mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-07 22:11:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
666d826c78
@ -0,0 +1,86 @@
|
||||
页面缓存、内存和文件之间的那些事
|
||||
============================================================
|
||||
|
||||
|
||||
上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存][2],而没有提及文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
|
||||
|
||||
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘寻道][3]。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间*共享*文件内容。如果你在 Windows 中使用 [进程浏览器][4] 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLL。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLL 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 ld.so 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
|
||||
|
||||
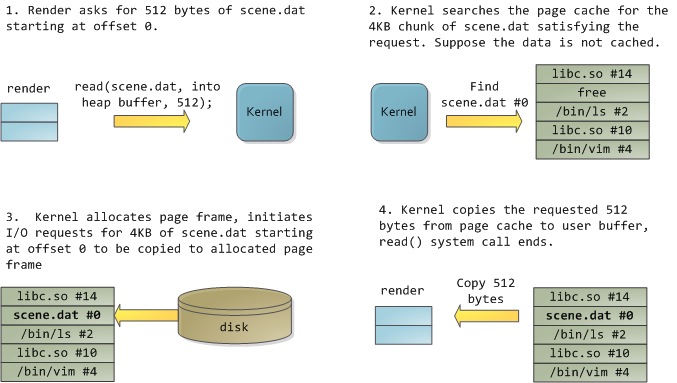
幸运的是,这两个问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 `render` 的 Linux 程序,它打开了文件 `scene.dat`,并且一次读取 512 字节,并将文件内容存储到一个分配到堆中的块上。第一次读取的过程如下:
|
||||
|
||||
|
||||
|
||||
1. `render` 请求 `scene.dat` 从位移 0 开始的 512 字节。
|
||||
2. 内核搜寻页面缓存中 `scene.dat` 的 4kb 块,以满足该请求。假设该数据没有缓存。
|
||||
3. 内核分配页面帧,初始化 I/O 请求,将 `scend.dat` 从位移 0 开始的 4kb 复制到分配的页面帧。
|
||||
4. 内核从页面缓存复制请求的 512 字节到用户缓冲区,系统调用 `read()` 结束。
|
||||
|
||||
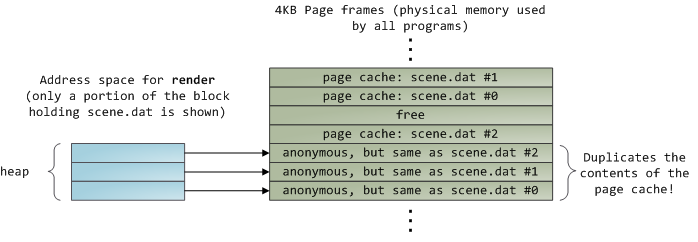
读取完 12KB 的文件内容以后,`render` 程序的堆和相关的页面帧如下图所示:
|
||||
|
||||
|
||||
|
||||
它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取(`read`)调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,**普通的文件 I/O 就是这样通过页面缓存来进行的**。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序一般也不会从磁盘区域仅仅读取几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 `#0`、`#1` 等等来描述。Windows 使用 256KB 大小的<ruby>视图<rt>view</rt></ruby>,类似于 Linux 的页面缓存中的<ruby>页面<rt>page</rt></ruby>。
|
||||
|
||||
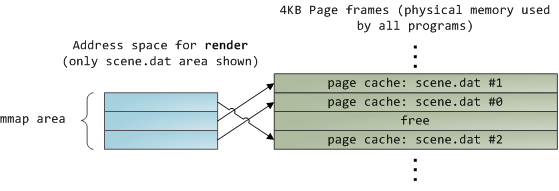
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到用户缓冲区中,它不仅花费 CPU 时间和影响 [CPU 缓存][6],**在复制数据时也浪费物理内存**。如前面的图示,`scene.dat` 的内存被存储了两次,并且,程序中的每个实例都用另外的时间去存储内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
|
||||
|
||||
|
||||
|
||||
当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程][7] 报告指出,在相关的普通文件读取上运行时性能提升多达 30% ,在 [Unix 环境中的高级编程][8] 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。这取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
|
||||
|
||||
对高性能的追求是永恒不变的目标,[测量是很重要的事情][9],内存映射应该是程序员始终要使用的工具。这个 API 提供了非常好用的实现方式,它允许你在内存中按字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap][11] 查看你的 [地址空间][10],在 Windows 中,可以使用 [CreateFileMapping][12],或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障][13] 来按需映射的。在 [获取][15] 需要的文件内容的页面帧后,页面故障句柄 [映射你的虚拟页面][14] 到页面缓存上。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
|
||||
|
||||
现在出现一个突发的状况,假设我们的 `render` 程序的最后一个实例退出了。在页面缓存中保存着 `scene.dat` 内容的页面要立刻释放掉吗?人们通常会如此考虑,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该保持全满。并且,这一原则适用于所有的进程。如果你现在运行 `render` 一周后, `scene.dat` 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(LCTT 译注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
|
||||
|
||||
由于页面缓存架构的原因,当程序调用 [write()][16] 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“脏”页面。磁盘 I/O 通常并**不会**立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。副作用是,如果这时候发生了电脑死机,你的写入将不会完成,因此,对于至关重要的文件,像数据库事务日志,要求必须进行 [fsync()][17](仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,直到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()][18]、[readahead()][19]、[Windows 缓存提示][20] ),你可以通过<ruby>提示<rt>hint</rt></ruby>帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取][21],但是我不确定 Windows 的行为。当然,在 Linux 中它可能会使用 [O_DIRECT][22] 跳过预读取,或者,在 Windows 中使用 [NO_BUFFERING][23] 去跳过预读,一些数据库软件就经常这么做。
|
||||
|
||||
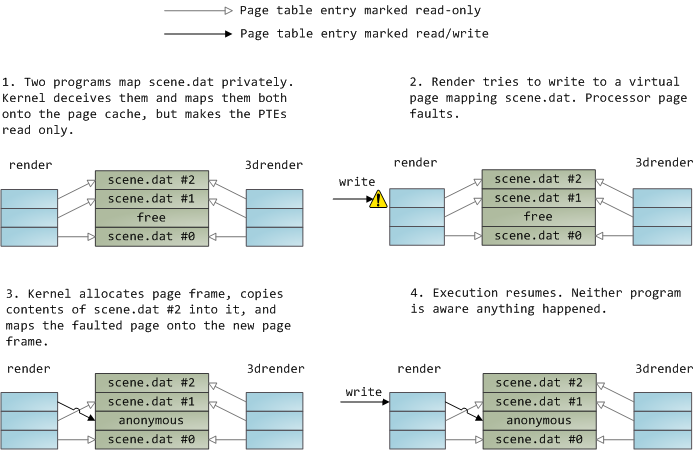
一个文件映射可以是私有的,也可以是共享的。当然,这只是针对内存中内容的**更新**而言:在一个私有的内存映射上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核使用<ruby>写时复制<rt>copy on write</rt></ruby>(CoW)机制,这是通过<ruby>页面表条目<rt>page table entry</rt></ruby>(PTE)来实现这种私有的映射。在下面的例子中,`render` 和另一个被称为 `render3d` 的程序都私有映射到 `scene.dat` 上。然后 `render` 去写入映射的文件的虚拟内存区域:
|
||||
|
||||
|
||||
|
||||
1. 两个程序私有地映射 `scene.dat`,内核误导它们并将它们映射到页面缓存,但是使该页面表条目只读。
|
||||
2. `render` 试图写入到映射 `scene.dat` 的虚拟页面,处理器发生页面故障。
|
||||
3. 内核分配页面帧,复制 `scene.dat` 的第二块内容到其中,并映射故障的页面到新的页面帧。
|
||||
4. 继续执行。程序就当做什么都没发生。
|
||||
|
||||
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
|
||||
|
||||
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 API 为你提供与私有文件映射相同的效果。下面的示例展示了映射文件的 `render` 程序的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
|
||||
|
||||
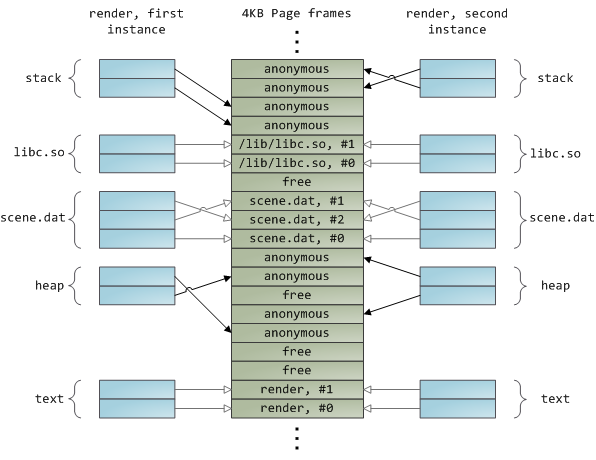
|
||||
|
||||
这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://linux.cn/article-9393-1.html
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
@ -39,7 +39,7 @@ $ ansible <group> -m setup -a "filter=ansible_distribution"
|
||||
|
||||
### 传输文件
|
||||
|
||||
对于传输文件,我们使用模块 “copy” ,完整的命令是这样的:
|
||||
对于传输文件,我们使用模块 `copy` ,完整的命令是这样的:
|
||||
|
||||
```
|
||||
$ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
@ -47,7 +47,7 @@ $ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
|
||||
### 管理用户
|
||||
|
||||
要管理已连接主机上的用户,我们使用一个名为 “user” 的模块,并如下使用它。
|
||||
要管理已连接主机上的用户,我们使用一个名为 `user` 的模块,并如下使用它。
|
||||
|
||||
#### 创建新用户
|
||||
|
||||
@ -65,7 +65,7 @@ $ ansible <group> -m user -a "name=testuser state=absent"
|
||||
|
||||
### 更改权限和所有者
|
||||
|
||||
要改变已连接主机文件的所有者,我们使用名为 ”file“ 的模块,使用如下。
|
||||
要改变已连接主机文件的所有者,我们使用名为 `file` 的模块,使用如下。
|
||||
|
||||
#### 更改文件权限
|
||||
|
||||
@ -81,7 +81,7 @@ $ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777 owner=dan group=
|
||||
|
||||
### 管理软件包
|
||||
|
||||
我们可以通过使用 ”yum“ 和 ”apt“ 模块来管理所有已连接主机的软件包,完整的命令如下:
|
||||
我们可以通过使用 `yum` 和 `apt` 模块来管理所有已连接主机的软件包,完整的命令如下:
|
||||
|
||||
#### 检查包是否已安装并更新
|
||||
|
||||
@ -109,7 +109,7 @@ $ ansible <group> -m yum -a "name=ntp state=absent"
|
||||
|
||||
### 管理服务
|
||||
|
||||
要管理服务,我们使用模块 “service” ,完整命令如下:
|
||||
要管理服务,我们使用模块 `service` ,完整命令如下:
|
||||
|
||||
#### 启动服务
|
||||
|
||||
@ -129,7 +129,7 @@ $ ansible <group> -m service -a "name=httpd state=stopped"
|
||||
$ ansible <group> -m service -a "name=httpd state=restarted"
|
||||
```
|
||||
|
||||
这样我们简单的,单行 Ansible 命令的教程就完成了。此外,在未来的教程中,我们将学习创建 playbook,来帮助我们更轻松高效地管理主机。
|
||||
这样我们简单的、单行 Ansible 命令的教程就完成了。此外,在未来的教程中,我们将学习创建 playbook,来帮助我们更轻松高效地管理主机。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -0,0 +1,72 @@
|
||||
防止文档陷阱的 7 条准则
|
||||
======
|
||||
> 让我们了解一下如何使国外读者更容易理解你的技术文章。
|
||||
|
||||

|
||||
|
||||
英语是开源社区的通用语言。为了减少翻译成本,很多团队都改成用英语来写他们的文档。 但奇怪的是,为国际读者写英语并不一定就意味着以英语为母语的人就占据更多的优势。 相反, 他们往往忘记了该文档用的语言可能并不是读者的母语。
|
||||
|
||||
我们以下面这个简单的句子为例: “Encrypt the password using the `foo bar` command。”语法上来说,这个句子是正确的。 鉴于动名词的 “-ing” 形式在英语中很常见,大多数的母语人士都认为这是一种优雅的表达方式, 他们通常会很自然的写出这样的句子。 但是仔细观察, 这个句子存在歧义因为 “using” 可能指的宾语(“the password”)也可能指的动词(“encrypt”)。 因此这个句子有两种解读方式:
|
||||
|
||||
* “加密使用了 `foo bar` 命令的密码。”
|
||||
* “使用命令 `foo bar` 来加密密码。”
|
||||
|
||||
如果你有相关的先验知识(密码加密或者 `foo bar` 命令),你可以消除这种不确定性并且明白第二种方式才是真正的意思。 但是若你没有足够深入的知识怎么办呢? 如果你并不是这方面的专家,而只是一个拥有泛泛相关知识的翻译者而已怎么办呢? 再或者,如果你只是个非母语人士且对像动名词这种高级语法不熟悉怎么办呢?
|
||||
|
||||
即使是英语为母语的人也需要经过训练才能写出清晰直接的技术文档。训练的第一步就是提高对文本可用性以及潜在问题的警觉性, 下面让我们来看一下可以帮助避免常见陷阱的 7 条规则。
|
||||
|
||||
### 1、了解你的目标读者并代入其中。
|
||||
|
||||
如果你是一名开发者,而写作的对象是最终用户, 那么你需要站在他们的角度来看这个产品。 文档的结构是否反映了用户的目标? [<ruby>人格面具<rt>persona</rt></ruby> 技术][1] 能帮你专注于目标受众并为你的读者提供合适层次的细节。
|
||||
|
||||
### 2、遵循 KISS 原则——保持文档简短而简单
|
||||
|
||||
这个原则适用于多个层次,从语法,句子到单词。 比如:
|
||||
|
||||
* 使用合适的最简单时态。比如, 当提到一个动作的结果时使用现在时:
|
||||
* " ~~Click 'OK.' The 'Printer Options' dialog will appear.~~ " -> "Click 'OK.' The 'Printer Options' dialog appears."
|
||||
* 按经验来说,一个句子表达一个主题;然而, 短句子并不一定就容易理解(尤其当这些句子都是由名词组成时)。 有时, 将句子裁剪过度可能会引起歧义,而反过来太多单词则又难以理解。
|
||||
* 不常用的以及很长的单词会降低阅读速度,而且可能成为非母语人士的障碍。 使用更简单的替代词语:
|
||||
* " ~~utilize~~ " -> "use"
|
||||
* " ~~indicate~~ " -> "show","tell" 或 "say"
|
||||
* " ~~prerequisite~~ " -> "requirement"
|
||||
|
||||
### 3、不要干扰阅读流
|
||||
|
||||
将虚词和较长的插入语移到句子的首部或者尾部:
|
||||
|
||||
* " ~~They are not, however, marked as installed.~~ " -> "However, they are not marked as installed."
|
||||
|
||||
将长命令放在句子的末尾可以让自动/半自动的翻译拥有更好的断句。
|
||||
|
||||
### 4、区别对待两种基本的信息类型
|
||||
|
||||
描述型信息以及任务导向型信息有必要区分开来。描述型信息的一个典型例子就是命令行参考, 而 HOWTO 则是属于基于任务的信息;(LCTT 译注:HOWTO 文档是 Linux 文档中的一种)然而, 技术写作中都会涉及这两种类型的信息。 仔细观察, 就会发现许多文本都同时包含了两种类型的信息。 然而如果能够清晰地划分这两种类型的信息那必是极好的。 为了更好地区分它们,可以对它们进行分别标记。 标题应该能够反映章节的内容以及信息的类型。 对描述性章节使用基于名词的标题(比如“Types of Frobnicators”),而对基于任务的章节使用口头表达式的标题(例如“Installing Frobnicators”)。 这可以让读者快速定位感兴趣的章节而跳过对他无用的章节。
|
||||
|
||||
### 5、考虑不同的阅读场景和阅读模式
|
||||
|
||||
有些读者在阅读产品文档时会由于自己搞不定而感到十分的沮丧。他们在一个嘈杂的环境中工作,也很难专注于阅读。 同时,不要期望你的读者会一页一页的进行阅读,很多人都是快速浏览文本,搜索关键字或者通过表格、索引以及全文搜索的方式来查找主题。 请牢记这一点, 从不同的角度来看待你的文字。 通常需要折中才能找到一种适合多种情况的文本结构。
|
||||
|
||||
### 6、将复杂的信息分成小块
|
||||
|
||||
这会让读者更容易记住和吸收信息。例如, 过程不应该超过 7 到 10 个步骤(根据认知心理学中的 [米勒法则][2])。 如果需要更多的步骤, 那么就将任务分拆成不同的过程。
|
||||
|
||||
### 7、形式遵循功能
|
||||
|
||||
根据以下问题检查你的文字:某句话/段落/章节的 _目的_(功能)是什么?比如,它是一个指令呢?还是一个结果呢?还是一个警告呢?如果是指令, 使用主动语气: “Configure the system.” 被动语气可能适合于进行描述: “The system is configured automatically.” 将警告放在危险操作的 _前面_ 。 专注于目的还有助于发现冗余的内容,可以清除类似 “basically” 或者 “easily” 这一类的填充词,类似 “~~already~~ existing ” 或“ ~~completely~~ new” 这一类的不必要的修饰, 以及任何与你的目标大众无关的内容。
|
||||
|
||||
你现在可能已经猜到了,写作就是一个不断重写的过程。 好的写作需要付出努力和练习。 即使你只是偶尔写点东西, 你也可以通过关注目标大众并遵循上述规则来显著地改善你的文字。 文字的可读性越好, 理解就越容易, 这一点对不同语言能力的读者来说都是适合的。 尤其是当进行本地化时, 高质量的原始文本至关重要:“垃圾进, 垃圾出”。 如果原始文本就有缺陷, 翻译所需要的时间就会变长, 从而导致更高的成本。 最坏的情况下, 翻译会导致缺陷成倍增加,需要在不同的语言版本中修正这个缺陷。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/7-rules
|
||||
|
||||
作者:[Tanja Roth][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://en.wikipedia.org/wiki/Persona_(user_experience)
|
||||
[2]:https://en.wikipedia.org/wiki/The_Magical_Number_Seven,_Plus_or_Minus_Two
|
||||
@ -1,51 +1,45 @@
|
||||
深入看看 Facebook 的开源计划
|
||||
Facebook 的开源计划一窥
|
||||
============================================================
|
||||
|
||||
### Facebook 开发人员 Christine Abernathy 讨论了开源如何帮助公司分享见解并推动创新。
|
||||
> Facebook 开发人员 Christine Abernathy 讨论了开源如何帮助公司分享见解并推动创新。
|
||||
|
||||

|
||||
|
||||
图像来源:opensource.com
|
||||
|
||||
开源逐年变得无处不在,从[政府直辖市][11]到[大学][12]都有。各种规模的公司也越来越多地转向开源软件。事实上,一些公司正在通过财务支持项目或与开发人员合作进一步推进开源。
|
||||
|
||||
开源每年在变得无处不在,从[政府直辖市][11]到[大学] [12]都有。各种规模的公司也越来越多地转向开源软件。事实上,一些公司正在通过财务支持项目或与开发人员合作进一步推进开源。
|
||||
|
||||
例如,Facebook 的开源计划鼓励其他人开源发布他们的代码,同时与社区合作支持开源项目。 [Christine Abernathy][13],一名 Facebook 开发者,开源支持者,公司开源团队成员,去年 11 月访问了罗切斯特理工学院,在[ 11 月][14] 的 FOSS 系列演讲中发表了演讲。在她的演讲中,Abernathy 解释了 Facebook 如何开源以及为什么它是公司所做工作的重要组成部分。
|
||||
例如,Facebook 的开源计划鼓励其他人开源发布他们的代码,同时与社区合作支持开源项目。 [Christine Abernathy][13],是一名 Facebook 开发者、开源支持者,也是该公司开源团队成员,去年 11 月访问了罗切斯特理工学院,在 [11 月][14] 的 FOSS 系列演讲中发表了演讲。在她的演讲中,Abernathy 解释了 Facebook 如何开源以及为什么它是公司所做工作的重要组成部分。
|
||||
|
||||
### Facebook 和开源
|
||||
|
||||
Abernathy 说,开源在 Facebook 创建社区和使世界更加紧密的使命中扮演着重要的角色。这种意识形态的匹配是 Facebook 参与开源的一个激励因素。此外,Facebook 面临着独特的基础设施和开发挑战,而开源则为公司提供了一个平台,以共享可帮助他人的解决方案。开源还提供了一种加速创新和创建更好软件的方法,帮助工程团队生产更好的软件并更透明地工作。今天,Facebook 在 GitHub 上有 443个 项目包括 122,000 个分支,292,000 个提交和 732,000 个关注。
|
||||
|
||||
Abernathy 说,开源在 Facebook 创建社区并使世界更加紧密的使命中扮演着重要的角色。这种意识形态的匹配是 Facebook 参与开源的一个激励因素。此外,Facebook 面临着独特的基础设施和开发挑战,而开源则为公司提供了一个平台,以共享可帮助他人的解决方案。开源还提供了一种加速创新和创建更好软件的方法,帮助工程团队生产更好的软件并更透明地工作。今天,Facebook 在 GitHub 的 443 个项目有 122,000 个分支、292,000 个提交和 732,000 个关注。
|
||||
|
||||

|
||||
|
||||
一些以开源方式发布的 Facebook 项目包括 React、GraphQL、Caffe2 等等。(图片提供:Christine Abernathy 图片,经许可使用)
|
||||
*一些以开源方式发布的 Facebook 项目包括 React、GraphQL、Caffe2 等等。(图片提供:Christine Abernathy 图片,经许可使用)*
|
||||
|
||||
### 得到的教训
|
||||
|
||||
Abernathy 强调说 Facebook 已经从开源社区吸取了很多教训,并期待学到更多。她明确了三个最重要的:
|
||||
|
||||
* 分享有用的东西
|
||||
|
||||
* 突出你的英雄
|
||||
|
||||
* 修复常见的痛点
|
||||
|
||||
_Christine Abernathy 作为 FOSS 演讲系列的嘉宾一员参观了 RIT。每个月,来自开源世界的演讲嘉宾都会与对免费和开源软件感兴趣的学生分享关于开源世界智慧、见解、建议。 [FOSS @MAGIC][3]社区感谢 Abernathy 作为演讲嘉宾出席。_
|
||||
_Christine Abernathy 作为 FOSS 演讲系列的嘉宾一员参观了 RIT。每个月,来自开源世界的演讲嘉宾都会与对自由和开源软件感兴趣的学生分享关于开源世界智慧、见解、建议。 [FOSS @MAGIC][3]社区感谢 Abernathy 作为演讲嘉宾出席。_
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][15]
|
||||
Justin 是[罗切斯特理工学院][4]主修网络与系统管理的学生。他目前是 [Fedora Project][5] 的贡献者。在 Fedora 中,Justin 是 [Fedora Magazine][6] 的主编,[社区的领导][7]。。。[更多关于 Justin W. Flory][8]
|
||||
|
||||
[关于我更多][9]
|
||||
Justin 是[罗切斯特理工学院][4]主修网络与系统管理的学生。他目前是 [Fedora Project][5] 的贡献者。在 Fedora 中,Justin 是 [Fedora Magazine][6] 的主编,[社区的领导][7]... [更多关于 Justin W. Flory][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/inside-facebooks-open-source-program
|
||||
|
||||
作者:[Justin W. Flory][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
#fuyongXu 翻译中
|
||||
# [Google launches TensorFlow-based vision recognition kit for RPi Zero W][26]
|
||||
|
||||
|
||||
|
||||
@ -1,120 +0,0 @@
|
||||
Linux LAN Routing for Beginners: Part 2
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
In this tutorial, we show how to manually configure LAN routers.[Creative Commons Zero][1]
|
||||
|
||||
Last week [we reviewed IPv4 addressing][3] and using the network admin's indispensible ipcalc tool: Now we're going to make some nice LAN routers.
|
||||
|
||||
VirtualBox and KVM are wonderful for testing routing, and the examples in this article are all performed in KVM. If you prefer to use physical hardware, then you need three computers: one to act as the router, and the other two to represent two different networks. You also need two Ethernet switches and cabling.
|
||||
|
||||
The examples assume a wired Ethernet LAN, and we shall pretend there are some bridged wireless access points for a realistic scenario, although we're not going to do anything with them. (I have not yet tried all-WiFi routing and have had mixed success with connecting a mobile broadband device to an Ethernet LAN, so look for those in a future installment.)
|
||||
|
||||
### Network Segments
|
||||
|
||||
The simplest network segment is two computers in the same address space connected to the same switch. These two computers do not need a router to communicate with each other. A useful term is _broadcast domain_ , which describes a group of hosts that are all in the same network. They may be all connected to a single Ethernet switch, or multiple switches. A broadcast domain may include two different networks connected by an Ethernet bridge, which makes the two networks behave as a single network. Wireless access points are typically bridged to a wired Ethernetwork.
|
||||
|
||||
A broadcast domain can talk to a different broadcast domain only when they are connected by a network router.
|
||||
|
||||
### Simple Network
|
||||
|
||||
The following example commands are not persistent, and your changes will vanish with a restart.
|
||||
|
||||
A broadcast domain needs a router to talk to other broadcast domains. Let's illustrate this with two computers and the `ip` command. Our two computers are 192.168.110.125 and 192.168.110.126, and they are plugged into the same Ethernet switch. In VirtualBox or KVM, you automatically create a virtual switch when you configure a new network, so when you assign a network to a virtual machine it's like plugging it into a switch. Use `ip addr show` to see your addresses and network interface names. The two hosts can ping each other.
|
||||
|
||||
Now add an address in a different network to one of the hosts:
|
||||
|
||||
```
|
||||
# ip addr add 192.168.120.125/24 dev ens3
|
||||
```
|
||||
|
||||
You have to specify the network interface name, which in the example is ens3\. It is not required to add the network prefix, in this case /24, but it never hurts to be explicit. Check your work with `ip`. The example output is trimmed for clarity:
|
||||
|
||||
```
|
||||
$ ip addr show
|
||||
ens3:
|
||||
inet 192.168.110.125/24 brd 192.168.110.255 scope global dynamic ens3
|
||||
valid_lft 875sec preferred_lft 875sec
|
||||
inet 192.168.120.125/24 scope global ens3
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
The host at 192.168.120.125 can ping itself (`ping 192.168.120.125`), and that is a good basic test to verify that your configuration is working correctly, but the second computer can't ping that address.
|
||||
|
||||
Now we need to do bit of network juggling. Start by adding a third host to act as the router. This needs two virtual network interfaces and a second virtual network. In real life you want your router to have static IP addresses, but for now we'll let the KVM DHCP server do the work of assigning addresses, so you only need these two virtual networks:
|
||||
|
||||
* First network: 192.168.110.0/24
|
||||
|
||||
* Second network: 192.168.120.0/24
|
||||
|
||||
Then your router must be configured to forward packets. Packet forwarding should be disabled by default, which you can check with `sysctl`:
|
||||
|
||||
```
|
||||
$ sysctl net.ipv4.ip_forward
|
||||
net.ipv4.ip_forward = 0
|
||||
```
|
||||
|
||||
The zero means it is disabled. Enable it with this command:
|
||||
|
||||
```
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
```
|
||||
|
||||
Then configure one of your other hosts to play the part of the second network by assigning the 192.168.120.0/24 virtual network to it in place of the 192.168.110.0/24 network, and then reboot the two "network" hosts, but not the router. (Or restart networking; I'm old and lazy and don't care what weird commands are required to restart services when I can just reboot.) The addressing should look something like this:
|
||||
|
||||
* Host 1: 192.168.110.125
|
||||
|
||||
* Host 2: 192.168.120.135
|
||||
|
||||
* Router: 192.168.110.126 and 192.168.120.136
|
||||
|
||||
Now go on a ping frenzy, and ping everyone from everyone. There are some quirks with virtual machines and the various Linux distributions that produce inconsistent results, so some pings will succeed and some will not. Not succeeding is good, because it means you get to practice creating a static route. First, view the existing routing tables. The first example is from Host 1, and the second is from the router:
|
||||
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link src 192.168.110.164 metric 100
|
||||
```
|
||||
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
default via 192.168.120.1 dev ens3 proto static metric 101
|
||||
169.254.0.0/16 dev ens3 scope link metric 1000
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link
|
||||
src 192.168.110.126 metric 100
|
||||
192.168.120.0/24 dev ens9 proto kernel scope link
|
||||
src 192.168.120.136 metric 100
|
||||
```
|
||||
|
||||
This shows us that the default routes are the ones assigned by KVM. The 169.* address is the automatic link local address, and we can ignore it. Then we see two more routes, the two that belong to our router. You can have multiple routes, and this example shows how to add a non-default route to Host 1:
|
||||
|
||||
```
|
||||
# ip route add 192.168.120.0/24 via 192.168.110.126 dev ens3
|
||||
```
|
||||
|
||||
This means Host 1 can access the 192.168.110.0/24 network via the router interface 192.168.110.126\. See how it works? Host 1 and the router need to be in the same address space to connect, then the router forwards to the other network.
|
||||
|
||||
This command deletes a route:
|
||||
|
||||
```
|
||||
# ip route del 192.168.120.0/24
|
||||
```
|
||||
|
||||
In real life, you're not going to be setting up routes manually like this, but rather using a router daemon and advertising your router via DHCP but understanding the fundamentals is key. Come back next week to learn how to set up a nice easy router daemon that does the work for you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/linux-lan-routing-beginners-part-2
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/dortmund-hbf-12595591920jpg
|
||||
[3]:https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
@ -0,0 +1,109 @@
|
||||
Memories of writing a parser for man pages
|
||||
======
|
||||
|
||||
I generally enjoy being bored, but sometimes enough is enough—that was the case a Sunday afternoon of 2015 when I decided to start an open source project to overcome my boredom.
|
||||
|
||||
In my quest for ideas, I stumbled upon a request to build a [“Man page viewer built with web standards”][1] by [Mathias Bynens][2] and without thinking too much, I started coding a man page parser in JavaScript, which after a lot of back and forths, ended up being [Jroff][3].
|
||||
|
||||
Back then, I was familiar with manual pages as a concept and used them a fair amount of times, but that was all I knew, I had no idea how they were generated or if there was a standard in place. Two years later, here are some thoughts on the matter.
|
||||
|
||||
### How man pages are written
|
||||
|
||||
The first thing that surprised me at the time, was the notion that manpages at their core are just plain text files stored somewhere in the system (you can check this directory using the `manpath` command).
|
||||
|
||||
This files not only contain the documentation, but also formatting information using a typesetting system from the 1970s called `troff`.
|
||||
|
||||
> troff, and its GNU implementation groff, are programs that process a textual description of a document to produce typeset versions suitable for printing. **It’s more ‘What you describe is what you get’ rather than WYSIWYG.**
|
||||
>
|
||||
> — extracted from [troff.org][4]
|
||||
|
||||
If you are totally unfamiliar with typesetting formats, you can think of them as Markdown on steroids, but in exchange for the flexibility you have a more complex syntax:
|
||||
|
||||
![groff-compressor][5]
|
||||
|
||||
The `groff` file can be written manually, or generated from other formats such as Markdown, Latex, HTML, and so on with many different tools.
|
||||
|
||||
Why `groff` and man pages are tied together has to do with history, the format has [mutated along time][6], and his lineage is composed of a chain of similarly-named programs: RUNOFF > roff > nroff > troff > groff.
|
||||
|
||||
But this doesn’t necessarily mean that `groff` is strictly related to man pages, it’s a general-purpose format that has been used to [write books][7] and even for [phototypesetting][8].
|
||||
|
||||
Moreover, It’s worth noting that `groff` can also call a postprocessor to convert its intermediate output to a final format, which is not necessarily ascii for terminal display! some of the supported formats are: TeX DVI, HTML, Canon, HP LaserJet4 compatible, PostScript, utf8 and many more.
|
||||
|
||||
### Macros
|
||||
|
||||
Other of the cool features of the format is its extensibility, you can write macros that enhance the basic functionalities.
|
||||
|
||||
With the vast history of *nix systems, there are several macro packages that group useful macros together for specific functionalities according to the output that you want to generate, examples of macro packages are `man`, `mdoc`, `mom`, `ms`, `mm`, and the list goes on.
|
||||
|
||||
Manual pages are conventionally written using `man` and `mdoc`.
|
||||
|
||||
You can easily distinguish native `groff` commands from macros by the way standard `groff` packages capitalize their macro names. For `man`, each macro’s name is uppercased, like .PP, .TH, .SH, etc. For `mdoc`, only the first letter is uppercased: .Pp, .Dt, .Sh.
|
||||
|
||||
![groff-example][9]
|
||||
|
||||
### Challenges
|
||||
|
||||
Whether you are considering to write your own `groff` parser, or just curious, these are some of the problems that I have found more challenging.
|
||||
|
||||
#### Context-sensitive grammar
|
||||
|
||||
Formally, `groff` has a context-free grammar, unfortunately, since macros describe opaque bodies of tokens, the set of macros in a package may not itself implement a context-free grammar.
|
||||
|
||||
This kept me away (for good or bad) from the parser generators that were available at the time.
|
||||
|
||||
#### Nested macros
|
||||
|
||||
Most of the macros in `mdoc` are callable, this roughly means that macros can be used as arguments of other macros, for example, consider this:
|
||||
|
||||
* The macro `Fl` (Flag) adds a dash to its argument, so `Fl s` produces `-s`
|
||||
* The macro `Ar` (Argument) provides facilities to define arguments
|
||||
* The `Op` (Optional) macro wraps its argument in brackets, as this is the standard idiom to define something as optional.
|
||||
* The following combination `.Op Fl s Ar file` produces `[-s file]` because `Op` macros can be nested.
|
||||
|
||||
|
||||
|
||||
#### Lack of beginner-friendly resources
|
||||
|
||||
Something that really confused me was the lack of a canonical, well defined and clear source to look at, there’s a lot of information in the web which assumes a lot about the reader that it takes time to grasp.
|
||||
|
||||
### Interesting macros
|
||||
|
||||
To wrap up, I will offer to you a very short list of macros that I found interesting while developing jroff:
|
||||
|
||||
**man**
|
||||
|
||||
* TH: when writing manual pages with `man` macros, your first line that is not a comment must be this macro, it accepts five parameters: title section date source manual
|
||||
* BI: bold alternating with italics (especially useful for function specifications)
|
||||
* BR: bold alternating with Roman (especially useful for referring to other manual pages)
|
||||
|
||||
|
||||
|
||||
**mdoc**
|
||||
|
||||
* .Dd, .Dt, .Os: similar to how `man` macros require the `.TH` the `mdoc` macros require these three macros, in that particular order. Their initials stand for: Document date, Document title and Operating system.
|
||||
* .Bl, .It, .El: these three macros are used to create list, their names are self-explanatory: Begin list, Item and End list.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://monades.roperzh.com/memories-writing-parser-man-pages/
|
||||
|
||||
作者:[Roberto Dip][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://monades.roperzh.com
|
||||
[1]:https://github.com/h5bp/lazyweb-requests/issues/114
|
||||
[2]:https://mathiasbynens.be/
|
||||
[3]:jroff
|
||||
[4]:https://www.troff.org/
|
||||
[5]:https://user-images.githubusercontent.com/4419992/37868021-2e74027c-2f7f-11e8-894b-80829ce39435.gif
|
||||
[6]:https://manpages.bsd.lv/history.html
|
||||
[7]:https://rkrishnan.org/posts/2016-03-07-how-is-gopl-typeset.html
|
||||
[8]:https://en.wikipedia.org/wiki/Phototypesetting
|
||||
[9]:https://user-images.githubusercontent.com/4419992/37866838-e602ad78-2f6e-11e8-97a9-2a4494c766ae.jpg
|
||||
@ -0,0 +1,255 @@
|
||||
9 Useful touch command examples in Linux
|
||||
======
|
||||
Touch command is used to create empty files and also changes the timestamps of existing files on Unix & Linux System. Changing timestamps here means updating the access and modification time of files and directories.
|
||||
|
||||
[![touch-command-examples-linux][1]![touch-command-examples-linux][2]][2]
|
||||
|
||||
Let’s have a look on the syntax and options used in touch command,
|
||||
|
||||
**Syntax** : # touch {options} {file}
|
||||
|
||||
Options used in touch command,
|
||||
|
||||
![touch-command-options][1]
|
||||
|
||||
![touch-command-options][3]
|
||||
|
||||
In this article we will walk through 9 useful touch command examples in Linux,
|
||||
|
||||
### Example:1 Create an empty file using touch
|
||||
|
||||
To create an empty file using touch command on Linux systems, type touch followed by the file name, example is shown below,
|
||||
```
|
||||
[root@linuxtechi ~]# touch devops.txt
|
||||
[root@linuxtechi ~]# ls -l devops.txt
|
||||
-rw-r--r--. 1 root root 0 Mar 29 22:39 devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:2 Create empty files in bulk using touch
|
||||
|
||||
There can be some scenario where we have to create lots of empty files for some testing, this can be easily achieved using touch command,
|
||||
```
|
||||
[root@linuxtechi ~]# touch sysadm-{1..20}.txt
|
||||
|
||||
```
|
||||
|
||||
In the above example we have created 20 empty files with name sysadm-1.txt to sysadm-20.txt, you can change the name and numbers based on your requirements.
|
||||
|
||||
### Example:3 Change / Update access time of a file and directory
|
||||
|
||||
Let’s assume we want to change access time of a file called “ **devops.txt** “, to do this use ‘ **-a** ‘ option in touch command followed by file name, example is shown below,
|
||||
```
|
||||
[root@linuxtechi ~]# touch -a devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
Now verify whether access time of a file has been updated or not using ‘stat’ command
|
||||
```
|
||||
[root@linuxtechi ~]# stat devops.txt
|
||||
File: ‘devops.txt’
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Context: unconfined_u:object_r:admin_home_t:s0
|
||||
Access: 2018-03-29 23:03:10.902000000 -0400
|
||||
Modify: 2018-03-29 22:39:29.365000000 -0400
|
||||
Change: 2018-03-29 23:03:10.902000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
**Change access time of a directory** ,
|
||||
|
||||
Let’s assume we have a ‘nfsshare’ folder under /mnt, Let’s change the access time of this folder using the below command,
|
||||
```
|
||||
[root@linuxtechi ~]# touch -m /mnt/nfsshare/
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
[root@linuxtechi ~]# stat /mnt/nfsshare/
|
||||
File: ‘/mnt/nfsshare/’
|
||||
Size: 6 Blocks: 0 IO Block: 4096 directory
|
||||
Device: fd00h/64768d Inode: 2258 Links: 2
|
||||
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Context: unconfined_u:object_r:mnt_t:s0
|
||||
Access: 2018-03-29 23:34:38.095000000 -0400
|
||||
Modify: 2018-03-03 10:42:45.194000000 -0500
|
||||
Change: 2018-03-29 23:34:38.095000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:4 Change Access time without creating new file
|
||||
|
||||
There can be some situations where we want to change access time of a file if it exists and avoid creating the file. Using ‘ **-c** ‘ option in touch command, we can change access time of a file if it exists and will not a create a file, if it doesn’t exist.
|
||||
```
|
||||
[root@linuxtechi ~]# touch -c sysadm-20.txt
|
||||
[root@linuxtechi ~]# touch -c winadm-20.txt
|
||||
[root@linuxtechi ~]# ls -l winadm-20.txt
|
||||
ls: cannot access winadm-20.txt: No such file or directory
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:5 Change Modification time of a file and directory
|
||||
|
||||
Using ‘ **-m** ‘ option in touch command, we can change the modification time of a file and directory,
|
||||
|
||||
Let’s change the modification time of a file called “devops.txt”,
|
||||
```
|
||||
[root@linuxtechi ~]# touch -m devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
Now verify whether modification time has been changed or not using stat command,
|
||||
```
|
||||
[root@linuxtechi ~]# stat devops.txt
|
||||
File: ‘devops.txt’
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Context: unconfined_u:object_r:admin_home_t:s0
|
||||
Access: 2018-03-29 23:03:10.902000000 -0400
|
||||
Modify: 2018-03-29 23:59:49.106000000 -0400
|
||||
Change: 2018-03-29 23:59:49.106000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
Similarly, we can change modification time of a directory,
|
||||
```
|
||||
[root@linuxtechi ~]# touch -m /mnt/nfsshare/
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:6 Changing access and modification time in one go
|
||||
|
||||
Use “ **-am** ” option in touch command to change the access and modification together or in one go, example is shown below,
|
||||
```
|
||||
[root@linuxtechi ~]# touch -am devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
Cross verify the access and modification time using stat,
|
||||
```
|
||||
[root@linuxtechi ~]# stat devops.txt
|
||||
File: ‘devops.txt’
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Context: unconfined_u:object_r:admin_home_t:s0
|
||||
Access: 2018-03-30 00:06:20.145000000 -0400
|
||||
Modify: 2018-03-30 00:06:20.145000000 -0400
|
||||
Change: 2018-03-30 00:06:20.145000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:7 Set the Access & modification time to a specific date and time
|
||||
|
||||
Whenever we do change access and modification time of a file & directory using touch command, then it set the current time as access & modification time of that file or directory,
|
||||
|
||||
Let’s assume we want to set specific date and time as access & modification time of a file, this is can be achieved using ‘-c’ & ‘-t’ option in touch command,
|
||||
|
||||
Date and Time can be specified in the format: {CCYY}MMDDhhmm.ss
|
||||
|
||||
Where:
|
||||
|
||||
* CC – First two digits of a year
|
||||
* YY – Second two digits of a year
|
||||
* MM – Month of the Year (01-12)
|
||||
* DD – Day of the Month (01-31)
|
||||
* hh – Hour of the day (00-23)
|
||||
* mm – Minutes of the hour (00-59)
|
||||
|
||||
|
||||
|
||||
Let’s set the access & modification time of devops.txt file for future date and time( 2025 year, 10th Month, 19th day of month, 18th hours and 20th minute)
|
||||
```
|
||||
[root@linuxtechi ~]# touch -c -t 202510191820 devops.txt
|
||||
|
||||
```
|
||||
|
||||
Use stat command to view the update access & modification time,
|
||||
|
||||
![stat-command-output-linux][1]
|
||||
|
||||
![stat-command-output-linux][4]
|
||||
|
||||
Set the Access and Modification time based on date string, Use ‘-d’ option in touch command and then specify the date string followed by the file name, example is shown below,
|
||||
```
|
||||
[root@linuxtechi ~]# touch -c -d "2010-02-07 20:15:12.000000000 +0530" sysadm-29.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
Verify the status using stat command,
|
||||
```
|
||||
[root@linuxtechi ~]# stat sysadm-20.txt
|
||||
File: ‘sysadm-20.txt’
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324189 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Context: unconfined_u:object_r:admin_home_t:s0
|
||||
Access: 2010-02-07 20:15:12.000000000 +0530
|
||||
Modify: 2010-02-07 20:15:12.000000000 +0530
|
||||
Change: 2018-03-30 10:23:31.584000000 +0530
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
**Note:** In above commands, if we don’t specify ‘-c’ then touch command will create a new file in case it doesn’t exist on the system and will set the timestamps whatever is mentioned in the command.
|
||||
|
||||
### Example:8 Set the timestamps to a file using a reference file (-r)
|
||||
|
||||
In touch command we can use a reference file for setting the timestamps of file or directory. Let’s assume I want to set the same timestamps of file “sysadm-20.txt” on “devops.txt” file. This can be easily achieved using ‘-r’ option in touch.
|
||||
|
||||
**Syntax:** # touch -r {reference-file} actual-file
|
||||
```
|
||||
[root@linuxtechi ~]# touch -r sysadm-20.txt devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:9 Change Access & Modification time on symbolic link file
|
||||
|
||||
By default, whenever we try to change timestamps of a symbolic link file using touch command then it will change the timestamps of original file only, In case you want to change timestamps of a symbolic link file then this can be achieved using ‘-h’ option in touch command,
|
||||
|
||||
**Syntax:** # touch -h {symbolic link file}
|
||||
```
|
||||
[root@linuxtechi opt]# ls -l /root/linuxgeeks.txt
|
||||
lrwxrwxrwx. 1 root root 15 Mar 30 10:56 /root/linuxgeeks.txt -> linuxadmins.txt
|
||||
[root@linuxtechi ~]# touch -t 203010191820 -h linuxgeeks.txt
|
||||
[root@linuxtechi ~]# ls -l linuxgeeks.txt
|
||||
lrwxrwxrwx. 1 root root 15 Oct 19 2030 linuxgeeks.txt -> linuxadmins.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
That’s all from this tutorial, I hope these examples help you to understand touch command. Please do share your valuable feedback and comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/9-useful-touch-command-examples-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/plugins/lazy-load/images/1x1.trans.gif
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2018/03/touch-command-examples-linux.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2018/03/touch-command-options.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2018/03/stat-command-output-linux.jpg
|
||||
@ -0,0 +1,129 @@
|
||||
10 fundamental commands for new Linux users
|
||||
======
|
||||
|
||||

|
||||
You may think you're new to Linux, but you're really not. There are [3.74 billion][1] global internet users, and all of them use Linux in some way since Linux servers power 90% of the internet. Most modern routers run Linux or Unix, and the [TOP500 supercomputers][2] also rely on Linux. If you own an Android smartphone, your operating system is constructed from the Linux kernel.
|
||||
|
||||
In other words, Linux is everywhere.
|
||||
|
||||
But there's a difference between using Linux-based technologies and using Linux itself. If you're interested in Linux, but have been using a PC or Mac desktop, you may be wondering what you need to know to use the Linux command line interface (CLI). You've come to the right place.
|
||||
|
||||
The following are the fundamental Linux commands you need to know. Each is simple and easy to commit to memory. In other words, you don't have to be Bill Gates to understand them.
|
||||
|
||||
### 1\. ls
|
||||
|
||||
You're probably thinking, "Is what?" No, that wasn't a typographical error – I really intended to type a lower-case L. `ls`, or "list," is the number one command you need to know to use the Linux CLI. This list command functions within the Linux terminal to reveal all the major directories filed under a respective filesystem. For example, this command:
|
||||
|
||||
`ls /applications`
|
||||
|
||||
shows every folder stored in the applications folder. You'll use it to view files, folders, and directories.
|
||||
|
||||
All hidden files are viewable by using the command `ls -a`.
|
||||
|
||||
### 2\. cd
|
||||
|
||||
This command is what you use to go (or "change") to a directory. It is how you navigate from one folder to another. Say you're in your Downloads folder, but you want to go to a folder called Gym Playlist. Simply typing `cd Gym Playlist` won't work, as the shell won't recognize it and will report the folder you're looking for doesn't exist. To bring up that folder, you'll need to include a backslash. The command should look like this:
|
||||
|
||||
`cd Gym\ Playlist`
|
||||
|
||||
To go back from the current folder to the previous one, you can type in the folder name followed by `cd ..`. Think of the two dots like a back button.
|
||||
|
||||
### 3\. mv
|
||||
|
||||
This command transfers a file from one folder to another; `mv` stands for "move." You can use this short command like you would drag a file to a folder on a PC.
|
||||
|
||||
For example, if I create a file called `testfile` to demonstrate all the basic Linux commands, and I want to move it to my Documents folder, I would issue this command:
|
||||
|
||||
`mv /home/sam/testfile /home/sam/Documents/`
|
||||
|
||||
The first piece of the command (`mv`) says I want to move a file, the second part (`home/sam/testfile`) names the file I want to move, and the third part (`/home/sam/Documents/`) indicates the location where I want the file transferred.
|
||||
|
||||
### 4\. Keyboard shortcuts
|
||||
|
||||
Okay, this is more than one command, but I couldn't resist including them all here. Why? Because they save time and take the headache out of your experience.
|
||||
|
||||
`CTRL+K` Cuts text from the cursor until the end of the line
|
||||
|
||||
`CTRL+Y` Pastes text
|
||||
|
||||
`CTRL+E` Moves the cursor to the end of the line
|
||||
|
||||
`CTRL+A` Moves the cursor to the beginning of the line
|
||||
|
||||
`ALT+F`Jumps forward to the next space
|
||||
|
||||
`ALT+B` Skips back to the previous space
|
||||
|
||||
`ALT+Backspace` Deletes the previous word
|
||||
|
||||
`CTRL+W` Cuts the word behind the cursor
|
||||
|
||||
`Shift+Insert` Pastes text into the terminal
|
||||
|
||||
`Ctrl+D` Logs you out
|
||||
|
||||
These commands come in handy in many ways. For example, imagine you misspell a word in your command text:
|
||||
|
||||
`sudo apt-get intall programname`
|
||||
|
||||
You probably noticed "install" is misspelled, so the command won't work. But keyboard shortcuts make it easy to go back and fix it. If my cursor is at the end of the line, I can click `ALT+B` twice to move the cursor to the place noted below with the `^` symbol:
|
||||
|
||||
`sudo apt-get^intall programname`
|
||||
|
||||
Now, we can quickly add the letter `s` to fix `install`. Easy peasy!
|
||||
|
||||
### 5\. mkdir
|
||||
|
||||
This is the command you use to make a directory or a folder in the Linux environment. For example, if you're big into DIY hacks like I am, you could enter `mkdir DIY` to make a directory for your DIY projects.
|
||||
|
||||
### 6\. at
|
||||
|
||||
If you want to run a Linux command at a certain time, you can add `at` to the equation. The syntax is `at` followed by the date and time you want the command to run. Then the command prompt changes to `at>` so you can enter the command(s) you want to run at the time you specified above
|
||||
|
||||
For example:
|
||||
|
||||
`at 4:08 PM Sat`
|
||||
`at> cowsay 'hello'`
|
||||
`at> CTRL+D`
|
||||
|
||||
This will run the program cowsay at 4:08 p.m. on Saturday night.
|
||||
|
||||
### 7\. rmdir
|
||||
|
||||
This command allows you to remove a directory through the Linux CLI. For example:
|
||||
|
||||
`rmdir testdirectory`
|
||||
|
||||
Bear in mind that this command will not remove a directory that has files inside. This only works when removing empty directories.
|
||||
|
||||
### 8\. rm
|
||||
|
||||
If you want to remove files, the `rm` command is what you want. It can delete files and directories. To delete a single file, type `rm testfile`, or to delete a directory and the files inside it, type `rm -r`.
|
||||
|
||||
### 9\. touch
|
||||
|
||||
The `touch` command, otherwise known as the "make file command," allows you to create new, empty files using the Linux CLI. Much like `mkdir` creates directories, `touch` creates files. For example, `touch testfile` will make an empty file named testfile.
|
||||
|
||||
### 10\. locate
|
||||
|
||||
This command is what you use to find a file in a Linux system. Think of it like search in Windows. It's very useful if you forget where you stored a file or what you named it.
|
||||
|
||||
For example, if you have a document about blockchain use cases, but you can't think of the title, you can punch in `locate -blockchain`or you can look for "blockchain use cases" by separating the words with an asterisk or asterisks (`*`). For example:
|
||||
|
||||
`locate -i*blockchain*use*cases*`.
|
||||
|
||||
There are tons of other helpful Linux CLI commands, like the `pkill` command, which is great if you start a shutdown and realize you didn't mean to. But the 10 simple and useful commands described here are the essentials you need to get started using the Linux command line.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/10-commands-new-linux-users
|
||||
|
||||
作者:[Sam Bocetta][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sambocetta
|
||||
[1]:https://hostingcanada.org/state-of-the-internet/
|
||||
[2]:https://www.top500.org/statistics/details/osfam/1
|
||||
@ -0,0 +1,459 @@
|
||||
17 Ways To Check Size Of Physical Memory (RAM) In Linux
|
||||
======
|
||||
Most of the system administrators checks CPU & Memory utilization when they were facing some performance issue.
|
||||
|
||||
There is lot of utilities are available in Linux to check physical memory.
|
||||
|
||||
These commands are help us to check the physical RAM present in system, also allow users to check memory utilization in varies aspect.
|
||||
|
||||
Most of us know only few commands and we are trying to include all the possible commands in this article.
|
||||
|
||||
You may think, why i want to know all these commands instead of knowing some of the specific and routine commands.
|
||||
|
||||
Don’t think bad or don’t take in negative way because each one has different requirement and perception so, who’s looking for other purpose then this will very helpful for them.
|
||||
|
||||
### What Is RAM
|
||||
|
||||
Computer memory is a physical device which capable to store information temporarily or permanently. RAM stands for Random Access Memory is a volatile memory that stores information used by the operating system, software, and hardware.
|
||||
|
||||
Two types of memory is available.
|
||||
|
||||
* Primary Memory
|
||||
* Secondary Memory
|
||||
|
||||
|
||||
|
||||
Primary memory is the main memory of the computer. CPU can directly read or write on this memory. It is fixed on the motherboard of the computer.
|
||||
|
||||
* **`RAM:`** Random Access Memory is a temporary memory. This information will go away when the computer is turned off.
|
||||
* **`ROM:`** Read Only Memory is permanent memory, that holds the data even if the system is switched off.
|
||||
|
||||
|
||||
|
||||
### Method-1 : Using free Command
|
||||
|
||||
free displays the total amount of free and used physical and swap memory in the system, as well as the buffers and caches used by the kernel. The information is gathered by parsing /proc/meminfo.
|
||||
|
||||
**Suggested Read :** [free – A Standard Command to Check Memory Usage Statistics (Free & Used) in Linux][1]
|
||||
```
|
||||
$ free -m
|
||||
total used free shared buff/cache available
|
||||
Mem: 1993 1681 82 81 228 153
|
||||
Swap: 12689 1213 11475
|
||||
|
||||
$ free -g
|
||||
total used free shared buff/cache available
|
||||
Mem: 1 1 0 0 0 0
|
||||
Swap: 12 1 11
|
||||
|
||||
```
|
||||
|
||||
### Method-2 : Using /proc/meminfo file
|
||||
|
||||
/proc/meminfo is a virtual text file that contains a large amount of valuable information about the systems RAM usage.
|
||||
|
||||
It’s report the amount of free and used memory (both physical and swap) on the system.
|
||||
```
|
||||
$ grep MemTotal /proc/meminfo
|
||||
MemTotal: 2041396 kB
|
||||
|
||||
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024}'
|
||||
1993.55
|
||||
|
||||
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024 / 1024}'
|
||||
1.94683
|
||||
|
||||
```
|
||||
|
||||
### Method-3 : Using top Command
|
||||
|
||||
Top command is one of the basic command to monitor real-time system processes in Linux. It display system information and running processes information like uptime, average load, tasks running, number of users logged in, number of CPUs & cpu utilization, Memory & swap information. Run top command then hit `E` to bring the memory utilization in MB.
|
||||
|
||||
**Suggested Read :** [TOP Command Examples to Monitor Server Performance][2]
|
||||
```
|
||||
$ top
|
||||
|
||||
top - 14:38:36 up 1:59, 1 user, load average: 1.83, 1.60, 1.52
|
||||
Tasks: 223 total, 2 running, 221 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 48.6 us, 11.2 sy, 0.0 ni, 39.3 id, 0.3 wa, 0.0 hi, 0.5 si, 0.0 st
|
||||
MiB Mem : 1993.551 total, 94.184 free, 1647.367 used, 252.000 buff/cache
|
||||
MiB Swap: 12689.58+total, 11196.83+free, 1492.750 used. 306.465 avail Mem
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
9908 daygeek 20 0 2971440 649324 39700 S 55.8 31.8 11:45.74 Web Content
|
||||
21942 daygeek 20 0 2013760 308700 69272 S 35.0 15.1 4:13.75 Web Content
|
||||
4782 daygeek 20 0 3687116 227336 39156 R 14.5 11.1 16:47.45 gnome-shell
|
||||
|
||||
```
|
||||
|
||||
### Method-4 : Using vmstat Command
|
||||
|
||||
vmstat is a standard nifty tool that report virtual memory statistics of Linux system. vmstat reports information about processes, memory, paging, block IO, traps, and cpu activity. It helps Linux administrator to identify system bottlenecks while troubleshooting the issues.
|
||||
|
||||
**Suggested Read :** [vmstat – A Standard Nifty Tool to Report Virtual Memory Statistics][3]
|
||||
```
|
||||
$ vmstat -s | grep "total memory"
|
||||
2041396 K total memory
|
||||
|
||||
$ vmstat -s -S M | egrep -ie 'total memory'
|
||||
1993 M total memory
|
||||
|
||||
$ vmstat -s | awk '{print $1 / 1024 / 1024}' | head -1
|
||||
1.94683
|
||||
|
||||
```
|
||||
|
||||
### Method-5 : Using nmon Command
|
||||
|
||||
nmon is a another nifty tool to monitor various system resources such as CPU, memory, network, disks, file systems, NFS, top processes, Power micro-partition and resources (Linux version & processors) on Linux terminal.
|
||||
|
||||
Just press `m` key to see memory utilization stats (cached, active, inactive, buffered, free in MB & free percent)
|
||||
|
||||
**Suggested Read :** [nmon – A Nifty Tool To Monitor System Resources On Linux][4]
|
||||
```
|
||||
┌nmon─14g──────[H for help]───Hostname=2daygeek──Refresh= 2secs ───07:24.44─────────────────┐
|
||||
│ Memory Stats ─────────────────────────────────────────────────────────────────────────────│
|
||||
│ RAM High Low Swap Page Size=4 KB │
|
||||
│ Total MB 32079.5 -0.0 -0.0 20479.0 │
|
||||
│ Free MB 11205.0 -0.0 -0.0 20479.0 │
|
||||
│ Free Percent 34.9% 100.0% 100.0% 100.0% │
|
||||
│ MB MB MB │
|
||||
│ Cached= 19763.4 Active= 9617.7 │
|
||||
│ Buffers= 172.5 Swapcached= 0.0 Inactive = 10339.6 │
|
||||
│ Dirty = 0.0 Writeback = 0.0 Mapped = 11.0 │
|
||||
│ Slab = 636.6 Commit_AS = 118.2 PageTables= 3.5 │
|
||||
│───────────────────────────────────────────────────────────────────────────────────────────│
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
└───────────────────────────────────────────────────────────────────────────────────────────┘
|
||||
|
||||
```
|
||||
|
||||
### Method-6 : Using dmidecode Command
|
||||
|
||||
Dmidecode is a tool which reads a computer’s DMI (stands for Desktop Management Interface)
|
||||
(some say SMBIOS – stands for System Management BIOS) table contents and display system hardware information in a human-readable format.
|
||||
|
||||
This table contains a description of the system’s hardware components, as well as other useful information such as serial number, Manufacturer information, Release Date, and BIOS revision, etc,.
|
||||
|
||||
**Suggested Read :**
|
||||
[Dmidecode – Easy Way To Get Linux System Hardware Information][5]
|
||||
```
|
||||
# dmidecode -t memory | grep Size:
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
|
||||
```
|
||||
|
||||
Print only installed RAM modules.
|
||||
```
|
||||
|
||||
# dmidecode -t memory | grep Size: | grep -v "No Module Installed"
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
|
||||
```
|
||||
|
||||
Sum all the installed RAM modules.
|
||||
```
|
||||
# dmidecode -t memory | grep Size: | grep -v "No Module Installed" | awk '{sum+=$2}END{print sum}'
|
||||
32768
|
||||
|
||||
```
|
||||
|
||||
### Method-7 : Using hwinfo Command
|
||||
|
||||
hwinfo stands for hardware information tool is another great utility that used to probe for the hardware present in the system and display detailed information about varies hardware components in human readable format.
|
||||
|
||||
It reports information about CPU, RAM, keyboard, mouse, graphics card, sound, storage, network interface, disk, partition, bios, and bridge, etc,.
|
||||
|
||||
**Suggested Read :** [hwinfo (Hardware Info) – A Nifty Tool To Detect System Hardware Information On Linux][6]
|
||||
```
|
||||
$ hwinfo --memory
|
||||
01: None 00.0: 10102 Main Memory
|
||||
[Created at memory.74]
|
||||
Unique ID: rdCR.CxwsZFjVASF
|
||||
Hardware Class: memory
|
||||
Model: "Main Memory"
|
||||
Memory Range: 0x00000000-0x7a4abfff (rw)
|
||||
Memory Size: 1 GB + 896 MB
|
||||
Config Status: cfg=new, avail=yes, need=no, active=unknown
|
||||
|
||||
```
|
||||
|
||||
### Method-8 : Using lshw Command
|
||||
|
||||
lshw (stands for Hardware Lister) is a small nifty tool that generates detailed reports about various hardware components on the machine such as memory configuration, firmware version, mainboard configuration, CPU version and speed, cache configuration, usb, network card, graphics cards, multimedia, printers, bus speed, etc.
|
||||
|
||||
It’s generating hardware information by reading varies files under /proc directory and DMI table.
|
||||
|
||||
**Suggested Read :** [LSHW (Hardware Lister) – A Nifty Tool To Get A Hardware Information On Linux][7]
|
||||
```
|
||||
$ sudo lshw -short -class memory
|
||||
[sudo] password for daygeek:
|
||||
H/W path Device Class Description
|
||||
==================================================
|
||||
/0/0 memory 128KiB BIOS
|
||||
/0/1 memory 1993MiB System memory
|
||||
|
||||
```
|
||||
|
||||
### Method-9 : Using inxi Command
|
||||
|
||||
inxi is a nifty tool to check hardware information on Linux and offers wide range of option to get all the hardware information on Linux system that i never found in any other utility which are available in Linux. It was forked from the ancient and mindbendingly perverse yet ingenius infobash, by locsmif.
|
||||
|
||||
inxi is a script that quickly shows system hardware, CPU, drivers, Xorg, Desktop, Kernel, GCC version(s), Processes, RAM usage, and a wide variety of other useful information, also used for forum technical support & debugging tool.
|
||||
|
||||
**Suggested Read :** [inxi – A Great Tool to Check Hardware Information on Linux][8]
|
||||
```
|
||||
$ inxi -F | grep "Memory"
|
||||
Info: Processes: 234 Uptime: 3:10 Memory: 1497.3/1993.6MB Client: Shell (bash) inxi: 2.3.37
|
||||
|
||||
```
|
||||
|
||||
### Method-10 : Using screenfetch Command
|
||||
|
||||
screenFetch is a bash script. It will auto-detect your distribution and display an ASCII art version of that distribution’s logo and some valuable information to the right.
|
||||
|
||||
**Suggested Read :** [ScreenFetch – Display Linux System Information On Terminal With Distribution ASCII Art Logo][9]
|
||||
```
|
||||
$ screenfetch
|
||||
./+o+- [email protected]
|
||||
yyyyy- -yyyyyy+ OS: Ubuntu 17.10 artful
|
||||
://+//////-yyyyyyo Kernel: x86_64 Linux 4.13.0-37-generic
|
||||
.++ .:/++++++/-.+sss/` Uptime: 44m
|
||||
.:++o: /++++++++/:--:/- Packages: 1831
|
||||
o:+o+:++.`..```.-/oo+++++/ Shell: bash 4.4.12
|
||||
.:+o:+o/. `+sssoo+/ Resolution: 1920x955
|
||||
.++/+:+oo+o:` /sssooo. DE: GNOME
|
||||
/+++//+:`oo+o /::--:. WM: GNOME Shell
|
||||
\+/+o+++`o++o ++////. WM Theme: Adwaita
|
||||
.++.o+++oo+:` /dddhhh. GTK Theme: Azure [GTK2/3]
|
||||
.+.o+oo:. `oddhhhh+ Icon Theme: Papirus-Dark
|
||||
\+.++o+o``-````.:ohdhhhhh+ Font: Ubuntu 11
|
||||
`:o+++ `ohhhhhhhhyo++os: CPU: Intel Core i7-6700HQ @ 2x 2.592GHz
|
||||
.o:`.syhhhhhhh/.oo++o` GPU: llvmpipe (LLVM 5.0, 256 bits)
|
||||
/osyyyyyyo++ooo+++/ RAM: 1521MiB / 1993MiB
|
||||
````` +oo+++o\:
|
||||
`oo++.
|
||||
|
||||
```
|
||||
|
||||
### Method-11 : Using neofetch Command
|
||||
|
||||
Neofetch is a cross-platform and easy-to-use command line (CLI) script that collects your Linux system information and display it on the terminal next to an image, either your distributions logo or any ascii art of your choice.
|
||||
|
||||
**Suggested Read :** [Neofetch – Shows Linux System Information With ASCII Distribution Logo][10]
|
||||
```
|
||||
$ neofetch
|
||||
.-/+oossssoo+/-. [email protected]
|
||||
`:+ssssssssssssssssss+:` --------------
|
||||
-+ssssssssssssssssssyyssss+- OS: Ubuntu 17.10 x86_64
|
||||
.ossssssssssssssssssdMMMNysssso. Host: VirtualBox 1.2
|
||||
/ssssssssssshdmmNNmmyNMMMMhssssss/ Kernel: 4.13.0-37-generic
|
||||
+ssssssssshmydMMMMMMMNddddyssssssss+ Uptime: 47 mins
|
||||
/sssssssshNMMMyhhyyyyhmNMMMNhssssssss/ Packages: 1832
|
||||
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Shell: bash 4.4.12
|
||||
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ Resolution: 1920x955
|
||||
ossyNMMMNyMMhsssssssssssssshmmmhssssssso DE: ubuntu:GNOME
|
||||
ossyNMMMNyMMhsssssssssssssshmmmhssssssso WM: GNOME Shell
|
||||
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ WM Theme: Adwaita
|
||||
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Theme: Azure [GTK3]
|
||||
/sssssssshNMMMyhhyyyyhdNMMMNhssssssss/ Icons: Papirus-Dark [GTK3]
|
||||
+sssssssssdmydMMMMMMMMddddyssssssss+ Terminal: gnome-terminal
|
||||
/ssssssssssshdmNNNNmyNMMMMhssssss/ CPU: Intel i7-6700HQ (2) @ 2.591GHz
|
||||
.ossssssssssssssssssdMMMNysssso. GPU: VirtualBox Graphics Adapter
|
||||
-+sssssssssssssssssyyyssss+- Memory: 1620MiB / 1993MiB
|
||||
`:+ssssssssssssssssss+:`
|
||||
.-/+oossssoo+/-.
|
||||
|
||||
```
|
||||
|
||||
### Method-12 : Using dmesg Command
|
||||
|
||||
dmesg (stands for display message or driver message) is a command on most Unix-like operating systems that prints the message buffer of the kernel.
|
||||
```
|
||||
$ dmesg | grep "Memory"
|
||||
[ 0.000000] Memory: 1985916K/2096696K available (12300K kernel code, 2482K rwdata, 4000K rodata, 2372K init, 2368K bss, 110780K reserved, 0K cma-reserved)
|
||||
[ 0.012044] x86/mm: Memory block size: 128MB
|
||||
|
||||
```
|
||||
|
||||
### Method-13 : Using atop Command
|
||||
|
||||
Atop is an ASCII full-screen system performance monitoring tool for Linux that is capable of reporting the activity of all server processes (even if processes have finished during the interval).
|
||||
|
||||
It’s logging of system and process activity for long-term analysis (By default, the log files are preserved for 28 days), highlighting overloaded system resources by using colors, etc. It shows network activity per process/thread with combination of the optional kernel module netatop.
|
||||
|
||||
**Suggested Read :** [Atop – Monitor real time system performance, resources, process & check resource utilization history][11]
|
||||
```
|
||||
$ atop -m
|
||||
|
||||
ATOP - ubuntu 2018/03/31 19:34:08 ------------- 10s elapsed
|
||||
PRC | sys 0.47s | user 2.75s | | | #proc 219 | #trun 1 | #tslpi 802 | #tslpu 0 | #zombie 0 | clones 7 | | | #exit 4 |
|
||||
CPU | sys 7% | user 22% | irq 0% | | | idle 170% | wait 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
cpu | sys 3% | user 11% | irq 0% | | | idle 85% | cpu001 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
cpu | sys 4% | user 11% | irq 0% | | | idle 85% | cpu000 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
CPL | avg1 1.98 | | avg5 3.56 | avg15 3.20 | | | csw 14894 | | intr 6610 | | | numcpu 2 | |
|
||||
MEM | tot 1.9G | free 101.7M | cache 244.2M | dirty 0.2M | buff 6.9M | slab 92.9M | slrec 35.6M | shmem 97.8M | shrss 21.0M | shswp 3.2M | vmbal 0.0M | hptot 0.0M | hpuse 0.0M |
|
||||
SWP | tot 12.4G | free 11.6G | | | | | | | | | vmcom 7.9G | | vmlim 13.4G |
|
||||
PAG | scan 0 | steal 0 | | stall 0 | | | | | | | swin 3 | | swout 0 |
|
||||
DSK | sda | busy 0% | | read 114 | write 37 | KiB/r 21 | KiB/w 6 | | MBr/s 0.2 | MBw/s 0.0 | avq 6.50 | | avio 0.26 ms |
|
||||
NET | transport | tcpi 11 | tcpo 17 | udpi 4 | udpo 8 | tcpao 3 | tcppo 0 | | tcprs 3 | tcpie 0 | tcpor 0 | udpnp 0 | udpie 0 |
|
||||
NET | network | ipi 20 | | ipo 33 | ipfrw 0 | deliv 20 | | | | | icmpi 5 | | icmpo 0 |
|
||||
NET | enp0s3 0% | pcki 11 | pcko 28 | sp 1000 Mbps | si 1 Kbps | so 1 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
|
||||
NET | lo ---- | pcki 9 | pcko 9 | sp 0 Mbps | si 0 Kbps | so 0 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
|
||||
|
||||
PID TID MINFLT MAJFLT VSTEXT VSLIBS VDATA VSTACK VSIZE RSIZE PSIZE VGROW RGROW SWAPSZ RUID EUID MEM CMD 1/1
|
||||
2536 - 941 0 188K 127.3M 551.2M 144K 2.3G 281.2M 0K 0K 344K 6556K daygeek daygeek 14% Web Content
|
||||
2464 - 75 0 188K 187.7M 680.6M 132K 2.3G 226.6M 0K 0K 212K 42088K daygeek daygeek 11% firefox
|
||||
2039 - 4199 6 16K 163.6M 423.0M 132K 3.5G 220.2M 0K 0K 2936K 109.6M daygeek daygeek 11% gnome-shell
|
||||
10822 - 1 0 4K 16680K 377.0M 132K 3.4G 193.4M 0K 0K 0K 0K root root 10% java
|
||||
|
||||
```
|
||||
|
||||
### Method-14 : Using htop Command
|
||||
|
||||
htop is an interactive process viewer for Linux which was developed by Hisham using ncurses library. Htop have many of features and options compared to top command.
|
||||
|
||||
**Suggested Read :** [Monitor system resources using Htop command][12]
|
||||
```
|
||||
$ htop
|
||||
|
||||
1 [||||||||||||| 13.0%] Tasks: 152, 587 thr; 1 running
|
||||
2 [||||||||||||||||||||||||| 25.0%] Load average: 0.91 2.03 2.66
|
||||
Mem[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||1.66G/1.95G] Uptime: 01:14:53
|
||||
Swp[|||||| 782M/12.4G]
|
||||
|
||||
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
|
||||
2039 daygeek 20 0 3541M 214M 46728 S 36.6 10.8 22:36.77 /usr/bin/gnome-shell
|
||||
2045 daygeek 20 0 3541M 214M 46728 S 10.3 10.8 3:02.92 /usr/bin/gnome-shell
|
||||
2046 daygeek 20 0 3541M 214M 46728 S 8.3 10.8 3:04.96 /usr/bin/gnome-shell
|
||||
6080 daygeek 20 0 807M 37228 24352 S 2.1 1.8 0:11.99 /usr/lib/gnome-terminal/gnome-terminal-server
|
||||
2880 daygeek 20 0 2205M 164M 17048 S 2.1 8.3 7:16.50 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
6125 daygeek 20 0 1916M 159M 92352 S 2.1 8.0 2:09.14 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
2536 daygeek 20 0 2335M 243M 26792 S 2.1 12.2 6:25.77 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
2653 daygeek 20 0 2237M 185M 20788 S 1.4 9.3 3:01.76 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
|
||||
```
|
||||
|
||||
### Method-15 : Using corefreq Utility
|
||||
|
||||
CoreFreq is a CPU monitoring software designed for Intel 64-bits Processors and supported architectures are Atom, Core2, Nehalem, SandyBridge and superior, AMD Family 0F.
|
||||
|
||||
CoreFreq provides a framework to retrieve CPU data with a high degree of precision.
|
||||
|
||||
**Suggested Read :** [CoreFreq – A Powerful CPU monitoring Tool for Linux Systems][13]
|
||||
```
|
||||
$ ./corefreq-cli -k
|
||||
Linux:
|
||||
|- Release [4.13.0-37-generic]
|
||||
|- Version [#42-Ubuntu SMP Wed Mar 7 14:13:23 UTC 2018]
|
||||
|- Machine [x86_64]
|
||||
Memory:
|
||||
|- Total RAM 2041396 KB
|
||||
|- Shared RAM 99620 KB
|
||||
|- Free RAM 108428 KB
|
||||
|- Buffer RAM 8108 KB
|
||||
|- Total High 0 KB
|
||||
|- Free High 0 KB
|
||||
|
||||
$ ./corefreq-cli -k | grep "Total RAM" | awk '{print $4 / 1024 }'
|
||||
1993.55
|
||||
|
||||
$ ./corefreq-cli -k | grep "Total RAM" | awk '{print $4 / 1024 / 1024}'
|
||||
1.94683
|
||||
|
||||
```
|
||||
|
||||
### Method-16 : Using glances Command
|
||||
|
||||
Glances is a cross-platform curses-based system monitoring tool written in Python. We can say all in one place, like maximum of information in a minimum of space. It uses psutil library to get information from your system.
|
||||
|
||||
Glances capable to monitor CPU, Memory, Load, Process list, Network interface, Disk I/O, Raid, Sensors, Filesystem (and folders), Docker, Monitor, Alert, System info, Uptime, Quicklook (CPU, MEM, LOAD), etc,.
|
||||
|
||||
**Suggested Read :** [Glances (All in one Place)– An Advanced Real Time System Performance Monitoring Tool for Linux][14]
|
||||
```
|
||||
$ glances
|
||||
|
||||
ubuntu (Ubuntu 17.10 64bit / Linux 4.13.0-37-generic) - IP 192.168.1.6/24 Uptime: 1:08:40
|
||||
|
||||
CPU [|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 90.6%] CPU - 90.6% nice: 0.0% ctx_sw: 4K MEM \ 78.4% active: 942M SWAP - 5.9% LOAD 2-core
|
||||
MEM [||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 78.0%] user: 55.1% irq: 0.0% inter: 1797 total: 1.95G inactive: 562M total: 12.4G 1 min: 4.35
|
||||
SWAP [|||| 5.9%] system: 32.4% iowait: 1.8% sw_int: 897 used: 1.53G buffers: 14.8M used: 749M 5 min: 4.38
|
||||
idle: 7.6% steal: 0.0% free: 431M cached: 273M free: 11.7G 15 min: 3.38
|
||||
|
||||
NETWORK Rx/s Tx/s TASKS 211 (735 thr), 4 run, 207 slp, 0 oth sorted automatically by memory_percent, flat view
|
||||
docker0 0b 232b
|
||||
enp0s3 12Kb 4Kb Systemd 7 Services loaded: 197 active: 196 failed: 1
|
||||
lo 616b 616b
|
||||
_h478e48e 0b 232b CPU% MEM% VIRT RES PID USER NI S TIME+ R/s W/s Command
|
||||
63.8 18.9 2.33G 377M 2536 daygeek 0 R 5:57.78 0 0 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
DefaultGateway 83ms 78.5 10.9 3.46G 217M 2039 daygeek 0 S 21:07.46 0 0 /usr/bin/gnome-shell
|
||||
8.5 10.1 2.32G 201M 2464 daygeek 0 S 8:45.69 0 0 /usr/lib/firefox/firefox -new-window
|
||||
DISK I/O R/s W/s 1.1 8.5 2.19G 170M 2653 daygeek 0 S 2:56.29 0 0 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
dm-0 0 0 1.7 7.2 2.15G 143M 2880 daygeek 0 S 7:10.46 0 0 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
sda1 9.46M 12K 0.0 4.9 1.78G 97.2M 6125 daygeek 0 S 1:36.57 0 0 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
|
||||
```
|
||||
|
||||
### Method-17 : Using gnome-system-monitor
|
||||
|
||||
System Monitor is a tool to manage running processes and monitor system resources. It shows you what programs are running and how much processor time, memory, and disk space are being used.
|
||||
![][16]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/easy-ways-to-check-size-of-physical-memory-ram-in-linux/
|
||||
|
||||
作者:[Ramya Nuvvula][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/ramya/
|
||||
[1]:https://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/
|
||||
[2]:https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/
|
||||
[3]:https://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/
|
||||
[4]:https://www.2daygeek.com/nmon-system-performance-monitor-system-resources-on-linux/
|
||||
[5]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[6]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
[7]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[8]:https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
[9]:https://www.2daygeek.com/screenfetch-display-linux-systems-information-ascii-distribution-logo-terminal/
|
||||
[10]:https://www.2daygeek.com/neofetch-display-linux-systems-information-ascii-distribution-logo-terminal/
|
||||
[11]:https://www.2daygeek.com/atop-system-process-performance-monitoring-tool/
|
||||
[12]:https://www.2daygeek.com/htop-command-examples-to-monitor-system-resources/
|
||||
[13]:https://www.2daygeek.com/corefreq-linux-cpu-monitoring-tool/
|
||||
[14]:https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/
|
||||
[15]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[16]:https://www.2daygeek.com/wp-content/uploads/2018/03/check-memory-information-using-gnome-system-monitor.png
|
||||
@ -0,0 +1,362 @@
|
||||
Bring some JavaScript to your Java enterprise with Vert.x
|
||||
======
|
||||

|
||||
If you are a Java programmer, chances are that you've either used JavaScript in the past or will in the near future. Not only is it one of the most popular (and useful) programming languages, understanding some of JavaScript's features could help you build the next uber-popular web application.
|
||||
|
||||
### JavaScript on the server
|
||||
|
||||
The idea to run JavaScript on the server is not new; in fact, in December 1995, soon after releasing JavaScript for browsers, Netscape introduced an implementation of the language for server-side scripting with Netscape Enterprise Server. Microsoft also adopted it on Internet Information Server as JScript, a reverse-engineered implementation of Netscape's JavaScript.
|
||||
|
||||
The seed was planted, but the real boom happened in 2009 when Ryan Dahl introduced Node.js. Node's success was not based on the language but on the runtime itself. It introduced a single process event loop that followed the reactive programming principles and could scale like other platforms couldn't.
|
||||
|
||||
### The enterprise and the JVM
|
||||
|
||||
Many enterprises have standardized on the Java virtual machine (JVM) as the platform of choice to run their mission-critical business applications, and large investments have been made on the JVM, so it makes sense for those organizations to look for a JVM-based JavaScript runtime.
|
||||
|
||||
[Eclipse Vert.x][1] is a polyglot-reactive runtime that runs on the JVM. Using Eclipse Vert.x with JavaScript is not much different from what you would expect from Node.js. There are limitations, such as that the JVM JavaScript engine is not fully compatible with the ES6 standard and not all Node.js package manager (npm) modules can be used with it. But it can still do interesting things.
|
||||
|
||||
### Why Eclipse Vert.x?
|
||||
|
||||
Having a large investment in the JVM and not wanting to switch to a different runtime might be reason enough for an enterprise to be interested in Eclipse Vert.x. But other benefits are that it can interact with any existing Java application and offers one of the best performances possible on the JVM.
|
||||
|
||||
To demonstrate, let's look at how Vert.x works with an existing business rules management system. Imagine for a moment that our fictional enterprise has a mission-critical application running inside JBoss Drools. We now need to create a new web application that can interact with this legacy app.
|
||||
|
||||
For the sake of simplicity, let's say our existing rules are a simple Hello World:
|
||||
```
|
||||
package drools
|
||||
|
||||
|
||||
|
||||
//list any import classes here.
|
||||
|
||||
|
||||
|
||||
//declare any global variables here
|
||||
|
||||
|
||||
|
||||
rule "Greetings"
|
||||
|
||||
when
|
||||
|
||||
greetingsReferenceObject: Greeting( message == "Hello World!" )
|
||||
|
||||
then
|
||||
|
||||
greetingsReferenceObject.greet();
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
When this engine runs, we get "Drools Hello World!" This is not amazing, but let's imagine this was a really complex process.
|
||||
|
||||
### Implementing the Eclipse Vert.x JavaScript project
|
||||
|
||||
Like with any other JavaScript project, we'll use the standard npm commands to bootstrap a project. Here's how to bootstrap the project `drools-integration` and prepare it to use Vert.x:
|
||||
```
|
||||
# create an empty project directory
|
||||
|
||||
mkdir drools-integration
|
||||
|
||||
cd drools-integration
|
||||
|
||||
|
||||
|
||||
# create the initial package.json
|
||||
|
||||
npm init -y
|
||||
|
||||
|
||||
|
||||
# add a couple of dependencies
|
||||
|
||||
npm add vertx-scripts --save-dev
|
||||
|
||||
# You should see a tip like:
|
||||
|
||||
#Please add the following scripts to your 'package.json':
|
||||
|
||||
# "scripts": {
|
||||
|
||||
# "postinstall": "vertx-scripts init",
|
||||
|
||||
# "test": "vertx-scripts launcher test -t",
|
||||
|
||||
# "start": "vertx-scripts launcher run",
|
||||
|
||||
# "package": "vertx-scripts package"
|
||||
|
||||
# }
|
||||
|
||||
|
||||
|
||||
# add
|
||||
|
||||
npm add @vertx/web --save-prod
|
||||
|
||||
```
|
||||
|
||||
We have initialized a bare-bones project so we can start writing the JavaScript code. We'll start by adding a simple HTTP server that exposes a simple API. Every time a request is made to the URL `http://localhost:8080/greetings`, we should see the existing Drools engine's execution result in the terminal.
|
||||
|
||||
Start by creating an `index.js` file. If you're using VisualStudio Code, it's wise to add the following two lines to the beginning of your file:
|
||||
```
|
||||
/// <reference types="@vertx/core/runtime" />
|
||||
|
||||
/// @ts-check
|
||||
|
||||
```
|
||||
|
||||
These lines will enable full support and check the code for syntax errors. They aren't required, but they sure help during the development phase.
|
||||
|
||||
Next, add the simple HTTP server. Running on the JVM is not exactly the same as running on Node, and many libraries will not be available. Think of the JVM as a headless browser, and in many cases, code that runs in a browser can run on the JVM. This does not mean we can't have a high-performance HTTP server; in fact, this is exactly what Vert.x does. Let's start writing our server:
|
||||
```
|
||||
import { Router } from '@vertx/web';
|
||||
|
||||
|
||||
|
||||
// route all request based on the request path
|
||||
|
||||
const app = Router.router(vertx);
|
||||
|
||||
|
||||
|
||||
app.get('/greetings').handler(function (ctx) {
|
||||
|
||||
// will invoke our existing drools engine here...
|
||||
|
||||
});
|
||||
|
||||
|
||||
|
||||
vertx
|
||||
|
||||
// create a HTTP server
|
||||
|
||||
.createHttpServer()
|
||||
|
||||
// on each request pass it to our APP
|
||||
|
||||
.requestHandler(function (req) {
|
||||
|
||||
app.accept(req);
|
||||
|
||||
})
|
||||
|
||||
// listen on port 8080
|
||||
|
||||
.listen(8080);
|
||||
|
||||
```
|
||||
|
||||
The code is not complicated and should be self-explanatory, so let's focus on the integration with existing JVM code and libraries in the form of a Drools rule. Since Drools is a Java-based tool, we should build our application with a `java` build tool. Fortunately, because, behind the scenes, `vertx-scripts` delegates the JVM bits to Apache Maven, our work is easy.
|
||||
```
|
||||
mkdir -p src/main/java/drools
|
||||
|
||||
mkdir -p src/main/resources/drools
|
||||
|
||||
```
|
||||
|
||||
Next, we add the file `src/main/resources/drools/rules.drl` with the following content:
|
||||
```
|
||||
package drools
|
||||
|
||||
|
||||
|
||||
//list any import classes here.
|
||||
|
||||
|
||||
|
||||
//declare any global variables here
|
||||
|
||||
|
||||
|
||||
rule "Greetings"
|
||||
|
||||
when
|
||||
|
||||
greetingsReferenceObject: Greeting( message == "Hello World!" )
|
||||
|
||||
then
|
||||
|
||||
greetingsReferenceObject.greet();
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
Then we'll add the file `src/main/java/drools/Greeting.java` with the following content:
|
||||
```
|
||||
package drools;
|
||||
|
||||
|
||||
|
||||
public interface Greeting {
|
||||
|
||||
|
||||
|
||||
();
|
||||
|
||||
|
||||
|
||||
void greet();
|
||||
|
||||
}Greeting String getMessagegreet
|
||||
|
||||
```
|
||||
|
||||
Finally, we'll add the helper utility class `src/main/java/drools/DroolsHelper.java`:
|
||||
```
|
||||
package drools;
|
||||
|
||||
|
||||
|
||||
import org.drools.compiler.compiler.*;
|
||||
|
||||
import org.drools.core.*;
|
||||
|
||||
import java.io.*;
|
||||
|
||||
|
||||
|
||||
public final class DroolsHelper {
|
||||
|
||||
|
||||
|
||||
/**
|
||||
|
||||
* Simple factory to create a Drools WorkingMemory from the given `drl` file.
|
||||
|
||||
*/
|
||||
|
||||
public static WorkingMemory load( drl) throws {
|
||||
|
||||
PackageBuilder packageBuilder = new PackageBuilder();
|
||||
|
||||
packageBuilder.addPackageFromDrl(new StringReader(drl));
|
||||
|
||||
RuleBase ruleBase = RuleBaseFactory.newRuleBase();
|
||||
|
||||
ruleBase.addPackage(packageBuilder.getPackage());
|
||||
|
||||
return ruleBase.newStatefulSession();
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
/**
|
||||
|
||||
* Simple factory to create a Greeting objects.
|
||||
|
||||
*/
|
||||
|
||||
public static Greeting createGreeting( message, ) {
|
||||
|
||||
return new Greeting() {
|
||||
|
||||
@Override
|
||||
|
||||
public () {
|
||||
|
||||
return message;
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
@Override
|
||||
|
||||
public void greet() {
|
||||
|
||||
andThen.run();
|
||||
|
||||
}
|
||||
|
||||
};
|
||||
|
||||
}
|
||||
|
||||
}DroolsHelperWorkingMemory load String drl IOException , DroolsParserExceptionPackageBuilder packageBuilderPackageBuilderpackageBuilder.drlRuleBase ruleBaseRuleBaseFactory.ruleBase.packageBuilder.ruleBase.Greeting createGreeting String message, Runnable andThenGreeting@Override String getMessagemessage@OverridegreetandThen.
|
||||
|
||||
```
|
||||
|
||||
We cannot use the file directly; we need to have `drools`. To do this, we add a custom property to our `package.json` named `mvnDependencies` (following the usual pattern):
|
||||
```
|
||||
{
|
||||
|
||||
"mvnDependencies": {
|
||||
|
||||
"org.drools:drools-compiler": "6.0.1.Final"
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Of course, since we updated the project file, we should update npm:
|
||||
```
|
||||
npm install
|
||||
|
||||
```
|
||||
|
||||
We are now entering the final step of this project, where we mix Java and JavaScript. We had a placeholder before, so let's fill in the gaps. We first use the helper Java class to create an engine (you can now see the power of Vert.x, a truly polyglot runtime), then invoke our engine whenever an HTTP request arrives.
|
||||
```
|
||||
// get a reference from Java to the JavaScript runtime
|
||||
|
||||
const DroolsHelper = Java.type('drools.DroolsHelper');
|
||||
|
||||
// get a drools engine instance
|
||||
|
||||
const engine = DroolsHelper.load(vertx.fileSystem().readFileBlocking("drools/rules.drl"));
|
||||
|
||||
|
||||
|
||||
app.get('/greetings').handler(function (ctx) {
|
||||
|
||||
// create a greetings message
|
||||
|
||||
var greeting = DroolsHelper.createGreeting('Hello World!', function () {
|
||||
|
||||
// when a match happens you should see this message
|
||||
|
||||
console.log('Greetings from Drools!');
|
||||
|
||||
});
|
||||
|
||||
|
||||
|
||||
// run the engine
|
||||
|
||||
engine.insert(greeting);
|
||||
|
||||
engine.fireAllRules();
|
||||
|
||||
|
||||
|
||||
// complete the HTTP response
|
||||
|
||||
ctx.response().end();
|
||||
|
||||
});
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
As this simple example shows, Vert.x allows you to be truly polyglot. The reason to choose Vert.x is not because it's another JavaScript runtime, rather it's a runtime that allows you to reuse what you already have and quickly build new code using the tools and language that run the internet. We didn't touch on performance here (as it is a topic on its own), but I encourage you to look at independent benchmarks such as [TechEmpower][2] to explore that topic.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/benefits-javascript-vertx
|
||||
|
||||
作者:[Paulo Lopes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pml0pes
|
||||
[1]:http://vertx.io/
|
||||
[2]:https://www.techempower.com/benchmarks/#section=data-r15
|
||||
@ -1,76 +0,0 @@
|
||||
[页面缓存,内存和文件之间的那些事][1]
|
||||
============================================================
|
||||
|
||||
|
||||
上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存][2],而忽略了文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
|
||||
|
||||
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘查找][3]。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间共享文件内容。如果你在 Windows 中使用 [进程浏览器][4] 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLLs。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLLs 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 [ld.so][5] 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
|
||||
|
||||
幸运的是,所有的这些问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 Render 的 Linux 程序,它打开了文件 scene.dat,并且一次读取 512 字节,并将文件内容存储到一个分配的堆块中。第一次读取的过程如下:
|
||||
|
||||

|
||||
|
||||
读取完 12KB 的文件内容以后,Render 程序的堆和相关的页面帧如下图所示:
|
||||
|
||||

|
||||
|
||||
它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,普通的文件 I/O 就是这样通过页面缓存来进行的。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序读取的磁盘区域也不仅仅只保存几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 #0、#1、等等来描述。Windows 也是类似的,使用 256KB 大小的页面缓存。
|
||||
|
||||
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到一个用户缓存中,它不仅花费 CPU 时间和影响 [CPU 缓存][6],在复制数据时也浪费物理内存。如前面的图示,scene.dat 的内存被保存了两次,并且,程序中的每个实例都在另外的时间中去保存了内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
|
||||
|
||||

|
||||
|
||||
当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程][7] 的报告指出,在相关的普通文件读取上运行时性能有多达 30% 的提升,在 [Unix 环境中的高级编程][8] 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
|
||||
|
||||
对高性能的追求是永衡不变的目标,[测量是很重要的事情][9],内存映射应该是程序员始终要使用的工具。而 API 提供了非常好用的实现方式,它允许你通过内存中的字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap][11] 查看你的 [地址空间][10],在 Windows 中,可以使用 [CreateFileMapping][12],或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障][13] 来按需映射的。在 [获取][15] 需要的文件内容的页面帧后,页面故障句柄在页面缓存上 [映射你的虚拟页面][14] 。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
|
||||
|
||||
假设我们的 Reader 程序是持续存在的实例,现在出现一个突发的状况。在页面缓存中保存着 scene.dat 内容的页面要立刻释放掉吗?这是一个人们经常要考虑的问题,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该始终完整保存。并且,这一原则适用于所有的进程。如果你现在运行 Render,一周后 scene.dat 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(译者注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
|
||||
|
||||
由于页面缓存架构的原因,当程序调用 [write()][16] 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“赃”页面。磁盘 I/O 通常并不会立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。如果这时候发生了电脑死机,你的写入将不会被标记,因此,对于至关重要的文件,像数据库事务日志,必须要求 [fsync()][17]ed(仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,走到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()][18]、[readahead()][19]、[Windows cache hints][20] ),你可以通过提示(hint)帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取][21],但是,在 Windows 上并不能确保被内存映射的文件也会预读。当然,在 Linux 中它可能会使用 [O_DIRECT][22] 跳过预读取,或者,在 Windows 中使用 [NO_BUFFERING][23] 去跳过预读,一些数据库软件就经常这么做。
|
||||
|
||||
一个内存映射的文件可以是私有的,也可以是共享的。当然,这只是针对内存中内容的更新而言:在一个私有的内存映射文件上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射文件,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核在写机制上使用拷贝,这是通过页面表条目来实现这种私有的映射。在下面的例子中,Render 和另一个被称为 render3d 都私有映射到 scene.dat 上。然后 Render 去写入映射的文件的虚拟内存区域:
|
||||
|
||||

|
||||
|
||||
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于去共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
|
||||
|
||||
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 APIs 为你提供与私有文件映射相同的效果。下面的示例展示了 Reader 程序映射的文件的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
|
||||
|
||||

|
||||
|
||||
这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://manybutfinite.com/post/how-the-kernel-manages-your-memory
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
@ -1,69 +0,0 @@
|
||||
防止文档陷阱的 7 条准则
|
||||
======
|
||||
英语是开源社区的通用语言。为了减少翻译成本,很多团队都改成用英语来写他们的文档。 但奇怪的是,为国际读者写英语并不一定就意味着英语为母语的人就占据更多的优势。 相反, 他们往往忘记了写文档用的语言可能并不是读者的母语。
|
||||
|
||||
我们以下面这个简单的句子为例: "Encrypt the password using the `foo bar` command。" 语法上来说,这个句子是正确的。 鉴于动名词的 '-ing' 形式在英语中很常见,大多数的母语人士都认为这是一种优雅的表达方式, 他们通常会很自然的写出这样的句子。 但是仔细观察, 这个句子存在歧义因为 "using" 可能指的宾语 ("the password") 也可能指的动词 ("encrypt")。 因此这个句子有两种解读方式:
|
||||
|
||||
* "加密使用了 `foo bar` 命令的密码。"
|
||||
* "使用命令 `foo bar` 来加密密码。"
|
||||
|
||||
如果你有相关的先验知识 (密码加密或这 `foo bar` 命令),你可以消除这种不确定性并且明白第二种方式才是真正的意思。 但是若你没有足够深入的知识怎么办呢? 如果你并不是这方面的专家,而只是一个拥有泛泛相关知识的翻译者而已怎么办呢? 再或者,如果你只是个非母语人士且对像动名词这种高级语法不熟悉怎么办呢?
|
||||
|
||||
即使是英语为母语的人也需要经过训练才能写出清晰直接的技术文档。训练的第一步就是提高对文本可用性以及潜在问题的警觉性, 下面让我们来看一下可以帮助避免常见陷阱的 7 条规则。
|
||||
|
||||
### 1。了解你的目标读者并代入其中。
|
||||
|
||||
如果你是一名开发者,而写作的对象是终端用户, 那么你需要站在他们的角度来看这个产品。 文档的结构是否反映了用户的目标? [人格面具 (persona) 技术][1] 能帮你专注于目标受众并为你的读者提供合适层次的细节。
|
||||
|
||||
### 2。准训 KISS 原则--保持文档简短而简单
|
||||
|
||||
这个原则适用于多个层次,从语法,句子到单词。 比如:
|
||||
|
||||
* 使用合适的最简单时态。比如, 当提到一个动作的结果时使用现在时:
|
||||
* " ~~Click 'OK。' The 'Printer Options' dialog will appear。~~" -> "Click 'OK。' The 'Printer Options' dialog appears。"
|
||||
* 按经验来说,一个句子表达一个主题; 然而, 短句子并不一定就容易理解(尤其当这些句子都是由名词组成时)。 有时, 将句子裁剪过度可能会引起歧义,而反过来太多单词则又难以理解。
|
||||
* 不常用的以及很长的单词会降低阅读速度,而且可能成为非母语人士的障碍。 使用更简单的替代词语:
|
||||
* " ~~utilize~~ " -> "use"
|
||||
* " ~~indicate~~ " -> "show," "tell," or "say"
|
||||
* " ~~prerequisite~~ " -> "requirement"
|
||||
|
||||
### 3。不要干扰阅读流
|
||||
|
||||
将虚词和较长的插入语移到句子的首部或者尾部:
|
||||
|
||||
* " ~~They are not,however, marked as installed。~~ " -> "However, they are not marked as installed。"
|
||||
|
||||
将长命令放在句子的末尾可以让自动/半自动的翻译拥有更好的断句。
|
||||
|
||||
### 4。区别对待两种基本的信息类型
|
||||
|
||||
描述型信息以及任务导向型信息有必要区分开来。描述型信息的一个典型例子就是命令行参考, 而 how-to 则是属于基于任务的信息; 然而, 技术写作中都会涉及这两种类型的信息。 仔细观察, 就会发现许多文本都同时包含了两种类型的信息。 然而如果能够清晰地划分这两种类型的信息那必是极好的。 为了跟好地区分他们,可以对他们进行分别标记(For better orientation, label them accordingly)。 标题应该能够反应章节的内容以及信息的类型。 对描述性章节使用基于名词的标题(比如"Types of Frobnicators"),而对基于任务的章节使用口头表达式的标题(例如"Installing Frobnicators")。 这可以让读者快速定位感兴趣的章节而跳过他无用的章节。
|
||||
|
||||
### 5。考虑不同的阅读场景和阅读模式
|
||||
|
||||
有些读者在转向阅读产品文档时会由于自己搞不定而感到十分的沮丧。他们也在一个嘈杂的环境中工作,很难专注于阅读。 同时,不要期望你的读者会一页一页的进行阅读,很多人都是快速浏览文本搜索关键字或者通过表格,索引以及全文搜索的方式来查找主题。 请牢记这一点, 从不同的角度来看待你的文字。 通常需要妥协才能找到一种适合多种情况的文本结构。
|
||||
|
||||
### 6。将复杂的信息分成小块。
|
||||
|
||||
这会让读者更容易记住和吸收信息。例如, 过程不应该超过 7 到 10 个步骤(根据认知心理学中的 [Miller's Law][2])。 如果需要更多的步骤, 那么就将任务分拆成不同的过程。
|
||||
|
||||
### 7。形式遵循功能
|
||||
|
||||
根据以下问题检查你的文字: 某句话/段落/章节的 _目的_ (功能)是什么?比如, 它是一个指令呢?还是一个结果呢?还是一个警告呢?如果是指令, 使用主动语气: "Configure the system。" 被动语气可能适合于进行描述: "The system is configured automatically。" 将警告放在危险操作的 _前面_ 。 专注于目的还有助于发现冗余的内容,可以清除类似 "basically" 或者 "easily" 这一类的填充词,类似 " ~~already~~ existing " or " ~~completely~~ new" 这一类的不必要的修改, 以及任何与你的目标大众无关的内容。
|
||||
|
||||
你现在可能已经猜到了,写作就是一个不断重写的过程。 好的写作需要付出努力和练习。 即使你只是偶尔写点东西, 你也可以通过关注目标大众并遵循上述规则来显著地改善你的文字。 文字的可读性越好, 理解就越容易, 这一点对不同语言能力的读者来说都是适合的。 尤其是当进行本地化时, 高质量的原始文本至关重要: "垃圾进, 垃圾出"。 如果原始文本就有缺陷, 翻译所需要的时间就会变长, 从而导致更高的成本。 最坏的情况下, 翻译会导致缺陷成倍增加,需要在不同的语言版本中修正这个缺陷。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/7-rules
|
||||
|
||||
作者:[Tanja Roth][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://en.wikipedia.org/wiki/Persona_(user_experience)
|
||||
[2]:https://en.wikipedia.org/wiki/The_Magical_Number_Seven,_Plus_or_Minus_Two
|
||||
Loading…
Reference in New Issue
Block a user