mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-23 21:20:42 +08:00
Merge pull request #11093 from HankChow/master
翻译完成 20181105 Introducing pydbgen- A random dataframe-database table generator.md
This commit is contained in:
commit
66e579826d
@ -1,171 +0,0 @@
|
|||||||
HankChow translating
|
|
||||||
|
|
||||||
Introducing pydbgen: A random dataframe/database table generator
|
|
||||||
======
|
|
||||||
Simple tool generates large database files with multiple tables to practice SQL commands for data science.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
When you start learning data science, often your biggest worry is not the algorithms or techniques but getting access to raw data. While there are many high-quality, real-life datasets available on the web for trying out cool machine learning techniques, I've found that the same is not true when it comes to learning SQL.
|
|
||||||
|
|
||||||
For data science, having a basic familiarity with SQL is almost as important as knowing how to write code in Python or R. But it's far easier to find toy datasets on Kaggle than it is to access a large enough database with real data (such as name, age, credit card, social security number, address, birthday, etc.) specifically designed or curated for machine learning tasks.
|
|
||||||
|
|
||||||
Wouldn't it be great to have a simple tool or library to generate a large database with multiple tables filled with data of your own choice?
|
|
||||||
|
|
||||||
Aside from beginners in data science, even seasoned software testers may find it useful to have a simple tool where, with a few lines of code, they can generate arbitrarily large data sets with random (fake), yet meaningful entries.
|
|
||||||
|
|
||||||
For this reason, I am glad to introduce a lightweight Python library called **[pydbgen][1]**. In this article, I'll briefly share some information about the package, and you can learn much more [by reading the docs][2].
|
|
||||||
|
|
||||||
### What is pydbgen?
|
|
||||||
|
|
||||||
Pydbgen is a lightweight, pure-Python library to generate random useful entries (e.g., name, address, credit card number, date, time, company name, job title, license plate number, etc.) and save them in a Pandas dataframe object, as an SQLite table in a database file, or in a Microsoft Excel file.
|
|
||||||
|
|
||||||
### How to install pydbgen
|
|
||||||
|
|
||||||
The current version (1.0.5) is hosted on PyPI (the Python Package Index repository). You need to have [Faker][3] installed to make this work. To install Pydbgen, enter:
|
|
||||||
|
|
||||||
```
|
|
||||||
pip install pydbgen
|
|
||||||
```
|
|
||||||
|
|
||||||
It has been tested on Python 3.6 and won't work on Python 2 installations.
|
|
||||||
|
|
||||||
### How to use it
|
|
||||||
|
|
||||||
To start using Pydbgen, initiate a **pydb** object.
|
|
||||||
|
|
||||||
```
|
|
||||||
import pydbgen
|
|
||||||
from pydbgen import pydbgen
|
|
||||||
myDB=pydbgen.pydb()
|
|
||||||
```
|
|
||||||
|
|
||||||
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
|
||||||
|
|
||||||
```
|
|
||||||
myDB.city_real()
|
|
||||||
>> 'Otterville'
|
|
||||||
for _ in range(10):
|
|
||||||
print(myDB.license_plate())
|
|
||||||
>> 8NVX937
|
|
||||||
6YZH485
|
|
||||||
XBY-564
|
|
||||||
SCG-2185
|
|
||||||
XMR-158
|
|
||||||
6OZZ231
|
|
||||||
CJN-850
|
|
||||||
SBL-4272
|
|
||||||
TPY-658
|
|
||||||
SZL-0934
|
|
||||||
```
|
|
||||||
|
|
||||||
By the way, if you enter **city** instead of **city_real** , it will return fictitious city names.
|
|
||||||
|
|
||||||
```
|
|
||||||
print(myDB.gen_data_series(num=8,data_type='city'))
|
|
||||||
>>
|
|
||||||
New Michelle
|
|
||||||
Robinborough
|
|
||||||
Leebury
|
|
||||||
Kaylatown
|
|
||||||
Hamiltonfort
|
|
||||||
Lake Christopher
|
|
||||||
Hannahstad
|
|
||||||
West Adamborough
|
|
||||||
```
|
|
||||||
|
|
||||||
### Generate a Pandas dataframe with random entries
|
|
||||||
|
|
||||||
You can choose how many and what data types will be generated. Note that everything returns as string/texts.
|
|
||||||
|
|
||||||
```
|
|
||||||
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
|
|
||||||
testdf
|
|
||||||
```
|
|
||||||
|
|
||||||
The resulting dataframe looks like the following image.
|
|
||||||
|
|
||||||
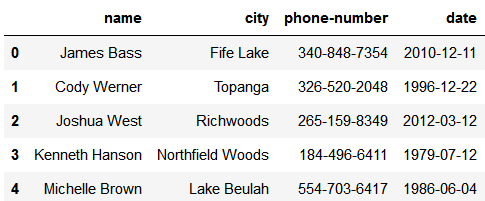
|
|
||||||
|
|
||||||
### Generate a database table
|
|
||||||
|
|
||||||
You can choose how many and what data types will be generated. Everything is returned in the text/VARCHAR data type for the database. You can specify the database filename and the table name.
|
|
||||||
|
|
||||||
```
|
|
||||||
myDB.gen_table(db_file='Testdb.DB',table_name='People',
|
|
||||||
|
|
||||||
fields=['name','city','street_address','email'])
|
|
||||||
```
|
|
||||||
|
|
||||||
This generates a .db file which can be used with MySQL or the SQLite database server. The following image shows a database table opened in DB Browser for SQLite.
|
|
||||||
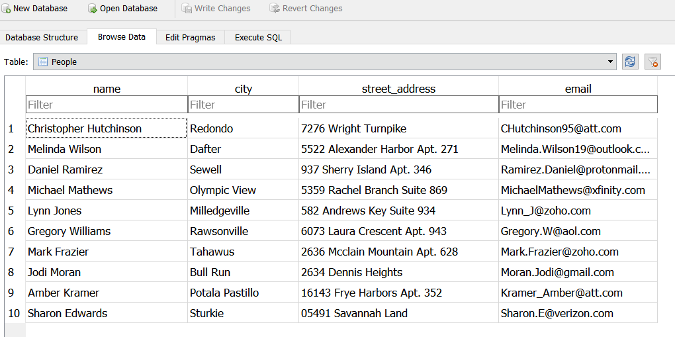
|
|
||||||
|
|
||||||
### Generate an Excel file
|
|
||||||
|
|
||||||
Similar to the examples above, the following code will generate an Excel file with random data. Note that **phone_simple** is set to **False** so it can generate complex, long-form phone numbers. This can come in handy when you want to experiment with more involved data extraction codes.
|
|
||||||
|
|
||||||
```
|
|
||||||
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
|
||||||
phone_simple=False,filename='TestExcel.xlsx')
|
|
||||||
```
|
|
||||||
|
|
||||||
The resulting file looks like this image:
|
|
||||||
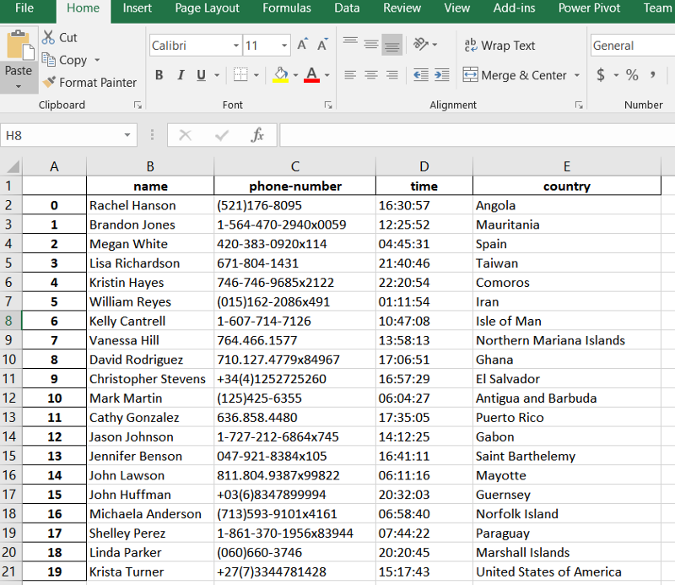
|
|
||||||
|
|
||||||
### Generate random email IDs for scrap use
|
|
||||||
|
|
||||||
A built-in method in pydbgen is **realistic_email** , which generates random email IDs from a seed name. This is helpful when you don't want to use your real email address on the web—but something close.
|
|
||||||
|
|
||||||
```
|
|
||||||
for _ in range(10):
|
|
||||||
print(myDB.realistic_email('Tirtha Sarkar'))
|
|
||||||
>>
|
|
||||||
Tirtha_Sarkar@gmail.com
|
|
||||||
Sarkar.Tirtha@outlook.com
|
|
||||||
Tirtha_S48@verizon.com
|
|
||||||
Tirtha_Sarkar62@yahoo.com
|
|
||||||
Tirtha.S46@yandex.com
|
|
||||||
Tirtha.S@att.com
|
|
||||||
Sarkar.Tirtha60@gmail.com
|
|
||||||
TirthaSarkar@zoho.com
|
|
||||||
Sarkar.Tirtha@protonmail.com
|
|
||||||
Tirtha.S@comcast.net
|
|
||||||
```
|
|
||||||
|
|
||||||
### Future improvements and user contributions
|
|
||||||
|
|
||||||
There may be many bugs in the current version—if you notice any and your program crashes during execution (except for a crash due to your incorrect entry), please let me know. Also, if you have a cool idea to contribute to the source code, the [GitHub repo][1] is open. Some questions readily come to mind:
|
|
||||||
|
|
||||||
* Can we integrate some machine learning/statistical modeling with this random data generator?
|
|
||||||
* Should a visualization function be added to the generator?
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
The possibilities are endless and exciting!
|
|
||||||
|
|
||||||
If you have any questions or ideas to share, please contact me at [tirthajyoti[AT]gmail.com][4]. If you are, like me, passionate about machine learning and data science, please [add me on LinkedIn][5] or [follow me on Twitter][6]. Also, check my [GitHub repo][7] for other fun code snippets in Python, R, or MATLAB and some machine learning resources.
|
|
||||||
|
|
||||||
Originally published on [Towards Data Science][8]. Licensed under [CC BY-SA 4.0][9].
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/18/11/pydbgen-random-database-table-generator
|
|
||||||
|
|
||||||
作者:[Tirthajyoti Sarkar][a]
|
|
||||||
选题:[lujun9972][b]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://opensource.com/users/tirthajyoti
|
|
||||||
[b]: https://github.com/lujun9972
|
|
||||||
[1]: https://github.com/tirthajyoti/pydbgen
|
|
||||||
[2]: http://pydbgen.readthedocs.io/en/latest/
|
|
||||||
[3]: https://faker.readthedocs.io/en/latest/index.html
|
|
||||||
[4]: mailto:tirthajyoti@gmail.com
|
|
||||||
[5]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
|
||||||
[6]: https://twitter.com/tirthajyotiS
|
|
||||||
[7]: https://github.com/tirthajyoti?tab=repositories
|
|
||||||
[8]: https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5
|
|
||||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
|
||||||
@ -0,0 +1,169 @@
|
|||||||
|
pydbgen:一个数据库随机生成器
|
||||||
|
======
|
||||||
|
> 用这个简单的工具生成大型数据库,让你更好地研究数据科学。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在研究数据科学的过程中,最麻烦的往往不是算法或者技术,而是如何获取到一批原始数据。尽管网上有很多真实优质的数据集可以用于机器学习,然而在学习 SQL 时却不是如此。
|
||||||
|
|
||||||
|
对于数据科学来说,熟悉 SQL 的重要性不亚于了解 Python 或 R 编程。如果想收集诸如姓名、年龄、信用卡信息、地址这些信息用于机器学习任务,在 Kaggle 上查找专门的数据集比使用足够大的真实数据库要容易得多。
|
||||||
|
|
||||||
|
如果有一个简单的工具或库来帮助你生成一个大型数据库,表里还存放着大量你需要的数据,岂不美哉?
|
||||||
|
|
||||||
|
不仅仅是数据科学的入门者,即使是经验丰富的软件测试人员也会需要这样一个简单的工具,只需编写几行代码,就可以通过随机(但是是假随机)生成任意数量但有意义的数据集。
|
||||||
|
|
||||||
|
因此,我要推荐这个名为 [pydbgen][1] 的轻量级 Python 库。在后文中,我会简要说明这个库的相关内容,你也可以[阅读它的文档][2]详细了解更多信息。
|
||||||
|
|
||||||
|
### pydbgen 是什么
|
||||||
|
|
||||||
|
`pydbgen` 是一个轻量的纯 Python 库,它可以用于生成随机但有意义的数据记录(包括姓名、地址、信用卡号、日期、时间、公司名称、职位、车牌号等等),存放在 Pandas Dataframe 对象中,并保存到 SQLite 数据库或 Excel 文件。
|
||||||
|
|
||||||
|
### 如何安装 pydbgen
|
||||||
|
|
||||||
|
目前 1.0.5 版本的 pydbgen 托管在 PyPI(<ruby>Python 包索引存储库<rt>Python Package Index repository</rt></ruby>)上,并且对 [Faker][3] 有依赖关系。安装 pydbgen 只需要执行命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
pip install pydbgen
|
||||||
|
```
|
||||||
|
|
||||||
|
已经在 Python 3.6 环境下测试安装成功,但在 Python 2 环境下无法正常安装。
|
||||||
|
|
||||||
|
### 如何使用 pydbgen
|
||||||
|
|
||||||
|
在使用 `pydbgen` 之前,首先要初始化 `pydb` 对象。
|
||||||
|
|
||||||
|
```
|
||||||
|
import pydbgen
|
||||||
|
from pydbgen import pydbgen
|
||||||
|
myDB=pydbgen.pydb()
|
||||||
|
```
|
||||||
|
|
||||||
|
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
||||||
|
随后就可以调用 `pydb` 对象公开的各种内部函数了。可以按照下面的例子,输出随机的美国城市和车牌号码:
|
||||||
|
|
||||||
|
```
|
||||||
|
myDB.city_real()
|
||||||
|
>> 'Otterville'
|
||||||
|
for _ in range(10):
|
||||||
|
print(myDB.license_plate())
|
||||||
|
>> 8NVX937
|
||||||
|
6YZH485
|
||||||
|
XBY-564
|
||||||
|
SCG-2185
|
||||||
|
XMR-158
|
||||||
|
6OZZ231
|
||||||
|
CJN-850
|
||||||
|
SBL-4272
|
||||||
|
TPY-658
|
||||||
|
SZL-0934
|
||||||
|
```
|
||||||
|
|
||||||
|
另外,如果你输入的是 city 而不是 city_real,返回的将会是虚构的城市名。
|
||||||
|
|
||||||
|
```
|
||||||
|
print(myDB.gen_data_series(num=8,data_type='city'))
|
||||||
|
>>
|
||||||
|
New Michelle
|
||||||
|
Robinborough
|
||||||
|
Leebury
|
||||||
|
Kaylatown
|
||||||
|
Hamiltonfort
|
||||||
|
Lake Christopher
|
||||||
|
Hannahstad
|
||||||
|
West Adamborough
|
||||||
|
```
|
||||||
|
|
||||||
|
### 生成随机的 Pandas Dataframe
|
||||||
|
|
||||||
|
你可以指定生成数据的数量和种类,但需要注意的是,返回结果均为字符串或文本类型。
|
||||||
|
|
||||||
|
```
|
||||||
|
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
|
||||||
|
testdf
|
||||||
|
```
|
||||||
|
|
||||||
|
最终产生的 Dataframe 类似下图所示。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 生成数据库表
|
||||||
|
|
||||||
|
你也可以指定生成数据的数量和种类,而返回结果是数据库中的文本或者变长字符串类型。在生成过程中,你可以指定对应的数据库文件名和表名。
|
||||||
|
|
||||||
|
```
|
||||||
|
myDB.gen_table(db_file='Testdb.DB',table_name='People',
|
||||||
|
|
||||||
|
fields=['name','city','street_address','email'])
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的例子种生成了一个能被 MySQL 和 SQLite 支持的 `.db` 文件。下图则显示了这个文件中的数据表在 SQLite 可视化客户端中打开的画面。
|
||||||
|

|
||||||
|
|
||||||
|
### 生成 Excel 文件
|
||||||
|
|
||||||
|
和上面的其它示例类似,下面的代码可以生成一个具有随机数据的 Excel 文件。值得一提的是,通过将`phone_simple` 参数设为 `False` ,可以生成较长较复杂的电话号码。如果你想要提高自己在数据提取方面的能力,不妨尝试一下这个功能。
|
||||||
|
|
||||||
|
```
|
||||||
|
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
||||||
|
phone_simple=False,filename='TestExcel.xlsx')
|
||||||
|
```
|
||||||
|
|
||||||
|
最终的结果类似下图所示:
|
||||||
|

|
||||||
|
|
||||||
|
### 生成随机电子邮箱地址
|
||||||
|
|
||||||
|
`pydbgen` 内置了一个 `realistic_email` 方法,它基于种子来生成随机的电子邮箱地址。如果你不想在网络上使用真实的电子邮箱地址时,这个功能可以派上用场。
|
||||||
|
|
||||||
|
```
|
||||||
|
for _ in range(10):
|
||||||
|
print(myDB.realistic_email('Tirtha Sarkar'))
|
||||||
|
>>
|
||||||
|
Tirtha_Sarkar@gmail.com
|
||||||
|
Sarkar.Tirtha@outlook.com
|
||||||
|
Tirtha_S48@verizon.com
|
||||||
|
Tirtha_Sarkar62@yahoo.com
|
||||||
|
Tirtha.S46@yandex.com
|
||||||
|
Tirtha.S@att.com
|
||||||
|
Sarkar.Tirtha60@gmail.com
|
||||||
|
TirthaSarkar@zoho.com
|
||||||
|
Sarkar.Tirtha@protonmail.com
|
||||||
|
Tirtha.S@comcast.net
|
||||||
|
```
|
||||||
|
|
||||||
|
### 未来的改进和用户贡献
|
||||||
|
|
||||||
|
目前的版本中并不完美。如果你发现了 pydbgen 的 bug 导致 pydbgen 在运行期间发生崩溃,请向我反馈。如果你打算对这个项目贡献代码,[也随时欢迎你][1]。当然现在也还有很多改进的方向:
|
||||||
|
|
||||||
|
* pydbgen 作为随机数据生成器,可以集成一些机器学习或统计建模的功能吗?
|
||||||
|
* pydbgen 是否会添加可视化功能?
|
||||||
|
|
||||||
|
一切皆有可能!
|
||||||
|
|
||||||
|
如果你有任何问题或想法想要分享,都可以通过 [tirthajyoti@gmail.com][4] 与我联系。如果你像我一样对机器学习和数据科学感兴趣,也可以添加我的 [LinkedIn][5] 或在 [Twitter][6] 上关注我。另外,还可以在我的 [GitHub][7] 上找到更多 Python、R 或 MATLAB 的有趣代码和机器学习资源。
|
||||||
|
|
||||||
|
本文以 [CC BY-SA 4.0][9] 许可在 [Towards Data Science][8] 首发。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/11/pydbgen-random-database-table-generator
|
||||||
|
|
||||||
|
作者:[Tirthajyoti Sarkar][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[HankChow](https://github.com/HankChow)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/tirthajyoti
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://github.com/tirthajyoti/pydbgen
|
||||||
|
[2]: http://pydbgen.readthedocs.io/en/latest/
|
||||||
|
[3]: https://faker.readthedocs.io/en/latest/index.html
|
||||||
|
[4]: mailto:tirthajyoti@gmail.com
|
||||||
|
[5]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||||
|
[6]: https://twitter.com/tirthajyotiS
|
||||||
|
[7]: https://github.com/tirthajyoti?tab=repositories
|
||||||
|
[8]: https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5
|
||||||
|
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
|
||||||
Loading…
Reference in New Issue
Block a user