mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
658543d03b
@ -1,17 +1,19 @@
|
||||
MPV 播放器:Linux 下的极简视频播放器
|
||||
======
|
||||
MPV 是一个开源的,跨平台视频播放器,带有极简的 GUI 界面以及丰富的命令行控制。
|
||||
|
||||
> MPV 是一个开源的,跨平台视频播放器,带有极简的 GUI 界面以及丰富的命令行控制。
|
||||
|
||||
VLC 可能是 Linux 或者其他平台下最好的视频播放器。我已经使用 VLC 很多年了,它现在仍是我最喜欢的播放器。
|
||||
|
||||
不过最近,我倾向于使用简洁界面的极简应用。这也是我偶然发现 MPV 的原因。我太喜欢这个软件,并把它加入了 [Ubuntu 最佳应用][1]列表里。
|
||||
|
||||
[MPV][2] 是一个开源的视频播放器,有 Linux,Windows,MacOS,BSD 以及 Android 等平台下的版本。它实际上是从 [MPlayer][3] 分支出来的。
|
||||
[MPV][2] 是一个开源的视频播放器,有 Linux、Windows、MacOS、BSD 以及 Android 等平台下的版本。它实际上是从 [MPlayer][3] 分支出来的。
|
||||
|
||||
它的图形界面只有必须的元素而且非常整洁。
|
||||
|
||||
![MPV 播放器在 Linux 下的界面][4]
|
||||
MPV 播放器
|
||||
|
||||
*MPV 播放器*
|
||||
|
||||
### MPV 的功能
|
||||
|
||||
@ -24,20 +26,18 @@ MPV 有标准播放器该有的所有功能。你可以播放各种视频,以
|
||||
* 可以通过命令行播放 YouTube 等流媒体视频。
|
||||
* 命令行模式的 MPV 可以嵌入到网页或其他应用中。
|
||||
|
||||
|
||||
|
||||
尽管 MPV 播放器只有极简的界面以及有限的选项,但请不要怀疑它的功能。它主要的能力都来自命令行版本。
|
||||
|
||||
只需要输入命令 mpv --list-options,然后你会看到它所提供的 447 个不同的选项。但是本文不会介绍 MPV 的高级应用。让我们看看作为一个普通的桌面视频播放器,它能有多么优秀。
|
||||
只需要输入命令 `mpv --list-options`,然后你会看到它所提供的 447 个不同的选项。但是本文不会介绍 MPV 的高级应用。让我们看看作为一个普通的桌面视频播放器,它能有多么优秀。
|
||||
|
||||
### 在 Linux 上安装 MPV
|
||||
|
||||
MPV 是一个常用应用,加入了大多数 Linux 发行版默认仓库里。在软件中心里搜索一下就可以了。
|
||||
|
||||
我可以确认在 Ubuntu 的软件中心里能找到。你可以在里面选择安装,或者通过下面的命令安装:
|
||||
|
||||
```
|
||||
sudo apt install mpv
|
||||
|
||||
```
|
||||
|
||||
你可以在 [MPV 网站][5]上查看其他平台的安装指引。
|
||||
@ -47,13 +47,14 @@ sudo apt install mpv
|
||||
在安装完成以后,你可以通过鼠标右键点击视频文件,然后在列表里选择 MPV 来播放。
|
||||
|
||||
![MPV 播放器界面][6]
|
||||
MPV 播放器界面
|
||||
|
||||
*MPV 播放器界面*
|
||||
|
||||
整个界面只有一个控制面板,只有在鼠标移动到播放窗口上才会显示出来。控制面板上有播放/暂停,选择视频轨道,切换音轨,字幕以及全屏等选项。
|
||||
|
||||
MPV 的默认大小取决于你所播放视频的画质。比如一个 240p 的视频,播放窗口会比较小,而在全高清显示器上播放 1080p 视频时,会几乎占满整个屏幕。不管视频大小,你总是可以在播放窗口上双击鼠标切换成全屏。
|
||||
|
||||
#### The subtitle struggle
|
||||
#### 字幕
|
||||
|
||||
如果你的视频带有字幕,MPV 会[自动加载字幕][7],你也可以选择关闭。不过,如果你想使用其他外挂字幕文件,不能直接在播放器界面上操作。
|
||||
|
||||
@ -66,17 +67,18 @@ MPV 的默认大小取决于你所播放视频的画质。比如一个 240p 的
|
||||
要播放在线视频,你只能使用命令行模式的 MPV。
|
||||
|
||||
打开终端窗口,然后用类似下面的方式来播放:
|
||||
|
||||
```
|
||||
mpv <URL_of_Video>
|
||||
|
||||
```
|
||||
|
||||
![在 Linux 桌面上使用 MPV 播放 YouTube 视频][8]
|
||||
在 Linux 桌面上使用 MPV 播放 YouTube 视频
|
||||
|
||||
*在 Linux 桌面上使用 MPV 播放 YouTube 视频*
|
||||
|
||||
用 MPV 播放 YouTube 视频的体验不怎么好。它总是在缓冲缓冲,有点烦。
|
||||
|
||||
#### 是否需要安装 MPV 播放器?
|
||||
### 是否安装 MPV 播放器?
|
||||
|
||||
这个看你自己。如果你想体验各种应用,大可以试试 MPV。否则,默认的视频播放器或者 VLC 就足够了。
|
||||
|
||||
@ -95,7 +97,7 @@ via: https://itsfoss.com/mpv-video-player/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
How blockchain can complement open source
|
||||
======
|
||||
|
||||

|
||||
|
||||
[The Cathedral and The Bazaar][1] is a classic open source story, written 20 years ago by Eric Steven Raymond. In the story, Eric describes a new revolutionary software development model where complex software projects are built without (or with a very little) central management. This new model is open source.
|
||||
|
||||
Eric's story compares two models:
|
||||
|
||||
* The classic model (represented by the cathedral), in which software is crafted by a small group of individuals in a closed and controlled environment through slow and stable releases.
|
||||
* And the new model (represented by the bazaar), in which software is crafted in an open environment where individuals can participate freely but still produce a stable and coherent system.
|
||||
|
||||
|
||||
|
||||
Some of the reasons open source is so successful can be traced back to the founding principles Eric describes. Releasing early, releasing often, and accepting the fact that many heads are inevitably better than one allows open source projects to tap into the world’s pool of talent (and few companies can match that using the closed source model).
|
||||
|
||||
Two decades after Eric's reflective analysis of the hacker community, we see open source becoming dominant. It is no longer a model only for scratching a developer’s personal itch, but instead, the place where innovation happens. Even the world's [largest][2] software companies are transitioning to this model in order to continue dominating.
|
||||
|
||||
### A barter system
|
||||
|
||||
If we look closely at how the open source model works in practice, we realize that it is a closed system, exclusive only to open source developers and techies. The only way to influence the direction of a project is by joining the open source community, understanding the written and the unwritten rules, learning how to contribute, the coding standards, etc., and doing it yourself.
|
||||
|
||||
This is how the bazaar works, and it is where the barter system analogy comes from. A barter system is a method of exchanging services and goods in return for other services and goods. In the bazaar—where the software is built—that means in order to take something, you must also be a producer yourself and give something back in return. And that is by exchanging your time and knowledge for getting something done. A bazaar is a place where open source developers interact with other open source developers and produce open source software the open source way.
|
||||
|
||||
The barter system is a great step forward and an evolution from the state of self-sufficiency where everybody must be a jack of all trades. The bazaar (open source model) using the barter system allows people with common interests and different skills to gather, collaborate, and create something that no individual can create on their own. The barter system is simple and lacks complex problems of the modern monetary systems, but it also has some limitations, such as:
|
||||
|
||||
* Lack of divisibility: In the absence of a common medium of exchange, a large indivisible commodity/value cannot be exchanged for a smaller commodity/value. For example, if you want to do even a small change in an open source project, you may sometimes still need to go through a high entry barrier.
|
||||
* Storing value: If a project is important to your company, you may want to have a large investment/commitment in it. But since it is a barter system among open source developers, the only way to have a strong say is by employing many open source committers, and that is not always possible.
|
||||
* Transferring value: If you have invested in a project (trained employees, hired open source developers) and want to move focus to another project, it is not possible to transfer expertise, reputation, and influence quickly.
|
||||
* Temporal decoupling: The barter system does not provide a good mechanism for deferred or advance commitments. In the open source world, that means a user cannot express commitment or interest in a project in a measurable way in advance, or continuously for future periods.
|
||||
|
||||
|
||||
|
||||
Below, we will explore how to address these limitations using the back door to the bazaar.
|
||||
|
||||
### A currency system
|
||||
|
||||
People are hanging at the bazaar for different reasons: Some are there to learn, some are there to scratch a personal developer's itch, and some work for large software farms. Because the only way to have a say in the bazaar is to become part of the open source community and join the barter system, in order to gain credibility in the open source world, many large software companies employ these developers and pay them in monetary value. This represents the use of a currency system to influence the bazaar. Open source is no longer only for scratching the personal developer itch. It also accounts for a significant part of the overall software production worldwide, and there are many who want to have an influence.
|
||||
|
||||
Open source sets the guiding principles through which developers interact and build a coherent system in a distributed way. It dictates how a project is governed, how software is built, and how the output distributed to users. It is an open consensus model for decentralized entities for building quality software together. But the open source model does not cover how open source is subsidized. Whether it is sponsored, directly or indirectly, through intrinsic or extrinsic motivators is irrelevant to the bazaar.
|
||||
|
||||
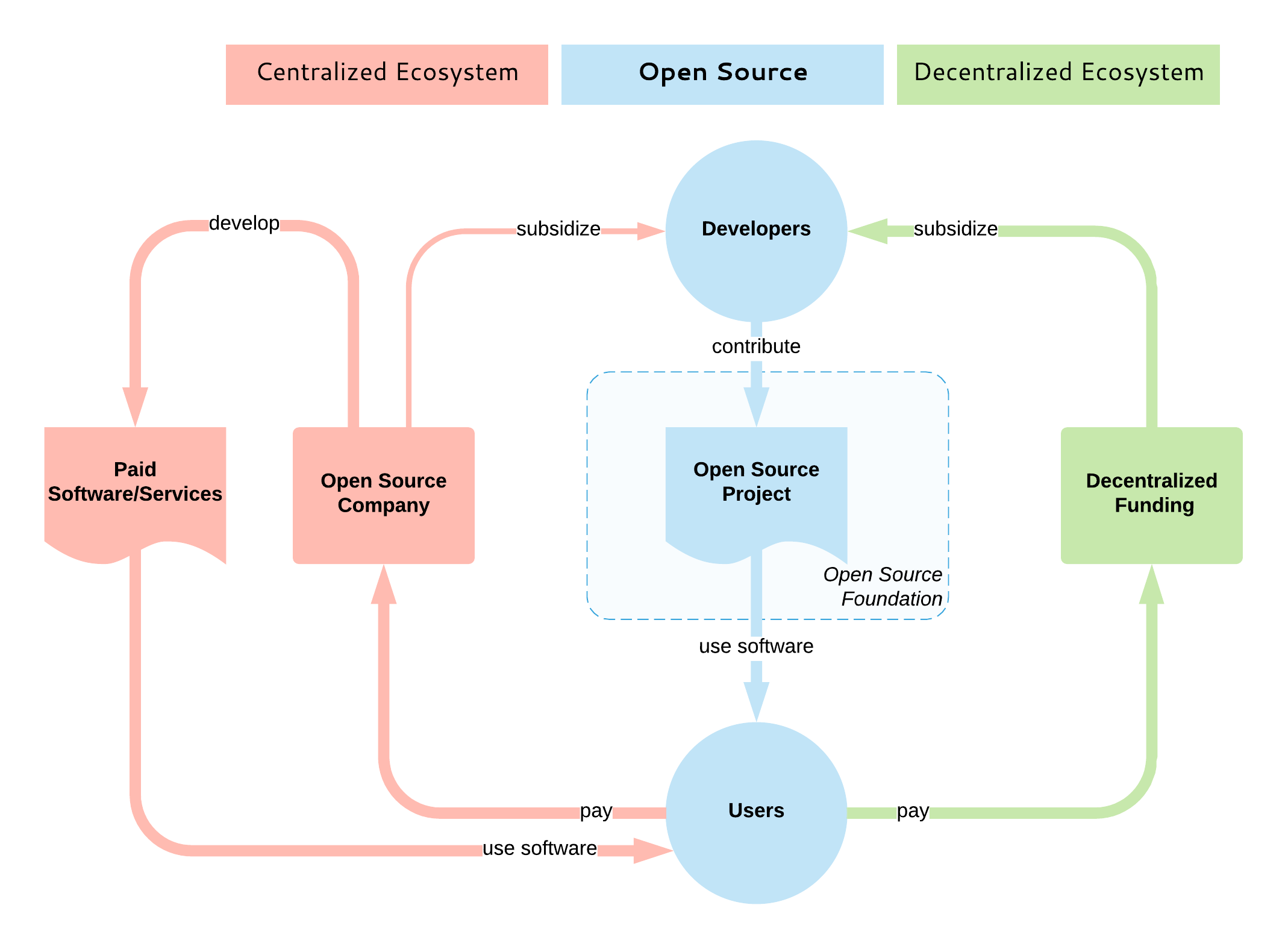
|
||||
|
||||
Currently, there is no equivalent of the decentralized open source development model for subsidization purposes. The majority of open source subsidization is centralized, where typically one company dominates a project by employing the majority of the open source developers of that project. And to be honest, this is currently the best-case scenario, as it guarantees that the developers will be paid for a long period and the project will continue to flourish.
|
||||
|
||||
There are also exceptions for the project monopoly scenario: For example, some Cloud Native Computing Foundation projects are developed by a large number of competing companies. Also, the Apache Software Foundation aims for their projects not to be dominated by a single vendor by encouraging diverse contributors, but most of the popular projects, in reality, are still single-vendor projects.
|
||||
|
||||
What we are missing is an open and decentralized model that works like the bazaar without a central coordination and ownership, where consumers (open source users) and producers (open source developers) interact with each other, driven by market forces and open source value. In order to complement open source, such a model must also be open and decentralized, and this is why I think the blockchain technology would [fit best here][3].
|
||||
|
||||
Most of the existing blockchain (and non-blockchain) platforms that aim to subsidize open source development are targeting primarily bug bounties, small and piecemeal tasks. A few also focus on funding new open source projects. But not many aim to provide mechanisms for sustaining continued development of open source projects—basically, a system that would emulate the behavior of an open source service provider company, or open core, open source-based SaaS product company: ensuring developers get continued and predictable incentives and guiding the project development based on the priorities of the incentivizers; i.e., the users. Such a model would address the limitations of the barter system listed above:
|
||||
|
||||
* Allow divisibility: If you want something small fixed, you can pay a small amount rather than the full premium of becoming an open source developer for a project.
|
||||
* Storing value: You can invest a large amount into a project and ensure both its continued development and that your voice is heard.
|
||||
* Transferring value: At any point, you can stop investing in the project and move funds into other projects.
|
||||
* Temporal decoupling: Allow regular recurring payments and subscriptions.
|
||||
|
||||
|
||||
|
||||
There would be also other benefits, purely from the fact that such a blockchain-based system is transparent and decentralized: to quantify a project’s value/usefulness based on its users’ commitment, open roadmap commitment, decentralized decision making, etc.
|
||||
|
||||
### Conclusion
|
||||
|
||||
On the one hand, we see large companies hiring open source developers and acquiring open source startups and even foundational platforms (such as Microsoft buying GitHub). Many, if not most, long-running successful open source projects are centralized around a single vendor. The significance of open source and its centralization is a fact.
|
||||
|
||||
On the other hand, the challenges around [sustaining open source][4] software are becoming more apparent, and many are investigating this space and its foundational issues more deeply. There are a few projects with high visibility and a large number of contributors, but there are also many other still-important projects that lack enough contributors and maintainers.
|
||||
|
||||
There are [many efforts][3] trying to address the challenges of open source through blockchain. These projects should improve the transparency, decentralization, and subsidization and establish a direct link between open source users and developers. This space is still very young, but it is progressing quickly, and with time, the bazaar is going to have a cryptocurrency system.
|
||||
|
||||
Given enough time and adequate technology, decentralization is happening at many levels:
|
||||
|
||||
* The internet is a decentralized medium that has unlocked the world’s potential for sharing and acquiring knowledge.
|
||||
* Open source is a decentralized collaboration model that has unlocked the world’s potential for innovation.
|
||||
* Similarly, blockchain can complement open source and become the decentralized open source subsidization model.
|
||||
|
||||
|
||||
|
||||
Follow me on [Twitter][5] for other posts in this space.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/barter-currency-system
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bibryam
|
||||
[1]: http://catb.org/
|
||||
[2]: http://oss.cash/
|
||||
[3]: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
[4]: https://www.youtube.com/watch?v=VS6IpvTWwkQ
|
||||
[5]: http://twitter.com/bibryam
|
||||
48
sources/talk/20180904 Why schools of the future are open.md
Normal file
48
sources/talk/20180904 Why schools of the future are open.md
Normal file
@ -0,0 +1,48 @@
|
||||
Why schools of the future are open
|
||||
======
|
||||
|
||||

|
||||
|
||||
Someone recently asked me what education will look like in the modern era. My response: Much like it has for the last 100 years. How's that for a pessimistic view of our education system?
|
||||
|
||||
It's not a pessimistic view as much as it is a pragmatic one. Anyone who spends time in schools could walk away feeling similarly, given that the ways we teach young people are stubbornly resistant to change. As schools in the United States begin a new year, most students are returning to classrooms where desks are lined-up in rows, the instructional environment is primarily teacher-centred, progress is measured by Carnegie units and A-F grading, and collaboration is often considered cheating.
|
||||
|
||||
Were we able to point to evidence that this industrialized model was producing the kind of results that are required, where every child is given the personal attention needed to grow a love of learning and develop the skills needed to thrive in today's innovation economy, then we could very well be satisfied with the status quo. But any honest and objective look at current metrics speaks to the need for fundamental change.
|
||||
|
||||
But my view isn't a pessimistic one. In fact, it's quite optimistic.
|
||||
|
||||
For as easy as it is to dwell on what's wrong with our current education model, I also know of example after example of where education stakeholders are willing to step out of what's comfortable and challenge this system that is so immune to change. Teachers are demanding more collaboration with peers and more ways to be open and transparent about prototyping ideas that lead to true innovation for students—not just repackaging of traditional methods with technology. Administrators are enabling deeper, more connected learning to real-world applications through community-focused, project-based learning—not just jumping through hoops of "doing projects" in isolated classrooms. And parents are demanding that the joy and wonder of learning return to the culture of their schools that have been corrupted by an emphasis on test prep.
|
||||
|
||||
These and other types of cultural changes are never easy, especially in an environment so reluctant to take risks in the face of political backlash from any dip in test scores (regardless of statistical significance). So why am I optimistic that we are approaching a tipping point where the type of changes we desperately need can indeed overcome the inertia that has thwarted them for too long?
|
||||
|
||||
Because there is something else in water at this point in our modern era that was not present before: an ethos of openness, catalyzed by digital technology.
|
||||
|
||||
Think for a moment: If you need to learn how to speak basic French for an upcoming trip to France, where do you turn? You could sign up for a course at a local community college or check out a book from the library, but in all likelihood, you'll access a free online video and learn the basics you will need for your trip. Never before in human history has free, on-demand learning been so accessible. In fact, one can sign up right now for a free, online course from MIT on "[Special Topics in Mathematics with Applications: Linear Algebra and the Calculus of Variations][1]." Sign me up!
|
||||
|
||||
Why do schools such as MIT, Stanford, and Harvard offer free access to their courses? Why are people and corporations willing to openly share what was once tightly controlled intellectual property? Why are people all over the planet willing to invest their time—for no pay—to help with citizen science projects?
|
||||
|
||||
There is something else in water at this point in our modern era that was not present before: an ethos of openness, catalyzed by digital technology.
|
||||
|
||||
In his wonderful book [Open: How We'll Work Live and Learn in the Future][2], author David Price clearly describes how informal, social learning is becoming the new norm of learning, especially among young people accustomed to being able to get the "just in time" knowledge they need. Through a series of case studies, Price paints a clear picture of what happens when traditional institutions don't adapt to this new reality and thus become less and less relevant. That's the missing ingredient that has the crowdsourced power of creating positive disruption.
|
||||
|
||||
What Price points out (and what people are now demanding at a grassroots level) is nothing short of an open movement, one recognizing that open collaboration and free exchange of ideas have already disrupted ecosystems from music to software to publishing. And more than any top-down driven "reform," this expectation for openness has the potential to fundamentally alter an educational system that has resisted change for too long. In fact, one of the hallmarks of the open ethos is that it expects the transparent and fair democratization of knowledge for the benefit of all. So what better ecosystem for such an ethos to thrive than within the one that seeks to prepare young people to inherit the world and make it better?
|
||||
|
||||
Sure, the pessimist in me says that my earlier prediction about the future of education may indeed be the state of education in the short term future. But I am also very optimistic that this prediction will be proven to be dead wrong. I know that I and many other kindred-spirit educators are working every day to ensure that it's wrong. Won't you join me as we start a movement to help our schools [transform into open organizations][3]—to transition from from an outdated, legacy model to one that is more open, nimble, and responsive to the needs of every student and the communities in which they serve?
|
||||
|
||||
That's a true education model appropriate for the modern era.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/9/modern-education-open-education
|
||||
|
||||
作者:[Ben Owens][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/engineerteacher
|
||||
[1]: https://ocw.mit.edu/courses/mechanical-engineering/2-035-special-topics-in-mathematics-with-applications-linear-algebra-and-the-calculus-of-variations-spring-2007/
|
||||
[2]: https://www.goodreads.com/book/show/18730272-open
|
||||
[3]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
@ -0,0 +1,234 @@
|
||||
Translating by qhwdw
|
||||
|
||||
# Caffeinated 6.828:Lab 2: Memory Management
|
||||
|
||||
### Introduction
|
||||
|
||||
In this lab, you will write the memory management code for your operating system. Memory management has two components.
|
||||
|
||||
The first component is a physical memory allocator for the kernel, so that the kernel can allocate memory and later free it. Your allocator will operate in units of 4096 bytes, called pages. Your task will be to maintain data structures that record which physical pages are free and which are allocated, and how many processes are sharing each allocated page. You will also write the routines to allocate and free pages of memory.
|
||||
|
||||
The second component of memory management is virtual memory, which maps the virtual addresses used by kernel and user software to addresses in physical memory. The x86 hardware’s memory management unit (MMU) performs the mapping when instructions use memory, consulting a set of page tables. You will modify JOS to set up the MMU’s page tables according to a specification we provide.
|
||||
|
||||
### Getting started
|
||||
|
||||
In this and future labs you will progressively build up your kernel. We will also provide you with some additional source. To fetch that source, use Git to commit changes you’ve made since handing in lab 1 (if any), fetch the latest version of the course repository, and then create a local branch called lab2 based on our lab2 branch, origin/lab2:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab2 origin/lab2
|
||||
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
|
||||
Switched to a new branch "lab2"
|
||||
athena%
|
||||
```
|
||||
|
||||
You will now need to merge the changes you made in your lab1 branch into the lab2 branch, as follows:
|
||||
|
||||
```
|
||||
athena% git merge lab1
|
||||
Merge made by recursive.
|
||||
kern/kdebug.c | 11 +++++++++--
|
||||
kern/monitor.c | 19 +++++++++++++++++++
|
||||
lib/printfmt.c | 7 +++----
|
||||
3 files changed, 31 insertions(+), 6 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
Lab 2 contains the following new source files, which you should browse through:
|
||||
|
||||
- inc/memlayout.h
|
||||
- kern/pmap.c
|
||||
- kern/pmap.h
|
||||
- kern/kclock.h
|
||||
- kern/kclock.c
|
||||
|
||||
memlayout.h describes the layout of the virtual address space that you must implement by modifying pmap.c. memlayout.h and pmap.h define the PageInfo structure that you’ll use to keep track of which pages of physical memory are free. kclock.c and kclock.h manipulate the PC’s battery-backed clock and CMOS RAM hardware, in which the BIOS records the amount of physical memory the PC contains, among other things. The code in pmap.c needs to read this device hardware in order to figure out how much physical memory there is, but that part of the code is done for you: you do not need to know the details of how the CMOS hardware works.
|
||||
|
||||
Pay particular attention to memlayout.h and pmap.h, since this lab requires you to use and understand many of the definitions they contain. You may want to review inc/mmu.h, too, as it also contains a number of definitions that will be useful for this lab.
|
||||
|
||||
Before beginning the lab, don’t forget to add exokernel to get the 6.828 version of QEMU.
|
||||
|
||||
### Hand-In Procedure
|
||||
|
||||
When you are ready to hand in your lab code and write-up, add your answers-lab2.txt to the Git repository, commit your changes, and then run make handin.
|
||||
|
||||
```
|
||||
athena% git add answers-lab2.txt
|
||||
athena% git commit -am "my answer to lab2"
|
||||
[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
|
||||
athena% make handin
|
||||
```
|
||||
|
||||
### Part 1: Physical Page Management
|
||||
|
||||
The operating system must keep track of which parts of physical RAM are free and which are currently in use. JOS manages the PC’s physical memory with page granularity so that it can use the MMU to map and protect each piece of allocated memory.
|
||||
|
||||
You’ll now write the physical page allocator. It keeps track of which pages are free with a linked list of struct PageInfo objects, each corresponding to a physical page. You need to write the physical page allocator before you can write the rest of the virtual memory implementation, because your page table management code will need to allocate physical memory in which to store page tables.
|
||||
|
||||
> Exercise 1
|
||||
>
|
||||
> In the file kern/pmap.c, you must implement code for the following functions (probably in the order given).
|
||||
>
|
||||
> boot_alloc()
|
||||
>
|
||||
> mem_init() (only up to the call to check_page_free_list())
|
||||
>
|
||||
> page_init()
|
||||
>
|
||||
> page_alloc()
|
||||
>
|
||||
> page_free()
|
||||
>
|
||||
> check_page_free_list() and check_page_alloc() test your physical page allocator. You should boot JOS and see whether check_page_alloc() reports success. Fix your code so that it passes. You may find it helpful to add your own assert()s to verify that your assumptions are correct.
|
||||
|
||||
This lab, and all the 6.828 labs, will require you to do a bit of detective work to figure out exactly what you need to do. This assignment does not describe all the details of the code you’ll have to add to JOS. Look for comments in the parts of the JOS source that you have to modify; those comments often contain specifications and hints. You will also need to look at related parts of JOS, at the Intel manuals, and perhaps at your 6.004 or 6.033 notes.
|
||||
|
||||
### Part 2: Virtual Memory
|
||||
|
||||
Before doing anything else, familiarize yourself with the x86’s protected-mode memory management architecture: namely segmentationand page translation.
|
||||
|
||||
> Exercise 2
|
||||
>
|
||||
> Look at chapters 5 and 6 of the Intel 80386 Reference Manual, if you haven’t done so already. Read the sections about page translation and page-based protection closely (5.2 and 6.4). We recommend that you also skim the sections about segmentation; while JOS uses paging for virtual memory and protection, segment translation and segment-based protection cannot be disabled on the x86, so you will need a basic understanding of it.
|
||||
|
||||
### Virtual, Linear, and Physical Addresses
|
||||
|
||||
In x86 terminology, a virtual address consists of a segment selector and an offset within the segment. A linear address is what you get after segment translation but before page translation. A physical address is what you finally get after both segment and page translation and what ultimately goes out on the hardware bus to your RAM.
|
||||
|
||||

|
||||
|
||||
Recall that in part 3 of lab 1, we installed a simple page table so that the kernel could run at its link address of 0xf0100000, even though it is actually loaded in physical memory just above the ROM BIOS at 0x00100000. This page table mapped only 4MB of memory. In the virtual memory layout you are going to set up for JOS in this lab, we’ll expand this to map the first 256MB of physical memory starting at virtual address 0xf0000000 and to map a number of other regions of virtual memory.
|
||||
|
||||
> Exercise 3
|
||||
>
|
||||
> While GDB can only access QEMU’s memory by virtual address, it’s often useful to be able to inspect physical memory while setting up virtual memory. Review the QEMU monitor commands from the lab tools guide, especially the xp command, which lets you inspect physical memory. To access the QEMU monitor, press Ctrl-a c in the terminal (the same binding returns to the serial console).
|
||||
>
|
||||
> Use the xp command in the QEMU monitor and the x command in GDB to inspect memory at corresponding physical and virtual addresses and make sure you see the same data.
|
||||
>
|
||||
> Our patched version of QEMU provides an info pg command that may also prove useful: it shows a compact but detailed representation of the current page tables, including all mapped memory ranges, permissions, and flags. Stock QEMU also provides an info mem command that shows an overview of which ranges of virtual memory are mapped and with what permissions.
|
||||
|
||||
From code executing on the CPU, once we’re in protected mode (which we entered first thing in boot/boot.S), there’s no way to directly use a linear or physical address. All memory references are interpreted as virtual addresses and translated by the MMU, which means all pointers in C are virtual addresses.
|
||||
|
||||
The JOS kernel often needs to manipulate addresses as opaque values or as integers, without dereferencing them, for example in the physical memory allocator. Sometimes these are virtual addresses, and sometimes they are physical addresses. To help document the code, the JOS source distinguishes the two cases: the type uintptr_t represents opaque virtual addresses, and physaddr_trepresents physical addresses. Both these types are really just synonyms for 32-bit integers (uint32_t), so the compiler won’t stop you from assigning one type to another! Since they are integer types (not pointers), the compiler will complain if you try to dereference them.
|
||||
|
||||
The JOS kernel can dereference a uintptr_t by first casting it to a pointer type. In contrast, the kernel can’t sensibly dereference a physical address, since the MMU translates all memory references. If you cast a physaddr_t to a pointer and dereference it, you may be able to load and store to the resulting address (the hardware will interpret it as a virtual address), but you probably won’t get the memory location you intended.
|
||||
|
||||
To summarize:
|
||||
|
||||
| C type | Address type |
|
||||
| ------------ | ------------ |
|
||||
| `T*` | Virtual |
|
||||
| `uintptr_t` | Virtual |
|
||||
| `physaddr_t` | Physical |
|
||||
|
||||
>Question
|
||||
>
|
||||
>Assuming that the following JOS kernel code is correct, what type should variable x have, >uintptr_t or physaddr_t?
|
||||
>
|
||||
>
|
||||
>
|
||||
|
||||
The JOS kernel sometimes needs to read or modify memory for which it knows only the physical address. For example, adding a mapping to a page table may require allocating physical memory to store a page directory and then initializing that memory. However, the kernel, like any other software, cannot bypass virtual memory translation and thus cannot directly load and store to physical addresses. One reason JOS remaps of all of physical memory starting from physical address 0 at virtual address 0xf0000000 is to help the kernel read and write memory for which it knows just the physical address. In order to translate a physical address into a virtual address that the kernel can actually read and write, the kernel must add 0xf0000000 to the physical address to find its corresponding virtual address in the remapped region. You should use KADDR(pa) to do that addition.
|
||||
|
||||
The JOS kernel also sometimes needs to be able to find a physical address given the virtual address of the memory in which a kernel data structure is stored. Kernel global variables and memory allocated by boot_alloc() are in the region where the kernel was loaded, starting at 0xf0000000, the very region where we mapped all of physical memory. Thus, to turn a virtual address in this region into a physical address, the kernel can simply subtract 0xf0000000. You should use PADDR(va) to do that subtraction.
|
||||
|
||||
### Reference counting
|
||||
|
||||
In future labs you will often have the same physical page mapped at multiple virtual addresses simultaneously (or in the address spaces of multiple environments). You will keep a count of the number of references to each physical page in the pp_ref field of thestruct PageInfo corresponding to the physical page. When this count goes to zero for a physical page, that page can be freed because it is no longer used. In general, this count should equal to the number of times the physical page appears below UTOP in all page tables (the mappings above UTOP are mostly set up at boot time by the kernel and should never be freed, so there’s no need to reference count them). We’ll also use it to keep track of the number of pointers we keep to the page directory pages and, in turn, of the number of references the page directories have to page table pages.
|
||||
|
||||
Be careful when using page_alloc. The page it returns will always have a reference count of 0, so pp_ref should be incremented as soon as you’ve done something with the returned page (like inserting it into a page table). Sometimes this is handled by other functions (for example, page_insert) and sometimes the function calling page_alloc must do it directly.
|
||||
|
||||
### Page Table Management
|
||||
|
||||
Now you’ll write a set of routines to manage page tables: to insert and remove linear-to-physical mappings, and to create page table pages when needed.
|
||||
|
||||
> Exercise 4
|
||||
>
|
||||
> In the file kern/pmap.c, you must implement code for the following functions.
|
||||
>
|
||||
> pgdir_walk()
|
||||
>
|
||||
> boot_map_region()
|
||||
>
|
||||
> page_lookup()
|
||||
>
|
||||
> page_remove()
|
||||
>
|
||||
> page_insert()
|
||||
>
|
||||
> check_page(), called from mem_init(), tests your page table management routines. You should make sure it reports success before proceeding.
|
||||
|
||||
### Part 3: Kernel Address Space
|
||||
|
||||
JOS divides the processor’s 32-bit linear address space into two parts. User environments (processes), which we will begin loading and running in lab 3, will have control over the layout and contents of the lower part, while the kernel always maintains complete control over the upper part. The dividing line is defined somewhat arbitrarily by the symbol ULIM in inc/memlayout.h, reserving approximately 256MB of virtual address space for the kernel. This explains why we needed to give the kernel such a high link address in lab 1: otherwise there would not be enough room in the kernel’s virtual address space to map in a user environment below it at the same time.
|
||||
|
||||
You’ll find it helpful to refer to the JOS memory layout diagram in inc/memlayout.h both for this part and for later labs.
|
||||
|
||||
### Permissions and Fault Isolation
|
||||
|
||||
Since kernel and user memory are both present in each environment’s address space, we will have to use permission bits in our x86 page tables to allow user code access only to the user part of the address space. Otherwise bugs in user code might overwrite kernel data, causing a crash or more subtle malfunction; user code might also be able to steal other environments’ private data.
|
||||
|
||||
The user environment will have no permission to any of the memory above ULIM, while the kernel will be able to read and write this memory. For the address range [UTOP,ULIM), both the kernel and the user environment have the same permission: they can read but not write this address range. This range of address is used to expose certain kernel data structures read-only to the user environment. Lastly, the address space below UTOP is for the user environment to use; the user environment will set permissions for accessing this memory.
|
||||
|
||||
### Initializing the Kernel Address Space
|
||||
|
||||
Now you’ll set up the address space above UTOP: the kernel part of the address space. inc/memlayout.h shows the layout you should use. You’ll use the functions you just wrote to set up the appropriate linear to physical mappings.
|
||||
|
||||
> Exercise 5
|
||||
>
|
||||
> Fill in the missing code in mem_init() after the call to check_page().
|
||||
|
||||
Your code should now pass the check_kern_pgdir() and check_page_installed_pgdir() checks.
|
||||
|
||||
> Question
|
||||
>
|
||||
> 1、What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:
|
||||
>
|
||||
> EntryBase Virtual AddressPoints to (logically):
|
||||
>
|
||||
> 1023 ? Page table for top 4MB of phys memory
|
||||
>
|
||||
> 1022 ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> 2 0x00800000 ?
|
||||
>
|
||||
> 1 0x00400000 ?
|
||||
>
|
||||
> 0 0x00000000 [see next question]
|
||||
>
|
||||
> 2、(From 20 Lecture3) We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel’s memory? What specific mechanisms protect the kernel memory?
|
||||
>
|
||||
> 3、What is the maximum amount of physical memory that this operating system can support? Why?
|
||||
>
|
||||
> 4、How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
|
||||
>
|
||||
> 5、Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
|
||||
|
||||
### Address Space Layout Alternatives
|
||||
|
||||
The address space layout we use in JOS is not the only one possible. An operating system might map the kernel at low linear addresses while leaving the upper part of the linear address space for user processes. x86 kernels generally do not take this approach, however, because one of the x86’s backward-compatibility modes, known as virtual 8086 mode, is “hard-wired” in the processor to use the bottom part of the linear address space, and thus cannot be used at all if the kernel is mapped there.
|
||||
|
||||
It is even possible, though much more difficult, to design the kernel so as not to have to reserve any fixed portion of the processor’s linear or virtual address space for itself, but instead effectively to allow allow user-level processes unrestricted use of the entire 4GB of virtual address space - while still fully protecting the kernel from these processes and protecting different processes from each other!
|
||||
|
||||
Generalize the kernel’s memory allocation system to support pages of a variety of power-of-two allocation unit sizes from 4KB up to some reasonable maximum of your choice. Be sure you have some way to divide larger allocation units into smaller ones on demand, and to coalesce multiple small allocation units back into larger units when possible. Think about the issues that might arise in such a system.
|
||||
|
||||
This completes the lab. Make sure you pass all of the make grade tests and don’t forget to write up your answers to the questions inanswers-lab2.txt. Commit your changes (including adding answers-lab2.txt) and type make handin in the lab directory to hand in your lab.
|
||||
|
||||
------
|
||||
|
||||
via: <https://sipb.mit.edu/iap/6.828/lab/lab2/>
|
||||
|
||||
作者:[Mit][<https://sipb.mit.edu/iap/6.828/lab/lab2/>]
|
||||
译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID)
|
||||
校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
297
sources/tech/20180823 CLI- improved.md
Normal file
297
sources/tech/20180823 CLI- improved.md
Normal file
@ -0,0 +1,297 @@
|
||||
CLI: improved
|
||||
======
|
||||
I'm not sure many web developers can get away without visiting the command line. As for me, I've been using the command line since 1997, first at university when I felt both super cool l33t-hacker and simultaneously utterly out of my depth.
|
||||
|
||||
Over the years my command line habits have improved and I often search for smarter tools for the jobs I commonly do. With that said, here's my current list of improved CLI tools.
|
||||
|
||||
|
||||
### Ignoring my improvements
|
||||
|
||||
In a number of cases I've aliased the new and improved command line tool over the original (as with `cat` and `ping`).
|
||||
|
||||
If I want to run the original command, which is sometimes I do need to do, then there's two ways I can do this (I'm on a Mac so your mileage may vary):
|
||||
```
|
||||
$ \cat # ignore aliases named "cat" - explanation: https://stackoverflow.com/a/16506263/22617
|
||||
$ command cat # ignore functions and aliases
|
||||
|
||||
```
|
||||
|
||||
### bat > cat
|
||||
|
||||
`cat` is used to print the contents of a file, but given more time spent in the command line, features like syntax highlighting come in very handy. I found [ccat][3] which offers highlighting then I found [bat][4] which has highlighting, paging, line numbers and git integration.
|
||||
|
||||
The `bat` command also allows me to search during output (only if the output is longer than the screen height) using the `/` key binding (similarly to `less` searching).
|
||||
|
||||
![Simple bat output][5]
|
||||
|
||||
I've also aliased `bat` to the `cat` command:
|
||||
```
|
||||
alias cat='bat'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][4]
|
||||
|
||||
### prettyping > ping
|
||||
|
||||
`ping` is incredibly useful, and probably my goto tool for the "oh crap is X down/does my internet work!!!". But `prettyping` ("pretty ping" not "pre typing"!) gives ping a really nice output and just makes me feel like the command line is a bit more welcoming.
|
||||
|
||||
![/images/cli-improved/ping.gif][6]
|
||||
|
||||
I've also aliased `ping` to the `prettyping` command:
|
||||
```
|
||||
alias ping='prettyping --nolegend'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][7]
|
||||
|
||||
### fzf > ctrl+r
|
||||
|
||||
In the terminal, using `ctrl+r` will allow you to [search backwards][8] through your history. It's a nice trick, albeit a bit fiddly.
|
||||
|
||||
The `fzf` tool is a **huge** enhancement on `ctrl+r`. It's a fuzzy search against the terminal history, with a fully interactive preview of the possible matches.
|
||||
|
||||
In addition to searching through the history, `fzf` can also preview and open files, which is what I've done in the video below:
|
||||
|
||||
For this preview effect, I created an alias called `preview` which combines `fzf` with `bat` for the preview and a custom key binding to open VS Code:
|
||||
```
|
||||
alias preview="fzf --preview 'bat --color \"always\" {}'"
|
||||
# add support for ctrl+o to open selected file in VS Code
|
||||
export FZF_DEFAULT_OPTS="--bind='ctrl-o:execute(code {})+abort'"
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][9]
|
||||
|
||||
### htop > top
|
||||
|
||||
`top` is my goto tool for quickly diagnosing why the CPU on the machine is running hard or my fan is whirring. I also use these tools in production. Annoyingly (to me!) `top` on the Mac is vastly different (and inferior IMHO) to `top` on linux.
|
||||
|
||||
However, `htop` is an improvement on both regular `top` and crappy-mac `top`. Lots of colour coding, keyboard bindings and different views which have helped me in the past to understand which processes belong to which.
|
||||
|
||||
Handy key bindings include:
|
||||
|
||||
* P - sort by CPU
|
||||
* M - sort by memory usage
|
||||
* F4 - filter processes by string (to narrow to just "node" for instance)
|
||||
* space - mark a single process so I can watch if the process is spiking
|
||||
|
||||
|
||||
|
||||
![htop output][10]
|
||||
|
||||
There is a weird bug in Mac Sierra that can be overcome by running `htop` as root (I can't remember exactly what the bug is, but this alias fixes it - though annoying that I have to enter my password every now and again):
|
||||
```
|
||||
alias top="sudo htop" # alias top and fix high sierra bug
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][11]
|
||||
|
||||
### diff-so-fancy > diff
|
||||
|
||||
I'm pretty sure I picked this one up from Paul Irish some years ago. Although I rarely fire up `diff` manually, my git commands use diff all the time. `diff-so-fancy` gives me both colour coding but also character highlight of changes.
|
||||
|
||||
![diff so fancy][12]
|
||||
|
||||
Then in my `~/.gitconfig` I have included the following entry to enable `diff-so-fancy` on `git diff` and `git show`:
|
||||
```
|
||||
[pager]
|
||||
diff = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
show = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][13]
|
||||
|
||||
### fd > find
|
||||
|
||||
Although I use a Mac, I've never been a fan of Spotlight (I found it sluggish, hard to remember the keywords, the database update would hammer my CPU and generally useless!). I use [Alfred][14] a lot, but even the finder feature doesn't serve me well.
|
||||
|
||||
I tend to turn the command line to find files, but `find` is always a bit of a pain to remember the right expression to find what I want (and indeed the Mac flavour is slightly different non-mac find which adds to frustration).
|
||||
|
||||
`fd` is a great replacement (by the same individual who wrote `bat`). It is very fast and the common use cases I need to search with are simple to remember.
|
||||
|
||||
A few handy commands:
|
||||
```
|
||||
$ fd cli # all filenames containing "cli"
|
||||
$ fd -e md # all with .md extension
|
||||
$ fd cli -x wc -w # find "cli" and run `wc -w` on each file
|
||||
|
||||
```
|
||||
|
||||
![fd output][15]
|
||||
|
||||
💾 [Installation directions][16]
|
||||
|
||||
### ncdu > du
|
||||
|
||||
Knowing where disk space is being taking up is a fairly important task for me. I've used the Mac app [Disk Daisy][17] but I find that it can be a little slow to actually yield results.
|
||||
|
||||
The `du -sh` command is what I'll use in the terminal (`-sh` means summary and human readable), but often I'll want to dig into the directories taking up the space.
|
||||
|
||||
`ncdu` is a nice alternative. It offers an interactive interface and allows for quickly scanning which folders or files are responsible for taking up space and it's very quick to navigate. (Though any time I want to scan my entire home directory, it's going to take a long time, regardless of the tool - my directory is about 550gb).
|
||||
|
||||
Once I've found a directory I want to manage (to delete, move or compress files), I'll use the cmd + click the pathname at the top of the screen in [iTerm2][18] to launch finder to that directory.
|
||||
|
||||
![ncdu output][19]
|
||||
|
||||
There's another [alternative called nnn][20] which offers a slightly nicer interface and although it does file sizes and usage by default, it's actually a fully fledged file manager.
|
||||
|
||||
My `ncdu` is aliased to the following:
|
||||
```
|
||||
alias du="ncdu --color dark -rr -x --exclude .git --exclude node_modules"
|
||||
|
||||
```
|
||||
|
||||
The options are:
|
||||
|
||||
* `--color dark` \- use a colour scheme
|
||||
* `-rr` \- read-only mode (prevents delete and spawn shell)
|
||||
* `--exclude` ignore directories I won't do anything about
|
||||
|
||||
|
||||
|
||||
💾 [Installation directions][21]
|
||||
|
||||
### tldr > man
|
||||
|
||||
It's amazing that nearly every single command line tool comes with a manual via `man <command>`, but navigating the `man` output can be sometimes a little confusing, plus it can be daunting given all the technical information that's included in the manual output.
|
||||
|
||||
This is where the TL;DR project comes in. It's a community driven documentation system that's available from the command line. So far in my own usage, I've not come across a command that's not been documented, but you can [also contribute too][22].
|
||||
|
||||
![TLDR output for 'fd'][23]
|
||||
|
||||
As a nicety, I've also aliased `tldr` to `help` (since it's quicker to type!):
|
||||
```
|
||||
alias help='tldr'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][24]
|
||||
|
||||
### ack || ag > grep
|
||||
|
||||
`grep` is no doubt a powerful tool on the command line, but over the years it's been superseded by a number of tools. Two of which are `ack` and `ag`.
|
||||
|
||||
I personally flitter between `ack` and `ag` without really remembering which I prefer (that's to say they're both very good and very similar!). I tend to default to `ack` only because it rolls of my fingers a little easier. Plus, `ack` comes with the mega `ack --bar` argument (I'll let you experiment)!
|
||||
|
||||
Both `ack` and `ag` will (by default) use a regular expression to search, and extremely pertinent to my work, I can specify the file types to search within using flags like `--js` or `--html` (though here `ag` includes more files in the js filter than `ack`).
|
||||
|
||||
Both tools also support the usual `grep` options, like `-B` and `-A` for before and after context in the grep.
|
||||
|
||||
![ack in action][25]
|
||||
|
||||
Since `ack` doesn't come with markdown support (and I write a lot in markdown), I've got this customisation in my `~/.ackrc` file:
|
||||
```
|
||||
--type-set=md=.md,.mkd,.markdown
|
||||
--pager=less -FRX
|
||||
|
||||
```
|
||||
|
||||
💾 Installation directions: [ack][26], [ag][27]
|
||||
|
||||
[Futher reading on ack & ag][28]
|
||||
|
||||
### jq > grep et al
|
||||
|
||||
I'm a massive fanboy of [jq][29]. At first I struggled with the syntax, but I've since come around to the query language and use `jq` on a near daily basis (whereas before I'd either drop into node, use grep or use a tool called [json][30] which is very basic in comparison).
|
||||
|
||||
I've even started the process of writing a jq tutorial series (2,500 words and counting) and have published a [web tool][31] and a native mac app (yet to be released).
|
||||
|
||||
`jq` allows me to pass in JSON and transform the source very easily so that the JSON result fits my requirements. One such example allows me to update all my node dependencies in one command (broken into multiple lines for readability):
|
||||
```
|
||||
$ npm i $(echo $(\
|
||||
npm outdated --json | \
|
||||
jq -r 'to_entries | .[] | "\(.key)@\(.value.latest)"' \
|
||||
))
|
||||
|
||||
```
|
||||
|
||||
The above command will list all the node dependencies that are out of date, and use npm's JSON output format, then transform the source JSON from this:
|
||||
```
|
||||
{
|
||||
"node-jq": {
|
||||
"current": "0.7.0",
|
||||
"wanted": "0.7.0",
|
||||
"latest": "1.2.0",
|
||||
"location": "node_modules/node-jq"
|
||||
},
|
||||
"uuid": {
|
||||
"current": "3.1.0",
|
||||
"wanted": "3.2.1",
|
||||
"latest": "3.2.1",
|
||||
"location": "node_modules/uuid"
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
…to this:
|
||||
|
||||
That result is then fed into the `npm install` command and voilà, I'm all upgraded (using the sledgehammer approach).
|
||||
|
||||
### Honourable mentions
|
||||
|
||||
Some of the other tools that I've started poking around with, but haven't used too often (with the exception of ponysay, which appears when I start a new terminal session!):
|
||||
|
||||
* [ponysay][32] > cowsay
|
||||
* [csvkit][33] > awk et al
|
||||
* [noti][34] > `display notification`
|
||||
* [entr][35] > watch
|
||||
|
||||
|
||||
|
||||
### What about you?
|
||||
|
||||
So that's my list. How about you? What daily command line tools have you improved? I'd love to know.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://remysharp.com/2018/08/23/cli-improved
|
||||
|
||||
作者:[Remy Sharp][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://remysharp.com
|
||||
[1]: https://remysharp.com/images/terminal-600.jpg
|
||||
[2]: https://training.leftlogic.com/buy/terminal/cli2?coupon=READERS-DISCOUNT&utm_source=blog&utm_medium=banner&utm_campaign=remysharp-discount
|
||||
[3]: https://github.com/jingweno/ccat
|
||||
[4]: https://github.com/sharkdp/bat
|
||||
[5]: https://remysharp.com/images/cli-improved/bat.gif (Sample bat output)
|
||||
[6]: https://remysharp.com/images/cli-improved/ping.gif (Sample ping output)
|
||||
[7]: http://denilson.sa.nom.br/prettyping/
|
||||
[8]: https://lifehacker.com/278888/ctrl%252Br-to-search-and-other-terminal-history-tricks
|
||||
[9]: https://github.com/junegunn/fzf
|
||||
[10]: https://remysharp.com/images/cli-improved/htop.jpg (Sample htop output)
|
||||
[11]: http://hisham.hm/htop/
|
||||
[12]: https://remysharp.com/images/cli-improved/diff-so-fancy.jpg (Sample diff output)
|
||||
[13]: https://github.com/so-fancy/diff-so-fancy
|
||||
[14]: https://www.alfredapp.com/
|
||||
[15]: https://remysharp.com/images/cli-improved/fd.png (Sample fd output)
|
||||
[16]: https://github.com/sharkdp/fd/
|
||||
[17]: https://daisydiskapp.com/
|
||||
[18]: https://www.iterm2.com/
|
||||
[19]: https://remysharp.com/images/cli-improved/ncdu.png (Sample ncdu output)
|
||||
[20]: https://github.com/jarun/nnn
|
||||
[21]: https://dev.yorhel.nl/ncdu
|
||||
[22]: https://github.com/tldr-pages/tldr#contributing
|
||||
[23]: https://remysharp.com/images/cli-improved/tldr.png (Sample tldr output for 'fd')
|
||||
[24]: http://tldr-pages.github.io/
|
||||
[25]: https://remysharp.com/images/cli-improved/ack.png (Sample ack output with grep args)
|
||||
[26]: https://beyondgrep.com
|
||||
[27]: https://github.com/ggreer/the_silver_searcher
|
||||
[28]: http://conqueringthecommandline.com/book/ack_ag
|
||||
[29]: https://stedolan.github.io/jq
|
||||
[30]: http://trentm.com/json/
|
||||
[31]: https://jqterm.com
|
||||
[32]: https://github.com/erkin/ponysay
|
||||
[33]: https://csvkit.readthedocs.io/en/1.0.3/
|
||||
[34]: https://github.com/variadico/noti
|
||||
[35]: http://www.entrproject.org/
|
||||
130
sources/tech/20180904 Why I love Xonsh.md
Normal file
130
sources/tech/20180904 Why I love Xonsh.md
Normal file
@ -0,0 +1,130 @@
|
||||
Why I love Xonsh
|
||||
======
|
||||
|
||||

|
||||
|
||||
Shell languages are useful for interactive use. But this optimization often comes with trade-offs against using them as programming languages, which is sometimes felt when writing shell scripts.
|
||||
|
||||
What if your shell also understood a more scalable programming language? Say, Python?
|
||||
|
||||
Enter [Xonsh][1].
|
||||
|
||||
Installing Xonsh is as simple as creating a virtual environment, running `pip install xonsh[ptk,linux]`, and then running `xonsh`.
|
||||
|
||||
At first, you might wonder why your Python shell has a weird prompt:
|
||||
```
|
||||
$ 1+1
|
||||
2
|
||||
```
|
||||
|
||||
Nice calculator!
|
||||
```
|
||||
$ print("hello world")
|
||||
hello world
|
||||
```
|
||||
|
||||
We can also call other functions:
|
||||
```
|
||||
$ from antigravity import geohash
|
||||
$ geohash(37.421542, -122.085589, b'2005-05-26-10458.68')
|
||||
37.857713 -122.544543
|
||||
```
|
||||
|
||||
However, we can still use it like a regular shell:
|
||||
```
|
||||
$ echo "hello world"
|
||||
hello world
|
||||
```
|
||||
|
||||
We can even mix and match!
|
||||
```
|
||||
$ for i in range(3):
|
||||
. echo "hello world"
|
||||
.
|
||||
hello world
|
||||
hello world
|
||||
hello world
|
||||
```
|
||||
|
||||
Xonsh supports completion for both shell commands and Python expressions by using the [Prompt Toolkit][2]. Completions are visually informative, showing possible completions and having in-band dropdown lists.
|
||||
|
||||
It also supports environment access. It uses a simple but powerful heuristic for applying Python types to environment variables. The default is "string," but, for example, path variables are automatically lists.
|
||||
```
|
||||
$ '/usr/bin' in $PATH
|
||||
True
|
||||
```
|
||||
|
||||
Xonsh accepts either shell-style or Python-style boolean shortcut operators:
|
||||
```
|
||||
$ cat things
|
||||
foo
|
||||
$ grep -q foo things and echo "found"
|
||||
found
|
||||
$ grep -q bar things && echo "found"
|
||||
$ grep -q foo things or echo "found"
|
||||
$ grep -q bar things || echo "found"
|
||||
found
|
||||
```
|
||||
|
||||
This means that Python keywords are interpreted. If we want to print the title of a famous Dr. Seuss book, we need to quote the keywords.
|
||||
```
|
||||
$ echo green eggs "and" ham
|
||||
green eggs and ham
|
||||
```
|
||||
|
||||
If we do not, we are in for a surprise:
|
||||
```
|
||||
$ echo green eggs and ham
|
||||
green eggs
|
||||
xonsh: For full traceback set: $XONSH_SHOW_TRACEBACK = True
|
||||
xonsh: subprocess mode: command not found: ham
|
||||
Did you mean one of the following?
|
||||
as: Command (/usr/bin/as)
|
||||
ht: Command (/usr/bin/ht)
|
||||
mag: Command (/usr/bin/mag)
|
||||
ar: Command (/usr/bin/ar)
|
||||
nm: Command (/usr/bin/nm)
|
||||
```
|
||||
|
||||
Virtual environments can get a little tricky. Regular virtual environments, depending as they do on Bash-like syntax, cannot work. However, Xonsh comes with its own virtual environment management system called `vox`.
|
||||
|
||||
`vox` can create, activate and deactivate environments in `~/.virtualenvs`; if you've used `virtualenvwrapper`, this is where the environments were.
|
||||
|
||||
Note that the current activated environment doesn't affect `x``onsh`. It can't import anything from an activated environment.
|
||||
```
|
||||
$ xontrib load vox
|
||||
$ vox create my-environment
|
||||
...
|
||||
$ vox activate my-environment
|
||||
Activated "my-environment".
|
||||
$ pip install money
|
||||
...
|
||||
$ python
|
||||
...
|
||||
>>> import money
|
||||
>>> money.Money('3.14')
|
||||
$ import money
|
||||
xonsh: For full traceback set: $XONSH_SHOW_TRACEBACK = True
|
||||
ModuleNotFoundError: No module named 'money'
|
||||
```
|
||||
|
||||
The first line enables `vox`: it is a `xontrib`, a third-party extension for Xonsh. The `xontrib` manager can list all possible `xontribs` and their current state (installed, loaded, or neither).
|
||||
|
||||
It's possible to write a `xontrib` and just upload it to `PyPi` to make it available. However, it's good practice to add it to the `xontrib` index so Xonsh knows about it in advance. This allows, for example, the configuration wizard to suggest it.
|
||||
|
||||
If you've ever wondered, "can Python be my shell?" then you are only a `pip install xonsh` away from finding out.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/xonsh-bash-alternative
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[1]: https://xon.sh/
|
||||
[2]: https://python-prompt-toolkit.readthedocs.io/en/master/
|
||||
Loading…
Reference in New Issue
Block a user