mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
65cb7b69cb
@ -161,7 +161,6 @@ LCTT的组成
|
||||
- itsang,
|
||||
- JeffDing,
|
||||
- Yuking-net,
|
||||
|
||||
- MikeCoder,
|
||||
- zhangboyue,
|
||||
- liaoishere,
|
||||
|
||||
46
published/20151202 A new Mindcraft moment.md
Normal file
46
published/20151202 A new Mindcraft moment.md
Normal file
@ -0,0 +1,46 @@
|
||||
又一次 Mindcraft 事件?
|
||||
=======================
|
||||
|
||||
Linux 内核开发很少吸引像华盛顿邮报这样主流媒体的关注,内核社区在安全方面进展的冗长功能列表就更少人看了。所以当[这样一个专题][1]发布到网上,就吸引了很多人的注意(LCTT 译注:华盛顿邮报发表了一篇很长的[专题文章][2],批评 Linux “没有一个系统性的机制以在骇客之前发现和解决安全问题,或引入更新的防御技术”,“Linux 内核开发社区没有一个首席安全官”等等)。关于这篇文章有不同的反应,很多人认为这是对 Linux 直接的攻击。文章背后的动机很难知道,但是从历史经验来看,它也可以看作对我们早就该前进的方向的一次非常必要的推动。
|
||||
|
||||
回顾一件昏暗遥远过去的事件 - 确切地说是在 1999 年 4 月。一家叫 Mindcraft 的分析公司发布了一份[报告][3]显示 Windows NT 在 Web 服务器开销方面完胜 Red Hat Linux 5.2 加 Apache。Linux 社区,包括当时还[很年轻的 LWN][4],对此反应很迅速而且强烈。这份报告是微软资助的 FUD 的一部分,用来消除那些全球垄断计划的新兴威胁。报告中所用的 Linux 系统有意配置成低性能,同时选择了当时 Linux 并不能很好支持的硬件,等等。
|
||||
|
||||
在大家稍微冷静一点后,尽管如此,事实很明显:Mindcraft 的人,不管什么动机,说的也有一定道理。当时 Linux 确实在性能方面存在一些已经被充分认识到的问题。然后社区做了最正确的事情:我们坐下来解决问题。比如,单独唤醒的调度器可以解决接受连接请求时的[惊群问题][5]。其他很多小问题也都解决了。在差不多一年里,内核在这类开销方面的性能已经有了非常大的改善。
|
||||
|
||||
这份 Mindcraft 的报告,某种意义上来说,往 Linux 屁股上踢了很有必要的一脚,推动整个社区去处理一些当时被忽略的事情。
|
||||
|
||||
华盛顿邮报的文章明显以负面的看法看待 Linux 内核以及它的贡献者。它随意地混淆了内核问题和其他根本不是内核脆弱性引起的问题(比如,AshleyMadison.com 被黑)。不过供应商没什么兴趣为他们的客户提供安全补丁的事实,就像一头在房间里巨象一样明显。还有谣言说这篇文章后面的黑暗势力希望打击一下 Linux 的势头。这些也许都是真的,但是也不能掩盖一个简单的事实,就是文章说的确实是真的。
|
||||
|
||||
我们会合理地测试并解决问题。而这些问题,不管是不是安全相关,能很快得到修复,然后再通过稳定更新的机制将这些补丁发布给内核用户。比起外面很多应用程序(自由的和商业的),内核的支持工作做的非常好。但是指责我们解决问题的能力时却遗漏了关键的一点:解决安全问题终究来说是一个打鼹鼠游戏。总是会出来更多的鼹鼠,其中有一些在攻击者发现并利用后很长时间我们都还不知道(所以没法使劲打下去)。尽管 Linux 的商业支持已经非常努力地在将补丁传递给用户,这种问题还是会让我们的用户很受伤 - 只是这并不是故意的。
|
||||
|
||||
关键是只是解决问题并不够,一些关心安全性的开发者也已经开始尝试做些什么。我们必须认识到,缺陷永远都解决不完,所以要让缺陷更难被发现和利用。这意思就是限制访问内核信息,绝对不允许内核执行用户空间内存中的指令,让内核去侦测整形溢出,以及 [Kee Cook 在十月底内核峰会的讲话][6]中所提出的其他所有事情。其中许多技术被其他操作系统深刻理解并采用了;另外一些需要我们去创新。但是,如果我们想充分保护我们的用户免受攻击,这些改变是必须要做的。
|
||||
|
||||
为什么内核还没有引入这些技术?华盛顿邮报的文章坚定地指责开发社区,特别是 Linus Torvalds。内核社区的传统就是相对安全性更侧重于性能和功能,在需要牺牲性能来改善内核安全性时并不愿意折衷处理。这些指责一定程度上是对的;好的一面是,因为问题的范围变得清晰,态度看上去有所改善。Kee 的演讲都听进去了,而且很明显让开发者开始思考和讨论这些问题了。
|
||||
|
||||
而被忽略的一点是,并不仅仅是 Linus 在拒绝有用的安全补丁。而是就没有多少这种补丁在内核社区里流传。特别是,在这个领域工作的开发者就那么些人,而且从没有认真地尝试把自己的工作整合到上游。要合并任何大的侵入性补丁,需要和内核社区一起工作,为这些改动编写用例,将改动分割成方便审核的碎片,处理审核意见,等等。整个过程可能会有点无聊而且让人沮丧,但这却是内核维护的运作方式,而且很明显只有这样才能在长时间的开发中形成更有用更可维护的内核。
|
||||
|
||||
几乎没有人会走这个流程来将最新的安全技术引入内核。对于这类补丁可能收到的不利反应,有人觉得也许会导致“寒蝉效应”,但是这个说法并不充分:不管最初的反应有多麻烦,多年以来开发者已经合并了大量的改动。而少数安全开发者连试都没试过。
|
||||
|
||||
他们为什么不愿意尝试?一个比较明显的答案是,几乎没有人会因此拿到报酬。几乎所有引入内核的工作都由付费开发者完成,而且已经持续多年。公司能看到利润的领域在内核里都有大量的工作以及很好的进展。而公司觉得和它们没关系的领域就不会这样了。为实时 Linux 的开发找到赞助支持的困难就是很明显的例子。其他领域,比如文档,也在慢慢萧条。安全性很明显也属于这类领域。可能有很多原因导致 Linux 落后于防御式安全技术,但是其中最关键的一条是,靠 Linux 赚钱的公司没有重视这些技术的开发和应用。
|
||||
|
||||
有迹象显示局面已有所转变。越来越多的开发人员开始关注安全相关问题,尽管对他们工作的商业支持还仍然不够。对于安全相关的改变已经没有之前那样的下意识反应了。像[内核自我保护项目][7]这样,已经开始把现有的安全技术集成进入内核了。
|
||||
|
||||
我们还有很长的路要走,但是,如果能有一些支持以及正确的观念,短期内就能有很大的进展。内核社区在确定了自己的想法后可以做到很让人惊叹的事情。幸运的是,华盛顿邮报的文章将有助于提供形成这种想法的必要动力。以历史的角度看,我们很可能会把这次事件看作一个转折点,我们最终被倒逼着去完成之前很明确需要做的事情。Linux 不应该再继续讲述这个安全不合格的故事了。
|
||||
|
||||
---------------------------
|
||||
|
||||
via: https://lwn.net/Articles/663474/
|
||||
|
||||
作者:Jonathan Corbet
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://lwn.net/Articles/663338/
|
||||
[2]:http://www.washingtonpost.com/sf/business/2015/11/05/net-of-insecurity-the-kernel-of-the-argument/
|
||||
[3]: http://www.mindcraft.com/whitepapers/nts4rhlinux.html
|
||||
[4]: https://static.lwn.net/1999/features/MindCraft1.0.php3
|
||||
[5]: https://en.wikipedia.org/wiki/Thundering_herd_problem
|
||||
[6]: https://lwn.net/Articles/662219/
|
||||
[7]: https://lwn.net/Articles/663361/
|
||||
@ -1,18 +1,14 @@
|
||||
|
||||
Linux / Unix 桌面娱乐 :
|
||||
文字模式的带有ASCII艺术的Box与评论绘制
|
||||
|
||||
Linux/Unix 桌面趣事:文字模式下的 ASCII 艺术与注释绘画
|
||||
================================================================================
|
||||
Boxes 命令不仅是一个文本过滤器,同时是一个很少人知道的可以为了乐趣或者需要在它的输入文本或者代码周围画各种ASCII艺术画的工具。你可以迅速创建邮件签名,或者使用各种编程语言创建局部评论。这个命令计划被vim文本编辑器使用,但是也可以被支持过滤的文本编辑器使用,同时从命令行作为一个单独的工具使用。
|
||||
|
||||
boxes 命令不仅是一个文本过滤器,同时是一个很少人知道的有趣工具,它可以在输入的文本或者代码周围框上各种ASCII 艺术画。你可以用它快速创建邮件签名,或者在各种编程语言中留下评论块。这个命令可以在 vim 文本编辑器中使用,但是也可以在各种支持过滤器的文本编辑器中使用,同时也可以在命令行中单独使用。
|
||||
|
||||
### 任务: 安装 boxes ###
|
||||
|
||||
使用 [apt-get command][1] 在 Debian / Ubuntu Linux中安装 boxes :
|
||||
使用 [apt-get 命令][1] 在 Debian / Ubuntu Linux 中安装 boxes:
|
||||
|
||||
$ sudo apt-get install boxes
|
||||
|
||||
输出示例 :
|
||||
输出示例:
|
||||
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
@ -28,11 +24,11 @@ Boxes 命令不仅是一个文本过滤器,同时是一个很少人知道的
|
||||
Processing triggers for man-db ...
|
||||
Setting up boxes (1.0.1a-2.3) ...
|
||||
|
||||
RHEL / CentOS / Fedora Linux 用户, 使用 [yum command to install boxes][2] (首先 [enable EPEL repo as described here][3]):
|
||||
RHEL / CentOS / Fedora Linux 用户, 使用 [yum 命令来安装][2] boxes,(请先[启用 EPEL 软件仓库][3]):
|
||||
|
||||
# yum install boxes
|
||||
|
||||
输出示例 :
|
||||
输出示例:
|
||||
|
||||
Loaded plugins: rhnplugin
|
||||
Setting up Install Process
|
||||
@ -64,21 +60,21 @@ RHEL / CentOS / Fedora Linux 用户, 使用 [yum command to install boxes][2] (
|
||||
boxes.x86_64 0:1.1-8.el6
|
||||
Complete!
|
||||
|
||||
FreeBSD 用户可以按如下来使用 :
|
||||
FreeBSD 用户可以按如下使用:
|
||||
|
||||
cd /usr/ports/misc/boxes/ && make install clean
|
||||
|
||||
或者,使用 pkg_add 命令来增加包:
|
||||
或者,使用 pkg_add 命令来增加包:
|
||||
|
||||
# pkg_add -r boxes
|
||||
|
||||
### 在一些给定文本周围画出任何种类的box ###
|
||||
### 在一些给定文本周围画出任何种类的包围框 ###
|
||||
|
||||
输入下列命令 :
|
||||
输入下列命令:
|
||||
|
||||
echo "This is a test" | boxes
|
||||
|
||||
或者,通过设置要使用的设计的名字来使用 :
|
||||
或者,指定要使用的图案的名字:
|
||||
|
||||
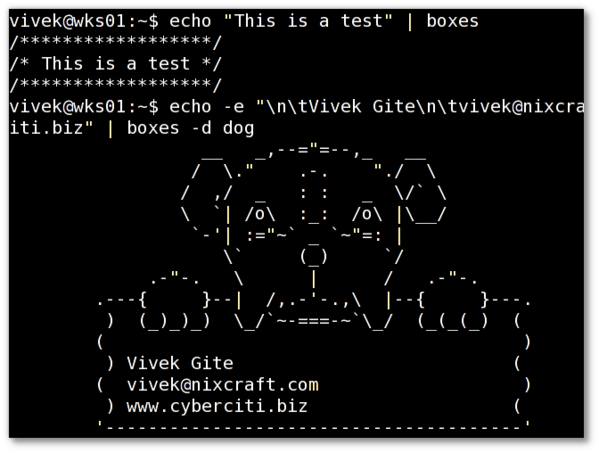
echo -e "\n\tVivek Gite\n\tvivek@nixcraft.com\n\twww.cyberciti.biz" | boxes -d dog
|
||||
|
||||
@ -86,31 +82,29 @@ FreeBSD 用户可以按如下来使用 :
|
||||
|
||||
|
||||
|
||||
Fig.01: Unix / Linux: Boxes 命令来画出各式各样的设计
|
||||
*图01: Unix / Linux: Boxes 命令来画出各式各样的图案 *
|
||||
|
||||
#### 怎么样输出所有的设计 ####
|
||||
#### 怎么样输出所有的图案 ####
|
||||
|
||||
语法如下:
|
||||
语法如下:
|
||||
|
||||
boxes option
|
||||
pipe | boxes options
|
||||
echo "text" | boxes -d foo
|
||||
boxes -l
|
||||
|
||||
设计 -d 选项设置要使用的设计的名字 . 语法如下:
|
||||
|
||||
-d 选项用来设置要使用的图案的名字。语法如下:
|
||||
|
||||
echo "Text" | boxes -d design
|
||||
pipe | boxes -d desig
|
||||
|
||||
-l 选项列出所有设计 . 它显示在配置文件中的所有的box设计图,同时也显示关于其创作者的信息。
|
||||
-l 选项列出所有图案。它显示了在配置文件中的所有的框线设计图,同时也显示关于其创作者的信息。
|
||||
|
||||
|
||||
boxes -l
|
||||
boxes -l | more
|
||||
boxes -l | less
|
||||
|
||||
输出示例:
|
||||
输出示例:
|
||||
|
||||
43 Available Styles in "/etc/boxes/boxes-config":
|
||||
-------------------------------------------------
|
||||
@ -146,20 +140,21 @@ Fig.01: Unix / Linux: Boxes 命令来画出各式各样的设计
|
||||
output truncated
|
||||
..
|
||||
|
||||
### 在使用vi/vim文本编辑器时如何通过boxes过滤文本? ###
|
||||
### 在使用 vi/vim 文本编辑器时如何通过 boxes 过滤文本? ###
|
||||
|
||||
你可以使用vi或vim支持的任何附加命令,在这个例子中, [insert current date and time][4], 输入:
|
||||
你可以在 vi 或 vim 中使用任何外部命令,比如在这个例子中,[插入当前日期和时间][4],输入:
|
||||
|
||||
!!date
|
||||
|
||||
或者
|
||||
|
||||
:r !date
|
||||
你需要在vim中输入以上命令来读取数据命令的输出,这将在当前行后面加入日期和时分秒:
|
||||
|
||||
你需要在 vim 中输入以上命令来读取 date 命令的输出,这将在当前行后面加入日期和时分秒:
|
||||
|
||||
Tue Jun 12 00:05:38 IST 2012
|
||||
|
||||
你可以用boxes命令做到同样的. 创建一个作为样本的shell脚本或者如下的一个c程序:
|
||||
你可以用 boxes 命令做到同样的功能。如下创建一个作为示例的 shell 脚本或者c程序:
|
||||
|
||||
|
||||
#!/bin/bash
|
||||
@ -167,7 +162,7 @@ Fig.01: Unix / Linux: Boxes 命令来画出各式各样的设计
|
||||
Author: Vivek Gite
|
||||
Last updated on: Tue Jun, 12 2012
|
||||
|
||||
现在输入如下 (将光标移到第二行,也就是以"Purpose: ..."开头的行)
|
||||
现在输入如下(将光标移到第二行,也就是以“Purpose: ...”开头的行)
|
||||
|
||||
3!!boxes
|
||||
|
||||
@ -184,11 +179,10 @@ Fig.01: Unix / Linux: Boxes 命令来画出各式各样的设计
|
||||
注:youtube 视频
|
||||
<iframe width="595" height="446" frameborder="0" src="http://www.youtube.com/embed/glzXjNvrYOc?rel=0"></iframe>
|
||||
|
||||
(Video:01: boxes command in action. BTW, this is my first video so go easy on me and let me know what you think.)
|
||||
|
||||
另见
|
||||
参见
|
||||
|
||||
- boxes man 手册
|
||||
- boxes 帮助手册
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -196,7 +190,7 @@ via: http://www.cyberciti.biz/tips/unix-linux-draw-any-kind-of-boxes-around-text
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[zky001](https://github.com/zky001)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,34 @@
|
||||
Intel 展示了可在大屏幕显示 Linux 系统的低端 Android 手机
|
||||
==============================================================
|
||||
|
||||
|
||||
|
||||
在世界移动大会 **MWC16** 上 Intel 展示了称之为“大屏体验”的一款的 Android 智能手机,它在插入一个外部显示后运行了一个完整的 Linux 桌面。
|
||||
|
||||
这个概念大体上与微软在 Windows 10 手机中的 Continuum 相似,但是 Continuum 面向的是高端设备,Intel 的项目面向的是低端智能机和新兴市场。
|
||||
|
||||
在巴塞罗那的这场大会上展示的是拥有 Atom x3、2GB RAM 和 16GB 存储以及支持外部显示的的 SoFIA(Intel 架构的智能或功能手机)智能机原型。插上键盘、鼠标和显示,它就变成了一台桌面 Linux,并可以选择在大屏幕的一个窗口中显示 Android 桌面。
|
||||
|
||||
Intel 的拓荒小组(Path Finding Group)经理 Nir Metzer 告诉我们:“Android 基于 Linux 内核,因此我们运行在一个内核上,我们有一个 Android 栈和一个 Linux 栈,并且我们共享同一个环境,因此文件系统是相同的。电话是全功能的。”
|
||||
|
||||
Metzer 说:“我有一个多窗口环境。只要我插入显示器后就可以使用电子表格,我可以进行拖放操作,播放音频。在一个低端平台实现这一切是一个挑战。”
|
||||
|
||||
现在当连上外部显示器时设备的屏幕显示是空白的,但是 Metzer 说下个版本的 Atom X3 会支持双显示。
|
||||
|
||||
其使用的 Linux 版本是由 Intel 维护的。Metzer 说:“我们需要将 Linux 和 Android 保持一致。框架是预安装的,你不能下载任何 app。”
|
||||
|
||||
英特尔在移动世界大会上向手机制造商们推销这一想法,但却没有实际说希望购买该设备的消费者。Metzer 说:“芯片已经准备好了,已经为量产准备好了。明天就可以进入生产。但是这要看商业需求。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theregister.co.uk/2016/02/23/move_over_continuum_intel_shows_android_smartphone_powering_bigscreen_linux/
|
||||
|
||||
作者:[Tim Anderson][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/2878
|
||||
|
||||
|
||||
@ -0,0 +1,83 @@
|
||||
怎样将开源经历添加到你的简历中去
|
||||
==================================================
|
||||

|
||||
|
||||
在这篇文章中,我将会分享我的方法,让大家利用开源贡献在技术领域的求职中脱颖而出,成为强有力的候选者。
|
||||
|
||||
凡事预则立,不预则废。在你即将进入一个新的领域或者正准备熬夜修订你的简历之前,清楚地定义你正在寻找的工作的特征是值得的。你的简历是一部有说服力的作品,因此你必须了解你的观众,从而让它发挥出所有的潜力。看你简历的可能是任何需要你的技能并且能在预算之内聘用你的人。当编辑简历的时候,读一读你的简历上的内容,同时想象一下,以他们的角度怎么看待这份简历。你看起来像是一个“你”将会聘用的候选人吗?
|
||||
|
||||
我个人认为,对于目标职位的理想候选人所表现出来的关键特征,列出一张清单是很有帮助的。我结合了个人经验、阅读工作招聘信息、询问相同角色的同事等方面来收集这个清单。LinkedIn 和各种会议是寻求一些乐意提供这种建议的人的很好的地方。一些人喜欢谈论他们自己,那么通过邀请他们讲述他们自己的一些故事可以帮助你来拓展你的知识面,这样大家都会感觉很好。当你和其他人谈论他们的职业路线时,你不仅将会明白怎样去得到你想要从事的工作,而且还能知道你应该避免那些容易让你失去工作机会的特征或行为。
|
||||
|
||||
例如,对于一个不太资深的工作位置来说,关键特征列表可能如下所示:
|
||||
|
||||
###技术方面:
|
||||
|
||||
- 拥有 CI (持续集成) 方面的经验,特别是 Jenkins
|
||||
- 深厚的脚本编写背景,如 Python 和 Ruby
|
||||
- 精通 Eclipse IDE
|
||||
- 基本的 Git 和 Bash 知识
|
||||
|
||||
###个人而言:
|
||||
|
||||
- 自我驱动的学习者
|
||||
- 良好的交流和文档技巧
|
||||
- 在团队开发方面富有经验(团队成员)
|
||||
- 精通事件跟踪的工作流
|
||||
|
||||
###尽管去申请职位
|
||||
|
||||
记住,你没有必要为了得到一份工作而去满足上面的工作描述列表中列出的每个标准。
|
||||
|
||||
工作细节(JD)描述了这个角色,让你一开始就知道你即将签约并为之工作几年的公司的全部信息,并且这份工作并不会让你觉得有什么挑战性,或者要求你去拓展你的技能。如果你对你无法满足清单上的技能列表而感到紧张,那么检查一下自己是否有来自其他方面的经历并能与之媲美的技能。例如,即使有些人从来没有使用过 [Jenkins][1],那他也可能从之前使用过 [Buildbot][2] 或者 [travis CI][3] 的项目经验中明白持续集成测试的原则。
|
||||
|
||||
如果你正在申请一家大型公司,他们可能拥有一个专门的部门和一套完整的筛选过程来确保他们不会聘用任何不能胜任职位的候选人。也就是说,在你求职的过程中,你所能做的只是提交申请,而决定是否拒绝你是公司管理层的工作。不要过早地将工作拒之门外。
|
||||
|
||||
现在你已经知道了你的任务是什么,并且还知道你将需要让面试官印象深刻的技巧。下一步要做的取决于你已有的经验。
|
||||
|
||||
### 制造已经存在的事物之间的关联
|
||||
|
||||
列出一张你过去几年曾经参与过的所有项目。下面是一条快速得到这张清单的方法,跳转到你的 Github profile 中的**Repositories**标签页,并且过滤掉 fork 过来的项目。除此之外,检查下你的清单上是否有曾经处于领导地位的[Organizations][4]。如果你已经有了一份简历,那么请确保你已经将你所有的经历都列在了上面。
|
||||
|
||||
考虑下任何一个你曾经作为一个潜在的领导经历并拥有过特权的 IRC 频道。检查下你的 Meetup 和Eventbrite 账号,并将你曾经组织过或者作为志愿者参与过的活动添加到你的清单上。浏览你前几年的日程并且标注所有志愿服务,或者有作为导师的经历,又或者参与过的公共演讲。
|
||||
|
||||
现在进入了比较艰难的环节了,将清单上列出的必备技能与个人经历列表上的内容一一对照,我喜欢给该工作所需要的每个特征用一个字母或者数字作为标记,然后在每一段你经历或参与过并表现出了某一特征的地方标记相同的符号。当你不太确定的时候,那就毫不犹豫地标记上它,尽管这样做更像是在吹嘘,但也好过显示出你的无能。
|
||||
|
||||
在我们写简历的时候常常被这样的情况所困扰,就是我们不愿冒着过分吹嘘自己的技能的风险。通常应该这样去想,“那些组织了聚会的人会表现出了更好的领导才能和计划技巧吗?”,而不是“当我组织了这个聚会的时候我是否展示出了这些技巧?”。
|
||||
|
||||
如果你已经充分了解了你在过去的一两年里的业余时间都是怎么度过的,而且你写了很多代码,那么你可能现在正面临着一个令人奇怪的问题,你已经拥有了太多的经验以至于一张纸的简历已经无法容纳下这些经验了。那么,如果那些列在你的清单上的经验,但无法证明你尝试去表现的任何技能的话,那么请扔掉它们吧。如果这份已经被缩短的简历清单上的内容仍然超过一张单页纸的容量的话,那么将你的经验按照一定的优先级排序,例如根据与所需技术的相关经历或丰富经验。
|
||||
|
||||
在这一方面,显而易见,如果你想要磨练一个独特的技能,那么你就需要一个不错的经历。考虑使用一个类似 [OpenHatch][7] 的问题聚合器,并用它来寻找一个通过使用你从没使用过的工具和技术来锻炼你的技能的开源项目。
|
||||
|
||||
### 让你的简历更加漂亮
|
||||
|
||||
一份简历是否美观取决于它的简洁度、清晰度和布局。每一段经历都应该通过足够的信息来展示给读者,并让他们立刻明白为什么你要将它包含进去,而且恰到好处。每种类型的信息都应该使用一致的文档格式来表示,一份含有斜体格式的日期或者右对齐的或者与整体风格不协调的部分绝对会让人分心。
|
||||
|
||||
使用工具来给你的简历排版会使之前设定的目标更加容易实现。我喜欢使用 [LaTeX][5],因为它的宏系统能够使可视化一致性变得更加容易,并且大量的面试官都能一眼就认出它。你的工具的选择可能是 [LibreOffice][6] 或者 HTML,这取决于你的技能和你希望怎样去发布你的简历。
|
||||
|
||||
记住一点,一份以电子方式提交的简历可以通过关键字被浏览到。因此,当你需要描述你的工作经历的时候使用和工作招聘告示一样的英文缩写对你的求职会有很大的帮助。为了让你的简历更加容易被面试官看到,首先就要放上最重要的信息。
|
||||
|
||||
程序员通常难以在为文档排版时量化平衡和布局。我最喜欢的修改和评估我的文档中的空格是否处于正确位置的技术,就是全屏显示我的 PDF 或者打印出来,然后在镜子里面查看它。如果你正在使用 LibreOffice Writer,保存一份你的简历的副本,然后将你的简历中的字体换成一种你看不懂的语言。这两种技术都强制将你从阅读的内容中脱离出来,让你以一种新的方式查看文档的整体布局。他们把你从一个“那句话措辞不当!”这样的批评转到了注意如“在这行上只有一个字,看起来挺逗”之类的事情。
|
||||
|
||||
最后,再次检查你的简历是否在它将要的展示的多媒体上看起来完全正确。如果你以网页的形式发布它,那么在不同屏幕大小的浏览器中测试它的效果。如果它是一份 PDF 文档,那么在你的手机或者你的朋友的电脑上打开它,并确保它所需要的字体都是可用的。
|
||||
|
||||
###接下来的步骤
|
||||
|
||||
最后,不要让你辛苦做出来的简历内容浪费了,将它完整的复制到你的 LinkedIn 帐号上(完全使用招聘公告中的流行词),然后毫无疑问招聘人员就会找到你了。尽管他们描述的工作内容并不是恰好适合你,但是你可以利用他们的时间和兴趣来得到关于你的简历中有哪些地方好与不好的反馈信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://opensource.com/business/16/2/add-open-source-to-your-resume
|
||||
|
||||
作者:[edunham][a]
|
||||
译者:[pengkai](https://github.com/pengkai)
|
||||
校对:[mudongliang](https://github.com/mudongliang),[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/edunham
|
||||
[1]: https://jenkins-ci.org/
|
||||
[2]: http://buildbot.net/
|
||||
[3]: https://travis-ci.org/
|
||||
[4]: https://github.com/settings/organizations
|
||||
[5]: https://www.latex-project.org/
|
||||
[6]: https://www.libreoffice.org/download/libreoffice-fresh/
|
||||
[7]: http://openhatch.org/
|
||||
56
published/20160301 Linux gives me all the tools I need.md
Normal file
56
published/20160301 Linux gives me all the tools I need.md
Normal file
@ -0,0 +1,56 @@
|
||||
Linux 给了我所有所需的工具
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
[Linux][0] 就在我们身边。它以 Android 的形式[存在我们的手机中][1],它[用在国际空间站中][2],它[还是互联网的主要支柱][3],可是迄今为止很多人从未留意过它。对 Linux 的探索是一种很有成就感的尝试。很多人都在 Opensource.com [分享过他们与 Linux 的故事][4]。现在,轮到我了。
|
||||
|
||||
我依然记得我在 2008 年第一次探索 Linux 的时刻。协助我探索 Linux 的人是我的父亲,Socrates Ballais。他是菲律宾塔克洛班的一名经济学专家,也是一个技术狂热者。他教会了我许多计算机技术方面的知识,但只提倡我将 Linux 作为 Windows 崩溃后的备用操作系统。
|
||||
|
||||
### 从前的日子
|
||||
|
||||
在我们在家中购置电脑之前,我曾是一个 Windows 用户。我使用电脑玩游戏,制作文档,做那些小孩子都会用电脑做的事。我不知道什么是 Linux,更不知道它的用处。在那个时候,电脑在我心中的象征就是一个 Windows 的商标。
|
||||
|
||||
当我们买到第一台电脑时,我爸爸在上面安装了 Linux ([Ubuntu][5] 8.04)。充满了好奇心的我,第一次引导进入了那个操作系统。我被它的用户界面震惊了。它非常漂亮,而且我发现它对用户很友好。在那之后的一段时间,我只会使用 Linux 它内置的几款游戏。我还是会在 Windows 中做我的家庭作业。
|
||||
|
||||
### 第一次安装
|
||||
|
||||
4 年后,我决定为家里的电脑重新安装 Windows。我同时毫不犹豫地安装了 Ubuntu。从那次开始,我(再次)爱上了 Linux。随着时间推移,我慢慢适应了 Ubuntu,还会无意地将它推荐给我的朋友。当我拿到我的第一台笔记本电脑时,我立刻在上面安装了它。
|
||||
|
||||
### 现在
|
||||
|
||||
如今,Linux 是我的默认操作系统。当我需要使用电脑做一些工作时,我会在 Linux 中完成。至于文档和幻灯片,我会通过 [Wine][6] 来使用微软的 Office 办公软件。我会用 [Chrome 和 Firefox][7] 来满足我的上网需要,会用 [Geary][8] 来收发邮件。你可以使用 Linux 来做很多很多事情。
|
||||
|
||||
我的大多数——并不是全部——编程工作都会在 Linux 中完成。像 [Visual Studio][9] 和 [XCode][10] 这样的基本集成开发环境 (IDE) 的缺乏教会我这个程序员如何变得灵活、如何去学习更多知识。现在,我只需要一个文本编辑器和一个编译器/解释器就可以开始编程。只有当 IDE 是我完成手头上的任务的最佳最佳工具时,我才会使用它。总而言之,Linux 给了我开发软件所需要的一切工具。
|
||||
|
||||
现在,我是一个名叫 [Creatomiv Studios][11] 的初创公司的联合创始人和首席技术官。我使用 Linux 来编写我们的最新产品 Basyang 的后端服务器代码。我还是一个业余摄影家,使用 [GIMP][12] 和 [Darktable][13] 来编辑、管理照片。至于团队沟通,我会使用 [Telegram][14]。
|
||||
|
||||
### Linux 之美
|
||||
|
||||
很多人认为 Linux 只是为那些喜欢解决复杂问题或者在命令行中工作的人而生的操作系统。还有些人会认为它就是一个缺乏公司支持维护的垃圾。不过,我认为 Linux 是一个完美的操作系统,也是一个为创造而生的绝佳工具。所以我热爱 Linux,同时希望看到它继续成长。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-sean-ballais
|
||||
|
||||
作者:[Sean Francis N. Ballais][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
[a]: https://opensource.com/users/seanballais
|
||||
[0]: https://opensource.com/resources/what-is-linux
|
||||
[1]: http://www.howtogeek.com/189036/android-is-based-on-linux-but-what-does-that-mean/
|
||||
[2]: http://www.extremetech.com/extreme/155392-international-space-station-switches-from-windows-to-linux-for-improved-reliability
|
||||
[3]: https://www.youtube.com/watch?v=JzsLkbwi1LA
|
||||
[4]: https://opensource.com/tags/my-linux-story
|
||||
[5]: http://ubuntu.com/
|
||||
[6]: https://www.winehq.org/
|
||||
[7]: https://www.google.com/chrome/browser/desktop/index.html
|
||||
[8]: https://wiki.gnome.org/Apps/Geary
|
||||
[9]: https://www.visualstudio.com/en-us/visual-studio-homepage-vs.aspx
|
||||
[10]: https://developer.apple.com/xcode/
|
||||
[11]: https://www.facebook.com/CreatomivStudios/
|
||||
[12]: https://www.gimp.org/
|
||||
[13]: http://www.darktable.org/
|
||||
[14]: https://telegram.org/
|
||||
@ -0,0 +1,53 @@
|
||||
Ubuntu 的 snap 软件包封装真的安全吗?
|
||||
==========================================
|
||||
|
||||
最近发布的 [Ubuntu 16.04 LTS 版本带来了一些新功能[1],其中之一就是对 [ZFS 格式文件系统的支持][2]。另一个值得广为讨论的特性就是 Snap 软件包格式。不过,据 [CoreOS][3] 的开发者之一所述,Snap 软件包并不像声称的那样安全。
|
||||
|
||||
### 什么是 Snap 软件包?
|
||||
|
||||
Snap 软件包的灵感来自容器。这种新的封装格式允许[开发人员为运行于 Ubuntu 长期支持版本 (LTS)之上的应用程序发布更新][4]。这就可以让用户虽然运行着稳定版本的操作系统,但却能够让应用程序保持最新的状态。之所以能够这样,是因为软件包本身就包含了程序运行的所有依赖。这可以防止依赖的软件更新后软件挂掉。
|
||||
|
||||
snap 软件包的另外一个优势是应用与系统的其它部分是隔离的。这意味着如果你改变了 snap 软件包的一些东西,它不会影响到系统的其它部分。这也可以防止其它的应用访问你的隐私信息,从而使骇客根据难以获取你的数据。
|
||||
|
||||
### 然而……
|
||||
|
||||
据 [Matthew Garrett][5] 的说法,Snap 软件包不能完全兑现上述承诺。Garret 作为 Linux 内核的开发人员和 CoreOS 的安全性方面的开发者,我想他一定知道自己在说些什么。
|
||||
|
||||
[据 Garret 说][6], “仅需要克服一点点困难,安装的任何 Snap 格式的软件包就完全能够将你所有的私有数据复制到任何地方”。
|
||||
|
||||
[ZDnet][7] 的报道:
|
||||
|
||||
> “为了证明自己的观点,他在 Snap 中构建了一个仅用于验证其原理的用于破坏的软件包,它首先会显示一个可爱的泰迪熊,然后将会记录 Firefox 的键盘按键事件,并且能够窃取 SSH 私钥。这个仅用于验证原理的软件包实际上注入的是一个无害的命令,但是却能够修改成一个窃取 SSH 密钥的 cURL 会话。”
|
||||
|
||||
### 但是稍等……
|
||||
|
||||
难道 Snap 真的有安全缺陷?事实上却不是!
|
||||
|
||||
Garret 自己也说,此问题仅出现在使用 X11 窗口系统上,而对于那些使用 Mir 的移动设备无效。所以这个缺陷是 X11 的而不是 Snap 的。
|
||||
|
||||
> X11 是如何信任应用程序的,这是一个众所周知的安全风险。Snap 并没有更改 X11 的信任模型。所以一个应用程序能够看到其它应用程序的行为并不是这种新的封装格式的缺点,而是 X11 的。
|
||||
|
||||
Garrett 实际上想表达的只是,当 Canonical 歌颂 Snap 和它的安全性时,Snap 应用程序并不是完全沙盒化的。和其他二进制文件一样,它们也存在风险。
|
||||
|
||||
请牢记 Ubuntu 16.04 当前还在使用 X11 而不是 Mir 的事实,从未知的源下载和安装 Snap 格式的软件包也许还是有风险的,然而其它不也是如此嘛?!
|
||||
|
||||
相关链接: [如何在 Ubuntu 16.04 中使用 Snap 软件包][8]。期待您分享关于 Snap 格式及其安全性的观点。
|
||||
|
||||
----------
|
||||
via: http://itsfoss.com/snap-package-securrity-issue/
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[dongfengweixiao](https://github.com/dongfengweixiao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/john/
|
||||
[1]: http://itsfoss.com/features-ubuntu-1604/
|
||||
[2]: http://itsfoss.com/oracle-canonical-lawsuit/
|
||||
[3]: https://en.wikipedia.org/wiki/CoreOS
|
||||
[4]: https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/
|
||||
[5]: https://mjg59.dreamwidth.org/l
|
||||
[6]: https://mjg59.dreamwidth.org/42320.html
|
||||
[7]: http://www.zdnet.com/article/linux-expert-matthew-garrett-ubuntu-16-04s-new-snap-format-is-a-security-risk/
|
||||
[8]: http://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
@ -1,18 +1,17 @@
|
||||
Master OpenStack with 5 new tutorials
|
||||
5篇文章快速掌握OpenStack
|
||||
推荐五篇 OpenStack 的新指南
|
||||
=======================================
|
||||
|
||||

|
||||
|
||||
回顾这周的 OpenStack 峰会,我仍然回味着开源云生态系统的浩瀚无垠,并且需要熟悉多少个不同的项目和概念才能获得成功。但是,我们是幸运的,因为有许多资源让我们跟随项目的脚步。除了[官方文档][1]外,我们还有许多来自三方组织的培训和认证、个人分享,以及许多社区贡献的学习资源。
|
||||
回顾这周的 OpenStack 峰会,我仍然回味着开源云生态系统的浩瀚无垠,有那么多需要了解的项目及概念才能获得成功。不过我们很幸运,因为有许多资源让我们跟随着项目的脚步。除了[官方文档][1]外,我们还有许多来自第三方提供的培训和认证、个人分享,以及许多社区贡献的学习资源。
|
||||
|
||||
为了让我们保持获得最新消息,每个月我们将会整合发布 OpenStack 社区的最新教程、指导和小贴士等。下面是我们过去几个月最棒的发布分享。
|
||||
|
||||
- 首先,如果你正在寻找一个靠谱实惠的 OpenStack 测试实验室, Intel NUC 是最值得考虑的平台.麻雀虽小,五脏俱全,通过指导文章,可以很轻松的按照教程在 NUC 上使用 [TripleO 部署 OpenStack][2] ,并且还可以轻松预防一些常见的怪异问题。
|
||||
- 首先,如果你正在寻找一个靠谱实惠的 OpenStack 测试实验室, Intel NUC 是最值得考虑的平台。麻雀虽小,五脏俱全,通过指导文章,可以很轻松的按照教程在 NUC 上使用 [TripleO 部署 OpenStack][2] ,并且还可以轻松避开一些常见的古怪问题。
|
||||
- 当你已经运行的一段时间 OpenStack 后,你会发现在你的云系统上许多组件生成了大量日志。其中一些是可以安全删除的,而你需要一个管理这些日志的方案。参考在部署生产 9 个月后使用 Celiometer 管理日志的[一些思考][3]。
|
||||
- 对于 OpenStack 基础设施项目的新手,想要提交补丁到 OpenStack 是相当困难的。入口在哪里,测试怎么做,我的提交步骤是怎么样的?可以通过 Arie Bregman 的[博客文章][4]快速了解整个提交过程。
|
||||
- 突发计算节点失效,不知道是硬件还是软件问题。好消息是 OpenStack 提供了一套非常简单的迁移计划可以让迁移当机节点到别的主机。然而,迁移过程中使用的命令令许多人感到困惑。可以通过[这篇文章][5]来理解 migrate 和 evacuate 命令的不同。
|
||||
- 网络功能虚拟化技术需要 OpenStack 中的额外的功能,而用户可能不熟悉它们。例如, SR-IOV 和 PCI 直通是最大限度地提高物理硬件性能的方式。可以学习[部署步骤][6]以使 OpenStack 的性能最大化。
|
||||
- 对于 OpenStack 基础设施项目的新手,想要提交补丁到 OpenStack 是相当困难的。入口在哪里,测试怎么做,我的提交步骤是怎么样的?可以通过 Arie Bregman 的这篇[博客文章][4]快速了解整个提交过程。
|
||||
- 突发计算节点失效,不知道是硬件还是软件问题。不过好消息是 OpenStack 提供了一套非常简单的迁移计划可以让你迁移当机节点到别的主机。然而,迁移过程中使用的命令令许多人感到困惑。可以通过[这篇文章][5]来理解 migrate 和 evacuate 命令的不同。
|
||||
- 网络功能虚拟化技术需要 OpenStack 之外的一些功能,而用户可能不熟悉它们。例如, SR-IOV 和 PCI 直通是最大限度地提高物理硬件性能的方式。可以学习[部署步骤][6]以使 OpenStack 的性能最大化。
|
||||
|
||||
这些文章基本涵盖了本月(译者注: 4 月)推送,如果你还需要更多文章,可以检索过去推送的 [OpenStack 文献][7]来获取更多资源。如果有你认为我们应该推荐的新教程,请在评论中告诉我们,谢谢。
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
猎头们怎么看开源
|
||||
============================================
|
||||
|
||||

|
||||
|
||||
2012 年时候,我出席了一个开源社区的聚会,打那之后我就喜欢上了这个行业。
|
||||
|
||||
我做猎头很多年,现在我在 [Greythorn][1] 公司专门从事大数据方向招聘。我自己之前学习了几个月大数据,可是当我参加了 [OSCON][2] 开源大会,才发现之前的学习多么低效率。OSCON 里聚集了非常多聪明的人,他们每个人都很愿意分享他们的心得。分享的原因不是他们想推销产品,纯粹是因为喜欢。
|
||||
|
||||
我很快意识到,与其说开源和大数据是一个行业,不如说他们是一个社区(community)。这也是为什么我现在特别想把我从开源中学到的东西分享给大家,特别是给那些刚刚踏入工作的新人。
|
||||
|
||||
### 为什么雇主喜欢开源贡献者(contributor)
|
||||
|
||||
我的许多客户跟我说过:一个人的技术虽然重要,但真心**喜欢**自己从事的工作更重要。如果你热爱自己的工作,即便老板不给加班工资你都忍不住想加班。
|
||||
|
||||
我的客户也经常问,“这个人没事儿的时候写代码吗?”“我能在哪儿找到他们的作品呢?”“他们有什么爱好呀?”这时候开源社区贡献者的优势就出来了,因为上面的问题就是给他们量身定做的。他们做的项目开源,这就是他们编码能力的例证。
|
||||
|
||||
#### 为什么猎头在寻找开源贡献者
|
||||
|
||||
硬派科技行业猎头了解技术,知道自己在找一个什么样的人,这样的猎头也能正确的了解对象的技能。我发现,猎头们找到的最优秀的人才很多时候也在做开源,所以我们经常直接去开源社区寻找我们的目标。猎头们会告诉雇主,“我们找到的那个人喜欢和团队一起创造了不起的产品”,而这基本上是优秀雇主共同的要求。
|
||||
|
||||
所以说:如果你的项目目标是改变人类的未来,那当这些聪明人来到你的团队之后,他们自己就会爱上自己的工作。
|
||||
|
||||
### 开源贡献者如何得到更好的职业生涯呢
|
||||
|
||||
怎么让你的贡献更广为人知呢:把代码放到 Github 上;做开源项目;参加会议和研讨等等。做这些事情你会有意想不到的收获的。
|
||||
|
||||
可以尝试问一下自己:
|
||||
|
||||
* **你觉得所在的公司是否回馈开源社区这件事重要吗?**很多优秀的人才都强调这一点,回馈社区也会极大的提升他们对工作本身的满意度。
|
||||
* **你在做产品是否基于开源软件?**基于开源软件的公司的文化氛围会与其他公司与众不同,这也是你选择职位时候需要考虑的问题。
|
||||
* **你有没有特别想与之工作的人?**虽然你可以随时换项目,但如果团队里有你崇拜或者欣赏的人,那工作就棒极了。
|
||||
|
||||
假如你了解自己的人生追求,那么过滤掉那些不适合你的职位就简单多了;假如你有一个相熟的猎头,那找到相合的雇主和团队的机会就大多了。
|
||||
|
||||
虽然我自己不写代码,但我会把我从开源社区中学到的东西分享给大家。开源社区是由一大群聪明又乐于分享的人组成,我很开心我也是其中小小的一份子。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/open-source-recruiters-perspective
|
||||
|
||||
作者:[Lindsey Thorne][a]
|
||||
译者:[eriwoon](https://github.com/eriwoon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lindsey-thorne
|
||||
[1]: http://www.greythorn.com/
|
||||
[2]: http://conferences.oreilly.com/oscon
|
||||
@ -1,52 +0,0 @@
|
||||
eriwoon 翻译中 -- 2106-May-19
|
||||
Open source from a recruiter's perspective
|
||||
============================================
|
||||
|
||||

|
||||
|
||||
I fell in love with technology when I went to my first open source convention in 2012.
|
||||
|
||||
After spending years in recruiting, I decided to take a job specializing in big data at [Greythorn][1]. I had been trying to learn the ropes for a few months leading up to [OSCON][2], but going to the conference sped that process up like crazy. There were so many brilliant people all in one place, and everyone was willing to share what they knew. It wasn't because they were trying to sell me anything, but because they were all so passionate about what they were working on.
|
||||
|
||||
I soon realized that, in many ways, the open source and big data industry was less an industry and more of a community. That's why I now try to pay it forward and share what I've learned about open source with those who are just getting started in their careers.
|
||||
|
||||
### Why employers want open source contributors
|
||||
|
||||
Many clients tell me that although they want a candidate who has an exceptional technical mind, the ideal person should also really like this stuff. When you are passionate about something, you find yourself working on it even when you aren't getting paid.
|
||||
|
||||
My clients often ask, "Do they code in their spare time?" "Can I find their work anywhere?" "What do they really enjoy?" Open source contributors are often at an advantage because they check these boxes, and not only are their projects out in the open—so is the evidence of their coding proficiency.
|
||||
|
||||
#### Why recruiters search for open source contributors
|
||||
|
||||
Solid tech recruiters understand the technologies and roles they're recruiting for, and they're going to assess your skills accordingly. But I'll admit that many of us have found that the best candidates we've come across have a tendency to be involved in open source, so we often just start our search there. Recruiters provide value to clients when they find candidates who are motivated to work on a team to create something awesome, because that's basically the description of a top-performing employee.
|
||||
|
||||
It makes sense to me: When you take really smart people and give them the chance to be collaborative—for the sake of making something that works really well or may change the landscape of our everyday lives—it creates an energy that can be addictive.
|
||||
|
||||
### What open source contributors can do to build a happy career
|
||||
|
||||
There are obvious things you can do to leverage your open source work to build your career: Put your code on GitHub, participate in projects, go to conferences and join panels and workshops, etc. These are worthwhile, but more than anything you need to know what will make you happy in your work.
|
||||
|
||||
Ask yourself questions like...
|
||||
|
||||
* **Is it important to work for a company that gives back to the open source and software community?** I find that some of my best candidates insist on this, and it makes a huge difference in their job satisfaction.
|
||||
* **Do you want to work for a company that is based on open source?** The culture is often different in these environments, and it helps to know if that's where you think you'll fit best.
|
||||
* **Are there people you'd specifically like to work with?** Although you can always try to join the same projects, the odds of collaborating with and learning from someone you admire are better if your day jobs align at the same company.
|
||||
|
||||
Once you know your own career priorities, it's easier to filter out the jobs that won't move you closer to your goals—and if you're working with a recruiter, it helps them match you with the right employer and team.
|
||||
|
||||
Although I don't contribute code, I'll always share what I've learned with those who are working on their career in open source. This community is made up of supportive and smart people, and I love that I've been able to be a small part of it.
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/open-source-recruiters-perspective
|
||||
|
||||
作者:[Lindsey Thorne][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lindsey-thorne
|
||||
[1]: http://www.greythorn.com/
|
||||
[2]: http://conferences.oreilly.com/oscon
|
||||
@ -1,56 +0,0 @@
|
||||
Linux gives me all the tools I need
|
||||
==========================================
|
||||
|
||||

|
||||
|
||||
[Linux][0] is all around us. It's [on our phones][1] in the form of Android. It's [used on the International Space Station][2]. It [provides much of the backbone of the Internet][3]. And yet many people never notice it. Discovering Linux is a rewarding endeavor. Lots of other people have [shared their Linux stories][4] on Opensource.com, and now it's my turn.
|
||||
|
||||
I still remember when I first discovered Linux in 2008. The person who helped me discover Linux was my father, Socrates Ballais. He was an economics professor here in Tacloban City, Philippines. He was also a technology enthusiast. He taught me a lot about computers and technology, but only advocated using Linux as a fallback operating system in case Windows fails.
|
||||
|
||||
### My earliest days
|
||||
|
||||
Before we had a computer in the home, I was a Windows user. I played games, created documents, and did all the other things kids do with computers. I didn't know what Linux was or what it was used for. The Windows logo was my symbol for a computer.
|
||||
|
||||
When we got our first computer, my father installed Linux ([Ubuntu][5] 8.04) on it. Being the curious kid I was, I booted into the operating system. I was astonished with the interface. It was beautiful. I found it to be very user friendly. For some time, all I did in Ubuntu was play the bundled games. I would do my school work in Windows.
|
||||
|
||||
### The first install
|
||||
|
||||
Four years later, I decided that I would reinstall Windows on our family computer. Without hesitation, I also decided to install Ubuntu. With that, I had fallen in love with Linux (again). Over time, I became more adept with Ubuntu and would casually advocate its use to my friends. When I got my first laptop, I installed it right away.
|
||||
|
||||
### Today
|
||||
|
||||
Today, Linux is my go-to operating system. When I need to do something on a computer, I do it in Linux. For documents and presentations, I use Microsoft Office via [Wine][6]. For my web needs, there's [Chrome and Firefox][7]. For email, there's [Geary][8]. You can do pretty much everything with Linux.
|
||||
|
||||
Most, if not all, of my programming work is done in Linux. The lack of a standard Integrated Development Environment (IDE) like [Visual Studio][9] or [XCode][10] taught me to be flexible and learn more things as a programmer. Now a text editor and a compiler/interpreter are all I need to start coding. I only use an IDE in cases when it's the best tool for accomplishing a task at hand. I find Linux to be more developer-friendly than Windows. To generalize, Linux gives me all the tools I need to develop software.
|
||||
|
||||
Today, I am the co-founder and CTO of a startup called [Creatomiv Studios][11]. I use Linux to develop code for the backend server of our latest project, Basyang. I'm also an amateur photographer, and use [GIMP][12] and [Darktable][13] to edit and manage photos. For communication with my team, I use [Telegram][14].
|
||||
|
||||
### The beauty of Linux
|
||||
|
||||
Many may see Linux as an operating system only for those who love solving complicated problems and working on the command line. Others may see it as a rubbish operating system lacking the support of many companies. However, I see Linux as a thing of beauty and a tool for creation. I love Linux the way it is and hope to see it continue to grow.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-sean-ballais
|
||||
|
||||
作者:[Sean Francis N. Ballais][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/seanballais
|
||||
[0]: https://opensource.com/resources/what-is-linux
|
||||
[1]: http://www.howtogeek.com/189036/android-is-based-on-linux-but-what-does-that-mean/
|
||||
[2]: http://www.extremetech.com/extreme/155392-international-space-station-switches-from-windows-to-linux-for-improved-reliability
|
||||
[3]: https://www.youtube.com/watch?v=JzsLkbwi1LA
|
||||
[4]: https://opensource.com/tags/my-linux-story
|
||||
[5]: http://ubuntu.com/
|
||||
[6]: https://www.winehq.org/
|
||||
[7]: https://www.google.com/chrome/browser/desktop/index.html
|
||||
[8]: https://wiki.gnome.org/Apps/Geary
|
||||
[9]: https://www.visualstudio.com/en-us/visual-studio-homepage-vs.aspx
|
||||
[10]: https://developer.apple.com/xcode/
|
||||
[11]: https://www.facebook.com/CreatomivStudios/
|
||||
[12]: https://www.gimp.org/
|
||||
[13]: http://www.darktable.org/
|
||||
[14]: https://telegram.org/
|
||||
@ -1,111 +0,0 @@
|
||||
How to Best Manage Encryption Keys on Linux
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
Storing SSH encryption **keys** and memorizing passwords can be a headache. But unfortunately in today's world of malicious hackers and exploits, basic security precautions are an essential practice. For a lot of general users, this amounts to simply memorizing passwords and perhaps finding a good program to store the passwords, as we remind such users not to use the same password for every site. But for those of us in various IT fields, we need to take this up a level. We have to deal with encryption keys such as SSH keys, not just passwords.
|
||||
|
||||
Here's a scenario: I have a server running on a cloud that I use for my main git repository. I have multiple computers I work from. All of those computers need to log into that central server to push to and pull from. I have git set up to use SSH. When git uses SSH, git essentially logs into the server in the same way you would if you were to launch a command line into the server with the SSH command. In order to configure everything, I created a config file in my .ssh directory that contains a Host entry providing a name for the server, the host name, the user to log in as, and the path to a key file. I can then test this configuration out by simply typing the command
|
||||
|
||||
>ssh gitserver
|
||||
|
||||
And soon I'm presented with the server's bash shell. Now I can configure git to use this same entry to log in with the stored key. Easy enough, except for one problem: For each computer I use to log into that server, I need to have a key file. That means more than one key file floating around. I have several such keys on this computer, and several such keys on my other computers. In the same way everyday users have a gazillion passwords, it's easy for us IT folks to end up with a gazillion key files. What to do?
|
||||
|
||||
## Cleaning Up
|
||||
|
||||
Before starting out with a program to help you manage your keys, you have to lay some groundwork on how your keys should be handled, and whether the questions we're asking even make sense. And that requires first and foremost that you understand where your public keys go and where your private keys go. I'm going to assume you know:
|
||||
|
||||
1. The difference between a public key and private key
|
||||
|
||||
2. Why you can't generate a private key from a public key but you can do the reverse
|
||||
|
||||
3. The purpose of the authorized_keys file and what goes in it
|
||||
|
||||
4. How you use private keys to log into a server that has the corresponding public key in its authorized_keys file.
|
||||
|
||||
Here's an example. When you create a cloud server on Amazon Web Services, you have to provide an SSH key that you'll use for connecting to your server. Each key has a public part and a private part. Because you want your server to stay secure, at first glance it might seem you put the private key onto that server, and that you take the public key with you. After all, you don't want that server to be publicly accessible, right? But that's actually backwards.
|
||||
|
||||
You put the public key on the AWS server, and you hold onto your private key for logging into the server. You guard that private key and keep it by your side, not on some remote server, as shown in the figure above.
|
||||
|
||||
Here's why: If the public key were to become known to others, they wouldn't be able to log into the server since they don't have the private key. Further, if somebody did manage to break into your server, all they would find is a public key. You can't generate a private key from a public key. And so if you're using that same key on other servers, they wouldn't be able to use it to log into those other computers.
|
||||
|
||||
And that's why you put your public key on your servers for logging into them through SSH. The private keys stay with you. You don't let those private keys out of your hands.
|
||||
|
||||
But there's still trouble. Consider the case of my git server. I had some decisions to make. Sometimes I'm logged into a development server that's hosted elsewhere. While on that dev box, I need to connect to my git server. How can the dev box connect to the git server? By using the private key. And therein lies trouble. This scenario requires I put a private key on a server that is hosted elsewhere, which is potentially dangerous.
|
||||
|
||||
Now a further scenario: What if I were to use a single key to log into multiple servers? If an intruder got hold of this one private key, he or she would have that private key and gain access to the full virtual network of servers, ready to do some serious damage. Not good at all.
|
||||
|
||||
And that, of course, brings up the other question: Should I really use the same key for those other servers? That's could be dangerous because of what I just described.
|
||||
|
||||
In the end, this sounds messy, but there are some simple solutions. Let's get organized.
|
||||
|
||||
(Note that there are many places you need to use keys besides just logging into servers, but I'm presenting this as one scenario to show you what you're faced with when dealing with keys.)
|
||||
|
||||
## Regarding Passphrases
|
||||
|
||||
When you create your keys, you have the option to include a passphrase that is required when using the private key. With this passphrase, the private key file itself is encrypted using the passphrase. For example, if you have a public key stored on a server and you use the private key to log into that server, you'll be prompted to enter a passphrase. Without the passphrase, the key cannot be used. Alternatively, you can configure your key without a passphrase to begin with. Then all you need is the key file to log into the server.
|
||||
|
||||
Generally going without a passphrase is easier on the users, but one reason I strongly recommend using the passphrase in many situations is this: If the private key file gets stolen, the person who steals it still can't use it until he or she is able to find out the passphrase. In theory, this will save you time as you remove the public key from the server before the attacker can discover the passphrase, thus protecting your system. There are other reasons to use a passphrase, but this one alone makes it worth it to me in many situations. (As an example, I have VNC software on an Android tablet. The tablet holds my private key. If my tablet gets stolen, I'll immediately revoke the public key from the server it logs into, rendering its private key useless, with or without the passphrase.) But in some cases I don't use it, because the server I'm logging into might not have much valuable data on it. It depends on the situation.
|
||||
|
||||
## Server Infrastructure
|
||||
|
||||
How you design your infrastructure of servers will impact how you manage your keys. For example, if you have multiple users logging in, you'll need to decide whether each user gets a separate key. (Generally speaking, they should; you don't want users sharing private keys. That way if one user leaves the organization or loses trust, you can revoke that user's key without having to generate new keys for everyone else. And similarly, by sharing keys they could log in as each other, which is also bad.) But another issue is how you're allocating your servers. Do you allocate a lot of servers using tools such as Puppet, for example? And do you create multiple servers based on your own images? When you replicate your servers, do you need to have the same key for each? Different cloud server software allows you to configure this how you choose; you can have the servers get the same key, or have a new one generated for each.
|
||||
|
||||
If you're dealing with replicated servers, it can get confusing if the users need to use different keys to log into two different servers that are otherwise similar. But on the other hand, there could be security risks by having the servers share the same keys. Or, on the third hand, if your keys are needed for something other than logging in (such as mounting an encrypted drive), then you would need the same key in multiple places. As you can see, whether you need to use the same keys across different servers is not a decision I can make for you; there are trade offs, and you need to decide for yourself what's best.
|
||||
|
||||
In the end, you're likely to have:
|
||||
|
||||
- Multiple servers that need to be logged into
|
||||
|
||||
- Multiple users logging into different servers, each with their own key
|
||||
|
||||
- Multiple keys for each user as they log into different servers.
|
||||
|
||||
(If you're using keys in other situations, as you likely are, the same general concepts will apply regarding how keys are used, how many keys are needed, whether they're shared, and how you handle private and public parts of keys.)
|
||||
|
||||
## Method of safety
|
||||
|
||||
Knowing your infrastructure and unique situation, you need to put together a key management plan that will help guide you on how you distribute and store your keys. For example, earlier I mentioned that if my tablet gets stolen, I will revoke the public key from my server, hopefully before the tablet can be used to access the server. As such, I can allow for the following in my overall plan:
|
||||
|
||||
1. Private keys are okay on mobile devices, but they must include a passphrase
|
||||
|
||||
2. There must exist a way to quickly revoke public keys from a server.
|
||||
|
||||
In your situation, you might decide you just don't want to use passphrases for a system you log into regularly; for example, the system might be a test machine that the developers log into many times a day. That's fine, but then you'll need to adjust your rules a bit. You might include a rule that that machine is not to be logged into from mobile devices. In other words, you need to build your protocols based on your own situation, and not assume one size fits all.
|
||||
|
||||
## Software
|
||||
|
||||
On to software. Surprisingly, there aren't a lot of good, solid software solutions for storing and managing your private keys. But should there be? Consider this: If you have a program storing all your keys for all your servers, and that program is locked down by a quick password, are your keys really secure? Or, similarly, if your private keys are sitting on your hard drive for quick access by the SSH program, is a key management software really providing any protection?
|
||||
|
||||
But for overall infrastructure and creating and managing public keys, there are some solutions. I already mentioned Puppet. In the Puppet world, you create modules to manage your servers in different ways. The idea is that servers are dynamic and not necessarily exact duplicates of each other. [Here's one clever approach](http://manuel.kiessling.net/2014/03/26/building-manageable-server-infrastructures-with-puppet-part-4/) that uses the same keys on different servers, but uses a different Puppet module for each user. This solution may or may not apply to you.
|
||||
|
||||
Or, another option is to shift gears altogether. In the world of Docker, you can take a different approach, as described in [this blog regarding SSH and Docker](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/).
|
||||
|
||||
But what about managing the private keys? If you search, you're not going to find many software options, for the reasons I mentioned earlier; the private keys are sitting on your hard drive, and a management program might not provide much additional security. But I do manage my keys using this method:
|
||||
|
||||
First, I have multiple Host entries in my .ssh/config file. I have an entry for hosts that I log into, but sometimes I have more than one entry for a single host. That happens if I have multiple logins. I have two different logins for the server hosting my git repository; one is strictly for git, and the other is for general-purpose bash access. The one for git has greatly restricted rights on that machine. Remember what I said earlier about my git keys living on remote development machines? There we go. Although those keys can log into one of my servers, the accounts used are severely limited.
|
||||
|
||||
Second, most of these private keys include a passphrase. (For dealing with having to type the passphrase multiple times, considering using [ssh-agent](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/).)
|
||||
|
||||
Third, I do have some servers that I want to guard a bit more carefully, and I don't have an entry into my Host file. This is more a social engineering aspect, because the key files are still present, but it might take an intruder a bit longer to locate the key file and figure out which machine they go with. In those cases, I just type out the long ssh command manually. (It's really not that bad.)
|
||||
|
||||
And you can see that I'm not using any special software to manage these private keys.
|
||||
|
||||
## One Size Doesn't Fit All
|
||||
|
||||
We occasionally get questions at linux.com for advice on good software for managing keys. But let's take a step back. The question actually needs to be re-framed, because there isn't a one-size-fits-all solution. The questions you ask should be based on your own situation. Are you simply trying to find a place to store your key files? Are you looking for a way to manage multiple users each with their own public key that needs to be inserted into the authorized_keys file?
|
||||
|
||||
Throughout this article, I've covered the basics of how all this fits together, and hopefully at this point you'll see that how you manage your keys, and whatever software you look for (if you even need additional software at all), should happen only after you ask the right questions.
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/838235-how-to-best-manage-encryption-keys-on-linux
|
||||
|
||||
作者:[Jeff Cogswell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/62256
|
||||
@ -1,50 +0,0 @@
|
||||
Linux Systems Patched for Critical glibc Flaw
|
||||
=================================================
|
||||
|
||||
**Google exposed a critical flaw affecting major Linux distributions. The glibc flaw could have potentially led to remote code execution.**
|
||||
|
||||
Linux users today are scrambling to patch a critical flaw in the core glibc open-source library that could be exposing systems to a remote code execution risk. The glibc vulnerability is identified as CVE-2015-7547 and is titled, "getaddrinfo stack-based buffer overflow."
|
||||
|
||||
The glibc, or GNU C Library, is an open-source implementation of the C and C++ programming language libraries and is part of every major Linux distribution. Google engineers came across the CVE-2015-7547 issue when they were attempting to connect into a certain host system and a segmentation fault (segfault) occurred, causing the connection to crash. Further investigation revealed that glibc was at fault and the crash could potentially achieve an arbitrary remote code execution condition.
|
||||
|
||||
"The glibc DNS client side resolver is vulnerable to a stack-based buffer overflow when the getaddrinfo() library function is used," Google wrote in a blog post. "Software using this function may be exploited with attacker-controlled domain names, attacker-controlled DNS [Domain Name System] servers, or through a man-in-the-middle attack."
|
||||
|
||||
Actually exploiting the CVE-2015-7547 issue is not trivial, but it is possible. To prove that the issue can be exploited, Google has published proof-of-concept (PoC) code on GitHub that demonstrates if an end user or system is vulnerable.
|
||||
|
||||
"The server code triggers the vulnerability and therefore will crash the client code," the GitHub PoC page states.
|
||||
|
||||
Mark Loveless, senior security researcher at Duo Security, explained that the main risk of CVE-2015-7547 is to Linux client-based applications that rely on DNS responses.
|
||||
|
||||
"There are some specific conditions, so not every single application will be impacted, but it appears that several command-line utilities, including the popular SSH [Secure Shell] client could trigger the flaw," Loveless told eWEEK. "We deem this serious mainly because of the existing risks to Linux systems, but also because of the potential for other issues."
|
||||
|
||||
Other issues could potentially include a risk of an email-based attack that triggers the vulnerable glibc getaddrinfo() library call. Also of note is the fact that the vulnerability was in the code for years before it was discovered.
|
||||
|
||||
Google's engineers were not the first or only group to discover the security risk in glibc. The issue was first reported to a glibc bug [tracker](https://sourceware.org/bugzilla/show_bug.cgi?id=1866) on July 13, 2015. The roots of the flaw go back even further with the actual code commit that introduced the flaw first in glibc 2.9, which was released in May 2008.
|
||||
|
||||
Linux vendor Red Hat also independently was looking at the bug in glibc and on Jan. 6, 2016, Google and Red Hat developers confirmed that they had been independently working on the same vulnerability as part of the initial private discussion with upstream glibc maintainers.
|
||||
|
||||
"Once it was confirmed that both teams were working on the same vulnerability, we collaborated on potential fixes, mitigations and regression testing," Florian Weimer, principal software engineer for product security at Red Hat, told eWEEK. "We also worked together to make the test coverage as wide as possible to catch any related problems in the code to help prevent future issues."
|
||||
|
||||
It took years to discover that there was a security issue with the glibc code because that flaw isn't obvious or immediately apparent.
|
||||
|
||||
"To diagnose bugs in a networking component, like a DNS resolver, it is common to look at packet traces which were captured while the issue was encountered," Weimer said. "Such packet captures were not available in this case, so some experimentation was needed to reproduce the exact scenario that triggered the bug."
|
||||
|
||||
Weimer added that once the packet captures were available, considerable effort went into validating the fix, leading to a series of refinements culminating in the regression test suite that was contributed upstream to the glibc project.
|
||||
|
||||
In many cases in Linux, the Security Enhanced Linux (SELinux) mandatory access security controls can mitigate the risk of potential vulnerabilities, but that's not the case with the new glibc issue.
|
||||
|
||||
"The risk is a compromise of important system functionality due to the execution of arbitrary code supplied by an attacker," Weimer said. "A suitable SELinux policy can contain some of the damage an attacker might do and constrain their access to the system, but DNS is used by many applications and system components, so SELinux policies offer only limited containment for this issue."
|
||||
|
||||
Alongside the vulnerability disclosure today, there is now a patch available to mitigate the potential risk of CVE-2015-7547.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.eweek.com/security/linux-systems-patched-for-critical-glibc-flaw.html
|
||||
|
||||
作者:[Michael Kerner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/TechJournalist
|
||||
@ -1,54 +0,0 @@
|
||||
IS UBUNTU’S SNAP PACKAGING REALLY SECURE
|
||||
==========================================
|
||||
|
||||
|
||||
The recent release of [Ubuntu 16.04 LTS has brought a number of new features][1], one of which we covered was the [inclusion of ZFS][2]. Another feature that many people have been talking about is the Snap package format. But according to one of the developers of [CoreOS][3], the Snap packages are not as safe as the claim.
|
||||
|
||||
### WHAT ARE SNAP PACKAGES?
|
||||
|
||||
Snap packages are inspired by containers. This new package format allows [developers to issue updates for applications running on Ubuntu Long-Term-Support (LTS) releases][4]. This gives users the option to run a stable operating system, but keep their applications updated. This is accomplished by including all of the application’s dependencies in the same package. This prevents the program from breaking when a dependency updates.
|
||||
|
||||
Another advantage of Snap packages is that the applications are isolated from the rest of the system. This means that if you change something with a Snap package, it will not affect the rest of the system. It also prevents other applications from accessing your private information, which makes it harder for hackers to get your data.
|
||||
|
||||
### BUT WAIT…
|
||||
|
||||
According to [Matthew Garrett][5], Snap can’t quite deliver on the last promise. Garret works as a Linux kernel developer and security developer at CoreOS, so he should know what he’s talking about.
|
||||
|
||||
[According to Garret][6], “Any Snap package you install is completely capable of copying all your private data to wherever it wants with very little difficulty.”
|
||||
|
||||
[ZDnet][7] reported:
|
||||
|
||||
>*“To prove his point, he built a proof-of-concept attack package in Snap, which first shows an “adorable” teddy bear and then logs keystrokes from Firefox and could be used to steal private SSH keys. The PoC actually injects a harmless command, but could be tweaked to include a cURL session to steal SSH keys.”*
|
||||
|
||||
### BUT WAIT A LITTLE MORE…
|
||||
|
||||
Is it really that Snap has security flaws? Apparently not so.
|
||||
|
||||
Garret himself said that this problem was caused by the X11 window system and did not affect mobile devices that use Mir. So, it is the flaw in X11 that does it. It’s not Snap itself.
|
||||
|
||||
>how X11 trusts applications is a well-known security risk. Snap doesn’t change X11’s trust model, so the fact that applications can see what other applications are doing isn’t a weakness in the new package format, but rather X11’s.
|
||||
|
||||
Garrett is just actually trying to show that when Canonical is all praises for Snap and its security; Snap applications are not fully sandboxed. They are as risky as any other binaries.
|
||||
|
||||
Keeping the fact in mind that Ubuntu 16.04 still uses X11 display, and not Mir, downloading and installing Snap packages from unknown sources might be harmful. But that’s the case with any other packaging, isn’t it?
|
||||
|
||||
In related articles, you should check out [how to use Snap packages in Ubuntu 16.04][8]. And do let us know of your views on Snap and its security.
|
||||
|
||||
----------
|
||||
via: http://itsfoss.com/snap-package-securrity-issue/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[ John Paul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/john/
|
||||
[1]: http://itsfoss.com/features-ubuntu-1604/
|
||||
[2]: http://itsfoss.com/oracle-canonical-lawsuit/
|
||||
[3]: https://en.wikipedia.org/wiki/CoreOS
|
||||
[4]: https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/
|
||||
[5]: https://mjg59.dreamwidth.org/l
|
||||
[6]: https://mjg59.dreamwidth.org/42320.html
|
||||
[7]: http://www.zdnet.com/article/linux-expert-matthew-garrett-ubuntu-16-04s-new-snap-format-is-a-security-risk/
|
||||
[8]: http://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by Bestony
|
||||
Scaling Collaboration in DevOps
|
||||
=================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[Translating by cposture]
|
||||
Python 3: An Intro to Encryption
|
||||
===================================
|
||||
|
||||
|
||||
@ -1,142 +0,0 @@
|
||||
ORB: NEW GENERATION OF LINUX APPS ARE HERE
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
We have talked about [installing applications offline in Ubuntu][1] before. And we are going to talk about it once again.
|
||||
|
||||
[Orbital Apps][2] has brought us a new type of application package, **ORB**, with portable applications, interactive installer support and offline usage ability.
|
||||
|
||||
Portable applications are always handy. Mostly because they can run on-the-fly without needing any administrator privileges, and also it can be carried around on small USB sticks along with all their settings and data. And these interactive installers will be able to allow us to install applications with ease.
|
||||
|
||||
### OPEN RUNNABLE BUNDLE (ORB)
|
||||
|
||||
ORB is a free & open-source package format and it’s different from the others in numerous ways. Some of the specifications of ORB is followings:
|
||||
|
||||
- **Compression**: All the packages are compressed with squashfs making them up-to 60% smaller.
|
||||
- **Portable Mode**: If a portable ORB application is run from a removable drive, it’ll store its settings and data on that drive.
|
||||
- **Security**: All ORB packages are signed with PGP/RSA and distributed via TLS 1.2.
|
||||
- **Offline**: All the dependencies are bundled with the package, so no downloading dependencies anymore.
|
||||
- **Open package**: ORB packages can be mounted as ISO images.
|
||||
|
||||
### VARIETY
|
||||
|
||||
ORB applications are now available in two varieties:
|
||||
|
||||
- Portable Applications
|
||||
- SuperDEB
|
||||
|
||||
#### 1. PORTABLE ORB APPLICATIONS
|
||||
|
||||
Portable ORB Applications is capable of running right away without needing any installation beforehand. That means it’ll need no administrator privileges and no dependencies! You can just download them from the Orbital Apps website and get to work.
|
||||
|
||||
And as it supports Portable Mode, you can copy it on a USB stick and carry it around. All its settings and data will be stored with it on that USB stick. Just connect the USB stick with any system running on Ubuntu 16.04 and you’ll be ready to go.
|
||||
|
||||
##### AVAILABLE PORTABLE APPLICATIONS
|
||||
|
||||
Currently, more than 35 applications are available as portable packages, including some very popular applications like: [Deluge][3], [Firefox][4], [GIMP][5], [Libreoffice][6], [uGet][7] & [VLC][8].
|
||||
|
||||
For a full list of available packages, check the [Portable ORB Apps list][9].
|
||||
|
||||
##### USING PORTABLE APPLICATION
|
||||
|
||||
Follow the steps for using Portable ORB Applications:
|
||||
|
||||
- Download your desired package from the Orbital Apps site.
|
||||
- Move it wherever you want (local drive / USB stick).
|
||||
- Open the directory where you’ve stored the ORB package.
|
||||
|
||||

|
||||
|
||||
- Open Properties of the ORB package.
|
||||
|
||||

|
||||
>Add Execute permission to ORB package
|
||||
|
||||
- Add Execute permission from Permissions tab.
|
||||
- Double-click on it.
|
||||
|
||||
Wait for a few seconds as it prepares itself for running. And you’re good to go.
|
||||
|
||||
#### 2. SUPERDEB
|
||||
|
||||
Another variety of ORB Applications is SuperDEB. SuperDEBs are easy and interactive installers that make the software installation process a lot smoother. If you don’t like to install software from terminal or software centers, SuperDEB is exactly for you.
|
||||
|
||||
And the most interesting part is that you won’t need an active internet connection for installing as all the dependencies are bundled with the installer.
|
||||
|
||||
##### AVAILABLE SUPERDEBS
|
||||
|
||||
More than 60 applications are currently available as SuperDEB. Some of the popular software among them are: [Chromium][10], [Deluge][3], [Firefox][4], [GIMP][5], [Libreoffice][6], [uGet][7] & [VLC][8].
|
||||
|
||||
For a full list of available SuperDEBs, check the [SuperDEB list][11].
|
||||
|
||||
##### USING SUPERDEB INSTALLER
|
||||
|
||||
- Download your desired SuperDEB from Orbital Apps site.
|
||||
- Add **Execute permission** to it just like before ( Properties > Permissions ).
|
||||
- Double-click on the SuperDEB installer and follow the interactive instructions:
|
||||
|
||||

|
||||
>Click OK
|
||||
|
||||

|
||||
>Enter your password and proceed
|
||||
|
||||

|
||||
>It’ll start Installing…
|
||||
|
||||

|
||||
>And soon it’ll be done…
|
||||
|
||||
- After finishing the installation, you’re good to use it normally.
|
||||
|
||||
### ORB APPS COMPATIBILITY
|
||||
|
||||
According to Orbital Apps, they are fully compatible with Ubuntu 16.04 [64 bit].
|
||||
|
||||
>Reading suggestion: [How To Know If You Have 32 Bit or 64 Bit Computer in Ubuntu][12].
|
||||
|
||||
As for other distros compatibility is not guaranteed. But we can say that, it’ll work on any Ubuntu 16.04 flavors (UbuntuMATE, UbuntuGNOME, Lubuntu, Xubuntu etc.) and Ubuntu 16.04 based distros (like upcoming Linux Mint 18). We currently have no information if Orbital Apps is planning on expanding its support for other Ubuntu versions/Linux Distros or not.
|
||||
|
||||
If you’re going to use Portable ORB applications often on your system, you can consider installing ORB Launcher. It’s not necessary but is recommended installing to get an improved experience. The shortest method of installing ORB Launcher is opening the terminal and enter the following command:
|
||||
|
||||
```
|
||||
wget -O - https://www.orbital-apps.com/orb.sh | bash
|
||||
```
|
||||
|
||||
You can find the detailed instructions at [official documentation][13].
|
||||
|
||||
### WHAT IF I NEED AN APP THAT’S NOT LISTED?
|
||||
|
||||
If you need an application as ORB package that is not available right now, you can [contact][14] Orbital Apps. And the good news is, Orbital Apps is working hard and planning on releasing a tool for creating ORB packages. So, hopefully, soon we’ll be able to make ORB packages ourselves!
|
||||
|
||||
Just to add, this was about installing apps offline. If you are interested, you should read [how to update or upgrade Ubuntu offline][15].
|
||||
|
||||
So, what do you think about Orbital Apps’ Portable Applications and SuperDEB installers? Will you try them?
|
||||
|
||||
|
||||
----------------------------------
|
||||
via: http://itsfoss.com/orb-linux-apps/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/munif/
|
||||
[1]: http://itsfoss.com/cube-lets-install-linux-applications-offline/
|
||||
[2]: https://www.orbital-apps.com/
|
||||
[3]: https://www.orbital-apps.com/download/portable_apps_linux/deluge
|
||||
[4]: https://www.orbital-apps.com/download/portable_apps_linux/firefox
|
||||
[5]: https://www.orbital-apps.com/download/portable_apps_linux/gimp
|
||||
[6]: https://www.orbital-apps.com/download/portable_apps_linux/libreoffice
|
||||
[7]: https://www.orbital-apps.com/download/portable_apps_linux/uget
|
||||
[8]: https://www.orbital-apps.com/download/portable_apps_linux/vlc
|
||||
[9]: https://www.orbital-apps.com/download/portable_apps_linux/
|
||||
[10]: https://www.orbital-apps.com/download/superdeb_installers/ubuntu_16.04_64bits/chromium/
|
||||
[11]: https://www.orbital-apps.com/superdebs/ubuntu_16.04_64bits/
|
||||
[12]: http://itsfoss.com/32-bit-64-bit-ubuntu/
|
||||
[13]: https://www.orbital-apps.com/documentation
|
||||
[14]: https://www.orbital-apps.com/contact
|
||||
[15]: http://itsfoss.com/upgrade-or-update-ubuntu-offline-without-internet/
|
||||
@ -0,0 +1,77 @@
|
||||
Test Fedora 24 Beta in an OpenStack cloud
|
||||
===========================================
|
||||
|
||||

|
||||
|
||||
Although there are a few weeks remaining before [Fedora 24][1] is released, you can test out the Fedora 24 Beta release today! This is a great way to get [a sneak peek at new features][2] and help find bugs that still need a fix.
|
||||
|
||||
The [Fedora Cloud][3] image is available for download from your favorite [local mirror][4] or directly from [Fedora’s servers][5]. In this post, I’ll show you how to import this image into an OpenStack environment and begin testing Fedora 24 Beta.
|
||||
|
||||
One last thing: this is beta software. It has been reliable for me so far, but your experience may vary. I would recommend waiting for the final release before deploying any mission critical applications on it.
|
||||
|
||||
### Importing the image
|
||||
|
||||
The older glance client (version 1) allows you to import an image from a URL that is reachable from your OpenStack environment. This is helpful since my OpenStack cloud has a much faster connection to the internet (1 Gbps) than my home does (~ 20 mbps upload speed). However, the functionality to import from a URL was [removed in version 2 of the glance client][6]. The [OpenStackClient][7] doesn’t offer the feature either.
|
||||
|
||||
There are two options here:
|
||||
|
||||
- Install an older version of the glance client
|
||||
- Use Horizon (the web dashboard)
|
||||
|
||||
Getting an older version of glance client installed is challenging. The OpenStack requirements file for the liberty release [leaves the version of glance client without a maximum version cap][8] and it’s difficult to get all of the dependencies in order to make the older glance client work.
|
||||
|
||||
Let’s use Horizon instead so we can get back to the reason for the post.
|
||||
|
||||
### Adding an image in Horizon
|
||||
|
||||
Log into the Horizon panel and click Compute > Images. Click + Create Image at the top right of the page and a new window should appear. Add this information in the window:
|
||||
|
||||
- **Name**: Fedora 24 Cloud Beta
|
||||
- **Image Source**: Image Location
|
||||
- **Image Location**: http://mirrors.kernel.org/fedora/releases/test/24_Beta/CloudImages/x86_64/images/Fedora-Cloud-Base-24_Beta-1.6.x86_64.qcow2
|
||||
- **Format**: QCOW2 – QEMU Emulator
|
||||
- **Copy Data**: ensure the box is checked
|
||||
|
||||
When you’re finished, the window should look like this:
|
||||
|
||||

|
||||
|
||||
Click Create Image and the images listing should show Saving for a short period of time. Once it switches to Active, you’re ready to build an instance.
|
||||
|
||||
### Building the instance
|
||||
|
||||
Since we’re already in Horizon, we can finish out the build process there.
|
||||
|
||||
On the image listing page, find the row with the image we just uploaded and click Launch Instance on the right side. A new window will appear. The Image Name drop down should already have the Fedora 24 Beta image selected. From here, just choose an instance name, select a security group and keypair (on the Access & Security tab), and a network (on the Networking tab). Be sure to choose a flavor that has some available storage as well (m1.tiny is not enough).
|
||||
|
||||
Click Launch and wait for the instance to boot.
|
||||
|
||||
Once the instance build has finished, you can connect to the instance over ssh as the fedora user. If your [security group allows the connection][9] and your keypair was configured correctly, you should be inside your new Fedora 24 Beta instance!
|
||||
|
||||
Not sure what to do next? Here are some suggestions:
|
||||
|
||||
- Update all packages and reboot (to ensure that you are testing the latest updates)
|
||||
- Install some familiar applications and verify that they work properly
|
||||
- Test out your existing automation or configuration management tools
|
||||
- Open bug tickets!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://major.io/2016/05/24/test-fedora-24-beta-openstack-cloud/
|
||||
|
||||
作者:[major.io][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://major.io/about-the-racker-hacker/
|
||||
[1]: https://fedoraproject.org/wiki/Releases/24/Schedule
|
||||
[2]: https://fedoraproject.org/wiki/Releases/24/ChangeSet
|
||||
[3]: https://getfedora.org/en/cloud/
|
||||
[4]: https://admin.fedoraproject.org/mirrormanager/mirrors/Fedora/24/x86_64
|
||||
[5]: https://getfedora.org/en/cloud/download/
|
||||
[6]: https://wiki.openstack.org/wiki/Glance-v2-v1-client-compatability
|
||||
[7]: http://docs.openstack.org/developer/python-openstackclient/
|
||||
[8]: https://github.com/openstack/requirements/blob/stable/liberty/global-requirements.txt#L159
|
||||
[9]: https://major.io/2016/05/16/troubleshooting-openstack-network-connectivity/
|
||||
@ -0,0 +1,302 @@
|
||||
Install LEMP with MariaDB 10, PHP 7 and HTTP 2.0 Support for Nginx on Ubuntu 16.04
|
||||
=====================================================================================
|
||||
|
||||
|
||||
The LEMP stack is an acronym which represents is a group of packages (Linux OS, Nginx web server, MySQL\MariaDB database and PHP server-side dynamic programming language) which are used to deploy dynamic web applications and web pages.
|
||||
|
||||

|
||||
>Install Nginx with MariaDB 10, PHP 7 and HTTP 2.0 Support on Ubuntu 16.04
|
||||
|
||||
This tutorial will guide you on how to install a LEMP stack (Nginx with MariaDB and PHP7) on Ubuntu 16.04 server.
|
||||
|
||||
Requirements
|
||||
|
||||
[Installation of Ubuntu 16.04 Server Edition][1]
|
||||
|
||||
### Step 1: Install the Nginx Web Server
|
||||
|
||||
#### 1. Nginx is a modern and resources efficient web server used to display web pages to visitors on the internet. We’ll start by installing Nginx web server from Ubuntu official repositories by using the [apt command line][2].
|
||||
|
||||
```
|
||||
$ sudo apt-get install nginx
|
||||
```
|
||||
|
||||
|
||||
>Install Nginx on Ubuntu 16.04
|
||||
|
||||
#### 2. Next, issue the [netstat][3] and [systemctl][4] commands in order to confirm if Nginx is started and binds on port 80.
|
||||
|
||||
```
|
||||
$ netstat -tlpn
|
||||
```
|
||||
|
||||
|
||||
>Check Nginx Network Port Connection
|
||||
|
||||
```
|
||||
$ sudo systemctl status nginx.service
|
||||
```
|
||||
|
||||
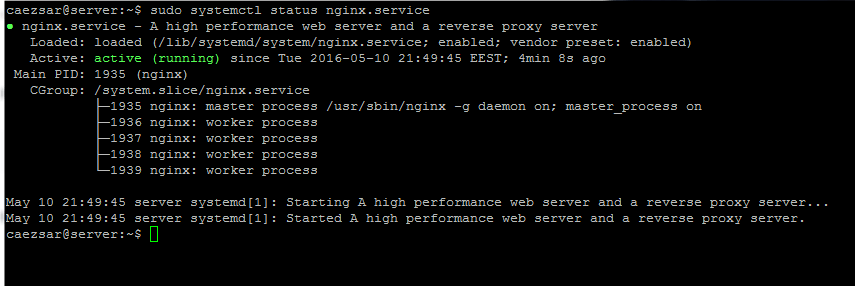
|
||||
>Check Nginx Service Status
|
||||
|
||||
Once you have the confirmation that the server is started you can open a browser and navigate to your server IP address or DNS record using HTTP protocol in order to visit Nginx default web page.
|
||||
|
||||
```
|
||||
http://IP-Address
|
||||
```
|
||||
|
||||
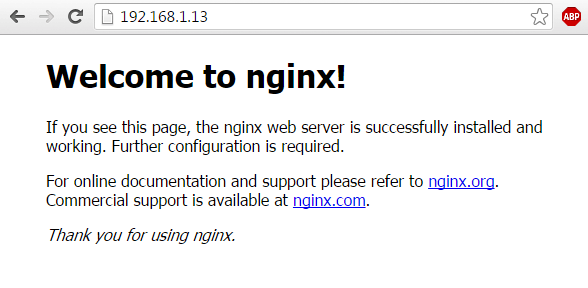
|
||||
>Verify Nginx Webpage
|
||||
|
||||
### Step 2: Enable Nginx HTTP/2.0 Protocol
|
||||
|
||||
#### 3. The HTTP/2.0 protocol which is build by default in the latest release of Nginx binaries on Ubuntu 16.04 works only in conjunction with SSL and promises a huge speed improvement in loading web SSL web pages.
|
||||
|
||||
To enable the protocol in Nginx on Ubuntu 16.04, first navigate to Nginx available sites configuration files and backup the default configuration file by issuing the below command.
|
||||
|
||||
```
|
||||
$ cd /etc/nginx/sites-available/
|
||||
$ sudo mv default default.backup
|
||||
```
|
||||
|
||||

|
||||
>Backup Nginx Sites Configuration File
|
||||
|
||||
#### 4. Then, using a text editor create a new default page with the below instructions:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 443 ssl http2 default_server;
|
||||
listen [::]:443 ssl http2 default_server;
|
||||
|
||||
root /var/www/html;
|
||||
|
||||
index index.html index.htm index.php;
|
||||
|
||||
server_name 192.168.1.13;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ =404;
|
||||
}
|
||||
|
||||
ssl_certificate /etc/nginx/ssl/nginx.crt;
|
||||
ssl_certificate_key /etc/nginx/ssl/nginx.key;
|
||||
|
||||
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
|
||||
ssl_prefer_server_ciphers on;
|
||||
ssl_ciphers EECDH+CHACHA20:EECDH+AES128:RSA+AES128:EECDH+AES256:RSA+AES256:EECDH+3DES:RSA+3DES:!MD5;
|
||||
ssl_dhparam /etc/nginx/ssl/dhparam.pem;
|
||||
ssl_session_cache shared:SSL:20m;
|
||||
ssl_session_timeout 180m;
|
||||
resolver 8.8.8.8 8.8.4.4;
|
||||
add_header Strict-Transport-Security "max-age=31536000;
|
||||
#includeSubDomains" always;
|
||||
|
||||
|
||||
location ~ \.php$ {
|
||||
include snippets/fastcgi-php.conf;
|
||||
fastcgi_pass unix:/run/php/php7.0-fpm.sock;
|
||||
}
|
||||
|
||||
location ~ /\.ht {
|
||||
deny all;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
server {
|
||||
listen 80;
|
||||
listen [::]:80;
|
||||
server_name 192.168.1.13;
|
||||
return 301 https://$server_name$request_uri;
|
||||
}
|
||||
```
|
||||
|
||||
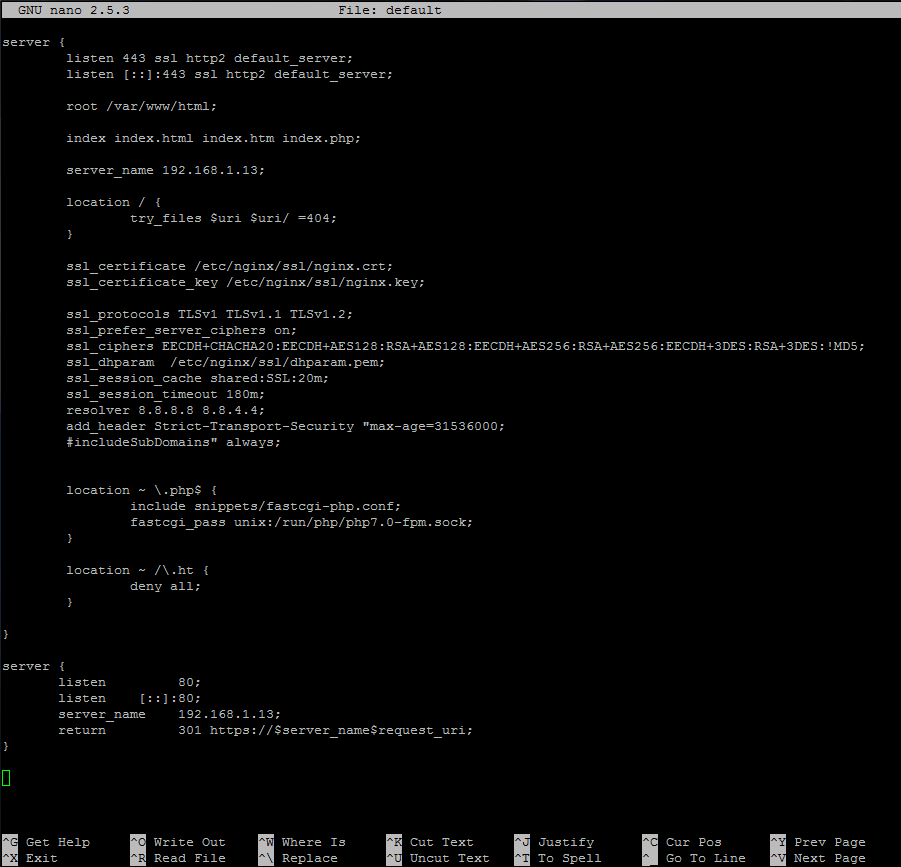
|
||||
>Enable Nginx HTTP 2 Protocol
|
||||
|
||||
The above configuration snippet enables the use of `HTTP/2.0` by adding the http2 parameter to all SSL listen directives.
|
||||
|
||||
Also, the last part of the excerpt enclosed in server directive is used to redirect all non-SSL traffic to SSL/TLS default host. Also, replace the `server_name` directive to match your own IP address or DNS record (FQDN preferably).
|
||||
|
||||
#### 5. Once you finished editing Nginx default configuration file with the above settings, generate and list the SSL certificate file and key by executing the below commands.
|
||||
|
||||
Fill the certificate with your own custom settings and pay attention to Common Name setting to match your DNS FQDN record or your server IP address that will be used to access the web page.
|
||||
|
||||
```
|
||||
$ sudo mkdir /etc/nginx/ssl
|
||||
$ sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/nginx/ssl/nginx.key -out /etc/nginx/ssl/nginx.crt
|
||||
$ ls /etc/nginx/ssl/
|
||||
```
|
||||
|
||||
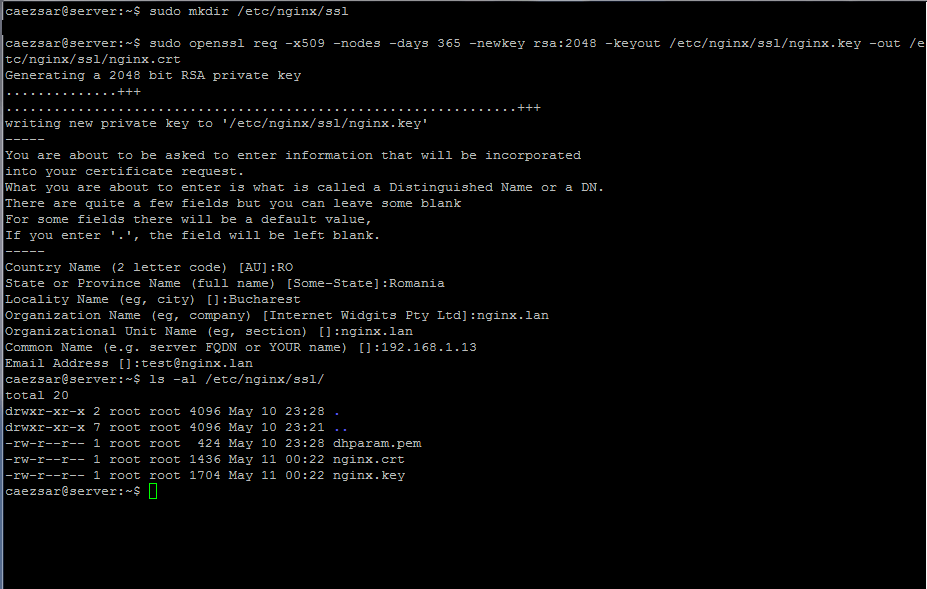
|
||||
>Generate SSL Certificate and Key for Nginx
|
||||
|
||||
#### 6. Also, create a strong DH cypher, which was changed on the above configuration file on `ssl_dhparam` instruction line, by issuing the below command:
|
||||
|
||||
```
|
||||
$ sudo openssl dhparam -out /etc/nginx/ssl/dhparam.pem 2048
|
||||
```
|
||||
|
||||
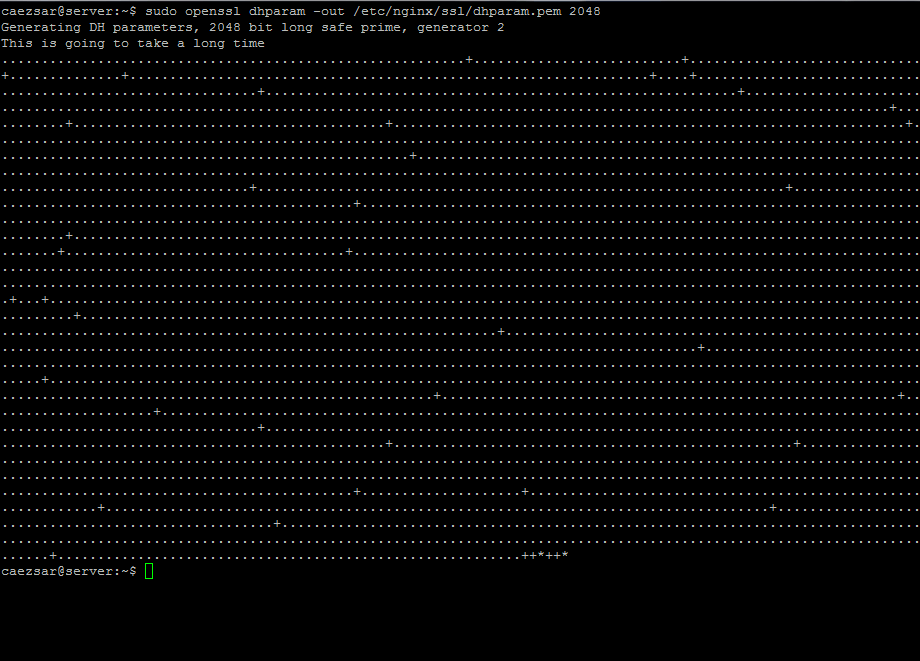
|
||||
>Create Diffie-Hellman Key
|
||||
|
||||
#### 7. Once the `Diffie-Hellman` key has been created, verify if Nginx configuration file is correctly written and can be applied by Nginx web server and restart the daemon to reflect changes by running the below commands.
|
||||
|
||||
```
|
||||
$ sudo nginx -t
|
||||
$ sudo systemctl restart nginx.service
|
||||
```
|
||||
|
||||
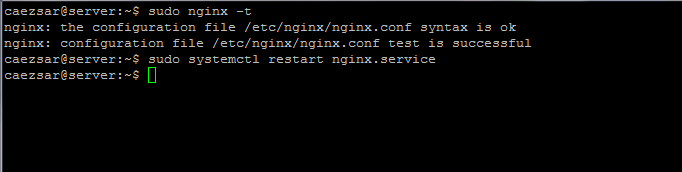
|
||||
>Check Nginx Configuration
|
||||
|
||||
#### 8. In order to test if Nginx uses HTTP/2.0 protocol issue the below command. The presence of `h2` advertised protocol confirms that Nginx has been successfully configured to use HTTP/2.0 protocol. All modern up-to-date browsers should support this protocol by default.
|
||||
|
||||
```
|
||||
$ openssl s_client -connect localhost:443 -nextprotoneg ''
|
||||
```
|
||||
|
||||
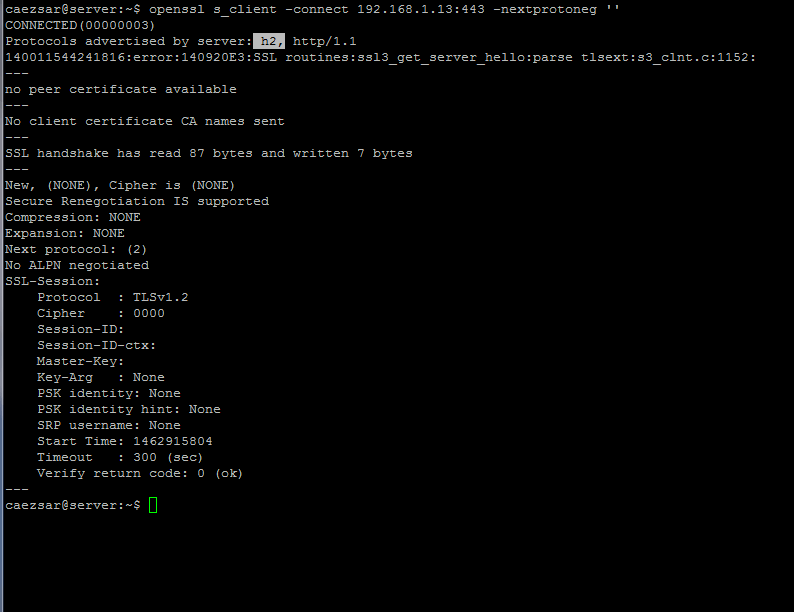
|
||||
>Test Nginx HTTP 2.0 Protocol
|
||||
|
||||
### Step 3: Install PHP 7 Interpreter
|
||||
|
||||
Nginx can be used with PHP dynamic processing language interpreter to generate dynamic web content with the help of FastCGI process manager obtained by installing the php-fpm binary package from Ubuntu official repositories.
|
||||
|
||||
#### 9. In order to grab PHP7.0 and the additional packages that will allow PHP to communicate with Nginx web server issue the below command on your server console:
|
||||
|
||||
```
|
||||
$ sudo apt install php7.0 php7.0-fpm
|
||||
```
|
||||
|
||||
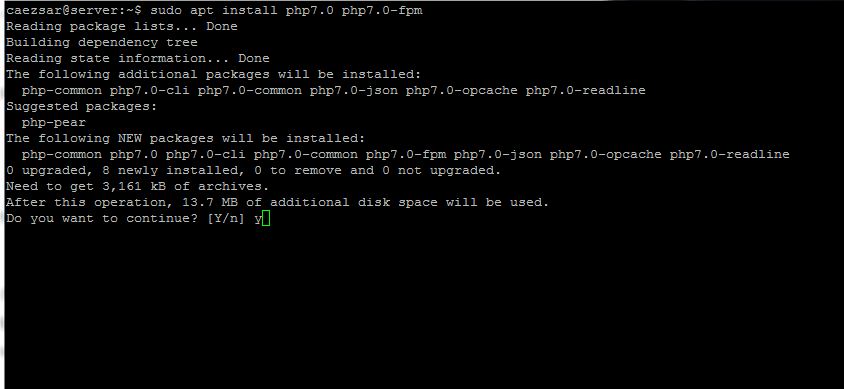
|
||||
>Install PHP 7 and PHP-FPM for Ngin
|
||||
|
||||
#### 10. Once the PHP7.0 interpreter has been successfully installed on your machine, start and check php7.0-fpm daemon by issuing the below command:
|
||||
|
||||
```
|
||||
$ sudo systemctl start php7.0-fpm
|
||||
$ sudo systemctl status php7.0-fpm
|
||||
```
|
||||
|
||||
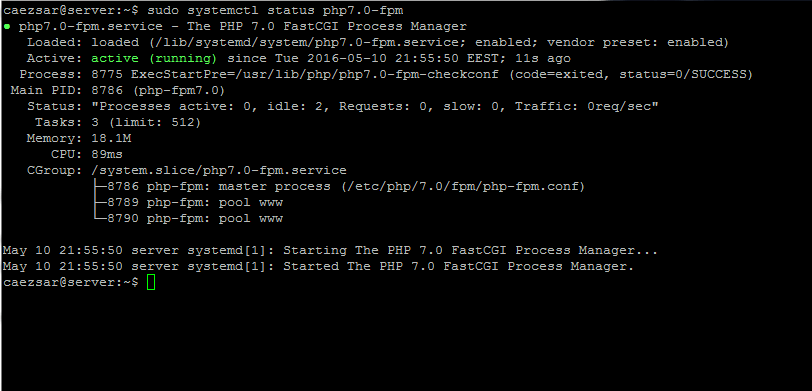
|
||||
>Start and Verify php-fpm Service
|
||||
|
||||
#### 11. The current configuration file of Nginx is already configured to use PHP FastCGI process manager in order to server dynamic content.
|
||||
|
||||
The server block that enables Nginx to use PHP interpreter is presented on the below excerpt, so no further modifications of default Nginx configuration file are required.
|
||||
|
||||
```
|
||||
location ~ \.php$ {
|
||||
include snippets/fastcgi-php.conf;
|
||||
fastcgi_pass unix:/run/php/php7.0-fpm.sock;
|
||||
}
|
||||
```
|
||||
|
||||
Below is a screenshot of what instructions you need to uncomment and modify is case of an original Nginx default configuration file.
|
||||
|
||||
|
||||
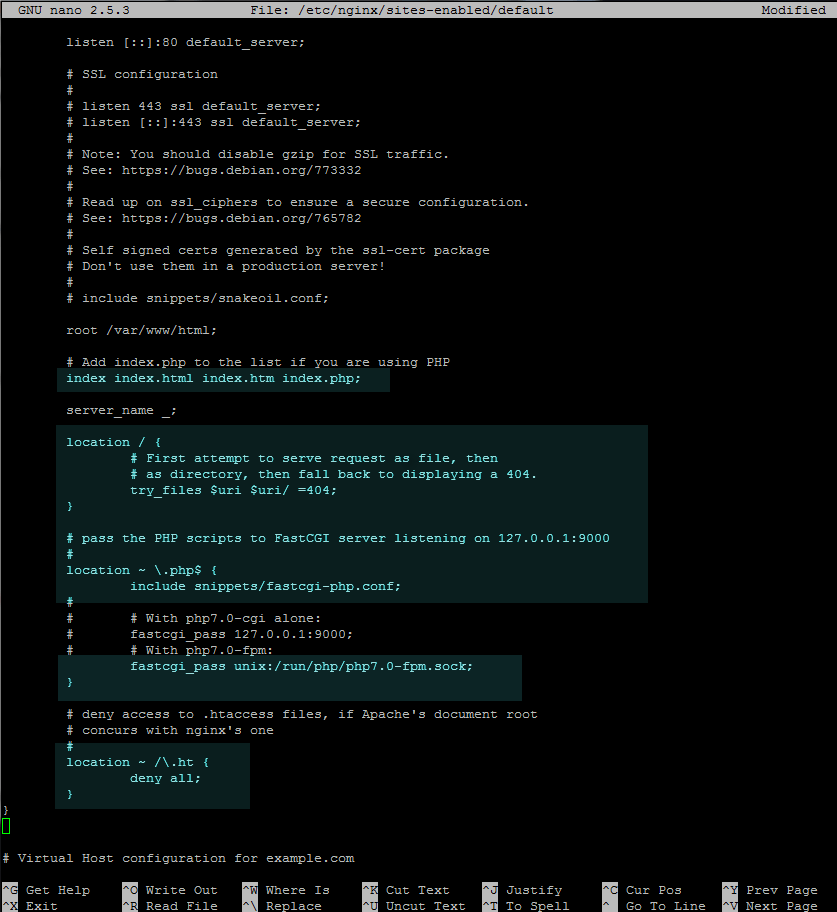
|
||||
>Enable PHP FastCGI for Nginx
|
||||
|
||||
#### 12. To test Nginx web server relation with PHP FastCGI process manager create a PHP `info.php` test configuration file by issuing the below command and verify the settings by visiting this configuration file using the below address: `http://IP_or domain/info.php`.
|
||||
|
||||
```
|
||||
$ sudo su -c 'echo "<?php phpinfo(); ?>" |tee /var/www/html/info.php'
|
||||
```
|
||||
|
||||

|
||||
>Create PHP Info File
|
||||
|
||||

|
||||
>Verify PHP FastCGI Info
|
||||
|
||||
Also check if HTTP/2.0 protocol is advertised by the server by locating the line `$_SERVER[‘SERVER_PROTOCOL’]` on PHP Variables block as illustrated on the below screenshot.
|
||||
|
||||
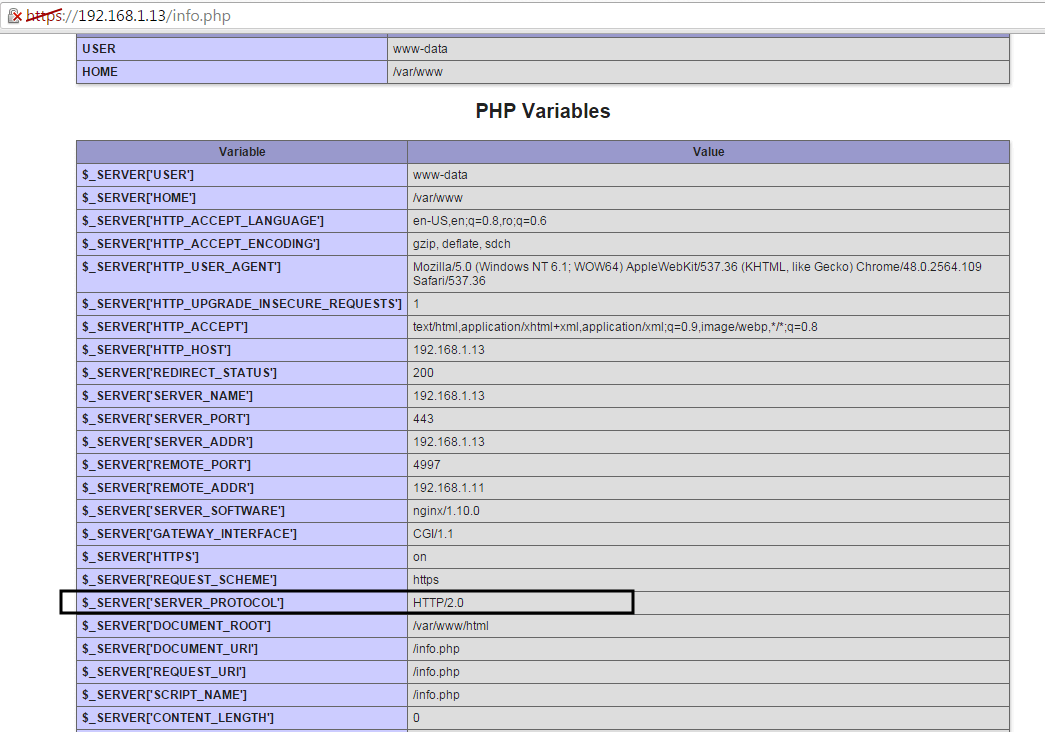
|
||||
>Check HTTP 2.0 Protocol Info
|
||||
|
||||
#### 13. In order to install extra PHP7.0 modules use the `apt search php7.0` command to find a PHP module and install it.
|
||||
|
||||
Also, try to install the following PHP modules which can come in handy in case you are planning to [install WordPress][5] or other CMS.
|
||||
|
||||
```
|
||||
$ sudo apt install php7.0-mcrypt php7.0-mbstring
|
||||
```
|
||||
|
||||
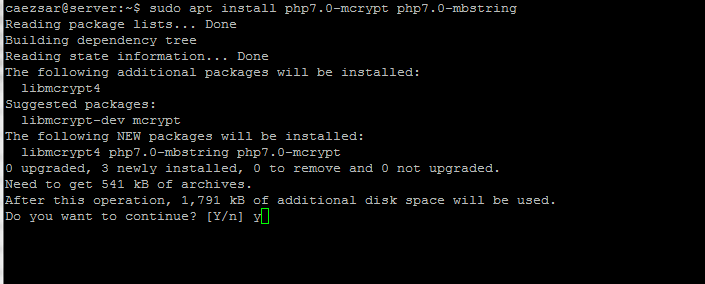
|
||||
>Install PHP 7 Modules
|
||||
|
||||
#### 14. To register the PHP extra modules just restart PHP-FPM daemon by issuing the below command.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart php7.0-fpm.service
|
||||
```
|
||||
|
||||
### Step 4: Install MariaDB Database
|
||||
|
||||
#### 15. Finally, in order to complete our LEMP stack we need the MariaDB database component to store and manage website data.
|
||||
|
||||
Install MariaDB database management system by running the below command and restart PHP-FPM service in order to use MySQL module to access the database.
|
||||
|
||||
```
|
||||
$ sudo apt install mariadb-server mariadb-client php7.0-mysql
|
||||
$ sudo systemctl restart php7.0-fpm.service
|
||||
```
|
||||
|
||||
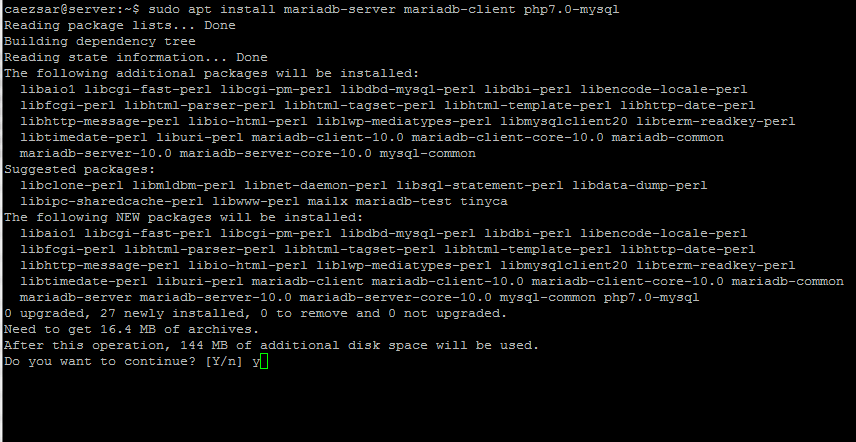
|
||||
>Install MariaDB for Nginx
|
||||
|
||||
#### 16. To secure the MariaDB installation, run the security script provided by the binary package from Ubuntu repositories which will ask you set a root password, remove anonymous users, disable root login remotely and remove test database.
|
||||
|
||||
Run the script by issuing the below command and answer all questions with yes. Use the below screenshot as a guide.
|
||||
|
||||
```
|
||||
$ sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
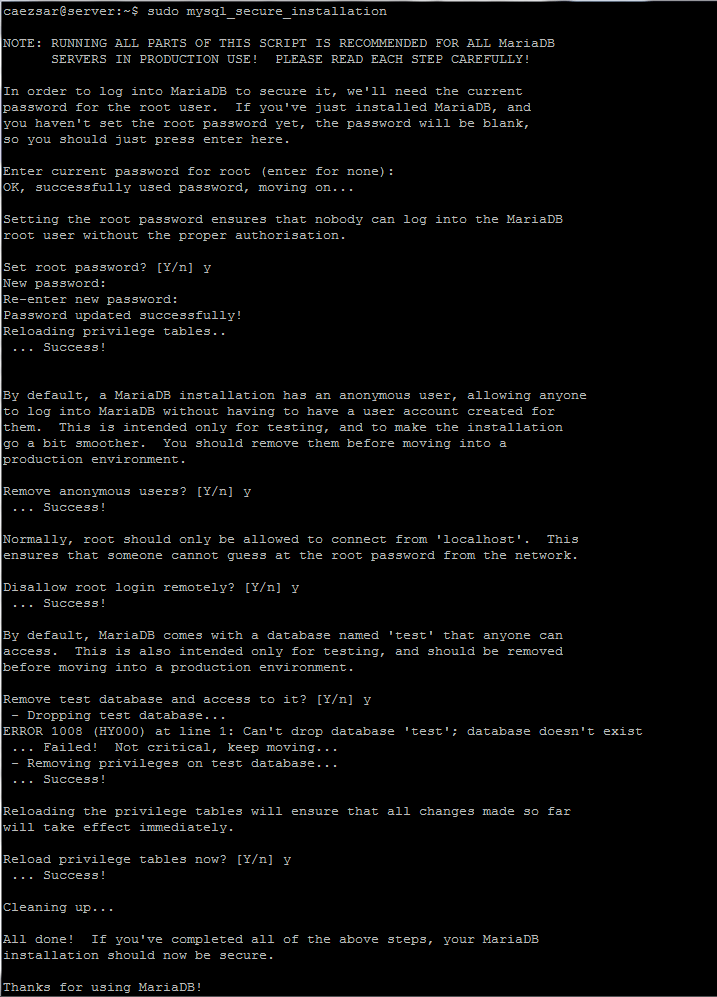
|
||||
>Secure MariaDB Installation for Nginx
|
||||
|
||||
#### 17. To configure MariaDB so that ordinary users can access the database without system sudo privileges, go to MySQL command line interface with root privileges and run the below commands on MySQL interpreter:
|
||||
|
||||
```
|
||||
$ sudo mysql
|
||||
MariaDB> use mysql;
|
||||
MariaDB> update user set plugin=’‘ where User=’root’;
|
||||
MariaDB> flush privileges;
|
||||
MariaDB> exit
|
||||
```
|
||||
|
||||
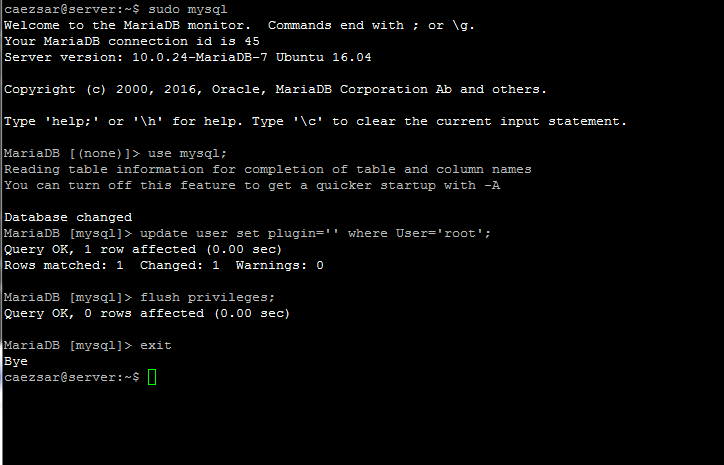
|
||||
>MariaDB User Permissions
|
||||
|
||||
Finally, login to MariaDB database and run an arbitrary command without root privileges by executing the below command:
|
||||
|
||||
```
|
||||
$ mysql -u root -p -e 'show databases'
|
||||
```
|
||||
|
||||
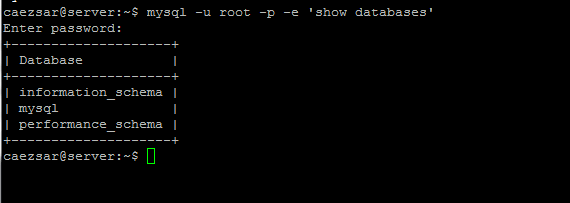
|
||||
>Check MariaDB Databases
|
||||
|
||||
That’ all! Now you have a **LEMP** stack configured on **Ubuntu 16.04** server that allows you to deploy complex dynamic web applications that can interact with databases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-nginx-mariadb-php7-http2-on-ubuntu-16-04/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
作者:[Matei Cezar ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/cezarmatei/
|
||||
[1]: http://www.tecmint.com/installation-of-ubuntu-16-04-server-edition/
|
||||
[2]: http://www.tecmint.com/apt-advanced-package-command-examples-in-ubuntu/
|
||||
[3]: http://www.tecmint.com/20-netstat-commands-for-linux-network-management/
|
||||
[4]: http://www.tecmint.com/manage-services-using-systemd-and-systemctl-in-linux/
|
||||
[5]: http://www.tecmint.com/install-wordpress-using-lamp-or-lemp-on-rhel-centos-fedora/
|
||||
180
sources/tech/20160531 HOW TO USE WEBP IMAGES IN UBUNTU LINUX.md
Normal file
180
sources/tech/20160531 HOW TO USE WEBP IMAGES IN UBUNTU LINUX.md
Normal file
@ -0,0 +1,180 @@
|
||||
HOW TO USE WEBP IMAGES IN UBUNTU LINUX
|
||||
=========================================
|
||||
|
||||

|
||||
>Brief: This guide shows you how to view WebP images in Linux and how to convert WebP images to JPEG or PNG format.
|
||||
|
||||
###WHAT IS WEBP?
|
||||
|
||||
It’s been over five years since Google introduced [WebP file format][0] for images. WebP provides lossy and lossless compression and WebP compressed files are around 25% smaller in size when compared to JPEG compression, Google claims.
|
||||
|
||||
Google aimed WebP to become the new standard for images on the web but I don’t see it happening. It’s over five years and it’s still not adopted as a standard except in Google’s ecosystem. But as we know, Google is pushy about its technologies. Few months back Google changed all the images on Google Plus to WebP.
|
||||
|
||||
If you download those images from Google Plus using Google Chrome, you’ll have WebP images, no matter if you had uploaded PNG or JPEG. And that’s not the problem. The actual problem is when you try to open that files in Ubuntu using the default GNOME Image Viewer and you see this error:
|
||||
|
||||
>**Could not find XYZ.webp**
|
||||
>**Unrecognized image file format**
|
||||
|
||||

|
||||
>GNOME Image Viewer doesn’t support WebP images
|
||||
|
||||
In this tutorial, we shall see
|
||||
|
||||
- how to add WebP support in Linux
|
||||
- list of programs that support WebP images
|
||||
- how to convert WebP images to PNG or JPEG
|
||||
- how to download WebP images directly as PNG images
|
||||
|
||||
### HOW TO VIEW WEBP IMAGES IN UBUNTU AND OTHER LINUX
|
||||
|
||||
[GNOME Image Viewer][3], the default image viewer in many Linux distributions including Ubuntu, doesn’t support WebP images. There are no plugins available at present that could enable GNOME Image Viewer to add WebP support.
|
||||
|
||||
This means that we simply cannot use GNOME Image Viewer to open WebP files in Linux. A better alternative is [gThumb][4] that supports WebP images by default.
|
||||
|
||||
To install gThumb in Ubuntu and other Ubuntu based Linux distributions, use the command below:
|
||||
|
||||
```
|
||||
sudo apt-get install gthumb
|
||||
```
|
||||
|
||||
Once installed, you can simply rightly click on the WebP image and select gThumb to open it. You should be able to see it now:
|
||||
|
||||

|
||||
>WebP image in gThumb
|
||||
|
||||
### MAKE GTHUMB THE DEFAULT APPLICATION FOR WEBP IMAGES IN UBUNTU
|
||||
|
||||
For Ubuntu beginners, if you like to make gThumb the default application for opening WebP files, just follow the steps below:
|
||||
|
||||
#### Step 1: Right click on the WebP image and select Properties.
|
||||
|
||||

|
||||
>Select Properties from Right Click menu
|
||||
|
||||
#### Step 2: Go to Open With tab, select gThumb and click on Set as default.
|
||||
|
||||

|
||||
>Make gThumb the default application for WebP images in Ubuntu
|
||||
|
||||
### MAKE GTHUMB THE DEFAULT APPLICATIONS FOR ALL IMAGES
|
||||
|
||||
gThumb has a lot more to offer than Image Viewer. For example, you can do simple editing, add color filters to the images etc. Adding the filter is not as effective as XnRetro, the dedicated tool for [adding Instagram like effects on Linux][5], but the basic filters are available.
|
||||
|
||||
I liked gThumb a lot and decided to make it the default image viewer. If you also want to make gThumb the default application for all kind of images in Ubuntu, follow the steps below:
|
||||
|
||||
####Step 1: Open System Settings
|
||||
|
||||

|
||||
|
||||
#### Step 2: Go to Details.
|
||||
|
||||

|
||||
|
||||
#### Step 3: Select gThumb as the default applications for images here.
|
||||
|
||||

|
||||
|
||||
### ALTERNATIVE PROGRAMS TO OPEN WEBP FILES IN LINUX
|
||||
|
||||
It is possible that you might not like gThumb. If that’s the case, you can choose one of the following applications to view WebP images in Linux:
|
||||
|
||||
- [XnView][6] (Not open source)
|
||||
- GIMP with unofficial WebP plugin that can be installed via this [PPA][7] that is available until Ubuntu 15.10. I’ll cover this part in another article.
|
||||
- [Gwenview][8]
|
||||
|
||||
### CONVERT WEBP IMAGES TO PNG AND JPEG IN LINUX
|
||||
|
||||
There are two ways to convert WebP images in Linux:
|
||||
|
||||
- Command line
|
||||
- GUI
|
||||
|
||||
#### 1. USING COMMAND LINE TO CONVERT WEBP IMAGES IN LINUX
|
||||
|
||||
You need to install WebP tools first. Open a terminal and use the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install webp
|
||||
```
|
||||
|
||||
##### CONVERT JPEG/PNG TO WEBP
|
||||
|
||||
We’ll use cwebp command (does it mean compress to WebP?) to convert JPEG or PNG files to WebP. The command format is like:
|
||||
|
||||
```
|
||||
cwebp -q [image_quality] [JPEG/PNG_filename] -o [WebP_filename]
|
||||
```
|
||||
|
||||
For example, you can use the following command:
|
||||
|
||||
```
|
||||
cwebp -q 90 example.jpeg -o example.webp
|
||||
```
|
||||
|
||||
##### CONVERT WEBP TO JPEG/PNG
|
||||
|
||||
To convert WebP images to JPEG or PNG, we’ll use dwebp command. The command format is:
|
||||
|
||||
```
|
||||
dwebp [WebP_filename] -o [PNG_filename]
|
||||
```
|
||||
|
||||
An example of this command could be:
|
||||
|
||||
```
|
||||
dwebp example.webp -o example.png
|
||||
```
|
||||
|
||||
#### 2. USING GUI TOOL TO CONVERT WEBP TO JPEG/PNG
|
||||
|
||||
For this purpose, we will use XnConvert which is a free but not open source application. You can download the installer files from their website:
|
||||
|
||||
[Download XnConvert][1]
|
||||
|
||||
Note that XnConvert is a powerful tool that you can use for batch resizing images. However, in this tutorial, we shall only see how to convert a single WebP image to PNG/JPEG.
|
||||
|
||||
Open XnConvert and select the input file:
|
||||
|
||||

|
||||
|
||||
In the Output tab, select the output format you want it to be converted. Once you have selected the output format, click on Convert.
|
||||
|
||||

|
||||
|
||||
That’s all you need to do to convert WebP images to PNG, JPEg or any other image format of your choice.
|
||||
|
||||
### DOWNLOAD WEBP IMAGES AS PNG DIRECTLY IN CHROME WEB BROWSER
|
||||
|
||||
Probably you don’t like WebP image format at all and you don’t want to install a new software just to view WebP images in Linux. It will be a bigger pain if you have to convert the WebP file for future use.
|
||||
|
||||
An easier and less painful way to deal with is to install a Chrome extension Save Image as PNG. With this extension, you can simply right click on a WebP image and save it as PNG directly.
|
||||
|
||||

|
||||
>Saving WebP image as PNG in Google Chrome
|
||||
|
||||
[Get Save Image as PNG extension][2]
|
||||
|
||||
### WHAT’S YOUR PICK?
|
||||
|
||||
I hope this detailed tutorial helped you to get WebP support on Linux and helped you to convert WebP images. How do you handle WebP images in Linux? Which tool do you use? From the above described methods, which one did you like the most?
|
||||
|
||||
|
||||
----------------------
|
||||
via: http://itsfoss.com/webp-ubuntu-linux/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/abhishek/
|
||||
[0]: https://developers.google.com/speed/webp/
|
||||
[1]: http://www.xnview.com/en/xnconvert/#downloads
|
||||
[2]: https://chrome.google.com/webstore/detail/save-image-as-png/nkokmeaibnajheohncaamjggkanfbphi?utm_source=chrome-ntp-icon
|
||||
[3]: https://wiki.gnome.org/Apps/EyeOfGnome
|
||||
[4]: https://wiki.gnome.org/Apps/gthumb
|
||||
[5]: http://itsfoss.com/add-instagram-effects-xnretro-ubuntu-linux/
|
||||
[6]: http://www.xnview.com/en/xnviewmp/#downloads
|
||||
[7]: https://launchpad.net/~george-edison55/+archive/ubuntu/webp
|
||||
[8]: https://userbase.kde.org/Gwenview
|
||||
@ -1,52 +1,54 @@
|
||||
GHLandy Translating
|
||||
LFCS 第十讲:学习简单的 Shell 脚本编程和文件系统故障排除
|
||||
|
||||
Part 10 - LFCS: Understanding & Learning Basic Shell Scripting and Linux Filesystem Troubleshooting
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new initiative whose purpose is to allow individuals everywhere (and anywhere) to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
Linux 基金会发起了 LFCS 认证 (Linux Foundation Certified Sysadmin, Linux 基金会认证系统管理员),这是一个全新的认证体系,主要目标是让全世界任何人都有机会考取认证。认证内容为 Linux 中间系统的管理,主要包括:系统运行和服务的维护、全面监控和分析的能力以及问题来临时何时想上游团队请求帮助的决策能力
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 10
|
||||
LFCS 系列第十讲
|
||||
|
||||
Check out the following video that guides you an introduction to the Linux Foundation Certification Program.
|
||||
请看以下视频,这里边介绍了 Linux 基金会认证程序。
|
||||
|
||||
注:youtube 视频
|
||||
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
<video src="https://dn-linuxcn.qbox.me/static%2Fvideo%2FIntroducing%20The%20Linux%20Foundation%20Certification%20Program-Y29qZ71Kicg.mp4" controls="controls" width="100%">
|
||||
</video>
|
||||
|
||||
This is the last article (Part 10) of the present 10-tutorial long series. In this article we will focus on basic shell scripting and troubleshooting Linux file systems. Both topics are required for the LFCS certification exam.
|
||||
本讲是系列教程中的第十讲,主要集中讲解简单的 Shell 脚本编程和文件系统故障排除。这两块内容都是 LFCS 认证中的必备考点。
|
||||
|
||||
### Understanding Terminals and Shells ###
|
||||
### 理解终端 (Terminals) 和 Shell ###
|
||||
|
||||
Let’s clarify a few concepts first.
|
||||
首先要声明一些概念。
|
||||
|
||||
- A shell is a program that takes commands and gives them to the operating system to be executed.
|
||||
- A terminal is a program that allows us as end users to interact with the shell. One example of a terminal is GNOME terminal, as shown in the below image.
|
||||
- Shell 是一个程序,它将命令传递给操作系统来执行。
|
||||
- Terminal 也是一个程序,作为最终用户,我们需要使用它与 Shell 来交互。比如,下边的图片是 GNOME Terminal。
|
||||
|
||||

|
||||
|
||||
Gnome Terminal
|
||||
|
||||
When we first start a shell, it presents a command prompt (also known as the command line), which tells us that the shell is ready to start accepting commands from its standard input device, which is usually the keyboard.
|
||||
启动 Shell 之后,会呈现一个命令提示符 (也称为命令行) 提示我们 Shell 已经做好了准备,接受标准输入设备输入的命令,这个标准输入设备通常是键盘。
|
||||
|
||||
You may want to refer to another article in this series ([Use Command to Create, Edit, and Manipulate files – Part 1][1]) to review some useful commands.
|
||||
你可以参考该系列文章的 [第一讲 使用命令创建、编辑和操作文件][1] 来温习一些常用的命令。
|
||||
|
||||
Linux provides a range of options for shells, the following being the most common:
|
||||
Linux 为提供了许多可以选用的 Shell,下面列出一些常用的:
|
||||
|
||||
**bash Shell**
|
||||
|
||||
Bash stands for Bourne Again SHell and is the GNU Project’s default shell. It incorporates useful features from the Korn shell (ksh) and C shell (csh), offering several improvements at the same time. This is the default shell used by the distributions covered in the LFCS certification, and it is the shell that we will use in this tutorial.
|
||||
Bash 代表 Bourne Again Shell,它是 GNU 项目默认的 Shell。它借鉴了 Korn shell (ksh) 和 C shell (csh) 中有用的特性,并同时对性能进行了提升。它同时也是 LFCS 认证中所涵盖的风发行版中默认 Shell,也是本系列教程将使用的 Shell。
|
||||
|
||||
**sh Shell**
|
||||
|
||||
The Bourne SHell is the oldest shell and therefore has been the default shell of many UNIX-like operating systems for many years.
|
||||
ksh Shell
|
||||
Bash Shell 是一个比较古老的 shell,一次多年来都是多数类 Unix 系统的默认 shell。
|
||||
|
||||
The Korn SHell is a Unix shell which was developed by David Korn at Bell Labs in the early 1980s. It is backward-compatible with the Bourne shell and includes many features of the C shell.
|
||||
**ksh Shell**
|
||||
|
||||
A shell script is nothing more and nothing less than a text file turned into an executable program that combines commands that are executed by the shell one after another.
|
||||
Korn SHell (ksh shell) 也是一个 Unix shell,是贝尔实验室 (Bell Labs) 的 David Korn 在 19 世纪 80 年代初的时候开发的。它兼容 Bourne shell ,并同时包含了 C shell 中的多数特性。
|
||||
|
||||
### Basic Shell Scripting ###
|
||||
|
||||
一个 shell 脚本仅仅只是一个可执行的文本文件,里边包含一条条可执行命令。
|
||||
|
||||
### 简单的 Shell 脚本编程 ###
|
||||
|
||||
As mentioned earlier, a shell script is born as a plain text file. Thus, can be created and edited using our preferred text editor. You may want to consider using vi/m (refer to [Usage of vi Editor – Part 2][2] of this series), which features syntax highlighting for your convenience.
|
||||
|
||||
@ -292,7 +294,7 @@ If we’re only interested in finding out what’s wrong (without trying to fix
|
||||
|
||||
Depending on the error messages in the output of fsck, we will know whether we can try to solve the issue ourselves or escalate it to engineering teams to perform further checks on the hardware.
|
||||
|
||||
### Summary ###
|
||||
### 总结 ###
|
||||
|
||||
We have arrived at the end of this 10-article series where have tried to cover the basic domain competencies required to pass the LFCS exam.
|
||||
|
||||
@ -305,7 +307,7 @@ If you have any questions or comments, they are always welcome – so don’t he
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,43 +0,0 @@
|
||||
又一次 Mindcraft 事件?
|
||||
=======================
|
||||
|
||||
感谢:Jonathan Corbet
|
||||
|
||||
Linux 内核开发很少吸引像华盛顿邮报这样主流媒体的关注,内核社区在安全方面进展的冗长功能列表就更少人看了。所以当这样一个功能发布到网上,就吸引了很多人的注意。关于这篇文章有不同的反应,很多人认为这是对 Linux 直接的攻击。文章背后的动机很难知道,但是从历史经验来看,它也可以看作对我们早就该前进的方向的一次非常必要的推动。
|
||||
|
||||
回顾一次在昏暗遥远过去的事件 - 确切地说是 1999 年 4 月。一家叫 Mindcraft 的分析公司发布了一份报告显示 Windows NT 在服务器开销方面完胜 Red Hat Linux 5.2 加 Apache。Linux 社区,包括当时还很年轻的 LWN,的反应很迅速而且强烈。这份报告是微软资助的 FUD 的一部分,用来消除那些全球垄断计划的新兴威胁。报告指出,Linux 系统有意配置成低性能,Linux 不支持当时的很多硬件,等等。
|
||||
|
||||
在大家稍微冷静一点后,尽管如此,事实很明显:Mindcraft 的人,不管什么动机,说的也有道理。当时 Linux 确实在性能方面存在一些已经被充分认识到的问题。然后社区做了最正确的事情:我们坐下来解决问题。比如,单独唤醒的调度器可以终结接受连接请求时的惊群问题。其他很多小问题也都解决了。在差不多一年里,内核在这类开销方面的性能已经有了非常大的改善。
|
||||
|
||||
这份 Mindcraft 的报告,某种意义上来说,往 Linux 背后踢了很有必要的一脚,推动整个社区去处理一些当时被忽略的事情。
|
||||
|
||||
华盛顿邮报的文章明显在鄙视 Linux 内核以及它的贡献者。它随意地混淆了内核问题和其他根本不是内核脆弱性引起的问题(比如,AshleyMadison.com 被黑)。不过供应商没什么兴趣为他们的客户提供安全补丁的事实,就像一头巨象在房间里跳舞一样明显。还有谣言说这篇文章后面的黑暗势力希望打击一下 Linux 的势头。这些也许都是真的,但是也不能掩盖一个简单的事实,就是文章说的确实是真的。
|
||||
|
||||
我们会合理地测试并解决问题。而问题,不管是不是安全相关,能很快得到修复,然后再通过稳定更新的机制将这些补丁发布给内核用户。比起外面很多应用程序(免费的和付费的),内核的支持非常好。但是指责我们解决问题的能力时却遗漏了关键的一点:解决安全问题最终是一个打鼹鼠游戏。总是会出来更多的鼹鼠,其中有一些在攻击者发现并利用后很长时间我们都还不知道(所以没法使劲打下去)。尽管商业 Linux 已经非常努力地在将补丁传递给用户,这种问题还是会让我们的用户很受伤 - 只是这并不是故意的。
|
||||
|
||||
关键是只是解决问题并不够,一些关心安全性的开发者也已经开始尝试。我们必须认识到,问题永远都解不完,所以要让问题更难被发现和利用。意思就是限制访问内核信息,绝对不允许内核执行用户空间内存的指令,指示内核侦测整数溢出,以及 Kee Cook 在十月底内核峰会的讲话中所提出的其他所有事情。其中许多技术被其他操作系统深刻理解并采用了;它们的创新也有我们的功劳。但是,如果我们想充分保护我们的用户免受攻击,这些改变是必须要做的。
|
||||
|
||||
为什么内核还没有引入这些技术?华盛顿邮报的文章坚定地指责开发社区,特别是 Linus Torvalds。内核社区的传统就是相对安全性更侧重于性能和功能,在需要牺牲性能来改善内核安全性时并不愿意折中处理。这些指责一定程度上是对的;好的一面是,因为问题的范围变得清晰,态度看上去有点改善。Kee 的演讲都听进去了,而且很明显让开发者开始思考和讨论这些问题。
|
||||
|
||||
而被忽略的一点是,并不仅仅是 Linus 在拒绝有用的安全补丁。而是就没有多少这种补丁在内核社区里流传。特别是,在这个领域工作的开发者就那么些人,而且从没有认真地尝试把自己的工作合并到上游。要合并任何大的侵入性补丁,需要和内核社区一起工作,为改动编写用例,将改动分割成方便审核的碎片,处理审核意见,等等。整个过程可能会有点无聊而且让人沮丧,但这却是内核维护的运作方式,而且很明显只有这样才能在长时间的开发中形成更有用更可维护的内核。
|
||||
|
||||
几乎没有人会走这个流程来将最新的安全技术引入内核。对于这类补丁可能收到的不利反应,有人觉得也许会导致“寒蝉效应”,但是这个说法并不充分:不管最初的反应有多麻烦,多年以来开发者已经合并了大量的改动。而少数安全开发者连试都没试过。
|
||||
|
||||
他们为什么不愿意尝试?一个比较明显的答案是,几乎没有人会因此拿到报酬。几乎所有引入内核的工作都由付费开发者完成,而且已经持续多年。公司能看到利润的领域在内核里都有大量的工作以及很好的进展。而公司觉得和它们没关系的领域就不会这样了。为实时开发找到赞助支持的困难就是很明显的例子。其他领域,比如文档,也在慢慢萧条。安全性很明显也属于这类领域。可能有很多原因导致 Linux 落后于防御式安全技术,但是其中最关键的一条是,靠 Linux 赚钱的公司没有重视这些技术的开发和应用。
|
||||
|
||||
有迹象显示局面已有所转变。越来越多的开发人员开始关注安全相关问题,尽管对他们工作的商业支持还仍然不够。对于安全相关的改变已经没有之前那样的下意识反应了。像内核自我保护项目这样,已经开始把现存的安全技术集成进入内核了。
|
||||
|
||||
我们还有很长的路要走,但是,如果能有一些支持以及正确的思想,短期内能有很大的进展。内核社区在确定了自己的想法后可以做到很让人惊叹的事情。幸运的是,华盛顿邮报的文章将有助于提供形成这种想法的必要动力。在历史的角度上,我们很可能会把这次事件看作一个转折点,我们最终被倒逼着去完成之前很明确需要做的事情。Linux 不应该再继续讲述这个安全不合格的故事了。
|
||||
|
||||
---------------------------
|
||||
|
||||
via: https://lwn.net/Articles/663474/
|
||||
|
||||
作者:Jonathan Corbet
|
||||
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,16 +1,15 @@
|
||||
初识Linux文件权限
|
||||
================================================================================
|
||||
|
||||
在 Linux 中最基本的任务之一就是设置文件权限。理解如何实现是你进入 LInux 世界的第一步。如您所料,这一基本操作在类 UNIX 操作系统中大同小异。实际上,Linux 文件权限系统就直接取自于 UNIX 文件权限(甚至使用许多相同的工具)。
|
||||
|
||||
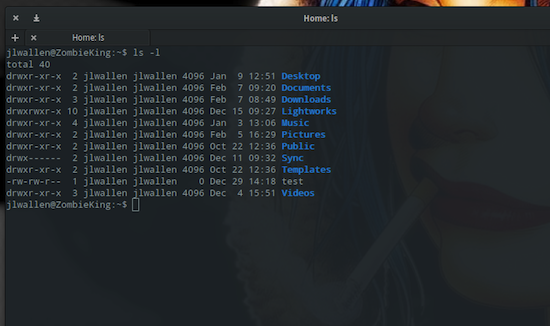
|
||||
|
||||
在Linux中最基本的任务就是设置文件权限。理解如何实现是你进入LInux世界的第一步。如您所料,这一基本操作在类UNIX操作系统中大同小异。
|
||||
实际上,Linux文件权限系统就直接取自UNIX文件权限(甚至使用许多相同的工具)。
|
||||
|
||||
但不要以为在学习第二种文件权限系统的时候你需要再次一点一点的学起。事实上会很简单,让我们一起来看看你需要了解哪些内容以及如何使用它们。
|
||||
但不要以为理解文件权限需要长时间的学习。事实上会很简单,让我们一起来看看你需要了解哪些内容以及如何使用它们。
|
||||
|
||||
##基础概念
|
||||
|
||||
首先你要知道文件权限适用于什么,如何有效的设置一个分组的权限。当你将其分解,那这个概念就真的简单多了。那到底什么是权限什么是分组呢。
|
||||
你要明白的第一件事是文件权限适用于什么。你做的更有效的就是设置一个分组的权限。当你将其分解,那这个概念就真的简单多了。那到底什么是权限,什么是分组呢?
|
||||
|
||||
你可以设置的3种权限:
|
||||
|
||||
@ -20,32 +19,31 @@
|
||||
|
||||
- 执行 — 允许该组执行(运行)文件(用`x`表示)
|
||||
|
||||
为了更好的解释为何是应用于一个分组,你可是尝试允许一个分组读和写一个文件,但不能执行。或者你可以允许一个组读和执行一个文件,但不能写。
|
||||
甚至你可以允许一组有读、写、执行全部的权限,也可以删除全部权限。
|
||||
为了更好地解释这如何应用于一个分组,例如,你允许一个分组读和写一个文件,但不能执行。或者,你可以允许一个组读和执行一个文件,但不能写。甚至你可以允许一组有读、写、执行全部的权限,也可以删除全部权限来剥夺组权限。
|
||||
|
||||
什么是分组呢,有以下4个:
|
||||
现在,什么是分组呢,有以下4个:
|
||||
|
||||
- user — 文件实际的拥有者
|
||||
|
||||
- group — 用户所在的组
|
||||
|
||||
- others — 用户组内的其他用户
|
||||
- others — 用户组外的其他用户
|
||||
|
||||
- all — 所有用户
|
||||
|
||||
大多数情况,你只会对前3组进行操作,all这一组只是作为快捷方式(稍后我会解释)。
|
||||
大多数情况,你只会对前3组进行操作,`all` 这一组只是作为快捷方式(稍后我会解释)。
|
||||
|
||||
到目前为止很简单,对吧?接下来我们将深入一层。
|
||||
|
||||
如果你打开一个终端并运行命令 ls -l ,你将会看到逐行列出当前工作目录下所有的文件和文件夹的列表(如图1).
|
||||
如果你打开一个终端并运行命令 `ls -l`,你将会看到逐行列出当前工作目录下所有的文件和文件夹的列表(如图1).
|
||||
|
||||
你会留意到最左边那列是像·-rw-rw-r--·这样的。
|
||||
你会留意到最左边那列是像 `-rw-rw-r--` 这样的。
|
||||
|
||||
实际上这列表该这样看的:
|
||||
|
||||
>rw- rw- r--
|
||||
|
||||
将其分为如下3部分:
|
||||
正如你所见,列表将其分为如下3部分:
|
||||
|
||||
- rw-
|
||||
|
||||
@ -55,11 +53,11 @@
|
||||
|
||||
权限和组的顺序都很重要,顺序总是:
|
||||
|
||||
- 用户 组 其他 — 分组
|
||||
- 所属者 所属组 其他人 — 分组
|
||||
|
||||
- 读 写 操作 — 权限
|
||||
- 读 写 执行 — 权限
|
||||
|
||||
在我们上面示例的权限列表中,用户拥有读/写权限,用户组拥有读/写权限,其他用户仅拥有读权限。这些分组中赋予执行权限的话,就用一个x表示。
|
||||
在我们上面示例的权限列表中,所属者拥有读/写权限,所属组拥有读/写权限,其他人用户仅拥有读权限。这些分组中赋予执行权限的话,就用一个x表示。
|
||||
|
||||
## 等效数值
|
||||
|
||||
@ -75,8 +73,7 @@
|
||||
|
||||
>-42-42-4--
|
||||
|
||||
你该把每个分组的数值相加,给用户读和写权限,你该用4 + 2 得到6。给用户组相同的权限,也是使用相同的数值。假如你只想给其他用户读的权限,
|
||||
那就设置它为4。现在用数只表示为:
|
||||
你该把每个分组的数值相加,给用户读和写权限,你该用 4 + 2 得到 6。给用户组相同的权限,也是使用相同的数值。假如你只想给其他用户读的权限,那就设置它为4。现在用数值表示为:
|
||||
|
||||
>664
|
||||
|
||||
@ -84,27 +81,24 @@
|
||||
|
||||
>chmod 664 FILENAME
|
||||
|
||||
FILENAME处为文件名。
|
||||
FILENAME 处为文件名。
|
||||
|
||||
## 更改权限
|
||||
|
||||
既然你已经理解了文件权限,那是时候学习如何更改这些权限了。就是使用chmod命令来实现。第一步你要知道你能否更改文件权限,
|
||||
你必须是文件的所有者或者有权限编辑文件(或者使用su或sudo进行操作)。正因为这样,你不能随意切换目录和更改文件权限。
|
||||
既然你已经理解了文件权限,那是时候学习如何更改这些权限了。就是使用chmod命令来实现。第一步你要知道你能否更改文件权限,你必须是文件的所有者或者有权限编辑文件(或者使用su或sudo进行操作)。正因为这样,你不能随意切换目录和更改文件权限。
|
||||
|
||||
|
||||
继续用我们的例子(`-rw-rw-r--`),假设这个文件(命名为script.sh)实际是个shell脚本,需要执行。但是你你只想让自己有权限执行这个脚本。
|
||||
这个时候,你可能会想:“我需要是文件的权限如`-rwx-rw-r--`这样来设置`x`”。实际你可以这样使用chmod命令:
|
||||
继续用我们的例子 (`-rw-rw-r--`)。假设这个文件(命名为 script.sh)实际是个shell脚本,需要被执行,但是你只想让自己有权限执行这个脚本。这个时候,你可能会想:“我需要是文件的权限如 `-rwx-rw-r--`”。为了设置 `x` 权限位,你可以这样使用 `chmod` 命令:
|
||||
|
||||
>chmod u+x script.sh
|
||||
|
||||
这时候,列表中显示的应该是 -rwx-rw-r-- 。
|
||||
|
||||
如果你想同时让用户及其所在组同时拥有执行权限,命令应该这样:
|
||||
如果你想同时让用户及其所属组同时拥有执行权限,命令应该这样:
|
||||
|
||||
>chmod ug+x script.sh
|
||||
|
||||
明白这是怎么工作的了吗?下面我们让它更有趣些。不管什么原因,你不小心给了所有分组对文件的执行权限(列表中是这样的 `-rwx-rwx-r-x`)。
|
||||
|
||||
明白这是怎么工作的了,下面我们让它更有趣些。不管什么原因,你不小心给了所有分组对文件的执行权限(列表中是这样的 `-rwx-rwx-r-x` )。
|
||||
如果你想去除其他用户的执行权限,只需运行命令:
|
||||
|
||||
>chmod o-x script.sh
|
||||
@ -117,35 +111,29 @@ FILENAME处为文件名。
|
||||
|
||||
>chmod a-x script.sh
|
||||
|
||||
以上就是所有内容,能使操作更有效率。我希望能避免哪些可能会导致一些问题的操作(例如你不小心对script.sh使用`a-rwx`这样的chmod命令)。
|
||||
以上就是所有内容,能使操作更有效率。我希望能避免哪些可能会导致一些问题的操作(例如你不小心对 script.sh 使用 `a-rwx` 这样的chmod命令)。
|
||||
|
||||
## 目录权限
|
||||
|
||||
You can also execute the chmod command on a directory. When you create a new directory as a user, it is typically created with the following permissions:
|
||||
你也可以对一个目录执行chmod命令,当你创建一个新的目录,通常新建目录具有这样的权限:
|
||||
你也可以对一个目录执行 `chmod` 命令。当你作为用户创建一个新的目录,通常新建目录具有这样的权限:
|
||||
|
||||
>drwxrwxr-x
|
||||
|
||||
注:开头的d表示这是一个目录。
|
||||
注:开头的 `d` 表示这是一个目录。
|
||||
|
||||
正如你所见,用户及其所在组都对文件夹具有操作权限,但这并不意味着在这文件夹中出创建的问价也具有与其相同的权限
|
||||
(创建的文件使用默认系统的权限`-rw-rw-r--`)。但如果你想在新文件夹中创建文件,并且移除用户组的写权限,
|
||||
你不用切换到该目录下并对所有文件使用chmod命令。你可以用加上参数R(意味着递归)的chmod命令,同时更改该文件夹及其目录下所有的文件的权限。
|
||||
正如你所见,用户及其所在组都对文件夹具有操作权限,但这并不意味着在这文件夹中出创建的问价也具有与其相同的权限(创建的文件使用默认系统的权限 `-rw-rw-r--`)。但如果你想在新文件夹中创建文件,并且移除用户组的写权限,你不用切换到该目录下并对所有文件使用chmod命令。你可以用加上参数R(意味着递归)的 `chmod` 命令,同时更改该文件夹及其目录下所有的文件的权限。
|
||||
|
||||
现在,假设有一文件夹TEST,里面有一些脚本,所有这些(包括TEST文件夹)拥有权限`-rwxrwxr-x`。如果你想移除用户组的写权限,
|
||||
你可以运行命令:
|
||||
现在,假设有一文件夹 TEST,里面有一些脚本,所有这些(包括 TEST 文件夹)拥有权限 `-rwxrwxr-x`。如果你想移除用户组的写权限,你可以运行命令:
|
||||
|
||||
>chmod -R g-w TEST
|
||||
|
||||
运行命令`ls -l`,你讲看到列出的TEST文件夹的权限信息是`drwxr-xr-x`。用户组被去除了写权限(其目录下的所有文件也如此)。
|
||||
运行命令 `ls -l`,你讲看到列出的 TEST 文件夹的权限信息是 `drwxr-xr-x`。用户组被去除了写权限(其目录下的所有文件也如此)。
|
||||
|
||||
## 总结
|
||||
|
||||
现在,你应该对基本的Linux文件权限有了深入的理解。对于更高级的东西学起来会很轻松,像setid,setuid和ACLs这些。没有良好的基础,
|
||||
你很快就会混淆不清概念的。
|
||||
|
||||
Linux文件权限从早期到现在没有太大变化,而且很可能以后也不会。
|
||||
现在,你应该对基本的Linux文件权限有了深入的理解。对于更高级的东西学起来会很轻松,像`setid`,`setuid` 和 `ACLs` 这些。没有良好的基础,你很快就会混淆不清概念的。
|
||||
|
||||
Linux 文件权限从早期到现在没有太大变化,而且很可能以后也不会。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
|
||||
@ -0,0 +1,110 @@
|
||||
Linux 如何最好地管理加密密钥
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
存储 SSH 的加密秘钥以及记住密码一直是一个让人头疼的问题。但是不幸的是,在当前充满了恶意黑客和攻击的世界中,基本的安全预警是必不可少的。对于大量的普通用户,它相当于简单地记住密码,也可能寻找一个好程序去存储密码,正如我们提醒这些用户不要在每个网站都有相同的密码。但是对于在各个 IT 领域的我们,我们需要将这个提高一个层次。我们不得不处理加密秘钥,比如 SSH 密钥,而不只是密码。
|
||||
|
||||
设想一个场景:我有一个运行在云上的服务器,用于我的主 git 库。我有很多台工作电脑。所有电脑都需要登陆中央服务器去 push 与 pull。我设置 git 使用 SSH。当 git 使用 SSH, git 实际上以相同的方式登陆服务器,就好像你通过 SSH 命令打开一个服务器的命令行。为了配置所有内容,我在我的 .ssh 目录下创建一个配置文件,其中包含一个有服务器名字,主机名,登陆用户,密钥文件的路径的主机项。之后我可以通过输入命令来测试这个配置。
|
||||
|
||||
>ssh gitserver
|
||||
|
||||
很快我得到了服务器的 bash shell。现在我可以配置 git 使用相同项与存储的密钥来登陆服务器。很简单,除了一个问题,对于每一个我用于登陆服务器的电脑,我需要有一个密钥文件。那意味着需要不止一个密钥文件。当前这台电脑和我的其他电脑都存储有这些密钥文件。同样的,用户每天有特大量的密码,对于我们 IT人员,很容易结束这特大量的密钥文件。怎么办呢?
|
||||
|
||||
## 清理
|
||||
|
||||
在开始使用程序去帮助你管理你的密钥之前,你不得不在你的密码应该怎么处理和我们问的问题是否有意义这两个方面打下一些基础。同时,这需要第一,也是最重要的,你明白你的公钥和私钥的使用位置。我将设想你知道:
|
||||
|
||||
1. 公钥和私钥之间的差异;
|
||||
|
||||
2. 为什么你不可以从公钥生成私钥,但是你可以逆向生成?
|
||||
|
||||
3. `authorized_keys` 文件的目的以及它的内容;
|
||||
|
||||
4. 你如何使用私钥去登陆服务器,其中服务器上的 `authorized_keys` 文件中存有相应的公钥;
|
||||
|
||||
这里有一个例子。当你在亚马逊的网络服务上创建一个云服务器,你必须提供一个 SSH 密码,用于连接你的服务器。每一个密钥有一个公开的部分,和私密的部分。因为你想保持你的服务器安全,乍看之下你可能要将你的私钥放到服务器上,同时你自己带着公钥。毕竟,你不想你的服务器被公开访问,对吗?但是实际上这是逆向的。
|
||||
|
||||
你把自己的公钥放到 AWS 服务器,同时你持有你自己的私钥用于登陆服务器。你保护私钥,同时保持私钥在自己一方,而不是在一些远程服务器上,正如上图中所示。
|
||||
|
||||
原因如下:如果公钥公之于众,他们不可以登陆服务器,因为他们没有私钥。进一步说,如果有人成功攻入你的服务器,他们所能找到的只是公钥。你不可以从公钥生成私钥。同时如果你在其他的服务器上使用相同的密钥,他们不可以使用它去登陆别的电脑。
|
||||
|
||||
这就是为什么你把你自己的公钥放到你的服务器上以便通过 SSH 登陆这些服务器。你持有这些私钥,不要让这些私钥脱离你的控制。
|
||||
|
||||
但是还有麻烦。试想一下我 git 服务器的例子。我要做一些决定。有时我登陆架设在别的地方的开发服务器。在开发服务器上,我需要连接我的 git 服务器。如何使我的开发服务器连接 git 服务器?通过使用私钥。同时这里面还有麻烦。这个场景需要我把私钥放置到一个架设在别的地方的服务器上。这相当危险。
|
||||
|
||||
一个进一步的场景:如果我要使用一个密钥去登陆许多的服务器,怎么办?如果一个入侵者得到这个私钥,他或她将拥有私钥,并且得到服务器的全部虚拟网络的权限,同时准备做一些严重的破坏。这一点也不好。
|
||||
|
||||
同时那当然会带来一个别的问题,我真的应该在这些其他服务器上使用相同的密钥?因为我刚才描述的,那会非常危险的。
|
||||
|
||||
最后,这听起来有些混乱,但是有一些简单的解决方案。让我们有条理地组织一下:
|
||||
|
||||
(注意你有很多地方需要密钥登陆服务器,但是我提出这个作为一个场景去向你展示当你处理密钥的时候你面对的问题)
|
||||
|
||||
## 关于口令句
|
||||
|
||||
当你创建你的密钥时,你可以选择是否包含一个口令字,这个口令字会在使用私钥的时候是必不可少的。有了这个口令字,私钥文件本身会被口令字加密。例如,如果你有一个公钥存储在服务器上,同时你使用私钥去登陆服务器的时候,你会被提示,输入口令字。没有口令字,这个密钥是无法使用的。或者,你可以配置你的密钥不需要口令字。然后所有你需要的只是用于登陆服务器的密钥文件。
|
||||
|
||||
普遍上,不使用口令字对于用户来说是更容易的,但是我强烈建议在很多情况下使用口令字,原因是,如果私钥文件被偷了,偷密钥的人仍然不可以使用它,除非他或者她可以找到口令字。在理论上,这个将节省你很多时间,因为你可以在攻击者发现口令字之前,从服务器上删除公钥文件,从而保护你的系统。还有一些别的原因去使用口令字,但是这个原因对我来说在很多场合更有价值。(举一个例子,我的 Android 平板上有 VNC 软件。平板上有我的密钥。如果我的平板被偷了之后,我会马上从服务器上删除公钥,使得它的私钥没有作用,无论有没有口令字。)但是在一些情况下我不使用口令字,是因为我正在登陆的服务器上没有什么有价值的数据。它取决于情境。
|
||||
|
||||
## 服务器基础设施
|
||||
|
||||
你如何设置自己服务器的基础设置将会影响到你如何管理你的密钥。例如,如果你有很多用户登陆,你将需要决定每个用户是否需要一个单独的密钥。(普遍来说,他们应该;你不会想要用户之间共享私钥。那样当一个用户离开组织或者失去信任时,你可以删除那个用户的公钥,而不需要必须给其他人生成新的密钥。相似地,通过共享密钥,他们能以其他人的身份登录,这就更坏了。)但是另外一个问题,你如何配置你的服务器。你是否使用工具,比如 Puppet,配置大量的服务器?同时你是否基于你自己的镜像创建大量的服务器?当你复制你的服务器,你是否需要为每个人设置相同的密钥?不同的云服务器软件允许你配置这个;你可以让这些服务器使用相同的密钥,或者给每一个生成一个新的密钥。
|
||||
|
||||
如果你在处理复制的服务器,它可能导致混淆如果用户需要使用不同的密钥登陆两个不同的系统。但是另一方面,服务器共享相同的密钥会有安全风险。或者,第三,如果你的密钥有除了登陆之外的需要(比如挂载加密的驱动),之后你会在很多地方需要相同的密钥。正如你所看到的,你是否需要在不同的服务器上使用相同的密钥不是我为你做的决定;这其中有权衡,而且你需要去决定什么是最好的。
|
||||
|
||||
最终,你可能会有:
|
||||
|
||||
- 需要登录的多个服务器
|
||||
|
||||
- 多个用户登陆不同的服务器,每个都有自己的密钥
|
||||
|
||||
- 每个用户多个密钥当他们登陆不同的服务器的时候
|
||||
|
||||
(如果你正在别的情况下使用密钥,相同的普遍概念会应用于如何使用密钥,需要多少密钥,他们是否共享,你如何处理密钥的私密部分和公开部分。)
|
||||
|
||||
## 安全方法
|
||||
|
||||
知道你的基础设施和独一无二的情况,你需要组合一个密钥管理方案,它会引导你去分发和存储你的密钥。比如,正如我之前提到的,如果我的平板被偷了,我会从我服务器上删除公钥,期望在平板在用于访问服务器。同样的,我会在我的整体计划中考虑以下内容:
|
||||
|
||||
1. 移动设备上的私钥没有问题,但是必须包含口令字;
|
||||
|
||||
2. 必须有一个方法可以快速地从服务器上删除公钥。
|
||||
|
||||
在你的情况中,你可能决定,你不想在自己经常登录的系统上使用口令字;比如,这个系统可能是一个开发者一天登录多次的测试机器。这没有问题,但是你需要调整你的规则。你可能添加一条规则,不可以通过移动设备登录机器。换句话说,你需要根据自己的状况构建你的协议,不要假设某个方案放之四海而皆准。
|
||||
|
||||
## 软件
|
||||
|
||||
至于软件,毫不意外,现实世界中并没有很多好的,可用的软件解决方案去存储和管理你的私钥。但是应该有吗?考虑到这个,如果你有一个程序存储你所有服务器的全部密钥,并且这个程序被一个核心密钥锁住,那么你的密钥就真的安全了吗?或者,同样的,如果你的密钥被放置在你的硬盘上,用于 SSH 程序快速访问,那样一个密钥管理软件是否真正提供了任何保护吗?
|
||||
|
||||
但是对于整体基础设施和创建,管理公钥,有许多的解决方案。我已经提到了 Puppet。在 Puppet 的世界中,你创建模块来以不同的方式管理你的服务器。这个想法是服务器是动态的,而且不必要准确地复制其他机器。[这里有一个聪明的途径](http://manuel.kiessling.net/2014/03/26/building-manageable-server-infrastructures-with-puppet-part-4/),它在不同的服务器上使用相同的密钥,但是对于每一个用户使用不同的 Puppet 模块。这个方案可能适合你,也可能不适合你。
|
||||
|
||||
或者,另一个选项就是完全换挡。在 Docker 的世界中,你可以采取一个不同的方式,正如[关于 SSH 和 Docker 博客](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/)所描述的。
|
||||
|
||||
但是怎么样管理私钥?如果你搜索,你无法找到很多的软件选择,原因我之前提到过;密钥存放在你的硬盘上,一个管理软件可能无法提到很多额外的安全。但是我确实使用这种方法来管理我的密钥:
|
||||
|
||||
首先,我的 `.ssh/config` 文件中有很多的主机项。我有一个我登陆的主机项,但是有时我对于一个单独的主机有不止一项。如果我有很多登陆,那种情况就会发生。对于架设我的 git 库的服务器,我有两个不同的登陆项;一个限制于 git,另一个为普遍目的的 bash 访问。这个为 git 设置的登陆选项在机器上有极大的限制。还记得我之前说的关于我存在于远程开发机器上的 git 密钥吗?好了。虽然这些密钥可以登陆到我其中一个服务器,但是使用的账号是被严格限制的。
|
||||
|
||||
其次,大部分的私钥都包含口令字。(对于处理不得不多次输入口令字的情况,考虑使用 [ssh-agent](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/)。)
|
||||
|
||||
再次,我确实有许多服务器,我想要更加小心地防御,并且在我 host 文件中并没有这样的项。这更加接近于社交工程方面,因为密钥文件还存在于那里,但是可能需要攻击者花费更长的时间去定位这个密钥文件,分析出来他们攻击的机器。在这些例子中,我只是手动打出来长的 SSH 命令。(这真不怎么坏。)
|
||||
|
||||
同时你可以看出来我没有使用任何特别的软件去管理这些私钥。
|
||||
|
||||
## 无放之四海而皆准的方案
|
||||
|
||||
我们偶然间收到 linux.com 的问题,关于管理密钥的好软件的建议。但是让我们后退一步。这个问题事实上需要重新定制,因为没有一个普适的解决方案。你问的问题基于你自己的状况。你是否简单地尝试找到一个位置去存储你的密钥文件?你是否寻找一个方法去管理多用户问题,其中每个人都需要将他们自己的公钥插入到 `authorized_keys` 文件中?
|
||||
|
||||
通过这篇文章,我已经囊括了基础知识,希望到此你明白如何管理你的密钥,并且,只有当你问了正确的问题,无论你寻找任何软件(甚至你需要另外的软件),它都会出现。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/838235-how-to-best-manage-encryption-keys-on-linux
|
||||
|
||||
作者:[Jeff Cogswell][a]
|
||||
译者:[mudongliang](https://github.com/mudongliang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/62256
|
||||
@ -0,0 +1,50 @@
|
||||
修补 Linux 系统 glibc 严重漏洞
|
||||
=================================================
|
||||
|
||||
**谷歌揭露的一个严重漏洞影响主流的 Linux 发行版。glibc 的漏洞可能导致远程代码执行。**
|
||||
|
||||
Linux 用户今天都竞相给一个可以使系统暴露在远程代码执行风险中的核心 glibc 开放源码库的严重漏洞打补丁。glibc 的漏洞被确定为 CVE-2015-7547,题为“getaddrinfo 基于堆栈的缓冲区溢出”。
|
||||
|
||||
glibc,或 GNU C 库,是一个开放源码的 C 和 C++ 编程语言库的实现,是每一个主流 Linux 发行版的一部分。谷歌工程师们在他们试图连接到某个主机系统时发生了一个段错误导致连接崩溃,偶然发现了 CVE-2015-7547 问题。进一步的研究表明, glibc 有缺陷而且该崩溃可能实现任意远程代码执行的条件。
|
||||
|
||||
谷歌在一篇博客文章中写道, “当 getaddrinfo() 库函数被使用时,glibc 的 DNS 客户端解析器易受基于堆栈缓冲区溢出的攻击,使用该功能的软件可能被利用为攻击者控制的域名,攻击者控制的 DNS[域名系统] 服务器,或通过中间人攻击。”
|
||||
|
||||
其实利用 CVE-2015-7547 问题并不简单,但它是可能的。为了证明这个问题能被利用,谷歌发布了论证一个终端用户或系统是否易受攻击的概念验证(POC)代码到 GitHub 上。
|
||||
|
||||
GitHub 上的 POC 网页声明“服务器代码触发漏洞,因此会使客户端代码崩溃”。
|
||||
|
||||
Duo Security 公司的高级安全研究员 Mark Loveless 解释说 CVE-2015-7547 的主要风险在于 Linux 上依赖于 DNS 响应的基于客户端的应用程序。
|
||||
|
||||
Loveless 告诉 eWEEK “需要一些特定的条件,所以不是每个应用程序都会受到影响,但似乎一些命令行工具,包括流行的 SSH[安全 Shell] 客户端都可能触发该漏洞,我们认为这是严重的,主要是因为对 Linux 系统存在的风险,但也因为潜在的其他问题。”
|
||||
|
||||
其他问题可能包括一种触发调用易受攻击的 glibc 库 getaddrinfo() 的基于电子邮件攻击的风险。另外值得注意的是,该漏洞被发现之前已存在于代码之中多年。
|
||||
|
||||
谷歌的工程师不是第一或唯一发现 glibc 中的安全风险的团体。这个问题于 2015 年 7 月 13 日首先被报告给了 glibc 的 bug[跟踪系统](https://sourceware.org/bugzilla/show_bug.cgi?id=1866)。该缺陷的根源可以更进一步追溯到在 2008 五月发布的 glibc 2.9 的代码提交时首次引入缺陷。
|
||||
|
||||
Linux 厂商红帽也独立找到了 glibc 中的这个 bug,而且在 2016 年 1 月 6 日,谷歌和红帽开发人员证实,他们作为最初与上游 glibc 的维护者私下讨论的部分人员,已经独立在为同一个漏洞工作。
|
||||
|
||||
红帽产品安全首席软件工程师 Florian Weimer 告诉 eWEEK “一旦确认了两个团队都在为同一个漏洞工作,我们合作进行可能的修复,缓解措施和回归测试,我们还共同努力,使测试覆盖尽可能广,捕捉代码中的任何相关问题,以帮助避免今后更多问题。”
|
||||
|
||||
由于缺陷不明显或不易立即显现,我们花了几年时间才发现 glibc 代码有一个安全问题。
|
||||
|
||||
Weimer 说“要诊断一个网络组件的漏洞,如 DNS 解析器,当遇到问题时通常要看被抓数据包的踪迹,在这种情况下这样的抓包不适用,所以需要一些实验来重现触发这个 bug 的确切场景。”
|
||||
|
||||
Weimer 补充说,一旦可以抓取数据包,大量精力投入到验证修复程序中,最终导致回归测试套件一系列的改进,有助于上游 glibc 项目。
|
||||
|
||||
在许多情况下,安全增强式 Linux (SELinux) 的强制访问安全控制可以减少潜在漏洞风险,除了这个 glibc 的新问题。
|
||||
|
||||
Weimer 说“由于攻击者提供的任意代码的执行,风险是重要系统功能的一个妥协。一个合适的 SELinux 策略可以遏制一些攻击者可能会做的损害,并限制他们访问系统,但是 DNS 被许多应用程序和系统组件使用,所以 SELinux 策略只提供了针对此问题有限的遏制。”
|
||||
|
||||
在揭露漏洞的今天,现在有一个可用的补丁来减少 CVE-2015-7547 的潜在风险。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.eweek.com/security/linux-systems-patched-for-critical-glibc-flaw.html
|
||||
|
||||
作者:[Michael Kerner][a]
|
||||
译者:[robot527](https://github.com/robot527)
|
||||
校对:[校对者 ID](https://github.com/校对者 ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/TechJournalist
|
||||
@ -1,34 +0,0 @@
|
||||
Intel展示了带动大屏幕Linux的便宜Android手机
|
||||
==============================================================
|
||||
|
||||

|
||||
|
||||
在世界移动会议**MWC16**上Intel展示了称之为“大屏体验”的一款的Android智能手机,它在插入一个外部显示后运行了一个完整的Linux桌面。
|
||||
|
||||
这个概念大体上与微软在Windows 10手机中的Continuum相似,但是Continuum面向的是高端设备,Intel的项目面向的是低端智能机何新兴市场。
|
||||
|
||||
显示上Barcelona是拥有Atom x3、2GB RAM和16GB存储以及支持外部显示的的SoFIA(Intel架构的只能或功能手机)智能机原型。插上键盘、鼠标何显示,它就变成了一台桌面Linux,可以选择在大屏幕中显示Android桌面。
|
||||
|
||||
Intel的拓荒小组经理Nir Metzer告诉Reg:“Android基于Linux内核,因此我们运行的是一个内核,我们有一个Android栈和一个Linux栈,并且我们共享一个上下文,因此文件系统是相同的。电话是全功能的。”
|
||||
|
||||
Metzer说:“我有一个多窗口环境。只要我插入后就可以做电子表格,我可以拖拽、播放音频。在一个低端平台实现这一切是一个挑战。”
|
||||
|
||||
现在当连上外部显示器时设备的屏幕显示的空白,但是Metzer说下个版本的Atom X3会支持双显示。
|
||||
|
||||
使用的Linux版本是由Intel维护的。Metzer说:“我们需要将Linux和Android保持一致。框架是预安装的,你不能下载任何app”
|
||||
|
||||
英特尔在移动世界大会上向手机制造商们推销这一想法,但却没有实际报告购买该设备的消费者。Metzer说:“芯片已经准备好了,已经为量产准备好了。这可以明天进入生产。这是一个商业决定。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theregister.co.uk/2016/02/23/move_over_continuum_intel_shows_android_smartphone_powering_bigscreen_linux/
|
||||
|
||||
作者:[Tim Anderson][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/2878
|
||||
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
怎样将开源经历添加到你的简历中去
|
||||
==================================================
|
||||

|
||||
在这篇文章中,我将会分享我的一些方法,目的是让你因为曾经为开源事业作出贡献的经历使得你在技术领域的求职中脱颖而出。
|
||||
凡事预则立,不预则废。在你即将进入一个新的领域或者正准备花费整个晚上来彻底完善你的简历之前,先来定义你正在寻找的工作的特征是值得的。你的简历是一张有说服力的作品,因此你必须了解你的观众,从而让它发挥出所有的潜力。看你简历的可能是任何需要你的技能并且恰好能在预算之内聘用你的人。当编辑简历的时候,读一读你的简历上的内容,同时想象一下它们最应该被书写的位置。你看起来像是一个你将会聘用的候选人吗?
|
||||
|
||||
在我看来,我发现对于我所要求的目标职位的所有理想候选人,针对他们每个人的特点列出一张清单有时候是很有帮助的。我将他们每个人的特点清单合并到他们的个人经历中,并阅读工作记录,然后以同样的角色询问同事们。人际关系网和会议是很好的地方去寻求一些乐意提供这种建议的人。一些人喜欢谈论他们自己,并且邀请他们去讲述他们自己的故事的一部分来帮助你去拓展你的知识面,通过这样方式可以使每个人感觉更好。当你和其他人谈论他们的职业路线时,你不仅将会明白怎样去得到你想要从事的工作,而且还能知道你应该避免哪些容易让你失去工作机会的情况和行为。
|
||||
例如,对于一个差劲的角色,有关于他的关键特性列表可能看起来像下面这样:
|
||||
###技术:
|
||||
- 拥有计算机从业方面的经验,更加容易受到Jenkins的青睐。
|
||||
- 深厚的脚本编写背景,如Python和Ruby
|
||||
- 精通eclipse的使用
|
||||
- 基本的git和bash知识
|
||||
###个人而言:
|
||||
- 自我学习者
|
||||
- 良好的交流和文档技巧
|
||||
- 在团队开发方面富有经验
|
||||
- 精通事件捕捉工作流
|
||||
###以任意方式应用
|
||||
记住,你没有必要为了得到一份工作而去满足上面的工作描述列表中列出的每个标准。工作细节描述了任何人都可以离开这个角色,如果你已经知道你即将签约并为之工作几年的公司的全部信息,并且这份工作并不会让你觉得有什么挑战性,或者要求你去拓展你你的技能。如果你对你无法满足清单上的技能列表而感到紧张,那么检查一下自己是否有来自其他经历并能与之媲美的技能。
|
||||
例如,即使有些人从来没有使用过Jenkins,那他也可能从之前使用过Buildbot或者travis CI的项目经验中明白持续集成测试的原则。
|
||||
如果你正在申请一家大型公司,而他们可能拥有一个专门的部门和一套完整的筛选过程来确保他们不会聘用任何不能胜任职位的候选人。也就是说,在你求职的过程中,你所能做的只是提交申请,而决定是否拒绝你是公司管理层的工作。不要过早的将工作拒之门外。
|
||||
现在你已经知道了你的任务是什么,并且还知道你将需要哪些技能去完成这次面试。下一步要做的取决与你已经获取到的经验。
|
||||
### 制造已经存在的事物之间的关联
|
||||
列出一张你过去几年曾经参与过的所有项目。下面是一条快速得到这张清单的方式,生成一个跳转到你的github上的库的导航器,但是需要过滤掉你从其他地方复制过来的项目。除此之外,检查下你的清单上是否有曾经处于领导地位的项目。如果你已经有了一份简历,那么请确保你已经将你所有的经历都列在了上面。
|
||||
考虑下任何一个你曾经作为一个潜在的领导经历并拥有过特权的IRC项目。检查你的会唔和聚会并将你曾经组织过或者作为志愿者参与过的事情添加到你的清单上面。略过你前几年的日程并且标注所有志愿行动或者有作为导师的经历又或者有接触过的公共演讲.
|
||||
现在进入了比较艰难的环节了,将清单上列出的必备技能与个人经历列表上的内容一一对照,我喜欢给工作需要的每个特性用一个字母或者数字作为标记,然后在每一段你经历或参与过并表现出了某一特性的地方标记相同的符号。当你产生怀疑的时候,无论如何也要加上它,尽管这样做更像是在吹嘘,但也好过显示出你的无能。
|
||||
在我们写简历的时候常常被这样的情况所困扰,就是我们不愿冒着过分吹嘘自己的技能的风险。这通常会帮助我们重新考虑这个问题,比如我们会考虑那些组织了会晤的人会表现出更好的领导才能和计划技巧吗?而不是当我组织这个会晤的时候我是否展示出了这些技巧。
|
||||
如果你已经充分了解了你在过去的几年里的业余时间都是怎么度过的或者你写了很多代码,那么你可能现在正面临着一个令人奇怪的问题,你已经拥有了太多的经验以至于一张纸的简历已经无法容纳下这些经验了。那么,如果那些列在你的清单上的经验无法证明你尝试去表现的任何技能的话,那么请扔掉它们吧。如果这份已经被缩短的简历清单上的内容仍然超过一张单页纸的容量的话,那么将你的经验按照一定的优先级排序,例如根据你获得了相关的故事或丰富的经验与所需的技术。
|
||||
在这一方面,显而易见,如果你想要磨练一个独特的技能,那么你就需要一个不错的经历。考虑使用一个类似OpenHatch的问题聚合器,并用它来寻找一个通过使用你从没使用过的工具和技术来锻炼你的技能的开源项目。
|
||||
让你的简历更加漂亮
|
||||
一份简历是否美观取决于它的简洁度,清晰度和布局。每一段经历都应该通过足够的信息来展示给读者并让他们立刻就能明白为什么你要将它包含进去,而且恰到好处。每种类型的信息都应该使用一致的文档格式来表示,一份含有斜体格式或者右对齐格式的或者其他与整体风格不协调的数据绝对会让看的人十分反感。
|
||||
使用工具来给你的简历排版会使之前设定的目标更加容易实现。我喜欢使用LaTeX,因为它
|
||||
的宏系统能够使可视化一致性变得更加容易,并且大量的面试官都能一眼就认出他。你的工具的选择可能是LibreOffice或者HTML,这取决于你的技能和你希望怎样去发布你的简历。
|
||||
记住一点,一份以数字方式提交的简历可以通过关键字被浏览到。因此,当你需要描述你的工作经历的时候使用和工作招聘告示一样的英文缩写对你的求职会有很大的帮助。为了让你的简历更加容易被面试官所使用,首先就要放上最重要的信息。
|
||||
程序员通常难以在为文档排版时量化平衡和布局。我最喜欢的技术是回退并评估我的文档的空格是否处于正确的位置,而这样做的目的就是我的PDF可以全屏显示或者打印出来,然后
|
||||
在镜像里面查看它。如果你正在使用LibreOffice Writer,保存一份你的简历的副本,然后将你的简历中的字体换成一种你无法阅读的语言。这两种技术都强制将你从阅读的内容中脱离出来,让你以一种新的方式查看文档的整体布局。他们把你从一个”那句话措辞不当!”对注意到的事物的批评,比如“在这条线上只有一个字,看起来很有趣”。
|
||||
最后,再次检查你的简历是否在它将要的展示的多媒体上看起来完全正确。如果你以网页的形式发布它,那么在不同屏幕大小的浏览器中测试它的效果。如果它是一份PDF文档,那么在你的手机或者你的朋友的电脑上面打开它,并确保它所需要的字体都是可用的。
|
||||
接下来的步骤
|
||||
最后,不要让你辛苦做出来的简历被浪费了,利用你的LinkedIn帐号把它做成一个镜像。当招聘人员找到你的时候也不要感到奇怪。尽管他们描述的工作内容并不是恰好适合你,但是你可以利用他们的时间和兴趣来得到关于你的简历中有哪些地方好与不好的反馈信息。
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://opensource.com/business/16/2/add-open-source-to-your-resume
|
||||
|
||||
作者:[edunham][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/edunham
|
||||
[1]: https://jenkins-ci.org/
|
||||
[2]: http://buildbot.net/
|
||||
[3]: https://travis-ci.org/
|
||||
[4]: https://github.com/settings/organizations
|
||||
[5]: https://www.latex-project.org/
|
||||
[6]: https://www.libreoffice.org/download/libreoffice-fresh/
|
||||
@ -0,0 +1,53 @@
|
||||
NODEOS: NODE爱好者的Linux发行版
|
||||
================================================
|
||||
|
||||

|
||||
|
||||
[NodeOS][1]是一个基于[Node.js][2]的操作系统,自去年的首个[发布候选版][3]之后正朝着它的1.0版本进发。
|
||||
|
||||
如果你是第一次听到它,NodeOS是首个在[Linux][5]内核之上由Node.js和[npm][4]驱动的操作系统。[Jacob Groundwater][6]仔2013年中介绍了这个项目。操作系统中用到的主要技术是:
|
||||
|
||||
- **Linux 内核**: 这个系统内置了Linux内核
|
||||
- **Node.js 运行时**: Node作为主要的运行时
|
||||
- **npm 包管理**: npm作为包管理
|
||||
|
||||
NodeOS源码托管在[Github][7]上,因此,任何感兴趣的人都可以轻松贡献或者报告bug。用户可以从源码构建或者使用[预编译镜像][8]。构建过程及使用可以在项目仓库中找到。
|
||||
|
||||
NodeOS背后的思想是提供足够npm运行的环境,剩余的功能就可以来自npm包管理。因此,用户可以使用大量的大约250,000的包,并且这个数目每天都还在增长。并且所有的都是开源的,你可以根据你的需要很容易地打补丁或者增加更多的包。
|
||||
|
||||
NodeOS核心开发被分离成了不同的层,基本的结构包含:
|
||||
|
||||
- **barebones** – 带有可以启动到Node.js REPL的initramfs的自定义内核
|
||||
- **initramfs** – =用于挂载用户分区以及启动系统的initram文件系统
|
||||
- **rootfs** – 托管linux内核及initramfs文件的只读分区
|
||||
- **usersfs** – 多用户文件系统(如传统系统一样)
|
||||
|
||||
NodeOS的目标是可以仔任何平台上运行,包括- **真实的硬件(用户计算机或者SoC)**、**云平台、虚拟机、PaaS提供商,容器**(Docker和Vagga)等等。如今看来,它做得似乎不错。在3.3号,NodeOS的成员[Jesús Leganés Combarro][9]在Github上[宣布][10]:
|
||||
|
||||
>**NodeOS不再是一个玩具系统了**,它现在开始可以用在有实际需求的生产环境中了。
|
||||
|
||||
因此,如果你是Node.js的死忠或者乐于尝试新鲜事物,这或许值得你一试。在相关的文章中,你应该了解这些[Linux发行版的具体用法][11]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/nodeos-operating-system/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/munif/
|
||||
[1]: http://node-os.com/
|
||||
[2]: https://nodejs.org/en/
|
||||
[3]: https://github.com/NodeOS/NodeOS/releases/tag/v1.0-RC1
|
||||
[4]: https://www.npmjs.com/
|
||||
[5]: http://itsfoss.com/tag/linux/
|
||||
[6]: https://github.com/groundwater
|
||||
[7]: https://github.com/nodeos/nodeos
|
||||
[8]: https://github.com/NodeOS/NodeOS/releases
|
||||
[9]: https://github.com/piranna
|
||||
[10]: https://github.com/NodeOS/NodeOS/issues/216
|
||||
[11]: http://itsfoss.com/weird-ubuntu-based-linux-distributions/
|
||||
@ -0,0 +1,142 @@
|
||||
ORB:新一代 Linux 应用
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
我们之前讨论过[在 Ubuntu 上离线安装应用][1]。我们现在要再次讨论它。
|
||||
|
||||
[Orbital Apps][2] 给我们带来了新的软件包类型,**ORB**,它带有便携软件,交互式安装向导支持,以及离线使用的能力。
|
||||
|
||||
便携软件很方便。主要是因为它们能够无需任何管理员权限直接运行,也能够带着所有的设置和数据随U盘存储。而交互式的安装向导也能让我们轻松地安装应用。
|
||||
|
||||
### 开放可运行包 OPEN RUNNABLE BUNDLE (ORB)
|
||||
|
||||
ORB 是一个免费和开源的包格式,它和其它包格式在很多方面有所不同。ORB 的一些特性:
|
||||
|
||||
- **压缩**:所有的包经过压缩,使用 squashfs,体积最多减少 60%。
|
||||
- **便携模式**:如果一个便携 ORB 应用是从可移动设备运行的,它会把所有设置和数据存储在那之上。
|
||||
- **安全**:所有的 ORB 包使用 PGP/RSA 签名,通过 TLS 1.2 分发。
|
||||
- **离线**:所有的依赖都打包进软件包,所以不再需要下载依赖。
|
||||
- **开放包**:ORB 包可以作为 ISO 镜像挂载。
|
||||
|
||||
### 种类
|
||||
|
||||
ORB 应用现在有两种类别:
|
||||
|
||||
- 便携软件
|
||||
- SuperDEB
|
||||
|
||||
#### 1. 便携 ORB 软件
|
||||
|
||||
便携 ORB 软件可以立即运行而不需要任何的事先安装。那意味着它不需要管理员权限和依赖!你可以直接从 Orbital Apps 网站下载下来就能使用。
|
||||
|
||||
并且由于它支持便携模式,你可以将它拷贝到U盘携带。它所有的设置和数据会和它一起存储在U盘。只需将U盘连接到任何运行 Ubuntu 16.04 的机器上就行了。
|
||||
|
||||
##### 可用便携软件
|
||||
|
||||
目前有超过 35 个软件以便携包的形式提供,包括一些十分流行的软件,比如:[Deluge][3],[Firefox][4],[GIMP][5],[Libreoffice][6],[uGet][7] 以及 [VLC][8]。
|
||||
|
||||
完整的可用包列表可以查阅 [便携 ORB 软件列表][9]。
|
||||
|
||||
##### 使用便携软件
|
||||
|
||||
按照以下步骤使用便携 ORB 软件:
|
||||
|
||||
- 从 Orbital Apps 网站下载想要的软件包。
|
||||
- 将其移动到想要的位置(本地磁盘/U盘)。
|
||||
- 打开存储 ORB 包的目录。
|
||||
|
||||

|
||||
|
||||
- 打开 ORB 包的属性。
|
||||
|
||||

|
||||
>给 ORB 包添加运行权限
|
||||
|
||||
- 在权限标签页添加运行权限。
|
||||
- 双击打开它。
|
||||
|
||||
等待几秒,让它准备好运行。大功告成。
|
||||
|
||||
#### 2. SuperDEB
|
||||
|
||||
另一种类型的 ORB 软件是 SuperDEB。SuperDEB 很简单,交互式安装向导能够让软件安装过程顺利得多。如果你不喜欢从终端或软件中心安装软件,superDEB 就是你的菜。
|
||||
|
||||
最有趣的部分是你安装时不需要一个互联网连接,因为所有的依赖都由安装向导打包了。
|
||||
|
||||
##### 可用的 SuperDEB
|
||||
|
||||
超过 60 款软件以 SuperDEB 的形式提供。其中一些流行的有:[Chromium][10],[Deluge][3],[Firefox][4],[GIMP][5],[Libreoffice][6],[uGet][7] 以及 [VLC][8]。
|
||||
|
||||
完整的可用 SuperDEB 列表,参阅 [SuperDEB 列表][11]。
|
||||
|
||||
##### 使用 SuperDEB 安装向导
|
||||
|
||||
- 从 Orbital Apps 网站下载需要的 SuperDEB。
|
||||
- 像前面一样给它添加**运行权限**(属性 > 权限)。
|
||||
- 双击 SuperDEB 安装向导并按下列说明操作:
|
||||
|
||||

|
||||
>点击 OK
|
||||
|
||||

|
||||
>输入你的密码并继续
|
||||
|
||||

|
||||
>它会开始安装…
|
||||
|
||||

|
||||
>一会儿他就完成了…
|
||||
|
||||
- 完成安装之后,你就可以正常使用了。
|
||||
|
||||
### ORB 软件兼容性
|
||||
|
||||
从 Orbital Apps 可知,它们完全适配 Ubuntu 16.04 [64 bit]。
|
||||
|
||||
>阅读建议:[如何在 Ubuntu 获知你的是电脑 32 位还是 64 位的][12]。
|
||||
|
||||
至于其它发行版兼容性不受保证。但我们可以说,它在所有 Ubuntu 16.04 衍生版(UbuntuMATE,UbuntuGNOME,Lubuntu,Xubuntu 等)以及基于 Ubuntu 16.04 的发行版(比如即将到来的 Linux Mint 18)上都适用。我们现在还不清楚 Orbital Apps 是否有计划拓展它的支持到其它版本 Ubuntu 或 Linux 发行版上。
|
||||
|
||||
如果你在你的系统上经常使用便携 ORB 软件,你可以考虑安装 ORB 启动器。它不是必需的,但是推荐安装它以获取更佳的体验。最简短的 ORB 启动器安装流程是打开终端输入以下命令:
|
||||
|
||||
```
|
||||
wget -O - https://www.orbital-apps.com/orb.sh | bash
|
||||
```
|
||||
|
||||
你可以在[官方文档][13]找到更加详细的介绍。
|
||||
|
||||
### 如果我需要的软件不在列表里?
|
||||
|
||||
如果你需要一个当前并没有可用 ORB 包的软件,你可以[联系][14] Orbital Apps。好消息是,Orbital Apps 正在致力于推出一个创建 ORB 包的工具。所以,不久后我们有希望可以自己制作 ORB 包!
|
||||
|
||||
多说一句,这个文章是关于离线安装软件的。如果你感兴趣的话,你可以看看[如何离线更新或升级 Ubuntu][15]。
|
||||
|
||||
所以,你怎么看 Orbital Apps 的便携软件和 SuperDEB 安装向导?你会试试吗?
|
||||
|
||||
|
||||
----------------------------------
|
||||
via: http://itsfoss.com/orb-linux-apps/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/munif/
|
||||
[1]: http://itsfoss.com/cube-lets-install-linux-applications-offline/
|
||||
[2]: https://www.orbital-apps.com/
|
||||
[3]: https://www.orbital-apps.com/download/portable_apps_linux/deluge
|
||||
[4]: https://www.orbital-apps.com/download/portable_apps_linux/firefox
|
||||
[5]: https://www.orbital-apps.com/download/portable_apps_linux/gimp
|
||||
[6]: https://www.orbital-apps.com/download/portable_apps_linux/libreoffice
|
||||
[7]: https://www.orbital-apps.com/download/portable_apps_linux/uget
|
||||
[8]: https://www.orbital-apps.com/download/portable_apps_linux/vlc
|
||||
[9]: https://www.orbital-apps.com/download/portable_apps_linux/
|
||||
[10]: https://www.orbital-apps.com/download/superdeb_installers/ubuntu_16.04_64bits/chromium/
|
||||
[11]: https://www.orbital-apps.com/superdebs/ubuntu_16.04_64bits/
|
||||
[12]: http://itsfoss.com/32-bit-64-bit-ubuntu/
|
||||
[13]: https://www.orbital-apps.com/documentation
|
||||
[14]: https://www.orbital-apps.com/contact
|
||||
[15]: http://itsfoss.com/upgrade-or-update-ubuntu-offline-without-internet/
|
||||
@ -0,0 +1,187 @@
|
||||
Linux 平台下 Python 脚本编程入门 – Part 1
|
||||
===============================================================================
|
||||
|
||||
|
||||
众所周知,系统管理员需要精通一门脚本语言,而且招聘机构列出的职位需求上也会这么写。大多数人会认为 Bash (或者其他的 shell 语言)用起来很方便,但一些强大的语言(比如 Python)会给你带来一些其它的好处。
|
||||
|
||||

|
||||
> 在 Linux 中学习 Python 脚本编程
|
||||
|
||||
首先,我们会使用 Python 的命令行工具,还会接触到 Python 的面向对象特性(这篇文章的后半部分会谈到它)。
|
||||
|
||||
最后,学习 Python
|
||||
可以助力于你在[桌面应用开发][2]及[数据科学领域][3]的事业。
|
||||
|
||||
容易上手,广泛使用,拥有海量“开箱即用”的模块(它是一组包含 Python 声明的外部文件),Python 理所当然地成为了美国计算机专业大学生在一年级时所上的程序设计课所用语言的不二之选。
|
||||
|
||||
在这个由两篇文章构成的系列中,我们将回顾 Python
|
||||
的基础部分,希望初学编程的你能够将这篇实用的文章作为一个编程入门的跳板,和日后使用 Python 时的一篇快速指引。
|
||||
|
||||
### Linux 中的 Python
|
||||
|
||||
Python 2.x 和 3.x 通常已经内置在现代 Linux 发行版中,你可以立刻使用它。你可以终端模拟器中输入 `python` 或 `python3` 来进入 Python shell, 并输入 `quit()` 退出。
|
||||
|
||||
```
|
||||
$ which python
|
||||
$ which python3
|
||||
$ python -v
|
||||
$ python3 -v
|
||||
$ python
|
||||
>>> quit()
|
||||
$ python3
|
||||
>>> quit()
|
||||
```
|
||||
|
||||
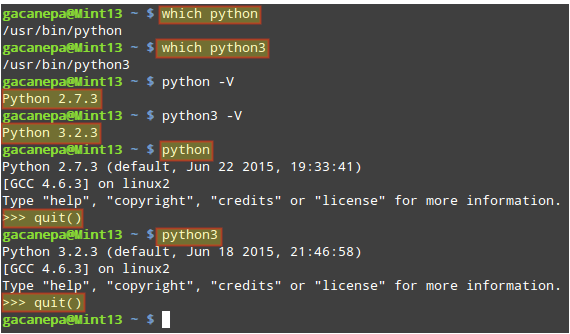
|
||||
> 在 Linux 中运行 Python 命令
|
||||
|
||||
如果你希望在键入 `python` 时使用 Python 3.x 而不是 2.x,你可以像下面一样更改对应的符号链接:
|
||||
|
||||
```
|
||||
$ sudo rm /usr/bin/python
|
||||
$ cd /usr/bin
|
||||
$ ln -s python3.2 python # Choose the Python 3.x binary here
|
||||
```
|
||||
|
||||
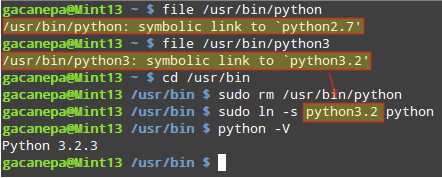
|
||||
> 删除 Python 2,使用 Python 3
|
||||
|
||||
顺便一提,有一点需要注意:尽管 Python 2.x 仍旧被使用,但它并不会被积极维护。因此,你可能要考虑像上面指示的那样来切换到 3.x。2.x 和 3.x 的语法有一些不同,我们会在这个系列文章中使用后者。
|
||||
|
||||
另一个在 Linux 中使用 Python 的方法是通过 IDLE (the Python Integrated Development Environment),一个为编写 Python 代码而生的图形用户界面。在安装它之前,你最好查看一下适用于你的 Linux 发行版的 IDLE 可用版本。
|
||||
|
||||
```
|
||||
# aptitude search idle [Debian 及其衍生发行版]
|
||||
# yum search idle [CentOS 和 Fedora]
|
||||
# dnf search idle [Fedora 23+ 版本]
|
||||
```
|
||||
|
||||
然后,你可以像下面一样安装它:
|
||||
|
||||
```
|
||||
$ sudo aptitude install idle-python3.2 # I'm using Linux Mint 13
|
||||
```
|
||||
|
||||
安装成功后,你会看到 IDLE 的运行画面。它很像 Python shell,但是你可以用它做更多 Python shell 做不了的事。
|
||||
|
||||
比如,你可以:
|
||||
|
||||
1. 轻松打开外部文件 (File → Open);
|
||||
|
||||
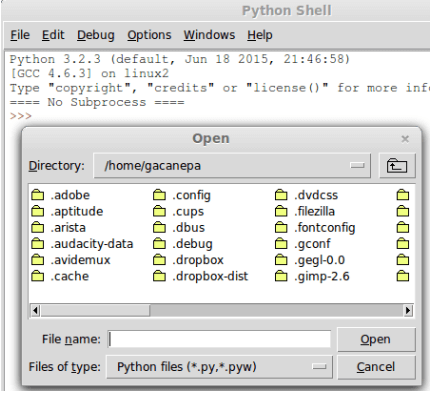
|
||||
> Python Shell
|
||||
|
||||
2. 复制 (`Ctrl + C`) 和粘贴 (`Ctrl + V`) 文本;
|
||||
3. 查找和替换文本;
|
||||
4. 显示可能的代码补全(一个在其他 IDE 里可能叫做 Intellisense 或者 Autocompletion 的功能);
|
||||
5. 更改字体和字号,等等。
|
||||
|
||||
最厉害的是,你可以用 IDLE 创建桌面工程。
|
||||
|
||||
我们在这两篇文章中不会开发桌面应用,所以你可以根据喜好来选择 IDLE 或 Python shell 去运行下面的例子。
|
||||
|
||||
### Python 中的基本运算
|
||||
|
||||
就像你预料的那样,你能够直接进行算术操作(你可以在所有操作中使用足够多的括号!),还可以轻松地使用 Python 拼接字符串。
|
||||
|
||||
你还可以将运算结果赋给一个变量,然后在屏幕上显示它。Python 有一个叫做输出 (concatenation) 的实用功能——把一串变量和/或字符串用逗号分隔,然后在 print 函数中插入,它会返回一个由你刚才提供的变量依序构成的句子:
|
||||
|
||||
```
|
||||
>>> a = 5
|
||||
>>> b = 8
|
||||
>>> x = b / a
|
||||
>>> x
|
||||
1.6
|
||||
>>> print(b, "divided by", a, "equals", x)
|
||||
```
|
||||
|
||||
注意,你可以将不同类型的变量(数字,字符串,布尔符号等等)混合在一起。当你将一个值赋给一个变量后,你可以随后更改它的类型,不会有任何问题(因此,Python 被称为动态类型语言)。
|
||||
|
||||
如果你尝试在静态类型语言中(如 Java 或 C#)做这件事,它将抛出一个错误。
|
||||
|
||||
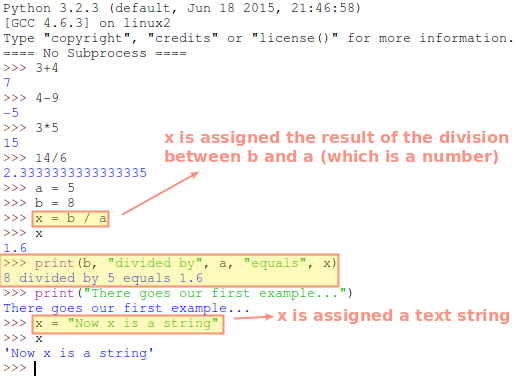
|
||||
> 学习 Python 的基本操作
|
||||
|
||||
### 面向对象编程的简单介绍
|
||||
|
||||
在面向对象编程(OOP)中,程序中的所有实体都会由对象的形式呈现,所以它们可以与其他对象交互。因此,对象拥有属性,而且大多数对象可以完成动作(这被称为对象的方法)。
|
||||
|
||||
举个例子:我们来想象一下,创建一个对象“狗”。它可能拥有的一些属性有`颜色`、`品种`、`年龄`等等,而它可以完成的动作有 `叫()`、`吃()`、`睡觉()`,诸如此类。
|
||||
|
||||
你可以看到,方法名后面会跟着一对括号,他们当中可能会包含一个或多个参数(向方法中传递的值),也有可能什么都不包含。
|
||||
|
||||
我们用 Python 的基本对象类型之一——列表来解释这些概念。
|
||||
|
||||
### 解释对象的属性和方法:Python 中的列表
|
||||
|
||||
列表是条目的有序组合,而这些条目所属的数据类型并不需要相同。我们像下面一样来使用一对方括号,来创建一个名叫 `rockBands` 的列表:
|
||||
|
||||
你可以向 `rockBands` 的 `append()` 方法传递条目,来将它添加到列表的尾部,就像下面这样:
|
||||
|
||||
```
|
||||
>>> rockBands = []
|
||||
>>> rockBands.append("The Beatles")
|
||||
>>> rockBands.append("Pink Floyd")
|
||||
>>> rockBands.append("The Rolling Stones")
|
||||
```
|
||||
|
||||
为了从列表中移除元素,我们可以向 `remove()` 方法传递特定元素,或向 `pop()` 中传递列表中待删除元素的位置(从 0 开始计数)。
|
||||
|
||||
换句话说,我们可以用下面这种方法来从列表中删除 “The Beatles”:
|
||||
|
||||
```
|
||||
>>> rockBands.remove("The Beatles")
|
||||
```
|
||||
|
||||
或者用这种方法:
|
||||
|
||||
```
|
||||
>>> rockBands.pop(0)
|
||||
```
|
||||
|
||||
如果你输入了对象的名字,然后在后面输入了一个点,你可以按 Ctrl + 空格来显示这个对象的可用方法列表。
|
||||
|
||||
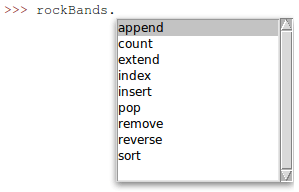
|
||||
> 列出可用的 Python 方法
|
||||
|
||||
列表中含有的元素个数是它的一个属性。它通常被叫做“长度”,你可以通过向内建函数 `len` 传递一个列表作为它的参数来显示该列表的长度(顺便一提,之前的例子中提到的 print 语句,是 Python 的另一个内建函数)。
|
||||
|
||||
如果你在 IDLE 中输入 `len`,然后跟上一个不闭合的括号,你会看到这个函数的默认语法:
|
||||
|
||||
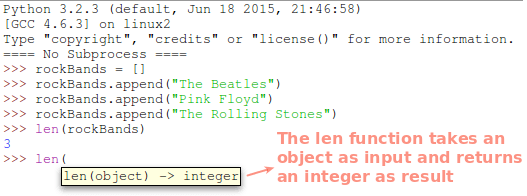
|
||||
> Python 的 len 函数
|
||||
|
||||
现在我们来看看列表中的特定条目。他们也有属性和方法吗?答案是肯定的。比如,你可以将一个字符串条目装换为大写形式,并获取这个字符串所包含的字符数量。像下面这样做:
|
||||
|
||||
```
|
||||
>>> rockBands[0].upper()
|
||||
'THE BEATLES'
|
||||
>>> len(rockBands[0])
|
||||
11
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇文章中,我们简要介绍了 Python,它的命令行 shell,IDLE,展示了如何执行算术运算,如何在变量中存储数据,如何使用 `print` 函数在屏幕上重新显示那些数据(无论是它们本身还是它们的一部分),还通过一个实际的例子解释了对象的属性和方法。
|
||||
|
||||
下一篇文章中,我们会展示如何使用条件语句和循环语句来实现流程控制。我们也会解释如何编写一个脚本来帮助我们完成系统管理任务。
|
||||
|
||||
你是不是想继续学习一些有关 Python 的知识呢?敬请期待本系列的第二部分(我们会将 Python 的慷慨、脚本中的命令行工具与其他部分结合在一起),你还可以考虑购买我们的《终极 Python 编程》系列教程([这里][4]有详细信息)。
|
||||
|
||||
像往常一样,如果你对这篇文章有什么问题,可以向我们寻求帮助。你可以使用下面的联系表单向我们发送留言,我们会尽快回复你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/learn-python-programming-and-scripting-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/category/bash-shell/
|
||||
[2]: http://www.tecmint.com/create-gui-applications-in-linux/
|
||||
[3]: http://www.datasciencecentral.com/profiles/blogs/the-guide-to-learning-python-for-data-science-2
|
||||
[4]: http://www.tecmint.com/learn-python-programming-online-with-ultimate-python-coding/
|
||||
@ -0,0 +1,172 @@
|
||||
2016年最佳 Linux 图像管理软件
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
通常谈及 Linux 上的应用程序时,我们有很多选择,但有时候选择的余地却很小。
|
||||
|
||||
有一些读者要我们做一个合宜的**图像管理软件**列表,来代替 Linux 上已被弃用的 Picasa 应用。
|
||||
|
||||
其实 Linux 平台上还是有很多很好的图像管理软件的,你可以根据你图片库的大小选择合适的应用。
|
||||
|
||||
这个列表和我们先前的 [最佳图像程序应用][1] 有些差别,上次我们介绍了图像编辑软件,绘图软件等,而这次的介绍主要集中在图像管理软件上。
|
||||
|
||||
好,下面我们开始介绍。我会详细说明在 Ubuntu 下的安装命令以及衍生的命令,我们只需要打开终端运行这些命令。
|
||||
|
||||
### [GTHUMB](https://wiki.gnome.org/Apps/gthumb)
|
||||
|
||||

|
||||
>gThumb 图像编辑器
|
||||
|
||||
gThumb 是在 GNOME 桌面环境下的一个轻量级的图像管理应用,它涵盖了基本图像管理功能,编辑图片以及更加高级的操作,gThumb 主要功能如下:
|
||||
|
||||
- 图片查看:支持所有主流的图片格式(包括gif)和元数据(EXIF, XMP 等)。
|
||||
|
||||
- 图片浏览:所有基础的浏览操作(缩略图,移动,复制,删除等)以及书签支持。
|
||||
|
||||
- 图片管理:使用标签操作图片,目录和图片库。从数码相机,网络相册(Picasa,Flickr,Facebook等)整合,导入图片。
|
||||
|
||||
- 图片编辑:基本图像编辑操作,滤镜,格式转换等。
|
||||
|
||||
- 更多功能请参考官方 [gThumb功能][2] 列表。如果你使用的是 GNOME 或者基于 GNOME 的桌面环境(如 MATE),那么你一定要试用一下。
|
||||
|
||||
#### GTHUMB 安装
|
||||
|
||||
```
|
||||
sudo apt-get install gthumb
|
||||
```
|
||||
|
||||
|
||||
### [DIGIKAM][3]
|
||||
|
||||

|
||||
>digiKam
|
||||
|
||||
digiKam 主要为 KDE 而设计,在其他桌面环境下也可以使用。它有很多很好的图像界面功能,主要功能如下所示:
|
||||
|
||||
- 图片管理:相册,子相册,标签,评论,元数据,排序支持。
|
||||
|
||||
- 图片导入:支持从数码相机,USB设备,网络相册(包括 Picasa 和 Facebook)导入,以及另外一些功能。
|
||||
|
||||
- 图片输出:支持输出至很多网络在线平台,以及各式转换。
|
||||
|
||||
- 图片编辑:支持很多图像编辑的操作。
|
||||
|
||||
digiKam 是众多优秀图像管理软件之一。
|
||||
|
||||
#### DIGIKAM 安装
|
||||
|
||||
```
|
||||
sudo apt-get install digikam
|
||||
```
|
||||
|
||||
### [SHOTWELL][4]
|
||||
|
||||

|
||||
>Shotwell
|
||||
|
||||
Shotwell 图像管理也是为 GNOME 桌面环境设计,虽然功能不及 gThumb 多,但满足了基本需求。主要功能如下:
|
||||
|
||||
- 从磁盘或数码相机导入图片。
|
||||
|
||||
- 项目,标签和文件夹管理。
|
||||
|
||||
- 基本图片编辑功能和格式转换。
|
||||
|
||||
- 支持上传至网络平台(Facebook,Flickr,Tumblr 等)。
|
||||
|
||||
如果你想要一款功能相对简单的应用,你可以尝试一下这个。
|
||||
|
||||
#### SHOTWELL 安装
|
||||
|
||||
```
|
||||
sudo apt-get install shotwell
|
||||
```
|
||||
|
||||
### [KPHOTOALBUM][5]
|
||||
|
||||

|
||||
>KPhotoAlbum
|
||||
|
||||
KPhotoAlbum 是一款在 KDE 桌面环境下的图像管理应用。它有一些独特的功能:分类和基于时间浏览。你可以基于人物,地点,时间分类;另外在用户图形界面底部会显示时间栏。
|
||||
|
||||
KPhotoAlbum 有很多图像管理和编辑功能,主要功能包括:
|
||||
|
||||
- 高级图片操作(目录,子目录,标签,元数据,注释等)。
|
||||
|
||||
- 图片导入导出功能(包括主流图片分享平台)。
|
||||
|
||||
- 众多编辑功能(包括批量处理)。
|
||||
|
||||
这些高级的功能有它们的缺点,就是用户需要手工操作。但如果你是KDE爱好者,这是个好的选择。它完美适用 KDE,但是你也可以在非 KDE 桌面环境下使用 KPhotoAlbum。
|
||||
|
||||
#### KPHOTOALBUM 安装
|
||||
|
||||
```
|
||||
sudo apt-get install kphotoalbum
|
||||
```
|
||||
|
||||
### [DARKTABLE][7]
|
||||
|
||||

|
||||
>Darktable
|
||||
|
||||
Darktable 相较于图像管理更偏向于图像编辑。Darktable 有良好的用户图形界面,对桌面环境没有特殊的要求,以及图像编辑功能。它的基本功能如下:
|
||||
|
||||
- 基本图片管理。
|
||||
|
||||
- 众多高级的图片编辑功能。
|
||||
|
||||
- 支持导出至 Picasa 和 Flickr 和格式转换。
|
||||
|
||||
如果你喜欢照片编辑和润色,Darktable 是个好的选择。
|
||||
|
||||
> 推荐阅读:[怎样在Ubuntu下通过PPA安装Darktable 2.0][8]
|
||||
|
||||
#### DARKTABLE 安装
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:pmjdebruijn/darktable-release
|
||||
sudo apt-get update
|
||||
sudo apt-get install darktable
|
||||
```
|
||||
|
||||
### 其它
|
||||
|
||||
如果你想要功能简单的应用,比如从便携设备(相机,手机,便携设备等)中导入照片并存入磁盘,使用 [Rapid Photo Downloader][9],它很适合从便携设备中导入和备份图片,而且安装配置过程简单。
|
||||
|
||||
在 Ubuntu 上安装 Rapid Photo Downloade,打开终端输入命令:
|
||||
|
||||
```
|
||||
sudo apt-get install rapid-photo-downloader
|
||||
```
|
||||
|
||||
如果你想尝试更多的选择:
|
||||
- [GNOME Photos][10] (GNOME桌面环境下的图像查看器)
|
||||
- [Gwenview][11] (KDE桌面环境下的图像查看器)
|
||||
- [Picty][12] (开源图像管理器)
|
||||
|
||||
那么,你正在使用,或者打算使用其中一款应用吗?你有其它更好的推荐吗?你有最喜欢的 Linux 图像管理软件吗?分享你的观点。
|
||||
|
||||
----------
|
||||
via: http://itsfoss.com/linux-photo-management-software/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[sarishinohara](https://github.com/sarishinohara)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/munif/
|
||||
[1]: http://itsfoss.com/image-applications-ubuntu-linux/
|
||||
[2]: https://wiki.gnome.org/Apps/gthumb/features
|
||||
[3]: https://www.digikam.org/
|
||||
[4]: https://wiki.gnome.org/Apps/Shotwell
|
||||
[5]: https://www.kphotoalbum.org/
|
||||
[6]: https://www.kde.org/
|
||||
[7]: http://www.darktable.org/
|
||||
[8]: http://itsfoss.com/darktable-20-released-installation-ppa/
|
||||
[9]: http://www.damonlynch.net/rapid/index.html
|
||||
[10]: https://wiki.gnome.org/Apps/Photos
|
||||
[11]: https://userbase.kde.org/Gwenview
|
||||
[12]: https://github.com/spillz/picty
|
||||
@ -0,0 +1,996 @@
|
||||
用Python实现Python解释器
|
||||
===
|
||||
|
||||
_Allison是Dropbox的工程师,在那里她维护着世界上最大的由Python客户组成的网络。在Dropbox之前,她是Recurse Center的导师, 曾在纽约写作。在北美的PyCon做过关于Python内部机制的演讲,并且她喜欢奇怪的bugs。她的博客地址是[akaptur.com](http://akaptur.com)._
|
||||
|
||||
## Introduction
|
||||
|
||||
Byterun是一个用Python实现的Python解释器。随着我在Byterun上的工作,我惊讶并很高兴地的发现,这个Python解释器的基础结构可以满足500行的限制。在这一章我们会搞清楚这个解释器的结构,给你足够的知识探索下去。我们的目标不是向你展示解释器的每个细节---像编程和计算机科学其他有趣的领域一样,你可能会投入几年的时间去搞清楚这个主题。
|
||||
|
||||
Byterun是Ned Batchelder和我完成的,建立在Paul Swartz的工作之上。它的结构和主要的Python实现(CPython)差不多,所以理解Byterun会帮助你理解大多数解释器特别是CPython解释器。(如果你不知道你用的是什么Python,那么很可能它就是CPython)。尽管Byterun很小,但它能执行大多数简单的Python程序。
|
||||
|
||||
### A Python Interpreter
|
||||
|
||||
在开始之前,让我们缩小一下“Pyhton解释器”的意思。在讨论Python的时候,“解释器”这个词可以用在很多不同的地方。有的时候解释器指的是REPL,当你在命令行下敲下`python`时所得到的交互式环境。有时候人们会相互替代的使用Python解释器和Python来说明执行Python代码的这一过程。在本章,“解释器”有一个更精确的意思:执行Python程序过程中的最后一步。
|
||||
|
||||
在解释器接手之前,Python会执行其他3个步骤:词法分析,语法解析和编译。这三步合起来把源代码转换成_code object_,它包含着解释器可以理解的指令。而解释器的工作就是解释code object中的指令。
|
||||
|
||||
你可能很奇怪执行Python代码会有编译这一步。Python通常被称为解释型语言,就像Ruby,Perl一样,它们和编译型语言相对,比如C,Rust。然而,这里的术语并不是它看起来的那样精确。大多数解释型语言包括Python,确实会有编译这一步。而Python被称为解释型的原因是相对于编译型语言,它在编译这一步的工作相对较少(解释器做相对多的工作)。在这章后面你会看到,Python的编译器比C语言编译器需要更少的关于程序行为的信息。
|
||||
|
||||
### A Python Python Interpreter
|
||||
|
||||
Byterun是一个用Python写的Python解释器,这点可能让你感到奇怪,但没有比用C语言写C语言编译器更奇怪。(事实上,广泛使用的gcc编译器就是用C语言本身写的)你可以用几乎的任何语言写一个Python解释器。
|
||||
|
||||
用Python写Python既有优点又有缺点。最大的缺点就是速度:用Byterun执行代码要比用CPython执行慢的多,CPython解释器是用C语言实现的并做了优化。然而Byterun是为了学习而设计的,所以速度对我们不重要。使用Python最大优点是我们可以*仅仅*实现解释器,而不用担心Python运行时的部分,特别是对象系统。比如当Byterun需要创建一个类时,它就会回退到“真正”的Python。另外一个优势是Byterun很容易理解,部分原因是它是用高级语言写的(Python!)(另外我们不会对解释器做优化 --- 再一次,清晰和简单比速度更重要)
|
||||
|
||||
## Building an Interpreter
|
||||
|
||||
在我们考察Byterun代码之前,我们需要一些对解释器结构的高层次视角。Python解释器是如何工作的?
|
||||
|
||||
Python解释器是一个_虚拟机_,模拟真实计算机的软件。我们这个虚拟机是栈机器,它用几个栈来完成操作(与之相对的是寄存器机器,它从特定的内存地址读写数据)。
|
||||
|
||||
Python解释器是一个_字节码解释器_:它的输入是一些命令集合称作_字节码_。当你写Python代码时,词法分析器,语法解析器和编译器生成code object让解释器去操作。每个code object都包含一个要被执行的指令集合 --- 它就是字节码 --- 另外还有一些解释器需要的信息。字节码是Python代码的一个_中间层表示_:它以一种解释器可以理解的方式来表示源代码。这和汇编语言作为C语言和机器语言的中间表示很类似。
|
||||
|
||||
### A Tiny Interpreter
|
||||
|
||||
为了让说明更具体,让我们从一个非常小的解释器开始。它只能计算两个数的和,只能理解三个指令。它执行的所有代码只是这三个指令的不同组合。下面就是这三个指令:
|
||||
|
||||
- `LOAD_VALUE`
|
||||
- `ADD_TWO_VALUES`
|
||||
- `PRINT_ANSWER`
|
||||
|
||||
我们不关心词法,语法和编译,所以我们也不在乎这些指令是如何产生的。你可以想象,你写下`7 + 5`,然后一个编译器为你生成那三个指令的组合。如果你有一个合适的编译器,你甚至可以用Lisp的语法来写,只要它能生成相同的指令。
|
||||
|
||||
假设
|
||||
|
||||
```python
|
||||
7 + 5
|
||||
```
|
||||
|
||||
生成这样的指令集:
|
||||
|
||||
```python
|
||||
what_to_execute = {
|
||||
"instructions": [("LOAD_VALUE", 0), # the first number
|
||||
("LOAD_VALUE", 1), # the second number
|
||||
("ADD_TWO_VALUES", None),
|
||||
("PRINT_ANSWER", None)],
|
||||
"numbers": [7, 5] }
|
||||
```
|
||||
|
||||
Python解释器是一个_栈机器_,所以它必须通过操作栈来完成这个加法。(\aosafigref{500l.interpreter.stackmachine}.)解释器先执行第一条指令,`LOAD_VALUE`,把第一个数压到栈中。接着它把第二个数也压到栈中。然后,第三条指令,`ADD_TWO_VALUES`,先把两个数从栈中弹出,加起来,再把结果压入栈中。最后一步,把结果弹出并输出。
|
||||
|
||||
\aosafigure[240pt]{interpreter-images/interpreter-stack.png}{A stack machine}{500l.interpreter.stackmachine}
|
||||
|
||||
`LOAD_VALUE`这条指令告诉解释器把一个数压入栈中,但指令本身并没有指明这个数是多少。指令需要一个额外的信息告诉解释器去哪里找到这个数。所以我们的指令集有两个部分:指令本身和一个常量列表。(在Python中,字节码就是我们称为的“指令”,而解释器执行的是_code object_。)
|
||||
|
||||
为什么不把数字直接嵌入指令之中?想象一下,如果我们加的不是数字,而是字符串。我们可不想把字符串这样的东西加到指令中,因为它可以有任意的长度。另外,我们这种设计也意味着我们只需要对象的一份拷贝,比如这个加法 `7 + 7`, 现在常量表 `"numbers"`只需包含一个`7`。
|
||||
|
||||
你可能会想为什么会需要除了`ADD_TWO_VALUES`之外的指令。的确,对于我们两个数加法,这个例子是有点人为制作的意思。然而,这个指令却是建造更复杂程序的轮子。比如,就我们目前定义的三个指令,只要给出正确的指令组合,我们可以做三个数的加法,或者任意个数的加法。同时,栈提供了一个清晰的方法去跟踪解释器的状态,这为我们增长的复杂性提供了支持。
|
||||
|
||||
现在让我们来完成我们的解释器。解释器对象需要一个栈,它可以用一个列表来表示。它还需要一个方法来描述怎样执行每条指令。比如,`LOAD_VALUE`会把一个值压入栈中。
|
||||
|
||||
```python
|
||||
class Interpreter:
|
||||
def __init__(self):
|
||||
self.stack = []
|
||||
|
||||
def LOAD_VALUE(self, number):
|
||||
self.stack.append(number)
|
||||
|
||||
def PRINT_ANSWER(self):
|
||||
answer = self.stack.pop()
|
||||
print(answer)
|
||||
|
||||
def ADD_TWO_VALUES(self):
|
||||
first_num = self.stack.pop()
|
||||
second_num = self.stack.pop()
|
||||
total = first_num + second_num
|
||||
self.stack.append(total)
|
||||
```
|
||||
|
||||
这三个方法完成了解释器所理解的三条指令。但解释器还需要一样东西:一个能把所有东西结合在一起并执行的方法。这个方法就叫做`run_code`, 它把我们前面定义的字典结构`what-to-execute`作为参数,循环执行里面的每条指令,如何指令有参数,处理参数,然后调用解释器对象中相应的方法。
|
||||
|
||||
```python
|
||||
def run_code(self, what_to_execute):
|
||||
instructions = what_to_execute["instructions"]
|
||||
numbers = what_to_execute["numbers"]
|
||||
for each_step in instructions:
|
||||
instruction, argument = each_step
|
||||
if instruction == "LOAD_VALUE":
|
||||
number = numbers[argument]
|
||||
self.LOAD_VALUE(number)
|
||||
elif instruction == "ADD_TWO_VALUES":
|
||||
self.ADD_TWO_VALUES()
|
||||
elif instruction == "PRINT_ANSWER":
|
||||
self.PRINT_ANSWER()
|
||||
```
|
||||
|
||||
为了测试,我们创建一个解释器对象,然后用前面定义的 7 + 5 的指令集来调用`run_code`。
|
||||
|
||||
```python
|
||||
interpreter = Interpreter()
|
||||
interpreter.run_code(what_to_execute)
|
||||
```
|
||||
|
||||
显然,它会输出12
|
||||
|
||||
尽管我们的解释器功能受限,但这个加法过程几乎和真正的Python解释器是一样的。这里,我们还有几点要注意。
|
||||
|
||||
首先,一些指令需要参数。在真正的Python bytecode中,大概有一半的指令有参数。像我们的例子一样,参数和指令打包在一起。注意_指令_的参数和传递给对应方法的参数是不同的。
|
||||
|
||||
第二,指令`ADD_TWO_VALUES`不需要任何参数,它从解释器栈中弹出所需的值。这正是以栈为基础的解释器的特点。
|
||||
|
||||
记得我们说过只要给出合适的指令集,不需要对解释器做任何改变,我们就能做多个数的加法。考虑下面的指令集,你觉得会发生什么?如果你有一个合适的编译器,什么代码才能编译出下面的指令集?
|
||||
|
||||
```python
|
||||
what_to_execute = {
|
||||
"instructions": [("LOAD_VALUE", 0),
|
||||
("LOAD_VALUE", 1),
|
||||
("ADD_TWO_VALUES", None),
|
||||
("LOAD_VALUE", 2),
|
||||
("ADD_TWO_VALUES", None),
|
||||
("PRINT_ANSWER", None)],
|
||||
"numbers": [7, 5, 8] }
|
||||
```
|
||||
|
||||
从这点出发,我们开始看到这种结构的可扩展性:我们可以通过向解释器对象增加方法来描述更多的操作(只要有一个编译器能为我们生成组织良好的指令集)。
|
||||
|
||||
#### Variables
|
||||
|
||||
接下来给我们的解释器增加变量的支持。我们需要一个保存变量值的指令,`STORE_NAME`;一个取变量值的指令`LOAD_NAME`;和一个变量到值的映射关系。目前,我们会忽略命名空间和作用域,所以我们可以把变量和值的映射直接存储在解释器对象中。最后,我们要保证`what_to_execute`除了一个常量列表,还要有个变量名字的列表。
|
||||
|
||||
```python
|
||||
>>> def s():
|
||||
... a = 1
|
||||
... b = 2
|
||||
... print(a + b)
|
||||
# a friendly compiler transforms `s` into:
|
||||
what_to_execute = {
|
||||
"instructions": [("LOAD_VALUE", 0),
|
||||
("STORE_NAME", 0),
|
||||
("LOAD_VALUE", 1),
|
||||
("STORE_NAME", 1),
|
||||
("LOAD_NAME", 0),
|
||||
("LOAD_NAME", 1),
|
||||
("ADD_TWO_VALUES", None),
|
||||
("PRINT_ANSWER", None)],
|
||||
"numbers": [1, 2],
|
||||
"names": ["a", "b"] }
|
||||
```
|
||||
|
||||
我们的新的的实现在下面。为了跟踪哪名字绑定到那个值,我们在`__init__`方法中增加一个`environment`字典。我们也增加了`STORE_NAME`和`LOAD_NAME`方法,它们获得变量名,然后从`environment`字典中设置或取出这个变量值。
|
||||
|
||||
现在指令参数就有两个不同的意思,它可能是`numbers`列表的索引,也可能是`names`列表的索引。解释器通过检查所执行的指令就能知道是那种参数。而我们打破这种逻辑 ,把指令和它所用何种参数的映射关系放在另一个单独的方法中。
|
||||
|
||||
```python
|
||||
class Interpreter:
|
||||
def __init__(self):
|
||||
self.stack = []
|
||||
self.environment = {}
|
||||
|
||||
def STORE_NAME(self, name):
|
||||
val = self.stack.pop()
|
||||
self.environment[name] = val
|
||||
|
||||
def LOAD_NAME(self, name):
|
||||
val = self.environment[name]
|
||||
self.stack.append(val)
|
||||
|
||||
def parse_argument(self, instruction, argument, what_to_execute):
|
||||
""" Understand what the argument to each instruction means."""
|
||||
numbers = ["LOAD_VALUE"]
|
||||
names = ["LOAD_NAME", "STORE_NAME"]
|
||||
|
||||
if instruction in numbers:
|
||||
argument = what_to_execute["numbers"][argument]
|
||||
elif instruction in names:
|
||||
argument = what_to_execute["names"][argument]
|
||||
|
||||
return argument
|
||||
|
||||
def run_code(self, what_to_execute):
|
||||
instructions = what_to_execute["instructions"]
|
||||
for each_step in instructions:
|
||||
instruction, argument = each_step
|
||||
argument = self.parse_argument(instruction, argument, what_to_execute)
|
||||
|
||||
if instruction == "LOAD_VALUE":
|
||||
self.LOAD_VALUE(argument)
|
||||
elif instruction == "ADD_TWO_VALUES":
|
||||
self.ADD_TWO_VALUES()
|
||||
elif instruction == "PRINT_ANSWER":
|
||||
self.PRINT_ANSWER()
|
||||
elif instruction == "STORE_NAME":
|
||||
self.STORE_NAME(argument)
|
||||
elif instruction == "LOAD_NAME":
|
||||
self.LOAD_NAME(argument)
|
||||
```
|
||||
|
||||
仅仅五个指令,`run_code`这个方法已经开始变得冗长了。如果保持这种结构,那么每条指令都需要一个`if`分支。这里,我们要利用Python的动态方法查找。我们总会给一个称为`FOO`的指令定义一个名为`FOO`的方法,这样我们就可用Python的`getattr`函数在运行时动态查找方法,而不用这个大大的分支结构。`run_code`方法现在是这样:
|
||||
|
||||
```python
|
||||
def execute(self, what_to_execute):
|
||||
instructions = what_to_execute["instructions"]
|
||||
for each_step in instructions:
|
||||
instruction, argument = each_step
|
||||
argument = self.parse_argument(instruction, argument, what_to_execute)
|
||||
bytecode_method = getattr(self, instruction)
|
||||
if argument is None:
|
||||
bytecode_method()
|
||||
else:
|
||||
bytecode_method(argument)
|
||||
```
|
||||
|
||||
## Real Python Bytecode
|
||||
|
||||
现在,放弃我们的小指令集,去看看真正的Python字节码。字节码的结构和我们的小解释器的指令集差不多,除了字节码用一个字节而不是一个名字来指示这条指令。为了理解它的结构,我们将考察一个函数的字节码。考虑下面这个例子:
|
||||
|
||||
```python
|
||||
>>> def cond():
|
||||
... x = 3
|
||||
... if x < 5:
|
||||
... return 'yes'
|
||||
... else:
|
||||
... return 'no'
|
||||
...
|
||||
```
|
||||
|
||||
Python在运行时会暴露一大批内部信息,并且我们可以通过REPL直接访问这些信息。对于函数对象`cond`,`cond.__code__`是与其关联的code object,而`cond.__code__.co_code`就是它的字节码。当你写Python代码时,你永远也不会想直接使用这些属性,但是这可以让我们做出各种恶作剧,同时也可以看看内部机制。
|
||||
|
||||
```python
|
||||
>>> cond.__code__.co_code # the bytecode as raw bytes
|
||||
b'd\x01\x00}\x00\x00|\x00\x00d\x02\x00k\x00\x00r\x16\x00d\x03\x00Sd\x04\x00Sd\x00
|
||||
\x00S'
|
||||
>>> list(cond.__code__.co_code) # the bytecode as numbers
|
||||
[100, 1, 0, 125, 0, 0, 124, 0, 0, 100, 2, 0, 107, 0, 0, 114, 22, 0, 100, 3, 0, 83,
|
||||
100, 4, 0, 83, 100, 0, 0, 83]
|
||||
```
|
||||
|
||||
当我们直接输出这个字节码,它看起来完全无法理解 --- 唯一我们了解的是它是一串字节。很幸运,我们有一个很强大的工具可以用:Python标准库中的`dis`模块。
|
||||
|
||||
`dis`是一个字节码反汇编器。反汇编器以为机器而写的底层代码作为输入,比如汇编代码和字节码,然后以人类可读的方式输出。当我们运行`dis.dis`, 它输出每个字节码的解释。
|
||||
|
||||
```python
|
||||
>>> dis.dis(cond)
|
||||
2 0 LOAD_CONST 1 (3)
|
||||
3 STORE_FAST 0 (x)
|
||||
|
||||
3 6 LOAD_FAST 0 (x)
|
||||
9 LOAD_CONST 2 (5)
|
||||
12 COMPARE_OP 0 (<)
|
||||
15 POP_JUMP_IF_FALSE 22
|
||||
|
||||
4 18 LOAD_CONST 3 ('yes')
|
||||
21 RETURN_VALUE
|
||||
|
||||
6 >> 22 LOAD_CONST 4 ('no')
|
||||
25 RETURN_VALUE
|
||||
26 LOAD_CONST 0 (None)
|
||||
29 RETURN_VALUE
|
||||
```
|
||||
|
||||
这些都是什么意思?让我们以第一条指令`LOAD_CONST`为例子。第一列的数字(`2`)表示对应源代码的行数。第二列的数字是字节码的索引,告诉我们指令`LOAD_CONST`在0位置。第三列是指令本身对应的人类可读的名字。如果第四列存在,它表示指令的参数。如果第5列存在,它是一个关于参数是什么的提示。
|
||||
|
||||
考虑这个字节码的前几个字节:[100, 1, 0, 125, 0, 0]。这6个字节表示两条带参数的指令。我们可以使用`dis.opname`,一个字节到可读字符串的映射,来找到指令100和指令125代表是什么:
|
||||
|
||||
```python
|
||||
>>> dis.opname[100]
|
||||
'LOAD_CONST'
|
||||
>>> dis.opname[125]
|
||||
'STORE_FAST'
|
||||
```
|
||||
|
||||
第二和第三个字节 --- 1 ,0 ---是`LOAD_CONST`的参数,第五和第六个字节 --- 0,0 --- 是`STORE_FAST`的参数。就像我们前面的小例子,`LOAD_CONST`需要知道的到哪去找常量,`STORE_FAST`需要找到名字。(Python的`LOAD_CONST`和我们小例子中的`LOAD_VALUE`一样,`LOAD_FAST`和`LOAD_NAME`一样)。所以这六个字节代表第一行源代码`x = 3`.(为什么用两个字节表示指令的参数?如果Python使用一个字节,每个code object你只能有256个常量/名字,而用两个字节,就增加到了256的平方,65536个)。
|
||||
|
||||
### Conditionals and Loops
|
||||
|
||||
到目前为止,我们的解释器只能一条接着一条的执行指令。这有个问题,我们经常会想多次执行某个指令,或者在特定的条件下跳过它们。为了可以写循环和分支结构,解释器必须能够在指令中跳转。在某种程度上,Python在字节码中使用`GOTO`语句来处理循环和分支!让我们再看一个`cond`函数的反汇编结果:
|
||||
|
||||
```python
|
||||
>>> dis.dis(cond)
|
||||
2 0 LOAD_CONST 1 (3)
|
||||
3 STORE_FAST 0 (x)
|
||||
|
||||
3 6 LOAD_FAST 0 (x)
|
||||
9 LOAD_CONST 2 (5)
|
||||
12 COMPARE_OP 0 (<)
|
||||
15 POP_JUMP_IF_FALSE 22
|
||||
|
||||
4 18 LOAD_CONST 3 ('yes')
|
||||
21 RETURN_VALUE
|
||||
|
||||
6 >> 22 LOAD_CONST 4 ('no')
|
||||
25 RETURN_VALUE
|
||||
26 LOAD_CONST 0 (None)
|
||||
29 RETURN_VALUE
|
||||
```
|
||||
|
||||
第三行的条件表达式`if x < 5`被编译成四条指令:`LOAD_FAST`, `LOAD_CONST`, `COMPARE_OP`和 `POP_JUMP_IF_FALSE`。`x < 5`对应加载`x`,加载5,比较这两个值。指令`POP_JUMP_IF_FALSE`完成`if`语句。这条指令把栈顶的值弹出,如果值为真,什么都不发生。如果值为假,解释器会跳转到另一条指令。
|
||||
|
||||
这条将被加载的指令称为跳转目标,它作为指令`POP_JUMP`的参数。这里,跳转目标是22,索引为22的指令是`LOAD_CONST`,对应源码的第6行。(`dis`用`>>`标记跳转目标。)如果`X < 5`为假,解释器会忽略第四行(`return yes`),直接跳转到第6行(`return "no"`)。因此解释器通过跳转指令选择性的执行指令。
|
||||
|
||||
Python的循环也依赖于跳转。在下面的字节码中,`while x < 5`这一行产生了和`if x < 10`几乎一样的字节码。在这两种情况下,解释器都是先执行比较,然后执行`POP_JUMP_IF_FALSE`来控制下一条执行哪个指令。第四行的最后一条字节码`JUMP_ABSOLUT`(循环体结束的地方),让解释器返回到循环开始的第9条指令处。当 `x < 10`变为假,`POP_JUMP_IF_FALSE`会让解释器跳到循环的终止处,第34条指令。
|
||||
|
||||
```python
|
||||
>>> def loop():
|
||||
... x = 1
|
||||
... while x < 5:
|
||||
... x = x + 1
|
||||
... return x
|
||||
...
|
||||
>>> dis.dis(loop)
|
||||
2 0 LOAD_CONST 1 (1)
|
||||
3 STORE_FAST 0 (x)
|
||||
|
||||
3 6 SETUP_LOOP 26 (to 35)
|
||||
>> 9 LOAD_FAST 0 (x)
|
||||
12 LOAD_CONST 2 (5)
|
||||
15 COMPARE_OP 0 (<)
|
||||
18 POP_JUMP_IF_FALSE 34
|
||||
|
||||
4 21 LOAD_FAST 0 (x)
|
||||
24 LOAD_CONST 1 (1)
|
||||
27 BINARY_ADD
|
||||
28 STORE_FAST 0 (x)
|
||||
31 JUMP_ABSOLUTE 9
|
||||
>> 34 POP_BLOCK
|
||||
|
||||
5 >> 35 LOAD_FAST 0 (x)
|
||||
38 RETURN_VALUE
|
||||
```
|
||||
|
||||
### Explore Bytecode
|
||||
|
||||
我希望你用`dis.dis`来试试你自己写的函数。一些有趣的问题值得探索:
|
||||
|
||||
- 对解释器而言for循环和while循环有什么不同?
|
||||
- 能不能写出两个不同函数,却能产生相同的字节码?
|
||||
- `elif`是怎么工作的?列表推导呢?
|
||||
|
||||
## Frames
|
||||
|
||||
到目前为止,我们已经知道了Python虚拟机是一个栈机器。它能顺序执行指令,在指令间跳转,压入或弹出栈值。但是这和我们期望的解释器还有一定距离。在前面的那个例子中,最后一条指令是`RETURN_VALUE`,它和`return`语句相对应。但是它返回到哪里去呢?
|
||||
|
||||
为了回答这个问题,我们必须再增加一层复杂性:frame。一个frame是一些信息的集合和代码的执行上下文。frames在Python代码执行时动态的创建和销毁。每个frame对应函数的一次调用。--- 所以每个frame只有一个code object与之关联,而一个code object可以有多个frame。比如你有一个函数递归的调用自己10次,这会产生11个frame,每次调用对应一个,再加上启动模块对应的一个frame。总的来说,Python程序的每个作用域有一个frame,比如,模块,函数,类。
|
||||
|
||||
Frame存在于_调用栈_中,一个和我们之前讨论的完全不同的栈。(你最熟悉的栈就是调用栈,就是你经常看到的异常回溯,每个以"File 'program.py'"开始的回溯对应一个frame。)解释器在执行字节码时操作的栈,我们叫它_数据栈_。其实还有第三个栈,叫做_块栈_,用于特定的控制流块,比如循环和异常处理。调用栈中的每个frame都有它自己的数据栈和块栈。
|
||||
|
||||
让我们用一个具体的例子来说明。假设Python解释器执行到标记为3的地方。解释器正在`foo`函数的调用中,它接着调用`bar`。下面是frame调用栈,块栈和数据栈的示意图。我们感兴趣的是解释器先从最底下的`foo()`开始,接着执行`foo`的函数体,然后到达`bar`。
|
||||
|
||||
```python
|
||||
>>> def bar(y):
|
||||
... z = y + 3 # <--- (3) ... and the interpreter is here.
|
||||
... return z
|
||||
...
|
||||
>>> def foo():
|
||||
... a = 1
|
||||
... b = 2
|
||||
... return a + bar(b) # <--- (2) ... which is returning a call to bar ...
|
||||
...
|
||||
>>> foo() # <--- (1) We're in the middle of a call to foo ...
|
||||
3
|
||||
```
|
||||
|
||||
\aosafigure[240pt]{interpreter-images/interpreter-callstack.png}{The call stack}{500l.interpreter.callstack}
|
||||
|
||||
现在,解释器在`bar`函数的调用中。调用栈中有3个frame:一个对应于模块层,一个对应函数`foo`,别一个对应函数`bar`。(\aosafigref{500l.interpreter.callstack}.)一旦`bar`返回,与它对应的frame就会从调用栈中弹出并丢弃。
|
||||
|
||||
字节码指令`RETURN_VALUE`告诉解释器在frame间传递一个值。首先,它把位于调用栈栈顶的frame中的数据栈的栈顶值弹出。然后把整个frame弹出丢弃。最后把这个值压到下一个frame的数据栈中。
|
||||
|
||||
当Ned Batchelder和我在写Byterun时,很长一段时间我们的实现中一直有个重大的错误。我们整个虚拟机中只有一个数据栈,而不是每个frame都有一个。我们写了很多测试代码,同时在Byterun和真正的Python上运行,希望得到一致结果。我们几乎通过了所有测试,只有一样东西不能通过,那就是生成器。最后,通过仔细的阅读CPython的源码,我们发现了错误所在[^thanks]。把数据栈移到每个frame就解决了这个问题。
|
||||
|
||||
[^thanks]: 感谢 Michael Arntzenius 对这个bug的洞悉。
|
||||
|
||||
回头在看看这个bug,我惊讶的发现Python真的很少依赖于每个frame有一个数据栈这个特性。在Python中几乎所有的操作都会清空数据栈,所以所有的frame公用一个数据栈是没问题的。在上面的例子中,当`bar`执行完后,它的数据栈为空。即使`foo`公用这一个栈,它的值也不会受影响。然而,对应生成器,一个关键的特点是它能暂停一个frame的执行,返回到其他的frame,一段时间后它能返回到原来的frame,并以它离开时的相同状态继续执行。
|
||||
|
||||
## Byterun
|
||||
|
||||
现在我们有足够的Python解释器的知识背景去考察Byterun。
|
||||
|
||||
Byterun中有四种对象。
|
||||
|
||||
- `VirtualMachine`类,它管理高层结构,frame调用栈,指令到操作的映射。这是一个比前面`Inteprter`对象更复杂的版本。
|
||||
- `Frame`类,每个`Frame`类都有一个code object,并且管理者其他一些必要的状态信息,全局和局部命名空间,指向调用它的frame的指针和最后执行的字节码指令。
|
||||
- `Function`类,它被用来代替真正的Python函数。回想一下,调用函数时会创建一个新的frame。我们自己实现`Function`,所以我们控制新frame的创建。
|
||||
- `Block`类,它只是包装了block的3个属性。(block的细节不是解释器的核心,我们不会花时间在它身上,把它列在这里,是因为Byterun需要它。)
|
||||
|
||||
### The `VirtualMachine` Class
|
||||
|
||||
程序运行时只有一个`VirtualMachine`被创建,因为我们只有一个解释器。`VirtualMachine`保存调用栈,异常状态,在frame中传递的返回值。它的入口点是`run_code`方法,它以编译后的code object为参数,以创建一个frame为开始,然后运行这个frame。这个frame可能再创建出新的frame;调用栈随着程序的运行增长缩短。当第一个frame返回时,执行结束。
|
||||
|
||||
```python
|
||||
class VirtualMachineError(Exception):
|
||||
pass
|
||||
|
||||
class VirtualMachine(object):
|
||||
def __init__(self):
|
||||
self.frames = [] # The call stack of frames.
|
||||
self.frame = None # The current frame.
|
||||
self.return_value = None
|
||||
self.last_exception = None
|
||||
|
||||
def run_code(self, code, global_names=None, local_names=None):
|
||||
""" An entry point to execute code using the virtual machine."""
|
||||
frame = self.make_frame(code, global_names=global_names,
|
||||
local_names=local_names)
|
||||
self.run_frame(frame)
|
||||
|
||||
```
|
||||
|
||||
### The `Frame` Class
|
||||
|
||||
接下来,我们来写`Frame`对象。frame是一个属性的集合,它没有任何方法。前面提到过,这些属性包括由编译器生成的code object;局部,全局和内置命名空间;前一个frame的引用;一个数据栈;一个块栈;最后执行的指令指针。(对于内置命名空间我们需要多做一点工作,Python在不同模块中对这个命名空间有不同的处理;但这个细节对我们的虚拟机不重要。)
|
||||
|
||||
```python
|
||||
class Frame(object):
|
||||
def __init__(self, code_obj, global_names, local_names, prev_frame):
|
||||
self.code_obj = code_obj
|
||||
self.global_names = global_names
|
||||
self.local_names = local_names
|
||||
self.prev_frame = prev_frame
|
||||
self.stack = []
|
||||
if prev_frame:
|
||||
self.builtin_names = prev_frame.builtin_names
|
||||
else:
|
||||
self.builtin_names = local_names['__builtins__']
|
||||
if hasattr(self.builtin_names, '__dict__'):
|
||||
self.builtin_names = self.builtin_names.__dict__
|
||||
|
||||
self.last_instruction = 0
|
||||
self.block_stack = []
|
||||
```
|
||||
|
||||
接着,我们在虚拟机中增加对frame的操作。这有3个帮助函数:一个创建新的frame的方法,和压栈和出栈的方法。第四个函数,`run_frame`,完成执行frame的主要工作,待会我们再讨论这个方法。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
[... snip ...]
|
||||
|
||||
# Frame manipulation
|
||||
def make_frame(self, code, callargs={}, global_names=None, local_names=None):
|
||||
if global_names is not None and local_names is not None:
|
||||
local_names = global_names
|
||||
elif self.frames:
|
||||
global_names = self.frame.global_names
|
||||
local_names = {}
|
||||
else:
|
||||
global_names = local_names = {
|
||||
'__builtins__': __builtins__,
|
||||
'__name__': '__main__',
|
||||
'__doc__': None,
|
||||
'__package__': None,
|
||||
}
|
||||
local_names.update(callargs)
|
||||
frame = Frame(code, global_names, local_names, self.frame)
|
||||
return frame
|
||||
|
||||
def push_frame(self, frame):
|
||||
self.frames.append(frame)
|
||||
self.frame = frame
|
||||
|
||||
def pop_frame(self):
|
||||
self.frames.pop()
|
||||
if self.frames:
|
||||
self.frame = self.frames[-1]
|
||||
else:
|
||||
self.frame = None
|
||||
|
||||
def run_frame(self):
|
||||
pass
|
||||
# we'll come back to this shortly
|
||||
```
|
||||
|
||||
### The `Function` Class
|
||||
|
||||
`Function`的实现有点扭曲,但是大部分的细节对理解解释器不重要。重要的是当调用函数时 --- `__call__`方法被调用 --- 它创建一个新的`Frame`并运行它。
|
||||
|
||||
```python
|
||||
class Function(object):
|
||||
"""
|
||||
Create a realistic function object, defining the things the interpreter expects.
|
||||
"""
|
||||
__slots__ = [
|
||||
'func_code', 'func_name', 'func_defaults', 'func_globals',
|
||||
'func_locals', 'func_dict', 'func_closure',
|
||||
'__name__', '__dict__', '__doc__',
|
||||
'_vm', '_func',
|
||||
]
|
||||
|
||||
def __init__(self, name, code, globs, defaults, closure, vm):
|
||||
"""You don't need to follow this closely to understand the interpreter."""
|
||||
self._vm = vm
|
||||
self.func_code = code
|
||||
self.func_name = self.__name__ = name or code.co_name
|
||||
self.func_defaults = tuple(defaults)
|
||||
self.func_globals = globs
|
||||
self.func_locals = self._vm.frame.f_locals
|
||||
self.__dict__ = {}
|
||||
self.func_closure = closure
|
||||
self.__doc__ = code.co_consts[0] if code.co_consts else None
|
||||
|
||||
# Sometimes, we need a real Python function. This is for that.
|
||||
kw = {
|
||||
'argdefs': self.func_defaults,
|
||||
}
|
||||
if closure:
|
||||
kw['closure'] = tuple(make_cell(0) for _ in closure)
|
||||
self._func = types.FunctionType(code, globs, **kw)
|
||||
|
||||
def __call__(self, *args, **kwargs):
|
||||
"""When calling a Function, make a new frame and run it."""
|
||||
callargs = inspect.getcallargs(self._func, *args, **kwargs)
|
||||
# Use callargs to provide a mapping of arguments: values to pass into the new
|
||||
# frame.
|
||||
frame = self._vm.make_frame(
|
||||
self.func_code, callargs, self.func_globals, {}
|
||||
)
|
||||
return self._vm.run_frame(frame)
|
||||
|
||||
def make_cell(value):
|
||||
"""Create a real Python closure and grab a cell."""
|
||||
# Thanks to Alex Gaynor for help with this bit of twistiness.
|
||||
fn = (lambda x: lambda: x)(value)
|
||||
return fn.__closure__[0]
|
||||
```
|
||||
|
||||
接着,回到`VirtualMachine`对象,我们对数据栈的操作也增加一些帮助方法。字节码操作的栈总是在当前frame的数据栈。这些帮助函数让我们能实现`POP_TOP`,`LOAD_FAST`字节码,并且让其他操作栈的指令可读性更高。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
[... snip ...]
|
||||
|
||||
# Data stack manipulation
|
||||
def top(self):
|
||||
return self.frame.stack[-1]
|
||||
|
||||
def pop(self):
|
||||
return self.frame.stack.pop()
|
||||
|
||||
def push(self, *vals):
|
||||
self.frame.stack.extend(vals)
|
||||
|
||||
def popn(self, n):
|
||||
"""Pop a number of values from the value stack.
|
||||
A list of `n` values is returned, the deepest value first.
|
||||
"""
|
||||
if n:
|
||||
ret = self.frame.stack[-n:]
|
||||
self.frame.stack[-n:] = []
|
||||
return ret
|
||||
else:
|
||||
return []
|
||||
```
|
||||
|
||||
在我们运行frame之前,我们还需两个方法。
|
||||
|
||||
第一个方法,`parse_byte_and_args`,以一个字节码为输入,先检查它是否有参数,如果有,就解析它的参数。这个方法同时也更新frame的`last_instruction`属性,它指向最后执行的指令。一条没有参数的指令只有一个字节长度,而有参数的字节有3个字节长。参数的意义依赖于指令是什么。比如,前面说过,指令`POP_JUMP_IF_FALSE`,它的参数指的是跳转目标。`BUILD_LIST`, 它的参数是列表的个数。`LOAD_CONST`,它的参数是常量的索引。
|
||||
|
||||
一些指令用简单的数字作为参数。对于另一些,虚拟机需要一点努力去发现它含意。标准库中的`dis`模块中有一个备忘单,它解释什么参数有什么意思,这让我们的代码更加简洁。比如,列表`dis.hasname`告诉我们`LOAD_NAME`, `IMPORT_NAME`,`LOAD_GLOBAL`,以及另外的9个指令都有同样的意思:名字列表的索引。
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
[... snip ...]
|
||||
|
||||
def parse_byte_and_args(self):
|
||||
f = self.frame
|
||||
opoffset = f.last_instruction
|
||||
byteCode = f.code_obj.co_code[opoffset]
|
||||
f.last_instruction += 1
|
||||
byte_name = dis.opname[byteCode]
|
||||
if byteCode >= dis.HAVE_ARGUMENT:
|
||||
# index into the bytecode
|
||||
arg = f.code_obj.co_code[f.last_instruction:f.last_instruction+2]
|
||||
f.last_instruction += 2 # advance the instruction pointer
|
||||
arg_val = arg[0] + (arg[1] * 256)
|
||||
if byteCode in dis.hasconst: # Look up a constant
|
||||
arg = f.code_obj.co_consts[arg_val]
|
||||
elif byteCode in dis.hasname: # Look up a name
|
||||
arg = f.code_obj.co_names[arg_val]
|
||||
elif byteCode in dis.haslocal: # Look up a local name
|
||||
arg = f.code_obj.co_varnames[arg_val]
|
||||
elif byteCode in dis.hasjrel: # Calculate a relative jump
|
||||
arg = f.last_instruction + arg_val
|
||||
else:
|
||||
arg = arg_val
|
||||
argument = [arg]
|
||||
else:
|
||||
argument = []
|
||||
|
||||
return byte_name, argument
|
||||
```
|
||||
|
||||
下一个方法是`dispatch`,它查看给定的指令并执行相应的操作。在CPython中,这个分派函数用一个巨大的switch语句实现,有超过1500行的代码。幸运的是,我们用的是Python,我们的代码会简洁的多。我们会为每一个字节码名字定义一个方法,然后用`getattr`来查找。就像我们前面的小解释器一样,如果一条指令叫做`FOO_BAR`,那么它对应的方法就是`byte_FOO_BAR`。现在,我们先把这些方法当做一个黑盒子。每个指令方法都会返回`None`或者一个字符串`why`,有些情况下虚拟机需要这个额外`why`信息。这些指令方法的返回值,仅作为解释器状态的内部指示,千万不要和执行frame的返回值相混淆。
|
||||
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
[... snip ...]
|
||||
|
||||
def dispatch(self, byte_name, argument):
|
||||
""" Dispatch by bytename to the corresponding methods.
|
||||
Exceptions are caught and set on the virtual machine."""
|
||||
|
||||
# When later unwinding the block stack,
|
||||
# we need to keep track of why we are doing it.
|
||||
why = None
|
||||
try:
|
||||
bytecode_fn = getattr(self, 'byte_%s' % byte_name, None)
|
||||
if bytecode_fn is None:
|
||||
if byte_name.startswith('UNARY_'):
|
||||
self.unaryOperator(byte_name[6:])
|
||||
elif byte_name.startswith('BINARY_'):
|
||||
self.binaryOperator(byte_name[7:])
|
||||
else:
|
||||
raise VirtualMachineError(
|
||||
"unsupported bytecode type: %s" % byte_name
|
||||
)
|
||||
else:
|
||||
why = bytecode_fn(*argument)
|
||||
except:
|
||||
# deal with exceptions encountered while executing the op.
|
||||
self.last_exception = sys.exc_info()[:2] + (None,)
|
||||
why = 'exception'
|
||||
|
||||
return why
|
||||
|
||||
def run_frame(self, frame):
|
||||
"""Run a frame until it returns (somehow).
|
||||
Exceptions are raised, the return value is returned.
|
||||
"""
|
||||
self.push_frame(frame)
|
||||
while True:
|
||||
byte_name, arguments = self.parse_byte_and_args()
|
||||
|
||||
why = self.dispatch(byte_name, arguments)
|
||||
|
||||
# Deal with any block management we need to do
|
||||
while why and frame.block_stack:
|
||||
why = self.manage_block_stack(why)
|
||||
|
||||
if why:
|
||||
break
|
||||
|
||||
self.pop_frame()
|
||||
|
||||
if why == 'exception':
|
||||
exc, val, tb = self.last_exception
|
||||
e = exc(val)
|
||||
e.__traceback__ = tb
|
||||
raise e
|
||||
|
||||
return self.return_value
|
||||
```
|
||||
|
||||
### The `Block` Class
|
||||
|
||||
在我们完成每个字节码方法前,我们简单的讨论一下块。一个块被用于某种控制流,特别是异常处理和循环。它负责保证当操作完成后数据栈处于正确的状态。比如,在一个循环中,一个特殊的迭代器会存在栈中,当循环完成时它从栈中弹出。解释器需要检查循环仍在继续还是已经停止。
|
||||
|
||||
为了跟踪这些额外的信息,解释器设置了一个标志来指示它的状态。我们用一个变量`why`实现这个标志,它可以是`None`或者是下面几个字符串这一,`"continue"`, `"break"`,`"excption"`,`return`。他们指示对块栈和数据栈进行什么操作。回到我们迭代器的例子,如果块栈的栈顶是一个`loop`块,`why`是`continue`,迭代器就因该保存在数据栈上,不是如果`why`是`break`,迭代器就会被弹出。
|
||||
|
||||
块操作的细节比较精细,我们不会花时间在这上面,但是有兴趣的读者值得仔细的看看。
|
||||
|
||||
```python
|
||||
Block = collections.namedtuple("Block", "type, handler, stack_height")
|
||||
|
||||
class VirtualMachine(object):
|
||||
[... snip ...]
|
||||
|
||||
# Block stack manipulation
|
||||
def push_block(self, b_type, handler=None):
|
||||
level = len(self.frame.stack)
|
||||
self.frame.block_stack.append(Block(b_type, handler, stack_height))
|
||||
|
||||
def pop_block(self):
|
||||
return self.frame.block_stack.pop()
|
||||
|
||||
def unwind_block(self, block):
|
||||
"""Unwind the values on the data stack corresponding to a given block."""
|
||||
if block.type == 'except-handler':
|
||||
# The exception itself is on the stack as type, value, and traceback.
|
||||
offset = 3
|
||||
else:
|
||||
offset = 0
|
||||
|
||||
while len(self.frame.stack) > block.level + offset:
|
||||
self.pop()
|
||||
|
||||
if block.type == 'except-handler':
|
||||
traceback, value, exctype = self.popn(3)
|
||||
self.last_exception = exctype, value, traceback
|
||||
|
||||
def manage_block_stack(self, why):
|
||||
""" """
|
||||
frame = self.frame
|
||||
block = frame.block_stack[-1]
|
||||
if block.type == 'loop' and why == 'continue':
|
||||
self.jump(self.return_value)
|
||||
why = None
|
||||
return why
|
||||
|
||||
self.pop_block()
|
||||
self.unwind_block(block)
|
||||
|
||||
if block.type == 'loop' and why == 'break':
|
||||
why = None
|
||||
self.jump(block.handler)
|
||||
return why
|
||||
|
||||
if (block.type in ['setup-except', 'finally'] and why == 'exception'):
|
||||
self.push_block('except-handler')
|
||||
exctype, value, tb = self.last_exception
|
||||
self.push(tb, value, exctype)
|
||||
self.push(tb, value, exctype) # yes, twice
|
||||
why = None
|
||||
self.jump(block.handler)
|
||||
return why
|
||||
|
||||
elif block.type == 'finally':
|
||||
if why in ('return', 'continue'):
|
||||
self.push(self.return_value)
|
||||
|
||||
self.push(why)
|
||||
|
||||
why = None
|
||||
self.jump(block.handler)
|
||||
return why
|
||||
return why
|
||||
```
|
||||
|
||||
## The Instructions
|
||||
|
||||
剩下了的就是完成那些指令方法了:`byte_LOAD_FAST`,`byte_BINARY_MODULO`等等。而这些指令的实现并不是很有趣,这里我们只展示了一小部分,完整的实现在这儿https://github.com/nedbat/byterun。(足够执行我们前面所述的所有代码了。)
|
||||
|
||||
```python
|
||||
class VirtualMachine(object):
|
||||
[... snip ...]
|
||||
|
||||
## Stack manipulation
|
||||
|
||||
def byte_LOAD_CONST(self, const):
|
||||
self.push(const)
|
||||
|
||||
def byte_POP_TOP(self):
|
||||
self.pop()
|
||||
|
||||
## Names
|
||||
def byte_LOAD_NAME(self, name):
|
||||
frame = self.frame
|
||||
if name in frame.f_locals:
|
||||
val = frame.f_locals[name]
|
||||
elif name in frame.f_globals:
|
||||
val = frame.f_globals[name]
|
||||
elif name in frame.f_builtins:
|
||||
val = frame.f_builtins[name]
|
||||
else:
|
||||
raise NameError("name '%s' is not defined" % name)
|
||||
self.push(val)
|
||||
|
||||
def byte_STORE_NAME(self, name):
|
||||
self.frame.f_locals[name] = self.pop()
|
||||
|
||||
def byte_LOAD_FAST(self, name):
|
||||
if name in self.frame.f_locals:
|
||||
val = self.frame.f_locals[name]
|
||||
else:
|
||||
raise UnboundLocalError(
|
||||
"local variable '%s' referenced before assignment" % name
|
||||
)
|
||||
self.push(val)
|
||||
|
||||
def byte_STORE_FAST(self, name):
|
||||
self.frame.f_locals[name] = self.pop()
|
||||
|
||||
def byte_LOAD_GLOBAL(self, name):
|
||||
f = self.frame
|
||||
if name in f.f_globals:
|
||||
val = f.f_globals[name]
|
||||
elif name in f.f_builtins:
|
||||
val = f.f_builtins[name]
|
||||
else:
|
||||
raise NameError("global name '%s' is not defined" % name)
|
||||
self.push(val)
|
||||
|
||||
## Operators
|
||||
|
||||
BINARY_OPERATORS = {
|
||||
'POWER': pow,
|
||||
'MULTIPLY': operator.mul,
|
||||
'FLOOR_DIVIDE': operator.floordiv,
|
||||
'TRUE_DIVIDE': operator.truediv,
|
||||
'MODULO': operator.mod,
|
||||
'ADD': operator.add,
|
||||
'SUBTRACT': operator.sub,
|
||||
'SUBSCR': operator.getitem,
|
||||
'LSHIFT': operator.lshift,
|
||||
'RSHIFT': operator.rshift,
|
||||
'AND': operator.and_,
|
||||
'XOR': operator.xor,
|
||||
'OR': operator.or_,
|
||||
}
|
||||
|
||||
def binaryOperator(self, op):
|
||||
x, y = self.popn(2)
|
||||
self.push(self.BINARY_OPERATORS[op](x, y))
|
||||
|
||||
COMPARE_OPERATORS = [
|
||||
operator.lt,
|
||||
operator.le,
|
||||
operator.eq,
|
||||
operator.ne,
|
||||
operator.gt,
|
||||
operator.ge,
|
||||
lambda x, y: x in y,
|
||||
lambda x, y: x not in y,
|
||||
lambda x, y: x is y,
|
||||
lambda x, y: x is not y,
|
||||
lambda x, y: issubclass(x, Exception) and issubclass(x, y),
|
||||
]
|
||||
|
||||
def byte_COMPARE_OP(self, opnum):
|
||||
x, y = self.popn(2)
|
||||
self.push(self.COMPARE_OPERATORS[opnum](x, y))
|
||||
|
||||
## Attributes and indexing
|
||||
|
||||
def byte_LOAD_ATTR(self, attr):
|
||||
obj = self.pop()
|
||||
val = getattr(obj, attr)
|
||||
self.push(val)
|
||||
|
||||
def byte_STORE_ATTR(self, name):
|
||||
val, obj = self.popn(2)
|
||||
setattr(obj, name, val)
|
||||
|
||||
## Building
|
||||
|
||||
def byte_BUILD_LIST(self, count):
|
||||
elts = self.popn(count)
|
||||
self.push(elts)
|
||||
|
||||
def byte_BUILD_MAP(self, size):
|
||||
self.push({})
|
||||
|
||||
def byte_STORE_MAP(self):
|
||||
the_map, val, key = self.popn(3)
|
||||
the_map[key] = val
|
||||
self.push(the_map)
|
||||
|
||||
def byte_LIST_APPEND(self, count):
|
||||
val = self.pop()
|
||||
the_list = self.frame.stack[-count] # peek
|
||||
the_list.append(val)
|
||||
|
||||
## Jumps
|
||||
|
||||
def byte_JUMP_FORWARD(self, jump):
|
||||
self.jump(jump)
|
||||
|
||||
def byte_JUMP_ABSOLUTE(self, jump):
|
||||
self.jump(jump)
|
||||
|
||||
def byte_POP_JUMP_IF_TRUE(self, jump):
|
||||
val = self.pop()
|
||||
if val:
|
||||
self.jump(jump)
|
||||
|
||||
def byte_POP_JUMP_IF_FALSE(self, jump):
|
||||
val = self.pop()
|
||||
if not val:
|
||||
self.jump(jump)
|
||||
|
||||
## Blocks
|
||||
|
||||
def byte_SETUP_LOOP(self, dest):
|
||||
self.push_block('loop', dest)
|
||||
|
||||
def byte_GET_ITER(self):
|
||||
self.push(iter(self.pop()))
|
||||
|
||||
def byte_FOR_ITER(self, jump):
|
||||
iterobj = self.top()
|
||||
try:
|
||||
v = next(iterobj)
|
||||
self.push(v)
|
||||
except StopIteration:
|
||||
self.pop()
|
||||
self.jump(jump)
|
||||
|
||||
def byte_BREAK_LOOP(self):
|
||||
return 'break'
|
||||
|
||||
def byte_POP_BLOCK(self):
|
||||
self.pop_block()
|
||||
|
||||
## Functions
|
||||
|
||||
def byte_MAKE_FUNCTION(self, argc):
|
||||
name = self.pop()
|
||||
code = self.pop()
|
||||
defaults = self.popn(argc)
|
||||
globs = self.frame.f_globals
|
||||
fn = Function(name, code, globs, defaults, None, self)
|
||||
self.push(fn)
|
||||
|
||||
def byte_CALL_FUNCTION(self, arg):
|
||||
lenKw, lenPos = divmod(arg, 256) # KWargs not supported here
|
||||
posargs = self.popn(lenPos)
|
||||
|
||||
func = self.pop()
|
||||
frame = self.frame
|
||||
retval = func(*posargs)
|
||||
self.push(retval)
|
||||
|
||||
def byte_RETURN_VALUE(self):
|
||||
self.return_value = self.pop()
|
||||
return "return"
|
||||
```
|
||||
|
||||
## Dynamic Typing: What the Compiler Doesn't Know
|
||||
|
||||
你可能听过Python是一种动态语言 --- 是它是动态类型的。在我们建造解释器的过程中,已经透露出这样的信息。
|
||||
|
||||
动态的一个意思是很多工作在运行时完成。前面我们看到Python的编译器没有很多关于代码真正做什么的信息。举个例子,考虑下面这个简单的函数`mod`。它取两个参数,返回它们的模运算值。从它的字节码中,我们看到变量`a`和`b`首先被加载,然后字节码`BINAY_MODULO`完成这个模运算。
|
||||
|
||||
```python
|
||||
>>> def mod(a, b):
|
||||
... return a % b
|
||||
>>> dis.dis(mod)
|
||||
2 0 LOAD_FAST 0 (a)
|
||||
3 LOAD_FAST 1 (b)
|
||||
6 BINARY_MODULO
|
||||
7 RETURN_VALUE
|
||||
>>> mod(19, 5)
|
||||
4
|
||||
```
|
||||
|
||||
计算19 % 5得4,--- 一点也不奇怪。如果我们用不同类的参数呢?
|
||||
|
||||
```python
|
||||
>>> mod("by%sde", "teco")
|
||||
'bytecode'
|
||||
```
|
||||
|
||||
刚才发生了什么?你可能见过这样的语法,格式化字符串。
|
||||
|
||||
```
|
||||
>>> print("by%sde" % "teco")
|
||||
bytecode
|
||||
```
|
||||
|
||||
用符号`%`去格式化字符串会调用字节码`BUNARY_MODULO`.它取栈顶的两个值求模,不管这两个值是字符串,数字或是你自己定义的类的实例。字节码在函数编译时生成(或者说,函数定义时)相同的字节码会用于不同类的参数。
|
||||
|
||||
Python的编译器关于字节码的功能知道的很少。而取决于解释器来决定`BINAYR_MODULO`应用于什么类型的对象并完成正确的操作。这就是为什么Python被描述为_动态类型_:直到运行前你不必知道这个函数参数的类型。相反,在一个静态类型语言中,程序员需要告诉编译器参数的类型是什么(或者编译器自己推断出参数的类型。)
|
||||
|
||||
编译器的无知是优化Python的一个挑战 --- 只看字节码,而不真正运行它,你就不知道每条字节码在干什么!你可以定义一个类,实现`__mod__`方法,当你对这个类的实例使用`%`时,Python就会自动调用这个方法。所以,`BINARY_MODULO`其实可以运行任何代码。
|
||||
|
||||
看看下面的代码,第一个`a % b`看起来没有用。
|
||||
|
||||
```python
|
||||
def mod(a,b):
|
||||
a % b
|
||||
return a %b
|
||||
```
|
||||
|
||||
不幸的是,对这段代码进行静态分析 --- 不运行它 --- 不能确定第一个`a % b`没有做任何事。用 `%`调用`__mod__`可能会写一个文件,或是和程序的其他部分交互,或者其他任何可以在Python中完成的事。很难优化一个你不知道它会做什么的函数。在Russell Power和Alex Rubinsteyn的优秀论文中写道,“我们可以用多快的速度解释Python?”,他们说,“在普遍缺乏类型信息下,每条指令必须被看作一个`INVOKE_ARBITRARY_METHOD`。”
|
||||
|
||||
## Conclusion
|
||||
|
||||
Byterun是一个比CPython容易理解的简洁的Python解释器。Byterun复制了CPython的主要结构:一个基于栈的指令集称为字节码,它们顺序执行或在指令间跳转,向栈中压入和从中弹出数据。解释器随着函数和生成器的调用和返回,动态的创建,销毁frame,并在frame间跳转。Byterun也有着和真正解释器一样的限制:因为Python使用动态类型,解释器必须在运行时决定指令的正确行为。
|
||||
|
||||
我鼓励你去反汇编你的程序,然后用Byterun来运行。你很快会发现这个缩短版的Byterun所没有实现的指令。完整的实现在https://github.com/nedbat/byterun,或者仔细阅读真正的CPython解释器`ceval.c`,你也可以实现自己的解释器!
|
||||
|
||||
## Acknowledgements
|
||||
|
||||
Thanks to Ned Batchelder for originating this project and guiding my contributions, Michael Arntzenius for his help debugging the code and editing the prose, Leta Montopoli for her edits, and the entire Recurse Center community for their support and interest. Any errors are my own.
|
||||
|
||||
--------------------------------------
|
||||
via:http://aosabook.org/en/500L/a-python-interpreter-written-in-python.html
|
||||
|
||||
作者: Allison Kaptur Allison
|
||||
|
||||
译者:[qingyunha](https://github.com/qingyunha)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user