mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
6860fa36ee
@ -0,0 +1,109 @@
|
||||
并发服务器(五):Redis 案例研究
|
||||
======
|
||||
|
||||
这是我写的并发网络服务器系列文章的第五部分。在前四部分中我们讨论了并发服务器的结构,这篇文章我们将去研究一个在生产系统中大量使用的服务器的案例—— [Redis][10]。
|
||||
|
||||

|
||||
|
||||
Redis 是一个非常有魅力的项目,我关注它很久了。它最让我着迷的一点就是它的 C 源代码非常清晰。它也是一个高性能、大并发的内存数据库服务器的非常好的例子,它是研究网络并发服务器的一个非常好的案例,因此,我们不能错过这个好机会。
|
||||
|
||||
我们来看看前四部分讨论的概念在真实世界中的应用程序。
|
||||
|
||||
本系列的所有文章有:
|
||||
|
||||
* [第一节 - 简介][3]
|
||||
* [第二节 - 线程][4]
|
||||
* [第三节 - 事件驱动][5]
|
||||
* [第四节 - libuv][6]
|
||||
* [第五节 - Redis 案例研究][7]
|
||||
|
||||
### 事件处理库
|
||||
|
||||
Redis 最初发布于 2009 年,它最牛逼的一件事情大概就是它的速度 —— 它能够处理大量的并发客户端连接。需要特别指出的是,它是用*一个单线程*来完成的,而且还不对保存在内存中的数据使用任何复杂的锁或者同步机制。
|
||||
|
||||
Redis 之所以如此牛逼是因为,它在给定的系统上使用了其可用的最快的事件循环,并将它们封装成由它实现的事件循环库(在 Linux 上是 epoll,在 BSD 上是 kqueue,等等)。这个库的名字叫做 [ae][11]。ae 使得编写一个快速服务器变得很容易,只要在它内部没有阻塞即可,而 Redis 则保证 ^注1 了这一点。
|
||||
|
||||
在这里,我们的兴趣点主要是它对*文件事件*的支持 —— 当文件描述符(如网络套接字)有一些有趣的未决事情时将调用注册的回调函数。与 libuv 类似,ae 支持多路事件循环(参阅本系列的[第三节][5]和[第四节][6])和不应该感到意外的 `aeCreateFileEvent` 信号:
|
||||
|
||||
```
|
||||
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
|
||||
aeFileProc *proc, void *clientData);
|
||||
```
|
||||
|
||||
它在 `fd` 上使用一个给定的事件循环,为新的文件事件注册一个回调(`proc`)函数。当使用的是 epoll 时,它将调用 `epoll_ctl` 在文件描述符上添加一个事件(可能是 `EPOLLIN`、`EPOLLOUT`、也或许两者都有,取决于 `mask` 参数)。ae 的 `aeProcessEvents` 功能是 “运行事件循环和发送回调函数”,它在底层调用了 `epoll_wait`。
|
||||
|
||||
### 处理客户端请求
|
||||
|
||||
我们通过跟踪 Redis 服务器代码来看一下,ae 如何为客户端事件注册回调函数的。`initServer` 启动时,通过注册一个回调函数来读取正在监听的套接字上的事件,通过使用回调函数 `acceptTcpHandler` 来调用 `aeCreateFileEvent`。当新的连接可用时,这个回调函数被调用。它调用 `accept` ^注2 ,接下来是 `acceptCommonHandler`,它转而去调用 `createClient` 以初始化新客户端连接所需要的数据结构。
|
||||
|
||||
`createClient` 的工作是去监听来自客户端的入站数据。它将套接字设置为非阻塞模式(一个异步事件循环中的关键因素)并使用 `aeCreateFileEvent` 去注册另外一个文件事件回调函数以读取事件 —— `readQueryFromClient`。每当客户端发送数据,这个函数将被事件循环调用。
|
||||
|
||||
`readQueryFromClient` 就让我们期望的那样 —— 解析客户端命令和动作,并通过查询和/或操作数据来回复。因为客户端套接字是非阻塞的,所以这个函数必须能够处理 `EAGAIN`,以及部分数据;从客户端中读取的数据是累积在客户端专用的缓冲区中,而完整的查询可能被分割在回调函数的多个调用当中。
|
||||
|
||||
### 将数据发送回客户端
|
||||
|
||||
在前面的内容中,我说到了 `readQueryFromClient` 结束了发送给客户端的回复。这在逻辑上是正确的,因为 `readQueryFromClient` *准备*要发送回复,但它不真正去做实质的发送 —— 因为这里并不能保证客户端套接字已经准备好写入/发送数据。我们必须为此使用事件循环机制。
|
||||
|
||||
Redis 是这样做的,它注册一个 `beforeSleep` 函数,每次事件循环即将进入休眠时,调用它去等待套接字变得可以读取/写入。`beforeSleep` 做的其中一件事情就是调用 `handleClientsWithPendingWrites`。它的作用是通过调用 `writeToClient` 去尝试立即发送所有可用的回复;如果一些套接字不可用时,那么*当*套接字可用时,它将注册一个事件循环去调用 `sendReplyToClient`。这可以被看作为一种优化 —— 如果套接字可用于立即发送数据(一般是 TCP 套接字),这时并不需要注册事件 ——直接发送数据。因为套接字是非阻塞的,它从不会去阻塞循环。
|
||||
|
||||
### 为什么 Redis 要实现它自己的事件库?
|
||||
|
||||
在 [第四节][14] 中我们讨论了使用 libuv 来构建一个异步并发服务器。需要注意的是,Redis 并没有使用 libuv,或者任何类似的事件库,而是它去实现自己的事件库 —— ae,用 ae 来封装 epoll、kqueue 和 select。事实上,Antirez(Redis 的创建者)恰好在 [2011 年的一篇文章][15] 中回答了这个问题。他的回答的要点是:ae 只有大约 770 行他理解的非常透彻的代码;而 libuv 代码量非常巨大,也没有提供 Redis 所需的额外功能。
|
||||
|
||||
现在,ae 的代码大约增长到 1300 多行,比起 libuv 的 26000 行(这是在没有 Windows、测试、示例、文档的情况下的数据)来说那是小巫见大巫了。libuv 是一个非常综合的库,这使它更复杂,并且很难去适应其它项目的特殊需求;另一方面,ae 是专门为 Redis 设计的,与 Redis 共同演进,只包含 Redis 所需要的东西。
|
||||
|
||||
这是我 [前些年在一篇文章中][16] 提到的软件项目依赖关系的另一个很好的示例:
|
||||
|
||||
> 依赖的优势与在软件项目上花费的工作量成反比。
|
||||
|
||||
在某种程度上,Antirez 在他的文章中也提到了这一点。他提到,提供大量附加价值(在我的文章中的“基础” 依赖)的依赖比像 libuv 这样的依赖更有意义(它的例子是 jemalloc 和 Lua),对于 Redis 特定需求,其功能的实现相当容易。
|
||||
|
||||
### Redis 中的多线程
|
||||
|
||||
[在 Redis 的绝大多数历史中][17],它都是一个不折不扣的单线程的东西。一些人觉得这太不可思议了,有这种想法完全可以理解。Redis 本质上是受网络束缚的 —— 只要数据库大小合理,对于任何给定的客户端请求,其大部分延时都是浪费在网络等待上,而不是在 Redis 的数据结构上。
|
||||
|
||||
然而,现在事情已经不再那么简单了。Redis 现在有几个新功能都用到了线程:
|
||||
|
||||
1. “惰性” [内存释放][8]。
|
||||
2. 在后台线程中使用 fsync 调用写一个 [持久化日志][9]。
|
||||
3. 运行需要执行一个长周期运行的操作的用户定义模块。
|
||||
|
||||
对于前两个特性,Redis 使用它自己的一个简单的 bio(它是 “Background I/O" 的首字母缩写)库。这个库是根据 Redis 的需要进行了硬编码,它不能用到其它的地方 —— 它运行预设数量的线程,每个 Redis 后台作业类型需要一个线程。
|
||||
|
||||
而对于第三个特性,[Redis 模块][18] 可以定义新的 Redis 命令,并且遵循与普通 Redis 命令相同的标准,包括不阻塞主线程。如果在模块中自定义的一个 Redis 命令,希望去执行一个长周期运行的操作,这将创建一个线程在后台去运行它。在 Redis 源码树中的 `src/modules/helloblock.c` 提供了这样的一个示例。
|
||||
|
||||
有了这些特性,Redis 使用线程将一个事件循环结合起来,在一般的案例中,Redis 具有了更快的速度和弹性,这有点类似于在本系统文章中 [第四节][19] 讨论的工作队列。
|
||||
|
||||
- 注1: Redis 的一个核心部分是:它是一个 _内存中_ 数据库;因此,查询从不会运行太长的时间。当然了,这将会带来各种各样的其它问题。在使用分区的情况下,服务器可能最终路由一个请求到另一个实例上;在这种情况下,将使用异步 I/O 来避免阻塞其它客户端。
|
||||
- 注2: 使用 `anetAccept`;`anet` 是 Redis 对 TCP 套接字代码的封装。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id2
|
||||
[3]:https://linux.cn/article-8993-1.html
|
||||
[4]:https://linux.cn/article-9002-1.html
|
||||
[5]:https://linux.cn/article-9117-1.html
|
||||
[6]:https://linux.cn/article-9397-1.html
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
[8]:http://antirez.com/news/93
|
||||
[9]:https://redis.io/topics/persistence
|
||||
[10]:https://redis.io/
|
||||
[11]:https://redis.io/topics/internals-rediseventlib
|
||||
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id4
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id5
|
||||
[14]:https://linux.cn/article-9397-1.html
|
||||
[15]:http://oldblog.antirez.com/post/redis-win32-msft-patch.html
|
||||
[16]:http://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/
|
||||
[17]:http://antirez.com/news/93
|
||||
[18]:https://redis.io/topics/modules-intro
|
||||
[19]:https://linux.cn/article-9397-1.html
|
||||
@ -1,35 +1,38 @@
|
||||
如何在 Linux 上使用 Vundle 管理 Vim 插件
|
||||
======
|
||||
|
||||
|
||||
|
||||
毋庸置疑,**Vim** 是一款强大的文本文件处理的通用工具,能够管理系统配置文件,编写代码。通过插件,vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 **~/.vim** 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
毋庸置疑,Vim 是一款强大的文本文件处理的通用工具,能够管理系统配置文件和编写代码。通过插件,Vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 `~/.vim` 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
|
||||
Vundle 为每一个你安装和存储的拓展配置文件创建各自独立的目录树。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已存在的插件、更新插件配置、搜索安装插件和清理不使用的插件。所有的操作都可以在单一按键的交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
Vundle 为每一个你安装的插件创建一个独立的目录树,并在相应的插件目录中存储附加的配置文件。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已有的插件、更新插件配置、搜索安装的插件和清理不使用的插件。所有的操作都可以在一键交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
|
||||
### Vundle 安装
|
||||
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 **vim**。如果没有,安装 vim,尽情 **git**(下载 vundle)去吧。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 Vim。如果没有,请安装 Vim 和 git(以下载 Vundle)。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
|
||||
```
|
||||
sudo apt-get install vim git
|
||||
```
|
||||
|
||||
**下载 Vundle**
|
||||
#### 下载 Vundle
|
||||
|
||||
复制 Vundle 的 GitHub 仓库地址:
|
||||
|
||||
```
|
||||
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
|
||||
```
|
||||
|
||||
**配置 Vundle**
|
||||
#### 配置 Vundle
|
||||
|
||||
创建 **~/.vimrc** 文件,通知 vim 使用新的插件管理器。这个文件获得有安装、更新、配置和移除插件的权限。
|
||||
创建 `~/.vimrc` 文件,以通知 Vim 使用新的插件管理器。安装、更新、配置和移除插件需要这个文件。
|
||||
|
||||
```
|
||||
vim ~/.vimrc
|
||||
```
|
||||
|
||||
在此文件顶部,加入如下若干行内容:
|
||||
|
||||
```
|
||||
set nocompatible " be iMproved, required
|
||||
filetype off " required
|
||||
@ -76,35 +79,39 @@ filetype plugin indent on " required
|
||||
" Put your non-Plugin stuff after this line
|
||||
```
|
||||
|
||||
被标记的行中,是 Vundle 的请求项。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。一旦你安装过,键入 **:wq** 保存退出。
|
||||
被标记为 “required” 的行是 Vundle 的所需配置。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。完成后,键入 `:wq` 保存退出。
|
||||
|
||||
最后,打开 Vim:
|
||||
|
||||
最后,打开 vim
|
||||
```
|
||||
vim
|
||||
```
|
||||
|
||||
然后键入下列命令安装插件。
|
||||
然后键入下列命令安装插件:
|
||||
|
||||
```
|
||||
:PluginInstall
|
||||
```
|
||||
|
||||
[![][1]][2]
|
||||
![][2]
|
||||
|
||||
将会弹出一个新的分窗口,.vimrc 中陈列的项目都会自动安装。
|
||||
将会弹出一个新的分窗口,我们加在 `.vimrc` 文件中的所有插件都会自动安装。
|
||||
|
||||
[![][1]][3]
|
||||
![][3]
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口:
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口。
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
在终端上使用下面命令,规避使用 vim 安装插件
|
||||
你也可以在终端上使用下面命令安装插件,而不用打开 Vim:
|
||||
|
||||
```
|
||||
vim +PluginInstall +qall
|
||||
```
|
||||
|
||||
使用 [**fish shell**][4] 的朋友,添加下面这行到你的 **.vimrc** 文件中。
|
||||
使用 [fish shell][4] 的朋友,添加下面这行到你的 `.vimrc` 文件中。
|
||||
|
||||
```
|
||||
set shell=/bin/bash
|
||||
@ -112,123 +119,138 @@ set shell=/bin/bash
|
||||
|
||||
### 使用 Vundle 管理 Vim 插件
|
||||
|
||||
**添加新的插件**
|
||||
#### 添加新的插件
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件:
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件。
|
||||
```
|
||||
:PluginSearch
|
||||
```
|
||||
|
||||
命令之后添加 **"! "**,刷新 vimscripts 网站内容到本地。
|
||||
要从 vimscripts 网站刷新本地的列表,请在命令之后添加 `!`。
|
||||
|
||||
```
|
||||
:PluginSearch!
|
||||
```
|
||||
|
||||
一个陈列可用插件列表的新分窗口将会被弹出。
|
||||
会弹出一个列出可用插件列表的新分窗口:
|
||||
|
||||
[![][1]][5]
|
||||
![][5]
|
||||
|
||||
你还可以通过直接指定插件名的方式,缩小搜索范围。
|
||||
|
||||
```
|
||||
:PluginSearch vim
|
||||
```
|
||||
|
||||
这样将会列出包含关键词“vim”的插件。
|
||||
这样将会列出包含关键词 “vim” 的插件。
|
||||
|
||||
当然你也可以指定确切的插件名,比如:
|
||||
|
||||
```
|
||||
:PluginSearch vim-dasm
|
||||
```
|
||||
|
||||
移动焦点到正确的一行上,点击 **" i"** 来安装插件。现在,被选择的插件将会被安装。
|
||||
移动焦点到正确的一行上,按下 `i` 键来安装插件。现在,被选择的插件将会被安装。
|
||||
|
||||
[![][1]][6]
|
||||
![][6]
|
||||
|
||||
类似的,在你的系统中安装所有想要的插件。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
|
||||
在你的系统中,所有想要的的插件都以类似的方式安装。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
现在,插件已经安装完成。在 .vimrc 文件中添加安装好的插件名,让插件正确加载。
|
||||
现在,插件已经安装完成。为了让插件正确的自动加载,我们需要在 `.vimrc` 文件中添加安装好的插件名。
|
||||
|
||||
这样做:
|
||||
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
添加这一行:
|
||||
|
||||
```
|
||||
[...]
|
||||
Plugin 'vim-dasm'
|
||||
[...]
|
||||
```
|
||||
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 ESC,键入 **:wq** 保存退出。
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 `ESC`,键入 `:wq` 保存退出。
|
||||
|
||||
请注意,所有插件都必须在 `.vimrc` 文件中追加如下内容。
|
||||
|
||||
请注意,所有插件都必须在 .vimrc 文件中追加如下内容。
|
||||
```
|
||||
[...]
|
||||
filetype plugin indent on
|
||||
```
|
||||
|
||||
**列出已安装的插件**
|
||||
#### 列出已安装的插件
|
||||
|
||||
键入下面命令列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
[![][1]][7]
|
||||
![][7]
|
||||
|
||||
**更新插件**
|
||||
#### 更新插件
|
||||
|
||||
键入下列命令更新插件:
|
||||
|
||||
```
|
||||
:PluginUpdate
|
||||
```
|
||||
|
||||
键入下列命令重新安装所有插件
|
||||
键入下列命令重新安装所有插件:
|
||||
|
||||
```
|
||||
:PluginInstall!
|
||||
```
|
||||
|
||||
**卸载插件**
|
||||
#### 卸载插件
|
||||
|
||||
首先,列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
之后将焦点置于正确的一行上,敲 **" SHITF+d"** 组合键。
|
||||
之后将焦点置于正确的一行上,按下 `SHITF+d` 组合键。
|
||||
|
||||
[![][1]][8]
|
||||
![][8]
|
||||
|
||||
然后编辑你的 `.vimrc` 文件:
|
||||
|
||||
然后编辑你的 .vimrc 文件:
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
再然后删除插件入口。最后,键入 **:wq** 保存退出。
|
||||
删除插件入口。最后,键入 `:wq` 保存退出。
|
||||
|
||||
或者,你可以通过移除插件所在 `.vimrc` 文件行,并且执行下列命令,卸载插件:
|
||||
|
||||
或者,你可以通过移除插件所在 .vimrc 文件行,并且执行下列命令,卸载插件:
|
||||
```
|
||||
:PluginClean
|
||||
```
|
||||
|
||||
这个命令将会移除所有不在你的 .vimrc 文件中但是存在于 bundle 目录中的插件。
|
||||
这个命令将会移除所有不在你的 `.vimrc` 文件中但是存在于 bundle 目录中的插件。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 Vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
```
|
||||
:h vundle
|
||||
```
|
||||
|
||||
**捎带看看:**
|
||||
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注 OSTechNix!
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注!
|
||||
|
||||
干杯!
|
||||
|
||||
**来源:**
|
||||
### 资源
|
||||
|
||||
[Vundle GitHub 仓库][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -236,16 +258,17 @@ via: https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png ()
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png
|
||||
[9]:https://github.com/VundleVim/Vundle.vim
|
||||
98
sources/talk/20180214 11 awesome vi tips and tricks.md
Normal file
98
sources/talk/20180214 11 awesome vi tips and tricks.md
Normal file
@ -0,0 +1,98 @@
|
||||
11 awesome vi tips and tricks
|
||||
======
|
||||
|
||||

|
||||
|
||||
The [vi editor][1] is one of the most popular text editors on Unix and Unix-like systems, such as Linux. Whether you're new to vi or just looking for a refresher, these 11 tips will enhance how you use it.
|
||||
|
||||
### Editing
|
||||
|
||||
Editing a long script can be tedious, especially when you need to edit a line so far down that it would take hours to scroll to it. Here's a faster way.
|
||||
|
||||
1. The command `:set number` numbers each line down the left side.
|
||||
|
||||

|
||||
|
||||
You can directly reach line number 26 by opening the file and entering this command on the CLI: `vi +26 sample.txt`. To edit line 26 (for example), the command `:26` will take you directly to it.
|
||||
|
||||

|
||||
|
||||
### Fast navigation
|
||||
|
||||
2. `i` changes your mode from "command" to "insert" and starts inserting text at the current cursor position.
|
||||
3. `a` does the same, except it starts just after the current cursor position.
|
||||
4. `o` starts the cursor position from the line below the current cursor position.
|
||||
|
||||
|
||||
|
||||
### Delete
|
||||
|
||||
If you notice an error or typo, being able to make a quick fix is important. Good thing vi has it all figured out.
|
||||
|
||||
Understanding vi's delete function so you don't accidentally press a key and permanently remove a line, paragraph, or more, is critical.
|
||||
|
||||
5. `x` deletes the character under the cursor.
|
||||
6. `dd` deletes the current line. (Yes, the whole line!)
|
||||
|
||||
|
||||
|
||||
Here's the scary part: `30dd` would delete 30 lines starting with the current line! Proceed with caution when using this command.
|
||||
|
||||
### Search
|
||||
|
||||
You can search for keywords from the "command" mode rather than manually navigating and looking for a specific word in a plethora of text.
|
||||
|
||||
7. `:/<keyword>` searches for the word mentioned in the `< >` space and takes your cursor to the first match.
|
||||
8. To navigate to the next instance of that word, type `n`, and keep pressing it until you get to the match you're looking for.
|
||||
|
||||
|
||||
|
||||
For example, in the image below I searched for `ssh`, and vi highlighted the beginning of the first result.
|
||||
|
||||

|
||||
|
||||
After I pressed `n`, vi highlighted the next instance.
|
||||
|
||||

|
||||
|
||||
### Save and exit
|
||||
|
||||
Developers (and others) will probably find this next command useful.
|
||||
|
||||
9. `:x` saves your work and exits vi.
|
||||
|
||||

|
||||
|
||||
10. If you think every nanosecond is worth saving, here's a faster way to shift to terminal mode in vi. Instead of pressing `Shift+:` on the keyboard, you can press `Shift+q` (or Q, in caps) to access [Ex mode][2], but this doesn't really make any difference if you just want to save and quit by typing `x` (as shown above).
|
||||
|
||||
|
||||
|
||||
### Substitution
|
||||
|
||||
Here is a neat trick if you want to substitute every occurrence of one word with another. For example, if you want to substitute "desktop" with "laptop" in a large file, it would be monotonous and waste time to search for each occurrence of "desktop," delete it, and type "laptop."
|
||||
|
||||
11. The command `:%s/desktop/laptop/g` would replace each occurrence of "desktop" with "laptop" throughout the file; it works just like the Linux `sed` command.
|
||||
|
||||
|
||||
|
||||
In this example, I replaced "root" with "user":
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
These tricks should help anyone get started using vi. Are there other neat tips I missed? Share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/top-11-vi-tips-and-tricks
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:http://ex-vi.sourceforge.net/
|
||||
[2]:https://en.wikibooks.org/wiki/Learning_the_vi_Editor/Vim/Modes#Ex-mode
|
||||
@ -0,0 +1,53 @@
|
||||
Beyond metrics: How to operate as team on today's open source project
|
||||
======
|
||||
|
||||

|
||||
|
||||
How do we traditionally think about community health and vibrancy?
|
||||
|
||||
We might quickly zero in on metrics related primarily to code contributions: How many companies are contributing? How many individuals? How many lines of code? Collectively, these speak to both the level of development activity and the breadth of the contributor base. The former speaks to whether the project continues to be enhanced and expanded; the latter to whether it has attracted a diverse group of developers or is controlled primarily by a single organization.
|
||||
|
||||
The [Linux Kernel Development Report][1] tracks these kinds of statistics and, unsurprisingly, it appears extremely healthy on all counts.
|
||||
|
||||
However, while development cadence and code contributions are still clearly important, other aspects of the open source communities are also coming to the forefront. This is in part because, increasingly, open source is about more than a development model. It’s also about making it easier for users and other interested parties to interact in ways that go beyond being passive recipients of code. Of course, there have long been user groups. But open source streamlines the involvement of users, just as it does software development.
|
||||
|
||||
This was the topic of my discussion with Diane Mueller, the director of community development for OpenShift.
|
||||
|
||||
When OpenShift became a container platform based in part on Kubernetes in version 3, Mueller saw a need to broaden the community beyond the core code contributors. In part, this was because OpenShift was increasingly touching a broad range of open source projects and organizations such those associated with the [Open Container Initiative (OCI)][2] and the [Cloud Native Computing Foundation (CNCF)][3]. In addition to users, cloud service providers who were offering managed services also wanted ways to get involved in the project.
|
||||
|
||||
“What we tried to do was open up our minds about what the community constituted,” Mueller explained, adding, “We called it the [Commons][4] because Red Hat's near Boston, and I'm from that area. Boston Common is a shared resource, the grass where you bring your cows to graze, and you have your farmer's hipster market or whatever it is today that they do on Boston Common.”
|
||||
|
||||
This new model, she said, was really “a new ecosystem that incorporated all of those different parties and different perspectives. We used a lot of virtual tools, a lot of new tools like Slack. We stepped up beyond the mailing list. We do weekly briefings. We went very virtual because, one, I don't scale. The Evangelist and Dev Advocate team didn't scale. We need to be able to get all that word out there, all this new information out there, so we went very virtual. We worked with a lot of people to create online learning stuff, a lot of really good tooling, and we had a lot of community help and support in doing that.”
|
||||
|
||||
![diane mueller open shift][6]
|
||||
|
||||
Diane Mueller, director of community development at Open Shift, discusses the role of strong user communities in open source software development. (Credit: Gordon Haff, CC BY-SA 4.0)
|
||||
|
||||
However, one interesting aspect of the Commons model is that it isn’t just virtual. We see the same pattern elsewhere in many successful open source communities, such as the Linux kernel. Lots of day-to-day activities happen on mailings lists, IRC, and other collaboration tools. But this doesn’t eliminate the benefits of face-to-face time that allows for both richer and informal discussions and exchanges.
|
||||
|
||||
This interview with Mueller took place in London the day after the [OpenShift Commons Gathering][7]. Gatherings are full-day events, held a number of times a year, which are typically attended by a few hundred people. Much of the focus is on users and user stories. In fact, Mueller notes, “Here in London, one of the Commons members, Secnix, was really the major reason we actually hosted the gathering here. Justin Cook did an amazing job organizing the venue and helping us pull this whole thing together in less than 50 days. A lot of the community gatherings and things are driven by the Commons members.”
|
||||
|
||||
Mueller wants to focus on users more and more. “The OpenShift Commons gathering at [Red Hat] Summit will be almost entirely case studies,” she noted. “Users talking about what's in their stack. What lessons did they learn? What are the best practices? Sharing those ideas that they've done just like we did here in London.”
|
||||
|
||||
Although the Commons model grew out of some specific OpenShift needs at the time it was created, Mueller believes it’s an approach that can be applied more broadly. “I think if you abstract what we've done, you can apply it to any existing open source community,” she said. “The foundations still, in some ways, play a nice role in giving you some structure around governance, and helping incubate stuff, and helping create standards. I really love what OCI is doing to create standards around containers. There's still a role for that in some ways. I think the lesson that we can learn from the experience and we can apply to other projects is to open up the community so that it includes feedback mechanisms and gives the podium away.”
|
||||
|
||||
The evolution of the community model though approaches like the OpenShift Commons mirror the healthy evolution of open source more broadly. Certainly, some users have been involved in the development of open source software for a long time. What’s striking today is how widespread and pervasive direct user participation has become. Sure, open source remains central to much of modern software development. But it’s also becoming increasingly central to how users learn from each other and work together with their partners and developers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-communities-are-evolving
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://www.linuxfoundation.org/2017-linux-kernel-report-landing-page/
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://www.cncf.io/
|
||||
[4]:https://commons.openshift.org/
|
||||
[5]:/file/388586
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/39369010275_7df2c3c260_z.jpg?itok=gIhnBl6F (diane mueller open shift)
|
||||
[7]:https://www.meetup.com/London-OpenShift-User-Group/events/246498196/
|
||||
75
sources/talk/20180303 4 meetup ideas- Make your data open.md
Normal file
75
sources/talk/20180303 4 meetup ideas- Make your data open.md
Normal file
@ -0,0 +1,75 @@
|
||||
4 meetup ideas: Make your data open
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Open Data Day][1] (ODD) is an annual, worldwide celebration of open data and an opportunity to show the importance of open data in improving our communities.
|
||||
|
||||
Not many individuals and organizations know about the meaningfulness of open data or why they might want to liberate their data from the restrictions of copyright, patents, and more. They also don't know how to make their data open—that is, publicly available for anyone to use, share, or republish with modifications.
|
||||
|
||||
This year ODD falls on Saturday, March 3, and there are [events planned][2] in every continent except Antarctica. While it might be too late to organize an event for this year, it's never too early to plan for next year. Also, since open data is important every day of the year, there's no reason to wait until ODD 2019 to host an event in your community.
|
||||
|
||||
There are many ways to build local awareness of open data. Here are four ideas to help plan an excellent open data event any time of year.
|
||||
|
||||
### 1. Organize an entry-level event
|
||||
|
||||
You can host an educational event at a local library, college, or another public venue about how open data can be used and why it matters for all of us. If possible, invite a [local speaker][3] or have someone present remotely. You could also have a roundtable discussion with several knowledgeable people in your community.
|
||||
|
||||
Consider offering resources such as the [Open Data Handbook][4], which not only provides a guide to the philosophy and rationale behind adopting open data, but also offers case studies, use cases, how-to guides, and other material to support making data open.
|
||||
|
||||
### 2. Organize an advanced-level event
|
||||
|
||||
For a deeper experience, organize a hands-on training event for open data newbies. Ideas for good topics include [training teachers on open science][5], [creating audiovisual expressions from open data][6], and using [open government data][7] in meaningful ways.
|
||||
|
||||
The options are endless. To choose a topic, think about what is locally relevant, identify issues that open data might be able to address, and find people who can do the training.
|
||||
|
||||
### 3. Organize a hackathon
|
||||
|
||||
Open data hackathons can be a great way to bring open data advocates, developers, and enthusiasts together under one roof. Hackathons are more than just training sessions, though; the idea is to build prototypes or solve real-life challenges that are tied to open data. In a hackathon, people in various groups can contribute to the entire assembly line in multiple ways, such as identifying issues by working collaboratively through [Etherpad][8] or creating focus groups.
|
||||
|
||||
Once the hackathon is over, make sure to upload all the useful data that is produced to the internet with an open license.
|
||||
|
||||
### 4. Release or relicense data as open
|
||||
|
||||
Open data is about making meaningful data publicly available under open licenses while protecting any data that might put people's private information at risk. (Learn [how to protect private data][9].) Try to find existing, interesting, and useful data that is privately owned by individuals or organizations and negotiate with them to relicense or release the data online under any of the [recommended open data licenses][10]. The widely popular [Creative Commons licenses][11] (particularly the CC0 license and the 4.0 licenses) are quite compatible with relicensing public data. (See this FAQ from Creative Commons for more information on [openly licensing data][12].)
|
||||
|
||||
Open data can be published on multiple platforms—your website, [GitHub][13], [GitLab][14], [DataHub.io][15], or anywhere else that supports open standards.
|
||||
|
||||
### Tips for event success
|
||||
|
||||
No matter what type of event you decide to do, here are some general planning tips to improve your chances of success.
|
||||
|
||||
* Find a venue that's accessible to the people you want to reach, such as a library, a school, or a community center.
|
||||
* Create a curriculum that will engage the participants.
|
||||
* Invite your target audience—make sure to distribute information through social media, community events calendars, Meetup, and the like.
|
||||
|
||||
|
||||
|
||||
Have you attended or hosted a successful open data event? If so, please share your ideas in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/celebrate-open-data-day
|
||||
|
||||
作者:[Subhashish Panigraphi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psubhashish
|
||||
[1]:http://www.opendataday.org/
|
||||
[2]:http://opendataday.org/#map
|
||||
[3]:https://openspeakers.org/
|
||||
[4]:http://opendatahandbook.org/
|
||||
[5]:https://docs.google.com/forms/d/1BRsyzlbn8KEMP8OkvjyttGgIKuTSgETZW9NHRtCbT1s/viewform?edit_requested=true
|
||||
[6]:http://dattack.lv/en/
|
||||
[7]:https://www.eventbrite.co.nz/e/open-data-open-potential-event-friday-2-march-2018-tickets-42733708673
|
||||
[8]:http://etherpad.org/
|
||||
[9]:https://ssd.eff.org/en/module/keeping-your-data-safe
|
||||
[10]:https://opendatacommons.org/licenses/
|
||||
[11]:https://creativecommons.org/share-your-work/licensing-types-examples/
|
||||
[12]:https://wiki.creativecommons.org/wiki/Data#Frequently_asked_questions_about_data_and_CC_licenses
|
||||
[13]:https://github.com/MartinBriza/MediaWriter
|
||||
[14]:https://about.gitlab.com/
|
||||
[15]:https://datahub.io/
|
||||
@ -1,215 +0,0 @@
|
||||
translating by imquanquan
|
||||
|
||||
9 Lightweight Linux Applications to Speed Up Your System
|
||||
======
|
||||
**Brief:** One of the many ways to [speed up Ubuntu][1] system is to use lightweight alternatives of the popular applications. We have already seen [must have Linux application][2] earlier. we'll see the lightweight alternative applications for Ubuntu and other Linux distributions.
|
||||
|
||||
![Use these Lightweight alternative applications in Ubuntu Linux][4]
|
||||
|
||||
## 9 Lightweight alternatives of popular Linux applications
|
||||
|
||||
Is your Linux system slow? Are the applications taking a long time to open? The best option you have is to use a [light Linux distro][5]. But it's not always possible to reinstall an operating system, is it?
|
||||
|
||||
So if you want to stick to your present Linux distribution, but want improved performance, you should use lightweight alternatives of the applications you are using. Here, I'm going to put together a small list of lightweight alternatives to various Linux applications.
|
||||
|
||||
Since I am using Ubuntu, I have provided installation instructions for Ubuntu-based Linux distributions. But these applications will work on almost all other Linux distribution. You just have to find a way to install these lightweight Linux software in your distro.
|
||||
|
||||
### 1. Midori: Web Browser
|
||||
|
||||
Midori is one of the most lightweight web browsers that have reasonable compatibility with the modern web. It is open source and uses the same rendering engine that Google Chrome was initially built on -- WebKit. It is super fast and minimal yet highly customizable.
|
||||
|
||||
![Midori Browser][6]
|
||||
|
||||
It has plenty of extensions and options to tinker with. So if you are a power user, it's a great choice for you too. If you face any problems browsing round the web, check the [Frequently Asked Question][7] section of their website -- it contains the common problems you might face along with their solution.
|
||||
|
||||
[Midori][8]
|
||||
|
||||
#### Installing Midori on Ubuntu based distributions
|
||||
|
||||
Midori is available on Ubuntu via the official repository. Just run the following commands for installing it:
|
||||
```
|
||||
sudo apt install midori
|
||||
```
|
||||
|
||||
### 2. Trojita: email client
|
||||
|
||||
Trojita is an open source robust IMAP e-mail client. It is fast and resource efficient. I can certainly call it one of the [best email clients for Linux][9]. If you can live with only IMAP support on your e-mail client, you might not want to look any further.
|
||||
|
||||
![Trojitá][10]
|
||||
|
||||
Trojita uses various techniques -- on-demand e-mail loading, offline caching, bandwidth-saving mode etc. -- for achieving its impressive performance.
|
||||
|
||||
[Trojita][11]
|
||||
|
||||
#### Installing Trojita on Ubuntu based distributions
|
||||
|
||||
Trojita currently doesn't have an official PPA for Ubuntu. But that shouldn't be a problem. You can install it quite easily using the following commands:
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
|
||||
wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
|
||||
sudo apt-key add - < Release.key
|
||||
sudo apt update
|
||||
sudo apt install trojita
|
||||
```
|
||||
|
||||
### 3. GDebi: Package Installer
|
||||
|
||||
Sometimes you need to quickly install DEB packages. Ubuntu Software Center is a resource-heavy application and using it just for installing .deb files is not wise.
|
||||
|
||||
Gdebi is certainly a nifty tool for the same purpose, just with a minimal graphical interface.
|
||||
|
||||
![GDebi][12]
|
||||
|
||||
GDebi is totally lightweight and does its job flawlessly. You should even [make Gdebi the default installer for DEB files][13].
|
||||
|
||||
#### Installing GDebi on Ubuntu based distributions
|
||||
|
||||
You can install GDebi on Ubuntu with this simple one-liner:
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
### 4. App Grid: Software Center
|
||||
|
||||
If you use software center frequently for searching, installing and managing applications on Ubuntu, App Grid is a must have application. It is the most visually appealing and yet fast alternative to the default Ubuntu Software Center.
|
||||
|
||||
![App Grid][14]
|
||||
|
||||
App Grid supports ratings, reviews and screenshots for applications.
|
||||
|
||||
[App Grid][15]
|
||||
|
||||
#### Installing App Grid on Ubuntu based distributions
|
||||
|
||||
App Grid has its official PPA for Ubuntu. Use the following commands for installing App Grid:
|
||||
```
|
||||
sudo add-apt-repository ppa:appgrid/stable
|
||||
sudo apt update
|
||||
sudo apt install appgrid
|
||||
```
|
||||
|
||||
### 5. Yarock: Music Player
|
||||
|
||||
Yarock is an elegant music player with a modern and minimal user interface. It is lightweight in design and yet it has a comprehensive list of advanced features.
|
||||
|
||||
![Yarock][16]
|
||||
|
||||
The main features of Yarock include multiple music collections, rating, smart playlist, multiple back-end option, desktop notification, scrobbling, context fetching etc.
|
||||
|
||||
[Yarock][17]
|
||||
|
||||
#### Installing Yarock on Ubuntu based distributions
|
||||
|
||||
You will have to install Yarock on Ubuntu via PPA using the following commands:
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
sudo apt update
|
||||
sudo apt install yarock
|
||||
```
|
||||
|
||||
### 6. VLC: Video Player
|
||||
|
||||
Who doesn't need a video player? And who has never heard about VLC? It doesn't really need any introduction.
|
||||
|
||||
![VLC][18]
|
||||
|
||||
VLC is all you need to play various media files on Ubuntu and it is quite lightweight too. It works flawlessly on even on very old PCs.
|
||||
|
||||
[VLC][19]
|
||||
|
||||
#### Installing VLC on Ubuntu based distributions
|
||||
|
||||
VLC has official PPA for Ubuntu. Enter the following commands for installing it:
|
||||
```
|
||||
sudo apt install vlc
|
||||
```
|
||||
|
||||
### 7. PCManFM: File Manager
|
||||
|
||||
PCManFM is the standard file manager from LXDE. As with the other applications from LXDE, this one too is lightweight. If you are looking for a lighter alternative for your file manager, try this one.
|
||||
|
||||
![PCManFM][20]
|
||||
|
||||
Although coming from LXDE, PCManFM works with other desktop environments just as well.
|
||||
|
||||
#### Installing PCManFM on Ubuntu based distributions
|
||||
|
||||
Installing PCManFM on Ubuntu will just take one simple command:
|
||||
```
|
||||
sudo apt install pcmanfm
|
||||
```
|
||||
|
||||
### 8. Mousepad: Text Editor
|
||||
|
||||
Nothing can beat command-line text editors like - nano, vim etc. in terms of being lightweight. But if you want a graphical interface, here you go -- Mousepad is a minimal text editor. It's extremely lightweight and blazing fast. It comes with a simple customizable user interface with multiple themes.
|
||||
|
||||
![Mousepad][21]
|
||||
|
||||
Mousepad supports syntax highlighting. So, you can also use it as a basic code editor.
|
||||
|
||||
#### Installing Mousepad on Ubuntu based distributions
|
||||
|
||||
For installing Mousepad use the following command:
|
||||
```
|
||||
sudo apt install mousepad
|
||||
```
|
||||
|
||||
### 9. GNOME Office: Office Suite
|
||||
|
||||
Many of us need to use office applications quite often. Generally, most of the office applications are bulky in size and resource hungry. Gnome Office is quite lightweight in that respect. Gnome Office is technically not a complete office suite. It's composed of different standalone applications and among them, **AbiWord** & **Gnumeric** stands out.
|
||||
|
||||
**AbiWord** is the word processor. It is lightweight and a lot faster than other alternatives. But that came to be at a cost -- you might miss some features like macros, grammar checking etc. It's not perfect but it works.
|
||||
|
||||
![AbiWord][22]
|
||||
|
||||
**Gnumeric** is the spreadsheet editor. Just like AbiWord, Gnumeric is also very fast and it provides accurate calculations. If you are looking for a simple and lightweight spreadsheet editor, Gnumeric has got you covered.
|
||||
|
||||
![Gnumeric][23]
|
||||
|
||||
There are some other applications listed under Gnome Office. You can find them in the official page.
|
||||
|
||||
[Gnome Office][24]
|
||||
|
||||
#### Installing AbiWord & Gnumeric on Ubuntu based distributions
|
||||
|
||||
For installing AbiWord & Gnumeric, simply enter the following command in your terminal:
|
||||
```
|
||||
sudo apt install abiword gnumeric
|
||||
```
|
||||
|
||||
That's all for today. Would you like to add some other **lightweight Linux applications** to this list? Do let us know!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
|
||||
[5]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
|
||||
[7]:http://midori-browser.org/faqs/
|
||||
[8]:http://midori-browser.org/
|
||||
[9]:https://itsfoss.com/best-email-clients-linux/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Trojit%C3%A1-800x608.png
|
||||
[11]:http://trojita.flaska.net/
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
|
||||
[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
|
||||
[15]:http://www.appgrid.org/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
|
||||
[17]:https://seb-apps.github.io/yarock/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
|
||||
[19]:http://www.videolan.org/index.html
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
|
||||
[24]:https://gnome.org/gnome-office/
|
||||
@ -0,0 +1,256 @@
|
||||
Build a bikesharing app with Redis and Python
|
||||
======
|
||||
|
||||

|
||||
|
||||
I travel a lot on business. I'm not much of a car guy, so when I have some free time, I prefer to walk or bike around a city. Many of the cities I've visited on business have bikeshare systems, which let you rent a bike for a few hours. Most of these systems have an app to help users locate and rent their bikes, but it would be more helpful for users like me to have a single place to get information on all the bikes in a city that are available to rent.
|
||||
|
||||
To solve this problem and demonstrate the power of open source to add location-aware features to a web application, I combined publicly available bikeshare data, the [Python][1] programming language, and the open source [Redis][2] in-memory data structure server to index and query geospatial data.
|
||||
|
||||
The resulting bikeshare application incorporates data from many different sharing systems, including the [Citi Bike][3] bikeshare in New York City. It takes advantage of the General Bikeshare Feed provided by the Citi Bike system and uses its data to demonstrate some of the features that can be built using Redis to index geospatial data. The Citi Bike data is provided under the [Citi Bike data license agreement][4].
|
||||
|
||||
### General Bikeshare Feed Specification
|
||||
|
||||
The General Bikeshare Feed Specification (GBFS) is an [open data specification][5] developed by the [North American Bikeshare Association][6] to make it easier for map and transportation applications to add bikeshare systems into their platforms. The specification is currently in use by over 60 different sharing systems in the world.
|
||||
|
||||
The feed consists of several simple [JSON][7] data files containing information about the state of the system. The feed starts with a top-level JSON file referencing the URLs of the sub-feed data:
|
||||
```
|
||||
{
|
||||
|
||||
"data": {
|
||||
|
||||
"en": {
|
||||
|
||||
"feeds": [
|
||||
|
||||
{
|
||||
|
||||
"name": "system_information",
|
||||
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/system_information.json"
|
||||
|
||||
},
|
||||
|
||||
{
|
||||
|
||||
"name": "station_information",
|
||||
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
|
||||
|
||||
},
|
||||
|
||||
. . .
|
||||
|
||||
]
|
||||
|
||||
}
|
||||
|
||||
},
|
||||
|
||||
"last_updated": 1506370010,
|
||||
|
||||
"ttl": 10
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The first step is loading information about the bikesharing stations into Redis using data from the `system_information` and `station_information` feeds.
|
||||
|
||||
The `system_information` feed provides the system ID, which is a short code that can be used to create namespaces for Redis keys. The GBFS spec doesn't specify the format of the system ID, but does guarantee it is globally unique. Many of the bikeshare feeds use short names like coast_bike_share, boise_greenbike, or topeka_metro_bikes for system IDs. Others use familiar geographic abbreviations such as NYC or BA, and one uses a universally unique identifier (UUID). The bikesharing application uses the identifier as a prefix to construct unique keys for the given system.
|
||||
|
||||
The `station_information` feed provides static information about the sharing stations that comprise the system. Stations are represented by JSON objects with several fields. There are several mandatory fields in the station object that provide the ID, name, and location of the physical bike stations. There are also several optional fields that provide helpful information such as the nearest cross street or accepted payment methods. This is the primary source of information for this part of the bikesharing application.
|
||||
|
||||
### Building the database
|
||||
|
||||
I've written a sample application, [load_station_data.py][8], that mimics what would happen in a backend process for loading data from external sources.
|
||||
|
||||
### Finding the bikeshare stations
|
||||
|
||||
Loading the bikeshare data starts with the [systems.csv][9] file from the [GBFS repository on GitHub][5].
|
||||
|
||||
The repository's [systems.csv][9] file provides the discovery URL for registered bikeshare systems with an available GBFS feed. The discovery URL is the starting point for processing bikeshare information.
|
||||
|
||||
The `load_station_data` application takes each discovery URL found in the systems file and uses it to find the URL for two sub-feeds: system information and station information. The system information feed provides a key piece of information: the unique ID of the system. (Note: the system ID is also provided in the systems.csv file, but some of the identifiers in that file do not match the identifiers in the feeds, so I always fetch the identifier from the feed.) Details on the system, like bikeshare URLs, phone numbers, and emails, could be added in future versions of the application, so the data is stored in a Redis hash using the key `${system_id}:system_info`.
|
||||
|
||||
### Loading the station data
|
||||
|
||||
The station information provides data about every station in the system, including the system's location. The `load_station_data` application iterates over every station in the station feed and stores the data about each into a Redis hash using a key of the form `${system_id}:station:${station_id}`. The location of each station is added to a geospatial index for the bikeshare using the `GEOADD` command.
|
||||
|
||||
### Updating data
|
||||
|
||||
On subsequent runs, I don't want the code to remove all the feed data from Redis and reload it into an empty Redis database, so I carefully considered how to handle in-place updates of the data.
|
||||
|
||||
The code starts by loading the dataset with information on all the bikesharing stations for the system being processed into memory. When information is loaded for a station, the station (by key) is removed from the in-memory set of stations. Once all station data is loaded, we're left with a set containing all the station data that must be removed for that system.
|
||||
|
||||
The application iterates over this set of stations and creates a transaction to delete the station information, remove the station key from the geospatial indexes, and remove the station from the list of stations for the system.
|
||||
|
||||
### Notes on the code
|
||||
|
||||
There are a few interesting things to note in [the sample code][8]. First, items are added to the geospatial indexes using the `GEOADD` command but removed with the `ZREM` command. As the underlying implementation of the geospatial type uses sorted sets, items are removed using `ZREM`. A word of caution: For simplicity, the sample code demonstrates working with a single Redis node; the transaction blocks would need to be restructured to run in a cluster environment.
|
||||
|
||||
If you are using Redis 4.0 (or later), you have some alternatives to the `DELETE` and `HMSET` commands in the code. Redis 4.0 provides the [`UNLINK`][10] command as an asynchronous alternative to the `DELETE` command. `UNLINK` will remove the key from the keyspace, but it reclaims the memory in a separate thread. The [`HMSET`][11] command is [deprecated in Redis 4.0 and the `HSET` command is now variadic][12] (that is, it accepts an indefinite number of arguments).
|
||||
|
||||
### Notifying clients
|
||||
|
||||
At the end of the process, a notification is sent to the clients relying on our data. Using the Redis pub/sub mechanism, the notification goes out over the `geobike:station_changed` channel with the ID of the system.
|
||||
|
||||
### Data model
|
||||
|
||||
When structuring data in Redis, the most important thing to think about is how you will query the information. The two main queries the bikeshare application needs to support are:
|
||||
|
||||
* Find stations near us
|
||||
* Display information about stations
|
||||
|
||||
|
||||
|
||||
Redis provides two main data types that will be useful for storing our data: hashes and sorted sets. The [hash type][13] maps well to the JSON objects that represent stations; since Redis hashes don't enforce a schema, they can be used to store the variable station information.
|
||||
|
||||
Of course, finding stations geographically requires a geospatial index to search for stations relative to some coordinates. Redis provides [several commands][14] to build up a geospatial index using the [sorted set][15] data structure.
|
||||
|
||||
We construct keys using the format `${system_id}:station:${station_id}` for the hashes containing information about the stations and keys using the format `${system_id}:stations:location` for the geospatial index used to find stations.
|
||||
|
||||
### Getting the user's location
|
||||
|
||||
The next step in building out the application is to determine the user's current location. Most applications accomplish this through built-in services provided by the operating system. The OS can provide applications with a location based on GPS hardware built into the device or approximated from the device's available WiFi networks.
|
||||
|
||||
|
||||
|
||||
### Finding stations
|
||||
|
||||
After the user's location is found, the next step is locating nearby bikesharing stations. Redis' geospatial functions can return information on stations within a given distance of the user's current coordinates. Here's an example of this using the Redis command-line interface.
|
||||
|
||||
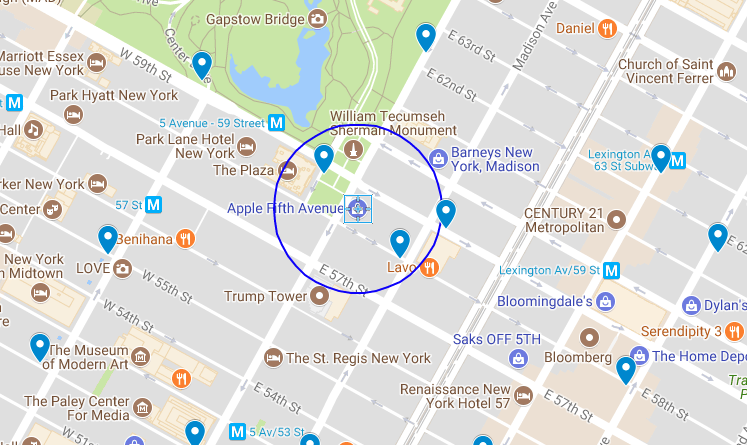
Imagine I'm at the Apple Store on Fifth Avenue in New York City, and I want to head downtown to Mood on West 37th to catch up with my buddy [Swatch][16]. I could take a taxi or the subway, but I'd rather bike. Are there any nearby sharing stations where I could get a bike for my trip?
|
||||
|
||||
The Apple store is located at 40.76384, -73.97297. According to the map, two bikeshare stations—Grand Army Plaza & Central Park South and East 58th St. & Madison—fall within a 500-foot radius (in blue on the map above) of the store.
|
||||
|
||||
I can use Redis' `GEORADIUS` command to query the NYC system index for stations within a 500-foot radius:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft
|
||||
|
||||
1) "NYC:station:3457"
|
||||
|
||||
2) "NYC:station:281"
|
||||
|
||||
```
|
||||
|
||||
Redis returns the two bikeshare locations found within that radius, using the elements in our geospatial index as the keys for the metadata about a particular station. The next step is looking up the names for the two stations:
|
||||
```
|
||||
127.0.0.1:6379> hget NYC:station:281 name
|
||||
|
||||
"Grand Army Plaza & Central Park S"
|
||||
|
||||
|
||||
|
||||
127.0.0.1:6379> hget NYC:station:3457 name
|
||||
|
||||
"E 58 St & Madison Ave"
|
||||
|
||||
```
|
||||
|
||||
Those keys correspond to the stations identified on the map above. If I want, I can add more flags to the `GEORADIUS` command to get a list of elements, their coordinates, and their distance from our current point:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft WITHDIST WITHCOORD ASC
|
||||
|
||||
1) 1) "NYC:station:281"
|
||||
|
||||
2) "289.1995"
|
||||
|
||||
3) 1) "-73.97371262311935425"
|
||||
|
||||
2) "40.76439830559216659"
|
||||
|
||||
2) 1) "NYC:station:3457"
|
||||
|
||||
2) "383.1782"
|
||||
|
||||
3) 1) "-73.97209256887435913"
|
||||
|
||||
2) "40.76302702144496237"
|
||||
|
||||
```
|
||||
|
||||
Looking up the names associated with those keys generates an ordered list of stations I can choose from. Redis doesn't provide directions or routing capability, so I use the routing features of my device's OS to plot a course from my current location to the selected bike station.
|
||||
|
||||
The `GEORADIUS` function can be easily implemented inside an API in your favorite development framework to add location functionality to an app.
|
||||
|
||||
### Other query commands
|
||||
|
||||
In addition to the `GEORADIUS` command, Redis provides three other commands for querying data from the index: `GEOPOS`, `GEODIST`, and `GEORADIUSBYMEMBER`.
|
||||
|
||||
The `GEOPOS` command can provide the coordinates for a given element from the geohash. For example, if I know there is a bikesharing station at West 38th and 8th and its ID is 523, then the element name for that station is NYC🚉523. Using Redis, I can find the station's longitude and latitude:
|
||||
```
|
||||
127.0.0.1:6379> geopos NYC:stations:location NYC:station:523
|
||||
|
||||
1) 1) "-73.99138301610946655"
|
||||
|
||||
2) "40.75466497634030105"
|
||||
|
||||
```
|
||||
|
||||
The `GEODIST` command provides the distance between two elements of the index. If I wanted to find the distance between the station at Grand Army Plaza & Central Park South and the station at East 58th St. & Madison, I would issue the following command:
|
||||
```
|
||||
127.0.0.1:6379> GEODIST NYC:stations:location NYC:station:281 NYC:station:3457 ft
|
||||
|
||||
"671.4900"
|
||||
|
||||
```
|
||||
|
||||
Finally, the `GEORADIUSBYMEMBER` command is similar to the `GEORADIUS` command, but instead of taking a set of coordinates, the command takes the name of another member of the index and returns all the members within a given radius centered on that member. To find all the stations within 1,000 feet of the Grand Army Plaza & Central Park South, enter the following:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUSBYMEMBER NYC:stations:location NYC:station:281 1000 ft WITHDIST
|
||||
|
||||
1) 1) "NYC:station:281"
|
||||
|
||||
2) "0.0000"
|
||||
|
||||
2) 1) "NYC:station:3132"
|
||||
|
||||
2) "793.4223"
|
||||
|
||||
3) 1) "NYC:station:2006"
|
||||
|
||||
2) "911.9752"
|
||||
|
||||
4) 1) "NYC:station:3136"
|
||||
|
||||
2) "940.3399"
|
||||
|
||||
5) 1) "NYC:station:3457"
|
||||
|
||||
2) "671.4900"
|
||||
|
||||
```
|
||||
|
||||
While this example focused on using Python and Redis to parse data and build an index of bikesharing system locations, it can easily be generalized to locate restaurants, public transit, or any other type of place developers want to help users find.
|
||||
|
||||
This article is based on [my presentation][17] at Open Source 101 in Raleigh this year.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools
|
||||
|
||||
作者:[Tague Griffith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tague
|
||||
[1]:https://www.python.org/
|
||||
[2]:https://redis.io/
|
||||
[3]:https://www.citibikenyc.com/
|
||||
[4]:https://www.citibikenyc.com/data-sharing-policy
|
||||
[5]:https://github.com/NABSA/gbfs
|
||||
[6]:http://nabsa.net/
|
||||
[7]:https://www.json.org/
|
||||
[8]:https://gist.github.com/tague/5a82d96bcb09ce2a79943ad4c87f6e15
|
||||
[9]:https://github.com/NABSA/gbfs/blob/master/systems.csv
|
||||
[10]:https://redis.io/commands/unlink
|
||||
[11]:https://redis.io/commands/hmset
|
||||
[12]:https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES
|
||||
[13]:https://redis.io/topics/data-types#Hashes
|
||||
[14]:https://redis.io/commands#geo
|
||||
[15]:https://redis.io/topics/data-types-intro#redis-sorted-sets
|
||||
[16]:https://twitter.com/swatchthedog
|
||||
[17]:http://opensource101.com/raleigh/talks/building-location-aware-apps-open-source-tools/
|
||||
@ -0,0 +1,264 @@
|
||||
Check Linux Distribution Name and Version
|
||||
======
|
||||
You have joined new company and want to install some software’s which is requested by DevApp team, also want to restart few of the service after installation. What to do?
|
||||
|
||||
In this situation at least you should know what Distribution & Version is running on it. It will help you perform the activity without any issue.
|
||||
|
||||
Administrator should gather some of the information about the system before doing any activity, which is first task for him.
|
||||
|
||||
There are many ways to find the Linux distribution name and version. You might ask, why i want to know this basic things?
|
||||
|
||||
We have four major distributions such as RHEL, Debian, openSUSE & Arch Linux. Each distribution comes with their own package manager which help us to install packages on the system.
|
||||
|
||||
If you don’t know the distribution name then you wont be able to perform the package installation.
|
||||
|
||||
Also you won’t able to run the proper command for service bounces because most of the distributions implemented systemd command instead of SysVinit script.
|
||||
|
||||
It’s good to have the basic commands which will helps you in many ways.
|
||||
|
||||
Use the following Methods to Check Your Linux Distribution Name and Version.
|
||||
|
||||
### List of methods
|
||||
|
||||
* lsb_release command
|
||||
* /etc/*-release file
|
||||
* uname command
|
||||
* /proc/version file
|
||||
* dmesg Command
|
||||
* YUM or DNF Command
|
||||
* RPM command
|
||||
* APT-GET command
|
||||
|
||||
|
||||
|
||||
### Method-1: lsb_release Command
|
||||
|
||||
LSB stands for Linux Standard Base that prints distribution-specific information such as Distribution name, Release version and codename.
|
||||
```
|
||||
# lsb_release -a
|
||||
No LSB modules are available.
|
||||
Distributor ID: Ubuntu
|
||||
Description: Ubuntu 16.04.3 LTS
|
||||
Release: 16.04
|
||||
Codename: xenial
|
||||
|
||||
```
|
||||
|
||||
### Method-2: /etc/arch-release /etc/os-release File
|
||||
|
||||
release file typically known as Operating system identification. The `/etc` directory contains many files that contains various information about the distribution. Each distribution has their own set of files, which display this information.
|
||||
|
||||
The below set of files are present on Ubuntu/Debian system.
|
||||
```
|
||||
# cat /etc/issue
|
||||
Ubuntu 16.04.3 LTS \n \l
|
||||
|
||||
# cat /etc/issue.net
|
||||
Ubuntu 16.04.3 LTS
|
||||
|
||||
# cat /etc/lsb-release
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=16.04
|
||||
DISTRIB_CODENAME=xenial
|
||||
DISTRIB_DESCRIPTION="Ubuntu 16.04.3 LTS"
|
||||
|
||||
# cat /etc/os-release
|
||||
NAME="Ubuntu"
|
||||
VERSION="16.04.3 LTS (Xenial Xerus)"
|
||||
ID=ubuntu
|
||||
ID_LIKE=debian
|
||||
PRETTY_NAME="Ubuntu 16.04.3 LTS"
|
||||
VERSION_ID="16.04"
|
||||
HOME_URL="http://www.ubuntu.com/"
|
||||
SUPPORT_URL="http://help.ubuntu.com/"
|
||||
BUG_REPORT_URL="http://bugs.launchpad.net/ubuntu/"
|
||||
VERSION_CODENAME=xenial
|
||||
UBUNTU_CODENAME=xenial
|
||||
|
||||
# cat /etc/debian_version
|
||||
9.3
|
||||
|
||||
```
|
||||
|
||||
The below set of files are present on RHEL/CentOS/Fedora system. The `/etc/redhat-release` & `/etc/system-release` files symlinks with `/etc/[distro]-release` file.
|
||||
```
|
||||
# cat /etc/centos-release
|
||||
CentOS release 6.9 (Final)
|
||||
|
||||
# cat /etc/fedora-release
|
||||
Fedora release 27 (Twenty Seven)
|
||||
|
||||
# cat /etc/os-release
|
||||
NAME=Fedora
|
||||
VERSION="27 (Twenty Seven)"
|
||||
ID=fedora
|
||||
VERSION_ID=27
|
||||
PRETTY_NAME="Fedora 27 (Twenty Seven)"
|
||||
ANSI_COLOR="0;34"
|
||||
CPE_NAME="cpe:/o:fedoraproject:fedora:27"
|
||||
HOME_URL="https://fedoraproject.org/"
|
||||
SUPPORT_URL="https://fedoraproject.org/wiki/Communicating_and_getting_help"
|
||||
BUG_REPORT_URL="https://bugzilla.redhat.com/"
|
||||
REDHAT_BUGZILLA_PRODUCT="Fedora"
|
||||
REDHAT_BUGZILLA_PRODUCT_VERSION=27
|
||||
REDHAT_SUPPORT_PRODUCT="Fedora"
|
||||
REDHAT_SUPPORT_PRODUCT_VERSION=27
|
||||
PRIVACY_POLICY_URL="https://fedoraproject.org/wiki/Legal:PrivacyPolicy"
|
||||
|
||||
# cat /etc/redhat-release
|
||||
Fedora release 27 (Twenty Seven)
|
||||
|
||||
# cat /etc/system-release
|
||||
Fedora release 27 (Twenty Seven)
|
||||
|
||||
```
|
||||
|
||||
### Method-3: uname Command
|
||||
|
||||
uname (stands for unix name) is an utility that prints the system information like kernel name, version and other details about the system and the operating system running on it.
|
||||
|
||||
**Suggested Read :** [6 Methods To Check The Running Linux Kernel Version On System][1]
|
||||
```
|
||||
# uname -a
|
||||
Linux localhost.localdomain 4.12.14-300.fc26.x86_64 #1 SMP Wed Sep 20 16:28:07 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
|
||||
|
||||
```
|
||||
|
||||
The above colored words describe the version of operating system as Fedora Core 26.
|
||||
|
||||
### Method-4: /proc/version File
|
||||
|
||||
This file specifies the version of the Linux kernel, the version of gcc used to compile the kernel, and the time of kernel compilation. It also contains the kernel compiler’s user name (in parentheses).
|
||||
```
|
||||
# cat /proc/version
|
||||
Linux version 4.12.14-300.fc26.x86_64 ([email protected]) (gcc version 7.2.1 20170915 (Red Hat 7.2.1-2) (GCC) ) #1 SMP Wed Sep 20 16:28:07 UTC 2017
|
||||
|
||||
```
|
||||
|
||||
### Method-5: dmesg Command
|
||||
|
||||
dmesg (stands for display message or driver message) is a command on most Unix-like operating systems that prints the message buffer of the kernel.
|
||||
```
|
||||
# dmesg | grep "Linux"
|
||||
[ 0.000000] Linux version 4.12.14-300.fc26.x86_64 ([email protected]) (gcc version 7.2.1 20170915 (Red Hat 7.2.1-2) (GCC) ) #1 SMP Wed Sep 20 16:28:07 UTC 2017
|
||||
[ 0.001000] SELinux: Initializing.
|
||||
[ 0.001000] SELinux: Starting in permissive mode
|
||||
[ 0.470288] SELinux: Registering netfilter hooks
|
||||
[ 0.616351] Linux agpgart interface v0.103
|
||||
[ 0.630063] usb usb1: Manufacturer: Linux 4.12.14-300.fc26.x86_64 ehci_hcd
|
||||
[ 0.688949] usb usb2: Manufacturer: Linux 4.12.14-300.fc26.x86_64 ohci_hcd
|
||||
[ 2.564554] SELinux: Disabled at runtime.
|
||||
[ 2.564584] SELinux: Unregistering netfilter hooks
|
||||
|
||||
```
|
||||
|
||||
### Method-6: Yum/Dnf Command
|
||||
|
||||
Yum (Yellowdog Updater Modified) is one of the package manager utility in Linux operating system. Yum command is used to install, update, search & remove packages on some Linux distributions based on RedHat.
|
||||
|
||||
**Suggested Read :** [YUM Command To Manage Packages on RHEL/CentOS Systems][2]
|
||||
```
|
||||
# yum info nano
|
||||
Loaded plugins: fastestmirror, ovl
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: centos.zswap.net
|
||||
* extras: mirror2.evolution-host.com
|
||||
* updates: centos.zswap.net
|
||||
Available Packages
|
||||
Name : nano
|
||||
Arch : x86_64
|
||||
Version : 2.3.1
|
||||
Release : 10.el7
|
||||
Size : 440 k
|
||||
Repo : base/7/x86_64
|
||||
Summary : A small text editor
|
||||
URL : http://www.nano-editor.org
|
||||
License : GPLv3+
|
||||
Description : GNU nano is a small and friendly text editor.
|
||||
|
||||
```
|
||||
|
||||
The below yum repolist command shows that Base, Extras, and Updates repositories are coming from CentOS 7 repository.
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, ovl
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: centos.zswap.net
|
||||
* extras: mirror2.evolution-host.com
|
||||
* updates: centos.zswap.net
|
||||
repo id repo name status
|
||||
base/7/x86_64 CentOS-7 - Base 9591
|
||||
extras/7/x86_64 CentOS-7 - Extras 388
|
||||
updates/7/x86_64 CentOS-7 - Updates 1929
|
||||
repolist: 11908
|
||||
|
||||
```
|
||||
|
||||
We can also use Dnf command to check distribution name and version.
|
||||
|
||||
**Suggested Read :** [DNF (Fork of YUM) Command To Manage Packages on Fedora System][3]
|
||||
```
|
||||
# dnf info nano
|
||||
Last metadata expiration check: 0:01:25 ago on Thu Feb 15 01:59:31 2018.
|
||||
Installed Packages
|
||||
Name : nano
|
||||
Version : 2.8.7
|
||||
Release : 1.fc27
|
||||
Arch : x86_64
|
||||
Size : 2.1 M
|
||||
Source : nano-2.8.7-1.fc27.src.rpm
|
||||
Repo : @System
|
||||
From repo : fedora
|
||||
Summary : A small text editor
|
||||
URL : https://www.nano-editor.org
|
||||
License : GPLv3+
|
||||
Description : GNU nano is a small and friendly text editor.
|
||||
|
||||
```
|
||||
|
||||
### Method-7: RPM Command
|
||||
|
||||
RPM stands for RedHat Package Manager is a powerful, command line Package Management utility for Red Hat based system such as CentOS, Oracle Linux & Fedora. This help us to identify the running system version.
|
||||
|
||||
**Suggested Read :** [RPM commands to manage packages on RHEL based systems][4]
|
||||
```
|
||||
# rpm -q nano
|
||||
nano-2.8.7-1.fc27.x86_64
|
||||
|
||||
```
|
||||
|
||||
### Method-8: APT-GET Command
|
||||
|
||||
Apt-Get stands for Advanced Packaging Tool (APT). apg-get is a powerful command-line tool which is used to automatically download and install new software packages, upgrade existing software packages, update the package list index, and to upgrade the entire Debian based systems.
|
||||
|
||||
**Suggested Read :** [Apt-Get & Apt-Cache commands to manage packages on Debian Based Systems][5]
|
||||
```
|
||||
# apt-cache policy nano
|
||||
nano:
|
||||
Installed: 2.5.3-2ubuntu2
|
||||
Candidate: 2.5.3-2ubuntu2
|
||||
Version table:
|
||||
* 2.5.3-2ubuntu2 500
|
||||
500 http://nova.clouds.archive.ubuntu.com/ubuntu xenial-updates/main amd64 Packages
|
||||
100 /var/lib/dpkg/status
|
||||
2.5.3-2 500
|
||||
500 http://nova.clouds.archive.ubuntu.com/ubuntu xenial/main amd64 Packages
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-find-linux-distribution-name-and-version/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/check-find-determine-running-installed-linux-kernel-version/
|
||||
[2]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[3]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[4]:https://www.2daygeek.com/rpm-command-examples/
|
||||
[5]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
68
sources/tech/20180215 What is a Linux -oops.md
Normal file
68
sources/tech/20180215 What is a Linux -oops.md
Normal file
@ -0,0 +1,68 @@
|
||||
What is a Linux 'oops'?
|
||||
======
|
||||
If you check the processes running on your Linux systems, you might be curious about one called "kerneloops." And that’s “kernel oops,” not “kerne loops” just in case you didn’t parse that correctly.
|
||||
|
||||
Put very bluntly, an “oops” is a deviation from correct behavior on the part of the Linux kernel. Did you do something wrong? Probably not. But something did. And the process that did something wrong has probably at least just been summarily knocked off the CPU. At worst, the kernel may have panicked and abruptly shut the system down.
|
||||
|
||||
For the record, “oops” is NOT an acronym. It doesn’t stand for something like “object-oriented programming and systems” or “out of procedural specs”; it actually means “oops” like you just dropped your glass of wine or stepped on your cat. Oops! The plural of "oops" is "oopses."
|
||||
|
||||
An oops means that something running on the system has violated the kernel’s rules about proper behavior. Maybe the code tried to take a code path that was not allowed or use an invalid pointer. Whatever it was, the kernel — always on the lookout for process misbehavior — most likely will have stopped the particular process in its tracks and written some messages about what it did to the console, to /var/log/dmesg or the /var/log/kern.log file.
|
||||
|
||||
An oops can be caused by the kernel itself or by some process that tries to get the kernel to violate its rules about how things are allowed to run on the system and what they're allowed to do.
|
||||
|
||||
An oops will generate a crash signature that can help kernel developers figure out what went wrong and improve the quality of their code.
|
||||
|
||||
The kerneloops process running on your system will probably look like this:
|
||||
```
|
||||
kernoops 881 1 0 Feb11 ? 00:00:01 /usr/sbin/kerneloops
|
||||
|
||||
```
|
||||
|
||||
You might notice that the process isn't run by root, but by a user named "kernoops" and that it's accumulated extremely little run time. In fact, the only task assigned to this particular user is running kerneloops.
|
||||
```
|
||||
$ sudo grep kernoops /etc/passwd
|
||||
kernoops:x:113:65534:Kernel Oops Tracking Daemon,,,:/:/bin/false
|
||||
|
||||
```
|
||||
|
||||
If your Linux system isn't one that ships with kerneloops (like Debian), you might consider adding it. Check out this [Debian page][1] for more information.
|
||||
|
||||
### When should you be concerned about an oops?
|
||||
|
||||
An oops is not a big deal, except when it is. It depends in part on the role that the particular process was playing. It also depends on the class of oops.
|
||||
|
||||
Some oopses are so severe that they result in system panics. Technically speaking, a panic is a subset of the oops (i.e., the more serious of the oopses). A panic occurs when a problem detected by the kernel is bad enough that the kernel decides that it (the kernel) must stop running immediately to prevent data loss or other damage to the system. So, the system then needs to be halted and rebooted to keep any inconsistencies from making it unusable or unreliable. So a system that panics is actually trying to protect itself from irrevocable damage.
|
||||
|
||||
In short, all panics are oops, but not all oops are panics.
|
||||
|
||||
The /var/log/kern.log and related rotated logs (/var/log/kern.log.1, /var/log/kern.log.2 etc.) contain the logs produced by the kernel and handled by syslog.
|
||||
|
||||
The kerneloops program collects and by default submits information on the problems it runs into <http://oops.kernel.org/> where it can be analyzed and presented to kernel developers. Configuration details for this process are specified in the /etc/kerneloops.conf file. You can look at the settings easily with the command shown below:
|
||||
```
|
||||
$ sudo cat /etc/kerneloops.conf | grep -v ^# | grep -v ^$
|
||||
[sudo] password for shs:
|
||||
allow-submit = ask
|
||||
allow-pass-on = yes
|
||||
submit-url = http://oops.kernel.org/submitoops.php
|
||||
log-file = /var/log/kern.log
|
||||
submit-pipe = /usr/share/apport/kernel_oops
|
||||
|
||||
```
|
||||
|
||||
In the above (default) settings, information on kernel problems can be submitted, but the user is asked for permission. If set to allow-submit = always, the user will not be asked.
|
||||
|
||||
Debugging kernel problems is one of the finer arts of working with Linux systems. Fortunately, most Linux users seldom or never experience oops or panics. Still, it's nice to know what processes like kerneloops are doing on your system and to understand what might be reported and where when your system runs into a serious kernel violation.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3254778/linux/what-is-a-linux-oops.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://packages.debian.org/stretch/kerneloops
|
||||
140
sources/tech/20180216 Q4OS Makes Linux Easy for Everyone.md
Normal file
140
sources/tech/20180216 Q4OS Makes Linux Easy for Everyone.md
Normal file
@ -0,0 +1,140 @@
|
||||
Q4OS Makes Linux Easy for Everyone
|
||||
======
|
||||
|
||||

|
||||
|
||||
Modern Linux distributions tend to target a variety of users. Some claim to offer a flavor of the open source platform that anyone can use. And, I’ve seen some such claims succeed with aplomb, while others fall flat. [Q4OS][1] is one of those odd distributions that doesn’t bother to make such a claim but pulls off the feat anyway.
|
||||
|
||||
So, who is the primary market for Q4OS? According to its website, the distribution is a:
|
||||
|
||||
“fast and powerful operating system based on the latest technologies while offering highly productive desktop environment. We focus on security, reliability, long-term stability and conservative integration of verified new features. System is distinguished by speed and very low hardware requirements, runs great on brand new machines as well as legacy computers. It is also very applicable for virtualization and cloud computing.”
|
||||
|
||||
What’s very interesting here is that the Q4OS developers offer commercial support for the desktop. Said support can cover the likes of system customization (including core level API programming) as well as user interface modifications.
|
||||
|
||||
Once you understand this (and have installed Q4OS), the target audience becomes quite obvious: Business users looking for a Windows XP/7 replacement. But that should not prevent home users from giving Q4OS at try. It’s a Linux distribution that has a few unique tools that come together to make a solid desktop distribution.
|
||||
|
||||
Let’s take a look at Q4OS and see if it’s a version of Linux that might work for you.
|
||||
|
||||
### What Q4OS all about
|
||||
|
||||
Q4OS that does an admirable job of being the open source equivalent of Windows XP/7. Out of the box, it pulls this off with the help of the [Trinity Desktop][2] (a fork of KDE). With a few tricks up its sleeve, Q4OS turns the Trinity Desktop into a remarkably similar desktop (Figure 1).
|
||||
|
||||
![default desktop][4]
|
||||
|
||||
Figure 1: The Q4OS default desktop.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
When you fire up the desktop, you will be greeted by a Welcome screen that makes it very easy for new users to start setting up their desktop with just a few clicks. From this window, you can:
|
||||
|
||||
* Run the Desktop Profiler (which allows you to select which desktop environment to use as well as between a full-featured desktop, a basic desktop, or a minimal desktop—Figure 2).
|
||||
|
||||
* Install applications (which opens the Synaptic Package Manager).
|
||||
|
||||
* Install proprietary codecs (which installs all the necessary media codecs for playing audio and video).
|
||||
|
||||
* Turn on Desktop effects (if you want more eye candy, turn this on).
|
||||
|
||||
* Switch to Kickoff start menu (switches from the default start menu to the newer kickoff menu).
|
||||
|
||||
* Set Autologin (allows you to set login such that it won’t require your password upon boot).
|
||||
|
||||
|
||||
|
||||
|
||||
![Desktop Profiler][7]
|
||||
|
||||
Figure 2: The Desktop Profiler allows you to further customize your desktop experience.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
If you want to install a different desktop environment, open up the Desktop Profiler and then click the Desktop environments drop-down, in the upper left corner of the window. A new window will appear, where you can select your desktop of choice from the drop-down (Figure 3). Once back at the main Profiler Window, select which type of desktop profile you want, and then click Install.
|
||||
|
||||
![Desktop Profiler][9]
|
||||
|
||||
Figure 3: Installing a different desktop is quite simple from within the Desktop Profiler.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Note that installing a different desktop will not wipe the default desktop. Instead, it will allow you to select between the two desktops (at the login screen).
|
||||
|
||||
### Installed software
|
||||
|
||||
After selecting full-featured desktop, from the Desktop Profiler, I found the following user applications ready to go:
|
||||
|
||||
* LibreOffice 5.2.7.2
|
||||
|
||||
* VLC 2.2.7
|
||||
|
||||
* Google Chrome 64.0.3282
|
||||
|
||||
* Thunderbird 52.6.0 (Includes Lightning addon)
|
||||
|
||||
* Synaptic 0.84.2
|
||||
|
||||
* Konqueror 14.0.5
|
||||
|
||||
* Firefox 52.6.0
|
||||
|
||||
* Shotwell 0.24.5
|
||||
|
||||
|
||||
|
||||
|
||||
Obviously some of those applications are well out of date. Since this distribution is based on Debian, we can run and update/upgrade with the commands:
|
||||
```
|
||||
sudo apt update
|
||||
|
||||
sudo apt upgrade
|
||||
|
||||
```
|
||||
|
||||
However, after running both commands, it seems everything is up to date. This particular release (2.4) is an LTS release (supported until 2022). Because of this, expect software to be a bit behind. If you want to test out the bleeding edge version (based on Debian “Buster”), you can download the testing image [here][10].
|
||||
|
||||
### Security oddity
|
||||
|
||||
There is one rather disturbing “feature” found in Q4OS. In the developer’s quest to make the distribution closely resemble Windows, they’ve made it such that installing software (from the command line) doesn’t require a password! You read that correctly. If you open the Synaptic package manager, you’re asked for a password. However (and this is a big however), open up a terminal window and issue a command like sudo apt-get install gimp. At this point, the software will install… without requiring the user to type a sudo password.
|
||||
|
||||
Did you cringe at that? You should.
|
||||
|
||||
I get it, the developers want to ease away the burden of Linux and make a platform the masses could easily adapt to. They’ve done a splendid job of doing just that. However, in the process of doing so, they’ve bypassed a crucial means of security. Is having as near an XP/7 clone as you can find on Linux worth that lack of security? I would say that if it enables more people to use Linux, then yes. But the fact that they’ve required a password for Synaptic (the GUI tool most Windows users would default to for software installation) and not for the command-line tool makes no sense. On top of that, bypassing passwords for the apt and dpkg commands could make for a significant security issue.
|
||||
|
||||
Fear not, there is a fix. For those that prefer to require passwords for the command line installation of software, you can open up the file /etc/sudoers.d/30_q4os_apt and comment out the following three lines:
|
||||
```
|
||||
%sudo ALL = NOPASSWD: /usr/bin/apt-get *
|
||||
|
||||
%sudo ALL = NOPASSWD: /usr/bin/apt-key *
|
||||
|
||||
%sudo ALL = NOPASSWD: /usr/bin/dpkg *
|
||||
|
||||
```
|
||||
|
||||
Once commented out, save and close the file, and reboot the system. At this point, users will now be prompted for a password, should they run the apt-get, apt-key, or dpkg commands.
|
||||
|
||||
### A worthy contender
|
||||
|
||||
Setting aside the security curiosity, Q4OS is one of the best attempts at recreating Windows XP/7 I’ve come across in a while. If you have users who fear change, and you want to migrate them away from Windows, this distribution might be exactly what you need. I would, however, highly recommend you re-enable passwords for the apt-get, apt-key, and dpkg commands… just to be on the safe side.
|
||||
|
||||
In any case, the addition of the Desktop Profiler, and the ability to easily install alternative desktops, makes Q4OS a distribution that just about anyone could use.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][11]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/q4os-makes-linux-easy-everyone
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://q4os.org
|
||||
[2]:https://www.trinitydesktop.org/
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_1.jpg?itok=dalJk9Xf (default desktop)
|
||||
[5]:/licenses/category/used-permission
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_2.jpg?itok=GlouIm73 (Desktop Profiler)
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_3.jpg?itok=riSTP_1z (Desktop Profiler)
|
||||
[10]:https://q4os.org/downloads2.html
|
||||
[11]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
59
sources/tech/20180217 Louis-Philippe Véronneau .md
Normal file
59
sources/tech/20180217 Louis-Philippe Véronneau .md
Normal file
@ -0,0 +1,59 @@
|
||||
Louis-Philippe Véronneau -
|
||||
======
|
||||
I've been watching [Critical Role][1]1 for a while now and since I've started my master's degree I haven't had much time to sit down and watch the show on YouTube as I used to do.
|
||||
|
||||
I thus started listening to the podcasts instead; that way, I can listen to the show while I'm doing other productive tasks. Pretty quickly, I grew tired of manually downloading every episode each time I finished the last one. To make things worst, the podcast is hosted on PodBean and they won't let you download episodes on a mobile device without their app. Grrr.
|
||||
|
||||
After the 10th time opening the terminal on my phone to download the podcast using some `wget` magic I decided enough was enough: I was going to write a dumb script to download them all in one batch.
|
||||
|
||||
I'm a little ashamed to say it took me more time than I had intended... The PodBean website uses semi-randomized URLs, so I could not figure out a way to guess the paths to the hosted audio files. I considered using `youtube-dl` to get the DASH version of the show on YouTube, but Google has been heavily throttling DASH streams recently. Not cool Google.
|
||||
|
||||
I then had the idea to use iTune's RSS feed to get the audio files. Surely they would somehow be included there? Of course Apple doesn't give you a simple RSS feed link on the iTunes podcast page, so I had to rummage around and eventually found out this is the link you have to use:
|
||||
```
|
||||
https://itunes.apple.com/lookup?id=1243705452&entity=podcast
|
||||
|
||||
```
|
||||
|
||||
Surprise surprise, from the json file this links points to, I found out the main Critical Role podcast page [has a proper RSS feed][2]. To my defense, the RSS button on the main podcast page brings you to some PodBean crap page.
|
||||
|
||||
Anyway, once you have the RSS feed, it's only a matter of using `grep` and `sed` until you get what you want.
|
||||
|
||||
Around 20 minutes later, I had downloaded all the episodes, for a total of 22Gb! Victory dance!
|
||||
|
||||
Video clip loop of the Critical Role doing a victory dance.
|
||||
|
||||
### Script
|
||||
|
||||
Here's the bash script I wrote. You will need `recode` to run it, as the RSS feed includes some HTML entities.
|
||||
```
|
||||
# Get the whole RSS feed
|
||||
wget -qO /tmp/criticalrole.rss http://criticalrolepodcast.geekandsundry.com/feed/
|
||||
|
||||
# Extract the URLS and the episode titles
|
||||
mp3s=( $(grep -o "http.\+mp3" /tmp/criticalrole.rss) )
|
||||
titles=( $(tail -n +45 /tmp/criticalrole.rss | grep -o "<title>.\+</title>" \
|
||||
| sed -r 's@</?title>@@g; s@ @\\@g' | recode html..utf8) )
|
||||
|
||||
# Download all the episodes under their titles
|
||||
for i in ${!titles[*]}
|
||||
do
|
||||
wget -qO "$(sed -e "s@\\\@\\ @g" <<< "${titles[$i]}").mp3" ${mp3s[$i]}
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
1 - For those of you not familiar with Critical Role, it's web series where a group of voice actresses and actors from LA play Dungeons & Dragons. It's so good even people like me who never played D&D can enjoy it..
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://veronneau.org/downloading-all-the-critical-role-podcasts-in-one-batch.html
|
||||
|
||||
作者:[Louis-Philippe Véronneau][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://veronneau.org/
|
||||
[1]:https://en.wikipedia.org/wiki/Critical_Role
|
||||
[2]:http://criticalrolepodcast.geekandsundry.com/feed/
|
||||
@ -0,0 +1,135 @@
|
||||
Getting started with Python for data science
|
||||
======
|
||||
|
||||

|
||||
|
||||
Whether you're a budding data science enthusiast with a math or computer science background or an expert in an unrelated field, the possibilities data science offers are within your reach. And you don't need expensive, highly specialized enterprise software—the open source tools discussed in this article are all you need to get started.
|
||||
|
||||
[Python][1], its machine-learning and data science libraries ([pandas][2], [Keras][3], [TensorFlow][4], [scikit-learn][5], [SciPy][6], [NumPy][7], etc.), and its extensive list of visualization libraries ([Matplotlib][8], [pyplot][9], [Plotly][10], etc.) are excellent FOSS tools for beginners and experts alike. Easy to learn, popular enough to offer community support, and armed with the latest emerging techniques and algorithms developed for data science, these comprise one of the best toolsets you can acquire when starting out.
|
||||
|
||||
Many of these Python libraries are built on top of each other (known as dependencies), and the basis is the [NumPy][7] library. Designed specifically for data science, NumPy is often used to store relevant portions of datasets in its ndarray datatype, which is a convenient datatype for storing records from relational tables as `cvs` files or in any other format, and vice-versa. It is particularly convenient when scikit functions are applied to multidimensional arrays. SQL is great for querying databases, but to perform complex and resource-intensive data science operations, storing data in ndarray boosts efficiency and speed (but make sure you have ample RAM when dealing with large datasets). When you get to using pandas for knowledge extraction and analysis, the almost seamless conversion between DataFrame datatype in pandas and ndarray in NumPy creates a powerful combination for extraction and compute-intensive operations, respectively.
|
||||
|
||||
For a quick demonstration, let’s fire up the Python shell and load an open dataset on crime statistics from the city of Baltimore in a pandas DataFrame variable, and view a portion of the loaded frame:
|
||||
```
|
||||
>>> import pandas as pd
|
||||
|
||||
>>> crime_stats = pd.read_csv('BPD_Arrests.csv')
|
||||
|
||||
>>> crime_stats.head()
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
We can now perform most of the queries on this pandas DataFrame that we can with SQL in databases. For instance, to get all the unique values of the "Description" attribute, the SQL query is:
|
||||
```
|
||||
$ SELECT unique(“Description”) from crime_stats;
|
||||
|
||||
```
|
||||
|
||||
This same query written for a pandas DataFrame looks like this:
|
||||
```
|
||||
>>> crime_stats['Description'].unique()
|
||||
|
||||
['COMMON ASSAULT' 'LARCENY' 'ROBBERY - STREET' 'AGG. ASSAULT'
|
||||
|
||||
'LARCENY FROM AUTO' 'HOMICIDE' 'BURGLARY' 'AUTO THEFT'
|
||||
|
||||
'ROBBERY - RESIDENCE' 'ROBBERY - COMMERCIAL' 'ROBBERY - CARJACKING'
|
||||
|
||||
'ASSAULT BY THREAT' 'SHOOTING' 'RAPE' 'ARSON']
|
||||
|
||||
```
|
||||
|
||||
which returns a NumPy array (ndarray):
|
||||
```
|
||||
>>> type(crime_stats['Description'].unique())
|
||||
|
||||
<class 'numpy.ndarray'>
|
||||
|
||||
```
|
||||
|
||||
Next let’s feed this data into a neural network to see how accurately it can predict the type of weapon used, given data such as the time the crime was committed, the type of crime, and the neighborhood in which it happened:
|
||||
```
|
||||
>>> from sklearn.neural_network import MLPClassifier
|
||||
|
||||
>>> import numpy as np
|
||||
|
||||
>>>
|
||||
|
||||
>>> prediction = crime_stats[[‘Weapon’]]
|
||||
|
||||
>>> predictors = crime_stats['CrimeTime', ‘CrimeCode’, ‘Neighborhood’]
|
||||
|
||||
>>>
|
||||
|
||||
>>> nn_model = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5,
|
||||
|
||||
2), random_state=1)
|
||||
|
||||
>>>
|
||||
|
||||
>>>predict_weapon = nn_model.fit(prediction, predictors)
|
||||
|
||||
```
|
||||
|
||||
Now that the learning model is ready, we can perform several tests to determine its quality and reliability. For starters, let’s feed a training set data (the portion of the original dataset used to train the model and not included in creating the model):
|
||||
```
|
||||
>>> predict_weapon.predict(training_set_weapons)
|
||||
|
||||
array([4, 4, 4, ..., 0, 4, 4])
|
||||
|
||||
```
|
||||
|
||||
As you can see, it returns a list, with each number predicting the weapon for each of the records in the training set. We see numbers rather than weapon names, as most classification algorithms are optimized with numerical data. For categorical data, there are techniques that can reliably convert attributes into numerical representations. In this case, the technique used is Label Encoding, using the LabelEncoder function in the sklearn preprocessing library: `preprocessing.LabelEncoder()`. It has a function to transform and inverse transform data and their numerical representations. In this example, we can use the `inverse_transform` function of LabelEncoder() to see what Weapons 0 and 4 are:
|
||||
```
|
||||
>>> preprocessing.LabelEncoder().inverse_transform(encoded_weapons)
|
||||
|
||||
array(['HANDS', 'FIREARM', 'HANDS', ..., 'FIREARM', 'FIREARM', 'FIREARM']
|
||||
|
||||
```
|
||||
|
||||
This is fun to see, but to get an idea of how accurate this model is, let's calculate several scores as percentages:
|
||||
```
|
||||
>>> nn_model.score(X, y)
|
||||
|
||||
0.81999999999999995
|
||||
|
||||
```
|
||||
|
||||
This shows that our neural network model is ~82% accurate. That result seems impressive, but it is important to check its effectiveness when used on a different crime dataset. There are other tests, like correlations, confusion, matrices, etc., to do this. Although our model has high accuracy, it is not very useful for general crime datasets as this particular dataset has a disproportionate number of rows that list ‘FIREARM’ as the weapon used. Unless it is re-trained, our classifier is most likely to predict ‘FIREARM’, even if the input dataset has a different distribution.
|
||||
|
||||
It is important to clean the data and remove outliers and aberrations before we classify it. The better the preprocessing, the better the accuracy of our insights. Also, feeding the model/classifier with too much data to get higher accuracy (generally over ~90%) is a bad idea because it looks accurate but is not useful due to [overfitting][11].
|
||||
|
||||
[Jupyter notebooks][12] are a great interactive alternative to the command line. While the CLI is fine for most things, Jupyter shines when you want to run snippets on the go to generate visualizations. It also formats data better than the terminal.
|
||||
|
||||
[This article][13] has a list of some of the best free resources for machine learning, but plenty of additional guidance and tutorials are available. You will also find many open datasets available to use, based on your interests and inclinations. As a starting point, the datasets maintained by [Kaggle][14], and those available at state government websites are excellent resources.
|
||||
|
||||
Payal Singh will be presenting at SCaLE16x this year, March 8-11 in Pasadena, California. To attend and get 50% of your ticket, [register][15] using promo code **OSDC**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/getting-started-data-science
|
||||
|
||||
作者:[Payal Singh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/payalsingh
|
||||
[1]:https://www.python.org/
|
||||
[2]:https://pandas.pydata.org/
|
||||
[3]:https://keras.io/
|
||||
[4]:https://www.tensorflow.org/
|
||||
[5]:http://scikit-learn.org/stable/
|
||||
[6]:https://www.scipy.org/
|
||||
[7]:http://www.numpy.org/
|
||||
[8]:https://matplotlib.org/
|
||||
[9]:https://matplotlib.org/api/pyplot_api.html
|
||||
[10]:https://plot.ly/
|
||||
[11]:https://www.kdnuggets.com/2014/06/cardinal-sin-data-mining-data-science.html
|
||||
[12]:http://jupyter.org/
|
||||
[13]:https://machinelearningmastery.com/best-machine-learning-resources-for-getting-started/
|
||||
[14]:https://www.kaggle.com/
|
||||
[15]:https://register.socallinuxexpo.org/reg6/
|
||||
@ -0,0 +1,220 @@
|
||||
9 个提高系统运行速度的轻量级 Linux 应用
|
||||
======
|
||||
**简介:** [加速 Ubuntu ][1]有很多方法,众多办法之一是使用轻量级应用来替代一些常用应用程序。可以查看之前发布的一篇文章[ Linux 必备的应用程序][2]。我们将分享这些应用程序在 Ubuntu 或其他 Linux 发行版的轻量级替代方案。
|
||||
|
||||
![在 ubunt 使用轻量级应用程序替代方案][4]
|
||||
|
||||
## 9 个常用 Linux 应用程序的轻量级替代方案
|
||||
|
||||
你的 Linux 系统很慢吗?应用程序是不是很久才能打开?你最好的选择是使用[轻量级的 Linux 系统][5]。但是重装系统并非总是可行,不是吗?
|
||||
|
||||
所以如果你想坚持使用你现在用的 Linux 发行版,但是想要提高性能,你应该使用更轻量级应用来替代你一些常用的应用。这篇文章会列出各种 Linux 应用程序的轻量级替代方案。
|
||||
|
||||
由于我使用的是 Ubuntu,因此我只提供了基于 Ubuntu 的 Linux 发行版的安装说明。但是这些应用程序可以用于几乎所有其他 Linux 发行版。你只需去找这些轻量级应用在你的 Linux 发行版中的安装方法就可以了。
|
||||
|
||||
### 1. Midori: Web 浏览器
|
||||
|
||||
Midori 是与现代互联网环境具有良好兼容性的最轻量级网页浏览器之一。它是开源的,使用与 Google Chrome 最初构建的相同的渲染引擎引擎 - WebKit。并且超快速,最小化但高度可定制。
|
||||
|
||||
![Midori Browser][6]
|
||||
|
||||
Midori 浏览器有很多可以定制的扩展和选项。如果你有最高权限,使用这个浏览器也是一个不错的选择。如果在浏览网页的时候遇到了某些问题,请查看其网站上[常见问题][7]部分 -- 这包含了你可能遇到的常见问题及其解决方案。
|
||||
|
||||
[Midori][8]
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Midori
|
||||
|
||||
在 Ubuntu 上,可通过官方源找到Midori 。运行以下指令即可安装它:
|
||||
|
||||
```
|
||||
sudo apt install midori
|
||||
```
|
||||
|
||||
|
||||
### 2. Trojita:电子邮件客户端
|
||||
|
||||
Trojita 是一款开源强大的 IMAP 电子邮件客户端。它速度快,资源效率高。我可以肯定地称它是 [Linux 最好的电子邮件客户端之一][9]。如果你只需在电子邮件客户端上提供 IMAP 支持,那么也许你不用再往更深一层去考虑了。
|
||||
|
||||
![Trojitá][10]
|
||||
|
||||
Trojita 使用各种技术 - 按需电子邮件加载,离线缓存,带宽节省模式等 -- 以实现其令人印象深刻的性能。
|
||||
|
||||
[Trojita][11]
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Trojita
|
||||
|
||||
Trojita 目前没有针对 Ubuntu 的官方 PPA 。但这应该不成问题。您可以使用以下命令轻松安装它:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
|
||||
wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
|
||||
sudo apt-key add - < Release.key
|
||||
sudo apt update
|
||||
sudo apt install trojita
|
||||
```
|
||||
|
||||
### 3. GDebi:包安装程序
|
||||
|
||||
有时您需要快速安装 DEB 软件包。Ubuntu 软件中心是一个消耗资源严重的应用程序,仅用于安装 .deb 文件并不明智。
|
||||
|
||||
Gdebi 无疑是一款可以完成同样目的的漂亮工具,而它只需最小化的图形界面。
|
||||
|
||||
![GDebi][12]
|
||||
|
||||
GDebi 是完全轻量级的,完美无缺地完成了它的工作。你甚至应该[让 Gdebi 成为 DEB 文件的默认安装程序][13]。
|
||||
|
||||
#### 在基于Ubuntu的发行版上安装GDebi
|
||||
|
||||
只需一行指令,你便可以在 Ubuntu 上安装 GDebi:
|
||||
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
### 4. App Grid:软件中心
|
||||
|
||||
如果您经常在 Ubuntu 上使用软件中心搜索,安装和管理应用程序,则 App Grid 是必备的应用程序。它是默认的 Ubuntu 软件中心最具视觉吸引力且速度最快的替代方案。
|
||||
|
||||
![App Grid][14]
|
||||
|
||||
App Grid 支持应用程序的评分,评论和屏幕截图。
|
||||
|
||||
[App Grid][15]
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 App Grid
|
||||
|
||||
App Grid 拥有 Ubuntu 的官方 PPA。使用以下指令安装 App Grid:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:appgrid/stable
|
||||
sudo apt update
|
||||
sudo apt install appgrid
|
||||
```
|
||||
|
||||
### 5. Yarock:音乐播放器
|
||||
|
||||
Yarock 是一个优雅的音乐播放器,拥有现代而最轻量级的用户界面。尽管在设计上是轻量级的,但 Yarock 有一个全面的高级功能列表。
|
||||
|
||||
![Yarock][16]
|
||||
|
||||
Yarock 的主要功能包括多种音乐收藏、评级、智能播放列表、多种后端选项、桌面通知、音乐剪辑、上下文获取等。
|
||||
|
||||
[Yarock][17]
|
||||
|
||||
### 在基于 Ubuntu 的发行版上安装 Yarock
|
||||
|
||||
您得通过PPA使用以下指令在 Ubuntu上 安装 Yarock:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
sudo apt update
|
||||
sudo apt install yarock
|
||||
```
|
||||
|
||||
### 6. VLC:视频播放器
|
||||
|
||||
谁不需要视频播放器?谁还从未听说过 VLC?我想并不需要对它做任何介绍。
|
||||
|
||||
![VLC][18]
|
||||
|
||||
VLC 能满足你在 Ubuntu 上播放各种媒体文件的全部需求,而且他非常轻便。它甚至可以再非常旧的 PC 上完美运行。
|
||||
|
||||
[VLC][19]
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 VLC
|
||||
|
||||
VLC 为 Ubuntu 提供官方PPA。可以输入以下命令来安装它:
|
||||
|
||||
```
|
||||
sudo apt install vlc
|
||||
```
|
||||
|
||||
### 7. PCManFM:文件管理器
|
||||
|
||||
PCManFM 是 LXDE 的标准文件管理器。与 LXDE 的其他应用程序一样,它也是轻量级的。如果您正在为文件管理器寻找更轻量级的替代品,可以尝试使用这个应用。
|
||||
|
||||
![PCManFM][20]
|
||||
|
||||
尽管来自 LXDE,PCManFM 也同样适用于其他桌面环境。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 PCManFM
|
||||
|
||||
在 Ubuntu 上安装 PCManFM 只需要一条简单的指令:
|
||||
|
||||
```
|
||||
sudo apt install pcmanfm
|
||||
```
|
||||
|
||||
### 8. Mousepad:文本编辑器
|
||||
|
||||
在轻量级方面,没有什么可以击败像 nano、vim 等命令行文本编辑器。但是,如果你想要一个图形界面,你可以尝试一下 Mousepad -- 一个最轻量级的文本编辑器。它非常轻巧,速度非常快。带有简单的可定制的用户界面和多个主题。
|
||||
|
||||
![Mousepad][21]
|
||||
|
||||
Mousepad 支持语法高亮显示。所以,你也可以使用它作为基础的代码编辑器。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Mousepad
|
||||
|
||||
想要安装 Mousepad ,可以使用以下指令:
|
||||
|
||||
```
|
||||
sudo apt install mousepad
|
||||
```
|
||||
|
||||
### 9. GNOME Office:办公软件
|
||||
|
||||
许多人需要经常使用办公应用程序。通常,大多数办公应用程序体积庞大且资源匮乏。Gnome Office 在这方面非常轻便。Gnome Office 在技术上不是一个完整的办公套件。它由不同的独立应用程序组成,在这之中 AbiWord&Gnumeric 脱颖而出。
|
||||
|
||||
**AbiWord** 是文字处理器。它比其他替代品轻巧并且快得多。但是这样做是有代价的 -- 你可能会失去宏、语法检查等一些功能。AdiWord 并不完美,但它可以满足你基本的需求。
|
||||
![AbiWord][22]
|
||||
|
||||
**Gnumeric** 是电子表格编辑器。就像 AbiWord 一样,Gnumeric 也非常快速,提供了精确的计算功能。如果你正在寻找一个简单轻便的电子表格编辑器,Gnumeric 已经能满足你的需求了。
|
||||
|
||||
![Gnumeric][23]
|
||||
|
||||
下面列出一些其他 Gnome Office 应用程序。你可以在官方页面找到它们。
|
||||
|
||||
[Gnome Office][24]
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 AbiWord&Gnumeric
|
||||
|
||||
要安装 AbiWord&Gnumeric,只需在终端中输入以下指令:
|
||||
|
||||
```
|
||||
sudo apt install abiword gnumeric
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
|
||||
[5]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
|
||||
[7]:http://midori-browser.org/faqs/
|
||||
[8]:http://midori-browser.org/
|
||||
[9]:https://itsfoss.com/best-email-clients-linux/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Trojit%C3%A1-800x608.png
|
||||
[11]:http://trojita.flaska.net/
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
|
||||
[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
|
||||
[15]:http://www.appgrid.org/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
|
||||
[17]:https://seb-apps.github.io/yarock/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
|
||||
[19]:http://www.videolan.org/index.html
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
|
||||
[24]:https://gnome.org/gnome-office/
|
||||
@ -1,119 +0,0 @@
|
||||
并发服务器(五):Redis 案例研究
|
||||
======
|
||||
这是我写的并发网络服务器系列文章的第五部分。在前四部分中我们讨论了并发服务器的结构,这篇文章我们将去研究一个在生产系统中大量使用的服务器的案例—— [Redis][10]。
|
||||
|
||||

|
||||
|
||||
Redis 是一个非常有魅力的项目,我关注它很久了。它最让我着迷的一点就是它的 C 源代码非常清晰。它也是一个高性能大并发内存数据库服务器的非常好的例子,它是研究网络并发服务器的一个非常好的案例,因此,我们不能错过这个好机会。
|
||||
|
||||
我们来看看前四部分讨论的概念在真实世界中的应用程序。
|
||||
|
||||
本系列的所有文章有:
|
||||
|
||||
* [第一节 - 简介][3]
|
||||
|
||||
* [第二节 - 线程][4]
|
||||
|
||||
* [第三节 - 事件驱动][5]
|
||||
|
||||
* [第四节 - libuv][6]
|
||||
|
||||
* [第五节 - Redis 案例研究][7]
|
||||
|
||||
### 事件处理库
|
||||
|
||||
Redis 最初发布于 2009 年,它最牛逼的一件事情大概就是它的速度 —— 它能够处理大量的并发客户端连接。需要特别指出的是,它是用一个单线程来完成的,而且还不对保存在内存中的数据使用任何复杂的锁或者同步机制。
|
||||
|
||||
Redis 之所以如此牛逼是因为,它在一个给定的系统上使用了可用的最快事件循环,并将它们封装成由它实现的事件循环库(在 Linux 上是 epoll,在 BSD 上是 kqueue,等等)。这个库的名字叫做 [ae][11]。使用 ae 来写一个快速服务器变得很容易,只要在它内部没有阻塞即可,而 Redis 则保证[[1]][12]了这一点。
|
||||
|
||||
在这里,我们的兴趣点主要是它对文件事件的支持 —— 当文件描述符(类似于网络套接字)有一些有趣的未决事情时将调用注册的回调函数。与 libuv 类似,ae 支持多路事件循环和不应该感到意外的 aeCreateFileEvent 信号:
|
||||
|
||||
```
|
||||
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
|
||||
aeFileProc *proc, void *clientData);
|
||||
```
|
||||
|
||||
它在 fd 上使用一个给定的事件循环,为新的文件事件注册一个回调(proc)函数。当使用的是 epoll 时,它将调用 epoll_ctl 在文件描述符上添加一个事件(可能是 EPOLLIN、EPOLLOUT、也或许两者都有,取决于 mask 参数)。ae 的 aeProcessEvents 功能是 “运行事件循环和发送回调函数”,它在 hood 下,命名为 epoll_wait。
|
||||
|
||||
### 处理客户端请求
|
||||
|
||||
我们通过跟踪 Redis 服务器代码来看一下,ae 如何为客户端事件注册回调函数的。initServer 启动时,通过注册一个回调函数来读取正在监听的套接字上的事件,通过使用回调函数 acceptTcpHandler 来调用 aeCreateFileEvent。当新的连接可用的,这个回调函数被调用。它被称为 accept [[2]][13],接下来是 acceptCommonHandler,它转而去调用 createClient 以初始化新客户端连接所需要的数据结构。
|
||||
|
||||
createClient 的工作是去监听来自客户端的入站数据。它设置套接字为非阻塞模式(一个异步事件循环中的关键因素)并使用 aeCreateFileEvent 去注册另外一个文件事件回调函数以读取事件 —— readQueryFromClient。每当客户端发送数据,这个函数将被事件循环调用。
|
||||
|
||||
readQueryFromClient 只做一些我们预期之内的事情 —— 解析客户端命令和动作,并通过查询和/或操作数据来回复。因为客户端套接字是非阻塞的,这个函数可以处理 EAGAIN,以及部分数据;从客户端中读取的数据是累积在客户端专用的缓冲区中,而完整的查询可能在回调函数的多个调用中被分割。
|
||||
|
||||
### 将数据发送回客户端
|
||||
|
||||
在前面的内容中,我说到了 readQueryFromClient 结束了发送给客户端的回复。这在逻辑上是正确的,因为 readQueryFromClient 准备要发送回复,但它不真正去做实质的发送—— 因为这里并不能保证客户端套接字是做好写入/发送数据的准备的。我们为它使用事件循环机制。
|
||||
|
||||
Redis 是这样做的,每次事件循环即将进入休眠时,它注册一个 beforeSleep 函数,去等待对套接字的读取/写入。beforeSleep 做的其中一件事情就是调用 handleClientsWithPendingWrites。它的作用是通过调用 writeToClient 立即去尝试发送所有可用的回复;如果一些套接字不可用时,那么当套接字可用时,它将注册一个事件循环去调用 sendReplyToClient。这可以被看作为一种优化 —— 如果套接字可用于立即发送数据(一般是 TCP 套接字),这时并不需要注册事件 ——只发送数据。因为套接字是非阻塞的,它从不会去阻塞循环。
|
||||
|
||||
### 为什么 Redis 要实现它自己的事件库?
|
||||
|
||||
在 [第四部分][14] 中我们讨论了使用 libuv 来构建一个异步并发服务器。需要注意的是,Redis 并没有使用 libuv,或者任何类似的事件库,而是它去实现自己的事件库 —— ae,用 ae 来封装 epoll、kqueue 和 select。事实上,Antirez(Redis 的创建者)恰好在 [2011 年的一篇文章][15] 中回答了这个问题。他的回答的要点是:ae 只有大约 770 行代码,他理解的非常透彻;而 libuv 代码量非常巨大,也没有提供 Redis 所需的额外功能。
|
||||
|
||||
现在,ae 的代码大约增长到 1300 多行,比起 libuv 的 26000 行(这是在没有 Windows、测试、示例、文档的情况下的数据)来说那是小巫见大巫了。libuv 是一个非常综合的库,这使它更复杂,并且很难去适应其它项目的特殊需求;另一方面,ae 是专门为 Redis 设计的,与 Redis 共同演进,只包含 Redis 所需要的东西。
|
||||
|
||||
这是我 [前些年在一篇文章中][16] 提到的软件项目依赖关系的另一个很好的示例:
|
||||
|
||||
> 依赖的优势与花费在软件项目上的工作量成反比。
|
||||
|
||||
在某种程序上,Antirez 在他的文章中也提到了这一点。他提到,依赖提供的一些附加价值(在我的文章中的“基础” 依赖)更有意义(它的例子是 jemalloc 和 Lua),就像 libuv 这样的依赖关系,为特定的 Redis 需求,去实现整个功能是非常容易的。
|
||||
|
||||
### Redis 中的多线程
|
||||
|
||||
[在 Redis 的绝大多数历史中][17],它都是一个不折不扣的单线程的东西。一些人觉得这太不可思议了,有这种想法完全可以理解。Redis 本质上是受网络束缚的 —— 只要数据库大小合理,对于任何给定的客户端请求,其大部分延时都是浪费在网络等待上,而不是在 Redis 的数据结构上。
|
||||
|
||||
然而,现在事情已经不再那么简单了。Redis 现在有几个新功能都用到了线程:
|
||||
|
||||
1. "缓慢地" [释放内存][8]。
|
||||
|
||||
2. 在后台进程中使用 fsync 调用写一个 [持久化日志][9]。
|
||||
|
||||
3. 运行需要的用户定义模块去执行一个长周期运行的操作。
|
||||
|
||||
对于前两个特性,Redis 使用它自己的一个简单的 bio(它是 “Background I/O" 的首字母缩写)库。这个库是根据 Redis 的需要进行了硬编码,它不能用到其它的地方 —— 它按预设的进程数量运行,每个 Redis 后台作业类型需要一个进程。
|
||||
|
||||
而对于第三个特性,[Redis 模块][18] 可以定义新的 Redis 命令,并且遵循与普通 Redis 命令相同的标准,包括不阻塞主线程。如果在模块中自定义的一个 Redis 命令,希望去执行一个长周期运行的操作,这将创建一个线程在后台去运行它。在 Redis 源码树中的 src/modules/helloblock.c 提供了这样的一个示例。
|
||||
|
||||
有了这些特性,Redis 使用线程将一个事件循环结合起来,在一般的案例中,Redis 具有了更快的速度和弹性,这有点类似于在本系统文章中 [第四节][19] 讨论的工作队列。
|
||||
|
||||
|
||||
| [[1]][1] | Redis 的一个核心部分是:它是一个 _内存中_ 数据库;因此,查询从不会运行太长的时间。当然了,这将会带来各种各样的其它问题。在使用分区的情况下,服务器可能最终路由一个请求到另一个实例上;在这种情况下,将使用异步 I/O 来避免阻塞其它客户端。|
|
||||
|
||||
|
||||
| [[2]][2] | 使用 anetAccept;anet 是 Redis 对 TCP 套接字代码的封装。|
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id2
|
||||
[3]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[4]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[5]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[6]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
[8]:http://antirez.com/news/93
|
||||
[9]:https://redis.io/topics/persistence
|
||||
[10]:https://redis.io/
|
||||
[11]:https://redis.io/topics/internals-rediseventlib
|
||||
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id4
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id5
|
||||
[14]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
[15]:http://oldblog.antirez.com/post/redis-win32-msft-patch.html
|
||||
[16]:http://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/
|
||||
[17]:http://antirez.com/news/93
|
||||
[18]:https://redis.io/topics/modules-intro
|
||||
[19]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
Loading…
Reference in New Issue
Block a user