mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-22 00:40:10 +08:00
commit
65f6a50b5a
@ -17,11 +17,11 @@
|
||||
|
||||
如果 **Jeb (Jeb!?) Bush** 使用 Linux,它一定是 [Debian][2]。Debian 属于一个相当无趣的分支,它是为真正意义上的、成熟的黑客设计的,这些人将清理那些由经验不甚丰富的开源爱好者所造成的混乱视为一大使命。当然,这也使得 Debian 显得很枯燥,所以它已有的用户基数一直在缩减。
|
||||
|
||||
**Scott Walker** ,对于他来说,应该是一个 [Damn Small Linux][3] (DSL) 用户。这个系统仅仅需要 50MB 的硬盘空间和 16MB 的 RAM 便可运行。DSL 可以使一台 20 年前的 486 计算机焕发新春,而这恰好符合了 **Scott Walker** 所主张的消减成本计划。当然,你在 DSL 上的用户体验也十分原始,这个系统平台只能够运行一个浏览器。但是至少你你不用浪费钱财购买新的电脑硬件,你那台 1993 年购买的机器仍然可以为你好好的工作。
|
||||
**Scott Walker** ,对于他来说,应该是一个 [Damn Small Linux][3] (DSL) 用户。这个系统仅仅需要 50MB 的硬盘空间和 16MB 的 RAM 便可运行。DSL 可以使一台 20 年前的 486 计算机焕发新春,而这恰好符合了 **Scott Walker** 所主张的消减成本计划。当然,你在 DSL 上的用户体验也十分原始,这个系统平台只能够运行一个浏览器。但是至少你不用浪费钱财购买新的电脑硬件,你那台 1993 年购买的机器仍然可以为你好好的工作。
|
||||
|
||||
**Chris Christie** 会使用哪种系统呢?他肯定会使用 [Relax-and-Recover Linux][4],它号称“一次搞定(Setup-and-forget)的裸机 Linux 灾难恢复方案” 。从那次不幸的华盛顿大桥事故后,“一次搞定(Setup-and-forget)”基本上便成了 Christie 的政治主张。不管灾难恢复是否能够让 Christie 最终挽回一切,但是当他的电脑死机的时候,至少可以找到一两封意外丢失的机密邮件。
|
||||
|
||||
至于 **Carly Fiorina**,她无疑将要使用 [惠普][6] (HPQ)为“[The Machine][5]”开发的操作系统,她在 1999 年到 2005 年这 6 年期间管理的这个公司。事实上,The Machine 可以运行几种不同的操作系统,也许是基于 Linux 的,也许不是,我们并不太清楚,它的开发始于 **Carly Fiorina** 在惠普公司的任期结束后。不管怎么说,作为 IT 圈里一个成功的管理者,这是她履历里面重要的组成部分,同时这也意味着她很难与惠普彻底断绝关系。
|
||||
至于 **Carly Fiorina**,她无疑将要使用 [惠普][6] (HPQ)为“[The Machine][5]”开发的操作系统,她在 1999 年到 2005 年这 6 年期间管理该公司。事实上,The Machine 可以运行几种不同的操作系统,也许是基于 Linux 的,也许不是,我们并不太清楚,它的开发始于 **Carly Fiorina** 在惠普公司的任期结束后。不管怎么说,作为 IT 圈里一个成功的管理者,这是她履历里面重要的组成部分,同时这也意味着她很难与惠普彻底断绝关系。
|
||||
|
||||
最后,但并不是不重要,你也猜到了——**Donald Trump**。他显然会动用数百万美元去雇佣一个精英黑客团队去定制属于自己的操作系统——尽管他原本是想要免费获得一个完美的、现成的操作系统——然后还能向别人炫耀自己的财力。他可能会吹嘘自己的操作系统是目前最好的系统,虽然它可能没有兼容 POSIX 或者一些其它的标准,因为那样的话就需要花掉更多的钱。同时这个系统也将根本不会提供任何文档,因为如果 **Donald Trump** 向人们解释他的系统的实际运行方式,他会冒着所有机密被泄露至伊斯兰国家的风险,绝对是这样的。
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Linux内核中的数据结构 —— 基数树
|
||||
Linux 内核里的数据结构 —— 基数树
|
||||
================================================================================
|
||||
|
||||
基数树 Radix tree
|
||||
@ -11,35 +11,35 @@ Linux内核中的数据结构 —— 基数树
|
||||
让我们先说说什么是 `基数树` 吧。基数树是一种 `压缩的字典树 (compressed trie)` ,而[字典树](http://en.wikipedia.org/wiki/Trie)是实现了关联数组接口并允许以 `键值对` 方式存储值的一种数据结构。这里的键通常是字符串,但可以使用任意数据类型。字典树因为它的节点而与 `n叉树` 不同。字典树的节点不存储键,而是存储单个字符的标签。与一个给定节点关联的键可以通过从根遍历到该节点获得。举个例子:
|
||||
|
||||
```
|
||||
+-----------+
|
||||
| |
|
||||
| " " |
|
||||
+-----------+
|
||||
| |
|
||||
+------+-----------+------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| g | | c |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| o | | a |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
|
|
||||
|
|
||||
+-----v-----+
|
||||
| |
|
||||
| t |
|
||||
| " " |
|
||||
| |
|
||||
+-----------+
|
||||
+------+-----------+------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| g | | c |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| o | | a |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
|
|
||||
|
|
||||
+-----v-----+
|
||||
| |
|
||||
| t |
|
||||
| |
|
||||
+-----------+
|
||||
```
|
||||
|
||||
因此在这个例子中,我们可以看到一个有着两个键 `go` 和 `cat` 的 `字典树` 。压缩的字典树或者说 `基数树` ,它和 `字典树` 的不同之处在于,所有只有一个孩子的中间节点都被删除。
|
||||
因此在这个例子中,我们可以看到一个有着两个键 `go` 和 `cat` 的 `字典树` 。压缩的字典树也叫做 `基数树` ,它和 `字典树` 的不同之处在于,所有只有一个子节点的中间节点都被删除。
|
||||
|
||||
Linux 内核中的基数树是把值映射到整形键的一种数据结构。[include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)文件中的以下结构体描述了基数树:
|
||||
|
||||
@ -86,10 +86,10 @@ struct radix_tree_node {
|
||||
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
|
||||
};
|
||||
```
|
||||
这个结构体包含的信息有父节点中的偏移以及到底端(叶节点)的高度、孩子节点的个数以及用于访问和释放节点的字段成员。这些字段成员描述如下:
|
||||
这个结构体包含的信息有父节点中的偏移以及到底端(叶节点)的高度、子节点的个数以及用于访问和释放节点的字段成员。这些字段成员描述如下:
|
||||
|
||||
* `path` - 父节点中的偏移和到底端(叶节点)的高度
|
||||
* `count` - 孩子节点的个数;
|
||||
* `count` - 子节点的个数;
|
||||
* `parent` - 父节点指针;
|
||||
* `private_data` - 由树的用户使用;
|
||||
* `rcu_head` - 用于释放节点;
|
||||
@ -188,9 +188,9 @@ unsigned int radix_tree_gang_lookup(struct radix_tree_root *root,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/radix-tree.md
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/DataStructures/radix-tree.md
|
||||
|
||||
作者:[0xAX]
|
||||
作者:0xAX
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
@ -1,50 +1,51 @@
|
||||
点评:Linux编程中五款内存调试器
|
||||
点评五款用于 Linux 编程的内存调试器
|
||||
================================================================================
|
||||

|
||||
Credit: [Moini][1]
|
||||
>Credit: [Moini][1]
|
||||
|
||||
作为一个程序员,我知道我总在犯错误——事实是,怎么可能会不犯错的!程序员也是人啊。有的错误能在编码过程中及时发现,而有些却得等到软件测试才显露出来。然而,还有一类错误并不能在这两个时期被排除,从而导致软件不能正常运行,甚至是提前中止。
|
||||
作为一个程序员,我知道我肯定会犯错误——怎么可能不犯错!程序员也是人啊。有的错误能在编码过程中及时发现,而有些却得等到软件测试了才能显露出来。然而,还有一类错误并不能在这两个阶段被解决,这就导致软件不能正常运行,甚至是提前终止。
|
||||
|
||||
想到了吗?我说的就是内存相关的错误。手动调试这些错误不仅耗时,而且很难发现并纠正。值得一提的是,这种错误非常常见,特别是在用 C/C++ 这类允许[手动管理内存][2]的语言编写的软件里。
|
||||
如果你还没猜出是那种错误,我说的就是和内存相关的错误。手动调试这些错误不仅耗时,而且很难发现并纠正。值得一提的是,这种错误很常见,特别是在用 C/C++ 这类允许[手动管理内存][2]的语言编写的软件里。
|
||||
|
||||
幸运的是,现行有一些编程工具能够帮你找到软件程序中这些内存相关的错误。在这些工具集中,我评定了五款Linux可用的,流行、免费并且开源的内存调试器: Dmalloc 、 Electric Fence 、 Memcheck 、 Memwatch 以及 Mtrace 。在日常编码中,我已经把这五个调试器用了个遍,所以这些点评是建立在我的实际体验之上的。
|
||||
幸运的是,现行有一些编程工具能够帮你在软件程序中找到这些和内存相关的错误。在这些工具集中,我评估了五款支持 Linux 的、流行的、自由开源的内存调试器: Dmalloc 、 Electric Fence 、 Memcheck 、 Memwatch 以及 Mtrace 。在日常编码中,我已经用过这五个调试器了,所以这些评估是建立在我的实际体验之上的。
|
||||
|
||||
### [Dmalloc][3] ###
|
||||
|
||||
**开发者**:Gray Watson
|
||||
|
||||
**点评版本**:5.5.2
|
||||
**评估版本**:5.5.2
|
||||
|
||||
**支持的 Linux**:所有种类
|
||||
**支持的 Linux 版本**:所有种类
|
||||
|
||||
**许可**:知识共享署名-相同方式共享许可证 3.0
|
||||
**许可**: CC 3.0
|
||||
|
||||
Dmalloc 是 Gray Watson 开发的一款内存调试工具。它实现成库,封装了标准内存管理函数如 *malloc() , calloc() , free()* 等,使程序员得以检测出有问题的代码。
|
||||
Dmalloc 是 Gray Watson 开发的一款内存调试工具。它是作为库来实现的,封装了标准内存管理函数如`malloc() , calloc() , free()`等,使程序员得以检测出有问题的代码。
|
||||
|
||||

|
||||
Dmalloc
|
||||
|
||||
如同工具的网页所列,这个调试器提供的特性包括内存泄漏跟踪、[重复释放(double free)][4]错误跟踪、以及[越界写入(fence-post write)][5]检测。其它特性包括文件/行号报告、普通统计记录。
|
||||
*Dmalloc*
|
||||
|
||||
如同工具的网页所示,这个调试器提供的特性包括内存泄漏跟踪、[重复释放内存(double free)][4]错误跟踪、以及[越界写入(fence-post write)][5]检测。其它特性包括报告错误的文件/行号、通用的数据统计记录。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
5.5.2 版本是一个 [bug 修复发行版][6],同时修复了构建和安装的问题。
|
||||
5.5.2 版本是一个 [bug 修正发行版][6],修复了几个有关构建和安装的问题。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
Dmalloc 最大的优点就是高度可配置性。比如说,你可以配置以支持 C++ 程序和多线程应用。 Dmalloc 还提供一个有用的功能:运行时可配置,这表示在 Dmalloc 执行时,可以轻易地使能或者禁能它提供的特性。
|
||||
Dmalloc 最大的优点就是高度可配置性。比如说,你可以配置它以支持 C++ 程序和多线程应用。 Dmalloc 还提供一个有用的功能:运行时可配置,这表示在 Dmalloc 执行时,可以轻易地启用或者禁用它提供的一些特性。
|
||||
|
||||
你还可以配合 [GNU Project Debugger (GDB)][7]来使用 Dmalloc ,只需要将 *dmalloc.gdb* 文件(位于 Dmalloc 源码包中的 contrib 子目录里)的内容添加到你的主目录中的 *.gdbinit* 文件里即可。
|
||||
你还可以配合 [GNU Project Debugger (GDB)][7]来使用 Dmalloc ,只需要将`dmalloc.gdb`文件(位于 Dmalloc 源码包中的 contrib 子目录里)的内容添加到你的主目录中的`.gdbinit`文件里即可。
|
||||
|
||||
另外一个让我对 Dmalloc 爱不释手的优点是它有大量的资料文献。前往官网的 [Documentation 标签][8],可以获取所有关于如何下载、安装、运行,怎样使用库,和 Dmalloc 所提供特性的细节描述,及其输入文件的解释。其中还有一个章节介绍了一般问题的解决方法。
|
||||
另外一个让我对 Dmalloc 爱不释手的优点是它有大量的资料文献。前往官网的 [Documentation 栏目][8],可以获取所有关于如何下载、安装、运行、怎样使用库,和 Dmalloc 所提供特性的细节描述,及其生成的输出文件的解释。其中还有一个章节介绍了一般问题的解决方法。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
跟 Mtrace 一样, Dmalloc 需要程序员改动他们的源代码。比如说你可以(必须的)添加头文件 *dmalloc.h* ,工具就能汇报产生问题的调用的文件或行号。这个功能非常有用,因为它节省了调试的时间。
|
||||
跟 Mtrace 一样, Dmalloc 需要程序员改动他们的源代码。比如说你可以(也是必须的)添加头文件`dmalloc.h`,工具就能汇报产生问题的调用的文件或行号。这个功能非常有用,因为它节省了调试的时间。
|
||||
|
||||
除此之外,还需要在编译你的程序时,把 Dmalloc 库(编译源码包时产生的)链接进去。
|
||||
除此之外,还需要在编译你的程序时,把 Dmalloc 库(编译 Dmalloc 源码包时产生的)链接进去。
|
||||
|
||||
然而,还有点更麻烦的事,需要设置一个环境变量,命名为 *DMALLOC_OPTION* ,以供工具在运行时配置内存调试特性,以及输出文件的路径。可以手动为该环境变量分配一个值,不过初学者可能会觉得这个过程有点困难,因为该值的一部分用来表示要启用的 Dmalloc 特性——表示为各自的十六进制值的累加。[这里][9]有详细介绍。
|
||||
然而,还有点更麻烦的事,需要设置一个环境变量,命名为`DMALLOC_OPTION`,以供工具在运行时配置内存调试特性,比如定义输出文件的路径。可以手动为该环境变量分配一个值,不过初学者可能会觉得这个过程有点困难,因为该值的一部分用来表示要启用的 Dmalloc 特性——以十六进制值的累加值表示。[这里][9]有详细介绍。
|
||||
|
||||
一个比较简单方法设置这个环境变量是使用 [Dmalloc 实用指令][10],这是专为这个目的设计的方法。
|
||||
|
||||
@ -56,19 +57,19 @@ Dmalloc 真正的优势在于它的可配置选项。而且高度可移植,曾
|
||||
|
||||
**开发者**:Bruce Perens
|
||||
|
||||
**点评版本**:2.2.3
|
||||
**评估版本**:2.2.3
|
||||
|
||||
**支持的 Linux**:所有种类
|
||||
**支持的 Linux 版本**:所有种类
|
||||
|
||||
**许可**:GNU 通用公共许可证 (第二版)
|
||||
**许可**:GPL v2
|
||||
|
||||
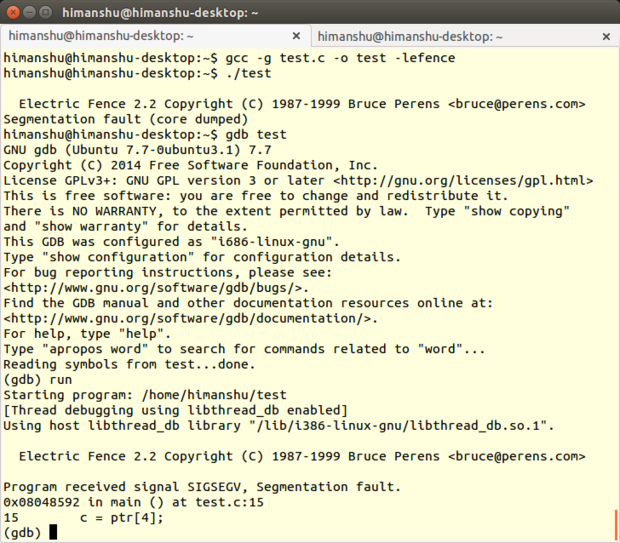
Electric Fence 是 Bruce Perens 开发的一款内存调试工具,它以库的形式实现,你的程序需要链接它。Electric Fence 能检测出[栈][11]内存溢出和访问已经释放的内存。
|
||||
Electric Fence 是 Bruce Perens 开发的一款内存调试工具,它以库的形式实现,你的程序需要链接它。Electric Fence 能检测出[堆][11]内存溢出和访问已经释放的内存。
|
||||
|
||||
|
||||
Electric Fence
|
||||
|
||||
顾名思义, Electric Fence 在每个申请的缓存边界建立了 virtual fence(虚拟围栏),任何非法内存访问都会导致[段错误][12]。这个调试工具同时支持 C 和 C++ 程序。
|
||||
*Electric Fence*
|
||||
|
||||
顾名思义, Electric Fence 在每个所申请的缓存边界建立了虚拟围栏,这样一来任何非法的内存访问都会导致[段错误][12]。这个调试工具同时支持 C 和 C++ 程序。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
@ -76,19 +77,19 @@ Electric Fence
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
我喜欢 Electric Fence 首要的一点是它(不同于 Memwatch 、 Dmalloc 和 Mtrace ,)不需要你的源码做任何的改动,你只需要在编译的时候把它的库链接进你的程序即可。
|
||||
我喜欢 Electric Fence 的首要一点是它不同于 Memwatch 、 Dmalloc 和 Mtrace ,不需要对你的源码做任何的改动,你只需要在编译的时候把它的库链接进你的程序即可。
|
||||
|
||||
其次, Electric Fence 的实现保证了导致越界访问( a bounds violation )的第一个指令就是引起段错误的原因。这比在后面再发现问题要好多了。
|
||||
其次, Electric Fence 的实现保证了产生越界访问的第一个指令就会引起段错误。这比在后面再发现问题要好多了。
|
||||
|
||||
不管是否有检测出错误, Electric Fence 都会在输出产生版权信息。这一点非常有用,由此可以确定你所运行的程序已经启用了 Electric Fence 。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
另一方面,我对 Electric Fence 真正念念不忘的是它检测内存泄漏的能力。内存泄漏是 C/C++ 软件最常见也是最难隐秘的问题之一。不过, Electric Fence 不能检测出堆内存溢出,而且也不是线程安全的。
|
||||
另一方面,我对 Electric Fence 真正念念不忘的是它检测内存泄漏的能力。内存泄漏是 C/C++ 软件最常见也是最不容易发现的问题之一。不过, Electric Fence 不能检测出栈溢出,而且也不是线程安全的。
|
||||
|
||||
由于 Electric Fence 会在用户分配内存区的前后分配禁止访问的虚拟内存页,如果你过多的进行动态内存分配,将会导致你的程序消耗大量的额外内存。
|
||||
|
||||
Electric Fence 还有一个局限是不能明确指出错误代码所在的行号。它所能做只是在监测到内存相关错误时产生段错误。想要定位行号,需要借助 [The Gnu Project Debugger ( GDB )][14]这样的调试工具来调试启用了 Electric Fence 的程序。
|
||||
Electric Fence 还有一个局限是不能明确指出错误代码所在的行号。它所能做只是在检测到内存相关错误时产生段错误。想要定位错误的行号,需要借助 [GDB][14]这样的调试工具来调试启用了 Electric Fence 的程序。
|
||||
|
||||
最后一点,尽管 Electric Fence 能检测出大部分的缓冲区溢出,有一个例外是,如果所申请的缓冲区大小不是系统字长的倍数,这时候溢出(即使只有几个字节)就不能被检测出来。
|
||||
|
||||
@ -96,94 +97,95 @@ Electric Fence 还有一个局限是不能明确指出错误代码所在的行
|
||||
|
||||
尽管局限性较大, Electric Fence 的易用性仍然是加分项。只要链接一次程序, Electric Fence 就可以在监测出内存相关问题的时候报警。不过,如同前面所说, Electric Fence 需要配合像 GDB 这样的源码调试器使用。
|
||||
|
||||
|
||||
### [Memcheck][16] ###
|
||||
|
||||
**开发者**:[Valgrind 开发团队][17]
|
||||
|
||||
**点评版本**:3.10.1
|
||||
**评估版本**:3.10.1
|
||||
|
||||
**支持的 Linux**:所有种类
|
||||
**支持的 Linux 发行版**:所有种类
|
||||
|
||||
**许可**:通用公共许可证
|
||||
**许可**:GPL
|
||||
|
||||
[Valgrind][18] 是一个提供好几款调试和 Linux 程序性能分析工具的套件。虽然 Valgrind 能和编写语言各不相同(有 Java 、 Perl 、 Python 、 Assembly code 、 ortran 、 Ada等等)的程序配合工作,但是它所提供的工具主要针对用 C/C++ 所编写的程序。
|
||||
[Valgrind][18] 是一个提供好几款调试和分析 Linux 程序性能的工具的套件。虽然 Valgrind 能和不同语言——Java 、 Perl 、 Python 、 Assembly code 、 ortran 、 Ada 等——编写的程序一起工作,但是它主要还是针对使用 C/C++ 所编写的程序。
|
||||
|
||||
Memcheck ,一款内存错误检测器,是其中最受欢迎的工具。它能够检测出如内存泄漏、无效的内存访问、未定义变量的使用以及栈内存分配和释放相关的问题等诸多问题。
|
||||
Memcheck ,一款内存错误检测器,是其中最受欢迎的工具。它能够检测出如内存泄漏、无效的内存访问、未定义变量的使用以及堆内存分配和释放相关的问题等诸多问题。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
工具套件( 3.10.1 )的[发行版][19]是一个副版本,主要修复了 3.10.0 版本发现的 bug 。除此之外,从主版本向后移植(标音: backport )一些包,修复了缺失的 AArch64 ARMv8 指令和系统调用。
|
||||
[工具套件( 3.10.1 )][19]主要修复了 3.10.0 版本发现的 bug 。除此之外,“从主干开发版本向后移植的一些补丁,修复了缺失的 AArch64 ARMv8 指令和系统调用”。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
同其它所有 Valgrind 工具一样, Memcheck 也是命令行实用程序。它的操作非常简单:通常我们会使用诸如 prog arg1 arg2 格式的命令来运行程序,而 Memcheck 只要求你多加几个值即可,如 valgrind --leak-check=full prog arg1 arg2 。
|
||||
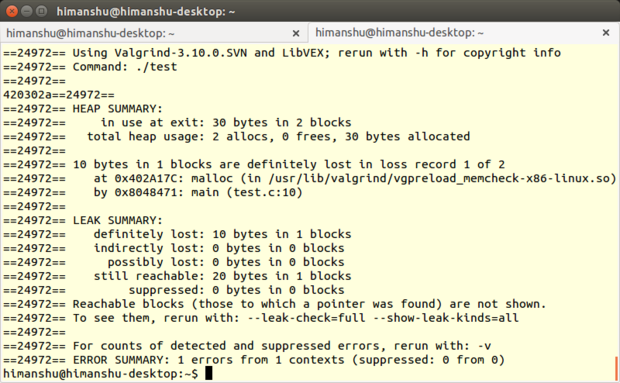
同其它所有 Valgrind 工具一样, Memcheck 也是命令行程序。它的操作非常简单:通常我们会使用诸如 `prog arg1 arg2` 格式的命令来运行程序,而 Memcheck 只要求你多加几个值即可,如 `valgrind --leak-check=full prog arg1 arg2` 。
|
||||
|
||||
|
||||
Memcheck
|
||||
|
||||
(注意:因为 Memcheck 是 Valgrind 的默认工具所以无需提及 Memcheck。但是,需要在编译程序之初带上 -g 参数选项,这一步会添加调试信息,使得 Memcheck 的错误信息会包含正确的行号。)
|
||||
*Memcheck*
|
||||
|
||||
我真正倾心于 Memcheck 的是它提供了很多命令行选项(如上所述的 *--leak-check* 选项),如此不仅能控制工具运转还可以控制它的输出。
|
||||
(注意:因为 Memcheck 是 Valgrind 的默认工具,所以在命令行执行命令时无需提及 Memcheck。但是,需要在编译程序之初带上 `-g` 参数选项,这一步会添加调试信息,使得 Memcheck 的错误信息会包含正确的行号。)
|
||||
|
||||
举个例子,可以开启 *--track-origins* 选项,以查看程序源码中未初始化的数据;可以开启 *--show-mismatched-frees* 选项让 Memcheck 匹配内存的分配和释放技术。对于 C 语言所写的代码, Memcheck 会确保只能使用 *free()* 函数来释放内存, *malloc()* 函数来申请内存。而对 C++ 所写的源码, Memcheck 会检查是否使用了 *delete* 或 *delete[]* 操作符来释放内存,以及 *new* 或者*new[]* 来申请内存。
|
||||
我真正倾心于 Memcheck 的是它提供了很多命令行选项(如上所述的`--leak-check`选项),如此不仅能控制工具运转还可以控制它的输出。
|
||||
|
||||
Memcheck 最好的特点,尤其是对于初学者来说,是它会给用户建议使用哪个命令行选项能让输出更加有意义。比如说,如果你不使用基本的 *--leak-check* 选项, Memcheck 会在输出时建议“使用 --leak-check=full 重新运行以查看更多泄漏内存细节”。如果程序有未初始化的变量, Memcheck 会产生信息“使用 --track-origins=yes 以查看未初始化变量的定位”。
|
||||
举个例子,可以开启`--track-origins`选项,以查看程序源码中未初始化的数据;可以开启`--show-mismatched-frees`选项让 Memcheck 匹配内存的分配和释放技术。对于 C 语言所写的代码, Memcheck 会确保只能使用`free()`函数来释放内存,`malloc()`函数来申请内存。而对 C++ 所写的源码, Memcheck 会检查是否使用了`delete`或`delete[]`操作符来释放内存,以及`new`或者`new[]`来申请内存。
|
||||
|
||||
Memcheck 另外一个有用的特性是它可以[创建抑制文件( suppression files )][20],由此可以忽略特定不能修正的错误,这样 Memcheck 运行时就不会每次都报警了。值得一提的是, Memcheck 会去读取默认抑制文件来忽略系统库(比如 C 库)中的报错,这些错误在系统创建之前就已经存在了。可以选择创建一个新的抑制文件,或是编辑现有的文件(通常是*/usr/lib/valgrind/default.supp*)。
|
||||
Memcheck 最好的特点,尤其是对于初学者来说,是它会给用户建议使用哪个命令行选项能让输出更加有意义。比如说,如果你不使用基本的`--leak-check`选项, Memcheck 会在输出时给出建议:“使用 --leak-check=full 重新运行以查看更多泄漏内存细节”。如果程序有未初始化的变量, Memcheck 会产生信息:“使用 --track-origins=yes 以查看未初始化变量的定位”。
|
||||
|
||||
Memcheck 另外一个有用的特性是它可以[创建抑制文件( suppression files )][20],由此可以略过特定的不能修正的错误,这样 Memcheck 运行时就不会每次都报警了。值得一提的是, Memcheck 会去读取默认抑制文件来忽略系统库(比如 C 库)中的报错,这些错误在系统创建之前就已经存在了。可以选择创建一个新的抑制文件,或是编辑现有的文件(通常是`/usr/lib/valgrind/default.supp`)。
|
||||
|
||||
Memcheck 还有高级功能,比如可以使用[定制内存分配器][22]来[检测内存错误][21]。除此之外, Memcheck 提供[监控命令][23],当用到 Valgrind 内置的 gdbserver ,以及[客户端请求][24]机制(不仅能把程序的行为告知 Memcheck ,还可以进行查询)时可以使用。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
毫无疑问, Memcheck 可以节省很多调试时间以及省去很多麻烦。但是它使用了很多内存,导致程序执行变慢([由文档可知][25],大概花上 20 至 30 倍时间)。
|
||||
毫无疑问, Memcheck 可以节省很多调试时间以及省去很多麻烦。但是它使用了很多内存,导致程序执行变慢([由文档可知][25],大概会花费 20 至 30 倍时间)。
|
||||
|
||||
除此之外, Memcheck 还有其它局限。根据用户评论, Memcheck 明显不是[线程安全][26]的;它不能检测出 [静态缓冲区溢出][27];还有就是,一些 Linux 程序如 [GNU Emacs][28] 目前还不能使用 Memcheck 。
|
||||
除此之外, Memcheck 还有其它局限。根据用户评论, Memcheck 很明显不是[线程安全][26]的;它不能检测出 [静态缓冲区溢出][27];还有就是,一些 Linux 程序如 [GNU Emacs][28] 目前还不能配合 Memcheck 工作。
|
||||
|
||||
如果有兴趣,可以在[这里][29]查看 Valgrind 详尽的局限性说明。
|
||||
如果有兴趣,可以在[这里][29]查看 Valgrind 局限性的详细说明。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
无论是对于初学者还是那些需要高级特性的人来说, Memcheck 都是一款便捷的内存调试工具。如果你仅需要基本调试和错误核查, Memcheck 会非常容易上手。而当你想要使用像抑制文件或者监控指令这样的特性,就需要花一些功夫学习了。
|
||||
无论是对于初学者还是那些需要高级特性的人来说, Memcheck 都是一款便捷的内存调试工具。如果你仅需要基本调试和错误检查, Memcheck 会非常容易上手。而当你想要使用像抑制文件或者监控指令这样的特性,就需要花一些功夫学习了。
|
||||
|
||||
虽然罗列了大量的局限性,但是 Valgrind(包括 Memcheck )在它的网站上声称全球有[成千上万程序员][30]使用了此工具。开发团队称收到来自超过 30 个国家的用户反馈,而这些用户的工程代码有的高达 2.5 千万行。
|
||||
虽然罗列了大量的局限性,但是 Valgrind(包括 Memcheck )在它的网站上声称全球有[成千上万程序员][30]使用了此工具。开发团队称收到来自超过 30 个国家的用户反馈,而这些用户的工程代码有的高达两千五百万行。
|
||||
|
||||
### [Memwatch][31] ###
|
||||
|
||||
**开发者**:Johan Lindh
|
||||
|
||||
**点评版本**:2.71
|
||||
**评估版本**:2.71
|
||||
|
||||
**支持的 Linux**:所有种类
|
||||
**支持的 Linux 发行版**:所有种类
|
||||
|
||||
**许可**:GNU通用公共许可证
|
||||
**许可**:GNU GPL
|
||||
|
||||
Memwatch 是由 Johan Lindh 开发的内存调试工具,虽然它主要扮演内存泄漏检测器的角色,但是(根据网页介绍)它也具有检测其它如[重复释放跟踪和内存错误释放][32]、缓冲区溢出和下溢、[野指针][33]写入等等内存相关问题的能力。
|
||||
Memwatch 是由 Johan Lindh 开发的内存调试工具,虽然它扮演的主要角色是内存泄漏检测器,但是(根据网页介绍)它也具有检测其它如[内存重复释放和错误释放][32]、缓冲区溢出和下溢、[野指针][33]写入等等内存相关问题的能力。
|
||||
|
||||
Memwatch 支持用 C 语言所编写的程序。也可以在 C++ 程序中使用它,但是这种做法并不提倡(由 Memwatch 源码包随附的 Q&A 文件中可知)。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
这个版本添加了 *ULONG_LONG_MAX* 以区分 32 位和 64 位程序。
|
||||
这个版本添加了`ULONG_LONG_MAX`以区分 32 位和 64 位程序。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
跟 Dmalloc 一样, Memwatch 也有优秀的文档资料。参考 USING 文件,可以学习如何使用 Memwatch ,可以了解 Memwatch 是如何初始化、如何清理以及如何进行 I/O 操作,等等。还有一个 FAQ 文件,旨在帮助用户解决使用过程遇到的一般问题。最后还有一个 *test.c* 文件提供工作案例参考。
|
||||
跟 Dmalloc 一样, Memwatch 也有优秀的文档资料。参考 USING 文件,可以学习如何使用 Memwatch ,可以了解 Memwatch 是如何初始化、如何清理以及如何进行 I/O 操作,等等。还有一个 FAQ 文件,旨在帮助用户解决使用过程遇到的一般问题。最后还有一个`test.c`文件提供工作案例参考。
|
||||
|
||||
|
||||
Memwatch
|
||||
|
||||
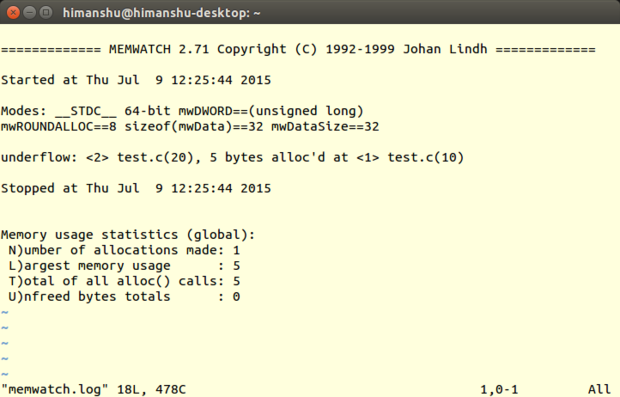
不同于 Mtrace , Memwatch 的输出产生的日志文件(通常是 *memwatch.log* )是人类可阅读格式。而且, Memwatch 每次运行时总会拼接内存调试输出到文件末尾。如此便可在需要之时,轻松查看之前的输出信息。
|
||||
*Memwatch*
|
||||
|
||||
不同于 Mtrace , Memwatch 产生的日志文件(通常是`memwatch.log`)是人类可阅读的格式。而且, Memwatch 每次运行时总会把内存调试结果拼接到输出该文件的末尾。如此便可在需要之时轻松查看之前的输出信息。
|
||||
|
||||
同样值得一提的是当你执行了启用 Memwatch 的程序, Memwatch 会在[标准输出][34]中产生一个单行输出,告知发现了错误,然后你可以在日志文件中查看输出细节。如果没有产生错误信息,就可以确保日志文件不会写入任何错误,多次运行的话确实能节省时间。
|
||||
|
||||
另一个我喜欢的优点是 Memwatch 还提供了在源码中获取其输出信息的方式,你可以获取信息,然后任由你进行处理(参考 Memwatch 源码中的 *mwSetOutFunc()* 函数获取更多有关的信息)。
|
||||
另一个我喜欢的优点是 Memwatch 还提供了在源码中获取其输出信息的方式,你可以获取信息,然后任由你进行处理(参考 Memwatch 源码中的`mwSetOutFunc()`函数获取更多有关的信息)。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
跟 Mtrace 和 Dmalloc 一样, Memwatch 也需要你往你的源文件里增加代码:你需要把 *memwatch.h* 这个头文件包含进你的代码。而且,编译程序的时候,你需要连同 *memwatch.c* 一块编译;或者你可以把已经编译好的目标模块包含起来,然后在命令行定义 *MEMWATCH* 和 *MW_STDIO* 变量。不用说,想要在输出中定位行号, -g 编译器选项也少不了。
|
||||
跟 Mtrace 和 Dmalloc 一样, Memwatch 也需要你往你的源文件里增加代码:你需要把`memwatch.h`这个头文件包含进你的代码。而且,编译程序的时候,你需要连同`memwatch.c`一块编译;或者你可以把已经编译好的目标模块包含起来,然后在命令行定义`MEMWATCH`和`MW_STDIO`变量。不用说,想要在输出中定位行号, -g 编译器选项也少不了。
|
||||
|
||||
此外, Memwatch 缺少一些特性。比如 Memwatch 不能检测出往一块已经被释放的内存写入操作,或是在分配的内存块之外的读取操作。而且, Memwatch 也不是线程安全的。还有一点,正如我在开始时指出,在 C++ 程序上运行 Memwatch 的结果是不能预料的。
|
||||
此外, Memwatch 缺少一些特性。比如 Memwatch 不能检测出对一块已经被释放的内存进行写入操作,或是在分配的内存块之外的进行读取操作。而且, Memwatch 也不是线程安全的。还有一点,正如我在开始时指出,在 C++ 程序上运行 Memwatch 的结果是不能预料的。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
@ -191,20 +193,21 @@ Memcheck 可以检测很多内存相关的问题,在处理 C 程序时是非
|
||||
|
||||
### [Mtrace][35] ###
|
||||
|
||||
**开发者**: Roland McGrath and Ulrich Drepper
|
||||
**开发者**: Roland McGrath 和 Ulrich Drepper
|
||||
|
||||
**点评版本**: 2.21
|
||||
**评估版本**: 2.21
|
||||
|
||||
**支持的 Linux**:所有种类
|
||||
**支持的 Linux 发行版**:所有种类
|
||||
|
||||
**许可**:GNU 通用公共许可证
|
||||
**许可**:GNU GPL
|
||||
|
||||
Mtrace 是 [GNU C 库][36]中的一款内存调试工具,同时支持 Linux 上的 C 和 C++ 程序,检测由 *malloc()* 和 *free()* 函数的不对等调用所引起的内存泄漏问题。
|
||||
Mtrace 是 [GNU C 库][36]中的一款内存调试工具,同时支持 Linux 上的 C 和 C++ 程序,可以检测由函数`malloc()`和`free()`不匹配的调用所引起的内存泄漏问题。
|
||||
|
||||
|
||||
Mtrace
|
||||
|
||||
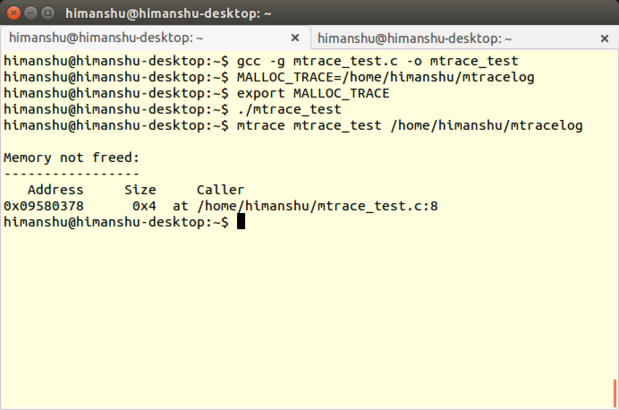
Mtrace 实现为对 *mtrace()* 函数的调用,跟踪程序中所有 malloc/free 调用,并在用户指定的文件中记录相关信息。文件以一种机器可读的格式记录数据,所以有一个 Perl 脚本(同样命名为 mtrace )用来把文件转换并展示为人类可读格式。
|
||||
*Mtrace*
|
||||
|
||||
Mtrace 实际上是实现了一个名为`mtrace()`的函数,它可以跟踪程序中所有 malloc/free 调用,并在用户指定的文件中记录相关信息。文件以一种机器可读的格式记录数据,所以有一个 Perl 脚本——同样命名为 mtrace ——用来把文件转换并为人类可读格式。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
@ -212,21 +215,21 @@ Mtrace 实现为对 *mtrace()* 函数的调用,跟踪程序中所有 malloc/fr
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
Mtrace 最优秀的特点是非常简单易学。你只需要了解在你的源码中如何以及何处添加mtrace()及其对立的muntrace()函数,还有如何使用Mtrace的Perl脚本。后者非常简单,只需要运行指令 *mtrace <program-executable> <log-file-generated-upon-program-execution>*(例子见开头截图最后一条指令)。
|
||||
Mtrace 最好的地方是它非常简单易学。你只需要了解在你的源码中如何以及何处添加 mtrace() 及对应的 muntrace() 函数,还有如何使用 Mtrace 的 Perl 脚本。后者非常简单,只需要运行指令`mtrace <program-executable> <log-file-generated-upon-program-execution>`(例子见开头截图最后一条指令)。
|
||||
|
||||
Mtrace 另外一个优点是它的可收缩性,体现在,不仅可以使用它来调试完整的程序,还可以使用它来检测程序中独立模块的内存泄漏。只需在每个模块里调用 *mtrace()* 和 *muntrace()* 即可。
|
||||
Mtrace 另外一个优点是它的可伸缩性,这体现在不仅可以使用它来调试完整的程序,还可以使用它来检测程序中独立模块的内存泄漏。只需在每个模块里调用`mtrace()`和`muntrace()`即可。
|
||||
|
||||
最后一点,因为 Mtrace 会在 *mtace()*(在源码中添加的函数)执行时被触发,因此可以很灵活地[使用信号][39]动态地(在程序执行周期内)使能 Mtrace 。
|
||||
最后一点,因为 Mtrace 会在`mtrace()`——在源码中添加的函数——执行时被触发,因此可以很灵活地[使用信号][39]动态地(在程序执行时)使能 Mtrace 。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
因为 *mtrace()* 和 *mauntrace()* 函数(声明在 *mcheck.h* 文件中,所以必须在源码中包含此头文件)的调用是 Mtrace 运行( *mauntrace()* 函数并非[总是必要][40])的根本,因此 Mtrace 要求程序员至少改动源码一次。
|
||||
因为`mtrace()`和`mauntrace()`函数 —— 声明在`mcheck.h`文件中,所以必须在源码中包含此头文件 —— 的调用是 Mtrace 工作的基础(`mauntrace()`函数并非[总是必要][40]),因此 Mtrace 要求程序员至少改动源码一次。
|
||||
|
||||
需要注意的是,在编译程序的时候带上 -g 选项( [GCC][41] 和 [G++][42] 编译器均有提供),才能使调试工具在输出展示正确的行号。除此之外,有些程序(取决于源码体积有多大)可能会花很长时间进行编译。最后,带 -g 选项编译会增加了可执行文件的内存(因为提供了额外的调试信息),因此记得程序需要在测试结束后,不带 -g 选项重新进行编译。
|
||||
需要注意的是,在编译程序的时候带上 -g 选项( [GCC][41] 和 [G++][42] 编译器均有提供),才能使调试工具在输出结果时展示正确的行号。除此之外,有些程序(取决于源码体积有多大)可能会花很长时间进行编译。最后,带 -g 选项编译会增加了可执行文件的大小(因为提供了额外的调试信息),因此记得程序需要在测试结束后,不带 -g 选项重新进行编译。
|
||||
|
||||
使用 Mtrace ,你需要掌握 Linux 环境变量的基本知识,因为在程序执行之前,需要把用户指定的文件( *mtrace()* 函数将会记录全部信息到其中)路径设置为环境变量 *MALLOC_TRACE* 的值。
|
||||
使用 Mtrace ,你需要掌握 Linux 环境变量的基本知识,因为在程序执行之前,需要把用户把环境变量`MALLOC_TRACE`的值设为指定的文件(`mtrace()`函数将会记录全部信息到其中)路径。
|
||||
|
||||
Mtrace 在检测内存泄漏和尝试释放未经过分配的内存方面存在局限。它不能检测其它内存相关问题如非法内存访问、使用未初始化内存。而且,[有人抱怨][43] Mtrace 不是[线程安全][44]的。
|
||||
Mtrace 在检测内存泄漏和试图释放未经过分配的内存方面存在局限。它不能检测其它内存相关问题如非法内存访问、使用未初始化内存。而且,[有人抱怨][43] Mtrace 不是[线程安全][44]的。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
@ -238,7 +241,7 @@ Mtrace 在检测内存泄漏和尝试释放未经过分配的内存方面存在
|
||||
|
||||
虽然 Memwatch 的资料比 Dmalloc 的更加丰富,而且还能检测更多的错误种类,但是你只能在 C 语言写就的程序中使用它。一个让 Memwatch 脱颖而出的特性是它允许在你的程序源码中处理它的输出,这对于想要定制输出格式来说是非常有用的。
|
||||
|
||||
如果改动程序源码非你所愿,那么使用 Electric Fence 吧。不过,请记住, Electric Fence 只能检测两种错误类型,而此二者均非内存泄漏。还有就是,需要了解 GDB 基础以最大化发挥这款内存调试工具的作用。
|
||||
如果改动程序源码非你所愿,那么使用 Electric Fence 吧。不过,请记住, Electric Fence 只能检测两种错误类型,而此二者均非内存泄漏。还有就是,需要基本了解 GDB 以最大化发挥这款内存调试工具的作用。
|
||||
|
||||
Memcheck 可能是其中综合性最好的了。相比这里提及的其它工具,它能检测更多的错误类型,提供更多的特性,而且不需要你的源码做任何改动。但请注意,基本功能并不难上手,但是想要使用它的高级特性,就必须学习相关的专业知识了。
|
||||
|
||||
@ -248,7 +251,7 @@ via: http://www.computerworld.com/article/3003957/linux/review-5-memory-debugger
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[soooogreen](https://github.com/soooogreen)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki),[ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,44 @@
|
||||
使用 SystemBack 备份/还原你的 Ubuntu/Linux Mint
|
||||
=================================================
|
||||
|
||||
对于任何一款允许用户还原电脑到之前状态(包括文件系统,安装的应用,以及系统设置)的操作系统来说,系统还原功能都是必备功能,它可以恢复系统故障以及其他的问题。
|
||||
|
||||
有的时候安装一个程序或者驱动可能让你的系统黑屏。系统还原则可以让你电脑里面的系统文件(LCTT 译注:是系统文件,并非普通文件,详情请看**注意**部分)和程序恢复到之前工作正常时候的状态,进而让你远离那让人头痛的排障过程了,而且它也不会影响你的文件,照片或者其他数据。
|
||||
|
||||
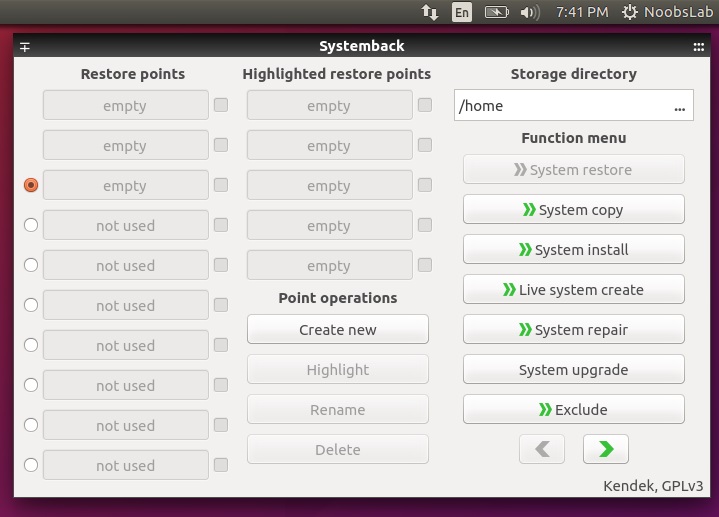
简单的系统备份还原工具 [Systemback](https://launchpad.net/systemback) 可以让你很容易地创建系统备份以及用户配置文件。一旦遇到问题,你可以简单地恢复到系统先前的状态。它还有一些额外的特征包括系统复制,系统安装以及Live系统创建。
|
||||
|
||||
**截图**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
**注意**:使用系统还原不会还原你自己的文件、音乐、电子邮件或者其他任何类型的私人文件。对不同用户来讲,这既是优点又是缺点。坏消息是它不会还原你意外删除的文件,不过你可以通过一个文件恢复程序来解决这个问题。如果你的计算机没有创建还原点,那么系统恢复就无法奏效,所以这个工具就无法帮助你(还原系统),如果你尝试恢复一个主要问题,你将需要移步到另外的步骤来进行故障排除。
|
||||
|
||||
> 适用于 Ubuntu 15.10 Wily/16.04/15.04 Vivid/14.04 Trusty/Linux Mint 14.x/其他Ubuntu衍生版,打开终端,将下面这些命令复制过去:
|
||||
|
||||
终端命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nemh/systemback
|
||||
sudo apt-get update
|
||||
sudo apt-get install systemback
|
||||
|
||||
```
|
||||
|
||||
大功告成。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.noobslab.com/2015/11/backup-system-restore-point-your.html
|
||||
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://launchpad.net/systemback
|
||||
@ -6,18 +6,20 @@
|
||||
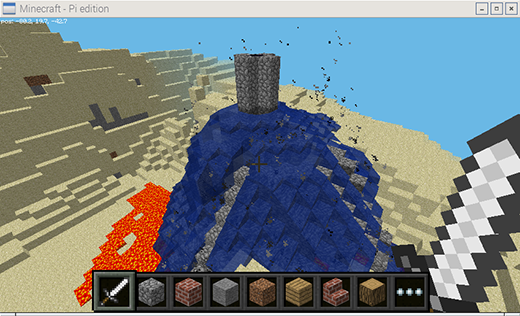
### 1. 我的世界: Pi
|
||||
|
||||
|
||||
>源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1].
|
||||
|
||||
我的世界是世界上几乎每一个青少年都特别喜欢的一款游戏,而且它成功抓住了年轻人眼球,成为目前最能激发年轻人创造力的游戏之一。这个树莓派版本自带的我的世界不仅仅是一个具有创造性的建筑游戏,还是一个具有编程接口,可以通过 Python 与之交互的版本。
|
||||
*源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1]*
|
||||
|
||||
“我的世界”是世界上几乎每一个青少年都特别喜欢的一款游戏,而且它成功抓住了年轻人眼球,成为目前最能激发年轻人创造力的游戏之一。这个树莓派版本自带的我的世界不仅仅是一个具有创造性的建筑游戏,还是一个具有编程接口,可以通过 Python 与之交互的版本。
|
||||
|
||||
我的世界:Pi 版对于老师来说是一个教授学生解决问题和编写代码完成任务的好方式。你可以使用 Python API 创建一个房子,并且一直跟随这你的脚步移动,在所到之处建造一座桥,让天空落下熔岩雨滴,在空中显示温度,以及其它你可以想象到的一切东西。
|
||||
|
||||
详情请见 "[Getting Started with Minecraft Pi][2]."
|
||||
详情请见 "[我的世界: Pi 入门][2]"
|
||||
|
||||
### 2. 反应游戏和交通灯
|
||||
|
||||

|
||||
>源于 [Low Voltage Labs][3]. [CC BY-SA 4.0][1].
|
||||
|
||||
*源于 [Low Voltage Labs][3]. [CC BY-SA 4.0][1]*
|
||||
|
||||
使用树莓派可以很轻松地进行物理计算,只需要连接几个 LED 和按钮到开发板上的 GPIO 接口,再用几行代码你就可以按下按钮来开灯。一旦你了解了如何使用代码来完成这些基本的操作,接下来就可以根据你的想象来做其它事情了。
|
||||
|
||||
@ -26,7 +28,8 @@
|
||||
代码并不是全部——这只是一个演练,让你理解现实世界里系统是如何完成设计的。计算思维是一个让你终身受用的技能。
|
||||
|
||||

|
||||
>源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1].
|
||||
|
||||
*源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1]*
|
||||
|
||||
接下来试着接通两个按钮和 LED 灯的电源,实现一个双玩家的反应游戏 —— 让 LED 灯随机时间点亮,然后看是谁抢先按下按钮。
|
||||
|
||||
@ -38,25 +41,25 @@ Astro Pi —— 一个增强版的树莓派 —— 将在 12 月问世,但是
|
||||
|
||||
[video](https://youtu.be/gfRDFvEVz-w)
|
||||
|
||||
>详见 "[探索 Sense HAT][9]."
|
||||
> 详见 "[探索 Sense HAT][9]."
|
||||
|
||||
### 4. 红外鸟笼
|
||||
|
||||

|
||||
>源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1].
|
||||
|
||||
*源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1]*
|
||||
|
||||
让整个班级都可以参与进来的好主意是在鸟笼里放置一个树莓派和夜视镜头,以及一些红外线灯,这样子你就可以在黑暗中看见鸟笼里的情况了,然后使用树莓派通过网络串流视频。然后就可以等待小鸟归笼了,你可以在不打扰的情况下近距离观察小窝里的它们了。
|
||||
|
||||
要了解更多有关红外线和光谱的知识,以及如何校准摄像头焦点和使用软件控制摄像头,可以访问 [Make an infrared bird box][10]。
|
||||
|
||||
|
||||
要了解更多有关红外线和光谱的知识,以及如何校准摄像头焦点和使用软件控制摄像头,可以访问 [打造一个红外鸟笼][10]。
|
||||
|
||||
### 5. 机器人
|
||||
|
||||

|
||||
>源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1].
|
||||
|
||||
只需要一个树莓派、很少的几个电机和电机控制器,你就可以自己动手制作一个机器人。可以制作的机器人有很多种,从简单的由几个轮子和自制底盘拼凑的简单小车,到由游戏控制器驱动、具有自我意识、配备了传感器,安装了摄像头的金属种马。
|
||||
*源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1]*
|
||||
|
||||
只需要一个树莓派、很少的几个电机和电机控制器,你就可以自己动手制作一个机器人。可以制作的机器人有很多种,从简单的由几个轮子和自制底盘拼凑的简单小车,到由游戏控制器驱动、具有自我意识、配备了传感器,安装了摄像头的金属小马。
|
||||
|
||||
要学习如何控制不同的电机,可以使用 RTK 电机驱动开发板入门或者使用配置了电机、轮子和传感器的 CamJam 机器人开发套件——具有很大的价值和大量的学习潜力。
|
||||
|
||||
200
published/20160225 The Tao of project management.md
Normal file
200
published/20160225 The Tao of project management.md
Normal file
@ -0,0 +1,200 @@
|
||||
《道德经》之项目管理
|
||||
=================================
|
||||
|
||||
|
||||

|
||||
|
||||
[道德经][1],[被认为][2]是由圣人[老子][3]于公元前六世纪时所编写,是现存最为广泛翻译的经文之一。从[宗教][4]到[关于约会的有趣电影][5]等方方面面,它都深深地影响着它们,作者们借用它来做隐喻,以解释各种各样的事情(甚至是[编程][6])。
|
||||
|
||||
在思考有关开放性组织的项目管理时,我的脑海中便立马浮现出上面的这段文字。
|
||||
|
||||
这听起来可能会有点奇怪。若要理解我的这种想法从何而来,你应该读读 *《开放性组织:点燃激情提升执行力》* 这本书,它是红帽公司总裁、首席执行官 Jim Whitehurst 所写的一本有关企业文化和新领导力范式的宣言。在这本书中,Jim(还有来自其他红帽人的一点帮助)解释了传统组织机构(一种 “自上而下” 的方式,来自高层的决策被传达到员工,而员工通过晋升和薪酬来激励)和开放性组织机构(一种 自下而上 的方式,领导专注于激励和鼓励,员工被充分授权以各尽其能)之间的差异。
|
||||
|
||||
在开放性组织中的员工都是被激情、目标和参与感所激励,这个观点正是我认为项目管理者所应该关注的。
|
||||
|
||||
要解释这一切,我将从*道德经*上寻找依据。
|
||||
|
||||
### 不要让工作职衔框住自身
|
||||
|
||||
> 道,可道也,(The tao that can be told)
|
||||
|
||||
> 非恒道也。(is not the eternal Tao)
|
||||
|
||||
> 名,可名也,(The name that can be named)
|
||||
|
||||
> 非恒名也。(is not the eternal Name.)
|
||||
|
||||
> “无”,名天地之始;(The unnameable is the eternally real.)
|
||||
|
||||
> “有”,名万物之母。(Naming is the origin of all particular things.)
|
||||
[[1]][7]
|
||||
|
||||
项目管理到底是什么?作为一个项目管理者应该做些什么呢?
|
||||
|
||||
如您所想,项目管理者的一部分工作就是管理项目:收集需求、与项目相关人员沟通、设置项目优先级、安排任务、帮助团队解决困扰。许多机构都可以教你如何做好项目管理,并且这些技能你值得拥有。
|
||||
|
||||
然而,在开放性组织中,字面上的项目管理技能仅仅只是项目管理者需要做到的一小部分,这些组织需要更多其他的东西:即勇气。如果你擅长于管理项目(或者是真的擅长于任何工作),那么你就进入了舒适区。这时候就是需要鼓起勇气开始尝试冒险之时。
|
||||
|
||||
您有勇气跨出舒适区吗?向权威人士提出挑战性的问题,可能会引发对方的不快,但也可能会开启一个更好的方法,您有勇气这样做吗?有确定需要做的下一件事,然后真正去完成它的勇气吗?有主动去解决因为交流的鸿沟而遗留下来的问题的勇气吗?有去尝试各种事情的勇气吗?有失败的勇气吗?
|
||||
|
||||
道德经的开篇(上面引用的)就表明词语(words)、标签(labels)、名字(names)这些是有限制的,当然也包括工作职衔。在开放性组织中,项目经理不仅仅是执行管理项目所需的机械任务,而且要帮助团队完成组织的使命,尽管这已经被限定了。
|
||||
|
||||
### 联系起合适的人
|
||||
|
||||
> 三十辐共一轂,(We join spokes together in a wheel,)
|
||||
|
||||
> 当其无,(but it is the center hole)
|
||||
|
||||
> 有车之用。(that makes the wagon move.)
|
||||
[[11]][8]
|
||||
|
||||
当我过渡到项目管理的工作时,我必须学会的最为困难的一课是:并不是所有解决方案都是可完全地接受,甚至有的连预期都达不到。这对我来说是全新的一页。我*喜欢*全部都能解决。但作为项目管理者,我的角色更多的是与人沟通--使得那些确实有解决方案的人可以更高效地合作。
|
||||
|
||||
这并不是逃避责任或者不负责。这意味着可以很舒适的说,“我不知道,但我会给你找出答案”,然后就可迅速地结束这个循环。
|
||||
|
||||
想像一下马车的车轮,如果没有毂中的孔洞所提供的稳定性和方向,辐条便会失去支持,车轮也会散架。在一个开放性的组织中,项目管理者可以通过把合适的人凝聚在一起,培养正确的讨论话题来帮助团队保持持续向前的动力。
|
||||
|
||||
### 信任你的团队
|
||||
|
||||
>太上,不知有之;(When the Master governs, the people
|
||||
are hardly aware that he exists.)
|
||||
|
||||
> 其次,亲而誉之;(Next best is a leader who is loved.)
|
||||
|
||||
> 其次,畏之;(Next, one who is feared.)
|
||||
|
||||
> 其次,侮之。(The worst is one who is despised.)
|
||||
|
||||
>信不足焉,(If you don't trust the people,)
|
||||
|
||||
>有不信焉。(you make them untrustworthy.)
|
||||
|
||||
>悠兮,其贵言。(The Master doesn't talk, he acts.)
|
||||
|
||||
> 功成事遂,(When his work is done,)
|
||||
|
||||
> 百姓皆谓:“我自然”。(the people say, "Amazing:
|
||||
we did it, all by ourselves!")
|
||||
[[17]][9]
|
||||
|
||||
[Rebecca Fernandez][10] 曾经告诉我开放性组织的领导与其它组织的领导者最大的不同点在于,我们不是去取得别人的信任,而是信任别人。
|
||||
|
||||
开放性组织会雇佣那些非常聪明的,且对公司正在做的事情充满激情的人来做工作。为了能使他们能更好的工作,我们会提供其所需,并尊重他们的工作方式。
|
||||
|
||||
至于原因,我认为从道德经中摘出的上面一段就说的很清楚。
|
||||
|
||||
### 顺其自然
|
||||
|
||||
>上德无为而无以为;(The Master does nothing
|
||||
yet he leaves nothing undone.)
|
||||
|
||||
>下德为之而有以为。(The ordinary man is always doing things,
|
||||
yet many more are left to be done.)
|
||||
[[38]][11]
|
||||
|
||||
你认识那类总是极其忙碌的人吗?认识那些因为有太多事情要做而看起来疲倦和压抑的人吗?
|
||||
|
||||
不要成为那样的人。
|
||||
|
||||
我知道说比做容易。帮助我没有成为那类人的最重要的东西是:我时刻记着*大家都很忙*这件事。我没有一个那样无聊的同事。
|
||||
|
||||
但总需要有人成为在狂风暴雨中仍保持镇定的人。总需要有人能够宽慰团队告诉他们一切都会好起来,我们将在现实和一天中工作时间有限的情况下,找到方法使得任务能够完成(因为事实就是这样的,而且我们必须这样)。
|
||||
|
||||
成为那样的人吧。
|
||||
|
||||
对于上面这段道德经所说的,我的理解是那些总是谈论他或她正在做什么的人实际上并*没有时间*去做他们谈论的事。如果相比于你周围的人,你能把你的工作做的毫不费劲,那就说明你的工作做对了。
|
||||
|
||||
### 做一名文化传教士
|
||||
|
||||
>上士闻道,(When a superior man hears of the Tao,)
|
||||
|
||||
> 勤而行之;(he immediately begins to embody it.)
|
||||
|
||||
> 中士闻道,(When an average man hears of the Tao,)
|
||||
|
||||
>若存若亡;(he half believes it, half doubts it.)
|
||||
|
||||
> 下士闻道,(When a foolish man hears of the Tao,)
|
||||
|
||||
> 大笑之。(he laughs out loud.)
|
||||
|
||||
> 不笑不足以為道。(If he didn't laugh,it wouldn't be the Tao.)
|
||||
[[41]][12]
|
||||
|
||||
去年秋天,我和一群联邦雇员参加了一堂 MBA 的商业准则课程。当我开始介绍我们公司的文化、价值和伦理框架时,我得到的直接印象是:我的同学和教授都认为我就像一个天真可爱的小姑娘,做着许多关于公司应该如何运作的[甜美白日梦][13]。他们告诉我事情不可能是他们看起来的那样,他们还告诉我应该进一步考察。
|
||||
|
||||
所以我照做了。
|
||||
|
||||
然而我发现的是:事情*恰好*是他们看起来的那样。
|
||||
|
||||
在开放性组织,关于企业文化,人们应该随着企业的成长而时时维护那些文化,以使它随时精神焕发,充满斗志。我(和其它开源组织的成员)并不想过着如我同学们所描述的那样,“为生活而工作”。我需要有激情、有目标,需要明白自己的日常工作是如何对那些我所坚信的东西做贡献的。
|
||||
|
||||
作为一个项目管理者,你可能会认为在你的团队中,你的工作对培养你们公司的企业文化没有多少帮助。然而你的工作正是孕育文化本身。
|
||||
|
||||
### Kaizen (持续改善)
|
||||
|
||||
>为学日益,(In pursuit of knowledge,every day something is added.)
|
||||
|
||||
> 为道日损。(In the practice of the Tao,every day something is dropped.)
|
||||
|
||||
> 损之又损,(Less and less do you need to force things,)
|
||||
|
||||
> 以至于无为。(until finally you arrive at non-action. )
|
||||
|
||||
> 无为而无不为。(When nothing is done,nothing is left undone.)
|
||||
[[48]][14]
|
||||
|
||||
项目管理的常规领域都太过于专注最新、最强大的的工具,但对于应该使用哪种工具,这个问题的答案总是一致的:“最简单的”。
|
||||
|
||||
例如,我将任务列表放在桌面的一个文本文件中,因为它很单纯,不会受到不必要的干扰。您想介绍给团队的,无论是何种工具、流程和程序都应该是能提高效率,排除障碍的,而不是引入额外的复杂性。所以与其专注于工具,还不如专注于要使用这些工具来解决的*问题*。
|
||||
|
||||
作为一个项目经理,我最喜爱的部分是在敏捷世界中,我有自由抛弃那些没有成效的东西的权利。这与 [kaizen][16] 的概念相关,或叫 “持续改进”。不要害怕尝试和失败。失败是我们在探索什么能够起作用,什么不能起作用的过程中所用的标签,这是提高的唯一方式。
|
||||
|
||||
最好的过程都不是一蹴而就的。作为项目管理者,你应该通过支持他们,而不是强迫他们去做某些事来帮助你的团队。
|
||||
|
||||
### 实践
|
||||
|
||||
>天下皆谓我"道"大,(Some say that my teaching is nonsense.)
|
||||
|
||||
> 似不肖。(Others call it lofty but impractical.)
|
||||
|
||||
> 夫唯大,(But to those who have looked inside themselves,)
|
||||
|
||||
> 故似不肖。(this nonsense makes perfect sense.)
|
||||
|
||||
>若肖,(And to those who put it into practice,)
|
||||
|
||||
> 久矣其细也夫!(this loftiness has roots that go deep.)
|
||||
[[67]][15]
|
||||
|
||||
我相信开放性组织正在做的事。开放性组织在管理领域的工作几乎与他们提供的产品和服务一样重要。我们有机会以身作则,激发他人的激情和目的,创造激励和充分授权的工作环境。
|
||||
|
||||
我鼓励你们找到办法把这些想法融入到自己的项目和团队中,看看会发生什么。了解你们组织的使命,知晓你的项目是如何为这个使命做贡献的。鼓起勇气,尝试某些看起来没有多少成效的事,同时不要忘记和我们的社区分享你所学到的经验,这样我们就可以继续改进。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/16/2/tao-project-management
|
||||
|
||||
作者:[Allison Matlack][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[FSSlc](https://github.com/FSSlc)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/amatlack
|
||||
[1]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html
|
||||
[2]: https://en.wikipedia.org/wiki/Tao_Te_Ching
|
||||
[3]: http://plato.stanford.edu/entries/laozi/
|
||||
[4]: https://en.wikipedia.org/wiki/Taoism
|
||||
[5]: http://www.imdb.com/title/tt0234853/
|
||||
[6]: http://www.mit.edu/~xela/tao.html
|
||||
[7]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#1
|
||||
[8]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#11
|
||||
[9]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#17
|
||||
[10]: https://opensource.com/users/rebecca
|
||||
[11]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#38
|
||||
[12]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#41
|
||||
[13]: https://opensource.com/open-organization/15/9/reflections-open-organization-starry-eyed-dreamer
|
||||
[14]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#48
|
||||
[15]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#67
|
||||
[16]: https://www.kaizen.com/about-us/definition-of-kaizen.html
|
||||
@ -0,0 +1,48 @@
|
||||
Docker 1.11 采纳了开源容器项目(OCP)组件
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
> Docker 在开放容器项目(Open Container Project,OCP)中的参与度达成圆满,最新构建的Docker采用了Docker 贡献给 OCP 的组件。
|
||||
|
||||
新发布的 [Docker 1.11][1] 的最大新闻并不是它的功能,而是它使用了在 OCP 支持下的标准化的组件版本。
|
||||
|
||||
去年,Docker 贡献了它的 [runC][2] 核心给 OCP 作为构建构建容器工具的基础。同样还有 [containerd][3],作为守护进程或者服务端用于控制 runC 的实例。Docker 1.11 现在使用的就是这个捐赠和公开的版本。
|
||||
|
||||
|
||||
Docker 此举挑战了它的容器生态仍[主要由 Docker 自身决定][6]这个说法。它并不是为了作秀才将容器规范和运行时细节贡献给 OCP。它希望项目将来的开发越开放和广泛越好。
|
||||
|
||||
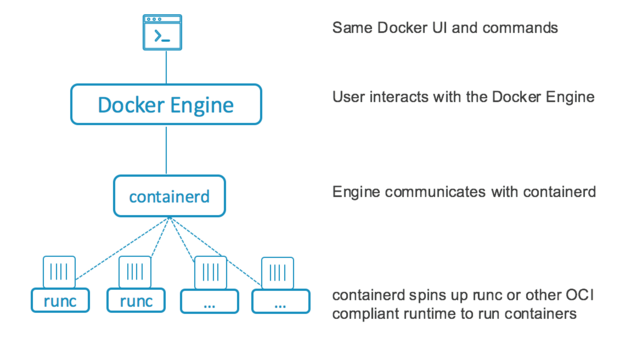
|
||||
|
||||
> Docker 1.11 已经用贡献给 OCP 的 runC 和 containerd 进行了重构。runC 如果需要的话可以换成另外一个。
|
||||
|
||||
runC 的[两位主要提交者][7]来自 Docker,但是来自 Virtuozzo(Parallels fame)、OpenShift、Project Atomic、华为、GE Healthcare、Suse Linux 也都是提交人员里面的常客。
|
||||
|
||||
Docker 1.11 中一个更明显的变化是先前 Docker runtime 在 Docker 中是唯一可用的,并且评论家认为这个会限制用户的选择。runC runtime 现在是可替换的;虽然 Docker 在发布时将 runC 作为默认引擎,但是任何兼容的引擎都可以用来替换它。(Docker 同样希望它可以不用杀死并重启现在运行的容器,但是这个作为今后的改进规划。)
|
||||
|
||||
Docker 正在将基于 OCP 的开发流程作为内部创建其产品的更好方式。在它发布 1.11 的[官方博客中称][8]:“将 Docker 切分成独立的工具意味着更专注的维护者,最终会有更好的软件质量。”
|
||||
|
||||
除了修复长期以来存在的问题和确保 Docker 的 runC/containerd 跟上步伐,Docker 还在 Docker 1.11 中加入了一些改进。Docker Engine 现在支持 VLAN 和 IPv6 服务发现,并且会自动在多个相同别名容器间执行 DNS 轮询负载均衡。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3055966/open-source-tools/docker-111-adopts-open-container-project-components.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]: https://blog.docker.com/2016/04/docker-engine-1-11-runc/
|
||||
[2]: http://runc.io/
|
||||
[3]: https://containerd.tools/
|
||||
[4]: http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker#tk.ifw-infsb
|
||||
[5]: http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
[6]: http://www.infoworld.com/article/2876801/application-virtualization/docker-reorganization-grows-up.html
|
||||
[7]: https://github.com/opencontainers/runc/graphs/contributors
|
||||
[8]: https://blog.docker.com/2016/04/docker-engine-1-11-runc/
|
||||
|
||||
|
||||
@ -1,35 +1,35 @@
|
||||
LFCS 系列第七讲: 通过 SysVinit、Systemd 和 Upstart 管理系统自启动进程和服务
|
||||
LFCS 系列第七讲:通过 SysVinit、Systemd 和 Upstart 管理系统自启动进程和服务
|
||||
================================================================================
|
||||
几个月前, Linux 基金会宣布 LFCS(Linux 基金会认证系统管理员) 认证诞生了,这个令人兴奋的新计划定位于让来自全球各地的初级到中级的 Linux 系统管理员得到认证。这其中包括维护已经在运行的系统和服务能力、第一手的问题查找和分析能力、以及决定何时向开发团队提交问题的能力。
|
||||
几个月前, Linux 基金会宣布 LFCS (Linux 基金会认证系统管理员) 认证诞生了,这个令人兴奋的新计划定位于让来自全球各地的初级到中级的 Linux 系统管理员得到认证。这其中包括维护已经在运行的系统和服务的能力、第一手的问题查找和分析能力、以及决定何时向开发团队提交问题的能力。
|
||||
|
||||

|
||||
|
||||
第七讲: Linux 基金会认证系统管理员
|
||||
*第七讲: Linux 基金会认证系统管理员*
|
||||
|
||||
下面的视频简要介绍了 Linux 基金会认证计划。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
这篇博文是 10 指南系列中的第七篇,在这篇文章中,我们会介绍如何管理 Linux 系统自启动进程和服务,这是 LFCS 认证考试要求的一部分。
|
||||
本讲是系列教程中的第七讲,在这篇文章中,我们会介绍如何管理 Linux 系统自启动进程和服务,这是 LFCS 认证考试要求的一部分。
|
||||
|
||||
### 管理 Linux 自启动进程 ###
|
||||
|
||||
Linux 系统的启动程序包括多个阶段,每个阶段由一个不同的组件表示。下面的图示简要总结了启动过程以及所有包括的主要组件。
|
||||
Linux 系统的启动程序包括多个阶段,每个阶段由一个不同的图示块表示。下面的图示简要总结了启动过程以及所有包括的主要组件。
|
||||
|
||||

|
||||
|
||||
Linux 启动过程
|
||||
*Linux 启动过程*
|
||||
|
||||
当你按下你机器上的电源键时, 存储在主板 EEPROM 芯片中的固件初始化 POST(通电自检) 检查系统硬件资源的状态。POST 结束后,固件会搜索并加载位于第一块可用磁盘上的 MBR 或 EFI 分区的第一阶段引导程序,并把控制权交给引导程序。
|
||||
当你按下你机器上的电源键时,存储在主板 EEPROM 芯片中的固件初始化 POST(通电自检) 检查系统硬件资源的状态。POST 结束后,固件会搜索并加载位于第一块可用磁盘上的 MBR 或 EFI 分区的第一阶段引导程序,并把控制权交给引导程序。
|
||||
|
||||
#### MBR 方式 ####
|
||||
|
||||
MBR 是位于 BISO 设置中标记为可启动磁盘上的第一个扇区,大小是 512 个字节。
|
||||
MBR 是位于 BIOS 设置中标记为可启动磁盘上的第一个扇区,大小是 512 个字节。
|
||||
|
||||
- 前面 446 个字节:包括可执行代码和错误信息文本的引导程序
|
||||
- 接下来的 64 个字节:四个分区(主分区或扩展分区)中每个分区一条记录的分区表。其中,每条记录标示了每个一个分区的状态(是否活跃)、大小以及开始和结束扇区。
|
||||
- 最后 2 个字节: MBR 有效性检查的魔数。
|
||||
- 最后 2 个字节: MBR 有效性检查的魔法数。
|
||||
|
||||
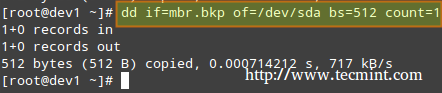
下面的命令对 MBR 进行备份(在本例中,/dev/sda 是第一块硬盘)。结果文件 mbr.bkp 在分区表被破坏、例如系统不可引导时能排上用场。
|
||||
|
||||
@ -41,7 +41,7 @@ MBR 是位于 BISO 设置中标记为可启动磁盘上的第一个扇区,大
|
||||
|
||||

|
||||
|
||||
在 Linux 中备份 MBR
|
||||
*在 Linux 中备份 MBR*
|
||||
|
||||
**恢复 MBR**
|
||||
|
||||
@ -49,7 +49,7 @@ MBR 是位于 BISO 设置中标记为可启动磁盘上的第一个扇区,大
|
||||
|
||||
|
||||
|
||||
在 Linux 中恢复 MBR
|
||||
*在 Linux 中恢复 MBR*
|
||||
|
||||
#### EFI/UEFI 方式 ####
|
||||
|
||||
@ -74,11 +74,11 @@ init 和 systemd 都是管理其它守护进程的守护进程(后台进程)
|
||||
|
||||

|
||||
|
||||
Systemd 和 Init
|
||||
*Systemd 和 Init*
|
||||
|
||||
### 自启动服务(SysVinit) ###
|
||||
|
||||
Linux 中运行等级的概念表示通过控制运行哪些服务来以不同方式使用系统。换句话说,运行等级控制着当前执行状态下可以完成什么任务(以及什么不能完成)。
|
||||
Linux 中运行等级通过控制运行哪些服务来以不同方式使用系统。换句话说,运行等级控制着当前执行状态下可以完成什么任务(以及什么不能完成)。
|
||||
|
||||
传统上,这个启动过程是基于起源于 System V Unix 的形式,通过执行脚本启动或者停止服务从而使机器进入指定的运行等级(换句话说,是一个不同的系统运行模式)。
|
||||
|
||||
@ -88,47 +88,17 @@ Linux 中运行等级的概念表示通过控制运行哪些服务来以不同
|
||||
|
||||
除了启动系统进程,init 还会查看 /etc/inittab 来决定进入哪个运行等级。
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="85">
|
||||
</colgroup>
|
||||
<colgroup width="1514">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;"><b>Runlevel</b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><b> Description</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">0</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 停止系统。运行等级 0 是一个用于快速关闭系统的特殊过渡状态。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="20" style="border: 1px solid #000001;">1</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 别名为 s 或 S,这个运行等级有时候也称为维护模式。在这个运行等级启动的服务由于发行版不同而不同。通常用于正常系统操作损坏时低级别的系统维护。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">2</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 多用户。在 Debian 系统及其衍生版中,这是默认的运行等级,还包括了一个图形化登录(如果有的话)。在基于红帽的系统中,这是没有网络的多用户模式。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">3</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 在基于红帽的系统中,这是默认的多用户模式,运行除了图形化环境以外的所有东西。基于 Debian 的系统中通常不会使用这个运行等级以及等级 4 和 5。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">4</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 通常默认情况下不使用,可用于自定制。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">5</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 基于红帽的系统中,支持 GUI 登录的完全多用户模式。这个运行等级和等级 3 类似,但是有可用的 GUI 登录。</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000001;">6</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 重启系统。</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|Runlevel| Description|
|
||||
|--------|------------|
|
||||
|0|停止系统。运行等级 0 是一个用于快速关闭系统的特殊过渡状态。|
|
||||
|1|别名为 s 或 S,这个运行等级有时候也称为维护模式。在这个运行等级启动的服务由于发行版不同而不同。通常用于正常系统操作损坏时低级别的系统维护。|
|
||||
|2|多用户。在 Debian 系统及其衍生版中,这是默认的运行等级,还包括了一个图形化登录(如果有的话)。在基于红帽的系统中,这是没有网络的多用户模式。|
|
||||
|3|在基于红帽的系统中,这是默认的多用户模式,运行除了图形化环境以外的所有东西。基于 Debian 的系统中通常不会使用这个运行等级以及等级 4 和 5。|
|
||||
|4|通常默认情况下不使用,可用于自定制。|
|
||||
|5|基于红帽的系统中,支持 GUI 登录的完全多用户模式。这个运行等级和等级 3 类似,但是有可用的 GUI 登录。|
|
||||
|6|重启系统。|
|
||||
|
||||
|
||||
要在运行等级之间切换,我们只需要使用 init 命令更改运行等级:init N(其中 N 是上面列出的一个运行等级)。
|
||||
请注意这并不是运行中的系统切换运行等级的推荐方式,因为它不会给已经登录的用户发送警告(因而导致他们丢失工作以及进程异常终结)。
|
||||
@ -139,7 +109,7 @@ Linux 中运行等级的概念表示通过控制运行哪些服务来以不同
|
||||
|
||||
id:2:initdefault:
|
||||
|
||||
并用你喜欢的文本编辑器,例如 vim(本系列的[第二讲 : 如何在 Linux 中使用 vi/vim 编辑器][2]),更改数字 2 为想要的运行等级。
|
||||
并用你喜欢的文本编辑器,例如 vim(本系列的 [LFCS 系列第二讲:如何安装和使用纯文本编辑器 vi/vim][2]),更改数字 2 为想要的运行等级。
|
||||
|
||||
然后,以 root 用户执行
|
||||
|
||||
@ -149,7 +119,7 @@ Linux 中运行等级的概念表示通过控制运行哪些服务来以不同
|
||||
|
||||

|
||||
|
||||
在 Linux 中更改运行等级
|
||||
*在 Linux 中更改运行等级*
|
||||
|
||||
#### 使用 chkconfig 管理服务 ####
|
||||
|
||||
@ -165,7 +135,7 @@ Linux 中运行等级的概念表示通过控制运行哪些服务来以不同
|
||||
|
||||

|
||||
|
||||
列出运行等级配置
|
||||
*列出运行等级配置*
|
||||
|
||||
从上图中我们可以看出,当系统进入运行等级 2 到 5 的时候就会启动 postfix,而默认情况下运行等级 2 到 4 时会运行 mysqld。现在假设我们并不希望如此。
|
||||
|
||||
@ -183,7 +153,7 @@ Linux 中运行等级的概念表示通过控制运行哪些服务来以不同
|
||||
|
||||
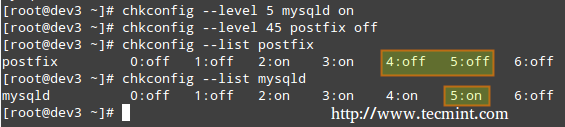
|
||||
|
||||
启用/停用服务
|
||||
*启用/停用服务*
|
||||
|
||||
我们在基于 Debian 的系统中使用 sysv-rc-conf 完成类似任务。
|
||||
|
||||
@ -196,29 +166,29 @@ Linux 中运行等级的概念表示通过控制运行哪些服务来以不同
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
查看运行中服务的运行等级
|
||||
*查看运行中服务的运行等级*
|
||||
|
||||
2. 我们使用 sysv-rc-conf 设置防止 mdadm 在运行等级2 之外的其它等级启动。只需根据需要(你可以使用上下左右按键)选中或取消选中(通过空格键)。
|
||||
|
||||
# sysv-rc-conf
|
||||
|
||||

|
||||

|
||||
|
||||
Sysv 运行等级配置
|
||||
*Sysv 运行等级配置*
|
||||
|
||||
然后输入 q 退出。
|
||||
然后输入 q 退出。
|
||||
|
||||
3. 重启系统并从步骤 1 开始再操作一遍。
|
||||
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||

|
||||

|
||||
|
||||
验证服务运行等级
|
||||
*验证服务运行等级*
|
||||
|
||||
从上图中我们可以看出 mdadm 配置为只在运行等级 2 上启动。
|
||||
从上图中我们可以看出 mdadm 配置为只在运行等级 2 上启动。
|
||||
|
||||
### 那关于 systemd 呢? ###
|
||||
|
||||
@ -232,11 +202,11 @@ systemd 是另外一个被多种主流 Linux 发行版采用的服务和系统
|
||||
|
||||

|
||||
|
||||
查看运行中的进程
|
||||
*查看运行中的进程*
|
||||
|
||||
LOAD 一列显示了单元(UNIT 列,显示服务或者由 systemd 维护的其它进程)是否正确加载,ACTIVE 和 SUB 列则显示了该单元当前的状态。
|
||||
|
||||
显示服务当前状态的信息
|
||||
**显示服务当前状态的信息**
|
||||
|
||||
当 ACTIVE 列显示某个单元状态并非活跃时,我们可以使用以下命令查看具体原因。
|
||||
|
||||
@ -248,7 +218,7 @@ LOAD 一列显示了单元(UNIT 列,显示服务或者由 systemd 维护的
|
||||
|
||||

|
||||
|
||||
查看服务状态
|
||||
*查看服务状态*
|
||||
|
||||
我们可以看到 media-samba.mount 失败的原因是 host dev1 上的挂载进程无法找到 //192.168.0.10/gacanepa 上的共享网络。
|
||||
|
||||
@ -262,9 +232,9 @@ LOAD 一列显示了单元(UNIT 列,显示服务或者由 systemd 维护的
|
||||
# systemctl restart media-samba.mount
|
||||
# systemctl status media-samba.mount
|
||||
|
||||

|
||||

|
||||
|
||||
启动停止服务
|
||||
*启动停止服务*
|
||||
|
||||
**启用或停用某服务随系统启动**
|
||||
|
||||
@ -278,7 +248,7 @@ LOAD 一列显示了单元(UNIT 列,显示服务或者由 systemd 维护的
|
||||
|
||||

|
||||
|
||||
启用或停用服务
|
||||
*启用或停用服务*
|
||||
|
||||
你也可以用下面的命令查看某个服务的当前状态(启用或者停用)。
|
||||
|
||||
@ -358,13 +328,13 @@ via: http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[2]:https://linux.cn/article-7165-1.html
|
||||
[3]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
[4]:http://www.tecmint.com/remove-unwanted-services-from-linux/
|
||||
[5]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
@ -0,0 +1,38 @@
|
||||
Linux will be the major operating system of 21st century cars
|
||||
===============================================================
|
||||
|
||||
>Cars are more than engines and good looking bodies. They're also complex computing devices so, of course, Linux runs inside them.
|
||||
|
||||
Linux doesn't just run your servers and, via Android, your phones. It also runs your cars. Of course, no one has ever bought a car for its operating system. But Linux is already powering the infotainment, heads-up display and connected car 4G and Wi-Fi systems for such major car manufacturers as Toyota, Nissan, and Jaguar Land Rover and [Linux is on its way to Ford][1], Mazda, Mitsubishi, and Subaru cars.
|
||||
|
||||

|
||||
>All the Linux and open-source car software efforts have now been unified under the Automotive Grade Linux project.
|
||||
|
||||
Software companies are also getting into this Internet of mobile things act. Movimento, Oracle, Qualcomm, Texas Instruments, UIEvolution and VeriSilicon have all [joined the Automotive Grade Linux (AGL)][2] project. The [AGL][3] is a collaborative open-source project devoted to creating a common, Linux-based software stack for the connected car.
|
||||
|
||||
AGL has seen tremendous growth over the past year as demand for connected car technology and infotainment are rapidly increasing," said Dan Cauchy, the Linux Foundation's General Manager of Automotive, in a statement.
|
||||
|
||||
Cauchy continued, "Our membership base is not only growing rapidly, but it is also diversifying across various business interests, from semiconductors and in-vehicle software to IoT and connected cloud services. This is a clear indication that the connected car revolution has broad implications across many industry verticals."
|
||||
|
||||
These companies have joined after AGL's recent announcement of a new AGL Unified Code Base (UCB). This new Linux distribution is based on AGL and two other car open-source projects: [Tizen][4] and the [GENIVI Alliance][5]. UCB is a second-generation car Linux. It was built from the ground up to address automotive specific applications. It handles navigation, communications, safety, security and infotainment functionality,
|
||||
|
||||
"The automotive industry needs a standard open operating system and framework to enable automakers and suppliers to quickly bring smartphone-like capabilities to the car," said Cauchy. "This new distribution integrates the best components from AGL, Tizen, GENIVI and related open-source code into a single AGL Unified Code Base, allowing car-makers to leverage a common platform for rapid innovation. The AGL UCB distribution will play a huge role in the adoption of Linux-based systems for all functions in the vehicle."
|
||||
|
||||
He's right. Since its release in January 2016, four car companies and ten new software businesses have joined AGL. Esso, now Exxon, made the advertising slogan, "Put a tiger in your tank!" famous. I doubt that "Put a penguin under your hood" will ever become well-known, but that's exactly what's happening. Linux is well on its way to becoming the major operating system of 21st century cars.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/the-linux-in-your-car-movement-gains-momentum/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]: https://www.automotivelinux.org/news/announcement/2016/01/ford-mazda-mitsubishi-motors-and-subaru-join-linux-foundation-and
|
||||
[2]: https://www.automotivelinux.org/news/announcement/2016/05/oracle-qualcomm-innovation-center-texas-instruments-and-others-support
|
||||
[3]: https://www.automotivelinux.org/
|
||||
[4]: https://www.tizen.org/
|
||||
[5]: http://www.genivi.org/
|
||||
@ -0,0 +1,52 @@
|
||||
eriwoon 翻译中 -- 2106-May-19
|
||||
Open source from a recruiter's perspective
|
||||
============================================
|
||||
|
||||

|
||||
|
||||
I fell in love with technology when I went to my first open source convention in 2012.
|
||||
|
||||
After spending years in recruiting, I decided to take a job specializing in big data at [Greythorn][1]. I had been trying to learn the ropes for a few months leading up to [OSCON][2], but going to the conference sped that process up like crazy. There were so many brilliant people all in one place, and everyone was willing to share what they knew. It wasn't because they were trying to sell me anything, but because they were all so passionate about what they were working on.
|
||||
|
||||
I soon realized that, in many ways, the open source and big data industry was less an industry and more of a community. That's why I now try to pay it forward and share what I've learned about open source with those who are just getting started in their careers.
|
||||
|
||||
### Why employers want open source contributors
|
||||
|
||||
Many clients tell me that although they want a candidate who has an exceptional technical mind, the ideal person should also really like this stuff. When you are passionate about something, you find yourself working on it even when you aren't getting paid.
|
||||
|
||||
My clients often ask, "Do they code in their spare time?" "Can I find their work anywhere?" "What do they really enjoy?" Open source contributors are often at an advantage because they check these boxes, and not only are their projects out in the open—so is the evidence of their coding proficiency.
|
||||
|
||||
#### Why recruiters search for open source contributors
|
||||
|
||||
Solid tech recruiters understand the technologies and roles they're recruiting for, and they're going to assess your skills accordingly. But I'll admit that many of us have found that the best candidates we've come across have a tendency to be involved in open source, so we often just start our search there. Recruiters provide value to clients when they find candidates who are motivated to work on a team to create something awesome, because that's basically the description of a top-performing employee.
|
||||
|
||||
It makes sense to me: When you take really smart people and give them the chance to be collaborative—for the sake of making something that works really well or may change the landscape of our everyday lives—it creates an energy that can be addictive.
|
||||
|
||||
### What open source contributors can do to build a happy career
|
||||
|
||||
There are obvious things you can do to leverage your open source work to build your career: Put your code on GitHub, participate in projects, go to conferences and join panels and workshops, etc. These are worthwhile, but more than anything you need to know what will make you happy in your work.
|
||||
|
||||
Ask yourself questions like...
|
||||
|
||||
* **Is it important to work for a company that gives back to the open source and software community?** I find that some of my best candidates insist on this, and it makes a huge difference in their job satisfaction.
|
||||
* **Do you want to work for a company that is based on open source?** The culture is often different in these environments, and it helps to know if that's where you think you'll fit best.
|
||||
* **Are there people you'd specifically like to work with?** Although you can always try to join the same projects, the odds of collaborating with and learning from someone you admire are better if your day jobs align at the same company.
|
||||
|
||||
Once you know your own career priorities, it's easier to filter out the jobs that won't move you closer to your goals—and if you're working with a recruiter, it helps them match you with the right employer and team.
|
||||
|
||||
Although I don't contribute code, I'll always share what I've learned with those who are working on their career in open source. This community is made up of supportive and smart people, and I love that I've been able to be a small part of it.
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/open-source-recruiters-perspective
|
||||
|
||||
作者:[Lindsey Thorne][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lindsey-thorne
|
||||
[1]: http://www.greythorn.com/
|
||||
[2]: http://conferences.oreilly.com/oscon
|
||||
104
sources/talk/20160523 Driving cars into the future with Linux.md
Normal file
104
sources/talk/20160523 Driving cars into the future with Linux.md
Normal file
@ -0,0 +1,104 @@
|
||||
Driving cars into the future with Linux
|
||||
===========================================
|
||||
|
||||

|
||||
|
||||
I don't think much about it while I'm driving, but I sure do love that my car is equipped with a system that lets me use a few buttons and my voice to call my wife, mom, and children. That same system allows me to choose whether I listen to music streaming from the cloud, satellite radio, or the more traditional AM/FM radio. I also get weather updates and can direct my in-vehicle GPS to find the fastest route to my next destination. [In-vehicle infotainment][1], or IVI as it's known in the industry, has become ubiquitous in today's newest automobiles.
|
||||
|
||||
A while ago, I had to travel hundreds of miles by plane and then rent a car. Happily, I discovered that my rental vehicle was equipped with IVI technology similar to my own car. In no time, I was connected via Bluetooth, had uploaded my contacts into the system, and was calling home to let my family know I arrived safely and my hosts to let them know I was en route to their home.
|
||||
|
||||
In a recent [news roundup][2], Scott Nesbitt cited an article that said Ford Motor Company is getting substantial backing from a rival automaker for its open source [Smart Device Link][3] (SDL) middleware framework, which supports mobile phones. SDL is a project of the [GENIVI Alliance][4], a nonprofit committed to building middleware to support open source in-vehicle infotainment systems. According to [Steven Crumb][5], executive director of GENIVI, their [membership][6] is broad and includes Daimler Group, Hyundai, Volvo, Nissan, Honda, and 170 others.
|
||||
|
||||
In order to remain competitive in the industry, automotive companies need a middleware system that can support the various human machine interface technologies available to consumers today. Whether you own an Android, iOS, or other device, automotive OEMs want their units to be able to support these systems. Furthermore, these IVI systems must be adaptable enough to support the ever decreasing half-life of mobile technology. OEMs want to provide value and add services in their IVI stacks that will support a variety of options for their customers. Enter Linux and open source software.
|
||||
|
||||
In addition to GENIVI's efforts, the [Linux Foundation][7] sponsors the [Automotive Grade Linux][8] (AGL) workgroup, a software foundation dedicated to finding open source solutions for automotive applications. Although AGL will initially focus on IVI systems, they envision branching out to include [telematics][9], heads up displays, and other control systems. AGL has over 50 members at this time, including Jaguar, Toyota, and Nissan, and in a [recent press release][10] announced that Ford, Mazda, Mitsubishi, and Subaru have joined.
|
||||
|
||||
To find out more, we interviewed two leaders in this emerging field. Specifically, we wanted to know how Linux and open source software are being used and if they are in fact changing the face of the automotive industry. First, we talk to [Alison Chaiken][11], a software engineer at Peloton Technology and an expert on automotive Linux, cybersecurity, and transparency. She previously worked for Mentor Graphics, Nokia, and the Stanford Linear Accelerator. Then, we chat with [Steven Crumb][12], executive director of GENIVI, who got started in open source in high-performance computing environments (supercomputers and early cloud computing). He says that though he's not a coder anymore, he loves to help organizations solve real business problems with open source software.
|
||||
|
||||
### Interview with Alison Chaiken (by [Deb Nicholson][13])
|
||||
|
||||
#### How did you get interested in the automotive software space?
|
||||
|
||||
I was working on [MeeGo][14] in phones at Nokia in 2009 when the project was cancelled. I thought, what's next? A colleague was working on [MeeGo-IVI][15], an early automotive Linux distribution. "Linux is going to be big in cars," I thought, so I headed in that direction.
|
||||
|
||||
#### Can you tell us what aspects you're working on these days?
|
||||
|
||||
I'm currently working for a startup on an advanced cruise control system that uses real-time Linux to increase the safety and fuel economy of big-rig trucks. I love working in this area, as no one would disagree that trucking can be improved.
|
||||
|
||||
#### There have been a few stories about hacked cars in recent years. Can open source solutions help address this issue?
|
||||
|
||||
I presented a talk on precisely this topic, on how Linux can (and cannot) contribute to security solutions in automotive at Southern California Linux Expo 2016 ([Slides][16]). Notably, GENIVI and Automotive Grade Linux have published their code and both projects take patches via Git. Please send your fixes upstream! Many eyes make all bugs shallow.
|
||||
|
||||
#### Law enforcement agencies and insurance companies could find plenty of uses for data about drivers. How easy will it be for them to obtain this information?
|
||||
|
||||
Good question. The Dedicated Short Range Communication Standard (IEEE-1609) takes great pains to keep drivers participating in Wi-Fi safety messaging anonymous. Still, if you're posting to Twitter from your car, someone will be able to track you.
|
||||
|
||||
#### What can developers and private citizens do to make sure civil liberties are protected as automotive technology evolves?
|
||||
|
||||
The Electronic Frontier Foundation (EFF) has done an excellent job of keeping on top of automotive issues, having commented through official channels on what data may be stored in automotive "black boxes" and on how DMCA's Provision 1201 applies to cars.
|
||||
|
||||
#### What are some of the exciting things you see coming for drivers in the next few years?
|
||||
|
||||
Adaptive cruise control and collision avoidance systems are enough of an advance to save lives. As they roll out through vehicle fleets, I truly believe that fatalities will decline. If that's not exciting, I don't know what is. Furthermore, capabilities like automated parking assist will make cars easier to drive and reduce fender-benders.
|
||||
|
||||
#### What needs to be built and how can people get involved?
|
||||
|
||||
Automotive Grade Linux is developed in the open and runs on cheap hardware (e.g. Raspberry Pi 2 and moderately priced Renesas Porter board) that anyone can buy. GENIVI automotive Linux middleware consortium has lots of software publicly available via Git. Furthermore, there is the ultra cool [OSVehicle open hardware][17] automotive platform.
|
||||
|
||||
#### There are many ways for Linux software and open hardware folks with moderate budgets to get involved. Join us at #automotive on Freenode IRC if you have questions.
|
||||
|
||||
### Interview with Steven Crumb (by Don Watkins)
|
||||
|
||||
#### What's so huge about GENIVI's approach to IVI?
|
||||
|
||||
GENIVI filled a huge gap in the automotive industry by pioneering the use of free and open source software, including Linux, for non-safety-critical automotive software like in-vehicle infotainment (IVI) systems. As consumers came to expect the same functionality in their vehicles as on their smartphones, the amount of software required to support IVI functions grew exponentially. The increased amount of software has also increased the costs of building the IVI systems and thus slowed time to market.
|
||||
|
||||
GENIVI's use of open source software and a community development model has saved automakers and their software suppliers significant amounts of money while significantly reducing the time to market. I'm excited about GENIVI because we've been fortunate to lead a revolution of sorts in the automotive industry by slowly evolving organizations from a highly structured and proprietary methodology to a community-based approach. We're not done yet, but it's been a privilege to take part in a transformation that is yielding real benefits.
|
||||
|
||||
#### How do your major members drive the direction of GENIVI?
|
||||
|
||||
GENIVI has a lot of members and non-members contributing to our work. As with many open source projects, any company can influence the technical output by simply contributing code, patches, and time to test. With that said, BMW, Mercedes-Benz, Hyundai Motor, Jaguar Land Rover, PSA, Renault/Nissan, and Volvo are all active adopters of and contributors to GENIVI—and many other OEMs have IVI solutions in their cars that extensively use GENIVI's software.
|
||||
|
||||
#### What licenses cover the contributed code?
|
||||
|
||||
GENIVI employs a number of licenses ranging from (L)GPLv2 to MPLv2 to Apache 2.0. Some of our tools use the Eclipse license. We have a [public licensing policy][18] that details our licensing preferences.
|
||||
|
||||
#### How does a person or group get involved? How important are community contributions to the ongoing success of the project?
|
||||
|
||||
GENIVI does its development completely in the open ([projects.genivi.org][19]) and thus, anyone interested in using open software in automotive is welcome to participate. That said, the alliance can fund its continued development in the open through companies [joining GENIVI][20] as members. GENIVI members enjoy a wide variety of benefits, not the least of which is participation in the global community of 140 companies that has been developed over the last six years.
|
||||
|
||||
Community is hugely important to GENIVI, and we could not have produced and maintained the valuable software we developed over the years without an active community of contributors. We've worked hard to make contributing to GENIVI as simple as joining an [email list][21] and connecting to the people in the various software projects. We use standard practices employed by many open source projects and provide high-quality tools and infrastructure to help developers feel at home and be productive.
|
||||
|
||||
Regardless of someone's familiarity with the automotive software, they are welcome to join our community. People have modified cars for years, so for many people there is a natural draw to anything automotive. Software is the new domain for cars, and GENIVI wants to be the open door for anyone interested in working with automotive, open source software.
|
||||
|
||||
-------------------------------
|
||||
via: https://opensource.com/business/16/5/interview-alison-chaiken-steven-crumb
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[1]: https://en.wikipedia.org/wiki/In_car_entertainment
|
||||
[2]: https://opensource.com/life/16/1/weekly-news-jan-9
|
||||
[3]: http://projects.genivi.org/smartdevicelink/home
|
||||
[4]: http://www.genivi.org/
|
||||
[5]: https://www.linkedin.com/in/stevecrumb
|
||||
[6]: http://www.genivi.org/genivi-members
|
||||
[7]: http://www.linuxfoundation.org/
|
||||
[8]: https://www.automotivelinux.org/
|
||||
[9]: https://en.wikipedia.org/wiki/Telematics
|
||||
[10]: https://www.automotivelinux.org/news/announcement/2016/01/ford-mazda-mitsubishi-motors-and-subaru-join-linux-foundation-and
|
||||
[11]: https://www.linkedin.com/in/alison-chaiken-3ba456b3
|
||||
[12]: https://www.linkedin.com/in/stevecrumb
|
||||
[13]: https://opensource.com/users/eximious
|
||||
[14]: https://en.wikipedia.org/wiki/MeeGo
|
||||
[15]: http://webinos.org/deliverable-d026-target-platform-requirements-and-ipr/automotive/
|
||||
[16]: http://she-devel.com/Chaiken_automotive_cybersecurity.pdf
|
||||
[17]: https://www.osvehicle.com/
|
||||
[18]: http://projects.genivi.org/how
|
||||
[19]: http://projects.genivi.org/
|
||||
[20]: http://genivi.org/join
|
||||
[21]: http://lists.genivi.org/mailman/listinfo/genivi-projects
|
||||
@ -0,0 +1,51 @@
|
||||
What containers and unikernels can learn from Arduino and Raspberry Pi
|
||||
==========================================================================
|
||||
|
||||

|
||||
|
||||
|
||||
Just the other day, I was speaking with a friend who is a mechanical engineer. He works on computer assisted braking systems for semi trucks and mentioned that his company has [Arduinos][1] all over the office. The idea is to encourage people to quickly experiment with new ideas. He also mentioned that Arduinos are more expensive than printed circuits. I was surprised by his comment about price, because coming from the software side of things, my perceptions of Arduinos was that they cost less than designing a specialized circuit.
|
||||
|
||||
I had always viewed [Arduinos][2] and [Raspberry Pi][3] as these cool, little, specialized devices that can be used to make all kinds of fun gadgets. I came from the software side of the world and have always considered Linux on x86 and x86-64 "general purpose." The truth is, Arduinos are not specialized. In fact, they are very general purpose. They are fairly small, fairly cheap, and extremely flexible—that's why they caught on like wildfire. They have all kinds of I/O ports and expansion cards. They allow a maker to go out and build something cool really quickly. They even allow companies to build new products quickly.
|
||||
|
||||
The unit price for an Arduino is much higher than a printed circuit, but time to a minimum viable idea is much lower. With a printed circuit, the unit price can be driven much lower but the upfront capital investment is much higher. So, long story short, the answer is—it depends.
|
||||
|
||||
### Unikernels, rump kernels, and container hosts
|
||||
|
||||
Enter unikernels, rump kernels, and minimal Linux distributions—these operating systems are purpose-built for specific use cases. These specialized operating systems are kind of like printed circuits. They require some up-front investment in planning and design to utilize, but could provide a great performance increase when deploying a specific workload at scale.
|
||||
|
||||
Minimal operating systems such as Red Hat Enterprise Linux Atomic or CoreOS are purpose-built to run containers. They are small, quick, easily configured at boot time, and run containers quite well. The downside is that it requires extra engineering to add third-party extensions such as monitoring agents or tools for virtualization. Some side-loaded tooling needs redesigned as super-privileged containers. This extra engineering could be worth it if you are building a big enough container environment, but might not be necessary to just try out containers.
|
||||
|
||||
Containers provide the ability to run standard workloads (things built on [glibc][4], etc.). The advantage is that the workload artifact (Docker image) can be built and tested on your desktop and deployed in production on completely different hardware or in the cloud with confidence that it will run with the same characteristics. In the production environment, container hosts are still configured by the operations teams, but the application is controlled by the developer. This is a sort of a best of both worlds.
|
||||
|
||||
Unikernels and rump kernels are also purpose-built, but go a step further. The entire operating system is configured at build time by the developer or architect. This has benefits and challenges.
|
||||
|
||||
One benefit is that the developer can control a lot about how the workload will run. Theoretically, a developer could try out [different TCP stacks][5] for different performance characteristics and choose the best one. The developer can configure the IP address ahead of time or have the system configure itself at boot with DHCP. The developer can also cut out anything that is not necessary for their application. There is also the promise of increased performance because of less [context switching][6].
|
||||
|
||||
There are also challenges with unikernels. Currently, there is a lot of tooling missing. It's much like a printed circuit world right now. A developer has to invest a lot of time and energy discerning if all of the right libraries exist, or they have to change the way their application works. There may also be challenges with how the "embedded" operating system is configured at runtime. Finally, every time a major change is made to the OS, it requires [going back to the developer][7] to change it. This is not a clean separation between development and operations, so I envision some organizational changes being necessary to truly adopt this model.
|
||||
|
||||
### Conclusion
|
||||
|
||||
There is a lot of interesting buzz around specialized container hosts, rump kernels, and unikernels because they hold the potential to revolutionize certain workloads (embedded, cloud, etc.). Keep your eye on this exciting, fast moving space, but cautiously.
|
||||
|
||||
Currently, unikernels seem quite similar to building printed circuits. They require a lot of upfront investment to utilize and are very specialized, providing benefits for certain workloads. In the meantime containers are quite interesting even for conventional workloads and don't require as much investment. Typically an operations team should be able to port an application to containers, whereas it takes real re-engineering to port an application to unikernels and the industry is still not quite sure what workloads can be ported to unikernels.
|
||||
|
||||
Here's to an exciting future of containers, rump kernels, and unikernels!
|
||||
|
||||
--------------------------------------
|
||||
via: https://opensource.com/business/16/5/containers-unikernels-learn-arduino-raspberry-pi
|
||||
|
||||
作者:[Scott McCarty][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/fatherlinux
|
||||
[1]: https://opensource.com/resources/what-arduino
|
||||
[2]: https://opensource.com/life/16/4/arduino-day-3-projects
|
||||
[3]: https://opensource.com/resources/what-raspberry-pi
|
||||
[4]: https://en.wikipedia.org/wiki/GNU_C_Library
|
||||
[5]: http://www.eetasia.com/ARTICLES/2001JUN/2001JUN18_NTEK_CT_AN5.PDF
|
||||
[6]: https://en.wikipedia.org/wiki/Context_switch
|
||||
[7]: http://developers.redhat.com/blog/2016/05/18/3-reasons-i-should-build-my-containerized-applications-on-rhel-and-openshift/
|
||||
@ -1,75 +0,0 @@
|
||||
hkurj translating
|
||||
A four year, action-packed experience with Wikipedia
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
|
||||
I consider myself to be an Odia Wikimedian. I contribute [Odia][1] knowledge (the predominant language of the Indian state of [Odisha][2]) to many Wikimedia projects, like Wikipedia and Wikisource, by writing articles and correcting mistakes in articles. I also contribute to Hindi and English Wikipedia articles.
|
||||
|
||||

|
||||
|
||||
My love for Wikimedia started while I was reading an article about the [Bangladesh Liberation war][3] on the English Wikipedia after my 10th board exam (like, an annual exam for 10th grade students in America). By mistake I clicked on a link that took me to an India Wikipedia article, and I started reading. Something was written in Odia on the lefthand side of the article, so I clicked on that, and reached a [ଭାରତ/Bhārat][4] article on the Odia Wikipedia. I was excited to find a Wikipedia article in my native language!
|
||||
|
||||

|
||||
|
||||
A banner inviting readers to be part of the 2nd Bhubaneswar workshop on April 1, 2012 sparked my curiousity. I had never contributed to Wikipedia before, only used it for research, and I wasn't familiar with open source and the community contribution process. Plus, I was only 15 years old. I registered. There were many language enthusiasts at the workshop, and all older than me. My father encouraged me to the participate despite my fear; he has played an important role—he's not a Wikimedian, like me, but his encouragement has helped me change Odia Wikipedia and participate in community activities.
|
||||
|
||||
I believe that knowledge about Odia language and literature needs to improve—there are many misconceptions and knowledge gaps—so, I help organize events and workshops for Odia Wikipedia. On my accomplished list at the point, I have:
|
||||
|
||||
* initiated three major edit-a-thons in Odia Wikipedia: Women's Day 2015, Women's Day 2016, abd [Nabakalebara edit-a-thon 2015][5]
|
||||
* initiated a photograph contest to get more [Rathyatra][6] images from all over the India
|
||||
* represented Odia Wikipedia during two events by Google ([Google I/O extended][7] and Google Dev Fest)
|
||||
* spoke at [Perception][8] 2015 and the first [Open Access India][9] meetup
|
||||
|
||||

|
||||
|
||||
I was just an editor to Wikipedia projects until last year, in January 2015, when I attended [Bengali Wikipedia's 10th anniversary conference][10] and [Vishnu][11], the director of the [Center for Internet and Society][12] at the time, invited me to attend the [Train the Trainer][13] Program. I was inspired to start doing outreach for Odia Wikipedia and hosting meetups for [GLAM]14] activities and training new Wikimedians. These experience taught me how to work with a community of contributors.
|
||||
|
||||
[Ravi][15], the director of Wikimedia India at the time, also played an important role in my journey. He trusted me and made me a part of [Wiki Loves Food][16], a public photo competition on Wikimedia Commons, and the organizing committee of [Wikiconference India 2016][17]. During Wiki Loves Food 2015, my team helped add 10,000+ CC BY-SA images on Wikimedia Commons. Ravi further solidified my commitment by sharing a lot of information with me about the Wikimedia movement, and his own journey, during [Odia Wikipedia's 13th anniversary][18].
|
||||
|
||||
Less than a year later, in December 2015, I became a Program Associate at the Center for Internet and Society's [Access to Knowledge program][19] (CIS-A2K). One of my proud moments was at a workshop in Puri, India where we helped bring 20 new Wikimedian editors to the Odia Wikimedia community. Now, I mentor Wikimedians during an informal meetup called [WikiTungi][20] Puri. I am working with this group to make Odia Wikiquotes a live project. I am also dedicated to bridging the gender gap in Odia Wikipedia. [Eight female editors][21] are now helping to organize meetups and workshops, and participate in the [Women's History month edit-a-thon][22].
|
||||
|
||||
During my brief but action-packed journey during the four years since, I have also been involved in the [Wikipedia Education Program][23], the [newsletter team][24], and two global edit-a-thons: [Art and Feminsim][25] and [Menu Challenge][26]. I look forward to the many more to come!
|
||||
|
||||
I would also like to thank [Sameer][27] and [Anna][28] (both previous members of the Wikipedia Education Program).
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/4/my-open-source-story-sailesh-patnaik
|
||||
|
||||
作者:[Sailesh Patnaik][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/saileshpat
|
||||
[1]: https://en.wikipedia.org/wiki/Odia_language
|
||||
[2]: https://en.wikipedia.org/wiki/Odisha
|
||||
[3]: https://en.wikipedia.org/wiki/Bangladesh_Liberation_War
|
||||
[4]: https://or.wikipedia.org/s/d2
|
||||
[5]: https://or.wikipedia.org/s/toq
|
||||
[6]: https://commons.wikimedia.org/wiki/Commons:The_Rathyatra_Challenge
|
||||
[7]: http://cis-india.org/openness/blog-old/odia-wikipedia-meets-google-developer-group
|
||||
[8]: http://perception.cetb.in/events/odia-wikipedia-event/
|
||||
[9]: https://opencon2015kolkata.sched.org/speaker/sailesh.patnaik007
|
||||
[10]: https://meta.wikimedia.org/wiki/Bengali_Wikipedia_10th_Anniversary_Celebration_Kolkata
|
||||
[11]: https://www.facebook.com/vishnu.vardhan.50746?fref=ts
|
||||
[12]: http://cis-india.org/
|
||||
[13]: https://meta.wikimedia.org/wiki/CIS-A2K/Events/Train_the_Trainer_Program/2015
|
||||
[14]: https://en.wikipedia.org/wiki/Wikipedia:GLAM
|
||||
[15]: https://www.facebook.com/ravidreams?fref=ts
|
||||
[16]: https://commons.wikimedia.org/wiki/Commons:Wiki_Loves_Food
|
||||
[17]: https://meta.wikimedia.org/wiki/WikiConference_India_2016
|
||||
[18]: https://or.wikipedia.org/s/sml
|
||||
[19]: https://meta.wikimedia.org/wiki/CIS-A2K
|
||||
[20]: https://or.wikipedia.org/s/xgx
|
||||
[21]: https://or.wikipedia.org/s/ysg
|
||||
[22]: https://or.wikipedia.org/s/ynj
|
||||
[23]: https://outreach.wikimedia.org/wiki/Education
|
||||
[24]: https://outreach.wikimedia.org/wiki/Talk:Education/News#Call_for_volunteers
|
||||
[25]: https://en.wikipedia.org/wiki/User_talk:Saileshpat#Barnstar_for_Art_.26_Feminism_Challenge
|
||||
[26]: https://opensource.com/life/15/11/tasty-translations-the-open-source-way
|
||||
[27]: https://www.facebook.com/samirsharbaty?fref=ts
|
||||
[28]: https://www.facebook.com/anna.koval.737?fref=ts
|
||||
@ -1,103 +0,0 @@
|
||||
translating by martin2011qi
|
||||
|
||||
Why and how I became a software engineer
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
The year was 1989. The city was Kampala, Uganda.
|
||||
|
||||
In their infinite wisdom, my parents decided that instead of all the troublemaking I was getting into at home, they would send me off to my uncle's office to learn how to use a computer. A few days later, I found myself on the 21st floor in a cramped room with six or seven other teens and a brand new computer on a desk perpendicular to the teacher's desk. It was made abundantly clear that we were not skilled enough to touch it. After three frustrating weeks of writing and perfecting DOS commands, the magic moment happened. It was my turn to type **copy doc.txt d:**.
|
||||
|
||||
The alien scratching noises that etched a simple text file onto the five-inch floppy sounded like beautiful music. For a while, that floppy disk was my most prized possession. I copied everything I could onto it. However, in 1989, Ugandans tended to take life pretty seriously, and messing around with computers, copying files, and formatting disks did not count as serious. I had to focus on my education, which led me away from computer science and into architectural engineering.
|
||||
|
||||
Like any young person of my generation, a multitude of job titles and skills acquisition filled the years in between. I taught kindergarten, taught adults how to use software, worked in a clothing store, and served as a paid usher in a church. While I earned my degree at the University of Kansas, I worked as a tech assistant to the technical administrator, which is really just a fancy title for someone who messes around with the student database.
|
||||
|
||||
By the time I graduated in 2007, technology had become inescapable. Every aspect of architectural engineering was deeply intertwined with computer science, so we all inadvertently learned simple programming skills. For me, that part was always more fascinating. But because I had to be a serious engineer, I developed a secret hobby: writing science fiction.
|
||||
|
||||
In my stories, I lived vicariously through the lives of my heroines. They were scientists with amazing programming skills who were always getting embroiled in adventures and fighting tech scallywags with technology they invented, sometimes inventing them on the spot. Sometimes the new tech I came up with was based on real-world inventions. Other times it was the stuff I read about or saw in the science fiction I consumed. This meant that I had to understand how the tech worked and my research led me to some interesting subreddits and e-zines.
|
||||
|
||||
### Open source: The ultimate goldmine
|
||||
|
||||
Throughout my experiences, the fascinating weeks I'd spent writing out DOS commands remained a prominent influence, bleeding into little side projects and occupying valuable study time. As soon as Geocities became available to all Yahoo! Users, I created a website where I published blurry pictures that I'd taken on a tiny digital camera. I created websites for free, helped friends and family fix issues they had with their computers, and created a library database for a church.
|
||||
|
||||
This meant that I was always researching and trying to find more information about how things could be made better. The Internet gods blessed me and open source fell into my lap. Suddenly, 30-day trials and restrictive licenses became a ghost of computing past. I could continue to create using GIMP, Inkscape, and OpenOffice.
|
||||
|
||||
### Time to get serious
|
||||
|
||||
I was fortunate to have a business partner who saw the magic in my stories. She too is a dreamer and visionary who imagines a better connected world that functions efficiently and conveniently. Together, we came up with several solutions to pain points we experienced in the journey to success, but implementation had been a problem. We both lacked the skills to make our products come to life, something that was made evident every time we approached investors with our ideas.
|
||||
|
||||
We needed to learn to program. So, at the end of the summer in 2015, we embarked on a journey that would lead us right to the front steps of Holberton School, a community-driven, project-based school in San Francisco.
|
||||
|
||||
My business partner came to me one morning and started a conversation the way she does when she has a new crazy idea that I'm about to get sucked into.
|
||||
|
||||
**Zee**: Gloria, I'm going to tell you something and I want you to listen first before you say no.
|
||||
|
||||
**Me**: No.
|
||||
|
||||
**Zee**: We're going to be applying to go to a school for full-stack engineers.
|
||||
|
||||
**Me**: What?
|
||||
|
||||
**Zee**: Here, look! We're going to learn how to program by applying to this school.
|
||||
|
||||
**Me**: I don't understand. We're doing online courses in Python and...
|
||||
|
||||
**Zee**: This is different. Trust me.
|
||||
|
||||
**Me**: What about the...
|
||||
|
||||
**Zee**: That's not trusting me.
|
||||
|
||||
**Me**: Fine. Show me.
|
||||
|
||||
### Removing the bias
|
||||
|
||||
What I read sounded similar to something we had seen online. It was too good to be true, but we decided to give it a try, jump in with both feet, and see what would come out of it.
|
||||
|
||||
To become students, we had to go through a four-step selection process based solely on talent and motivation, not on the basis of educational degree or programming experience. The selection process is the beginning of the curriculum, so we started learning and collaborating through it.
|
||||
|
||||
It has been my experience—and that of my business partner—that the process of applying for anything was an utter bore compared to the application process Holberton School created. It was like a game. If you completed a challenge, you got to go to the next level, where another fascinating challenge awaited. We created Twitter accounts, blogged on Medium, learned HTML and CSS in order to create a website, and created a vibrant community online even before we knew who was going to get to go.
|
||||
|
||||
The most striking thing about the online community was how varied our experience with computers was, and how our background and gender did not factor into the choices that were being made by the founders (who we secretly called "The Trinity"). We just enjoyed being together and talking to each other. We were all smart people on a journey to increasing our nerd cred by learning how to code.
|
||||
|
||||
For much of the application process, our identities were not very evident. For example, my business partner's name does not indicate her gender or race. It was during the final step, a video chat, that The Trinity even knew she was a woman of color. Thus far, only her enthusiasm and talent had propelled her through the levels. The color of her skin and her gender did not hinder nor help her. How cool is that?
|
||||
|
||||
The night we got our acceptance letters, we knew our lives were about to change in ways we had only dreamt of. On the 22nd of January 2016, we walked into 98 Battery Street to meet our fellow [Hippokampoiers][2] for the first time. It was evident then, as it had been before, that the Trinity had started something amazing. They had assembled a truly diverse collection of passionate and enthusiastic people who had dedicated themselves to become full-stack engineers.
|
||||
|
||||
The school is an experience like no other. Every day is an intense foray into some facet of programming. We're handed a project and, with a little guidance, we use every resource available to us to find the solution. The premise that [Holberton School][1] is built upon is that information is available to us in more places than we've ever had before. MOOCs, tutorials, the availability of open source software and projects, and online communities are all bursting at the seams with knowledge that shakes up some of the projects we have to complete. And with the support of the invaluable team of mentors to guide us to solutions, the school becomes more than just a school; we've become a community of learners. I would highly recommend this school for anyone who is interested in software engineering and is also interested in the learning style. The next class is in October 2016 and is accepting new applications. It's both terrifying and exhilarating, but so worth it.
|
||||
|
||||
### Open source matters
|
||||
|
||||
My earliest experience with an open source operating system was [Fedora][3], a [Red Hat][4]-sponsored project. During a panicked conversation with an IRC member, she recommended this free OS. I had never installed my own OS before, but it sparked my interest in open source and my dependence on open source software for my computing needs. We are advocates for open source contribution, creation, and use. Our projects are on GitHub where anyone can use or contribute to them. We also have the opportunity to access existing open source projects to use or contribute to in our own way. Many of the tools that we use at school are open source, such as Fedora, [Vagrant][5], [VirtualBox][6], [GCC][7], and [Discourse][8], to name a few.
|
||||
|
||||
As I continue on my journey to becoming a software engineer, I still dream of a time when I will be able to contribute to the open source community and be able to share my knowledge with others.
|
||||
|
||||
### Diversity Matters
|
||||
|
||||
Standing in the room and talking to 29 other bright-eyed learners was intoxicating. 40% of the people there were women and 44% were people of color. These numbers become very important when you are a woman of color in a field that has been famously known for its lack of diversity. It was an oasis in the tech Mecca of the world. I knew I had arrived.
|
||||
|
||||
The notion of becoming a full-stack engineer is daunting, and you may even struggle to know what that means. It is a challenging road to travel with immeasurable rewards to reap. The future is run by technology, and you are an important part of that bright future. While the media continues to trip over handling the issue of diversity in tech companies, know that whoever you are, whatever your background is, whatever your reasons might be for becoming a full-stack engineer, you can find a place to thrive.
|
||||
|
||||
But perhaps most importantly, a strong reminder of the role of women in the history of computing can help more women return to the tech world, and they can be fully engaged without hesitation due to their gender or their capabilities as women. Their talents will help shape the future not just of tech, but of the world.
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/4/my-open-source-story-gloria-bwandungi
|
||||
|
||||
作者:[Gloria Bwandungi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nappybrain
|
||||
[1]: https://www.holbertonschool.com/
|
||||
[2]: https://twitter.com/hippokampoiers
|
||||
[3]: https://en.wikipedia.org/wiki/Fedora_(operating_system)
|
||||
[4]: https://www.redhat.com/
|
||||
[5]: https://www.vagrantup.com/
|
||||
[6]: https://www.virtualbox.org/
|
||||
[7]: https://gcc.gnu.org/
|
||||
[8]: https://www.discourse.org/
|
||||
@ -0,0 +1,54 @@
|
||||
IS UBUNTU’S SNAP PACKAGING REALLY SECURE
|
||||
==========================================
|
||||
|
||||
|
||||
The recent release of [Ubuntu 16.04 LTS has brought a number of new features][1], one of which we covered was the [inclusion of ZFS][2]. Another feature that many people have been talking about is the Snap package format. But according to one of the developers of [CoreOS][3], the Snap packages are not as safe as the claim.
|
||||
|
||||
### WHAT ARE SNAP PACKAGES?
|
||||
|
||||
Snap packages are inspired by containers. This new package format allows [developers to issue updates for applications running on Ubuntu Long-Term-Support (LTS) releases][4]. This gives users the option to run a stable operating system, but keep their applications updated. This is accomplished by including all of the application’s dependencies in the same package. This prevents the program from breaking when a dependency updates.
|
||||
|
||||
Another advantage of Snap packages is that the applications are isolated from the rest of the system. This means that if you change something with a Snap package, it will not affect the rest of the system. It also prevents other applications from accessing your private information, which makes it harder for hackers to get your data.
|
||||
|
||||
### BUT WAIT…
|
||||
|
||||
According to [Matthew Garrett][5], Snap can’t quite deliver on the last promise. Garret works as a Linux kernel developer and security developer at CoreOS, so he should know what he’s talking about.
|
||||
|
||||
[According to Garret][6], “Any Snap package you install is completely capable of copying all your private data to wherever it wants with very little difficulty.”
|
||||
|
||||
[ZDnet][7] reported:
|
||||
|
||||
>*“To prove his point, he built a proof-of-concept attack package in Snap, which first shows an “adorable” teddy bear and then logs keystrokes from Firefox and could be used to steal private SSH keys. The PoC actually injects a harmless command, but could be tweaked to include a cURL session to steal SSH keys.”*
|
||||
|
||||
### BUT WAIT A LITTLE MORE…
|
||||
|
||||
Is it really that Snap has security flaws? Apparently not so.
|
||||
|
||||
Garret himself said that this problem was caused by the X11 window system and did not affect mobile devices that use Mir. So, it is the flaw in X11 that does it. It’s not Snap itself.
|
||||
|
||||
>how X11 trusts applications is a well-known security risk. Snap doesn’t change X11’s trust model, so the fact that applications can see what other applications are doing isn’t a weakness in the new package format, but rather X11’s.
|
||||
|
||||
Garrett is just actually trying to show that when Canonical is all praises for Snap and its security; Snap applications are not fully sandboxed. They are as risky as any other binaries.
|
||||
|
||||
Keeping the fact in mind that Ubuntu 16.04 still uses X11 display, and not Mir, downloading and installing Snap packages from unknown sources might be harmful. But that’s the case with any other packaging, isn’t it?
|
||||
|
||||
In related articles, you should check out [how to use Snap packages in Ubuntu 16.04][8]. And do let us know of your views on Snap and its security.
|
||||
|
||||
----------
|
||||
via: http://itsfoss.com/snap-package-securrity-issue/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[ John Paul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/john/
|
||||
[1]: http://itsfoss.com/features-ubuntu-1604/
|
||||
[2]: http://itsfoss.com/oracle-canonical-lawsuit/
|
||||
[3]: https://en.wikipedia.org/wiki/CoreOS
|
||||
[4]: https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/
|
||||
[5]: https://mjg59.dreamwidth.org/l
|
||||
[6]: https://mjg59.dreamwidth.org/42320.html
|
||||
[7]: http://www.zdnet.com/article/linux-expert-matthew-garrett-ubuntu-16-04s-new-snap-format-is-a-security-risk/
|
||||
[8]: http://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating KevinSJ
|
||||
An introduction to data processing with Cassandra and Spark
|
||||
==============================================================
|
||||
|
||||
|
||||
142
sources/tech/20160512 Rapid prototyping with docker-compose.md
Normal file
142
sources/tech/20160512 Rapid prototyping with docker-compose.md
Normal file
@ -0,0 +1,142 @@
|
||||
|
||||
Rapid prototyping with docker-compose
|
||||
========================================
|
||||
|
||||
In this write-up we'll look at a Node.js prototype for **finding stock of the Raspberry PI Zero** from three major outlets in the UK.
|
||||
|
||||
I wrote the code and deployed it to an Ubuntu VM in Azure within a single evening of hacking. Docker and the docker-compose tool made the deployment and update process extremely quick.
|
||||
|
||||
### Remember linking?
|
||||
|
||||
If you've already been through the [Hands-On Docker tutorial][1] then you will have experience linking Docker containers on the command line. Linking a Node hit counter to a Redis server on the command line may look like this:
|
||||
|
||||
```
|
||||
$ docker run -d -P --name redis1
|
||||
$ docker run -d hit_counter -p 3000:3000 --link redis1:redis
|
||||
```
|
||||
|
||||
Now imagine your application has three tiers
|
||||
|
||||
- Web front-end
|
||||
- Batch tier for processing long running tasks
|
||||
- Redis or mongo database
|
||||
|
||||
Explicit linking through `--link` is just about manageable with a couple of containers, but can get out of hand as we add more tiers or containers to the application.
|
||||
|
||||
### Enter docker-compose
|
||||
|
||||

|
||||
>Docker Compose logo
|
||||
|
||||
The docker-compose tool is part of the standard Docker Toolbox and can also be downloaded separately. It provides a rich set of features to configure all of an application's parts through a plain-text YAML file.
|
||||
|
||||
The above example would look like this:
|
||||
|
||||
```
|
||||
version: "2.0"
|
||||
services:
|
||||
redis1:
|
||||
image: redis
|
||||
hit_counter:
|
||||
build: ./hit_counter
|
||||
ports:
|
||||
- 3000:3000
|
||||
```
|
||||
|
||||
From Docker 1.10 onwards we can take advantage of network overlays to help us scale out across multiple hosts. Prior to this linking only worked across a single host. The `docker-compose scale` command can be used to bring on more computing power as the need arises.
|
||||
|
||||
>View the [docker-compose][2] reference on docker.com
|
||||
|
||||
### Real-world example: Raspberry PI Stock Alert
|
||||
|
||||

|
||||
>The new Raspberry PI Zero v1.3 image courtesy of Pimoroni
|
||||
|
||||
There is a huge buzz around the Raspberry PI Zero - a tiny microcomputer with a 1GHz CPU and 512MB RAM capable of running full Linux, Docker, Node.js, Ruby and many other popular open-source tools. One of the best things about the PI Zero is that costs only 5 USD. That also means that stock gets snapped up really quickly.
|
||||
|
||||
*If you want to try Docker or Swarm on the PI check out the tutorial below.*
|
||||
|
||||
>[Docker Swarm on the PI Zero][3]
|
||||
|
||||
### Original site: whereismypizero.com
|
||||
|
||||
I found a webpage which used screen scraping to find whether 4-5 of the most popular outlets had stock.
|
||||
|
||||
- The site contained a static HTML page
|
||||
- Issued one XMLHttpRequest per outlet accessing /public/api/
|
||||
- The server issued the HTTP request to each shop and performed the scraping
|
||||
|
||||
Every call to /public/api/ took 3 seconds to execute and using Apache Bench (ab) I was only able to get through 0.25 requests per second.
|
||||
|
||||
### Reinventing the wheel
|
||||
|
||||
The retailers didn't seem to mind whereismypizero.com scraping their sites for stock, so I set about writing a similar tool from the ground up. I had the intention of handing a much higher amount of requests per second through caching and de-coupling the scrape from the web tier. Redis was the perfect tool for the job. It allowed me to set an automatically expiring key/value pair (i.e. a simple cache) and also to transmit messages between Node processes through pub/sub.
|
||||
|
||||
>Fork or star the code on Github: [alexellis/pi_zero_stock][4]
|
||||
|
||||
If you've worked with Node.js before then you will know it is single-threaded and that any CPU intensive tasks such as parsing HTML or JSON could lead to a slow-down. One way to mitigate that is to use a second worker process and a Redis messaging channel as connective tissue between this and the web tier.
|
||||
|
||||
- Web tier
|
||||
-Gives 200 for cache hit (Redis key exists for store)
|
||||
-Gives 202 for cache miss (Redis key doesn't exist, so issues message)
|
||||
-Since we are only ever reading a Redis key the response time is very quick.
|
||||
- Stock Fetcher
|
||||
-Performs HTTP request
|
||||
-Scrapes for different types of web stores
|
||||
-Updates a Redis key with a cache expire of 60 seconds
|
||||
-Also locks a Redis key to prevent too many in-flight HTTP requests to the web stores.
|
||||
```
|
||||
version: "2.0"
|
||||
services:
|
||||
web:
|
||||
build: ./web/
|
||||
ports:
|
||||
- "3000:3000"
|
||||
stock_fetch:
|
||||
build: ./stock_fetch/
|
||||
redis:
|
||||
image: redis
|
||||
```
|
||||
|
||||
*The docker-compose.yml file from the example.*
|
||||
|
||||
Once I had this working locally deploying to an Ubuntu 16.04 image in the cloud (Azure) took less than 5 minutes. I logged in, cloned the repository and typed in `docker compose up -d`. That was all it took - rapid prototyping a whole system doesn't get much better. Anyone (including the owner of whereismypizero.com) can deploy the new solution with just two lines:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/pi_zero_stock
|
||||
$ docker-compose up -d
|
||||
```
|
||||
|
||||
Updating the site is easy and just involves a `git pull` followed by a `docker-compose up -d` with the `--build` argument passed along.
|
||||
|
||||
If you are still linking your Docker containers manually, try Docker Compose for yourself or my code below:
|
||||
|
||||
>Fork or star the code on Github: [alexellis/pi_zero_stock][5]
|
||||
|
||||
### Check out the test site
|
||||
|
||||
The test site is currently deployed now using docker-compose.
|
||||
|
||||
>[stockalert.alexellis.io][6]
|
||||
|
||||
|
||||
|
||||
Preview as of 16th of May 2016
|
||||
|
||||
----------
|
||||
via: http://blog.alexellis.io/rapid-prototype-docker-compose/
|
||||
|
||||
作者:[Alex Ellis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://blog.alexellis.io/author/alex/
|
||||
[1]: http://blog.alexellis.io/handsondocker
|
||||
[2]: https://docs.docker.com/compose/compose-file/
|
||||
[3]: http://blog.alexellis.io/dockerswarm-pizero/
|
||||
[4]: https://github.com/alexellis/pi_zero_stock
|
||||
[5]: https://github.com/alexellis/pi_zero_stock
|
||||
[6]: http://stockalert.alexellis.io/
|
||||
|
||||
398
sources/tech/20160512 Bitmap in Linux Kernel.md
Normal file
398
sources/tech/20160512 Bitmap in Linux Kernel.md
Normal file
@ -0,0 +1,398 @@
|
||||
[Translating By cposture 20160520]
|
||||
Data Structures in the Linux Kernel
|
||||
================================================================================
|
||||
|
||||
Bit arrays and bit operations in the Linux kernel
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Besides different [linked](https://en.wikipedia.org/wiki/Linked_data_structure) and [tree](https://en.wikipedia.org/wiki/Tree_%28data_structure%29) based data structures, the Linux kernel provides [API](https://en.wikipedia.org/wiki/Application_programming_interface) for [bit arrays](https://en.wikipedia.org/wiki/Bit_array) or `bitmap`. Bit arrays are heavily used in the Linux kernel and following source code files contain common `API` for work with such structures:
|
||||
|
||||
* [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c)
|
||||
* [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h)
|
||||
|
||||
Besides these two files, there is also architecture-specific header file which provides optimized bit operations for certain architecture. We consider [x86_64](https://en.wikipedia.org/wiki/X86-64) architecture, so in our case it will be:
|
||||
|
||||
* [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h)
|
||||
|
||||
header file. As I just wrote above, the `bitmap` is heavily used in the Linux kernel. For example a `bit array` is used to store set of online/offline processors for systems which support [hot-plug](https://www.kernel.org/doc/Documentation/cpu-hotplug.txt) cpu (more about this you can read in the [cpumasks](https://0xax.gitbooks.io/linux-insides/content/Concepts/cpumask.html) part), a `bit array` stores set of allocated [irqs](https://en.wikipedia.org/wiki/Interrupt_request_%28PC_architecture%29) during initialization of the Linux kernel and etc.
|
||||
|
||||
So, the main goal of this part is to see how `bit arrays` are implemented in the Linux kernel. Let's start.
|
||||
|
||||
Declaration of bit array
|
||||
================================================================================
|
||||
|
||||
Before we will look on `API` for bitmaps manipulation, we must know how to declare it in the Linux kernel. There are two common method to declare own bit array. The first simple way to declare a bit array is to array of `unsigned long`. For example:
|
||||
|
||||
```C
|
||||
unsigned long my_bitmap[8]
|
||||
```
|
||||
|
||||
The second way is to use the `DECLARE_BITMAP` macro which is defined in the [include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) header file:
|
||||
|
||||
```C
|
||||
#define DECLARE_BITMAP(name,bits) \
|
||||
unsigned long name[BITS_TO_LONGS(bits)]
|
||||
```
|
||||
|
||||
We can see that `DECLARE_BITMAP` macro takes two parameters:
|
||||
|
||||
* `name` - name of bitmap;
|
||||
* `bits` - amount of bits in bitmap;
|
||||
|
||||
and just expands to the definition of `unsigned long` array with `BITS_TO_LONGS(bits)` elements, where the `BITS_TO_LONGS` macro converts a given number of bits to number of `longs` or in other words it calculates how many `8` byte elements in `bits`:
|
||||
|
||||
```C
|
||||
#define BITS_PER_BYTE 8
|
||||
#define DIV_ROUND_UP(n,d) (((n) + (d) - 1) / (d))
|
||||
#define BITS_TO_LONGS(nr) DIV_ROUND_UP(nr, BITS_PER_BYTE * sizeof(long))
|
||||
```
|
||||
|
||||
So, for example `DECLARE_BITMAP(my_bitmap, 64)` will produce:
|
||||
|
||||
```python
|
||||
>>> (((64) + (64) - 1) / (64))
|
||||
1
|
||||
```
|
||||
|
||||
and:
|
||||
|
||||
```C
|
||||
unsigned long my_bitmap[1];
|
||||
```
|
||||
|
||||
After we are able to declare a bit array, we can start to use it.
|
||||
|
||||
Architecture-specific bit operations
|
||||
================================================================================
|
||||
|
||||
We already saw above a couple of source code and header files which provide [API](https://en.wikipedia.org/wiki/Application_programming_interface) for manipulation of bit arrays. The most important and widely used API of bit arrays is architecture-specific and located as we already know in the [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) header file.
|
||||
|
||||
First of all let's look at the two most important functions:
|
||||
|
||||
* `set_bit`;
|
||||
* `clear_bit`.
|
||||
|
||||
I think that there is no need to explain what these function do. This is already must be clear from their name. Let's look on their implementation. If you will look into the [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) header file, you will note that each of these functions represented by two variants: [atomic](https://en.wikipedia.org/wiki/Linearizability) and not. Before we will start to dive into implementations of these functions, first of all we must to know a little about `atomic` operations.
|
||||
|
||||
In simple words atomic operations guarantees that two or more operations will not be performed on the same data concurrently. The `x86` architecture provides a set of atomic instructions, for example [xchg](http://x86.renejeschke.de/html/file_module_x86_id_328.html) instruction, [cmpxchg](http://x86.renejeschke.de/html/file_module_x86_id_41.html) instruction and etc. Besides atomic instructions, some of non-atomic instructions can be made atomic with the help of the [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) instruction. It is enough to know about atomic operations for now, so we can begin to consider implementation of `set_bit` and `clear_bit` functions.
|
||||
|
||||
First of all, let's start to consider `non-atomic` variants of this function. Names of non-atomic `set_bit` and `clear_bit` starts from double underscore. As we already know, all of these functions are defined in the [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) header file and the first function is `__set_bit`:
|
||||
|
||||
```C
|
||||
static inline void __set_bit(long nr, volatile unsigned long *addr)
|
||||
{
|
||||
asm volatile("bts %1,%0" : ADDR : "Ir" (nr) : "memory");
|
||||
}
|
||||
```
|
||||
|
||||
As we can see it takes two arguments:
|
||||
|
||||
* `nr` - number of bit in a bit array.
|
||||
* `addr` - address of a bit array where we need to set bit.
|
||||
|
||||
Note that the `addr` parameter is defined with `volatile` keyword which tells to compiler that value maybe changed by the given address. The implementation of the `__set_bit` is pretty easy. As we can see, it just contains one line of [inline assembler](https://en.wikipedia.org/wiki/Inline_assembler) code. In our case we are using the [bts](http://x86.renejeschke.de/html/file_module_x86_id_25.html) instruction which selects a bit which is specified with the first operand (`nr` in our case) from the bit array, stores the value of the selected bit in the [CF](https://en.wikipedia.org/wiki/FLAGS_register) flags register and set this bit.
|
||||
|
||||
Note that we can see usage of the `nr`, but there is `addr` here. You already might guess that the secret is in `ADDR`. The `ADDR` is the macro which is defined in the same header code file and expands to the string which contains value of the given address and `+m` constraint:
|
||||
|
||||
```C
|
||||
#define ADDR BITOP_ADDR(addr)
|
||||
#define BITOP_ADDR(x) "+m" (*(volatile long *) (x))
|
||||
```
|
||||
|
||||
Besides the `+m`, we can see other constraints in the `__set_bit` function. Let's look on they and try to understand what do they mean:
|
||||
|
||||
* `+m` - represents memory operand where `+` tells that the given operand will be input and output operand;
|
||||
* `I` - represents integer constant;
|
||||
* `r` - represents register operand
|
||||
|
||||
Besides these constraint, we also can see - the `memory` keyword which tells compiler that this code will change value in memory. That's all. Now let's look at the same function but at `atomic` variant. It looks more complex that its `non-atomic` variant:
|
||||
|
||||
```C
|
||||
static __always_inline void
|
||||
set_bit(long nr, volatile unsigned long *addr)
|
||||
{
|
||||
if (IS_IMMEDIATE(nr)) {
|
||||
asm volatile(LOCK_PREFIX "orb %1,%0"
|
||||
: CONST_MASK_ADDR(nr, addr)
|
||||
: "iq" ((u8)CONST_MASK(nr))
|
||||
: "memory");
|
||||
} else {
|
||||
asm volatile(LOCK_PREFIX "bts %1,%0"
|
||||
: BITOP_ADDR(addr) : "Ir" (nr) : "memory");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
First of all note that this function takes the same set of parameters that `__set_bit`, but additionally marked with the `__always_inline` attribute. The `__always_inline` is macro which defined in the [include/linux/compiler-gcc.h](https://github.com/torvalds/linux/blob/master/include/linux/compiler-gcc.h) and just expands to the `always_inline` attribute:
|
||||
|
||||
```C
|
||||
#define __always_inline inline __attribute__((always_inline))
|
||||
```
|
||||
|
||||
which means that this function will be always inlined to reduce size of the Linux kernel image. Now let's try to understand implementation of the `set_bit` function. First of all we check a given number of bit at the beginning of the `set_bit` function. The `IS_IMMEDIATE` macro defined in the same [header](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) file and expands to the call of the builtin [gcc](https://en.wikipedia.org/wiki/GNU_Compiler_Collection) function:
|
||||
|
||||
```C
|
||||
#define IS_IMMEDIATE(nr) (__builtin_constant_p(nr))
|
||||
```
|
||||
|
||||
The `__builtin_constant_p` builtin function returns `1` if the given parameter is known to be constant at compile-time and returns `0` in other case. We no need to use slow `bts` instruction to set bit if the given number of bit is known in compile time constant. We can just apply [bitwise or](https://en.wikipedia.org/wiki/Bitwise_operation#OR) for byte from the give address which contains given bit and masked number of bits where high bit is `1` and other is zero. In other case if the given number of bit is not known constant at compile-time, we do the same as we did in the `__set_bit` function. The `CONST_MASK_ADDR` macro:
|
||||
|
||||
```C
|
||||
#define CONST_MASK_ADDR(nr, addr) BITOP_ADDR((void *)(addr) + ((nr)>>3))
|
||||
```
|
||||
|
||||
expands to the give address with offset to the byte which contains a given bit. For example we have address `0x1000` and the number of bit is `0x9`. So, as `0x9` is `one byte + one bit` our address with be `addr + 1`:
|
||||
|
||||
```python
|
||||
>>> hex(0x1000 + (0x9 >> 3))
|
||||
'0x1001'
|
||||
```
|
||||
|
||||
The `CONST_MASK` macro represents our given number of bit as byte where high bit is `1` and other bits are `0`:
|
||||
|
||||
```C
|
||||
#define CONST_MASK(nr) (1 << ((nr) & 7))
|
||||
```
|
||||
|
||||
```python
|
||||
>>> bin(1 << (0x9 & 7))
|
||||
'0b10'
|
||||
```
|
||||
|
||||
In the end we just apply bitwise `or` for these values. So, for example if our address will be `0x4097` and we need to set `0x9` bit:
|
||||
|
||||
```python
|
||||
>>> bin(0x4097)
|
||||
'0b100000010010111'
|
||||
>>> bin((0x4097 >> 0x9) | (1 << (0x9 & 7)))
|
||||
'0b100010'
|
||||
```
|
||||
|
||||
the `ninth` bit will be set.
|
||||
|
||||
Note that all of these operations are marked with `LOCK_PREFIX` which is expands to the [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) instruction which guarantees atomicity of this operation.
|
||||
|
||||
As we already know, besides the `set_bit` and `__set_bit` operations, the Linux kernel provides two inverse functions to clear bit in atomic and non-atomic context. They are `clear_bit` and `__clear_bit`. Both of these functions are defined in the same [header file](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) and takes the same set of arguments. But not only arguments are similar. Generally these functions are very similar on the `set_bit` and `__set_bit`. Let's look on the implementation of the non-atomic `__clear_bit` function:
|
||||
|
||||
```C
|
||||
static inline void __clear_bit(long nr, volatile unsigned long *addr)
|
||||
{
|
||||
asm volatile("btr %1,%0" : ADDR : "Ir" (nr));
|
||||
}
|
||||
```
|
||||
|
||||
Yes. As we see, it takes the same set of arguments and contains very similar block of inline assembler. It just uses the [btr](http://x86.renejeschke.de/html/file_module_x86_id_24.html) instruction instead of `bts`. As we can understand form the function's name, it clears a given bit by the given address. The `btr` instruction acts like `btr`. This instruction also selects a given bit which is specified in the first operand, stores its value in the `CF` flag register and clears this bit in the given bit array which is specifed with second operand.
|
||||
|
||||
The atomic variant of the `__clear_bit` is `clear_bit`:
|
||||
|
||||
```C
|
||||
static __always_inline void
|
||||
clear_bit(long nr, volatile unsigned long *addr)
|
||||
{
|
||||
if (IS_IMMEDIATE(nr)) {
|
||||
asm volatile(LOCK_PREFIX "andb %1,%0"
|
||||
: CONST_MASK_ADDR(nr, addr)
|
||||
: "iq" ((u8)~CONST_MASK(nr)));
|
||||
} else {
|
||||
asm volatile(LOCK_PREFIX "btr %1,%0"
|
||||
: BITOP_ADDR(addr)
|
||||
: "Ir" (nr));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
and as we can see it is very similar on `set_bit` and just contains two differences. The first difference it uses `btr` instruction to clear bit when the `set_bit` uses `bts` instruction to set bit. The second difference it uses negated mask and `and` instruction to clear bit in the given byte when the `set_bit` uses `or` instruction.
|
||||
|
||||
That's all. Now we can set and clear bit in any bit array and and we can go to other operations on bitmasks.
|
||||
|
||||
Most widely used operations on a bit arrays are set and clear bit in a bit array in the Linux kernel. But besides this operations it is useful to do additional operations on a bit array. Yet another widely used operation in the Linux kernel - is to know is a given bit set or not in a bit array. We can achieve this with the help of the `test_bit` macro. This macro is defined in the [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) header file and expands to the call of the `constant_test_bit` or `variable_test_bit` depends on bit number:
|
||||
|
||||
```C
|
||||
#define test_bit(nr, addr) \
|
||||
(__builtin_constant_p((nr)) \
|
||||
? constant_test_bit((nr), (addr)) \
|
||||
: variable_test_bit((nr), (addr)))
|
||||
```
|
||||
|
||||
So, if the `nr` is known in compile time constant, the `test_bit` will be expanded to the call of the `constant_test_bit` function or `variable_test_bit` in other case. Now let's look at implementations of these functions. Let's start from the `variable_test_bit`:
|
||||
|
||||
```C
|
||||
static inline int variable_test_bit(long nr, volatile const unsigned long *addr)
|
||||
{
|
||||
int oldbit;
|
||||
|
||||
asm volatile("bt %2,%1\n\t"
|
||||
"sbb %0,%0"
|
||||
: "=r" (oldbit)
|
||||
: "m" (*(unsigned long *)addr), "Ir" (nr));
|
||||
|
||||
return oldbit;
|
||||
}
|
||||
```
|
||||
|
||||
The `variable_test_bit` function takes similar set of arguments as `set_bit` and other function take. We also may see inline assembly code here which executes [bt](http://x86.renejeschke.de/html/file_module_x86_id_22.html) and [sbb](http://x86.renejeschke.de/html/file_module_x86_id_286.html) instruction. The `bt` or `bit test` instruction selects a given bit which is specified with first operand from the bit array which is specified with the second operand and stores its value in the [CF](https://en.wikipedia.org/wiki/FLAGS_register) bit of flags register. The second `sbb` instruction substracts first operand from second and subscrtact value of the `CF`. So, here write a value of a given bit number from a given bit array to the `CF` bit of flags register and execute `sbb` instruction which calculates: `00000000 - CF` and writes the result to the `oldbit`.
|
||||
|
||||
The `constant_test_bit` function does the same as we saw in the `set_bit`:
|
||||
|
||||
```C
|
||||
static __always_inline int constant_test_bit(long nr, const volatile unsigned long *addr)
|
||||
{
|
||||
return ((1UL << (nr & (BITS_PER_LONG-1))) &
|
||||
(addr[nr >> _BITOPS_LONG_SHIFT])) != 0;
|
||||
}
|
||||
```
|
||||
|
||||
It generates a byte where high bit is `1` and other bits are `0` (as we saw in `CONST_MASK`) and applies bitwise [and](https://en.wikipedia.org/wiki/Bitwise_operation#AND) to the byte which contains a given bit number.
|
||||
|
||||
The next widely used bit array related operation is to change bit in a bit array. The Linux kernel provides two helper for this:
|
||||
|
||||
* `__change_bit`;
|
||||
* `change_bit`.
|
||||
|
||||
As you already can guess, these two variants are atomic and non-atomic as for example `set_bit` and `__set_bit`. For the start, let's look at the implementation of the `__change_bit` function:
|
||||
|
||||
```C
|
||||
static inline void __change_bit(long nr, volatile unsigned long *addr)
|
||||
{
|
||||
asm volatile("btc %1,%0" : ADDR : "Ir" (nr));
|
||||
}
|
||||
```
|
||||
|
||||
Pretty easy, is not it? The implementation of the `__change_bit` is the same as `__set_bit`, but instead of `bts` instruction, we are using [btc](http://x86.renejeschke.de/html/file_module_x86_id_23.html). This instruction selects a given bit from a given bit array, stores its value in the `CF` and changes its value by the applying of complement operation. So, a bit with value `1` will be `0` and vice versa:
|
||||
|
||||
```python
|
||||
>>> int(not 1)
|
||||
0
|
||||
>>> int(not 0)
|
||||
1
|
||||
```
|
||||
|
||||
The atomic version of the `__change_bit` is the `change_bit` function:
|
||||
|
||||
```C
|
||||
static inline void change_bit(long nr, volatile unsigned long *addr)
|
||||
{
|
||||
if (IS_IMMEDIATE(nr)) {
|
||||
asm volatile(LOCK_PREFIX "xorb %1,%0"
|
||||
: CONST_MASK_ADDR(nr, addr)
|
||||
: "iq" ((u8)CONST_MASK(nr)));
|
||||
} else {
|
||||
asm volatile(LOCK_PREFIX "btc %1,%0"
|
||||
: BITOP_ADDR(addr)
|
||||
: "Ir" (nr));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
It is similar on `set_bit` function, but also has two differences. The first difference is `xor` operation instead of `or` and the second is `bts` instead of `bts`.
|
||||
|
||||
For this moment we know the most important architecture-specific operations with bit arrays. Time to look at generic bitmap API.
|
||||
|
||||
Common bit operations
|
||||
================================================================================
|
||||
|
||||
Besides the architecture-specific API from the [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) header file, the Linux kernel provides common API for manipulation of bit arrays. As we know from the beginning of this part, we can find it in the [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) header file and additionally in the * [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c) source code file. But before these source code files let's look into the [include/linux/bitops.h](https://github.com/torvalds/linux/blob/master/include/linux/bitops.h) header file which provides a set of useful macro. Let's look on some of they.
|
||||
|
||||
First of all let's look at following four macros:
|
||||
|
||||
* `for_each_set_bit`
|
||||
* `for_each_set_bit_from`
|
||||
* `for_each_clear_bit`
|
||||
* `for_each_clear_bit_from`
|
||||
|
||||
All of these macros provide iterator over certain set of bits in a bit array. The first macro iterates over bits which are set, the second does the same, but starts from a certain bits. The last two macros do the same, but iterates over clear bits. Let's look on implementation of the `for_each_set_bit` macro:
|
||||
|
||||
```C
|
||||
#define for_each_set_bit(bit, addr, size) \
|
||||
for ((bit) = find_first_bit((addr), (size)); \
|
||||
(bit) < (size); \
|
||||
(bit) = find_next_bit((addr), (size), (bit) + 1))
|
||||
```
|
||||
|
||||
As we may see it takes three arguments and expands to the loop from first set bit which is returned as result of the `find_first_bit` function and to the last bit number while it is less than given size.
|
||||
|
||||
Besides these four macros, the [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) provides API for rotation of `64-bit` or `32-bit` values and etc.
|
||||
|
||||
The next [header](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) file which provides API for manipulation with a bit arrays. For example it provdes two functions:
|
||||
|
||||
* `bitmap_zero`;
|
||||
* `bitmap_fill`.
|
||||
|
||||
To clear a bit array and fill it with `1`. Let's look on the implementation of the `bitmap_zero` function:
|
||||
|
||||
```C
|
||||
static inline void bitmap_zero(unsigned long *dst, unsigned int nbits)
|
||||
{
|
||||
if (small_const_nbits(nbits))
|
||||
*dst = 0UL;
|
||||
else {
|
||||
unsigned int len = BITS_TO_LONGS(nbits) * sizeof(unsigned long);
|
||||
memset(dst, 0, len);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
First of all we can see the check for `nbits`. The `small_const_nbits` is macro which defined in the same header [file](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) and looks:
|
||||
|
||||
```C
|
||||
#define small_const_nbits(nbits) \
|
||||
(__builtin_constant_p(nbits) && (nbits) <= BITS_PER_LONG)
|
||||
```
|
||||
|
||||
As we may see it checks that `nbits` is known constant in compile time and `nbits` value does not overflow `BITS_PER_LONG` or `64`. If bits number does not overflow amount of bits in a `long` value we can just set to zero. In other case we need to calculate how many `long` values do we need to fill our bit array and fill it with [memset](http://man7.org/linux/man-pages/man3/memset.3.html).
|
||||
|
||||
The implementation of the `bitmap_fill` function is similar on implementation of the `biramp_zero` function, except we fill a given bit array with `0xff` values or `0b11111111`:
|
||||
|
||||
```C
|
||||
static inline void bitmap_fill(unsigned long *dst, unsigned int nbits)
|
||||
{
|
||||
unsigned int nlongs = BITS_TO_LONGS(nbits);
|
||||
if (!small_const_nbits(nbits)) {
|
||||
unsigned int len = (nlongs - 1) * sizeof(unsigned long);
|
||||
memset(dst, 0xff, len);
|
||||
}
|
||||
dst[nlongs - 1] = BITMAP_LAST_WORD_MASK(nbits);
|
||||
}
|
||||
```
|
||||
|
||||
Besides the `bitmap_fill` and `bitmap_zero` functions, the [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) header file provides `bitmap_copy` which is similar on the `bitmap_zero`, but just uses [memcpy](http://man7.org/linux/man-pages/man3/memcpy.3.html) instead of [memset](http://man7.org/linux/man-pages/man3/memset.3.html). Also it provides bitwise operations for bit array like `bitmap_and`, `bitmap_or`, `bitamp_xor` and etc. We will not consider implementation of these functions because it is easy to understand implementations of these functions if you understood all from this part. Anyway if you are interested how did these function implemented, you may open [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) header file and start to research.
|
||||
|
||||
That's all.
|
||||
|
||||
Links
|
||||
================================================================================
|
||||
|
||||
* [bitmap](https://en.wikipedia.org/wiki/Bit_array)
|
||||
* [linked data structures](https://en.wikipedia.org/wiki/Linked_data_structure)
|
||||
* [tree data structures](https://en.wikipedia.org/wiki/Tree_%28data_structure%29)
|
||||
* [hot-plug](https://www.kernel.org/doc/Documentation/cpu-hotplug.txt)
|
||||
* [cpumasks](https://0xax.gitbooks.io/linux-insides/content/Concepts/cpumask.html)
|
||||
* [IRQs](https://en.wikipedia.org/wiki/Interrupt_request_%28PC_architecture%29)
|
||||
* [API](https://en.wikipedia.org/wiki/Application_programming_interface)
|
||||
* [atomic operations](https://en.wikipedia.org/wiki/Linearizability)
|
||||
* [xchg instruction](http://x86.renejeschke.de/html/file_module_x86_id_328.html)
|
||||
* [cmpxchg instruction](http://x86.renejeschke.de/html/file_module_x86_id_41.html)
|
||||
* [lock instruction](http://x86.renejeschke.de/html/file_module_x86_id_159.html)
|
||||
* [bts instruction](http://x86.renejeschke.de/html/file_module_x86_id_25.html)
|
||||
* [btr instruction](http://x86.renejeschke.de/html/file_module_x86_id_24.html)
|
||||
* [bt instruction](http://x86.renejeschke.de/html/file_module_x86_id_22.html)
|
||||
* [sbb instruction](http://x86.renejeschke.de/html/file_module_x86_id_286.html)
|
||||
* [btc instruction](http://x86.renejeschke.de/html/file_module_x86_id_23.html)
|
||||
* [man memcpy](http://man7.org/linux/man-pages/man3/memcpy.3.html)
|
||||
* [man memset](http://man7.org/linux/man-pages/man3/memset.3.html)
|
||||
* [CF](https://en.wikipedia.org/wiki/FLAGS_register)
|
||||
* [inline assembler](https://en.wikipedia.org/wiki/Inline_assembler)
|
||||
* [gcc](https://en.wikipedia.org/wiki/GNU_Compiler_Collection)
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/DataStructures/bitmap.md
|
||||
|
||||
作者:[0xAX][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/0xAX
|
||||
67
sources/tech/20160516 Scaling Collaboration in DevOps.md
Normal file
67
sources/tech/20160516 Scaling Collaboration in DevOps.md
Normal file
@ -0,0 +1,67 @@
|
||||
Scaling Collaboration in DevOps
|
||||
=================================
|
||||
|
||||

|
||||
|
||||
Those familiar with DevOps generally agree that it is equally as much about culture as it is about technology. There are certainly tools and practices involved in the effective implementation of DevOps, but the foundation of DevOps success is how well [teams and individuals collaborate][1] across the enterprise to get things done more rapidly, efficiently and effectively.
|
||||
|
||||
Most DevOps platforms and tools are designed with scalability in mind. DevOps environments often run in the cloud and tend to be volatile. It’s important for the software that supports DevOps to be able to scale in real time to address spikes and lulls in demand. The same thing is true for the human element as well, but scaling collaboration is a whole different story.
|
||||
|
||||
Collaboration across the enterprise is critical for DevOps success. Great code and development needs to make it over the finish line to production to benefit customers. The challenge organizations face is how to do that seamlessly and with as much speed and automation as possible without sacrificing quality or performance. How can businesses streamline code development and deployment, while maintaining visibility, governance and compliance?
|
||||
|
||||
### Emerging Trends
|
||||
|
||||
First, I want to provide some background and share some data gathered by 451 Research on DevOps and DevOps adoption in general. Cloud, agile and DevOps capabilities are important for organizations today—both in perception and reality. 451 sees enterprise adoption of these things, as well as container technologies, growing—including increased usage in production environments.
|
||||
|
||||
There are a number of advantages to embracing these technologies and methodologies, such as increased flexibility and speed, reduction of costs, improvements in resilience and reliability, and fitness for new or emerging applications. According to 451 Research, organizations also face some barriers including a lack of familiarity and required skills internally, the immaturity of these emerging technologies, and cost and security concerns.
|
||||
|
||||
In the “[Voice of the Enterprise: SDI Q4 2015 survey][2],” 451 Research found that more than half of the respondents (51.7 percent) consider themselves to be late adopters, or even the last adopters of new technology. The flip side of that is that almost half (48.3 percent) label themselves as first or early adopters.
|
||||
|
||||
Those general sentiments are reflected in the survey responses to other questions. When asked about implementation of containers, 50.3 percent stated it is not in their plans at all, while the remaining 49.7 percent are in some state of planning, pilot or active use of container technologies. Nearly two-thirds (65.1 percent) indicated that they use agile development methodologies for application development, but only 39.6 percent responded that they’ve embraced DevOps approaches. Nevertheless, while agile software development has been in the industry for years, 451 notes the impressive adoption of containers and DevOps, given they are emergent trends.
|
||||
|
||||
When asked what the top three IT pain points are, the leading responses were cost or budget, insufficient staff and legacy software issues. As organizations move to cloud, DevOps, and containers issues such as these will need to be addressed, along with how to scale both technologies and collaboration effectively.
|
||||
|
||||
### The Current State
|
||||
|
||||
The industry—driven in large part by the DevOps revolution—is in the midst of a sea change, where software development is becoming more highly integrated across the entire business. The creation of software is less segregated and is more and more a function of collaboration and socialization.
|
||||
|
||||
Concepts and methodologies that were novel or niche just a few years ago have matured quickly to become the mainstream technologies and frameworks that are driving value today. Businesses rely on concepts such as agile, lean, virtualization, cloud, automation and microservices to streamline development and enable them to work more effectively and efficiently at the same time.
|
||||
|
||||
To adapt and evolve, enterprises need to accomplish a number of key tasks. The challenge companies face today is how to accelerate development while reducing costs. Organizations need to eliminate the barriers that exist between IT and the rest of the business, and work cooperatively toward a strategy that provides more effectiveness in a technology-driven, competitive environment.
|
||||
|
||||
Agile, cloud, DevOps and containers all play a role in that process, but the one thing that binds it all is effective collaboration. Each of these technologies and methodologies provides unique benefits, but the real value comes from the organization as a whole—and the tools and platforms used by the organization—being able to collaborate at scale. Successful DevOps implementations also require participation from other stakeholders beyond development and IT operations teams, including security, database, storage and line-of-business teams.
|
||||
|
||||
### Collaboration-as-a-Platform
|
||||
|
||||
There are services and platforms online—such as GitHub—that facilitate and streamline collaboration. The online platform functions as a code repository, but the value extends beyond just providing a place to store code.
|
||||
|
||||
Such a [collaboration platform][4] helps developers and teams collaborate more effectively because it provides a community where the code and process can be shared and discussed. Managers can monitor progress and track what code is shipping next. Developers can experiment with new ideas in a safe environment before taking those experiments to a live production environment, and new ideas and experiments can be effectively communicated to the appropriate teams.
|
||||
|
||||
One of the keys to more agile development and DevOps is to allow developers to test things and gather relevant feedback quickly. The goal is to produce quality code and features faster, not to waste time setting up and managing infrastructure or scheduling more meetings to talk about it. The GitHub platform, for example, enables more effective and scalable collaboration because code review can occur when it is most convenient for the participants. There is no need to try and coordinate and schedule code review meetings, so the developers can continue to work uninterrupted, resulting in greater productivity and job satisfaction.
|
||||
|
||||
Steven Anderson of Sendachi noted that GitHub is a collaboration platform, but it’s also a place for your tools to work with you, too. This means it can help not only with collaboration and continuous integration, but also with code quality.
|
||||
|
||||
One of the benefits of a collaboration platform is that large teams of developers can be broken down into smaller teams that can focus more efficiently on specific components. It also allows things such as document sharing alongside code development to blur the lines between technical and non-technical contributions and enable increased collaboration and visibility.
|
||||
|
||||
### Collaboration is Key
|
||||
|
||||
The importance of collaboration can’t be stressed enough. It is a key tenet of DevOps culture, and it’s vital to agile development and maintaining a competitive edge in today’s world. Executive or management support and internal evangelism are important. Organizations also need to embrace the culture shift—blending skills across functional areas toward a common goal.
|
||||
|
||||
With that culture established, though, effective collaboration is crucial. A collaboration platform is an essential element of collaborating at scale because it streamlines productivity and reduces redundancy and effort, and yields higher quality results at the same time.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://devops.com/2016/05/16/scaling-collaboration-devops/
|
||||
|
||||
作者:[TONY BRADLEY][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://devops.com/author/tonybsg/
|
||||
[1]: http://devops.com/2014/12/15/four-strategies-supporting-devops-collaboration/
|
||||
[2]: https://451research.com/
|
||||
[3]: https://451research.com/customer-insight-voice-of-the-enterprise-overview
|
||||
[4]: http://devops.com/events/analytics-of-collaboration-on-github/
|
||||
278
sources/tech/20160518 Python 3: An Intro to Encryption.md
Normal file
278
sources/tech/20160518 Python 3: An Intro to Encryption.md
Normal file
@ -0,0 +1,278 @@
|
||||
Python 3: An Intro to Encryption
|
||||
===================================
|
||||
|
||||
Python 3 doesn’t have very much in its standard library that deals with encryption. Instead, you get hashing libraries. We’ll take a brief look at those in the chapter, but the primary focus will be on the following 3rd party packages: PyCrypto and cryptography. We will learn how to encrypt and decrypt strings with both of these libraries.
|
||||
|
||||
---
|
||||
|
||||
### Hashing
|
||||
|
||||
If you need secure hashes or message digest algorithms, then Python’s standard library has you covered in the **hashlib** module. It includes the FIPS secure hash algorithms SHA1, SHA224, SHA256, SHA384, and SHA512 as well as RSA’s MD5 algorithm. Python also supports the adler32 and crc32 hash functions, but those are in the **zlib** module.
|
||||
|
||||
One of the most popular uses of hashes is storing the hash of a password instead of the password itself. Of course, the hash has to be a good one or it can be decrypted. Another popular use case for hashes is to hash a file and then send the file and its hash separately. Then the person receiving the file can run a hash on the file to see if it matches the hash that was sent. If it does, then that means no one has changed the file in transit.
|
||||
|
||||
|
||||
Let’s try creating an md5 hash:
|
||||
|
||||
```
|
||||
>>> import hashlib
|
||||
>>> md5 = hashlib.md5()
|
||||
>>> md5.update('Python rocks!')
|
||||
Traceback (most recent call last):
|
||||
File "<pyshell#5>", line 1, in <module>
|
||||
md5.update('Python rocks!')
|
||||
TypeError: Unicode-objects must be encoded before hashing
|
||||
>>> md5.update(b'Python rocks!')
|
||||
>>> md5.digest()
|
||||
b'\x14\x82\xec\x1b#d\xf6N}\x16*+[\x16\xf4w'
|
||||
```
|
||||
|
||||
Let’s take a moment to break this down a bit. First off, we import **hashlib** and then we create an instance of an md5 HASH object. Next we add some text to the hash object and we get a traceback. It turns out that to use the md5 hash, you have to pass it a byte string instead of a regular string. So we try that and then call it’s **digest** method to get our hash. If you prefer the hex digest, we can do that too:
|
||||
|
||||
```
|
||||
>>> md5.hexdigest()
|
||||
'1482ec1b2364f64e7d162a2b5b16f477'
|
||||
```
|
||||
|
||||
There’s actually a shortcut method of creating a hash, so we’ll look at that next when we create our sha512 hash:
|
||||
|
||||
```
|
||||
>>> sha = hashlib.sha1(b'Hello Python').hexdigest()
|
||||
>>> sha
|
||||
'422fbfbc67fe17c86642c5eaaa48f8b670cbed1b'
|
||||
```
|
||||
|
||||
As you can see, we can create our hash instance and call its digest method at the same time. Then we print out the hash to see what it is. I chose to use the sha1 hash as it has a nice short hash that will fit the page better. But it’s also less secure, so feel free to try one of the others.
|
||||
|
||||
---
|
||||
|
||||
### Key Derivation
|
||||
|
||||
Python has pretty limited support for key derivation built into the standard library. In fact, the only method that hashlib provides is the **pbkdf2_hmac** method, which is the PKCS#5 password-based key derivation function 2. It uses HMAC as its psuedorandom function. You might use something like this for hashing your password as it supports a salt and iterations. For example, if you were to use SHA-256 you would need a salt of at least 16 bytes and a minimum of 100,000 iterations.
|
||||
|
||||
As a quick aside, a salt is just random data that you use as additional input into your hash to make it harder to “unhash” your password. Basically it protects your password from dictionary attacks and pre-computed rainbow tables.
|
||||
|
||||
Let’s look at a simple example:
|
||||
|
||||
```
|
||||
>>> import binascii
|
||||
>>> dk = hashlib.pbkdf2_hmac(hash_name='sha256',
|
||||
password=b'bad_password34',
|
||||
salt=b'bad_salt',
|
||||
iterations=100000)
|
||||
>>> binascii.hexlify(dk)
|
||||
b'6e97bad21f6200f9087036a71e7ca9fa01a59e1d697f7e0284cd7f9b897d7c02'
|
||||
```
|
||||
|
||||
Here we create a SHA256 hash on a password using a lousy salt but with 100,000 iterations. Of course, SHA is not actually recommended for creating keys of passwords. Instead you should use something like **scrypt** instead. Another good option would be the 3rd party package, bcrypt. It is designed specifically with password hashing in mind.
|
||||
|
||||
---
|
||||
|
||||
### PyCryptodome
|
||||
|
||||
The PyCrypto package is probably the most well known 3rd party cryptography package for Python. Sadly PyCrypto’s development stopping in 2012. Others have continued to release the latest version of PyCryto so you can still get it for Python 3.5 if you don’t mind using a 3rd party’s binary. For example, I found some binary Python 3.5 wheels for PyCrypto on Github (https://github.com/sfbahr/PyCrypto-Wheels).
|
||||
|
||||
Fortunately there is a fork of the project called PyCrytodome that is a drop-in replacement for PyCrypto. To install it for Linux, you can use the following pip command:
|
||||
|
||||
|
||||
```
|
||||
pip install pycryptodome
|
||||
```
|
||||
|
||||
Windows is a bit different:
|
||||
|
||||
```
|
||||
pip install pycryptodomex
|
||||
```
|
||||
|
||||
If you run into issues, it’s probably because you don’t have the right dependencies installed or you need a compiler for Windows. Check out the PyCryptodome [website][1] for additional installation help or to contact support.
|
||||
|
||||
Also worth noting is that PyCryptodome has many enhancements over the last version of PyCrypto. It is well worth your time to visit their home page and see what new features exist.
|
||||
|
||||
### Encrypting a String
|
||||
|
||||
Once you’re done checking their website out, we can move on to some examples. For our first trick, we’ll use DES to encrypt a string:
|
||||
|
||||
```
|
||||
>>> from Crypto.Cipher import DES
|
||||
>>> key = 'abcdefgh'
|
||||
>>> def pad(text):
|
||||
while len(text) % 8 != 0:
|
||||
text += ' '
|
||||
return text
|
||||
>>> des = DES.new(key, DES.MODE_ECB)
|
||||
>>> text = 'Python rocks!'
|
||||
>>> padded_text = pad(text)
|
||||
>>> encrypted_text = des.encrypt(text)
|
||||
Traceback (most recent call last):
|
||||
File "<pyshell#35>", line 1, in <module>
|
||||
encrypted_text = des.encrypt(text)
|
||||
File "C:\Programs\Python\Python35-32\lib\site-packages\Crypto\Cipher\blockalgo.py", line 244, in encrypt
|
||||
return self._cipher.encrypt(plaintext)
|
||||
ValueError: Input strings must be a multiple of 8 in length
|
||||
>>> encrypted_text = des.encrypt(padded_text)
|
||||
>>> encrypted_text
|
||||
b'>\xfc\x1f\x16x\x87\xb2\x93\x0e\xfcH\x02\xd59VQ'
|
||||
```
|
||||
|
||||
This code is a little confusing, so let’s spend some time breaking it down. First off, it should be noted that the key size for DES encryption is 8 bytes, which is why we set our key variable to a size letter string. The string that we will be encrypting must be a multiple of 8 in length, so we create a function called **pad** that can pad any string out with spaces until it’s a multiple of 8. Next we create an instance of DES and some text that we want to encrypt. We also create a padded version of the text. Just for fun, we attempt to encrypt the original unpadded variant of the string which raises a **ValueError**. Here we learn that we need that padded string after all, so we pass that one in instead. As you can see, we now have an encrypted string!
|
||||
|
||||
Of course the example wouldn’t be complete if we didn’t know how to decrypt our string:
|
||||
|
||||
```
|
||||
>>> des.decrypt(encrypted_text)
|
||||
b'Python rocks! '
|
||||
```
|
||||
|
||||
Fortunately, that is very easy to accomplish as all we need to do is call the **decrypt** method on our des object to get our decrypted byte string back. Our next task is to learn how to encrypt and decrypt a file with PyCrypto using RSA. But first we need to create some RSA keys!
|
||||
|
||||
### Create an RSA Key
|
||||
|
||||
If you want to encrypt your data with RSA, then you’ll need to either have access to a public / private RSA key pair or you will need to generate your own. For this example, we will just generate our own. Since it’s fairly easy to do, we will do it in Python’s interpreter:
|
||||
|
||||
```
|
||||
>>> from Crypto.PublicKey import RSA
|
||||
>>> code = 'nooneknows'
|
||||
>>> key = RSA.generate(2048)
|
||||
>>> encrypted_key = key.exportKey(passphrase=code, pkcs=8,
|
||||
protection="scryptAndAES128-CBC")
|
||||
>>> with open('/path_to_private_key/my_private_rsa_key.bin', 'wb') as f:
|
||||
f.write(encrypted_key)
|
||||
>>> with open('/path_to_public_key/my_rsa_public.pem', 'wb') as f:
|
||||
f.write(key.publickey().exportKey())
|
||||
```
|
||||
|
||||
First we import **RSA** from **Crypto.PublicKey**. Then we create a silly passcode. Next we generate an RSA key of 2048 bits. Now we get to the good stuff. To generate a private key, we need to call our RSA key instance’s **exportKey** method and give it our passcode, which PKCS standard to use and which encryption scheme to use to protect our private key. Then we write the file out to disk.
|
||||
|
||||
Next we create our public key via our RSA key instance’s **publickey** method. We used a shortcut in this piece of code by just chaining the call to exportKey with the publickey method call to write it to disk as well.
|
||||
|
||||
### Encrypting a File
|
||||
|
||||
Now that we have both a private and a public key, we can encrypt some data and write it to a file. Here’s a pretty standard example:
|
||||
|
||||
```
|
||||
from Crypto.PublicKey import RSA
|
||||
from Crypto.Random import get_random_bytes
|
||||
from Crypto.Cipher import AES, PKCS1_OAEP
|
||||
|
||||
with open('/path/to/encrypted_data.bin', 'wb') as out_file:
|
||||
recipient_key = RSA.import_key(
|
||||
open('/path_to_public_key/my_rsa_public.pem').read())
|
||||
session_key = get_random_bytes(16)
|
||||
|
||||
cipher_rsa = PKCS1_OAEP.new(recipient_key)
|
||||
out_file.write(cipher_rsa.encrypt(session_key))
|
||||
|
||||
cipher_aes = AES.new(session_key, AES.MODE_EAX)
|
||||
data = b'blah blah blah Python blah blah'
|
||||
ciphertext, tag = cipher_aes.encrypt_and_digest(data)
|
||||
|
||||
out_file.write(cipher_aes.nonce)
|
||||
out_file.write(tag)
|
||||
out_file.write(ciphertext)
|
||||
```
|
||||
|
||||
The first three lines cover our imports from PyCryptodome. Next we open up a file to write to. Then we import our public key into a variable and create a 16-byte session key. For this example we are going to be using a hybrid encryption method, so we use PKCS#1 OAEP, which is Optimal asymmetric encryption padding. This allows us to write a data of an arbitrary length to the file. Then we create our AES cipher, create some data and encrypt the data. This will return the encrypted text and the MAC. Finally we write out the nonce, MAC (or tag) and the encrypted text.
|
||||
|
||||
As an aside, a nonce is an arbitrary number that is only used for crytographic communication. They are usually random or pseudorandom numbers. For AES, it must be at least 16 bytes in length. Feel free to try opening the encrypted file in your favorite text editor. You should just see gibberish.
|
||||
|
||||
Now let’s learn how to decrypt our data:
|
||||
|
||||
```
|
||||
from Crypto.PublicKey import RSA
|
||||
from Crypto.Cipher import AES, PKCS1_OAEP
|
||||
|
||||
code = 'nooneknows'
|
||||
|
||||
with open('/path/to/encrypted_data.bin', 'rb') as fobj:
|
||||
private_key = RSA.import_key(
|
||||
open('/path_to_private_key/my_rsa_key.pem').read(),
|
||||
passphrase=code)
|
||||
|
||||
enc_session_key, nonce, tag, ciphertext = [ fobj.read(x)
|
||||
for x in (private_key.size_in_bytes(),
|
||||
16, 16, -1) ]
|
||||
|
||||
cipher_rsa = PKCS1_OAEP.new(private_key)
|
||||
session_key = cipher_rsa.decrypt(enc_session_key)
|
||||
|
||||
cipher_aes = AES.new(session_key, AES.MODE_EAX, nonce)
|
||||
data = cipher_aes.decrypt_and_verify(ciphertext, tag)
|
||||
|
||||
print(data)
|
||||
```
|
||||
|
||||
If you followed the previous example, this code should be pretty easy to parse. In this case, we are opening our encrypted file for reading in binary mode. Then we import our private key. Note that when you import the private key, you must give it your passcode. Otherwise you will get an error. Next we read in our file. You will note that we read in the private key first, then the next 16 bytes for the nonce, which is followed by the next 16 bytes which is the tag and finally the rest of the file, which is our data.
|
||||
|
||||
Then we need to decrypt our session key, recreate our AES key and decrypt the data.
|
||||
|
||||
You can use PyCryptodome to do much, much more. However we need to move on and see what else we can use for our cryptographic needs in Python.
|
||||
|
||||
---
|
||||
|
||||
### The cryptography package
|
||||
|
||||
The **cryptography** package aims to be “cryptography for humans” much like the **requests** library is “HTTP for Humans”. The idea is that you will be able to create simple cryptographic recipes that are safe and easy-to-use. If you need to, you can drop down to low=level cryptographic primitives, which require you to know what you’re doing or you might end up creating something that’s not very secure.
|
||||
|
||||
If you are using Python 3.5, you can install it with pip, like so:
|
||||
|
||||
```
|
||||
pip install cryptography
|
||||
```
|
||||
|
||||
You will see that cryptography installs a few dependencies along with itself. Assuming that they all completed successfully, we can try encrypting some text. Let’s give the **Fernet** symmetric encryption algorithm. The Fernet algorithm guarantees that any message you encrypt with it cannot be manipulated or read without the key you define. Fernet also support key rotation via **MultiFernet**. Let’s take a look at a simple example:
|
||||
|
||||
```
|
||||
>>> from cryptography.fernet import Fernet
|
||||
>>> cipher_key = Fernet.generate_key()
|
||||
>>> cipher_key
|
||||
b'APM1JDVgT8WDGOWBgQv6EIhvxl4vDYvUnVdg-Vjdt0o='
|
||||
>>> cipher = Fernet(cipher_key)
|
||||
>>> text = b'My super secret message'
|
||||
>>> encrypted_text = cipher.encrypt(text)
|
||||
>>> encrypted_text
|
||||
(b'gAAAAABXOnV86aeUGADA6mTe9xEL92y_m0_TlC9vcqaF6NzHqRKkjEqh4d21PInEP3C9HuiUkS9f'
|
||||
b'6bdHsSlRiCNWbSkPuRd_62zfEv3eaZjJvLAm3omnya8=')
|
||||
>>> decrypted_text = cipher.decrypt(encrypted_text)
|
||||
>>> decrypted_text
|
||||
b'My super secret message'
|
||||
```
|
||||
|
||||
First off we need to import Fernet. Next we generate a key. We print out the key to see what it looks like. As you can see, it’s a random byte string. If you want, you can try running the **generate_key** method a few times. The result will always be different. Next we create our Fernet cipher instance using our key.
|
||||
|
||||
Now we have a cipher we can use to encrypt and decrypt our message. The next step is to create a message worth encrypting and then encrypt it using the **encrypt** method. I went ahead and printed our the encrypted text so you can see that you can no longer read the text. To **decrypt** our super secret message, we just call decrypt on our cipher and pass it the encrypted text. The result is we get a plain text byte string of our message.
|
||||
|
||||
---
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
This chapter barely scratched the surface of what you can do with PyCryptodome and the cryptography packages. However it does give you a decent overview of what can be done with Python in regards to encrypting and decrypting strings and files. Be sure to read the documentation and start experimenting to see what else you can do!
|
||||
|
||||
---
|
||||
|
||||
### Related Reading
|
||||
|
||||
PyCrypto Wheels for Python 3 on [github][2]
|
||||
|
||||
PyCryptodome [documentation][3]
|
||||
|
||||
Python’s Cryptographic [Services][4]
|
||||
|
||||
The cryptography package’s [website][5]
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blog.pythonlibrary.org/2016/05/18/python-3-an-intro-to-encryption/
|
||||
|
||||
作者:[Mike][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.blog.pythonlibrary.org/author/mld/
|
||||
[1]: http://pycryptodome.readthedocs.io/en/latest/
|
||||
[2]: https://github.com/sfbahr/PyCrypto-Wheels
|
||||
[3]: http://pycryptodome.readthedocs.io/en/latest/src/introduction.html
|
||||
[4]: https://docs.python.org/3/library/crypto.html
|
||||
[5]: https://cryptography.io/en/latest/
|
||||
@ -0,0 +1,65 @@
|
||||
The future of sharing: integrating Pydio and ownCloud
|
||||
=========================================================
|
||||
|
||||

|
||||
>Image by :
|
||||
opensource.com
|
||||
|
||||
The open source file sharing ecosystem accommodates a large variety of projects, each supplying their own solution, and each with a different approach. There are a lot of reasons to choose an open source solution rather than commercial solutions like Dropbox, Google Drive, iCloud, or OneDrive. These solutions offer to take away worries about managing your data but come with certain limitations, including a lack of control and integration into existing infrastructure.
|
||||
|
||||
There are quite a few file sharing and sync alternatives available to users, including ownCloud and Pydio.
|
||||
|
||||
### Pydio
|
||||
|
||||
The Pydio (Put your data in orbit) project was founded by musician Charles du Jeu, who needed a way to share large audio files with his bandmates. [Pydio][1] is a file sharing and sync solution, with multiple storage backends, designed with developers and system administrators in mind. It has over one million downloads worldwide and has been translated into 27 languages.
|
||||
|
||||
Open source from the very start, the project grew organically on [SourceForge][2] and now finds its home on [GitHub][3].
|
||||
|
||||
The user interface is based on Google's [Material Design][4]. Users can use an existing legacy file infrastructure or set up Pydio with an on-premise approach, and use web, desktop, and mobile applications to manage their assets everywhere. For administrators, the fine-grained access rights are a powerful tool for configuring access to assets.
|
||||
|
||||
On the [Pydio community page][5], you will find several resources to get you up to speed quickly. The Pydio website gives some clear guidelines on [how to contribute][6] to the Pydio repositories on GitHub. The [forum][7] includes sections for developers and community.
|
||||
|
||||
### ownCloud
|
||||
|
||||
[ownCloud][8] has over 8 million users worldwide and is an open source, self-hosted file sync and sharing technology. There are sync clients for all major platforms as well as WebDAV through a web interface. ownCloud has an easy to use interface, powerful administrator tools, and extensive sharing and collaboration features—designed to give users control over their data.
|
||||
|
||||
ownCloud's open architecture is extensible via an API and offers a platform for apps. Over 300 applications have been written, featuring capabilities like handling calendar, contacts, mail, music, passwords, notes, and many other types of data. ownCloud provides security, scales from a Raspberry Pi to a cluster with petabytes of storage and millions of users, and is developed by an international community of hundreds of contributors.
|
||||
|
||||
### Federated sharing
|
||||
|
||||
File sharing is starting to shift toward teamwork, and standardization provides a solid basis for such collaboration.
|
||||
|
||||
Federated sharing, a new open standard supported by the [OpenCloudMesh][9] project, is a step in that direction. Among other things, it allows for the sharing of files and folders between servers that support this, like Pydio and ownCloud instances.
|
||||
|
||||
First introduced in ownCloud 7, this server-to-server sharing allows you to mount file shares from remote servers, in effect creating your own cloud of clouds. You can create direct share links with users on other servers that support federated cloud sharing.
|
||||
|
||||
Implementing this new API allows for deeper integration between storage solutions while maintaining the security, control, and attributes of the original platforms.
|
||||
|
||||
"Exchanging and sharing files is something that is essential today and tomorrow," ownCloud founder Frank Karlitschek said. "Because of that, it is important to do this in a federated and distributed way without centralized data silos. The number one design goal [of federated sharing] is to enable sharing in the most seamless and easiest way while protecting the security and privacy of the users."
|
||||
|
||||
### What's next?
|
||||
|
||||
An initiative like OpenCloudMesh will extend this new open standard of file sharing through cooperation of institutions and companies like Pydio and ownCloud. ownCloud 9 has already introduced the ability for federated servers to exchange user lists, enabling the same seamless auto-complete experience you have with users on your own server. In the future, the idea of having a (federated!) set of central address book servers that can be used to search for others' federated cloud IDs might bring inter-cloud collaboration to an even higher level.
|
||||
|
||||
The initiative will undoubtedly contribute to already growing open technical community within which members can easily discuss, develop, and contribute to the "OCM sharing API" as a vendor-neutral protocol. All leading partners of the OCM project are fully committed to the open API design principle and welcome other open source file share and sync communities to participate and join the connected cloud.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/sharing-files-pydio-owncloud
|
||||
|
||||
作者:[ben van 't ende][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/benvantende
|
||||
[1]: https://pydio.com/
|
||||
[2]: https://sourceforge.net/projects/ajaxplorer/
|
||||
[3]: https://github.com/pydio/
|
||||
[4]: https://www.google.com/design/spec/material-design/introduction.html
|
||||
[5]: https://pydio.com/en/community
|
||||
[6]: https://pydio.com/en/community/contribute
|
||||
[7]: https://pydio.com/forum/f
|
||||
[8]: https://owncloud.org/
|
||||
[9]: https://wiki.geant.org/display/OCM/Open+Cloud+Mesh
|
||||
@ -0,0 +1,142 @@
|
||||
ORB: NEW GENERATION OF LINUX APPS ARE HERE
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
We have talked about [installing applications offline in Ubuntu][1] before. And we are going to talk about it once again.
|
||||
|
||||
[Orbital Apps][2] has brought us a new type of application package, **ORB**, with portable applications, interactive installer support and offline usage ability.
|
||||
|
||||
Portable applications are always handy. Mostly because they can run on-the-fly without needing any administrator privileges, and also it can be carried around on small USB sticks along with all their settings and data. And these interactive installers will be able to allow us to install applications with ease.
|
||||
|
||||
### OPEN RUNNABLE BUNDLE (ORB)
|
||||
|
||||
ORB is a free & open-source package format and it’s different from the others in numerous ways. Some of the specifications of ORB is followings:
|
||||
|
||||
- **Compression**: All the packages are compressed with squashfs making them up-to 60% smaller.
|
||||
- **Portable Mode**: If a portable ORB application is run from a removable drive, it’ll store its settings and data on that drive.
|
||||
- **Security**: All ORB packages are signed with PGP/RSA and distributed via TLS 1.2.
|
||||
- **Offline**: All the dependencies are bundled with the package, so no downloading dependencies anymore.
|
||||
- **Open package**: ORB packages can be mounted as ISO images.
|
||||
|
||||
### VARIETY
|
||||
|
||||
ORB applications are now available in two varieties:
|
||||
|
||||
- Portable Applications
|
||||
- SuperDEB
|
||||
|
||||
#### 1. PORTABLE ORB APPLICATIONS
|
||||
|
||||
Portable ORB Applications is capable of running right away without needing any installation beforehand. That means it’ll need no administrator privileges and no dependencies! You can just download them from the Orbital Apps website and get to work.
|
||||
|
||||
And as it supports Portable Mode, you can copy it on a USB stick and carry it around. All its settings and data will be stored with it on that USB stick. Just connect the USB stick with any system running on Ubuntu 16.04 and you’ll be ready to go.
|
||||
|
||||
##### AVAILABLE PORTABLE APPLICATIONS
|
||||
|
||||
Currently, more than 35 applications are available as portable packages, including some very popular applications like: [Deluge][3], [Firefox][4], [GIMP][5], [Libreoffice][6], [uGet][7] & [VLC][8].
|
||||
|
||||
For a full list of available packages, check the [Portable ORB Apps list][9].
|
||||
|
||||
##### USING PORTABLE APPLICATION
|
||||
|
||||
Follow the steps for using Portable ORB Applications:
|
||||
|
||||
- Download your desired package from the Orbital Apps site.
|
||||
- Move it wherever you want (local drive / USB stick).
|
||||
- Open the directory where you’ve stored the ORB package.
|
||||
|
||||

|
||||
|
||||
- Open Properties of the ORB package.
|
||||
|
||||

|
||||
>Add Execute permission to ORB package
|
||||
|
||||
- Add Execute permission from Permissions tab.
|
||||
- Double-click on it.
|
||||
|
||||
Wait for a few seconds as it prepares itself for running. And you’re good to go.
|
||||
|
||||
#### 2. SUPERDEB
|
||||
|
||||
Another variety of ORB Applications is SuperDEB. SuperDEBs are easy and interactive installers that make the software installation process a lot smoother. If you don’t like to install software from terminal or software centers, SuperDEB is exactly for you.
|
||||
|
||||
And the most interesting part is that you won’t need an active internet connection for installing as all the dependencies are bundled with the installer.
|
||||
|
||||
##### AVAILABLE SUPERDEBS
|
||||
|
||||
More than 60 applications are currently available as SuperDEB. Some of the popular software among them are: [Chromium][10], [Deluge][3], [Firefox][4], [GIMP][5], [Libreoffice][6], [uGet][7] & [VLC][8].
|
||||
|
||||
For a full list of available SuperDEBs, check the [SuperDEB list][11].
|
||||
|
||||
##### USING SUPERDEB INSTALLER
|
||||
|
||||
- Download your desired SuperDEB from Orbital Apps site.
|
||||
- Add **Execute permission** to it just like before ( Properties > Permissions ).
|
||||
- Double-click on the SuperDEB installer and follow the interactive instructions:
|
||||
|
||||

|
||||
>Click OK
|
||||
|
||||

|
||||
>Enter your password and proceed
|
||||
|
||||

|
||||
>It’ll start Installing…
|
||||
|
||||

|
||||
>And soon it’ll be done…
|
||||
|
||||
- After finishing the installation, you’re good to use it normally.
|
||||
|
||||
### ORB APPS COMPATIBILITY
|
||||
|
||||
According to Orbital Apps, they are fully compatible with Ubuntu 16.04 [64 bit].
|
||||
|
||||
>Reading suggestion: [How To Know If You Have 32 Bit or 64 Bit Computer in Ubuntu][12].
|
||||
|
||||
As for other distros compatibility is not guaranteed. But we can say that, it’ll work on any Ubuntu 16.04 flavors (UbuntuMATE, UbuntuGNOME, Lubuntu, Xubuntu etc.) and Ubuntu 16.04 based distros (like upcoming Linux Mint 18). We currently have no information if Orbital Apps is planning on expanding its support for other Ubuntu versions/Linux Distros or not.
|
||||
|
||||
If you’re going to use Portable ORB applications often on your system, you can consider installing ORB Launcher. It’s not necessary but is recommended installing to get an improved experience. The shortest method of installing ORB Launcher is opening the terminal and enter the following command:
|
||||
|
||||
```
|
||||
wget -O - https://www.orbital-apps.com/orb.sh | bash
|
||||
```
|
||||
|
||||
You can find the detailed instructions at [official documentation][13].
|
||||
|
||||
### WHAT IF I NEED AN APP THAT’S NOT LISTED?
|
||||
|
||||
If you need an application as ORB package that is not available right now, you can [contact][14] Orbital Apps. And the good news is, Orbital Apps is working hard and planning on releasing a tool for creating ORB packages. So, hopefully, soon we’ll be able to make ORB packages ourselves!
|
||||
|
||||
Just to add, this was about installing apps offline. If you are interested, you should read [how to update or upgrade Ubuntu offline][15].
|
||||
|
||||
So, what do you think about Orbital Apps’ Portable Applications and SuperDEB installers? Will you try them?
|
||||
|
||||
|
||||
----------------------------------
|
||||
via: http://itsfoss.com/orb-linux-apps/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/munif/
|
||||
[1]: http://itsfoss.com/cube-lets-install-linux-applications-offline/
|
||||
[2]: https://www.orbital-apps.com/
|
||||
[3]: https://www.orbital-apps.com/download/portable_apps_linux/deluge
|
||||
[4]: https://www.orbital-apps.com/download/portable_apps_linux/firefox
|
||||
[5]: https://www.orbital-apps.com/download/portable_apps_linux/gimp
|
||||
[6]: https://www.orbital-apps.com/download/portable_apps_linux/libreoffice
|
||||
[7]: https://www.orbital-apps.com/download/portable_apps_linux/uget
|
||||
[8]: https://www.orbital-apps.com/download/portable_apps_linux/vlc
|
||||
[9]: https://www.orbital-apps.com/download/portable_apps_linux/
|
||||
[10]: https://www.orbital-apps.com/download/superdeb_installers/ubuntu_16.04_64bits/chromium/
|
||||
[11]: https://www.orbital-apps.com/superdebs/ubuntu_16.04_64bits/
|
||||
[12]: http://itsfoss.com/32-bit-64-bit-ubuntu/
|
||||
[13]: https://www.orbital-apps.com/documentation
|
||||
[14]: https://www.orbital-apps.com/contact
|
||||
[15]: http://itsfoss.com/upgrade-or-update-ubuntu-offline-without-internet/
|
||||
@ -1,561 +0,0 @@
|
||||
kylepeng93 is translating
|
||||
Part 3 - LXD 2.0: Your first LXD container
|
||||
==========================================
|
||||
|
||||
This is the third blog post [in this series about LXD 2.0][0].
|
||||
|
||||
As there are a lot of commands involved with managing LXD containers, this post is rather long. If you’d instead prefer a quick step-by-step tour of those same commands, you can [try our online demo instead][1]!
|
||||
|
||||

|
||||
|
||||
### Creating and starting a new container
|
||||
|
||||
As I mentioned in the previous posts, the LXD command line client comes pre-configured with a few image sources. Ubuntu is the best covered with official images for all its releases and architectures but there also are a number of unofficial images for other distributions. Those are community generated and maintained by LXC upstream contributors.
|
||||
|
||||
### Ubuntu
|
||||
|
||||
If all you want is the best supported release of Ubuntu, all you have to do is:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:
|
||||
```
|
||||
|
||||
Note however that the meaning of this will change as new Ubuntu LTS releases are released. So for scripting use, you should stick to mentioning the actual release you want (see below).
|
||||
|
||||
### Ubuntu 14.04 LTS
|
||||
|
||||
To get the latest, tested, stable image of Ubuntu 14.04 LTS, you can simply run:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04
|
||||
```
|
||||
|
||||
In this mode, a random container name will be picked.
|
||||
If you prefer to specify your own name, you may instead do:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04 c1
|
||||
```
|
||||
|
||||
Should you want a specific (non-primary) architecture, say a 32bit Intel image, you can do:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04/i386 c2
|
||||
```
|
||||
|
||||
### Current Ubuntu development release
|
||||
|
||||
The “ubuntu:” remote used above only provides official, tested images for Ubuntu. If you instead want untested daily builds, as is appropriate for the development release, you’ll want to use the “ubuntu-daily:” remote instead.
|
||||
|
||||
```
|
||||
lxc launch ubuntu-daily:devel c3
|
||||
```
|
||||
|
||||
In this example, whatever the latest Ubuntu development release is will automatically be picked.
|
||||
|
||||
You can also be explicit, for example by using the code name:
|
||||
|
||||
```
|
||||
lxc launch ubuntu-daily:xenial c4
|
||||
```
|
||||
|
||||
### Latest Alpine Linux
|
||||
|
||||
Alpine images are available on the “images:” remote and can be launched with:
|
||||
|
||||
```
|
||||
lxc launch images:alpine/3.3/amd64 c5
|
||||
```
|
||||
|
||||
### And many more
|
||||
|
||||
A full list of the Ubuntu images can be obtained with:
|
||||
|
||||
```
|
||||
lxc image list ubuntu:
|
||||
lxc image list ubuntu-daily:
|
||||
```
|
||||
|
||||
And of all the unofficial images:
|
||||
|
||||
```
|
||||
lxc image list images:
|
||||
```
|
||||
|
||||
A list of all the aliases (friendly names) available on a given remote can also be obtained with (for the “ubuntu:” remote):
|
||||
|
||||
```
|
||||
lxc image alias list ubuntu:
|
||||
```
|
||||
|
||||
### Creating a container without starting it
|
||||
|
||||
If you want to just create a container or a batch of container but not also start them immediately, you can just replace “lxc launch” by “lxc init”. All the options are identical, the only different is that it will not start the container for you after creation.
|
||||
|
||||
```
|
||||
lxc init ubuntu:
|
||||
```
|
||||
|
||||
### Information about your containers
|
||||
|
||||
#### Listing the containers
|
||||
|
||||
To list all your containers, you can do:
|
||||
|
||||
```
|
||||
lxc list
|
||||
```
|
||||
|
||||
There are a number of options you can pass to change what columns are displayed. On systems with a lot of containers, the default columns can be a bit slow (due to having to retrieve network information from the containers), you may instead want:
|
||||
|
||||
```
|
||||
lxc list --fast
|
||||
```
|
||||
|
||||
Which shows a different set of columns that require less processing on the server side.
|
||||
|
||||
You can also filter based on name or properties:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list security.privileged=true
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| suse | RUNNING | 172.17.0.105 (eth0) | 2607:f2c0:f00f:2700:216:3eff:fef2:aff4 (eth0) | PERSISTENT | 0 |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
In this example, only containers that are privileged (user namespace disabled) are listed.
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list --fast alpine
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| NAME | STATE | ARCHITECTURE | CREATED AT | PROFILES | TYPE |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| alpine | RUNNING | x86_64 | 2016/03/20 02:11 UTC | default | PERSISTENT |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| alpine-edge | RUNNING | x86_64 | 2016/03/20 02:19 UTC | default | PERSISTENT |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
```
|
||||
|
||||
And in this example, only the containers which have “alpine” in their names (complex regular expressions are also supported).
|
||||
|
||||
#### Getting detailed information from a container
|
||||
|
||||
As the list command obviously can’t show you everything about a container in a nicely readable way, you can query information about an individual container with:
|
||||
|
||||
```
|
||||
lxc info <container>
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc info zerotier
|
||||
Name: zerotier
|
||||
Architecture: x86_64
|
||||
Created: 2016/02/20 20:01 UTC
|
||||
Status: Running
|
||||
Type: persistent
|
||||
Profiles: default
|
||||
Pid: 31715
|
||||
Processes: 32
|
||||
Ips:
|
||||
eth0: inet 172.17.0.101
|
||||
eth0: inet6 2607:f2c0:f00f:2700:216:3eff:feec:65a8
|
||||
eth0: inet6 fe80::216:3eff:feec:65a8
|
||||
lo: inet 127.0.0.1
|
||||
lo: inet6 ::1
|
||||
lxcbr0: inet 10.0.3.1
|
||||
lxcbr0: inet6 fe80::c0a4:ceff:fe52:4d51
|
||||
zt0: inet 29.17.181.59
|
||||
zt0: inet6 fd80:56c2:e21c:0:199:9379:e711:b3e1
|
||||
zt0: inet6 fe80::79:e7ff:fe0d:5123
|
||||
Snapshots:
|
||||
zerotier/blah (taken at 2016/03/08 23:55 UTC) (stateless)
|
||||
```
|
||||
|
||||
### Life-cycle management commands
|
||||
|
||||
Those are probably the most obvious commands of any container or virtual machine manager but they still need to be covered.
|
||||
|
||||
Oh and all of them accept multiple container names for batch operation.
|
||||
|
||||
#### start
|
||||
|
||||
Starting a container is as simple as:
|
||||
|
||||
```
|
||||
lxc start <container>
|
||||
```
|
||||
|
||||
#### stop
|
||||
|
||||
Stopping a container can be done with:
|
||||
|
||||
```
|
||||
lxc stop <container>
|
||||
```
|
||||
|
||||
If the container isn’t cooperating (not responding to SIGPWR), you can force it with:
|
||||
|
||||
```
|
||||
lxc stop <container> --force
|
||||
```
|
||||
|
||||
#### restart
|
||||
|
||||
Restarting a container is done through:
|
||||
|
||||
```
|
||||
lxc restart <container>
|
||||
```
|
||||
|
||||
And if not cooperating (not responding to SIGINT), you can force it with:
|
||||
|
||||
```
|
||||
lxc restart <container> --force
|
||||
```
|
||||
|
||||
#### pause
|
||||
|
||||
You can also “pause” a container. In this mode, all the container tasks will be sent the equivalent of a SIGSTOP which means that they will still be visible and will still be using memory but they won’t get any CPU time from the scheduler.
|
||||
|
||||
This is useful if you have a CPU hungry container that takes quite a while to start but that you aren’t constantly using. You can let it start, then pause it, then start it again when needed.
|
||||
|
||||
```
|
||||
lxc pause <container>
|
||||
```
|
||||
|
||||
#### delete
|
||||
|
||||
Lastly, if you want a container to go away, you can delete it for good with:
|
||||
|
||||
```
|
||||
lxc delete <container>
|
||||
```
|
||||
|
||||
Note that you will have to pass “–force” if the container is currently running.
|
||||
|
||||
### Container configuration
|
||||
|
||||
LXD exposes quite a few container settings, including resource limitation, control of container startup and a variety of device pass-through options. The full list is far too long to cover in this post but it’s available [here][2].
|
||||
|
||||
As far as devices go, LXD currently supports the following device types:
|
||||
|
||||
- disk
|
||||
This can be a physical disk or partition being mounted into the container or a bind-mounted path from the host.
|
||||
- nic
|
||||
A network interface. It can be a bridged virtual ethernet interrface, a point to point device, an ethernet macvlan device or an actual physical interface being passed through to the container.
|
||||
- unix-block
|
||||
A UNIX block device, e.g. /dev/sda
|
||||
- unix-char
|
||||
A UNIX character device, e.g. /dev/kvm
|
||||
- none
|
||||
This special type is used to hide a device which would otherwise be inherited through profiles.
|
||||
|
||||
#### Configuration profiles
|
||||
|
||||
The list of all available profiles can be obtained with:
|
||||
|
||||
```
|
||||
lxc profile list
|
||||
```
|
||||
|
||||
To see the content of a given profile, the easiest is to use:
|
||||
|
||||
```
|
||||
lxc profile show <profile>
|
||||
```
|
||||
|
||||
And should you want to change anything inside it, use:
|
||||
|
||||
```
|
||||
lxc profile edit <profile>
|
||||
```
|
||||
|
||||
You can change the list of profiles which apply to a given container with:
|
||||
|
||||
```
|
||||
lxc profile apply <container> <profile1>,<profile2>,<profile3>,...
|
||||
```
|
||||
|
||||
#### Local configuration
|
||||
|
||||
For things that are unique to a container and so don’t make sense to put into a profile, you can just set them directly against the container:
|
||||
|
||||
```
|
||||
lxc config edit <container>
|
||||
```
|
||||
|
||||
This behaves the exact same way as “profile edit” above.
|
||||
|
||||
Instead of opening the whole thing in a text editor, you can also modify individual keys with:
|
||||
|
||||
```
|
||||
lxc config set <container> <key> <value>
|
||||
```
|
||||
Or add devices, for example:
|
||||
|
||||
```
|
||||
lxc config device add my-container kvm unix-char path=/dev/kvm
|
||||
```
|
||||
|
||||
Which will setup a /dev/kvm entry for the container named “my-container”.
|
||||
|
||||
The same can be done for a profile using “lxc profile set” and “lxc profile device add”.
|
||||
|
||||
#### Reading the configuration
|
||||
|
||||
You can read the container local configuration with:
|
||||
|
||||
```
|
||||
lxc config show <container>
|
||||
```
|
||||
|
||||
Or to get the expanded configuration (including all the profile keys):
|
||||
|
||||
```
|
||||
lxc config show --expanded <container>
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc config show --expanded zerotier
|
||||
name: zerotier
|
||||
profiles:
|
||||
- default
|
||||
config:
|
||||
security.nesting: "true"
|
||||
user.a: b
|
||||
volatile.base_image: a49d26ce5808075f5175bf31f5cb90561f5023dcd408da8ac5e834096d46b2d8
|
||||
volatile.eth0.hwaddr: 00:16:3e:ec:65:a8
|
||||
volatile.last_state.idmap: '[{"Isuid":true,"Isgid":false,"Hostid":100000,"Nsid":0,"Maprange":65536},{"Isuid":false,"Isgid":true,"Hostid":100000,"Nsid":0,"Maprange":65536}]'
|
||||
devices:
|
||||
eth0:
|
||||
name: eth0
|
||||
nictype: macvlan
|
||||
parent: eth0
|
||||
type: nic
|
||||
limits.ingress: 10Mbit
|
||||
limits.egress: 10Mbit
|
||||
root:
|
||||
path: /
|
||||
size: 30GB
|
||||
type: disk
|
||||
tun:
|
||||
path: /dev/net/tun
|
||||
type: unix-char
|
||||
ephemeral: false
|
||||
```
|
||||
|
||||
That one is very convenient to check what will actually be applied to a given container.
|
||||
|
||||
#### Live configuration update
|
||||
|
||||
Note that unless indicated in the documentation, all configuration keys and device entries are applied to affected containers live. This means that you can add and remove devices or alter the security profile of running containers without ever having to restart them.
|
||||
|
||||
### Getting a shell
|
||||
|
||||
LXD lets you execute tasks directly into the container. The most common use of this is to get a shell in the container or to run some admin tasks.
|
||||
|
||||
The benefit of this compared to SSH is that you’re not dependent on the container being reachable over the network or on any software or configuration being present inside the container.
|
||||
|
||||
Execution environment
|
||||
|
||||
One thing that’s a bit unusual with the way LXD executes commands inside the container is that it’s not itself running inside the container, which means that it can’t know what shell to use, what environment variables to set or what path to use for your home directory.
|
||||
|
||||
Commands executed through LXD will always run as the container’s root user (uid 0, gid 0) with a minimal PATH environment variable set and a HOME environment variable set to /root.
|
||||
|
||||
Additional environment variables can be passed through the command line or can be set permanently against the container through the “environment.<key>” configuration options.
|
||||
|
||||
#### Executing commands
|
||||
|
||||
Getting a shell inside a container is typically as simple as:
|
||||
|
||||
```
|
||||
lxc exec <container> bash
|
||||
```
|
||||
|
||||
That’s assuming the container does actually have bash installed.
|
||||
|
||||
|
||||
More complex commands require the use of a separator for proper argument parsing:
|
||||
|
||||
```
|
||||
lxc exec <container> -- ls -lh /
|
||||
```
|
||||
|
||||
To set or override environment variables, you can use the “–env” argument, for example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec zerotier --env mykey=myvalue env | grep mykey
|
||||
mykey=myvalue
|
||||
```
|
||||
|
||||
### Managing files
|
||||
|
||||
Because LXD has direct access to the container’s file system, it can directly read and write any file inside the container. This can be very useful to pull log files or exchange files with the container.
|
||||
|
||||
#### Pulling a file from the container
|
||||
|
||||
To get a file from the container, simply run:
|
||||
|
||||
```
|
||||
lxc file pull <container>/<path> <dest>
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts hosts
|
||||
```
|
||||
|
||||
Or to read it to standard output:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts -
|
||||
127.0.0.1 localhost
|
||||
|
||||
# The following lines are desirable for IPv6 capable hosts
|
||||
::1 ip6-localhost ip6-loopback
|
||||
fe00::0 ip6-localnet
|
||||
ff00::0 ip6-mcastprefix
|
||||
ff02::1 ip6-allnodes
|
||||
ff02::2 ip6-allrouters
|
||||
ff02::3 ip6-allhosts
|
||||
```
|
||||
|
||||
#### Pushing a file to the container
|
||||
|
||||
Push simply works the other way:
|
||||
|
||||
```
|
||||
lxc file push <source> <container>/<path>
|
||||
```
|
||||
|
||||
#### Editing a file directly
|
||||
|
||||
Edit is a convenience function which simply pulls a given path, opens it in your default text editor and then pushes it back to the container when you close it:
|
||||
|
||||
```
|
||||
lxc file edit <container>/<path>
|
||||
```
|
||||
|
||||
### Snapshot management
|
||||
|
||||
LXD lets you snapshot and restore containers. Snapshots include the entirety of the container’s state (including running state if –stateful is used), which means all container configuration, container devices and the container file system.
|
||||
|
||||
#### Creating a snapshot
|
||||
|
||||
You can snapshot a container with:
|
||||
|
||||
```
|
||||
lxc snapshot <container>
|
||||
```
|
||||
|
||||
It’ll get named snapX where X is an incrementing number.
|
||||
|
||||
Alternatively, you can name your snapshot with:
|
||||
|
||||
```
|
||||
lxc snapshot <container> <snapshot name>
|
||||
```
|
||||
|
||||
#### Listing snapshots
|
||||
|
||||
The number of snapshots a container has is listed in “lxc list”, but the actual snapshot list is only visible in “lxc info”.
|
||||
|
||||
```
|
||||
lxc info <container>
|
||||
```
|
||||
|
||||
#### Restoring a snapshot
|
||||
|
||||
To restore a snapshot, simply run:
|
||||
|
||||
```
|
||||
lxc restore <container> <snapshot name>
|
||||
```
|
||||
|
||||
#### Renaming a snapshot
|
||||
|
||||
Renaming a snapshot can be done by moving it with:
|
||||
|
||||
```
|
||||
lxc move <container>/<snapshot name> <container>/<new snapshot name>
|
||||
```
|
||||
|
||||
#### Creating a new container from a snapshot
|
||||
|
||||
You can create a new container which will be identical to another container’s snapshot except for the volatile information being reset (MAC address):
|
||||
|
||||
```
|
||||
lxc copy <source container>/<snapshot name> <destination container>
|
||||
```
|
||||
|
||||
#### Deleting a snapshot
|
||||
|
||||
And finally, to delete a snapshot, just run:
|
||||
|
||||
```
|
||||
lxc delete <container>/<snapshot name>
|
||||
```
|
||||
|
||||
### Cloning and renaming
|
||||
|
||||
Getting clean distribution images is all nice and well, but sometimes you want to install a bunch of things into your container, configure it and then branch it into a bunch of other containers.
|
||||
|
||||
#### Copying a container
|
||||
|
||||
To copy a container and effectively clone it into a new one, just run:
|
||||
|
||||
```
|
||||
lxc copy <source container> <destination container>
|
||||
```
|
||||
|
||||
The destination container will be identical in every way to the source one, except it won’t have any snapshot and volatile keys (MAC address) will be reset.
|
||||
|
||||
#### Moving a container
|
||||
|
||||
LXD lets you copy and move containers between hosts, but that will get covered in a later post.
|
||||
|
||||
For now, the “move” command can be used to rename a container with:
|
||||
|
||||
```
|
||||
lxc move <old name> <new name>
|
||||
```
|
||||
|
||||
The only requirement is that the container be stopped, everything else will be kept exactly as it was, including the volatile information (MAC address and such).
|
||||
|
||||
### Conclusion
|
||||
|
||||
This pretty long post covered most of the commands you’re likely to use in day to day operation.
|
||||
|
||||
Obviously a lot of those commands have extra arguments that let you be more efficient or tweak specific aspects of your LXD containers. The best way to learn about all of those is to go through the help for those you care about (–help).
|
||||
|
||||
### Extra information
|
||||
|
||||
The main LXD website is at: <https://linuxcontainers.org/lxd>
|
||||
Development happens on Github at: <https://github.com/lxc/lxd>
|
||||
Mailing-list support happens on: <https://lists.linuxcontainers.org>
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
|
||||
And if you don’t want or can’t install LXD on your own machine, you can always [try it online instead][1]!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.stgraber.org/2016/03/19/lxd-2-0-your-first-lxd-container-312/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://linuxcontainers.org/lxd/try-it
|
||||
[2]: https://github.com/lxc/lxd/blob/master/doc/configuration.md
|
||||
@ -0,0 +1,74 @@
|
||||
在维基激动人心的四年
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
|
||||
我自认为自己是个奥迪亚的维基人。我通过写文章和纠正错误的文章贡献[奥迪亚][1]知识(在印度的[奥里萨邦][2]的主要的语言 )给很多维基项目,像维基百科和维基文库,我也为用印地语和英语写的维基文章做贡献。
|
||||
|
||||

|
||||
|
||||
我对维基的爱从我第 10 次考试(像在美国的 10 年级学生的年级考试)之后看到的英文维基文章[孟加拉解放战争][3]开始。一不小心我打开了印度维基文章的链接,,并且开始阅读它. 在文章左边有用奥迪亚语写的东西, 所以我点击了一下, 打开了一篇在奥迪亚维基上的 [????/Bhārat][4] 文章. 发现了用母语写的维基让我很激动!
|
||||
|
||||

|
||||
|
||||
一个邀请读者参加 2014 年 4 月 1 日第二次布巴内斯瓦尔的研讨会的标语引起了我的好奇。我过去从来没有为维基做过贡献, 只用它搜索过, 我并不熟悉开源和社区贡献流程。加上,我只有 15 岁。我注册了。在研讨会上有很多语言爱好者,我是中间最年轻的一个。尽管我害怕我父亲还是鼓励我去参与。他起了非常重要的作用—他不是一个维基媒体人,和我不一样,但是他的鼓励给了我改变奥迪亚维基的动力和参加社区活动的勇气。
|
||||
|
||||
我相信奥迪亚语言和文学需要改进很多错误的想法和知识缺口所以,我帮助组织关于奥迪亚维基的活动和和研讨会,我完成了如下列表:
|
||||
|
||||
* 发起3次主要的 edit-a-thons 在奥迪亚维基:2015 年妇女节,2016年妇女节, abd [Nabakalebara edit-a-thon 2015][5]
|
||||
* 在全印度发起了征集[檀车节][6]图片的比赛
|
||||
* 在谷歌的两大事件([谷歌I/O大会扩展][7]和谷歌开发节)中代表奥迪亚维基
|
||||
* 在2015[Perception][8]和第一次[Open Access India][9]会议
|
||||
|
||||

|
||||
|
||||
我只编辑维基项目到了去年,在 2015 年一月,当我出席[孟加拉语维基百科的十周年会议][10]和[毗瑟挐][11]活动时,[互联网和社会中心][12]主任,邀请我参加[培训培训师][13] 计划。我的灵感始于扩展奥迪亚维基,为[华丽][14]的活动举办的聚会和培训新的维基人。这些经验告诉我作为一个贡献者该如何为社区工作。
|
||||
|
||||
[Ravi][15],在当时维基的主任,在我的旅程也发挥了重要作用。他非常相信我让我参与到了[Wiki Loves Food][16],维基共享中的公共摄影比赛,组织方是[2016 印度维基会议][17]。在2015的 Loves Food 活动期间,我的团队在维基共享中加入了 10,000+ 有 CC BY-SA 协议的图片。Ravi 进一步巩固了我的承诺,和我分享很多关于维基媒体运动的信息,和他自己在 [奥迪亚维基百科13周年][18]的经历。
|
||||
|
||||
不到一年后,在 2015 年十二月,我成为了网络与社会中心的[获取知识的程序][19]的项目助理( CIS-A2K 运动)。我自豪的时刻之一是在普里的研讨会,我们从印度带了 20 个新的维基人来编辑奥迪亚维基媒体社区。现在,我的指导者在一个普里非正式聚会被叫作[WikiTungi][20]。我和这个小组一起工作,把 wikiquotes 变成一个真实的计划项目。在奥迪亚维基我也致力于缩小性别差距。[八个女编辑][21]也正帮助组织聚会和研讨会,参加 [Women's History month edit-a-thon][22]。
|
||||
|
||||
在我四年短暂而令人激动的旅行之中,我也参与到 [维基百科的教育项目][23],[通讯团队][24],两个全球的 edit-a-thons: [Art and Feminsim][25] 和 [Menu Challenge][26]。我期待着更多的到来!
|
||||
|
||||
我还要感谢 [Sameer][27] 和 [Anna][28](都是之前维基百科教育计划的成员)。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/4/my-open-source-story-sailesh-patnaik
|
||||
|
||||
作者:[Sailesh Patnaik][a]
|
||||
译者:[译者ID](https://github.com/hkurj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/saileshpat
|
||||
[1]: https://en.wikipedia.org/wiki/Odia_language
|
||||
[2]: https://en.wikipedia.org/wiki/Odisha
|
||||
[3]: https://en.wikipedia.org/wiki/Bangladesh_Liberation_War
|
||||
[4]: https://or.wikipedia.org/s/d2
|
||||
[5]: https://or.wikipedia.org/s/toq
|
||||
[6]: https://commons.wikimedia.org/wiki/Commons:The_Rathyatra_Challenge
|
||||
[7]: http://cis-india.org/openness/blog-old/odia-wikipedia-meets-google-developer-group
|
||||
[8]: http://perception.cetb.in/events/odia-wikipedia-event/
|
||||
[9]: https://opencon2015kolkata.sched.org/speaker/sailesh.patnaik007
|
||||
[10]: https://meta.wikimedia.org/wiki/Bengali_Wikipedia_10th_Anniversary_Celebration_Kolkata
|
||||
[11]: https://www.facebook.com/vishnu.vardhan.50746?fref=ts
|
||||
[12]: http://cis-india.org/
|
||||
[13]: https://meta.wikimedia.org/wiki/CIS-A2K/Events/Train_the_Trainer_Program/2015
|
||||
[14]: https://en.wikipedia.org/wiki/Wikipedia:GLAM
|
||||
[15]: https://www.facebook.com/ravidreams?fref=ts
|
||||
[16]: https://commons.wikimedia.org/wiki/Commons:Wiki_Loves_Food
|
||||
[17]: https://meta.wikimedia.org/wiki/WikiConference_India_2016
|
||||
[18]: https://or.wikipedia.org/s/sml
|
||||
[19]: https://meta.wikimedia.org/wiki/CIS-A2K
|
||||
[20]: https://or.wikipedia.org/s/xgx
|
||||
[21]: https://or.wikipedia.org/s/ysg
|
||||
[22]: https://or.wikipedia.org/s/ynj
|
||||
[23]: https://outreach.wikimedia.org/wiki/Education
|
||||
[24]: https://outreach.wikimedia.org/wiki/Talk:Education/News#Call_for_volunteers
|
||||
[25]: https://en.wikipedia.org/wiki/User_talk:Saileshpat#Barnstar_for_Art_.26_Feminism_Challenge
|
||||
[26]: https://opensource.com/life/15/11/tasty-translations-the-open-source-way
|
||||
[27]: https://www.facebook.com/samirsharbaty?fref=ts
|
||||
[28]: https://www.facebook.com/anna.koval.737?fref=ts
|
||||
@ -0,0 +1,101 @@
|
||||
我成为一名软件工程师的原因和经历
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
1989 年乌干达首都,坎帕拉。
|
||||
|
||||
赞美我的父母,他们机智的把我送到叔叔的办公室,去学着用电脑,而非将我留在家里添麻烦。几日后,我和另外六、七个小孩,还有一台放置在与讲台相垂直课桌子上的崭新电脑,一起置身于 21 层楼高的狭小房间中。很明显我们还不够格去碰那家伙。在长达三周无趣的 DOS 命令学习后,终于迎来了这美妙的时光。终于轮到我来输 **copy doc.txt d:** 了。
|
||||
|
||||
那奇怪的声音其实是将一个简单文件写入五英寸软盘的声音,但听起来却像音乐般美妙。那段时间,这块软盘简直成为了我的至宝。我把所有我可以拷贝的东西都放在上面了。然而,1989 年的乌干达,人们的生活十分正经,相较而言捣鼓电脑,拷贝文件还有格式化磁盘就称不上正经。我不得不专注于自己的学业,这让我离开了计算机科学走入了建筑工程学。
|
||||
|
||||
在这些年里,我和同龄人一样,干过很多份工作也学到了许多技能。我教过幼儿园的小朋友,也教过大人如何使用软件,在服装店工作过,还在教堂中担任过付费招待。在我获取堪萨斯大学的学位时,我正在技术高管的手下做技术助理,其实也就听上去比较洋气,也就是搞搞学生数据库而已。
|
||||
|
||||
当我 2007 年毕业时,这些技术已经变得不可或缺。建筑工程学的方方面面都与计算机科学深深的交织在一起,所以我们也都在不经意间也都学了些简单的编程知识。我对于这方面一直很着迷。但由于我不得不成为一位正经的工程师,所以我发展了一项私人爱好:写科幻小说。
|
||||
|
||||
在我的故事中,我以我笔下的女英雄的形式存在。她们都是编程能力出众的科学家,总是在冒险的途中用自己的技术发明战胜那些渣渣们,有时发明要在战斗中进行。我想出的这些“新技术”,一般基于真实世界中的发明。也有些是从买来的科幻小说中读到的。这就意味着我需要了解这些技术的原理,而且我的研究使我有意无意的关注了许多有趣的 subreddit 和电子杂志
|
||||
|
||||
### 开源:巨大的宝库
|
||||
|
||||
在我的经历中,那几周花在 DOS 命令上的时间仍然记忆犹新,在一些偏门的项目上耗费心血,并占据了宝贵的学习时间。Geocities 一向所有 Yahoo! 用户开放,我就创建了一个网站,用于发布一些由我用小型数码相机拍摄的个人图片。这个网站是我随性而为的,用来帮助家人和朋友,解决一些他们所遇到的电脑问题。同时也为教堂搭建了一个图书馆数据库。
|
||||
|
||||
这意味着,我需要一直研究并尝试获取更多的信息,使它们变得更棒。上帝保佑,让互联网和开源砸在了我的面前。然后,30 天试用和 license 限制对我而言就变成了过去式。我可以完全不受这些限制,持续的使用 GIMP、Inkscape 和 OpenOffice。
|
||||
|
||||
### 是时候正经了
|
||||
|
||||
我很幸运,有商业伙伴看出了我故事中的奇妙。她也是个想象力丰富的人,对更高效、更便捷的互联这个世界,充满了各种美好的想法。我们根据我们以往成功道路中经历的痛点制定了解决方案,但执行却成了一个问题。我们都缺乏那种将产品带入生活的能力,每当我们试图将想法带到投资人面前时,都表现的尤为突出。
|
||||
|
||||
我们需要学习编程。所以在 2015 年的夏末,我们踏上了征途,来到了 Holberton 学校的阶前。那是一所座落于旧金山由社区推进,基于项目教学的学校。
|
||||
|
||||
我的商业伙伴一天早上找到我,并开始了一段充满她方式的对话,每当她有疯狂想法想要拉我入伙时。
|
||||
|
||||
**Zee**: Gloria,我想和你说点事,在拒绝前能先听我说完吗?
|
||||
|
||||
**Me**: 不行。
|
||||
|
||||
**Zee**: 我们想要申请一所学校的全栈工程师。
|
||||
|
||||
**Me**: 什么?
|
||||
|
||||
**Zee**: 就是这,看!就是这所学校,我们要申请这所学校学习编程。
|
||||
|
||||
**Me**: 我不明白。我们不是正在网上学 Python 和…
|
||||
|
||||
**Zee**: 这不一样。相信我。
|
||||
|
||||
**Me**: 那…
|
||||
|
||||
**Zee**: 还不相信吗?
|
||||
|
||||
**Me**: 好吧…我看看。
|
||||
|
||||
### 抛开偏见
|
||||
|
||||
我看到的和我们在网上听说的几乎差不多。这简直太棒了,以至于让人觉得不太真实,但我们还是决定尝试一下,双脚起跳,看看结果如何。
|
||||
|
||||
要成为学生,我们需要经历四个步骤,仅仅是针对才能和态度,无关学历和编程经历的筛选。筛选便是课程的开始,通过它我们开始学习与合作。
|
||||
|
||||
根据我和我合作伙伴的经验,相比 Holberton 学校的申请流程,其他的申请流程实在是太无聊了。就像场游戏。如果你完成了一项挑战,你就能通往下一关,在那里有别的有趣的挑战正等着你。我们创建了 Twitter 账号,在 Medium 上写博客,为了创建网站而学习 HTML 和 CSS, 打造了一个充满活力的社区,虽然在此之前我们并不知晓有谁会来。
|
||||
|
||||
在线社区最吸引人的就是我们使用电脑的经验是多种多样的,而我们的背景和性别并非创始人(我们私下里称他为“The Trinity(三位一体)”)做出选择的因素。大家只是喜欢聚在一块交流。我们都是通过学习编程来提升自己计算机技术的聪明人。
|
||||
|
||||
相较于其他的的申请流程,我们不需要泄露很多的身份信息。就像我的商业伙伴,她的名字里看不出她的性别和种族。直到最后一个步骤,在视频聊天的时候, The Trinity 才知道她是一位有色人种女性。迄今为止,促使她达到这个程度的只是她的热情和才华。肤色和性别,并没有妨碍或者帮助到她。还有比这更酷的吗?
|
||||
|
||||
那个我们获得录取通知书的晚上,我们知道我们的命运已经改变,我们获得了原先梦寐以求的生活。2016 年 1 月 22 日,我们来到北至巴特瑞大街 98 号,去见我们的小伙伴 [Hippokampoiers][2],这是我们的初次见面。很明显,在见面之前,“The Trinity”就已经开始做一些令人激动的事了。他们已经聚集了一批形形色色的人,他们都专注于成为全栈工程师,并为之乐此不疲。
|
||||
|
||||
这所大学有种与众不同的体验。感觉每天都是向编程的一次竭力的冲锋。我们着手的工程,并不会有很多指导,我们需要使用一切我们可以使用的资源找出解决方案。[Holberton 学校][1] 的办学宗旨便是向学员提供,相较于我们已知而言,更为多样的信息渠道。MOOCs(大型开放式课程)、教程、可用的开源软件和项目,以及线上社区层出不穷,将我们完成项目所需要的知识全都衔接了起来。加之宝贵的导师团队来指导我们制定解决方案,这所学校变得并不仅仅是一所学校;我们已经成为了求学者的社区。任何对软件工程感兴趣并对这种学习方法感兴趣的人,我都十分推荐这所学校。下次开课在 2016 年 10 月,并且会接受新的申请。虽然会让人有些悲喜交加,但是那真的很值得。
|
||||
|
||||
### 开源问题
|
||||
|
||||
我最早使用的开源系统是 [Fedora][3],一个 [Red Hat][4] 赞助的项目。在与 IRC 中一名成员一番惊慌失措的交流后,她推荐了这款免费的系统。 虽然在此之前,我还未独自安装过操作系统,但是这激起了我对开源的兴趣和日常使用计算机时对开源软件的依赖性。我们提倡为开源贡献代码,创造并使用开源的项目。我们的项目就在 Github 上,任何人都可以使用或是向它贡献出自己的力量。我们也会使用或以自己的方式为一些既存的开源项目做出贡献。在学校里,我们使用的大部分工具是开源的,例如 Fedora、[Vagrant][5]、[VirtualBox][6]、[GCC][7] 和 [Discourse][8],仅举几例。
|
||||
|
||||
重回软件工程师之路以后,我始终憧憬着有这样一个时刻——能为开源社区做出一份贡献,能与他人分享我所掌握的知识。
|
||||
|
||||
### Diversity Matters
|
||||
|
||||
站在教室里,在着 29 双明亮的眼睛关注下交流心得,真是令人陶醉。学员中有 40% 是女性,有 44% 的有色人种。当你是一位有色人种且为女性,并身处于这个以缺乏多样而著名的领域时,这些数字就变得非常重要了。那是高科技圣地麦加上的绿洲。我知道我做到了。
|
||||
|
||||
想要成为一个全栈的工程师是十分困难的,你甚至很难了解这意味着什么。这是一条充满挑战的路途,道路四周布满了对收获的未知。科技推动着未来飞速发展,而你也是美好未来很重要的一部分。虽然媒体在持续的关注解决科技公司的多样化的问题,但是如果能认清自己,了解自己,知道自己为什么想成为一名全栈工程师,这样你便能觅得一处生根发芽。
|
||||
|
||||
不过可能最重要的是,提醒人们女性在计算机的发展史上扮演着多么重要的角色,以帮助更多的女性回归到科技界,并使她们充满期待,而非对自己的性别与能力感到犹豫。她们的才能将会描绘出不仅仅是科技的未来,而是整个世界的未来。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/4/my-open-source-story-gloria-bwandungi
|
||||
|
||||
作者:[Gloria Bwandungi][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nappybrain
|
||||
[1]: https://www.holbertonschool.com/
|
||||
[2]: https://twitter.com/hippokampoiers
|
||||
[3]: https://en.wikipedia.org/wiki/Fedora_(operating_system)
|
||||
[4]: https://www.redhat.com/
|
||||
[5]: https://www.vagrantup.com/
|
||||
[6]: https://www.virtualbox.org/
|
||||
[7]: https://gcc.gnu.org/
|
||||
[8]: https://www.discourse.org/
|
||||
@ -1,43 +0,0 @@
|
||||
# 使用 SystemBack 备份你的 Ubuntu/Linux Mint(系统还原)
|
||||
|
||||
对于任何一款允许用户还原电脑到之前状态(包括文件系统,安装的应用,以及系统设置)的操作系统来说,系统还原都是必备功能,可以恢复系统故障以及其他的问题。
|
||||
|
||||
有的时候安装一个程序或者驱动可能让你的系统黑屏。系统还原则让你电脑里面的系统文件(译者注:是系统文件,并非普通文件,详情请看**注意**部分)和程序恢复到之前工作正常时候的状态,进而让你远离那让人头痛的排障过程了。而且它也不会影响你的文件,照片或者其他数据。
|
||||
|
||||
简单的系统备份还原工具[Systemback](https://launchpad.net/systemback)让你很容易地创建系统备份以及用户配置文件。一旦遇到问题,你可以简单地恢复到系统先前的状态。它还有一些额外的特征包括系统复制,系统安装以及Live系统创建。
|
||||
|
||||
截图
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**注意**:使用系统还原不会还原你的文件,音乐,电子邮件或者其他任何类型的私人文件。对不同用户来讲,这既是优点又是缺点。坏消息是它不会还原你意外删除的文件,不过你可以通过一个文件恢复程序来解决这个问题。如果你的计算机没有还原点,那么系统恢复就无法奏效,所以这个工具就无法帮助你(还原系统),如果你尝试恢复一个主要问题,你将需要移步到另外的步骤来进行故障排除。
|
||||
|
||||
> > >适用于Ubuntu 15.10 Wily/16.04/15.04 Vivid/14.04 Trusty/Linux Mint 14.x/其他Ubuntu衍生版,打开终端,将下面这些命令复制过去:
|
||||
|
||||
终端命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nemh/systemback
|
||||
sudo apt-get update
|
||||
sudo apt-get install systemback
|
||||
|
||||
```
|
||||
|
||||
大功告成。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.noobslab.com/2015/11/backup-system-restore-point-your.html
|
||||
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://launchpad.net/systemback
|
||||
@ -1,156 +0,0 @@
|
||||
项目管理之道
|
||||
=================================
|
||||
|
||||
|
||||

|
||||
|
||||
[道德经][1],[据确认][2]为公元前六世纪的圣人[老子][3]所编写,是现存被翻译的语言版本最多的经文。从[宗教][4]到[关于约会的有趣电影][5]等一切的一切,它都影响至深,作者们借用它来隐喻,以解释各种各样的事情(甚至是[编程][6])。
|
||||
|
||||
当考虑开放性组织的项目管理时上面这段文字会立马浮现在我脑海。
|
||||
|
||||
这听起来会很奇怪。要理解我为什么会有这种想法,应该是从读了*《开放性组织:点燃激情提升执行力》*这书开始的,它是红帽公司总裁、CEO Jim Whitehurst 所著作的关于企业文化和新领导榜样的宣言。在这本书里,Jim(给予其它红帽子人的一点帮助而) 解释了传统组织机构(“自上而下”的方式,做决定的是高层,命令下达到员工,而员工是通过薪酬和晋升来激励的)和开放组织机构(自下而上,领导专注于激励和鼓励,员工被充分授权使其发挥主观能动性而做得最好)的差异。
|
||||
|
||||
在开放性组织中的员工意味有激情、有目的性和有参与感,这些我认为是项目管理者应该关注的。
|
||||
|
||||
要解释这一切,让我们回到*道德经*上来。
|
||||
|
||||
### 不要让工作职衔框住自身
|
||||
|
||||
>道,可道,
|
||||
>非常道;
|
||||
>名,可名,
|
||||
>非常名。
|
||||
|
||||
>无,名天地之始;
|
||||
>有,名万物之母。
|
||||
[[1]][7]
|
||||
|
||||
项目管理到底是什么?做为一个项目管理者应该做些什么呢?
|
||||
|
||||
如您所想,项目管理者的一部分工作就是管理项目:收集需求、项目相关人员的沟通、设置项目优先级、安排任务、帮助团队解决困扰。许多教育培训机构都可以教授如何做好项目管理,这些技能值得去学习。
|
||||
|
||||
然而,在开放性组织中,字面上的项目管理技能仅仅只是项目管理者需要做到一小部分,这些组织需要更多的:勇气。如果您擅长于管理项目(或者是真的擅长于任何工作),那么您就进入了舒适区。这时候就是需要鼓起勇气开始尝试冒险之时。
|
||||
|
||||
您有勇气跨出舒适区吗?向权威人士提出提出挑战性问题,可能会引发对方的不快,也可能会发现一个好的方法,您有勇气这样做吗?有确定需要做的下一件事,然后真正去完成它的勇气吗?有主动去解决因为沟通空白而留下的问题的勇气吗?有去尝试各种事情的勇气吗?有失败的勇气吗?
|
||||
|
||||
道德经的开篇(上面引用的)就表明词语、标签、名字这些是有限制的,也包括工作职衔。在开放性组织中,项目经理不仅仅是执行管理项目所需的机械任务,而且要帮助团队完成组织的使命,尽管只是定义。
|
||||
|
||||
### 结交正确的人
|
||||
|
||||
>三十辐共一毂,
|
||||
>当其无,
|
||||
>有车之用。
|
||||
[[11]][8]
|
||||
|
||||
当我开始学习要过渡到项目管理时,遇到最困难的一课就是并不是所有解决方案都是可接受的,甚至有的连预期都达不到。那对我来说是全新的,我喜欢所有的解决方案。但作为项目管理者,我的角色更多的是与人沟通--因此与那些有解决方案的人合作更有效率。
|
||||
|
||||
这决不是逃避责任和不负责的意思。这意味着可以很舒适的说,“我不知道,但我会给您找出答案”,然后就可迅速的关闭此循环。
|
||||
|
||||
想像马车的车轮。无中心孔的稳定性和方向,辐条车轮会自行崩溃。在一个开放性的组织中,项目管理者可以帮助一个团队,把正确的人凝聚在一起,主持积极讨论,以保持团队一直前进。
|
||||
|
||||
### 信任您的团队
|
||||
|
||||
>太上, 不知有之;
|
||||
>其次,亲而誉之;
|
||||
>其次,畏之;
|
||||
>其次,侮之。
|
||||
>
|
||||
>信不足焉,有不信焉。
|
||||
>
|
||||
>悠兮,其贵言。功成事遂,百姓皆谓“我自然”。
|
||||
[[17]][9]
|
||||
|
||||
[Rebecca Fernandez][10]曾经告诉我开放性组织的领导与其它最大的不同点,不是取得别人的信任,而是信任别人。
|
||||
|
||||
开放性组织会雇佣那些非常聪明的,且对公司正在做的事情充满激情的人来做工作。为了能使他们能更好的工作,我们会提供其所需,并尊重他们的工作方式。
|
||||
|
||||
至于原因,我认为从道德经中摘出的上面一段就说的很清楚。
|
||||
|
||||
### 顺其自然
|
||||
|
||||
>上德无为而无以为;下德为之而有以为。
|
||||
[[38]][11]
|
||||
|
||||
你认识总是忙忙碌碌的这种类型的人吗?认识因为有太多事情要做而看起来疲倦和压抑的人吗?
|
||||
|
||||
不要成为那样的人。
|
||||
|
||||
我知道说比做容易。要远离那种人最有帮助的事就是请记住大家都很忙。我没有那样讨厌的同事。
|
||||
|
||||
但需要有人在狂风暴雨中保持镇定;需要这样的人,能根据实际和一天工作时间的数量找到平衡参数的方式来做工作,并安慰团队让一切都好(因为这是我们正在做的事实)。
|
||||
|
||||
要成为那样的人。
|
||||
|
||||
道德经所说的,在我理解来就是总是夸夸其谈的人其实并没有干实事。如里您能把工作做的得心应手的话,那就说明您的工作做对了。
|
||||
|
||||
### 作为一个文化传教士
|
||||
|
||||
>上士闻道,勤而行之;
|
||||
>中士闻道,若存若亡;
|
||||
>下士闻道,大笑之。
|
||||
>不笑不足以为道。
|
||||
[[41]][12]
|
||||
|
||||
去年秋天,我跟着一群联邦雇员注册了一个工商管理硕士课程。当我开始介绍我公司的文化、价值和伦理框架以及公司如何运行时,我的同学和教授都认为我就像一个天真可爱的小姑娘在做着[许多甜美的白日梦][13],这就是我得到的直接印象。他们告诉我事情并不是如此的。他们告诉我应该进一步考察。
|
||||
|
||||
所有我照做了。
|
||||
|
||||
到现在我发现:正是如此。
|
||||
|
||||
开放性组织的企业文化。应该跟随着企业的成长而时时维护那些文化,以使它随时精神焕发,充满斗志。我(和其它开源组织的成员)并不想过如我同学所描述的“为生活而工作”。我需要有激情和有目的性;我需要明白自己的日常工作如何对那些有价值的东西服务。
|
||||
|
||||
作为一个项目管理者,虽然你的工作与培养你的团队的文化无关,但是工作本身就是文化。
|
||||
|
||||
### 持续改善
|
||||
|
||||
>为学日益,
|
||||
>为道日损,
|
||||
>损之又损,以至于无为。无为而无不为,取天下常以无事
|
||||
[[48]][14]
|
||||
|
||||
虽然项目管理的一般领域都太过于专注最新最强大的的工具,但是您应该使用哪种工具这问题的答案总是一致的:“最简单的”。
|
||||
|
||||
例如,我将任务列表放在桌面的一个文本文件中,因为它很单纯,没有不必要的干扰。您想介绍给团队的,无论是何种工具、流程和程序都应该是能提高效率,排除障碍的,而不是引入额外的复杂性。所以不应该专注于工具本身,而应该专注于使用这些工具来解决的问题。
|
||||
|
||||
我最喜欢的一个项目经理在一个灵活的世界是有自由扔什么不工作。在 Agile world 中我喜欢项目管理者能自由的做决定,抛出不能做的工作。这就是改善的概念,或叫“持续改进”。不要害怕尝试和失败。失败是我们在学习的过程中所用的标签,不能代表什么,但这是提高的唯一方式。
|
||||
|
||||
|
||||
最好的过程都不是一蹴而就的。作为项目管理者,您应该帮助您的团队,支持团队让其自己提升,而不是强迫团队。
|
||||
|
||||
### 实践
|
||||
|
||||
>天下皆谓我"道"大,似不肖。夫唯大,故似不肖。若肖,久矣其细也夫!
|
||||
[[67]][15]
|
||||
|
||||
我相信开放性组织正在做的。开放性组织在管理领域的工作几乎和他们所提供的产品和服务一样重要。我们有机会以身作则,激发他人的激情和目的,创造激励和充分授权的工作环境。
|
||||
|
||||
我鼓励您们找到办法把这些想法融入到自己的项目和团队中,看看会发生什么。了解组织的使命和您的项目怎么样帮助它们。鼓起勇气,尝试一些不好的事情,同时不要忘记和我们的社区分享你所学到的经验,这样我们就可以继续改进。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/16/2/tao-project-management
|
||||
|
||||
作者:[Allison Matlack][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/amatlack
|
||||
[1]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html
|
||||
[2]: https://en.wikipedia.org/wiki/Tao_Te_Ching
|
||||
[3]: http://plato.stanford.edu/entries/laozi/
|
||||
[4]: https://en.wikipedia.org/wiki/Taoism
|
||||
[5]: http://www.imdb.com/title/tt0234853/
|
||||
[6]: http://www.mit.edu/~xela/tao.html
|
||||
[7]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#1
|
||||
[8]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#11
|
||||
[9]:http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#17
|
||||
[10]: https://opensource.com/users/rebecca
|
||||
[11]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#38
|
||||
[12]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#41
|
||||
[13]: https://opensource.com/open-organization/15/9/reflections-open-organization-starry-eyed-dreamer
|
||||
[14]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#48
|
||||
[15]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#67
|
||||
|
||||
@ -1,50 +0,0 @@
|
||||
Docker 1.11采纳了开源容器项目组件
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
>Docker参与的开源项目完成了一个闭环,最新构建的Docker采用了Docker贡献给OCP的组件。
|
||||
|
||||
[Docker 1.11][1]最大的新闻并不是它的功能,而是它使用了在OCP支持下的标准化的组件版本。
|
||||
|
||||
去年,Docker贡献了它的[runC][2]核心给OCP作为构建构建容器工具的基础。同样还有[containerd][3],作为守护进程或者服务端用于控制runC的实例。Docker 1.11现在使用的是捐赠和公开的版本。
|
||||
|
||||
>在InfoWorld的[Docker初学者指南][4]中深入这个热门开源框架。今天就拿来看!|在[InfoWorld每日简讯][5]中获取今日的技术新闻。
|
||||
|
||||
>Docker此举挑战了它的容器生态仍[主要由Docker自身决定][6]的传说。它并不是为了作秀才将容器规范和运行时细节贡献给OCP。它希望项目将来的开发越开放和广泛越好。
|
||||
|
||||

|
||||
|
||||
>Docker 1.11已经用贡献给OCP的runC和containerd进行了重构。runC如果需要可以被交换出去并被替换。
|
||||
|
||||
runC的[两位主要提交者][7]来自Docker,但是来自Virtuozzo(Parallels fame)、OpenShift、Project Atomic、华为、GE Healthcare、Suse Linux也都是提交的常客。
|
||||
|
||||
Docker 1.11中一个更明显的变化是先前Docker运行时在Docker中是唯一可用的,并且评论家认为这个会限制用户的选择。runC运行时现在是可交换的;虽然Docker在发布时将runC作为默认的引擎,但是任何兼容的引擎都可以被交换进入。(Docker同样希望它可以不用杀死并重启现在运行的容器,但是这个作为今后的改进规划。)
|
||||
|
||||
Docker正在将基于OCP开发流程作为内部更好的方式去创建它的产品。在它的发布1.11的[官方博客中称][8]:“将Docker切分成独立的工具意味着更专注的维护者,最终有更好的软件质量。”
|
||||
|
||||
除了修复长期以来存在的问题何确保Docker的runC/containerd跟上步伐,Docker还在Docker 1.11中加入了一些改进。Docker Engine现在支持VLAN和IPv6服务发现,并且会自动在多个相同别名容器间执行DNS轮询负载均衡。
|
||||
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3055966/open-source-tools/docker-111-adopts-open-container-project-components.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]: https://blog.docker.com/2016/04/docker-engine-1-11-runc/
|
||||
[2]: http://runc.io/
|
||||
[3]: https://containerd.tools/
|
||||
[4]: http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker#tk.ifw-infsb
|
||||
[5]: http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
[6]: http://www.infoworld.com/article/2876801/application-virtualization/docker-reorganization-grows-up.html
|
||||
[7]: https://github.com/opencontainers/runc/graphs/contributors
|
||||
[8]: https://blog.docker.com/2016/04/docker-engine-1-11-runc/
|
||||
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
Linux 上四个最佳的现代开源代码编辑器
|
||||
==================================================
|
||||
|
||||

|
||||
|
||||
在寻找 **Linux 上最好的代码编辑器**?如果你问那些老派的 Linux 用户,他们的答案肯定是 Vi,Vim,Emacs,Nano 等等。但我不讨论它们。我要讨论的是最新的,美观,优美强大,功能丰富,能够提高你编程体验的,**最好的 Linux 开源代码编辑器**。
|
||||
|
||||
### Linux 上最佳的现代开源代码编辑器
|
||||
|
||||
我使用 Ubuntu 作为我的主力系统,因此提供的安装说明适用于基于 Ubuntu 的发行版。但这并不会让这个列表变成 **Ubuntu 上的最佳文本编辑器**,因为这些编辑器对所有 Linux 发行版都适用。多说一句,这个清单没有任何先后顺序。
|
||||
|
||||
### BRACKETS
|
||||
|
||||

|
||||
|
||||
[Brackets][1] 是 [Adobe][2] 的一个开源代码编辑器。Brackets 专注于 web 设计师的需求,内置 HTML,CSS 和 JavaScript 支持。它很轻量,也很强大。它提供了行内编辑和实时预览。还有无数可用的插件,进一步加强你在 Brackets 上的体验。
|
||||
|
||||
在 Ubuntu 以及基于 Ubuntu 的发行版(比如 Linux Mint)上[安装 Brackets][3] 的话,你可以用这个非官方的 PPA:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:webupd8team/brackets
|
||||
sudo apt-get update
|
||||
sudo apt-get install brackets
|
||||
```
|
||||
|
||||
至于其它 Linux 发行版,你可以从它的网站上获取到适用于 Linux,OS X 和 Windows 源码和二进制文件。
|
||||
|
||||
[下载 Brackets 源码和二进制包](https://github.com/adobe/brackets/releases)
|
||||
|
||||
### ATOM
|
||||
|
||||

|
||||
|
||||
[Atom][4] 是另一个给程序员的开源代码编辑器,现代而且美观。Atom 是由 Github 开发的,宣称是“21世纪的可定制文本编辑器”。Atom 的外观看起来类似 Sublime Text,一个在程序员中很流行但是闭源的文本编辑器。
|
||||
|
||||
Atom 最近发布了 .deb 和 .rpm 包,所以你可以轻而易举地在基于 Debian 和 Fedora 的 Linux 发行版上安装它。当然,它也提供了源代码。
|
||||
|
||||
|
||||
[下载 Atom .deb](https://atom.io/download/deb)
|
||||
|
||||
[下载 Atom .rpm](https://atom.io/download/rpm)
|
||||
|
||||
[获取 Atom 源码](https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md)
|
||||
|
||||
### LIME TEXT
|
||||
|
||||

|
||||
|
||||
你喜欢 Sublime Text 但是你对它是闭源的这一事实感觉不是很舒服?别担心,我们有 [Sublime Text 的开源克隆版][5],叫做 [Lime Text][6]。它是基于 Go,HTML 和 QT 的。克隆 Sublime Text 的原因是 Sublime Text 2 中有无数 bug,而 Sublime Text 3 看起来会永远处于 beta 之中。它的开发过程并不透明,也就无从得知 bug 是否被修复了。
|
||||
|
||||
所以开源爱好者们,开心地去下面这个链接下载 Lime Text 的源码吧:
|
||||
|
||||
[获取 Lime Text 源码](https://github.com/limetext/lime)
|
||||
|
||||
### LIGHT TABLE
|
||||
|
||||

|
||||
|
||||
[Light Table][7] 是另一个外观现代,功能丰富的开源代码编辑器,标榜“下一代代码编辑器”,它更像一个 IDE 而不仅仅是个文本编辑器。它还有无数扩展用以加强它的功能。也许你会喜欢它的行内求值。你得用用它才会相信 Light Table 有多好用。
|
||||
|
||||
[在 Ubuntu 上安装 Light Table](http://itsfoss.com/install-lighttable-ubuntu/)
|
||||
|
||||
### 你的选择是?
|
||||
|
||||
不,我们的选择没有限制在这四个 Linux 代码编辑器之中。这个清单只是关于程序员的现代编辑器。当然,你还有很多选择,比如 [Notepad++ 的替代选择 Notepadqq][8] 或 [SciTE][9] 以及更多。那么,上面四个中,在 Linux 上而言你最喜欢哪个代码编辑器?
|
||||
|
||||
|
||||
----------
|
||||
via: http://itsfoss.com/best-modern-open-source-code-editors-for-linux/?utm_source=newsletter&utm_medium=email&utm_campaign=offline_and_portable_linux_apps_and_other_linux_stories
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/abhishek/
|
||||
[1]: http://brackets.io/
|
||||
[2]: http://www.adobe.com/
|
||||
[3]: http://itsfoss.com/install-brackets-ubuntu/
|
||||
[4]: https://atom.io/
|
||||
[5]: http://itsfoss.com/lime-text-open-source-alternative/
|
||||
[6]: http://limetext.org/
|
||||
[7]: http://lighttable.com/
|
||||
[8]: http://itsfoss.com/notepadqq-notepad-for-linux/
|
||||
[9]: http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
@ -7,19 +7,19 @@ Part 2 - LXD 2.0: 安装与配置
|
||||
|
||||
### 安装篇
|
||||
|
||||
获得 LXD 有很多种办法。我们推荐你是用配合最新版的 LXC 和 Linux 内核使用 LXD,这样就可以享受到它的全部特性,但是注意,我们现在也在慢慢的降低对旧版本 Linux 发布版的支持。
|
||||
有很多种办法可以获得 LXD。我们推荐你配合最新版的 LXC 和 Linux 内核使用 LXD,这样就可以享受到它的全部特性。需要注意的是,我们现在也在慢慢的降低对旧版本 Linux 发布版的支持。
|
||||
|
||||
#### Ubuntu 标准版
|
||||
|
||||
所有新发布的 LXD 都会在发布几分钟后上传到 Ubuntu 开发版的安装源里。这个安装包然后就会当作种子给全部其他的安装包源,供 Ubuntu 用户使用。
|
||||
|
||||
如果使用 Ubuntu 16.04 则可以直接安装:
|
||||
如果使用 Ubuntu 16.04,可以直接安装:
|
||||
|
||||
```
|
||||
sudo apt install lxd
|
||||
```
|
||||
|
||||
如果运行的是 Ubuntu 14.04,可以这样安装:
|
||||
如果运行的是 Ubuntu 14.04,则可以这样安装:
|
||||
|
||||
```
|
||||
sudo apt -t trusty-backports install lxd
|
||||
@ -27,15 +27,15 @@ sudo apt -t trusty-backports install lxd
|
||||
|
||||
#### Ubuntu Core
|
||||
|
||||
使用Ubuntu Core 稳定版的用户可以使用下面的命令安装 LXD:
|
||||
使用 Ubuntu Core 稳定版的用户可以使用下面的命令安装 LXD:
|
||||
|
||||
```
|
||||
sudo snappy install lxd.stgraber
|
||||
```
|
||||
|
||||
#### ubuntu 官方 PPA
|
||||
#### Ubuntu 官方 PPA
|
||||
|
||||
是哟个其他 Ubuntu 发布版 —— 比如 Ubuntu 15.10 —— 的用户可以添加下面的 PPA (Personal Package Archive) 来安装:
|
||||
使用其他 Ubuntu 发布版 —— 比如 Ubuntu 15.10 —— 的用户可以添加下面的 PPA(Personal Package Archive)来安装:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:ubuntu-lxc/stable
|
||||
@ -46,23 +46,23 @@ sudo apt install lxd
|
||||
|
||||
#### Gentoo
|
||||
|
||||
Gentoo 已经有了最新的 LXD 安装包,你可以直接安装:
|
||||
Gentoo 已经有了最新的 LXD 包,你可以直接安装:
|
||||
|
||||
```
|
||||
sudo emerge --ask lxd
|
||||
```
|
||||
|
||||
#### 源代码
|
||||
#### 使用源代码安装
|
||||
|
||||
如果你曾经编译过 Go 工程,那么从源代码编译 LXD 并不是十分困难。然而要住你的是你需要 LXC 的开发头文件。为了运行 LXD , 你的 发布版铜须也需要使用比较新的内核(最起码是 3.13),比较新的 LXC (1.1.4 或更高版本) ,LXCFS 以及支持用户子 uid/gid 分配的 shadow 。
|
||||
如果你曾经编译过 Go 语言的项目,那么从源代码编译 LXD 并不是十分困难。然而注意,你需要 LXC 的开发头文件。为了运行 LXD, 你的发布版需也要使用比较新的内核(最起码是 3.13)、比较新的 LXC (1.1.4 或更高版本)、LXCFS 以及支持用户子 uid/gid 分配的 shadow。
|
||||
|
||||
从源代码编译 LXD 的最新指令可以在[上游 README][2]里找到。
|
||||
从源代码编译 LXD 的最新教程可以在[上游 README][2]里找到。
|
||||
|
||||
### ubuntu 上的网络配置
|
||||
### Ubuntu 上的网络配置
|
||||
|
||||
Ubuntu 的安装包会很方便的给你提供一个 "lxdbr0" 网桥。这个网桥默认是没有配置过的,只提供通过 HTTP 代理的 IPV6 的本地连接。
|
||||
Ubuntu 的安装包会很方便的给你提供一个“lxdbr0”网桥。这个网桥默认是没有配置过的,只提供通过 HTTP 代理的 IPv6 的本地连接。
|
||||
|
||||
要配置这个网桥和添加 IPV4 、 IPV6 子网,你可以运行下面的命令:
|
||||
要配置这个网桥并添加 IPv4 、 IPv6 子网,你可以运行下面的命令:
|
||||
|
||||
```
|
||||
sudo dpkg-reconfigure -p medium lxd
|
||||
@ -74,15 +74,15 @@ sudo dpkg-reconfigure -p medium lxd
|
||||
sudo lxd init
|
||||
```
|
||||
|
||||
### 存储系统
|
||||
### 存储后端
|
||||
|
||||
LXD 提供了集中存储后端。在开始使用 LXD 之前,你最好直到自己想要的后端,因为我们不支持在后端之间迁移已经生成的容器。
|
||||
LXD 提供了许多集中存储后端。在开始使用 LXD 之前,你应该决定将要使用的后端,因为我们不支持在后端之间迁移已经生成的容器。
|
||||
|
||||
各个[后端特性的比较表格][3]可以在这里找到。
|
||||
各个[后端特性比较表][3]可以在[这里][3]找到。
|
||||
|
||||
#### ZFS
|
||||
|
||||
我们的推荐是 ZFS , 因为他能支持 LXD 的全部特性,同时提供最快和最可靠的容器体验。它包括了以容器为单位的磁盘配额,直接快照和恢复,优化了的迁移(发送/接收),以及快速从镜像创建容器。它同时也被认为要比 btrfs 更成熟。
|
||||
我们的推荐是 ZFS, 因为它能支持 LXD 的全部特性,同时提供最快和最可靠的容器体验。它包括了以容器为单位的磁盘配额,即时快照和恢复,优化了的迁移(发送/接收),以及快速从镜像创建容器的能力。它同时也被认为要比 btrfs 更成熟。
|
||||
|
||||
要和 LXD 一起使用 ZFS ,你需要首先在你的系统上安装 ZFS。
|
||||
|
||||
@ -98,7 +98,7 @@ sudo apt install zfsutils-linux
|
||||
sudo apt install zfsutils-linux zfs-dkms
|
||||
```
|
||||
|
||||
如果是更旧的版本,你需要这样安装:
|
||||
如果是更旧的版本,你需要从 zfsonlinux PPA 安装:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:zfs-native/stable
|
||||
@ -106,27 +106,27 @@ sudo apt update
|
||||
sudo apt install ubuntu-zfs
|
||||
```
|
||||
|
||||
配置 LXD 只需要简单的执行下面的命令:
|
||||
配置 LXD 只需要执行下面的命令:
|
||||
|
||||
```
|
||||
sudo lxd init
|
||||
```
|
||||
|
||||
这条命令接下来会想你提问一下你想要的 ZFS 的配置,然后为你配置好 ZFS 。
|
||||
这条命令接下来会向你提问一下一些 ZFS 的配置细节,然后为你配置好 ZFS。
|
||||
|
||||
#### btrfs
|
||||
|
||||
如果 ZFS 不可用,那么 btrfs 可以提供相同级别的集成,除了不会合理的报告容器内的磁盘使用情况(虽然配额还是可以用的)。
|
||||
如果 ZFS 不可用,那么 btrfs 可以提供相同级别的集成,但不会合理地报告容器内的磁盘使用情况(虽然配额仍然可用)。
|
||||
|
||||
btrfs 同时拥有很好的嵌套属性,而这时 ZFS 所不具有的。也就是说如果你计划在 LXD 中再使用 LXD ,那么 btrfs 就很值得你考虑一下。
|
||||
btrfs 同时拥有很好的嵌套属性,而这是 ZFS 所不具有的。也就是说如果你计划在 LXD 中再使用 LXD,那么 btrfs 就很值得你考虑。
|
||||
|
||||
使用 btrfs 的话,LXD 不需要进行任何的配置,你只需要保证 `/var/lib/lxd` 是保存在 btrfs 文件系统中,然后 LXD 就会自动为你使用 btrfs 了。
|
||||
使用 btrfs 的话,LXD 不需要进行任何的配置,你只需要保证 `/var/lib/lxd` 保存在 btrfs 文件系统中,然后 LXD 就会自动为你使用 btrfs 了。
|
||||
|
||||
#### LVM
|
||||
|
||||
如果 ZFS 和 btrfs 都不是你想要的,你仍然可以考虑使用 LVM。 LXD 会以自动精简配置的方式使用 LVM,为每个镜像和容器创建 LV,如果需要的话也会使用 LVM 的快照功能。
|
||||
如果 ZFS 和 btrfs 都不是你想要的,你还可以考虑使用 LVM 以获得部分特性。 LXD 会以自动精简配置的方式使用 LVM,为每个镜像和容器创建 LV,如果需要的话也会使用 LVM 的快照功能。
|
||||
|
||||
要配置 LXD 使用 LVM,需要创建一个 LVM 的 VG ,然后运行:
|
||||
要配置 LXD 使用 LVM,需要创建一个 LVM VG,然后运行:
|
||||
|
||||
|
||||
```
|
||||
@ -141,9 +141,9 @@ lxc config set storage.lvm_fstype xfs
|
||||
|
||||
#### 简单目录
|
||||
|
||||
如果上面全部方案你都不打算使用, LXD 还可以工作,但是不会使用任何高级特性。它只会为每个容器创建一个目录,然后在创建每个容器时解压缩镜像的压缩包,在容器拷贝和快照时会进行一次完整的文件系统拷贝。
|
||||
如果上面全部方案你都不打算使用,LXD 依然能在不使用任何高级特性情况下工作。它会为每个容器创建一个目录,然后在创建每个容器时解压缩镜像的压缩包,并在容器拷贝和快照时进行一次完整的文件系统拷贝。
|
||||
|
||||
除了磁盘配额以外的特性都是支持的,但是很浪费磁盘空间,并且非常慢。如果你没有其他选择,这还是可以工作的,但是你还是需要认真的考虑一下上面的几个方案。
|
||||
除了磁盘配额以外的特性都是支持的,但是很浪费磁盘空间,并且非常慢。如果你没有其他选择,这还是可以工作的,但是你还是需要认真的考虑一下上面的几个替代方案。
|
||||
|
||||
### 配置篇
|
||||
|
||||
@ -151,7 +151,7 @@ LXD 守护进程的完整配置项列表可以在[这里找到][4]。
|
||||
|
||||
#### 网络配置
|
||||
|
||||
默认情况下 LXD 不会监听网络。和它通信的唯一办法是使用本地 unix socket 通过 `/var/lib/lxd/unix.socket` 进行通信。
|
||||
默认情况下 LXD 不会监听网络。和它通信的唯一办法是通过 `/var/lib/lxd/unix.socket` 使用本地 unix socket 进行通信。
|
||||
|
||||
要让 LXD 监听网络,下面有两个有用的命令:
|
||||
|
||||
@ -160,11 +160,11 @@ lxc config set core.https_address [::]
|
||||
lxc config set core.trust_password some-secret-string
|
||||
```
|
||||
|
||||
第一条命令将 LXD 绑定到 IPV6 地址 “::”,也就是监听机器的所有 IPV6 地址。你可以显式的使用一个特定的 IPV4 或者 IPV6 地址替代默认地址,如果你想绑定 TCP 端口(默认是 8443)的话可以在地址后面添加端口号即可。
|
||||
第一条命令将 LXD 绑定到 IPv6 地址 “::”,也就是监听机器的所有 IPv6 地址。你可以显式的使用一个特定的 IPv4 或者 IPv6 地址替代默认地址,如果你想绑定 TCP 端口(默认是 8443)的话可以在地址后面添加端口号即可。
|
||||
|
||||
第二条命令设置了密码,可以让远程客户端用来把自己添加到 LXD 可信证书中心。如果已经给主机设置了密码,当添加 LXD 主机时会提示输入密码, LXD 守护进程会保存他们的客户端的证书以确保客户端是可信的,这样就不需要再次输入密码(可以随时设置和取消)
|
||||
第二条命令设置了密码,用于让远程客户端用来把自己添加到 LXD 可信证书中心。如果已经给主机设置了密码,当添加 LXD 主机时会提示输入密码,LXD 守护进程会保存他们的客户端的证书以确保客户端是可信的,这样就不需要再次输入密码(可以随时设置和取消)。
|
||||
|
||||
你也可以选择不设置密码,然后通过给每个客户端发送 "client.crt" (来自于 `~/.config/lxc`)文件,然后把它添加到你自己的可信中信来实现人工验证每个新客户端是否可信,可以使用下面的命令:
|
||||
你也可以选择不设置密码,然后通过给每个客户端发送“client.crt”(来自于 `~/.config/lxc`)文件,然后把它添加到你自己的可信中信来实现人工验证每个新客户端是否可信,可以使用下面的命令:
|
||||
|
||||
```
|
||||
lxc config trust add client.crt
|
||||
@ -172,9 +172,9 @@ lxc config trust add client.crt
|
||||
|
||||
#### 代理配置
|
||||
|
||||
In most setups, you’ll want the LXD daemon to fetch images from remote servers.
|
||||
大多数情况下,你会想让 LXD 守护进程从远程服务器上获取镜像。
|
||||
|
||||
If you are in an environment where you must go through a HTTP(s) proxy to reach the outside world, you’ll want to set a few configuration keys or alternatively make sure that the standard PROXY environment variables are set in the daemon’s environment.
|
||||
如果你处在一个必须通过 HTTP(s) 代理链接外网的环境下,你需要对 LXD 做一些配置,或保证已在守护进程的环境中设置正确的 PROXY 环境变量。
|
||||
|
||||
```
|
||||
lxc config set core.proxy_http http://squid01.internal:3128
|
||||
@ -182,11 +182,11 @@ lxc config set core.proxy_https http://squid01.internal:3128
|
||||
lxc config set core.proxy_ignore_hosts image-server.local
|
||||
```
|
||||
|
||||
With those, all transfers initiated by LXD will use the squid01.internal HTTP proxy, except for traffic to the server at image-server.local
|
||||
以上代码使所有 LXD 发起的数据传输都使用 squid01.internal HTTP 代理,但与在 image-server.local 的服务器的数据传输则是例外。
|
||||
|
||||
#### 镜像管理
|
||||
|
||||
LXD 使用动态镜像缓存。当从远程镜像创建容器的时候,它会自动把镜像下载到本地镜像商店,同时标志为已缓存并记录来源。几天后(默认10天)如果没有再被使用,那么这个镜像就会自动被删除。每个几小时(默认是6小时) LXD 还会检查一下这个镜像是否有新版本,然后更新镜像的本地拷贝。
|
||||
LXD 使用动态镜像缓存。当从远程镜像创建容器的时候,它会自动把镜像下载到本地镜像商店,同时标志为已缓存并记录来源。几天后(默认 10 天)如果某个镜像没有被使用过,那么它就会自动地被删除。每个几小时(默认是 6 小时)LXD 还会检查一下这个镜像是否有新版本,然后更新镜像的本地拷贝。
|
||||
|
||||
所有这些都可以通过下面的配置选项进行配置:
|
||||
|
||||
@ -196,12 +196,12 @@ lxc config set images.auto_update_interval 24
|
||||
lxc config set images.auto_update_cached false
|
||||
```
|
||||
|
||||
这些命令让 LXD 修改了它的默认属性,缓存期替换为 5 天,更新间隔为 24 小时,而且只更新那些标志为自动更新的镜像(lxc 镜像拷贝有标志 `–auto-update`)而不是 LXD 自动缓存的镜像。
|
||||
这些命令让 LXD 修改了它的默认属性,缓存期替换为 5 天,更新间隔为 24 小时,而且只更新那些标记为自动更新的镜像(lxc 镜像拷贝被标记为 `–auto-update`)而不是 LXD 自动缓存的镜像。
|
||||
|
||||
|
||||
### 总结
|
||||
|
||||
到这里为止,你就应该有了一个可以工作的、最新版的 LXD ,现在你可以开始用 LXD 了,或者等待我们的下一条博文,那时我们会介绍如何创建第一个容器以及使用 LXD 命令行工具操作容器。
|
||||
到这里为止,你就应该有了一个可以工作的、最新版的 LXD,现在你可以开始用 LXD 了,或者等待我们的下一篇博文,我们会在其中介绍如何创建第一个容器以及使用 LXD 命令行工具操作容器。
|
||||
|
||||
### 额外信息
|
||||
|
||||
@ -213,7 +213,7 @@ LXD 的邮件列表: <https://lists.linuxcontainers.org>
|
||||
|
||||
LXD 的 IRC 频道: #lxcontainers on irc.freenode.net
|
||||
|
||||
如果你不想或者不能在你的机器上安装 LXD ,你可以[试试在线版的 LXD][1] 。
|
||||
如果你不想或者不能在你的机器上安装 LXD ,你可以[试试在线版的 LXD][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -221,7 +221,7 @@ via: https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,438 @@
|
||||
kylepeng93 is translating
|
||||
你的地一个LXD容器
|
||||
==========================================
|
||||
|
||||
这是第三篇发布的博客[LXD2.0系列]
|
||||
由于在管理LXD容器时涉及到大量的命令,所以这篇文章的篇幅是比较长的,如果你更喜欢使用同样的命令来快速的一步步实现整个过程,你可以[尝试我们的在线示例]!
|
||||

|
||||
|
||||
### 创建并启动一个新的容器
|
||||
正如我在先前的文章中提到的一样,LXD命令行客户端使用了少量的图片来做了一个预配置。Ubuntu的所有发行版和架构平台都拥有最好的官方图片,但是对于其他的发行版仍然有大量的非官方图片,那些图片都是由社区制作并且被LXC上层贡献者所维护。
|
||||
### Ubuntu
|
||||
如果你想要支持最为完善的ubuntu版本,你可以按照下面的去做:
|
||||
```
|
||||
lxc launch ubuntu:
|
||||
```
|
||||
注意,这里所做的解释会随着ubuntu LTS的发布而变化。因此对于你使用的脚本应该取决于下面提到的具体你想要安装的版本:
|
||||
###Ubuntu14.04 LTS
|
||||
得到最新的,已经测试过的,稳定的ubuntu14.04 LTS镜像,你可以简单的执行:
|
||||
```
|
||||
lxc launch ubuntu:14.04
|
||||
```
|
||||
这该模式下,一个任意的容器名将会被指定给它。
|
||||
如果你更喜欢指定一个你自己的命令,你可以这样做:
|
||||
```
|
||||
lxc launch ubuntu:14.04 c1
|
||||
```
|
||||
|
||||
如果你想要指定一个特定的体系架构(非主要的),比如32位Intel镜像,你可以这样做:
|
||||
```
|
||||
lxc launch ubuntu:14.04/i386 c2
|
||||
```
|
||||
|
||||
### 当前的Ubuntu开发版本
|
||||
上面使用的“ubuntu:”远程方式只会给你提供官方的并经过测试的ubuntu镜像。但是如果你想要未经测试过的日常构建版本,开发版可能对你来说是合适的,你将要使用“ubuntu-daily”来远程获取。
|
||||
```
|
||||
lxc launch ubuntu-daily:devel c3
|
||||
```
|
||||
|
||||
在这个例子中,最新的ubuntu开发版本将会被选自动选中。
|
||||
你也可以更加精确,比如你可以使用代号名:
|
||||
```
|
||||
lxc launch ubuntu-daily:xenial c4
|
||||
```
|
||||
|
||||
### 最新的Alpine Linux
|
||||
Alpine镜像在“Images:”远程中可用,可以通过如下命令执行:
|
||||
```
|
||||
lxc launch images:alpine/3.3/amd64 c5
|
||||
```
|
||||
|
||||
### And many more
|
||||
### 其他
|
||||
所有ubuntu镜像列表可以这样获得:
|
||||
```
|
||||
lxc image list ubuntu:
|
||||
lxc image list ubuntu-daily:
|
||||
```
|
||||
|
||||
所有的非官方镜像:
|
||||
```
|
||||
lxc image list images:
|
||||
```
|
||||
|
||||
所有给定的可用远程别名清单可以这样获得(针对“ubuntu:”远程):
|
||||
```
|
||||
lxc image alias list ubuntu:
|
||||
```
|
||||
|
||||
|
||||
### 创建但不启动一个容器
|
||||
如果你想创建一个容器或者一批容器,但是你不想马上启动他们,你可以使用“lxc init”替换掉“lxc launch”。所有的选项都是相同的,唯一的不同就是它并不会在你创建完成之后启动容器。
|
||||
```
|
||||
lxc init ubuntu:
|
||||
```
|
||||
|
||||
### 关于你的容器的信息
|
||||
### 列出所有的容器
|
||||
为了列出你的所有容器,你可以这样这做:
|
||||
```
|
||||
lxc list
|
||||
```
|
||||
|
||||
有大量的选项供你选择来改变被显示出来的列。在一个拥有大量容器的系统上,默认显示的列可能会有点慢(因为必须获取容器中的网络信息),你可以这样做来避免这种情况:
|
||||
```
|
||||
lxc list --fast
|
||||
```
|
||||
|
||||
上面的命令显示了一个不同的列的集合,这个集合在服务器端需要处理的信息更少。
|
||||
你也可以基于名字或者属性来过滤掉一些东西:
|
||||
```
|
||||
stgraber@dakara:~$ lxc list security.privileged=true
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| suse | RUNNING | 172.17.0.105 (eth0) | 2607:f2c0:f00f:2700:216:3eff:fef2:aff4 (eth0) | PERSISTENT | 0 |
|
||||
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
在这个例子中,只有那些有特权(用户命名空间不可用)的容器才会被列出来。
|
||||
```
|
||||
stgraber@dakara:~$ lxc list --fast alpine
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| NAME | STATE | ARCHITECTURE | CREATED AT | PROFILES | TYPE |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| alpine | RUNNING | x86_64 | 2016/03/20 02:11 UTC | default | PERSISTENT |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
| alpine-edge | RUNNING | x86_64 | 2016/03/20 02:19 UTC | default | PERSISTENT |
|
||||
+-------------+---------+--------------+----------------------+----------+------------+
|
||||
```
|
||||
|
||||
在这个例子中,只有在名字中带有“alpine”的容器才会被列出来(支持复杂的正则表达式)。
|
||||
### 获取容器的详细信息
|
||||
由于list命令显然不能以一种友好的可读方式显示容器的所有信息,因此你可以使用如下方式来查询单个容器的信息:
|
||||
```
|
||||
lxc info <container>
|
||||
```
|
||||
|
||||
例如:
|
||||
```
|
||||
stgraber@dakara:~$ lxc info zerotier
|
||||
Name: zerotier
|
||||
Architecture: x86_64
|
||||
Created: 2016/02/20 20:01 UTC
|
||||
Status: Running
|
||||
Type: persistent
|
||||
Profiles: default
|
||||
Pid: 31715
|
||||
Processes: 32
|
||||
Ips:
|
||||
eth0: inet 172.17.0.101
|
||||
eth0: inet6 2607:f2c0:f00f:2700:216:3eff:feec:65a8
|
||||
eth0: inet6 fe80::216:3eff:feec:65a8
|
||||
lo: inet 127.0.0.1
|
||||
lo: inet6 ::1
|
||||
lxcbr0: inet 10.0.3.1
|
||||
lxcbr0: inet6 fe80::c0a4:ceff:fe52:4d51
|
||||
zt0: inet 29.17.181.59
|
||||
zt0: inet6 fd80:56c2:e21c:0:199:9379:e711:b3e1
|
||||
zt0: inet6 fe80::79:e7ff:fe0d:5123
|
||||
Snapshots:
|
||||
zerotier/blah (taken at 2016/03/08 23:55 UTC) (stateless)
|
||||
```
|
||||
|
||||
### 生命周期管理命令
|
||||
这些命令对于任何容器或者虚拟机管理器或许都是最普通的命令,但是它们仍然需要被涉及到。
|
||||
所有的这些命令在批量操作时都能接受多个容器名。
|
||||
### 启动
|
||||
启动一个容器就向下面一样简单:
|
||||
```
|
||||
lxc start <container>
|
||||
```
|
||||
|
||||
### 停止
|
||||
停止一个容器可以这样来完成:
|
||||
```
|
||||
lxc stop <container>
|
||||
```
|
||||
|
||||
如果容器不合作(即没有对发出的信号产生回应),这时候,你可以使用下面的方式强制执行:
|
||||
```
|
||||
lxc stop <container> --force
|
||||
```
|
||||
|
||||
### 重启
|
||||
通过下面的命令来重启一个容器:
|
||||
```
|
||||
lxc restart <container>
|
||||
```
|
||||
|
||||
如果容器不合作(即没有对发出的信号产生回应),你可以使用下面的方式强制执行:
|
||||
```
|
||||
lxc restart <container> --force
|
||||
```
|
||||
|
||||
### 暂停
|
||||
你也可以“暂停”一个容器,在这种模式下,所有的容器任务将会被发送相同的信号,这也意味着他们将仍然是可见的,并且仍然会占用内存,但是他们不会从调度程序中得到任何的CPU时间片。
|
||||
如果你有一个CPU的饥饿容器,而这个容器需要一点时间来启动,但是你却并 不会经常用到它。这时候,你可以先启动它,然后将它暂停,并在你需要它的时候再启动它。
|
||||
```
|
||||
lxc pause <container>
|
||||
```
|
||||
|
||||
### 删除
|
||||
最后,如果你不需要这个容器了,你可以用下面的命令删除它:
|
||||
```
|
||||
lxc delete <container>
|
||||
```
|
||||
|
||||
注意,如果容器还处于运行状态时你将必须使用“-forece”。
|
||||
### 容器的配置
|
||||
LXD拥有大量的容器配置设定,包括资源限制,容器启动控制以及对各种设备是否允许访问的配置选项。完整的清单因为太长所以并没有在本文中列出,但是,你可以从[here]获取它。
|
||||
就设备而言,LXD当前支持下面列出的这些设备:
|
||||
- 磁盘
|
||||
既可以是一块物理磁盘,也可以只是一个被挂挂载到容器上的分区,还可以是一个来自主机的绑定挂载路径。
|
||||
- 网络接口卡
|
||||
一块网卡。它可以是一块桥接的虚拟网卡,或者是一块点对点设备,还可以是一块以太局域网设备或者一块已经被连接到容器的真实物理接口。
|
||||
- unix块
|
||||
一个UNIX块设备,比如/dev/sda
|
||||
- unix字符
|
||||
一块UNIX字符设备,比如/dev/kvm
|
||||
- none
|
||||
这种特殊类型被用来隐藏那种可以通过profiles文件被继承的设备。
|
||||
|
||||
### 配置profiles文件
|
||||
所有可用的profiles的文件列表可以这样获取:
|
||||
```
|
||||
lxc profile list
|
||||
```
|
||||
|
||||
为了看到给定profile文件的内容,最简单的方式是这样做:
|
||||
```
|
||||
lxc profile show <profile>
|
||||
```
|
||||
|
||||
你可能想要改变文件里面的内容,可以这样做:
|
||||
```
|
||||
lxc profile edit <profile>
|
||||
```
|
||||
|
||||
你可以使用如下命令来改变profiles的列表并将这种变化应用到给定的容器中:
|
||||
```
|
||||
lxc profile apply <container> <profile1>,<profile2>,<profile3>,...
|
||||
```
|
||||
|
||||
### 本地配置
|
||||
For things that are unique to a container and so don’t make sense to put into a profile, you can just set them directly against the container:
|
||||
|
||||
```
|
||||
lxc config edit <container>
|
||||
```
|
||||
|
||||
上面的命令将会完成和“profile edit”命令一样的功能。
|
||||
|
||||
即使不在文本编辑器中打开整个文件的内容,你也可以像这样修改单独的键:
|
||||
```
|
||||
lxc config set <container> <key> <value>
|
||||
```
|
||||
或者添加设备,例如
|
||||
```
|
||||
lxc config device add my-container kvm unix-char path=/dev/kvm
|
||||
```
|
||||
|
||||
上面的命令将会为名为“my-container”的容器打开一个/dev/kvm入口。
|
||||
对一个profile文件使用“lxc profile set”和“lxc profile device add”命令也能实现上面的功能。
|
||||
#### 读取配置
|
||||
你可以使用如下命令来阅读容器的本地配置:
|
||||
```
|
||||
lxc config show <container>
|
||||
```
|
||||
|
||||
或者得到已经被展开了的配置(包含了所有的键值):
|
||||
```
|
||||
lxc config show --expanded <container>
|
||||
```
|
||||
|
||||
例如:
|
||||
```
|
||||
stgraber@dakara:~$ lxc config show --expanded zerotier
|
||||
name: zerotier
|
||||
profiles:
|
||||
- default
|
||||
config:
|
||||
security.nesting: "true"
|
||||
user.a: b
|
||||
volatile.base_image: a49d26ce5808075f5175bf31f5cb90561f5023dcd408da8ac5e834096d46b2d8
|
||||
volatile.eth0.hwaddr: 00:16:3e:ec:65:a8
|
||||
volatile.last_state.idmap: '[{"Isuid":true,"Isgid":false,"Hostid":100000,"Nsid":0,"Maprange":65536},{"Isuid":false,"Isgid":true,"Hostid":100000,"Nsid":0,"Maprange":65536}]'
|
||||
devices:
|
||||
eth0:
|
||||
name: eth0
|
||||
nictype: macvlan
|
||||
parent: eth0
|
||||
type: nic
|
||||
limits.ingress: 10Mbit
|
||||
limits.egress: 10Mbit
|
||||
root:
|
||||
path: /
|
||||
size: 30GB
|
||||
type: disk
|
||||
tun:
|
||||
path: /dev/net/tun
|
||||
type: unix-char
|
||||
ephemeral: false
|
||||
```
|
||||
|
||||
这样做可以很方便的检查有哪些配置属性被应用到了给定的容器。
|
||||
### 实时配置更新
|
||||
注意,除非在文档中已经被明确指出,否则所有的键值和设备入口都会被应用到受影响的实时容器。这意味着你可以添加和移除某些设备或者在不重启容器的情况下修改正在运行的容器的安全profile配置文件。
|
||||
### 获得一个shell
|
||||
LXD允许你对容器中的任务进行直接的操作。最常用的做法是在容器中得到一个shell或者执行一些管理员任务。
|
||||
和SSH相比,这样做的好处是你可以接触到独立与容器之外的网络或者任何一个软件又或者任何一个能够在容器内可见的文件配置。
|
||||
执行环境
|
||||
对比LXD在容器内执行命令的方式,有一点是不同的,那就是它自身并不是在容器中运行。这也意味着它不知道该使用什么样的shell,以及设置什么样的环境变量和哪里是它的家目录。
|
||||
通过LXD来执行命令必须总是在最小路径环境变量集并且HONE环境变量必须为/root的情况下以容器的超级用户身份来执行(即uid为0,gid为0)。
|
||||
其他的环境变量可以通过命令行来设置,或者在“environment.<key>”配置文件中设置成永久环境变量。
|
||||
### 执行命令
|
||||
在容器中获得一个shell可以简单的执行下列命令得到:
|
||||
```
|
||||
lxc exec <container> bash
|
||||
```
|
||||
|
||||
当然,这样做的前提是容器内已经安装了bash。
|
||||
|
||||
更多复杂的命令要求有对参数分隔符的合理使用。
|
||||
```
|
||||
lxc exec <container> -- ls -lh /
|
||||
```
|
||||
|
||||
如果想要设置或者重写变量,你可以使用“-env”参数,例如:
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec zerotier --env mykey=myvalue env | grep mykey
|
||||
mykey=myvalue
|
||||
```
|
||||
|
||||
### 管理文件
|
||||
因为LXD可以直接访问容器的文件系统,因此,它可以直接往容器中读取和写入任意文件。当我们需要提取日志文件或者与容器发生交互时,这个特性是很有用的。
|
||||
#### 从容器中取回一个文件
|
||||
想要从容器中获得一个文件,简单的执行下列命令:
|
||||
```
|
||||
lxc file pull <container>/<path> <dest>
|
||||
```
|
||||
|
||||
例如:
|
||||
```
|
||||
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts hosts
|
||||
```
|
||||
|
||||
或者将它读取到标准输出:
|
||||
```
|
||||
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts -
|
||||
127.0.0.1 localhost
|
||||
|
||||
# 下面的所有行对于支持IPv6的主机是有用的
|
||||
::1 ip6-localhost ip6-loopback
|
||||
fe00::0 ip6-localnet
|
||||
ff00::0 ip6-mcastprefix
|
||||
ff02::1 ip6-allnodes
|
||||
ff02::2 ip6-allrouters
|
||||
ff02::3 ip6-allhosts
|
||||
```
|
||||
|
||||
#### 向容器发送一个文件
|
||||
|
||||
发送会简单的以另一种方式完成:
|
||||
```
|
||||
lxc file push <source> <container>/<path>
|
||||
```
|
||||
|
||||
#### 直接编辑一个文件
|
||||
当只是简单的提取一个给定的路径时,编辑是一个很方便的功能,在你的默认文本编辑器中打开它,这样在你关闭编辑器时会自动将编辑的内容保存到容器。
|
||||
```
|
||||
lxc file edit <container>/<path>
|
||||
```
|
||||
|
||||
### 快照管理
|
||||
LXD允许你对容器执行快照功能并恢复它。快照包括了容器在某一时刻的完整状态(如果-stateful被使用的话将会包括运行状态),这也意味着所有的容器配置,容器设备和容器文件系统也会被包保存。
|
||||
#### 创建一个快照
|
||||
你可以使用下面的命令来执行快照功能:
|
||||
```
|
||||
lxc snapshot <container>
|
||||
```
|
||||
|
||||
命令执行完成之后将会生成名为snapX(X为一个自动增长的数)的记录。
|
||||
除此之外,你还可以使用如下命令命名你的快照:
|
||||
```
|
||||
lxc snapshot <container> <snapshot name>
|
||||
```
|
||||
|
||||
#### 列出所有的快照
|
||||
一个容器的所有快照的数量可以使用“lxc list”来得到,但是真正的快照列表只能执行“lxc info”命令才能看到。
|
||||
```
|
||||
lxc info <container>
|
||||
```
|
||||
|
||||
#### 恢复快照
|
||||
为了恢复快照,你可以简单的执行下面的命令:
|
||||
```
|
||||
lxc restore <container> <snapshot name>
|
||||
```
|
||||
|
||||
#### 给快照重命名
|
||||
可以使用如下命令来给快照重命名:
|
||||
```
|
||||
lxc move <container>/<snapshot name> <container>/<new snapshot name>
|
||||
```
|
||||
|
||||
#### 从快照中创建一个新的容器
|
||||
你可以使用快照来创建一个新的容器,而这个新的容器除了一些可变的信息将会被重置之外(例如MAC地址)其余所有信息都将和快照完全相同。
|
||||
```
|
||||
lxc copy <source container>/<snapshot name> <destination container>
|
||||
```
|
||||
|
||||
#### 删除一个快照
|
||||
|
||||
最后,你可以执行下面的命令来删除一个快照:
|
||||
```
|
||||
lxc delete <container>/<snapshot name>
|
||||
```
|
||||
|
||||
### 克隆并重命名
|
||||
得到一个纯净的发行版镜像总是让人感到愉悦,但是,有时候你想要安装一系列的软件到你的容器中,这时,你需要配置它然后将它分割并分配到多个其他的容器中。
|
||||
#### 复制一个容器
|
||||
为了复制一个容器并有效的将它克隆到一个新的容器中,你可以执行下面的命令:
|
||||
```
|
||||
lxc copy <source container> <destination container>
|
||||
```
|
||||
目标容器在所有方面将会完全和源容器等同。除非它没有
|
||||
目标容器在所有方面将会完全和源容器等同。除了新的容器没有任何源容器的快照以及一些可变值将会被重置之外(例如MAC地址)。
|
||||
#### 移除一个快照
|
||||
LXD允许你复制容器并在主机之间移动它。但是,关于这一点将在后面的文章中介绍。
|
||||
现在,“move”命令将会被用作给容器重命名。
|
||||
```
|
||||
lxc move <old name> <new name>
|
||||
```
|
||||
|
||||
唯一的要求就是当容器被停止时,容器内的任何事情都会被保存成它本来的样子,包括可变化的信息(类似MAC地址等)。
|
||||
### 结论
|
||||
这篇如此长的文章介绍了大多数你可能会在日常操作中使用到的命令。
|
||||
很显然,那些如此之多的命令都会有额外的可以让你的命令更加有效率或者可以让你指定你的LXD容器的某个具体方面的参数。最好的学习这些命令的方式就是深入学习它们的帮助文档,当然。只是对于那些你真正需要用到的命令参数。
|
||||
### 额外的信息
|
||||
LXD的主要网站是:<https://linuxcontainers.org/lxd>
|
||||
Github上的开发说明: <https://github.com/lxc/lxd>
|
||||
邮件列表支持:<https://lists.linuxcontainers.org>
|
||||
IRC支持: #lxcontainers on irc.freenode.net
|
||||
如果你不想或者不能在你的机器上安装LXD,你可以[try it online instead][1]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
来自于:https://www.stgraber.org/2016/03/19/lxd-2-0-your-first-lxd-container-312/
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[kylepeng93](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.stgraber.org/author/stgraber/
|
||||
[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
|
||||
[1]: https://linuxcontainers.org/lxd/try-it
|
||||
[2]: https://github.com/lxc/lxd/blob/master/doc/configuration.md
|
||||
Loading…
Reference in New Issue
Block a user