所以引擎作者致力于关注新代码的性能没有反映在旧基准中,相反,使得 `eval` 在 `string-tagcloud.js` 中赢得不必要的复杂性是有益的。
|
||||
|
||||
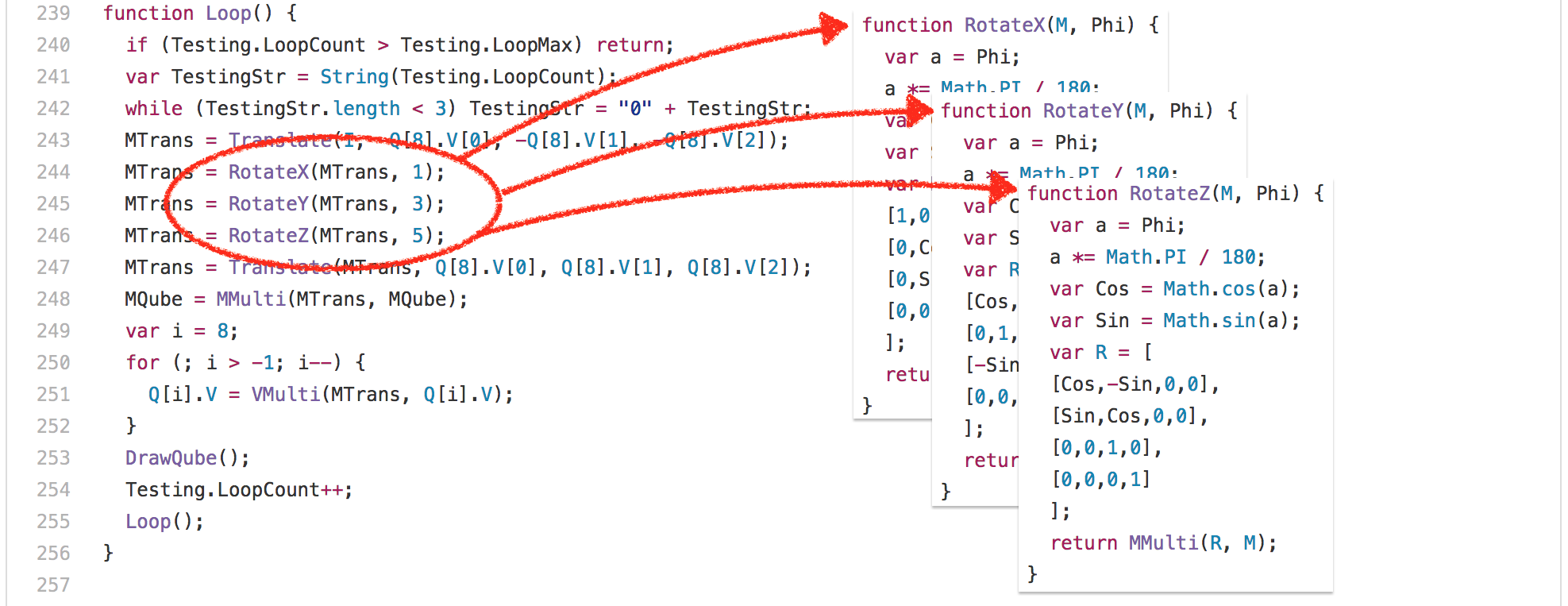
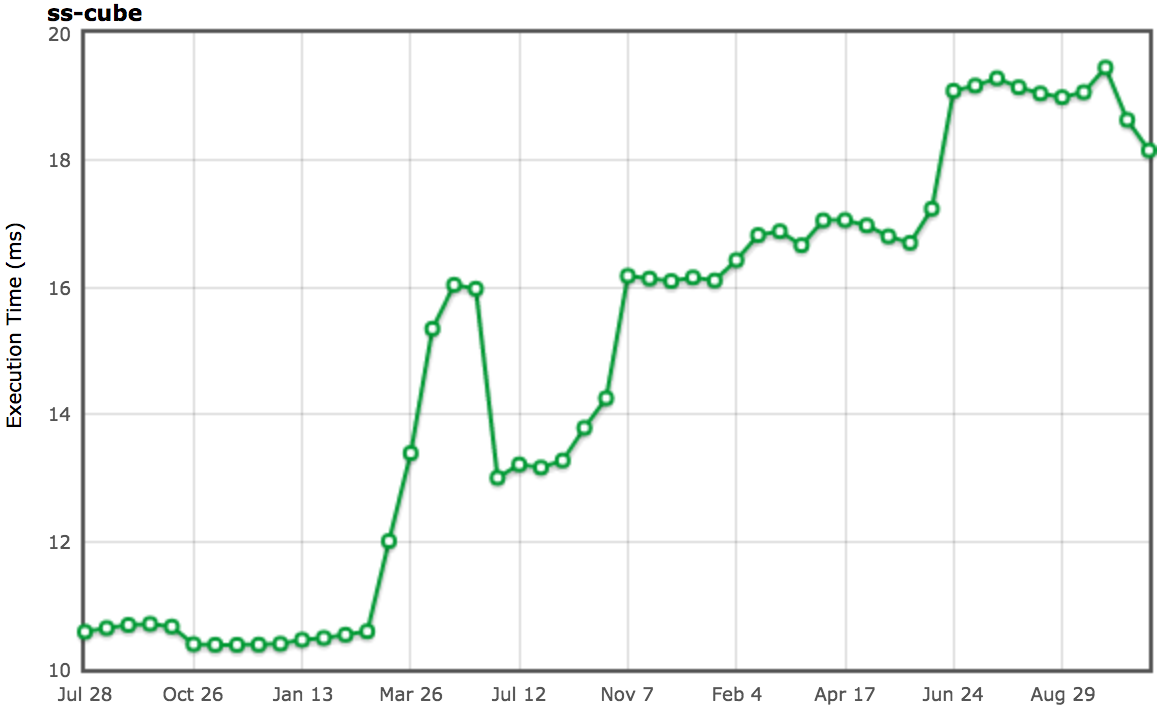
Ok, so let’s look at yet another example: the [`3d-cube.js`][47]. This benchmark does a lot of matrix operations, where even the smartest compiler can’t do a lot about it, but just has to execute it. Essentially the benchmark spends a lot of time executing the `Loop` function and functions called by it.
|
||||
好吧,让我们看看另一个例子:[`3d-cube.js`][47]。这个基准做了很多矩阵运算,即使最聪明的编译器都做不了很多,但只是必须要执行它。基本上,基准花了很多时间执行 `loop` 函数以及其调用的函数。
|
||||
|
||||
[
|
||||
|
||||
][48]
|
||||
[][48]
|
||||
|
||||
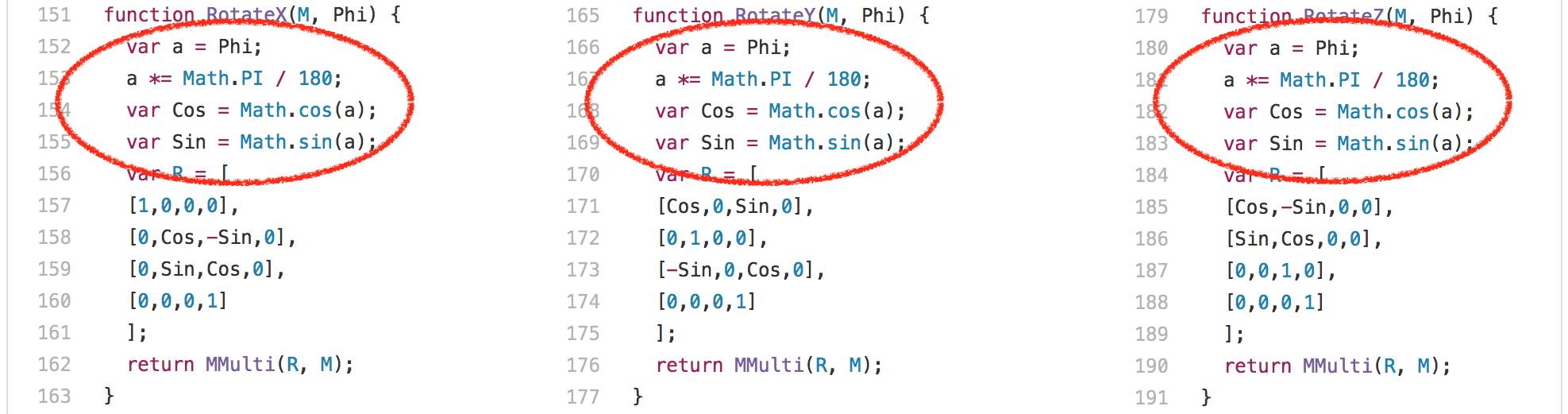
One interesting observation here is that the `RotateX`, `RotateY` and `RotateZ` functions are always called with the same constant parameter `Phi`.
|
||||
一个有趣的发现是:`RotateX`、`RotateY` 和 `RotateZ` 函数总是使用相同的常量参数 `Phi`。
|
||||
|
||||
[
|
||||
|
||||
][49]
|
||||
[][49]
|
||||
|
||||
This means that we basically always compute the same values for [`Math.sin`][50] and [`Math.cos`][51], 204 times each. There are only three different inputs,
|
||||
这意味着我们基本上总是计算 [`Math.sin`][50] 和 [`Math.cos`][51] 的相同值,每次执行都要计算 204 次。只有 3 个不同的输入值:
|
||||
|
||||
* 0.017453292519943295,
|
||||
* 0.05235987755982989, and
|
||||
* 0.08726646259971647
|
||||
* 0.017453292519943295,
|
||||
* 0.05235987755982989,
|
||||
* 以及 0.08726646259971647
|
||||
|
||||
obviously. So, one thing you could do here to avoid recomputing the same sine and cosine values all the time is to cache the previously computed values, and in fact, that’s what V8 used to do in the past, and other engines like SpiderMonkey still do. We removed the so-called _transcendental cache_ from V8 because the overhead of the cache was noticable in actual workloads where you don’t always compute the same values in a row, which is unsurprisingly very common in the wild. We took serious hits on the SunSpider benchmark when we removed this benchmark specific optimizations back in 2013 and 2014, but we totally believe that it doesn’t make sense to optimize for a benchmark while at the same time penalizing the real world use case in such a way.
|
||||
显然,这里你可以做的一件事就是通过缓存先前的计算值来避免重复计算相同的正弦值和余弦值。事实上,这是 V8 以前的做法,而其它引擎例如 SpiderMonkey 仍然这样做。我们从 V8 中删除了所谓的超载缓存,因为缓存的开销在实际工作负载中是不可忽视的,你不总是在一行中计算相同的值,这在其它地方倒不稀奇。当我们在 2013 和 2014 年移除这个基准特定的优化时,我们对 SunSpider 基准产生了强烈的冲击,但我们完全相信,优化基准并没有意义,同时以这种方式批判真实使用案例。
|
||||
|
||||
[
|
||||
|
||||
][52]
|
||||
[][52]
|
||||
|
||||
显然,处理恒定正弦/余弦输入的更好方法是一个内联的启发式计算,它试图平衡内联因素并考虑到其它不同因素,例如在调用位置处优先选择内联,其中恒定折叠可能是有益的,例如在 `RotateX`、`RotateY` 和 `RotateZ` 调用网站。但是出于各种原因这对于 Crankshaft 编译器并不真的是可行的。使用 Ignition 和 TurboFan 将是一个明智的选择,我们已经在做更好的 [内联启发式计算][53]。
|
||||
|
||||
Obviously a better way to deal with the constant sine/cosine inputs is a sane inlining heuristic that tries to balance inlining and take into account different factors like prefer inlining at call sites where constant folding can be beneficial, like in case of the `RotateX`, `RotateY`, and `RotateZ` call sites. But this was not really possible with the Crankshaft compiler for various reasons. With Ignition and TurboFan, this becomes a sensible option, and we are already working on better [inlining heuristics][53].
|
||||
### 垃圾回收是有害的
|
||||
|
||||
### Garbage collection considered harmful
|
||||
除了这些非常特定的测试问题,SunSpider 还有另一个根本的问题:总体执行时间。V8 在体面的英特尔硬件上运行整个基准测试目前大概只需要 200ms(使用默认配置)。次要的 GC 在 1ms 到 25ms 之间(取决于新空间中的活对象和旧空间的碎片),而主 GC 暂停可以浪费 30ms(甚至不考虑增量标记的开销),这超过了 SunSpider 总体运行时间的 10%!因此,任何不想承受由于 GC 循环而造成 10-20% 的减速的引擎,必须以某种方式确保它在运行 SunSpider 时不会触发 GC。
|
||||
|
||||
Besides these very test specific issues, there’s another fundamental problem with the SunSpider benchmark: The overall execution time. V8 on decent Intel hardware runs the whole benchmark in roughly 200ms currently (with the default configuration). A minor GC can take anything between 1ms and 25ms currently (depending on live objects in new space and old space fragmentation), while a major GC pause can easily take 30ms (not even taking into account the overhead from incremental marking), that’s more than 10% of the overall execution time of the whole SunSpider suite! So any engine that doesn’t want to risk a 10-20% slowdown due to a GC cycle has to somehow ensure it doesn’t trigger GC while running SunSpider.
|
||||
[][54]
|
||||
|
||||
[
|
||||

|
||||
][54]
|
||||
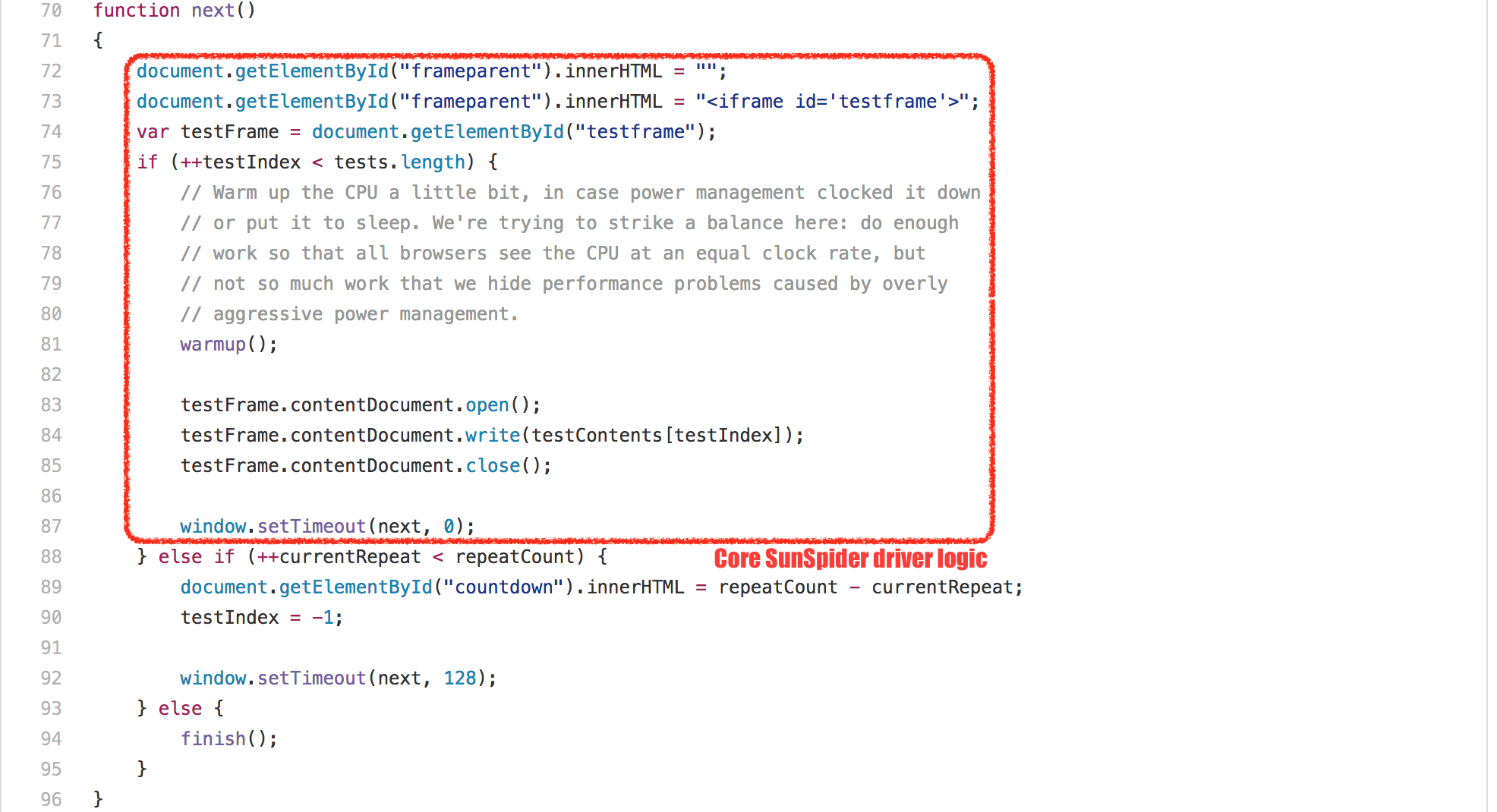
有不同的技巧来实现这个想法,不过就我所知,没有一个在现实世界中有任何积极的影响。V8 使用了一个相当简单的技巧:由于每个 SunSpider 测试运行在一个新的 `<iframe>` 中,这对应于 V8 中一个新的本地上下文,我们只需检测快速的 `<iframe>` 创建和处理(所有的 SunSpider 测试花费的时间小于 50ms),在这种情况下,在处理和创建之间执行垃圾回收,以确保我们不会触发 GC,而实际运行测试。这个技巧很好,99.9% 的情况下不会与真正的用途冲突;除了每一个非常时刻,它可以给你强烈冲击,如果无论什么原因,你做的东西,让你看起来像是 V8 的 SunSpider 测试驱动者,然后你就可以得到强制 GC 的强烈冲击,这对你的应用可能会有负面影响。所以紧记一点:**不要让你的应用看起来像 SunSpider!**
|
||||
|
||||
There are different tricks to accomplish this, none of which has any positive impact in real world as far as I can tell. V8 uses a rather simple trick: Since every SunSpider test is run in a new `<iframe>`, which corresponds to a new _native context_ in V8 speak, we just detect rapid `<iframe>` creation and disposal (all SunSpider tests take less than 50ms each), and in that case perform a garbage collection between the disposal and creation, to ensure that we never trigger a GC while actually running a test. This trick works pretty well, and in 99.9% of the cases doesn’t clash with real uses; except every now and then, it can hit you hard if for whatever reason you do something that makes you look like you are the SunSpider test driver to V8, then you can get hit hard by forced GCs, and that can have a negative effect on your application. So rule of thumb: **Don’t let your application look like SunSpider!**
|
||||
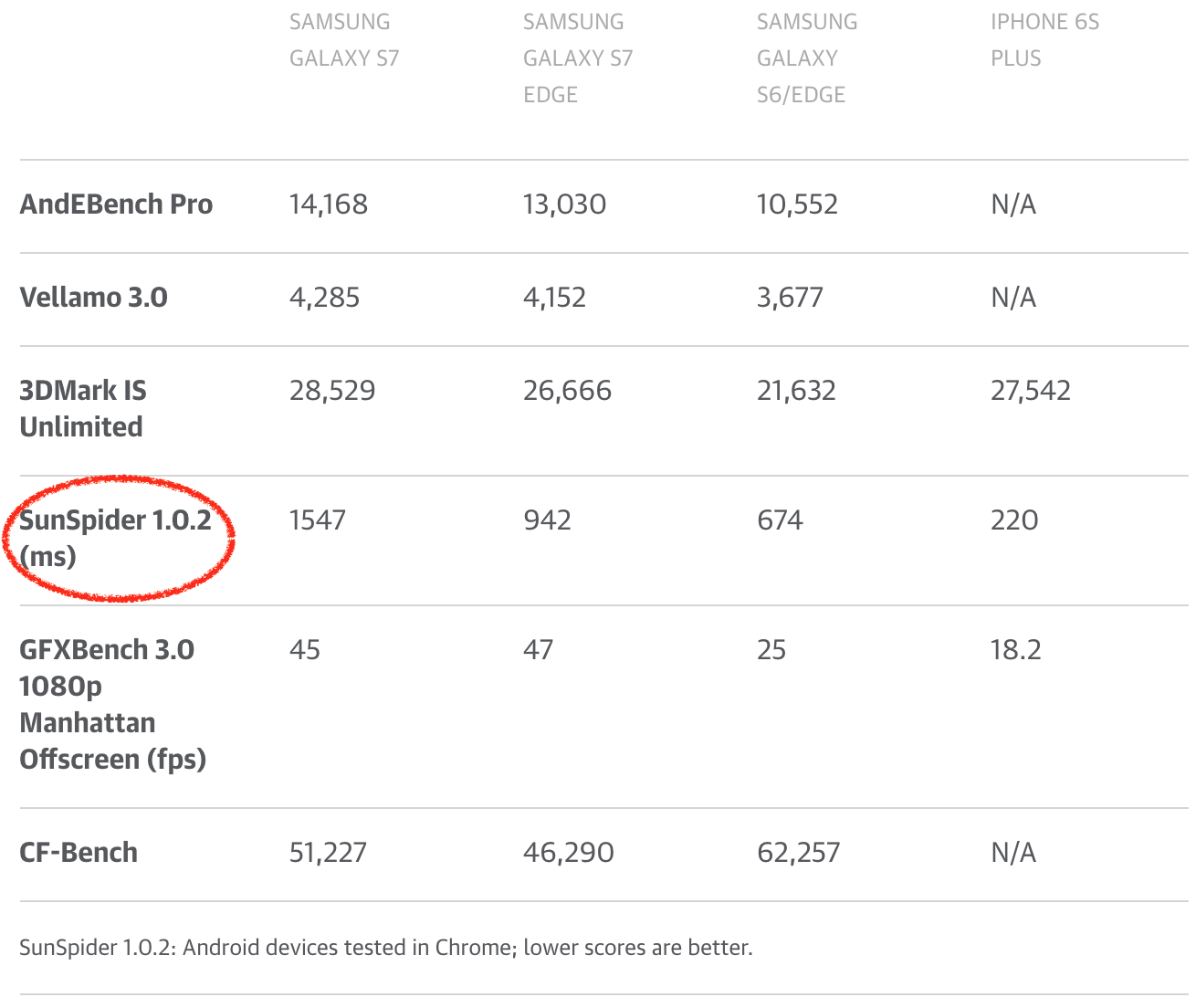
我可以继续展示更多的 SunSpider 示例,但我不认为这非常有用。到目前为止,应该清楚的是,对于 SunSpider 的进一步优化,超过良好性能的阔值将不会反映真实世界的任何好处。事实上,世界可能会从 SunSpider 消失中受益,因为引擎可以放弃只是用于 SunSpider 的奇淫技巧,甚至可以伤害到真实用例。不幸的是,SunSpider 仍然被(科技)媒体大量使用来比较他们所认为的浏览器性能,或者甚至用来比较收集!所以手机制造商和安卓制造商对于让 SunSpider(以及其它现在毫无意义的基准 FWIW) 上的 Chrome 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 SunSpider 中得分较高的旧版 V8,向他们的用户展示各种未修复的安全漏洞(在新版中早已被修复),并保护用户免受最新版本的 V8 的任何真实世界的性能优势!
|
||||
|
||||
I could go on with more SunSpider examples here, but I don’t think that’d be very useful. By now it should be clear that optimizing further for SunSpider above the threshold of good performance will not reflect any benefits in real world. In fact the world would probably benefit a lot from not having SunSpider any more, as engines could drop weird hacks that are only useful for SunSpider and can even hurt real world use cases. Unfortunately SunSpider is still being used heavily by the (tech) press to compare what they think is browser performance, or even worse compare phones! So there’s a certain natural interest from phone makers and also from Android in general to have Chrome look somewhat decent on SunSpider (and other nowadays meaningless benchmarks FWIW). The phone makers generate money by selling phones, so getting good reviews is crucial for the success of the phone division or even the whole company, and some of them even went as far as shipping old versions of V8 in their phones that had a higher score on SunSpider, exposing their users to all kinds of unpatched security holes that had long been fixed, and shielding their users from any real world performance benefits that come with more recent V8 versions!
|
||||
[][55]
|
||||
|
||||
[
|
||||

|
||||
][55]
|
||||
作为 JavaScript 社区的一员,如果我们真的想认真对待 JavaScript 领域的真实世界性能,我们需要使技术新闻停止使用传统的 JavaScript 基准来比较浏览器或手机。我看到有一个好处是能够在每个浏览器中运行一个基准,并比较它的数量,但是请使用一个基准与今天的事物是相关的,例如真实的 web 页面;如果你觉得需要通过浏览器基准来比较两部手机,请至少考虑使用 [Speedometer][56]。
|
||||
|
||||
### 轻松一刻
|
||||
|
||||
If we as the JavaScript community really want to be serious about real world performance in JavaScript land, we need to make the tech press stop using traditional JavaScript benchmarks to compare browsers or phones. I see that there’s a benefit in being able to just run a benchmark in each browser and compare the number that comes out of it, but then please, please use a benchmark that has something in common with what is relevant today, i.e. real world web pages; if you feel the need to compare two phones via a browser benchmark, please at least consider using [Speedometer][56].
|
||||

|
||||
|
||||
### Cuteness break!
|
||||
我总是喜欢这个在 [Myles Borins][57] 的谈话,所以我不得不无情地偷取了他的想法。所以现在我们从 SunSpider 的咆哮中回过头来,让我们继续检查其它经典基准。
|
||||
|
||||
### 不是那么明显的 Kraken 案例
|
||||
|
||||

|
||||
Kraken 基准是 [Mozilla 于 2010 年 9 月 发布的][58],据说它包含了真实世界应用的片段/内核,并且与 SunSpider 相比少了一个微基准。我不想花太多时间在 Kraken 上,因为我认为它不像 SunSpider 和 Octane 一样对 JavaScript 性能有着深远的影响,所以我将强调一个特别的案例——[`audio-oscillator.js`][59] 测试。
|
||||
|
||||
[][60]
|
||||
|
||||
I always loved this in [Myles Borins][57]’ talks, so I had to shamelessly steal his idea. So now that we recovered from the SunSpider rant, let’s go on to check the other classic benchmarks…
|
||||
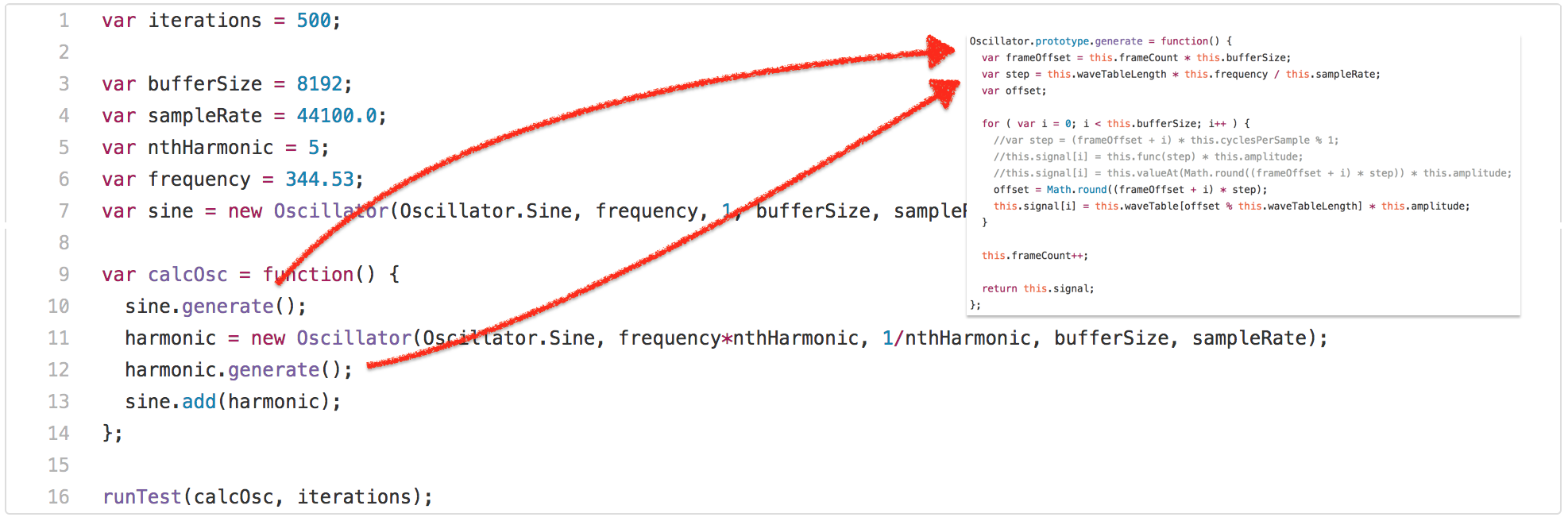
正如你所见,测试调用 `calcOsc` 函数 500 次。`calcOsc` 首先在全局的正弦 `Oscillator` 上调用 `generate`,然后创建一个新的 `Oscillator`,调用 `generate` 并将其添加到全局正弦的振荡器。没有详细说明测试为什么是这样做的,让我们看看 `Oscillator` 原型上的 `generate` 方法。
|
||||
|
||||
### The not so obvious Kraken case
|
||||
[][61]
|
||||
|
||||
The Kraken benchmark was [released by Mozilla in September 2010][58], and it was said to contain snippets/kernels of real world applications, and be less of a micro-benchmark compared to SunSpider. I don’t want to spend too much time on Kraken, because I think it wasn’t as influential on JavaScript performance as SunSpider and Octane, so I’ll highlight one particular example from the [`audio-oscillator.js`][59] test.
|
||||
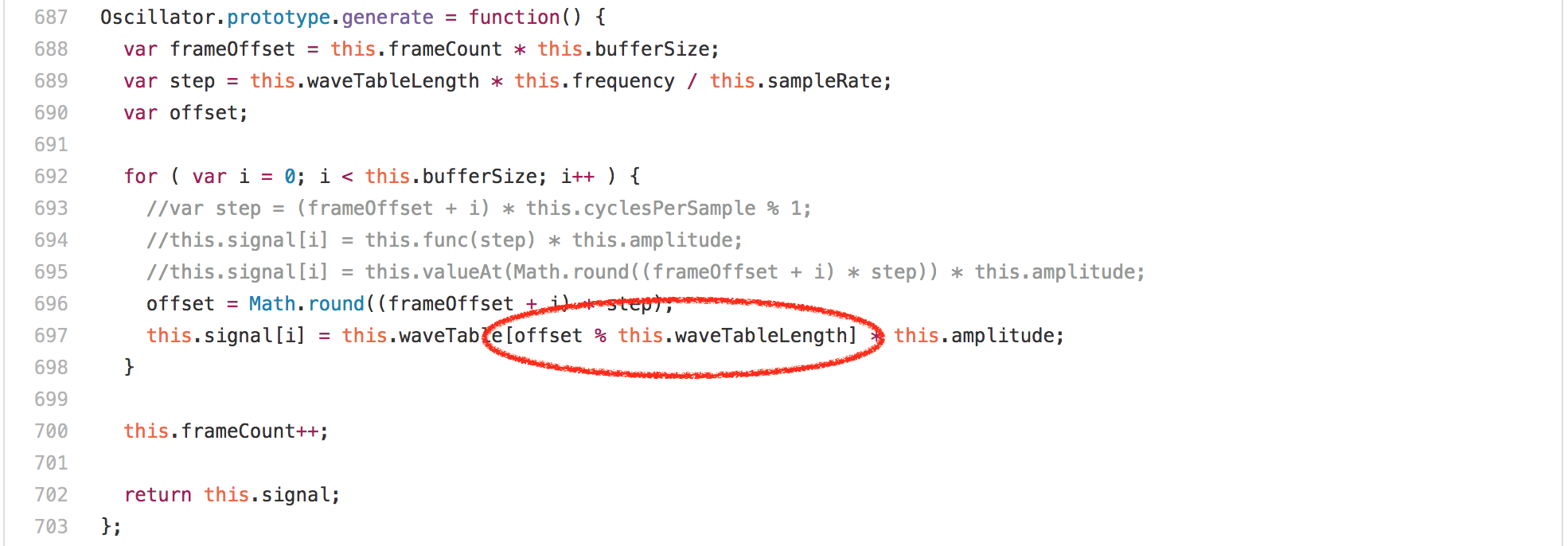
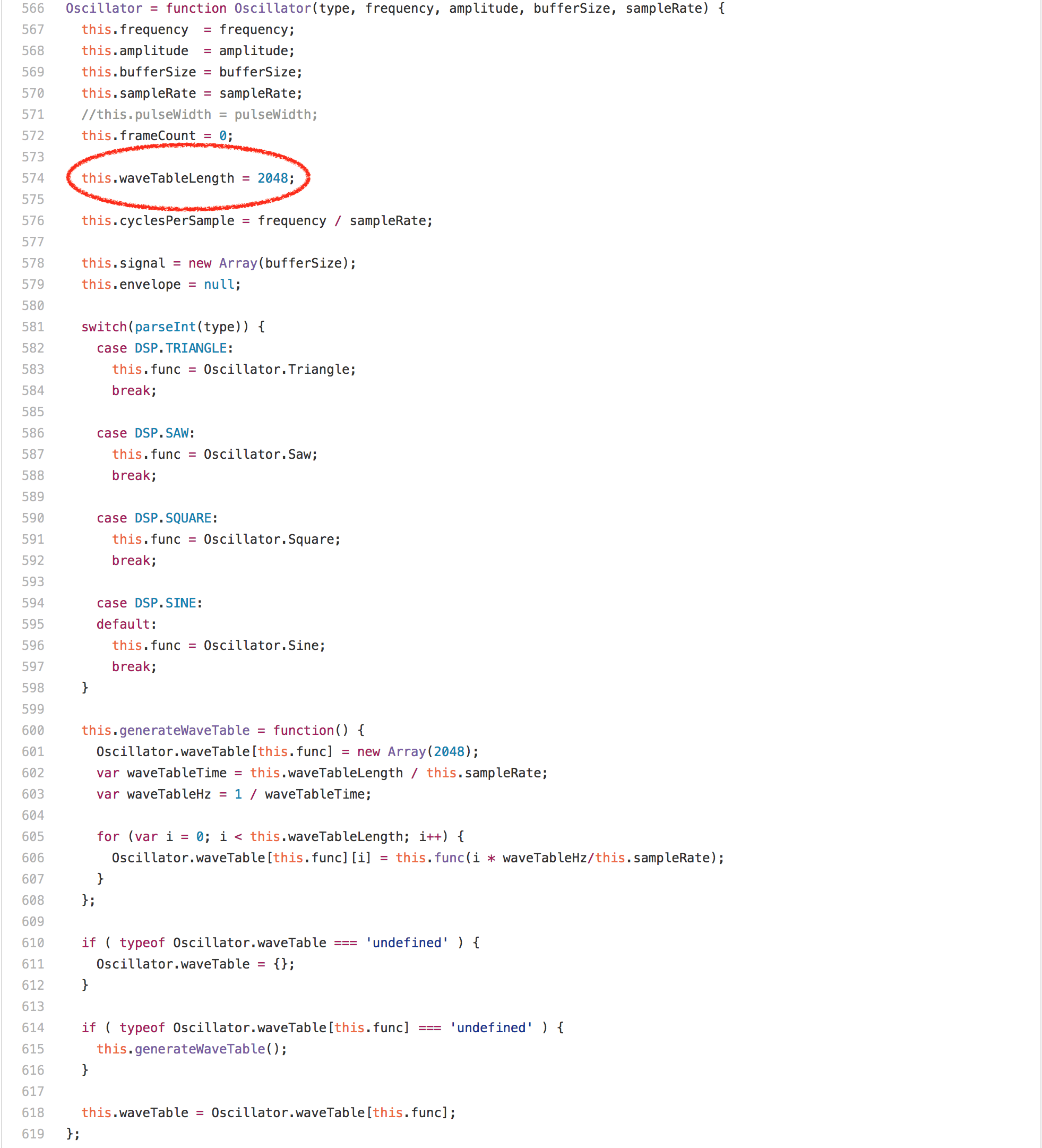
看看代码,你会期望这被数组访问或乘法循环中的 [`Math.round`][62] 调用所主导,但令人惊讶的是 `offset % this.waveTableLength` 表达式完全支配了 `Oscillator.prototype.generate` 的运行时。在任何的英特尔机器上的分析器中运行此基准测试显示,超过 20% 的通过都归功于我们为模数生成的 `idiv` 指令。然而一个有趣的发现是,`Oscillator` 实例的 `waveTableLength` 字段总是包含相同的值——2048,因为它在 `Oscillator` 构造器中只分配一次。
|
||||
|
||||
[
|
||||

|
||||
][60]
|
||||
[][63]
|
||||
|
||||
So the test invokes the `calcOsc` function 500 times. `calcOsc` first calls `generate` on the global `sine``Oscillator`, then creates a new `Oscillator`, calls `generate` on that and adds it to the global `sine` oscillator. Without going into detail why the test is doing this, let’s have a look at the `generate` method on the `Oscillator` prototype.
|
||||
如果我们知道整数模数运算的右边是 2 的幂,我们可以生成[更好的代码][64],显然完全避免了英特尔上的 `idiv` 指令。所以我们需要的是一个方法来获取信息,从 `Oscillator` 构造器到 `Oscillator.prototype.generate` 中的模运算,`this.waveTableLength` 的值总是 2048。一个显而易见的方法是尝试依赖内联的一切进入 `calcOsc` 函数,并让 load/store 消除为我们的常数传播,但这不会为正弦振荡器工作,这只是分配在 `calcOsc` 函数。
|
||||
|
||||
[
|
||||

|
||||
][61]
|
||||
|
||||
Looking at the code, you’d expect this to be dominated by the array accesses or the multiplications or the[`Math.round`][62] calls in the loop, but surprisingly what’s completely dominating the runtime of `Oscillator.prototype.generate` is the `offset % this.waveTableLength` expression. Running this benchmark in a profiler on any Intel machine reveals that more than 20% of the ticks are attributed to the `idiv`instruction that we generate for the modulus. One interesting observation however is that the `waveTableLength` field of the `Oscillator` instances always contains the same value 2048, as it’s only assigned once in the `Oscillator` constructor.
|
||||
|
||||
[
|
||||

|
||||
][63]
|
||||
|
||||
If we know that the right hand side of an integer modulus operation is a power of two, we can generate [way better code][64] obviously and completely avoid the `idiv` instruction on Intel. So what we needed was a way to get the information that `this.waveTableLength` is always 2048 from the `Oscillator` constructor to the modulus operation in `Oscillator.prototype.generate`. One obvious way would be to try to rely on inlining of everything into the `calcOsc` function and let load/store elimination do the constant propagation for us, but this would not work for the `sine` oscillator, which is allocated outside the `calcOsc` function.
|
||||
|
||||
So what we did instead is add support for tracking certain constant values as right-hand side feedback for the modulus operator. This does make some sense in V8, since we track type feedback for binary operations like `+`, `*` and `%` on uses, which means the operator tracks the types of inputs it has seen and the types of outputs that were produced (see the slides from the round table talk on [Fast arithmetic for dynamic languages][65]recently for some details). Hooking this up with fullcodegen and Crankshaft was even fairly easy back then, the `BinaryOpIC` for `MOD` can also track known power of two right hand sides. In fact running the default configuration of V8 (with Crankshaft and fullcodegen)
|
||||
因此,我们做的是添加支持跟踪某些常数值作为模运算符的右侧反馈。这在 V8 中是有意义的,因为我们为诸如 `+`、`*` 和 `%` 的二进制操作跟踪类型反馈,这意味着操作者跟踪输入的类型和产生的输出类型(参见最近圆桌讨论关于 [动态语言的快速运算][65] 的幻灯片)。当然,用 fullcodegen 和 Crankshaft 挂接起来也是相当容易的,`MOD` 的 `BinaryOpIC` 也可以跟踪两个右边的已知权。
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
@ -211,7 +173,7 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
$
|
||||
```
|
||||
|
||||
shows that the `BinaryOpIC` is picking up the proper constant feedback for the right hand side of the modulus, and properly tracks that the left hand side was always a small integer (a `Smi` in V8 speak), and we also always produced a small integer result. Looking at the generated code using `--print-opt-code --code-comments` quickly reveals that Crankshaft utilizes the feedback to generate an efficient code sequence for the integer modulus in `Oscillator.prototype.generate`:
|
||||
实际上运行默认配置的 V8(的 Crankshaft 和 fullcodegen)显示 `BinaryOpIC` 正在为模数的右侧拾取恰当的恒定反馈,并且正确地跟踪左手边总是一个小整数(V8 中的 `Smi`),我们也总是生成一个小的整数结果。查看生成的代码使用 `--print-opt-code --code-comments` 快速显示,Crankshaft 利用反馈在 `Oscillator.prototype.generate` 中生成一个高效的代码序列的整数模数:
|
||||
|
||||
```
|
||||
[...SNIP...]
|
||||
@ -235,11 +197,11 @@ shows that the `BinaryOpIC` is picking up the proper constant feedback for the
|
||||
[...SNIP...]
|
||||
```
|
||||
|
||||
So you see we load the value of `this.waveTableLength` (`rbx` holds the `this` reference), check that it’s still 2048 (hexadecimal 0x800), and if so just perform a bitwise and with the proper bitmask 0x7ff (`r11` contains the value of the loop induction variable `i`) instead of using the `idiv` instruction (paying proper attention to preserve the sign of the left hand side).
|
||||
所以你看到我们加载 `this.waveTableLength`(`rbx` 持有 `this` 的引用)的值,检查它仍然是 2048(十六进制的 0x800),如果是这样,只是执行一个位和适当的掩码 0x7ff(`r11` 包含循环感应变量 `i` 的值),而不是使用 `idiv` 指令(注意保留左侧的符号)。
|
||||
|
||||
### The over-specialization issue
|
||||
### 过度专业化的问题
|
||||
|
||||
So this trick is pretty damn cool, but as with many benchmark focused tricks, it has one major drawback: It’s over-specialized! As soon as the right hand side ever changes, all optimized code will have to be deoptimized (as the assumption that the right hand is always a certain power of two no longer holds) and any further optimization attempts will have to use `idiv` again, as the `BinaryOpIC` will most likely report feedback in the form `Smi*Smi->Smi` then. For example, let’s assume we instantiate another `Oscillator`, set a different`waveTableLength` on it, and call `generate` for the oscillator, then we’d lose 20% performance even though the actually interesting `Oscillator`s are not affected (i.e. the engine does non-local penalization here).
|
||||
所以这个技巧酷毙了,但正如许多基准关注的技巧都有一个主要的缺点:太过于专业了!一旦右手侧发生变化,所有优化过的代码需要重新优化(假设右手始终是两个不再拥有的权),任何进一步的优化尝试都必须再次使用 `idiv`,因为 `BinaryOpIC` 很可能以 `Smi * Smi -> Smi` 的形式报告反馈。例如,假设我们实例化另一个 `Oscillator`,在其上设置不同的 `waveTableLength`,并为振荡器调用 `generate`,那么即使实际上有趣的 `Oscillator` 不受影响,我们也会损失 20% 的性能(例如,引擎在这里实行非局部惩罚)。
|
||||
|
||||
```
|
||||
--- audio-oscillator.js.ORIG 2016-12-15 22:01:43.897033156 +0100
|
||||
@ -256,7 +218,7 @@ So this trick is pretty damn cool, but as with many benchmark focused tricks, it
|
||||
sine.generate();
|
||||
```
|
||||
|
||||
Comparing the execution times of the original `audio-oscillator.js` and the version that contains an additional unused `Oscillator` instance with a modified `waveTableLength` shows the expected results:
|
||||
将原始的 `audio-oscillator.js` 的执行时间与包含额外未使用的 `Oscillator` 实例与修改的 `waveTableLength` 的版本进行比较,可以显示预期的结果:
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
|
||||
@ -266,9 +228,9 @@ Time (audio-oscillator-once): 81 ms.
|
||||
$
|
||||
```
|
||||
|
||||
This is an example for a pretty terrible performance cliff: Let’s say a developer writes code for a library and does careful tweaking and optimizations using certain sample input values, and the performance is decent. Now a user starts using that library reading through the performance notes, but somehow falls off the performance cliff, because she/he is using the library in a slightly different way, i.e. somehow polluting type feedback for a certain `BinaryOpIC`, and is hit by a 20% slowdown (compared to the measurements of the library author) that neither the library author nor the user can explain, and that seems rather arbitrary.
|
||||
这是一个非常可怕的性能悬崖的例子:让我们说开发人员为库编写代码,并使用某些样本输入值进行仔细的调整和优化,性能是体面的。现在,用户开始使用该库读取性能笔记,但不知何故从性能悬崖下降,因为她/他正在以一种稍微不同的方式使用库,即以某种方式污染某个 `BinaryOpIC` 的类型反馈,并且受到减速 20% 的打击(与该库作者的测量相比),该库的作者和用户都无法解释,这似乎是任意的。
|
||||
|
||||
Now this is not uncommon in JavaScript land, and unfortunately quite a couple of these cliffs are just unavoidable, because they are due to the fact that JavaScript performance is based on optimistic assumptions and speculation. We have been spending **a lot** of time and energy trying to come up with ways to avoid these performance cliffs, and still provide (nearly) the same performance. As it turns out it makes a lot of sense to avoid `idiv` whenever possible, even if you don’t necessarily know that the right hand side is always a power of two (via dynamic feedback), so what TurboFan does is different from Crankshaft, in that it always checks at runtime whether the input is a power of two, so general case for signed integer modulus, with optimization for (unknown) power of two right hand side looks like this (in pseudo code):
|
||||
现在这在 JavaScript 的领域并不少见,不幸的是,这些悬崖中有几个是不可避免的,因为它们是由于 JavaScript 的性能是基于乐观的假设和猜测的事实。我们已经花了 **很多** 时间和精力来试图找到避免这些性能悬崖的方法,并且仍然提供(几乎)相同的性能。事实证明,尽可能避免 `idiv`,即使你不一定知道右边总是一个 2 的幂(通过动态反馈),所以为什么 TurboFan 的做法有异于 Crankshaft 的做法,因为它总是在运行时检查输入是否是 2 的幂,所以一般情况下,对于有符整数模数,优化两个右手侧的(未知)权看起来像这样(在伪代码中):
|
||||
|
||||
```
|
||||
if 0 < rhs then
|
||||
@ -287,7 +249,7 @@ else
|
||||
zero
|
||||
```
|
||||
|
||||
And that leads to a lot more consistent and predictable performance (with TurboFan):
|
||||
这导致更加一致的和可预测的性能(与 TurboFan):
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
|
||||
@ -297,21 +259,21 @@ Time (audio-oscillator-once): 69 ms.
|
||||
$
|
||||
```
|
||||
|
||||
The problem with benchmarks and over-specialization is that the benchmark can give you hints where to look and what to do, but it doesn’t tell you how far you have to go and doesn’t protect the optimization properly. For example, all JavaScript engines use benchmarks as a way to guard against performance regressions, but running Kraken for example wouldn’t protect the general approach that we have in TurboFan, i.e. we could _degrade_ the modulus optimization in TurboFan to the over-specialized version of Crankshaft and the benchmark wouldn’t tell us that we regressed, because from the point of view of the benchmark it’s fine! Now you could extend the benchmark, maybe in the same way that I did above, and try to cover everything with benchmarks, which is what engine implementors do to a certain extent, but that approach doesn’t scale arbitrarily. Even though benchmarks are convenient and easy to use for communication and competition, you’ll also need to leave space for common sense, otherwise over-specialization will dominate everything and you’ll have a really, really fine line of acceptable performance and big performance cliffs.
|
||||
基准和过度专业化的问题是,基准可以给你提示在哪里看和做什么,但它不告诉你你要走多元,不能正确保护优化。例如,所有 JavaScript 引擎都使用基准来防止性能下降,但是运行 Kraken 不能保护我们在 TurboFan 中的一般方法,即我们可以将 TurboFan 中的模优化降级到过度专业版本的 Crankshaft,而基准不会告诉我们却在倒退的事实,因为从基准的角度来看这很好!现在你可以扩展基准,也许以上面我们做的相同的方式,并试图用基准覆盖一切,这是引擎实现者在一定程度上做的事情,但这种方法不会任意缩放。即使基准测试方便,易于用来沟通和竞争,以常识所见你还是需要留下空间,否则过度专业化将支配一切,你会有一个真正的、可接受的、巨大的性能悬崖线。
|
||||
|
||||
There are various other issues with the Kraken tests, but let’s move on the probably most influential JavaScript benchmark of the last five years… the Octane benchmark.
|
||||
Kraken 测试还有许多其它的问题,不过现在让我们继续讨论过去五年中最有影响力的 JavaScript 基准测试—— Octane 测试。
|
||||
|
||||
### A closer look at Octane
|
||||
### 仔细看看 Octane
|
||||
|
||||
The [Octane benchmark][66] is the successor of the V8 benchmark and was initially [announced by Google in mid 2012][67] and the current version Octane 2.0 was [announced in late 2013][68]. This version contains 15 individual tests, where for two of them - Splay and Mandreel - we measure both the throughput and the latency. These tests range from [Microsofts TypeScript compiler][69] compiling itself, to raw [asm.js][70] performance being measured by the zlib test, to a performance test for the RegExp engine, to a ray tracer, to a full 2D physics engine, etc. See the [description][71] for a detailed overview of the individual benchmark line items. All these line items were carefully chosen to reflect a certain aspect of JavaScript performance that we considered important in 2012 or expected to become important in the near future.
|
||||
[Octane][66] 基准是 V8 基准的继承者,最初[由谷歌于 2012 年中期发布][67],目前的版本 Octane 2.0 [与 2013 年年底发布][68]。这个版本包含 15 个独立测试,其中对于 Splay 和 Mandreel,我们用来测试吞吐量和延迟。这些测试范围从 [微软 TypeScript 编译器][69] 编译自身到 zlib 测试测量原生的 [asm.js][70] 性能,再到 RegExp 引擎的性能测试、光线追踪器、2D 物理引擎等。有关各个基准测试项的详细概述,请参阅[说明书][71]。所有这些测试项目都经过仔细的筛选,以反映 JavaScript 性能的方方面面,我们认为这在 2012 年非常重要,或许预计在不久的将来会变得更加重要。
|
||||
|
||||
To a large extent Octane was super successful in achieving its goals of taking JavaScript performance to the next level, it resulted in a healthy competition in 2012 and 2013 where great performance achievements were driven by Octane. But it’s almost 2017 now, and the world looks fairly different than in 2012, really, really different actually. Besides the usual and often cited criticism that most items in Octane are essentially outdated (i.e. ancient versions of TypeScript, zlib being compiled via an ancient version of [Emscripten][72], Mandreel not even being available anymore, etc.), something way more important affects Octanes usefulness:
|
||||
在很大程度上 Octane 在实现其将 JavaScript 性能提高到更高水平的目标方面无比成功,它在 2012 年和 2013 年引导了良性的竞争,Octane 带来了巨大的业绩的成就。但是现在几乎是 2017 年,世界看起来与 2012 年真的迥然不同了。除了通常的和经常引用的批评,Octane 中的大多数项目基本上已经过时(例如,老版本的 TypeScript,zlib 通过老版本的 [Emscripten][72] 编译而成,Mandreel 甚至不再可用等等),某种更重要的方式影响了 Octane 的用途:
|
||||
|
||||
We saw big web frameworks winning the race on the web, especially heavy frameworks like [Ember][73] and [AngularJS][74], that use patterns of JavaScript execution, which are not reflected at all by Octane and are often hurt by (our) Octane specific optimizations. We also saw JavaScript winning on the server and tooling front, which means there are large scale JavaScript applications that now often run for weeks if not years, which also not captured by Octane. As stated in the beginning we have hard data that suggests that the execution and memory profile of Octane is completely different than what we see on the web daily.
|
||||
我们看到大型 web 框架赢得了 web 种族之争,尤其是像 [Ember][73] 和 [AngularJS][74] 这样的重型框架,它们使用了 JavaScript 执行模式,不过根本没有被 Octane 所反映,并且经常受到(我们)Octane 具体优化的损害。我们还看到 JavaScript 在服务器和工具前端获胜,这意味着有大规模的 JavaScript 应用现在通常运行上数星期,如果不是运行上数年都不会被 Octane 捕获。正如开篇所述,我们有硬数据表明 Octane 的执行和内存配置文件与我们每天在 web 上看到的截然不同。
|
||||
|
||||
So, let’s look into some concrete examples of benchmark gaming that is happening today with Octane, where optimizations are no longer reflected in real world. Note that even though this might sound a bit negative in retrospect, it’s definitely not meant that way! As I said a couple of times already, Octane is an important chapter in the JavaScript performance story, and it played a very important role. All the optimizations that went into JavaScript engines driven by Octane in the past were added on good faith that Octane is a good proxy for real world performance! _Every age has its benchmark, and for every benchmark there comes a time when you have to let go!_
|
||||
让我们来看看今天 Octane 一些基准游戏的具体例子,其中优化不再反映在现实世界。请注意,即使这可能听起来有点负面回顾,它绝对不意味着这样!正如我已经说过好几遍,Octane 是 JavaScript 性能故事中的重要一章,它发挥了非常重要的作用。在过去由 Octane 驱动的 JavaScript 引擎中的所有优化都是善意地添加的,因为 Octane 是真实世界性能的好代理!每个年代都有它的基准,而对于每一个基准都有一段时间你必须要放手!
|
||||
|
||||
That being said, let’s get this show on the road and start by looking at the Box2D test, which is based on[Box2DWeb][75], a popular 2D physics engine originally written by Erin Catto, ported to JavaScript. Overall does a lot of floating point math and drove a lot of good optimizations in JavaScript engines, however as it turns out it contains a bug that can be exploited to game the benchmark a bit (blame it on me, I spotted the bug and added the exploit in this case). There’s a function `D.prototype.UpdatePairs` in the benchmark that looks like this (deminified):
|
||||
话虽这么说,让我们在路上看这个节目,首先看看 Box2D 测试,它是基于 [Box2DWeb][75] (一个最初由 Erin Catto 写的移植到 JavaScript 的流行的 2D 物理引擎)的。总的来说,很多浮点数学驱动了很多 JavaScript 引擎下很好的优化,但是,事实证明它包含一个可以肆意玩弄基准的漏洞(怪我,我发现了漏洞,并添加在这种情况下的漏洞)。在基准中有一个函数 `D.prototype.UpdatePairs`,看起来像这样:
|
||||
|
||||
```
|
||||
D.prototype.UpdatePairs = function(b) {
|
||||
@ -346,7 +308,7 @@ D.prototype.UpdatePairs = function(b) {
|
||||
};
|
||||
```
|
||||
|
||||
Some profiling shows that a lot of time is spent in the innocent looking inner function passed to `e.m_tree.Query` in the first loop:
|
||||
一些分析显示,在第一个循环中传递给 `e.m_tree.Query` 的无害的内部函数花费了大量的时间:
|
||||
|
||||
```
|
||||
function(t) {
|
||||
@ -360,32 +322,30 @@ function(t) {
|
||||
}
|
||||
```
|
||||
|
||||
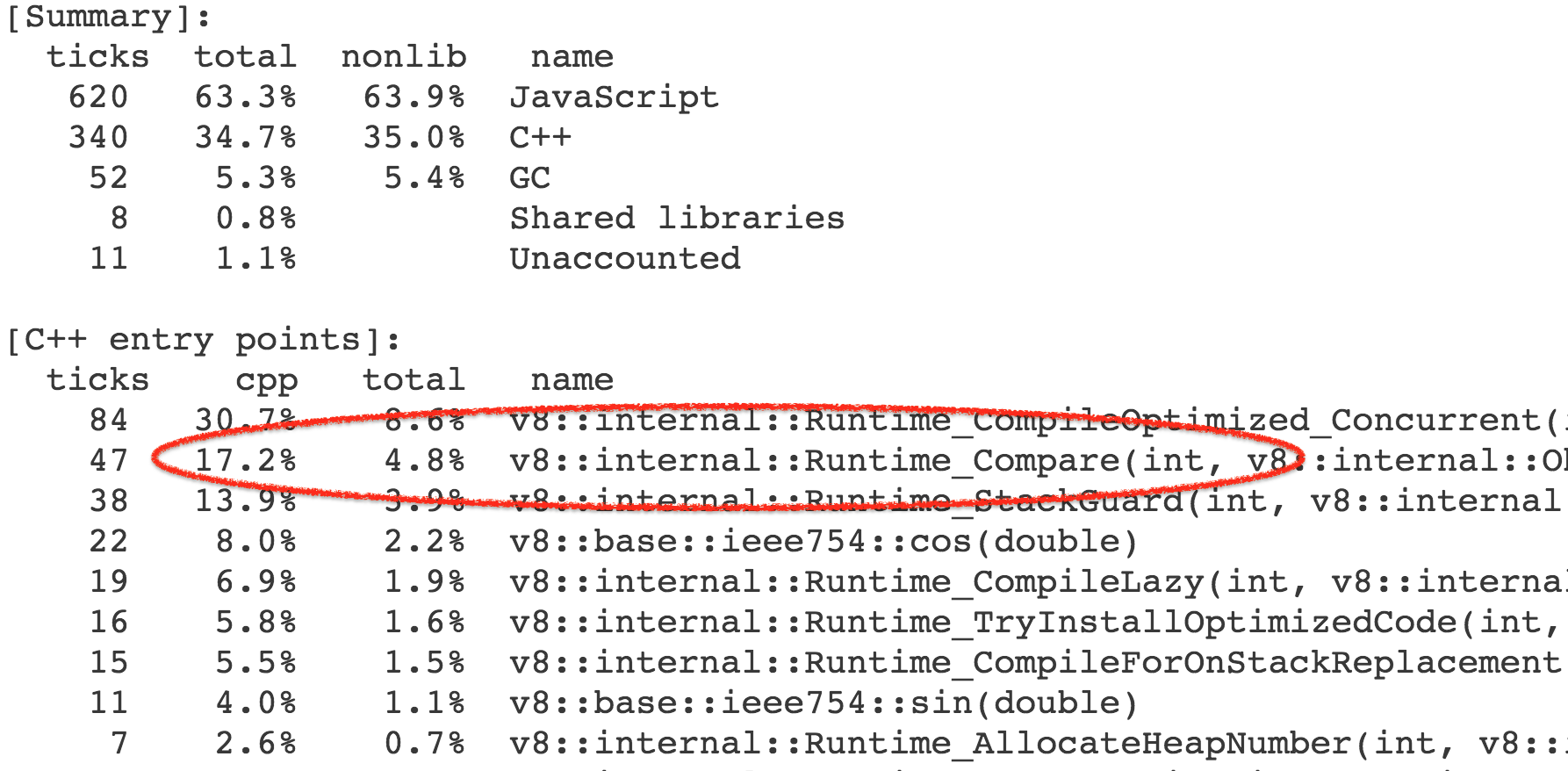
More precisely the time is not spent in this function itself, but rather operations and builtin library functions triggered by this. As it turned out we spent 4-7% of the overall execution time of the benchmark calling into the [`Compare` runtime function][76], which implements the general case for the [abstract relational comparison][77].
|
||||
更准确地说,时间并不是开销在这个函数本身,而是由此触发的操作和内置库函数。结果,我们花费了基准调用的总体执行时间的 4-7% 在 [`Compare` 运行时函数][76]上,它实现了[抽象关系][77]比较的一般情况。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Almost all the calls to the runtime function came from the [`CompareICStub`][78], which is used for the two relational comparisons in the inner function:
|
||||
几乎所有对运行时函数的调用都来自 [`CompareICStub`][78],它用于内部函数中的两个关系比较:
|
||||
|
||||
```
|
||||
x.proxyA = t < m ? t : m;
|
||||
x.proxyB = t >= m ? t : m;
|
||||
```
|
||||
|
||||
So these two innocent looking lines of code are responsible for 99% of the time spent in this function! How come? Well, as with so many things in JavaScript, the [abstract relational comparison][79] is not necessarily intuitive to use properly. In this function both `t` and `m` are always instances of `L`, which is a central class in this application, but doesn’t override either any of `Symbol.toPrimitive`, `"toString"`, `"valueOf"` or `Symbol.toStringTag` properties, that are relevant for the abstract relation comparison. So what happens if you write `t < m` is this:
|
||||
所以这两行无辜的代码要负起 99% 的时间开销的责任!这怎么来的?好吧,与 JavaScript 中的许多东西一样,[抽象关系比较][79] 的直观用法不一定是正确的。在这个函数中,`t` 和 `m` 都是 `L` 的实例,它是这个应用的一个中心类,但不会覆盖 `Symbol.toPrimitive`、`“toString”`、`“valueOf”` 或 `Symbol.toStringTag` 属性,它们与抽象关系比较相关。所以如果你写 `t < m` 会发生什么呢?
|
||||
|
||||
1. Calls [ToPrimitive][12](`t`, `hint Number`).
|
||||
2. Runs [OrdinaryToPrimitive][13](`t`, `"number"`) since there’s no `Symbol.toPrimitive`.
|
||||
3. Executes `t.valueOf()`, which yields `t` itself since it calls the default [`Object.prototype.valueOf`][14].
|
||||
4. Continues with `t.toString()`, which yields `"[object Object]"`, since the default[`Object.prototype.toString`][15] is being used and no [`Symbol.toStringTag`][16] was found for `L`.
|
||||
5. Calls [ToPrimitive][17](`m`, `hint Number`).
|
||||
6. Runs [OrdinaryToPrimitive][18](`m`, `"number"`) since there’s no `Symbol.toPrimitive`.
|
||||
7. Executes `m.valueOf()`, which yields `m` itself since it calls the default [`Object.prototype.valueOf`][19].
|
||||
8. Continues with `m.toString()`, which yields `"[object Object]"`, since the default[`Object.prototype.toString`][20] is being used and no [`Symbol.toStringTag`][21] was found for `L`.
|
||||
9. Does the comparison `"[object Object]" < "[object Object]"` which yields `false`.
|
||||
1. 调用 [ToPrimitive][12](`t`, `hint Number`)。
|
||||
2. 运行 [OrdinaryToPrimitive][13](`t`, `"number"`),因为这里没有 `Symbol.toPrimitive`。
|
||||
3. 执行 `t.valueOf()`,这会获得 `t` 自身的值,因为它调用了默认的 [`Object.prototype.valueOf`][14]。
|
||||
4. 接着执行 `t.toString()`,这会生成 `"[object Object]"`,因为调用了默认的 [`Object.prototype.toString`][15],并且没有找到 `L` 的 [`Symbol.toStringTag`][16]。
|
||||
5. 调用 [ToPrimitive][17](`m`, `hint Number`)。
|
||||
6. 运行 [OrdinaryToPrimitive][18](`m`, `"number"`),因为这里没有 `Symbol.toPrimitive`。
|
||||
7. 执行 `m.valueOf()`,这会获得 `m` 自身的值,因为它调用了默认的 [`Object.prototype.valueOf`][19]。
|
||||
8. 接着执行 `m.toString()`,这会生成 `"[object Object]"`,因为调用了默认的 [`Object.prototype.toString`][20],并且没有找到 `L` 的 [`Symbol.toStringTag`][21]。
|
||||
9. 执行比较 `"[object Object]" < "[object Object]"`,结果是 `false`。
|
||||
|
||||
Same for `t >= m`, which always produces `true` then. So the bug here is that using abstract relational comparison this way just doesn’t make sense. And the way to exploit it is to have the compiler constant-fold it, i.e. similar to applying this patch to the benchmark:
|
||||
至于 `t >= m` 亦复如是,它总会输出 `true`。所以这里是一个漏洞——使用抽象关系比较这种方法没有意义。而利用它的方法是使编译器常数折叠,即给基准打补丁:
|
||||
|
||||
```
|
||||
--- octane-box2d.js.ORIG 2016-12-16 07:28:58.442977631 +0100
|
||||
@ -403,7 +363,7 @@ Same for `t >= m`, which always produces `true` then. So the bug here is that
|
||||
},
|
||||
```
|
||||
|
||||
Because doing so results in a serious speed-up of 13% by not having to do the comparison, and all the propery lookups and builtin function calls triggered by it.
|
||||
由于这样做会跳过比较来达到 13% 的惊人加速,并且所有的属性查找和内置函数的调用都会被触发。
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIG
|
||||
@ -413,7 +373,7 @@ Score (Box2D): 55359
|
||||
$
|
||||
```
|
||||
|
||||
So how did we do that? As it turned out we already had a mechanism for tracking the shape of objects that are being compared in the `CompareIC`, the so-called _known receiver_ map tracking (where _map_ is V8 speak for object shape+prototype), but that was limited to abstract and strict equality comparisons. But I could easily extend the tracking to also collect the feedback for abstract relational comparison:
|
||||
那么我们是怎么做的呢?事实证明,我们已经有一种用于跟踪比较对象的形状的机制,比较发生于 `CompareIC`,即所谓的已知接收器映射跟踪(其中的映射是 V8 的对象形状+原型),不过这是有限的抽象和严格相等比较。但是我可以很容易地扩展跟踪,并且收集反馈进行抽象的关系比较:
|
||||
|
||||
```
|
||||
$ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||
@ -424,40 +384,31 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||
$
|
||||
```
|
||||
|
||||
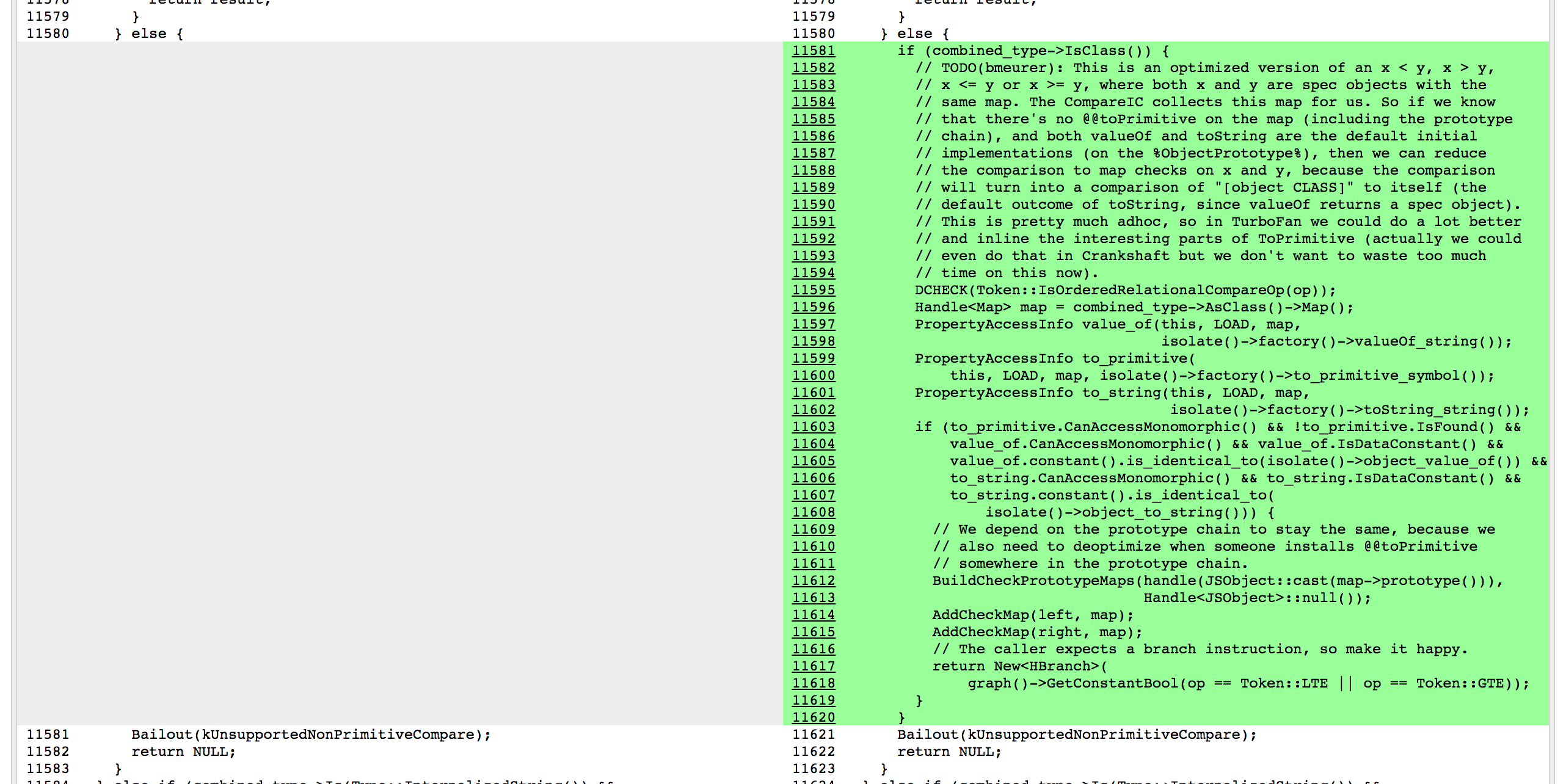
Here the `CompareIC` used in the baseline code tells us that for the LT (less than) and the GTE (greather than or equal) comparisons in the function we’re looking at, it had only seen `RECEIVER`s so far (which is V8 speak for JavaScript objects), and all these receivers had the same map `0x1d5a860493a1`, which corresponds to the map of `L` instances. So in optimized code, we can constant-fold these operations to `false` and `true`respectively as long as we know that both sides of the comparison are instances with the map `0x1d5a860493a1` and noone messed with `L`s prototype chain, i.e. the `Symbol.toPrimitive`, `"valueOf"` and `"toString"` methods are the default ones, and noone installed a `Symbol.toStringTag` accessor property. The rest of the story is _black voodoo magic_ in Crankshaft, with a lot of cursing and initially forgetting to check `Symbol.toStringTag` properly:
|
||||
这里基准代码中使用的 `CompareIC` 告诉我们,对于我们正在查看的函数中的 LT(小于)和 GTE(大于或等于)比较,到目前为止这只能看到`接收器`(V8 的 JavaScript 对象),并且所有这些接收器具有相同的映射 `0x1d5a860493a1`,其对应于 `L` 实例的映射。因此,在优化的代码中,只要我们知道比较的两侧映射的结果都为 `0x1d5a860493a1`,并且没人混淆 `L` 的原型链(即 `Symbol.toPrimitive`、`"valueOf"` 和 `"toString"` 这些方法都是默认的,并且没人赋予过 `Symbol.toStringTag` 的访问权限),我们可以将这些操作分别常量折叠为 `false` 和 `true`。剩下的故事都是关于 Crankshaft 的黑魔法,有很多一部分都是由于初始化的时候忘记正确地检查 `Symbol.toStringTag` 属性:
|
||||
|
||||
[
|
||||
|
||||
][80]
|
||||
[][80]
|
||||
|
||||
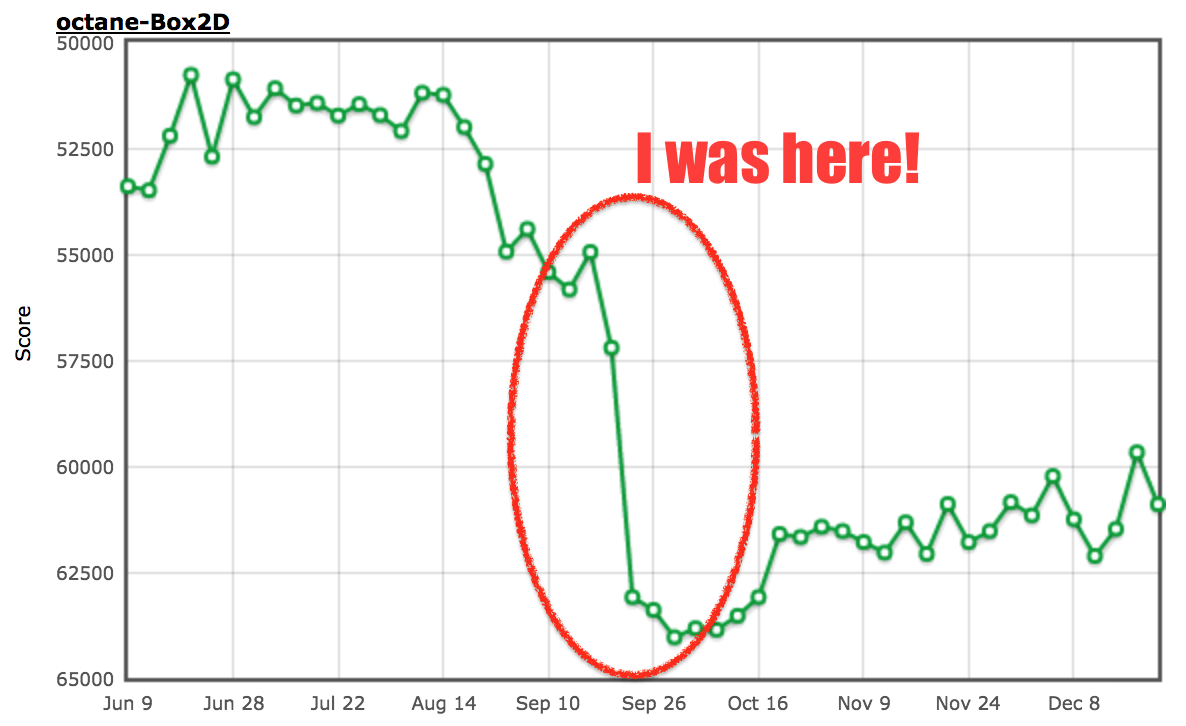
And in the end there was a rather huge performance boost on this particular benchmark:
|
||||
最后,性能在这个特定的基准上有了质的飞跃:
|
||||
|
||||
|
||||

|
||||
|
||||
我要声明一下,当时我并不相信这个特定的行为总是指向源代码中的漏洞,所以我甚至期望外部代码经常会遇到这种情况,同时也因为我假设 JavaScript 开发人员不会总是关心这些种类的潜在错误。但是,我大错特错了,在此我马上悔改!我不得不承认,这个特殊的优化纯粹是一个基准测试的东西,并不会有助于任何真实代码(除非代码是为了从这个优化中获益而写,不过以后你可以在代码中直接写入 `true` 或 `false`,而不用再总是使用常量关系比较)。你可能想知道我们为什么在打补丁后又马上回滚了一下。这是我们整个团队投入到 ES2015 实施的非常时期,这才是真正的恶魔之舞,我们需要在没有严格的回归测试的情况下将所有新特性(ES2015 就是个怪兽)纳入传统基准。
|
||||
|
||||
To my defense, back then I was not convinced that this particular behavior would always point to a bug in the original code, so I was even expecting that code in the wild might hit this case fairly often, also because I was assuming that JavaScript developers wouldn’t always care about these kinds of potential bugs. However, I was so wrong, and here I stand corrected! I have to admit that this particular optimization is purely a benchmark thing, and will not help any real code (unless the code is written to benefit from this optimization, but then you could as well write `true` or `false` directly in your code instead of using an always-constant relational comparison). You might wonder why we slightly regressed soon after my patch. That was the period where we threw the whole team at implementing ES2015, which was really a dance with the devil to get all the new stuff in (ES2015 is a monster!) without seriously regressing the traditional benchmarks.
|
||||
关于 Box2D 点到为止了,让我们看看 Mandreel 基准。Mandreel 是一个用来将 C/C++ 代码编译成 JavaScript 的编译器,它并没有用上新一代的 [Emscripten][82] 编译器所使用,并且已经被弃用(或多或少已经从互联网消失了)大约三年的 JavaScript 子集 [asm.js][81]。然而,Octane 仍然有一个通过 [Mandreel][84] 编译的[子弹物理引擎][83]。MandreelLatency 测试十分有趣,它测试 Mandreel 基准与频繁的时间测量检测点。有一种说法是,由于 Mandreel 强制使用虚拟机编译器,此测试提供了由编译器引入的延迟的指示,并且测量检测点之间的长时间停顿降低了最终得分。这听起来似乎合情合理,确实有一定的意义。然而,像往常一样,供应商找到了在这个基准上作弊的方法。
|
||||
|
||||
Enough said about Box2D, let’s have a look at the Mandreel benchmark. Mandreel was a compiler for compiling C/C++ code to JavaScript, it didn’t use the [asm.js][81] subset of JavaScript that is being used by the more recent [Emscripten][82] compiler, and has been deprecated (and more or less disappeared from the internet) since roughly three years now. Nevertheless, Octane still has a version of the [Bullet physics engine][83] compiled via [Mandreel][84]. An interesting test here is the MandreelLatency test, which instruments the Mandreel benchmark with frequent time measurement checkpoints. The idea here was that since Mandreel stresses the VM’s compiler, this test provides an indication of the latency introduced by the compiler, and long pauses between measurement checkpoints lower the final score. In theory that sounds very reasonable, and it does indeed make some sense. However as usual vendors figured out ways to cheat on this benchmark.
|
||||
[][85]
|
||||
|
||||
[
|
||||

|
||||
][85]
|
||||
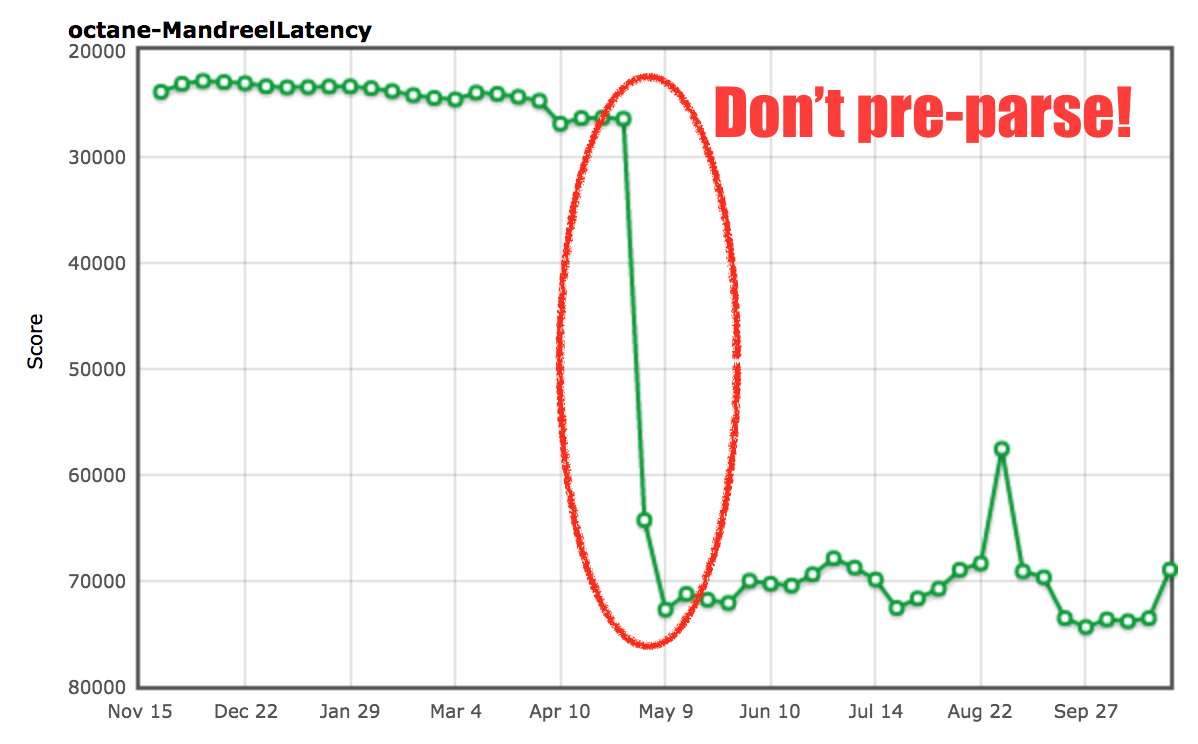
Mandreel 自带一个重型初始化函数 `global_init`,光是解析这个函数并为其生成基线代码就花费了不可思议的时间。因为引擎通常在脚本中多次解析各种函数,一个所谓的预解析步骤用来发现脚本内的函数。然后作为函数第一次被调用完整的解析步骤以生成基线代码(或者说字节码)。这在 V8 中被称为[懒解析][86]。V8 有一些启发式检测函数,当预解析浪费时间的时候可以立刻调用,不过对于 Mandreel 基准的 `global_init` 函数就不太清楚了,于是我们将经历这个大家伙“预解析+解析+编译”的长时间停顿。所以我们[添加了一个额外的启发式函数][87]以避免 `global_init` 函数的预解析。
|
||||
|
||||
Mandreel contains a huge initialization function `global_init` that takes an incredible amount of time just parsing this function, and generating baseline code for it. Since engines usually parse various functions in scripts multiple times, one so-called pre-parse step to discover functions inside the script, and then as the function is invoked for the first time a full parse step to actually generate baseline code (or bytecode) for the function. This is called [_lazy parsing_][86] in V8 speak. V8 has some heuristics in place to detect functions that are invoked immediately where pre-parsing is actually a waste of time, but that’s not clear for the `global_init`function in the Mandreel benchmark, thus we’d would have an incredible long pause for pre-parsing + parsing + compiling the big function. So we [added an additional heuristic][87] that would also avoids the pre-parsing for this `global_init` function.
|
||||
[][88]
|
||||
|
||||
[
|
||||

|
||||
][88]
|
||||
由此可见,在检测 `global_init` 和避免昂贵的预解析步骤我们几乎提升了 2 倍。我们不太确定这是否会对真实用例产生负面影响,不过保证你在预解析大函数的时候将会受益匪浅(因为它们不会立即执行)。
|
||||
|
||||
So we saw an almost 200% improvement just by detecting `global_init` and avoiding the expensive pre-parse step. We are somewhat certain that this should not negatively impact real world use cases, but there’s no guarantee that this won’t bite you on large functions where pre-parsing would be beneficial (because they aren’t immediately executed).
|
||||
让我们来看看另一个稍有争议的基准测试:[`splay.js`][89] 测试,一个用于处理伸展树(二叉查找树的一种)和练习自动内存管理子系统(也被成为垃圾回收器)的数据操作基准。它自带一个延迟测试,这会引导 Splay 代码通过频繁的测量检测点,检测点之间的长时间停顿表明垃圾回收器的延迟很高。此测试测量延迟暂停的频率,将它们分类到桶中,并以较低的分数惩罚频繁的长暂停。这听起来很棒!没有 GC 停顿,没有垃圾。纸上谈兵到此为止。让我们看看这个基准,以下是整个伸展树业务的核心:
|
||||
|
||||
So let’s look into another slightly less controversial benchmark: the [`splay.js`][89] test, which is meant to be a data manipulation benchmark that deals with splay trees and exercises the automatic memory management subsystem (aka the garbage collector). It comes bundled with a latency test that instruments the Splay code with frequent measurement checkpoints, where a long pause between checkpoints is an indication of high latency in the garbage collector. This test measures the frequency of latency pauses, classifies them into buckets and penalizes frequent long pauses with a low score. Sounds great! No GC pauses, no jank. So much for the theory. Let’s have a look at the benchmark, here’s what’s at the core of the whole splay tree business:
|
||||
[][90]
|
||||
|
||||
[
|
||||

|
||||
][90]
|
||||
|
||||
This is the core of the splay tree construction, and despite what you might think looking at the full benchmark, this is more or less all that matters for the SplayLatency score. How come? Actually what the benchmark does is to construct huge splay trees, so that the majority of nodes survive, thus making it to old space. With a generational garbage collector like the one in V8 this is super expensive if a program violates the [generational hypothesis][91] leading to extreme pause times for essentially evacuating everything from new space to old space. Running V8 in the old configuration clearly shows this problem:
|
||||
这是伸展树结构的核心,尽管你可能想看完整的基准,不过这或多或少是 SplayLatency 得分的重要来源。怎么回事?实际上,基准测试是建立巨大的伸展树,尽可能保留所有节点,从而还原它原本的空间。使用像 V8 这样的代数垃圾回收器,如果程序违反了[代数假设][91],导致极端的时间停顿,从本质上看,将所有东西从新空间撤回到旧空间的开销是非常昂贵的。在旧配置中运行 V8 可以清楚地展示这个问题:
|
||||
|
||||
```
|
||||
$ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
|
||||
@ -540,7 +491,7 @@ $ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
|
||||
$
|
||||
```
|
||||
|
||||
So the key observation here is that allocating the splay tree nodes in old space directly would avoid essentially all the overhead of copying objects around and reduce the number of minor GC cycles to the bare minimum (thereby reducing the pauses caused by the GC). So we came up with a mechanism called [_Allocation Site Pretenuring_][92] that would try to dynamically gather feedback at allocation sites when run in baseline code to decide whether a certain percent of the objects allocated here survives, and if so instrument the optimized code to allocate objects in old space directly - i.e. _pretenure the objects_.
|
||||
因此这里关键的发现是直接在旧空间中分配伸展树节点可基本避免在周围复制对象的所有开销,并且将次要 GC 周期的数量减少到最小(从而减少 GC 引起的停顿时间)。我们想出了一种称为[分配站点预占][92]的机制,当运行到基线代码时,将尝试动态收集分配站点的反馈,以决定在此分配的对象的部分是否确切存在,如果是,则优化代码以直接在旧空间分配对象——即预占对象。
|
||||
|
||||
```
|
||||
$ out/Release/d8 --trace-gc octane-splay.js
|
||||
@ -567,44 +518,37 @@ $ out/Release/d8 --trace-gc octane-splay.js
|
||||
$
|
||||
```
|
||||
|
||||
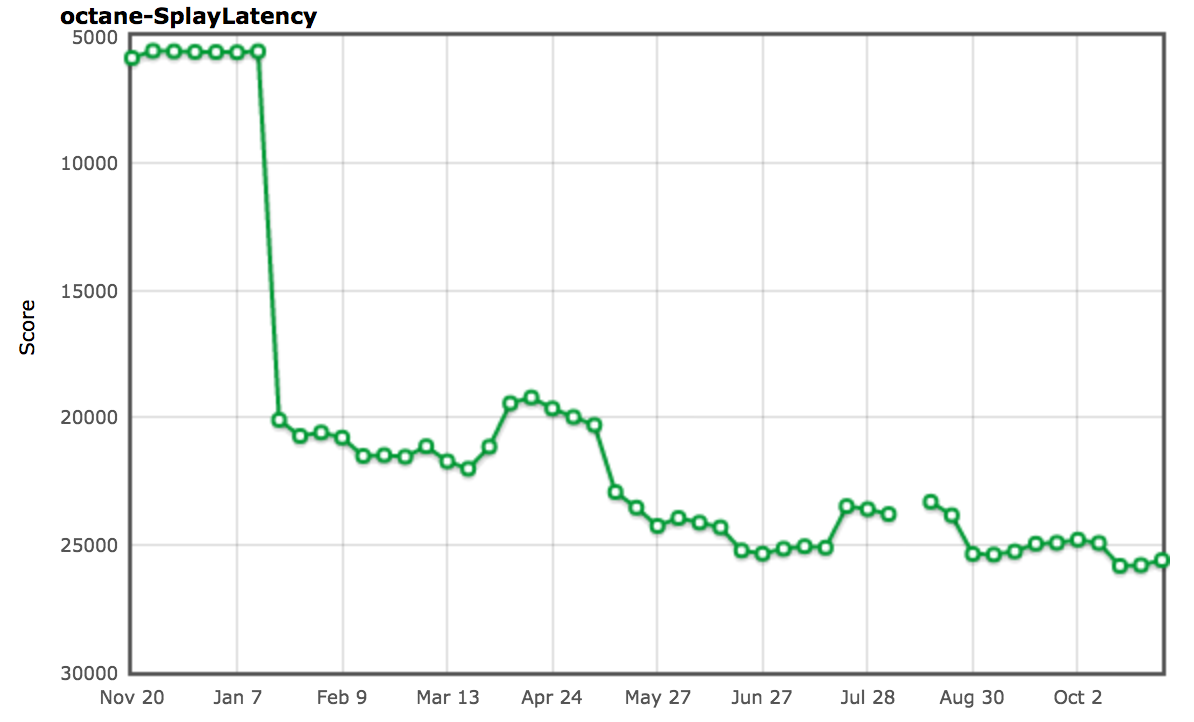
And indeed that essentially fixed the problem for the SplayLatency benchmark completely and boosted our score by over 250%!
|
||||
事实上,这完全解决了 SplayLatency 基准的问题,并将我们的得分超过 250%!
|
||||
|
||||
[
|
||||
|
||||
][93]
|
||||
[][93]
|
||||
|
||||
As mentioned in the [SIGPLAN paper][94] we had good reasons to believe that allocation site pretenuring might be a win for real world applications, and were really looking forward to seeing improvements and extending the mechanism to cover more than just object and array literals. But it didn’t take [long][95] [to][96] [realize][97] that allocation site pretenuring can have a pretty serious negative impact on real world application performance. We actually got a lot of negative press, including a shit storm from Ember.js developers and users, not only because of allocation site pretenuring, but that was big part of the story.
|
||||
正如 [SIGPLAN 论文][94] 中所提及的,我们有充分的理由相信,分配站点预占机制可能真的赢得了真实世界应用的欢心,并真正期待看到改进和扩展后的机制,那时将不仅仅是对象和数组字面量。但是不久后我们意识到[分配站点预占机制对真实世界引用产生了相当严重的负面影响][97]。我们实际上得到很多负面新闻,包括 Ember.js 开发者和用户的唇枪舌战,不仅是因为分配站点预占机制,不过它是事故的罪魁祸首。
|
||||
|
||||
The fundamental problem with allocation site pretenuring as we learned are factories, which are very common in applications today (mostly because of frameworks, but also for other reasons), and assuming that your object factory is initially used to create the long living objects that form your object model and the views, which transitions the allocation site in your factory method(s) to _tenured_ state, and everything allocated from the factory immediately goes to old space. Now after the initial setup is done, your application starts doing stuff, and as part of that, allocates temporary objects from the factory, that now start polluting old space, eventually leading to expensive major garbage collection cycles, and other negative side effects like triggering incremental marking way too early.
|
||||
分配站点预占机制的基本问题数之不尽,这在今天的应用中非常常见(主要是由于框架,同时还有其它原因),假设你的对象工厂最初是用于创建构成你的对象模型和视图的长周期对象的,它将你的工厂方法中的分配站点转换为永久状态,并且从工厂分配的所有内容都立即转到旧空间。现在初始设置完成后,你的应用开始工作,作为其中的一部分,从工厂分配临时对象会污染旧空间,最终导致开销昂贵的垃圾回收周期以及其它负面的副作用,例如过早触发增量标记。
|
||||
|
||||
So we started to reconsider the benchmark driven effort and started looking for real world driven solutions instead, which resulted in an effort called [Orinoco][98] with the goal to incrementally improve the garbage collector; part of that effort is a project called _unified heap_, which will try to avoid copying objects if almost everything in a page survives. I.e. on a high level: If new space is full of live objects, just mark all new space pages as belonging to old space now, and create a fresh new space from empty pages. This might not yield the same score on the SplayLatency benchmark, but it’s a lot better for real world use cases and it automatically adapts to the concrete use case. We are also considering _concurrent marking_ to offload the marking work to a separate thread and thus further reducing the negative impact of incremental marking on both latency and throughput.
|
||||
我们开始重新考虑基准驱动的努力,并开始寻找驱动真实世界的替代方案,这导致了 [Orinoco][98] 的诞生,它的目标是逐步改进垃圾回收器;这个努力的一部分是一个称为“统一堆”的项目,如果页面中的所有内容都存在,它将尝试避免复制对象。也就是说站在更高的层面看:如果新空间充满活动对象,只需将所有新空间页面标记为属于旧空间,然后从空白页面创建一个新空间。这可能不会在 SplayLatency 基准测试中得到相同的分数,但是这对于真实世界的用例更友好,它可以自动适配具体的用例。我们还考虑并发标记,将标记工作卸载到单独的线程,从而进一步减少增量标记对延迟和吞吐量的负面影响。
|
||||
|
||||
### Cuteness break!
|
||||
### 轻松一刻
|
||||
|
||||

|
||||

|
||||
|
||||
Breathe.
|
||||
喘口气。
|
||||
|
||||
Ok, I think that should be sufficient to underline the point. I could go on pointing to even more examples where Octane driven improvements turned out to be a bad idea later, and maybe I’ll do that another day. But let’s stop right here for today…
|
||||
好吧,我想这对于我的观点的强调应该足够了。我可以继续指出更多的例子,其中 Octane 驱动的改进后来变成了一个坏主意,也许改天我会接着写下去。但是今天就到此为止了吧。
|
||||
|
||||
### Conclusion
|
||||
### 结论
|
||||
|
||||
I hope it should be clear by now why benchmarks are generally a good idea, but are only useful to a certain level, and once you cross the line of _useful competition_, you’ll start wasting the time of your engineers or even start hurting your real world performance! If we are serious about performance for the web, we need to start judging browser by real world performance and not their ability to game four year old benchmarks. We need to start educating the (tech) press, or failing that, at least ignore them.
|
||||
我希望现在应该清楚为什么基准测试通常是一个好主意,但是只对某个特定的级别有用,一旦你跨越了有用竞争的界限,你就会开始浪费你们工程师的时间,甚至开始损害到你的真实世界的性能!如果我们认真考虑 web 的性能,我们需要根据真实世界的性能来测评浏览器,而不是它们玩弄一个四年的基准的能力。我们需要开始教育(技术)媒体,可能这没用,但至少请忽略他们。
|
||||
|
||||
[
|
||||
|
||||
][99]
|
||||
[][99]
|
||||
|
||||
Noone is afraid of competition, but gaming potentially broken benchmarks is not really useful investment of engineering time. We can do a lot more, and take JavaScript to the next level. Let’s work on meaningful performance tests that can drive competition on areas of interest for the end user and the developer. Additionally let’s also drive meaningful improvements for server and tooling side code running in Node.js (either on V8 or ChakraCore)!
|
||||
没人害怕竞争,但是玩弄可能已经坏掉的基准不像是在合理使用工程时间。我们可以尽更大的努力,并把 JavaScript 提高到更高的水平。让我们开展有意义的性能测试,以便为最终用户和开发者带来有意思的领域竞争。此外,让我们再对服务器和运行在 Node.js(还有 V8 和 ChakraCore)中的工具代码做一些有意义的改进!
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
One closing comment: Don’t use traditional JavaScript benchmarks to compare phones. It’s really the most useless thing you can do, as the JavaScript performance often depends a lot on the software and not necessarily on the hardware, and Chrome ships a new version every six weeks, so whatever you measure in March maybe irrelevant already in April. And if there’s no way to avoid running something in a browser that assigns a number to a phone, then at least use a recent full browser benchmark that has at least something to do with what people will do with their browsers, i.e. consider [Speedometer benchmark][100].
|
||||
|
||||
Thank you!
|
||||
结束语:不要用传统的 JavaScript 基准来比较手机。这是真正最没用的事情,因为 JavaScript 的性能通常取决于软件,而不一定是硬件,并且 Chrome 每 6 周发布一个新版本,所以你在三月的测试结果到了四月就已经毫不相关了。如果在浏览器中发送一个数字都一部手机不可避免,那么至少请使用一个现代健全的浏览器基准来测试,至少这个基准要知道人们会用浏览器来干什么,比如 [Speedometer 基准][100]。
|
||||
|
||||
感谢你花时间阅读!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -612,14 +556,14 @@ Thank you!
|
||||
|
||||

|
||||
|
||||
I am Benedikt Meurer, a software engineer living in Ottobrunn, a municipality southeast of Munich, Bavaria, Germany. I received my diploma in applied computer science with electrical engineering from the Universität Siegen in 2007, and since then I have been working as a research associate at the Lehrstuhl für Compilerbau und Softwareanalyse (and the Lehrstuhl für Mikrosystementwurf in 2007/2008) for five years. In 2013 I joined Google to work on the V8 JavaScript Engine in the Munich office, where I am currently working as tech lead for the JavaScript execution optimization team.
|
||||
我是 Benedikt Meurer,住在 Ottobrunn(德国巴伐利亚州慕尼黑东南部的一个市镇)的一名软件工程师。我于 2007 年在锡根大学获得应用计算机科学与电气工程的文凭,打那以后的 5 年里我在编译器和软件分析领域担任研究员(2007 至 2008 年间还研究过微系统设计)。2013 年我加入了谷歌的慕尼黑办公室,我的工作目标主要是 V8 JavaScript 引擎,目前是 JavaScript 执行性能优化团队的一名技术领导。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://benediktmeurer.de/2016/12/16/the-truth-about-traditional-javascript-benchmarks
|
||||
|
||||
作者:[Benedikt Meurer][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[译者ID](https://github.com/OneNewLife)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Loading…
Reference in New Issue
Block a user