diff --git a/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md b/published/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md
similarity index 75%
rename from translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md
rename to published/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md
index 76573c4bd8..523394f8a2 100644
--- a/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md
+++ b/published/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md
@@ -1,73 +1,72 @@
[#]: collector: (lujun9972)
[#]: translator: (qhwdw)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10605-1.html)
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 9 Screen04)
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html)
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
-计算机实验室 – 树莓派:课程 9 屏幕04
+计算机实验室之树莓派:课程 9 屏幕04
======
屏幕04 课程基于屏幕03 课程来构建,它教你如何操作文本。假设你已经有了[课程 8:屏幕03][1] 的操作系统代码,我们将以它为基础。
### 1、操作字符串
-```
-变长函数在汇编代码中看起来似乎不好理解,然而 ,它却是非常有用和很强大的概念。
-```
-
能够绘制文本是极好的,但不幸的是,现在你只能绘制预先准备好的字符串。如果能够像命令行那样显示任何东西才是完美的,而理想情况下应该是,我们能够显示任何我们期望的东西。一如既往地,如果我们付出努力而写出一个非常好的函数,它能够操作我们所希望的所有字符串,而作为回报,这将使我们以后写代码更容易。曾经如此复杂的函数,在 C 语言编程中只不过是一个 `sprintf` 而已。这个函数基于给定的另一个字符串和作为描述的额外的一个参数而生成一个字符串。我们对这个函数感兴趣的地方是,这个函数是个变长函数。这意味着它可以带可变数量的参数。参数的数量取决于具体的格式字符串,因此它的参数的数量不能预先确定。
-完整的函数有许多选项,而我们在这里只列出了几个。在本教程中将要实现的选项我做了高亮处理,当然,你可以尝试去实现更多的选项。
+> 变长函数在汇编代码中看起来似乎不好理解,然而 ,它却是非常有用和很强大的概念。
-函数通过读取格式字符串来工作,然后使用下表的意思去解释它。一旦一个参数已经使用了,就不会再次考虑它了。函数 的返回值是写入的字符数。如果方法失败,将返回一个负数。
+这个完整的函数有许多选项,而我们在这里只列出了几个。在本教程中将要实现的选项我做了高亮处理,当然,你可以尝试去实现更多的选项。
+
+函数通过读取格式化字符串来工作,然后使用下表的意思去解释它。一旦一个参数已经使用了,就不会再次考虑它了。函数的返回值是写入的字符数。如果方法失败,将返回一个负数。
表 1.1 sprintf 格式化规则
+
| 选项 | 含义 |
| -------------------------- | ------------------------------------------------------------ |
-| ==Any character except %== | 复制字符到输出。 |
-| ==%%== | 写一个 % 字符到输出。 |
-| ==%c== | 将下一个参数写成字符格式。 |
-| ==%d or %i== | 将下一个参数写成十进制的有符号整数。 |
-| %e | 将下一个参数写成科学记数法,使用 eN 意思是 ×10N。 |
-| %E | 将下一个参数写成科学记数法,使用 EN 意思是 ×10N。 |
-| %f | 将下一个参数写成十进制的 IEEE 754 浮点数。 |
-| %g | 与 %e 和 %f 的指数表示形式相同。 |
-| %G | 与 %E 和 %f 的指数表示形式相同。 |
-| ==%o== | 将下一个参数写成八进制的无符号整数。 |
-| ==%s== | 下一个参数如果是一个指针,将它写成空终止符字符串。 |
-| ==%u== | 将下一个参数写成十进制无符号整数。 |
-| ==%x== | 将下一个参数写成十六进制无符号整数(使用小写的 a、b、c、d、e 和 f)。 |
-| %X | 将下一个参数写成十六进制的无符号整数(使用大写的 A、B、C、D、E 和 F)。 |
-| %p | 将下一个参数写成指针地址。 |
-| ==%n== | 什么也不输出。而是复制到目前为止被下一个参数在本地处理的字符个数。 |
+| ==除了 `%` 之外的任何支付== | 复制字符到输出。 |
+| ==`%%`== | 写一个 % 字符到输出。 |
+| ==`%c`== | 将下一个参数写成字符格式。 |
+| ==`%d` 或 `%i`== | 将下一个参数写成十进制的有符号整数。 |
+| `%e` | 将下一个参数写成科学记数法,使用 eN,意思是 ×10N。 |
+| `%E` | 将下一个参数写成科学记数法,使用 EN,意思是 ×10N。 |
+| `%f` | 将下一个参数写成十进制的 IEEE 754 浮点数。 |
+| `%g` | 与 `%e` 和 `%f` 的指数表示形式相同。 |
+| `%G` | 与 `%E` 和 `%f` 的指数表示形式相同。 |
+| ==`%o`== | 将下一个参数写成八进制的无符号整数。 |
+| ==`%s`== | 下一个参数如果是一个指针,将它写成空终止符字符串。 |
+| ==`%u`== | 将下一个参数写成十进制无符号整数。 |
+| ==`%x`== | 将下一个参数写成十六进制无符号整数(使用小写的 a、b、c、d、e 和 f)。 |
+| `%X` | 将下一个参数写成十六进制的无符号整数(使用大写的 A、B、C、D、E 和 F)。 |
+| `%p` | 将下一个参数写成指针地址。 |
+| ==`%n`== | 什么也不输出。而是复制到目前为止被下一个参数在本地处理的字符个数。 |
除此之外,对序列还有许多额外的处理,比如指定最小长度,符号等等。更多信息可以在 [sprintf - C++ 参考][2] 上找到。
下面是调用方法和返回的结果的示例。
表 1.2 sprintf 调用示例
+
| 格式化字符串 | 参数 | 结果 |
-| "%d" | 13 | "13" |
-| "+%d degrees" | 12 | "+12 degrees" |
-| "+%x degrees" | 24 | "+1c degrees" |
-| "'%c' = 0%o" | 65, 65 | "'A' = 0101" |
-| "%d * %d%% = %d" | 200, 40, 80 | "200 * 40% = 80" |
-| "+%d degrees" | -5 | "+-5 degrees" |
-| "+%u degrees" | -5 | "+4294967291 degrees" |
+|---------------|-------|---------------------|
+| `"%d"` | 13 | "13" |
+| `"+%d degrees"` | 12 | "+12 degrees" |
+| `"+%x degrees"` | 24 | "+1c degrees" |
+| `"'%c' = 0%o"` | 65, 65 | "'A' = 0101" |
+| `"%d * %d%% = %d"` | 200, 40, 80 | "200 * 40% = 80" |
+| `"+%d degrees"` | -5 | "+-5 degrees" |
+| `"+%u degrees"` | -5 | "+4294967291 degrees" |
希望你已经看到了这个函数是多么有用。实现它需要大量的编程工作,但给我们的回报却是一个非常有用的函数,可以用于各种用途。
### 2、除法
-```
-除法是非常慢的,也是非常复杂的基础数学运算。它在 ARM 汇编代码中不能直接实现,因为如果直接实现的话,它得出答案需要花费很长的时间,因此它不是个“简单的”运算。
-```
-
虽然这个函数看起来很强大、也很复杂。但是,处理它的许多情况的最容易的方式可能是,编写一个函数去处理一些非常常见的任务。它是个非常有用的函数,可以为任何底的一个有符号或无符号的数字生成一个字符串。那么,我们如何去实现呢?在继续阅读之前,尝试快速地设计一个算法。
+> 除法是非常慢的,也是非常复杂的基础数学运算。它在 ARM 汇编代码中不能直接实现,因为如果直接实现的话,它得出答案需要花费很长的时间,因此它不是个“简单的”运算。
+
最简单的方法或许就是我在 [课程 1:OK01][3] 中提到的“除法余数法”。它的思路如下:
1. 用当前值除以你使用的底。
@@ -75,11 +74,10 @@
3. 如果得到的新值不为 0,转到第 1 步。
4. 将余数反序连起来就是答案。
-
-
例如:
表 2.1 以 2 为底的例子
+
转换
| 值 | 新值 | 余数 |
@@ -100,7 +98,8 @@
我们复习一下长除法
> 假如我们想把 4135 除以 17。
->
+>
+> ```
> 0243 r 4
> 17)4135
> 0 0 × 17 = 0000
@@ -111,9 +110,10 @@
> 55 735 - 680 = 55
> 51 3 × 17 = 51
> 4 55 - 51 = 4
+> ```
> 答案:243 余 4
>
-> 首先我们来看被除数的最高位。 我们看到它是小于或等于除数的最小倍数,因此它是 0。我们在结果中写一个 0。
+> 首先我们来看被除数的最高位。我们看到它是小于或等于除数的最小倍数,因此它是 0。我们在结果中写一个 0。
>
> 接下来我们看被除数倒数第二位和所有的高位。我们看到小于或等于那个数的除数的最小倍数是 34。我们在结果中写一个 2,和减去 3400。
>
@@ -124,16 +124,18 @@
在汇编代码中做除法,我们将实现二进制的长除法。我们之所以实现它是因为,数字都是以二进制方式保存的,这让我们很容易地访问所有重要位的移位操作,并且因为在二进制中做除法比在其它高进制中做除法都要简单,因为它的数更少。
-> 1011 r 1
->1010)1101111
-> 1010
-> 11111
-> 1010
-> 1011
-> 1010
-> 1
-这个示例展示了如何做二进制的长除法。简单来说就是,在不超出被除数的情况下,尽可能将除数右移,根据位置输出一个 1,和减去这个数。剩下的就是余数。在这个例子中,我们展示了 11011112 ÷ 10102 = 10112 余数为 12。用十进制表示就是,111 ÷ 10 = 11 余 1。
+```
+ 1011 r 1
+1010)1101111
+ 1010
+ 11111
+ 1010
+ 1011
+ 1010
+ 1
+```
+这个示例展示了如何做二进制的长除法。简单来说就是,在不超出被除数的情况下,尽可能将除数右移,根据位置输出一个 1,和减去这个数。剩下的就是余数。在这个例子中,我们展示了 11011112 ÷ 10102 = 10112 余数为 12。用十进制表示就是,111 ÷ 10 = 11 余 1。
你自己尝试去实现这个长除法。你应该去写一个函数 `DivideU32` ,其中 `r0` 是被除数,而 `r1` 是除数,在 `r0` 中返回结果,在 `r1` 中返回余数。下面,我们将完成一个有效的实现。
@@ -155,7 +157,7 @@ end function
这段代码实现了我们的目标,但却不能用于汇编代码。我们出现的问题是,我们的寄存器只能保存 32 位,而 `divisor << shift` 的结果可能在一个寄存器中装不下(我们称之为溢出)。这确实是个问题。你的解决方案是否有溢出的问题呢?
-幸运的是,有一个称为 `clz` 或 `计数前导零(count leading zeros)` 的指令,它能计算一个二进制表示的数字的前导零的个数。这样我们就可以在溢出发生之前,可以将寄存器中的值进行相应位数的左移。你可以找出的另一个优化就是,每个循环我们计算 `divisor << shift` 了两遍。我们可以通过将除数移到开始位置来改进它,然后在每个循环结束的时候将它移下去,这样可以避免将它移到别处。
+幸运的是,有一个称为 `clz`(计数前导零)的指令,它能计算一个二进制表示的数字的前导零的个数。这样我们就可以在溢出发生之前,可以将寄存器中的值进行相应位数的左移。你可以找出的另一个优化就是,每个循环我们计算 `divisor << shift` 了两遍。我们可以通过将除数移到开始位置来改进它,然后在每个循环结束的时候将它移下去,这样可以避免将它移到别处。
我们来看一下进一步优化之后的汇编代码。
@@ -192,11 +194,10 @@ mov pc,lr
.unreq shift
```
-```assembly
-clz dest,src 将第一个寄存器 dest 中二进制表示的值的前导零的数量,保存到第二个寄存器 src 中。
-```
+你可能毫无疑问的认为这是个非常高效的作法。它是很好,但是除法是个代价非常高的操作,并且我们的其中一个愿望就是不要经常做除法,因为如果能以任何方式提升速度就是件非常好的事情。当我们查看有循环的优化代码时,我们总是重点考虑一个问题,这个循环会运行多少次。在本案例中,在输入为 1 的情况下,这个循环最多运行 31 次。在不考虑特殊情况的时候,这很容易改进。例如,当 1 除以 1 时,不需要移位,我们将把除数移到它上面的每个位置。这可以通过简单地在被除数上使用新的 `clz` 命令并从中减去它来改进。在 `1 ÷ 1` 的案例中,这意味着移位将设置为 0,明确地表示它不需要移位。如果它设置移位为负数,表示除数大于被除数,因此我们就可以知道结果是 0,而余数是被除数。我们可以做的另一个快速检查就是,如果当前值为 0,那么它是一个整除的除法,我们就可以停止循环了。
+
+> `clz dest,src` 将第一个寄存器 `dest` 中二进制表示的值的前导零的数量,保存到第二个寄存器 `src` 中。
-你可能毫无疑问的认为这是个非常高效的作法。它是很好,但是除法是个代价非常高的操作,并且我们的其中一个愿望就是不要经常做除法,因为如果能以任何方式提升速度就是件非常好的事情。当我们查看有循环的优化代码时,我们总是重点考虑一个问题,这个循环会运行多少次。在本案例中,在输入为 1 的情况下,这个循环最多运行 31 次。在不考虑特殊情况的时候,这很容易改进。例如,当 1 除以 1 时,不需要移位,我们将把除数移到它上面的每个位置。这可以通过简单地在被除数上使用新的 clz 命令并从中减去它来改进。在 `1 ÷ 1` 的案例中,这意味着移位将设置为 0,明确地表示它不需要移位。如果它设置移位为负数,表示除数大于被除数,因此我们就可以知道结果是 0,而余数是被除数。我们可以做的另一个快速检查就是,如果当前值为 0,那么它是一个整除的除法,我们就可以停止循环了。
```assembly
.globl DivideU32
@@ -291,17 +292,15 @@ end function
### 4、格式化字符串
-我们继续回到我们的字符串格式化方法。因为我们正在编写我们自己的操作系统,我们根据我们自己的意愿来添加或修改格式化规则。我们可以发现,添加一个 `a %b` 操作去输出一个二进制的数字比较有用,而如果你不使用空终止符字符串,那么你应该去修改 `%s` 的行为,让它从另一个参数中得到字符串的长度,或者如果你愿意,可以从长度前缀中获取。我在下面的示例中使用了一个空终止符。
+我们继续回到我们的字符串格式化方法。因为我们正在编写我们自己的操作系统,我们根据我们自己的意愿来添加或修改格式化规则。我们可以发现,添加一个 `a % b` 操作去输出一个二进制的数字比较有用,而如果你不使用空终止符字符串,那么你应该去修改 `%s` 的行为,让它从另一个参数中得到字符串的长度,或者如果你愿意,可以从长度前缀中获取。我在下面的示例中使用了一个空终止符。
实现这个函数的一个主要的障碍是它的参数个数是可变的。根据 ABI 规定,额外的参数在调用方法之前以相反的顺序先推送到栈上。比如,我们使用 8 个参数 1、2、3、4、5、6、7 和 8 来调用我们的方法,我们将按下面的顺序来处理:
- 1. Set r0 = 5、r1 = 6、r2 = 7、r3 = 8
- 2. Push {r0,r1,r2,r3}
- 3. Set r0 = 1、r1 = 2、r2 = 3、r3 = 4
- 4. 调用函数
- 5. Add sp,#4*4
-
-
+1. 设置 r0 = 5、r1 = 6、r2 = 7、r3 = 8
+2. 推入 {r0,r1,r2,r3}
+3. 设置 r0 = 1、r1 = 2、r2 = 3、r3 = 4
+4. 调用函数
+5. 将 sp 和 #4*4 加起来
现在,我们必须确定我们的函数确切需要的参数。在我的案例中,我将寄存器 `r0` 用来保存格式化字符串地址,格式化字符串长度则放在寄存器 `r1` 中,目标字符串地址放在寄存器 `r2` 中,紧接着是要求的参数列表,从寄存器 `r3` 开始和像上面描述的那样在栈上继续。如果你想去使用一个空终止符格式化字符串,在寄存器 r1 中的参数将被移除。如果你想有一个最大缓冲区长度,你可以将它保存在寄存器 `r3` 中。由于有额外的修改,我认为这样修改函数是很有用的,如果目标字符串地址为 0,意味着没有字符串被输出,但如果仍然返回一个精确的长度,意味着能够精确的判断格式化字符串的长度。
@@ -526,13 +525,13 @@ via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
作者:[Alex Chadwick][a]
选题:[lujun9972][b]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]: https://www.cl.cam.ac.uk
[b]: https://github.com/lujun9972
-[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
+[1]: https://linux.cn/article-10585-1.html
[2]: http://www.cplusplus.com/reference/clibrary/cstdio/sprintf/
-[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html
+[3]: https://linux.cn/article-10458-1.html
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
diff --git a/published/20170519 zsh shell inside Emacs on Windows.md b/published/20170519 zsh shell inside Emacs on Windows.md
new file mode 100644
index 0000000000..894c924416
--- /dev/null
+++ b/published/20170519 zsh shell inside Emacs on Windows.md
@@ -0,0 +1,103 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10610-1.html)
+[#]: subject: (zsh shell inside Emacs on Windows)
+[#]: via: (https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html)
+[#]: author: (Peter Mosmans https://www.onwebsecurity.com/)
+
+Windows 下 Emacs 中的 zsh shell
+======
+
+![zsh shell inside Emacs on Windows][5]
+
+运行跨平台 shell(例如 Bash 或 zsh)的最大优势在于你能在多平台上使用同样的语法和脚本。在 Windows 上设置(替换)shell 挺麻烦的,但所获得的回报远远超出这小小的付出。
+
+MSYS2 子系统允许你在 Windows 上运行 Bash 或 zsh 之类的 shell。使用 MSYS2 很重要的一点在于确保搜索路径都指向 MSYS2 子系统本身:存在太多依赖关系了。
+
+MSYS2 安装后默认的 shell 就是 Bash;zsh 则可以通过包管理器进行安装:
+
+```
+pacman -Sy zsh
+```
+
+通过修改 `etc/passwd` 文件可以设置 zsh 作为默认 shell,例如:
+
+```
+mkpasswd -c | sed -e 's/bash/zsh/' | tee -a /etc/passwd
+```
+
+这会将默认 shell 从 bash 改成 zsh。
+
+要在 Windows 上的 Emacs 中运行 zsh ,需要修改 `shell-file-name` 变量,将它指向 MSYS2 子系统中的 zsh 二进制文件。该二进制 shell 文件在 Emacs `exec-path` 变量中的某个地方。
+
+```
+(setq shell-file-name (executable-find "zsh.exe"))
+```
+
+不要忘了修改 Emacs 的 `PATH` 环境变量,因为 MSYS2 路径应该先于 Windows 路径。接上一个例子,假设 MSYS2 安装在 `c:\programs\msys2` 中,那么执行:
+
+```
+(setenv "PATH" "C:\\programs\\msys2\\mingw64\\bin;C:\\programs\\msys2\\usr\\local\\bin;C:\\programs\\msys2\\usr\\bin;C:\\Windows\\System32;C:\\Windows")
+```
+
+在 Emacs 配置文件中设置好这两个变量后,在 Emacs 中运行:
+
+```
+M-x shell
+```
+
+应该就能看到熟悉的 zsh 提示符了。
+
+Emacs 的终端设置(eterm)与 MSYS2 的标准终端设置(xterm-256color)不一样。这意味着某些插件和主题(提示符)可能不能正常工作 - 尤其在使用 oh-my-zsh 时。
+
+检测 zsh 否则在 Emacs 中运行很简单,使用变量 `$INSIDE_EMACS`。
+
+下面这段代码片段取自 `.zshrc`(当以交互式 shell 模式启动时会被加载),它会在 zsh 在 Emacs 中运行时启动 git 插件并更改主题:
+
+```
+# Disable some plugins while running in Emacs
+if [[ -n "$INSIDE_EMACS" ]]; then
+ plugins=(git)
+ ZSH_THEME="simple"
+else
+ ZSH_THEME="compact-grey"
+fi
+```
+
+通过在本地 `~/.ssh/config` 文件中将 `INSIDE_EMACS` 变量设置为 `SendEnv` 变量……
+
+```
+Host myhost
+SendEnv INSIDE_EMACS
+```
+
+……同时在 ssh 服务器的 `/etc/ssh/sshd_config` 中设置为 `AcceptEnv` 变量……
+
+```
+AcceptEnv LANG LC_* INSIDE_EMACS
+```
+
+……这使得在 Emacs shell 会话中通过 ssh 登录另一个运行着 zsh 的 ssh 服务器也能工作的很好。当在 Windows 下的 Emacs 中的 zsh 上通过 ssh 远程登录时,记得使用参数 `-t`,`-t` 参数会强制分配伪终端(之所以需要这样,时因为 Windows 下的 Emacs 并没有真正的 tty)。
+
+跨平台,开源真是个好东西……
+
+--------------------------------------------------------------------------------
+
+via: https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html
+
+作者:[Peter Mosmans][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.onwebsecurity.com/
+[b]: https://github.com/lujun9972
+[1]: https://www.onwebsecurity.com/category/configuration.html
+[2]: https://www.onwebsecurity.com/tag/emacs.html
+[3]: https://www.onwebsecurity.com/tag/msys2.html
+[4]: https://www.onwebsecurity.com/tag/zsh.html
+[5]: https://www.onwebsecurity.com//images/zsh-shell-inside-emacs-on-windows.png
diff --git a/published/20180314 Pi Day- 12 fun facts and ways to celebrate.md b/published/20180314 Pi Day- 12 fun facts and ways to celebrate.md
new file mode 100644
index 0000000000..4c03a28074
--- /dev/null
+++ b/published/20180314 Pi Day- 12 fun facts and ways to celebrate.md
@@ -0,0 +1,59 @@
+关于圆周率日的趣事与庆祝方式
+======
+
+> 技术团队喜欢 3 月 14 日的圆周率日:你是否知道这也是阿尔伯特·爱因斯坦的生日和 Linux 内核1.0.0 发布周年纪念日?来看一些树莓派的趣事和 DIY 项目。
+
+
+
+今天,全世界的技术团队都会为一个数字庆祝。3 月 14 日是圆周率日,人们会在这一天举行吃派比赛、披萨舞会,玩数学梗。如果这个数学领域中的重要常数不足以让 3 月 14 日成为一个节日的话,再加上爱因斯坦的生日、Linux 内核 1.0.0 发布的周年纪念日,莱伊·惠特尼在这一天申请了轧花机的专利这些原因,应该足够了吧。(LCTT译注:[轧花机](https://zh.wikipedia.org/wiki/%E8%BB%8B%E6%A3%89%E6%A9%9F)是一种快速而且简单地分开棉花纤维和种子的机器,生产力比人手分离高得多。)
+
+很荣幸,我们能在这一个特殊的日子里一起了解有关它的趣事和与 π 相关的好玩的活动。来吧,和你的团队一起庆祝圆周率日:找一两个点子来进行团队建设,或用新兴技术做一个项目。如果你有为这个大家所喜爱的无限小数庆祝的独特方式,请在评论区与大家分享。
+
+### 圆周率日的庆祝方法:
+
+ * 今天是圆周率日的第 31 次周年纪念(LCTT 译注:本文写于 2018 年的圆周率日,故在细节上存在出入。例如今天(2019 年 3 月 14 日)是圆周率日的第 31 次周年纪念)。第一次为它庆祝是在旧金山的探索博物馆由物理学家 Larry Shaw 举行。“在[第 1 次周年纪念日][1]当天,工作人员带来了水果派和茶壶来庆祝它。在 1 点 59 分(圆周率中紧接着 3.14 的数字),Shaw 在博物馆外领着队伍环馆一周。队伍中用扩音器播放着‘Pomp and Circumstance’。” 直到 21 年后,在 2009 年 3 月,圆周率正式成为了美国的法定假日。
+ * 虽然该纪念日起源于旧金山,可规模最大的庆祝活动却是在普林斯顿举行的,这个小镇举办了为期五天的[许多活动][2],包括爱因斯坦模仿比赛、掷派比赛,圆周率背诵比赛等等。其中的某些活动甚至会给获胜者提供价值 314.5 美元的奖金。
+ * 麻省理工的斯隆管理学院正在庆祝圆周率日。他们在 Twitter 上分享着关于 π 和派的圆周率日趣事,详情请关注推特话题 #PiVersusPie 。
+
+### 与圆周率有关的项目与活动:
+
+ * 如果你想锻炼你的数学技能,美国国家航空航天局(NASA)的喷气推进实验室(JPL)发布了[一系列新的数学问题][4],希望通过这些问题展现如何把圆周率用于空间探索。这也是美国国家航天局面向学生举办的第五届圆周率日挑战。
+ * 想要领略圆周率日的精神,最好的方法也许就是开展一个[树莓派][5]项目了,无论是和你的孩子还是和你的团队一起完成,都是不错的。树莓派作为一项从 2012 年开启的项目,现在已经售出了数百万块的基本型的电脑主板。事实上,它已经在[通用计算机畅销榜上排名第三][6]了。这里列举一些可能会吸引你的树莓派项目或活动:
+ * 来自谷歌的自己做 AI(AIY)项目让你自己创造一个[语音控制的数字助手][7]或者[一个图像识别设备][8]。
+ * 在树莓派上[使用 Kubernets][9]。
+ * 组装一台[怀旧游戏系统][10],目标:拯救桃子公主!
+ * 和你的团队举办一场[树莓派 Jam][11]。树莓派基金会发布了一个帮助大家顺利举办活动的[指导手册][12]。据该网站说明,树莓派 Jam 旨在“给数字创作中所有年龄段的人提供支持,让世界各地志同道合的人们汇聚起来讨论和分享他们的最新项目,举办讲习班,讨论和派相关的一切。”
+
+### 其他有关圆周率的事情:
+
+ * 当前背诵圆周率的[世界纪录保持者][13]是 Suresh Kumar Sharma,他在 2015 年 10 月花了 17 小时零 14 分钟背出了 70,030 位数字。然而,[非官方记录][14]的保持者 Akira Haraguchi 声称他可以背出 111,700 位数字。
+ * 现在,已知的圆周率数字的长度比以往都要多。在 2016 年 11 月,R&D 科学家 Peter Trueb 计算出了 22,459,157,718,361 位圆周率数字,比 2013 年的世界记录多了 [9 万亿数字][15]。据新科学家所述,“最终文件包含了圆周率的 22 万亿位数字,大小接近 9 TB。如果将其打印出来,能用数百万本 1000 页的书装满一整个图书馆。”
+
+祝你圆周率日快乐!
+
+--------------------------------------------------------------------------------
+
+via: https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate
+
+作者:[Carla Rudder][a]
+译者:[wwhio](https://github.com/wwhio)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://enterprisersproject.com/user/crudder
+[1]:https://www.exploratorium.edu/pi/pi-day-history
+[2]:https://princetontourcompany.com/activities/pi-day/
+[3]:https://twitter.com/MITSloan
+[4]:https://www.jpl.nasa.gov/news/news.php?feature=7074
+[5]:https://opensource.com/resources/raspberry-pi
+[6]:https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64
+[7]:http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/
+[8]:http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/
+[9]:https://opensource.com/article/17/3/kubernetes-raspberry-pi
+[10]:https://opensource.com/article/18/1/retro-gaming
+[11]:https://opensource.com/article/17/5/how-run-raspberry-pi-meetup
+[12]:https://www.raspberrypi.org/blog/support-raspberry-jam-community/
+[13]:http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi
+[14]:https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi
+[15]:https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071
diff --git a/translated/tech/20180629 How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers.md b/published/20180629 How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers.md
similarity index 57%
rename from translated/tech/20180629 How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers.md
rename to published/20180629 How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers.md
index 33b8b8e530..9c95bb2b81 100644
--- a/translated/tech/20180629 How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers.md
+++ b/published/20180629 How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers.md
@@ -1,6 +1,6 @@
[#]: collector: (lujun9972)
[#]: translator: (geekpi)
-[#]: reviewer: ( )
+[#]: reviewer: (wxy)
[#]: publisher: ( )
[#]: url: ( )
[#]: subject: (How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers)
@@ -9,9 +9,12 @@
如何使得支持 OpenGL 的 Flatpak 应用和游戏在专有 Nvidia 图形驱动下工作
======
-**一些支持 OpenGL 并打包为 Flatpak 的应用和游戏无法使用专有 Nvidia 驱动启动。本文将介绍如何在不安装开源驱动(Nouveau)的情况下启动这些 Flatpak 应用或游戏。**
+> 一些支持 OpenGL 并打包为 Flatpak 的应用和游戏无法使用专有 Nvidia 驱动启动。本文将介绍如何在不安装开源驱动(Nouveau)的情况下启动这些 Flatpak 应用或游戏。
+
+
+
+这有个例子。我在我的 Ubuntu 18.04 桌面上使用专有的 Nvidia 驱动程序 (`nvidia-driver-390`),当我尝试启动以 Flatpak 形式安装的最新版本 [Krita 4.1][2] (构建了 OpenGL 支持)时,显示了如下错误:
-这有个例子。我在我的 Ubuntu 18.04 桌面上使用专有的 Nvidia 驱动程序 (`nvidia-driver-390`),当我尝试启动最新版本时:
```
$ /usr/bin/flatpak run --branch=stable --arch=x86_64 --command=krita --file-forwarding org.kde.krita
Gtk-Message: Failed to load module "canberra-gtk-module"
@@ -19,89 +22,85 @@ Gtk-Message: Failed to load module "canberra-gtk-module"
libGL error: No matching fbConfigs or visuals found
libGL error: failed to load driver: swrast
Could not initialize GLX
-
```
-要修复使用 OpenGL 和专有 Nvidia 图形驱动时无法启动的 Flatpak 游戏和应用,你需要为已安装的专有驱动安装运行时。以下是步骤。
+[Winepak][3] 游戏(以 Flatpak 方式打包的绑定了 Wine 的 Windows 游戏)似乎也受到了这个问题的影响,这个问题从 2016 年出现至今。
-**1\. 如果尚未添加 FlatHub 仓库,请添加它。你可以在[此处][1]找到针对 Linux 发行版的说明。**
+要修复使用 OpenGL 和专有 Nvidia 图形驱动时无法启动的 Flatpak 游戏和应用的问题,你需要为已安装的专有驱动安装一个运行时环境。以下是步骤。
-**2. 现在,你需要确定系统上安装的专有 Nvidia 驱动的确切版本。**
+1、如果尚未添加 FlatHub 仓库,请添加它。你可以在[此处][1]找到针对 Linux 发行版的说明。
-_这一步取决于你使用的 Linux 发行版,我无法涵盖所有情况。下面的说明是面向 Ubuntu(以及 Ubuntu 风格的版本),但希望你可以自己弄清楚系统上安装的 Nvidia 驱动版本._
+2、现在,你需要确定系统上安装的专有 Nvidia 驱动的确切版本。
-要在 Ubuntu 中执行此操作,请打开 `Software&Updates`,切换到 `Additional Drivers` 选项卡并记下 Nvidia 驱动包的名称。
+_这一步取决于你使用的 Linux 发行版,我无法涵盖所有情况。下面的说明是面向 Ubuntu(以及 Ubuntu 风格的版本),但希望你可以自己弄清楚系统上安装的 Nvidia 驱动版本。_
-比如,你可以看到我的是 `nvidia-driver-390`:
+要在 Ubuntu 中执行此操作,请打开 “软件与更新”,切换到 “附加驱动” 选项卡并记下 Nvidia 驱动包的名称。
+
+比如,你可以看到我的是 “nvidia-driver-390”:
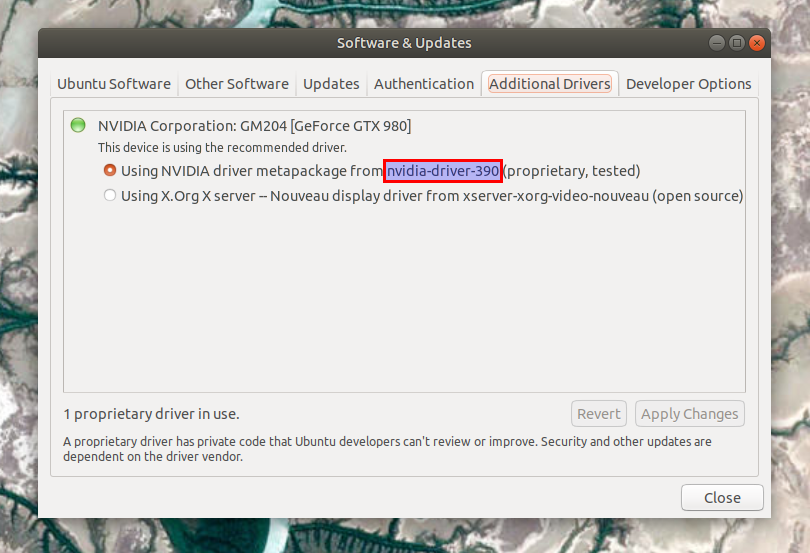
这里还没完成。我们只是找到了 Nvidia 驱动的主要版本,但我们还需要知道次要版本。要获得我们下一步所需的确切 Nvidia 驱动版本,请运行此命令(应该适用于任何基于 Debian 的 Linux 发行版,如 Ubuntu、Linux Mint 等):
+
```
apt-cache policy NVIDIA-PACKAGE-NAME
-
```
-NVIDIA-PACKAGE-NAME 是 `Software & Updates` 中列出的 Nvidia 驱动包名称。例如,要查看 `nvidia-driver-390` 包的确切安装版本,请运行以下命令:
+这里的 “NVIDIA-PACKAGE-NAME” 是 “软件与更新” 中列出的 Nvidia 驱动包名称。例如,要查看 “nvidia-driver-390” 包的确切安装版本,请运行以下命令:
+
```
$ apt-cache policy nvidia-driver-390
nvidia-driver-390:
- Installed: 390.48-0ubuntu3
- Candidate: 390.48-0ubuntu3
- Version table:
- * 390.48-0ubuntu3 500
- 500 http://ro.archive.ubuntu.com/ubuntu bionic/restricted amd64 Packages
- 100 /var/lib/dpkg/status
-
+ Installed: 390.48-0ubuntu3
+ Candidate: 390.48-0ubuntu3
+ Version table:
+ *** 390.48-0ubuntu3 500
+ 500 http://ro.archive.ubuntu.com/ubuntu bionic/restricted amd64 Packages
+ 100 /var/lib/dpkg/status
```
-在这个命令的输出中,查找 `Installed` 部分并记下版本号(不包括 `-0ubuntu3` 之类)。现在我们知道了已安装的 Nvidia 驱动的确切版本(我例子中的是 `390.48`)。记住它,因为下一步我们需要。
+在这个命令的输出中,查找 “Installed” 部分并记下版本号(不包括 “-0ubuntu3” 之类)。现在我们知道了已安装的 Nvidia 驱动的确切版本(我例子中的是 “390.48”)。记住它,因为下一步我们需要。
-**3\. 最后,你可以从 FlatHub 为你已安装的专有 Nvidia 图形驱动安装运行时。**
+3、最后,你可以从 FlatHub 为你已安装的专有 Nvidia 图形驱动安装运行时环境。
要列出 FlatHub 上所有可用的 Nvidia 运行时包,你可以使用以下命令:
+
```
flatpak remote-ls flathub | grep nvidia
-
```
-幸运地是 FlatHub 上提供这个 Nvidia 驱动的运行时。你现在可以使用以下命令继续安装运行时:
-
- * 针对 64 位系统:
+幸运地是 FlatHub 上提供这个 Nvidia 驱动的运行时环境。你现在可以使用以下命令继续安装运行时:
+针对 64 位系统:
```
flatpak install flathub org.freedesktop.Platform.GL.nvidia-MAJORVERSION-MINORVERSION
-
```
-将 MAJORVERSION 替换为 Nvidia 驱动的主要版本(在上面的示例中为 390),将 MINORVERSION 替换为次要版本(步骤2,我例子中的为 48)。
+将 “MAJORVERSION” 替换为 Nvidia 驱动的主要版本(在上面的示例中为 390),将 “MINORVERSION” 替换为次要版本(步骤2,我例子中的为 48)。
例如,要为 Nvidia 图形驱动版本 390.48 安装运行时,你必须使用以下命令:
+
```
flatpak install flathub org.freedesktop.Platform.GL.nvidia-390-48
-
```
- * 对于 32 位系统(或能够在 64 位上运行 32 位的应用或游戏),使用以下命令安装 32 位运行时:
-
+对于 32 位系统(或能够在 64 位上运行 32 位的应用或游戏),使用以下命令安装 32 位运行时:
```
flatpak install flathub org.freedesktop.Platform.GL32.nvidia-MAJORVERSION-MINORVERSION
-
```
-再说一次,将 MAJORVERSION 替换为 Nvidia 驱动的主要版本(在上面的示例中为 390),将 MINORVERSION 替换为次要版本(步骤2,我例子中的为 48)。
+再说一次,将 “MAJORVERSION” 替换为 Nvidia 驱动的主要版本(在上面的示例中为 390),将 “MINORVERSION” 替换为次要版本(步骤2,我例子中的为 48)。
比如,要为 Nvidia 图形驱动版本 390.48 安装 32 位运行时,你需要使用以下命令:
+
```
flatpak install flathub org.freedesktop.Platform.GL32.nvidia-390-48
-
```
以上就是你要运行支持 OpenGL 的 Flatpak 的应用或游戏的方法。
-
--------------------------------------------------------------------------------
via: https://www.linuxuprising.com/2018/06/how-to-get-flatpak-apps-and-games-built.html
@@ -109,7 +108,7 @@ via: https://www.linuxuprising.com/2018/06/how-to-get-flatpak-apps-and-games-bui
作者:[Logix][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180926 HTTP- Brief History of HTTP.md b/published/20180926 HTTP- Brief History of HTTP.md
new file mode 100644
index 0000000000..5d95730284
--- /dev/null
+++ b/published/20180926 HTTP- Brief History of HTTP.md
@@ -0,0 +1,246 @@
+[#]: collector: (lujun9972)
+[#]: translator: (MjSeven)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10621-1.html)
+[#]: subject: (HTTP: Brief History of HTTP)
+[#]: via: (https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol)
+[#]: author: (Ilya Grigorik https://www.igvita.com/)
+
+HTTP 简史
+======
+
+译注:本文来源于 2013 年出版的《High Performance Browser Networking》的第九章,因此有些信息略有过时。事实上,现在 HTTP/2 已经有相当的不是,而新的 HTTP/3 也在设计和标准制定当中。
+
+### 介绍
+
+超文本传输协议(HTTP)是互联网上最普遍和广泛采用的应用程序协议之一。它是客户端和服务器之间的通用语言,支持现代 Web。从最初作为单个的关键字和文档路径开始,它已成为不仅仅是浏览器的首选协议,而且几乎是所有连接互联网硬件和软件应用程序的首选协议。
+
+在本文中,我们将简要回顾 HTTP 协议的发展历史。对 HTTP 不同语义的完整讨论超出了本文的范围,但理解 HTTP 的关键设计变更以及每个变更背后的动机将为我们讨论 HTTP 性能提供必要的背景,特别是在 HTTP/2 中即将进行的许多改进。
+
+### HTTP 0.9: 单行协议
+
+蒂姆·伯纳斯·李 最初的 HTTP 提案在设计时考虑到了简单性,以帮助他采用他的另一个新想法:万维网。这个策略看起来奏效了:注意,他是一个有抱负的协议设计者。
+
+1991 年,伯纳斯·李概述了这个新协议的动机,并列出了几个高级设计目标:文件传输功能、请求超文档存档索引搜索的能力,格式协商以及将客户端引用到另一个服务器的能力。为了证明该理论的实际应用,构建了一个简单原型,它实现了所提议功能的一小部分。
+
+ * 客户端请求是一个 ASCII 字符串。
+ * 客户端请求以回车符(CRLF)终止。
+ * 服务器响应是 ASCII 字符流。
+ * 服务器响应是一种超文本标记语言(HTML)。
+ * 文档传输完成后连接终止。
+
+然而,即使这听起来也比实际复杂得多。这些规则支持的是一种非常简单的,对 Telnet 友好的协议,一些 Web 服务器至今仍然支持这种协议:
+
+```
+$> telnet google.com 80
+
+Connected to 74.125.xxx.xxx
+
+GET /about/
+
+(hypertext response)
+(connection closed)
+```
+
+请求包含这样一行:`GET` 方法和请求文档的路径。响应是一个超文本文档,没有标题或任何其他元数据,只有 HTML。真的是再简单不过了。此外,由于之前的交互是预期协议的子集,因此它获得了一个非官方的 HTTP 0.9 标签。其余的,就像他们所说的,都是历史。
+
+从 1991 年这些不起眼的开始,HTTP 就有了自己的生命,并在接下来几年里迅速发展。让我们快速回顾一下 HTTP 0.9 的特性:
+
+ * 采用客户端-服务器架构,是一种请求-响应协议。
+ * 采用 ASCII 协议,运行在 TCP/IP 链路上。
+ * 旨在传输超文本文档(HTML)。
+ * 每次请求后,服务器和客户端之间的连接都将关闭。
+
+> 流行的 Web 服务器,如 Apache 和 Nginx,仍然支持 HTTP 0.9 协议,部分原因是因为它没有太多功能!如果你感兴趣,打开 Telnet 会话并尝试通过 HTTP 0.9 访问 google.com 或你最喜欢的网站,并检查早期协议的行为和限制。
+
+### HTTP/1.0: 快速增长和 Informational RFC
+
+1991 年至 1995 年期间,HTML 规范和一种称为 “web 浏览器”的新型软件快速发展,面向消费者的公共互联网基础设施也开始出现并快速增长。
+
+> **完美风暴:1990 年代初的互联网热潮**
+
+> 基于蒂姆·伯纳斯·李最初的浏览器原型,美国国家超级计算机应用中心(NCSA)的一个团队决定实现他们自己的版本。就这样,第一个流行的浏览器诞生了:NCSA Mosaic。1994 年 10 月,NCSA 团队的一名程序员 Marc Andreessen 与 Jim Clark 合作创建了 Mosaic Communications,该公司后来改名为 Netscape(网景),并于 1994 年 12 月发布了 Netscape Navigator 1.0。从这一点来说,已经很清楚了,万维网已经不仅仅是学术上的好奇心了。
+
+> 实际上,同年在瑞士日内瓦组织了第一次万维网会议,这导致万维网联盟(W3C)的成立,以帮助指导 HTML 的发展。同样,在 IETF 内部建立了一个并行的HTTP 工作组(HTTP-WG),专注于改进 HTTP 协议。后来这两个团体一直对 Web 的发展起着重要作用。
+
+> 最后,完美风暴来临,CompuServe,AOL 和 Prodigy 在 1994-1995 年的同一时间开始向公众提供拨号上网服务。凭借这股迅速的浪潮,Netscape 在 1995 年 8 月 9 日凭借其成功的 IPO 创造了历史。这预示着互联网热潮已经到来,人人都想分一杯羹!
+
+不断增长的新 Web 所需功能及其在公共网站上的应用场景很快暴露了 HTTP 0.9 的许多基础限制:我们需要一种能够提供超文本文档、提供关于请求和响应的更丰富的元数据,支持内容协商等等的协议。相应地,新兴的 Web 开发人员社区通过一个特殊的过程生成了大量实验性的 HTTP 服务器和客户端实现来回应:实现,部署,并查看其他人是否采用它。
+
+从这些急速增长的实验开始,一系列最佳实践和常见模式开始出现。1996 年 5 月,HTTP 工作组(HTTP-WG)发布了 RFC 1945,它记录了许多被广泛使用的 HTTP/1.0 实现的“常见用法”。请注意,这只是一个信息性 RFC:HTTP/1.0,如你所知的,它不是一个正式规范或 Internet 标准!
+
+话虽如此,HTTP/1.0 请求看起来应该是:
+
+```
+$> telnet website.org 80
+
+Connected to xxx.xxx.xxx.xxx
+
+GET /rfc/rfc1945.txt HTTP/1.0 ❶
+User-Agent: CERN-LineMode/2.15 libwww/2.17b3
+Accept: */*
+
+HTTP/1.0 200 OK ❷
+Content-Type: text/plain
+Content-Length: 137582
+Expires: Thu, 01 Dec 1997 16:00:00 GMT
+Last-Modified: Wed, 1 May 1996 12:45:26 GMT
+Server: Apache 0.84
+
+(plain-text response)
+(connection closed)
+```
+
+- ❶ 请求行有 HTTP 版本号,后面跟请求头
+- ❷ 响应状态,后跟响应头
+
+前面的交互并不是 HTTP/1.0 功能的详尽列表,但它确实说明了一些关键的协议更改:
+
+* 请求可能多个由换行符分隔的请求头字段组成。
+* 响应对象的前缀是响应状态行。
+* 响应对象有自己的一组由换行符分隔的响应头字段。
+* 响应对象不限于超文本。
+* 每次请求后,服务器和客户端之间的连接都将关闭。
+
+请求头和响应头都保留为 ASCII 编码,但响应对象本身可以是任何类型:HTML 文件、纯文本文件、图像或任何其他内容类型。因此,HTTP 的“超文本传输”部分在引入后不久就变成了用词不当。实际上,HTTP 已经迅速发展成为一种超媒体传输,但最初的名称没有改变。
+
+除了媒体类型协商之外,RFC 还记录了许多其他常用功能:内容编码、字符集支持、多部分类型、授权、缓存、代理行为、日期格式等。
+
+> 今天,几乎所有 Web 上的服务器都可以并且仍将使用 HTTP/1.0。不过,现在你应该更加清楚了!每个请求都需要一个新的 TCP 连接,这会对 HTTP/1.0 造成严重的性能损失。参见[三次握手][1],接着会[慢启动][2]。
+
+### HTTP/1.1: Internet 标准
+
+将 HTTP 转变为官方 IETF 互联网标准的工作与围绕 HTTP/1.0 的文档工作并行进行,并计划从 1995 年至 1999 年完成。事实上,第一个正式的 HTTP/1.1 标准定义于 RFC 2068,它在 HTTP/1.0 发布大约六个月后,即 1997 年 1 月正式发布。两年半后,即 1999 年 6 月,一些新的改进和更新被纳入标准,并作为 RFC 2616 发布。
+
+HTTP/1.1 标准解决了早期版本中发现的许多协议歧义,并引入了一些关键的性能优化:保持连接,分块编码传输,字节范围请求,附加缓存机制,传输编码和请求管道。
+
+有了这些功能,我们现在可以审视一下由任何现代 HTTP 浏览器和客户端执行的典型 HTTP/1.1 会话:
+
+```
+$> telnet website.org 80
+Connected to xxx.xxx.xxx.xxx
+
+GET /index.html HTTP/1.1 ❶
+Host: website.org
+User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
+Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
+Accept-Encoding: gzip,deflate,sdch
+Accept-Language: en-US,en;q=0.8
+Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
+Cookie: __qca=P0-800083390... (snip)
+
+HTTP/1.1 200 OK ❷
+Server: nginx/1.0.11
+Connection: keep-alive
+Content-Type: text/html; charset=utf-8
+Via: HTTP/1.1 GWA
+Date: Wed, 25 Jul 2012 20:23:35 GMT
+Expires: Wed, 25 Jul 2012 20:23:35 GMT
+Cache-Control: max-age=0, no-cache
+Transfer-Encoding: chunked
+
+100 ❸
+
+(snip)
+
+100
+(snip)
+
+0 ❹
+
+GET /favicon.ico HTTP/1.1 ❺
+Host: www.website.org
+User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
+Accept: */*
+Referer: http://website.org/
+Connection: close ❻
+Accept-Encoding: gzip,deflate,sdch
+Accept-Language: en-US,en;q=0.8
+Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
+Cookie: __qca=P0-800083390... (snip)
+
+HTTP/1.1 200 OK ❼
+Server: nginx/1.0.11
+Content-Type: image/x-icon
+Content-Length: 3638
+Connection: close
+Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT
+Cache-Control: max-age=315360000
+Accept-Ranges: bytes
+Via: HTTP/1.1 GWA
+Date: Sat, 21 Jul 2012 21:35:22 GMT
+Expires: Thu, 31 Dec 2037 23:55:55 GMT
+Etag: W/PSA-GAu26oXbDi
+
+(icon data)
+(connection closed)
+```
+
+- ❶ 请求的 HTML 文件,包括编、字符集和 cookie 元数据
+- ❷ 原始 HTML 请求的分块响应
+- ❸ 以 ASCII 十六进制数字(256 字节)表示块中的八位元的数量
+- ❹ 分块流响应结束
+- ❺ 在相同的 TCP 连接上请求一个图标文件
+- ❻ 通知服务器不再重用连接
+- ❼ 图标响应后,然后关闭连接
+
+哇,这里发生了很多事情!第一个也是最明显的区别是我们有两个对象请求,一个用于 HTML 页面,另一个用于图像,它们都通过一个连接完成。这就是保持连接的实际应用,它允许我们重用现有的 TCP 连接到同一个主机的多个请求,提供一个更快的最终用户体验。参见[TCP 优化][3]。
+
+要终止持久连接,注意第二个客户端请求通过 `Connection` 请求头向服务器发送显示的 `close`。类似地,一旦传输响应,服务器就可以通知客户端关闭当前 TCP 连接。从技术上讲,任何一方都可以在没有此类信号的情况下终止 TCP 连接,但客户端和服务器应尽可能提供此类信号,以便双方都启用更好的连接重用策略。
+
+> HTTP/1.1 改变了 HTTP 协议的语义,默认情况下使用保持连接。这意味着,除非另有说明(通过 `Connection:close` 头),否则服务器应默认保持连接打开。
+
+> 但是,同样的功能也被反向移植到 HTTP/1.0 上,通过 `Connection:keep-Alive` 头启用。因此,如果你使用 HTTP/1.1,从技术上讲,你不需要 `Connection:keep-Alive` 头,但许多客户端仍然选择提供它。
+
+此外,HTTP/1.1 协议还添加了内容、编码、字符集,甚至语言协商、传输编码、缓存指令、客户端 cookie,以及可以针对每个请求协商的十几个其他功能。
+
+我们不打算详细讨论每个 HTTP/1.1 特性的语义。这个主题可以写一本专门的书了,已经有了很多很棒的书。相反,前面的示例很好地说明了 HTTP 的快速进展和演变,以及每个客户端-服务器交换的错综复杂的过程,里面发生了很多事情!
+
+> 要了解 HTTP 协议所有内部工作原理,参考 David Gourley 和 Brian Totty 共同撰写的权威指南: The Definitive Guide。
+
+### HTTP/2: 提高传输性能
+
+RFC 2616 自发布以来,已经成为互联网空前增长的基础:数十亿各种形状和大小的设备,从台式电脑到我们口袋里的小型网络设备,每天都在使用 HTTP 来传送新闻,视频,在我们生活中的数百万的其他网络应用程序都在依靠它。
+
+一开始是一个简单的,用于检索超文本的简单协议,很快演变成了一种通用的超媒体传输,现在十年过去了,它几乎可以为你所能想象到的任何用例提供支持。可以使用协议的服务器无处不在,客户端也可以使用协议,这意味着现在许多应用程序都是专门在 HTTP 之上设计和部署的。
+
+需要一个协议来控制你的咖啡壶?RFC 2324 已经涵盖了超文本咖啡壶控制协议(HTCPCP/1.0)- 它原本是 IETF 在愚人节开的一个玩笑,但在我们这个超链接的新世界中,它不仅仅意味着一个玩笑。
+
+> 超文本传输协议(HTTP)是一个应用程序级的协议,用于分布式、协作、超媒体信息系统。它是一种通用的、无状态的协议,可以通过扩展请求方法、错误码和头,用于超出超文本之外的许多任务,比如名称服务器和分布式对象管理系统。HTTP 的一个特性是数据表示的类型和协商,允许独立于传输的数据构建系统。
+>
+> RFC 2616: HTTP/1.1, June 1999
+
+HTTP 协议的简单性是它最初被采用和快速增长的原因。事实上,现在使用 HTTP 作为主要控制和数据协议的嵌入式设备(传感器,执行器和咖啡壶)并不罕见。但在其自身成功的重压下,随着我们越来越多地继续将日常互动转移到网络 —— 社交、电子邮件、新闻和视频,以及越来越多的个人和工作空间,它也开始显示出压力的迹象。用户和 Web 开发人员现在都要求 HTTP/1.1 提供近乎实时的响应能力和协议
+性能,如果不进行一些修改,就无法满足这些要求。
+
+为了应对这些新挑战,HTTP 必须继续发展,因此 HTTPbis 工作组在 2012 年初宣布了一项针对 HTTP/2 的新计划:
+
+> 已经有一个协议中出现了新的实现经验和兴趣,该协议保留了 HTTP 的语义,但是没有保留 HTTP/1.x 的消息框架和语法,这些问题已经被确定为妨碍性能和鼓励滥用底层传输。
+>
+> 工作组将使用有序的双向流中生成 HTTP 当前语义的新表达式的规范。与 HTTP/1.x 一样,主要传输目标是 TCP,但是应该可以使用其他方式传输。
+>
+> HTTP/2 charter, January 2012
+
+HTTP/2 的主要重点是提高传输性能并支持更低的延迟和更高的吞吐量。主要的版本增量听起来像是一个很大的步骤,但就性能而言,它将是一个重大的步骤,但重要的是要注意,没有任何高级协议语义收到影响:所有的 HTTP 头,值和用例是相同的。
+
+任何现有的网站或应用程序都可以并且将通过 HTTP/2 传送而无需修改。你无需修改应用程序标记来利用 HTTP/2。HTTP 服务器将来一定会使用 HTTP/2,但这对大多数用户来说应该是透明的升级。如果工作组实现目标,唯一的区别应该是我们的应用程序以更低的延迟和更好的网络连接利用率来传送数据。
+
+话虽如此,但我们不要走的太远了。在讨论新的 HTTP/2 协议功能之前,有必要回顾一下我们现有的 HTTP/1.1 部署和性能最佳实践。HTTP/2 工作组正在新规范上取得快速的进展,但即使最终标准已经完成并准备就绪,在可预见的未来,我们仍然必须支持旧的 HTTP/1.1 客户端,实际上,这得十年或更长时间。
+
+--------------------------------------------------------------------------------
+
+via: https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol
+
+作者:[Ilya Grigorik][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.igvita.com/
+[b]: https://github.com/lujun9972
+[1]: https://hpbn.co/building-blocks-of-tcp/#three-way-handshake
+[2]: https://hpbn.co/building-blocks-of-tcp/#slow-start
+[3]: https://hpbn.co/building-blocks-of-tcp/#optimizing-for-tcp
diff --git a/translated/tech/20181216 Schedule a visit with the Emacs psychiatrist.md b/published/20181216 Schedule a visit with the Emacs psychiatrist.md
similarity index 67%
rename from translated/tech/20181216 Schedule a visit with the Emacs psychiatrist.md
rename to published/20181216 Schedule a visit with the Emacs psychiatrist.md
index 7e05a0e930..304beda2ff 100644
--- a/translated/tech/20181216 Schedule a visit with the Emacs psychiatrist.md
+++ b/published/20181216 Schedule a visit with the Emacs psychiatrist.md
@@ -1,16 +1,18 @@
-[#]:collector:(lujun9972)
-[#]:translator:(lujun9972)
-[#]:reviewer:( )
-[#]:publisher:( )
-[#]:url:( )
-[#]:subject:(Schedule a visit with the Emacs psychiatrist)
-[#]:via:(https://opensource.com/article/18/12/linux-toy-eliza)
-[#]:author:(Jason Baker https://opensource.com/users/jason-baker)
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10601-1.html)
+[#]: subject: (Schedule a visit with the Emacs psychiatrist)
+[#]: via: (https://opensource.com/article/18/12/linux-toy-eliza)
+[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
预约 Emacs 心理医生
======
-Eliza 是一个隐藏于某个 Linux 最流行文本编辑器中的自然语言处理聊天机器人。
-
+
+> Eliza 是一个隐藏于某个 Linux 最流行文本编辑器中的自然语言处理聊天机器人。
+
+
欢迎你,今天时期 24 天的 Linux 命令行玩具的又一天。如果你是第一次访问本系列,你可能会问什么是命令行玩具呢。我们将会逐步确定这个概念,但一般来说,它可能是一个游戏,或任何能让你在终端玩的开心的其他东西。
@@ -22,24 +24,23 @@ Eliza 是一个隐藏于某个 Linux 最流行文本编辑器中的自然语言
要启动 [Eliza][1],首先,你需要启动 Emacs。很有可能 Emacs 已经安装在你的系统中了,但若没有,它基本上也肯定在你默认的软件仓库中。
-由于我要求本系列的工具一定要时运行在终端内,因此使用 **-nw** 标志来启动 Emacs 让它在你的终端模拟器中运行。
+由于我要求本系列的工具一定要时运行在终端内,因此使用 `-nw` 标志来启动 Emacs 让它在你的终端模拟器中运行。
```
$ emacs -nw
```
-在 Emacs 中,输入 M-x doctor 来启动 Eliza。对于像我这样有 Vim 背景的人可能不知道这是什么意思,只需要按下 escape,输入 x 然后输入 doctor。然后,向它倾述所有假日的烦恼吧。
+在 Emacs 中,输入 `M-x doctor` 来启动 Eliza。对于像我这样有 Vim 背景的人可能不知道这是什么意思,只需要按下 `escape`,输入 `x` 然后输入 `doctor`。然后,向它倾述所有假日的烦恼吧。
-Eliza 历史悠久,最早可以追溯到 1960 年代中期的 MIT 人工智能实验室。[维基百科 ][2] 上有它历史的详细说明。
-
-Eliza 并不是 Emacs 中唯一的娱乐工具。查看 [手册 ][3] 可以看到一整列好玩的玩具。
+Eliza 历史悠久,最早可以追溯到 1960 年代中期的 MIT 人工智能实验室。[维基百科][2] 上有它历史的详细说明。
+Eliza 并不是 Emacs 中唯一的娱乐工具。查看 [手册][3] 可以看到一整列好玩的玩具。
![Linux toy:eliza animated][5]
你有什么喜欢的命令行玩具值得推荐吗?我们时间不多了,但我还是想听听你的建议。请在下面评论中告诉我,我会查看的。另外也欢迎告诉我你们对本次玩具的想法。
-请一定要看看昨天的玩具,[带着这个复刻版吃豆人来到 Linux 终端游乐中心 ][6],然后明天再来看另一个玩具!
+请一定要看看昨天的玩具,[带着这个复刻版吃豆人来到 Linux 终端游乐中心][6],然后明天再来看另一个玩具!
--------------------------------------------------------------------------------
@@ -48,7 +49,7 @@ via: https://opensource.com/article/18/12/linux-toy-eliza
作者:[Jason Baker][a]
选题:[lujun9972][b]
译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20190104 Midori- A Lightweight Open Source Web Browser.md b/published/20190104 Midori- A Lightweight Open Source Web Browser.md
similarity index 80%
rename from translated/tech/20190104 Midori- A Lightweight Open Source Web Browser.md
rename to published/20190104 Midori- A Lightweight Open Source Web Browser.md
index 9cc0673527..e263fc38ca 100644
--- a/translated/tech/20190104 Midori- A Lightweight Open Source Web Browser.md
+++ b/published/20190104 Midori- A Lightweight Open Source Web Browser.md
@@ -1,8 +1,8 @@
[#]: collector: (lujun9972)
[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10602-1.html)
[#]: subject: (Midori: A Lightweight Open Source Web Browser)
[#]: via: (https://itsfoss.com/midori-browser)
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
@@ -10,13 +10,13 @@
Midori:轻量级开源 Web 浏览器
======
-**这是一个对再次回归的轻量级、快速、开源的 Web 浏览器 Midori 的快速回顾**
+> 这是一个对再次回归的轻量级、快速、开源的 Web 浏览器 Midori 的快速回顾。
如果你正在寻找一款轻量级[网络浏览器替代品][1],请试试 Midori。
[Midori][2]是一款开源的网络浏览器,它更注重轻量级而不是提供大量功能。
-如果你从未听说过 Midori,你可能会认为它是一个新的应用程序,但实际上 Midori 于 2007 年首次发布。
+如果你从未听说过 Midori,你可能会认为它是一个新的应用程序,但实际上 Midori 首次发布于 2007 年。
因为它专注于速度,所以 Midori 很快就聚集了一群爱好者,并成为了 Bodhi Linux、SilTaz 等轻量级 Linux 发行版的默认浏览器。
@@ -28,25 +28,23 @@ Midori:轻量级开源 Web 浏览器
![Midori web browser][4]
-以下是Midori浏览器的一些主要功能
+以下是 Midori 浏览器的一些主要功能
- * 使用 Vala 编写,带有 GTK+3 和 WebKit 渲染引擎。
- * 标签、窗口和会话管理
- * 快速拨号
- * 默认保存下一个会话的选项卡
+ * 使用 Vala 编写,使用 GTK+3 和 WebKit 渲染引擎。
+ * 标签、窗口和会话管理。
+ * 快速拨号。
+ * 默认保存下一个会话的选项卡。
* 使用 DuckDuckGo 作为默认搜索引擎。可以更改为 Google 或 Yahoo。
- * 书签管理
- * 可定制和可扩展的界面
- * 扩展模块可以用 C 和 Vala 编写
- * 支持 HTML5
+ * 书签管理。
+ * 可定制和可扩展的界面。
+ * 扩展模块可以用 C 和 Vala 编写。
+ * 支持 HTML5。
* 少量的扩展程序包括广告拦截器、彩色标签等。没有第三方扩展程序。
- * 表格历史
- * 隐私浏览
- * 可用于 Linux 和 Windows
+ * 表单历史。
+ * 隐私浏览。
+ * 可用于 Linux 和 Windows。
-
-
-小知识:Midori 是日语单词,意思是绿色。如果你因此在猜想一些东西,Midori 的开发者实际不是日本人。
+小知识:Midori 是日语单词,意思是绿色。如果你因此而猜想的话,但 Midori 的开发者实际不是日本人。
### 体验 Midori
@@ -54,7 +52,7 @@ Midori:轻量级开源 Web 浏览器
这几天我一直在使用 Midori。体验基本很好。它支持 HTML5 并能快速渲染网站。广告拦截器也没问题。正如你对任何标准 Web 浏览器所期望的那样,浏览体验挺顺滑。
-缺少扩展一直是 Midori 的弱点所以我不打算谈论这个。
+缺少扩展一直是 Midori 的弱点,所以我不打算谈论这个。
我注意到的是它不支持国际语言。我找不到添加新语言支持的方法。它根本无法渲染印地语字体,我猜对其他非[罗曼语言][6]也是一样。
@@ -70,7 +68,7 @@ Midori 没有像 Chrome 那样吃我的内存,所以这是一个很大的优
如果你使用的是 Ubuntu,你可以在软件中心找到 Midori(Snap 版)并从那里安装。
-![Midori browser is available in Ubuntu Software Center][8]Midori browser is available in Ubuntu Software Center
+![Midori browser is available in Ubuntu Software Center][8]
对于其他 Linux 发行版,请确保你[已启用 Snap 支持][9],然后你可以使用以下命令安装 Midori:
@@ -80,6 +78,8 @@ sudo snap install midori
你可以选择从源代码编译。你可以从 Midori 的网站下载它的代码。
+- [下载 Midori](https://www.midori-browser.org/download/)
+
如果你喜欢 Midori 并希望帮助这个开源项目,请向他们捐赠或[从他们的商店购买 Midori 商品][10]。
你在使用 Midori 还是曾经用过么?你的体验如何?你更喜欢使用哪种其他网络浏览器?请在下面的评论栏分享你的观点。
@@ -91,7 +91,7 @@ via: https://itsfoss.com/midori-browser
作者:[Abhishek Prakash][a]
选题:[lujun9972][b]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20190109 Configure Anaconda on Emacs - iD.md b/published/20190109 Configure Anaconda on Emacs - iD.md
similarity index 55%
rename from translated/tech/20190109 Configure Anaconda on Emacs - iD.md
rename to published/20190109 Configure Anaconda on Emacs - iD.md
index 09dcfd9a1c..5c6125e2e9 100644
--- a/translated/tech/20190109 Configure Anaconda on Emacs - iD.md
+++ b/published/20190109 Configure Anaconda on Emacs - iD.md
@@ -1,25 +1,23 @@
-[#]:collector:(lujun9972)
-[#]:translator:(lujun9972)
-[#]:reviewer:( )
-[#]:publisher:( )
-[#]:url:( )
-[#]:subject:(Configure Anaconda on Emacs – iD)
-[#]:via:(https://idevji.com/configure-anaconda-on-emacs/)
-[#]:author:(Devji Chhanga https://idevji.com/author/admin/)
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10604-1.html)
+[#]: subject: (Configure Anaconda on Emacs – iD)
+[#]: via: (https://idevji.com/configure-anaconda-on-emacs/)
+[#]: author: (Devji Chhanga https://idevji.com/author/admin/)
在 Emacs 上配置 Anaconda
======
-也许我所最求的究极 IDE 就是 [Emacs][1] 了。我的目标是使 Emacs 成为一款全能的 Python IDE。本文描述了如何在 Emacs 上配置 Anaconda。
+也许我所追求的究极 IDE 就是 [Emacs][1] 了。我的目标是使 Emacs 成为一款全能的 Python IDE。本文描述了如何在 Emacs 上配置 Anaconda。(LCTT 译注:Anaconda 自称“世界上最流行的 Python/R 的数据分析平台”)
我的配置信息:
-```
-OS: Trisquel 8.0
-Emacs: GNU Emacs 25.3.2
-```
+- OS:Trisquel 8.0
+- Emacs:GNU Emacs 25.3.2
-快捷键说明 [(参见完全指南 )][2]:
+快捷键说明([参见完全指南][2]):
```
C-x = Ctrl + x
@@ -27,25 +25,26 @@ M-x = Alt + x
RET = ENTER
```
-### 1。下载并安装 Anaconda
+### 1、下载并安装 Anaconda
-#### 1.1 下载:
-[从这儿 ][3] 下载 Anaconda。你应该下载 Python 3.x 版本因为 Python 2 在 2020 年就不再支持了。你无需预先安装 Python 3.x。安装脚本会自动进行安装。
+#### 1.1 下载
-#### 1.2 安装:
+[从这儿][3] 下载 Anaconda。你应该下载 Python 3.x 的版本,因为 Python 2 在 2020 年就不再支持了。你无需预先安装 Python 3.x。这个安装脚本会自动安装它。
+
+#### 1.2 安装
```
- cd ~/Downloads
+cd ~/Downloads
bash Anaconda3-2018.12-Linux-x86.sh
```
-
-### 2。将 Anaconda 添加到 Emacs
+### 2、将 Anaconda 添加到 Emacs
#### 2.1 将 MELPA 添加到 Emacs
-我们需要用到 _anaconda-mode_ 这个 Emacs 包。该包位于 MELPA 仓库中。Emacs25 需要手工添加该仓库。
-[注意:点击本文查看如何将 MELPA 添加到 Emacs。][4]
+我们需要用到 `anaconda-mode` 这个 Emacs 包。该包位于 MELPA 仓库中。Emacs25 需要手工添加该仓库。
+
+- [注意:点击本文查看如何将 MELPA 添加到 Emacs][4]
#### 2.2 为 Emacs 安装 anaconda-mode 包
@@ -60,8 +59,7 @@ anaconda-mode RET
echo "(add-hook 'python-mode-hook 'anaconda-mode)" > ~/.emacs.d/init.el
```
-
-### 3。在 Emacs 上通过 Anaconda 运行你第一个脚本
+### 3、在 Emacs 上通过 Anaconda 运行你第一个脚本
#### 3.1 创建新 .py 文件
@@ -83,7 +81,7 @@ C-c C-p
C-c C-c
```
-输出为
+输出为:
```
Python 3.7.1 (default, Dec 14 2018, 19:46:24)
@@ -94,8 +92,9 @@ Type "help", "copyright", "credits" or "license" for more information.
>>>
```
-我是受到 [Codingquark;][5] 的影响才开始使用 Emacs 的。
-有任何错误和遗漏请在评论中之处。干杯!
+我是受到 [Codingquark][5] 的影响才开始使用 Emacs 的。
+
+有任何错误和遗漏请在评论中写下。干杯!
--------------------------------------------------------------------------------
@@ -104,7 +103,7 @@ via: https://idevji.com/configure-anaconda-on-emacs/
作者:[Devji Chhanga][a]
选题:[lujun9972][b]
译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20190121 Akira- The Linux Design Tool We-ve Always Wanted.md b/published/20190121 Akira- The Linux Design Tool We-ve Always Wanted.md
similarity index 55%
rename from translated/tech/20190121 Akira- The Linux Design Tool We-ve Always Wanted.md
rename to published/20190121 Akira- The Linux Design Tool We-ve Always Wanted.md
index ad957f697d..427bb2d50c 100644
--- a/translated/tech/20190121 Akira- The Linux Design Tool We-ve Always Wanted.md
+++ b/published/20190121 Akira- The Linux Design Tool We-ve Always Wanted.md
@@ -1,28 +1,28 @@
[#]: collector: (lujun9972)
[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10608-1.html)
[#]: subject: (Akira: The Linux Design Tool We’ve Always Wanted?)
[#]: via: (https://itsfoss.com/akira-design-tool)
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
-Akira:我们一直想要的 Linux 设计工具?
+Akira 是我们一直想要的 Linux 设计工具吗?
======
-先说一下,我不是一个专业的设计师 - 但我在 Windows 上使用了某些工具(如 Photoshop、Illustrator 等)和 [Figma] [1](这是一个基于浏览器的界面设计工具)。我相信 Mac 和 Windows 上还有更多的设计工具。
+先说一下,我不是一个专业的设计师,但我在 Windows 上使用过某些工具(如 Photoshop、Illustrator 等)和 [Figma] [1](这是一个基于浏览器的界面设计工具)。我相信 Mac 和 Windows 上还有更多的设计工具。
-即使在 Linux 上,也只有有限的专用[图形设计工具][2]。其中一些工具如 [GIMP][3] 和 [Inkscape][4] 也被专业人士使用。但不幸的是,它们中的大多数都不被视为专业级。
+即使在 Linux 上,也有数量有限的专用[图形设计工具][2]。其中一些工具如 [GIMP][3] 和 [Inkscape][4] 也被专业人士使用。但不幸的是,它们中的大多数都不被视为专业级。
-即使有更多解决方案 - 我也从未遇到过可以取代 [Sketch][5]、Figma 或 Adobe XD 的原生 Linux 应用。任何专业设计师都同意这点,不是吗?
+即使有更多解决方案,我也从未遇到过可以取代 [Sketch][5]、Figma 或 Adobe XD 的原生 Linux 应用。任何专业设计师都同意这点,不是吗?
### Akira 是否会在 Linux 上取代 Sketch、Figma 和 Adobe XD?
-所以,为了开发一些能够取代那些专有工具的应用 - [Alessandro Castellani][6] 发起了一个 [Kickstarter 活动][7],并与几位经验丰富的开发人员 [Alberto Fanjul][8]、[Bilal Elmoussaoui][9] 和 [Felipe Escoto][10] 组队合作。
+所以,为了开发一些能够取代那些专有工具的应用,[Alessandro Castellani][6] 发起了一个 [Kickstarter 活动][7],并与几位经验丰富的开发人员 [Alberto Fanjul][8]、[Bilal Elmoussaoui][9] 和 [Felipe Escoto][10] 组队合作。
是的,Akira 仍然只是一个想法,只有一个界面原型(正如我最近在 Kickstarter 的[直播流][11]中看到的那样)。
-### 如果它还没有,为什么会发起 Kickstarter 活动?
+### 如果它还不存在,为什么会发起 Kickstarter 活动?
![][12]
@@ -30,37 +30,38 @@ Kickstarter 活动的目的是收集资金,以便雇用开发人员,并花
尽管如此,如果你想支持这个项目,你应该知道一些细节,对吧?
-不用担心,我们在他们的直播中问了几个问题 - 让我们看下
+不用担心,我们在他们的直播中问了几个问题 - 让我们看下:
### Akira:更多细节
![Akira prototype interface][13]
-图片来源:Kickstarter
+
+*图片来源:Kickstarter*
如 Kickstarter 活动描述的那样:
-> Akira 的主要目的是提供一个快速而直观的工具来**创建 Web 和移动界面**,更像是 **Sketch**、**Figma** 或 **Adobe XD**,并且是 Linux 原生体验。
+> Akira 的主要目的是提供一个快速而直观的工具来**创建 Web 和移动端界面**,更像是 **Sketch**、**Figma** 或 **Adobe XD**,并且是 Linux 原生体验。
-他们还详细描述了该工具与 Inkscape、Glade 或 QML Editor 的不同之处。当然,如果你想要所有的技术细节,请查看 [Kickstarter][7]。但是,在此之前,让我们看一看当我询问有关 Akira 的一些问题时他们说了些什么。
+他们还详细描述了该工具与 Inkscape、Glade 或 QML Editor 的不同之处。当然,如果你想要了解所有的技术细节,请查看 [Kickstarter][7]。但是,在此之前,让我们看一看当我询问有关 Akira 的一些问题时他们说了些什么。
-问:如果你认为你的项目类似于 Figma - 人们为什么要考虑安装 Akira 而不是使用基于网络的工具?它是否只是这些工具的克隆 - 提供原生 Linux 体验,还是有一些非常有趣的东西可以鼓励用户切换(除了是开源解决方案之外)?
+**问:**如果你认为你的项目类似于 Figma,人们为什么要考虑安装 Akira 而不是使用基于网络的工具?它是否只是这些工具的克隆 —— 提供原生 Linux 体验,还是有一些非常有趣的东西可以鼓励用户切换(除了是开源解决方案之外)?
-** Akira:** 与基于网络的 electron 应用相比,Linux 原生体验总是更好、更快。此外,如果你选择使用 Figma,硬件配置也很重要 - 但 Akira 将会占用很少的系统资源,并且你可以在不需要上网的情况下完成类似工作。
+**Akira:** 与基于网络的 electron 应用相比,Linux 原生体验总是更好、更快。此外,如果你选择使用 Figma,硬件配置也很重要,但 Akira 将会占用很少的系统资源,并且你可以在不需要上网的情况下完成类似工作。
-问:假设它成为了 Linux用户一直在等待的开源方案(拥有专有工具的类似功能)。你有什么维护计划?你是否计划引入定价 - 或依赖捐赠?
+**问:**假设它成为了 Linux 用户一直在等待的开源方案(拥有专有工具的类似功能)。你有什么维护计划?你是否计划引入定价方案,或依赖捐赠?
-**Akira:**该项目主要依靠捐赠(类似于 [Krita 基金会][14] 这样的想法)。但是,不会有“专业版”计划 - 它将免费提供,它将是一个开源项目。
+**Akira:**该项目主要依靠捐赠(类似于 [Krita 基金会][14] 这样的想法)。但是,不会有“专业版”计划,它将免费提供,它将是一个开源项目。
根据我得到的回答,它看起来似乎很有希望,我们应该支持。
+- [查看该 Kickstarter 活动](https://www.kickstarter.com/projects/alecaddd/akira-the-linux-design-tool/description)
+
### 总结
-你怎么认为 Akira?它只是一个概念吗?或者你希望看到进展?
+你怎么看 Akira?它只是一个概念吗?或者你希望看到进展?
请在下面的评论中告诉我们你的想法。
-![][15]
-
--------------------------------------------------------------------------------
via: https://itsfoss.com/akira-design-tool
@@ -68,7 +69,7 @@ via: https://itsfoss.com/akira-design-tool
作者:[Ankush Das][a]
选题:[lujun9972][b]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20190121 Booting Linux faster.md b/published/20190121 Booting Linux faster.md
new file mode 100644
index 0000000000..8b1f9ce50e
--- /dev/null
+++ b/published/20190121 Booting Linux faster.md
@@ -0,0 +1,57 @@
+[#]: collector: (lujun9972)
+[#]: translator: (alim0x)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10607-1.html)
+[#]: subject: (Booting Linux faster)
+[#]: via: (https://opensource.com/article/19/1/booting-linux-faster)
+[#]: author: (Stewart Smith https://opensource.com/users/stewart-ibm)
+
+让 Linux 启动更快
+======
+
+> 进行 Linux 内核与固件开发的时候,往往需要多次的重启,会浪费大把的时间。
+
+
+
+在所有我拥有或使用过的电脑中,启动最快的那台是 20 世纪 80 年代的电脑。在你把手从电源键移到键盘上的时候,BASIC 解释器已经在等待你输入命令了。对于现代的电脑,启动时间从笔记本电脑的 15 秒到小型家庭服务器的数分钟不等。为什么它们的启动时间有差别?
+
+那台直接启动到 BASIC 命令行提示符的 20 世纪 80 年代微电脑,有着一颗非常简单的 CPU,它在通电的时候就立即开始从一个内存地址中获取和执行指令。因为这些系统的 BASIC 在 ROM 里面,基本不需要载入的时间——你很快就进到 BASIC 命令提示符中了。同时代更加复杂的系统,比如 IBM PC 或 Macintosh,需要一段可观的时间来启动(大约 30 秒),尽管这主要是因为需要从软盘上读取操作系统的缘故。在可以加载操作系统之前,只有很小一部分时间是花费在固件上的。
+
+现代服务器往往在从磁盘上读取操作系统之前,在固件上花费了数分钟而不是数秒。这主要是因为现代系统日益增加的复杂性。CPU 不再能够只是运行起来就开始全速执行指令,我们已经习惯于 CPU 频率变化、节省能源的待机状态以及 CPU 多核。实际上,在现代 CPU 内部有数量惊人的更简单的处理器,它们协助主 CPU 核心启动并提供运行时服务,比如在过热的时候压制频率。在绝大多数 CPU 架构中,在你的 CPU 内的这些核心上运行的代码都以不透明的二进制 blob 形式提供。
+
+在 OpenPOWER 系统上,所有运行在 CPU 内部每个核心的指令都是开源的。在有 [OpenBMC][1](比如 IBM 的 AC922 系统和 Raptor 的 TALOS II 以及 Blackbird 系统)的机器上,这还延伸到了运行在基板管理控制器上的代码。这就意味着我们可以一探究竟,到底为什么从接入电源线到显示出熟悉的登录界面花了这么长时间。
+
+如果你是内核相关团队的一员,你可能启动过许多内核。如果你是固件相关团队的一员,你可能要启动许多不同的固件映像,接着是一个操作系统,来确保你的固件仍能工作。如果我们可以减少硬件的启动时间,这些团队可以更有生产力,并且终端用户在搭建系统或重启安装固件或系统更新的时候会对此表示感激。
+
+过去的几年,Linux 发行版的启动时间已经做了很多改善。现代的初始化系统在处理并行和按需任务上做得很好。在一个现代系统上,一旦内核开始执行,它可以在短短数秒内进入登录提示符界面。这里短短的数秒不是优化启动时间的下手之处,我们要到更早的地方:在我们到达操作系统之前。
+
+在 OpenPOWER 系统上,固件通过启动一个存储在固件闪存芯片上的 Linux 内核来加载操作系统,它运行一个叫做 [Petitboot][2] 的用户态程序去寻找用户想要启动的系统所在磁盘,并通过 [kexec][3] 启动它。有了这些优化,启动 Petitboot 环境只占了启动时间的百分之几,所以我们还得从其他地方寻找优化项。
+
+在 Petitboot 环境启动前,有一个先导固件,叫做 [Skiboot][4],在它之前有个 [Hostboot][5]。在 Hostboot 之前是 [Self-Boot Engine][6],一个晶圆切片(die)上的单独核心,它启动单个 CPU 核心并执行来自 Level 3 缓存的指令。这些组件是我们可以在减少启动时间上取得进展的主要部分,因为它们花费了启动的绝大部分时间。或许这些组件中的一部分没有进行足够的优化或尽可能做到并行?
+
+另一个研究路径是重启时间而不是启动时间。在重启的时候,我们真的需要对所有硬件重新初始化吗?
+
+正如任何现代系统那样,改善启动(或重启)时间的方案已经变成了更多的并行执行、解决遗留问题、(可以认为)作弊的结合体。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/booting-linux-faster
+
+作者:[Stewart Smith][a]
+选题:[lujun9972][b]
+译者:[alim0x](https://github.com/alim0x)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/stewart-ibm
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/OpenBMC
+[2]: https://github.com/open-power/petitboot
+[3]: https://en.wikipedia.org/wiki/Kexec
+[4]: https://github.com/open-power/skiboot
+[5]: https://github.com/open-power/hostboot
+[6]: https://github.com/open-power/sbe
+[7]: https://linux.conf.au/schedule/presentation/105/
+[8]: https://linux.conf.au/
diff --git a/published/20190128 Top Hex Editors for Linux.md b/published/20190128 Top Hex Editors for Linux.md
new file mode 100644
index 0000000000..b2db0ad8f1
--- /dev/null
+++ b/published/20190128 Top Hex Editors for Linux.md
@@ -0,0 +1,154 @@
+[#]: collector: "lujun9972"
+[#]: translator: "zero-mk"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-10614-1.html"
+[#]: subject: "Top Hex Editors for Linux"
+[#]: via: "https://itsfoss.com/hex-editors-linux"
+[#]: author: "Ankush Das https://itsfoss.com/author/ankush/"
+
+Linux 上最好的十进制编辑器
+======
+
+十六进制编辑器可以让你以十六进制的形式查看/编辑文件的二进制数据,因此其被命名为“十六进制”编辑器。说实话,并不是每个人都需要它。只有必须处理二进制数据的特定用户组才会使用到它。
+
+如果你不知道它是什么,让我来举个例子。假设你拥有一个游戏的配置文件,你可以使用十六进制编辑器打开它们并更改某些值以获得更多的弹药/分数等等。想要了解有关十六进制编辑器的更多信息,你可以参阅 [Wikipedia 页面][1]。
+
+如果你已经知道它用来干什么了 —— 让我们来看看 Linux 上最好的十六进制编辑器。
+
+### 5 个最好的十六进制编辑器
+
+![Best Hex Editors for Linux][2]
+
+**注意:**这里提到的十六进制编辑器没有特定的排名顺序。
+
+#### 1、Bless Hex Editor
+
+![bless hex editor][3]
+
+**主要特点:**
+
+ * 编辑裸设备(Raw disk)
+ * 多级撤消/重做操作
+ * 多个标签页
+ * 转换表
+ * 支持插件扩展功能
+
+Bless 是 Linux 上最流行的十六进制编辑器之一。你可以在应用中心或软件中心中找到它。否则,你可以查看它们的 [GitHub 页面][4] 获取构建和相关的说明。
+
+它可以轻松处理编辑大文件而不会降低速度 —— 因此它是一个快速的十六进制编辑器。
+
+- [GitHub 项目](https://github.com/bwrsandman/Bless)
+
+#### 2、GNOME Hex Editor
+
+![gnome hex editor][5]
+
+**主要特点:**
+
+ * 以十六进制/ASCII 格式查看/编辑
+ * 编辑大文件
+
+另一个神奇的十六进制编辑器 —— 专门为 GNOME 量身定做的。我个人用的是 Elementary OS, 所以我可以在应用中心找到它。你也可以在软件中心找到它。否则请参考 [GitHub 页面][6] 获取源代码。
+
+你可以使用此编辑器以十六进制或 ASCII 格式查看/编辑文件。用户界面非常简单 —— 正如你在上面的图像中看到的那样。
+
+- [官方网站](https://wiki.gnome.org/Apps/Ghex)
+
+#### 3、Okteta
+
+![okteta][7]
+
+**主要特点:**
+
+ * 可自定义的数据视图
+ * 多个标签页
+ * 字符编码:支持 Qt、EBCDIC 的所有 8 位编码
+ * 解码表列出常见的简单数据类型
+
+Okteta 是一个简单的十六进制编辑器,没有那么奇特的功能。虽然它可以处理大部分任务。它有一个单独的模块,你可以使用它嵌入其他程序来查看/编辑文件。
+
+与上述所有编辑器类似,你也可以在应用中心和软件中心上找到列出的编辑器。
+
+- [官方网站](https://www.kde.org/applications/utilities/okteta/)
+
+#### 4、wxHexEditor
+
+![wxhexeditor][8]
+
+**主要特点:**
+
+ * 轻松处理大文件
+ * 支持 x86 反汇编
+ * 对磁盘设备可以显示扇区指示
+ * 支持自定义十六进制面板格式和颜色
+
+这很有趣。它主要是一个十六进制编辑器,但你也可以将其用作低级磁盘编辑器。例如,如果你的硬盘有问题,可以使用此编辑器以 RAW 格式编辑原始数据以修复它。
+
+你可以在你的应用中心和软件中心找到它。否则,可以去看看 [Sourceforge][9]。
+
+- [官方网站](http://www.wxhexeditor.org/home.php)
+
+#### 5、Hexedit (命令行工具)
+
+![hexedit][10]
+
+**主要特点:**
+
+ * 运行在命令行终端上
+ * 它又快又简单
+
+如果你想在终端上工作,可以继续通过控制台安装 hexedit。它是我最喜欢的 Linux 命令行的十六进制编辑器。
+
+当你启动它时,你必须指定要打开的文件的位置,然后它会为你打开它。
+
+要安装它,只需输入:
+
+```
+sudo apt install hexedit
+```
+
+### 结束
+
+十六进制编辑器可以方便地进行实验和学习。如果你是一个有经验的人,你应该选择一个有更多功能的——GUI。 尽管这一切都取决于个人喜好。
+
+你认为十六进制编辑器的有用性如何?你用哪一个?我们没有列出你最喜欢的吗?请在评论中告诉我们!
+
+### 额外福利
+
+译者注:要我说,以上这些十六进制编辑器都太丑了。如果你只是想美美的查看查看一下十六进制输出,那么下面的这个查看器十分值得看看。虽然在功能上还有些不够成熟,但至少在美颜方面可以将上面在座的各位都视作垃圾。
+
+它就是 hexyl,是一个面向终端的简单的十六进制查看器。它使用颜色来区分不同的字节类型(NULL、可打印的 ASCII 字符、ASCII 空白字符、其它 ASCII 字符和非 ASCII 字符)。
+
+上图:
+
+
+
+
+
+它不仅支持各种 Linux 发行版,还支持 MacOS、FreeBSD、Windows,请自行去其[项目页](https://github.com/sharkdp/hexyl)选用,
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/hex-editors-linux
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[zero-mk](https://github.com/zero-mk)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Hex_editor
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-hex-editors-800x450.jpeg?resize=800%2C450&ssl=1
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/bless-hex-editor.jpg?ssl=1
+[4]: https://github.com/bwrsandman/Bless
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/ghex-hex-editor.jpg?ssl=1
+[6]: https://github.com/GNOME/ghex
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/okteta-hex-editor-800x466.jpg?resize=800%2C466&ssl=1
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/wxhexeditor.jpg?ssl=1
+[9]: https://sourceforge.net/projects/wxhexeditor/
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/hexedit-console.jpg?resize=800%2C566&ssl=1
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-hex-editors.jpeg?fit=800%2C450&ssl=1
diff --git a/published/20190208 7 steps for hunting down Python code bugs.md b/published/20190208 7 steps for hunting down Python code bugs.md
new file mode 100644
index 0000000000..1d89b8fd2d
--- /dev/null
+++ b/published/20190208 7 steps for hunting down Python code bugs.md
@@ -0,0 +1,116 @@
+[#]: collector: (lujun9972)
+[#]: translator: (LazyWolfLin)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10603-1.html)
+[#]: subject: (7 steps for hunting down Python code bugs)
+[#]: via: (https://opensource.com/article/19/2/steps-hunting-code-python-bugs)
+[#]: author: (Maria Mckinley https://opensource.com/users/parody)
+
+Python 七步捉虫法
+======
+
+> 了解一些技巧助你减少代码查错时间。
+
+
+
+在周五的下午三点钟(为什么是这个时间?因为事情总会在周五下午三点钟发生),你收到一条通知,客户发现你的软件出现一个错误。在有了初步的怀疑后,你联系运维,查看你的软件日志以了解发生了什么,因为你记得收到过日志已经搬家了的通知。
+
+结果这些日志被转移到了你获取不到的地方,但它们正在导入到一个网页应用中——所以到时候你可以用这个漂亮的应用来检索日志,但是,这个应用现在还没完成。这个应用预计会在几天内完成。我知道,你觉得这完全不切实际。然而并不是,日志或者日志消息似乎经常在错误的时间消失不见。在我们开始查错前,一个忠告:经常检查你的日志以确保它们还在你认为它们应该在的地方,并记录你认为它们应该记的东西。当你不注意的时候,这些东西往往会发生令人惊讶的变化。
+
+好的,你找到了日志或者尝试了呼叫运维人员,而客户确实发现了一个错误。甚至你可能认为你已经知道错误在哪儿。
+
+你立即打开你认为可能有问题的文件并开始查错。
+
+### 1、先不要碰你的代码
+
+阅读代码,你甚至可能会想到该阅读哪些部分。但是在开始搞乱你的代码前,请重现导致错误的调用并把它变成一个测试。这将是一个集成测试,因为你可能还有其他疑问,目前你还不能准确地知道问题在哪儿。
+
+确保这个测试结果是失败的。这很重要,因为有时你的测试不能重现失败的调用,尤其是你使用了可以混淆测试的 web 或者其他框架。很多东西可能被存储在变量中,但遗憾的是,只通过观察测试,你在测试里调用的东西并不总是明显可见的。当我尝试着重现这个失败的调用时,我并不是说我要创建一个可以通过的测试,但是,好吧,我确实是创建了一个测试,但我不认为这特别不寻常。
+
+> 从自己的错误中吸取教训。
+
+### 2、编写错误的测试
+
+现在,你有了一个失败的测试,或者可能是一个带有错误的测试,那么是时候解决问题了。但是在你开干之前,让我们先检查下调用栈,因为这样可以更轻松地解决问题。
+
+调用栈包括你已经启动但尚未完成地所有任务。因此,比如你正在烤蛋糕并准备往面糊里加面粉,那你的调用栈将是:
+
+* 做蛋糕
+* 打面糊
+* 加面粉
+
+你已经开始做蛋糕,开始打面糊,而你现在正在加面粉。往锅底抹油不在这个列表中,因为你已经完成了,而做糖霜不在这个列表上因为你还没开始做。
+
+如果你对调用栈不清楚,我强烈建议你使用 [Python Tutor][1],它能帮你在执行代码时观察调用栈。
+
+现在,如果你的 Python 程序出现了错误, Python 解释器会帮你打印出当前调用栈。这意味着无论那一时刻程序在做什么,很明显错误发生在调用栈的底部。
+
+### 3、始终先检查调用栈底部
+
+在栈底你不仅能看到发生了哪个错误,而且通常可以在调用栈的最后一行发现问题。如果栈底对你没有帮助,而你的代码还没有经过代码分析,那么使用代码分析是非常有用的。我推荐 pylint 或者 flake8。通常情况下,它会指出我一直忽略的错误的地方。
+
+如果错误看起来很迷惑,你下一步行动可能是用 Google 搜索它。如果你搜索的内容不包含你的代码的相关信息,如变量名、文件等,那你将获得更好的搜索结果。如果你使用的是 Python 3(你应该使用它),那么搜索内容包含 Python 3 是有帮助的,否则 Python 2 的解决方案往往会占据大多数。
+
+很久以前,开发者需要在没有搜索引擎的帮助下解决问题。那是一段黑暗时光。充分利用你可以使用的所有工具。
+
+不幸的是,有时候问题发生在更早阶段,但只有在调用栈底部执行的地方才显现出来。就像当蛋糕没有膨胀时,忘记加发酵粉的事才被发现。
+
+那就该检查整个调用栈。问题更可能在你的代码而不是 Python 标准库或者第三方包,所以先检查调用栈内你的代码。另外,在你的代码中放置断点通常会更容易检查代码。在调用栈的代码中放置断点,然后看看周围是否如你预期。
+
+“但是,玛丽,”我听到你说,“如果我有一个调用栈,那这些都是有帮助的,但我只有一个失败的测试。我该从哪里开始?”
+
+pdb,一个 Python 调试器。
+
+找到你代码里会被这个调用命中的地方。你应该能够找到至少一个这样的地方。在那里打上一个 pdb 的断点。
+
+#### 一句题外话
+
+为什么不使用 `print` 语句呢?我曾经依赖于 `print` 语句。有时候,它们仍然很方便。但当我开始处理复杂的代码库,尤其是有网络调用的代码库,`print` 语句就变得太慢了。我最终在各种地方都加上了 `print` 语句,但我没法追踪它们的位置和原因,而且变得更复杂了。但是主要使用 pdb 还有一个更重要的原因。假设你添加一条 `print` 语句去发现错误问题,而且 `print` 语句必须早于错误出现的地方。但是,看看你放 `print` 语句的函数,你不知道你的代码是怎么执行到那个位置的。查看代码是寻找调用路径的好方法,但看你以前写的代码是恐怖的。是的,我会用 `grep` 处理我的代码库以寻找调用函数的地方,但这会变得乏味,而且搜索一个通用函数时并不能缩小搜索范围。pdb 就变得非常有用。
+
+你遵循我的建议,打上 pdb 断点并运行你的测试。然而测试再次失败,但是没有任何一个断点被命中。留着你的断点,并运行测试套件中一个同这个失败的测试非常相似的测试。如果你有个不错的测试套件,你应该能够找到一个这样的测试。它会命中了你认为你的失败测试应该命中的代码。运行这个测试,然后当它运行到你的断点,按下 `w` 并检查调用栈。如果你不知道如何查看因为其他调用而变得混乱的调用栈,那么在调用栈的中间找到属于你的代码,并在堆栈中该代码的上一行放置一个断点。再试一次新的测试。如果仍然没命中断点,那么继续,向上追踪调用栈并找出你的调用在哪里脱轨了。如果你一直没有命中断点,最后到了追踪的顶部,那么恭喜你,你发现了问题:你的应用程序名称拼写错了。
+
+> 没有经验,小白,一点都没有经验。
+
+### 4、修改代码
+
+如果你仍觉得迷惑,在你稍微改变了一些的地方尝试新的测试。你能让新的测试跑起来么?有什么是不同的呢?有什么是相同的呢?尝试改变一下别的东西。当你有了你的测试,以及可能也还有其它的测试,那就可以开始安全地修改代码了,确定是否可以缩小问题范围。记得从一个新提交开始解决问题,以便于可以轻松地撤销无效地更改。(这就是版本控制,如果你没有使用过版本控制,这将会改变你的生活。好吧,可能它只是让编码更容易。查阅“[版本控制可视指南][2]”,以了解更多。)
+
+### 5、休息一下
+
+尽管如此,当它不再感觉起来像一个有趣的挑战或者游戏而开始变得令人沮丧时,你最好的举措是脱离这个问题。休息一下。我强烈建议你去散步并尝试考虑别的事情。
+
+### 6、把一切写下来
+
+当你回来了,如果你没有突然受到启发,那就把你关于这个问题所知的每一个点信息写下来。这应该包括:
+
+ * 真正造成问题的调用
+ * 真正发生了什么,包括任何错误信息或者相关的日志信息
+ * 你真正期望发生什么
+ * 到目前为止,为了找出问题,你做了什么工作;以及解决问题中你发现的任何线索。
+
+有时这里有很多信息,但相信我,从零碎中挖掘信息是很烦人。所以尽量简洁,但是要完整。
+
+### 7、寻求帮助
+
+我经常发现写下所有信息能够启迪我想到还没尝试过的东西。当然,有时候我在点击求助邮件(或表单)的提交按钮后立刻意识到问题是是什么。无论如何,当你在写下所有东西仍一无所获时,那就试试向他人发邮件求助。首先是你的同事或者其他参与你的项目的人,然后是该项目的邮件列表。不要害怕向人求助。大多数人都是友善和乐于助人的,我发现在 Python 社区里尤其如此。
+
+Maria McKinley 已在 [PyCascades 2019][4] 演讲 [代码查错][3],2 月 23-24,于西雅图。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/steps-hunting-code-python-bugs
+
+作者:[Maria Mckinley][a]
+选题:[lujun9972][b]
+译者:[LazyWolfLin](https://github.com/LazyWolfLin)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/parody
+[b]: https://github.com/lujun9972
+[1]: http://www.pythontutor.com/
+[2]: https://betterexplained.com/articles/a-visual-guide-to-version-control/
+[3]: https://2019.pycascades.com/talks/hunting-the-bugs
+[4]: https://2019.pycascades.com/
diff --git a/translated/tech/20190213 How To Install, Configure And Use Fish Shell In Linux.md b/published/20190213 How To Install, Configure And Use Fish Shell In Linux.md
similarity index 64%
rename from translated/tech/20190213 How To Install, Configure And Use Fish Shell In Linux.md
rename to published/20190213 How To Install, Configure And Use Fish Shell In Linux.md
index 95fb75b1b2..417f170517 100644
--- a/translated/tech/20190213 How To Install, Configure And Use Fish Shell In Linux.md
+++ b/published/20190213 How To Install, Configure And Use Fish Shell In Linux.md
@@ -1,50 +1,40 @@
[#]: collector: "lujun9972"
[#]: translator: "zero-MK"
-[#]: reviewer: " "
-[#]: publisher: " "
-[#]: url: " "
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-10622-1.html"
[#]: subject: "How To Install, Configure And Use Fish Shell In Linux?"
[#]: via: "https://www.2daygeek.com/linux-fish-shell-friendly-interactive-shell/"
[#]: author: "Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/"
-如何在Linux中安装,配置和使用Fish Shell?
+如何在 Linux 中安装、配置和使用 Fish Shell?
======
-每个 Linux 管理员都可能听到过 shell 这个词。
-
-你知道什么是 shell 吗? 你知道 shell 在 Linux 中的作用是什么吗? Linux 中有多少 shell 可用?
+每个 Linux 管理员都可能听到过 shell 这个词。你知道什么是 shell 吗? 你知道 shell 在 Linux 中的作用是什么吗? Linux 中有多少个 shell 可用?
shell 是一个程序,它是提供用户和内核之间交互的接口。
-内核是 Linux 操作系统的核心,它管理用户和操作系统( OS )之间的所有内容。
+内核是 Linux 操作系统的核心,它管理用户和操作系统之间的所有内容。Shell 可供所有用户在启动终端时使用。终端启动后,用户可以运行任何可用的命令。当 shell 完成命令的执行时,你将在终端窗口上获取输出。
-Shell 可供所有用户在启动终端时使用。
-
-终端启动后,用户可以运行任何可用的命令。
-
-当shell完成命令执行时,您将在终端窗口上获取输出。
-
-Bash 全称是 Bourne Again Shell 是默认的 shell ,它运行在今天的大多数 Linux 发行版上。
-
-它非常受欢迎,并具有很多功能。今天我们将讨论 Fish Shell 。
+Bash(全称是 Bourne Again Shell)是运行在今天的大多数 Linux 发行版上的默认的 shell,它非常受欢迎,并具有很多功能。但今天我们将讨论 Fish Shell 。
### 什么是 Fish Shell?
-[Fish][1] 是友好的交互式 shell , 是一个功能齐全,智能且对用户友好的 Linux 命令行 shell ,它带有一些在大多数 shell 中都不具备的方便功能。
+[Fish][1] 是友好的交互式 shell ,是一个功能齐全,智能且对用户友好的 Linux 命令行 shell ,它带有一些在大多数 shell 中都不具备的方便功能。
-这些功能包括 自动补全建议,Sane Scripting,手册页完成,基于 Web 的配置器和 Glorious VGA Color 。你对它感到好奇并想测试它吗?如果是这样,请按照以下安装步骤继续安装。
+这些功能包括自动补全建议、Sane Scripting、手册页补全、基于 Web 的配置器和 Glorious VGA Color 。你对它感到好奇并想测试它吗?如果是这样,请按照以下安装步骤继续安装。
### 如何在 Linux 中安装 Fish Shell ?
-它的安装非常简单,但除了少数几个发行版外,它在大多数发行版中都不可用。但是,可以使用以下 [fish repository][2] 轻松安装。
+它的安装非常简单,除了少数几个发行版外,它在大多数发行版中都没有。但是,可以使用以下 [fish 仓库][2] 轻松安装。
-对于基于 **`Arch Linux`** 的系统, 使用 **[Pacman Command][3]** 来安装 fish shell。
+对于基于 Arch Linux 的系统, 使用 [Pacman 命令][3] 来安装 fish shell。
```
$ sudo pacman -S fish
```
-对于 **`Ubuntu 16.04/18.04`** 系统来说,,请使用 **[APT-GET Command][4]** 或者 **[APT Command][5]** 安装 fish shell。
+对于 Ubuntu 16.04/18.04 系统来说,请使用 [APT-GET 命令][4] 或者 [APT 命令][5] 安装 fish shell。
```
$ sudo apt-add-repository ppa:fish-shell/release-3
@@ -52,7 +42,7 @@ $ sudo apt-get update
$ sudo apt-get install fish
```
-对于 **`Fedora`** 系统来说,请使用 **[DNF Command][6]** 安装 fish shell。
+对于 Fedora 系统来说,请使用 [DNF 命令][6] 安装 fish shell。
对于 Fedora 29 系统来说:
@@ -68,7 +58,7 @@ $ sudo dnf config-manager --add-repo https://download.opensuse.org/repositories/
$ sudo dnf install fish
```
-对于 **`Debian`** 系统来说,,请使用 **[APT-GET Command][4]** 或者 **[APT Command][5]** 安装 fish shell。
+对于 Debian 系统来说,请使用 [APT-GET 命令][4] 或者 [APT 命令][5] 安装 fish shell。
对于 Debian 9 系统来说:
@@ -90,7 +80,7 @@ $ sudo apt-get update
$ sudo apt-get install fish
```
-对于 **`RHEL/CentOS`** 系统来说,请使用 **[YUM Command][7]** 安装 fish shell。
+对于 RHEL/CentOS 系统来说,请使用 [YUM 命令][7] 安装 fish shell。
对于 RHEL 7 系统来说:
@@ -120,7 +110,7 @@ $ sudo yum-config-manager --add-repo https://download.opensuse.org/repositories/
$ sudo yum install fish
```
-对于 **`openSUSE Leap`** 系统来说,请使用 **[Zypper Command][8]** 安装 fish shell。
+对于 openSUSE Leap 系统来说,请使用 [Zypper 命令][8] 安装 fish shell。
```
$ sudo zypper addrepo https://download.opensuse.org/repositories/shells:/fish:/release:/3/openSUSE_Leap_42.3/shells:fish:release:3.repo
@@ -130,7 +120,7 @@ $ sudo zypper install fish
### 如何使用 Fish Shell ?
-一旦你成功安装了 fish shell 。只需在您的终端上输入 `fish` ,它将自动从默认的 bash shell 切换到 fish shell 。
+一旦你成功安装了 fish shell 。只需在你的终端上输入 `fish` ,它将自动从默认的 bash shell 切换到 fish shell 。
```
$ fish
@@ -140,33 +130,39 @@ $ fish
### 自动补全建议
-当你在 fish shell 中键入任何命令时,它会在输入几个字母后自动建议一个浅灰色的命令。
+当你在 fish shell 中键入任何命令时,它会在输入几个字母后以浅灰色自动建议一个命令。
+
![][11]
-一旦你得到一个建议然后点击 ` Right Arrow Mark` (译者注:原文是左,错的)就能完成它而不是输入完整的命令。
+一旦你得到一个建议然后按下向右光标键(LCTT 译注:原文是左,错的)就能完成它而不是输入完整的命令。
+
![][12]
-您可以在键入几个字母后立即按下 `Up Arrow Mark` 检索该命令以前的历史记录。它类似于 bash shell 的 `CTRL+r `选项。
+你可以在键入几个字母后立即按下向上光标键检索该命令以前的历史记录。它类似于 bash shell 的 `CTRL+r` 选项。
### Tab 补全
-如果您想查看给定命令是否还有其他可能性,那么在键入几个字母后,只需按一下 `Tab` 按钮即可。
+如果你想查看给定命令是否还有其他可能性,那么在键入几个字母后,只需按一下 `Tab` 键即可。
+
![][13]
-再次按 `Tab` 按钮可查看完整列表。
+再次按 `Tab` 键可查看完整列表。
+
![][14]
### 语法高亮
-fish 执行语法高亮显示,您可以在终端中键入任何命令时看到。 无效的命令被着色为 `RED color` 。
+fish 会进行语法高亮显示,你可以在终端中键入任何命令时看到。无效的命令被着色为 `RED color` 。
+
![][15]
-同样的,有效命令以不同的颜色显示。此外,当您键入有效的文件路径时,fish会在其下面加下划线,如果路径无效,则不会显示下划线。
+同样的,有效的命令以不同的颜色显示。此外,当你键入有效的文件路径时,fish 会在其下面加下划线,如果路径无效,则不会显示下划线。
+
![][16]
### 基于 Web 的配置器
-fish shell 中有一个很酷的功能,它允许我们通过网络浏览器设置颜色,提示,功能,变量,历史和绑定。
+fish shell 中有一个很酷的功能,它允许我们通过网络浏览器设置颜色、提示符、功能、变量、历史和键绑定。
在终端上运行以下命令以启动 Web 配置界面。只需按下 `Ctrl+c` 即可退出。
@@ -180,11 +176,11 @@ Shutting down.
![][17]
-### Man Page Completions
+### 手册页补全
-其他 shell 支持 programmable completions, 但只有 fish 可以通过解析已安装的手册页自动生成它们。
+其他 shell 支持可编程的补全,但只有 fish 可以通过解析已安装的手册页自动生成它们。
-如果是这样,请运行以下命令
+要使用该功能,请运行以下命令:
```
$ fish_update_completions
@@ -194,9 +190,9 @@ Parsing man pages and writing completions to /home/daygeek/.local/share/fish/gen
### 如何将 Fish 设置为默认 shell
-If you would like to test the fish shell for some times then you can set the fish shell as your default shell instead of switching it every time.
+如果你想测试 fish shell 一段时间,你可以将 fish shell 设置为默认 shell,而不用每次都切换它。
-如果是这样,首先使用以下命令获取 Fish Shell 的位置。
+要这样做,首先使用以下命令获取 Fish Shell 的位置。
```
$ whereis fish
@@ -211,7 +207,7 @@ $ chsh -s /usr/bin/fish
![][18]
-`Make note:` 只需验证 Fish Shell 是否已添加到 `/etc/shells` 目录中。如果不是,则运行以下命令以附加它。
+提示:只需验证 Fish Shell 是否已添加到 `/etc/shells` 目录中。如果不是,则运行以下命令以附加它。
```
$ echo /usr/bin/fish | sudo tee -a /etc/shells
@@ -219,13 +215,13 @@ $ echo /usr/bin/fish | sudo tee -a /etc/shells
完成测试后,如果要返回 bash shell ,请使用以下命令。
-暂时的:
+暂时返回:
```
$ bash
```
-永久性的:
+永久返回:
```
$ chsh -s /bin/bash
@@ -238,7 +234,7 @@ via: https://www.2daygeek.com/linux-fish-shell-friendly-interactive-shell/
作者:[Magesh Maruthamuthu][a]
选题:[lujun9972][b]
译者:[zero-MK](https://github.com/zero-MK)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20190220 An Automated Way To Install Essential Applications On Ubuntu.md b/published/20190220 An Automated Way To Install Essential Applications On Ubuntu.md
similarity index 64%
rename from translated/tech/20190220 An Automated Way To Install Essential Applications On Ubuntu.md
rename to published/20190220 An Automated Way To Install Essential Applications On Ubuntu.md
index a8adecc72a..fb7f2ffde2 100644
--- a/translated/tech/20190220 An Automated Way To Install Essential Applications On Ubuntu.md
+++ b/published/20190220 An Automated Way To Install Essential Applications On Ubuntu.md
@@ -1,19 +1,20 @@
[#]: collector: (lujun9972)
[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10600-1.html)
[#]: subject: (An Automated Way To Install Essential Applications On Ubuntu)
[#]: via: (https://www.ostechnix.com/an-automated-way-to-install-essential-applications-on-ubuntu/)
[#]: author: (SK https://www.ostechnix.com/author/sk/)
在 Ubuntu 上自动化安装基本应用的方法
======
+

-默认的 Ubuntu 安装并未预先安装所有必需的应用。你可能需要在网上花几个小时或者向其他 Linux 用户寻求帮助寻找和安装 Ubuntu 所需的应用。如果你是新手,那么你肯定需要花更多的时间来学习如何从命令行(使用 apt-get 或 dpkg)或从 Ubuntu 软件中心搜索和安装应用。一些用户,特别是新手,可能希望轻松快速地安装他们喜欢的每个应用。如果你是其中之一,不用担心。在本指南中,我们将了解如何使用名为 **“Alfred”** 的简单命令行程序在 Ubuntu 上安装基本应用。
+默认安装的 Ubuntu 并未预先安装所有必需的应用。你可能需要在网上花几个小时或者向其他 Linux 用户寻求帮助才能找到并安装 Ubuntu 所需的应用。如果你是新手,那么你肯定需要花更多的时间来学习如何从命令行(使用 `apt-get` 或 `dpkg`)或从 Ubuntu 软件中心搜索和安装应用。一些用户,特别是新手,可能希望轻松快速地安装他们喜欢的每个应用。如果你是其中之一,不用担心。在本指南中,我们将了解如何使用名为 “Alfred” 的简单命令行程序在 Ubuntu 上安装基本应用。
-Alfred是用 **Python** 语言编写的免费开源脚本。它使用 **Zenity** 创建了一个简单的图形界面,用户只需点击几下鼠标即可轻松选择和安装他们选择的应用。你不必花费数小时来搜索所有必要的应用程序、PPA、deb、AppImage、snap 或 flatpak。Alfred 将所有常见的应用、工具和小程序集中在一起,并自动安装所选的应用。如果你是最近从 Windows 迁移到 Ubuntu Linux 的新手,Alfred 会帮助你在新安装的 Ubuntu 系统上进行无人值守的软件安装,而无需太多用户干预。请注意,还有一个名称相似的 Mac OS 应用,但两者有不同的用途。
+Alfred 是用 Python 语言编写的自由、开源脚本。它使用 Zenity 创建了一个简单的图形界面,用户只需点击几下鼠标即可轻松选择和安装他们选择的应用。你不必花费数小时来搜索所有必要的应用程序、PPA、deb、AppImage、snap 或 flatpak。Alfred 将所有常见的应用、工具和小程序集中在一起,并自动安装所选的应用。如果你是最近从 Windows 迁移到 Ubuntu Linux 的新手,Alfred 会帮助你在新安装的 Ubuntu 系统上进行无人值守的软件安装,而无需太多用户干预。请注意,还有一个名称相似的 Mac OS 应用,但两者有不同的用途。
### 在 Ubuntu 上安装 Alfred
@@ -21,11 +22,10 @@ Alfred 安装很简单!只需下载脚本并启动它。就这么简单。
```
$ wget https://raw.githubusercontent.com/derkomai/alfred/master/alfred.py
-
$ python3 alfred.py
```
-或者,使用 wget 下载脚本,如上所示,只需将 **alfred.py** 移动到 $PATH 中:
+或者,使用 `wget` 下载脚本,如上所示,只需将 `alfred.py` 移动到 `$PATH` 中:
```
$ sudo cp alfred.py /usr/local/bin/alfred
@@ -53,7 +53,7 @@ $ alfred
* 网络浏览器,
* 邮件客户端,
- * 短消息,
+ * 消息,
* 云存储客户端,
* 硬件驱动程序,
* 编解码器,
@@ -67,21 +67,19 @@ $ alfred
* 录屏工具,
* 视频编码器,
* 流媒体应用,
- * 3D建模和动画工具,
+ * 3D 建模和动画工具,
* 图像查看器和编辑器,
* CAD 软件,
- * Pdf 工具,
+ * PDF 工具,
* 游戏模拟器,
* 磁盘管理工具,
* 加密工具,
* 密码管理器,
* 存档工具,
- * Ftp 软件,
+ * FTP 软件,
* 系统资源监视器,
* 应用启动器等。
-
-
你可以选择任何一个或多个应用并立即安装它们。在这里,我将安装 “Developer bundle”,因此我选择它并单击 OK 按钮。
![][3]
@@ -90,13 +88,13 @@ $ alfred
![][4]
-安装完成后,不将看到以下消息。
+安装完成后,你将看到以下消息。
![][5]
恭喜你!已安装选定的软件包。
-你可以使用以下命令[**在 Ubuntu 上查看最近安装的应用**][6]:
+你可以使用以下命令[在 Ubuntu 上查看最近安装的应用][6]:
```
$ grep " install " /var/log/dpkg.log
@@ -104,7 +102,9 @@ $ grep " install " /var/log/dpkg.log
你可能需要重启系统才能使用某些已安装的应用。类似地,你可以方便地安装列表中的任何程序。
-提示一下,还有一个由不同的开发人员编写的类似脚本,名为 **post_install.sh**。它与 Alfred 完全相同,但提供了一些不同的应用。请查看以下链接获取更多详细信息。
+提示一下,还有一个由不同的开发人员编写的类似脚本,名为 `post_install.sh`。它与 Alfred 完全相同,但提供了一些不同的应用。请查看以下链接获取更多详细信息。
+
+- [Ubuntu Post Installation Script](https://www.ostechnix.com/ubuntu-post-installation-script/)
这两个脚本能让懒惰的用户,特别是新手,只需点击几下鼠标就能够轻松快速地安装他们想要在 Ubuntu Linux 中使用的大多数常见应用、工具、更新、小程序,而无需依赖官方或者非官方文档的帮助。
@@ -121,7 +121,7 @@ via: https://www.ostechnix.com/an-automated-way-to-install-essential-application
作者:[SK][a]
选题:[lujun9972][b]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20190226 How To SSH Into A Particular Directory On Linux.md b/published/20190226 How To SSH Into A Particular Directory On Linux.md
new file mode 100644
index 0000000000..2706735314
--- /dev/null
+++ b/published/20190226 How To SSH Into A Particular Directory On Linux.md
@@ -0,0 +1,111 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10618-1.html)
+[#]: subject: (How To SSH Into A Particular Directory On Linux)
+[#]: via: (https://www.ostechnix.com/how-to-ssh-into-a-particular-directory-on-linux/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+如何 SSH 登录到 Linux 上的特定目录
+======
+
+
+
+你是否遇到过需要 SSH 登录到远程服务器并立即 `cd` 到一个目录来继续交互式作业?你找对地方了!这个简短的教程描述了如何直接 SSH 登录到远程 Linux 系统的特定目录。而且不仅是 SSH 登录到特定目录,你还可以在连接到 SSH 服务器后立即运行任何命令。这些没有你想的那么难。请继续阅读。
+
+### SSH 登录到远程系统的特定目录
+
+在我知道这个方法之前,我通常首先使用以下命令 SSH 登录到远程系统:
+
+```
+$ ssh user@remote-system
+```
+
+然后如下 `cd` 进入某个目录:
+
+```
+$ cd
+```
+
+然而,你不需要使用两个单独的命令。你可以用一条命令组合并简化这个任务。
+
+看看下面的例子。
+
+```
+$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix ; bash'
+```
+
+上面的命令将通过 SSH 连接到远程系统 (192.168.225.22) 并立即进入名为 `/home/sk/ostechnix/` 的目录,并停留在提示符中。
+
+这里,`-t` 标志用于强制分配伪终端,这是一个必要的交互式 shell。
+
+以下是上面命令的输出:
+
+
+
+你也可以使用此命令:
+
+```
+$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix ; exec bash'
+```
+
+或者,
+
+```
+$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix && exec bash -l'
+```
+
+这里,`-l` 标志将 bash 设置为登录 shell。
+
+在上面的例子中,我在最后一个参数中使用了 `bash`。它是我的远程系统中的默认 shell。如果你不知道远程系统上的 shell 类型,请使用以下命令:
+
+```
+$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix && exec $SHELL'
+```
+
+就像我已经说过的,它不仅仅是连接到远程系统后 `cd` 进入目录。你也可以使用此技巧运行其他命令。例如,以下命令将进入 `/home/sk/ostechnix/`,然后执行命令 `uname -a` 。
+
+```
+$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix && uname -a && exec $SHELL'
+```
+
+或者,你可以在远程系统上的 `.bash_profile` 文件中添加你想在 SSH 登录后执行的命令。
+
+编辑 `.bash_profile` 文件:
+
+```
+$ nano ~/.bash_profile
+```
+
+每个命令一行。在我的例子中,我添加了下面这行:
+
+```
+cd /home/sk/ostechnix >& /dev/null
+```
+
+保存并关闭文件。最后,运行以下命令更新修改。
+
+```
+$ source ~/.bash_profile
+```
+
+请注意,你应该在远程系统的 `.bash_profile` 或 `.bashrc` 文件中添加此行,而不是在本地系统中。从现在开始,无论何时登录(无论是通过 SSH 还是直接登录),`cd` 命令都将执行,你将自动进入 `/home/sk/ostechnix/` 目录。
+
+就是这些了。希望这篇文章有用。还有更多好东西。敬请关注!
+
+干杯!
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-ssh-into-a-particular-directory-on-linux/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
diff --git a/published/20190227 How To Check Password Complexity-Strength And Score In Linux.md b/published/20190227 How To Check Password Complexity-Strength And Score In Linux.md
new file mode 100644
index 0000000000..6ab262f592
--- /dev/null
+++ b/published/20190227 How To Check Password Complexity-Strength And Score In Linux.md
@@ -0,0 +1,155 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10623-1.html)
+[#]: subject: (How To Check Password Complexity/Strength And Score In Linux?)
+[#]: via: (https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+如何在 Linux 中检查密码的复杂性/强度和评分?
+======
+
+我们都知道密码的重要性。最好的密码就是使用难以猜测密码。另外,我建议你为每个服务使用不同的密码,如电子邮件、ftp、ssh 等。最重要的是,我建议你们经常更改密码,以避免不必要的黑客攻击。
+
+默认情况下,RHEL 和它的衍生版使用 cracklib 模块来检查密码强度。我们将教你如何使用 cracklib 模块检查密码强度。
+
+如果你想检查你创建的密码评分,请使用 pwscore 包。
+
+如果你想创建一个好密码,最起码它应该至少有 12-15 个字符长度。它应该按以下组合创建,如字母(小写和大写)、数字和特殊字符。Linux 中有许多程序可用于检查密码复杂性,我们今天将讨论有关 cracklib 模块和 pwscore 评分。
+
+### 如何在 Linux 中安装 cracklib 模块?
+
+cracklib 模块在大多数发行版仓库中都有,因此,请使用发行版官方软件包管理器来安装它。
+
+对于 Fedora 系统,使用 [DNF 命令][1]来安装 cracklib。
+
+```
+$ sudo dnf install cracklib
+```
+
+对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][2] 或 [APT 命令][3]来安装 libcrack2。
+
+```
+$ sudo apt install libcrack2
+```
+
+对于基于 Arch Linux 的系统,使用 [Pacman 命令][4]来安装 cracklib。
+
+```
+$ sudo pacman -S cracklib
+```
+
+对于 RHEL/CentOS 系统,使用 [YUM 命令][5]来安装 cracklib。
+
+```
+$ sudo yum install cracklib
+```
+
+对于 openSUSE Leap 系统,使用 [Zypper 命令][6]来安装 cracklib。
+
+```
+$ sudo zypper install cracklib
+```
+
+### 如何在 Linux 中使用 cracklib 模块检查密码复杂性?
+
+我在本文中添加了一些示例来助你更好地了解此模块。
+
+如果你提供了任何如人名或地名或常用字,那么你将看到一条消息“它存在于字典的单词中”。
+
+```
+$ echo "password" | cracklib-check
+password: it is based on a dictionary word
+```
+
+Linux 中的默认密码长度为 7 个字符。如果你提供的密码少于 7 个字符,那么你将看到一条消息“它太短了”。
+
+```
+$ echo "123" | cracklib-check
+123: it is WAY too short
+```
+
+当你提供像我们这样的好密码时,你会看到 “OK”。
+
+```
+$ echo "ME$2w!@fgty6723" | cracklib-check
+ME!@fgty6723: OK
+```
+
+### 如何在 Linux 中安装 pwscore?
+
+pwscore 包在大多数发行版仓库中都有,因此,请使用发行版官方软件包管理器来安装它。
+
+对于 Fedora 系统,使用 [DNF 命令][1]来安装 libpwquality。
+
+```
+$ sudo dnf install libpwquality
+```
+
+对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][2] 或 [APT 命令][3]来安装 libpwquality。
+
+```
+$ sudo apt install libpwquality
+```
+
+对于基于 Arch Linux 的系统,使用 [Pacman 命令][4]来安装 libpwquality。
+
+```
+$ sudo pacman -S libpwquality
+```
+
+对于 RHEL/CentOS 系统,使用 [YUM 命令][5]来安装 libpwquality。
+
+```
+$ sudo yum install libpwquality
+```
+
+对于 openSUSE Leap 系统,使用 [Zypper 命令][6]来安装 libpwquality。
+
+```
+$ sudo zypper install libpwquality
+```
+
+如果你提供了任何如人名或地名或常用字,那么你将看到一条消息“它存在于字典的单词中”。
+
+```
+$ echo "password" | pwscore
+Password quality check failed:
+ The password fails the dictionary check - it is based on a dictionary word
+```
+
+Linux 中的默认密码长度为 7 个字符。如果你提供的密码少于 7 个字符,那么你将看到一条消息“密码短于 8 个字符”。
+
+```
+$ echo "123" | pwscore
+Password quality check failed:
+ The password is shorter than 8 characters
+```
+
+当你像我们这样提供了一个好的密码时,你将会看到“密码评分”。
+
+```
+$ echo "ME!@fgty6723" | pwscore
+90
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
+[2]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
+[3]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
+[4]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
+[5]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[6]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
diff --git a/published/20190228 Connecting a VoIP phone directly to an Asterisk server.md b/published/20190228 Connecting a VoIP phone directly to an Asterisk server.md
new file mode 100644
index 0000000000..e3abdb310b
--- /dev/null
+++ b/published/20190228 Connecting a VoIP phone directly to an Asterisk server.md
@@ -0,0 +1,75 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10620-1.html)
+[#]: subject: (Connecting a VoIP phone directly to an Asterisk server)
+[#]: via: (https://feeding.cloud.geek.nz/posts/connecting-voip-phone-directly-to-asterisk-server/)
+[#]: author: (François Marier https://fmarier.org/)
+
+将 VoIP 电话直接连接到 Asterisk 服务器
+======
+
+在我的 [Asterisk][1] 服务器上正好有张以太网卡。由于我只用了其中一个,因此我决定将我的 VoIP 电话从本地网络交换机换成连接到 Asterisk 服务器。
+
+主要的好处是这台运行着未知质量的专有软件的电话,在我的一般家庭网络中不能用了。最重要的是,它不再能访问互联网,因此无需手动配置防火墙。
+
+以下是我配置的方式。
+
+### 私有网络配置
+
+在服务器上,我在 `/etc/network/interfaces` 中给第二块网卡分配了一个静态 IP:
+
+```
+auto eth1
+iface eth1 inet static
+ address 192.168.2.2
+ netmask 255.255.255.0
+```
+
+在 VoIP 电话上,我将静态 IP 设置成 `192.168.2.3`,DNS 服务器设置成 `192.168.2.2`。我接着将 SIP 注册 IP 地址设置成 `192.168.2.2`。
+
+DNS 服务器实际上是一个在 Asterisk 服务器上运行的 [unbound 守护进程][2]。我唯一需要更改的配置是监听第二张网卡,并允许 VoIP 电话进入:
+
+```
+server:
+ interface: 127.0.0.1
+ interface: 192.168.2.2
+ access-control: 0.0.0.0/0 refuse
+ access-control: 127.0.0.1/32 allow
+ access-control: 192.168.2.3/32 allow
+```
+
+最后,我在 `/etc/network/iptables.up.rules` 中打开了服务器防火墙上的正确端口:
+
+```
+-A INPUT -s 192.168.2.3/32 -p udp --dport 5060 -j ACCEPT
+-A INPUT -s 192.168.2.3/32 -p udp --dport 10000:20000 -j ACCEPT
+```
+
+### 访问管理页面
+
+现在 VoIP 电话不能在本地网络上用了,因此无法访问其管理页面。从安全的角度来看,这是一件好事,但它有点不方便。
+
+因此,在通过 ssh 连接到 Asterisk 服务器之后,我将以下内容放在我的 `~/.ssh/config` 中以便通过 `http://localhost:8081` 访问管理页面:
+
+```
+Host asterisk
+ LocalForward 8081 192.168.2.3:80
+```
+
+--------------------------------------------------------------------------------
+
+via: https://feeding.cloud.geek.nz/posts/connecting-voip-phone-directly-to-asterisk-server/
+
+作者:[François Marier][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fmarier.org/
+[b]: https://github.com/lujun9972
+[1]: https://www.asterisk.org/
+[2]: https://feeding.cloud.geek.nz/posts/setting-up-your-own-dnssec-aware/
diff --git a/published/20190301 How to use sudo access in winSCP.md b/published/20190301 How to use sudo access in winSCP.md
new file mode 100644
index 0000000000..17f2e5ede9
--- /dev/null
+++ b/published/20190301 How to use sudo access in winSCP.md
@@ -0,0 +1,65 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10616-1.html)
+[#]: subject: (How to use sudo access in winSCP)
+[#]: via: (https://kerneltalks.com/tools/how-to-use-sudo-access-in-winscp/)
+[#]: author: (kerneltalks https://kerneltalks.com)
+
+如何在 winSCP 中使用 sudo
+======
+
+> 用截图了解如何在 winSCP 中使用 sudo。
+
+![How to use sudo access in winSCP][1]
+
+*sudo access in winSCP*
+
+首先你需要检查你尝试使用 winSCP 连接的 sftp 服务器的二进制文件的位置。
+
+你可以使用以下命令检查 SFTP 服务器二进制文件位置:
+
+```
+[root@kerneltalks ~]# cat /etc/ssh/sshd_config |grep -i sftp-server
+Subsystem sftp /usr/libexec/openssh/sftp-server
+```
+
+你可以看到 sftp 服务器的二进制文件位于 `/usr/libexec/openssh/sftp-server`。
+
+打开 winSCP 并单击“高级”按钮打开高级设置。
+
+![winSCP advance settings][2]
+
+*winSCP 高级设置*
+
+它将打开如下高级设置窗口。在左侧面板上选择“Environment”下的 “SFTP”。你会在右侧看到选项。
+
+现在,使用命令 `sudo su -c` 在这里添加 SFTP 服务器值,如下截图所示:
+
+![SFTP server setting in winSCP][3]
+
+*winSCP 中的 SFTP 服务器设置*
+
+所以我们在设置中添加了 `sudo su -c /usr/libexec/openssh/sftp-server`。单击“Ok”并像平常一样连接到服务器。
+
+连接之后,你将可以从你以前需要 sudo 权限的目录传输文件了。
+
+完成了!你已经使用 winSCP 使用 sudo 登录服务器了。
+
+--------------------------------------------------------------------------------
+
+via: https://kerneltalks.com/tools/how-to-use-sudo-access-in-winscp/
+
+作者:[kerneltalks][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://kerneltalks.com
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/kerneltalks.com/wp-content/uploads/2019/03/How-to-use-sudo-access-in-winSCP.png?ssl=1
+[2]: https://i0.wp.com/kerneltalks.com/wp-content/uploads/2019/03/winscp-advanced-settings.jpg?ssl=1
+[3]: https://i1.wp.com/kerneltalks.com/wp-content/uploads/2019/03/SFTP-server-setting-in-winSCP.jpg?ssl=1
diff --git a/published/20190301 Which Raspberry Pi should you choose.md b/published/20190301 Which Raspberry Pi should you choose.md
new file mode 100644
index 0000000000..f0aefd5dea
--- /dev/null
+++ b/published/20190301 Which Raspberry Pi should you choose.md
@@ -0,0 +1,47 @@
+[#]: collector: (lujun9972)
+[#]: translator: (qhwdw)
+[#]: reviewer: (wxy)
+[#]: publisher: (wxy)
+[#]: url: (https://linux.cn/article-10611-1.html)
+[#]: subject: (Which Raspberry Pi should you choose?)
+[#]: via: (https://opensource.com/article/19/3/which-raspberry-pi-choose)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+树莓派使用入门:你应该选择哪种树莓派?
+======
+
+> 在我们的《树莓派使用入门》系列的第一篇文章中,我们将学习选择符合你要求的树莓派型号的三个标准。
+
+
+
+本文是《14 天学会[树莓派][1]使用》系列文章的第一篇。虽然本系列文章主要面向没有使用过树莓派或 Linux 或没有编程经验的人群,但是肯定有些东西还是需要有经验的读者的,我希望这些读者能够留下他们有益的评论、提示和补充。如果每个人都能贡献,这将会让本系列文章对初学者、其它有经验的读者、甚至是我更受益!
+
+言归正传,如果你想拥有一个树莓派,但不知道应该买哪个型号。或许你希望为你的教学活动或你的孩子买一个,但面对这么多的选择,却不知道应该买哪个才是正确的决定。
+
+
+
+关于选择一个新的树莓派,我有三个主要的标准:
+
+ * **成本:** 不能只考虑树莓派板的成本,还需要考虑到你使用它时外围附件的成本。在美国,树莓派的成本区间是从 5 美元(树莓派 Zero)到 35 美元(树莓派 3 B 和 3 B+)。但是,如果你选择 Zero,那么你或许还需要一个 USB hub 去连接你的鼠标、键盘、无线网卡、以及某种显示适配器。不论你想使用树莓派做什么,除非你已经有了(假如不是全部)大部分的外设,那么你一定要把这些外设考虑到预算之中。此外,在一些国家,对于许多学生和老师,树莓派(即便没有任何外设)的购置成本也或许是一个不少的成本负担。
+ * **可获得性:** 根据你所在地去查找你想要的树莓派,因为在一些国家得到某些版本的树莓派可能很容易(或很困难)。在新型号刚发布后,可获得性可能是个很大的问题,在你的市场上获得最新版本的树莓派可能需要几天或几周的时间。
+ * **用途:** 所在地和成本可能并不会影响每个人,但每个购买者必须要考虑的是买树莓派做什么。因内存、CPU 核心、CPU 速度、物理尺寸、网络连接、外设扩展等不同衍生出八个不同的型号。比如,如果你需要一个拥有更大的“马力”时健壮性更好的解决方案,那么你或许应该选择树莓派 3 B+,它有更大的内存、最快的 CPU、以及更多的核心数。如果你的解决方案并不需要网络连接,并不用于 CPU 密集型的工作,并且需要将它隐藏在一个非常小的空间中,那么一个树莓派 Zero 将是你的最佳选择。
+
+[维基百科的树莓派规格表][2] 是比较八种树莓派型号的好办法。
+
+现在,你已经知道了如何找到适合你的树莓派了,下一篇文章中,我将介绍如何购买它。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/which-raspberry-pi-choose
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://www.raspberrypi.org/
+[2]: https://en.wikipedia.org/wiki/Raspberry_Pi#Specifications
diff --git a/published/20190302 How to buy a Raspberry Pi.md b/published/20190302 How to buy a Raspberry Pi.md
new file mode 100644
index 0000000000..12e6359a9c
--- /dev/null
+++ b/published/20190302 How to buy a Raspberry Pi.md
@@ -0,0 +1,52 @@
+[#]: collector: "lujun9972"
+[#]: translator: "qhwdw"
+[#]: reviewer: "wxy"
+[#]: publisher: "wxy"
+[#]: url: "https://linux.cn/article-10615-1.html"
+[#]: subject: "How to buy a Raspberry Pi"
+[#]: via: "https://opensource.com/article/19/3/how-buy-raspberry-pi"
+[#]: author: "Anderson Silva https://opensource.com/users/ansilva"
+
+树莓派使用入门:如何购买一个树莓派
+======
+
+> 在我们的《树莓派使用入门》系列文章的第二篇中,我们将介绍获取树莓派的最佳途径。
+
+
+
+在本系列指南的第一篇文章中,我们提供了一个关于 [你应该购买哪个版本的树莓派][1] 的一些建议。哪个版本才是你想要的,你应该有了主意了,现在,我们来看一下如何获得它。
+
+最显而易见的方式 —— 并且也或许是最安全最简单的方式 —— 非 [树莓派的官方网站][2] 莫属了。如果你从官网主页上点击 “Buy a Raspberry Pi”,它将跳转到官方的 [在线商店][3],在那里,它可以给你提供你的国家所在地的授权销售商。如果你的国家没有在清单中,还有一个“其它”选项,它可以提供国际订购。
+
+第二,查看亚马逊或在你的国家里允许销售新的或二手商品的其它主流技术类零售商。鉴于树莓派比较便宜并且尺寸很小,一些小商家基于转售目的的进出口它,应该是非常容易的。在你下订单时,一定要关注对卖家的评价。
+
+第三,打听你的极客朋友!你可能从没想过一些人的树莓派正在“吃灰”。我已经给家人送了至少三个树莓派,当然它们并不是计划要送的礼物,只是因为他们对这个“迷你计算机”感到很好奇而已。我身边有好多个,因此我让他们拿走一个!
+
+### 不要忘了外设
+
+最后一个建设是:不要忘了外设,你将需要一些外设去配置和操作你的树莓派。至少你会用到键盘、一个 HDMI 线缆去连接显示器、一个 Micro SD 卡去安装操作系统,一个电源线、以及一个好用的鼠标。
+
+
+
+如果你没有准备好这些东西,试着从朋友那儿借用,或与树莓派一起购买。你可以从授权的树莓派销售商那儿考虑订购一个起步套装 —— 它可以让你避免查找的麻烦而一次性搞定。
+
+
+
+现在,你有了树莓派,在本系列的下一篇文章中,我们将安装树莓派的操作系统并开始使用它。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/how-buy-raspberry-pi
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://linux.cn/article-10611-1.html
+[2]: https://www.raspberrypi.org/
+[3]: https://www.raspberrypi.org/products/
diff --git a/sources/talk/20180314 Pi Day- 12 fun facts and ways to celebrate.md b/sources/talk/20180314 Pi Day- 12 fun facts and ways to celebrate.md
deleted file mode 100644
index 292afeb895..0000000000
--- a/sources/talk/20180314 Pi Day- 12 fun facts and ways to celebrate.md
+++ /dev/null
@@ -1,65 +0,0 @@
-Translating by wwhio
-
-Pi Day: 12 fun facts and ways to celebrate
-======
-
-
-Today, tech teams around the world will celebrate a number. March 14 (written 3/14 in the United States) is known as Pi Day, a holiday that people ring in with pie eating contests, pizza parties, and math puns. If the most important number in mathematics wasn’t enough of a reason to reach for a slice of pie, March 14 also happens to be Albert Einstein’s birthday, the release anniversary of Linux kernel 1.0.0, and the day Eli Whitney patented the cotton gin.
-
-In honor of this special day, we’ve rounded up a dozen fun facts and interesting pi-related projects. Master you team’s Pi Day trivia, or borrow an idea or two for a team-building exercise. Do a project with a budding technologist. And let us know in the comments if you are doing anything unique to celebrate everyone’s favorite never-ending number.
-
-### Pi Day celebrations:
-
- * Today is the 30th anniversary of Pi Day. The first was held in 1988 in San Francisco at the Exploratorium by physicist Larry Shaw. “On [the first Pi Day][1], staff brought in fruit pies and a tea urn for the celebration. At 1:59 – the pi numbers that follow 3.14 – Shaw led a circular parade around the museum with his boombox blaring the digits of pi to the music of ‘Pomp and Circumstance.’” It wasn’t until 21 years later, March 2009, that Pi Day became an official national holiday in the U.S.
- * Although it started in San Francisco, one of the biggest Pi Day celebrations can be found in Princeton. The town holds a [number of events][2] over the course of five days, including an Einstein look-alike contest, a pie-throwing event, and a pi recitation competition. Some of the activities even offer a cash prize of $314.15 for the winner.
- * MIT Sloan School of Management (on Twitter as [@MITSloan][3]) is celebrating Pi Day with fun facts about pi – and pie. Follow along with the Twitter hashtag #PiVersusPie
-
-
-
-### Pi-related projects and activities:
-
- * If you want to keep your math skills sharpened, NASA Jet Propulsion Lab has posted a [new set of math problems][4] that illustrate how pi can be used to unlock the mysteries of space. This marks the fifth year of NASA’s Pi Day Challenge, geared toward students.
- * There's no better way to get into the spirit of Pi Day than to take on a [Raspberry Pi][5] project. Whether you are looking for a project to do with your kids or with your team, there’s no shortage of ideas out there. Since its launch in 2012, millions of the basic computer boards have been sold. In fact, it’s the [third best-selling general purpose computer][6] of all time. Here are a few Raspberry Pi projects and activities that caught our eye:
- * Grab an AIY (AI-Yourself) kit from Google. You can create a [voice-controlled digital assistant][7] or an [image-recognition device][8].
- * [Run Kubernetes][9] on a Raspberry Pi.
- * Save Princess Peach by building a [retro gaming system][10].
- * Host a [Raspberry Jam][11] with your team. The Raspberry Pi Foundation has released a [Guidebook][12] to make hosting easy. According to the website, Raspberry Jams provide, “a support network for people of all ages in digital making. All around the world, like-minded people meet up to discuss and share their latest projects, give workshops, and chat about all things Pi.”
-
-
-
-### Other fun Pi facts:
-
- * The current [world record holder][13] for reciting pi is Suresh Kumar Sharma, who in October 2015 recited 70,030 digits. It took him 17 hours and 14 minutes to do so. However, the [unofficial record][14] goes to Akira Haraguchi, who claims he can recite up to 111,700 digits.
- * And, there’s more to remember than ever before. In November 2016, R&D scientist Peter Trueb calculated 22,459,157,718,361 digits of pi – [9 trillion more digits][15] than the previous world record set in 2013. According to New Scientist, “The final file containing the 22 trillion digits of pi is nearly 9 terabytes in size. If printed out, it would fill a library of several million books containing a thousand pages each."
-
-
-
-Happy Pi Day!
-
-
---------------------------------------------------------------------------------
-
-via: https://enterprisersproject.com/article/2018/3/pi-day-12-fun-facts-and-ways-celebrate
-
-作者:[Carla Rudder][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://enterprisersproject.com/user/crudder
-[1]:https://www.exploratorium.edu/pi/pi-day-history
-[2]:https://princetontourcompany.com/activities/pi-day/
-[3]:https://twitter.com/MITSloan
-[4]:https://www.jpl.nasa.gov/news/news.php?feature=7074
-[5]:https://opensource.com/resources/raspberry-pi
-[6]:https://www.theverge.com/circuitbreaker/2017/3/17/14962170/raspberry-pi-sales-12-5-million-five-years-beats-commodore-64
-[7]:http://www.zdnet.com/article/raspberry-pi-this-google-kit-will-turn-your-pi-into-a-voice-controlled-digital-assistant/
-[8]:http://www.zdnet.com/article/google-offers-raspberry-pi-owners-this-new-ai-vision-kit-to-spot-cats-people-emotions/
-[9]:https://opensource.com/article/17/3/kubernetes-raspberry-pi
-[10]:https://opensource.com/article/18/1/retro-gaming
-[11]:https://opensource.com/article/17/5/how-run-raspberry-pi-meetup
-[12]:https://www.raspberrypi.org/blog/support-raspberry-jam-community/
-[13]:http://www.pi-world-ranking-list.com/index.php?page=lists&category=pi
-[14]:https://www.theguardian.com/science/alexs-adventures-in-numberland/2015/mar/13/pi-day-2015-memory-memorisation-world-record-japanese-akira-haraguchi
-[15]:https://www.newscientist.com/article/2124418-celebrate-pi-day-with-9-trillion-more-digits-than-ever-before/?utm_medium=Social&utm_campaign=Echobox&utm_source=Facebook&utm_term=Autofeed&cmpid=SOC%7CNSNS%7C2017-Echobox#link_time=1489480071
diff --git a/sources/talk/20190121 Booting Linux faster.md b/sources/talk/20190121 Booting Linux faster.md
deleted file mode 100644
index 871efc1957..0000000000
--- a/sources/talk/20190121 Booting Linux faster.md
+++ /dev/null
@@ -1,54 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (alim0x)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Booting Linux faster)
-[#]: via: (https://opensource.com/article/19/1/booting-linux-faster)
-[#]: author: (Stewart Smith https://opensource.com/users/stewart-ibm)
-
-Booting Linux faster
-======
-Doing Linux kernel and firmware development leads to lots of reboots and lots of wasted time.
-
-Of all the computers I've ever owned or used, the one that booted the quickest was from the 1980s; by the time your hand moved from the power switch to the keyboard, the BASIC interpreter was ready for your commands. Modern computers take anywhere from 15 seconds for a laptop to minutes for a small home server to boot. Why is there such a difference in boot times?
-
-A microcomputer from the 1980s that booted straight to a BASIC prompt had a very simple CPU that started fetching and executing instructions from a memory address immediately upon getting power. Since these systems had BASIC in ROM, there was no loading time—you got to the BASIC prompt really quickly. More complex systems of that same era, such as the IBM PC or Macintosh, took a significant time to boot (~30 seconds), although this was mostly due to having to read the operating system (OS) off a floppy disk. Only a handful of seconds were spent in firmware before being able to load an OS.
-
-Modern servers typically spend minutes, rather than seconds, in firmware before getting to the point of booting an OS from disk. This is largely due to modern systems' increased complexity. No longer can a CPU just come up and start executing instructions at full speed; we've become accustomed to CPU frequency scaling, idle states that save a lot of power, and multiple CPU cores. In fact, inside modern CPUs are a surprising number of simpler CPUs that help start the main CPU cores and provide runtime services such as throttling the frequency when it gets too hot. On most CPU architectures, the code running on these cores inside your CPU is provided as opaque binary blobs.
-
-On OpenPOWER systems, every instruction executed on every core inside the CPU is open source software. On machines with [OpenBMC][1] (such as IBM's AC922 system and Raptor's TALOS II and Blackbird systems), this extends to the code running on the Baseboard Management Controller as well. This means we can get a tremendous amount of insight into what takes so long from the time you plug in a power cable to the time a familiar login prompt is displayed.
-
-If you're part of a team that works on the Linux kernel, you probably boot a lot of kernels. If you're part of a team that works on firmware, you're probably going to boot a lot of different firmware images, followed by an OS to ensure your firmware still works. If we can reduce the hardware's boot time, these teams can become more productive, and end users may be grateful when they're setting up systems or rebooting to install firmware or OS updates.
-
-Over the years, many improvements have been made to Linux distributions' boot time. Modern init systems deal well with doing things concurrently and on-demand. On a modern system, once the kernel starts executing, it can take very few seconds to get to a login prompt. This handful of seconds are not the place to optimize boot time; we have to go earlier: before we get to the OS.
-
-On OpenPOWER systems, the firmware loads an OS by booting a Linux kernel stored in the firmware flash chip that runs a userspace program called [Petitboot][2] to find the disk that holds the OS the user wants to boot and [kexec][3][()][3] to it. This code reuse leverages the efforts that have gone into making Linux boot quicker. Even so, we found places in our kernel config and userspace where we could improve and easily shave seconds off boot time. With these optimizations, booting the Petitboot environment is a single-digit percentage of boot time, so we had to find more improvements elsewhere.
-
-Before the Petitboot environment starts, there's a prior bit of firmware called [Skiboot][4], and before that there's [Hostboot][5]. Prior to Hostboot is the [Self-Boot Engine][6], a separate core on the die that gets a single CPU core up and executing instructions out of Level 3 cache. These components are where we can make the most headway in reducing boot time, as they take up the overwhelming majority of it. Perhaps some of these components aren't optimized enough or doing as much in parallel as they could be?
-
-Another avenue of attack is reboot time rather than boot time. On a reboot, do we really need to reinitialize all the hardware?
-
-Like any modern system, the solutions to improving boot (and reboot) time have been a mixture of doing more in parallel, dealing with legacy, and (arguably) cheating.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/1/booting-linux-faster
-
-作者:[Stewart Smith][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/stewart-ibm
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/OpenBMC
-[2]: https://github.com/open-power/petitboot
-[3]: https://en.wikipedia.org/wiki/Kexec
-[4]: https://github.com/open-power/skiboot
-[5]: https://github.com/open-power/hostboot
-[6]: https://github.com/open-power/sbe
-[7]: https://linux.conf.au/schedule/presentation/105/
-[8]: https://linux.conf.au/
diff --git a/sources/talk/20190306 How to pack an IT travel kit.md b/sources/talk/20190306 How to pack an IT travel kit.md
new file mode 100644
index 0000000000..b05ee460b7
--- /dev/null
+++ b/sources/talk/20190306 How to pack an IT travel kit.md
@@ -0,0 +1,100 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to pack an IT travel kit)
+[#]: via: (https://opensource.com/article/19/3/it-toolkit-remote)
+[#]: author: (Peter Cheer https://opensource.com/users/petercheer)
+
+How to pack an IT travel kit
+======
+Before you travel, make sure you're ready for challenges in hardware, infrastructure, and software.
+
+
+I've had several opportunities to do IT work in less-developed and remote areas, where internet coverage and technology access aren't at the high level we have in our first-world cities. Many people heading off to undeveloped areas ask me for advice on preparing for the local technology landscape. Since conditions vary greatly around this big world, it's impossible to give specific advice for most areas, but I do have some general suggestions based on my experience that may help you.
+
+Also, before you leave home, do as much research as you can about the general IT and telecom environment where you are traveling so you're a little better prepared for what you may encounter there.
+
+### Planning for the local hardware and infrastructure
+
+ * Even in many cities, internet connections tend to be expensive, slow, and not reliable for large downloads. Don't forget that internet coverage, speeds, and cost in cities are unlikely to be matched in more remote areas.
+
+
+ * The electricity supply may be unreliable with inconsistent voltage. If you are taking your computer, bring some surge protection—although in my experience, the electricity voltage is more likely to drop than to spike.
+
+
+ * It is always useful to have a small selection of hand tools, such as screwdrivers and needle-nose pliers, for repairing computer hardware. A lack of spare parts can limit opportunities for much beyond basic troubleshooting, although stripping usable components from dead computers can be worthwhile.
+
+
+
+### Planning for the software you'll find
+
+ * You can assume that most of the computer systems you'll find will be some incarnation of Microsoft Windows. You can expect that many will not be officially licensed, not be getting updates nor security patches, and are infected by multiple viruses and other malware.
+
+
+ * You can also expect that most application software will be proprietary and much of it will be unlicensed and lag behind the latest release versions. These conditions are depressing for open source enthusiasts, but this is the world as it is, rather than the world we would like it to be.
+
+
+ * It is wise to view any Windows system you do not control as potentially infected with viruses and malware. It's good practice to reserve a USB thumb drive for files you'll use with these Windows systems; this means that if (or more likely when) that thumb drive becomes infected, you can just reformat it at no cost.
+
+
+ * Bring copies of free antivirus software such as [AVG][1] and [Avast][2], including recent virus definition files for them, as well as virus removal and repair tools such as [Sophos][3] and [Hirens Boot CD][4].
+
+
+ * Trying to keep software current on machines that have no or infrequent access to the internet is a challenge. This is particularly true with web browsers, which tend to go through rapid release cycles. My preferred web browser is Mozilla Firefox and having a copy of the latest release is useful.
+
+
+ * Bring repair discs for a selection of recent Microsoft operating systems, and make sure that includes service packs for Windows and Microsoft Office.
+
+
+
+### Planning for the software you'll bring
+
+There's no better way to convey the advantages of open source software than by showing it to people. Here are some recommendations along that line.
+
+ * When gathering software to take with you, make sure you get the full offline installation option. Often, the most prominently displayed download links on websites are stubs that require internet access to download the components. They won't work if you're in an area with poor (or no) internet service.
+
+
+ * Also, make sure to get the 32-bit and 64-bit versions of the software. While 32-bit machines are becoming less common, you may encounter them and it's best to be prepared.
+
+
+ * Having a [bootable version of Linux][5] is vital for two reasons. First, it can be used to rescue data from a seriously damaged Windows machine. Second, it's an easy way to show off Linux without installing it on someone's machine. [Linux Mint][6] is my favorite distro for this purpose, because the graphical interface (GUI) is similar enough to Windows to appear non-threatening and it includes a good range of application software.
+
+
+ * Bring the widest selection of open source applications you can—you can't count on being able to download something from the internet.
+
+
+ * When possible, bring your open source software library as portable applications that will run without installing them. One of the many ways to mess up those Windows machines is to install and uninstall a lot of software, and using portable apps gets around this problem. Many open source applications, including Libre Office, GIMP, Blender, and Inkscape, have portable app versions for Windows.
+
+
+ * It's smart to bring a supply of blank disks so you can give away copies of your open source software stash on media that is a bit more secure than a USB thumb drive.
+
+
+ * Don't forget to bring programs and resources related to projects you will be working on. (For example, most of my overseas work involves tuition, mentoring, and skills transfer, so I usually add a selection of open source software tools for creating learning resources.)
+
+
+
+### Your turn
+
+There are many variables and surprises when doing IT work in undeveloped areas. If you have suggestions—for programs I've missed or tips that I didn't cover—please share them in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/it-toolkit-remote
+
+作者:[Peter Cheer][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/petercheer
+[b]: https://github.com/lujun9972
+[1]: https://www.avg.com/en-gb/free-antivirus-download
+[2]: https://www.avast.com/en-gb/free-antivirus-download
+[3]: https://www.sophos.com/en-us/products/free-tools/virus-removal-tool.aspx
+[4]: https://www.hiren.info/
+[5]: https://opensource.com/article/18/7/getting-started-etcherio
+[6]: https://linuxmint.com/
diff --git a/sources/talk/20190307 Small Scale Scrum vs. Large Scale Scrum.md b/sources/talk/20190307 Small Scale Scrum vs. Large Scale Scrum.md
new file mode 100644
index 0000000000..7da83306a5
--- /dev/null
+++ b/sources/talk/20190307 Small Scale Scrum vs. Large Scale Scrum.md
@@ -0,0 +1,106 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Small Scale Scrum vs. Large Scale Scrum)
+[#]: via: (https://opensource.com/article/19/3/small-scale-scrum-vs-large-scale-scrum)
+[#]: author: (Agnieszka Gancarczyk https://opensource.com/users/agagancarczyk)
+
+Small Scale Scrum vs. Large Scale Scrum
+======
+We surveyed individual members of small and large scrum teams. Here are some key findings.
+
+
+Following the publication of the [Small Scale Scrum framework][1], we wanted to collect feedback on how teams in our target demographic (consultants, open source developers, and students) work and what they value. With this first opportunity to inspect, adapt, and help shape the next stage of Small Scale Scrum, we decided to create a survey to capture some data points and begin to validate some of our assumptions and hypotheses.
+
+**[[Download the Introduction to Small Scale Scrum guide]][2]**
+
+Our reasons for using the survey were multifold, but chief among them were the global distribution of teams, the small local data sample available in our office, access to customers, and the industry’s utilization of surveys (e.g., the [Stack Overflow Developer Survey 2018][3], [HackerRank 2018 Developer Skills Report][4], and [GitLab 2018 Global Developer Report][5]).
+
+The scrum’s iterative process was used to facilitate the creation of the survey shown below:
+
+
+
+[The survey][6], which we invite you to complete, consisted of 59 questions and was distributed at a local college ([Waterford Institute of Technology][7]) and to Red Hat's consultancy and engineering teams. Our initial data was gathered from the responses of 54 individuals spread across small and large scrum teams, who were asked about their experiences with agile within their teams.
+
+Here are the main results and initial findings of the survey:
+
+ * A full 96% of survey participants practice a form of agile, work in distributed teams, think scrum principles help them reduce development complexity, and believe agile contributes to the success of their projects.
+
+ * Only 8% of survey participants belong to small (one- to three-person) teams, and 10 out of 51 describe their typical project as short-lived (three months or less).
+
+ * The majority of survey participants were software engineers, but quality engineers (QE), project managers (PM), product owners (PO), and scrum masters were also represented.
+
+ * Scrum master, PO, and team member are typical roles in projects.
+
+ * Nearly half of survey respondents work on, or are assigned to, more than one project at the same time.
+
+ * Almost half of projects are customer/value-generating vs. improvement/not directly value-generating or unclassified.
+
+ * Almost half of survey participants said that their work is clarified sometimes or most of the time and estimated before development with extensions available sometimes or most of the time. They said asking for clarification of work items is the team’s responsibility.
+
+ * Almost half of survey respondents said they write tests for their code, and they adhere to best coding practices, document their code, and get their code reviewed before merging.
+
+ * Almost all survey participants introduce bugs to the codebase, which are prioritized by them, the team, PM, PO, team lead, or the scrum master.
+
+ * Participants ask for help and mentoring when a task is complex. They also take on additional roles on their projects when needed, including business analyst, PM, QE, and architect, and they sometimes find changing roles difficult.
+
+ * When changing roles on a daily basis, individuals feel they lose one to two hours on average, but they still complete their work on time most of the time.
+
+ * Most survey participants use scrum (65%), followed by hybrid (18%) and Kanban (12%). This is consistent with results of [VersionOne’s State of Agile Report][8].
+
+ * The daily standup, sprint, sprint planning and estimating, backlog grooming, and sprint retrospective are among the top scrum ceremonies and principles followed, and team members do preparation work before meetings.
+
+ * The majority of sprints (62%) are three weeks long, followed by two-week sprints (26%), one-week sprints (6%), and four-week sprints (4%). Two percent of participants are not using sprints due to strict release and update timings, with all activities organized and planned around those dates.
+
+ * Teams use [planning poker][9] to estimate (storypoint) user stories. User stories contain acceptance criteria.
+
+ * Teams create and use a [Definition of Done][10] mainly in respect to features and determining completion of user stories.
+
+ * The majority of teams don’t have or use a [Definition of Ready][11] to ensure that user stories are actionable, testable, and clear.
+
+ * Unit, integration, functional, automated, performance/load, and acceptance tests are commonly used.
+
+ * Overall collaboration between team members is considered high, and team members use various communication channels.
+
+ * The majority of survey participants spend more than four hours weekly in meetings, including face-to-face meetings, web conferences, and email communication.
+
+ * The majority of customers are considered large, and half of them understand and follow scrum principles.
+
+ * Customers respect “no deadlines” most of the time and sometimes help create user stories and participate in sprint planning, sprint review and demonstration, sprint retrospective, and backlog review and refinement.
+
+ * Only 27% of survey participants know their customers have a high level of satisfaction with the adoption of agile, while the majority (58%) don’t know this information at all.
+
+
+
+
+These survey results will inform the next stage of our data-gathering exercise. We will apply Small Scale Scrum to real-world projects, and the guidance obtained from the survey will help us gather key data points as we move toward version 2.0 of Small Scale Scrum. If you want to help, take our [survey][6]. If you have a project to which you'd like to apply Small Scale Scrum, please get in touch.
+
+[Download the Introduction to Small Scale Scrum guide][2]
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/small-scale-scrum-vs-large-scale-scrum
+
+作者:[Agnieszka Gancarczyk][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/agagancarczyk
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/2/small-scale-scrum-framework
+[2]: https://opensource.com/downloads/small-scale-scrum
+[3]: https://insights.stackoverflow.com/survey/2018/
+[4]: https://research.hackerrank.com/developer-skills/2018/
+[5]: https://about.gitlab.com/developer-survey/2018/
+[6]: https://docs.google.com/forms/d/e/1FAIpQLScAXf52KMEiEzS68OOIsjLtwZJto_XT7A3b9aB0RhasnE_dEw/viewform?c=0&w=1
+[7]: https://www.wit.ie/
+[8]: https://explore.versionone.com/state-of-agile/versionone-12th-annual-state-of-agile-report
+[9]: https://en.wikipedia.org/wiki/Planning_poker
+[10]: https://www.scruminc.com/definition-of-done/
+[11]: https://www.scruminc.com/definition-of-ready/
diff --git a/sources/talk/20190311 Discuss everything Fedora.md b/sources/talk/20190311 Discuss everything Fedora.md
new file mode 100644
index 0000000000..5795fbf3f7
--- /dev/null
+++ b/sources/talk/20190311 Discuss everything Fedora.md
@@ -0,0 +1,45 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Discuss everything Fedora)
+[#]: via: (https://fedoramagazine.org/discuss-everything-fedora/)
+[#]: author: (Ryan Lerch https://fedoramagazine.org/introducing-flatpak/)
+
+Discuss everything Fedora
+======
+
+
+Are you interested in how Fedora is being developed? Do you want to get involved, or see what goes into making a release? You want to check out [Fedora Discussion][1]. It is a relatively new place where members of the Fedora Community meet to discuss, ask questions, and interact. Keep reading for more information.
+
+Note that the Fedora Discussion system is mainly aimed at contributors. If you have questions on using Fedora, check out [Ask Fedora][2] (which is being migrated in the future).
+
+![][3]
+
+Fedora Discussion is a forum and discussion site that uses the [Discourse open source discussion platform][4].
+
+There are already several categories useful for Fedora users, including [Desktop][5] (covering Fedora Workstation, Fedora Silverblue, KDE, XFCE, and more) and the [Server, Cloud, and IoT][6] category . Additionally, some of the [Fedora Special Interest Groups (SIGs) have discussions as well][7]. Finally, the [Fedora Friends][8] category helps you connect with other Fedora users and Community members by providing discussions about upcoming meetups and hackfests.
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/discuss-everything-fedora/
+
+作者:[Ryan Lerch][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/introducing-flatpak/
+[b]: https://github.com/lujun9972
+[1]: https://discussion.fedoraproject.org/
+[2]: https://ask.fedoraproject.org
+[3]: https://fedoramagazine.org/wp-content/uploads/2019/03/discussion-screenshot-1024x663.png
+[4]: https://www.discourse.org/about
+[5]: https://discussion.fedoraproject.org/c/desktop
+[6]: https://discussion.fedoraproject.org/c/server
+[7]: https://discussion.fedoraproject.org/c/sigs
+[8]: https://discussion.fedoraproject.org/c/friends
diff --git a/sources/talk/20190312 When the web grew up- A browser story.md b/sources/talk/20190312 When the web grew up- A browser story.md
new file mode 100644
index 0000000000..6a168939ad
--- /dev/null
+++ b/sources/talk/20190312 When the web grew up- A browser story.md
@@ -0,0 +1,65 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (When the web grew up: A browser story)
+[#]: via: (https://opensource.com/article/19/3/when-web-grew)
+[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
+
+When the web grew up: A browser story
+======
+A personal story of when the internet came of age.
+
+
+
+Recently, I [shared how][1] upon leaving university in 1994 with a degree in English literature and theology, I somehow managed to land a job running a web server in a world where people didn't really know what a web server was yet. And by "in a world," I don't just mean within the organisation in which I worked, but the world in general. The web was new—really new—and people were still trying to get their heads around it.
+
+That's not to suggest that the place where I was working—an academic publisher—particularly "got it" either. This was a world in which a large percentage of the people visiting their website were still running 28k8 modems. I remember my excitement in getting a 33k6 modem. At least we were past the days of asymmetric upload/download speeds,1 where 1200/300 seemed like an eminently sensible bandwidth description. This meant that the high-design, high-colour, high-resolution documents created by the print people (with whom I shared a floor) were completely impossible on the web. I wouldn't allow anything bigger than a 40k GIF on the front page of the website, and that was pushing it for many of our visitors. Anything larger than 60k or so would be explicitly linked as a standalone image from a thumbnail on the referring page.
+
+To say that the marketing department didn't like this was an understatement. Even worse was the question of layout. "Browsers decide how to lay out documents," I explained, time after time, "you can use headers or paragraphs, but how documents appear on the page isn't defined by the document, but by the renderer!" They wanted control. They wanted different coloured backgrounds. After a while, they got that. I went to what I believe was the first W3C meeting at which the idea of Cascading Style Sheets (CSS) was discussed. And argued vehemently against them. The suggestion that document writers should control layout was anathema.2 It took some while for CSS to be adopted, and in the meantime, those who cared about such issues adopted the security trainwreck that was Portable Document Format (PDF).
+
+How documents were rendered wasn't the only issue. Being a publisher of actual physical books, the whole point of having a web presence, as far as the marketing department was concerned, was to allow customers—or potential customers—to know not only what a book was about, but also how much it was going to cost them to buy. This, however, presented a problem. You see, the internet—in which I include the rapidly growing World Wide Web—was an open, free-for-all libertarian sort of place where nobody was interested in money; in fact, where talk of money was to be shunned and avoided.
+
+I took the mainstream "Netizen" view that there was no place for pricing information online. My boss—and, indeed, pretty much everybody else in the organisation—took a contrary view. They felt that customers should be able to see how much books would cost them. They also felt that my bank manager would like to see how much money was coming into my bank account on a monthly basis, which might be significantly reduced if I didn't come round to their view.
+
+Luckily, by the time I'd climbed down from my high horse and got over myself a bit—probably only a few weeks after I'd started digging my heels in—the web had changed, and there were other people putting pricing information up about their products. These newcomers were generally looked down upon by the old schoolers who'd been running web servers since the early days,3 but it was clear which way the wind was blowing. This didn't mean that the battle was won for our website, however. As an academic publisher, we shared an academic IP name ("ac.uk") with the University. The University was less than convinced that publishing pricing information was appropriate until some senior folks at the publisher pointed out that Princeton University Press was doing it, and wouldn't we look a bit silly if…?
+
+The fun didn't stop there, either. A few months into my tenure as webmaster ("webmaster@…"), we started to see a worrying trend, as did lots of other websites. Certain visitors were single-handedly bringing our webserver to its knees. These visitors were running a new web browser: Netscape. Netscape was badly behaved. Netscape was multi-threaded.
+
+Why was this an issue? Well, before Netscape, all web browsers had been single-threaded. They would open one connection at a time, so even if you had, say five GIFs on a page,4 they would request the HTML base file, parse that, then download the first GIF, complete that, then the second, complete that, and so on. In fact, they often did the GIFs in the wrong order, which made for very odd page loading, but still, that was the general idea. The rude people at Netscape decided that they could open multiple connections to the webserver at a time to request all the GIFs at the same time, for example! And why was this a problem? Well, the problem was that most webservers were single-threaded. They weren't designed to have multiple connections open at any one time. Certainly, the HTTP server that we ran (MacHTTP) was single-threaded. Even though we had paid for it (it was originally shareware), the version we had couldn't cope with multiple requests at a time.
+
+The debate raged across the internet. Who did these Netscape people think they were, changing how the world worked? How it was supposed to work? The world settled into different camps, and as with all technical arguments, heated words were exchanged on both sides. The problem was that not only was Netscape multi-threaded, it was also just better than the alternatives. Lots of web server code maintainers, MacHTTP author Chuck Shotton among them, sat down and did some serious coding to produce multi-threaded beta versions of their existing code. Everyone moved almost immediately to the beta versions, they got stable, and in the end, single-threaded browsers either adapted and became multi-threaded themselves, or just went the way of all outmoded products and died a quiet death.6
+
+This, for me, is when the web really grew up. It wasn't prices on webpages nor designers being able to define what you'd see on a page,8 but rather when browsers became easier to use and when the network effect of thousands of viewers moving to many millions tipped the balance in favour of the consumer, not the producer. There were more steps in my journey—which I'll save for another time—but from around this point, my employers started looking at our monthly, then weekly, then daily logs, and realising that this was actually going to be something big and that they'd better start paying some real attention.
+
+1\. How did they come back, again?
+
+2\. It may not surprise you to discover that I'm still happiest at the command line.
+
+3\. About six months before.
+
+4\. Reckless, true, but it was beginning to happen.5
+
+5\. Oh, and no—it was GIFs or BMP. JPEG was still a bright idea that hadn't yet taken off.
+
+6\. It's never actually quiet: there are always a few diehard enthusiasts who insist that their preferred solution is technically superior and bemoan the fact that the rest of the internet has gone to the devil.7
+
+7\. I'm not one to talk: I still use Lynx from time to time.
+
+8\. Creating major and ongoing problems for those with different accessibility needs, I would point out.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/when-web-grew
+
+作者:[Mike Bursell][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mikecamel
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/18/11/how-web-was-won
diff --git a/sources/talk/20190313 Why is no one signing their emails.md b/sources/talk/20190313 Why is no one signing their emails.md
new file mode 100644
index 0000000000..b2b862951a
--- /dev/null
+++ b/sources/talk/20190313 Why is no one signing their emails.md
@@ -0,0 +1,104 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Why is no one signing their emails?)
+[#]: via: (https://arp242.net/weblog/signing-emails.html)
+[#]: author: (Martin Tournoij https://arp242.net/)
+
+Why is no one signing their emails?
+======
+
+
+I received this email a while ago:
+
+> Queensland University of Technology sent you an Amazon.com Gift Card!
+>
+> You’ve received an Amazon.com gift card! You’ll need the claim code below to place your order.
+>
+> Happy shopping!
+
+Queensland University of Technology? Why would they send me anything? Where is that even? Australia right? That’s the other side of the world! Looks like spam!
+
+It did look pretty good for spam, so I took a second look. And a very close third look, and then I decided it wasn’t spam.
+
+I was still confused why they sent me this. A week later I remembered: half a year prior I had done an interview regarding my participation on Stack Overflow for someone’s paper; she was studying somewhere in Australia – presumably the university of Queensland. No one had ever mentioned anything about a reward or Amazon gift card so I wasn’t expecting it. It’s a nice bonus though.
+
+Here’s the thing: I’ve spent several years professionally developing email systems; I administered email servers; I read all the relevant RFCs. While there are certainly people who are more knowledgable, I know more about email than the vast majority of the population. And I still had to take a careful look to verify the email wasn’t a phishing attempt.
+
+And I’m not even a target; I’m just this guy, you know? [Ask John Podesta what it is to be targeted][1]:
+
+> SecureWorks concluded Fancy Bear had sent Podesta an email on March 19, 2016, that had the appearance of a Google security alert, but actually contained a misleading link—a strategy known as spear-phishing. [..] The email was initially sent to the IT department as it was suspected of being a fake but was described as “legitimate” in an e-mail sent by a department employee, who later said he meant to write “illegitimate”.
+
+Yikes! If I was even remotely high-profile I’d be crazy paranoid about all emails I get.
+
+It seems to me that there is a fairly easy solution to verify the author of an email: sign it with a digital signature; PGP is probably the best existing solution right now. I don’t even care about encryption here, just signing to prevent phishing.
+
+PGP has a well-deserved reputation for being hard, but that’s only for certain scenarios. A lot of the problems/difficulties stem from trying to accommodate the “random person A emails random person B” use case, but this isn’t really what I care about here. “Large company with millions of users sends thousands of emails daily” is a very different use case.
+
+Much of the key exchange/web-of-trust dilemma can be bypassed by shipping email clients with keys for large organisations (PayPal, Google, etc.) baked in, like browsers do with some certificates. Even just publishing your key on your website (or, if you’re a bank, in local branches etc.) is already a lot better than not signing anything at all. Right now there seems to be a catch-22 scenario: clients don’t implement better support as very few people are using PGP, while very few companies bother signing their emails with PGP because so few people can benefit from it.
+
+On the end-user side, things are also not very hard; we’re just conceded with validating signatures, nothing more. For this purpose PGP isn’t hard. It’s like verifying your Linux distro’s package system: all of them sign their packages (usually with PGP) and they get verified on installation, but as an end-user I never see it unless something goes wrong.
+
+There are many aspects of PGP that are hard to set up and manage, but verifying signatures isn’t one of them. The user-visible part of this is very limited. Remember, no one is expected to sign their own emails: just verify that the signature is correct (which the software will do). Conceptually, it’s not that different from verifying a handwritten signature.
+
+DKIM and SPF already exist and are useful, but limited. All both do is verify that an email which claims to be from `amazon.com` is really from `amazon.com`. If I send an email from `mail.amazon-account-security.com` or `amazonn.com` then it just verifies that it was sent from that domain, not that it was sent from the organisation Amazon.
+
+What I am proposing is subtly different. In my (utopian) future every serious organisation will sign their email with PGP (just like every serious organisation uses https). Then every time I get an email which claims to be from Amazon I can see it’s either not signed, or not signed by a key I know. If adoption is broad enough we can start showing warnings such as “this email wasn’t signed, do you want to trust it?” and “this signature isn’t recognized, yikes!”
+
+There’s also S/MIME, which has better client support and which works more or less the same as HTTPS: you get a certificate from the Certificate Authority Mafia, sign your email with it, and presto. The downside of this is that anyone can sign their emails with a valid key, which isn’t necessarily telling you much (just because haxx0r.ru has a certificate doesn’t mean it’s trustworthy).
+
+Is it perfect? No. I understand stuff like key exchange is hard and that baking in keys isn’t perfect. Is it better? Hell yes. Would probably have avoided Podesta and the entire Democratic Party a lot of trouble. Here’s a “[sophisticated new phishing campaign][2]” targeted at PayPal users. How “sophisticated”? Well, by not having glaring stupid spelling errors, duplicating the PayPal layout in emails, duplicating the PayPal login screen, a few forms, and getting an SSL certificate. Truly, the pinnacle of Computer Science.
+
+Okay sure, they spent some effort on it; but any nincompoop can do it; if this passes for “sophisticated phishing” where “it’s easy to see how users could be fooled” then the bar is pretty low.
+
+I can’t recall receiving a single email from any organisation that is signed (much less encrypted). Banks, financial services, utilities, immigration services, governments, tax services, voting registration, Facebook, Twitter, a zillion websites … all happily sent me emails hoping I wouldn’t consider them spam and hoping I wouldn’t confuse a phishing email for one of theirs.
+
+Interesting experiment: send invoices for, say, a utility bill for a local provider. Just copy the layout from the last utility bill you received. I’ll bet you’ll make more money than freelancing on UpWork if you do it right.
+
+I’ve been intending to write this post for years, but never quite did because “surely not everyone is stupid?” I’m not a crypto expert, so perhaps I’m missing something here, but I wouldn’t know what. Let me know if I am.
+
+In the meanwhile PayPal is attempting to solve the problem by publishing [articles which advise you to check for spelling errors][3]. Okay, it’s good advice, but do we really want this to be the barrier between an attacker and your money? Or Russian hacking groups and your emails? Anyone can sign any email with any key, but “unknown signature” warnings strike me as a lot better UX than “carefully look for spelling errors or misleading domain names”.
+
+The way forward is to make it straight-forward to implement signing in apps and then just do it as a developer, whether asked or not; just as you set up https whether you’re asked or not. I’ll write a follow-up with more technical details later, assuming no one pokes holes in this article :-)
+
+#### Response to some feedback
+
+Some response to some feedback that I couldn’t be bothered to integrate in the article’s prose:
+
+ * “You can’t trust webmail with crypto!”
+If you use webmail then you’re already trusting the email provider with everything. What’s so bad with trusting them to verify a signature, too?
+
+We’re not communicating state secrets over encrypted email here; we’re just verifying the signature on “PayPal sent you a message, click here to view it”-kind of emails.
+
+ * “Isn’t this ignoring the massive problem that is key management?”
+Yes, it’s hard problem; but that doesn’t mean it can’t be done. I already mentioned some possible solutions in the article.
+
+
+
+
+**Footnotes**
+
+ 1. We could make something better; PGP contians a lot of cruft. But for now PGP is “good enough”.
+
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://arp242.net/weblog/signing-emails.html
+
+作者:[Martin Tournoij][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://arp242.net/
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Podesta_emails#Data_theft
+[2]: https://www.eset.com/us/about/newsroom/corporate-blog/paypal-users-targeted-in-sophisticated-new-phishing-campaign/
+[3]: https://www.paypal.com/cs/smarthelp/article/how-to-spot-fake,-spoof,-or-phishing-emails-faq2340
diff --git a/sources/tech/20160301 How To Set Password Policies In Linux.md b/sources/tech/20160301 How To Set Password Policies In Linux.md
new file mode 100644
index 0000000000..bad7c279bc
--- /dev/null
+++ b/sources/tech/20160301 How To Set Password Policies In Linux.md
@@ -0,0 +1,356 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Set Password Policies In Linux)
+[#]: via: (https://www.ostechnix.com/how-to-set-password-policies-in-linux/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+How To Set Password Policies In Linux
+======
+
+
+Even though Linux is secure by design, there are many chances for the security breach. One of them is weak passwords. As a System administrator, you must provide a strong password for the users. Because, mostly system breaches are happening due to weak passwords. This tutorial describes how to set password policies such as **password length** , **password complexity** , **password** **expiration period** etc., in DEB based systems like Debian, Ubuntu, Linux Mint, and RPM based systems like RHEL, CentOS, Scientific Linux.
+
+### Set password length in DEB based systems
+
+By default, all Linux operating systems requires **password length of minimum 6 characters** for the users. I strongly advice you not to go below this limit. Also, don’t use your real name, parents/spouse/kids name, or your date of birth as a password. Even a novice hacker can easily break such kind of passwords in minutes. The good password must always contains more than 6 characters including a number, a capital letter, and a special character.
+
+Usually, the password and authentication-related configuration files will be stored in **/etc/pam.d/** location in DEB based operating systems.
+
+To set minimum password length, edit**/etc/pam.d/common-password** file;
+
+```
+$ sudo nano /etc/pam.d/common-password
+```
+
+Find the following line:
+
+```
+password [success=2 default=ignore] pam_unix.so obscure sha512
+```
+
+![][2]
+
+And add an extra word: **minlen=8** at the end. Here I set the minimum password length as **8**.
+
+```
+password [success=2 default=ignore] pam_unix.so obscure sha512 minlen=8
+```
+
+
+
+Save and close the file. So, now the users can’t use less than 8 characters for their password.
+
+### Set password length in RPM based systems
+
+**In RHEL, CentOS, Scientific Linux 7.x** systems, run the following command as root user to set password length.
+
+```
+# authconfig --passminlen=8 --update
+```
+
+To view the minimum password length, run:
+
+```
+# grep "^minlen" /etc/security/pwquality.conf
+```
+
+**Sample output:**
+
+```
+minlen = 8
+```
+
+**In RHEL, CentOS, Scientific Linux 6.x** systems, edit **/etc/pam.d/system-auth** file:
+
+```
+# nano /etc/pam.d/system-auth
+```
+
+Find the following line and add the following at the end of the line:
+
+```
+password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8
+```
+
+
+
+As per the above setting, the minimum password length is **8** characters.
+
+### Set password complexity in DEB based systems
+
+This setting enforces how many classes, i.e upper-case, lower-case, and other characters, should be in a password.
+
+First install password quality checking library using command:
+
+```
+$ sudo apt-get install libpam-pwquality
+```
+
+Then, edit **/etc/pam.d/common-password** file:
+
+```
+$ sudo nano /etc/pam.d/common-password
+```
+
+To set at least one **upper-case** letters in the password, add a word **‘ucredit=-1’** at the end of the following line.
+
+```
+password requisite pam_pwquality.so retry=3 ucredit=-1
+```
+
+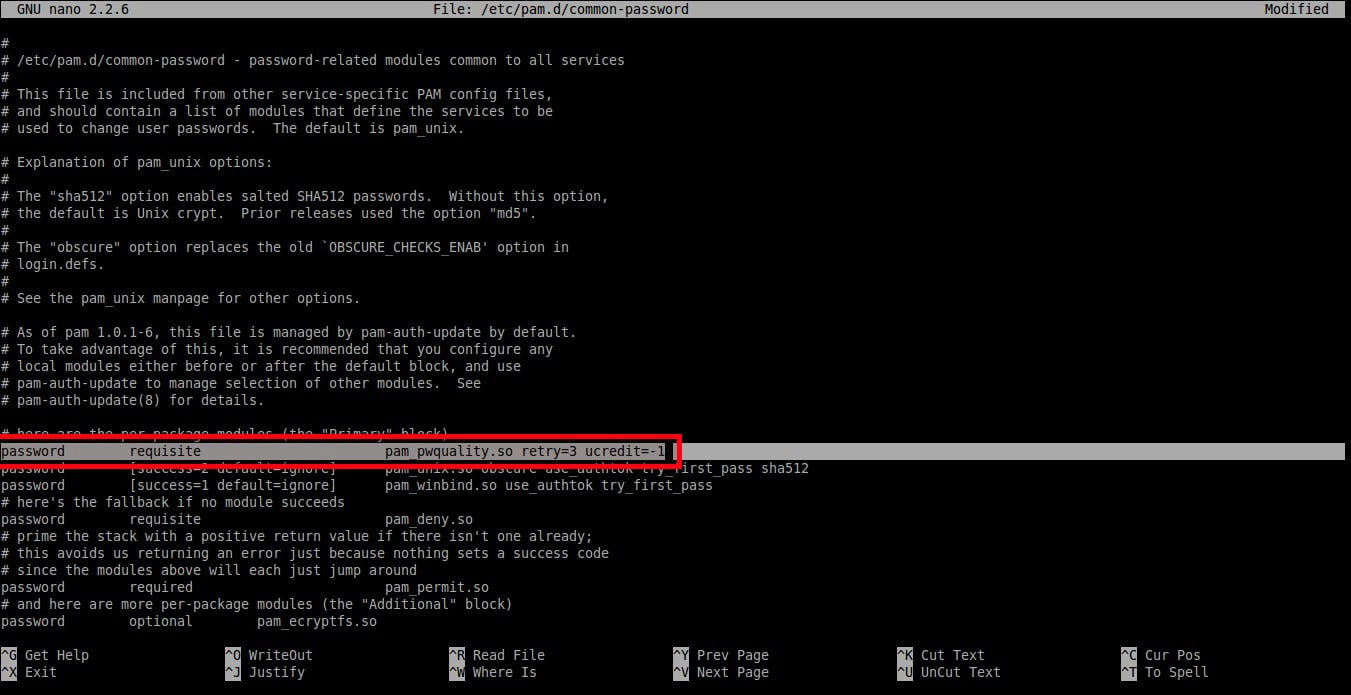
+
+Set at least one **lower-case** letters in the password as shown below.
+
+```
+password requisite pam_pwquality.so retry=3 dcredit=-1
+```
+
+Set at least **other** letters in the password as shown below.
+
+```
+password requisite pam_pwquality.so retry=3 ocredit=-1
+```
+
+As you see in the above examples, we have set at least (minimum) one upper-case, lower-case, and a special character in the password. You can set any number of maximum allowed upper-case, lower-case, and other letters in your password.
+
+You can also set the minimum/maximum number of allowed classes in the password.
+
+The following example shows the minimum number of required classes of characters for the new password:
+
+```
+password requisite pam_pwquality.so retry=3 minclass=2
+```
+
+### Set password complexity in RPM based systems
+
+**In RHEL 7.x / CentOS 7.x / Scientific Linux 7.x:**
+
+To set at least one lower-case letter in the password, run:
+
+```
+# authconfig --enablereqlower --update
+```
+
+To view the settings, run:
+
+```
+# grep "^lcredit" /etc/security/pwquality.conf
+```
+
+**Sample output:**
+
+```
+lcredit = -1
+```
+
+Similarly, set at least one upper-case letter in the password using command:
+
+```
+# authconfig --enablerequpper --update
+```
+
+To view the settings:
+
+```
+# grep "^ucredit" /etc/security/pwquality.conf
+```
+
+**Sample output:**
+
+```
+ucredit = -1
+```
+
+To set at least one digit in the password, run:
+
+```
+# authconfig --enablereqdigit --update
+```
+
+To view the setting, run:
+
+```
+# grep "^dcredit" /etc/security/pwquality.conf
+```
+
+**Sample output:**
+
+```
+dcredit = -1
+```
+
+To set at least one other character in the password, run:
+
+```
+# authconfig --enablereqother --update
+```
+
+To view the setting, run:
+
+```
+# grep "^ocredit" /etc/security/pwquality.conf
+```
+
+**Sample output:**
+
+```
+ocredit = -1
+```
+
+In **RHEL 6.x / CentOS 6.x / Scientific Linux 6.x systems** , edit **/etc/pam.d/system-auth** file as root user:
+
+```
+# nano /etc/pam.d/system-auth
+```
+
+Find the following line and add the following at the end of the line:
+
+```
+password requisite pam_cracklib.so try_first_pass retry=3 type= minlen=8 dcredit=-1 ucredit=-1 lcredit=-1 ocredit=-1
+```
+
+As per the above setting, the password must have at least 8 characters. In addtion, the password should also have at least one upper-case letter, one lower-case letter, one digit, and one other characters.
+
+### Set password expiration period in DEB based systems
+
+Now, We are going to set the following policies.
+
+ 1. Maximum number of days a password may be used.
+ 2. Minimum number of days allowed between password changes.
+ 3. Number of days warning given before a password expires.
+
+
+
+To set this policy, edit:
+
+```
+$ sudo nano /etc/login.defs
+```
+
+Set the values as per your requirement.
+
+```
+PASS_MAX_DAYS 100
+PASS_MIN_DAYS 0
+PASS_WARN_AGE 7
+```
+
+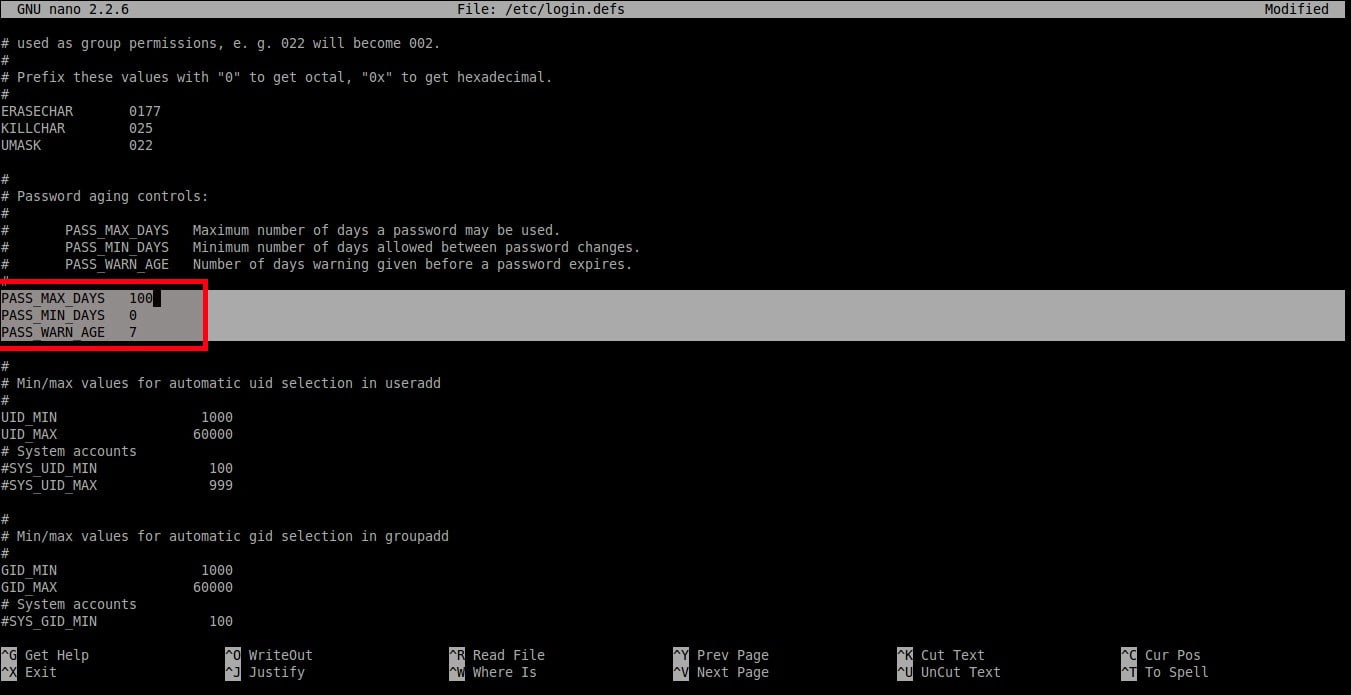
+
+As you see in the above example, the user should change the password once in every **100** days and the warning message will appear **7** days before password expiration.
+
+Be mindful that these settings will impact the newly created users.
+
+To set maximum number of days between password change to existing users, you must run the following command:
+
+```
+$ sudo chage -M
+```
+
+To set minimum number of days between password change, run:
+
+```
+$ sudo chage -m
+```
+
+To set warning before password expires, run:
+
+```
+$ sudo chage -W
+```
+
+To display the password for the existing users, run:
+
+```
+$ sudo chage -l sk
+```
+
+Here, **sk** is my username.
+
+**Sample output:**
+
+```
+Last password change : Feb 24, 2017
+Password expires : never
+Password inactive : never
+Account expires : never
+Minimum number of days between password change : 0
+Maximum number of days between password change : 99999
+Number of days of warning before password expires : 7
+```
+
+As you see in the above output, the password never expires.
+
+To change the password expiration period of an existing user,
+
+```
+$ sudo chage -E 24/06/2018 -m 5 -M 90 -I 10 -W 10 sk
+```
+
+The above command will set password of the user **‘sk’** to expire on **24/06/2018**. Also the the minimum number days between password change is set 5 days and the maximum number of days between password changes is set to **90** days. The user account will be locked automatically after **10 days** and It will display a warning message for **10 days** before password expiration.
+
+### Set password expiration period in RPM based systems
+
+This is same as DEB based systems.
+
+### Forbid previously used passwords in DEB based systems
+
+You can limit the users to set a password which is already used in the past. To put this in layman terms, the users can’t use the same password again.
+
+To do so, edit**/etc/pam.d/common-password** file:
+
+```
+$ sudo nano /etc/pam.d/common-password
+```
+
+Find the following line and add the word **‘remember=5’** at the end:
+
+```
+password [success=2 default=ignore] pam_unix.so obscure use_authtok try_first_pass sha512 remember=5
+```
+
+The above policy will prevent the users to use the last 5 used passwords.
+
+### Forbid previously used passwords in RPM based systems
+
+This is same for both RHEL 6.x and RHEL 7.x and it’s clone systems like CentOS, Scientific Linux.
+
+Edit **/etc/pam.d/system-auth** file as root user,
+
+```
+# vi /etc/pam.d/system-auth
+```
+
+Find the following line, and add **remember=5** at the end.
+
+```
+password sufficient pam_unix.so sha512 shadow nullok try_first_pass use_authtok remember=5
+```
+
+You know now what is password policies in Linux, and how to set different password policies in DEB and RPM based systems.
+
+That’s all for now. I will be here soon with another interesting and useful article. Until then stay tuned with OSTechNix. If you find this tutorial helpful, share it on your social, professional networks and support us.
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-set-password-policies-in-linux/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: http://www.ostechnix.com/wp-content/uploads/2016/03/sk@sk-_003-2-1.jpg
diff --git a/sources/tech/20170519 zsh shell inside Emacs on Windows.md b/sources/tech/20170519 zsh shell inside Emacs on Windows.md
deleted file mode 100644
index 3a93941d0b..0000000000
--- a/sources/tech/20170519 zsh shell inside Emacs on Windows.md
+++ /dev/null
@@ -1,121 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (lujun9972)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (zsh shell inside Emacs on Windows)
-[#]: via: (https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html)
-[#]: author: (Peter Mosmans https://www.onwebsecurity.com/)
-
-zsh shell inside Emacs on Windows
-======
-
-![zsh shell inside Emacs on Windows][5]
-
-The most obvious advantage of running a cross-platform shell (for example Bash or zsh) is that you can use the same syntax and scripts on multiple platforms. Setting up (alternative) shells on Windows can be pretty tricky, but the small investment is well worth the reward.
-
-The MSYS2 subsystem allows you to run shells like Bash or zsh on Windows. An important part of MSYS2 is making sure that the search paths are all pointing to the MSYS2 subsystem: There are a lot of dependencies.
-
-Bash is the default shell once MSYS2 is installed; zsh can be installed using the package manager:
-
-```
-pacman -Sy zsh
-```
-
-Setting zsh as default shell can be done by modifying the ` /etc/passwd` file, for instance:
-
-```
-mkpasswd -c | sed -e 's/bash/zsh/' | tee -a /etc/passwd
-```
-
-This will change the default shell from bash to zsh.
-
-Running zsh under Emacs on Windows can be done by modifying the ` shell-file-name` variable, and pointing it to the zsh binary from the MSYS2 subsystem. The shell binary has to be somewhere in the Emacs ` exec-path` variable.
-
-```
-(setq shell-file-name (executable-find "zsh.exe"))
-```
-
-Don't forget to modify the PATH environment variable for Emacs, as the MSYS2 paths should be resolved before Windows paths. Using the same example, where MSYS2 is installed under
-
-```
-c:\programs\msys2
-```
-
-:
-
-```
-(setenv "PATH" "C:\\programs\\msys2\\mingw64\\bin;C:\\programs\\msys2\\usr\\local\\bin;C:\\programs\\msys2\\usr\\bin;C:\\Windows\\System32;C:\\Windows")
-```
-
-After setting these two variables in the Emacs configuration file, running
-
-```
-M-x shell
-```
-
-in Emacs should bring up the familiar zsh prompt.
-
-Emacs' terminal settings (eterm) are different than MSYS2' standard terminal settings (xterm-256color). This means that some plugins or themes (prompts) might not work - especially when using oh-my-zsh.
-
-Detecting whether zsh is started under Emacs is easy, using the variable
-
-```
-$INSIDE_EMACS
-```
-
-. This codesnippet in
-
-```
-.zshrc
-```
-
-(which will be sourced for interactive shells) only enables the git plugin when being run in Emacs, and changes the theme
-
-```
-# Disable some plugins while running in Emacs
-if [[ -n "$INSIDE_EMACS" ]]; then
- plugins=(git)
- ZSH_THEME="simple"
-else
- ZSH_THEME="compact-grey"
-fi
-```
-
-. This codesnippet in(which will be sourced for interactive shells) only enables the git plugin when being run in Emacs, and changes the theme
-
-By adding the ` INSIDE_EMACS` variable to the local ` ~/.ssh/config` as ` SendEnv` variable...
-
-```
-Host myhost
-SendEnv INSIDE_EMACS
-```
-
-... and to a ssh server as ` AcceptEnv` variable in ` /etc/ssh/sshd_config` ...
-
-```
-AcceptEnv LANG LC_* INSIDE_EMACS
-```
-
-... this even works when ssh'ing inside an Emacs shell session to another ssh server, running zsh. When ssh'ing in the zsh shell inside Emacs on Windows, using the parameters ` -t -t` forces pseudo-tty allocation (which is necessary, as Emacs on Windows don't have a true tty).
-
-Cross-platform, open-source goodyness...
-
---------------------------------------------------------------------------------
-
-via: https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html
-
-作者:[Peter Mosmans][a]
-选题:[lujun9972][b]
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.onwebsecurity.com/
-[b]: https://github.com/lujun9972
-[1]: https://www.onwebsecurity.com/category/configuration.html
-[2]: https://www.onwebsecurity.com/tag/emacs.html
-[3]: https://www.onwebsecurity.com/tag/msys2.html
-[4]: https://www.onwebsecurity.com/tag/zsh.html
-[5]: https://www.onwebsecurity.com//images/zsh-shell-inside-emacs-on-windows.png
diff --git a/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md b/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md
index 20c14074c6..3c61f6dd8f 100644
--- a/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md
+++ b/sources/tech/20171010 In Device We Trust Measure Twice Compute Once with Xen Linux TPM 2.0 and TXT.md
@@ -1,3 +1,6 @@
+ezio is translating
+
+
In Device We Trust: Measure Twice, Compute Once with Xen, Linux, TPM 2.0 and TXT
============================================================
diff --git a/sources/tech/20171119 Advanced Techniques for Reducing Emacs Startup Time.md b/sources/tech/20171119 Advanced Techniques for Reducing Emacs Startup Time.md
new file mode 100644
index 0000000000..6a761ac7d1
--- /dev/null
+++ b/sources/tech/20171119 Advanced Techniques for Reducing Emacs Startup Time.md
@@ -0,0 +1,252 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Advanced Techniques for Reducing Emacs Startup Time)
+[#]: via: (https://blog.d46.us/advanced-emacs-startup/)
+[#]: author: (Joe Schafer https://blog.d46.us/)
+
+Advanced Techniques for Reducing Emacs Startup Time
+======
+
+Six techniques to reduce Emacs startup time by the author of the [Emacs Start Up Profiler][1].
+
+tl;dr: Do these steps:
+
+ 1. Profile with Esup.
+ 2. Adjust the garbage collection threshold.
+ 3. Autoload **everything** with use-package.
+ 4. Avoid helper functions which cause eager loads.
+ 5. See my Emacs [config][2] for an example.
+
+
+
+### From .emacs.d Bankruptcy to Now
+
+I recently declared my third .emacs.d bankruptcy and finished the fourth iteration of my Emacs configuration. The evolution was:
+
+ 1. Copy and paste elisp snippets into `~/.emacs` and hope it works.
+ 2. Adopt a more structured approach with `el-get` to manage dependencies.
+ 3. Give up and outsource to Spacemacs.
+ 4. Get tired of Spacemacs intricacies and rewrite with `use-package`.
+
+
+
+This article is a collection of tips collected during the 3 rewrites and from creating the Emacs Start Up Profiler. Many thanks to the teams behind Spacemacs, use-package and general. Without these dedicated voluteers, this task would be vastly more difficult.
+
+### But What About Daemon Mode
+
+Before we get started, let me acknowledge the common retort when optimizing Emacs: “Emacs is meant to run as a daemon so you’ll only start it once.” That’s all well and good except:
+
+ * Fast things feel nicer.
+ * When customizing Emacs, you sometimes get into weird states that can be hard to recover from without restarting. For example, if you add a slow `lambda` function to your `post-command-hook`, it’s tough to remove it.
+ * Restarting Emacs helps verify that customization will persist between sessions.
+
+
+
+### 1\. Establish the Current and Best Possible Start Up Time
+
+The first step is to measure the current start up time. The easy way is to display the information at startup which will show progress through the next steps.
+
+```
+(add-hook 'emacs-startup-hook
+ (lambda ()
+ (message "Emacs ready in %s with %d garbage collections."
+ (format "%.2f seconds"
+ (float-time
+ (time-subtract after-init-time before-init-time)))
+ gcs-done)))
+```
+
+Second, measure the best possible startup speed so you know what’s possible. Mine is 0.3 seconds.
+
+```
+emacs -q --eval='(message "%s" (emacs-init-time))'
+
+;; For macOS users:
+open -n /Applications/Emacs.app --args -q --eval='(message "%s" (emacs-init-time))'
+```
+
+### 2\. Profile Emacs Startup for Easy Wins
+
+The [Emacs StartUp Profiler][1] (ESUP) will give you detailed metrics for top-level expressions.
+
+![esup.png][3]
+
+Figure 1:
+
+Emacs Start Up Profiler Screenshot
+
+WARNING: Spacemacs users, ESUP currently chokes on the Spacemacs init.el file. Follow for updates.
+
+### 3\. Set the Garbage Collection Threshold Higher during Startup
+
+This saves about ****0.3 seconds**** on my configuration.
+
+The default value for Emacs is 760kB which is extremely conservative on a modern machine. The real trick is to lower it back to something reasonable after initialization. This saves about 0.3 seconds on my init files.
+
+```
+;; Make startup faster by reducing the frequency of garbage
+;; collection. The default is 800 kilobytes. Measured in bytes.
+(setq gc-cons-threshold (* 50 1000 1000))
+
+;; The rest of the init file.
+
+;; Make gc pauses faster by decreasing the threshold.
+(setq gc-cons-threshold (* 2 1000 1000))
+```
+
+### 4\. Never require anything; autoload with use-package instead
+
+The best way to make Emacs faster is to do less. Running `require` eagerly loads the underlying source file. It’s rare the you’ll need functionality immediately at startup time.
+
+With [`use-package`][4], you declare which features you need from a package and `use-package` does the right thing. Here’s what it looks like:
+
+```
+(use-package evil-lisp-state ; the Melpa package name
+
+ :defer t ; autoload this package
+
+ :init ; Code to run immediately.
+ (setq evil-lisp-state-global nil)
+
+ :config ; Code to run after the package is loaded.
+ (abn/define-leader-keys "k" evil-lisp-state-map))
+```
+
+To see what packages Emacs currently has loaded, examine the `features` variable. For nice output see [lpkg explorer][5] or my variant in [abn-funcs-benchmark.el][6]. The output looks like:
+
+```
+479 features currently loaded
+ - abn-funcs-benchmark: /Users/jschaf/.dotfiles/emacs/funcs/abn-funcs-benchmark.el
+ - evil-surround: /Users/jschaf/.emacs.d/elpa/evil-surround-20170910.1952/evil-surround.elc
+ - misearch: /Applications/Emacs.app/Contents/Resources/lisp/misearch.elc
+ - multi-isearch: nil
+ -
+```
+
+### 5\. Avoid Helper Functions to Set Up Modes
+
+Often, Emacs packages will suggest running a helper function to set up keybindings. Here’s a few examples:
+
+ * `(evil-escape-mode)`
+ * `(windmove-default-keybindings) ; Sets up keybindings.`
+ * `(yas-global-mode 1) ; Complex snippet setup.`
+
+
+
+Rewrite these with use-package to improve startup speed. These helper functions are really just sneaky ways to trick you into eagerly loading packages before you need them.
+
+As an example, here’s how to autoload `evil-escape-mode`.
+
+```
+;; The definition of evil-escape-mode.
+(define-minor-mode evil-escape-mode
+ (if evil-escape-mode
+ (add-hook 'pre-command-hook 'evil-escape-pre-command-hook)
+ (remove-hook 'pre-command-hook 'evil-escape-pre-command-hook)))
+
+;; Before:
+(evil-escape-mode)
+
+;; After:
+(use-package evil-escape
+ :defer t
+ ;; Only needed for functions without an autoload comment (;;;###autoload).
+ :commands (evil-escape-pre-command-hook)
+
+ ;; Adding to a hook won't load the function until we invoke it.
+ ;; With pre-command-hook, that means the first command we run will
+ ;; load evil-escape.
+ :init (add-hook 'pre-command-hook 'evil-escape-pre-command-hook))
+```
+
+For a much trickier example, consider `org-babel`. The common recipe is:
+
+```
+(org-babel-do-load-languages
+ 'org-babel-load-languages
+ '((shell . t)
+ (emacs-lisp . nil)))
+```
+
+This is bad because `org-babel-do-load-languages` is defined in `org.el`, which is over 24k lines of code and takes about 0.2 seconds to load. After examining the source code, `org-babel-do-load-languages` is simply requiring the `ob-` package like so:
+
+```
+;; From org.el in the org-babel-do-load-languages function.
+(require (intern (concat "ob-" lang)))
+```
+
+In the `ob-.el`, there’s only two methods we care about, `org-babel-execute:` and `org-babel-expand-body:`. We can autoload the org-babel functionality instead of `org-babel-do-load-languages` like so:
+
+```
+;; Avoid `org-babel-do-load-languages' since it does an eager require.
+(use-package ob-python
+ :defer t
+ :ensure org-plus-contrib
+ :commands (org-babel-execute:python))
+
+(use-package ob-shell
+ :defer t
+ :ensure org-plus-contrib
+ :commands
+ (org-babel-execute:sh
+ org-babel-expand-body:sh
+
+ org-babel-execute:bash
+ org-babel-expand-body:bash))
+```
+
+### 6\. Defer Packages you don’t need Immediately with Idle Timers
+
+This saves about ****0.4 seconds**** for the 9 packages I defer.
+
+Some packages are useful and you want them available soon, but are not essential for immediate editing. These modes include:
+
+ * `recentf`: Saves recent files.
+ * `saveplace`: Saves point of visited files.
+ * `server`: Starts Emacs daemon.
+ * `autorevert`: Automatically reloads files that changed on disk.
+ * `paren`: Highlight matching parenthesis.
+ * `projectile`: Project management tools.
+ * `whitespace`: Highlight trailing whitespace.
+
+
+
+Instead of requiring these modes, ****load them after N seconds of idle time****. I use 1 second for the more important packages and 2 seconds for everything else.
+
+```
+(use-package recentf
+ ;; Loads after 1 second of idle time.
+ :defer 1)
+
+(use-package uniquify
+ ;; Less important than recentf.
+ :defer 2)
+```
+
+### Optimizations that aren’t Worth It
+
+Don’t bother byte-compiling your personal Emacs files. It saved about 0.05 seconds. Byte compiling causes difficult to debug errors when the source file gets out of sync with compiled file.
+
+
+--------------------------------------------------------------------------------
+
+via: https://blog.d46.us/advanced-emacs-startup/
+
+作者:[Joe Schafer][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://blog.d46.us/
+[b]: https://github.com/lujun9972
+[1]: https://github.com/jschaf/esup
+[2]: https://github.com/jschaf/dotfiles/blob/master/emacs/start.el
+[3]: https://blog.d46.us/images/esup.png
+[4]: https://github.com/jwiegley/use-package
+[5]: https://gist.github.com/RockyRoad29/bd4ca6fdb41196a71662986f809e2b1c
+[6]: https://github.com/jschaf/dotfiles/blob/master/emacs/funcs/abn-funcs-benchmark.el
diff --git a/sources/tech/20171214 Build a game framework with Python using the module Pygame.md b/sources/tech/20171214 Build a game framework with Python using the module Pygame.md
new file mode 100644
index 0000000000..704c74e042
--- /dev/null
+++ b/sources/tech/20171214 Build a game framework with Python using the module Pygame.md
@@ -0,0 +1,283 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Build a game framework with Python using the module Pygame)
+[#]: via: (https://opensource.com/article/17/12/game-framework-python)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Build a game framework with Python using the module Pygame
+======
+The first part of this series explored Python by creating a simple dice game. Now it's time to make your own game from scratch.
+
+
+In my [first article in this series][1], I explained how to use Python to create a simple, text-based dice game. This time, I'll demonstrate how to use the Python module Pygame to create a graphical game. It will take several articles to get a game that actually does anything, but by the end of the series, you will have a better understanding of how to find and learn new Python modules and how to build an application from the ground up.
+
+Before you start, you must install [Pygame][2].
+
+### Installing new Python modules
+
+There are several ways to install Python modules, but the two most common are:
+
+ * From your distribution's software repository
+ * Using the Python package manager, pip
+
+
+
+Both methods work well, and each has its own set of advantages. If you're developing on Linux or BSD, leveraging your distribution's software repository ensures automated and timely updates.
+
+However, using Python's built-in package manager gives you control over when modules are updated. Also, it is not OS-specific, meaning you can use it even when you're not on your usual development machine. Another advantage of pip is that it allows local installs of modules, which is helpful if you don't have administrative rights to a computer you're using.
+
+### Using pip
+
+If you have both Python and Python3 installed on your system, the command you want to use is probably `pip3`, which differentiates it from Python 2.x's `pip` command. If you're unsure, try `pip3` first.
+
+The `pip` command works a lot like most Linux package managers. You can search for Python modules with `search`, then install them with `install`. If you don't have permission to install software on the computer you're using, you can use the `--user` option to just install the module into your home directory.
+
+```
+$ pip3 search pygame
+[...]
+Pygame (1.9.3) - Python Game Development
+sge-pygame (1.5) - A 2-D game engine for Python
+pygame_camera (0.1.1) - A Camera lib for PyGame
+pygame_cffi (0.2.1) - A cffi-based SDL wrapper that copies the pygame API.
+[...]
+$ pip3 install Pygame --user
+```
+
+Pygame is a Python module, which means that it's just a set of libraries that can be used in your Python programs. In other words, it's not a program that you launch, like [IDLE][3] or [Ninja-IDE][4] are.
+
+### Getting started with Pygame
+
+A video game needs a setting; a world in which it takes place. In Python, there are two different ways to create your setting:
+
+ * Set a background color
+ * Set a background image
+
+
+
+Your background is only an image or a color. Your video game characters can't interact with things in the background, so don't put anything too important back there. It's just set dressing.
+
+### Setting up your Pygame script
+
+To start a new Pygame project, create a folder on your computer. All your game files go into this directory. It's vitally important that you keep all the files needed to run your game inside of your project folder.
+
+
+
+A Python script starts with the file type, your name, and the license you want to use. Use an open source license so your friends can improve your game and share their changes with you:
+
+```
+#!/usr/bin/env python3
+# by Seth Kenlon
+
+## GPLv3
+# This program is free software: you can redistribute it and/or
+# modify it under the terms of the GNU General Public License as
+# published by the Free Software Foundation, either version 3 of the
+# License, or (at your option) any later version.
+#
+# This program is distributed in the hope that it will be useful, but
+# WITHOUT ANY WARRANTY; without even the implied warranty of
+# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
+# General Public License for more details.
+#
+# You should have received a copy of the GNU General Public License
+# along with this program. If not, see .
+```
+
+Then you tell Python what modules you want to use. Some of the modules are common Python libraries, and of course, you want to include the one you just installed, Pygame.
+
+```
+import pygame # load pygame keywords
+import sys # let python use your file system
+import os # help python identify your OS
+```
+
+Since you'll be working a lot with this script file, it helps to make sections within the file so you know where to put stuff. You do this with block comments, which are comments that are visible only when looking at your source code. Create three blocks in your code.
+
+```
+'''
+Objects
+'''
+
+# put Python classes and functions here
+
+'''
+Setup
+'''
+
+# put run-once code here
+
+'''
+Main Loop
+'''
+
+# put game loop here
+```
+
+Next, set the window size for your game. Keep in mind that not everyone has a big computer screen, so it's best to use a screen size that fits on most people's computers.
+
+There is a way to toggle full-screen mode, the way many modern video games do, but since you're just starting out, keep it simple and just set one size.
+
+```
+'''
+Setup
+'''
+worldx = 960
+worldy = 720
+```
+
+The Pygame engine requires some basic setup before you can use it in a script. You must set the frame rate, start its internal clock, and start (`init`) Pygame.
+
+```
+fps = 40 # frame rate
+ani = 4 # animation cycles
+clock = pygame.time.Clock()
+pygame.init()
+```
+
+Now you can set your background.
+
+### Setting the background
+
+Before you continue, open a graphics application and create a background for your game world. Save it as `stage.png` inside a folder called `images` in your project directory.
+
+There are several free graphics applications you can use.
+
+ * [Krita][5] is a professional-level paint materials emulator that can be used to create beautiful images. If you're very interested in creating art for video games, you can even purchase a series of online [game art tutorials][6].
+ * [Pinta][7] is a basic, easy to learn paint application.
+ * [Inkscape][8] is a vector graphics application. Use it to draw with shapes, lines, splines, and Bézier curves.
+
+
+
+Your graphic doesn't have to be complex, and you can always go back and change it later. Once you have it, add this code in the setup section of your file:
+
+```
+world = pygame.display.set_mode([worldx,worldy])
+backdrop = pygame.image.load(os.path.join('images','stage.png').convert())
+backdropbox = world.get_rect()
+```
+
+If you're just going to fill the background of your game world with a color, all you need is:
+
+```
+world = pygame.display.set_mode([worldx,worldy])
+```
+
+You also must define a color to use. In your setup section, create some color definitions using values for red, green, and blue (RGB).
+
+```
+'''
+Setup
+'''
+
+BLUE = (25,25,200)
+BLACK = (23,23,23 )
+WHITE = (254,254,254)
+```
+
+At this point, you could theoretically start your game. The problem is, it would only last for a millisecond.
+
+To prove this, save your file as `your-name_game.py` (replace `your-name` with your actual name). Then launch your game.
+
+If you are using IDLE, run your game by selecting `Run Module` from the Run menu.
+
+If you are using Ninja, click the `Run file` button in the left button bar.
+
+
+
+You can also run a Python script straight from a Unix terminal or a Windows command prompt.
+
+```
+$ python3 ./your-name_game.py
+```
+
+If you're using Windows, use this command:
+
+```
+py.exe your-name_game.py
+```
+
+However you launch it, don't expect much, because your game only lasts a few milliseconds right now. You can fix that in the next section.
+
+### Looping
+
+Unless told otherwise, a Python script runs once and only once. Computers are very fast these days, so your Python script runs in less than a second.
+
+To force your game to stay open and active long enough for someone to see it (let alone play it), use a `while` loop. To make your game remain open, you can set a variable to some value, then tell a `while` loop to keep looping for as long as the variable remains unchanged.
+
+This is often called a "main loop," and you can use the term `main` as your variable. Add this anywhere in your setup section:
+
+```
+main = True
+```
+
+During the main loop, use Pygame keywords to detect if keys on the keyboard have been pressed or released. Add this to your main loop section:
+
+```
+'''
+Main loop
+'''
+while main == True:
+ for event in pygame.event.get():
+ if event.type == pygame.QUIT:
+ pygame.quit(); sys.exit()
+ main = False
+
+ if event.type == pygame.KEYDOWN:
+ if event.key == ord('q'):
+ pygame.quit()
+ sys.exit()
+ main = False
+```
+
+Also in your main loop, refresh your world's background.
+
+If you are using an image for the background:
+
+```
+world.blit(backdrop, backdropbox)
+```
+
+If you are using a color for the background:
+
+```
+world.fill(BLUE)
+```
+
+Finally, tell Pygame to refresh everything on the screen and advance the game's internal clock.
+
+```
+ pygame.display.flip()
+ clock.tick(fps)
+```
+
+Save your file, and run it again to see the most boring game ever created.
+
+To quit the game, press `q` on your keyboard.
+
+In the [next article][9] of this series, I'll show you how to add to your currently empty game world, so go ahead and start creating some graphics to use!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/12/game-framework-python
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/17/10/python-101
+[2]: http://www.pygame.org/wiki/about
+[3]: https://en.wikipedia.org/wiki/IDLE
+[4]: http://ninja-ide.org/
+[5]: http://krita.org
+[6]: https://gumroad.com/l/krita-game-art-tutorial-1
+[7]: https://pinta-project.com/pintaproject/pinta/releases
+[8]: http://inkscape.org
+[9]: https://opensource.com/article/17/12/program-game-python-part-3-spawning-player
diff --git a/sources/tech/20171215 How to add a player to your Python game.md b/sources/tech/20171215 How to add a player to your Python game.md
new file mode 100644
index 0000000000..caa1e4754e
--- /dev/null
+++ b/sources/tech/20171215 How to add a player to your Python game.md
@@ -0,0 +1,162 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to add a player to your Python game)
+[#]: via: (https://opensource.com/article/17/12/game-python-add-a-player)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+How to add a player to your Python game
+======
+Part three of a series on building a game from scratch with Python.
+
+
+In the [first article of this series][1], I explained how to use Python to create a simple, text-based dice game. In the second part, I showed you how to build a game from scratch, starting with [creating the game's environment][2]. But every game needs a player, and every player needs a playable character, so that's what we'll do next in the third part of the series.
+
+In Pygame, the icon or avatar that a player controls is called a sprite. If you don't have any graphics to use for a player sprite yet, create something for yourself using [Krita][3] or [Inkscape][4]. If you lack confidence in your artistic skills, you can also search [OpenClipArt.org][5] or [OpenGameArt.org][6] for something pre-generated. Then, if you didn't already do so in the previous article, create a directory called `images` alongside your Python project directory. Put the images you want to use in your game into the `images` folder.
+
+To make your game truly exciting, you ought to use an animated sprite for your hero. It means you have to draw more assets, but it makes a big difference. The most common animation is a walk cycle, a series of drawings that make it look like your sprite is walking. The quick and dirty version of a walk cycle requires four drawings.
+
+
+
+Note: The code samples in this article allow for both a static player sprite and an animated one.
+
+Name your player sprite `hero.png`. If you're creating an animated sprite, append a digit after the name, starting with `hero1.png`.
+
+### Create a Python class
+
+In Python, when you create an object that you want to appear on screen, you create a class.
+
+Near the top of your Python script, add the code to create a player. In the code sample below, the first three lines are already in the Python script that you're working on:
+
+```
+import pygame
+import sys
+import os # new code below
+
+class Player(pygame.sprite.Sprite):
+ '''
+ Spawn a player
+ '''
+ def __init__(self):
+ pygame.sprite.Sprite.__init__(self)
+ self.images = []
+ img = pygame.image.load(os.path.join('images','hero.png')).convert()
+ self.images.append(img)
+ self.image = self.images[0]
+ self.rect = self.image.get_rect()
+```
+
+If you have a walk cycle for your playable character, save each drawing as an individual file called `hero1.png` to `hero4.png` in the `images` folder.
+
+Use a loop to tell Python to cycle through each file.
+
+```
+'''
+Objects
+'''
+
+class Player(pygame.sprite.Sprite):
+ '''
+ Spawn a player
+ '''
+ def __init__(self):
+ pygame.sprite.Sprite.__init__(self)
+ self.images = []
+ for i in range(1,5):
+ img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
+ self.images.append(img)
+ self.image = self.images[0]
+ self.rect = self.image.get_rect()
+```
+
+### Bring the player into the game world
+
+Now that a Player class exists, you must use it to spawn a player sprite in your game world. If you never call on the Player class, it never runs, and there will be no player. You can test this out by running your game now. The game will run just as well as it did at the end of the previous article, with the exact same results: an empty game world.
+
+To bring a player sprite into your world, you must call the Player class to generate a sprite and then add it to a Pygame sprite group. In this code sample, the first three lines are existing code, so add the lines afterwards:
+
+```
+world = pygame.display.set_mode([worldx,worldy])
+backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
+backdropbox = screen.get_rect()
+
+# new code below
+
+player = Player() # spawn player
+player.rect.x = 0 # go to x
+player.rect.y = 0 # go to y
+player_list = pygame.sprite.Group()
+player_list.add(player)
+```
+
+Try launching your game to see what happens. Warning: it won't do what you expect. When you launch your project, the player sprite doesn't spawn. Actually, it spawns, but only for a millisecond. How do you fix something that only happens for a millisecond? You might recall from the previous article that you need to add something to the main loop. To make the player spawn for longer than a millisecond, tell Python to draw it once per loop.
+
+Change the bottom clause of your loop to look like this:
+
+```
+ world.blit(backdrop, backdropbox)
+ player_list.draw(screen) # draw player
+ pygame.display.flip()
+ clock.tick(fps)
+```
+
+Launch your game now. Your player spawns!
+
+### Setting the alpha channel
+
+Depending on how you created your player sprite, it may have a colored block around it. What you are seeing is the space that ought to be occupied by an alpha channel. It's meant to be the "color" of invisibility, but Python doesn't know to make it invisible yet. What you are seeing, then, is the space within the bounding box (or "hit box," in modern gaming terms) around the sprite.
+
+
+
+You can tell Python what color to make invisible by setting an alpha channel and using RGB values. If you don't know the RGB values your drawing uses as alpha, open your drawing in Krita or Inkscape and fill the empty space around your drawing with a unique color, like #00ff00 (more or less a "greenscreen green"). Take note of the color's hex value (#00ff00, for greenscreen green) and use that in your Python script as the alpha channel.
+
+Using alpha requires the addition of two lines in your Sprite creation code. Some version of the first line is already in your code. Add the other two lines:
+
+```
+ img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
+ img.convert_alpha() # optimise alpha
+ img.set_colorkey(ALPHA) # set alpha
+```
+
+Python doesn't know what to use as alpha unless you tell it. In the setup area of your code, add some more color definitions. Add this variable definition anywhere in your setup section:
+
+```
+ALPHA = (0, 255, 0)
+```
+
+In this example code, **0,255,0** is used, which is the same value in RGB as #00ff00 is in hex. You can get all of these color values from a good graphics application like [GIMP][7], Krita, or Inkscape. Alternately, you can also detect color values with a good system-wide color chooser, like [KColorChooser][8].
+
+
+
+If your graphics application is rendering your sprite's background as some other value, adjust the values of your alpha variable as needed. No matter what you set your alpha value, it will be made "invisible." RGB values are very strict, so if you need to use 000 for alpha, but you need 000 for the black lines of your drawing, just change the lines of your drawing to 111, which is close enough to black that nobody but a computer can tell the difference.
+
+Launch your game to see the results.
+
+
+
+In the [fourth part of this series][9], I'll show you how to make your sprite move. How exciting!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/12/game-python-add-a-player
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/17/10/python-101
+[2]: https://opensource.com/article/17/12/program-game-python-part-2-creating-game-world
+[3]: http://krita.org
+[4]: http://inkscape.org
+[5]: http://openclipart.org
+[6]: https://opengameart.org/
+[7]: http://gimp.org
+[8]: https://github.com/KDE/kcolorchooser
+[9]: https://opensource.com/article/17/12/program-game-python-part-4-moving-your-sprite
diff --git a/sources/tech/20180220 JSON vs XML vs TOML vs CSON vs YAML.md b/sources/tech/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
index eeb290c82b..bb723b75e6 100644
--- a/sources/tech/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
+++ b/sources/tech/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (GraveAccent)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/tech/20180330 Asynchronous rsync with Emacs, dired and tramp..md b/sources/tech/20180330 Asynchronous rsync with Emacs, dired and tramp..md
new file mode 100644
index 0000000000..954644918b
--- /dev/null
+++ b/sources/tech/20180330 Asynchronous rsync with Emacs, dired and tramp..md
@@ -0,0 +1,77 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Asynchronous rsync with Emacs, dired and tramp.)
+[#]: via: (https://vxlabs.com/2018/03/30/asynchronous-rsync-with-emacs-dired-and-tramp/)
+[#]: author: (cpbotha https://vxlabs.com/author/cpbotha/)
+
+Asynchronous rsync with Emacs, dired and tramp.
+======
+
+[tmtxt-dired-async][1] by [Trần Xuân Trường][2] is an unfortunately lesser known Emacs package which extends dired, the Emacs file manager, to be able to run rsync and other commands (zip, unzip, downloading) asynchronously.
+
+This means you can copy gigabytes of directories around whilst still happily continuing with all of your other tasks in the Emacs operating system.
+
+It has a feature where you can add any number of files from different locations into a wait list with `C-c C-a`, and then asynchronously rsync the whole wait list into a final destination directory with `C-c C-v`. This alone is worth the price of admission.
+
+For example here it is pointlessly rsyncing the arduino 1.9 beta archive to another directory:
+
+[![][3]][4]
+
+When the process is complete, the window at the bottom will automatically be killed after 5 seconds. Here is a separate session right after the asynchronous unzipping of the above-mentioned arduino archive:
+
+[![][5]][6]
+
+This package has further increased the utility of my dired configuration.
+
+I just contributed [a pull request that enables tmtxt-dired-async to rsync to remote tramp-based directories][7], and I immediately used this new functionality to sort a few gigabytes of new photos onto the Linux server.
+
+To add tmtxt-dired-async to your config, download [tmtxt-async-tasks.el][8] (a required library) and [tmtxt-dired-async.el][9] (check that my PR is in there if you plan to use this with tramp) into your `~/.emacs.d/` and add the following to your config:
+
+```
+;; no MELPA packages of this, so we have to do a simple check here
+(setq dired-async-el (expand-file-name "~/.emacs.d/tmtxt-dired-async.el"))
+(when (file-exists-p dired-async-el)
+ (load (expand-file-name "~/.emacs.d/tmtxt-async-tasks.el"))
+ (load dired-async-el)
+ (define-key dired-mode-map (kbd "C-c C-r") 'tda/rsync)
+ (define-key dired-mode-map (kbd "C-c C-z") 'tda/zip)
+ (define-key dired-mode-map (kbd "C-c C-u") 'tda/unzip)
+
+ (define-key dired-mode-map (kbd "C-c C-a") 'tda/rsync-multiple-mark-file)
+ (define-key dired-mode-map (kbd "C-c C-e") 'tda/rsync-multiple-empty-list)
+ (define-key dired-mode-map (kbd "C-c C-d") 'tda/rsync-multiple-remove-item)
+ (define-key dired-mode-map (kbd "C-c C-v") 'tda/rsync-multiple)
+
+ (define-key dired-mode-map (kbd "C-c C-s") 'tda/get-files-size)
+
+ (define-key dired-mode-map (kbd "C-c C-q") 'tda/download-to-current-dir))
+```
+
+Enjoy!
+
+
+--------------------------------------------------------------------------------
+
+via: https://vxlabs.com/2018/03/30/asynchronous-rsync-with-emacs-dired-and-tramp/
+
+作者:[cpbotha][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://vxlabs.com/author/cpbotha/
+[b]: https://github.com/lujun9972
+[1]: https://truongtx.me/tmtxt-dired-async.html
+[2]: https://truongtx.me/about.html
+[3]: https://i0.wp.com/vxlabs.com/wp-content/uploads/2018/03/rsync-arduino-zip.png?resize=660%2C340&ssl=1
+[4]: https://i0.wp.com/vxlabs.com/wp-content/uploads/2018/03/rsync-arduino-zip.png?ssl=1
+[5]: https://i1.wp.com/vxlabs.com/wp-content/uploads/2018/03/progress-window-5s.png?resize=660%2C310&ssl=1
+[6]: https://i1.wp.com/vxlabs.com/wp-content/uploads/2018/03/progress-window-5s.png?ssl=1
+[7]: https://github.com/tmtxt/tmtxt-dired-async/pull/6
+[8]: https://github.com/tmtxt/tmtxt-async-tasks
+[9]: https://github.com/tmtxt/tmtxt-dired-async
diff --git a/sources/tech/20180518 What-s a hero without a villain- How to add one to your Python game.md b/sources/tech/20180518 What-s a hero without a villain- How to add one to your Python game.md
deleted file mode 100644
index 52b46c1adb..0000000000
--- a/sources/tech/20180518 What-s a hero without a villain- How to add one to your Python game.md
+++ /dev/null
@@ -1,277 +0,0 @@
-Translating by cycoe
-Cycoe 翻译中
-What's a hero without a villain? How to add one to your Python game
-======
-
-
-In the previous articles in this series (see [part 1][1], [part 2][2], [part 3][3], and [part 4][4]), you learned how to use Pygame and Python to spawn a playable character in an as-yet empty video game world. But, what's a hero without a villain?
-
-It would make for a pretty boring game if you had no enemies, so in this article, you'll add an enemy to your game and construct a framework for building levels.
-
-It might seem strange to jump ahead to enemies when there's still more to be done to make the player sprite fully functional, but you've learned a lot already, and creating villains is very similar to creating a player sprite. So relax, use the knowledge you already have, and see what it takes to stir up some trouble.
-
-For this exercise, you can download some pre-built assets from [Open Game Art][5]. Here are some of the assets I use:
-
-
-+ Inca tileset
-+ Some invaders
-+ Sprites, characters, objects, and effects
-
-
-### Creating the enemy sprite
-
-Yes, whether you realize it or not, you basically already know how to implement enemies. The process is very similar to creating a player sprite:
-
- 1. Make a class so enemies can spawn.
- 2. Create an `update` function so enemies can detect collisions.
- 3. Create a `move` function so your enemy can roam around.
-
-
-
-Start with the class. Conceptually, it's mostly the same as your Player class. You set an image or series of images, and you set the sprite's starting position.
-
-Before continuing, make sure you have a graphic for your enemy, even if it's just a temporary one. Place the graphic in your game project's `images` directory (the same directory where you placed your player image).
-
-A game looks a lot better if everything alive is animated. Animating an enemy sprite is done the same way as animating a player sprite. For now, though, keep it simple, and use a non-animated sprite.
-
-At the top of the `objects` section of your code, create a class called Enemy with this code:
-```
-class Enemy(pygame.sprite.Sprite):
-
- '''
-
- Spawn an enemy
-
- '''
-
- def __init__(self,x,y,img):
-
- pygame.sprite.Sprite.__init__(self)
-
- self.image = pygame.image.load(os.path.join('images',img))
-
- self.image.convert_alpha()
-
- self.image.set_colorkey(ALPHA)
-
- self.rect = self.image.get_rect()
-
- self.rect.x = x
-
- self.rect.y = y
-
-```
-
-If you want to animate your enemy, do it the [same way][4] you animated your player.
-
-### Spawning an enemy
-
-You can make the class useful for spawning more than just one enemy by allowing yourself to tell the class which image to use for the sprite and where in the world the sprite should appear. This means you can use this same enemy class to generate any number of enemy sprites anywhere in the game world. All you have to do is make a call to the class, and tell it which image to use and the X and Y coordinates of your desired spawn point.
-
-Again, this is similar in principle to spawning a player sprite. In the `setup` section of your script, add this code:
-```
-enemy = Enemy(20,200,'yeti.png')# spawn enemy
-
-enemy_list = pygame.sprite.Group() # create enemy group
-
-enemy_list.add(enemy) # add enemy to group
-
-```
-
-In that sample code, `20` is the X position and `200` is the Y position. You might need to adjust these numbers, depending on how big your enemy sprite is, but try to get it to spawn in a place so that you can reach it with your player sprite. `Yeti.png` is the image used for the enemy.
-
-Next, draw all enemies in the enemy group to the screen. Right now, you have only one enemy, but you can add more later if you want. As long as you add an enemy to the enemies group, it will be drawn to the screen during the main loop. The middle line is the new line you need to add:
-```
- player_list.draw(world)
-
- enemy_list.draw(world) # refresh enemies
-
- pygame.display.flip()
-
-```
-
-Launch your game. Your enemy appears in the game world at whatever X and Y coordinate you chose.
-
-### Level one
-
-Your game is in its infancy, but you will probably want to add another level. It's important to plan ahead when you program so your game can grow as you learn more about programming. Even though you don't even have one complete level yet, you should code as if you plan on having many levels.
-
-Think about what a "level" is. How do you know you are at a certain level in a game?
-
-You can think of a level as a collection of items. In a platformer, such as the one you are building here, a level consists of a specific arrangement of platforms, placement of enemies and loot, and so on. You can build a class that builds a level around your player. Eventually, when you create more than one level, you can use this class to generate the next level when your player reaches a specific goal.
-
-Move the code you wrote to create an enemy and its group into a new function that will be called along with each new level. It requires some modification so that each time you create a new level, you can create several enemies:
-```
-class Level():
-
- def bad(lvl,eloc):
-
- if lvl == 1:
-
- enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
-
- enemy_list = pygame.sprite.Group() # create enemy group
-
- enemy_list.add(enemy) # add enemy to group
-
- if lvl == 2:
-
- print("Level " + str(lvl) )
-
-
-
- return enemy_list
-
-```
-
-The `return` statement ensures that when you use the `Level.bad` function, you're left with an `enemy_list` containing each enemy you defined.
-
-Since you are creating enemies as part of each level now, your `setup` section needs to change, too. Instead of creating an enemy, you must define where the enemy will spawn and what level it belongs to.
-```
-eloc = []
-
-eloc = [200,20]
-
-enemy_list = Level.bad( 1, eloc )
-
-```
-
-Run the game again to confirm your level is generating correctly. You should see your player, as usual, and the enemy you added in this chapter.
-
-### Hitting the enemy
-
-An enemy isn't much of an enemy if it has no effect on the player. It's common for enemies to cause damage when a player collides with them.
-
-Since you probably want to track the player's health, the collision check happens in the Player class rather than in the Enemy class. You can track the enemy's health, too, if you want. The logic and code are pretty much the same, but, for now, just track the player's health.
-
-To track player health, you must first establish a variable for the player's health. The first line in this code sample is for context, so add the second line to your Player class:
-```
- self.frame = 0
-
- self.health = 10
-
-```
-
-In the `update` function of your Player class, add this code block:
-```
- hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
-
- for enemy in hit_list:
-
- self.health -= 1
-
- print(self.health)
-
-```
-
-This code establishes a collision detector using the Pygame function `sprite.spritecollide`, called `enemy_hit`. This collision detector sends out a signal any time the hitbox of its parent sprite (the player sprite, where this detector has been created) touches the hitbox of any sprite in `enemy_list`. The `for` loop is triggered when such a signal is received and deducts a point from the player's health.
-
-Since this code appears in the `update` function of your player class and `update` is called in your main loop, Pygame checks for this collision once every clock tick.
-
-### Moving the enemy
-
-An enemy that stands still is useful if you want, for instance, spikes or traps that can harm your player, but the game is more of a challenge if the enemies move around a little.
-
-Unlike a player sprite, the enemy sprite is not controlled by the user. Its movements must be automated.
-
-Eventually, your game world will scroll, so how do you get an enemy to move back and forth within the game world when the game world itself is moving?
-
-You tell your enemy sprite to take, for example, 10 paces to the right, then 10 paces to the left. An enemy sprite can't count, so you have to create a variable to keep track of how many paces your enemy has moved and program your enemy to move either right or left depending on the value of your counting variable.
-
-First, create the counter variable in your Enemy class. Add the last line in this code sample:
-```
- self.rect = self.image.get_rect()
-
- self.rect.x = x
-
- self.rect.y = y
-
- self.counter = 0 # counter variable
-
-```
-
-Next, create a `move` function in your Enemy class. Use an if-else loop to create what is called an infinite loop:
-
- * Move right if the counter is on any number from 0 to 100.
- * Move left if the counter is on any number from 100 to 200.
- * Reset the counter back to 0 if the counter is greater than 200.
-
-
-
-An infinite loop has no end; it loops forever because nothing in the loop is ever untrue. The counter, in this case, is always either between 0 and 100 or 100 and 200, so the enemy sprite walks right to left and right to left forever.
-
-The actual numbers you use for how far the enemy will move in either direction depending on your screen size, and possibly, eventually, the size of the platform your enemy is walking on. Start small and work your way up as you get used to the results. Try this first:
-```
- def move(self):
-
- '''
-
- enemy movement
-
- '''
-
- distance = 80
-
- speed = 8
-
-
-
- if self.counter >= 0 and self.counter <= distance:
-
- self.rect.x += speed
-
- elif self.counter >= distance and self.counter <= distance*2:
-
- self.rect.x -= speed
-
- else:
-
- self.counter = 0
-
-
-
- self.counter += 1
-
-```
-
-You can adjust the distance and speed as needed.
-
-Will this code work if you launch your game now?
-
-Of course not, and you probably know why. You must call the `move` function in your main loop. The first line in this sample code is for context, so add the last two lines:
-```
- enemy_list.draw(world) #refresh enemy
-
- for e in enemy_list:
-
- e.move()
-
-```
-
-Launch your game and see what happens when you hit your enemy. You might have to adjust where the sprites spawn so that your player and your enemy sprite can collide. When they do collide, look in the console of [IDLE][6] or [Ninja-IDE][7] to see the health points being deducted.
-
-
-
-You may notice that health is deducted for every moment your player and enemy are touching. That's a problem, but it's a problem you'll solve later, after you've had more practice with Python.
-
-For now, try adding some more enemies. Remember to add each enemy to the `enemy_list`. As an exercise, see if you can think of how you can change how far different enemy sprites move.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/5/pygame-enemy
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth
-[1]:https://opensource.com/article/17/10/python-101
-[2]:https://opensource.com/article/17/12/game-framework-python
-[3]:https://opensource.com/article/17/12/game-python-add-a-player
-[4]:https://opensource.com/article/17/12/game-python-moving-player
-[5]:https://opengameart.org
-[6]:https://docs.python.org/3/library/idle.html
-[7]:http://ninja-ide.org/
diff --git a/sources/tech/20180725 Put platforms in a Python game with Pygame.md b/sources/tech/20180725 Put platforms in a Python game with Pygame.md
new file mode 100644
index 0000000000..759bfc01df
--- /dev/null
+++ b/sources/tech/20180725 Put platforms in a Python game with Pygame.md
@@ -0,0 +1,590 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Put platforms in a Python game with Pygame)
+[#]: via: (https://opensource.com/article/18/7/put-platforms-python-game)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Put platforms in a Python game with Pygame
+======
+In part six of this series on building a Python game from scratch, create some platforms for your characters to travel.
+
+
+This is part 6 in an ongoing series about creating video games in Python 3 using the Pygame module. Previous articles are:
+
++ [Learn how to program in Python by building a simple dice game][24]
++ [Build a game framework with Python using the Pygame module][25]
++ [How to add a player to your Python game][26]
++ [Using Pygame to move your game character around][27]
++ [What's a hero without a villain? How to add one to your Python game][28]
+
+
+A platformer game needs platforms.
+
+In [Pygame][1], the platforms themselves are sprites, just like your playable sprite. That's important because having platforms that are objects makes it a lot easier for your player sprite to interact with them.
+
+There are two major steps in creating platforms. First, you must code the objects, and then you must map out where you want the objects to appear.
+
+### Coding platform objects
+
+To build a platform object, you create a class called `Platform`. It's a sprite, just like your [`Player`][2] [sprite][2], with many of the same properties.
+
+Your `Platform` class needs to know a lot of information about what kind of platform you want, where it should appear in the game world, and what image it should contain. A lot of that information might not even exist yet, depending on how much you have planned out your game, but that's all right. Just as you didn't tell your Player sprite how fast to move until the end of the [Movement article][3], you don't have to tell `Platform` everything upfront.
+
+Near the top of the script you've been writing in this series, create a new class. The first three lines in this code sample are for context, so add the code below the comment:
+
+```
+import pygame
+import sys
+import os
+## new code below:
+
+class Platform(pygame.sprite.Sprite):
+# x location, y location, img width, img height, img file
+def __init__(self,xloc,yloc,imgw,imgh,img):
+ pygame.sprite.Sprite.__init__(self)
+ self.image = pygame.image.load(os.path.join('images',img)).convert()
+ self.image.convert_alpha()
+ self.image.set_colorkey(ALPHA)
+ self.rect = self.image.get_rect()
+ self.rect.y = yloc
+ self.rect.x = xloc
+```
+
+When called, this class creates an object onscreen in some X and Y location, with some width and height, using some image file for texture. It's very similar to how players or enemies are drawn onscreen.
+
+### Types of platforms
+
+The next step is to map out where all your platforms need to appear.
+
+#### The tile method
+
+There are a few different ways to implement a platform game world. In the original side-scroller games, such as Mario Super Bros. and Sonic the Hedgehog, the technique was to use "tiles," meaning that there were a few blocks to represent the ground and various platforms, and these blocks were used and reused to make a level. You have only eight or 12 different kinds of blocks, and you line them up onscreen to create the ground, floating platforms, and whatever else your game needs. Some people find this the easier way to make a game since you just have to make (or download) a small set of level assets to create many different levels. The code, however, requires a little more math.
+
+![Supertux, a tile-based video game][5]
+
+[SuperTux][6], a tile-based video game.
+
+#### The hand-painted method
+
+Another method is to make each and every asset as one whole image. If you enjoy creating assets for your game world, this is a great excuse to spend time in a graphics application, building each and every part of your game world. This method requires less math, because all the platforms are whole, complete objects, and you tell [Python][7] where to place them onscreen.
+
+Each method has advantages and disadvantages, and the code you must use is slightly different depending on the method you choose. I'll cover both so you can use one or the other, or even a mix of both, in your project.
+
+### Level mapping
+
+Mapping out your game world is a vital part of level design and game programming in general. It does involve math, but nothing too difficult, and Python is good at math so it can help some.
+
+You might find it helpful to design on paper first. Get a sheet of paper and draw a box to represent your game window. Draw platforms in the box, labeling each with its X and Y coordinates, as well as its intended width and height. The actual positions in the box don't have to be exact, as long as you keep the numbers realistic. For instance, if your screen is 720 pixels wide, then you can't fit eight platforms at 100 pixels each all on one screen.
+
+Of course, not all platforms in your game have to fit in one screen-sized box, because your game will scroll as your player walks through it. So keep drawing your game world to the right of the first screen until the end of the level.
+
+If you prefer a little more precision, you can use graph paper. This is especially helpful when designing a game with tiles because each grid square can represent one tile.
+
+![Example of a level map][9]
+
+Example of a level map.
+
+#### Coordinates
+
+You may have learned in school about the [Cartesian coordinate system][10]. What you learned applies to Pygame, except that in Pygame, your game world's coordinates place `0,0` in the top-left corner of your screen instead of in the middle, which is probably what you're used to from Geometry class.
+
+![Example of coordinates in Pygame][12]
+
+Example of coordinates in Pygame.
+
+The X axis starts at 0 on the far left and increases infinitely to the right. The Y axis starts at 0 at the top of the screen and extends down.
+
+#### Image sizes
+
+Mapping out a game world is meaningless if you don't know how big your players, enemies, and platforms are. You can find the dimensions of your platforms or tiles in a graphics program. In [Krita][13], for example, click on the **Image** menu and select **Properties**. You can find the dimensions at the very top of the **Properties** window.
+
+Alternately, you can create a simple Python script to tell you the dimensions of an image. Open a new text file and type this code into it:
+
+```
+#!/usr/bin/env python3
+
+from PIL import Image
+import os.path
+import sys
+
+if len(sys.argv) > 1:
+ print(sys.argv[1])
+else:
+ sys.exit('Syntax: identify.py [filename]')
+
+pic = sys.argv[1]
+dim = Image.open(pic)
+X = dim.size[0]
+Y = dim.size[1]
+
+print(X,Y)
+```
+
+Save the text file as `identify.py`.
+
+To set up this script, you must install an extra set of Python modules that contain the new keywords used in the script:
+
+```
+$ pip3 install Pillow --user
+```
+
+Once that is installed, run your script from within your game project directory:
+
+```
+$ python3 ./identify.py images/ground.png
+(1080, 97)
+```
+
+The image size of the ground platform in this example is 1080 pixels wide and 97 high.
+
+### Platform blocks
+
+If you choose to draw each asset individually, you must create several platforms and any other elements you want to insert into your game world, each within its own file. In other words, you should have one file per asset, like this:
+
+![One image file per object][15]
+
+One image file per object.
+
+You can reuse each platform as many times as you want, just make sure that each file only contains one platform. You cannot use a file that contains everything, like this:
+
+![Your level cannot be one image file][17]
+
+Your level cannot be one image file.
+
+You might want your game to look like that when you've finished, but if you create your level in one big file, there is no way to distinguish a platform from the background, so either paint your objects in their own file or crop them from a large file and save individual copies.
+
+**Note:** As with your other assets, you can use [GIMP][18], Krita, [MyPaint][19], or [Inkscape][20] to create your game assets.
+
+Platforms appear on the screen at the start of each level, so you must add a `platform` function in your `Level` class. The special case here is the ground platform, which is important enough to be treated as its own platform group. By treating the ground as its own special kind of platform, you can choose whether it scrolls or whether it stands still while other platforms float over the top of it. It's up to you.
+
+Add these two functions to your `Level` class:
+
+```
+def ground(lvl,x,y,w,h):
+ ground_list = pygame.sprite.Group()
+ if lvl == 1:
+ ground = Platform(x,y,w,h,'block-ground.png')
+ ground_list.add(ground)
+
+ if lvl == 2:
+ print("Level " + str(lvl) )
+
+ return ground_list
+
+def platform( lvl ):
+ plat_list = pygame.sprite.Group()
+ if lvl == 1:
+ plat = Platform(200, worldy-97-128, 285,67,'block-big.png')
+ plat_list.add(plat)
+ plat = Platform(500, worldy-97-320, 197,54,'block-small.png')
+ plat_list.add(plat)
+ if lvl == 2:
+ print("Level " + str(lvl) )
+
+ return plat_list
+```
+
+The `ground` function requires an X and Y location so Pygame knows where to place the ground platform. It also requires the width and height of the platform so Pygame knows how far the ground extends in each direction. The function uses your `Platform` class to generate an object onscreen, and then adds that object to the `ground_list` group.
+
+The `platform` function is essentially the same, except that there are more platforms to list. In this example, there are only two, but you can have as many as you like. After entering one platform, you must add it to the `plat_list` before listing another. If you don't add a platform to the group, then it won't appear in your game.
+
+> **Tip:** It can be difficult to think of your game world with 0 at the top, since the opposite is what happens in the real world; when figuring out how tall you are, you don't measure yourself from the sky down, you measure yourself from your feet to the top of your head.
+>
+> If it's easier for you to build your game world from the "ground" up, it might help to express Y-axis values as negatives. For instance, you know that the bottom of your game world is the value of `worldy`. So `worldy` minus the height of the ground (97, in this example) is where your player is normally standing. If your character is 64 pixels tall, then the ground minus 128 is exactly twice as tall as your player. Effectively, a platform placed at 128 pixels is about two stories tall, relative to your player. A platform at -320 is three more stories. And so on.
+
+As you probably know by now, none of your classes and functions are worth much if you don't use them. Add this code to your setup section (the first line is just for context, so add the last two lines):
+
+```
+enemy_list = Level.bad( 1, eloc )
+ground_list = Level.ground( 1,0,worldy-97,1080,97 )
+plat_list = Level.platform( 1 )
+```
+
+And add these lines to your main loop (again, the first line is just for context):
+
+```
+enemy_list.draw(world) # refresh enemies
+ground_list.draw(world) # refresh ground
+plat_list.draw(world) # refresh platforms
+```
+
+### Tiled platforms
+
+Tiled game worlds are considered easier to make because you just have to draw a few blocks upfront and can use them over and over to create every platform in the game. There are even sets of tiles for you to use on sites like [OpenGameArt.org][21].
+
+The `Platform` class is the same as the one provided in the previous sections.
+
+The `ground` and `platform` in the `Level` class, however, must use loops to calculate how many blocks to use to create each platform.
+
+If you intend to have one solid ground in your game world, the ground is simple. You just "clone" your ground tile across the whole window. For instance, you could create a list of X and Y values to dictate where each tile should be placed, and then use a loop to take each value and draw one tile. This is just an example, so don't add this to your code:
+
+```
+# Do not add this to your code
+gloc = [0,656,64,656,128,656,192,656,256,656,320,656,384,656]
+```
+
+If you look carefully, though, you can see all the Y values are always the same, and the X values increase steadily in increments of 64, which is the size of the tiles. That kind of repetition is exactly what computers are good at, so you can use a little bit of math logic to have the computer do all the calculations for you:
+
+Add this to the setup part of your script:
+
+```
+gloc = []
+tx = 64
+ty = 64
+
+i=0
+while i <= (worldx/tx)+tx:
+ gloc.append(i*tx)
+ i=i+1
+
+ground_list = Level.ground( 1,gloc,tx,ty )
+```
+
+Now, regardless of the size of your window, Python divides the width of the game world by the width of the tile and creates an array listing each X value. This doesn't calculate the Y value, but that never changes on flat ground anyway.
+
+To use the array in a function, use a `while` loop that looks at each entry and adds a ground tile at the appropriate location:
+
+```
+def ground(lvl,gloc,tx,ty):
+ ground_list = pygame.sprite.Group()
+ i=0
+ if lvl == 1:
+ while i < len(gloc):
+ ground = Platform(gloc[i],worldy-ty,tx,ty,'tile-ground.png')
+ ground_list.add(ground)
+ i=i+1
+
+ if lvl == 2:
+ print("Level " + str(lvl) )
+
+ return ground_list
+```
+
+This is nearly the same code as the `ground` function for the block-style platformer, provided in a previous section above, aside from the `while` loop.
+
+For moving platforms, the principle is similar, but there are some tricks you can use to make your life easier.
+
+Rather than mapping every platform by pixels, you can define a platform by its starting pixel (its X value), the height from the ground (its Y value), and how many tiles to draw. That way, you don't have to worry about the width and height of every platform.
+
+The logic for this trick is a little more complex, so copy this code carefully. There is a `while` loop inside of another `while` loop because this function must look at all three values within each array entry to successfully construct a full platform. In this example, there are only three platforms defined as `ploc.append` statements, but your game probably needs more, so define as many as you need. Of course, some won't appear yet because they're far offscreen, but they'll come into view once you implement scrolling.
+
+```
+def platform(lvl,tx,ty):
+ plat_list = pygame.sprite.Group()
+ ploc = []
+ i=0
+ if lvl == 1:
+ ploc.append((200,worldy-ty-128,3))
+ ploc.append((300,worldy-ty-256,3))
+ ploc.append((500,worldy-ty-128,4))
+ while i < len(ploc):
+ j=0
+ while j <= ploc[i][2]:
+ plat = Platform((ploc[i][0]+(j*tx)),ploc[i][1],tx,ty,'tile.png')
+ plat_list.add(plat)
+ j=j+1
+ print('run' + str(i) + str(ploc[i]))
+ i=i+1
+
+ if lvl == 2:
+ print("Level " + str(lvl) )
+
+ return plat_list
+```
+
+To get the platforms to appear in your game world, they must be in your main loop. If you haven't already done so, add these lines to your main loop (again, the first line is just for context):
+
+```
+ enemy_list.draw(world) # refresh enemies
+ ground_list.draw(world) # refresh ground
+ plat_list.draw(world) # refresh platforms
+```
+
+Launch your game, and adjust the placement of your platforms as needed. Don't worry that you can't see the platforms that are spawned offscreen; you'll fix that soon.
+
+Here is the game so far in a picture and in code:
+
+![Pygame game][23]
+
+Our Pygame platformer so far.
+
+```
+ #!/usr/bin/env python3
+# draw a world
+# add a player and player control
+# add player movement
+# add enemy and basic collision
+# add platform
+
+# GNU All-Permissive License
+# Copying and distribution of this file, with or without modification,
+# are permitted in any medium without royalty provided the copyright
+# notice and this notice are preserved. This file is offered as-is,
+# without any warranty.
+
+import pygame
+import sys
+import os
+
+'''
+Objects
+'''
+
+class Platform(pygame.sprite.Sprite):
+ # x location, y location, img width, img height, img file
+ def __init__(self,xloc,yloc,imgw,imgh,img):
+ pygame.sprite.Sprite.__init__(self)
+ self.image = pygame.image.load(os.path.join('images',img)).convert()
+ self.image.convert_alpha()
+ self.rect = self.image.get_rect()
+ self.rect.y = yloc
+ self.rect.x = xloc
+
+class Player(pygame.sprite.Sprite):
+ '''
+ Spawn a player
+ '''
+ def __init__(self):
+ pygame.sprite.Sprite.__init__(self)
+ self.movex = 0
+ self.movey = 0
+ self.frame = 0
+ self.health = 10
+ self.score = 1
+ self.images = []
+ for i in range(1,9):
+ img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
+ img.convert_alpha()
+ img.set_colorkey(ALPHA)
+ self.images.append(img)
+ self.image = self.images[0]
+ self.rect = self.image.get_rect()
+
+ def control(self,x,y):
+ '''
+ control player movement
+ '''
+ self.movex += x
+ self.movey += y
+
+ def update(self):
+ '''
+ Update sprite position
+ '''
+
+ self.rect.x = self.rect.x + self.movex
+ self.rect.y = self.rect.y + self.movey
+
+ # moving left
+ if self.movex < 0:
+ self.frame += 1
+ if self.frame > ani*3:
+ self.frame = 0
+ self.image = self.images[self.frame//ani]
+
+ # moving right
+ if self.movex > 0:
+ self.frame += 1
+ if self.frame > ani*3:
+ self.frame = 0
+ self.image = self.images[(self.frame//ani)+4]
+
+ # collisions
+ enemy_hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
+ for enemy in enemy_hit_list:
+ self.health -= 1
+ print(self.health)
+
+ ground_hit_list = pygame.sprite.spritecollide(self, ground_list, False)
+ for g in ground_hit_list:
+ self.health -= 1
+ print(self.health)
+
+
+class Enemy(pygame.sprite.Sprite):
+ '''
+ Spawn an enemy
+ '''
+ def __init__(self,x,y,img):
+ pygame.sprite.Sprite.__init__(self)
+ self.image = pygame.image.load(os.path.join('images',img))
+ #self.image.convert_alpha()
+ #self.image.set_colorkey(ALPHA)
+ self.rect = self.image.get_rect()
+ self.rect.x = x
+ self.rect.y = y
+ self.counter = 0
+
+ def move(self):
+ '''
+ enemy movement
+ '''
+ distance = 80
+ speed = 8
+
+ if self.counter >= 0 and self.counter <= distance:
+ self.rect.x += speed
+ elif self.counter >= distance and self.counter <= distance*2:
+ self.rect.x -= speed
+ else:
+ self.counter = 0
+
+ self.counter += 1
+
+class Level():
+ def bad(lvl,eloc):
+ if lvl == 1:
+ enemy = Enemy(eloc[0],eloc[1],'yeti.png') # spawn enemy
+ enemy_list = pygame.sprite.Group() # create enemy group
+ enemy_list.add(enemy) # add enemy to group
+
+ if lvl == 2:
+ print("Level " + str(lvl) )
+
+ return enemy_list
+
+ def loot(lvl,lloc):
+ print(lvl)
+
+ def ground(lvl,gloc,tx,ty):
+ ground_list = pygame.sprite.Group()
+ i=0
+ if lvl == 1:
+ while i < len(gloc):
+ print("blockgen:" + str(i))
+ ground = Platform(gloc[i],worldy-ty,tx,ty,'ground.png')
+ ground_list.add(ground)
+ i=i+1
+
+ if lvl == 2:
+ print("Level " + str(lvl) )
+
+ return ground_list
+
+'''
+Setup
+'''
+worldx = 960
+worldy = 720
+
+fps = 40 # frame rate
+ani = 4 # animation cycles
+clock = pygame.time.Clock()
+pygame.init()
+main = True
+
+BLUE = (25,25,200)
+BLACK = (23,23,23 )
+WHITE = (254,254,254)
+ALPHA = (0,255,0)
+
+world = pygame.display.set_mode([worldx,worldy])
+backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
+backdropbox = world.get_rect()
+player = Player() # spawn player
+player.rect.x = 0
+player.rect.y = 0
+player_list = pygame.sprite.Group()
+player_list.add(player)
+steps = 10 # how fast to move
+
+eloc = []
+eloc = [200,20]
+gloc = []
+#gloc = [0,630,64,630,128,630,192,630,256,630,320,630,384,630]
+tx = 64 #tile size
+ty = 64 #tile size
+
+i=0
+while i <= (worldx/tx)+tx:
+ gloc.append(i*tx)
+ i=i+1
+ print("block: " + str(i))
+
+enemy_list = Level.bad( 1, eloc )
+ground_list = Level.ground( 1,gloc,tx,ty )
+
+'''
+Main loop
+'''
+while main == True:
+ for event in pygame.event.get():
+ if event.type == pygame.QUIT:
+ pygame.quit(); sys.exit()
+ main = False
+
+ if event.type == pygame.KEYDOWN:
+ if event.key == pygame.K_LEFT or event.key == ord('a'):
+ player.control(-steps,0)
+ if event.key == pygame.K_RIGHT or event.key == ord('d'):
+ player.control(steps,0)
+ if event.key == pygame.K_UP or event.key == ord('w'):
+ print('jump')
+
+ if event.type == pygame.KEYUP:
+ if event.key == pygame.K_LEFT or event.key == ord('a'):
+ player.control(steps,0)
+ if event.key == pygame.K_RIGHT or event.key == ord('d'):
+ player.control(-steps,0)
+ if event.key == ord('q'):
+ pygame.quit()
+ sys.exit()
+ main = False
+
+# world.fill(BLACK)
+ world.blit(backdrop, backdropbox)
+ player.update()
+ player_list.draw(world) #refresh player position
+ enemy_list.draw(world) # refresh enemies
+ ground_list.draw(world) # refresh enemies
+ for e in enemy_list:
+ e.move()
+ pygame.display.flip()
+ clock.tick(fps)
+```
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/7/put-platforms-python-game
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://www.pygame.org/news
+[2]: https://opensource.com/article/17/12/game-python-add-a-player
+[3]: https://opensource.com/article/17/12/game-python-moving-player
+[4]: /file/403841
+[5]: https://opensource.com/sites/default/files/uploads/supertux.png (Supertux, a tile-based video game)
+[6]: https://www.supertux.org/
+[7]: https://www.python.org/
+[8]: /file/403861
+[9]: https://opensource.com/sites/default/files/uploads/layout.png (Example of a level map)
+[10]: https://en.wikipedia.org/wiki/Cartesian_coordinate_system
+[11]: /file/403871
+[12]: https://opensource.com/sites/default/files/uploads/pygame_coordinates.png (Example of coordinates in Pygame)
+[13]: https://krita.org/en/
+[14]: /file/403876
+[15]: https://opensource.com/sites/default/files/uploads/pygame_floating.png (One image file per object)
+[16]: /file/403881
+[17]: https://opensource.com/sites/default/files/uploads/pygame_flattened.png (Your level cannot be one image file)
+[18]: https://www.gimp.org/
+[19]: http://mypaint.org/about/
+[20]: https://inkscape.org/en/
+[21]: https://opengameart.org/content/simplified-platformer-pack
+[22]: /file/403886
+[23]: https://opensource.com/sites/default/files/uploads/pygame_platforms.jpg (Pygame game)
+[24]: Learn how to program in Python by building a simple dice game
+[25]: https://opensource.com/article/17/12/game-framework-python
+[26]: https://opensource.com/article/17/12/game-python-add-a-player
+[27]: https://opensource.com/article/17/12/game-python-moving-player
+[28]: https://opensource.com/article/18/5/pygame-enemy
+
diff --git a/sources/tech/20180826 Be productive with Org-mode.md b/sources/tech/20180826 Be productive with Org-mode.md
new file mode 100644
index 0000000000..3c6f3c4519
--- /dev/null
+++ b/sources/tech/20180826 Be productive with Org-mode.md
@@ -0,0 +1,202 @@
+[#]: collector: (lujun9972)
+[#]: translator: (lujun9972)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Be productive with Org-mode)
+[#]: via: (https://www.badykov.com/emacs/2018/08/26/be-productive-with-org-mode/)
+[#]: author: (Ayrat Badykov https://www.badykov.com)
+
+Be productive with Org-mode
+======
+
+
+![org-mode-collage][1]
+
+### Introduction
+
+In my [previous post about emacs][2] I mentioned [Org-mode][3], a note manager and organizer. In this post, I’ll describe my day-to-day Org-mode use cases.
+
+### Notes and to-do lists
+
+First and foremost, Org-mode is a tool for managing notes and to-do lists and all work in Org-mode is centered around writing notes in plain text files. I manage several kinds of notes using Org-mode.
+
+#### General notes
+
+The most basic Org-mode use case is writing simple notes about things that you want to remember. For example, here are my notes about things I’m learning right now:
+
+```
+* Learn
+** Emacs LISP
+*** Plan
+
+ - [ ] Read best practices
+ - [ ] Finish reading Emacs Manual
+ - [ ] Finish Exercism Exercises
+ - [ ] Write a couple of simple plugins
+ - Notification plugin
+
+*** Resources
+
+ https://www.gnu.org/software/emacs/manual/html_node/elisp/index.html
+ http://exercism.io/languages/elisp/about
+ [[http://batsov.com/articles/2011/11/30/the-ultimate-collection-of-emacs-resources/][The Ultimate Collection of Emacs Resources]]
+
+** Rust gamedev
+*** Study [[https://github.com/SergiusIW/gate][gate]] 2d game engine with web assembly support
+*** [[ggez][https://github.com/ggez/ggez]]
+*** [[https://www.amethyst.rs/blog/release-0-8/][Amethyst 0.8 Relesed]]
+
+** Upgrade Elixir/Erlang Skills
+*** Read Erlang in Anger
+```
+
+How it looks using [org-bullets][4]:
+
+![notes][5]
+
+In this simple example you can see some of the Org-mode features:
+
+ * nested notes
+ * links
+ * lists with checkboxes
+
+
+
+#### Project todos
+
+Often when I’m working on some task I notice things that I can improve or fix. Instead of leaving TODO comment in source code files (bad smell) I use [org-projectile][6] which allows me to write TODO items with a single shortcut in a separate file. Here’s an example of this file:
+
+```
+* [[elisp:(org-projectile-open-project%20"mana")][mana]] [3/9]
+ :PROPERTIES:
+ :CATEGORY: mana
+ :END:
+** DONE [[file:~/Development/mana/apps/blockchain/lib/blockchain/contract/create_contract.ex::insufficient_gas_before_homestead%20=][fix this check using evm.configuration]]
+ CLOSED: [2018-08-08 Ср 09:14]
+ [[https://github.com/ethereum/EIPs/blob/master/EIPS/eip-2.md][eip2]]:
+ If contract creation does not have enough gas to pay for the final gas fee for
+ adding the contract code to the state, the contract creation fails (i.e. goes out-of-gas)
+ rather than leaving an empty contract.
+** DONE Upgrade Elixir to 1.7.
+ CLOSED: [2018-08-08 Ср 09:14]
+** TODO [#A] Difficulty tests
+** TODO [#C] Upgrage to OTP 21
+** DONE [#A] EIP150
+ CLOSED: [2018-08-14 Вт 21:25]
+*** DONE operation cost changes
+ CLOSED: [2018-08-08 Ср 20:31]
+*** DONE 1/64th for a call and create
+ CLOSED: [2018-08-14 Вт 21:25]
+** TODO [#C] Refactor interfaces
+** TODO [#B] Caching for storage during execution
+** TODO [#B] Removing old merkle trees
+** TODO do not calculate cost twice
+* [[elisp:(org-projectile-open-project%20".emacs.d")][.emacs.d]] [1/3]
+ :PROPERTIES:
+ :CATEGORY: .emacs.d
+ :END:
+** TODO fix flycheck issues (emacs config)
+** TODO use-package for fetching dependencies
+** DONE clean configuration
+ CLOSED: [2018-08-26 Вс 11:48]
+```
+
+How it looks in Emacs:
+
+![project-todos][7]
+
+In this example you can see more Org mode features:
+
+ * todo items have states - `TODO`, `DONE`. You can define your own states (`WAITING` etc)
+ * closed items have `CLOSED` timestamp
+ * some items have priorities - A, B, C.
+ * links can be internal (`[[file:~/...]`)
+
+
+
+#### Capture templates
+
+As described in Org-mode’s documentation, capture lets you quickly store notes with little interruption of your workflow.
+
+I configured several capture templates which help me to quickly create notes about things that I want to remember.
+
+```
+(setq org-capture-templates
+'(("t" "Todo" entry (file+headline "~/Dropbox/org/todo.org" "Todo soon")
+"* TODO %? \n %^t")
+("i" "Idea" entry (file+headline "~/Dropbox/org/ideas.org" "Ideas")
+"* %? \n %U")
+("e" "Tweak" entry (file+headline "~/Dropbox/org/tweaks.org" "Tweaks")
+"* %? \n %U")
+("l" "Learn" entry (file+headline "~/Dropbox/org/learn.org" "Learn")
+"* %? \n")
+("w" "Work note" entry (file+headline "~/Dropbox/org/work.org" "Work")
+"* %? \n")
+("m" "Check movie" entry (file+headline "~/Dropbox/org/check.org" "Movies")
+"* %? %^g")
+("n" "Check book" entry (file+headline "~/Dropbox/org/check.org" "Books")
+"* %^{book name} by %^{author} %^g")))
+```
+
+For a book note I should add its name and its author, for a movie note I should add tags etc.
+
+### Planning
+
+Another great feature of Org-mode is that you can use it as a day planner. Let’s see an example of one of my days:
+
+![schedule][8]
+
+I didn’t give a lot of thought to this example, it’s my real file for today. It doesn’t look like much but it helps to spend your time on things that important to you and fight with procrastination.
+
+#### Habits
+
+From Org mode’s documentation, Org has the ability to track the consistency of a special category of TODOs, called “habits”. I use this feature along with day planning when I want to create new habits:
+
+![habits][9]
+
+As you can see currently I’m trying to wake early every day and workout once in two days. Also, it helped to start reading books every day.
+
+#### Agenda views
+
+Last but not least I use agenda views. Todo items can be scattered throughout different files (in my case daily plan and habits are in separate files), agenda views give an overview of all todo items:
+
+![agenda][10]
+
+### More Org mode features
+
+
++ Smartphone apps (Android, ios)
+
++ Exporting Org mode files into different formats (html, markdown, pdf, latex etc)
+
++ Tracking Finances with ledger
+
+### Conclusion
+
+In this post, I described a small subset of Org-mode’s extensive functionality that helps me be productive every day, spending time on things that important to me.
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.badykov.com/emacs/2018/08/26/be-productive-with-org-mode/
+
+作者:[Ayrat Badykov][a]
+选题:[lujun9972][b]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.badykov.com
+[b]: https://github.com/lujun9972
+[1]: https://i.imgur.com/hgqCyen.jpg
+[2]: http://www.badykov.com/emacs/2018/07/31/why-emacs-is-a-great-editor/
+[3]: https://orgmode.org/
+[4]: https://github.com/sabof/org-bullets
+[5]: https://i.imgur.com/lGi60Uw.png
+[6]: https://github.com/IvanMalison/org-projectile
+[7]: https://i.imgur.com/Hbu8ilX.png
+[8]: https://i.imgur.com/z5HpuB0.png
+[9]: https://i.imgur.com/YJIp3d0.png
+[10]: https://i.imgur.com/CKX9BL9.png
diff --git a/sources/tech/20180926 HTTP- Brief History of HTTP.md b/sources/tech/20180926 HTTP- Brief History of HTTP.md
deleted file mode 100644
index 64e2abfd6b..0000000000
--- a/sources/tech/20180926 HTTP- Brief History of HTTP.md
+++ /dev/null
@@ -1,286 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (MjSeven)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (HTTP: Brief History of HTTP)
-[#]: via: (https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol)
-[#]: author: (Ilya Grigorik https://www.igvita.com/)
-
-HTTP: Brief History of HTTP
-======
-
-### Introduction
-
-The Hypertext Transfer Protocol (HTTP) is one of the most ubiquitous and widely adopted application protocols on the Internet: it is the common language between clients and servers, enabling the modern web. From its simple beginnings as a single keyword and document path, it has become the protocol of choice not just for browsers, but for virtually every Internet-connected software and hardware application.
-
-In this chapter, we will take a brief historical tour of the evolution of the HTTP protocol. A full discussion of the varying HTTP semantics is outside the scope of this book, but an understanding of the key design changes of HTTP, and the motivations behind each, will give us the necessary background for our discussions on HTTP performance, especially in the context of the many upcoming improvements in HTTP/2.
-
-### §HTTP 0.9: The One-Line Protocol
-
-The original HTTP proposal by Tim Berners-Lee was designed with simplicity in mind as to help with the adoption of his other nascent idea: the World Wide Web. The strategy appears to have worked: aspiring protocol designers, take note.
-
-In 1991, Berners-Lee outlined the motivation for the new protocol and listed several high-level design goals: file transfer functionality, ability to request an index search of a hypertext archive, format negotiation, and an ability to refer the client to another server. To prove the theory in action, a simple prototype was built, which implemented a small subset of the proposed functionality:
-
- * Client request is a single ASCII character string.
-
- * Client request is terminated by a carriage return (CRLF).
-
- * Server response is an ASCII character stream.
-
-
-
- * Server response is a hypertext markup language (HTML).
-
- * Connection is terminated after the document transfer is complete.
-
-
-
-
-However, even that sounds a lot more complicated than it really is. What these rules enable is an extremely simple, Telnet-friendly protocol, which some web servers support to this very day:
-
-```
-$> telnet google.com 80
-
-Connected to 74.125.xxx.xxx
-
-GET /about/
-
-(hypertext response)
-(connection closed)
-```
-
-The request consists of a single line: `GET` method and the path of the requested document. The response is a single hypertext document—no headers or any other metadata, just the HTML. It really couldn’t get any simpler. Further, since the previous interaction is a subset of the intended protocol, it unofficially acquired the HTTP 0.9 label. The rest, as they say, is history.
-
-From these humble beginnings in 1991, HTTP took on a life of its own and evolved rapidly over the coming years. Let us quickly recap the features of HTTP 0.9:
-
- * Client-server, request-response protocol.
-
- * ASCII protocol, running over a TCP/IP link.
-
- * Designed to transfer hypertext documents (HTML).
-
- * The connection between server and client is closed after every request.
-
-
-```
-Popular web servers, such as Apache and Nginx, still support the HTTP 0.9 protocol—in part, because there is not much to it! If you are curious, open up a Telnet session and try accessing google.com, or your own favorite site, via HTTP 0.9 and inspect the behavior and the limitations of this early protocol.
-```
-
-### §HTTP/1.0: Rapid Growth and Informational RFC
-
-The period from 1991 to 1995 is one of rapid coevolution of the HTML specification, a new breed of software known as a "web browser," and the emergence and quick growth of the consumer-oriented public Internet infrastructure.
-
-```
-##### §The Perfect Storm: Internet Boom of the Early 1990s
-
-Building on Tim Berner-Lee’s initial browser prototype, a team at the National Center of Supercomputing Applications (NCSA) decided to implement their own version. With that, the first popular browser was born: NCSA Mosaic. One of the programmers on the NCSA team, Marc Andreessen, partnered with Jim Clark to found Mosaic Communications in October 1994. The company was later renamed Netscape, and it shipped Netscape Navigator 1.0 in December 1994. By this point, it was already clear that the World Wide Web was bound to be much more than just an academic curiosity.
-
-In fact, that same year the first World Wide Web conference was organized in Geneva, Switzerland, which led to the creation of the World Wide Web Consortium (W3C) to help guide the evolution of HTML. Similarly, a parallel HTTP Working Group (HTTP-WG) was established within the IETF to focus on improving the HTTP protocol. Both of these groups continue to be instrumental to the evolution of the Web.
-
-Finally, to create the perfect storm, CompuServe, AOL, and Prodigy began providing dial-up Internet access to the public within the same 1994–1995 time frame. Riding on this wave of rapid adoption, Netscape made history with a wildly successful IPO on August 9, 1995—the Internet boom had arrived, and everyone wanted a piece of it!
-```
-
-The growing list of desired capabilities of the nascent Web and their use cases on the public Web quickly exposed many of the fundamental limitations of HTTP 0.9: we needed a protocol that could serve more than just hypertext documents, provide richer metadata about the request and the response, enable content negotiation, and more. In turn, the nascent community of web developers responded by producing a large number of experimental HTTP server and client implementations through an ad hoc process: implement, deploy, and see if other people adopt it.
-
-From this period of rapid experimentation, a set of best practices and common patterns began to emerge, and in May 1996 the HTTP Working Group (HTTP-WG) published RFC 1945, which documented the "common usage" of the many HTTP/1.0 implementations found in the wild. Note that this was only an informational RFC: HTTP/1.0 as we know it is not a formal specification or an Internet standard!
-
-Having said that, an example HTTP/1.0 request should look very familiar:
-
-```
-$> telnet website.org 80
-
-Connected to xxx.xxx.xxx.xxx
-
-GET /rfc/rfc1945.txt HTTP/1.0
-User-Agent: CERN-LineMode/2.15 libwww/2.17b3
-Accept: */*
-
-HTTP/1.0 200 OK
-Content-Type: text/plain
-Content-Length: 137582
-Expires: Thu, 01 Dec 1997 16:00:00 GMT
-Last-Modified: Wed, 1 May 1996 12:45:26 GMT
-Server: Apache 0.84
-
-(plain-text response)
-(connection closed)
-```
-
- 1. Request line with HTTP version number, followed by request headers
-
- 2. Response status, followed by response headers
-
-
-
-
-The preceding exchange is not an exhaustive list of HTTP/1.0 capabilities, but it does illustrate some of the key protocol changes:
-
- * Request may consist of multiple newline separated header fields.
-
- * Response object is prefixed with a response status line.
-
- * Response object has its own set of newline separated header fields.
-
- * Response object is not limited to hypertext.
-
- * The connection between server and client is closed after every request.
-
-
-
-
-Both the request and response headers were kept as ASCII encoded, but the response object itself could be of any type: an HTML file, a plain text file, an image, or any other content type. Hence, the "hypertext transfer" part of HTTP became a misnomer not long after its introduction. In reality, HTTP has quickly evolved to become a hypermedia transport, but the original name stuck.
-
-In addition to media type negotiation, the RFC also documented a number of other commonly implemented capabilities: content encoding, character set support, multi-part types, authorization, caching, proxy behaviors, date formats, and more.
-
-```
-Almost every server on the Web today can and will still speak HTTP/1.0. Except that, by now, you should know better! Requiring a new TCP connection per request imposes a significant performance penalty on HTTP/1.0; see [Three-Way Handshake][1], followed by [Slow-Start][2].
-```
-
-### §HTTP/1.1: Internet Standard
-
-The work on turning HTTP into an official IETF Internet standard proceeded in parallel with the documentation effort around HTTP/1.0 and happened over a period of roughly four years: between 1995 and 1999. In fact, the first official HTTP/1.1 standard is defined in RFC 2068, which was officially released in January 1997, roughly six months after the publication of HTTP/1.0. Then, two and a half years later, in June of 1999, a number of improvements and updates were incorporated into the standard and were released as RFC 2616.
-
-The HTTP/1.1 standard resolved a lot of the protocol ambiguities found in earlier versions and introduced a number of critical performance optimizations: keepalive connections, chunked encoding transfers, byte-range requests, additional caching mechanisms, transfer encodings, and request pipelining.
-
-With these capabilities in place, we can now inspect a typical HTTP/1.1 session as performed by any modern HTTP browser and client:
-
-```
-$> telnet website.org 80
-Connected to xxx.xxx.xxx.xxx
-
-GET /index.html HTTP/1.1
-Host: website.org
-User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
-Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
-Accept-Encoding: gzip,deflate,sdch
-Accept-Language: en-US,en;q=0.8
-Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
-Cookie: __qca=P0-800083390... (snip)
-
-HTTP/1.1 200 OK
-Server: nginx/1.0.11
-Connection: keep-alive
-Content-Type: text/html; charset=utf-8
-Via: HTTP/1.1 GWA
-Date: Wed, 25 Jul 2012 20:23:35 GMT
-Expires: Wed, 25 Jul 2012 20:23:35 GMT
-Cache-Control: max-age=0, no-cache
-Transfer-Encoding: chunked
-
-100
-
-(snip)
-
-100
-(snip)
-
-0
-
-GET /favicon.ico HTTP/1.1
-Host: www.website.org
-User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
-Accept: */*
-Referer: http://website.org/
-Connection: close
-Accept-Encoding: gzip,deflate,sdch
-Accept-Language: en-US,en;q=0.8
-Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
-Cookie: __qca=P0-800083390... (snip)
-
-HTTP/1.1 200 OK
-Server: nginx/1.0.11
-Content-Type: image/x-icon
-Content-Length: 3638
-Connection: close
-Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT
-Cache-Control: max-age=315360000
-Accept-Ranges: bytes
-Via: HTTP/1.1 GWA
-Date: Sat, 21 Jul 2012 21:35:22 GMT
-Expires: Thu, 31 Dec 2037 23:55:55 GMT
-Etag: W/PSA-GAu26oXbDi
-
-(icon data)
-(connection closed)
-```
-
- 1. Request for HTML file, with encoding, charset, and cookie metadata
-
- 2. Chunked response for original HTML request
-
- 3. Number of octets in the chunk expressed as an ASCII hexadecimal number (256 bytes)
-
- 4. End of chunked stream response
-
- 5. Request for an icon file made on same TCP connection
-
- 6. Inform server that the connection will not be reused
-
- 7. Icon response, followed by connection close
-
-
-
-
-Phew, there is a lot going on in there! The first and most obvious difference is that we have two object requests, one for an HTML page and one for an image, both delivered over a single connection. This is connection keepalive in action, which allows us to reuse the existing TCP connection for multiple requests to the same host and deliver a much faster end-user experience; see [Optimizing for TCP][3].
-
-To terminate the persistent connection, notice that the second client request sends an explicit `close` token to the server via the `Connection` header. Similarly, the server can notify the client of the intent to close the current TCP connection once the response is transferred. Technically, either side can terminate the TCP connection without such signal at any point, but clients and servers should provide it whenever possible to enable better connection reuse strategies on both sides.
-
-```
-HTTP/1.1 changed the semantics of the HTTP protocol to use connection keepalive by default. Meaning, unless told otherwise (via `Connection: close` header), the server should keep the connection open by default.
-
-However, this same functionality was also backported to HTTP/1.0 and enabled via the `Connection: Keep-Alive` header. Hence, if you are using HTTP/1.1, technically you don’t need the `Connection: Keep-Alive` header, but many clients choose to provide it nonetheless.
-```
-
-Additionally, the HTTP/1.1 protocol added content, encoding, character set, and even language negotiation, transfer encoding, caching directives, client cookies, plus a dozen other capabilities that can be negotiated on each request.
-
-We are not going to dwell on the semantics of every HTTP/1.1 feature. This is a subject for a dedicated book, and many great ones have been written already. Instead, the previous example serves as a good illustration of both the quick progress and evolution of HTTP, as well as the intricate and complicated dance of every client-server exchange. There is a lot going on in there!
-
-```
-For a good reference on all the inner workings of the HTTP protocol, check out O’Reilly’s HTTP: The Definitive Guide by David Gourley and Brian Totty.
-```
-
-### §HTTP/2: Improving Transport Performance
-
-Since its publication, RFC 2616 has served as a foundation for the unprecedented growth of the Internet: billions of devices of all shapes and sizes, from desktop computers to the tiny web devices in our pockets, speak HTTP every day to deliver news, video, and millions of other web applications we have all come to depend on in our lives.
-
-What began as a simple, one-line protocol for retrieving hypertext quickly evolved into a generic hypermedia transport, and now a decade later can be used to power just about any use case you can imagine. Both the ubiquity of servers that can speak the protocol and the wide availability of clients to consume it means that many applications are now designed and deployed exclusively on top of HTTP.
-
-Need a protocol to control your coffee pot? RFC 2324 has you covered with the Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0)—originally an April Fools’ Day joke by IETF, and increasingly anything but a joke in our new hyper-connected world.
-
-> The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. It is a generic, stateless, protocol that can be used for many tasks beyond its use for hypertext, such as name servers and distributed object management systems, through extension of its request methods, error codes and headers. A feature of HTTP is the typing and negotiation of data representation, allowing systems to be built independently of the data being transferred.
->
-> RFC 2616: HTTP/1.1, June 1999
-
-The simplicity of the HTTP protocol is what enabled its original adoption and rapid growth. In fact, it is now not unusual to find embedded devices—sensors, actuators, and coffee pots alike—using HTTP as their primary control and data protocols. But under the weight of its own success and as we increasingly continue to migrate our everyday interactions to the Web—social, email, news, and video, and increasingly our entire personal and job workspaces—it has also begun to show signs of stress. Users and web developers alike are now demanding near real-time responsiveness and protocol performance from HTTP/1.1, which it simply cannot meet without some modifications.
-
-To meet these new challenges, HTTP must continue to evolve, and hence the HTTPbis working group announced a new initiative for HTTP/2 in early 2012:
-
-> There is emerging implementation experience and interest in a protocol that retains the semantics of HTTP without the legacy of HTTP/1.x message framing and syntax, which have been identified as hampering performance and encouraging misuse of the underlying transport.
->
-> The working group will produce a specification of a new expression of HTTP’s current semantics in ordered, bi-directional streams. As with HTTP/1.x, the primary target transport is TCP, but it should be possible to use other transports.
->
-> HTTP/2 charter, January 2012
-
-The primary focus of HTTP/2 is on improving transport performance and enabling both lower latency and higher throughput. The major version increment sounds like a big step, which it is and will be as far as performance is concerned, but it is important to note that none of the high-level protocol semantics are affected: all HTTP headers, values, and use cases are the same.
-
-Any existing website or application can and will be delivered over HTTP/2 without modification: you do not need to modify your application markup to take advantage of HTTP/2. The HTTP servers will have to speak HTTP/2, but that should be a transparent upgrade for the majority of users. The only difference if the working group meets its goal, should be that our applications are delivered with lower latency and better utilization of the network link!
-
-Having said that, let’s not get ahead of ourselves. Before we get to the new HTTP/2 protocol features, it is worth taking a step back and examining our existing deployment and performance best practices for HTTP/1.1. The HTTP/2 working group is making fast progress on the new specification, but even if the final standard was already done and ready, we would still have to support older HTTP/1.1 clients for the foreseeable future—realistically, a decade or more.
-
---------------------------------------------------------------------------------
-
-via: https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol
-
-作者:[Ilya Grigorik][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.igvita.com/
-[b]: https://github.com/lujun9972
-[1]: https://hpbn.co/building-blocks-of-tcp/#three-way-handshake
-[2]: https://hpbn.co/building-blocks-of-tcp/#slow-start
-[3]: https://hpbn.co/building-blocks-of-tcp/#optimizing-for-tcp
diff --git a/sources/tech/20181218 Using Pygame to move your game character around.md b/sources/tech/20181218 Using Pygame to move your game character around.md
new file mode 100644
index 0000000000..96daf8da7d
--- /dev/null
+++ b/sources/tech/20181218 Using Pygame to move your game character around.md
@@ -0,0 +1,353 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Using Pygame to move your game character around)
+[#]: via: (https://opensource.com/article/17/12/game-python-moving-player)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Using Pygame to move your game character around
+======
+In the fourth part of this series, learn how to code the controls needed to move a game character.
+
+
+In the first article in this series, I explained how to use Python to create a simple, [text-based dice game][1]. In the second part, we began building a game from scratch, starting with [creating the game's environment][2]. And, in the third installment, we [created a player sprite][3] and made it spawn in your (rather empty) game world. As you've probably noticed, a game isn't much fun if you can't move your character around. In this article, we'll use Pygame to add keyboard controls so you can direct your character's movement.
+
+There are functions in Pygame to add other kinds of controls, but since you certainly have a keyboard if you're typing out Python code, that's what we'll use. Once you understand keyboard controls, you can explore other options on your own.
+
+You created a key to quit your game in the second article in this series, and the principle is the same for movement. However, getting your character to move is a little more complex.
+
+Let's start with the easy part: setting up the controller keys.
+
+### Setting up keys for controlling your player sprite
+
+Open your Python game script in IDLE, Ninja-IDE, or a text editor.
+
+Since the game must constantly "listen" for keyboard events, you'll be writing code that needs to run continuously. Can you figure out where to put code that needs to run constantly for the duration of the game?
+
+If you answered "in the main loop," you're correct! Remember that unless code is in a loop, it will run (at most) only once—and it may not run at all if it's hidden away in a class or function that never gets used.
+
+To make Python monitor for incoming key presses, add this code to the main loop. There's no code to make anything happen yet, so use `print` statements to signal success. This is a common debugging technique.
+
+```
+while main == True:
+ for event in pygame.event.get():
+ if event.type == pygame.QUIT:
+ pygame.quit(); sys.exit()
+ main = False
+
+ if event.type == pygame.KEYDOWN:
+ if event.key == pygame.K_LEFT or event.key == ord('a'):
+ print('left')
+ if event.key == pygame.K_RIGHT or event.key == ord('d'):
+ print('right')
+ if event.key == pygame.K_UP or event.key == ord('w'):
+ print('jump')
+
+ if event.type == pygame.KEYUP:
+ if event.key == pygame.K_LEFT or event.key == ord('a'):
+ print('left stop')
+ if event.key == pygame.K_RIGHT or event.key == ord('d'):
+ print('right stop')
+ if event.key == ord('q'):
+ pygame.quit()
+ sys.exit()
+ main = False
+```
+
+Some people prefer to control player characters with the keyboard characters W, A, S, and D, and others prefer to use arrow keys. Be sure to include both options.
+
+**Note: **It's vital that you consider all of your users when programming. If you write code that works only for you, it's very likely that you'll be the only one who uses your application. More importantly, if you seek out a job writing code for money, you are expected to write code that works for everyone. Giving your users choices, such as the option to use either arrow keys or WASD, is a sign of a good programmer.
+
+Launch your game using Python, and watch the console window for output as you press the right, left, and up arrows, or the A, D, and W keys.
+
+```
+$ python ./your-name_game.py
+ left
+ left stop
+ right
+ right stop
+ jump
+```
+
+This confirms that Pygame detects key presses correctly. Now it's time to do the hard work of making the sprite move.
+
+### Coding the player movement function
+
+To make your sprite move, you must create a property for your sprite that represents movement. When your sprite is not moving, this variable is set to `0`.
+
+If you are animating your sprite, or should you decide to animate it in the future, you also must track frames to enable the walk cycle to stay on track.
+
+Create the variables in the Player class. The first two lines are for context (you already have them in your code, if you've been following along), so add only the last three:
+
+```
+ def __init__(self):
+ pygame.sprite.Sprite.__init__(self)
+ self.movex = 0 # move along X
+ self.movey = 0 # move along Y
+ self.frame = 0 # count frames
+```
+
+With those variables set, it's time to code the sprite's movement.
+
+The player sprite doesn't need to respond to control all the time; sometimes it will not be moving. The code that controls the sprite, therefore, is only one small part of all the things the player sprite will do. When you want to make an object in Python do something independent of the rest of its code, you place your new code in a function. Python functions start with the keyword `def`, which stands for define.
+
+Make a function in your Player class to add some number of pixels to your sprite's position on screen. Don't worry about how many pixels you add yet; that will be decided in later code.
+
+```
+ def control(self,x,y):
+ '''
+ control player movement
+ '''
+ self.movex += x
+ self.movey += y
+```
+
+To move a sprite in Pygame, you have to tell Python to redraw the sprite in its new location—and where that new location is.
+
+Since the Player sprite isn't always moving, the updates need to be only one function within the Player class. Add this function after the `control` function you created earlier.
+
+To make it appear that the sprite is walking (or flying, or whatever it is your sprite is supposed to do), you need to change its position on screen when the appropriate key is pressed. To get it to move across the screen, you redefine its position, designated by the `self.rect.x` and `self.rect.y` properties, to its current position plus whatever amount of `movex` or `movey` is applied. (The number of pixels the move requires is set later.)
+
+```
+ def update(self):
+ '''
+ Update sprite position
+ '''
+ self.rect.x = self.rect.x + self.movex
+```
+
+Do the same thing for the Y position:
+
+```
+ self.rect.y = self.rect.y + self.movey
+```
+
+For animation, advance the animation frames whenever your sprite is moving, and use the corresponding animation frame as the player image:
+
+```
+ # moving left
+ if self.movex < 0:
+ self.frame += 1
+ if self.frame > 3*ani:
+ self.frame = 0
+ self.image = self.images[self.frame//ani]
+
+ # moving right
+ if self.movex > 0:
+ self.frame += 1
+ if self.frame > 3*ani:
+ self.frame = 0
+ self.image = self.images[(self.frame//ani)+4]
+```
+
+Tell the code how many pixels to add to your sprite's position by setting a variable, then use that variable when triggering the functions of your Player sprite.
+
+First, create the variable in your setup section. In this code, the first two lines are for context, so just add the third line to your script:
+
+```
+player_list = pygame.sprite.Group()
+player_list.add(player)
+steps = 10 # how many pixels to move
+```
+
+Now that you have the appropriate function and variable, use your key presses to trigger the function and send the variable to your sprite.
+
+Do this by replacing the `print` statements in your main loop with the Player sprite's name (player), the function (.control), and how many steps along the X axis and Y axis you want the player sprite to move with each loop.
+
+```
+ if event.type == pygame.KEYDOWN:
+ if event.key == pygame.K_LEFT or event.key == ord('a'):
+ player.control(-steps,0)
+ if event.key == pygame.K_RIGHT or event.key == ord('d'):
+ player.control(steps,0)
+ if event.key == pygame.K_UP or event.key == ord('w'):
+ print('jump')
+
+ if event.type == pygame.KEYUP:
+ if event.key == pygame.K_LEFT or event.key == ord('a'):
+ player.control(steps,0)
+ if event.key == pygame.K_RIGHT or event.key == ord('d'):
+ player.control(-steps,0)
+ if event.key == ord('q'):
+ pygame.quit()
+ sys.exit()
+ main = False
+```
+
+Remember, `steps` is a variable representing how many pixels your sprite moves when a key is pressed. If you add 10 pixels to the location of your player sprite when you press D or the right arrow, then when you stop pressing that key you must subtract 10 (`-steps`) to return your sprite's momentum back to 0.
+
+Try your game now. Warning: it won't do what you expect.
+
+Why doesn't your sprite move yet? Because the main loop doesn't call the `update` function.
+
+Add code to your main loop to tell Python to update the position of your player sprite. Add the line with the comment:
+
+```
+ player.update() # update player position
+ player_list.draw(world)
+ pygame.display.flip()
+ clock.tick(fps)
+```
+
+Launch your game again to witness your player sprite move across the screen at your bidding. There's no vertical movement yet because those functions will be controlled by gravity, but that's another lesson for another article.
+
+In the meantime, if you have access to a joystick, try reading Pygame's documentation for its [joystick][4] module and see if you can make your sprite move that way. Alternately, see if you can get the [mouse][5] to interact with your sprite.
+
+Most importantly, have fun!
+
+### All the code used in this tutorial
+
+For your reference, here is all the code used in this series of articles so far.
+
+```
+#!/usr/bin/env python3
+# draw a world
+# add a player and player control
+# add player movement
+
+# GNU All-Permissive License
+# Copying and distribution of this file, with or without modification,
+# are permitted in any medium without royalty provided the copyright
+# notice and this notice are preserved. This file is offered as-is,
+# without any warranty.
+
+import pygame
+import sys
+import os
+
+'''
+Objects
+'''
+
+class Player(pygame.sprite.Sprite):
+ '''
+ Spawn a player
+ '''
+ def __init__(self):
+ pygame.sprite.Sprite.__init__(self)
+ self.movex = 0
+ self.movey = 0
+ self.frame = 0
+ self.images = []
+ for i in range(1,5):
+ img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
+ img.convert_alpha()
+ img.set_colorkey(ALPHA)
+ self.images.append(img)
+ self.image = self.images[0]
+ self.rect = self.image.get_rect()
+
+ def control(self,x,y):
+ '''
+ control player movement
+ '''
+ self.movex += x
+ self.movey += y
+
+ def update(self):
+ '''
+ Update sprite position
+ '''
+
+ self.rect.x = self.rect.x + self.movex
+ self.rect.y = self.rect.y + self.movey
+
+ # moving left
+ if self.movex < 0:
+ self.frame += 1
+ if self.frame > 3*ani:
+ self.frame = 0
+ self.image = self.images[self.frame//ani]
+
+ # moving right
+ if self.movex > 0:
+ self.frame += 1
+ if self.frame > 3*ani:
+ self.frame = 0
+ self.image = self.images[(self.frame//ani)+4]
+
+
+'''
+Setup
+'''
+worldx = 960
+worldy = 720
+
+fps = 40 # frame rate
+ani = 4 # animation cycles
+clock = pygame.time.Clock()
+pygame.init()
+main = True
+
+BLUE = (25,25,200)
+BLACK = (23,23,23 )
+WHITE = (254,254,254)
+ALPHA = (0,255,0)
+
+world = pygame.display.set_mode([worldx,worldy])
+backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
+backdropbox = world.get_rect()
+player = Player() # spawn player
+player.rect.x = 0
+player.rect.y = 0
+player_list = pygame.sprite.Group()
+player_list.add(player)
+steps = 10 # how fast to move
+
+'''
+Main loop
+'''
+while main == True:
+ for event in pygame.event.get():
+ if event.type == pygame.QUIT:
+ pygame.quit(); sys.exit()
+ main = False
+
+ if event.type == pygame.KEYDOWN:
+ if event.key == pygame.K_LEFT or event.key == ord('a'):
+ player.control(-steps,0)
+ if event.key == pygame.K_RIGHT or event.key == ord('d'):
+ player.control(steps,0)
+ if event.key == pygame.K_UP or event.key == ord('w'):
+ print('jump')
+
+ if event.type == pygame.KEYUP:
+ if event.key == pygame.K_LEFT or event.key == ord('a'):
+ player.control(steps,0)
+ if event.key == pygame.K_RIGHT or event.key == ord('d'):
+ player.control(-steps,0)
+ if event.key == ord('q'):
+ pygame.quit()
+ sys.exit()
+ main = False
+
+# world.fill(BLACK)
+ world.blit(backdrop, backdropbox)
+ player.update()
+ player_list.draw(world) #refresh player position
+ pygame.display.flip()
+ clock.tick(fps)
+```
+
+You've come far and learned much, but there's a lot more to do. In the next few articles, you'll add enemy sprites, emulated gravity, and lots more. In the mean time, practice with Python!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/12/game-python-moving-player
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/17/10/python-101
+[2]: https://opensource.com/article/17/12/program-game-python-part-2-creating-game-world
+[3]: https://opensource.com/article/17/12/program-game-python-part-3-spawning-player
+[4]: http://pygame.org/docs/ref/joystick.html
+[5]: http://pygame.org/docs/ref/mouse.html#module-pygame.mouse
diff --git a/sources/tech/20190116 Get started with Cypht, an open source email client.md b/sources/tech/20190116 Get started with Cypht, an open source email client.md
new file mode 100644
index 0000000000..64be2e4a02
--- /dev/null
+++ b/sources/tech/20190116 Get started with Cypht, an open source email client.md
@@ -0,0 +1,58 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with Cypht, an open source email client)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-cypht-email)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+Get started with Cypht, an open source email client
+======
+Integrate your email and news feeds into one view with Cypht, the fourth in our series on 19 open source tools that will make you more productive in 2019.
+
+
+There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
+
+Here's the fourth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
+
+### Cypht
+
+We spend a lot of time dealing with email, and effectively [managing your email][1] can make a huge impact on your productivity. Programs like Thunderbird, Kontact/KMail, and Evolution all seem to have one thing in common: they seek to duplicate the functionality of Microsoft Outlook, which hasn't really changed in the last 10 years or so. Even the [console standard-bearers][2] like Mutt and Cone haven't changed much in the last decade.
+
+
+
+[Cypht][3] is a simple, lightweight, and modern webmail client that aggregates several accounts into a single view. Along with email accounts, it includes Atom/RSS feeds. It makes reading items from these different sources very simple by using an "Everything" screen that shows not just the mail from your inbox, but also the newest articles from your news feeds.
+
+
+
+It uses a simplified version of HTML messages to display mail or you can set it to view a plain-text version. Since Cypht doesn't load images from remote sources (to help maintain security), HTML rendering can be a little rough, but it does enough to get the job done. You'll get plain-text views with most rich-text mail—meaning lots of links and hard to read. I don't fault Cypht, since this is really the email senders' doing, but it does detract a little from the reading experience. Reading news feeds is about the same, but having them integrated with your email accounts makes it much easier to keep up with them (something I sometimes have issues with).
+
+
+
+Users can use a preconfigured mail server and add any additional servers they use. Cypht's customization options include plain-text vs. HTML mail display, support for multiple profiles, and the ability to change the theme (and make your own). You have to remember to click the "Save" button on the left navigation bar, though, or your custom settings will disappear after that session. If you log out and back in without saving, all your changes will be lost and you'll end up with the settings you started with. This does make it easy to experiment, and if you need to reset things, simply logging out without saving will bring back the previous setup when you log back in.
+
+
+
+[Installing Cypht][4] locally is very easy. While it is not in a container or similar technology, the setup instructions were very clear and easy to follow and didn't require any changes on my part. On my laptop, it took about 10 minutes from starting the installation to logging in for the first time. A shared installation on a server uses the same steps, so it should be about the same.
+
+In the end, Cypht is a fantastic alternative to desktop and web-based email clients with a simple interface to help you handle your email quickly and efficiently.
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-cypht-email
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/17/7/email-alternatives-thunderbird
+[2]: https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
+[3]: https://cypht.org/
+[4]: https://cypht.org/install.html
diff --git a/sources/tech/20190117 Get started with CryptPad, an open source collaborative document editor.md b/sources/tech/20190117 Get started with CryptPad, an open source collaborative document editor.md
new file mode 100644
index 0000000000..94e880cf41
--- /dev/null
+++ b/sources/tech/20190117 Get started with CryptPad, an open source collaborative document editor.md
@@ -0,0 +1,58 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with CryptPad, an open source collaborative document editor)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-cryptpad)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+Get started with CryptPad, an open source collaborative document editor
+======
+Securely share your notes, documents, kanban boards, and more with CryptPad, the fifth in our series on open source tools that will make you more productive in 2019.
+
+
+There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
+
+Here's the fifth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
+
+### CryptPad
+
+We already talked about [Joplin][1], which is good for keeping your own notes but—as you may have noticed—doesn't have any sharing or collaboration features.
+
+[CryptPad][2] is a secure, shareable note-taking app and document editor that allows for secure, collaborative editing. Unlike Joplin, it is a NodeJS app, which means you can run it on your desktop or a server elsewhere and access it with any modern web browser. Out of the box, it supports rich text, Markdown, polls, whiteboards, kanban, and presentations.
+
+
+
+The different document types are robust and fully featured. The rich text editor covers all the bases you'd expect from a good editor and allows you to export files to HTML. The Markdown editor is on par with Joplin, and the kanban board, though not as full-featured as [Wekan][3], is really well done. The rest of the supported document types and editors are also very polished and have the features you'd expect from similar apps, although polls feel a little clunky.
+
+
+
+CryptPad's real power, though, comes in its sharing and collaboration features. Sharing a document is as simple as getting the sharable URL from the "share" option, and CryptPad supports embedding documents in iFrame tags on other websites. Documents can be shared in Edit or View mode with a password and with links that expire. The built-in chat allows editors to talk to each other (note that people with View access can also see the chat but can't comment).
+
+
+
+All files are stored encrypted with the user's password. Server administrators can't read the documents, which also means if you forget or lose your password, the files are unrecoverable. So make sure you keep the password in a secure place, like a [password vault][4].
+
+
+
+When it's run locally, CryptPad is a robust app for creating and editing documents. When run on a server, it becomes an excellent collaboration platform for multi-user document creation and editing. Installation took less than five minutes on my laptop, and it just worked out of the box. The developers also include instructions for running CryptPad in Docker, and there is a community-maintained Ansible role for ease of deployment. CryptPad does not support any third-party authentication methods, so users must create their own accounts. CryptPad also has a community-supported hosted version if you don't want to run your own server.
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-cryptpad
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/1/productivity-tool-joplin
+[2]: https://cryptpad.fr/index.html
+[3]: https://opensource.com/article/19/1/productivity-tool-wekan
+[4]: https://opensource.com/article/18/4/3-password-managers-linux-command-line
diff --git a/sources/tech/20190124 ODrive (Open Drive) - Google Drive GUI Client For Linux.md b/sources/tech/20190124 ODrive (Open Drive) - Google Drive GUI Client For Linux.md
index 71a91ec3d8..65787015dd 100644
--- a/sources/tech/20190124 ODrive (Open Drive) - Google Drive GUI Client For Linux.md
+++ b/sources/tech/20190124 ODrive (Open Drive) - Google Drive GUI Client For Linux.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (geekpi)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/tech/20190125 Get started with Freeplane, an open source mind mapping application.md b/sources/tech/20190125 Get started with Freeplane, an open source mind mapping application.md
new file mode 100644
index 0000000000..cefca12303
--- /dev/null
+++ b/sources/tech/20190125 Get started with Freeplane, an open source mind mapping application.md
@@ -0,0 +1,61 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with Freeplane, an open source mind mapping application)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-freeplane)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+Get started with Freeplane, an open source mind mapping application
+======
+
+Map your brainstorming sessions with Freeplane, the 13th in our series on open source tools that will make you more productive in 2019.
+
+
+
+There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
+
+Here's the 13th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
+
+### Freeplane
+
+[Mind maps][1] are one of the more valuable tools I've used for quickly brainstorming ideas and capturing data. Mind mapping is a versatile process that helps show how things are related and can be used to quickly organize interrelated information. From a planning perspective, mind mapping allows you to quickly perform a brain dump around a single concept, idea, or technology.
+
+
+
+[Freeplane][2] is a desktop application that makes it easy to create, view, edit, and share mind maps. It is a redesign of [FreeMind][3], which was the go-to mind-mapping application for quite some time.
+
+Installing Freeplane is pretty easy. It is a [Java][4] application and distributed as a ZIP file with scripts to start the application on Linux, Windows, and MacOS. At its first startup, its main window includes an example mind map with links to documentation about all the different things you can do with Freeplane.
+
+
+
+You have a choice of templates when you create a new mind map. The standard template (likely at the bottom of the list) works for most cases. Just start typing the idea or phrase you want to start with, and your text will replace the center text. Pressing the Insert key will add a branch (or node) off the center with a blank field where you can fill in something associated with the idea. Pressing Insert again will add another node connected to the first one. Pressing Enter on a node will add a node parallel to that one.
+
+
+
+As you add nodes, you may come up with another thought or idea related to the main topic. Using either the mouse or the Arrow keys, go back to the center of the map and press Insert. A new node will be created off the main topic.
+
+If you want to go beyond Freeplane's base functionality, right-click on any of the nodes to bring up a Properties menu for that node. The Tool pane (activated under the View–>Controls menu) contains customization options galore, including line shape and thickness, border shapes, colors, and much, much more. The Calendar tab allows you to insert dates into the nodes and set reminders for when nodes are due. (Note that reminders work only when Freeplane is running.) Mind maps can be exported to several formats, including common images, XML, Microsoft Project, Markdown, and OPML.
+
+
+
+Freeplane gives you all the tools you'll need to create vibrant and useful mind maps, getting your ideas out of your head and into a place where you can take action on them.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-freeplane
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Mind_map
+[2]: https://www.freeplane.org/wiki/index.php/Home
+[3]: https://sourceforge.net/projects/freemind/
+[4]: https://java.com
diff --git a/sources/tech/20190131 19 days of productivity in 2019- The fails.md b/sources/tech/20190131 19 days of productivity in 2019- The fails.md
deleted file mode 100644
index aa9a1d62fe..0000000000
--- a/sources/tech/20190131 19 days of productivity in 2019- The fails.md
+++ /dev/null
@@ -1,78 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (19 days of productivity in 2019: The fails)
-[#]: via: (https://opensource.com/article/19/1/productivity-tool-wish-list)
-[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
-
-19 days of productivity in 2019: The fails
-======
-Here are some tools the open source world doesn't do as well as it could.
-
-
-There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
-
-Part of being productive is accepting that failure happens. I am a big proponent of [Howard Tayler's][1] Maxim 70: "Failure is not an option—it is mandatory. The option is whether or not to let failure be the last thing you do." And there were many things I wanted to talk about in this series that I failed to find good answers for.
-
-So, for the final edition of my 19 new (or new-to-you) open source tools to help you be more productive in 2019, I present the tools I wanted but didn't find. I am hopeful that you, the reader, will be able to help me find some good solutions to the items below. If you do, please share them in the comments.
-
-### Calendaring
-
-
-
-If there is one thing the open source world is weak on, it is calendaring. I've tried about as many calendar programs as I've tried email programs. There are basically three good options for shared calendaring: [Evolution][2], the [Lightning add-on to Thunderbird][3], or [KOrganizer][4]. All the other applications I've tried (including [Orage][5], [Osmo][6], and almost all of the [Org mode][7] add-ons) seem to reliably support only read-only access to remote calendars. If the shared calendar uses either [Google Calendar][8] or [Microsoft Exchange][9] as the server, the first three are the only easily configured options (and even then, additional add-ons are often required).
-
-### Linux on the inside
-
-
-
-I love [Chrome OS][10], with its simplicity and lightweight requirements. I have owned several Chromebooks, including the latest models from Google. I find it to be reasonably distraction-free, lightweight, and easy to use. With the addition of Android apps and a Linux container, it's easy to be productive almost anywhere.
-
-I'd like to carry that over to some of the older laptops I have hanging around, but unless I do a full compile of Chromium OS, it is hard to find that same experience. The desktop [Android][11] projects like [Bliss OS][12], [Phoenix OS][13], and [Android-x86][14] are getting close, and I'm keeping an eye on them for the future.
-
-### Help desks
-
-
-
-Customer service is a big deal for companies big and small. And with the added focus on DevOps these days, it is important to have tools to help bridge the gap. Almost every company I've worked with uses either [Jira][15], [GitHub][16], or [GitLab][17] for code issues, but none of these tools are very good at customer support tickets (without a lot of work). While there are many applications designed around customer support tickets and issues, most (if not all) of them are silos that don't play nice with other systems, again without a lot of work.
-
-On my wishlist is an open source solution that allows customers, support, and developers to work together without an unwieldy pile of code to glue multiple systems together.
-
-### Your turn
-
-
-
-I'm sure there are a lot of options I missed during this series. I try new applications regularly, in the hopes that they will help me be more productive. I encourage everyone to do the same, because when it comes to being productive with open source tools, there is always something new to try. And, if you have favorite open source productivity apps that didn't make it into this series, please make sure to share them in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/1/productivity-tool-wish-list
-
-作者:[Kevin Sonney][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/ksonney (Kevin Sonney)
-[b]: https://github.com/lujun9972
-[1]: https://www.schlockmercenary.com/
-[2]: https://wiki.gnome.org/Apps/Evolution
-[3]: https://www.thunderbird.net/en-US/calendar/
-[4]: https://userbase.kde.org/KOrganizer
-[5]: https://github.com/xfce-mirror/orage
-[6]: http://clayo.org/osmo/
-[7]: https://orgmode.org/
-[8]: https://calendar.google.com
-[9]: https://products.office.com/
-[10]: https://en.wikipedia.org/wiki/Chrome_OS
-[11]: https://www.android.com/
-[12]: https://blissroms.com/
-[13]: http://www.phoenixos.com/
-[14]: http://www.android-x86.org/
-[15]: https://www.atlassian.com/software/jira
-[16]: https://github.com
-[17]: https://about.gitlab.com/
diff --git a/sources/tech/20190218 Emoji-Log- A new way to write Git commit messages.md b/sources/tech/20190218 Emoji-Log- A new way to write Git commit messages.md
deleted file mode 100644
index e821337a60..0000000000
--- a/sources/tech/20190218 Emoji-Log- A new way to write Git commit messages.md
+++ /dev/null
@@ -1,176 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Emoji-Log: A new way to write Git commit messages)
-[#]: via: (https://opensource.com/article/19/2/emoji-log-git-commit-messages)
-[#]: author: (Ahmad Awais https://opensource.com/users/mrahmadawais)
-
-Emoji-Log: A new way to write Git commit messages
-======
-Add context to your commits with Emoji-Log.
-
-
-I'm a full-time open source developer—or, as I like to call it, an 🎩 open sourcerer. I've been working with open source software for over a decade and [built hundreds][1] of open source software applications.
-
-I also am a big fan of the Don't Repeat Yourself (DRY) philosophy and believe writing better Git commit messages—ones that are contextual enough to serve as a changelog for your open source software—is an important component of DRY. One of the many workflows I've written is [Emoji-Log][2], a straightforward, open source Git commit log standard. It improves the developer experience (DX) by using emoji to create better Git commit messages.
-
-I've used Emoji-Log while building the [VSCode Tips & Tricks repo][3], my 🦄 [Shades of Purple VSCode theme repo][4], and even an [automatic changelog][5] that looks beautiful.
-
-### Emoji-Log's philosophy
-
-I like emoji (which is, in fact, the plural of emoji). I like 'em a lot. Programming, code, geeks/nerds, open source… all of that is inherently dull and sometimes boring. Emoji help me add colors and emotions to the mix. There's nothing wrong with wanting to attach feelings to the 2D, flat, text-based world of code.
-
-Instead of memorizing [hundreds of emoji][6], I've learned it's better to keep the categories small and general. Here's the philosophy that guides writing commit messages with Emoji-Log:
-
- 1. **Imperative**
- * Make your Git commit messages imperative.
- * Write commit message like you're giving an order.
- * e.g., Use ✅ **Add** instead of ❌ **Added**
- * e.g., Use ✅ **Create** instead of ❌ **Creating**
- 2. **Rules**
- * A small number of categories are easy to memorize.
- * Nothing more, nothing less
- * e.g. **📦 NEW** , **👌 IMPROVE** , **🐛 FIX** , **📖 DOC** , **🚀 RELEASE** , and **✅ TEST**
- 3. **Actions**
- * Make Git commits based on actions you take.
- * Use a good editor like [VSCode][7] to commit the right files with commit messages.
-
-
-
-### Writing commit messages
-
-Use only the following Git commit messages. The simple and small footprint is the key to Emoji-Logo.
-
- 1. **📦 NEW: IMPERATIVE_MESSAGE**
- * Use when you add something entirely new.
- * e.g., **📦 NEW: Add Git ignore file**
- 2. **👌 IMPROVE: IMPERATIVE_MESSAGE**
- * Use when you improve/enhance piece of code like refactoring etc.
- * e.g., **👌 IMPROVE: Remote IP API Function**
- 3. **🐛 FIX: IMPERATIVE_MESSAGE**
- * Use when you fix a bug. Need I say more?
- * e.g., **🐛 FIX: Case converter**
- 4. **📖 DOC: IMPERATIVE_MESSAGE**
- * Use when you add documentation, like README.md or even inline docs.
- * e.g., **📖 DOC: API Interface Tutorial**
- 5. **🚀 RELEASE: IMPERATIVE_MESSAGE**
- * Use when you release a new version. e.g., **🚀 RELEASE: Version 2.0.0**
- 6. **✅ TEST: IMPERATIVE_MESSAGE**
- * Use when you release a new version.
- * e.g., **✅ TEST: Mock User Login/Logout**
-
-
-
-That's it for now. Nothing more, nothing less.
-
-### Emoji-Log functions
-
-For quick prototyping, I have made the following functions that you can add to your **.bashrc** / **.zshrc** files to use Emoji-Log quickly.
-
-```
-#.# Better Git Logs.
-
-### Using EMOJI-LOG (https://github.com/ahmadawais/Emoji-Log).
-
-
-
-# Git Commit, Add all and Push — in one step.
-
-function gcap() {
- git add . && git commit -m "$*" && git push
-}
-
-# NEW.
-function gnew() {
- gcap "📦 NEW: $@"
-}
-
-# IMPROVE.
-function gimp() {
- gcap "👌 IMPROVE: $@"
-}
-
-# FIX.
-function gfix() {
- gcap "🐛 FIX: $@"
-}
-
-# RELEASE.
-function grlz() {
- gcap "🚀 RELEASE: $@"
-}
-
-# DOC.
-function gdoc() {
- gcap "📖 DOC: $@"
-}
-
-# TEST.
-function gtst() {
- gcap "✅ TEST: $@"
-}
-```
-
-To install these functions for the [fish shell][8], run the following commands:
-
-```
-function gcap; git add .; and git commit -m "$argv"; and git push; end;
-function gnew; gcap "📦 NEW: $argv"; end
-function gimp; gcap "👌 IMPROVE: $argv"; end;
-function gfix; gcap "🐛 FIX: $argv"; end;
-function grlz; gcap "🚀 RELEASE: $argv"; end;
-function gdoc; gcap "📖 DOC: $argv"; end;
-function gtst; gcap "✅ TEST: $argv"; end;
-funcsave gcap
-funcsave gnew
-funcsave gimp
-funcsave gfix
-funcsave grlz
-funcsave gdoc
-funcsave gtst
-```
-
-If you prefer, you can paste these aliases directly in your **~/.gitconfig** file:
-
-```
-# Git Commit, Add all and Push — in one step.
-cap = "!f() { git add .; git commit -m \"$@\"; git push; }; f"
-
-# NEW.
-new = "!f() { git cap \"📦 NEW: $@\"; }; f"
-# IMPROVE.
-imp = "!f() { git cap \"👌 IMPROVE: $@\"; }; f"
-# FIX.
-fix = "!f() { git cap \"🐛 FIX: $@\"; }; f"
-# RELEASE.
-rlz = "!f() { git cap \"🚀 RELEASE: $@\"; }; f"
-# DOC.
-doc = "!f() { git cap \"📖 DOC: $@\"; }; f"
-# TEST.
-tst = "!f() { git cap \"✅ TEST: $@\"; }; f"
-```
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/2/emoji-log-git-commit-messages
-
-作者:[Ahmad Awais][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/mrahmadawais
-[b]: https://github.com/lujun9972
-[1]: https://github.com/ahmadawais
-[2]: https://github.com/ahmadawais/Emoji-Log/
-[3]: https://github.com/ahmadawais/VSCode-Tips-Tricks
-[4]: https://github.com/ahmadawais/shades-of-purple-vscode/commits/master
-[5]: https://github.com/ahmadawais/shades-of-purple-vscode/blob/master/CHANGELOG.md
-[6]: https://gitmoji.carloscuesta.me/
-[7]: https://VSCode.pro
-[8]: https://en.wikipedia.org/wiki/Friendly_interactive_shell
diff --git a/sources/tech/20190218 SPEED TEST- x86 vs. ARM for Web Crawling in Python.md b/sources/tech/20190218 SPEED TEST- x86 vs. ARM for Web Crawling in Python.md
deleted file mode 100644
index 439bd682e5..0000000000
--- a/sources/tech/20190218 SPEED TEST- x86 vs. ARM for Web Crawling in Python.md
+++ /dev/null
@@ -1,533 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (HankChow)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (SPEED TEST: x86 vs. ARM for Web Crawling in Python)
-[#]: via: (https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/)
-[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
-
-SPEED TEST: x86 vs. ARM for Web Crawling in Python
-======
-
-![][1]
-
-Can you imagine if your job was to trawl competitor websites and jot prices down by hand, again and again and again? You’d burn your whole office down by lunchtime.
-
-So, little wonder web crawlers are huge these days. They can keep track of customer sentiment and trending topics, monitor job openings, real estate transactions, UFC results, all sorts of stuff.
-
-For those of a certain bent, this is fascinating stuff. Which is how I found myself playing around with [Scrapy][2], an open source web crawling framework written in Python.
-
-Being wary of the potential to do something catastrophic to my computer while poking with things I didn’t understand, I decided to install it on my main machine but a Raspberry Pi.
-
-And wouldn’t you know it? It actually didn’t run too shabby on the little tacker. Maybe this is a good use case for an ARM server?
-
-Google had no solid answer. The nearest thing I found was [this Drupal hosting drag race][3], which showed an ARM server outperforming a much more expensive x86 based account.
-
-That was definitely interesting. I mean, isn’t a web server kind of like a crawler in reverse? But with one operating on a LAMP stack and the other on a Python interpreter, it’s hardly the exact same thing.
-
-So what could I do? Only one thing. Get some VPS accounts and make them race each other.
-
-### What’s the Deal With ARM Processors?
-
-ARM is now the most popular CPU architecture in the world.
-
-But it’s generally seen as something you’d opt for to save money and battery life, rather than a serious workhorse.
-
-It wasn’t always that way: this CPU was designed in Cambridge, England to power the fiendishly expensive [Acorn Archimedes][4]. This was the most powerful desktop computer in the world, and by a long way too: it was multiple times the speed of the fastest 386.
-
-Acorn, like Commodore and Atari, somewhat ignorantly believed that the making of a great computer company was in the making of great computers. Bill Gates had a better idea. He got DOS on as many x86 machines – of the most widely varying quality and expense – as he could.
-
-Having the best user base made you the obvious platform for third party developers to write software for; having all the software support made yours the most useful computer.
-
-Even Apple nearly bit the dust. All the $$$$ were in building a better x86 chip, this was the architecture that ended up being developed for serious computing.
-
-That wasn’t the end for ARM though. Their chips weren’t just fast, they could run well without drawing much power or emitting much heat. That made them a preferred technology in set top boxes, PDAs, digital cameras, MP3 players, and basically anything that either used a battery or where you’d just rather avoid the noise of a large fan.
-
-So it was that Acorn spun off ARM, who began an idiosyncratic business model that continues to today: ARM doesn’t actually manufacture any chips, they license their intellectual property to others who do.
-
-Which is more or less how they ended up in so many phones and tablets. When Linux was ported to the architecture, the door opened to other open source technologies, which is how we can run a web crawler on these chips today.
-
-#### ARM in the Server Room
-
-Some big names, like [Microsoft][5] and [Cloudflare][6], have placed heavy bets on the British Bulldog for their infrastructure. But for those of us with more modest budgets, the options are fairly sparse.
-
-In fact, when it comes to cheap and cheerful VPS accounts that you can stick on the credit card for a few bucks a month, for years the only option was [Scaleway][7].
-
-This changed a few months ago when public cloud heavyweight [AWS][8] launched its own ARM processor: the [AWS Graviton][9].
-
-I decided to grab one of each, and race them against the most similar Intel offering from the same provider.
-
-### Looking Under the Hood
-
-So what are we actually racing here? Let’s jump right in.
-
-#### Scaleway
-
-Scaleway positions itself as “designed for developers”. And you know what? I think that’s fair enough: it’s definitely been a good little sandbox for developing and prototyping.
-
-The dirt simple product offering and clean, easy dashboard guides you from home page to bash shell in minutes. That makes it a strong option for small businesses, freelancers and consultants who just want to get straight into a good VPS at a great price to run some crawls.
-
-The ARM account we will be using is their [ARM64-2GB][10], which costs 3 euros a month and has 4 Cavium ThunderX cores. This launched in 2014 as the first server-class ARMv8 processor, but is now looking a bit middle-aged, having been superseded by the younger, prettier ThunderX2.
-
-The x86 account we will be comparing it to is the [1-S][11], which costs a more princely 4 euros a month and has 2 Intel Atom C3995 cores. Intel’s Atom range is a low power single-threaded system on chip design, first built for laptops and then adapted for server use.
-
-These accounts are otherwise fairly similar: they each have 2 gigabytes of memory, 50 gigabytes of SSD storage and 200 Mbit/s bandwidth. The disk drives possibly differ, but with the crawls we’re going to run here, this won’t come into play, we’re going to be doing everything in memory.
-
-When I can’t use a package manager I’m familiar with, I become angry and confused, a bit like an autistic toddler without his security blanket, entirely beyond reasoning or consolation, it’s quite horrendous really, so both of these accounts will use Debian Stretch.
-
-#### Amazon Web Services
-
-In the same length of time as it takes you to give Scaleway your credit card details, launch a VPS, add a sudo user and start installing dependencies, you won’t even have gotten as far as registering your AWS account. You’ll still be reading through the product pages trying to figure out what’s going on.
-
-There’s a serious breadth and depth here aimed at enterprises and others with complicated or specialised needs.
-
-The AWS Graviton we wanna drag race is part of AWS’s “Elastic Compute Cloud” or EC2 range. I’ll be running it as an on-demand instance, which is the most convenient and expensive way to use EC2. AWS also operates a [spot market][12], where you get the server much cheaper if you can be flexible about when it runs. There’s also a [mid-priced option][13] if you want to run it 24/7.
-
-Did I mention that AWS is complicated? Anyhoo..
-
-The two accounts we’re comparing are [a1.medium][14] and [t2.small][15]. They both offer 2GB of RAM. Which begs the question: WTF is a vCPU? Confusingly, it’s a different thing on each account.
-
-On the a1.medium account, a vCPU is a single core of the new AWS Graviton chip. This was built by Annapurna Labs, an Israeli chip maker bought by Amazon in 2015. This is a single-threaded 64-bit ARMv8 core exclusive to AWS. This has an on-demand price of 0.0255 US dollars per hour.
-
-Our t2.small account runs on an Intel Xeon – though exactly which Xeon chip it is, I couldn’t really figure out. This has two threads per core – though we’re not really getting the whole core, or even the whole thread.
-
-Instead we’re getting a “baseline performance of 20%, with the ability to burst above that baseline using CPU credits”. Which makes sense in principle, though it’s completely unclear to me what to actually expect from this. The on-demand price for this account is 0.023 US dollars per hour.
-
-I couldn’t find Debian in the image library here, so both of these accounts will run Ubuntu 18.04.
-
-### Beavis and Butthead Do Moz’s Top 500
-
-To test these VPS accounts, I need a crawler to run – one that will let the CPU stretch its legs a bit. One way to do this would be to just hammer a few websites with as many requests as fast as possible, but that’s not very polite. What we’ll do instead is a broad crawl of many websites at once.
-
-So it’s in tribute to my favourite physicist turned filmmaker, Mike Judge, that I wrote beavis.py. This crawls Moz’s Top 500 Websites to a depth of 3 pages to count how many times the words “wood” and “ass” occur anywhere within the HTML source.
-
-Not all 500 websites will actually get crawled here – some will be excluded by robots.txt and others will require javascript to follow links and so on. But it’s a wide enough crawl to keep the CPU busy.
-
-Python’s [global interpreter lock][16] means that beavis.py can only make use of a single CPU thread. To test multi-threaded we’re going to have to launch multiple spiders as seperate processes.
-
-This is why I wrote butthead.py. Any true fan of the show knows that, as crude as Butthead was, he was always slightly more sophisticated than Beavis.
-
-Splitting the crawl into multiple lists of start pages and allowed domains might slightly impact what gets crawled – fewer external links to other websites in the top 500 will get followed. But every crawl will be different anyway, so we will count how many pages are scraped as well as how long they take.
-
-### Installing Scrapy on an ARM Server
-
-Installing Scrapy is basically the same on each architecture. You install pip and various other dependencies, then install Scrapy from pip.
-
-Installing Scrapy from pip to an ARM device does take noticeably longer though. I’m guessing this is because it has to compile the binary parts from source.
-
-Once Scrapy is installed, I ran it from the shell to check that it’s fetching pages.
-
-On Scaleway’s ARM account, there seemed to be a hitch with the service_identity module: it was installed but not working. This issue had come up on the Raspberry Pi as well, but not the AWS Graviton.
-
-Not to worry, this was easily fixed with the following command:
-
-```
-sudo pip3 install service_identity --force --upgrade
-```
-
-Then we were off and racing!
-
-### Single Threaded Crawls
-
-The Scrapy docs say to try to [keep your crawls running between 80-90% CPU usage][17]. In practice, it’s hard – at least it is with the script I’ve written. What tends to happen is that the CPU gets very busy early in the crawl, drops a little bit and then rallies again.
-
-The last part of the crawl, where most of the domains have been finished, can go on for quite a few minutes, which is frustrating, because at that point it feels like more a measure of how big the last website is than anything to do with the processor.
-
-So please take this for what it is: not a state of the art benchmarking tool, but a short and slightly balding Australian in his underpants running some scripts and watching what happens.
-
-So let’s get down to brass tacks. We’ll start with the Scaleway crawls.
-
-| VPS | Account | Time | Pages | Scraped | Pages/Hour | €/million | pages |
-| --------- | ------- | ------- | ------ | ---------- | ---------- | --------- | ----- |
-| Scaleway | | | | | | | |
-| ARM64-2GB | 108m | 59.27s | 38,205 | 21,032.623 | 0.28527 | | |
-| --------- | ------- | ------- | ------ | ---------- | ---------- | --------- | ----- |
-| Scaleway | | | | | | | |
-| 1-S | 97m | 44.067s | 39,476 | 24,324.648 | 0.33011 | | |
-
-I kept an eye on the CPU use of both of these crawls using [top][18]. Both crawls hit 100% CPU use at the beginning, but the ThunderX chip was definitely redlining a lot more. That means these figures understate how much faster the Atom core crawls than the ThunderX.
-
-While I was watching CPU use in top, I could also see how much RAM was in use – this increased as the crawl continued. The ARM account used 14.7% at the end of the crawl, while the x86 was at 15%.
-
-Watching the logs of these crawls, I also noticed a lot more pages timing out and going missing when the processor was maxed out. That makes sense – if the CPU’s too busy to respond to everything then something’s gonna go missing.
-
-That’s not such a big deal when you’re just racing the things to see which is fastest. But in a real-world situation, with business outcomes at stake in the quality of your data, it’s probably worth having a little bit of headroom.
-
-And what about AWS?
-
-| VPS Account | Time | Pages Scraped | Pages / Hour | $ / Million Pages |
-| ----------- | ---- | ------------- | ------------ | ----------------- |
-| a1.medium | 100m 39.900s | 41,294 | 24,612.725 | 1.03605 |
-| t2.small | 78m 53.171s | 41,200 | 31,336.286 | 0.73397 |
-
-I’ve included these results for sake of comparison with the Scaleway crawls, but these crawls were kind of a bust. Monitoring the CPU use – this time through the AWS dashboard rather than through top – showed that the script wasn’t making good use of the available processing power on either account.
-
-This was clearest with the a1.medium account – it hardly even got out of bed. It peaked at about 45% near the beginning and then bounced around between 20% and 30% for the rest.
-
-What’s intriguing to me about this is that the exact same script ran much slower on the ARM processor – and that’s not because it hit a limit of the Graviton’s CPU power. It had oodles of headroom left. Even the Intel Atom core managed to finish, and that was maxing out for some of the crawl. The settings were the same in the code, the way they were being handled differently on the different architecture.
-
-It’s a bit of a black box to me whether that’s something inherent to the processor itself, the way the binaries were compiled, or some interaction between the two. I’m going to speculate that we might have seen the same thing on the Scaleway ARM VPS, if we hadn’t hit the limit of the CPU core’s processing power first.
-
-It was harder to know how the t2.small account was doing. The crawl sat at about 20%, sometimes going as high as 35%. Was that it meant by “baseline performance of 20%, with the ability to burst to a higher level”? I had no idea. But I could see on the dashboard I wasn’t burning through any CPU credits.
-
-Just to make extra sure, I installed [stress][19] and ran it for a few minutes; sure enough, this thing could do 100% if you pushed it.
-
-Clearly, I was going to need to crank the settings up on both these processors to make them sweat a bit, so I set CONCURRENT_REQUESTS to 5000 and REACTOR_THREADPOOL_MAXSIZE to 120 and ran some more crawls.
-
-| VPS Account | Time | Pages Scraped | Pages/hr | $/10000 Pages |
-| ----------- | ---- | ------------- | -------- | ------------- |
-| a1.medium | 46m 13.619s | 40,283 | 52,285.047 | 0.48771 |
-| t2.small | 41m7.619s | 36,241 | 52,871.857 | 0.43501 |
-| t2.small (No CPU credits) | 73m 8.133s | 34,298 | 28,137.8891 | 0.81740 |
-
-The a1 instance hit 100% usage about 5 minutes into the crawl, before dropping back to 80% use for another 20 minutes, climbing up to 96% again and then dropping down again as it was wrapping things up. That was probably about as well-tuned as I was going to get it.
-
-The t2 instance hit 50% early in the crawl and stayed there for until it was nearly done. With 2 threads per core, 50% CPU use is one thread maxed out.
-
-Here we see both accounts produce similar speeds. But the Xeon thread was redlining for most of the crawl, and the Graviton was not. I’m going to chalk this up as a slight win for the Graviton.
-
-But what about once you’ve burnt through all your CPU credits? That’s probably the fairer comparison – to only use them as you earn them. I wanted to test that as well. So I ran stress until all the CPU credits were exhausted and ran the crawl again.
-
-With no credits in the bank, the CPU usage maxed out at 27% and stayed there. So many pages ended up going missing that it actually performed worse than when on the lower settings.
-
-### Multi Threaded Crawls
-
-Dividing our crawl up between multiple spiders in separate processes offers a few more options to make use of the available cores.
-
-I first tried dividing everything up between 10 processes and launching them all at once. This turned out to be slower than just dividing them up into 1 process per core.
-
-I got the best result by combining these methods – dividing the crawl up into 10 processes and then launching 1 process per core at the start and then the rest as these crawls began to wind down.
-
-To make this even better, you could try to minimise the problem of the last lingering crawler by making sure the longest crawls start first. I actually attempted to do this.
-
-Figuring that the number of links on the home page might be a rough proxy for how large the crawl would be, I built a second spider to count them and then sort them in descending order of number of outgoing links. This preprocessing worked well and added a little over a minute.
-
-It turned out though that blew the crawling time out beyond two hours! Putting all the most link heavy websites together in the same process wasn’t a great idea after all.
-
-You might effectively deal with this by tweaking the number of domains per process as well – or by shuffling the list after it’s ordered. That’s a bit much for Beavis and Butthead though.
-
-So I went back to my earlier method that had worked somewhat well:
-
-| VPS Account | Time | Pages Scraped | Pages/hr | €/10,000 pages |
-| ----------- | ---- | ------------- | -------- | -------------- |
-| Scaleway ARM64-2GB | 62m 10.078s | 36,158 | 34,897.0719 | 0.17193 |
-| Scaleway 1-S | 60m 56.902s | 36,725 | 36,153.5529 | 0.22128 |
-
-After all that, using more cores did speed up the crawl. But it’s hardly a matter of just halving or quartering the time taken.
-
-I’m certain that a more experienced coder could better optimise this to take advantage of all the cores. But, as far as “out of the box” Scrapy performance goes, it seems to be a lot easier to speed up a crawl by using faster threads rather than by throwing more cores at it.
-
-As it is, the Atom has scraped slightly more pages in slightly less time. On a value for money metric, you could possibly say that the ThunderX is ahead. Either way, there’s not a lot of difference here.
-
-### Everything You Always Wanted to Know About Ass and Wood (But Were Afraid to Ask)
-
-After scraping 38,205 pages, our crawler found 24,170,435 mentions of ass and 54,368 mentions of wood.
-
-![][20]
-
-Considered on its own, this is a respectable amount of wood.
-
-But when you set it against the sheer quantity of ass we’re dealing with here, the wood looks miniscule.
-
-### The Verdict
-
-From what’s visible to me at the moment, it looks like the CPU architecture you use is actually less important than how old the processor is. The AWS Graviton from 2018 was the winner here in single-threaded performance.
-
-You could of course argue that the Xeon still wins, core for core. But then you’re not really going dollar for dollar anymore, or even thread for thread.
-
-The Atom from 2017, on the other hand, comfortably bested the ThunderX from 2014. Though, on the value for money metric, the ThunderX might be the clear winner. Then again, if you can run your crawls on Amazon’s spot market, the Graviton is still ahead.
-
-All in all, I think this shows that, yes, you can crawl the web with an ARM device, and it can compete on both performance and price.
-
-Whether the difference is significant enough for you to turn what you’re doing upside down is a whole other question of course. Certainly, if you’re already on the AWS cloud – and your code is portable enough – then it might be worthwhile testing out their a1 instances.
-
-Hopefully we will see more ARM options on the public cloud in near future.
-
-### The Scripts
-
-This is my first real go at doing anything in either Python or Scrapy. So this might not be great code to learn from. Some of what I’ve done here – such as using global variables – is definitely a bit kludgey.
-
-Still, I want to be transparent about my methods, so here are my scripts.
-
-To run them, you’ll need Scrapy installed and you will need the CSV file of [Moz’s top 500 domains][21]. To run butthead.py you will also need [psutil][22].
-
-##### beavis.py
-
-```
-import scrapy
-from scrapy.spiders import CrawlSpider, Rule
-from scrapy.linkextractors import LinkExtractor
-from scrapy.crawler import CrawlerProcess
-
-ass = 0
-wood = 0
-totalpages = 0
-
-def getdomains():
-
- moz500file = open('top500.domains.05.18.csv')
-
- domains = []
- moz500csv = moz500file.readlines()
-
- del moz500csv[0]
-
- for csvline in moz500csv:
- leftquote = csvline.find('"')
- rightquote = leftquote + csvline[leftquote + 1:].find('"')
- domains.append(csvline[leftquote + 1:rightquote])
-
- return domains
-
-def getstartpages(domains):
-
- startpages = []
-
- for domain in domains:
- startpages.append('http://' + domain)
-
- return startpages
-
-class AssWoodItem(scrapy.Item):
- ass = scrapy.Field()
- wood = scrapy.Field()
- url = scrapy.Field()
-
-class AssWoodPipeline(object):
- def __init__(self):
- self.asswoodstats = []
-
- def process_item(self, item, spider):
- self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
-
- def close_spider(self, spider):
- asstally, woodtally = 0, 0
-
- for asswoodcount in self.asswoodstats:
- asstally += asswoodcount[1]
- woodtally += asswoodcount[2]
-
- global ass, wood, totalpages
- ass = asstally
- wood = woodtally
- totalpages = len(self.asswoodstats)
-
-class BeavisSpider(CrawlSpider):
- name = "Beavis"
- allowed_domains = getdomains()
- start_urls = getstartpages(allowed_domains)
- #start_urls = [ 'http://medium.com' ]
- custom_settings = {
- 'DEPTH_LIMIT': 3,
- 'DOWNLOAD_DELAY': 3,
- 'CONCURRENT_REQUESTS': 1500,
- 'REACTOR_THREADPOOL_MAXSIZE': 60,
- 'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
- 'LOG_LEVEL': 'INFO',
- 'RETRY_ENABLED': False,
- 'DOWNLOAD_TIMEOUT': 30,
- 'COOKIES_ENABLED': False,
- 'AJAXCRAWL_ENABLED': True
- }
-
- rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
-
- def parse_asswood(self, response):
- if isinstance(response, scrapy.http.TextResponse):
- item = AssWoodItem()
- item['ass'] = response.text.casefold().count('ass')
- item['wood'] = response.text.casefold().count('wood')
- item['url'] = response.url
- yield item
-
-
-if __name__ == '__main__':
-
- process = CrawlerProcess({
- 'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
- })
-
- process.crawl(BeavisSpider)
- process.start()
-
- print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
- print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
- print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
-```
-
-##### butthead.py
-
-```
-import scrapy, time, psutil
-from scrapy.spiders import CrawlSpider, Rule, Spider
-from scrapy.linkextractors import LinkExtractor
-from scrapy.crawler import CrawlerProcess
-from multiprocessing import Process, Queue, cpu_count
-
-ass = 0
-wood = 0
-totalpages = 0
-linkcounttuples =[]
-
-def getdomains():
-
- moz500file = open('top500.domains.05.18.csv')
-
- domains = []
- moz500csv = moz500file.readlines()
-
- del moz500csv[0]
-
- for csvline in moz500csv:
- leftquote = csvline.find('"')
- rightquote = leftquote + csvline[leftquote + 1:].find('"')
- domains.append(csvline[leftquote + 1:rightquote])
-
- return domains
-
-def getstartpages(domains):
-
- startpages = []
-
- for domain in domains:
- startpages.append('http://' + domain)
-
- return startpages
-
-class AssWoodItem(scrapy.Item):
- ass = scrapy.Field()
- wood = scrapy.Field()
- url = scrapy.Field()
-
-class AssWoodPipeline(object):
- def __init__(self):
- self.asswoodstats = []
-
- def process_item(self, item, spider):
- self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
-
- def close_spider(self, spider):
- asstally, woodtally = 0, 0
-
- for asswoodcount in self.asswoodstats:
- asstally += asswoodcount[1]
- woodtally += asswoodcount[2]
-
- global ass, wood, totalpages
- ass = asstally
- wood = woodtally
- totalpages = len(self.asswoodstats)
-
-
-class ButtheadSpider(CrawlSpider):
- name = "Butthead"
- custom_settings = {
- 'DEPTH_LIMIT': 3,
- 'DOWNLOAD_DELAY': 3,
- 'CONCURRENT_REQUESTS': 250,
- 'REACTOR_THREADPOOL_MAXSIZE': 30,
- 'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
- 'LOG_LEVEL': 'INFO',
- 'RETRY_ENABLED': False,
- 'DOWNLOAD_TIMEOUT': 30,
- 'COOKIES_ENABLED': False,
- 'AJAXCRAWL_ENABLED': True
- }
-
- rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
-
-
- def parse_asswood(self, response):
- if isinstance(response, scrapy.http.TextResponse):
- item = AssWoodItem()
- item['ass'] = response.text.casefold().count('ass')
- item['wood'] = response.text.casefold().count('wood')
- item['url'] = response.url
- yield item
-
-def startButthead(domainslist, urlslist, asswoodqueue):
- crawlprocess = CrawlerProcess({
- 'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
- })
-
- crawlprocess.crawl(ButtheadSpider, allowed_domains = domainslist, start_urls = urlslist)
- crawlprocess.start()
- asswoodqueue.put( (ass, wood, totalpages) )
-
-
-if __name__ == '__main__':
- asswoodqueue = Queue()
- domains=getdomains()
- startpages=getstartpages(domains)
- processlist =[]
- cores = cpu_count()
-
- for i in range(10):
- domainsublist = domains[i * 50:(i + 1) * 50]
- pagesublist = startpages[i * 50:(i + 1) * 50]
- p = Process(target = startButthead, args = (domainsublist, pagesublist, asswoodqueue))
- processlist.append(p)
-
- for i in range(cores):
- processlist[i].start()
-
- time.sleep(180)
-
- i = cores
-
- while i != 10:
- time.sleep(60)
- if psutil.cpu_percent() < 66.7:
- processlist[i].start()
- i += 1
-
- for i in range(10):
- processlist[i].join()
-
- for i in range(10):
- asswoodtuple = asswoodqueue.get()
- ass += asswoodtuple[0]
- wood += asswoodtuple[1]
- totalpages += asswoodtuple[2]
-
- print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
- print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
- print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
-```
-
---------------------------------------------------------------------------------
-
-via: https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/
-
-作者:[James Mawson][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
-[b]: https://github.com/lujun9972
-[1]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/quadbike-1024x683.jpg
-[2]: https://scrapy.org/
-[3]: https://www.info2007.net/blog/2018/review-scaleway-arm-based-cloud-server.html
-[4]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
-[5]: https://www.computerworld.com/article/3178544/microsoft-windows/microsoft-and-arm-look-to-topple-intel-in-servers.html
-[6]: https://www.datacenterknowledge.com/design/cloudflare-bets-arm-servers-it-expands-its-data-center-network
-[7]: https://www.scaleway.com/
-[8]: https://aws.amazon.com/
-[9]: https://www.theregister.co.uk/2018/11/27/amazon_aws_graviton_specs/
-[10]: https://www.scaleway.com/virtual-cloud-servers/#anchor_arm
-[11]: https://www.scaleway.com/virtual-cloud-servers/#anchor_starter
-[12]: https://aws.amazon.com/ec2/spot/pricing/
-[13]: https://aws.amazon.com/ec2/pricing/reserved-instances/
-[14]: https://aws.amazon.com/ec2/instance-types/a1/
-[15]: https://aws.amazon.com/ec2/instance-types/t2/
-[16]: https://wiki.python.org/moin/GlobalInterpreterLock
-[17]: https://docs.scrapy.org/en/latest/topics/broad-crawls.html
-[18]: https://linux.die.net/man/1/top
-[19]: https://linux.die.net/man/1/stress
-[20]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/Screenshot-from-2019-02-16-17-01-08.png
-[21]: https://moz.com/top500
-[22]: https://pypi.org/project/psutil/
diff --git a/sources/tech/20190226 All about -Curly Braces- in Bash.md b/sources/tech/20190226 All about -Curly Braces- in Bash.md
deleted file mode 100644
index 42d37abdec..0000000000
--- a/sources/tech/20190226 All about -Curly Braces- in Bash.md
+++ /dev/null
@@ -1,239 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (All about {Curly Braces} in Bash)
-[#]: via: (https://www.linux.com/blog/learn/2019/2/all-about-curly-braces-bash)
-[#]: author: (Paul Brown https://www.linux.com/users/bro66)
-
-All about {Curly Braces} in Bash
-======
-
-
-
-At this stage of our Bash basics series, it would be hard not to see some crossover between topics. For example, you have already seen a lot of brackets in the examples we have shown over the past several weeks, but the focus has been elsewhere.
-
-For the next phase of the series, we’ll take a closer look at brackets, curly, curvy, or straight, how to use them, and what they do depending on where you use them. We will also tackle other ways of enclosing things, like when to use quotes, double-quotes, and backquotes.
-
-This week, we're looking at curly brackets or _braces_ : `{}`.
-
-### Array Builder
-
-You have already encountered curly brackets before in [The Meaning of Dot][1]. There, the focus was on the use of the dot/period (`.`), but using braces to build a sequence was equally important.
-
-As we saw then:
-
-```
-echo {0..10}
-```
-
-prints out the numbers from 0 to 10. Using:
-
-```
-echo {10..0}
-```
-
-prints out the same numbers, but in reverse order. And,
-
-```
-echo {10..0..2}
-```
-
-prints every second number, starting with 10 and making its way backwards to 0.
-
-Then,
-
-```
-echo {z..a..2}
-```
-
-prints every second letter, starting with _z_ and working its way backwards until _a_.
-
-And so on and so forth.
-
-Another thing you can do is combine two or more sequences:
-
-```
-echo {a..z}{a..z}
-```
-
-This prints out all the two letter combinations of the alphabet, from _aa_ to _zz_.
-
-Is this useful? Well, actually it is. You see, arrays in Bash are defined by putting elements between parenthesis `()` and separating each element using a space, like this:
-
-```
-month=("Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec")
-```
-
-To access an element within the array, you use its index within brackets `[]`:
-
-```
-$ echo ${month[3]} # Array indexes start at [0], so [3] points to the fourth item
-
-Apr
-```
-
-You can accept all those brackets, parentheses, and braces on faith for a moment. We'll talk about them presently.
-
-Notice that, all things being equal, you can create an array with something like this:
-
-```
-letter_combos=({a..z}{a..z})
-```
-
-and `letter_combos` points to an array that contains all the 2-letter combinations of the entire alphabet.
-
-You can also do this:
-
-```
-dec2bin=({0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1})
-```
-
-This last one is particularly interesting because `dec2bin` now contains all the binary numbers for an 8-bit register, in ascending order, starting with 00000000, 00000001, 00000010, etc., until reaching 11111111. You can use this to build yourself an 8-bit decimal-to-binary converter. Say you want to know what 25 is in binary. You can do this:
-
-```
-$ echo ${dec2bin[25]}
-
-00011001
-```
-
-Yes, there are better ways of converting decimal to binary as we saw in [the article where we discussed & as a logical operator][2], but it is still interesting, right?
-
-### Parameter expansion
-
-Getting back to
-
-```
-echo ${month[3]}
-```
-
-Here the braces `{}` are not being used as apart of a sequence builder, but as a way of generating _parameter expansion_. Parameter expansion involves what it says on the box: it takes the variable or expression within the braces and expands it to whatever it represents.
-
-In this case, `month` is the array we defined earlier, that is:
-
-```
-month=("Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec")
-```
-
-And, item 3 within the array points to `"Apr"` (remember: the first index in an array in Bash is `[0]`). That means that `echo ${month[3]}`, after the expansion, translates to `echo "Apr"`.
-
-Interpreting a variable as its value is one way of expanding it, but there are a few more you can leverage. You can use parameter expansion to manipulate what you read from variable, say, by cutting a chunk off the end.
-
-Suppose you have a variable like:
-
-```
-a="Too longgg"
-```
-
-The command:
-
-```
-echo ${a%gg}
-```
-
-chops off the last two gs and prints " _Too long_ ".
-
-Breaking this down,
-
- * `${...}` tells the shell to expand whatever is inside it
- * `a` is the variable you are working with
- * `%` tells the shell you want to chop something off the end of the expanded variable ("Too longgg")
- * and `gg` is what you want to chop off.
-
-
-
-This can be useful for converting files from one format to another. Allow me to explain with a slight digression:
-
-[ImageMagick][3] is a set of command line tools that lets you manipulate and modify images. One of its most useful tools ImageMagick comes with is `convert`. In its simplest form `convert` allows you to, given an image in a certain format, make a copy of it in another format.
-
-The following command takes a JPEG image called _image.jpg_ and creates a PNG copy called _image.png_ :
-
-```
-convert image.jpg image.png
-```
-
-ImageMagick is often pre-installed on most Linux distros. If you can't find it, look for it in your distro's software manager.
-
-Okay, end of digression. On to the example:
-
-With variable expansion, you can do the same as shown above like this:
-
-```
-i=image.jpg
-
-convert $i ${i%jpg}png
-```
-
-What you are doing here is chopping off the extension `jpg` from `i` and then adding `png`, making the command `convert image.jpg image.png`.
-
-You may be wondering how this is more useful than just writing in the name of the file. Well, when you have a directory containing hundreds of JPEG images, you need to convert to PNG, run the following in it:
-
-```
-for i in *.jpg; do convert $i ${i%jpg}png; done
-```
-
-... and, hey presto! All the pictures get converted automatically.
-
-If you need to chop off a chunk from the beginning of a variable, instead of `%`, use `#`:
-
-```
-$ a="Hello World!"
-
-$ echo Goodbye${a#Hello}
-
-Goodbye World!
-```
-
-There's quite a bit more to parameter expansion, but a lot of it makes sense only when you are writing scripts. We'll explore more on that topic later in this series.
-
-### Output Grouping
-
-Meanwhile, let's finish up with something simple: you can also use `{ ... }` to group the output from several commands into one big blob. The command:
-
-```
-echo "I found all these PNGs:"; find . -iname "*.png"; echo "Within this bunch of files:"; ls > PNGs.txt
-```
-
-will execute all the commands but will only copy into the _PNGs.txt_ file the output from the last `ls` command in the list. However, doing
-
-```
-{ echo "I found all these PNGs:"; find . -iname "*.png"; echo "Within this bunch of files:"; ls; } > PNGs.txt
-```
-
-creates the file _PNGs.txt_ with everything, starting with the line " _I found all these PNGs:_ ", then the list of PNG files returned by `find`, then the line "Within this bunch of files:" and finishing up with the complete list of files and directories within the current directory.
-
-Notice that there is space between the braces and the commands enclosed within them. That’s because `{` and `}` are _reserved words_ here, commands built into the shell. They would roughly translate to " _group the outputs of all these commands together_ " in plain English.
-
-Also notice that the list of commands has to end with a semicolon (`;`) or the whole thing will bork.
-
-### Next Time
-
-In our next installment, we'll be looking at more things that enclose other things, but of different shapes. Until then, have fun!
-
-Read more:
-
-[And, Ampersand, and & in Linux][4]
-
-[Ampersands and File Descriptors in Bash][5]
-
-[Logical & in Bash][2]
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/blog/learn/2019/2/all-about-curly-braces-bash
-
-作者:[Paul Brown][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linux.com/users/bro66
-[b]: https://github.com/lujun9972
-[1]: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
-[2]: https://www.linux.com/blog/learn/2019/2/logical-ampersand-bash
-[3]: http://www.imagemagick.org/
-[4]: https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux
-[5]: https://www.linux.com/blog/learn/2019/2/ampersands-and-file-descriptors-bash
diff --git a/sources/tech/20190226 How To SSH Into A Particular Directory On Linux.md b/sources/tech/20190226 How To SSH Into A Particular Directory On Linux.md
deleted file mode 100644
index 37d52656a8..0000000000
--- a/sources/tech/20190226 How To SSH Into A Particular Directory On Linux.md
+++ /dev/null
@@ -1,114 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How To SSH Into A Particular Directory On Linux)
-[#]: via: (https://www.ostechnix.com/how-to-ssh-into-a-particular-directory-on-linux/)
-[#]: author: (SK https://www.ostechnix.com/author/sk/)
-
-How To SSH Into A Particular Directory On Linux
-======
-
-
-
-Have you ever been in a situation where you want to SSH to a remote server and immediately cd into a directory and continue work interactively? You’re on the right track! This brief tutorial describes how to directly SSH into a particular directory of a remote Linux system. Not just SSH into a specific directory, you can run any command immediately right after connecting to an SSH server as described in this guide. It is not that difficult as you might think. Read on.
-
-### SSH Into A Particular Directory Of A Remote System
-
-Before I knew this method, I would usually first SSH to the remote remote system using command:
-
-```
-$ ssh user@remote-system
-```
-
-And then cd into a directory like below:
-
-```
-$ cd
-```
-
-However, you need not to use two separate commands. You can combine these commands and simplify the task with one command.
-
-Have a look at the following example.
-
-```
-$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix ; bash'
-```
-
-The above command will SSH into a remote system (192.168.225.22) and immediately cd into a directory named **‘/home/sk/ostechnix/’** directory and leave yourself at the prompt.
-
-Here, the **-t** flag is used to force pseudo-terminal allocation, which is necessary or an interactive shell.
-
-Here is the sample output of the above command:
-
-
-
-You can also use this command as well.
-
-```
-$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix ; exec bash'
-```
-
-Or,
-
-```
-$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix && exec bash -l'
-```
-
-Here, the **-l** flag sets the bash as login shell.
-
-In the above example, I have used **bash** in the last argument. It is the default shell in my remote system. If you don’t know the shell type on the remote system, use the following command:
-
-```
-$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix && exec $SHELL'
-```
-
-Like I already said, this is not just for cd into directory after connecting to an remote system. You can use this trick to run other commands as well. For example, the following command will land you inside ‘/home/sk/ostechnix/’ directory and then execute ‘uname -a’ command.
-
-```
-$ ssh -t sk@192.168.225.22 'cd /home/sk/ostechnix && uname -a && exec $SHELL'
-```
-
-Alternatively, you can add the command(s) you wanted to run after connecting to an SSH server on the remote system’s **.bash_profile** file.
-
-Edit **.bash_profile** file:
-
-```
-$ nano ~/.bash_profile
-```
-
-Add the command(s) one by one. In my case, I am adding the following line:
-
-```
-cd /home/sk/ostechnix >& /dev/null
-```
-
-Save and close the file. Finally, run the following command to update the changes.
-
-```
-$ source ~/.bash_profile
-```
-
-Please note that you should add this line on the remote system’s **.bash_profile** or **.bashrc** file, not in your local system’s. From now on, whenever you login (whether by SSH or direct), the cd command will execute and you will be automatically landed inside “/home/sk/ostechnix/” directory.
-
-
-And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/how-to-ssh-into-a-particular-directory-on-linux/
-
-作者:[SK][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[b]: https://github.com/lujun9972
diff --git a/sources/tech/20190226 Linux security- Cmd provides visibility, control over user activity.md b/sources/tech/20190226 Linux security- Cmd provides visibility, control over user activity.md
index 952e76f1f3..2a1dc8ff53 100644
--- a/sources/tech/20190226 Linux security- Cmd provides visibility, control over user activity.md
+++ b/sources/tech/20190226 Linux security- Cmd provides visibility, control over user activity.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (geekpi)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/tech/20190227 How To Check Password Complexity-Strength And Score In Linux.md b/sources/tech/20190227 How To Check Password Complexity-Strength And Score In Linux.md
deleted file mode 100644
index 59b18f8a87..0000000000
--- a/sources/tech/20190227 How To Check Password Complexity-Strength And Score In Linux.md
+++ /dev/null
@@ -1,165 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How To Check Password Complexity/Strength And Score In Linux?)
-[#]: via: (https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/)
-[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
-
-How To Check Password Complexity/Strength And Score In Linux?
-======
-
-We all know the password importance. It’s a best practices to use hard and guess password.
-
-Also, i advise you to use the different password for each services such as email, ftp, ssh, etc.,
-
-In top of that i suggest you guys to change the password frequently to avoid an unnecessary hacking attempt.
-
-By default RHEL and it’s clone uses `cracklib` module to check password strength.
-
-We are going to teach you, how to check the password strength using cracklib module.
-
-If you would like to check the password score which you have created then use the `pwscore` package.
-
-If you would like to create a good password, basically it should have minimum 12-15 characters length.
-
-It should be created in the following combinations like, Alphabets (Lower case & Upper case), Numbers and Special Characters.
-
-There are many utilities are available in Linux to check a password complexity and we are going to discuss about `cracklib` module today.
-
-### How To Install cracklib module In Linux?
-
-The cracklib module is available in most of the distribution repository so, use the distribution official package manager to install it.
-
-For **`Fedora`** system, use **[DNF Command][1]** to install cracklib.
-
-```
-$ sudo dnf install cracklib
-```
-
-For **`Debian/Ubuntu`** systems, use **[APT-GET Command][2]** or **[APT Command][3]** to install libcrack2.
-
-```
-$ sudo apt install libcrack2
-```
-
-For **`Arch Linux`** based systems, use **[Pacman Command][4]** to install cracklib.
-
-```
-$ sudo pacman -S cracklib
-```
-
-For **`RHEL/CentOS`** systems, use **[YUM Command][5]** to install cracklib.
-
-```
-$ sudo yum install cracklib
-```
-
-For **`openSUSE Leap`** system, use **[Zypper Command][6]** to install cracklib.
-
-```
-$ sudo zypper install cracklib
-```
-
-### How To Use The cracklib module In Linux To Check Password Complexity?
-
-I have added few example in this article to make you understand better about this module.
-
-If you are given any words like, person name or place name or common word then you will be getting an message “it is based on a dictionary word”.
-
-```
-$ echo "password" | cracklib-check
-password: it is based on a dictionary word
-```
-
-The default password length in Linux is `Seven` characters. If you give any password less than seven characters then you will be getting an message “it is WAY too short”.
-
-```
-$ echo "123" | cracklib-check
-123: it is WAY too short
-```
-
-You will be getting `OK` When you give good password like us.
-
-```
-$ echo "ME$2w!@fgty6723" | cracklib-check
-ME!@fgty6723: OK
-```
-
-### How To Install pwscore In Linux?
-
-The pwscore package is available in most of the distribution official repository so, use the distribution package manager to install it.
-
-For **`Fedora`** system, use **[DNF Command][1]** to install libpwquality.
-
-```
-$ sudo dnf install libpwquality
-```
-
-For **`Debian/Ubuntu`** systems, use **[APT-GET Command][2]** or **[APT Command][3]** to install libpwquality.
-
-```
-$ sudo apt install libpwquality
-```
-
-For **`Arch Linux`** based systems, use **[Pacman Command][4]** to install libpwquality.
-
-```
-$ sudo pacman -S libpwquality
-```
-
-For **`RHEL/CentOS`** systems, use **[YUM Command][5]** to install libpwquality.
-
-```
-$ sudo yum install libpwquality
-```
-
-For **`openSUSE Leap`** system, use **[Zypper Command][6]** to install libpwquality.
-
-```
-$ sudo zypper install libpwquality
-```
-
-If you are given any words like, person name or place name or common word then you will be getting a message “it is based on a dictionary word”.
-
-```
-$ echo "password" | pwscore
-Password quality check failed:
- The password fails the dictionary check - it is based on a dictionary word
-```
-
-The default password length in Linux is `Seven` characters. If you give any password less than seven characters then you will be getting an message “it is WAY too short”.
-
-```
-$ echo "123" | pwscore
-Password quality check failed:
- The password is shorter than 8 characters
-```
-
-You will be getting `password score` When you give good password like us.
-
-```
-$ echo "ME!@fgty6723" | pwscore
-90
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/magesh/
-[b]: https://github.com/lujun9972
-[1]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
-[2]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
-[3]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
-[4]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
-[5]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
-[6]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
diff --git a/sources/tech/20190228 Connecting a VoIP phone directly to an Asterisk server.md b/sources/tech/20190228 Connecting a VoIP phone directly to an Asterisk server.md
deleted file mode 100644
index 07027a097d..0000000000
--- a/sources/tech/20190228 Connecting a VoIP phone directly to an Asterisk server.md
+++ /dev/null
@@ -1,75 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Connecting a VoIP phone directly to an Asterisk server)
-[#]: via: (https://feeding.cloud.geek.nz/posts/connecting-voip-phone-directly-to-asterisk-server/)
-[#]: author: (François Marier https://fmarier.org/)
-
-Connecting a VoIP phone directly to an Asterisk server
-======
-
-On my [Asterisk][1] server, I happen to have two on-board ethernet boards. Since I only used one of these, I decided to move my VoIP phone from the local network switch to being connected directly to the Asterisk server.
-
-The main advantage is that this phone, running proprietary software of unknown quality, is no longer available on my general home network. Most importantly though, it no longer has access to the Internet, without my having to firewall it manually.
-
-Here's how I configured everything.
-
-### Private network configuration
-
-On the server, I started by giving the second network interface a static IP address in `/etc/network/interfaces`:
-
-```
-auto eth1
-iface eth1 inet static
- address 192.168.2.2
- netmask 255.255.255.0
-```
-
-On the VoIP phone itself, I set the static IP address to `192.168.2.3` and the DNS server to `192.168.2.2`. I then updated the SIP registrar IP address to `192.168.2.2`.
-
-The DNS server actually refers to an [unbound daemon][2] running on the Asterisk server. The only configuration change I had to make was to listen on the second interface and allow the VoIP phone in:
-
-```
-server:
- interface: 127.0.0.1
- interface: 192.168.2.2
- access-control: 0.0.0.0/0 refuse
- access-control: 127.0.0.1/32 allow
- access-control: 192.168.2.3/32 allow
-```
-
-Finally, I opened the right ports on the server's firewall in `/etc/network/iptables.up.rules`:
-
-```
--A INPUT -s 192.168.2.3/32 -p udp --dport 5060 -j ACCEPT
--A INPUT -s 192.168.2.3/32 -p udp --dport 10000:20000 -j ACCEPT
-```
-
-### Accessing the admin page
-
-Now that the VoIP phone is no longer available on the local network, it's not possible to access its admin page. That's a good thing from a security point of view, but it's somewhat inconvenient.
-
-Therefore I put the following in my `~/.ssh/config` to make the admin page available on `http://localhost:8081` after I connect to the Asterisk server via ssh:
-
-```
-Host asterisk
- LocalForward 8081 192.168.2.3:80
-```
-
---------------------------------------------------------------------------------
-
-via: https://feeding.cloud.geek.nz/posts/connecting-voip-phone-directly-to-asterisk-server/
-
-作者:[François Marier][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fmarier.org/
-[b]: https://github.com/lujun9972
-[1]: https://www.asterisk.org/
-[2]: https://feeding.cloud.geek.nz/posts/setting-up-your-own-dnssec-aware/
diff --git a/sources/tech/20190301 Blockchain 2.0- An Introduction -Part 1.md b/sources/tech/20190301 Blockchain 2.0- An Introduction -Part 1.md
new file mode 100644
index 0000000000..e8922aa789
--- /dev/null
+++ b/sources/tech/20190301 Blockchain 2.0- An Introduction -Part 1.md
@@ -0,0 +1,61 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Blockchain 2.0: An Introduction [Part 1])
+[#]: via: (https://www.ostechnix.com/blockchain-2-0-an-introduction/)
+[#]: author: (EDITOR https://www.ostechnix.com/author/editor/)
+
+Blockchain 2.0: An Introduction [Part 1]
+======
+
+
+
+### Blockchain 2.0 – The next paradigm of computing
+
+The **Blockchain** is now easily distinguishable as a transformational technology poised to bring in revolutionary changes in the way people use the internet. The present series of posts will explore the upcoming wave of Blockchain 2.0 based technologies and applications. The Blockchain is here to stay as evidenced by the tremendous interest in it shown by different stakeholders.
+
+Staying on top of what it is and how it works is paramount to anyone who plans on using the internet for literally anything. Even if all you do is just stare at your friends’ morning breakfast pics on Instagram or looking for the next best clip to watch, you need to know what this technology can do to all of that.
+
+Even though the basic concept behind the Blockchain was first talked about in academia in the **1990s** , its prominence to being a trending buzzword among netizens is owed to the rise of payment platforms such as **Bitcoins** and **Ethers**.
+
+Bitcoin started off as a decentralized digital currency. Its advent meant that you could basically pay people over the internet being totally anonymous, safe and secure. What lay beneath the simple financial token system that was bitcoin though was the BLOCKCHAIN. You can think of Bitcoin technology or any cryptocurrency for that matter as being built up from 3 layers. There’s the foundational Blockchain tech that verifies, records and confirms transactions, on top of the foundation rests the protocol, basically, a rule or an online etiquette to honor, record and confirm transactions and of course, on top of it all is the cryptocurrency token commonly called Bitcoin. A token is generated by the Blockchain once a transaction respecting the protocol is recorded on it.
+
+While most people only saw the top layer, the coins or tokens being representative of what bitcoin really was, few ventured deep enough to understand that financial transactions were just one of many such possibilities that could be accomplished with the help of the Blockchain foundation. These possibilities are now being explored to generate and develop new standards for decentralizing all manners of transactions.
+
+At its very basic level, the Blockchain can be thought of as an all-encompassing ledger of records and transactions. This in effect means that all kinds of records can theoretically be handled by the Blockchain. Developments in this area will possibly in the future result in all kinds of hard (Such as real estate deeds, physical keys, etc.) and soft intangible assets (Such as identity records, patents, trademarks, reservations etc.) can be encoded as digital assets to be protected and transferred via the blockchain.
+
+For the uninitiated, transactions on the Blockchain are inherently thought of and designed to be unbiased, permanent records. This is possible because of a **“consensus system”** that is built into the protocol. All transactions are confirmed, vetted and recorded by the participants of the system, in the case of the Bitcoin cryptocurrency platform, this role is taken care of by **miners** and exchanges. This can vary from platform to platform or from blockchain to blockchain. The protocol stack on which the platform is built is by definition supposed to be open-source and free for anyone with the technical know-how to verify. Transparency is woven into the system unlike much of the other platforms that the internet currently runs on.
+
+Once transactions are recorded and coded into the Blockchain, they will be seen through. Participants are bound to honor their transactions and contracts the way they were originally intended to be executed. The execution itself will be automatically taken care of by the platform since it’s hardcoded into it, unless of course if the original terms forbid it. This resilience of the Blockchain platform toward attempts of tampering with records, permanency of the records etc., are hitherto unheard of for something working over the internet. This is the added layer of trust that is often talked about while supporters of the technology claim its rising significance.
+
+These features are not recently discovered hidden potentials of the platform, these were envisioned from the start. In a communique, **Satoshi Nakamoto** , the fabled creator(s) of Bitcoin mentioned, **“the design supports a tremendous variety of possible transaction types that I designed years ago… If Bitcoin catches on in a big way, these are things we’ll want to explore in the future… but they all had to be designed at the beginning to make sure they would be possible later.”**. Cementing the fact that these features are designed and baked into the already existing protocols. The key idea being that the decentralized transaction ledger like the functionality of the Blockchain could be used to transfer, deploy and execute all manner of contracts.
+
+Leading institutions are currently exploring the possibility of re-inventing financial instruments such as stocks, pensions, and derivatives, while governments all over the world are concerned more with the tamper-proof permanent record keeping potential of the Blockchain. Supporters of the platform claim that once development reaches a critical threshold, everything from your hotel key cards to copyrights and patents will from then on be recorded and implemented via the use of Blockchains.
+
+An almost full list of items and particulars that could theoretically be implemented via a Blockchain model is compiled and maintained on [**this**][1] page by **Ledra Capital**. A thought experiment to actually realize how much of our lives the Blockchain might effect is a daunting task, but a look at that list will reiterate the importance of doing so.
+
+Now, all of the bureaucratic and commercial uses mentioned above might lead you to believe that a technology such as this will be solely in the domain of Governments and Large private corporations. However, the truth is far from that. Given the fact that the vast potentials of the system make it attractive for such uses, there are other possibilities and features harbored by Blockchains. There are other more intricate concepts related to the technology such as **DApps** , **DAOs** , **DACs** , **DASs** etc., more of which will be covered in depth in this series of articles.
+
+Basically, development is going on in full swing and its early for anyone to comment on definitions, standards, and capabilities of such Blockchain based systems for a wider roll-out, but the possibilities and its imminent effects are doubtless. There are even talks about Blockchain based smartphones and polling during elections.
+
+This was just a brief birds-eye view of what the platform is capable of. We’ll look at the distinct possibilities through a series of such detailed posts and articles. Keep an eye out for the [**next post of the series**][2], which will explore how the Blockchain is revolutionizing transactions and contracts.
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/blockchain-2-0-an-introduction/
+
+作者:[EDITOR][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/editor/
+[b]: https://github.com/lujun9972
+[1]: http://ledracapital.com/blog/2014/3/11/bitcoin-series-24-the-mega-master-blockchain-list
+[2]: https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/
diff --git a/sources/tech/20190301 How to use sudo access in winSCP.md b/sources/tech/20190301 How to use sudo access in winSCP.md
deleted file mode 100644
index a2821fefab..0000000000
--- a/sources/tech/20190301 How to use sudo access in winSCP.md
+++ /dev/null
@@ -1,61 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to use sudo access in winSCP)
-[#]: via: (https://kerneltalks.com/tools/how-to-use-sudo-access-in-winscp/)
-[#]: author: (kerneltalks https://kerneltalks.com)
-
-How to use sudo access in winSCP
-======
-
-Learn how to use sudo access in winSCP with screenshots.
-
-![How to use sudo access in winSCP][1]sudo access in winSCP
-
-First of all you need to check where is your SFTP server binary located on server you are trying to connect with winSCP.
-
-You can check SFTP server binary location with below command –
-
-```
-[root@kerneltalks ~]# cat /etc/ssh/sshd_config |grep -i sftp-server
-Subsystem sftp /usr/libexec/openssh/sftp-server
-```
-
-Here you can see sftp server binary is located at `/usr/libexec/openssh/sftp-server`
-
-Now open winSCP and click `Advanced` button to open up advanced settings.
-
-![winSCP advance settings][2]
-winSCP advance settings
-
-It will open up advanced setting window like one below. Here select `SFTP `under `Environment` on left hand side panel. You will be presented with option on right hand side.
-
-Now, add SFTP server value here with command `sudo su -c` here as displayed in screenshot below –
-
-![SFTP server setting in winSCP][3]
-SFTP server setting in winSCP
-
-So we added `sudo su -c /usr/libexec/openssh/sftp-server` in settings here. Now click Ok and connect to server as you normally do.
-
-After connection you will be able to transfer files from directory where you normally need sudo permission to access.
-
-That’s it! You logged to server using winSCP and sudo access.
-
---------------------------------------------------------------------------------
-
-via: https://kerneltalks.com/tools/how-to-use-sudo-access-in-winscp/
-
-作者:[kerneltalks][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://kerneltalks.com
-[b]: https://github.com/lujun9972
-[1]: https://i2.wp.com/kerneltalks.com/wp-content/uploads/2019/03/How-to-use-sudo-access-in-winSCP.png?ssl=1
-[2]: https://i0.wp.com/kerneltalks.com/wp-content/uploads/2019/03/winscp-advanced-settings.jpg?ssl=1
-[3]: https://i1.wp.com/kerneltalks.com/wp-content/uploads/2019/03/SFTP-server-setting-in-winSCP.jpg?ssl=1
diff --git a/sources/tech/20190301 Which Raspberry Pi should you choose.md b/sources/tech/20190301 Which Raspberry Pi should you choose.md
deleted file mode 100644
index b7c5009051..0000000000
--- a/sources/tech/20190301 Which Raspberry Pi should you choose.md
+++ /dev/null
@@ -1,48 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Which Raspberry Pi should you choose?)
-[#]: via: (https://opensource.com/article/19/3/which-raspberry-pi-choose)
-[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
-
-Which Raspberry Pi should you choose?
-======
-In the first article in our series on getting started with Raspberry Pi, learn the three criteria for choosing the right model for you.
-
-
-This is the first article in a 14-day series on getting started with the [Raspberry Pi][1]. Although the series is geared towards people who have never used a Raspberry Pi or Linux or programming, there will definitely be things for more experienced readers—and I encourage those readers to leave comments and tips that build on what I write. If everyone contributes, we can make this series even more useful for beginners, other experienced readers, and even me!
-
-So, you want to give the Raspberry Pi a shot, but you don't know which model to buy. Maybe you want one for your classroom or your kid, but there are so many options, and you aren't sure which one is right for you.
-
-
-
-My three main criteria for choosing a new Raspberry Pi are:
-
- * **Cost:** Don't just consider the cost of the Raspberry Pi board, but also factor the peripherals you will need in order to use it. In the US, the Raspberry Pi's cost varies from $5 (for the Raspberry Pi Zero) to $35 (for the Raspberry Pi 3 B and 3 B+). However, if you pick the Zero you will probably also need a USB hub for your mouse and keyboard, possibly a wireless adapter, and some sort of display adapter. Unless you have most (if not all) of the peripherals needed for whatever you want to do with your Raspberry Pi, make sure to add those to your Pi budget. Also, in some countries, a Raspberry Pi on its own (even without any peripherals) may be a cost burden for many students and teachers.
-
- * **Availability:** Finding the Raspberry Pi you want can vary depending on your location, as it may be easier (or harder) to get certain versions in some countries. Availability is an even bigger issue after new models are released, and it can take a few days or even weeks for new versions to become available in your market.
-
- * **Purpose:** Location and cost may not affect everyone, but every buyer must consider why they want a Raspberry Pi. The eight different models vary in RAM, CPU core, CPU speed, physical size, network connectivity, peripheral expansion, etc. For example, if you want the most robust solution with more "horsepower," you probably will want the Raspberry Pi 3 B+, which has the most RAM, fastest CPU, and largest number of cores. If you want something that won't require network connectivity, won't be used for CPU-intensive work, and can be hidden in a small space, you could go with a Raspberry Pi Zero.
-
-
-[Wikipedia's Raspberry Pi specs chart][2] is an easy way to compare the eight Raspberry Pis models.
-
-Now that you know what to look for in a Raspberry Pi, in the next article, I will explain how to buy one.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/3/which-raspberry-pi-choose
-
-作者:[Anderson Silva][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/ansilva
-[b]: https://github.com/lujun9972
-[1]: https://www.raspberrypi.org/
-[2]: https://en.wikipedia.org/wiki/Raspberry_Pi#Specifications
diff --git a/sources/tech/20190302 How to buy a Raspberry Pi.md b/sources/tech/20190302 How to buy a Raspberry Pi.md
deleted file mode 100644
index 974a6b75fb..0000000000
--- a/sources/tech/20190302 How to buy a Raspberry Pi.md
+++ /dev/null
@@ -1,51 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to buy a Raspberry Pi)
-[#]: via: (https://opensource.com/article/19/3/how-buy-raspberry-pi)
-[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
-
-How to buy a Raspberry Pi
-======
-Find out the best ways to get a Raspberry Pi in the second article in our getting started guide
-
-
-
-The first article in this series on getting started with Raspberry Pi offered some advice on [which model you should buy][1]. Now that you have an idea of which version you want, let's find out how to get one.
-
-The most obvious—and probably the safest and simplest—way is through the [official Raspberry Pi website][2]. If you click on "Buy a Raspberry Pi" from the homepage, you'll be taken to the organization's [online store][3], where you can find authorized Raspberry Pi sellers in your country where you can place an order. If your country isn't listed, there is a "Rest of the World" option, which should let you put in an international order.
-
-Second, check Amazon.com or another major online technology retailer in your country that allows smaller shops to sell new and used items. Given the relatively low cost and size of the Raspberry Pi, it should be fairly easy for smaller shop owners to import and export the boards for reselling purposes. Before you place an order, keep an eye on the sellers' reviews though.
-
-Third, ask your geek friends! You never know if someone has an unused Raspberry Pi gathering dust. I have given at least three Raspberry Pis away to family, not as planned gifts, but because they were just so curious about this mini-computer. I had so many lying around that I just told them to keep one!
-
-### Don't forget the extras
-
-One final thought: don't forget that you'll need some peripherals to set up and operate your Raspberry Pi. At a minimum, you'll need a keyboard, an HDMI cable to connect to a display (and a display), a Micro SD card to install the operating system, a power cord, and a mouse will be handy, too.
-
-
-
-If you don't already have these items, try borrowing them from friends or order them at the same time you buy your Raspberry Pi. You may want to consider one of the starter kits available from the authorized Raspberry Pi vendors—that will avoid the hassle of searching for parts one at a time.
-
-
-
-Now that you have a Raspberry Pi, in the next article in this series, we'll install the operating system and start using it.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/3/how-buy-raspberry-pi
-
-作者:[Anderson Silva][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/ansilva
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/article/19/2/which-raspberry-pi-should-you-get
-[2]: https://www.raspberrypi.org/
-[3]: https://www.raspberrypi.org/products/
diff --git a/sources/tech/20190303 How to boot up a new Raspberry Pi.md b/sources/tech/20190303 How to boot up a new Raspberry Pi.md
new file mode 100644
index 0000000000..87ab3ea268
--- /dev/null
+++ b/sources/tech/20190303 How to boot up a new Raspberry Pi.md
@@ -0,0 +1,69 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to boot up a new Raspberry Pi)
+[#]: via: (https://opensource.com/article/19/3/how-boot-new-raspberry-pi)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+How to boot up a new Raspberry Pi
+======
+Learn how to install a Linux operating system, in the third article in our guide to getting started with Raspberry Pi.
+
+
+If you've been following along in this series, you've [chosen][1] and [bought][2] your Raspberry Pi board and peripherals and now you're ready to start using it. Here, in the third article, let's look at what you need to do to boot it up.
+
+Unlike your laptop, desktop, smartphone, or tablet, the Raspberry Pi doesn't come with built-in storage. Instead, it uses a Micro SD card to store the operating system and your files. The great thing about this is it gives you the flexibility to carry your files (even if you don't have your Raspberry Pi with you). The downside is it may also increase the risk of losing or damaging the card—and thus losing your files. Just protect your Micro SD card, and you should be fine.
+
+You should also know that SD cards aren't as fast as mechanical or solid state drives, so booting, reading, and writing from your Pi will not be as speedy as you would expect from other devices.
+
+### How to install Raspbian
+
+The first thing you need to do when you get a new Raspberry Pi is to install its operating system on a Micro SD card. Even though there are other operating systems (both Linux- and non-Linux-based) available for the Raspberry Pi, this series focuses on [Raspbian][3] , Raspberry Pi's official Linux version.
+
+
+
+The easiest way to install Raspbian is with [NOOBS][4], which stands for "New Out Of Box Software." Raspberry Pi offers great [documentation for NOOBS][5], so I won't repeat the installation instructions here.
+
+NOOBS gives you the choice of installing the following operating systems:
+
++ [Raspbian][6]
++ [LibreELEC][7]
++ [OSMC][8]
++ [Recalbox][9]
++ [Lakka][10]
++ [RISC OS][11]
++ [Screenly OSE][12]
++ [Windows 10 IoT Core][13]
++ [TLXOS][14]
+
+Again, Raspbian is the operating system we'll use in this series, so go ahead, grab your Micro SD and follow the NOOBS documentation to install it. I'll meet you in the fourth article in this series, where we'll look at how to use Linux, including some of the main commands you'll need to know.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/how-boot-new-raspberry-pi
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/3/which-raspberry-pi-choose
+[2]: https://opensource.com/article/19/2/how-buy-raspberry-pi
+[3]: https://www.raspbian.org/RaspbianFAQ
+[4]: https://www.raspberrypi.org/downloads/noobs/
+[5]: https://www.raspberrypi.org/documentation/installation/noobs.md
+[6]: https://www.raspbian.org/RaspbianFAQ
+[7]: https://libreelec.tv/
+[8]: https://osmc.tv/
+[9]: https://www.recalbox.com/
+[10]: http://www.lakka.tv/
+[11]: https://www.riscosopen.org/wiki/documentation/show/Welcome%20to%20RISC%20OS%20Pi
+[12]: https://www.screenly.io/ose/
+[13]: https://developer.microsoft.com/en-us/windows/iot
+[14]: https://thinlinx.com/
diff --git a/sources/tech/20190304 Learn Linux with the Raspberry Pi.md b/sources/tech/20190304 Learn Linux with the Raspberry Pi.md
deleted file mode 100644
index 079e42dbc1..0000000000
--- a/sources/tech/20190304 Learn Linux with the Raspberry Pi.md
+++ /dev/null
@@ -1,53 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Learn Linux with the Raspberry Pi)
-[#]: via: (https://opensource.com/article/19/3/learn-linux-raspberry-pi)
-[#]: author: (Andersn Silva https://opensource.com/users/ansilva)
-
-Learn Linux with the Raspberry Pi
-======
-The fourth article in our guide to getting started with the Raspberry Pi dives into the Linux command line.
-
-
-In the [third article][1] in this series on getting started with Raspberry Pi, I shared info on installing Raspbian, the official version of Linux for Raspberry Pi. Now that you've installed Raspbian and booted up your new Pi, you're ready to start learning about Linux.
-
-It's impossible to tackle a topic as big as "how to use Linux" in a short article like this, so instead I'll give you some ideas about how you can use the Raspberry Pi to learn more about Linux in general.
-
-Start by spending time on the command line (aka the "terminal"). Linux [window managers][2] and graphical interfaces have come a long way since the mid-'90s. Nowadays you can use Linux by pointing-and-clicking on things, just as easily as you can in other operating systems. In my opinion, there is a difference between just "using Linux" and being "a Linux user," and the latter means at a minimum being able to navigate in the terminal.
-
-
-
-If you want to become a Linux user, start by trying out the following on the command line:
-
- * Navigate your home directory with commands like **ls** , **cd** , and **pwd**.
- * Create, delete, and rename directories using the **mkdir** , **rm** , **mv** , and **cp** commands.
- * Create a text file with a command line editor such as Vi, Vim, Emacs, or Nano.
- * Try out some other useful commands, such as **chmod** , **chown** , **w** , **cat** , **more** , **less** , **tail** , **free** , **df** , **ps** , **uname** , and **kill**
- * Look around **/bin** and **/usr/bin** for other commands.
-
-
-
-The best way to get help with a command is by reading its "man page" (short for manual); type **man ** on the command line to pull it up. And make sure to search the internet for Linux command cheat sheets—you should find a lot of options that will help you learn.
-
-Raspbian, like most Linux distributions, has many commands and over time you will end up using some commands a lot more than others. I've been using Linux on the command line for over two decades, and there are still some commands that I've never used, even ones that have been around as long as I've been using Linux.
-
-At the end of the day, you can use your graphical interface environment to get work done faster, but make sure to dive into the Linux command line, for that's where you will get the true power and knowledge of the operating system.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/3/learn-linux-raspberry-pi
-
-作者:[Andersn Silva][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/ansilva
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/article/19/2/how-boot-new-raspberry-pi
-[2]: https://opensource.com/article/18/8/window-manager
diff --git a/sources/tech/20190305 5 Ways To Generate A Random-Strong Password In Linux Terminal.md b/sources/tech/20190305 5 Ways To Generate A Random-Strong Password In Linux Terminal.md
index 0f12c53e56..4458722bbc 100644
--- a/sources/tech/20190305 5 Ways To Generate A Random-Strong Password In Linux Terminal.md
+++ b/sources/tech/20190305 5 Ways To Generate A Random-Strong Password In Linux Terminal.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: ( )
+[#]: translator: (leommxj)
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
@@ -350,7 +350,7 @@ via: https://www.2daygeek.com/5-ways-to-generate-a-random-strong-password-in-lin
作者:[Magesh Maruthamuthu][a]
选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
+译者:[leommx](https://github.com/leommxj)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/tech/20190305 5 ways to teach kids to program with Raspberry Pi.md b/sources/tech/20190305 5 ways to teach kids to program with Raspberry Pi.md
deleted file mode 100644
index bfd980e56e..0000000000
--- a/sources/tech/20190305 5 ways to teach kids to program with Raspberry Pi.md
+++ /dev/null
@@ -1,65 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (5 ways to teach kids to program with Raspberry Pi)
-[#]: via: (https://opensource.com/article/19/3/teach-kids-program-raspberry-pi)
-[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
-
-5 ways to teach kids to program with Raspberry Pi
-======
-The fifth article in our guide to getting started with the Raspberry Pi explores resources for helping kids learn to program.
-
-
-As countless schools, libraries, and families have proven, the Raspberry Pi is a great way to expose kids to programming. In the first four articles in this series, you've learned about [purchasing][1], [installing][2], and [configuring][3] a Raspberry Pi. In this fifth article, I'll share some helpful resources to get kids started programming with the Raspberry Pi.
-
-### Scratch
-
-[Scratch][4] is a great way to introduce kids to basic programming concepts like variables, boolean logic, loops, and more. It's included in Raspbian, and you can find numerous articles and tutorials about Scratch on the internet, including [Is Scratch today like the Logo of the '80s for teaching kids to code?][5] on Opensource.com.
-
-
-
-### Code.org
-
-[Code.org][6] is another great online resource for kids learning to program. The organization's mission is to expose more people to coding through courses, tutorials, and the popular Hour of Code event. Many schools—including my fifth-grade son's—use it to expose more kids to programming and computer science concepts.
-
-### Reading
-
-Reading books is another great way to learn how to program. You don't necessarily need to speak English to learn how to program, but the more you know, the easier it will be, as most programming languages use English keywords to describe the commands. If your English is good enough to follow this Raspberry Pi series, you are most likely well-equipped to read books, forums, and other publications about programming. One book I recommend is [Python for Kids: A Playful Introduction to Programming][7] by Jason Biggs.
-
-### Raspberry Jam
-
-Another way to get your kids into programming is by helping them interact with others at meetups. The Raspberry Pi Foundation sponsors events called [Raspberry Jams][8] around the world where kids and adults can join forces and learn together on the Raspberry Pi. If there isn't a Raspberry Jam in your area, the foundation has a [guidebook][9] and other resources to help you start one.
-
-### Gaming
-
-Last, but not least, there's a version of [Minecraft][10] for the Raspberry Pi. Minecraft has grown from a multi-player "digital Lego"-like game into a programming platform where anyone can use Python and other languages to build on Minecraft's virtual world. Check out [Getting Started with Minecraft Pi][11] and [Minecraft Hour of Code Tutorials][12].
-
-What are your favorite resources for teaching kids to program with Raspberry Pi? Please share them in the comments.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/3/teach-kids-program-raspberry-pi
-
-作者:[Anderson Silva][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/ansilva
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/article/19/2/how-buy-raspberry-pi
-[2]: https://opensource.com/article/19/2/how-boot-new-raspberry-pi
-[3]: https://opensource.com/article/19/3/learn-linux-raspberry-pi
-[4]: https://scratch.mit.edu/
-[5]: https://opensource.com/article/17/3/logo-scratch-teach-programming-kids
-[6]: https://code.org/
-[7]: https://www.amazon.com/Python-Kids-Playful-Introduction-Programming/dp/1593274076
-[8]: https://www.raspberrypi.org/jam/#map-section
-[9]: https://static.raspberrypi.org/files/jam/Raspberry-Jam-Guidebook-2017-04-26.pdf
-[10]: https://minecraft.net/en-us/edition/pi/
-[11]: https://projects.raspberrypi.org/en/projects/getting-started-with-minecraft-pi
-[12]: https://code.org/minecraft
diff --git a/sources/tech/20190305 How rootless Buildah works- Building containers in unprivileged environments.md b/sources/tech/20190305 How rootless Buildah works- Building containers in unprivileged environments.md
new file mode 100644
index 0000000000..cf046ec1b3
--- /dev/null
+++ b/sources/tech/20190305 How rootless Buildah works- Building containers in unprivileged environments.md
@@ -0,0 +1,133 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How rootless Buildah works: Building containers in unprivileged environments)
+[#]: via: (https://opensource.com/article/19/3/tips-tricks-rootless-buildah)
+[#]: author: (Daniel J Walsh https://opensource.com/users/rhatdan)
+
+How rootless Buildah works: Building containers in unprivileged environments
+======
+Buildah is a tool and library for building Open Container Initiative (OCI) container images.
+
+
+In previous articles, including [How does rootless Podman work?][1], I talked about [Podman][2], a tool that enables users to manage pods, containers, and container images.
+
+[Buildah][3] is a tool and library for building Open Container Initiative ([OCI][4]) container images that is complementary to Podman. (Both projects are maintained by the [containers][5] organization, of which I'm a member.) In this article, I will talk about rootless Buildah, including the differences between it and Podman.
+
+Our goal with Buildah was to build a low-level tool that could be used either directly or vendored into other tools to build container images.
+
+### Why Buildah?
+
+Here is how I describe a container image: It is basically a rootfs directory that contains the code needed to run your container. This directory is called a rootfs because it usually looks like **/ (root)** on a Linux machine, meaning you are likely to find directories in a rootfs like **/etc** , **/usr** , **/bin** , etc.
+
+The second part of a container image is a JSON file that describes the contents of the rootfs. It contains fields like the command to run the container, the entrypoint, the environment variables required to run the container, the working directory of the container, etc. Basically this JSON file allows the developer of the container image to describe how the container image is expected to be used. The fields in this JSON file have been standardized in the [OCI Image Format specification][6]
+
+The rootfs and the JSON file then get tar'd together to create an image bundle that is stored in a container registry. To create a layered image, you install more software into the rootfs and modify the JSON file. Then you tar up the differences of the new and the old rootfs and store that in another image tarball. The second JSON file refers back to the first JSON file via a checksum.
+
+Many years ago, Docker introduced Dockerfile, a simplified scripting language for building container images. Dockerfile was great and really took off, but it has many shortcomings that users have complained about. For example:
+
+ * Dockerfile encourages the inclusion of tools used to build containers inside the container image. Container images do not need to include yum/dnf/apt, but most contain one of them and all their dependencies.
+
+ * Each line causes a layer to be created. Because of this, secrets can mistakenly get added to container images. If you create a secret in one line of the Dockerfile and delete it in the next, the secret is still in the image.
+
+
+
+
+One of my biggest complaints about the "container revolution" is that six years since it started, the only way to build a container image was still with Dockerfiles. Lots of tools other than **docker build** have appeared besides Buildah, but most still deal only with Dockerfile. So users continue hacking around the problems with Dockerfile.
+
+Note that [umoci][7] is an alternative to **docker build** that allows you to build container images without Dockerfile.
+
+Our goal with Buildah was to build a simple tool that could just create a rootfs directory on disk and allow other tools to populate the directory, then create the JSON file. Finally, Buildah would create the OCI image and push it to a container registry where it could be used by any container engine, like [Docker][8], Podman, [CRI-O][9], or another Buildah.
+
+Buildah also supports Dockerfile, since we know the bulk of people building containers have created Dockerfiles.
+
+### Using Buildah directly
+
+Lots of people use Buildah directly. A cool feature of Buildah is that you can script up the container build directly in Bash.
+
+The example below creates a Bash script called **myapp.sh** , which uses Buildah to pull down the Fedora image, and then uses **dnf** and **make** on a machine to install software into the container image rootfs, **$mnt**. It then adds some fields to the JSON file using **buildah config** and commits the container to a container image **myapp**. Finally, it pushes the container image to a container registry, **quay.io**. (It could push it to any container registry.) Now this OCI image can be used by any container engine or Kubernetes.
+
+```
+cat myapp.sh
+#!/bin/sh
+ctr=$(buildah from fedora)
+mnt=($buildah mount $ctr)
+dnf -y install --installroot $mnt httpd
+make install DESTDIR=$mnt myapp
+rm -rf $mnt/var/cache $mnt/var/log/*
+buildah config --command /usr/bin/myapp -env foo=bar --working-dir=/root $ctr
+buildah commit $ctr myapp
+buildah push myapp http://quay.io/username/myapp
+```
+
+To create really small images, you could replace **fedora** in the script above with **scratch** , and Buildah will build a container image that only has the requirements for the **httpd** package inside the container image. No need for Python or DNF.
+
+### Podman's relationship to Buildah
+
+With Buildah, we have a low-level tool for building container images. Buildah also provides a library for other tools to build container images. Podman was designed to replace the Docker command line interface (CLI). One of the Docker CLI commands is **docker build**. We needed to have **podman build** to support building container images with Dockerfiles. Podman vendored in the Buildah library to allow it to do **podman build**. Any time you do a **podman build** , you are executing Buildah code to build your container images. If you are only going to use Dockerfiles to build container images, we recommend you only use Podman; there's no need for Buildah at all.
+
+### Other tools using the Buildah library
+
+Podman is not the only tool to take advantage of the Buildah library. [OpenShift 4 Source-to-Image][10] (S2I) will also use Buildah to build container images. OpenShift S2I allows developers using OpenShift to use Git commands to modify source code; when they push the changes for their source code to the Git repository, OpenShift kicks off a job to compile the source changes and create a container image. It also uses Buildah under the covers to build this image.
+
+[Ansible-Bender][11] is a new project to build container images via an Ansible playbook. For those familiar with Ansible, Ansible-Bender makes it easy to describe the contents of the container image and then uses Buildah to package up the container image and send it to a container registry.
+
+We would love to see other tools and languages for describing and building a container image and would welcome others use Buildah to do the conversion.
+
+### Problems with rootless
+
+Buildah works fine in rootless mode. It uses user namespace the same way Podman does. If you execute
+
+```
+$ buildah bud --tag myapp -f Dockerfile .
+$ buildah push myapp http://quay.io/username/myapp
+```
+
+in your home directory, everything works great.
+
+However, if you execute the script described above, it will fail!
+
+The problem is that, when running the **buildah mount** command in rootless mode, the **buildah** command must put itself inside the user namespace and create a new mount namespace. Rootless users are not allowed to mount filesystems when not running in a user namespace.
+
+When the Buildah executable exits, the user namespace and mount namespace disappear, so the mount point no longer exists. This means the commands after **buildah mount** that attempt to write to **$mnt** will fail since **$mnt** is no longer mounted.
+
+How can we make the script work in rootless mode?
+
+#### Buildah unshare
+
+Buildah has a special command, **buildah unshare** , that allows you to enter the user namespace. If you execute it with no commands, it will launch a shell in the user namespace, and your shell will seem like it is running as root and all the contents of the home directory will seem like they are owned by root. If you look at the owner or files in **/usr** , it will list them as owned by **nfsnobody** (or nobody). This is because your user ID (UID) is now root inside the user namespace and real root (UID=0) is not mapped into the user namespace. The kernel represents all files owned by UIDs not mapped into the user namespace as the NFSNOBODY user. When you exit the shell, you will exit the user namespace, you will be back to your normal UID, and the home directory will be owned by your UID again.
+
+If you want to execute the **myapp.sh** command defined above, you can execute **buildah unshare myapp.sh** and the script will now run correctly.
+
+#### Conclusion
+
+Building and running containers in unprivileged environments is now possible and quite useable. There is little reason for developers to develop containers as root.
+
+If you want to use a traditional container engine, and use Dockerfile's for builds, then you should probably just use Podman. But if you want to experiment with building container images in new ways without using Dockerfile, then you should really take a look at Buildah.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/tips-tricks-rootless-buildah
+
+作者:[Daniel J Walsh][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rhatdan
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/2/how-does-rootless-podman-work
+[2]: https://podman.io/
+[3]: https://github.com/containers/buildah
+[4]: https://www.opencontainers.org/
+[5]: https://github.com/containers
+[6]: https://github.com/opencontainers/image-spec
+[7]: https://github.com/openSUSE/umoci
+[8]: https://github.com/docker
+[9]: https://cri-o.io/
+[10]: https://github.com/openshift/source-to-image
+[11]: https://github.com/TomasTomecek/ansible-bender
diff --git a/sources/tech/20190306 3 popular programming languages you can learn with Raspberry Pi.md b/sources/tech/20190306 3 popular programming languages you can learn with Raspberry Pi.md
new file mode 100644
index 0000000000..33670e525a
--- /dev/null
+++ b/sources/tech/20190306 3 popular programming languages you can learn with Raspberry Pi.md
@@ -0,0 +1,65 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (3 popular programming languages you can learn with Raspberry Pi)
+[#]: via: (https://opensource.com/article/19/3/programming-languages-raspberry-pi)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+3 popular programming languages you can learn with Raspberry Pi
+======
+Become more valuable on the job market by learning to program with the Raspberry Pi.
+
+
+In the last article in this series, I shared some ways to [teach kids to program with Raspberry Pi][1]. In theory, there is absolutely nothing stopping an adult from using resources designed for kids, but you might be better served by learning the programming languages that are in demand in the job market.
+
+Here are three programming languages you can learn with the Raspberry Pi.
+
+### Python
+
+[Python][2] has become one of the [most popular programming languages][3] in the open source world. Its interpreter has been packaged and made available in every popular Linux distribution. If you install Raspbian on your Raspberry Pi, you will see an app called [Thonny][4], which is a Python integrated development environment (IDE) for beginners. In a nutshell, an IDE is an application that provides all you need to get your code executed, often including things like debuggers, documentation, auto-completion, and emulators. Here is a [great little tutorial][5] to get you started using Thonny and Python on the Raspberry Pi.
+
+
+
+### Java
+
+Although arguably not as attractive as it once was, [Java][6] remains heavily used in universities around the world and deeply embedded in the enterprise. So, even though some will disagree that I'm recommending it as a beginner's language, I am compelled to do so; for one thing, it still very popular, and for another, there are a lot of books, classes, and other information available for you to learn Java. Get started on the Raspberry Pi by using the [BlueJ][7] Java IDE.
+
+
+
+### JavaScript
+
+"Back in my day…" [JavaScript][8] was a client-side language that basically allowed people to streamline and automate user events in a browser and modify HTML elements. Today, JavaScript has escaped the browser and is available for other types of clients like mobile apps and even server-side programming. [Node.js][9] is a popular runtime environment that allows developers to code beyond the client-browser paradigm. To learn more about running Node.js on the Raspberry Pi, check out [W3Schools tutorial][10].
+
+### Other languages
+
+If there's another language you want to learn, don't despair. There's a high likelihood that you can use your Raspberry Pi to compile or interpret any language of choice, including C, C++, PHP, and Ruby.
+
+Microsoft's [Visual Studio Code][11] also [runs on the Raspberry Pi][12]. It's an open source code editor from Microsoft that supports several markup and programming languages.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/programming-languages-raspberry-pi
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/2/teach-kids-program-raspberry-pi
+[2]: https://opensource.com/resources/python
+[3]: https://www.economist.com/graphic-detail/2018/07/26/python-is-becoming-the-worlds-most-popular-coding-language
+[4]: https://thonny.org/
+[5]: https://raspberrypihq.com/getting-started-with-python-programming-and-the-raspberry-pi/
+[6]: https://opensource.com/resources/java
+[7]: https://www.bluej.org/raspberrypi/
+[8]: https://developer.mozilla.org/en-US/docs/Web/JavaScript
+[9]: https://nodejs.org/en/
+[10]: https://www.w3schools.com/nodejs/nodejs_raspberrypi.asp
+[11]: https://code.visualstudio.com/
+[12]: https://pimylifeup.com/raspberry-pi-visual-studio-code/
diff --git a/sources/tech/20190306 Blockchain 2.0- Revolutionizing The Financial System -Part 2.md b/sources/tech/20190306 Blockchain 2.0- Revolutionizing The Financial System -Part 2.md
new file mode 100644
index 0000000000..59389e2ca3
--- /dev/null
+++ b/sources/tech/20190306 Blockchain 2.0- Revolutionizing The Financial System -Part 2.md
@@ -0,0 +1,52 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Blockchain 2.0: Revolutionizing The Financial System [Part 2])
+[#]: via: (https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/)
+[#]: author: (EDITOR https://www.ostechnix.com/author/editor/)
+
+Blockchain 2.0: Revolutionizing The Financial System [Part 2]
+======
+
+This is the second part of our [**Blockchain 2.0**][1] series. The blockchain can transform how individuals and institutions deal with their finances. This post looks at how the existing monetary system evolved and how new blockchain systems are bringing in change as the next crucial step in the evolution of money.
+
+Two key ideas will lay the foundation for this article. **PayPal** , when it was launched, was revolutionary in terms of its operation. The company would gather, process and confirm massive amounts of consumer data to facilitate online transactions of all kinds, virtually allowing platforms such as eBay to grow into trustful sources for commerce, and laying the benchmark for digital payment systems worldwide. The second, albeit much more important key idea to be highlighted here, is a somewhat existential question. We all use money or rather currency for our day-to-day needs. A ten-dollar bill will get you a cup or two from your favorite coffee shop and get you a head start on your day for instance. We depend on our respective national currencies for virtually everything.
+
+Sure, mankind has come a long way since the **barter system** ruled what you ate for breakfast, but still, what exactly is currency? Who or what gives it it’s a value? And as the popular rumor suggests, does going to a bank and giving them a dollar bill actually get you the true value of whatever that currency “token” stands for?
+
+The answer to most of those questions doesn’t exist. If they do, they’ll to be undependably vague and subjective at best. Back in the day when civilization started off establishing small cities and towns, the local currency deemed legal by the guy who ruled over them, was almost always made of something precious to that community. Indians are thought to have transacted in peppercorns while ancient Greeks and Romans in **salt** [1]. Gradually most of these little prehistoric civilizations adopted precious metals and stones as their tokens to transact. Gold coins, silver heirlooms, and rubies became eponymous with “value”. With the industrial revolution, people started printing these tokens of transaction and we finally seemed to have found our calling in paper currencies. They were dependable and cheap to produce and as long as a nation-state guaranteed its users that the piece of paper, they were holding was just a token for an amount of “value” they had and as long as they were able to show them that this value when demanded could be supported with precious substances such as gold or hard assets, people were happy to use them. However, if you still believe that the currency note you hold in your hand right now has the same guarantee, you’re wrong. We currently live in an age where almost all the major currencies in circulation around the globe are what economists would call a **fiat currency** [2]. Value-less pieces of paper that are only backed by the guarantees of the nation-state you’re residing in. The exact nature of fiat currencies and why they may possibly be a flawed system falls into the domain of economics and we won’t get into that now.
+
+In fact, the only takeaway from all of this history that is relevant to this post is that civilizations started using tokens that hinted or represented value for trading goods and services rather than the non-practical barter system. Tokens. Naturally, this is the crucial concept behind cryptocurrencies as well. They don’t have any inherent value attached to them. Their value is tied to the number of people adopting that particular platform, the trust the adopters have on the system, and of course if released by a supervising entity, the background of the entity itself. The high price and market cap of **Bitcoin (BTC)** isn’t a coincidence, they were among the first in business and had a lot of early adopters. This ultimate truth behind cryptocurrencies is what makes it so important yet so unforgivingly complex to understand. It’s the natural next step in the evolution of “money”. Some understand this and some still like to think of the solid currency concept where “real” money is always backed by something of inherent value.[3] Though there have been countless debates and studies on this dilemma, there is no looking back from a blockchain powered future.
+
+For instance, the country of **Ecuador** made headlines in 2015 for its purported plans to develop and release **its own national cryptocurrency** [4]. Albeit the attempt officially was to aid and support their existing currency system. Since then other countries and their regulatory bodies have or are drafting up papers to control the “epidemic” that is cryptocurrency with some already having published frameworks to the extent of creating a roadmap for blockchain and crypto development. **Germany** is thought to be investing in a long term blockchain project to streamline its taxation and financial systems[5]. Banks in developing countries are joining in on something called a Bank chain, cooperating in creating a **private blockchain** to increase efficiency in and optimize their operations
+
+Now is when we tie both the ends of the stories together, remember the first mention of PayPal before the casual history lesson? Experts have compared Bitcoin’s (BTC) adoption rate with that of PayPal when it was launched. Initial consumer hesitation, where only a few early adopters are ready to jump into using the said product and then all a wider adoption gradually becoming a benchmark for similar platforms. Bitcoin (BTC) is already a benchmark for similar cryptocurrency platforms with major coins such as **Ethereum (ETH)** and **Ripple (XRP)** [6]. Adoption is steadily increasing, legal and regulatory frameworks being made to support it, and active research and development being done on the front as well. And not unlike PayPal, experts believe that cryptocurrencies and platforms utilizing blockchain tech for their digital infrastructure will soon become the standard norm rather than the exception.
+
+Although the rise in cryptocurrency prices in 2018 can be termed as an economic bubble, companies and governments have continued to invest as much or more into the development of their own blockchain platforms and financial tokens. To counteract and prevent such an incident in the future while still looking forward to investing in the area, an alternative to traditional cryptocurrencies called **stablecoins** have made the rounds recently.
+
+Financial behemoth **JP Morgan** came out with their own enterprise ready blockchain solution called **Quorum** handling their stablecoin called **JPM Coin** [7]. Each such JPM coin is tied to 1 USD and their value is guaranteed by the parent organization under supporting legal frameworks, in this case, JP Morgan. Platforms such as this one make it easier for large financial transactions to the tunes of millions or billions of dollars to be transferred instantaneously over the internet without having to rely on conventional banking systems such as SWIFT which involve lengthy procedures and are themselves decades old.
+
+In the same spirit of making the niceties of the blockchain available for everyone, The Ethereum platform allows 3rd parties to utilize their blockchain or derive from it to create and administer their own takes on the triad of the **Blockchain-protocol-token** system thereby leading to wider adoption of the standard with lesser work on its foundations.
+
+The blockchain allows for digital versions of existing financial instruments to be created, recorded, and traded quickly over a network without the need for third-party monitoring. The inherent safety and security features of the system makes the entire process totally safe and immune to fraud and tampering, basically the only reason why third-party monitoring was required in the sector. Another area where governmental and regulatory bodies presided over when it came to financial services and instruments were in regards to transparency and auditing. With blockchain banks and other financial institutes will be able to maintain a fully transparent, layered, almost permanent and tamper-proof record of all their transactions rendering auditing tasks near useless. Much needed developments and changes to the current financial system and services industry can be made possible by exploiting blockchains. The platform being distributed, tamper-proof, near permanent, and quick to execute is highly valuable to bankers and government regulators alike and their investments in this regard seem to be well placed[8].
+
+In the next article of the series, we see how companies are using blockchains to deliver the next generation of financial services. Looking at individual firms creating ripples in the industry, we explore how the future of a blockchain backed economy would look like.
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/
+
+作者:[EDITOR][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/editor/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/blockchain-2-0-an-introduction/
diff --git a/sources/tech/20190306 ClusterShell - A Nifty Tool To Run Commands On Cluster Nodes In Parallel.md b/sources/tech/20190306 ClusterShell - A Nifty Tool To Run Commands On Cluster Nodes In Parallel.md
new file mode 100644
index 0000000000..8f69143d36
--- /dev/null
+++ b/sources/tech/20190306 ClusterShell - A Nifty Tool To Run Commands On Cluster Nodes In Parallel.md
@@ -0,0 +1,309 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (ClusterShell – A Nifty Tool To Run Commands On Cluster Nodes In Parallel)
+[#]: via: (https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+ClusterShell – A Nifty Tool To Run Commands On Cluster Nodes In Parallel
+======
+
+We had written two articles in the past to run commands on multiple remote server in parallel.
+
+These are **[Parallel SSH (PSSH)][1]** or **[Distributed Shell (DSH)][2]**.
+
+Today also, we are going to discuss about the same kind of topic but it allows us to perform the same on cluster nodes as well.
+
+You may think, i can write a small shell script to archive this instead of installing these third party packages.
+
+Of course you are right and if you are going to run some commands in 10-15 remote systems then you don’t need to use this.
+
+However, the scripts take some time to complete this task as it’s running in a sequential order.
+
+Think about if you would like to run some commands on 1000+ servers what will be the options?
+
+In this case your script won’t help you. Also, it would take good amount of time to complete a task.
+
+So, to overcome this kind of issue and situation. We need to run the command in parallel on remote machines.
+
+For that, we need use in one of the Parallel applications. I hope this explanation might fulfilled your doubts about parallel utilities.
+
+### What Is ClusterShell?
+
+clush stands for [ClusterShell][3]. ClusterShell is an event-driven open source Python library, designed to run local or distant commands in parallel on server farms or on large Linux clusters.
+
+It will take care of common issues encountered on HPC clusters, such as operating on groups of nodes, running distributed commands using optimized execution algorithms, as well as gathering results and merging identical outputs, or retrieving return codes.
+
+ClusterShell takes advantage of existing remote shell facilities already installed on your systems, like SSH.
+
+ClusterShell’s primary goal is to improve the administration of high- performance clusters by providing a lightweight but scalable Python API for developers. It also provides clush, clubak and cluset/nodeset, convenient command-line tools that allow traditional shell scripts to benefit from some of the library features.
+
+ClusterShell’s written in Python and it requires Python (v2.6+ or v3.4+) to run on your system.
+
+### How To Install ClusterShell On Linux?
+
+ClusterShell package is available in most of the distribution official package manager. So, use the distribution package manager tool to install it.
+
+For **`Fedora`** system, use **[DNF Command][4]** to install clustershell.
+
+```
+$ sudo dnf install clustershell
+```
+
+Python 2 module and tools are installed and if it’s default on your system then run the following command to install Python 3 development on Fedora System.
+
+```
+$ sudo dnf install python3-clustershell
+```
+
+Make sure you should have enabled the **[EPEL repository][5]** on your system before performing clustershell installation.
+
+For **`RHEL/CentOS`** systems, use **[YUM Command][6]** to install clustershell.
+
+```
+$ sudo yum install clustershell
+```
+
+Python 2 module and tools are installed and if it’s default on your system then run the following command to install Python 3 development on CentOS/RHEL System.
+
+```
+$ sudo yum install python34-clustershell
+```
+
+For **`openSUSE Leap`** system, use **[Zypper Command][7]** to install clustershell.
+
+```
+$ sudo zypper install clustershell
+```
+
+Python 2 module and tools are installed and if it’s default on your system then run the following command to install Python 3 development on OpenSUSE System.
+
+```
+$ sudo zypper install python3-clustershell
+```
+
+For **`Debian/Ubuntu`** systems, use **[APT-GET Command][8]** or **[APT Command][9]** to install clustershell.
+
+```
+$ sudo apt install clustershell
+```
+
+### How To Install ClusterShell In Linux Using PIP?
+
+Use PIP to install ClusterShell because it’s written in Python.
+
+Make sure you should have enabled the **[Python][10]** and **[PIP][11]** on your system before performing clustershell installation.
+
+```
+$ sudo pip install ClusterShell
+```
+
+### How To Use ClusterShell On Linux?
+
+It’s straight forward and awesome tool compared with other utilities such as pssh and dsh. It has so many options to perform the remote execution in parallel.
+
+Make sure you should have enabled the **[password less login][12]** on your system before start using clustershell.
+
+The following configuration file defines system-wide default values. You no need to modify anything here.
+
+```
+$ cat /etc/clustershell/clush.conf
+```
+
+If you would like to create a servers group. Here you can go. By default some examples were available so, do the same for your requirements.
+
+```
+$ cat /etc/clustershell/groups.d/local.cfg
+```
+
+Just run the clustershell command in the following format to get the information from the given nodes.
+
+```
+$ clush -w 192.168.1.4,192.168.1.9 cat /proc/version
+192.168.1.9: Linux version 4.15.0-45-generic ([email protected]) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #48-Ubuntu SMP Tue Jan 29 16:28:13 UTC 2019
+192.168.1.4: Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018
+```
+
+**Option:**
+
+ * **`-w:`** nodes where to run the command.
+
+
+
+You can use the regular expressions instead of using full hostname and IPs.
+
+```
+$ clush -w 192.168.1.[4,9] uname -r
+192.168.1.9: 4.15.0-45-generic
+192.168.1.4: 3.10.0-957.el7.x86_64
+```
+
+Alternatively you can use the following format if you have the servers in the same IP series.
+
+```
+$ clush -w 192.168.1.[4-9] date
+192.168.1.6: Mon Mar 4 21:08:29 IST 2019
+192.168.1.7: Mon Mar 4 21:08:29 IST 2019
+192.168.1.8: Mon Mar 4 21:08:29 IST 2019
+192.168.1.5: Mon Mar 4 09:16:30 CST 2019
+192.168.1.9: Mon Mar 4 21:08:29 IST 2019
+192.168.1.4: Mon Mar 4 09:16:30 CST 2019
+```
+
+clustershell allow us to run the command in batch mode. Use the following format to achieve this.
+
+```
+$ clush -w 192.168.1.4,192.168.1.9 -b
+Enter 'quit' to leave this interactive mode
+Working with nodes: 192.168.1.[4,9]
+clush> hostnamectl
+---------------
+192.168.1.4
+---------------
+ Static hostname: CentOS7.2daygeek.com
+ Icon name: computer-vm
+ Chassis: vm
+ Machine ID: 002f47b82af248f5be1d67b67e03514c
+ Boot ID: f9b37a073c534dec8b236885e754cb56
+ Virtualization: kvm
+ Operating System: CentOS Linux 7 (Core)
+ CPE OS Name: cpe:/o:centos:centos:7
+ Kernel: Linux 3.10.0-957.el7.x86_64
+ Architecture: x86-64
+---------------
+192.168.1.9
+---------------
+ Static hostname: Ubuntu18
+ Icon name: computer-vm
+ Chassis: vm
+ Machine ID: 27f6c2febda84dc881f28fd145077187
+ Boot ID: f176f2eb45524d4f906d12e2b5716649
+ Virtualization: oracle
+ Operating System: Ubuntu 18.04.2 LTS
+ Kernel: Linux 4.15.0-45-generic
+ Architecture: x86-64
+clush> free -m
+---------------
+192.168.1.4
+---------------
+ total used free shared buff/cache available
+Mem: 1838 641 217 19 978 969
+Swap: 2047 0 2047
+---------------
+192.168.1.9
+---------------
+ total used free shared buff/cache available
+Mem: 1993 352 1067 1 573 1473
+Swap: 1425 0 1425
+clush> w
+---------------
+192.168.1.4
+---------------
+ 09:21:14 up 3:21, 3 users, load average: 0.00, 0.01, 0.05
+USER TTY FROM [email protected] IDLE JCPU PCPU WHAT
+daygeek :0 :0 06:02 ?xdm? 1:28 0.30s /usr/libexec/gnome-session-binary --session gnome-classic
+daygeek pts/0 :0 06:03 3:17m 0.06s 0.06s bash
+daygeek pts/1 192.168.1.6 06:03 52:26 0.10s 0.10s -bash
+---------------
+192.168.1.9
+---------------
+ 21:13:12 up 3:12, 1 user, load average: 0.08, 0.03, 0.00
+USER TTY FROM [email protected] IDLE JCPU PCPU WHAT
+daygeek pts/0 192.168.1.6 20:42 29:41 0.05s 0.05s -bash
+clush> quit
+```
+
+If you would like to run the command on a group of nodes then use the following format.
+
+```
+$ clush -w @dev uptime
+or
+$ clush -g dev uptime
+or
+$ clush --group=dev uptime
+
+192.168.1.9: 21:10:10 up 3:09, 1 user, load average: 0.09, 0.03, 0.01
+192.168.1.4: 09:18:12 up 3:18, 3 users, load average: 0.01, 0.02, 0.05
+```
+
+If you would like to run the command on more than one group of nodes then use the following format.
+
+```
+$ clush -w @dev,@uat uptime
+or
+$ clush -g dev,uat uptime
+or
+$ clush --group=dev,uat uptime
+
+192.168.1.7: 07:57:19 up 59 min, 1 user, load average: 0.08, 0.03, 0.00
+192.168.1.9: 20:27:20 up 1:00, 1 user, load average: 0.00, 0.00, 0.00
+192.168.1.5: 08:57:21 up 59 min, 1 user, load average: 0.00, 0.01, 0.05
+```
+
+clustershell allow us to copy a file to remote machines. To copy local file or directory to the remote nodes in the same location.
+
+```
+$ clush -w 192.168.1.[4,9] --copy /home/daygeek/passwd-up.sh
+```
+
+We can verify the same by running the following command.
+
+```
+$ clush -w 192.168.1.[4,9] ls -lh /home/daygeek/passwd-up.sh
+192.168.1.4: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 4 09:00 /home/daygeek/passwd-up.sh
+192.168.1.9: -rwxr-xr-x 1 daygeek daygeek 159 Mar 4 20:52 /home/daygeek/passwd-up.sh
+```
+
+To copy local file or directory to the remote nodes in the different location.
+
+```
+$ clush -g uat --copy /home/daygeek/passwd-up.sh --dest /tmp
+```
+
+We can verify the same by running the following command.
+
+```
+$ clush --group=uat ls -lh /tmp/passwd-up.sh
+192.168.1.7: -rwxr-xr-x. 1 daygeek daygeek 159 Mar 6 07:44 /tmp/passwd-up.sh
+```
+
+To copy file or directory from remote nodes to local system.
+
+```
+$ clush -w 192.168.1.7 --rcopy /home/daygeek/Documents/magi.txt --dest /tmp
+```
+
+We can verify the same by running the following command.
+
+```
+$ ls -lh /tmp/magi.txt.192.168.1.7
+-rw-r--r-- 1 daygeek daygeek 35 Mar 6 20:24 /tmp/magi.txt.192.168.1.7
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/clustershell-clush-run-commands-on-cluster-nodes-remote-system-in-parallel-linux/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/pssh-parallel-ssh-run-execute-commands-on-multiple-linux-servers/
+[2]: https://www.2daygeek.com/dsh-run-execute-shell-commands-on-multiple-linux-servers-at-once/
+[3]: https://cea-hpc.github.io/clustershell/
+[4]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
+[5]: https://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
+[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
+[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
+[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
+[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
+[10]: https://www.2daygeek.com/3-methods-to-install-latest-python3-package-on-centos-6-system/
+[11]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
+[12]: https://www.2daygeek.com/linux-passwordless-ssh-login-using-ssh-keygen/
diff --git a/sources/tech/20190306 Get cooking with GNOME Recipes on Fedora.md b/sources/tech/20190306 Get cooking with GNOME Recipes on Fedora.md
new file mode 100644
index 0000000000..0c2eabdcdf
--- /dev/null
+++ b/sources/tech/20190306 Get cooking with GNOME Recipes on Fedora.md
@@ -0,0 +1,64 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get cooking with GNOME Recipes on Fedora)
+[#]: via: (https://fedoramagazine.org/get-cooking-with-gnome-recipes-on-fedora/)
+[#]: author: (Ryan Lerch https://fedoramagazine.org/introducing-flatpak/)
+
+Get cooking with GNOME Recipes on Fedora
+======
+
+
+Do you love to cook? Looking for a better way to manage your recipes using Fedora? GNOME Recipes is an awesome application available to install in Fedora to store and organize your recipe collection.
+
+![][1]
+
+GNOME Recipes is an recipe management tool from the GNOME project. It has the visual style of a modern GNOME style application, and feels similar to GNOME Software, but for food.
+
+### Installing GNOME Recipes
+
+Recipes is available to install from the 3rd party Flathub repositories. If you have never installed an application from Flathub before, set it up using the following guide:
+
+[Install Flathub apps on Fedora](https://fedoramagazine.org/install-flathub-apps-fedora/)
+
+After correctly setting up Flathub as a software source, you will be able to search for and install Recipes via GNOME Software.
+
+### Recipe management
+
+Recipes allows you to manually add your own collection of recipes, including photos, ingredients, directions, as well as extra metadata like preparation time, cuisine style, and spiciness.
+
+![][2]
+
+When entering in a new item, GNOME Recipes there are a range of different measurement units to choose from, as well as special tags for items like temperature, allowing you to easily switch units.
+
+### Community recipes
+
+In addition to manually entering in your favourite dishes for your own use, it also allows you to find, use, and contribute recipes to the community. Additionally, you can mark your favourites, and search the collection by the myriad of metadata available for each recipe.
+
+![][3]
+
+### Step by step guidance
+
+One of the awesome little features in GNOME Recipes is the step by step fullscreen mode. When you are ready to cook, simply activate this mode, move you laptop to the kitchen, and you will have a full screen display of the current step in the cooking method. Futhermore, you can set up the recipes to have timers displayed on this mode when something is in the oven.
+
+![][4]
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/get-cooking-with-gnome-recipes-on-fedora/
+
+作者:[Ryan Lerch][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/introducing-flatpak/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-06-19-45-06-1024x727.png
+[2]: https://fedoramagazine.org/wp-content/uploads/2019/03/gnome-recipes1-1024x727.png
+[3]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-06-20-08-45-1024x725.png
+[4]: https://fedoramagazine.org/wp-content/uploads/2019/03/Screenshot-from-2019-03-06-20-39-44-1024x640.png
diff --git a/sources/tech/20190306 Getting started with the Geany text editor.md b/sources/tech/20190306 Getting started with the Geany text editor.md
new file mode 100644
index 0000000000..7da5f95686
--- /dev/null
+++ b/sources/tech/20190306 Getting started with the Geany text editor.md
@@ -0,0 +1,141 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Getting started with the Geany text editor)
+[#]: via: (https://opensource.com/article/19/3/getting-started-geany-text-editor)
+[#]: author: (James Mawson https://opensource.com/users/dxmjames)
+
+Getting started with the Geany text editor
+======
+Geany is a light and swift text editor with IDE features.
+
+
+
+I have to admit, it took me a rather embarrassingly long time to really get into Linux as a daily driver. One thing I recall from these years in the wilderness was how strange it was to watch open source types get so worked up about text editors.
+
+It wasn't just that opinions differed. Disagreements were intense. And you'd see them again and again.
+
+I mean, I suppose it makes some sense. Doing dev or admin work means you're spending a lot of time with a text editor. And when it gets in the way or won't do quite what you want? In that exact moment, that's the most frustrating thing in the world.
+
+And I know what it means to really hate a text editor. I learned this many years ago in the computer labs at university trying to figure out Emacs. I was quite shocked that a piece of software could have so many sadomasochistic overtones. People were doing that to each other deliberately!
+
+So perhaps it's a rite of passage that now I have one I very much like. It's called [Geany][1], it's on GPL, and it's [in the repositories][2] of most popular distributions.
+
+Here's why it works for me.
+
+### I'm into simplicity
+
+The main thing I want from a text editor is just to edit text. I don't think there should be any kind of learning curve in the way. I should be able to open it and use it.
+
+For that reason, I've generally used whatever is included with an operating system. On Windows 10, I used Notepad far longer than I should have. When I finally replaced it, it was with Notepad++. In the Linux terminal, I like Nano.
+
+I was perfectly aware I was missing out on a lot of useful functionality. But it was never enough of a pain point to make a change. And it's not that I've never tried anything more elaborate. I did some of my first real programming on Visual Basic and Borland Delphi.
+
+These development environments gave you a graphical interface to design your windows visually, various windows where you could configure properties and settings, a text interface to write your functions, and various odds and ends for debugging. This was a great way to build desktop applications, so long as you used it the way it was intended.
+
+But if you wanted to do something the authors didn't anticipate, all these extra moving parts suddenly got in the way. As software became more and more about the web and the internet, this situation started happening all the time.
+
+In the past, I used HTML editing suites like Macromedia Dreamweaver (as it was back then) and FirstPage for static websites. Again, I found the features could get in the way as much as they helped. These applications had their own ideas about how to organize your project, and if you had a different view, it was an awful bother.
+
+More recently, after a long break from programming, I started learning the people's language: [Python][3]. I bought a book of introductory tutorials, which said to install [IDLE][4], so I did. I think I got about five minutes into it before ditching it to run the interpreter from the command line. It had way too many moving parts to deal with. Especially for HelloWorld.py.
+
+But I always went back to Notepad++ and Nano whenever I could get away with it.
+
+So what changed? Well, a few months ago I [ditched Windows 10][5] completely (hooray!). Sticking with what I knew, I used Nano as my main text editor for a few weeks.
+
+I learned that Nano is great when you're already on the command line and you need to launch a Navy SEAL mission. You know what I mean. A lightning-fast raid. Get in, complete the objective, and get out.
+
+It's less ideal for long campaigns—or even moderately short ones. Even just adding a new page to a static website turns out to involve many repetitive keystrokes. As much as anything else, I really missed being able to navigate and select text with the mouse.
+
+### Introducing Geany
+
+The Geany project began in 2005 and is still actively developed.
+
+It has minimal dependencies: just the [GTK Toolkit][6] and the libraries that GTK depends on. If you have any kind of desktop environment installed, you almost certainly have GTK on your machine.
+
+I'm using it on Xfce, but thanks to these minimal dependencies, Geany is portable across desktop environments.
+
+Geany is fast and light. Installing Geany from the package manager took mere moments, and it uses only 3.1MB of space on my machine.
+
+So far, I've used it for HTML, CSS, and Python and to edit configuration files. It also recognizes C, Java, JavaScript, Perl, and [more][7].
+
+### No-compromise simplicity
+
+Geany has a lot of great features that make life easier. Just listing them would miss the best bit, which is this: Geany makes sense right out of the box. As soon as it's installed, you can start editing files straightaway, and it just works.
+
+For all the IDE functionality, none of it gets in the way. The default settings are set intelligently, and the menus are laid out nicely enough that it's no hassle to change them.
+
+It doesn't try to organize your project for you, and it doesn't have strong opinions about how you should do anything.
+
+### Handles whitespace beautifully
+
+By default, every time you press Enter, Geany preserves the indentation on the new line. In addition to saving a few tedious keystrokes, it avoids the inconsistent use of tabs and spaces, which can sometimes sneak in when your mind's elsewhere and make your code hard to follow for anyone with a different text editor.
+
+But what if you're editing a file that's already suffered this treatment? For example, I needed to edit an HTML file that was indented with a mix of tabs and spaces, making it a nightmare to figure out how the tags were nested.
+
+With Geany, it took just seconds to hunt through the menus to change the tab length from four spaces to eight. Even better was the option to convert those tabs to spaces. Problem solved!
+
+### Clever shortcuts and automation
+
+How often do you write the correct code on the wrong line? I do it all the time.
+
+Geany makes it easy to move lines of code up and down using Alt+PgUp and Alt+PgDn. This is a little nicer than just a regular cut and paste—instead of needing four or five key presses, you only need one.
+
+When coding HTML, Geany automatically closes tags for you. As well as saving time, this avoids a lot of annoying bugs. When you forget to close a tag, you can spend ages scouring the document looking for something far more complex.
+
+It gets even better in Python, where indentation is crucial. Whenever you end a line with a colon, Geany automatically indents it for you.
+
+One nice little side effect is that when you forget to include the colon—something I do with embarrassing regularity—you realize it immediately when you don't get the automatic indentation you expected.
+
+The default indentation is a single tab, while I prefer two spaces. Because Geany's menus are very well laid out, it took me only a few seconds to figure out how to change it.
+
+You, of course, get syntax highlighting too. In addition, it tracks your [variable scope][8] and offers useful autocompletion.
+
+### Large plugin library
+
+Geany has a [big library of plugins][9], but so far I haven't needed to try any. Even so, I still feel like I benefit from them. How? Well, it means that my editor isn't crammed with functionality I don't use.
+
+I reckon this attitude of adding extra functionality into a big library of plugins is a great ethos—no matter your specific needs, you get to have all the stuff you want and none of what you don't.
+
+### Remote file editing
+
+One thing that's really nice about terminal text editors is that it's no problem to use them in a remote shell.
+
+Geany handles this beautifully, as well. You can open remote files anywhere you have SSH access as easily as you can open files on your own machine.
+
+One frustration I had at first was I only seemed to be able to authenticate with a username and password, which was annoying, because certificates are so much nicer. It turned out that this was just me being a noob by keeping certificates in my home directory rather than in ~/.ssh.
+
+When editing Python scripts remotely, autocompletion doesn't work when you use packages installed on the server and not on your local machine. This isn't really that big a deal for me, but it's there.
+
+### In summary
+
+Text editors are such a personal preference that the right one will be different for different people.
+
+Geany is excellent if you already know what you want to write and want to just get on with it while enjoying plenty of useful shortcuts to speed up the menial parts.
+
+Geany is a great way to have your cake and eat it too.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/getting-started-geany-text-editor
+
+作者:[James Mawson][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dxmjames
+[b]: https://github.com/lujun9972
+[1]: https://www.geany.org/
+[2]: https://www.geany.org/Download/ThirdPartyPackages
+[3]: https://opensource.com/resources/python
+[4]: https://en.wikipedia.org/wiki/IDLE
+[5]: https://blog.dxmtechsupport.com.au/linux-on-the-desktop-are-we-nearly-there-yet/
+[6]: https://www.gtk.org/
+[7]: https://www.geany.org/Main/AllFiletypes
+[8]: https://cscircles.cemc.uwaterloo.ca/11b-how-functions-work/
+[9]: https://plugins.geany.org/
diff --git a/sources/tech/20190307 13 open source backup solutions.md b/sources/tech/20190307 13 open source backup solutions.md
new file mode 100644
index 0000000000..86c5547e8b
--- /dev/null
+++ b/sources/tech/20190307 13 open source backup solutions.md
@@ -0,0 +1,72 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (13 open source backup solutions)
+[#]: via: (https://opensource.com/article/19/3/backup-solutions)
+[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
+
+13 open source backup solutions
+======
+Readers suggest more than a dozen of their favorite solutions for protecting data.
+
+
+Recently, we published a [poll][1] that asked readers to vote on their favorite open source backup solution. We offered six solutions recommended by our [moderator community][2]—Cronopete, Deja Dup, Rclone, Rdiff-backup, Restic, and Rsync—and invited readers to share other options in the comments. And you came through, offering 13 other solutions (so far) that we either hadn't considered or hadn't even heard of.
+
+By far the most popular suggestion was [BorgBackup][3]. It is a deduplicating backup solution that features compression and encryption. It is supported on Linux, MacOS, and BSD and has a BSD License.
+
+Second was [UrBackup][4], which does full and incremental image and file backups; you can save whole partitions or single directories. It has clients for Windows, Linux, and MacOS and has a GNU Affero Public License.
+
+Third was [LuckyBackup][5]; according to its website, "it is simple to use, fast (transfers over only changes made and not all data), safe (keeps your data safe by checking all declared directories before proceeding in any data manipulation), reliable, and fully customizable." It carries a GNU Public License.
+
+[Casync][6] is content-addressable synchronization—it's designed for backup and synchronizing and stores and retrieves multiple related versions of large file systems. It is licensed with the GNU Lesser Public License.
+
+[Syncthing][7] synchronizes files between two computers. It is licensed with the Mozilla Public License and, according to its website, is secure and private. It works on MacOS, Windows, Linux, FreeBSD, Solaris, and OpenBSD.
+
+[Duplicati][8] is a free backup solution that works on Windows, MacOS, and Linux and a variety of standard protocols, such as FTP, SSH, and WebDAV, and cloud services. It features strong encryption and is licensed with the GPL.
+
+[Dirvish][9] is a disk-based virtual image backup system licensed under OSL-3.0. It also requires Rsync, Perl5, and SSH to be installed.
+
+[Bacula][10]'s website says it "is a set of computer programs that permits the system administrator to manage backup, recovery, and verification of computer data across a network of computers of different kinds." It is supported on Linux, FreeBSD, Windows, MacOS, OpenBSD, and Solaris and the bulk of its source code is licensed under AGPLv3.
+
+[BackupPC][11] "is a high-performance, enterprise-grade system for backing up Linux, Windows, and MacOS PCs and laptops to a server's disk," according to its website. It is licensed under the GPLv3.
+
+[Amanda][12] is a backup system written in C and Perl that allows a system administrator to back up an entire network of client machines to a single server using tape, disk, or cloud-based systems. It was developed and copyrighted in 1991 at the University of Maryland and has a BSD-style license.
+
+[Back in Time][13] is a simple backup utility designed for Linux. It provides a command line client and a GUI, both written in Python. To do a backup, just specify where to store snapshots, what folders to back up, and the frequency of the backups. BackInTime is licensed with GPLv2.
+
+[Timeshift][14] is a backup utility for Linux that is similar to System Restore for Windows and Time Capsule for MacOS. According to its GitHub repository, "Timeshift protects your system by taking incremental snapshots of the file system at regular intervals. These snapshots can be restored at a later date to undo all changes to the system."
+
+[Kup][15] is a backup solution that was created to help users back up their files to a USB drive, but it can also be used to perform network backups. According to its GitHub repository, "When you plug in your external hard drive, Kup will automatically start copying your latest changes."
+
+Thanks for sharing your favorite open source backup solutions in our poll! If there are still others that haven't been mentioned yet, please share them in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/backup-solutions
+
+作者:[Don Watkins][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/don-watkins
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/2/linux-backup-solutions
+[2]: https://opensource.com/opensourcecom-team
+[3]: https://www.borgbackup.org/
+[4]: https://www.urbackup.org/
+[5]: http://luckybackup.sourceforge.net/
+[6]: http://0pointer.net/blog/casync-a-tool-for-distributing-file-system-images.html
+[7]: https://syncthing.net/
+[8]: https://www.duplicati.com/
+[9]: http://dirvish.org/
+[10]: https://www.bacula.org/
+[11]: https://backuppc.github.io/backuppc/
+[12]: http://www.amanda.org/
+[13]: https://github.com/bit-team/backintime
+[14]: https://github.com/teejee2008/timeshift
+[15]: https://github.com/spersson/Kup
diff --git a/sources/tech/20190307 How to Restart a Network in Ubuntu -Beginner-s Tip.md b/sources/tech/20190307 How to Restart a Network in Ubuntu -Beginner-s Tip.md
new file mode 100644
index 0000000000..44d5531d83
--- /dev/null
+++ b/sources/tech/20190307 How to Restart a Network in Ubuntu -Beginner-s Tip.md
@@ -0,0 +1,208 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Restart a Network in Ubuntu [Beginner’s Tip])
+[#]: via: (https://itsfoss.com/restart-network-ubuntu)
+[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
+
+How to Restart a Network in Ubuntu [Beginner’s Tip]
+======
+
+You’re [using an Ubuntu-based system and you just can’t seem to connect to your network][1]? You’d be surprised how many problems can a simple restart fix.
+
+In this article, I’ll go over multiple ways you can restart network in Ubuntu and other Linux distributions, so you can use whatever suits your needs. The methods are basically divided into two parts:
+
+![Ubuntu Restart Network][2]
+
+### Restart network in Ubuntu using command line
+
+If you are using Ubuntu server edition, you are already in the terminal. If you are using the desktop edition, you can access the terminal using Ctrl+Alt+T [keyboard shortcut in Ubuntu][3].
+
+Now you have several commands at your disposal to restart network in Ubuntu. Some (or perhaps most) commands mentioned here should be applicable for restarting network in Debian and other Linux distributions as well.
+
+#### 1\. network manager service
+
+This is the easiest way to restart your network using the command line. It’s equivalent to the graphical way of doing it (restarts the Network-Manager service).
+
+```
+sudo service network-manager restart
+```
+
+The network icon should disappear for a moment and then reappear.
+
+#### 2\. systemd
+
+The **service** command is just a wrapper for this method (and also for init.d scripts and Upstart commands). The **systemctl** command is much more versatile than **service**. This is what I usually prefer.
+
+```
+sudo systemctl restart NetworkManager.service
+```
+
+The network icon (again) should disappear for a moment. To check out other **systemctl** options, you can refer to its man page.
+
+#### 3\. nmcli
+
+This is yet another tool for handling networks on a Linux machine. It is a pretty powerful tool that I find very practical. Many sysadmins prefer it since it is easy to use.
+
+There are two steps to this method: turning the network off, and then turning it back on.
+
+```
+sudo nmcli networking off
+```
+
+The network will shut down and the icon will disappear. To turn it back on:
+
+```
+sudo nmcli networking on
+```
+
+You can check out the man page of nmcli for more options.
+
+#### 4\. ifup & ifdown
+
+This commands handle a network interface directly, changing it’s state to one in which it either can or can not transmit and receive data. It’s one of the [must know networking commands in Linux][4].
+
+To shut down all network interfaces, use ifdown and then use ifup to turn all network interfaces back on.
+
+A good practice would be to combine both of these commands:
+
+```
+sudo ifdown -a && sudo ifup -a
+```
+
+**Note:** This method will not make the network icon in your systray disappear, and yet you won’t be able to have a connection of any sort.
+
+**Bonus tool: nmtui (click to expand)**
+
+This is another method often used by system administrators. It is a text menu for managing networks right in your terminal.
+
+```
+nmtui
+```
+
+This should open up the following menu:
+
+![nmtui Menu][5]
+
+**Note** that in **nmtui** , you can select another option by using the **up** and **down arrow keys**.
+
+Select **Activate a connection** :
+
+![nmtui Menu Select "Activate a connection"][6]
+
+Press **Enter**. This should now open the **connections** menu.
+
+![nmtui Connections Menu][7]
+
+Here, go ahead and select the network with a **star (*)** next to it. In my case, it’s MGEO72.
+
+![Select your connection in the nmtui connections menu.][8]
+
+Press **Enter**. This should **deactivate** your connection.
+
+![nmtui Connections Menu with no active connection][9]
+
+Select the connection you want to activate:
+
+![Select the connection you want in the nmtui connections menu.][10]
+
+Press **Enter**. This should reactivate the selected connection.
+
+![nmtui Connections Menu][11]
+
+Press **Tab** twice to select **Back** :
+
+![Select "Back" in the nmtui connections menu.][12]
+
+Press **Enter**. This should bring you back to the **nmtui** main menu.
+
+![nmtui Main Menu][13]
+
+Select **Quit** :
+
+![nmtui Quit Main Menu][14]
+
+This should exit the application and bring you back to your terminal.
+
+That’s it! You have successfully restarted your network
+
+### Restart network in Ubuntu graphically
+
+This is, of course, the easiest way of restarting the network for Ubuntu desktop users. If this one doesn’t work, you can of course check the command line options mentioned in the previous section.
+
+NM-applet is the system tray applet indicator for [NetworkManager][15]. That’s what we’re going to use to restart our network.
+
+First of all, check out your top panel. You should find a network icon in your system tray (in my case, it is a Wi-Fi icon, since that’s what I use).
+
+Go ahead and click on that icon (or the sound or battery icon). This will open up the menu. Select “Turn Off” here.
+
+![Restart network in Ubuntu][16]Turn off your network
+
+The network icon should now disappear from the top panel. This means the network has been successfully turned off.
+
+Click again on your systray to reopen the menu. Select “Turn On”.
+
+![Restarting network in Ubuntu][17]Turn the network back on
+
+Congratulations! You have now restarted your network.
+
+#### Bonus Tip: Refresh available network list
+
+Suppose you are connected to a network already but you want to connect to another network. How do you refresh the WiFi to see what other networks are available? Let me show you that.
+
+Ubuntu doesn’t have a ‘refresh wifi networks’ option directly. It’s sort of hidden.
+
+You’ll have to open the setting menu again and this time, click on “Select Network”.
+
+![Refresh wifi network list in Ubuntu][18]Select Network to change your WiFi connection
+
+Now, you won’t see the list of available wireless networks immediately. When you open the networks list, it takes around 5 seconds to refresh and show up other available wireless networks.
+
+![Select another wifi network in Ubuntu][19]Wait for around 5- seconds to see other available networks
+
+And here, you can select the network of your choice and click connect. That’s it.
+
+**Wrapping Up**
+
+Restarting your network or connection is something that every Linux user has to go through at some point in their experience.
+
+We hope that we helped you with plenty of methods for handling such issues!
+
+What do you use to restart/handle your network? Is there something we missed? Leave us a comment below.
+
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/restart-network-ubuntu
+
+作者:[Sergiu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/sergiu/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/fix-no-wireless-network-ubuntu/
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/ubuntu-restart-network.png?resize=800%2C450&ssl=1
+[3]: https://itsfoss.com/ubuntu-shortcuts/
+[4]: https://itsfoss.com/basic-linux-networking-commands/
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmtui_menu.png?fit=800%2C602&ssl=1
+[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmtui_menu_select_option.png?fit=800%2C579&ssl=1
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_connection_menu_on.png?fit=800%2C585&ssl=1
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_select_connection_on.png?fit=800%2C576&ssl=1
+[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_connection_menu_off.png?fit=800%2C572&ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_select_connection_off.png?fit=800%2C566&ssl=1
+[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_connection_menu_on-1.png?fit=800%2C585&ssl=1
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_connection_menu_back.png?fit=800%2C585&ssl=1
+[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmtui_menu_select_option-1.png?fit=800%2C579&ssl=1
+[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/nmui_menu_quit.png?fit=800%2C580&ssl=1
+[15]: https://wiki.gnome.org/Projects/NetworkManager
+[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/restart-network-ubuntu-1.jpg?resize=800%2C400&ssl=1
+[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/restart-network-ubuntu-2.jpg?resize=800%2C400&ssl=1
+[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/select-wifi-network-ubuntu.jpg?resize=800%2C400&ssl=1
+[19]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/select-wifi-network-ubuntu-1.jpg?resize=800%2C400&ssl=1
+[20]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/ubuntu-restart-network.png?fit=800%2C450&ssl=1
diff --git a/sources/tech/20190307 How to keep your Raspberry Pi updated.md b/sources/tech/20190307 How to keep your Raspberry Pi updated.md
new file mode 100644
index 0000000000..65218c64c9
--- /dev/null
+++ b/sources/tech/20190307 How to keep your Raspberry Pi updated.md
@@ -0,0 +1,51 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to keep your Raspberry Pi updated)
+[#]: via: (https://opensource.com/article/19/3/how-raspberry-pi-update)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+How to keep your Raspberry Pi updated
+======
+Learn how to keep your Raspberry Pi patched and working well in the seventh article in our guide to getting started with the Raspberry Pi.
+
+
+Just like your tablet, cellphone, and laptop, you need to keep your Raspberry Pi updated. Not only will the latest enhancements keep your Pi running smoothly, they will also keep you safer, especially if you are connected to a network. The seventh article in our guide to getting started with the Raspberry Pi shares two pieces of advice on keeping your Pi working well.
+
+### Update Raspbian
+
+Updating your Raspbian installation is a [two-step process][1]:
+
+ 1. In your terminal type: **sudo apt-get update**
+The command **sudo** allows you to run **apt-get update** as admin (aka root). Note that **apt-get update** will not install anything new on your system; rather it will update the list of packages and dependencies that need to be updated.
+
+
+ 2. Then type: **sudo apt-get dist-upgrade**
+From the documentation: "Generally speaking, doing this regularly will keep your installation up to date, in that it will be equivalent to the latest released image available from [raspberrypi.org/downloads][2]."
+
+
+
+### Be careful with rpi-update
+
+Raspbian comes with another little update utility called [rpi-update][3]. This utility can be used to upgrade your Pi to the latest firmware which may or may not be broken/buggy. You may find information explaining how to use it, but as of late it is recommended never to use this application unless you have a really good reason to do so.
+
+Bottom line: Keep your systems updated!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/how-raspberry-pi-update
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://www.raspberrypi.org/documentation/raspbian/updating.md
+[2]: https://www.raspberrypi.org/downloads/
+[3]: https://github.com/Hexxeh/rpi-update
diff --git a/sources/tech/20190308 How to use your Raspberry Pi for entertainment.md b/sources/tech/20190308 How to use your Raspberry Pi for entertainment.md
new file mode 100644
index 0000000000..039b0b4598
--- /dev/null
+++ b/sources/tech/20190308 How to use your Raspberry Pi for entertainment.md
@@ -0,0 +1,57 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to use your Raspberry Pi for entertainment)
+[#]: via: (https://opensource.com/article/19/3/raspberry-pi-entertainment)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+How to use your Raspberry Pi for entertainment
+======
+Learn how to watch Netflix and listen to music on your Raspberry Pi, in the eighth article in our guide to getting started with Raspberry Pi.
+
+
+So far, this series has focused on more serious topics—how to [choose][1], [buy][2], [set up][3], and [update][4] your Raspberry Pi, and different things [kids][5] and [adults][6] can learn with it (including [Linux][7]). But now it's time to change up the subject and have some fun! Today we'll look at ways to use your Raspberry Pi for entertainment, and tomorrow we'll continue the fun with gaming.
+
+### Watch TV and movies
+
+You can use your Raspberry Pi and the [Open Source Media Center][8] (OSMC) to [watch Netflix][9]! The OSMC is a system based on the [Kodi][10] project that allows you to play back media from your local network, attached storage, and the internet. It's also known for having the best feature set and community among media center applications.
+
+NOOBS (which we talked about in the [third article][11] in this series) allows you to [install OSMC][12] on your Raspberry Pi as easily as possible. NOOBS also offers another media center system based on Kodi called [LibreELEC][13].
+
+### Listen to music
+
+
+
+You can also stream music on your network via attached storage or services like Spotify on your Raspberry Pi with the [Pi Music Box][14] project. I [wrote about it][15] a while ago, but you can find newer instructions, including how to's and DIY projects, on the [Pi Music Box website][16].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/raspberry-pi-entertainment
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/3/which-raspberry-pi-choose
+[2]: https://opensource.com/article/19/2/how-buy-raspberry-pi
+[3]: https://opensource.com/article/19/2/how-boot-new-raspberry-pi
+[4]: https://opensource.com/article/19/2/how-keep-your-raspberry-pi-updated-and-patched
+[5]: https://opensource.com/article/19/3/teach-kids-program-raspberry-pi
+[6]: https://opensource.com/article/19/2/3-popular-programming-languages-you-can-learn-raspberry-pi
+[7]: https://opensource.com/article/19/2/learn-linux-raspberry-pi
+[8]: https://osmc.tv/
+[9]: https://www.dailydot.com/upstream/netflix-raspberry-pi/
+[10]: http://kodi.tv/
+[11]: https://opensource.com/article/19/3/how-boot-new-raspberry-pi
+[12]: https://www.raspberrypi.org/documentation/usage/kodi/
+[13]: https://libreelec.tv/
+[14]: https://github.com/pimusicbox/pimusicbox/tree/master
+[15]: https://opensource.com/life/15/3/pi-musicbox-guide
+[16]: https://www.pimusicbox.com/
diff --git a/sources/tech/20190308 Virtual filesystems in Linux- Why we need them and how they work.md b/sources/tech/20190308 Virtual filesystems in Linux- Why we need them and how they work.md
new file mode 100644
index 0000000000..1114863bf7
--- /dev/null
+++ b/sources/tech/20190308 Virtual filesystems in Linux- Why we need them and how they work.md
@@ -0,0 +1,196 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Virtual filesystems in Linux: Why we need them and how they work)
+[#]: via: (https://opensource.com/article/19/3/virtual-filesystems-linux)
+[#]: author: (Alison Chariken )
+
+Virtual filesystems in Linux: Why we need them and how they work
+======
+Virtual filesystems are the magic abstraction that makes the "everything is a file" philosophy of Linux possible.
+
+
+What is a filesystem? According to early Linux contributor and author [Robert Love][1], "A filesystem is a hierarchical storage of data adhering to a specific structure." However, this description applies equally well to VFAT (Virtual File Allocation Table), Git, and [Cassandra][2] (a [NoSQL database][3]). So what distinguishes a filesystem?
+
+### Filesystem basics
+
+The Linux kernel requires that for an entity to be a filesystem, it must also implement the **open()** , **read()** , and **write()** methods on persistent objects that have names associated with them. From the point of view of [object-oriented programming][4], the kernel treats the generic filesystem as an abstract interface, and these big-three functions are "virtual," with no default definition. Accordingly, the kernel's default filesystem implementation is called a virtual filesystem (VFS).
+
+
+![][5]
+If we can open(), read(), and write(), it is a file as this console session shows.
+
+VFS underlies the famous observation that in Unix-like systems "everything is a file." Consider how weird it is that the tiny demo above featuring the character device /dev/console actually works. The image shows an interactive Bash session on a virtual teletype (tty). Sending a string into the virtual console device makes it appear on the virtual screen. VFS has other, even odder properties. For example, it's [possible to seek in them][6].
+
+The familiar filesystems like ext4, NFS, and /proc all provide definitions of the big-three functions in a C-language data structure called [file_operations][7] . In addition, particular filesystems extend and override the VFS functions in the familiar object-oriented way. As Robert Love points out, the abstraction of VFS enables Linux users to blithely copy files to and from foreign operating systems or abstract entities like pipes without worrying about their internal data format. On behalf of userspace, via a system call, a process can copy from a file into the kernel's data structures with the read() method of one filesystem, then use the write() method of another kind of filesystem to output the data.
+
+The function definitions that belong to the VFS base type itself are found in the [fs/*.c files][8] in kernel source, while the subdirectories of fs/ contain the specific filesystems. The kernel also contains filesystem-like entities such as cgroups, /dev, and tmpfs, which are needed early in the boot process and are therefore defined in the kernel's init/ subdirectory. Note that cgroups, /dev, and tmpfs do not call the file_operations big-three functions, but directly read from and write to memory instead.
+
+The diagram below roughly illustrates how userspace accesses various types of filesystems commonly mounted on Linux systems. Not shown are constructs like pipes, dmesg, and POSIX clocks that also implement struct file_operations and whose accesses therefore pass through the VFS layer.
+
+![How userspace accesses various types of filesystems][9]
+VFS are a "shim layer" between system calls and implementors of specific file_operations like ext4 and procfs. The file_operations functions can then communicate either with device-specific drivers or with memory accessors. tmpfs, devtmpfs and cgroups don't make use of file_operations but access memory directly.
+
+VFS's existence promotes code reuse, as the basic methods associated with filesystems need not be re-implemented by every filesystem type. Code reuse is a widely accepted software engineering best practice! Alas, if the reused code [introduces serious bugs][10], then all the implementations that inherit the common methods suffer from them.
+
+### /tmp: A simple tip
+
+An easy way to find out what VFSes are present on a system is to type **mount | grep -v sd | grep -v :/** , which will list all mounted filesystems that are not resident on a disk and not NFS on most computers. One of the listed VFS mounts will assuredly be /tmp, right?
+
+![Man with shocked expression][11]
+Everyone knows that keeping /tmp on a physical storage device is crazy! credit:
+
+Why is keeping /tmp on storage inadvisable? Because the files in /tmp are temporary(!), and storage devices are slower than memory, where tmpfs are created. Further, physical devices are more subject to wear from frequent writing than memory is. Last, files in /tmp may contain sensitive information, so having them disappear at every reboot is a feature.
+
+Unfortunately, installation scripts for some Linux distros still create /tmp on a storage device by default. Do not despair should this be the case with your system. Follow simple instructions on the always excellent [Arch Wiki][12] to fix the problem, keeping in mind that memory allocated to tmpfs is not available for other purposes. In other words, a system with a gigantic tmpfs with large files in it can run out of memory and crash. Another tip: when editing the /etc/fstab file, be sure to end it with a newline, as your system will not boot otherwise. (Guess how I know.)
+
+### /proc and /sys
+
+Besides /tmp, the VFSes with which most Linux users are most familiar are /proc and /sys. (/dev relies on shared memory and has no file_operations). Why two flavors? Let's have a look in more detail.
+
+The procfs offers a snapshot into the instantaneous state of the kernel and the processes that it controls for userspace. In /proc, the kernel publishes information about the facilities it provides, like interrupts, virtual memory, and the scheduler. In addition, /proc/sys is where the settings that are configurable via the [sysctl command][13] are accessible to userspace. Status and statistics on individual processes are reported in /proc/ directories.
+
+![Console][14]
+/proc/meminfo is an empty file that nonetheless contains valuable information.
+
+The behavior of /proc files illustrates how unlike on-disk filesystems VFS can be. On the one hand, /proc/meminfo contains the information presented by the command **free**. On the other hand, it's also empty! How can this be? The situation is reminiscent of a famous article written by Cornell University physicist N. David Mermin in 1985 called "[Is the moon there when nobody looks?][15] Reality and the quantum theory." The truth is that the kernel gathers statistics about memory when a process requests them from /proc, and there actually is nothing in the files in /proc when no one is looking. As [Mermin said][16], "It is a fundamental quantum doctrine that a measurement does not, in general, reveal a preexisting value of the measured property." (The answer to the question about the moon is left as an exercise.)
+
+![Full moon][17]
+The files in /proc are empty when no process accesses them. ([Source][18])
+
+The apparent emptiness of procfs makes sense, as the information available there is dynamic. The situation with sysfs is different. Let's compare how many files of at least one byte in size there are in /proc versus /sys.
+
+
+
+Procfs has precisely one, namely the exported kernel configuration, which is an exception since it needs to be generated only once per boot. On the other hand, /sys has lots of larger files, most of which comprise one page of memory. Typically, sysfs files contain exactly one number or string, in contrast to the tables of information produced by reading files like /proc/meminfo.
+
+The purpose of sysfs is to expose the readable and writable properties of what the kernel calls "kobjects" to userspace. The only purpose of kobjects is reference-counting: when the last reference to a kobject is deleted, the system will reclaim the resources associated with it. Yet, /sys constitutes most of the kernel's famous "[stable ABI to userspace][19]" which [no one may ever, under any circumstances, "break."][20] That doesn't mean the files in sysfs are static, which would be contrary to reference-counting of volatile objects.
+
+The kernel's stable ABI instead constrains what can appear in /sys, not what is actually present at any given instant. Listing the permissions on files in sysfs gives an idea of how the configurable, tunable parameters of devices, modules, filesystems, etc. can be set or read. Logic compels the conclusion that procfs is also part of the kernel's stable ABI, although the kernel's [documentation][19] doesn't state so explicitly.
+
+![Console][21]
+Files in sysfs describe exactly one property each for an entity and may be readable, writable or both. The "0" in the file reveals that the SSD is not removable.
+
+### Snooping on VFS with eBPF and bcc tools
+
+The easiest way to learn how the kernel manages sysfs files is to watch it in action, and the simplest way to watch on ARM64 or x86_64 is to use eBPF. eBPF (extended Berkeley Packet Filter) consists of a [virtual machine running inside the kernel][22] that privileged users can query from the command line. Kernel source tells the reader what the kernel can do; running eBPF tools on a booted system shows instead what the kernel actually does.
+
+Happily, getting started with eBPF is pretty easy via the [bcc][23] tools, which are available as [packages from major Linux distros][24] and have been [amply documented][25] by Brendan Gregg. The bcc tools are Python scripts with small embedded snippets of C, meaning anyone who is comfortable with either language can readily modify them. At this count, [there are 80 Python scripts in bcc/tools][26], making it highly likely that a system administrator or developer will find an existing one relevant to her/his needs.
+
+To get a very crude idea about what work VFSes are performing on a running system, try the simple [vfscount][27] or [vfsstat][28], which show that dozens of calls to vfs_open() and its friends occur every second.
+
+![Console - vfsstat.py][29]
+vfsstat.py is a Python script with an embedded C snippet that simply counts VFS function calls.
+
+For a less trivial example, let's watch what happens in sysfs when a USB stick is inserted on a running system.
+
+![Console when USB is inserted][30]
+Watch with eBPF what happens in /sys when a USB stick is inserted, with simple and complex examples.
+
+In the first simple example above, the [trace.py][31] bcc tools script prints out a message whenever the sysfs_create_files() command runs. We see that sysfs_create_files() was started by a kworker thread in response to the USB stick insertion, but what file was created? The second example illustrates the full power of eBPF. Here, trace.py is printing the kernel backtrace (-K option) plus the name of the file created by sysfs_create_files(). The snippet inside the single quotes is some C source code, including an easily recognizable format string, that the provided Python script [induces a LLVM just-in-time compiler][32] to compile and execute inside an in-kernel virtual machine. The full sysfs_create_files() function signature must be reproduced in the second command so that the format string can refer to one of the parameters. Making mistakes in this C snippet results in recognizable C-compiler errors. For example, if the **-I** parameter is omitted, the result is "Failed to compile BPF text." Developers who are conversant with either C or Python will find the bcc tools easy to extend and modify.
+
+When the USB stick is inserted, the kernel backtrace appears showing that PID 7711 is a kworker thread that created a file called "events" in sysfs. A corresponding invocation with sysfs_remove_files() shows that removal of the USB stick results in removal of the events file, in keeping with the idea of reference counting. Watching sysfs_create_link() with eBPF during USB stick insertion (not shown) reveals that no fewer than 48 symbolic links are created.
+
+What is the purpose of the events file anyway? Using [cscope][33] to find the function [__device_add_disk()][34] reveals that it calls disk_add_events(), and either "media_change" or "eject_request" may be written to the events file. Here, the kernel's block layer is informing userspace about the appearance and disappearance of the "disk." Consider how quickly informative this method of investigating how USB stick insertion works is compared to trying to figure out the process solely from the source.
+
+### Read-only root filesystems make embedded devices possible
+
+Assuredly, no one shuts down a server or desktop system by pulling out the power plug. Why? Because mounted filesystems on the physical storage devices may have pending writes, and the data structures that record their state may become out of sync with what is written on the storage. When that happens, system owners will have to wait at next boot for the [fsck filesystem-recovery tool][35] to run and, in the worst case, will actually lose data.
+
+Yet, aficionados will have heard that many IoT and embedded devices like routers, thermostats, and automobiles now run Linux. Many of these devices almost entirely lack a user interface, and there's no way to "unboot" them cleanly. Consider jump-starting a car with a dead battery where the power to the [Linux-running head unit][36] goes up and down repeatedly. How is it that the system boots without a long fsck when the engine finally starts running? The answer is that embedded devices rely on [a read-only root fileystem][37] (ro-rootfs for short).
+
+![Photograph of a console][38]
+ro-rootfs are why embedded systems don't frequently need to fsck. Credit (with permission):
+
+A ro-rootfs offers many advantages that are less obvious than incorruptibility. One is that malware cannot write to /usr or /lib if no Linux process can write there. Another is that a largely immutable filesystem is critical for field support of remote devices, as support personnel possess local systems that are nominally identical to those in the field. Perhaps the most important (but also most subtle) advantage is that ro-rootfs forces developers to decide during a project's design phase which system objects will be immutable. Dealing with ro-rootfs may often be inconvenient or even painful, as [const variables in programming languages][39] often are, but the benefits easily repay the extra overhead.
+
+Creating a read-only rootfs does require some additional amount of effort for embedded developers, and that's where VFS comes in. Linux needs files in /var to be writable, and in addition, many popular applications that embedded systems run will try to create configuration dot-files in $HOME. One solution for configuration files in the home directory is typically to pregenerate them and build them into the rootfs. For /var, one approach is to mount it on a separate writable partition while / itself is mounted as read-only. Using bind or overlay mounts is another popular alternative.
+
+### Bind and overlay mounts and their use by containers
+
+Running **[man mount][40]** is the best place to learn about bind and overlay mounts, which give embedded developers and system administrators the power to create a filesystem in one path location and then provide it to applications at a second one. For embedded systems, the implication is that it's possible to store the files in /var on an unwritable flash device but overlay- or bind-mount a path in a tmpfs onto the /var path at boot so that applications can scrawl there to their heart's delight. At next power-on, the changes in /var will be gone. Overlay mounts provide a union between the tmpfs and the underlying filesystem and allow apparent modification to an existing file in a ro-rootfs, while bind mounts can make new empty tmpfs directories show up as writable at ro-rootfs paths. While overlayfs is a proper filesystem type, bind mounts are implemented by the [VFS namespace facility][41].
+
+Based on the description of overlay and bind mounts, no one will be surprised that [Linux containers][42] make heavy use of them. Let's spy on what happens when we employ [systemd-nspawn][43] to start up a container by running bcc's mountsnoop tool:
+
+![Console - system-nspawn invocation][44]
+The system-nspawn invocation fires up the container while mountsnoop.py runs.
+
+And let's see what happened:
+
+![Console - Running mountsnoop][45]
+Running mountsnoop during the container "boot" reveals that the container runtime relies heavily on bind mounts. (Only the beginning of the lengthy output is displayed)
+
+Here, systemd-nspawn is providing selected files in the host's procfs and sysfs to the container at paths in its rootfs. Besides the MS_BIND flag that sets bind-mounting, some of the other flags that the "mount" system call invokes determine the relationship between changes in the host namespace and in the container. For example, the bind-mount can either propagate changes in /proc and /sys to the container, or hide them, depending on the invocation.
+
+### Summary
+
+Understanding Linux internals can seem an impossible task, as the kernel itself contains a gigantic amount of code, leaving aside Linux userspace applications and the system-call interface in C libraries like glibc. One way to make progress is to read the source code of one kernel subsystem with an emphasis on understanding the userspace-facing system calls and headers plus major kernel internal interfaces, exemplified here by the file_operations table. The file operations are what makes "everything is a file" actually work, so getting a handle on them is particularly satisfying. The kernel C source files in the top-level fs/ directory constitute its implementation of virtual filesystems, which are the shim layer that enables broad and relatively straightforward interoperability of popular filesystems and storage devices. Bind and overlay mounts via Linux namespaces are the VFS magic that makes containers and read-only root filesystems possible. In combination with a study of source code, the eBPF kernel facility and its bcc interface makes probing the kernel simpler than ever before.
+
+Much thanks to [Akkana Peck][46] and [Michael Eager][47] for comments and corrections.
+
+Alison Chaiken will present [Virtual filesystems: why we need them and how they work][48] at the 17th annual Southern California Linux Expo ([SCaLE 17x][49]) March 7-10 in Pasadena, Calif.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/virtual-filesystems-linux
+
+作者:[Alison Chariken][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:
+[b]: https://github.com/lujun9972
+[1]: https://www.pearson.com/us/higher-education/program/Love-Linux-Kernel-Development-3rd-Edition/PGM202532.html
+[2]: http://cassandra.apache.org/
+[3]: https://en.wikipedia.org/wiki/NoSQL
+[4]: http://lwn.net/Articles/444910/
+[5]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_1-console.png (Console)
+[6]: https://lwn.net/Articles/22355/
+[7]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/fs.h
+[8]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/fs
+[9]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_2-shim-layer.png (How userspace accesses various types of filesystems)
+[10]: https://lwn.net/Articles/774114/
+[11]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_3-crazy.jpg (Man with shocked expression)
+[12]: https://wiki.archlinux.org/index.php/Tmpfs
+[13]: http://man7.org/linux/man-pages/man8/sysctl.8.html
+[14]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_4-proc-meminfo.png (Console)
+[15]: http://www-f1.ijs.si/~ramsak/km1/mermin.moon.pdf
+[16]: https://en.wikiquote.org/wiki/David_Mermin
+[17]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_5-moon.jpg (Full moon)
+[18]: https://commons.wikimedia.org/wiki/Moon#/media/File:Full_Moon_Luc_Viatour.jpg
+[19]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/stable
+[20]: https://lkml.org/lkml/2012/12/23/75
+[21]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_7-sysfs.png (Console)
+[22]: https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
+[23]: https://github.com/iovisor/bcc
+[24]: https://github.com/iovisor/bcc/blob/master/INSTALL.md
+[25]: http://brendangregg.com/ebpf.html
+[26]: https://github.com/iovisor/bcc/tree/master/tools
+[27]: https://github.com/iovisor/bcc/blob/master/tools/vfscount_example.txt
+[28]: https://github.com/iovisor/bcc/blob/master/tools/vfsstat.py
+[29]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_8-vfsstat.png (Console - vfsstat.py)
+[30]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_9-ebpf.png (Console when USB is inserted)
+[31]: https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt
+[32]: https://events.static.linuxfound.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
+[33]: http://northstar-www.dartmouth.edu/doc/solaris-forte/manuals/c/user_guide/cscope.html
+[34]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/block/genhd.c#n665
+[35]: http://www.man7.org/linux/man-pages/man8/fsck.8.html
+[36]: https://wiki.automotivelinux.org/_media/eg-rhsa/agl_referencehardwarespec_v0.1.0_20171018.pdf
+[37]: https://elinux.org/images/1/1f/Read-only_rootfs.pdf
+[38]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_10-code.jpg (Photograph of a console)
+[39]: https://www.meetup.com/ACCU-Bay-Area/events/drpmvfytlbqb/
+[40]: http://man7.org/linux/man-pages/man8/mount.8.html
+[41]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/filesystems/sharedsubtree.txt
+[42]: https://coreos.com/os/docs/latest/kernel-modules.html
+[43]: https://www.freedesktop.org/software/systemd/man/systemd-nspawn.html
+[44]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_11-system-nspawn.png (Console - system-nspawn invocation)
+[45]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_12-mountsnoop.png (Console - Running mountsnoop)
+[46]: http://shallowsky.com/
+[47]: http://eagercon.com/
+[48]: https://www.socallinuxexpo.org/scale/17x/presentations/virtual-filesystems-why-we-need-them-and-how-they-work
+[49]: https://www.socallinuxexpo.org/
diff --git a/sources/tech/20190309 Emulators and Native Linux games on the Raspberry Pi.md b/sources/tech/20190309 Emulators and Native Linux games on the Raspberry Pi.md
new file mode 100644
index 0000000000..91670b7015
--- /dev/null
+++ b/sources/tech/20190309 Emulators and Native Linux games on the Raspberry Pi.md
@@ -0,0 +1,48 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Emulators and Native Linux games on the Raspberry Pi)
+[#]: via: (https://opensource.com/article/19/3/play-games-raspberry-pi)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+Emulators and Native Linux games on the Raspberry Pi
+======
+The Raspberry Pi is a great platform for gaming; learn how in the ninth article in our series on getting started with the Raspberry Pi.
+
+
+
+Back in the [fifth article][1] in our series on getting started with the Raspberry Pi, I mentioned Minecraft as a way to teach kids to program using a gaming platform. Today we'll talk about other ways you can play games on your Raspberry Pi, as it's a great platform for gaming—with and without emulators.
+
+### Gaming with emulators
+
+Emulators are software that allow you to play games from different systems and different decades on your Raspberry Pi. Of the many emulators available today, the most popular for the Raspberry Pi is [RetroPi][2]. You can use it to play games from systems such as Apple II, Amiga, Atari 2600, Commodore 64, Game Boy Advance, and [many others][3].
+
+If RetroPi sounds interesting, check out [these instructions][4] on how to get started, and start having fun today!
+
+### Native Linux games
+
+There are also plenty of native Linux games available on Raspbian, Raspberry Pi's operating system. Make Use Of has a great article on [how to play 10 old favorites][5] like Doom and Nuke Dukem 3D on the Raspberry Pi.
+
+You can also use your Raspberry Pi as a [game server][6]. For example, you can set up Terraria, Minecraft, and QuakeWorld servers on the Raspberry Pi.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/play-games-raspberry-pi
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/3/teach-kids-program-raspberry-pi
+[2]: https://retropie.org.uk/
+[3]: https://retropie.org.uk/about/systems
+[4]: https://opensource.com/article/19/1/retropie
+[5]: https://www.makeuseof.com/tag/classic-games-raspberry-pi-without-emulators/
+[6]: https://www.makeuseof.com/tag/raspberry-pi-game-servers/
diff --git a/sources/tech/20190309 How To Fix -Network Protocol Error- On Mozilla Firefox.md b/sources/tech/20190309 How To Fix -Network Protocol Error- On Mozilla Firefox.md
new file mode 100644
index 0000000000..da752b07ee
--- /dev/null
+++ b/sources/tech/20190309 How To Fix -Network Protocol Error- On Mozilla Firefox.md
@@ -0,0 +1,67 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Fix “Network Protocol Error” On Mozilla Firefox)
+[#]: via: (https://www.ostechnix.com/how-to-fix-network-protocol-error-on-mozilla-firefox/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+How To Fix “Network Protocol Error” On Mozilla Firefox
+======
+
+
+Mozilla Firefox is my default web browser for years. I have been using it for my day to day web activities, such as accessing my mails, browsing favorite websites etc. Today, I experienced a strange error while using Firefox. I tried to share one of our guide on Reddit platform and got the following error message.
+
+```
+Network Protocol Error
+
+Firefox has experienced a network protocol violation that cannot be repaired.
+
+The page you are trying to view cannot be shown because an error in the network protocol was detected.
+
+Please contact the website owners to inform them of this problem.
+```
+
+
+
+To be honest, I panicked a bit and thought my system might be affected with some kind of malware. LOL! I was wrong! I am using latest Firefox version on my Arch Linux desktop. I opened the same link in Chromium browser. It’s working fine! I guessed it is Firefox related error. After Googling a bit, I fixed this issue as described below.
+
+This kind of problems occurs mostly because of the **browser’s cache**. If you’ve encountered these kind of errors, such as “Network Protocol Error” or “Corrupted Content Error”, follow any one of these methods.
+
+**Method 1:**
+
+To fix “Network Protocol Error” or “Corrupted Content Error”, you need to reload the webpage while bypassing the cache. To do so, Press **Ctrl + F5** or **Ctrl + Shift + R** keys. It will reload the webpage fresh from the server, not from the Firefox cache. Now the web page should work just fine.
+
+**Method 2:**
+
+If the method1 doesn’t work, please try this method.
+
+Go to **Edit - > Preferences**. From the Preferences window, navigate to **Privacy & Security** tab on the left pane. Now clear the Firefox cache by clicking on **“Clear Data”** option.
+
+
+Make sure you have checked both “Cookies and Site Data” and “Cached Web Content” options and click **“Clear”**.
+
+
+
+Done! Now the cookies and offline content will be removed. Please note that Firefox may sign you out of the logged-in websites. You can re-login to those websites later. Finally, close the Firefox browser and restart your system. Now the webpage will load without any issues.
+
+Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-fix-network-protocol-error-on-mozilla-firefox/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
diff --git a/sources/tech/20190310 Let-s get physical- How to use GPIO pins on the Raspberry Pi.md b/sources/tech/20190310 Let-s get physical- How to use GPIO pins on the Raspberry Pi.md
new file mode 100644
index 0000000000..d22887e15f
--- /dev/null
+++ b/sources/tech/20190310 Let-s get physical- How to use GPIO pins on the Raspberry Pi.md
@@ -0,0 +1,48 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Let's get physical: How to use GPIO pins on the Raspberry Pi)
+[#]: via: (https://opensource.com/article/19/3/gpio-pins-raspberry-pi)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+Let's get physical: How to use GPIO pins on the Raspberry Pi
+======
+The 10th article in our series on getting started with Raspberry Pi explains how the GPIO pins work.
+
+
+Until now, this series has focused on the Raspberry Pi's software side, but today we'll get into the hardware. The availability of [general-purpose input/output][1] (GPIO) pins was one of the main features that interested me in the Pi when it first came out. GPIO allows you to programmatically interact with the physical world by attaching sensors, relays, and other types of circuitry to the Raspberry Pi.
+
+
+
+Each pin on the board either has a predefined function or is designated as general purpose. Also, different Raspberry Pi models have either 26 or 40 pins for you to use at your discretion. Wikipedia has a [good overview of each pin][2] and its functionality.
+
+You can do many things with the Pi's GPIO pins. I've written some other articles about using the GPIOs, including a trio of articles ([Part I][3], [Part II][4], and [Part III][5]) about controlling holiday lights with the Raspberry Pi while using open source software to pair the lights with music.
+
+The Raspberry Pi community has done a great job in creating libraries in different programming languages, so you should be able to interact with the pins using [C][6], [Python][7], [Scratch][8], and other languages.
+
+Also, if you want the ultimate experience to interact with the physical world, pick up a [Raspberry Pi Sense Hat][9]. It is an affordable expansion board for the Pi that plugs into the GPIO pins so you can programmatically interact with LEDs, joysticks, and barometric pressure, temperature, humidity, gyroscope, accelerometer, and magnetometer sensors.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/gpio-pins-raspberry-pi
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://www.raspberrypi.org/documentation/usage/gpio/
+[2]: https://en.wikipedia.org/wiki/Raspberry_Pi#General_purpose_input-output_(GPIO)_connector
+[3]: https://opensource.com/life/15/2/music-light-show-with-raspberry-pi
+[4]: https://opensource.com/life/15/12/ssh-your-christmas-tree-raspberry-pi
+[5]: https://opensource.com/article/18/12/lightshowpi-raspberry-pi
+[6]: https://www.bigmessowires.com/2018/05/26/raspberry-pi-gpio-programming-in-c/
+[7]: https://www.raspberrypi.org/documentation/usage/gpio/python/README.md
+[8]: https://www.raspberrypi.org/documentation/usage/gpio/scratch2/README.md
+[9]: https://opensource.com/life/16/4/experimenting-raspberry-pi-sense-hat
diff --git a/sources/tech/20190311 7 resources for learning to use your Raspberry Pi.md b/sources/tech/20190311 7 resources for learning to use your Raspberry Pi.md
new file mode 100644
index 0000000000..4ee4fdf8c8
--- /dev/null
+++ b/sources/tech/20190311 7 resources for learning to use your Raspberry Pi.md
@@ -0,0 +1,80 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (7 resources for learning to use your Raspberry Pi)
+[#]: via: (https://opensource.com/article/19/3/resources-raspberry-pi)
+[#]: author: (Manuel Dewald https://opensource.com/users/ntlx)
+
+7 resources for learning to use your Raspberry Pi
+======
+Books, courses, and websites to shorten your Raspberry Pi learning curve.
+
+
+The [Raspberry Pi][1] is a small, single-board computer originally intended for teaching and learning programming and computer science. But today it's so much more. It is affordable, low-energy computing power that people can use for all kinds of things—from home entertainment over server applications to Internet of Things (IoT) projects.
+
+There are so many resources on the topic and so many different projects you can do, it's hard to know where to begin. Following are some resources that will help you get started with the Raspberry Pi. Have fun browsing through it, but don't stop here. By looking left and right you will find a lot to discover and get deeper into the rabbit hole of the Raspberry Pi wonderland.
+
+### Books
+
+There are many books available in different languages about the Raspberry Pi. These two will help you start—then dive deep—into Raspberry Pi topics.
+
+#### Raspberry Pi Cookbook: Software and Hardware Problems and Solutions by Simon Monk
+
+Simon Monk is a software engineer and was a hobbyist maker for years. He was first attracted to the Arduino as an easy-to-use board for electronics development and later published a [book][2] about it. Later, he moved on to the Raspberry Pi and wrote [Raspberry Pi Cookbook: Software and Hardware Problems and Solutions][3]. In the book, you can find a lot of best practices for Raspberry Pi projects and solutions for all kinds of challenges you may face.
+
+#### Programming the Raspberry Pi: Getting Started with Python by Simon Monk
+
+Python has evolved as the go-to programming language for getting started with Raspberry Pi projects, as it is easy to learn and use, even if you don't have any programming experience. Also, a lot of its libraries help you focus on what makes your project special instead of implementing protocols to communicate with your sensors again and again. Monk wrote two chapters about Python programming in the Raspberry Pi Cookbook, but [Programming the Raspberry Pi: Getting Started with Python][4] is a more thorough quickstart. It introduces you to Python and shows you some projects you can create with it on the Raspberry Pi.
+
+### Online course
+
+There are many online courses and tutorials new Raspberry Pi users can choose from, including this introductory class.
+
+#### Raspberry Pi Class
+
+Instructables' free [Raspberry Pi Class][5] online course offers you an all-around introduction to the Raspberry Pi. It starts with Raspberry Pi and Linux operating basics, then gets into Python programming and GPIO communication. This makes it a good top-to-bottom Raspberry Pi guide if you are new to the topic and want to get started quickly.
+
+### Websites
+
+The web is rife with excellent information about Raspberry Pi, but these four sites should be on the top of any new user's list.
+
+#### RaspberryPi.org
+
+The official [Raspberry Pi][6] website is one of the best places to get started. Many articles about specific projects link to the site for the basics like installing Raspbian onto the Raspberry Pi. (This is what I tend to do, instead of repeating the instructions in every how-to.) You can also find [sample projects][7] and courses on [teaching][8] tech topics to students.
+
+#### Opensource.com
+
+On Opensource.com, you can find a number of different Raspberry Pi project how-to's, getting started guides, success stories, updates, and more. Take a look at the [Raspberry Pi topic page][9] to find out what people are doing with Raspberry Pi.
+
+#### Instructables and Hackaday
+
+Do you want to build your own retro arcade gaming console? Or for your mirror to display weather information, the time, and the first event on the day's calendar? Are you looking to create a word clock or maybe a photo booth for a party? Chances are good that you will find instructions on how to do all of this (and more!) with a Raspberry Pi on sites like [Instructables][10] and [Hackaday][11]. If you're not sure if you should get a Raspberry Pi, browse these sites, and you'll find plenty of reasons to buy one.
+
+What are your favorite Raspberry Pi resources? Please share them in the comments!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/resources-raspberry-pi
+
+作者:[Manuel Dewald][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ntlx
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/resources/raspberry-pi
+[2]: http://simonmonk.org/progardui2ed/
+[3]: http://simonmonk.org/raspberry-pi-cookbook-ed2/
+[4]: http://simonmonk.org/programming-raspberry-pi-ed2/
+[5]: https://www.instructables.com/class/Raspberry-Pi-Class/
+[6]: https://raspberrypi.org
+[7]: https://projects.raspberrypi.org/
+[8]: https://www.raspberrypi.org/training/online
+[9]: https://opensource.com/tags/raspberry-pi
+[10]: https://www.instructables.com/technology/raspberry-pi/
+[11]: https://hackaday.io/projects?tag=raspberry%20pi
diff --git a/sources/tech/20190311 Blockchain 2.0- Redefining Financial Services -Part 3.md b/sources/tech/20190311 Blockchain 2.0- Redefining Financial Services -Part 3.md
new file mode 100644
index 0000000000..5f82bc87ff
--- /dev/null
+++ b/sources/tech/20190311 Blockchain 2.0- Redefining Financial Services -Part 3.md
@@ -0,0 +1,63 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Blockchain 2.0: Redefining Financial Services [Part 3])
+[#]: via: (https://www.ostechnix.com/blockchain-2-0-redefining-financial-services/)
+[#]: author: (EDITOR https://www.ostechnix.com/author/editor/)
+
+Blockchain 2.0: Redefining Financial Services [Part 3]
+======
+
+
+
+The [**previous article of this series**][1] focused on building context to bring forth why moving our existing monetary system to a futuristic [**blockchain**][2] system is the next natural step in the evolution of “money”. We looked at the features of a blockchain platform which would aid in such a move. However, the financial markets are far more complex and composed of numerous other instruments that people trade rather than just a currency.
+
+This part will explore the features of blockchain which will enable institutions to transform and interlace traditional banking and financing systems with it. As previously discussed, and proved, if enough people participate in a given blockchain network and support the protocols for transactions, the nominal value that can be attributed to the “token” increases and becomes more stable. Take, for instance, Bitcoin (BTC). Like the simple paper currency, we’re all used to, cryptocurrencies such as Bitcoin and Ether can be utilized for all the former’s purposes from buying food to ships and from loaning money to insurance.
+
+Chances are you are already involved with a bank or any other financial institution that makes use of blockchain ledger technology. The most significant uses of blockchain tech in the finance industry will be in setting up payments infrastructure, fund transfer technologies, and digital identity management. The latter two have traditionally been handled by legacy systems in the financial services industry. These systems are slowly being migrated to blockchain systems owing to their efficiency in handling work like this. The blockchain also offers high-quality data analytics solutions to these firms, an aspect that is quickly gaining prominence because of recent developments in data sciences.[1]
+
+Considering the start-ups and projects at the cutting edge of innovation in this space first seems warranted due to their products or services already doing the rounds in the market today.
+
+Starting with PayPal, an online payments company started in 1998, and now among the largest of such platforms, it is considered to be a benchmark in terms of operations and technical prowess. PayPal derives largely from the existing monetary system. Its contribution to innovation came by how it collected and leveraged consumer data to provide services online at instantaneous speeds. Online transactions are taken for granted today with minimal innovation in the industry in terms of the tech that it’s based on. Having a solid foundation is a good thing, but that won’t give anyone an edge over their competition in this fast-paced IT world with new standards and technology being pioneered every other day. In 2014 PayPal subsidiary, **Braintree** announced partnerships with popular cryptocurrency payment solutions including **Coinbase** and **GoCoin** , in a bid to gradually integrate Bitcoin and other popular cryptocurrencies into its service platform. This basically gave its consumers a chance to explore and experience the side of what’s to come under the familiar umbrella cover and reliability of PayPal. In fact, ride-hailing company **Uber** had an exclusive partnership with Braintree to allow customers to pay for rides using Bitcoin.[2][3]
+
+**Ripple** is making it easier for people to operate between multiple blockchains. Ripple has been in the headlines for moving ahead with regional banks in the US, for instance, to facilitate transferring money bilaterally to other regional banks without the need for a 3rd party intermediary resulting in reduced cost and time overheads. Ripple’s **Codius platform** allows for interoperability between blockchains and opens the doors to smart contracts programmed into the system for minimal tampering and confusion. Built on technology that is highly advanced, secure and scalable to suit needs, Ripple’s platform currently has names such as UBS and Standard Chartered on their client’s list. Many more are expected to join in.[4][5]
+
+**Kraken** , a US-based cryptocurrency exchange operating in locations around the globe is known for their reliable **crypto quant** estimates even providing Bitcoin pricing data real time to the Bloomberg terminal. In 2015, they partnered with **Fidor Bank** to form what was then the world’s first Cryptocurrency Bank offering customers banking services and products which dealt with cryptocurrencies.[6]
+
+**Circle** , another FinTech company is currently among the largest of its sorts involved with allowing users to invest and trade in cryptocurrency derived assets, similar to traditional money market assets.[7]
+
+Companies such as **Wyre** and **Stellar** today have managed to bring down the lead time involved in international wire transfers from an average of 3 days to under 6 hours. Claims have been made saying that once a proper regulatory system is in place the same 6 hours can be brought down to a matter of seconds.[8]
+
+Now while all of the above have focused on the start-up projects involved, it has to be remembered that the reach and capabilities of the older more respectable financial institutions should not be ignored. Institutions that have existed for decades if not centuries moving billions of dollars worldwide are equally interested in leveraging the blockchain and its potential.
+
+As we already mentioned in the previous article, **JP Morgan** recently unveiled their plans to exploit cryptocurrencies and the underlying ledger like the functionality of the blockchain for enterprises. The project, called **Quorum** , is defined as an **“Enterprise-ready distributed ledger and smart contract platform”**. The main goal being that gradually the bulk of the bank’s operations would one day be migrated to Quorum thus cutting significant investments that firms such as JP Morgan need to make in order to guarantee privacy, security, and transparency. They’re claimed to be the only player in the industry now to have complete ownership over the whole stack of the blockchain, protocol, and token system. They also released a cryptocurrency called **JPM Coin** meant to be used in transacting high volume settlements instantaneously. JPM coin is among the first “stable coins” to be backed by a major bank such as JP Morgan. A stable coin is a cryptocurrency whose price is linked to an existing major monetary system. Quorum is also touted for its capabilities to process almost 100 transactions a second which is leaps and bounds ahead of its contemporaries.[9]
+
+**Barclay’s** , a British multinational financial giant is reported to have registered two blockchain-based patents supposedly with the aim of streamlining fund transfers and KYC procedures. Barclay’s proposals though are more aimed toward improving their banking operations’ efficiency. One of the application deals with creating a private blockchain network for storing KYC details of consumers. Once verified, stored and confirmed, these details are immutable and nullifies the need for further verifications down the line. If implemented the protocol will do away with the need for multiple verifications of KYC details. Developing and densely populated countries such as India where a bulk of the population is yet to be inducted into a formal banking system will find the innovative KYC system useful in reducing random errors and lead times involved in the process[10]. Barclay’s is also rumored to be exploring the capabilities of a blockchain system to address credit status ratings and insurance claims.
+
+Such blockchain backed systems are designed to eliminate needless maintenance costs and leverage the power of smart contracts for enterprises which operate in industries where discretion, security, and speed determine competitive advantage. Being enterprise products, they’re built on protocols that ensure complete transaction and contract privacy along with a consensus mechanism which essentially nullifies corruption and bribery.
+
+**PwC’s Global Fintech Report** from 2017 states that by 2020, an estimated 77% of all Fintech companies are estimated to switch to blockchain based technologies and processes concerning their operations. A whopping 90 percent of their respondents said that they were planning to adopt blockchain technology as part of an in-production system by 2020. Their judgments are not misplaced as significant cost savings and transparency gains from a regulatory point of view are guaranteed by moving to a blockchain based system.[11]
+
+Since regulatory capabilities are built into the blockchain platform by default the migration of firms from legacy systems to modern networks running blockchain ledgers is a welcome move for industry regulators as well. Transactions and trade movements can be verified and tracked on the fly once and for all rather than after. This, in the long run, will likely result in better regulation and risk management. Not to mention improved accountability from the part of firms and individuals alike.[11]
+
+While considerable investments in the space and leaping innovations are courtesy of large investments by established corporates it is misleading to think that such measures wouldn’t permeate the benefits to the end user. As banks and financial institutions start to adopt the blockchain, it will result in increased cost savings and efficiency for them which will ultimately mean good for the end consumer too. The added benefits of transparency and fraud protection will improve customer sentiments and more importantly improve the trust that people place on the banking and financial system. A much-needed revolution in the financial services industry is possible with blockchains and their integration into traditional services.
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/blockchain-2-0-redefining-financial-services/
+
+作者:[EDITOR][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/editor/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/blockchain-2-0-revolutionizing-the-financial-system/
+[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction/
diff --git a/sources/tech/20190311 Building the virtualization stack of the future with rust-vmm.md b/sources/tech/20190311 Building the virtualization stack of the future with rust-vmm.md
new file mode 100644
index 0000000000..b1e7fbf046
--- /dev/null
+++ b/sources/tech/20190311 Building the virtualization stack of the future with rust-vmm.md
@@ -0,0 +1,76 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Building the virtualization stack of the future with rust-vmm)
+[#]: via: (https://opensource.com/article/19/3/rust-virtual-machine)
+[#]: author: (Andreea Florescu )
+
+Building the virtualization stack of the future with rust-vmm
+======
+rust-vmm facilitates sharing core virtualization components between Rust Virtual Machine Monitors.
+
+
+More than a year ago we started developing [Firecracker][1], a virtual machine monitor (VMM) that runs on top of KVM (the kernel-based virtual machine). We wanted to create a lightweight VMM that starts virtual machines (VMs) in a fraction of a second, with a low memory footprint, to enable high-density cloud environments.
+
+We started out developing Firecracker by forking the Chrome OS VMM ([CrosVM][2]), but we diverged shortly after because we targeted different customer use cases. CrosVM provides Linux application isolation in ChromeOS, while Firecracker is used for running multi-tenant workloads at scale. Even though we now walk different paths, we still have common virtualization components, such as wrappers over KVM input/output controls (ioctls), a minimal kernel loader, and use of the [Virtio][3] device models.
+
+With this in mind, we started thinking about the best approach for sharing the common code. Having a shared codebase raises the security and quality bar for both projects. Currently, fixing security bugs requires duplicated work in terms of porting the changes from one project to the other and going through different review processes for merging the changes. After open sourcing Firecracker, we've received requests for adding features including GPU support and booting [bzImage][4] files. Some of the requests didn't align with Firecracker's goals, but were otherwise valid use cases that just haven't found the right place for an implementation.
+
+### The rust-vmm project
+
+The [rust-vmm][5] project came to life in December 2018 when Amazon, Google, Intel, and Red Hat employees started talking about the best way of sharing virtualization packages. More contributors have joined this initiative along the way. We are still at the beginning of this journey, with only one component published to [Crates.io][6] (Rust's package registry) and several others (such as Virtio devices, Linux kernel loaders, and KVM ioctls wrappers) being developed. With two VMMs written in Rust under active development and growing interest in building other specialized VMMs, rust-vmm was born as the host for sharing core virtualization components.
+
+The goal of rust-vmm is to enable the community to create custom VMMs that import just the required building blocks for their use case. We decided to organize rust-vmm as a multi-repository project, where each repository corresponds to an independent virtualization component. Each individual building block is published on Crates.io.
+
+### Creating custom VMMs with rust-vmm
+
+The components discussed below are currently under development.
+
+
+
+Each box on the right side of the diagram is a GitHub repository corresponding to one package, which in Rust is called a crate. The functionality of one crate can be further split into modules, for example virtio-devices. Let's have a look at these components and some of their potential use cases.
+
+ * **KVM interface:** Creating our VMM on top of KVM requires an interface that can invoke KVM functionality from Rust. The kvm-bindings crate represents the Rust Foreign Function Interface (FFI) to KVM kernel headers. Because headers only include structures and defines, we also have wrappers over the KVM ioctls (kvm-ioctls) that we use for opening dev/kvm, creating a VM, creating vCPUs, and so on.
+
+ * **Virtio devices and rate limiting:** Virtio has a frontend-backend architecture. Currently in rust-vmm, the frontend is implemented in the virtio-devices crate, and the backend lies in the vhost package. Vhost has support for both user-land and kernel-land drivers, but users can also plug virtio-devices to their custom backend. The virtio-bindings are the bindings for Virtio devices generated using the Virtio Linux headers. All devices in the virtio-devices crate are exported independently as modules using conditional compilation. Some devices, such as block, net, and vsock support rate limiting in terms of I/O per second and bandwidth. This can be achieved by using the functionality provided in the rate-limiter crate.
+
+ * The kernel-loader is responsible for loading the contents of an [ELF][7] kernel image in guest memory.
+
+
+
+
+For example, let's say we want to build a custom VMM that allows users to create and configure a single VM running on top of KVM. As part of the configuration, users will be able to specify the kernel image file, the root file system, the number of vCPUs, and the memory size. Creating and configuring the resources of the VM can be implemented using the kvm-ioctls crate. The kernel image can be loaded in guest memory with kernel-loader, and specifying a root filesystem can be achieved with the virtio-devices block module. The last thing needed for our VMM is writing VMM Glue, the code that takes care of integrating rust-vmm components with the VMM user interface, which allows users to create and manage VMs.
+
+### How you can help
+
+This is the beginning of an exciting journey, and we are looking forward to getting more people interested in VMMs, Rust, and the place where you can find both: [rust-vmm][5].
+
+We currently have [sync meetings][8] every two weeks to discuss the future of the rust-vmm organization. The meetings are open to anyone willing to participate. If you have any questions, please open an issue in the [community repository][9] or send an email to the rust-vmm [mailing list][10] (you can also [subscribe][11]). We also have a [Slack channel][12] and encourage you to join, if you are interested.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/rust-virtual-machine
+
+作者:[Andreea Florescu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:
+[b]: https://github.com/lujun9972
+[1]: https://github.com/firecracker-microvm/firecracker
+[2]: https://chromium.googlesource.com/chromiumos/platform/crosvm/
+[3]: https://www.linux-kvm.org/page/Virtio
+[4]: https://en.wikipedia.org/wiki/Vmlinux#bzImage
+[5]: https://github.com/rust-vmm
+[6]: https://crates.io/
+[7]: https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
+[8]: http://lists.opendev.org/pipermail/rust-vmm/2019-January/000103.html
+[9]: https://github.com/rust-vmm/community
+[10]: mailto:rust-vmm@lists.opendev.org
+[11]: http://lists.opendev.org/cgi-bin/mailman/listinfo/rust-vmm
+[12]: https://join.slack.com/t/rust-vmm/shared_invite/enQtNTI3NDM2NjA5MzMzLTJiZjUxOGEwMTJkZDVkYTcxYjhjMWU3YzVhOGQ0M2Y5NmU5MzExMjg5NGE3NjlmNzNhZDlhMmY4ZjVhYTQ4ZmQ
diff --git a/sources/tech/20190311 Learn about computer security with the Raspberry Pi and Kali Linux.md b/sources/tech/20190311 Learn about computer security with the Raspberry Pi and Kali Linux.md
new file mode 100644
index 0000000000..72c6f32baa
--- /dev/null
+++ b/sources/tech/20190311 Learn about computer security with the Raspberry Pi and Kali Linux.md
@@ -0,0 +1,62 @@
+[#]: collector: (lujun9972)
+[#]: translator: (hopefully2333)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Learn about computer security with the Raspberry Pi and Kali Linux)
+[#]: via: (https://opensource.com/article/19/3/computer-security-raspberry-pi)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+Learn about computer security with the Raspberry Pi and Kali Linux
+======
+Raspberry Pi is a great way to learn about computer security. Learn how in the 11th article in our getting-started series.
+
+
+Is there a hotter topic in technology than securing your computer? Some experts will tell you that there is no such thing as perfect security. They joke that if you want your server or application to be truly secure, then turn off your server, unplug it from the network, and put it in a safe somewhere. The problem with that should be obvious: What good is an app or server that nobody can use?
+
+That's the conundrum around security. How can we make something secure enough and still usable and valuable? I am not a security expert by any means, although I hope to be one day. With that in mind, I thought it would make sense to share some ideas about what you can do with a Raspberry Pi to learn more about security.
+
+I should note that, like the other articles in this series dedicated to Raspberry Pi beginners, my goal is not to dive in deep, rather to light a fire of interest for you to learn more about these topics.
+
+### Kali Linux
+
+When it comes to "doing security things," one of the Linux distributions that comes to mind is [Kali Linux][1]. Kali's development is primarily focused on forensics and penetration testing. It has more than 600 preinstalled [penetration-testing programs][2] to test your computer's security, and a [forensics mode][3], which prevents it from touching the internal hard drive or swap space of the system being examined.
+
+
+
+Like Raspbian, Kali Linux is based on the Debian distribution, and you can find directions on installing it on the Raspberry Pi in its main [documentation portal][4]. If you installed Raspbian or another Linux distribution on your Raspberry Pi, you should have no problem installing Kali. Kali Linux's creators have even put together [training, workshops, and certifications][5] to help boost your career in the security field.
+
+### Other Linux distros
+
+Most standard Linux distributions, like Raspbian, Ubuntu, and Fedora, also have [many security tools available][6] in their repositories. Some great tools to explore include [Nmap][7], [Wireshark][8], [auditctl][9], and [SELinux][10].
+
+### Projects
+
+There are many other security-related projects you can run on your Raspberry Pi, such as [Honeypots][11], [Ad blockers][12], and [USB sanitizers][13]. Take some time and learn about them!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/computer-security-raspberry-pi
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://www.kali.org/
+[2]: https://en.wikipedia.org/wiki/Kali_Linux#Development
+[3]: https://docs.kali.org/general-use/kali-linux-forensics-mode
+[4]: https://docs.kali.org/kali-on-arm/install-kali-linux-arm-raspberry-pi
+[5]: https://www.kali.org/penetration-testing-with-kali-linux/
+[6]: https://linuxblog.darkduck.com/2019/02/9-best-linux-based-security-tools.html
+[7]: https://nmap.org/
+[8]: https://www.wireshark.org/
+[9]: https://linux.die.net/man/8/auditctl
+[10]: https://opensource.com/article/18/7/sysadmin-guide-selinux
+[11]: https://trustfoundry.net/honeypi-easy-honeypot-raspberry-pi/
+[12]: https://pi-hole.net/
+[13]: https://www.circl.lu/projects/CIRCLean/
diff --git a/sources/tech/20190312 BackBox Linux for Penetration Testing.md b/sources/tech/20190312 BackBox Linux for Penetration Testing.md
new file mode 100644
index 0000000000..b79a4a5cee
--- /dev/null
+++ b/sources/tech/20190312 BackBox Linux for Penetration Testing.md
@@ -0,0 +1,200 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (BackBox Linux for Penetration Testing)
+[#]: via: (https://www.linux.com/blog/learn/2019/3/backbox-linux-penetration-testing)
+[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
+
+BackBox Linux for Penetration Testing
+======
+
+
+Any given task can succeed or fail depending upon the tools at hand. For security engineers in particular, building just the right toolkit can make life exponentially easier. Luckily, with open source, you have a wide range of applications and environments at your disposal, ranging from simple commands to complicated and integrated tools.
+
+The problem with the piecemeal approach, however, is that you might wind up missing out on something that can make or break a job… or you waste a lot of time hunting down the right tools for the job. To that end, it’s always good to consider an operating system geared specifically for penetration testing (aka pentesting).
+
+Within the world of open source, the most popular pentesting distribution is [Kali Linux][1]. It is, however, not the only tool in the shop. In fact, there’s another flavor of Linux, aimed specifically at pentesting, called [BackBox][2]. BackBox is based on Ubuntu Linux, which also means you have easy access to a host of other outstanding applications besides those that are included, out of the box.
+
+### What Makes BackBox Special?
+
+BackBox includes a suite of ethical hacking tools, geared specifically toward pentesting. These testing tools include the likes of:
+
+ * Web application analysis
+
+ * Exploitation testing
+
+ * Network analysis
+
+ * Stress testing
+
+ * Privilege escalation
+
+ * Vulnerability assessment
+
+ * Computer forensic analysis and exploitation
+
+ * And much more
+
+
+
+
+Out of the box, one of the most significant differences between Kali Linux and BackBox is the number of installed tools. Whereas Kali Linux ships with hundreds of tools pre-installed, BackBox significantly limits that number to around 70. Nonetheless, BackBox includes many of the tools necessary to get the job done, such as:
+
+ * Ettercap
+
+ * Msfconsole
+
+ * Wireshark
+
+ * ZAP
+
+ * Zenmap
+
+ * BeEF Browser Exploitation
+
+ * Sqlmap
+
+ * Driftnet
+
+ * Tcpdump
+
+ * Cryptcat
+
+ * Weevely
+
+ * Siege
+
+ * Autopsy
+
+
+
+
+BackBox is in active development, the latest version (5.3) was released February 18, 2019. But how is BackBox as a usable tool? Let’s install and find out.
+
+### Installation
+
+If you’ve installed one Linux distribution, you’ve installed them all … with only slight variation. BackBox is pretty much the same as any other installation. [Download the ISO][3], burn the ISO onto a USB drive, boot from the USB drive, and click the Install icon.
+
+The installer (Figure 1) will be instantly familiar to anyone who has installed a Ubuntu or Debian derivative. Just because BackBox is a distribution geared specifically toward security administrators, doesn’t mean the operating system is a challenge to get up and running. In fact, BackBox is a point-and-click affair that anyone, regardless of skills, can install.
+
+![installation][5]
+
+Figure 1: The installation of BackBox will be immediately familiar to anyone.
+
+[Used with permission][6]
+
+The trickiest section of the installation is the Installation Type. As you can see (Figure 2), even this step is quite simple.
+
+![BackBox][8]
+
+Figure 2: Selecting the type of installation for BackBox.
+
+[Used with permission][6]
+
+Once you’ve installed BackBox, reboot the system, remove the USB drive, and wait for it to land on the login screen. Log into the desktop and you’re ready to go (Figure 3).
+
+![desktop][10]
+
+Figure 3: The BackBox Linux desktop, running as a VirtualBox virtual machine.
+
+[Used with permission][6]
+
+### Using BackBox
+
+Thanks to the [Xfce desktop environment][11], BackBox is easy enough for a Linux newbie to navigate. Click on the menu button in the top left corner to reveal the menu (Figure 4).
+
+![desktop menu][13]
+
+Figure 4: The BackBox desktop menu in action.
+
+[Used with permission][6]
+
+From the desktop menu, click on any one of the favorites (in the left pane) or click on a category to reveal the related tools (Figure 5).
+
+![Auditing][15]
+
+Figure 5: The Auditing category in the BackBox menu.
+
+[Used with permission][6]
+
+The menu entries you’ll most likely be interested in are:
+
+ * Anonymous - allows you to start an anonymous networking session.
+
+ * Auditing - the majority of the pentesting tools are found in here.
+
+ * Services - allows you to start/stop services such as Apache, Bluetooth, Logkeys, Networking, Polipo, SSH, and Tor.
+
+
+
+
+Before you run any of the testing tools, I would recommend you first making sure to update and upgrade BackBox. This can be done via a GUI or the command line. If you opt to go the GUI route, click on the desktop menu, click System, and click Software Updater. When the updater completes its check for updates, it will prompt you if any are available, or if (after an upgrade) a reboot is necessary (Figure 6).
+
+![reboot][17]
+
+Figure 6: Time to reboot after an upgrade.
+
+[Used with permission][6]
+
+Should you opt to go the manual route, open a terminal window and issue the following two commands:
+
+```
+sudo apt-get update
+
+sudo apt-get upgrade -y
+```
+
+Many of the BackBox pentesting tools do require a solid understanding of how each tool works, so before you attempt to use any given tool, make sure you know how to use said tool. Some tools (such as Metasploit) are made a bit easier to work with, thanks to BackBox. To run Metasploit, click on the desktop menu button and click msfconsole from the favorites (left pane). When the tool opens for the first time, you’ll be asked to configure a few options. Simply select each default given by clicking your keyboard Enter key when prompted. Once you see the Metasploit prompt, you can run commands like:
+
+```
+db_nmap 192.168.0/24
+```
+
+The above command will list out all discovered ports on a 192.168.1.x network scheme (Figure 7).
+
+![Metasploit][19]
+
+Figure 7: Open port discovery made simple with Metasploit on BackBox.
+
+[Used with permission][6]
+
+Even often-challenging tools like Metasploit are made far easier than they are with other distributions (partially because you don’t have to bother with installing the tools). That alone is worth the price of entry for BackBox (which is, of course, free).
+
+### The Conclusion
+
+Although BackBox usage may not be as widespread as Kali Linux, it still deserves your attention. For anyone looking to do pentesting on their various environments, BackBox makes the task far easier than so many other operating systems. Give this Linux distribution a go and see if it doesn’t aid you in your journey to security nirvana.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/2019/3/backbox-linux-penetration-testing
+
+作者:[Jack Wallen][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[b]: https://github.com/lujun9972
+[1]: https://www.kali.org/
+[2]: https://linux.backbox.org/
+[3]: https://www.backbox.org/download/
+[4]: /files/images/backbox1jpg
+[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/backbox_1.jpg?itok=pn4fQVp7 (installation)
+[6]: /licenses/category/used-permission
+[7]: /files/images/backbox2jpg
+[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/backbox_2.jpg?itok=tf-1zo8Z (BackBox)
+[9]: /files/images/backbox3jpg
+[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/backbox_3.jpg?itok=GLowoAUb (desktop)
+[11]: https://www.xfce.org/
+[12]: /files/images/backbox4jpg
+[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/backbox_4.jpg?itok=VmQXtuZL (desktop menu)
+[14]: /files/images/backbox5jpg
+[15]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/backbox_5.jpg?itok=UnfM_OxG (Auditing)
+[16]: /files/images/backbox6jpg
+[17]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/backbox_6.jpg?itok=2t1BiKPn (reboot)
+[18]: /files/images/backbox7jpg
+[19]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/backbox_7.jpg?itok=Vw_GEub3 (Metasploit)
diff --git a/sources/tech/20190312 Do advanced math with Mathematica on the Raspberry Pi.md b/sources/tech/20190312 Do advanced math with Mathematica on the Raspberry Pi.md
new file mode 100644
index 0000000000..c39b7dc7e5
--- /dev/null
+++ b/sources/tech/20190312 Do advanced math with Mathematica on the Raspberry Pi.md
@@ -0,0 +1,49 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Do advanced math with Mathematica on the Raspberry Pi)
+[#]: via: (https://opensource.com/article/19/3/do-math-raspberry-pi)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+Do advanced math with Mathematica on the Raspberry Pi
+======
+Wolfram bundles a version of Mathematica with Raspbian. Learn how to use it in the 12th article in our series on getting started with Raspberry Pi.
+
+
+
+In the mid-'90s, I started college as a math major, and, even though I graduated with a computer science degree, I had taken enough classes to graduate with a minor—and only two classes short of a double-major—in math. At the time, I was introduced to an application called [Mathematica][1] by [Wolfram][2], where we would take many of our algebraic and differential equations from the blackboard into the computer. I spent a few hours a month in the lab learning the Wolfram Language and solving integrals and such on Mathematica.
+
+Mathematica was closed source and expensive for a college student, so it was a nice surprise to see almost 20 years later Wolfram bundling a version of Mathematica with Raspbian and the Raspberry Pi. If you decide to use another Debian-based distribution, you can [download it][3] on your Pi. Note that this version is free for non-commercial use only.
+
+The Raspberry Pi Foundation's [introduction to Mathematica][4] covers some basic concepts such as variables and loops, solving some math problems, creating graphs, doing linear algebra, and even interacting with the GPIO pins through the application.
+
+
+
+To dive deeper into Mathematica, check out the [Wolfram Language documentation][5]. If you just want to solve some basic calculus problems, [check out its functions][6]. And read this tutorial if you want to [plot some 2D and 3D graphs][7].
+
+Or, if you want to stick with open source tools while doing math, check out the command-line tools **expr** , **factor** , and **bc**. (Remember to use the [**man** command][8] to read up on these utilities.) And if you want to graph something, [Gnuplot][9] is a great option.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/do-math-raspberry-pi
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Wolfram_Mathematica
+[2]: https://wolfram.com/
+[3]: https://www.wolfram.com/raspberry-pi/
+[4]: https://projects.raspberrypi.org/en/projects/getting-started-with-mathematica/
+[5]: https://www.wolfram.com/language/
+[6]: https://reference.wolfram.com/language/guide/Calculus.html
+[7]: https://reference.wolfram.com/language/howto/PlotAGraph.html
+[8]: https://opensource.com/article/19/3/learn-linux-raspberry-pi
+[9]: http://gnuplot.info/
diff --git a/sources/tech/20190312 Star LabTop Mk III Open Source Edition- An Interesting Laptop.md b/sources/tech/20190312 Star LabTop Mk III Open Source Edition- An Interesting Laptop.md
new file mode 100644
index 0000000000..2e4b8f098a
--- /dev/null
+++ b/sources/tech/20190312 Star LabTop Mk III Open Source Edition- An Interesting Laptop.md
@@ -0,0 +1,93 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Star LabTop Mk III Open Source Edition: An Interesting Laptop)
+[#]: via: (https://itsfoss.com/star-labtop-open-source-edition)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Star LabTop Mk III Open Source Edition: An Interesting Laptop
+======
+
+[Star Labs Systems][1] have been producing Laptops tailored for Linux for some time. While you can purchase other variants available on their website, they have recently launched a [Kickstarter campaign][2] for their upcoming ‘Open Source Edition’ laptop that incorporates more features as per the requests by the users or reviewers.
+
+It may not be the best laptop you’ve ever come across for around a **1000 Euros** – but it certainly is interesting for some specific features.
+
+In this article, we will talk about what makes it an interesting deal and whether or not it’s worth investing for.
+
+![star labtop mk III][3]
+
+### Key Highlight: Open-source Coreboot Firmware
+
+Normally, you will observe proprietary firmware (BIOS) on computers, American Megatrends Inc, for example.
+
+But, here, Star Labs have tailored the [coreboot firmware][4] (a.k.a known as the LinuxBIOS) which is an open source alternative to proprietary solutions for this laptop.
+
+Not just open source but it is also a lighter firmware for better control over your laptop. With [TianoCore EDK II][5], it ensures that you get the maximum compatibility for most of the major Operating Systems.
+
+### Other Features of Star LabTop Mk III
+
+![sat labtop mk III][6]
+
+In addition to the open source firmware, the laptop features an **8th-gen i7 chipse** t ( **i7-8550u** ) coupled with **16 Gigs of LPDDR4 RAM** clocked at **2400 MHz**.
+
+The GPU being the integrated **Intel UHD Graphics 620** should be enough for professional tasks – except video editing and gaming. It will be rocking a **Full HD 13.3-inch IPS** panel as the display.
+
+The storage option includes **480 GB or 960 GB of PCIe SSD** – which is impressive as well. In addition to all this, it comes with the **USB Type-C** support.
+
+Interestingly, the **BIOS, Embedded Controller and SSD** will be receiving automatic [firmware updates][7] via the [LVFS][8] (the Mk III standard edition has this feature already).
+
+You should also check out a review video of [Star LabTob Mk III][9] to get an idea of how the open source edition could look like:
+
+If you are curious about the detailed tech specs, you should check out the [Kickstarter page][2].
+
+
+
+### Our Opinion
+
+![star labtop mk III][10]
+
+The inclusion of coreboot firmware and being something tailored for various Linux distributions originally is the reason why it is being termed as the “ **Open Source Edition”**.
+
+The price for the ultimate bundle on Kickstarter is **1087 Euros**.
+
+Can you get better laptop deals at this price? **Yes** , definitely. But, it really comes down to your preference and your passion for open source – of what you require.
+
+However, if you want a performance-driven laptop specifically tailored for Linux, yes, this is an option you might want to consider with something new to offer (and potentially considering your requests for their future builds).
+
+Of course, you cannot consider this for video editing and gaming – for obvious reasons. So, they should considering adding a dedicated GPU to make it a complete package for computing, gaming, video editing and much more. Maybe even a bigger screen, say 15.6-inch?
+
+### Wrapping Up
+
+For what it is worth, if you are a Linux and open source enthusiast and want a performance-driven laptop, this could be an option to go with and back this up on Kickstarter right now.
+
+What do you think about it? Will you be interested in a laptop like this? If not, why?
+
+Let us know your thoughts in the comments below.
+
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/star-labtop-open-source-edition
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://starlabs.systems
+[2]: https://www.kickstarter.com/projects/starlabs/star-labtop-mk-iii-open-source-edition
+[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/star-labtop-mkiii-2.jpg?resize=800%2C450&ssl=1
+[4]: https://en.wikipedia.org/wiki/Coreboot
+[5]: https://github.com/tianocore/tianocore.github.io/wiki/EDK-II
+[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/star-labtop-mkiii-1.jpg?ssl=1
+[7]: https://itsfoss.com/update-firmware-ubuntu/
+[8]: https://fwupd.org/
+[9]: https://starlabs.systems/pages/star-labtop
+[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/star-labtop-mkiii.jpg?resize=800%2C435&ssl=1
+[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/star-labtop-mkiii-2.jpg?fit=800%2C450&ssl=1
diff --git a/sources/tech/20190313 Game Review- Steel Rats is an Enjoyable Bike-Combat Game.md b/sources/tech/20190313 Game Review- Steel Rats is an Enjoyable Bike-Combat Game.md
new file mode 100644
index 0000000000..5af0ae30d3
--- /dev/null
+++ b/sources/tech/20190313 Game Review- Steel Rats is an Enjoyable Bike-Combat Game.md
@@ -0,0 +1,95 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Game Review: Steel Rats is an Enjoyable Bike-Combat Game)
+[#]: via: (https://itsfoss.com/steel-rats)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Game Review: Steel Rats is an Enjoyable Bike-Combat Game
+======
+
+Steel Rats is a quite impressive 2.5D motorbike combat game with exciting stunts involved. It was already available for Windows on [Steam][1] – however, recently it has been made available for Linux and Mac as well.
+
+In case you didn’t know, you can easily [install Steam on Ubuntu][2] or other distributions and [enable Steam Play feature to run some Windows games on Linux][3].
+
+So, in this article, we shall take a look at what the game is all about and if it is a good purchase for you.
+
+This game is neither free nor open source. We have covered it here because the game developers made an effort to port it to Linux.
+
+### Story Overview
+
+![steel rats][4]
+
+You belong to a biker gang – “ **Steel Rats** ” – who stepped up to protect their city from alien robots invasion. The alien robots aren’t just any tiny toys that you can easily defeat but with deadly weapons and abilities.
+
+The games features the setting as an alternative version of 1940’s USA – with the retro theme in place. You have to use your bike as the ultimate weapon to go against waves of alien robot and boss fights as well.
+
+You will encounter 4 different characters with unique abilities to switch from after progressing through a couple of rounds.
+
+You will start playing as “ **Toshi** ” and unlock other characters as you progress. **Toshi** is a genius and will be using a drone as his gadget to fight the alien robots. **James** – is the leader with the hammer attack as his special ability. **Lisa** would be the one utilizing fire to burn the junk robots. And, **Randall** will have his harpoon ready to destroy aerial robots with ease.
+
+### Gameplay
+
+![][5]
+
+Honestly, I am not a fan of 2.5 D (or 2D games). But, games like [Unravel][6] will be the exception – which is still not available for Linux, such a shame – EA.
+
+In this case, I did end up enjoying “ **Steel Rats** ” as one of the few 2D games I play.
+
+There is really no rocket science for this game – you just have to get good with the controls. No matter whether you use a controller or a keyboard, it is definitely challenging to get comfortable with the controls.
+
+You do not need to plan ahead in order to save your health or nitro boost because you will always have it when needed while also having checkpoints to resume your progress.
+
+You just need to keep the right pace and the perfect jump while hitting every enemy to get the best score in the leader boards. Once you do that, the game ends up being an easy and fun experience.
+
+If you’re curious about the gameplay, we recommend watching this video:
+
+ = 0 and self.counter <= distance:
+
+ self.rect.x += speed
+
+ elif self.counter >= distance and self.counter <= distance*2:
+
+ self.rect.x -= speed
+
+ else:
+
+ self.counter = 0
+
+
+
+ self.counter += 1
+
+```
+
+你可以根据需要调整距离和速度。
+
+当你现在启动游戏,这段代码有效果吗?
+
+当然不,你应该也知道原因。你必须在主循环中调用 `move` 方法。如下示例代码中的第一行是上下文提示,那么添加最后两行代码:
+```
+ enemy_list.draw(world) #refresh enemy
+
+ for e in enemy_list:
+
+ e.move()
+
+```
+
+启动你的游戏看看当你打击敌人时发生了什么。你可能需要调整妖精的生成地点,使得你的玩家和敌人能够碰撞。当他们发生碰撞时,查看 [IDLE][6] 或 [Ninja-IDE][7] 的控制台,你可以看到生命值正在被扣除。
+
+
+
+你应该已经注意到,在你的玩家和敌人接触时,生命值在时刻被扣除。这是一个问题,但你将在对 Python 进行更多练习以后解决它。
+
+现在,尝试添加更多敌人。记得将每个敌人加入 `enemy_list`。作为一个练习,看看你能否想到如何改变不同敌方妖精的移动距离。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/5/pygame-enemy
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[cycoe](https://github.com/cycoe)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[1]:https://opensource.com/article/17/10/python-101
+[2]:https://opensource.com/article/17/12/game-framework-python
+[3]:https://opensource.com/article/17/12/game-python-add-a-player
+[4]:https://opensource.com/article/17/12/game-python-moving-player
+[5]:https://opengameart.org
+[6]:https://docs.python.org/3/library/idle.html
+[7]:http://ninja-ide.org/
diff --git a/translated/tech/20190128 Top Hex Editors for Linux.md b/translated/tech/20190128 Top Hex Editors for Linux.md
deleted file mode 100644
index ed3eba4c9f..0000000000
--- a/translated/tech/20190128 Top Hex Editors for Linux.md
+++ /dev/null
@@ -1,147 +0,0 @@
-[#]: collector: "lujun9972"
-[#]: translator: "zero-mk "
-[#]: reviewer: " "
-[#]: publisher: " "
-[#]: url: " "
-[#]: subject: "Top Hex Editors for Linux"
-[#]: via: "https://itsfoss.com/hex-editors-linux"
-[#]: author: "Ankush Das https://itsfoss.com/author/ankush/"
-
-Top Hex Editors for Linux
-======
-
-十六进制编辑器可以让你以十六进制的形式查看/编辑文件的二进制数据,因此其被命名为“十六进制”编辑器。说实话,并不是每个人都需要它。只有必须处理二进制数据的特定用户组才会使用到它。
-
-如果您不知道,它是什么,让我举个例子。假设您拥有游戏的配置文件,您可以使用十六进制编辑器打开它们并更改某些值以获得更多的弹药/分数等等。 想要了解有关Hex编辑器的更多信息,你可以参阅 [Wikipedia page][1]。
-
-如果你已经知道它用来干什么了 —— 让我们来看看Linux最好的Hex编辑器。
-
-### 5个最好的十六进制编辑器
-
-![Best Hex Editors for Linux][2]
-
-**注意:**提到的十六进制编辑器没有特定的排名顺序。
-
-#### 1\. Bless Hex Editor
-
-![bless hex editor][3]
-
-**主要特点:**
-
- * 编辑裸设备(Raw disk )
- * 多级撤消/重做操作
- * 多个标签
- * 转换表
- * 支持插件扩展功能
-
-
-
-Bless是Linux上最流行的Hex编辑器之一。您可以在AppCenter或软件中心中找到它。 如果不是这种情况,您可以查看他们的 [GitHub page][4] 获取构建和相关的说明。
-
-它可以轻松处理编辑大文件而不会降低速度——因此它是一个快速的十六进制编辑器。
-
-#### 2\. GNOME Hex Editor
-
-![gnome hex editor][5]
-
-**主要特点:**
-
- * 以 十六进制/Ascii格式 查看/编辑
-
- * 编辑大文件
-
- *
-
-
-另一个神奇的十六进制编辑器-专门为GNOME量身定做的。 我个人用的是 Elementary OS, 所以我可以在 软件中心(AppCenter)找到它.。您也可以在软件中心找到它。如果没有,请参考 [GitHub page][6] 获取源代码。
-
-您可以使用此编辑器以十六进制或ASCII格式 查看/编辑 文件。用户界面非常简单——正如您在上面的图像中看到的那样。
-
-#### 3\. Okteta
-
-![okteta][7]
-
-**主要特点:**
-
- * 可自定义的数据视图
- * 多个选项卡
- * 字符编码:支持Qt、EBCDIC的所有8位编码
- * 解码表列出常见的简单数据类型
-
-
-
-Okteta是一个简单的十六进制编辑器,没有那么奇特的功能。虽然它可以处理大部分任务。它有一个单独的模块,你可以使用它嵌入其他程序来查看/编辑文件。
-
-
-与上述所有编辑器类似,您也可以在应用中心(App Center)和软件中心(Software Center)上找到列出的编辑器。
-
-#### 4\. wxHexEditor
-
-![wxhexeditor][8]
-
-**主要特点:**
-
- * 轻松处理大文件
- * 支持x86反汇编
- * **** Sector Indication **** on Disk devices
- * 支持自定义十六进制面板格式和颜色
-
-
-
-这很有趣。它主要是一个十六进制编辑器,但您也可以将其用作低级磁盘编辑器。例如,如果您的硬盘有问题,可以使用此编辑器编辑RAW格式原始数据镜像文件,在十六进制中的扇区并修复它。
-
-你可以在你的应用中心(App Center)和软件中心(Software Center)找到它。 如果不是, [Sourceforge][9] 是个正确的选择。
-
-#### 5\. Hexedit (命令行工具)
-
-![hexedit][10]
-
-**主要特点:**
-
- * 运行在命令行终端上
- * 它又快又简单
-
-
-
-如果您想在终端上工作,可以继续通过控制台安装hexedit。它是我最喜欢的命令行Linux十六进制编辑器。
-
-当你启动它时,你必须指定要打开的文件的位置,然后它会为你打开它。
-
-要安装它,只需输入:
-
-```
-sudo apt install hexedit
-```
-
-### 结束
-
-十六进制编辑器可以方便地进行实验和学习。如果你是一个有经验的人,你应该选择一个有更多功能的——GUI。 尽管这一切都取决于个人喜好。
-
-你认为十六进制编辑器的有用性如何?你用哪一个?我们没有列出你最喜欢的吗?请在评论中告诉我们!
-
-![][11]
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/hex-editors-linux
-
-作者:[Ankush Das][a]
-选题:[lujun9972][b]
-译者:[zero-mk](https://github.com/zero-mk)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ankush/
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/Hex_editor
-[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-hex-editors-800x450.jpeg?resize=800%2C450&ssl=1
-[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/bless-hex-editor.jpg?ssl=1
-[4]: https://github.com/bwrsandman/Bless
-[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/ghex-hex-editor.jpg?ssl=1
-[6]: https://github.com/GNOME/ghex
-[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/okteta-hex-editor-800x466.jpg?resize=800%2C466&ssl=1
-[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/wxhexeditor.jpg?ssl=1
-[9]: https://sourceforge.net/projects/wxhexeditor/
-[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/hexedit-console.jpg?resize=800%2C566&ssl=1
-[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-hex-editors.jpeg?fit=800%2C450&ssl=1
diff --git a/translated/tech/20190131 19 days of productivity in 2019- The fails.md b/translated/tech/20190131 19 days of productivity in 2019- The fails.md
new file mode 100644
index 0000000000..a0a7100a00
--- /dev/null
+++ b/translated/tech/20190131 19 days of productivity in 2019- The fails.md
@@ -0,0 +1,78 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (19 days of productivity in 2019: The fails)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-wish-list)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+2019 年的 19 个高效日:失败了
+======
+以下是开源世界没有做到的一些工具。
+
+
+每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
+
+保持高效一部分是接受失败发生。我是 [Howard Tayler's][1] 的第 70 条座右铭的支持者:“失败不是一种选择,它是一定的。可以选择的是是否让失败成为你做的最后一件事。”我对这个系列的有很多话想多,但是我没有找到好的答案。
+
+关于我的 19 个新的(或对你而言新的)帮助你在 2019 年更高效的工具的最终版,我想到了一些我想要的,但是没有找到的。我希望读者你能够帮我找到下面这些项目的好的方案。如果你发现了,请在下面的留言中分享。
+
+### 日历
+
+
+
+如果开源世界有一件事缺乏,那就是日历。我尝试过的日历程序和尝试电子邮件程序的数量一样多。共享日历基本上有三个很好的选择:[Evolution][2]、[Thunderbird 中的 Lightning 附加组件][3] 或 [KOrganizer][4]。我尝试过的所有其他应用 (包括 [Orage][5]、[Osmo][6] 以及几乎所有 [Org 模式][7]附加组件) 似乎只可靠地支持对远程日历的只读访问。如果共享日历使用 [Google 日历][8] 或 [Microsoft Exchange][9] 作为服务器,那么前三个是唯一易于配置的选择(即便如此,通常还需要其他附加组件)。
+
+### Linux 内核的系统
+
+
+
+我喜欢 [Chrome OS][10] 的简单性和轻量需求。我有几款 Chromebook,包括谷歌的最新型号。我发现它不会分散注意力、重量轻、易于使用。通过添加 Android 应用和 Linux 容器,几乎可以在任何地方轻松高效工作。
+
+我想把它安装到我一些闲置的笔记本上,但除非我对 Chromium OS 进行全面编译,否则很难有相同的体验。像 [Bliss OS][12]、[Phoenix OS][13] 和 [Android-x86][14] 这样的桌面 [Android][11] 项目快要完成了,我正在关注它们的未来。
+
+### 客户服务
+
+
+
+对于大大小小的公司来说,客户服务是一件大事。现在,随着近来对 DevOps 的关注,有必要使用工具来弥补差距。我工作的几乎每家公司都使用 [Jira][15]、[GitHub][16] 或 [GitLab][17] 来提代码问题,但这些工具都不是很擅长客户支持工单(没有很多工作)。虽然围绕客户支持工单和问题设计了许多应用,但大多数(如果不是全部)应用都是与其他系统不兼容的孤岛,同样没有大量工作。
+
+我的愿望是有一个开源解决方案,它能让客户、支持人员和开发人员一起工作,而无需笨重的代码将多个系统粘合在一起。
+
+### 轮到你了
+
+
+
+我相信这个系列中我错过了很多选择。我经常尝试新的应用,希望它们能帮助我提高工作效率。我鼓励每个人都这样做,因为当谈到使用开源工具提高工作效率时,总会有新的选择。如果你有喜欢的开源生产力应用没有进入本系列,请务必在评论中分享它们。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-wish-list
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://www.schlockmercenary.com/
+[2]: https://wiki.gnome.org/Apps/Evolution
+[3]: https://www.thunderbird.net/en-US/calendar/
+[4]: https://userbase.kde.org/KOrganizer
+[5]: https://github.com/xfce-mirror/orage
+[6]: http://clayo.org/osmo/
+[7]: https://orgmode.org/
+[8]: https://calendar.google.com
+[9]: https://products.office.com/
+[10]: https://en.wikipedia.org/wiki/Chrome_OS
+[11]: https://www.android.com/
+[12]: https://blissroms.com/
+[13]: http://www.phoenixos.com/
+[14]: http://www.android-x86.org/
+[15]: https://www.atlassian.com/software/jira
+[16]: https://github.com
+[17]: https://about.gitlab.com/
diff --git a/translated/tech/20190208 7 steps for hunting down Python code bugs.md b/translated/tech/20190208 7 steps for hunting down Python code bugs.md
deleted file mode 100644
index 5f280ae17c..0000000000
--- a/translated/tech/20190208 7 steps for hunting down Python code bugs.md
+++ /dev/null
@@ -1,110 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (LazyWolfLin)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (7 steps for hunting down Python code bugs)
-[#]: via: (https://opensource.com/article/19/2/steps-hunting-code-python-bugs)
-[#]: author: (Maria Mckinley https://opensource.com/users/parody)
-
-7 步检查 Python 代码错误
-======
-了解一些技巧助你减少代码查错时间。
-
-
-在周五的下午三点钟。为什么是这个时间?因为事情总会在周五下午三点钟发生。你收到一条通知,客户发现你的软件出现一个错误。在有了初步的怀疑后,你联系运维,查看你的软件日志以了解发生了什么,因为你记得收到过日志已经移动了的通知。
-
-结果这些日志被转移到了你获取不到的地方,但他们正在导到一个网页应用中——所以你将可以用这个漂亮的应用来检索日志,但是,这个应用现在还没完成。这个应用预计会在几天内完成。我知道,这完全不符合实际情况,对吧?然而并不是,日志或者日志消息似乎经常在错误的时间出现缺失。在我们开始查错前,一个忠告:经常检查你的日志以确保他们在你认为它们应该在的地方并记录你认为它们应该记的东西。当你不检查的时候,这些东西往往会发生令人惊讶的变化。
-
-好的,你找到了日志或者尝试了呼叫运维人员,而客户确实发现了一个错误。甚至你可能认为你已经知道错误在哪儿。
-
-你立即打开你认为可能有问题的文件并开始查错。
-
-### 1. 不要碰你的代码
-
-阅读代码,你甚至可能会想到一个假设。但是在开始修改你的代码前,请重现导致错误的调用并把它变成一个测试。这将是一个集成测试,因为你可能还有其他疑问,目前你还没能准确地知道问题在哪儿。
-
-确保这个测试是失败的。这很重要,因为有时你的测试不能重现失败的调用,尤其是你使用了可以混淆测试的 web 或者其他框架。很多东西可能被存储在变量中,但遗憾的是,只通过观察测试,你在测试里调用的东西并不总是明显可见的。当我尝试着重现这个失败的调用时,我不准备说我创建了一个新测试,但是,对的,我确实已经创建了新的一个测试,但我不认为这是特别不寻常的。从自己的错误中吸取教训。
-
-### 2. 编写错误的测试
-
-现在,你有了一个失败的测试或者可能是一个带有错误的测试,那么是时候解决问题了。但是在你开干之前,让我们先检查下调用栈,因为这样可以更轻松地解决问题。
-
-调用栈包括你已经启动但尚未完成地所有任务。因此,比如你正在烤蛋糕并准备往面糊里加面粉,那你的调用栈将是:
-
-* 做蛋糕
-* 打面糊
-* 加面粉
-
-你已经开始做蛋糕,开始打面糊,而你现在正在加面粉。往锅底抹油不在这个列表中因为你已经完成了,而做糖霜不在这个列表上因为你还没开始做。
-
-如果你对调用栈不清楚,我强烈建议你使用 [Python Tutor][1],它能帮你在执行代码时观察调用栈。
-
-现在,如果你的 Python 程序出现了错误,接收器会帮你打印出当前调用栈。这意味着无论那一时刻程序在做什么,很明显错误发生在调用栈的底部。
-
-### 3. 始终先检查 stack 的底部
-
-你不仅能在栈底看到发生了哪个错误,而且通常可以在调用栈的最后一行发现问题。如果栈底对你没有帮助,而你的代码还没有经过代码分析,那么使用代码分析非常有用。我推荐 pylint 或者 flake8。通常情况下,它会指出我一直忽略的错误的地方。
-
-如果对错误看起来很迷惑,你下一步行动可能是用 Google 搜索它。如果你搜索的内容不包含你的代码的相关信息,如变量名、文件等,那你将获得更好的搜索结果。如果你使用的是 Python 3(你应该使用它),那么搜索内容包含 Python 3 是有帮助的,否则 Python 2 的解决方案往往会占据大多数。
-
-很久以前,开发者需要在没有搜索引擎的帮助下解决问题。那是一段黑暗的时光。充分利用你可以使用的所有工具。
-
-不幸的是,有时候问题发生得比较早但只有在调用栈底部执行的地方才变得明显。就像当蛋糕没有膨胀时,忘记加发酵粉的事才被发现。
-
-那就该检查整个调用栈。问题更可能在你的代码而不是 Python 标准库或者第三方包,所以先检查调用栈内你的代码。另外,在你的代码中放置断点通常会更容易检查代码。在调用栈的代码中放置断点然后看看周围是否如你预期。
-
-“但是,玛丽,”我听到你说,“如果我有一个调用栈,那这些都是有帮助的,但我只有一个失败的测试。我该从哪里开始?”
-
-Pdb, 一个 Python 调试器。
-
-找到你代码里会被这个调用命中的地方。你应该能够找到至少一个这样的地方。在那里打上一个 pdb 的断点。
-
-#### 一句题外话
-
-为什么不使用 print 语句呢?我曾经依赖于 print 语句。有时候,他们仍然派得上用场。但当我开始处理复杂的代码库,尤其是有网络调用的代码库,print 语句就变得太慢了。我最终得到所有打印出来的数据,但我没法追踪他们的位置和原因,而且他们变得复杂了。但是主要使用 pdb 还有一个更重要的原因。假设你添加一条 print 语句去发现错误问题,而且 print 语句必须早于错误出现的地方。但是,看看你放 print 语句的函数,你不知道你的代码是怎么执行到那个位置的。查看代码是寻找调用路径的好方法,但看你以前写的代码是恐怖的。是的,我会用 grep 处理我的代码库以寻找调用函数的地方,但这会变得乏味,而且搜索一个通用函数时并不能缩小搜索范围。Pdb 就变得非常有用。
-
-你遵循我的建议,打上 pdb 断点并运行你的测试。然而测试再次失败,但是没有任何一个断点被打到。保留你的断点,并运行测试套件中一个同这个失败的测试非常相似的测试。如果你有个不错的测试,你应该能够找到一个测试。它会击中了你认为你的失败测试应该击中的代码。运行这个测试,然后当它打到你的断点,按下 `w` 并检查调用栈。如果你不知道如何查看因为其他调用而变得混乱的调用栈,那么在调用栈的中间找到属于你的代码,并在其中堆栈中代码的上一行放置一个断点。再试一次新的测试。如果仍然没打到断点,那么继续,向上追踪调用栈并找出你的调用在哪里脱轨了。如果你一直没有打到断点,最后到了追踪的顶部,那么恭喜你,你发现了问题:你的应用程序拼写错了。没有经验,没有经验,一点都没有经验。
-
-### 4. 修改代码
-
-如果你仍觉得迷惑,在你稍微改变了一些的地方尝试新的测试。你能让新的测试跑起来么?有什么不同的呢?有什么相同的呢?尝试改变别的东西。当你有了你的测试,可能也还有其他测试,那就可以开始安全地修改代码,确定是否可以缩小问题范围。记得从一个新提交开始解决问题,以便于可以轻松地撤销无效地更改。(这就是版本控制,如果你没有使用版本控制,这将会改变你的生活。好吧,可能它只是让编码更容易。查阅“版本控制可视指南”,以了解更多。)
-
-### 5. 休息一下
-
-尽管如此,当它不再感觉起来像一个有趣的挑战或者游戏而开始变得令人沮丧时,你最好的举措是脱离这个问题。休息一下。我强烈建议你去散步并尝试考虑别的事情。
-
-### 6. 把一切写下来
-
-当你回来了,如果你没有突然受到启发,那就把你关于这个问题所知的每一个点信息写下来。这应该包括:
-
- * 真正造成问题的调用
- * 真正发生了什么,包括任何错误信息或者相关的日志信息
- * 你真正期望发生什么
- * 到目前为止,为了找出问题,你做了什么工作;以及解决问题中你发现的任何线索。
-
-有时这里有很多信息,但相信我,从零碎中挖掘信息是很烦人。所以尽量简洁,但是要完整。
-
-### 7. 寻求帮助
-
-我经常发现写下所有信息能够启迪我想到还没尝试过的东西。当然,有时候我在点击提交按钮后立刻意识到问题是是什么。无论如何,当你在写下所有东西仍一无所获,那就试试向他人发邮件求助。首先是你的同事或者其他参与你的项目的人,然后是项目的邮件列表。不要害怕向人求助。大多数人都是友善和乐于助人的,我发现在 Python 社区里尤其如此。
-
-Maria McKinley 将在 [PyCascades 2019][4] 发表[代码查错][3],二月 23-24,于西雅图。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/2/steps-hunting-code-python-bugs
-
-作者:[Maria Mckinley][a]
-选题:[lujun9972][b]
-译者:[LazyWolfLin](https://github.com/LazyWolfLin)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/parody
-[b]: https://github.com/lujun9972
-[1]: http://www.pythontutor.com/
-[2]: https://betterexplained.com/articles/a-visual-guide-to-version-control/
-[3]: https://2019.pycascades.com/talks/hunting-the-bugs
-[4]: https://2019.pycascades.com/
diff --git a/translated/tech/20190218 Emoji-Log- A new way to write Git commit messages.md b/translated/tech/20190218 Emoji-Log- A new way to write Git commit messages.md
new file mode 100644
index 0000000000..2b4d41ecb3
--- /dev/null
+++ b/translated/tech/20190218 Emoji-Log- A new way to write Git commit messages.md
@@ -0,0 +1,169 @@
+[#]: collector: (lujun9972)
+[#]: translator: (MjSeven)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Emoji-Log: A new way to write Git commit messages)
+[#]: via: (https://opensource.com/article/19/2/emoji-log-git-commit-messages)
+[#]: author: (Ahmad Awais https://opensource.com/users/mrahmadawais)
+
+Emoji-Log:编写 Git 提交信息的新方法
+======
+使用 Emoji-Log 为你的提交添加上下文。
+
+
+我是一名全职开源开发人员,我喜欢称自己为“开源者”。我从事开源软件工作已经超过十年,并[构建了数百个][1]开源软件应用程序。
+
+同时我也是不要重复自己 Don't Repeat Yourself(DRY)哲学的忠实粉丝,并且相信编写更好的 Git 提交消息是 DRY 的一个重要组成部分。它们具有足够的上下文关联可以作为你开源软件的变更日志。我编写的众多工作流之一是 [Emoji-Log][2],它是一个简单易用的开源 Git 提交日志标准。它通过使用表情符号来创建更好的 Git 提交消息,从而改善了开发人员的体验(DX)。
+
+我使用 Emoji-Log 构建了 [VSCode Tips & Tricks 仓库][3] 和我的 🦄 [紫色 VSCode 主题仓库][4],以及一个看起来很漂亮的[自动变更日志][5]。
+
+### Emoji-Log 的哲学
+
+我喜欢表情符号,我很喜欢它们。编程,代码,极客/书呆子,开源...所有这一切本质上都很枯燥,有时甚至很无聊。表情符号帮助我添加颜色和情感。想要将感受添加到 2D、平面和基于文本的代码世界并没有错。
+
+相比于[数百个表情符号][6],我学会了更好的办法是保持小类别和普遍性。以下是指导使用 Emoji-Log 编写提交信息的原则:
+
+ 1. **必要的**
+ * Git 提交信息是必要的。
+ * 像下订单一样编写提交信息。
+ * 例如,使用 ✅ **Add** 而不是 ❌ **Added**
+ * 例如,使用 ✅ **Create** 而不是 ❌ **Creating**
+ 2. **规则**
+ * 少数类别易于记忆。
+ * 不多不也少
+ * 例如 **📦 NEW** , **👌 IMPROVE** , **🐛 FIX** , **📖 DOC** , **🚀 RELEASE**, **✅ TEST**
+ 3. **行为**
+ * 让 Git 基于你所采取的操作提交
+ * 使用像 [VSCode][7] 这样的编辑器来提交带有提交信息的正确文件。
+
+### 编写提交信息
+
+仅使用以下 Git 提交信息。简单而小巧的占地面积是 Emoji-Log 的核心。
+
+ 1. **📦 NEW: 必要的信息**
+ * 当你添加一些全新的东西时使用。
+ * 例如 **📦 NEW: 添加 Git 忽略的文件**
+ 2. **👌 IMPROVE: 必要的信息**
+ * 用于改进/增强代码段,如重构等。
+ * 例如 **👌 IMPROVE: 远程 IP API 函数**
+ 3. **🐛 FIX: 必要的信息**
+ * 修复 bug 时使用,不用解释了吧?
+ * 例如 **🐛 FIX: Case converter**
+ 4. **📖 DOC: 必要的信息**
+ * 添加文档时使用,比如 README.md 甚至是内联文档。
+ * 例如 **📖 DOC: API 接口教程**
+ 5. **🚀 RELEASE: 必要的信息**
+ * 发布新版本时使用。例如, **🚀 RELEASE: Version 2.0.0**
+ 6. **✅ TEST: 必要的信息**
+ * 发布新版本时使用。
+ * 例如 **✅ TEST: 模拟用户登录/注销**
+
+就这些了,不多不少。
+
+### Emoji-Log 函数
+
+为了快速构建原型,我写了以下函数,你可以将它们添加到 **.bashrc** 或者 **.zshrc** 文件中以快速使用 Emoji-Log。
+
+```
+#.# Better Git Logs.
+
+### Using EMOJI-LOG (https://github.com/ahmadawais/Emoji-Log).
+
+# Git Commit, Add all and Push — in one step.
+
+function gcap() {
+ git add . && git commit -m "$*" && git push
+}
+
+# NEW.
+function gnew() {
+ gcap "📦 NEW: $@"
+}
+
+# IMPROVE.
+function gimp() {
+ gcap "👌 IMPROVE: $@"
+}
+
+# FIX.
+function gfix() {
+ gcap "🐛 FIX: $@"
+}
+
+# RELEASE.
+function grlz() {
+ gcap "🚀 RELEASE: $@"
+}
+
+# DOC.
+function gdoc() {
+ gcap "📖 DOC: $@"
+}
+
+# TEST.
+function gtst() {
+ gcap "✅ TEST: $@"
+}
+```
+
+要为 [fish shell][8] 安装这些函数,运行以下命令:
+
+```
+function gcap; git add .; and git commit -m "$argv"; and git push; end;
+function gnew; gcap "📦 NEW: $argv"; end
+function gimp; gcap "👌 IMPROVE: $argv"; end;
+function gfix; gcap "🐛 FIX: $argv"; end;
+function grlz; gcap "🚀 RELEASE: $argv"; end;
+function gdoc; gcap "📖 DOC: $argv"; end;
+function gtst; gcap "✅ TEST: $argv"; end;
+funcsave gcap
+funcsave gnew
+funcsave gimp
+funcsave gfix
+funcsave grlz
+funcsave gdoc
+funcsave gtst
+```
+
+如果你愿意,可以将这些别名直接粘贴到 **~/.gitconfig** 文件:
+```
+# Git Commit, Add all and Push — in one step.
+cap = "!f() { git add .; git commit -m \"$@\"; git push; }; f"
+
+# NEW.
+new = "!f() { git cap \"📦 NEW: $@\"; }; f"
+# IMPROVE.
+imp = "!f() { git cap \"👌 IMPROVE: $@\"; }; f"
+# FIX.
+fix = "!f() { git cap \"🐛 FIX: $@\"; }; f"
+# RELEASE.
+rlz = "!f() { git cap \"🚀 RELEASE: $@\"; }; f"
+# DOC.
+doc = "!f() { git cap \"📖 DOC: $@\"; }; f"
+# TEST.
+tst = "!f() { git cap \"✅ TEST: $@\"; }; f"
+```
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/emoji-log-git-commit-messages
+
+作者:[Ahmad Awais][a]
+选题:[lujun9972][b]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mrahmadawais
+[b]: https://github.com/lujun9972
+[1]: https://github.com/ahmadawais
+[2]: https://github.com/ahmadawais/Emoji-Log/
+[3]: https://github.com/ahmadawais/VSCode-Tips-Tricks
+[4]: https://github.com/ahmadawais/shades-of-purple-vscode/commits/master
+[5]: https://github.com/ahmadawais/shades-of-purple-vscode/blob/master/CHANGELOG.md
+[6]: https://gitmoji.carloscuesta.me/
+[7]: https://VSCode.pro
+[8]: https://en.wikipedia.org/wiki/Friendly_interactive_shell
diff --git a/translated/tech/20190218 SPEED TEST- x86 vs. ARM for Web Crawling in Python.md b/translated/tech/20190218 SPEED TEST- x86 vs. ARM for Web Crawling in Python.md
new file mode 100644
index 0000000000..38344a444b
--- /dev/null
+++ b/translated/tech/20190218 SPEED TEST- x86 vs. ARM for Web Crawling in Python.md
@@ -0,0 +1,525 @@
+[#]: collector: (lujun9972)
+[#]: translator: (HankChow)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (SPEED TEST: x86 vs. ARM for Web Crawling in Python)
+[#]: via: (https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/)
+[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
+
+x86 和 ARM 的 Python 爬虫速度对比
+======
+
+![][1]
+
+如果你的老板给你的任务是不断地访问竞争对手的网站,把对方商品的价格记录下来,而且要纯手工操作,恐怕你会想要把整个办公室都烧掉。
+
+之所以现在网络爬虫的影响力如此巨大,就是因为网络爬虫可以被用于追踪客户的情绪和趋向、搜寻空缺的职位、监控房地产的交易,甚至是获取 UFC 的比赛结果。除此以外,还有很多意想不到的用途。
+
+对于有这方面爱好的人来说,爬虫无疑是一个很好的工具。因此,我使用了 [Scrapy][2] 这个基于 Python 编写的开源网络爬虫框架。
+
+鉴于我不太了解这个工具是否会对我的计算机造成伤害,我并没有将它搭建在我的主力机器上,而是搭建在了一台树莓派上面。
+
+令人感到意外的是,Scrapy 在树莓派上面的性能并不差,或许这是 ARM 架构服务器的又一个成功例子?
+
+我尝试 Google 了一下,但并没有得到令我满意的结果,仅仅找到了一篇相关的《[Drupal 建站对比][3]》。这篇文章的结论是,ARM 架构服务器性能比昂贵的 x86 架构服务器要更好。
+
+从另一个角度来看,这种 web 服务可以看作是一个“被爬虫”服务,但和 Scrapy 对比起来,前者是基于 LAMP 技术栈,而后者则依赖于 Python,这就导致两者之间没有太多的可比性。
+
+那我们该怎样做呢?只能在一些 VPS 上搭建服务来对比一下了。
+
+### 什么是 ARM 架构处理器?
+
+ARM 是目前世界上最流行的 CPU 架构。
+
+但 ARM 架构处理器在很多人眼中的地位只是作为一个节省成本的选择,而不是跑在生产环境中的处理器的首选。
+
+然而,诞生于英国剑桥的 ARM CPU,最初是用于昂贵的 [Acorn Archimedes][4] 计算机上的,这是当时世界上最强大的计算机,它的运算速度甚至比最快的 386 还要快好几倍。
+
+Acorn 公司和 Commodore、Atari 的理念类似,他们认为一家伟大的计算机公司就应该制造出伟大的计算机,让人感觉有点目光短浅。而比尔盖茨的想法则有所不同,他力图在更多不同种类和价格的 x86 机器上使用他的 DOS 系统。
+
+拥有大量用户基础的平台会让更多开发者开发出众多适应平台的软件,而软件资源丰富又让计算机更受用户欢迎。
+
+即使是苹果公司也在这上面吃到了苦头,不得不在 x86 芯片上投入大量的财力。最终,这些芯片不再仅仅用于专业的计算任务,走进了人们的日常生活中。
+
+ARM 架构也并没有消失。基于 ARM 架构的芯片不仅运算速度快,同时也非常节能。因此诸如机顶盒、PDA、数码相机、MP3 播放器这些电子产品多数都会采用 ARM 架构的芯片,甚至在很多需要用电池、不配备大散热风扇的电子产品上,都可以见到 ARM 芯片的身影。
+
+而 ARM 则脱离 Acorn 成为了一种独立的商业模式,他们不生产实物芯片,仅仅是向芯片生产厂商出售相关的知识产权。
+
+因此,ARM 芯片被应用于很多手机和平板电脑上。当 Linux 被移植到这种架构的芯片上时,开源技术的大门就已经向它打开了,这才让我们今天得以在这些芯片上运行 web 爬虫程序。
+
+#### 服务器端的 ARM
+
+诸如[微软][5]和 [Cloudflare][6] 这些大厂都在基础设施建设上花了重金,所以对于我们这些预算不高的用户来说,可以选择的余地并不多。
+
+实际上,如果你的信用卡只够付每月数美元的 VPS 费用,一直以来只能考虑 [Scaleway][7] 这个高性价比的厂商。
+
+但自从数个月前公有云巨头 [AWS][8] 推出了他们自研的 ARM 处理器 [AWS Graviton][9] 之后,选择似乎就丰富了一些。
+
+我决定在其中选择一款 VPS 厂商,将它提供的 ARM 处理器和 x86 处理器作出对比。
+
+### 深入了解
+
+所以我们要对比的是什么指标呢?
+
+#### Scaleway
+
+Scaleway 自身的定位是“专为开发者设计”。我觉得这个定位很准确,对于开发原型来说,Scaleway 提供的产品确实可以作为一个很好的沙盒环境。
+
+Scaleway 提供了一个简洁的页面,让用户可以快速地从主页进入 bash shell 界面。对于很多小企业、自由职业者或者技术顾问,如果想要运行 web 爬虫,这个产品毫无疑问是一个物美价廉的选择。
+
+ARM 方面我们选择 [ARM64-2GB][10] 这一款服务器,每月只需要 3 欧元。它带有 4 个 Cavium ThunderX 核心,是在 2014 年推出的第一款服务器级的 ARMv8 处理器。但现在看来它已经显得有点落后了,并逐渐被更新的 ThunderX2 取代。
+
+x86 方面我们选择 [1-S][11],每月的费用是 4 欧元。它拥有 2 个英特尔 Atom C3995 核心。英特尔的 Atom 系列处理器的特点是低功耗、单线程,最初是用在笔记本电脑上的,后来也被服务器所采用。
+
+两者在处理器以外的条件都大致相同,都使用 2 GB 的内存、50 GB 的 SSD 存储以及 200 Mbit/s 的带宽。磁盘驱动器可能会有所不同,但由于我们运行的是 web 爬虫,基本都是在内存中完成操作,因此这方面的差异可以忽略不计。
+
+为了避免我不能熟练使用包管理器的尴尬局面,两方的操作系统我都会选择使用 Debian 9。
+
+#### Amazon Web Services
+
+当你还在注册 AWS 账号的时候,使用 Scaleway 的用户可能已经把提交信用卡信息、启动 VPS 实例、添加sudoer、安装依赖包这一系列流程都完成了。AWS 的操作相对来说比较繁琐,甚至需要详细阅读手册才能知道你正在做什么。
+
+当然这也是合理的,对于一些需求复杂或者特殊的企业用户,确实需要通过详细的配置来定制合适的使用方案。
+
+我们所采用的 AWS Graviton 处理器是 AWS EC2(Elastic Compute Cloud)的一部分,我会以按需实例的方式来运行,这也是最贵但最简捷的方式。AWS 同时也提供[竞价实例][12],这样可以用较低的价格运行实例,但实例的运行时间并不固定。如果实例需要长时间持续运行,还可以选择[预留实例][13]。
+
+看,AWS 就是这么复杂……
+
+我们分别选择 [a1.medium][14] 和 [t2.small][15] 两种型号的实例进行对比,两者都带有 2GB 内存。这个时候问题来了,手册中提到的 vCPU 又是什么?两种型号的不同之处就在于此。
+
+对于 a1.medium 型号的实例,vCPU 是 AWS Graviton 芯片提供的单个计算核心。这个芯片由被亚马逊在 2015 收购的以色列厂商 Annapurna Labs 研发,是 AWS 独有的单线程 64 位 ARMv8 内核。它的按需价格为每小时 0.0255 美元。
+
+而 t2.small 型号实例使用英特尔至强系列芯片,但我不确定具体是其中的哪一款。它每个核心有两个线程,但我们并不能用到整个核心,甚至整个线程。我们能用到的只是“20% 的基准性能,可以使用 CPU 积分突破这个基准”。这可能有一定的原因,但我没有弄懂。它的按需价格是每小时 0.023 美元。
+
+在镜像库中没有 Debian 发行版的镜像,因此我选择了 Ubuntu 18.04。
+
+### Beavis and Butthead Do Moz’s Top 500
+
+要测试这些 VPS 的 CPU 性能,就该使用爬虫了。一般来说都是对几个网站在尽可能短的时间里发出尽可能多的请求,但这种操作太暴力了,我的做法是只向大量网站发出少数几个请求。
+
+为此,我编写了 `beavs.py` 这个爬虫程序(致敬我最喜欢的物理学家和制片人 Mike Judge)。这个程序会将 Moz 上排行前 500 的网站都爬取 3 层的深度,并计算 “wood” 和 “ass” 这两个单词在 HTML 文件中出现的次数。
+
+但我实际爬取的网站可能不足 500 个,因为我需要遵循网站的 `robot.txt` 协定,另外还有些网站需要提交 javascript 请求,也不一定会计算在内。但这已经是一个足以让 CPU 保持繁忙的爬虫任务了。
+
+Python 的[全局解释器锁][16]机制会让我的程序只能用到一个 CPU 线程。为了测试多线程的性能,我需要启动多个独立的爬虫程序进程。
+
+因此我还编写了 `butthead.py`,尽管 Butthead 很粗鲁,它也比 Beavis 要略胜一筹(译者注:beavis 和 butt-head 都是 Mike Judge 的动画片《Beavis and Butt-head》中的角色)。
+
+我将整个爬虫任务拆分为多个部分,这可能会对爬取到的链接数量有一点轻微的影响。但无论如何,每次爬取都会有所不同,我们要关注的是爬取了多少个页面,以及耗时多长。
+
+### 在 ARM 服务器上安装 Scrapy
+
+安装 Scrapy 的过程与芯片的不同架构没有太大的关系,都是安装 pip 和相关的依赖包之后,再使用 pip 来安装Scrapy。
+
+据我观察,在使用 ARM 的机器上使用 pip 安装 Scrapy 确实耗时要长一点,我估计是由于需要从源码编译为二进制文件。
+
+在 Scrapy 安装结束后,就可以通过 shell 来查看它的工作状态了。
+
+在 Scaleway 的 ARM 机器上,Scrapy 安装完成后会无法正常运行,这似乎和 `service_identity` 模块有关。这个现象也会在树莓派上出现,但在 AWS Graviton 上不会出现。
+
+对于这个问题,可以用这个命令来解决:
+
+```
+sudo pip3 install service_identity --force --upgrade
+```
+
+接下来就可以开始对比了。
+
+### 单线程爬虫
+
+Scrapy 的官方文档建议[将爬虫程序的 CPU 使用率控制在 80% 到 90% 之间][17],在真实操作中并不容易,尤其是对于我自己写的代码。根据我的观察,实际的 CPU 使用率变动情况是一开始非常繁忙,随后稍微下降,接着又再次升高。
+
+在爬取任务的最后,也就是大部分目标网站都已经被爬取了的这个阶段,会持续数分钟的时间。这让人有点失望,因为在这个阶段当中,任务的运行时长只和网站的大小有比较直接的关系,并不能以之衡量 CPU 的性能。
+
+所以这并不是一次严谨的基准测试,只是我通过自己写的爬虫程序来观察实际的现象。
+
+下面我们来看看最终的结果。首先是 Scaleway 的机器:
+
+| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每百万页面费用(欧元) |
+| ------------------ | ----------- | ---------- | ---------------- | ---------------------- |
+| Scaleway ARM64-2GB | 108m 59.27s | 38,205 | 21,032.623 | 0.28527 |
+| Scaleway 1-S | 97m 44.067s | 39,476 | 24,324.648 | 0.33011 |
+
+我使用了 [top][18] 工具来查看爬虫程序运行期间的 CPU 使用率。在任务刚开始的时候,两者的 CPU 使用率都达到了 100%,但 ThunderX 大部分时间都达到了 CPU 的极限,无法看出来 Atom 的性能会比 ThunderX 超出多少。
+
+通过 top 工具,我还观察了它们的内存使用情况。随着爬取任务的进行,ARM 机器的内存使用率最终达到了 14.7%,而 x86 则最终是 15%。
+
+从运行日志还可以看出来,当 CPU 使用率到达极限时,会有大量的超时页面产生,最终导致页面丢失。这也是合理出现的现象,因为 CPU 过于繁忙会无法完整地记录所有爬取到的页面。
+
+如果仅仅是为了对比爬虫的速度,页面丢失并不是什么大问题。但在实际中,业务成果和爬虫数据的质量是息息相关的,因此必须为 CPU 留出一些用量,以防出现这种现象。
+
+再来看看 AWS 这边:
+
+| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每百万页面费用(美元) |
+| --------- | ------------ | ---------- | ---------------- | ---------------------- |
+| a1.medium | 100m 39.900s | 41,294 | 24,612.725 | 1.03605 |
+| t2.small | 78m 53.171s | 41,200 | 31,336.286 | 0.73397 |
+
+为了方便比较,对于在 AWS 上跑的爬虫,我记录的指标和 Scaleway 上一致,但似乎没有达到预期的效果。这里我没有使用 top,而是使用了 AWS 提供的控制台来监控 CPU 的使用情况,从监控结果来看,我的爬虫程序并没有完全用到这两款服务器所提供的所有性能。
+
+a1.medium 型号的机器尤为如此,在任务开始阶段,它的 CPU 使用率达到了峰值 45%,但随后一直在 20% 到 30% 之间。
+
+让我有点感到意外的是,这个程序在 ARM 处理器上的运行速度相当慢,但却远未达到 Graviton CPU 能力的极限,而在 Inter 处理器上则可以在某些时候达到 CPU 能力的极限。它们运行的代码是完全相同的,处理器的不同架构可能导致了对代码的不同处理方式。
+
+个中原因无论是由于处理器本身的特性,还是而今是文件的编译,又或者是两者皆有,对我来说都是一个黑盒般的存在。我认为,既然在 AWS 机器上没有达到 CPU 处理能力的极限,那么只有在 Scaleway 机器上跑出来的性能数据是可以作为参考的。
+
+t2.small 型号的机器性能让人费解。CPU 利用率大概 20%,最高才达到 35%,是因为手册中说的“20% 的基准性能,可以使用 CPU 积分突破这个基准”吗?但在控制台中可以看到 CPU 积分并没有被消耗。
+
+为了确认这一点,我安装了 [stress][19] 这个软件,然后运行了一段时间,这个时候发现居然可以把 CPU 使用率提高到 100% 了。
+
+显然,我需要调整一下它们的配置文件。我将 CONCURRENT_REQUESTS 参数设置为 5000,将 REACTOR_THREADPOOL_MAXSIZE 参数设置为 120,将爬虫任务的负载调得更大。
+
+| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每万页面费用(美元) |
+| ----------------------- | ----------- | ---------- | ---------------- | -------------------- |
+| a1.medium | 46m 13.619s | 40,283 | 52,285.047 | 0.48771 |
+| t2.small | 41m7.619s | 36,241 | 52,871.857 | 0.43501 |
+| t2.small(无 CPU 积分) | 73m 8.133s | 34,298 | 28,137.8891 | 0.81740 |
+
+a1.medium 型号机器的 CPU 使用率在爬虫任务开始后 5 分钟飙升到了 100%,随后下降到 80% 并持续了 20 分钟,然后再次攀升到 96%,直到任务接近结束时再次下降。这大概就是我想要的效果了。
+
+而 t2.small 型号机器在爬虫任务的前期就达到了 50%,并一直保持在这个水平直到任务接近结束。如果每个核心都有两个线程,那么 50% 的 CPU 使用率确实是单个线程可以达到的极限了。
+
+现在我们看到它们的性能都差不多了。但至强处理器的线程持续跑满了 CPU,Graviton 处理器则只是有一段时间如此。可以认为 Graviton 略胜一筹。
+
+然而,如果 CPU 积分耗尽了呢?这种情况下的对比可能更为公平。为了测试这种情况,我使用 stress 把所有的 CPU 积分用完,然后再次启动了爬虫任务。
+
+在没有 CPU 积分的情况下,CPU 使用率在 27% 就到达极限不再上升了,同时又出现了丢失页面的现象。这么看来,它的性能比负载较低的时候更差。
+
+### 多线程爬虫
+
+将爬虫任务分散到不同的进程中,可以有效利用机器所提供的多个核心。
+
+一开始,我将爬虫任务分布在 10 个不同的进程中并同时启动,结果发现比仅使用 1 个进程的时候还要慢。
+
+经过尝试,我得到了一个比较好的方案。把爬虫任务分布在 10 个进程中,但每个核心只启动 1 个进程,在每个进程接近结束的时候,再从剩余的进程中选出 1 个进程启动起来。
+
+如果还需要优化,还可以让运行时间越长的爬虫进程在启动顺序中排得越靠前,我也在尝试实现这个方法。
+
+想要预估某个域名的页面量,一定程度上可以参考这个域名主页的链接数量。我用另一个程序来对这个数量进行了统计,然后按照降序排序。经过这样的预处理之后,只会额外增加 1 分钟左右的时间。
+
+结果,爬虫运行的总耗时找过了两个小时!毕竟把链接最多的域名都堆在同一个进程中也存在一定的弊端。
+
+针对这个问题,也可以通过调整各个进程爬取的域名数量来进行优化,又或者在排序之后再作一定的修改。不过这种优化可能有点复杂了。
+
+因此,我还是用回了最初的方法,它的效果还是相当不错的:
+
+| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每万页面费用(欧元) |
+| ------------------ | ----------- | ---------- | ---------------- | -------------------- |
+| Scaleway ARM64-2GB | 62m 10.078s | 36,158 | 34,897.0719 | 0.17193 |
+| Scaleway 1-S | 60m 56.902s | 36,725 | 36,153.5529 | 0.22128 |
+
+毕竟,使用多个核心能够大大加快爬虫的速度。
+
+我认为,如果让一个经验丰富的程序员来优化的话,一定能够更好地利用所有的计算核心。但对于开箱即用的 Scrapy 来说,想要提高性能,使用更快的线程似乎比使用更多核心要简单得多。
+
+从数量来看,Atom 处理器在更短的时间内爬取到了更多的页面。但如果从性价比角度来看,ThunderX 又是稍稍领先的。不过总的来说差距不大。
+
+### 爬取结果分析
+
+在爬取了 38205 个页面之后,我们可以统计到在这些页面中 “ass” 出现了 24170435 次,而 “wood” 出现了 54368 次。
+
+![][20]
+
+“wood” 的出现次数不少,但和 “ass” 比起来简直微不足道。
+
+### 结论
+
+从上面的数据来看,不同架构的 CPU 性能和它们的问世时间没有直接的联系,AWS Graviton 是单线程情况下性能最佳的。
+
+另外在性能方面 2017 年生产的 Atom 轻松击败了 2014 年生产的 ThunderX,而 ThunderX 则在性价比方面占优。当然,如果你使用 AWS 的机器的话,还是使用 Graviton 吧。
+
+总之,ARM 架构的硬件是可以用来运行爬虫程序的,而且在性能和费用方面也相当有竞争力。
+
+而这种差异是否足以让你将整个技术架构迁移到 ARM 上?这就是另一回事了。当然,如果你已经是 AWS 用户,并且你的代码有很强的可移植性,那么不妨尝试一下 a1 型号的实例。
+
+希望 ARM 设备在不久的将来能够在公有云上大放异彩。
+
+### 源代码
+
+这是我第一次使用 Python 和 Scrapy 来做一个项目,所以我的代码写得可能不是很好,例如代码中使用全局变量就有点力不从心。
+
+不过我仍然会在下面开源我的代码。
+
+要运行这些代码,需要预先安装 Scrapy,并且需要 [Moz 上排名前 500 的网站][21]的 csv 文件。如果要运行 `butthead.py`,还需要安装 [psutil][22] 这个库。
+
+##### beavis.py
+
+```
+import scrapy
+from scrapy.spiders import CrawlSpider, Rule
+from scrapy.linkextractors import LinkExtractor
+from scrapy.crawler import CrawlerProcess
+
+ass = 0
+wood = 0
+totalpages = 0
+
+def getdomains():
+
+ moz500file = open('top500.domains.05.18.csv')
+
+ domains = []
+ moz500csv = moz500file.readlines()
+
+ del moz500csv[0]
+
+ for csvline in moz500csv:
+ leftquote = csvline.find('"')
+ rightquote = leftquote + csvline[leftquote + 1:].find('"')
+ domains.append(csvline[leftquote + 1:rightquote])
+
+ return domains
+
+def getstartpages(domains):
+
+ startpages = []
+
+ for domain in domains:
+ startpages.append('http://' + domain)
+
+ return startpages
+
+class AssWoodItem(scrapy.Item):
+ ass = scrapy.Field()
+ wood = scrapy.Field()
+ url = scrapy.Field()
+
+class AssWoodPipeline(object):
+ def __init__(self):
+ self.asswoodstats = []
+
+ def process_item(self, item, spider):
+ self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
+
+ def close_spider(self, spider):
+ asstally, woodtally = 0, 0
+
+ for asswoodcount in self.asswoodstats:
+ asstally += asswoodcount[1]
+ woodtally += asswoodcount[2]
+
+ global ass, wood, totalpages
+ ass = asstally
+ wood = woodtally
+ totalpages = len(self.asswoodstats)
+
+class BeavisSpider(CrawlSpider):
+ name = "Beavis"
+ allowed_domains = getdomains()
+ start_urls = getstartpages(allowed_domains)
+ #start_urls = [ 'http://medium.com' ]
+ custom_settings = {
+ 'DEPTH_LIMIT': 3,
+ 'DOWNLOAD_DELAY': 3,
+ 'CONCURRENT_REQUESTS': 1500,
+ 'REACTOR_THREADPOOL_MAXSIZE': 60,
+ 'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
+ 'LOG_LEVEL': 'INFO',
+ 'RETRY_ENABLED': False,
+ 'DOWNLOAD_TIMEOUT': 30,
+ 'COOKIES_ENABLED': False,
+ 'AJAXCRAWL_ENABLED': True
+ }
+
+ rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
+
+ def parse_asswood(self, response):
+ if isinstance(response, scrapy.http.TextResponse):
+ item = AssWoodItem()
+ item['ass'] = response.text.casefold().count('ass')
+ item['wood'] = response.text.casefold().count('wood')
+ item['url'] = response.url
+ yield item
+
+
+if __name__ == '__main__':
+
+ process = CrawlerProcess({
+ 'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
+ })
+
+ process.crawl(BeavisSpider)
+ process.start()
+
+ print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
+ print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
+ print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
+```
+
+##### butthead.py
+
+```
+import scrapy, time, psutil
+from scrapy.spiders import CrawlSpider, Rule, Spider
+from scrapy.linkextractors import LinkExtractor
+from scrapy.crawler import CrawlerProcess
+from multiprocessing import Process, Queue, cpu_count
+
+ass = 0
+wood = 0
+totalpages = 0
+linkcounttuples =[]
+
+def getdomains():
+
+ moz500file = open('top500.domains.05.18.csv')
+
+ domains = []
+ moz500csv = moz500file.readlines()
+
+ del moz500csv[0]
+
+ for csvline in moz500csv:
+ leftquote = csvline.find('"')
+ rightquote = leftquote + csvline[leftquote + 1:].find('"')
+ domains.append(csvline[leftquote + 1:rightquote])
+
+ return domains
+
+def getstartpages(domains):
+
+ startpages = []
+
+ for domain in domains:
+ startpages.append('http://' + domain)
+
+ return startpages
+
+class AssWoodItem(scrapy.Item):
+ ass = scrapy.Field()
+ wood = scrapy.Field()
+ url = scrapy.Field()
+
+class AssWoodPipeline(object):
+ def __init__(self):
+ self.asswoodstats = []
+
+ def process_item(self, item, spider):
+ self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
+
+ def close_spider(self, spider):
+ asstally, woodtally = 0, 0
+
+ for asswoodcount in self.asswoodstats:
+ asstally += asswoodcount[1]
+ woodtally += asswoodcount[2]
+
+ global ass, wood, totalpages
+ ass = asstally
+ wood = woodtally
+ totalpages = len(self.asswoodstats)
+
+
+class ButtheadSpider(CrawlSpider):
+ name = "Butthead"
+ custom_settings = {
+ 'DEPTH_LIMIT': 3,
+ 'DOWNLOAD_DELAY': 3,
+ 'CONCURRENT_REQUESTS': 250,
+ 'REACTOR_THREADPOOL_MAXSIZE': 30,
+ 'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
+ 'LOG_LEVEL': 'INFO',
+ 'RETRY_ENABLED': False,
+ 'DOWNLOAD_TIMEOUT': 30,
+ 'COOKIES_ENABLED': False,
+ 'AJAXCRAWL_ENABLED': True
+ }
+
+ rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
+
+
+ def parse_asswood(self, response):
+ if isinstance(response, scrapy.http.TextResponse):
+ item = AssWoodItem()
+ item['ass'] = response.text.casefold().count('ass')
+ item['wood'] = response.text.casefold().count('wood')
+ item['url'] = response.url
+ yield item
+
+def startButthead(domainslist, urlslist, asswoodqueue):
+ crawlprocess = CrawlerProcess({
+ 'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
+ })
+
+ crawlprocess.crawl(ButtheadSpider, allowed_domains = domainslist, start_urls = urlslist)
+ crawlprocess.start()
+ asswoodqueue.put( (ass, wood, totalpages) )
+
+
+if __name__ == '__main__':
+ asswoodqueue = Queue()
+ domains=getdomains()
+ startpages=getstartpages(domains)
+ processlist =[]
+ cores = cpu_count()
+
+ for i in range(10):
+ domainsublist = domains[i * 50:(i + 1) * 50]
+ pagesublist = startpages[i * 50:(i + 1) * 50]
+ p = Process(target = startButthead, args = (domainsublist, pagesublist, asswoodqueue))
+ processlist.append(p)
+
+ for i in range(cores):
+ processlist[i].start()
+
+ time.sleep(180)
+
+ i = cores
+
+ while i != 10:
+ time.sleep(60)
+ if psutil.cpu_percent() < 66.7:
+ processlist[i].start()
+ i += 1
+
+ for i in range(10):
+ processlist[i].join()
+
+ for i in range(10):
+ asswoodtuple = asswoodqueue.get()
+ ass += asswoodtuple[0]
+ wood += asswoodtuple[1]
+ totalpages += asswoodtuple[2]
+
+ print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
+ print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
+ print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
+```
+
+--------------------------------------------------------------------------------
+
+via: https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/
+
+作者:[James Mawson][a]
+选题:[lujun9972][b]
+译者:[HankChow](https://github.com/HankChow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
+[b]: https://github.com/lujun9972
+[1]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/quadbike-1024x683.jpg
+[2]: https://scrapy.org/
+[3]: https://www.info2007.net/blog/2018/review-scaleway-arm-based-cloud-server.html
+[4]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
+[5]: https://www.computerworld.com/article/3178544/microsoft-windows/microsoft-and-arm-look-to-topple-intel-in-servers.html
+[6]: https://www.datacenterknowledge.com/design/cloudflare-bets-arm-servers-it-expands-its-data-center-network
+[7]: https://www.scaleway.com/
+[8]: https://aws.amazon.com/
+[9]: https://www.theregister.co.uk/2018/11/27/amazon_aws_graviton_specs/
+[10]: https://www.scaleway.com/virtual-cloud-servers/#anchor_arm
+[11]: https://www.scaleway.com/virtual-cloud-servers/#anchor_starter
+[12]: https://aws.amazon.com/ec2/spot/pricing/
+[13]: https://aws.amazon.com/ec2/pricing/reserved-instances/
+[14]: https://aws.amazon.com/ec2/instance-types/a1/
+[15]: https://aws.amazon.com/ec2/instance-types/t2/
+[16]: https://wiki.python.org/moin/GlobalInterpreterLock
+[17]: https://docs.scrapy.org/en/latest/topics/broad-crawls.html
+[18]: https://linux.die.net/man/1/top
+[19]: https://linux.die.net/man/1/stress
+[20]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/Screenshot-from-2019-02-16-17-01-08.png
+[21]: https://moz.com/top500
+[22]: https://pypi.org/project/psutil/
+
diff --git a/translated/tech/20190226 All about -Curly Braces- in Bash.md b/translated/tech/20190226 All about -Curly Braces- in Bash.md
new file mode 100644
index 0000000000..8f148b33ce
--- /dev/null
+++ b/translated/tech/20190226 All about -Curly Braces- in Bash.md
@@ -0,0 +1,235 @@
+[#]: collector: (lujun9972)
+[#]: translator: (HankChow)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (All about {Curly Braces} in Bash)
+[#]: via: (https://www.linux.com/blog/learn/2019/2/all-about-curly-braces-bash)
+[#]: author: (Paul Brown https://www.linux.com/users/bro66)
+
+浅析 Bash 中的 {花括号}
+======
+
+
+
+在前面的 Bash 基础系列文章中,我们或多或少地使用了一些还没有讲到的符号。在之前文章的很多例子中,我们都使用到了括号,但并没有重点讲解关于括号的内容。
+
+这个系列接下来的文章中,我们会研究括号们的用法:如何使用这些括号?将它们放在不同的位置会有什么不同的效果?除了圆括号、方括号、花括号以外,我们还会接触另外的将一些内容“包裹”起来的符号,例如单引号、双引号和反引号。
+
+在这周,我们先来看看花括号 `{}`。
+
+### 构造序列
+
+花括号在之前的《[点的含义][1]》这篇文章中已经出现过了,当时我们只对点号 `.` 的用法作了介绍。但在构建一个序列的过程中,同样不可以缺少花括号。
+
+我们使用
+
+```
+echo {0..10}
+```
+
+来顺序输出 0 到 10 这 11 个数。使用
+
+```
+echo {10..0}
+```
+
+可以将这 11 个数倒序输出。更进一步,可以使用
+
+```
+echo {10..0..2}
+```
+
+来跳过其中的奇数。
+
+而
+
+```
+echo {z..a..2}
+```
+
+则从倒序输出字母表,并跳过其中的第奇数个字母。
+
+以此类推。
+
+还可以将两个序列进行组合:
+
+```
+echo {a..z}{a..z}
+```
+
+这个命令会将从 aa 到 zz 的所有双字母组合依次输出。
+
+这是很有用的。在 Bash 中,定义一个数组的方法是在圆括号 `()` 中放置各个元素并使用空格隔开,就像这样:
+
+```
+month=("Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec")
+```
+
+如果需要获取数组中的元素,就要使用方括号 `[]` 并在其中填入元素的索引:
+
+```
+$ echo ${month[3]} # 数组索引从 0 开始,因此 [3] 对应第 4 个元素
+
+Apr
+```
+
+先不要过分关注这里用到的三种括号,我们等下会讲到。
+
+注意,像上面这样,我们可以定义这样一个数组:
+
+```
+letter_combos=({a..z}{a..z})
+```
+
+其中 `letter_combos` 变量指向的数组依次包含了从 aa 到 zz 的所有双字母组合。
+
+因此,还可以这样定义一个数组:
+
+```
+dec2bin=({0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1}{0..1})
+```
+
+在这里,`dec2bin` 变量指向的数组按照升序依次包含了所有 8 位的二进制数,也就是 00000000、00000001、00000010,……,11111111。这个数组可以作为一个十进制数到 8 位二进制数的转换器。例如将十进制数 25 转换为二进制数,可以这样执行:
+
+```
+$ echo ${dec2bin[25]}
+
+00011001
+```
+
+对于进制转换,确实还有更好的方法,但这不失为一个有趣的方法。
+
+### 参数展开
+
+再看回前面的
+
+```
+echo ${month[3]}
+```
+
+在这里,花括号的作用就不是构造序列了,而是用于参数展开。顾名思义,参数展开就是将花括号中的变量展开为这个变量实际的内容。
+
+我们继续使用上面的 `month` 数组来举例:
+
+```
+month=("Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec")
+```
+
+注意,Bash 中的数组索引从 0 开始,因此 3 代表第 4 个元素 `"Apr"`。因此 `echo ${month[3]}` 在经过参数展开之后,相当于 `echo "Apr"`。
+
+像上面这样将一个数组展开成它所有的元素,只是参数展开的其中一种用法。另外,还可以通过参数展开的方式读取一个字符串变量,并对其进行处理。
+
+例如对于以下这个变量:
+
+```
+a="Too longgg"
+```
+
+如果执行:
+
+```
+echo ${a%gg}
+```
+
+可以输出“too long”,也就是去掉了最后的两个 g。
+
+在这里,
+
+ * `${...}` 告诉 shell 展开花括号里的内容
+ * `a` 就是需要操作的变量
+ * `%` 告诉 shell 需要在展开字符串之后从字符串的末尾去掉某些内容
+ * `gg` 是被去掉的内容
+
+
+
+这个特性在转换文件格式的时候会比较有用,我来举个例子:
+
+[ImageMagick][3] 是一套可以用于操作图像文件的命令行工具,它有一个 `convert` 命令。这个 `convert` 命令的作用是可以为某个格式的图像文件制作一个另一格式的副本。
+
+下面这个命令就是使用 `convert` 为 JPEG 格式图像 `image.jpg` 制作一个 PNG 格式的图像副本 `image.png`:
+
+```
+convert image.jpg image.png
+```
+
+在很多 Linux 发行版中都预装了 ImageMagick,如果没有预装,一般可以在发行版对应的软件管理器中找到。
+
+继续来看,在对变量进行展开之后,就可以批量执行相类似的操作了:
+
+```
+i=image.jpg
+convert $i ${i%jpg}png
+```
+
+这实际上是将变量 `i` 末尾的 `"jpg"` 去掉,然后加上 `"png"`,最终将整个命令拼接成 `convert image.jpg image.png`。
+
+如果你觉得并不怎么样,可以想象一下有成百上千个图像文件需要进行这个操作,而仅仅运行:
+
+```
+for i in *.jpg; do convert $i ${i%jpg}png; done
+```
+
+就瞬间完成任务了。
+
+如果需要去掉字符串开头的部分,就要将上面的 `%` 改成 `#` 了:
+
+```
+$ a="Hello World!"
+$ echo Goodbye${a#Hello}
+Goodbye World!
+```
+
+参数展开还有很多用法,但一般在写脚本的时候才会需要用到。在这个系列以后的文章中就继续提到。
+
+### 合并输出
+
+最后介绍一个花括号的用法,这个用法很简单,就是可以将多个命令的输出合并在一起。首先看下面这个命令:
+
+```
+echo "I found all these PNGs:"; find . -iname "*.png"; echo "Within this bunch of files:"; ls > PNGs.txt
+```
+
+以分号分隔开的几条命令都会执行,但只有最后的 `ls` 命令的结果输出会被重定向到 `PNGs.txt` 文件中。如果将这几条命令用花括号包裹起来,就像这样:
+
+```
+{ echo "I found all these PNGs:"; find . -iname "*.png"; echo "Within this bunch of files:"; ls; } > PNGs.txt
+```
+
+执行完毕后,可以看到 `PNGs.txt` 文件中会包含两次 `echo` 的内容、`find` 命令查找到的 PNG 文件以及最后的 `ls` 命令结果。
+
+需要注意的是,花括号与命令之间需要有空格隔开。因为这里的花括号 `{` 和 `}` 是作为 shell 中的保留字,shell 会将这两个符号之间的输出内容组合到一起。
+
+另外,各个命令之间要用分号 `;` 分隔,否则命令无法正常运行。
+
+### 下期预告
+
+在后续的文章中,我会介绍其它“包裹”类符号的用法,敬请关注。
+
+相关阅读:
+
+[And, Ampersand, and & in Linux][4]
+
+[Ampersands and File Descriptors in Bash][5]
+
+[Logical & in Bash][2]
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/2019/2/all-about-curly-braces-bash
+
+作者:[Paul Brown][a]
+选题:[lujun9972][b]
+译者:[HankChow](https://github.com/HankChow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/bro66
+[b]: https://github.com/lujun9972
+[1]: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
+[2]: https://www.linux.com/blog/learn/2019/2/logical-ampersand-bash
+[3]: http://www.imagemagick.org/
+[4]: https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux
+[5]: https://www.linux.com/blog/learn/2019/2/ampersands-and-file-descriptors-bash
+
diff --git a/translated/tech/20190304 Learn Linux with the Raspberry Pi.md b/translated/tech/20190304 Learn Linux with the Raspberry Pi.md
new file mode 100644
index 0000000000..5946082838
--- /dev/null
+++ b/translated/tech/20190304 Learn Linux with the Raspberry Pi.md
@@ -0,0 +1,53 @@
+[#]: collector: (lujun9972)
+[#]: translator: (qhwdw)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Learn Linux with the Raspberry Pi)
+[#]: via: (https://opensource.com/article/19/3/learn-linux-raspberry-pi)
+[#]: author: (Andersn Silva https://opensource.com/users/ansilva)
+
+用树莓派学 Linux
+======
+我们的《树莓派使用入门》的第四篇文章将进入到 Linux 命令行。
+
+
+在本系列的 [第三篇文章][1] 中开始了我们的树莓派探索之旅,我分享了如何安装 `Raspbian`,它是树莓派的官方 Linux 版本。现在,你已经安装好了 `Raspbian` 并用它引导你的新树莓派,你已经具备学习 Linux 相关知识的条件了。
+
+在这样简短的文章中去解决像“如何使用 Linux” 这样的宏大主题显然是不切实际的,因此,我只是给你提供一些如何使用树莓派来学习更多的 Linux 知识的一些创意而已。
+
+我们花一些时间从命令行(又称“终端”)开始。自上世纪九十年代中期以来,Linux 的 [窗口管理器][2] 和图形界面已经得到长足的发展。如今,你可以在 Linux 上通过鼠标点击来做一些事情了,就如同其它的操作系统一样容易。在我看来,只是“使用 Linux”和成为“一个 Linux 用户”是有区别的,后者至少能够在终端中“遨游“。
+
+
+
+如果你想成为一个 Linux 用户,从终端中尝试以下的命令行开始:
+
+ * 使用像 **ls**、**cd**、和 **pwd** 这样的命令导航到你的 Home 目录。
+ * 使用 **mkdir**、**rm**、**mv**、和 **cp** 命令创建、删除、和重命名目录。
+ * 使用命令行编辑器(如 Vi、Vim、Emacs 或 Nano)去创建一个文本文件。
+ * 尝试一些其它命令,比如 **chmod**、**chown**、**w**、**cat**、**more**、**less**、**tail**、**free**、**df**、**ps**、**uname**、和 **kill**。
+ * 尝试一下 **/bin** 和 **/usr/bin** 目录中的其它命令。
+
+
+
+学习命令行的最佳方式还是阅读它的 “man 手册”(简称手册);在命令行中输入 **man ** 就可以像上面那样打开它。并且在互联网上搜索 Linux 命令速查表可以让你更清楚地了解命令的用法 — 你应该会找到一大堆能帮你学习的资料。
+
+Raspbian 就像主流的 Linux 发行版一样有非常多的命令,假以时日,你最终将比其他人会用更多的命令。我使用 Linux 命令行已经超过二十年了,即便这样仍然有些一些命令我从来没有使用过,即便是那些我使用的过程中一直就存在的命令。
+
+最后,你可以使用图形环境去更快地工作,但是只有深入到 Linux 命令行,你才能够获得操作系统真正的强大功能和知识。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/learn-linux-raspberry-pi
+
+作者:[Andersn Silva][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/2/how-boot-new-raspberry-pi
+[2]: https://opensource.com/article/18/8/window-manager
diff --git a/translated/tech/20190305 5 ways to teach kids to program with Raspberry Pi.md b/translated/tech/20190305 5 ways to teach kids to program with Raspberry Pi.md
new file mode 100644
index 0000000000..2886c4bf69
--- /dev/null
+++ b/translated/tech/20190305 5 ways to teach kids to program with Raspberry Pi.md
@@ -0,0 +1,65 @@
+[#]: collector: (lujun9972)
+[#]: translator: (qhwdw)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (5 ways to teach kids to program with Raspberry Pi)
+[#]: via: (https://opensource.com/article/19/3/teach-kids-program-raspberry-pi)
+[#]: author: (Anderson Silva https://opensource.com/users/ansilva)
+
+教孩子们使用树莓派学编程的 5 种方法。
+======
+这是我们的《树莓派入门指南》系列的第五篇文章,它探索了帮助孩子们学习编程的一些资源。
+
+
+无数的学校、图书馆和家庭已经证明,树莓派是让孩子们接触编程的最好方式。在本系列的前四篇文章中,你已经学习了如何去[购买][1]、[安装][2]、和[配置][3]一个树莓派。在第五篇文章中,我们将分享一些帮助孩子们使用树莓派编程的入门级资源。
+
+### Scratch
+
+[Scratch][4] 是让孩子们了解编程基本概念(比如变量、布尔逻辑、循环等等)的一个很好的方式。你在 Raspbian 中就可以找到它,并且在互联网上你可以找到非常多的有关 Scratch 的文章和教程,包括在 `Opensource.com` 上的 [今天的 Scratch 是不是像“上世纪八十年代教孩子学LOGO编程”?][5]。
+
+
+
+### Code.org
+
+[Code.org][6] 是另一个非常好的教孩子学编程的在线资源。这个组织的使命是让更多的人通过课程、教程和流行的一小时学编程来接触编程。许多学校 — 包括我五年级的儿子就读的学校 — 都使用它,让更多的孩子学习编程和计算机科学的概念。
+
+### 阅读
+
+读书是学习编程的另一个很好的方式。学习如何编程并不需要你会说英语,当然,如果你会英语的话,学习起来将更容易,因为大多数的编程语言都是使用英文关键字去描述命令的。如果你的英语很好,能够轻松地阅读接下来的这个树莓派系列文章,那么你就完全有能力去阅读有关编程的书籍、论坛和其它的出版物。我推荐一本由 `Jason Biggs` 写的书: [儿童学 Python:非常有趣的 Python 编程入门][7]。
+
+### Raspberry Jam
+
+另一个让你的孩子进入编程世界的好方法是在聚会中让他与其他人互动。树莓派基金会赞助了一个称为 [Raspberry Jams][8] 的活动,让世界各地的孩子和成人共同参与在树莓派上学习。如果你所在的地区没有 `Raspberry Jam`,基金会有一个[指南][9]和其它资源帮你启动一个 `Raspberry Jam`。
+
+### 游戏
+
+最后一个(是本文的最后一个,当然还有其它的方式),[Minecraft][10] 有一个树莓派版本。我的世界已经从一个多玩家的、类似于”数字乐高“这样的游戏,成长为一个任何人都能使用 Pythonb 和其它编程语言去构建我自己的虚拟世界。更多内容查看 [Minecraft Pi 入门][11] 和 [Minecraft 一小时入门教程][12]。
+
+你还有教孩子用树莓派学编程的珍藏资源吗?请在下面的评论区共享出来吧。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/3/teach-kids-program-raspberry-pi
+
+作者:[Anderson Silva][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ansilva
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/2/how-buy-raspberry-pi
+[2]: https://opensource.com/article/19/2/how-boot-new-raspberry-pi
+[3]: https://opensource.com/article/19/3/learn-linux-raspberry-pi
+[4]: https://scratch.mit.edu/
+[5]: https://opensource.com/article/17/3/logo-scratch-teach-programming-kids
+[6]: https://code.org/
+[7]: https://www.amazon.com/Python-Kids-Playful-Introduction-Programming/dp/1593274076
+[8]: https://www.raspberrypi.org/jam/#map-section
+[9]: https://static.raspberrypi.org/files/jam/Raspberry-Jam-Guidebook-2017-04-26.pdf
+[10]: https://minecraft.net/en-us/edition/pi/
+[11]: https://projects.raspberrypi.org/en/projects/getting-started-with-minecraft-pi
+[12]: https://code.org/minecraft