mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
63c1511179
@ -1,12 +1,12 @@
|
|||||||
如何在 Linux 上使用 BackupPC 来设置一个跨平台的备份服务器
|
如何在 Linux 上使用 BackupPC 来架设跨平台的备份服务器
|
||||||
================================================================================
|
================================================================================
|
||||||
为了防止你不能分辨这篇教程和我先前关于[backupninja][1] 和 [backup-manager][2] 的帖子,=== 我是一个积极的备份迷。当提到备份,我宁愿备份的太多而不希望备份不足,因为如果我们有需要的话,你将会感激你花费了时间和精力来为你的重要数据生成额外的拷贝。
|
也许你没有从我先前关于 [backupninja][1] 和 [backup-manager][2] 的两篇文章中发现,我是一个超级备“粉”。当提到备份,我宁愿备份的太多而不希望备份不足,因为如果我们有需要的话,你将会感激你为重要数据生成额外的拷贝所付出的时间和精力。
|
||||||
|
|
||||||
在这篇帖子中,我将向你介绍 [BackupPC][3],一个跨平台的备份服务器软件,它可以通过网络为 Linux,Windows 和 MacOS 等系统上的客户端主机拉取备份。BackupPC 添加了一系列的特点使得管理备份变为一件快乐的事。
|
在这篇文章中,我将向你介绍 [BackupPC][3],一个跨平台的备份服务器软件,它可以通过网络为 Linux,Windows 和 MacOS 等系统上的客户端主机拉取备份。BackupPC 添加了一系列的特点使得管理备份变为一件快乐的事。
|
||||||
|
|
||||||
### BackupPC 的特点 ###
|
### BackupPC 的特点 ###
|
||||||
|
|
||||||
BackupPC 自带有一个健壮的 Web 界面,允许你以集中的方式来收集和管理其他远程客户端主机上的备份。通过使用它的 Web 界面,你可以检查日志和配置文件、为其他远程主机启动/取消/安排备份任务以及可视化备份任务的当前状态。你也可以非常容易地浏览归档的文件以及从备份的归档中恢复个人文件或整个作业。为了恢复单一的个人文件,你可以直接通过 Web 界面来下载任何先前备份的文件。若如这还不够,针对客户端主机,没有特别的客户端软件需要安装。在 Windows 客户端上, 本机 SMB 协议将被使用,而对于 *nix 客户端,你将使用 `rsync` 或 通过 SSH, RSH 或 NFS 来使用 `tar` 。
|
BackupPC 自带有一个健壮的 Web 界面,允许你以集中化的方式来收集和管理其他远程客户端主机上的备份。通过使用它的 Web 界面,你可以检查日志和配置文件、为其他远程主机启动/取消/安排备份任务以及可视化备份任务的当前状态。你也可以非常容易地浏览归档的文件以及从备份的归档中恢复单个文件或整个备份。要恢复单个文件,你可以直接通过 Web 界面来下载任何先前备份的文件。不仅如此,客户端主机并不需要安装特别的客户端软件。在 Windows 客户端上, 使用的是原生的 SMB 协议,而对于 *nix 客户端,你将使用 `rsync` 或 通过 SSH, RSH 或 NFS 来使用 `tar` 。
|
||||||
|
|
||||||
### 安装 BackupPC ###
|
### 安装 BackupPC ###
|
||||||
|
|
||||||
@ -20,13 +20,13 @@ BackupPC 自带有一个健壮的 Web 界面,允许你以集中的方式来收
|
|||||||
|
|
||||||
# yum install BackupPC
|
# yum install BackupPC
|
||||||
|
|
||||||
同往常一样,这两种包管理系统都会自动地对依赖问题进行解决。另外,作为安装过程中的一部分,你可能会被要求去配置或重新配置用于图形用户界面的 Web 服务器。下面的截图来自于 Debian 系统:
|
同往常一样,这两种包管理系统都会自动解决依赖问题。另外,作为安装过程中的一部分,你可能需要新配置或修改配置用于图形用户界面的 Web 服务器。下面的截图来自于 Debian 系统:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
通过空格键来确定你的选择,然后使用 tab 键移动到 Ok 选项并敲回车键。
|
通过空格键来确定你的选择,然后使用 tab 键移动到 Ok 选项并敲回车键。
|
||||||
|
|
||||||
接着类似于下面的截屏将会呈现在你眼前,通知你一个用来管理 BackupPC 的名为 ‘backuppc’的管理员用户以及相应的密码(这个密码可以在以后被更改,如果你希望的话)已经被创建。这里需要注意的是:同样名为 ‘backuppc’的一个 HTTP 账户和一个常规的 Linux 账户将会被创建,它们使用同一个密码。需要前者的目的是来访问受保护的 BackupPC 的 Web 界面,而后者则是为了通过 SSH 来使用 `rsync` 来执行备份任务。
|
接着类似于下面的截屏将会呈现在你眼前,通知你创建了一个用来管理 BackupPC 的名为 ‘backuppc’的管理员用户以及相应的密码(如果你需要,这个密码以后可以更改)。这里需要注意的是:这里创建了同样名为 ‘backuppc’的 HTTP 账户和常规的 Linux 账户,它们使用相同的密码。需要前者的目的是来访问受保护的 BackupPC 的 Web 界面,而后者则是为了通过 SSH 来使用 `rsync` 来执行备份任务。
|
||||||
|
|
||||||
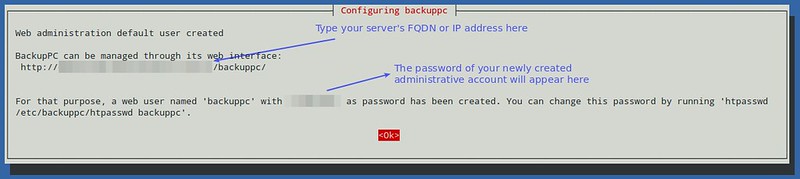
|

|
||||||
|
|
||||||
@ -42,7 +42,7 @@ BackupPC 自带有一个健壮的 Web 界面,允许你以集中的方式来收
|
|||||||
|
|
||||||
### 启动 BackupPC 并设置备份 ###
|
### 启动 BackupPC 并设置备份 ###
|
||||||
|
|
||||||
首先,打开一个浏览器窗口并指向 http://<server's FQDN or IP address>/backuppc/ 。当弹出提示框时,输入先前向你提供的默认 HTTP 用户凭据(注:即用户名 backuppc 和相应的默认密码)。假如认证成功,你就会被带入到 Web 界面的主页:
|
首先,打开一个浏览器窗口并指向 http://\<服务器名称或 IP 地址>/backuppc/ 。当弹出提示框时,输入先前向你创建的默认 HTTP 用户凭据(注:即用户名 backuppc 和相应的默认密码)。假如认证成功,你就会被带入到 Web 界面的主页:
|
||||||
|
|
||||||
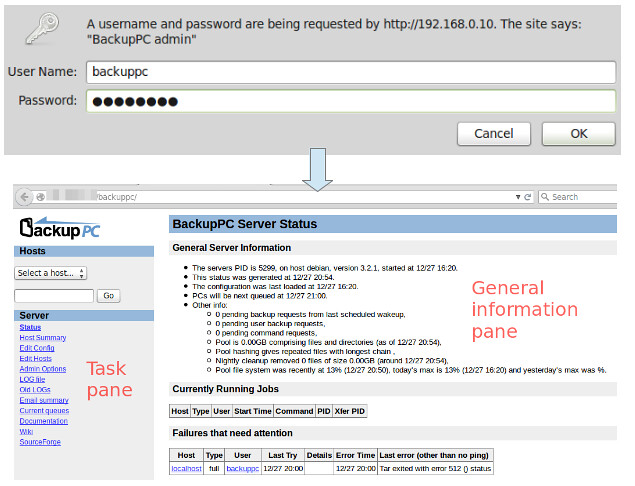
|

|
||||||
|
|
||||||
@ -51,9 +51,9 @@ BackupPC 自带有一个健壮的 Web 界面,允许你以集中的方式来收
|
|||||||
- Host #1: CentOS 7 [IP 192.168.0.17]
|
- Host #1: CentOS 7 [IP 192.168.0.17]
|
||||||
- Host #2: Windows 7 [IP 192.168.0.103]
|
- Host #2: Windows 7 [IP 192.168.0.103]
|
||||||
|
|
||||||
我们将通过 SSH 使用 `rsync`来备份 CentOS 主机,使用 SMB 来备份 Windows 主机。在执行备份之前,我们需要向我们的 CentOS 主机设置 [基于密码认证][7](注:这里我不知如何翻译,根据链接,感觉是无需密码来连接主机)以及在我们的 Windows 主机中设置一个共享目录。
|
我们将通过 SSH 使用 `rsync`来备份 CentOS 主机,使用 SMB 来备份 Windows 主机。在执行备份之前,我们需要向我们的 CentOS 主机设置 [基于密钥认证][7] 以及在我们的 Windows 主机中设置一个共享目录。
|
||||||
|
|
||||||
下面是关于如何为一个远程 CentOS 主机设置 key-based authentication 的指导。我们创建 ‘backuppc’ 用户的 RSA 密钥对,并向 CentOS 主机上的 root 账户传递它的公共密钥。
|
下面是关于如何为一个远程 CentOS 主机设置基于密钥认证的指导。我们创建 ‘backuppc’ 用户的 RSA 密钥对,并将其公钥传输给 CentOS 主机上的 root 账户。
|
||||||
|
|
||||||
# usermod -s /bin/bash backuppc
|
# usermod -s /bin/bash backuppc
|
||||||
# su - backuppc
|
# su - backuppc
|
||||||
@ -64,13 +64,13 @@ BackupPC 自带有一个健壮的 Web 界面,允许你以集中的方式来收
|
|||||||
|
|
||||||
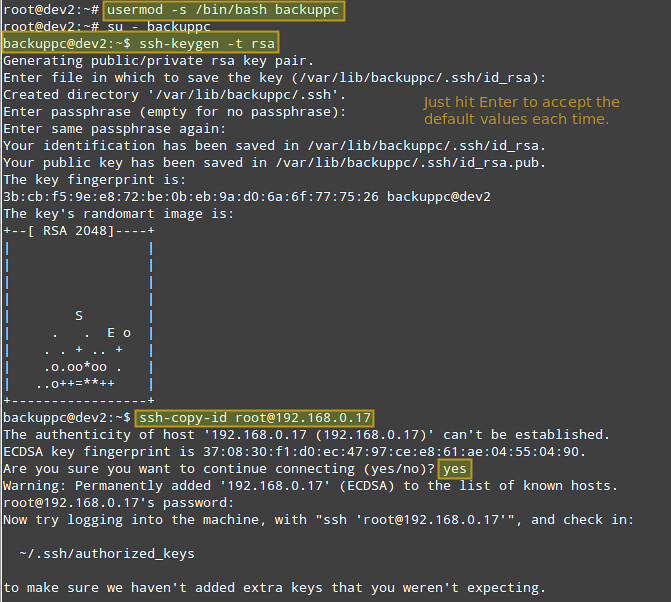
|

|
||||||
|
|
||||||
你需要一个远程的 CentOS 主机的 root 权限来在该主机中的文件系统中发放写权限,以防要恢复的备份文件或目录的所有者为 root 账户。
|
你需要一个远程的 CentOS 主机的 root 权限,以获得在该主机中的文件系统中写权限,以防要恢复的备份文件或目录的所有者为 root 账户。
|
||||||
|
|
||||||
一旦 CentOS 和 Windows 主机都准备完毕,使用 Web 界面将它们添加到 BackupPC:
|
一旦 CentOS 和 Windows 主机都准备完毕,使用 Web 界面将它们添加到 BackupPC:
|
||||||
|
|
||||||
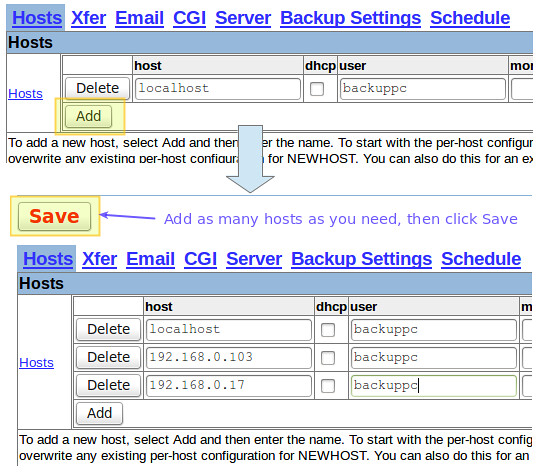
|

|
||||||
|
|
||||||
下一步的内容由更改每个主机的备份设置组成:
|
下一步更改每个主机的备份设置:
|
||||||
|
|
||||||
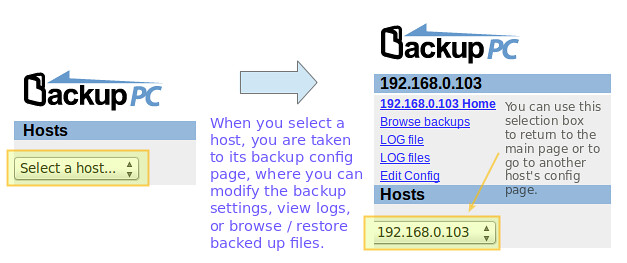
|

|
||||||
|
|
||||||
@ -88,7 +88,7 @@ BackupPC 自带有一个健壮的 Web 界面,允许你以集中的方式来收
|
|||||||
|
|
||||||
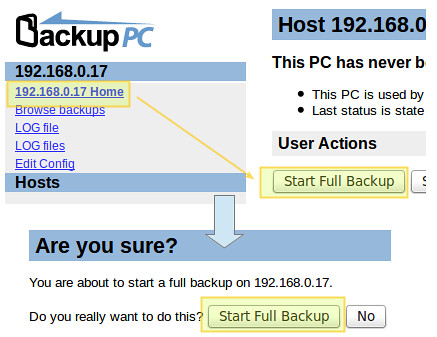
|

|
||||||
|
|
||||||
在任何时候,你都可以通过点击如上图展示的每个主机的备份主页来查看备份任务的状态。假如因为某些原因备份失败,在主机菜单中将会出现一个指向包含错误信息的网页的链接。当一个备份任务被成功地完成,一个被命名为主机名或 IP 地址的目录将会在服务器的 /var/lib/backuppc/pc 目录下被创建。
|
在任何时候,你都可以通过点击如上图展示的每个主机的备份主页来查看备份任务的状态。假如因为某些原因备份失败,在主机菜单中将会出现一个指向包含错误信息的网页的链接。当一个备份任务成功完成后,在服务器的 /var/lib/backuppc/pc 目录下会创建一个命名为主机名或 IP 地址的目录。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -96,7 +96,7 @@ BackupPC 自带有一个健壮的 Web 界面,允许你以集中的方式来收
|
|||||||
|
|
||||||
### 恢复备份 ###
|
### 恢复备份 ###
|
||||||
|
|
||||||
为了浏览已经保存过的文件。进入每个主机的主菜单下的 “浏览备份”选项,你可以一目了然地看到目录和文件,并选择那些你想恢复的文件。另外,你还可以通过点击文件来使用默认程序打开文件或右击文件并选择“另存为”来下载该文件到你正在工作的机器上:
|
要浏览这些保存的文件,进入每个主机的主菜单下的 “浏览备份”选项,你可以一目了然地看到目录和文件,并选择那些你想恢复的文件。另外,你还可以通过点击文件来使用默认程序打开文件或右击文件并选择“另存为”来下载该文件到你当前的机器上:
|
||||||
|
|
||||||
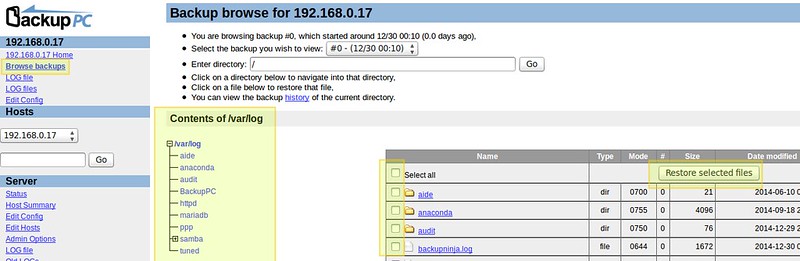
|

|
||||||
|
|
||||||
@ -113,21 +113,22 @@ BackupPC 自带有一个健壮的 Web 界面,允许你以集中的方式来收
|
|||||||
有句俗话说,"越简单,越好",而这正是 BackupPC 所提供的东西。在 BackupPC 中,你将不仅找到了一个备份工具,而且还找到了一个无需任何客户端应用来在几个不同的操作系统中管理你的备份的方法。我相信这就有足够的理由让你去尝试一下。
|
有句俗话说,"越简单,越好",而这正是 BackupPC 所提供的东西。在 BackupPC 中,你将不仅找到了一个备份工具,而且还找到了一个无需任何客户端应用来在几个不同的操作系统中管理你的备份的方法。我相信这就有足够的理由让你去尝试一下。
|
||||||
|
|
||||||
欢迎使用下面的评论框来留下你的评论和问题,假如你有的话。我总是乐于听取读者想说的话!
|
欢迎使用下面的评论框来留下你的评论和问题,假如你有的话。我总是乐于听取读者想说的话!
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: http://xmodulo.com/backuppc-cross-platform-backup-server-linux.html
|
via: http://xmodulo.com/backuppc-cross-platform-backup-server-linux.html
|
||||||
|
|
||||||
作者:[Gabriel Cánepa][a]
|
作者:[Gabriel Cánepa][a]
|
||||||
译者:[FSSlc](https://github.com/FSSlc)
|
译者:[FSSlc](https://github.com/FSSlc)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
[a]:http://xmodulo.com/author/gabriel
|
[a]:http://xmodulo.com/author/gabriel
|
||||||
[1]:http://xmodulo.com/backup-debian-system-backupninja.html
|
[1]:http://linux.cn/article-5096-1.html
|
||||||
[2]:http://xmodulo.com/linux-backup-manager.html
|
[2]:http://linux.cn/article-4586-1.html
|
||||||
[3]:http://backuppc.sourceforge.net/
|
[3]:http://backuppc.sourceforge.net/
|
||||||
[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
[4]:http://linux.cn/article-2324-1.html
|
||||||
[5]:http://ask.xmodulo.com/enable-nux-dextop-repository-centos-rhel.html
|
[5]:http://linux.cn/article-3889-1.html
|
||||||
[6]:http://xmodulo.com/recommend/linuxguide
|
[6]:http://xmodulo.com/recommend/linuxguide
|
||||||
[7]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
[7]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||||
@ -1,4 +1,4 @@
|
|||||||
如何在Ubuntu 14.04 LTS安装网络爬虫工具
|
如何在Ubuntu 14.04 LTS安装网络爬虫工具:Scrapy
|
||||||
================================================================================
|
================================================================================
|
||||||
这是一款提取网站数据的开源工具。Scrapy框架用Python开发而成,它使抓取工作又快又简单,且可扩展。我们已经在virtual box中创建一台虚拟机(VM)并且在上面安装了Ubuntu 14.04 LTS。
|
这是一款提取网站数据的开源工具。Scrapy框架用Python开发而成,它使抓取工作又快又简单,且可扩展。我们已经在virtual box中创建一台虚拟机(VM)并且在上面安装了Ubuntu 14.04 LTS。
|
||||||
|
|
||||||
@ -6,13 +6,13 @@
|
|||||||
|
|
||||||
Scrapy依赖于Python、开发库和pip。Python最新的版本已经在Ubuntu上预装了。因此我们在安装Scrapy之前只需安装pip和python开发库就可以了。
|
Scrapy依赖于Python、开发库和pip。Python最新的版本已经在Ubuntu上预装了。因此我们在安装Scrapy之前只需安装pip和python开发库就可以了。
|
||||||
|
|
||||||
pip是作为python包索引器easy_install的替代品。用于安装和管理Python包。pip包的安装可见图 1。
|
pip是作为python包索引器easy_install的替代品,用于安装和管理Python包。pip包的安装可见图 1。
|
||||||
|
|
||||||
sudo apt-get install python-pip
|
sudo apt-get install python-pip
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
图:1 pip安装
|
*图:1 pip安装*
|
||||||
|
|
||||||
我们必须要用下面的命令安装python开发库。如果包没有安装那么就会在安装scrapy框架的时候报关于python.h头文件的错误。
|
我们必须要用下面的命令安装python开发库。如果包没有安装那么就会在安装scrapy框架的时候报关于python.h头文件的错误。
|
||||||
|
|
||||||
@ -20,42 +20,41 @@ pip是作为python包索引器easy_install的替代品。用于安装和管理Py
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
图:2 Python 开发库
|
*图:2 Python 开发库*
|
||||||
|
|
||||||
scrapy框架即可从deb包安装也可以从源码安装。然而在图3中我们已经用pip(Python 包管理器)安装了deb包了。
|
scrapy框架既可从deb包安装也可以从源码安装。在图3中我们用pip(Python 包管理器)安装了deb包了。
|
||||||
|
|
||||||
sudo pip install scrapy
|
sudo pip install scrapy
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
图:3 Scrapy 安装
|
*图:3 Scrapy 安装*
|
||||||
|
|
||||||
图4中scrapy的成功安装需要一些时间。
|
图4中scrapy的成功安装需要一些时间。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
图:4 成功安装Scrapy框架
|
*图:4 成功安装Scrapy框架*
|
||||||
|
|
||||||
### 使用scrapy框架提取数据 ###
|
### 使用scrapy框架提取数据 ###
|
||||||
|
|
||||||
**(基础教程)**
|
####基础教程####
|
||||||
|
|
||||||
我们将用scrapy从fatwallet.com上提取店名(提供卡的店)。首先,我们使用下面的命令新建一个scrapy项目“store name”, 见图5。
|
我们将用scrapy从fatwallet.com上提取商店名称(卖卡的店)。首先,我们使用下面的命令新建一个scrapy项目“store name”, 见图5。
|
||||||
|
|
||||||
$sudo scrapy startproject store_name
|
$sudo scrapy startproject store_name
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
图:5 Scrapy框架新建项目
|
*图:5 Scrapy框架新建项目*
|
||||||
|
|
||||||
Above command creates a directory with title “store_name” at current path. This main directory of the project contains files/folders which are shown in the following Figure 6.
|
|
||||||
上面的命令在当前路径创建了一个“store_name”的目录。项目主目录下包含的文件/文件夹见图6。
|
上面的命令在当前路径创建了一个“store_name”的目录。项目主目录下包含的文件/文件夹见图6。
|
||||||
|
|
||||||
$sudo ls –lR store_name
|
$sudo ls –lR store_name
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
图:6 store_name项目的内容
|
*图:6 store_name项目的内容*
|
||||||
|
|
||||||
每个文件/文件夹的概要如下:
|
每个文件/文件夹的概要如下:
|
||||||
|
|
||||||
@ -66,13 +65,13 @@ Above command creates a directory with title “store_name” at current path. T
|
|||||||
- store_name/settings.py 是项目的配置文件
|
- store_name/settings.py 是项目的配置文件
|
||||||
- store_name/spiders/, 包含了用于爬取的蜘蛛
|
- store_name/spiders/, 包含了用于爬取的蜘蛛
|
||||||
|
|
||||||
由于我们要从fatwallet.com上如提取店名,因此我们如下修改文件。
|
由于我们要从fatwallet.com上如提取店名,因此我们如下修改文件(LCTT 译注:这里没说明是哪个文件,译者认为应该是 items.py)。
|
||||||
|
|
||||||
import scrapy
|
import scrapy
|
||||||
|
|
||||||
class StoreNameItem(scrapy.Item):
|
class StoreNameItem(scrapy.Item):
|
||||||
|
|
||||||
name = scrapy.Field() # extract the names of Cards store
|
name = scrapy.Field() # 取出卡片商店的名称
|
||||||
|
|
||||||
之后我们要在项目的store_name/spiders/文件夹下写一个新的蜘蛛。蜘蛛是一个python类,它包含了下面几个必须的属性:
|
之后我们要在项目的store_name/spiders/文件夹下写一个新的蜘蛛。蜘蛛是一个python类,它包含了下面几个必须的属性:
|
||||||
|
|
||||||
@ -80,7 +79,7 @@ Above command creates a directory with title “store_name” at current path. T
|
|||||||
2. 爬取起点url (start_urls)
|
2. 爬取起点url (start_urls)
|
||||||
3. 包含了从响应中提取需要内容相应的正则表达式的解析方法。解析方法对爬虫而言很重要。
|
3. 包含了从响应中提取需要内容相应的正则表达式的解析方法。解析方法对爬虫而言很重要。
|
||||||
|
|
||||||
我们在store_name/spiders/目录下创建了“store_name.py”爬虫,并添加如下的代码来从fatwallet.com上提取点名。爬虫的输出到文件(**StoreName.txt**)中,见图7。
|
我们在store_name/spiders/目录下创建了“store_name.py”爬虫,并添加如下的代码来从fatwallet.com上提取店名。爬虫的输出写到文件(**StoreName.txt**)中,见图7。
|
||||||
|
|
||||||
from scrapy.selector import Selector
|
from scrapy.selector import Selector
|
||||||
from scrapy.spider import BaseSpider
|
from scrapy.spider import BaseSpider
|
||||||
@ -113,7 +112,7 @@ Above command creates a directory with title “store_name” at current path. T
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
图:7 爬虫的输出
|
*图:7 爬虫的输出*
|
||||||
|
|
||||||
*注意: 本教程的目的仅用于理解scrapy框架*
|
*注意: 本教程的目的仅用于理解scrapy框架*
|
||||||
|
|
||||||
@ -123,7 +122,7 @@ via: http://linoxide.com/ubuntu-how-to/scrapy-install-ubuntu/
|
|||||||
|
|
||||||
作者:[nido][a]
|
作者:[nido][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,6 +1,6 @@
|
|||||||
20个Unix命令技巧 - 第一部分
|
20个 Unix/Linux 命令技巧(一)
|
||||||
================================================================================
|
================================================================================
|
||||||
让我们用**这些Unix命令技巧**开启新的一年,提高在终端下的生产力。我已经找了很久了,现在就与你们分享。
|
让我们用**这些Unix/Linux命令技巧**开启新的一年,提高在终端下的生产力。我已经找了很久了,现在就与你们分享。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -9,16 +9,15 @@
|
|||||||
我在生产服务器上有一个很大的200GB的日志文件需要删除。我的rm和ls命令已经崩溃,我担心这是由于巨大的磁盘IO造成的,要删除这个大文件,输入:
|
我在生产服务器上有一个很大的200GB的日志文件需要删除。我的rm和ls命令已经崩溃,我担心这是由于巨大的磁盘IO造成的,要删除这个大文件,输入:
|
||||||
|
|
||||||
> /path/to/file.log
|
> /path/to/file.log
|
||||||
# or use the following syntax
|
# 或使用如下格式
|
||||||
: > /path/to/file.log
|
: > /path/to/file.log
|
||||||
|
|
||||||
# finally delete it
|
# 然后删除它
|
||||||
rm /path/to/file.log
|
rm /path/to/file.log
|
||||||
|
|
||||||
### 如何缓存终端输出? ###
|
### 如何记录终端输出? ###
|
||||||
|
|
||||||
尝试使用script命令行工具来为你的终端输出创建typescript。
|
|
||||||
|
|
||||||
|
试试使用script命令行工具来为你的终端输出创建输出记录。
|
||||||
|
|
||||||
script my.terminal.sessio
|
script my.terminal.sessio
|
||||||
|
|
||||||
@ -28,7 +27,7 @@
|
|||||||
date
|
date
|
||||||
sudo service foo stop
|
sudo service foo stop
|
||||||
|
|
||||||
要退出(结束script绘画),输入*exit* 或者 *logout* 或者按下 *control-D*
|
要退出(结束script会话),输入 *exit* 或者 *logout* 或者按下 *control-D*。
|
||||||
|
|
||||||
exit
|
exit
|
||||||
|
|
||||||
@ -38,11 +37,10 @@
|
|||||||
less my.terminal.session
|
less my.terminal.session
|
||||||
cat my.terminal.session
|
cat my.terminal.session
|
||||||
|
|
||||||
### 还原删除的 /tmp 文件夹 ###
|
### 还原被删除的 /tmp 文件夹 ###
|
||||||
|
|
||||||
我在文章[Linux和Unix shell,我犯了一些错误][1]。我意外地删除了/tmp文件夹。要还原它,我需要这么做:
|
我在文章[Linux和Unix shell,我犯了一些错误][1]。我意外地删除了/tmp文件夹。要还原它,我需要这么做:
|
||||||
|
|
||||||
|
|
||||||
mkdir /tmp
|
mkdir /tmp
|
||||||
chmod 1777 /tmp
|
chmod 1777 /tmp
|
||||||
chown root:root /tmp
|
chown root:root /tmp
|
||||||
@ -50,11 +48,11 @@
|
|||||||
|
|
||||||
### 锁定一个文件夹 ###
|
### 锁定一个文件夹 ###
|
||||||
|
|
||||||
为了我的数据隐私,我想要锁定我文件服务器下的/downloads文件夹。因此我运行:
|
为了我的数据隐私,我想要锁定我文件服务器下的/downloads文件夹。因此我运行了:
|
||||||
|
|
||||||
chmod 0000 /downloads
|
chmod 0000 /downloads
|
||||||
|
|
||||||
root用户仍旧可以访问,但是ls和cd命令还不可用。要还原它用:
|
root用户仍旧可以访问,而ls和cd命令则不工作。要还原它用:
|
||||||
|
|
||||||
chmod 0755 /downloads
|
chmod 0755 /downloads
|
||||||
|
|
||||||
@ -66,40 +64,40 @@ root用户仍旧可以访问,但是ls和cd命令还不可用。要还原它用
|
|||||||
|
|
||||||
或者,在退出vim之前使用:X 命令来加密你的文件,vim会提示你输入一个密码。
|
或者,在退出vim之前使用:X 命令来加密你的文件,vim会提示你输入一个密码。
|
||||||
|
|
||||||
### 清除屏幕上的输出 ###
|
### 清除屏幕上的乱码 ###
|
||||||
|
|
||||||
只要输入:
|
只要输入:
|
||||||
|
|
||||||
reset
|
reset
|
||||||
|
|
||||||
### 成为人类 ###
|
### 易读格式 ###
|
||||||
|
|
||||||
传递*-h*或者*-H*(和其他选项)选项给GNU或者BSD工具来获取像ls、df、du等命令以人类可读的格式输出:
|
传递*-h*或者*-H*(和其他选项)选项给GNU或者BSD工具来获取像ls、df、du等命令以易读的格式输出:
|
||||||
|
|
||||||
ls -lh
|
ls -lh
|
||||||
# 以人类可读的格式 (比如: 1K 234M 2G)
|
# 以易读的格式 (比如: 1K 234M 2G)
|
||||||
df -h
|
df -h
|
||||||
df -k
|
df -k
|
||||||
# 已字节输出如: KB, MB, or GB
|
# 以字节、KB、MB 或 GB 输出:
|
||||||
free -b
|
free -b
|
||||||
free -k
|
free -k
|
||||||
free -m
|
free -m
|
||||||
free -g
|
free -g
|
||||||
# 以人类可读的格式打印 (比如 1K 234M 2G)
|
# 以易读的格式输出 (比如 1K 234M 2G)
|
||||||
du -h
|
du -h
|
||||||
# 以人类可读的格式获取系统perms
|
# 以易读的格式显示文件系统权限
|
||||||
stat -c %A /boot
|
stat -c %A /boot
|
||||||
# 比较人类可读的数字
|
# 比较易读的数字
|
||||||
sort -h -a file
|
sort -h -a file
|
||||||
# 在Linux上以人类可读的形式显示cpu信息
|
# 在Linux上以易读的形式显示cpu信息
|
||||||
lscpu
|
lscpu
|
||||||
lscpu -e
|
lscpu -e
|
||||||
lscpu -e=cpu,node
|
lscpu -e=cpu,node
|
||||||
# 以人类可读的形式显示每个文件的大小
|
# 以易读的形式显示每个文件的大小
|
||||||
tree -h
|
tree -h
|
||||||
tree -h /boot
|
tree -h /boot
|
||||||
|
|
||||||
### 在Linux系统中显示已知用户的信息 ###
|
### 在Linux系统中显示已知的用户信息 ###
|
||||||
|
|
||||||
只要输入:
|
只要输入:
|
||||||
|
|
||||||
@ -143,7 +141,7 @@ root用户仍旧可以访问,但是ls和cd命令还不可用。要还原它用
|
|||||||
|
|
||||||
### 我如何删除意外在当前文件夹下解压的文件? ###
|
### 我如何删除意外在当前文件夹下解压的文件? ###
|
||||||
|
|
||||||
我意外在/var/www/html/而不是/home/projects/www/current下解压了一个tarball。它混乱了/var/www/html下的文件。最简单修复这个问题的方法是:
|
我意外在/var/www/html/而不是/home/projects/www/current下解压了一个tarball。它搞乱了/var/www/html下的文件,你甚至不知道哪些是误解压出来的。最简单修复这个问题的方法是:
|
||||||
|
|
||||||
cd /var/www/html/
|
cd /var/www/html/
|
||||||
/bin/rm -f "$(tar ztf /path/to/file.tar.gz)"
|
/bin/rm -f "$(tar ztf /path/to/file.tar.gz)"
|
||||||
@ -166,7 +164,7 @@ root用户仍旧可以访问,但是ls和cd命令还不可用。要还原它用
|
|||||||
## 以root用户运行最后运行的命令
|
## 以root用户运行最后运行的命令
|
||||||
sudo !!
|
sudo !!
|
||||||
|
|
||||||
!!会运行最近使用的命令。要运行最近运行的“foo”命令:
|
!!会运行最近使用的命令。要运行最近运行的以“foo”开头命令:
|
||||||
|
|
||||||
!foo
|
!foo
|
||||||
# 以root用户运行上一次以“service”开头的命令
|
# 以root用户运行上一次以“service”开头的命令
|
||||||
@ -180,12 +178,11 @@ root用户仍旧可以访问,但是ls和cd命令还不可用。要还原它用
|
|||||||
# 测试 nginx.conf
|
# 测试 nginx.conf
|
||||||
/sbin/nginx -t -c /etc/nginx/nginx.conf
|
/sbin/nginx -t -c /etc/nginx/nginx.conf
|
||||||
|
|
||||||
# 测试完 "/sbin/nginx -t -c /etc/nginx/nginx.conf"你可以用vi编辑了
|
# 测试完 "/sbin/nginx -t -c /etc/nginx/nginx.conf"你可以用vi再次编辑这个文件了
|
||||||
sudo vi !$
|
sudo vi !$
|
||||||
|
|
||||||
### 在你要离开的时候留下一个提醒 ###
|
### 在终端上提醒你必须得走了 ###
|
||||||
|
|
||||||
If you need a reminder to leave your terminal, type the following command:
|
|
||||||
如果你需要提醒离开你的终端,输入下面的命令:
|
如果你需要提醒离开你的终端,输入下面的命令:
|
||||||
|
|
||||||
leave +hhmm
|
leave +hhmm
|
||||||
@ -200,26 +197,26 @@ If you need a reminder to leave your terminal, type the following command:
|
|||||||
|
|
||||||
cd -
|
cd -
|
||||||
|
|
||||||
需要快速地回到家目录?输入:
|
需要快速地回到你的家目录?输入:
|
||||||
|
|
||||||
cd
|
cd
|
||||||
|
|
||||||
变量*CDPATH*定义了含有这个目录的搜索目录路径:
|
变量*CDPATH*定义了目录的搜索路径:
|
||||||
|
|
||||||
export CDPATH=/var/www:/nas10
|
export CDPATH=/var/www:/nas10
|
||||||
|
|
||||||
现在,不用输入cd */var/www/html/ ,我可以直接输入下面的命令进入/var/www/html:
|
现在,不用输入cd */var/www/html/ 这样长了,我可以直接输入下面的命令进入 /var/www/html:
|
||||||
|
|
||||||
cd html
|
cd html
|
||||||
|
|
||||||
### 编辑一个用less浏览的文件 ###
|
### 在less浏览时编辑文件 ###
|
||||||
|
|
||||||
要编辑一个用less浏览的文件,按下v。你就可以用变量$EDITOR下的编辑器来编辑了:
|
要编辑一个正在用less浏览的文件,可以按下v。你就可以用变量$EDITOR所指定的编辑器来编辑了:
|
||||||
|
|
||||||
less *.c
|
less *.c
|
||||||
less foo.html
|
less foo.html
|
||||||
## 下载v编辑文件 ##
|
## 按下v键来编辑文件 ##
|
||||||
## 退出编辑器,你可以继续用less浏览了 ##
|
## 退出编辑器后,你可以继续用less浏览了 ##
|
||||||
|
|
||||||
### 列出你系统中的所有文件和目录 ###
|
### 列出你系统中的所有文件和目录 ###
|
||||||
|
|
||||||
@ -237,14 +234,14 @@ If you need a reminder to leave your terminal, type the following command:
|
|||||||
# 列出 $HOME 中所有的文件
|
# 列出 $HOME 中所有的文件
|
||||||
find $HOME -type f -ls | less
|
find $HOME -type f -ls | less
|
||||||
|
|
||||||
### 用一条命令构造命令树 ###
|
### 用一条命令构造目录树 ###
|
||||||
|
|
||||||
你可以用mkdir加上-p选项一次创建目录树:
|
你可以用mkdir加上-p选项一次创建一颗目录树:
|
||||||
|
|
||||||
mkdir -p /jail/{dev,bin,sbin,etc,usr,lib,lib64}
|
mkdir -p /jail/{dev,bin,sbin,etc,usr,lib,lib64}
|
||||||
ls -l /jail/
|
ls -l /jail/
|
||||||
|
|
||||||
### 复制文件到多个目录中 ###
|
### 将文件复制到多个目录中 ###
|
||||||
|
|
||||||
不必运行:
|
不必运行:
|
||||||
|
|
||||||
@ -260,16 +257,16 @@ If you need a reminder to leave your terminal, type the following command:
|
|||||||
|
|
||||||
### 快速找出两个目录的不同 ###
|
### 快速找出两个目录的不同 ###
|
||||||
|
|
||||||
diff命令会按行比较文件。它也可以比较两个目录:
|
diff命令会按行比较文件。但是它也可以比较两个目录:
|
||||||
|
|
||||||
ls -l /tmp/r
|
ls -l /tmp/r
|
||||||
ls -l /tmp/s
|
ls -l /tmp/s
|
||||||
# Compare two folders using diff ##
|
# 使用 diff 比较两个文件夹
|
||||||
diff /tmp/r/ /tmp/s/
|
diff /tmp/r/ /tmp/s/
|
||||||
|
|
||||||
[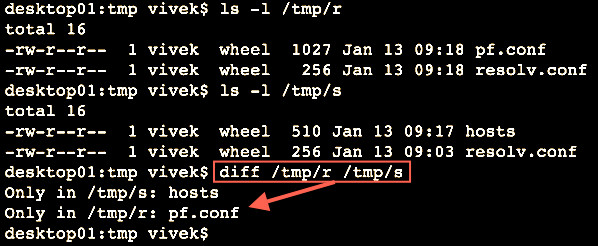][3]
|
[][3]
|
||||||
|
|
||||||
图片: 找出目录之间的不同
|
*图片: 找出目录之间的不同*
|
||||||
|
|
||||||
### 文本格式化 ###
|
### 文本格式化 ###
|
||||||
|
|
||||||
@ -281,13 +278,13 @@ diff命令会按行比较文件。它也可以比较两个目录:
|
|||||||
|
|
||||||
fmt -s file.txt
|
fmt -s file.txt
|
||||||
|
|
||||||
### 看见输出并写入到一个文件中 ###
|
### 可以看见输出并将其写入到一个文件中 ###
|
||||||
|
|
||||||
如下使用tee命令在屏幕上看见输出并同样写入到日志文件my.log中:
|
如下使用tee命令在屏幕上看见输出并同样写入到日志文件my.log中:
|
||||||
|
|
||||||
mycoolapp arg1 arg2 input.file | tee my.log
|
mycoolapp arg1 arg2 input.file | tee my.log
|
||||||
|
|
||||||
tee可以保证你同时在屏幕上看到mycoolapp的输出和写入文件。
|
tee可以保证你同时在屏幕上看到mycoolapp的输出并写入文件 my.log。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -295,7 +292,7 @@ via: http://www.cyberciti.biz/open-source/command-line-hacks/20-unix-command-lin
|
|||||||
|
|
||||||
作者:[nixCraft][a]
|
作者:[nixCraft][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,7 +1,8 @@
|
|||||||
Ubuntu With XFCE vs Xubuntu Linux
|
Ubuntu & XFCE vs Xubuntu
|
||||||
=========================================================
|
=========================================================
|
||||||
|
|
||||||
Ubuntu vs Xubuntu。Ubuntu拥有漂亮的桌面体验以及强大的应用程序。Xubuntu轻量、快速并且可定制,哪个更适合你?
|
Ubuntu拥有漂亮的桌面体验以及强大的应用程序。Xubuntu轻量、快速并且可定制,哪个更适合你?
|
||||||
|
|
||||||
---------------------------------------------------------
|
---------------------------------------------------------
|
||||||
|
|
||||||

|

|
||||||
@ -10,11 +11,11 @@ Ubuntu vs Xubuntu。Ubuntu拥有漂亮的桌面体验以及强大的应用程序
|
|||||||
|
|
||||||
并且,我同时也会在这篇文章中介绍Ubuntu用户如何获取基本的XFCE桌面,以及如何安装完整的Xubuntu桌面。
|
并且,我同时也会在这篇文章中介绍Ubuntu用户如何获取基本的XFCE桌面,以及如何安装完整的Xubuntu桌面。
|
||||||
|
|
||||||
[Ubuntu][1]以及[Xubuntu][2]是针对不同目的开发的操作系统,为什么我会强调这一点,是为了说明什么时候或者为什么你应该使用Ubuntu以及什么时候应该使用Xubuntu。
|
[Ubuntu][1]以及[Xubuntu][2]是针对不同目的开发的操作系统,为什么我会强调这一点,是为了说明什么时候或者为什么你应该使用Ubuntu或Xubuntu。
|
||||||
|
|
||||||
比较这两个操作系统就像比较[劳斯莱斯][3]与[保时捷][4]。这两个都是很棒的车,但是如果把劳斯莱斯给一个赛车迷,他们也许会卖掉它买个其他的车,同样,如果把保时捷给舒格勋爵或者休·海夫纳这类人可能也不那么合适。
|
比较这两个操作系统就像比较[劳斯莱斯][3]与[保时捷][4]。这两个都是很棒的车,但是如果把劳斯莱斯给一个赛车迷,他们也许会卖掉它买个其他的车,同样,如果把保时捷给舒格勋爵或者休·海夫纳这类人可能也不那么合适。
|
||||||
|
|
||||||
Ubuntu拥有一个适用性很强的桌面环境,叫做Unity,并且默认会安装一些很棒的Linux应用程序,包括Rhythmbox以及[LibreOffic][5]。Ubuntu就像是劳斯莱斯。它为舒适而生,并且尽可能的提供从A到B的最时髦的方法。
|
Ubuntu拥有一个适用性很强的桌面环境,叫做Unity,并且默认会安装一些很棒的Linux应用程序,包括Rhythmbox以及[LibreOffic][5]。Ubuntu就像是劳斯莱斯。它为舒适而生,并且尽可能的提供满足需要的漂亮的解决方案。
|
||||||
|
|
||||||
作为一个Ubuntu用户,就像汽车里面的乘客。你在到达目的地的过程中就可以同时把事情搞定,并且所有的事看起来都很漂亮并且很简单。
|
作为一个Ubuntu用户,就像汽车里面的乘客。你在到达目的地的过程中就可以同时把事情搞定,并且所有的事看起来都很漂亮并且很简单。
|
||||||
|
|
||||||
@ -92,7 +93,7 @@ Xubuntu就像一个改装过的跑车。你可以把它改装成任何你想要
|
|||||||
|
|
||||||
接下来,我会使用命令行工具[apt-get][7]介绍在Ubuntu安装XFCE桌面的方法。
|
接下来,我会使用命令行工具[apt-get][7]介绍在Ubuntu安装XFCE桌面的方法。
|
||||||
|
|
||||||
打开一个终端窗口,在Unity环境,你可以在[Dash][8]中搜索“TERM”,或者使用组合键 CTRL+ALT+T。
|
打开一个终端窗口,在Unity环境,你可以在[Dash][8]中搜索“TERM”,或者使用组合键 `CTRL+ALT+T`。
|
||||||
|
|
||||||
安装XFCE桌面十分简单,输入下列命令就可以了:
|
安装XFCE桌面十分简单,输入下列命令就可以了:
|
||||||
|
|
||||||
@ -105,7 +106,7 @@ Xubuntu就像一个改装过的跑车。你可以把它改装成任何你想要
|
|||||||
|
|
||||||
系统会显示一个消息,提示你是否使用默认的面板布局或者使用单独的面板。
|
系统会显示一个消息,提示你是否使用默认的面板布局或者使用单独的面板。
|
||||||
|
|
||||||
[最新版本的Xubuntu][10]在顶部包含一个单独的面板,不过我更喜欢两个面板,顶部一个标准面板,底部一个常用程序的停靠面板。
|
[最新版本的Xubuntu][10]在顶部包含一个单独的面板,不过我更喜欢双面板,顶部一个标准面板,底部一个常用程序的停靠面板。
|
||||||
|
|
||||||
需要注意的是,XFCE桌面菜单系统和Xubuntu的菜单有些差异,除非你安装[一个更好的菜单系统][11],设置两个面板或许是个更好的选择。
|
需要注意的是,XFCE桌面菜单系统和Xubuntu的菜单有些差异,除非你安装[一个更好的菜单系统][11],设置两个面板或许是个更好的选择。
|
||||||
|
|
||||||
@ -117,7 +118,7 @@ Xubuntu就像一个改装过的跑车。你可以把它改装成任何你想要
|
|||||||
|
|
||||||
如果你想全都使用Xubuntu的东西,但是又不想按照那些介绍重新安装系统的话,看看下面的东西。
|
如果你想全都使用Xubuntu的东西,但是又不想按照那些介绍重新安装系统的话,看看下面的东西。
|
||||||
|
|
||||||
通过搜索“TERM”,或者组合键CTRL+ALT+T,打开一个终端窗口。
|
通过搜索“TERM”,或者组合键`CTRL+ALT+T`,打开一个终端窗口。
|
||||||
|
|
||||||
在终端输入如下命令:
|
在终端输入如下命令:
|
||||||
|
|
||||||
@ -132,16 +133,17 @@ Xubuntu就像一个改装过的跑车。你可以把它改装成任何你想要
|
|||||||
|
|
||||||
Xubuntu桌面就会显示出来啦。
|
Xubuntu桌面就会显示出来啦。
|
||||||
|
|
||||||
这里会有一些差异。菜单仍然是XFCE菜单,而不是Xubuntu菜单。某些图标也不会出现在顶部面板中。但是这些问题都不足以让我们花时间卸载Ubuntu然后重装Xubuntu。
|
这里会有一些差异。菜单仍然是XFCE菜单,而不是Xubuntu菜单。某些图标也不会出现在顶部面板中。但是这些小问题都不足以让我们花时间卸载Ubuntu然后重装Xubuntu。
|
||||||
|
|
||||||
下一篇文章中,我会介绍如何自定义Xubuntu以及XFCE桌面。
|
下一篇文章中,我会介绍如何自定义Xubuntu以及XFCE桌面。
|
||||||
|
|
||||||
|
-----
|
||||||
|
|
||||||
via : http://linux.about.com/od/dist/fl/Ubuntu-With-XFCE-vs-Xubuntu-Linux.htm
|
via : http://linux.about.com/od/dist/fl/Ubuntu-With-XFCE-vs-Xubuntu-Linux.htm
|
||||||
|
|
||||||
作者:[Gary Newell][a]
|
作者:[Gary Newell][a]
|
||||||
译者:[zhouj-sh](https://github.com/Zhouj-sh)
|
译者:[zhouj-sh](https://github.com/Zhouj-sh)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,56 @@
|
|||||||
|
Linux 有问必答:如何使用yum来下载RPM包而不进行安装
|
||||||
|
================================================================================
|
||||||
|
> **问题**:我想从Red Hat 的标准仓库中下载一个RPM包,我能使用yum命令来下载一个RPM包但是不进行安装吗?
|
||||||
|
|
||||||
|
yum是基于Red Hat的系统(如CentOS、Fedora、RHEl)上的默认包管理器。使用yum,你可以安装或者更新一个RPM包,并且他会自动解决包依赖关系。但是如果你只想将一个RPM包下载到你的系统上该怎么办呢? 例如,你可能想要获取一些RPM包在以后使用,或者将他们安装在另外的机器上。
|
||||||
|
|
||||||
|
这里说明了如何从yum仓库上下载一个RPM包。
|
||||||
|
|
||||||
|
### 方法一:yum###
|
||||||
|
|
||||||
|
yum命令本身就可以用来下载一个RPM包,标准的yum命令提供了`--downloadonly(只下载)`的选项来达到这个目的。
|
||||||
|
|
||||||
|
$ sudo yum install --downloadonly <package-name>
|
||||||
|
|
||||||
|
默认情况下,一个下载的RPM包会保存在下面的目录中:
|
||||||
|
|
||||||
|
/var/cache/yum/x86_64/[centos/fedora-version]/[repository]/packages
|
||||||
|
|
||||||
|
以上的[repository]表示下载包的来源仓库的名称(例如:base、fedora、updates)
|
||||||
|
|
||||||
|
如果你想要将一个包下载到一个指定的目录(如/tmp):
|
||||||
|
|
||||||
|
$ sudo yum install --downloadonly --downloaddir=/tmp <package-name>
|
||||||
|
|
||||||
|
注意,如果下载的包包含了任何没有满足的依赖关系,yum将会把所有的依赖关系包下载,但是都不会被安装。
|
||||||
|
|
||||||
|
另外一个重要的事情是,在CentOS/RHEL 6或更早期的版本中,你需要安装一个单独yum插件(名称为 yum-plugin-downloadonly)才能使用`--downloadonly`命令选项:
|
||||||
|
|
||||||
|
$ sudo yum install yum-plugin-downloadonly
|
||||||
|
|
||||||
|
如果没有该插件,你会在使用yum时得到以下错误:
|
||||||
|
|
||||||
|
Command line error: no such option: --downloadonly
|
||||||
|
|
||||||
|
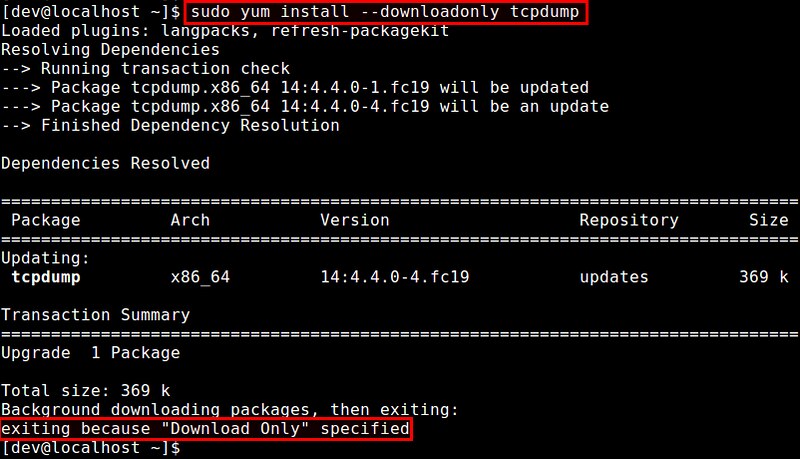
|
||||||
|
|
||||||
|
### 方法二: Yumdownloader###
|
||||||
|
|
||||||
|
另外一个下载RPM包的方法就是通过一个专门的包下载工具--yumdownloader。 这个工具是yum工具包(包含了用来进行yum包管理的帮助工具套件)的子集。
|
||||||
|
|
||||||
|
$ sudo yum install yum-utils
|
||||||
|
|
||||||
|
下载一个RPM包:
|
||||||
|
|
||||||
|
$ sudo yumdownloader <package-name>
|
||||||
|
|
||||||
|
下载的包会被保存在当前目录中。你需要使用root权限,因为yumdownloader会在下载过程中更新包索引文件。与yum命令不同的是,任何依赖包不会被下载。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://ask.xmodulo.com/yum-download-rpm-package.html
|
||||||
|
|
||||||
|
译者:[theo-l](https://github.com/theo-l)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
@ -1,10 +1,10 @@
|
|||||||
如何使用 backupninja 来备份一个 Debian 系统
|
如何使用 backupninja 来备份 Debian 系统
|
||||||
================================================================================
|
================================================================================
|
||||||
面临灾难时的小心谨慎或体验可以教会每一个系统管理采取频繁的系统备份的重要性。你可以通过编写存在已久的管用的 shell 脚本,或使用一个(或多个) 适合这项工作的备份工具来完成备份任务。因此,当你要实施一个备份解决方案时,你了解的备份工具越多,你做出的决策就会越明智。
|
小心谨慎或灾难体验会让每一个系统管理都认识到频繁的系统备份的重要性。你可以通过编写管用的旧式 shell 脚本,或使用一个(或几个)适合这项工作的备份工具来完成备份任务。因此,当你要实施一个备份解决方案时,你了解的备份工具越多,你做出的决策就会越明智。
|
||||||
|
|
||||||
在这篇文章中,我们将为你介绍 [backupninja][2] ,一个轻量且易于配置的系统备份工具。在诸如 **rdiff-backup**, **duplicity**, **mysqlhotcopy** 和 **mysqldump** 等程序的帮助下, Backupninja 可以提供常用的备份功能,如执行远程的、安全的和增量式的文件系统备份,加密备份以及 MySQL/MariaDB 数据库备份。你可以选择性地开启使用 email 进行状态报告功能,也可以对一般的硬件和系统的信息进行备份。 backupninja 的一个关键功能是它拥有一个内建的基于控制台的向导程序(被称为 **ninjahelper**),而后者允许你为不同的备份情景轻松地创建配置文件。
|
在这篇文章中,我们将为你介绍 [backupninja][2] ,这是一个轻量且易于配置的系统备份工具。在诸如 **rdiff-backup**, **duplicity**, **mysqlhotcopy** 和 **mysqldump** 等程序的帮助下, Backupninja 可以提供常用的备份功能,如执行远程的、安全的和增量式的文件系统备份,加密备份以及 MySQL/MariaDB 数据库备份。你可以选择性地开启使用 Email 状态报告功能,也可以对一般的硬件和系统的信息进行备份。 backupninja 的一个关键功能是它拥有一个内建的基于控制台的向导程序(被称为 **ninjahelper**),而后者允许你为不同的备份情景轻松地创建配置文件。
|
||||||
|
|
||||||
如果非要说的话,backupninja 的缺点是:为了充分使用其所有的功能,它要求一些其他“助手”程序已经被安装在了计算机中。尽管 backupninja 有针对基于 Red Hat(红帽) 的发行版本的 RPM 安装包,但 backupninja 针对 Debian 和它的衍生发行版本的依赖进行了优化。所以不建议在基于 Red Hat 的系统上尝试 backupninja 。
|
如果非要说的话,backupninja 的缺点是:为了充分使用其所有的功能,它要求安装一些其他“助手”程序。尽管 backupninja 有针对基于 Red Hat(红帽)的发行版本的 RPM 安装包,但 backupninja 针对 Debian 及其衍生发行版本的依赖进行了优化。所以不建议在基于 Red Hat 的系统上尝试 backupninja 。
|
||||||
|
|
||||||
在这篇教程中,我们将介绍如何在基于 Debian 的发行版本上安装 backupninja 。
|
在这篇教程中,我们将介绍如何在基于 Debian 的发行版本上安装 backupninja 。
|
||||||
|
|
||||||
@ -16,17 +16,17 @@
|
|||||||
|
|
||||||
在安装的过程中,有几个文件和目录将被创建:
|
在安装的过程中,有几个文件和目录将被创建:
|
||||||
|
|
||||||
- **/usr/sbin/backupninja** 是 bash shell 主脚本;
|
- **/usr/sbin/backupninja** 是个 bash shell 的主脚本;
|
||||||
- **/etc/cron.d/backupninja**, 默认情况下,构建 cron 任务来每隔一个小时运行上面的主脚本;
|
- **/etc/cron.d/backupninja**, 默认情况下,设置 cron 任务来每隔一个小时运行上面的主脚本;
|
||||||
- **/etc/logrotate.d/backupninja** 处理由 backupninja 程序产生的日志;(注:我不知道这里的 rotate 该如何翻译)
|
- **/etc/logrotate.d/backupninja** 截断由 backupninja 程序产生的日志;
|
||||||
- **/etc/backup.d/** 是备份操作的配置文件驻留的目录;
|
- **/etc/backup.d/** 是备份操作的配置文件驻留的目录;
|
||||||
- **/etc/backupninja.conf** 是包含一般选项的主配置文件。这个文件带有良好的注释且详细解释了每个选项的含义;
|
- **/etc/backupninja.conf** 是包含一般选项的主配置文件。这个文件带有良好的注释且详细解释了每个选项的含义;
|
||||||
- **/usr/share/backupninja** 是那些被 backupninja 使用的脚本所处的目录。这些脚本文件负责执行实际的工作。在这个目录中,你还可以找到 `.helper` 文件,它们可以被用来配置和设定 ninjahelper 的菜单;
|
- **/usr/share/backupninja** 是那些 backupninja 所使用的脚本所处的目录。这些脚本文件负责执行实际的工作。在这个目录中,你还可以找到 `.helper` 文件,它们可以被用来配置和设定 ninjahelper 的菜单;
|
||||||
- **/usr/share/doc/backupninja/examples** 含有操作配置文件(即通过 ninjahelper 产生的文件)的模板。
|
- **/usr/share/doc/backupninja/examples** 含有操作配置文件(即通过 ninjahelper 产生的文件)的模板。
|
||||||
|
|
||||||
### 首次运行 Ninjahelper ###
|
### 首次运行 Ninjahelper ###
|
||||||
|
|
||||||
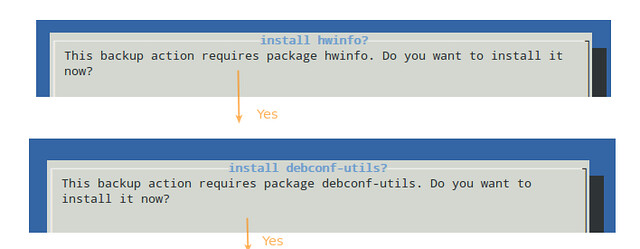
当我们尝试启动 ninjahelper 时,我们可以看到一个内部依赖可能会被需要。假如系统进行了提示,请输入 “yes” 并敲下回车键来安装 dialog(一个用于从 shell 脚本中显示友好对话框的工具)。
|
当我们尝试启动 ninjahelper 时,我们可以看到可能需要一个内部依赖程序。假如系统进行了提示,请输入 “yes” 并敲下回车键来安装 dialog(一个用于从 shell 脚本中显示友好对话框的工具)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -44,11 +44,11 @@
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
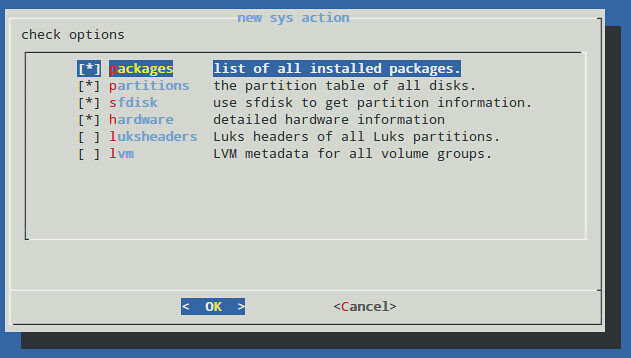
接下来的一步需要你选取相关条目来作为此次备份任务的一部分。前四个条目已经默认被选上了,但你可以通过按空格键来撤消选择。
|
接下来的一步需要你选取相关条目来作为此次备份任务的一部分。前四个条目已经默认被选上了,但你可以通过在条目上按空格键来撤消选择。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
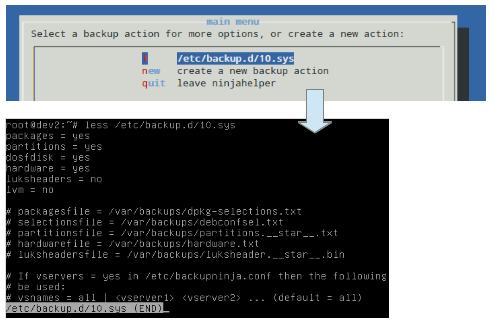
一旦你完成了上面的步骤,按 OK 选项来继续。接着你将能够选择 是愿意使用默认的配置文件(/etc/backup.d/10.sys)来完成这次备份操作,还是创建一个新的配置文件。若为后者,一个含有与默认配置文件内容相同的文件将会在相同的目录下被创建,但它被命名为 11.sys,后续的备份操作将会创建类似的文件(注:只不过命名的序号不同)。需要说明的是一旦这个新的配置文件被创建,你便可以使用你喜爱的文本编辑器来编辑该文件。
|
一旦你完成了上面的步骤,按 OK 选项来继续。接着你将能够选择是愿意使用默认的配置文件(/etc/backup.d/10.sys)来完成这次备份操作,还是创建一个新的配置文件。若为后者,一个含有与默认配置文件内容相同的文件将会在相同的目录下被创建,但它被命名为 11.sys,后续的备份操作将会创建类似的文件(注:只不过命名的序号不同)。需要说明的是一旦这个新的配置文件被创建,你便可以使用你喜爱的文本编辑器来编辑该文件。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -56,7 +56,7 @@
|
|||||||
|
|
||||||
正如你最有可能知道的那样, rsync 被广泛地用于通过网络同步文件或文件夹。在接下来的例子中,我们将讨论一个使用硬链接来为一个远程目录做增量式拉取备份的方法,它被用来保存历史数据以及在我们本地的文件服务器中恢复这些历史数据。这个方法将帮助我们节省空间并增强位于服务器端的安全性。
|
正如你最有可能知道的那样, rsync 被广泛地用于通过网络同步文件或文件夹。在接下来的例子中,我们将讨论一个使用硬链接来为一个远程目录做增量式拉取备份的方法,它被用来保存历史数据以及在我们本地的文件服务器中恢复这些历史数据。这个方法将帮助我们节省空间并增强位于服务器端的安全性。
|
||||||
|
|
||||||
**步骤 1**:编写一个位于 `/etc/backup.d`的带有如下内容的自定义脚本,并将它的权限设置为 600 。需要说明的是,除了一般的配置文件,这个目录可能还包含当 backupninja 被执行时你想运行的一些脚本文件,它们可以发挥出位于主配置文件中的变量的优势。
|
**步骤 1**:编写一个带有如下内容的自定义脚本,放在 `/etc/backup.d`,并将它的权限设置为 600 。需要说明的是,除了一般的配置文件,这个目录可能还包含当 backupninja 执行时你想运行的一些脚本文件,它们可以发挥出位于主配置文件中的变量的优势。
|
||||||
|
|
||||||
# REMOTE USER
|
# REMOTE USER
|
||||||
user=root
|
user=root
|
||||||
@ -72,36 +72,37 @@
|
|||||||
# RSYNC
|
# RSYNC
|
||||||
rsync -av --delete --recursive --link-dest=$localdirold $user@$host:$remotedir $localdir
|
rsync -av --delete --recursive --link-dest=$localdirold $user@$host:$remotedir $localdir
|
||||||
|
|
||||||
在上面的配置中, rsync 的 ‘--link-dest’ 选项的作用是为位于 $localdir-old 目录中那些没有改变的文件(包含所有属性) 硬链接到目标目录 ($localdir)。
|
在上面的配置中, rsync 的 ‘--link-dest’ 选项的作用是为位于 $localdir-old 目录中那些没有改变的文件(包含所有属性) 硬链接到目标目录($localdir)。
|
||||||
|
|
||||||
**步骤 2**:在 backupninja 第一次运行之前,上层目录(这个例子中指的是 /home/gacanepa) 是空的。第一次我们执行下面的命令:
|
**步骤 2**:在 backupninja 第一次运行之前,上层目录(这个例子中指的是 /home/gacanepa) 是空的。第一次我们执行下面的命令:
|
||||||
|
|
||||||
# backupninja -n
|
# backupninja -n
|
||||||
|
|
||||||
backup.0 目录就被创建了,并在接下来的过程中,它的名称将会被更改为 backup.1。
|
backup.0 目录就被创建了,并在接下来的过程中,它的名称将会被更改为 backup.1。
|
||||||
|
|
||||||
当我们第二次运行 backupninja 时, backup.0 将会被重新创建,而 backup.1 被保留。
|
当我们第二次运行 backupninja 时, backup.0 将会被重新创建,而 backup.1 保持不动。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
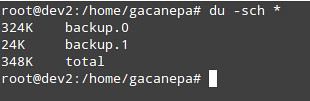
**步骤 3**: 确保 backup.1 里面的文件硬链接到 backup.0 里的文件,我们可以通过比较文件的 inode( i 节点) 数和目录的大小来达到此目的。
|
**步骤 3**: 确保 backup.1 里面的文件硬链接到 backup.0 里的文件,我们可以通过比较文件的 inode(i 节点)数和目录的大小来达到此目的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 总结 ###
|
### 总结 ###
|
||||||
|
|
||||||
Backupninja 不仅是一个经典的备份工具,它也是一个易于配置的实用程序。你可以通过编写你自己的 handler(注:我不知道该如何翻译 handler 这个单词) 来运行 backupninja 并将它们作为位于 `/etc.backup.d` 的个人配置文件。甚至你还可以为 ninjahelper 编写助手程序,以达到将它们包括在 ninjahelper 的主界面上。
|
Backupninja 不仅是一个经典的备份工具,它也是一个易于配置的实用程序。你可以通过编写你自己的控制脚本,用放在 `/etc.backup.d` 中的不同的配置文件来运行 backupninja 。甚至你还可以为 ninjahelper 编写助手程序,并将其包括在 ninjahelper 的主界面上。
|
||||||
|
|
||||||
例如,假如你在 `/usr/share/backupninja`目录中创建了一个名为 modulo 的 handler,它将自动运行那些位于 `/etc/backup.d` 目录中以 .xmodulo 为后缀的每个文件。如果你决定添加你的 xmodulo handler 到 ninjahelper 中, 你可以编写相应的助手程序,即 xmodulo.helper 。另外,假如你想 让 backupninja 运行任意一个脚本,只需把它添加到 `/etc/backup.d` 目录中,这样你的目的便可以达到了。
|
例如,假如你在 `/usr/share/backupninja`目录中创建了一个名为 xmodulo 的控制脚本,它将自动运行那些位于 `/etc/backup.d` 目录中以 .xmodulo 为后缀的每个文件。如果你决定添加你的 xmodulo 控制脚本到 ninjahelper 中, 你可以编写相应的助手程序,即 xmodulo.helper 。另外,假如你想 让 backupninja 运行其它的脚本,只需把它添加到 `/etc/backup.d` 目录中就可以了。
|
||||||
|
|
||||||
欢迎使用下面的评论框来留下你的评论、问题或建议。听到你的回应将会使我们很高兴。
|
欢迎使用下面的评论框来留下你的评论、问题或建议。听到你的回应将会使我们很高兴。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: http://xmodulo.com/backup-debian-system-backupninja.html
|
via: http://xmodulo.com/backup-debian-system-backupninja.html
|
||||||
|
|
||||||
作者:[Gabriel Cánepa][a]
|
作者:[Gabriel Cánepa][a]
|
||||||
译者:[FSSlc](https://github.com/FSSlc)
|
译者:[FSSlc](https://github.com/FSSlc)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,86 +0,0 @@
|
|||||||
translating wi-cuckoo LLAP
|
|
||||||
10 best uses for open source software in the business world
|
|
||||||
================================================================================
|
|
||||||
> Open source offers some compelling benefits for businesses large and small -- but you might be surprised at some of the ways it's being used.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Certain inevitabilities occur in technology. For instance, open source software will make its way into your business. Ten years ago, this could easily have been called into question. Now? There's no way to avoid it -- and there's no reason to. With so many powerful (and necessary) pieces of technology, open source has become, in various cases, the savior of tech. But what areas of your business are best suited for open source? The answer to that question is, of course, will be different from one company to the next. But some applications can apply in almost every circumstance.
|
|
||||||
|
|
||||||
Let's take a look at 10 possible best-case uses for open source software that can help make your business grow, bring you a level of flexibility and reliability you haven't experienced, or just save you a welcome percentage of your budget.
|
|
||||||
|
|
||||||
### 1: Server software ###
|
|
||||||
|
|
||||||
If you're still battling Microsoft's IIS platform, you need to experience Apache. The flagship open source web server software is one of the most widely used on the planet. It's free, incredibly reliable, easy to manage, and doesn't require the enormous overhead needed for IIS. But open source isn't limited to just web servers. If you need SMB sharing across your company, consider Samba. Samba 4 even integrates with Active Directory, so you don't have to worry about setting up separate user accounts on the Samba server.
|
|
||||||
|
|
||||||
### 2: Development ###
|
|
||||||
|
|
||||||
Developing with open source is a no-brainer. PHP, Rails, Perl -- there are as many languages to develop with as there are tools (from IDEs to bug tracking). There are a lot of options for developing for open source or with open source tools (as are there with proprietary development). The biggest difference between open source and proprietary is the access you have to the software code. Within the world of FOSS (free open source software) the code is readily available. For many developers, the Linux operating system has everything they need to develop, built right in (especially those who code without a full-blown IDE). If you do require GUI development tools, open source has you covered.
|
|
||||||
|
|
||||||
### 3: Security ###
|
|
||||||
|
|
||||||
The route to security is a challenging one, but there are many paths to success. You can opt for the "security in a box" solution and go with the likes of Cisco (a solid solution) or you can craft your security to perfectly fit your needs with the likes of iptables. Yes, the open source security route will take a bit more time to deploy (with a much higher learning curve), but the end results are generally incredible. This doesn't even address the idea that using open source on the desktop is, generally speaking, a more secure platform than most proprietary systems. Deploy Linux on the desktops and your security woes will drop dramatically.
|
|
||||||
|
|
||||||
### 4: Desktops ###
|
|
||||||
|
|
||||||
This area is where most of the pushback happens. However, you must take into consideration the fact that the daily workflow has undergone a major paradigm shift. Most of what we do now is done via a web browser. So why not deploy Linux on the desktop? Not only does it work with the majority of today's tasks, it will do so without suffering from viruses, malware, and updates that cripple a system. It's not perfect -- what platform is? But it's solid, and in the end, it can save you money. That's a win-win.
|
|
||||||
|
|
||||||
### 5: Workflow ###
|
|
||||||
|
|
||||||
Every business depends upon workflow. For some businesses, a smooth workflow depends upon tools. Open source has this arena covered. CRM, HRM, ERP, BI, BPM... you name it, open source handles just about every possible acronym you can think of -- and it does it very well. With the likes of [Pentaho][1], [Collabtive][2], and [SugarCRM][3], open source can keep up with closed source tools any day.
|
|
||||||
|
|
||||||
### 6: Collaboration ###
|
|
||||||
|
|
||||||
Without the ability to work together on projects, your staff wouldn't be able to get the job done. So the collaboration tools you choose are crucial. You'll find plenty of quality collaboration tools within the world of open source. [Cyn.in community edition][4], [Zimbra Open Source Edition][5], and [Kolab][6] are just three examples of the excellent collaboration tools that exist within the open source world.
|
|
||||||
|
|
||||||
### 7: Big data ###
|
|
||||||
|
|
||||||
When it comes to big data, open source can't be matched. Thanks to the likes of [SUSE][7], big data and open source now go hand in hand. Innovations like in-memory data and live kernel patching make open source an ideal solution for big data. It can be perfectly tuned to meet the massive demands big data places on the platform. Closed source software can't touch this level of flexibility.
|
|
||||||
|
|
||||||
### 8: Cloud ###
|
|
||||||
|
|
||||||
The major players in the cloud are open source. [Red Hat][8], [Ubuntu][9], [SUSE][10], [Amazon][11], [Rackspace][12] -- they all get it and know that open source is the best solution for cloud deployments. But if you don't want to go with the larger companies, there are always up and coming tools like [ownCloud][12], where you can either take advantage of its hosted cloud solutions or build your own.
|
|
||||||
|
|
||||||
### 9: Multimedia ###
|
|
||||||
|
|
||||||
If your company does podcasting or video for PR, open source has you covered. With tools like [Audacity][14] and [OpenShot][15], you can do just about anything with audio or video you need -- and do so on the cheap. In fact, you'll be hard-pressed to find a better podcasting tool than Audacity or an easier-to-use video editor than OpenShot. Both pieces of software do an outstanding job of creating professional-quality results without the steep learning curves or the high prices often associated with closed source tools
|
|
||||||
|
|
||||||
### 10: E-commerce ###
|
|
||||||
|
|
||||||
If your business sells products online, you'd be remiss not to give a tool like [PrestaShop][16] a try. PrestaShop is, hands down, one of the most powerful e-commerce solutions available -- regardless of license. With just about every feature you could possible want (and some you probably haven't even thought of), the open source platform excels at e-commerce on every level.
|
|
||||||
|
|
||||||
### FOSS for business ###
|
|
||||||
|
|
||||||
Open source is no longer hanging around the periphery of the business conversation. In many instances, FOSS leads and dominates that conversation. If you've been looking for areas to consider deploying open source solutions, look no further than these 10.
|
|
||||||
|
|
||||||
### Your turn ###
|
|
||||||
|
|
||||||
Have you added open source software to your business? If so, in what way?
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.techrepublic.com/blog/10-things/10-best-uses-for-open-source-software-in-the-business-world/
|
|
||||||
|
|
||||||
作者:[Jack Wallen][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.techrepublic.com/search/?a=jack+wallen
|
|
||||||
[1]:http://community.pentaho.com/
|
|
||||||
[2]:http://collabtive.o-dyn.de/
|
|
||||||
[3]:http://www.sugarcrm.com/
|
|
||||||
[4]:http://cynapse.com/cyn-in/
|
|
||||||
[5]:https://www.zimbra.com/open-source
|
|
||||||
[6]:http://kolab.org/
|
|
||||||
[7]:http://www.suse.org/
|
|
||||||
[8]:http://www.redhat.com/
|
|
||||||
[9]:http://www.ubuntu.com/
|
|
||||||
[10]:http://www.suse.com/
|
|
||||||
[11]:http://aws.amazon.com/ec2/
|
|
||||||
[12]:http://www.rackspace.com/cloud
|
|
||||||
[13]:https://owncloud.org/
|
|
||||||
[14]:http://audacity.sourceforge.net/
|
|
||||||
[15]:http://www.openshot.org/
|
|
||||||
[16]:https://www.prestashop.com/
|
|
||||||
@ -0,0 +1,66 @@
|
|||||||
|
Revealed: The best and worst of Docker
|
||||||
|
================================================================================
|
||||||
|

|
||||||
|
Credit: [Shutterstock][1]
|
||||||
|
|
||||||
|
> Docker experts talk about the good, the bad, and the ugly of the ubiquitous application container system
|
||||||
|
|
||||||
|
No question about it: Docker's app container system has made its mark and become a staple in many IT environments. With its accelerating adoption, it's bound to stick around for a good long time.
|
||||||
|
|
||||||
|
But there's no end to the debate about what Docker's best for, where it falls short, or how to most sensibly move it forward without alienating its existing users or damaging its utility. Here, we've turned to a few of the folks who have made Docker their business to get their takes on Docker's good, bad, and ugly sides.
|
||||||
|
|
||||||
|
### The good ###
|
||||||
|
|
||||||
|
One hardly expects Steve Francia, chief of operations of the Docker open source project, to speak of Docker in anything less than glowing terms. When asked by email about Docker's best attributes, he didn't disappoint: "I think the best thing about Docker is that it enables people, enables developers, enables users to very easily run an application anywhere," he said. "It's almost like the Holy Grail of development in that you can run an application on your desktop, and the exact same application without any changes can run on the server. That's never been done before."
|
||||||
|
|
||||||
|
Alexis Richardson of [Weaveworks][2], a virtual networking product, praised Docker for enabling simplicity. "Docker offers immense potential to radically simplify and speed up how software gets built," he replied in an email. "This is why it has delivered record-breaking initial mind share and traction."
|
||||||
|
|
||||||
|
Bob Quillin, CEO of [StackEngine][3], which makes Docker management and automation solutions, noted in an email that Docker (the company) has done a fine job of maintaining Docker's (the product) appeal to its audience. "Docker has been best at delivering strong developer support and focused investment in its product," he wrote. "Clearly, they know they have to keep the momentum, and they are doing that by putting intense effort into product functionality." He also mentioned that Docker's commitment to open source has accelerated adoption by "[allowing] people to build around their features as they are being built."
|
||||||
|
|
||||||
|
Though containerization itself isn't new, as Rob Markovich of IT monitoring-service makers [Moogsoft][4] pointed out, Docker's implementation makes it new. "Docker is considered a next-generation virtualization technology given its more modern, lightweight form [of containerization]," he wrote in an email. "[It] brings an opportunity for an order-of-magnitude leap forward for software development teams seeking to deploy code faster."
|
||||||
|
|
||||||
|
### The bad ###
|
||||||
|
|
||||||
|
What's less appealing about Docker boils down to two issues: the complexity of using the product, and the direction of the company behind it.
|
||||||
|
|
||||||
|
Samir Ghosh, CEO of enterprise PaaS outfit [WaveMaker][5], gave Docker a thumbs-up for simplifying the complex scripting typically needed for continuous delivery. That said, he added, "That doesn't mean Docker is simple. Implementing Docker is complicated. There are a lot of supporting technologies needed for things like container management, orchestration, app stack packaging, intercontainer networking, data snapshots, and so on."
|
||||||
|
|
||||||
|
Ghosh noted the ones who feel the most of that pain are enterprises that want to leverage Docker for continuous delivery, but "it's even more complicated for enterprises that have diverse workloads, various app stacks, heterogenous infrastructures, and limited resources, not to mention unique IT needs for visibility, control and security."
|
||||||
|
|
||||||
|
Complexity also becomes an issue in troubleshooting and analysis, and Markovich cited the fact that Docker provides application abstraction as the reason why. "It is nearly impossible to relate problems with application performance running on Docker to the performance of the underlying infrastructure domains," he said in an email. "IT teams are going to need visibility -- a new class of monitoring and analysis tools that can correlate across and relate how everything is working up and down the Docker stack, from the applications down to the private or public infrastructure."
|
||||||
|
|
||||||
|
Quillin is most concerned about Docker's direction vis-à-vis its partner community: "Where will Docker make money, and where will their partners? If [Docker] wants to be the next VMware, it will need to take a page out of VMware's playbook in how to build and support a thriving partner ecosystem.
|
||||||
|
|
||||||
|
"Additionally, to drive broader adoption, especially in the enterprise, Docker needs to start acting like a market leader by releasing more fully formed capabilities that organizations can count on, versus announcements of features with 'some assembly required,' that don't exist yet, or that require you to 'submit a pull request' to fix it yourself."
|
||||||
|
|
||||||
|
Francia pointed to Docker's rapid ascent for creating its own difficulties. "[Docker] caught on so quickly that there's definitely places that we're focused on to add some features that a lot of users are looking forward to."
|
||||||
|
|
||||||
|
One such feature, he noted, was having a GUI. "Right now to use Docker," he said, "you have to be comfortable with the command line. There's no visual interface to using Docker. Right now it's all command line-based. And we know if we want to really be as successful as we think we can be, we need to be more approachable and a lot of people when they see a command line, it's a bit intimidating for a lot of users."
|
||||||
|
|
||||||
|
### The future ###
|
||||||
|
|
||||||
|
In that last respect, Docker recently started to make advances. Last week it [bought the startup Kitematic][6], whose product gave Docker a convenient GUI on Mac OS X (and will eventually do the same for Windows). Another acqui-hire, [SocketPlane][7], is being spun in to work on Docker's networking.
|
||||||
|
|
||||||
|
What remains to be seen is whether Docker's proposed solutions to its problems will be adopted, or whether another party -- say, [Red Hat][8] -- will provide a more immediately useful solution for enterprise customers who can't wait around for the chips to stop falling.
|
||||||
|
|
||||||
|
"Good technology is hard and takes time to build," said Richardson. "The big risk is that expectations spin wildly out of control and customers are disappointed."
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.infoworld.com/article/2896895/application-virtualization/best-and-worst-about-docker.html
|
||||||
|
|
||||||
|
作者:[Serdar Yegulalp][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||||
|
[1]:http://shutterstock.com/
|
||||||
|
[2]:http://weave.works/
|
||||||
|
[3]:http://stackengine.com/
|
||||||
|
[4]:http://www.moogsoft.com/
|
||||||
|
[5]:http://www.wavemaker.com/
|
||||||
|
[6]:http://www.infoworld.com/article/2896099/application-virtualization/dockers-new-acquisition-does-containers-on-the-desktop.html
|
||||||
|
[7]:http://www.infoworld.com/article/2892916/application-virtualization/docker-snaps-up-socketplane-to-fix-networking-flaws.html
|
||||||
|
[8]:http://www.infoworld.com/article/2895804/application-virtualization/red-hat-wants-to-do-for-containers-what-its-done-for-linux.html
|
||||||
@ -1,63 +0,0 @@
|
|||||||
Vic020
|
|
||||||
|
|
||||||
Linux FAQs with Answers--How to convert between local time and UNIX timestamp in Perl
|
|
||||||
================================================================================
|
|
||||||
> **Question**: I need to convert readable date and time to a corresponding UNIX timestamp (i.e., Epoch time), or vice versa in a Perl program. Can you show me Perl code examples of converting date/time to UNIX timestamp, or conversely, converting UNIX timestamp to human-readable date and time?
|
|
||||||
|
|
||||||
When your Perl script needs to deal with time information, there are two different ways to represent and manipulate date and time in the script. One way is a human-readable string representation of time (e.g., "Sat Mar 14 10:14:05 EDT 2015"), and the other is via UNIX timestamp (also known as "Epoch time") which is the number of elapsed seconds since 00:00:00 UTC, 1 Jaunary 1970. Either method has its own pros and cons, and depending on your requirements you may want to convert one format to the other.
|
|
||||||
|
|
||||||
### Convert Local Time to UNIX Timestamp in Perl ###
|
|
||||||
|
|
||||||
To obtain UNIX time from a date string, you can use str2time() in Date::Parse module. It can handle a variety of date formats, such as:
|
|
||||||
|
|
||||||
- Sat Mar 14 10:14:05 EDT 2015
|
|
||||||
- 3/14/2015 10:14:05 -0400
|
|
||||||
- 14/Mar/15 10:14:05
|
|
||||||
- 14 Mar 15 10:14:05
|
|
||||||
|
|
||||||
use Date::Parse;
|
|
||||||
|
|
||||||
my $local_time = "Sat Mar 14 10:14:05 EDT 2015";
|
|
||||||
|
|
||||||
# 1426342445 will be stored in $unix_time
|
|
||||||
my $unix_time = str2time($local_time);
|
|
||||||
|
|
||||||
Date:Parse module supports multiple languages (English, French, German and Italian) and timezones. For example:
|
|
||||||
|
|
||||||
use Date::Parse;
|
|
||||||
use Date::Language;
|
|
||||||
|
|
||||||
my $lang = Date::Language->new('French');
|
|
||||||
my $unix_time = $lang->str2time("12:14:05, Ago 16, 2014 (CEST)");
|
|
||||||
|
|
||||||
### Convert UNIX Timestmp to Human-Readable Date and Time in Perl ###
|
|
||||||
|
|
||||||
If you want to show a UNIX timestamp in a human-readable format, you can use localtime() function which converts a UNIX timestamp into a 9-element list. You can use the returned list to construct any kind of human-readable date/time string as you want. Here is a code snippet.
|
|
||||||
|
|
||||||
# $sec, $min, $hour: seconds, minutes and hours
|
|
||||||
# $mday: the day of the month (0-31)
|
|
||||||
# $mon: month in the range of 0 (Jaunary) and 11 (December)
|
|
||||||
# $year: the number of years that have elapsed since 1900
|
|
||||||
# $wday: the day of the week in the range of 0 (Sunday) and 6 (Saturday)
|
|
||||||
# $yday: the day of the year in the range of 0 and 364 (or 365 in leap years)
|
|
||||||
# $isdst: whether or not it's in daylight saving time
|
|
||||||
|
|
||||||
my ($sec, $min, $hour, $mday, $mon, $year, $wday, $yday, $isdst) = localtime($unix_timestamp);
|
|
||||||
|
|
||||||
# necessary conversion of $mon and $year
|
|
||||||
$mon += 1;
|
|
||||||
$year += 1900;
|
|
||||||
|
|
||||||
print "Current time: $year-$mon-$mday $hour:$min:$sec\n";
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://ask.xmodulo.com/convert-local-time-unix-timestamp-perl.html
|
|
||||||
|
|
||||||
作者:[Dan Nanni][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://ask.xmodulo.com/author/nanni
|
|
||||||
@ -1,3 +1,4 @@
|
|||||||
|
translating wi-cuckoo LLAP
|
||||||
Install And Use ‘Go For It!’ To Do App In Linux
|
Install And Use ‘Go For It!’ To Do App In Linux
|
||||||
================================================================================
|
================================================================================
|
||||||

|

|
||||||
@ -90,4 +91,4 @@ via: http://itsfoss.com/go-for-it-to-do-app-in-linux/
|
|||||||
[8]:http://manuel-kehl.de/projects/go-for-it/download-windows-version/
|
[8]:http://manuel-kehl.de/projects/go-for-it/download-windows-version/
|
||||||
[9]:http://todotxt.com/
|
[9]:http://todotxt.com/
|
||||||
[10]:https://play.google.com/store/apps/details?id=nl.mpcjanssen.todotxtholo&hl=en
|
[10]:https://play.google.com/store/apps/details?id=nl.mpcjanssen.todotxtholo&hl=en
|
||||||
[11]:http://itsfoss.com/install-latex-ubuntu-1404/
|
[11]:http://itsfoss.com/install-latex-ubuntu-1404/
|
||||||
|
|||||||
@ -0,0 +1,70 @@
|
|||||||
|
Locate Stolen laptops and Smart phones Using Prey Tool in Ubuntu
|
||||||
|
================================================================================
|
||||||
|
Prey is an open source, cross platform tool which helps recover your stolen laptops, desktops, tablet computers and smart phones. It has gained vast popularity and has claimed to help recover hundreds of missing laptops and smart phones. The working of this tool is pretty simple, install it on your Laptop or smart phone, and if your device goes missing, login the Prey website with your credentials and mark your device as “Missing” there. As soon as the thief connects your device with internet, it will immediately send you the Geo location of your device. If your laptop is having webcam, it will also capture the screenshot of the thief.
|
||||||
|
|
||||||
|
Prey consumes minimum system resources; it does not affect your device’s performance in any way. You can also use it alongside any other anti-theft application you had installed on your device. It uses secure and encrypted channels to communicate your device data with Prey servers.
|
||||||
|
|
||||||
|
### Installing and configuring Prey on Ubuntu ###
|
||||||
|
|
||||||
|
Let’s see how we can install and configure Prey on ubuntu, note that during configuration process, we will have to register an account at Prey official website. Once done, it will be able to monitor your devices. Its free account monitors up-to 3 devices, if you need to add more devices to its watch list, you need to purchase appropriate plan.
|
||||||
|
|
||||||
|
Considering the popularity and use of Prey, it has been added to the official ubuntu repository now. That means you don’t need to add any additional PPA to the package manager. Simply launch your terminal application and run the following command to install it:
|
||||||
|
|
||||||
|
sudo apt-get install prey
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
It is a very lightweight application, uses only few MB of space on the system, once installation is completed, launch it from Applications >> Prey and it will ask you for the configuration.
|
||||||
|
|
||||||
|
Choose “New user” if you are using this app for first time.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
This second step is actually the process to sign you up on Prey official website. Please provide your username, email address and password for free account.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Hit “Apply” once done, that’s all, your computer is now protected by Prey.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Login your newly created [Prey account][1] and you should be able to see your device information there under “Devices” menu.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
As soon as your laptop or any other device goes missing, simply login your Prey web account and change the device status to “missing” by clicking “Set Device to Missing” option.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Choose report frequency from here and hit “Yes, my device is missing”. Report Frequency option is the time interval after which this app will send you status updates for your device location. It will email you as soon as the device status is changed from web interface.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
As soon as your stolen device is connected to the internet, it will immediately send you report, containing your device's Geo whereabouts and IP address.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Click the report link and you should be able to see your device’s Geo location and IP address.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
There is one known drawback in Prey , It needs your device to be connected to internet for sending Geo location, if thief is smart enough to format your device hard disk before connecting it to the network, then you’ll never get report of its recovery. But there is still a work around to overcome this drawback, make sure to add a BIOS password and disable booting the system from removable devices.
|
||||||
|
|
||||||
|
### Conclusion ###
|
||||||
|
|
||||||
|
It is a small, very useful security application which lets you track all of your devices on a single place, although not perfect, but still provides good level of recovery chances for your stolen devices. It runs seamlessly on Linux, Windows and Mac operating system. Here are details about Prey Pro plans.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://linoxide.com/ubuntu-how-to/anti-theft-application-prey-ubuntu/
|
||||||
|
|
||||||
|
作者:[Aun Raza][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://linoxide.com/author/arunrz/
|
||||||
|
[1]:https://preyproject.com/
|
||||||
@ -0,0 +1,159 @@
|
|||||||
|
Sleuth Kit - Open Source Forensic Tool to Analyze Disk Images and Recover Files
|
||||||
|
================================================================================
|
||||||
|
SIFT is a Ubuntu based forensics distribution provided by SANS Inc. It consist of many forensics tools such as Sleuth kit / Autopsy etc . However, Sleuth kit/Autopsy tools can be installed on Ubuntu/Fedora distribution instead of downloading complete distribution of SIFT.
|
||||||
|
|
||||||
|
Sleuth Kit /Autopsy is open source digital forensics investigation tool which is used for recovering the lost files from disk image and analysis of images for incident response. Autopsy tool is a web interface of sleuth kit which supports all features of sleuth kit. This tool is available for both Windows and Linux Platforms.
|
||||||
|
|
||||||
|
### Install Sleuth kit ###
|
||||||
|
|
||||||
|
First of all, download Sleuth kit software from [sleuthkit][1] website. Use wget command to download it in terminal which is shown in the figure.
|
||||||
|
|
||||||
|
# wget http://cznic.dl.sourceforge.net/project/sleuthkit/sleuthkit/4.1.3/sleuthkit-4.1.3.tar.gz
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Extract the sleuthkit-4.1.3.tar.gz using following command and go inside the extracted directory
|
||||||
|
|
||||||
|
# tar -xvzf sleuthkit-4.1.3.tar.gz
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Run following command which perform the requirement check before sleuth kit installation
|
||||||
|
|
||||||
|
#./configure
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Make command compile the sleuth kit code.
|
||||||
|
|
||||||
|
#make
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Finally following command install it under **/usr/local** path.
|
||||||
|
|
||||||
|
#make install
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Install Autopsy Tool ###
|
||||||
|
|
||||||
|
Sleuth kit installation is complete and now we will install autopsy interface. Download Autopsy software from [sleuthkit's autopsy page][2] . Use wget command to download it in terminal which is shown in the figure.
|
||||||
|
|
||||||
|
# wget http://kaz.dl.sourceforge.net/project/autopsy/autopsy/2.24/autopsy-2.24.tar.gz
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Extract the autopsy-2.24.tar.gz using following command and go inside the extracted directory
|
||||||
|
|
||||||
|
# tar -xvzf autopsy-2.24.tar.gz
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Configuration script of autopsy asks for NSRL (National Software Reference Library) and path of **Evidence_Locker** folder.
|
||||||
|
|
||||||
|
Enter "n" for NSRL prompt and create Evidence_Locker folder under **/usr/local** directory. Autopsy stores the configuration files, audit logs and output under Evidence_Locker folder.
|
||||||
|
|
||||||
|
#mkdir /usr/local/Evidence_Locker
|
||||||
|
|
||||||
|
#cd autopsy-2.24
|
||||||
|
|
||||||
|
#./configure
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
After adding Evidence_Locker path in installation process , autopsy stores configuration files in it and shows a following message to run the autopsy program.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Type **./autopsy** command in terminal to start the graphical interface of Sleuth kit tool.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Type following address in the web browser to access the interface of autopsy .
|
||||||
|
|
||||||
|
http://localhost:9999/autopsy
|
||||||
|
|
||||||
|
Main web page of autopsy plugin is shown int the following figure.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Click on the **New Case** button to start analysis in autopsy tool. Enter the case name, description about the investigation and name of agent which is shown in the following figure.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Following web page will appear after entering the details in the above page. Click on **Add Host** button to add details for the analyst machine.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Enter host name, description and time zone setting of analyst machine on the next page.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Click on the **Add Image** button to add image file for forensics analysis.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Click on the **Add Image File** button on the following web page. It opens new web page which require Path of image file and select type & importing method.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
As shown in the following figure, we have entered path of Linux image file. In our case, image file is partition of disk.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Click on the next button and select **Calculate hash** option in the next page which is shown in the following figure. It also detect the file system type of the given image.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Following window shows the MD5 hash of the image file before static analysis .
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
On the next web page, autopsy shows following information about the image file.
|
||||||
|
|
||||||
|
- mount point for the image
|
||||||
|
- name of image
|
||||||
|
- file system type of given image
|
||||||
|
|
||||||
|
Click on the **details** button to get more information about the given image file. It also offer extraction of unallocated fragments and strings from the volume of image file which is shown in the following figure.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Click on **Analyze** button which is shown in the below figure to start analysis on given image . It opens another page which shows the multiple options for image analysis.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Autopsy offer following features during image analysis process.
|
||||||
|
|
||||||
|
- File Analysis
|
||||||
|
- Keyword Search
|
||||||
|
- File Type
|
||||||
|
- Image Details
|
||||||
|
- Data Unit
|
||||||
|
|
||||||
|
File Analysis on given image of Linux partition is shown in the following figure.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
It extracts all files and folders from the given image . Extraction of deleted files are shown int he figure.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Conclusion ###
|
||||||
|
|
||||||
|
Hopefully this article will be useful for the beginner in static forensics analysis of disk image. Autopsy is web interface for sleuth kit which provides features such as extraction of strings , recovery of deleted files, timeline analysis, extraction of web surfing history, keyword search and email analysis on windows and linux disk images.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://linoxide.com/ubuntu-how-to/autopsy-sleuth-kit-installation-ubuntu/
|
||||||
|
|
||||||
|
作者:[nido][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://linoxide.com/author/naveeda/
|
||||||
|
[1]:http://www.sleuthkit.org/sleuthkit/download.php
|
||||||
|
[2]:http://www.sleuthkit.org/autopsy/download.php
|
||||||
@ -0,0 +1,85 @@
|
|||||||
|
10种将开源用于商业的最佳途径
|
||||||
|
===============================================================================
|
||||||
|
> 开源为大大小小的商业带来了一些显著的效益 -- 但是你可能会对某些用途感到惊讶。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
技术上出现了一些不可避免的东西。举个例子,开源会以自己的方式来协助你的工作。10年前,这很容易成为问题。现在呢?仍然无法避免 -- 也没有理由要去避免。有如此多强大(和必要的)的方方面面技术,开源在许多方面已经成为了技术的救世主。但是你哪一块的工作最适合开源呢?当然,这个问题的答案会因公司而异。然而许多的应用可以部署到几乎每个场景中。
|
||||||
|
|
||||||
|
让我们来看看这10种可能是最佳的使用方法,帮助你的公司成长,带给你从未体验过的灵活性与可靠性,或者仅仅是帮你节省一笔可观的预算。
|
||||||
|
|
||||||
|
### 1: 服务器软件 ###
|
||||||
|
|
||||||
|
如果你还在微软的互联网信息服务(IIS,Internet Information Services)平台苦苦挣扎,那么你需要体验一下Apache。这款旗舰开源网页服务器软件是这个星球上使用最广泛的软件之一。Apsche免费,难以置信的可靠,易于管理,而且不需要大量如IIS需要的费用。然而,开源并不局限于网页服务器。如果你需要在公司内共享服务器信息块(SMB,Server Message Block),考虑一下Samba, Samba 4甚至集成了活动的目录,所以你不需要担心在Samba服务器上建立单独的用户账号。
|
||||||
|
|
||||||
|
### 2: 开发 ###
|
||||||
|
|
||||||
|
用开源开发是很简单的事。PHP,Rails,Perl -- 开源上面的开发语言如同开发的工具(从I集成开发环境到调试)一样多。为开源或者开源工具做开发可以有很多种选择(如同私有的开发一样)。开源与私有最大的不同之处在于开源可以接触到软件源代码。在免费开源软件的世界里(FOSS,free open source software),代码都是公开的。对许多开发者来说,Linux操作系统有他们开发和建立需要的一切(特别那些写代码没有一个成熟环境的人)。如果你确实需要图形用户界面(GNU)的开发工具,开源能满足你。
|
||||||
|
|
||||||
|
### 3: 安全 ###
|
||||||
|
|
||||||
|
通往安全的道路是充满挑战的,但还是很多途径可以达到。你可以选择“安全盒子”的解决方案,跟随Cisco(一个可靠的解决方案)的节奏,或者你可以借助iptables打造最适合你需求的安全。是的,开源的安全之路会需要更多的时间去配置(有很高的学习壁垒),但是结果通常是不错的。这里甚至不强调一种观点,就是一般来说在桌面上使用开源比起大多数封闭的系统来说是一个比较安全的平台。不过在桌面上部署Linux,你的安全性会大大降低。
|
||||||
|
|
||||||
|
### 4: 桌面 ###
|
||||||
|
|
||||||
|
桌面是大多数宏机发生的地方。尽管如此,你必须考虑一个事实,那就是你每天的工作流程已经经历了一个主要的思维模式的转换。我们现在做的大部分事情都是通过网络浏览器。那么为什么不在桌面上部署Linux呢?不但可以能做如今要做的许多工作,而且不用遭受病毒,恶意软件和能破外系统的更新。它不完美 -- 但哪个平台敢说完美?但是它很强大,最后,还可以节省你的开支。这是一个双赢的结局。
|
||||||
|
|
||||||
|
### 5: 工作流程 ###
|
||||||
|
|
||||||
|
每一种工作都依赖于工作的流程。对于某些工作来说,一个流畅的工作流程又取决于所用的工具。开源已经登上这个舞台了。CRM(客户关系管理),HRM(人力资源管理),ERP(企业资源计划),BI(商业智能),BPM(业务流程管理) 。。。。。。只要你叫得出名字,开源就可以做到几乎你能想到的每一种可能的缩写 -- 并且干得不错。借助于[Pentaho][1], [Collabtive][2]和[SugarCRM][3], 开源可以在任何时候与最新的源工具保持同步。
|
||||||
|
|
||||||
|
### 6: 协作 ###
|
||||||
|
|
||||||
|
没有一起合作项目的能力,你的员工就不能干好工作。所以你选择的协作工具是十分重要的。你会在开源的世界里发现大量的优质协作工具。[Cyn.in community edition][4], [Zimbra Open Source Edition][5]和[Kolab][6]都是不错的协作工具,但仅仅是开源世界里的三个代表而已。
|
||||||
|
|
||||||
|
### 7: 大数据 ###
|
||||||
|
|
||||||
|
以前说道大数据的时候,往往不会想到开源。多亏了[SUSE][7]的努力,大数据和开源现在可以携手共进了。许多如内存数据和现场内核修复的创意,使得开源成为大数据一个理想的解决方案。 它可以完美地满足大数据在平台上所需的大量要求。而封闭的软件则达不到如此灵活的水平。
|
||||||
|
|
||||||
|
### 8: 云 ###
|
||||||
|
|
||||||
|
云的主要玩家都是开源的。[Red Hat][8], [Ubuntu][9], [SUSE][10], [Amazon][11], [Rackspace][12] -- 他们都提供云服务,而且知道开源是云配置的最好解决方案。但是,如果你不想用大公司的服务,仍然有很多后起之秀如[OwnCloud][13],你可以选择OwnCloud的特色云方案,或者建立自己的一套。
|
||||||
|
|
||||||
|
### 9: 多媒体 ###
|
||||||
|
|
||||||
|
如果你的公司为产品发布做播客或视频,开源可以为你提供服务。借助像[Audacity][14]和[OpenShot][15]这样的工具,你可以对音频和视频做你需要的任何处理 -- 而且十分的廉价。实际上,你会感觉到很难再去找到比Audacity更好的播客工具,或者比OpenShot更易用的视频编辑器。没有太大的学习壁垒,或者封闭软件工具要求的高额费用,开源的软件在帮助你创造专业水准的作品方面已经做得很好了。 #这里前一个意群不明白如何翻译
|
||||||
|
|
||||||
|
### 10: 电子商务 ###
|
||||||
|
|
||||||
|
如果你做在线销售,如果不尝试一下像[PrestaShop][16]之类的工具,你会觉得很没效率的。PrestaShop是最强大的电子商务解决方案之一,易于获取 -- 不需要许可证。 PrestaShop有你可能想要的所有功能(而且有些你可能都没有想过),这个开源平台已经在任何水平上超出了电子商务的范畴。
|
||||||
|
|
||||||
|
### FOSS 之于商业 ###
|
||||||
|
|
||||||
|
开源已经不再局限于商业交流的范围了。在许多情况下,FOSS已经主导这种交流。如果你已经在寻找将开源解决方案运用的领域,看上面的10条就行了。
|
||||||
|
|
||||||
|
### 该你了 ###
|
||||||
|
|
||||||
|
你已经将开源用到你的工作中了吗?如果是,属于哪一条方法呢?
|
||||||
|
|
||||||
|
-------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.techrepublic.com/blog/10-things/10-best-uses-for-open-source-software-in-the-business-world/
|
||||||
|
|
||||||
|
作者:[Jack Wallen][a]
|
||||||
|
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.techrepublic.com/search/?a=jack+wallen
|
||||||
|
[1]:http://community.pentaho.com/
|
||||||
|
[2]:http://collabtive.o-dyn.de/
|
||||||
|
[3]:http://www.sugarcrm.com/
|
||||||
|
[4]:http://cynapse.com/cyn-in/
|
||||||
|
[5]:https://www.zimbra.com/open-source
|
||||||
|
[6]:http://kolab.org/
|
||||||
|
[7]:http://www.suse.org/
|
||||||
|
[8]:http://www.redhat.com/
|
||||||
|
[9]:http://www.ubuntu.com/
|
||||||
|
[10]:http://www.suse.com/
|
||||||
|
[11]:http://aws.amazon.com/ec2/
|
||||||
|
[12]:http://www.rackspace.com/cloud
|
||||||
|
[13]:https://owncloud.org/
|
||||||
|
[14]:http://audacity.sourceforge.net/
|
||||||
|
[15]:http://www.openshot.org/
|
||||||
|
[16]:https://www.prestashop.com/
|
||||||
@ -1,55 +0,0 @@
|
|||||||
Linux 常见问题解答--如何使用yum来下载RPM包而不进行安装.
|
|
||||||
================================================================================
|
|
||||||
> **问题**:我想从Red Hat's的标准仓库中下载一个RPM包,我能使用yum命令来下载一个RPM包但是不进行安装吗?
|
|
||||||
|
|
||||||
yum是基于Red Hat的系统(如CentOS,Fedora,RHEl)上的默认包管理器.使用yum,你可以安装或者更新一个RPM包,并且他会自动解决包依赖关系.但是如果你只想将一个RPM包下载到你的系统上该怎么办呢? 例如,你可能想要获取一些RPM包在以后使用,或者将他们安装在另外的机器上.
|
|
||||||
|
|
||||||
这里说明了如何从yum仓库上下载一个RPM包.
|
|
||||||
|
|
||||||
### 方法一:yum###
|
|
||||||
|
|
||||||
yum命令本身就可以用来下载一个RPM包,标准的yum命令提供了`--downloadonly(只下载)`的选项来达到这个目的.
|
|
||||||
|
|
||||||
$ sudo yum install --downloadonly <package-name>
|
|
||||||
|
|
||||||
默认情况下,一个下载的RPM包会保存在下面的目录中:
|
|
||||||
|
|
||||||
/var/cache/yum/x86_64/[centos/fedora-version]/[repository]/packages
|
|
||||||
|
|
||||||
以上的[repository]表示下载包的来源仓库的名称(例如,base,fedora,updates)
|
|
||||||
|
|
||||||
如果你想要讲一个包下载到一个指定的目录(如/tmp):
|
|
||||||
|
|
||||||
$ sudo yum install --downloadonly --downloaddir=/tmp <package-name>
|
|
||||||
|
|
||||||
注意,如果下载的包包含了任意没有满足的依赖关系,yum将会把所有的依赖关系包下载,但是都不会被安装.
|
|
||||||
|
|
||||||
另外一个重要的事情时,在CentOS/RHEL 6或更早期的版本中,你需要安装一个单独yum插件(名称为 yum-plugin-downloadonly)才能使用`--downloadonly`命令选项:
|
|
||||||
|
|
||||||
$ sudo yum install yum-plugin-downloadonly
|
|
||||||
|
|
||||||
如果没有该插件,你会在使用yum时得到以下错误:
|
|
||||||
|
|
||||||
Command line error: no such option: --downloadonly
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 方法二: Yumdownloader###
|
|
||||||
另外一个下载RPM包的方法就是通过一个专门的包下载工具--yumdownloader. 这个工具时yum工具包(包含了用来进行yum包管理的帮助工具套件)的子集.
|
|
||||||
|
|
||||||
$ sudo yum install yum-utils
|
|
||||||
|
|
||||||
下载一个RPM包:
|
|
||||||
|
|
||||||
$ sudo yumdownloader <package-name>
|
|
||||||
|
|
||||||
下载的包会被保存在当前目录中.你需要使用root权限,因为yumdownloader会在下载过程中更新包索引文件.与yum命令不同的是,任何依赖包不会被下载.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://ask.xmodulo.com/yum-download-rpm-package.html
|
|
||||||
|
|
||||||
译者:[theo-l](https://github.com/theo-l)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
@ -1,61 +1,61 @@
|
|||||||
Install Mate desktop in FreeBSD 10.1
|
在FreeBSD 10.1中安装Mate桌面
|
||||||
================================================================================
|
================================================================================
|
||||||

|

|
||||||
|
|
||||||
FreeBSD is fully text mode system, however some times new users might want to use GUI desktop environment. This tutorial will help you to install Mate Desktop in Freebsd 10.1.
|
FreeBSD是全文本模式的系统,然而有些新用户想要使用GUI桌面环境。这个教程就是帮助你在Freebsd 10.1中安装Mate桌面。
|
||||||
|
|
||||||
Here is my test system details:
|
下面是我的系统细节:
|
||||||
|
|
||||||
root@Freebsd-unixmen:~ # uname -a
|
root@Freebsd-unixmen:~ # uname -a
|
||||||
FreeBSD Freebsd-unixmen 10.1-RELEASE FreeBSD 10.1-RELEASE #0 r274401: Tue Nov 11 21:02:49 UTC 2014 root@releng1.nyi.freebsd.org:/usr/obj/usr/src/sys/GENERIC amd64
|
FreeBSD Freebsd-unixmen 10.1-RELEASE FreeBSD 10.1-RELEASE #0 r274401: Tue Nov 11 21:02:49 UTC 2014 root@releng1.nyi.freebsd.org:/usr/obj/usr/src/sys/GENERIC amd64
|
||||||
root@Freebsd-unixmen:~
|
root@Freebsd-unixmen:~
|
||||||
|
|
||||||
To start installing Mate desktop in FreeBSD 10.1, the following steps can be used.
|
要在FreeBSD 10.1 中开始安装Mate桌面,按照下面的步骤。
|
||||||
|
|
||||||
pkg install xf86-video-fbdev mate-desktop mate xorg
|
pkg install xf86-video-fbdev mate-desktop mate xorg
|
||||||
|
|
||||||
### Add the following lines to /etc/rc.conf ###
|
### 在 /etc/rc.conf 中加入下面的行 ###
|
||||||
|
|
||||||
moused_enable="YES"
|
moused_enable="YES"
|
||||||
dbus_enable="YES"
|
dbus_enable="YES"
|
||||||
hald_enable="YES"
|
hald_enable="YES"
|
||||||
|
|
||||||
### Test the installation. ###
|
### 测试安装 ###
|
||||||
|
|
||||||
xinit mate-session
|
xinit mate-session
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Mate doesn’t have a display manager of its own. Hence we can use any other display managers like XDM, GDM, slim etc to use the login manager. Here let’s see how to configure Slim DM with Mate desktop.
|
Mate本身没有显示管理器。因此我们会使用其他的显示管理器如XDM、GDM、slim等等来作为登录管理器。这里让我们看看如何在Mate桌面中配置Slim DM
|
||||||
|
|
||||||
### Install Slim ###
|
### 安装 Slim ###
|
||||||
|
|
||||||
pkg install slim
|
pkg install slim
|
||||||
|
|
||||||
Add the following line to **/etc/rc.conf**:
|
在**/etc/rc.conf**中加入下面的行:
|
||||||
|
|
||||||
slim_enable="YES"
|
slim_enable="YES"
|
||||||
|
|
||||||
Add the following line to .xinitrc file in the user’s home directory
|
在用户的家目录下的.xinitrc文件加入下面的行。
|
||||||
|
|
||||||
exec mate-session
|
exec mate-session
|
||||||
|
|
||||||
Reboot the machine. Now the machine will boot into Slim login where you can login to Mate session.
|
重启电脑。现在在你登录Mate时就会进入Slim登录界面了。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
That’s it. Cheers!
|
就是这样。干杯!
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: http://www.unixmen.com/install-mate-desktop-freebsd-10-1/
|
via: http://www.unixmen.com/install-mate-desktop-freebsd-10-1/
|
||||||
|
|
||||||
作者:[M.el Khamlichi][a]
|
作者:[M.el Khamlichi][a]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
[a]:http://www.unixmen.com/author/pirat9/
|
[a]:http://www.unixmen.com/author/pirat9/
|
||||||
@ -0,0 +1,62 @@
|
|||||||
|
Linux有问必答:Perl中本地时间和UNIX时间戳间相互转换
|
||||||
|
================================================================================
|
||||||
|
> **问题**: 在Perl语言中,我需要转换易读的日期和时间到对应的UNIX时间戳,反之亦然。你可以给我一些Perl代码例子吗?关于日期及时间转换到UNIX时间戳,或者相反,转换UNIX时间戳到可读的日期和时间。
|
||||||
|
|
||||||
|
当你的Perl脚本需要解决时间信息,这里有两种方法来表示和处理日期和时间。一种方法是易读的时间表示(例,"Sat Mar 14 10:14:05 EDT 2015"),另外一种是使用UNIX时间戳(也叫“新纪元时间”),这是从1970年1月1日到今所消耗的时间秒数。每一种方法都有它自己的优劣势,取决于你的需要,也许也就需要转换一种格式到另一种。
|
||||||
|
|
||||||
|
### Perl中转换本地时间到UNIX时间戳 ###
|
||||||
|
|
||||||
|
为了从日期字符串中获得UNIX时间,可以使用Date::Parse模块中str2time()函数。此函数可以处理多种格式,例如:
|
||||||
|
|
||||||
|
- Sat Mar 14 10:14:05 EDT 2015
|
||||||
|
- 3/14/2015 10:14:05 -0400
|
||||||
|
- 14/Mar/15 10:14:05
|
||||||
|
- 14 Mar 15 10:14:05
|
||||||
|
|
||||||
|
use Date::Parse;
|
||||||
|
|
||||||
|
my $local_time = "Sat Mar 14 10:14:05 EDT 2015";
|
||||||
|
|
||||||
|
# 1426342445 will be stored in $unix_time
|
||||||
|
my $unix_time = str2time($local_time);
|
||||||
|
|
||||||
|
Date:Parse 模块支持多种语言(英语,法语,德语和意大利语)和时区。例如:
|
||||||
|
|
||||||
|
use Date::Parse;
|
||||||
|
use Date::Language;
|
||||||
|
|
||||||
|
my $lang = Date::Language->new('French');
|
||||||
|
my $unix_time = $lang->str2time("12:14:05, Ago 16, 2014 (CEST)");
|
||||||
|
|
||||||
|
### Perl中UNIX时间戳到可读的日期和时间 ###
|
||||||
|
|
||||||
|
|
||||||
|
如果你想要转换UNIX时间戳到可读的格式,可以使用localtime()函数,此函数可以转换UNIX时间戳为一个9元素列表。然后你可以使用返回的list构造任何你需要的可读格式。这里有一个代码片段:
|
||||||
|
|
||||||
|
# $sec, $min, $hour: 秒,分,时
|
||||||
|
# $mday: 月中的某天 (0-31)
|
||||||
|
# $mon: 月份,范围 0 (一月) 至 11 (十二月)
|
||||||
|
# $year: 年份,与1900年的差值(2015年为2015-1900=115)
|
||||||
|
# $wday: 星期,范围 0 (星期天) 至 6 (星期六)
|
||||||
|
# $yday: 年中的某天,范围 0 至 364 (或 365 闰年)
|
||||||
|
# $isdst: 是否是夏令时
|
||||||
|
|
||||||
|
my ($sec, $min, $hour, $mday, $mon, $year, $wday, $yday, $isdst) = localtime($unix_timestamp);
|
||||||
|
|
||||||
|
# necessary conversion of $mon and $year
|
||||||
|
$mon += 1;
|
||||||
|
$year += 1900;
|
||||||
|
|
||||||
|
print "Current time: $year-$mon-$mday $hour:$min:$sec\n";
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://ask.xmodulo.com/convert-local-time-unix-timestamp-perl.html
|
||||||
|
|
||||||
|
作者:[Dan Nanni][a]
|
||||||
|
译者:[VicYu/Vic020](http://vicyu.net)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://ask.xmodulo.com/author/nanni
|
||||||
Loading…
Reference in New Issue
Block a user